KR20200088805A - 게놈-편집 조류 - Google Patents
게놈-편집 조류 Download PDFInfo
- Publication number
- KR20200088805A KR20200088805A KR1020207011278A KR20207011278A KR20200088805A KR 20200088805 A KR20200088805 A KR 20200088805A KR 1020207011278 A KR1020207011278 A KR 1020207011278A KR 20207011278 A KR20207011278 A KR 20207011278A KR 20200088805 A KR20200088805 A KR 20200088805A
- Authority
- KR
- South Korea
- Prior art keywords
- dna
- bird
- nucleic acid
- chromosome
- cells
- Prior art date
Links
- 241000195493 Cryptophyta Species 0.000 title claims description 30
- 238000010362 genome editing Methods 0.000 title description 14
- 229940123611 Genome editing Drugs 0.000 title description 3
- 210000004027 cell Anatomy 0.000 claims abstract description 160
- 150000007523 nucleic acids Chemical group 0.000 claims abstract description 100
- 108091028043 Nucleic acid sequence Proteins 0.000 claims abstract description 98
- 210000000349 chromosome Anatomy 0.000 claims abstract description 79
- 238000010442 DNA editing Methods 0.000 claims abstract description 54
- 239000003795 chemical substances by application Substances 0.000 claims abstract description 54
- 231100000518 lethal Toxicity 0.000 claims abstract description 48
- 230000001665 lethal effect Effects 0.000 claims abstract description 48
- 230000001939 inductive effect Effects 0.000 claims abstract description 39
- 210000003837 chick embryo Anatomy 0.000 claims abstract description 12
- 235000013601 eggs Nutrition 0.000 claims description 81
- 238000000034 method Methods 0.000 claims description 77
- 108090000623 proteins and genes Proteins 0.000 claims description 63
- 241000287828 Gallus gallus Species 0.000 claims description 49
- 230000014509 gene expression Effects 0.000 claims description 45
- 230000008685 targeting Effects 0.000 claims description 39
- 102000004169 proteins and genes Human genes 0.000 claims description 35
- 210000001161 mammalian embryo Anatomy 0.000 claims description 31
- 241000271566 Aves Species 0.000 claims description 30
- 108010042407 Endonucleases Proteins 0.000 claims description 29
- 102000004190 Enzymes Human genes 0.000 claims description 29
- 108090000790 Enzymes Proteins 0.000 claims description 29
- 239000002773 nucleotide Substances 0.000 claims description 29
- 125000003729 nucleotide group Chemical group 0.000 claims description 29
- 210000004602 germ cell Anatomy 0.000 claims description 28
- 210000002149 gonad Anatomy 0.000 claims description 22
- 108091033319 polynucleotide Proteins 0.000 claims description 22
- 102000040430 polynucleotide Human genes 0.000 claims description 22
- 239000002157 polynucleotide Substances 0.000 claims description 22
- 108020005004 Guide RNA Proteins 0.000 claims description 20
- 108010091086 Recombinases Proteins 0.000 claims description 20
- 102000018120 Recombinases Human genes 0.000 claims description 20
- 238000010459 TALEN Methods 0.000 claims description 18
- 108010017070 Zinc Finger Nucleases Proteins 0.000 claims description 16
- 239000000411 inducer Substances 0.000 claims description 16
- 230000012447 hatching Effects 0.000 claims description 15
- 238000004519 manufacturing process Methods 0.000 claims description 14
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 14
- 241000894007 species Species 0.000 claims description 13
- 238000002347 injection Methods 0.000 claims description 12
- 239000007924 injection Substances 0.000 claims description 12
- 210000004369 blood Anatomy 0.000 claims description 11
- 239000008280 blood Substances 0.000 claims description 11
- 235000015220 hamburgers Nutrition 0.000 claims description 9
- 108010008532 Deoxyribonuclease I Proteins 0.000 claims description 8
- 102000007260 Deoxyribonuclease I Human genes 0.000 claims description 8
- 241000286209 Phasianidae Species 0.000 claims description 8
- 230000006698 induction Effects 0.000 claims description 8
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 8
- 230000001568 sexual effect Effects 0.000 claims description 8
- 239000005557 antagonist Substances 0.000 claims description 7
- 108700039887 Essential Genes Proteins 0.000 claims description 6
- 229920001184 polypeptide Polymers 0.000 claims description 6
- 230000001105 regulatory effect Effects 0.000 claims description 6
- 238000002604 ultrasonography Methods 0.000 claims description 6
- 102000004533 Endonucleases Human genes 0.000 claims description 5
- 239000000126 substance Substances 0.000 claims description 5
- 239000003053 toxin Substances 0.000 claims description 5
- 231100000765 toxin Toxicity 0.000 claims description 5
- 108700012359 toxins Proteins 0.000 claims description 5
- 230000009261 transgenic effect Effects 0.000 claims description 5
- 102000010565 Apoptosis Regulatory Proteins Human genes 0.000 claims description 4
- 108010063104 Apoptosis Regulatory Proteins Proteins 0.000 claims description 4
- 102100024505 Bone morphogenetic protein 4 Human genes 0.000 claims description 4
- 101000762379 Homo sapiens Bone morphogenetic protein 4 Proteins 0.000 claims description 4
- 239000003112 inhibitor Substances 0.000 claims description 4
- 231100000225 lethality Toxicity 0.000 claims description 4
- 102100024506 Bone morphogenetic protein 2 Human genes 0.000 claims description 3
- 102100025423 Bone morphogenetic protein receptor type-1A Human genes 0.000 claims description 3
- ZEOWTGPWHLSLOG-UHFFFAOYSA-N Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F Chemical compound Cc1ccc(cc1-c1ccc2c(n[nH]c2c1)-c1cnn(c1)C1CC1)C(=O)Nc1cccc(c1)C(F)(F)F ZEOWTGPWHLSLOG-UHFFFAOYSA-N 0.000 claims description 3
- 102100023593 Fibroblast growth factor receptor 1 Human genes 0.000 claims description 3
- 101710182386 Fibroblast growth factor receptor 1 Proteins 0.000 claims description 3
- 101000762366 Homo sapiens Bone morphogenetic protein 2 Proteins 0.000 claims description 3
- 101000934638 Homo sapiens Bone morphogenetic protein receptor type-1A Proteins 0.000 claims description 3
- 230000013011 mating Effects 0.000 claims description 3
- 241000272525 Anas platyrhynchos Species 0.000 claims description 2
- 102000004039 Caspase-9 Human genes 0.000 claims description 2
- 108090000566 Caspase-9 Proteins 0.000 claims description 2
- 108010043645 Transcription Activator-Like Effector Nucleases Proteins 0.000 claims description 2
- 230000004156 Wnt signaling pathway Effects 0.000 claims description 2
- 210000001766 X chromosome Anatomy 0.000 claims description 2
- 102000039446 nucleic acids Human genes 0.000 abstract description 9
- 108020004707 nucleic acids Proteins 0.000 abstract description 9
- 108020004414 DNA Proteins 0.000 description 191
- 210000001173 gonocyte Anatomy 0.000 description 93
- 239000005090 green fluorescent protein Substances 0.000 description 92
- 239000013612 plasmid Substances 0.000 description 71
- 239000013598 vector Substances 0.000 description 67
- 210000002257 embryonic structure Anatomy 0.000 description 57
- 108091034117 Oligonucleotide Proteins 0.000 description 46
- 239000000047 product Substances 0.000 description 45
- 235000013330 chicken meat Nutrition 0.000 description 40
- 230000006801 homologous recombination Effects 0.000 description 30
- 238000002744 homologous recombination Methods 0.000 description 30
- 108091033409 CRISPR Proteins 0.000 description 29
- 235000018102 proteins Nutrition 0.000 description 28
- 102100031780 Endonuclease Human genes 0.000 description 25
- 101710163270 Nuclease Proteins 0.000 description 25
- 108091027544 Subgenomic mRNA Proteins 0.000 description 23
- 230000000694 effects Effects 0.000 description 22
- 238000004520 electroporation Methods 0.000 description 22
- 230000010354 integration Effects 0.000 description 22
- 238000001890 transfection Methods 0.000 description 21
- 238000005286 illumination Methods 0.000 description 18
- 238000003776 cleavage reaction Methods 0.000 description 17
- 230000007017 scission Effects 0.000 description 17
- 238000003556 assay Methods 0.000 description 15
- 230000004913 activation Effects 0.000 description 14
- 239000013642 negative control Substances 0.000 description 13
- 239000000523 sample Substances 0.000 description 13
- 238000002105 Southern blotting Methods 0.000 description 12
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 12
- 239000000203 mixture Substances 0.000 description 12
- 108091008146 restriction endonucleases Proteins 0.000 description 12
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 11
- 108700028369 Alleles Proteins 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 10
- 238000013461 design Methods 0.000 description 10
- 230000005782 double-strand break Effects 0.000 description 10
- 230000005684 electric field Effects 0.000 description 10
- 238000003780 insertion Methods 0.000 description 10
- 230000037431 insertion Effects 0.000 description 10
- 239000002609 medium Substances 0.000 description 10
- 230000006798 recombination Effects 0.000 description 10
- 238000005215 recombination Methods 0.000 description 10
- 108020004705 Codon Proteins 0.000 description 9
- 108700005090 Lethal Genes Proteins 0.000 description 9
- 230000013020 embryo development Effects 0.000 description 9
- 239000012634 fragment Substances 0.000 description 9
- 230000006780 non-homologous end joining Effects 0.000 description 9
- 108091079001 CRISPR RNA Proteins 0.000 description 8
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 8
- 108700008625 Reporter Genes Proteins 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 238000000338 in vitro Methods 0.000 description 8
- 230000035772 mutation Effects 0.000 description 8
- 238000012163 sequencing technique Methods 0.000 description 8
- 230000014616 translation Effects 0.000 description 8
- 238000010200 validation analysis Methods 0.000 description 8
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 7
- 230000034431 double-strand break repair via homologous recombination Effects 0.000 description 7
- 239000012636 effector Substances 0.000 description 7
- 239000001963 growth medium Substances 0.000 description 7
- 239000013641 positive control Substances 0.000 description 7
- 239000011701 zinc Substances 0.000 description 7
- 229910052725 zinc Inorganic materials 0.000 description 7
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 6
- 238000013459 approach Methods 0.000 description 6
- 230000027455 binding Effects 0.000 description 6
- 238000009395 breeding Methods 0.000 description 6
- 230000001488 breeding effect Effects 0.000 description 6
- 238000010276 construction Methods 0.000 description 6
- 230000000875 corresponding effect Effects 0.000 description 6
- 239000013604 expression vector Substances 0.000 description 6
- 238000011534 incubation Methods 0.000 description 6
- 239000012528 membrane Substances 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 239000002953 phosphate buffered saline Substances 0.000 description 6
- 230000008488 polyadenylation Effects 0.000 description 6
- 238000001243 protein synthesis Methods 0.000 description 6
- 238000000926 separation method Methods 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- 108091026890 Coding region Proteins 0.000 description 5
- 108010051219 Cre recombinase Proteins 0.000 description 5
- 102100026280 Cryptochrome-2 Human genes 0.000 description 5
- 101710119767 Cryptochrome-2 Proteins 0.000 description 5
- 241000588724 Escherichia coli Species 0.000 description 5
- 108010046276 FLP recombinase Proteins 0.000 description 5
- 239000012097 Lipofectamine 2000 Substances 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- 238000012512 characterization method Methods 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 210000003746 feather Anatomy 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 210000004379 membrane Anatomy 0.000 description 5
- 230000008439 repair process Effects 0.000 description 5
- 230000002441 reversible effect Effects 0.000 description 5
- 239000013605 shuttle vector Substances 0.000 description 5
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 4
- 238000010453 CRISPR/Cas method Methods 0.000 description 4
- 102100032216 Calcium and integrin-binding protein 1 Human genes 0.000 description 4
- 108090000204 Dipeptidase 1 Proteins 0.000 description 4
- 101150021185 FGF gene Proteins 0.000 description 4
- 101000943475 Homo sapiens Calcium and integrin-binding protein 1 Proteins 0.000 description 4
- 241000283973 Oryctolagus cuniculus Species 0.000 description 4
- 108010076504 Protein Sorting Signals Proteins 0.000 description 4
- 230000003213 activating effect Effects 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 102000006635 beta-lactamase Human genes 0.000 description 4
- 230000003197 catalytic effect Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 239000003102 growth factor Substances 0.000 description 4
- 238000001638 lipofection Methods 0.000 description 4
- 108020004999 messenger RNA Proteins 0.000 description 4
- 230000001850 reproductive effect Effects 0.000 description 4
- 210000002966 serum Anatomy 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 210000001519 tissue Anatomy 0.000 description 4
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 4
- 238000011144 upstream manufacturing Methods 0.000 description 4
- 239000013603 viral vector Substances 0.000 description 4
- 239000011782 vitamin Substances 0.000 description 4
- 229940088594 vitamin Drugs 0.000 description 4
- 229930003231 vitamin Natural products 0.000 description 4
- 235000013343 vitamin Nutrition 0.000 description 4
- 102000053602 DNA Human genes 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 108010000912 Egg Proteins Proteins 0.000 description 3
- 102000002322 Egg Proteins Human genes 0.000 description 3
- 208000009701 Embryo Loss Diseases 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 3
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 3
- 206010027476 Metastases Diseases 0.000 description 3
- 241001045988 Neogene Species 0.000 description 3
- 238000010222 PCR analysis Methods 0.000 description 3
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 3
- 108020004511 Recombinant DNA Proteins 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 101150063416 add gene Proteins 0.000 description 3
- 239000011543 agarose gel Substances 0.000 description 3
- 239000000427 antigen Substances 0.000 description 3
- 108091007433 antigens Proteins 0.000 description 3
- 102000036639 antigens Human genes 0.000 description 3
- 230000006907 apoptotic process Effects 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 238000012761 co-transfection Methods 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 210000003278 egg shell Anatomy 0.000 description 3
- 238000001962 electrophoresis Methods 0.000 description 3
- 210000002216 heart Anatomy 0.000 description 3
- 238000009396 hybridization Methods 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 239000003550 marker Substances 0.000 description 3
- 230000008774 maternal effect Effects 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 101150091879 neo gene Proteins 0.000 description 3
- 210000000276 neural tube Anatomy 0.000 description 3
- 230000037361 pathway Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000005783 single-strand break Effects 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 230000002103 transcriptional effect Effects 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 102100024321 Alkaline phosphatase, placental type Human genes 0.000 description 2
- 241000272517 Anseriformes Species 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 102100026189 Beta-galactosidase Human genes 0.000 description 2
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 2
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 2
- 239000003298 DNA probe Substances 0.000 description 2
- 230000007018 DNA scission Effects 0.000 description 2
- 238000001712 DNA sequencing Methods 0.000 description 2
- 230000004568 DNA-binding Effects 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 description 2
- 108700039839 Drosophila grim Proteins 0.000 description 2
- 108700007861 Drosophila rpr Proteins 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 108010067770 Endopeptidase K Proteins 0.000 description 2
- 241000283074 Equus asinus Species 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 2
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 2
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 2
- 101150078517 Hint1 gene Proteins 0.000 description 2
- 101000821100 Homo sapiens Synapsin-1 Proteins 0.000 description 2
- 101000575685 Homo sapiens Synembryn-B Proteins 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 239000005089 Luciferase Substances 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- 229930193140 Neomycin Natural products 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 102000003992 Peroxidases Human genes 0.000 description 2
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 2
- 102000045595 Phosphoprotein Phosphatases Human genes 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 102100026014 Synembryn-B Human genes 0.000 description 2
- 108010022394 Threonine synthase Proteins 0.000 description 2
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 2
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 2
- 238000002679 ablation Methods 0.000 description 2
- 108010023082 activin A Proteins 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 108010005774 beta-Galactosidase Proteins 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 229960002092 busulfan Drugs 0.000 description 2
- 230000030833 cell death Effects 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000002425 crystallisation Methods 0.000 description 2
- 230000008025 crystallization Effects 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000034994 death Effects 0.000 description 2
- 231100000517 death Toxicity 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 102000004419 dihydrofolate reductase Human genes 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- 230000005611 electricity Effects 0.000 description 2
- 231100001129 embryonic lethality Toxicity 0.000 description 2
- 239000012467 final product Substances 0.000 description 2
- 244000144992 flock Species 0.000 description 2
- 108091006047 fluorescent proteins Proteins 0.000 description 2
- 102000034287 fluorescent proteins Human genes 0.000 description 2
- 235000013305 food Nutrition 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 238000012239 gene modification Methods 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 230000005017 genetic modification Effects 0.000 description 2
- 235000013617 genetically modified food Nutrition 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 239000008103 glucose Substances 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 244000144980 herd Species 0.000 description 2
- 239000000833 heterodimer Substances 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 102000056115 human SYN1 Human genes 0.000 description 2
- 210000004408 hybridoma Anatomy 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 238000007726 management method Methods 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 235000013372 meat Nutrition 0.000 description 2
- 239000003068 molecular probe Substances 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 229960004927 neomycin Drugs 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 239000002777 nucleoside Substances 0.000 description 2
- 150000003833 nucleoside derivatives Chemical class 0.000 description 2
- 210000004940 nucleus Anatomy 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 210000004681 ovum Anatomy 0.000 description 2
- 238000004806 packaging method and process Methods 0.000 description 2
- 108040007629 peroxidase activity proteins Proteins 0.000 description 2
- -1 phosphoribosyl Chemical group 0.000 description 2
- 108010031345 placental alkaline phosphatase Proteins 0.000 description 2
- 238000013492 plasmid preparation Methods 0.000 description 2
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 2
- 235000019419 proteases Nutrition 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 239000013608 rAAV vector Substances 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 238000003757 reverse transcription PCR Methods 0.000 description 2
- 210000003705 ribosome Anatomy 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 230000020509 sex determination Effects 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 210000001082 somatic cell Anatomy 0.000 description 2
- 238000002798 spectrophotometry method Methods 0.000 description 2
- 238000003756 stirring Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 210000001550 testis Anatomy 0.000 description 2
- 229960000187 tissue plasminogen activator Drugs 0.000 description 2
- 230000010474 transient expression Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 230000002792 vascular Effects 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 150000003722 vitamin derivatives Chemical class 0.000 description 2
- CXNPLSGKWMLZPZ-GIFSMMMISA-N (2r,3r,6s)-3-[[(3s)-3-amino-5-[carbamimidoyl(methyl)amino]pentanoyl]amino]-6-(4-amino-2-oxopyrimidin-1-yl)-3,6-dihydro-2h-pyran-2-carboxylic acid Chemical compound O1[C@@H](C(O)=O)[C@H](NC(=O)C[C@@H](N)CCN(C)C(N)=N)C=C[C@H]1N1C(=O)N=C(N)C=C1 CXNPLSGKWMLZPZ-GIFSMMMISA-N 0.000 description 1
- LAQPKDLYOBZWBT-NYLDSJSYSA-N (2s,4s,5r,6r)-5-acetamido-2-{[(2s,3r,4s,5s,6r)-2-{[(2r,3r,4r,5r)-5-acetamido-1,2-dihydroxy-6-oxo-4-{[(2s,3s,4r,5s,6s)-3,4,5-trihydroxy-6-methyloxan-2-yl]oxy}hexan-3-yl]oxy}-3,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy}-4-hydroxy-6-[(1r,2r)-1,2,3-trihydrox Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]([C@@H](NC(C)=O)C=O)[C@@H]([C@H](O)CO)O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@H]([C@H](NC(C)=O)[C@@H](O)C2)[C@H](O)[C@H](O)CO)C(O)=O)[C@@H](O)[C@@H](CO)O1 LAQPKDLYOBZWBT-NYLDSJSYSA-N 0.000 description 1
- KRQUFUKTQHISJB-YYADALCUSA-N 2-[(E)-N-[2-(4-chlorophenoxy)propoxy]-C-propylcarbonimidoyl]-3-hydroxy-5-(thian-3-yl)cyclohex-2-en-1-one Chemical compound CCC\C(=N/OCC(C)OC1=CC=C(Cl)C=C1)C1=C(O)CC(CC1=O)C1CCCSC1 KRQUFUKTQHISJB-YYADALCUSA-N 0.000 description 1
- JLIDBLDQVAYHNE-LXGGSRJLSA-N 2-cis-abscisic acid Chemical compound OC(=O)/C=C(/C)\C=C\C1(O)C(C)=CC(=O)CC1(C)C JLIDBLDQVAYHNE-LXGGSRJLSA-N 0.000 description 1
- 108020005345 3' Untranslated Regions Proteins 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- GSRTWXVBHGOUBU-UHFFFAOYSA-N 6,7-diphenyl-2-sulfanylidene-1h-pteridin-4-one Chemical compound C=1C=CC=CC=1C=1N=C2C(=O)NC(S)=NC2=NC=1C1=CC=CC=C1 GSRTWXVBHGOUBU-UHFFFAOYSA-N 0.000 description 1
- 102100029457 Adenine phosphoribosyltransferase Human genes 0.000 description 1
- 108010024223 Adenine phosphoribosyltransferase Proteins 0.000 description 1
- HJCMDXDYPOUFDY-WHFBIAKZSA-N Ala-Gln Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O HJCMDXDYPOUFDY-WHFBIAKZSA-N 0.000 description 1
- 239000012103 Alexa Fluor 488 Substances 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 241000219195 Arabidopsis thaliana Species 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 239000012583 B-27 Supplement Substances 0.000 description 1
- 108091007065 BIRCs Proteins 0.000 description 1
- 108020004513 Bacterial RNA Proteins 0.000 description 1
- 101150078024 CRY2 gene Proteins 0.000 description 1
- 102000000905 Cadherin Human genes 0.000 description 1
- 108050007957 Cadherin Proteins 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 108090000397 Caspase 3 Proteins 0.000 description 1
- 102100029855 Caspase-3 Human genes 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- 102000008169 Co-Repressor Proteins Human genes 0.000 description 1
- 108010060434 Co-Repressor Proteins Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 241001442234 Cosa Species 0.000 description 1
- 101150090523 DAZL gene Proteins 0.000 description 1
- 108020003215 DNA Probes Proteins 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 102100033672 Deleted in azoospermia-like Human genes 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 102000003974 Fibroblast growth factor 2 Human genes 0.000 description 1
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- 101150039660 HA gene Proteins 0.000 description 1
- MAJYPBAJPNUFPV-BQBZGAKWSA-N His-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 MAJYPBAJPNUFPV-BQBZGAKWSA-N 0.000 description 1
- 101000871280 Homo sapiens Deleted in azoospermia-like Proteins 0.000 description 1
- 101100281008 Homo sapiens FGF2 gene Proteins 0.000 description 1
- 101001139134 Homo sapiens Krueppel-like factor 4 Proteins 0.000 description 1
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 1
- 101000687905 Homo sapiens Transcription factor SOX-2 Proteins 0.000 description 1
- 102000002265 Human Growth Hormone Human genes 0.000 description 1
- 108010000521 Human Growth Hormone Proteins 0.000 description 1
- 239000000854 Human Growth Hormone Substances 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- 102000055031 Inhibitor of Apoptosis Proteins Human genes 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102100024392 Insulin gene enhancer protein ISL-1 Human genes 0.000 description 1
- 102100039068 Interleukin-10 Human genes 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 102100020873 Interleukin-2 Human genes 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 101150070110 Isl1 gene Proteins 0.000 description 1
- 102100020677 Krueppel-like factor 4 Human genes 0.000 description 1
- 108700021430 Kruppel-Like Factor 4 Proteins 0.000 description 1
- 101000844802 Lacticaseibacillus rhamnosus Teichoic acid D-alanyltransferase Proteins 0.000 description 1
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 1
- 108050000637 N-cadherin Proteins 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 108020003217 Nuclear RNA Proteins 0.000 description 1
- 102000043141 Nuclear RNA Human genes 0.000 description 1
- 102000007399 Nuclear hormone receptor Human genes 0.000 description 1
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 108010058846 Ovalbumin Proteins 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 102100027913 Peptidyl-prolyl cis-trans isomerase FKBP1A Human genes 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 108010039918 Polylysine Proteins 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 101100247004 Rattus norvegicus Qsox1 gene Proteins 0.000 description 1
- 101710200251 Recombinase cre Proteins 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 108010052160 Site-specific recombinase Proteins 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- 241000272534 Struthio camelus Species 0.000 description 1
- 101150057615 Syn gene Proteins 0.000 description 1
- 108010006877 Tacrolimus Binding Protein 1A Proteins 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 102100024270 Transcription factor SOX-2 Human genes 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 108010020764 Transposases Proteins 0.000 description 1
- 102000008579 Transposases Human genes 0.000 description 1
- 102000013814 Wnt Human genes 0.000 description 1
- 108050003627 Wnt Proteins 0.000 description 1
- 210000005006 adaptive immune system Anatomy 0.000 description 1
- 210000001691 amnion Anatomy 0.000 description 1
- 210000003484 anatomy Anatomy 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 230000003466 anti-cipated effect Effects 0.000 description 1
- 210000001367 artery Anatomy 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- CXNPLSGKWMLZPZ-UHFFFAOYSA-N blasticidin-S Natural products O1C(C(O)=O)C(NC(=O)CC(N)CCN(C)C(N)=N)C=CC1N1C(=O)N=C(N)C=C1 CXNPLSGKWMLZPZ-UHFFFAOYSA-N 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 239000012888 bovine serum Substances 0.000 description 1
- 238000010804 cDNA synthesis Methods 0.000 description 1
- 108020001778 catalytic domains Proteins 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 239000013000 chemical inhibitor Substances 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 210000003555 cloaca Anatomy 0.000 description 1
- 210000001520 comb Anatomy 0.000 description 1
- 239000003636 conditioned culture medium Substances 0.000 description 1
- 238000004624 confocal microscopy Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000037416 cystogenesis Effects 0.000 description 1
- 230000002498 deadly effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 239000000412 dendrimer Substances 0.000 description 1
- 229920000736 dendritic polymer Polymers 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 210000001840 diploid cell Anatomy 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- UKWLRLAKGMZXJC-QIECWBMSSA-L disodium;[4-chloro-3-[(3r,5s)-1-chloro-3'-methoxyspiro[adamantane-4,4'-dioxetane]-3'-yl]phenyl] phosphate Chemical compound [Na+].[Na+].O1OC2([C@@H]3CC4C[C@H]2CC(Cl)(C4)C3)C1(OC)C1=CC(OP([O-])([O-])=O)=CC=C1Cl UKWLRLAKGMZXJC-QIECWBMSSA-L 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 239000003937 drug carrier Substances 0.000 description 1
- 230000008144 egg development Effects 0.000 description 1
- 238000001493 electron microscopy Methods 0.000 description 1
- 230000000408 embryogenic effect Effects 0.000 description 1
- 230000008011 embryonic death Effects 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 238000010195 expression analysis Methods 0.000 description 1
- 230000004720 fertilization Effects 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 238000002376 fluorescence recovery after photobleaching Methods 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 230000007045 gastrulation Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000037442 genomic alteration Effects 0.000 description 1
- 210000004907 gland Anatomy 0.000 description 1
- 102000005396 glutamine synthetase Human genes 0.000 description 1
- 108020002326 glutamine synthetase Proteins 0.000 description 1
- 230000002710 gonadal effect Effects 0.000 description 1
- 210000003313 haploid nucleated cell Anatomy 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- ZFGMDIBRIDKWMY-PASTXAENSA-N heparin Chemical compound CC(O)=N[C@@H]1[C@@H](O)[C@H](O)[C@@H](COS(O)(=O)=O)O[C@@H]1O[C@@H]1[C@@H](C(O)=O)O[C@@H](O[C@H]2[C@@H]([C@@H](OS(O)(=O)=O)[C@@H](O[C@@H]3[C@@H](OC(O)[C@H](OS(O)(=O)=O)[C@H]3O)C(O)=O)O[C@@H]2O)CS(O)(=O)=O)[C@H](O)[C@H]1O ZFGMDIBRIDKWMY-PASTXAENSA-N 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 238000013537 high throughput screening Methods 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 238000003165 hybrid screening Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 210000001822 immobilized cell Anatomy 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 208000000509 infertility Diseases 0.000 description 1
- 230000036512 infertility Effects 0.000 description 1
- 231100000535 infertility Toxicity 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 229940076144 interleukin-10 Drugs 0.000 description 1
- 229940028885 interleukin-4 Drugs 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 208000017169 kidney disease Diseases 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 230000005499 meniscus Effects 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 230000002906 microbiologic effect Effects 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 230000009456 molecular mechanism Effects 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 239000012120 mounting media Substances 0.000 description 1
- 229910052754 neon Inorganic materials 0.000 description 1
- GKAOGPIIYCISHV-UHFFFAOYSA-N neon atom Chemical compound [Ne] GKAOGPIIYCISHV-UHFFFAOYSA-N 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 102000045246 noggin Human genes 0.000 description 1
- 108700007229 noggin Proteins 0.000 description 1
- 108020004017 nuclear receptors Proteins 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 230000009437 off-target effect Effects 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 229940092253 ovalbumin Drugs 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- RLZZZVKAURTHCP-UHFFFAOYSA-N phenanthrene-3,4-diol Chemical compound C1=CC=C2C3=C(O)C(O)=CC=C3C=CC2=C1 RLZZZVKAURTHCP-UHFFFAOYSA-N 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 229920000656 polylysine Polymers 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- 235000013594 poultry meat Nutrition 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 238000012514 protein characterization Methods 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 230000000384 rearing effect Effects 0.000 description 1
- 230000033764 rhythmic process Effects 0.000 description 1
- 238000007789 sealing Methods 0.000 description 1
- 239000003566 sealing material Substances 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 230000003007 single stranded DNA break Effects 0.000 description 1
- 229960002930 sirolimus Drugs 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 230000036962 time dependent Effects 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 230000037303 wrinkles Effects 0.000 description 1
- 210000001325 yolk sac Anatomy 0.000 description 1
- 150000003751 zinc Chemical class 0.000 description 1
Images
















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0608—Germ cells
- C12N5/0611—Primordial germ cells, e.g. embryonic germ cells [EG]
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/30—Bird
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/02—Animal zootechnically ameliorated
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/106—Plasmid DNA for vertebrates
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Biotechnology (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Wood Science & Technology (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical & Material Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Environmental Sciences (AREA)
- Molecular Biology (AREA)
- Veterinary Medicine (AREA)
- Developmental Biology & Embryology (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Cell Biology (AREA)
- Physics & Mathematics (AREA)
- Animal Behavior & Ethology (AREA)
- Animal Husbandry (AREA)
- Biodiversity & Conservation Biology (AREA)
- Mycology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Saccharide Compounds (AREA)
Abstract
조류의 난에서 수컷 병아리 배아의 치사성 표현형을 유도성 방식으로 유도하기 위한 제1 핵산 서열 및 상기 치사성 표현형을 달성하기 위한 상기 핵산 서열을 상기 조류의 세포의 Z 염색체에 안내하기 위한 제2 핵산 서열을 포함하는 DNA 편집제가 개시된다. DNA 편집제의 용도가 또한 개시된다.
Description
본 발명은 이의 일부 실시형태에서, 생존 불가능한 수컷 병아리 배아를 포함하는 알을 낳는 게놈 편집 조류(genome edited bird)에 관한 것이다.
성별 분리는 모든 조류 종 생산에 있어 중요한 양상이지만, 특히 육계 및 본질적으로 모든 난 층(egg layer) 및 칠면조 생산에 중요하다. 육계 및 칠면조의 경우, 성별 분리는 두 성별 모두의 필요에 따라 보다 적합한 관리 및 사육을 가능하게 하며, 이는 대부분의 경우에 현재 수행되고 있는 성별 비구별 사육(unisex rearing)과는 다소 상이하다. 본질적으로 식품용 난(table egg)을 낳는 암탉이 될 어린 닭의 모든 상업적인 부화장은 무리(flock)의 성별 분리를 사용한다. 수컷 닭은 부화장에서 채집되는 반면, 암컷 닭은 명백하게 난 생산을 위해서 활용된다.
현재 가금류를 성별 구별에 사용 가능한 3가지 방법이 있다. 햇 병아리(day-old chick)는 벤트/클로아카(Vent/cloaca) 성별 구별 또는 깃털 성별 구별 방법에 의해서 성별 구별될 수 있다. 대안적으로 수컷 및 암컷 병아리는 이차 성징이 분명해질 때까지 함께 양육될 수 있으며, 이어서 병아리는 성별에 따라 분리될 수 있다. 벤트/클로아카 성별 구별은 성별 관련 해부학적 구조의 외관을 기반으로 하는 성별의 시각적 식별에 의존한다. 깃털 성별 구별은 수컷 병아리와 암컷 병아리 사이에 상이한 깃털 특징, 예를 들어, 다운 컬러 패턴 및 날개 깃털의 빠른/느린 성장 속도를 기반으로 한다. 세 번째 방법은 예를 들어, 빗과 주름살이 암컷의 것보다 커지는 수컷에서의 자연적인 이차 성징의 외관에 의존한다.
햇 병아리의 벤트/클로아카 성별 결정은 어렵고, 고비용이다. 조류의 성별을 식별하는 것은 고도로 숙련된 인력이 필요하다. 수행하기는 더 쉽지만, 깃털 성별 구별은 조류의 특정 유전적 교배(genetic cross)로 제한되는 단점이 있다. 이차 성징에 의한 성별 구별은 수행하기 가장 쉬운 방법이지만, 부화 후 첫 주 동안 두 성별의 조류를 함께 사육해야 한다는 단점이 있는데, 이는 사료 비용 및 사료 전환 고려사항으로 인해서 벤트/클로아카 성별 구별의 비용보다 부화장에 대해서 더 고비용일 수 있다.
가장 중요하게는, 한편으로는 육류 생산의 최적화 및 다른 한편으로는 난 생산의 최적화로 인해서, 난 생산에 최적화된 닭 품종의 수컷의 어린 닭은 더 이상 육류 생산에 적합하지 않거나 경제적으로 매력적이지 않다. 따라서, 미국 및 유럽에서는 매년 5억 마리 초과의 수컷 병아리가 단지 가스 처리, 감전 또는 파쇄(shredding)에 의해서 파괴된다. 이것은 경제적인 문제일 뿐만 아니라 점점 윤리적인 문제가 되고 있다.
분명히, 상업적인 부화장 산업은 고도로 숙련된 개인에게 의존하지 않는, 여전히 난 내에서 조류를 분류할 수 있는 방법이 필요하다.
Oishi 등(문헌 [Scientific Reports 6, Article number: 23980 (2016) doi:10.1038/srep23980])은 CRISPR/Cas9 시스템을 사용하여 닭 원시 생식 세포(primordial germ cell)에서 표적화된 돌연변이유발을 교시한다.
Macdonald 등(문헌 [PNAS, 2012, p. 1466-1472])은 piggyBac 및 Tol2 트랜스포손을 사용한 원시 생식 세포의 유전자 변형 및 생식선 전달을 교시한다.
미국 출원 제20060095980호에는 암컷과 상반되게 수컷일 가능성이 높은 자손을 생산하도록 암컷 조류의 내생 원시 생식 세포 수를 조작하는 것이 교시되어 있다.
추가 배경 기술은 국제 특허 공개 제2017094015호를 포함한다.
본 발명의 일부 실시형태의 양상에 따르면, 조류의 난에서 수컷 병아리 배아의 치사성 표현형(lethal phenotype)을 유도성 방식으로 유도하기 위한 제1 핵산 서열 및 치사성 표현형을 달성하기 위한 제1 핵산 서열을 상기 조류의 세포의 Z 염색체에 안내하기 위한 제2 핵산 서열을 포함하는, DNA 편집제가 제공된다.
본 발명의 일부 실시형태의 양상에 따르면, 세포의 Z 염색체에 안정적으로 통합되는 외인성 폴리뉴클레오타이드를 포함하는 조류의 세포를 포함하는 세포 집단이 제공되며, 외인성 폴리뉴클레오타이드는 조류의 수컷 자손에서 치사성 표현형을 유도하기 위한 것이다.
본 발명의 일부 실시형태의 양상에 따르면, 본 명세서에 기재된 방법에 따라서 생성된 키메라 조류(chimeric bird)가 제공된다.
본 발명의 일부 실시형태의 양상에 따르면, 본 명세서에 기재된 키메라 조류의 생식세포(gamete)를 사용하여 생성된 트랜스제닉 조류(transgenic bird)가 제공된다.
발명의 일부 실시형태의 양상에 따르면, 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 방법이 제공되며, 여기서 외인성 폴리뉴클레오타이드는 조류의 Z 염색체에 안정적으로 통합되고, 외인성 폴리뉴클레오타이드는 조류의 수컷 자손에서 치사성 표현형을 유도성 방식으로 유도하기 위한 것이고, 방법은 난을 치사성 표현형을 유도하는 유도자(inducer)에 노출시켜, 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 단계를 포함한다.
본 발명의 일부 실시형태의 양상에 따르면, 본 명세서에 기재된 세포 집단을 포함하는 키메라 조류가 제공된다.
본 발명의 일부 실시형태의 양상에 따르면, 세포 집단의 원시 생식 세포(primordial germ cell: PGC) 중 적어도 하나가 수용자 조류 배아의 생식선에 군집(colonizing)하여 키메라 조류를 생성시키기에 충분한 조건 하에서 본 명세서에 기재된 세포 집단을 수용자 조류 배아에 투여하는 단계를 포함하는 키메라 조류를 생산하는 방법이 제공된다.
본 발명의 일부 실시형태의 양상에 따르면,
(i) 리콤비나제 인식 부위에 작동 가능하게 연결된 조류의 난에서 치사성 표현형을 유도하기 위한 제1 핵산 서열 및 치사성 표현형을 달성하기 위한 제1 핵산 서열을 새의 세포의 Z 염색체에 안내하기 위한 서열을 포함하는 제1 작용제; 및
(ii) 리콤비나제 효소를 암호화하는 제2 핵산 서열 및 제2 핵산 서열을 조류 세포의 Z 염색체에 안내하기 위한 서열을 포함하는 제2 작용제를 포함하는, DNA 편집 시스템이 제공된다.
본 발명의 일부 실시형태의 양상에 따르면, 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 방법이 제공되며, 이 방법은,
암컷 조류와 수컷 조류를 짝짓기시키는 단계를 포함하고, 여기서 리콤비나제 인식 부위에 작동 가능하게 연결된 제1 외인성 폴리뉴클레오타이드는 수컷 조류의 Z 염색체에 안정적으로 통합되고, 외인성 폴리뉴클레오타이드는 조류의 난에서 치사성 표현형을 유도하기 위한 것이고, 리콤비나제 효소를 암호화하는 제2 외인성 폴리뉴클레오타이드는 암컷 조류의 Z 염색체에 안정적으로 통합되거나, 또는
리콤비나제 인식 부위에 작동 가능하게 연결된 제1 외인성 폴리뉴클레오타이드는 암컷 조류의 Z 염색체에 안정적으로 통합되고, 외인성 폴리뉴클레오타이드는 조류의 난에서 치사성 표현형을 유도하기 위한 것이고, 리콤비나제 효소를 암호화하는 제2 외인성 폴리뉴클레오타이드는 수컷 조류의 Z 염색체에 안정적으로 통합되어,
조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시킨다.
본 발명의 일부 실시형태에 따르면, 유도는 유도성 방식으로 달성된다.
본 발명의 일부 실시형태에 따르면, 제1 핵산 서열은 치사 단백질의 발현을 제어하는 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결된 치사 단백질을 암호화하고, 스위치는 유도자에 의해서 조절된다.
본 발명의 일부 실시형태에 따르면, 치사 단백질은 독소, 프로-아포토시스 단백질(pro-apoptotic protein), BMP 길항제, Wnt 신호전달 경로의 저해제 및 FGF 길항제로 이루어진 군으로부터 선택된다.
본 발명의 일부 실시형태에 따르면, DNA 편집제는 단일 분자이다.
본 발명의 일부 실시형태에 따르면, 제1 핵산 서열 및 제2 핵산 서열은 동일하지 않은 분자로 구성된다.
본 발명의 일부 실시형태에 따르면, 제1 핵산 서열은 엔도뉴클레아제 단백질의 발현을 제어하는 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결된 게놈 편집을 수행할 수 있는 엔도뉴클레아제 효소를 암호화하며, 스위치는 유도자에 의해 조절된다.
본 발명의 일부 실시형태에 따르면, 제2 핵산 서열은,
(i) 조류의 상기 Z 염색체 내의 표적 유전자 좌위에 측접한 5' 영역과 실질적으로 상동성인 좌측 상동성 아암(left homology arm: LHA) 뉴클레오타이드 서열; 및
(i) 조류의 상기 Z 염색체 내의 상기 표적 유전자 좌위에 측접한 3' 영역과 실질적으로 상동성인 우측 상동성 아암(right homology arm: RHA) 뉴클레오타이드 서열을 포함한다.
본 발명의 일부 실시형태에 따르면, 유도자는 열, 초음파, 전자기 에너지 및 화학 물질로 이루어진 군으로부터 선택된다.
본 발명의 일부 실시형태에 따르면, 스위치는 조합되어 유도자의 존재 하에서 활성 효소를 형성하는 스플리트 리콤비나제 효소(split recombinase enzyme)를 포함한다.
본 발명의 일부 실시형태에 따르면, 스위치는 유도성 프로모터를 포함한다.
본 발명의 일부 실시형태에 따르면, 엔도뉴클레아제 효소는 RNA-안내(RNA-guided) DNA 엔도뉴클레아제 효소이다.
본 발명의 일부 실시형태에 따르면, DNA 편집제는 조류의 필수 유전자를 표적으로 하는 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 더 포함하고, 뉴클레오타이드 서열은 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결되어 있다.
본 발명의 일부 실시형태에 따르면, 필수 유전자는 BMPR1A, BMP2, BMP4 및 FGFR1로 이루어진 군으로부터 선택된다.
본 발명의 일부 실시형태에 따르면, RNA-안내 DNA 엔도뉴클레아제 효소는 아연-핑거 뉴클레아제(zinc-finger nuclease: ZFN), 전사 활성화제-유사 효과기 뉴클레아제(transcription activator-like effector nuclease: TALEN) 및 카스파제 9로 이루어진 군으로부터 선택된다.
본 발명의 일부 실시형태에 따르면, DNA 편집제는 리포터 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 추가로 포함한다.
본 발명의 일부 실시형태에 따르면, 유도자는 전자기 에너지이다.
본 발명의 일부 실시형태에 따르면, 전자기 에너지는 가시광의 성분이다.
본 발명의 일부 실시형태에 따르면, 가시광의 성분은 청색광이다.
본 발명의 일부 실시형태에 따르면, 조류는 닭, 칠면조, 오리 및 메추라기로 이루어진 군으로부터 선택된다.
본 발명의 일부 실시형태에 따르면, 세포는 원시 생식 세포(PGC)를 포함한다.
본 발명의 일부 실시형태에 따르면, 세포는 생식세포를 포함한다.
본 발명의 일부 실시형태에 따르면, PGC는 생식선 PGC, 혈액 PGC 및 생식신월환(germinal crescent) PGC로 이루어진 군으로부터 선택된다.
본 발명의 일부 실시형태에 따르면, 방법은 투여 후 키메라 조류를 인큐베이션시켜 부화시키는 단계를 추가로 포함한다.
본 발명의 일부 실시형태에 따르면, 방법은 키메라 조류를 성적 성숙도로 성장시키는 단계를 추가로 포함하며, 여기서 키메라 조류는 공여자 PGC로부터 유래된 생식세포를 생산한다.
본 발명의 일부 실시형태에 따르면, 투여는 난내(in-ovo) 주사에 의해서 수행된다.
본 발명의 일부 실시형태에 따르면, 세포 집단은 수용자 조류와 동일한 조류 종으로부터 유래된다.
본 발명의 일부 실시형태에 따르면, 세포 집단은 수용자 조류와 상이한 조류 종으로부터 유래된다.
본 발명의 일부 실시형태에 따르면, 세포 집단은 상기 수용자 배아가 이알-길라디 및 코차브 기 결정 시스템(Eyal-Giladi & Kochav staging system)에 따라서 약 IX기와 햄버거 및 해밀턴 기 결정 시스템(Hamburger & Hamilton staging system)에 따라서 약 30기 사이인 경우에 투여된다.
본 발명의 일부 실시형태에 따르면, 세포 집단은 수용자 배아가 햄버거 및 해밀턴 기 결정 시스템에 따라서 14기 이후인 경우 투여된다.
본 발명의 일부 실시형태에 따르면, 제1 핵산 서열은 게놈 편집을 수행할 수 있는 치사 단백질 또는 엔도뉴클레아제 효소를 암호화한다.
본 발명의 일부 실시형태에 따르면, 상기 제1 핵산 서열 또는 상기 제2 핵산 서열을 상기 X 염색체에 안내하기 위한 서열은,
(i) 조류의 Z 염색체 내의 표적 유전자 좌위에 측접한 5' 영역과 실질적으로 상동성인 좌측 상동성 아암(LHA) 뉴클레오타이드 서열; 및
(i) 조류의 Z 염색체 내의 표적 유전자 좌위에 측접한 3' 영역과 실질적으로 상동성인 우측 상동성 아암(RHA) 뉴클레오타이드 서열을 포함한다.
달리 정의되지 않는 한, 본 명세서에 사용된 모든 기술 및/또는 과학 용어는 본 발명이 속하는 기술 분야의 당업자에 의해 일반적으로 이해되는 것과 동일한 의미를 갖는다. 본 명세서에 기재된 것과 유사하거나 동등한 방법 및 물질이 본 발명의 실시형태의 실시 또는 시험에 사용될 수 있지만, 예시적인 방법 및/또는 물질을 하기에 기재한다. 상충되는 경우, 정의를 포함한 본 특허 명세서가 우선한다. 또한, 물질, 방법 및 실시예는 단지 예시일 뿐이며 반드시 제한하려는 것은 아니다.
본 발명의 일부 실시형태는 첨부된 도면을 참조하여 단지 예의 방식으로 기재된다. 이제 도면을 구체적으로 참조하면, 도시된 세부 사항은 예로서 그리고 본 발명의 실시형태의 예시적인 논의의 목적으로 강조된다. 이와 관련하여, 도면과 함께 이루어진 설명은 본 발명의 실시형태가 어떻게 실시될 수 있는지 당업자에게 명백하다.
도면에서,
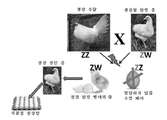
도 1은 단지 암컷 층 병아리만 부화될 옵토제틱(Optogenetic) 유도성 닭 라인의 생성을 도시하는 도면. 야생형 수탉(ZZ)과 유전적으로 변형된 암탉( Z W)을 교배시킴으로써, 모든 암컷 수정란은 야생형 ZW 염색체를 보유할 것이고, Z 염색체는 WT 수탉으로부터 유래된다. 모든 수컷 수정란은 Z Z 염색체를 보유할 것이고, 여기서 적색 표지된 Z는 암탉의 게놈으로부터 유래된다. 이것이 목표하는 염색체이다. 수정란의 청색광 조명 시에, 이 염색체의 옵토제틱 시스템이 활성화되어 산란 후 곧바로 초기 배아 사망을 초래할 사멸 기전을 활성화할 것이다. 청색광 조명에 의해서 영향을 받지 않을 암컷은 성계로 자라며 식품용 무정란을 낳을 것이다.
도 2는 청색광 조명에 의해 유전자 발현을 제어하는 전략을 예시한 도면. 2개의 융합 단백질은 생성된 Cre의 N-말단을 갖는 Cry2(Cry2-Cre-N-말단) 및 Cre의 C-말단과 융합된 CIBN(CIBN-Cre-C-말단)이다. 청색광 조명이 없으면, Cre는 비활성화된다. 청색광 조명 시, CRY2 및 CIBN은 이종이합체를 형성하고, Cre의 두 부분은 함께 모여 활성 Cre 효소를 형성한다11.
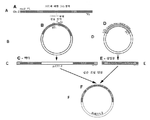
도 3은 염색체 Z 상의 상동성 아암을 예시한 도면. Hint1 좌위(녹색 화살표)에 대한 하류의 게놈 영역이 도시된다. 5' 아암 및 3' 아암, HA-1 및 HA-2는 각각 적색으로 도시된다. 아암을 증폭시키기 위한 프라이머는 황색 화살표로 표시된다. 상동성 아암들 사이에서, 두 DNA 가닥 모두에, CRISPR-Cas9(녹색 박스)에 대해서 특이적이고 적절한 매우 고유한 서열이 존재한다. 도면의 하단 부분은 두 상동성 아암 사이의 영역을 자세히 보여준다.
서열번호 1에 제시된 서열이 예시된다.
도 4A 내지 도 4C는 본 발명의 실시형태에 따른 표적화 벡터를 도시한 도면. 표적화 벡터는 3개의 주요 요소를 함유한다. 첫 번째, 전체 삽입 카세트에 측접한, 상동 재조합(HR)을 위한 5' 상동성 아암 및 3' 상동성 암(HA, 밝은 청색), 두 번째, 광-유도성 시스템 - 이 경우 Cry2-CreN 및 CIBN-CreC, 및 세 번째 치사 유전자 카세트. (A) 5' HA, 그 다음 자가-절단 펩타이드 P2A(보라색 상자)에 의해서 분리된 Cry2-CreN 및 CIBN-CreC 유전자(적색 박스)의 발현을 유도하는 pGK 프로모터(진한 청색 박스)를 함유하는, 단일 표적화 벡터 전략의 구조. 이 요소 다음에는 pGK 프로모터, 그 다음 LoxP(황색 원) STOP(적색 팔각형) LoxP 부위(LSL)를 함유하는 치사 유전자 카세트, 그 다음에는 치사-유도 유전자가 이어진다. 이 카세트 다음에는 3' HA(밝은 청색 상자)가 이어진다. 광 유도 시, Cry2-CreN 및 CIBN-CreC는 이합체화되어 활성 형태의 Cre를 형성한다. 이어서, 후자는 LSL 요소를 절제하여, 치사-유도 유전자의 발현을 허용하는데, 이것은 이 벡터를 보유하는 모든 배아에서 배아 사멸로 이어진다. (B) LSL 요소를 사용하는 대신, A에 대한 대안적인 접근법인 Dio-lox 플리핑(flipping) 전략이 사용된다(노란색 삼각형). Dio-Lox 부위 사이에, GFP, 그 다음 폴리아데닐화 부위 #1(PA1, 회색 박스) 및 역 배향의 치사 유전자, 그 다음 다른 폴리아데닐화 부위 #2(PA2)가 도입된다. 이 경우, 광 활성화 전에, pGK 프로모터는 GFP의 발현을 유도한다. 광 활성화 시, Dio-Lox 부위 사이의 카세트가 플리핑되고, 이제 치사 유전자는 발현될 올바른 배향으로 존재하는 반면, GFP는 이제 역 배향으로 놓여서 더 이상 활성화되지 않는다. C) A 또는 B에 대한 대안적인 접근법. Cre의 활성화 후, LSL이 제거되고, Cas9 및 sgRNA가 발현된다. 이것은 필수 유전자의 암호 영역에서 미스센스 돌연변이의 도입으로 이어지고, 따라서 배아 치사를 유도한다.
도 5A 내지 도 5F: PGC 라인 도출 및 특징규명. A, PGC 배양; B, 좌측, 제시된 바와 같이 상이한 다능성(pluripotent) 마커 및 생식 세포 마커의 mRNA 발현. 우측, 암컷 PGC(좌측, 리보솜 S18 및 W 염색체의 두 PCR 산물) 및 수컷 PGC(오른쪽, 리보솜 S18 단독)의 대표적인 성별 식별 특징규명. C, SSEA1 항원의 PGC 항체 염색. D, 리포펙타민 2000 시약을 사용한 pCAGG-GFP 암호화 플라스미드로 PGC의 형질주입. E, pCAGG-GFP 암호화 플라스미드의 전기천공법을 사용한 PGC 형질주입. F, GFP-발현 배양된 PGC로 이식한지 10일 후, 배아의 생식선(고환).
도 6A 내지 도 6C. CRISPR-매개된 표적화를 위한 sgRNA 부위 설계. 최적의 CRISPR 표적 부위에 대한 설계를 위한 Z 염색체의 게놈 영역의 표현. 12개의 상위 sgRNA 서열이 제시되며(가이드 #1 내지 #12), 이들 중 반대 배향으로 부분적으로 겹치는 가이드 #1 및 #3가 선택되었다. 가이드 #1의 가능한 오프-타깃이 제시된다. 하기 표 1은 도 6B에 제시된 바와 같은 가이드 RNA의 서열을 제공한다.
[표 1]

도 6C에 도시된 가이드 #1에 대한 가능한 오프 타깃에 대한 검색 결과 상위 10개 결과, 이의 서열이 표 2에 요약되어 있다.
[표 2]

도 7A 내지 도 7C는 엔도뉴클레아제 검정을 사용하여 CRISPR 활성도를 검증한 도면. A. 어닐링된 WT 320bp PCR 생성물 및 CRISPR1의 예측된 절단 부위에서 돌연변이된 생성물을 제시된 비율로 사용한 엔도뉴클레아제 검정의 양성 대조군. B. CRISPR1 플라스미드가 형질주입된 12개 집락에 대한 엔도뉴클레아제 검정. C. CRISPR3 플라스미드가 형질주입된 12개 집락에 대한 엔도뉴클레아제 검정. CRISPR1 및 CRISPR3의 2개의 예측된 절단 부위 사이에는 12bp 거리가 존재함을 주목하기 바란다.
도 8A 내지 도 8D는 DNA 서열결정을 사용한 CRISPR 활성도의 검증을 도시한 도면. A. 음성 대조군으로서의 정상 서열을 나타내는, CRISPR1의 예측된 절단 부위에서 WT 게놈 영역의 DNA 크로마토그램. B.양성 대조군으로서, 예측된 절단 부위 후 이중-피크(청색 화살촉)의 출현을 나타내는, WT 및 인공적으로 돌연변이된 PCR 생성물의 혼합물의 서열. C. 정상적인 서열을 나타내는 음성 집락의 서열결정. D. CRISPR1 절단 부위(청색 화살촉) 이후에 이중 피크의 출현을 나타내는 양성 집락의 서열. 서열 AGATAACGT(서열번호 65)가 제시되어 있다.
도 9A 내지 도 9F는 Z 염색체 내의 게놈 통합을 위한 표적화 벡터의 작제를 도시한 도면. A - 게놈 DNA를 프라이머 P1 및 P2와의 PCR 반응의 주형으로 사용하였다. 이 영역은 CRISPR-부위-함유 영역에 측접한 5'HA 및 3'HA를 함유한다. B - HINTZ 좌위 하류에 위치한 약 3kb 생성물은 셔틀 벡터 pJet1.2에 결찰시켰다. 이 플라스미드를 프라이머 P3 및 P4를 갖는 PCR의 주형으로 사용하였다. 이 프라이머는 연장 서열(색으로 구분된 중괄호로 구분)을 갖는데, 이것은 pCAGG-Neo-IRES-GFP 단편(D)의 상의 등가 영역에 상응한다. C - 선형화된 생성물 - 깁슨 반응 동안 pCAGG-Neo-IRES-GFP 카세트의 단부에 결합하는 서열이 측접된, CRISPR-부위-함유 영역을 제외한, 2개의 상동성 아암을 함유하는 벡터. D - pCAGG-Neo-IRES-GFP 플라스미드를 프라이머 P5 및 P6과의 PCR 반응의 주형으로 사용하였다. 이들 프라이머는 상동성 아암의 가장자리 상의 등가 영역에 상응하는 연장 서열(색으로 구분된 중괄호로 구분)을 함유한다. E - 상동성 아암의 단부에 결합한 서열이 측접된 선형화된 삽입 카세트. 깁슨 조립 반응10을 사용하여, 벡터 및 삽입물을 함께 스티칭(stitching)하여 최종 표적화 벡터 플라스미드를 생성하였다. F- 표적화 벡터.
도 10A 내지 도 10D는 표적화 벡터 및 CRISPR 플라스미드의 PGC로의 공동 형질주입을 도시한 도면. A. CRISPR1 및 HR 표적화 벡터 플라스미드를 사용한 PGC에 대한 리포펙션-매개된 공동-형질주입. B. G-418 선택 2주 후에, 내성 PGC의 99% 초과가 GFP에 대해 양성이었다. C. 표적화된 PGC를 숙주 배아에 주사한 후 10일째에, 다수의 세포가 생식선(고환)에 국지화되는 것을 발견하였다. D. 생식선을 절개하고, 항-GFP 항체로 면역-염색하고, 공초점 현미경(GFP 항체는 녹색으로 염색되고, 핵은 4',6-다이아미디노-2-페닐인돌(DAPI)로 대비염색됨)을 사용하여 스캔하였다.
도 11A 내지 도 11D - FACS 분류된 PGC에서 HR 통합의 PCR 검증. A. G-418 내성 PGC의 FACS 분류. FACS 게이팅은 96웰 플레이트에서 풀 또는 개별 세포로 분류된 단일(sin) GFP-양성 세포를 분류하도록 설계되었다. B. PCR 분석을 위해, 5' 통합 부위(P7 및 P8) 및 3' 통합 부위(P9 및 P10)에 대한 두 세트의 프라이머를 설계하였다. C. 풀링된 세포로부터 추출된 게놈 DNA를 PCR의 주형으로 사용하고, WT DNA를 음성 대조군으로 사용하였다. 예측된 1.6kb 및 1.8kb 밴드는 각각 5' 및 3' 영역에서 올바른 HR 통합에 대해 명백하였다. D. 단일 세포 FACS 분류된 PGC로부터 유래된 수컷 및 암컷 세포 집락으로부터 추출된 게놈 DNA를 PCR의 주형으로 사용하였고, WT DNA를 음성 대조군으로 사용하였다. 예측된 1.6kb 및 1.8kb 밴드는 각각 5' 및 3' 영역에서 올바른 HR 통합에 대해 명백하였다.
도 12A 내지 도 12D - HR 통합의 서던 블롯 분석. A - HR 통합을 거친 WT 대립유전자 및 대립유전자에 대한 서던 블롯 분석에서 예상되는 BglII 절단 생성물의 도식적 표현. 5', 3' 통합 부위 및 neo에 사용되는 프로브를 황색 사각형으로 표현한다. 각각의 DNA 프로브에 대한 BglII 소화 후 예상되는 생성물 크기를 기재한다. B - PCR에 의한 dig-표지된 프로브의 제조. dig-표지된 프로브(+) 또는 비표지된 프로브(-)를 아가로스겔 상에서 분석하였다. dig-표지된 생성물은 실제 크기보다 더 크게 이동하여, dig-표지된 뉴클레오타이드의 통합을 확인해준다. 프로브 증폭에 사용되는 프라이머 세트를 나타낸다. C - 수컷 유래된 PGC의 풀링된 집락 및 순수한 집락으로부터 추출된 DNA 상의 5' 및 3' 프로브를 이용한 서던 블롯 분석. HR 이전에 본래 세포주로부터 추출된 WT DNA를 음성 대조군으로 사용하였다. D - 암컷 유래된 PGC에서 5'및 Neo 프로브를 사용한 서던 블롯 분석. 두 경우 모두에서 단일 7.5kb 밴드가 명백하며, 이는 올바른 HR이 발생하였고, 단지 단일 카피의 표적화 벡터가 통합되었음을 나타낸다.
도 13 - 시험관 내에서 HEK293 세포에서 옵토제틱 시스템의 검증. pmCherry-Cry2-CreN, pmCherry-CIBN-CreC 및 PB-RAGE-GFP 플라스미드로의 삼중 형질주입. 형질주입 후 24시간째에, 실험군 세포를 15초 동안 청색광 조명에 노출시키면서, 대조군 세포를 암실에서 유지시켰다(상단). 조명 후(하단), 세포를 24시간 동안 추가로 인큐베이션시켰다. 이들 세포에서, GFP 발현이 명백하였는데, 이는 청색광 조명 시 Cre 효소의 활성화를 확인해준다.
도 14. 전기천공법 이전에 54 내지 60시간 동안 인큐베이션된 병아리 배아에서 난내 옵토제틱 시스템의 검증. pmCherry-Cry2-CreN, pmCherry-CIBN-CreC 및 pB-RAGE-GFP 플라스미드로의 닭 배아에 대한 삼중 전기천공. 전기천공 후 12시간째에, 실험군 배아를 15초 동안 청색광에 난내에서 노출시키면서, 대조군 배아를 암실에서 유지시켰다(상단). 조명 후(하단), 두 군으로부터의 배아를 추가로 12시간 동안 인큐베이션시켰다. 인큐베이션 후, GFP 발현 세포는 조명된 군에서 분명히 명백하였는데, 이는 난내에서 닭 배아의 청색광 조명 시 옵토제틱 시스템 및 Cre 효소의 활성화를 확인해준다.
도 15A 내지 도 15F - CAGG 프로모터 하에서의 단일 옵토젠 발현 벡터의 작제. 옵토젠 플라스미드 pmCherry-CIBN-CreC 및 pmCherry-Cry2-CreN을 P40-P41 및 P42-P43 프라이머를 각각 사용하여 옵토젠 융합 단백질을 증폭시키는 주형으로서 사용하였다(15A). 두 생성물은 프라이머 P41 및 P42에 도입된 P2A 부위에서 중첩 서열을 공유한다. 이는 단일-사이클 오버행 연장 PCR이 2개의 단편과 하나로 통합하고(15B), pJet1.2 셔틀 벡터에 결찰되도록 하였다(15C). 각각 SmaI 및 NheI 제한 부위를 갖는 꼬리를 함유하는 프라이머 P44 및 P45를 사용하여 15D의 생성물을 생성하였다. 이 생성물을 적절한 제한 효소를 사용하여 소화시키고, pCAGG-IRES-GFP에 결찰시키고(15E), 이것을 동일한 효소를 사용하여 소화시켰다(15F).
도 16. HEK293 세포에서 pCAGG-옵토젠 플라스미드의 활성 검증. pCAGG-옵토젠 및 pB-RAGE-mCherry 플라스미드로의 공동 형질주입. 형질주입 후 24 시간째에, 음성-대조군을 암실에서 유지시키면서(상단), 실험군 세포를 15초 동안 청색광 조명에 노출시켰다(하단). 조명 후(하단), 세포를 24시간 동안 추가로 인큐베이션시켰다. 이들 세포에서, mCherry발현이 명백하였는데(흰색 화살표), 이는 청색광 조명 시, pCAGG-옵토젠 플라스미드에 의한 Cre 효소의 활성화를 확인해준다.
도 17. 난내에서 pCAGG-옵토젠 플라스미드를 사용한 단일-벡터 전략의 검증. 14-16H&H기에서 닭 배아를 pCAGG-옵토젠 및 pB-RAGE-mCherry 플라스미드로 공동-전기천공시켰다. 후자 플라스미드는 옵토제닉 시스템(optogenic system)의 활성에 대한 리포터 유전자로서 작용한다. 전기천공 후 12시간째에, 실험군 배아(하단)를 난내에서 15초 동안 난내의 청색광 조명에 노출시키면서, 대조군 배아를 암실에서 유지시켰다(상단). 배아를 12시간 동안 추가로 인큐베이션시켰다. 인큐베이션 후, GFP 발현 세포는 두 군 모두에서 분명하게 나타났는데, 이는 성공적인 전기천공을 나타내지만, 조명된 군에서만 mCherry-발현 세포가 명백하였는데, 이는 난내에서 닭 배아에 청색광 조명 시 옵토제틱 시스템 및 Cre 효소의 활성화를 확인해준다.
도 18. pGK 프로모터 하에서 DTA의 발현이 난내에서 단백질 합성을 저해하는 것을 보여주는 도면. 14-16 H&H기 배아를 pGK-IRES-GFP(상단) 또는 pGK-DTA-IRES-GFP(하단) 발현 벡터로 전기천공시켰다. 음성 대조군 배아는 GFP(상단, 화살표)를 광범위하게 발현하는데, 이는 정상 단백질 합성을 나타낸다. DTA 발현 세포는 GFP 발현(하단)을 나타내지 않는데, 이는 이들 배아에서 단백질 합성이 저해됨을 나타낸다. GFP-단독, 명시야-단독 및 명시야 영상 상에 겹쳐진 GFP를 나타낸다.
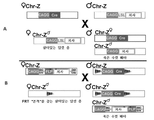
도 19A 및 도 19B는 본 발명의 추가실시형태에 따른 표적화 벡터를 도시한 도면. 이들 벡터에서, 활성화 효소(예를 들어, Cre)는 치사 유전자 카세트로부터 분리된다. 도 19A에서, 활성화 효소는 모 암탉의 게놈 내에 삽입되고, 비활성 치사 카세트는 수탉의 Z 염색체 상에 삽입되는데, 이는 이러한 대립유전자에 대해서 동형접합성이다. 이 경우 수컷 배아에서 치사의 활성화는 광 유도가 필요없는 두 트랜스제닉 부모를 교배시킴으로써 수행된다. 모든 수컷의 Cre는 모체 Z 염색체에서 LSL을 제거하여 치사 유전자가 발현될 수 있게 하며, 암컷 배아는 비활성 치사 카세트를 보유하므로 영향을 받지 않는다. 대안적으로, 모 암탉의 Z 염색체는 우측 방향의 FLP 리콤비나제, 그 다음 CAGG 프로모터에 의해서 지시되는 역 배향의 치사 유전자를 함유하는 Dio-Lox 플리핑 카세트로 표적화된다(도 19B). 수탉은 다시 FRT 부위가 측접한 CAGG-Cre 카세트로 표적화된 Z 염색체에 동형접합된다. 둘을 교배시키면, 수컷 배아는 부계 Z 염색체 상에 위치한 Cre를 발현할 것이고, Dio-Lox 카세트가 플리핑되고, 치사 유전자가 활성화됨으로써, 수컷 배아의 배아 치사로 이어진다. 이러한 교배로부터의 암컷 배아의 접합체는 난자발생 중에 생성된 FLP 리콤비나제 효소의 모계 기여를 포함한다. 이러한 모계 단백질은 Z 염색체로부터 CAGG-Cre 카세트를 제거하여, Z 염색체에 FRT "흔적" 만을 갖고 암컷 배아가 살아남도록 한다.
도면에서,
도 1은 단지 암컷 층 병아리만 부화될 옵토제틱(Optogenetic) 유도성 닭 라인의 생성을 도시하는 도면. 야생형 수탉(ZZ)과 유전적으로 변형된 암탉( Z W)을 교배시킴으로써, 모든 암컷 수정란은 야생형 ZW 염색체를 보유할 것이고, Z 염색체는 WT 수탉으로부터 유래된다. 모든 수컷 수정란은 Z Z 염색체를 보유할 것이고, 여기서 적색 표지된 Z는 암탉의 게놈으로부터 유래된다. 이것이 목표하는 염색체이다. 수정란의 청색광 조명 시에, 이 염색체의 옵토제틱 시스템이 활성화되어 산란 후 곧바로 초기 배아 사망을 초래할 사멸 기전을 활성화할 것이다. 청색광 조명에 의해서 영향을 받지 않을 암컷은 성계로 자라며 식품용 무정란을 낳을 것이다.
도 2는 청색광 조명에 의해 유전자 발현을 제어하는 전략을 예시한 도면. 2개의 융합 단백질은 생성된 Cre의 N-말단을 갖는 Cry2(Cry2-Cre-N-말단) 및 Cre의 C-말단과 융합된 CIBN(CIBN-Cre-C-말단)이다. 청색광 조명이 없으면, Cre는 비활성화된다. 청색광 조명 시, CRY2 및 CIBN은 이종이합체를 형성하고, Cre의 두 부분은 함께 모여 활성 Cre 효소를 형성한다11.
도 3은 염색체 Z 상의 상동성 아암을 예시한 도면. Hint1 좌위(녹색 화살표)에 대한 하류의 게놈 영역이 도시된다. 5' 아암 및 3' 아암, HA-1 및 HA-2는 각각 적색으로 도시된다. 아암을 증폭시키기 위한 프라이머는 황색 화살표로 표시된다. 상동성 아암들 사이에서, 두 DNA 가닥 모두에, CRISPR-Cas9(녹색 박스)에 대해서 특이적이고 적절한 매우 고유한 서열이 존재한다. 도면의 하단 부분은 두 상동성 아암 사이의 영역을 자세히 보여준다.
서열번호 1에 제시된 서열이 예시된다.
도 4A 내지 도 4C는 본 발명의 실시형태에 따른 표적화 벡터를 도시한 도면. 표적화 벡터는 3개의 주요 요소를 함유한다. 첫 번째, 전체 삽입 카세트에 측접한, 상동 재조합(HR)을 위한 5' 상동성 아암 및 3' 상동성 암(HA, 밝은 청색), 두 번째, 광-유도성 시스템 - 이 경우 Cry2-CreN 및 CIBN-CreC, 및 세 번째 치사 유전자 카세트. (A) 5' HA, 그 다음 자가-절단 펩타이드 P2A(보라색 상자)에 의해서 분리된 Cry2-CreN 및 CIBN-CreC 유전자(적색 박스)의 발현을 유도하는 pGK 프로모터(진한 청색 박스)를 함유하는, 단일 표적화 벡터 전략의 구조. 이 요소 다음에는 pGK 프로모터, 그 다음 LoxP(황색 원) STOP(적색 팔각형) LoxP 부위(LSL)를 함유하는 치사 유전자 카세트, 그 다음에는 치사-유도 유전자가 이어진다. 이 카세트 다음에는 3' HA(밝은 청색 상자)가 이어진다. 광 유도 시, Cry2-CreN 및 CIBN-CreC는 이합체화되어 활성 형태의 Cre를 형성한다. 이어서, 후자는 LSL 요소를 절제하여, 치사-유도 유전자의 발현을 허용하는데, 이것은 이 벡터를 보유하는 모든 배아에서 배아 사멸로 이어진다. (B) LSL 요소를 사용하는 대신, A에 대한 대안적인 접근법인 Dio-lox 플리핑(flipping) 전략이 사용된다(노란색 삼각형). Dio-Lox 부위 사이에, GFP, 그 다음 폴리아데닐화 부위 #1(PA1, 회색 박스) 및 역 배향의 치사 유전자, 그 다음 다른 폴리아데닐화 부위 #2(PA2)가 도입된다. 이 경우, 광 활성화 전에, pGK 프로모터는 GFP의 발현을 유도한다. 광 활성화 시, Dio-Lox 부위 사이의 카세트가 플리핑되고, 이제 치사 유전자는 발현될 올바른 배향으로 존재하는 반면, GFP는 이제 역 배향으로 놓여서 더 이상 활성화되지 않는다. C) A 또는 B에 대한 대안적인 접근법. Cre의 활성화 후, LSL이 제거되고, Cas9 및 sgRNA가 발현된다. 이것은 필수 유전자의 암호 영역에서 미스센스 돌연변이의 도입으로 이어지고, 따라서 배아 치사를 유도한다.
도 5A 내지 도 5F: PGC 라인 도출 및 특징규명. A, PGC 배양; B, 좌측, 제시된 바와 같이 상이한 다능성(pluripotent) 마커 및 생식 세포 마커의 mRNA 발현. 우측, 암컷 PGC(좌측, 리보솜 S18 및 W 염색체의 두 PCR 산물) 및 수컷 PGC(오른쪽, 리보솜 S18 단독)의 대표적인 성별 식별 특징규명. C, SSEA1 항원의 PGC 항체 염색. D, 리포펙타민 2000 시약을 사용한 pCAGG-GFP 암호화 플라스미드로 PGC의 형질주입. E, pCAGG-GFP 암호화 플라스미드의 전기천공법을 사용한 PGC 형질주입. F, GFP-발현 배양된 PGC로 이식한지 10일 후, 배아의 생식선(고환).
도 6A 내지 도 6C. CRISPR-매개된 표적화를 위한 sgRNA 부위 설계. 최적의 CRISPR 표적 부위에 대한 설계를 위한 Z 염색체의 게놈 영역의 표현. 12개의 상위 sgRNA 서열이 제시되며(가이드 #1 내지 #12), 이들 중 반대 배향으로 부분적으로 겹치는 가이드 #1 및 #3가 선택되었다. 가이드 #1의 가능한 오프-타깃이 제시된다. 하기 표 1은 도 6B에 제시된 바와 같은 가이드 RNA의 서열을 제공한다.
[표 1]
도 6C에 도시된 가이드 #1에 대한 가능한 오프 타깃에 대한 검색 결과 상위 10개 결과, 이의 서열이 표 2에 요약되어 있다.
[표 2]
도 7A 내지 도 7C는 엔도뉴클레아제 검정을 사용하여 CRISPR 활성도를 검증한 도면. A. 어닐링된 WT 320bp PCR 생성물 및 CRISPR1의 예측된 절단 부위에서 돌연변이된 생성물을 제시된 비율로 사용한 엔도뉴클레아제 검정의 양성 대조군. B. CRISPR1 플라스미드가 형질주입된 12개 집락에 대한 엔도뉴클레아제 검정. C. CRISPR3 플라스미드가 형질주입된 12개 집락에 대한 엔도뉴클레아제 검정. CRISPR1 및 CRISPR3의 2개의 예측된 절단 부위 사이에는 12bp 거리가 존재함을 주목하기 바란다.
도 8A 내지 도 8D는 DNA 서열결정을 사용한 CRISPR 활성도의 검증을 도시한 도면. A. 음성 대조군으로서의 정상 서열을 나타내는, CRISPR1의 예측된 절단 부위에서 WT 게놈 영역의 DNA 크로마토그램. B.양성 대조군으로서, 예측된 절단 부위 후 이중-피크(청색 화살촉)의 출현을 나타내는, WT 및 인공적으로 돌연변이된 PCR 생성물의 혼합물의 서열. C. 정상적인 서열을 나타내는 음성 집락의 서열결정. D. CRISPR1 절단 부위(청색 화살촉) 이후에 이중 피크의 출현을 나타내는 양성 집락의 서열. 서열 AGATAACGT(서열번호 65)가 제시되어 있다.
도 9A 내지 도 9F는 Z 염색체 내의 게놈 통합을 위한 표적화 벡터의 작제를 도시한 도면. A - 게놈 DNA를 프라이머 P1 및 P2와의 PCR 반응의 주형으로 사용하였다. 이 영역은 CRISPR-부위-함유 영역에 측접한 5'HA 및 3'HA를 함유한다. B - HINTZ 좌위 하류에 위치한 약 3kb 생성물은 셔틀 벡터 pJet1.2에 결찰시켰다. 이 플라스미드를 프라이머 P3 및 P4를 갖는 PCR의 주형으로 사용하였다. 이 프라이머는 연장 서열(색으로 구분된 중괄호로 구분)을 갖는데, 이것은 pCAGG-Neo-IRES-GFP 단편(D)의 상의 등가 영역에 상응한다. C - 선형화된 생성물 - 깁슨 반응 동안 pCAGG-Neo-IRES-GFP 카세트의 단부에 결합하는 서열이 측접된, CRISPR-부위-함유 영역을 제외한, 2개의 상동성 아암을 함유하는 벡터. D - pCAGG-Neo-IRES-GFP 플라스미드를 프라이머 P5 및 P6과의 PCR 반응의 주형으로 사용하였다. 이들 프라이머는 상동성 아암의 가장자리 상의 등가 영역에 상응하는 연장 서열(색으로 구분된 중괄호로 구분)을 함유한다. E - 상동성 아암의 단부에 결합한 서열이 측접된 선형화된 삽입 카세트. 깁슨 조립 반응10을 사용하여, 벡터 및 삽입물을 함께 스티칭(stitching)하여 최종 표적화 벡터 플라스미드를 생성하였다. F- 표적화 벡터.
도 10A 내지 도 10D는 표적화 벡터 및 CRISPR 플라스미드의 PGC로의 공동 형질주입을 도시한 도면. A. CRISPR1 및 HR 표적화 벡터 플라스미드를 사용한 PGC에 대한 리포펙션-매개된 공동-형질주입. B. G-418 선택 2주 후에, 내성 PGC의 99% 초과가 GFP에 대해 양성이었다. C. 표적화된 PGC를 숙주 배아에 주사한 후 10일째에, 다수의 세포가 생식선(고환)에 국지화되는 것을 발견하였다. D. 생식선을 절개하고, 항-GFP 항체로 면역-염색하고, 공초점 현미경(GFP 항체는 녹색으로 염색되고, 핵은 4',6-다이아미디노-2-페닐인돌(DAPI)로 대비염색됨)을 사용하여 스캔하였다.
도 11A 내지 도 11D - FACS 분류된 PGC에서 HR 통합의 PCR 검증. A. G-418 내성 PGC의 FACS 분류. FACS 게이팅은 96웰 플레이트에서 풀 또는 개별 세포로 분류된 단일(sin) GFP-양성 세포를 분류하도록 설계되었다. B. PCR 분석을 위해, 5' 통합 부위(P7 및 P8) 및 3' 통합 부위(P9 및 P10)에 대한 두 세트의 프라이머를 설계하였다. C. 풀링된 세포로부터 추출된 게놈 DNA를 PCR의 주형으로 사용하고, WT DNA를 음성 대조군으로 사용하였다. 예측된 1.6kb 및 1.8kb 밴드는 각각 5' 및 3' 영역에서 올바른 HR 통합에 대해 명백하였다. D. 단일 세포 FACS 분류된 PGC로부터 유래된 수컷 및 암컷 세포 집락으로부터 추출된 게놈 DNA를 PCR의 주형으로 사용하였고, WT DNA를 음성 대조군으로 사용하였다. 예측된 1.6kb 및 1.8kb 밴드는 각각 5' 및 3' 영역에서 올바른 HR 통합에 대해 명백하였다.
도 12A 내지 도 12D - HR 통합의 서던 블롯 분석. A - HR 통합을 거친 WT 대립유전자 및 대립유전자에 대한 서던 블롯 분석에서 예상되는 BglII 절단 생성물의 도식적 표현. 5', 3' 통합 부위 및 neo에 사용되는 프로브를 황색 사각형으로 표현한다. 각각의 DNA 프로브에 대한 BglII 소화 후 예상되는 생성물 크기를 기재한다. B - PCR에 의한 dig-표지된 프로브의 제조. dig-표지된 프로브(+) 또는 비표지된 프로브(-)를 아가로스겔 상에서 분석하였다. dig-표지된 생성물은 실제 크기보다 더 크게 이동하여, dig-표지된 뉴클레오타이드의 통합을 확인해준다. 프로브 증폭에 사용되는 프라이머 세트를 나타낸다. C - 수컷 유래된 PGC의 풀링된 집락 및 순수한 집락으로부터 추출된 DNA 상의 5' 및 3' 프로브를 이용한 서던 블롯 분석. HR 이전에 본래 세포주로부터 추출된 WT DNA를 음성 대조군으로 사용하였다. D - 암컷 유래된 PGC에서 5'및 Neo 프로브를 사용한 서던 블롯 분석. 두 경우 모두에서 단일 7.5kb 밴드가 명백하며, 이는 올바른 HR이 발생하였고, 단지 단일 카피의 표적화 벡터가 통합되었음을 나타낸다.
도 13 - 시험관 내에서 HEK293 세포에서 옵토제틱 시스템의 검증. pmCherry-Cry2-CreN, pmCherry-CIBN-CreC 및 PB-RAGE-GFP 플라스미드로의 삼중 형질주입. 형질주입 후 24시간째에, 실험군 세포를 15초 동안 청색광 조명에 노출시키면서, 대조군 세포를 암실에서 유지시켰다(상단). 조명 후(하단), 세포를 24시간 동안 추가로 인큐베이션시켰다. 이들 세포에서, GFP 발현이 명백하였는데, 이는 청색광 조명 시 Cre 효소의 활성화를 확인해준다.
도 14. 전기천공법 이전에 54 내지 60시간 동안 인큐베이션된 병아리 배아에서 난내 옵토제틱 시스템의 검증. pmCherry-Cry2-CreN, pmCherry-CIBN-CreC 및 pB-RAGE-GFP 플라스미드로의 닭 배아에 대한 삼중 전기천공. 전기천공 후 12시간째에, 실험군 배아를 15초 동안 청색광에 난내에서 노출시키면서, 대조군 배아를 암실에서 유지시켰다(상단). 조명 후(하단), 두 군으로부터의 배아를 추가로 12시간 동안 인큐베이션시켰다. 인큐베이션 후, GFP 발현 세포는 조명된 군에서 분명히 명백하였는데, 이는 난내에서 닭 배아의 청색광 조명 시 옵토제틱 시스템 및 Cre 효소의 활성화를 확인해준다.
도 15A 내지 도 15F - CAGG 프로모터 하에서의 단일 옵토젠 발현 벡터의 작제. 옵토젠 플라스미드 pmCherry-CIBN-CreC 및 pmCherry-Cry2-CreN을 P40-P41 및 P42-P43 프라이머를 각각 사용하여 옵토젠 융합 단백질을 증폭시키는 주형으로서 사용하였다(15A). 두 생성물은 프라이머 P41 및 P42에 도입된 P2A 부위에서 중첩 서열을 공유한다. 이는 단일-사이클 오버행 연장 PCR이 2개의 단편과 하나로 통합하고(15B), pJet1.2 셔틀 벡터에 결찰되도록 하였다(15C). 각각 SmaI 및 NheI 제한 부위를 갖는 꼬리를 함유하는 프라이머 P44 및 P45를 사용하여 15D의 생성물을 생성하였다. 이 생성물을 적절한 제한 효소를 사용하여 소화시키고, pCAGG-IRES-GFP에 결찰시키고(15E), 이것을 동일한 효소를 사용하여 소화시켰다(15F).
도 16. HEK293 세포에서 pCAGG-옵토젠 플라스미드의 활성 검증. pCAGG-옵토젠 및 pB-RAGE-mCherry 플라스미드로의 공동 형질주입. 형질주입 후 24 시간째에, 음성-대조군을 암실에서 유지시키면서(상단), 실험군 세포를 15초 동안 청색광 조명에 노출시켰다(하단). 조명 후(하단), 세포를 24시간 동안 추가로 인큐베이션시켰다. 이들 세포에서, mCherry발현이 명백하였는데(흰색 화살표), 이는 청색광 조명 시, pCAGG-옵토젠 플라스미드에 의한 Cre 효소의 활성화를 확인해준다.
도 17. 난내에서 pCAGG-옵토젠 플라스미드를 사용한 단일-벡터 전략의 검증. 14-16H&H기에서 닭 배아를 pCAGG-옵토젠 및 pB-RAGE-mCherry 플라스미드로 공동-전기천공시켰다. 후자 플라스미드는 옵토제닉 시스템(optogenic system)의 활성에 대한 리포터 유전자로서 작용한다. 전기천공 후 12시간째에, 실험군 배아(하단)를 난내에서 15초 동안 난내의 청색광 조명에 노출시키면서, 대조군 배아를 암실에서 유지시켰다(상단). 배아를 12시간 동안 추가로 인큐베이션시켰다. 인큐베이션 후, GFP 발현 세포는 두 군 모두에서 분명하게 나타났는데, 이는 성공적인 전기천공을 나타내지만, 조명된 군에서만 mCherry-발현 세포가 명백하였는데, 이는 난내에서 닭 배아에 청색광 조명 시 옵토제틱 시스템 및 Cre 효소의 활성화를 확인해준다.
도 18. pGK 프로모터 하에서 DTA의 발현이 난내에서 단백질 합성을 저해하는 것을 보여주는 도면. 14-16 H&H기 배아를 pGK-IRES-GFP(상단) 또는 pGK-DTA-IRES-GFP(하단) 발현 벡터로 전기천공시켰다. 음성 대조군 배아는 GFP(상단, 화살표)를 광범위하게 발현하는데, 이는 정상 단백질 합성을 나타낸다. DTA 발현 세포는 GFP 발현(하단)을 나타내지 않는데, 이는 이들 배아에서 단백질 합성이 저해됨을 나타낸다. GFP-단독, 명시야-단독 및 명시야 영상 상에 겹쳐진 GFP를 나타낸다.
도 19A 및 도 19B는 본 발명의 추가실시형태에 따른 표적화 벡터를 도시한 도면. 이들 벡터에서, 활성화 효소(예를 들어, Cre)는 치사 유전자 카세트로부터 분리된다. 도 19A에서, 활성화 효소는 모 암탉의 게놈 내에 삽입되고, 비활성 치사 카세트는 수탉의 Z 염색체 상에 삽입되는데, 이는 이러한 대립유전자에 대해서 동형접합성이다. 이 경우 수컷 배아에서 치사의 활성화는 광 유도가 필요없는 두 트랜스제닉 부모를 교배시킴으로써 수행된다. 모든 수컷의 Cre는 모체 Z 염색체에서 LSL을 제거하여 치사 유전자가 발현될 수 있게 하며, 암컷 배아는 비활성 치사 카세트를 보유하므로 영향을 받지 않는다. 대안적으로, 모 암탉의 Z 염색체는 우측 방향의 FLP 리콤비나제, 그 다음 CAGG 프로모터에 의해서 지시되는 역 배향의 치사 유전자를 함유하는 Dio-Lox 플리핑 카세트로 표적화된다(도 19B). 수탉은 다시 FRT 부위가 측접한 CAGG-Cre 카세트로 표적화된 Z 염색체에 동형접합된다. 둘을 교배시키면, 수컷 배아는 부계 Z 염색체 상에 위치한 Cre를 발현할 것이고, Dio-Lox 카세트가 플리핑되고, 치사 유전자가 활성화됨으로써, 수컷 배아의 배아 치사로 이어진다. 이러한 교배로부터의 암컷 배아의 접합체는 난자발생 중에 생성된 FLP 리콤비나제 효소의 모계 기여를 포함한다. 이러한 모계 단백질은 Z 염색체로부터 CAGG-Cre 카세트를 제거하여, Z 염색체에 FRT "흔적" 만을 갖고 암컷 배아가 살아남도록 한다.
본 발명은 이의 일부 실시형태에서, 생존 불가능한 수컷 병아리 배아를 포함하는 알을 낳는 게놈 편집 조류에 관한 것이다.
본 발명의 적어도 하나의 실시형태를 상세히 설명하기 전에, 본 발명은 그 응용에 있어서 하기 설명에서 설명되거나 실시예에 의해서 예시된 세부 사항으로 반드시 제한되는 것은 아니라는 것이 이해되어야 한다. 본 발명은 다른 실시형태가 가능하거나 다양한 방식으로 실시 또는 수행될 수 있다.
성별 분리는 모든 조류 종 생산에 있어 중요한 양상이지만, 특히 육계 및 본질적으로 모든 난 층 및 칠면조 생산에 중요하다. 육계 및 칠면조의 경우, 성별 분리는 두 성별 모두의 필요에 따라 보다 적합한 관리 및 사육을 가능하게 하며, 이는 대부분의 경우에 현재 수행되고 있는 성별 비구별 사육과는 다소 상이하다. 본질적으로 알을 낳는 암탉이 될 어린 닭의 모든 상업적인 부화장은 무리의 성별 분리를 사용한다. 수컷 닭은 부화장에서 채집되는 반면, 암컷 닭은 명백하게 난 생산을 위해서 활용된다.
본 발명자들은 본 발명에 이르러서 전세계적으로 수 십억 마리의 수컷 병아리를 대량으로 골라낼 필요성을 제거할 수 있는 방법을 고안하였다. 구체적으로, 본 발명자들은 번식 무리로부터의 "모체"가 수정란을 낳고, 이로부터 암컷 층만이 부화되고, 수컷 배아는 수정 후 곳 발달을 중단하는 닭 품종을 생성시키는 방법을 고안하였다. 따라서, 수컷 병아리를 골라낼 필요성이 제거될 것이고, 가치있는 인큐베이션 공간의 50%가 또한 절약될 것이다. 중요하게는, 소비자를 위한 최종 생성물인 산란 암탉과 무정란은 모두 산업계에서 현재 생산되고 있는 층 암탉 및 식용란(food-egg)과 모든 양상에서 동일할 것이다(유전자 변형되지 않음).
본 발명의 실시를 감소시키면서, 본 발명자들은 CAGG 프로모터 하에서 Neo 및 GFP 유전자에 측접한 HA를 함유하는 표적화 벡터를 설계하였고, PCR(도 11A 내지 도 11D) 및 서던 블롯(도 12A 내지 도 12D) 둘 다를 사용하여 검증된 바와 같이 Z 염색체에 대해 올바른 HR을 겪는 것을 보여주었다. 또한, pCAGG-옵토젠 벡터 상에서 작제된 옵토제닉 시스템의 단일 벡터 전략은 살아있는 병아리 배아에서 시험관내 및 난내 둘 다에서 활성인 것을 발견하였다(도 14) 마지막으로, 닭 배아에서 DTA의 발현은 단백질 합성의 저해를 초래하였다(도 18).
따라서, 본 발명의 제1 양상에 따르면, 조류의 난에서 수컷 병아리 배아의 치사성 표현형을 유도성 방식으로 유도하기 위한 제1 핵산 서열 및 치사성 표현형을 달성하기 위한 제1 핵산 서열을 상기 조류의 세포의 Z 염색체에 안내하기 위한 제2 핵산 서열을 포함하는, DNA 편집제가 제공된다.
본 명세서에서 사용되는 바와 같이, 용어 "조류" 및 "조류 종"은 닭, 칠면조, 오리, 거위, 메추라기, 꿩 및 타조를 포함하지만 이들로 제한되지 않는 임의의 조류 종을 지칭한다.
본 명세서에서 사용되는 바와 같이, 용어 "난"은 살아있는 배아 조류를 함유하는 조류 난을 지칭한다. 따라서, 용어 "난"은 수정된 조류 난, 일 실시형태에서, 정상적인 배아 발생을 겪을 수 있는 조류 배아를 함유한 난을 의미한다.
DNA 편집제(단일 핵산 작제물 또는 핵산 작제물의 조합으로 구성됨)는 조류 세포의 Z 염색체 내의 제1 핵산 서열의 안정적인 통합을 초래하는 표적화 서열을 포함한다. DNA 편집제는 당업자에게 널리 공지된 재조합 DNA 기술을 사용하여 작제될 수 있다.
표적화 서열은 제1 핵산 서열이 세포의 임의의 다른 염색체가 아닌 Z 염색체 내에 특이적으로 통합되도록 선택된다. 또한, 표적화 서열은 제1 핵산 서열을 염색체 내에 통합시키기 위해서 어떠한 방법에 의존되는지에 따라서 선택된다. 핵산 서열을 염색체 내에 통합시키는 방법은 당업계에 널리 공지되어 있고[예를 들어, 문헌[Menke D. Genesis (2013) 51: - 618; Capecchi, Science (1989) 244:1288-1292; Santiago et al. Proc Natl Acad Sci USA (2008) 105:5809-5814]; 국제 특허 공개 제WO 2014085593호, 제WO 2009071334호 및 제WO 2011146121호; 미국 특허 제8771945호, 제8586526호, 제6774279호 및 미국 특허 출원 공개 제20030232410호, 제20050026157호, 제20060014264호](이들의 내용은 전문이 참조에 의해서 포함됨), 표적화된 상동 재조합, 부위 특이적 재조합 및 조작된 뉴클레아제에 의한 게놈 편집을 포함한다. PB 트랜스포사제가 또한 고려된다. 관심대상 유전자에 핵산 변경을 도입하기 위한 작용제는 공개적으로 이용 가능한 공급원으로부터 설계될 수 있거나 트랜스포사젠사(Transposagen), 애드젠사(Addgene) 및 산가모 바이오사이언시스사(Sangamo Biosciences)로부터 상업적으로 입수 가능하다.
일 실시형태에서, DNA 편집제는 자발적인 상동 재조합에 의존하여 제1 핵산 서열을 세포의 Z 염색체에 삽입한다. 이러한 실시형태에서, DNA 편집제는 표적화 서열로서 기능하는 상동성 아암을 포함한다.
DNA 편집제는 HDR을 통한 특이적 통합을 용이하게 하기 위한 통합 부위로서 작용하는 Z 염색체 내의 표적 좌위 내에 포함된 적어도 하나의 핵산 서열과 상동성이거나 또는 약 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100%의 상동성 또는 동일성을 나타내는 2개의 아암과 측접될 수 있다.
상동성 아암은 Z 염색체 상에 존재하는 게놈 서열에 상응한다. 바람직하게는, 게놈 서열은 전사적으로 활성인 유전자의 하류(예를 들어, Hint1 유전자의 하류)에 존재한다. 상동성 아암은 전형적으로 500개 이상의 뉴클레오타이드 길이, 예를 들어 500 내지 3000개의 뉴클레오타이드 길이이다. 전형적으로, 요구되는 상동성 아암의 크기는 이들 아암이 측접된 카세트의 길이에 의존한다. 작은 카세트는 짧은 암이 필요하며, 그 반대도 가능하다. 상동 재조합은 자발적으로 발생할 수 있다. 고려되는 또 다른 표적은 또한 배아발생의 초기 단계에서 시작하여 발현되는 염색체 Z 상의 Isl1(유전자 ID 369383)이다.
하기는 본 발명의 구체적인 실시형태에 따라서 제1 핵산 서열을 Z 염색체 내에 통합시키기 위해서 DNA 편집제에 의해 사용될 수 있는 다양한 추가의 예시적인 방법의 설명 및 이러한 목적을 수행하는데 필요한 표적화 서열의 설명이다.
조작된 엔도뉴클레아제를 사용한 게놈 편집 - 이 접근법은 인공적으로 조작된 뉴클레아제를 사용하여 게놈 내의(예를 들어, Z 염색체 상의) 목적하는 위치에서 특정 이중 가닥을 브레이크를 절단 및 생성하고, 이어서 이것을 세포 내인성 과정, 예컨대, 상동성 직접 수선(homology directed repair: HDR) 및 비상동성 단부-연결(non-homologous end-joining: NHEJ)에 의해서 수선하는 역 유전학(reverse genetics) 방법이다. NHEJ는 이중 가닥 브레이크에서 DNA 단부를 직접 연결하는 반면, HDR은 브레이크 지점에서 결손된 DNA 서열을 재생시키기 위한 주형으로서 상동성 서열을 이용한다. 게놈 DNA에 특이적인 뉴클레오타이드 변형을 도입하기 위해서, HDR 동안 목적하는 서열을 함유하는 DNA 수선 주형이 존재해야 한다. 게놈 편집은 전통적인 제한 엔도뉴클레아제를 사용하여 수행될 수 없는데, 그 이유는 대부분의 제한 효소가 DNA 상의 몇 개의 염기쌍을 표적으로 인식하고, 인식된 염기쌍 조합이 게놈의 다수의 위치에서 발견되어, 목적하는 위치에 제한되지 않는 다중 절단을 초래할 가능성이 매우 높기 때문이다. 이러한 도전을 극복하고, 부위-특이적 단일- 또는 이중-가닥 브레이크를 생성시키기 위해서, 현재까지 몇 가지 구별되는 부류의 뉴클레아제가 발견되고, 생물조작되었다. 이것은 메가뉴클레아제, 아연 핑거 뉴클레아제(ZFN), 전사-활성화제 유사 효과기 뉴클레아제(TALEN) 및 CRISPR/Cas 시스템을 포함한다.
메가뉴클레아제 - 메가뉴클레아제는 일반적으로 4개의 패밀리로 분류된다:
LAGLIDADG 패밀리, GIY-YIG 패밀리, His-Cys 박스 패밀리 및 HNH 패밀리. 이들 패밀리는 촉매 활성 및 인식 서열에 영향을 미치는 구조적 모티프를 특징으로 한다. 예를 들어, LAGLIDADG 패밀리의 구성원은 보존된 LAGLIDADG 모티프의 하나 또는 두 개의 카피를 갖는 것을 특징으로 한다. 메가뉴클레아제의 4개의 패밀리는 보존된 구조 요소 및 결과적으로 DNA 인식 서열 특이성 및 촉매 활성과 관련하여 서로 넓게 나뉜다. 메가뉴클레아제는 미생물 종에서 흔히 발견되며, 매우 긴 인식 서열(14bp 초과)을 갖는 고유한 특성을 갖고, 따라서 이것이 목적하는 위치에서의 절단에 자연적으로 매우 특이적이게 한다. 이것은 게놈 편집에서 부위-특이적 이중-가닥 브레이크를 제조하기 위해서 활용될 수 있다. 당업자는 이러한 자연 발생 메가뉴클레아제를 사용할 수 있지만, 그러한 자연 발생 메가뉴클레아제의 수는 제한되어 있다. 이러한 과제를 극복하기 위해서, 돌연변이유발 및 고 처리량 스크리닝 방법이 고유한 서열을 인식하는 메가뉴클레아제 변이체를 생성시키는데 사용되어 왔다. 예를 들어, 다양한 메가뉴클레아제는 융합되어 새로운 서열을 인식하는 혼성 효소를 생성시켰다. 대안적으로, 메가뉴클레아제의 DNA 상호작용 아미노산은 서열 특이적 메가뉴클레아제를 설계하도록 변경될 수 있다(예를 들어, 미국 특허 제8,021,867호 참조). 메가뉴클레아제는 예를 들어 문헌[Certo, MT et al. Nature Methods (2012) 9:073-975]; 미국 특허 제8,304,222호; 제8,021,867호; 제8,119,381호; 제8,124,369호; 제8,129,134호; 제8,133,697호; 제8,143,015호; 제8,143,016호; 제8,148,098호; 또는 제8,163,514호(각각의 내용은 전문이 본 명세서에 참조에 의해 포함됨)에 기재된 방법을 사용하여 설계될 수 있다. 대안적으로, 부위 특이적 절단 특징을 갖는 메가뉴클레아제는 상업적으로 입수 가능한 기술, 예를 들어, 프리시젼 바이오사이언시스사(Precision Biosciences)의 Directed Nuclease Editor(상표명) 게놈 편집 기술을 사용하여 획득될 수 있다.
ZFN 및 TALEN - 2개의 구별되는 부류의 조작된 뉴클레아인, 아연-핑거 뉴클레아제(ZFN) 및 전사 활성화제-유사 효과기 뉴클레아제(TALEN)는 모두 표적화된 이중-가닥 브레이크를 생성시키는데 효과적인 것으로 증명되어 있다(Christian et al., 2010; Kim et al., 1996; Li et al., 2011; Mahfouz et al., 2011; Miller et al., 2010).
기본적으로, ZFN 및 TALEN 제한 엔도뉴클레아제 기술은 특이적 DNA 결합 도메인(각각 일련의 아연 핑거 도메인 또는 TALE 반복부)에 연결된 비특이적 DNA 절단 효소를 이용한다. 전형적으로, DNA 인식 부위 및 절단 부위가 서로 분리된 제한 효소가 선택된다. 절단 부분이 분리된 다음 DNA 결합 도메인에 연결되어 목적하는 서열에 대해 매우 높은 특이성을 갖는 엔도뉴클레아제가 생성된다. 이러한 특성을 갖는 예시적인 제한 효소는 Fokl이다. 또한, Fokl은 뉴클레아제 활성을 갖기 위해 이합체화가 필요한 이점을 가지며, 이는 각각의 뉴클레아제 파트너가 고유한 DNA 서열을 인식함에 따라서 특이성이 급격히 증가한다는 것을 의미한다. 이러한 효과를 향상시키기 위해서, 이종이합체로서만 기능할 수 있고, 증가된 촉매 활성을 갖는 Fokl 뉴클레아제가 조작되었다. 이종이합체 기능성 뉴클레아제는 원치않는 동종이합체 활성의 가능성을 회피하고, 따라서 이중-가닥 브레이크의 특이성을 증가시킨다.
따라서, 예를 들어, 특이적 부위를 표적화하기 위해, ZFN 및 TALEN은 뉴클레아제 쌍으로서 작제되며, 쌍의 각각의 구성원은 표적화된 부위에서 인접한 서열에 결합하도록 설계된다. 세포에서 일시적인 발현 시, 뉴클레아제는 그들의 표적 부위에 결합하고, FokI 도메인은 이종이합체화되어 이중 가닥 브레이크를 생성한다. 비상동성 단부-연결(Nonhomologous end-joining: NHEJ) 경로를 통한 이러한 이중-가닥 브레이크의 수선은 가장 자주 작은 결실 또는 작은 서열 삽입물인 indel을 초래한다. NHEJ에 의해 일어난 각각의 수선은 고유하기 때문에, 단일 뉴클레아제 쌍의 사용은 표적 부위에서 다양한 상이한 결실을 갖는 대립유전자 시리즈를 생성시킬 수 있다. 결실은 전형적으로 수 개의 염기쌍 내지 수 백 개의 염기쌍 길이의 범위이지만, 두 쌍의 뉴클레아제를 동시에 사용함으로써 세포 배양에서 더 큰 결실이 성공적으로 생성되었다(Carlson et al., 2012; Lee et al., 2010). 또한, 표적화 영역에 대한 상동성을 갖는 DNA 단편이 뉴클레아제 쌍과 함께 도입되는 경우, 이중-가닥 브레이크는 상동성 직접 수선을 통해서 수선되어 특정 변형을 생성시킬 수 있다(Li et al., 2011; Miller et al., 2010; Urnov et al., 2005).
ZFN 및 TALEN 둘 다의 뉴클레아제 부분은 유사한 특성을 갖지만, 이들 조작된 뉴클레아제 사이의 차이는 그들의 DNA 인식 펩타이드에 있다. ZFN은 Cys2- His2 아연 핑거에 좌우되고, TALEN은 TALE에 좌우된다. 이들 DNA 인식 펩타이드 도메인 둘 다는 이들이 이들의 단백질에서 조합하여 자연적으로 발견되는 특징을 갖는다. Cys2-His2 아연 핑거는 전형적으로 3bp 간격으로 반복적으로 발견되고, 다양한 핵산 상호 작용 단백질에서 다양한 조합으로 발견된다. 한편, TALE는 아미노산과 인식된 뉴클레오타이드 쌍 사이의 일대일 인식 비율로 반복적으로 발견된다. 아연 핑거 및 TALE 둘 다는 반복된 패턴으로 발생하기 때문에, 다양한 서열 특이성을 생성시키기 위해서 다른 조합이 시도될 수 있다. 부위-특이적 아연 핑거 엔도뉴클레아제를 제조하기 위한 접근법은, 예를 들어, 특히 모듈형 어셈블리(삼중항 서열과 상관된 아연 핑거가 요구되는 서열을 커버하기 위해 일렬로 부착되는 경우), OPEN(펩타이드 도메인의 저-엄격성 선택 대 삼중 뉴클레오타이드, 그 다음 펩타이드 조합물의 고-엄격성 선택 대 박테리아 시스템에서의 최종 표적) 및 아연 핑거 라이브러리의 박테리아 1-혼성 스크리닝을 포함한다. ZFN은 또한 예를 들어 Sangamo Biosciences(상표명)(미국 캘리포니아주 리치몬드 소재)로부터 상업적으로 설계되고, 입수될 수 있다.
TALEN의 설계 및 입수 방법은 예를 들어 문헌[Reyon et al. Nature Biotechnology 2012 May;30(5):460-5; Miller et al. Nat Biotechnol. (2011) 29: 143-148; Cermaket al. Nucleic Acids Research (2011) 39 (12): e82 및 Zhang et al. Nature Biotechnology (2011)29 (2): 149-53]에 기재되어 있다. Mojo Hand라는 최근에 개발된 웹-기반 프로그램이 게놈 편집 어플리케이션을 위한 TAL 및 TALEN 작제물 설계를 위한 Mayo Clinic에 의해서 도입되었다(www (dot) talendesign (dot) org를 통해 접근할 수 있음). TALEN은 또한 예를 들어 Sangamo Biosciences(상표명)(리치몬드사, 미국 캘리포니아주 소재)로부터 상업적으로 설계되고, 입수될 수 있다.
CRISPR-Cas 시스템 - 많은 박테리아 및 고세균은 침입 파지 및 플라스미드의 핵산을 분해할 수 있는 내인성 RNA-기반 적응 면역 시스템을 함유한다. 이러한 시스템은 RNA 성분을 생산하는 클러스터링된 규칙적으로 이격된 짧은 회문형 삽입부(clustered regularly interspaced short palindromic repeat: CRISPR) 유전자 및 단백질 성분을 암호화하는 CRISPR 연관(Cas) 유전자로 이루어진다. CRISPR RNA(crRNA)는 특정 바이러스 및 플라스미드에 대한 짧은 스트레치의 상동성을 함유하고, 상응하는 병원체의 상보성 핵산을 분해하도록 Cas 뉴클레아제를 지시하는 가이드로서 작용한다. 스트렙토코쿠스 파이오제네스(Streptococcus pyogenes)의 타입 II CRISPR/Cas 시스템에 대한 연구는, 3개의 성분이 RNA/단백질 복합체를 형성하고, 이것은 함께 서열-특이적 뉴클레아제 활성: Cas9 뉴클레아제, 표적 서열에 상동성인 20개의 염기쌍을 함유하는 crRNA, 및 트랜스-활성화 crRNA(tracrRNA)에 충분하다는 것을 발견하였다(Jinek et al. Science (2012) 337: 816-821). 추가로 crRNA와 tracrRNA 간의 융합으로 구성된 합성 키메라 가이드 RNA(gRNA)는 Cas9가 시험관내에서 crRNA에 상보성인 DNA 표적을 절단하도록 지시할 수 있다는 것이 입증되어 있다. 또한 합성 gRNA와 함께 Cas9의 일시적 발현이 다양한 상이한 종에서 표적화된 이중-가닥 브레이크를 생성시키는데 사용될 수 있음이 입증되어 있다(Cho et al., 2013; Cong et al., 2013; DiCarlo et al., 2013; Hwang et al., 2013a,b; Jinek et al., 2013; Mali et al., 2013).
게놈 편집을 위한 CRIPSR/Cas 시스템은 두 개의 구별되는 성분: gRNA 및 엔도뉴클레아제, 예컨대 Cas9를 함유한다.
gRNA는 전형적으로 단일 키메라 전사체에서 crRNA를 Cas9 뉴클레아제(tracrRNA)에 연결하는 내인성 박테리아 RNA와 표적 상동성 서열 (crRNA)의 조합물을 암호화하는 20개의 뉴클레오타이드 서열이다. gRNA/Cas9 복합체는 gRNA 서열과 보체 게놈 DNA 사이의 염기 짝지움에 의해서 표적 서열에 동원된다. Cas9의 성공적인 결합을 위해서, 게놈 표적 서열은 또한 표적 서열 바로 다음에 정확한 프로토스페이서 인접 모티프(Protospacer Adjacent Motif: PAM) 서열을 함유해야 한다. gRNA/Cas9 복합체의 결합은 Cas9를 게놈 표적 서열에 국지화시켜 Cas9가 DNA의 두 가닥을 절단하여 이중-가닥 브레이크를를 유발할 수 있도록 한다. ZFN 및 TALEN과 마찬가지로 CRISPR/Cas에서 생산된 이중-가닥 브레이크는 상동 재조합 또는 NHEJ를 겪을 수 있다.
Cas9 뉴클레아제는 2개의 기능성 도메인: RuvC 및 HNH를 가지며, 각각은 상이한 DNA 가닥을 절단한다. 이들 도메인 둘 다가 활성인 경우, Cas9는 게놈 DNA에서 이중 가닥 브레이크를 일으킨다.
CRISPR/CAS의 중요한 장점은, 합성 gRNA를 용이하게 생성시킬 수 있는 능력과 결합된 이러한 시스템의 높은 효율이 다수의 유전자가 동시에 표적화되는 것을 가능하게 한다는 것이다. 또한, 돌연변이를 보유한 대부분의 세포는 표적화된 유전자에서 이대립유전자성 돌연변이를 제공한다.
그러나, gRNA 서열과 게놈 DNA 표적 서열 사이의 염기 짝지움 상호 작용에서의 명백한 유연성은 표적 서열에 대한 불완전한 매칭이 Cas9에 의해서 절단되는 것을 가능하게 한다.
단일 비활성 촉매 도메인, RuvC- 또는 HNH-를 함유하는 Cas9 효소의 변형된 버전은 '닉카제'(nickase)로 불린다. 단지 하나의 활성 뉴클레아제 도메인으로 Cas9 닉카제는 표적 DNA의 한 가닥만을 절단하여, 단일-가닥 브레이크 또는 '닉'을 생성시킨다. 단일 가닥 브레이크 또는 닉은 일반적으로 주형으로서 무손상 상보성 DNA 가닥을 사용하여 HDR 경로를 통해서 신속하게 수선된다. 그러나, Cas9 닉카제에 의해 도입된 2개의 근위의 반대 가닥 닉은 종종 '이중 닉' CRISPR 시스템으로 지칭되는 이중-가닥 브레이크로 취급된다. 이중-닉은 유전자 표적에 대한 목적하는 효과에 따라서 NHEJ 또는 HDR에 의해서 수선될 수 있다. 따라서, 특이성 및 감소된 오프-타깃 효과가 중요하다면, Cas9 닉카제를 사용하여 근접부에 그리고 게놈 DNA의 반대 가닥 상에 표적 서열을 갖는 2개의 gRNA를 설계함으로써 이중-닉을 생성하여 오프-타깃 효과를 감소시킬 것인데, 그 이유는 gRNA 단독이 게놈 DNA를 변화시키지 않을 닉을 초래할 것이기 때문이다.
2개의 비활성 촉매 도메인(죽은 Cas9 또는 dCas9)을 함유하는 Cas9 효소의 변형된 버전은 뉴클레아제 활성이 없지만, gRNA 특이성에 기초하여 DNA에 여전히 결합할 수 있다. dCas9는 비활성화 효소를 공지된 조절 도메인에 융합시킴으로써 유전자 발현을 활성화 또는 억제하기 위한 DNA 전사 조절제를 위한 플랫폼으로서 이용될 수 있다. 예를 들어, 게놈 DNA에서 표적 서열에 대한 dCas9 단독의 결합은 유전자 전사를 방해할 수 있다.
상이한 종의 상이한 유전자에 대해서 생물정보학적으로 결정된 고유한 gRNA의 목록뿐만 아니라 표적 서열을 선택 및/또는 설계하는 것을 돕기 위한 다수의 공개적으로 입수 가능한 툴, 예컨대, Feng Zhang lab으로부터의 CRISPR 설계 툴, Michael Boutros lab's Target Finder(E-CRISP), RGEN 툴: Cas-OFFinder, CasFinder: 게놈에서 특이적 Cas9 표적을 식별하기 위한 유연한 알고리즘 및 CRISPR Optimal Target Finder가 존재한다.
CRISPR 시스템을 사용하기 위해서 gRNA 및 Cas9 둘 다는 표적 세포에서 발현되어야한다. 삽입 벡터는 단일 플라스미드 상에 카세트 둘 다를 함유할 수 있거나 또는 카세트는 2개의 별개의 플라스미드로부터 발현된다. CRISPR 플라스미드는 애드젠사(Addgene)로부터의 px330 플라스미드와 같이 공개적으로 입수 가능하다. 또한, Cas9 및 gRNA를 암호화하는 mRNA는 gRNA와 복합체로 재조합 Cas9 단백질뿐만 아니라 표적 세포에 삽입될 수 있다(즉, RNP 복합체를 세포에 삽입함).
재조합 아데노-연관 바이러스(recombinant adeno-associated virus: rAAV) 플랫폼을 사용한 게놈 편집 - 이 게놈-편집 플랫폼은 살아있는 포유동물 세포의 게놈에서 DNA 서열의 삽입, 결실 또는 치환을 가능하게 하는 rAAV 벡터에 기초한다. rAAV 게놈은 단일-가닥 데옥시리보핵산(ssDNA) 분자이며, 양 또는 음으로 감지되며, 길이는 약 4.7kb이다. 이들 단일-가닥 DNA 바이러스 벡터는 높은 형질도입 속도를 가지며, 게놈에서 이중 가닥 DNA 브레이크가 없는 경우 내인성 상동 재조합을 자극하는 고유한 특성을 갖는다. 당업자는 목적하는 게놈 좌위를 표적으로 하고, 세포에서 총 및/또는 미묘한 내인성 유전자 변경 둘 다를 수행하도록 rAAV 벡터를 설계할 수 있다. rAAV 게놈 편집은 단일 대립 유전자를 표적으로 하고, 오프-타깃 게놈 변경이 발생하지 않는다는 이점을 갖는다. rAAV 게놈 편집 기술은 예를 들어 Horizon(상표명)(영국 캠브리지 소재)의 rAAV GENESIS(상표명) 시스템과 같이 상업적으로 입수 가능하다.
효능을 확인하고 서열 변경을 검출하는 방법은 당업계에 널리 공지되어 있고, DNA 서열결정, 전기영동, 효소 기반 미스매치 검출 검정 및 혼성화 검정, 예컨대, PCR, RT-PCR, RNase 보호, 동소 혼성화, 프라이머 연장, 서던 블롯, 노던 블롯 및 도트 블롯 분석을 포함하지만 이들로 제한되지 않는다.
특정 유전자에서의 서열 변경은 또한 예를 들어, 크로마토그래피, 전기영동 방법, 면역검출 검정, 예컨대 ELISA 및 웨스턴 블롯 분석 및 면역조직화학을 사용하여 단백질 수준에서 결정될 수 있다.
DNA 편집제는 루시퍼라제, 형광 단백질(예를 들어, 녹색 형광 단백질), 클로람페니콜 아세틸 트랜스퍼라제, 베타-갈락토시다제, 분비된 태반 알칼리성 포스파타제, 베타-락타마제, 인간 성장 호르몬 및 기타 분비 효소 리포터를 포함하지만 이들로 제한되지 않는 그의 존재 또는 활성에 의해서 쉽게 검출될 수 있는 리포터 단백질을 암호화할 수 있다. 일반적으로, 리포터 유전자는 숙주 세포에 의해 달리 생산되지 않는 폴리펩타이드를 암호화하는데, 이는 세포(들)의 분석, 예를 들어, 세포(들)의 직접적인 형광측정, 방사성동위원소 또는 분광광도 분석에 의해 검출될 수 있으며 전형적으로 신호 분석을 위해 세포를 사멸시킬 필요가 없다. 특정 예에서, 리포터 유전자는 효소를 암호화하는데, 이것은 정성적, 정량적, 또는 반정성적 기능 또는 전사 활성화에 의해 검출될 수 있는 숙주 세포의 형광측정 특성의 변화를 생성시킨다. 예시적인 효소는 에스테라제, β-락타마제, 포스파타제, 퍼옥시다제, 프로테아제(조직 플라스미노겐 활성화제 또는 유로키나제) 및 당업자에게 공지되어 있거나 미래에 개발될 적절한 발색성 또는 형광성 기질에 의해 기능이 검출될 수 있는 다른 효소를 포함한다.
또한, 당업자는 작제물로 상동 재조합 사례를 경험한 형질전환된 세포를 효율적으로 선택하기 위한 양성 및/또는 음성 선택 마커를 포함하는 DNA 편집제를 쉽게 설계할 수 있다. 양성 선택은 외래 DNA를 흡수한 클론 집단을 풍부하게 하는 수단을 제공한다. 이러한 양성 마커의 비제한적 예는 글루타민 합성효소, 다이하이드로폴레이트 리덕타제(dihydrofolate reductase: DHFR), 항생제 내성을 부여하는 마커, 예를 들어, 네오마이신, 하이그로마이신, 퓨로마이신 및 블라스티시딘 S 내성 카세트를 포함한다. 마커 서열(예를 들어, 양성 마커)의 무작위 통합 및/또는 제거를 선택하기 위해 음성 선별 마커가 필요하다. 이러한 음성 마커의 비제한적 예는 간실로비어(GCV)를 세포 독성 뉴 클레오사이드 유사체, 하이포잔틴으로 전환시키는 단순 포진-티미딘 키나제(HSV-TK), 포스포리보실 트랜스퍼라제(HPRT), 디프테리아 독소(DT) 및 아데닌 포스포리보실 트랜스퍼라제(ARPT)를 포함한다.
상동 재조합을 용이하게 하기 위해서, SCR7 피라진과 같은 NHEJ의 화학적 저해제를 사용하여 CRISPR 게놈 편집-매개 HR 효율을 향상시킬 수 있다. 언급된 바와 같이, 본 발명의 이러한 양상의 DNA 편집제는 조류의 난으로부터 부화하는 수컷 병아리 치사성 표현형을 유도성 방식으로 유도하기 위한 제1 핵산 서열을 포함한다.
바람직하게는, 수컷 배아는 X-XIII EG&K기로 알려진 초기 포배기(blastulation stage)를 지나서 난에서 생존하지 못한다(Eyal-Giladi and Kochav, 1976).
일 실시형태에서, 제1 핵산 서열은 치사 단백질의 발현을 제어하는 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결된 치사 단백질을 암호화할 수 있고, 여기서 스위치는 유도제에 의해서 조절된다.
본 명세서에서 사용되는 바와 같이, 용어 "치사 단백질"은 조류 배아(예를 들어, 수컷 배아)에 치명적이므로 난으로부터 살아있는 수컷 조류의 부화를 방지하는 단백질을 지칭한다. 치사 단백질 예는 독소, 세포 독성 단백질, 프로-아포토시스 단백질, BMP 길항제, Wnt 신호전달의 저해제 및 FGF 길항제를 포함하지만 이들로 제한되지 않는다.
본 발명에 의해 고려되는 예시적인 독소는 슈도모나스 외독소(젠뱅크 수탁 번호 ABU63124), 디프테리아 독소(젠뱅크 수탁 번호 AAV70486) 및 리신 독소(ricin toxin)(젠뱅크 수탁 번호 EEF27734)를 포함하지만 이들로 제한되지 않는다.
예시적인 세포독성 단백질은 인터류킨 2(젠뱅크 수탁 번호 CAA00227), CD3(젠뱅크 수탁 번호 P07766), CD16(젠뱅크 수탁 번호 NP_000560.5), 인터류킨 4(젠뱅크 수탁 번호 NP_000580.1) 및 인터류킨 10(젠뱅크 수탁 번호 P22301)을 포함하지만 이들로 제한되지 않는다.
본 발명에 의해 고려되는 예시적인 프로-아포토시스 단백질은 포유동물 세포에서 또한 아포토시스를 유도한다고 공지된 드로소필라 리퍼(Drosophila Reaper) 및 그림(Grim)을 포함하지만 이들로 제한되지 않는다[McCarthy, J. V & Dixit, V. M. Apoptosis induced by Drosophila reaper and grim in a humansystem. Attenuation by inhibitor of apoptosis proteins (cIAPs). J. Biol. Chem. 273, 24009-15(1998)] and those proteins that activate apoptosis such as CASP3 [Julien, O. & Wells, J. A.Caspases and their substrates. Cell Death Differ. (2017). doi:10.1038/cdd.2017.44].
다른 고려되는 치사 단백질은 기본적인 초기 배아생성기를 방해하는 것, 예컨대, 초기 낭배형성기에 발현되는 N-카드헤린을 방해하는 것이다. 이러한 접착 분자의 우세한-음성 형태의 발현은 초기 배아 사망을 초래할 것이다.
추가 치사 단백질은 필수 신호전달 경로, 예컨대, BMP & FGF 경로를 방해하는 것이다. BMP4 길항제, 예를 들어, - Noggin의 과발현은 배발생 과정을 중단시키고, 초기 배아 사망을 초래할 것이다.
또 다른 실시형태에서, 제1 핵산 서열은 엔도뉴클레아제 단백질의 발현을 제어하는 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결된 게놈 편집을 수행할 수 있는 엔도뉴클레아제 효소를 암호화할 수 있고, 스위치는 유도자에 의해 조절된다.
엔도뉴클레아제 단백질의 예는 아연 핑거 뉴클레아제(ZFN), 전사 활성화 제-유사 효과기 뉴클레아제(TALEN) 및 CRISPR/Cas 시스템을 포함하며, 이들 각각은 상기 본 명세서에 추가로 기재되어 있다.
이러한 실시형태에서, 핵산 서열은 배아 생존에 필수적인 유전자를 파괴하기 위해 엔도뉴클레아제를 표적으로 하는 표적화 서열(또는 가이드 서열)을 추가로 포함한다. 이런 방식으로, 치사성 표현형이 배아에서 생겨나고 살아있는(수컷) 병아리는 난에서 부화할 수 없다.
파괴될 수 있는 필수 유전자의 예는 BMPR1A(유전자 ID: 396308), BMP2(유전자 ID: 378779), BMP4(유전자 ID: 396165) 및 FGFR1(유전자 ID: 396516)을 포함하지만 이들로 제한되지 않는다.
본 발명의 이러한 양상의 DNA 편집제는 전형적으로 치사 단백질 또는 엔도뉴클레아제 효소의 발현을 유도하기 위해 작동 가능하게 연결된 프로모터를 포함할 것이다.
DNA 편집제에 사용될 수있는 프로모터의 예는 pCAGGS 발현 벡터에서와 같이 렌티바이러스의 PGK 프로모터, CMV 프로모터, 인간 시냅신 I 프로모터(hSyn) 및 CAG 프로모터를 포함하지만 이들로 제한되지 않는다.
치사 단백질 또는 엔도뉴클레아제 효소의 발현을 제어하는 프로모터 및 다른 서열은 수컷 병아리 배아에서 치사 표현형을 초래하기에 충분한 단백질의 발현이 존재하도록 선택된다.
DNA 편집제가 엔도뉴클레아제 또는 치사 단백질을 암호화하는지에 관계없이, 효과기 단백질의 발현은 DNA 편집제에 포함된(예를 들어, 암호화된) 스위치에 의해서 조절된다.
본 명세서에서 사용되는 바와 같이, 용어 "스위치"는 변화, 기능의 활성화, 억제, 향상 또는 종결과 같은 생물학적 기능의 모든 양상을 포함하여 변화에 영향을 주기 위해 조화되는 방식으로 작용하는 단일 성분 또는 성분 세트를 지칭한다. 일 실시형태에서, 스위치는 유전자 조절에 사용되는 유도성 및 억제성 시스템에 관한 것이다. 일반적으로, 유전자 발현을 가능하게 하는 일부 분자 또는 에너지 형태(유도자로 지칭됨)가 존재하지 않으면 유도성 시스템이 꺼질 수 있다. 이러한 분자는 "발현을 유도한다"고 한다. 이것이 일어나는 방식은 제어 기전과 세포 유형의 차이에 좌우된다. 유전자 발현을 억제하는 일부 분자 또는 에너지 형태(코레프레서(corepressor)로 지칭됨)가 존재하는 경우를 제외하고는 억제 시스템이 켜져 있다. 이러한 분자는 "발현을 억제한다"라고 한다. 이것이 일어나는 방식은 제어 기전뿐만 아니라 세포 유형의 차이에 좌우된다.
본 명세서에서 사용되는 바와 같이, 용어 "유도성"은 관련된 분자 기전에 관계없이 스위치의 모든 양상을 포함할 수 있다. 따라서, 본 발명에 의해 이해되는 스위치는 항생제 기반 유도성 시스템, 전자기 에너지 기반 유도성 시스템, 소분자 기반 유도성 시스템, 핵 수용체 기반 유도성 시스템 및 호르몬 기반 유도성 시스템을 포함할 수 있지만 이들로 제한되지 않는다. 일부 실시형태에서, 스위치는 테트라사이클린(Tet)/DOX 유도성 시스템, 광 유도성 시스템, 아브시스산(ABA) 유도성 시스템, 큐메이트 억제인자/작동자 시스템, 40HT/에스트로겐 유도성 시스템, 엑디손계 유도성 시스템 또는 FKBP12/FRAP(FKBP12-라파마이신 복합체) 유도성 시스템일 수 있다.
유도자는 조류의 난을 관통할 수 있어야 한다는 것이 인지될 것이다. 또한, 유도자 자체는 난 내에서 배아의 발달에 독성이거나 배아의 발달을 변경시키지 않아야 한다.
본 발명에 의해 고려되는 예시적인 유도자는 열, 초음파, 전자기 에너지 및 화학 물질을 포함하지만 이들로 제한되지는 않는다. 유도자는 산란 전에 암탉의 체내에서 난 생성 과정 동안 난으로 전달될 수 있다.
구체적인 실시형태에 따르면, 스위치는 전자기 에너지(예를 들어, 가시광의 성분)를 사용하여 유도된다. 가시광의 성분은 450㎚ 내지 700㎚ 범위 또는 450㎚ 내지 500㎚ 범위의 파장, 즉 청색광을 가질 수 있다. 청색광은 적어도 0.2mW/㎠ 이상의 강도 또는 적어도 4mW/㎠의 강도일 수 있다.
가시광의 성분은 620㎚ 내지 700㎚ 범위의 파장, 즉 적색광을 가질 수 있다.
임의의 순서로 그리고 임의의 조합으로, 가시광의 단일 또는 다수의 응용이 고려된다. 가시광은 단일 또는 다수의 연속 적용으로 또는 펄스(박동 전달)로 전달될 수 있다.
이러한 옵토제틱 스위치의 예는 문헌[Muller et al., Biol Chem. 2015Feb;396(2):145-52. doi: 10.1515/hsz-2014-0199; Motta Mena et al., Nat Chem Biol. 2014 Mar;10(3): 196-202]; 및 국제 특허 공개 제WO 2014018423호(각각의 내용은 본 명세서세 참조에 의해 포함됨)에 기재되어 있다.
일 실시형태에서, 스위치는 유도자를 사용하여 스위치가 켜질 때 발현되는 효과기 분자의 발현을 유도한다. 효과기 분자의 발현을 유도하기 위한 예시적인 프로모터는 렌티바이러스의 PGK 프로모터, pCAGG 프로모터, CMV 프로모터, EF1-α 프로모터 및 인간 시냅신 I 프로모터(hSyn)를 포함하지만 이들로 제한되지 않는다.
특정 실시형태에 따르면, 효과기 분자는 부위 특이적 리콤비나제이다.
예시적인 옵토제틱 스위치가 도 4A 내지 도 4C에 도시되어 있으며, 이들 각각은 아라비돕시스 탈리아나(Arabidopsis thaliana)로부터의 감광성 이합체화 단백질 도메인 크립토크롬 2(CRY2) 및 CIB1 및 효과기 분자로서 부위 특이적 재조합을 이용한다. CRY2는 Cre 리콤비나제의 절반에 프레임으로 융합되는 반면, CIB1은 Cre 리콤비나제의 다른 절반, 즉 분할 리콤비나제에 프레임으로 융합된다. 따라서, 유도자가 제공될 때(청색 광이 조사됨), CRY2 및 CIB1이 이종이합체화되어 부위 특이적 재조합을 수행할 수 있는 기능성 Cre 리콤비나제를 생성한다.
부위 특이적 재조합은 하기에 추가로 기재되어 있다.
부위-특이적 리콤비나제 - P1 박테리오파지로부터 유래된 Cre 및 사카로코마이세스 세레비지애(Saccharomyces cerevisiae)로부터 유래된 Flp 리콤비나제는 각각 고유한 34개의 염기쌍 DNA 서열(각각 "Lox"및 "FRT"로 지칭됨)을 인식하는 부위-특이적 DNA 리콤비나제이고, Lox 부위 또는 FRT 부위 중 어느 것과 측접된 서열은 각각 Cre 또는 Flp 리콤비나제의 발현 시에 부위-특이적 재조합을 통해서 용이하게 제거될 수 있다.
또한, 고려되는 리콤비나제 인식 부위는 Lox511, Lox5171, Lox2272, m2, Lox71, Lox66, FRT, F1, F2, F3, F4, F5, FRT(LE), FRT(RE), attB, attP, attL 및 attR을 포함하지만 이들로 제한되지 않는다.
예를 들어, Lox 서열은 13개의 염기쌍 반전 반복부가 측접된 비대칭적인 8개의 염기쌍 스페이서 영역으로 구성된다. Cre는 13개의 염기쌍 반전 반복부에 결합하고, 스페이서 영역 내에서 가닥 절단 및 재결찰을 촉매함으로써 34개의 염기쌍 lox DNA 서열을 재조합시킨다. 스페이서 영역에서 Cre에 의해 만들어진 엇갈린 DNA 절단부는 6개의 염기쌍으로 분리되어 동일한 중첩 영역을 갖는 재조합 부위만이 재조합되는 것을 보장하기 위해 상동성 센서로서 작용하는 중첩 영역을 제공한다.
기본적으로, 부위 특이적 재조합 시스템은 상동 재조합 후 선택 카세트를 제거하기 위한 수단을 제공한다. 이러한 시스템은 또한 일시적 또는 조직-특이적 방식으로 비활성화 또는 활성화될 수 있는 조건부 변경된 대립유전자의 생성을 허용한다. 특히, Cre 및 Flp 리콤비나제는 34개 염기의 Lox 또는 FRT "흔적"을 남긴다. 남아있는 Lox 또는 FRT 부위는 일반적으로 인트론 또는 변형된 좌위의 3' UTR에 남겨지는데, 현재 증거는 이러한 부위는 일반적으로 유전자 기능을 상당히 방해하지 않는다는 것을 시사한다.
따라서, Cre/Lox 및 Flp/FRT 재조합은 관심대상 돌연변이, 2개의 Lox 또는 FRT 서열, 및 전형적으로 2개의 Lox 또는 FRT 서열 사이에 배치된 선택 가능한 카세트를 함유하는 3' 상동성 아암 및 5' 상동성 아암을 갖는 표적화 벡터의 도입을 포함한다. 양성 선택이 적용되고, 표적화된 돌연변이를 함유하는 상동 재조합체가 식별된다. 음성 선택과 함께 Cre 또는 Flp의 일시적인 발현은 선택 카세트의 절제를 초래하고, 카세트가 손실된 세포를 선택한다. 최종 표적화된 대립유전자는 외인성 서열의 Lox 또는 FRT 흔적을 함유한다. Cre/Lox 재조합을 사용하는 예시적인 표적화 벡터가 도 4A 및 도 4C에 도시되어 있다. Flp/FRT 재조합을 사용하는 예시적인 표적화 벡터가 도 4B에 도시되어 있다.
다른 에너지 활성화 방법, 특히 유사한 효과를 갖는 전기장 에너지 및/또는 초음파가 고려된다. 필요한 경우, 스위치의 단백질 짝지움은 또 다른 에너지원에 의한 최대 효과를 위해 변경 및/또는 변형될 수 있다.
전기장 에너지는 바람직하게는 생체 내 조건 하에서 약 1볼트/㎝ 내지 약 10킬로볼트/㎝의 하나 이상의 전기 펄스를 사용하여 당업계에 기재된 바와 같이 실질적으로 투여된다. 펄스 대신에 또는 펄스에 추가하여, 전기장은 연속 방식으로 전달될 수 있다. 전기 펄스는 1 내지 500밀리초, 바람직하게는 1 내지 100밀리초 동안 적용될 수 있다. 전기장은 약 5분 동안 연속적으로 또는 펄스 방식으로 적용될 수 있다. 본 명세서에서 사용된 '전계 에너지'는 세포가 노출되는 전기 에너지이다. 바람직하게는, 전기장은 생체 내 조건 하에서 약 1볼트/㎝ 내지 약 10 킬로볼트/㎝ 또는 그 초과의 강도를 갖는다(국제 특허 제WO97/49450호 참고).
본 명세서에서 사용되는 바와 같이, 용어 "전기장"은 가변 용량 및 전압의 하나 이상의 펄스를 포함하며, 지수 및/또는 구형파(square wave) 및/또는 변조된 파형 및/또는 변조된 구형파 형태를 포함한다. 전계 및 전기에 대한 언급은 세포 환경에서의 전위차의 존재에 대한 언급을 포함하는 것으로 간주되어야 한다. 이러한 환경은 당업계에 공지된 바와 같은 정전기, 교류(AC), 직류(DC) 등을 통해 설정될 수 있다. 전기장은 균일하거나, 불균일하거나 또는 다른 방식일 수 있으며, 시간 의존 방식으로 강도 및/또는 방향이 달라질 수 있다.
단일 또는 다중 전계의 응용뿐만 아니라 단일 또는 다중 초음파의 응용도 임의의 순서 및 임의의 조합으로 가능하다. 초음파 및/또는 전기장은 단일 또는 다수의 연속적인 적용으로 또는 펄스(박동 전달)로서 전달될 수 있다.
특히, 활성화 효소(즉, 예를 들어, Cre와 같은 리콤비나제 효소)가 치사 유전자 카세트로부터 분리되는 대안적인 접근법이 사용될 수 있다. 이 경우, 활성화 효소는 수컷 또는 암컷 조류의 게놈 내에 삽입되고, 비활성 치사 카세트는 조류의 상응하는 성별의 Z 염색체 상에 삽입된다. 이 경우, 수컷 배아에서 치사의 활성화는 두 트랜스제닉 부모를 교배시킴으로써 단지 수행된다.
따라서, 본 발명의 또 다른 양상에 따르면, 하기를 포함하는 DNA 편집 시스템이 제공된다:
(i) 리콤비나제 인식 부위에 작동 가능하게 연결된 조류의 난에서 치사성 표현형을 유도하기 위한 제1 핵산 서열 및 치사성 표현형을 달성하기 위한 제1 핵산 서열을 새의 세포의 Z 염색체에 안내하기 위한 서열을 포함하는 제1 작용제; 및
(ii) 리콤비나제 효소를 암호화하는 제2 핵산 서열 및 제2 핵산 서열을 조류 세포의 Z 염색체로 안내하기 위한 서열을 포함하는 제2 작용제.
본 발명의 DNA 편집제 및 시스템은 또한 루시퍼라제, 형광 단백질(예를 들어, 녹색 형광 단백질), 클로람페니콜 아세틸 트랜스퍼라제, 베타-갈락토시다제, 분비된 태반 알칼리성 포스파타제, 베타-락타마제, 인간 성장 호르몬 및 기타 분비 효소 리포터를 포함하지만 이들로 제한되지 않는 그의 존재 또는 활성에 의해서 쉽게 검출될 수 있는 리포터 폴리펩타이드를 암호화하는 리포터 유전자를 포함할 수 있다. 일반적으로, 리포터 유전자는 숙주 세포에 의해 달리 생산되지 않는 폴리펩타이드를 암호화하는데, 이는 세포(들)의 분석, 예를 들어, 세포(들)의 직접적인 형광측정, 방사성동위원소 또는 분광광도 분석에 의해 검출될 수 있으며 전형적으로 신호 분석을 위해 세포를 사멸시킬 필요가 없다. 특정 예에서, 리포터 유전자는 효소를 암호화하는데, 이것은 정성적, 정량적, 또는 반정성적 기능 또는 전사 활성화에 의해 검출될 수 있는 숙주 세포의 형광측정 특성의 변화를 생성시킨다. 예시적인 효소는 에스테라제, 베타-락타마제, 포스파타제, 퍼옥시다제, 프로테아제(조직 플라스미노겐 활성화제 또는 유로키나제) 및 당업자에게 공지되어 있거나 미래에 개발될 적절한 발색성 또는 형광성 기질에 의해 기능이 검출될 수 있는 다른 효소를 포함한다. 리포터 유전자는 작제물이 Z 염색체에 성공적으로 통합되었다고 보고할 수 있다.
DNA 편집제의 다른 성분은 자가-절단 펩타이드, 예컨대, P2A, T2A, E2A (Wang et al., Scientific Report 5, Article 16273 (2015) 또는 내부 리보솜 진입 부위(IRES) 서열을 포함하지만 이들로 제한되지 않는 2A를 포함한다.
DNA 편집제는 (단일 벡터 또는 다수의 벡터를 사용하여) 바이러스 벡터에서 작제될 수 있다. 이러한 벡터는 일반적으로 유전자 전달 및 유전자 요법 응용에 사용된다. 상이한 바이러스 벡터 시스템에는 고유한 장단점이 있다. 본 발명의 제1 핵산 서열을 Z 염색체 내에 통합시키는데 사용될 수 있는 바이러스 벡터는 하기에 보다 상세히 기재되는 아데노바이러스 벡터, 아데노-연관 바이러스 벡터, 알파바이러스 벡터, 단순 포진 바이러스 벡터 및 레트로바이러스 벡터를 포함하지만 이들로 제한되지 않는다. 특정 실시형태에 따르면, 벡터는 렌티바이러스 벡터이다.
레트로바이러스 작제물과 같은 바이러스 작제물은 적어도 하나의 전사 프로모터/증강제 또는 좌위-한정 요소(들), 또는 대안적인 스플라이싱, 핵 RNA 외수송 또는 메신저의 번역후 변형과 같은 다른 수단에 의해 유전자 발현을 제어하는 다른 요소를 포함한다. 이러한 벡터 작제물은, 그것이 바이러스 작제물에 이미 존재하지 않는 한, 패키징 신호, 긴 말단 반복부(LTR) 또는 이의 일부, 및 사용된 바이러스에 적절한 양성 및 음성 가닥 프라이머 결합 부위를 포함한다. 또한, 이러한 작제물은 전형적으로 그것이 위치된 숙주 세포로부터 펩타이드의 분비를 위한 신호 서열을 포함한다. 바람직하게는 이러한 목적을 위한 신호 서열은 포유동물 신호 서열 또는 본 발명의 일부 실시형태의 폴리펩타이드 변이체의 신호 서열이다. 선택적으로, 작제물은 또한 하나 이상의 제한 부위 및 번역 종결 서열뿐만 아니라 폴리아데닐화를 지시하는 신호를 포함할 수 있다. 예를 들어, 그러한 작제물은 전형적으로 5' LTR, tRNA 결합 부위, 패키징 신호, 제2 가닥 DNA 합성의 기원 및 3' LTR 또는 이의 일부를 포함할 것이다. 양이온성 지질, 폴리라이신 및 덴드리머와 같은 비바이러스성인 다른 벡터가 사용될 수 있다.
바람직하게는, DNA 편집제의 단백질을 암호화하는 코돈은 "최적화된" 코돈이고, 즉, 코돈은 예를 들어, 인플루엔자 바이러스에 의해서 빈번하게 사용되는 그러한 코돈 대신에 조류 종 내에서 높게 발현되는 유전자에서 빈번하게 나타나는 것이다. 이러한 코돈 사용은 조류 세포에서 단백질의 효율적인 발현을 제공한다. 코돈 사용 패턴은 많은 종의 고도로 발현된 유전자에 대해서 문헌에 공지되어 있다(예를 들어, 문헌[Nakamura et al, 1996; Wang et al, 1998; McEwan et al. 1998]).
언급된 바와 같이, DNA 편집제(또는 시스템)는 생존 가능한 암컷 새끼만 생산할 수 있고 생존 가능한 수컷 새끼를 생산할 수 없는 암컷 닭의 생성에 사용된다.
제1 단계로서, DNA 편집제는 조류의 원시 생식 세포 또는 조류의 정자 세포에 직접 도입된다.
수용자 세포 내에 관심대상 핵산을 도입하기 위한 접근법은 공지되어 있으며, 리포펙션, 형질주입, 미세주사, 전기천공, 형질전환 및 미세돌출 기술(microprojectic technique) 등을 포함한다.
따라서, 본 발명의 또 다른 양상에 따르면, 세포의 Z 염색체에 안정적으로 통합되는 외인성 폴리뉴클레오타이드를 포함하는 조류의 세포(예를 들어, 원시 생식 세포 또는 생식세포)를 포함하는 세포 집단이 제공되며, 상기 외인성 폴리뉴클레오타이드는 조류의 수컷 자손(조류의 암컷 자손에서는 아님)에서 (유도성 방식으로) 치사성 표현형을 유도한다.
본 명세서에서 사용되는 바와 같이, 용어 "원시 생식 세포" 및 "PGC"는 초기 배아에 존재하고, 성체 조류에서 반수체 생식세포(즉, 정자 및 난자)로 분화/발달할 수있는 이배체 세포를 지칭한다. 원시 생식 세포는 생식 기능선, 생식선, 혈액 및 발달 중인 생식선, 혈액 및 생식신월환을 포함하지만 이들로 제한되지 않는 발달 중인 조류 배아의 다양한 발달 단계 및 다양한 부위로부터 단리될 수 있다(예를 들어, 문헌[Chang et al., Cell Biol Int 21:495-9, 1997; Chang et al., CellBiol Int 19:143-9, 1995; Allioli et al., Dev Biol 165:30-7, 1994; Swift, Am J Physiol 15:483-516]; 및 PCT 국제 공개 제WO 99/06533호 참고). 생식 기능선은 당업자에게 공지된 발달 중인 배아의 한 부분이다(예를 들어, 문헌[Theriogenology 45: 130-141, 1996; Lavoir, J Reprod Dev 37: 413-424, 1994] 참고). 전형적으로, PGC는 과요오드산-쉬프(periodic acid-Schiff: PAS) 기술에서 양성으로 염색된다. 여러 종에서 PGC는 항-SSEA 항체(주목할 만한 예외는 SSEA 항원을 표시하지 않는 PGC 형태인 칠면조임)를 사용하여 식별될 수 있다. 피콜 밀도 구배 원심 분리를 사용한 혈액으로부터의 PGC의 농축을 비롯한 PGC의 단리 및 정제를 위한 다양한 기술은 당업계에 공지되어 있다(Yasuda et al., J Reprod Fertil 96 : 521-528, 1992)
PGC의 시험관내 배양은 닭 및 소 혈청을 함유한 배지, 컨디셔닝된 배지, 피더 세포(feeder cell) 및 성장 인자, 예컨대, FGF2를 사용하여 가능하다(van de Lavoir et al. 2006, Nature 441:766-769. doi:10.1038/nature04831); Choi et al. 2010, PLoS ONE 5:e12968. doi:10.1371/journal.pone.0012968; MacDonald et al.2010. PLoS ONE 5:e15518. doi:10.1371/journal.pone.0015518). 최근에, FGF, 인슐린 및 TGF-β 신호전달 경로를 활성화시키기 위한 성장 인자를 함유하는 피더 대체 배지가 PGC를 전파하는데 사용될 수 있다는 것이 밝혀졌다(Whyte et al. 2015, Stem Cell Rep 5:1171-1182. doi:10.1016/j.stemcr.2015.10.008). 또한, 이 보고서에는, 철-운반 단백질에 대한 대체물로서 오보트랜스페린의 사용이 PGC의 조류 혈청 허용된 피더-무함유 및 혈청-무함유 전파에 제공되며, 세포는 높은 증식 속도를 유지한다.
원시 생식 세포(PGC)는 임의의 적합한 기술에 의해 본 발명에 개시된 주제를 수행하고, 바람직할 때 사용하기 전에 저장, 냉동, 배양 등을 제공하기 위해 제공되고 제형화될 수 있다. 예를 들어, 원시 생식 세포는 적절한 배아기에서 공여자 배아로부터 수집될 수 있다. 조류 발달 단계는 본 명세서에서 2개의 당업계에 인식된 기 결정 시스템 중 하나에 의해서 지칭된다: 이알-길라디 및 코차브 시스템(EG&K; 문헌[Eyal- Giladi & Kochav, Dev Biol 49:321-327, 1976] 참고)(이것은 원시선 발달기(preprimitive streak stages of development)를 지칭하기 위해서 로마 숫자를 사용함) 및 햄버거 및 해밀턴 기 결정 시스템(H&H; 문헌[Hamburger & Hamilton, J Morphol 88:49-92, 1951] 참고)(이것은 산란후 단계(post-laying stage)에 대한 언급에서 아라비아 숫자를 사용함). 달리 지시되지 않는 한, 본 명세서에 언급된 단계는 H&H 기 결정 시스템에 따른 단계이다.
예를 들어, PGC는 4기 또는 30기를 통해 생식신월환기에서 단리될 수 있으며, 후기 단계에서는 혈액, 생식 기능선 또는 생식선으로부터 세포가 수집된다. 원시 생식 세포는 일반적으로 체세포의 두 배 크기이며, 크기를 기준으로 쉽게 구별되고 분리된다. 수컷(또는 동형배우자) 원시 생식 세포(ZZ)는 특정 공여자로부터 생식 세포를 수집하고, 그 공여자로부터 다른 세포를 유형 분석(typing)하는 것과 같은 임의의 적절한 기술에 의해서 이형배우자 원시 생식 세포(Zw)와 구별될 수 있고. 수집된 세포는 유형 분석된 세포와 동일한 염색체 유형을 갖는다.
PGC 사용에 대한 대안은 본 명세서에 개시된 DNA 편집제를 사용한 정자의 직접 형질주입이다(문헌[Cooper et al., 2016 Transgenic Res 26:331-347, doi:10.1007/s11248-016-0003-0] 참고).
시험관내에서 편집된 PGC로부터 키메라 조류를 생산하기 위해서, 외인성의 편집된 세포를 내인성 PGC가 생식 기능선으로 이동하는 단계에서 대용(surrogate) 숙주 배아에 정맥내 주사한다. "공여자" PGC는 대용 숙주 배아와 동일한 종 또는 상이한 종일 수 있다. 편집된 "공여자" PGC는 생존 가능해야 하며, 일 실시형태에서, 형성되는 생식선에 군집하고 편집된 염색체(들)를 생식선을 통해 전달하는 경우 내인성 PGC를 능가해야 한다. 공여자 PGC에 이점을 제공하기 위해, 내인성 PGC의 수는 화학적 또는 유전적 절제에 의해서 감소될 수 있다(Smith et al. 2015, Andrology 3:1035-1049. doi:10.1111/andr.12107). 대용 배아의 배반엽을 유화된 부설판에 노출시키는 것은 공여자 PGC의 생식선 전이를 90% 이상으로 증가시키는 것으로 나타났지만, PGC가 배양되거나 냉동보존된 경우 이 비율은 현저하게 낮아진다(Nakamura et al. 2008, Reprod Fertil Dev 20:900-907. doi:10.1071/ RD08138; Naito et al. 2015, Anim Reprod Sci. 153:50-61. doi:10.1016/j.anireprosci.2014.12.003). 편집된 PGC 대 네이티브 PGC의 비율을 왜곡시키는 다른 방법은 미국 출원 제20060095980호에 기재되어 있다.
선택적으로, PGC는 당업계에 공지된 바와 같이 성체 생식선에 이식될 수 있다(예를 들어, 문헌[Trefil et al., 2017 Sci Rep, Oct 27;7(1):14246 doi: 10.1038/s41598-017-14475-w] 참고).
유전자 변형 세포(예를 들어, PGC)는 세포를 해리하고(예를 들어, 기계적 해리에 의해), 세포를 약제학적으로 허용 가능한 담체(예를 들어, 인산염 완충 식염수 용액)와 친밀하게 혼합함으로써 다른 조류에 투여하기 위해 제형화될 수 있다. 원시 생식 세포는 일 실시형태에서 생식선 원시 생식 세포이고, 또 다른 실시형태에서는 혈액 원시 생식 세포(원래 배아 공여자에서의 기원 조직을 지칭하는 "생식선"또는 "혈액")이다. 투여되는 원시 생식 세포는 이형배우자(Zw) 또는 동형배우자(ZZ)일 수 있다. PGC는 생리학적으로 허용 가능한 담체, 일 실시형태에서 약 6 내지 약 8 또는 8.5의 pH에서 목적하는 효과를 달성하기에 적합한 양으로(예를 들어, 배아당 100 내지 30,000PGC) 투여될 수 있다. PGC는 다른 성분 또는 세포 없이 투여될 수 있거나, 다른 세포 및 성분은 PGC와 함께 투여될 수 있다.
원시 생식 세포의 수용자 동물 난내로의 투여는 PGC가 여전히 발달 중인 생식선으로 이동할 수 있는 임의의 적합한 시간에 수행될 수 있다. 일 실시형태에서, 투여는 이알-길라디 및 코차브(EG&K) 기결정 시스템에 따라서 약 IX기와 햄버거 및 배아 발달의 해밀턴 기결정 시스템에 따라서 약 30기 사이, 또는 15기에 수행된다. 닭의 경우, 따라서 투여 시간은 배아 발생 1일, 2일, 3일 또는 4일 동안: 일 실시형태에서 2일 내지 2.5일이다. 투여는 전형적으로 임의의 적합한 표적 부위, 예컨대, 양막(배아 포함), 난황낭 등에 의해 정의된 영역에 주사함으로써 수행된다. 일 실시형태에서, 주사는 배아 자체(배아 체벽 포함)에 주사되고, 대안적인 실시형태에서, 배아로의 혈관내 또는 체강내(intracoelomic) 주사가 사용될 수 있다. 다른 실시형태에서, 주사는 심장 내에 수행된다. 본 발명에 개시된 주제의 방법은 (예를 들어, 부설판을 사용한 화학적 처리에 의해서 또는 감마 또는 X-선 조사에 의해서) 난내에서 수용자 조류의 사전 단종(sterilization)으로 수행될 수 있다. 본 명세서에서 사용되는 바와 같이, 용어 "단종"은 내인성 PGC로부터 유래된 생식세포를 부분적으로 또는 완전히 생산할 수 없게 하는 것을 지칭한다. 그러한 수용자로부터 공여자 생식세포를 수집하는 경우, 그것은 공여자와 수용자의 생식세포와의 혼합물로서 수집될 수 있다. 이 혼합물은 직접적으로 사용될 수 있거나, 혼합물은 내부에 공여자 생식세포의 비율을 풍부하게 하기 위해 추가로 가공될 수 있다.
원시 생식 세포의 난내 투여는 임의의 적합한 기술에 의해서 수동으로 또는 자동 방식으로 수행될 수 있다. 일 실시형태에서, 난내 투여는 주사에 의해 수행된다. 난내 투여 기전은 중요하지 않지만, 그 기전은 배아의 조직 및 기관 또는 그것을 둘러싼 배아외부막을 과도하게 손상시키지 않아서 처리가 부화율을 과도하게 감소시키지 않아야 한다. 약 18 내지 26게이지의 바늘이 장착된 피하 주사기가 목적에 적합하다. 직경이 약 20 내지 50미크론인 개구부를 갖는 날카로워진 유리 피펫이 사용될 수 있다. 배아의 정확한 발달 단계 및 위치에 따라 1인치 바늘은 병아리 위의 유체 또는 병아리 자체에서 종결될 것이다. 바늘의 손상 또는 무뎌짐을 방지하기 위해서 바늘을 삽입하기 전에 쉘을 통해 파일럿 구멍을 뚫거나 드릴링할 수 있다. 필요한 경우, 난은 바람직하지 않은 박테리아의 후속 유입을 방지하기 위해서 왁스 등과 같은 실질적으로 박테리아 불투과성 밀봉 물질로 밀봉될 수 있다. 조류 배아를 위한 고속 주사 시스템이 본 발명에 개시된 주제를 실시하는데 특히 적합할 것으로 예상된다. 본 명세서에 개시된 방법을 실시하기에 적합한 모든 이러한 장치는 본 명세서에 기술된 바와 같은 원시 생식 세포의 제형을 함유하는 주입기를 포함하며, 주입기는 장치에 의해 운반된 난을 난 내의 적절한 위치에 주입하도록 위치된다. 또한, 주사 장치에 작동 가능하게 연결된 밀봉 장치가 주사 후 난에 구멍을 밀봉하기 위해 제공될 수 있다. 다른 실시형태에서, 풀링된(pulled) 유리 마이크로 피펫을 사용하여 PGS를 난 내의 적절한 위치, 예를 들어 혈류 내에, 정맥 또는 동맥 또는 심장으로 직접 도입할 수 있다.
난에 변형된 PGC가 주사되면, 키메라 배아를 인큐베이션시켜 부화시킨다. 그것은 키메라 조류가 공여자 PGC로부터 유래 생식세포를 생산하는 성적 성숙도로 키운다.
이어서 키메라(또는 본 명세서에 기재된 바와 같이 직접 유전자 조작된 물질)로부터의 생식세포(난 또는 정자)는 파운더(founder) 닭(F1)을 성장시키는데 사용된다. 당업계에 공지된 분자 생물학 기술(예를 들어, PCR 및/또는 서던 블롯)을 이용하여 생식선 전이를 확인할 수 있다. F1 닭을 역교배시켜 동형접합성 ZZ 보유자 수컷 및 보유자 암컷(F2)을 생성할 수 있다.
이어서 파운더 닭으로부터의 생식세포-F2를 사용하여 사육 집락을 확장시킬 수 있다. 집락은 전형적으로 성적으로 성숙할 때까지 성장된다. 이러한 플록으로부터 획득된 수정란을 치사성 표현형을 유도하는 유도자(예를 들어, 청색광 조명)에 노출시킴으로써 수컷의 초기 배아 사망률에 대해 시험할 수 있다. 유도 후, 난을 초기 배아 사망률을 검출하기 위해 인큐베이션시키고(예를 들어 8일 동안), 스크리닝(예를 들어, 광-캔들링)한다.
본 출원으로부터 유래된 특허의 수명 동안 많은 관련 DNA 편집 툴이 개발될 것이며, DNA 편집제라는 용어의 범주는 이러한 모든 새로운 기술을 우선적으로 포함하는 것으로 예측된다.
본 명세서에서 사용되는 바와 같이, "약"은 ± 10%를 지칭한다.
용어 "포함하다", "포함하는", "포함하는", "포함하는", "갖는" 및 이들의 활용은 "포함하지만 이들로 제한되지 않는"을 의미한다.
용어 "로 이루어진"은 "포함하고 이들로 제한되는"을 의미한다.
용어 "본질적으로 이루어진"은 단지 추가 성분, 단계 및/또는 부분이 청구된 조성물, 방법 또는 구조의 기본적인 특징 및 신규한 특징을 실질적으로 변경시키지 않는 경우에만, 조성물, 방법 또는 구조가 추가 성분, 단계 및/또는 부분을 포함할 수 있음을 의미한다.
본 명세서에서 사용되는 바와 같이, 단수 표현은 달리 명확하게 제시되지 않는 한 복수 대상을 포함한다. 예를 들어, 용어 "화합물" 또는 "적어도 하나의 화합물"은 이들의 혼합물을 포함하는 복수의 화합물을 포함할 수 있다.
본 출원 전체에서, 본 발명의 다양한 실시형태는 범위 형식으로 제시될 수 있다. 범위 형식의 설명은 단지 편의 및 간결성을 위한 것이며, 본 발명의 범위에 대한 융통성있는 제한으로 해석되어서는 안된다는 것을 이해해야 한다.
따라서, 범위의 설명은 모든 가능한 하위 범위 및 그 범위 내의 개별 수치 값을 구체적으로 개시한 것으로 간주되어야 한다. 예를 들어, 1 내지 6과 같은 범위의 설명은 1 내지 3, 1 내지 4, 1 내지 5, 2 내지 4, 2 내지 6, 3 내지 6 등과 같은 하위 범위뿐만 아니라 그 범위 내의 개별 수치, 예를 들어 1, 2, 3, 4, 5 및 6을 구체적으로 개시한 것으로 간주되어야 한다 이는 범위의 폭에 관계없이 적용된다.
수치 범위가 본 명세서에 제시될 때마다, 제시된 범위 내의 임의의 인용된 수치(분수 또는 정수)를 포함하는 것으로 의도된다. 구 제1 제시된 숫자와 제2 제시된 숫자 상이의 "범위의/범위" 및 제1 제시된 숫자 "내지" 제2 제시된 숫자의 "범위의/범위"는 본 명세서에서 상호 교환 가능하게 사용되고, 제1 제시된 숫자와 제2 제시된 숫자 및 그 사이의 모든 분수 및 정수를 포함하는 의미이다.
본 명세서에서 사용되는 바와 같이, 용어 "방법"은 화학, 약리학, 생물학, 생화학 및 의학 분야의 실무자에 의해 공지된 방식, 수단, 기술 및 절차를 포함하지만 이들로 제한되지 않는 주어진 작업 또는 상기 실무자에 의해서 공지된 방식, 수단, 기술 및 절차로부터 쉽게 개발되는 주어진 작업을 달성하기 위한 방식, 수단, 기술 및 절차를 지칭한다.
명확성을 위해, 별도의 실시형태와 관련하여 기재된 본 발명의 특정 특징부는 또한 단일 실시형태에서 조합하여 또한 제공될 수 있다는 것이 인식된다. 반대로, 간결성을 위해서, 단일 실시형태와 관련하여 기재된 본 발명의 다양한 특징부는 또한 개별적으로 또는 임의의 적합한 하위조합으로 또는 본 발명의 임의의 다른 기재된 실시형태에 적합하게 제공될 수 있다.
다양한 실시형태와 관련하여 기재된 특정 특징부는 실시형태가 그러한 요소 없이 작동하지 않는 한, 이들 실시형태의 필수 특징부인 것으로 간주되지 않아야 한다.
상기 및 하기 청구범위에 청구된 바와 같은 본 발명의 다양한 실시형태 및 양상은 하기 실시예에서 실험적 지지를 찾는다.
실시예
이제 상기 설명과 함께 본 발명의 일부 실시형태를 비제한적인 방식으로 설명하는 하기 실시예를 참조한다.
일반적으로, 본 명세서에서 사용되는 명명법 및 본 발명에서 사용되는 실험실 절차는 분자, 생화학, 미생물학 및 재조합 DNA 기술을 포함한다. 이러한 기술은 문헌에 철저히 설명되어 있다(예를 들어, 문헌["Molecular Cloning: A laboratory Manual" Sambrook et al., (1989); "Current Protocols in Molecular Biology" Volumes I-III Ausubel, R. M., ed. (1994); Ausubel et al., "Current Protocols in Molecular Biology", John Wiley and Sons, Baltimore, Maryland (1989); Perbal, "A Practical Guide to Molecular Cloning", John Wiley & Sons, New York (1988); Watson et al., "Recombinant DNA", Scientific American Books, New York; Birren et al. (eds) "Genome Analysis: A Laboratory Manual Series", Vols. 1-4, Cold Spring Harbor Laboratory Press, New York (1998); methodologies as set forth in U.S. Pat. Nos. 4,666,828; 4,683,202; 4,801,531; 5,192,659 and 5,272,057; "Cell Biology: A Laboratory Handbook", Volumes I-III Cellis, J. E., ed. (1994); "Culture of Animal Cells - A Manual of Basic Technique" by Freshney, Wiley-Liss, N. Y. (1994), Third Edition; "Current Protocols in Immunology" Volumes I-III Coligan J. E., ed. (1994); Stites et al. (eds), "Basic and Clinical Immunology" (8th Edition), Appleton & Lange, Norwalk, CT (1994); Mishell and Shiigi (eds), "Selected Methods in Cellular Immunology", W. H. Freeman and Co., New York (1980)] 참고; 사용 가능한 면역 검정은 특허 및 과학 문헌에 기재되어 있음, 예를 들어, 미국 특허 3,791,932; 3,839,153; 3,850,752; 3,850,578; 3,853,987; 3,867,517; 3,879,262; 3,901,654; 3,935,074; 3,984,533; 3,996,345; 4,034,074; 4,098,876; 4,879,219; 5,011,771 및 5,281,521; 문헌["Oligonucleotide Synthesis" Gait, M. J., ed. (1984); "Nucleic Acid Hybridization" Hames, B. D., and Higgins S. J., eds. (1985); "Transcription and Translation" Hames, B. D., and Higgins S. J., eds. (1984); "Animal Cell Culture" Freshney, R. I., ed. (1986); "Immobilized Cells and Enzymes" IRL Press, (1986); "A Practical Guide to Molecular Cloning" Perbal, B., (1984) and "Methods in Enzymology" Vol. 1317, Academic Press; "PCR Protocols: A Guide To Methods And Applications", Academic Press, San Diego, CA (1990); Marshak et al., "Strategies for Protein Purification and Characterization - A Laboratory Course Manual" CSHL Press (1996)](이들 모두는 본 명세서에 완전히 언급된 것처럼 참조에 의해 포함됨) 참고). 본 명세서 전체에서 다른 일반적인 참조가 제공된다. 그 절차는 당업계에 널리 공지되어 있고, 독자의 편의를 위해 제공되는 것으로 여겨진다. 본 명세서에 포함된 모든 정보는 참조에 의해 본 명세서에 포함된다.
작업흐름
게놈 변형 닭 세포주를 생성시키는 것을 다단계 공정이다. 최종 생성물은 게놈 내용물과 관련하여 현재 업계에서 사용되는 층과 완전히 동일한 암컷 층-암탉 세포주이다. 마찬가지로, 식품에 사용되는 무정란인 최종 제품은 동일하다 - 도 1 참고.
작업흐름은 5개의 주요 단계로 이루어진다:
1. 원시 생식 세포(PGC)주의 생성 및 배양.
2. 배양 PGC 내의 게놈 변형.
3. 변형된 PGC를 배아에 이식하고, 잠재적 보유자에 대해서 스크리닝될 키메라 닭을 생산함.
4. 키메라에서 얻은 유전 물질로부터 파운더 닭을 번식시킴.
5. 파운더 닭 집락을 파운더 플록으로 확장시키고, 생식선 전이를 재검증함.
재료 및 방법
PGC 배양 배지: 조류 PGC 배양 배지는 물로 250mosmol/L까지 희석되고, 조류 DMEM 중에 12.0mM 글루코스, 2.0mM GlutaMax(깁코사(Gibco)), 1.2mM 피루베이트(깁코사), 1×MEM 비타민(깁코사), 1×B-27 보충제(깁코사), 1×NEAA(깁코사), 0.1mM P-머캅토에탄올(깁코사), 1×뉴클레오사이드(바이올로지컬 인더스트리즈사(Biological industries)), 0.2% 오브알브민(시그마사(Sigma)), 0.1㎎/㎖ 소듐 헤파린(시그마사), CaCl2 0.15mM(시그마사), 1×MEM 비타민(깁코사), 1×Pen/Strep(바이올로지컬 인더스트리즈사), 0.2% 닭 혈청(시그마사)을 함유하는 DMEM(깁코사) 칼슘 무함유 배지로 이루어진다. 하기 성장 인자가 사용 전에 첨가되었다: 인간 액티빈 A, 25ng/㎖(페프로테크사(Peprotech)); 인간 FGF2 4ng/㎖(알앤디 바이오시스템즈사(R&D Biosystems)), 오보트랜스페린(5pg/㎖)(시그마사). AkoDMEM은 글루코스, 피루베이트 및 비타민을 함유한 희석된 배지를 지칭한다.
PGC 세포주 유도: PGC 세포주는 48웰 플레이트에서 300㎕ 배지 중에 15 내지 16기(H&H) 배아로부터 단리된 혈액 약 1.0 내지 3.0㎕를 넣음으로써 유도되었다. 배지를 2일마다 교체하였다. 총 세포 수가 1×105에 도달했을 때, 배지의 총 부피를 2일마다 교체하였고, 세포는 2 내지 4×105개 세포/㎖ 배지로 증식하였다. 세포를 10% DMSO를 함유하는 PGC 배양 배지에서 동결시키고, 온도를 -80℃까지 서서히 낮추고, 1 내지 3일 동안 저장하고, 액체 질소로 옮겼다.
성별 결정 및 PGC 세포주 특징규명 : 각각의 PGC 세포주를 성별, PGC 마커의 mRNA 발현 및 공지된 PGC 마커 SSEA1의 단백질 발현에 대해서 특징규명하였다4. 공여자 배아로부터의 DNA를 단리시키고, 추후 참조를 위해 유지시켰다. 성별 결정을 위해서, 2 내지 4×105개 PGC 세포로부터의 DNA를 수집하고, 100㎍/㎖ 프로테이나제 K(시그마사)를 함유하는 테일 완충액(102-T, 비아젠사(Viagen))에 재현탁시키고, 3시간 동안 55℃에서 인큐베이션시켰다. 프로테이나제 K를 45분 동안 85℃에서 비활성화시켰다. 성별 결정을 위한 PCR은 대조군6으로서 암컷 염색체(P17, P18) 및 리보솜 S18(P19, P20)을 표적으로 하는 W 염색체로부터의 프라이머를 사용하여 수행하였다. 유전자 발현 분석을 위해서, TRIZOL 시약을 사용하여 RNA를 정제시키고, 역전사 PCR 반응(GoScript 역전사효소, 프로메가사)에 의한 cDNA 라이브러리 생산을 위해서 1㎍의 RNA를 사용하였다. cDNA는 Dazl, Sox2, cPouV, Nanog, Klf4, cVH 프라이머, P21-P22, P23-P24, P25-P26, P27-P28, P29-P30, P31-P32를 각각 사용함으로써 PCR에 대한 주형으로 제공되었다.
항 SSEA1 항체를 사용한 면역조직화학: 세포를 수집하고, 4% PFA로 고정시키고, PBS 0.1% 트리톤 중의 5% 정상 염소 혈청으로 차단시키고, 차단 완충액 중의 항-SSEA1 항체(DSHB, 하이브리도마 뱅크사(Hybridoma bank)13)의 1:100 희석물로 염색하였다. PBS로 30분 동안 세포를 세척한 후, 0.1% 트리톤 이차 항체(Alexa Fluor 488, 분자 프로브)를 1시간 동안 첨가하고, 세포를 DAPI(시그마사)로 대비 염색하고, 장착 매질(Histomount, electron microscopy sciences)을 장착하고, 덮었다.
PGC 형질주입, 선택 및 FACS 분류: PGC의 플라스미드 형질주입을 리포펙타민 또는 전기천공을 사용하여 수행하였다. 리포펙션의 경우, 리포펙타민 2000을 제조사의 프로토콜에 따라 사용하였다. 3 내지 5×105개의 세포를 NEAA, 피루베이트, 비타민, CaCl2 및 성장 인자(액티빈A, hFGF 및 오바트랜스페린)를 함유하는 AkoDMEM 중에 96웰 플레이트에 시딩하였다. 100ng의 플라스미드 및 0.25㎕의 리포펙타민 2000(인비트로젠사)을 20㎕의 OPTI-MEM 믹스와 함께 개별 희석하고, 20분 동안 인큐베이션시키고, 세포 상에 피펫팅하였다. 전기천공의 경우, 5×105 또는 1.5×106개의 세포를 AkoDMEM에서 세척하고, Neon 전기천공기(인비트로젠사) 상에서 1000V, 12㎳, 3펄스로 전기 천공하고, 항생제-무함유 PGC 매질 중에서 각각 96웰 플레이트 또는 48웰 플레이트 중에 즉시 시딩하였다. 1 내지 3시간 후에 배지를 교체하였다. 25 내지 100㎍/㎖의 G418로의 선택을 7시간 후에 2 내지 4주 동안 시작하였다. 선택 후, 세포를 개별적으로 수동으로 또는 FACS 분류에 의해서 단리시켰다. FACS 분류의 경우, 약한 세포 피펫팅을 수행하고, 세포를 PGC 배양 배지에서 분류하였다. FACS Aria II를 사용하여 양성 GFP 세포를 새로운 96웰 플레이트에, 웰당 단일 세포로 분류하거나 또는 풀링시켰다. FACS 분석은 BD FACS Aria II 유세포 분석기(BD, 미국 소재)를 사용하여 수행하였다.
플라스미드 제조:
CRISPR 플라스미드의 클로닝: CRISPR 디자인 툴(Zhang lab, MIT)을 사용하여 CRISPR 서열을 설계하였다(www(dot)crispr(dot)mit(dot)edu)9. px330-GFP 플라스미드(Addgene 플라스미드 # 42230로 변형됨)14를 BbsI 제한 효소를 사용하여 절단하고, CRISPR 부위 삽입을 위한 골격으로서 제공하여 sgRNA를 형성하였다. sgRNA CRISPR 부위에 대한 올리고 - CRISPR1, CRISPR3(각각 P34-P35 및 P36-P37 올리고)을 30초 동안 95℃에서 변성시키고, 서서히 어닐링시키고, BbsI 절단부 플라스미드에 결찰시키고, 이.콜라이 내에서 형질전환시키고, 정제시키고, 상기에 기재된 바와 같이 서열을 검증하였다[mediadotaddgenedotorg/cms/filer_public/e6/5a/e65a9ef8-c8ac-4f88-98da-3b7d7960394c/zhang-lab-general-cloning-protocoldotpdf; and Cong L, et al., Science. 2013 Jan10.1126/science.1231143 PubMed 23287718]
pJet-HAs 플라스미드의 클로닝: 5'HA 및 3'HA를 둘 다를 함유하는 Z 염색체 상의 HINTZ 좌위 하류의 게놈 영역을 PCR(Kapa, 로슈사(Roche))을 사용하여 P1 및 P2 프라이머를 사용하여 PGC DNA로부터 증폭시켰다. PCR 생성물을 정제시키고, 제조사 프로토콜에 따라 pJet1.2 플라스미드(인비트로젠사)에 결찰시켰다.
표적화 벡터의 작제: pCAGG-IRES-Neo-GFP 플라스미드를 P5-P6 프라이머를 사용하여 PCR에 대한 주형으로 사용하여, 삽입물 pCAGG-IRES-Neo-GFP를 증폭시켰다. pJet-HAs 플라스미드를 P3-P4 프라이머를 사용하여 PCR에 대한 주형으로 사용하여 5'HA 및 3'HA를 함유하는 벡터를 증폭시켰다(도 3). 깁슨 조립 반응을 정제된 벡터 및 삽입 PCR 생성물에 대해서 수행하여, 각각 0.03pm, 0.06pm의 선형화된 생성물을 취하였다. 깁슨 조립 반응10 생성물을 플라스미드 제조를 위해서 이.콜라이에 형질전환시켰고, 서열을 검증하였다.
pCAGG-옵토젠 벡터의 작제
pCAGG-옵토젠 벡터를 생성시키기 위해서, 옵토젠 플라스미드 pmCherry-CIBN-CreC 및 pmCherry-Cry2-CreN11을 주형으로서 사용하여, P40-P41 및 P42-P43 프라이머를 사용하여 옵토젠을 증폭시켰고, 이것은 각각 1.3kb 및 2.1kb 생성물을 산출하였다. 이들 두 생성물은 프라이머 P41 및 P42에 도입된 P2A 부위에서 중첩 서열을 공유한다. 단일사이클 오버행 연장 PCR을 사용하여 2개의 단편을 단일 3.5kb 생성물로 단일화시키고, 이것을 아가로스겔로부터 세정하였다. 이 생성물을 각각 SmaI 및 NheI 제한 부위를 갖는 꼬리를 함유하는 프라이머 P44 및 P45를 사용하여 PCR을 위한 주형으로서 사용된 pJet1.2 셔틀 벡터에 결찰시켰다. 이 생성물을 적절한 제한 효소를 사용하여 소화시키고, 결찰을 위한 삽입물로서 사용하여 벡터로서 작용하는 SmaI 및 NheI 소화된 pCAGG-IRES-GFP 플라스미드에 결찰시켰다. 결찰 생성물을 이. 콜라이 박테리아에 형질전환시키고, 증식된 플라스미드를 서열 검정하였다.
pGK-DTA-IRES-GFP 벡터의 작제
pGK-DTA-IRES-GFP를 생성시키기 위해서, 발현 벡터 pSK BS-PGK-DTA를 각각 XmaI 및 NheI 제한 부위에 대한 연장 서열을 함유하는 프라이머 P46 및 P47을 갖는 PCR에 대한 주형으로 사용하였다. 0.65kb 생성물을 각각의 효소로 소화시키고, 결찰을 위한 벡터로서 작용하는 pGK-IRES-GFP 플라스미드 내의 XmaI-NheI 상보성 부위에 대한 결찰을 위한 삽입물로서 사용하였다. 결찰 생성물을 이.콜라이 박테리아에 형질전환시키고, 증식된 플라스미드를 서열 검증하였다.
난내 전기천공: 난내 전기 천공을 본질적으로 상기에 기재된 바와 같이7 수행하였다. 수정란을 37.8℃에서 56 내지 60시간 동안 인큐베이션시켰고, 난각에 창을 내고, 약 2㎍/㎕의 농도의 플라스미드 DNA를 10 내지 15㎛의 직경의 개구부를 갖는 뾰족한 마이크로피펫을 사용하여 신경관에 주사하였다. ECM 830 구형파 전기 천공 시스템(BTX)을 사용하여 25V, 30㎳의 3회 펄스를 전달하였다. 전기천공 후, 난각을 파라필름으로 밀봉하고, 배아를 분석 시까지 추가로 인큐베이션시켰다.
엔도뉴클레아제 검정: PGC를 리포펙타민 2000 시약을 사용하여 CRISPR1 또는 CRISPR3 플라스미드에 형질주입시켰다. 48시간 후, 개별 GFP 양성 세포를 96웰 플레이트로 단리시키고, 성장시켜 순수한 집락을 형성하였다. DNA를 수집하고 CRISPR 부위에 측접한 350bp 영역을 P38-P39 프라이머로 PCR 증폭시켰다. PCR 생성물은 95℃에서 변성시키고, 서서히 어닐링시키고, 37℃에서 1시간 동안 T7 엔도뉴클레아제와 함께 인큐베이션시켰다. 교정 목적 및 양성 대조군으로서, 350bp PCR 생성물을 pJet1.2에 서브클로닝시키고, CRISPR 부위를 부위-지향 돌연변이유발을 사용하여 돌연변이시켰다. 도입된 돌연변이는 WT 서열 ATACCAGATAACGTgCCTTATTTGGCCGTT(서열번호 2)를ATACCAGATAACGTaatCCTTATTTGGCCGTT(서열번호 3)로 대체하였다. 이러한 인공 돌연변이는 엔도뉴클레아제 검정(도 7A) 및 제어 서열결정(도 8B) 둘 다에 대해서 양성 대조군으로서 작용하였다.
서던 블롯 검정 : 5'HA, 3'HA 및 Neo 유전자 프로브에 대한 Dig-표지는 DIG DNA 표지 믹스(로슈사)를 사용하여, 각각 프라이머 P13-P14, P15-P16 및 P11-P12로의 PCR 증폭(Longamp, NEB)에 의해서 제조하였다. 15㎍의 게놈 DNA를 BglII 제한 효소로 37℃에서 밤새 소화시켰다. DNA 단편을 0.8%(w/v) 아가로스 겔 상에서 전기영동(20V, 12시간)에 의해 분리시키고, 양으로 하전된 나일론 막(지이 헬쓰케어사(GE Healthcare))으로 옮겼다. 전달 후, 습한 막을 각각의 면 상에서 3분 동안 254㎚로 설정된 UV 광을 사용하여 가교시킨 다음, 2×SSC로 헹구었다. 막을 DIG Easy-Hyb 혼성화 용액(로슈사)을 사용하여 42℃에서 2시간 동안 사전-혼성화시켰다. 5분 동안 95℃까지 가열시킴으로써 프로브(50ng/㎖)를 변성시키고, 즉시 얼음에 넣었다. 변성 프로브를 10㎖의 따뜻한 DIG Easy-Hyb 용액에 첨가하고, 42℃에서 12시간 동안 혼성화시켰다. 막을 교반 하에 실온에서 2×SSC, 0.1% SDS에서 10분 동안 2회 세척한 후, 교반 하에서 65℃에서 0.2×SSC, 0.1% SDS에서 30분 동안 3회 세척하였다. DIG 세척 및 차단 완충액 세트(로슈사)를 사용하고, 이의 프로토콜에 따라서 추가의 세척 및 차단을 수행하였다. 항-디곡시게닌-AP 항체 1:10000(로슈사)을 사용한 후, CDP-Star시약(로슈사)을 사용하여 화학발광 반응에 의해서 DIG 표지를 검출하였다. G:BOX 겔 영상 시스템(신젠사(Syngene))을 사용하여 영상을 촬영하였다.
배아에 대한 PGC 주사 및 전체 마운트 염색(whole mount staining) : 새로 낳은 난을 55% 습도로 37.8℃에서 58 내지 62시간 동안 뾰족한 단부를 위로 향하게 하여 인큐베이션시켰다. 인큐베이션 후, 난각에 4 내지 8㎜의 창을 내고, 3000 내지 8000 PGC를 약 30 내지 40㎛의 개구부를 갖는 뾰족한 마이크로피펫을 사용하여 혈류에 주사하였다. 창을 흰 난막으로 감싸고, 파라필름(파라필름사) 또는 류코플라스트(Leukoplast)(비에스엔 메디컬 게엠베하사(BSN medical GmbH)) 테이프로 추가로 밀봉하였다. 부화할 때까지 배아를 인큐베이션시켰다. 주사된 배아의 일부 생식선을 단리시키고, 전체-마운트 GFP 염색을 위해서 취하였다. 생식선을 4% PFA 중에서 고정시키고, PBS로 2시간 동안 세척하고, PBS 1% 트리톤 중의 5% 정상 당나귀 혈청으로 차단시키고, 차단 완충액 중의 마우스 항-SSEA1 항체13의 1:20 희석물 또는 토끼 항 GFP 항체 1:500(압캠사(Abcam))으로 밤새 염색하였다. PBS 1% 트리톤으로 2시간 동안 세척한 후, 이차 당나귀 항 마우스 cy3 항체 1:500을 첨가하거나(잭슨 이뮤노리서치 래보로토리즈사(Jackson Immunoresearch Laboratories)) 또는 이차 alexa488 항 토끼 항체 1:500(몰레큘러 프로브즈사(Molecular Probes))을 3시간 동안 차단 완충액 중에 첨가하였다. 조직을 DAPI(시그마사)로 대비염색시키고, 글리세롤 중에 마운팅시키고, 공초점 현미경(라이카사(Leica), TCS SPE, 독일 베출라어 소재)으로 영상화하였다.
[표 3]


플라스미드 서열
1. pX330-GFP(서열번호 50)
2. CRISPR1(서열번호 51)
3. CRISPR3(서열번호 52)
4. pJet-Has(서열번호 53)
5. pCAGG-Neo-IRES-GFP(서열번호 54)
6. 표적화 벡터(서열번호 55)
7. pmCherry-Cry2-CreN(서열번호 56)
8. pmCherry-CIBN-CreC(서열번호 57)
9. pB-RAGE-GFP(서열번호 58)
10. pCAGG-IRES-GFP(서열번호 59)
11. pCAGG- 유전자(서열번호 60)
12. pB-RAGE-mCherry(서열번호 61)
13. pSK BS-PGK-DTA(서열번호 62)
14. pGK-IRES-GFP(서열번호 63)
15. pGK-DTA-IRES-GFP(서열번호 64)
결과.
PGC 세포주 유도 및 특징규명
배아 발생의 초기 단계 동안, 산란 직후 및 난배형성(gastrulation) 개시 이전에, PGC는 배아외 중배엽 층의 앞 부분에 있는 생식신월환 영역으로 문측으로(rostrally) 이동한다. 이러한 이동은 체세포가 하는 것처럼 PGC가 분화 과정을 거치지 않도록 "보호"하는 것으로 생각된다. 약 2.5일 인큐베이션 후(14-17 H&H기1), Area Opaca Vasculosa, 혈액 및 심장 박동이 형성되고 나서야, 세포가 혈류를 통해 배아로 돌아가 생식 기능선에 군집하는데, 이것이 생식선을 생성할 것이다. 이러한 단계에서, 약 40 내지 60㎛ 직경의 개구부를 갖는 마이크로피펫을 사용하여, 배아의 혈관계로부터 1 내지 3㎕의 혈액을 수집하고, 48웰 플레이트에 PGC 배양 배지를 함유하는 웰로 옮겼다. PGC 배양 배지는 피더가 무함유 조건 하에서 미분화 상태를 유지하면서 PGC의 빠른 분열(20 내지 24시간의 세포주기)을 허용한다. 배양 2 내지 3주 후, 혈액 세포가 분해되어 사라졌다2. 추가의 1 내지 2주 내에, 배양된 PGC는 융합성이 되었다(도 5A). 이들 세포는 유전자 변형을 위해 추가로 성장될 수 있거나, 추후 변형을 위해 성공적으로 동결 및 해동될 수 있다. 배양물 중의 닭 PGC는 형태학적 특징, 단백질 및 mRNA 발현 패턴을 이용하여 문헌에 광범위하게 특징규명되어 있고, 최종적으로 단계-매칭된 수용자 배아3-5의 혈관 구조로 다시 주사될 때 생식선 이동 능력에 의해 특징규명되어 있다. 이러한 특징을 생산된 PGC 세포 배양물에서 조사하여 널리 확립된 PGC 특징부를 유지한다는 것을 나타내었다. 형태학적으로, PGC는 큰 핵을 함유하는 직경이 약 15 내지 20㎛인 크고 약간 과립화된 세포이다. PGC는 전능성(totipotent) 세포이므로, 다능성 마커, 예컨대, cPouV, SOX2, KLF4 및 Nanog 및 2개의 고유한 생식 세포 마커 - cVH 및 DAZL을 발현한다. 각 PGC 세포주에 대해, DNA를 양성 대조군으로서 리보솜 S18(P19-P20, 256bp 생성물 크기)에 대한 프라이머 및 W 염색체(P17-P18, 415bp 생성물 크기)에 대한 프라이머를 사용하여 성별 결정을 위해서 추출하여 암컷을 식별하였다(도 5B)6. 추가로, PGC는 막 SSEA-1 항원4을 발현한다(도 5C).
PGC의 10개 세포주를 수컷 및 암컷 둘 다의 층 및 어린 닭으로부터 확립하였다. 음으로 하전된 DNA와 상호작용하여 세포 내로의 침투를 허용하는 양이온-지질 형질주입 시약 리포펙타민 2000을 사용하여 플라스미드 형질주입을 수행하였다. GFP 암호화 플라스미드(pCAGG-GFP7)로 형질주입시켜 약 15 내지 20%의 형질주입 효율을 달성하였다(도 5D). 또한, 전기천공법을 사용한 PGC의 형질주입 효율은 최대 90%의 높은 효율을 나타냈다(도 5E). 배양된 PGC가 생식선에 성공적으로 군집한다는 것을 입증하기 위해, GFP-발현 PGC를 14-16 H&H기의 혈류에 주사하고, 배아를 10일 동안 인큐베이션시켰다. 배아를 해부하였고, 생식선에서 GFP-양성 세포가 식별되었다(도 5F).
Z 염색체 상의 CRISPR-Cas9 표적의 설계
Z 염색체 내의 DNA 편집은 CRISPR-Cas9 및 상동 재조합 과정을 사용하여 수행되었다. CRISPR-Cas9 시스템은 Z 염색체의 특정 부위에서 DNA를 직접 절단하지만, 상동 재조합 과정을 사용하는 내인성 수선 시스템은 목적하는 DNA를 정확한 위치에 표적화 삽입할 수 있을 것이다. 이를 위해, Z 염색체 상의 삽입 부위에 상응하는 상동성 아암을 함유하는 표적화 벡터 플라스미드를 작제하는 것이 필요하다. 암호 유전자 HINTZ 하류의 Z 염색체에서의 DNA 삽입 부위를 선택하였다. CRISPR 시스템의 사용은 많은 연구에서 직접적인 DNA 삽입 사례를 개선시키는 것이 밝혀져 있다. 이러한 목적으로 광범위하게 사용되는 px330 플라스미드는 sgRNA 부위 및 Cas9 효소8를 포함한다. sgRNA 부위는 Cas9 효소를 표적 부위로 안내하고, 특정 게놈 표적화된 DSDB를 유도하는 고유한 서열을 함유한다. CRISPR 설계 엔진 툴을 사용하여, sgRNA에 대한 고유한 서열을 도 6A에 나타낸 바와 같이 식별하였다. 점수에 따른 상위 12개의 가이드를 도 6B 및 표 1에 도시한다.
20개의 뉴클레오타이드 서열 - 가이드 # 1 및 # 3은 이차 구조의 통상적인 유사성에 의해서 그리고 미스매치 정도에 의해 점수매겨진 닭 게놈 내의 가능한 오프-타깃 부위를 확인함으로써 선택되었다. 가이드 # 1에 대한 잠재적인 오프-타깃에 대한 검색 결과 상위 10개 결과를 도 6C 및 표 2에 도시한다. 특히, 상위 6개의 오프-타깃은 4개의 미스매치를 가져서, 이러한 가이드의 특이성을 강조한다.
Cas-9의 c-말단에 융합된 인-프레임 GFP를 함유하는 변형된 px330 플라스미드를 절단함으로써 DNA 서열 삽입을 수행하였다. sgRNA 서열을 함유하는 어닐링된 프라이머를 전술한 바와 같이 BbsI 제한 효소에 결찰시켰다(도 6B). 결찰 생성물을 이.콜라이에 형질전환시키고, 플라스미드를 정제시키고, sgRNA 삽입물을 서열결정에 의해 검증하였다.
CRISPR-Cas9 시스템의 활성 검증
피더 무함유 배양 배지에서 PGC를 성장시킴으로써, 단일 세포로부터 기원하는 순수한 집락을 수득하여, CRISPR-Cas9 시스템의 효율성의 특징규명이 가능하였다. 이를 위해, PGC에 pX330-GFP-CRISPR1 및 pX330-GFP CRISPR3 플라스미드를 형질주입시키고, 클론 집락을 성장시켰다. GFP를 발현하는 단일 세포로부터 유래된 집락으로부터 총 게놈 DNA를 추출하였다. 엔도뉴클레아제 검정에 의해 DNA를 분석하고, 서열결정하였다. 엔도뉴클레아제 검정을 위해, 양성 대조군을 설계하였다. 이 대조군은 CRISPR-Cas9 호라성에 대한 예측된 부위에서 삽입 돌연변이를 갖는 320bp PCR 생성물이었다. 이 생성물을 각각 동일한 길이의 WT 생성물과 상이한 비, 1:15, 1:7,1:1 - 돌연변이:WT로 혼합하고, 어닐링된 혼합물을 엔도뉴클레아제 활성에 적용하였다(도 7A). 136bp 및 184bp의 예측된 크기에서의 2개의 짧은 밴드가 1:7 및 1:1의 비에서 명확하게 보였는데, 이는 이러한 검정이 적절하게 기능함을 나타낸다. 유사하게, CRISPR1 및 CRISPR3 플라스미드로 형질주입된 12개의 집락으로부터 얻은 게놈 DNA에 대해 동일한 검정을 수행하였다(도 7B, 도 7C). 12개 집락 중 9개에서 예측된 크기에서 분명한 이중선이 관찰되었다. 이는 CRISPR1 및 CRISPR3 플라스미드가 예측된 부위에서 효율적으로 DSDB를 생성함을 나타낸다.
서열결정 분석을 위해서, 엔도뉴클레아제 검정에 사용된 PCR 산물(도 7A 내지 도 7C)을 또한 서열결정하였다(도 8A 내지 도 8D). WT 음성 대조군의 서열결정은 CRISPR1의 예측된 절단 부위를 나타내었다(도 8A). 양성 대조군으로서 WT 및 인공적으로 돌연변이된 생성물의 혼합물을 서열결정하는 것은, 예측된 절단 부위 직후에 DNA 크로마토 그램에서 이중 피크의 출현을 나타내었다(청색 화살표, 도 8B). 형질주입된 집락에서 동일한 게놈 영역의 유사한 서열결정은, 음성(도 8C)과 양성(청색 화살표, 도 8D) 집락이 모두 나타난 반면, 후자는 사례의 70% 초과였다.
게놈 통합을 위한 표적화 벡터의 작제
HR을 사용하여, Z 염색체에 대한 표적화 게놈 통합을 입증하기 위해, 표적화 벡터를 설계하였다(도 9A 내지 도 9F). 벡터는 pCAGG 프로모터, 그 다음 네오마이신 선택 유전자, 내부 리보솜 진입 부위(IRES), GFP 및 토끼 베타-글로빈 폴리아데닐화 부위를 함유한다. 이 카세트는 각각 5' 및 3' 단부에서 약 1.5kb의 상동성 아암이 측접된다. 이러한 벡터를 생성시키기 위해, 상동성 아암 둘 다를 함유하는 약 3kb의 DNA 단편을 프라이머 P1 및 P2를 사용하여 증폭시키고, 셔틀 벡터 pjet1.2에 결찰시켰다. 이러한 단편의 전체 서열결정은 닭 게놈 서열과 동일한 것을 발견하였다. 이 플라스미 -pJet-HAs를 CRISPR sgRNA 부위를 함유하는, 그들 사이에 23bp 서열을 배제한 2개의 분리된 상동성 아암을 함유하는 선형화된 PCR 생성물을 생성시키기 위한 주형으로서 사용하였다. pCAGG-Neo-IRES-GFP 카세트의 가장자리에 상응하는 5' 단부에서 서열을 함유하는 P3 및 P4 프라이머를 사용하여 증폭을 수행하였다. 이 선형 PCR 산물을 "벡터"로 지칭한다. pCAGG-Neo-IRES-GFP 플라스미드를 선형 PCR 생성물을 생성시키기 위한 주형으로 사용하였다. 이 단편을 각각 5'HA 및 3'HA 단부의 3 ' 및 5' 단부에 상응하는 프라이머 P5 및 P6 함유 서열을 사용하여 증폭시켰다. 이 산물을 "삽입물"로 지칭한다. 깁슨 조립 반응10을 사용하여, 벡터 및 삽입물을 함께 스티칭하여 최종 표적화 벡터 플라스미드를 생성하였다.
표적화 벡터 및 CRISPR 플라스미드를 사용한 Z 염색체에 대한 상동 재조합.
단일 세포로부터 순수한 PGC 집락을 얻는 능력은 PCR 및 서던 블롯과 같은 방법을 사용하여 HR이 정확하게 삽입된 양성 집락의 식별을 가능하게 한다. PGC 형질주입을 위해서, 5 내지 10%의 형질주입 효율을 갖는 리포펙션(도 10A) 또는 40% 초과의 효율을 갖는 전기천공법을 사용하였다. 형질주입은 2개의 플라스미드, 표적화 벡터 및 상기에 기재된 2개의 CRISPR 플라스미드 중 하나(CRISPR1 또는 CRISPR3)를 사용하여 수행하였다. 형질주입 후, 세포를 24시간 동안 회수하고, 선택을 위해 G-418 함유 배지로 옮겼다. 선택 2주 후, G-418 내성 세포만이 생존하였으며, 그 중 99% 초과가 GFP 양성이었다(도 10B). 세포가 생식선에 군집하는 능력을 보유하고 있음을 검증하기 위해서, 상기 도 1F(도 8C)에 기재된 바와 같이 이들을 숙주 배아에 주사하였다. 생식선을 항-GFP 항체로 면역 염색하였고, 생식선에서 GFP-양성 PGC 세포의 군집화를 공초점 현미경을 사용하여 검증하였다(도 10D).
G-418 내성, GFP-양성 세포는 잠재적으로 이질 집단으로 이루어진다. 따라서, HR 통합을 검증하고, 순수한 균질 집단을 얻기 위해서, 단일 GFP-양성 세포를 96웰 플레이트로 FACS 분류를 사용하여 분리하였다(도 11A). 순수한 집락을 증가시키고, PCR 및 서던 블롯 분석을 위해 게놈 DNA를 추출하였다. 동시에, 풀링된 GFP-양성 세포를 FACS 분류하였다. PCR 분석을 위해서, 두 세트의 프라이머를 설계하였다. 첫 번째, 5' HA에 대한 상류의 정방향 P7, CAGG 프로모터로부터의 역방향 P8(1.6kb 생성물 크기) 및 두 번째, 토끼 베타-글로빈 폴리아데닐화 부위로부터 정방향 P9 및 3'HA에 대한 하류의 역방향 P10(1.8kb 생성물 길이, 도 11B). 풀링된 세포(도 11C) 및 순수한 집락(도 11D) 둘 다에서, 예상되는 5' 및 3'에 대한 생성물이 검출되었는데, 이는 이들 세포에서 올바른 HR 통합이 일어났음을 나타낸다.
올바른 HR 통합을 추가로 검증하고, 표적화 벡터의 단일 카피만이 게놈에 통합되었음을 확인하기 위해서, 서던 블롯 분석을 수행하였다. 수컷 및 암컷 공여자로부터 2개의 PGC 세포주를 분석하였다. 특히, 암컷 세포주는 Z 염색체의 단일 카피만을 갖는다. 3개의 dig-표지된 DNA 프로브를 설계하였다(도 12A 및 도 12B의 황색 박스). 각각 500bp 길이의 프라이머 P11-P12 및 P13-P14를 사용하여 증폭된 첫 번째 2개의 프로브는 각각 5' 및 3'HA의 상류 및 하류에 위치한다. 704bp 길이의 프라이머 P15-P16을 사용하여 증폭된 세 번째 프로브는 표적화 벡터 내부의 Neo 유전자를 검출하도록 설계되었으므로, 벡터의 단일 카피만 통합되었음을 확인할 수 있다. BglII 제한 효소를 사용하여 분석을 위해서 게놈 DNA를 절단하였다. 서로 약 6.5kb 떨어진 2개의 제한 부위가 각각 WT 염색체 상에 5' 및 3'프로브의 상류 및 하류에 위치한다. 추가의 BglII 부위는 올바른 HR 통합을 식별하기 위해 예측된 7.5kb 및 3.3kb 단편을 생성하는 표적화 벡터에 위치된다. 수컷 PGC 세포주로부터 추출된 게놈 DNA에 대한 서던 블롯 분석 결과는, 각각 5' 및 3' 부위에 대해서 올바른 HR 통합을 거친 대립유전자에 대해서 7.5kb 및 3.3kb 및 WT 대립유전자에 대해서 예측된 크기, 6.5kb에서 2개의 밴드를 나타내었다. 이것은 풀링된 세포로부터의 DNA 및 순수한 집락 둘 다에 대해 확인되었다(도 12C). 암컷 PGC 세포주에 대해 유사한 분석을 수행하였다. 이 경우, 5' 통합 부위에 대한 예측된 7.5kb 크기의 단일 밴드를 발견하였다. 암컷 게놈은 Z 염색체의 단일 카피만을 함유하므로, WT 대립 유전자(6.5kb)는 검출되지 않았다. Neo 유전자의 프로빙은 예측된 7.5kb 크기의 단일 밴드를 나타내었는데, 이는, 표적화 벡터의 단일 카피만이 게놈에 통합되었음을 확인해 주었다(도 12D).
시험관내 HEK293 세포 및 난내 닭 배아에서의 옵토제틱 시스템의 검증.
시험관내 및 난내의 닭 배아에서 유도성 시스템의 활성을 검증하기 위해서, 3개의 플라스미드: pmCherry-Cry2-CreN, pmCherry-CIBN-CreC 및 리포터 PB-RAGE-GFP를 HEK293 세포(도 13) 및 닭 배아(도 14)에 형질주입하였다. 처음 2개의 옵토제닉 플라스미드는 성공적인 형질주입을 확인해 주는 리포터 유전자 mCherry를 암호화한다. PB-RAGE-GFP 발현 벡터는 GFP 암호 영역에 대한 하류에 LoxP 부위가 측접된 다중 중단 코돈을 함유한다. Cre 활성화시, 중단 코돈이 제거되어 GFP가 발현될 수 있다. 삼중 형질주입되고, 암실에서 유지된 음성 대조군 HEK293 세포에서는 GFP-양성 세포가 없었다(도 13, 상단). 청색광 조명에 노출된 세포에서, 형질주입 후 24시간 후에, 다수의 세포가 GFP를 발현하였는데(도 13, 하단), 이는 이들 세포에서 옵토제틱 시스템의 활성화를 확인해준다.
난내에서의 옵토제틱 시스템의 활성을 검증하기 위해, 16 H&H기에서 닭 배아 신경관 내의 전기천공에 의해 pmCherry-Cry2-CreN, pmCherry-CIBN-CreC 및 PB-RAGE-GFP 플라스미드를 사용한 삼중 형질주입을 수행하였다. 전기천공 후 12시간에, 실험군 배아를 15초의 청색광 조명에 적용한 반면, 음성 대조군 배아는 암실에서 유지시켰다. 배아를 추가로 12시간 동안 인큐베이션시키고, 형광 입체현미경에서 GFP 발현을 확인하였다(도 14). 암실에서 유지된 배아(도 14, 상단)에서는 mCherry만 발현되었는데 - 이는, 실험군의 배아에서 성공적인 전기천공을 확인해주었으며, GFP 양성 세포가 명백하게 나타났는데(도 9, 하단), 이는 광-유도성 Cre가 활성화되었음을 확인해준다.
옵토젠 플라스미드 pmCherry-Cry2-CreN 및 pmCherry-CIBN-CreC는 닭 세포에서 바람직하지 않은 CMV 프로모터11를 사용하여 유전자의 발현을 유도한다. 이를 해결하고, 두 벡터를 단일 벡터로 조합하기 위해서, 본 발명자들은 닭 세포에서 고도로 활성인 CAGG 프로모터 하에서 P2A 자가-절단 펩타이드, 그 다음 IREG-GFP에 의해서 연결된 CIBN-CreC 및 Cry2-CreN의 발현을 유도하는 플라스미드를 설계하였다. pCAGG-CIBN-CREC-P2A-Cry2-CREN-IRES-GFP의 합성은 케네디 등11에 기재된 본래 옵토젠 플라스미드의 변형에 기초하였다. 이들 플라스미드 각각은 CIBN-CreC(Cre 효소의 C-말단에 융합된 CIB1의 절두 형태) 또는 CRY2-CreN(Cre 효소의 N-말단에 융합된 크립토크롬 2)과 함께 mCherry, 이어서 IRES 서열을 암호화한다(도 5A). 하기 클로닝의 목적은, CAGG 프로모터 하에서 자가-절단 펩타이드 P2A와 2개의 융합 옵토젠를 연결하고, 이어서 IRES-GFP를 연결하는 것이었다. 이를 위해, CIBN-CreC 플라스미드를 P40 및 P41 프라이머를 갖는 PCR의 주형으로 사용하고, CRY2-CreN 플라스미드를 P42 및 P43 프라이머를 갖는 PCR의 주형으로 사용하였다(도 15A). 특히, P2A 절단 부위를 함유하는 프라이머 P41 및 P42는 단일-사이클 오버행 연장 PCR에 의해 두 생성물이 병합될 수 있게 하는 중첩 서열을 공유한다(도 15B). CIBN-CreC-P2A-CRY2-CreN을 함유하는 이러한 생성물을 셔틀 벡터 pJet1.2에 결찰시키고, 이것을 서열 검증하였다(도 15C). 이 플라스미드는 각각 5' 및 3' 말단에 SmaI 및 NheI 제한 부위를 생성물에 첨가하는 프라이머 P44 및 P45를 갖는 PCR에 대한 주형으로서 제공되었다(도 15D). 이 생성물을 제한 효소로 소화시키고, 동일한 효소를 사용하여 또한 절단한 pCAGG-IRES-GFP 플라스미드에 결찰시켰다(도 15E). 이러한 결찰 생성물은 CAGG 프로모터, 그 다음 CIBN-CreC, P2A 자가-절단 펩타이드, Cry2-CreN, IRES, GFP 및 토끼 베타-글로빈 폴리아데닐화 부위(본 명세서에서 pCAGG-옵토젠으로 지칭됨)를 함유하며, 이것을 서열 검증하였다(도 15F).
시험관내에서 pCAGG-옵토젠 벡터의 활성을 검증하기 위해서, 성공적인 형질주입을 위한 리포터로서 GFP를 발현하는 플라스미드를 pB-RAGE-mCherry와 함께 HEK293 세포 내에 공동 형질주입시켰다. 상기에 기재된 PB-RAGE-GFP 벡터(도 13)와 마찬가지로, pB-RAGE-mCherry는 mCherry 암호 영역에 대한 하류에 LoxP 부위가 측접된 다중 중단 코돈을 함유한다. Cre 활성화시, 중단 코돈이 제거되어 mCherry가 발현될 수 있다(도 16). 공동 형질주입되고, 암실에서 유지된 HEK293 세포는 mCherry-양성 세포가 존재하지 않았지만(도 16, 상단), 청색광 조명에 노출된 세포에서는, 다수의 세포가 mCherry를 발현하였는데(도 16, 하단), 이는 pCAGG-옵토젠의 단일-벡터 전략이 시스템의 옵토제닉 특성을 보존한다는 것을 확인해준다.
난내의 살아있는 병아리 배아에서 pCAGG-옵토젠 벡터의 활성을 검증하기 위해서, 플라스미드를 pB-RAGE-mCherry와 함께 14-16 H&H기 병아리 배아에 전기천공에 의해서 동시 형질주입시켰다. 전기천공 후 12시간째에, 음성-대조군 난을 암실에서 유지시켰고, 실험군 배아를 15초 동안 청색광에 노출시켰다(도 17). 두 군 모두를 추가로 12시간 동안 인큐베이션시키고, 형광 입체현미경으로 조사하였다. 인큐베이션 후, 두 군 모두 높은 수준의 GFP 발현을 나타내었는데, 이는 성공적인 전기천공을 나타내었다. 그러나 광 노출군(도 17, 하단)에서만, mCherry-양성 발현 세포가 식별되었는데, 이는, pCAGG-옵토젠의 단일 벡터 전략을 사용한 옵토제닉 시스템이 광-유도성 방식으로 활성화되었음을 나타낸다.
병아리 배아에서 치사 유도
독소를 사용하여 사망을 초래할 가능성을 입증하기 위해서, 일반적으로 음성 선택 마커로서 사용되는 DTA12의 암호 영역을 pGK 프로모터, 그 다음 IRES GFP를 함유하는 발현 벡터(pGK-IRES-GFP) 내에 클로닝하였다. 이 플라스미드는 또한 음성 대조군으로서 제공되었다. DTA 암호 영역을 IRES 서열의 상류에 클로닝하여 pGK-DTA-IRES-GFP를 생성시켰는데, 이것은 세포에서 발현 시 단백질 합성을 저해하여 세포 사멸로 이어진다.
닭 배아에서 DTA 발현의 효과를 시험하기 위해서, 음성 대조군으로서 pGK-IRES-GFP 또는 pGK-DTA-IRES- GFP 벡터를 사용하여 14-16 H&H기 배아를 전기천공하였다. 전기천공 후 12시간째에, 배아를 형광 현미경 하에서 GFP의 발현에 대해 분석하였다(도 18). 대조군 배아에서는, 신경관 내에서 GFP가 광범위하게 발현된 반면(도 18), DTA 발현 배아에서는, GFP 발현이 검출되지 않았는데, 이는, 이들 세포에서 단백질 합성이 차단되었음을 나타낸다.
본 발명이 특정 실시형태와 관련하여 기재되어 있지만, 다수의 대안, 수정 및 변형이 당업자에게 명백할 것이다. 따라서, 첨부된 청구범위의 사상 및 넓은 범주에 속하는 모든 그러한 대안, 수정 및 변형을 포함하도록 의도된다.
본 명세서에 언급된 모든 간행물, 특허 및 특허 출원은 각각의 개별 간행물, 특허 또는 특허 출원이 본 명세서에 참조에 의해 구체적으로 그리고 개별적으로 포함되는 것과 동일한 정도로 전문이 본 명세서에 참조에 의해 포함된다. 또한, 본 출원에서 임의의 참조 문헌의 인용 또는 식별은 이러한 참고 문헌이 본 발명에 대한 선행 기술로서 이용 가능하다는 것으로 이해되어서는 안 된다. 섹션 제목이 사용되는 정도로, 그것은 반드시 제한으로서 간주되어서는 안 된다.
참고 문헌

SEQUENCE LISTING
<110> The State of Israel, Ministry of Agriculture & Rural
Development, Agricultural Research Organization (ARO)
(Volcani Center)
<120> GENOME-EDITED BIRDS
<130> WO/2019/058376
<140> PCT/IL2018/051056
<141> 2018-09-17
<150> US 62/560,218
<151> 2017-09-19
<160> 87
<170> PatentIn version 3.5
<210> 1
<211> 149
<212> DNA
<213> Artificial sequence
<220>
<223> Nucleic Acid sequence of the region between the two homology arms
depicted in Fig 3
<400> 1
aacacagctt atatacattt ttacctacaa aatcgtgctg tcatgtccca ctctgattgg 60
ttcataccag ataacgtgcc ttatttggcc gtttccacat tcttttctca tccttcttct 120
cctgttttct ctgcatcaag gtcagcacg 149
<210> 2
<211> 30
<212> DNA
<213> Artificial sequence
<220>
<223> wt nucleic acid sequence of the area flanking the CRISPR cleavage
site
<400> 2
ataccagata acgtgcctta tttggccgtt 30
<210> 3
<211> 32
<212> DNA
<213> Artificial sequence
<220>
<223> mutated nucleic acid sequence of the area flanking the CRISPR
cleavage site
<400> 3
ataccagata acgtaatcct tatttggccg tt 32
<210> 4
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 4
ttttgaatga agggcctgag 20
<210> 5
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 5
tgaaccaatc agagtgggac 20
<210> 6
<211> 45
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 6
gtccctcttc tcttatggag atcgccgttt ccacattctt ttctc 45
<210> 7
<211> 49
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 7
ggtggcactt ttcggggaaa tgtgtgaacc aatcagagtg ggacatgac 49
<210> 8
<211> 49
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 8
gtcatgtccc actctgattg gttcacacat ttccccgaaa agtgccacc 49
<210> 9
<211> 45
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 9
gagaaaagaa tgtggaaacg gcgatctcca taagagaaga gggac 45
<210> 10
<211> 19
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 10
gaagtgtgct gctaacctg 19
<210> 11
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 11
gctatgaact aatgaccccg 20
<210> 12
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 12
ttttcctcct ctcctgacta c 21
<210> 13
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 13
ggcctggatg ataagagtct tc 22
<210> 14
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 14
gctattcggc tatgactggg 20
<210> 15
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 15
gaaggcgata gaaggcgatg 20
<210> 16
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 16
gtggaacaca gcttttccag 20
<210> 17
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 17
gctcttcaac ttgccatttg 20
<210> 18
<211> 19
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 18
tcaacagcac gtaagcaac 19
<210> 19
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 19
cctgactcca tttttgagcc 20
<210> 20
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 20
cccaaatata acacgcttca ct 22
<210> 21
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 21
gaaatgaatt attttctggc gac 23
<210> 22
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 22
agctctttct cgattccgtg 20
<210> 23
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 23
gggtagacac aagctgagcc 20
<210> 24
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 24
caactatcag gctccaccac 20
<210> 25
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 25
ctcagacggt tttcagggtt 20
<210> 26
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 26
aggctatggg atgatgcaag 20
<210> 27
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 27
gtaggtaggc gatccgttca 20
<210> 28
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 28
cgagaccaac gtgaagggaa 20
<210> 29
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 29
cagacccgga caacgtcttt 20
<210> 30
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 30
ctctggggct cacctacaag 20
<210> 31
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 31
agccctggtg aaatgtaggg 20
<210> 32
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 32
agctctcatc tcaaggcaca 20
<210> 33
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 33
ggaaagatcc actgcttcca 20
<210> 34
<211> 22
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 34
agcacaggtg gtgaacgaac ca 22
<210> 35
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 35
tccaggcctc ttgatgctac cga 23
<210> 36
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 36
caccgccaaa taaggcacgt tatc 24
<210> 37
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 37
aaacgataac gtgccttatt tggc 24
<210> 38
<211> 25
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 38
caccgaccag ataacgtgcc ttatt 25
<210> 39
<211> 24
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 39
aaacaataag gcacgttatc tggt 24
<210> 40
<211> 19
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 40
ttgcagtggt taccgttcg 19
<210> 41
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 41
tagtaggcat cttgtggggg 20
<210> 42
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 42
atgaatggag ctataggagg 20
<210> 43
<211> 61
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 43
ccacgtctcc tgcttgcttt aacagagaga agttcgtggc atcgccatct tccagcaggc 60
g 61
<210> 44
<211> 61
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 44
tgttaaagca agcaggagac gtggaagaaa accccggtcc tatgaagatg gacaaaaaga 60
c 61
<210> 45
<211> 21
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 45
ttacagcccg gaccgacgat g 21
<210> 46
<211> 32
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 46
atctgacccg ggatgaatgg agctatagga gg 32
<210> 47
<211> 33
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 47
gtagctgcta gcttacagcc cggaccgacg atg 33
<210> 48
<211> 31
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 48
caggtccccg ggatggatcc tgatgatgtt g 31
<210> 49
<211> 31
<212> DNA
<213> Artificial sequence
<220>
<223> Single strand DNA oligonucleotide
<400> 49
gcatgtgcta gcttagagct ttaaatctct g 31
<210> 50
<211> 9289
<212> DNA
<213> Artificial sequence
<220>
<223> pX330-GFP plasmid nucleic acid sequence
<400> 50
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag ttaaaataag 300
gctagtccgt tatcaacttg aaaaagtggc accgagtcgg tgcttttttg ttttagagct 360
agaaatagca agttaaaata aggctagtcc gtttttagcg cgtgcgccaa ttctgcagac 420
aaatggctct agaggtaccc gttacataac ttacggtaaa tggcccgcct ggctgaccgc 480
ccaacgaccc ccgcccattg acgtcaatag taacgccaat agggactttc cattgacgtc 540
aatgggtgga gtatttacgg taaactgccc acttggcagt acatcaagtg tatcatatgc 600
caagtacgcc ccctattgac gtcaatgacg gtaaatggcc cgcctggcat tgtgcccagt 660
acatgacctt atgggacttt cctacttggc agtacatcta cgtattagtc atcgctatta 720
ccatggtcga ggtgagcccc acgttctgct tcactctccc catctccccc ccctccccac 780
ccccaatttt gtatttattt attttttaat tattttgtgc agcgatgggg gcgggggggg 840
ggggggggcg cgcgccaggc ggggcggggc ggggcgaggg gcggggcggg gcgaggcgga 900
gaggtgcggc ggcagccaat cagagcggcg cgctccgaaa gtttcctttt atggcgaggc 960
ggcggcggcg gcggccctat aaaaagcgaa gcgcgcggcg ggcgggagtc gctgcgacgc 1020
tgccttcgcc ccgtgccccg ctccgccgcc gcctcgcgcc gcccgccccg gctctgactg 1080
accgcgttac tcccacaggt gagcgggcgg gacggccctt ctcctccggg ctgtaattag 1140
ctgagcaaga ggtaagggtt taagggatgg ttggttggtg gggtattaat gtttaattac 1200
ctggagcacc tgcctgaaat cacttttttt caggttggac cggtgccacc atggactata 1260
aggaccacga cggagactac aaggatcatg atattgatta caaagacgat gacgataaga 1320
tggccccaaa gaagaagcgg aaggtcggta tccacggagt cccagcagcc gacaagaagt 1380
acagcatcgg cctggacatc ggcaccaact ctgtgggctg ggccgtgatc accgacgagt 1440
acaaggtgcc cagcaagaaa ttcaaggtgc tgggcaacac cgaccggcac agcatcaaga 1500
agaacctgat cggagccctg ctgttcgaca gcggcgaaac agccgaggcc acccggctga 1560
agagaaccgc cagaagaaga tacaccagac ggaagaaccg gatctgctat ctgcaagaga 1620
tcttcagcaa cgagatggcc aaggtggacg acagcttctt ccacagactg gaagagtcct 1680
tcctggtgga agaggataag aagcacgagc ggcaccccat cttcggcaac atcgtggacg 1740
aggtggccta ccacgagaag taccccacca tctaccacct gagaaagaaa ctggtggaca 1800
gcaccgacaa ggccgacctg cggctgatct atctggccct ggcccacatg atcaagttcc 1860
ggggccactt cctgatcgag ggcgacctga accccgacaa cagcgacgtg gacaagctgt 1920
tcatccagct ggtgcagacc tacaaccagc tgttcgagga aaaccccatc aacgccagcg 1980
gcgtggacgc caaggccatc ctgtctgcca gactgagcaa gagcagacgg ctggaaaatc 2040
tgatcgccca gctgcccggc gagaagaaga atggcctgtt cggaaacctg attgccctga 2100
gcctgggcct gacccccaac ttcaagagca acttcgacct ggccgaggat gccaaactgc 2160
agctgagcaa ggacacctac gacgacgacc tggacaacct gctggcccag atcggcgacc 2220
agtacgccga cctgtttctg gccgccaaga acctgtccga cgccatcctg ctgagcgaca 2280
tcctgagagt gaacaccgag atcaccaagg cccccctgag cgcctctatg atcaagagat 2340
acgacgagca ccaccaggac ctgaccctgc tgaaagctct cgtgcggcag cagctgcctg 2400
agaagtacaa agagattttc ttcgaccaga gcaagaacgg ctacgccggc tacattgacg 2460
gcggagccag ccaggaagag ttctacaagt tcatcaagcc catcctggaa aagatggacg 2520
gcaccgagga actgctcgtg aagctgaaca gagaggacct gctgcggaag cagcggacct 2580
tcgacaacgg cagcatcccc caccagatcc acctgggaga gctgcacgcc attctgcggc 2640
ggcaggaaga tttttaccca ttcctgaagg acaaccggga aaagatcgag aagatcctga 2700
ccttccgcat cccctactac gtgggccctc tggccagggg aaacagcaga ttcgcctgga 2760
tgaccagaaa gagcgaggaa accatcaccc cctggaactt cgaggaagtg gtggacaagg 2820
gcgcttccgc ccagagcttc atcgagcgga tgaccaactt cgataagaac ctgcccaacg 2880
agaaggtgct gcccaagcac agcctgctgt acgagtactt caccgtgtat aacgagctga 2940
ccaaagtgaa atacgtgacc gagggaatga gaaagcccgc cttcctgagc ggcgagcaga 3000
aaaaggccat cgtggacctg ctgttcaaga ccaaccggaa agtgaccgtg aagcagctga 3060
aagaggacta cttcaagaaa atcgagtgct tcgactccgt ggaaatctcc ggcgtggaag 3120
atcggttcaa cgcctccctg ggcacatacc acgatctgct gaaaattatc aaggacaagg 3180
acttcctgga caatgaggaa aacgaggaca ttctggaaga tatcgtgctg accctgacac 3240
tgtttgagga cagagagatg atcgaggaac ggctgaaaac ctatgcccac ctgttcgacg 3300
acaaagtgat gaagcagctg aagcggcgga gatacaccgg ctggggcagg ctgagccgga 3360
agctgatcaa cggcatccgg gacaagcagt ccggcaagac aatcctggat ttcctgaagt 3420
ccgacggctt cgccaacaga aacttcatgc agctgatcca cgacgacagc ctgaccttta 3480
aagaggacat ccagaaagcc caggtgtccg gccagggcga tagcctgcac gagcacattg 3540
ccaatctggc cggcagcccc gccattaaga agggcatcct gcagacagtg aaggtggtgg 3600
acgagctcgt gaaagtgatg ggccggcaca agcccgagaa catcgtgatc gaaatggcca 3660
gagagaacca gaccacccag aagggacaga agaacagccg cgagagaatg aagcggatcg 3720
aagagggcat caaagagctg ggcagccaga tcctgaaaga acaccccgtg gaaaacaccc 3780
agctgcagaa cgagaagctg tacctgtact acctgcagaa tgggcgggat atgtacgtgg 3840
accaggaact ggacatcaac cggctgtccg actacgatgt ggaccatatc gtgcctcaga 3900
gctttctgaa ggacgactcc atcgacaaca aggtgctgac cagaagcgac aagaaccggg 3960
gcaagagcga caacgtgccc tccgaagagg tcgtgaagaa gatgaagaac tactggcggc 4020
agctgctgaa cgccaagctg attacccaga gaaagttcga caatctgacc aaggccgaga 4080
gaggcggcct gagcgaactg gataaggccg gcttcatcaa gagacagctg gtggaaaccc 4140
ggcagatcac aaagcacgtg gcacagatcc tggactcccg gatgaacact aagtacgacg 4200
agaatgacaa gctgatccgg gaagtgaaag tgatcaccct gaagtccaag ctggtgtccg 4260
atttccggaa ggatttccag ttttacaaag tgcgcgagat caacaactac caccacgccc 4320
acgacgccta cctgaacgcc gtcgtgggaa ccgccctgat caaaaagtac cctaagctgg 4380
aaagcgagtt cgtgtacggc gactacaagg tgtacgacgt gcggaagatg atcgccaaga 4440
gcgagcagga aatcggcaag gctaccgcca agtacttctt ctacagcaac atcatgaact 4500
ttttcaagac cgagattacc ctggccaacg gcgagatccg gaagcggcct ctgatcgaga 4560
caaacggcga aaccggggag atcgtgtggg ataagggccg ggattttgcc accgtgcgga 4620
aagtgctgag catgccccaa gtgaatatcg tgaaaaagac cgaggtgcag acaggcggct 4680
tcagcaaaga gtctatcctg cccaagagga acagcgataa gctgatcgcc agaaagaagg 4740
actgggaccc taagaagtac ggcggcttcg acagccccac cgtggcctat tctgtgctgg 4800
tggtggccaa agtggaaaag ggcaagtcca agaaactgaa gagtgtgaaa gagctgctgg 4860
ggatcaccat catggaaaga agcagcttcg agaagaatcc catcgacttt ctggaagcca 4920
agggctacaa agaagtgaaa aaggacctga tcatcaagct gcctaagtac tccctgttcg 4980
agctggaaaa cggccggaag agaatgctgg cctctgccgg cgaactgcag aagggaaacg 5040
aactggccct gccctccaaa tatgtgaact tcctgtacct ggccagccac tatgagaagc 5100
tgaagggctc ccccgaggat aatgagcaga aacagctgtt tgtggaacag cacaagcact 5160
acctggacga gatcatcgag cagatcagcg agttctccaa gagagtgatc ctggccgacg 5220
ctaatctgga caaagtgctg tccgcctaca acaagcaccg ggataagccc atcagagagc 5280
aggccgagaa tatcatccac ctgtttaccc tgaccaatct gggagcccct gccgccttca 5340
agtactttga caccaccatc gaccggaaga ggtacaccag caccaaagag gtgctggacg 5400
ccaccctgat ccaccagagc atcaccggcc tgtacgagac acggatcgac ctgtctcagc 5460
tgggaggcga caaaaggccg gcggccacga aaaaggccgg ccaggcaaaa aagaaaaagg 5520
aattcggcag tggagagggc agaggaagtc tgctaacatg cggtgacgtc gaggagaatc 5580
ctggcccagt gagcaagggc gaggagctgt tcaccggggt ggtgcccatc ctggtcgagc 5640
tggacggcga cgtaaacggc cacaagttca gcgtgtccgg cgagggcgag ggcgatgcca 5700
cctacggcaa gctgaccctg aagttcatct gcaccaccgg caagctgccc gtgccctggc 5760
ccaccctcgt gaccaccctg acctacggcg tgcagtgctt cagccgctac cccgaccaca 5820
tgaagcagca cgacttcttc aagtccgcca tgcccgaagg ctacgtccag gagcgcacca 5880
tcttcttcaa ggacgacggc aactacaaga cccgcgccga ggtgaagttc gagggcgaca 5940
ccctggtgaa ccgcatcgag ctgaagggca tcgacttcaa ggaggacggc aacatcctgg 6000
ggcacaagct ggagtacaac tacaacagcc acaacgtcta tatcatggcc gacaagcaga 6060
agaacggcat caaggtgaac ttcaagatcc gccacaacat cgaggacggc agcgtgcagc 6120
tcgccgacca ctaccagcag aacaccccca tcggcgacgg ccccgtgctg ctgcccgaca 6180
accactacct gagcacccag tccgccctga gcaaagaccc caacgagaag cgcgatcaca 6240
tggtcctgct ggagttcgtg accgccgccg ggatcactct cggcatggac gagctgtaca 6300
aggaattcta actagagctc gctgatcagc ctcgactgtg ccttctagtt gccagccatc 6360
tgttgtttgc ccctcccccg tgccttcctt gaccctggaa ggtgccactc ccactgtcct 6420
ttcctaataa aatgaggaaa ttgcatcgca ttgtctgagt aggtgtcatt ctattctggg 6480
gggtggggtg gggcaggaca gcaaggggga ggattgggaa gagaatagca ggcatgctgg 6540
ggagcggccg caggaacccc tagtgatgga gttggccact ccctctctgc gcgctcgctc 6600
gctcactgag gccgggcgac caaaggtcgc ccgacgcccg ggctttgccc gggcggcctc 6660
agtgagcgag cgagcgcgca gctgcctgca ggggcgcctg atgcggtatt ttctccttac 6720
gcatctgtgc ggtatttcac accgcatacg tcaaagcaac catagtacgc gccctgtagc 6780
ggcgcattaa gcgcggcggg tgtggtggtt acgcgcagcg tgaccgctac acttgccagc 6840
gccctagcgc ccgctccttt cgctttcttc ccttcctttc tcgccacgtt cgccggcttt 6900
ccccgtcaag ctctaaatcg ggggctccct ttagggttcc gatttagtgc tttacggcac 6960
ctcgacccca aaaaacttga tttgggtgat ggttcacgta gtgggccatc gccctgatag 7020
acggtttttc gccctttgac gttggagtcc acgttcttta atagtggact cttgttccaa 7080
actggaacaa cactcaaccc tatctcgggc tattcttttg atttataagg gattttgccg 7140
atttcggcct attggttaaa aaatgagctg atttaacaaa aatttaacgc gaattttaac 7200
aaaatattaa cgtttacaat tttatggtgc actctcagta caatctgctc tgatgccgca 7260
tagttaagcc agccccgaca cccgccaaca cccgctgacg cgccctgacg ggcttgtctg 7320
ctcccggcat ccgcttacag acaagctgtg accgtctccg ggagctgcat gtgtcagagg 7380
ttttcaccgt catcaccgaa acgcgcgaga cgaaagggcc tcgtgatacg cctattttta 7440
taggttaatg tcatgataat aatggtttct tagacgtcag gtggcacttt tcggggaaat 7500
gtgcgcggaa cccctatttg tttatttttc taaatacatt caaatatgta tccgctcatg 7560
agacaataac cctgataaat gcttcaataa tattgaaaaa ggaagagtat gagtattcaa 7620
catttccgtg tcgcccttat tccctttttt gcggcatttt gccttcctgt ttttgctcac 7680
ccagaaacgc tggtgaaagt aaaagatgct gaagatcagt tgggtgcacg agtgggttac 7740
atcgaactgg atctcaacag cggtaagatc cttgagagtt ttcgccccga agaacgtttt 7800
ccaatgatga gcacttttaa agttctgcta tgtggcgcgg tattatcccg tattgacgcc 7860
gggcaagagc aactcggtcg ccgcatacac tattctcaga atgacttggt tgagtactca 7920
ccagtcacag aaaagcatct tacggatggc atgacagtaa gagaattatg cagtgctgcc 7980
ataaccatga gtgataacac tgcggccaac ttacttctga caacgatcgg aggaccgaag 8040
gagctaaccg cttttttgca caacatgggg gatcatgtaa ctcgccttga tcgttgggaa 8100
ccggagctga atgaagccat accaaacgac gagcgtgaca ccacgatgcc tgtagcaatg 8160
gcaacaacgt tgcgcaaact attaactggc gaactactta ctctagcttc ccggcaacaa 8220
ttaatagact ggatggaggc ggataaagtt gcaggaccac ttctgcgctc ggcccttccg 8280
gctggctggt ttattgctga taaatctgga gccggtgagc gtggaagccg cggtatcatt 8340
gcagcactgg ggccagatgg taagccctcc cgtatcgtag ttatctacac gacggggagt 8400
caggcaacta tggatgaacg aaatagacag atcgctgaga taggtgcctc actgattaag 8460
cattggtaac tgtcagacca agtttactca tatatacttt agattgattt aaaacttcat 8520
ttttaattta aaaggatcta ggtgaagatc ctttttgata atctcatgac caaaatccct 8580
taacgtgagt tttcgttcca ctgagcgtca gaccccgtag aaaagatcaa aggatcttct 8640
tgagatcctt tttttctgcg cgtaatctgc tgcttgcaaa caaaaaaacc accgctacca 8700
gcggtggttt gtttgccgga tcaagagcta ccaactcttt ttccgaaggt aactggcttc 8760
agcagagcgc agataccaaa tactgtcctt ctagtgtagc cgtagttagg ccaccacttc 8820
aagaactctg tagcaccgcc tacatacctc gctctgctaa tcctgttacc agtggctgct 8880
gccagtggcg ataagtcgtg tcttaccggg ttggactcaa gacgatagtt accggataag 8940
gcgcagcggt cgggctgaac ggggggttcg tgcacacagc ccagcttgga gcgaacgacc 9000
tacaccgaac tgagatacct acagcgtgag ctatgagaaa gcgccacgct tcccgaaggg 9060
agaaaggcgg acaggtatcc ggtaagcggc agggtcggaa caggagagcg cacgagggag 9120
cttccagggg gaaacgcctg gtatctttat agtcctgtcg ggtttcgcca cctctgactt 9180
gagcgtcgat ttttgtgatg ctcgtcaggg gggcggagcc tatggaaaaa cgccagcaac 9240
gcggcctttt tacggttcct ggccttttgc tggccttttg ctcacatgt 9289
<210> 51
<211> 9291
<212> DNA
<213> Artificial sequence
<220>
<223> CRISPR1 nucleic acid sequence
<400> 51
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ccaaataagg cacgttatcg ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcaact tgaaaaagtg gcaccgagtc ggtgcttttt tgttttagag 360
ctagaaatag caagttaaaa taaggctagt ccgtttttag cgcgtgcgcc aattctgcag 420
acaaatggct ctagaggtac ccgttacata acttacggta aatggcccgc ctggctgacc 480
gcccaacgac ccccgcccat tgacgtcaat agtaacgcca atagggactt tccattgacg 540
tcaatgggtg gagtatttac ggtaaactgc ccacttggca gtacatcaag tgtatcatat 600
gccaagtacg ccccctattg acgtcaatga cggtaaatgg cccgcctggc attgtgccca 660
gtacatgacc ttatgggact ttcctacttg gcagtacatc tacgtattag tcatcgctat 720
taccatggtc gaggtgagcc ccacgttctg cttcactctc cccatctccc ccccctcccc 780
acccccaatt ttgtatttat ttatttttta attattttgt gcagcgatgg gggcgggggg 840
gggggggggg cgcgcgccag gcggggcggg gcggggcgag gggcggggcg gggcgaggcg 900
gagaggtgcg gcggcagcca atcagagcgg cgcgctccga aagtttcctt ttatggcgag 960
gcggcggcgg cggcggccct ataaaaagcg aagcgcgcgg cgggcgggag tcgctgcgac 1020
gctgccttcg ccccgtgccc cgctccgccg ccgcctcgcg ccgcccgccc cggctctgac 1080
tgaccgcgtt actcccacag gtgagcgggc gggacggccc ttctcctccg ggctgtaatt 1140
agctgagcaa gaggtaaggg tttaagggat ggttggttgg tggggtatta atgtttaatt 1200
acctggagca cctgcctgaa atcacttttt ttcaggttgg accggtgcca ccatggacta 1260
taaggaccac gacggagact acaaggatca tgatattgat tacaaagacg atgacgataa 1320
gatggcccca aagaagaagc ggaaggtcgg tatccacgga gtcccagcag ccgacaagaa 1380
gtacagcatc ggcctggaca tcggcaccaa ctctgtgggc tgggccgtga tcaccgacga 1440
gtacaaggtg cccagcaaga aattcaaggt gctgggcaac accgaccggc acagcatcaa 1500
gaagaacctg atcggagccc tgctgttcga cagcggcgaa acagccgagg ccacccggct 1560
gaagagaacc gccagaagaa gatacaccag acggaagaac cggatctgct atctgcaaga 1620
gatcttcagc aacgagatgg ccaaggtgga cgacagcttc ttccacagac tggaagagtc 1680
cttcctggtg gaagaggata agaagcacga gcggcacccc atcttcggca acatcgtgga 1740
cgaggtggcc taccacgaga agtaccccac catctaccac ctgagaaaga aactggtgga 1800
cagcaccgac aaggccgacc tgcggctgat ctatctggcc ctggcccaca tgatcaagtt 1860
ccggggccac ttcctgatcg agggcgacct gaaccccgac aacagcgacg tggacaagct 1920
gttcatccag ctggtgcaga cctacaacca gctgttcgag gaaaacccca tcaacgccag 1980
cggcgtggac gccaaggcca tcctgtctgc cagactgagc aagagcagac ggctggaaaa 2040
tctgatcgcc cagctgcccg gcgagaagaa gaatggcctg ttcggaaacc tgattgccct 2100
gagcctgggc ctgaccccca acttcaagag caacttcgac ctggccgagg atgccaaact 2160
gcagctgagc aaggacacct acgacgacga cctggacaac ctgctggccc agatcggcga 2220
ccagtacgcc gacctgtttc tggccgccaa gaacctgtcc gacgccatcc tgctgagcga 2280
catcctgaga gtgaacaccg agatcaccaa ggcccccctg agcgcctcta tgatcaagag 2340
atacgacgag caccaccagg acctgaccct gctgaaagct ctcgtgcggc agcagctgcc 2400
tgagaagtac aaagagattt tcttcgacca gagcaagaac ggctacgccg gctacattga 2460
cggcggagcc agccaggaag agttctacaa gttcatcaag cccatcctgg aaaagatgga 2520
cggcaccgag gaactgctcg tgaagctgaa cagagaggac ctgctgcgga agcagcggac 2580
cttcgacaac ggcagcatcc cccaccagat ccacctggga gagctgcacg ccattctgcg 2640
gcggcaggaa gatttttacc cattcctgaa ggacaaccgg gaaaagatcg agaagatcct 2700
gaccttccgc atcccctact acgtgggccc tctggccagg ggaaacagca gattcgcctg 2760
gatgaccaga aagagcgagg aaaccatcac cccctggaac ttcgaggaag tggtggacaa 2820
gggcgcttcc gcccagagct tcatcgagcg gatgaccaac ttcgataaga acctgcccaa 2880
cgagaaggtg ctgcccaagc acagcctgct gtacgagtac ttcaccgtgt ataacgagct 2940
gaccaaagtg aaatacgtga ccgagggaat gagaaagccc gccttcctga gcggcgagca 3000
gaaaaaggcc atcgtggacc tgctgttcaa gaccaaccgg aaagtgaccg tgaagcagct 3060
gaaagaggac tacttcaaga aaatcgagtg cttcgactcc gtggaaatct ccggcgtgga 3120
agatcggttc aacgcctccc tgggcacata ccacgatctg ctgaaaatta tcaaggacaa 3180
ggacttcctg gacaatgagg aaaacgagga cattctggaa gatatcgtgc tgaccctgac 3240
actgtttgag gacagagaga tgatcgagga acggctgaaa acctatgccc acctgttcga 3300
cgacaaagtg atgaagcagc tgaagcggcg gagatacacc ggctggggca ggctgagccg 3360
gaagctgatc aacggcatcc gggacaagca gtccggcaag acaatcctgg atttcctgaa 3420
gtccgacggc ttcgccaaca gaaacttcat gcagctgatc cacgacgaca gcctgacctt 3480
taaagaggac atccagaaag cccaggtgtc cggccagggc gatagcctgc acgagcacat 3540
tgccaatctg gccggcagcc ccgccattaa gaagggcatc ctgcagacag tgaaggtggt 3600
ggacgagctc gtgaaagtga tgggccggca caagcccgag aacatcgtga tcgaaatggc 3660
cagagagaac cagaccaccc agaagggaca gaagaacagc cgcgagagaa tgaagcggat 3720
cgaagagggc atcaaagagc tgggcagcca gatcctgaaa gaacaccccg tggaaaacac 3780
ccagctgcag aacgagaagc tgtacctgta ctacctgcag aatgggcggg atatgtacgt 3840
ggaccaggaa ctggacatca accggctgtc cgactacgat gtggaccata tcgtgcctca 3900
gagctttctg aaggacgact ccatcgacaa caaggtgctg accagaagcg acaagaaccg 3960
gggcaagagc gacaacgtgc cctccgaaga ggtcgtgaag aagatgaaga actactggcg 4020
gcagctgctg aacgccaagc tgattaccca gagaaagttc gacaatctga ccaaggccga 4080
gagaggcggc ctgagcgaac tggataaggc cggcttcatc aagagacagc tggtggaaac 4140
ccggcagatc acaaagcacg tggcacagat cctggactcc cggatgaaca ctaagtacga 4200
cgagaatgac aagctgatcc gggaagtgaa agtgatcacc ctgaagtcca agctggtgtc 4260
cgatttccgg aaggatttcc agttttacaa agtgcgcgag atcaacaact accaccacgc 4320
ccacgacgcc tacctgaacg ccgtcgtggg aaccgccctg atcaaaaagt accctaagct 4380
ggaaagcgag ttcgtgtacg gcgactacaa ggtgtacgac gtgcggaaga tgatcgccaa 4440
gagcgagcag gaaatcggca aggctaccgc caagtacttc ttctacagca acatcatgaa 4500
ctttttcaag accgagatta ccctggccaa cggcgagatc cggaagcggc ctctgatcga 4560
gacaaacggc gaaaccgggg agatcgtgtg ggataagggc cgggattttg ccaccgtgcg 4620
gaaagtgctg agcatgcccc aagtgaatat cgtgaaaaag accgaggtgc agacaggcgg 4680
cttcagcaaa gagtctatcc tgcccaagag gaacagcgat aagctgatcg ccagaaagaa 4740
ggactgggac cctaagaagt acggcggctt cgacagcccc accgtggcct attctgtgct 4800
ggtggtggcc aaagtggaaa agggcaagtc caagaaactg aagagtgtga aagagctgct 4860
ggggatcacc atcatggaaa gaagcagctt cgagaagaat cccatcgact ttctggaagc 4920
caagggctac aaagaagtga aaaaggacct gatcatcaag ctgcctaagt actccctgtt 4980
cgagctggaa aacggccgga agagaatgct ggcctctgcc ggcgaactgc agaagggaaa 5040
cgaactggcc ctgccctcca aatatgtgaa cttcctgtac ctggccagcc actatgagaa 5100
gctgaagggc tcccccgagg ataatgagca gaaacagctg tttgtggaac agcacaagca 5160
ctacctggac gagatcatcg agcagatcag cgagttctcc aagagagtga tcctggccga 5220
cgctaatctg gacaaagtgc tgtccgccta caacaagcac cgggataagc ccatcagaga 5280
gcaggccgag aatatcatcc acctgtttac cctgaccaat ctgggagccc ctgccgcctt 5340
caagtacttt gacaccacca tcgaccggaa gaggtacacc agcaccaaag aggtgctgga 5400
cgccaccctg atccaccaga gcatcaccgg cctgtacgag acacggatcg acctgtctca 5460
gctgggaggc gacaaaaggc cggcggccac gaaaaaggcc ggccaggcaa aaaagaaaaa 5520
ggaattcggc agtggagagg gcagaggaag tctgctaaca tgcggtgacg tcgaggagaa 5580
tcctggccca gtgagcaagg gcgaggagct gttcaccggg gtggtgccca tcctggtcga 5640
gctggacggc gacgtaaacg gccacaagtt cagcgtgtcc ggcgagggcg agggcgatgc 5700
cacctacggc aagctgaccc tgaagttcat ctgcaccacc ggcaagctgc ccgtgccctg 5760
gcccaccctc gtgaccaccc tgacctacgg cgtgcagtgc ttcagccgct accccgacca 5820
catgaagcag cacgacttct tcaagtccgc catgcccgaa ggctacgtcc aggagcgcac 5880
catcttcttc aaggacgacg gcaactacaa gacccgcgcc gaggtgaagt tcgagggcga 5940
caccctggtg aaccgcatcg agctgaaggg catcgacttc aaggaggacg gcaacatcct 6000
ggggcacaag ctggagtaca actacaacag ccacaacgtc tatatcatgg ccgacaagca 6060
gaagaacggc atcaaggtga acttcaagat ccgccacaac atcgaggacg gcagcgtgca 6120
gctcgccgac cactaccagc agaacacccc catcggcgac ggccccgtgc tgctgcccga 6180
caaccactac ctgagcaccc agtccgccct gagcaaagac cccaacgaga agcgcgatca 6240
catggtcctg ctggagttcg tgaccgccgc cgggatcact ctcggcatgg acgagctgta 6300
caaggaattc taactagagc tcgctgatca gcctcgactg tgccttctag ttgccagcca 6360
tctgttgttt gcccctcccc cgtgccttcc ttgaccctgg aaggtgccac tcccactgtc 6420
ctttcctaat aaaatgagga aattgcatcg cattgtctga gtaggtgtca ttctattctg 6480
gggggtgggg tggggcagga cagcaagggg gaggattggg aagagaatag caggcatgct 6540
ggggagcggc cgcaggaacc cctagtgatg gagttggcca ctccctctct gcgcgctcgc 6600
tcgctcactg aggccgggcg accaaaggtc gcccgacgcc cgggctttgc ccgggcggcc 6660
tcagtgagcg agcgagcgcg cagctgcctg caggggcgcc tgatgcggta ttttctcctt 6720
acgcatctgt gcggtatttc acaccgcata cgtcaaagca accatagtac gcgccctgta 6780
gcggcgcatt aagcgcggcg ggtgtggtgg ttacgcgcag cgtgaccgct acacttgcca 6840
gcgccctagc gcccgctcct ttcgctttct tcccttcctt tctcgccacg ttcgccggct 6900
ttccccgtca agctctaaat cgggggctcc ctttagggtt ccgatttagt gctttacggc 6960
acctcgaccc caaaaaactt gatttgggtg atggttcacg tagtgggcca tcgccctgat 7020
agacggtttt tcgccctttg acgttggagt ccacgttctt taatagtgga ctcttgttcc 7080
aaactggaac aacactcaac cctatctcgg gctattcttt tgatttataa gggattttgc 7140
cgatttcggc ctattggtta aaaaatgagc tgatttaaca aaaatttaac gcgaatttta 7200
acaaaatatt aacgtttaca attttatggt gcactctcag tacaatctgc tctgatgccg 7260
catagttaag ccagccccga cacccgccaa cacccgctga cgcgccctga cgggcttgtc 7320
tgctcccggc atccgcttac agacaagctg tgaccgtctc cgggagctgc atgtgtcaga 7380
ggttttcacc gtcatcaccg aaacgcgcga gacgaaaggg cctcgtgata cgcctatttt 7440
tataggttaa tgtcatgata ataatggttt cttagacgtc aggtggcact tttcggggaa 7500
atgtgcgcgg aacccctatt tgtttatttt tctaaataca ttcaaatatg tatccgctca 7560
tgagacaata accctgataa atgcttcaat aatattgaaa aaggaagagt atgagtattc 7620
aacatttccg tgtcgccctt attccctttt ttgcggcatt ttgccttcct gtttttgctc 7680
acccagaaac gctggtgaaa gtaaaagatg ctgaagatca gttgggtgca cgagtgggtt 7740
acatcgaact ggatctcaac agcggtaaga tccttgagag ttttcgcccc gaagaacgtt 7800
ttccaatgat gagcactttt aaagttctgc tatgtggcgc ggtattatcc cgtattgacg 7860
ccgggcaaga gcaactcggt cgccgcatac actattctca gaatgacttg gttgagtact 7920
caccagtcac agaaaagcat cttacggatg gcatgacagt aagagaatta tgcagtgctg 7980
ccataaccat gagtgataac actgcggcca acttacttct gacaacgatc ggaggaccga 8040
aggagctaac cgcttttttg cacaacatgg gggatcatgt aactcgcctt gatcgttggg 8100
aaccggagct gaatgaagcc ataccaaacg acgagcgtga caccacgatg cctgtagcaa 8160
tggcaacaac gttgcgcaaa ctattaactg gcgaactact tactctagct tcccggcaac 8220
aattaataga ctggatggag gcggataaag ttgcaggacc acttctgcgc tcggcccttc 8280
cggctggctg gtttattgct gataaatctg gagccggtga gcgtggaagc cgcggtatca 8340
ttgcagcact ggggccagat ggtaagccct cccgtatcgt agttatctac acgacgggga 8400
gtcaggcaac tatggatgaa cgaaatagac agatcgctga gataggtgcc tcactgatta 8460
agcattggta actgtcagac caagtttact catatatact ttagattgat ttaaaacttc 8520
atttttaatt taaaaggatc taggtgaaga tcctttttga taatctcatg accaaaatcc 8580
cttaacgtga gttttcgttc cactgagcgt cagaccccgt agaaaagatc aaaggatctt 8640
cttgagatcc tttttttctg cgcgtaatct gctgcttgca aacaaaaaaa ccaccgctac 8700
cagcggtggt ttgtttgccg gatcaagagc taccaactct ttttccgaag gtaactggct 8760
tcagcagagc gcagatacca aatactgtcc ttctagtgta gccgtagtta ggccaccact 8820
tcaagaactc tgtagcaccg cctacatacc tcgctctgct aatcctgtta ccagtggctg 8880
ctgccagtgg cgataagtcg tgtcttaccg ggttggactc aagacgatag ttaccggata 8940
aggcgcagcg gtcgggctga acggggggtt cgtgcacaca gcccagcttg gagcgaacga 9000
cctacaccga actgagatac ctacagcgtg agctatgaga aagcgccacg cttcccgaag 9060
ggagaaaggc ggacaggtat ccggtaagcg gcagggtcgg aacaggagag cgcacgaggg 9120
agcttccagg gggaaacgcc tggtatcttt atagtcctgt cgggtttcgc cacctctgac 9180
ttgagcgtcg atttttgtga tgctcgtcag gggggcggag cctatggaaa aacgccagca 9240
acgcggcctt tttacggttc ctggcctttt gctggccttt tgctcacatg t 9291
<210> 52
<211> 9292
<212> DNA
<213> Artificial sequence
<220>
<223> CRISPR3 nucleic acid sequence
<400> 52
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg accagataac gtgccttatt gttttagagc tagaaatagc aagttaaaat 300
aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt ttgttttaga 360
gctagaaata gcaagttaaa ataaggctag tccgttttta gcgcgtgcgc caattctgca 420
gacaaatggc tctagaggta cccgttacat aacttacggt aaatggcccg cctggctgac 480
cgcccaacga cccccgccca ttgacgtcaa tagtaacgcc aatagggact ttccattgac 540
gtcaatgggt ggagtattta cggtaaactg cccacttggc agtacatcaa gtgtatcata 600
tgccaagtac gccccctatt gacgtcaatg acggtaaatg gcccgcctgg cattgtgccc 660
agtacatgac cttatgggac tttcctactt ggcagtacat ctacgtatta gtcatcgcta 720
ttaccatggt cgaggtgagc cccacgttct gcttcactct ccccatctcc cccccctccc 780
cacccccaat tttgtattta tttatttttt aattattttg tgcagcgatg ggggcggggg 840
gggggggggg gcgcgcgcca ggcggggcgg ggcggggcga ggggcggggc ggggcgaggc 900
ggagaggtgc ggcggcagcc aatcagagcg gcgcgctccg aaagtttcct tttatggcga 960
ggcggcggcg gcggcggccc tataaaaagc gaagcgcgcg gcgggcggga gtcgctgcga 1020
cgctgccttc gccccgtgcc ccgctccgcc gccgcctcgc gccgcccgcc ccggctctga 1080
ctgaccgcgt tactcccaca ggtgagcggg cgggacggcc cttctcctcc gggctgtaat 1140
tagctgagca agaggtaagg gtttaaggga tggttggttg gtggggtatt aatgtttaat 1200
tacctggagc acctgcctga aatcactttt tttcaggttg gaccggtgcc accatggact 1260
ataaggacca cgacggagac tacaaggatc atgatattga ttacaaagac gatgacgata 1320
agatggcccc aaagaagaag cggaaggtcg gtatccacgg agtcccagca gccgacaaga 1380
agtacagcat cggcctggac atcggcacca actctgtggg ctgggccgtg atcaccgacg 1440
agtacaaggt gcccagcaag aaattcaagg tgctgggcaa caccgaccgg cacagcatca 1500
agaagaacct gatcggagcc ctgctgttcg acagcggcga aacagccgag gccacccggc 1560
tgaagagaac cgccagaaga agatacacca gacggaagaa ccggatctgc tatctgcaag 1620
agatcttcag caacgagatg gccaaggtgg acgacagctt cttccacaga ctggaagagt 1680
ccttcctggt ggaagaggat aagaagcacg agcggcaccc catcttcggc aacatcgtgg 1740
acgaggtggc ctaccacgag aagtacccca ccatctacca cctgagaaag aaactggtgg 1800
acagcaccga caaggccgac ctgcggctga tctatctggc cctggcccac atgatcaagt 1860
tccggggcca cttcctgatc gagggcgacc tgaaccccga caacagcgac gtggacaagc 1920
tgttcatcca gctggtgcag acctacaacc agctgttcga ggaaaacccc atcaacgcca 1980
gcggcgtgga cgccaaggcc atcctgtctg ccagactgag caagagcaga cggctggaaa 2040
atctgatcgc ccagctgccc ggcgagaaga agaatggcct gttcggaaac ctgattgccc 2100
tgagcctggg cctgaccccc aacttcaaga gcaacttcga cctggccgag gatgccaaac 2160
tgcagctgag caaggacacc tacgacgacg acctggacaa cctgctggcc cagatcggcg 2220
accagtacgc cgacctgttt ctggccgcca agaacctgtc cgacgccatc ctgctgagcg 2280
acatcctgag agtgaacacc gagatcacca aggcccccct gagcgcctct atgatcaaga 2340
gatacgacga gcaccaccag gacctgaccc tgctgaaagc tctcgtgcgg cagcagctgc 2400
ctgagaagta caaagagatt ttcttcgacc agagcaagaa cggctacgcc ggctacattg 2460
acggcggagc cagccaggaa gagttctaca agttcatcaa gcccatcctg gaaaagatgg 2520
acggcaccga ggaactgctc gtgaagctga acagagagga cctgctgcgg aagcagcgga 2580
ccttcgacaa cggcagcatc ccccaccaga tccacctggg agagctgcac gccattctgc 2640
ggcggcagga agatttttac ccattcctga aggacaaccg ggaaaagatc gagaagatcc 2700
tgaccttccg catcccctac tacgtgggcc ctctggccag gggaaacagc agattcgcct 2760
ggatgaccag aaagagcgag gaaaccatca ccccctggaa cttcgaggaa gtggtggaca 2820
agggcgcttc cgcccagagc ttcatcgagc ggatgaccaa cttcgataag aacctgccca 2880
acgagaaggt gctgcccaag cacagcctgc tgtacgagta cttcaccgtg tataacgagc 2940
tgaccaaagt gaaatacgtg accgagggaa tgagaaagcc cgccttcctg agcggcgagc 3000
agaaaaaggc catcgtggac ctgctgttca agaccaaccg gaaagtgacc gtgaagcagc 3060
tgaaagagga ctacttcaag aaaatcgagt gcttcgactc cgtggaaatc tccggcgtgg 3120
aagatcggtt caacgcctcc ctgggcacat accacgatct gctgaaaatt atcaaggaca 3180
aggacttcct ggacaatgag gaaaacgagg acattctgga agatatcgtg ctgaccctga 3240
cactgtttga ggacagagag atgatcgagg aacggctgaa aacctatgcc cacctgttcg 3300
acgacaaagt gatgaagcag ctgaagcggc ggagatacac cggctggggc aggctgagcc 3360
ggaagctgat caacggcatc cgggacaagc agtccggcaa gacaatcctg gatttcctga 3420
agtccgacgg cttcgccaac agaaacttca tgcagctgat ccacgacgac agcctgacct 3480
ttaaagagga catccagaaa gcccaggtgt ccggccaggg cgatagcctg cacgagcaca 3540
ttgccaatct ggccggcagc cccgccatta agaagggcat cctgcagaca gtgaaggtgg 3600
tggacgagct cgtgaaagtg atgggccggc acaagcccga gaacatcgtg atcgaaatgg 3660
ccagagagaa ccagaccacc cagaagggac agaagaacag ccgcgagaga atgaagcgga 3720
tcgaagaggg catcaaagag ctgggcagcc agatcctgaa agaacacccc gtggaaaaca 3780
cccagctgca gaacgagaag ctgtacctgt actacctgca gaatgggcgg gatatgtacg 3840
tggaccagga actggacatc aaccggctgt ccgactacga tgtggaccat atcgtgcctc 3900
agagctttct gaaggacgac tccatcgaca acaaggtgct gaccagaagc gacaagaacc 3960
ggggcaagag cgacaacgtg ccctccgaag aggtcgtgaa gaagatgaag aactactggc 4020
ggcagctgct gaacgccaag ctgattaccc agagaaagtt cgacaatctg accaaggccg 4080
agagaggcgg cctgagcgaa ctggataagg ccggcttcat caagagacag ctggtggaaa 4140
cccggcagat cacaaagcac gtggcacaga tcctggactc ccggatgaac actaagtacg 4200
acgagaatga caagctgatc cgggaagtga aagtgatcac cctgaagtcc aagctggtgt 4260
ccgatttccg gaaggatttc cagttttaca aagtgcgcga gatcaacaac taccaccacg 4320
cccacgacgc ctacctgaac gccgtcgtgg gaaccgccct gatcaaaaag taccctaagc 4380
tggaaagcga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag atgatcgcca 4440
agagcgagca ggaaatcggc aaggctaccg ccaagtactt cttctacagc aacatcatga 4500
actttttcaa gaccgagatt accctggcca acggcgagat ccggaagcgg cctctgatcg 4560
agacaaacgg cgaaaccggg gagatcgtgt gggataaggg ccgggatttt gccaccgtgc 4620
ggaaagtgct gagcatgccc caagtgaata tcgtgaaaaa gaccgaggtg cagacaggcg 4680
gcttcagcaa agagtctatc ctgcccaaga ggaacagcga taagctgatc gccagaaaga 4740
aggactggga ccctaagaag tacggcggct tcgacagccc caccgtggcc tattctgtgc 4800
tggtggtggc caaagtggaa aagggcaagt ccaagaaact gaagagtgtg aaagagctgc 4860
tggggatcac catcatggaa agaagcagct tcgagaagaa tcccatcgac tttctggaag 4920
ccaagggcta caaagaagtg aaaaaggacc tgatcatcaa gctgcctaag tactccctgt 4980
tcgagctgga aaacggccgg aagagaatgc tggcctctgc cggcgaactg cagaagggaa 5040
acgaactggc cctgccctcc aaatatgtga acttcctgta cctggccagc cactatgaga 5100
agctgaaggg ctcccccgag gataatgagc agaaacagct gtttgtggaa cagcacaagc 5160
actacctgga cgagatcatc gagcagatca gcgagttctc caagagagtg atcctggccg 5220
acgctaatct ggacaaagtg ctgtccgcct acaacaagca ccgggataag cccatcagag 5280
agcaggccga gaatatcatc cacctgttta ccctgaccaa tctgggagcc cctgccgcct 5340
tcaagtactt tgacaccacc atcgaccgga agaggtacac cagcaccaaa gaggtgctgg 5400
acgccaccct gatccaccag agcatcaccg gcctgtacga gacacggatc gacctgtctc 5460
agctgggagg cgacaaaagg ccggcggcca cgaaaaaggc cggccaggca aaaaagaaaa 5520
aggaattcgg cagtggagag ggcagaggaa gtctgctaac atgcggtgac gtcgaggaga 5580
atcctggccc agtgagcaag ggcgaggagc tgttcaccgg ggtggtgccc atcctggtcg 5640
agctggacgg cgacgtaaac ggccacaagt tcagcgtgtc cggcgagggc gagggcgatg 5700
ccacctacgg caagctgacc ctgaagttca tctgcaccac cggcaagctg cccgtgccct 5760
ggcccaccct cgtgaccacc ctgacctacg gcgtgcagtg cttcagccgc taccccgacc 5820
acatgaagca gcacgacttc ttcaagtccg ccatgcccga aggctacgtc caggagcgca 5880
ccatcttctt caaggacgac ggcaactaca agacccgcgc cgaggtgaag ttcgagggcg 5940
acaccctggt gaaccgcatc gagctgaagg gcatcgactt caaggaggac ggcaacatcc 6000
tggggcacaa gctggagtac aactacaaca gccacaacgt ctatatcatg gccgacaagc 6060
agaagaacgg catcaaggtg aacttcaaga tccgccacaa catcgaggac ggcagcgtgc 6120
agctcgccga ccactaccag cagaacaccc ccatcggcga cggccccgtg ctgctgcccg 6180
acaaccacta cctgagcacc cagtccgccc tgagcaaaga ccccaacgag aagcgcgatc 6240
acatggtcct gctggagttc gtgaccgccg ccgggatcac tctcggcatg gacgagctgt 6300
acaaggaatt ctaactagag ctcgctgatc agcctcgact gtgccttcta gttgccagcc 6360
atctgttgtt tgcccctccc ccgtgccttc cttgaccctg gaaggtgcca ctcccactgt 6420
cctttcctaa taaaatgagg aaattgcatc gcattgtctg agtaggtgtc attctattct 6480
ggggggtggg gtggggcagg acagcaaggg ggaggattgg gaagagaata gcaggcatgc 6540
tggggagcgg ccgcaggaac ccctagtgat ggagttggcc actccctctc tgcgcgctcg 6600
ctcgctcact gaggccgggc gaccaaaggt cgcccgacgc ccgggctttg cccgggcggc 6660
ctcagtgagc gagcgagcgc gcagctgcct gcaggggcgc ctgatgcggt attttctcct 6720
tacgcatctg tgcggtattt cacaccgcat acgtcaaagc aaccatagta cgcgccctgt 6780
agcggcgcat taagcgcggc gggtgtggtg gttacgcgca gcgtgaccgc tacacttgcc 6840
agcgccctag cgcccgctcc tttcgctttc ttcccttcct ttctcgccac gttcgccggc 6900
tttccccgtc aagctctaaa tcgggggctc cctttagggt tccgatttag tgctttacgg 6960
cacctcgacc ccaaaaaact tgatttgggt gatggttcac gtagtgggcc atcgccctga 7020
tagacggttt ttcgcccttt gacgttggag tccacgttct ttaatagtgg actcttgttc 7080
caaactggaa caacactcaa ccctatctcg ggctattctt ttgatttata agggattttg 7140
ccgatttcgg cctattggtt aaaaaatgag ctgatttaac aaaaatttaa cgcgaatttt 7200
aacaaaatat taacgtttac aattttatgg tgcactctca gtacaatctg ctctgatgcc 7260
gcatagttaa gccagccccg acacccgcca acacccgctg acgcgccctg acgggcttgt 7320
ctgctcccgg catccgctta cagacaagct gtgaccgtct ccgggagctg catgtgtcag 7380
aggttttcac cgtcatcacc gaaacgcgcg agacgaaagg gcctcgtgat acgcctattt 7440
ttataggtta atgtcatgat aataatggtt tcttagacgt caggtggcac ttttcgggga 7500
aatgtgcgcg gaacccctat ttgtttattt ttctaaatac attcaaatat gtatccgctc 7560
atgagacaat aaccctgata aatgcttcaa taatattgaa aaaggaagag tatgagtatt 7620
caacatttcc gtgtcgccct tattcccttt tttgcggcat tttgccttcc tgtttttgct 7680
cacccagaaa cgctggtgaa agtaaaagat gctgaagatc agttgggtgc acgagtgggt 7740
tacatcgaac tggatctcaa cagcggtaag atccttgaga gttttcgccc cgaagaacgt 7800
tttccaatga tgagcacttt taaagttctg ctatgtggcg cggtattatc ccgtattgac 7860
gccgggcaag agcaactcgg tcgccgcata cactattctc agaatgactt ggttgagtac 7920
tcaccagtca cagaaaagca tcttacggat ggcatgacag taagagaatt atgcagtgct 7980
gccataacca tgagtgataa cactgcggcc aacttacttc tgacaacgat cggaggaccg 8040
aaggagctaa ccgctttttt gcacaacatg ggggatcatg taactcgcct tgatcgttgg 8100
gaaccggagc tgaatgaagc cataccaaac gacgagcgtg acaccacgat gcctgtagca 8160
atggcaacaa cgttgcgcaa actattaact ggcgaactac ttactctagc ttcccggcaa 8220
caattaatag actggatgga ggcggataaa gttgcaggac cacttctgcg ctcggccctt 8280
ccggctggct ggtttattgc tgataaatct ggagccggtg agcgtggaag ccgcggtatc 8340
attgcagcac tggggccaga tggtaagccc tcccgtatcg tagttatcta cacgacgggg 8400
agtcaggcaa ctatggatga acgaaataga cagatcgctg agataggtgc ctcactgatt 8460
aagcattggt aactgtcaga ccaagtttac tcatatatac tttagattga tttaaaactt 8520
catttttaat ttaaaaggat ctaggtgaag atcctttttg ataatctcat gaccaaaatc 8580
ccttaacgtg agttttcgtt ccactgagcg tcagaccccg tagaaaagat caaaggatct 8640
tcttgagatc ctttttttct gcgcgtaatc tgctgcttgc aaacaaaaaa accaccgcta 8700
ccagcggtgg tttgtttgcc ggatcaagag ctaccaactc tttttccgaa ggtaactggc 8760
ttcagcagag cgcagatacc aaatactgtc cttctagtgt agccgtagtt aggccaccac 8820
ttcaagaact ctgtagcacc gcctacatac ctcgctctgc taatcctgtt accagtggct 8880
gctgccagtg gcgataagtc gtgtcttacc gggttggact caagacgata gttaccggat 8940
aaggcgcagc ggtcgggctg aacggggggt tcgtgcacac agcccagctt ggagcgaacg 9000
acctacaccg aactgagata cctacagcgt gagctatgag aaagcgccac gcttcccgaa 9060
gggagaaagg cggacaggta tccggtaagc ggcagggtcg gaacaggaga gcgcacgagg 9120
gagcttccag ggggaaacgc ctggtatctt tatagtcctg tcgggtttcg ccacctctga 9180
cttgagcgtc gatttttgtg atgctcgtca ggggggcgga gcctatggaa aaacgccagc 9240
aacgcggcct ttttacggtt cctggccttt tgctggcctt ttgctcacat gt 9292
<210> 53
<211> 6061
<212> DNA
<213> Artificial sequence
<220>
<223> pJet-Has nucleic acid sequence
<400> 53
gcccctgcag ccgaattata ttatttttgc caaataattt ttaacaaaag ctctgaagtc 60
ttcttcattt aaattcttag atgatacttc atctggaaaa ttgtcccaat tagtagcatc 120
acgctgtgag taagttctaa accatttttt tattgttgta ttatctctaa tcttactact 180
cgatgagttt tcggtattat ctctattttt aacttggagc aggttccatt cattgttttt 240
ttcatcatag tgaataaaat caactgcttt aacacttgtg cctgaacacc atatccatcc 300
ggcgtaatac gactcactat agggagagcg gccgccagat cttccggatg gctcgagttt 360
ttcagcaaga tttttgaatg aagggcctga gggtgggcag tctgtctatc atgtacatct 420
ccatattctg ggaggtcgtc agttgggctg gcctcctggc taagattttt gcaccacaag 480
agatgctgca tgtgtacaaa tcactagcaa atagatttgt ttcccatcaa cttagccact 540
gttaatgtaa attgttcttg gatatgtgtc tttggagggc aataaatgct ctgaacagca 600
cttgcacaat aaagatacag catgtgggaa tgatctgtct catgtgtctt actgatggta 660
ttggttctgt aagataaaat attgtgtctg ggatgtgttt ggctctacta ttaatggtgc 720
tctattgatt gtgatttgtc atttgaaacc tgaggatgcg actgtatagc agtctttcat 780
gcatttttgg aaaaaaactt aagctttttg aaagctgctg ctacaacttt ttgtattgtt 840
ataaagtttt gtattgtttt tttaattgtg aaattataaa gatgccgtgc agggactgtt 900
tgaagcaaag tgcattgttt tagaaaccta caactctagt tcaagcactc catcagtatc 960
tgcttaatct ttgtcatcct ttgctatgag aaaatattaa gcagtagtct aaaggtacta 1020
tgaaactata acatagctga cattgtattt ataactacgt catgattttg atagaattga 1080
ggacttgaaa atgttaaact attcatgtag ggcctcttaa gatgcttaag ttgtttagta 1140
atgtaagtgt gcatttaatt gagattttat tgggcataat ttgtccatca gtatgacact 1200
ccttgtcagt gttgccttat acttgatgtt gttaccggat ctctgcaagg cagttattct 1260
tgaattaggc tcattgaagt gtctgccagt ataaatatat agcaactgtt ctttgtgtta 1320
aaattgagaa gctaaccagt ttttagtgct tctgactgtt ggaattcttt aagcagatgc 1380
cataagaaaa ttgtatttgt gatcaccact tctccagagt ggttttaaca ccaagggcat 1440
tagagaaaga aaggcaggcg tgtagagaat agtggacaga caaaagctgt gagttacgtt 1500
atgtttttca gctgaaaagc tgtgtttggt aaaagcatat gaaatcactc aacttggaag 1560
cattctctta gttctctgat agttctgagc agcagaactc ttcacctaag aggttacttc 1620
aactggaaga ctacctagtg cttctgatgg caactatatt taagatgaga ataagaggtg 1680
tttccagtgt ggtagcctca catctgttgc agtggttacc gttcgtcctc ctccgaggga 1740
cacagcttgg ccattcactg tggtgacacc aatatgatga tcagcaaatg gtgtttattc 1800
actactaaac acagcttata tacattttta cctacaaaat cgtgctgtca tgtcccactc 1860
tgattggttc ataccagata acgtgcctta tttggccgtt tccacattct tttctcatcc 1920
ttcttctcct gttttctctg catcaaggtc agcacgatag cactgtctct ctatgcttag 1980
ggagaggcct gtcctgtaca tcccgtgccc ccacaagatg cctactacaa caacatcttc 2040
tgcatgtcct gcatagcagt gttgggagaa tgtgcactac ttccactctt ctgatttcta 2100
ttttatgtgt ttgctttata ccagtgttgc catttgggaa ttaatacatg gttgatcaaa 2160
tcaattgcat cacagctgta tcctgtatca gaggaacatt atcaaagctt ttgttgctgt 2220
atttggtatc tgacctgcag ataaacatgt tttaggaagg ttttgcaaaa gtagctgtga 2280
aatgagctgg tgttgtgatt taacctgaca ggcagctaaa cagtatacca cagagctatt 2340
cacctacttt ccctcagtgg gaaaagggaa gagaactgag ggggggggga ataaataagt 2400
aaataacaaa ataaaactca tggattaaga aaaagacttt gtactggaat ggatgagaag 2460
aataatagta atgataataa tatgtcactc tgaaagtaat gcctcttatt tctgtggaga 2520
ctacaaacat acaaagagca caacattcca tagagcaaat tctcagttac agaatgctat 2580
tttttttttc aacacagtca aaatcattaa tttttttttg cctgcaatgg acaagagctt 2640
tgaagctgtt ctcgtaaaaa tctgtactag cagaagtgac ctgcaatcac tactgctgaa 2700
atgcacaacc caccacatca ttgtgctcac attcactgtt tggtttctgt aaatgtacag 2760
gaattgtctg aaattagata tgattttttt tttctccatg aaggaattca attacacacc 2820
tttgcctcat gcacttcttt gtcatttttg tcagactgct tctctcctgc aatttgtctc 2880
atggcaacaa aatataatgg agttctgctg ggaacttccc tactgccata ccactatcat 2940
ctgcctctga cattttggac aaatgtaata aaataggagg tattactttc agagcagacc 3000
ttgtatgtat ttacaaaaca agtggtacac aaaaaaaatt gttcatccca ccaaccaatg 3060
cccatcctgt ccctgaatag tagctgtccc ccacagcctt gaccagttta ggtcaacagt 3120
tctgcttctg tcccctccca gctccttgta acccctcagc cccccttgct ggcaggacag 3180
tatgagaagc tgaaaaacta gaatgtccta gttctttgca gtgctgctaa tcaacaacca 3240
aaacagtggt gtgttaccaa tattgttgat atcacagcat cataccatta tgaaggaagt 3300
aacccagcca aaatcaggtc agcttgctaa caagagaact gtgcataagt ttaagatgtg 3360
tgtgttcctc agtaccttaa aaaataagta gtaacgttca aatgagtaga agagtagaac 3420
tgagcttaaa acatctgtca gacaacagtg aaccaaccat ctttctagaa gatctcctac 3480
aatattctca gctgccatgg aaaatcgatg ttcttctttt attctctcaa gattttcagg 3540
ctgtatatta aaacttatat taagaactat gctaaccacc tcatcaggaa ccgttgtagg 3600
tggcgtgggt tttcttggca atcgactctc atgaaaacta cgagctaaat attcaatatg 3660
ttcctcttga ccaactttat tctgcatttt ttttgaacga ggtttagagc aagcttcagg 3720
aaactgagac aggaatttta ttaaaaattt aaattttgaa gaaagttcag ggttaatagc 3780
atccattttt tgctttgcaa gttcctcagc attcttaaca aaagacgtct cttttgacat 3840
gtttaaagtt taaacctcct gtgtgaaatt attatccgct cataattcca cacattatac 3900
gagccggaag cataaagtgt aaagcctggg gtgcctaatg agtgagctaa ctcacattaa 3960
ttgcgttgcg ctcactgcca attgctttcc agtcgggaaa cctgtcgtgc cagctgcatt 4020
aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct tccgcttcct 4080
cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca gctcactcaa 4140
aggcggtaat acggttatcc acagaatcag gggataacgc aggaaagaac atgtgagcaa 4200
aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt ttccataggc 4260
tccgcccccc tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg cgaaacccga 4320
caggactata aagataccag gcgtttcccc ctggaagctc cctcgtgcgc tctcctgttc 4380
cgaccctgcc gcttaccgga tacctgtccg cctttctccc ttcgggaagc gtggcgcttt 4440
ctcatagctc acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc aagctgggct 4500
gtgtgcacga accccccgtt cagcccgacc gctgcgcctt atccggtaac tatcgtcttg 4560
agtccaaccc ggtaagacac gacttatcgc cactggcagc agccactggt aacaggatta 4620
gcagagcgag gtatgtaggc ggtgctacag agttcttgaa gtggtggcct aactacggct 4680
acactagaag gacagtattt ggtatctgcg ctctgctgaa gccagttacc ttcggaaaaa 4740
gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt ttttttgttt 4800
gcaagcagca gattacgcgc agaaaaaaag gatctcaaga agatcctttg atcttttcta 4860
cggggtctga cgctcagtgg aacgaaaact cacgttaagg gattttggtc atgagattat 4920
caaaaaggat cttcacctag atccttttaa attaaaaatg aagttttaaa tcaatctaaa 4980
gtatatatga gtaaacttgg tctgacagtt accaatgctt aatcagtgag gcacctatct 5040
cagcgatctg tctatttcgt tcatccatag ttgcctgact ccccgtcgtg tagataacta 5100
cgatacggga gggcttacca tctggcccca gtgctgcaat gataccgcga gacccacgct 5160
caccggctcc agatttatca gcaataaacc agccagccgg aagggccgag cgcagaagtg 5220
gtcctgcaac tttatccgcc tccatccagt ctattaattg ttgccgggaa gctagagtaa 5280
gtagttcgcc agttaatagt ttgcgcaacg ttgttgccat tgctacaggc atcgtggtgt 5340
cacgctcgtc gtttggtatg gcttcattca gctccggttc ccaacgatca aggcgagtta 5400
catgatcccc catgttgtgc aaaaaagcgg ttagctcctt cggtcctccg atcgttgtca 5460
gaagtaagtt ggccgcagtg ttatcactca tggttatggc agcactgcat aattctctta 5520
ctgtcatgcc atccgtaaga tgcttttctg tgactggtga gtactcaacc aagtcattct 5580
gagaatagtg tatgcggcga ccgagttgct cttgcccggc gtcaatacgg gataataccg 5640
cgccacatag cagaacttta aaagtgctca tcattggaaa acgttcttcg gggcgaaaac 5700
tctcaaggat cttaccgctg ttgagatcca gttcgatgta acccactcgt gcacccaact 5760
gatcttcagc atcttttact ttcaccagcg tttctgggtg agcaaaaaca ggaaggcaaa 5820
atgccgcaaa aaagggaata agggcgacac ggaaatgttg aatactcata ctcttccttt 5880
ttcaatatta ttgaagcatt tatcagggtt attgtctcat gagcggatac atatttgaat 5940
gtatttagaa aaataaacaa ataggggttc cgcgcacatt tccccgaaaa gtgccacctg 6000
acgtctaaga aaccattatt atcatgacat taacctataa aaataggcgt atcacgaggc 6060
c 6061
<210> 54
<211> 6929
<212> DNA
<213> Artificial sequence
<220>
<223> pCAGG-Neo-IRES-GFP nucleic acid sequence
<400> 54
tcgacattga ttattgacta gttattaata gtaatcaatt acggggtcat tagttcatag 60
cccatatatg gagttccgcg ttacataact tacggtaaat ggcccgcctg gctgaccgcc 120
caacgacccc cgcccattga cgtcaataat gacgtatgtt cccatagtaa cgccaatagg 180
gactttccat tgacgtcaat gggtggagta tttacggtaa actgcccact tggcagtaca 240
tcaagtgtat catatgccaa gtacgccccc tattgacgtc aatgacggta aatggcccgc 300
ctggcattat gcccagtaca tgaccttatg ggactttcct acttggcagt acatctacgt 360
attagtcatc gctattacca tggtcgaggt gagccccacg ttctgcttca ctctccccat 420
ctcccccccc tccccacccc caattttgta tttatttatt ttttaattat tttgtgcagc 480
gatgggggcg gggggggggg gggggcgcgc gccaggcggg gcggggcggg gcgaggggcg 540
gggcggggcg aggcggagag gtgcggcggc agccaatcag agcggcgcgc tccgaaagtt 600
tccttttatg gcgaggcggc ggcggcggcg gccctataaa aagcgaagcg cgcggcgggc 660
ggggagtcgc tgcgacgctg ccttcgcccc gtgccccgct ccgccgccgc ctcgcgccgc 720
ccgccccggc tctgactgac cgcgttactc ccacaggtga gcgggcggga cggcccttct 780
cctccgggct gtaattagcg cttggtttaa tgacggcttg tttcttttct gtggctgcgt 840
gaaagccttg aggggctccg ggagggccct ttgtgcgggg ggagcggctc ggggggtgcg 900
tgcgtgtgtg tgtgcgtggg gagcgccgcg tgcggctccg cgctgcccgg cggctgtgag 960
cgctgcgggc gcggcgcggg gctttgtgcg ctccgcagtg tgcgcgaggg gagcgcggcc 1020
gggggcggtg ccccgcggtg cggggggggc tgcgagggga acaaaggctg cgtgcggggt 1080
gtgtgcgtgg gggggtgagc agggggtgtg ggcgcgtcgg tcgggctgca accccccctg 1140
cacccccctc cccgagttgc tgagcacggc ccggcttcgg gtgcggggct ccgtacgggg 1200
cgtggcgcgg ggctcgccgt gccgggcggg gggtggcggc aggtgggggt gccgggcggg 1260
gcggggccgc ctcgggccgg ggagggctcg ggggaggggc gcggcggccc ccggagcgcc 1320
ggcggctgtc gaggcgcggc gagccgcagc cattgccttt tatggtaatc gtgcgagagg 1380
gcgcagggac ttcctttgtc ccaaatctgt gcggagccga aatctgggag gcgccgccgc 1440
accccctcta gcgggcgcgg ggcgaagcgg tgcggcgccg gcaggaagga aatgggcggg 1500
gagggccttc gtgcgtcgcc gcgccgccgt ccccttctcc ctctccagcc tcggggctgt 1560
ccgcgggggg acggctgcct tcggggggga cggggcaggg cggggttcgg cttctggcgt 1620
gtgaccggcg gctctagagc ctctgctaac catgttcatg ccttcttctt tttcctacag 1680
ctcctgggca acgtgctggt tattgtgctg tctcatcatt ttggcaaaga attgatggga 1740
tcggccattg aacaagatgg attgcacgca ggttctccgg ccgcttgggt ggagaggcta 1800
ttcggctatg actgggcaca acagacaatc ggctgctctg atgccgccgt gttccggctg 1860
tcagcgcagg ggcgcccggt tctttttgtc aagaccgacc tgtccggtgc cctgaatgaa 1920
ctgcaggacg aggcagcgcg gctatcgtgg ctggccacga cgggcgttcc ttgcgcagct 1980
gtgctcgacg ttgtcactga agcgggaagg gactggctgc tattgggcga agtgccgggg 2040
caggatctcc tgtcatctca ccttgctcct gccgagaaag tatccatcat ggctgatgca 2100
atgcggcggc tgcatacgct tgatccggct acctgcccat tcgaccacca agcgaaacat 2160
cgcatcgagc gagcacgtac tcggatggaa gccggtcttg tcgatcagga tgatctggac 2220
gaagagcatc aggggctcgc gccagccgaa ctgttcgcca ggctcaaggc gcgcatgccc 2280
gacggcgagg atctcgtcgt gacccatggc gatgcctgct tgccgaatat catggtggaa 2340
aatggccgct tttctggatt catcgactgt ggccggctgg gtgtggcgga ccgctatcag 2400
gacatagcgt tggctacccg tgatattgct gaagagcttg gcggcgaatg ggctgaccgc 2460
ttcctcgtgc tttacggtat cgccgctccc gattcgcagc gcatcgcctt ctatcgcctt 2520
cttgacgagt tcttctgatc tagcctccgc ccctctccct cccccccccc taacgttact 2580
ggccgaagcc gcttggaata aggccggtgt gcgtttgtct atatgttatt ttccaccata 2640
ttgccgtctt ttggcaatgt gagggcccgg aaacctggcc ctgtcttctt gacgagcatt 2700
cctaggggtc tttcccctct cgccaaagga atgcaaggtc tgttgaatgt cgtgaaggaa 2760
gcagttcctc tggaagcttc ttgaagacaa acaacgtctg tagcgaccct ttgcaggcag 2820
cggaaccccc cacctggcga caggtgcctc tgcggccaaa agccacgtgt ataagataca 2880
cctgcaaagg cggcacaacc ccagtgccac gttgtgagtt ggatagttgt ggaaagagtc 2940
aaatggctct cctcaagcgt attcaacaag gggctgaagg atgcccagaa ggtaccccat 3000
tgtatgggat ctgatctggg gcctcggtgc acatgcttta catgtgttta gtcgaggtta 3060
aaaaaacgtc taggcccccc gaaccacggg gacgtggttt tcctttgaaa aacacgatga 3120
taatatggcc acaaccatgg tgagcaaggg cgaggagctg ttcaccgggg tggtgcccat 3180
cctggtcgag ctggacggcg acgtaaacgg ccacaagttc agcgtgtccg gcgagggcga 3240
gggcgatgcc acctacggca agctgaccct gaagttcatc tgcaccaccg gcaagctgcc 3300
cgtgccctgg cccaccctcg tgaccaccct gacctacggc gtgcagtgct tcagccgcta 3360
ccccgaccac atgaagcagc acgacttctt caagtccgcc atgcccgaag gctacgtcca 3420
ggagcgcacc atcttcttca aggacgacgg caactacaag acccgcgccg aggtgaagtt 3480
cgagggcgac accctggtga accgcatcga gctgaagggc atcgacttca aggaggacgg 3540
caacatcctg gggcacaagc tggagtacaa ctacaacagc cacaacgtct atatcatggc 3600
cgacaagcag aagaacggca tcaaggtgaa cttcaagatc cgccacaaca tcgaggacgg 3660
cagcgtgcag ctcgccgacc actaccagca gaacaccccc atcggcgacg gccccgtgct 3720
gctgcccgac aaccactacc tgagcaccca gtccgccctg agcaaagacc ccaacgagaa 3780
gcgcgatcac atggtcctgc tggagttcgt gaccgccgcc gggatcactc tcggcatgga 3840
cgagctgtac aagtaaagcg gccgccaatt cactcctcag gtgcaggctg cctatcagaa 3900
ggtggtggct ggtgtggcca atgccctggc tcacaaatac cactgagatc tttttccctc 3960
tgccaaaaat tatggggaca tcatgaagcc ccttgagcat ctgacttctg gctaataaag 4020
gaaatttatt ttcattgcaa tagtgtgttg gaattttttg tgtctctcac tcggaaggac 4080
atatgggagg gcaaatcatt taaaacatca gaatgagtat ttggtttaga gtttggcaac 4140
atatgcccat atgctggctg ccatgaacaa aggttggcta taaagaggtc atcagtatat 4200
gaaacagccc cctgctgtcc attccttatt ccatagaaaa gccttgactt gaggttagat 4260
tttttttata ttttgttttg tgttattttt ttctttaaca tccctaaaat tttccttaca 4320
tgttttacta gccagatttt tcctcctctc ctgactactc ccagtcatag ctgtccctct 4380
tctcttatgg agatccctcg acctgcagcc caagcttggc gtaatcatgg tcatagctgt 4440
ttcctgtgtg aaattgttat ccgctcacaa ttccacacaa catacgagcc ggaagcataa 4500
agtgtaaagc ctggggtgcc taatgagtga gctaactcac attaattgcg ttgcgctcac 4560
tgcccgcttt ccagtcggga aacctgtcgt gccagcggat ccgcatctca attagtcagc 4620
aaccatagtc ccgcccctaa ctccgcccat cccgccccta actccgccca gttccgccca 4680
ttctccgccc catggctgac taattttttt tatttatgca gaggccgagg ccgcctcggc 4740
ctctgagcta ttccagaagt agtgaggagg cttttttgga ggcctaggct tttgcaaaaa 4800
gctaacttgt ttattgcagc ttataatggt tacaaataaa gcaatagcat cacaaatttc 4860
acaaataaag catttttttc actgcattct agttgtggtt tgtccaaact catcaatgta 4920
tcttatcatg tctggatccg ctgcattaat gaatcggcca acgcgcgggg agaggcggtt 4980
tgcgtattgg gcgctcttcc gcttcctcgc tcactgactc gctgcgctcg gtcgttcggc 5040
tgcggcgagc ggtatcagct cactcaaagg cggtaatacg gttatccaca gaatcagggg 5100
ataacgcagg aaagaacatg tgagcaaaag gccagcaaaa ggccaggaac cgtaaaaagg 5160
ccgcgttgct ggcgtttttc cataggctcc gcccccctga cgagcatcac aaaaatcgac 5220
gctcaagtca gaggtggcga aacccgacag gactataaag ataccaggcg tttccccctg 5280
gaagctccct cgtgcgctct cctgttccga ccctgccgct taccggatac ctgtccgcct 5340
ttctcccttc gggaagcgtg gcgctttctc atagctcacg ctgtaggtat ctcagttcgg 5400
tgtaggtcgt tcgctccaag ctgggctgtg tgcacgaacc ccccgttcag cccgaccgct 5460
gcgccttatc cggtaactat cgtcttgagt ccaacccggt aagacacgac ttatcgccac 5520
tggcagcagc cactggtaac aggattagca gagcgaggta tgtaggcggt gctacagagt 5580
tcttgaagtg gtggcctaac tacggctaca ctagaagaac agtatttggt atctgcgctc 5640
tgctgaagcc agttaccttc ggaaaaagag ttggtagctc ttgatccggc aaacaaacca 5700
ccgctggtag cggtggtttt tttgtttgca agcagcagat tacgcgcaga aaaaaaggat 5760
ctcaagaaga tcctttgatc ttttctacgg ggtctgacgc tcagtggaac gaaaactcac 5820
gttaagggat tttggtcatg agattatcaa aaaggatctt cacctagatc cttttaaatt 5880
aaaaatgaag ttttaaatca atctaaagta tatatgagta aacttggtct gacagttacc 5940
aatgcttaat cagtgaggca cctatctcag cgatctgtct atttcgttca tccatagttg 6000
cctgactccc cgtcgtgtag ataactacga tacgggaggg cttaccatct ggccccagtg 6060
ctgcaatgat accgcgagac ccacgctcac cggctccaga tttatcagca ataaaccagc 6120
cagccggaag ggccgagcgc agaagtggtc ctgcaacttt atccgcctcc atccagtcta 6180
ttaattgttg ccgggaagct agagtaagta gttcgccagt taatagtttg cgcaacgttg 6240
ttgccattgc tacaggcatc gtggtgtcac gctcgtcgtt tggtatggct tcattcagct 6300
ccggttccca acgatcaagg cgagttacat gatcccccat gttgtgcaaa aaagcggtta 6360
gctccttcgg tcctccgatc gttgtcagaa gtaagttggc cgcagtgtta tcactcatgg 6420
ttatggcagc actgcataat tctcttactg tcatgccatc cgtaagatgc ttttctgtga 6480
ctggtgagta ctcaaccaag tcattctgag aatagtgtat gcggcgaccg agttgctctt 6540
gcccggcgtc aatacgggat aataccgcgc cacatagcag aactttaaaa gtgctcatca 6600
ttggaaaacg ttcttcgggg cgaaaactct caaggatctt accgctgttg agatccagtt 6660
cgatgtaacc cactcgtgca cccaactgat cttcagcatc ttttactttc accagcgttt 6720
ctgggtgagc aaaaacagga aggcaaaatg ccgcaaaaaa gggaataagg gcgacacgga 6780
aatgttgaat actcatactc ttcctttttc aatattattg aagcatttat cagggttatt 6840
gtctcatgag cggatacata tttgaatgta tttagaaaaa taaacaaata ggggttccgc 6900
gcacatttcc ccgaaaagtg ccacctggg 6929
<210> 55
<211> 10461
<212> DNA
<213> Artificial sequence
<220>
<223> Targeting Vector nucleic acid sequence
<400> 55
gcccctgcag ccgaattata ttatttttgc caaataattt ttaacaaaag ctctgaagtc 60
ttcttcattt aaattcttag atgatacttc atctggaaaa ttgtcccaat tagtagcatc 120
acgctgtgag taagttctaa accatttttt tattgttgta ttatctctaa tcttactact 180
cgatgagttt tcggtattat ctctattttt aacttggagc aggttccatt cattgttttt 240
ttcatcatag tgaataaaat caactgcttt aacacttgtg cctgaacacc atatccatcc 300
ggcgtaatac gactcactat agggagagcg gccgccagat cttccggatg gctcgagttt 360
ttcagcaaga tttttgaatg aagggcctga gggtgggcag tctgtctatc atgtacatct 420
ccatattctg ggaggtcgtc agttgggctg gcctcctggc taagattttt gcaccacaag 480
agatgctgca tgtgtacaaa tcactagcaa atagatttgt ttcccatcaa cttagccact 540
gttaatgtaa attgttcttg gatatgtgtc tttggagggc aataaatgct ctgaacagca 600
cttgcacaat aaagatacag catgtgggaa tgatctgtct catgtgtctt actgatggta 660
ttggttctgt aagataaaat attgtgtctg ggatgtgttt ggctctacta ttaatggtgc 720
tctattgatt gtgatttgtc atttgaaacc tgaggatgcg actgtatagc agtctttcat 780
gcatttttgg aaaaaaactt aagctttttg aaagctgctg ctacaacttt ttgtattgtt 840
ataaagtttt gtattgtttt tttaattgtg aaattataaa gatgccgtgc agggactgtt 900
tgaagcaaag tgcattgttt tagaaaccta caactctagt tcaagcactc catcagtatc 960
tgcttaatct ttgtcatcct ttgctatgag aaaatattaa gcagtagtct aaaggtacta 1020
tgaaactata acatagctga cattgtattt ataactacgt catgattttg atagaattga 1080
ggacttgaaa atgttaaact attcatgtag ggcctcttaa gatgcttaag ttgtttagta 1140
atgtaagtgt gcatttaatt gagattttat tgggcataat ttgtccatca gtatgacact 1200
ccttgtcagt gttgccttat acttgatgtt gttaccggat ctctgcaagg cagttattct 1260
tgaattaggc tcattgaagt gtctgccagt ataaatatat agcaactgtt ctttgtgtta 1320
aaattgagaa gctaaccagt ttttagtgct tctgactgtt ggaattcttt aagcagatgc 1380
cataagaaaa ttgtatttgt gatcaccact tctccagagt ggttttaaca ccaagggcat 1440
tagagaaaga aaggcaggcg tgtagagaat agtggacaga caaaagctgt gagttacgtt 1500
atgtttttca gctgaaaagc tgtgtttggt aaaagcatat gaaatcactc aacttggaag 1560
cattctctta gttctctgat agttctgagc agcagaactc ttcacctaag aggttacttc 1620
aactggaaga ctacctagtg cttctgatgg caactatatt taagatgaga ataagaggtg 1680
tttccagtgt ggtagcctca catctgttgc agtggttacc gttcgtcctc ctccgaggga 1740
cacagcttgg ccattcactg tggtgacacc aatatgatga tcagcaaatg gtgtttattc 1800
actactaaac acagcttata tacattttta cctacaaaat cgtgctgtca tgtcccactc 1860
tgattggttc acacatttcc ccgaaaagtg ccacctgggt cgacattgat tattgactag 1920
ttattaatag taatcaatta cggggtcatt agttcatagc ccatatatgg agttccgcgt 1980
tacataactt acggtaaatg gcccgcctgg ctgaccgccc aacgaccccc gcccattgac 2040
gtcaataatg acgtatgttc ccatagtaac gccaataggg actttccatt gacgtcaatg 2100
ggtggagtat ttacggtaaa ctgcccactt ggcagtacat caagtgtatc atatgccaag 2160
tacgccccct attgacgtca atgacggtaa atggcccgcc tggcattatg cccagtacat 2220
gaccttatgg gactttccta cttggcagta catctacgta ttagtcatcg ctattaccat 2280
ggtcgaggtg agccccacgt tctgcttcac tctccccatc tcccccccct ccccaccccc 2340
aattttgtat ttatttattt tttaattatt ttgtgcagcg atgggggcgg gggggggggg 2400
ggggcgcgcg ccaggcgggg cggggcgggg cgaggggcgg ggcggggcga ggcggagagg 2460
tgcggcggca gccaatcaga gcggcgcgct ccgaaagttt ccttttatgg cgaggcggcg 2520
gcggcggcgg ccctataaaa agcgaagcgc gcggcgggcg gggagtcgct gcgacgctgc 2580
cttcgccccg tgccccgctc cgccgccgcc tcgcgccgcc cgccccggct ctgactgacc 2640
gcgttactcc cacaggtgag cgggcgggac ggcccttctc ctccgggctg taattagcgc 2700
ttggtttaat gacggcttgt ttcttttctg tggctgcgtg aaagccttga ggggctccgg 2760
gagggccctt tgtgcggggg gagcggctcg gggggtgcgt gcgtgtgtgt gtgcgtgggg 2820
agcgccgcgt gcggctccgc gctgcccggc ggctgtgagc gctgcgggcg cggcgcgggg 2880
ctttgtgcgc tccgcagtgt gcgcgagggg agcgcggccg ggggcggtgc cccgcggtgc 2940
ggggggggct gcgaggggaa caaaggctgc gtgcggggtg tgtgcgtggg ggggtgagca 3000
gggggtgtgg gcgcgtcggt cgggctgcaa ccccccctgc acccccctcc ccgagttgct 3060
gagcacggcc cggcttcggg tgcggggctc cgtacggggc gtggcgcggg gctcgccgtg 3120
ccgggcgggg ggtggcggca ggtgggggtg ccgggcgggg cggggccgcc tcgggccggg 3180
gagggctcgg gggaggggcg cggcggcccc cggagcgccg gcggctgtcg aggcgcggcg 3240
agccgcagcc attgcctttt atggtaatcg tgcgagaggg cgcagggact tcctttgtcc 3300
caaatctgtg cggagccgaa atctgggagg cgccgccgca ccccctctag cgggcgcggg 3360
gcgaagcggt gcggcgccgg caggaaggaa atgggcgggg agggccttcg tgcgtcgccg 3420
cgccgccgtc cccttctccc tctccagcct cggggctgtc cgcgggggga cggctgcctt 3480
cgggggggac ggggcagggc ggggttcggc ttctggcgtg tgaccggcgg ctctagagcc 3540
tctgctaacc atgttcatgc cttcttcttt ttcctacagc tcctgggcaa cgtgctggtt 3600
attgtgctgt ctcatcattt tggcaaagaa ttgatgggat cggccattga acaagatgga 3660
ttgcacgcag gttctccggc cgcttgggtg gagaggctat tcggctatga ctgggcacaa 3720
cagacaatcg gctgctctga tgccgccgtg ttccggctgt cagcgcaggg gcgcccggtt 3780
ctttttgtca agaccgacct gtccggtgcc ctgaatgaac tgcaggacga ggcagcgcgg 3840
ctatcgtggc tggccacgac gggcgttcct tgcgcagctg tgctcgacgt tgtcactgaa 3900
gcgggaaggg actggctgct attgggcgaa gtgccggggc aggatctcct gtcatctcac 3960
cttgctcctg ccgagaaagt atccatcatg gctgatgcaa tgcggcggct gcatacgctt 4020
gatccggcta cctgcccatt cgaccaccaa gcgaaacatc gcatcgagcg agcacgtact 4080
cggatggaag ccggtcttgt cgatcaggat gatctggacg aagagcatca ggggctcgcg 4140
ccagccgaac tgttcgccag gctcaaggcg cgcatgcccg acggcgagga tctcgtcgtg 4200
acccatggcg atgcctgctt gccgaatatc atggtggaaa atggccgctt ttctggattc 4260
atcgactgtg gccggctggg tgtggcggac cgctatcagg acatagcgtt ggctacccgt 4320
gatattgctg aagagcttgg cggcgaatgg gctgaccgct tcctcgtgct ttacggtatc 4380
gccgctcccg attcgcagcg catcgccttc tatcgccttc ttgacgagtt cttctgatct 4440
agcctccgcc cctctccctc ccccccccct aacgttactg gccgaagccg cttggaataa 4500
ggccggtgtg cgtttgtcta tatgttattt tccaccatat tgccgtcttt tggcaatgtg 4560
agggcccgga aacctggccc tgtcttcttg acgagcattc ctaggggtct ttcccctctc 4620
gccaaaggaa tgcaaggtct gttgaatgtc gtgaaggaag cagttcctct ggaagcttct 4680
tgaagacaaa caacgtctgt agcgaccctt tgcaggcagc ggaacccccc acctggcgac 4740
aggtgcctct gcggccaaaa gccacgtgta taagatacac ctgcaaaggc ggcacaaccc 4800
cagtgccacg ttgtgagttg gatagttgtg gaaagagtca aatggctctc ctcaagcgta 4860
ttcaacaagg ggctgaagga tgcccagaag gtaccccatt gtatgggatc tgatctgggg 4920
cctcggtgca catgctttac atgtgtttag tcgaggttaa aaaaacgtct aggccccccg 4980
aaccacgggg acgtggtttt cctttgaaaa acacgatgat aatatggcca caaccatggt 5040
gagcaagggc gaggagctgt tcaccggggt ggtgcccatc ctggtcgagc tggacggcga 5100
cgtaaacggc cacaagttca gcgtgtccgg cgagggcgag ggcgatgcca cctacggcaa 5160
gctgaccctg aagttcatct gcaccaccgg caagctgccc gtgccctggc ccaccctcgt 5220
gaccaccctg acctacggcg tgcagtgctt cagccgctac cccgaccaca tgaagcagca 5280
cgacttcttc aagtccgcca tgcccgaagg ctacgtccag gagcgcacca tcttcttcaa 5340
ggacgacggc aactacaaga cccgcgccga ggtgaagttc gagggcgaca ccctggtgaa 5400
ccgcatcgag ctgaagggca tcgacttcaa ggaggacggc aacatcctgg ggcacaagct 5460
ggagtacaac tacaacagcc acaacgtcta tatcatggcc gacaagcaga agaacggcat 5520
caaggtgaac ttcaagatcc gccacaacat cgaggacggc agcgtgcagc tcgccgacca 5580
ctaccagcag aacaccccca tcggcgacgg ccccgtgctg ctgcccgaca accactacct 5640
gagcacccag tccgccctga gcaaagaccc caacgagaag cgcgatcaca tggtcctgct 5700
ggagttcgtg accgccgccg ggatcactct cggcatggac gagctgtaca agtaaagcgg 5760
ccgccaattc actcctcagg tgcaggctgc ctatcagaag gtggtggctg gtgtggccaa 5820
tgccctggct cacaaatacc actgagatct ttttccctct gccaaaaatt atggggacat 5880
catgaagccc cttgagcatc tgacttctgg ctaataaagg aaatttattt tcattgcaat 5940
agtgtgttgg aattttttgt gtctctcact cggaaggaca tatgggaggg caaatcattt 6000
aaaacatcag aatgagtatt tggtttagag tttggcaaca tatgcccata tgctggctgc 6060
catgaacaaa ggttggctat aaagaggtca tcagtatatg aaacagcccc ctgctgtcca 6120
ttccttattc catagaaaag ccttgacttg aggttagatt ttttttatat tttgttttgt 6180
gttatttttt tctttaacat ccctaaaatt ttccttacat gttttactag ccagattttt 6240
cctcctctcc tgactactcc cagtcatagc tgtccctctt ctcttatgga gatcgccgtt 6300
tccacattct tttctcatcc ttcttctcct gttttctctg catcaaggtc agcacgatag 6360
cactgtctct ctatgcttag ggagaggcct gtcctgtaca tcccgtgccc ccacaagatg 6420
cctactacaa caacatcttc tgcatgtcct gcatagcagt gttgggagaa tgtgcactac 6480
ttccactctt ctgatttcta ttttatgtgt ttgctttata ccagtgttgc catttgggaa 6540
ttaatacatg gttgatcaaa tcaattgcat cacagctgta tcctgtatca gaggaacatt 6600
atcaaagctt ttgttgctgt atttggtatc tgacctgcag ataaacatgt tttaggaagg 6660
ttttgcaaaa gtagctgtga aatgagctgg tgttgtgatt taacctgaca ggcagctaaa 6720
cagtatacca cagagctatt cacctacttt ccctcagtgg gaaaagggaa gagaactgag 6780
ggggggggga ataaataagt aaataacaaa ataaaactca tggattaaga aaaagacttt 6840
gtactggaat ggatgagaag aataatagta atgataataa tatgtcactc tgaaagtaat 6900
gcctcttatt tctgtggaga ctacaaacat acaaagagca caacattcca tagagcaaat 6960
tctcagttac agaatgctat tttttttttc aacacagtca aaatcattaa tttttttttg 7020
cctgcaatgg acaagagctt tgaagctgtt ctcgtaaaaa tctgtactag cagaagtgac 7080
ctgcaatcac tactgctgaa atgcacaacc caccacatca ttgtgctcac attcactgtt 7140
tggtttctgt aaatgtacag gaattgtctg aaattagata tgattttttt tttctccatg 7200
aaggaattca attacacacc tttgcctcat gcacttcttt gtcatttttg tcagactgct 7260
tctctcctgc aatttgtctc atggcaacaa aatataatgg agttctgctg ggaacttccc 7320
tactgccata ccactatcat ctgcctctga cattttggac aaatgtaata aaataggagg 7380
tattactttc agagcagacc ttgtatgtat ttacaaaaca agtggtacac aaaaaaaatt 7440
gttcatccca ccaaccaatg cccatcctgt ccctgaatag tagctgtccc ccacagcctt 7500
gaccagttta ggtcaacagt tctgcttctg tcccctccca gctccttgta acccctcagc 7560
cccccttgct ggcaggacag tatgagaagc tgaaaaacta gaatgtccta gttctttgca 7620
gtgctgctaa tcaacaacca aaacagtggt gtgttaccaa tattgttgat atcacagcat 7680
cataccatta tgaaggaagt aacccagcca aaatcaggtc agcttgctaa caagagaact 7740
gtgcataagt ttaagatgtg tgtgttcctc agtaccttaa aaaataagta gtaacgttca 7800
aatgagtaga agagtagaac tgagcttaaa acatctgtca gacaacagtg aaccaaccat 7860
ctttctagaa gatctcctac aatattctca gctgccatgg aaaatcgatg ttcttctttt 7920
attctctcaa gattttcagg ctgtatatta aaacttatat taagaactat gctaaccacc 7980
tcatcaggaa ccgttgtagg tggcgtgggt tttcttggca atcgactctc atgaaaacta 8040
cgagctaaat attcaatatg ttcctcttga ccaactttat tctgcatttt ttttgaacga 8100
ggtttagagc aagcttcagg aaactgagac aggaatttta ttaaaaattt aaattttgaa 8160
gaaagttcag ggttaatagc atccattttt tgctttgcaa gttcctcagc attcttaaca 8220
aaagacgtct cttttgacat gtttaaagtt taaacctcct gtgtgaaatt attatccgct 8280
cataattcca cacattatac gagccggaag cataaagtgt aaagcctggg gtgcctaatg 8340
agtgagctaa ctcacattaa ttgcgttgcg ctcactgcca attgctttcc agtcgggaaa 8400
cctgtcgtgc cagctgcatt aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat 8460
tgggcgctct tccgcttcct cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg 8520
agcggtatca gctcactcaa aggcggtaat acggttatcc acagaatcag gggataacgc 8580
aggaaagaac atgtgagcaa aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt 8640
gctggcgttt ttccataggc tccgcccccc tgacgagcat cacaaaaatc gacgctcaag 8700
tcagaggtgg cgaaacccga caggactata aagataccag gcgtttcccc ctggaagctc 8760
cctcgtgcgc tctcctgttc cgaccctgcc gcttaccgga tacctgtccg cctttctccc 8820
ttcgggaagc gtggcgcttt ctcatagctc acgctgtagg tatctcagtt cggtgtaggt 8880
cgttcgctcc aagctgggct gtgtgcacga accccccgtt cagcccgacc gctgcgcctt 8940
atccggtaac tatcgtcttg agtccaaccc ggtaagacac gacttatcgc cactggcagc 9000
agccactggt aacaggatta gcagagcgag gtatgtaggc ggtgctacag agttcttgaa 9060
gtggtggcct aactacggct acactagaag gacagtattt ggtatctgcg ctctgctgaa 9120
gccagttacc ttcggaaaaa gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg 9180
tagcggtggt ttttttgttt gcaagcagca gattacgcgc agaaaaaaag gatctcaaga 9240
agatcctttg atcttttcta cggggtctga cgctcagtgg aacgaaaact cacgttaagg 9300
gattttggtc atgagattat caaaaaggat cttcacctag atccttttaa attaaaaatg 9360
aagttttaaa tcaatctaaa gtatatatga gtaaacttgg tctgacagtt accaatgctt 9420
aatcagtgag gcacctatct cagcgatctg tctatttcgt tcatccatag ttgcctgact 9480
ccccgtcgtg tagataacta cgatacggga gggcttacca tctggcccca gtgctgcaat 9540
gataccgcga gacccacgct caccggctcc agatttatca gcaataaacc agccagccgg 9600
aagggccgag cgcagaagtg gtcctgcaac tttatccgcc tccatccagt ctattaattg 9660
ttgccgggaa gctagagtaa gtagttcgcc agttaatagt ttgcgcaacg ttgttgccat 9720
tgctacaggc atcgtggtgt cacgctcgtc gtttggtatg gcttcattca gctccggttc 9780
ccaacgatca aggcgagtta catgatcccc catgttgtgc aaaaaagcgg ttagctcctt 9840
cggtcctccg atcgttgtca gaagtaagtt ggccgcagtg ttatcactca tggttatggc 9900
agcactgcat aattctctta ctgtcatgcc atccgtaaga tgcttttctg tgactggtga 9960
gtactcaacc aagtcattct gagaatagtg tatgcggcga ccgagttgct cttgcccggc 10020
gtcaatacgg gataataccg cgccacatag cagaacttta aaagtgctca tcattggaaa 10080
acgttcttcg gggcgaaaac tctcaaggat cttaccgctg ttgagatcca gttcgatgta 10140
acccactcgt gcacccaact gatcttcagc atcttttact ttcaccagcg tttctgggtg 10200
agcaaaaaca ggaaggcaaa atgccgcaaa aaagggaata agggcgacac ggaaatgttg 10260
aatactcata ctcttccttt ttcaatatta ttgaagcatt tatcagggtt attgtctcat 10320
gagcggatac atatttgaat gtatttagaa aaataaacaa ataggggttc cgcgcacatt 10380
tccccgaaaa gtgccacctg acgtctaaga aaccattatt atcatgacat taacctataa 10440
aaataggcgt atcacgaggc c 10461
<210> 56
<211> 7679
<212> DNA
<213> Artificial sequence
<220>
<223> pmCherry-Cry2-CreN nucleic acid sequence
<400> 56
tagttattaa tagtaatcaa ttacggggtc attagttcat agcccatata tggagttccg 60
cgttacataa cttacggtaa atggcccgcc tggctgaccg cccaacgacc cccgcccatt 120
gacgtcaata atgacgtatg ttcccatagt aacgccaata gggactttcc attgacgtca 180
atgggtggag tatttacggt aaactgccca cttggcagta catcaagtgt atcatatgcc 240
aagtacgccc cctattgacg tcaatgacgg taaatggccc gcctggcatt atgcccagta 300
catgacctta tgggactttc ctacttggca gtacatctac gtattagtca tcgctattac 360
catggtgatg cggttttggc agtacatcaa tgggcgtgga tagcggtttg actcacgggg 420
atttccaagt ctccacccca ttgacgtcaa tgggagtttg ttttggcacc aaaatcaacg 480
ggactttcca aaatgtcgta acaactccgc cccattgacg caaatgggcg gtaggcgtgt 540
acggtgggag gtctatataa gcagagctgg tttagtgaac cgtcagatcc gctagcgcta 600
ccggtcgcca ccatggtgag caagggcgag gaggataaca tggccatcat caaggagttc 660
atgcgcttca aggtgcacat ggagggctcc gtgaacggcc acgagttcga gatcgagggc 720
gagggcgagg gccgccccta cgagggcacc cagaccgcca agctgaaggt gaccaagggt 780
ggccccctgc ccttcgcctg ggacatcctg tcccctcagt tcatgtacgg ctccaaggcc 840
tacgtgaagc accccgccga catccccgac tacttgaagc tgtccttccc cgagggcttc 900
aagtgggagc gcgtgatgaa cttcgaggac ggcggcgtgg tgaccgtgac ccaggactcc 960
tccctgcagg acggcgagtt catctacaag gtgaagctgc gcggcaccaa cttcccctcc 1020
gacggccccg taatgcagaa gaagaccatg ggctgggagg cctcctccga gcggatgtac 1080
cccgaggacg gcgccctgaa gggcgagatc aagcagaggc tgaagctgaa ggacggcggc 1140
cactacgacg ctgaggtcaa gaccacctac aaggccaaga agcccgtgca gctgcccggc 1200
gcctacaacg tcaacatcaa gttggacatc acctcccaca acgaggacta caccatcgtg 1260
gaacagtacg aacgcgccga gggccgccac tccaccggcg gcatggacga gctgtacaag 1320
tgtggcggct agtactccgg tattgcggta cccttgtacg cctgttttat actcccttcc 1380
cgtaacttag acgcacaaaa ccaagttcaa tagaaggggg tacaaaccag taccaccacg 1440
aacaagcact tctgtttccc cggtgatgtc gtatagactg cttgcgtggt tgaaagcgac 1500
ggatccgtta tccgcttatg tacttcgaga agcccagtac cacctcggaa tcttcgatgc 1560
gttgcgctca gcactcaacc ccagagtgta gcttaggctg atgagtctgg acatccctca 1620
ccggtgacgg tggtccaggc tgcgttggcg gcctacctat ggctaacgcc atgggacgct 1680
agttgtgaac aaggtgtgaa gagcctattg agctacataa gaatcctccg gcccctgaat 1740
gcggctaatc ccaacctcgg agcaggtggt cacaaaccag tgattggcct gtcgtaacgc 1800
gcaagtccgt ggcggaaccg actactttgg gtgtccgtgt ttccttttat tttattgtgg 1860
ctgcttatgg tgacaatcac agattgttat cataaagcga attggatagg atcaagctta 1920
tcgataccgt cgacctcgag ctcgccacca tgaagatgga caaaaagact atagtttggt 1980
ttagaagaga cctaaggatt gaggataatc ctgcattagc agcagctgct cacgaaggat 2040
ctgtttttcc tgtcttcatt tggtgtcctg aagaagaagg acagttttat cctggaagag 2100
cttcaagatg gtggatgaaa caatcacttg ctcacttatc tcaatccttg aaggctcttg 2160
gatctgacct cactttaatc aaaacccaca acacgatttc agcgatcttg gattgtatcc 2220
gcgttaccgg tgctacaaaa gtcgtcttta accacctcta tgatcctgtt tcgttagttc 2280
gggaccatac cgtaaaggag aagctggtgg aacgtgggat ctctgtgcaa agctacaatg 2340
gagatctatt gtatgaaccg tgggagatat actgcgaaaa gggcaaacct tttacgagtt 2400
tcaattctta ctggaagaaa tgcttagata tgtcgattga atccgttatg cttcctcctc 2460
cttggcggtt gatgccaata actgcagcgg ctgaagcgat ttgggcgtgt tcgattgaag 2520
aactagggct ggagaatgag gccgagaaac cgagcaatgc gttgttaact agagcttggt 2580
ctccaggatg gagcaatgct gataagttac taaatgagtt catcgagaag cagttgatag 2640
attatgcaaa gaacagcaag aaagttgttg ggaattctac ttcactactt tctccgtatc 2700
tccatttcgg ggaaataagc gtcagacacg ttttccagtg tgcccggatg aaacaaatta 2760
tatgggcaag agataagaac agtgaaggag aagaaagtgc agatcttttt cttaggggaa 2820
tcggtttaag agagtattct cggtatatat gtttcaactt cccgtttact cacgagcaat 2880
cgttgttgag tcatcttcgg tttttccctt gggatgctga tgttgataag ttcaaggcct 2940
ggagacaagg caggaccggt tatccgttgg tggatgccgg aatgagagag ctttgggcta 3000
ccggatggat gcataacaga ataagagtga ttgtttcaag ctttgctgtg aagtttcttc 3060
tccttccatg gaaatgggga atgaagtatt tctgggatac acttttggat gctgatttgg 3120
aatgtgacat ccttggctgg cagtatatct ctgggagtat ccccgatggc cacgagcttg 3180
atcgcttgga caatcccgcg ttacaaggcg ccaaatatga cccagaaggt gagtacataa 3240
ggcaatggct tcccgagctt gcgagattgc caactgaatg gatccatcat ccatgggacg 3300
ctcctttaac cgtactcaaa gcttctggtg tggaactcgg aacaaactat gcgaaaccca 3360
ttgtagacat cgacacagct cgtgagctac tagctaaagc tatttcaaga acccgtgaag 3420
cacagatcat gatcggagca gcacctgatg agattgtagc agatagcttc gaggccttag 3480
gggctaatac cattaaagaa cctggtcttt gcccatctgt gtcttctaat gaccaacaag 3540
taccttcggc tgttcgttac aacgggtcaa agagagtgaa acctgaggaa gaagaagaga 3600
gagacatgaa gaaatctagg ggattcgatg aaagggagtt gttttcgact gctgaatctt 3660
cttcttcttc gagtgtgttt ttcgtttcgc agtcttgctc gttggcatca gaagggaaga 3720
atctggaagg tattcaagat tcatctgatc agattactac aagtttggga aaaaatggtt 3780
gcaaaggtgg cggtggctct ggaggtggtg ggtccggagg aggcggccgc acgagtgatg 3840
aggttcgcaa gaacctgatg gacatgttca gggatcgcca ggcgttttct gagcatacct 3900
ggaaaatgct tctgtccgtt tgccggtcgt gggcggcatg gtgcaagttg aataaccgga 3960
aatggtttcc cgcagaacct gaagatgttc gcgattatct tctatatctt caggcgcgcg 4020
gtctggcagt aaaaactatc cagcaacatt tgggccagct aaacatgctt catcgtcggt 4080
ccgggctgta acccgggatc caccggatct agataactga tcataatcag ccataccaca 4140
tttgtagagg ttttacttgc tttaaaaaac ctcccacacc tccccctgaa cctgaaacat 4200
aaaatgaatg caattgttgt tgttaacttg tttattgcag cttataatgg ttacaaataa 4260
agcaatagca tcacaaattt cacaaataaa gcattttttt cactgcattc tagttgtggt 4320
ttgtccaaac tcatcaatgt atcttaacgc gtaaattgta agcgttaata ttttgttaaa 4380
attcgcgtta aatttttgtt aaatcagctc attttttaac caataggccg aaatcggcaa 4440
aatcccttat aaatcaaaag aatagaccga gatagggttg agtgttgttc cagtttggaa 4500
caagagtcca ctattaaaga acgtggactc caacgtcaaa gggcgaaaaa ccgtctatca 4560
gggcgatggc ccactacgtg aaccatcacc ctaatcaagt tttttggggt cgaggtgccg 4620
taaagcacta aatcggaacc ctaaagggag cccccgattt agagcttgac ggggaaagcc 4680
ggcgaacgtg gcgagaaagg aagggaagaa agcgaaagga gcgggcgcta gggcgctggc 4740
aagtgtagcg gtcacgctgc gcgtaaccac cacacccgcc gcgcttaatg cgccgctaca 4800
gggcgcgtca ggtggcactt ttcggggaaa tgtgcgcgga acccctattt gtttattttt 4860
ctaaatacat tcaaatatgt atccgctcat gagacaataa ccctgataaa tgcttcaata 4920
atattgaaaa aggaagagtc ctgaggcgga aagaaccagc tgtggaatgt gtgtcagtta 4980
gggtgtggaa agtccccagg ctccccagca ggcagaagta tgcaaagcat gcatctcaat 5040
tagtcagcaa ccaggtgtgg aaagtcccca ggctccccag caggcagaag tatgcaaagc 5100
atgcatctca attagtcagc aaccatagtc ccgcccctaa ctccgcccat cccgccccta 5160
actccgccca gttccgccca ttctccgccc catggctgac taattttttt tatttatgca 5220
gaggccgagg ccgcctcggc ctctgagcta ttccagaagt agtgaggagg cttttttgga 5280
ggcctaggct tttgcaaaga tcgatcaaga gacaggatga ggatcgtttc gcatgattga 5340
acaagatgga ttgcacgcag gttctccggc cgcttgggtg gagaggctat tcggctatga 5400
ctgggcacaa cagacaatcg gctgctctga tgccgccgtg ttccggctgt cagcgcaggg 5460
gcgcccggtt ctttttgtca agaccgacct gtccggtgcc ctgaatgaac tgcaagacga 5520
ggcagcgcgg ctatcgtggc tggccacgac gggcgttcct tgcgcagctg tgctcgacgt 5580
tgtcactgaa gcgggaaggg actggctgct attgggcgaa gtgccggggc aggatctcct 5640
gtcatctcac cttgctcctg ccgagaaagt atccatcatg gctgatgcaa tgcggcggct 5700
gcatacgctt gatccggcta cctgcccatt cgaccaccaa gcgaaacatc gcatcgagcg 5760
agcacgtact cggatggaag ccggtcttgt cgatcaggat gatctggacg aagagcatca 5820
ggggctcgcg ccagccgaac tgttcgccag gctcaaggcg agcatgcccg acggcgagga 5880
tctcgtcgtg acccatggcg atgcctgctt gccgaatatc atggtggaaa atggccgctt 5940
ttctggattc atcgactgtg gccggctggg tgtggcggac cgctatcagg acatagcgtt 6000
ggctacccgt gatattgctg aagagcttgg cggcgaatgg gctgaccgct tcctcgtgct 6060
ttacggtatc gccgctcccg attcgcagcg catcgccttc tatcgccttc ttgacgagtt 6120
cttctgagcg ggactctggg gttcgaaatg accgaccaag cgacgcccaa cctgccatca 6180
cgagatttcg attccaccgc cgccttctat gaaaggttgg gcttcggaat cgttttccgg 6240
gacgccggct ggatgatcct ccagcgcggg gatctcatgc tggagttctt cgcccaccct 6300
agggggaggc taactgaaac acggaaggag acaataccgg aaggaacccg cgctatgacg 6360
gcaataaaaa gacagaataa aacgcacggt gttgggtcgt ttgttcataa acgcggggtt 6420
cggtcccagg gctggcactc tgtcgatacc ccaccgagac cccattgggg ccaatacgcc 6480
cgcgtttctt ccttttcccc accccacccc ccaagttcgg gtgaaggccc agggctcgca 6540
gccaacgtcg gggcggcagg ccctgccata gcctcaggtt actcatatat actttagatt 6600
gatttaaaac ttcattttta atttaaaagg atctaggtga agatcctttt tgataatctc 6660
atgaccaaaa tcccttaacg tgagttttcg ttccactgag cgtcagaccc cgtagaaaag 6720
atcaaaggat cttcttgaga tccttttttt ctgcgcgtaa tctgctgctt gcaaacaaaa 6780
aaaccaccgc taccagcggt ggtttgtttg ccggatcaag agctaccaac tctttttccg 6840
aaggtaactg gcttcagcag agcgcagata ccaaatactg tccttctagt gtagccgtag 6900
ttaggccacc acttcaagaa ctctgtagca ccgcctacat acctcgctct gctaatcctg 6960
ttaccagtgg ctgctgccag tggcgataag tcgtgtctta ccgggttgga ctcaagacga 7020
tagttaccgg ataaggcgca gcggtcgggc tgaacggggg gttcgtgcac acagcccagc 7080
ttggagcgaa cgacctacac cgaactgaga tacctacagc gtgagctatg agaaagcgcc 7140
acgcttcccg aagggagaaa ggcggacagg tatccggtaa gcggcagggt cggaacagga 7200
gagcgcacga gggagcttcc agggggaaac gcctggtatc tttatagtcc tgtcgggttt 7260
cgccacctct gacttgagcg tcgatttttg tgatgctcgt caggggggcg gagcctatgg 7320
aaaaacgcca gcaacgcggc ctttttacgg ttcctggcct tttgctggcc ttttgctcac 7380
atgttctttc ctgcgttatc ccctgattct gtggataacc gtattaccgc catgcattag 7440
caccgcctac atacctcgct ctgctaatcc tgttaccagt ggctgctgcc agtggcgata 7500
agtcgtgtct taccgggttg gactcaagac gatagttacc ggataaggcg cagcggtcgg 7560
gctgaacggg gggttcgtgc acacagccca gcttggagcg aacgacctac accgaactga 7620
gatacctaca gcgtgagcta tgagaaagcg ccacgcttcc cgaagggaga aaggcggac 7679
<210> 57
<211> 6655
<212> DNA
<213> Artificial sequence
<220>
<223> pmCherry-CIBN-CreC nucleic acid sequence
<220>
<221> misc_feature
<222> (1717)..(1717)
<223> n is a, c, g, or t
<400> 57
tagttattaa tagtaatcaa ttacggggtc attagttcat agcccatata tggagttccg 60
cgttacataa cttacggtaa atggcccgcc tggctgaccg cccaacgacc cccgcccatt 120
gacgtcaata atgacgtatg ttcccatagt aacgccaata gggactttcc attgacgtca 180
atgggtggag tatttacggt aaactgccca cttggcagta catcaagtgt atcatatgcc 240
aagtacgccc cctattgacg tcaatgacgg taaatggccc gcctggcatt atgcccagta 300
catgacctta tgggactttc ctacttggca gtacatctac gtattagtca tcgctattac 360
catggtgatg cggttttggc agtacatcaa tgggcgtgga tagcggtttg actcacgggg 420
atttccaagt ctccacccca ttgacgtcaa tgggagtttg ttttggcacc aaaatcaacg 480
ggactttcca aaatgtcgta acaactccgc cccattgacg caaatgggcg gtaggcgtgt 540
acggtgggag gtctatataa gcagagctgg tttagtgaac cgtcagatcc gctagcgcta 600
ccggtcgcca ccatggtgag caagggcgag gaggataaca tggccatcat caaggagttc 660
atgcgcttca aggtgcacat ggagggctcc gtgaacggcc acgagttcga gatcgagggc 720
gagggcgagg gccgccccta cgagggcacc cagaccgcca agctgaaggt gaccaagggt 780
ggccccctgc ccttcgcctg ggacatcctg tcccctcagt tcatgtacgg ctccaaggcc 840
tacgtgaagc accccgccga catccccgac tacttgaagc tgtccttccc cgagggcttc 900
aagtgggagc gcgtgatgaa cttcgaggac ggcggcgtgg tgaccgtgac ccaggactcc 960
tccctgcagg acggcgagtt catctacaag gtgaagctgc gcggcaccaa cttcccctcc 1020
gacggccccg taatgcagaa gaagaccatg ggctgggagg cctcctccga gcggatgtac 1080
cccgaggacg gcgccctgaa gggcgagatc aagcagaggc tgaagctgaa ggacggcggc 1140
cactacgacg ctgaggtcaa gaccacctac aaggccaaga agcccgtgca gctgcccggc 1200
gcctacaacg tcaacatcaa gttggacatc acctcccaca acgaggacta caccatcgtg 1260
gaacagtacg aacgcgccga gggccgccac tccaccggcg gcatggacga gctgtacaag 1320
tgtggcggct agtactccgg tattgcggta cccttgtacg cctgttttat actcccttcc 1380
cgtaacttag acgcacaaaa ccaagttcaa tagaaggggg tacaaaccag taccaccacg 1440
aacaagcact tctgtttccc cggtgatgtc gtatagactg cttgcgtggt tgaaagcgac 1500
ggatccgtta tccgcttatg tacttcgaga agcccagtac cacctcggaa tcttcgatgc 1560
gttgcgctca gcactcaacc ccagagtgta gcttaggctg atgagtctgg acatccctca 1620
ccggtgacgg tggtccaggc tgcgttggcg gcctacctat ggctaacgcc atgggacgct 1680
agttgtgaac aaggtgtgaa gagcctattg agctacntaa gaatcctccg gcccctgaat 1740
gcggctaatc ccaacctcgg agcaggtggt cacaaaccag tgattggcct gtcgtaacgc 1800
gcaagtccgt ggcggaaccg actactttgg gtgtccgtgt ttccttttat tttattgtgg 1860
ctgcttatgg tgacaatcac agattgttat cataaagcga attggatagg atcaagctta 1920
tcgataccgt cgacctcgag ctcgccacca tgaatggagc tataggaggt gaccttttgc 1980
tcaattttcc tgacatgtcg gtcctagagc gccaaagggc tcacctcaag tacctcaatc 2040
ccacctttga ttctcctctc gccggcttct ttgccgattc ttcaatgatt accggcggcg 2100
agatggacag ctatctttcg actgccggtt tgaatcttcc gatgatgtac ggtgagacga 2160
cggtggaagg tgattcaaga ctctcaattt cgccggaaac gacgcttggg actggaaatt 2220
tcaagaaacg gaagtttgat acagagacta aggattgtaa tgagaagaag aagaagatga 2280
cgatgaacag agatgaccta gtagaagaag gagaagaaga gaagtcgaaa ataacagagc 2340
aaaacaatgg gagcacaaaa agcatcaaga agatgaaaca caaagccaag aaagaagaga 2400
acaatttctc taatgattca tctaaagtga cgaaggaatt ggagaaaacg gattatattc 2460
atggtggcgg tggctctgga ggtggtgggt ccggaggagg cggccgccga ccaagtgaca 2520
gcaatgctgt ttcactggtt atgcggcgga tccgaaaaga aaacgttgat gccggtgaac 2580
gtgcaaaaca ggctctagcg ttcgaacgca ctgatttcga ccaggttcgt tcactcatgg 2640
aaaatagcga tcgctgccag gatatacgta atctggcatt tctggggatt gcttataaca 2700
ccctgttacg tatagccgaa attgccagga tcagggttaa agatatctca cgtactgacg 2760
gtgggagaat gttaatccat attggcagaa cgaaaacgct ggttagcacc gcaggtgtag 2820
agaaggcact tagcctgggg gtaactaaac tggtcgagcg atggatttcc gtctctggtg 2880
tagctgatga tccgaataac tacctgtttt gccgggtcag aaaaaatggt gttgccgcgc 2940
catctgccac cagccagcta tcaactcgcg ccctggaagg gatttttgaa gcaactcatc 3000
gattgattta cggcgctaag gatgactctg gtcagagata cctggcctgg tctggacaca 3060
gtgcccgtgt cggagccgcg cgagatatgg cccgcgctgg agtttcaata ccggagatca 3120
tgcaagctgg tggctggacc aatgtaaata ttgtcatgaa ctatatccgt aacctggata 3180
gtgaaacagg ggcaatggtg cgcctgctgg aagatggcga ttagcccggg atccaccgga 3240
tctagataac tgatcataat cagccatacc acatttgtag aggttttact tgctttaaaa 3300
aacctcccac acctccccct gaacctgaaa cataaaatga atgcaattgt tgttgttaac 3360
ttgtttattg cagcttataa tggttacaaa taaagcaata gcatcacaaa tttcacaaat 3420
aaagcatttt tttcactgca ttctagttgt ggtttgtcca aactcatcaa tgtatcttaa 3480
cgcgtaaatt gtaagcgtta atattttgtt aaaattcgcg ttaaattttt gttaaatcag 3540
ctcatttttt aaccaatagg ccgaaatcgg caaaatccct tataaatcaa aagaatagac 3600
cgagataggg ttgagtgttg ttccagtttg gaacaagagt ccactattaa agaacgtgga 3660
ctccaacgtc aaagggcgaa aaaccgtcta tcagggcgat ggcccactac gtgaaccatc 3720
accctaatca agttttttgg ggtcgaggtg ccgtaaagca ctaaatcgga accctaaagg 3780
gagcccccga tttagagctt gacggggaaa gccggcgaac gtggcgagaa aggaagggaa 3840
gaaagcgaaa ggagcgggcg ctagggcgct ggcaagtgta gcggtcacgc tgcgcgtaac 3900
caccacaccc gccgcgctta atgcgccgct acagggcgcg tcaggtggca cttttcgggg 3960
aaatgtgcgc ggaaccccta tttgtttatt tttctaaata cattcaaata tgtatccgct 4020
catgagacaa taaccctgat aaatgcttca ataatattga aaaaggaaga gtcctgaggc 4080
ggaaagaacc agctgtggaa tgtgtgtcag ttagggtgtg gaaagtcccc aggctcccca 4140
gcaggcagaa gtatgcaaag catgcatctc aattagtcag caaccaggtg tggaaagtcc 4200
ccaggctccc cagcaggcag aagtatgcaa agcatgcatc tcaattagtc agcaaccata 4260
gtcccgcccc taactccgcc catcccgccc ctaactccgc ccagttccgc ccattctccg 4320
ccccatggct gactaatttt ttttatttat gcagaggccg aggccgcctc ggcctctgag 4380
ctattccaga agtagtgagg aggctttttt ggaggcctag gcttttgcaa agatcgatca 4440
agagacagga tgaggatcgt ttcgcatgat tgaacaagat ggattgcacg caggttctcc 4500
ggccgcttgg gtggagaggc tattcggcta tgactgggca caacagacaa tcggctgctc 4560
tgatgccgcc gtgttccggc tgtcagcgca ggggcgcccg gttctttttg tcaagaccga 4620
cctgtccggt gccctgaatg aactgcaaga cgaggcagcg cggctatcgt ggctggccac 4680
gacgggcgtt ccttgcgcag ctgtgctcga cgttgtcact gaagcgggaa gggactggct 4740
gctattgggc gaagtgccgg ggcaggatct cctgtcatct caccttgctc ctgccgagaa 4800
agtatccatc atggctgatg caatgcggcg gctgcatacg cttgatccgg ctacctgccc 4860
attcgaccac caagcgaaac atcgcatcga gcgagcacgt actcggatgg aagccggtct 4920
tgtcgatcag gatgatctgg acgaagagca tcaggggctc gcgccagccg aactgttcgc 4980
caggctcaag gcgagcatgc ccgacggcga ggatctcgtc gtgacccatg gcgatgcctg 5040
cttgccgaat atcatggtgg aaaatggccg cttttctgga ttcatcgact gtggccggct 5100
gggtgtggcg gaccgctatc aggacatagc gttggctacc cgtgatattg ctgaagagct 5160
tggcggcgaa tgggctgacc gcttcctcgt gctttacggt atcgccgctc ccgattcgca 5220
gcgcatcgcc ttctatcgcc ttcttgacga gttcttctga gcgggactct ggggttcgaa 5280
atgaccgacc aagcgacgcc caacctgcca tcacgagatt tcgattccac cgccgccttc 5340
tatgaaaggt tgggcttcgg aatcgttttc cgggacgccg gctggatgat cctccagcgc 5400
ggggatctca tgctggagtt cttcgcccac cctaggggga ggctaactga aacacggaag 5460
gagacaatac cggaaggaac ccgcgctatg acggcaataa aaagacagaa taaaacgcac 5520
ggtgttgggt cgtttgttca taaacgcggg gttcggtccc agggctggca ctctgtcgat 5580
accccaccga gaccccattg gggccaatac gcccgcgttt cttccttttc cccaccccac 5640
cccccaagtt cgggtgaagg cccagggctc gcagccaacg tcggggcggc aggccctgcc 5700
atagcctcag gttactcata tatactttag attgatttaa aacttcattt ttaatttaaa 5760
aggatctagg tgaagatcct ttttgataat ctcatgacca aaatccctta acgtgagttt 5820
tcgttccact gagcgtcaga ccccgtagaa aagatcaaag gatcttcttg agatcctttt 5880
tttctgcgcg taatctgctg cttgcaaaca aaaaaaccac cgctaccagc ggtggtttgt 5940
ttgccggatc aagagctacc aactcttttt ccgaaggtaa ctggcttcag cagagcgcag 6000
ataccaaata ctgtccttct agtgtagccg tagttaggcc accacttcaa gaactctgta 6060
gcaccgccta catacctcgc tctgctaatc ctgttaccag tggctgctgc cagtggcgat 6120
aagtcgtgtc ttaccgggtt ggactcaaga cgatagttac cggataaggc gcagcggtcg 6180
ggctgaacgg ggggttcgtg cacacagccc agcttggagc gaacgaccta caccgaactg 6240
agatacctac agcgtgagct atgagaaagc gccacgcttc ccgaagggag aaaggcggac 6300
aggtatccgg taagcggcag ggtcggaaca ggagagcgca cgagggagct tccaggggga 6360
aacgcctggt atctttatag tcctgtcggg tttcgccacc tctgacttga gcgtcgattt 6420
ttgtgatgct cgtcaggggg gcggagccta tggaaaaacg ccagcaacgc ggccttttta 6480
cggttcctgg ccttttgctg gccttttgct cacatgttct ttcctgcgtt atcccctgat 6540
tctgtggata accgtattac cgccatgcat tagcaccgcc tacatacctc gctctgctaa 6600
tcctgttacc agtggctgct gccagtggcg ataagtcgtg tcttaccggg ttgga 6655
<210> 58
<211> 8968
<212> DNA
<213> Artificial sequence
<220>
<223> pB-RAGE-GFP nucleic acid sequence
<400> 58
caggtggcac ttttcgggga aatgtgcgcg gaacccctat ttgtttattt ttctaaatac 60
attcaaatat gtatccgctc atgagacaat aaccctgata aatgcttcaa taatattgaa 120
aaaggaagag tatgagtatt caacatttcc gtgtcgccct tattcccttt tttgcggcat 180
tttgccttcc tgtttttgct cacccagaaa cgctggtgaa agtaaaagat gctgaagatc 240
agttgggtgc acgagtgggt tacatcgaac tggatctcaa cagcggtaag atccttgaga 300
gttttcgccc cgaagaacgt tttccaatga tgagcacttt taaagttctg ctatgtggcg 360
cggtattatc ccgtattgac gccgggcaag agcaactcgg tcgccgcata cactattctc 420
agaatgactt ggttgagtac tcaccagtca cagaaaagca tcttacggat ggcatgacag 480
taagagaatt atgcagtgct gccataacca tgagtgataa cactgcggcc aacttacttc 540
tgacaacgat cggaggaccg aaggagctaa ccgctttttt gcacaacatg ggggatcatg 600
taactcgcct tgatcgttgg gaaccggagc tgaatgaagc cataccaaac gacgagcgtg 660
acaccacgat gcctgtagca atggcaacaa cgttgcgcaa actattaact ggcgaactac 720
ttactctagc ttcccggcaa caattaatag actggatgga ggcggataaa gttgcaggac 780
cacttctgcg ctcggccctt ccggctggct ggtttattgc tgataaatct ggagccggtg 840
agcgtgggtc tcgcggtatc attgcagcac tggggccaga tggtaagccc tcccgtatcg 900
tagttatcta cacgacgggg agtcaggcaa ctatggatga acgaaataga cagatcgctg 960
agataggtgc ctcactgatt aagcattggt aactgtcaga ccaagtttac tcatatatac 1020
tttagattga tttaaaactt catttttaat ttaaaaggat ctaggtgaag atcctttttg 1080
ataatctcat gaccaaaatc ccttaacgtg agttttcgtt ccactgagcg tcagaccccg 1140
tagaaaagat caaaggatct tcttgagatc ctttttttct gcgcgtaatc tgctgcttgc 1200
aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc ggatcaagag ctaccaactc 1260
tttttccgaa ggtaactggc ttcagcagag cgcagatacc aaatactgtc cttctagtgt 1320
agccgtagtt aggccaccac ttcaagaact ctgtagcacc gcctacatac ctcgctctgc 1380
taatcctgtt accagtggct gctgccagtg gcgataagtc gtgtcttacc gggttggact 1440
caagacgata gttaccggat aaggcgcagc ggtcgggctg aacggggggt tcgtgcacac 1500
agcccagctt ggagcgaacg acctacaccg aactgagata cctacagcgt gagctatgag 1560
aaagcgccac gcttcccgaa gggagaaagg cggacaggta tccggtaagc ggcagggtcg 1620
gaacaggaga gcgcacgagg gagcttccag ggggaaacgc ctggtatctt tatagtcctg 1680
tcgggtttcg ccacctctga cttgagcgtc gatttttgtg atgctcgtca ggggggcgga 1740
gcctatggaa aaacgccagc aacgcggcct ttttacggtt cctggccttt tgctggcctt 1800
ttgctcacat gttctttcct gcgttatccc ctgattctgt ggataaccgt attaccgcct 1860
ttgagtgagc tgataccgct cgccgcagcc gaacgaccga gcgcagcgag tcagtgagcg 1920
aggaagcgga agagcgccca atacgcaaac cgcctctccc cgcgcgttgg ccgattcatt 1980
aatgcagctg gcacgacagg tttcccgact ggaaagcggg cagtgagcgc aacgcaatta 2040
atgtgagtta gctcactcat taggcacccc aggctttaca ctttatgctt ccggctcgta 2100
tgttgtgtgg aattgtgagc ggataacaat ttcacacagg aaacagctat gaccatgatt 2160
acgccaagct cggaattaac cctcactaaa gggaacaaaa gctggctcgc gcgacttggt 2220
ttgccattct ttagcgcgcg tcgcgtcaca cagcttggcc acaatgtggt ttttgtcaaa 2280
cgaagattct atgacgtgtt taaagtttag gtcgagtaaa gcgcaaatct tttttaaccc 2340
tagaaagata gtctgcgtaa aattgacgca tgcattcttg aaatattgct ctctctttct 2400
aaatagcgcg aatccgtcgc tgtgcattta ggacatctca gtcgccgctt ggagctcccg 2460
tgaggcgtgc ttgtcaatgc ggtaagtgtc actgattttg aactataacg accgcgtgag 2520
tcaaaatgac gcatgattat cttttacgtg acttttaaga tttaactcat acgataatta 2580
tattgttatt tcatgttcta cttacgtgat aacttattat atatatattt tcttgttata 2640
gatatcgtga ctaatatata ataaaatggg tagttcttta gacgatgagc atatcctctc 2700
tgctcttctg caaagcgatg acgagcttgt tggctagtta ttaatagtaa tcaattacgg 2760
ggtcattagt tcatagccca tatatggagt tccgcgttac ataacttacg gtaaatggcc 2820
cgcctggctg accgcccaac gacccccgcc cattgacgtc aataatgacg tatgttccca 2880
tagtaacgcc aatagggact ttccattgac gtcaatgggt ggagtattta cggtaaactg 2940
cccacttggc agtacatcaa gtgtatcata tgccaagtac gccccctatt gacgtcaatg 3000
acggtaaatg gcccgcctgg cattatgccc agtacatgac cttatgggac tttcctactt 3060
ggcagtacat ctacgtatta gtcatcgcta ttaccatggt cgaggtgagc cccacgttct 3120
gcttcactct ccccatctcc cccccctccc cacccccaat tttgtattta tttatttttt 3180
aattattttg tgcagcgatg ggggcggggg gggggggggg gcgcgcgcca ggcggggcgg 3240
ggcggggcga ggggcggggc ggggcgaggc ggagaggtgc ggcggcagcc aatcagagcg 3300
gcgcgctccg aaagtttcct tttatggcga ggcggcggcg gcggcggccc tataaaaagc 3360
gaagcgcgcg gcgggcgggg agtcgctgcg acgctgcctt cgccccgtgc cccgctccgc 3420
cgccgcctcg cgccgcccgc cccggctctg actgaccgcg ttactcccac aggtgagcgg 3480
gcgggacggc ccttctcctc cgggctgtaa ttagcgcttg gtttaatgac ggcttgtttc 3540
ttttctgtgg ctgcgtgaaa gccttgaggg gctccgggag ggccctttgt gcggggggag 3600
cggctcgggg ggtgcgtgcg tgtgtgtgtg cgtggggagc gccgcgtgcg gctccgcgct 3660
gcccggcggc tgtgagcgct gcgggcgcgg cgcggggctt tgtgcgctcc gcagtgtgcg 3720
cgaggggagc gcggccgggg gcggtgcccc gcggtgcggg gggggctgcg aggggaacaa 3780
aggctgcgtg cggggtgtgt gcgtgggggg gtgagcaggg ggtgtgggcg cgtcggtcgg 3840
gctgcaaccc cccctgcacc cccctccccg agttgctgag cacggcccgg cttcgggtgc 3900
ggggctccgt acggggcgtg gcgcggggct cgccgtgccg ggcggggggt ggcggcaggt 3960
gggggtgccg ggcggggcgg ggccgcctcg ggccggggag ggctcggggg aggggcgcgg 4020
cggcccccgg agcgccggcg gctgtcgagg cgcggcgagc cgcagccatt gccttttatg 4080
gtaatcgtgc gagagggcgc agggacttcc tttgtcccaa atctgtgcgg agccgaaatc 4140
tgggaggcgc cgccgcaccc cctctagcgg gcgcggggcg aagcggtgcg gcgccggcag 4200
gaaggaaatg ggcggggagg gccttcgtgc gtcgccgcgc cgccgtcccc ttctccctct 4260
ccagcctcgg ggctgtccgc ggggggacgg ctgccttcgg gggggacggg gcagggcggg 4320
gttcggcttc tggcgtgtga ccggcggctc tagagcctct gctaaccatg ttcatgcctt 4380
cttctttttc ctacagctcc tgggcaacgt gctggttatt gtgctgtctc atcattttgg 4440
caaagaattc catcaagctt aggatccgga acccttaata taacttcgta taatgtatgc 4500
tatacgaagt tattaggtcc ctcgacctgc agcccaagct tacttaccat gtcagatcca 4560
gacatgataa gatacattga tgagtttgga caaaccacaa ctagaatgca gtgaaaaaaa 4620
tgctttattt gtgaaatttg tgatgctatt gctttatttg taaccattat aagctgcaat 4680
aaacaagtta acaacaacaa ttgcattcat tttatgtttc aggttcaggg ggaggtgtgg 4740
gaggtttttt aaagcaagta aaacctctac aaatgtggta tggctgatta tgatctctag 4800
tcaaggcact atacatcaaa tattccttat taaccccttt acaaattaaa aagctaaagg 4860
tacacaattt ttgagcatag ttattaatag cagacactct atgcctgtgt ggagtaagaa 4920
aaaacagtat gttatgatta taactgttat gcctacttat aaaggttaca gaatattttt 4980
ccataatttt cttgtatagc agtgcagctt tttcctttgt ggtgtaaata gcaaagcaag 5040
caagagttct attactaaac acagcatgac tcaaaaaact tagcaattct gaaggaaagt 5100
ccttggggtc ttctaccttt ctcttctttt ttggaggagt agaatgttga gagtcagcag 5160
tagcctcatc atcactagat ggcatttctt ctgagcaaaa caggttttcc tcattaaagg 5220
cattccacca ctgctcccat tcatcagttc cataggttgg aatctaaaat acacaaacaa 5280
ttagaatcag tagtttaaca cattatacac ttaaaaattt tatatttacc ttagagcttt 5340
aaatctctgt aggtagtttg tccaattatg tcacaccaca gaagtaaggt tccttcacaa 5400
agatccctcg agaaaaaaaa tataaaagag atggaggaac gggaaaaagt tagttgtggt 5460
gataggtggc aagtggtatt ccgtaagaac aacaagaaaa gcatttcata ttatggctga 5520
actgagcgaa caagtgcaaa atttaagcat caacgacaac aacgagaatg gttatgttcc 5580
tcctcactta agaggaaaac caagaagtgc cagaaataac atgagcaact acaataacaa 5640
caacggcggc tacaacggtg gccgtggcgg tggcagcttc tttagcaaca accgtcgtgg 5700
tggttacggc aacggtggtt tcttcggtgg aaacaacggt ggcagcagat ctaacggccg 5760
ttctggtggt agatggatcg atggcaaaca tgtcccagct ccaagaaacg aaaaggccga 5820
gatcgccata tttggtgtcc ccgaggatcc ggaaccctta atataacttc gtataatgta 5880
tgctatacga agttattagg tccctcgaag aggttcacta gggctagcat ggtgagcaag 5940
ggcgaggagc tgttcaccgg ggtggtgccc atcctggtcg agctggacgg cgacgtaaac 6000
ggccacaagt tcagcgtgtc cggcgagggc gagggcgatg ccacctacgg caagctgacc 6060
ctgaagttca tctgcaccac cggcaagctg cccgtgccct ggcccaccct cgtgaccacc 6120
ctgacctacg gcgtgcagtg cttcagccgc taccccgacc acatgaagca gcacgacttc 6180
ttcaagtccg ccatgcccga aggctacgtc caggagcgca ccatcttctt caaggacgac 6240
ggcaactaca agacccgcgc cgaggtgaag ttcgagggcg acaccctggt gaaccgcatc 6300
gagctgaagg gcatcgactt caaggaggac ggcaacatcc tggggcacaa gctggagtac 6360
aactacaaca gccacaacgt ctatatcatg gccgacaagc agaagaacgg catcaaggtg 6420
aacttcaaga tccgccacaa catcgaggac ggcagcgtgc agctcgccga ccactaccag 6480
cagaacaccc ccatcggcga cggccccgtg ctgctgcccg acaaccacta cctgagcacc 6540
cagtccgccc tgagcaaaga ccccaacgag aagcgcgatc acatggtcct gctggagttc 6600
gtgaccgccg ccgggatcac tctcggcatg gacgagctgt acaagtaaag cggccgccaa 6660
ttcactcctc aggtgcaggc tgcctatcag aaggtggtgg ctggtgtggc caatgccctg 6720
gctcacaaat accactgaga tctttttccc tctgccaaaa attatgggga catcatgaag 6780
ccccttgagc atctgacttc tggctaataa aggaaattta ttttcattgc aatagtgtgt 6840
tggaattttt tgtgtctctc actcggaagg acatatggga gggcaaatca tttaaaacat 6900
cagaatgagt atttggttta gagtttggca acatatgccc atatgctggc tgccatgaac 6960
aaaggttggc tataaagagg tcatcagtat atgaaacagc cccctgctgt ccattcctta 7020
ttccatagaa aagccttgac ttgaggttag atttttttta tattttgttt tgtgttattt 7080
ttttctttaa catccctaaa attttcctta catgttttac tagccagatt tttcctcctc 7140
tcctgactac tcccagtcat agctgtccct cttctcttat ggagatccct cgacctgcag 7200
cccaagcttg gcgtaatcat ggtcatagct gtttcctgtg tgaaattgtt atccgctcac 7260
aattccacac aacatacgag ccggaagcat aaagtgtaaa gcctggggtg cctaatgagt 7320
gagctaactc acattaattg cgttgcgctc actgcccgct ttccagtcgg gaaacctgtc 7380
gtgccagcgg atccgcatct caattagtca gcaaccatag tcccgcccct aactccgccc 7440
atcccgcccc taactccgcc cagttccgcc cattctccgc cccatggctg actaattttt 7500
tttatttatg cagaggccga ggccgcctcg gcctctgagc tattccagaa gtagtgagga 7560
ggcttttttg gaggcctagg gccgctgatc agcctcgact gtgccttcta gttgccagcc 7620
atctgttgtt tgcccctccc ccgtgccttc cttgaccctg gaaggtgcca ctcccactgt 7680
cctttcctaa taaaatgagg aaattgcatc gcattgtctg agtaggtgtc attctattct 7740
ggggagtggg gtggggcagg acagcaaggg ggaggattgg gaagacaata gcaggcatgc 7800
tggggatgcg gtgggctcta tggcttctga ggcggaaaga accagctggg gcttaattaa 7860
cgagagcata atattgatat gtgccaaagt tgtttctgac tgactaataa gtataatttg 7920
tttctattat gtataggtta agctaattac ttattttata atacaacatg actgttttta 7980
aagtacaaaa taagtttatt tttgtaaaag agagaatgtt taaaagtttt gttactttat 8040
agaagaaatt ttgagttttt gttttttttt aataaataaa taaacataaa taaattgttt 8100
gttgaattta ttattagtat gtaagtgtaa atataataaa acttaatatc tattcaaatt 8160
aataaataaa cctcgatata cagaccgata aaacacatgc gtcaatttta cgcatgatta 8220
tctttaacgt acgtcacaat atgattatct ttctagggtt aaataatagt ttctaatttt 8280
tttattattc agcctgctgt cgtgaatacc gagctccaat tcgccctata gtgagtcgta 8340
ttacaattca ctggccgtcg ttttacaacg tcgtgactgg gaaaaccctg gcgttaccca 8400
acttaatcgc cttgcagcac atcccccttt cgccagctgg cgtaatagcg aagaggcccg 8460
caccgatcgc ccttcccaac agttgcgcag cctgaatggc gaatggcgcg acgcgccctg 8520
tagcggcgca ttaagcgcgg cgggtgtggt ggttacgcgc agcgtgaccg ctacacttgc 8580
cagcgcccta gcgcccgctc ctttcgcttt cttcccttcc tttctcgcca cgttcgccgg 8640
ctttccccgt caagctctaa atcgggggct ccctttaggg ttccgattta gtgctttacg 8700
gcacctcgac cccaaaaaac ttgattaggg tgatggttca cgtagtgggc catcgccctg 8760
atagacggtt tttcgccctt tgacgttgga gtccacgttc tttaatagtg gactcttgtt 8820
ccaaactgga acaacactca accctatctc ggtctattct tttgatttat aagggatttt 8880
gccgatttcg gcctattggt taaaaaatga gctgatttaa caaaaattta acgcgaattt 8940
taacaaaata ttaacgttta caatttcc 8968
<210> 59
<211> 6188
<212> DNA
<213> Artificial sequence
<220>
<223> pCAGG-IRES-GFP nucleic acid sequence
<400> 59
actagttatt aatagtaatc aattacgggg tcattagttc atagcccata tatggagttc 60
cgcgttacat aacttacggt aaatggcccg cctggctgac cgcccaacga cccccgccca 120
ttgacgtcaa taatgacgta tgttcccata gtaacgccaa tagggacttt ccattgacgt 180
caatgggtgg agtatttacg gtaaactgcc cacttggcag tacatcaagt gtatcatatg 240
ccaagtacgc cccctattga cgtcaatgac ggtaaatggc ccgcctggca ttatgcccag 300
tacatgacct tatgggactt tcctacttgg cagtacatct acgtattagt catcgctatt 360
accatggtcg aggtgagccc cacgttctgc ttcactctcc ccatctcccc cccctcccca 420
cccccaattt tgtatttatt tattttttaa ttattttgtg cagcgatggg ggcggggggg 480
gggggggggc gcgcgccagg cggggcgggg cggggcgagg ggcggggcgg ggcgaggcgg 540
agaggtgcgg cggcagccaa tcagagcggc gcgctccgaa agtttccttt tatggcgagg 600
cggcggcggc ggcggcccta taaaaagcga agcgcgcggc gggcggggag tcgctgcgac 660
gctgccttcg ccccgtgccc cgctccgccg ccgcctcgcg ccgcccgccc cggctctgac 720
tgaccgcgtt actcccacag gtgagcgggc gggacggccc ttctcctccg ggctgtaatt 780
agcgcttggt ttaatgacgg cttgtttctt ttctgtggct gcgtgaaagc cttgaggggc 840
tccgggaggg ccctttgtgc ggggggagcg gctcgggggg tgcgtgcgtg tgtgtgtgcg 900
tggggagcgc cgcgtgcggc tccgcgctgc ccggcggctg tgagcgctgc gggcgcggcg 960
cggggctttg tgcgctccgc agtgtgcgcg aggggagcgc ggccgggggc ggtgccccgc 1020
ggtgcggggg gggctgcgag gggaacaaag gctgcgtgcg gggtgtgtgc gtgggggggt 1080
gagcaggggg tgtgggcgcg tcggtcgggc tgcaaccccc cctgcacccc cctccccgag 1140
ttgctgagca cggcccggct tcgggtgcgg ggctccgtac ggggcgtggc gcggggctcg 1200
ccgtgccggg cggggggtgg cggcaggtgg gggtgccggg cggggcgggg ccgcctcggg 1260
ccggggaggg ctcgggggag gggcgcggcg gcccccggag cgccggcggc tgtcgaggcg 1320
cggcgagccg cagccattgc cttttatggt aatcgtgcga gagggcgcag ggacttcctt 1380
tgtcccaaat ctgtgcggag ccgaaatctg ggaggcgccg ccgcaccccc tctagcgggc 1440
gcggggcgaa gcggtgcggc gccggcagga aggaaatggg cggggagggc cttcgtgcgt 1500
cgccgcgccg ccgtcccctt ctccctctcc agcctcgggg ctgtccgcgg ggggacggct 1560
gccttcgggg gggacggggc agggcggggt tcggcttctg gcgtgtgacc ggcggctcta 1620
gagcctctgc taaccatgtt catgccttct tctttttcct acagctcctg ggcaacgtgc 1680
tggttattgt gctgtctcat cattttggca aagaattcag cacctgcaca tgggacgtcg 1740
acctgaggta attataaccc gggccctata tatggatcgg ctagccgatc cgcccctctc 1800
cctccccccc ccctaacgtt actggccgaa gccgcttgga ataaggccgg tgtgcgtttg 1860
tctatatgtt attttccacc atattgccgt cttttggcaa tgtgagggcc cggaaacctg 1920
gccctgtctt cttgacgagc attcctaggg gtctttcccc tctcgccaaa ggaatgcaag 1980
gtctgttgaa tgtcgtgaag gaagcagttc ctctggaagc ttcttgaaga caaacaacgt 2040
ctgtagcgac cctttgcagg cagcggaacc ccccacctgg cgacaggtgc ctctgcggcc 2100
aaaagccacg tgtataagat acacctgcaa aggcggcaca accccagtgc cacgttgtga 2160
gttggatagt tgtggaaaga gtcaaatggc tctcctcaag cgtattcaac aaggggctga 2220
aggatgccca gaaggtaccc cattgtatgg gatctgatct ggggcctcgg tgcacatgct 2280
ttacatgtgt ttagtcgagg ttaaaaaaac gtctaggccc cccgaaccac ggggacgtgg 2340
ttttcctttg aaaaacacga tgataatatg gccacaacca tggtgagcaa gggcgaggag 2400
ctgttcaccg gggtggtgcc catcctggtc gagctggacg gcgacgtaaa cggccacaag 2460
ttcagcgtgt ccggcgaggg cgagggcgat gccacctacg gcaagctgac cctgaagttc 2520
atctgcacca ccggcaagct gcccgtgccc tggcccaccc tcgtgaccac cctgacctac 2580
ggcgtgcagt gcttcagccg ctaccccgac cacatgaagc agcacgactt cttcaagtcc 2640
gccatgcccg aaggctacgt ccaggagcgc accatcttct tcaaggacga cggcaactac 2700
aagacccgcg ccgaggtgaa gttcgagggc gacaccctgg tgaaccgcat cgagctgaag 2760
ggcatcgact tcaaggagga cggcaacatc ctggggcaca agctggagta caactacaac 2820
agccacaacg tctatatcat ggccgacaag cagaagaacg gcatcaaggt gaacttcaag 2880
atccgccaca acatcgagga cggcagcgtg cagctcgccg accactacca gcagaacacc 2940
cccatcggcg acggccccgt gctgctgccc gacaaccact acctgagcac ccagtccgcc 3000
ctgagcaaag accccaacga gaagcgcgat cacatggtcc tgctggagtt cgtgaccgcc 3060
gccgggatca ctctcggcat ggacgagctg tacaagtaaa gcggccgcca attcactcct 3120
caggtgcagg ctgcctatca gaaggtggtg gctggtgtgg ccaatgccct ggctcacaaa 3180
taccactgag atctttttcc ctctgccaaa aattatgggg acatcatgaa gccccttgag 3240
catctgactt ctggctaata aaggaaattt attttcattg caatagtgtg ttggaatttt 3300
ttgtgtctct cactcggaag gacatatggg agggcaaatc atttaaaaca tcagaatgag 3360
tatttggttt agagtttggc aacatatgcc catatgctgg ctgccatgaa caaaggttgg 3420
ctataaagag gtcatcagta tatgaaacag ccccctgctg tccattcctt attccataga 3480
aaagccttga cttgaggtta gatttttttt atattttgtt ttgtgttatt tttttcttta 3540
acatccctaa aattttcctt acatgtttta ctagccagat ttttcctcct ctcctgacta 3600
ctcccagtca tagctgtccc tcttctctta tggagatccc tcgacctgca gcccaagctt 3660
ggcgtaatca tggtcatagc tgtttcctgt gtgaaattgt tatccgctca caattccaca 3720
caacatacga gccggaagca taaagtgtaa agcctggggt gcctaatgag tgagctaact 3780
cacattaatt gcgttgcgct cactgcccgc tttccagtcg ggaaacctgt cgtgccagcg 3840
gatccgcatc tcaattagtc agcaaccata gtcccgcccc taactccgcc catcccgccc 3900
ctaactccgc ccagttccgc ccattctccg ccccatggct gactaatttt ttttatttat 3960
gcagaggccg aggccgcctc ggcctctgag ctattccaga agtagtgagg aggctttttt 4020
ggaggcctag gcttttgcaa aaagctaact tgtttattgc agcttataat ggttacaaat 4080
aaagcaatag catcacaaat ttcacaaata aagcattttt ttcactgcat tctagttgtg 4140
gtttgtccaa actcatcaat gtatcttatc atgtctggat ccgctgcatt aatgaatcgg 4200
ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct tccgcttcct cgctcactga 4260
ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca gctcactcaa aggcggtaat 4320
acggttatcc acagaatcag gggataacgc aggaaagaac atgtgagcaa aaggccagca 4380
aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt ttccataggc tccgcccccc 4440
tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg cgaaacccga caggactata 4500
aagataccag gcgtttcccc ctggaagctc cctcgtgcgc tctcctgttc cgaccctgcc 4560
gcttaccgga tacctgtccg cctttctccc ttcgggaagc gtggcgcttt ctcatagctc 4620
acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc aagctgggct gtgtgcacga 4680
accccccgtt cagcccgacc gctgcgcctt atccggtaac tatcgtcttg agtccaaccc 4740
ggtaagacac gacttatcgc cactggcagc agccactggt aacaggatta gcagagcgag 4800
gtatgtaggc ggtgctacag agttcttgaa gtggtggcct aactacggct acactagaag 4860
aacagtattt ggtatctgcg ctctgctgaa gccagttacc ttcggaaaaa gagttggtag 4920
ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt ttttttgttt gcaagcagca 4980
gattacgcgc agaaaaaaag gatctcaaga agatcctttg atcttttcta cggggtctga 5040
cgctcagtgg aacgaaaact cacgttaagg gattttggtc atgagattat caaaaaggat 5100
cttcacctag atccttttaa attaaaaatg aagttttaaa tcaatctaaa gtatatatga 5160
gtaaacttgg tctgacagtt accaatgctt aatcagtgag gcacctatct cagcgatctg 5220
tctatttcgt tcatccatag ttgcctgact ccccgtcgtg tagataacta cgatacggga 5280
gggcttacca tctggcccca gtgctgcaat gataccgcga gacccacgct caccggctcc 5340
agatttatca gcaataaacc agccagccgg aagggccgag cgcagaagtg gtcctgcaac 5400
tttatccgcc tccatccagt ctattaattg ttgccgggaa gctagagtaa gtagttcgcc 5460
agttaatagt ttgcgcaacg ttgttgccat tgctacaggc atcgtggtgt cacgctcgtc 5520
gtttggtatg gcttcattca gctccggttc ccaacgatca aggcgagtta catgatcccc 5580
catgttgtgc aaaaaagcgg ttagctcctt cggtcctccg atcgttgtca gaagtaagtt 5640
ggccgcagtg ttatcactca tggttatggc agcactgcat aattctctta ctgtcatgcc 5700
atccgtaaga tgcttttctg tgactggtga gtactcaacc aagtcattct gagaatagtg 5760
tatgcggcga ccgagttgct cttgcccggc gtcaatacgg gataataccg cgccacatag 5820
cagaacttta aaagtgctca tcattggaaa acgttcttcg gggcgaaaac tctcaaggat 5880
cttaccgctg ttgagatcca gttcgatgta acccactcgt gcacccaact gatcttcagc 5940
atcttttact ttcaccagcg tttctgggtg agcaaaaaca ggaaggcaaa atgccgcaaa 6000
aaagggaata agggcgacac ggaaatgttg aatactcata ctcttccttt ttcaatatta 6060
ttgaagcatt tatcagggtt attgtctcat gagcggatac atatttgaat gtatttagaa 6120
aaataaacaa ataggggttc cgcgcacatt tccccgaaaa gtgccacctg ggtcgacatt 6180
gattattg 6188
<210> 60
<211> 9644
<212> DNA
<213> Artificial sequence
<220>
<223> pCAGG-Optogenes nucleic acid sequence
<400> 60
actagttatt aatagtaatc aattacgggg tcattagttc atagcccata tatggagttc 60
cgcgttacat aacttacggt aaatggcccg cctggctgac cgcccaacga cccccgccca 120
ttgacgtcaa taatgacgta tgttcccata gtaacgccaa tagggacttt ccattgacgt 180
caatgggtgg agtatttacg gtaaactgcc cacttggcag tacatcaagt gtatcatatg 240
ccaagtacgc cccctattga cgtcaatgac ggtaaatggc ccgcctggca ttatgcccag 300
tacatgacct tatgggactt tcctacttgg cagtacatct acgtattagt catcgctatt 360
accatggtcg aggtgagccc cacgttctgc ttcactctcc ccatctcccc cccctcccca 420
cccccaattt tgtatttatt tattttttaa ttattttgtg cagcgatggg ggcggggggg 480
gggggggggc gcgcgccagg cggggcgggg cggggcgagg ggcggggcgg ggcgaggcgg 540
agaggtgcgg cggcagccaa tcagagcggc gcgctccgaa agtttccttt tatggcgagg 600
cggcggcggc ggcggcccta taaaaagcga agcgcgcggc gggcggggag tcgctgcgac 660
gctgccttcg ccccgtgccc cgctccgccg ccgcctcgcg ccgcccgccc cggctctgac 720
tgaccgcgtt actcccacag gtgagcgggc gggacggccc ttctcctccg ggctgtaatt 780
agcgcttggt ttaatgacgg cttgtttctt ttctgtggct gcgtgaaagc cttgaggggc 840
tccgggaggg ccctttgtgc ggggggagcg gctcgggggg tgcgtgcgtg tgtgtgtgcg 900
tggggagcgc cgcgtgcggc tccgcgctgc ccggcggctg tgagcgctgc gggcgcggcg 960
cggggctttg tgcgctccgc agtgtgcgcg aggggagcgc ggccgggggc ggtgccccgc 1020
ggtgcggggg gggctgcgag gggaacaaag gctgcgtgcg gggtgtgtgc gtgggggggt 1080
gagcaggggg tgtgggcgcg tcggtcgggc tgcaaccccc cctgcacccc cctccccgag 1140
ttgctgagca cggcccggct tcgggtgcgg ggctccgtac ggggcgtggc gcggggctcg 1200
ccgtgccggg cggggggtgg cggcaggtgg gggtgccggg cggggcgggg ccgcctcggg 1260
ccggggaggg ctcgggggag gggcgcggcg gcccccggag cgccggcggc tgtcgaggcg 1320
cggcgagccg cagccattgc cttttatggt aatcgtgcga gagggcgcag ggacttcctt 1380
tgtcccaaat ctgtgcggag ccgaaatctg ggaggcgccg ccgcaccccc tctagcgggc 1440
gcggggcgaa gcggtgcggc gccggcagga aggaaatggg cggggagggc cttcgtgcgt 1500
cgccgcgccg ccgtcccctt ctccctctcc agcctcgggg ctgtccgcgg ggggacggct 1560
gccttcgggg gggacggggc agggcggggt tcggcttctg gcgtgtgacc ggcggctcta 1620
gagcctctgc taaccatgtt catgccttct tctttttcct acagctcctg ggcaacgtgc 1680
tggttattgt gctgtctcat cattttggca aagaattcag cacctgcaca tgggacgtcg 1740
acctgaggta attataaccc cccgggatga atggagctat aggaggtgac cttttgctca 1800
attttcctga catgtcggtc ctagagcgcc aaagggctca cctcaagtac ctcaatccca 1860
cctttgattc tcctctcgcc ggcttctttg ccgattcttc aatgattacc ggcggcgaga 1920
tggacagcta tctttcgact gccggtttga atcttccgat gatgtacggt gagacgacgg 1980
tggaaggtga ttcaagactc tcaatttcgc cggaaacgac gcttgggact ggaaatttca 2040
agaaacggaa gtttgataca gagactaagg attgtaatga gaagaagaag aagatgacga 2100
tgaacagaga tgacctagta gaagaaggag aagaagagaa gtcgaaaata acagagcaaa 2160
acaatgggag cacaaaaagc atcaagaaga tgaaacacaa agccaagaaa gaagagaaca 2220
atttctctaa tgattcatct aaagtgacga aggaattgga gaaaacggat tatattcatg 2280
gtggcggtgg ctctggaggt ggtgggtccg gaggaggcgg ccgccgacca agtgacagca 2340
atgctgtttc actggttatg cggcggatcc gaaaagaaaa cgttgatgcc ggtgaacgtg 2400
caaaacaggc tctagcgttc gaacgcactg atttcgacca ggttcgttca ctcatggaaa 2460
atagcgatcg ctgccaggat atacgtaatc tggcatttct ggggattgct tataacaccc 2520
tgttacgtat agccgaaatt gccaggatca gggttaaaga tatctcacgt actgacggtg 2580
ggagaatgtt aatccatatt ggcagaacga aaacgctggt tagcaccgca ggtgtagaga 2640
aggcacttag cctgggggta actaaactgg tcgagcgatg gatttccgtc tctggtgtag 2700
ctgatgatcc gaataactac ctgttttgcc gggtcagaaa aaatggtgtt gccgcgccat 2760
ctgccaccag ccagctatca actcgcgccc tggaagggat ttttgaagca actcatcgat 2820
tgatttacgg cgctaaggat gactctggtc agagatacct ggcctggtct ggacacagtg 2880
cccgtgtcgg agccgcgcga gatatggccc gcgctggagt ttcaataccg gagatcatgc 2940
aagctggtgg ctggaccaat gtaaatattg tcatgaacta tatccgtaac ctggatagtg 3000
aaacaggggc aatggtgcgc ctgctggaag atggcgatgc cacgaacttc tctctgttaa 3060
agcaagcagg agacgtggaa gaaaaccccg gtcctatgaa gatggacaaa aagactatag 3120
tttggtttag aagagaccta aggattgagg ataatcctgc attagcagca gctgctcacg 3180
aaggatctgt ttttcctgtc ttcatttggt gtcctgaaga agaaggacag ttttatcctg 3240
gaagagcttc aagatggtgg atgaaacaat cacttgctca cttatctcaa tccttgaagg 3300
ctcttggatc tgacctcact ttaatcaaaa cccacaacac gatttcagcg atcttggatt 3360
gtatccgcgt taccggtgct acaaaagtcg tctttaacca cctctatgat cctgtttcgt 3420
tagttcggga ccataccgta aaggagaagc tggtggaacg tgggatctct gtgcaaagct 3480
acaatggaga tctattgtat gaaccgtggg agatatactg cgaaaagggc aaacctttta 3540
cgagtttcaa ttcttactgg aagaaatgct tagatatgtc gattgaatcc gttatgcttc 3600
ctcctccttg gcggttgatg ccaataactg cagcggctga agcgatttgg gcgtgttcga 3660
ttgaagaact agggctggag aatgaggccg agaaaccgag caatgcgttg ttaactagag 3720
cttggtctcc aggatggagc aatgctgata agttactaaa tgagttcatc gagaagcagt 3780
tgatagatta tgcaaagaac agcaagaaag ttgttgggaa ttctacttca ctactttctc 3840
cgtatctcca tttcggggaa ataagcgtca gacacgtttt ccagtgtgcc cggatgaaac 3900
aaattatatg ggcaagagat aagaacagtg aaggagaaga aagtgcagat ctttttctta 3960
ggggaatcgg tttaagagag tattctcggt atatatgttt caacttcccg tttactcacg 4020
agcaatcgtt gttgagtcat cttcggtttt tcccttggga tgctgatgtt gataagttca 4080
aggcctggag acaaggcagg accggttatc cgttggtgga tgccggaatg agagagcttt 4140
gggctaccgg atggatgcat aacagaataa gagtgattgt ttcaagcttt gctgtgaagt 4200
ttcttctcct tccatggaaa tggggaatga agtatttctg ggatacactt ttggatgctg 4260
atttggaatg tgacatcctt ggctggcagt atatctctgg gagtatcccc gatggccacg 4320
agcttgatcg cttggacaat cccgcgttac aaggcgccaa atatgaccca gaaggtgagt 4380
acataaggca atggcttccc gagcttgcga gattgccaac tgaatggatc catcatccat 4440
gggacgctcc tttaaccgta ctcaaagctt ctggtgtgga actcggaaca aactatgcga 4500
aacccattgt agacatcgac acagctcgtg agctactagc taaagctatt tcaagaaccc 4560
gtgaagcaca gatcatgatc ggagcagcac ctgatgagat tgtagcagat agcttcgagg 4620
ccttaggggc taataccatt aaagaacctg gtctttgccc atctgtgtct tctaatgacc 4680
aacaagtacc ttcggctgtt cgttacaacg ggtcaaagag agtgaaacct gaggaagaag 4740
aagagagaga catgaagaaa tctaggggat tcgatgaaag ggagttgttt tcgactgctg 4800
aatcttcttc ttcttcgagt gtgtttttcg tttcgcagtc ttgctcgttg gcatcagaag 4860
ggaagaatct ggaaggtatt caagattcat ctgatcagat tactacaagt ttgggaaaaa 4920
atggttgcaa aggtggcggt ggctctggag gtggtgggtc cggaggaggc ggccgcacga 4980
gtgatgaggt tcgcaagaac ctgatggaca tgttcaggga tcgccaggcg ttttctgagc 5040
atacctggaa aatgcttctg tccgtttgcc ggtcgtgggc ggcatggtgc aagttgaata 5100
accggaaatg gtttcccgca gaacctgaag atgttcgcga ttatcttcta tatcttcagg 5160
cgcgcggtct ggcagtaaaa actatccagc aacatttggg ccagctaaac atgcttcatc 5220
gtcggtccgg gctgtaagct agcctccgcc cctctccctc ccccccccct aacgttactg 5280
gccgaagccg cttggaataa ggccggtgtg cgtttgtcta tatgttattt tccaccatat 5340
tgccgtcttt tggcaatgtg agggcccgga aacctggccc tgtcttcttg acgagcattc 5400
ctaggggtct ttcccctctc gccaaaggaa tgcaaggtct gttgaatgtc gtgaaggaag 5460
cagttcctct ggaagcttct tgaagacaaa caacgtctgt agcgaccctt tgcaggcagc 5520
ggaacccccc acctggcgac aggtgcctct gcggccaaaa gccacgtgta taagatacac 5580
ctgcaaaggc ggcacaaccc cagtgccacg ttgtgagttg gatagttgtg gaaagagtca 5640
aatggctctc ctcaagcgta ttcaacaagg ggctgaagga tgcccagaag gtaccccatt 5700
gtatgggatc tgatctgggg cctcggtgca catgctttac atgtgtttag tcgaggttaa 5760
aaaaacgtct aggccccccg aaccacgggg acgtggtttt cctttgaaaa acacgatgat 5820
aatatggcca caaccatggt gagcaagggc gaggagctgt tcaccggggt ggtgcccatc 5880
ctggtcgagc tggacggcga cgtaaacggc cacaagttca gcgtgtccgg cgagggcgag 5940
ggcgatgcca cctacggcaa gctgaccctg aagttcatct gcaccaccgg caagctgccc 6000
gtgccctggc ccaccctcgt gaccaccctg acctacggcg tgcagtgctt cagccgctac 6060
cccgaccaca tgaagcagca cgacttcttc aagtccgcca tgcccgaagg ctacgtccag 6120
gagcgcacca tcttcttcaa ggacgacggc aactacaaga cccgcgccga ggtgaagttc 6180
gagggcgaca ccctggtgaa ccgcatcgag ctgaagggca tcgacttcaa ggaggacggc 6240
aacatcctgg ggcacaagct ggagtacaac tacaacagcc acaacgtcta tatcatggcc 6300
gacaagcaga agaacggcat caaggtgaac ttcaagatcc gccacaacat cgaggacggc 6360
agcgtgcagc tcgccgacca ctaccagcag aacaccccca tcggcgacgg ccccgtgctg 6420
ctgcccgaca accactacct gagcacccag tccgccctga gcaaagaccc caacgagaag 6480
cgcgatcaca tggtcctgct ggagttcgtg accgccgccg ggatcactct cggcatggac 6540
gagctgtaca agtaaagcgg ccgccaattc actcctcagg tgcaggctgc ctatcagaag 6600
gtggtggctg gtgtggccaa tgccctggct cacaaatacc actgagatct ttttccctct 6660
gccaaaaatt atggggacat catgaagccc cttgagcatc tgacttctgg ctaataaagg 6720
aaatttattt tcattgcaat agtgtgttgg aattttttgt gtctctcact cggaaggaca 6780
tatgggaggg caaatcattt aaaacatcag aatgagtatt tggtttagag tttggcaaca 6840
tatgcccata tgctggctgc catgaacaaa ggttggctat aaagaggtca tcagtatatg 6900
aaacagcccc ctgctgtcca ttccttattc catagaaaag ccttgacttg aggttagatt 6960
ttttttatat tttgttttgt gttatttttt tctttaacat ccctaaaatt ttccttacat 7020
gttttactag ccagattttt cctcctctcc tgactactcc cagtcatagc tgtccctctt 7080
ctcttatgga gatccctcga cctgcagccc aagcttggcg taatcatggt catagctgtt 7140
tcctgtgtga aattgttatc cgctcacaat tccacacaac atacgagccg gaagcataaa 7200
gtgtaaagcc tggggtgcct aatgagtgag ctaactcaca ttaattgcgt tgcgctcact 7260
gcccgctttc cagtcgggaa acctgtcgtg ccagcggatc cgcatctcaa ttagtcagca 7320
accatagtcc cgcccctaac tccgcccatc ccgcccctaa ctccgcccag ttccgcccat 7380
tctccgcccc atggctgact aatttttttt atttatgcag aggccgaggc cgcctcggcc 7440
tctgagctat tccagaagta gtgaggaggc ttttttggag gcctaggctt ttgcaaaaag 7500
ctaacttgtt tattgcagct tataatggtt acaaataaag caatagcatc acaaatttca 7560
caaataaagc atttttttca ctgcattcta gttgtggttt gtccaaactc atcaatgtat 7620
cttatcatgt ctggatccgc tgcattaatg aatcggccaa cgcgcgggga gaggcggttt 7680
gcgtattggg cgctcttccg cttcctcgct cactgactcg ctgcgctcgg tcgttcggct 7740
gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg ttatccacag aatcagggga 7800
taacgcagga aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc gtaaaaaggc 7860
cgcgttgctg gcgtttttcc ataggctccg cccccctgac gagcatcaca aaaatcgacg 7920
ctcaagtcag aggtggcgaa acccgacagg actataaaga taccaggcgt ttccccctgg 7980
aagctccctc gtgcgctctc ctgttccgac cctgccgctt accggatacc tgtccgcctt 8040
tctcccttcg ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc tcagttcggt 8100
gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc ccgaccgctg 8160
cgccttatcc ggtaactatc gtcttgagtc caacccggta agacacgact tatcgccact 8220
ggcagcagcc actggtaaca ggattagcag agcgaggtat gtaggcggtg ctacagagtt 8280
cttgaagtgg tggcctaact acggctacac tagaagaaca gtatttggta tctgcgctct 8340
gctgaagcca gttaccttcg gaaaaagagt tggtagctct tgatccggca aacaaaccac 8400
cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa aaaaaggatc 8460
tcaagaagat cctttgatct tttctacggg gtctgacgct cagtggaacg aaaactcacg 8520
ttaagggatt ttggtcatga gattatcaaa aaggatcttc acctagatcc ttttaaatta 8580
aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa acttggtctg acagttacca 8640
atgcttaatc agtgaggcac ctatctcagc gatctgtcta tttcgttcat ccatagttgc 8700
ctgactcccc gtcgtgtaga taactacgat acgggagggc ttaccatctg gccccagtgc 8760
tgcaatgata ccgcgagacc cacgctcacc ggctccagat ttatcagcaa taaaccagcc 8820
agccggaagg gccgagcgca gaagtggtcc tgcaacttta tccgcctcca tccagtctat 8880
taattgttgc cgggaagcta gagtaagtag ttcgccagtt aatagtttgc gcaacgttgt 8940
tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt cattcagctc 9000
cggttcccaa cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa aagcggttag 9060
ctccttcggt cctccgatcg ttgtcagaag taagttggcc gcagtgttat cactcatggt 9120
tatggcagca ctgcataatt ctcttactgt catgccatcc gtaagatgct tttctgtgac 9180
tggtgagtac tcaaccaagt cattctgaga atagtgtatg cggcgaccga gttgctcttg 9240
cccggcgtca atacgggata ataccgcgcc acatagcaga actttaaaag tgctcatcat 9300
tggaaaacgt tcttcggggc gaaaactctc aaggatctta ccgctgttga gatccagttc 9360
gatgtaaccc actcgtgcac ccaactgatc ttcagcatct tttactttca ccagcgtttc 9420
tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg cgacacggaa 9480
atgttgaata ctcatactct tcctttttca atattattga agcatttatc agggttattg 9540
tctcatgagc ggatacatat ttgaatgtat ttagaaaaat aaacaaatag gggttccgcg 9600
cacatttccc cgaaaagtgc cacctgggtc gacattgatt attg 9644
<210> 61
<211> 9166
<212> DNA
<213> Artificial sequence
<220>
<223> pB-RAGE-mCherry nucleic acid sequence
<400> 61
caggtggcac ttttcgggga aatgtgcgcg gaacccctat ttgtttattt ttctaaatac 60
attcaaatat gtatccgctc atgagacaat aaccctgata aatgcttcaa taatattgaa 120
aaaggaagag tatgagtatt caacatttcc gtgtcgccct tattcccttt tttgcggcat 180
tttgccttcc tgtttttgct cacccagaaa cgctggtgaa agtaaaagat gctgaagatc 240
agttgggtgc acgagtgggt tacatcgaac tggatctcaa cagcggtaag atccttgaga 300
gttttcgccc cgaagaacgt tttccaatga tgagcacttt taaagttctg ctatgtggcg 360
cggtattatc ccgtattgac gccgggcaag agcaactcgg tcgccgcata cactattctc 420
agaatgactt ggttgagtac tcaccagtca cagaaaagca tcttacggat ggcatgacag 480
taagagaatt atgcagtgct gccataacca tgagtgataa cactgcggcc aacttacttc 540
tgacaacgat cggaggaccg aaggagctaa ccgctttttt gcacaacatg ggggatcatg 600
taactcgcct tgatcgttgg gaaccggagc tgaatgaagc cataccaaac gacgagcgtg 660
acaccacgat gcctgtagca atggcaacaa cgttgcgcaa actattaact ggcgaactac 720
ttactctagc ttcccggcaa caattaatag actggatgga ggcggataaa gttgcaggac 780
cacttctgcg ctcggccctt ccggctggct ggtttattgc tgataaatct ggagccggtg 840
agcgtgggtc tcgcggtatc attgcagcac tggggccaga tggtaagccc tcccgtatcg 900
tagttatcta cacgacgggg agtcaggcaa ctatggatga acgaaataga cagatcgctg 960
agataggtgc ctcactgatt aagcattggt aactgtcaga ccaagtttac tcatatatac 1020
tttagattga tttaaaactt catttttaat ttaaaaggat ctaggtgaag atcctttttg 1080
ataatctcat gaccaaaatc ccttaacgtg agttttcgtt ccactgagcg tcagaccccg 1140
tagaaaagat caaaggatct tcttgagatc ctttttttct gcgcgtaatc tgctgcttgc 1200
aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc ggatcaagag ctaccaactc 1260
tttttccgaa ggtaactggc ttcagcagag cgcagatacc aaatactgtc cttctagtgt 1320
agccgtagtt aggccaccac ttcaagaact ctgtagcacc gcctacatac ctcgctctgc 1380
taatcctgtt accagtggct gctgccagtg gcgataagtc gtgtcttacc gggttggact 1440
caagacgata gttaccggat aaggcgcagc ggtcgggctg aacggggggt tcgtgcacac 1500
agcccagctt ggagcgaacg acctacaccg aactgagata cctacagcgt gagctatgag 1560
aaagcgccac gcttcccgaa gggagaaagg cggacaggta tccggtaagc ggcagggtcg 1620
gaacaggaga gcgcacgagg gagcttccag ggggaaacgc ctggtatctt tatagtcctg 1680
tcgggtttcg ccacctctga cttgagcgtc gatttttgtg atgctcgtca ggggggcgga 1740
gcctatggaa aaacgccagc aacgcggcct ttttacggtt cctggccttt tgctggcctt 1800
ttgctcacat gttctttcct gcgttatccc ctgattctgt ggataaccgt attaccgcct 1860
ttgagtgagc tgataccgct cgccgcagcc gaacgaccga gcgcagcgag tcagtgagcg 1920
aggaagcgga agagcgccca atacgcaaac cgcctctccc cgcgcgttgg ccgattcatt 1980
aatgcagctg gcacgacagg tttcccgact ggaaagcggg cagtgagcgc aacgcaatta 2040
atgtgagtta gctcactcat taggcacccc aggctttaca ctttatgctt ccggctcgta 2100
tgttgtgtgg aattgtgagc ggataacaat ttcacacagg aaacagctat gaccatgatt 2160
acgccaagct cggaattaac cctcactaaa gggaacaaaa gctggctcgc gcgacttggt 2220
ttgccattct ttagcgcgcg tcgcgtcaca cagcttggcc acaatgtggt ttttgtcaaa 2280
cgaagattct atgacgtgtt taaagtttag gtcgagtaaa gcgcaaatct tttttaaccc 2340
tagaaagata gtctgcgtaa aattgacgca tgcattcttg aaatattgct ctctctttct 2400
aaatagcgcg aatccgtcgc tgtgcattta ggacatctca gtcgccgctt ggagctcccg 2460
tgaggcgtgc ttgtcaatgc ggtaagtgtc actgattttg aactataacg accgcgtgag 2520
tcaaaatgac gcatgattat cttttacgtg acttttaaga tttaactcat acgataatta 2580
tattgttatt tcatgttcta cttacgtgat aacttattat atatatattt tcttgttata 2640
gatatcgtga ctaatatata ataaaatggg tagttcttta gacgatgagc atatcctctc 2700
tgctcttctg caaagcgatg acgagcttgt tggctagtta ttaatagtaa tcaattacgg 2760
ggtcattagt tcatagccca tatatggagt tccgcgttac ataacttacg gtaaatggcc 2820
cgcctggctg accgcccaac gacccccgcc cattgacgtc aataatgacg tatgttccca 2880
tagtaacgcc aatagggact ttccattgac gtcaatgggt ggagtattta cggtaaactg 2940
cccacttggc agtacatcaa gtgtatcata tgccaagtac gccccctatt gacgtcaatg 3000
acggtaaatg gcccgcctgg cattatgccc agtacatgac cttatgggac tttcctactt 3060
ggcagtacat ctacgtatta gtcatcgcta ttaccatggt cgaggtgagc cccacgttct 3120
gcttcactct ccccatctcc cccccctccc cacccccaat tttgtattta tttatttttt 3180
aattattttg tgcagcgatg ggggcggggg gggggggggg gcgcgcgcca ggcggggcgg 3240
ggcggggcga ggggcggggc ggggcgaggc ggagaggtgc ggcggcagcc aatcagagcg 3300
gcgcgctccg aaagtttcct tttatggcga ggcggcggcg gcggcggccc tataaaaagc 3360
gaagcgcgcg gcgggcgggg agtcgctgcg acgctgcctt cgccccgtgc cccgctccgc 3420
cgccgcctcg cgccgcccgc cccggctctg actgaccgcg ttactcccac aggtgagcgg 3480
gcgggacggc ccttctcctc cgggctgtaa ttagcgcttg gtttaatgac ggcttgtttc 3540
ttttctgtgg ctgcgtgaaa gccttgaggg gctccgggag ggccctttgt gcggggggag 3600
cggctcgggg ggtgcgtgcg tgtgtgtgtg cgtggggagc gccgcgtgcg gctccgcgct 3660
gcccggcggc tgtgagcgct gcgggcgcgg cgcggggctt tgtgcgctcc gcagtgtgcg 3720
cgaggggagc gcggccgggg gcggtgcccc gcggtgcggg gggggctgcg aggggaacaa 3780
aggctgcgtg cggggtgtgt gcgtgggggg gtgagcaggg ggtgtgggcg cgtcggtcgg 3840
gctgcaaccc cccctgcacc cccctccccg agttgctgag cacggcccgg cttcgggtgc 3900
ggggctccgt acggggcgtg gcgcggggct cgccgtgccg ggcggggggt ggcggcaggt 3960
gggggtgccg ggcggggcgg ggccgcctcg ggccggggag ggctcggggg aggggcgcgg 4020
cggcccccgg agcgccggcg gctgtcgagg cgcggcgagc cgcagccatt gccttttatg 4080
gtaatcgtgc gagagggcgc agggacttcc tttgtcccaa atctgtgcgg agccgaaatc 4140
tgggaggcgc cgccgcaccc cctctagcgg gcgcggggcg aagcggtgcg gcgccggcag 4200
gaaggaaatg ggcggggagg gccttcgtgc gtcgccgcgc cgccgtcccc ttctccctct 4260
ccagcctcgg ggctgtccgc ggggggacgg ctgccttcgg gggggacggg gcagggcggg 4320
gttcggcttc tggcgtgtga ccggcggctc tagagcctct gctaaccatg ttcatgcctt 4380
cttctttttc ctacagctcc tgggcaacgt gctggttatt gtgctgtctc atcattttgg 4440
caaagaattc catcaagctt aggatccgga acccttaata taacttcgta taatgtatgc 4500
tatacgaagt tattaggtcc ctcgacctgc agcccaagct tacttaccat gtcagatcca 4560
gacatgataa gatacattga tgagtttgga caaaccacaa ctagaatgca gtgaaaaaaa 4620
tgctttattt gtgaaatttg tgatgctatt gctttatttg taaccattat aagctgcaat 4680
aaacaagtta acaacaacaa ttgcattcat tttatgtttc aggttcaggg ggaggtgtgg 4740
gaggtttttt aaagcaagta aaacctctac aaatgtggta tggctgatta tgatctctag 4800
tcaaggcact atacatcaaa tattccttat taaccccttt acaaattaaa aagctaaagg 4860
tacacaattt ttgagcatag ttattaatag cagacactct atgcctgtgt ggagtaagaa 4920
aaaacagtat gttatgatta taactgttat gcctacttat aaaggttaca gaatattttt 4980
ccataatttt cttgtatagc agtgcagctt tttcctttgt ggtgtaaata gcaaagcaag 5040
caagagttct attactaaac acagcatgac tcaaaaaact tagcaattct gaaggaaagt 5100
ccttggggtc ttctaccttt ctcttctttt ttggaggagt agaatgttga gagtcagcag 5160
tagcctcatc atcactagat ggcatttctt ctgagcaaaa caggttttcc tcattaaagg 5220
cattccacca ctgctcccat tcatcagttc cataggttgg aatctaaaat acacaaacaa 5280
ttagaatcag tagtttaaca cattatacac ttaaaaattt tatatttacc ttagagcttt 5340
aaatctctgt aggtagtttg tccaattatg tcacaccaca gaagtaaggt tccttcacaa 5400
agatccctcg agaaaaaaaa tataaaagag atggaggaac gggaaaaagt tagttgtggt 5460
gataggtggc aagtggtatt ccgtaagaac aacaagaaaa gcatttcata ttatggctga 5520
actgagcgaa caagtgcaaa atttaagcat caacgacaac aacgagaatg gttatgttcc 5580
tcctcactta agaggaaaac caagaagtgc cagaaataac atgagcaact acaataacaa 5640
caacggcggc tacaacggtg gccgtggcgg tggcagcttc tttagcaaca accgtcgtgg 5700
tggttacggc aacggtggtt tcttcggtgg aaacaacggt ggcagcagat ctaacggccg 5760
ttctggtggt agatggatcg atggcaaaca tgtcccagct ccaagaaacg aaaaggccga 5820
gatcgccata tttggtgtcc ccgaggatcc ggaaccctta atataacttc gtataatgta 5880
tgctatacga agttattagg tccctcgaag aggttcacta gggctagcag ttataggatc 5940
tccgccacca tgctgtgctg catcagaaga actaaaccgg ttgagaagaa tgaagaggcc 6000
gatcaggagc tgcagtcgac ggtaccgcgg gcccgggatc caccggtagc atccgccacc 6060
atggtgagca agggcgagga ggataacatg gccatcatca aggagttcat gcgcttcaag 6120
gtgcacatgg agggctccgt gaacggccac gagttcgaga tcgagggcga gggcgagggc 6180
cgcccctacg agggcaccca gaccgccaag ctgaaggtga ccaagggtgg ccccctgccc 6240
ttcgcctggg acatcctgtc ccctcagttc atgtacggct ccaaggccta cgtgaagcac 6300
cccgccgaca tccccgacta cttgaagctg tccttccccg agggcttcaa gtgggagcgc 6360
gtgatgaact tcgaggacgg cggcgtggtg accgtgaccc aggactcctc cctgcaggac 6420
ggcgagttca tctacaaggt gaagctgcgc ggcaccaact tcccctccga cggccccgta 6480
atgcagaaga agaccatggg ctgggaggcc tcctccgagc ggatgtaccc cgaggacggc 6540
gccctgaagg gcgagatcaa gcagaggctg aagctgaagg acggcggcca ctacgacgct 6600
gaggtcaaga ccacctacaa ggccaagaag cccgtgcagc tgcccggcgc ctacaacgtc 6660
aacatcaagt tggacatcac ctcccacaac gaggactaca ccatcgtgga acagtacgaa 6720
cgcgccgagg gccgccactc caccggcggc atggacgagc tgtacaaggg cagtggagag 6780
ggcagaggaa gtctgctaac atgcggtgac gtcgaggaga atcctggccc aactagtgtt 6840
taaacgcggc cgcggcaatt cactcctcag gtgcaggctg cctatcagaa ggtggtggct 6900
ggtgtggcca atgccctggc tcacaaatac cactgagatc tttttccctc tgccaaaaat 6960
tatggggaca tcatgaagcc ccttgagcat ctgacttctg gctaataaag gaaatttatt 7020
ttcattgcaa tagtgtgttg gaattttttg tgtctctcac tcggaaggac atatgggagg 7080
gcaaatcatt taaaacatca gaatgagtat ttggtttaga gtttggcaac atatgcccat 7140
atgctggctg ccatgaacaa aggttggcta taaagaggtc atcagtatat gaaacagccc 7200
cctgctgtcc attccttatt ccatagaaaa gccttgactt gaggttagat tttttttata 7260
ttttgttttg tgttattttt ttctttaaca tccctaaaat tttccttaca tgttttacta 7320
gccagatttt tcctcctctc ctgactactc ccagtcatag ctgtccctct tctcttatgg 7380
agatccctcg acctgcagcc caagcttggc gtaatcatgg tcatagctgt ttcctgtgtg 7440
aaattgttat ccgctcacaa ttccacacaa catacgagcc ggaagcataa agtgtaaagc 7500
ctggggtgcc taatgagtga gctaactcac attaattgcg ttgcgctcac tgcccgcttt 7560
ccagtcggga aacctgtcgt gccagcggat ccgcatctca attagtcagc aaccatagtc 7620
ccgcccctaa ctccgcccat cccgccccta actccgccca gttccgccca ttctccgccc 7680
catggctgac taattttttt tatttatgca gaggccgagg ccgcctcggc ctctgagcta 7740
ttccagaagt agtgaggagg cttttttgga ggcctagggc cgctgatcag cctcgactgt 7800
gccttctagt tgccagccat ctgttgtttg cccctccccc gtgccttcct tgaccctgga 7860
aggtgccact cccactgtcc tttcctaata aaatgaggaa attgcatcgc attgtctgag 7920
taggtgtcat tctattctgg ggagtggggt ggggcaggac agcaaggggg aggattggga 7980
agacaatagc aggcatgctg gggatgcggt gggctctatg gcttctgagg cggaaagaac 8040
cagctggggc ttaattaacg agagcataat attgatatgt gccaaagttg tttctgactg 8100
actaataagt ataatttgtt tctattatgt ataggttaag ctaattactt attttataat 8160
acaacatgac tgtttttaaa gtacaaaata agtttatttt tgtaaaagag agaatgttta 8220
aaagttttgt tactttatag aagaaatttt gagtttttgt ttttttttaa taaataaata 8280
aacataaata aattgtttgt tgaatttatt attagtatgt aagtgtaaat ataataaaac 8340
ttaatatcta ttcaaattaa taaataaacc tcgatataca gaccgataaa acacatgcgt 8400
caattttacg catgattatc tttaacgtac gtcacaatat gattatcttt ctagggttaa 8460
ataatagttt ctaatttttt tattattcag cctgctgtcg tgaataccga gctccaattc 8520
gccctatagt gagtcgtatt acaattcact ggccgtcgtt ttacaacgtc gtgactggga 8580
aaaccctggc gttacccaac ttaatcgcct tgcagcacat ccccctttcg ccagctggcg 8640
taatagcgaa gaggcccgca ccgatcgccc ttcccaacag ttgcgcagcc tgaatggcga 8700
atggcgcgac gcgccctgta gcggcgcatt aagcgcggcg ggtgtggtgg ttacgcgcag 8760
cgtgaccgct acacttgcca gcgccctagc gcccgctcct ttcgctttct tcccttcctt 8820
tctcgccacg ttcgccggct ttccccgtca agctctaaat cgggggctcc ctttagggtt 8880
ccgatttagt gctttacggc acctcgaccc caaaaaactt gattagggtg atggttcacg 8940
tagtgggcca tcgccctgat agacggtttt tcgccctttg acgttggagt ccacgttctt 9000
taatagtgga ctcttgttcc aaactggaac aacactcaac cctatctcgg tctattcttt 9060
tgatttataa gggattttgc cgatttcggc ctattggtta aaaaatgagc tgatttaaca 9120
aaaatttaac gcgaatttta acaaaatatt aacgtttaca atttcc 9166
<210> 62
<211> 4526
<212> DNA
<213> Artificial sequence
<220>
<223> pSK BS-PGK-DTA nucleic acid sequence
<400> 62
gtggcacttt tcggggaaat gtgcgcggaa cccctatttg tttatttttc taaatacatt 60
caaatatgta tccgctcatg agacaataac cctgataaat gcttcaataa tattgaaaaa 120
ggaagagtat gagtattcaa catttccgtg tcgcccttat tccctttttt gcggcatttt 180
gccttcctgt ttttgctcac ccagaaacgc tggtgaaagt aaaagatgct gaagatcagt 240
tgggtgcacg agtgggttac atcgaactgg atctcaacag cggtaagatc cttgagagtt 300
ttcgccccga agaacgtttt ccaatgatga gcacttttaa agttctgcta tgtggcgcgg 360
tattatcccg tattgacgcc gggcaagagc aactcggtcg ccgcatacac tattctcaga 420
atgacttggt tgagtactca ccagtcacag aaaagcatct tacggatggc atgacagtaa 480
gagaattatg cagtgctgcc ataaccatga gtgataacac tgcggccaac ttacttctga 540
caacgatcgg aggaccgaag gagctaaccg cttttttgca caacatgggg gatcatgtaa 600
ctcgccttga tcgttgggaa ccggagctga atgaagccat accaaacgac gagcgtgaca 660
ccacgatgcc tgtagcaatg gcaacaacgt tgcgcaaact attaactggc gaactactta 720
ctctagcttc ccggcaacaa ttaatagact ggatggaggc ggataaagtt gcaggaccac 780
ttctgcgctc ggcccttccg gctggctggt ttattgctga taaatctgga gccggtgagc 840
gtgggtctcg cggtatcatt gcagcactgg ggccagatgg taagccctcc cgtatcgtag 900
ttatctacac gacggggagt caggcaacta tggatgaacg aaatagacag atcgctgaga 960
taggtgcctc actgattaag cattggtaac tgtcagacca agtttactca tatatacttt 1020
agattgattt aaaacttcat ttttaattta aaaggatcta ggtgaagatc ctttttgata 1080
atctcatgac caaaatccct taacgtgagt tttcgttcca ctgagcgtca gaccccgtag 1140
aaaagatcaa aggatcttct tgagatcctt tttttctgcg cgtaatctgc tgcttgcaaa 1200
caaaaaaacc accgctacca gcggtggttt gtttgccgga tcaagagcta ccaactcttt 1260
ttccgaaggt aactggcttc agcagagcgc agataccaaa tactgtcctt ctagtgtagc 1320
cgtagttagg ccaccacttc aagaactctg tagcaccgcc tacatacctc gctctgctaa 1380
tcctgttacc agtggctgct gccagtggcg ataagtcgtg tcttaccggg ttggactcaa 1440
gacgatagtt accggataag gcgcagcggt cgggctgaac ggggggttcg tgcacacagc 1500
ccagcttgga gcgaacgacc tacaccgaac tgagatacct acagcgtgag ctatgagaaa 1560
gcgccacgct tcccgaaggg agaaaggcgg acaggtatcc ggtaagcggc agggtcggaa 1620
caggagagcg cacgagggag cttccagggg gaaacgcctg gtatctttat agtcctgtcg 1680
ggtttcgcca cctctgactt gagcgtcgat ttttgtgatg ctcgtcaggg gggcggagcc 1740
tatggaaaaa cgccagcaac gcggcctttt tacggttcct ggccttttgc tggccttttg 1800
ctcacatgtt ctttcctgcg ttatcccctg attctgtgga taaccgtatt accgcctttg 1860
agtgagctga taccgctcgc cgcagccgaa cgaccgagcg cagcgagtca gtgagcgagg 1920
aagcggaaga gcgcccaata cgcaaaccgc ctctccccgc gcgttggccg attcattaat 1980
gcagctggca cgacaggttt cccgactgga aagcgggcag tgagcgcaac gcaattaatg 2040
tgagttagct cactcattag gcaccccagg ctttacactt tatgcttccg gctcgtatgt 2100
tgtgtggaat tgtgagcgga taacaatttc acacaggaaa cagctatgac catgattacg 2160
ccaagcgcgc aattaaccct cactaaaggg aacaaaagct ggagctccac cgcggtggcg 2220
gccgctctag aactagtgga tccccaattc taccgggtag gggaggcgct tttcccaagg 2280
cagtctggag catgcgcttt agcagccccg ctgggcactt ggcgctacac aagtggcctc 2340
tggcctcgca cacattccac atccaccggt aggcgccaac cggctccgtt ctttggtggc 2400
cccttcgcgc caccttctac tcctccccta gtcaggaagt tcccccccgc cccgcagctc 2460
gcgtcgtgca ggacgtgaca aatggaagta gcacgtctca ctagtctcgt gcagatggac 2520
agcaccgctg agcaatggaa gcgggtaggc ctttggggca gcggccaata gcagctttgc 2580
tccttcgctt tctgggctca gaggctggga aggggtgggt ccgggggcgg gctcaggggc 2640
gggctcaggg gcggggcggg cgcccgaagg tcctccggag gcccggcatt ctgcacgctt 2700
caaaagcgca cgtctgccgc gctgttctcc tcttcctcat ctccgggcct ttcgacctgc 2760
aggtcctcgc catggatcct gatgatgttg ttgattcttc taaatctttt gtgatggaaa 2820
acttttcttc gtaccacggg actaaacctg gttatgtaga ttccattcaa aaaggtatac 2880
aaaagccaaa atctggtaca caaggaaatt atgacgatga ttggaaaggg ttttatagta 2940
ccgacaataa atacgacgct gcgggatact ctgtagataa tgaaaacccg ctctctggaa 3000
aagctggagg cgtggtcaaa gtgacgtatc caggactgac gaaggttctc gcactaaaag 3060
tggataatgc cgaaactatt aagaaagagt taggtttaag tctcactgaa ccgttgatgg 3120
agcaagtcgg aacggaagag tttatcaaaa ggttcggtga tggtgcttcg cgtgtagtgc 3180
tcagccttcc cttcgctgag gggagttcta gcgttgaata tattaataac tgggaacagg 3240
cgaaagcgtt aagcgtagaa cttgagatta attttgaaac ccgtggaaaa cgtggccaag 3300
atgcgatgta tgagtatatg gctcaagcct gtgcaggaaa tcgtgtcagg cgatctcttt 3360
gtgaaggaac cttacttctg tggtgtgaca taattggaca aactacctac agagatttaa 3420
agctctaagg taaatataaa atttttaagt gtataatgtg ttaaactact gattctaatt 3480
gtttgtgtat tttagattcc aacctatgga actgatgaat gggagcagtg gtggaatgca 3540
gatcctagag ctcgctgatc agcctcgact gtgccttcta gttgccagcc atctgttgtt 3600
tgcccctccc ccgtgccttc cttgaccctg gaaggtgcca ctcccactgt cctttcctaa 3660
taaaatgagg aaattgcatc gcattgtctg agtaggtgtc attctattct ggggggtggg 3720
gtggggcagg acagcaaggg ggaggattgg gaagacaata gcaggcatgc tggggatgcg 3780
gtgggctcta tggcttctga ggcggaaaga accagctggg gctcgagata tcaagcttat 3840
cgataccgtc gacctcgagg gggggcccgg tacccaattc gccctatagt gagtcgtatt 3900
acgcgcgctc actggccgtc gttttacaac gtcgtgactg ggaaaaccct ggcgttaccc 3960
aacttaatcg ccttgcagca catccccctt tcgccagctg gcgtaatagc gaagaggccc 4020
gcaccgatcg cccttcccaa cagttgcgca gcctgaatgg cgaatggaaa ttgtaagcgt 4080
taatattttg ttaaaattcg cgttaaattt ttgttaaatc agctcatttt ttaaccaata 4140
ggccgaaatc ggcaaaatcc cttataaatc aaaagaatag accgagatag ggttgagtgt 4200
tgttccagtt tggaacaaga gtccactatt aaagaacgtg gactccaacg tcaaagggcg 4260
aaaaaccgtc tatcagggcg atggcccact acgtgaacca tcaccctaat caagtttttt 4320
ggggtcgagg tgccgtaaag cactaaatcg gaaccctaaa gggagccccc gatttagagc 4380
ttgacgggga aagccggcga acgtggcgag aaaggaaggg aagaaagcga aaggagcggg 4440
cgctagggcg ctggcaagtg tagcggtcac gctgcgcgta accaccacac ccgccgcgct 4500
taatgcgccg ctacagggcg cgtcag 4526
<210> 63
<211> 4929
<212> DNA
<213> Artificial sequence
<220>
<223> pGK-IRES-GFP nucleic acid sequence
<400> 63
tcgacaccgg gtaggggagg cgcttttccc aaggcagtct ggagcatgcg ctttagcagc 60
cccgctgggc acttggcgct acacaagtgg cctctggcct cgcacacatt ccacatccac 120
cggtaggcgc caaccggctc cgttctttgg tggccccttc gcgccacctt ctactcctcc 180
cctagtcagg aagttccccc ccgccccgca gctcgcgtcg tgcaggacgt gacaaatgga 240
agtagcacgt ctcactagtc tcgtgcagat ggacagcacc gctgagcaat ggaagcgggt 300
aggcctttgg ggcagcggcc aatagcagct ttgctccttc gctttctggg ctcagaggct 360
gggaaggggt gggtccgggg gcgggctcag gggcgggctc aggggcgggg cgggcgcccg 420
aaggtcctcc ggaggcccgg cattctgcac gcttcaaaag cgcacgtctg ccgcgctgtt 480
ctcctcttcc tcatctccgg gcctttcgac ctgccccggg ccctatatat ggatcggcta 540
gccgatccgc ccctctccct cccccccccc taacgttact ggccgaagcc gcttggaata 600
aggccggtgt gcgtttgtct atatgttatt ttccaccata ttgccgtctt ttggcaatgt 660
gagggcccgg aaacctggcc ctgtcttctt gacgagcatt cctaggggtc tttcccctct 720
cgccaaagga atgcaaggtc tgttgaatgt cgtgaaggaa gcagttcctc tggaagcttc 780
ttgaagacaa acaacgtctg tagcgaccct ttgcaggcag cggaaccccc cacctggcga 840
caggtgcctc tgcggccaaa agccacgtgt ataagataca cctgcaaagg cggcacaacc 900
ccagtgccac gttgtgagtt ggatagttgt ggaaagagtc aaatggctct cctcaagcgt 960
attcaacaag gggctgaagg atgcccagaa ggtaccccat tgtatgggat ctgatctggg 1020
gcctcggtgc acatgcttta catgtgttta gtcgaggtta aaaaaacgtc taggcccccc 1080
gaaccacggg gacgtggttt tcctttgaaa aacacgatga taatatggcc acaaccatgg 1140
tgagcaaggg cgaggagctg ttcaccgggg tggtgcccat cctggtcgag ctggacggcg 1200
acgtaaacgg ccacaagttc agcgtgtccg gcgagggcga gggcgatgcc acctacggca 1260
agctgaccct gaagttcatc tgcaccaccg gcaagctgcc cgtgccctgg cccaccctcg 1320
tgaccaccct gacctacggc gtgcagtgct tcagccgcta ccccgaccac atgaagcagc 1380
acgacttctt caagtccgcc atgcccgaag gctacgtcca ggagcgcacc atcttcttca 1440
aggacgacgg caactacaag acccgcgccg aggtgaagtt cgagggcgac accctggtga 1500
accgcatcga gctgaagggc atcgacttca aggaggacgg caacatcctg gggcacaagc 1560
tggagtacaa ctacaacagc cacaacgtct atatcatggc cgacaagcag aagaacggca 1620
tcaaggtgaa cttcaagatc cgccacaaca tcgaggacgg cagcgtgcag ctcgccgacc 1680
actaccagca gaacaccccc atcggcgacg gccccgtgct gctgcccgac aaccactacc 1740
tgagcaccca gtccgccctg agcaaagacc ccaacgagaa gcgcgatcac atggtcctgc 1800
tggagttcgt gaccgccgcc gggatcactc tcggcatgga cgagctgtac aagtaaagcg 1860
gccgccaatt cactcctcag gtgcaggctg cctatcagaa ggtggtggct ggtgtggcca 1920
atgccctggc tcacaaatac cactgagatc tttttccctc tgccaaaaat tatggggaca 1980
tcatgaagcc ccttgagcat ctgacttctg gctaataaag gaaatttatt ttcattgcaa 2040
tagtgtgttg gaattttttg tgtctctcac tcggaaggac atatgggagg gcaaatcatt 2100
taaaacatca gaatgagtat ttggtttaga gtttggcaac atatgcccat atgctggctg 2160
ccatgaacaa aggttggcta taaagaggtc atcagtatat gaaacagccc cctgctgtcc 2220
attccttatt ccatagaaaa gccttgactt gaggttagat tttttttata ttttgttttg 2280
tgttattttt ttctttaaca tccctaaaat tttccttaca tgttttacta gccagatttt 2340
tcctcctctc ctgactactc ccagtcatag ctgtccctct tctcttatgg agatccctcg 2400
acctgcagcc caagcttggc gtaatcatgg tcatagctgt ttcctgtgtg aaattgttat 2460
ccgctcacaa ttccacacaa catacgagcc ggaagcataa agtgtaaagc ctggggtgcc 2520
taatgagtga gctaactcac attaattgcg ttgcgctcac tgcccgcttt ccagtcggga 2580
aacctgtcgt gccagcggat ccgcatctca attagtcagc aaccatagtc ccgcccctaa 2640
ctccgcccat cccgccccta actccgccca gttccgccca ttctccgccc catggctgac 2700
taattttttt tatttatgca gaggccgagg ccgcctcggc ctctgagcta ttccagaagt 2760
agtgaggagg cttttttgga ggcctaggct tttgcaaaaa gctaacttgt ttattgcagc 2820
ttataatggt tacaaataaa gcaatagcat cacaaatttc acaaataaag catttttttc 2880
actgcattct agttgtggtt tgtccaaact catcaatgta tcttatcatg tctggatccg 2940
ctgcattaat gaatcggcca acgcgcgggg agaggcggtt tgcgtattgg gcgctcttcc 3000
gcttcctcgc tcactgactc gctgcgctcg gtcgttcggc tgcggcgagc ggtatcagct 3060
cactcaaagg cggtaatacg gttatccaca gaatcagggg ataacgcagg aaagaacatg 3120
tgagcaaaag gccagcaaaa ggccaggaac cgtaaaaagg ccgcgttgct ggcgtttttc 3180
cataggctcc gcccccctga cgagcatcac aaaaatcgac gctcaagtca gaggtggcga 3240
aacccgacag gactataaag ataccaggcg tttccccctg gaagctccct cgtgcgctct 3300
cctgttccga ccctgccgct taccggatac ctgtccgcct ttctcccttc gggaagcgtg 3360
gcgctttctc atagctcacg ctgtaggtat ctcagttcgg tgtaggtcgt tcgctccaag 3420
ctgggctgtg tgcacgaacc ccccgttcag cccgaccgct gcgccttatc cggtaactat 3480
cgtcttgagt ccaacccggt aagacacgac ttatcgccac tggcagcagc cactggtaac 3540
aggattagca gagcgaggta tgtaggcggt gctacagagt tcttgaagtg gtggcctaac 3600
tacggctaca ctagaagaac agtatttggt atctgcgctc tgctgaagcc agttaccttc 3660
ggaaaaagag ttggtagctc ttgatccggc aaacaaacca ccgctggtag cggtggtttt 3720
tttgtttgca agcagcagat tacgcgcaga aaaaaaggat ctcaagaaga tcctttgatc 3780
ttttctacgg ggtctgacgc tcagtggaac gaaaactcac gttaagggat tttggtcatg 3840
agattatcaa aaaggatctt cacctagatc cttttaaatt aaaaatgaag ttttaaatca 3900
atctaaagta tatatgagta aacttggtct gacagttacc aatgcttaat cagtgaggca 3960
cctatctcag cgatctgtct atttcgttca tccatagttg cctgactccc cgtcgtgtag 4020
ataactacga tacgggaggg cttaccatct ggccccagtg ctgcaatgat accgcgagac 4080
ccacgctcac cggctccaga tttatcagca ataaaccagc cagccggaag ggccgagcgc 4140
agaagtggtc ctgcaacttt atccgcctcc atccagtcta ttaattgttg ccgggaagct 4200
agagtaagta gttcgccagt taatagtttg cgcaacgttg ttgccattgc tacaggcatc 4260
gtggtgtcac gctcgtcgtt tggtatggct tcattcagct ccggttccca acgatcaagg 4320
cgagttacat gatcccccat gttgtgcaaa aaagcggtta gctccttcgg tcctccgatc 4380
gttgtcagaa gtaagttggc cgcagtgtta tcactcatgg ttatggcagc actgcataat 4440
tctcttactg tcatgccatc cgtaagatgc ttttctgtga ctggtgagta ctcaaccaag 4500
tcattctgag aatagtgtat gcggcgaccg agttgctctt gcccggcgtc aatacgggat 4560
aataccgcgc cacatagcag aactttaaaa gtgctcatca ttggaaaacg ttcttcgggg 4620
cgaaaactct caaggatctt accgctgttg agatccagtt cgatgtaacc cactcgtgca 4680
cccaactgat cttcagcatc ttttactttc accagcgttt ctgggtgagc aaaaacagga 4740
aggcaaaatg ccgcaaaaaa gggaataagg gcgacacgga aatgttgaat actcatactc 4800
ttcctttttc aatattattg aagcatttat cagggttatt gtctcatgag cggatacata 4860
tttgaatgta tttagaaaaa taaacaaata ggggttccgc gcacatttcc ccgaaaagtg 4920
ccacctggg 4929
<210> 64
<211> 5568
<212> DNA
<213> Artificial sequence
<220>
<223> pGK-DTA-IRES-GFP nucleic acid sequence
<400> 64
tcgacaccgg gtaggggagg cgcttttccc aaggcagtct ggagcatgcg ctttagcagc 60
cccgctgggc acttggcgct acacaagtgg cctctggcct cgcacacatt ccacatccac 120
cggtaggcgc caaccggctc cgttctttgg tggccccttc gcgccacctt ctactcctcc 180
cctagtcagg aagttccccc ccgccccgca gctcgcgtcg tgcaggacgt gacaaatgga 240
agtagcacgt ctcactagtc tcgtgcagat ggacagcacc gctgagcaat ggaagcgggt 300
aggcctttgg ggcagcggcc aatagcagct ttgctccttc gctttctggg ctcagaggct 360
gggaaggggt gggtccgggg gcgggctcag gggcgggctc aggggcgggg cgggcgcccg 420
aaggtcctcc ggaggcccgg cattctgcac gcttcaaaag cgcacgtctg ccgcgctgtt 480
ctcctcttcc tcatctccgg gcctttcgac ctgccccggg atggatcctg atgatgttgt 540
tgattcttct aaatcttttg tgatggaaaa cttttcttcg taccacggga ctaaacctgg 600
ttatgtagat tccattcaaa aaggtataca aaagccaaaa tctggtacac aaggaaatta 660
tgacgatgat tggaaagggt tttatagtac cgacaataaa tacgacgctg cgggatactc 720
tgtagataat gaaaacccgc tctctggaaa agctggaggc gtggtcaaag tgacgtatcc 780
aggactgacg aaggttctcg cactaaaagt ggataatgcc gaaactatta agaaagagtt 840
aggtttaagt ctcactgaac cgttgatgga gcaagtcgga acggaagagt ttatcaaaag 900
gttcggtgat ggtgcttcgc gtgtagtgct cagccttccc ttcgctgagg ggagttctag 960
cgttgaatat attaataact gggaacaggc gaaagcgtta agcgtagaac ttgagattaa 1020
ttttgaaacc cgtggaaaac gtggccaaga tgcgatgtat gagtatatgg ctcaagcctg 1080
tgcaggaaat cgtgtcaggc gatctctttg tgaaggaacc ttacttctgt ggtgtgacat 1140
aattggacaa actacctaca gagatttaaa gctctaagct agcctccgcc cctctccctc 1200
ccccccccct aacgttactg gccgaagccg cttggaataa ggccggtgtg cgtttgtcta 1260
tatgttattt tccaccatat tgccgtcttt tggcaatgtg agggcccgga aacctggccc 1320
tgtcttcttg acgagcattc ctaggggtct ttcccctctc gccaaaggaa tgcaaggtct 1380
gttgaatgtc gtgaaggaag cagttcctct ggaagcttct tgaagacaaa caacgtctgt 1440
agcgaccctt tgcaggcagc ggaacccccc acctggcgac aggtgcctct gcggccaaaa 1500
gccacgtgta taagatacac ctgcaaaggc ggcacaaccc cagtgccacg ttgtgagttg 1560
gatagttgtg gaaagagtca aatggctctc ctcaagcgta ttcaacaagg ggctgaagga 1620
tgcccagaag gtaccccatt gtatgggatc tgatctgggg cctcggtgca catgctttac 1680
atgtgtttag tcgaggttaa aaaaacgtct aggccccccg aaccacgggg acgtggtttt 1740
cctttgaaaa acacgatgat aatatggcca caaccatggt gagcaagggc gaggagctgt 1800
tcaccggggt ggtgcccatc ctggtcgagc tggacggcga cgtaaacggc cacaagttca 1860
gcgtgtccgg cgagggcgag ggcgatgcca cctacggcaa gctgaccctg aagttcatct 1920
gcaccaccgg caagctgccc gtgccctggc ccaccctcgt gaccaccctg acctacggcg 1980
tgcagtgctt cagccgctac cccgaccaca tgaagcagca cgacttcttc aagtccgcca 2040
tgcccgaagg ctacgtccag gagcgcacca tcttcttcaa ggacgacggc aactacaaga 2100
cccgcgccga ggtgaagttc gagggcgaca ccctggtgaa ccgcatcgag ctgaagggca 2160
tcgacttcaa ggaggacggc aacatcctgg ggcacaagct ggagtacaac tacaacagcc 2220
acaacgtcta tatcatggcc gacaagcaga agaacggcat caaggtgaac ttcaagatcc 2280
gccacaacat cgaggacggc agcgtgcagc tcgccgacca ctaccagcag aacaccccca 2340
tcggcgacgg ccccgtgctg ctgcccgaca accactacct gagcacccag tccgccctga 2400
gcaaagaccc caacgagaag cgcgatcaca tggtcctgct ggagttcgtg accgccgccg 2460
ggatcactct cggcatggac gagctgtaca agtaaagcgg ccgccaattc actcctcagg 2520
tgcaggctgc ctatcagaag gtggtggctg gtgtggccaa tgccctggct cacaaatacc 2580
actgagatct ttttccctct gccaaaaatt atggggacat catgaagccc cttgagcatc 2640
tgacttctgg ctaataaagg aaatttattt tcattgcaat agtgtgttgg aattttttgt 2700
gtctctcact cggaaggaca tatgggaggg caaatcattt aaaacatcag aatgagtatt 2760
tggtttagag tttggcaaca tatgcccata tgctggctgc catgaacaaa ggttggctat 2820
aaagaggtca tcagtatatg aaacagcccc ctgctgtcca ttccttattc catagaaaag 2880
ccttgacttg aggttagatt ttttttatat tttgttttgt gttatttttt tctttaacat 2940
ccctaaaatt ttccttacat gttttactag ccagattttt cctcctctcc tgactactcc 3000
cagtcatagc tgtccctctt ctcttatgga gatccctcga cctgcagccc aagcttggcg 3060
taatcatggt catagctgtt tcctgtgtga aattgttatc cgctcacaat tccacacaac 3120
atacgagccg gaagcataaa gtgtaaagcc tggggtgcct aatgagtgag ctaactcaca 3180
ttaattgcgt tgcgctcact gcccgctttc cagtcgggaa acctgtcgtg ccagcggatc 3240
cgcatctcaa ttagtcagca accatagtcc cgcccctaac tccgcccatc ccgcccctaa 3300
ctccgcccag ttccgcccat tctccgcccc atggctgact aatttttttt atttatgcag 3360
aggccgaggc cgcctcggcc tctgagctat tccagaagta gtgaggaggc ttttttggag 3420
gcctaggctt ttgcaaaaag ctaacttgtt tattgcagct tataatggtt acaaataaag 3480
caatagcatc acaaatttca caaataaagc atttttttca ctgcattcta gttgtggttt 3540
gtccaaactc atcaatgtat cttatcatgt ctggatccgc tgcattaatg aatcggccaa 3600
cgcgcgggga gaggcggttt gcgtattggg cgctcttccg cttcctcgct cactgactcg 3660
ctgcgctcgg tcgttcggct gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg 3720
ttatccacag aatcagggga taacgcagga aagaacatgt gagcaaaagg ccagcaaaag 3780
gccaggaacc gtaaaaaggc cgcgttgctg gcgtttttcc ataggctccg cccccctgac 3840
gagcatcaca aaaatcgacg ctcaagtcag aggtggcgaa acccgacagg actataaaga 3900
taccaggcgt ttccccctgg aagctccctc gtgcgctctc ctgttccgac cctgccgctt 3960
accggatacc tgtccgcctt tctcccttcg ggaagcgtgg cgctttctca tagctcacgc 4020
tgtaggtatc tcagttcggt gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc 4080
cccgttcagc ccgaccgctg cgccttatcc ggtaactatc gtcttgagtc caacccggta 4140
agacacgact tatcgccact ggcagcagcc actggtaaca ggattagcag agcgaggtat 4200
gtaggcggtg ctacagagtt cttgaagtgg tggcctaact acggctacac tagaagaaca 4260
gtatttggta tctgcgctct gctgaagcca gttaccttcg gaaaaagagt tggtagctct 4320
tgatccggca aacaaaccac cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt 4380
acgcgcagaa aaaaaggatc tcaagaagat cctttgatct tttctacggg gtctgacgct 4440
cagtggaacg aaaactcacg ttaagggatt ttggtcatga gattatcaaa aaggatcttc 4500
acctagatcc ttttaaatta aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa 4560
acttggtctg acagttacca atgcttaatc agtgaggcac ctatctcagc gatctgtcta 4620
tttcgttcat ccatagttgc ctgactcccc gtcgtgtaga taactacgat acgggagggc 4680
ttaccatctg gccccagtgc tgcaatgata ccgcgagacc cacgctcacc ggctccagat 4740
ttatcagcaa taaaccagcc agccggaagg gccgagcgca gaagtggtcc tgcaacttta 4800
tccgcctcca tccagtctat taattgttgc cgggaagcta gagtaagtag ttcgccagtt 4860
aatagtttgc gcaacgttgt tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt 4920
ggtatggctt cattcagctc cggttcccaa cgatcaaggc gagttacatg atcccccatg 4980
ttgtgcaaaa aagcggttag ctccttcggt cctccgatcg ttgtcagaag taagttggcc 5040
gcagtgttat cactcatggt tatggcagca ctgcataatt ctcttactgt catgccatcc 5100
gtaagatgct tttctgtgac tggtgagtac tcaaccaagt cattctgaga atagtgtatg 5160
cggcgaccga gttgctcttg cccggcgtca atacgggata ataccgcgcc acatagcaga 5220
actttaaaag tgctcatcat tggaaaacgt tcttcggggc gaaaactctc aaggatctta 5280
ccgctgttga gatccagttc gatgtaaccc actcgtgcac ccaactgatc ttcagcatct 5340
tttactttca ccagcgtttc tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag 5400
ggaataaggg cgacacggaa atgttgaata ctcatactct tcctttttca atattattga 5460
agcatttatc agggttattg tctcatgagc ggatacatat ttgaatgtat ttagaaaaat 5520
aaacaaatag gggttccgcg cacatttccc cgaaaagtgc cacctggg 5568
<210> 65
<211> 9
<212> DNA
<213> Artificial sequence
<220>
<223> CRISPR1 cleavage site nucleic acid sequence
<400> 65
agataacgt 9
<210> 66
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 66
gccaaataag gcacgttatc 20
<210> 67
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 67
aatgtggaaa cggccaaata 20
<210> 68
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 68
accagataac gtgccttatt 20
<210> 69
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 69
acatgacagc acgattttgt 20
<210> 70
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 70
ctggtatgaa ccaatcagag 20
<210> 71
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 71
tggtatgaac caatcagagt 20
<210> 72
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 72
gaccttgatg cagagaaaac 20
<210> 73
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 73
ctcctgtttt ctctgcatca 20
<210> 74
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 74
gcagagaaaa caggagaaga 20
<210> 75
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 75
agaaggatga gaaaagaatg 20
<210> 76
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 76
ctgtcatgtc ccactctgat 20
<210> 77
<211> 20
<212> DNA
<213> Artificial sequence
<220>
<223> sgRNA nucleic acid sequence
<400> 77
atgagaaaag aatgtggaaa 20
<210> 78
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 78
ccaacagaag gcacgttatc cag 23
<210> 79
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 79
tcaaaataaa gtacgttatc tag 23
<210> 80
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 80
ggcatataaa gcacgttata cag 23
<210> 81
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 81
gcataataat gtacgttatc tgg 23
<210> 82
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 82
actaaatcag gcacgtgatc tgg 23
<210> 83
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 83
gctaaattaa gctcgttatc ggg 23
<210> 84
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 84
gtcaaatgag gcatgttatc agg 23
<210> 85
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 85
ttcaaataag ccacgttatt cag 23
<210> 86
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 86
gtcaaacaag gcatgttatc agg 23
<210> 87
<211> 23
<212> DNA
<213> Artificial sequence
<220>
<223> off-targets nucleic acid sequence for guide #1
<400> 87
ccctaataaa gcacgttttc agg 23
Claims (40)
- DNA 편집제(DNA editing agent)로서,
조류의 난에서 수컷 병아리 배아의 치사성 표현형(lethal phenotype)을 유도성 방식으로 유도하기 위한 제1 핵산 서열, 및 상기 치사성 표현형을 달성하기 위한 상기 제1 핵산 서열을 상기 조류의 세포의 Z 염색체에 안내하기 위한 제2 핵산 서열을 포함하는, DNA 편집제. - 제1항에 있어서, 상기 제1 핵산 서열은 치사 단백질(lethality protein)의 발현을 제어하는 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결된 치사 단백질을 암호화하되, 상기 스위치는 유도자(inducer)에 의해서 조절되는, DNA 편집제.
- 제2항에 있어서, 상기 치사 단백질은 독소, 프로-아포토시스 단백질(pro-apoptotic protein), Wnt 신호전달 경로의 저해제, BMP 길항제 및 FGF 길항제로 이루어진 군으로부터 선택되는, DNA 편집제.
- 제1항에 있어서, 단일 분자인, DNA 편집제.
- 제1항에 있어서, 상기 제1 핵산 서열 및 상기 제2 핵산 서열은 동일하지 않은 분자로 구성되는, DNA 편집제.
- 제1항에 있어서, 상기 제1 핵산 서열은 엔도뉴클레아제 단백질의 발현을 제어하는 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결된 게놈 편집을 수행할 수 있는 엔도뉴클레아제 효소를 암호화하되, 상기 스위치는 유도자에 의해서 조절되는, DNA 편집제.
- 제4항에 있어서, 상기 제2 핵산 서열은,
(i) 상기 조류의 상기 Z 염색체 내의 표적 유전자 좌위에 측접한 5' 영역과 실질적으로 상동성인 좌측 상동성 아암(left homology arm: LHA) 뉴클레오타이드 서열; 및
(i) 상기 조류의 상기 Z 염색체 내의 상기 표적 유전자 좌위에 측접한 3' 영역과 실질적으로 상동성인 우측 상동성 아암(right homology arm: RHA) 뉴클레오타이드 서열
을 포함하는, DNA 편집제. - 제2항 또는 제6항에 있어서, 상기 유도자는 열, 초음파, 전자기 에너지 및 화학 물질로 이루어진 군으로부터 선택되는, DNA 편집제.
- 제2항 또는 제6항에 있어서, 상기 스위치는 조합되어 상기 유도자의 존재 하에서 활성 효소를 형성하는 스플리트 리콤비나제 효소(split recombinase enzyme)를 포함하는, DNA 편집제.
- 제2항 또는 제6항에 있어서, 상기 스위치는 유도성 프로모터를 포함하는, DNA 편집제.
- 제6항에 있어서, 상기 엔도뉴클레아제 효소는 RNA-안내(RNA-guided) DNA 엔도뉴클레아제 효소인, DNA 편집제.
- 제11항에 있어서, 상기 조류의 필수 유전자를 표적으로 하는 가이드 RNA를 암호화하는 뉴클레오타이드 서열을 더 포함하되, 상기 뉴클레오타이드 서열은 상기 스위치를 암호화하는 뉴클레오타이드 서열에 작동 가능하게 연결되어 있는, DNA 편집제.
- 제12항에 있어서, 상기 필수 유전자는 BMPR1A, BMP2, BMP4 및 FGFR1로 이루어진 군으로부터 선택되는, DNA 편집제.
- 제11항에 있어서, 상기 RNA-안내 DNA 엔도뉴클레아제 효소는 아연-핑거 뉴클레아제(zinc-finger nuclease: ZFN), 전사 활성화제-유사 효과기 뉴클레아제(transcription activator-like effector nuclease: TALEN) 및 카스파제 9로 이루어진 군으로부터 선택되는, DNA 편집제.
- 제1항 내지 제14항 중 어느 한 항에 있어서, 리포터 폴리펩타이드를 암호화하는 뉴클레오타이드 서열을 더 포함하는, DNA 편집제.
- 제2항 또는 제6항에 있어서, 상기 유도자는 전자기 에너지인, DNA 편집제.
- 제16항에 있어서, 상기 전자기 에너지는 가시광의 성분인, DNA 편집제.
- 제17항에 있어서, 가시광의 성분은 청색광인, DNA 편집제.
- 제1항 내지 제18항 중 어느 한 항에 있어서, 상기 조류는 닭, 칠면조, 오리 및 메추라기로 이루어진 군으로부터 선택되는, DNA 편집제.
- 세포 집단으로서,
상기 세포의 Z 염색체에 안정적으로 통합되는 외인성 폴리뉴클레오타이드를 포함하는 조류의 세포를 포함하되, 상기 외인성 폴리뉴클레오타이드는 상기 조류의 수컷 자손에서 치사성 표현형을 유도하기 위한 것인, 세포 집단. - 제20항에 있어서, 상기 유도는 유도성 방식으로 달성되는, 세포 집단.
- 제20항에 있어서, 상기 세포는 원시 생식 세포(primordial germ cell: PGC)를 포함하는, 세포 집단.
- 제20항에 있어서, 상기 세포는 생식세포(gamete)를 포함하는, 세포 집단.
- 제20항에 있어서, 상기 PGC는 생식선 PGC, 혈액 PGC 및 생식신월환(germinal crescent) PGC로 이루어진 군으로부터 선택되는, 세포 집단.
- 제20항 또는 제24항의 세포 집단을 포함하는 키메라 조류.
- 키메라 조류의 생성 방법으로서,
세포 집단의 PGC 중 적어도 하나가 수용자 조류 배아의 생식선에 군집(colonizing)하여 키메라 조류를 생성시키기에 충분한 조건 하에서 제22항의 세포 집단을 상기 수용자 조류 배아에 투여하는 단계를 포함하는, 키메라 조류의 생성 방법. - 제26항에 있어서, 상기 투여 후 상기 키메라 조류를 인큐베이션시켜 부화시키는 단계를 더 포함하는, 키메라 조류의 생성 방법.
- 제27항에 있어서, 상기 키메라 조류를 성적 성숙도로 성장시키는 단계를 더 포함하되, 상기 키메라 조류는 공여자 PGC로부터 유래된 생식세포를 생산하는, 키메라 조류의 생성 방법.
- 제26항에 있어서, 상기 투여는 난내(in-ovo) 주사에 의한 것인, 키메라 조류의 생성 방법.
- 제26항에 있어서, 상기 세포 집단은 상기 수용자 조류와 동일한 조류 종으로부터 유래되는, 키메라 조류의 생성 방법.
- 제26항에 있어서, 상기 세포 집단은 상기 수용자 조류와 상이한 조류 종으로부터 유래되는, 키메라 조류의 생성 방법.
- 제26항에 있어서, 상기 세포 집단은 상기 수용자 배아가 이알-길라디 및 코차브 기 결정 시스템(Eyal-Giladi & Kochav staging system)에 따라서 약 IX기와 햄버거 및 해밀턴 기 결정 시스템(Hamburger & Hamilton staging system)에 따라서 약 30기 사이인 경우에 투여되는, 키메라 조류의 생성 방법.
- 제32항에 있어서, 상기 세포 집단은 상기 수용자 배아가 햄버거 및 해밀턴 기 결정 시스템에 따라 14기 이후인 경우에 투여되는, 키메라 조류의 생성 방법.
- 제26항 내지 제28항 중 어느 한 항의 방법에 따라서 생성된 키메라 조류.
- 제34항의 키메라 조류의 생식세포를 사용하여 생성된 트랜스제닉(transgenic) 조류.
- 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 방법으로서,
외인성 폴리뉴클레오타이드가 상기 조류의 Z 염색체에 안정적으로 통합되되, 상기 외인성 폴리뉴클레오타이드는 상기 조류의 수컷 자손에서 치사성 표현형을 유도성 방식으로 유도하기 위한 것이고,
상기 난을 상기 치사성 표현형을 유도하는 유도자에 노출시켜, 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 단계를 포함하는, 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 방법. - NA 편집 시스템으로서,
(i) 리콤비나제 인식 부위에 작동 가능하게 연결된 조류의 난에서 치사성 표현형을 유도하기 위한 제1 핵산 서열 및 상기 치사성 표현형을 달성하기 위한 상기 제1 핵산 서열을 상기 새의 세포의 Z 염색체에 안내하기 위한 서열을 포함하는 제1 작용제; 및
(ii) 리콤비나제 효소를 암호화하는 제2 핵산 서열 및 상기 제2 핵산 서열을 조류 세포의 Z 염색체에 안내하기 위한 서열을 포함하는 제2 작용제
를 포함하는, DNA 편집 시스템. - 제37항에 있어서, 상기 제1 핵산 서열은 게놈 편집을 수행할 수 있는 치사 단백질 또는 엔도뉴클레아제 효소를 암호화하는, DNA 편집 시스템.
- 제37항에 있어서, 상기 제1 핵산 서열 또는 상기 제2 핵산 서열을 상기 X 염색체에 안내하기 위한 상기 서열은,
(i) 상기 조류의 상기 Z 염색체 내의 표적 유전자 좌위에 측접한 5' 영역과 실질적으로 상동성인 좌측 상동성 아암(LHA) 뉴클레오타이드 서열; 및
(i) 상기 조류의 상기 Z 염색체 내의 상기 표적 유전자 좌위에 측접한 3' 영역과 실질적으로 상동성인 우측 상동성 아암(RHA) 뉴클레오타이드 서열
을 포함하는, DNA 편집 시스템. - 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 방법으로서,
암컷 조류와 수컷 조류를 짝짓기시키는 단계를 포함하되, 리콤비나제 인식 부위에 작동 가능하게 연결된 제1 외인성 폴리뉴클레오타이드가 상기 수컷 조류의 Z 염색체에 안정적으로 통합되고, 상기 외인성 폴리뉴클레오타이드는 조류의 난에서 치사성 표현형을 유도하기 위한 것이고, 리콤비나제 효소를 암호화하는 제2 외인성 폴리뉴클레오타이드는 상기 암컷 조류의 Z 염색체에 안정적으로 통합되거나, 또는
리콤비나제 인식 부위에 작동 가능하게 연결된 제1 외인성 폴리뉴클레오타이드가 상기 암컷 조류의 Z 염색체에 안정적으로 통합되고, 상기 외인성 폴리뉴클레오타이드는 조류의 난에서 치사성 표현형을 유도하기 위한 것이고, 리콤비나제 효소를 암호화하는 제2 외인성 폴리뉴클레오타이드는 상기 수컷 조류의 상기 Z 염색체에 안정적으로 통합되어,
상기 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는, 조류의 수정란으로부터 부화하는 수컷 병아리의 수를 감소시키는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762560218P | 2017-09-19 | 2017-09-19 | |
| US62/560,218 | 2017-09-19 | ||
| PCT/IL2018/051056 WO2019058376A1 (en) | 2017-09-19 | 2018-09-17 | BIRDS WITH GENOME EDITION |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200088805A true KR20200088805A (ko) | 2020-07-23 |
Family
ID=65811120
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207011278A KR20200088805A (ko) | 2017-09-19 | 2018-09-17 | 게놈-편집 조류 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US20200214273A1 (ko) |
| EP (1) | EP3684172A4 (ko) |
| JP (1) | JP2020536580A (ko) |
| KR (1) | KR20200088805A (ko) |
| CN (2) | CN111315212B (ko) |
| AU (1) | AU2018336161A1 (ko) |
| BR (1) | BR112020005272A2 (ko) |
| CA (1) | CA3075956A1 (ko) |
| EA (1) | EA202090585A1 (ko) |
| IL (1) | IL273190A (ko) |
| MX (1) | MX2020003123A (ko) |
| WO (1) | WO2019058376A1 (ko) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MX2021010611A (es) * | 2019-03-05 | 2021-11-12 | The State Of Israel Ministry Of Agriculture & Rural Development Agricultural Res Organization Aro Vo | Aves con genoma editado. |
| CN112522315B (zh) * | 2020-12-08 | 2023-04-11 | 广东省农业科学院动物科学研究所 | 一种鸡原始生殖细胞转染方法 |
| TW202241259A (zh) * | 2020-12-31 | 2022-11-01 | 以色列國家農業部、農村發展農業研究組織(沃爾卡尼研究所) | 不育禽類胚胎、其產生及用途 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2355459B (en) * | 1999-11-29 | 2001-09-26 | Isis Innovation | A dominant conditional lethal genetic system |
| FR2810048A1 (fr) * | 2000-06-07 | 2001-12-14 | Centre Nat Rech Scient | Construction d'acide nucleique utile pour l'expression de transgenes notamment dans les cellules souches embryonnaires |
| CN1141391C (zh) * | 2001-11-02 | 2004-03-10 | 浙江省农业科学院 | 家蚕性连锁平衡致死系性别控制基因的导入方法 |
| DE10248361A1 (de) * | 2002-06-30 | 2004-01-22 | Beisswanger, Roland, Dr. | Unterdrückung eines Geschlechtes durch die Veränderung von Geschlechtschromosomen |
| WO2009023800A1 (en) * | 2007-08-14 | 2009-02-19 | Origen Therapeutics | Transgenic chickens with an inactivated endogenous gene locus |
| EP2376641A4 (en) * | 2008-12-17 | 2013-01-09 | Commw Scient Ind Res Org | METHODS OF MODULATING THE SEX OF AVIAN SPECIES |
| US20120084873A1 (en) * | 2009-02-08 | 2012-04-05 | Andrew Sinclair | Sex-determination and methods of specifying same |
| JP2015527889A (ja) * | 2012-07-25 | 2015-09-24 | ザ ブロード インスティテュート, インコーポレイテッド | 誘導可能なdna結合タンパク質およびゲノム撹乱ツール、ならびにそれらの適用 |
| WO2015199225A1 (ja) * | 2014-06-27 | 2015-12-30 | 国立研究開発法人産業技術総合研究所 | 家禽始原生殖細胞の遺伝子改変方法、遺伝子改変された家禽始原生殖細胞、遺伝子改変家禽の生産方法及び家禽卵 |
| CN108474034A (zh) * | 2015-12-03 | 2018-08-31 | 艾吉伊特有限公司 | 对未孵化卵中的禽类胚胎进行性别确定的方法及其用具 |
| CN106359073A (zh) * | 2016-08-23 | 2017-02-01 | 吉林省农业科学院 | 孤雄诱导基因表达盒和孤雄诱导表达载体及其应用 |
| MX2021010611A (es) * | 2019-03-05 | 2021-11-12 | The State Of Israel Ministry Of Agriculture & Rural Development Agricultural Res Organization Aro Vo | Aves con genoma editado. |
-
2018
- 2018-09-17 AU AU2018336161A patent/AU2018336161A1/en active Pending
- 2018-09-17 MX MX2020003123A patent/MX2020003123A/es unknown
- 2018-09-17 CA CA3075956A patent/CA3075956A1/en active Pending
- 2018-09-17 JP JP2020537300A patent/JP2020536580A/ja active Pending
- 2018-09-17 US US16/647,474 patent/US20200214273A1/en active Pending
- 2018-09-17 BR BR112020005272-8A patent/BR112020005272A2/pt unknown
- 2018-09-17 CN CN201880064933.3A patent/CN111315212B/zh active Active
- 2018-09-17 KR KR1020207011278A patent/KR20200088805A/ko not_active Application Discontinuation
- 2018-09-17 EA EA202090585A patent/EA202090585A1/ru unknown
- 2018-09-17 EP EP18859163.0A patent/EP3684172A4/en active Pending
- 2018-09-17 WO PCT/IL2018/051056 patent/WO2019058376A1/en unknown
- 2018-09-17 CN CN202210600684.3A patent/CN114958913A/zh active Pending
-
2020
- 2020-03-09 IL IL273190A patent/IL273190A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020536580A (ja) | 2020-12-17 |
| EP3684172A1 (en) | 2020-07-29 |
| EA202090585A1 (ru) | 2020-07-08 |
| WO2019058376A1 (en) | 2019-03-28 |
| CN114958913A (zh) | 2022-08-30 |
| BR112020005272A2 (pt) | 2020-11-17 |
| EP3684172A4 (en) | 2021-06-23 |
| CA3075956A1 (en) | 2019-03-28 |
| CN111315212B (zh) | 2022-06-14 |
| US20200214273A1 (en) | 2020-07-09 |
| CN111315212A (zh) | 2020-06-19 |
| MX2020003123A (es) | 2020-09-14 |
| IL273190A (en) | 2020-04-30 |
| AU2018336161A1 (en) | 2020-03-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101982360B1 (ko) | 콤팩트 tale-뉴클레아제의 발생 방법 및 이의 용도 | |
| US11667890B2 (en) | Engineered artificial antigen presenting cells for tumor infiltrating lymphocyte expansion | |
| KR20210149060A (ko) | Tn7-유사 트랜스포존을 사용한 rna-유도된 dna 통합 | |
| DK2718440T3 (en) | NUCLEASE ACTIVITY PROTEIN, FUSION PROTEINS AND APPLICATIONS THEREOF | |
| CA2834053C (en) | Yeast strains engineered to produce ethanol from glycerol | |
| US20040003420A1 (en) | Modified recombinase | |
| CN113692225B (zh) | 经基因组编辑的鸟类 | |
| KR102516697B1 (ko) | 조작된 캐스케이드 구성성분 및 캐스케이드 복합체 | |
| KR20150125994A (ko) | 세포 발현 시스템 | |
| CN111315212B (zh) | 经过基因组编辑的鸟 | |
| PT1984512T (pt) | Sistema de expressão génica utilizando excisão-união em insetos | |
| US11033638B2 (en) | Single-vector gene construct comprising insulin and glucokinase genes | |
| KR102584628B1 (ko) | T-세포 수용체, t-세포 항원 및 이들의 기능성 상호작용의 식별 및 특징규명을 위한 조작된 다성분 시스템 | |
| CN111094569A (zh) | 光控性病毒蛋白质、其基因及包含该基因的病毒载体 | |
| CN114835821B (zh) | 一种高效特异实现碱基颠换的编辑系统、方法及用途 | |
| CN114585392A (zh) | 通过抑制linc复合物治疗/预防疾病 | |
| CN112877292A (zh) | 产生人抗体的细胞 | |
| KR20230131229A (ko) | 부위 특이적 유전자 변형 | |
| WO2002038613A2 (en) | Modified recombinase | |
| KR20140043890A (ko) | 조절된 유전자 발현 시스템 및 그의 작제물 | |
| KR20240029020A (ko) | Dna 변형을 위한 crispr-트랜스포손 시스템 | |
| CN116323942A (zh) | 用于基因组编辑的组合物及其使用方法 | |
| CN114958758B (zh) | 一种乳腺癌模型猪的构建方法及应用 | |
| CA2395490A1 (en) | Repressible sterility of animals | |
| AU782109B2 (en) | Repressible sterility of animals |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E90F | Notification of reason for final refusal |