KR20220104033A - 항-pd-1-항-vegfa 이중특이항체, 약학 조성물 및 이의 용도 - Google Patents
항-pd-1-항-vegfa 이중특이항체, 약학 조성물 및 이의 용도 Download PDFInfo
- Publication number
- KR20220104033A KR20220104033A KR1020227021354A KR20227021354A KR20220104033A KR 20220104033 A KR20220104033 A KR 20220104033A KR 1020227021354 A KR1020227021354 A KR 1020227021354A KR 20227021354 A KR20227021354 A KR 20227021354A KR 20220104033 A KR20220104033 A KR 20220104033A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- variable region
- cancer
- chain variable
- antibody
- Prior art date
Links
Images






























Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6845—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a cytokine, e.g. growth factors, VEGF, TNF, a lymphokine or an interferon
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/22—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against growth factors ; against growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57407—Specifically defined cancers
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
- G01N33/57492—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites involving compounds localized on the membrane of tumor or cancer cells
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/74—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving hormones or other non-cytokine intercellular protein regulatory factors such as growth factors, including receptors to hormones and growth factors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/51—Complete heavy chain or Fd fragment, i.e. VH + CH1
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/734—Complement-dependent cytotoxicity [CDC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/475—Assays involving growth factors
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/70503—Immunoglobulin superfamily, e.g. VCAMs, PECAM, LFA-3
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/70503—Immunoglobulin superfamily, e.g. VCAMs, PECAM, LFA-3
- G01N2333/70521—CD28, CD152
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/70503—Immunoglobulin superfamily, e.g. VCAMs, PECAM, LFA-3
- G01N2333/70532—B7 molecules, e.g. CD80, CD86
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/70—Mechanisms involved in disease identification
- G01N2800/7014—(Neo)vascularisation - Angiogenesis
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Hematology (AREA)
- Biochemistry (AREA)
- Urology & Nephrology (AREA)
- Biomedical Technology (AREA)
- Cell Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Microbiology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- General Physics & Mathematics (AREA)
- Biotechnology (AREA)
- Pathology (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Food Science & Technology (AREA)
- Oncology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Hospice & Palliative Care (AREA)
- Epidemiology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Endocrinology (AREA)
- Mycology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
본 발명에서 항-VEGFA-항-PD-1 이중특이항체 및 이의 용도가 제공된다. 구체적으로, 항-VEGFA-항-PD-1 이중특이항체는 다음을 포함한다: PD-1-표적 제1단백질 기능부위 및 VEGFA-표적 제2단백질 기능부위. EU 넘버링 시스템에 따라, 이중특이항체에 함유된 면역글로불린의 중쇄 불변부위의 234 위치 및 235 위치의 두 위치에서 돌연변이가 발생하고, 돌연변이 이후, 이중특이항체의 FcγRI, FcγRIIa, FcγRIIIa, 및/또는 C1q와의 친화도 상수는 돌연변이 이전에 비해 감소한다. 이중특이항체는 VEGFA 및 PD-1에 특이적으로 결합할 수 있고, 생물체에서 VEGFA 및 PD-1의 면역억제를 특이적으로 완화할 수 있고, 종양-유도 혈관 신생을 억제할 수 있으므로, 응용 전망이 좋다.
Description
본 발명은 종양 치료 및 면역생물학 분야에 속하고, 항-PD-1-항-VEGFA 이중특이항체, 이의 약학 조성물 및 이의 용도에 관한 것이다. 구체적으로, 본 발명은 항-인체 PD-1-항-인체 VEGFA 이중특이항체, 이의 약학 조성물 및 이의 용도에 관한 것이다.
종양, 특히 악성 종양은, 오늘날 세계적으로 건강을 위협하는 심각한 질병으로, 이는 다양한 질병 사이에서 두 번째로 높은 사망 원인이다. 최근 몇 년간, 이 질병의 발생은 눈에 띄게 증가해왔다. 악성 종양은 낮은 치료 반응, 높은 후기 전이율 및 나쁜 예후로 특징지어진다. 비록 현재 임상적으로 도입된 관례적인 치료 방법 (예를 들어 방사선 치료법, 화학 치료요법 및 수술 치료법) 은 뛰어난 수준으로 고통을 완화하며 생존 기간을 연장하지만, 이러한 방법은 커다란 한계를 지니며, 추후 그 효능을 개선하기 어렵다.
종양 생장에는, 구체적으로, 혈관이 관여하지 않는 느린 생장 단계부터 혈관이 관여하는 급속 증식 단계까지 두 특징적인 단계가 있다. 혈관 신생은 종양이 혈관 전환 단계를 완료하기에 충분한 영양을 얻을 수 있도록 하며, 혈관 신생이 없다면, 초기 종양은 1-2 mm 보다 작을 것이고, 따라서 전이가 발생할 수 없다.
혈관 내피 성장인자 (Vascular Endothelial Growth Factor; VEGF)는 내피 세포의 분열 및 증식을 촉진하고, 새로운 혈관 형성을 촉진하고 혈관 투과성을 개선할 수 있는 성장 인자이며, 이는 세포 표면에 제시되는 혈관 내피 성장 인자 수용체에 결합하고 타이로신 인산화효소 신호 전달 경로를 활성화시키는 역할을 한다. 종양 조직에서, 종양세포, 및 종양으로 침투하는 대식세포 및 비만세포는 높은 수준의 VEGF를 분비하고, 측분비 형태로 종양 혈관 내피세포를 자극하고, 내피세포의 증식 및 이동을 촉진하고, 혈관 신생을 유도하고, 종양의 지속적인 생장을 촉진하고, 혈관 투과성을 개선하고, 주변 조직의 섬유소 침착을 유발하고, 종양 기질 형성 및 새로운 혈관으로의 종양 유입을 촉진하는, 단핵세포, 섬유아세포 및 내피세포의 침입을 촉진하고, 종양 전이를 촉진한다. 그러므로, 종양 혈관 신생을 억제하는 것은 현재 종양 치료법 중 가장 유망한 것 중 하나로 여겨진다. VEGF 패밀리는: VEGFA, VEGFB, VEGFC, VEGFD 및 IPGF를 포함한다. 혈관 내피 성장인자 수용체 (VEGFRs)는 VEGFR1 (Flt1로도 알려짐), VEGFR2 (KDR 또는 Flk1로도 알려짐), VEGFR3 (Flt4로도 알려짐), 및 Neuropilin-1 (NRP-1)을 포함한다. 첫 세 종의 수용체는 구조가 유사하고, 타이로신 인산화효소 슈퍼패밀리에 속하고, 막외 영역, 막관통 분절, 막내 영역으로 구성되며, 막외 영역은 면역글로불린-유사 도메인으로 구성되고, 막내 영역은 타이로신 인산화효소 영역이다. VEGFR1과 VEGFR2는 주로 혈관 내피세포 표면에 위치하며, VEGFR3는 주로 림프관 내피세포 표면에 위치한다.
VEGF 패밀리의 분자는 이러한 수용체에 대해 다른 친화도를 가진다. VEGFA는 주로 VEGFR1, VEGFR2 및 NRP-1과 결합하여 작용한다. VEGF1은 가장 일찍 발견된 수용체이고 일반적인 생리적 조건에서 VEGFA에 대해 VEGFR2보다 더 높은 친화도를 지니지만, VEGFR2보다 막내 영역의 타이로시네이즈 (tyrosinase) 활성이 낮다 (Ma Li, Chinese Journal of Birth Health and Heredity, 2016, 24 (5): 146-148).
VEGFR2는 혈관 신생 및 혈관 엔지니어링의 주조절자이고, VEGFR1보다 훨씬 높은 타이로신 인산화효소 활성을 지닌다. VEGFR2는, 리간드인 VEGFA와 결합한 후, 혈관 내피세포의 증식, 분화 등을 매개하고, 혈관 형성과정과 혈관 투과성을 매개한다 (Roskoski R Jr. et al., Crit Rev Oncol Hematol, 2007, 62(3): 179-213). VEGFA는, VEGFR2와 결합한 후, 다운스트림 PLC-γ-PKC-Raf-MEK-MAPK 신호 경로를 통해 세포 내 관련 단백질 유전자의 전사적 발현을 매개하고, 따라서 혈관 내피세포의 증식을 촉진한다 (Takahashi T et al., Oncogene, 1999, 18(13): 2221-2230).
VEGFR3는 타이로신 인산화효소 패밀리의 하나이고, 주로 배아 내피세포 및 성체 림프관 내피세포를 발현하고, VEGFC 및 VEGFD가 VEGFR3와 결합하여 림프관 내피세포의 이동을 자극하고 림프관의 신생을 촉진하고; NRP-1은 비-타이로신 인산화효소인 막관통 단백질이고 독자적으로 생물학적 신호를 전달할 수 없고, VEGF 타이로신 인산화효소 수용체와 복합체를 형성한 후에만 신호를 매개할 수 있다. (Ma Li, Chinese Journal of Birth Health and Heredity, 2016, 24 (5): 146-148).
VEGFA와 VEGFR2는 주로 혈관 신생의 조절에 관여되며, VEGFA와 VEGFR2의 결합 전후로, 업스트림 및 다운스트림 경로의 많은 중간 신호의 캐스케이드 반응이 형성되고, 최종적으로 내피세포의 증식, 생존, 이동, 투과성 증가 및 말초 조직으로의 침윤 등으로 생리적 기능이 변화된다 (Dong Hongchao et al., Journal of Modern Oncology, Sep. 2014, 22 (9): 2231-3).
현재, 2004년 연속으로 비소세포성 폐암, 신장세포 암종, 자궁경부암, 및 전이성 대장암과 같은 다양한 종양의 치료제로서 미국 식품의약국 (FDA) 승인을 받은, bevacizumab과 같은, 인체 VEGF, 특히 VEGFA를 표적으로 하는 인간화 단일클론항체가 존재한다.
CD279로도 알려진, 세포예정사 수용체-1 (PD-1)는 1형 막관통 당단백질 막표면 수용체이고, CD28 면역글로불린 슈퍼패밀리에 속하고, T 세포, B 세포, 및 골수세포에서 보통 발현된다. PD-1은, PD-L1과 PD-L2의 두 천연 리간드를 가진다. PD-L1과 PD-L2는 모두 B7 슈퍼패밀리에 속하고 비조혈모세포와 다양한 종양세포를 포함하는, 다양한 세포의 막표면에서 지속적으로 또는 유도적으로 발현된다. PD-L1은 주로 T 세포, B 세포, 수지상세포 (DC) 와 미세혈관 내피세포 및 다양한 종양세포에서 발현되는 반면, PD-L2는 수지상세포 및 대식세포와 같은 항원제시세포에서만 발현된다. PD-1과 이의 리간드 사이의 상호작용은 림프의 활성화, T 세포의 증식, 및 IL-2와 IFN-γ와 같은 사이토카인의 분비를 억제할 수 있다.
많은 연구가 종양 미세환경이 면역세포에 의한 손상으로부터 종양세포를 보호할 수 있고, 종양 미세환경에 침윤된 림프구의 PD-1 발현이 상향조절되며, 폐암, 간암, 난소암, 피부암, 대장암 및 신경교종과 같은, 다양한 원발성 암 조직이 면역조직화학적 분석에서 PD-L1 양성이라는 것을 보여준다. 한편, 종양에서의 PD-L1 발현은 암 환자의 나쁜 예후와 상당히 연관되어 있다. PD-1과 이의 리간드 간의 상호작용을 차단하는 것은 종양-특이적 T 세포 면역을 촉진하고 종양세포의 면역 제거 효율을 증진시킬 수 있다. 많은 임상 시험은 PD-1 또는 PD-L1을 표적으로 하는 항체는 CD8+ T 세포의 종양 조직으로의 침투를 촉진하고 IL-2, IFN-γ, 그랜자임 B 및 퍼포린과 같은 항-종양 면역 이펙터 인자를 상향조절하고, 그에 따라 효과적으로 종양 생장을 억제할 수 있다는 것을 보여준다.
또한, 항-PD-1 항체는 바이러스성 만성 감염의 치료에도 사용될 수 있다. 바이러스성 만성 감염은 바이러스-특이 이펙터 T 세포의 기능 상실 및 수량 감소를 자주 동반한다. PD-1과 PD-L1 사이의 상호작용은 PD-1 항체 투여를 통해 차단될 수 있고, 그에 따라 바이러스성 만성 감염에서 이펙터 T 세포의 고갈을 억제할 수 있다. PD-1 항체의 넓은 항-종양 가능성과 탁월한 효능 덕분에, PD-1 경로를 표적으로 하는 항체가 다양한 종양: 비소세포성 폐암, 신장세포암, 난소암 및 흑색종 (Homet M. B., Parisi G., et al., Anti-PD-1 Therapy in Melanoma. Semin Oncol., Jun. 2015, 42 (3): 466-473), 림프종 및 빈혈 (Held SA, Heine A, et al., Advances in immunotherapy of chronic myeloid leukemia CML. Curr Cancer Drug Targets., Sep. 2013, 13 (7): 768-74), 고-미세부수체 불안정성 (MSI-H) 및 미스매치 수선 결함 (dMMR) 암 (여러 항-PD-1 항체 약물은 MSI-H/dMMR 특징의 종양 치료에 대해 FDA 등의 승인을 받음) 의 치료에 있어 돌파구가 될 것이라는 점이 당업계에 널리 받아들여진다.
현재의 항-혈관 신생 요법 및 면역 체크포인트 억제제의 조합은 많은 종양에 있어 좋은 효능을 보인다. 예를 들어, 난소암 (Joyce F. Liu et al., JAMA Oncol., 2019; 5(12): 1731-1738), 비소세포성 페암 (EGFR 및/또는 ALK 감수성 돌연변이를 포함) (Manegold C, et al., J Thorac Oncol., Feb. 2017; 12(2): 194-207), 신장세포암 ((Dudek AZ et al., J Clin Oncol., 2018; 36 (suppl; abstr., 4558)), 간세포암 (Stein S et al., J Clin Oncol, 2018, 36(15_suppl): 4074; bevacizumab in combination with atezolizumab for use in the treatment of hepatocellular carcinoma endorsed by the FDA in 2020), 대장암 (MSI-H/dMMR 및 비-MSI-H/dMMR 타입을 포함) (Bendell JC et al., Safety and efficacy of MPDL3280A (anti-PDL1) in combination with bevacizumab (bev) and/or FOLFOX in patients (pts) with metastatic colorectal cancer (mCRC). Presented at: American Society of Clinical Oncology; May 29-June 2, 2015; Chicago, IL. 2015; abstract 704; Hochster HS et al., Efficacy and safety of atezolizumab (atezo) and bevacizumab (bev) in a phase Ib study of microsatellite instability (MSI)-high metastatic colorectal cancer (mCRC). Presented at: American Society of Clinical Oncology Gastrointestinal Cancers Symposium; January 19-21, 2017; San Francisco, CA. 2017; abstract 673), 유방암 (Yukinori Ozaki et al., A multicenter phase II study evaluating the efficacy of nivolumab plus paclitaxel plus bevacizumab triple-combination therapy as a first-line treatment in patients with HER2-negative metastatic breast cancer: WJOG9917B NEWBEAT trial [abstract]. In: Proceedings of the 2019 San Antonio Breast Cancer Symposium; 2019 Dec 10-14; San Antonio, TX. Philadelphia (PA): AACR; Cancer Res 2020; 80(4 Suppl): Abstract nr PD1-03)의 치료를 위한 항-VEGF 항체 (bevacizumab 등)와 PD-1/PD-L1 항체 (nivolumab, pembrolizumab 및 atezolizumab 등)의 결합; VEGFR2 항체 및 PD-1 항체의 조합 역시 위의 선암종 및 위식도 접합부 선암종에 대해 좋은 항-종양 효과를 보였고; 또한, PD-1 항체 (Pembrolizumab) 및 혈관 신생 억제제 (Lenvatinib)의 복합 요법은 자궁내막암의 치료에 좋은 효능을 보였고, 자궁내막암 치료제로서 2019년 FDA의 승인을 받았다. 흑색종 (PD-1 항체 nivolumab 및 pembrolizumab은 흑색종 치료제로서 FDA 승인을 받음), 자궁경부암 (Krishnansu S. et al., N Engl J Med., 2014; 370: 734-743), 신경교종, 전립선암 (Antonarakis ES. et al., J Clin Oncol., Feb 10, 2020; 38(5): 395-405), 요로상피암 (Joaquim Bellmunt. et al., N Engl J Med., 2017; 376: 1015-1026; 방광암 치료제로서 2017년 FDA 승인을 받은 nivolumab), 식도암 (Kato K et al., Lancet Oncol., 2019; 20(11): 1506-17), 중피종 (Scherpereel A et al., Lancet Oncol., 2019; 20(2): 239-253) 등에 대해, PD-1/PD-L1 항체는 좋은 효능을 보이고, PD-1 경로가 종양 형성에 있어서 VEGF 경로와 시너지 효과를 낸다는 점을 고려할 때, PD-1 및 VEGF 경로를 모두 차단하는 약물은 더 나은 항-종양 효과를 가질 것으로 예측할 수 있다.
이중특이항체로도 알려진, 이중특이항체는 두 종의 다른 항원을 동시에 표적으로 삼는 특정한 약물이고, 면역선택 정제법으로 생산될 수 있다. 또한, 이중특이항체는 유전 공학으로도 생산될 수 있으며, 이는 결합 부위의 최적화, 합성 형태의 고려, 및 수율과 같은 측면에 상응하는 유연성 덕분에 특정한 이점을 지닌다. 현재, 이중특이항체는 45개 이상의 형태로 존재하는 것으로 설명된다 (Muller D, Kontermann RE. Bispecific antibodies for cancer immunotherapy: current perspectives. BioDrugs 2010; 24: 89-98). 많은 이중특이항체는 IgG-ScFv의 형태, 즉 모리슨 형태 (the Morrison form)로 개발되었으며 (Coloma M. J., Morrison S. L. Design and production of novel tetravalent bispecific antibodies. Nat Biotechnol., 1997; 15: 159-163), 이는 자연에 존재하는 IgG 형태와의 유사성 및 항체 엔지니어링, 발현 및 정제에서의 이점으로 인해 가장 이상적인 이중특이항체의 형태 중 하나로 설명된다 (Miller B. R., Demarest S. J., et al., Stability engineering of scFvs for the development of bispecific and multivalent antibodies. Protein Eng Des Sel 2010; 23: 549-57; Fitzgerald J, Lugovskoy A. Rational engineering of antibody therapeutics targeting multiple oncogene pathways. MAbs 2011; 3: 299-309).
ADCC (antibody-dependent cell-mediated cytotoxicity)는 항체의 Fab 단편과 바이러스 감염세포 또는 종양세포의 항원결정기 (epitope)의 결합 및 항체의 Fc 단편과 킬러세포 표면의 Fc 수용체 (FcR)의 결합을 통해 매개되는 킬러세포 (NK 세포, 대식세포 등)에 의한 표적세포 제거를 의미한다.
CDC (complement dependent cytotoxicity)는 항체와 세포막 표면의 상응하는 항원의 특정한 결합이 복합체를 형성하고 보체 시스템을 활성화시키며, 이는 나아가 표적세포의 표면에 후속 표적세포 용해를 일으키는 MAC을 형성하는 것을 의미한다. 보체는 다양한 박테리아와 다른 병원성 유기체의 용해를 유발할 수 있으며, 병원성 유기체 감염에 대한 중요한 방어 기작이다.
Fc 수용체는 항체 Fc 부위를 인식하기 위해 특정 면역세포의 표면에서 발현되고 면역반응을 매개할 수 있는 면역글로불린 패밀리에 속한다. Fab 부위가 항원을 인식한 후, 항체의 Fc 부위는 식세포 작용 및 ADCC와 같은, 면역세포의 면역반응을 개시하기 위해 면역세포 (예를 들어, 킬러세포)의 Fc 수용체에 결합한다.
Fc 수용체에 의해 인식되는 항체의 종류 및 발현세포의 종류에 따라, Fc 수용체는 주로 세 유형, FcγR, FcαR 및 FcεR로 분류된다. FcγR는 나아가 4개의 아형, FcγRI (CD64), FcγRII (CD32), FcγRIII (CD16) 및 FcγRn (신생아 Fc 수용체)으로 분류된다. 이들 중에서, FcγRI, FcγRII 및 FcγRIII는 ADCC 효과와 긴밀하게 연관되어 있다. FcγRIII는, 다른 세포 종류에서 높은 상동성을 지닌 두 아형, FcγRIIIa 및 FcγRIIIb을 가지며, ADCC를 매개하는 가장 주된 분자이다. FcγRIIIa 집단에서, 단일염기 다형성 (single nucleotide polymorphism; SNP)의 위치로 구분되는 두 아형, 높은 친화도의 FcγRIIIa_V158 및 낮은 친화도의 FcγRIIIa_F158가 존재한다. FcγRI은 IgG의 Fc 부위에 대해 더 높은 친화도를 가지며 ADCC 과정에 참여하고; FcγRII는 FcγRIIa, FcγRIIb 및 FcγRIIc의 세 아형 (각각 CD32a, CD32b, CD32c로도 지칭됨)을 포함하며, 그중 FcγRIIa가 ADCC 활성을 가지고; 인간에서 FcγRIIa에는 단일염기 돌연변이에 의한 FcγRIIa_H131 및 FcγRIIa_R131의 두 아형이 존재한다 (Hogarth PM, Pietersz GA. 2012, NATURE REVIEWS DRUG DISCOVERY, 11(4): 311-331).
IgG 패밀리는 네 멤버, IgG1, IgG2, IgG3 및 IgG4를 포함하며, 이들은 FcγR에 대한 다른 친화도를 유발하는, 중쇄 불변부위의 단편 결정화가능 (Fc) 부위의 아미노산이 상이하다. IgG1은 인간에서 가장 풍부한 아형이고, 또한 단일클론항체 약물에서 가장 흔히 사용되는 아형이다. IgG1은 다양한 FcγR에 결합할 수 있고 ADCC 및 CDD 효과를 유도할 수 있다. IgG2는 FcγR에 대해 가장 낮은 친화도를 가지지만, 여전히 FcγRIIa에 결합하여 단핵구-매개 ADCC를 유도할 수 있다. IgG3는 FcγR에 대한 가장 높은 결합력을 특징으로 하고, ADCC 및 IgG1보다 더 큰 CDC 효과를 유도할 수 있다. IgG4 분자는 FcγRI 이외의 FcγR에 약하게 결합하고, IgG4 분자는 낮은 CDC 및 NK 세포-매개 ADCC 유발 확률을 가진다.
현재, 항체-매개 항-PD-1-항-VEGFA 이중특이항체가 결합하는 면역세포에 대한 ADCC 및/또는 CDC 활성에 의해 유발되는 손상을 감소시키거나 제거하고, 항체 약물의 효능을 향상시키기 위해 여전히 신규한 항-PD-1-항-VEGFA 이중특이항체의 개발이 요구된다.
집중적인 연구와 창의적인 노력으로, 본 발명자들은 그에 상응하여 Fc 부위의 Fc 수용체에 대한 결합력을 감소시키기 위해 항-PD-1-항-VEGFA 이중특이항체 구조의 Fc 단편을 변경하였고, 그에 따라 면역세포에 대한 ADCC와 CDC 독성 및 부작용을 감소시키고 항-PD-1-항-VEGFA 이중특이항체 약물의 약물 효능을 증가시켰다.
본 발명은 하기에 상세하게 설명된다.
본 발명의 일 양태는 하기의 구성을 포함하는, 이중특이항체에 관한 것이다:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
제1단백질 기능부위는 면역글로불린이고, 제2단백질 기능부위는 단일사슬항체이고; 또는, 제1단백질 기능부위는 단일사슬항체이고, 제2단백질 기능부위는 면역글로불린이고;
면역글로불린은 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 단일사슬항체는 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
또는,
면역글로불린은 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 단일사슬항체는 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
면역글로불린은 인간 IgG1 아형이고;
면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 234, 235 및 237 위치 중 어느 2 또는 3곳에 돌연변이를 가지고, 이중특이항체의 FcγRIIIa 및/또는 C1q에 대한 친화도 상수 (affinity constant)가 돌연변이 발생 전과 비교하여 돌연변이 발생 후 감소하고; 바람직하게는, 친화도 상수는 포르테비오 옥텟 시스템 (Fortebio Octet system)으로 측정되는 것임.
본 발명의 하나 이상의 구현예에서, 이중특이항체에 있어서, 면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 하기의 돌연변이를 가진다:
L234A 및 L235A;
L234A 및 G237A;
L235A 및 G237A;
또는
L234A, L235A 및 G237A.
본 발명에 있어서, 달리 명시되지 않는 한, 위치 번호 전에 위치한 글자는 돌연변이 전의 아미노산을 뜻하고, 위치 번호 후에 위치한 글자는 돌연변이 후의 아미노산을 뜻한다.
본 발명은 추가로 하기의 구성을 포함하는, 이중특이항체에 관한 것이다:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
제1단백질 기능부위는 면역글로불린이고, 제2단백질 기능부위는 단일사슬항체이고; 또는, 제1단백질 기능부위는 단일사슬항체이고, 제2단백질 기능부위는 면역글로불린이고;
면역글로불린은 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 단일사슬항체는 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
또는,
면역글로불린은 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 단일사슬항체는 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
면역글로불린은 인간 IgG1 아형임.
본 발명은 추가로 하기의 구성을 포함하는, 이중특이항체에 관한 것이다:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
제1단백질 기능부위는 면역글로불린이고, 제2단백질 기능부위는 단일사슬항체이고; 또는, 제1단백질 기능부위는 단일사슬항체이고, 제2단백질 기능부위는 면역글로불린이고;
면역글로불린은 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33로 제시된 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 단일사슬항체는 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
또는,
면역글로불린은 중쇄 가변부위가 각각 서열번호 34 내지 36ㅡ이 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 단일사슬항체는 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
면역글로불린은 인간 IgG1 아형이고;
면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 하기의 돌연변이를 가지는 것임:
L234A 및 L235A;
L234A 및 G237A;
L235A 및 G237A; 또는
L234A, L235A 및 G237A.
본 발명의 하나 이상의 구현예에서, 이중특이항체에 있어서, 면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 하기에서 선택된 하나 이상의 돌연변이를 가지거나 추가로 가진다:
N297A, D265A, D270A, P238D, L328E, E233D, H268D, P271G, A330R, C226S, C229S, E233P, P331S, S267E, L328F, A330L, M252Y, S254T, T256E, N297Q, P238S, P238A, A327Q, A327G, P329A, K322A, T394D, G236R, G236A, L328R, A330S, P331S, H268A, E318A 및 K320A.
본 발명의 하나 이상의 구현예에서, 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위의 아미노산 서열은 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 5 및 서열번호 9에서 선택되고, 단일사슬항체의 경쇄 가변부위의 아미노산 서열은 서열번호 7, 서열번호 11 및 서열번호 17에서 선택되고;
또는,
면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 5 및 서열번호 9에서 선택되고, 면역글로불린의 경쇄 가변부위의 아미노산 서열은 서열번호 7, 서열번호 11 및 서열번호 17에서 선택되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위의 아미노산 서열은 서열번호 3으로 제시되는, 이중특이항체가 제공된다.
본 발명의 하나 이상의 구현예에서, 이중특이항체는 하기 (1) 내지 (12)에서 선택되는 어느 하나인 것이다:
(1) 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위는 서열번호 5로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 7로 제시되는 것이고;
(2) 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위는 서열번호 5로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 11로 제시되는 것이고;
(3) 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위는 서열번호 5로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 17로 제시되는 것이고;
(4) 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위는 서열번호 9로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 7로 제시되는 것이고;
(5) 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위는 서열번호 9로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 11로 제시되는 것이고;
(6) 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 단일사슬항체의 중쇄 가변부위는 서열번호 9로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 17로 제시되는 것이고;
(7) 면역글로불린의 중쇄 가변부위는 서열번호 5로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 7로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(8) 면역글로불린의 중쇄 가변부위는 서열번호 5로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 11로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(9) 면역글로불린의 중쇄 가변부위는 서열번호 5로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 17로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(10) 면역글로불린의 중쇄 가변부위는 서열번호 9로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 7로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(11) 면역글로불린의 중쇄 가변부위는 서열번호 9로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 11로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고; 및
(12) 면역글로불린의 중쇄 가변부위는 서열번호 9로 제시되고, 면역글로불린의 경쇄 가변부위는 서열번호 17로 제시되고; 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것임.
본 발명의 하나 이상의 구현예에서, 면역글로불린의 중쇄의 아미노산 서열은 서열번호 24로 제시되고, 면역글로불린의 경쇄의 아미노산 서열은 서열번호 26으로 제시되는, 이중특이항체가 제공된다.
본 발명의 하나 이상의 구현예에서, 이중특이항체는 IgG-scFv의 형태, 즉, 모리슨 형식이다.
본 발명의 일부 구현예에서, 본 발명의 하나 이상의 구현예의 이중특이항체에서, 면역글로불린의 중쇄 불변부위는 인간 Ig 감마-1 사슬 C 부위 또는 인간 Ig 감마-4 사슬 C 부위이고, 면역글로불린의 경쇄 불변부위는 인간 Ig 카파 사슬 C 부위이다.
본 발명의 일부 구현예에서, 면역글로불린의 불변부위는 인간화된 것이다. 예를 들어, 중쇄 불변부위는 Ig 감마-1 사슬 C 부위, 고유번호 (ACCESSION): P01857, 및 경쇄 불변부위는 Ig 카파 사슬 C 부위, 고유번호: P01834; 또는
면역글로불린의 중쇄 불변부위는 Ig 감마-4 사슬 C 부위, 고유번호: P01861.1; 면역글로불린의 경쇄 불변부위는 Ig 카파 사슬 C 부위, 고유번호: P01834이다.
본 발명의 일 구현예에서, 중쇄 불변부위 Ig 감마-1 사슬 C 부위 (고유번호: P01857)의 아미노산 서열은 하기와 같다:
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK (서열번호: 40)
본 발명의 일 구현예에서, 중쇄 불변부위 Ig 감마-4 사슬 C 부위 (고유번호: P01861.1)의 아미노산 서열은 하기와 같다:
ASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPSCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK (서열번호: 41)
본 발명의 일 구현예에서, 경쇄 불변부위 Ig 카파 사슬 C 부위 (고유번호: P01834)는 하기와 같다:
RTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (서열번호: 42)
본 발명의 일부 구현예에서, 단일사슬항체가 면역글로불린의 중쇄의 C-말단에 연결되는, 이중특이항체가 제공된다. 면역글로불린은 두 개의 중쇄를 가지기 때문에, 두 개의 단일사슬항체 분자는 하나의 면역글로불린 분자에 연결된다. 바람직하게는, 두 단일사슬항체 분자는 동일한 것이다.
본 발명의 일부 구현예에서, 두 개의 단일사슬항체가 존재하고, 각 단일사슬항체의 일 말단은 면역글로불린의 두 개의 중쇄의 C-말단 또는 N-말단에 연결되는, 이중특이항체가 제공된다.
본 발명의 일부 구현예에서, 단일사슬항체의 VH 및 VL 간에 이황화 결합이 존재한다. 항체의 VH 및 VL 간의 이황화 결합을 도입하는 방법은 당업계에 공지되어 있으며, 예를 들어, 미국 특허번호 5,747,654; Rajagopal et. al., Prot. Engin., 10(1997)1453-1459; Reiter et. Al., Nat. Biotechnol., 14(1996)1239-1245; Reiter et. al., Protein Engineering, 8(1995)1323-1331; Webber et. al., Molecular Immunology, 32(1995)249-258; Reiter et. al., Immunity, 2(1995)281-287; Reiter et. al., JBC, 269(1994)18327-18331; Reiter et. al., Inter. J. of Cancer, 58(1994)142-149; 또는 Reiter et al., Cancer Res. 54(1994)2714-2718를 참고할 수 있으며, 이들은 본 명세서에 참고문헌으로 포함되어 있다.
본 발명의 하나 이상의 구현예에서, 제1단백질 기능부위는 제2단백질 기능부위와 직접 또는 링커 단편을 통해 연결되고; 및/또는 단일사슬항체의 중쇄 가변부위는 단일사슬항체의 경쇄 가변부위와 직접 또는 링커 단편을 통해 연결되는, 이중특이항체가 제공된다.
본 발명의 하나 이상의 구현예에서, 이중특이항체에서, 링커 단편은 (GGGGS)n, n은 양의 정수이고; 바람직하게는, n는 1, 2, 3, 4, 5 또는 6이다.
본 발명의 하나 이상의 구현예에서, 이중특이항체에서, 제1단백질 기능부위 및 제2단백질 기능부위의 수는 각각 독립적으로 1, 2 또는 그 이상이다.
본 발명의 하나 이상의 구현예에서, 단일사슬항체가 면역글로불린의 중쇄의 C-말단에 연결되는, 이중특이항체가 제공된다.
본 발명은 추가로 하기의 구성을 포함하는, 이중특이항체에 관한 것이다:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
제1단백질 기능부위의 수는 1이고, 제2단백질 기능부위의 수는 2이고;
제1단백질 기능부위는 면역글로불린이고, 제2단백질 기능부위는 단일사슬항체이고;
면역글로불린의 중쇄의 아미노산 서열은 서열번호 24로 제시되고, 면역글로불린의 경쇄의 아미노산 서열은 서열번호 26으로 제시되고;
단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 9로 제시되고, 단일사슬항체의 경쇄 가변부위의 아미노산 서열은 서열번호 17로 제시되고;
단일사슬항체는 면역글로불린의 중쇄의 C-말단에 연결되고;
제1단백질 기능부위는 제1링커 단편을 통해 제2단백질 기능부위에 연결되고; 단일사슬항체의 중쇄 가변부위는 제2링커 단편을 통해 단일사슬항체의 경쇄 가변부위에 연결되고; 제1링커 단편과 제2링커 단편은 같거나 다른 것이고;
바람직하게는, 제1링커 단편 및 제2링커 단편의 아미노산 서열은 서열번호 18 및 서열번호 19에서 독립적으로 선택되는 것이고;
바람직하게는, 제1링커 단편 및 제2링커 단편의 아미노산 서열은 서열번호 18로 제시되는 것임.
본 발명의 하나 이상의 구현예에서, 면역글로불린 또는 이의 항원-결합 단편이 FcγR1에 약 10-7 M, 10-8 M 또는 10-9 M 미만과 같은, 약 10-6 M 미만의 친화도 상수로 결합하고; 바람직하게는, 친화도 상수는 포르테비오 옥텟 시스템으로 측정되는, 이중특이항체가 제공된다.
본 발명의 일부 구현예에서, 면역글로불린 또는 이의 항원-결합 단편이 C1q에 약 10-7 M, 10-8 M 또는 10-9 M 미만과 같은, 약 10-9 M 미만의 친화도 상수로 결합하고; 바람직하게는, 친화도 상수는 포르테비오 옥텟 시스템으로 측정되는, 이중특이항체가 제공된다.
본 발명의 일부 구현예에서, 이중특이항체가 VEGFA 단백질에 1 nM 미만, 0.5 nM 미만, 0.2 nM 미만, 0.15 nM 미만, 또는 0.14 nM 미만의 EC50으로 결합하고; 바람직하게는, EC50은 간접적 ELISA로 검출되고;
및/또는,
이중특이항체가 PD-1 단백질에 1 nM 미만, 0.5 nM 미만, 0.2 nM 미만, 0.17 nM 미만, 0.16 nM 미만, 또는 0.15 nM 미만의 EC50으로 결합하고; 바람직하게는, EC50은 간접적 ELISA로 검출되는, 이중특이항체가 제공된다.
본 발명의 하나 이상의 구현예에서, 이중특이항체는 단일클론항체이다.
본 발명의 하나 이상의 구현예에서, 이중특이항체는 인간화 항체이다.
본 발명의 다른 양태는 본 발명의 어느 구현예에 따른 이중특이항체를 코딩하는 단리된 핵산 분자에 관한 것이다.
본 발명의 또 다른 양태는 본 명세서에 개시된 단리된 핵산 분자를 포함하는 벡터에 관한 것이다.
본 발명의 또 다른 양태는 본 명세서에 개시된 단리된 핵산 또는 벡터를 포함하는 숙주세포에 관한 것이다.
본 발명의 다른 양태는 항체 또는 이의 항원-결합 단편 및 결합된 모이어티 (conjugated moiety)를 포함하고, 면역글로불린은 본 발명의 어느 구현예에 따른 이중특이항체이고, 결합된 모이어티는 검출 가능한 라벨이고; 바람직하게는, 결합된 모이어티는 방사성 동위원소, 형광물질, 발광물질, 착색물질, 또는 효소인 것인, 콘쥬게이트에 관한 것이다.
본 발명의 다른 양태는 본 발명의 어느 구현예에 따른 이중특이항체를 포함하거나 본 발명의 콘쥬게이트를 포함하는 키트로;
바람직하게는, 키트는 면역글로불린 또는 이의 항원 결합 단편을 특이적으로 인식할 수 있는 제2항체를 더 포함하고; 선택적으로, 제2항체는 검출 가능한 라벨, 예를 들어, 방사성 동위원소, 형광물질, 발광물질, 착색물질, 또는 효소를 더 포함하는 키트에 관한 것이다.
본 발명의 또 다른 양태는 시료 내의 PD-1 및/또는 VEGFA의 존재 또는 수준을 검출하기 위한 키트의 제조에서의 본 발명의 어느 구현예에 따른 이중특이항체 또는 콘쥬게이트의 용도에 관한 것이다.
본 발명의 다른 양태는 본 발명의 어느 구현예에 따른 이중특이항체 또는 콘쥬게이트를 포함하고; 선택적으로, 약학적으로 허용 가능한 벡터 및/또는 부형제를 더 포함하는 약학 조성물에 관한 것이다.
본 발명의 이중특이항체 또는 본 발명의 약학 조성물은 정제, 환제, 현탁제, 유제, 용액제, 겔제, 캡슐제, 산제, 과립제, 엘릭서, 트로키제, 좌제, 주사제 (주사액, 주사용 멸균 분말 및 주사용 농축액 포함), 흡입제 및 스프레이 등, 약학 분야에 공지된 임의의 제형으로 제형화될 수 있다. 바람직한 제형은 의도된 투여 방식 및 치료 용도에 따라 다르다. 본 발명의 약학 조성물은 제조 및 보관 조건 하에서 멸균되고 안정해야 한다. 하나의 바람직한 제형은 주사제이다. 이러한 주사제는 멸균된 주사액일 수 있다. 예를 들어, 멸균된 주사액은 다음의 방법으로 제조될 수 있다: 필요한 양의 본 발명의 이중특이항체가 적절한 용매에 첨가되고, 선택적으로, 다른 원하는 성분 (pH 조절제, 계면활성제, 면역증강제 (adjuvant), 이온 강도 향상제, 등장제, 방부제, 희석제, 또는 이들의 조합을 포함하나, 이에 한정되지 않음)이 동시에 첨가되고, 여과 및 멸균을 거친다. 또한, 멸균된 주사액은 편리한 저장 및 사용을 위해 멸균 동결건조 분말로 제조 (예를 들어, 진공 건조 또는 동결 건조를 통해)될 수 있다. 이러한 멸균 동결건조 분말은 사용 전에 적합한 운반체 (예를 들어, 멸균된 무발열원 물)에 분산될 수 있다.
또한, 본 발명의 이중특이항체는 투여의 용이성을 위해 약학 조성물 내에 단위 용량 형태로 존재할 수 있다. 일부 구현예에서, 단위 용량은 적어도 1 mg, 적어도 5 mg, 적어도 10 mg, 적어도 15 mg, 적어도 20 mg, 적어도 25 mg, 적어도 30 mg, 적어도 45 mg, 적어도 50 mg, 적어도 75 mg, 또는 적어도 100 mg일 수 있다. 약학 조성물이 액체 (예를 들어, 주사제) 제형인 경우, 이는 본 발명의 이중특이항체를 적어도 0.1 mg/mL, 예컨대 적어도 0.25 mg/mL, 적어도 0.5 mg/mL, 적어도 1 mg/mL, 적어도 2.5 mg/mL, 적어도 5 mg/mL, 적어도 8 mg/mL, 적어도 10 mg/mL, 적어도 15 mg/mL, 적어도 25 mg/mL, 적어도 50 mg/mL, 적어도 75 mg/mL, 또는 적어도 100 mg/mL의 농도로 포함할 수 있다.
본 발명의 이중특이항체 또는 약학 조성물은 경구투여, 볼점막투여, 설하투여, 안구투여, 국소투여, 비경구투여, 직장투여, 척수강내투여, 수조내투여, 서혜부투여, 방광내투여, 국소투여 (예를 들어, 분말, 연고, 또는 점적제), 또는 비강투여를 포함하지만, 이에 한정되지 않는, 당업계에 공지된 임의의 적절한 방법으로 투여될 수 있다. 그러나, 많은 치료 용도에 있어서, 바람직한 투여 경로/방식은 비경구적 투여 (정맥주사, 피하주사, 복강주사, 및 근육주사 등)이다. 당업자는 투여 경로 및/또는 방식이 의도된 목적에 따라 달라질 것임을 이해할 것이다. 바람직한 구현예에서, 본 발명의 이중특이항체 또는 약학 조성물은 정맥 주입 또는 주사를 통해 투여된다.
본 명세서에서 제공되는 이중특이항체 또는 약학조성물은 단독으로 또는 조합으로 사용될 수 있거나, 추가적인 약학적 활성제 (예를 들어, 종양 화학요법 약물)와 조합하여 사용될 수 있다. 이러한 추가적인 약학적 활성제는 본 발명의 이중특이항체 또는 본 발명의 약학 조성물의 투여 전에, 동시에, 또는 후에 투여될 수 있다.
본 발명에서, 투여 요법은 최적의 원하는 반응 (예를 들어, 치료 또는 예방 반응)을 달성하도록 조정될 수 있다. 예를 들어, 이는 단일 투여일 수 있고, 일정 기간에 걸친 다중 투여일 수 있고, 또는 치료의 응급 정도에 비례하여 투여량을 감소시키거나 증가시키는 것을 특징으로 할 수 있다.
본 발명의 또 다른 양태는 악성 종양의 치료 및/또는 예방을 위한 약의 제조에서의 본 발명의 어느 구현예에 따른 이중특이항체 또는 본 발명에 따른 콘쥬게이트의 용도에 관한 것으로; 바람직하게는, 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 간암은 간세포 암종이고,
바람직하게는, 신장 종양은 신장 세포 암종이고,
바람직하게는, 유방암은 삼중 음성 유방암이고,
바람직하게는, 요로상피암은 방광암이다.
본 발명의 또 다른 양태는 하기의 약물의 제조에서의 본 발명의 어느 구현예에 따른 이중특이항체 또는 본 발명에 따른 약학 조성물의 용도에 관한 것이다:
(1) 시료 내 VEGFA 수준을 검출하기 위한 약물 또는 제제,
VEGFR2에 대한 VEGFA의 결합을 차단하기 위한 약물 또는 제제,
VEGFA의 활성 또는 수준을 하향조절하기 위한 약물 또는 제제,
혈관 내피 세포 증식에 대한 VEGFA의 자극을 완화하기 위한 약물 또는 제제,
혈관 내피 세포 증식을 억제하기 위한 약물 또는 제제, 또는
종양 혈관 신생을 차단하기 위한 약물 또는 제제;
및/또는
(2) PD-L1에 대한 PD-1의 결합을 차단하기 위한 약물 또는 제제,
PD-1의 활성 또는 수준을 하향조절하기 위한 약물 또는 제제,
생물체에서 PD-1의 면역억제를 완화하기 위한 약물 또는 제제,
T 림프구의 IFN-γ분비를 촉진하기 위한 약물 또는 제제, 또는
T 림프구의 IL-2 분비를 촉진하기 위한 약물 또는 제제.
본 발명의 생체 외 (in vitro) 실험에서, 항-VEGFA 항체 및 항-VEGFA-항-PD-1 이중특이항체는 모두 HUVEC 세포 증식을 억제할 수 있고, 항-PD-1- 항체 및 항-VEGFA-항-PD-1 이중특이항체는 모두 IFN-γ 및/또는 IL-2의 분비를 촉진시키고 면역반응을 활성화시킬 수 있다.
본 발명의 또 다른 양태는 악성 종양 치료 및/또는 예방을 위한 방법에 관한 것으로, 본 발명의 어느 구현예에 따른 이중특이항체 또는 본 발명에 따른 콘쥬게이트의 유효량을 이를 필요로 하는 대상에게 투여하는 단계를 포함하고; 바람직하게는, 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 간암은 간세포 암종이고,
바람직하게는, 신장 종양은 신장 세포 암종이고,
바람직하게는, 유방암은 삼중 음성 유방암이고,
바람직하게는, 요로상피암은 방광암이다.
본 발명의 이중특이항체의 치료적 또는 예방적 유효량의 전형적인 비제한적 범위는 0.02-50 mg/kg, 예컨대 0.1-50 mg/kg, 0.1-25 mg/kg, 또는 1-10 mg/kg이다. 투여량은 치료할 증상의 유형 및 중증도에 따라 달라질 수 있음을 유의해야 한다. 또한, 당업자는 임의의 특정 환자에 있어서, 특정한 투여 요법이 환자의 요구 및 의사의 전문적 판단에 따라 시간이 지남에 따라 조정될 것임을 이해할 것이고; 본 명세서에 제시된 투여량은 단지 예시적인 목적을 위한 것이고 본 발명의 약학 조성물의 용도 또는 범위를 제한하지 않는다.
본 발명에서, 대상은 포유류, 예컨대 인간일 수 있다.
본 발명의 또 다른 양태는 하기에서 선택되는 생체 내 (in vivo) 또는 생체 외 방법에 관한 것이다:
(1) 시료 내 VEGFA 수준을 검출하기 위한 방법,
VEGFR2에 대한 VEGFA의 결합을 차단하기 위한 방법,
VEGFA의 활성 또는 수준을 하향조절하기 위한 방법,
혈관 내피 세포 증식에 대한 VEGFA의 자극을 완화하기 위한 방법,
혈관 내피 세포 증식을 억제하기 위한 방법, 또는
종양 혈관 신생을 차단하기 위한 방법;
및/또는
(2) PD-L1에 대한 PD-1의 결합을 차단하기 위한 방법,
PD-1의 활성 또는 수준을 하향조절하기 위한 방법,
생물체에서 PD-1의 면역억제를 완화하기 위한 방법,
T 림프구의 IFN-γ분비를 촉진하기 위한 방법, 또는
T 림프구의 IL-2 분비를 촉진하기 위한 방법.
본 발명의 하나 이상의 구현예에서, 이중특이항체 또는 콘쥬게이트는 악성종양의 치료 및/또는 예방에 사용되고; 바람직하게는, 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 간암은 간세포 암종이고,
바람직하게는, 신장 종양은 신장 세포 암종이고,
바람직하게는, 유방암은 삼중 음성 유방암이고,
바람직하게는, 요로상피암은 방광암이다.
본 발명의 하나 이상의 구현예에서, 이중특이항체 또는 콘쥬게이트는 하기를 위해 사용된다:
(1) 시료 내 VEGFA 수준의 검출,
VEGFR2에 대한 VEGFA의 결합의 차단,
VEGFA의 활성 또는 수준의 하향조절,
혈관 내피 세포 증식에 대한 VEGFA의 자극의 완화,
혈관 내피 세포 증식의 억제, 또는
종양 혈관 신생의 차단;
및/또는
(2) PD-L1에 대한 PD-1의 결합의 차단,
PD-1의 활성 또는 수준의 하향조절,
생물체에서 PD-1의 면역억제의 완화,
T 림프구의 IFN-γ분비의 촉진
T 림프구의 IL-2 분비의 촉진.
항체 약물, 특히 단일클론항체는, 다양한 질병의 치료에서 좋은 효능을 달성하였다. 이러한 치료 항체를 획득하기 위한 전통적인 실험 방법은 동물을 항원으로 면역화하고 면역화된 동물에서 항원을 표적으로 하는 항체를 획득하거나, 친화도 성숙을 통해 항원에 대해 더 낮은 친화도를 갖는 항체를 개선하는 것이다.
경쇄 및 중쇄의 가변부위는 항원의 결합을 결정하고; 각 사슬의 가변부위는 상보성 결정부위 (CDRs)라고 하는 세 개의 초가변부위를 포함한다. 경쇄 (H 사슬)의 CDR은 HCDR1, HCDR2, 및 HCDR3를 포함하고, 경쇄 (L 사슬)의 CDR은 LCDR1, LCDR2, 및 LCDR3를 포함하며, 이는 Kabat 등에 의해 명명되었으며, Bethesda M.d., Sequences of Proteins of Immunological Interest, Fifth Edition, NIH Publication 1991, (1-3): 91-3242를 참고할 수 있다.
바람직하게는, CDR은 또한 IMGT 넘버링 시스템을 통해서도 정의될 수 있으며, Ehrenmann, Francois, Quentin Kaas, and Marie-Paule Lefranc. "IMGT/3Dstructure-DB and IMGT/DomainGapAlign: a database and a tool for immunoglobulins or antibodies, T cell receptors, MHC, IgSF and MhcSF." Nucleic acids research 38.suppl_1 (2009): D301-D307를 참고할 수 있다.
하기 (1) 내지 (3)의 단일클론항체 서열의 CDR 부위의 아미노산 서열은 당업자에게 공지된 기술적 수단, 예를 들어 VBASE2 데이터베이스 및 IMGT 정의에 따라 분석되고, 결과는 하기와 같다:
(1) Bevacizumab
중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 경쇄 가변부위의 아미노산 서열은 서열번호 3으로 제시된다.
중쇄 가변부위의 3개의 CDR 부위의 아미노산 서열은 하기와 같고:
HCDR1: GYTFTNYG (서열번호: 28)
HCDR2: INTYTGEP (서열번호: 29)
HCDR3: AKYPHYYGSSHWYFDV (서열번호: 30)
경쇄 가변부위의 3개의 CDR 부위의 아미노산 서열은 하기와 같다:
LCDR1: QDISNY (서열번호: 31)
LCDR2: FTS (서열번호: 32)
LCDR3: QQYSTVPWT (서열번호: 33)
(2) 14C12, 14C12H1L1 또는 14C12H1L1 (M)
중쇄 가변부위의 3개의 CDR 부위의 아미노산 서열은 하기와 같고:
HCDR1: GFAFSSYD (서열번호: 34)
HCDR2: ISGGGRYT (서열번호: 35)
HCDR3: ANRYGEAWFAY (서열번호: 36)
경쇄 가변부위의 3개의 CDR 부위의 아미노산 서열은 하기와 같다:
LCDR1: QDINTY (서열번호: 37)
LCDR2: RAN (서열번호: 38)
LCDR3: LQYDEFPLT (서열번호: 39)
(3) VP101 (hG1WT) 또는 VP101 (hG1DM)
중쇄 가변부위의 9개의 CDR 부위의 아미노산 서열은 하기와 같고:
HCDR1: GYTFTNYG (서열번호: 28)
HCDR2: INTYTGEP (서열번호: 29)
HCDR3: AKYPHYYGSSHWYFDV (서열번호: 30)
HCDR4: GFAFSSYD (서열번호: 34)
HCDR5: ISGGGRYT (서열번호: 35)
HCDR6: ANRYGEAWFAY (서열번호: 36)
HCDR7: QDINTY (서열번호: 37)
HCDR8: RAN (서열번호: 38)
HCDR9: LQYDEFPLT (서열번호: 39)
경쇄 가변부위의 3개의 CDR 부위의 아미노산 서열은 하기와 같다:
LCDR1: QDISNY (서열번호: 31)
LCDR2: FTS (서열번호: 32)
LCDR3: QQYSTVPWT (서열번호: 33).
본 발명의 항체 VP101 (hG1DM)에 있어서, 아미노산 돌연변이가 VP101 (hG1WT)의 비-가변부위에 도입된다. EU 넘버링 시스템에 따라, 아미노산 돌연변이는 234 및 235 위치에 도입된다:
VP101 (hG1DM)은 중쇄의 경첩 (hinge) 부위의 234 위치에 류신-알라닌 점돌연변이 (L234A) 및 235 위치에 류신-알라닌 점돌연변이 (L235A)를 도입하여 수득된다.
본 발명에서, 달리 정의되지 않는 한, 본 명세서에 사용된 과학적이고 기술적인 용어는 당업자에 의해 일반적으로 이해되는 의미를 갖는다. 또한, 본 명세서에 사용된 세포 배양, 분자 유전학, 핵산 화학 및 면역학의 실험실 작업은 해당 분야에서 널리 사용되는 일상적인 절차이다. 한편, 본 발명을 보다 잘 이해하기 위하여, 관련 용어의 정의 및 설명이 이하 제공된다.
본 명세서에서, VEGFA 단백질 (GenBank ID: NP_001165097.1)의 아미노산 서열을 언급할 때, 이는 VEGFA 단백질의 전체 길이뿐만 아니라, 마우스 또는 인간 IgG (mFc 또는 hFc)의 Fc 단백질 단편에 융합된 단편과 같은, VEGFA의 융합 단백질을 포함한다. 그러나, 당업자는 VEGFA 단백질의 아미노산 서열에서, 돌연변이 또는 변이 (치환, 결실 및/또는 첨가를 포함하나, 이에 한정되지 않음)가 이의 생물학적 기능에 대한 영향 없이 자연적으로 생성되거나 인공적으로 도입될 수 있음을 이해할 것이다. 따라서, 본 발명에서, 용어 "VEGFA 단백질"은 이의 천연 또는 인공 변이체를 포함하는, 이러한 모든 서열을 포함해야 한다. 또한, VEGFA 단백질의 서열 단편을 기술할 때, 이의 천연 또는 인공 변이체에 상응하는 서열 단편도 포함한다. 본 발명의 일 구현예에서, VEGFA 단백질의 아미노산 서열은 서열번호 33의 밑줄 친 부분 (마지막 6개의 His 없이, 총 302개의 아미노산)으로 표시된다.
본 명세서에서, VEGFR2 단백질 (KDR로도 알려져 있으며, GenBank ID: NP_002244)의 아미노산 서열을 언급할 때, 이는 VEGFR2 단백질의 전체 길이, 또는 VEGFR2의 세포 외 단편 VEGFR2-ECD, 또는 VEGFR2-ECD를 포함하는 단편을 포함하고, 마우스 또는 인간 IgG (mFc 또는 hFc)의 Fc 단백질 단편에 융합된 단편과 같은, VEGFR2-ECD의 융합 단백질도 포함한다. 그러나, 당업자는 VEGFR2 단백질의 아미노산 서열에서, 돌연변이 또는 변이 (치환, 결실 및/또는 첨가를 포함하나, 이에 한정되지 않음)가 이의 생물학적 기능에 대한 영향 없이 자연적으로 생성되거나 인공적으로 도입될 수 있음을 이해할 것이다. 따라서, 본 발명에서, 용어 "VEGFR2 단백질"은 이의 천연 또는 인공 변이체를 포함하는, 이러한 모든 서열을 포함해야 한다. 또한, VEGFR2 단백질의 서열 단편을 기술할 때, 이의 천연 또는 인공 변이체에 상응하는 서열 단편도 포함한다. 본 발명의 일 구현예에서, VEGFR2의 세포 외 단편 VEGFR2-ECD의 아미노산 서열은 서열번호 34 (766개의 아미노산)로 제시된다.
본 명세서에서, 달리 명시되지 않는 한, VEGFR은 VEGFR1 및/또는 VEGFR2이고; 이의 특정 단백질 서열은 당업계에 공지된 서열이고, 기존 문헌 또는 GenBank에 개시된 서열을 참고할 수 있다. 예를 들어, VEGFR1 (VEGFR1, NCBI 유전자 ID: 2321); VEGFR2 (VEGFR2, NCBI 유전자 ID: 3791).
본 명세서에서, PD-1 단백질 (programmed cell death protein 1, NCBI GenBank: NM_005018)의 아미노산 서열을 언급할 때, 이는 PD-1 단백질의 전체길이, 또는 PD-1의 세포 외 단편 PD-1ECD 또는 PD-1ECD를 포함하는 단편을 포함하고, 이는 마우스 또는 인간 IgG (mFc 또는 hFc)의 Fc 단백질 단편에 융합된 단편과 같은, PD-1ECD의 융합 단백질을 추가로 포함한다. 그러나, 당업자는 PD-1 단백질의 아미노산 서열에서, 돌연변이 또는 변이 (치환, 결실 및/또는 첨가를 포함하나, 이에 한정되지 않음)가 이의 생물학적 기능에 대한 영향 없이 자연적으로 생성되거나 인공적으로 도입될 수 있음을 이해할 것이다. 따라서, 본 발명에서, 용어 "PD-1 단백질"은 이의 천연 또는 인공 변이체를 포함하는, 이러한 모든 서열을 포함해야 한다. 또한, PD-1 단백질의 서열 단편을 기술할 때, 이의 천연 또는 인공 변이체에 상응하는 서열 단편도 포함한다.
본 명세서에서, 용어 EC50은 최대 효과의 50%의 농도, 즉 최대 효과의 50%를 유발할 수 있는 농도를 의미한다.
본 명세서에서, 용어"항체"는 일반적으로 두 쌍의 폴리펩타이드 사슬 (각 쌍이 하나의 "가벼운" (L) 사슬 및 하나의 "무거운" (H) 사슬을 지님)로 구성되는 면역글로불린 분자를 의미한다. 일반적인 의미에서, 중쇄는 항체에서 더 큰 분자량을 지닌 폴리펩타이드 사슬로 해석될 수 있고, 경쇄는 항체에서 더 작은 분자량을 지닌 폴리펩타이드 사슬을 의미한다. 경쇄는 к 및 γ 경쇄로 분류된다. 중쇄는 일반적으로 μ, δ, γ, α, 또는 ε으로 구분되고, 항체의 아이소타입 (isotype)은 각각 IgM, IgD, IgG, IgA, 및 IgE로 정의된다. 경쇄 및 중쇄에서, 가변부위와 불변부위는 약 12개 이상의 아미노산의 "J" 부위로 연결되고, 중쇄는 약 3개 이상의 아미노산의 "D" 부위도 포함한다. 각 중쇄는 중쇄 가변부위 (VH) 및 중쇄 불변부위 (CH)로 구성된다. 중쇄 불변부위는 3개의 도메인 (CH1, CH2, 및 CH3)으로 구성된다. 각 경쇄는 경쇄 가변부위 (VL) 및 경쇄 불변부위 (CL)로 구성된다. 경쇄 불변부위는 하나의 도메인 CL로 구성된다. 항체의 불변부위는 고전적 보체 시스템의 첫 번째 구성요소 (C1q)에 대한 면역계의 다양한 세포 (예를 들어, 이펙터 세포)의 결합을 포함하여, 숙주 조직 또는 인자에 대한 면역글로불린의 결합을 매개할 수 있다. VH 및 VL 부위는 고도 가변부위 (상보성 결정부위 (complementarity determining region; CDR)라고 함)로 더 세분화될 수 있으며, 그 사이에 프레임워크 부위 (framework region; FR)라고 하는 보존 부위가 분포되어 있다. 각 VH 및 VL은 다음의 순서로 아미노 말단에서 카르복실 말단으로 배열되는 3개의 CDR 및 4개의 FR로 구성된다: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. 각 중쇄/경쇄 쌍의 가변부위 (VH 및 VL)는 항체결합부위를 형성한다. 부위 또는 도메인에 대한 아미노산 할당은 Kabat Sequences of Proteins of Immunological Interest (National Institutes of Health, Bethesda, Md. (1987 and 1991)), 또는 Chothia & Lesk J. Mol. Biol. 196(1987): 901-917; Chothia et al. Nature 342(1989): 878-883 또는 Ehrenmann, Francois, Quentin Kaas, and Marie-Paule Lefranc. "IMGT/3Dstructure-DB and IMGT/DomainGapAlign: a database and a tool for immunoglobulins or antibodies, T cell receptors, MHC, IgSF and MhcSF." Nucleic acids research 38.suppl_1 (2009): D301-D307를 참고할 수 있는, IMGT 넘버링 시스템의 정의에 기반할 수 있다. 특히, 중쇄는 또한 6개, 9개 또는 12개와 같은, 3개 초과의 CDR을 포함할 수 있다. 예를 들어, 본 발명의 이중특이항체에서, 중쇄는 IgG 항체의 중쇄의 C-말단이 다른 항체와 연결된 ScFv인 것일 수 있고, 이 경우, 중쇄는 9개의 CDR을 포함한다. 용어 "항체"는 항체를 생산하는 임의의 특정한 방법에 의해 한정되지 않는다. 예를 들어, 항체는, 특히, 재조합항체, 단일클론항체, 및 다중클론항체를 포함한다. 항체는 IgG (예를 들어, IgG1, IgG2, IgG3 또는 IgG4 아형), IgA1, IgA2, IgD, IgE 또는 IgM과 같은, 다른 아이소타입의 항체가 될 수 있다.
본 명세서에서, "항원 결합 부분"으로도 알려진, 용어 "항원 결합 단편"은 전장 항체가 결합하는 동일한 항원에 특이적으로 결합하는 능력을 유지하고/유지하거나, 항원에 대한 특이적 결합에 대해 전장 항체와 경쟁하는, 전장 항체의 단편을 포함하는 폴리펩타이드를 의미한다. 일반적으로, Fundamental Immunology, Ch. 7 (Paul, W., ed., 2nd edition, Raven Press, N.Y. (1989))를 참고할 수 있다. 항체의 항원 결합 단편은 재조합 DNA 기술 또는 온전한 항체의 효소적 또는 화학적 절단을 통해 생성될 수 있다. 일부 경우에, 항원 결합 단편은 Fab, Fab', F(ab')2, Fd, Fv, dAb 및 상보성 결정부위 (CDR) 단편, 단일사슬항체 단편 (예를 들어, scFv), 키메라 항체, 디아바디 (diabody) 및 폴리펩타이드에 특이적 항원 결합 능력을 부여하기에 충분한 항체의 적어도 일부를 포함하는 폴리펩타이드를 포함한다.
본 명세서에서, 용어 "Fd 단편"은 VH 및 CH1 도메인으로 구성된 항체 단편을 의미하고; "Fv 단편"은 항체의 단일 팔 (single arm)의 VL 및 VH 도메인으로 구성된 항체 단편을 의미하고; 용어 "dAb 단편"는 VH 도메인 (Ward et al., Nature 341 (1989): 544-546)으로 구성된 항체 단편을 의미하고; 용어 "Fab 단편"은 VL, VH, CL 및 CH1 도메인으로 구성된 항체 단편을 의미하고; 용어 "F(ab')2 단편"은 경첩 부위에서부터 이황화 결합으로 연결된 두 Fab 단편을 포함하는 항체 단편을 의미한다.
일부 경우에, 항체의 항원 결합 단편은 VL 및 VH 도메인이 이들이 단일 폴리펩타이드 사슬을 생성할 수 있도록 하는 링커를 통해 짝을 이루어 1가의 (monovalent) 분자를 형성하는 (예를 들어, Bird et al., Science 242 (1988): 423-426 및 Huston et al., Proc. Natl. Acad. Sci. USA 85 (1988): 5879-5883 참고) 단일사슬항체 (예를 들어, scFv)이다. 이러한 scFv 분자는 일반적인 구조를 가지는 것일 수 있다: NH2-VL-링커-VH-COOH 또는 NH2-VH-링커-VL-COOH. 선행기술에서 적절한 링커는 반복되는 GGGGS 아미노산 서열 또는 이의 변이체로 구성된다. 예를 들어, (GGGGS)4의 아미노산 서열을 갖는 링커가 사용될 수 있고, 이의 변이체 역시 사용될 수 있다 (Holliger et al., Proc. Natl. Acad. Sci. USA 90 (1993): 6444-6448). 본 발명에 유용한 다른 링커는 Alfthan et al., Protein Eng. 8 (1995): 725-731, Choi et al., Eur. J. Immunol., 31 (2001): 94-106, Hu et al., Cancer Res. 56 (1996): 3055-3061, Kipriyanov et al., J. Mol. Biol., 293 (1999): 41-56, 및 Roovers et al., Cancer Immunol. (2001)을 통해 기술된다.
일부 경우에, 항체의 항원 결합 단편은 이량항체 (diabody) 이고, 즉, VH 및 VL 도메인이 단일 폴리펩타이드 사슬에 발현된, 2가의 (divalent) 항체이다. 그러나, 사용된 링커가 너무 짧아서 동일 사슬에서 두 도메인이 짝을 이룰 수 없으므로, 도메인은 다른 사슬의 상보적 도메인과 짝을 이루도록 되고 두 개의 항원 결합 부위가 생성된다 (예를 들어, Holliger P. et al., Proc. Natl. Acad. Sci. USA 90 (1993): 6444 6448, 및 Poljak R. J. et al., Structure 2 (1994): 1121-1123 참고).
항체의 항원 결합 단편 (예를 들어, 상기 언급된 항체 단편)은 당업자에게 공지된 종래의 기술 (예를 들어, 재조합 DNA 기술, 또는 효소적 또는 화학적 절단)을 통해 주어진 항체로부터 수득될 수 있고, 항체의 항원 결합 단편은 온전한 항체와 동일한 방식으로 특이성에 대해 스크리닝된다.
본 명세서에서, 문맥상 달리 명확히 정의되지 않는 한, 용어 "항체"를 언급할 때, 이는 온전한 항체뿐 아니라 항체의 항원 결합 단편도 포함한다.
본 명세서에서, 용어 "mAb" 및 "단일클론항체"는 매우 상동적인 항체의 집단으로부터, 즉, 자연적으로 발생할 수 있는 자연 돌연변이를 제외한, 동일한 항체 분자의 집단으로부터 유래된 항체 또는 이의 단편을 의미한다. 단일클론항체는 항원의 단일 항원결정기에 대해 매우 특이적이다. 다중클론항체는, 단일클론항체에 비해, 일반적으로 항원의 상이한 항원결정기를 일반적으로 인식하는 적어도 두 개 이상의 상이한 항체를 포함한다. 단일클론항체는 일반적으로 Kohler 등 (Nature, 256: 495, 1975)에 의해 최초로 보고된 하이브리도마 (hybridoma) 기술을 통해 수득될 수 있고, 재조합 DNA 기술 (예를 들어, 미국 특허번호 4,816,567 참고)로도 수득될 수 있다.
본 명세서에서, "키메라 항체"는 경쇄 및/또는 중쇄의 일부가 하나의 항체 (특정 종에서 유래하거나 특정한 항체 클래스 또는 하위 클래스에 속할 수 있음)로부터 유래하고, 경쇄 및/또는 중쇄의 다른 일부가 다른 항체 (특정 종에서 유래하거나 특정한 항체 클래스 또는 하위 클래스에 속할 수 있음)로부터 유래한 항체를 의미한다. 하지만 어떤 경우에도, 이는 표적 항원에 대한 결합 활성을 유지한다 (미국 특허번호 4,816,567, Cabilly et al.; Morrison et al., Proc. Natl. Acad. Sci. USA, 81 (1984): 6851-6855).
본 명세서에서, 용어 "인간화 항체"는 인간 면역글로불린 (수용체 항체)의 CDR 부위의 전부 또는 일부가 비인간 항체 (공여자 항체)의 CDR 부위로 대체될 때 수득되는 항체 또는 항체 단편을 의미하며, 이때 공여자 항체는 예상된 특이성, 친화도 또는 반응성을 가지는 비인간 (예를 들어, 마우스, 쥐 또는 토끼) 항체일 수 있다. 또한, 수용체 항체의 프레임워크 부위 (FR)의 일부 아미노산 잔기는 상응하는 비인간 항체의 아미노산 잔기 또는 다른 항체의 아미노산 잔기로 대체되어 항체의 성능을 추가로 개선하거나 최적화할 수도 있다. 인간화 항체에 대한 구체적인 내용은, 예를 들어, Jones et al., Nature, 1986, 321: 522-525; Reichmann et al., Nature, 1988, 332: 323 329; Presta, Curr. Op. Struct. Biol., 1992, 2: 593-596, 및 Clark, Immunol. Today 2000, 21: 397-402를 참고할 수 있다.
본 명세서에서, 용어 "항원결정기 (epitope)"는 면역글로불린 또는 항체가 특이적으로 결합하는 항원의 부위를 의미한다. "항원결정기"는 기술 분야에서 "항원결정자 (antigen determinant)"라고도 한다. 항원결정기 또는 항원결정자는 일반적으로 아미노산, 탄수화물 또는 당 측쇄와 같은 분자의 화학적 활성 표면 그룹으로 구성되고, 일반적으로 특정한 3차원 구조적 특성 및 특정한 전하 특성을 가진다. 예를 들어, 항원결정기는 적어도 특별한 공간적 구성의 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 또는 15개의 연속적 또는 비연속적 아미노산을 포함하며, 이는 "선형적 (linear)"이거나 "입체구조적 (conformational)"일 수 있다. 예를 들어, Epitope Mapping Protocols in Methods in Molecular Biology, Vol. 66, G. E. Morris, Ed. (1996)를 참고할 수 있다. 선형 항원결정기에서, 단백질 및 상호작용 분자 (예를 들어, 항체) 간의 모든 상호작용 부위는 단백질의 1차 아미노산 서열을 따라 선형적으로 위치한다. 입체구조 항원결정기에서, 상호작용 부위는 단백질의 서로 분리된 아미노산 잔기에 걸쳐 위치한다.
본 명세서에서, 용어 "단리된"은 자연상태에서 인공적인 방법을 통해 수득하는 것을 의미한다. 특정 "단리된" 물질 또는 구성요소가 자연에 나타나는 경우, 이는 자연환경에 변화가 발생하거나, 또는 자연환경으로부터 단리되거나, 또는 이들 모두인 경우일 수 있다. 예를 들어, 특정 비단리 폴리뉴클레오타이드 또는 폴리펩타이드는 특정한 살아있는 동물에서 발생하며, 이러한 자연상태에서 단리된 고순도의 동일한 폴리뉴클레오타이드 또는 폴리펩타이드는 단리된 폴리뉴클레오타이드 도는 폴리펩타이드로 지칭된다. 용어 "단리된"은 물질의 활성에 영향을 미치지 않는 인공 또는 합성 물질 또는 기타 불순물의 존재를 배제하지 않는다.
본 명세서에서, 용어 "벡터"는 폴리뉴클레오타이드가 삽입될 수 있는 핵산 운반체를 의미한다. 벡터가 삽입된 폴리뉴클레오타이드에 의해 코딩된 단백질의 발현을 허용하는 경우, 벡터는 발현 벡터로 지칭된다. 벡터는 벡터에 의해 운반되는 유전 물질 요소는 숙주세포에서 발현될 수 있도록 형질전환 (transformation), 형질도입 (transduction), 또는 형질주입(transfection)을 통해 숙주세포에 도입될 수 있다. 벡터는 당업자에게 공지되어 있으며, 다음을 포함하지만, 이에 한정되지 않는다: 플라스미드; 파지미드; 코스미드; 효모 인공 염색체(YAC), 박테리아 인공 염색체(BAC) 또는 P1 유래 인공 염색체(PAC)와 같은, 인공 염색체; 람다 파지 또는 M13 파지와 같은 파지; 및 동물 바이러스. 벡터로 이용될 수 있는 동물 바이러스는 레트로바이러스 (렌티바이러스 포함), 아데노바이러스, 아데노-관련 바이러스, 헤르페스 바이러스 (단순 포진 바이러스 등), 폭스바이러스, 배큘로바이러스, 유두종 바이러스 및 파포바바이러스 (SV40 등)를 포함하지만, 이에 한정되지 않는다. 벡터는 프로모터 서열, 전사 개시 서열, 인핸서 서열, 선별 요소, 및 리포터 유전자를 포함하지만 이에 한정되지 않는, 발현을 조절하는 다양한 요소를 포함할 수 있다. 또한, 벡터는 복제 개시 부위를 추가로 포함할 수 있다.
본 명세서에서, 용어 "숙주세포"는 대장균 또는 고초균과 같은 원핵세포, 효모세포 또는 아스페르길루스 (aspergillus)와 같은 진균세포, S2 초파리세포 또는 Sf9와 같은 곤충세포, 또는 섬유아세포, CHO 세포, COS 세포, NSO 세포, HeLa 세포, BHK 세포, HEK 293 세포, 또는 인간 세포와 같은 동물세포를 포함하지만, 이에 한정되지 않는, 벡터가 도입될 수 있는 세포를 의미한다.
본 발명에서, 용어 "특이적으로 결합"은 항체와 이것이 표적으로 하는 항원 간의 반응과 같이, 두 분자 간의 비임의적 결합 반응을 의미한다. 일부 구현예에서, 항원에 특이적으로 결합하는 항체 (또는 항원에 특이적인 항체)는 항원에 대해 약 10-6 M, 10-7 M, 10-8 M, 10-9 M 또는 10-10 M 미만과 같은, 약 10-5 M 미만의 친화도 (KD)로 결합하는 것을 의미한다. 본 발명의 일부 구현예에서, 용어 "표적"은 특이적 결합을 의미한다.
본 명세서에서, 용어 "KD"는 특정 항체-항원 상호작용의 해리 평형 상수를 의미하며, 이는 항체 및 항원 간의 결합 친화도를 설명하기 위해 사용된다. 더 작은 평형 해리 상수는 강한 항체-항원 결합 및 항체 및 항원 간의 높은 친화도를 나타낸다. 일반적으로, 항체는 항원에 대해, 예를 들어 BIACORE 표면 플라스몬 공명 (surface plasmon resonance; SPR) 기기 또는 포르테비오 시스템으로 측정되는, 약 10-6 M, 10-7 M, 10-8 M, 10-9 M 또는 10-10 M 미만과 같은, 약 10-5 M 미만의 해리 평형 상수 (KD)로 결합한다.
본 명세서에서, 용어 "단일클론항체" 및 "mAb"는 동일한 의미를 가지며 상호교환적으로 사용될 수 있고; 용어 "다중클론항체" 및 "pAb"는 동일한 의미를 가지며 상호교환적으로 사용될 수 있고; 용어 "폴리펩타이드"와 "단백질"은 동일한 의미를 가지며 상호교환적으로 사용될 수 있다. 또한, 본 명세서에서, 아미노산은 일반적으로 당업계에 공지된 1자 및 3자 약어로 표시된다. 예를 들어, 알라닌은 A 또는 Ala로 나타낼 수 있다.
본 명세서에서, 용어 "약학적으로 허용가능한 보조제"는 약리학적 및/또는 생리학적으로 대상과 양립 가능한 벡터 및/또는 부형제 및 당업계에 공지된 (예를 들어, Remington's Pharmaceutical Sciences. Edited by Gennaro AR, 19th ed. Pennsylvania: Mack Publishing Company, 1995 참고), 활성 성분을 의미하고 pH 조절제, 계면활성제, 면역증강제, 및 이온 강도 향상제를 포함하지만, 이에 한정되지 않는다. 예를 들어, pH 조절제는 인산 버퍼를 포함하지만, 이에 한정되지 않고; 계면활성제는 양이온, 음이온, 또는 Tween-80과 같은, 비이온 계면활성제를 포함하지만, 이에 한정되지 않고; 이온 강도 향상제는 염화나트륨을 포함하지만, 이에 한정되지 않는다.
본 명세서에서, 용어 "면역증강제 (adjuvant)"는 비특이적 면역 강화제를 의미하며, 이는 생물체에 항원과 함께 또는 항원에 앞서 전달되는 경우 항원에 대한 생물체의 면역반응을 강화하거나 면역반응의 유형을 바꿀 수 있다. 알루미늄 면역증강제 (예를 들어, 수산화알루미늄), 프로인트 면역증강제 (Freund's adjuvant) (예를 들어, 완전 프로인트 면역증강제 및 불완전 프로인트 면역증강제), Corynebacterium parvum, 지질다당류 (lipopolysaccharide), 사이토카인 등을 포함하지만 이에 한정되지 않는, 다양한 면역증강제가 있다. 프로인트 면역증강제는 동물 실험에서 가장 일반적으로 사용되는 면역증강제이다. 수산화알루미늄 면역증강제는 임상 시험에서 더 자주 사용된다.
본 명세서에서, 용어 "유효량"은 원하는 효과를 얻거나 또는 적어도 부분적으로 얻기에 충분한 양을 의미한다. 예를 들어, 예방적 유효량 (예를 들어, 종양과 같은, PD-L1에 대한 PD-1의 결합 또는 VEGF 과발현과 연관된 질병에 대해)은 질병 (예를 들어, 종양과 같은, PD-L1에 대한 PD-1의 결합 또는 VEGF 과발현과 연관된 질병)의 발병을 예방, 중지, 또는 지연시키기에 충분한 양이고; 치료적 유효량은 질병을 앓는 환자에서 질병 및 그의 합병증을 치료하거나 적어도 부분적으로 중단시키기에 충분한 양이다. 이러한 유효량의 결정은 의심할 여지없이 당업자의 능력범위 내에 있다. 예를 들어, 치료 목적의 유효량은 치료할 질병의 중증도, 환자 자신의 면역 체계의 전반적인 상태, 연령, 체중 및 성별 와 같은 환자의 일반적인 상태, 투여 경로, 및 동시에 제공되는 기타 치료법 등에 따라 다를 것이다.
용어 "MSI"는 미세부수체 불안정성 (microsatellites instability)을 의미한다. 미세부수체는 하나 또는 둘 이상의 뉴클레오타이드의 10-50회 반복을 포함하는, 인간 유전체에 걸친 짧은연쇄반복 (short tandem repeat)이다. 종양과 같은, 특정 비정상 세포의 미세부수체는 정상 세포와 비교하여 반복 단위의 삽입 또는 결실에 의해 길이가 변경된다. 이러한 변경은 MSI로 지칭된다. 불안정성 및 정도를 기반으로, MSI는 고-미세부수체 불안정성 (MSI-H), 저-미세부수체 불안정성 (MSI-L) 및 미세부수체 안정 (MSS)으로 분류될 수 있다. MSI의 주된 요인은 DNA 미스매치 수선 (mismatch repair; MMR) 결함이다. 인간 미스매치 수선 유전자 (MMR 유전자)는 전사 및 번역을 통해 상응하는 미스매치 수선 단백질을 발현할 수 있다. 임의의 MMR 단백질의 부재는 미스매치 수선 결함으로 이어질 수 있고, 염기쌍 미스매치가 이러한 결함으로 인해 DNA 복제 과정에서 누적되어, 결과적으로 MSI를 초래한다. 대장암의 약 15%가 MSI 경로에 기인한다. 이것은 대장암에서 최초로 보고되었고, 위암, 자궁내막암, 부신피질 암종 등에서도 발생할 수 있다 (Baretti M et al., Pharmacol Ther., 2018; 189: 45-62). 후속 연구에서 MSI-H/dMMR 특징은 중피종, 육종, 부신피질 암종, 악성 흑색종 및 난소배아세포종양에서도 발견되었다.
MSI-H 및 dMMR은 두 가지 상이한 분석의 결과를 나타내고, MSI-H/dMMR 또는 MSI-high/dMMR로 불리어, 생물학적으로 일관된 반면, MSI-L/MMS는 능숙한 미스매치 수선 (proficient mismatch repair; pMMR)의 표현형이다. dMMR의 검출은 종양 표본 (수술적출표본 및 흡인표본 포함)을 기반으로 MSH2, MLH1, MSH6 및 PMS2의 네 가지 미스매치 유전자에 대한 단백질 발현의 면역조직화학적 분석을 수행하는 것이다. 네 가지 단백질 중 어느 하나의 부재는 dMMR을 확인하고; 네 가지 단백질 모두의 양성 결과는 pMMR, 즉, 완전한 미스매치 수선 기능을 나타낸다. MSI의 검출은 종양세포 및 체세포의 반복 DNA 서열 (미세부수체 서열)의 길이를 맞추고, 길이를 비교하는 것이다. 미국 NCI 표준을 기반으로 PCR을 통해 5개 표준 유전자좌 (locus)를 검출할 때, 2개 이상의 유전자좌의 불일치는, MSI-H로 정의되는, 불안정성을 나타내고, 1개의 불일치 유전자좌는 MSI-L을 나타내고, 5개의 일치 유전자좌는 MSS를 나타낸다. 고-처리량 염기분석 (차세대 염기분석, 또는 NGS라고도 지칭함) 역시 미세부수체 불안정성의 검출을 위한 방법으로 사용될 수 있다. 5개 초과의 유전자좌 또는 추가적인 미세부수체 유전자좌와 같이, PCR 분석을 위한 더 많은 미세부수체 유전자좌가 선택될 때, 30% 이상의 유전자좌의 불일치는 MSI-H로 정의되고, 모든 유전자좌의 일치는 MSS로 정의되고, 0 내지 30% 사이의 불일치는 MSI-L로 정의된다.
본 발명은 하기의 기술적 효과 (1) 내지 (4)의 하나 이상을 달성한다:
(1) 본 발명의 항체의 Fc 단편의 변형이 VP101(hG1WT) 및 Fc 수용체 FcγRI 및 FcγRIIIa_F158의 결합 능력을 완전히 제거함으로써, ADCC 활성을 완전히 제거한다.
(2) 본 발명의 항체의 Fc 단편의 변형이 VP101(hG1WT) 및 보체 C1q의 결합 능력을 완전히 제거함으로써, CDC 활성을 완전히 제거한다.
(3) 본 발명의 이중특이항체는 VEGFA에 특이적으로 잘 결합할 수 있고, VEGFR2에 대한 VEGFA의 결합을 효과적으로 차단할 수 있고, 생물체에서 VEGFA의 면역억제 및 혈관 신생에 대한 VEGFA의 촉진 효과를 특이적으로 완화할 수 있다.
(4) 본 발명의 이중특이항체는 PD-1에 특이적으로 잘 결합할 수 있고, PD-L1에 대한 PD-1의 결합을 효과적으로 차단할 수 있고, 생물체에서 PD-1의 면억억제를 완화하고 면역반응을 활성화시킬 수 있다.
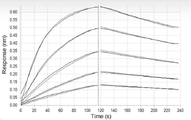
도 1은 VP101(hG1DM)의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 2는 bevacizumab의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 3은 nivolumab의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 4는 VP101(hG1WT)의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 5는 VP101(hG4WT)의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
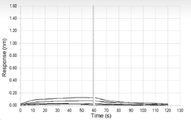
도 6은 VP101(hG1DM)의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 7은 bevacizumab의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 8은 nivolumab의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 9는 VP101(hG1WT)의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 10은 VP101(hG4WT)의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 11은 VP101(hG1DM)의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 12는 bevacizumab의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 13은 nivolumab의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 14는 VP101(hG1WT)의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 15는 VP101(hG4WT)의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 16은 VP101(hG1DM)의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 17은 bevacizumab의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 18은 nivolumab의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 19는 VP101(hG1WT)의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 20은 VP101(hG4WT)의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 21은 VP101(hG1DM)의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 22는 bevacizumab의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 23은 nivolumab의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 24는 VP101(hG1WT)의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 25는 VP101(hG4WT)의 FcγRIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 26은 VP101(hG1DM)의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 27은 bevacizumab의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 28은 nivolumab의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 29은 VP101(hG1WT)의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 30은 VP101(hG4WT)의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 31은 PD-1 항원을 발현하는 CHO-K1-PD1 표적세포 시스템에서 VP101(hG1WT) 및 VP101(hG1DM)의 ADCC 활성 어세이 결과를 나타낸 것이다.
도 32는 PD-1 항원을 발현하는 CHO-K1-PD1 표적세포 시스템에서 VP101(hG1WT) 및 VP101(hG1DM)의 CDC 활성 어세이 결과를 나타낸 것이다.
도 33은 PBMC 및 Raji-PDL1 세포 혼합 배양을 통해 유도되는 사이토카인 IFN-γ의 분비에 대한 항체 VP101(hG1DM)의 효과를 ELISA 방법으로 검출한 결과를 나타낸 것이다.
도 34는 PBMC 및 Raji-PDL1 세포 혼합 배양을 통해 유도되는 사이토카인 IL-2의 분비에 대한 항체 VP101(hG1DM)의 효과를 ELISA 방법으로 검출한 결과를 나타낸 것이다.
도 35는 PD-1 항원을 발현하는 CHO-K1-PD1 표적세포 시스템에서 VP101(hG1DM)의 ADCP 활성 어세이 결과를 나타낸 것이다.
도 2는 bevacizumab의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 3은 nivolumab의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 4는 VP101(hG1WT)의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 5는 VP101(hG4WT)의 FcγRI에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 50 nM, 25 nM, 12.5 nM, 6.25 nM, 3.12 nM이다.
도 6은 VP101(hG1DM)의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 7은 bevacizumab의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 8은 nivolumab의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
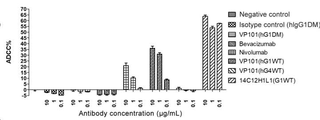
도 9는 VP101(hG1WT)의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 10은 VP101(hG4WT)의 FcγRIIa_H131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 11은 VP101(hG1DM)의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 12는 bevacizumab의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 13은 nivolumab의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 14는 VP101(hG1WT)의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 15는 VP101(hG4WT)의 FcγRIIa_R131에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 200 nM, 100 nM, 50 nM, 25 nM, 12.5 nM이다.
도 16은 VP101(hG1DM)의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 17은 bevacizumab의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 18은 nivolumab의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 19는 VP101(hG1WT)의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 20은 VP101(hG4WT)의 FcγRIIIa_V158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 21은 VP101(hG1DM)의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 22는 bevacizumab의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 23은 nivolumab의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 24는 VP101(hG1WT)의 FcγRIIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 25는 VP101(hG4WT)의 FcγRIIa_F158에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 500 nM, 250 nM, 125 nM, 62.5 nM, 31.25 nM이다.
도 26은 VP101(hG1DM)의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 27은 bevacizumab의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 28은 nivolumab의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 29은 VP101(hG1WT)의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 30은 VP101(hG4WT)의 C1q에 대한 친화도 상수 어세이 결과를 나타낸 것이다. 곡선 쌍의 항체 농도는 위에서부터 아래로 각각 10 nM, 5 nM, 2.5 nM, 1.25 nM, 0.625 nM이다.
도 31은 PD-1 항원을 발현하는 CHO-K1-PD1 표적세포 시스템에서 VP101(hG1WT) 및 VP101(hG1DM)의 ADCC 활성 어세이 결과를 나타낸 것이다.
도 32는 PD-1 항원을 발현하는 CHO-K1-PD1 표적세포 시스템에서 VP101(hG1WT) 및 VP101(hG1DM)의 CDC 활성 어세이 결과를 나타낸 것이다.
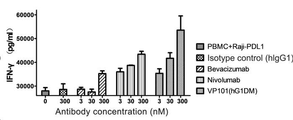
도 33은 PBMC 및 Raji-PDL1 세포 혼합 배양을 통해 유도되는 사이토카인 IFN-γ의 분비에 대한 항체 VP101(hG1DM)의 효과를 ELISA 방법으로 검출한 결과를 나타낸 것이다.
도 34는 PBMC 및 Raji-PDL1 세포 혼합 배양을 통해 유도되는 사이토카인 IL-2의 분비에 대한 항체 VP101(hG1DM)의 효과를 ELISA 방법으로 검출한 결과를 나타낸 것이다.
도 35는 PD-1 항원을 발현하는 CHO-K1-PD1 표적세포 시스템에서 VP101(hG1DM)의 ADCP 활성 어세이 결과를 나타낸 것이다.
이하 본 발명의 구현예를 예시를 참조하여 상세하게 설명한다. 당업자는 하기 예시가 본 발명을 예시하기 위한 것일 뿐이고, 본 발명의 범위에 대한 제한으로 해석되어서는 안 된다는 것을 이해할 것이다. 기술 또는 조건에 대한 구체적인 설명이 없는 경우는 해당 기술분야의 문헌에 기재된 기술이나 조건에 따르거나 (예를 들어, Guide to Molecular Cloning Experiments, J. Sambrook 등 저, Huang Peitang 등 역, third edition, Science Press를 참고) 제품 설명서에 따라 수행되었다. 사용된 시약 또는 기기는 이의 제조사가 특정되지 않았다면 모두 상업적으로 이용가능한 종래 제품이다.
본 발명의 하기 실시예에서, 동일 표적에 대한 시판 항체 bevacizumab (상품명 Avastin®) 은 대조군 항체로서 Roche에서 구입하거나, 제조예 1에 따라 제조하였다.
본 발명의 하기 실시예에서, 동일 표적에 대한 시판 항체 nivolumab (상품명 Opdivo®)은 대조군 항체로서 BMS에서 구입하였다.
본 발명의 하기 실시예에서, 사용된 아이소타입 대조군 항체는 가변부위 서열이 Acierno 등에 의해 발표된, "Affinity maturation increases the stability and plasticity of the Fv domain of anti-protein antibodies"라는 연구 (Acierno et al., J Mol Biol., 2007; 374(1): 130-46)에서 유래된 인간 항-계란 라이소자임 (anti-hen egg lysozyme) IgG (항-HEL, 또는 human IgG, 약칭 hIgG)이다. 예시에서 사용된 hIgG1DM 및 hIgG4WT는 hG1DM 및 hG4WT 불변부위 서열을 가진 항-HEL의 아이소타입 대조군 항체이다. 아이소타입 대조군 항체는 Akeso Biopharma, Inc.의 실험실에서 제조되었다.
제조예 1: 항-VEGFA 항체 Bevacizumab의 제조
중국 공개특허 CN1259962A가 시판되는 항-VEGFA 단일클론항체 Avastin (bevacizumab)의 중쇄 가변부위 및 경쇄 가변부위의 아미노산 서열에 대해 참조된다. Genscript가 중쇄 가변부위 및 경쇄 가변부위를 코딩하는 뉴클레오타이드 서열을 합성하도록 위임되었다.
bevacizumab의 중쇄 가변부위 (bevacizumab-Hv)의 아미노산 서열: (123 aa)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEWVGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVYYCAKYPHYYGSSHWYFDVWGQGTLVTVSS (서열번호 1)
bevacizumab의 중쇄 가변부위를 코딩하는 뉴클레오타이드 서열: (369 bp)
GAGGTGCAGCTGGTCGAGTCCGGGGGGGGGCTGGTGCAGCCAGGCGGGTCTCTGAGGCTGAGTTGCGCCGCTTCAGGGTACACCTTCACAAACTATGGAATGAATTGGGTGCGCCAGGCACCAGGAAAGGGACTGGAGTGGGTCGGCTGGATCAACACTTACACCGGGGAACCTACCTATGCAGCCGACTTTAAGCGGCGGTTCACCTTCAGCCTGGATACAAGCAAATCCACTGCCTACCTGCAGATGAACAGCCTGCGAGCTGAGGACACCGCAGTCTACTATTGTGCTAAATATCCCCACTACTATGGGAGCAGCCATTGGTATTTTGACGTGTGGGGGCAGGGGACTCTGGTGACAGTGAGCAGC (서열번호 2)
bevacizumab의 경쇄 가변부위 (bevacizumab-Lv)의 아미노산 서열: (107 aa)
DIQMTQSPSSLSASVGDRVTITCSASQDISNYLNWYQQKPGKAPKVLIYFTSSLHSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYSTVPWTFGQGTKVEIK (서열번호 3)
bevacizumab의 경쇄 가변부위를 코딩하는 뉴클레오타이드 서열: (321 bp)
GATATTCAGATGACTCAGAGCCCCTCCTCCCTGTCCGCCTCTGTGGGCGACAGGGTCACCATCACATGCAGTGCTTCACAGGATATTTCCAACTACCTGAATTGGTATCAGCAGAAGCCAGGAAAAGCACCCAAGGTGCTGATCTACTTCACTAGCTCCCTGCACTCAGGAGTGCCAAGCCGGTTCAGCGGATCCGGATCTGGAACCGACTTTACTCTGACCATTTCTAGTCTGCAGCCTGAGGATTTCGCTACATACTATTGCCAGCAGTATTCTACCGTGCCATGGACATTTGGCCAGGGGACTAAAGTCGAGATCAAG (서열번호 4)
중쇄 불변부위는 모두 Ig 감마-1 사슬 C 부위, 고유번호: P01857였고; 경쇄 불변부위는 모두 Ig 카파 사슬 C 부위, 고유번호: P01834였다.
bevacizumab의 중쇄 cDNA 및 경쇄 cDNA를 벡터 pcDNA3.1로 클로닝하였고, 항체 bevacizumab의 재조합 발현 플라스미드를 수득하였다. 재조합 플라스미드를 293F 세포로 형질주입 하였다. 293F 세포 배양 배지를 정제한 후 검출하였다.
이에 따라 항-VEGFA 단일클론항체 Avastin (bevacizumab)을 수득하였다.
제조예 2: 항-PD-1 항체 14C12와 이의 인간화 항체 14C12H1L1 및 돌연변이체 14C12H1L1(M)의 서열 디자인
항-PD-1 항체 14C12 및 이의 인간화 항체 14C12H1L1의 중쇄 및 경쇄의 아미노산 서열및 코딩 뉴클레오타이드 서열은 각각 중국 공개특허 CN106967172A의 14C12 및 14C12H1L1의 아미노산 서열 및 코딩 뉴클레오타이드 서열과 동일하다.
(1) 14C12의 중쇄 및 경쇄 가변부위 서열
14C12의 중쇄 가변부의의 아미노산 서열: (118 aa)
EVKLVESGGGLVKPGGSLKLSCAASGFAFSSYDMSWVRQTPEKRLEWVATISGGGRYTYYPDSVKGRFTISRDNARNTLYLQMSSLRSEDTALYYCANRYGEAWFAYWGQGTLVTVSA (서열번호 5)
14C12의 중쇄 가변부위를 코딩하는 뉴클레오타이드 서열: (354 bp)
GAGGTCAAACTGGTGGAGAGCGGCGGCGGGCTGGTGAAGCCCGGCGGGTCACTGAAACTGAGCTGCGCCGCTTCCGGCTTCGCCTTTAGCTCCTACGACATGTCATGGGTGAGGCAGACCCCTGAGAAGCGCCTGGAATGGGTCGCTACTATCAGCGGAGGCGGGCGATACACCTACTATCCTGACTCTGTCAAAGGGAGATTCACAATTAGTCGGGATAACGCCAGAAATACTCTGTATCTGCAGATGTCTAGTCTGCGGTCCGAGGATACAGCTCTGTACTATTGTGCAAACCGGTACGGCGAAGCATGGTTTGCCTATTGGGGACAGGGCACCCTGGTGACAGTCTCTGCC (서열번호 6)
14C12의 경쇄 가변부의의 아미노산 서열: (107 aa)
DIKMTQSPSSMYASLGERVTFTCKASQDINTYLSWFQQKPGKSPKTLIYRANRLVDGVPSRFSGSGSGQDYSLTISSLEYEDMGIYYCLQYDEFPLTFGAGTKLELK (서열번호 7)
14C12의 경쇄 가변부위를 코딩하는 뉴클레오타이드 서열: (321 bp)
GACATTAAGATGACACAGTCCCCTTCCTCAATGTACGCTAGCCTGGGCGAGCGAGTGACCTTCACATGCAAAGCATCCCAGGACATCAACACATACCTGTCTTGGTTTCAGCAGAAGCCAGGCAAAAGCCCCAAGACCCTGATCTACCGGGCCAATAGACTGGTGGACGGGGTCCCCAGCAGATTCTCCGGATCTGGCAGTGGGCAGGATTACTCCCTGACCATCAGCTCCCTGGAGTATGAAGACATGGGCATCTACTATTGCCTGCAGTATGATGAGTTCCCTCTGACCTTTGGAGCAGGCACAAAACTGGAACTGAAG (서열번호 8)
(2) 인간화 단일클론항체 14C12H1L1의 중쇄 및 경쇄 가변부위 및 중쇄 및 경쇄 서열
14C12H1L1의 중쇄 가변부의의 아미노산 서열: (118 aa)
EVQLVESGGGLVQPGGSLRLSCAASGFAFSSYDMSWVRQAPGKGLDWVATISGGGRYTYYPDSVKGRFTISRDNSKNNLYLQMNSLRAEDTALYYCANRYGEAWFAYWGQGTLVTVSS (서열번호 9)
14C12H1L1의 중쇄 가변부위를 코딩하는 뉴클레오타이드 서열: (354 bp)
GAAGTGCAGCTGGTCGAGTCTGGGGGAGGGCTGGTGCAGCCCGGCGGGTCACTGCGACTGAGCTGCGCAGCTTCCGGATTCGCCTTTAGCTCCTACGACATGTCCTGGGTGCGACAGGCACCAGGAAAGGGACTGGATTGGGTCGCTACTATCTCAGGAGGCGGGAGATACACCTACTATCCTGACAGCGTCAAGGGCCGGTTCACAATCTCTAGAGATAACAGTAAGAACAATCTGTATCTGCAGATGAACAGCCTGAGGGCTGAGGACACCGCACTGTACTATTGTGCCAACCGCTACGGGGAAGCATGGTTTGCCTATTGGGGGCAGGGAACCCTGGTGACAGTCTCTAGT (서열번호 10)
14C12H1L1의 경쇄 가변부의의 아미노산 서열: (107 aa)
DIQMTQSPSSMSASVGDRVTFTCRASQDINTYLSWFQQKPGKSPKTLIYRANRLVSGVPSRFSGSGSGQDYTLTISSLQPEDMATYYCLQYDEFPLTFGAGTKLELK (서열번호 11)
14C12H1L1의 경쇄 가변부위를 코딩하는 뉴클레오타이드 서열: (321 bp)
GACATTCAGATGACTCAGAGCCCCTCCTCCATGTCCGCCTCTGTGGGCGACAGGGTCACCTTCACATGCCGCGCTAGTCAGGATATCAACACCTACCTGAGCTGGTTTCAGCAGAAGCCAGGGAAAAGCCCCAAGACACTGATCTACCGGGCTAATAGACTGGTGTCTGGAGTCCCAAGTCGGTTCAGTGGCTCAGGGAGCGGACAGGACTACACTCTGACCATCAGCTCCCTGCAGCCTGAGGACATGGCAACCTACTATTGCCTGCAGTATGATGAGTTCCCACTGACCTTTGGCGCCGGGACAAAACTGGAGCTGAAG (서열번호 12)
14C12H1L1의 중쇄 (14C12H1)의 아미노산 서열: (448 aa)
EVQLVESGGGLVQPGGSLRLSCAASGFAFSSYDMSWVRQAPGKGLDWVATISGGGRYTYYPDSVKGRFTISRDNSKNNLYLQMNSLRAEDTALYYCANRYGEAWFAYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK (서열번호 13)
14C12H1L1의 중쇄 (14C12H1)를 코딩하는 뉴클레오타이드 서열: (1344 bp)
GAAGTGCAGCTGGTCGAGTCTGGGGGAGGGCTGGTGCAGCCCGGCGGGTCACTGCGACTGAGCTGCGCAGCTTCCGGATTCGCCTTTAGCTCCTACGACATGTCCTGGGTGCGACAGGCACCAGGAAAGGGACTGGATTGGGTCGCTACTATCTCAGGAGGCGGGAGATACACCTACTATCCTGACAGCGTCAAGGGCCGGTTCACAATCTCTAGAGATAACAGTAAGAACAATCTGTATCTGCAGATGAACAGCCTGAGGGCTGAGGACACCGCACTGTACTATTGTGCCAACCGCTACGGGGAAGCATGGTTTGCCTATTGGGGGCAGGGAACCCTGGTGACAGTCTCTAGTGCCAGCACCAAAGGACCTAGCGTGTTTCCTCTCGCCCCCTCCTCCAAAAGCACCAGCGGAGGAACCGCTGCTCTCGGATGTCTGGTGAAGGACTACTTCCCTGAACCCGTCACCGTGAGCTGGAATAGCGGCGCTCTGACAAGCGGAGTCCATACATTCCCTGCTGTGCTGCAAAGCAGCGGACTCTATTCCCTGTCCAGCGTCGTCACAGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACATCTGTAACGTCAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAAGTGGAGCCCAAATCCTGCGACAAGACACACACCTGTCCCCCCTGTCCTGCTCCCGAACTCCTCGGAGGCCCTAGCGTCTTCCTCTTTCCTCCCAAACCCAAGGACACCCTCATGATCAGCAGAACCCCTGAAGTCACCTGTGTCGTCGTGGATGTCAGCCATGAGGACCCCGAGGTGAAATTCAACTGGTATGTCGATGGCGTCGAGGTGCACAACGCCAAAACCAAGCCCAGGGAGGAACAGTACAACTCCACCTACAGGGTGGTGTCCGTGCTGACAGTCCTCCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCTCTCCCTGCCCCCATTGAGAAGACCATCAGCAAGGCCAAAGGCCAACCCAGGGAGCCCCAGGTCTATACACTGCCTCCCTCCAGGGACGAACTCACCAAGAACCAGGTGTCCCTGACCTGCCTGGTCAAGGGCTTTTATCCCAGCGACATCGCCGTCGAGTGGGAGTCCAACGGACAGCCCGAGAATAACTACAAGACCACCCCTCCTGTCCTCGACTCCGACGGCTCCTTCTTCCTGTACAGCAAGCTGACCGTGGACAAAAGCAGGTGGCAGCAGGGAAACGTGTTCTCCTGCAGCGTGATGCACGAAGCCCTCCACAACCACTACACCCAGAAAAGCCTGTCCCTGAGCCCCGGCAAA (서열번호 14)
14C12H1L1의 경쇄 (14C12L1)의 아미노산 서열: (214 aa)
DIQMTQSPSSMSASVGDRVTFTCRASQDINTYLSWFQQKPGKSPKTLIYRANRLVSGVPSRFSGSGSGQDYTLTISSLQPEDMATYYCLQYDEFPLTFGAGTKLELKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (서열번호 15)
14C12H1L1의 경쇄 (14C12L1)를 코딩하는 뉴클레오타이드 서열: (642 bp)
GACATTCAGATGACTCAGAGCCCCTCCTCCATGTCCGCCTCTGTGGGCGACAGGGTCACCTTCACATGCCGCGCTAGTCAGGATATCAACACCTACCTGAGCTGGTTTCAGCAGAAGCCAGGGAAAAGCCCCAAGACACTGATCTACCGGGCTAATAGACTGGTGTCTGGAGTCCCAAGTCGGTTCAGTGGCTCAGGGAGCGGACAGGACTACACTCTGACCATCAGCTCCCTGCAGCCTGAGGACATGGCAACCTACTATTGCCTGCAGTATGATGAGTTCCCACTGACCTTTGGCGCCGGGACAAAACTGGAGCTGAAGCGAACTGTGGCCGCTCCCTCCGTCTTCATTTTTCCCCCTTCTGACGAACAGCTGAAATCAGGCACAGCCAGCGTGGTCTGTCTGCTGAACAATTTCTACCCTAGAGAGGCAAAAGTGCAGTGGAAGGTCGATAACGCCCTGCAGTCCGGCAACAGCCAGGAGAGTGTGACTGAACAGGACTCAAAAGATAGCACCTATTCCCTGTCTAGTACACTGACTCTGTCCAAGGCTGATTACGAGAAGCACAAAGTGTATGCATGCGAAGTGACACATCAGGGACTGTCAAGCCCCGTGACTAAGTCTTTTAACCGGGGCGAATGT (서열번호 16)
(3) 14C12H1L1(M)의 중쇄 및 경쇄 가변부위 서열
프레임워크 부위 (경쇄)의 개별 아미노산을 14C12H1L1에 기초하여 돌연변이시켜 14C12H1L1(M)를 수득하였다.
14C12H1L1(M)의 중쇄 가변부위 14C12H1(M)는:
14C12H1L1의 중쇄 가변부위 14C12H1와 동일하며, 즉, 아미노산 서열은 서열번호 9로 제시된다.
14C12H1L1(M)의 경쇄 가변부위 14C12L1(M): (108 aa, 14C12H1L1에 기초한 아미노산 서열에 돌연변이 위치가 밑줄 그어짐)
DIQMTQSPSSMSASVGDRVTFTCRASQDINTYLSWFQQKPGKSPKTLIYRANRLVSGVPSRFSGSGSGQDYTLTISSLQPEDMATYYCLQYDEFPLTFGAGTKLELKR (서열번호 17)
제조예 3: 이중특이항체의 서열 디자인
1. 서열 디자인
본 발명의 이중특이항체의 구조는 모리슨 형태 (IgG-scFv), 즉, IgG 항체의 두 중쇄의 C-말단이 각각 다른 항체의 scFv 단편에 연결되는 것이고, 중쇄 및 경쇄의 주요 구성 디자인은 하기 표 1에 제시된 것과 같다.
bevacizumab에 기초하여, 14C12H1L1(M)의 중쇄 가변부위 및 경쇄 가변부위의 아미노산 구조가 ScFv 단편 부분으로 취해지는, VP101 항체는 VP101(M)으로 지칭된다. 14C12H1L1과 비교하여, 14C12H1L1(M)은 이중특이항체의 구조를 효과적으로 최적화하였고, 유효성을 향상시켰다.
| VP101(M) 및 VP101(G4M)의 중쇄 및 경쇄의 구성 디자인 | ||||
| 이중특이항체 번호 |
면역글로불린 모이어티 | 링커 단편 | scFv 부분 | |
| 중쇄 | 경쇄 | |||
| VP101(M) | Bevacizumab-H | Bevacizumab-L | Linker1 | 14C12H1(M)V-Linker1-14C12L1(M)V |
| VP101(G4M) | Bevacizumab-G4H | Bevacizumab-L | Linker1 | 14C12H1(M)V-Linker1-14C12L1(M)V |
상기 표 1에서:
(1) 우측 하단 모서리에 "V" 표시가 있는 항목은 상응하는 중쇄의 가변부위 또는 상응하는 경쇄의 가변부의를 의미한다. "V" 표시가 없는 항목에서, 상응하는 중쇄 또는 경쇄는 불변부위를 포함하는 전장 (full length)이다. 상기 제조예에 기재된 상응하는 서열은 이러한 가변부위 또는 전장의 아미노산 서열 및 이를 코딩하는 뉴클레오타이드 서열에 참조된다.
(2) Linker 1의 아미노산 서열은 GGGGSGGGGSGGGGSGGGGS (서열번호 18)이다.
선택적으로, 아미노산 서열 GGGGSGGGGSGGGGS (서열번호 19)는 앞서 언급한 Linker 1 대신 Linker 2로 사용될 수 있다.
(3) Bevacizumab-H는 중쇄 불변부위로서 Ig 감마-1 사슬 C 부위 (고유번호: P01857)를 사용하였다.
(4) Bevacizumab-G4H는 중쇄 불변부위로서 Ig 감마-4 사슬 C 부위 (고유번호: P01861.1)를 사용하였다.
2. 항체 VP101(M)의 발현 및 정제
VP101의 중쇄 cDNA 서열 및 경쇄 cDNA 서열은 플라스미드 pUC57simple-VP101H 및 pUC57simple-VP101L을 얻기 위해 벡터 pUC57simple (Genscript 제공)에 각각 클로닝되었다.
플라스미드 pUC57simple-VP101H 및 pUC57simple-VP101L를 효소-소화 (HindIII&EcoRI) 하였고(enzyme-digested), 전기영동으로 단리된 중쇄 및 경쇄를 벡터 pcDNA3.1에 서브클로닝하고, 재조합 플라스미드를 추출하여 293F 세포를 공동 형질주입 (co-tranfect)시켰다. 세포 배양 7일 후, 배양 배지를 고속으로 원심분리하였고, 상층액을 농축하고 HiTrap MabSelect SuRe 칼럼에 로딩하였다. 단백질을 용출 버퍼 (elution buffer)로 한 단계 더 용출시키고, 표적 시료 항체 VP101을 단리하고 PBS로 버퍼 교환 (buffer exchange)하였다.
3. 항체 VP101(M)의 검출
정제된 시료를 환원된 단백질 전기영동 로딩버퍼 및 비환원된 단백질 전이영동 로딩버퍼에 모두 첨가한 후, SPS-PAGE 전기영동 검출을 위해 끓였다.
제조예 4의 돌연변이 항체와의 구별을 위해, 본 발명에서 VP101(M)은 VP101(hG1WT)로도 지칭된다. 상술된 VP101(M)은 "야생형 (wild-type)"으로, 중쇄 불변부위로서 Ig 감마-1 사슬 C 부위 (고유번호: P01857) 및 경쇄 불변부위로서 Ig 카파 사슬 C 부위 (고유번호: P01834)를 포함한다.
VP101(hG1WT)에서 면역글로불린 모이어티의 중쇄의 아미노산 서열: (453 aa)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEWVGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVYYCAKYPHYYGSSHWYFDVWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK (서열번호 20)
VP101(hG1WT)에서 면역글로불린 모이어티의 중쇄를 코딩하는 뉴클레오타이드 서열: (1359 bp)
GAGGTGCAGCTGGTCGAGTCCGGGGGGGGGCTGGTGCAGCCAGGCGGGTCTCTGAGGCTGAGTTGCGCCGCTTCAGGGTACACCTTCACAAACTATGGAATGAATTGGGTGCGCCAGGCACCAGGAAAGGGACTGGAGTGGGTCGGCTGGATCAACACTTACACCGGGGAACCTACCTATGCAGCCGACTTTAAGCGGCGGTTCACCTTCAGCCTGGATACAAGCAAATCCACTGCCTACCTGCAGATGAACAGCCTGCGAGCTGAGGACACCGCAGTCTACTATTGTGCTAAATATCCCCACTACTATGGGAGCAGCCATTGGTATTTTGACGTGTGGGGGCAGGGGACTCTGGTGACAGTGAGCAGCGCAAGCACCAAAGGGCCCAGCGTGTTTCCTCTCGCCCCCTCCTCCAAAAGCACCAGCGGAGGAACCGCTGCTCTCGGATGTCTGGTGAAGGACTACTTCCCTGAACCCGTCACCGTGAGCTGGAATAGCGGCGCTCTGACAAGCGGAGTCCATACATTCCCTGCTGTGCTGCAAAGCAGCGGACTCTATTCCCTGTCCAGCGTCGTCACAGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACATCTGTAACGTCAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAAGTGGAGCCCAAATCCTGCGACAAGACACACACCTGTCCCCCCTGTCCTGCTCCCGAACTCCTCGGAGGCCCTAGCGTCTTCCTCTTTCCTCCCAAACCCAAGGACACCCTCATGATCAGCAGAACCCCTGAAGTCACCTGTGTCGTCGTGGATGTCAGCCATGAGGACCCCGAGGTGAAATTCAACTGGTATGTCGATGGCGTCGAGGTGCACAACGCCAAAACCAAGCCCAGGGAGGAACAGTACAACTCCACCTACAGGGTGGTGTCCGTGCTGACAGTCCTCCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCTCTCCCTGCCCCCATTGAGAAGACCATCAGCAAGGCCAAAGGCCAACCCAGGGAGCCCCAGGTCTATACACTGCCTCCCTCCAGGGACGAACTCACCAAGAACCAGGTGTCCCTGACCTGCCTGGTCAAGGGCTTTTATCCCAGCGACATCGCCGTCGAGTGGGAGTCCAACGGACAGCCCGAGAATAACTACAAGACCACCCCTCCTGTCCTCGACTCCGACGGCTCCTTCTTCCTGTACAGCAAACTGACCGTCGATAAATCTAGGTGGCAGCAGGGCAACGTGTTCTCTTGTTCCGTGATGCATGAAGCACTGCACAACCATTATACCCAGAAGTCTCTGAGCCTGTCCCCCGGCAAG (서열번호 21)
제조예 4의 돌연변이 항체와의 구별을 위해, 본 발명에서 VP101(G4M)은 VP101(hG4WT)로도 지칭된다. 상술된 VP101(G4M)은 "야생형 (wild-type)"으로, 중쇄 불변부위로서 Ig 감마-4 사슬 C 부위 (고유번호: P01861.1) 및 경쇄 불변부위로서 Ig 카파 사슬 C 부위 (고유번호: P01834)를 포함한다.
VP101(hG4WT)에서 면역글로불린 모이어티의 중쇄의 아미노산 서열: (450 aa)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEWVGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVYYCAKYPHYYGSSHWYFDVWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK (서열번호 22)
VP101(hG4WT)에서 면역글로불린 모이어티의 중쇄를 코딩하는 뉴클레오타이드 서열: (1350 bp)
GAGGTGCAGCTGGTCGAGTCCGGGGGGGGGCTGGTGCAGCCAGGCGGGTCTCTGAGGCTGAGTTGCGCCGCTTCAGGGTACACCTTCACAAACTATGGAATGAATTGGGTGCGCCAGGCACCAGGAAAGGGACTGGAGTGGGTCGGCTGGATCAACACTTACACCGGGGAACCTACCTATGCAGCCGACTTTAAGCGGCGGTTCACCTTCAGCCTGGATACAAGCAAATCCACTGCCTACCTGCAGATGAACAGCCTGCGAGCTGAGGACACCGCAGTCTACTATTGTGCTAAATATCCCCACTACTATGGGAGCAGCCATTGGTATTTTGACGTGTGGGGGCAGGGGACTCTGGTGACAGTGAGCAGCGCAAGCACCAAAGGGCCCTCGGTCTTCCCCCTGGCGCCCTGCTCCAGGAGCACCTCCGAGAGCACAGCCGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACGAAGACCTACACCTGCAACGTAGATCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGTCCAAATATGGTCCCCCATGCCCACCATGCCCAGCACCTGAGTTCCTGGGGGGACCATCAGTCTTCCTGTTCCCCCCAAAACCCAAGGACACTCTCATGATCTCCCGGACCCCTGAGGTCACGTGCGTGGTGGTGGACGTGAGCCAGGAAGACCCCGAGGTCCAGTTCAACTGGTACGTGGATGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTTCAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGGCCTCCCGTCCTCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAGCCACAGGTGTACACCCTGCCCCCATCCCAGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAGGCTAACCGTGGACAAGAGCAGGTGGCAGGAGGGGAATGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACACAGAAGTCTCTGAGCCTGTCCCTCGGCAAG (서열번호 23)
제조예 4: 인간화 이중특이항체 VP101(hG1WT)에 기초한 비-가변부위 아미노산 돌연변이 디자인
제조예 3에서 수득한 VP101(hG1WT)에 기초하여, 중쇄의 234 위치의 류신-알라닌 점돌연변이 (L234A) 및 235 위치의 류신-알라닌 점돌연변이 (L235A)를 도입함으로써 VP101(hG1DM)를 수득하였다.
VP101(hG1DM)에서 면역글로불린 모이어티의 중쇄의 아미노산 서열: (453 aa, 돌연변이 위치가 밑줄 그어짐)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEWVGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVYYCAKYPHYYGSSHWYFDVWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK (서열번호 24)
VP101(hG1DM)에서 면역글로불린 모이어티의 중쇄를 코딩하는 뉴클레타이드 서열: (1359 bp, 돌연변이 위치가 밑줄 그어짐)
GAGGTGCAGCTGGTCGAGTCCGGGGGGGGGCTGGTGCAGCCAGGCGGGTCTCTGAGGCTGAGTTGCGCCGCTTCAGGGTACACCTTCACAAACTATGGAATGAATTGGGTGCGCCAGGCACCAGGAAAGGGACTGGAGTGGGTCGGCTGGATCAACACTTACACCGGGGAACCTACCTATGCAGCCGACTTTAAGCGGCGGTTCACCTTCAGCCTGGATACAAGCAAATCCACTGCCTACCTGCAGATGAACAGCCTGCGAGCTGAGGACACCGCAGTCTACTATTGTGCTAAATATCCCCACTACTATGGGAGCAGCCATTGGTATTTTGACGTGTGGGGGCAGGGGACTCTGGTGACAGTGAGCAGCGCAAGCACCAAAGGGCCCAGCGTGTTTCCTCTCGCCCCCTCCTCCAAAAGCACCAGCGGAGGAACCGCTGCTCTCGGATGTCTGGTGAAGGACTACTTCCCTGAACCCGTCACCGTGAGCTGGAATAGCGGCGCTCTGACAAGCGGAGTCCATACATTCCCTGCTGTGCTGCAAAGCAGCGGACTCTATTCCCTGTCCAGCGTCGTCACAGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACATCTGTAACGTCAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAAGTGGAGCCCAAATCCTGCGACAAGACACACACCTGTCCCCCCTGTCCTGCTCCCGAAGCTGCTGGAGGCCCTAGCGTCTTCCTCTTTCCTCCCAAACCCAAGGACACCCTCATGATCAGCAGAACCCCTGAAGTCACCTGTGTCGTCGTGGATGTCAGCCATGAGGACCCCGAGGTGAAATTCAACTGGTATGTCGATGGCGTCGAGGTGCACAACGCCAAAACCAAGCCCAGGGAGGAACAGTACAACTCCACCTACAGGGTGGTGTCCGTGCTGACAGTCCTCCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCTCTCCCTGCCCCCATTGAGAAGACCATCAGCAAGGCCAAAGGCCAACCCAGGGAGCCCCAGGTCTATACACTGCCTCCCTCCAGGGACGAACTCACCAAGAACCAGGTGTCCCTGACCTGCCTGGTCAAGGGCTTTTATCCCAGCGACATCGCCGTCGAGTGGGAGTCCAACGGACAGCCCGAGAATAACTACAAGACCACCCCTCCTGTCCTCGACTCCGACGGCTCCTTCTTCCTGTACAGCAAACTGACCGTCGATAAATCTAGGTGGCAGCAGGGCAACGTGTTCTCTTGTTCCGTGATGCATGAAGCACTGCACAACCATTATACCCAGAAGTCTCTGAGCCTGTCCCCCGGCAAG (서열번호 25)
VP101(hG1DM), VP101(hG1WT) 및 VP101(hG4WT)의 면역글로불린 모이어티의 경쇄의 아미노산 서열 및 코딩 뉴클레오타이드 서열은 동일하다.
VP101(hG1DM)에서 면역글로불린 모이어티의 경쇄의 아미노산 서열: (214 aa)
DIQMTQSPSSLSASVGDRVTITCSASQDISNYLNWYQQKPGKAPKVLIYFTSSLHSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYSTVPWTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (서열번호 26)
VP101(hG1DM)에서 면역글로불린 모이어티의 경쇄를 코딩하는 뉴클레오타이드 서열: (642 bp)
GATATTCAGATGACTCAGAGCCCCTCCTCCCTGTCCGCCTCTGTGGGCGACAGGGTCACCATCACATGCAGTGCTTCACAGGATATTTCCAACTACCTGAATTGGTATCAGCAGAAGCCAGGAAAAGCACCCAAGGTGCTGATCTACTTCACTAGCTCCCTGCACTCAGGAGTGCCAAGCCGGTTCAGCGGATCCGGATCTGGAACCGACTTTACTCTGACCATTTCTAGTCTGCAGCCTGAGGATTTCGCTACATACTATTGCCAGCAGTATTCTACCGTGCCATGGACATTTGGCCAGGGGACTAAAGTCGAGATCAAGCGGACCGTGGCCGCTCCCAGTGTCTTCATTTTTCCCCCTAGCGACGAACAGCTGAAATCCGGGACAGCCTCTGTGGTCTGTCTGCTGAACAACTTCTACCCTAGAGAGGCAAAAGTGCAGTGGAAGGTCGATAACGCCCTGCAGAGTGGCAATTCACAGGAGAGCGTGACAGAACAGGACTCCAAAGATTCTACTTATAGTCTGTCAAGCACACTGACTCTGAGCAAGGCTGACTACGAAAAGCATAAAGTGTATGCATGTGAGGTCACCCACCAGGGGCTGAGCAGTCCAGTCACCAAGTCATTCAACAGAGGCGAGTGC (서열번호 27)
실시예 1: VP101(hG1WT) 및 VP101(hG1DM) 대한 FcγRI의 친화도 상수 어세이
CD64로도 알려진, Fc 수용체 FcγRI은 IgG 항체의 Fc 단편에 결합할 수 있고, 항체-의존적 세포-매개 세포독성 (ADCC)에 관여한다. Fc에 대한 치료 단일클론항체의 결합 능력은 항체의 안전성 및 효능에 영향을 미칠 것이다.
VP101(hG1WT) 및 VP101(hG1DM)의 FcγRI에 대한 친화도 상수는 각 항체의 ADCC 활성을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 FcγRI에 대한 항체의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 시료 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었다. 1 ug/mL의 FcγRIa를 H1S1K 센서에 50초간 고정하였다. 센서를 버퍼에 60초간 평형화시키고, 3.12 내지 50 nM (연속 2배 희석) 농도의 항체에 대한 센서에 고정된 CD64의 결합을 120초간 측정하였다. 항체를 버퍼에 120초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.5에서 4회, 각각 5초간 리프레시하였다. 검출 온도는 30 ℃, 주파수는 0.3 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다.
VP101(hG1WT), VP101(hG4WT) 및 VP101(hG1DM)뿐 아니라 대조군 항체인 nivolumab 및 bevacizumab에 대한 FcγRI의 친화도 상수를 표 2 및 도 1 내지 5에 나타내었다.
| FcγRI에 대한 VP101(hG1WT) 및 VP101(hG1DM) 및 이의 아이소타입의 결합의 동역학 | ||||||
| 항체 | KD (M) | kon (1/Ms) | SE (kon) | kdis (1/s) | SE (kdis) | Rmax (nm) |
| VP101(hG1DM) | N/A | N/A | N/A | N/A | N/A | N/A |
| Bevacizumab | 3.68E-09 | 6.61E+05 | 2.07E+04 | 2.44E-03 | 9.02E-05 | 0.46-0.49 |
| Nivolumab | 6.20E-09 | 6.98E+05 | 2.22E+04 | 4.32E-03 | 9.88E-05 | 0.48-0.53 |
| VP101(hG1WT) | 3.95E-09 | 5.67E+05 | 1.82E+04 | 2.24E-03 | 9.02E-05 | 0.68-0.80 |
| VP101(hG4WT) | 8.52E-09 | 6.28E+05 | 2.12E+04 | 5.35E-03 | 1.07E-04 | 0.61-0.65 |
N/A는 항원에 대해 항체가 결합하지 않거나 극도로 약한 결합신호를 가지는 것을 나타내는 것으로, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 VP101(hG1WT)는 FcγRI에 3.95E-09M의 친화도 상수로 결합할 수 있고; VP101(hG4WT)는 FcγRI에 8.52E-09M의 친화도 상수로 결합할 수 있고; bevacizumab은 FcγRI에 3.68E-09M의 친화도 상수로 결합할 수 있고; nivolumab은 FcγRI에 6.20E-09M의 친화도 상수로 결합할 수 있고; VP101(hG1DM)는 FcγRI에 대해 결합하지 않거나 극도로 약한 결합신호를 가지는 것으로 나타났고, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 FcγRI에 VP101(hG1DM)가 결합하지 않는 것을 제외하면 FcγRI에 대한 다른 항체의 친화도가 유사한 것으로 나타났다. VP101(hG1DM)의 결합 활성은 효과적으로 제거되었다.
실시예 2: VP101(hG1WT) 및 VP101(hG1DM) 대한 FcγRIIa_H131의 친화도 상수 어세이
Fc 수용체 FcγRIIa_H131 (CD32a_H131로도 알려짐)은, IgG 항체의 Fc 단편에 결합하고 ADCC 효과를 매개할 수 있다.
VP101(hG1WT) 및 VP101(hG1DM)의 FcγRIIa_H131에 대한 친화도 상수는 각 항체의 ADCC 활성을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 FcγRIIa_H131에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 고정 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었고, 분석물 희석 버퍼는 PBS, 0.02% Tween-20, 0.02% 카제인 및 0.1% BSA, pH 7.4의 용액이었다. 5 ug/mL의 FcγRIIa_H131를 NTA 센서에 고정시간 60초간 고정하였다. 센서를 PBS, 0.02% Tween-20, 0.02% 카제인 및 0.1% BSA의 버퍼 (pH 7.4)에 600초의 블로킹으로 평형화시키고, 12.5 내지 200 nM (연속 2배 희석) 농도의 항체에 대한 센서에 고정된 FcγRIIa_H131의 결합을 60초간 측정하였다. 항체를 버퍼에 60초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.7 및 10 nM 황산 니켈에서 리프레시하였다. 검출 온도는 30 ℃, 주파수는 0.6 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다.
VP101(hG1WT), VP101(hG4WT) 및 VP101(hG1DM)뿐 아니라 대조군 항체인 nivolumab 및 bevacizumab에 대한 FcγRIIa_H131의 친화도 상수를 표 3 및 도 6 내지 10에 나타내었다.
| FcγRIIa_H131에 대한 VP101(hG1WT)및 VP101(hG1DM) 및 이의 아이소타입의 결합의 동역학 | ||||||
| 항체 | KD (M) | kon (1/Ms) | SE (kon) | kdis (1/s) | SE (kdis) | Rmax (nm) |
| VP101(hG1DM) | 3.57E-08 | 1.15E+05 | 1.01E+04 | 4.11E-03 | 3.27E-04 | 0.41-0.53 |
| Bevacizumab | 6.44E-08 | 2.10E+05 | 1.78E+04 | 1.36E-02 | 5.14E-04 | 0.49-0.68 |
| Nivolumab | N/A | N/A | N/A | N/A | N/A | N/A |
| VP101(hG1WT) | 2.28E-08 | 2.41E+05 | 1.48E+04 | 5.50E-03 | 3.49E-04 | 1.40-1.52 |
| VP101(hG4WT) | 3.68E-08 | 2.13E+05 | 2.43E+04 | 7.83E-03 | 6.65E-04 | 0.41-0.57 |
N/A는 항원에 대해 항체가 결합하지 않거나 극도로 약한 결합신호를 가지는 것을 나타내는 것으로, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 VP101(hG1WT)는 FcγRIIa_H131에 2.28E-08M의 친화도 상수로 결합할 수 있고; VP101(hG4WT)는 FcγRIIa_H131에 3.68E-08M의 친화도 상수로 결합할 수 있고; bevacizumab은 FcγRIIa_H131에 6.44E-08M의 친화도 상수로 결합할 수 있고; VP101(hG1DM)은 FcγRIIa_H131에 3.57E-08M의 친화도 상수로 결합할 수 있는 반면; nivolumab은 FcγRIIa_H131에 대해 결합하지 않거나 극도로 약한 결합신호를 가지는 것으로 나타났고, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과, FcγRIIa_H131에 nivolumab이 결합하지 않는 것을 제외하면, 다른 항체는 FcγRIIa_H131에 다음의 강-약 친화도 순서로 결합하는 것으로 나타났다: VP101(hG1WT), VP101(hG1DM), VP101(hG4WT) 및 bevacizumab.
실시예 3: VP101(hG1WT) 및 VP101(hG1DM) 대한 FcγRIIa_R131의 친화도 상수 어세이
Fc 수용체 FcγRIIa_R131 (CD32a_R131로도 알려짐)은, IgG 항체의 Fc 단편에 결합하고 ADCC 효과를 매개할 수 있다.
VP101(hG1WT) 및 VP101(hG1DM)의 FcγRIIa_R131에 대한 친화도 상수는 각 항체의 ADCC 활성을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 VP101(hG1WT) 및 VP101(hG1DM)의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 고정 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었고, 분석물 희석 버퍼는 PBS, 0.02% Tween-20, 0.02% 카제인 및 0.1% BSA, pH 7.4의 용액이었다. 5 ug/mL의 FcγRIIa_R131를 NTA 센서에 고정시간 60초간 고정하였다. 센서를 PBS, 0.02% Tween-20, 0.02% 카제인 및 0.1% BSA의 버퍼 (pH 7.4)에 600초의 블로킹으로 평형화시키고, 12.5 내지 200 nM (연속 2배 희석) 농도의 항체에 대한 센서에 고정된 FcγRIIa_R131의 결합을 60초간 측정하였다. 항체를 버퍼에 60초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.7 및 10 nM 황산 니켈에서 리프레시하였다. 검출 온도는 30 ℃, 주파수는 0.6 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다.
VP101(hG1WT), VP101(hG4WT) 및 VP101(hG1DM)뿐 아니라 대조군 항체인 nivolumab 및 bevacizumab에 대한 FcγRIIa_R131의 친화도 상수를 표 4 및 도 11 내지 15에 나타내었다.
| FcγRIIa_R131에 대한 VP101(hG1WT)및 VP101(hG1DM) 및 이의 아이소타입의 결합의 동역학 | ||||||
| 항체 | KD (M) | kon (1/Ms) | SE (kon) | kdis (1/s) | SE (kdis) | Rmax (nm) |
| VP101(hG1DM) | 3.35E-08 | 1.20E+05 | 9.72E+03 | 4.03E-03 | 3.08E-04 | 0.57-0.69 |
| Bevacizumab | 5.16E-08 | 2.59E+05 | 1.72E+04 | 1.33E-02 | 4.52E-04 | 0.42-0.69 |
| Nivolumab | 6.93E-08 | 4.78E+05 | 1.09E+05 | 3.31E-02 | 2.54E-03 | 0.08-0.16 |
| VP101(hG1WT) | 2.42E-08 | 2.14E+05 | 1.30E+04 | 5.17E-03 | 3.28E-04 | 1.75-1.92 |
| VP101(hG4WT) | 3.57E-08 | 1.99E+05 | 1.23E+04 | 7.09E-03 | 3.40E-04 | 0.81-1.05 |
N/A는 항원에 대해 항체가 결합하지 않거나 극도로 약한 결합신호를 가지는 것을 나타내는 것으로, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 VP101(hG1WT)는 FcγRIIa_R131에 2.42E-08M의 친화도 상수로 결합할 수 있고; VP101(hG4WT)는 FcγRIIa_R131에 3.57E-08M의 친화도 상수로 결합할 수 있고; bevacizumab은 FcγRIIa_R131에 5.16E-08M의 친화도 상수로 결합할 수 있고; nivolumab은 FcγRIIa_R131에 6.93E-08M의 친화도 상수로 결합할 수 있고; VP101(hG1DM)은 FcγRIIa_R131에 3.35E-08M의 친화도 상수로 결합할 수 있는 것으로 나타났다.
실험 결과 항체는 FcγRIIa_R131에 다음의 강-약 친화도 순서로 결합하는 것으로 나타났다: VP101(hG1WT), VP101(hG1DM), VP101(hG4WT), bevacizumab 및 nivolumab.
실시예 4: VP101(hG1WT) 및 VP101(hG1DM) 대한 FcγRIIb의 친화도 상수 어세이
Fc 수용체 FcγRIIb (CD32b로도 알려짐)는, IgG 항체의 Fc 단편에 결합하고 면역세포 기능을 조절할 수 있다.
VP101(hG1WT) 및 VP101(hG1DM)의 FcγRIIb에 대한 친화도 상수는 VP101(hG1WT) 및 VP101(hG1DM)의 Fc 수용체에 대한 결합 능력을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 FcγRIIb에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 고정 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었고, 분석물 희석 버퍼는 PBS, 0.02% Tween-20, 0.02% 카제인 및 0.1% BSA, pH 7.4의 용액이었다. 5 ug/mL의 hFCGR2B-his를 NTA 센서에 고정시간 60초간 고정하였다. 센서를 PBS, 0.02% Tween-20, 0.02% 카제인 및 0.1% BSA의 버퍼 (pH 7.4)에 600초의 블로킹으로 평형화시키고, 12.5 내지 200 nM (연속 2배 희석) 농도의 항체에 대한 센서에 고정된 hFCGR2B-his의 결합을 60초간 측정하였다. 항체를 버퍼에 60초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.7 및 10 nM 황산 니켈에서 리프레시하였다. 검출 온도는 30 ℃, 주파수는 0.6 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다.
실시예 5: VP101(hG1WT) 및 VP101(hG1DM) 대한 FcγRIIIa_V158의 친화도 상수 어세이
Fc 수용체 FcγRIIIa_V158 (CD16a_V158로도 알려짐)은, IgG 항체의 Fc 단편에 결합하고 ADCC 효과를 매개할 수 있다.
VP101(hG1WT) 및 VP101(hG1DM)의 FcγRIIIa_V158에 대한 친화도 상수는 각 항체의 ADCC 활성을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 FcγRIIIa_V158에 대한 항체의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 시료 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었다. 1 ug/mL의 FcγRIIIa_V158를 H1S1K 센서에 120초간 고정하였다. 센서를 버퍼에 60초간 평형화시키고, 31.25 내지 500 nM (연속 2배 희석) 농도의 항체에 대한 센서에 고정된 hFcGR3A(V158)-his의 결합을 60초간 측정하였다. 항체를 버퍼에 60초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.5에서 4회, 각각 5초간 리프레시하였다. 검출 온도는 30 ℃, 주파수는 0.3 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다
VP101(hG1WT), VP101(hG4WT) 및 VP101(hG1DM)뿐 아니라 대조군 항체인 nivolumab 및 bevacizumab에 대한 FcγRIIIa_V158의 친화도 상수를 표 5 및 도 16 내지 20에 나타내었다.
| FcγRIIIa_V158에 대한 VP101(hG1WT)및 VP101(hG1DM) 및 이의 아이소타입의 결합의 동역학 | ||||||
| 항체 | KD (M) | kon (1/Ms) | SE (kon) | kdis (1/s) | SE (kdis) | Rmax (nm) |
| VP101(hG1DM) | 1.34E-07 | 6.05E+05 | 2.36E+05 | 8.11E-02 | 7.42E-03 | 0.07-0.21 |
| Bevacizumab | 2.76E-08 | 5.06E+05 | 1.14E+05 | 1.39E-02 | 1.41E-03 | 0.13-0.51 |
| Nivolumab | N/A | N/A | N/A | N/A | N/A | N/A |
| VP101(hG1WT) | 4.35E-08 | 2.39E+05 | 3.14E+04 | 1.04E-02 | 8.73E-04 | 0.80-1.22 |
| VP101(hG4WT) | N/A | N/A | N/A | N/A | N/A | N/A |
N/A는 항원에 대해 항체가 결합하지 않거나 극도로 약한 결합신호를 가지는 것을 나타내는 것으로, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 VP101(hG1WT)는 FcγRIIIa_V158에 4.35E-08M의 친화도 상수로 결합할 수 있고; VP101(hG1DM)은 FcγRIIIa_V158에 1.34E-07M의 친화도 상수로 결합할 수 있고; bevacizumab은 FcγRIIIa_V158에 2.76E-08M의 친화도 상수로 결합할 수 있는 반면; nivolumab 및 VP101(hG4WT)은 FcγRIIIa_V158에 대해 결합하지 않거나 극도로 약한 결합신호를 가지는 것으로 나타났고, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과, FcγRIIIa_V158에 nivolumab 및 VP101(hG4WT)이 결합하지 않는 것을 제외하면, 다른 항체는 FcγRIIIa_V158에 다음의 강-약 친화도 순서로 결합하는 것으로 나타났다: bevacizumab, VP101(hG1WT) 및 VP101(hG1DM).
실시예 6: VP101(hG1WT) 및 VP101(hG1DM) 대한 FcγRIIIa_F158의 친화도 상수 어세이
Fc 수용체 FcγRIIIa_F158 (CD16a_F158로도 알려짐)은, IgG 항체의 Fc 단편에 결합하고 ADCC 효과를 매개할 수 있다.
VP101(hG1WT) 및 VP101(hG1DM)의 FcγRIIIa_F158에 대한 친화도 상수는 각 항체의 ADCC 활성을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 FcγRIIIa_F158에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 시료 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었다. 1 ug/mL의 FcγRIIIa_F158를 H1S1K 센서에 120초간 고정하였다. 센서를 버퍼에 60초간 평형화시키고, 31.25 내지 500 nM (연속 2배 희석) 농도의 항체에 대한 센서에 고정된 hFcGR3A(F158)-his의 결합을 60초간 측정하였다. 항체를 버퍼에 60초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.5에서 4회, 각각 5초간 리프레시하였다. 검출 온도는 30 ℃, 주파수는 0.3 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다
VP101(hG1WT), VP101(hG4WT) 및 VP101(hG1DM)뿐 아니라 대조군 항체인 nivolumab 및 bevacizumab에 대한 FcγRIIIa_F158의 친화도 상수를 표 6 및 도 21 내지 25에 나타내었다.
| FcγRIIIa_F158에 대한 VP101(hG1WT)및 VP101(hG1DM) 및 이의 아이소타입의 결합의 동역학 | ||||||
| 항체 | KD (M) | kon (1/Ms) | SE (kon) | kdis (1/s) | SE (kdis) | Rmax (nm) |
| VP101(hG1DM) | N/A | N/A | N/A | N/A | N/A | N/A |
| Bevacizumab | 9.32E-08 | 2.64E+05 | 7.16E+04 | 2.46E-02 | 2.09E-03 | 0.08-0.20 |
| Nivolumab | N/A | N/A | N/A | N/A | N/A | N/A |
| VP101(hG1WT) | 7.41E-08 | 2.47E+05 | 5.20E+04 | 1.83E-02 | 1.55E-03 | 0.15-0.48 |
| VP101(hG4WT) | N/A | N/A | N/A | N/A | N/A | N/A |
N/A는 항원에 대해 항체가 결합하지 않거나 극도로 약한 결합신호를 가지는 것을 나타내는 것으로, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 VP101(hG1WT)는 FcγRIIIa_F158에 7.41E-08M의 친화도 상수로 결합할 수 있고; bevacizumab은 FcγRIIIa_F158에 9.32E-08M의 친화도 상수로 결합할 수 있는 반면; nivolumab, VP101(hG4WT) 및 VP101(hG1DM)은 FcγRIIIa_F158에 대해 결합하지 않거나 극도로 약한 결합신호를 가지는 것으로 나타났고, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과, FcγRIIIa_F158에 nivolumab, VP101(hG4WT) 및 VP101(hG1DM)이 결합하지 않는 것을 제외하면, 다른 항체는 FcγRIIIa_F158에 다음의 강-약 친화도 순서로 결합하는 것으로 나타났다: VP101(hG1WT) 및 bevacizumab.
실시예 7: VP101(hG1WT) 및 VP101(hG1DM) 대한 C1q의 친화도 상수 어세이
혈청 보체 C1q는 IgG 항체의 Fc 단편에 결합하고 ADCC 효과를 매개할 수 있다. C1q에 대한 치료 단일클론항체의 결합 능력은 항체의 안전성 및 효능에 영향을 미칠 것이다.
VP101(hG1WT) 및 VP101(hG1DM)의 C1q에 대한 친화도 상수는 각 항체의 CDC 활성을 평가하기 위해 이 실험에서 포르테비오 옥텟 시스템을 사용하여 결정되었다.
포르테비오 옥텟 시스템을 사용하여 C1q에 대한 항체의 친화도 상수를 결정하는 방법은 다음으로 간략하게 설명된다: 시료 희석 버퍼는 PBS, 0.02% Tween-20 및 0.1% BSA, pH 7.4의 용액이었다. 50 ug/mL의 항체를 약 2.0 nm의 고정 높이로 FAB2G 센서에 고정하였다. 센서를 버퍼에 60초간 평형화시키고, 0.625 내지 10 nM (연속 2배 희석) 농도의 C1q에 대한 센서에 고정된 항체의 결합을 60초간 측정하였다. 항원 및 항체를 버퍼에 120초간 해리시켰다. 센서를 10 mM 글라이신 pH 1.7에서 4회, 각각 5초간 리프레시하였다. 시료 플레이트의 교반 속도는 1000 rpm, 온도는 30 ℃ 및 주파수는 0.6 Hz였다. 데이터는 친화도 상수를 얻기 위해 1:1 모델 피팅으로 분석되었다. 데이터 획득 소프트웨어는 Fortebio Data Acquisition 7.0이었고, 데이터 분석 소프트웨어는 Fortebio Data Analysis 7.0이었다.
VP101(hG1WT), VP101(hG4WT) 및 VP101(hG1DM)뿐 아니라 대조군 항체인 nivolumab 및 bevacizumab에 대한 C1q의 친화도 상수를 표 7 및 도 26 내지 30에 나타내었다.
| C1q에 대한 VP101(hG1WT)및 VP101(hG1DM) 및 이의 아이소타입의 결합의 동역학 | ||||||
| 항체 | KD (M) | kon (1/Ms) | SE (kon) | kdis (1/s) | SE (kdis) | Rmax (nm) |
| VP101(hG1DM) | N/A | N/A | N/A | N/A | N/A | N/A |
| Bevacizumab | 1.14E-09 | 6.52E+06 | 5.64E+05 | 7.40E-03 | 5.58E-04 | 0.51-0.63 |
| Nivolumab | N/A | N/A | N/A | N/A | N/A | N/A |
| VP101(hG1WT) | 9.76E-10 | 5.73E+06 | 5.49E+05 | 5.59E-03 | 6.12E-04 | 0.32-0.51 |
| VP101(hG4WT) | N/A | N/A | N/A | N/A | N/A | N/A |
N/A는 항원에 대해 항체가 결합하지 않거나 극도로 약한 결합신호를 가지는 것을 나타내는 것으로, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과 VP101(hG1WT)는 C1q에 9.76E-10M의 친화도 상수로 결합할 수 있고; bevacizumab은 C1q에 1.14E-09M의 친화도 상수로 결합할 수 있는 반면; nivolumab, VP101(hG4WT) 및 VP101(hG1DM)은 C1q에 대해 결합하지 않거나 극도로 약한 결합신호를 가지는 것으로 나타났고, 따라서 실험 결과를 분석하지 않았고 상응하는 데이터를 얻지 않았다.
실험 결과, FcγRIIIa_F158에 nivolumab, VP101(hG4WT) 및 VP101(hG1DM)가 결합하지 않는 것을 제외하면, 다른 항체는 C1q에 결합하였고, VP101(hG1WT)는 bevacizumab과 유사한 친화도를 가진 것으로 나타났다.
실시예 8: PD-1 항원을 발현하는 CHO-K1-PD1 세포에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 ADCC 활성 어세이
세포적 수준에서 항체 VP101(hG1WT) 및 VP101(hG1DM)의 ADCC 효과를 검출하기 위해, 본 발명자들은 PD-1 항원을 발현하는 CHO-K1-PD1 세포를 구성하고, 세포학적 수준에서 항체의 ADCC 활성을 검출하기 위한 정상 인간 PBMC 및 표적세포의 공동 배양 시스템을 구축하였다.
PD-1 항원을 발현하는 CHO-K1-PD1 세포에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 ADCC 활성을 검출하는 방법은 하기와 같이 상술된다:
이 실험에서, 인간 PD-1 과발현 벡터 pCDH-CMV-PD1FL-Puro (pCDH-CMV-Puro는 Youbio에서 구입)를 먼저 구성하고, 발현 벡터를 바이러스에 패키징한 후 CHO-K1 세포를 감염시키고, 약물-내성 안정 발현 막 PD-1 단백질을 지닌 CHO-K1-PD1 안정화 세포주를 퓨로마이신 (2 ug/mL) 투여 및 스크리닝 후 수득하였다. 정상 인간 PBMC는 피콜 (Ficoll) 말초혈액 단핵세포 단리 지침에 따라 단리되었다. 단리된 PBMC를 1640 완전 배지에 재현탁하고 트리판 블루로 염색하여, 세포를 계수하고 세포의 생존력을 측정하였다. 세포를 37 ℃ 및 5% CO2의 포화 습도 인큐베이터에서 밤새 인큐베이션 하였다. 다음날, CHO-K1-PD1 세포 및 PBMC를 회수하고 원심분리하여 상층액을 제거한 후, 세포 펠렛을 RPMI-1640 (1% BSA 함유) (이하 어세이 배지로 지칭)에 재현탁하고, 원심분리하고 2회 세척하고; 세포를 계수하고 세포의 생존력을 측정하고, 어세이 배지를 사용하여 세포의 농도를 적절한 범위로 조정하고, CHO-K1-PD1 세포 현탁액 (30,000/웰)을 실험 설계에 따라 96-웰 플레이트에 첨가하고; 50 uL의 항체를 첨가하고, 잘 혼합하고, 실온에서 1시간 사전-인큐베이션하고; 사전-인큐베이션 후, 세포에 PBMC (900,000/50 uL/웰)를 첨가하고, 잘 혼합하고, 37 ℃ 및 5% CO2의 인큐베이터에서 4시간 인큐베이션 하였다. 4시간 후, 96-웰 플레이트를 제거하고 250× g로 5분간 원심분리하고; 세포 상층액 100 uL을 새로운 96-웰 플랫-바텀 마이크로플레이트에 조심스럽게 옮겼다 (세포 침전물을 피페팅하면 안됨). 새로 준비된 100 uL의 반응 용액을 세포독성 검출 키트 지침에 따라 각 웰에 첨가하였다. 세포를 암실에서 실온으로 30분간 인큐베이션 하였다. 490 nm 및 650 nm의 OD값을 측정하였으며, 여기서 각 그룹의 OD값 = OD490nm - OD650nm이다. 식 ADCC (%) = (처리군 - 음성 대조군)/(표적세포에서 최대 LDH 방출량 - 표적세포에서 자발적 LDH 방출량) × 100%에 따라 각 그룹의 ADCC 활성을 계산하였다.
PD-1 항원을 발현하는 CHO-K1-PD1 세포에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 ADCC 활성의 검출 결과는 ADCC%로 표현되고, 실험 결과를 도 31에 나타내었다.
실험 결과 양성 대조군 14C12H1L1(G1WT)가 PMBC 및 CHO-K1-PD1 혼합 배양 시스템에서 상당한 ADCC 활성을 보이는 것으로 나타났으며, 이는 ADCC 시스템이 정상임을 의미한다. 아이소타입 대조군 항체 hIgG1DM과 비교하여, VP101(hG1WT)는 상당한 ADCC 활성을 보이고 투여량-의존성을 나타낸 반면, VP101(G1DM)은 ADCC 활성을 보이지 않았다. 실험 결과 VP101(hG1WT)에 기초한 돌연변이를 통해 생성된 VP101(hG1DM)은 세포학적 수준에서 ADCC 활성을 가지지 않는 것으로 나타났으며, ADCC 효과는 제거되었다.
실시예 9: PD-1 항원을 발현하는 CHO-K1-PD1 세포에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 CDC 활성 어세이
세포학적 수준에서 항체 VP101(hG1WT) 및 VP101(hG1DM)의 CDC 효과를 검출하기 위해, 본 발명자들은 PD-1 항원을 발현하는 CHO-K1-PD1 세포를 구성하고 (구성 방법에 대해 실시예 8 참고), 세포학적 수준에서 항체의 CDC 활성을 검출하기 위한 표적세포 및 정상 인간 보체 혈청의 공동 배양 시스템을 구축하였다.
PD-1 항원을 발현하는 CHO-K1-PD1 세포에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 CDC 활성을 검출하는 방법은 하기와 같이 상술된다:
검출 당일, CHO-K1-PD1 세포를 트립신화를 통해 회수하고 170× g로 5분간 원심분리하고; 세포 펠렛을 RPMI-1640 (1% BSA 함유) (이하 어세이 배지로 지칭)에 재현탁하고, 반복적으로 원심분리하고 2회 세척하고; 세포를 계수하고 세포의 생존력을 측정하고, 어세이 배지를 사용하여 세포의 농도를 적절한 범위로 조정하고, CHO-K1-PD1 세포 현탁액 (30,000/웰)을 실험 설계에 따라 96-웰 플레이트에 첨가하고; 50 uL의 항체를 첨가하고, 잘 혼합하고, 실온에서 10분간 사전-인큐베이션하고; 사전-인큐베이션 후, 세포에 정상 인간 보체 혈청 (최종 농도: 2%)을 50 uL/웰로 첨가하고, 잘 혼합하고, 37 ℃ 및 5% CO2의 인큐베이터에서 4시간 인큐베이션 하였다. 4시간 후, 세포를 250× g로 5분간 원심분리하고; 세포 상층액 100 uL을 새로운 96-웰 플랫-바텀 마이크로플레이트에 조심스럽게 옮겼다 (세포 침전물을 피페팅하면 안됨). 새로 준비된 100 uL의 반응 용액을 세포독성 검출 키트 지침에 따라 각 웰에 첨가하였다. 세포를 암실에서 실온으로 30분간 인큐베이션 하였다. 490 nm 및 650 nm의 OD값을 측정하였으며, 여기서 각 그룹의 OD값 = OD490nm - OD650nm이다. 식 CDC(%) = (처리군 - 음성 대조군)/(표적세포에서 최대 LDH 방출량 - 표적세포에서 자발적 LDH 방출량) × 100%에 따라 각 그룹의 CDC 활성을 계산하였다.
PD-1 항원을 발현하는 CHO-K1-PD1 세포에 대한 VP101(hG1WT) 및 VP101(hG1DM)의 CDC 활성의 검출 결과는 CDC%로 표현되고, 실험 결과를 도 32에 나타내었다.
실험 결과 양성 대조군 항체 14C12H1L1(G1WT)의 CDC%가 정상 인간 보체 혈청 및 CHO-K1-PD1의 혼합 배양 시스템에서 아이소타입 대조군 항체 hIgG1DM 그룹의 CDC%와 상당한 차이를 갖는 것으로 나타났으며, 이는 CDC 검출 시스템이 정상임을 의미한다. 동일 투여량 수준에서, VP101(hG1WT) 및 VP101(hG1DM) 모두 아이소타입 대조군과 비교하여 CDC%의 유의미한 차이는 없었다.
실시예 10: 말초혈액 단핵세포 및 Raji-PDL1 세포의 혼합 배양 시스템 (Mixed Culture System; MCS)에서 VP101(hG1DM)의 약력학적 활성
이 실험에서, 인간 PD-1 과발현 벡터 plenti6.3-PD-L1-BSD (plenti6.3-BSD는 invitrogen에서 구매)를 먼저 구성하고, 발현 벡터를 바이러스에 패키징한 후 Raji 세포를 감염시키고, 안정적으로 막 PD-L1 단백질을 발현하기 위한 Raji-PDL1 안정화 세포주를 BSD (10 ug/mL) 투여 및 스크리닝 후 수득하였다. 정상 인간 PBMC를 피콜 말초혈액 단핵세포 단리 지침에 따라 단리하고, 단리된 PBMC를 1640 완전 배지에 재현탁하고, 계수하고 동결시켰다. PBMC를 회복시키고, SEB (Staphylococcus aureus enterotoxin B)를 첨가하고 이틀간 배양 자극하였다. 이틀 후, 지수생장기의 Raji-PDL1 세포를 회수하고, mitomycin C (Sigma, 작업 농도는 25 ug/mL)를 첨가하고 인큐베이터에서 60분간 인큐베이션하고, mitomycin C-처리 Raji-PDL1 세포를 원심분리하고 세척하고; 이틀간 SEB로 자극된 PBMC를 회수하고 세척하고; 항체의 존재 또는 부재 조건 하에 이 세포를 세포수 1:1 비율로 혼합하고 배양하였다. 3일 후, 세포 상층액을 원심분리로 회수하고, 상층액의 IL-2 및 IFN-γ 농도를 ELISA로 측정하였다.
IFN-γ 분비 결과를 도 33에 나타내었다. 실험 결과 VP101(hG1DM)는 효과적으로 IFN-γ 분비를 촉진할 수 있고, 그 활성은 nivolumab의 활성보다 현저히 우수한 것으로 나타났다.
IL-2의 분비 결과를 도 34에 나타내었다. 실험 결과 VP101(hG1DM)는 투여량-의존적 관계에서 IL-2 분비를 효과적으로 촉진할 수 있고, 그 활성은 nivolumab의 활성보다 현저히 우수한 것으로 나타났다.
실시예 11: PD-1 양성 세포에 대한 VP101(hG1DM)의 항체-의존적 식세포 활성 없음
항체 의존적 세포 식세포 작용 (antibody dependent cellular phagoxytosis; ADCP)은 세포 표면 항원에 결합한 항체 Fc 단편이 식세포 활성 세포 (대식세포 등)의 Fc 수용체에 결합하고, 따라서 항체-결합 세포의 식세포 작용을 매개하는 것을 의미한다. PD-1 항체와 같은, 면역 체크포인트 억제제 항체의 경우, ADCP 활성의 존재는 항-종양 살해 효과를 보이는 PD-1 발현 면역세포에 손상을 일으켜, 항-종양 활성에 영향을 미칠 것이다.
이 실험에서, 쥐 대식세포를 이펙터 세포로 설정하고, PD-1 과발현 CHO-K1-PD1 세포주 (구성 방법에 대해 실시예 8 참고)를 표적세포로 설정하였다. 세포에 의해 매개되는 ADCP 효과가 검출되었다. 이 실험에서, PD-1 발현 세포에서 VP101(hG1DM)의 ADCP 활성을 검출하기 위해 유세포분석법을 채택하였고, 실험 결과 VP101(hG1DM)는 ADCP 활성이 없는 반면, 동일 표적세포에 대한 시판되는 항체 nivolumab은 상당한 ADCP 활성을 가지는 것으로 나타났다. 실험 방법은 구체적으로 하기와 같다:
C57 마우스의 대퇴골 골수 (Guangdong Medical Laboratory Animal Center에서 구입)를 먼저 무균적으로 채취하고 적혈구 용해 버퍼로 얼음에서 5분간 용해하였다. 용해를 DMEM 완전 배지 (10% FBS 함유)로 종결시키고, 용해물을 1000 rpm으로 원심분리하고 2회 세척하였다. 세포 펠렛을 10 mL DMEM 완전 배지에 재현탁하고 M-CSF를 작업 농도 100 ng/mL로 첨가하였다. 세포는 유도용 세포 배양 챔버에서 37 ℃ 및 5% CO2로 7일간 배양하였다. 3일 및 5일에 배지의 절반을 교환하고 M-CSF를 첨가하였다. 세포의 유도는 7일에 완료되었다. 세포를 0.25% 트립신으로 소화시켰다. 대식세포를 회수하고, 750× g로 5분간 원심분리하였다. 상층액을 제거하고 세포를 DMEM 완전 배지 (10% FBS 함유)에 재현탁하고 계수하였다. 세포를 적절한 밀도로 조정하고, 추후 사용하기 위해 96-웰 코니컬 바텀 플레이트에 채웠다.
CHO-K1-PD1 세포는 통상적인 방법으로 회수하였고, 170× g로 5분간 원심분리하고, 재현탁하고 계수하고, 생존력을 측정하였다. 세포를 PBS로 1회 세척하였다. 카르복시플루오레세인 디아세테이트 석시미딜 숙신이미딜 에스테르 (Carboxyfluorescein diacetate succinimidyl ester; CFSE)를 PBS로 2.5 uM로 희석하였고, 세포를 적절한 양의 희석 CFSE (염색 밀도: 10,000,000 세포/mL)로 재현탁하고 인큐베이터에서 20분간 인큐베이션 하였다. 염색 중지를 위해 6 mL의 DMEM 완전 배지 (10% FBS 함유)를 첨가하였다. 세포를 170× g로 5분간 원심분리하고, 상층액을 제거하고; 1 mL의 DMEM 완전 배지를 첨가하였다. 세포를 인큐베이터에서 10분간 인큐베이션 하였다. 항체를 DMEM 완전 배지로 20 ug/Ml, 2 ug/mL 및 0.2 ug/mL (작업 농도는 10 ug/mL, 1 ug/mL 및 0.1 ug/mL)로 희석하였고, 아이소타입 대조군 항체 hIgG1DM 및 hIgG4를 디자인하였다. 신선한 유도 성숙 대식세포를 회수하고 750× g로 5분간 원심분리하고, 상층액을 제거하고; 세포를 계수하고 96-웰 코니컬 바텀 플레이트에 옮기고, 1000× g로 5분간 원심분리하고, 상층액을 제거하고; CHO-K1-PD 1-CFSE의 세포 밀도를 조정하고; 희석된 항체 및 표적세포를 실험 설계에 따라 대식세포를 포함하는 96-웰 코니컬 바텀 플레이트에 50 uL: 50 uL의 비율로 혼합하였다. 세포를 재현탁하고 잘 혼합하고, 인큐베이터에서 37 ℃로 2시간 인큐베이션 하였다.
150 uL의 상온 1% PBSA를 각 웰에 첨가하고 1000× g로 5분간 원심분리하고, 상층액을 제거하고; 세포를 200 uL의 PBSA로 1회 세척하고; APC 항-마우스/인간 CD11b 항체 (PBAS로 500배 희석)를 상응하는 시료에 100 uL/시료로 첨가하고, 잘 혼합하고 얼음에서 40분간 인큐베이션 하였다. 150 uL의 1% PBSA를 각 웰에 첨가하고 1000× g로 5분간 원심분리하고, 상층액을 제거하고; 각 웰을 200 uL의 PBSA로 1회 세척하였다. 200 uL의 1% PBSA를 재현탁을 위해 각 웰에 첨가한 후 Beckman 유세포분석기를 사용하여 분석하였다.
시스템의 대식세포는 APC+ 양성이었고, 식세포 작용에 관여한 대식세포는 APC 및 CFSF 이중 양성이었다. 식세포율는 APC 양성 세포수에 대한 이중 양성 세포수의 비율로서 결정하였고, 항체-의존적 ADCP 활성을 평가하였다. P%로 표현되는, 각 그룹의 ADCP 활성은 하기의 식에 따라 계산되었다:

실험 결과를 도 35에 나타내었다.
실험 결과 nivolumab은 대식세포 + CHO-K1-PD1 시스템에서 상당한 ADCP 효과를 가지고; VP101(hG1DM)의 식세포율은 아이소타입 대조군 항체의 식세포율과 유사한 것으로 나타났으며, 이는 VP101(hG1DM)의 ADCP 효과가 없음을 의미한다. 이러한 결과는 VP101(hG1DM)가 더 나은 항-종양 효과를 가질 가능성이 있음을 의미한다.
본 발명의 특정 구현예가 상세하게 설명되었지만, 당업자는 이해할 것이다. 개시된 모든 교시에 따라 이러한 세부사항에 대해 다양한 수정 및 대체가 이루어질 수 있고, 이러한 변경은 모두 본 발명의 보호범위 내에 속한다. 본 발명의 전체 범위는 첨부된 청구항 및 이의 임의의 동등물로써 주어진다.
<110> AKESO BIOPHARMA, INC
<120> ANTI-PD-1-ANTI-VEGFA BISPECIFIC ANTIBODY, PHARMACEUTICAL
COMPOSITION AND USE THEREOF
<130> PI220014CN
<150> CN201911164156.2
<151> 2019-11-25
<160> 42
<170> PatentIn version 3.5
<210> 1
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Bevacizumab-Hv
<400> 1
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Ala Asp Phe
50 55 60
Lys Arg Arg Phe Thr Phe Ser Leu Asp Thr Ser Lys Ser Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 2
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding Bevacizumab-Hv
<400> 2
gaggtgcagc tggtcgagtc cggggggggg ctggtgcagc caggcgggtc tctgaggctg 60
agttgcgccg cttcagggta caccttcaca aactatggaa tgaattgggt gcgccaggca 120
ccaggaaagg gactggagtg ggtcggctgg atcaacactt acaccgggga acctacctat 180
gcagccgact ttaagcggcg gttcaccttc agcctggata caagcaaatc cactgcctac 240
ctgcagatga acagcctgcg agctgaggac accgcagtct actattgtgc taaatatccc 300
cactactatg ggagcagcca ttggtatttt gacgtgtggg ggcaggggac tctggtgaca 360
gtgagcagc 369
<210> 3
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Bevacizumab-Lv
<400> 3
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile
35 40 45
Tyr Phe Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Thr Val Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 4
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding Bevacizumab-Lv
<400> 4
gatattcaga tgactcagag cccctcctcc ctgtccgcct ctgtgggcga cagggtcacc 60
atcacatgca gtgcttcaca ggatatttcc aactacctga attggtatca gcagaagcca 120
ggaaaagcac ccaaggtgct gatctacttc actagctccc tgcactcagg agtgccaagc 180
cggttcagcg gatccggatc tggaaccgac tttactctga ccatttctag tctgcagcct 240
gaggatttcg ctacatacta ttgccagcag tattctaccg tgccatggac atttggccag 300
gggactaaag tcgagatcaa g 321
<210> 5
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> VH of 14C12
<400> 5
Glu Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Thr Ile Ser Gly Gly Gly Arg Tyr Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Arg Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ser Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Asn Arg Tyr Gly Glu Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ala
115
<210> 6
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding VH of 14C12
<400> 6
gaggtcaaac tggtggagag cggcggcggg ctggtgaagc ccggcgggtc actgaaactg 60
agctgcgccg cttccggctt cgcctttagc tcctacgaca tgtcatgggt gaggcagacc 120
cctgagaagc gcctggaatg ggtcgctact atcagcggag gcgggcgata cacctactat 180
cctgactctg tcaaagggag attcacaatt agtcgggata acgccagaaa tactctgtat 240
ctgcagatgt ctagtctgcg gtccgaggat acagctctgt actattgtgc aaaccggtac 300
ggcgaagcat ggtttgccta ttggggacag ggcaccctgg tgacagtctc tgcc 354
<210> 7
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> VL of 14C12
<400> 7
Asp Ile Lys Met Thr Gln Ser Pro Ser Ser Met Tyr Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Phe Thr Cys Lys Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Ser Leu Thr Ile Ser Ser Leu Glu Tyr
65 70 75 80
Glu Asp Met Gly Ile Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 8
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding VL of 14C12
<400> 8
gacattaaga tgacacagtc cccttcctca atgtacgcta gcctgggcga gcgagtgacc 60
ttcacatgca aagcatccca ggacatcaac acatacctgt cttggtttca gcagaagcca 120
ggcaaaagcc ccaagaccct gatctaccgg gccaatagac tggtggacgg ggtccccagc 180
agattctccg gatctggcag tgggcaggat tactccctga ccatcagctc cctggagtat 240
gaagacatgg gcatctacta ttgcctgcag tatgatgagt tccctctgac ctttggagca 300
ggcacaaaac tggaactgaa g 321
<210> 9
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> VH of 14C12H1L1
<400> 9
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Asp Trp Val
35 40 45
Ala Thr Ile Ser Gly Gly Gly Arg Tyr Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Asn Arg Tyr Gly Glu Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 10
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding VH of 14C12H1L1
<400> 10
gaagtgcagc tggtcgagtc tgggggaggg ctggtgcagc ccggcgggtc actgcgactg 60
agctgcgcag cttccggatt cgcctttagc tcctacgaca tgtcctgggt gcgacaggca 120
ccaggaaagg gactggattg ggtcgctact atctcaggag gcgggagata cacctactat 180
cctgacagcg tcaagggccg gttcacaatc tctagagata acagtaagaa caatctgtat 240
ctgcagatga acagcctgag ggctgaggac accgcactgt actattgtgc caaccgctac 300
ggggaagcat ggtttgccta ttgggggcag ggaaccctgg tgacagtctc tagt 354
<210> 11
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> VL of 14C12H1L1
<400> 11
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Met Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Phe Thr Cys Arg Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Met Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 12
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding VL of 14C12H1L1
<400> 12
gacattcaga tgactcagag cccctcctcc atgtccgcct ctgtgggcga cagggtcacc 60
ttcacatgcc gcgctagtca ggatatcaac acctacctga gctggtttca gcagaagcca 120
gggaaaagcc ccaagacact gatctaccgg gctaatagac tggtgtctgg agtcccaagt 180
cggttcagtg gctcagggag cggacaggac tacactctga ccatcagctc cctgcagcct 240
gaggacatgg caacctacta ttgcctgcag tatgatgagt tcccactgac ctttggcgcc 300
gggacaaaac tggagctgaa g 321
<210> 13
<211> 448
<212> PRT
<213> Artificial Sequence
<220>
<223> heavy chain of 14C12H1L1
<400> 13
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Asp Trp Val
35 40 45
Ala Thr Ile Ser Gly Gly Gly Arg Tyr Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Asn Arg Tyr Gly Glu Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro
115 120 125
Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly
130 135 140
Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn
145 150 155 160
Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln
165 170 175
Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser
180 185 190
Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser
195 200 205
Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr
210 215 220
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
225 230 235 240
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
245 250 255
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
260 265 270
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
275 280 285
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
290 295 300
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
305 310 315 320
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
325 330 335
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
340 345 350
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
355 360 365
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
370 375 380
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
385 390 395 400
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
405 410 415
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
420 425 430
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
435 440 445
<210> 14
<211> 1344
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding heavy chain of 14C12H1L1
<400> 14
gaagtgcagc tggtcgagtc tgggggaggg ctggtgcagc ccggcgggtc actgcgactg 60
agctgcgcag cttccggatt cgcctttagc tcctacgaca tgtcctgggt gcgacaggca 120
ccaggaaagg gactggattg ggtcgctact atctcaggag gcgggagata cacctactat 180
cctgacagcg tcaagggccg gttcacaatc tctagagata acagtaagaa caatctgtat 240
ctgcagatga acagcctgag ggctgaggac accgcactgt actattgtgc caaccgctac 300
ggggaagcat ggtttgccta ttgggggcag ggaaccctgg tgacagtctc tagtgccagc 360
accaaaggac ctagcgtgtt tcctctcgcc ccctcctcca aaagcaccag cggaggaacc 420
gctgctctcg gatgtctggt gaaggactac ttccctgaac ccgtcaccgt gagctggaat 480
agcggcgctc tgacaagcgg agtccataca ttccctgctg tgctgcaaag cagcggactc 540
tattccctgt ccagcgtcgt cacagtgccc agcagcagcc tgggcaccca gacctacatc 600
tgtaacgtca accacaagcc ctccaacacc aaggtggaca agaaagtgga gcccaaatcc 660
tgcgacaaga cacacacctg tcccccctgt cctgctcccg aactcctcgg aggccctagc 720
gtcttcctct ttcctcccaa acccaaggac accctcatga tcagcagaac ccctgaagtc 780
acctgtgtcg tcgtggatgt cagccatgag gaccccgagg tgaaattcaa ctggtatgtc 840
gatggcgtcg aggtgcacaa cgccaaaacc aagcccaggg aggaacagta caactccacc 900
tacagggtgg tgtccgtgct gacagtcctc caccaggact ggctgaacgg caaggagtac 960
aagtgcaagg tgtccaacaa ggctctccct gcccccattg agaagaccat cagcaaggcc 1020
aaaggccaac ccagggagcc ccaggtctat acactgcctc cctccaggga cgaactcacc 1080
aagaaccagg tgtccctgac ctgcctggtc aagggctttt atcccagcga catcgccgtc 1140
gagtgggagt ccaacggaca gcccgagaat aactacaaga ccacccctcc tgtcctcgac 1200
tccgacggct ccttcttcct gtacagcaag ctgaccgtgg acaaaagcag gtggcagcag 1260
ggaaacgtgt tctcctgcag cgtgatgcac gaagccctcc acaaccacta cacccagaaa 1320
agcctgtccc tgagccccgg caaa 1344
<210> 15
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> light chain of 14C12H1L1
<400> 15
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Met Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Phe Thr Cys Arg Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Met Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 16
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> lnucleic acid encoding ight chain of 14C12H1L1
<400> 16
gacattcaga tgactcagag cccctcctcc atgtccgcct ctgtgggcga cagggtcacc 60
ttcacatgcc gcgctagtca ggatatcaac acctacctga gctggtttca gcagaagcca 120
gggaaaagcc ccaagacact gatctaccgg gctaatagac tggtgtctgg agtcccaagt 180
cggttcagtg gctcagggag cggacaggac tacactctga ccatcagctc cctgcagcct 240
gaggacatgg caacctacta ttgcctgcag tatgatgagt tcccactgac ctttggcgcc 300
gggacaaaac tggagctgaa gcgaactgtg gccgctccct ccgtcttcat ttttccccct 360
tctgacgaac agctgaaatc aggcacagcc agcgtggtct gtctgctgaa caatttctac 420
cctagagagg caaaagtgca gtggaaggtc gataacgccc tgcagtccgg caacagccag 480
gagagtgtga ctgaacagga ctcaaaagat agcacctatt ccctgtctag tacactgact 540
ctgtccaagg ctgattacga gaagcacaaa gtgtatgcat gcgaagtgac acatcaggga 600
ctgtcaagcc ccgtgactaa gtcttttaac cggggcgaat gt 642
<210> 17
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> light chain of 14C12H1L1(M)1
<400> 17
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Met Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Phe Thr Cys Arg Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Met Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg
100 105
<210> 18
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker 1
<400> 18
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 19
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> linker 2
<400> 19
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 20
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> Bevacizumab-G4H
<400> 20
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Ala Asp Phe
50 55 60
Lys Arg Arg Phe Thr Phe Ser Leu Asp Thr Ser Lys Ser Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
225 230 235 240
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 21
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding Bevacizumab-G4H
<400> 21
gaggtgcagc tggtcgagtc cggggggggg ctggtgcagc caggcgggtc tctgaggctg 60
agttgcgccg cttcagggta caccttcaca aactatggaa tgaattgggt gcgccaggca 120
ccaggaaagg gactggagtg ggtcggctgg atcaacactt acaccgggga acctacctat 180
gcagccgact ttaagcggcg gttcaccttc agcctggata caagcaaatc cactgcctac 240
ctgcagatga acagcctgcg agctgaggac accgcagtct actattgtgc taaatatccc 300
cactactatg ggagcagcca ttggtatttt gacgtgtggg ggcaggggac tctggtgaca 360
gtgagcagcg caagcaccaa agggcccagc gtgtttcctc tcgccccctc ctccaaaagc 420
accagcggag gaaccgctgc tctcggatgt ctggtgaagg actacttccc tgaacccgtc 480
accgtgagct ggaatagcgg cgctctgaca agcggagtcc atacattccc tgctgtgctg 540
caaagcagcg gactctattc cctgtccagc gtcgtcacag tgcccagcag cagcctgggc 600
acccagacct acatctgtaa cgtcaaccac aagccctcca acaccaaggt ggacaagaaa 660
gtggagccca aatcctgcga caagacacac acctgtcccc cctgtcctgc tcccgaactc 720
ctcggaggcc ctagcgtctt cctctttcct cccaaaccca aggacaccct catgatcagc 780
agaacccctg aagtcacctg tgtcgtcgtg gatgtcagcc atgaggaccc cgaggtgaaa 840
ttcaactggt atgtcgatgg cgtcgaggtg cacaacgcca aaaccaagcc cagggaggaa 900
cagtacaact ccacctacag ggtggtgtcc gtgctgacag tcctccacca ggactggctg 960
aacggcaagg agtacaagtg caaggtgtcc aacaaggctc tccctgcccc cattgagaag 1020
accatcagca aggccaaagg ccaacccagg gagccccagg tctatacact gcctccctcc 1080
agggacgaac tcaccaagaa ccaggtgtcc ctgacctgcc tggtcaaggg cttttatccc 1140
agcgacatcg ccgtcgagtg ggagtccaac ggacagcccg agaataacta caagaccacc 1200
cctcctgtcc tcgactccga cggctccttc ttcctgtaca gcaaactgac cgtcgataaa 1260
tctaggtggc agcagggcaa cgtgttctct tgttccgtga tgcatgaagc actgcacaac 1320
cattataccc agaagtctct gagcctgtcc cccggcaag 1359
<210> 22
<211> 450
<212> PRT
<213> Artificial Sequence
<220>
<223> heavy chain of VP101(hG4WT)
<400> 22
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Ala Asp Phe
50 55 60
Lys Arg Arg Phe Thr Phe Ser Leu Asp Thr Ser Lys Ser Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val
195 200 205
Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys
210 215 220
Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly
225 230 235 240
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
245 250 255
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu
260 265 270
Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
275 280 285
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg
290 295 300
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
305 310 315 320
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
325 330 335
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
340 345 350
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
355 360 365
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
370 375 380
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
385 390 395 400
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
405 410 415
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
420 425 430
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
435 440 445
Gly Lys
450
<210> 23
<211> 1350
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding heavy chain of VP101(hG4WT)
<400> 23
gaggtgcagc tggtcgagtc cggggggggg ctggtgcagc caggcgggtc tctgaggctg 60
agttgcgccg cttcagggta caccttcaca aactatggaa tgaattgggt gcgccaggca 120
ccaggaaagg gactggagtg ggtcggctgg atcaacactt acaccgggga acctacctat 180
gcagccgact ttaagcggcg gttcaccttc agcctggata caagcaaatc cactgcctac 240
ctgcagatga acagcctgcg agctgaggac accgcagtct actattgtgc taaatatccc 300
cactactatg ggagcagcca ttggtatttt gacgtgtggg ggcaggggac tctggtgaca 360
gtgagcagcg caagcaccaa agggccctcg gtcttccccc tggcgccctg ctccaggagc 420
acctccgaga gcacagccgc cctgggctgc ctggtcaagg actacttccc cgaaccggtg 480
acggtgtcgt ggaactcagg cgccctgacc agcggcgtgc acaccttccc ggctgtccta 540
cagtcctcag gactctactc cctcagcagc gtggtgaccg tgccctccag cagcttgggc 600
acgaagacct acacctgcaa cgtagatcac aagcccagca acaccaaggt ggacaagaga 660
gttgagtcca aatatggtcc cccatgccca ccatgcccag cacctgagtt cctgggggga 720
ccatcagtct tcctgttccc cccaaaaccc aaggacactc tcatgatctc ccggacccct 780
gaggtcacgt gcgtggtggt ggacgtgagc caggaagacc ccgaggtcca gttcaactgg 840
tacgtggatg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagttcaac 900
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaacggcaag 960
gagtacaagt gcaaggtctc caacaaaggc ctcccgtcct ccatcgagaa aaccatctcc 1020
aaagccaaag ggcagccccg agagccacag gtgtacaccc tgcccccatc ccaggaggag 1080
atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctaccc cagcgacatc 1140
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 1200
ctggactccg acggctcctt cttcctctac agcaggctaa ccgtggacaa gagcaggtgg 1260
caggagggga atgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacaca 1320
cagaagtctc tgagcctgtc cctcggcaag 1350
<210> 24
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin heavy chain of VP101(hG1DM)
<400> 24
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Ala Asp Phe
50 55 60
Lys Arg Arg Phe Thr Phe Ser Leu Asp Thr Ser Lys Ser Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala
225 230 235 240
Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys
450
<210> 25
<211> 1359
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding Immunoglobulin heavy chain of VP101(hG1DM)
<400> 25
gaggtgcagc tggtcgagtc cggggggggg ctggtgcagc caggcgggtc tctgaggctg 60
agttgcgccg cttcagggta caccttcaca aactatggaa tgaattgggt gcgccaggca 120
ccaggaaagg gactggagtg ggtcggctgg atcaacactt acaccgggga acctacctat 180
gcagccgact ttaagcggcg gttcaccttc agcctggata caagcaaatc cactgcctac 240
ctgcagatga acagcctgcg agctgaggac accgcagtct actattgtgc taaatatccc 300
cactactatg ggagcagcca ttggtatttt gacgtgtggg ggcaggggac tctggtgaca 360
gtgagcagcg caagcaccaa agggcccagc gtgtttcctc tcgccccctc ctccaaaagc 420
accagcggag gaaccgctgc tctcggatgt ctggtgaagg actacttccc tgaacccgtc 480
accgtgagct ggaatagcgg cgctctgaca agcggagtcc atacattccc tgctgtgctg 540
caaagcagcg gactctattc cctgtccagc gtcgtcacag tgcccagcag cagcctgggc 600
acccagacct acatctgtaa cgtcaaccac aagccctcca acaccaaggt ggacaagaaa 660
gtggagccca aatcctgcga caagacacac acctgtcccc cctgtcctgc tcccgaagct 720
gctggaggcc ctagcgtctt cctctttcct cccaaaccca aggacaccct catgatcagc 780
agaacccctg aagtcacctg tgtcgtcgtg gatgtcagcc atgaggaccc cgaggtgaaa 840
ttcaactggt atgtcgatgg cgtcgaggtg cacaacgcca aaaccaagcc cagggaggaa 900
cagtacaact ccacctacag ggtggtgtcc gtgctgacag tcctccacca ggactggctg 960
aacggcaagg agtacaagtg caaggtgtcc aacaaggctc tccctgcccc cattgagaag 1020
accatcagca aggccaaagg ccaacccagg gagccccagg tctatacact gcctccctcc 1080
agggacgaac tcaccaagaa ccaggtgtcc ctgacctgcc tggtcaaggg cttttatccc 1140
agcgacatcg ccgtcgagtg ggagtccaac ggacagcccg agaataacta caagaccacc 1200
cctcctgtcc tcgactccga cggctccttc ttcctgtaca gcaaactgac cgtcgataaa 1260
tctaggtggc agcagggcaa cgtgttctct tgttccgtga tgcatgaagc actgcacaac 1320
cattataccc agaagtctct gagcctgtcc cccggcaag 1359
<210> 26
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunoglobulin light chain of VP101(hG1DM)
<400> 26
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile
35 40 45
Tyr Phe Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Thr Val Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 27
<211> 642
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid encoding Immunoglobulin light chain of VP101(hG1DM)
<400> 27
gatattcaga tgactcagag cccctcctcc ctgtccgcct ctgtgggcga cagggtcacc 60
atcacatgca gtgcttcaca ggatatttcc aactacctga attggtatca gcagaagcca 120
ggaaaagcac ccaaggtgct gatctacttc actagctccc tgcactcagg agtgccaagc 180
cggttcagcg gatccggatc tggaaccgac tttactctga ccatttctag tctgcagcct 240
gaggatttcg ctacatacta ttgccagcag tattctaccg tgccatggac atttggccag 300
gggactaaag tcgagatcaa gcggaccgtg gccgctccca gtgtcttcat ttttccccct 360
agcgacgaac agctgaaatc cgggacagcc tctgtggtct gtctgctgaa caacttctac 420
cctagagagg caaaagtgca gtggaaggtc gataacgccc tgcagagtgg caattcacag 480
gagagcgtga cagaacagga ctccaaagat tctacttata gtctgtcaag cacactgact 540
ctgagcaagg ctgactacga aaagcataaa gtgtatgcat gtgaggtcac ccaccagggg 600
ctgagcagtc cagtcaccaa gtcattcaac agaggcgagt gc 642
<210> 28
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> HCDR1
<400> 28
Gly Tyr Thr Phe Thr Asn Tyr Gly
1 5
<210> 29
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> HCDR2
<400> 29
Ile Asn Thr Tyr Thr Gly Glu Pro
1 5
<210> 30
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> HCDR3
<400> 30
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
1 5 10 15
<210> 31
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> LCDR1
<400> 31
Gln Asp Ile Ser Asn Tyr
1 5
<210> 32
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> LCDR2
<400> 32
Phe Thr Ser
1
<210> 33
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LCDR3
<400> 33
Gln Gln Tyr Ser Thr Val Pro Trp Thr
1 5
<210> 34
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> HCDR1
<400> 34
Gly Phe Ala Phe Ser Ser Tyr Asp
1 5
<210> 35
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> HCDR2
<400> 35
Ile Ser Gly Gly Gly Arg Tyr Thr
1 5
<210> 36
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> HCDR3
<400> 36
Ala Asn Arg Tyr Gly Glu Ala Trp Phe Ala Tyr
1 5 10
<210> 37
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> LCDR1
<400> 37
Gln Asp Ile Asn Thr Tyr
1 5
<210> 38
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> LCDR2
<400> 38
Arg Ala Asn
1
<210> 39
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> LCDR3
<400> 39
Leu Gln Tyr Asp Glu Phe Pro Leu Thr
1 5
<210> 40
<211> 330
<212> PRT
<213> Artificial Sequence
<220>
<223> Ig gamma-1 chain C region
<400> 40
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 41
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> Ig gamma-4 chain C region
<400> 41
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Ser Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 42
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Ig kappa chain C region
<400> 42
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
Claims (25)
- 하기의 구성을 포함하는, 이중특이항체:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
상기 제1단백질 기능부위는 면역글로불린이고, 상기 제2단백질 기능부위는 단일사슬항체이고; 또는, 상기 제1단백질 기능부위는 단일사슬항체이고, 상기 제2단백질 기능부위는 면역글로불린이고;
상기 면역글로불린은 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 상기 단일사슬항체는 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
또는,
상기 면역글로불린은 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 상기 단일사슬항체는 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
상기 면역글로불린은 인간 IgG1 아형이고;
상기 면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 234, 235 및 237 위치 중 어느 2 또는 3곳에 돌연변이를 가지고, 상기 이중특이항체의 FcγRIIIa 및/또는 C1q에 대한 친화도 상수 (affinity constant)가 돌연변이 발생 전과 비교하여 돌연변이 발생 후 감소하고; 바람직하게는, 친화도 상수는 포르테비오 옥텟 시스템 (Fortebio Octet system)으로 측정되는 것임. - 제1항에 있어서, 상기 면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 하기의 돌연변이를 가지는 것인, 이중특이항체:
L234A 및 L235A;
L234A 및 G237A;
L235A 및 G237A;
또는
L234A, L235A 및 G237A. - 하기의 구성을 포함하는, 이중특이항체:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
상기 제1단백질 기능부위는 면역글로불린이고, 상기 제2단백질 기능부위는 단일사슬항체이고; 또는, 상기 제1단백질 기능부위는 단일사슬항체이고, 상기 제2단백질 기능부위는 면역글로불린이고;
상기 면역글로불린은 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33로 제시된 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 상기 단일사슬항체는 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
또는,
상기 면역글로불린은 중쇄 가변부위가 각각 서열번호 34 내지 36의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 37 내지 39의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고; 상기 단일사슬항체는 중쇄 가변부위가 각각 서열번호 28 내지 30의 아미노산 서열로 이루어진 HCDR1 내지 HCDR3을 포함하고, 경쇄 가변부위가 각각 서열번호 31 내지 33의 아미노산 서열로 이루어진 LCDR1 내지 LCDR3을 포함하고;
상기 면역글로불린은 인간 IgG1 아형이고;
상기 면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 하기의 돌연변이를 가지는 것임:
L234A 및 L235A;
L234A 및 G237A;
L235A 및 G237A; 또는
L234A, L235A 및 G237A. - 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 면역글로불린의 중쇄 불변부위는, EU 넘버링 시스템에 따라, 하기에서 선택된 하나 이상의 돌연변이를 가지는 것인, 이중특이항체:
N297A, D265A, D270A, P238D, L328E, E233D, H268D, P271G, A330R, C226S, C229S, E233P, P331S, S267E, L328F, A330L, M252Y, S254T, T256E, N297Q, P238S, P238A, A327Q, A327G, P329A, K322A, T394D, G236R, G236A, L328R, A330S, P331S, H268A, E318A 및 K320A. - 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위의 아미노산 서열은 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 5 및 서열번호 9에서 선택되고, 상기 단일사슬항체의 경쇄 가변부위의 아미노산 서열은 서열번호 7, 서열번호 11 및 서열번호 17에서 선택되고;
또는,
상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 5 및 서열번호 9에서 선택되고, 상기 면역글로불린의 경쇄 가변부위의 아미노산 서열은 서열번호 7, 서열번호 11 및 서열번호 17에서 선택되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위의 아미노산 서열은 서열번호 3으로 제시되는 것인, 이중특이항체. - 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 이중특이항체는 하기 (1) 내지 (12)에서 선택되는 어느 하나인 것인, 이중특이항체:
(1) 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위는 서열번호 5로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 7로 제시되는 것이고;
(2) 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위는 서열번호 5로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 11로 제시되는 것이고;
(3) 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위는 서열번호 5로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 17로 제시되는 것이고;
(4) 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위는 서열번호 9로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 7로 제시되는 것이고;
(5) 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위는 서열번호 9로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 11로 제시되는 것이고;
(6) 상기 면역글로불린의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 3으로 제시되고; 상기 단일사슬항체의 중쇄 가변부위는 서열번호 9로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 17로 제시되는 것이고;
(7) 상기 면역글로불린의 중쇄 가변부위는 서열번호 5로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 7로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(8) 상기 면역글로불린의 중쇄 가변부위는 서열번호 5로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 11로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(9) 상기 면역글로불린의 중쇄 가변부위는 서열번호 5로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 17로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(10) 상기 면역글로불린의 중쇄 가변부위는 서열번호 9로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 7로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고;
(11) 상기 면역글로불린의 중쇄 가변부위는 서열번호 9로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 11로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것이고; 및
(12) 상기 면역글로불린의 중쇄 가변부위는 서열번호 9로 제시되고, 상기 면역글로불린의 경쇄 가변부위는 서열번호 17로 제시되고; 상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 1로 제시되고, 상기 단일사슬항체의 경쇄 가변부위는 서열번호 3으로 제시되는 것임. - 제1항 내지 제6항 중 어느 한 항에 있어서, 상기 면역글로불린의 중쇄의 아미노산 서열은 서열번호 24로 제시되고, 상기 면역글로불린의 경쇄의 아미노산 서열은 서열번호 26으로 제시되는 것인, 이중특이항체.
- 제1항 내지 제7항 중 어느 한 항에 있어서, 상기 면역글로불린 또는 이의 항원-결합 단편이 FcγR1에 약 10-7 M, 10-8 M 또는 10-9 M 미만과 같은, 약 10-6 M 미만의 친화도 상수로 결합하고; 바람직하게는, 상기 친화도 상수는 포르테비오 옥텟 시스템으로 측정되는 것인, 이중특이항체.
- 제1항 내지 제8항 중 어느 한 항에 있어서, 상기 면역글로불린 또는 이의 항원-결합 단편이 C1q에 약 10-7 M, 10-8 M 또는 10-9 M 미만과 같은, 약 10-9 M 미만의 친화도 상수로 결합하고; 바람직하게는, 상기 친화도 상수는 포르테비오 옥텟 시스템으로 측정되는 것인, 이중특이항체.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 제1단백질 기능부위는 상기 제2단백질 기능부위와 직접 또는 링커 단편을 통해 연결되고; 및/또는 상기 단일사슬항체의 중쇄 가변부위는 상기 단일사슬항체의 경쇄 가변부위와 직접 또는 링커 단편을 통해 연결되는 것인, 이중특이항체.
- 제10항에 있어서, 상기 링커 단편은 (GGGGS)n, n은 양의 정수이고; 바람직하게는, n는 1, 2, 3, 4, 5 또는 6인 것인, 이중특이항체.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 제1단백질 기능부위 및 상기 제2단백질 기능부위의 수는 각각 독립적으로 1, 2 또는 그 이상인 것인, 이중특이항체.
- 제1항 내지 제12항 중 어느 한 항에 있어서, 상기 단일사슬항체는 상기 면역글로불린의 상기 중쇄의 C-말단에 연결되는 것인, 이중특이항체.
- 하기의 구성을 포함하는, 이중특이항체:
PD-1을 표적으로 하는 제1단백질 기능부위, 및
VEGFA를 표적으로 하는 제2단백질 기능부위를 포함하고;
상기 제1단백질 기능부위의 수는 1이고, 상기 제2단백질 기능부위의 수는 2이고;
상기 제1단백질 기능부위는 면역글로불린이고, 상기 제2단백질 기능부위는 단일사슬항체이고;
상기 면역글로불린의 중쇄의 아미노산 서열은 서열번호 24로 제시되고, 상기 면역글로불린의 경쇄의 아미노산 서열은 서열번호 26으로 제시되고;
상기 단일사슬항체의 중쇄 가변부위의 아미노산 서열은 서열번호 9로 제시되고, 상기 단일사슬항체의 경쇄 가변부위의 아미노산 서열은 서열번호 17로 제시되고;
상기 단일사슬항체는 상기 면역글로불린의 중쇄의 C-말단에 연결되고;
상기 제1단백질 기능부위는 제1링커 단편을 통해 상기 제2단백질 기능부위에 연결되고; 상기 단일사슬항체의 중쇄 가변부위는 제2링커 단편을 통해 상기 단일사슬항체의 경쇄 가변부위에 연결되고; 상기 제1링커 단편과 상기 제2링커 단편은 같거나 다른 것이고;
바람직하게는, 상기 제1링커 단편 및 상기 제2링커 단편의 아미노산 서열은 서열번호 18 및 서열번호 19에서 독립적으로 선택되는 것이고;
바람직하게는, 상기 제1링커 단편 및 상기 제2링커 단편의 아미노산 서열은 서열번호 18로 제시되는 것임. - 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체를 암호화하는, 단리된 핵산 분자.
- 제15항에 따른 단리된 핵산 분자를 포함하는, 벡터.
- 제15항에 따른 단리된 핵산 분자 또는 제16항에 따른 벡터를 포함하는, 숙주세포.
- 항체 또는 이의 항원-결합 단편 및 결합된 모이어티 (conjugated moiety)를 포함하고, 상기 면역글로불린은 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체이고, 상기 결합된 모이어티는 검출 가능한 라벨이고; 바람직하게는, 상기 결합된 모이어티는 방사성 동위원소, 형광물질, 발광물질, 착색물질, 또는 효소인 것인, 콘쥬게이트.
- 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체 또는 제18항에 따른 콘쥬게이트를 포함하는, 키트로;
바람직하게는, 상기 키트는 상기 면역글로불린 또는 이의 항원 결합 단편을 특이적으로 인식할 수 있는 제2항체를 더 포함하고; 선택적으로, 상기 제2항체는 검출 가능한 라벨, 예를 들어, 방사성 동위원소, 형광물질, 발광물질, 착색물질, 또는 효소를 더 포함하는 것인, 키트. - 샘플 내의 PD-1 및/또는 VEGFA의 존재 또는 수준을 검출하기 위한 키트의 제조에서의 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체 또는 제18항에 따른 콘쥬게이트의 용도.
- 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체 또는 제18항에 따른 콘쥬게이트를 포함하고, 선택적으로, 약학적으로 허용 가능한 벡터 및/또는 부형제를 더 포함하는, 약학 조성물.
- 악성 종양의 치료 및/또는 예방을 위한 약의 제조에서의 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체 또는 제18항에 따른 콘쥬게이트의 용도로; 바람직하게는, 상기 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 상기 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 상기 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 상기 간암은 간세포 암종이고,
바람직하게는, 상기 신장 종양은 신장 세포 암종이고,
바람직하게는, 상기 유방암은 삼중 음성 유방암이고,
바람직하게는, 상기 요로상피암은 방광암인 것인, 용도. - 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체 또는 제18항에 따른 콘쥬게이트의 유효량을 이를 필요로 하는 대상에게 투여하는 단계를 포함하는, 악성 종양의 치료 및/또는 예방 방법으로; 바람직하게는, 상기 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 상기 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 상기 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 상기 간암은 간세포 암종이고,
바람직하게는, 상기 신장 종양은 신장 세포 암종이고,
바람직하게는, 상기 유방암은 삼중 음성 유방암이고,
바람직하게는, 상기 요로상피암은 방광암인 것인, 방법. - 악성 종양의 치료 및/또는 예방에 사용하기 위한 제1항 내지 제14항 중 어느 한 항에 따른 이중특이항체로; 바람직하게는, 상기 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 상기 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 상기 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 상기 간암은 간세포 암종이고,
바람직하게는, 상기 신장 종양은 신장 세포 암종이고,
바람직하게는, 상기 유방암은 삼중 음성 유방암이고,
바람직하게는, 상기 요로상피암은 방광암인 것인, 이중특이항체. - 악성 종양의 치료 및/또는 예방에 사용하기 위한 제18항에 따른 콘쥬게이트로; 바람직하게는, 상기 악성 종양은 결장암, 직장암, 폐암, 간암, 난소암, 피부암, 신경교종, 흑색종, 림프종, 신장 종양, 전립선암, 방광암, 위장관암, 유방암, 뇌암, 자궁경부암, 식도암, 고-미세부수체 불안정성(MSI-H) 및 미스매치 수선 결함 (dMMR) 암, 요로상피암, 중피종, 자궁내막암, 위 선암종, 위식도 접합부 선암종 및 백혈병에서 선택되는 것이고;
바람직하게는, 상기 폐암은 비-소세포성 폐암 또는 소세포성 폐암이고; 바람직하게는, 상기 비-소세포성 폐암은 EGFR 및/또는 ALK 감수성 돌연변이 비-소세포성 폐암이고;
바람직하게는, 상기 간암은 간세포 암종이고,
바람직하게는, 상기 신장 종양은 신장 세포 암종이고,
바람직하게는, 상기 유방암은 삼중 음성 유방암이고,
바람직하게는, 상기 요로상피암은 방광암인 것인, 콘쥬게이트.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911164156.2 | 2019-11-25 | ||
| CN201911164156 | 2019-11-25 | ||
| PCT/CN2020/131447 WO2021104302A1 (zh) | 2019-11-25 | 2020-11-25 | 抗pd-1-抗vegfa的双特异性抗体、其药物组合物及其用途 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220104033A true KR20220104033A (ko) | 2022-07-25 |
Family
ID=75923361
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227021354A KR20220104033A (ko) | 2019-11-25 | 2020-11-25 | 항-pd-1-항-vegfa 이중특이항체, 약학 조성물 및 이의 용도 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US20230027029A1 (ko) |
| EP (1) | EP4067387A4 (ko) |
| JP (1) | JP2023504003A (ko) |
| KR (1) | KR20220104033A (ko) |
| CN (1) | CN112830972A (ko) |
| AU (1) | AU2020390967A1 (ko) |
| BR (1) | BR112022010069A2 (ko) |
| CA (1) | CA3162748A1 (ko) |
| IL (1) | IL293241A (ko) |
| MX (1) | MX2022006330A (ko) |
| WO (1) | WO2021104302A1 (ko) |
| ZA (1) | ZA202206885B (ko) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024509018A (ja) * | 2021-03-12 | 2024-02-29 | 中山康方生物医▲藥▼有限公司 | 抗pd-1-抗vegfa二重特異性抗体を含有する組合せ医薬及びその使用 |
| IL305363A (en) * | 2021-04-14 | 2023-10-01 | Akeso Biopharma Inc | Anti-CD47 monoclonal antibody and use thereof |
| CN115558029B (zh) * | 2021-10-22 | 2024-01-30 | 立凌生物制药(苏州)有限公司 | 靶向pd-1的双特异性抗体、及其制备和应用 |
| CN114181310B (zh) | 2022-02-14 | 2022-07-05 | 中山康方生物医药有限公司 | 抗tigit抗体、其药物组合物及用途 |
| CN116731188A (zh) * | 2022-03-02 | 2023-09-12 | 三优生物医药(上海)有限公司 | 抗pd-l1和vegf双特异性抗体及其应用 |
| CN114736303A (zh) * | 2022-03-17 | 2022-07-12 | 英诺湖医药(杭州)有限公司 | 抗pd-l1和4-1bb的双功能抗体及其医药用途 |
| EP4321537A1 (en) | 2022-06-22 | 2024-02-14 | Akeso Biopharma, Inc. | Pharmaceutical composition and use thereof |
| WO2024051223A1 (zh) | 2022-09-09 | 2024-03-14 | 中山康方生物医药有限公司 | 药物组合及用途 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5747654A (en) | 1993-06-14 | 1998-05-05 | The United States Of America As Represented By The Department Of Health And Human Services | Recombinant disulfide-stabilized polypeptide fragments having binding specificity |
| KR100816621B1 (ko) | 1997-04-07 | 2008-03-24 | 제넨테크, 인크. | 항-vegf 항체 |
| US20040132101A1 (en) * | 2002-09-27 | 2004-07-08 | Xencor | Optimized Fc variants and methods for their generation |
| US20090148435A1 (en) * | 2007-10-30 | 2009-06-11 | Genentech, Inc. | Antibody purification by cation exchange chromatography |
| CN105175545B (zh) * | 2015-10-20 | 2019-01-25 | 安徽瀚海博兴生物技术有限公司 | 一种抗vegf-抗pd-1双功能抗体及其应用 |
| CN107151269B (zh) * | 2016-03-04 | 2021-07-27 | 四川科伦博泰生物医药股份有限公司 | 一种pdl-1抗体、其药物组合物及其用途 |
| CN106967172B (zh) | 2016-08-23 | 2019-01-08 | 康方药业有限公司 | 抗ctla4-抗pd-1 双功能抗体、其药物组合物及其用途 |
| CN106939050B (zh) * | 2017-03-27 | 2019-05-10 | 顺昊细胞生物技术(天津)股份有限公司 | 抗pd1和cd19双特异性抗体及其应用 |
| CN109963592B (zh) * | 2017-06-05 | 2022-11-22 | 江苏恒瑞医药股份有限公司 | Pd-1抗体与vegf配体或vegf受体抑制剂联合在制备治疗肿瘤的药物中的用途 |
| BR112020013133A2 (pt) * | 2017-12-29 | 2020-12-08 | Ap Biosciences, Inc. | Proteínas monospecíficas e bispecíficas com regulação do ponto de verificação imune para terapia do câncer |
| EP3750920A4 (en) * | 2018-02-11 | 2021-11-10 | Beijing Hanmi Pharmaceutical Co., Ltd. | BISPECIFIC ANTIBODY IN HETERODIMER FORM SIMILAR TO A NATURAL ANTI-PD-1 / ANTI-VEGF ANTIBODY STRUCTURE AND PRODUCTION OF IT |
| CN109053895B (zh) * | 2018-08-30 | 2020-06-09 | 中山康方生物医药有限公司 | 抗pd-1-抗vegfa的双功能抗体、其药物组合物及其用途 |
| CN110498857B (zh) * | 2019-08-09 | 2022-09-09 | 安徽瀚海博兴生物技术有限公司 | 一种抗vegf-抗pd1双特异性抗体 |
| CN110563849B (zh) * | 2019-08-09 | 2022-09-09 | 安徽瀚海博兴生物技术有限公司 | 一种抗vegf-抗pd1双特异性抗体 |
| CN110960543A (zh) * | 2019-12-10 | 2020-04-07 | 安徽瀚海博兴生物技术有限公司 | 一种联合抗vegf-抗pd1双特异性抗体用于制备抗癌药物 |
-
2020
- 2020-11-25 AU AU2020390967A patent/AU2020390967A1/en active Pending
- 2020-11-25 JP JP2022530820A patent/JP2023504003A/ja active Pending
- 2020-11-25 CN CN202011341655.7A patent/CN112830972A/zh active Pending
- 2020-11-25 WO PCT/CN2020/131447 patent/WO2021104302A1/zh active Application Filing
- 2020-11-25 KR KR1020227021354A patent/KR20220104033A/ko unknown
- 2020-11-25 US US17/779,425 patent/US20230027029A1/en active Pending
- 2020-11-25 CA CA3162748A patent/CA3162748A1/en active Pending
- 2020-11-25 EP EP20892544.6A patent/EP4067387A4/en active Pending
- 2020-11-25 IL IL293241A patent/IL293241A/en unknown
- 2020-11-25 BR BR112022010069A patent/BR112022010069A2/pt unknown
- 2020-11-25 MX MX2022006330A patent/MX2022006330A/es unknown
-
2022
- 2022-06-21 ZA ZA2022/06885A patent/ZA202206885B/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| IL293241A (en) | 2022-07-01 |
| CA3162748A1 (en) | 2021-06-03 |
| US20230027029A1 (en) | 2023-01-26 |
| MX2022006330A (es) | 2022-08-17 |
| AU2020390967A1 (en) | 2022-06-23 |
| CN112830972A (zh) | 2021-05-25 |
| EP4067387A1 (en) | 2022-10-05 |
| JP2023504003A (ja) | 2023-02-01 |
| EP4067387A4 (en) | 2023-12-27 |
| ZA202206885B (en) | 2023-04-26 |
| BR112022010069A2 (pt) | 2022-09-06 |
| WO2021104302A1 (zh) | 2021-06-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7374995B2 (ja) | 抗pd-1/抗vegfa二官能性抗体、その医薬組成物およびその使用 | |
| KR20220104033A (ko) | 항-pd-1-항-vegfa 이중특이항체, 약학 조성물 및 이의 용도 | |
| WO2021023117A1 (zh) | 抗ctla4-抗pd-1双特异性抗体及其用途 | |
| KR20160067978A (ko) | Vegf 길항제와 항-ctla-4 항체의 조합물을 포함하는 조성물 및 방법 | |
| CN112300280B (zh) | 一种抗pd-1抗体及其医药用途 | |
| CN114181310B (zh) | 抗tigit抗体、其药物组合物及用途 | |
| JP2023522730A (ja) | 抗cd73/抗pd-1二重特異性抗体及びその使用 | |
| EP4190819A1 (en) | Pharmaceutical combination containing anti-pd-1-anti-vegfa bispecific antibody, and use thereof | |
| KR20230170648A (ko) | 항-cd47 단일클론 항체 및 이의 용도 | |
| EP4357367A1 (en) | Pharmaceutical composition and use thereof | |
| WO2023160647A1 (zh) | 包含抗ctla4-抗pd-1双特异性抗体和西奥罗尼的药物组合 | |
| WO2024051223A1 (zh) | 药物组合及用途 | |
| CA3208473A1 (en) | Pharmaceutical composition and use thereof | |
| TW202243691A (zh) | 使用抗tigit抗體與抗pd1抗體組合治療癌症之方法 |