CN114181310B - 抗tigit抗体、其药物组合物及用途 - Google Patents
抗tigit抗体、其药物组合物及用途 Download PDFInfo
- Publication number
- CN114181310B CN114181310B CN202210132762.1A CN202210132762A CN114181310B CN 114181310 B CN114181310 B CN 114181310B CN 202210132762 A CN202210132762 A CN 202210132762A CN 114181310 B CN114181310 B CN 114181310B
- Authority
- CN
- China
- Prior art keywords
- antibody
- seq
- tigit
- vegfa
- antigen
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000008194 pharmaceutical composition Substances 0.000 title claims abstract description 57
- 230000027455 binding Effects 0.000 claims abstract description 122
- 239000012634 fragment Substances 0.000 claims abstract description 116
- 238000009739 binding Methods 0.000 claims abstract description 114
- 239000000427 antigen Substances 0.000 claims abstract description 112
- 108091007433 antigens Proteins 0.000 claims abstract description 111
- 102000036639 antigens Human genes 0.000 claims abstract description 111
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 100
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 claims abstract description 67
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 claims abstract description 59
- 239000003814 drug Substances 0.000 claims abstract description 50
- 229940079593 drug Drugs 0.000 claims abstract description 33
- 230000002265 prevention Effects 0.000 claims abstract description 8
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract 37
- 108090000623 proteins and genes Proteins 0.000 claims description 53
- 210000004027 cell Anatomy 0.000 claims description 51
- 102000004169 proteins and genes Human genes 0.000 claims description 46
- 108060003951 Immunoglobulin Proteins 0.000 claims description 31
- 102000018358 immunoglobulin Human genes 0.000 claims description 31
- 238000002360 preparation method Methods 0.000 claims description 24
- 210000004408 hybridoma Anatomy 0.000 claims description 23
- 239000002246 antineoplastic agent Substances 0.000 claims description 21
- 201000011510 cancer Diseases 0.000 claims description 21
- 239000000203 mixture Substances 0.000 claims description 20
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 claims description 19
- 229940127089 cytotoxic agent Drugs 0.000 claims description 15
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 14
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 claims description 14
- 101000808011 Homo sapiens Vascular endothelial growth factor A Proteins 0.000 claims description 13
- 206010009944 Colon cancer Diseases 0.000 claims description 12
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 11
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 10
- 230000035772 mutation Effects 0.000 claims description 10
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 9
- 206010033128 Ovarian cancer Diseases 0.000 claims description 9
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 9
- 201000010881 cervical cancer Diseases 0.000 claims description 9
- 230000002401 inhibitory effect Effects 0.000 claims description 8
- 201000001441 melanoma Diseases 0.000 claims description 8
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 claims description 8
- 238000004321 preservation Methods 0.000 claims description 8
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 7
- 208000034578 Multiple myelomas Diseases 0.000 claims description 7
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 claims description 7
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 7
- 239000003112 inhibitor Substances 0.000 claims description 7
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 7
- 201000002528 pancreatic cancer Diseases 0.000 claims description 7
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 7
- 230000008685 targeting Effects 0.000 claims description 7
- 208000032612 Glial tumor Diseases 0.000 claims description 6
- 206010018338 Glioma Diseases 0.000 claims description 6
- 239000003795 chemical substances by application Substances 0.000 claims description 6
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 6
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 5
- 101000840257 Homo sapiens Immunoglobulin kappa constant Proteins 0.000 claims description 5
- 101710138871 Ig gamma-1 chain C region Proteins 0.000 claims description 5
- 102100039345 Immunoglobulin heavy constant gamma 1 Human genes 0.000 claims description 5
- 102100029572 Immunoglobulin kappa constant Human genes 0.000 claims description 5
- 208000009956 adenocarcinoma Diseases 0.000 claims description 5
- 208000029742 colonic neoplasm Diseases 0.000 claims description 5
- 230000012010 growth Effects 0.000 claims description 5
- 229940124597 therapeutic agent Drugs 0.000 claims description 5
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 4
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 claims description 4
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 4
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 claims description 4
- 230000000340 anti-metabolite Effects 0.000 claims description 4
- 239000000611 antibody drug conjugate Substances 0.000 claims description 4
- 229940049595 antibody-drug conjugate Drugs 0.000 claims description 4
- 229940100197 antimetabolite Drugs 0.000 claims description 4
- 239000002256 antimetabolite Substances 0.000 claims description 4
- 229960002949 fluorouracil Drugs 0.000 claims description 4
- 206010017758 gastric cancer Diseases 0.000 claims description 4
- 229940043355 kinase inhibitor Drugs 0.000 claims description 4
- 229940124302 mTOR inhibitor Drugs 0.000 claims description 4
- 230000003211 malignant effect Effects 0.000 claims description 4
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 claims description 4
- 230000004001 molecular interaction Effects 0.000 claims description 4
- 201000000050 myeloid neoplasm Diseases 0.000 claims description 4
- 229910052697 platinum Inorganic materials 0.000 claims description 4
- 201000011549 stomach cancer Diseases 0.000 claims description 4
- 230000001225 therapeutic effect Effects 0.000 claims description 4
- 206010044412 transitional cell carcinoma Diseases 0.000 claims description 4
- 201000009030 Carcinoma Diseases 0.000 claims description 3
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 3
- 206010025323 Lymphomas Diseases 0.000 claims description 3
- 229940100198 alkylating agent Drugs 0.000 claims description 3
- 239000002168 alkylating agent Substances 0.000 claims description 3
- -1 anthracyclines Substances 0.000 claims description 3
- 229940034982 antineoplastic agent Drugs 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 3
- 208000005017 glioblastoma Diseases 0.000 claims description 3
- 239000003966 growth inhibitor Substances 0.000 claims description 3
- 238000001990 intravenous administration Methods 0.000 claims description 3
- 238000010253 intravenous injection Methods 0.000 claims description 3
- 239000007788 liquid Substances 0.000 claims description 3
- 201000005202 lung cancer Diseases 0.000 claims description 3
- 208000020816 lung neoplasm Diseases 0.000 claims description 3
- 230000001394 metastastic effect Effects 0.000 claims description 3
- 206010061289 metastatic neoplasm Diseases 0.000 claims description 3
- 239000003757 phosphotransferase inhibitor Substances 0.000 claims description 3
- 206010041823 squamous cell carcinoma Diseases 0.000 claims description 3
- KKVYYGGCHJGEFJ-UHFFFAOYSA-N 1-n-(4-chlorophenyl)-6-methyl-5-n-[3-(7h-purin-6-yl)pyridin-2-yl]isoquinoline-1,5-diamine Chemical compound N=1C=CC2=C(NC=3C(=CC=CN=3)C=3C=4N=CNC=4N=CN=3)C(C)=CC=C2C=1NC1=CC=C(Cl)C=C1 KKVYYGGCHJGEFJ-UHFFFAOYSA-N 0.000 claims description 2
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 2
- 208000003200 Adenoma Diseases 0.000 claims description 2
- 206010001233 Adenoma benign Diseases 0.000 claims description 2
- 102000015790 Asparaginase Human genes 0.000 claims description 2
- 108010024976 Asparaginase Proteins 0.000 claims description 2
- 206010004146 Basal cell carcinoma Diseases 0.000 claims description 2
- 206010005003 Bladder cancer Diseases 0.000 claims description 2
- 206010005949 Bone cancer Diseases 0.000 claims description 2
- 208000018084 Bone neoplasm Diseases 0.000 claims description 2
- 102000053642 Catalytic RNA Human genes 0.000 claims description 2
- 108090000994 Catalytic RNA Proteins 0.000 claims description 2
- 208000005243 Chondrosarcoma Diseases 0.000 claims description 2
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 claims description 2
- 208000007033 Dysgerminoma Diseases 0.000 claims description 2
- 229940122558 EGFR antagonist Drugs 0.000 claims description 2
- 206010014733 Endometrial cancer Diseases 0.000 claims description 2
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 2
- 229930189413 Esperamicin Natural products 0.000 claims description 2
- 201000001342 Fallopian tube cancer Diseases 0.000 claims description 2
- 208000013452 Fallopian tube neoplasm Diseases 0.000 claims description 2
- 101710113436 GTPase KRas Proteins 0.000 claims description 2
- 206010017993 Gastrointestinal neoplasms Diseases 0.000 claims description 2
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 claims description 2
- 108010069236 Goserelin Proteins 0.000 claims description 2
- 208000002250 Hematologic Neoplasms Diseases 0.000 claims description 2
- 206010073073 Hepatobiliary cancer Diseases 0.000 claims description 2
- 208000017604 Hodgkin disease Diseases 0.000 claims description 2
- 208000021519 Hodgkin lymphoma Diseases 0.000 claims description 2
- 208000010747 Hodgkins lymphoma Diseases 0.000 claims description 2
- 208000005016 Intestinal Neoplasms Diseases 0.000 claims description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 claims description 2
- 208000018142 Leiomyosarcoma Diseases 0.000 claims description 2
- 206010025598 Malignant hydatidiform mole Diseases 0.000 claims description 2
- 206010027406 Mesothelioma Diseases 0.000 claims description 2
- 241001529936 Murinae Species 0.000 claims description 2
- 101100381978 Mus musculus Braf gene Proteins 0.000 claims description 2
- 208000031888 Mycoses Diseases 0.000 claims description 2
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 claims description 2
- 208000001894 Nasopharyngeal Neoplasms Diseases 0.000 claims description 2
- 206010061306 Nasopharyngeal cancer Diseases 0.000 claims description 2
- 206010029260 Neuroblastoma Diseases 0.000 claims description 2
- 229930012538 Paclitaxel Natural products 0.000 claims description 2
- 208000027190 Peripheral T-cell lymphomas Diseases 0.000 claims description 2
- 206010060862 Prostate cancer Diseases 0.000 claims description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 2
- 229940079156 Proteasome inhibitor Drugs 0.000 claims description 2
- 229940078123 Ras inhibitor Drugs 0.000 claims description 2
- 208000015634 Rectal Neoplasms Diseases 0.000 claims description 2
- 206010038389 Renal cancer Diseases 0.000 claims description 2
- 206010039491 Sarcoma Diseases 0.000 claims description 2
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 2
- 206010041067 Small cell lung cancer Diseases 0.000 claims description 2
- 208000031672 T-Cell Peripheral Lymphoma Diseases 0.000 claims description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 claims description 2
- 206010057644 Testis cancer Diseases 0.000 claims description 2
- 208000000728 Thymus Neoplasms Diseases 0.000 claims description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 2
- 208000003721 Triple Negative Breast Neoplasms Diseases 0.000 claims description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 claims description 2
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 claims description 2
- 229940045799 anthracyclines and related substance Drugs 0.000 claims description 2
- 239000003242 anti bacterial agent Substances 0.000 claims description 2
- 229940044684 anti-microtubule agent Drugs 0.000 claims description 2
- 239000000051 antiandrogen Substances 0.000 claims description 2
- 229940088710 antibiotic agent Drugs 0.000 claims description 2
- 239000013059 antihormonal agent Substances 0.000 claims description 2
- 239000003972 antineoplastic antibiotic Substances 0.000 claims description 2
- 239000000074 antisense oligonucleotide Substances 0.000 claims description 2
- 238000012230 antisense oligonucleotides Methods 0.000 claims description 2
- 239000003886 aromatase inhibitor Substances 0.000 claims description 2
- 229960003272 asparaginase Drugs 0.000 claims description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-M asparaginate Chemical compound [O-]C(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-M 0.000 claims description 2
- 201000009036 biliary tract cancer Diseases 0.000 claims description 2
- 208000020790 biliary tract neoplasm Diseases 0.000 claims description 2
- 229930195731 calicheamicin Natural products 0.000 claims description 2
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 claims description 2
- 229960004562 carboplatin Drugs 0.000 claims description 2
- 190000008236 carboplatin Chemical compound 0.000 claims description 2
- 239000002738 chelating agent Substances 0.000 claims description 2
- 229940044683 chemotherapy drug Drugs 0.000 claims description 2
- 208000006990 cholangiocarcinoma Diseases 0.000 claims description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 claims description 2
- 229960004316 cisplatin Drugs 0.000 claims description 2
- 229960004397 cyclophosphamide Drugs 0.000 claims description 2
- 231100000599 cytotoxic agent Toxicity 0.000 claims description 2
- 230000002950 deficient Effects 0.000 claims description 2
- 239000003534 dna topoisomerase inhibitor Substances 0.000 claims description 2
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 claims description 2
- 238000000684 flow cytometry Methods 0.000 claims description 2
- 201000006585 gastric adenocarcinoma Diseases 0.000 claims description 2
- 201000007492 gastroesophageal junction adenocarcinoma Diseases 0.000 claims description 2
- 229960002913 goserelin Drugs 0.000 claims description 2
- 201000010536 head and neck cancer Diseases 0.000 claims description 2
- 208000014829 head and neck neoplasm Diseases 0.000 claims description 2
- 206010073071 hepatocellular carcinoma Diseases 0.000 claims description 2
- 231100000844 hepatocellular carcinoma Toxicity 0.000 claims description 2
- 229940121372 histone deacetylase inhibitor Drugs 0.000 claims description 2
- 239000003276 histone deacetylase inhibitor Substances 0.000 claims description 2
- 201000002313 intestinal cancer Diseases 0.000 claims description 2
- 201000010982 kidney cancer Diseases 0.000 claims description 2
- 208000032839 leukemia Diseases 0.000 claims description 2
- 150000002632 lipids Chemical class 0.000 claims description 2
- 201000007270 liver cancer Diseases 0.000 claims description 2
- 208000014018 liver neoplasm Diseases 0.000 claims description 2
- 208000020968 mature T-cell and NK-cell non-Hodgkin lymphoma Diseases 0.000 claims description 2
- 229960001786 megestrol Drugs 0.000 claims description 2
- RQZAXGRLVPAYTJ-GQFGMJRRSA-N megestrol acetate Chemical compound C1=C(C)C2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(C)=O)(OC(=O)C)[C@@]1(C)CC2 RQZAXGRLVPAYTJ-GQFGMJRRSA-N 0.000 claims description 2
- 230000033607 mismatch repair Effects 0.000 claims description 2
- 239000002829 mitogen activated protein kinase inhibitor Substances 0.000 claims description 2
- 108010093470 monomethyl auristatin E Proteins 0.000 claims description 2
- 208000010492 mucinous cystadenocarcinoma Diseases 0.000 claims description 2
- 201000002120 neuroendocrine carcinoma Diseases 0.000 claims description 2
- 201000008968 osteosarcoma Diseases 0.000 claims description 2
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 claims description 2
- 229960001756 oxaliplatin Drugs 0.000 claims description 2
- 229960001592 paclitaxel Drugs 0.000 claims description 2
- 229960005079 pemetrexed Drugs 0.000 claims description 2
- QOFFJEBXNKRSPX-ZDUSSCGKSA-N pemetrexed Chemical compound C1=N[C]2NC(N)=NC(=O)C2=C1CCC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 QOFFJEBXNKRSPX-ZDUSSCGKSA-N 0.000 claims description 2
- 201000002628 peritoneum cancer Diseases 0.000 claims description 2
- 239000002935 phosphatidylinositol 3 kinase inhibitor Substances 0.000 claims description 2
- 239000003207 proteasome inhibitor Substances 0.000 claims description 2
- 239000003197 protein kinase B inhibitor Substances 0.000 claims description 2
- 239000003909 protein kinase inhibitor Substances 0.000 claims description 2
- 206010038038 rectal cancer Diseases 0.000 claims description 2
- 201000001275 rectum cancer Diseases 0.000 claims description 2
- 230000000306 recurrent effect Effects 0.000 claims description 2
- 201000009410 rhabdomyosarcoma Diseases 0.000 claims description 2
- 108091092562 ribozyme Proteins 0.000 claims description 2
- 208000004548 serous cystadenocarcinoma Diseases 0.000 claims description 2
- 201000000849 skin cancer Diseases 0.000 claims description 2
- 208000000587 small cell lung carcinoma Diseases 0.000 claims description 2
- 241000894007 species Species 0.000 claims description 2
- 229960001603 tamoxifen Drugs 0.000 claims description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 claims description 2
- 201000003120 testicular cancer Diseases 0.000 claims description 2
- 201000009377 thymus cancer Diseases 0.000 claims description 2
- 201000002510 thyroid cancer Diseases 0.000 claims description 2
- 229940044693 topoisomerase inhibitor Drugs 0.000 claims description 2
- 208000022679 triple-negative breast carcinoma Diseases 0.000 claims description 2
- 239000005483 tyrosine kinase inhibitor Substances 0.000 claims description 2
- 229940121358 tyrosine kinase inhibitor Drugs 0.000 claims description 2
- 150000004917 tyrosine kinase inhibitor derivatives Chemical class 0.000 claims description 2
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 2
- 229960003048 vinblastine Drugs 0.000 claims description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 claims description 2
- 238000009472 formulation Methods 0.000 claims 19
- 108020001580 protein domains Proteins 0.000 claims 4
- 238000004519 manufacturing process Methods 0.000 claims 2
- 108020000948 Antisense Oligonucleotides Proteins 0.000 claims 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims 1
- 108091092878 Microsatellite Proteins 0.000 claims 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims 1
- 208000007452 Plasmacytoma Diseases 0.000 claims 1
- 206010043515 Throat cancer Diseases 0.000 claims 1
- 230000000118 anti-neoplastic effect Effects 0.000 claims 1
- 229940045988 antineoplastic drug protein kinase inhibitors Drugs 0.000 claims 1
- 229940046844 aromatase inhibitors Drugs 0.000 claims 1
- 230000000973 chemotherapeutic effect Effects 0.000 claims 1
- 239000002254 cytotoxic agent Substances 0.000 claims 1
- 208000024558 digestive system cancer Diseases 0.000 claims 1
- 201000004101 esophageal cancer Diseases 0.000 claims 1
- 201000010231 gastrointestinal system cancer Diseases 0.000 claims 1
- 229940125697 hormonal agent Drugs 0.000 claims 1
- 238000004806 packaging method and process Methods 0.000 claims 1
- 150000001413 amino acids Chemical group 0.000 description 106
- 235000001014 amino acid Nutrition 0.000 description 31
- 230000000694 effects Effects 0.000 description 31
- 239000002773 nucleotide Substances 0.000 description 30
- 125000003729 nucleotide group Chemical group 0.000 description 27
- 235000018102 proteins Nutrition 0.000 description 25
- 239000002299 complementary DNA Substances 0.000 description 20
- 238000000034 method Methods 0.000 description 20
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 19
- 238000001514 detection method Methods 0.000 description 17
- 108020004414 DNA Proteins 0.000 description 16
- 102100029740 Poliovirus receptor Human genes 0.000 description 16
- 229960000397 bevacizumab Drugs 0.000 description 16
- 108010048507 poliovirus receptor Proteins 0.000 description 15
- 239000013598 vector Substances 0.000 description 15
- 238000002965 ELISA Methods 0.000 description 13
- 241000699666 Mus <mouse, genus> Species 0.000 description 13
- 102100035488 Nectin-2 Human genes 0.000 description 13
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 13
- 150000007523 nucleic acids Chemical class 0.000 description 13
- 239000000047 product Substances 0.000 description 13
- 210000000170 cell membrane Anatomy 0.000 description 12
- UQLDLKMNUJERMK-UHFFFAOYSA-L di(octadecanoyloxy)lead Chemical compound [Pb+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O UQLDLKMNUJERMK-UHFFFAOYSA-L 0.000 description 12
- 239000000126 substance Substances 0.000 description 12
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 11
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 description 11
- 201000010099 disease Diseases 0.000 description 11
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 11
- 108010003137 tyrosyltyrosine Proteins 0.000 description 11
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 10
- 241000699670 Mus sp. Species 0.000 description 10
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 10
- 239000000562 conjugate Substances 0.000 description 10
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 10
- 108010044292 tryptophyltyrosine Proteins 0.000 description 10
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 9
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 9
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 9
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 9
- 229960002685 biotin Drugs 0.000 description 9
- 239000011616 biotin Substances 0.000 description 9
- UVCJGUGAGLDPAA-UHFFFAOYSA-N ensulizole Chemical compound N1C2=CC(S(=O)(=O)O)=CC=C2N=C1C1=CC=CC=C1 UVCJGUGAGLDPAA-UHFFFAOYSA-N 0.000 description 9
- 108010037850 glycylvaline Proteins 0.000 description 9
- 238000011534 incubation Methods 0.000 description 9
- 210000000822 natural killer cell Anatomy 0.000 description 9
- 229920009537 polybutylene succinate adipate Polymers 0.000 description 9
- 238000011830 transgenic mouse model Methods 0.000 description 9
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 8
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 8
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 8
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 8
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 8
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 8
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 8
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 8
- 108010068265 aspartyltyrosine Proteins 0.000 description 8
- 210000004204 blood vessel Anatomy 0.000 description 8
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 8
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 8
- 108010015792 glycyllysine Proteins 0.000 description 8
- 229920001184 polypeptide Polymers 0.000 description 8
- 102000004196 processed proteins & peptides Human genes 0.000 description 8
- 108090000765 processed proteins & peptides Proteins 0.000 description 8
- 239000006228 supernatant Substances 0.000 description 8
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 7
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 7
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 7
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 7
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 7
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 7
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 7
- 210000001744 T-lymphocyte Anatomy 0.000 description 7
- IQPWNQRRAJHOKV-KATARQTJSA-N Thr-Ser-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN IQPWNQRRAJHOKV-KATARQTJSA-N 0.000 description 7
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 7
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 7
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 7
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 7
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 7
- 239000013066 combination product Substances 0.000 description 7
- 229940127555 combination product Drugs 0.000 description 7
- 102000049823 human TIGIT Human genes 0.000 description 7
- 108020004707 nucleic acids Proteins 0.000 description 7
- 102000039446 nucleic acids Human genes 0.000 description 7
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 7
- 108010073969 valyllysine Proteins 0.000 description 7
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 6
- REAQAWSENITKJL-DDWPSWQVSA-N Ala-Met-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O REAQAWSENITKJL-DDWPSWQVSA-N 0.000 description 6
- YKZJPIPFKGYHKY-DCAQKATOSA-N Arg-Leu-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YKZJPIPFKGYHKY-DCAQKATOSA-N 0.000 description 6
- 206010006187 Breast cancer Diseases 0.000 description 6
- 208000026310 Breast neoplasm Diseases 0.000 description 6
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 6
- LPCKHUXOGVNZRS-YUMQZZPRSA-N Gly-His-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O LPCKHUXOGVNZRS-YUMQZZPRSA-N 0.000 description 6
- WLRJHVNFGAOYPS-HJPIBITLSA-N Ile-Ser-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N WLRJHVNFGAOYPS-HJPIBITLSA-N 0.000 description 6
- 241000880493 Leptailurus serval Species 0.000 description 6
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 6
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 6
- 108091028043 Nucleic acid sequence Proteins 0.000 description 6
- BPIMVBKDLSBKIJ-FCLVOEFKSA-N Phe-Thr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BPIMVBKDLSBKIJ-FCLVOEFKSA-N 0.000 description 6
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 6
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 6
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 6
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 6
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 6
- CDHQEOXPWBDFPL-QWRGUYRKSA-N Tyr-Gly-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDHQEOXPWBDFPL-QWRGUYRKSA-N 0.000 description 6
- HIINQLBHPIQYHN-JTQLQIEISA-N Tyr-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 HIINQLBHPIQYHN-JTQLQIEISA-N 0.000 description 6
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 230000037396 body weight Effects 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- 108010064235 lysylglycine Proteins 0.000 description 6
- 108010051242 phenylalanylserine Proteins 0.000 description 6
- 210000004180 plasmocyte Anatomy 0.000 description 6
- 239000013641 positive control Substances 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 108010038745 tryptophylglycine Proteins 0.000 description 6
- 108010017949 tyrosyl-glycyl-glycine Proteins 0.000 description 6
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 5
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 5
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 5
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 5
- 241000283707 Capra Species 0.000 description 5
- OOLCSQQPSLIETN-JYJNAYRXSA-N Gln-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)N)N)O OOLCSQQPSLIETN-JYJNAYRXSA-N 0.000 description 5
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 5
- 101000851018 Homo sapiens Vascular endothelial growth factor receptor 1 Proteins 0.000 description 5
- ANTFEOSJMAUGIB-KNZXXDILSA-N Ile-Thr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N ANTFEOSJMAUGIB-KNZXXDILSA-N 0.000 description 5
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 5
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 5
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 5
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 5
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 5
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 5
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 5
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 5
- DGHFNYXVIXNNMC-GUBZILKMSA-N Ser-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N DGHFNYXVIXNNMC-GUBZILKMSA-N 0.000 description 5
- KDGARKCAKHBEDB-NKWVEPMBSA-N Ser-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CO)N)C(=O)O KDGARKCAKHBEDB-NKWVEPMBSA-N 0.000 description 5
- GJFYFGOEWLDQGW-GUBZILKMSA-N Ser-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GJFYFGOEWLDQGW-GUBZILKMSA-N 0.000 description 5
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 5
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 5
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 5
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 5
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 5
- FBVGQXJIXFZKSQ-GMVOTWDCSA-N Tyr-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N FBVGQXJIXFZKSQ-GMVOTWDCSA-N 0.000 description 5
- VYQQQIRHIFALGE-UWJYBYFXSA-N Tyr-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 VYQQQIRHIFALGE-UWJYBYFXSA-N 0.000 description 5
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 5
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 5
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 5
- 108010028188 glycyl-histidyl-serine Proteins 0.000 description 5
- 230000001900 immune effect Effects 0.000 description 5
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 230000035755 proliferation Effects 0.000 description 5
- 210000003556 vascular endothelial cell Anatomy 0.000 description 5
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 4
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 4
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 4
- MFDPBZAFCRKYEY-LAEOZQHASA-N Asp-Val-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFDPBZAFCRKYEY-LAEOZQHASA-N 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 4
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 4
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 4
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 4
- 101000851030 Homo sapiens Vascular endothelial growth factor receptor 3 Proteins 0.000 description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 4
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 4
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 4
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 4
- 102000004207 Neuropilin-1 Human genes 0.000 description 4
- 108090000772 Neuropilin-1 Proteins 0.000 description 4
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 4
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 4
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 4
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 4
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 4
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 4
- 108091008605 VEGF receptors Proteins 0.000 description 4
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 4
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 4
- 102100033179 Vascular endothelial growth factor receptor 3 Human genes 0.000 description 4
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 4
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 4
- 229940125644 antibody drug Drugs 0.000 description 4
- 108010008355 arginyl-glutamine Proteins 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- 238000010790 dilution Methods 0.000 description 4
- 239000012895 dilution Substances 0.000 description 4
- 239000012636 effector Substances 0.000 description 4
- 210000002889 endothelial cell Anatomy 0.000 description 4
- 229940088598 enzyme Drugs 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 108010010147 glycylglutamine Proteins 0.000 description 4
- 210000002865 immune cell Anatomy 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 230000002147 killing effect Effects 0.000 description 4
- 238000005259 measurement Methods 0.000 description 4
- 230000035699 permeability Effects 0.000 description 4
- 108091033319 polynucleotide Proteins 0.000 description 4
- 102000040430 polynucleotide Human genes 0.000 description 4
- 239000002157 polynucleotide Substances 0.000 description 4
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 4
- 108010070643 prolylglutamic acid Proteins 0.000 description 4
- 102000005962 receptors Human genes 0.000 description 4
- 108020003175 receptors Proteins 0.000 description 4
- 238000012216 screening Methods 0.000 description 4
- 229950007133 tiragolumab Drugs 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 3
- XEXJJJRVTFGWIC-FXQIFTODSA-N Ala-Asn-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XEXJJJRVTFGWIC-FXQIFTODSA-N 0.000 description 3
- KQESEZXHYOUIIM-CQDKDKBSSA-N Ala-Lys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KQESEZXHYOUIIM-CQDKDKBSSA-N 0.000 description 3
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 3
- LLZXKVAAEWBUPB-KKUMJFAQSA-N Arg-Gln-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LLZXKVAAEWBUPB-KKUMJFAQSA-N 0.000 description 3
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 3
- UPAGTDJAORYMEC-VHWLVUOQSA-N Asn-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N UPAGTDJAORYMEC-VHWLVUOQSA-N 0.000 description 3
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 3
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 3
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 3
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 3
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 3
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 3
- UAQSZXGJGLHMNV-XEGUGMAKSA-N Ile-Gly-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N UAQSZXGJGLHMNV-XEGUGMAKSA-N 0.000 description 3
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 3
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 3
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 3
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 3
- 241000699660 Mus musculus Species 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- 101150065403 NECTIN2 gene Proteins 0.000 description 3
- JHSRGEODDALISP-XVSYOHENSA-N Phe-Thr-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O JHSRGEODDALISP-XVSYOHENSA-N 0.000 description 3
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 3
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 3
- XFFIGWGYMUFCCQ-ULQDDVLXSA-N Pro-His-Tyr Chemical compound C1=CC(O)=CC=C1C[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)[C@H]1[NH2+]CCC1)CC1=CN=CN1 XFFIGWGYMUFCCQ-ULQDDVLXSA-N 0.000 description 3
- KWMUAKQOVYCQJQ-ZPFDUUQYSA-N Pro-Ile-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 KWMUAKQOVYCQJQ-ZPFDUUQYSA-N 0.000 description 3
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 3
- NBUKGEFVZJMSIS-XIRDDKMYSA-N Ser-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)[C@H](CO)N NBUKGEFVZJMSIS-XIRDDKMYSA-N 0.000 description 3
- VIIJCAQMJBHSJH-FXQIFTODSA-N Ser-Met-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O VIIJCAQMJBHSJH-FXQIFTODSA-N 0.000 description 3
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 3
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 3
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 3
- FGBLCMLXHRPVOF-IHRRRGAJSA-N Ser-Tyr-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FGBLCMLXHRPVOF-IHRRRGAJSA-N 0.000 description 3
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 3
- GIOBXJSONRQHKQ-RYUDHWBXSA-N Tyr-Gly-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O GIOBXJSONRQHKQ-RYUDHWBXSA-N 0.000 description 3
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 3
- LMKKMCGTDANZTR-BZSNNMDCSA-N Tyr-Phe-Asp Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC(O)=O)C(O)=O)C1=CC=C(O)C=C1 LMKKMCGTDANZTR-BZSNNMDCSA-N 0.000 description 3
- ZPFLBLFITJCBTP-QWRGUYRKSA-N Tyr-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O ZPFLBLFITJCBTP-QWRGUYRKSA-N 0.000 description 3
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 3
- 102000009484 Vascular Endothelial Growth Factor Receptors Human genes 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 108010087924 alanylproline Proteins 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 230000000259 anti-tumor effect Effects 0.000 description 3
- 108010038633 aspartylglutamate Proteins 0.000 description 3
- 108010092854 aspartyllysine Proteins 0.000 description 3
- 230000001588 bifunctional effect Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 238000010494 dissociation reaction Methods 0.000 description 3
- 230000005593 dissociations Effects 0.000 description 3
- 239000013604 expression vector Substances 0.000 description 3
- 108010078144 glutaminyl-glycine Proteins 0.000 description 3
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 3
- 210000005073 lymphatic endothelial cell Anatomy 0.000 description 3
- 230000005012 migration Effects 0.000 description 3
- 238000013508 migration Methods 0.000 description 3
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 3
- 230000019491 signal transduction Effects 0.000 description 3
- 108010020532 tyrosyl-proline Proteins 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 2
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 2
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 2
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 2
- VQBULXOHAZSTQY-GKCIPKSASA-N Ala-Trp-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O VQBULXOHAZSTQY-GKCIPKSASA-N 0.000 description 2
- ZEAYJGRKRUBDOB-GARJFASQSA-N Arg-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZEAYJGRKRUBDOB-GARJFASQSA-N 0.000 description 2
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 2
- MFFOYNGMOYFPBD-DCAQKATOSA-N Asn-Arg-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MFFOYNGMOYFPBD-DCAQKATOSA-N 0.000 description 2
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 2
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 2
- IOXWDLNHXZOXQP-FXQIFTODSA-N Asp-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N IOXWDLNHXZOXQP-FXQIFTODSA-N 0.000 description 2
- 108010074708 B7-H1 Antigen Proteins 0.000 description 2
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 2
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 2
- CMYVIUWVYHOLRD-ZLUOBGJFSA-N Cys-Ser-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CMYVIUWVYHOLRD-ZLUOBGJFSA-N 0.000 description 2
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 2
- OACQOWPRWGNKTP-AVGNSLFASA-N Gln-Tyr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O OACQOWPRWGNKTP-AVGNSLFASA-N 0.000 description 2
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 2
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 2
- GZWOBWMOMPFPCD-CIUDSAMLSA-N Glu-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N GZWOBWMOMPFPCD-CIUDSAMLSA-N 0.000 description 2
- JMQFHZWESBGPFC-WDSKDSINSA-N Gly-Gln-Asp Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JMQFHZWESBGPFC-WDSKDSINSA-N 0.000 description 2
- ICUTTWWCDIIIEE-BQBZGAKWSA-N Gly-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN ICUTTWWCDIIIEE-BQBZGAKWSA-N 0.000 description 2
- WMGHDYWNHNLGBV-ONGXEEELSA-N Gly-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 WMGHDYWNHNLGBV-ONGXEEELSA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- WTUSRDZLLWGYAT-KCTSRDHCSA-N Gly-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN WTUSRDZLLWGYAT-KCTSRDHCSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 2
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 2
- 101001102797 Homo sapiens Transmembrane protein PVRIG Proteins 0.000 description 2
- 101000742596 Homo sapiens Vascular endothelial growth factor C Proteins 0.000 description 2
- 101000742599 Homo sapiens Vascular endothelial growth factor D Proteins 0.000 description 2
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 2
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 2
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 2
- 108091008036 Immune checkpoint proteins Proteins 0.000 description 2
- 102000037982 Immune checkpoint proteins Human genes 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 108010065920 Insulin Lispro Proteins 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- HXWALXSAVBLTPK-NUTKFTJISA-N Leu-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(C)C)N HXWALXSAVBLTPK-NUTKFTJISA-N 0.000 description 2
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 2
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 2
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 2
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 2
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 2
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 2
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 2
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 2
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 2
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 2
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 2
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 2
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 2
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 2
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 2
- DRRXXZBXDMLGFC-IHRRRGAJSA-N Lys-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN DRRXXZBXDMLGFC-IHRRRGAJSA-N 0.000 description 2
- BCRQJDMZQUHQSV-STQMWFEESA-N Met-Gly-Tyr Chemical compound [H]N[C@@H](CCSC)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BCRQJDMZQUHQSV-STQMWFEESA-N 0.000 description 2
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 2
- 108010079364 N-glycylalanine Proteins 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- IILUKIJNFMUBNF-IHRRRGAJSA-N Phe-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O IILUKIJNFMUBNF-IHRRRGAJSA-N 0.000 description 2
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 2
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 2
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 2
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 2
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 2
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 2
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 2
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 2
- VVAWNPIOYXAMAL-KJEVXHAQSA-N Pro-Thr-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VVAWNPIOYXAMAL-KJEVXHAQSA-N 0.000 description 2
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 208000006265 Renal cell carcinoma Diseases 0.000 description 2
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 2
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 2
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 2
- NMZXJDSKEGFDLJ-DCAQKATOSA-N Ser-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CCCCN)C(=O)O NMZXJDSKEGFDLJ-DCAQKATOSA-N 0.000 description 2
- ATEQEHCGZKBEMU-GQGQLFGLSA-N Ser-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N ATEQEHCGZKBEMU-GQGQLFGLSA-N 0.000 description 2
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 108091008874 T cell receptors Proteins 0.000 description 2
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 2
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 2
- AQAMPXBRJJWPNI-JHEQGTHGSA-N Thr-Gly-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AQAMPXBRJJWPNI-JHEQGTHGSA-N 0.000 description 2
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 2
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 2
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 2
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 2
- 102100039630 Transmembrane protein PVRIG Human genes 0.000 description 2
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 2
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 2
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 2
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 2
- VBFVQTPETKJCQW-RPTUDFQQSA-N Tyr-Phe-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VBFVQTPETKJCQW-RPTUDFQQSA-N 0.000 description 2
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 2
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 2
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 2
- SCBITHMBEJNRHC-LSJOCFKGSA-N Val-Asp-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C(C)C)C(=O)O)N SCBITHMBEJNRHC-LSJOCFKGSA-N 0.000 description 2
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 2
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 2
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 2
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 2
- 102100038232 Vascular endothelial growth factor C Human genes 0.000 description 2
- 102100038234 Vascular endothelial growth factor D Human genes 0.000 description 2
- 238000002835 absorbance Methods 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 230000033115 angiogenesis Effects 0.000 description 2
- 238000010171 animal model Methods 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 2
- 210000004436 artificial bacterial chromosome Anatomy 0.000 description 2
- 210000004507 artificial chromosome Anatomy 0.000 description 2
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 2
- 238000003556 assay Methods 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 230000008021 deposition Effects 0.000 description 2
- 230000014155 detection of activity Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 239000013613 expression plasmid Substances 0.000 description 2
- 210000002950 fibroblast Anatomy 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 2
- 108010049041 glutamylalanine Proteins 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 230000008595 infiltration Effects 0.000 description 2
- 238000001764 infiltration Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 239000007928 intraperitoneal injection Substances 0.000 description 2
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 238000010172 mouse model Methods 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 108010024607 phenylalanylalanine Proteins 0.000 description 2
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 210000004989 spleen cell Anatomy 0.000 description 2
- 239000012089 stop solution Substances 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 108010061238 threonyl-glycine Proteins 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 2
- 239000012224 working solution Substances 0.000 description 2
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 1
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 1
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 1
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 1
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 1
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 1
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- DEAGTWNKODHUIY-MRFFXTKBSA-N Ala-Tyr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DEAGTWNKODHUIY-MRFFXTKBSA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 1
- 102000009075 Angiopoietin-2 Human genes 0.000 description 1
- 108010048036 Angiopoietin-2 Proteins 0.000 description 1
- DBKNLHKEVPZVQC-LPEHRKFASA-N Arg-Ala-Pro Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O DBKNLHKEVPZVQC-LPEHRKFASA-N 0.000 description 1
- IIABBYGHLYWVOS-FXQIFTODSA-N Arg-Asn-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O IIABBYGHLYWVOS-FXQIFTODSA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- YNSUUAOAFCVINY-OSUNSFLBSA-N Arg-Thr-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YNSUUAOAFCVINY-OSUNSFLBSA-N 0.000 description 1
- IZSMEUDYADKZTJ-KJEVXHAQSA-N Arg-Tyr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IZSMEUDYADKZTJ-KJEVXHAQSA-N 0.000 description 1
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 1
- 229940122815 Aromatase inhibitor Drugs 0.000 description 1
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 1
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 1
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 1
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 1
- QHBMKQWOIYJYMI-BYULHYEWSA-N Asn-Asn-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O QHBMKQWOIYJYMI-BYULHYEWSA-N 0.000 description 1
- QUAWOKPCAKCHQL-SRVKXCTJSA-N Asn-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N QUAWOKPCAKCHQL-SRVKXCTJSA-N 0.000 description 1
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 1
- TZFQICWZWFNIKU-KKUMJFAQSA-N Asn-Leu-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 TZFQICWZWFNIKU-KKUMJFAQSA-N 0.000 description 1
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 1
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 1
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 1
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 1
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 1
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- OVPHVTCDVYYTHN-AVGNSLFASA-N Asp-Glu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OVPHVTCDVYYTHN-AVGNSLFASA-N 0.000 description 1
- WSGVTKZFVJSJOG-RCOVLWMOSA-N Asp-Gly-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O WSGVTKZFVJSJOG-RCOVLWMOSA-N 0.000 description 1
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 1
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 1
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 1
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 1
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 1
- GWOVSEVNXNVMMY-BPUTZDHNSA-N Asp-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N GWOVSEVNXNVMMY-BPUTZDHNSA-N 0.000 description 1
- KNOGLZBISUBTFW-QRTARXTBSA-N Asp-Trp-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O KNOGLZBISUBTFW-QRTARXTBSA-N 0.000 description 1
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 1
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 238000011725 BALB/c mouse Methods 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 206010004593 Bile duct cancer Diseases 0.000 description 1
- 101100381481 Caenorhabditis elegans baz-2 gene Proteins 0.000 description 1
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 1
- 208000006332 Choriocarcinoma Diseases 0.000 description 1
- 206010052358 Colorectal cancer metastatic Diseases 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 1
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 1
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 101100347633 Drosophila melanogaster Mhc gene Proteins 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 241001524679 Escherichia virus M13 Species 0.000 description 1
- 208000001382 Experimental Melanoma Diseases 0.000 description 1
- 102000009123 Fibrin Human genes 0.000 description 1
- 108010073385 Fibrin Proteins 0.000 description 1
- BWGVNKXGVNDBDI-UHFFFAOYSA-N Fibrin monomer Chemical compound CNC(=O)CNC(=O)CN BWGVNKXGVNDBDI-UHFFFAOYSA-N 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 1
- LOJYQMFIIJVETK-WDSKDSINSA-N Gln-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(O)=O LOJYQMFIIJVETK-WDSKDSINSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- XWIBVSAEUCAAKF-GVXVVHGQSA-N Gln-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)N)N XWIBVSAEUCAAKF-GVXVVHGQSA-N 0.000 description 1
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 1
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 1
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 1
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 1
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 1
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 1
- ZIYGTCDTJJCDDP-JYJNAYRXSA-N Glu-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZIYGTCDTJJCDDP-JYJNAYRXSA-N 0.000 description 1
- CBWKURKPYSLMJV-SOUVJXGZSA-N Glu-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CBWKURKPYSLMJV-SOUVJXGZSA-N 0.000 description 1
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 1
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- XUORRGAFUQIMLC-STQMWFEESA-N Gly-Arg-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN)O XUORRGAFUQIMLC-STQMWFEESA-N 0.000 description 1
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 1
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 1
- HQRHFUYMGCHHJS-LURJTMIESA-N Gly-Gly-Arg Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N HQRHFUYMGCHHJS-LURJTMIESA-N 0.000 description 1
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 1
- FXGRXIATVXUAHO-WEDXCCLWSA-N Gly-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN FXGRXIATVXUAHO-WEDXCCLWSA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- YPLYIXGKCRQZGW-SRVKXCTJSA-N His-Arg-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YPLYIXGKCRQZGW-SRVKXCTJSA-N 0.000 description 1
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 1
- NBWATNYAUVSAEQ-ZEILLAHLSA-N His-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O NBWATNYAUVSAEQ-ZEILLAHLSA-N 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101001001487 Homo sapiens Phosphatidylinositol-glycan biosynthesis class F protein Proteins 0.000 description 1
- 101000595923 Homo sapiens Placenta growth factor Proteins 0.000 description 1
- 101000586618 Homo sapiens Poliovirus receptor Proteins 0.000 description 1
- 101000596234 Homo sapiens T-cell surface protein tactile Proteins 0.000 description 1
- 101000742579 Homo sapiens Vascular endothelial growth factor B Proteins 0.000 description 1
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 1
- ZGGWRNBSBOHIGH-HVTMNAMFSA-N Ile-Gln-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ZGGWRNBSBOHIGH-HVTMNAMFSA-N 0.000 description 1
- NZGTYCMLUGYMCV-XUXIUFHCSA-N Ile-Lys-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N NZGTYCMLUGYMCV-XUXIUFHCSA-N 0.000 description 1
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 1
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 1
- AGGIYSLVUKVOPT-HTFCKZLJSA-N Ile-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N AGGIYSLVUKVOPT-HTFCKZLJSA-N 0.000 description 1
- 108091008028 Immune checkpoint receptors Proteins 0.000 description 1
- 102000037978 Immune checkpoint receptors Human genes 0.000 description 1
- 102000016844 Immunoglobulin-like domains Human genes 0.000 description 1
- 108050006430 Immunoglobulin-like domains Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- 206010023825 Laryngeal cancer Diseases 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- GBDMISNMNXVTNV-XIRDDKMYSA-N Leu-Asp-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GBDMISNMNXVTNV-XIRDDKMYSA-N 0.000 description 1
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 1
- KUEVMUXNILMJTK-JYJNAYRXSA-N Leu-Gln-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KUEVMUXNILMJTK-JYJNAYRXSA-N 0.000 description 1
- QJUWBDPGGYVRHY-YUMQZZPRSA-N Leu-Gly-Cys Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N QJUWBDPGGYVRHY-YUMQZZPRSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- YIRIDPUGZKHMHT-ACRUOGEOSA-N Leu-Tyr-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YIRIDPUGZKHMHT-ACRUOGEOSA-N 0.000 description 1
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 1
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 1
- 229940123917 Lipid kinase inhibitor Drugs 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 1
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 1
- GKFNXYMAMKJSKD-NHCYSSNCSA-N Lys-Asp-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GKFNXYMAMKJSKD-NHCYSSNCSA-N 0.000 description 1
- KSFQPRLZAUXXPT-GARJFASQSA-N Lys-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)C(=O)O KSFQPRLZAUXXPT-GARJFASQSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 1
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 1
- RIJCHEVHFWMDKD-SRVKXCTJSA-N Lys-Lys-Asn Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RIJCHEVHFWMDKD-SRVKXCTJSA-N 0.000 description 1
- PYFNONMJYNJENN-AVGNSLFASA-N Lys-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PYFNONMJYNJENN-AVGNSLFASA-N 0.000 description 1
- ODTZHNZPINULEU-KKUMJFAQSA-N Lys-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N ODTZHNZPINULEU-KKUMJFAQSA-N 0.000 description 1
- JCVOHUKUYSYBAD-DCAQKATOSA-N Lys-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCCCN)N)C(=O)N[C@@H](CS)C(=O)O JCVOHUKUYSYBAD-DCAQKATOSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 1
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 1
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 1
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 208000002030 Merkel cell carcinoma Diseases 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 208000032818 Microsatellite Instability Diseases 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- 230000006051 NK cell activation Effects 0.000 description 1
- 102000002356 Nectin Human genes 0.000 description 1
- 108060005251 Nectin Proteins 0.000 description 1
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 241001631646 Papillomaviridae Species 0.000 description 1
- LBSARGIQACMGDF-WBAXXEDZSA-N Phe-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 LBSARGIQACMGDF-WBAXXEDZSA-N 0.000 description 1
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- SRILZRSXIKRGBF-HRCADAONSA-N Phe-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N SRILZRSXIKRGBF-HRCADAONSA-N 0.000 description 1
- FQUUYTNBMIBOHS-IHRRRGAJSA-N Phe-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N FQUUYTNBMIBOHS-IHRRRGAJSA-N 0.000 description 1
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 1
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 1
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 1
- 102100035194 Placenta growth factor Human genes 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 208000006994 Precancerous Conditions Diseases 0.000 description 1
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 1
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 1
- AMBLXEMWFARNNQ-DCAQKATOSA-N Pro-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 AMBLXEMWFARNNQ-DCAQKATOSA-N 0.000 description 1
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 1
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 1
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 1
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 1
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 1
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 1
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 1
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 1
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 1
- VBZXFFYOBDLLFE-HSHDSVGOSA-N Pro-Trp-Thr Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H]([C@H](O)C)C(O)=O)C(=O)[C@@H]1CCCN1 VBZXFFYOBDLLFE-HSHDSVGOSA-N 0.000 description 1
- 238000010802 RNA extraction kit Methods 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 101100372762 Rattus norvegicus Flt1 gene Proteins 0.000 description 1
- 108090000873 Receptor Protein-Tyrosine Kinases Proteins 0.000 description 1
- 102000004278 Receptor Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- UEJYSALTSUZXFV-SRVKXCTJSA-N Rigin Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UEJYSALTSUZXFV-SRVKXCTJSA-N 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 1
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- NADLKBTYNKUJEP-KATARQTJSA-N Ser-Thr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NADLKBTYNKUJEP-KATARQTJSA-N 0.000 description 1
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 1
- VAIWUNAAPZZGRI-IHPCNDPISA-N Ser-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N VAIWUNAAPZZGRI-IHPCNDPISA-N 0.000 description 1
- UKKROEYWYIHWBD-ZKWXMUAHSA-N Ser-Val-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UKKROEYWYIHWBD-ZKWXMUAHSA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 1
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 206010042602 Supraventricular extrasystoles Diseases 0.000 description 1
- 102100035268 T-cell surface protein tactile Human genes 0.000 description 1
- DDPVJPIGACCMEH-XQXXSGGOSA-N Thr-Ala-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DDPVJPIGACCMEH-XQXXSGGOSA-N 0.000 description 1
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 1
- VIBXMCZWVUOZLA-OLHMAJIHSA-N Thr-Asn-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O VIBXMCZWVUOZLA-OLHMAJIHSA-N 0.000 description 1
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 1
- NRBUKAHTWRCUEQ-XGEHTFHBSA-N Thr-Cys-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCSC)C(O)=O NRBUKAHTWRCUEQ-XGEHTFHBSA-N 0.000 description 1
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 1
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 1
- SXAGUVRFGJSFKC-ZEILLAHLSA-N Thr-His-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SXAGUVRFGJSFKC-ZEILLAHLSA-N 0.000 description 1
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 1
- FLPZMPOZGYPBEN-PPCPHDFISA-N Thr-Leu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLPZMPOZGYPBEN-PPCPHDFISA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 1
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 1
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 1
- BGWSLEYVITZIQP-DCPHZVHLSA-N Trp-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O BGWSLEYVITZIQP-DCPHZVHLSA-N 0.000 description 1
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 1
- LNGFWVPNKLWATF-ZVZYQTTQSA-N Trp-Val-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LNGFWVPNKLWATF-ZVZYQTTQSA-N 0.000 description 1
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 1
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 1
- BXPOOVDVGWEXDU-WZLNRYEVSA-N Tyr-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BXPOOVDVGWEXDU-WZLNRYEVSA-N 0.000 description 1
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 1
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 1
- WPRVVBVWIUWLOH-UFYCRDLUSA-N Tyr-Phe-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CC2=CC=C(C=C2)O)N WPRVVBVWIUWLOH-UFYCRDLUSA-N 0.000 description 1
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 1
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- KHPLUFDSWGDRHD-SLFFLAALSA-N Tyr-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O KHPLUFDSWGDRHD-SLFFLAALSA-N 0.000 description 1
- 102000003425 Tyrosinase Human genes 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- CPTQYHDSVGVGDZ-UKJIMTQDSA-N Val-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N CPTQYHDSVGVGDZ-UKJIMTQDSA-N 0.000 description 1
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 1
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 1
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 1
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 1
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 1
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 1
- NSUUANXHLKKHQB-BZSNNMDCSA-N Val-Pro-Trp Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CNC2=CC=CC=C12 NSUUANXHLKKHQB-BZSNNMDCSA-N 0.000 description 1
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 1
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 1
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 1
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 1
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 1
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 1
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- 108010053096 Vascular Endothelial Growth Factor Receptor-1 Proteins 0.000 description 1
- 102000016548 Vascular Endothelial Growth Factor Receptor-1 Human genes 0.000 description 1
- 102000016549 Vascular Endothelial Growth Factor Receptor-2 Human genes 0.000 description 1
- 108010053100 Vascular Endothelial Growth Factor Receptor-3 Proteins 0.000 description 1
- 102000016663 Vascular Endothelial Growth Factor Receptor-3 Human genes 0.000 description 1
- 102100038217 Vascular endothelial growth factor B Human genes 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 108010081404 acein-2 Proteins 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 1
- 239000003708 ampul Substances 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 229940121369 angiogenesis inhibitor Drugs 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 239000003945 anionic surfactant Substances 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 229960003852 atezolizumab Drugs 0.000 description 1
- 208000026900 bile duct neoplasm Diseases 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 229940022399 cancer vaccine Drugs 0.000 description 1
- 238000009566 cancer vaccine Methods 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 238000010523 cascade reaction Methods 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 239000003093 cationic surfactant Substances 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 230000002301 combined effect Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000003113 dilution method Methods 0.000 description 1
- 230000006806 disease prevention Effects 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 230000000857 drug effect Effects 0.000 description 1
- 230000002357 endometrial effect Effects 0.000 description 1
- 208000023965 endometrium neoplasm Diseases 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 238000013401 experimental design Methods 0.000 description 1
- 229950003499 fibrin Drugs 0.000 description 1
- 238000009093 first-line therapy Methods 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 230000003325 follicular Effects 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000000703 high-speed centrifugation Methods 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- 108010028295 histidylhistidine Proteins 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 102000058223 human VEGFA Human genes 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 108091008042 inhibitory receptors Proteins 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 206010023841 laryngeal neoplasm Diseases 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 208000037841 lung tumor Diseases 0.000 description 1
- 210000001365 lymphatic vessel Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 238000001471 micro-filtration Methods 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 210000005087 mononuclear cell Anatomy 0.000 description 1
- 108700017028 mouse T cell Ig and ITIM domain Proteins 0.000 description 1
- 230000009707 neogenesis Effects 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 239000003002 pH adjusting agent Substances 0.000 description 1
- 208000003154 papilloma Diseases 0.000 description 1
- 230000003076 paracrine Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 108010053725 prolylvaline Proteins 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 150000004492 retinoid derivatives Chemical class 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000012898 sample dilution Substances 0.000 description 1
- 238000007789 sealing Methods 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 230000005748 tumor development Effects 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 238000007492 two-way ANOVA Methods 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 208000024719 uterine cervix neoplasm Diseases 0.000 description 1
- 238000003828 vacuum filtration Methods 0.000 description 1
- 239000002525 vasculotropin inhibitor Substances 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 150000003722 vitamin derivatives Chemical class 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images

















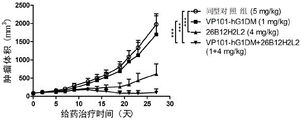

Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/22—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against growth factors ; against growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Abstract
本发明属于医药领域,涉及一种抗TIGIT抗体、其药物组合物及用途,特别是联合抗PD‑1‑抗VEGFA抗体预防或治疗肿瘤的用途。具体地,本发明涉及抗TIGIT抗体或其抗原结合片段,其中,所述抗体的重链可变区包含氨基酸序列分别如SEQ ID NOs:3‑5所示的HCDR1‑HCDR3;并且所述抗体的轻链可变区包含氨基酸序列分别如SEQ ID NOs:8‑10所示的LCDR1‑LCDR3。本发明的抗体能够有效地结合TIGIT,具有应用于肿瘤防治的潜力。
Description
技术领域
本发明属于医药领域,涉及一种抗TIGIT抗体、其药物组合物及用途。具体地,本发明涉及一种抗TIGIT的单克隆抗体。
背景技术
TIGIT(T cell Ig and ITIM domain, 又称为WUCAM,Vstm3,VSIG9)是脊髓灰质炎病毒受体(PVR)/Nectin家族的成员。TIGIT由细胞外免疫球蛋白可变区(IgV)结构域,I型跨膜结构域和具有经典免疫受体酪氨酸抑制基序(ITIM)和免疫球蛋白酪氨酸尾(ITT)基序的细胞内结构域组成。TIGIT在淋巴细胞特别是在效应和调节性CD4+ T细胞、滤泡辅助CD4+ T细胞和效应CD8+ T细胞以及自然杀伤(NK)细胞中高表达(Yu X, Harden K, Gonzalez LC, et al. The surface protein TIGIT suppresses T cell activation by promotingthe generation of mature immunoregulatory dendritic cells[J]. Natureimmunology, 2009, 10(1): 48)。
CD155(又称为PVR、Necl5或Tage4)、CD112(又称为PVRL2 / nectin 2)和CD113(又称为PVRL3)是TIGIT结合的配体(Martinet L, Smyth M J. Balancing natural killercell activation through paired receptors[J]. Nature Reviews Immunology, 2015,15(4): 243-254),其中CD155是TIGIT的高亲和力配体。在NK细胞中,TIGIT结合配体CD155和CD112可以抑制NK细胞对TIGIT高表达细胞的杀伤作用(Stanietsky N, Simic H,Arapovic J, et al. The interaction of TIGIT with PVR and PVRL2 inhibits humanNK cell cytotoxicity[J]. Proceedings of the National Academy of Sciences,2009, 106(42): 17858-17863)。而有报道发现在同时阻断PD-1和TIGIT时,可以增强CD8+T细胞的杀伤作用(Johnston R J, Comps-Agrar L, Hackney J, et al. Theimmunoreceptor TIGIT regulates antitumor and antiviral CD8+ T cell effectorfunction[J]. Cancer cell, 2014, 26(6): 923-937)。在最新的研究中发现,TIGIT作为NK细胞的免疫检查点,肿瘤发展过程中抑制性受体TIGIT可导致NK细胞耗竭,并证明抗TIGIT单抗可逆转NK细胞耗竭并用于多种肿瘤的免疫治疗(Zhang Q, Bi J, Zheng X, etal. Blockade of the checkpoint receptor TIGIT prevents NK cell exhaustion andelicits potent anti-tumor immunity[J]. Nature immunology, 2018, 19(7): 723-732)。
此外有报道,TIGIT阻断剂单独或与PD-1阻滞剂联合使用再加上CD96阻断剂,可以显著降低野生型和Cd155-/-小鼠模型中B16黑色素瘤的生长(Li X-Y, Das I, LepletierA, et al. . Cd155 loss enhances tumor suppression via combined host andtumor-intrinsic mechanisms. J Clin Invest 2018;128:2613–25)。CD112R阻断剂单独或与TIGIT阻断剂和/或PD-1阻断剂联合使用,能增加卵巢瘤、子宫内膜瘤和肺肿瘤中TIL产生细胞因子的能力 ( Whelan S, Ophir E, Kotturi MF, et al. . PVRIG and PVRL2Are Induced in Cancer and Inhibit CD8+ T-cell Function. Cancer Immunol Res2019;7:257–68)。
抗TIGIT抗体药物作为新型免疫检查点抗体药物具有广泛的应用前景,可用于肿瘤的免疫治疗。罗氏制药(Roche)研发的Tiragolumab已处于临床3期阶段,并且据报道TIGIT单抗Tiragolumab联合PD-L1药物Tecentrip(阿特珠单抗Atezolizumab)作为一线疗法,在治疗PD-L1阳性转移性非小细胞肺癌(NSCLC)患者的2期临床研究中发现Tiragolumab与Tecentriq的组合耐受性良好,疾病进展风险下降43%,联用效果显著(Exit C. Roche topresent first clinical data on novel anti-TIGIT cancer immunotherapytiragolumab at ASCO[J])。已有的临床信息记录表明,TIGIT是用于治疗非小细胞肺癌、小细胞肺癌、乳腺癌、卵巢癌、结直肠癌、黑色素癌、胰腺癌、宫颈瘤、多发性骨髓瘤、非霍奇金淋巴瘤、B淋巴细胞瘤、浆细胞癌的重要靶点。
然而,目前现有的抗人TIGIT抗体药物的亲和力较低,尚缺少具有高亲和力的抗TIGIT抗体。
因此,开发与TIGIT具有高亲和力的抗体药物,用于自身免疫疾病的治疗,使其具有更好的治疗效果、更低的毒副作用,具有非常重要的意义。
血管内皮生长因子(VEGF)是一类能促进内皮细胞分裂增殖、促进新生血管的形成、提高血管通透性的生长因子,它与细胞表面的血管内皮生长因子受体结合,通过激活酪氨酸激酶信号转导途径发挥功能。在肿瘤组织中,肿瘤细胞、肿瘤侵入的巨噬细胞和肥大细胞能分泌高水平的VEGF,以旁分泌的形式刺激肿瘤血管内皮细胞,促进内皮细胞增殖、迁移,诱导血管形成,促进肿瘤持续生长,并提高血管通透性,引起周围组织纤维蛋白沉着,促进单核细胞、成纤维细胞内皮细胞侵润,有利于肿瘤基质形成和肿瘤细胞进入新生血管,促进肿瘤转移,因而抑制肿瘤血管生成被认为是当前最具有前途的肿瘤治疗方法之一。VEGF家族包括:VEGFA、VEGFB、VEGFC、VEGFD和PIGF。血管内皮生长因子受体(VEGFR)包括VEGFR1(又称Flt1)、VEGFR2(又称KDR或Flk1)、VEGFR3(又称Flt4)和Neuropilin-1(NRP-1)。其中,前三种受体在结构上类似,都属于酪氨酸激酶超家族,均由膜外区、跨膜片段及膜内区三部分构成,其中膜外区由免疫球蛋白样结构域组成,膜内区属酪氨酸激酶区。VEGFR1和VEGFR2主要位于血管内皮细胞表面,VEGFR3主要位于淋巴管内皮细胞表面。
VEGF家族分子对于几种受体有不同的亲和力。VEGFA主要与VEGFR1、VEGFR2和NRP-1结合发挥作用。VEGFR1是最早发现的受体,在正常生理情况下VEGFR1与VEGFA的亲和力比VEGFR2与VEGFA的亲和力高,但是其胞内段酪氨酸酶活性比VEGFR2低(马莉,中国优生与遗传杂志,24(5)(2016):146-148)。
VEGFR2是血管发生和构建的主要调节者,与VEGFR1相比VEGFR2具有很高的酪氨酸激酶活性。VEGFR2与配体VEGFA结合后介导血管内皮细胞的增殖、分化等行为,以及血管的形成过程和血管的通透性(Roskoski R Jr.等人,Crit Rev Oncol Hematol, 62(3)(2007):179-213.),VEGFA与VEGFR2结合后通过下游PLC-γ-PKC-Raf-MEK-MAPK信号传导通路介导胞内相关蛋白基因转录表达,促进血管内皮细胞增殖(Takahashi T等人,Oncogene,18(13) (1999):2221-2230.)。
VEGFR3属于酪氨酸激酶家族成员之一,主要表达在胚胎时期的血管内皮细胞和成年期的淋巴管内皮细胞,VEGFC和VEGFD与VEGFR3结合以刺激淋巴管内皮细胞的增殖与迁移,促进淋巴管的新生;NRP-1是一种非酪氨酸激酶跨膜蛋白,不能独立转导生物信号,而与VEGF酪氨酸激酶受体形成复合物后才能介导信号传导。(马莉,中国优生与遗传杂志,24(5)(2016):146-148)。
VEGFA与VEGFR2主要参与调控血管生成,VEGFA与VEGFR2结合前后会引发上下游通路中众多中间信号形成级联反应,最终以内皮细胞增殖、存活、迁移、通透性增加及浸润到周围组织等不同形式改变其生理功能(董宏超等人,《现代肿瘤医学》,第22卷,第9期 2014年9月,第2231-3页)。
目前已经有多种靶向人VEGF特别是VEGFA的人源化单克隆抗体,如贝伐单抗(Bevacizumab),其于2004年期间陆续被美国食品药品管理局批准用于治疗非小细胞肺癌、肾细胞癌、宫颈癌、转移性结直肠癌等多种肿瘤。
发明内容
本发明人经过深入的研究和创造性的劳动,利用哺乳动物细胞表达系统表达出重组的人TIGIT作为抗原免疫小鼠,经小鼠脾脏细胞与骨髓瘤细胞融合获得杂交瘤细胞。发明人通过对大量样本的筛选,得到了杂交瘤细胞株LT019(保藏编号为CCTCC NO: C2020208)。
本发明人惊奇地发现,杂交瘤细胞株LT019分别能够分泌产生与人TIGIT特异性结合的特异性单克隆抗体(命名为26B12),并且该单克隆抗体能够十分有效地结合TIGIT,降低TIGIT抑制免疫细胞的作用,促进T细胞活性,逆转NK细胞耗竭,增强免疫细胞对肿瘤的杀伤作用。进一步地,本发明人创造性地制得了抗人TIGIT的人源化抗体(命名为26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4)。
本发明人还惊奇地发现,本发明的抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4具有与TIGIT结合的活性,并且具有极强的亲和力;26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4可以有效地降低TIGIT的活性。
此外,本发明人发现抗TIGIT抗体联合抗PD-1-抗VEGFA双特异性抗体能够有效地防治肿瘤。
本发明的抗体具有用于治疗和/或预防肿瘤(例如非小细胞肺癌、小细胞肺癌、乳腺癌、卵巢癌、结直肠癌、黑色素瘤、胰腺癌、宫颈癌、多发性骨髓瘤、非霍奇金淋巴瘤、浆细胞癌)等疾病的潜力。由此提供了下述发明:
本发明的一个方面涉及抗TIGIT抗体或其抗原结合片段,其中,
所述抗TIGIT抗体包含SEQ ID NO:1所示的重链可变区包含的HCDR1-HCDR3和SEQID NO:6所示的轻链可变区包含的LCDR1-LCDR3,
优选地,按照IMGT编号系统,所述抗体的重链可变区包含氨基酸序列分别如SEQID NOs: 3-5所示的HCDR1-HCDR3;并且所述抗体的轻链可变区包含氨基酸序列分别如SEQID NOs: 8-10所示的LCDR1-LCDR3。
在本发明的一个或多个实施方案中,所述抗体的重链可变区的氨基酸序列选自SEQ ID NO: 1、SEQ ID NO: 11、SEQ ID NO: 13、SEQ ID NO: 15和SEQ ID NO: 17;并且
所述抗体的轻链可变区的氨基酸序列选自SEQ ID NO: 6、SEQ ID NO: 19、SEQ IDNO: 21、SEQ ID NO: 23和SEQ ID NO: 25。
在本发明的一个或多个实施方案中,所述抗体的重链可变区的氨基酸序列如SEQID NO: 1所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 6所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 11所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 19所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 17所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 19所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 13所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 21所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 13所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 23所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 15所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 21所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 15所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 23所示;
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 11所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 25所示;或者
所述抗体的重链可变区的氨基酸序列如SEQ ID NO: 17所示,并且所述抗体的轻链可变区的氨基酸序列如SEQ ID NO: 25所示。
在本发明的一个或多个实施方案中,所述的抗体包括非-CDR区,且所述非-CDR区来自不是鼠类的物种,例如来自人抗体。
在本发明的一个或多个实施方案中,所述抗体的重链恒定区为Ig gamma-1 chainC region(例如NCBI ACCESSION: P01857);轻链恒定区为Ig kappa chain C region(例如NCBI ACCESSION: P01834)。
在本发明的一个或多个实施方案中,所述抗TIGIT抗体或其抗原结合片段选自Fab、Fab'、F(ab')2、Fd、Fv、dAb、互补决定区片段、单链抗体、人源化抗体、嵌合抗体或双抗体。
在本发明的一个或多个实施方案中,所述的抗TIGIT抗体或其抗原结合片段,其中,所述抗体以小于4E-10或小于4E-11的KD结合TIGIT-mFc;优选地,所述KD通过Fortebio分子相互作用仪测得。
在本发明的一个或多个实施方案中,所述的抗TIGIT抗体或其抗原结合片段,其中,所述抗体以小于1.5nM、小于1.2nM或小于1nM的EC50结合TIGIT;优选地,所述EC50通过流式细胞仪测得。
在本发明的一些实施方案中,所述的抗TIGIT抗体为单克隆抗体。
在本发明的一些实施方案中,所述的抗TIGIT抗体为人源化抗体、嵌合抗体、多特异性抗体(例如双特异性抗体)。
在本发明的一些实施方案中,所述抗原结合片段选自Fab、Fab'、F(ab')2、Fd、Fv、dAb、Fab/c、互补决定区片段、单链抗体(例如,scFv)、人源化抗体、嵌合抗体或双特异性抗体。
在本发明的一个或多个实施方案中,所述的抗TIGIT抗体或其抗原结合片段,其中所述抗体是由杂交瘤细胞株LT019产生的抗体,所述杂交瘤细胞株LT019保藏于中国典型培养物保藏中心(CCTCC),中国武汉,邮编430072,保藏编号为CCTCC NO: C2020208。
本发明的另一方面涉及分离的核酸分子,其编码本发明中任一项所述的抗TIGIT抗体或其抗原结合片段。
本发明的再一方面涉及一种载体,其包含本发明的分离的核酸分子。
本发明的再一方面涉及一种宿主细胞,其包含本发明的分离的核酸分子,或者本发明的载体。
本发明的再一方面涉及杂交瘤细胞株LT019,其保藏于中国典型培养物保藏中心(CCTCC),保藏编号为CCTCC NO: C2020208。
本发明的再一方面涉及偶联物,其包括抗体以及偶联部分,其中,所述抗体为本发明中任一项所述的抗TIGIT抗体或其抗原结合片段,所述偶联部分为可检测的标记;优选地,所述偶联部分为放射性同位素、荧光物质、发光物质、有色物质或酶。
本发明的再一方面涉及试剂盒,其包括本发明中任一项所述的抗TIGIT抗体或其抗原结合片段,或者包括本发明的偶联物;
优选地,所述试剂盒还包括第二抗体,其特异性识别所述抗体;任选地,所述第二抗体还包括可检测的标记,例如放射性同位素、荧光物质、发光物质、有色物质或酶。
本发明的再一方面涉及本发明中任一项所述的抗体或者本发明的偶联物在制备试剂盒中的用途,所述试剂盒用于检测TIGIT在样品中的存在或其水平。
本发明的再一方面涉及一种药物组合物,其包含本发明中任一项所述的抗TIGIT抗体或其抗原结合片段或者本发明的偶联物;可选地,所述药物组合物还包括药学上可接受的载体和/或赋形剂。
在本发明的一个或多个实施方案中,所述的药物组合物,其还包含一种或多种抗PD-1抗体或者抗VEGF抗体。
在本发明的一个或多个实施方案中,所述的药物组合物,其中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1抗体或者与抗VEGF抗体的质量比为(1:5)-(5:1),例如:1:5、1:4、1:3、1:2、1:1、2:1、3:1、4:1或5:1。
本发明的再一方面涉及一种组合产品(例如试剂盒),其包含独立包装的第一产品和第二产品,其中,
所述第一产品包含其包含本发明中任一项所述的抗TIGIT抗体或其抗原结合片段、本发明的偶联物或者本发明中任一项所述的药物组合物;
所述第二产品包含至少一种抗PD-1抗体或者一种抗VEGF抗体,例如抗PD-1-抗VEGFA双特异性抗体;
优选地,所述组合产品还包含独立包装的第三产品,所述第三产品包含一种或多种化疗药物,
优选地,所述第一产品和所述第二产品还独立地包含一种或多种药学上可接受的辅料;
优选地,所述组合产品还包含产品说明书。
在本发明的一个或多个实施方案中,所述的组合产品,其中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1抗体或者与抗VEGF抗体的质量比为(1:5)-(5:1),例如:1:5、1:4、1:3、1:2、1:1、2:1、3:1、4:1或5:1。
在本发明的一个或多个实施方案中,所述抗PD-1抗体或者抗VEGF抗体为抗PD-1-抗VEGFA双特异性抗体。
本发明的再一方面涉及本发明中任一项所述的抗体、本发明的偶联物、本发明中任一项所述的药物组合物或者本发明中任一项所述的组合产品在制备治疗和/或预防肿瘤的药物中的用途;优选地,所述肿瘤选自非小细胞肺癌、小细胞肺癌、乳腺癌、卵巢癌、结直肠癌、黑色素瘤、胰腺癌、宫颈癌、多发性骨髓瘤、非霍奇金淋巴瘤和浆细胞癌中的一种或多种。
根据本发明中任一项所述的抗体、本发明的偶联物、本发明中任一项所述的药物组合物或者本发明中任一项所述的组合产品,其用于治疗和/或预防肿瘤;优选地,所述肿瘤选自非小细胞肺癌、小细胞肺癌、乳腺癌、卵巢癌、结直肠癌、黑色素瘤、胰腺癌、宫颈癌、多发性骨髓瘤、非霍奇金淋巴瘤和浆细胞癌中的一种或多种。
本发明的再一方面涉及一种治疗和/或预防肿瘤的方法,包括给予有需求的受试者以有效量的本发明中任一项所述的抗体、本发明的偶联物、本发明中任一项所述的药物组合物或者本发明中任一项所述的组合产品的步骤;优选地,所述肿瘤选自非小细胞肺癌、小细胞肺癌、乳腺癌、卵巢癌、结直肠癌、黑色素瘤、胰腺癌、宫颈癌、多发性骨髓瘤、非霍奇金淋巴瘤和浆细胞癌中的一种或多种。
本发明涉及一种预防和/或治疗肿瘤(特别是恶性肿瘤)的方法,包括给受试者施用治疗有效量的抗TIGIT抗体,联合施用抗PD-1-抗VEGFA双特异性抗体,更优选地,进一步联合施用一种或多种用于治疗肿瘤的药物(优选所述药物为化疗剂或生长抑制剂,靶向治疗剂,抗体-药物缀合物,表达嵌合抗原受体的T细胞、抗体或抗原其结合片段、血管生成抑制剂、抗肿瘤剂、癌症疫苗、佐剂及其组合、烷化剂,抗代谢药物,抗生素,植物类药物和/或激素类药物,优选环磷酰胺,培美曲塞,铂类药物如顺铂、卡铂、奥沙利铂,阿霉素类,紫杉醇,长春碱类,他莫昔芬,甲地孕酮,戈舍瑞林,门冬酰胺酶和/或氟尿嘧啶类抗肿瘤药),优选地,所述抗TIGIT抗体、抗PD-1-抗VEGFA双特异性抗体和肿瘤化疗药物同时或顺序施用。
在本发明的一个或多个实施方案中,所述化疗剂或生长抑制剂选自烷化剂、蒽环类、抗激素剂、芳香酶抑制剂、抗雄激素剂、蛋白激酶抑制剂、脂质激酶抑制剂、反义寡核苷酸、核酶、抗代谢物、拓扑异构酶抑制剂、细胞毒剂或抗肿瘤抗生素、蛋白酶体抑制剂、抗微管剂、EGFR拮抗剂、VEGF拮抗剂、血管生成素2拮抗剂、类视色素、酪氨酸激酶抑制剂、组蛋白脱乙酰酶抑制剂及其组合。
在本发明的一个或多个实施方案中,所述靶向治疗剂选自B-raf抑制剂、MEK抑制剂、K-ras抑制剂、c-Met抑制剂、Alk抑制剂、磷脂酰肌醇3-激酶抑制剂、Akt 抑制剂、mTOR抑制剂、VEGF抑制剂、双磷脂酰肌醇 3-激酶/mTOR 抑制剂及其组合。
在本发明的一个或多个实施方案中,所述抗体-药物缀合物包含选自下组的药物:美登新碱、单甲基auristatin E、加利车霉素、esperamicin和放射性同位素螯合剂。
在本发明的一个或多个实施方案中,所述肿瘤选自如下的一种或多种:
宫颈癌(如转移性宫颈癌)、子宫内膜癌、肺癌如小细胞肺癌和非小细胞肺癌(例如鳞状非小细胞肺癌或非鳞状非小细胞肺癌)、咽喉癌、食管癌、食管鳞癌、甲状腺癌、间皮瘤、胃癌(例如晚期胃癌、胃肠道癌、胃腺癌或胃食管结合部腺癌)、肝癌(如肝细胞癌)、肠癌、直肠癌、结肠癌、结肠直肠癌、胆管癌、肝胆癌、胆道癌、胆管癌、胰腺癌、胰脏癌、肾癌(如肾细胞癌)、卵巢癌(如晚期卵巢癌)、输卵管癌、腹膜癌、胶质瘤(如神经胶质瘤、复发性胶质瘤)、皮肤癌、黑色素瘤、白血病(如急性髓系白血病)、淋巴瘤(如霍奇金淋巴瘤 , 非霍奇金淋巴瘤)、浆细胞癌、骨癌、肉瘤、骨肉瘤、软骨肉瘤、神经母细胞瘤、骨髓瘤(如多发性骨髓瘤)、大细胞神经内分泌癌、尿路上皮癌(例如上尿路上皮癌或膀胱癌)、前列腺癌、睾丸癌、外周T细胞淋巴瘤、鼻咽癌,高度微卫星不稳定型(MSI-H)或错配修复缺陷型(dMMR)实体瘤、头和颈癌、脑癌(如侵袭性脑癌,例如胶质母细胞瘤)、鳞状细胞癌、基底细胞癌、腺瘤、乳腺癌(如三阴乳腺癌)、胸腺癌、回盲部腺癌、壶腹部腺癌、粘液性或浆液性囊腺癌、平滑肌肉瘤、横纹肌肉瘤、绒毛膜上皮癌、恶性葡萄胎、恶性支持细胞-间质细胞瘤、恶性颗粒细胞瘤、无性细胞瘤、胶质母细胞瘤、真菌病、默克尔细胞癌和其他血液系统恶性肿瘤。
在本发明的一个或多个实施方案中,所述抗PD-1双特异性抗体包括:
靶向PD-1的第一蛋白功能区,和
靶向VEGFA的第二蛋白功能区;
其中,所述第一蛋白功能区为免疫球蛋白,所述第二蛋白功能区为单链抗体;或者,所述第一蛋白功能区为单链抗体,所述第二蛋白功能区为免疫球蛋白;
其中,
所述的免疫球蛋白的重链可变区包含:氨基酸序列如SEQ ID NO:31所示的重链可变区所包含的HCDR1-HCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 35-37所示的HCDR1-HCDR3),其轻链可变区包含:氨基酸序列如SEQ ID NO:33所示的轻链可变区所包含的LCDR1-LCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 38-40所示的LCDR1-LCDR3);
所述的单链抗体的重链可变区包含:氨基酸序列如SEQ ID NO:41所示的重链可变区所包含的HCDR1-HCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 45-47所示的HCDR1-HCDR3)并且其轻链可变区包含氨基酸序列43(优选按照IMGT编号系统分别如SEQID NOs: 48-50所示的LCDR1-LCDR3);
或者,
所述的免疫球蛋白的重链可变区包含:氨基酸序列如SEQ ID NO:41所示的重链可变区所包含的HCDR1-HCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 45-47所示的HCDR1-HCDR3),其轻链可变区包含:氨基酸序列如SEQ ID NO:43所示的轻链可变区所包含的LCDR1-LCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 48-50所示的LCDR1-LCDR3);
所述的单链抗体的重链可变区包含:氨基酸序列如SEQ ID NO:31所示的重链可变区所包含的HCDR1-HCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 35-37所示的HCDR1-HCDR3)并且其轻链可变区包含氨基酸序列如SEQ ID NO:33所示的轻链可变区所包含的LCDR1-LCDR3(优选按照IMGT编号系统分别如SEQ ID NOs: 38-40所示的LCDR1-LCDR3);
所述免疫球蛋白为人IgG1亚型。
在本发明的一个或多个实施方案中,所述的双特异性抗体,其中,按照EU编号系统,所述免疫球蛋白的重链恒定区具有如下突变:
L234A和L235A;或者
L234A和G237A;或者
L235A和G237A;
或者
L234A、L235A、G237A。
本发明中,如果没有特别说明,位点之前的字母表示突变前的氨基酸,位点之后的字母表示突变后的氨基酸。
在本发明的一个或多个实施方案中,所述的双特异性抗体,其中,按照EU编号系统,所述免疫球蛋白的重链恒定区具有或还具有选自如下的一个或多个突变:
N297A、D265A、D270A、P238D、L328E、E233D、H268D、P271G、A330R、C226S、C229S、E233P、P331S、S267E、L328F、A330L、M252Y、S254T、T256E、N297Q、P238S、P238A、A327Q、A327G、P329A、K322A、T394D、G236R、G236A、L328R、A330S、P331S、H268A、E318A和K320A。
在本发明的一个或多个实施方案中,所述的双特异性抗体,其中,
所述免疫球蛋白的重链可变区的氨基酸序列如SEQ ID NO: 31所示;并且所述免疫球蛋白的轻链可变区的氨基酸序列如SEQ ID NO: 33所示;和,所述单链抗体的重链可变区的氨基酸序列如SEQ ID NO: 41所示;并且所述单链抗体的轻链可变区的氨基酸序列如SEQ ID NO: 43所示。
在本发明的一个或多个实施方案中,所述的双特异性抗体:
所述免疫球蛋白的重链的氨基酸序列如SEQ ID NO: 27所示,并且其轻链的氨基酸序列如SEQ ID NO: 29所示。
在本发明的一些实施方案中,所述双特异性抗体中的所述单链抗体连接在免疫球蛋白的重链的C末端。由于免疫球蛋白有两条重链,因此,一个免疫球蛋白分子连接有两个单链抗体分子。优选地,两个单链抗体分子相同。
在本发明的一些实施方案中,所述双特异性抗体中的所述单链抗体为两条,每条单链抗体的一端分别连接在免疫球蛋白的两条重链的C末端或N末端。
在本发明的一些实施方案中,所述单链抗体的VH与VL之间存在二硫键。在抗体的VH和VL之间引入二硫键的方法是本领域熟知的,例如可参见美国专利US5,747,654;Rajagopal et. al,Prot. Engin. 10(1997)1453-1459;Reiter et. al,Nat.Biotechnol. 14(1996)1239-1245;Reiter et. al,Protein Engineering 8(1995)1323-1331;Webber et. al,Molecular Immunology 32(1995)249-258;Reiter et. al,Immunity 2(1995)281-287;Reiter et. al,JBC 269(1994)18327-18331;Reiter et. al,Inter. J. of Cancer 58(1994)142-149;或者Reiter et. al,Cancer Res.54(1994)2714-2718;其通过引用并入本文。
在本发明的一个或多个实施方案中,所述的双特异性抗体中的所述第一蛋白功能区与所述第二蛋白功能区直接连接或者通过连接片段连接;和/或所述单链抗体的重链可变区与所述单链抗体的轻链可变区直接连接或者通过连接片段连接。
在本发明的一个或多个实施方案中,所述双特异性抗体中的所述连接片段为(GGGGS)n,n为正整数;优选地,n为1、2、3、4、5或6。
在本发明的一个或多个实施方案中,所述双特异性抗体中的所述第一蛋白功能区和第二蛋白功能区独立地为1个、2个或者2个以上。
在本发明的一个或多个实施方案中,所述双特异性抗体中的所述单链抗体连接在免疫球蛋白的重链的C末端。
在本发明的一个或多个实施方案中,所述第一蛋白功能区与所述第二蛋白功能区通过第一连接片段连接;并且所述单链抗体的重链可变区与所述单链抗体的轻链可变区通过第二连接片段连接;所述第一连接片段和所述第二连接片段相同或不同;
优选地,所述第一连接片段和所述第二连接片段的氨基酸序列独立地选自SEQ IDNO: 52和SEQ ID NO: 53;
优选地,所述第一连接片段和所述第二连接片段的氨基酸序列均如SEQ ID NO:53所示。
在本发明的一个或多个实施方案中,所述双特异性抗体为单克隆抗体。
在本发明的一个或多个实施方案中,所述双特异性抗体为人源化抗体。
在本发明的另一个方面,涉及单位制剂,优选用于治疗肿瘤,其中所述单位制剂包含1~10000mg(优选10-1000mg,优选50-500mg、100-400mg、150-300mg、150-250mg或200mg)的本发明任一方面所述的抗TIGIT抗体和1~10000mg(优选1-1000mg,优选50-500mg、100-400mg、150-300mg、150-250mg、200mg或100mg)的本发明任一方面所述的抗PD-1-抗VEGFA双特异性抗体,和任选地一种或多种本发明所述的用于治疗肿瘤的药物(如化疗药,例如铂类药物和/或氟尿嘧啶类抗肿瘤药);其中,所述抗TIGIT抗体、所述抗 PD-1-抗VEGFA双特异性抗体和所述用于治疗肿瘤的药物分别单独包装。
本发明涉及用于预防或治疗癌症或肿瘤的方法,其中,向有需要的受试者给予一份或多份本发明所述的单位制剂,优选地,所述单位制剂中的抗PD-1-抗VEGFA双特异性抗体,抗TIGIT抗体和用于治疗肿瘤的药物各自分开施用。
在本发明的另一个方面,涉及单次药物剂量单元,优选用于治疗肿瘤,其包含0.1-10000mg(优选1-1000mg,优选50-500mg、100-400mg、150-300mg、150-250mg、200mg或100mg)的本发明任一项所述的抗TIGIT抗体和0.1-10000mg(优选1-1000mg,优选50-500mg、100-400mg、150-300mg、150-250mg、200mg或100mg)的本发明任一项所述的抗PD-1-抗VEGFA双特异性抗体。
在本发明的一个或多个实施方案中,其中所述抗TIGIT抗体,所述抗PD-1-抗VEGFA双特异性抗体和/或所述用于治疗肿瘤的药物为适于静脉注射或静脉滴注的形式,优选液体的形式。
在本发明的一个或多个实施方案中,其中给受试者施用有效量的本发明任一项所述抗TIGIT抗体和/或本发明任一项所述抗PD-1-抗VEGFA双特异性抗体的步骤为在手术治疗之前或之后,和/或在放射治疗之前或之后。
在本发明的一个或多个实施方案中,其中,本发明任一项所述抗TIGIT抗体和/或本发明任一项所述抗PD-1-抗VEGFA双特异性抗体的单次给药剂量为每千克体重0.1-100mg,优选1-10mg;或者,本发明任一项所述抗TIGIT抗体和/或本发明任一项所述抗PD-1-抗VEGFA双特异性抗体的单次给药剂量为每位受试者10-1000mg,优选50-500mg、100-400mg、150-300mg、150-250mg或200mg,
优选地,每天两次至约每隔一天一次给药,或每3天、4天、5天、6天、10天、1周、2周、3周、4周、5周或6周给药一次;
优选地,给药方式为静脉滴注或静脉注射。
轻链和重链的可变区决定抗原的结合;每条链的可变区均含有三个高变区,称互补决定区(CDR)(重链(H)的CDR包含HCDR1、HCDR2、HCDR3,轻链(L)的CDR包含LCDR1、LCDR2、LCDR3;其由Kabat等人命名,见Bethesda M.d., Sequences of Proteins ofImmunological Interest, Fifth Edition, NIH Publication 1991; 1-3:91-3242。在已知抗体重链和轻链可变区序列的情况下,目前有几种确定抗体CDR区的方法,包括Kabat,IMGT,Chothia 和AbM 编号系统。然而,每种关于抗体或其变体的CDR的定义的应用都将在本文定义和使用的术语的范围内。如果给定该抗体的可变区氨基酸序列,则本领域技术人员通常可确定特定CDR,而不依赖于该序列自身之外的任何实验数据。
优选地,CDR也可以由IMGT编号系统定义,请参见Ehrenmann, Francois, QuentinKaas, and Marie-Paule Lefranc. IMGT/3Dstructure-DB and IMGT/DomainGapAlign: adatabase and a tool for immunoglobulins or antibodies, T cell receptors, MHC,IgSF and MhcSF. Nucleic acids research 2009; 38(suppl_1): D301-D307。
通过本领域技术人员所熟知的技术手段,例如通过VBASE2数据库根据IMGT定义分析单克隆抗体序列的CDR区的氨基酸序列。
本发明的涉及的抗体26B12、26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4具有相同的CDR:
其重链可变区的3个CDR区的氨基酸序列如下:
HCDR1: GHSFTSDYA (SEQ ID NO: 3)
HCDR2: ISYSDST (SEQ ID NO: 4)
HCDR3: ARLDYGNYGGAMDY (SEQ ID NO: 5);
其轻链可变区的3个CDR区的氨基酸序列如下:
LCDR1:QHVSTA (SEQ ID NO: 8)
LCDR2:SAS (SEQ ID NO: 9)
LCDR3:QQHYITPWT (SEQ ID NO: 10)。
在本发明中,除非另有说明,否则本文中使用的科学和技术名词具有本领域技术人员所通常理解的含义。并且,本文中所用的细胞培养、分子遗传学、核酸化学、免疫学实验室操作步骤均为相应领域内广泛使用的常规步骤。同时,为了更好地理解本发明,下面提供相关术语的定义和解释。
如本文中所使用的,当提及TIGIT(NCBI GenBank ID:NP_776160.2)的氨基酸序列时,其包括TIGIT蛋白的全长,或者细胞外免疫球蛋白可变区(IgV)结构域或者包含细胞外免疫球蛋白可变区(IgV)结构域的片段;还包括TIGIT的融合蛋白,例如与小鼠或人IgG的Fc蛋白片段(mFc或hFc)进行融合的片段。然而,本领域技术人员理解,在TIGIT蛋白的氨基酸序列中,可天然产生或人工引入突变或变异(包括但不限于置换,缺失和/或添加),而不影响其生物学功能。因此,在本发明中,术语“TIGIT蛋白”或“TIGIT”应包括所有此类序列,包括所示的序列以及其天然或人工的变体。并且,当描述TIGIT蛋白的序列片段时,其不仅包括的序列片段,还包括其天然或人工变体中的相应序列片段。
如本文中所使用的,术语EC50是指半最大效应浓度(concentration for 50% ofmaximal effect),是指能引起50%最大效应的浓度。
如本文中所使用的,术语“抗体”是指通常由两对多肽链(每对具有一条“轻”(L)链和一条“重”(H)链)组成的免疫球蛋白分子。抗体轻链可分类为κ和λ轻链。重链可分类为μ、δ、γ、α或ε,并且分别将抗体的同种型定义为IgM、IgD、IgG、IgA和IgE。在轻链和重链内,可变区和恒定区通过大约12或更多个氨基酸的“J”区连接,重链还包含大约3个或更多个氨基酸的“D”区。各重链由重链可变区(VH)和重链恒定区(CH)组成。重链恒定区由3个结构域(CH1、CH2和CH3)组成。各轻链由轻链可变区(VL)和轻链恒定区(CL)组成。轻链恒定区由一个结构域CL组成。抗体的恒定区可介导免疫球蛋白与宿主组织或因子,包括免疫系统的各种细胞(例如,效应细胞)和经典补体系统的第一组分(C1q)的结合。VH和VL区还可被细分为具有高变性的区域(称为互补决定区(CDR)),其间散布有较保守的称为构架区(FR)的区域。各VH和VL由按下列顺序:FR1、CDR1、FR2、CDR2、FR3、CDR3、FR4从氨基末端至羧基末端排列的3个CDR和4个FR组成。各重链/轻链对的可变区(VH和VL)分别形成抗原结合部位。氨基酸至各区域或结构域的分配遵循Kabat Sequences of Proteins of Immunological Interest(National Institutes of Health, Bethesda M.d.(1987 and 1991)),或Chothia &Lesk J. Mol. Biol. 1987; 196:901-917; Chothia等人 Nature 1989; 342:878-883或者IMGT编号系统定义,见Ehrenmann, Francois, Quentin Kaas, and Marie-PauleLefranc. "IMGT/3Dstructure-DB and IMGT/DomainGapAlign: a database and a toolfor immunoglobulins or antibodies, T cell receptors, MHC, IgSF and MhcSF."Nucleic acids research 2009; 38(suppl_1): D301-D307.的定义。术语“抗体”不受任何特定的产生抗体的方法限制。例如,其包括,特别地,重组抗体、单克隆抗体和多克隆抗体。抗体可以是不同同种型的抗体,例如,IgG (例如,IgG1,IgG2,IgG3或IgG4亚型),IgA1,IgA2,IgD,IgE或IgM抗体。
如本文中所使用的,术语抗体的“抗原结合片段”是指包含全长抗体的片段的多肽,其保持特异性结合全长抗体所结合的相同抗原的能力,和/或与全长抗体竞争对抗原的特异性结合,其也被称为“抗原结合部分”。通常参见,Fundamental Immunology, Ch. 7(Paul, W., ed., 第2版,Raven Press, N.Y. (1989),其以其全文通过引用合并入本文,用于所有目的。可通过重组DNA技术或通过完整抗体的酶促或化学断裂产生抗体的抗原结合片段。在一些情况下,抗原结合片段包括Fab、Fab'、F(ab')2、Fd、Fv、dAb和互补决定区(CDR)片段、单链抗体(例如,scFv)、嵌合抗体、双抗体(diabody)和这样的多肽,其包含足以赋予多肽特异性抗原结合能力的抗体的至少一部分。
如本文中所使用的,术语“Fd片段”意指由VH和CH1结构域组成的抗体片段; 术语“Fv片段”意指由抗体的单臂的VL和VH结构域组成的抗体片段;术语“dAb片段”意指由VH结构域组成的抗体片段(Ward 等人, Nature 341:544 546 (1989));术语“Fab片段”意指由VL、VH、CL和CH1结构域组成的抗体片段;术语“F(ab')2片段”意指包含通过铰链区上的二硫桥连接的两个Fab片段的抗体片段。
在一些情况下,抗体的抗原结合片段是单链抗体(例如,scFv),其中VL和VH结构域通过使其能够产生为单个多肽链的连接体配对形成单价分子(参见,例如, Bird等人,Science 242:423 426 (1988)和Huston等人, Proc. Natl. Acad. Sci. USA 85:58795883 (1988))。此类scFv分子可具有一般结构:NH2-VL-接头-VH-COOH或NH2-VH-接头-VL-COOH。合适的现有技术接头由重复的GGGGS氨基酸序列或其变体组成。例如,可使用具有氨基酸序列(GGGGS)4的接头,但也可使用其变体(Holliger等人(1993),Proc. Natl. Acad.Sci. USA 90: 6444-6448)。可用于本发明的其他接头由Alfthan等人(1995),ProteinEng. 8:725-731,Choi等人(2001),Eur. J. Immunol. 31: 94-106,Hu等人(1996),CancerRes. 56:3055-3061,Kipriyanov等人(1999),J. Mol. Biol. 293:41-56和Roovers等人(2001),Cancer Immunol.描述。
在一些情况下,抗体的抗原结合片段是双抗体,即,双价抗体,其中VH和VL结构域在单个多肽链上表达,但使用太短的连接体以致不允许在相同链的两个结构域之间配对,从而迫使结构域与另一条链的互补结构域配对并且产生两个抗原结合部位(参见,例如,Holliger P.等人, Proc. Natl. Acad. Sci. USA 90:6444 6448 (1993),和Poljak R.J.等人, Structure 2:1121 1123 (1994))。
在另一些情况下,抗体的抗原结合片段是 “双特异性抗体”,指由第一抗体(片段)和第二抗体(片段)或抗体类似物通过偶联臂所形成的偶联物,偶联的方式包括但不限于化学反应、基因融合和酶促。 抗体的抗原结合片段可以是“多特异性抗体”包括例如:三特异性抗体和四特异性抗体,前者是具有三种不同抗原结合特异性的抗体,而后者是具有四种不同抗原结合特异性的抗体。例如,经设计的锚蛋白重复蛋白(DARPin),与IgG抗体,scFv-Fc抗体片段相连或其组合,如CN104341529A。抗IL-17a的fynomer与抗IL-6R抗体结合,如WO2015141862A1。
可使用本领域技术人员已知的常规技术(例如,重组DNA技术或酶促或化学断裂法)从给定的抗体(例如本发明提供的单克隆抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4)获得抗体的抗原结合片段(例如,上述抗体片段),并且以与用于完整抗体的方式相同的方式就特异性筛选抗体的抗原结合片段。
如本文中所使用的,术语“单抗”和“单克隆抗体”是指,来自一群高度同源的抗体分子中的一个抗体或抗体的一个片段,也即除可能自发出现的自然突变外,一群完全相同的抗体分子。单抗对抗原上的单一表位具有高特异性。多克隆抗体是相对于单克隆抗体而言的,其通常包含至少2种或更多种的不同抗体,这些不同的抗体通常识别抗原上的不同表位。单克隆抗体通常可采用Kohler等首次报道的杂交瘤技术获得(Köhler G, Milstein C.Continuous cultures of fused cells secreting antibody of predefinedspecificity[J]. nature, 1975; 256(5517): 495),但也可采用重组DNA技术获得(如参见U.S.Patent 4,816,567)。
如本文中所使用的,术语“人源化抗体”是指,人源免疫球蛋白(受体抗体)的全部或部分CDR区被一非人源抗体(供体抗体)的CDR区替换后得到的抗体或抗体片段,其中的供体抗体可以是具有预期特异性、亲和性或反应性的非人源(例如,小鼠、大鼠或兔)抗体。此外,受体抗体的构架区(FR)的一些氨基酸残基也可被相应的非人源抗体的氨基酸残基替换,或被其他抗体的氨基酸残基替换,以进一步完善或优化抗体的性能。关于人源化抗体的更多详细内容,可参见例如,Jones et al., Nature 1986; 321:522-525; Reichmann etal., Nature 1988; 332:323-329; Presta, Curr. Op. Struct. Biol., 1992; 2:593-596;和Clark M. Antibody humanization: a case of the ‘Emperor’s new clothes’[J]. Immunol. Today, 2000; 21(8): 397-402。
如本文中所使用的,术语“分离的”或“被分离的”指的是,从天然状态下经人工手段获得的。如果自然界中出现某一种“分离”的物质或成分,那么可能是其所处的天然环境发生了改变,或从天然环境下分离出该物质,或二者情况均有发生。例如,某一活体动物体内天然存在某种未被分离的多聚核苷酸或多肽,而从这种天然状态下分离出来的高纯度的相同的多聚核苷酸或多肽即称之为分离的。术语“分离的”或“被分离的”不排除混有人工或合成的物质,也不排除存在不影响物质活性的其它不纯物质。
如本文中所使用的,术语“载体(vector)”是指,可将多聚核苷酸插入其中的一种核酸运载工具。当载体能使插入的多核苷酸编码的蛋白获得表达时,载体称为表达载体。载体可以通过转化,转导或者转染导入宿主细胞,使其携带的遗传物质元件在宿主细胞中获得表达。载体是本领域技术人员公知的,包括但不限于:质粒;噬菌粒;柯斯质粒;人工染色体,例如酵母人工染色体(YAC)、细菌人工染色体(BAC)或P1来源的人工染色体(PAC);噬菌体如λ噬菌体或M13噬菌体及动物病毒等。可用作载体的动物病毒包括但不限于,逆转录酶病毒(包括慢病毒)、腺病毒、腺相关病毒、疱疹病毒(如单纯疱疹病毒)、痘病毒、杆状病毒、乳头瘤病毒、乳头多瘤空泡病毒(如SV40)。一种载体可以含有多种控制表达的元件,包括但不限于,启动子序列、转录起始序列、增强子序列、选择元件及报告基因。另外,载体还可含有复制起始位点。
如本文中所使用的,术语“宿主细胞”是指,可用于导入载体的细胞,其包括但不限于,如大肠杆菌或枯草杆菌等的原核细胞,如酵母细胞或曲霉菌等的真菌细胞,如S2果蝇细胞或Sf9等的昆虫细胞,或者如纤维原细胞,CHO细胞,COS细胞,NSO细胞,HeLa细胞,GS细胞,BHK细胞,HEK 293细胞或人细胞等的动物细胞。
如本文中使用的,术语“特异性结合”是指,两分子间的非随机的结合反应,如抗体和其所针对的抗原之间的反应。在某些实施方案中,特异性结合某抗原的抗体(或对某抗原具有特异性的抗体)是指,抗体以小于大约10-5 M,例如小于大约10-6 M、10-7 M、10-8 M、10-9M或10-10 M或更小的亲和力(KD)结合该抗原。
如本文中所使用的,术语“KD”是指特定抗体-抗原相互作用的解离平衡常数,其用于描述抗体与抗原之间的结合亲和力。平衡解离常数越小,抗体-抗原结合越紧密,抗体与抗原之间的亲和力越高。通常,抗体以小于大约10-5 M,例如小于大约10-6 M、10-7 M、10-8 M、10-9 M或10-10 M或更小的解离平衡常数(KD)结合抗原(例如,TIGIT蛋白)。可以使用本领域技术人员知悉的方法测定KD,例如使用Fortebio分子相互作用仪测定。
如本文中所使用的,术语“单克隆抗体”和“单抗”具有相同的含义且可互换使用;术语“多克隆抗体”和“多抗”具有相同的含义且可互换使用;术语“多肽”和“蛋白质”具有相同的含义且可互换使用。并且在本发明中,氨基酸通常用本领域公知的单字母和三字母缩写来表示。例如,丙氨酸可用A或Ala表示。
如本文中所使用的,术语“药学上可接受的载体和/或赋形剂”是指在药理学和/或生理学上与受试者和活性成分相容的载体和/或赋形剂,其是本领域公知的(参见例如Remington's Pharmaceutical Sciences. Edited by Gennaro AR, 19th ed.Pennsylvania: Mack Publishing Company, 1995),并且包括但不限于:pH调节剂,表面活性剂,佐剂,离子强度增强剂。例如,pH调节剂包括但不限于磷酸盐缓冲液;表面活性剂包括但不限于阳离子,阴离子或者非离子型表面活性剂,例如Tween-80;离子强度增强剂包括但不限于氯化钠。
如本文中所使用的,术语“有效量”是指足以获得或至少部分获得期望的效果的量。例如,预防疾病(例如肿瘤)有效量是指,足以预防,阻止,或延迟疾病(例如肿瘤)的发生的量;治疗疾病有效量是指,足以治愈或至少部分阻止已患有疾病的患者的疾病和其并发症的量。
如本文中所使用的,术语“杂交瘤”和“杂交瘤细胞株”可互换使用,并且当提及术语“杂交瘤”和“杂交瘤细胞株”时,其还包括杂交瘤的亚克隆和后代细胞。
术语“单次药物剂量单元”表示在给药方案时刻,(优选按照受试者每kg体重)待给药于受试者的包含本发明所述的抗TIGIT抗体和抗PD-1抗VEGFA双特异性抗体的单次药物剂型,如注射剂,例如置于安瓿瓶中。在本发明的具体实施方案中,给药方案例如包括根据每天两次至约每隔一天一次的给药周期来给药单次药物剂量单元,或者每3天、4天、5天、6天、10天、1周、2周、3周、4周、5周或6周给药一次。
在本发明中,如果没有特别说明,所述“第一”(例如第一蛋白功能区、第一连接片段)和“第二”(例如第二蛋白功能区、第二连接片段)是为了指代上的区分或表述上的清楚,并不具有典型的次序上的含义。
药物或治疗剂的“治疗有效量”或“治疗上有效的剂量”是当单独使用或与另一种治疗剂联合使用时保护主体免于疾病发作或促进疾病消退的药物的任何量,所述疾病消退通过疾病征状的严重程度的降低、无疾病征状阶段的频率和持续时间的增加、或由疾病折磨引起的损伤或失能的预防来证明。使用熟练的从业人员已知的多种方法可以评价治疗剂的促进疾病消退的能力,诸如在临床试验期间在人主体中,在预测对于人类的效力的动物模型系统中,或通过在体外测定法中测定所述药剂的活性。
药物的“预防有效量”是指,其为当单独地或与抗肿瘤剂联合施用给处于发生癌症的风险的主体(例如,具有恶化前病症的主体)或具有癌症复发的风险的主体时,抑制癌症的发生或复发的任何药物量。在某些实施方案中,预防有效量完全阻止癌症的发生或复发。“抑制”癌症的发生或复发是指减少癌症的发生或复发的可能性,或完全阻止癌症的发生或复发。
发明的有益效果
本发明的单克隆抗体能够很好地特异性与TIGIT结合,并且具有极强的亲和力,降低TIGIT抑制免疫细胞的作用,促进T细胞活性,逆转NK细胞耗竭,增强免疫细胞对肿瘤的杀伤作用。可用于制备抑制TIGIT的药物、联合抗PD-1抗VEGFA抗体可治疗或预防肿瘤等疾病的药物,具有良好的应用前景和市场价值。
附图说明
图1:26B12H1L1、26B12H2L2、26B12H2L3和26B12H3L2抗体与TIGIT-mFc的结合活性检测结果。
图2:26B12H3L3、26B12H1L4、26B12H4L1和26B12H4L4抗体与TIGIT-mFc的结合活性检测结果。
图3:26B12H1L1、26B12H2L2、26B12H2L3和26B12H3L2抗体与人CD155-hFc-Biotin竞争结合TIGIT-mFc的活性检测结果。
图4:26B12H3L3、26B12H1L4、26B12H4L1和26B12H4L4抗体与人CD155-hFc-Biotin竞争结合TIGIT-mFc的活性检测结果。
图5:26B12 H3L3与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图6:26B12 H1L1与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图7:26B12 H2L2与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图8:26B12 H2L3与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图9:26B12 H3L2与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图10:26B12 H4L4与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图11:26B12 H1L4与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图12:26B12 H4L1与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图13:RG6058与TIGIT-mFc亲和力常数检测结果图。图中从上到下的每对曲线中加入抗体的浓度分别为5nM、1.67nM、0.557nM、0.185nM、0.06 nM。
图14:FACS检测人源化抗体26B12H2L2和RG6058与293T-TIGIT细胞膜表面抗原TIGIT结合活性。
图15:FACS检测人源化抗体26B12H2L2和RG6058与CD155竞争结合293T-TIGIT细胞膜表面TIGIT的活性。
图16:FACS检测人源化抗体26B12H2L2和RG6058与CD112竞争结合293T-TIGIT细胞膜表面TIGIT的活性。
图17:hTIGIT-BALB/c转基因小鼠CT26肿瘤模型效果。
图18:hTIGIT-BALB/c转基因小鼠CT26肿瘤模型体重变化。
图19:26B12H2L2与抗PD-1-抗VEGFA双特异性抗体VP101(hG1DM)联用对BALB/c-hPD1/hTIGIT转基因小鼠CT26肿瘤模型效果。
图20:26B12H2L2与抗PD-1-抗VEGFA双特异性抗体VP101(hG1DM)联用对BALB/c-hPD1/hTIGIT转基因小鼠CT26肿瘤模型体重变化。
涉及保藏的生物材料:
杂交瘤细胞株LT019(TIGIT-26B12),其于2020年10月23日保藏于中国典型培养物保藏中心(CCTCC),保藏编号为CCTCC NO: C2020208,保藏地址为中国.武汉.武汉大学,邮编:430072。
具体实施方式
下面将结合实施例对本发明的实施方案进行详细描述。本领域技术人员将会理解,下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件(例如参考J.萨姆布鲁克等著,黄培堂等译的《分子克隆实验指南》,第三版,科学出版社)或按照产品说明书进行。所用试剂或仪器未注明生产厂商者,为可以通过市场购买获得的常规产品。例如293T可以购自ATCC。
在本发明的下述实施例中,使用的BALB/c小鼠购自广东省医学实验动物中心。
在本发明的下述实施例中,所用的阳性对照抗体RG6058,其序列可参中国专利公开CN108290946中的序列34和序列36。
在本发明的下述实施例中,所用的联用抗PD-1-抗VEGFA双特异性抗体VP101(hG1DM),生产自中山康方生物医药有限公司,其序列来源于公开专利CN112830972A中所述的抗体,其中VP101(hG1DM)重链氨基酸全长序列如SEQ ID NOs:27所示,轻链氨基酸全长序列如SEQ ID NOs:29所示。VP101(hG1DM)结构为IgG-scFv,其中IgG部分为抗VEGFA抗体,scFv部分为抗PD-1抗体,
抗VEGFA抗体的HCDR1序列如SEQ ID NO:35所示,HCDR2序列如SEQ ID NO:36所示,HCDR3序列如SEQ ID NO:37所示,VH序列SEQ ID NO:31所示,抗VEGFA抗体的LCDR1序列如SEQ ID NO:38所示,LCDR2序列如SEQ ID NO:39所示,LCDR3序列如SEQ ID NO:40所示,VL序列SEQ ID NO:33所示,
其中抗PD1抗体的HCDR1序列如SEQ ID NO:45所示,HCDR2序列如SEQ ID NO:46所示,HCDR3序列如SEQ ID NO:47所示,VH序列SEQ ID NO:41所示,抗PD1抗体的LCDR1序列如SEQ ID NO:48所示,LCDR2序列如SEQ ID NO:49所示,LCDR3序列如SEQ ID NO:50所示,VL序列SEQ ID NO:43所示。
实施例1:抗TIGIT抗体26B12的制备
1. 杂交瘤细胞株LT019的制备
制备抗TIGIT抗体所用的抗原为人TIGIT-mFc(TIGIT为GenbankID: NP_776160.2,mFc的序列如SEQ ID NO:51所示)。取免疫后的小鼠的脾细胞与小鼠骨髓瘤细胞融合,制成杂交瘤细胞。以人TIGIT-mFc作为抗原,对杂交瘤细胞进行间接ELISA法筛选,获得能够分泌与TIGIT特异性结合的抗体的杂交瘤细胞。对筛选得到的杂交瘤细胞,经过有限稀释法得到稳定的杂交瘤细胞株。将以上杂交瘤细胞株分别命名为杂交瘤细胞株LT019,其分泌的单克隆抗体分别命名为26B12。
杂交瘤细胞株LT019(又称TIGIT-26B12),其于2020年10月23日保藏于中国典型培养物保藏中心(CCTCC),保藏编号为CCTCC NO: C2020208,保藏地址为中国.武汉.武汉大学,邮编:430072。
2. 抗TIGIT抗体26B12的制备
用CD培养基(Chemical Defined Medium,含1%青链霉素)对上面制得的LT019细胞株在5% CO2,37°C条件下进行培养。7天后收集细胞培养上清,通过高速离心、微孔滤膜抽真空过滤,并使用HiTrap protein A HP柱进行纯化,制得抗体26B12。
实施例2:抗TIGIT的抗体26B12的序列分析
按照培养细胞细菌总RNA提取试剂盒(Tiangen,货号DP430)的方法,从实施例1中培养的LT019细胞株中提取mRNA。
按照Invitrogen SuperScript® III First-Strand Synthesis System forRT-PCR试剂盒说明书合成cDNA,并进行PCR扩增。
PCR扩增产物直接进行TA克隆,具体操作参考pEASY-T1 Cloning Kit(TransgenCT101)试剂盒说明书进行。
将TA克隆的产物直接进行测序,测序结果如下:
重链可变区的核酸序列如SEQ ID NO: 2所示,片段长363 bp。
其编码的氨基酸序列为SEQ ID NO: 1所示,长度为121个氨基酸。
其中重链HCDR1的序列如SEQ ID NO: 3所示,HCDR2的序列如SEQ ID NO: 4所示,HCDR3的序列如SEQ ID NO: 5所示。
轻链可变区的核酸序列如SEQ ID NO: 7所示,长度为321 bp。
其编码的氨基酸序列为SEQ ID NO: 6所示,长度为107个氨基酸。
其中轻链LCDR1的序列如SEQ ID NO: 8所示,LCDR2的序列如SEQ ID NO: 9所示,LCDR3的序列如SEQ ID NO: 10所示。
实施例3:抗人TIGIT的人源化抗体的轻链和重链设计和制备
1. 抗人TIGIT的人源化抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4的轻链和重链设计
根据人TIGIT蛋白的三维晶体结构以及实施例2获得的抗体26B12的序列,通过计算机模拟抗体模型,随后根据模型设计突变,得到抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4的可变区序列(抗体恒定区序列,来自NCBI的数据库,重链恒定区均采用Ig gamma-1 chain C region,ACCESSION:P01857;轻链恒定区为Ig kappa chain C region,ACCESSION: P01834)。
设计的可变区序列如下表所示。

(7)人源化单克隆抗体26B12H1L4的重链可变区和轻链可变区序列
以上的8个抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4,重链可变区的核酸序列的长度均为363 bp,其编码的氨基酸序列的长度均为121aa;轻链可变区的核酸序列的长度均为321 bp,其编码的氨基酸序列的长度均为107aa。
并且上述8个抗体具有相同的HCDR1-HCDR3和LCDR1-LCDR3,如下:
HCDR1的序列如SEQ ID NO: 3所示,HCDR2的序列如SEQ ID NO: 4所示,HCDR3的序列如SEQ ID NO: 5所示;
LCDR1的序列如SEQ ID NO: 8所示,LCDR2的序列如SEQ ID NO: 9所示,LCDR3的序列如SEQ ID NO: 10所示。
2. 人源化抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4的制备
重链恒定区均采用Ig gamma-1 chain C region,ACCESSION: P01857;轻链恒定区均采用Ig kappa chain C region,ACCESSION: P01834。
将26B12H1L1重链cDNA和轻链的cDNA、26B12H4L1重链cDNA和轻链的cDNA、26B12H2L2重链cDNA和轻链的cDNA、26B12H3L2重链cDNA和轻链的cDNA、26B12H2L3重链cDNA和轻链的cDNA、26B12H3L3重链cDNA和轻链的cDNA、26B12H1L4重链cDNA和轻链的cDNA、26B12H2L4重链cDNA和轻链的cDNA以及26B12H4L4重链cDNA和轻链的cDNA,分别克隆到pUC57simple(金斯瑞公司提供)载体中,分别获得pUC57simple-26B12H1、pUC57simple-26B12L1;pUC57simple-26B12H4、pUC57simple-26B12L1; pUC57simple-26B12H2、pUC57simple-26B12L2;pUC57simple-26B12H3、pUC57simple-26B12L2;pUC57simple-26B12H2、pUC57simple-26B12L3;pUC57simple-26B12H3、pUC57simple-26B12L3;pUC57simple-26B12H1、pUC57simple-26B12L4;pUC57simple-26B12H2、pUC57simple-26B12L4;和pUC57simple-26B12H4、pUC57simple-26B12L4。参照《分子克隆实验指南(第二版)》介绍的标准技术,EcoRI&HindIII酶切合成的重、轻链全长基因,通过限制酶(EcoRI&HindIII)的酶切亚克隆到表达载体pcDNA3.1中获得表达质粒pcDNA3.1-26B12H1、pcDNA3.1-26B12L1、pcDNA3.1-26B12H4、pcDNA3.1-126B12H2、pcDNA3.1-26B12L2、pcDNA3.1-26B12H3、pcDNA3.1-26B12L3和pcDNA3.1-26B12L4,并进一步对重组表达质粒的重/轻链基因进行测序分析。随后将含有相应的轻、重链重组质粒设计基因组合(pcDNA3.1-26B12H1/pcDNA3.1-26B12L1、pcDNA3.1-26B12H4/pcDNA3.1-26B12L1、pcDNA3.1-26B12H2/pcDNA3.1-26B12L2、pcDNA3.1-26B12H3/pcDNA3.1-26B12L2、pcDNA3.1-26B12H2/pcDNA3.1-26B12L3、pcDNA3.1-26B12H3/pcDNA3.1-26B12L3、pcDNA3.1-26B12H1/pcDNA3.1-26B12L4和pcDNA3.1-26B12H4/pcDNA3.1-26B12L4)分别共转染293F细胞后收集培养液进行纯化。测序验证正确后,制备去内毒素级别的表达质粒并将质粒瞬时转染HEK293细胞进行抗体表达,培养7天后收集细胞培养液,采用Protein A柱进行亲和纯化获得人源化抗体。
实施例4:ELISA方法测定抗体与抗原TIGIT-mFc的结合活性
实验步骤:将羊抗鼠IgG Fc(购自Jackson公司,批号:132560),2μg/mL包被酶标板后,4℃孵育16小时。孵育结束后使用PBST洗包被了羊抗鼠IgG Fc的酶标板1次,后使用1%BSA的PBST溶液作为酶标板封闭液,封闭2小时。酶标板结束封闭后用PBST洗板3次。再加入抗原人TIGIT-mFc 1μg/mL,置于37℃条件下孵育30分钟后用PBST洗板3次。在酶标板孔内加入PBST溶液梯度稀释的抗体,抗体稀释梯度详见表1和表2。将加入了待测抗体的酶标板置于37℃条件下孵育30分钟,孵育完成后用PBST洗板3次。洗板后加入1:5000比例稀释的HRP标记的羊抗人 IgG Fc(购自Jackson公司,批号:128332)二抗工作液,置于37℃条件下孵育30分钟。孵育完成后使用PBST洗板4次,后加入TMB(Neogen,308177)避光显色4min,加入终止液终止显色反应。立即把酶标板放入酶标仪中,选择450nm光波长读取酶标板各孔的OD数值。用SoftMax Pro 6.2.1软件对数据进行分析处理。
抗体与抗原TIGIT-mFc结合的结果如图1、图2所示。各剂量的OD值见表1和表2。以抗体浓度为横坐标,吸光度值为纵坐标进行曲线拟合,计算抗体与抗原的结合EC50,结果如表1、表2和图1、图2所示。
表1:26B12H1L1、26B12H2L2、26B12H2L3、26B12H3L2和RG6058与TIGIT-mFc的结合活性检测结果

表2:26B12H3L3、26B12H1L4、26B12H4L1、26B12H4L4和RG6058与TIGIT-mFc的结合活性检测结果

结果显示,抗体26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4均能有效地与人TIGIT-mFc结合,结合效率呈剂量依赖关系,结合活性与同靶点阳性药RG6058相当,表明26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4具有有效结合TIGIT的功能。
实施例5: 竞争ELISA方法分别测定抗体与CD155-hFc-Biotin竞争结合TIGIT-mFc的活性
实验步骤:将TIGIT-mFc,2μg/mL包被酶标板后, 4℃孵育过夜。孵育结束后使用PBST漂洗包被了抗原的酶标板1次,后使用1% BSA的PBST溶液作为酶标板封闭液,封闭2小时。酶标板结束封闭后用PBST洗板3次。在酶标板内加入PBST溶液梯度稀释的抗体,抗体浓度详见表3和表4,室温孵育10分钟后加入等体积的2 μg/mL(终浓度为1μg/mL)的CD155-hFc-Biotin(中山康方生物医药有限公司生产,批号:20170210,其中CD155的GenBank编号为NP_006496.4,hFc的序列如SEQ ID NO:54所示),和抗体混合均匀后将酶标板置于37℃条件下孵育30分钟,孵育完成后用PBST洗板3次。洗板后加入1:4000比例稀释的SA-HRP工作液,置于37℃条件下孵育30分钟。孵育完成后使用PBST洗板4次后加入TMB(Neogen,308177)避光显色5min,加入终止液终止显色反应。立即把酶标板放入酶标仪中,选择450nm光波长读取酶标板各孔的OD数值。用SoftMax Pro 6.2.1软件对数据进行分析处理。
抗体与CD155-hFc-Biotin竞争结合TIGIT-mFc的活性的结果见表3和表4。以抗体浓度为横坐标,吸光度值为纵坐标进行曲线拟合,计算抗体与CD155-hFc-Biotin竞争结合TIGIT-mFc的EC50,结果如下表3和表4、图3和图4所示。
表3:26B12H1L1、26B12H2L2、26B12H2L3、26B12H3L2和RG6058与CD155-hFc-Biotin竞争结合TIGIT-mFc的活性检测结果

表4:26B12H3L3、26B12H1L4、26B12H4L1、26B12H4L4和RG6058与CD155-hFc-Biotin竞争结合TIGIT-mFc的活性检测结果

结果表明,在相同实验条件下,26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4可分别与CD155-hFc-Biotin竞争结合抗原TIGIT-mFc,活性与同靶点阳性药RG6058相当,提示26B12H1L1、26B12H4L1、26B12H2L2、26B12H3L2、26B12H2L3、26B12H3L3、26B12H1L4和26B12H4L4具有有效与CD155-hFc-Biotin竞争结合TIGIT-mFc的功能。
实施例6:使用Fortebio分子相互作用仪测定人源化抗体26B12H3L3、26B12H1L1、26B12H2L2、26B12H2L3、26B12H3L2、26B12H4L4、26B12H1L4、26B12H4L1和RG6058与抗原TIGIT-mFc结合的动力学参数
样品稀释缓冲液为PBS,0.02%Tween-20,0.1%BSA,pH7.4。将TIGIT-mFc以3 μg/mL的浓度固定于AMC传感器上,时间为50s,传感器在缓冲液中平衡60s,固定在传感器上的TIGIT-mFc与抗体结合,浓度为0.06-5 nM(三倍稀释),时间120s,蛋白在缓冲液中解离,时间300s。传感器采用10mM甘氨酸,pH=1.7溶液再生。检测温度为37度,检测频率为0.3 Hz,样品板震动速率为1000 rpm。数据以1:1模型拟合分析,得到亲和力常数。
人源化抗体(作为对照抗体)与TIGIT的亲和力常数测定结果见表5,检测结果如图5至图13所示。
表5:人源化抗体与抗原TIGIT-mFc亲和力常数检测结果

KD为亲和力常数; KD=kdis/kon。
结果显示,人源化抗体26B12H3L3、26B12H1L1、26B12H2L2、26B12H2L3、26B12H3L2、26B12H4L4、26B12H1L4、26B12H4L1和RG6058与TIGIT-mFc的亲和力常数依次为9.64E-11M、1.64E-11M、8.40E-12M、4.85E-11M、5.40E-11M、3.69E-11M、4.63E-11M、8.57E-12 M和3.16E-11M。
结果表明,TIGIT各抗体与TIGIT-mFc结合的亲和力从强到弱依次为:26B12H2L2、26B12H4L1、26B12H1L1、RG6058、26B12H4L4、26B12H1L4、26B12H2L3、26B12H3L2、26B12H3L3。其中人源化抗体26B12H2L2、26B12H4L1、26B12H1L1的亲和力比阳性药物RG6058强,而26B12H4L4的亲和力与阳性药物RG6058亲和力相当。
实施例7 :FACS检测人源化抗体26B12H2L2和RG6058与293T-TIGIT细胞膜表面抗原TIGIT的结合活性
实验方法:
TIGIT载体plenti6.3-TIGITFL-BSD(TIGIT为GenbankID: NP_776160.2,委托金斯瑞基因合成人TIGIT全长cDNA序列,命名为TIGITFL,并克隆到pUC57simple(金斯瑞公司提供)载体中,获得pUC57simple-TIGITFL质粒。以BamHI&XhoI双酶切合成的pUC57simple-TIGITFL质粒,回收TIGITFL目的基因片段并通过限制性位点BamHI&XhoI亚克隆到plenti6.3表达载体,载体pLenti6.3购自Invitrogen公司)转染293T细胞,经筛选获得稳定表达TIGIT的细胞株293T-TIGIT细胞。
收集293T-TIGIT细胞 (DMEM+10%FBS),离心5min后去上清,重悬,计数及活率(P7,95.79%),稀释细胞,透明尖底96孔板每个孔中加入30w 细胞,每管加200 μL 1%PBSA,离心5min,去上清。按实验设计每孔对应加入100 μL抗体 (终浓度为300 nM,100nM,33.3nM,11.11nM,3.7nM,1.23nM,0.41nM,0.041nM,0.0041nM),并设计空白对照及同型对照,冰上孵育60min。每管加200 μL 1%PBSA,离心5min,去上清,洗两遍。每个样品加FITC 羊抗人IgG抗体(购自Jackson公司,货号:109-095-098,用PBSA 500倍稀释),冰上避光孵育40min;每管加入200 μL PBSA,离心5min,去上清。加入200 μL PBSA重悬细胞,转移到流式管中,流式细胞仪检测各浓度下细胞的平均荧光强度。
表6:FACS检测人源化抗体26B12H2L2和RG6058与293T-TIGIT细胞膜表面抗原TIGIT的结合活性

实验结果如表6和图14所示,阳性对照抗体RG6058与细胞膜表面抗原 TIGIT结合的EC50为1.257nM,而人源化抗体26B12H2L2与细胞膜表面抗原TIGIT结合的EC50为0.917nM。
实验结果表明,人源化抗体26B12H2L2结合细胞膜表面抗原 TIGIT的能力比阳性对照抗体RG6058强。
实施例8:FACS检测人源化抗体26B12H2L2和RG6058与CD155或者CD112竞争结合293T-TIGIT细胞膜表面抗原TIGIT的活性
实验方法:收集293T-TIGIT细胞,离心5min后去上清,重悬,计数及活率(94.95%),稀释细胞,透明尖底96孔板每个孔中加入30万个细胞,每管加200 μL 1%PBSA,离心5min,去上清。按实验设计每孔对应加入100 μL抗体 (终浓度为300 nM,100 nM,33.3nM,11.1nM,3.7nM,1.23nM,0.123nM,0.0123nM),并设计空白对照及同型对照,冰上孵育30min。每个样品加CD155 (终浓度为10nM,中山康方生物医药有限公司生产,批号:20190726,其中CD155的GenBank编号为NP_006496.4)或CD112(终浓度为30nM,中山康方生物医药有限公司生产,批号:20190726,其中CD112的GenBank编号为NP_001036189.1),冰上避光孵育60min,再每管加200μL 1%PBSA,离心5min,去上清,洗两遍。每个样品加APC 羊抗鼠 IgG (购自Biolegend公司,批号405308,最小交叉反应活性minimal x-reactivity) 抗体(PBSA 300倍稀释),冰上避光孵育40min;每管加入200μL PBSA,离心5min,去上清。加入200 μL PBSA重悬细胞,转移到流式管中,流式细胞仪检测各浓度下细胞的平均荧光强度。
实验结果分别如表7和图15、以及表8和图16所示。
表7:FACS检测人源化抗体26B12H2L2和RG6058与CD155竞争结合293T-TIGIT细胞膜表面抗原TIGIT的活性

表8:FACS检测人源化抗体26B12H2L2和RG6058与CD112竞争结合293T-TIGIT细胞膜表面抗原TIGIT的活性

结果显示:阳性对照抗体RG6058竞争CD155结合TIGIT的EC50为1.212nM,而人源化抗体26B12H2L2竞争CD155结合TIGIT的EC50为1.049nM;阳性对照抗体RG6058竞争CD112结合TIGIT的EC50为1.224nM,而人源化抗体26B12H2L2竞争CD112结合TIGIT的EC50为1.140nM。
结果表明,人源化抗体26B12H2L2竞争CD155或者CD112结合细胞膜表面抗原TIGIT的能力比阳性对照抗体RG6058强。
实施例9:26B12H2L2对在hTigit-BALB/c转基因小鼠接种CT26小鼠移植瘤的治疗作用
采用在hTigit-BALB/c转基因小鼠(小鼠购自江苏集萃药康生物科技有限公司,采购的转基因小鼠,该小鼠正常的小鼠 TIGIT基因被人 TIGIT基因替代)背部接种50万/只CT26细胞(小鼠结肠癌细胞株,购自ATCC),实验具体步骤为2500万/ml 的CT26细胞以每只接种200μl接种小鼠的方法建立小鼠肿瘤模型。实验小鼠每组8只,设同型对照组(给药剂量为20mg/kg,给药方式为腹腔注射(i.p.),每周两次,共给药6次),以及实验组(给药剂量为20mg/kg,给药方式为腹腔注射(i.p.),每周两次,共给药6次)。具体方案如表9所示。
表9:小鼠CT26肿瘤模型的建模和抗体的给药方案

实验结果如图17所示。
结果显示,26B12H2L2在hTIGIT-BALB/c转基因小鼠CT26肿瘤模型上,肿瘤体积有显著的减少。
结果表明,26B12H2L2在hTIGIT-BALB/c转基因小鼠CT26肿瘤模型上有着很强的药效;具有用于治疗和/或预防肿瘤特别是结肠癌的潜力。
同时,如图18所示,26B12H2L2对作为CT26肿瘤模型的hTIGIT-BALB/c转基因小鼠的体重没有影响,表明26B12H2L2抗体对小鼠没有产生毒副作用。
实施例10:抗TIGIT抗体与抗PD-1-抗VEGFA双功能抗体联用有效治疗肿瘤
为检测抗TIGIT抗体与抗PD-1-抗VEGFA双功能抗体VP101(hG1DM)联用的体内抑瘤活性,首先用CT26细胞(人结肠癌细胞,购自江苏集萃药康生物科技股份有限公司),接种于5-7周龄的雌性BALB/c-hPD1/hTIGIT小鼠(购买自江苏集萃药康生物科技股份有限公司)皮下,当平均肿瘤体积达到80-120 mm3 时,小鼠根据肿瘤体积随机分成4组,每组6只。分组当天定义为D0天,并于分组当天D0天开始给药。联合给药组给药方式为:药物单独配制,先后分别给药(无给药顺序和间隔时间特定要求,给完一种药物再给予另外一种药物)。造模与具体给药方式见表10。给药后测量各组肿瘤的长宽,计算肿瘤体积。
表10:抗TIGIT抗体与抗PD-1-抗VEGFA双功能抗体联用治疗CT26移植瘤BALB/c-hPD1/hTIGIT小鼠模型的给药方案

结果图19所示。结果表明:相比同型对照抗体hIgG,VP101(hG1DM),26B12H2L2均能有效抑制小鼠肿瘤的生长,且VP101(hG1DM)+26B12H2L2组对此模型展现联合抗肿瘤药效,其联合对肿瘤的抑制优于受试药单用组,*p<0.05,**p<0.01,***p<0.0001,Two-wayANOVA(Bnoferroni posttest)。
此外,如图20所示,荷瘤鼠对受试药VP101(hG1DM)和26B12H2L2单用和联用的耐受性均良好,各组对荷瘤小鼠体重无影响。
尽管本发明的具体实施方案已经得到详细的描述,本领域技术人员将会理解。根据已经公开的所有教导,可以对那些细节进行各种修改和替换,这些改变均在本发明的保护范围之内。本发明的全部范围由所附权利要求及其任何等同物给出。
序列表(注:下划线表示CDR序列)
26B12VH的氨基酸序列
EVQLQESGPGLVKPSQSLSLTCTVTGHSFTSDYAWNWIRQFPGNRLEWMGYISYSDSTNYNPSLKSRISITRDTSKNQFFLQMNSVTTEDTATYYCARLDYGNYGGAMDYWGQGTSVTVSS (SEQ ID NO: 1)
26B12VH的核苷酸序列
GAGGTGCAGCTGCAGGAGTCTGGACCTGGCCTGGTGAAACCCTCTCAGTCTCTGTCCCTCACCTGCACTGTCACTGGCCACTCATTCACCAGTGATTATGCCTGGAACTGGATCCGGCAGTTTCCAGGAAACAGACTGGAGTGGATGGGCTACATAAGCTACAGTGATAGCACTAACTACAACCCATCTCTCAAAAGTCGAATCTCTATCACTCGAGACACATCCAAGAACCAGTTCTTCTTGCAGATGAATTCTGTGACTACTGAGGACACAGCCACATATTACTGTGCAAGATT GGACTATGGTAACTACGGTGGGGCTATGGACTACTGGGGTCAAGGGACCTCAGTCACCGTCTCCTCA (SEQ IDNO: 2)
26B12VH的HCDR1:GHSFTSDYA (SEQ ID NO: 3)
26B12VH的HCDR2:ISYSDST (SEQ ID NO: 4)
26B12VH的HCDR3:ARLDYGNYGGAMDY (SEQ ID NO: 5)
26B12VL的氨基酸序列
DIVLTQSHEFMSTSLRDRVSITCKSSQHVSTAVAWYQQKPGQSPKLLIYSASYRYTGVPDRFTGSGSGTDFTFTISSVKAEDLAVYYCQQHYITPWTFGGGTKLEIK (SEQ ID NO: 6)
26B12VL的核苷酸序列
GATATTGTGCTAACTCAGTCTCACGAATTCATGTCCACCTCATTACGAGACAGGGTCAGCATCACCTGCAAATCCAGTCAACATGTGAGTACTGCTGTAGCCTGGTATCAACAGAAACCAGGACAATCTCCTAAACTACTGATTTACTCGGCATCCTACCGGTACACTGGAGTCCCTGATCGCTTCACTGGCAGTGGATCTGGGACGGATTTCACTTTCACCATCAGCAGTGTGAAGGCTGAAGACCTGGCAGTTTATTACTGTCAGCAACATTATATTACTCCGTGGACGTTCGGTGGAGGCACCAAGCTGGAAATAAAA (SEQ ID NO: 7)
26B12VL的LCDR1:QHVSTA (SEQ ID NO: 8)
26B12VL的LCDR2:SAS (SEQ ID NO: 9)
26B12VL的LCDR3:QQHYITPWT (SEQ ID NO: 10)
26B12H1的氨基酸序列
DVQLQESGPGLVKPSQTLSLTCTVSGHSFTSDYAWNWIRQFPGKGLEWIGYISYSDSTNYNPSLKSRITISRDTSKNQFFLQLNSVTAADTATYYCARLDYGNYGGAMDYWGQGTSVTVSS(SEQ ID NO: 11)
26B12H1的核苷酸序列
GATGTGCAGCTGCAGGAGAGCGGCCCCGGACTGGTGAAGCCTTCCCAGACCCTGTCTCTGACCTGTACAGTGTCTGGCCACAGCTTCACATCCGACTACGCCTGGAACTGGATCAGGCAGTTTCCAGGCAAGGGCCTGGAGTGGATCGGCTACATCTCTTATAGCGACTCCACCAACTATAATCCCTCTCTGAAGAGCCGGATCACCATCAGCAGAGATACATCCAAGAACCAGTTCTTTCTGCAGCTGAACAGCGTGACAGCCGCCGACACCGCCACATACTATTGCGCCCGGCT GGACTACGGCAATTATGGCGGAGCCATGGATTACTGGGGCCAGGGCACCTCCGTGACAGTGAGCTCC (SEQ IDNO: 12)
26B12H2的氨基酸序列
DVQLQESGPGLVKPSQTLSLTCTVSGHSFTSDYAWSWIRQPPGKGLEWIGYISYSDSTNYNPSLKSRVTISRDTSKNQFSLKLSSVTAADTAVYYCARLDYGNYGGAMDYWGQGTSVTVSS (SEQ ID NO: 13)
26B12H2的核苷酸序列
GATGTGCAGCTGCAGGAGTCTGGCCCAGGACTGGTGAAGCCAAGCCAGACCCTGTCCCTGACCTGTACAGTGTCCGGCCACTCTTTTACAAGCGACTACGCCTGGTCTTGGATCAGGCAGCCCCCTGGCAAGGGACTGGAGTGGATCGGCTACATCTCCTATTCTGACAGCACCAACTATAATCCCTCCCTGAAGTCTCGGGTGACCATCTCTAGAGATACAAGCAAGAACCAGTTCTCCCTGAAGCTGAGCTCCGTGACCGCAGCAGACACAGCCGTGTACTATTGCGCCCGGCT GGACTACGGCAATTATGGCGGAGCCATGGATTACTGGGGCCAGGGCACCAGCGTGACAGTGTCTAGC (SEQ IDNO: 14)
26B12H3的氨基酸序列
DVQLQESGPGLVKPSQTLSLTCTVSGHSFTSDYAWSWIRQPPGKGLEWIGYISYSDSTNYNPSLKSRVTISVDTSKNQFSLKLSSVTAADTAVYYCARLDYGNYGGAMDYWGQGTSVTVSS (SEQ ID NO: 15)
26B12H3的核苷酸序列
GATGTGCAGCTGCAGGAGTCTGGCCCAGGACTGGTGAAGCCAAGCCAGACCCTGTCCCTGACCTGTACAGTGTCCGGCCACTCTTTTACAAGCGACTACGCCTGGTCTTGGATCAGACAGCCCCCTGGCAAGGGACTGGAGTGGATCGGCTACATCTCCTATTCTGACAGCACCAACTATAATCCCTCCCTGAAGTCTAGAGTGACCATCTCTGTGGATACAAGCAAGAACCAGTTCTCCCTGAAGCTGAGCTCCGTGACCGCAGCAGACACAGCCGTGTACTATTGCGCCCGGCT GGACTACGGCAATTATGGCGGAGCCATGGATTACTGGGGCCAGGGCACCAGCGTGACAGTGTCTAGC (SEQ IDNO: 16)
26B12H4的氨基酸序列
DVQLQESGPGLVKPSQTLSLTCTVSGHSFTSDYAWNWIRQFPGKGLEWMGYISYSDSTNYNPSLKSRITISRDTSKNQFFLQLNSVTAADTATYYCARLDYGNYGGAMDYWGQGTSVTVSS (SEQ ID NO: 17)
26B12H4的核苷酸序列
GATGTGCAGCTGCAGGAGAGCGGCCCCGGACTGGTGAAGCCTTCCCAGACCCTGTCTCTGACCTGTACAGTGTCTGGCCACAGCTTCACATCCGACTACGCCTGGAACTGGATCAGGCAGTTTCCAGGCAAGGGCCTGGAGTGGATGGGCTACATCTCTTATAGCGACTCCACCAACTATAATCCCTCTCTGAAGAGCCGGATCACCATCAGCAGAGATACATCCAAGAACCAGTTCTTTCTGCAGCTGAACAGCGTGACAGCCGCCGACACCGCCACATACTATTGCGCCCGGCT GGACTACGGCAATTATGGCGGAGCCATGGATTACTGGGGCCAGGGCACCTCCGTGACAGTGAGCTCC (SEQ IDNO: 18)
26B12L1的氨基酸序列
DIQMTQSPKSLSTSVGDRVTITCRSSQHVSTAVAWYQQKPGKSPKLLIYSASYRYSGVPDRFSGSGSGTDFTFTISSVQPEDFATYYCQQHYITPWTFGGGTKLEIK (SEQ ID NO: 19)
26B12L1的核苷酸序列
GACATCCAGATGACCCAGTCCCCTAAGTCCCTGTCTACAAGCGTGGGCGATCGGGTGACCATCACATGTAGAAGCTCCCAGCACGTGTCTACCGCAGTGGCATGGTACCAGCAGAAGCCAGGCAAGAGCCCTAAGCTGCTGATCTATTCCGCCTCTTACAGGTATTCCGGAGTGCCAGACCGGTTTAGCGGCTCCGGCTCTGGCACCGATTTCACCTTTACAATCTCTAGCGTGCAGCCAGAGGACTTCGCCACATACTATTGCCAGCAGCACTACATCACCCCATGGACCTTCGGCGGCGGCACAAAGCTGGAGATCAAG (SEQ ID NO: 20)
26B12L2的氨基酸序列
DIQMTQSPSSLSASVGDRVTITCRSSQHVSTALAWYQQKPGKSPKLLIYSASSRYSGVPDRFSGSGSGTDFTFTISSLQPEDFATYYCQQHYITPWTFGGGTKLEIK (SEQ ID NO: 21)
26B12L2的核苷酸序列
GACATCCAGATGACCCAGTCCCCTAGCTCCCTGTCTGCCAGCGTGGGCGATAGGGTGACCATCACATGTAGATCTAGCCAGCACGTGTCTACAGCCCTGGCATGGTACCAGCAGAAGCCAGGCAAGAGCCCTAAGCTGCTGATCTACTCCGCCTCCTCTAGGTATTCTGGAGTGCCAGACCGGTTTTCCGGCTCTGGCAGCGGCACCGATTTCACCTTTACAATCAGCTCCCTGCAGCCAGAGGACTTCGCCACATACTATTGCCAGCAGCACTATATCACCCCATGGACCTTCGGCGGCGGCACCAAGCTGGAGATCAAG (SEQ ID NO: 22)
26B12L3的氨基酸序列
DIQMTQSPSSLSASVGDRVTITCRASQHVSTALAWYQQKPGKAPKLLIYSASSLQSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQHYITPWTFGGGTKLEIK (SEQ ID NO: 23)
26B12L3的核苷酸序列
GACATCCAGATGACCCAGTCCCCTAGCTCCCTGAGCGCCTCCGTGGGCGATAGGGTGACCATCACATGTAGAGCCTCTCAGCACGTGAGCACAGCCCTGGCATGGTACCAGCAGAAGCCAGGCAAGGCCCCTAAGCTGCTGATCTATAGCGCCTCTAGCCTGCAGTCCGGAGTGCCATCTCGGTTCTCTGGCAGCGGCTCCGGAACCGACTTTACCCTGACAATCTCCTCTCTGCAGCCAGAGGATTTCGCCACATACTATTGCCAGCAGCACTACATCACCCCATGGACCTTCGGCGGCGGCACCAAGCTGGAGATCAAG (SEQ ID NO: 24)
26B12L4的氨基酸序列
DIQMTQSPKSMSTSVGDRVTITCRSSQHVSTAVAWYQQKPGKSPKLLIYSASYRYSGVPDRFSGSGSGTDFTFTISSVQPEDFATYYCQQHYITPWTFGGGTKLEIK (SEQ ID NO: 25)
26B12L4的核苷酸序列
GACATCCAGATGACCCAGTCCCCTAAGTCCATGTCTACAAGCGTGGGCGACAGGGTGACCATCACATGTAGAAGCTCCCAGCACGTGTCTACCGCAGTGGCATGGTACCAGCAGAAGCCAGGCAAGAGCCCTAAGCTGCTGATCTATTCCGCCTCTTACAGGTATTCCGGAGTGCCAGACCGGTTTAGCGGCTCCGGCTCTGGCACCGATTTCACCTTTACAATCTCTAGCGTGCAGCCAGAGGACTTCGCCACATACTATTGCCAGCAGCACTACATCACCCCATGGACCTTCGGCGGCGGCACAAAGCTGGAGATCAAG (SEQ ID NO: 26)
VP101(hG1DM)的重链氨基酸序列EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEWVGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVYYCAKYPHYYGSSHWYFDVWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPEAAGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGSGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLRLSCAASGFAFSSYDMSWVRQAPGKGLDWVATISGGGRYTYYPDSVKGRFTISRDNSKNNLYLQMNSLRAEDTALYYCANRYGEAWFAYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSDIQMTQSPSSMSASVGDRVTFTCRASQDINTYLSWFQQKPGKSPKTLIYRANRLVSGVPSRFSGSGSGQDYTLTISSLQPEDMATYYCLQYDEFPLTFGAGTKLELKR (SEQID NO:27)
VP101(hG1DM)的重链核酸序列GAGGTGCAGCTGGTCGAGTCCGGGGGGGGGCTGGTGCAGCCAGGCGGGTCTCTGAGGCTGAGTTGCGCCGCTTCAGGGTACACCTTCACAAACTATGGAATGAATTGGGTGCGCCAGGCACCAGGAAAGGGACTGGAGTGGGTCGGCTGGATCAACACTTACACCGGGGAACCTACCTATGCAGCCGACTTTAAGCGGCGGTTCACCTTCAGCCTGGATACAAGCAAATCCACTGCCTACCTGCAGATGAACAGCCTGCGAGCTGAGGACACCGCAGTCTACTATTGTGCTAAATATCCCCACTACTATGGGAGCAGCCATTGGTATTTTGACGTGTGGGGGCAGGGGACTCTGGTGACAGTGAGCAGCGCAAGCACCAAAGGGCCCAGCGTGTTTCCTCTCGCCCCCTCCTCCAAAAGCACCAGCGGAGGAACCGCTGCTCTCGGATGTCTGGTGAAGGACTACTTCCCTGAACCCGTCACCGTGAGCTGGAATAGCGGCGCTCTGACAAGCGGAGTCCATACATTCCCTGCTGTGCTGCAAAGCAGCGGACTCTATTCCCTGTCCAGCGTCGTCACAGTGCCCAGCAGCAGCCTGGGCACCCAGACCTACATCTGTAACGTCAACCACAAGCCCTCCAACACCAAGGTGGACAAGAAAGTGGAGCCCAAATCCTGCGACAAGACACACACCTGTCCCCCCTGTCCTGCTCCCGAAGCTGCTGGAGGCCCTAGCGTCTTCCTCTTTCCTCCCAAACCCAAGGACACCCTCATGATCAGCAGAACCCCTGAAGTCACCTGTGTCGTCGTGGATGTCAGCCATGAGGACCCCGAGGTGAAATTCAACTGGTATGTCGATGGCGTCGAGGTGCACAACGCCAAAACCAAGCCCAGGGAGGAACAGTACAACTCCACCTACAGGGTGGTGTCCGTGCTGACAGTCCTCCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTGTCCAACAAGGCTCTCCCTGCCCCCATTGAGAAGACCATCAGCAAGGCCAAAGGCCAACCCAGGGAGCCCCAGGTCTATACACTGCCTCCCTCCAGGGACGAACTCACCAAGAACCAGGTGTCCCTGACCTGCCTGGTCAAGGGCTTTTATCCCAGCGACATCGCCGTCGAGTGGGAGTCCAACGGACAGCCCGAGAATAACTACAAGACCACCCCTCCTGTCCTCGACTCCGACGGCTCCTTCTTCCTGTACAGCAAACTGACCGTCGATAAATCTAGGTGGCAGCAGGGCAACGTGTTCTCTTGTTCCGTGATGCATGAAGCACTGCACAACCATTATACCCAGAAGTCTCTGAGCCTGTCCCCCGGCAAGGGCGGCGGCGGCTCTGGAGGAGGAGGCAGCGGCGGAGGAGGCTCCGGAGGCGGCGGCTCTGAGGTGCAGCTGGTGGAGTCTGGAGGAGGACTGGTGCAGCCTGGAGGCTCCCTGAGGCTGTCTTGCGCAGCAAGCGGATTCGCCTTTAGCTCCTACGACATGAGCTGGGTGCGGCAGGCACCTGGCAAGGGTCTGGATTGGGTGGCAACCATCAGCGGAGGCGGCAGATACACATACTATCCCGACTCCGTGAAGGGCAGGTTCACCATCTCCCGCGATAACTCTAAGAACAATCTGTATCTGCAGATGAACAGCCTGAGGGCCGAGGACACAGCCCTGTACTATTGCGCCAACCGCTACGGCGAGGCCTGGTTTGCCTATTGGGGCCAGGGCACCCTGGTGACAGTGTCTAGCGGCGGCGGCGGCAGCGGCGGCGGCGGCTCCGGAGGAGGCGGCTCTGGCGGCGGCGGCAGCGATATCCAGATGACCCAGTCCCCCTCCTCTATGTCTGCCAGCGTGGGCGACCGGGTGACCTTCACATGTAGAGCCTCCCAGGATATCAACACCTACCTGTCTTGGTTTCAGCAGAAGCCCGGCAAGAGCCCTAAGACACTGATCTATCGGGCCAATAGACTGGTGAGCGGAGTGCCTTCCCGGTTCTCCGGCTCTGGCAGCGGACAGGACTATACCCTGACAATCAGCTCCCTGCAGCCAGAGGATATGGCCACATACTATTGCCTGCAGTATGACGAGTTCCCCCTGACCTTCGGGGCTGGCACTAAGCTGGAGCTGAAAAGA (SEQ ID NO:28)
VP101(hG1DM)的轻链氨基酸序列
DIQMTQSPSSLSASVGDRVTITCSASQDISNYLNWYQQKPGKAPKVLIYFTSSLHSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYSTVPWTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (SEQID NO:29)
VP101(hG1DM)的轻链核苷酸序列
GATATTCAGATGACTCAGAGCCCCTCCTCCCTGTCCGCCTCTGTGGGCGACAGGGTCACCATCACATGCAGTGCTTCACAGGATATTTCCAACTACCTGAATTGGTATCAGCAGAAGCCAGGAAAAGCACCCAAGGTGCTGATCTACTTCACTAGCTCCCTGCACTCAGGAGTGCCAAGCCGGTTCAGCGGATCCGGATCTGGAACCGACTTTACTCTGACCATTTCTAGTCTGCAGCCTGAGGATTTCGCTACATACTATTGCCAGCAGTATTCTACCGTGCCATGGACATTTGGCCAGGGGACTAAAGTCGAGATCAAGCGGACCGTGGCCGCTCCCAGTGTCTTCATTTTTCCCCCTAGCGACGAACAGCTGAAATCCGGGACAGCCTCTGTGGTCTGTCTGCTGAACAACTTCTACCCTAGAGAGGCAAAAGTGCAGTGGAAGGTCGATAACGCCCTGCAGAGTGGCAATTCACAGGAGAGCGTGACAGAACAGGACTCCAAAGATTCTACTTATAGTCTGTCAAGCACACTGACTCTGAGCAAGGCTGACTACGAAAAGCATAAAGTGTATGCATGTGAGGTCACCCACCAGGGGCTGAGCAGTCCAGTCACCAAGTCATTCAACAGAGGCGAGTGC (SEQ ID NO:30)
Bevacizumab重链可变区(Bevacizumab-Hv)的氨基酸序列:(123 aa)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTNYGMNWVRQAPGKGLEWVGWINTYTGEPTYAADFKRRFTFSLDTSKSTAYLQMNSLRAEDTAVYYCAKYPHYYGSSHWYFDVWGQGTLVTVSS(SEQ ID NO:31)
Bevacizumab重链可变区的核苷酸序列:(369 bp)
GAGGTGCAGCTGGTCGAGTCCGGGGGGGGGCTGGTGCAGCCAGGCGGGTCTCTGAGGCTGAGTTGCGCCGCTTCAGGGTACACCTTCACAAACTATGGAATGAATTGGGTGCGCCAGGCACCAGGAAAGGGACTGGAGTGGGTCGGCTGGATCAACACTTACACCGGGGAACCTACCTATGCAGCCGACTTTAAGCGGCGGTTCACCTTCAGCCTGGATACAAGCAAATCCACTGCCTACCTGCAGATGAACAGCCTGCGAGCTGAGGACACCGCAGTCTACTATTGTGCTAAATATCCCCACTACTATGGGAGCAGCCATTGGTATTTTGACGTGTGGGGGCAGGGGACTCTGGTGACAGTGAGCAGC(SEQ ID NO: 32)
Bevacizumab轻链可变区(Bevacizumab-Lv)的氨基酸序列:(107 aa)
DIQMTQSPSSLSASVGDRVTITCSASQDISNYLNWYQQKPGKAPKVLIYFTSSLHSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYSTVPWTFGQGTKVEIK(SEQ ID NO: 33)
Bevacizumab轻链可变区的核苷酸序列:(321 bp)
GATATTCAGATGACTCAGAGCCCCTCCTCCCTGTCCGCCTCTGTGGGCGACAGGGTCACCATCACATGCAGTGCTTCACAGGATATTTCCAACTACCTGAATTGGTATCAGCAGAAGCCAGGAAAAGCACCCAAGGTGCTGATCTACTTCACTAGCTCCCTGCACTCAGGAGTGCCAAGCCGGTTCAGCGGATCCGGATCTGGAACCGACTTTACTCTGACCATTTCTAGTCTGCAGCCTGAGGATTTCGCTACATACTATTGCCAGCAGTATTCTACCGTGCCATGGACATTTGGCCAGGGGACTAAAGTCGAGATCAAG(SEQ ID NO:34)
Bevacizumab重链可变区的HCDR1: GYTFTNYG (SEQ ID NO: 35)
Bevacizumab重链可变区的HCDR2: INTYTGEP (SEQ ID NO: 36)
Bevacizumab重链可变区的HCDR3: AKYPHYYGSSHWYFDV (SEQ ID NO: 37)
Bevacizumab轻链可变区的LCDR1: QDISNY (SEQ ID NO: 38)
Bevacizumab轻链可变区的LCDR2: FTS (SEQ ID NO: 39)
Bevacizumab轻链可变区的LCDR3: QQYSTVPWT (SEQ ID NO:40)
人源化单克隆抗体14C12H1L1重链可变区的氨基酸序列:(118 aa)
EVQLVESGGGLVQPGGSLRLSCAASGFAFSSYDMSWVRQAPGKGLDWVATISGGGRYTYYPDSVKGRFTISRDNSKNNLYLQMNSLRAEDTALYYCANRYGEAWFAYWGQGTLVTVSS(SEQ ID NO: 41)
人源化单克隆抗体14C12H1L1重链可变区的核苷酸序列:(354 bp)
GAAGTGCAGCTGGTCGAGTCTGGGGGAGGGCTGGTGCAGCCCGGCGGGTCACTGCGACTGAGCTGCGCAGCTTCCGGATTCGCCTTTAGCTCCTACGACATGTCCTGGGTGCGACAGGCACCAGGAAAGGGACTGGATTGGGTCGCTACTATCTCAGGAGGCGGGAGATACACCTACTATCCTGACAGCGTCAAGGGCCGGTTCACAATCTCTAGAGATAACAGTAAGAACAATCTGTATCTGCAGATGAACAGCCTGAGGGCTGAGGACACCGCACTGTACTATTGTGCCAACCGCTACGGGGAAGCATGGTTTGCCTATTGGGGGCAGGGAACCCTGGTGACAGTCTCTAGT (SEQ ID NO: 42)
14C12H1L1(M)轻链可变区的氨基酸序列:(108 aa,基于14C12H1L1所做的氨基酸序列突变位点用下划线标出)
DIQMTQSPSSMSASVGDRVTFTCRASQDINTYLSWFQQKPGKSPKTLIYRANRLVSGVPSRFSGSGSGQDYTLTISSLQPEDMATYYCLQYDEFPLTFGAGTKLELKR(SEQ ID NO: 43)
14C12H1L1(M) 轻链可变区的核苷酸序列:
GATATCCAGATGACCCAGTCCCCCTCCTCTATGTCTGCCAGCGTGGGCGACCGGGTGACCTTCACATGTAGAGCCTCCCAGGATATCAACACCTACCTGTCTTGGTTTCAGCAGAAGCCCGGCAAGAGCCCTAAGACACTGATCTATCGGGCCAATAGACTGGTGAGCGGAGTGCCTTCCCGGTTCTCCGGCTCTGGCAGCGGACAGGACTATACCCTGACAATCAGCTCCCTGCAGCCAGAGGATATGGCCACATACTATTGCCTGCAGTATGACGAGTTCCCCCTGACCTTCGGGGCTGGCACTAAGCTGGAGCTGAAAAGA(SEQ ID NO:44)
14C12H1L1(M) 重链可变区的HCDR1: GFAFSSYD (SEQ ID NO: 45)
14C12H1L1(M) 重链可变区的HCDR2: ISGGGRYT (SEQ ID NO: 46)
14C12H1L1(M) 重链可变区的HCDR3: ANRYGEAWFAY (SEQ ID NO: 47)
14C12H1L1(M) 轻链可变区的LCDR1: QDINTY (SEQ ID NO: 48)
14C12H1L1(M) 轻链可变区的LCDR2: RAN (SEQ ID NO: 49)
14C12H1L1(M) 轻链可变区的LCDR3: LQYDEFPLT (SEQ ID NO: 50)
mFc的氨基酸序列
PRGPTIKPCPPCKCPAPNLLGGPSVFIFPPKIKDVLMISLSPIVTCVVVDVSEDDPDVQISWFVNNVEVHTAQTQTHREDYNSTLRVVSALPIQHQDWMSGKEFKCKVNNKDLPAPIERTISKPKGSVRAPQVYVLPPPEEEMTKKQVTLTCMVTDFMPEDIYVEWTNNGKTELNYKNTEPVLDSDGSYFMYSKLRVEKKNWVERNSYSCSVVHEGLHNHHTTKSFSRTPGK (SEQ ID NO:51)
第一连接片段氨基酸序列
GGGGSGGGGSGGGGS (SEQ ID NO:52)
第二连接片段氨基酸序列
GGGGSGGGGSGGGGSGGGGS (SEQ ID NO:53)
hFc的氨基酸序列
THTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:54)
序列表
<110> 中山康方生物医药有限公司
<120> 抗TIGIT抗体、其药物组合物及用途
<130> IB216071
<160> 54
<170> PatentIn version 3.5
<210> 1
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VH的氨基酸序列
<400> 1
Glu Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Ser Leu Ser Leu Thr Cys Thr Val Thr Gly His Ser Phe Thr Ser Asp
20 25 30
Tyr Ala Trp Asn Trp Ile Arg Gln Phe Pro Gly Asn Arg Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Ser Asp Ser Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Ile Ser Ile Thr Arg Asp Thr Ser Lys Asn Gln Phe Phe
65 70 75 80
Leu Gln Met Asn Ser Val Thr Thr Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Leu Asp Tyr Gly Asn Tyr Gly Gly Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 2
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VH的核苷酸序列
<400> 2
gaggtgcagc tgcaggagtc tggacctggc ctggtgaaac cctctcagtc tctgtccctc 60
acctgcactg tcactggcca ctcattcacc agtgattatg cctggaactg gatccggcag 120
tttccaggaa acagactgga gtggatgggc tacataagct acagtgatag cactaactac 180
aacccatctc tcaaaagtcg aatctctatc actcgagaca catccaagaa ccagttcttc 240
ttgcagatga attctgtgac tactgaggac acagccacat attactgtgc aagattggac 300
tatggtaact acggtggggc tatggactac tggggtcaag ggacctcagt caccgtctcc 360
tca 363
<210> 3
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VH的HCDR1氨基酸序列
<400> 3
Gly His Ser Phe Thr Ser Asp Tyr Ala
1 5
<210> 4
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VH的HCDR2氨基酸序列
<400> 4
Ile Ser Tyr Ser Asp Ser Thr
1 5
<210> 5
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VH的HCDR3氨基酸序列
<400> 5
Ala Arg Leu Asp Tyr Gly Asn Tyr Gly Gly Ala Met Asp Tyr
1 5 10
<210> 6
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VL的氨基酸序列
<400> 6
Asp Ile Val Leu Thr Gln Ser His Glu Phe Met Ser Thr Ser Leu Arg
1 5 10 15
Asp Arg Val Ser Ile Thr Cys Lys Ser Ser Gln His Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Val Lys Ala
65 70 75 80
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln His Tyr Ile Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 7
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VL的核苷酸序列
<400> 7
gatattgtgc taactcagtc tcacgaattc atgtccacct cattacgaga cagggtcagc 60
atcacctgca aatccagtca acatgtgagt actgctgtag cctggtatca acagaaacca 120
ggacaatctc ctaaactact gatttactcg gcatcctacc ggtacactgg agtccctgat 180
cgcttcactg gcagtggatc tgggacggat ttcactttca ccatcagcag tgtgaaggct 240
gaagacctgg cagtttatta ctgtcagcaa cattatatta ctccgtggac gttcggtgga 300
ggcaccaagc tggaaataaa a 321
<210> 8
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VL的LCDR1氨基酸序列
<400> 8
Gln His Val Ser Thr Ala
1 5
<210> 9
<211> 3
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VL的LCDR2氨基酸序列
<400> 9
Ser Ala Ser
1
<210> 10
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12VL的LCDR3氨基酸序列
<400> 10
Gln Gln His Tyr Ile Thr Pro Trp Thr
1 5
<210> 11
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H1的氨基酸序列
<400> 11
Asp Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly His Ser Phe Thr Ser Asp
20 25 30
Tyr Ala Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Tyr Ile Ser Tyr Ser Asp Ser Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Phe
65 70 75 80
Leu Gln Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Leu Asp Tyr Gly Asn Tyr Gly Gly Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 12
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H1的核苷酸序列
<400> 12
gatgtgcagc tgcaggagag cggccccgga ctggtgaagc cttcccagac cctgtctctg 60
acctgtacag tgtctggcca cagcttcaca tccgactacg cctggaactg gatcaggcag 120
tttccaggca agggcctgga gtggatcggc tacatctctt atagcgactc caccaactat 180
aatccctctc tgaagagccg gatcaccatc agcagagata catccaagaa ccagttcttt 240
ctgcagctga acagcgtgac agccgccgac accgccacat actattgcgc ccggctggac 300
tacggcaatt atggcggagc catggattac tggggccagg gcacctccgt gacagtgagc 360
tcc 363
<210> 13
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H2的氨基酸序列
<400> 13
Asp Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly His Ser Phe Thr Ser Asp
20 25 30
Tyr Ala Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Tyr Ile Ser Tyr Ser Asp Ser Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Asp Tyr Gly Asn Tyr Gly Gly Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 14
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H2的核苷酸序列
<400> 14
gatgtgcagc tgcaggagtc tggcccagga ctggtgaagc caagccagac cctgtccctg 60
acctgtacag tgtccggcca ctcttttaca agcgactacg cctggtcttg gatcaggcag 120
ccccctggca agggactgga gtggatcggc tacatctcct attctgacag caccaactat 180
aatccctccc tgaagtctcg ggtgaccatc tctagagata caagcaagaa ccagttctcc 240
ctgaagctga gctccgtgac cgcagcagac acagccgtgt actattgcgc ccggctggac 300
tacggcaatt atggcggagc catggattac tggggccagg gcaccagcgt gacagtgtct 360
agc 363
<210> 15
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H3的氨基酸序列
<400> 15
Asp Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly His Ser Phe Thr Ser Asp
20 25 30
Tyr Ala Trp Ser Trp Ile Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp
35 40 45
Ile Gly Tyr Ile Ser Tyr Ser Asp Ser Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Val Thr Ile Ser Val Asp Thr Ser Lys Asn Gln Phe Ser
65 70 75 80
Leu Lys Leu Ser Ser Val Thr Ala Ala Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Asp Tyr Gly Asn Tyr Gly Gly Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 16
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H3的核苷酸序列
<400> 16
gatgtgcagc tgcaggagtc tggcccagga ctggtgaagc caagccagac cctgtccctg 60
acctgtacag tgtccggcca ctcttttaca agcgactacg cctggtcttg gatcagacag 120
ccccctggca agggactgga gtggatcggc tacatctcct attctgacag caccaactat 180
aatccctccc tgaagtctag agtgaccatc tctgtggata caagcaagaa ccagttctcc 240
ctgaagctga gctccgtgac cgcagcagac acagccgtgt actattgcgc ccggctggac 300
tacggcaatt atggcggagc catggattac tggggccagg gcaccagcgt gacagtgtct 360
agc 363
<210> 17
<211> 121
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H4的氨基酸序列
<400> 17
Asp Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Thr Val Ser Gly His Ser Phe Thr Ser Asp
20 25 30
Tyr Ala Trp Asn Trp Ile Arg Gln Phe Pro Gly Lys Gly Leu Glu Trp
35 40 45
Met Gly Tyr Ile Ser Tyr Ser Asp Ser Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Ile Thr Ile Ser Arg Asp Thr Ser Lys Asn Gln Phe Phe
65 70 75 80
Leu Gln Leu Asn Ser Val Thr Ala Ala Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Leu Asp Tyr Gly Asn Tyr Gly Gly Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 18
<211> 363
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12H4的核苷酸序列
<400> 18
gatgtgcagc tgcaggagag cggccccgga ctggtgaagc cttcccagac cctgtctctg 60
acctgtacag tgtctggcca cagcttcaca tccgactacg cctggaactg gatcaggcag 120
tttccaggca agggcctgga gtggatgggc tacatctctt atagcgactc caccaactat 180
aatccctctc tgaagagccg gatcaccatc agcagagata catccaagaa ccagttcttt 240
ctgcagctga acagcgtgac agccgccgac accgccacat actattgcgc ccggctggac 300
tacggcaatt atggcggagc catggattac tggggccagg gcacctccgt gacagtgagc 360
tcc 363
<210> 19
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L1的氨基酸序列
<400> 19
Asp Ile Gln Met Thr Gln Ser Pro Lys Ser Leu Ser Thr Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ser Ser Gln His Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Ser Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Val Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ile Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 20
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L1的核苷酸序列
<400> 20
gacatccaga tgacccagtc ccctaagtcc ctgtctacaa gcgtgggcga tcgggtgacc 60
atcacatgta gaagctccca gcacgtgtct accgcagtgg catggtacca gcagaagcca 120
ggcaagagcc ctaagctgct gatctattcc gcctcttaca ggtattccgg agtgccagac 180
cggtttagcg gctccggctc tggcaccgat ttcaccttta caatctctag cgtgcagcca 240
gaggacttcg ccacatacta ttgccagcag cactacatca ccccatggac cttcggcggc 300
ggcacaaagc tggagatcaa g 321
<210> 21
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L2的氨基酸序列
<400> 21
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ser Ser Gln His Val Ser Thr Ala
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Ser Arg Tyr Ser Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ile Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 22
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L2的核苷酸序列
<400> 22
gacatccaga tgacccagtc ccctagctcc ctgtctgcca gcgtgggcga tagggtgacc 60
atcacatgta gatctagcca gcacgtgtct acagccctgg catggtacca gcagaagcca 120
ggcaagagcc ctaagctgct gatctactcc gcctcctcta ggtattctgg agtgccagac 180
cggttttccg gctctggcag cggcaccgat ttcaccttta caatcagctc cctgcagcca 240
gaggacttcg ccacatacta ttgccagcag cactatatca ccccatggac cttcggcggc 300
ggcaccaagc tggagatcaa g 321
<210> 23
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L3的氨基酸序列
<400> 23
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln His Val Ser Thr Ala
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ile Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 24
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L3的核苷酸序列
<400> 24
gacatccaga tgacccagtc ccctagctcc ctgagcgcct ccgtgggcga tagggtgacc 60
atcacatgta gagcctctca gcacgtgagc acagccctgg catggtacca gcagaagcca 120
ggcaaggccc ctaagctgct gatctatagc gcctctagcc tgcagtccgg agtgccatct 180
cggttctctg gcagcggctc cggaaccgac tttaccctga caatctcctc tctgcagcca 240
gaggatttcg ccacatacta ttgccagcag cactacatca ccccatggac cttcggcggc 300
ggcaccaagc tggagatcaa g 321
<210> 25
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L4的氨基酸序列
<400> 25
Asp Ile Gln Met Thr Gln Ser Pro Lys Ser Met Ser Thr Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ser Ser Gln His Val Ser Thr Ala
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Ser Ala Ser Tyr Arg Tyr Ser Gly Val Pro Asp Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Val Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln His Tyr Ile Thr Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 26
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-26B12L4的核苷酸序列
<400> 26
gacatccaga tgacccagtc ccctaagtcc atgtctacaa gcgtgggcga cagggtgacc 60
atcacatgta gaagctccca gcacgtgtct accgcagtgg catggtacca gcagaagcca 120
ggcaagagcc ctaagctgct gatctattcc gcctcttaca ggtattccgg agtgccagac 180
cggtttagcg gctccggctc tggcaccgat ttcaccttta caatctctag cgtgcagcca 240
gaggacttcg ccacatacta ttgccagcag cactacatca ccccatggac cttcggcggc 300
ggcacaaagc tggagatcaa g 321
<210> 27
<211> 719
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-VP101(hG1DM)的重链氨基酸序列
<400> 27
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Ala Asp Phe
50 55 60
Lys Arg Arg Phe Thr Phe Ser Leu Asp Thr Ser Lys Ser Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly
115 120 125
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
130 135 140
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
145 150 155 160
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
165 170 175
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
180 185 190
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
195 200 205
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys
210 215 220
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Ala
225 230 235 240
Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
245 250 255
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
260 265 270
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
275 280 285
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
290 295 300
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
305 310 315 320
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
325 330 335
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
340 345 350
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
355 360 365
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
370 375 380
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
385 390 395 400
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu
405 410 415
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
420 425 430
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
435 440 445
Leu Ser Pro Gly Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
450 455 460
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
465 470 475 480
Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala
485 490 495
Ala Ser Gly Phe Ala Phe Ser Ser Tyr Asp Met Ser Trp Val Arg Gln
500 505 510
Ala Pro Gly Lys Gly Leu Asp Trp Val Ala Thr Ile Ser Gly Gly Gly
515 520 525
Arg Tyr Thr Tyr Tyr Pro Asp Ser Val Lys Gly Arg Phe Thr Ile Ser
530 535 540
Arg Asp Asn Ser Lys Asn Asn Leu Tyr Leu Gln Met Asn Ser Leu Arg
545 550 555 560
Ala Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Asn Arg Tyr Gly Glu Ala
565 570 575
Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Met Ser Ala
610 615 620
Ser Val Gly Asp Arg Val Thr Phe Thr Cys Arg Ala Ser Gln Asp Ile
625 630 635 640
Asn Thr Tyr Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys
645 650 655
Thr Leu Ile Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg
660 665 670
Phe Ser Gly Ser Gly Ser Gly Gln Asp Tyr Thr Leu Thr Ile Ser Ser
675 680 685
Leu Gln Pro Glu Asp Met Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu
690 695 700
Phe Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg
705 710 715
<210> 28
<211> 2157
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-VP101(hG1DM)的重链核酸序列
<400> 28
gaggtgcagc tggtcgagtc cggggggggg ctggtgcagc caggcgggtc tctgaggctg 60
agttgcgccg cttcagggta caccttcaca aactatggaa tgaattgggt gcgccaggca 120
ccaggaaagg gactggagtg ggtcggctgg atcaacactt acaccgggga acctacctat 180
gcagccgact ttaagcggcg gttcaccttc agcctggata caagcaaatc cactgcctac 240
ctgcagatga acagcctgcg agctgaggac accgcagtct actattgtgc taaatatccc 300
cactactatg ggagcagcca ttggtatttt gacgtgtggg ggcaggggac tctggtgaca 360
gtgagcagcg caagcaccaa agggcccagc gtgtttcctc tcgccccctc ctccaaaagc 420
accagcggag gaaccgctgc tctcggatgt ctggtgaagg actacttccc tgaacccgtc 480
accgtgagct ggaatagcgg cgctctgaca agcggagtcc atacattccc tgctgtgctg 540
caaagcagcg gactctattc cctgtccagc gtcgtcacag tgcccagcag cagcctgggc 600
acccagacct acatctgtaa cgtcaaccac aagccctcca acaccaaggt ggacaagaaa 660
gtggagccca aatcctgcga caagacacac acctgtcccc cctgtcctgc tcccgaagct 720
gctggaggcc ctagcgtctt cctctttcct cccaaaccca aggacaccct catgatcagc 780
agaacccctg aagtcacctg tgtcgtcgtg gatgtcagcc atgaggaccc cgaggtgaaa 840
ttcaactggt atgtcgatgg cgtcgaggtg cacaacgcca aaaccaagcc cagggaggaa 900
cagtacaact ccacctacag ggtggtgtcc gtgctgacag tcctccacca ggactggctg 960
aacggcaagg agtacaagtg caaggtgtcc aacaaggctc tccctgcccc cattgagaag 1020
accatcagca aggccaaagg ccaacccagg gagccccagg tctatacact gcctccctcc 1080
agggacgaac tcaccaagaa ccaggtgtcc ctgacctgcc tggtcaaggg cttttatccc 1140
agcgacatcg ccgtcgagtg ggagtccaac ggacagcccg agaataacta caagaccacc 1200
cctcctgtcc tcgactccga cggctccttc ttcctgtaca gcaaactgac cgtcgataaa 1260
tctaggtggc agcagggcaa cgtgttctct tgttccgtga tgcatgaagc actgcacaac 1320
cattataccc agaagtctct gagcctgtcc cccggcaagg gcggcggcgg ctctggagga 1380
ggaggcagcg gcggaggagg ctccggaggc ggcggctctg aggtgcagct ggtggagtct 1440
ggaggaggac tggtgcagcc tggaggctcc ctgaggctgt cttgcgcagc aagcggattc 1500
gcctttagct cctacgacat gagctgggtg cggcaggcac ctggcaaggg tctggattgg 1560
gtggcaacca tcagcggagg cggcagatac acatactatc ccgactccgt gaagggcagg 1620
ttcaccatct cccgcgataa ctctaagaac aatctgtatc tgcagatgaa cagcctgagg 1680
gccgaggaca cagccctgta ctattgcgcc aaccgctacg gcgaggcctg gtttgcctat 1740
tggggccagg gcaccctggt gacagtgtct agcggcggcg gcggcagcgg cggcggcggc 1800
tccggaggag gcggctctgg cggcggcggc agcgatatcc agatgaccca gtccccctcc 1860
tctatgtctg ccagcgtggg cgaccgggtg accttcacat gtagagcctc ccaggatatc 1920
aacacctacc tgtcttggtt tcagcagaag cccggcaaga gccctaagac actgatctat 1980
cgggccaata gactggtgag cggagtgcct tcccggttct ccggctctgg cagcggacag 2040
gactataccc tgacaatcag ctccctgcag ccagaggata tggccacata ctattgcctg 2100
cagtatgacg agttccccct gaccttcggg gctggcacta agctggagct gaaaaga 2157
<210> 29
<211> 214
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-VP101(hG1DM)的轻链氨基酸序列
<400> 29
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile
35 40 45
Tyr Phe Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Thr Val Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 30
<211> 642
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-VP101(hG1DM)的轻链核苷酸序列
<400> 30
gatattcaga tgactcagag cccctcctcc ctgtccgcct ctgtgggcga cagggtcacc 60
atcacatgca gtgcttcaca ggatatttcc aactacctga attggtatca gcagaagcca 120
ggaaaagcac ccaaggtgct gatctacttc actagctccc tgcactcagg agtgccaagc 180
cggttcagcg gatccggatc tggaaccgac tttactctga ccatttctag tctgcagcct 240
gaggatttcg ctacatacta ttgccagcag tattctaccg tgccatggac atttggccag 300
gggactaaag tcgagatcaa gcggaccgtg gccgctccca gtgtcttcat ttttccccct 360
agcgacgaac agctgaaatc cgggacagcc tctgtggtct gtctgctgaa caacttctac 420
cctagagagg caaaagtgca gtggaaggtc gataacgccc tgcagagtgg caattcacag 480
gagagcgtga cagaacagga ctccaaagat tctacttata gtctgtcaag cacactgact 540
ctgagcaagg ctgactacga aaagcataaa gtgtatgcat gtgaggtcac ccaccagggg 600
ctgagcagtc cagtcaccaa gtcattcaac agaggcgagt gc 642
<210> 31
<211> 123
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab重链可变区的氨基酸序列
<400> 31
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Ala Asp Phe
50 55 60
Lys Arg Arg Phe Thr Phe Ser Leu Asp Thr Ser Lys Ser Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 32
<211> 369
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab重链可变区的核苷酸序列
<400> 32
gaggtgcagc tggtcgagtc cggggggggg ctggtgcagc caggcgggtc tctgaggctg 60
agttgcgccg cttcagggta caccttcaca aactatggaa tgaattgggt gcgccaggca 120
ccaggaaagg gactggagtg ggtcggctgg atcaacactt acaccgggga acctacctat 180
gcagccgact ttaagcggcg gttcaccttc agcctggata caagcaaatc cactgcctac 240
ctgcagatga acagcctgcg agctgaggac accgcagtct actattgtgc taaatatccc 300
cactactatg ggagcagcca ttggtatttt gacgtgtggg ggcaggggac tctggtgaca 360
gtgagcagc 369
<210> 33
<211> 107
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab轻链可变区的氨基酸序列
<400> 33
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Asp Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Val Leu Ile
35 40 45
Tyr Phe Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Thr Val Pro Trp
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 34
<211> 321
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab轻链可变区的核苷酸序列
<400> 34
gatattcaga tgactcagag cccctcctcc ctgtccgcct ctgtgggcga cagggtcacc 60
atcacatgca gtgcttcaca ggatatttcc aactacctga attggtatca gcagaagcca 120
ggaaaagcac ccaaggtgct gatctacttc actagctccc tgcactcagg agtgccaagc 180
cggttcagcg gatccggatc tggaaccgac tttactctga ccatttctag tctgcagcct 240
gaggatttcg ctacatacta ttgccagcag tattctaccg tgccatggac atttggccag 300
gggactaaag tcgagatcaa g 321
<210> 35
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab重链可变区的HCDR1氨基酸序列
<400> 35
Gly Tyr Thr Phe Thr Asn Tyr Gly
1 5
<210> 36
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab重链可变区的HCDR2氨基酸序列
<400> 36
Ile Asn Thr Tyr Thr Gly Glu Pro
1 5
<210> 37
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab重链可变区的HCDR3氨基酸序列
<400> 37
Ala Lys Tyr Pro His Tyr Tyr Gly Ser Ser His Trp Tyr Phe Asp Val
1 5 10 15
<210> 38
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab轻链可变区的LCDR1氨基酸序列
<400> 38
Gln Asp Ile Ser Asn Tyr
1 5
<210> 39
<211> 3
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab轻链可变区的LCDR2氨基酸序列
<400> 39
Phe Thr Ser
1
<210> 40
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-Bevacizumab轻链可变区的LCDR3氨基酸序列
<400> 40
Gln Gln Tyr Ser Thr Val Pro Trp Thr
1 5
<210> 41
<211> 118
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-人源化单克隆抗体14C12H1L1重链可变区的氨基酸序列
<400> 41
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Asp Trp Val
35 40 45
Ala Thr Ile Ser Gly Gly Gly Arg Tyr Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Asn Arg Tyr Gly Glu Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 42
<211> 354
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-人源化单克隆抗体14C12H1L1重链可变区的核苷酸序列
<400> 42
gaagtgcagc tggtcgagtc tgggggaggg ctggtgcagc ccggcgggtc actgcgactg 60
agctgcgcag cttccggatt cgcctttagc tcctacgaca tgtcctgggt gcgacaggca 120
ccaggaaagg gactggattg ggtcgctact atctcaggag gcgggagata cacctactat 180
cctgacagcg tcaagggccg gttcacaatc tctagagata acagtaagaa caatctgtat 240
ctgcagatga acagcctgag ggctgaggac accgcactgt actattgtgc caaccgctac 300
ggggaagcat ggtttgccta ttgggggcag ggaaccctgg tgacagtctc tagt 354
<210> 43
<211> 108
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M)轻链可变区的氨基酸序列
<400> 43
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Met Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Phe Thr Cys Arg Ala Ser Gln Asp Ile Asn Thr Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Met Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg
100 105
<210> 44
<211> 324
<212> DNA
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 轻链可变区的核苷酸序列
<400> 44
gatatccaga tgacccagtc cccctcctct atgtctgcca gcgtgggcga ccgggtgacc 60
ttcacatgta gagcctccca ggatatcaac acctacctgt cttggtttca gcagaagccc 120
ggcaagagcc ctaagacact gatctatcgg gccaatagac tggtgagcgg agtgccttcc 180
cggttctccg gctctggcag cggacaggac tataccctga caatcagctc cctgcagcca 240
gaggatatgg ccacatacta ttgcctgcag tatgacgagt tccccctgac cttcggggct 300
ggcactaagc tggagctgaa aaga 324
<210> 45
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 重链可变区的HCDR1氨基酸序列
<400> 45
Gly Phe Ala Phe Ser Ser Tyr Asp
1 5
<210> 46
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 重链可变区的HCDR2氨基酸序列
<400> 46
Ile Ser Gly Gly Gly Arg Tyr Thr
1 5
<210> 47
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 重链可变区的HCDR3氨基酸序列
<400> 47
Ala Asn Arg Tyr Gly Glu Ala Trp Phe Ala Tyr
1 5 10
<210> 48
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 轻链可变区的LCDR1氨基酸序列
<400> 48
Gln Asp Ile Asn Thr Tyr
1 5
<210> 49
<211> 3
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 轻链可变区的LCDR2氨基酸序列
<400> 49
Arg Ala Asn
1
<210> 50
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-14C12H1L1(M) 轻链可变区的LCDR3氨基酸序列
<400> 50
Leu Gln Tyr Asp Glu Phe Pro Leu Thr
1 5
<210> 51
<211> 232
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-mFc的氨基酸序列
<400> 51
Pro Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala
1 5 10 15
Pro Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile
20 25 30
Lys Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val
35 40 45
Val Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val
50 55 60
Asn Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp
65 70 75 80
Tyr Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln
85 90 95
Asp Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp
100 105 110
Leu Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val
115 120 125
Arg Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr
130 135 140
Lys Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu
145 150 155 160
Asp Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr
165 170 175
Lys Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr
180 185 190
Ser Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr
195 200 205
Ser Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys
210 215 220
Ser Phe Ser Arg Thr Pro Gly Lys
225 230
<210> 52
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-第一连接片段氨基酸序列
<400> 52
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 53
<211> 20
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-第二连接片段氨基酸序列
<400> 53
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 54
<211> 225
<212> PRT
<213> 人工序列
<220>
<223> 人工合成的序列-hFc的氨基酸序列
<400> 54
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
1 5 10 15
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
20 25 30
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
35 40 45
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
50 55 60
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
65 70 75 80
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
85 90 95
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
100 105 110
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
115 120 125
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
130 135 140
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
145 150 155 160
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
165 170 175
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
180 185 190
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
195 200 205
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
210 215 220
Lys
225
Claims (112)
1.药物组合物,其包含抗TIGIT抗体或其抗原结合片段和抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段,
其中根据Kabat,IMGT,Chothia 或AbM 编号系统,所述抗TIGIT抗体包含SEQ ID NO:1所示的重链可变区包含的HCDR1-HCDR3和SEQ ID NO:6所示的轻链可变区包含的LCDR1-LCDR3,
所述抗PD-1-抗VEGFA双特异性抗体包括:
靶向PD-1的第一蛋白功能区,和
靶向VEGFA的第二蛋白功能区;
其中,所述第一蛋白功能区为免疫球蛋白,所述第二蛋白功能区为单链抗体;或者,所述第一蛋白功能区为单链抗体,所述第二蛋白功能区为免疫球蛋白;其中,根据Kabat,IMGT,Chothia 或AbM 编号系统,
所述第二蛋白功能区,其包含SEQ ID NO:31所示的重链可变区中包含的HCDR1-HCDR3,和SEQ ID NO:33所示的轻链可变区中包含的LCDR1-LCDR3;和
所述的第一蛋白功能区,其包含SEQ ID NO:41所示的重链可变区中包含的HCDR1-HCDR3和SEQ ID NO:43所示的轻链可变区中包含的LCDR1-LCDR3;
其中,所述免疫球蛋白为人IgG1亚型,其中所述抗原结合片段选自Fab、Fab'、F(ab')2或Fv。
2.权利要求1所述的药物组合物,其中,按照IMGT编号系统,所述抗TIGIT抗体的重链可变区包含氨基酸序列分别如SEQ ID NO: 3-5所示的HCDR1-HCDR3;并且所述抗TIGIT抗体的轻链可变区包含氨基酸序列分别如SEQ ID NO: 8-10所示的LCDR1-LCDR3。
3.权利要求1所述的药物组合物,其中,按照IMGT编号系统,所述第二蛋白功能区的重链可变区包含如SEQ ID NO: 35-37所示的HCDR1-HCDR3,和所述第二蛋白功能区的轻链可变区包含如SEQ ID NO: 38-40所示的LCDR1-LCDR3。
4.权利要求1所述的药物组合物,其中,按照IMGT编号系统,所述第一蛋白功能区的重链可变区包含如SEQ ID NO:45-47所示的HCDR1-HCDR3和所述第一的蛋白功能区的轻链可变区包含如SEQ ID NO: 48-50所示的LCDR1-LCDR3。
5.权利要求1所述的药物组合物,其中,所述药物组合物还包括药学上可接受的载体和/或赋形剂。
6.权利要求1所述的药物组合物,其中所述抗TIGIT抗体的重链可变区的氨基酸序列选自SEQ ID NO: 1、SEQ ID NO: 11、SEQ ID NO: 13、SEQ ID NO: 15和SEQ ID NO: 17组成的组;并且所述抗TIGIT抗体的轻链可变区的氨基酸序列选自SEQ ID NO: 6、SEQ ID NO: 19、SEQ ID NO: 21、SEQ ID NO: 23和SEQ ID NO: 25组成的组。
7.权利要求6所述的药物组合物,其中,所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 1所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ IDNO: 6所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 11所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 19所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 17所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 19所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 13所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 21所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 13所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 23所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 15所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 21所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 15所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 23所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 11所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 25所示;或者
所述的抗TIGIT抗体的重链可变区的氨基酸序列如SEQ ID NO: 17所示,并且所述的抗TIGIT抗体的轻链可变区的氨基酸序列如SEQ ID NO: 25所示。
8.权利要求6所述的药物组合物,其中,所述的抗TIGIT抗体包括非-CDR区,且所述非-CDR区来自不是鼠类的物种。
9.权利要求8所述的药物组合物,其中,所述非-CDR区来自人抗体。
10.权利要求6所述的药物组合物,其中,所述的抗TIGIT抗体的重链恒定区为Iggamma-1 chain C region;轻链恒定区为Ig kappa chain C region。
11.权利要求10所述的药物组合物,其中,所述的抗TIGIT抗体的重链恒定区为NCBIACCESSION: P01857的Ig gamma-1 chain C region;轻链恒定区为NCBI ACCESSION:P01834的Ig kappa chain C region。
12.权利要求1所述的药物组合物,其中,所述抗PD-1-抗VEGFA双特异性抗体为人源化抗体或嵌合抗体。
13.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体或其抗原结合片段以小于4E-10或小于4E-11的KD结合TIGIT-mFc。
14.权利要求13所述的药物组合物,其中,所述KD通过Fortebio分子相互作用仪测得。
15.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体或其抗原结合片段以小于1.5nM的EC50结合TIGIT。
16.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体或其抗原结合片段以小于1.2nM的EC50结合TIGIT。
17.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体或其抗原结合片段以小于1nM的EC50结合TIGIT。
18.权利要求15所述的药物组合物,其中,所述EC50通过流式细胞仪测得。
19.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体为单克隆抗体、人源化抗体、嵌合抗体、多特异性抗体、单链抗体、双抗体。
20.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体为双特异性抗体。
21.权利要求1所述的药物组合物,其中,所述的抗TIGIT抗体是由杂交瘤细胞株LT019产生的抗体,所述杂交瘤细胞株LT019保藏于中国典型培养物保藏中心(CCTCC),保藏编号为CCTCC NO: C2020208。
22.权利要求1所述的药物组合物,所述的抗PD-1-抗VEGFA双特异性抗体的所述免疫球蛋白的重链可变区的氨基酸序列选自SEQ ID NO: 31或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列;并且所述免疫球蛋白的轻链可变区的氨基酸序列选自SEQ ID NO:33或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列;和,所述单链抗体的重链可变区的氨基酸序列选自SEQ IDNO: 41或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列;并且所述单链抗体的轻链可变区的氨基酸序列选自SEQ ID NO: 43或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列。
23.权利要求22所述的药物组合物,其中,所述的抗PD-1-抗VEGFA双特异性抗体中的所述第一蛋白功能区与所述第二蛋白功能区直接连接或者通过连接片段连接;和/或所述单链抗体的重链可变区与所述单链抗体的轻链可变区直接连接或者通过连接片段连接。
24.权利要求23所述的药物组合物,其中,所述的抗PD-1-抗VEGFA双特异性抗体中的所述连接片段为(GGGGS)n,n为正整数。
25.权利要求24所述的药物组合物,其中,n为1、2、3、4、5或6。
26.权利要求22所述的药物组合物,其中,所述的抗PD-1-抗VEGFA双特异性抗体中的所述第一蛋白功能区和第二蛋白功能区独立地为1个或者2个以上。
27.权利要求22所述的药物组合物,其中,所述的抗PD-1-抗VEGFA双特异性抗体中的所述单链抗体连接在免疫球蛋白的重链的C末端。
28.权利要求27所述的药物组合物,其中所述单链抗体的重链可变区连接在免疫球蛋白的重链的C末端。
29.权利要求22所述的药物组合物,其中,按照EU编号系统,所述免疫球蛋白的重链恒定区具有如下突变组合之一:
L234A和L235A;或者
L234A和G237A;或者
L235A和G237A;或者
L234A、L235A、G237A。
30.权利要求22所述的药物组合物,其中,所述的抗PD-1-抗VEGFA双特异性抗体包括:
靶向PD-1的第一蛋白功能区,和
靶向VEGFA的第二蛋白功能区;
所述第一蛋白功能区为2个,所述第二蛋白功能区为1个;
其中,所述第一蛋白功能区为单链抗体,其中所述单链抗体相同或不同;所述第二蛋白功能区为免疫球蛋白;
所述免疫球蛋白的重链可变区的氨基酸序列如SEQ ID NO:31或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列所示,并且其轻链可变区的氨基酸序列如SEQ ID NO: 33或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列所示;
所述单链抗体的重链可变区的氨基酸序列如SEQ ID NO: 41或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列所示,并且所述单链抗体的轻链可变区的氨基酸序列如SEQ ID NO: 43或与其具有至少60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%同源性的序列所示;
所述单链抗体连接在免疫球蛋白的重链的C末端;
所述第一蛋白功能区与所述第二蛋白功能区通过第一连接片段连接;并且所述单链抗体的重链可变区与所述单链抗体的轻链可变区通过第二连接片段连接;所述第一连接片段和所述第二连接片段相同或不同。
31.权利要求30所述的药物组合物,其中,所述第一连接片段和所述第二连接片段的氨基酸序列独立地选自SEQ ID NO: 52和SEQ ID NO: 53。
32.权利要求30所述的药物组合物,其中,所述第一连接片段和所述第二连接片段的氨基酸序列均如SEQ ID NO: 53所示。
33.权利要求30所述的药物组合物,其中,所述的抗PD-1-抗VEGFA双特异性抗体的重链氨基酸序列如SEQ ID NO:27所示,轻链氨基酸序列如SEQ ID NO:29所示,双特异性抗体结构为IgG-scFv,其中IgG部分为抗VEGFA抗体,scFv部分为抗PD-1抗体。
34.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为(1:5)-(5:1)。
35.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:5。
36.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:4。
37.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:3。
38.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:2。
39.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:1。
40.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为2:1。
41.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为3:1。
42.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为4:1。
43.权利要求1-33任一项所述的药物组合物,其中按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为5:1。
44.试剂盒,其包含独立包装的第一产品和第二产品,其中,
所述第一产品包含权利要求1-43任一项中所述的抗TIGIT抗体或其抗原结合片段;
所述第二产品包含权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段。
45.权利要求44所述的试剂盒,其中,所述试剂盒还包含独立包装的第三产品,所述第三产品包含一种或多种化疗药物。
46.权利要求45所述的试剂盒,其中,所述第一产品和所述第二产品还独立地包含一种或多种药学上可接受的辅料。
47.权利要求45所述的试剂盒,其中,所述第一产品、第二产品和第三产品还包含产品说明书。
48.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为(1:5)-(5:1)。
49.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:5。
50.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:4。
51.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:3。
52.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:2。
53.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为1:1。
54.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为2:1。
55.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为3:1。
56.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为4:1。
57.权利要求44所述的试剂盒,其中,所述的试剂盒中,按照抗体的质量计算,抗TIGIT抗体或其抗原结合片段与抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段的质量比为5:1。
58.有效量的权利要求1-43任一项中所述的抗TIGIT抗体或其抗原结合片段;和/或权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体或其抗原结合片段在制备用于治疗和/或预防肿瘤或真菌病的药物或试剂盒中的应用。
59.权利要求58所述的应用,其中,所述药物或试剂盒进一步包含一种或多种化疗药物,靶向治疗剂,抗代谢药物,抗生素,植物类药物和/或激素类药物。
60.权利要求59所述的应用,其中所述靶向治疗剂为抗体-药物缀合物。
61.权利要求59所述的应用,其中,所述抗TIGIT抗体,所述抗PD-1-抗VEGFA双特异性抗体和/或所述化疗药物为适于静脉注射或静脉滴注的形式。
62.权利要求61所述的应用,其中,所述抗TIGIT抗体,所述抗PD-1-抗VEGFA双特异性抗体和/或所述化疗药物为液体的形式。
63.权利要求59所述的应用,其中所述化疗药物是化疗剂或生长抑制剂。
64.权利要求63所述的应用,其中所述化疗剂或生长抑制剂选自烷化剂、蒽环类、抗激素剂、芳香酶抑制剂、蛋白激酶抑制剂、脂质激酶抑制剂、反义寡核苷酸、核酶、抗代谢物、拓扑异构酶抑制剂、蛋白酶体抑制剂、抗微管剂、EGFR拮抗剂、类视色素、组蛋白脱乙酰酶抑制剂及其组合。
65.权利要求63所述的应用,其中所述化疗剂或生长抑制剂选自细胞毒剂。
66.权利要求63所述的应用,其中所述化疗剂或生长抑制剂选自抗肿瘤抗生素、抗雄激素剂或酪氨酸激酶抑制剂。
67.权利要求59所述的应用,其中所述靶向治疗剂选自B-raf抑制剂、MEK抑制剂、K-ras抑制剂、c-Met抑制剂、Alk抑制剂、磷脂酰肌醇3-激酶抑制剂、Akt 抑制剂、mTOR 抑制剂、双磷脂酰肌醇 3-激酶/mTOR 抑制剂及其组合。
68.权利要求60所述的应用,其中所述抗体-药物缀合物包含选自下组的药物:美登新碱、单甲基auristatin E、加利车霉素、esperamicin和放射性同位素螯合剂。
69.权利要求58所述的应用,其中,所述药物或试剂盒进一步包含环磷酰胺,培美曲塞,铂类药物,阿霉素类,紫杉醇,长春碱类,他莫昔芬,甲地孕酮,戈舍瑞林,门冬酰胺酶和/或氟尿嘧啶类抗肿瘤药。
70.权利要求58所述的应用,其中,所述药物或试剂盒进一步包含顺铂、卡铂或奥沙利铂。
71.权利要求58所述的应用,其中所述肿瘤选自如下的一种或多种:
宫颈癌、子宫内膜癌、肺癌、咽喉癌、食管癌、甲状腺癌、间皮瘤、胃癌、肠癌、肝胆癌、肾癌、卵巢癌、输卵管癌、腹膜癌、胶质瘤、皮肤癌、黑色素瘤、骨癌、肉瘤、神经母细胞瘤、骨髓瘤、大细胞神经内分泌癌、尿路上皮癌、前列腺癌、睾丸癌、鼻咽癌,头和颈癌、脑癌、鳞状细胞癌、基底细胞癌、腺瘤、绒毛膜上皮癌、恶性葡萄胎、恶性支持细胞-间质细胞瘤、恶性颗粒细胞瘤、无性细胞瘤、默克尔细胞癌。
72.权利要求58所述的应用,其中所述肿瘤选自如下的一种或多种:平滑肌肉瘤、横纹肌肉瘤、肝癌、乳腺瘤、胰腺癌、胸腺癌、回盲部腺癌、壶腹部腺癌、粘液性和浆液性囊腺癌。
73.权利要求58所述的应用,其中所述肿瘤选自如下的一种或多种:白血病、淋巴瘤,和其他血液系统恶性肿瘤。
74.权利要求58所述的应用,其中所述肿瘤选自如下的一种或多种:浆细胞瘤、高度微卫星不稳定型(MSI-H)和错配修复缺陷型(dMMR)实体瘤。
75.权利要求58所述的应用,其中所述肿瘤选自如下的一种或多种:
结肠直肠癌、骨肉瘤、软骨肉瘤、外周T 细胞淋巴瘤、霍奇金淋巴瘤、非霍奇金淋巴瘤、急性髓系白血病和多发性骨髓瘤。
76.权利要求58所述的应用,其中所述肿瘤选自如下的一种或多种:
食管鳞癌、胆管癌、直肠癌、结肠癌、小细胞肺癌和非小细胞肺癌。
77.权利要求58所述的应用,其中所述肿瘤选自转移性宫颈癌,鳞状非小细胞肺癌,非鳞状非小细胞肺癌,胆道癌,胃肠道癌,胃食管结合部腺癌,肝细胞癌,晚期卵巢癌,神经胶质瘤、复发性胶质瘤,上尿路上皮癌,膀胱癌,侵袭性脑癌,或三阴乳腺癌。
78.权利要求58所述的应用,其中所述肿瘤为晚期胃癌。
79.权利要求58所述的应用,其中所述肿瘤为胃腺癌。
80.权利要求58所述的应用,其中所述肿瘤为胶质母细胞瘤。
81.单位制剂,其中,所述单位制剂包含:1~10000mg的权利要求1-43任一项中所述的抗TIGIT抗体和1~10000mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体,其中,所述抗TIGIT抗体、所述抗PD-1-抗VEGFA双特异性抗体和化疗药分别单独包装。
82.权利要求81所述的单位制剂,其中所述单位制剂包含10-1000mg的权利要求1-43任一项中所述的抗TIGIT抗体。
83.权利要求81所述的单位制剂,其中所述单位制剂包含50-500mg的权利要求1-43任一项中所述的抗TIGIT抗体。
84.权利要求81所述的单位制剂,其中所述单位制剂包含100-400mg的权利要求1-43任一项中所述的抗TIGIT抗体。
85.权利要求81所述的单位制剂,其中所述单位制剂包含150-300mg的权利要求1-43任一项中所述的抗TIGIT抗体。
86.权利要求81所述的单位制剂,其中所述单位制剂包含150-250mg的权利要求1-43任一项中所述的抗TIGIT抗体。
87.权利要求81所述的单位制剂,其中所述单位制剂包含200mg的权利要求1-43任一项中所述的抗TIGIT抗体。
88.权利要求81所述的单位制剂,其中所述单位制剂包含1-1000mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
89.权利要求81所述的单位制剂,其中所述单位制剂包含50-500mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
90.权利要求81所述的单位制剂,其中所述单位制剂包含100-400mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
91.权利要求81所述的单位制剂,其中所述单位制剂包含150-300mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
92.权利要求81所述的单位制剂,其中所述单位制剂包含150-250mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
93.权利要求81所述的单位制剂,其中所述单位制剂包含200mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
94.权利要求81所述的单位制剂,其中所述单位制剂包含100mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
95.权利要求81所述的单位制剂,其中所述单位制剂包含一种或多种权利要求63-68任一项中所述的化疗药物。
96.权利要求95所述的单位制剂,其中所述化疗药物是铂类药物和/或氟尿嘧啶类抗肿瘤药。
97.单次药物剂量单元,其包含0.1-10000mg的权利要求1-43任一项中所述的抗TIGIT抗体和0.1-10000mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
98.权利要求97所述的单次药物剂量单元,其包含1-1000mg的权利要求1-43任一项中所述的抗TIGIT抗体。
99.权利要求97所述的单次药物剂量单元,其包含50-500mg的权利要求1-43任一项中所述的抗TIGIT抗体。
100.权利要求97所述的单次药物剂量单元,其包含100-400mg的权利要求1-43任一项中所述的抗TIGIT抗体。
101.权利要求97所述的单次药物剂量单元,其包含150-300mg的权利要求1-43任一项中所述的抗TIGIT抗体。
102.权利要求97所述的单次药物剂量单元,其包含150-250mg的权利要求1-43任一项中所述的抗TIGIT抗体。
103.权利要求97所述的单次药物剂量单元,其包含200mg的权利要求1-43任一项中所述的抗TIGIT抗体。
104.权利要求97所述的单次药物剂量单元,其包含100mg的权利要求1-43任一项中所述的抗TIGIT抗体。
105.权利要求97所述的单次药物剂量单元,其包含1-1000mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
106.权利要求97所述的单次药物剂量单元,其包含50-500mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
107.权利要求97所述的单次药物剂量单元,其包含100-400mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
108.权利要求97所述的单次药物剂量单元,其包含150-300mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
109.权利要求97所述的单次药物剂量单元,其包含150-250mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
110.权利要求97所述的单次药物剂量单元,其包含200mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
111.权利要求97所述的单次药物剂量单元,其包含100mg的权利要求1-43任一项中所述的抗PD-1-抗VEGFA双特异性抗体。
112.权利要求81所述的单位制剂或权利要求97所述的单次药物剂量单元在制备用于治疗肿瘤的药物中的应用。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210132762.1A CN114181310B (zh) | 2022-02-14 | 2022-02-14 | 抗tigit抗体、其药物组合物及用途 |
| CA3208430A CA3208430A1 (en) | 2022-02-14 | 2023-02-14 | Pharmaceutical composition comprising anti-tigit antibody and anti-pd-1/anti-vegfa bispecific antibody, and use thereof |
| EP23745373.3A EP4273170A1 (en) | 2022-02-14 | 2023-02-14 | Pharmaceutical composition comprising anti-tigit antibody and anti-pd-1-anti-vegfa bispecific antibody, and use |
| PCT/CN2023/075862 WO2023151693A1 (zh) | 2022-02-14 | 2023-02-14 | 包含抗tigit抗体和抗pd-1-抗vegfa双特异性抗体的药物组合物及用途 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210132762.1A CN114181310B (zh) | 2022-02-14 | 2022-02-14 | 抗tigit抗体、其药物组合物及用途 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114181310A CN114181310A (zh) | 2022-03-15 |
| CN114181310B true CN114181310B (zh) | 2022-07-05 |
Family
ID=80607015
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210132762.1A Active CN114181310B (zh) | 2022-02-14 | 2022-02-14 | 抗tigit抗体、其药物组合物及用途 |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP4273170A1 (zh) |
| CN (1) | CN114181310B (zh) |
| CA (1) | CA3208430A1 (zh) |
| WO (1) | WO2023151693A1 (zh) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116003625A (zh) * | 2021-08-20 | 2023-04-25 | 中山康方生物医药有限公司 | 包含抗TIGIT抗体和TGF-βR的融合蛋白、其药物组合物及用途 |
| CN114181310B (zh) * | 2022-02-14 | 2022-07-05 | 中山康方生物医药有限公司 | 抗tigit抗体、其药物组合物及用途 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101355965A (zh) * | 2005-06-08 | 2009-01-28 | 达纳-法伯癌症研究院 | 通过抑制程序性细胞死亡1(pd-1)途经治疗持续性感染和癌症的方法及组合物 |
| CN104479018A (zh) * | 2008-12-09 | 2015-04-01 | 霍夫曼-拉罗奇有限公司 | 抗-pd-l1抗体及它们用于增强t细胞功能的用途 |
| CN107148430A (zh) * | 2014-08-19 | 2017-09-08 | 默沙东公司 | 抗tigit抗体 |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5747654A (en) | 1993-06-14 | 1998-05-05 | The United States Of America As Represented By The Department Of Health And Human Services | Recombinant disulfide-stabilized polypeptide fragments having binding specificity |
| KR102236367B1 (ko) | 2013-07-26 | 2021-04-05 | 삼성전자주식회사 | DARPin을 포함하는 이중 특이 키메라 단백질 |
| TWI674274B (zh) | 2014-03-17 | 2019-10-11 | 日商田邊三菱製藥股份有限公司 | 抗體-飛諾莫接合物 |
| BR112018005862A2 (pt) | 2015-09-25 | 2018-10-16 | Genentech, Inc. | anticorpos, anticorpos isolados, polinucleotídeo, vetor, célula hospedeira, método de produção do anticorpo, imunoconjugado, composição, usos dos anticorpos, métodos para tratar ou retardar a progressão de um câncer e de uma doença e para aumentar, potencializar ou estimular uma resposta ou função imune e kit |
| CA3062061A1 (en) * | 2017-05-01 | 2018-11-08 | Agenus Inc. | Anti-tigit antibodies and methods of use thereof |
| WO2019062832A1 (zh) * | 2017-09-29 | 2019-04-04 | 江苏恒瑞医药股份有限公司 | Tigit抗体、其抗原结合片段及医药用途 |
| CN109053895B (zh) * | 2018-08-30 | 2020-06-09 | 中山康方生物医药有限公司 | 抗pd-1-抗vegfa的双功能抗体、其药物组合物及其用途 |
| CN111196852A (zh) * | 2018-11-16 | 2020-05-26 | 四川科伦博泰生物医药股份有限公司 | 抗tigit抗体及其用途 |
| JP2023504003A (ja) * | 2019-11-25 | 2023-02-01 | 中山康方生物医▲藥▼有限公司 | 抗pd-1-抗vegfa二重特異性抗体、その医薬組成物および使用 |
| CN110960543A (zh) * | 2019-12-10 | 2020-04-07 | 安徽瀚海博兴生物技术有限公司 | 一种联合抗vegf-抗pd1双特异性抗体用于制备抗癌药物 |
| CN113214400B (zh) * | 2020-01-21 | 2022-11-08 | 甫康(上海)健康科技有限责任公司 | 一种双特异性抗pd-l1/vegf抗体及其用途 |
| JP2023511595A (ja) * | 2020-01-27 | 2023-03-20 | ジェネンテック, インコーポレイテッド | 抗tigitアンタゴニスト抗体を用いたがんを処置するための方法 |
| WO2021263085A2 (en) * | 2020-06-25 | 2021-12-30 | Arch Oncology, Inc. | Combination therapy for the treatment of solid and hematological cancers |
| CN116157418A (zh) * | 2020-08-05 | 2023-05-23 | 晶体生物科学股份有限公司 | 抗tigit抗体及其使用方法 |
| US11028172B1 (en) * | 2020-11-10 | 2021-06-08 | Lepu Biopharma Co., Ltd. | Anti-TIGIT antibodies and uses thereof |
| CN114181310B (zh) * | 2022-02-14 | 2022-07-05 | 中山康方生物医药有限公司 | 抗tigit抗体、其药物组合物及用途 |
-
2022
- 2022-02-14 CN CN202210132762.1A patent/CN114181310B/zh active Active
-
2023
- 2023-02-14 EP EP23745373.3A patent/EP4273170A1/en active Pending
- 2023-02-14 WO PCT/CN2023/075862 patent/WO2023151693A1/zh active Application Filing
- 2023-02-14 CA CA3208430A patent/CA3208430A1/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101355965A (zh) * | 2005-06-08 | 2009-01-28 | 达纳-法伯癌症研究院 | 通过抑制程序性细胞死亡1(pd-1)途经治疗持续性感染和癌症的方法及组合物 |
| CN104479018A (zh) * | 2008-12-09 | 2015-04-01 | 霍夫曼-拉罗奇有限公司 | 抗-pd-l1抗体及它们用于增强t细胞功能的用途 |
| CN107148430A (zh) * | 2014-08-19 | 2017-09-08 | 默沙东公司 | 抗tigit抗体 |
| CN113583131A (zh) * | 2014-08-19 | 2021-11-02 | 默沙东公司 | 抗tigit抗体 |
Also Published As
| Publication number | Publication date |
|---|---|
| CA3208430A1 (en) | 2023-08-14 |
| EP4273170A1 (en) | 2023-11-08 |
| CN114181310A (zh) | 2022-03-15 |
| WO2023151693A1 (zh) | 2023-08-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107151269B (zh) | 一种pdl-1抗体、其药物组合物及其用途 | |
| EP3882275A1 (en) | Anti-pd-1 and anti-vegfa bifunctional antibody, pharmaceutical composition thereof and use thereof | |
| WO2021023117A1 (zh) | 抗ctla4-抗pd-1双特异性抗体及其用途 | |
| CA3034849A1 (en) | Anti-pd1 monoclonal antibody, pharmaceutical composition thereof and use thereof | |
| EP4067387A1 (en) | Anti-pd-1-anti-vegfa bispecific antibody, pharmaceutical composition and use thereof | |
| KR20140113912A (ko) | Her3에 특이적인 결합 분자 및 이의 용도 | |
| CN114181310B (zh) | 抗tigit抗体、其药物组合物及用途 | |
| CN114106182B (zh) | 抗tigit的抗体及其用途 | |
| CN114478769B (zh) | 抗tigit抗体、其药物组合物及用途 | |
| KR20230170648A (ko) | 항-cd47 단일클론 항체 및 이의 용도 | |
| JP2024509018A (ja) | 抗pd-1-抗vegfa二重特異性抗体を含有する組合せ医薬及びその使用 | |
| WO2023001303A1 (zh) | 药物组合物及用途 | |
| WO2023246247A1 (zh) | 药物组合物及其用途 | |
| WO2022068809A1 (zh) | 抗cd3抗体以及其用途 | |
| WO2023241656A1 (zh) | 包含抗cldn18.2抗体的双特异性抗体、药物组合物及用途 | |
| WO2023016348A1 (en) | Cldn18.2-targeting antibody, bispecific antibody and use thereof | |
| WO2023094995A1 (en) | Human cxcl16 antibodies and the use thereof | |
| CN116997569A (zh) | 抗cd93构建体及其用途 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |