KR20210087108A - 전립선 특이 막 항원 결합 단백질 - Google Patents
전립선 특이 막 항원 결합 단백질 Download PDFInfo
- Publication number
- KR20210087108A KR20210087108A KR1020217020580A KR20217020580A KR20210087108A KR 20210087108 A KR20210087108 A KR 20210087108A KR 1020217020580 A KR1020217020580 A KR 1020217020580A KR 20217020580 A KR20217020580 A KR 20217020580A KR 20210087108 A KR20210087108 A KR 20210087108A
- Authority
- KR
- South Korea
- Prior art keywords
- gly
- binding protein
- ser
- thr
- psma
- Prior art date
Links
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 title claims abstract description 661
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 title claims abstract description 415
- 230000027455 binding Effects 0.000 claims abstract description 204
- 238000009739 binding Methods 0.000 claims abstract description 201
- 238000000034 method Methods 0.000 claims abstract description 95
- 108091008324 binding proteins Proteins 0.000 claims abstract description 81
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 11
- 102000023732 binding proteins Human genes 0.000 claims abstract 15
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 186
- 238000006467 substitution reaction Methods 0.000 claims description 167
- 108090000623 proteins and genes Proteins 0.000 claims description 143
- 102000004169 proteins and genes Human genes 0.000 claims description 139
- 235000018102 proteins Nutrition 0.000 claims description 135
- 235000001014 amino acid Nutrition 0.000 claims description 105
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims description 84
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims description 84
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 83
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims description 81
- 206010060862 Prostate cancer Diseases 0.000 claims description 74
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 74
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 63
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 63
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 claims description 62
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 claims description 61
- 108010003723 Single-Domain Antibodies Proteins 0.000 claims description 56
- 235000003704 aspartic acid Nutrition 0.000 claims description 54
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 claims description 54
- 201000010099 disease Diseases 0.000 claims description 50
- 102000025171 antigen binding proteins Human genes 0.000 claims description 46
- 230000014509 gene expression Effects 0.000 claims description 37
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims description 34
- 206010028980 Neoplasm Diseases 0.000 claims description 33
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 claims description 30
- 239000004472 Lysine Substances 0.000 claims description 27
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 claims description 27
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 claims description 26
- 102000046689 human FOLH1 Human genes 0.000 claims description 25
- 239000003446 ligand Substances 0.000 claims description 23
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 claims description 23
- 125000000539 amino acid group Chemical group 0.000 claims description 22
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 19
- 150000007523 nucleic acids Chemical group 0.000 claims description 18
- 239000013598 vector Substances 0.000 claims description 16
- 108091033319 polynucleotide Proteins 0.000 claims description 14
- 102000040430 polynucleotide Human genes 0.000 claims description 14
- 239000002157 polynucleotide Substances 0.000 claims description 14
- 210000002307 prostate Anatomy 0.000 claims description 10
- 238000004519 manufacturing process Methods 0.000 claims description 8
- 208000023275 Autoimmune disease Diseases 0.000 claims description 6
- 238000006243 chemical reaction Methods 0.000 claims description 6
- 239000003795 chemical substances by application Substances 0.000 claims description 6
- 208000035473 Communicable disease Diseases 0.000 claims description 5
- 208000009329 Graft vs Host Disease Diseases 0.000 claims description 5
- 206010020751 Hypersensitivity Diseases 0.000 claims description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 5
- 208000030961 allergic reaction Diseases 0.000 claims description 5
- 208000024908 graft versus host disease Diseases 0.000 claims description 5
- 208000026278 immune system disease Diseases 0.000 claims description 5
- 208000015181 infectious disease Diseases 0.000 claims description 5
- 208000027866 inflammatory disease Diseases 0.000 claims description 5
- 230000003071 parasitic effect Effects 0.000 claims description 5
- 230000002062 proliferating effect Effects 0.000 claims description 5
- 230000003612 virological effect Effects 0.000 claims description 5
- 238000012258 culturing Methods 0.000 claims description 4
- 230000009977 dual effect Effects 0.000 claims description 4
- 101710181478 Envelope glycoprotein GP350 Proteins 0.000 claims 5
- 230000001976 improved effect Effects 0.000 abstract description 10
- 230000009870 specific binding Effects 0.000 abstract description 6
- 238000004220 aggregation Methods 0.000 abstract description 2
- 230000002776 aggregation Effects 0.000 abstract description 2
- 210000004027 cell Anatomy 0.000 description 89
- 230000008685 targeting Effects 0.000 description 79
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 78
- 102000014914 Carrier Proteins Human genes 0.000 description 66
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 65
- 235000004400 serine Nutrition 0.000 description 63
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 58
- 102000004196 processed proteins & peptides Human genes 0.000 description 55
- 210000001744 T-lymphocyte Anatomy 0.000 description 53
- 229920001184 polypeptide Polymers 0.000 description 51
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 50
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 47
- 230000000694 effects Effects 0.000 description 46
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 45
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 45
- 235000014304 histidine Nutrition 0.000 description 45
- 108091000831 antigen binding proteins Proteins 0.000 description 41
- 239000000427 antigen Substances 0.000 description 37
- 102000036639 antigens Human genes 0.000 description 37
- 108091007433 antigens Proteins 0.000 description 37
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 35
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 35
- 239000012634 fragment Substances 0.000 description 29
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 26
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 26
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 26
- 229940024606 amino acid Drugs 0.000 description 26
- 150000001875 compounds Chemical class 0.000 description 26
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 25
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 25
- MSHXWFKYXJTLEZ-CIUDSAMLSA-N Gln-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MSHXWFKYXJTLEZ-CIUDSAMLSA-N 0.000 description 25
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 25
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 25
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 25
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 25
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 25
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 25
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 25
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 25
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 25
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 25
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 25
- 150000001413 amino acids Chemical class 0.000 description 25
- 108010008355 arginyl-glutamine Proteins 0.000 description 25
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 25
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 24
- 238000011282 treatment Methods 0.000 description 24
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 23
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 23
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 23
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 22
- 238000003556 assay Methods 0.000 description 22
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 22
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 21
- 239000003814 drug Substances 0.000 description 21
- 102220556665 Acetylcholinesterase_G97S_mutation Human genes 0.000 description 20
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 20
- 239000004471 Glycine Substances 0.000 description 20
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 20
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 20
- RATVAFHGEFAWDH-JYJNAYRXSA-N Arg-Phe-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCCN=C(N)N)N RATVAFHGEFAWDH-JYJNAYRXSA-N 0.000 description 19
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 19
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 19
- 239000004473 Threonine Substances 0.000 description 19
- 235000013930 proline Nutrition 0.000 description 19
- 235000008521 threonine Nutrition 0.000 description 19
- 108010005233 alanylglutamic acid Proteins 0.000 description 18
- 102000008100 Human Serum Albumin Human genes 0.000 description 17
- 108091006905 Human Serum Albumin Proteins 0.000 description 17
- 102220625480 RING finger protein 24_T50E_mutation Human genes 0.000 description 16
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 16
- 108010089804 glycyl-threonine Proteins 0.000 description 16
- 108010010147 glycylglutamine Proteins 0.000 description 16
- 108010073969 valyllysine Proteins 0.000 description 16
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 15
- 230000001404 mediated effect Effects 0.000 description 15
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 14
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 14
- PLTGTJAZQRGMPP-FXQIFTODSA-N Asn-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O PLTGTJAZQRGMPP-FXQIFTODSA-N 0.000 description 14
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 14
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 14
- ZNOBVZFCHNHKHA-KBIXCLLPSA-N Ile-Ser-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZNOBVZFCHNHKHA-KBIXCLLPSA-N 0.000 description 14
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 14
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 14
- AKXBNSZMYAOGLS-STQMWFEESA-N Tyr-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AKXBNSZMYAOGLS-STQMWFEESA-N 0.000 description 14
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 14
- 229940079593 drug Drugs 0.000 description 14
- 102000039446 nucleic acids Human genes 0.000 description 14
- 108020004707 nucleic acids Proteins 0.000 description 14
- 108010009962 valyltyrosine Proteins 0.000 description 14
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 13
- 208000035475 disorder Diseases 0.000 description 13
- 108010087823 glycyltyrosine Proteins 0.000 description 13
- 210000002966 serum Anatomy 0.000 description 13
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 12
- 241000282567 Macaca fascicularis Species 0.000 description 12
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 12
- 230000001965 increasing effect Effects 0.000 description 12
- 230000002147 killing effect Effects 0.000 description 12
- 230000004048 modification Effects 0.000 description 12
- 238000012986 modification Methods 0.000 description 12
- 239000000523 sample Substances 0.000 description 12
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 11
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 11
- NTAZNGWBXRVEDJ-FXQIFTODSA-N Arg-Asp-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NTAZNGWBXRVEDJ-FXQIFTODSA-N 0.000 description 11
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 description 11
- YVXRYLVELQYAEQ-SRVKXCTJSA-N Asn-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N YVXRYLVELQYAEQ-SRVKXCTJSA-N 0.000 description 11
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 11
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 11
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 11
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 11
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 11
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 11
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 11
- 108091008874 T cell receptors Proteins 0.000 description 11
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 11
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 11
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 11
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 11
- VYVBSMCZNHOZGD-RCWTZXSCSA-N Thr-Val-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O VYVBSMCZNHOZGD-RCWTZXSCSA-N 0.000 description 11
- QOEZFICGUZTRFX-IHRRRGAJSA-N Tyr-Cys-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O QOEZFICGUZTRFX-IHRRRGAJSA-N 0.000 description 11
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 11
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 11
- 230000015572 biosynthetic process Effects 0.000 description 11
- 201000011510 cancer Diseases 0.000 description 11
- 238000005755 formation reaction Methods 0.000 description 11
- 235000013922 glutamic acid Nutrition 0.000 description 11
- 239000004220 glutamic acid Substances 0.000 description 11
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 11
- 230000004044 response Effects 0.000 description 11
- 210000001519 tissue Anatomy 0.000 description 11
- 108010038745 tryptophylglycine Proteins 0.000 description 11
- 108010003137 tyrosyltyrosine Proteins 0.000 description 11
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 10
- DEAGTWNKODHUIY-MRFFXTKBSA-N Ala-Tyr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DEAGTWNKODHUIY-MRFFXTKBSA-N 0.000 description 10
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 10
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 10
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 10
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 10
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 10
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 10
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 10
- MYXNLWDWWOTERK-BHNWBGBOSA-N Gly-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN)O MYXNLWDWWOTERK-BHNWBGBOSA-N 0.000 description 10
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 10
- WLRJHVNFGAOYPS-HJPIBITLSA-N Ile-Ser-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N WLRJHVNFGAOYPS-HJPIBITLSA-N 0.000 description 10
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 10
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 10
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 10
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 10
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 10
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 10
- QJKPECIAWNNKIT-KKUMJFAQSA-N Ser-Lys-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QJKPECIAWNNKIT-KKUMJFAQSA-N 0.000 description 10
- MUMGGOZAMZWBJJ-DYKIIFRCSA-N Testostosterone Chemical compound O=C1CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 MUMGGOZAMZWBJJ-DYKIIFRCSA-N 0.000 description 10
- LYGKYFKSZTUXGZ-ZDLURKLDSA-N Thr-Cys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)NCC(O)=O LYGKYFKSZTUXGZ-ZDLURKLDSA-N 0.000 description 10
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 10
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 10
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 10
- UUZYQOUJTORBQO-ZVZYQTTQSA-N Trp-Val-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 UUZYQOUJTORBQO-ZVZYQTTQSA-N 0.000 description 10
- BURPTJBFWIOHEY-UWJYBYFXSA-N Tyr-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 BURPTJBFWIOHEY-UWJYBYFXSA-N 0.000 description 10
- 108010087924 alanylproline Proteins 0.000 description 10
- 239000000539 dimer Substances 0.000 description 10
- 108010050848 glycylleucine Proteins 0.000 description 10
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 10
- 125000003729 nucleotide group Chemical group 0.000 description 10
- 210000004881 tumor cell Anatomy 0.000 description 10
- PPCORQFLAZWUNO-QWRGUYRKSA-N Asn-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N PPCORQFLAZWUNO-QWRGUYRKSA-N 0.000 description 9
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 9
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 9
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 9
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 9
- -1 TR-66 or X35-3 Proteins 0.000 description 9
- SOAUMCDLIUGXJJ-SRVKXCTJSA-N Tyr-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O SOAUMCDLIUGXJJ-SRVKXCTJSA-N 0.000 description 9
- 238000010494 dissociation reaction Methods 0.000 description 9
- 230000005593 dissociations Effects 0.000 description 9
- 239000000203 mixture Substances 0.000 description 9
- 239000002773 nucleotide Substances 0.000 description 9
- 230000002829 reductive effect Effects 0.000 description 9
- RAAWHFXHAACDFT-FXQIFTODSA-N Ala-Met-Asn Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CC(N)=O)C(O)=O RAAWHFXHAACDFT-FXQIFTODSA-N 0.000 description 8
- MSILNNHVVMMTHZ-UWVGGRQHSA-N Arg-His-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CN=CN1 MSILNNHVVMMTHZ-UWVGGRQHSA-N 0.000 description 8
- ZCSHHTFOZULVLN-SZMVWBNQSA-N Arg-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 ZCSHHTFOZULVLN-SZMVWBNQSA-N 0.000 description 8
- DXHINQUXBZNUCF-MELADBBJSA-N Asn-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O DXHINQUXBZNUCF-MELADBBJSA-N 0.000 description 8
- 108020004705 Codon Proteins 0.000 description 8
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 8
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 8
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 8
- CMMBEMZGNGYJRJ-IHRRRGAJSA-N His-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N CMMBEMZGNGYJRJ-IHRRRGAJSA-N 0.000 description 8
- FLMYSKVSDVHLEW-SVSWQMSJSA-N Ser-Thr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLMYSKVSDVHLEW-SVSWQMSJSA-N 0.000 description 8
- IELISNUVHBKYBX-XDTLVQLUSA-N Tyr-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IELISNUVHBKYBX-XDTLVQLUSA-N 0.000 description 8
- 239000011230 binding agent Substances 0.000 description 8
- 239000000872 buffer Substances 0.000 description 8
- 238000010822 cell death assay Methods 0.000 description 8
- 239000013604 expression vector Substances 0.000 description 8
- 239000005090 green fluorescent protein Substances 0.000 description 8
- 239000013642 negative control Substances 0.000 description 8
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 8
- 238000001959 radiotherapy Methods 0.000 description 8
- 108010061238 threonyl-glycine Proteins 0.000 description 8
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 7
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 7
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 7
- KAHUBGWSIQNZQQ-KKUMJFAQSA-N Phe-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KAHUBGWSIQNZQQ-KKUMJFAQSA-N 0.000 description 7
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 7
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 7
- MCRPZFQGVZLTAI-UHFFFAOYSA-N Val-Leu-Trp-Tyr Natural products C=1NC2=CC=CC=C2C=1CC(NC(=O)C(NC(=O)C(N)C(C)C)CC(C)C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 MCRPZFQGVZLTAI-UHFFFAOYSA-N 0.000 description 7
- 230000034994 death Effects 0.000 description 7
- 238000009826 distribution Methods 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 150000003384 small molecules Chemical class 0.000 description 7
- 238000012360 testing method Methods 0.000 description 7
- 238000002560 therapeutic procedure Methods 0.000 description 7
- MYTHOBCLNIOFBL-SRVKXCTJSA-N Asn-Ser-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYTHOBCLNIOFBL-SRVKXCTJSA-N 0.000 description 6
- 241000699670 Mus sp. Species 0.000 description 6
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 6
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 6
- FOOZNBRFRWGBNU-DCAQKATOSA-N Ser-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N FOOZNBRFRWGBNU-DCAQKATOSA-N 0.000 description 6
- 108010090804 Streptavidin Proteins 0.000 description 6
- YRJOLUDFVAUXLI-GSSVUCPTSA-N Thr-Thr-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O YRJOLUDFVAUXLI-GSSVUCPTSA-N 0.000 description 6
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 6
- 230000009824 affinity maturation Effects 0.000 description 6
- 239000011324 bead Substances 0.000 description 6
- 230000001419 dependent effect Effects 0.000 description 6
- 230000002255 enzymatic effect Effects 0.000 description 6
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 6
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 108010062699 gamma-Glutamyl Hydrolase Proteins 0.000 description 6
- 230000036541 health Effects 0.000 description 6
- 239000002502 liposome Substances 0.000 description 6
- 231100000682 maximum tolerated dose Toxicity 0.000 description 6
- 230000035772 mutation Effects 0.000 description 6
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 6
- 239000000758 substrate Substances 0.000 description 6
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 6
- 230000004614 tumor growth Effects 0.000 description 6
- 239000011701 zinc Substances 0.000 description 6
- 229910052725 zinc Inorganic materials 0.000 description 6
- 206010006187 Breast cancer Diseases 0.000 description 5
- 208000026310 Breast neoplasm Diseases 0.000 description 5
- 102220573534 C-C motif chemokine 5_G55K_mutation Human genes 0.000 description 5
- 206010009944 Colon cancer Diseases 0.000 description 5
- 102000004127 Cytokines Human genes 0.000 description 5
- 108090000695 Cytokines Proteins 0.000 description 5
- 108020004414 DNA Proteins 0.000 description 5
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 5
- 102000003958 Glutamate Carboxypeptidase II Human genes 0.000 description 5
- 108090000369 Glutamate Carboxypeptidase II Proteins 0.000 description 5
- HQSKKSLNLSTONK-JTQLQIEISA-N Gly-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 HQSKKSLNLSTONK-JTQLQIEISA-N 0.000 description 5
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 5
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 5
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 5
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 5
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 5
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 5
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 5
- 102000035195 Peptidases Human genes 0.000 description 5
- 108091005804 Peptidases Proteins 0.000 description 5
- 239000004365 Protease Substances 0.000 description 5
- 230000006044 T cell activation Effects 0.000 description 5
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 5
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 5
- 230000030833 cell death Effects 0.000 description 5
- 230000009260 cross reactivity Effects 0.000 description 5
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 5
- 229960004671 enzalutamide Drugs 0.000 description 5
- WXCXUHSOUPDCQV-UHFFFAOYSA-N enzalutamide Chemical group C1=C(F)C(C(=O)NC)=CC=C1N1C(C)(C)C(=O)N(C=2C=C(C(C#N)=CC=2)C(F)(F)F)C1=S WXCXUHSOUPDCQV-UHFFFAOYSA-N 0.000 description 5
- 235000019152 folic acid Nutrition 0.000 description 5
- 239000011724 folic acid Substances 0.000 description 5
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 5
- 238000003367 kinetic assay Methods 0.000 description 5
- 238000005259 measurement Methods 0.000 description 5
- 201000001441 melanoma Diseases 0.000 description 5
- 239000013641 positive control Substances 0.000 description 5
- 238000011533 pre-incubation Methods 0.000 description 5
- 230000018883 protein targeting Effects 0.000 description 5
- 238000011472 radical prostatectomy Methods 0.000 description 5
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 229960003604 testosterone Drugs 0.000 description 5
- 238000005406 washing Methods 0.000 description 5
- CYCKJEFVFNRWEZ-UGYAYLCHSA-N Asp-Ile-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CYCKJEFVFNRWEZ-UGYAYLCHSA-N 0.000 description 4
- 201000009030 Carcinoma Diseases 0.000 description 4
- 102220468420 Elongin-A_S62Y_mutation Human genes 0.000 description 4
- 102000004157 Hydrolases Human genes 0.000 description 4
- 108090000604 Hydrolases Proteins 0.000 description 4
- JNLSTRPWUXOORL-MMWGEVLESA-N Ile-Ser-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N JNLSTRPWUXOORL-MMWGEVLESA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 4
- 206010039491 Sarcoma Diseases 0.000 description 4
- PAXANSWUSVPFNK-IUKAMOBKSA-N Thr-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N PAXANSWUSVPFNK-IUKAMOBKSA-N 0.000 description 4
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 4
- 239000012491 analyte Substances 0.000 description 4
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 239000005018 casein Substances 0.000 description 4
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 4
- 235000021240 caseins Nutrition 0.000 description 4
- 230000022534 cell killing Effects 0.000 description 4
- 230000003013 cytotoxicity Effects 0.000 description 4
- 231100000135 cytotoxicity Toxicity 0.000 description 4
- 229960003668 docetaxel Drugs 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 238000011068 loading method Methods 0.000 description 4
- 230000001394 metastastic effect Effects 0.000 description 4
- 206010061289 metastatic neoplasm Diseases 0.000 description 4
- 239000000178 monomer Substances 0.000 description 4
- 230000035515 penetration Effects 0.000 description 4
- 238000002823 phage display Methods 0.000 description 4
- 108010073101 phenylalanylleucine Proteins 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 230000001225 therapeutic effect Effects 0.000 description 4
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 description 3
- OPVPGKGADVGKTG-UHFFFAOYSA-N 2-[(2-acetamido-3-carboxy-1-oxopropyl)amino]pentanedioic acid Chemical compound CC(=O)NC(CC(O)=O)C(=O)NC(C(O)=O)CCC(O)=O OPVPGKGADVGKTG-UHFFFAOYSA-N 0.000 description 3
- 108090000915 Aminopeptidases Proteins 0.000 description 3
- 102000004400 Aminopeptidases Human genes 0.000 description 3
- 102100021023 Gamma-glutamyl hydrolase Human genes 0.000 description 3
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 3
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 3
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 3
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 3
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 3
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 3
- 230000006052 T cell proliferation Effects 0.000 description 3
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 230000002280 anti-androgenic effect Effects 0.000 description 3
- 239000000051 antiandrogen Substances 0.000 description 3
- 239000012131 assay buffer Substances 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 229960000997 bicalutamide Drugs 0.000 description 3
- 238000012575 bio-layer interferometry Methods 0.000 description 3
- 239000002981 blocking agent Substances 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 239000003636 conditioned culture medium Substances 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 230000008030 elimination Effects 0.000 description 3
- 238000003379 elimination reaction Methods 0.000 description 3
- 229960000304 folic acid Drugs 0.000 description 3
- 229930195712 glutamate Natural products 0.000 description 3
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 3
- 229940088597 hormone Drugs 0.000 description 3
- 239000005556 hormone Substances 0.000 description 3
- 238000001794 hormone therapy Methods 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000001990 intravenous administration Methods 0.000 description 3
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 3
- 210000003734 kidney Anatomy 0.000 description 3
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 3
- 150000002632 lipids Chemical class 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 230000000813 microbial effect Effects 0.000 description 3
- 239000002105 nanoparticle Substances 0.000 description 3
- 239000002953 phosphate buffered saline Substances 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 235000019419 proteases Nutrition 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 230000006010 pyroptosis Effects 0.000 description 3
- 230000002285 radioactive effect Effects 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 231100000331 toxic Toxicity 0.000 description 3
- 230000002588 toxic effect Effects 0.000 description 3
- 108010044292 tryptophyltyrosine Proteins 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 108010027345 wheylin-1 peptide Proteins 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- JARGNLJYKBUKSJ-KGZKBUQUSA-N (2r)-2-amino-5-[[(2r)-1-(carboxymethylamino)-3-hydroxy-1-oxopropan-2-yl]amino]-5-oxopentanoic acid;hydrobromide Chemical compound Br.OC(=O)[C@H](N)CCC(=O)N[C@H](CO)C(=O)NCC(O)=O JARGNLJYKBUKSJ-KGZKBUQUSA-N 0.000 description 2
- 230000005730 ADP ribosylation Effects 0.000 description 2
- HCAUEJAQCXVQQM-ACZMJKKPSA-N Asn-Glu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HCAUEJAQCXVQQM-ACZMJKKPSA-N 0.000 description 2
- NTWOPSIUJBMNRI-KKUMJFAQSA-N Asn-Lys-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTWOPSIUJBMNRI-KKUMJFAQSA-N 0.000 description 2
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 208000003174 Brain Neoplasms Diseases 0.000 description 2
- 102000005367 Carboxypeptidases Human genes 0.000 description 2
- 108010006303 Carboxypeptidases Proteins 0.000 description 2
- 208000030808 Clear cell renal carcinoma Diseases 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- 108030006877 Dipeptidyl-dipeptidases Proteins 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 102000018389 Exopeptidases Human genes 0.000 description 2
- 108010091443 Exopeptidases Proteins 0.000 description 2
- 108010010803 Gelatin Proteins 0.000 description 2
- 201000010915 Glioblastoma multiforme Diseases 0.000 description 2
- VOUSELYGTNGEPB-NUMRIWBASA-N Gln-Thr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O VOUSELYGTNGEPB-NUMRIWBASA-N 0.000 description 2
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 2
- VHPVBPCCWVDGJL-IRIUXVKKSA-N Glu-Thr-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VHPVBPCCWVDGJL-IRIUXVKKSA-N 0.000 description 2
- HBMRTXJZQDVRFT-DZKIICNBSA-N Glu-Tyr-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HBMRTXJZQDVRFT-DZKIICNBSA-N 0.000 description 2
- NPSWCZIRBAYNSB-JHEQGTHGSA-N Gly-Gln-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPSWCZIRBAYNSB-JHEQGTHGSA-N 0.000 description 2
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 2
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 2
- WZSHYFGOLPXPLL-RYUDHWBXSA-N Gly-Phe-Glu Chemical compound NCC(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CCC(O)=O)C(O)=O WZSHYFGOLPXPLL-RYUDHWBXSA-N 0.000 description 2
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 102100028206 Leucine-rich repeat-containing protein 59 Human genes 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 239000005089 Luciferase Substances 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 2
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 2
- 101800000507 Non-structural protein 6 Proteins 0.000 description 2
- 208000002193 Pain Diseases 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- APJPXSFJBMMOLW-KBPBESRZSA-N Phe-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 APJPXSFJBMMOLW-KBPBESRZSA-N 0.000 description 2
- 229920001213 Polysorbate 20 Polymers 0.000 description 2
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 2
- 206010038389 Renal cancer Diseases 0.000 description 2
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 2
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 2
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 2
- 230000010782 T cell mediated cytotoxicity Effects 0.000 description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 description 2
- 206010057644 Testis cancer Diseases 0.000 description 2
- ISLDRLHVPXABBC-IEGACIPQSA-N Thr-Leu-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O ISLDRLHVPXABBC-IEGACIPQSA-N 0.000 description 2
- QNCFWHZVRNXAKW-OEAJRASXSA-N Thr-Lys-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNCFWHZVRNXAKW-OEAJRASXSA-N 0.000 description 2
- 108010033576 Transferrin Receptors Proteins 0.000 description 2
- 108050003222 Transferrin receptor protein 1 Proteins 0.000 description 2
- JRXKIVGWMMIIOF-YDHLFZDLSA-N Tyr-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JRXKIVGWMMIIOF-YDHLFZDLSA-N 0.000 description 2
- NENACTSCXYHPOX-ULQDDVLXSA-N Tyr-His-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCSC)C(O)=O NENACTSCXYHPOX-ULQDDVLXSA-N 0.000 description 2
- PYJKETPLFITNKS-IHRRRGAJSA-N Tyr-Pro-Asn Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O PYJKETPLFITNKS-IHRRRGAJSA-N 0.000 description 2
- XYBNMHRFAUKPAW-IHRRRGAJSA-N Tyr-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XYBNMHRFAUKPAW-IHRRRGAJSA-N 0.000 description 2
- GOPQNCQSXBJAII-ULQDDVLXSA-N Tyr-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N GOPQNCQSXBJAII-ULQDDVLXSA-N 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 2
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 125000001931 aliphatic group Chemical group 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 2
- 239000002246 antineoplastic agent Substances 0.000 description 2
- 230000001640 apoptogenic effect Effects 0.000 description 2
- 238000003782 apoptosis assay Methods 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 108010093581 aspartyl-proline Proteins 0.000 description 2
- 230000004900 autophagic degradation Effects 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 210000004204 blood vessel Anatomy 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 210000004556 brain Anatomy 0.000 description 2
- 201000008275 breast carcinoma Diseases 0.000 description 2
- 201000010983 breast ductal carcinoma Diseases 0.000 description 2
- 230000004709 cell invasion Effects 0.000 description 2
- 230000012292 cell migration Effects 0.000 description 2
- 238000001516 cell proliferation assay Methods 0.000 description 2
- 230000005889 cellular cytotoxicity Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 206010073251 clear cell renal cell carcinoma Diseases 0.000 description 2
- 208000029742 colonic neoplasm Diseases 0.000 description 2
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 2
- 208000035250 cutaneous malignant susceptibility to 1 melanoma Diseases 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 229940127089 cytotoxic agent Drugs 0.000 description 2
- 238000002784 cytotoxicity assay Methods 0.000 description 2
- 231100000263 cytotoxicity test Toxicity 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 238000009795 derivation Methods 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 238000000375 direct analysis in real time Methods 0.000 description 2
- 238000012063 dual-affinity re-targeting Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 229940011871 estrogen Drugs 0.000 description 2
- 239000000262 estrogen Substances 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 229940014144 folate Drugs 0.000 description 2
- 230000006251 gamma-carboxylation Effects 0.000 description 2
- 108010044804 gamma-glutamyl-seryl-glycine Proteins 0.000 description 2
- 229920000159 gelatin Polymers 0.000 description 2
- 239000008273 gelatin Substances 0.000 description 2
- 235000019322 gelatine Nutrition 0.000 description 2
- 235000011852 gelatine desserts Nutrition 0.000 description 2
- 208000005017 glioblastoma Diseases 0.000 description 2
- 230000013595 glycosylation Effects 0.000 description 2
- 238000006206 glycosylation reaction Methods 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 230000033444 hydroxylation Effects 0.000 description 2
- 238000005805 hydroxylation reaction Methods 0.000 description 2
- 230000003100 immobilizing effect Effects 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 230000028993 immune response Effects 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 201000010982 kidney cancer Diseases 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 108010068488 methionylphenylalanine Proteins 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 230000017074 necrotic cell death Effects 0.000 description 2
- 201000002120 neuroendocrine carcinoma Diseases 0.000 description 2
- 230000004112 neuroprotection Effects 0.000 description 2
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 2
- 230000009871 nonspecific binding Effects 0.000 description 2
- 238000001668 nucleic acid synthesis Methods 0.000 description 2
- 101800000629 p34 Proteins 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 210000000277 pancreatic duct Anatomy 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 238000010647 peptide synthesis reaction Methods 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 238000004393 prognosis Methods 0.000 description 2
- 230000035755 proliferation Effects 0.000 description 2
- 108020001580 protein domains Proteins 0.000 description 2
- 230000005855 radiation Effects 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 150000003354 serine derivatives Chemical class 0.000 description 2
- 210000000813 small intestine Anatomy 0.000 description 2
- 230000000087 stabilizing effect Effects 0.000 description 2
- 239000007858 starting material Substances 0.000 description 2
- 230000019635 sulfation Effects 0.000 description 2
- 238000005670 sulfation reaction Methods 0.000 description 2
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 2
- 238000001356 surgical procedure Methods 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 230000002381 testicular Effects 0.000 description 2
- 201000003120 testicular cancer Diseases 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 2
- 230000009261 transgenic effect Effects 0.000 description 2
- 206010044412 transitional cell carcinoma Diseases 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 230000003442 weekly effect Effects 0.000 description 2
- CNKBMTKICGGSCQ-ACRUOGEOSA-N (2S)-2-[[(2S)-2-[[(2S)-2,6-diamino-1-oxohexyl]amino]-1-oxo-3-phenylpropyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CNKBMTKICGGSCQ-ACRUOGEOSA-N 0.000 description 1
- LFEGKCKGGNXWDV-KBPBESRZSA-N (2s)-2-[[(1s)-1-carboxy-5-[(4-iodophenyl)carbamoylamino]pentyl]carbamoylamino]pentanedioic acid Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)N[C@H](C(O)=O)CCCCNC(=O)NC1=CC=C(I)C=C1 LFEGKCKGGNXWDV-KBPBESRZSA-N 0.000 description 1
- OXUUJYOSVPMNKP-GJZGRUSLSA-N (2s)-2-[[(1s)-1-carboxy-5-[(4-iodophenyl)methylamino]pentyl]carbamoylamino]pentanedioic acid Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)N[C@H](C(O)=O)CCCCNCC1=CC=C(I)C=C1 OXUUJYOSVPMNKP-GJZGRUSLSA-N 0.000 description 1
- ISEYJGQFXSTPMQ-UHFFFAOYSA-N 2-(phosphonomethyl)pentanedioic acid Chemical compound OC(=O)CCC(C(O)=O)CP(O)(O)=O ISEYJGQFXSTPMQ-UHFFFAOYSA-N 0.000 description 1
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 1
- 241000607534 Aeromonas Species 0.000 description 1
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 1
- WYPUMLRSQMKIJU-BPNCWPANSA-N Ala-Arg-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WYPUMLRSQMKIJU-BPNCWPANSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- YIGLXQRFQVWFEY-NRPADANISA-N Ala-Gln-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O YIGLXQRFQVWFEY-NRPADANISA-N 0.000 description 1
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 1
- XYTNPQNAZREREP-XQXXSGGOSA-N Ala-Glu-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XYTNPQNAZREREP-XQXXSGGOSA-N 0.000 description 1
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 1
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- IFKQPMZRDQZSHI-GHCJXIJMSA-N Ala-Ile-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O IFKQPMZRDQZSHI-GHCJXIJMSA-N 0.000 description 1
- VHVVPYOJIIQCKS-QEJZJMRPSA-N Ala-Leu-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VHVVPYOJIIQCKS-QEJZJMRPSA-N 0.000 description 1
- UWIQWPWWZUHBAO-ZLIFDBKOSA-N Ala-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)CC(C)C)C(O)=O)=CNC2=C1 UWIQWPWWZUHBAO-ZLIFDBKOSA-N 0.000 description 1
- PIXQDIGKDNNOOV-GUBZILKMSA-N Ala-Lys-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O PIXQDIGKDNNOOV-GUBZILKMSA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 1
- LTTLSZVJTDSACD-OWLDWWDNSA-N Ala-Thr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LTTLSZVJTDSACD-OWLDWWDNSA-N 0.000 description 1
- LFFOJBOTZUWINF-ZANVPECISA-N Ala-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O)=CNC2=C1 LFFOJBOTZUWINF-ZANVPECISA-N 0.000 description 1
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- XCIGOVDXZULBBV-DCAQKATOSA-N Ala-Val-Lys Chemical compound CC(C)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCCCN)C(O)=O XCIGOVDXZULBBV-DCAQKATOSA-N 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 238000012815 AlphaLISA Methods 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- 101000642536 Apis mellifera Venom serine protease 34 Proteins 0.000 description 1
- 101100208110 Arabidopsis thaliana TRX4 gene Proteins 0.000 description 1
- SBVJJNJLFWSJOV-UBHSHLNASA-N Arg-Ala-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SBVJJNJLFWSJOV-UBHSHLNASA-N 0.000 description 1
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 1
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 1
- JCAISGGAOQXEHJ-ZPFDUUQYSA-N Arg-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N JCAISGGAOQXEHJ-ZPFDUUQYSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- NKNILFJYKKHBKE-WPRPVWTQSA-N Arg-Gly-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NKNILFJYKKHBKE-WPRPVWTQSA-N 0.000 description 1
- SLNCSSWAIDUUGF-LSJOCFKGSA-N Arg-His-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(O)=O SLNCSSWAIDUUGF-LSJOCFKGSA-N 0.000 description 1
- CVKOQHYVDVYJSI-QTKMDUPCSA-N Arg-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N)O CVKOQHYVDVYJSI-QTKMDUPCSA-N 0.000 description 1
- WKPXXXUSUHAXDE-SRVKXCTJSA-N Arg-Pro-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O WKPXXXUSUHAXDE-SRVKXCTJSA-N 0.000 description 1
- POZKLUIXMHIULG-FDARSICLSA-N Arg-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCN=C(N)N)N POZKLUIXMHIULG-FDARSICLSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- JZRLLSOWDYUKOK-SRVKXCTJSA-N Asn-Asp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N JZRLLSOWDYUKOK-SRVKXCTJSA-N 0.000 description 1
- GQRDIVQPSMPQME-ZPFDUUQYSA-N Asn-Ile-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O GQRDIVQPSMPQME-ZPFDUUQYSA-N 0.000 description 1
- ZMUQQMGITUJQTI-CIUDSAMLSA-N Asn-Leu-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZMUQQMGITUJQTI-CIUDSAMLSA-N 0.000 description 1
- JLNFZLNDHONLND-GARJFASQSA-N Asn-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N JLNFZLNDHONLND-GARJFASQSA-N 0.000 description 1
- NLDNNZKUSLAYFW-NHCYSSNCSA-N Asn-Lys-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLDNNZKUSLAYFW-NHCYSSNCSA-N 0.000 description 1
- RTFWCVDISAMGEQ-SRVKXCTJSA-N Asn-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N RTFWCVDISAMGEQ-SRVKXCTJSA-N 0.000 description 1
- NJSNXIOKBHPFMB-GMOBBJLQSA-N Asn-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N NJSNXIOKBHPFMB-GMOBBJLQSA-N 0.000 description 1
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 1
- DOURAOODTFJRIC-CIUDSAMLSA-N Asn-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N DOURAOODTFJRIC-CIUDSAMLSA-N 0.000 description 1
- NPZJLGMWMDNQDD-GHCJXIJMSA-N Asn-Ser-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NPZJLGMWMDNQDD-GHCJXIJMSA-N 0.000 description 1
- VTYQAQFKMQTKQD-ACZMJKKPSA-N Asp-Ala-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O VTYQAQFKMQTKQD-ACZMJKKPSA-N 0.000 description 1
- ILJQISGMGXRZQQ-IHRRRGAJSA-N Asp-Arg-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ILJQISGMGXRZQQ-IHRRRGAJSA-N 0.000 description 1
- FMWHSNJMHUNLAG-FXQIFTODSA-N Asp-Cys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FMWHSNJMHUNLAG-FXQIFTODSA-N 0.000 description 1
- DZQKLNLLWFQONU-LKXGYXEUSA-N Asp-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)O DZQKLNLLWFQONU-LKXGYXEUSA-N 0.000 description 1
- HRGGPWBIMIQANI-GUBZILKMSA-N Asp-Gln-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HRGGPWBIMIQANI-GUBZILKMSA-N 0.000 description 1
- NRIFEOUAFLTMFJ-AAEUAGOBSA-N Asp-Gly-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O NRIFEOUAFLTMFJ-AAEUAGOBSA-N 0.000 description 1
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 1
- KQBVNNAPIURMPD-PEFMBERDSA-N Asp-Ile-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KQBVNNAPIURMPD-PEFMBERDSA-N 0.000 description 1
- SDDAYZYYUJILPB-UHFFFAOYSA-N Asp-Leu-Val-Tyr Chemical compound OC(=O)CC(N)C(=O)NC(CC(C)C)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 SDDAYZYYUJILPB-UHFFFAOYSA-N 0.000 description 1
- HJCGDIGVVWETRO-ZPFDUUQYSA-N Asp-Lys-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O)C(O)=O HJCGDIGVVWETRO-ZPFDUUQYSA-N 0.000 description 1
- YFGUZQQCSDZRBN-DCAQKATOSA-N Asp-Pro-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YFGUZQQCSDZRBN-DCAQKATOSA-N 0.000 description 1
- LGGHQRZIJSYRHA-GUBZILKMSA-N Asp-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)O)N LGGHQRZIJSYRHA-GUBZILKMSA-N 0.000 description 1
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 208000035143 Bacterial infection Diseases 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 208000031648 Body Weight Changes Diseases 0.000 description 1
- XMWRBQBLMFGWIX-UHFFFAOYSA-N C60 fullerene Chemical class C12=C3C(C4=C56)=C7C8=C5C5=C9C%10=C6C6=C4C1=C1C4=C6C6=C%10C%10=C9C9=C%11C5=C8C5=C8C7=C3C3=C7C2=C1C1=C2C4=C6C4=C%10C6=C9C9=C%11C5=C5C8=C3C3=C7C1=C1C2=C4C6=C2C9=C5C3=C12 XMWRBQBLMFGWIX-UHFFFAOYSA-N 0.000 description 1
- 101100372806 Caenorhabditis elegans vit-3 gene Proteins 0.000 description 1
- 241000282832 Camelidae Species 0.000 description 1
- 108010080937 Carboxypeptidases A Proteins 0.000 description 1
- 102000000496 Carboxypeptidases A Human genes 0.000 description 1
- 238000003734 CellTiter-Glo Luminescent Cell Viability Assay Methods 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 208000000094 Chronic Pain Diseases 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- NXQCSPVUPLUTJH-WHFBIAKZSA-N Cys-Ser-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O NXQCSPVUPLUTJH-WHFBIAKZSA-N 0.000 description 1
- 108010025905 Cystine-Knot Miniproteins Proteins 0.000 description 1
- LEVWYRKDKASIDU-QWWZWVQMSA-N D-cystine Chemical compound OC(=O)[C@H](N)CSSC[C@@H](N)C(O)=O LEVWYRKDKASIDU-QWWZWVQMSA-N 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 208000032131 Diabetic Neuropathies Diseases 0.000 description 1
- 101100425276 Dictyostelium discoideum trxD gene Proteins 0.000 description 1
- 102000004860 Dipeptidases Human genes 0.000 description 1
- 108090001081 Dipeptidases Proteins 0.000 description 1
- 102000016622 Dipeptidyl Peptidase 4 Human genes 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 206010016654 Fibrosis Diseases 0.000 description 1
- 101000930822 Giardia intestinalis Dipeptidyl-peptidase 4 Proteins 0.000 description 1
- YJIUYQKQBBQYHZ-ACZMJKKPSA-N Gln-Ala-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YJIUYQKQBBQYHZ-ACZMJKKPSA-N 0.000 description 1
- QQAPDATZKKTBIY-YUMQZZPRSA-N Gln-Gly-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O QQAPDATZKKTBIY-YUMQZZPRSA-N 0.000 description 1
- HYPVLWGNBIYTNA-GUBZILKMSA-N Gln-Leu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HYPVLWGNBIYTNA-GUBZILKMSA-N 0.000 description 1
- QKWBEMCLYTYBNI-GVXVVHGQSA-N Gln-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O QKWBEMCLYTYBNI-GVXVVHGQSA-N 0.000 description 1
- LGWNISYVKDNJRP-FXQIFTODSA-N Gln-Ser-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGWNISYVKDNJRP-FXQIFTODSA-N 0.000 description 1
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 1
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 1
- DIXKFOPPGWKZLY-CIUDSAMLSA-N Glu-Arg-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O DIXKFOPPGWKZLY-CIUDSAMLSA-N 0.000 description 1
- AFODTOLGSZQDSL-PEFMBERDSA-N Glu-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N AFODTOLGSZQDSL-PEFMBERDSA-N 0.000 description 1
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 1
- ALCAUWPAMLVUDB-FXQIFTODSA-N Glu-Gln-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ALCAUWPAMLVUDB-FXQIFTODSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- ZWABFSSWTSAMQN-KBIXCLLPSA-N Glu-Ile-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O ZWABFSSWTSAMQN-KBIXCLLPSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- SOEPMWQCTJITPZ-SRVKXCTJSA-N Glu-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N SOEPMWQCTJITPZ-SRVKXCTJSA-N 0.000 description 1
- DCBSZJJHOTXMHY-DCAQKATOSA-N Glu-Pro-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DCBSZJJHOTXMHY-DCAQKATOSA-N 0.000 description 1
- JWNZHMSRZXXGTM-XKBZYTNZSA-N Glu-Ser-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWNZHMSRZXXGTM-XKBZYTNZSA-N 0.000 description 1
- BDISFWMLMNBTGP-NUMRIWBASA-N Glu-Thr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O BDISFWMLMNBTGP-NUMRIWBASA-N 0.000 description 1
- ZQNCUVODKOBSSO-XEGUGMAKSA-N Glu-Trp-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O ZQNCUVODKOBSSO-XEGUGMAKSA-N 0.000 description 1
- HVKAAUOFFTUSAA-XDTLVQLUSA-N Glu-Tyr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O HVKAAUOFFTUSAA-XDTLVQLUSA-N 0.000 description 1
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 1
- 108010048963 Glutamate carboxypeptidase Proteins 0.000 description 1
- 101710183768 Glutamate carboxypeptidase 2 Proteins 0.000 description 1
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 1
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 1
- JBRBACJPBZNFMF-YUMQZZPRSA-N Gly-Ala-Lys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN JBRBACJPBZNFMF-YUMQZZPRSA-N 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 1
- LURCIJSJAKFCRO-QWRGUYRKSA-N Gly-Asn-Tyr Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LURCIJSJAKFCRO-QWRGUYRKSA-N 0.000 description 1
- PDAWDNVHMUKWJR-ZETCQYMHSA-N Gly-Gly-His Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 PDAWDNVHMUKWJR-ZETCQYMHSA-N 0.000 description 1
- UTYGDAHJBBDPBA-BYULHYEWSA-N Gly-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN UTYGDAHJBBDPBA-BYULHYEWSA-N 0.000 description 1
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 1
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 1
- MXIULRKNFSCJHT-STQMWFEESA-N Gly-Phe-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 MXIULRKNFSCJHT-STQMWFEESA-N 0.000 description 1
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 1
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 1
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 1
- LYZYGGWCBLBDMC-QWHCGFSZSA-N Gly-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)CN)C(=O)O LYZYGGWCBLBDMC-QWHCGFSZSA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- DUAWRXXTOQOECJ-JSGCOSHPSA-N Gly-Tyr-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O DUAWRXXTOQOECJ-JSGCOSHPSA-N 0.000 description 1
- 239000000579 Gonadotropin-Releasing Hormone Substances 0.000 description 1
- 208000032843 Hemorrhage Diseases 0.000 description 1
- VBOFRJNDIOPNDO-YUMQZZPRSA-N His-Gly-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N VBOFRJNDIOPNDO-YUMQZZPRSA-N 0.000 description 1
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 1
- LVWIJITYHRZHBO-IXOXFDKPSA-N His-Leu-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LVWIJITYHRZHBO-IXOXFDKPSA-N 0.000 description 1
- XJFITURPHAKKAI-SRVKXCTJSA-N His-Pro-Gln Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(N)=O)C(O)=O)C1=CN=CN1 XJFITURPHAKKAI-SRVKXCTJSA-N 0.000 description 1
- WCHONUZTYDQMBY-PYJNHQTQSA-N His-Pro-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WCHONUZTYDQMBY-PYJNHQTQSA-N 0.000 description 1
- QLBXWYXMLHAREM-PYJNHQTQSA-N His-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC1=CN=CN1)N QLBXWYXMLHAREM-PYJNHQTQSA-N 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 1
- 101000633445 Homo sapiens Structural maintenance of chromosomes protein 2 Proteins 0.000 description 1
- 102000003839 Human Proteins Human genes 0.000 description 1
- 108090000144 Human Proteins Proteins 0.000 description 1
- 208000023105 Huntington disease Diseases 0.000 description 1
- JXUGDUWBMKIJDC-NAKRPEOUSA-N Ile-Ala-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JXUGDUWBMKIJDC-NAKRPEOUSA-N 0.000 description 1
- UKTUOMWSJPXODT-GUDRVLHUSA-N Ile-Asn-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N UKTUOMWSJPXODT-GUDRVLHUSA-N 0.000 description 1
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 1
- DFFTXLCCDFYRKD-MBLNEYKQSA-N Ile-Gly-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N DFFTXLCCDFYRKD-MBLNEYKQSA-N 0.000 description 1
- KEKTTYCXKGBAAL-VGDYDELISA-N Ile-His-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N KEKTTYCXKGBAAL-VGDYDELISA-N 0.000 description 1
- IDMNOFVUXYYZPF-DKIMLUQUSA-N Ile-Lys-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N IDMNOFVUXYYZPF-DKIMLUQUSA-N 0.000 description 1
- OTSVBELRDMSPKY-PCBIJLKTSA-N Ile-Phe-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OTSVBELRDMSPKY-PCBIJLKTSA-N 0.000 description 1
- MLSUZXHSNRBDCI-CYDGBPFRSA-N Ile-Pro-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)O)N MLSUZXHSNRBDCI-CYDGBPFRSA-N 0.000 description 1
- ANTFEOSJMAUGIB-KNZXXDILSA-N Ile-Thr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N ANTFEOSJMAUGIB-KNZXXDILSA-N 0.000 description 1
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 1
- RQZFWBLDTBDEOF-RNJOBUHISA-N Ile-Val-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N RQZFWBLDTBDEOF-RNJOBUHISA-N 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 101000734872 Lactobacillus delbrueckii subsp. lactis Beta-Ala-Xaa dipeptidase Proteins 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 1
- ZYLJULGXQDNXDK-GUBZILKMSA-N Leu-Gln-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ZYLJULGXQDNXDK-GUBZILKMSA-N 0.000 description 1
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- KYIIALJHAOIAHF-KKUMJFAQSA-N Leu-Leu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KYIIALJHAOIAHF-KKUMJFAQSA-N 0.000 description 1
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 1
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- ZDBMWELMUCLUPL-QEJZJMRPSA-N Leu-Phe-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 ZDBMWELMUCLUPL-QEJZJMRPSA-N 0.000 description 1
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 1
- DAYQSYGBCUKVKT-VOAKCMCISA-N Leu-Thr-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O DAYQSYGBCUKVKT-VOAKCMCISA-N 0.000 description 1
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 1
- VJGQRELPQWNURN-JYJNAYRXSA-N Leu-Tyr-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJGQRELPQWNURN-JYJNAYRXSA-N 0.000 description 1
- OZTZJMUZVAVJGY-BZSNNMDCSA-N Leu-Tyr-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N OZTZJMUZVAVJGY-BZSNNMDCSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- 102000010954 Link domains Human genes 0.000 description 1
- 108050001157 Link domains Proteins 0.000 description 1
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 1
- DGAAQRAUOFHBFJ-CIUDSAMLSA-N Lys-Asn-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DGAAQRAUOFHBFJ-CIUDSAMLSA-N 0.000 description 1
- YVSHZSUKQHNDHD-KKUMJFAQSA-N Lys-Asn-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N YVSHZSUKQHNDHD-KKUMJFAQSA-N 0.000 description 1
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 1
- QZONCCHVHCOBSK-YUMQZZPRSA-N Lys-Gly-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O QZONCCHVHCOBSK-YUMQZZPRSA-N 0.000 description 1
- SQJSXOQXJYAVRV-SRVKXCTJSA-N Lys-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N SQJSXOQXJYAVRV-SRVKXCTJSA-N 0.000 description 1
- KYNNSEJZFVCDIV-ZPFDUUQYSA-N Lys-Ile-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O KYNNSEJZFVCDIV-ZPFDUUQYSA-N 0.000 description 1
- WAIHHELKYSFIQN-XUXIUFHCSA-N Lys-Ile-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O WAIHHELKYSFIQN-XUXIUFHCSA-N 0.000 description 1
- ATNKHRAIZCMCCN-BZSNNMDCSA-N Lys-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N ATNKHRAIZCMCCN-BZSNNMDCSA-N 0.000 description 1
- DAHQKYYIXPBESV-UWVGGRQHSA-N Lys-Met-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O DAHQKYYIXPBESV-UWVGGRQHSA-N 0.000 description 1
- SPNKGZFASINBMR-IHRRRGAJSA-N Lys-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCCN)N SPNKGZFASINBMR-IHRRRGAJSA-N 0.000 description 1
- LUAJJLPHUXPQLH-KKUMJFAQSA-N Lys-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCCN)N LUAJJLPHUXPQLH-KKUMJFAQSA-N 0.000 description 1
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 1
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 1
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 1
- OZVXDDFYCQOPFD-XQQFMLRXSA-N Lys-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N OZVXDDFYCQOPFD-XQQFMLRXSA-N 0.000 description 1
- UNPGTBHYKJOCCZ-DCAQKATOSA-N Met-Lys-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O UNPGTBHYKJOCCZ-DCAQKATOSA-N 0.000 description 1
- VAGCEUUEMMXFEX-GUBZILKMSA-N Met-Met-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O VAGCEUUEMMXFEX-GUBZILKMSA-N 0.000 description 1
- OIFHHODAXVWKJN-ULQDDVLXSA-N Met-Phe-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 OIFHHODAXVWKJN-ULQDDVLXSA-N 0.000 description 1
- PHKBGZKVOJCIMZ-SRVKXCTJSA-N Met-Pro-Arg Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PHKBGZKVOJCIMZ-SRVKXCTJSA-N 0.000 description 1
- WYNIRYZIFZGWQD-BPUTZDHNSA-N Met-Trp-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WYNIRYZIFZGWQD-BPUTZDHNSA-N 0.000 description 1
- JACMWNXOOUYXCD-JYJNAYRXSA-N Met-Val-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JACMWNXOOUYXCD-JYJNAYRXSA-N 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 101100154863 Mus musculus Txndc2 gene Proteins 0.000 description 1
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- HOKKHZGPKSLGJE-GSVOUGTGSA-N N-Methyl-D-aspartic acid Chemical compound CN[C@@H](C(O)=O)CC(O)=O HOKKHZGPKSLGJE-GSVOUGTGSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 206010029113 Neovascularisation Diseases 0.000 description 1
- 108090000189 Neuropeptides Proteins 0.000 description 1
- 102000003797 Neuropeptides Human genes 0.000 description 1
- CGOMLCQJEMWMCE-STQMWFEESA-N Phe-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 CGOMLCQJEMWMCE-STQMWFEESA-N 0.000 description 1
- HTTYNOXBBOWZTB-SRVKXCTJSA-N Phe-Asn-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N HTTYNOXBBOWZTB-SRVKXCTJSA-N 0.000 description 1
- HHOOEUSPFGPZFP-QWRGUYRKSA-N Phe-Asn-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HHOOEUSPFGPZFP-QWRGUYRKSA-N 0.000 description 1
- HTKNPQZCMLBOTQ-XVSYOHENSA-N Phe-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N)O HTKNPQZCMLBOTQ-XVSYOHENSA-N 0.000 description 1
- WIVCOAKLPICYGY-KKUMJFAQSA-N Phe-Asp-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N WIVCOAKLPICYGY-KKUMJFAQSA-N 0.000 description 1
- KOUUGTKGEQZRHV-KKUMJFAQSA-N Phe-Gln-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O KOUUGTKGEQZRHV-KKUMJFAQSA-N 0.000 description 1
- KAGCQPSEVAETCA-JYJNAYRXSA-N Phe-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N KAGCQPSEVAETCA-JYJNAYRXSA-N 0.000 description 1
- WPTYDQPGBMDUBI-QWRGUYRKSA-N Phe-Gly-Asn Chemical compound N[C@@H](Cc1ccccc1)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O WPTYDQPGBMDUBI-QWRGUYRKSA-N 0.000 description 1
- OVJMCXAPGFDGMG-HKUYNNGSSA-N Phe-Gly-Trp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O OVJMCXAPGFDGMG-HKUYNNGSSA-N 0.000 description 1
- WEMYTDDMDBLPMI-DKIMLUQUSA-N Phe-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N WEMYTDDMDBLPMI-DKIMLUQUSA-N 0.000 description 1
- YKUGPVXSDOOANW-KKUMJFAQSA-N Phe-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YKUGPVXSDOOANW-KKUMJFAQSA-N 0.000 description 1
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 1
- DOXQMJCSSYZSNM-BZSNNMDCSA-N Phe-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O DOXQMJCSSYZSNM-BZSNNMDCSA-N 0.000 description 1
- BSHMIVKDJQGLNT-ACRUOGEOSA-N Phe-Lys-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 BSHMIVKDJQGLNT-ACRUOGEOSA-N 0.000 description 1
- MMJJFXWMCMJMQA-STQMWFEESA-N Phe-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CC=CC=C1 MMJJFXWMCMJMQA-STQMWFEESA-N 0.000 description 1
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 1
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 1
- QSWKNJAPHQDAAS-MELADBBJSA-N Phe-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O QSWKNJAPHQDAAS-MELADBBJSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- BSTPNLNKHKBONJ-HTUGSXCWSA-N Phe-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O BSTPNLNKHKBONJ-HTUGSXCWSA-N 0.000 description 1
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 1
- MSSXKZBDKZAHCX-UNQGMJICSA-N Phe-Thr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O MSSXKZBDKZAHCX-UNQGMJICSA-N 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 1
- MLQVJYMFASXBGZ-IHRRRGAJSA-N Pro-Asn-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O MLQVJYMFASXBGZ-IHRRRGAJSA-N 0.000 description 1
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 1
- VJLJGKQAOQJXJG-CIUDSAMLSA-N Pro-Asp-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJLJGKQAOQJXJG-CIUDSAMLSA-N 0.000 description 1
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 1
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 1
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 1
- STASJMBVVHNWCG-IHRRRGAJSA-N Pro-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 STASJMBVVHNWCG-IHRRRGAJSA-N 0.000 description 1
- HATVCTYBNCNMAA-AVGNSLFASA-N Pro-Leu-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O HATVCTYBNCNMAA-AVGNSLFASA-N 0.000 description 1
- BLJMJZOMZRCESA-GUBZILKMSA-N Pro-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@@H]1CCCN1 BLJMJZOMZRCESA-GUBZILKMSA-N 0.000 description 1
- HOTVCUAVDQHUDB-UFYCRDLUSA-N Pro-Phe-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 HOTVCUAVDQHUDB-UFYCRDLUSA-N 0.000 description 1
- FHZJRBVMLGOHBX-GUBZILKMSA-N Pro-Pro-Asp Chemical compound OC(=O)C[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H]1CCCN1)C(O)=O FHZJRBVMLGOHBX-GUBZILKMSA-N 0.000 description 1
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 1
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 208000006265 Renal cell carcinoma Diseases 0.000 description 1
- 238000011579 SCID mouse model Methods 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- PVDTYLHUWAEYGY-CIUDSAMLSA-N Ser-Glu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PVDTYLHUWAEYGY-CIUDSAMLSA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- DJACUBDEDBZKLQ-KBIXCLLPSA-N Ser-Ile-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O DJACUBDEDBZKLQ-KBIXCLLPSA-N 0.000 description 1
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 1
- VZQRNAYURWAEFE-KKUMJFAQSA-N Ser-Leu-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VZQRNAYURWAEFE-KKUMJFAQSA-N 0.000 description 1
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 1
- WGDYNRCOQRERLZ-KKUMJFAQSA-N Ser-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N WGDYNRCOQRERLZ-KKUMJFAQSA-N 0.000 description 1
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 1
- PMCMLDNPAZUYGI-DCAQKATOSA-N Ser-Lys-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMCMLDNPAZUYGI-DCAQKATOSA-N 0.000 description 1
- IFLVBVIYADZIQO-DCAQKATOSA-N Ser-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N IFLVBVIYADZIQO-DCAQKATOSA-N 0.000 description 1
- UGTZYIPOBYXWRW-SRVKXCTJSA-N Ser-Phe-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O UGTZYIPOBYXWRW-SRVKXCTJSA-N 0.000 description 1
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- GZGFSPWOMUKKCV-NAKRPEOUSA-N Ser-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO GZGFSPWOMUKKCV-NAKRPEOUSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- NVNPWELENFJOHH-CIUDSAMLSA-N Ser-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)N NVNPWELENFJOHH-CIUDSAMLSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- DKGRNFUXVTYRAS-UBHSHLNASA-N Ser-Ser-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DKGRNFUXVTYRAS-UBHSHLNASA-N 0.000 description 1
- UQGAAZXSCGWMFU-UBHSHLNASA-N Ser-Trp-Asp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N UQGAAZXSCGWMFU-UBHSHLNASA-N 0.000 description 1
- HAUVENOGHPECML-BPUTZDHNSA-N Ser-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 HAUVENOGHPECML-BPUTZDHNSA-N 0.000 description 1
- KIEIJCFVGZCUAS-MELADBBJSA-N Ser-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N)C(=O)O KIEIJCFVGZCUAS-MELADBBJSA-N 0.000 description 1
- BIWBTRRBHIEVAH-IHPCNDPISA-N Ser-Tyr-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O BIWBTRRBHIEVAH-IHPCNDPISA-N 0.000 description 1
- ODRUTDLAONAVDV-IHRRRGAJSA-N Ser-Val-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ODRUTDLAONAVDV-IHRRRGAJSA-N 0.000 description 1
- 102220590621 Spindlin-1_T19R_mutation Human genes 0.000 description 1
- 101000857870 Squalus acanthias Gonadoliberin Proteins 0.000 description 1
- 241000187392 Streptomyces griseus Species 0.000 description 1
- 102100029540 Structural maintenance of chromosomes protein 2 Human genes 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 239000012505 Superdex™ Substances 0.000 description 1
- MQBTXMPQNCGSSZ-OSUNSFLBSA-N Thr-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N MQBTXMPQNCGSSZ-OSUNSFLBSA-N 0.000 description 1
- QGXCWPNQVCYJEL-NUMRIWBASA-N Thr-Asn-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QGXCWPNQVCYJEL-NUMRIWBASA-N 0.000 description 1
- JEDIEMIJYSRUBB-FOHZUACHSA-N Thr-Asp-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O JEDIEMIJYSRUBB-FOHZUACHSA-N 0.000 description 1
- DCLBXIWHLVEPMQ-JRQIVUDYSA-N Thr-Asp-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DCLBXIWHLVEPMQ-JRQIVUDYSA-N 0.000 description 1
- QWMPARMKIDVBLV-VZFHVOOUSA-N Thr-Cys-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O QWMPARMKIDVBLV-VZFHVOOUSA-N 0.000 description 1
- OQCXTUQTKQFDCX-HTUGSXCWSA-N Thr-Glu-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O OQCXTUQTKQFDCX-HTUGSXCWSA-N 0.000 description 1
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 1
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 1
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 1
- SCSVNSNWUTYSFO-WDCWCFNPSA-N Thr-Lys-Glu Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O SCSVNSNWUTYSFO-WDCWCFNPSA-N 0.000 description 1
- UUSQVWOVUYMLJA-PPCPHDFISA-N Thr-Lys-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UUSQVWOVUYMLJA-PPCPHDFISA-N 0.000 description 1
- DCRHJDRLCFMEBI-RHYQMDGZSA-N Thr-Lys-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O DCRHJDRLCFMEBI-RHYQMDGZSA-N 0.000 description 1
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- WKGAAMOJPMBBMC-IXOXFDKPSA-N Thr-Ser-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WKGAAMOJPMBBMC-IXOXFDKPSA-N 0.000 description 1
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 1
- 102100026143 Transferrin receptor protein 2 Human genes 0.000 description 1
- 101710145355 Transferrin receptor protein 2 Proteins 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- 206010052779 Transplant rejections Diseases 0.000 description 1
- 108010070926 Tripeptide aminopeptidase Proteins 0.000 description 1
- XLYOFNOQVPJJNP-PWCQTSIFSA-N Tritiated water Chemical compound [3H]O[3H] XLYOFNOQVPJJNP-PWCQTSIFSA-N 0.000 description 1
- VIWQOOBRKCGSDK-RYQLBKOJSA-N Trp-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O VIWQOOBRKCGSDK-RYQLBKOJSA-N 0.000 description 1
- SNJAPSVIPKUMCK-NWLDYVSISA-N Trp-Glu-Thr Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SNJAPSVIPKUMCK-NWLDYVSISA-N 0.000 description 1
- CMXACOZDEJYZSK-XIRDDKMYSA-N Trp-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N CMXACOZDEJYZSK-XIRDDKMYSA-N 0.000 description 1
- HJXOFWKCWLHYIJ-SZMVWBNQSA-N Trp-Lys-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HJXOFWKCWLHYIJ-SZMVWBNQSA-N 0.000 description 1
- DYIXEGROAOVQPK-VFAJRCTISA-N Trp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O DYIXEGROAOVQPK-VFAJRCTISA-N 0.000 description 1
- IEESWNWYUOETOT-BVSLBCMMSA-N Trp-Val-Phe Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](Cc1ccccc1)C(O)=O IEESWNWYUOETOT-BVSLBCMMSA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- OOEUVMFKKZYSRX-LEWSCRJBSA-N Tyr-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OOEUVMFKKZYSRX-LEWSCRJBSA-N 0.000 description 1
- WTXQBCCKXIKKHB-JYJNAYRXSA-N Tyr-Arg-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WTXQBCCKXIKKHB-JYJNAYRXSA-N 0.000 description 1
- AYPAIRCDLARHLM-KKUMJFAQSA-N Tyr-Asn-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O AYPAIRCDLARHLM-KKUMJFAQSA-N 0.000 description 1
- DANHCMVVXDXOHN-SRVKXCTJSA-N Tyr-Asp-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DANHCMVVXDXOHN-SRVKXCTJSA-N 0.000 description 1
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 1
- LOOCQRRBKZTPKO-AVGNSLFASA-N Tyr-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LOOCQRRBKZTPKO-AVGNSLFASA-N 0.000 description 1
- JKUZFODWJGEQAP-KBPBESRZSA-N Tyr-Gly-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N)O JKUZFODWJGEQAP-KBPBESRZSA-N 0.000 description 1
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 1
- NXRGXTBPMOGFID-CFMVVWHZSA-N Tyr-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O NXRGXTBPMOGFID-CFMVVWHZSA-N 0.000 description 1
- HSBZWINKRYZCSQ-KKUMJFAQSA-N Tyr-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O HSBZWINKRYZCSQ-KKUMJFAQSA-N 0.000 description 1
- WTTRJMAZPDHPGS-KKXDTOCCSA-N Tyr-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(O)=O WTTRJMAZPDHPGS-KKXDTOCCSA-N 0.000 description 1
- GQVZBMROTPEPIF-SRVKXCTJSA-N Tyr-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GQVZBMROTPEPIF-SRVKXCTJSA-N 0.000 description 1
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 1
- KHPLUFDSWGDRHD-SLFFLAALSA-N Tyr-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O KHPLUFDSWGDRHD-SLFFLAALSA-N 0.000 description 1
- RGJZPXFZIUUQDN-BPNCWPANSA-N Tyr-Val-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O RGJZPXFZIUUQDN-BPNCWPANSA-N 0.000 description 1
- 108010064997 VPY tripeptide Proteins 0.000 description 1
- COYSIHFOCOMGCF-UHFFFAOYSA-N Val-Arg-Gly Natural products CC(C)C(N)C(=O)NC(C(=O)NCC(O)=O)CCCN=C(N)N COYSIHFOCOMGCF-UHFFFAOYSA-N 0.000 description 1
- IQQYYFPCWKWUHW-YDHLFZDLSA-N Val-Asn-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N IQQYYFPCWKWUHW-YDHLFZDLSA-N 0.000 description 1
- XTAUQCGQFJQGEJ-NHCYSSNCSA-N Val-Gln-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XTAUQCGQFJQGEJ-NHCYSSNCSA-N 0.000 description 1
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- LTTQCQRTSHJPPL-ZKWXMUAHSA-N Val-Ser-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N LTTQCQRTSHJPPL-ZKWXMUAHSA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- 241000607269 Vibrio proteolyticus Species 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- PTFCDOFLOPIGGS-UHFFFAOYSA-N Zinc dication Chemical compound [Zn+2] PTFCDOFLOPIGGS-UHFFFAOYSA-N 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 230000009435 amidation Effects 0.000 description 1
- 238000007112 amidation reaction Methods 0.000 description 1
- 150000001408 amides Chemical group 0.000 description 1
- 230000000202 analgesic effect Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001142 anti-diarrhea Effects 0.000 description 1
- 230000003474 anti-emetic effect Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 239000002111 antiemetic agent Substances 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010038850 arginyl-isoleucyl-tyrosine Proteins 0.000 description 1
- 230000010516 arginylation Effects 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 229940009098 aspartate Drugs 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 239000012911 assay medium Substances 0.000 description 1
- 208000022362 bacterial infectious disease Diseases 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 208000034158 bleeding Diseases 0.000 description 1
- 230000000740 bleeding effect Effects 0.000 description 1
- 230000004579 body weight change Effects 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 210000001043 capillary endothelial cell Anatomy 0.000 description 1
- 230000007681 cardiovascular toxicity Effects 0.000 description 1
- 231100000060 cardiovascular toxicity Toxicity 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 230000001010 compromised effect Effects 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 230000037029 cross reaction Effects 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000009109 curative therapy Methods 0.000 description 1
- 229960003067 cystine Drugs 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 238000011393 cytotoxic chemotherapy Methods 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000017858 demethylation Effects 0.000 description 1
- 238000010520 demethylation reaction Methods 0.000 description 1
- 239000000412 dendrimer Substances 0.000 description 1
- 229920000736 dendritic polymer Polymers 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- RGLYKWWBQGJZGM-ISLYRVAYSA-N diethylstilbestrol Chemical compound C=1C=C(O)C=CC=1C(/CC)=C(\CC)C1=CC=C(O)C=C1 RGLYKWWBQGJZGM-ISLYRVAYSA-N 0.000 description 1
- 229960000452 diethylstilbestrol Drugs 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 230000002183 duodenal effect Effects 0.000 description 1
- 238000013399 early diagnosis Methods 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 238000005401 electroluminescence Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 230000007515 enzymatic degradation Effects 0.000 description 1
- 206010015037 epilepsy Diseases 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 235000020774 essential nutrients Nutrition 0.000 description 1
- 230000003090 exacerbative effect Effects 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000002360 explosive Substances 0.000 description 1
- 238000011347 external beam therapy Methods 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 230000004761 fibrosis Effects 0.000 description 1
- 230000003176 fibrotic effect Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 150000002211 flavins Chemical class 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 229960002074 flutamide Drugs 0.000 description 1
- MKXKFYHWDHIYRV-UHFFFAOYSA-N flutamide Chemical compound CC(C)C(=O)NC1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 MKXKFYHWDHIYRV-UHFFFAOYSA-N 0.000 description 1
- 230000022244 formylation Effects 0.000 description 1
- 238000006170 formylation reaction Methods 0.000 description 1
- 229910003472 fullerene Inorganic materials 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 1
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 1
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 1
- 150000002333 glycines Chemical class 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 108010084389 glycyltryptophan Proteins 0.000 description 1
- XLXSAKCOAKORKW-AQJXLSMYSA-N gonadorelin Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)NCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 XLXSAKCOAKORKW-AQJXLSMYSA-N 0.000 description 1
- 229940035638 gonadotropin-releasing hormone Drugs 0.000 description 1
- 150000003278 haem Chemical group 0.000 description 1
- 201000005787 hematologic cancer Diseases 0.000 description 1
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 230000003301 hydrolyzing effect Effects 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 210000003405 ileum Anatomy 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 102000027411 intracellular receptors Human genes 0.000 description 1
- 108091008582 intracellular receptors Proteins 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 230000026045 iodination Effects 0.000 description 1
- 238000006192 iodination reaction Methods 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 230000001057 ionotropic effect Effects 0.000 description 1
- 208000028867 ischemia Diseases 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 1
- 108010034529 leucyl-lysine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 1
- 108010054155 lysyllysine Proteins 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 102000006239 metabotropic receptors Human genes 0.000 description 1
- 108020004083 metabotropic receptors Proteins 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000004877 mucosa Anatomy 0.000 description 1
- 239000002073 nanorod Substances 0.000 description 1
- 230000009826 neoplastic cell growth Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 239000000041 non-steroidal anti-inflammatory agent Substances 0.000 description 1
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 1
- 239000003956 nonsteroidal anti androgen Substances 0.000 description 1
- 230000000474 nursing effect Effects 0.000 description 1
- 238000011474 orchiectomy Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 229950002610 otelixizumab Drugs 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 239000006174 pH buffer Substances 0.000 description 1
- 230000036407 pain Effects 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 108010051242 phenylalanylserine Proteins 0.000 description 1
- 229940067626 phosphatidylinositols Drugs 0.000 description 1
- 150000003905 phosphatidylinositols Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 230000005195 poor health Effects 0.000 description 1
- 230000004492 positive regulation of T cell proliferation Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 229960004618 prednisone Drugs 0.000 description 1
- 230000013823 prenylation Effects 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 229940002612 prodrug Drugs 0.000 description 1
- 239000000651 prodrug Substances 0.000 description 1
- 208000037821 progressive disease Diseases 0.000 description 1
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 208000017497 prostate disease Diseases 0.000 description 1
- 208000023958 prostate neoplasm Diseases 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 210000000512 proximal kidney tubule Anatomy 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 229940043131 pyroglutamate Drugs 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 230000006340 racemization Effects 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000007363 ring formation reaction Methods 0.000 description 1
- 102220276574 rs1553130148 Human genes 0.000 description 1
- 102220024419 rs267607524 Human genes 0.000 description 1
- 102200153198 rs587777877 Human genes 0.000 description 1
- 210000003079 salivary gland Anatomy 0.000 description 1
- 201000000980 schizophrenia Diseases 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 230000009919 sequestration Effects 0.000 description 1
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 1
- 108010026333 seryl-proline Proteins 0.000 description 1
- 238000004904 shortening Methods 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 201000009032 substance abuse Diseases 0.000 description 1
- 231100000736 substance abuse Toxicity 0.000 description 1
- 208000011117 substance-related disease Diseases 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000024587 synaptic transmission, glutamatergic Effects 0.000 description 1
- 229950010127 teplizumab Drugs 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 108091007466 transmembrane glycoproteins Proteins 0.000 description 1
- 102000022575 tripeptide aminopeptidase activity proteins Human genes 0.000 description 1
- 230000005747 tumor angiogenesis Effects 0.000 description 1
- 239000000439 tumor marker Substances 0.000 description 1
- 108010005834 tyrosyl-alanyl-glycine Proteins 0.000 description 1
- 238000010798 ubiquitination Methods 0.000 description 1
- 230000034512 ubiquitination Effects 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 210000003932 urinary bladder Anatomy 0.000 description 1
- 201000002327 urinary tract obstruction Diseases 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
Images



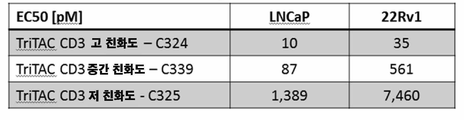
















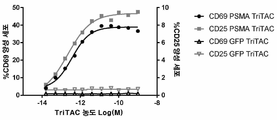


Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/39558—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against tumor tissues, cells, antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001193—Prostate associated antigens e.g. Prostate stem cell antigen [PSCA]; Prostate carcinoma tumor antigen [PCTA]; PAP or PSGR
- A61K39/001195—Prostate specific membrane antigen [PSMA]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464493—Prostate associated antigens e.g. Prostate stem cell antigen [PSCA]; Prostate carcinoma tumor antigen [PCTA]; Prostatic acid phosphatase [PAP]; Prostate-specific G-protein-coupled receptor [PSGR]
- A61K39/464495—Prostate specific membrane antigen [PSMA]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3069—Reproductive system, e.g. ovaria, uterus, testes, prostate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/31—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by the route of administration
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/38—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the dose, timing or administration schedule
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Abstract
개선된 결합 친화도 및 강력한 응집 프로파일을 갖는 PSMA 결합 단백질이 본원에서 개시된다. 또한, 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질이 설명된다. 본원에서 개시되는 결합 단백질을 포함하는 약학 조성물 및 상기 제제를 사용하는 방법이 추가로 제공된다.
Description
교차 참조
본원은 2016년 11월 23일자로 출원된 미국 가출원 제62/426,086호의 이익을 주장하며, 이는 그 전체가 본 명세서에서 참고로 포함된다.
서열 목록
본 출원은 ASCII 형식으로 전자적으로 제출되고 그 전체가 본 명세서에 참고로 포함된 서열 목록을 포함한다. 2017년 11월 22일 생성된 상기 ASCII 사본의 명칭은 47517-707_601_SL.txt이고, 크기는 148,650 바이트이다.
참조에 의한 통합
본 명세서에 언급되는 모든 간행물, 특허 및 특허 출원은 마치 각각의 개별 간행물, 특허 또는 특허 출원이 구체적이고 개별적으로 참조로 포함되도록 나타내고 그 전체가 제시된 것과 동일한 범위로 본 명세서에 참조로 포함된다.
본 개시내용은 전립선 병태 및 전립선 특이 막 항원(PSMA)의 발현과 상관 관계가 있는 다른 적응증의 진단 및 치료에 사용될 수 있는 PSMA 결합 단백질을 제공한다.
발명의 요약
본원의 한 실시양태에서, 상보성 결정 영역 CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원(PSMA) 결합 단백질이 제공되며, 여기서 (a) CDR1의 아미노산 서열은 RFMISX1YX2MH(서열 번호 1)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 X3INPAX4X5TDYAEX6VKG(서열 번호 2)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 DX7YGY(서열 번호 3)에 제시된 바와 같다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 화학식 f1-r1-f2-r2-f3-r3-f4을 포함하고, 여기서 r1은 서열 번호 1이고, r2는 서열 번호 2이고; r3은 서열 번호 3이고; f1, f2, f3 및 f4는 상기 단백질이 서열 번호 4에 제시된 아미노산 서열에 대해 적어도 80% 동일하도록 선택된 프레임워크 잔기이다. 일부 실시양태에서, X1은 프롤린이다. 일부 실시양태에서, X2는 히스티딘이다. 일부 실시양태에서, X3은 아스파르트산이다. 일부 실시양태에서, X4는 리신이다. 일부 실시양태에서, X5는 글루타민이다. 일부 실시양태에서, X6은 티로신이다. 일부 실시양태에서, X7은 세린이다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, X1은 프롤린이다. 일부 실시양태에서, X5는 글루타민이다. 일부 실시양태에서, X6은 티로신이다. 일부 실시양태에서, X4는 리신이고, X7은 세린이다. 일부 실시양태에서, X2는 히스티딘이고, X3은 아스파르트산이고, X4는 리신이고, X7은 세린이다. 일부 실시양태에서, X1은 프롤린이고, X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이다. 일부 실시양태에서, X2는 히스티딘이고, X3은 아스파르트산이고, X5는 글루타민이고, X7은 세린이다. 일부 실시양태에서, X2는 히스티딘이고, X3은 아스파르트산이고, X6은 티로신이고, X7은 세린이다. 일부 실시양태에서, X2는 히스티딘이고, X7은 세린이다. 일부 실시양태에서, X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 시노몰거스 전립선 특이 막 항원에 대해 더 높은 친화도를 추가로 갖는다. 일부 실시양태에서, r1은 서열 번호 5, 서열 번호 6 또는 서열 번호 7을 포함한다. 일부 실시양태에서, r2는 서열 번호 8, 서열 번호 9, 서열 번호 10, 서열 번호 11, 서열 번호 12, 서열 번호 13, 또는 서열 번호 14를 포함한다. 일부 실시양태에서, r3은 서열 번호 15를 포함한다.
본 발명의 또 다른 실시양태는 아미노산 위치 31, 33, 50, 55, 56, 62 및 97로부터 선택된 하나 이상의 아미노산 잔기가 치환된 서열 번호 4에 제시된 서열을 포함하는, CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질을 제공한다. 일부 실시양태에서, 결합 단백질은 위치 31, 33, 50, 55, 56, 62 및 97 이외의 다른 아미노산 위치에 하나 이상의 추가의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 31에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 33에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 50에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 55에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 56에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 62에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 위치 97에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 55 및 97에서의 치환을 포함한다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 33 및 97에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 33, 50 및 97에서의 치환을 포함한다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 시노몰거스 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 31, 33, 50 및 97에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 33, 50, 55 및 97에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 33, 50, 56 및 97에서의 치환을 포함한다. 일부 실시양태에서, 결합 단백질은 아미노산 위치 33, 50, 62 및 97에서의 치환을 포함한다.
추가의 실시양태는 CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질을 제공하며, 여기서 CDR1은 서열 번호 16에 제시된 서열을 포함한다. 일 실시양태는 CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질을 제공하며, 여기서 CDR2는 서열 번호 17에 제시된 서열을 포함한다. 추가의 실시양태는 CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질을 제공하며, 여기서 CDR3은 서열 번호 18에 제시된 서열을 포함한다. 한 실시양태에서, 서열 번호 4에 제시된 서열에 대해 적어도 80% 동일한 서열을 포함하는 전립선 특이 막 항원 결합 단백질이 제공된다. 한 실시양태에서, CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질이 제공되며, 여기서 CDR1은 서열 번호 16에 대해 적어도 80%의 동일성을 가지며, CDR2는 서열 번호 17에 대해 적어도 85%의 동일성을 가지며, CDR3은 서열 번호 18에 대해 적어도 80%의 동일성을 갖는다.
다른 실시양태는 CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질을 제공하며, 여기서 CDR1은 서열 번호 16에 제시된 서열을 포함하고, CDR2는 서열 번호 17에 나타낸 서열을 포함하고, CDR3은 서열 번호 18에 제시된 서열을 포함한다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 인간 전립선 특이 막 항원 및 시노몰거스 전립선 특이 막 항원 중의 하나 또는 둘 모두에 결합한다. 일부 실시양태에서, 결합 단백질은 인간 전립선 특이 막 항원 및 시노몰거스 전립선 특이 막 항원에 대등한 결합 친화도로 결합한다. 일부 실시양태에서, 결합 단백질은 시노몰거스 전립선 특이 막 항원보다 더 높은 결합 친화도로 인간 전립선 특이 막 항원에 결합한다.
또 다른 실시양태는 본 개시내용에 따른 PSMA 결합 단백질을 코딩하는 폴리뉴클레오티드를 제공한다. 또 다른 실시양태는 본 개시내용에 따른 PSMA 결합 단백질을 코딩하는 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 또 다른 실시양태에서, 상기 벡터로 형질전환된 숙주 세포가 제공된다. 다른 실시양태에서, (i) 본 개시내용에 따른 PSMA 결합 단백질, 본 개시내용에 따른 폴리뉴클레오티드, 본 개시내용에 따른 벡터 또는 본 개시내용에 따른 숙주 세포, 및 (ii) 약학적으로 허용 가능한 담체를 포함하는 약학 조성물이 제공된다. 또 다른 실시양태는 본 개시내용에 따른 PSMA 결합 단백질의 생산 방법을 제공하며, 상기 방법은 PSMA 결합 단백질의 발현을 허용하는 조건 하에 본 개시내용에 따른 PSMA 알부민 결합 단백질을 코딩하는 핵산 서열을 포함하는 벡터로 형질전환되거나 형질감염된 숙주를 배양하는 단계 및 배양물로부터 생산된 단백질을 회수하고 정제하는 단계를 포함한다.
한 실시양태에서, 본 발명은 본 개시내용에 따른 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 증식성 질환, 종양 질환, 염증성 질환, 면역 장애, 자가면역 질환, 감염성 질환, 바이러스성 질환, 알레르기 반응, 기생충 반응, 이식편 대 숙주 질환 또는 숙주 대 이식편 질환의 치료 또는 개선 방법이 제공된다. 일부 실시양태에서, 대상체는 인간이다. 일부 실시양태에서, 상기 방법은 본 개시내용에 따른 PSMA 결합 단백질과 조합하여 작용제를 투여하는 단계를 추가로 포함한다.
한 실시양태는 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질을 제공한다. 추가의 실시양태는 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 항체를 제공한다. 한 실시양태에서, 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 항체, 이중 특이적 항체, sdAb, 가변 중쇄 도메인, 펩티드 또는 리간드가 제공된다. 한 실시양태에서, 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 항체가 제공되며, 상기 항체는 단일 도메인 항체이다. 일부 실시양태에서, 단일 도메인 항체는 IgG의 중쇄 가변 영역으로부터 유도된다. 추가의 실시양태는 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질 또는 항체를 제공한다. 한 실시양태에서, 본 개시내용에 따른 다중 특이적 항체를 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 증식성 질환, 종양 질환, 염증성 질환, 면역 장애, 자가면역 질환, 감염성 질환, 바이러스성 질환, 알레르기 반응, 기생충 반응, 이식편 대 숙주 질환 또는 숙주 대 이식편 질환의 치료 또는 개선 방법이 제공된다. 추가의 실시양태에서, 본 개시내용에 따른 다중 특이적 항체를 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 전립선 병태의 치료 또는 개선 방법이 제공된다. 또 다른 실시양태는 상기 실시양태 중 어느 하나에 따른 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 전립선 병태의 치료 또는 개선 방법을 제공한다. 추가의 실시양태는 본 개시내용에 따른 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 전립선 병태의 치료 또는 개선 방법을 제공한다.
일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 다음 중 임의의 조합을 포함한다: (i) X1은 프롤린이고; (ii) X2는 히스티딘이고; (iii) X3은 아스파르트산이고; (iv) X4는 리신이고; (v) X5는 글루타민이고; (vi) X6은 티로신이고; (vii) X7은 세린이다. 일부 실시양태에서, 상기 실시양태의 전립선 특이 막 항원 결합 단백질은 서열 번호 4로 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 다음 중 임의의 조합을 포함한다: (i) X1은 프롤린이고 X5는 글루타민이고; (ii) X6은 티로신이고 X4는 리신이고 X7은 세린이고; (iii) X2는 히스티딘이고 X3은 아스파르트산이고 X4는 리신이고 X7은 세린이고; (iv) X1은 프롤린이고 X2는 히스티딘이고 X3은 아스파르트산이고 X7은 세린이고; (v) X2는 히스티딘이고 X3은 아스파르트산이고 X5는 글루타민이고 X7은 세린이고; (vi) X2는 히스티딘이고 X3은 아스파르트산이고 X4는 리신이고 X7은 세린이고; (vii) X1은 프롤린이고 X2는 히스티딘이고 X3은 아스파르트산이고 X7은 세린이고; (viii) X2는 히스티딘이고 X3은 아스파르트산이고 X5는 글루타민이고 X7은 세린이고; (ix) X2는 히스티딘이고 X3은 아스파르트산이고 X6은 티로신이고 X7은 세린이고; (x) X2는 히스티딘이고 X3은 아스파르트산이고 X7은 세린이다. 일부 경우에, 상기 실시양태의 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 경우에, 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 시노몰거스 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 다음 중 임의의 조합을 포함한다: (i) 위치 31에서의 치환; (ii) 위치 50에서의 치환; (iii) 위치 55에서의 치환; 위치 56에서의 치환; (iv) 위치 62에서의 치환; (v) 위치 97에서의 치환; (vi) 위치 55 및 97에서의 치환; (vii) 위치 33 및 97에서의 치환; (viii) 위치 33, 50 및 97에서의 치환; (ix) 위치 31, 33, 50 및 97에서의 치환; (x) 위치 33, 50, 55 및 97에서의 치환; (xi) 위치 33, 50, 56 및 97에서의 치환; 및 (xiii) 위치 33, 50, 62 및 97에서의 치환. 일부 경우에, 상기 실시양태의 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 경우에, 상기 실시양태의 전립선 특이 막 항원 결합 단백질은 서열 번호 4에 제시된 서열을 갖는 결합 단백질보다 시노몰거스 전립선 특이 막 항원에 대해 더 높은 친화도를 추가로 갖는다.
한 실시양태는 상보성 결정 영역 CDR1, CDR2 및 CDR3을 포함하는 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 전립선암의 치료 또는 개선 방법을 제공하며, 여기서 (a) CDR1의 아미노산 서열은 RFMISX1YX2MH(서열 번호 1)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 X3INPAX4X5TDYAEX6VKG(서열 번호 2)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 DX7YGY(서열 번호 3)에 제시된 바와 같다.
일부 실시양태에서, PSMA 결합 단백질은 단일 도메인 항체이다. 일부 실시양태에서, 상기 단일 도메인 항체는 삼중 특이적 항체의 일부이다.
본 발명의 신규한 특징은 첨부된 청구 범위에서 상세하게 제시된다. 본 발명의 특징 및 이점에 대한 더 나은 이해는 본 발명의 원리들이 이용되는 예시적인 실시양태를 제시하는 하기 상세한 설명 및 첨부 도면을 참고로 하여 이루어질 것이다.
도 1은 항-CD3ε 단일쇄 가변 단편(scFv) 및 항-HSA 가변 중쇄 영역을 포함하는 불변 코어 요소; 및 VH, scFv, 비-Ig 결합제 또는 리간드일 수 있는 PSMA 결합 도메인을 갖는, 예시적인 PSMA 표적화 삼중 특이적 항원 결합 단백질의 개략도이다.
도 2a-b는 CD3에 대한 상이한 친화도를 갖는 예시적인 PSMA 표적화 삼중 특이적 단백질(PSMA 표적화 TriTAC 분자)이 인간 전립선암 세포를 죽이기 위해 T 세포를 유도하는 능력을 비교한다. 도 2a는 전립선암 모델 LNCaP에서 상이한 PSMA 표적화 TriTAC 분자에 의한 사멸을 보여준다. 도 2b는 전립선암 모델 22Rv1에서 상이한 PSMA 표적화 TriTAC 분자에 의한 사멸을 보여준다. 도 2c는 LNCaP 및 22Rv1 전립선암 모델에서 PSMA 표적화 TriTAC 분자에 대한 EC50 값을 보여준다.
도 3은 3주에 걸쳐 i.v. 투여(100 ㎍/kg)한 후 시노몰거스 원숭이에서 PSMA 표적화 TriTAC C236의 혈청 농도를 보여준다.
도 4는 3주에 걸쳐 i.v. 투여(100 ㎍/kg)한 후 시노몰거스 원숭이에서 상이한 CD3 친화도를 갖는 PSMA 표적화 TriTAC 분자의 혈청 농도를 보여준다.
도 5a-c는 PSMA에 대한 상이한 친화도를 갖는 PSMA 표적화 TriTAC 분자가 인간 전립선암 세포주 LNCaP를 죽이기 위해 T 세포를 유도하는 능력을 보여준다. 도 5a는 양성 대조군으로서 PSMA 표적화 BiTE를 사용하여 인간 혈청 알부민의 부재 하에 수행된 실험을 보여준다. 도 5b는 양성 대조군으로서 PSMA 표적화 BiTE를 사용하여 인간 혈청 알부민의 존재 하에 수행된 실험을 보여준다. 도 5c는 LNCaP 전립선암 모델에서 양성 대조군으로서 PSMA 표적화 BiTE를 사용하여 HSA의 존재 또는 부재 하에 측정된 PSMA 표적화 TriTAC에 대한 EC50 값을 보여준다.
도 6은 마우스 이종이식 실험에서 인간 전립선암 세포의 종양 성장을 억제하는 PSMA 표적화 TriTAC 분자의 능력을 제시한다.
도 7a-d는 표적 단백질을 발현하거나 발현하지 않는 표적 세포주를 이용한 세포 사멸 검정에서 TriTAC 분자의 특이성을 제시한다. 도 7a는 LNCaP, KMS12BM 및 OVCAR8 세포주에서의 EGFR 및 PSMA 발현을 보여준다. 도 7b는 PSMA, EGFR 및 음성 대조군 TriTAC에 의한 LNCaP 종양 세포의 사멸을 보여준다. 도 7c는 PSMA, EGFR 및 음성 대조군 TriTAC에 의한 KMS12BM 종양 세포의 사멸을 보여준다. 도 7d는 PSMA, EGFR 및 음성 대조군 TriTAC에 의한 OVCAR8 세포의 사멸을 보여준다.
도 8a-d는 TriTAC 활성에 대한 37℃에서의 예비 인큐베이션 및 동결/해동 사이클의 영향을 나타낸 것이다. 도 8a는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C235 활성을 보여준다. 도 8b는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C359 활성을 보여준다. 도 8c는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C360 활성을 보여준다. 도 8d는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C361 활성을 보여준다.
도 9a 및 도 9b는 T 세포 의존성 세포성 세포독성 검정(TDCC)에서 재유도(redirecting)된 T 세포 사멸에서 본 개시내용의 PSMA 표적화 TriTAC 분자의 활성을 나타낸다. 도 9a는 LNCaP 세포의 사멸시에 시노몰거스 원숭이 공여자 G322로부터 시노몰거스 말초 혈액 단핵 세포(PBMC)를 재유도할 때 PSMA 표적화 TriTAC 분자의 영향을 보여준다. 도 9b는 MDAPCa2b 세포를 죽이기 위해 시노몰거스 원숭이 공여자 D173으로부터 시노몰거스 PBMC를 재유도할 때 PSMA 표적화 TriTAC 분자의 영향을 보여준다.
도 10은 T 세포 활성화 마커 CD25 및 CD69의 발현에 대한 본 개시내용의 PSMA 표적화 TriTAC 분자의 영향을 보여준다.
도 11은 PSMA 발현 표적 분자의 존재 하에 T 세포 증식을 자극하는 본 개시내용의 PSMA 표적화 TriTAC 분자의 능력을 보여준다.
도 12는 PSMA 표적화 TriTAC 분자인 PSMA Z2 TriTAC(서열 번호 156)에 의한 LnCaP 세포의 재유도된 T 세포 사멸을 보여준다.
도 1은 항-CD3ε 단일쇄 가변 단편(scFv) 및 항-HSA 가변 중쇄 영역을 포함하는 불변 코어 요소; 및 VH, scFv, 비-Ig 결합제 또는 리간드일 수 있는 PSMA 결합 도메인을 갖는, 예시적인 PSMA 표적화 삼중 특이적 항원 결합 단백질의 개략도이다.
도 2a-b는 CD3에 대한 상이한 친화도를 갖는 예시적인 PSMA 표적화 삼중 특이적 단백질(PSMA 표적화 TriTAC 분자)이 인간 전립선암 세포를 죽이기 위해 T 세포를 유도하는 능력을 비교한다. 도 2a는 전립선암 모델 LNCaP에서 상이한 PSMA 표적화 TriTAC 분자에 의한 사멸을 보여준다. 도 2b는 전립선암 모델 22Rv1에서 상이한 PSMA 표적화 TriTAC 분자에 의한 사멸을 보여준다. 도 2c는 LNCaP 및 22Rv1 전립선암 모델에서 PSMA 표적화 TriTAC 분자에 대한 EC50 값을 보여준다.
도 3은 3주에 걸쳐 i.v. 투여(100 ㎍/kg)한 후 시노몰거스 원숭이에서 PSMA 표적화 TriTAC C236의 혈청 농도를 보여준다.
도 4는 3주에 걸쳐 i.v. 투여(100 ㎍/kg)한 후 시노몰거스 원숭이에서 상이한 CD3 친화도를 갖는 PSMA 표적화 TriTAC 분자의 혈청 농도를 보여준다.
도 5a-c는 PSMA에 대한 상이한 친화도를 갖는 PSMA 표적화 TriTAC 분자가 인간 전립선암 세포주 LNCaP를 죽이기 위해 T 세포를 유도하는 능력을 보여준다. 도 5a는 양성 대조군으로서 PSMA 표적화 BiTE를 사용하여 인간 혈청 알부민의 부재 하에 수행된 실험을 보여준다. 도 5b는 양성 대조군으로서 PSMA 표적화 BiTE를 사용하여 인간 혈청 알부민의 존재 하에 수행된 실험을 보여준다. 도 5c는 LNCaP 전립선암 모델에서 양성 대조군으로서 PSMA 표적화 BiTE를 사용하여 HSA의 존재 또는 부재 하에 측정된 PSMA 표적화 TriTAC에 대한 EC50 값을 보여준다.
도 6은 마우스 이종이식 실험에서 인간 전립선암 세포의 종양 성장을 억제하는 PSMA 표적화 TriTAC 분자의 능력을 제시한다.
도 7a-d는 표적 단백질을 발현하거나 발현하지 않는 표적 세포주를 이용한 세포 사멸 검정에서 TriTAC 분자의 특이성을 제시한다. 도 7a는 LNCaP, KMS12BM 및 OVCAR8 세포주에서의 EGFR 및 PSMA 발현을 보여준다. 도 7b는 PSMA, EGFR 및 음성 대조군 TriTAC에 의한 LNCaP 종양 세포의 사멸을 보여준다. 도 7c는 PSMA, EGFR 및 음성 대조군 TriTAC에 의한 KMS12BM 종양 세포의 사멸을 보여준다. 도 7d는 PSMA, EGFR 및 음성 대조군 TriTAC에 의한 OVCAR8 세포의 사멸을 보여준다.
도 8a-d는 TriTAC 활성에 대한 37℃에서의 예비 인큐베이션 및 동결/해동 사이클의 영향을 나타낸 것이다. 도 8a는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C235 활성을 보여준다. 도 8b는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C359 활성을 보여준다. 도 8c는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C360 활성을 보여준다. 도 8d는 37℃에서의 예비 인큐베이션 또는 동결/해동 사이클 후에 PSMA TriTAC C361 활성을 보여준다.
도 9a 및 도 9b는 T 세포 의존성 세포성 세포독성 검정(TDCC)에서 재유도(redirecting)된 T 세포 사멸에서 본 개시내용의 PSMA 표적화 TriTAC 분자의 활성을 나타낸다. 도 9a는 LNCaP 세포의 사멸시에 시노몰거스 원숭이 공여자 G322로부터 시노몰거스 말초 혈액 단핵 세포(PBMC)를 재유도할 때 PSMA 표적화 TriTAC 분자의 영향을 보여준다. 도 9b는 MDAPCa2b 세포를 죽이기 위해 시노몰거스 원숭이 공여자 D173으로부터 시노몰거스 PBMC를 재유도할 때 PSMA 표적화 TriTAC 분자의 영향을 보여준다.
도 10은 T 세포 활성화 마커 CD25 및 CD69의 발현에 대한 본 개시내용의 PSMA 표적화 TriTAC 분자의 영향을 보여준다.
도 11은 PSMA 발현 표적 분자의 존재 하에 T 세포 증식을 자극하는 본 개시내용의 PSMA 표적화 TriTAC 분자의 능력을 보여준다.
도 12는 PSMA 표적화 TriTAC 분자인 PSMA Z2 TriTAC(서열 번호 156)에 의한 LnCaP 세포의 재유도된 T 세포 사멸을 보여준다.
본 발명의 바람직한 실시양태가 본 명세서에 제시되고 설명되었지만, 그러한 실시양태가 단지 예로서 제공된다는 것이 관련 기술 분야의 통상의 기술자에게 명백할 것이다. 많은 변형, 변경 및 대체가 이제 본 발명을 벗어나지 않으면서 관련 기술 분야의 통상의 기술자에 의해 이루어질 것이다. 본원에서 설명되는 본 발명의 실시양태에 대한 다양한 대안이 본 발명을 실시하는데 사용될 수 있음을 이해하여야 한다. 하기 청구 범위는 본 발명의 범위를 정의하고, 이들 청구 범위의 범위 내에 있는 방법 및 구조 및 그의 균등물은 청구 범위에 의해 커버되는 것으로 의도된다.
특정 정의
본 명세서에 사용된 용어는 특정 경우만을 설명하기 위한 것으로서, 제한하기 위한 것이 아니다. 본원에서 사용되는 바와 같이, 문맥이 달리 명시하지 않은 한, 단수 형태는 복수 형태도 포함하기 위한 것이다. 또한, 용어 "포함하는", "포함하다", "가진", "가진다", "갖는" 또는 이들의 변형 용어가 상세한 설명 및/또는 청구범위에서 사용되는 경우, 이러한 용어들은 용어 "포괄하는"과 유사한 방식으로 포괄하기 위한 것이다.
용어 "약" 또는 "대략"은 부분적으로는 값이 측정되거나 결정되는 방법, 예를 들면, 측정 시스템의 한계에 의존할, 관련 기술 분야의 통상의 기술자에 의해 결정된 특정 값에 대한 허용 가능한 오차 범위 내에 있다는 것을 의미한다. 예를 들면, "약"은 소정의 값에서 관례에 따라 1 이내 또는 1 초과의 표준 편차를 의미할 수 있다. 특정 값이 본원 및 청구범위에 기재되어 있는 경우, 달리 언급되어 있지 않은 한, 용어 "약"은 특정 값에 대한 허용 가능한 오차 범위를 의미하는 것으로 추정될 것이다.
개체", "환자" 또는 "대상체"는 교환 가능하게 사용된다. 상기 용어들 중 어느 것도 건강 관리 종사자(예를 들면, 의사, 등록된 간호사, 임상 간호사, 의사 보조자, 간호조무사 또는 호스피스 종사자)의 감독(예를 들면, 꾸준한 또는 간헐적인)을 특징으로 하는 상황을 요구하지 않거나 이러한 상황으로 한정되지 않는다.
용어 "프레임워크" 또는 "FR" 잔기(또는 영역)는 본원에서 정의된 CDR 또는 초가변 영역 잔기 이외의 다른 가변 도메인 잔기를 지칭한다. "인간 컨센서스 프레임워크"는 인간 면역글로불린 VL 또는 VH 프레임워크 서열의 선택에 있어서 가장 흔히 존재하는 아미노산 잔기를 나타내는 프레임워크이다.
본원에서 사용되는 바와 같이, "가변 영역" 또는 "가변 도메인"은 가변 도메인의 특정 부분이 항체들 사이에 서열 면에서 광범위하게 상이하고 그의 특정 항원에 대한 각각의 특정 항체의 결합 및 특이성에 사용된다는 사실을 의미한다. 그러나, 가변성은 항체의 가변 도메인 전체에 걸쳐 균일하게 분포되어 있지 않다. 가변성은 경쇄 가변 도메인 및 중쇄 가변 도메인 둘 모두에서 상보성 결정 영역(CDR) 또는 초가변 영역으로서 지칭되는 3개의 분절들에 집중되어 있다. 가변 도메인의 보다 고도로 보존된 부분은 프레임워크(FR)로서 지칭된다. 천연 중쇄 및 경쇄의 가변 도메인은 β 시트 구조의 루프 연결을 형성하고 일부 경우 β 시트 구조의 일부를 형성하는, 3개의 CDR들에 의해 연결된, 주로 β 시트 입체형태를 채택하는 4개의 FR 영역들을 각각 포함한다. 각각의 쇄에서 CDR들은 FR 영역에 의해 가깝게 인접하여 함께 모여 있고, 다른 쇄로부터의 CDR들과 함께 항체의 항원 결합 부위의 형성에 기여한다(문헌 [Kabat et al., Sequences of Proteins of Immunological Interest, Fifth Edition, National Institute of Health, Bethesda, Md. (1991)] 참조). 불변 도메인은 항체와 항원의 결합에 직접 관여하지 않으나, 다양한 이펙터 기능, 예컨대, 항체 의존적 세포 독성에 항체를 참여시키는 기능을 나타낸다. "카바트(Kabat)에서와 같은 가변 도메인 잔기 넘버링" 또는 "카바트에서와 같은 아미노산 위치 넘버링", 및 이들의 변형 표현은 문헌 [Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991)]에서 항체의 편집(compilation)의 중쇄 가변 도메인 또는 경쇄 가변 도메인에 대해 사용된 넘버링 시스템을 지칭한다. 이 넘버링 시스템을 사용할 때, 실제 선형 아미노산 서열은 가변 도메인의 FR 또는 CDR의 단축, 또는 이러한 FR 또는 CDR 내로의 삽입에 상응하는 보다 적은 또는 추가의 아미노산을 함유할 수 있다. 예를 들면, 중쇄 가변 도메인은 H2의 잔기 52 다음에 단일 아미노산 삽입물(카바트에 따른 잔기 52a) 및 중쇄 FR 잔기 82 다음에 삽입된 잔기(예를 들면, 카바트에 따른 잔기 82a, 82b 및 82c 등)를 포함할 수 있다. 잔기의 카바트 넘버링은 항체 서열의 상동성 영역에서 "표준" 카바트 넘버링된 서열과 정렬시킴으로써 소정의 항체에 대해 결정될 수 있다. 본 개시내용의 CDR이 반드시 카바트 넘버링 규약에 상응한다는 것은 아니다.
본원에서 사용되는 바와 같이, 서열과 관련하여 용어 "아미노산 서열 동일성 퍼센트(%)"는 서열들을 정렬하고 필요하다면 갭을 도입하여 최대 서열 동일성 퍼센트를 달성하고 어떠한 보존적 치환도 서열 동일성의 부분으로서 간주하지 않은 후, 특정 서열 내의 아미노산 잔기와 동일한 후보 서열 내의 아미노산 잔기의 백분율로서 정의된다. 아미노산 서열 동일성 퍼센트를 결정하기 위한 정렬은 예를 들면, 공개적으로 이용 가능한 컴퓨터 소프트웨어, 예컨대, EMBOSS MATCHER, EMBOSS WATER, EMBOSS STRETCHER, EMBOSS NEEDLE, EMBOSS LALIGN, BLAST, BLAST-2, ALIGN 또는 Megalign(DNASTAR) 소프트웨어를 이용함으로써 관련 기술 분야의 기술 내에 있는 다양한 방식들에 의해 달성될 수 있다. 관련 기술 분야의 통상의 기술자는 비교되는 서열들의 전체 길이에 걸쳐 최대 정렬을 달성하기 위해 요구되는 임의의 알고리즘을 포함하는, 정렬을 측정하기 위한 적절한 파라미터를 결정할 수 있다.
본원에서 사용되는 바와 같이, "제거 반감기"는 문헌 [Goodman and Gillman's The Pharmaceutical Basis of Therapeutics 21-25 (Alfred Goodman Gilman, Louis S. Goodman, and Alfred Gilman, eds., 6th ed. 1980)]에 기재된 바와 같이 그의 통상적인 의미로 사용된다. 간단히 설명하면, 상기 용어는 약물 제거의 시간 경과의 정량적 측정치를 포괄하는 의미이다. 약물 농도가 통상적으로 제거 과정의 포화를 위해 요구된 약물 농도에 도달하지 않기 때문에, 대부분의 약물의 제거는 기하급수적이다(즉, 1차 반응식을 따른다). 기하급수적 과정의 속도는 그의 속도 상수, 즉 시간 단위당 비율 변화를 표현하는 k, 또는 그의 반감기, 즉 상기 과정의 50% 완료를 위해 필요한 시간인 t1/2로 표현될 수 있다. 이들 두 상수의 단위는 각각 시간-1 및 시간이다. 반응의 1차 속도 상수 및 반감기는 단순하게 관련되어 있으므로(k x t1/2=0.693), 상호 교환될 수 있다. 1차 제거 반응식은 단위 시간당 일정한 비율의 약물이 손실되는 것을 좌우하기 때문에, 약물 농도의 로그 대 시간의 도표는 초기 분포 단계 후(즉, 약물 흡수 및 분포가 완료된 후) 모든 시간에서 선형이다. 약물 제거를 위한 반감기는 이러한 그래프로부터 정확히 결정될 수 있다.
본원에서 사용된 바와 같이, 용어 "결합 친화도"는 그의 결합 표적에 대한 본 개시내용에서 설명되는 단백질의 친화도를 지칭하고, "Kd" 값을 사용함으로써 수치적으로 표현된다. 2개 이상의 단백질이 그들의 결합 표적에 대한 대등한 결합 친화도를 가진 것으로 표시되는 경우, 그들의 결합 표적에 대한 각각의 단백질의 결합에 대한 Kd 값은 서로의 ±2배 이내에 있다. 2개 이상의 단백질이 단일 결합 표적에 대한 대등한 결합 친화도를 가진 것으로 표시되는 경우, 상기 단일 결합 표적에 대한 각각의 단백질의 결합에 대한 Kd 값은 서로의 ±2배 이내에 있다. 단백질이 대등한 결합 친화도로 2개 이상의 표적에 결합하는 것으로 표시되는 경우, 2개 이상의 표적에 대한 상기 단백질의 결합에 대한 Kd 값은 서로의 ±2배 이내에 있다. 일반적으로, 보다 높은 Kd 값은 보다 약한 결합에 상응한다. 일부 실시양태에서, "Kd"는 BIAcore™-2000 또는 BIAcore™-3000(BIAcore, Inc, 미국 뉴저지주 피스카타웨이 소재)을 이용하여 방사성 표지된 항원 결합 검정(RIA) 또는 표면 플라스몬 공명 검정에 의해 측정된다. 일부 실시양태에서, "온-속도(on-rate)" 또는 "회합의 속도" 또는 "회합 속도" 또는 "kon", 및 "오프-속도(off-rate)" 또는 "해리의 속도" 또는 "해리 속도" 또는 "koff"도 BIAcore™-2000 또는 BIAcore™-3000(BIAcore, Inc, 미국 뉴저지주 피스카타웨이 소재)을 이용하여 표면 플라스몬 공명 기술에 의해 측정된다. 추가의 실시양태에서, "Kd", "kon" 및 "koff"는 OCTET® 시스템(Pall Life Sciences)을 이용하여 측정된다. OCTET® 시스템을 사용하여 결합 친화도를 측정하는 예시적인 방법에서, 리간드, 예를 들어, 비오티닐된 인간 또는 시노몰거스 PSMA는 OCTET® 스트렙타비딘 모세관 센서 팁 표면 상에 고정되고, 상기 스트렙타비딘 팁은 제조사의 지시에 따라 약 20-50 ㎍/ml의 인간 또는 시노몰거스 PSMA 단백질을 사용하여 활성화된다. PBS/카제인의 용액이 또한 차단제로서 도입된다. 회합 반응 속도 측정을 위해, PSMA 결합 단백질 변이체는 약 10 ㎍/ml 내지 약 1000 ㎍/ml 범위의 농도로 도입된다. 완전한 해리는 음성 대조군의 경우에 결합 단백질이 없는 검정 버퍼에서 관찰된다. 그런 다음, 적절한 도구, 예를 들어, ForteBio 소프트웨어를 사용하여 결합 반응의 반응 속도 파라미터를 결정한다.
PSMA 결합 단백질, 약학 조성물뿐만 아니라 이러한 PSMA 결합 단백질을 제조하기 위한 핵산, 재조합 발현 벡터, 및 숙주 세포가 또한 본원에서 설명된다. 또한, 개시된 PSMA 결합 단백질을 질환, 병태 및 장애의 예방 및/또는 치료에 사용하는 방법이 제공된다. PSMA 결합 단백질은 PSMA에 특이적으로 결합할 수 있다. 일부 실시양태에서, PSMA 결합 단백질은 CD3 결합 도메인과 같은 추가의 도메인을 포함한다.
전립선 특이 막 항원(PSMA) 및 그의 전립선 병태에서의 역할
본원에서 전립선 특이 막 항원 결합 단백질이 고려된다. 글루타메이트 카르복시펩티다제 II, N-아세틸-α-연결 산성 디펩티다제 I(Naaladase (NLD) I) 또는 엽산 히드롤라제로도 알려진 전립선 특이 막 항원(PSMA)은 전립선암 세포 및 비전립선 고형 종양 신생혈관에서에서 고도로 발현되고 건강한 전립선, 신장, 간, 소장, 작은 창자, 타액선, 십이지장 점막, 근위 세뇨관 및 뇌를 비롯한 다른 조직에서 낮은 수준으로 발현되는 것으로 밝혀진 750개 잔기의 타입 II 트랜스멤브레인 당단백질이다. PSMA는 아연 의존성 엑소펩티다제의 수퍼패밀리의 구성원으로서, 단핵 아연 활성 부위를 갖는 카르복시펩티다제(예를 들어, 카르복시펩티다제 A) 및 이핵 아연 활성 부위를 갖는 카르복시- 및 아미노펩티다제[예를 들어, 카르복시펩티다제 G2 (CPG2), 펩티다제 T 및 V(PepT 및 PepV), 스트렙토마이세스 그리세우스(Streptomyces griseus) 아미노펩티다제(Sgap) 및 아에로모나스 프로테올리티카(Aeromonas proteolytica) 아미노펩티다제(AAP)]를 포함한다. 이러한 가용성 단일 도메인(예를 들어, AAP) 또는 이중 도메인(예를 들어, CPG2) 아연 의존성 엑소펩티다제와의 제한된 상동성 영역 이외에도, PSMA의 전체 서열은 다음과 같은 적어도 4개의 다른 인간 단백질과 상동성이 있다: NLDL(회장에서 발현됨; 35% 동일성), NLD2(난소, 고환 및 뇌에서 발현됨; 67% 동일성), 트랜스페린 수용체(TfR) 1(TfR1; 대부분의 세포 유형에서 발현됨; 26% 동일성), 및 TfR2(주로 간에서 발현됨; 28% 동일성).
PSMA의 결정 구조는 각각의 폴리펩티드 사슬이 3개의 TfR1 도메인, 즉 프로테아제 도메인, 정점(apical) 도메인 및 나선 도메인에 유사한 3개의 도메인을 포함하는 대칭 이량체를 포함하는 것으로 밝혀졌다. 3개의 도메인 사이의 계면에 존재하는 큰 공동( 1,100 Å2)은 이핵 아연 부위 및 우세하게 극성인 잔기(70개 잔기의 66%)를 포함한다. 2개의 아연 이온의 관찰 및 PSMA 오르톨로그(ortholog) 및 상동체 중 다수의 공동 형성 잔기의 보존에 의해, 공동을 가능한 기질 결합 부위로 확인한다.
1,100 Å2)은 이핵 아연 부위 및 우세하게 극성인 잔기(70개 잔기의 66%)를 포함한다. 2개의 아연 이온의 관찰 및 PSMA 오르톨로그(ortholog) 및 상동체 중 다수의 공동 형성 잔기의 보존에 의해, 공동을 가능한 기질 결합 부위로 확인한다.
전형적으로, PSMA 발현은 전립선 질환의 진행 및 전이와 함께 증가하는 것으로 밝혀졌다. PSMA의 발현은 전립선암에서, 특히 잘 분화되지 않은 전이성 및 호르몬 불응성 암종에서 증가한다. PSMA는 또한 신장 세포 암종 및 결장 암종을 비롯한 특정 악성 종양의 종양 주위 및 종양내 영역에서 모세 혈관의 내피 세포에서 발현되지만, 정상 조직의 혈관에서는 그렇지 않다. 또한, PSMA는 종양 혈관 신생과 관련된 것으로 보고되었다. PSMA는 결장, 유방, 방광, 췌장, 신장 및 흑색종의 암종에서 종양 관련 신생 혈관의 내피 세포에서 발현되는 것으로 입증되었다.
종양 마커로서의 역할 이외에, PSMA는 이핵 아연 부위를 함유하고, 펩티드 또는 소분자로부터 α- 또는 γ-연결 글루타메이트의 가수분해에 의한 절단을 촉매하는 글루타메이트 카르복시펩티다제로서 활성을 갖는다. 그의 기질은 필수 영양소인 폴리-γ-글루타메이트화 엽산, 및 절단이 그 효능을 저하시키는 항암 약물 메토트렉세이트의 폴리-γ-글루타메이트화 형태를 포함한다. PSMA의 효소 활성은 약물의 불활성 글루타메이트화 형태가 선택적으로 절단되어 PSMA를 발현하는 세포에서만 활성화되는 프로드러그의 설계에 이용될 수 있다. PSMA는 또한 NMDA 이온성(ionotropic) 수용체의 억제제이고 타입 II 대사성(metabotropic) 수용체 서브타입 3의 효능제인 풍부한 신경 펩티드 N-아세틸-1-아스파르틸-1-글루타메이트(α-NAAG)를 절단하고 불활성화한다. α-NAAG에 의한 글루타메이트성(glutamatergic) 신경 전달 조절의 붕괴는 정신 분열증, 발작 장애, 알츠하이머(Alzheimer) 병, 헌팅턴(Huntington) 병 및 근위축성 측삭 경화증과 관련된다. 따라서, PSMA의 억제는 글루타메이트를 감소시키고 α-NAAG를 증가시킴으로써 신경 보호를 잠재적으로 부여한다. 예를 들어, 나노몰 미만의 억제제 2-(포스포노메틸) 펜탄디오산은 세포 배양물 및/또는 허혈, 당뇨병성 신경병증, 약물 남용, 만성 통증 및 근위축성 측삭 경화증의 동물 모델에서 신경 보호를 제공하는 것으로 밝혀졌다.
전립선암은 가장 흔한 유형의 암이며, 미국 남성의 암으로 인한 주요 사망 원인 중 하나이다. 전립선암으로 진단된 남성의 수는 나이든 남성의 인구 증가 및 그의 조기 진단으로 이어지는 질환에 대한 인식 증가로 인해 꾸준히 증가하고 있다. 전립선암 발병에 대한 남성의 일생 동안의 위험은 대략 백인 5명 중 1명, 아프리카계 미국인 6명 중 1명이다. 고위험군은 전립선암의 가족력이 있는 사람들 또는 아프리카계 미국인이다. 일생 동안에 걸쳐, 전립선암으로 진단받은 남성의 3분의 2를 초과하는 남성이 이 질환으로 사망한다. 또한, 전립선암에 걸리지 않는 많은 환자들은 통증, 출혈 및 요로 폐색과 같은 증상을 개선하기 위해 지속적인 치료를 필요로 한다. 따라서, 전립선암은 또한 고통의 주요 원인 및 건강 관리 비용의 증가를 나타낸다. 전립선암이 국소화되고 환자의 기대 수명이 10년 이상인 경우, 근치적 전립선 절제술은 질환 퇴치를 위한 최상의 기회를 제공한다. 역사적으로, 이 시술의 단점은 대부분의 암이 검출된 시점에 그 수술 경계를 넘어 확산되었다는 것이다. 부피가 큰 고등급 종양이 존재하는 환자는 근치적 전립선 절제술에 의해 성공적으로 치료될 가능성이 작다. 방사선 요법은 근치적 전립선 절제술의 대안으로 널리 사용되고 있다. 일반적으로 방사선 요법으로 치료받는 환자는 나이가 많고 건강이 좋지 않은 환자 및 고등급의 보다 임상적으로 진행된 종양이 있는 환자이다. 특히 바람직한 치료법은 방사선장이 치료되는 조직의 부피와 일치하도록 설계된 3차원 공초점 방사선 요법; 방사성 화합물의 씨앗이 초음파 유도를 사용하여 이식되는 조직내(interstitial) 방사선 요법; 및 외부 빔 요법과 조직내 방사선 요법의 조합이다. 국소 진행성 질환이 있는 환자의 치료를 위해서는, 근치적 전립선 절제술 또는 방사선 요법 전 또는 후에 호르몬 요법이 이용되었다. 호르몬 요법은 산재성 전립선암이 존재하는 남성을 치료하는 주된 형태이다. 고환절제술은 혈청 테스토스테론 농도를 줄이고, 에스트로겐 치료도 마찬가지로 유익하다. 에스트로겐으로부터의 디에틸스틸베스트롤은 심혈관 독성을 일으키는 단점이 있는 또 다른 유용한 호르몬 요법이다. 고나도트로핀 방출 호르몬 효능제를 투여하면, 테스토스테론 농도가 궁극적으로 감소한다. 플루타미드 및 다른 비스테로이드성 항안드로겐제는 테스토스테론이 그의 세포 내 수용체에 결합하는 것을 차단한다. 그 결과, 이것은 테스토스테론의 효과를 차단하고, 혈청 테스토스테론 농도를 증가시키며, 근치적 전립선 절제술 및 방사선 치료 후에도 환자를 강력하게 유지할 수 있다. 세포독성 화학요법은 전립선암 치료에 크게 효과적이지 않다. 그것의 독성은 그 치료가 노인 환자에게 부적당하게 만든다. 또한, 전립선암은 세포독성제에 비교적 내성이다. 재발하거나 더 진행된 질환은 또한 항안드로겐 요법으로 치료된다. 불행히도, 거의 모든 종양은 호르몬에 내성을 갖게 되고, 임의의 효과적인 요법이 없을 경우 빠르게 진행된다. 따라서, 환자의 정상 조직에 압도적으로 큰 독성이 없고 전립선암 세포를 선택적으로 제거하는데 효과적인 전립선암 치료제가 필요하다. 본 개시내용은 특정 실시양태에서 전립선암 치료에 유용한 PSMA 결합 단백질을 제공한다. 추가의 실시양태에서, 본 개시내용은 본원에서 설명되는 PSMA 결합 단백질을 사용한 면역요법에 의해 전립선암을 치료하는 방법을 제공한다.
전립선 특이 막 항원 스크리닝 방법은 많은 위양성과 관련되기 때문에, 전립선암 또한 진단하기가 어렵다. 따라서, 일부 실시양태에서, 본 개시내용은 본원에서 설명되는 PSMA 결합 단백질을 사용하여 전립선암을 검출하는 개선된 방법을 제공한다.
PSMA 결합 단백질
특정 실시양태에서, PSMA 단백질에 결합하는 항-PSMA 항체 또는 항체 변이체와 같은 결합 단백질이 본원에서 제공된다. 일부 실시양태에서, PSMA 단백질은 다량체이다. 본원에서 사용되는 PSMA 단백질 다량체는 적어도 2개의 PSMA 단백질 또는 이의 단편의 단백질 복합체이다. PSMA 단백질 다량체는 전장 PSMA 단백질(예를 들어, 서열 번호 20), 재조합 가용성 PSMA(rsPSMA, 예를 들어, 서열 번호 20의 아미노산 44-750) 및 다량체를 형성하는(즉, PSMA의 이량체 및/또는 고차 다량체를 형성하는데 필요한 단백질 도메인을 보유하는) 상기 단백질의 단편의 다양한 조합물로 이루어질 수 있다. 일부 실시양태에서, 다량체를 형성하는 PSMA 단백질 중 적어도 하나는 재조합, 가용성 PSMA(rsPSMA) 폴리펩티드이다. 일부 실시양태에서, PSMA 단백질 다량체는 재조합 가용성 PSMA 단백질로 형성된 것과 같은 이량체이다. 일부 실시양태에서, rsPSMA는 동종이량체이다. 특정 이론에 구속되지는 않지만, 본원에서 언급되는 PSMA 단백질 다량체는 천연 입체형태를 취하는 것으로 생각되며, 바람직하게는 그러한 입체형태를 갖는다. 특정 실시양태에서, PSMA 단백질은 함께 비공유 결합되어 PSMA 단백질 다량체를 형성한다. 예를 들어, 비변성 조건 하에서 PSMA 단백질이 비공유 회합하여 이량체를 형성한다는 것이 밝혀졌다. PSMA 단백질 다량체는 PSMA의 활성을 보유할 수 있고, 바람직하게는 보유한다. PSMA 단백질의 활성은 특정 실시양태에서, 엽산 히드롤라제 활성, NAALADase 활성, 디펩티딜 펩티다제 IV 활성 및 γ-글루타밀 히드롤라제 활성과 같은 효소 활성이다. 다량체의 PSMA 활성을 시험하는 방법은 관련 기술 분야에 공지되어 있다(예를 들어, 문헌 [O'Keefe et al. in: Prostate Cancer: Biology, Genetics, and the New Therapeutics, L. W. K. Chung, W. B. Isaacs and J. W. Simons (eds.) Humana Press, Totowa, N.J., 2000, pp. 307-326] 참조).
일부 실시양태에서, PSMA 단백질 또는 PSMA 단백질 다량체에 결합하는 본 개시내용의 결합 단백질은 PSMA 단백질 또는 PSMA 단백질 다량체의 효소 활성을 조절한다. 일부 실시양태에서, PSMA 결합 단백질은 NAALADase 활성, 엽산 히드롤라제 활성, 디펩티딜 디펩티다제 IV 활성, γ-글루타밀 히드롤라제 활성 또는 이들의 조합물과 같은 적어도 하나의 효소 활성을 억제한다. 다른 실시양태에서, PSMA 결합 단백질은 NAALADase 활성, 엽산 히드롤라제 활성, 디펩티딜 디펩티다제 IV 활성, γ-글루타밀 히드롤라제 활성 또는 이들의 조합물과 같은 적어도 하나의 효소 활성을 향상시킨다.
본원에서 사용되는 바와 같이, 용어 "항체 변이체"는 본원에서 설명되는 항체의 변이체 및 유도체를 지칭한다. 특정 실시양태에서, 본원에서 설명되는 항-PSMA 항체의 아미노산 서열 변이체가 고려된다. 예를 들어, 특정 실시양태에서, 본원에서 설명되는 항-PSMA 항체의 아미노산 서열 변이체는 항체의 결합 친화도 및/또는 다른 생물학적 성질을 개선하는 것으로 고려된다. 아미노산 변이체를 제조하는 예시적인 방법은 항체를 코딩하는 뉴클레오티드 서열에 적절한 변형을 도입하는 것, 또는 펩티드 합성을 포함하고 이로 제한되지 않는다. 그러한 변형은 예를 들어, 항체의 아미노산 서열 내의 잔기의 결실 및/또는 삽입 및/또는 치환을 포함한다.
결실, 삽입 및 치환의 임의의 조합은 최종 구축물이 원하는 특징, 예를 들어 항원 결합을 보유한다면, 최종 구축물에 도입될 수 있다. 특정 실시양태에서, 하나 이상의 아미노산 치환을 갖는 항체 변이체가 제공된다. 치환 돌연변이 유발을 위한 관심 부위는 CDR 및 프레임워크 영역을 포함한다. 그러한 치환의 예는 아래에서 설명된다. 아미노산 치환은 관심 항체에 도입될 수 있으며, 원하는 활성, 예를 들어 항원 결합의 유지/개선, 면역원성의 감소 또는 항체 의존성 세포 매개 세포독성(ADCC) 또는 보체 의존성 세포독성(CDC)의 개선에 대해 스크리닝될 수 있다. 보존적 및 비보존적 아미노산 치환 둘 모두가 항체 변이체의 제조를 위해 고려된다.
변이체 항-PSMA 항체를 생성하기 위한 치환의 또 다른 예에서, 모 항체의 하나 이상의 초가변 영역 잔기가 치환된다. 일반적으로, 변이체는 모 항체와 비교하여 원하는 특성의 개선, 예를 들어 증가된 친화도, 감소된 친화도, 감소된 면역원성, 결합의 증가된 pH 의존성을 기초로 하여 선택된다. 예를 들어, 친화도 성숙 변이체 항체는 예를 들어, 본원에 설명되고 관련 기술 분야에서 공지된 것과 같은 파지 디스플레이 기반 친화도 성숙 기술을 사용하여 생성될 수 있다.
치환은 변이체를 생성하기 위해 모 항-PSMA 항체의 초가변 영역(HVR)에서 이루어질 수 있고, 이어서 변이체는 결합 친화도에 기초하여, 즉 친화도 성숙에 의해 선택된다. 친화도 성숙의 일부 실시양태에서, 다양성은 다양한 방법(예를 들어, 오류 빈발 PCR, 사슬 셔플링 또는 올리고뉴클레오티드 유도 돌연변이 유발) 중 임의의 방법에 의해 성숙을 위해 선택된 가변 유전자 내에 도입된다. 이에 의해, 2차 라이브러리가 생성된다. 이어서, 라이브러리를 스크리닝하여 원하는 친화도를 갖는 임의의 항체 변이체를 확인한다. 다양성을 도입하기 위한 또 다른 방법은 여러 HVR 잔기(예를 들어, 한 번에 4-6개의 잔기)가 무작위로 선발되는 HVR 유도 접근법을 포함한다. 항원 결합과 관련된 HVR 잔기는 예를 들어, 알라닌 스캐닝 돌연변이 유발 또는 모델링을 사용하여 특이적으로 확인될 수 있다. 치환은 모 항체 서열 내의 1, 2, 3, 4개 또는 그 초과의 부위에서 이루어질 수 있다.
일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질은 PSMA에 특이적인 단일 도메인 항체, 예컨대 중쇄 가변 도메인(VH), 낙타과 유래 sdAb의 가변 도메인(VHH), 펩티드, 리간드 또는 소분자 물질이다. 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질의 PSMA 결합 도메인은 모노클로날 항체, 폴리클로날 항체, 재조합 항체, 인간 항체, 인간화 항체로부터의 도메인을 포함하고 이로 제한되지 않는, PSMA에 결합하는 임의의 도메인이다. 특정 실시양태에서, PSMA 결합 단백질은 단일 도메인 항체이다. 다른 실시양태에서, PSMA 결합 단백질은 펩티드이다. 추가의 실시양태에서, PSMA 결합 단백질은 소분자이다.
일반적으로, 본 명세서에서 가장 넓은 의미로 사용되는 용어 단일 도메인 항체는 특정 생물학적 공급원 또는 특정 제조 방법으로 한정되지 않는다는 것을 알아야 한다. 예를 들어, 일부 실시양태에서, 본 개시내용의 단일 도메인 항체는 (1) 자연 발생 중쇄 항체의 VHH 도메인의 단리에 의해; (2) 자연 발생 VHH 도메인을 코딩하는 뉴클레오티드 서열의 발현에 의해; (3) 자연 발생 VHH 도메인의 "인간화" 또는 이러한 인간화 VHH 도메인을 코딩하는 핵산의 발현에 의해; (4) 임의의 동물 종으로부터, 특히 포유동물의 종으로부터, 예컨대 인간으로부터의 자연 발생 VH 도메인의 "낙타화(camelization)" 또는 이러한 낙타화 VH 도메인을 코딩하는 핵산의 발현에 의해; (5) "도메인 항체" 또는 "Dab"의 "낙타화" 또는 이러한 낙타화된 VH 도메인을 코딩하는 핵산의 발현에 의해; (6) 단백질, 폴리펩티드 또는 다른 아미노산 서열을 제조하기 위한 합성 또는 반합성 기술을 사용하여; (7) 관련 기술 분야에 공지된 핵산 합성 기술을 사용하여 단일 도메인 항체를 코딩하는 핵산의 제조, 이어서 이렇게 수득된 핵산의 발현에 의해; 및/또는 (8) 상기한 것 중 하나 이상의 임의의 조합에 의해 수득된다.
한 실시양태에서, 단일 도메인 항체는 PSMA에 대해 작용하는 자연 발생 중쇄 항체의 VHH 도메인에 상응한다. 본원에서 추가로 설명되는 바와 같이, 이러한 VHH 서열은 일반적으로 낙타과의 종을 PSMA로 적합하게 면역화함으로써(즉, PSMA에 대한 면역 반응 및/또는 중쇄 항체를 유도하기 위해), 상기 낙타과로부터 적합한 샘플(예를 들어, 혈액 샘플, 혈청 샘플 또는 B 세포의 샘플)을 수득함으로써, 및 관련 기술 분야에 공지된 임의의 적절한 기술을 사용하여 상기 샘플로부터 시작하여 PSMA에 대해 작용하는 VHH 서열을 생성함으로써 생성되거나 수득될 수 있다.
또 다른 실시양태에서, PSMA에 대한 상기 자연 발생 VHH 도메인은 예를 들어 관련 기술 분야에 공지된 하나 이상의 스크리닝 기술을 사용하여 PSMA, 또는 그의 하나 이상의 부분, 단편, 항원 결정자 또는 에피토프를 사용하여 상기 라이브러리를 스크리닝함으로써 낙타과 VHH 서열의 나이브 라이브러리로부터 수득된다. 이러한 라이브러리 및 기술은 예를 들어 WO 99/37681, WO 01/90190, WO 03/025020 및 WO 03/035694에 기술되어 있다. 대안적으로, 나이브 VHH 라이브러리로부터 유도된 개선된 합성 또는 반합성 라이브러리, 예를 들어 WO 00/43507에 기재된 바와 같이, 무작위 돌연변이 유발 및/또는 CDR 셔플링과 같은 기술에 의해 나이브 VHH 라이브러리로부터 수득된 VHH 라이브러리가 사용된다.
추가의 실시양태에서, PSMA에 대해 작용하는 VHH 서열을 수득하기 위한 또 다른 기술은 중쇄 항체를 발현할 수 있는 트랜스제닉 포유동물을 적합하게 면역화하고(즉, PSMA에 대한 면역 반응 및/또는 중쇄 항체를 유도하기 위해), 상기 트랜스제닉 포유동물로부터 적합한 생물학적 샘플(예를 들어, 혈액 샘플, 혈청 샘플 또는 B 세포의 샘플)을 수득한 후, 관련 기술 분야에 공지된 임의의 적절한 기술을 사용하여 상기 샘플로부터 시작하여 PSMA에 대해 작용하는 VHH 서열을 생성하는 것을 수반한다. 예를 들어, 이를 위해, 중쇄 항체 발현 래트 또는 마우스, 및 WO 02/085945 및 WO 04/049794에 기술된 추가의 방법 및 기술이 사용될 수 있다.
일부 실시양태에서, 본원에서 설명되는 단일 도메인 PSMA 항체는 자연 발생 VHH 도메인의 아미노산 서열에 상응하지만, 상기 자연 발생 VHH 서열(및 특히 프레임워크 서열)의 아미노산 서열 내의 하나 이상의 아미노산 잔기를 인간에서 유래한 통상적인 4개 사슬의 항체(예를 들어, 상기 나타낸 바와 같음)로부터의 VH 도메인 내의 상응하는 위치(들)에서 발생하는 하나 이상의 아미노산 잔기에 의해 대체함으로써 "인간화"된 아미노산 서열을 갖는 단일 도메인 항체를 포함한다. 이것은 관련 기술 분야에 공지된 방식으로 수행될 수 있으며, 이것은 예를 들어 본 명세서의 추가의 설명에 기초하여 통상의 기술자에게 명백할 것이다. 다시, 본 개시내용의 그러한 인간화된 항-PSMA 단일 도메인 항체는 그 자체로 공지된 임의의 적합한 방식으로(즉, 상기 (1)-(8)에 나타낸 바와 같이) 얻어지고, 따라서 출발 물질로서 자연 발생 VHH 도메인을 포함하는 폴리펩티드를 사용하여 수득한 폴리펩티드로 엄격하게 제한되지 않음에 유의하여야 한다. 일부 추가의 실시양태에서, 본원에서 설명되는 단일 도메인 PSMA 항체는 자연 발생 VH 도메인의 아미노산 서열에 상응하지만, 통상적인 4개 사슬의 항체로부터의 자연 발생 VH 서열의 아미노산 서열 내의 하나 이상의 아미노산 잔기를 중쇄의 VHH 도메인 내의 상응하는 위치(들)에서 발생하는 하나 이상의 아미노산 잔기에 의해 대체함으로써 "낙타화"된 아미노산 서열을 갖는 단일 도메인 항체를 포함한다. 이러한 "낙타화" 치환은 바람직하게는 VH-VL 계면을 형성하거나 이 계면에 존재하는 아미노산 위치에 및/또는 소위 낙타과의 특징적 잔기에 삽입된다(예를 들어, WO 94/04678 및 문헌 [Davies and Riechmann (1994 and 1996)] 참조). 바람직하게는, 낙타화 단일 도메인을 생성 또는 설계하기 위한 출발 물질 또는 출발점으로 사용되는 VH 서열은 바람직하게는 포유동물로부터의 VH 서열, 보다 바람직하게는 VH3 서열과 같은 인간의 VH 서열이다. 그러나, 특정 실시양태에서, 본 개시내용의 상기 낙타화 항-PSMA 단일 도메인 항체는 관련 기술 분야에 공지된 임의의 적합한 방식으로(즉, 상기 (1)-(8)에 나타낸 바와 같이) 얻어지고, 따라서 출발 물질로서 자연 발생 VH 도메인을 포함하는 폴리펩티드를 사용하여 수득한 폴리펩티드로 엄격하게 제한되지 않음에 유의하여야 한다. 예를 들어, 본 명세서에서 추가로 설명되는 바와 같이, "인간화" 및 "낙타화"는 각각 자연 발생 VHH 도메인 또는 VH 도메인을 코딩하는 뉴클레오티드 서열을 제공하고, 새로운 뉴클레오티드 서열이 각각 "인간화된" 또는 "낙타화된" 단일 도메인 항체를 코딩하는 방식으로 상기 뉴클레오티드 서열에 하나 이상의 코돈을 변경함으로써 수행된다. 이어서, 이 핵산을 발현시켜 본 개시내용의 목적하는 항-PSMA 단일 도메인 항체를 제공할 수 있다. 대안적으로, 다른 실시양태에서, 각각 자연 발생 VHH 도메인 또는 VH 도메인의 아미노산 서열에 기초하여, 본 개시내용의 목적하는 인간화 또는 낙타화 항-PSMA 단일 도메인 항체의 아미노산 서열이 설계된 후, 펩티드 합성을 위해 공지된 기술을 사용하여 새롭게 합성된다. 일부 실시양태에서, 각각 자연 발생 VHH 도메인 또는 VH 도메인의 아미노산 서열 또는 뉴클레오티드 서열에 기초하여, 각각 본 개시내용의 목적하는 인간화 또는 낙타화된 항-PSMA 단일 도메인 항체를 코딩하는 뉴클레오티드 서열이 설계된 후, 핵산 합성을 위해 공지된 기술을 사용하여 새롭게 합성되고, 이어서 이와 같이 수득된 핵산은 본 개시내용의 목적하는 인간화 또는 낙타화된 항-PSMA 단일 도메인 항체를 제공하기 위해 공지된 발현 기술을 사용하여 발현된다.
자연 발생 VH 서열 또는 VHH 서열로부터 출발하여 본 개시내용의 항-PSMA 단일 도메인 항체 및/또는 이를 코딩하는 핵산을 수득하기 위한 다른 적합한 방법 및 기술은 예를 들어 본 개시내용의 항-PSMA 단일 도메인 항체 또는 이를 코딩하는 뉴클레오티드 서열 또는 핵산을 제공하기 위해 하나 이상의 자연 발생 VH 서열의 하나 이상의 부분(예를 들어, 하나 이상의 프레임워크(FR) 서열 및/또는 상보성 결정 영역(CDR) 서열), 하나 이상의 자연 발생 VHH 서열의 하나 이상의 부분(예를 들어, 하나 이상의 FR 서열 또는 CDR 서열) 및/또는 하나 이상의 합성 또는 반합성 서열을 적절한 방식으로 조합하는 단계를 포함한다.
일부 실시양태에서, PSMA 결합 단백질은 상당히 작고, 일부 실시양태에서 25 kD 이하, 20 kD 이하, 15 kD 이하 또는 10 kD 이하인 것으로 고려된다. 특정 예에서, PSMA 결합 단백질은 펩티드 또는 소분자 물질인 경우 5 kD 이하이다.
일부 실시양태에서, PSMA 결합 단백질은 중쇄 가변 상보성 결정 영역(CDR), CDR1, 중쇄 가변 CDR2, 중쇄 가변 CDR3, 경쇄 가변 CDR1, 경쇄 가변 CDR2 및 경쇄 가변 CDR3을 포함하는 항-PSMA 특이적 항체이다. 일부 실시양태에서, PSMA 결합 단백질은 모노클로날 항체, 폴리클로날 항체, 재조합 항체, 인간 항체, 인간화 항체, 또는 항원 결합 단편, 예컨대 단일 도메인 항체(sdAb), Fab, Fab', F(ab)2, 및 Fv 단편, 하나 이상의 CDR을 포함하는 단편, 단일쇄 항체(예를 들어, 단일쇄 Fv 단편(scFv), 디술피드 안정화된(dsFv) Fv 단편, 이종접합체 항체(예를 들어, 이중 특이적 항체), pFv 단편, 중쇄 단량체 또는 이량체, 경쇄 단량체 또는 이량체, 및 하나의 중쇄 및 하나의 경쇄로 이루어진 이량체로부터의 도메인을 포함하고 이로 제한되지 않는, PSMA에 결합하는 임의의 도메인을 포함한다. 일부 경우에, PSMA 결합 도메인은 본원에서 설명되는 PSMA 결합 단백질이 궁극적으로 사용될 종과 동일한 종으로부터 유래되는 것이 유익하다. 예를 들어, 인간에서 사용하기 위해, PSMA 결합 단백질의 PSMA 결합 도메인은 항체 또는 항체 단편의 항원 결합 도메인으로부터의 인간 또는 인간화 잔기를 포함하는 것이 유익할 수 있다. 일부 실시양태에서, PSMA 결합 단백질은 중쇄 가변 CDR1, 중쇄 가변 CDR2 및 중쇄 가변 CDR3을 포함하는 항-PSMA 특이적 결합 단백질이다. 일부 실시양태에서, PSMA 결합 단백질은 중쇄 가변 CDR1, 중쇄 가변 CDR2 및 중쇄 가변 CDR3을 포함하는 항-PSMA 단일 도메인 항체이다.
일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 다음 식으로 표시되는 바와 같이 3개의 상보성 결정 영역/서열에 의해 차단된 4개의 프레임워크 영역/서열(f1-f4)로 이루어진 아미노산 서열을 포함하는 폴리펩티드이다: f1-r1-f2-r2-f3-r3-f4(여기서, r1, r2 및 r3은 각각 상보성 결정 영역 CDR1, CDR2 및 CDR3이고, f1, f2, f3 및 f4는 프레임워크 잔기이다. 본 개시내용의 PSMA 결합 단백질의 프레임워크 잔기는 예를 들어 75, 76, 77, 78, 79, 80, 81개의 아미노산 잔기를 포함하고, 상보성 결정 영역은 예를 들어 30, 31, 32, 33, 34, 35, 36개의 아미노산 잔기를 포함한다. 일부 실시양태에서, PSMA 결합 단백질은 프레임워크 잔기 및 CDR1, CDR2 및 CDR3을 포함하는 서열 번호 4에 제시된 아미노산 서열을 포함하고, 여기서 (a) CDR1은 서열 번호 16에 제시된 아미노산 서열 또는 서열 번호 16에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하고, (b) CDR2는 서열 번호 17에 제시된 서열 또는 서열 번호 17에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하고, (c) CDR3은 서열 번호 18에 제시된 서열 또는 서열 번호 18에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함한다.
일부 실시양태에서, PSMA 결합 단백질은 프레임워크 잔기 및 CDR1, CDR2 및 CDR3을 포함하는 서열 번호 19에 제시된 아미노산 서열을 포함하고, 여기서 (a) CDR1은 서열 번호 16에 제시된 아미노산 서열 또는 서열 번호 16에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하고, (b) CDR2는 서열 번호 17에 제시된 서열 또는 서열 번호 17에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하고, (c) CDR3은 서열 번호 18에 제시된 서열 또는 서열 번호 18에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함한다.
PSMA 결합 단백질의 CDR1이 서열 번호 16에 제시된 아미노산 서열 또는 서열 번호 16에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하는 실시양태에서, 상기 치환은 예를 들어 프롤린, 히스티딘을 포함한다. PSMA 결합 단백질의 CDR2가 서열 번호 17에 제시된 아미노산 서열 또는 서열 번호 17에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하는 실시양태에서, 상기 치환은 예를 들어 아스파르트산, 리신, 글루타민, 티로신을 포함한다.
PSMA 결합 단백질의 CDR3이 서열 번호 18에 제시된 아미노산 서열 또는 서열 번호 18에 1, 2, 3 또는 4개의 아미노산 치환을 갖는 변이체를 포함하는 실시양태에서, 상기 치환은 예를 들어 세린을 포함한다.
일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 식 f1-r1-f2-r2-f3-r3-f4로 표시되고, 여기서, r1, r2 및 r3은 각각 상보성 결정 영역 CDR1, CDR2 및 CDR3이고, f1, f2, f3 및 f4는 프레임워크 잔기이고, r1은 서열 번호 5, 서열 번호 6 또는 서열 번호 7을 포함하고, r2는 서열 번호 8, 서열 번호 9, 서열 번호 10, 서열 번호 11, 서열 번호 12, 서열 번호 13 또는 서열 번호 14를 포함하고, r3은 서열 번호 15를 포함한다. 일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 식 f1-r1-f2-r2-f3-r3-f4로 표시되고, 여기서, r1, r2 및 r3은 각각 상보성 결정 영역 CDR1, CDR2 및 CDR3이고, f1, f2, f3 및 f4는 프레임워크 잔기이고, r1은 서열 번호 5, 서열 번호 6, 또는 서열 번호 7이고, r2는 서열 번호 8, 서열 번호 9, 서열 번호 10, 서열 번호 11, 서열 번호 12, 서열 번호 13 또는 서열 번호 14이고, r3은 서열 번호 15이다.
일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 17에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 18에 제시된 바와 같다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 16에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 18에 제시된 바와 같다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 16에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 17에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 18에 제시된 바와 같다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 17에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 16에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같다.
일부 실시양태에서, 아미노산 잔기 X1, X2, X3, X4, X5, X6 및 X7은 독립적으로 글루탐산, 프롤린, 세린, 히스티딘, 트레오닌, 아스파르트산, 글리신, 리신, 트레오닌, 글루타민 및 티로신으로부터 선택된다. 일부 실시양태에서, X1은 프롤린이다. 일부 실시양태에서, X2는 히스티딘이다. 일부 실시양태에서, X3은 아스파르트산이다. 일부 실시양태에서, X4는 리신이다. 일부 실시양태에서, X5는 글루타민이다. 일부 실시양태에서, X6은 티로신이다. 일부 실시양태에서, X7은 세린이다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고 X2가 히스티딘이고, X3이 아스파르트산이고, X4가 글리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함한다.
일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X1은 프롤린이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X5는 글루타민이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X6은 티로신이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X4는 리신이고, X7은 세린이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X2는 히스티딘이고, X3은 아스파르트산이고, X4는 리신이고, X7은 세린이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X1은 프롤린이고, X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X2는 히스티딘이고, X3은 아스파르트산이고, X5는 글루타민이고, X7은 세린이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X2는 히스티딘이고, X3은 아스파르트산이고, X6은 티로신이고, X7은 세린이다. 일부 실시양태에서, PSMA 결합 단백질은 CDR1, CDR2 및 CDR3을 포함하며, 여기서 (a) CDR1의 아미노산 서열은 서열 번호 1(RFMISX1YX2MH)에 제시된 바와 같고; (b) CDR2의 아미노산 서열은 서열 번호 2(X3INPAX4X5TDYAEX6VKG)에 제시된 바와 같고; (c) CDR3의 아미노산 서열은 서열 번호 3(DX7YGY)에 제시된 바와 같고, X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이다.
본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고 X2가 히스티딘이고, X3이 아스파르트산이고, X4가 글리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고 X2가 히스티딘이고, X3이 트레오닌이고, X4가 글리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고 X2가 세린이고, X3이 트레오닌이고, X4가 리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 프롤린이고 X2가 세린이고, X3이 트레오닌이고, X4가 글리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 글리신인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고 X2가 세린이고, X3이 트레오닌이고, X4가 글리신이고, X5가 글루타민이고, X6이 세린이고, X7이 글리신인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고, X2가 세린이고, X3이 트레오닌이고, X4가 글리신이고, X5가 트레오닌이고, X6이 티로신이고, X7이 글리신인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고, X2가 히스티딘이고, X3이 아스파르트산이고, X4가 리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 프롤린이고, X2가 히스티딘이고, X3이 아스파르트산이고, X4가 글리신이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고, X2가 히스티딘이고, X3이 아스파르트산이고, X4가 글루타민이고, X5가 트레오닌이고, X6이 세린이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X1이 글루탐산이고, X2가 히스티딘이고, X3이 아스파르트산이고, X4가 글리신이고, X5가 트레오닌이고, X6이 티로신이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 X2가 히스티딘이고, X7이 세린인 CDR1, CDR2 및 CDR3 서열을 포함할 수 있다. 예시적인 프레임워크 서열은 서열 번호 165-168로서 개시된다.
일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 다음 중 임의의 조합을 포함한다: (i) X1은 프롤린이고; (ii) X2는 히스티딘이고; (iii) X3은 아스파르트산이고; (iv) X4는 리신이고; (v) X5는 글루타민이고; (vi) X6은 티로신이고; (vii) X7은 세린이다. 일부 실시양태에서, 상기 실시양태의 전립선 특이 막 항원 결합 단백질은 서열 번호 4로 제시된 서열을 갖는 결합 단백질보다 인간 전립선 특이 막 항원에 대해 더 높은 친화도를 갖는다. 일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 다음 중 임의의 조합을 포함한다: (i) X1은 프롤린이고 X5는 글루타민이고; (ii) X6은 티로신이고 X4는 리신이고 X7은 세린이고; (iii) X2는 히스티딘이고 X3은 아스파르트산이고 X4는 리신이고 X7은 세린이고; (iv) X1은 프롤린이고 X2는 히스티딘이고 X3은 아스파르트산이고 X7은 세린이고; (v) X2는 히스티딘이고 X3은 아스파르트산이고 X5는 글루타민이고 X7은 세린이고; (vi) X2는 히스티딘이고 X3은 아스파르트산이고 X4는 리신이고 X7은 세린이고; (vii) X1은 프롤린이고 X2는 히스티딘이고 X3은 아스파르트산이고 X7은 세린이고; (viii) X2는 히스티딘이고 X3은 아스파르트산이고 X5는 글루타민이고 X7은 세린이고; (ix) X2는 히스티딘이고 X3은 아스파르트산이고 X6은 티로신이고 X7은 세린이고; (x) X2는 히스티딘이고 X3은 아스파르트산이고 X7은 세린이다.
일부 실시양태에서, PSMA 결합 단백질은 서열 번호 4에 제시된 아미노산 서열을 갖는다. 일부 실시양태에서, PSMA 결합 단백질은 하나 이상의 아미노산 위치가 치환된 서열 번호 4로 제시된 아미노산 서열을 갖는다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 19, 86, 87 및 106 중 하나 이상의 위치가 치환된다. 아미노산 위치 19, 86, 87 및 106에서의 예시적인 치환은 T19R, K86R, P87A 및 Q106L을 포함하고 이로 제한되지 않는다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 31, 33, 50, 55, 56, 62 및 97 중 하나 이상의 위치가 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 31은 E31P로 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33은 S33H로 치환된다. 일부 실시양에서, 서열 번호 4의 아미노산 위치 50은 T50D로 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 55는 G55K로 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 56은 T56Q로 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 62는 S62Y로 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 97은 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33은 S33H로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 31에서의 치환은 위치 50 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 31, 50 및 97은 각각 E31P, T50D 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33 및 97은 각각 S33H 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 50 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33, 50 및 97은 각각 S33H, T50D 및 G97S. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 50, 55 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33, 50, 55 및 97은 각각 S33H, T50D, G55K 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 31, 50 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 31, 33, 50 및 97은 각각 E31P, S33H, T50D, 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 50, 56 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33, 50, 56 및 97은 각각 S33H, T50D, T56Q 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 50, 62 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33, 50, 62 및 97은 각각 S33H, T50D, S62Y 및 G97S로 치환된다.
일부 실시양태에서, PSMA 결합 단백질은 서열 번호 19에 제시된 아미노산 서열을 갖는다. 일부 실시양태에서, PSMA 결합 단백질은 하나 이상의 아미노산 위치가 치환된 서열 번호 19에 제시된 아미노산 서열을 갖는다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 31, 33, 50, 55, 56, 62 및 97 중 하나 이상의 위치가 치환된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 31은 E31P로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 33은 S33H로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 50은 T50D로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 55는 G55K로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 56은 T56Q로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 62는 S62Y로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 97은 G97S로 치환된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 33은 S33H로 치환된다. 일부 실시양태에서, 서열 번호 19의 위치 31에서의 치환은 위치 50 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 31, 50 및 97은 각각 E31P, T50D 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 19의 위치 33에서의 치환은 위치 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 33 및 97은 각각 S33H 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 19의 위치 33에서의 치환은 위치 50 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 33, 50 및 97은 각각 S33H, T50D 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 19의 위치 33에서의 치환은 위치 50, 55 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 33, 50, 55 및 97은 각각 S33H, T50D, G55K 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 19의 위치 33에서의 치환은 위치 31, 50 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 31, 33, 50 및 97은 각각 E31P, S33H, T50D 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 19의 위치 33에서의 치환은 위치 50, 56 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 19의 아미노산 위치 33, 50, 56 및 97은 각각 S33H, T50D, T56Q 및 G97S로 치환된다. 일부 실시양태에서, 서열 번호 4의 위치 33에서의 치환은 위치 50, 62 및 97에서의 치환과 조합된다. 일부 실시양태에서, 서열 번호 4의 아미노산 위치 33, 50, 62 및 97은 각각 S33H, T50D, S62Y 및 G97S로 치환된다.
일부 실시양태에서, 전립선 특이 막 항원 결합 단백질은 다음 중 임의의 조합을 포함한다: (i) 위치 31에서의 치환; (ii) 위치 50에서의 치환; (iii) 위치 55에서의 치환; 위치 56에서의 치환; (iv) 위치 62에서의 치환; (v) 위치 97에서의 치환; (vi) 위치 55 및 97에서의 치환; (vii) 위치 33 및 97에서의 치환; (viii) 위치 33, 50 및 97에서의 치환; (ix) 위치 31, 33, 50 및 97에서의 치환; (x) 위치 33, 50, 55 및 97에서의 치환; (xi) 위치 33, 50, 56 및 97에서의 치환; 및 (xiii) 위치 33, 50, 62 및 97에서의 치환.
일부 실시양태에서, PSMA 결합 단백질은 인간 및 시노몰거스 PSMA와 교차 반응성이다. 일부 실시양태에서, PSMA 결합 단백질은 인간 PSMA에 특이적이다. 다양한 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 4에 제시된 아미노산 서열에 대해 적어도 약 75%, 약 76%, 약 77%, 약 78%, 약 79%, 약 80%, 약 81%, 약 82%, 약 83%, 약 84%, 약 85%, 약 86%, 약 87%, 약 88%, 약 89%, 약 90%, 약 91%, 약 92%, 약 93%, 약 94%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100% 동일하다.
다양한 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 19에 제시된 아미노산 서열에 대해 적어도 약 75%, 약 76%, 약 77%, 약 78%, 약 79%, 약 80%, 약 81%, 약 82%, 약 83%, 약 84%, 약 85%, 약 86%, 약 87%, 약 88%, 약 89%, 약 90%, 약 91%, 약 92%, 약 93%, 약 94%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100% 동일하다.
다양한 실시양태에서, 본 개시내용의 PSMA 결합 단백질의 상보성 결정 영역은 서열 번호 16에 제시된 아미노산 서열에 대해 적어도 약 80%, 약 81%, 약 82%, 약 83%, 약 84%, 약 85%, 약 86%, 약 87%, 약 88%, 약 89%, 약 90%, 약 91%, 약 92%, 약 93%, 약 94%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100% 동일하다.
다양한 실시양태에서, 본 개시내용의 PSMA 결합 단백질의 상보성 결정 영역은 서열 번호 17에 제시된 아미노산 서열에 대해 적어도 약 75%, 약 76%, 약 77%, 약 78%, 약 79%, 약 80%, 약 81%, 약 82%, 약 83%, 약 84%, 약 85%, 약 86%, 약 87%, 약 88%, 약 89%, 약 90%, 약 91%, 약 92%, 약 93%, 약 94%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100% 동일하다.
다양한 실시양태에서, 본 개시내용의 PSMA 결합 단백질의 상보성 결정 영역은 서열 번호 18에 제시된 아미노산 서열에 대해 적어도 약 85%, 약 86%, 약 87%, 약 88%, 약 89%, 약 90%, 약 91%, 약 92%, 약 93%, 약 94%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 또는 약 100% 동일하다.
인간화 및 친화도 성숙
치료적 적용을 위한 결합 단백질을 설계함에 있어서, 예를 들어 표적의 기능적 활성을 조절하는 단백질, 및/또는 보다 높은 특이성 및/또는 친화도를 갖는 결합 단백질과 같은 개선된 결합 단백질 및/또는 보다 생물학적으로 이용 가능하거나, 또는 특정 세포 또는 조직 환경에서 안정하거나 가용성인 결합 단백질을 생성하는 것이 바람직하다.
본 개시내용에서 설명되는 PSMA 결합 단백질은 PSMA인 표적 결합 도메인에 대한 개선된 결합 친화도를 나타낸다. 본 개시내용은 인간 및 시노몰거스 PSMA 중 하나 또는 둘 모두에 대해 보다 높은 결합 친화도를 유도하는, 본원에서 설명되는 PSMA 결합 단백질의 상보성 결정 영역(CDR) 내의 아미노산 치환을 확인한다. 일부 실시양태에서, PSMA 결합 단백질은 항체이다. 특정 실시양태에서, PSMA 결합 단백질은 인간화 항체이다. 일반적으로, 인간화 항체는 CDR 또는 CDR의 일부가 비인간 항체로부터 유래되고 프레임워크 영역 또는 프레임워크 영역의 일부가 인간 항체 서열로부터 유래된 하나 이상의 가변 도메인을 포함한다. 선택적으로, 인간화 항체는 또한 인간 불변 영역의 적어도 일부를 포함한다. 일부 실시양태에서, 선택된 프레임워크 잔기는 예를 들어, 항체 특이성, 친화도 또는 pH 의존성을 회복 또는 개선하기 위해 비인간 항체(예를 들어, 그로부터 CDR이 유도되는 항체)로부터의 상응하는 잔기로 치환된다. 인간화를 위해 사용될 수 있는 인간 프레임워크 영역은 최적 맞춤(best-fit) 방법(예를 들어, Sims et al. J Immunol 151:2296, 1993)을 사용하여 선택된 프레임워크 영역; 경쇄 또는 중쇄 가변 영역의 특정 하위군의 인간 항체의 컨센서스 서열로부터 유도된 프레임워크 영역(예를 들어, Carter et al., Proc Natl Acad Sci USA, 89:4285, 1992; 및 Presta et al., J Immunol, 151:2623, 1993); 인간 성숙(체세포 돌연변이된) 프레임워크 영역 또는 인간 생식계열 프레임워크 영역(예를 들어, Almagro and Fransson, Front Biosci 13:1619-1633, 2008); 및 프레임워크 라이브러리 스크리닝으로부터 유도된 프레임워크 영역(예를 들어, Baca et al., J Biol Chem 272:10678-10684, 1997; 및 Rosok et al., J Biol Chem 271:22611-22618, 1996)을 포함하고 이로 제한되지 않는다. 따라서, 한 측면에서, PSMA 결합 단백질은 인간화 또는 인간 항체 또는 항체 단편을 포함한다. 한 실시양태에서, 인간화 또는 인간 항-PSMA 결합 단백질은 본원에서 설명되는 인간화 또는 인간 항-PSMA 결합 도메인의 하나 이상의(예를 들어, 3개의 모든) 경쇄 상보성 결정 영역 1(LC CDR1), 경쇄 상보성 결정 영역 2(LC CDR2) 및 경쇄 상보성 결정 영역 3(LC CDR3), 및/또는 본원에서 설명되는 인간화 또는 인간 항-PSMA 결합 도메인의 하나 이상의(예를 들어, 3개의 모든) 중쇄 상보성 결정 영역 1(HC CDR1), 중쇄 상보성 결정 영역 2(HC CDR2) 및 중쇄 상보성 결정 영역 3(HC CDR3), 예를 들어 하나 이상의, 예를 들어 3개의 모든 LC CDR 및 하나 이상의, 예를 들어 3개의 모든 HC CDR을 포함하는 인간화 또는 인간 항-PSMA 결합 도메인을 포함한다. 일부 실시양태에서, 인간화 또는 인간 항-PSMA 결합 도메인은 PSMA에 특이적인 인간화 또는 인간 경쇄 가변 영역을 포함하며, 여기서 PSMA에 특이적인 경쇄 가변 영역은 인간 경쇄 프레임워크 영역에 인간 또는 비인간 경쇄 CDR을 포함한다. 특정 예에서, 경쇄 프레임워크 영역은 λ(람다) 경쇄 프레임워크이다. 다른 예에서, 경쇄 프레임워크 영역은 κ(카파) 경쇄 프레임워크이다. 일부 실시양태에서, 인간화 또는 인간 항-PSMA 결합 도메인은 PSMA에 특이적인 인간화 또는 인간 중쇄 가변 영역을 포함하며, 여기서 PSMA에 특이적인 중쇄 가변 영역은 인간 중쇄 프레임워크 영역에 인간 또는 비인간 중쇄 CDR을 포함한다. 특정 경우에, 중쇄 및/또는 경쇄의 상보성 결정 영역은 예를 들어 7E11, EPR6253, 107.1A4, GCP-05, EP3253, BV9, SP29, 인간 PSMA/FOLH1/NAALADase I 항체와 같은 공지된 항-PSMA 항체로부터 유래된다.
본 개시내용의 PSMA 결합 단백질은 일부 실시양태에서 표적 결합 도메인에 대한 그의 결합 친화도를 증가시키도록 친화도 성숙된다. 하나 이상의 상기 언급된 CDR을 함유하는 항-PSMA 항체와 같은 본 개시내용의 PSMA 결합 단백질의 친화도를 개선하는 것이 요구되는 경우, 개선된 친화도를 갖는 그러한 항체는 CDR 유지, 사슬 셔플링, 이. 콜라이(E. coli)의 돌연변이 균주의 사용, DNA 셔플링, 파지 디스플레이 및 생식을 포함하고 이로 제한되지 않는 다수의 친화도 성숙 프로토콜에 의해 수득될 수 있다. 상기 친화도 성숙의 예시적인 방법은 문헌 [Vaughan et al. Nature Biotechnology, 16, 535-539, 1998]에 논의되어 있다. 따라서, 상기 섹션에서 논의된 PSMA 결합 단백질 변이체 이외에, 본 개시내용은 그의 표적, 즉 PSMA에 대한 결합 단백질의 친화도를 개선시키는 추가의 서열 변이체를 제공한다. 특정 실시양태에서, 이러한 서열 변이체는 PSMA 결합 단백질 서열 내에 하나 이상의 반보존적 또는 보존적 치환을 포함하고, 이러한 치환은 바람직하게는 결합 단백질의 목적하는 활성에 유의한 영향을 미치지 않는다. 치환은 자연 발생적이거나 또는 돌연변이 유발을 사용하여 도입될 수 있다(예를 들어, Hutchinson et al., 1978, J. Biol. Chem. 253:6551). 예를 들어, 아미노산 글리신, 알라닌, 발린, 류신 및 이소류신은 종종 서로 치환될 수 있다(지방족 측쇄를 갖는 아미노산). 이러한 가능한 치환 중, 전형적으로 글리신 및 알라닌이 상대적으로 짧은 측쇄를 갖기 때문에 서로 치환하기 위해 사용되고, 발린, 류신 및 이소류신은 소수성인 보다 큰 지방족 측쇄를 갖기 때문에 서로 치환하기 위해 사용된다. 서로 종종 치환될 수 있는 다른 아미노산은 다음을 포함하고 이로 제한되지 않는다: 페닐알라닌, 티로신 및 트립토판(방향족 측쇄를 갖는 아미노산); 리신, 아르기닌 및 히스티딘(염기성 측쇄를 갖는 아미노산); 아스파르테이트 및 글루타메이트(산성 측쇄를 갖는 아미노산); 아스파라긴 및 글루타민(아미드 측쇄를 갖는 아미노산); 및 시스테인 및 메티오닌(황 함유 측쇄를 갖는 아미노산).
일부 실시양태에서, PSMA 결합 단백질은 조합 라이브러리를 스크리닝함으로써, 예를 들어, 파지 디스플레이 라이브러리를 생성하고 원하는 결합 특성을 갖는 항체에 대해 그러한 라이브러리를 스크리닝함으로써 단리될 수 있다. 또한, 그의 결합 표적에 대한 PSMA 결합 단백질의 결합 친화도는 특정 PSMA 알부민 결합 단백질에서의 특정 제거 반감기를 표적화하도록 선택될 수 있다. 따라서, 일부 실시양태에서, PSMA 결합 단백질은 그의 결합 표적에 대해 높은 결합 친화도를 갖는다. 다른 실시양태에서, PSMA 결합 단백질은 그의 결합 표적에 대해 중간 결합 친화도를 갖는다. 또 다른 실시양태에서, PSMA 결합 단백질은 그의 결합 표적에 대해 낮은 또는 미미한 결합 친화도를 갖는다. 예시적인 결합 친화도는 10 nM 이하(고), 10 nM 내지 100 nM(중) 및 100 nM 초과(저)의 Kd를 포함한다. PSMA에 결합하는 친화도는 결합 단백질 자체 또는 그의 PSMA 결합 도메인이 예를 들어 검정 플레이트 상에 코팅된, 미생물 세포 표면에 제시된, 용액 내 등에 존재하는 PSMA에 결합하는 능력에 의해 결정될 수 있다. 본 개시내용의 단백질의 PSMA에 대한 결합 활성은 또한 리간드(예를 들어, PSMA) 또는 상기 결합 단백질 자체 또는 그의 PSMA 결합 도메인을 비드, 기질, 세포 등에 고정함으로써 검정할 수 있다. 일부 실시양태에서, PSMA 결합 단백질 자체 또는 그의 PSMA 결합 도메인과 표적 리간드(예를 들어, PSMA) 사이의 결합은 예를 들어 결합 동역학 검정에 의해 결정된다. 특정 실시양태에서 결합 동역학 검정은 OCTET® 시스템을 사용하여 수행된다. 이러한 실시양태에서, 제1 단계는 리간드(예를 들어, 비오티닐화된 PSMA)를 바이오센서(예를 들어, 스트렙타비딘 바이오센서)의 표면 상에 최적 로딩 밀도로 고정한 후, 검정 버퍼로 세척하여 미결합 리간드를 제거하고, 분석물, 즉 PSMA 결합 단백질 자체 또는 그의 PSMA 결합 도메인과 리간드를 회합시킨 후, 바이오센서를 분석물을 함유하지 않는 버퍼에 노출시켜 PSMA 결합 단백질 자체 또는 그의 PSMA 결합 도메인을 리간드로부터 해리시키는 것을 포함한다. BSA, 카제인, Tween-20, PEG, 젤라틴과 같은 적절한 차단제는 바이오센서 상의 비특이적 결합 부위를 차단하기 위해 사용된다. 이어서, PSMA 결합 단백질 자체 또는 그의 PSMA 결합 도메인과 리간드 사이의 결합 상호작용에 대한 회합 및 해리 속도 상수를 결정하기 위해 적절한 소프트웨어(예를 들어, ForteBio의 Octet 소프트웨어)를 사용하여 결합 동역학 데이터를 분석한다.
특정 실시양태에서, 본원에서 개시되는 PSMA 결합 단백질은 인간 PSMA에 인간 Kd(hKd)로 결합한다. 특정 실시양태에서, 본원에서 개시되는 PSMA 결합 단백질은 시노몰거스 PSMA에 시노몰거스 Kd(cKd)로 결합한다. 특정 실시양태에서, 본원에서 개시되는 PSMA 결합 단백질은 시노몰거스 PSMA에 시노몰거스 Kd(cKd)로 및 인간 PSMA에 인간 Kd(hKd)로 결합한다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 500 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 450 nM 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 400 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 350 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 300 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 250 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 200 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 150 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 100 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.1 nM 내지 약 90 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.2 nM 내지 약 80 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.3 nM 내지 약 70 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.4 nM 내지 약 50 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.5 nM 내지 약 30 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.6 nM 내지 약 10 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.7 nM 내지 약 8 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.8 nM 내지 약 6 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 0.9 nM 내지 약 4 nM의 범위이다. 일부 실시양태에서, hKd 및 cKd는 약 1 nM 내지 약 2 nM의 범위이다. 일부 실시양태에서, PSMA 결합 단백질은 인간 및 시노몰거스 PSMA에 대등한 결합 친화도(Kd)로 결합한다.
일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 4에 제시된 서열을 포함하고, 약 10 nM 내지 약 20 nM의 hKd를 갖는다. 일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 4의 아미노산 위치 31에서의 글루탐산으로부터 프롤린으로의 돌연변이를 포함하고, 약 5 nM 내지 약 10 nM의 hKd를 갖는다. 일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 4의 아미노산 서열 56에 트레오닌으로부터 글루타민으로의 돌연변이를 포함하고, 약 1 nM 내지 약 7 nM의 hKd를 갖는다. 일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 4의 아미노산 위치 55에서의 글리신으로부터 리신으로의 돌연변이를 포함하고, 약 0.5 nM 내지 약 5 nM의 hKd를 갖는다. 일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 아미노산 위치 33에서의 세린으로부터 히스티딘으로의 돌연변이, 아미노산 위치 50에서의 트레오닌에서 아스파르트산으로의 돌연변이, 및 서열 번호 4의 아미노산 위치 97에서의 글리신으로부터 세린으로의 치환을 포함하고, 약 5 nM 내지 약 10 nM의 hKd를 갖는다. 일부 실시양태에서, 본 개시내용의 PSMA 결합 단백질은 서열 번호 4의 아미노산 위치 33에서의 세린으로부터 히스티딘으로의 돌연변이 및 아미노산 위치 97에서의 글리신으로부터 세린으로의 치환을 포함하고, 약 0.05 nM 내지 약 2 nM의 hKd를 갖는다. 따라서, 다양한 실시양태에서, 서열 번호 4에 제시된 서열에 비해 하나 이상의 치환을 포함하는 PSMA 결합 단백질은 임의의 치환이 없이 서열 4의 서열을 포함하는 단백질보다 1.5배 내지 약 300배 더 높은 인간 PSMA에 대한 결합 친화도를 갖는다. 예를 들어, 결합 친화도는 서열 번호 4의 치환(들)이 E31P를 포함하는 경우 약 1.5배 내지 약 3배 더 높고; 서열 번호 4의 치환(들)이 T56Q를 포함하는 경우 약 2배 내지 약 15배 더 높고; 서열 번호 4의 치환(들)이 G55K를 포함하는 경우 약 3배 내지 약 30배 더 높고; 서열 번호 4의 치환(들)이 S33H T50D G97S를 포함하는 경우 약 2배 내지 약 3배 더 높고; 서열 번호 4의 치환(들)이 S33H G97S를 포함하는 경우 약 5배 내지 약 300배 더 높다. 일부 실시양태에서, 상기 설명된 바와 같은 서열 번호 4의 하나 이상의 아미노산 치환은 인간 및 시노몰거스 PSMA 둘 모두에 대해 향상된 결합 친화도를 유도하고, 예를 들어 서열 번호 4에 아미노산 치환 S33H 및 G97S를 포함하는 본 개시내용의 PSMA 결합 단백질은 임의의 치환이 없이 서열 번호 4의 서열을 포함하는 단백질에 비해 인간 및 시노몰거스 PSMA에 대한 증가된 친화도를 나타낸다. 이러한 이중 친화도 향상에 대한 추가의 예는 서열 번호 4에 아미노산 치환 S33H, T50D 및 G97S를 포함하는 PSMA 결합 단백질의 경우에서 관찰된다. 일부 실시양태에서, 상기 임의의 PSMA 결합 단백질(예를 들어, 서열 번호 21-32의 항-PSMA 단일 도메인 항체)은 정제의 용이함을 위해 친화도 펩티드 태그가 부착된다. 일부 실시양태에서, 친화도 펩티드 태그는 6his로도 언급되는 6개의 연속적인 히스티딘 잔기(서열 번호 33)이다.
본 개시내용의 PSMA 결합 단백질, 예를 들어, 항-PSMA 단일 도메인 항체의 결합 친화도는 상대적인 용어로, 또는 PSMA에 특이적으로 결합하는 제2 결합 단백질(예를 들어, 본원에서 "제2 PSMA 특이적 항체"로 지칭될 수 있는, PSMA에 특이적인 제2 항-PSMA 단일 도메인 항체)의 결합 친화도와 비교하여 설명될 수 있다. 일부 실시양태에서, 제2 PSMA 특이적 항체는 본원에서 설명되는 임의의 PSMA 결합 단백질 변이체, 예를 들어 서열 번호 21-32에 의해 정의된 결합 단백질이다. 따라서, 본 개시내용의 특정 실시양태는 서열 번호 4의 결합 단백질보다 더 큰 친화도로 또는 서열 번호 4의 결합 단백질의 Kd보다 더 낮은 Kd로 인간 PSMA 및/또는 시노몰거스 PSMA에 결합하는 항-PSMA 단일 도메인 항체에 관한 것이다. 또한, 본 개시내용의 추가의 실시양태는 서열 번호 19의 결합 단백질보다 더 큰 친화도로 또는 서열 번호 19의 결합 단백질의 Kd보다 더 낮은 Kd로 인간 PSMA 및/또는 시노몰거스 PSMA에 결합하는 항-PSMA 단일 도메인 항체에 관한 것이다.
CD3 결합 도메인
T 세포의 반응 특이성은 T 세포 수용체 복합체에 의한 항원(주요 조직 적합성 복합체(MHC)로 제시됨)의 인식에 의해 매개된다. T 세포 수용체 복합체의 일부로서, CD3은 CD3γ(감마) 사슬, CD3δ(델타) 사슬, 및 세포 표면에 존재하는 2개의 CD3ε(엡실론) 사슬을 포함하는 단백질 복합체이다. CD3은 T 세포 수용체 복합체를 구성하기 위해 T 세포 수용체(TCR)의 α(알파) 및 β(베타) 사슬 및 CD3ζ(제타)와 회합한다. 예를 들어 고정된 항-CD3 항체에 의한 T 세포 상의 CD3의 클러스터링은 T 세포 수용체의 결합과 유사하지만 그의 클론 전형적 특이성과는 무관하게 T 세포 활성화를 유도한다.
한 측면에서, 본 개시내용에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 단백질이 본원에서 설명된다. 일부 실시양태에서, 다중 특이적 단백질은 CD3에 특이적으로 결합하는 도메인을 추가로 포함한다. 일부 실시양태에서, 다중 특이적 단백질은 CD3γ에 특이적으로 결합하는 도메인을 추가로 포함한다. 일부 실시양태에서, 다중 특이적 단백질은 CD3δ에 특이적으로 결합하는 도메인을 추가로 포함한다. 일부 실시양태에서, 다중 특이적 단백질은 CD3ε에 특이적으로 결합하는 도메인을 추가로 포함한다.
추가의 실시양태에서, 다중 특이적 단백질은 T 세포 수용체(TCR)에 특이적으로 결합하는 도메인을 추가로 포함한다. 일부 실시양태에서, 다중 특이적 단백질은 TCR의 α 사슬과 특이적으로 결합하는 도메인을 추가로 포함한다. 일부 실시양태에서, 다중 특이적 단백질은 TCR의 β 사슬에 특이적으로 결합하는 도메인을 추가로 포함한다.
일부 실시양태에서, 다중 특이적 단백질은 인간 혈청 알부민(HSA)과 같은 벌크 혈청 단백질에 특이적으로 결합하는 도메인을 추가로 포함한다. 일부 실시양태에서, HSA 결합 도메인은 서열 번호 123-146로 이루어진 군으로부터 선택된 서열을 포함한다.
일부 실시양태에서, 다중 특이적 단백질은 본원에서 PSMA 표적화 TriTAC 분자 또는 PSMA 삼중 특이적 분자 또는 삼중 특이적 분자로도 언급되는 PSMA 표적화 삼중 특이적 항원 결합 단백질이다.
특정 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질을 포함하는 다중 특이적 단백질의 CD3 결합 도메인은 인간 CD3과의 강력한 CD3 결합 친화도를 나타낼 뿐만 아니라, 각각의 시노몰거스 원숭이 CD3 단백질과 우수한 교차 반응성을 나타낸다. 일부 경우에, 다중 특이적 단백질의 CD3 결합 도메인은 시노몰거스 원숭이의 CD3와 교차 반응성이다.
일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질을 포함하는 다중 특이적 단백질의 CD3 결합 도메인은 모노클로날 항체, 폴리클로날 항체, 재조합 항체, 인간 항체, 인간화 항체, 또는 CD3 결합 항체의 항원 결합 단편, 예컨대 단일 도메인 항체(sdAb), Fab, Fab', F(ab)2, 및 Fv 단편, 하나 이상의 CDR로 이루어진 단편, 단일쇄 항체(예를 들어, 단일쇄 Fv(scFv)), 디술파이드 안정화(dsFv) Fv 단편, 이종접합체 항체(예를 들어, 이중 특이적 항체), pFv 단편, 중쇄 단량체 또는 이량체, 경쇄 단량체 또는 이량체, 및 하나의 중쇄와 하나의 경쇄로 이루어진 이량체를 포함하고 이로 제한되지 않는, CD3에 결합하는 임의의 도메인일 수 있다. 일부 경우에, CD3 결합 도메인은 본원에서 설명되는 단일 PSMA 결합 단백질을 포함하는 다중 특이적 단백질이 궁극적으로 사용될 종과 동일한 종으로부터 유래하는 것이 유익하다. 예를 들어, 인간에서 사용하기 위해, 본원에서 설명되는 PSMA 결합 단백질을 포함하는 다중 특이적 단백질의 CD3 결합 도메인은 항체 또는 항체 단편의 PSMA 결합 도메인으로부터의 인간 또는 인간화 잔기를 포함하는 것이 유익할 수 있다.
따라서, 한 측면에서, PSMA 결합 단백질을 포함하는 다중 특이적 단백질의 CD3 결합 도메인은 인간화 또는 인간 항체 또는 항체 단편, 또는 뮤린 항체 또는 항체 단편을 포함한다. 한 실시양태에서, 인간화 또는 인간 항-CD3 결합 도메인은 본원에서 설명되는 인간화 또는 인간 항-CD3 결합 도메인의 하나 이상의(예를 들어, 3개의 모든) 경쇄 상보성 결정 영역 1(LC CDR1), 경쇄 상보성 결정 영역 2(LC CDR2) 및 경쇄 상보성 결정 영역 3(LC CDR3), 및/또는 본원에서 설명되는 인간화 또는 인간 항-CD3 결합 도메인의 하나 이상의(예를 들어, 3개의 모든) 중쇄 상보성 결정 영역, 중쇄 상보성 결정 영역 1(HC CDR1), 중쇄 상보성 결정 영역 2(HC CDR2) 및 중쇄 상보성 결정 영역 3(HC CDR3), 예를 들어 하나 이상의, 예를 들어 3개의 모든 LC CDR 및 하나 이상의, 예를 들어 3개의 모든 HC CDR을 포함하는 인간화 또는 인간 항-CD3 결합 도메인을 포함한다.
일부 실시양태에서, 인간화 또는 인간 항-CD3 결합 도메인은 CD3에 특이적인 인간화 또는 인간 경쇄 가변 영역을 포함하며, 여기서 CD3에 특이적인 경쇄 가변 영역은 인간 경쇄 프레임워크 영역에 인간 또는 비인간 경쇄 CDR을 포함한다. 특정 예에서, 경쇄 프레임워크 영역은 λ(람다) 경쇄 프레임워크이다. 다른 예에서, 경쇄 프레임워크 영역은 κ(카파) 경쇄 프레임워크이다.
일부 실시양태에서, 인간화 또는 인간 항-CD3 결합 도메인은 CD3에 특이적인 인간화 또는 인간 중쇄 가변 영역을 포함하며, 여기서 CD3에 특이적인 중쇄 가변 영역은 인간 중쇄 프레임워크 영역에 인간 또는 비인간 중쇄 CDR을 포함한다.
특정 예에서, 중쇄 및/또는 경쇄의 상보성 결정 영역은 공지의 항-CD3 항체, 예컨대 무로모납-CD3(OKT3), 오텔릭시주맙(TRX4), 테플리주맙(MGA031), 비실리주맙(Nuvion), SP34, TR-66 또는 X35-3, VIT3, BMA030 (BW264/56), CLB-T3/3, CRIS7, YTH12.5, F111-409, CLB-T3.4.2, TR-66, WT32, SPv-T3b, 11D8, XIII-141, XIII-46, XIII-87, 12F6, T3/RW2-8C8, T3/RW2-4B6, OKT3D, M-T301, SMC2, F101.01, UCHT-1 및 WT-31으로부터 유래된다.
한 실시양태에서, 항-CD3 결합 도메인은 본원에서 제공되는 아미노산 서열의 경쇄 및 중쇄를 포함하는 단일 사슬 가변 단편(scFv)이다. 본원에서 사용되는 바와 같이, "단일 사슬 가변 단편" 또는 "scFv"는 경쇄의 가변 영역을 포함하는 항체 단편 및 중쇄의 가변 영역을 포함하는 적어도 하나의 항체 단편을 지칭하며, 여기서 경쇄 및 중쇄 가변 영역은 짧은 가요성 폴리펩티드 링커를 통해 연속적으로 연결되고 단일 폴리펩티드 사슬로서 발현될 수 있고, scFv는 그것이 유래된 무손상 항체의 특이성을 보유한다. 한 실시양태에서, 항-CD3 결합 도메인은 본원에서 제공되는 경쇄 가변 영역의 아미노산 서열의 적어도 1, 2 또는 3개의 변형(예를 들어, 치환) 내지 30, 20 또는 10개 이하의 변형(예를 들어, 치환)을 갖는 아미노산 서열, 또는 본원에서 제공되는 아미노산 서열과 95-99%의 동일성을 갖는 서열을 포함하는 경쇄 가변 영역; 및/또는 본원에서 제공되는 중쇄 가변 영역의 아미노산 서열의 적어도 1, 2 또는 3개의 변형(예를 들어, 치환) 내지 30, 20 또는 10개 이하의 변형(예를 들어, 치환)을 갖는 아미노산 서열, 또는 본원에서 제공되는 아미노산 서열과 95-99%의 동일성을 갖는 서열을 포함하는 중쇄 가변 영역을 포함한다. 한 실시양태에서, 인간화 또는 인간 항-CD3 도메인은 scFv이고, 본원에서 설명되는 아미노산 서열을 포함하는 경쇄 가변 영역은 scFv 링커를 통해 본원에서 설명되는 아미노산 서열을 포함하는 중쇄 가변 영역에 부착된다. scFv의 경쇄 가변 영역 및 중쇄 가변 영역은 예를 들어 다음 중 임의의 배향으로 존재할 수 있다: 경쇄 가변 영역-scFv 링커-중쇄 가변 영역 또는 중쇄 가변 영역-scFv 링커-경쇄 가변 영역.
일부 경우에, CD3에 결합하는 scFv는 공지된 방법에 따라 제조된다. 예를 들어, scFv 분자는 가요성 폴리펩티드 링커를 사용하여 VH 및 VL 영역을 함께 연결함으로써 제조될 수 있다. scFv 분자는 최적화된 길이 및/또는 아미노산 조성을 갖는 scFv 링커(예를 들어, Ser-Gly 링커)를 포함한다. 따라서, 일부의 실시양태에서, scFv 링커의 길이는 VH 또는 VL 도메인이 CD3 결합 부위를 형성하기 위해 다른 가변 도메인과 분자 사이에서 결합할 수 있도록 하는 길이이다. 특정 실시양태에서, 이러한 scFv 링커는 "짧고", 즉, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 또는 12개의 아미노산 잔기로 이루어진다. 따라서, 특정 경우에, scFv 링커는 약 12개 이하의 아미노산 잔기로 이루어진다. 0개의 아미노산 잔기의 경우, scFv 링커는 펩티드 결합이다. 일부 실시양태에서, 이러한 scFv 링커는 약 3개 내지 약 15개, 예를 들어 8개, 9개 또는 10개의 인접한 아미노산 잔기로 이루어진다. scFv 링커의 아미노산 조성과 관련하여, 펩티드는 가요성을 부여하고 가변 도메인을 간섭하지 않고 2개의 가변 도메인을 함께 결합시켜 기능적 CD3 결합 부위를 형성하는 사슬간 접힘을 허용하도록 선택된다. 예를 들어, 글리신 및 세린 잔기를 포함하는 scFv 링커는 일반적으로 프로테아제 내성을 제공한다. 일부 실시양태에서, scFv 내의 링커는 글리신 및 세린 잔기를 포함한다. scFv 링커의 아미노산 서열은 예를 들어 scFv의 CD3 결합 및 생산 수율을 개선하기 위해 파지 디스플레이 방법에 의해 최적화될 수 있다. scFv에서 가변 경쇄 도메인과 가변 중쇄 도메인을 연결하기에 적합한 펩티드 scFv 링커의 예는 다음을 포함하고 이로 제한되지 않는다: (GS)n(서열 번호 157), (GGS)n(서열 번호 158), (GGGS)n(서열 번호 159), (GGSG)n(서열 번호 160), (GGSGG)n(서열 번호 161), 또는 (GGGGS)n(서열 번호 162)(여기서, n은 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10이다). 한 실시양태에서, scFv 링커는 (GGGGS)4(서열 번호 163) 또는 (GGGGS)3(서열 번호 164)일 수 있다. 링커 길이의 변화는 활성을 유지하거나 향상시켜, 활성 연구에서 우수한 효능을 발생시킬 수 있다.
일부 실시양태에서, PSMA 삼중 특이적 항원 결합 단백질의 CD3 결합 도메인은 1000 nM 이하, 500 nM 이하, 200 nM 이하, 100 nM 이하, 80 nM 이하, 50 nM 이하, 20 nM 이하, 10 nM 이하, 5 nM 이하, 1 nM 이하, 또는 0.5 nM 이하의 KD로 CD3 발현 세포 상의 CD3에 대한 친화도를 갖는다. 일부 실시양태에서, PSMA 삼중 특이적 항원 결합 단백질의 CD3 결합 도메인은 1000 nM 이하, 500 nM 이하, 200 nM 이하, 100 nM 이하, 80 nM 이하, 50 nM 이하, 20 nM 이하, 10 nM 이하, 5 nM 이하, 1 nM 이하, 또는 0.5 nM 이하의 KD로 CD3ε, γ, δ에 대한 친화도를 갖는다. 추가의 실시양태에서, PSMA 삼중 특이적 항원 결합 단백질의 CD3 결합 도메인은 CD3에 대한 낮은 친화도, 즉 약 100 nM 이상을 갖는다.
CD3에 결합하는 친화도는 PSMA 삼중 특이적 항원 결합 단백질 자체 또는 그의 CD3 결합 도메인이 예를 들어 검정 플레이트 상에 코팅된, 미생물 세포 표면에 제시된, 용액 내 등에 존재하는 CD3에 결합하는 능력에 의해 결정될 수 있다. 본 개시내용의 PSMA 삼중 특이적 항원 결합 단백질 자체 또는 그의 CD3 결합 도메인의 CD3에 대한 결합 활성은 또한 리간드(예를 들어, CD3) 또는 PSMA 삼중 특이적 항원 결합 단백질 자체 또는 그의 CD3 결합 도메인을 비드, 기질, 세포 등에 고정함으로써 검정할 수 있다. 작용제를 적절한 버퍼에 첨가하고, 결합 파트너를 주어진 온도에서 일정 시간 동안 인큐베이팅할 수 있다. 결합되지 않은 물질을 제거하기 위해 세척한 후, 결합된 단백질은 예를 들어 SDS, 고 pH의 버퍼 등으로 방출될 수 있고, 예를 들어 표면 플라스몬 공명(SPR)에 의해 분석될 수 있다.
일부 실시양태에서, 본원에서 설명되는 CD3 결합 도메인은 표 7에 제시된 서열(서열 번호 34-88) 및 그의 하위서열을 갖는 폴리펩티드를 포함한다. 일부 실시양태에서, CD3 결합 도메인은 표 7에 제시된 서열(서열 번호 34-122)과 적어도 70%-95% 또는 그 초과의 상동성을 갖는 폴리펩티드를 포함한다. 일부 실시양태에서, CD3 결합 도메인은 표 7에 제시된 서열(서열 번호 34-122)과 적어도 70%, 75%, 80%, 85%, 90%, 95%또는 그 초과의 상동성을 갖는 폴리펩티드를 포함한다. 일부 실시양태에서, CD3 결합 도메인은 표 7에 제시된 서열(서열 번호 34-122)의 적어도 일부를 포함하는 서열을 갖는다. 일부 실시양태에서, CD3 결합 도메인은 표 7에 제시된 서열(서열 번호 34-122)을 하나 이상 포함하는 폴리펩티드를 포함한다.
특정 실시양태에서, CD3 결합 도메인은 서열 번호 49 및 56-67을 포함하는 중쇄 CDR1을 갖는 scFv를 포함한다. 특정 실시양태에서, CD3 결합 도메인은 서열 번호 50 및 68-77을 포함하는 중쇄 CDR2를 갖는 scFv를 포함한다. 특정 실시양태에서, CD3 결합 도메인은 서열 번호 51 및 78-87을 포함하는 중쇄 CDR3을 갖는 scFv를 포함한다. 특정 실시양태에서, CD3 결합 도메인은 서열 번호 53 및 88-100을 포함하는 경쇄 CDR1을 갖는 scFv를 포함한다. 특정 실시양태에서, CD3 결합 도메인은 서열 번호 54 및 101-113을 포함하는 경쇄 CDR2를 갖는 scFv를 포함한다. 특정 실시양태에서, CD3 결합 도메인은 서열 번호 55 및 114-120을 포함하는 경쇄 CDR3을 갖는 scFv를 포함한다.
CD3에 결합하는 친화도는 예를 들어 PSMA 결합 단백질 자체 또는 그의 CD3 결합 도메인을 포함하는 다중 특이적 단백질이 검정 플레이트 상에 코팅된, 미생물 세포 표면에 제시된, 용액 내 등에 존재하는 CD3에 결합하는 능력에 의해 결정될 수 있다. 본 개시내용에 따른 PSMA 결합 단백질 자체 또는 그의 CD3 결합 도메인을 포함하는 다중 특이적 단백질의 CD3에 대한 결합 활성은 리간드(예를 들어, CD3) 또는 상기 다중 특이적 단백질 자체 또는 그의 CD3 결합 도메인을 비드, 기질, 세포 등에 고정함으로써 검정할 수 있다. PSMA 결합 단백질 자체 또는 그의 CD3 결합 도메인을 포함하는 다중 특이적 단백질이 CD3에 결합하는 결합 활성은 리간드(예를 들어, CD3) 또는 상기 다중 특이적 단백질 자체 또는 그의 PSMA 결합 도메인을 비드, 기질, 세포 등에 고정함으로써 결정될 수 있다. 일부 실시양태에서, PSMA 결합 단백질을 포함하는 다중 특이적 단백질과 표적 리간드(예를 들어, CD3) 사이의 결합은 예를 들어 결합 동역학 검정에 의해 결정된다. 특정 실시양태에서, 결합 동역학 검정은 OCTET® 시스템을 사용하여 수행된다. 이러한 실시양태에서, 제1 단계는 리간드(예를 들어, 비오티닐화된 CD3)를 바이오센서(예를 들어, 스트렙타비딘 바이오센서)의 표면 상에 최적 로딩 밀도로 고정한 후, 검정 버퍼로 세척하여 미결합 리간드를 제거하고, 분석물, 즉 PSMA 결합 단백질을 포함하는 다중 특이적 단백질과 리간드를 회합시킨 후, 바이오센서를 분석물을 함유하지 않는 버퍼에 노출시켜 PSMA 결합 단백질을 포함하는 다중 특이적 단백질을 리간드로부터 해리시키는 것을 포함한다. BSA, 카제인, Tween-20, PEG, 젤라틴과 같은 적절한 차단제는 동역학 검정 동안 바이오센서 상의 비특이적 결합 부위를 차단하기 위해 사용된다. 이어서, PSMA 결합 단백질을 포함하는 다중 특이적 단백질과 리간드 사이의 결합 상호작용에 대한 회합 및 해리 속도 상수를 결정하기 위해 적절한 소프트웨어(예를 들어, ForteBio의 Octet 소프트웨어)를 사용하여 결합 동역학 데이터를 분석한다.
한 측면에서, PSMA 표적화 삼중 특이적 단백질은 CD3에 특이적으로 결합하는 도메인 (A), 인간 혈청 알부민(HSA)에 특이적으로 결합하는 도메인 (B), 및 PSMA에 특이적으로 결합하는 도메인 (C)를 포함한다. PSMA 표적화 삼중 특이적 단백질에서 3개의 도메인은 임의의 순서로 배열된다. 따라서, PSMA 표적화 삼중 특이적 단백질의 도메인 순서는 다음과 같다 :
H2N-(A)-(B)-(C)-COOH,
H2N-(A)-(C)-(B)-COOH,
H2N-(B)-(A)-(C)-COOH,
H2N-(B)-(C)-(A)-COOH,
H2N-(C)-(B)-(A)-COOH, 또는
H2N-(C)-(A)-(B)-COOH.
일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 H2N-(A)-(B)-(C)-COOH의 도메인 순서를 갖는다. 일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 H2N-(A)-(C)-(B)-COOH의 도메인 순서를 갖는다. 일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 H2N-(B)-(A)-(C)-COOH의 도메인 순서를 갖는다. 일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 H2N-(B)-(C)-(A)-COOH의 도메인 순서를 갖는다. 일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 H2N-(C)-(B)-(A)-COOH의 도메인 순서를 갖는다. 일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 H2N-(C)-(A)-(B)-COOH의 도메인 순서를 갖는다.
일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 도메인 순서가 H2N-(A)-(B)-(C)-COOH 또는 H2N-(C)-(B)-(A)-COOH가 되도록 중앙 도메인으로서 HSA 결합 도메인을 갖는다. 중앙 도메인으로서 HSA 결합 도메인을 갖는 상기 실시양태에서, CD3 및 PSMA 결합 도메인에는 그 각각의 표적에 결합하기 위한 추가의 가요성이 제공되는 것이 고려된다.
일부 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 표 10에 제시된 서열(서열 번호 147-156) 및 그의 하위서열을 갖는 폴리펩티드를 포함한다. 일부 실시양태에서, 삼중 특이적 항원 결합 단백질은 표 10에 제시된 서열(서열 번호 147-156)에 대해 적어도 70%-95% 또는 그 초과의 상동성을 갖는 폴리펩티드를 포함한다. 일부 실시양태에서, 삼중 특이적 항원 결합 단백질은 표 10에 제시된 서열(서열 번호 147-156)에 대해 적어도 70%, 75%, 80%, 85%, 90%, 95% 또는 그 초과의 상동성을 갖는 폴리펩티드를 포함한다. 일부 실시양태에서, 삼중 특이적 항원 결합 단백질은 표 10에 제시된 서열(서열 번호 147-156)의 적어도 일부를 포함하는 서열을 갖는다. 일부 실시양태에서, PSMA 삼중 특이적 항원 결합 단백질은 표 10에 제시된 서열(서열 번호 147-156) 중 하나 이상의 서열을 포함하는 폴리펩티드를 포함한다. 추가의 실시양태에서, PSMA 삼중 특이적 항원 결합 단백질은 표 10의 서열(서열 번호 147-156)에 기재된 바와 같은 하나 이상의 CDR을 포함한다.
본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 세포독성 T 세포를 동원함으로써 PSMA를 발현하는 세포를 특이적으로 표적화하도록 설계된다. 이것은 단독 항원에 대해 작용하는 전장 항체를 사용하고 세포독성 T 세포를 직접적으로 동원할 수없는 ADCC(항체 의존성 세포 매개 세포독성)와 비교하여 효능을 향상시킨다. 이와 대조적으로, 이러한 세포 상에 특이적으로 발현되는 CD3 분자를 결합시킴으로써, PSMA 표적화 삼중 특이적 단백질은 세포독성 T 세포를 매우 특이적인 방식으로 PSMA를 발현하는 세포와 가교결합시켜 T 세포의 세포독성능을 표적 세포로 유도할 수 있다. 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 TCR의 일부를 형성하는 표면 발현 CD3 단백질에 결합함으로써 세포독성 T 세포에 결합한다. 여러 개의 PSMA 삼중 특이적 항원 결합 단백질이 CD3 및 특정 세포의 표면에 발현되는 PSMA에 동시에 결합하면, T 세포 활성화가 일어나고, 특정 PSMA 발현 세포의 후속적인 용해가 매개된다. 따라서, PSMA 표적화 삼중 특이적 단백질은 강력하고 특이적이고 효율적인 표적 세포 사멸을 나타내는 것으로 고려된다. 일부 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 병원성 세포(예를 들어, PSMA를 발현하는 종양 세포)를 제거하기 위해 세포독성 T 세포에 의한 표적 세포 사멸을 자극한다. 일부의 상기 실시양태에서, 세포는 선택적으로 제거되어 독성 부작용 가능성을 감소시킨다.
본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 전통적인 모노클로날 항체 및 다른 보다 작은 이중 특이적 분자에 비해 치료상 이점을 추가로 제공한다. 일반적으로, 재조합 단백질 의약품의 효과는 단백질 자체의 본질적인 약동학에 크게 의존한다. 그러한 이점의 하나는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질이 HSA에 특이적인 도메인과 같은 반감기 연장 도메인을 갖기 때문에 약동학적 제거 반감기를 연장한다는 것이다. 이와 관련하여, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 일부 실시양태에서 약 2, 3, 약 5, 약 7, 약 10, 약 12 또는 약 14일의 연장된 혈청 제거 반감기를 갖는다. 이것은 상대적으로 훨씬 더 짧은 제거 반감기를 갖는 BiTE 또는 DART 분자와 같은 다른 결합 단백질과 대조적이다. 예를 들어, BiTE CD19xCD3 이중 특이적 scFv-scFv 융합 분자는 그의 짧은 제거 반감기 때문에 연속적인 정맥 내 주입(i.v.)에 의한 약물 전달을 필요로 한다. PSMA 표적화 삼중 특이적 단백질의 보다 긴 고유한 반감기가 이 문제를 해결함으로써, 저용량 약학 제제, 감소된 주기적 투여 및/또는 신규 약학 조성물과 증가된 치료능을 가능하게 한다.
본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 또한 조직 침투 및 조직 분포를 향상시키기 위한 최적 크기를 갖는다. 더 큰 크기는 표적 조직에서 단백질의 침투 또는 분포를 제한하거나 억제한다. 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 조직의 침투 및 분포를 향상시킬 수 있는 작은 크기를 가짐으로써 이를 방지한다. 따라서, 일부 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질의 크기는 약 50 kD 내지 약 80 kD, 약 50 kD 내지 약 75 kD, 약 50 kD 내지 약 70 kD, 또는 약 50 kD 내지 약 65 kD이다. 따라서, PSMA 표적화 삼중 특이적 단백질의 크기는 약 150 kD인 IgG 및 약 55 kD이고 반감기가 연장되지 않고 따라서 신장을 통해 신속하게 청소되는 DART 디아바디 분자보다 유리하다.
추가의 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 조직 침투 및 분포를 향상시키기 위한 최적 크기를 갖는다. 이들 실시양태에서, PSMA 표적화 삼중 특이적 단백질은 그의 표적에 대한 특이성을 유지하면서 가능한 한 작게 구축된다. 따라서, 이들 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질의 크기는 약 20 kD 내지 약 40 kD 또는 약 25 kD 내지 약 35 kD, 약 40 kD, 약 45 kD, 약 50 kD, 약 55 kD, 약 60 kD, 약 65 kD이다. 일부 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질의 크기는 약 50 kD, 49 kD, 48 kD, 47 kD, 46 kD, 45 kD, 44 kD, 43 kD, 42 kD, 41 kD, 40 kD, 약 39 kD, 약 38 kD, 약 37 kD, 약 36 kD, 약 35 kD, 약 34 kD, 약 33 kD, 약 32 kD, 약 31 kD, 약 30 kD, 약 29 kD, 약 28 kD, 약 27 kD, 약 26 kD, 약 25 kD, 약 24 kD, 약 23 kD, 약 22 kD, 약 21 kD, 또는 약 20 kD이다. 작은 크기에 대한 예시적인 접근법은 각각의 도메인에 대해 단일 도메인 항체(sdAb) 단편의 사용을 통해 이루어진다. 예를 들어, 특정 PSMA 삼중 특이적 항원 결합 단백질은 항-CD3 sdAb, 항-HSA sdAb 및 PSMA에 대한 sdAb를 갖는다. 이는 예시적인 PSMA 삼중 특이적 항원 결합 단백질의 크기를 40 kD 미만으로 감소시킨다. 따라서, 일부 실시양태에서, PSMA 표적화 삼중 특이적 단백질의 도메인은 모두 단일 도메인 항체(sdAb) 단편이다. 다른 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 HSA 및/또는 PSMA에 대한 소분자 물질(SME) 결합제를 포함한다. SME 결합제는 평균 크기가 약 500 내지 2000 Da인 소분자이며, 소르타제 라이게이션 또는 접합과 같은 공지된 방법에 의해 PSMA 표적화 삼중 특이적 단백질에 부착된다. 이러한 경우, PSMA 삼중 특이적 항원 결합 단백질의 도메인 중 하나는 소르타제 인식 서열, 예를 들어 LPETG(서열 번호 57)이다. 소르타제 인식 서열을 갖는 PSMA 삼중 특이적 항원 결합 단백질에 SME 결합제를 부착시키기 위해, 단백질은 소르타제 및 SME 결합제와 함께 인큐베이팅되며, 이에 의해 소르타제는 SME 결합제를 인식 서열에 부착시킨다. 공지된 SME 결합제는 전립선 특이 막 항원(PSMA)에 결합하는 MIP-1072 및 MIP-1095를 포함한다. 또 다른 실시예에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질의 PSMA에 결합하는 도메인은 PSMA에 결합하기 위한 노틴(knottin) 펩티드를 포함한다. 노틴은 시스테인 매듭 스캐폴드가 있는 디술파이드 안정화된 펩티드이며, 평균 크기는 약 3.5 kD이다. 노틴은 PSMA와 같은 특정 종양 분자에 결합하는 것으로 고려되어 왔다. 추가의 실시양태에서, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질의 PSMA에 결합하는 도메인은 천연 PSMA 리간드를 포함한다.
본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질의 또 다른 특징은 이 단백질이 도메인들의 가요성 연결을 갖는 단일 폴리펩티드로 설계된다는 것이다. 이것은 벡터 내에 쉽게 통합되도록 단일 cDNA 분자에 의해 코딩될 수 있기 때문에 PSMA 표적화 삼중 특이적 단백질의 생산 및 제조를 용이하게 한다. 또한, 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 단량체성 단일 폴리펩티드 사슬이기 때문에, 사슬 쌍 형성 문제 또는 이량체화에 대한 필요성이 존재하지 않는다. 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질은 Fc-감마 면역글로불린 도메인을 갖는 이중 특이적 단백질과 같은 다른 보고된 분자와 달리 응집하는 경향이 감소되는 것으로 고려된다.
본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질에서, 도메인은 내부 링커 L1 및 L2에 의해 연결되고, 여기서 L1은 PSMA 표적화 삼중 특이적 단백질의 제1 및 제2 도메인을 연결하고, L2는 PSMA 표적화 삼중 특이적 단백질의 제2 및 제3 도메인을 연결한다. 링커 L1 및 L2는 최적화된 길이 및/또는 아미노산 조성을 갖는다. 일부 실시양태에서, 링커 L1 및 L2는 동일한 길이 및 아미노산 조성을 갖는다. 다른 실시양태에서, L1 및 L2는 상이하다. 특정 실시양태에서, 내부 링커 L1 및/또는 L2는 "짧고", 즉, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 또는 12개의 아미노산 잔기로 이루어진다. 따라서, 특정 경우에, 내부 링커는 약 12개 이하의 아미노산 잔기로 이루어진다. 0개 아미노산 잔기의 경우, 내부 링커는 펩티드 결합이다. 특정 실시양태에서, 내부 링커 L1 및/또는 L2는 "길고", 즉, 15, 20 또는 25개의 아미노산 잔기로 이루어진다. 일부 실시양태에서, 이들 내부 링커는 약 3 내지 약 15개, 예를 들어 8개, 9개 또는 10개의 연속적인 아미노산 잔기로 이루어진다. 내부 링커 L1 및 L2의 아미노산 조성과 관련하여, 펩티드는 PSMA 표적화 삼중 특이적 단백질에 가요성을 부여하고 결합 도메인을 저해하지 않을 뿐만 아니라 프로테아제로부터의 절단에 저항하는 특성을 갖도록 선택된다. 예를 들어, 글리신 및 세린 잔기는 일반적으로 프로테아제 내성을 제공한다. PSMA 표적화 삼중 특이적 단백질에서 도메인을 연결하기 적합한 내부 링커의 예는 다음을 포함하고 이로 제한되지 않는다: (GS)n(서열 번호 157), (GGS)n(서열 번호 158), (GGGS)n(서열 번호 159), (GGSG)n(서열 번호 160), (GGSGG)n(서열 번호 161), 또는 (GGGGS)n(서열 번호 162)(여기서, n은 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10이다). 한 실시양태에서, 내부 링커 L1 및/또는 L2는 (GGGGS)4(서열 번호 163) 또는 (GGGGS)3(서열 번호 164)이다.
PSMA 결합 단백질 변형
본원에서 설명되는 PSMA 결합 단백질은 (i) 아미노산이 유전자 코드에 의해 코딩되는 것이 아닌 아미노산 잔기로 치환되거나, (ii) 성숙 폴리펩티드가 다른 화합물, 예컨대 폴리에틸렌 글리콜과 융합되거나, 또는 (iii) 추가의 아미노산이 리더 또는 분비 서열 또는 면역원성 도메인의 차단 및/또는 단백질의 정제를 위한 서열과 같은 단백질에 융합된 유도체 또는 유사체를 포함한다.
전형적인 변형은 아세틸화, 아실화, ADP-리보실화, 아미드화, 플라빈의 공유 부착, 헴 모이어티의 공유 부착, 뉴클레오티드 또는 뉴클레오티드 유도체의 공유 부착, 지질 또는 지질 유도체의 공유 부착, 포스파티딜이노시톨의 공유 부착, 가교결합, 고리화, 디술파이드 결합 형성, 탈메틸화, 공유 가교결합의 형성, 시스틴의 형성, 피로글루타메이트의 형성, 포르밀화, 감마 카르복실화, 글리코실화, GPI 앵커 형성, 히드록실화, 요오드화, 메틸화, 미리스틸화, 산화, 단백질 분해 처리, 인산화, 프레닐화, 라세미화, 셀레노일화, 황산화, 아미노산의 단백질로의 전달-RNA 매개 부가, 예를 들어, 아르기닐화 및 유비퀴틴화를 포함하고 이로 제한되지 않는다.
변형은 펩티드 주쇄, 아미노산 측쇄, 및 아미노 또는 카르복실 말단을 비롯하여 본원에서 설명되는 PSMA 결합 단백질의 어느 곳에서나 일어난다. PSMA 결합 단백질의 변형에 유용한 공통적인 특정 펩티드 변형은 글리코실화, 지질 부착, 황산화, 글루탐산 잔기의 감마-카르복실화, 히드록실화, 폴리펩티드 내의 아미노 또는 카르복실기, 또는 둘 모두의 차단, 공유 변형 및 ADP-리보실화를 포함한다.
PSMA 결합 단백질을 코딩하는 폴리뉴클레오티드
또한, 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질을 코딩하는 폴리뉴클레오티드 분자가 제공된다. 일부 실시양태에서, 폴리뉴클레오티드 분자는 DNA 구축물로서 제공된다. 다른 실시양태에서, 폴리뉴클레오티드 분자는 메신저 RNA 전사체로서 제공된다.
폴리뉴클레오티드 분자는 적절한 프로모터에 작동 가능하게 연결된 항-PSMA 결합 단백질을 코딩하는 유전자, 및 선택적으로 적합한 전사 종결인자를 조합하고, 이를 박테리아 또는 다른 적절한 발현 시스템, 예를 들어 CHO 세포에서 발현시키는 것과 같은 공지된 방법에 의해 구축된다.
일부 실시양태에서, 폴리뉴클레오티드는 추가의 실시양태를 나타내는 벡터, 바람직하게는 발현 벡터에 삽입된다. 이 재조합 벡터는 공지의 방법에 따라 구축될 수 있다. 특히 관심있는 벡터는 플라스미드, 파지미드, 파지 유도체, 바이러스(예를 들어, 레트로바이러스, 아데노바이러스, 아데노 관련 바이러스, 헤르페스 바이러스, 렌티 바이러스 등) 및 코스미드를 포함한다.
다양한 발현 벡터/숙주 시스템이 설명된 PSMA 결합 단백질의 폴리펩티드를 코딩하는 폴리뉴클레오티드를 함유하고 발현시키기 위해 사용될 수 있다. 이. 콜라이에서의 발현을 위한 발현 벡터의 예는 pSKK(Le Gall et al., J Immunol Methods. (2004) 285(1):111-27), 포유동물 세포에서의 발현을 위한 pcDNA5(Invitrogen), PICHIAPINK™ 효모 발현 시스템(Invitrogen), BACUVANCE™ 바큘로바이러스 발현 시스템(GenScript)이다.
따라서, 본원에서 설명되는 PSMA 알부민 결합 단백질은 일부 실시양태에서 상기 기술된 바와 같은 단백질을 코딩하는 벡터를 숙주 세포에 도입하고 단백질 도메인이 발현되는 조건 하에 상기 숙주 세포를 배양함으로써 생산되며, 단리되고, 선택적으로 추가로 정제될 수 있다.
PSMA 결합 단백질의 생산
일부 실시양태에서, PSMA 결합 단백질의 생산 방법이 본원에서 개시된다. 일부 실시양태에서, 상기 방법은 PSMA 결합 단백질의 발현을 허용하는 조건 하에서 PSMA 결합 단백질을 코딩하는 핵산 서열을 포함하는 벡터로 형질전환되거나 형질감염된 숙주를 배양하는 단계, 및 배양물로부터 생산된 단백질을 회수 및 정제하는 단계를 포함한다.
추가의 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질 및/또는 PSMA를 포함하는 다중 특이적 결합 단백질의 하나 이상의 특성, 예를 들어, 친화도, 안정성, 내열성, 교차 반응성 등을 참조 결합 화합물에 비해 개선하기 위한 방법이 제공된다. 일부 실시양태에서, 단일 치환 라이브러리의 각각의 구성원이 그의 대응 도메인에서, 또는 아미노산 분절에서 단지 하나의 아미노산 변화만을 코딩하도록, PSMA 결합 단백질 또는 참조 결합 화합물의 상이한 도메인, 또는 아미노산 분절에 각각 상응하는 다수의 단일 치환 라이브러리가 제공된다. 전형적으로, 이것은 큰 단백질 또는 단백질 결합 부위의 모든 잠재적 치환을 몇 개의 작은 라이브러리를 사용하여 프로빙할 수 있게 한다. 일부 실시양태에서, 다수의 도메인은 PSMA 결합 단백질 또는 참조 결합 화합물의 아미노산의 인접한 서열을 형성하거나 커버한다. 상이한 단일 치환 라이브러리의 뉴클레오티드 서열은 적어도 하나의 다른 단일 치환 라이브러리의 뉴클레오티드 서열과 중첩된다. 일부 실시양태에서, 다수의 단일 치환 라이브러리는 모든 구성원이 인접 도메인을 코딩하는 각각의 단일 치환 라이브러리의 모든 구성원과 중첩도록 설계된다.
이러한 단일 치환 라이브러리로부터 발현된 결합 화합물은 적어도 참조 결합 화합물의 특성만큼 좋은 특성을 갖고 그의 생성되는 라이브러리의 크기가 감소된 각각의 라이브러리에서의 변이체의 하위세트를 수득하도록 개별적으로 선택된다. 일반적으로, 선택된 결합 화합물 세트를 코딩하는 핵산의 수는 원래의 단일 치환 라이브러리의 구성원을 코딩하는 핵산의 수보다 적다. 이러한 특성은 표적 화합물에 대한 친화도, 열, 고 pH 또는 저 pH와 같은 다양한 조건에 대한 안정성, 효소 분해, 다른 단백질에 대한 교차 반응성 등을 포함하고 이로 제한되지 않는다. 각각의 단일 치환 라이브러리로부터 선택된 화합물은 본원에서 상호 교환 가능하게 "예비 후보 화합물" 또는 "예비 후보 단백질"로 지칭된다. 이어서, 별개의 단일 치환 라이브러리로부터의 예비 후보 화합물을 코딩하는 핵산 서열은 PCR 기반 유전자 셔플링 기술을 사용하여 셔플링된 라이브러리를 생성하기 위해 PCR에서 셔플링된다.
스크리닝 과정의 예시적인 작업 흐름이 여기에서 설명된다. 예비 후보 화합물의 라이브러리는 단일 치환 라이브러리로부터 생성되고, 표적 단백질(들)에 대한 결합에 대해 선택된 후, 예비 후보 라이브러리를 셔플링하여 후보 화합물을 코딩하는 핵산 라이브러리를 생성하고, 이어서 편리한 발현 벡터, 예컨대 파지미드 발현 시스템 내로 클로닝한다. 후보 화합물을 발현하는 파지는 표적 분자에 대한 결합 친화도와 같은 목적하는 특성의 개선을 위해 1회 이상의 선택 라운드를 거친다. 표적 분자는 웰 또는 다른 반응 용기의 표면에 흡착되거나 달리 부착될 수 있거나, 표적 분자는 비오틴과 같은 결합 모이어티로 유도체화될 수 있으며, 이어서 후보 결합 화합물은 세척을 위해 비드, 예컨대 자성 비드에 결합된 상보성 모이어티, 예컨대 스트렙타비딘으로 포획될 수 있다. 예시적인 선택 방법에서, 후보 결합 화합물은 표적 분자로부터 매우 낮은 해리 속도를 갖는 후보 화합물만이 선택되도록 세척 단계를 거친다. 그러한 실시양태에 대한 예시적인 세척 시간은 약 10분, 약 15분, 약 20분, 약 20분, 약 30분, 약 35분, 약 40분, 약 45분, 약 50분, 약 55분, 약 1시간 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 8시간; 또는 다른 실시양태에서는, 약 24시간; 또는 다른 실시양태에서는, 약 48시간; 또는 다른 실시양태에서는 약 72시간이다. 선택 후 단리된 클론은 증폭되고 추가의 선택 사이클을 거치거나, 예를 들어 서열결정에 의해 및 예를 들어 ELISA, 표면 플라스몬 공명(SPR), 생물층 간섭 측정(예를 들어, OCTET® 시스템, Pall Life Sciences, ForteBio, 미국 캘리포니아주 멘로 파크 소재) 등에 의한 결합 친화도의 비교 측정에 의해 분석된다.
일부 실시양태에서, 상기 방법은 참조 PSMA 결합 단백질에 비해 개선된 결합 친화도, 선택된 세트의 결합 표적에 대한 개선된 교차 반응성을 가진 하나 이상의 PSMA 결합 단백질을 확인하기 위해 수행된다. 일부 실시양태에서, 참조 결합 단백질은 서열 번호 4에 제시된 아미노산 서열을 갖는 단백질이다. 일부 실시양태에서, 참조 결합 단백질은 서열 번호 19에 제시된 아미노산 서열을 갖는 단백질이다. 특정 실시양태에서, 단일 치환 라이브러리는 프레임워크 영역 내의 및 CDR 내의 코돈을 포함하는, 참조 PSMA 결합 단백질의 VH 영역 내의 코돈을 변경시킴으로써 제조된다. 또 다른 실시양태에서, 코돈이 변경되는 위치는 참조 PSMA 결합 단백질의 중쇄의 CDR, 또는 이러한 CDR의 하위세트, 예컨대, 유일하게 CDR1, 유일하게 CDR2, 유일하게 CDR3만을 또는 이들의 쌍을 포함한다. 또 다른 실시양태에서, 코돈이 변경되는 위치는 프레임워크 영역에만 존재한다. 일부 실시양태에서, 라이브러리는 오직 10부터 111까지의 VH 넘버링의 프레임워크 영역에서 참조 PSMA 결합 단백질로부터의 단일 코돈 변화만을 포함한다. 또 다른 실시양태에서, 코돈이 변경되는 위치는 참조 PSMA 결합 단백질의 중쇄의 CDR3, 또는 이러한 CDR3의 하위세트를 포함한다. 또 다른 실시양태에서, VH 코딩 영역의 코돈이 변경되는 위치의 수는 최대 80개의 위치가 프레임워크 영역 내에 있도록 10부터 111까지의 범위 내에 있다. 상기 요약된 바와 같이, 단일 치환 라이브러리의 제조 후, 다음 단계들을 수행한다: (a) 각각의 단일 치환 라이브러리의 각각의 구성원을 예비후보 단백질로서 별개로 발현시키는 단계; (b) 원래의 결합 표적[예를 들면, 원하는 교차 반응 표적(들)]과 상이할 수 있거나 상이하지 않을 수 있는 결합 파트너에 결합하는 예비 후보 단백질을 코딩하는 각각의 단일 치환 라이브러리의 구성원을 선택하는 단계; (c) PCR에서 선택된 라이브러리의 구성원을 셔플링하여 조합 셔플링된 라이브러리를 생성하는 단계; (d) 셔플링된 라이브러리의 구성원을 후보 PSMA 결합 단백질로서 발현시키는 단계; 및 (e) 셔플링된 라이브러리의 구성원을 원래의 결합 파트너에 결합하는 후보 PSMA 결합 단백질에 대해 1회 이상 선택하는 단계 및 잠재적으로 (f) 원하는 교차 반응성 표적(들)에 대한 결합에 대해 후보 단백질을 추가로 선택함으로써, 원래의 리간드에 대한 친화도를 상실하지 않으면서 참조 PSMA 결합 단백질에 비해 하나 이상의 물질에 대한 증가된 교차 반응성을 가진 핵산 코딩된 PSMA 결합 단백질을 제공하는 단계. 추가의 실시양태에서, 단계 (f)를 하기 단계로 대체함으로써 선택된 교차 반응성 물질(들) 또는 화합물(들) 또는 에피토프(들)에 대한 감소된 반응성을 가진 PSMA 결합 단백질을 수득하는 방법을 수행할 수 있다: 원치 않는 교차 반응성 화합물에 결합하는 후보 PSMA 결합 단백질의 하위세트로부터 후보 결합 화합물을 1회 이상 고갈시키는 단계.
약학 조성물
또한, 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질, PSMA 결합 단백질의 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 벡터 또는 이 벡터로 형질전환된 숙주 세포 및 적어도 하나의 약학적으로 허용 가능한 담체를 포함하는 약학 조성물도 제공된다. 용어 "약학적으로 허용 가능한 담체"는 성분의 생물학적 활성의 효능을 방해하지 않고 이것이 투여된 환자에게 독성을 나타내지 않는 임의의 담체를 포함하고 이로 제한되지 않는다. 적합한 약학적 담체의 예는 관련 기술 분야에서 잘 공지되어 있고, 포스페이트 완충 염수 용액, 물, 유화액, 예컨대, 유/수 유화액, 다양한 유형의 습윤제, 멸균 용액 등을 포함한다. 이러한 담체는 통상적인 방법에 의해 제제화될 수 있고, 적합한 용량으로 대상체에게 투여될 수 있다. 바람직하게는, 조성물은 멸균 조성물이다. 이 조성물은 보조제, 예컨대, 보존제, 유화제 및 분산제도 함유할 수 있다. 미생물 작용의 방지는 다양한 항박테리아제 및 항진균제의 포함에 의해 보장될 수 있다.
약학 조성물의 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질은 나노입자 내에 캡슐화된다. 일부 실시양태에서, 나노입자는 풀러렌, 액정, 리포솜, 양자 점, 초상자성 나노입자, 덴드리머 또는 나노막대이다. 약학 조성물의 다른 실시양태에서, PSMA 결합 단백질은 리포솜에 부착된다. 일부 경우에, PSMA 결합 단백질은 리포솜의 표면에 접합된다. 일부 경우에, PSMA 결합 단백질은 리포솜의 외피 내에 캡슐화된다. 일부 경우에, 리포솜은 양이온성 리포솜이다.
본원에서 설명되는 PSMA 결합 단백질은 약물로서 사용될 것으로 예상된다. 투여는 상이한 방식, 예를 들면, 정맥내, 복강내, 피하, 근육내, 국소 또는 피내 투여에 의해 달성된다. 일부 실시양태에서, 투여 경로는 요법의 종류 및 약학 조성물에 함유된 화합물의 종류에 의해 결정된다. 투여법은 담당 주치의 및 다른 임상 요인에 의해 결정될 것이다. 어느 한 환자를 위한 투여량은 환자의 크기, 신체 표면적, 연령, 성별, 투여될 특정 화합물, 투여 시간 및 경로, 요법의 종류, 일반적인 건강 및 동시에 투여되는 다른 약물을 비롯한 많은 요인들에 의존한다. "유효 용량"은 질환의 경과 및 중증도에 영향을 미침으로써, 이러한 병리학적 상태의 감소 또는 완화를 이끌어내기에 충분한 활성 성분의 양을 지칭하고, 공지된 방법을 이용함으로써 결정될 수 있다.
치료 방법
일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질 또는 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질의 투여를 포함하는, 이를 필요로 하는 개체의 면역계를 자극하기 위한 방법 및 용도가 또한 본원에서 제공된다. 일부 경우에, 본원에서 설명되는 PSMA 결합 단백질의 투여는 표적 항원을 발현하는 세포에 대해 세포독성을 유도 및/또는 유지시킨다. 일부 경우에, 표적 항원을 발현하는 세포는 암 또는 종양 세포, 바이러스 감염 세포, 박테리아 감염 세포, 자가반응성 T 또는 B 세포, 손상된 적혈구, 동맥 플라크 또는 섬유증 조직이다.
또한, 본원에서 설명되는 PSMA 결합 단백질 또는 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질을 이를 필요로 하는 개체에게 투여하는 것을 포함하는, 표적 항원과 관련된 질환, 장애 또는 병태를 치료하기 위한 방법 및 용도가 본원에서 제공된다. 표적 항원과 관련된 질환, 장애 또는 병태는 바이러스 감염, 박테리아 감염, 자가면역 질환, 이식 거부, 아테롬성 동맥 경화증 또는 섬유증을 포함하고 이로 제한되지 않는다. 다른 실시양태에서, 표적 항원과 관련된 질환, 장애 또는 병태는 증식성 질환, 종양 질환, 염증성 질환, 면역 장애, 자가면역 질환, 감염성 질환, 바이러스성 질환, 알레르기 반응, 기생충 반응, 이식편 대 숙주 질환 또는 숙주 대 이식편 질환이다. 한 실시양태에서, 표적 항원과 관련된 질환, 장애 또는 병태는 암이다. 하나의 경우에, 암은 혈액학적 암이다. 또 다른 경우에, 암은 전립선암이다.
일부 실시양태에서, 전립선암은 진행성 전립선암이다. 일부 실시양태에서, 전립선암은 약물 내성이다. 일부 실시양태에서, 전립선암은 항안드로겐 약물 내성이다. 일부 실시양태에서, 전립선암은 전이성이다. 일부 실시양태에서, 전립선암은 전이성 및 약물 내성(예, 항안드로겐 약제 내성)이다. 일부 실시양태에서, 전립선암은 거세 내성이다. 일부 실시양태에서, 전립선암은 전이성이고, 거세 내성이다. 일부 실시양태에서, 전립선암은 엔잘루타미드 내성이다. 일부 실시양태에서, 전립선암은 엔잘루타미드 및 아르비라테론 내성이다. 일부 실시양태에서, 전립선암은 엔잘루타미드, 아르비라테론 및 비칼루타미드 내성이다. 일부 실시양태에서, 전립선암은 도세탁셀 내성이다. 이들 실시양태 중 일부에서, 전립선암은 엔잘루타미드, 아르비라테론, 비칼루타미드 및 도세탁셀 내성이다.
일부 실시양태에서, 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여하는 것은 전립선암 세포 성장을 억제하거나, 전립선암 세포 이동을 억제하거나, 전립선암 세포 침습을 억제하거나, 전립선암의 증상을 개선하거나, 전립선암 종양의 크기를 감소시키거나, 전립선암 종양의 수를 감소시키거나, 전립선암 세포의 수를 감소시키거나, 전립선암 세포 괴사, 피롭토시스(pyroptosis), 종양병증, 아폽토시스(apoptosis), 자가포식증 또는 다른 세포 사멸을 유도하거나, 엔잘루타미드, 아르비라테론, 도세탁셀, 비칼루타미드, 및 이들의 임의의 조합으로 이루어진 군으로부터 선택된 화합물의 치료 효과를 향상시킨다.
일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 세포 성장을 억제하는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 세포 이동을 억제하는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 세포 침습을 억제하는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 세포의 증상을 개선하는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 종양의 크기를 감소시키는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 종양의 수를 감소시키는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 항-PSMA 단일 도메인 항체 또는 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 세포의 수를 감소시키는 것을 포함한다. 일부 실시양태에서, 상기 방법은 본원에서 설명되는 PSMA 표적화 삼중 특이적 단백질을 투여함으로써 전립선암 세포 괴사, 피롭토시스, 종양병증, 아폽토시스, 자가포식증 또는 다른 세포 사멸을 유도하는 것을 포함한다.
본원에서 사용되는 바와 같이, 일부 실시양태에서, "치료" 또는 "치료하는" 또는 "치료된"은 치유적 치료를 의미하고, 그 목적은 원치 않는 생리학적 병태, 장애 또는 질환을 늦추거나(경감시키거나), 유리한 또는 원하는 임상 결과를 수득하는 것이다. 본원에서 설명되는 목적을 위해, 유리한 또는 원하는 임상 결과는 증상의 완화; 병태, 장애 또는 질환의 정도의 감소; 병태, 장애 또는 질환의 상태의 안정화(즉, 악화되지 않음); 병태, 장애 또는 질환의 발병의 지연 또는 진행의 늦춤; 병태, 장애 또는 질환 상태의 개선; 및 병태, 장애 또는 질환의 검출 가능한 또는 검출 불가능한(부분적 또는 전체적) 차도, 또는 향상 또는 개선을 포함하고 이로 제한되지 않는다. 치료는 과도한 수준의 부작용 없이 임상적으로 유의한 반응을 이끌어내는 것을 포함한다. 치료는 또한 치료를 받지 않은 경우 예상된 생존에 비해 생존을 연장시키는 것도 포함한다. 다른 실시양태에서, "치료" 또는 "치료하는" 또는 "치료된"은 예방적 조치를 의미하고, 그 목적은 예를 들면, 질환에 걸리기 쉬운 사람(예를 들면, 질환, 예컨대, 유방암의 유전자 마커를 보유하는 개체)에서 원치 않는 생리학적 병태, 장애 또는 질환의 발병을 지연시키거나 이러한 병태, 장애 또는 질환의 중증도를 감소시키는 것이다.
본원에서 설명되는 방법의 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질 또는 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질은 특정 질환, 장애 또는 병태의 치료를 위한 작용제와 조합되어 투여된다. 작용제는 항체를 사용하는 요법, 소분자(예를 들면, 화학치료제), 호르몬(스테로이드, 펩티드 등), 방사선 요법(γ-선, X-선, 및/또는 방사성 동위원소의 유도 전달, 마이크로파, UV 방사선 조사 등), 유전자 요법(예를 들면, 안티센스, 레트로바이러스 요법 등) 및 다른 면역요법을 포함하고 이로 제한되지 않는다. 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질 또는 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질은 지사제, 진토제, 진통제, 오피오이드 및/또는 비스테로이드성 소염제와 조합하여 투여된다. 일부 실시양태에서, 본원에서 설명되는 PSMA 결합 단백질 또는 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질은 수술 전, 동안 또는 후 투여된다. 본 발명의 또 다른 실시양태에 따르면, 진단, 예측 또는 모니터링을 위해 전립선암을 검출하기 위한 키트가 제공된다. 상기 키트는 상기 PSMA 결합 단백질(예를 들어, 표지된 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편) 및 표지를 검출하기 위한 하나 이상의 화합물을 포함한다. 일부 실시양태에서, 표지는 형광 표지, 효소 표지, 방사성 표지, 핵 자기 공명 활성 표지, 발광 표지 및 발색단 표지로 이루어진 군으로부터 선택된다.
추가의 실시양태는 동결 건조된 형태로, 또는 수성 매질 중의 상태로 포장된, 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편과 같은 본원에서 설명되는 하나 이상의 결합 단백질을 제공한다. 본 개시내용의 다른 측면에서, 샘플에서 PSMA 또는 PSMA를 발현하는 세포의 존재를 검출하는 방법이 제공된다. 이러한 방법은 항체 또는 그의 항원 결합 단편과 PSMA 사이의 복합체 형성을 허용하기에 충분한 시간 동안, 샘플을 PSMA의 세포외 도메인에 특이적으로 결합하는 상기 PSMA 결합 단백질(예컨대, 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편) 중 임의의 것과 접촉시키는 단계, 및 PSMA-항체 복합체 또는 PSMA-항원 결합 단편 복합체를 검출하는 단계를 포함한다. 일부 실시양태에서, 샘플 내의 복합체의 존재는 PSMA 또는 PSMA를 발현하는 세포가 샘플에 존재함을 나타낸다. 다른 측면에서, 본 개시내용은 대상체에서 PSMA 매개 질환을 진단하기 위한 다른 방법을 제공한다. 그러한 방법은 PSMA 매개 질환을 갖고 있는 것으로 의심되거나 이전에 PSMA 매개 질환으로 진단된 대상체에게, 전립선 특이 막 항원의 세포외 도메인에 특이적으로 결합하는 일정량의 상기 임의의 PSMA 결합 단백질(예를 들어, 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편)을 투여하는 것을 포함한다. 상기 방법은 또한 항체 또는 그의 항원 결합 단편과 PSMA 사이의 복합체 형성을 허용하는 단계, 및 표적 에피토프에 대한 PSMA-항체 복합체 또는 PSMA-항원 결합 단편 항체 복합체의 형성을 검출하는 단계를 포함한다. 전립선암을 갖고 있는 것으로 의심되거나 이전에 전립선암으로 진단된 대상체에 복합체가 존재하는 것은 PSMA 매개 질환의 존재를 나타낸다.
상기 방법의 특정 실시양태에서, PSMA 매개 질환은 전립선암이다. 다른 실시양태에서, PSMA 매개 질환은 비전립선암, 예를 들어 이행 세포 암종을 포함하는 방광암; 췌관 암종을 포함하는 췌장암; 비소세포 폐 암종을 포함하는 폐암; 종래의 신장 세포 암종을 포함하는 신장암; 연조직 육종을 포함하는 육종; 유방 암종을 포함하는 유방암; 다형성 아교모세포종을 포함하는 뇌암; 신경내분비 암종; 결장 암종을 포함하는 결장암; 고환 배아 암종을 포함하는 고환암; 및 악성 흑색종을 포함하는 흑색종으로 이루어지는 군으로부터 선택된 암이다.
상기 방법의 일부 실시양태에서, PSMA 결합 단백질(예를 들어, 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편)을 표지된다. 상기 방법의 다른 실시양태에서, 제1 항체 또는 그의 항원 결합 단편을 검출하기 위해 제2 항체가 투여된다. 본 개시내용의 또 다른 측면에서, PSMA 매개 질환을 갖는 대상체의 예후를 평가하는 방법이 제공된다. 상기 방법은 PSMA 매개 질환을 갖고 있는 것으로 의심되거나 이전에 PSMA 매개 질환으로 진단된 대상체에게, 유효량의 상기 임의의 PSMA 결합 단백질(예를 들어, 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편)을 투여하는 단계, 항체 또는 그의 항원 결합 단편과 PSMA 사이의 복합체 형성을 허용하는 단계, 및 표적 에피토프에 대한 복합체의 형성을 검출하는 단계를 포함한다. PSMA 매개 질환을 갖고 있는 것으로 의심되거나 이전에 PSMA 매개 질환으로 진단된 대상체 내의 복합체의 양은 그 질환의 예후를 나타낸다.
본 개시내용의 또 다른 측면에서, PSMA 매개 질환을 갖는 대상체의 치료의 유효성을 평가하는 방법이 제공된다. 이 방법은 PSMA 매개 질환을 갖고 있거나 이전에 PSMA 매개 질환으로 진단된 대상체에게, 유효량의 상기 임의의 PSMA 결합 단백질, 예를 들어 항-PSMA 단일 도메인 항체 또는 이의 항원 결합 단편을 투여하는 단계, 항체 또는 그의 항원 결합 단편과 PSMA 사이의 복합체 형성을 허용하는 단계, 및 표적 에피토프에 대한 복합체의 형성을 검출하는 단계를 포함한다. PSMA 매개 질환을 갖고 있는 것으로 의심되거나 이전에 PSMA 매개 질환으로 진단된 대상체 내의 복합체의 양은 치료의 유효성을 나타낸다. 특정 실시양태에서, PSMA 매개 질환은 전립선암이다. 다른 실시양태에서, PSMA 매개 질환은 비전립선암이다. 이들 실시양태에서, 비전립선암은 바람직하게는 이행 세포 암종을 포함하는 방광암; 췌관 암종을 포함하는 췌장암; 비소세포 폐 암종을 포함하는 폐암; 종래의 신장 세포 암종을 포함하는 신장암; 연조직 육종을 포함하는 육종; 유방 암종을 포함하는 유방암; 다형성 아교모세포종을 포함하는 뇌암; 신경내분비 암종; 결장 암종을 포함하는 결장암; 고환 배아 암종을 포함하는 고환암; 및 악성 흑색종을 포함하는 흑색종으로 이루어지는 군으로부터 선택된 암이다. 또 다른 실시양태에서, 항체 또는 이의 항원 결합 단편은 표지된다. 추가의 실시양태에서, 제2 항체는 제1 항체 또는 이의 항원 결합 단편을 검출하기 위해 투여된다.
본 개시내용의 또 다른 측면에 따르면, PSMA를 발현하는 세포의 성장을 억제하는 방법이 제공된다. 이러한 방법은 PSMA의 세포외 도메인에 특이적으로 결합하는 상기 항체 또는 이의 항원 결합 단편 중 적어도 하나를 PSMA를 발현하는 세포의 성장을 억제하는데 효과적인 양으로 PSMA를 발현하는 세포와 접촉시키는 것을 포함한다.
실시예
이하의 실시예는 본 발명의 범위를 제한하지 않으면서 설명된 실시양태를 추가로 예시한다.
실시예 1: 모 항-PSMA 단일 도메인 항체와 동등하거나 개선된 결합 특성을 갖는 항-PSMA 단일 도메인 항체 변이체의 생성
모 항-PSMA 파지의 특성 결정
PSMA 항원에 대한 모 항-PMA 파지의 특이적 결합이 결정되었다(표 1).
cyno PSMA에 대해 선택된 단일 치환 PSMA sdAb 파지 라이브러리
단일 치환 라이브러리를 3개의 CDR 도메인 각각에 제공하였다. 단일 치환 라이브러리를 시노몰거스 PSMA에 결합시킨 다음, 버퍼 내에서 30분 동안 세척하였다. 0분 및 30분에 결합된 파지를 구제하고, 계수하였다. 버퍼 내에서의 30분 세척을 사용하여 선택된 파지를 사용하여 2개의 독립적인 조합 파지 라이브러리를 생성하였다.
조합 항-PSMA 라이브러리
시노몰거스 PSMA를 3라운드의 선택을 위한 선택 표적으로서 사용하였다. 3라운드의 선택을 위해 2개의 독립적인 라이브러리로부터의 조합 파지 결합 후 2 내지 4시간 동안 웰을 세척하였다. 제3 라운드의 선택으로부터 PCR된 삽입체를 p34 발현 벡터에 서브클로닝하였다. 96개의 클론을 채취하고, DNA를 정제하고, 서열결정하고, Expi293 세포 내로 형질감염시켰다.
huPSMA에 대해 선택된 단일 치환 PSMA sdAb 파지 라이브러리
단일 치환 라이브러리를 3개의 CDR 도메인 각각에 제공하였다. 단일 치환 라이브러리를 인간 PSMA에 결합시킨 다음, 30 ㎍/ml hPSMA-Fc를 함유하는 버퍼 내에서 24시간 동안 세척하였다. 0 및 24시간에 결합된 파지를 구제하고, 계수하였다. 24시간 경쟁 세척을 사용하여 선택된 파지를 사용하여 조합 파지 라이브러리를 생성하였다.
조합 항-PSMA 라이브러리
인간 PSMA를 3라운드의 선택을 위한 선택 표적으로서 사용하였다. 3라운드의 선택을 위해 조합 파지 결합 후 24 내지 96시간 동안 웰을 30 ㎍/ml - 850 ㎍/ml 인간 PSMA-Fc를 함유하는 버퍼 내에서 세척하였다. 제3 라운드의 선택으로부터 PCR된 삽입체를 p34 발현 벡터에 서브클로닝하였다. 96개의 클론을 채취하고, DNA를 정제하고, 서열결정하고, Expi293 세포 내로 형질감염시켰다.
결합 친화도 측정
OCTET® 시스템을 사용하여 인간 및 시노몰거스 PSMA에 대한 Kd, kon 및 koff(또는 kdis)를 추정하기 위해 상청액을 사용하였다. 모 sdAb와 비교하여 인간 PSMA와의 상호 작용을 위한 그의 결합 친화도 및 회합 및 해리 속도 상수, 및 강력한 생산, 응집 및 안정성 프로파일을 기초로 하여 추가의 특성 결정(표 1)을 위해 여러 클론을 선택하였다. 모 sdAb는 표 1에서 항-PSMA wt sdAb.6his로 제시된다.
표 1: 인간 PSMA에 대한 여러 PSMA 결합 단백질의 결합 친화도(Kd)

실시예 2: 예시적인 PSMA 표적화 삼중 특이적 항원 결합 분자의 결합 및 세포독성 활성을 평가하는 방법
단백질 생산
리더 서열을 앞에 두고 6x 히스티딘 태그(서열 번호 33)을 뒤에 두면서 삼중 특이적 분자의 서열을 포유동물 발현 벡터 pcDNA 3.4(Invitrogen) 내에 클로닝하였다. Expi293F 세포(Life Technologies A14527)를 Expi293 배지 중의 0.2 내지 8 x 1e6 세포/ml로 최적 성장 플라스크(Thomson) 내의 현탁액으로 유지하였다. 정제된 플라스미드 DNA를 Expi293 발현 시스템 키트(Life Technologies, A14635) 프로토콜에 따라 Expi293F 세포 내로 형질감염시켰고, 형질감염 후 4일 내지 6일 동안 유지하였다. 조건화된 배지를 친화도 및 탈염 크로마토그래피에 의해 부분적으로 정제하였다. 이어서, 삼중 특이적 단백질을 이온 교환에 의해 폴리싱하거나, 대안적으로 아미콘 울트라(Amicon Ultra) 원심분리 여과 유닛(EMD Millipore)으로 농축하고, 수퍼덱스(Superdex) 200 크기 배제 매질(GE Healthcare)에 적용하고, 부형제를 함유하는 중성 버퍼에 용해시켰다. 분획 풀링(pooling) 및 최종 순도를 SDS-PAGE 및 분석 SEC에 의해 평가하였다.
친화도 측정
모든 결합 도메인 분자의 친화도를 Octet 기기를 사용하여 생물층 간섭 측정에 의해 측정하였다.
PSMA 친화도는 항-인간 IgG Fc 바이오센서 상에 인간 PSMA-Fc 단백질(100 nM)을 120초 동안 로딩한 후, 60초의 기준선을 두고, 그 후 삼중 특이적 분자의 계열 희석액 중에서 센서 팁을 180초 동안 인큐베이팅하여 회합을 측정하고, 이어서 50초 동안 해리를 측정함으로써 측정하였다. EGFR 및 CD3 친화도는 인간 EGFR-Fc 단백질 또는 인간 CD3-Flag-Fc 단백질(100 nM)을 각각 항-인간 IgG Fc 바이오센서에 120초 동안 로딩하고, 이어서 60초의 기준선을 두고, 그 후 삼중 특이적 분자의 계열 희석액 중에서 센서 팁을 180초 동안 인큐베이팅하여 회합을 측정하고, 이어서 300초 동안 해리를 측정함으로써 측정하였다. 인간 혈청 알부민(HSA)에 대한 친화도는 비오티닐화 알부민을 스트렙타비딘 바이오센서에 로딩한 후, CD3 친화도 측정에서와 동일한 동역학 파라미터에 따라 측정하였다. 모든 단계들은 포스페이트 완충 염수 내의 0.25% 카제인에서 30℃에서 수행되었다.
세포독성 검정
T 세포로 하여금 종양 세포를 사멸시키도록 유도할 수 있는, 삼중특이적 분자를 비롯한 T 세포 결합물(engager)의 능력을 측정하기 위해, 인간 T 세포 의존성 세포성 세포독성(TDCC) 검정을 사용하였다(Nazarian et al. 2015. J Biomol Screen. 20:519-27). 이 검정에서, T 세포 및 표적 암세포 세포주를 384웰 플레이트에서 10:1의 비로 함께 혼합하고, 다양한 양의 T 세포 결합물을 첨가하였다. 48시간 후, T 세포를 세척 제거하여, T 세포에 의해 사멸되지 않은 표적 세포를 플레이트에 부착된 상태로 남겨두었다. 남아있는 생존 세포를 정량하기 위해, CellTiter-Glo® 발광 세포 생존성 검정(Promega)를 이용하였다. 일부 경우에는, 표적 세포가 루시퍼라제를 발현하도록 조작된다. 이러한 경우, 표적 세포의 생존성은 STEADYGLO® 시약 (Promega)을 사용하여 발광 루시퍼라제 검정을 수행함으로써 평가되며, 생존성은 루시퍼라제 활성의 양에 직접 비례한다.
안정성 검정
삼중 특이적 결합 단백질의 안정성을 비인간 영장류 혈청의 존재 하에 저농도에서 평가하였다. TriTAC는 시노몰거스 혈청(BioReclamationIVT)에 33 ㎍/ml로 희석하고, 37℃에서 2일 동안 인큐베이팅하거나 또는 5회의 동결/해동 사이클을 실시하였다. 처리 후, 샘플은 세포독성(TDCC) 검정에서 평가되었고, 그의 잔류 활성을 처리되지 않은 저장 용액과 비교하였다.
이종이식편 검정
삼중 특이적 결합 단백질의 생체 내 효능을 이종이식 실험(Crown Bioscience, Taicang)에서 평가하였다. 통상적인 감마 사슬이 결핍된 NOD/SCID 마우스(NCG, 난징 대학(Nanjing University)의 Model Animal Research Center)에게 제0일에 5e6 22Rv1 인간 전립선암 세포와 5e6 휴지기 인간 T 세포(건강한 인간 공여자로부터 단리됨)의 혼합물을 접종하였다. 마우스를 3개의 군으로 무작위 배정하고, 비히클, 0.5 mg/kg PSMA TriTAC C324 또는 0.5 mg/kg PSMA BiTE로 처리하였다. 처리제는 i.v. 볼러스 주입을 통해 10일 동안 매일 투여되었다. 매일 이환율 및 사망률을 조사하였다. 종양의 부피는 캘리퍼스로 매주 2회 결정하였다. 연구는 30일 후에 종료되었다.
PK 검정
이 연구의 목적은 정맥 내 주사 후 삼중 특이적 결합 단백질의 단일 용량 약동학을 평가하는 것이었다. 군당 2마리(수컷 1마리, 암컷 1마리)의 실험적으로 나이브한 시노몰거스 원숭이에게 약 1분에 걸쳐 느린 IV 볼러스를 통해 화합물을 투여하였다. 용량 투여 후, 케이지 측면 관찰은 1일 1회 실시하였고, 체중을 매주 기록하였다. 혈액 샘플을 수집하고, 용량 투여 후 21일에 걸쳐 약동학적 분석을 위해 혈청으로 처리하였다.
시험 물질의 농도는 전계 발광 판독(Meso Scale Diagnostics, 미국 록빌 소재)으로 원숭이 혈청으로부터 결정하였다. 고정된 재조합 CD3이 존재하는 96웰 플레이트를 사용하여 분석물을 포획하였다. 검출은 제조자의 지시에 따라 MSD 판독기에서 술포 태그 부착된 재조합 PSMA로 수행하였다.
실시예 3: CD3 친화도가 예시적인 PSMA 표적화 삼중 특이적 분자의 특성에 미치는 영향의 평가
CD3 친화도 변경의 효과를 입증하기 위해 별개의 CD3 결합 도메인을 갖는 PSMA 표적화 삼중 특이적 분자를 연구하였다. 예시적인 PSMA 표적화 삼중 특이적 분자는 도 1에 도시된다. 표 2는 3개의 결합 파트너(PSMA, CD3, HSA)에 대한 각각의 분자의 친화도를 제시한다. 친화도는 Octet 기기(Pall Forte Bio)를 사용하는 생물층 간섭 측정에 의해 측정하였다. 감소된 CD3 친화도는 T 세포 매개 세포 독성 측면에서 효력의 상실을 초래한다(도 2a-c). 이들 삼중 특이적 분자의 약동학적 성질은 시노몰거스 원숭이에서 평가되었다. TriTAC C236과 같은 CD3에 대한 높은 친화도를 갖는 분자는 약 90시간의 말단 반감기를 갖는다(도 3). T 세포 상의 CD3에 결합하는 능력이 변경되었지만, 도 4에 도시된 상이한 CD3 친화도를 갖는 2개의 분자의 말단 반감기는 매우 유사하다. 그러나, 감소된 CD3 친화도는 보다 큰 부피의 분포를 유도하는 것으로 보이고, 이것은 T 세포에 의한 삼중 특이적 분자의 감소된 격리와 일치한다. 연구 기간 동안 유해한 임상적 관찰 또는 체중 변화는 존재하지 않았다.
표 2: 인간 및 시노몰거스 항원에 대한 결합 친화도

실시예 4: 예시적인 PSMA 표적화 삼중 특이적 분자의 특성에 대한 PSMA 친화도의 영향의 평가
PSMA 친화도 변경의 효과를 입증하기 위해 별개의 PSMA 결합 도메인을 갖는 PSMA 표적화 삼중 특이적 분자를 연구하였다. 표 3은 3개의 결합 파트너(PSMA, CD3, HSA)에 대한 각각의 분자의 친화도를 제시한다. 감소된 PSMA 친화도는 T 세포 매개 세포 독성 측면에서 효력의 상실을 초래한다(도 5a-c).
표 3: 인간 및 시노몰거스 항원에 대한 결합 친화도

실시예 5: 예시적인 PSMA 표적화 삼중 특이적 분자의 생체 내 효능
예시적인 PSMA 표적화 삼중 특이적 분자 C324를 마우스에서 종양의 성장을 억제하는 그의 능력에 대해 평가하였다. 이 실험에서, 인간 T 세포로 재구성된 면역 손상 마우스에게 PSMA를 발현하는 인간 전립선 종양 세포(22Rv1)를 피하 접종하고, PSMA 표적화 BiTE 또는 TriTAC 분자로 0.5 mg/kg i.v.로 10일 동안 매일 처리하였다. 종양 성장은 30일 동안 측정되었다. 실험 과정 동안, 삼중 특이적 분자는 BiTE 분자와 대등한 효능으로 종양 성장을 억제할 수 있었다(도 6).
실시예 6: 예시적인 PSMA 표적화 삼중 특이적 분자의 특이성
PSMA 표적화 TriTAC 분자의 특이성을 평가하기 위해, 종양 세포를 사멸시키기 위해 T 세포를 유도하는 능력을 PSMA에 대해 음성인 종양 세포로 시험하였다(도 7a). EGFR 표적화 TriTAC 분자는 양성 대조군으로서, GFP 표적화 TriTAC 분자는 음성 대조군으로서 사용되었다. 별개의 PSMA 결합 도메인을 갖는 3개의 모든 TriTAC는 PSMA 양성 세포주 LNCaP에 대해 예상되는 활성을 나타내었지만(도 7b), PSMA 음성 종양 세포주 KMS12BM 및 OVCAR8에서는 EC50에 도달하지 않았다(도 7c 및 7d). EC50은 표 4에 요약되어 있다. 매우 높은 TriTAC 농도(> 1 nM)에서, TriTAC C362 및 C363에 대해 일부 제한된 표적을 벗어난 세포 사멸이 관찰될 수 있지만, C364는 시험된 임의의 조건 하에서 유의한 세포 사멸을 보이지 않았다.
표 4: 항원 양성 및 음성 종양 세포주에서 TriTAC 분자의 세포 사멸 활성(EC50 [pM])

실시예 7: 스트레스 시험 및 단백질 안정성
4개의 PSMA 표적화 삼중 특이적 분자를 저농도(33.3 ㎍/ml)로 시노몰거스 혈청 내에서 48시간 동안 인큐베이팅하거나 또는 시노몰거스 혈청에서 5회의 동결/해동 사이클을 실시하였다. 처리 후, TriTAC 분자의 생체 활성을 세포 사멸 검정에서 평가하고, 스트레스를 받지 않은 샘플("양성 대조군", 도 8a-d)과 비교하였다. 모든 분자는 세포 사멸 활성의 대부분을 유지하였다. TriTAC C362는 가장 스트레스 저항력이 강했으며, 여기에서 시험한 조건 하에서는 어떠한 활동도 잃지 않는 것으로 나타났다.
실시예 8: 이종이종 종양 모델
예시적인 PSMA 표적화 삼중 특이적 단백질을 이종이식 모델에서 평가한다.
수컷 면역 결핍 NCG 마우스에게 5 x 106개의 22Rv1 세포를 우측 등쪽 옆구리에 피하 접종하였다. 종양이 100 내지 200 mm3에 도달하면, 동물을 3개의 치료군으로 배분하였다. 군 2 및 3(각각 8마리의 동물)에게 1.5x107개의 활성화된 인간 T 세포를 복강 내로 주사하였다. 3일 후, 계속해서 군 3의 동물들을 본 개시내용의 예시적인 50 ㎍의 PSMA 삼중 특이적 항원 결합 단백질의 총 9회의 정맥 내 투여로 처리하였다(qdx9d). 군 1 및 2는 비히클만으로 처리하였다. 체중 및 종양 부피를 30일 동안 결정하였다. PSMA 삼중 특이적 항원 결합 단백질로 처리된 마우스에서의 종양 성장은 각각의 비히클로 처리된 대조군에서의 종양 성장에 비해 유의하게 감소될 것으로 예상된다.
실시예 9: 전립선암 환자에 대한 예시적인 PSMA 삼중 특이적 항원 결합 단백질의 투여를위한 개념 증명 임상 시험 프로토콜
이것은 전립선암 치료제로서 실시예 1의 PSMA 삼중 특이적 항원 결합 단백질을 연구하기 위한 I/II상 임상 시험이다.
연구 결과:
1차: 이전의 실시예의 PSMA 표적화 삼중 특이적 단백질의 최대 허용 용량.
2차: 이전의 실시예의 PSMA 표적화 삼중 특이적 단백질의 시험관 내 반응이 임상 반응과 연관되어 있는지를 확인하기 위함.
I상
최대 허용 용량(MTD: maximum tolerated dose)은 시험의 I상 섹션에서 결정될 것이다.
1.1 최대 허용 용량(MTD)은 시험의 I상 섹션에서 결정될 것이다.
1.2 적격성 기준을 충족하는 환자가 이전 실시예의 PSMA 표적화 삼중특이적 단백질의 시험에 참여할 것이다.
1.3 목표는 참여자에서 심각한 또는 관리 불가능한 부작용 없이 안전하게 투여될 수 있는 이전 실시예의 PSMA 표적화 삼중 특이적 단백질의 최고 용량을 확인하는 것이다. 해당 용량은 이전에 연구에 등록한 참여자의 수 및 그 용량을 얼마나 잘 견딜 수 있었는지에 따라 달라질 것이다. 모든 참여자가 동일한 용량을 투여받는 것은 아닐 것이다.
II상
2.1 후속 II상 섹션은 이전 실시예의 PSMA 표적화 삼중특이적 단백질 치료제를 사용한 치료가 적어도 20%의 반응률을 나타내는지를 결정하는 것을 목표로 하여 MTD로 치료될 것이다.
II상의 1차 결과 --- 이전 실시예의 PSMA 표적화 삼중특이적 단백질의 치료가 임상 반응(폭발 반응, 미미한 반응, 부분 반응 또는 완전 반응)을 달성한 환자의 적어도 20%에서 나타나는지를 결정인하기 위함.
적격성:
2001년부터 2007년까지의 현행 세계보건기구 분류(World Health Organisation Classification)에 따라 조직 검사로 확인된 새로 진단된 침습성 전립선암
임의의 단계의 질환
독세탁셀 또는 프레드니손으로 치료함(+/- 수술)
연령: 18세 이상
카노프스키 수행 상태(Karnofsky performance status) ≥ 50% 또는 ECOG 수행 상태 0-2
기대 여명 ≥ 6주
실시예 10: 상이한 공여자로부터의 PSMA 발현 세포주 및 T 세포의 패널을 사용하는 재유도된 T 세포 사멸 검정에서 예시적인 PSMA 항원 결합 단백질(PSMA 표적화 TriTAC 분자)의 활성
이 연구는 예시적인 PSMA 삼중 특이적 항원 결합 단백질의 활성이 LNCaP 세포 또는 단일 세포 공여자로 제한되지 않음을 입증하기 위해 수행되었다.
재유도된 T 세포 사멸 시험은 4개의 상이한 공여자로부터의 T 세포 및 인간 PSMA 발현 전립선암 세포주 VCaP, LNCaP, MDAPCa2b 및 22Rv1을 사용하여 수행하였다. 한 가지 예외를 제외하고, PSMA 삼중특이적 항원 결합 단백질은 표 5에 제시된 바와 같이, 0.2 내지 1.5 pM의 EC50을 갖는 모든 공여자로부터의 T 세포를 사용하여 이들 암세포주의 사멸을 유도할 수 있었다. 전립선암 세포주 22 Rv1 및 공여자 24에서, 사멸이 거의 또는 전혀 관찰되지 않았다(데이터는 나타내지 않음). 공여자 24는 또한 MDAPCa2b 세포주의 약 50%의 사멸을 초래하였지만, 다른 3개의 공여자로부터의 T 세포는 이 세포주의 거의 완전한 사멸을 초래하였다(데이터는 나타내지 않음). 대조군 검정은 PSMA 삼중 특이적 항원 결합 단백질에 의한 사멸이 PSMA 특이적임을 입증하였다. PSMA 발현 세포를 PSMA 대신에 녹색 형광 단백질(GFP)을 표적화하는 대조군 삼중 특이적 단백질로 처리하였을 때, 사멸은 관찰되지 않았다(데이터는 나타내지 않음). 이와 유사하게, PSMA 삼중 특이적 항원 결합 단백질은 PSMA 발현이 결여된 세포주, NCI-1563 및 HCT116에서 불활성이었고, 이것은 또한 표 5에 나타내었다.
표 5: 6개의 인간 암세포주 및 4개의 상이한 T 세포 공여자를 사용한 TDCC 검정법의 EC50 값

실시예 11: 재유도된 T 세포 사멸 검정에서 예시적인 PSMA 삼중 특이적 항원 결합 단백질(PSMA 표적화 TriTAC 분자)에 의한 사이토카인 발현의 자극
이 연구는 활성화된 T 세포에 의한 검정 배지 내로의 사이토카인 분비를 측정함으로써 재유도된 T 세포 사멸 검정 동안 예시적인 PSMA 삼중 특이적 항원 결합 단백질에 의한 T 세포의 활성화를 입증하기 위해 수행되었다.
상기 실시예 9에서 설명된 바와 같이, 재유도된 T 세포 사멸 검정으로부터 수집된 조건화된 매체를 사이토카인 TNFα 및 INFγ의 발현에 대해 분석하였다. 사이토카인은 AlphaLISA 검정(Perkin-Elmer)을 사용하여 측정되었다. 4개의 상이한 공여자 및 4개의 PSMA 발현 세포주 LNCaP, VCaP, MDAPCa2b 및 22Rv1로부터의 T 세포에 대해 PSMA 항원 결합 단백질을 부가하자 TNFα의 수준이 증가하였다. 조건화된 배지에서의 TNFα 발현 및 IFNγ 발현 수준에 대한 결과를 각각 표 6 및 표 7에 나타내었다. 이들 사이토카인의 PSMA 항원 결합 단백질 유도 발현에 대한 EC50 값은 3 내지 15 pM 범위이었다. 증가된 사이토카인 수준은 GFP를 표적화하는 대조군 삼중 특이적 단백질에서는 관찰되지 않았다. 이와 유사하게, PSMA 발현이 결여된 2개의 세포주 HCT116 및 NCI-H1563을 사용하여 검정을 수행한 경우, PSMA HTS TriTAC 역시 TNFα 또는 IFNγ 발현을 증가시키지 않았다.
표 6: 4개의 상이한 공여자로부터의 6개의 인간 암 세포주 및 T 세포를 이용한 PSMA 삼중 특이적 항원 결합 단백질 TDCC 검정에서 배지 내의 TNFα 발현에 대한 EC50 값

표 7: 4개의 상이한 공여자로부터의 6개의 인간 암 세포주 및 T 세포를 이용한 PSMA 삼중 특이적 항원 결합 단백질 TDCC 검정에서 배지 내의 IFNγ 발현에 대한 EC50 값

실시예 12: 시노몰거스 원숭이로부터의 T 세포를 사용한 재유도 T 세포 사멸 검정(TDCC)에서 예시적인 PSMA 삼중 특이적 항원 결합 단백질(PSMA 표적화 TriTAC)의 활성
이 연구는 PSMA 발현 세포주를 사멸시키기 위해 시노몰거스 원숭이로부터의 T 세포를 유도하는 예시적인 PSMA 삼중 특이적 항원 결합 단백질의 능력을 시험하기 위해 수행되었다.
TDCC 검정은 시노몰거스 원숭이로부터의 말초 혈액 단핵 세포(PBMC)를 사용하여 설정되었다. cyno PBMC를 10:1의 비율로 LNCaP 세포에 첨가하였다. PSMA 삼중 특이적 항원 결합 단백질이 11 pM의 EC50 값으로 cyno PBMC에 의한 LNCaP의 사멸을 재유도하는 것이 관찰되었다. 그 결과를 도 9a에 제시한다. 이러한 결과를 확인하기 위해, 제2 세포주 MDAPCa2b를 사용하고, 제2 시노몰거스 원숭이 공여자로부터의 PBMC를 시험하였다. 2.2 pM의 EC50 값으로 표적 세포의 재유도된 사멸이 관찰되었다. 그 결과를 도 9b에 제시한다. 사멸은 GFP를 표적화하는 음성 대조군 삼중 특이적 단백질을 사용한 경우에는 관찰되지 않았기 때문에, 사멸은 PSMA 삼중 특이적 항원 결합 단백질의 항-PMSA 아암(arm)에 특이적이었다. 이러한 데이터는 PSMA 항원 결합 삼중 특이적 단백질이 인간 PSMA를 발현하는 표적 세포를 사멸시키기 위해 시노몰거스 T 세포를 유도할 수 있음을 입증한다.
실시예 13: 예시적인 PSMA 삼중 특이적 항원 결합 단백질(PSMA 표적화 TriTAC 분자)을 사용한 재유도된 T 세포 사멸 검정에서 T 세포 활성화 마커의 발현
이 연구는 예시적인 PSMA 삼중 특이적 항원 결합 단백질이 표적 세포를 사멸시키도록 T 세포를 유도할 때 T 세포가 활성화되는지의 여부를 평가하기 위해 수행되었다.
검정은 상기 실시예에서 설명된 재유도된 T 세포 사멸 검정을 위한 조건을 사용하여 설정되었다. T 세포 활성화는 유동 세포 계측법을 사용하여 T 세포의 표면에서 CD25 및 CD69의 발현을 측정함으로써 평가하였다. PSMA 삼중 특이적 항원 결합 단백질을 정제된 인간 T 세포와 전립선암 세포주 VCaP의 10:1 혼합물에 첨가하였다. 증가하는 양의 PSMA 삼중 특이적 항원 결합 단백질을 첨가하면, 증가된 CD69 발현 및 CD25 발현이 도 10에 나타낸 바와 같이 관찰되었다. EC50 값은 CD69에 대해 0.3 pM, CD25에 대해 0.2 pM이었다. GFP를 표적화하는 삼중 특이적 단백질이 음성 대조군으로서 이들 검정에 포함되었고, CD69 또는 CD25 발현의 증가는 도 10에 도시된 바와 같이 GFP 표적화 삼중 특이적 단백질에서 거의 또는 전혀 관찰되지 않았다.
실시예 14: PSMA 발현 표적 세포의 존재 하에 예시적인 PSMA 삼중 특이적 항원 결합 단백질(PSMA 표적화 TriTAC 분자)에 의한 T 세포 증식의 자극
이 연구는 표적 세포를 사멸시키기 위해 T 세포를 재유도할 때 예시적인 PSMA 삼중 특이적 항원 결합 단백질이 T 세포를 활성화할 수 있음을 입증하는 추가의 방법으로 사용되었다.
T 세포 증식 검정은 상기 설명한 바와 같이 LNCaP 표적 세포를 사용하는 T 세포 재유도된 사멸 검정의 조건을 사용하고, 72시간에 존재하는 T 세포의 수를 측정함으로써 설정되었다. 예시적인 PSMA 삼중 특이적 항원 결합 단백질은 0.5 pM의 EC50 값으로 증식을 자극하였다. 음성 대조군으로서, GFP를 표적화하는 삼중 특이적 단백질이 검정에 포함되었고, 이 단백질에 의한 증가된 증식은 관찰되지 않았다. T 세포 증식 검정의 결과는 도 11에 도시된다.
실시예 15: 예시적인 PSMA 삼중 특이적 항원 결합 단백질(PSMA 표적화 TriTAC 분자 Z2)에 의한 LNCaP 세포의 재유도된 T 세포 사멸
이 연구는 서열 번호 156에 제시된 서열을 갖는 예시적인 PSMA 삼중 특이적 항원 결합 단백질이 LNCaP 세포주를 사멸시키도록 T 세포를 재유도하는 능력을 시험하기 위해 수행되었다.
상기 실시예에서 설명된 바와 같이 설정된 TDCC 검정에서, PSMA Z2 TriTAC(서열 번호 156) 단백질은 도 12에 나타낸 바와 같이 0.8 pM의 EC50 값으로 사멸을 재유도하였다.
표 8



표 9: CD3 결합 도메인 서열






표 10: HSA 결합 도메인 서열


표 11: PSMA 표적화 삼중 특이적 단백질 서열



표 12: 예시적인 프레임워크 서열

SEQUENCE LISTING
<110> HARPOON THERAPEUTICS, INC.
<120> PROSTATE SPECIFIC MEMBRANE ANTIGEN BINDING PROTEIN
<130> 47517-707.601
<140>
<141>
<150> 62/426,086
<151> 2016-11-23
<160> 168
<170> PatentIn version 3.5
<210> 1
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (6)..(6)
<223> Glu, Pro, Ser, His, Thr, Asp, Gly, Lys, Gln or Tyr
<220>
<221> MOD_RES
<222> (8)..(8)
<223> Glu, Pro, Ser, His, Thr, Asp, Gly, Lys, Gln or Tyr
<400> 1
Arg Phe Met Ile Ser Xaa Tyr Xaa Met His
1 5 10
<210> 2
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (1)..(1)
<223> Glu, Pro, Ser, His, Thr, Asp, Gly, Lys, Gln or Tyr
<220>
<221> MOD_RES
<222> (6)..(7)
<223> Glu, Pro, Ser, His, Thr, Asp, Gly, Lys, Gln or Tyr
<220>
<221> MOD_RES
<222> (13)..(13)
<223> Glu, Pro, Ser, His, Thr, Asp, Gly, Lys, Gln or Tyr
<400> 2
Xaa Ile Asn Pro Ala Xaa Xaa Thr Asp Tyr Ala Glu Xaa Val Lys Gly
1 5 10 15
<210> 3
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (2)..(2)
<223> Glu, Pro, Ser, His, Thr, Asp, Gly, Lys, Gln or Tyr
<400> 3
Asp Xaa Tyr Gly Tyr
1 5
<210> 4
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 4
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser
100 105 110
<210> 5
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 5
Arg Phe Met Ile Ser Glu Tyr His Met His
1 5 10
<210> 6
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 6
Arg Phe Met Ile Ser Pro Tyr Ser Met His
1 5 10
<210> 7
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 7
Arg Phe Met Ile Ser Pro Tyr His Met His
1 5 10
<210> 8
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 8
Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 9
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 9
Thr Ile Asn Pro Ala Lys Thr Thr Asp Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 10
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 10
Thr Ile Asn Pro Ala Gly Gln Thr Asp Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 11
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 11
Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Tyr Val Lys Gly
1 5 10 15
<210> 12
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 12
Asp Ile Asn Pro Ala Lys Thr Thr Asp Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 13
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 13
Asp Ile Asn Pro Ala Gly Gln Thr Asp Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 14
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 14
Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Tyr Val Lys Gly
1 5 10 15
<210> 15
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 15
Asp Ser Tyr Gly Tyr
1 5
<210> 16
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 16
Arg Phe Met Ile Ser Glu Tyr Ser Met His
1 5 10
<210> 17
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 17
Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys Gly
1 5 10 15
<210> 18
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 18
Asp Gly Tyr Gly Tyr
1 5
<210> 19
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 19
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 20
<211> 750
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 20
Met Trp Asn Leu Leu His Glu Thr Asp Ser Ala Val Ala Thr Ala Arg
1 5 10 15
Arg Pro Arg Trp Leu Cys Ala Gly Ala Leu Val Leu Ala Gly Gly Phe
20 25 30
Phe Leu Leu Gly Phe Leu Phe Gly Trp Phe Ile Lys Ser Ser Asn Glu
35 40 45
Ala Thr Asn Ile Thr Pro Lys His Asn Met Lys Ala Phe Leu Asp Glu
50 55 60
Leu Lys Ala Glu Asn Ile Lys Lys Phe Leu Tyr Asn Phe Thr Gln Ile
65 70 75 80
Pro His Leu Ala Gly Thr Glu Gln Asn Phe Gln Leu Ala Lys Gln Ile
85 90 95
Gln Ser Gln Trp Lys Glu Phe Gly Leu Asp Ser Val Glu Leu Ala His
100 105 110
Tyr Asp Val Leu Leu Ser Tyr Pro Asn Lys Thr His Pro Asn Tyr Ile
115 120 125
Ser Ile Ile Asn Glu Asp Gly Asn Glu Ile Phe Asn Thr Ser Leu Phe
130 135 140
Glu Pro Pro Pro Pro Gly Tyr Glu Asn Val Ser Asp Ile Val Pro Pro
145 150 155 160
Phe Ser Ala Phe Ser Pro Gln Gly Met Pro Glu Gly Asp Leu Val Tyr
165 170 175
Val Asn Tyr Ala Arg Thr Glu Asp Phe Phe Lys Leu Glu Arg Asp Met
180 185 190
Lys Ile Asn Cys Ser Gly Lys Ile Val Ile Ala Arg Tyr Gly Lys Val
195 200 205
Phe Arg Gly Asn Lys Val Lys Asn Ala Gln Leu Ala Gly Ala Lys Gly
210 215 220
Val Ile Leu Tyr Ser Asp Pro Ala Asp Tyr Phe Ala Pro Gly Val Lys
225 230 235 240
Ser Tyr Pro Asp Gly Trp Asn Leu Pro Gly Gly Gly Val Gln Arg Gly
245 250 255
Asn Ile Leu Asn Leu Asn Gly Ala Gly Asp Pro Leu Thr Pro Gly Tyr
260 265 270
Pro Ala Asn Glu Tyr Ala Tyr Arg Arg Gly Ile Ala Glu Ala Val Gly
275 280 285
Leu Pro Ser Ile Pro Val His Pro Ile Gly Tyr Tyr Asp Ala Gln Lys
290 295 300
Leu Leu Glu Lys Met Gly Gly Ser Ala Pro Pro Asp Ser Ser Trp Arg
305 310 315 320
Gly Ser Leu Lys Val Pro Tyr Asn Val Gly Pro Gly Phe Thr Gly Asn
325 330 335
Phe Ser Thr Gln Lys Val Lys Met His Ile His Ser Thr Asn Glu Val
340 345 350
Thr Arg Ile Tyr Asn Val Ile Gly Thr Leu Arg Gly Ala Val Glu Pro
355 360 365
Asp Arg Tyr Val Ile Leu Gly Gly His Arg Asp Ser Trp Val Phe Gly
370 375 380
Gly Ile Asp Pro Gln Ser Gly Ala Ala Val Val His Glu Ile Val Arg
385 390 395 400
Ser Phe Gly Thr Leu Lys Lys Glu Gly Trp Arg Pro Arg Arg Thr Ile
405 410 415
Leu Phe Ala Ser Trp Asp Ala Glu Glu Phe Gly Leu Leu Gly Ser Thr
420 425 430
Glu Trp Ala Glu Glu Asn Ser Arg Leu Leu Gln Glu Arg Gly Val Ala
435 440 445
Tyr Ile Asn Ala Asp Ser Ser Ile Glu Gly Asn Tyr Thr Leu Arg Val
450 455 460
Asp Cys Thr Pro Leu Met Tyr Ser Leu Val His Asn Leu Thr Lys Glu
465 470 475 480
Leu Lys Ser Pro Asp Glu Gly Phe Glu Gly Lys Ser Leu Tyr Glu Ser
485 490 495
Trp Thr Lys Lys Ser Pro Ser Pro Glu Phe Ser Gly Met Pro Arg Ile
500 505 510
Ser Lys Leu Gly Ser Gly Asn Asp Phe Glu Val Phe Phe Gln Arg Leu
515 520 525
Gly Ile Ala Ser Gly Arg Ala Arg Tyr Thr Lys Asn Trp Glu Thr Asn
530 535 540
Lys Phe Ser Gly Tyr Pro Leu Tyr His Ser Val Tyr Glu Thr Tyr Glu
545 550 555 560
Leu Val Glu Lys Phe Tyr Asp Pro Met Phe Lys Tyr His Leu Thr Val
565 570 575
Ala Gln Val Arg Gly Gly Met Val Phe Glu Leu Ala Asn Ser Ile Val
580 585 590
Leu Pro Phe Asp Cys Arg Asp Tyr Ala Val Val Leu Arg Lys Tyr Ala
595 600 605
Asp Lys Ile Tyr Ser Ile Ser Met Lys His Pro Gln Glu Met Lys Thr
610 615 620
Tyr Ser Val Ser Phe Asp Ser Leu Phe Ser Ala Val Lys Asn Phe Thr
625 630 635 640
Glu Ile Ala Ser Lys Phe Ser Glu Arg Leu Gln Asp Phe Asp Lys Ser
645 650 655
Asn Pro Ile Val Leu Arg Met Met Asn Asp Gln Leu Met Phe Leu Glu
660 665 670
Arg Ala Phe Ile Asp Pro Leu Gly Leu Pro Asp Arg Pro Phe Tyr Arg
675 680 685
His Val Ile Tyr Ala Pro Ser Ser His Asn Lys Tyr Ala Gly Glu Ser
690 695 700
Phe Pro Gly Ile Tyr Asp Ala Leu Phe Asp Ile Glu Ser Lys Val Asp
705 710 715 720
Pro Ser Lys Ala Trp Gly Glu Val Lys Arg Gln Ile Tyr Val Ala Ala
725 730 735
Phe Thr Val Gln Ala Ala Ala Glu Thr Leu Ser Glu Val Ala
740 745 750
<210> 21
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 21
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 22
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 22
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 23
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 23
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Lys Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 24
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 24
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Pro Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 25
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 25
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Gln Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 26
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 26
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Tyr Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 27
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 27
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Lys Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 28
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 28
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Pro Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 29
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 29
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Gly Gln Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 30
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 30
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Tyr Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
100 105 110
<210> 31
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 31
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser
100 105 110
<210> 32
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 32
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser
100 105 110
<210> 33
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
6xHis tag
<400> 33
His His His His His His
1 5
<210> 34
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 34
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Ala Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Gln Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Ala Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Ala Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Phe Leu Val Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 35
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 35
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Glu Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Lys Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Phe Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Asp Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 36
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 36
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser His Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Tyr Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Ser Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Ile Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 37
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 37
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Met Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Ser Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Thr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Phe Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Leu Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Ser Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 38
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 38
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Thr Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Lys Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Pro Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Val Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Glu Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 39
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 39
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Tyr Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Glu Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Pro Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Lys Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Glu Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 40
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 40
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Asn Thr Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Glu Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Thr Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Tyr Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Tyr Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 41
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 41
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ala Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Gln Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Asp Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Ile Lys Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 42
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 42
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Ala Val Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Glu Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Ile Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 43
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 43
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Pro Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Asn Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Asn Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Lys Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Met Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Ala Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 44
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 44
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Gly Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Glu Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Pro Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Val Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Glu Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 45
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 45
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Asn Thr Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asp Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr His Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Val Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 46
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 46
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Asn Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Gly Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Tyr Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Phe Asn Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ala Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 47
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 47
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Glu Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Glu Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Leu Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Ser Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Phe Gly Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 48
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 48
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Lys Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 49
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 49
Gly Phe Thr Phe Asn Lys Tyr Ala Met Asn
1 5 10
<210> 50
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 50
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys
<210> 51
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 51
His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 52
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 52
Leu Pro Glu Thr Gly
1 5
<210> 53
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 53
Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 54
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 54
Gly Thr Lys Phe Leu Ala Pro
1 5
<210> 55
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 55
Val Leu Trp Tyr Ser Asn Arg Trp Val
1 5
<210> 56
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 56
Gly Asn Thr Phe Asn Lys Tyr Ala Met Asn
1 5 10
<210> 57
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 57
Gly Phe Glu Phe Asn Lys Tyr Ala Met Asn
1 5 10
<210> 58
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 58
Gly Phe Met Phe Asn Lys Tyr Ala Met Asn
1 5 10
<210> 59
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 59
Gly Phe Thr Tyr Asn Lys Tyr Ala Met Asn
1 5 10
<210> 60
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 60
Gly Phe Thr Phe Asn Asn Tyr Ala Met Asn
1 5 10
<210> 61
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 61
Gly Phe Thr Phe Asn Gly Tyr Ala Met Asn
1 5 10
<210> 62
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 62
Gly Phe Thr Phe Asn Thr Tyr Ala Met Asn
1 5 10
<210> 63
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 63
Gly Phe Thr Phe Asn Glu Tyr Ala Met Asn
1 5 10
<210> 64
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 64
Gly Phe Thr Phe Asn Lys Tyr Pro Met Asn
1 5 10
<210> 65
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 65
Gly Phe Thr Phe Asn Lys Tyr Ala Val Asn
1 5 10
<210> 66
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 66
Gly Phe Thr Phe Asn Lys Tyr Ala Ile Asn
1 5 10
<210> 67
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 67
Gly Phe Thr Phe Asn Lys Tyr Ala Leu Asn
1 5 10
<210> 68
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 68
Arg Ile Arg Ser Gly Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys
<210> 69
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 69
Arg Ile Arg Ser Lys Ser Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys
<210> 70
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 70
Arg Ile Arg Ser Lys Tyr Asn Lys Tyr Ala Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys
<210> 71
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 71
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Glu Thr Tyr Tyr Ala Asp Ser
1 5 10 15
Val Lys
<210> 72
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 72
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Glu Tyr Ala Asp Ser
1 5 10 15
Val Lys
<210> 73
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 73
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Lys Asp Ser
1 5 10 15
Val Lys
<210> 74
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 74
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Glu
1 5 10 15
Val Lys
<210> 75
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 75
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ala
1 5 10 15
Val Lys
<210> 76
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 76
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Gln
1 5 10 15
Val Lys
<210> 77
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 77
Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Asp
1 5 10 15
Val Lys
<210> 78
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 78
His Ala Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 79
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 79
His Thr Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 80
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 80
His Gly Asn Phe Asn Asn Ser Tyr Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 81
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 81
His Gly Asn Phe Gly Asp Ser Tyr Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 82
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 82
His Gly Asn Phe Gly Asn Ser His Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 83
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 83
His Gly Asn Phe Gly Asn Ser Pro Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 84
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 84
His Gly Asn Phe Gly Asn Ser Gln Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 85
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 85
His Gly Asn Phe Gly Asn Ser Leu Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 86
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 86
His Gly Asn Phe Gly Asn Ser Gly Ile Ser Tyr Trp Ala Tyr
1 5 10
<210> 87
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 87
His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr Trp Ala Thr
1 5 10
<210> 88
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 88
Ala Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 89
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 89
Gly Glu Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 90
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 90
Gly Ser Tyr Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 91
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 91
Gly Ser Ser Phe Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 92
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 92
Gly Ser Ser Lys Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 93
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 93
Gly Ser Ser Ser Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 94
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 94
Gly Ser Ser Thr Gly Tyr Val Thr Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 95
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 95
Gly Ser Ser Thr Gly Ala Val Val Ser Gly Asn Tyr Pro Asn
1 5 10
<210> 96
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 96
Gly Ser Ser Thr Gly Ala Val Thr Asp Gly Asn Tyr Pro Asn
1 5 10
<210> 97
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 97
Gly Ser Ser Thr Gly Ala Val Thr Lys Gly Asn Tyr Pro Asn
1 5 10
<210> 98
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 98
Gly Ser Ser Thr Gly Ala Val Thr His Gly Asn Tyr Pro Asn
1 5 10
<210> 99
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 99
Gly Ser Ser Thr Gly Ala Val Thr Val Gly Asn Tyr Pro Asn
1 5 10
<210> 100
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 100
Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Tyr Tyr Pro Asn
1 5 10
<210> 101
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 101
Gly Ile Lys Phe Leu Ala Pro
1 5
<210> 102
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 102
Gly Thr Glu Phe Leu Ala Pro
1 5
<210> 103
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 103
Gly Thr Tyr Phe Leu Ala Pro
1 5
<210> 104
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 104
Gly Thr Ser Phe Leu Ala Pro
1 5
<210> 105
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 105
Gly Thr Asn Phe Leu Ala Pro
1 5
<210> 106
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 106
Gly Thr Lys Leu Leu Ala Pro
1 5
<210> 107
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 107
Gly Thr Lys Glu Leu Ala Pro
1 5
<210> 108
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 108
Gly Thr Lys Ile Leu Ala Pro
1 5
<210> 109
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 109
Gly Thr Lys Met Leu Ala Pro
1 5
<210> 110
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 110
Gly Thr Lys Val Leu Ala Pro
1 5
<210> 111
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 111
Gly Thr Lys Phe Asn Ala Pro
1 5
<210> 112
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 112
Gly Thr Lys Phe Gly Ala Pro
1 5
<210> 113
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 113
Gly Thr Lys Phe Leu Val Pro
1 5
<210> 114
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 114
Thr Leu Trp Tyr Ser Asn Arg Trp Val
1 5
<210> 115
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 115
Ala Leu Trp Tyr Ser Asn Arg Trp Val
1 5
<210> 116
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 116
Val Leu Trp Tyr Asp Asn Arg Trp Val
1 5
<210> 117
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 117
Val Leu Trp Tyr Ala Asn Arg Trp Val
1 5
<210> 118
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 118
Val Leu Trp Tyr Ser Asn Ser Trp Val
1 5
<210> 119
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 119
Val Leu Trp Tyr Ser Asn Arg Trp Ile
1 5
<210> 120
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 120
Val Leu Trp Tyr Ser Asn Arg Trp Ala
1 5
<210> 121
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 121
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys Tyr
20 25 30
Ala Leu Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Glu Tyr Ala Asp
50 55 60
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Pro Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Asn Phe Leu Ala Pro Gly Thr Pro Glu Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Ala Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 122
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 122
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Glu Tyr
20 25 30
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
50 55 60
Asp Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr
65 70 75 80
Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Gly Ile Ser Tyr Trp
100 105 110
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val Val
130 135 140
Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr Leu
145 150 155 160
Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Val Gly Asn Tyr Pro Asn
165 170 175
Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly Gly
180 185 190
Thr Glu Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser Leu
195 200 205
Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu Asp
210 215 220
Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Thr Val Leu
245
<210> 123
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 123
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 124
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 124
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Lys Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ala Asp Thr Leu Tyr Ala Asp Ser Leu
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Lys Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 125
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 125
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Tyr Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Lys Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 126
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 126
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Lys Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Thr Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 127
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 127
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Lys Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 128
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 128
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Lys Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Arg Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Val Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 129
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 129
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 130
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 130
Gly Phe Thr Phe Ser Ser Phe Gly Met Ser
1 5 10
<210> 131
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 131
Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys
1 5 10 15
<210> 132
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 132
Gly Gly Ser Leu Ser Arg
1 5
<210> 133
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 133
Gly Phe Thr Phe Ser Arg Phe Gly Met Ser
1 5 10
<210> 134
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 134
Gly Phe Thr Phe Ser Lys Phe Gly Met Ser
1 5 10
<210> 135
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 135
Gly Phe Thr Tyr Ser Ser Phe Gly Met Ser
1 5 10
<210> 136
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 136
Ser Ile Ser Gly Ser Gly Ala Asp Thr Leu Tyr Ala Asp Ser Leu Lys
1 5 10 15
<210> 137
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 137
Ser Ile Ser Gly Ser Gly Thr Asp Thr Leu Tyr Ala Asp Ser Val Lys
1 5 10 15
<210> 138
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 138
Ser Ile Ser Gly Ser Gly Arg Asp Thr Leu Tyr Ala Asp Ser Val Lys
1 5 10 15
<210> 139
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 139
Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Glu Ser Val Lys
1 5 10 15
<210> 140
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 140
Ser Ile Ser Gly Ser Gly Thr Asp Thr Leu Tyr Ala Glu Ser Val Lys
1 5 10 15
<210> 141
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 141
Ser Ile Ser Gly Ser Gly Arg Asp Thr Leu Tyr Ala Glu Ser Val Lys
1 5 10 15
<210> 142
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 142
Gly Gly Ser Leu Ser Lys
1 5
<210> 143
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 143
Gly Gly Ser Leu Ser Val
1 5
<210> 144
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 144
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Glu Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 145
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 145
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Lys Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Thr Asp Thr Leu Tyr Ala Glu Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 146
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 146
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Lys Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Arg Asp Thr Leu Tyr Ala Glu Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Val Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 147
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 147
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Lys Tyr Ala Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Gln Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Ala Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Ala Ser Ser Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Leu Val Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 148
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 148
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Asn Tyr Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Gly Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Gly Ser Tyr Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Asn Ala Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ala Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 149
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 149
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Glu
260 265 270
Phe Asn Lys Tyr Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Glu Thr
290 295 300
Tyr Tyr Ala Asp Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Leu
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Gly Ser Ser Ser Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Gly Ala Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 150
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 150
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Lys Tyr Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 151
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 151
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Lys Tyr Ala Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Gln Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Ala Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Ala Ser Ser Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Leu Val Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 152
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 152
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Asp Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Lys Tyr Ala Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Gln Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Ala Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Ala Ser Ser Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Leu Val Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 153
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 153
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Lys Tyr Ala Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Gln Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Ala Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Ala Ser Ser Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Leu Val Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 154
<211> 504
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 154
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ile Ile Ser Asp Gly Gly Tyr Tyr Thr Tyr Tyr Ser Asp Ile Ile
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Phe Pro Leu Leu Arg His Gly Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro
130 135 140
Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Lys
145 150 155 160
Ala Ser Gln Asn Val Asp Thr Asn Val Ala Trp Tyr Gln Gln Lys Pro
165 170 175
Gly Gln Ala Pro Lys Ser Leu Ile Tyr Ser Ala Ser Tyr Arg Tyr Ser
180 185 190
Asp Val Pro Ser Arg Phe Ser Gly Ser Ala Ser Gly Thr Asp Phe Thr
195 200 205
Leu Thr Ile Ser Ser Val Gln Ser Glu Asp Phe Ala Thr Tyr Tyr Cys
210 215 220
Gln Gln Tyr Asp Ser Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu
225 230 235 240
Glu Ile Lys Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
245 250 255
Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala
260 265 270
Ala Ser Gly Phe Thr Phe Asn Lys Tyr Ala Met Asn Trp Val Arg Gln
275 280 285
Ala Pro Gly Lys Gly Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr
290 295 300
Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp Ser Val Lys Asp Arg Phe Thr
305 310 315 320
Ile Ser Arg Asp Asp Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn
325 330 335
Leu Lys Thr Glu Asp Thr Ala Val Tyr Tyr Cys Val Arg His Gly Asn
340 345 350
Phe Gly Asn Ser Tyr Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr
355 360 365
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gly Gly Gly Gly Ser Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr
385 390 395 400
Val Ser Pro Gly Gly Thr Val Thr Leu Thr Cys Gly Ser Ser Thr Gly
405 410 415
Ala Val Thr Ser Gly Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly
420 425 430
Gln Ala Pro Arg Gly Leu Ile Gly Gly Thr Lys Phe Leu Ala Pro Gly
435 440 445
Thr Pro Ala Arg Phe Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu
450 455 460
Thr Leu Ser Gly Val Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Val
465 470 475 480
Leu Trp Tyr Ser Asn Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr
485 490 495
Val Leu His His His His His His
500
<210> 155
<211> 512
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 155
Gln Val Lys Leu Glu Glu Ser Gly Gly Gly Ser Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Thr Cys Ala Ala Ser Gly Arg Thr Ser Arg Ser Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ser Gly Ile Ser Trp Arg Gly Asp Ser Thr Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Asp
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Ala Ala Ala Gly Ser Ala Trp Tyr Gly Thr Leu Tyr Glu Tyr Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
130 135 140
Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
145 150 155 160
Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys
165 170 175
Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu
180 185 190
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
195 200 205
Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
210 215 220
Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln
225 230 235 240
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
245 250 255
Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly
260 265 270
Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Lys
275 280 285
Tyr Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
290 295 300
Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr Tyr Tyr Ala
305 310 315 320
Asp Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn
325 330 335
Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Val
340 345 350
Tyr Tyr Cys Val Arg His Gly Asn Phe Gly Asn Ser Tyr Ile Ser Tyr
355 360 365
Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly
370 375 380
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Thr Val
385 390 395 400
Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly Thr Val Thr
405 410 415
Leu Thr Cys Gly Ser Ser Thr Gly Ala Val Thr Ser Gly Asn Tyr Pro
420 425 430
Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly Leu Ile Gly
435 440 445
Gly Thr Lys Phe Leu Ala Pro Gly Thr Pro Ala Arg Phe Ser Gly Ser
450 455 460
Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val Gln Pro Glu
465 470 475 480
Asp Glu Ala Glu Tyr Tyr Cys Val Leu Trp Tyr Ser Asn Arg Trp Val
485 490 495
Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His His His His
500 505 510
<210> 156
<211> 499
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 156
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Arg Phe Met Ile Ser Glu Tyr
20 25 30
His Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Thr Ile Asn Pro Ala Gly Thr Thr Asp Tyr Ala Glu Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Asp
85 90 95
Ser Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
115 120 125
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Thr Phe Ser Lys Phe Gly Met Ser Trp Val Arg Gln Ala
145 150 155 160
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Arg
165 170 175
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
180 185 190
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Val
210 215 220
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
245 250 255
Gln Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr
260 265 270
Phe Asn Lys Tyr Ala Ile Asn Trp Val Arg Gln Ala Pro Gly Lys Gly
275 280 285
Leu Glu Trp Val Ala Arg Ile Arg Ser Lys Tyr Asn Asn Tyr Ala Thr
290 295 300
Tyr Tyr Ala Asp Gln Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
305 310 315 320
Ser Lys Asn Thr Ala Tyr Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
325 330 335
Thr Ala Val Tyr Tyr Cys Val Arg His Ala Asn Phe Gly Asn Ser Tyr
340 345 350
Ile Ser Tyr Trp Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
355 360 365
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
370 375 380
Gln Thr Val Val Thr Gln Glu Pro Ser Leu Thr Val Ser Pro Gly Gly
385 390 395 400
Thr Val Thr Leu Thr Cys Ala Ser Ser Thr Gly Ala Val Thr Ser Gly
405 410 415
Asn Tyr Pro Asn Trp Val Gln Gln Lys Pro Gly Gln Ala Pro Arg Gly
420 425 430
Leu Ile Gly Gly Thr Lys Phe Leu Val Pro Gly Thr Pro Ala Arg Phe
435 440 445
Ser Gly Ser Leu Leu Gly Gly Lys Ala Ala Leu Thr Leu Ser Gly Val
450 455 460
Gln Pro Glu Asp Glu Ala Glu Tyr Tyr Cys Thr Leu Trp Tyr Ser Asn
465 470 475 480
Arg Trp Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu His His His
485 490 495
His His His
<210> 157
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MISC_FEATURE
<222> (1)..(20)
<223> This sequence may encompass 1-10 "Gly Ser"
repeating units
<400> 157
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
1 5 10 15
Gly Ser Gly Ser
20
<210> 158
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(30)
<223> This sequence may encompass 1-10 "Gly Gly Ser"
repeating units
<400> 158
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly
1 5 10 15
Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser
20 25 30
<210> 159
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(40)
<223> This sequence may encompass 1-10 "Gly Gly Gly Ser"
repeating units
<400> 159
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
20 25 30
Gly Gly Gly Ser Gly Gly Gly Ser
35 40
<210> 160
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(40)
<223> This sequence may encompass 1-10 "Gly Gly Ser Gly"
repeating units
<400> 160
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
20 25 30
Gly Gly Ser Gly Gly Gly Ser Gly
35 40
<210> 161
<211> 50
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(50)
<223> This sequence may encompass 1-10 "Gly Gly Ser Gly Gly"
repeating units
<400> 161
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
1 5 10 15
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
20 25 30
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
35 40 45
Gly Gly
50
<210> 162
<211> 50
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(50)
<223> This sequence may encompass 1-10 "Gly Gly Gly Gly Ser"
repeating units
<400> 162
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser
50
<210> 163
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 163
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 164
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 164
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 165
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 165
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser
20 25
<210> 166
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 166
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
1 5 10
<210> 167
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 167
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
20 25 30
<210> 168
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 168
Asp Gly Tyr Gly Tyr Arg Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10 15
Claims (85)
- 전립선 특이 막 항원 결합 단백질로서, 상보성 결정 영역 CDR1, CDR2 및 CDR3을 포함하고, 여기서
(a) CDR1의 아미노산 서열은 RFMISX1YX2MH(서열 번호 1)에 제시된 서열이고;
(b) CDR2의 아미노산 서열은 X3INPAX4X5TDYAEX6VKG(서열 번호 2)에 제시된 서열이고;
(c) CDR3의 아미노산 서열은 DX7YGY(서열 번호 3)에 제시된 서열인 전립선 특이 막 항원 결합 단백질. - 제1항에 있어서, 하기 식을 포함하는 전립선 특이 막 항원 결합 단백질:
f1-r1-f2-r2-f3-r3-f4
여기서, r1은 서열 번호 1이고, r2는 서열 번호 2이고; r3은 서열 번호 3이고; f1, f2, f3 및 f4는 상기 단백질이 서열 번호 4에 제시된 아미노산 서열에 대해 적어도 80% 동일하도록 선택된 프레임워크 잔기이다. - 제2항에 있어서, X1이 프롤린인 전립선 특이 막 항원 결합 단백질.
- 제2항에 있어서, X2가 히스티딘인 전립선 특이 막 항원 결합 단백질.
- 제2항에 있어서, X3이 아스파르트산인 전립선 특이 막 항원 결합 단백질.
- 제2항에 있어서, X4가 리신인 전립선 특이 막 항원 결합 단백질.
- 제2항에 있어서, X5가 글루타민인 전립선 특이 막 항원 결합 단백질.
- 제2항에 있어서, X6이 티로신인 전립선 특이 막 항원 결합 단백질.
- 제2항에 있어서, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X1이 프롤린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X5가 글루타민인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X6이 티로신인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X4가 리신이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X2가 히스티딘이고, X3이 아스파르트산이고, X4가 리신이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X1이 프롤린이고, X2가 히스티딘이고, X3이 아스파르트산이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X2가 히스티딘이고, X3이 아스파르트산이고, X5가 글루타민이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X2가 히스티딘이고, X3이 아스파르트산이고, X6이 티로신이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X2가 히스티딘이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제9항 중 어느 한 항에 있어서, X2가 히스티딘이고, X3이 아스파르트산이고, X7이 세린인 전립선 특이 막 항원 결합 단백질.
- 제11항 내지 제20항 중 어느 한 항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제19항 내지 제21항 중 어느 한 항에 있어서, 시노몰거스 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 추가로 갖는 특이 막 항원 결합 단백질.
- 제1항 내지 제22항 중 어느 한 항에 있어서, r1이 서열 번호 5, 서열 번호 6 또는 서열 번호 7을 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제23항 중 어느 한 항에 있어서, r2가 서열 번호 8, 서열 번호 9, 서열 번호 10, 서열 번호 11, 서열 번호 12, 서열 번호 13 또는 서열 번호 14를 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제24항 중 어느 한 항에 있어서, r3이 서열 번호 15를 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질로서, 아미노산 위치 31, 33, 50, 55, 56, 62 및 97로부터 선택된 하나 이상의 아미노산 잔기가 치환된 서열 번호 4에 제시된 서열을 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- 제26항에 있어서, 위치 31, 33, 50, 55, 56, 62 및 97 이외의 아미노산 위치에 하나 이상의 추가의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 31에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 33에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 50에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 55에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 56에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 62에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 위치 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 55 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제28항 내지 제35항 중 어느 한 항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 33 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 33, 50 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제37항 또는 제38항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제37항 또는 제38항에 있어서, 시노몰거스 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 추가로 갖는 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 31, 33, 50 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 33, 50, 55 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 33, 50, 56 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- 제26항 또는 제27항에 있어서, 아미노산 위치 33, 50, 62 및 97에서의 치환을 포함하는 전립선 특이 막 항원 결합 단백질.
- CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질로서, CDR1이 서열 번호 16에 제시된 서열을 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 결합 단백질로서, CDR2가 서열 번호 17에 제시된 서열을 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질로서, CDR3이 서열 번호 18에 제시된 서열을 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- 서열 번호 4에 제시된 서열에 대해 적어도 80% 동일한 서열을 포함하는 전립선 특이 막 항원 결합 단백질.
- CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질로서, CDR1이 서열 번호 16에 대해 적어도 80%의 동일성을 가지며, CDR2가 서열 번호 17에 대해 적어도 85%의 동일성을 가지며, CDR3이 서열 번호 18에 대해 적어도 80%의 동일성을 갖는 것인 전립선 특이 막 항원 결합 단백질.
- CDR1, CDR2 및 CDR3을 포함하는 전립선 특이 막 항원 결합 단백질로서, CDR1이 서열 번호 16에 제시된 서열을 포함하고, CDR2가 서열 번호 17에 제시된 서열을 포함하고, CDR3이 서열 번호 18에 제시된 서열을 포함하는 것인 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제50항 중 어느 한 항에 있어서, 인간 전립선 특이 막 항원 및 시노몰거스 전립선 특이 막 항원 중 하나 또는 둘 모두에 결합하는 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제51항 중 어느 한 항에 있어서, 인간 전립선 특이 막 항원 및 시노몰거스 전립선 특이 막 항원에 대등한 결합 친화도로 결합하는 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제51항 중 어느 한 항에 있어서, 시노몰거스 전립선 특이 막 항원보다 더 높은 결합 친화도로 인간 전립선 특이 막 항원에 결합하는 전립선 특이 막 항원 결합 단백질.
- 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 결합 단백질을 코딩하는 폴리뉴클레오티드.
- 제54항의 폴리뉴클레오티드를 포함하는 벡터.
- 제55항에 따른 벡터로 형질전환된 숙주 세포.
- (i) 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 결합 단백질, 제54항에 따른 폴리뉴클레오티드, 제55항에 따른 벡터 또는 제56항에 따른 숙주 세포, 및 (ii) 약학적으로 허용 가능한 담체를 포함하는 약학 조성물.
- 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 결합 단백질의 생산 방법으로서, PSMA 결합 단백질의 발현을 허용하는 조건 하에 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 알부민 결합 단백질을 코딩하는 핵산 서열을 포함하는 벡터로 형질전환되거나 형질감염된 숙주를 배양하는 단계 및 배양물로부터 생산된 단백질을 회수하고 정제하는 단계를 포함하는 PSMA 결합 단백질의 생산 방법.
- 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 증식성 질환, 종양 질환, 염증성 질환, 면역 장애, 자가면역 질환, 감염성 질환, 바이러스성 질환, 알레르기 반응, 기생충 반응, 이식편 대 숙주 질환 또는 숙주 대 이식편 질환의 치료 또는 개선 방법.
- 제59항에 있어서, 대상체가 인간인 방법.
- 제60항에 있어서, 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 결합 단백질과 조합하여 작용제를 투여하는 것을 추가로 포함하는 방법.
- 제1항, 제26항 또는 제45항 내지 제50항 중 어느 한 항에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 결합 단백질.
- 제1항, 제26항 또는 제45항 내지 제50항 중 어느 한 항에 따른 PSMA 결합 단백질을 포함하는 항체.
- 제1항, 제26항 또는 제45항 내지 제50항 중 어느 한 항에 따른 PSMA 결합 단백질을 포함하는 다중 특이적 항체, 이중 특이적 항체, sdAb, 가변 중쇄 도메인, 펩티드 또는 리간드.
- 제1항, 제26항 또는 제45항 내지 제50항 중 어느 한 항에 따른 PSMA 결합 단백질을 포함하고 단일 도메인 항체인 항체.
- 제64항에 있어서, IgG의 중쇄 가변 영역으로부터 유래되는 단일 도메인 항체.
- 제1항, 제26항 및 제45항 내지 제50항 중 어느 한 항에 따른 PSMA 결합 단백질 및 CD3 결합 도메인을 포함하는 다중 특이적 결합 단백질 또는 항체.
- 제64항 내지 제68항 중 어느 한 항에 따른 다중 특이적 항체를 이를 필요로 하는 대상체에게 투여하는 것을 포함하는, 증식성 질환, 종양 질환, 염증성 질환, 면역 장애, 자가면역 질환, 감염성 질환, 바이러스성 질환, 알레르기 반응, 기생충 반응, 이식편 대 숙주 질환 또는 숙주 대 이식편 질환의 치료 또는 개선 방법.
- 제64항 내지 제68항 중 어느 한 항에 따른 다중 특이적 항체를 이를 필요로 하는 대상체에게 투여하는 것을 포함하는, 전립선 병태의 치료 또는 개선 방법.
- 제1항 내지 제53항 중 어느 한 항에 따른 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 것을 포함하는, 전립선 병태의 치료 또는 개선 방법.
- 제1항에 있어서, 하기의 임의의 조합을 포함하는 전립선 특이 막 항원 결합 단백질:
(i) X1은 프롤린이고;
(ii) X2는 히스티딘이고;
(iii) X3은 아스파르트산이고;
(iv) X4는 리신이고;
(v) X5는 글루타민이고;
(vi) X6은 티로신이고;
(vii) X7은 세린이다. - 제71항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제1항에 있어서, 하기의 임의의 조합을 포함하는 전립선 특이 막 항원 결합 단백질:
(i) X1은 프롤린이고, X5는 글루타민이고;
(ii) X6은 티로신이고, X4는 리신이고, X7은 세린이고;
(iii) X2는 히스티딘이고, X3은 아스파르트산이고, X4는 리신이고, X7은 세린이고;
(iv) X1은 프롤린이고, X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이고;
(v) X2는 히스티딘이고, X3은 아스파르트산이고, X5는 글루타민이고, X7은 세린이고;
(vi) X2는 히스티딘이고, X3은 아스파르트산이고, X4는 리신이고, X7은 세린이고;
(vii) X1은 프롤린이고, X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이고;
(viii) X2는 히스티딘이고, X3은 아스파르트산이고, X5는 글루타민이고, X7은 세린이고;
(ix) X2는 히스티딘이고, X3은 아스파르트산이고, X6은 티로신이고, X7은 세린이고;
(x) X2는 히스티딘이고, X3은 아스파르트산이고, X7은 세린이다. - 제73항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제74항에 있어서, 시노몰거스 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 추가로 갖는 특이 막 항원 결합 단백질.
- 제26항에 있어서, 하기의 임의의 조합을 포함하는 전립선 특이 막 항원 결합 단백질:
(i) 위치 31에서의 치환;
(ii) 위치 50에서의 치환;
(iii) 위치 55에서의 치환; 위치 56에서의 치환;
(iv) 위치 62에서의 치환;
(v) 위치 97에서의 치환;
(vi) 위치 55 및 97에서의 치환;
(vii) 위치 33 및 97에서의 치환;
(viii) 위치 33, 50 및 97에서의 치환;
(ix) 위치 31, 33, 50 및 97에서의 치환;
(x) 위치 33, 50, 55 및 97에서의 치환;
(xi) 위치 33, 50, 56 및 97에서의 치환; 및
(xiii) 위치 33, 50, 62 및 97에서의 치환. - 제76항에 있어서, 인간 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 갖는 전립선 특이 막 항원 결합 단백질.
- 제77항에 있어서, 시노몰거스 전립선 특이 막 항원에 대해 서열 번호 4에 제시된 서열을 갖는 결합 단백질의 친화도보다 더 높은 친화도를 추가로 갖는 특이 막 항원 결합 단백질.
- 전립선암의 치료 또는 개선 방법으로서, 상보성 결정 영역 CDR1, CDR2 및 CDR3을 포함하는 PSMA 결합 단백질을 이를 필요로 하는 대상체에게 투여하는 것을 포함하고, 여기서
(a) CDR1의 아미노산 서열은 RFMISX1YX2MH(서열 번호 1)에 제시된 서열이고;
(b) CDR2의 아미노산 서열은 X3INPAX4X5TDYAEX6VKG(서열 번호 2)에 제시된 서열이고;
(c) CDR3의 아미노산 서열은 DX7YGY(서열 번호 3)에 제시된 서열인 전립선암의 치료 또는 개선 방법. - 제1항에 따른 PSMA 결합 단백질을 포함하고, 단일 도메인 항체인 항체.
- 제80항에 있어서, 상기 단일 도메인 항체가 삼중 특이적 항체의 일부인 PSMA 결합 단백질을 포함하는 항체.
- 제26항에 따른 PSMA 결합 단백질을 포함하고, 단일 도메인 항체인 항체.
- 제82항에 있어서, 상기 단일 도메인 항체가 삼중 특이적 항체의 일부인 PSMA 결합 단백질을 포함하는 항체.
- 제49항에 따른 PSMA 결합 단백질을 포함하고, 단일 도메인 항체인 항체.
- 제84항에 있어서, 상기 단일 도메인 항체가 삼중 특이적 항체의 일부인 PSMA 결합 단백질을 포함하는 항체.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662426086P | 2016-11-23 | 2016-11-23 | |
| US62/426,086 | 2016-11-23 | ||
| KR1020197017995A KR102275008B1 (ko) | 2016-11-23 | 2017-11-22 | 전립선 특이 막 항원 결합 단백질 |
| PCT/US2017/063121 WO2018098354A1 (en) | 2016-11-23 | 2017-11-22 | Prostate specific membrane antigen binding protein |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197017995A Division KR102275008B1 (ko) | 2016-11-23 | 2017-11-22 | 전립선 특이 막 항원 결합 단백질 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210087108A true KR20210087108A (ko) | 2021-07-09 |
Family
ID=62196127
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197017995A KR102275008B1 (ko) | 2016-11-23 | 2017-11-22 | 전립선 특이 막 항원 결합 단백질 |
| KR1020217020580A KR20210087108A (ko) | 2016-11-23 | 2017-11-22 | 전립선 특이 막 항원 결합 단백질 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197017995A KR102275008B1 (ko) | 2016-11-23 | 2017-11-22 | 전립선 특이 막 항원 결합 단백질 |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US10849973B2 (ko) |
| EP (1) | EP3544997A4 (ko) |
| JP (2) | JP6812551B2 (ko) |
| KR (2) | KR102275008B1 (ko) |
| CN (1) | CN110198955A (ko) |
| AU (1) | AU2017363300A1 (ko) |
| BR (1) | BR112019010604A2 (ko) |
| CA (1) | CA3044659A1 (ko) |
| EA (1) | EA201991168A1 (ko) |
| IL (1) | IL266800A (ko) |
| MX (1) | MX2019006043A (ko) |
| WO (1) | WO2018098354A1 (ko) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101997241B1 (ko) | 2015-05-21 | 2019-07-09 | 하푼 테라퓨틱스, 인크. | 삼중특이성 결합 단백질 및 사용 방법 |
| US11623958B2 (en) | 2016-05-20 | 2023-04-11 | Harpoon Therapeutics, Inc. | Single chain variable fragment CD3 binding proteins |
| JP7042467B2 (ja) | 2016-05-20 | 2022-03-28 | ハープーン セラピューティクス,インク. | 単鎖可変フラグメントcd3結合タンパク質 |
| BR112018073739A2 (pt) | 2016-05-20 | 2019-02-26 | Harpoon Therapeutics, Inc. | proteína de ligação de albumina sérica de domínio único |
| MX2019006045A (es) | 2016-11-23 | 2019-11-11 | Harpoon Therapeutics Inc | Proteinas triespecificas dirigidas a psma y metodos de uso. |
| KR102275008B1 (ko) | 2016-11-23 | 2021-07-13 | 하푼 테라퓨틱스, 인크. | 전립선 특이 막 항원 결합 단백질 |
| EP3589662A4 (en) | 2017-02-28 | 2020-12-30 | Harpoon Therapeutics, Inc. | INDUCTIBLE MONOVALENT ANTIGBINDING PROTEIN |
| US10543271B2 (en) | 2017-05-12 | 2020-01-28 | Harpoon Therapeutics, Inc. | Mesothelin binding proteins |
| EP3621648A4 (en) | 2017-05-12 | 2021-01-20 | Harpoon Therapeutics, Inc. | TRISPECIFIC PROTEINS MSLN AND METHOD OF USE |
| US11136403B2 (en) | 2017-10-13 | 2021-10-05 | Harpoon Therapeutics, Inc. | Trispecific proteins and methods of use |
| EP3694871A4 (en) | 2017-10-13 | 2021-11-10 | Harpoon Therapeutics, Inc. | B-CELL MATURATION ANTIG-BINDING PROTEINS |
| CA3102562A1 (en) * | 2018-06-07 | 2019-12-12 | Cullinan Management, Inc. | Multi-specific binding proteins and methods of use thereof |
| WO2020061482A1 (en) * | 2018-09-21 | 2020-03-26 | Harpoon Therapeutics, Inc. | Egfr binding proteins and methods of use |
| JP7425049B2 (ja) | 2018-09-25 | 2024-01-30 | ハープーン セラピューティクス,インク. | Dll3結合タンパク質および使用方法 |
| EP4106806A1 (en) | 2020-02-21 | 2022-12-28 | Harpoon Therapeutics, Inc. | Flt3 binding proteins and methods of use |
| WO2021202376A1 (en) | 2020-03-30 | 2021-10-07 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Method for blocking uptake of prostate-specific membrane antigen (psma)-targeted radionuclides by exocrine organs |
| IL299748A (en) | 2020-07-08 | 2023-03-01 | Lava Therapeutics N V | Antibodies that bind PSMA and T gamma delta receptors |
| TW202317625A (zh) | 2021-06-17 | 2023-05-01 | 德商百靈佳殷格翰國際股份有限公司 | 新穎三特異性結合分子 |
Family Cites Families (198)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR901228A (fr) | 1943-01-16 | 1945-07-20 | Deutsche Edelstahlwerke Ag | Système d'aimant à entrefer annulaire |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US6548640B1 (en) | 1986-03-27 | 2003-04-15 | Btg International Limited | Altered antibodies |
| GB8607679D0 (en) | 1986-03-27 | 1986-04-30 | Winter G P | Recombinant dna product |
| US5858358A (en) | 1992-04-07 | 1999-01-12 | The United States Of America As Represented By The Secretary Of The Navy | Methods for selectively stimulating proliferation of T cells |
| US6905680B2 (en) | 1988-11-23 | 2005-06-14 | Genetics Institute, Inc. | Methods of treating HIV infected subjects |
| US6534055B1 (en) | 1988-11-23 | 2003-03-18 | Genetics Institute, Inc. | Methods for selectively stimulating proliferation of T cells |
| US6352694B1 (en) | 1994-06-03 | 2002-03-05 | Genetics Institute, Inc. | Methods for inducing a population of T cells to proliferate using agents which recognize TCR/CD3 and ligands which stimulate an accessory molecule on the surface of the T cells |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5703055A (en) | 1989-03-21 | 1997-12-30 | Wisconsin Alumni Research Foundation | Generation of antibodies through lipid mediated DNA delivery |
| US5399346A (en) | 1989-06-14 | 1995-03-21 | The United States Of America As Represented By The Department Of Health And Human Services | Gene therapy |
| US5585362A (en) | 1989-08-22 | 1996-12-17 | The Regents Of The University Of Michigan | Adenovirus vectors for gene therapy |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| GB8928874D0 (en) | 1989-12-21 | 1990-02-28 | Celltech Ltd | Humanised antibodies |
| US5061620A (en) | 1990-03-30 | 1991-10-29 | Systemix, Inc. | Human hematopoietic stem cell |
| EP0519596B1 (en) | 1991-05-17 | 2005-02-23 | Merck & Co. Inc. | A method for reducing the immunogenicity of antibody variable domains |
| US5199942A (en) | 1991-06-07 | 1993-04-06 | Immunex Corporation | Method for improving autologous transplantation |
| DE122004000008I1 (de) | 1991-06-14 | 2005-06-09 | Genentech Inc | Humanisierter Heregulin Antikörper. |
| US5565332A (en) | 1991-09-23 | 1996-10-15 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| AU2764792A (en) | 1991-10-04 | 1993-05-03 | Iit Research Institute | Conversion of plastic waste to useful oils |
| GB9125768D0 (en) | 1991-12-04 | 1992-02-05 | Hale Geoffrey | Therapeutic method |
| CA2103887C (en) | 1991-12-13 | 2005-08-30 | Gary M. Studnicka | Methods and materials for preparation of modified antibody variable domains and therapeutic uses thereof |
| US6005079A (en) | 1992-08-21 | 1999-12-21 | Vrije Universiteit Brussels | Immunoglobulins devoid of light chains |
| PT1498427E (pt) | 1992-08-21 | 2010-03-22 | Univ Bruxelles | Imunoglobulinas desprovidas de cadeias leves |
| US5350674A (en) | 1992-09-04 | 1994-09-27 | Becton, Dickinson And Company | Intrinsic factor - horse peroxidase conjugates and a method for increasing the stability thereof |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| US7175843B2 (en) | 1994-06-03 | 2007-02-13 | Genetics Institute, Llc | Methods for selectively stimulating proliferation of T cells |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| US7067318B2 (en) | 1995-06-07 | 2006-06-27 | The Regents Of The University Of Michigan | Methods for transfecting T cells |
| US6692964B1 (en) | 1995-05-04 | 2004-02-17 | The United States Of America As Represented By The Secretary Of The Navy | Methods for transfecting T cells |
| US5773292A (en) | 1995-06-05 | 1998-06-30 | Cornell University | Antibodies binding portions, and probes recognizing an antigen of prostate epithelial cells but not antigens circulating in the blood |
| US6107090A (en) | 1996-05-06 | 2000-08-22 | Cornell Research Foundation, Inc. | Treatment and diagnosis of prostate cancer with antibodies to extracellur PSMA domains |
| US6136311A (en) | 1996-05-06 | 2000-10-24 | Cornell Research Foundation, Inc. | Treatment and diagnosis of cancer |
| ATE461282T1 (de) | 1997-10-27 | 2010-04-15 | Bac Ip Bv | Multivalente antigenbindende proteine |
| BR9907241A (pt) | 1998-01-26 | 2000-10-17 | Unilever Nv | Biblioteca de expressão, processo para preparar a mesma, uso de uma fonte não imunizada de sequências de ácido nucleico, e, processos para preparar fragmentos de anticorpos e, para preparar um anticorpo |
| HUP9900956A2 (hu) | 1998-04-09 | 2002-04-29 | Aventis Pharma Deutschland Gmbh. | Egyláncú, több antigéntkötőhely kialakítására képes molekulák, előállításuk és alkalmazásuk |
| WO2000043507A1 (en) | 1999-01-19 | 2000-07-27 | Unilever Plc | Method for producing antibody fragments |
| US6326193B1 (en) | 1999-11-05 | 2001-12-04 | Cambria Biosciences, Llc | Insect control agent |
| US20060228364A1 (en) | 1999-12-24 | 2006-10-12 | Genentech, Inc. | Serum albumin binding peptides for tumor targeting |
| KR20030032922A (ko) | 2000-02-24 | 2003-04-26 | 싸이트 테라피스 인코포레이티드 | 세포의 동시 자극 및 농축 |
| US6867041B2 (en) | 2000-02-24 | 2005-03-15 | Xcyte Therapies, Inc. | Simultaneous stimulation and concentration of cells |
| US7572631B2 (en) | 2000-02-24 | 2009-08-11 | Invitrogen Corporation | Activation and expansion of T cells |
| US6797514B2 (en) | 2000-02-24 | 2004-09-28 | Xcyte Therapies, Inc. | Simultaneous stimulation and concentration of cells |
| CA2380443C (en) | 2000-05-26 | 2013-03-12 | Ginette Dubuc | Single-domain antigen-binding antibody fragments derived from llama antibodies |
| WO2001096584A2 (en) | 2000-06-12 | 2001-12-20 | Akkadix Corporation | Materials and methods for the control of nematodes |
| CN1294148C (zh) | 2001-04-11 | 2007-01-10 | 中国科学院遗传与发育生物学研究所 | 环状单链三特异抗体 |
| GB0110029D0 (en) | 2001-04-24 | 2001-06-13 | Grosveld Frank | Transgenic animal |
| CN1195779C (zh) | 2001-05-24 | 2005-04-06 | 中国科学院遗传与发育生物学研究所 | 抗人卵巢癌抗人cd3双特异性抗体 |
| US7666414B2 (en) | 2001-06-01 | 2010-02-23 | Cornell Research Foundation, Inc. | Methods for treating prostate cancer using modified antibodies to prostate-specific membrane antigen |
| US7371849B2 (en) | 2001-09-13 | 2008-05-13 | Institute For Antibodies Co., Ltd. | Methods of constructing camel antibody libraries |
| US20050215472A1 (en) | 2001-10-23 | 2005-09-29 | Psma Development Company, Llc | PSMA formulations and uses thereof |
| EP2360169B1 (en) | 2001-10-23 | 2015-10-14 | Psma Development Company, L.L.C. | PSMA antibodies |
| JP2005289809A (ja) | 2001-10-24 | 2005-10-20 | Vlaams Interuniversitair Inst Voor Biotechnologie Vzw (Vib Vzw) | 突然変異重鎖抗体 |
| JP2005518789A (ja) | 2002-01-28 | 2005-06-30 | メダレックス, インク. | 前立腺特異性膜抗原(psma)に対するヒトモノクローナル抗体 |
| US9321832B2 (en) | 2002-06-28 | 2016-04-26 | Domantis Limited | Ligand |
| JP2006512895A (ja) | 2002-06-28 | 2006-04-20 | ドマンティス リミテッド | リガンド |
| AU2003283860B2 (en) | 2002-11-07 | 2009-09-17 | Erasmus Universiteit Rotterdam | Fret probes and methods for detecting interacting molecules |
| EP2267032A3 (en) | 2002-11-08 | 2011-11-09 | Ablynx N.V. | Method of administering therapeutic polypeptides, and polypeptides therefor |
| EP1900753B1 (en) | 2002-11-08 | 2017-08-09 | Ablynx N.V. | Method of administering therapeutic polypeptides, and polypeptides therefor |
| CN102584997A (zh) | 2002-11-08 | 2012-07-18 | 埃博灵克斯股份有限公司 | 针对肿瘤坏死因子-α的单结构域抗体及其用途 |
| US9320792B2 (en) | 2002-11-08 | 2016-04-26 | Ablynx N.V. | Pulmonary administration of immunoglobulin single variable domains and constructs thereof |
| GB0228210D0 (en) | 2002-12-03 | 2003-01-08 | Babraham Inst | Single chain antibodies |
| CA2523716C (en) | 2003-05-31 | 2014-11-25 | Micromet Ag | Human anti-human cd3 binding molecules |
| US20050100543A1 (en) | 2003-07-01 | 2005-05-12 | Immunomedics, Inc. | Multivalent carriers of bi-specific antibodies |
| AU2004286198C1 (en) | 2003-08-18 | 2011-02-24 | Medimmune, Llc | Humanization of antibodies |
| WO2005035575A2 (en) | 2003-08-22 | 2005-04-21 | Medimmune, Inc. | Humanization of antibodies |
| CN100376599C (zh) | 2004-04-01 | 2008-03-26 | 北京安波特基因工程技术有限公司 | 基因工程重组抗cea抗cd3抗cd28线性单链三特异抗体 |
| US8921528B2 (en) | 2004-06-01 | 2014-12-30 | Domantis Limited | Bispecific fusion antibodies with enhanced serum half-life |
| JP2008512352A (ja) | 2004-07-17 | 2008-04-24 | イムクローン システムズ インコーポレイティド | 新規な四価の二重特異性抗体 |
| US20080069772A1 (en) | 2004-08-26 | 2008-03-20 | Eberhard-Karls-Universitaet Tuebingen Universitaetsklinikum | Treatment of transformed or infected biological cells |
| EP1634603A1 (de) | 2004-08-26 | 2006-03-15 | Eberhard-Karls-Universität Tübingen Universitätsklinikum | Behandlung von transformierten oder infizierten biologischen Zellen |
| FR2879605B1 (fr) | 2004-12-16 | 2008-10-17 | Centre Nat Rech Scient Cnrse | Production de formats d'anticorps et applications immunologiques de ces formats |
| JP4937138B2 (ja) | 2005-01-05 | 2012-05-23 | エフ−シュタール・ビオテヒノロギシェ・フォルシュングス−ウント・エントヴィックルングスゲゼルシャフト・ミット・ベシュレンクテル・ハフツング | 相補性決定領域とは異なる分子の領域に設計された結合性を持つ合成免疫グロブリンドメイン |
| US7833979B2 (en) | 2005-04-22 | 2010-11-16 | Amgen Inc. | Toxin peptide therapeutic agents |
| US20060252096A1 (en) | 2005-04-26 | 2006-11-09 | Glycofi, Inc. | Single chain antibody with cleavable linker |
| EP2949668B1 (en) | 2005-05-18 | 2019-08-14 | Ablynx N.V. | Improved nanobodies tm against tumor necrosis factor-alpha |
| CA2608873C (en) | 2005-05-20 | 2017-04-25 | Ablynx Nv | Single domain vhh antibodies against von willebrand factor |
| EP1726650A1 (en) * | 2005-05-27 | 2006-11-29 | Universitätsklinikum Freiburg | Monoclonal antibodies and single chain antibody fragments against cell-surface prostate specific membrane antigen |
| WO2007024715A2 (en) | 2005-08-19 | 2007-03-01 | Abbott Laboratories | Dual variable domain immunoglobin and uses thereof |
| ES2856451T3 (es) | 2005-10-11 | 2021-09-27 | Amgen Res Munich Gmbh | Composiciones que comprenden anticuerpos específicos para diferentes especies, y usos de las mismas |
| WO2007062466A1 (en) | 2005-11-29 | 2007-06-07 | The University Of Sydney | Demibodies: dimerisation-activated therapeutic agents |
| US20110038854A1 (en) | 2006-03-30 | 2011-02-17 | University Of Medicine And Dentistry Of New Jersey | Strategy for homo- or hetero-dimerization of various proteins in solution and in cell |
| US20070269422A1 (en) | 2006-05-17 | 2007-11-22 | Ablynx N.V. | Serum albumin binding proteins with long half-lives |
| WO2008020079A1 (en) | 2006-08-18 | 2008-02-21 | Ablynx N.V. | Amino acid sequences directed against il-6r and polypeptides comprising the same for the treatment of deseases and disorders associated with il-6-mediated signalling |
| EP2069402A2 (en) | 2006-09-08 | 2009-06-17 | Ablynx N.V. | Serum albumin binding proteins with long half-lives |
| US20100166734A1 (en) | 2006-12-20 | 2010-07-01 | Edward Dolk | Oral delivery of polypeptides |
| EP4059964A1 (en) | 2007-04-03 | 2022-09-21 | Amgen Research (Munich) GmbH | Cross-species-specific binding domain |
| RU2481355C2 (ru) | 2007-05-24 | 2013-05-10 | Аблинкс Н.В. | Аминокислотные последовательности, направленные на rank-l, и полипептиды, включающие их, для лечения заболеваний и нарушений костей |
| EP2014680A1 (en) | 2007-07-10 | 2009-01-14 | Friedrich-Alexander-Universität Erlangen-Nürnberg | Recombinant, single-chain, trivalent tri-specific or bi-specific antibody derivatives |
| JP6035009B2 (ja) | 2007-08-22 | 2016-11-30 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | 活性化可能な結合ポリペプチドおよびその同定方法ならびに使用 |
| EP2195342A1 (en) | 2007-09-07 | 2010-06-16 | Ablynx N.V. | Binding molecules with multiple binding sites, compositions comprising the same and uses thereof |
| ES2667729T3 (es) | 2007-09-26 | 2018-05-14 | Ucb Biopharma Sprl | Fusiones de anticuerpos con doble especificidad |
| CA2726652A1 (en) | 2008-06-05 | 2009-12-10 | Ablynx N.V. | Amino acid sequences directed against envelope proteins of a virus and polypeptides comprising the same for the treatment of viral diseases |
| US20100122358A1 (en) | 2008-06-06 | 2010-05-13 | Crescendo Biologics Limited | H-Chain-only antibodies |
| EP2310508A1 (en) | 2008-07-02 | 2011-04-20 | Emergent Product Development Seattle, LLC | Tgf-b antagonist multi-target binding proteins |
| US8444976B2 (en) * | 2008-07-02 | 2013-05-21 | Argen-X B.V. | Antigen binding polypeptides |
| US10981998B2 (en) | 2008-10-01 | 2021-04-20 | Amgen Research (Munich) Gmbh | Cross-species-specific single domain bispecific single chain antibody |
| PL2352763T5 (pl) | 2008-10-01 | 2023-01-30 | Amgen Research (Munich) Gmbh | Bispecyficzne przeciwciała jednołańcuchowe o specyficzności wobec antygenów docelowych o dużej masie cząsteczkowej |
| CA2738565C (en) | 2008-10-01 | 2023-10-10 | Micromet Ag | Cross-species-specific psmaxcd3 bispecific single chain antibody |
| WO2010043057A1 (en) | 2008-10-14 | 2010-04-22 | National Research Counsil Of Canada | Bsa-specific antibodies |
| EP2356131A4 (en) | 2008-12-08 | 2012-09-12 | Tegopharm Corp | MASKING LIGANDS FOR REVERSIBLE INHIBITION OF VERSATILE COMPOUNDS |
| EP2210902A1 (en) | 2009-01-14 | 2010-07-28 | TcL Pharma | Recombinant monovalent antibodies |
| PE20121094A1 (es) | 2009-03-05 | 2012-09-13 | Abbvie Inc | Proteinas de union a il-17 |
| UY32917A (es) | 2009-10-02 | 2011-04-29 | Boehringer Ingelheim Int | Moléculas de unión a dll-4 |
| WO2011051327A2 (en) | 2009-10-30 | 2011-05-05 | Novartis Ag | Small antibody-like single chain proteins |
| KR20120123299A (ko) | 2009-12-04 | 2012-11-08 | 제넨테크, 인크. | 다중특이적 항체, 항체 유사체, 조성물 및 방법 |
| EP2332994A1 (en) | 2009-12-09 | 2011-06-15 | Friedrich-Alexander-Universität Erlangen-Nürnberg | Trispecific therapeutics against acute myeloid leukaemia |
| EP2519544A1 (en) | 2009-12-29 | 2012-11-07 | Emergent Product Development Seattle, LLC | Polypeptide heterodimers and uses thereof |
| GB2476681B (en) * | 2010-01-04 | 2012-04-04 | Argen X Bv | Humanized camelid VH, VK and VL immunoglobulin domains |
| EP4012714A1 (en) | 2010-03-23 | 2022-06-15 | Iogenetics, LLC. | Bioinformatic processes for determination of peptide binding |
| US8937164B2 (en) | 2010-03-26 | 2015-01-20 | Ablynx N.V. | Biological materials related to CXCR7 |
| US9556273B2 (en) | 2010-03-29 | 2017-01-31 | Vib Vzw | Anti-macrophage mannose receptor single variable domains for targeting and in vivo imaging of tumor-associated macrophages |
| WO2012025530A1 (en) | 2010-08-24 | 2012-03-01 | F. Hoffmann-La Roche Ag | Bispecific antibodies comprising a disulfide stabilized - fv fragment |
| EP2609112B1 (en) | 2010-08-24 | 2017-11-22 | Roche Glycart AG | Activatable bispecific antibodies |
| EP2621953B1 (en) | 2010-09-30 | 2017-04-05 | Ablynx N.V. | Biological materials related to c-met |
| EP2640750A1 (en) | 2010-11-16 | 2013-09-25 | Boehringer Ingelheim International GmbH | Agents and methods for treating diseases that correlate with bcma expression |
| JP6130350B2 (ja) | 2011-03-30 | 2017-05-17 | アブリンクス エン.ヴェー. | TNFαに対する単一ドメイン抗体で免疫障害を処置する方法 |
| CN103596981B (zh) | 2011-04-08 | 2017-06-16 | 美国卫生和人力服务部 | 抗‑表皮生长因子受体变体iii嵌合抗原受体及其用于治疗癌症的用途 |
| CN103842383B (zh) * | 2011-05-16 | 2017-11-03 | 健能隆医药技术(上海)有限公司 | 多特异性fab融合蛋白及其使用方法 |
| UA117901C2 (uk) | 2011-07-06 | 2018-10-25 | Ґенмаб Б.В. | Спосіб посилення ефекторної функції вихідного поліпептиду, його варіанти та їх застосування |
| EP2753644A1 (en) | 2011-09-09 | 2014-07-16 | Universiteit Utrecht Holding B.V. | Broadly neutralizing vhh against hiv-1 |
| CA2846436A1 (en) | 2011-09-23 | 2013-03-28 | Universitat Stuttgart | Serum half-life extension using immunoglobulin binding domains |
| TWI679212B (zh) | 2011-11-15 | 2019-12-11 | 美商安進股份有限公司 | 針對bcma之e3以及cd3的結合分子 |
| KR102100817B1 (ko) | 2012-01-13 | 2020-04-17 | 율리우스-막시밀리안스 우니버지태트 뷔르츠부르크 | 이중 항원-유도된 이분 기능 상보성 |
| EP2807189B1 (en) | 2012-01-23 | 2019-03-20 | Ablynx N.V. | Sequences directed against hepatocyte growth factor (hgf) and polypeptides comprising the same for the treatment of cancers and/or tumors |
| BR112014020826A8 (pt) | 2012-02-24 | 2017-09-19 | Stem Centrx Inc | Anticorpo que se liga especificamente a um epítopo, ácido nucleico, vetor ou célula hospedeira, conjugado de fármaco anticorpo, composição farmacêutica compreendendo o referido anticorpo, uso do mesmo, kit e método de preparação do conjugado |
| GB201203442D0 (en) | 2012-02-28 | 2012-04-11 | Univ Birmingham | Immunotherapeutic molecules and uses |
| WO2013128027A1 (en) | 2012-03-01 | 2013-09-06 | Amgen Research (Munich) Gmbh | Long life polypeptide binding molecules |
| BR112014024373A2 (pt) | 2012-03-30 | 2017-08-08 | Bayer Healthcare Llc | anticorpos regulados por protease |
| WO2013158856A2 (en) | 2012-04-20 | 2013-10-24 | Emergent Product Development Seattle, Llc | Cd3 binding polypeptides |
| WO2013192546A1 (en) | 2012-06-22 | 2013-12-27 | Cytomx Therapeutics, Inc. | Activatable antibodies having non-binding steric moieties and mehtods of using the same |
| US20140004121A1 (en) | 2012-06-27 | 2014-01-02 | Amgen Inc. | Anti-mesothelin binding proteins |
| CN112587658A (zh) | 2012-07-18 | 2021-04-02 | 博笛生物科技有限公司 | 癌症的靶向免疫治疗 |
| JP6283030B2 (ja) | 2012-08-31 | 2018-02-21 | アルゲン−エックス ビーブイビーエー | 高度に多様なコンビナトリアル抗体ライブラリ |
| KR101963231B1 (ko) | 2012-09-11 | 2019-03-28 | 삼성전자주식회사 | 이중특이 항체의 제작을 위한 단백질 복합체 및 이를 이용한 이중특이 항체 제조 방법 |
| JOP20200236A1 (ar) | 2012-09-21 | 2017-06-16 | Regeneron Pharma | الأجسام المضادة لمضاد cd3 وجزيئات ربط الأنتيجين ثنائية التحديد التي تربط cd3 وcd20 واستخداماتها |
| ES2666131T3 (es) | 2012-09-27 | 2018-05-03 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Anticuerpos de mesotelina y métodos para provocar una potente actividad antitumoral |
| JO3519B1 (ar) | 2013-01-25 | 2020-07-05 | Amgen Inc | تركيبات أجسام مضادة لأجل cdh19 و cd3 |
| ES2681948T3 (es) | 2013-03-05 | 2018-09-17 | Baylor College Of Medicine | Células de acoplamiento para inmunoterapia |
| DK2971045T3 (da) | 2013-03-13 | 2019-09-16 | Health Research Inc | Sammensætninger og fremgangsmåder til anvendelse af rekombinante T-celle-receptorer til direkte genkendelse af tumorantigen |
| EP3424952A1 (en) | 2013-03-15 | 2019-01-09 | Amgen, Inc | Heterodimeric bispecific antibodies |
| US20140302037A1 (en) | 2013-03-15 | 2014-10-09 | Amgen Inc. | BISPECIFIC-Fc MOLECULES |
| WO2014140358A1 (en) | 2013-03-15 | 2014-09-18 | Amgen Research (Munich) Gmbh | Single chain binding molecules comprising n-terminal abp |
| ES2683268T3 (es) | 2013-07-25 | 2018-09-25 | Cytomx Therapeutics, Inc. | Anticuerpos multiespecíficos, anticuerpos activables multiespecíficos y métodos para usar los mismos |
| TWI647307B (zh) | 2013-09-24 | 2019-01-11 | 美國華盛頓大學商業中心 | 橋粒黏蛋白2(dsg2)之結合蛋白及其用途 |
| CA2925061C (en) | 2013-09-26 | 2023-02-14 | Ablynx Nv | Bispecific nanobodies |
| RU2016129959A (ru) | 2013-12-30 | 2018-02-02 | Эпимаб Биотерепьютикс Инк. | Иммуноглобулин с тандемным расположением fab-фрагментов и его применение |
| UA117289C2 (uk) | 2014-04-02 | 2018-07-10 | Ф. Хоффманн-Ля Рош Аг | Мультиспецифічне антитіло |
| US10647768B2 (en) | 2014-05-29 | 2020-05-12 | Macrogenics, Inc. | Multi-chain polypeptide-containing tri-specific binding molecules |
| GB201412659D0 (en) | 2014-07-16 | 2014-08-27 | Ucb Biopharma Sprl | Molecules |
| UY36245A (es) | 2014-07-31 | 2016-01-29 | Amgen Res Munich Gmbh | Constructos de anticuerpos para cdh19 y cd3 |
| US20170275373A1 (en) | 2014-07-31 | 2017-09-28 | Amgen Research (Munich) Gmbh | Bispecific single chain antibody construct with enhanced tissue distribution |
| PT3189081T (pt) | 2014-09-05 | 2020-05-25 | Janssen Pharmaceutica Nv | Agentes de ligação a cd123 e seus usos |
| CN105471609B (zh) | 2014-09-05 | 2019-04-05 | 华为技术有限公司 | 一种用于配置业务的方法和装置 |
| WO2016046778A2 (en) | 2014-09-25 | 2016-03-31 | Amgen Inc | Protease-activatable bispecific proteins |
| EP3204491A1 (en) | 2014-10-07 | 2017-08-16 | Cellectis | Method for modulating car-induced immune cells activity |
| CA2968878A1 (en) | 2014-11-26 | 2016-06-02 | Xencor, Inc. | Heterodimeric antibodies that bind cd3 and cd38 |
| EP3237449A2 (en) | 2014-12-22 | 2017-11-01 | Xencor, Inc. | Trispecific antibodies |
| AU2016214304B2 (en) | 2015-02-05 | 2021-11-11 | Janssen Vaccines & Prevention B.V. | Binding molecules directed against influenza hemagglutinin and uses thereof |
| EP3256495A4 (en) | 2015-02-11 | 2018-09-19 | Aptevo Research and Development LLC | Compositions and methods for combination therapy with prostate-specific membrane antigen binding proteins |
| RU2738424C2 (ru) * | 2015-04-22 | 2020-12-14 | Агбайоми, Инк. | Пестицидные гены и способы их применения |
| EP3778640A1 (en) | 2015-05-01 | 2021-02-17 | Genentech, Inc. | Masked anti-cd3 antibodies and methods of use |
| WO2016179518A2 (en) * | 2015-05-06 | 2016-11-10 | Janssen Biotech, Inc. | Prostate specific membrane antigen (psma) bispecific binding agents and uses thereof |
| KR101997241B1 (ko) | 2015-05-21 | 2019-07-09 | 하푼 테라퓨틱스, 인크. | 삼중특이성 결합 단백질 및 사용 방법 |
| WO2016187101A2 (en) | 2015-05-21 | 2016-11-24 | Full Spectrum Genetics, Inc. | Method of improving characteristics of proteins |
| BR112017025929A2 (pt) | 2015-06-03 | 2018-08-14 | Agbiome Inc | genes pesticidas e métodos de uso |
| CA2986604A1 (en) | 2015-06-26 | 2016-12-29 | University Of Southern California | Masking chimeric antigen receptor t cells for tumor-specific activation |
| TWI796283B (zh) | 2015-07-31 | 2023-03-21 | 德商安美基研究(慕尼黑)公司 | Msln及cd3抗體構築體 |
| US11667691B2 (en) | 2015-08-07 | 2023-06-06 | Novartis Ag | Treatment of cancer using chimeric CD3 receptor proteins |
| WO2017025698A1 (en) | 2015-08-11 | 2017-02-16 | Queen Mary University Of London | Bispecific, cleavable antibodies |
| CN106519037B (zh) | 2015-09-11 | 2019-07-23 | 科济生物医药(上海)有限公司 | 可活化的嵌合受体 |
| CN108697735A (zh) | 2015-11-05 | 2018-10-23 | 希望之城公司 | 用于制备供过继性t细胞疗法用的细胞的方法 |
| EP3903818A1 (en) | 2015-11-19 | 2021-11-03 | Revitope Limited | Functional antibody fragment complementation for a two-components system for redirected killing of unwanted cells |
| EP3411380A4 (en) | 2016-02-03 | 2020-01-22 | Youhealth Biotech, Limited | COMPOUNDS FOR THE TREATMENT OF EYE DISORDERS OR DISEASES |
| BR112018068189A2 (pt) | 2016-03-08 | 2019-02-05 | Maverick Therapeutics Inc | proteínas de ligação induzíveis e métodos de uso |
| BR112018073739A2 (pt) | 2016-05-20 | 2019-02-26 | Harpoon Therapeutics, Inc. | proteína de ligação de albumina sérica de domínio único |
| JP7042467B2 (ja) | 2016-05-20 | 2022-03-28 | ハープーン セラピューティクス,インク. | 単鎖可変フラグメントcd3結合タンパク質 |
| WO2018017863A1 (en) | 2016-07-21 | 2018-01-25 | Dcb-Usa Llc | Modified antigen-binding fab fragments and antigen-binding molecules comprising the same |
| US20190225702A1 (en) | 2016-10-14 | 2019-07-25 | Harpoon Therapeutics, Inc. | Innate immune cell trispecific binding proteins and methods of use |
| MX2019006045A (es) | 2016-11-23 | 2019-11-11 | Harpoon Therapeutics Inc | Proteinas triespecificas dirigidas a psma y metodos de uso. |
| KR102275008B1 (ko) * | 2016-11-23 | 2021-07-13 | 하푼 테라퓨틱스, 인크. | 전립선 특이 막 항원 결합 단백질 |
| WO2018136725A1 (en) | 2017-01-19 | 2018-07-26 | Harpoon Therapeutics, Inc. | Innate immune cell inducible binding proteins and methods of use |
| WO2018160671A1 (en) | 2017-02-28 | 2018-09-07 | Harpoon Therapeutics, Inc. | Targeted checkpoint inhibitors and methods of use |
| EP3589662A4 (en) | 2017-02-28 | 2020-12-30 | Harpoon Therapeutics, Inc. | INDUCTIBLE MONOVALENT ANTIGBINDING PROTEIN |
| US20180303952A1 (en) | 2017-03-09 | 2018-10-25 | Cytomx Therapeutics, Inc. | Cd147 antibodies, activatable cd147 antibodies, and methods of making and use thereof |
| EP3619234A4 (en) | 2017-05-03 | 2021-05-26 | Harpoon Therapeutics, Inc. | COMPOSITIONS AND METHODS FOR ADOPTIVE CELL THERAPIES |
| US10543271B2 (en) | 2017-05-12 | 2020-01-28 | Harpoon Therapeutics, Inc. | Mesothelin binding proteins |
| EP3621648A4 (en) | 2017-05-12 | 2021-01-20 | Harpoon Therapeutics, Inc. | TRISPECIFIC PROTEINS MSLN AND METHOD OF USE |
| US11136403B2 (en) | 2017-10-13 | 2021-10-05 | Harpoon Therapeutics, Inc. | Trispecific proteins and methods of use |
| EP3694871A4 (en) | 2017-10-13 | 2021-11-10 | Harpoon Therapeutics, Inc. | B-CELL MATURATION ANTIG-BINDING PROTEINS |
| WO2019222278A1 (en) | 2018-05-14 | 2019-11-21 | Harpoon Therapeutics, Inc. | Dual binding moiety |
| US20210269530A1 (en) | 2018-05-14 | 2021-09-02 | Harpoon Therapeutics, Inc. | Conditionally activated binding protein comprising a sterically occluded target binding domain |
| EP3794038A4 (en) | 2018-05-14 | 2022-02-16 | Harpoon Therapeutics, Inc. | BINDING FRACTION FOR CONDITIONAL ACTIVATION OF IMMUNOGLOBULIN MOLECULES |
| WO2020061526A1 (en) | 2018-09-21 | 2020-03-26 | Harpoon Therapeutics, Inc. | Conditionally activated target-binding molecules |
| US20220054544A1 (en) | 2018-09-21 | 2022-02-24 | Harpoon Therapeutics, Inc. | Conditionally active receptors |
| WO2020061482A1 (en) | 2018-09-21 | 2020-03-26 | Harpoon Therapeutics, Inc. | Egfr binding proteins and methods of use |
| JP7425049B2 (ja) | 2018-09-25 | 2024-01-30 | ハープーン セラピューティクス,インク. | Dll3結合タンパク質および使用方法 |
-
2017
- 2017-11-22 KR KR1020197017995A patent/KR102275008B1/ko active IP Right Grant
- 2017-11-22 EP EP17873939.7A patent/EP3544997A4/en not_active Withdrawn
- 2017-11-22 BR BR112019010604A patent/BR112019010604A2/pt unknown
- 2017-11-22 KR KR1020217020580A patent/KR20210087108A/ko not_active Application Discontinuation
- 2017-11-22 MX MX2019006043A patent/MX2019006043A/es unknown
- 2017-11-22 AU AU2017363300A patent/AU2017363300A1/en active Pending
- 2017-11-22 EA EA201991168A patent/EA201991168A1/ru unknown
- 2017-11-22 JP JP2019527508A patent/JP6812551B2/ja active Active
- 2017-11-22 US US15/821,498 patent/US10849973B2/en active Active
- 2017-11-22 WO PCT/US2017/063121 patent/WO2018098354A1/en unknown
- 2017-11-22 CN CN201780084346.6A patent/CN110198955A/zh active Pending
- 2017-11-22 CA CA3044659A patent/CA3044659A1/en active Pending
-
2019
- 2019-05-22 IL IL266800A patent/IL266800A/en unknown
-
2020
- 2020-09-23 US US17/030,118 patent/US20210100902A1/en not_active Abandoned
- 2020-12-15 JP JP2020207686A patent/JP2021061842A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US10849973B2 (en) | 2020-12-01 |
| KR102275008B1 (ko) | 2021-07-13 |
| JP2020501532A (ja) | 2020-01-23 |
| JP2021061842A (ja) | 2021-04-22 |
| CA3044659A1 (en) | 2018-05-31 |
| EP3544997A1 (en) | 2019-10-02 |
| US20210100902A1 (en) | 2021-04-08 |
| IL266800A (en) | 2019-08-29 |
| JP6812551B2 (ja) | 2021-01-13 |
| KR20190085542A (ko) | 2019-07-18 |
| AU2017363300A1 (en) | 2019-06-20 |
| US20180161428A1 (en) | 2018-06-14 |
| MX2019006043A (es) | 2019-09-26 |
| EP3544997A4 (en) | 2020-07-01 |
| WO2018098354A1 (en) | 2018-05-31 |
| BR112019010604A2 (pt) | 2019-12-17 |
| CN110198955A (zh) | 2019-09-03 |
| EA201991168A1 (ru) | 2019-12-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102275008B1 (ko) | 전립선 특이 막 항원 결합 단백질 | |
| US20210095047A1 (en) | PSMA Targeting Trispecific Proteins and Methods of Use | |
| AU2021201003B2 (en) | Trispecific binding proteins and methods of use | |
| US10066016B2 (en) | Single chain variable fragment CD3 binding proteins | |
| JP5513114B2 (ja) | 卵巣癌の放射免疫療法のためのヒト抗−葉酸受容体アルファ抗体および抗体フラグメント | |
| KR20150042828A (ko) | 타우병증을 치료하는 방법 | |
| KR20170138574A (ko) | 항암 융합 폴리펩타이드 | |
| US11623958B2 (en) | Single chain variable fragment CD3 binding proteins | |
| JP2023502876A (ja) | がんの治療のためのher2/4-1bb二重特異性融合タンパク質 | |
| US20230366884A1 (en) | Biomarker methods and uses | |
| EA042513B1 (ru) | Psma-нацеленные триспецифические белки и способы их применения |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| E601 | Decision to refuse application |