KR20180127966A - 암 치료를 위한 카드헤린-17 특이적 항체 및 세포독성 세포 - Google Patents
암 치료를 위한 카드헤린-17 특이적 항체 및 세포독성 세포 Download PDFInfo
- Publication number
- KR20180127966A KR20180127966A KR1020187023033A KR20187023033A KR20180127966A KR 20180127966 A KR20180127966 A KR 20180127966A KR 1020187023033 A KR1020187023033 A KR 1020187023033A KR 20187023033 A KR20187023033 A KR 20187023033A KR 20180127966 A KR20180127966 A KR 20180127966A
- Authority
- KR
- South Korea
- Prior art keywords
- gly
- ser
- leu
- arg
- antibody
- Prior art date
Links
- 206010028980 Neoplasm Diseases 0.000 title claims abstract description 91
- 201000011510 cancer Diseases 0.000 title claims abstract description 42
- 230000001472 cytotoxic effect Effects 0.000 title claims abstract description 20
- 231100000433 cytotoxic Toxicity 0.000 title claims abstract description 18
- 238000011282 treatment Methods 0.000 title abstract description 44
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract description 63
- 210000004027 cell Anatomy 0.000 claims description 76
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 46
- 229960004316 cisplatin Drugs 0.000 claims description 32
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 claims description 32
- 150000007523 nucleic acids Chemical class 0.000 claims description 25
- 102000039446 nucleic acids Human genes 0.000 claims description 22
- 108020004707 nucleic acids Proteins 0.000 claims description 22
- 238000000034 method Methods 0.000 claims description 19
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 16
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 16
- 206010017758 gastric cancer Diseases 0.000 claims description 16
- 230000014509 gene expression Effects 0.000 claims description 16
- 210000000822 natural killer cell Anatomy 0.000 claims description 16
- 201000011549 stomach cancer Diseases 0.000 claims description 16
- 239000013598 vector Substances 0.000 claims description 14
- 230000000259 anti-tumor effect Effects 0.000 claims description 10
- 239000012634 fragment Substances 0.000 claims description 10
- 208000014018 liver neoplasm Diseases 0.000 claims description 10
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 9
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 9
- 201000007270 liver cancer Diseases 0.000 claims description 9
- 102000006495 integrins Human genes 0.000 claims description 8
- 108010044426 integrins Proteins 0.000 claims description 8
- 239000008194 pharmaceutical composition Substances 0.000 claims description 8
- 239000013604 expression vector Substances 0.000 claims description 7
- 206010009944 Colon cancer Diseases 0.000 claims description 6
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 6
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 claims description 6
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims description 6
- 208000029742 colonic neoplasm Diseases 0.000 claims description 6
- 229940127089 cytotoxic agent Drugs 0.000 claims description 6
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 claims description 6
- 229960004768 irinotecan Drugs 0.000 claims description 6
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 claims description 6
- 102000005962 receptors Human genes 0.000 claims description 6
- 108020003175 receptors Proteins 0.000 claims description 6
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 claims description 5
- 239000002870 angiogenesis inducing agent Substances 0.000 claims description 5
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 claims description 4
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 4
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 claims description 4
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims description 4
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims description 4
- 239000002254 cytotoxic agent Substances 0.000 claims description 4
- 231100000599 cytotoxic agent Toxicity 0.000 claims description 4
- 239000003937 drug carrier Substances 0.000 claims description 4
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 4
- 201000005202 lung cancer Diseases 0.000 claims description 4
- 208000020816 lung neoplasm Diseases 0.000 claims description 4
- JPSHPWJJSVEEAX-OWPBQMJCSA-N (2s)-2-amino-4-fluoranylpentanedioic acid Chemical compound OC(=O)[C@@H](N)CC([18F])C(O)=O JPSHPWJJSVEEAX-OWPBQMJCSA-N 0.000 claims description 3
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 claims description 3
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 3
- 102100027207 CD27 antigen Human genes 0.000 claims description 3
- 101150013553 CD40 gene Proteins 0.000 claims description 3
- 108010021064 CTLA-4 Antigen Proteins 0.000 claims description 3
- 229940045513 CTLA4 antagonist Drugs 0.000 claims description 3
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 3
- 108010007712 Hepatitis A Virus Cellular Receptor 1 Proteins 0.000 claims description 3
- 102100034459 Hepatitis A virus cellular receptor 1 Human genes 0.000 claims description 3
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 claims description 3
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 claims description 3
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 claims description 3
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 claims description 3
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 claims description 3
- -1 ICOS Proteins 0.000 claims description 3
- 108010017515 Interleukin-12 Receptors Proteins 0.000 claims description 3
- 102000004560 Interleukin-12 Receptors Human genes 0.000 claims description 3
- 102000017578 LAG3 Human genes 0.000 claims description 3
- 101150030213 Lag3 gene Proteins 0.000 claims description 3
- 229930126263 Maytansine Natural products 0.000 claims description 3
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 claims description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 3
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 claims description 3
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 claims description 3
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 claims description 3
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 claims description 3
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 claims description 3
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 claims description 3
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 claims description 3
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 claims description 3
- 239000002246 antineoplastic agent Substances 0.000 claims description 3
- 108010044540 auristatin Proteins 0.000 claims description 3
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 claims description 3
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 claims description 3
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 claims description 3
- 229960005277 gemcitabine Drugs 0.000 claims description 3
- 239000003112 inhibitor Substances 0.000 claims description 3
- 108010052754 interleukin-14 receptor Proteins 0.000 claims description 3
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 3
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 claims description 3
- 201000002528 pancreatic cancer Diseases 0.000 claims description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 3
- 210000001236 prokaryotic cell Anatomy 0.000 claims description 2
- 210000001324 spliceosome Anatomy 0.000 claims description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 59
- 108010078144 glutaminyl-glycine Proteins 0.000 description 40
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 35
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 32
- 229960001904 epirubicin Drugs 0.000 description 32
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 32
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 28
- 108090000765 processed proteins & peptides Proteins 0.000 description 28
- 150000001413 amino acids Chemical class 0.000 description 27
- 108010060035 arginylproline Proteins 0.000 description 26
- 229920001184 polypeptide Polymers 0.000 description 25
- 102000004196 processed proteins & peptides Human genes 0.000 description 25
- 108091033319 polynucleotide Proteins 0.000 description 24
- 102000040430 polynucleotide Human genes 0.000 description 24
- 239000002157 polynucleotide Substances 0.000 description 24
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 22
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 21
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 21
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 20
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 20
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 20
- 108010081404 acein-2 Proteins 0.000 description 20
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 19
- 239000000427 antigen Substances 0.000 description 19
- 102000036639 antigens Human genes 0.000 description 19
- 108091007433 antigens Proteins 0.000 description 19
- 108010050848 glycylleucine Proteins 0.000 description 19
- 230000004083 survival effect Effects 0.000 description 19
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 18
- 108010034529 leucyl-lysine Proteins 0.000 description 18
- 108010089804 glycyl-threonine Proteins 0.000 description 17
- 108010047857 aspartylglycine Proteins 0.000 description 16
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 15
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 15
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 15
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 15
- 210000001519 tissue Anatomy 0.000 description 15
- 210000004881 tumor cell Anatomy 0.000 description 15
- 230000004614 tumor growth Effects 0.000 description 15
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 14
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 14
- 108010037850 glycylvaline Proteins 0.000 description 14
- PCDUALPXEOKZPE-DXCABUDRSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoyl]amino]-3-hydroxypropanoic acid Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O PCDUALPXEOKZPE-DXCABUDRSA-N 0.000 description 13
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 13
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 13
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 13
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 13
- 241001465754 Metazoa Species 0.000 description 13
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 13
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 13
- 108010068380 arginylarginine Proteins 0.000 description 13
- 239000003814 drug Substances 0.000 description 13
- 108010051242 phenylalanylserine Proteins 0.000 description 13
- 108090000623 proteins and genes Proteins 0.000 description 13
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 12
- XVLLUZMFSAYKJV-GUBZILKMSA-N Arg-Asp-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XVLLUZMFSAYKJV-GUBZILKMSA-N 0.000 description 12
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 12
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 12
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 12
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 12
- ODGNUUUDJONJSC-UFYCRDLUSA-N Phe-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O ODGNUUUDJONJSC-UFYCRDLUSA-N 0.000 description 12
- XDMMOISUAHXXFD-SRVKXCTJSA-N Phe-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O XDMMOISUAHXXFD-SRVKXCTJSA-N 0.000 description 12
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 12
- ONPFOYPPPOHMNH-UVBJJODRSA-N Pro-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@@H]3CCCN3 ONPFOYPPPOHMNH-UVBJJODRSA-N 0.000 description 12
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 12
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 12
- KZOZXAYPVKKDIO-UFYCRDLUSA-N Tyr-Met-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KZOZXAYPVKKDIO-UFYCRDLUSA-N 0.000 description 12
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 12
- 108010008355 arginyl-glutamine Proteins 0.000 description 12
- 108010068265 aspartyltyrosine Proteins 0.000 description 12
- 108010054813 diprotin B Proteins 0.000 description 12
- 229940079593 drug Drugs 0.000 description 12
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 12
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 12
- 230000035772 mutation Effects 0.000 description 12
- 239000002773 nucleotide Substances 0.000 description 12
- 125000003729 nucleotide group Chemical group 0.000 description 12
- 108010073969 valyllysine Proteins 0.000 description 12
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 11
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 11
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 11
- UGTZYIPOBYXWRW-SRVKXCTJSA-N Ser-Phe-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O UGTZYIPOBYXWRW-SRVKXCTJSA-N 0.000 description 11
- VXMHQKHDKCATDV-VEVYYDQMSA-N Thr-Asp-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VXMHQKHDKCATDV-VEVYYDQMSA-N 0.000 description 11
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 11
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 11
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 11
- 230000012010 growth Effects 0.000 description 11
- 108010018006 histidylserine Proteins 0.000 description 11
- 210000004408 hybridoma Anatomy 0.000 description 11
- 108010029020 prolylglycine Proteins 0.000 description 11
- 241000699666 Mus <mouse, genus> Species 0.000 description 10
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 10
- 230000000694 effects Effects 0.000 description 10
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 10
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 10
- 108010000998 wheylin-2 peptide Proteins 0.000 description 10
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 9
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 9
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 9
- 238000002965 ELISA Methods 0.000 description 9
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 9
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 9
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 9
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 9
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 9
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 9
- 241000699670 Mus sp. Species 0.000 description 9
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 9
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 9
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 9
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 9
- 201000010099 disease Diseases 0.000 description 9
- 238000005516 engineering process Methods 0.000 description 9
- 108010015792 glycyllysine Proteins 0.000 description 9
- 230000009036 growth inhibition Effects 0.000 description 9
- 108010064235 lysylglycine Proteins 0.000 description 9
- 108010017391 lysylvaline Proteins 0.000 description 9
- 102000004169 proteins and genes Human genes 0.000 description 9
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 8
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 8
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 8
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 8
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 8
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 8
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 8
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 8
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 8
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 8
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 8
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 8
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 8
- 108010079364 N-glycylalanine Proteins 0.000 description 8
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 8
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 8
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 8
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 8
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 8
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 8
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 8
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 8
- 230000003013 cytotoxicity Effects 0.000 description 8
- 231100000135 cytotoxicity Toxicity 0.000 description 8
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- 230000008685 targeting Effects 0.000 description 8
- 230000001225 therapeutic effect Effects 0.000 description 8
- 108010027345 wheylin-1 peptide Proteins 0.000 description 8
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 7
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 7
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 7
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 7
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 7
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 7
- 108091026890 Coding region Proteins 0.000 description 7
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 7
- HSHCEAUPUPJPTE-JYJNAYRXSA-N Gln-Leu-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HSHCEAUPUPJPTE-JYJNAYRXSA-N 0.000 description 7
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 7
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 7
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 7
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 7
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 7
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 7
- ZNTSGDNUITWTRA-WDSOQIARSA-N His-Trp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O ZNTSGDNUITWTRA-WDSOQIARSA-N 0.000 description 7
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 7
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 7
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 7
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 7
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 7
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 7
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 7
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 7
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 7
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 7
- ABWNZPOIUJMNKT-IXOXFDKPSA-N Thr-Phe-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O ABWNZPOIUJMNKT-IXOXFDKPSA-N 0.000 description 7
- DVLHKUWLNKDINO-PMVMPFDFSA-N Trp-Tyr-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DVLHKUWLNKDINO-PMVMPFDFSA-N 0.000 description 7
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 7
- MWUYSCVVPVITMW-IGNZVWTISA-N Tyr-Tyr-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 MWUYSCVVPVITMW-IGNZVWTISA-N 0.000 description 7
- AGKDVLSDNSTLFA-UMNHJUIQSA-N Val-Gln-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N AGKDVLSDNSTLFA-UMNHJUIQSA-N 0.000 description 7
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 7
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 7
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 7
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 239000012228 culture supernatant Substances 0.000 description 7
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 7
- 108010049041 glutamylalanine Proteins 0.000 description 7
- 238000003364 immunohistochemistry Methods 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- 238000011580 nude mouse model Methods 0.000 description 7
- 108010070643 prolylglutamic acid Proteins 0.000 description 7
- FWBHETKCLVMNFS-UHFFFAOYSA-N 4',6-Diamino-2-phenylindol Chemical compound C1=CC(C(=N)N)=CC=C1C1=CC2=CC=C(C(N)=N)C=C2N1 FWBHETKCLVMNFS-UHFFFAOYSA-N 0.000 description 6
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 6
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 6
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 6
- 102000003730 Alpha-catenin Human genes 0.000 description 6
- 108090000020 Alpha-catenin Proteins 0.000 description 6
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 6
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 6
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 6
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 6
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 6
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 6
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 6
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 6
- PGBLJHDDKCVSTC-CIUDSAMLSA-N Cys-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O PGBLJHDDKCVSTC-CIUDSAMLSA-N 0.000 description 6
- BBQIWFFTTQTNOC-AVGNSLFASA-N Cys-Phe-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N BBQIWFFTTQTNOC-AVGNSLFASA-N 0.000 description 6
- 108020004414 DNA Proteins 0.000 description 6
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 6
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 6
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 6
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 6
- BULIVUZUDBHKKZ-WDSKDSINSA-N Gly-Gln-Asn Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BULIVUZUDBHKKZ-WDSKDSINSA-N 0.000 description 6
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 6
- FBOMZVOKCZMDIG-XQQFMLRXSA-N His-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N FBOMZVOKCZMDIG-XQQFMLRXSA-N 0.000 description 6
- JCGMFFQQHJQASB-PYJNHQTQSA-N Ile-Val-His Chemical compound N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O JCGMFFQQHJQASB-PYJNHQTQSA-N 0.000 description 6
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 6
- ODRREERHVHMIPT-OEAJRASXSA-N Leu-Thr-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ODRREERHVHMIPT-OEAJRASXSA-N 0.000 description 6
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 6
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 6
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 6
- URGPVYGVWLIRGT-DCAQKATOSA-N Lys-Met-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O URGPVYGVWLIRGT-DCAQKATOSA-N 0.000 description 6
- JMNRXRPBHFGXQX-GUBZILKMSA-N Lys-Ser-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JMNRXRPBHFGXQX-GUBZILKMSA-N 0.000 description 6
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 6
- GHQFLTYXGUETFD-UFYCRDLUSA-N Met-Tyr-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N GHQFLTYXGUETFD-UFYCRDLUSA-N 0.000 description 6
- 206010027476 Metastases Diseases 0.000 description 6
- 241000699660 Mus musculus Species 0.000 description 6
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 6
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 6
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 6
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 6
- BLPYXIXXCFVIIF-FXQIFTODSA-N Ser-Cys-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N)CN=C(N)N BLPYXIXXCFVIIF-FXQIFTODSA-N 0.000 description 6
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 6
- MUARUIBTKQJKFY-WHFBIAKZSA-N Ser-Gly-Asp Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MUARUIBTKQJKFY-WHFBIAKZSA-N 0.000 description 6
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 6
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 6
- ATJFFYVFTNAWJD-UHFFFAOYSA-N Tin Chemical compound [Sn] ATJFFYVFTNAWJD-UHFFFAOYSA-N 0.000 description 6
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 6
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 6
- OLWFDNLLBWQWCP-STQMWFEESA-N Tyr-Gly-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O OLWFDNLLBWQWCP-STQMWFEESA-N 0.000 description 6
- KSCVLGXNQXKUAR-JYJNAYRXSA-N Tyr-Leu-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KSCVLGXNQXKUAR-JYJNAYRXSA-N 0.000 description 6
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 6
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 6
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 6
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 6
- 108010041407 alanylaspartic acid Proteins 0.000 description 6
- 108010005233 alanylglutamic acid Proteins 0.000 description 6
- 238000011284 combination treatment Methods 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 108010079547 glutamylmethionine Proteins 0.000 description 6
- 230000005764 inhibitory process Effects 0.000 description 6
- 108010003700 lysyl aspartic acid Proteins 0.000 description 6
- 230000001404 mediated effect Effects 0.000 description 6
- 230000009401 metastasis Effects 0.000 description 6
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 6
- 230000002829 reductive effect Effects 0.000 description 6
- 230000003248 secreting effect Effects 0.000 description 6
- 108010048818 seryl-histidine Proteins 0.000 description 6
- 108010026333 seryl-proline Proteins 0.000 description 6
- 238000010186 staining Methods 0.000 description 6
- 238000006467 substitution reaction Methods 0.000 description 6
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 5
- MTDDMSUUXNQMKK-BPNCWPANSA-N Ala-Tyr-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N MTDDMSUUXNQMKK-BPNCWPANSA-N 0.000 description 5
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 5
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 5
- WOZDCBHUGJVJPL-AVGNSLFASA-N Arg-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WOZDCBHUGJVJPL-AVGNSLFASA-N 0.000 description 5
- VITDJIPIJZAVGC-VEVYYDQMSA-N Asn-Met-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VITDJIPIJZAVGC-VEVYYDQMSA-N 0.000 description 5
- XMHFCUKJRCQXGI-CIUDSAMLSA-N Asn-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O XMHFCUKJRCQXGI-CIUDSAMLSA-N 0.000 description 5
- WOKXEQLPBLLWHC-IHRRRGAJSA-N Asp-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 WOKXEQLPBLLWHC-IHRRRGAJSA-N 0.000 description 5
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 5
- TWIAMTNJOMRDAK-GUBZILKMSA-N Gln-Lys-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O TWIAMTNJOMRDAK-GUBZILKMSA-N 0.000 description 5
- MQJDLNRXBOELJW-KKUMJFAQSA-N Gln-Pro-Phe Chemical compound N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O MQJDLNRXBOELJW-KKUMJFAQSA-N 0.000 description 5
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 5
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 5
- ITBHUUMCJJQUSC-LAEOZQHASA-N Glu-Ile-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O ITBHUUMCJJQUSC-LAEOZQHASA-N 0.000 description 5
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 5
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 5
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 5
- GLACUWHUYFBSPJ-FJXKBIBVSA-N Gly-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GLACUWHUYFBSPJ-FJXKBIBVSA-N 0.000 description 5
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 5
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 5
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 5
- NKRWVZQTPXPNRZ-SRVKXCTJSA-N His-Met-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CN=CN1 NKRWVZQTPXPNRZ-SRVKXCTJSA-N 0.000 description 5
- LRAUKBMYHHNADU-DKIMLUQUSA-N Ile-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=CC=C1 LRAUKBMYHHNADU-DKIMLUQUSA-N 0.000 description 5
- ZUWSVOYKBCHLRR-MGHWNKPDSA-N Ile-Tyr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUWSVOYKBCHLRR-MGHWNKPDSA-N 0.000 description 5
- ZSESFIFAYQEKRD-CYDGBPFRSA-N Ile-Val-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N ZSESFIFAYQEKRD-CYDGBPFRSA-N 0.000 description 5
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 5
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 5
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 5
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 5
- VHTIZYYHIUHMCA-JYJNAYRXSA-N Leu-Tyr-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VHTIZYYHIUHMCA-JYJNAYRXSA-N 0.000 description 5
- LMDVGHQPPPLYAR-IHRRRGAJSA-N Leu-Val-His Chemical compound N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O LMDVGHQPPPLYAR-IHRRRGAJSA-N 0.000 description 5
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 5
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 5
- SVSQSPICRKBMSZ-SRVKXCTJSA-N Lys-Pro-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O SVSQSPICRKBMSZ-SRVKXCTJSA-N 0.000 description 5
- 238000000134 MTT assay Methods 0.000 description 5
- 231100000002 MTT assay Toxicity 0.000 description 5
- AXHNAGAYRGCDLG-UWVGGRQHSA-N Met-Lys-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AXHNAGAYRGCDLG-UWVGGRQHSA-N 0.000 description 5
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 description 5
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 5
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 5
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 5
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 5
- DOSZISJPMCYEHT-NAKRPEOUSA-N Ser-Ile-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O DOSZISJPMCYEHT-NAKRPEOUSA-N 0.000 description 5
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 5
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 5
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 5
- 101710120037 Toxin CcdB Proteins 0.000 description 5
- BVDHHLMIZFCAAU-BZSNNMDCSA-N Tyr-Cys-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O BVDHHLMIZFCAAU-BZSNNMDCSA-N 0.000 description 5
- JFAWZADYPRMRCO-UBHSHLNASA-N Val-Ala-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JFAWZADYPRMRCO-UBHSHLNASA-N 0.000 description 5
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 5
- 230000004663 cell proliferation Effects 0.000 description 5
- 210000001072 colon Anatomy 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 108010060199 cysteinylproline Proteins 0.000 description 5
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 5
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 5
- 108010010147 glycylglutamine Proteins 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 230000037361 pathway Effects 0.000 description 5
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 5
- 238000011160 research Methods 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 4
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 4
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 4
- XEPSCVXTCUUHDT-AVGNSLFASA-N Arg-Arg-Leu Natural products CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCN=C(N)N XEPSCVXTCUUHDT-AVGNSLFASA-N 0.000 description 4
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 4
- DIIGDGJKTMLQQW-IHRRRGAJSA-N Arg-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N DIIGDGJKTMLQQW-IHRRRGAJSA-N 0.000 description 4
- KXOPYFNQLVUOAQ-FXQIFTODSA-N Arg-Ser-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KXOPYFNQLVUOAQ-FXQIFTODSA-N 0.000 description 4
- HOIFSHOLNKQCSA-FXQIFTODSA-N Asn-Arg-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O HOIFSHOLNKQCSA-FXQIFTODSA-N 0.000 description 4
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 4
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 4
- 208000005623 Carcinogenesis Diseases 0.000 description 4
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 4
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 4
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 4
- 108010065920 Insulin Lispro Proteins 0.000 description 4
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 4
- 241000880493 Leptailurus serval Species 0.000 description 4
- WIDZHJTYKYBLSR-DCAQKATOSA-N Leu-Glu-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WIDZHJTYKYBLSR-DCAQKATOSA-N 0.000 description 4
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 4
- HGUUMQWGYCVPKG-DCAQKATOSA-N Leu-Pro-Cys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N HGUUMQWGYCVPKG-DCAQKATOSA-N 0.000 description 4
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 4
- LUAJJLPHUXPQLH-KKUMJFAQSA-N Lys-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCCN)N LUAJJLPHUXPQLH-KKUMJFAQSA-N 0.000 description 4
- ZAJNRWKGHWGPDQ-SDDRHHMPSA-N Met-Arg-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N ZAJNRWKGHWGPDQ-SDDRHHMPSA-N 0.000 description 4
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 4
- 108010066427 N-valyltryptophan Proteins 0.000 description 4
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 4
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 4
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 4
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 4
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 4
- OBXVZEAMXFSGPU-FXQIFTODSA-N Ser-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)CN=C(N)N OBXVZEAMXFSGPU-FXQIFTODSA-N 0.000 description 4
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 4
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 4
- NCGUQWSJUKYCIT-SZZJOZGLSA-N Thr-His-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O NCGUQWSJUKYCIT-SZZJOZGLSA-N 0.000 description 4
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 4
- NMOIRIIIUVELLY-WDSOQIARSA-N Trp-Val-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)=CNC2=C1 NMOIRIIIUVELLY-WDSOQIARSA-N 0.000 description 4
- PEVVXUGSAKEPEN-AVGNSLFASA-N Tyr-Asn-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PEVVXUGSAKEPEN-AVGNSLFASA-N 0.000 description 4
- CKHQKYHIZCRTAP-SOUVJXGZSA-N Tyr-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O CKHQKYHIZCRTAP-SOUVJXGZSA-N 0.000 description 4
- PMHLLBKTDHQMCY-ULQDDVLXSA-N Tyr-Lys-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O PMHLLBKTDHQMCY-ULQDDVLXSA-N 0.000 description 4
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 4
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 4
- 230000009471 action Effects 0.000 description 4
- 238000007792 addition Methods 0.000 description 4
- 108010092854 aspartyllysine Proteins 0.000 description 4
- 230000036952 cancer formation Effects 0.000 description 4
- 231100000504 carcinogenesis Toxicity 0.000 description 4
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 4
- 239000000562 conjugate Substances 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 108010004914 prolylarginine Proteins 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 108010084932 tryptophyl-proline Proteins 0.000 description 4
- 108010044292 tryptophyltyrosine Proteins 0.000 description 4
- 108010003137 tyrosyltyrosine Proteins 0.000 description 4
- 238000001262 western blot Methods 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- XWTNPSHCJMZAHQ-QMMMGPOBSA-N 2-[[2-[[2-[[(2s)-2-amino-4-methylpentanoyl]amino]acetyl]amino]acetyl]amino]acetic acid Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(=O)NCC(O)=O XWTNPSHCJMZAHQ-QMMMGPOBSA-N 0.000 description 3
- YEELWQSXYBJVSV-UWJYBYFXSA-N Ala-Cys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YEELWQSXYBJVSV-UWJYBYFXSA-N 0.000 description 3
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 3
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 3
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 3
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 3
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 3
- MFAMTAVAFBPXDC-LPEHRKFASA-N Arg-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O MFAMTAVAFBPXDC-LPEHRKFASA-N 0.000 description 3
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 3
- GSUFZRURORXYTM-STQMWFEESA-N Arg-Phe-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 GSUFZRURORXYTM-STQMWFEESA-N 0.000 description 3
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 3
- 108010051330 Arg-Pro-Gly-Pro Proteins 0.000 description 3
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 3
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 3
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 3
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 3
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 3
- XPGVTUBABLRGHY-BIIVOSGPSA-N Asp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N XPGVTUBABLRGHY-BIIVOSGPSA-N 0.000 description 3
- NYQHSUGFEWDWPD-ACZMJKKPSA-N Asp-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N NYQHSUGFEWDWPD-ACZMJKKPSA-N 0.000 description 3
- JUWZKMBALYLZCK-WHFBIAKZSA-N Asp-Gly-Asn Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O JUWZKMBALYLZCK-WHFBIAKZSA-N 0.000 description 3
- BIVYLQMZPHDUIH-WHFBIAKZSA-N Asp-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)O BIVYLQMZPHDUIH-WHFBIAKZSA-N 0.000 description 3
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 3
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 3
- AITKTFCQOBRJTG-CIUDSAMLSA-N Asp-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N AITKTFCQOBRJTG-CIUDSAMLSA-N 0.000 description 3
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 3
- GXIUDSXIUSTSLO-QXEWZRGKSA-N Asp-Val-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N GXIUDSXIUSTSLO-QXEWZRGKSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 238000011537 Coomassie blue staining Methods 0.000 description 3
- PRXCTTWKGJAPMT-ZLUOBGJFSA-N Cys-Ala-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O PRXCTTWKGJAPMT-ZLUOBGJFSA-N 0.000 description 3
- WDQXKVCQXRNOSI-GHCJXIJMSA-N Cys-Asp-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WDQXKVCQXRNOSI-GHCJXIJMSA-N 0.000 description 3
- SWJYSDXMTPMBHO-FXQIFTODSA-N Cys-Pro-Ser Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SWJYSDXMTPMBHO-FXQIFTODSA-N 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 3
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 3
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 3
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 3
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 3
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 3
- UTKICHUQEQBDGC-ACZMJKKPSA-N Glu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N UTKICHUQEQBDGC-ACZMJKKPSA-N 0.000 description 3
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 3
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 3
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 3
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 3
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 3
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 3
- CGWHAXBNGYQBBK-JBACZVJFSA-N Glu-Trp-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CCC(O)=O)N)C(O)=O)C1=CC=C(O)C=C1 CGWHAXBNGYQBBK-JBACZVJFSA-N 0.000 description 3
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 3
- XEJTYSCIXKYSHR-WDSKDSINSA-N Gly-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN XEJTYSCIXKYSHR-WDSKDSINSA-N 0.000 description 3
- XXGQRGQPGFYECI-WDSKDSINSA-N Gly-Cys-Glu Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(O)=O XXGQRGQPGFYECI-WDSKDSINSA-N 0.000 description 3
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 3
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 3
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 3
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 3
- VAXIVIPMCTYSHI-YUMQZZPRSA-N Gly-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN VAXIVIPMCTYSHI-YUMQZZPRSA-N 0.000 description 3
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 3
- ZWRDOVYMQAAISL-UWVGGRQHSA-N Gly-Met-Lys Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCCN ZWRDOVYMQAAISL-UWVGGRQHSA-N 0.000 description 3
- GGAPHLIUUTVYMX-QWRGUYRKSA-N Gly-Phe-Ser Chemical compound OC[C@@H](C([O-])=O)NC(=O)[C@@H](NC(=O)C[NH3+])CC1=CC=CC=C1 GGAPHLIUUTVYMX-QWRGUYRKSA-N 0.000 description 3
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 3
- MKIAPEZXQDILRR-YUMQZZPRSA-N Gly-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN MKIAPEZXQDILRR-YUMQZZPRSA-N 0.000 description 3
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 3
- IZVICCORZOSGPT-JSGCOSHPSA-N Gly-Val-Tyr Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IZVICCORZOSGPT-JSGCOSHPSA-N 0.000 description 3
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 3
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 3
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 3
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 3
- VPKIQULSKFVCSM-SRVKXCTJSA-N Leu-Gln-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPKIQULSKFVCSM-SRVKXCTJSA-N 0.000 description 3
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 3
- MPSBSKHOWJQHBS-IHRRRGAJSA-N Leu-His-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCSC)C(=O)O)N MPSBSKHOWJQHBS-IHRRRGAJSA-N 0.000 description 3
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 3
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 3
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 3
- SXOFUVGLPHCPRQ-KKUMJFAQSA-N Leu-Tyr-Cys Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(O)=O SXOFUVGLPHCPRQ-KKUMJFAQSA-N 0.000 description 3
- 108060001084 Luciferase Proteins 0.000 description 3
- 239000005089 Luciferase Substances 0.000 description 3
- WXJKFRMKJORORD-DCAQKATOSA-N Lys-Arg-Ala Chemical compound NC(=N)NCCC[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@@H](N)CCCCN WXJKFRMKJORORD-DCAQKATOSA-N 0.000 description 3
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 3
- LECIJRIRMVOFMH-ULQDDVLXSA-N Lys-Pro-Phe Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LECIJRIRMVOFMH-ULQDDVLXSA-N 0.000 description 3
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 3
- YLLWCSDBVGZLOW-CIUDSAMLSA-N Met-Gln-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O YLLWCSDBVGZLOW-CIUDSAMLSA-N 0.000 description 3
- HUURTRNKPBHHKZ-JYJNAYRXSA-N Met-Phe-Val Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 HUURTRNKPBHHKZ-JYJNAYRXSA-N 0.000 description 3
- ZDJICAUBMUKVEJ-CIUDSAMLSA-N Met-Ser-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O ZDJICAUBMUKVEJ-CIUDSAMLSA-N 0.000 description 3
- 241001529936 Murinae Species 0.000 description 3
- JJHVFCUWLSKADD-ONGXEEELSA-N Phe-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O JJHVFCUWLSKADD-ONGXEEELSA-N 0.000 description 3
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 3
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 3
- SPLBRAKYXGOFSO-UNQGMJICSA-N Pro-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@@H]2CCCN2)O SPLBRAKYXGOFSO-UNQGMJICSA-N 0.000 description 3
- YYARMJSFDLIDFS-FKBYEOEOSA-N Pro-Phe-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O YYARMJSFDLIDFS-FKBYEOEOSA-N 0.000 description 3
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 3
- AIOWVDNPESPXRB-YTWAJWBKSA-N Pro-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2)O AIOWVDNPESPXRB-YTWAJWBKSA-N 0.000 description 3
- VBZXFFYOBDLLFE-HSHDSVGOSA-N Pro-Trp-Thr Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H]([C@H](O)C)C(O)=O)C(=O)[C@@H]1CCCN1 VBZXFFYOBDLLFE-HSHDSVGOSA-N 0.000 description 3
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 3
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 3
- ZUDXUJSYCCNZQJ-DCAQKATOSA-N Ser-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N ZUDXUJSYCCNZQJ-DCAQKATOSA-N 0.000 description 3
- KCNSGAMPBPYUAI-CIUDSAMLSA-N Ser-Leu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KCNSGAMPBPYUAI-CIUDSAMLSA-N 0.000 description 3
- NMZXJDSKEGFDLJ-DCAQKATOSA-N Ser-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CCCCN)C(=O)O NMZXJDSKEGFDLJ-DCAQKATOSA-N 0.000 description 3
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 3
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 3
- VAIWUNAAPZZGRI-IHPCNDPISA-N Ser-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CO)N VAIWUNAAPZZGRI-IHPCNDPISA-N 0.000 description 3
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 3
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 3
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 3
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 3
- OOEUVMFKKZYSRX-LEWSCRJBSA-N Tyr-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OOEUVMFKKZYSRX-LEWSCRJBSA-N 0.000 description 3
- LQGDFDYGDQEMGA-PXDAIIFMSA-N Tyr-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N LQGDFDYGDQEMGA-PXDAIIFMSA-N 0.000 description 3
- NYTKXWLZSNRILS-IFFSRLJSSA-N Val-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N)O NYTKXWLZSNRILS-IFFSRLJSSA-N 0.000 description 3
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 3
- APQIVBCUIUDSMB-OSUNSFLBSA-N Val-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N APQIVBCUIUDSMB-OSUNSFLBSA-N 0.000 description 3
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 3
- 108010087924 alanylproline Proteins 0.000 description 3
- 239000000611 antibody drug conjugate Substances 0.000 description 3
- 229940049595 antibody-drug conjugate Drugs 0.000 description 3
- 108010077245 asparaginyl-proline Proteins 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 238000002619 cancer immunotherapy Methods 0.000 description 3
- 238000001516 cell proliferation assay Methods 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 229940044683 chemotherapy drug Drugs 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 239000012091 fetal bovine serum Substances 0.000 description 3
- 239000000499 gel Substances 0.000 description 3
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 3
- 108010020688 glycylhistidine Proteins 0.000 description 3
- 239000001963 growth medium Substances 0.000 description 3
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 3
- 108010078274 isoleucylvaline Proteins 0.000 description 3
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 3
- 108010073093 leucyl-glycyl-glycyl-glycine Proteins 0.000 description 3
- 239000007788 liquid Substances 0.000 description 3
- 210000004185 liver Anatomy 0.000 description 3
- 230000004807 localization Effects 0.000 description 3
- 210000004072 lung Anatomy 0.000 description 3
- 206010061289 metastatic neoplasm Diseases 0.000 description 3
- 108010085203 methionylmethionine Proteins 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 108010079317 prolyl-tyrosine Proteins 0.000 description 3
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 108010061238 threonyl-glycine Proteins 0.000 description 3
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 2
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 2
- RUXQNKVQSKOOBS-JURCDPSOSA-N Ala-Phe-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RUXQNKVQSKOOBS-JURCDPSOSA-N 0.000 description 2
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 2
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 2
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 2
- BHFOJPDOQPWJRN-XDTLVQLUSA-N Ala-Tyr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CCC(N)=O)C(O)=O BHFOJPDOQPWJRN-XDTLVQLUSA-N 0.000 description 2
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 2
- SSZGOKWBHLOCHK-DCAQKATOSA-N Arg-Lys-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N SSZGOKWBHLOCHK-DCAQKATOSA-N 0.000 description 2
- JEPNYDRDYNSFIU-QXEWZRGKSA-N Asn-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(N)=O)C(O)=O JEPNYDRDYNSFIU-QXEWZRGKSA-N 0.000 description 2
- WPOLSNAQGVHROR-GUBZILKMSA-N Asn-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N WPOLSNAQGVHROR-GUBZILKMSA-N 0.000 description 2
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 2
- XYBJLTKSGFBLCS-QXEWZRGKSA-N Asp-Arg-Val Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC(O)=O XYBJLTKSGFBLCS-QXEWZRGKSA-N 0.000 description 2
- QCVXMEHGFUMKCO-YUMQZZPRSA-N Asp-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O QCVXMEHGFUMKCO-YUMQZZPRSA-N 0.000 description 2
- FQHBAQLBIXLWAG-DCAQKATOSA-N Asp-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N FQHBAQLBIXLWAG-DCAQKATOSA-N 0.000 description 2
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 2
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 2
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 2
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 2
- 101710196881 Cadherin-17 Proteins 0.000 description 2
- 102100024152 Cadherin-17 Human genes 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 description 2
- XMTDCXXLDZKAGI-ACZMJKKPSA-N Cys-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N XMTDCXXLDZKAGI-ACZMJKKPSA-N 0.000 description 2
- JTNKVWLMDHIUOG-IHRRRGAJSA-N Cys-Arg-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JTNKVWLMDHIUOG-IHRRRGAJSA-N 0.000 description 2
- KABHAOSDMIYXTR-GUBZILKMSA-N Cys-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N KABHAOSDMIYXTR-GUBZILKMSA-N 0.000 description 2
- VRJZMZGGAKVSIQ-SRVKXCTJSA-N Cys-Tyr-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VRJZMZGGAKVSIQ-SRVKXCTJSA-N 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 101150029707 ERBB2 gene Proteins 0.000 description 2
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 2
- 101000993347 Gallus gallus Ciliary neurotrophic factor Proteins 0.000 description 2
- KWUSGAIFNHQCBY-DCAQKATOSA-N Gln-Arg-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O KWUSGAIFNHQCBY-DCAQKATOSA-N 0.000 description 2
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 2
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 2
- YRHZWVKUFWCEPW-GLLZPBPUSA-N Gln-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O YRHZWVKUFWCEPW-GLLZPBPUSA-N 0.000 description 2
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 2
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 2
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 2
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 2
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 2
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 2
- HHSKZJZWQFPSKN-AVGNSLFASA-N Glu-Tyr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O HHSKZJZWQFPSKN-AVGNSLFASA-N 0.000 description 2
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 2
- QCTLGOYODITHPQ-WHFBIAKZSA-N Gly-Cys-Ser Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O QCTLGOYODITHPQ-WHFBIAKZSA-N 0.000 description 2
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 2
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 2
- RHRLHXQWHCNJKR-PMVVWTBXSA-N Gly-Thr-His Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 RHRLHXQWHCNJKR-PMVVWTBXSA-N 0.000 description 2
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 2
- 102100032530 Glypican-3 Human genes 0.000 description 2
- WZUVPPKBWHMQCE-UHFFFAOYSA-N Haematoxylin Chemical compound C12=CC(O)=C(O)C=C2CC2(O)C1C1=CC=C(O)C(O)=C1OC2 WZUVPPKBWHMQCE-UHFFFAOYSA-N 0.000 description 2
- 241000590002 Helicobacter pylori Species 0.000 description 2
- STGQSBKUYSPPIG-CIUDSAMLSA-N His-Ser-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 STGQSBKUYSPPIG-CIUDSAMLSA-N 0.000 description 2
- WSWAUVHXQREQQG-JYJNAYRXSA-N His-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O WSWAUVHXQREQQG-JYJNAYRXSA-N 0.000 description 2
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 2
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- LWWILHPVAKKLQS-QXEWZRGKSA-N Ile-Gly-Met Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N LWWILHPVAKKLQS-QXEWZRGKSA-N 0.000 description 2
- DMSVBUWGDLYNLC-IAVJCBSLSA-N Ile-Ile-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 DMSVBUWGDLYNLC-IAVJCBSLSA-N 0.000 description 2
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 2
- 102000037982 Immune checkpoint proteins Human genes 0.000 description 2
- 108091008036 Immune checkpoint proteins Proteins 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- KVRKAGGMEWNURO-CIUDSAMLSA-N Leu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N KVRKAGGMEWNURO-CIUDSAMLSA-N 0.000 description 2
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 2
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 2
- VWHGTYCRDRBSFI-ZETCQYMHSA-N Leu-Gly-Gly Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)NCC(O)=O VWHGTYCRDRBSFI-ZETCQYMHSA-N 0.000 description 2
- JRJLGNFWYFSJHB-HOCLYGCPSA-N Leu-Gly-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JRJLGNFWYFSJHB-HOCLYGCPSA-N 0.000 description 2
- MAXILRZVORNXBE-PMVMPFDFSA-N Leu-Phe-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 MAXILRZVORNXBE-PMVMPFDFSA-N 0.000 description 2
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 2
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 2
- NQCJGQHHYZNUDK-DCAQKATOSA-N Lys-Arg-Ser Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCN=C(N)N NQCJGQHHYZNUDK-DCAQKATOSA-N 0.000 description 2
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 2
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 2
- UETQMSASAVBGJY-QWRGUYRKSA-N Lys-Gly-His Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 UETQMSASAVBGJY-QWRGUYRKSA-N 0.000 description 2
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 2
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 2
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 2
- ONGCSGVHCSAATF-CIUDSAMLSA-N Met-Ala-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O ONGCSGVHCSAATF-CIUDSAMLSA-N 0.000 description 2
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 2
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 2
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 2
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- BJEYSVHMGIJORT-NHCYSSNCSA-N Phe-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BJEYSVHMGIJORT-NHCYSSNCSA-N 0.000 description 2
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 2
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 2
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 2
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 2
- DLZBBDSPTJBOOD-BPNCWPANSA-N Pro-Tyr-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O DLZBBDSPTJBOOD-BPNCWPANSA-N 0.000 description 2
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 2
- 206010070834 Sensitisation Diseases 0.000 description 2
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 2
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 2
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 2
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 2
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 2
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 2
- NAXBBCLCEOTAIG-RHYQMDGZSA-N Thr-Arg-Lys Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O NAXBBCLCEOTAIG-RHYQMDGZSA-N 0.000 description 2
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 2
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 2
- ZSPQUTWLWGWTPS-HJGDQZAQSA-N Thr-Lys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZSPQUTWLWGWTPS-HJGDQZAQSA-N 0.000 description 2
- UMFLBPIPAJMNIM-LYARXQMPSA-N Thr-Trp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=CC=C3)C(=O)O)N)O UMFLBPIPAJMNIM-LYARXQMPSA-N 0.000 description 2
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 2
- GDPDVIBHJDFRFD-RNXOBYDBSA-N Trp-Tyr-Tyr Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GDPDVIBHJDFRFD-RNXOBYDBSA-N 0.000 description 2
- XQMGDVVKFRLQKH-BBRMVZONSA-N Trp-Val-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O)=CNC2=C1 XQMGDVVKFRLQKH-BBRMVZONSA-N 0.000 description 2
- CDRYEAWHKJSGAF-BPNCWPANSA-N Tyr-Ala-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O CDRYEAWHKJSGAF-BPNCWPANSA-N 0.000 description 2
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 2
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 2
- RYSNTWVRSLCAJZ-RYUDHWBXSA-N Tyr-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RYSNTWVRSLCAJZ-RYUDHWBXSA-N 0.000 description 2
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 2
- KSGKJSFPWSMJHK-JNPHEJMOSA-N Tyr-Tyr-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KSGKJSFPWSMJHK-JNPHEJMOSA-N 0.000 description 2
- VMRFIKXKOFNMHW-GUBZILKMSA-N Val-Arg-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N VMRFIKXKOFNMHW-GUBZILKMSA-N 0.000 description 2
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 2
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 230000001093 anti-cancer Effects 0.000 description 2
- 238000011091 antibody purification Methods 0.000 description 2
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 238000011398 antitumor immunotherapy Methods 0.000 description 2
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000004624 confocal microscopy Methods 0.000 description 2
- 210000004748 cultured cell Anatomy 0.000 description 2
- 230000002498 deadly effect Effects 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 238000009509 drug development Methods 0.000 description 2
- 238000010828 elution Methods 0.000 description 2
- 208000028653 esophageal adenocarcinoma Diseases 0.000 description 2
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 2
- 201000006585 gastric adenocarcinoma Diseases 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 2
- 108010084389 glycyltryptophan Proteins 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 239000010931 gold Substances 0.000 description 2
- 229910052737 gold Inorganic materials 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 229940037467 helicobacter pylori Drugs 0.000 description 2
- 201000005787 hematologic cancer Diseases 0.000 description 2
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 2
- 210000002865 immune cell Anatomy 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000011503 in vivo imaging Methods 0.000 description 2
- 230000004073 interleukin-2 production Effects 0.000 description 2
- 230000009545 invasion Effects 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000001394 metastastic effect Effects 0.000 description 2
- 239000000203 mixture Substances 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 210000004940 nucleus Anatomy 0.000 description 2
- 239000012188 paraffin wax Substances 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 230000035755 proliferation Effects 0.000 description 2
- 108010090894 prolylleucine Proteins 0.000 description 2
- 230000005180 public health Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000008313 sensitization Effects 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 239000003381 stabilizer Substances 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 210000002784 stomach Anatomy 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- 238000013414 tumor xenograft model Methods 0.000 description 2
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 2
- CEHZCZCQHUNAJF-AVGNSLFASA-N (2s)-1-[2-[[(2s)-1-[(2s)-2-amino-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N1[C@H](C(O)=O)CCC1 CEHZCZCQHUNAJF-AVGNSLFASA-N 0.000 description 1
- IESDGNYHXIOKRW-YXMSTPNBSA-N (2s)-2-[[(2s)-1-[(2s)-6-amino-2-[[(2s,3r)-2-amino-3-hydroxybutanoyl]amino]hexanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IESDGNYHXIOKRW-YXMSTPNBSA-N 0.000 description 1
- DIBLBAURNYJYBF-XLXZRNDBSA-N (2s)-2-[[(2s)-2-[[2-[[(2s)-6-amino-2-[[(2s)-2-amino-3-methylbutanoyl]amino]hexanoyl]amino]acetyl]amino]-3-phenylpropanoyl]amino]-3-(4-hydroxyphenyl)propanoic acid Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 DIBLBAURNYJYBF-XLXZRNDBSA-N 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 208000036764 Adenocarcinoma of the esophagus Diseases 0.000 description 1
- 206010052747 Adenocarcinoma pancreas Diseases 0.000 description 1
- TTXMOJWKNRJWQJ-FXQIFTODSA-N Ala-Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N TTXMOJWKNRJWQJ-FXQIFTODSA-N 0.000 description 1
- ZIWWTZWAKYBUOB-CIUDSAMLSA-N Ala-Asp-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O ZIWWTZWAKYBUOB-CIUDSAMLSA-N 0.000 description 1
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 1
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 1
- LXAARTARZJJCMB-CIQUZCHMSA-N Ala-Ile-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LXAARTARZJJCMB-CIQUZCHMSA-N 0.000 description 1
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 1
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 1
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 1
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 1
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 1
- 101100273213 Arabidopsis thaliana CAR8 gene Proteins 0.000 description 1
- 101100273214 Arabidopsis thaliana CAR9 gene Proteins 0.000 description 1
- OTUQSEPIIVBYEM-IHRRRGAJSA-N Arg-Asn-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OTUQSEPIIVBYEM-IHRRRGAJSA-N 0.000 description 1
- PQWTZSNVWSOFFK-FXQIFTODSA-N Arg-Asp-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)CN=C(N)N PQWTZSNVWSOFFK-FXQIFTODSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- SLQQPJBDBVPVQV-JYJNAYRXSA-N Arg-Phe-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O SLQQPJBDBVPVQV-JYJNAYRXSA-N 0.000 description 1
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 1
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 1
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- MOGMYRUNTKYZFB-UNQGMJICSA-N Arg-Thr-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MOGMYRUNTKYZFB-UNQGMJICSA-N 0.000 description 1
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 1
- WONGRTVAMHFGBE-WDSKDSINSA-N Asn-Gly-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N WONGRTVAMHFGBE-WDSKDSINSA-N 0.000 description 1
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 1
- TZFQICWZWFNIKU-KKUMJFAQSA-N Asn-Leu-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 TZFQICWZWFNIKU-KKUMJFAQSA-N 0.000 description 1
- LSJQOMAZIKQMTJ-SRVKXCTJSA-N Asn-Phe-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O LSJQOMAZIKQMTJ-SRVKXCTJSA-N 0.000 description 1
- IDUUACUJKUXKKD-VEVYYDQMSA-N Asn-Pro-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O IDUUACUJKUXKKD-VEVYYDQMSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- FMNBYVSGRCXWEK-FOHZUACHSA-N Asn-Thr-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O FMNBYVSGRCXWEK-FOHZUACHSA-N 0.000 description 1
- YQPSDMUGFKJZHR-QRTARXTBSA-N Asn-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N YQPSDMUGFKJZHR-QRTARXTBSA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- UZNSWMFLKVKJLI-VHWLVUOQSA-N Asp-Ile-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O UZNSWMFLKVKJLI-VHWLVUOQSA-N 0.000 description 1
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 1
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 1
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- GHAHOJDCBRXAKC-IHPCNDPISA-N Asp-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N GHAHOJDCBRXAKC-IHPCNDPISA-N 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 101150011345 CA8 gene Proteins 0.000 description 1
- 238000011357 CAR T-cell therapy Methods 0.000 description 1
- 108010024755 CTL019 chimeric antigen receptor Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 1
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 1
- 108091007741 Chimeric antigen receptor T cells Proteins 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 description 1
- DCJNIJAWIRPPBB-CIUDSAMLSA-N Cys-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N DCJNIJAWIRPPBB-CIUDSAMLSA-N 0.000 description 1
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 1
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 1
- ZXCAQANTQWBICD-DCAQKATOSA-N Cys-Lys-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N ZXCAQANTQWBICD-DCAQKATOSA-N 0.000 description 1
- BCWIFCLVCRAIQK-ZLUOBGJFSA-N Cys-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O BCWIFCLVCRAIQK-ZLUOBGJFSA-N 0.000 description 1
- 208000000059 Dyspnea Diseases 0.000 description 1
- 206010013975 Dyspnoeas Diseases 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- 206010061968 Gastric neoplasm Diseases 0.000 description 1
- SHERTACNJPYHAR-ACZMJKKPSA-N Gln-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O SHERTACNJPYHAR-ACZMJKKPSA-N 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- TWHDOEYLXXQYOZ-FXQIFTODSA-N Gln-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N TWHDOEYLXXQYOZ-FXQIFTODSA-N 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 1
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 1
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 1
- LHMWTCWZARHLPV-CIUDSAMLSA-N Gln-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N LHMWTCWZARHLPV-CIUDSAMLSA-N 0.000 description 1
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 1
- DCWNCMRZIZSZBL-KKUMJFAQSA-N Gln-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)N)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O DCWNCMRZIZSZBL-KKUMJFAQSA-N 0.000 description 1
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 1
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 1
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 1
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 1
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 1
- PAQUJCSYVIBPLC-AVGNSLFASA-N Glu-Asp-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 PAQUJCSYVIBPLC-AVGNSLFASA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 1
- RFDHKPSHTXZKLL-IHRRRGAJSA-N Glu-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N RFDHKPSHTXZKLL-IHRRRGAJSA-N 0.000 description 1
- HNVFSTLPVJWIDV-CIUDSAMLSA-N Glu-Glu-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HNVFSTLPVJWIDV-CIUDSAMLSA-N 0.000 description 1
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 1
- KASDBWKLWJKTLJ-GUBZILKMSA-N Glu-Glu-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O KASDBWKLWJKTLJ-GUBZILKMSA-N 0.000 description 1
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 1
- UHVIQGKBMXEVGN-WDSKDSINSA-N Glu-Gly-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UHVIQGKBMXEVGN-WDSKDSINSA-N 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- MIWJDJAMMKHUAR-ZVZYQTTQSA-N Glu-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N MIWJDJAMMKHUAR-ZVZYQTTQSA-N 0.000 description 1
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 1
- YPHPEHMXOYTEQG-LAEOZQHASA-N Glu-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O YPHPEHMXOYTEQG-LAEOZQHASA-N 0.000 description 1
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 1
- MZZSCEANQDPJER-ONGXEEELSA-N Gly-Ala-Phe Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MZZSCEANQDPJER-ONGXEEELSA-N 0.000 description 1
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 1
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 1
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 1
- XZRZILPOZBVTDB-GJZGRUSLSA-N Gly-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)CN)C(O)=O)=CNC2=C1 XZRZILPOZBVTDB-GJZGRUSLSA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 1
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 1
- QITBQGJOXQYMOA-ZETCQYMHSA-N Gly-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QITBQGJOXQYMOA-ZETCQYMHSA-N 0.000 description 1
- LPCKHUXOGVNZRS-YUMQZZPRSA-N Gly-His-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O LPCKHUXOGVNZRS-YUMQZZPRSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 1
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 1
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 1
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 1
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 1
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 1
- YJDALMUYJIENAG-QWRGUYRKSA-N Gly-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN)O YJDALMUYJIENAG-QWRGUYRKSA-N 0.000 description 1
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 1
- NGBGZCUWFVVJKC-IRXDYDNUSA-N Gly-Tyr-Tyr Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NGBGZCUWFVVJKC-IRXDYDNUSA-N 0.000 description 1
- NGRPGJGKJMUGDM-XVKPBYJWSA-N Gly-Val-Gln Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NGRPGJGKJMUGDM-XVKPBYJWSA-N 0.000 description 1
- AFMOTCMSEBITOE-YEPSODPASA-N Gly-Val-Thr Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AFMOTCMSEBITOE-YEPSODPASA-N 0.000 description 1
- 101150046249 Havcr2 gene Proteins 0.000 description 1
- 206010019695 Hepatic neoplasm Diseases 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 1
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 1
- HZWWOGWOBQBETJ-CUJWVEQBSA-N His-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O HZWWOGWOBQBETJ-CUJWVEQBSA-N 0.000 description 1
- CSTDQOOBZBAJKE-BWAGICSOSA-N His-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CN=CN2)N)O CSTDQOOBZBAJKE-BWAGICSOSA-N 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000762247 Homo sapiens Cadherin-17 Proteins 0.000 description 1
- 101001037141 Homo sapiens Immunoglobulin heavy variable 3-21 Proteins 0.000 description 1
- 101001037153 Homo sapiens Immunoglobulin heavy variable 3-7 Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 1
- WNQKUUQIVDDAFA-ZPFDUUQYSA-N Ile-Gln-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N WNQKUUQIVDDAFA-ZPFDUUQYSA-N 0.000 description 1
- KLJKJVXDHVUMMZ-KKPKCPPISA-N Ile-Phe-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N KLJKJVXDHVUMMZ-KKPKCPPISA-N 0.000 description 1
- IVXJIMGDOYRLQU-XUXIUFHCSA-N Ile-Pro-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O IVXJIMGDOYRLQU-XUXIUFHCSA-N 0.000 description 1
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- GVEODXUBBFDBPW-MGHWNKPDSA-N Ile-Tyr-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 GVEODXUBBFDBPW-MGHWNKPDSA-N 0.000 description 1
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 102100040217 Immunoglobulin heavy variable 3-21 Human genes 0.000 description 1
- 102100040231 Immunoglobulin heavy variable 3-7 Human genes 0.000 description 1
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 description 1
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 description 1
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 102100037872 Intercellular adhesion molecule 2 Human genes 0.000 description 1
- 101710148794 Intercellular adhesion molecule 2 Proteins 0.000 description 1
- 108010002350 Interleukin-2 Proteins 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 1
- RSFGIMMPWAXNML-MNXVOIDGSA-N Leu-Gln-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RSFGIMMPWAXNML-MNXVOIDGSA-N 0.000 description 1
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- VZBIUJURDLFFOE-IHRRRGAJSA-N Leu-His-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VZBIUJURDLFFOE-IHRRRGAJSA-N 0.000 description 1
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 1
- USLNHQZCDQJBOV-ZPFDUUQYSA-N Leu-Ile-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O USLNHQZCDQJBOV-ZPFDUUQYSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- ZRHDPZAAWLXXIR-SRVKXCTJSA-N Leu-Lys-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O ZRHDPZAAWLXXIR-SRVKXCTJSA-N 0.000 description 1
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 1
- AUNMOHYWTAPQLA-XUXIUFHCSA-N Leu-Met-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AUNMOHYWTAPQLA-XUXIUFHCSA-N 0.000 description 1
- JLYUZRKPDKHUTC-WDSOQIARSA-N Leu-Pro-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JLYUZRKPDKHUTC-WDSOQIARSA-N 0.000 description 1
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 1
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 1
- NCTDKZKNBDZDOL-GARJFASQSA-N Lys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O NCTDKZKNBDZDOL-GARJFASQSA-N 0.000 description 1
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 1
- MQMIRLVJXQNTRJ-SDDRHHMPSA-N Lys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O MQMIRLVJXQNTRJ-SDDRHHMPSA-N 0.000 description 1
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- OIYWBDBHEGAVST-BZSNNMDCSA-N Lys-His-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OIYWBDBHEGAVST-BZSNNMDCSA-N 0.000 description 1
- YXPJCVNIDDKGOE-MELADBBJSA-N Lys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N)C(=O)O YXPJCVNIDDKGOE-MELADBBJSA-N 0.000 description 1
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 1
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 1
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 1
- 102000012750 Membrane Glycoproteins Human genes 0.000 description 1
- 108010090054 Membrane Glycoproteins Proteins 0.000 description 1
- DBOMZJOESVYERT-GUBZILKMSA-N Met-Asn-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N DBOMZJOESVYERT-GUBZILKMSA-N 0.000 description 1
- MHQXIBRPDKXDGZ-ZFWWWQNUSA-N Met-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MHQXIBRPDKXDGZ-ZFWWWQNUSA-N 0.000 description 1
- IHRFZLQEQVHXFA-RHYQMDGZSA-N Met-Thr-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCCN IHRFZLQEQVHXFA-RHYQMDGZSA-N 0.000 description 1
- NDJSSFWDYDUQID-YTWAJWBKSA-N Met-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N)O NDJSSFWDYDUQID-YTWAJWBKSA-N 0.000 description 1
- 101100165851 Mus musculus Ca9 gene Proteins 0.000 description 1
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- 108091008877 NK cell receptors Proteins 0.000 description 1
- 102000010648 Natural Killer Cell Receptors Human genes 0.000 description 1
- 206010030137 Oesophageal adenocarcinoma Diseases 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- CDNPIRSCAFMMBE-SRVKXCTJSA-N Phe-Asn-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CDNPIRSCAFMMBE-SRVKXCTJSA-N 0.000 description 1
- JOXIIFVCSATTDH-IHPCNDPISA-N Phe-Asn-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JOXIIFVCSATTDH-IHPCNDPISA-N 0.000 description 1
- CSYVXYQDIVCQNU-QWRGUYRKSA-N Phe-Asp-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O CSYVXYQDIVCQNU-QWRGUYRKSA-N 0.000 description 1
- MQVFHOPCKNTHGT-MELADBBJSA-N Phe-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O MQVFHOPCKNTHGT-MELADBBJSA-N 0.000 description 1
- FRPVPGRXUKFEQE-YDHLFZDLSA-N Phe-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FRPVPGRXUKFEQE-YDHLFZDLSA-N 0.000 description 1
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 1
- IEOHQGFKHXUALJ-JYJNAYRXSA-N Phe-Met-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IEOHQGFKHXUALJ-JYJNAYRXSA-N 0.000 description 1
- AXIOGMQCDYVTNY-ACRUOGEOSA-N Phe-Phe-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 AXIOGMQCDYVTNY-ACRUOGEOSA-N 0.000 description 1
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 1
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 1
- BTAIJUBAGLVFKQ-BVSLBCMMSA-N Phe-Trp-Val Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](C(C)C)C(O)=O)C1=CC=CC=C1 BTAIJUBAGLVFKQ-BVSLBCMMSA-N 0.000 description 1
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 1
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 1
- SSSFPISOZOLQNP-GUBZILKMSA-N Pro-Arg-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSFPISOZOLQNP-GUBZILKMSA-N 0.000 description 1
- HXOLCSYHGRNXJJ-IHRRRGAJSA-N Pro-Asp-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HXOLCSYHGRNXJJ-IHRRRGAJSA-N 0.000 description 1
- LSIWVWRUTKPXDS-DCAQKATOSA-N Pro-Gln-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LSIWVWRUTKPXDS-DCAQKATOSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 1
- PTLOFJZJADCNCD-DCAQKATOSA-N Pro-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 PTLOFJZJADCNCD-DCAQKATOSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 1
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 1
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 1
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 1
- UIUWGMRJTWHIJZ-ULQDDVLXSA-N Pro-Tyr-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCCN)C(=O)O UIUWGMRJTWHIJZ-ULQDDVLXSA-N 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 108091030071 RNAI Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- YMEXHZTVKDAKIY-GHCJXIJMSA-N Ser-Asn-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO)C(O)=O YMEXHZTVKDAKIY-GHCJXIJMSA-N 0.000 description 1
- BTPAWKABYQMKKN-LKXGYXEUSA-N Ser-Asp-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BTPAWKABYQMKKN-LKXGYXEUSA-N 0.000 description 1
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 1
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 1
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- MIJWOJAXARLEHA-WDSKDSINSA-N Ser-Gly-Glu Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O MIJWOJAXARLEHA-WDSKDSINSA-N 0.000 description 1
- CXBFHZLODKPIJY-AAEUAGOBSA-N Ser-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N CXBFHZLODKPIJY-AAEUAGOBSA-N 0.000 description 1
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 1
- DJACUBDEDBZKLQ-KBIXCLLPSA-N Ser-Ile-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O DJACUBDEDBZKLQ-KBIXCLLPSA-N 0.000 description 1
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 1
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 1
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 1
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- UKKROEYWYIHWBD-ZKWXMUAHSA-N Ser-Val-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UKKROEYWYIHWBD-ZKWXMUAHSA-N 0.000 description 1
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 1
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- 108010006785 Taq Polymerase Proteins 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 1
- DIPIPFHFLPTCLK-LOKLDPHHSA-N Thr-Gln-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O DIPIPFHFLPTCLK-LOKLDPHHSA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- NCXVJIQMWSGRHY-KXNHARMFSA-N Thr-Leu-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O NCXVJIQMWSGRHY-KXNHARMFSA-N 0.000 description 1
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- PCMDGXKXVMBIFP-VEVYYDQMSA-N Thr-Met-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O PCMDGXKXVMBIFP-VEVYYDQMSA-N 0.000 description 1
- KZURUCDWKDEAFZ-XVSYOHENSA-N Thr-Phe-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O KZURUCDWKDEAFZ-XVSYOHENSA-N 0.000 description 1
- MUAFDCVOHYAFNG-RCWTZXSCSA-N Thr-Pro-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MUAFDCVOHYAFNG-RCWTZXSCSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 1
- LXXCHJKHJYRMIY-FQPOAREZSA-N Thr-Tyr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O LXXCHJKHJYRMIY-FQPOAREZSA-N 0.000 description 1
- BEZTUFWTPVOROW-KJEVXHAQSA-N Thr-Tyr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O BEZTUFWTPVOROW-KJEVXHAQSA-N 0.000 description 1
- BZTSQFWJNJYZSX-JRQIVUDYSA-N Thr-Tyr-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O BZTSQFWJNJYZSX-JRQIVUDYSA-N 0.000 description 1
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 1
- LVRFMARKDGGZMX-IZPVPAKOSA-N Thr-Tyr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=C(O)C=C1 LVRFMARKDGGZMX-IZPVPAKOSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- VTHNLRXALGUDBS-BPUTZDHNSA-N Trp-Gln-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N VTHNLRXALGUDBS-BPUTZDHNSA-N 0.000 description 1
- UDCHKDYNMRJYMI-QEJZJMRPSA-N Trp-Glu-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UDCHKDYNMRJYMI-QEJZJMRPSA-N 0.000 description 1
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- XLMDWQNAOKLKCP-XDTLVQLUSA-N Tyr-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N XLMDWQNAOKLKCP-XDTLVQLUSA-N 0.000 description 1
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 1
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 1
- BSCBBPKDVOZICB-KKUMJFAQSA-N Tyr-Leu-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BSCBBPKDVOZICB-KKUMJFAQSA-N 0.000 description 1
- BYAKMYBZADCNMN-JYJNAYRXSA-N Tyr-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYAKMYBZADCNMN-JYJNAYRXSA-N 0.000 description 1
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 1
- RWOKVQUCENPXGE-IHRRRGAJSA-N Tyr-Ser-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RWOKVQUCENPXGE-IHRRRGAJSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 1
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 1
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 1
- JXGWQYWDUOWQHA-DZKIICNBSA-N Val-Gln-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N JXGWQYWDUOWQHA-DZKIICNBSA-N 0.000 description 1
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 1
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 1
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- RFKJNTRMXGCKFE-FHWLQOOXSA-N Val-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC(C)C)C(O)=O)=CNC2=C1 RFKJNTRMXGCKFE-FHWLQOOXSA-N 0.000 description 1
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 1
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 1
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 1
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 1
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 1
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 1
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 1
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 1
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 1
- ZNGPROMGGGFOAA-JYJNAYRXSA-N Val-Tyr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 ZNGPROMGGGFOAA-JYJNAYRXSA-N 0.000 description 1
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 102000013814 Wnt Human genes 0.000 description 1
- 108050003627 Wnt Proteins 0.000 description 1
- 230000004156 Wnt signaling pathway Effects 0.000 description 1
- 210000000683 abdominal cavity Anatomy 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 238000011467 adoptive cell therapy Methods 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 230000001270 agonistic effect Effects 0.000 description 1
- 230000000735 allogeneic effect Effects 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000012298 atmosphere Substances 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 239000003633 blood substitute Substances 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 230000009702 cancer cell proliferation Effects 0.000 description 1
- 229910002092 carbon dioxide Inorganic materials 0.000 description 1
- 239000001569 carbon dioxide Substances 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 238000002737 cell proliferation kit Methods 0.000 description 1
- 238000002659 cell therapy Methods 0.000 description 1
- 230000005889 cellular cytotoxicity Effects 0.000 description 1
- 230000030570 cellular localization Effects 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 230000014564 chemokine production Effects 0.000 description 1
- 230000003399 chemotactic effect Effects 0.000 description 1
- 208000018805 childhood acute lymphoblastic leukemia Diseases 0.000 description 1
- 201000011633 childhood acute lymphocytic leukemia Diseases 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 201000010897 colon adenocarcinoma Diseases 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 108010069495 cysteinyltyrosine Proteins 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000007711 cytoplasmic localization Effects 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 231100000517 death Toxicity 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 108010009297 diglycyl-histidine Proteins 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- BFMYDTVEBKDAKJ-UHFFFAOYSA-L disodium;(2',7'-dibromo-3',6'-dioxido-3-oxospiro[2-benzofuran-1,9'-xanthene]-4'-yl)mercury;hydrate Chemical compound O.[Na+].[Na+].O1C(=O)C2=CC=CC=C2C21C1=CC(Br)=C([O-])C([Hg])=C1OC1=C2C=C(Br)C([O-])=C1 BFMYDTVEBKDAKJ-UHFFFAOYSA-L 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000003255 drug test Methods 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 239000003480 eluent Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000000688 enterotoxigenic effect Effects 0.000 description 1
- 238000003912 environmental pollution Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 201000007550 esophagus adenocarcinoma Diseases 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 210000001808 exosome Anatomy 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 230000009368 gene silencing by RNA Effects 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 108010075431 glycyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 230000009422 growth inhibiting effect Effects 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 208000006454 hepatitis Diseases 0.000 description 1
- 231100000283 hepatitis Toxicity 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 102000051456 human CDH17 Human genes 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000006058 immune tolerance Effects 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 230000002055 immunohistochemical effect Effects 0.000 description 1
- 238000011532 immunohistochemical staining Methods 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 210000004347 intestinal mucosa Anatomy 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 230000004068 intracellular signaling Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 230000002147 killing effect Effects 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 108010057821 leucylproline Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 238000001325 log-rank test Methods 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 210000004379 membrane Anatomy 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- 239000003607 modifier Substances 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 229940126619 mouse monoclonal antibody Drugs 0.000 description 1
- 230000017066 negative regulation of growth Effects 0.000 description 1
- 239000000101 novel biomarker Substances 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 201000002094 pancreatic adenocarcinoma Diseases 0.000 description 1
- 210000000277 pancreatic duct Anatomy 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229940068965 polysorbates Drugs 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 230000007420 reactivation Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000007670 refining Methods 0.000 description 1
- 210000003289 regulatory T cell Anatomy 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 238000009118 salvage therapy Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 230000001235 sensitizing effect Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 239000012679 serum free medium Substances 0.000 description 1
- 230000011664 signaling Effects 0.000 description 1
- 238000005549 size reduction Methods 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 239000002512 suppressor factor Substances 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 108010080629 tryptophan-leucine Proteins 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 210000005239 tubule Anatomy 0.000 description 1
- 239000000107 tumor biomarker Substances 0.000 description 1
- 230000005909 tumor killing Effects 0.000 description 1
- 231100000588 tumorigenic Toxicity 0.000 description 1
- 230000000381 tumorigenic effect Effects 0.000 description 1
- 230000002100 tumorsuppressive effect Effects 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 238000002689 xenotransplantation Methods 0.000 description 1
Images
















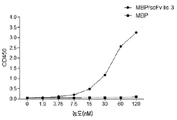
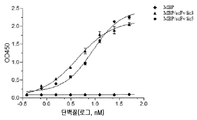
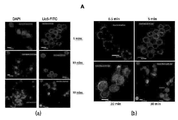












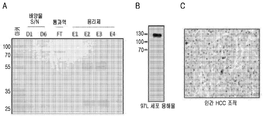
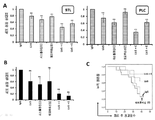
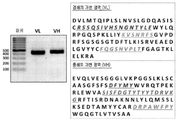
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2839—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the integrin superfamily
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0646—Natural killers cells [NK], NKT cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2300/00—Mixtures or combinations of active ingredients, wherein at least one active ingredient is fully defined in groups A61K31/00 - A61K41/00
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Abstract
본 개시내용의 실시양태는 암 치료를 위한 카드헤린-17 특이적 항체 및 세포독성 세포에 관한 것이다. 예를 들어, 항체는 카드헤린-17에 대하여 특이성을 가질 수 있고, 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 70%의 유사성을 가지는 아미노산 서열을 포함할 수 있다.
Description
관련 특허 출원에 관한 상호 참조
본 출원은 2016년 1월 9월 출원된 미국 가출원 번호 62,276,855 (발명의 명칭: "Cadherin-17 specific antibodies and cytotoxic cells for cancer treatment")에 대한 우선권을 주장하며, 상기 가출원은 그의 전문이 본원에서 참조로 포함된다.
기술분야
본 개시내용은 일반적으로 암 면역요법의 기술분야, 및 더욱 특히, 암 치료를 위한 카드헤린-17 특이적 항체 및 세포독성 세포에 관한 것이다.
최근 신약 개발과 임상 영상화의 발전에도 불구하고, 암은 인간에서 가장 치명적인 질환 중 하나로 남아 있다. 종양이 어떻게 개시되고, 스트레스하에서 생존하며, 콜로니화되고/원위부 기관 및 부위로 전이되고, 약물에 대해 내성을 띠게 되는지에 관한 본 발명자들의 이해는 여전히 제한되어 있다. 미국 암 학회(American Cancer Society)는 2014년 미국에서 신규 암 사례가 160만 건에 달할 것으로 추정하였으며, 지배적인 암 유형 대부분에 대하여 승인받은 치유 치료법은 없다. 중국에서, 암은 발병률 및 사망률이 점점 증가하고 있는 최고 살인자 중 하나로, 이는 바이러스성/박테리아성 풍토병 (B형 간염 바이러스 [HBV] 및 헬리코박터 파일로리(Helicobacter pylori) 감염), 환경 오염 및 식품 오염이 원인이 되는 것으로 간주되고 있다.
위암 및 간암은 전세계적으로 가장 치명적인 악성종양 중 하나이고, 중국에서는 발병된 것 중 절반 이상이 위암 및 간암의 진단을 받고 있으며, 전세계적으로 매년 142만건 초과의 사망 사례의 원인이 되고 있지만, 효과적인 요법은 없는 상태이다. 따라서, 상기 공격적인 암에 대한, 특히, 진행 단계에 있는 것에 대한 잠재적인 신약 개발을 위한 신규한 바이오마커(biomarker) 및 치료학적 표적이 요구되고 있다. 상기 두가지 암을 제거하거나, 또는 그의 성장을 억제시킬 수 있는 입증된 분자 표적화제가 중요한 임상적 가치를 가질 것이며, 시장에 상당한 영향을 미칠 것이다. 상기 질환이 조기 단계에서 진단을 받게 된다면, 이들 종양은 수술에 의해 효과적으로 절제될 수 있다. 불행하게도, 및 매우 빈번하게는, 상기 암 대부분은 증상이 없고, 진료소에서 진찰을 받을 때에는 매우 진행된 단계에서 검출된다. 효과적인 치료를 받지 않으면, 상기 환자는 진단 직후에 사망하거나, 또는 구제(salvage) 요법 후 재발된다.
CART-세포 치료는 항암 반응을 유도하는 T 세포의 생체외 변형을 포함하는 일종의 입양 세포 요법이다. CAR-변형된 T 세포는 사실상 임의의 종양 연관 항원을 표적화하도록 조작될 수 있다.
초기 단계의 CART 연구들은 거의 모두 소아 급성 림프아구성 백혈병에서의 CART19 (CD19 항원을 표적화하는 CAR-T 세포)에 관한 개념 입증 연구를 비롯하여 혈액암에 주력한다. CAR-T 세포 요법 및 관련 기술이 고형 종양 적응증, 예컨대, 간암, 위암 및 폐암에서 동일한 효능을 반복할 수 있는지 여부는 지켜봐야 한다. 현재, 총 72개의 임상 시험이 www.clinicaltrials.gov에 등록 기재되어 있으며, 15개의 연구가 중국에 등록되어 있다. 연구 중 절반 이상이 가장 일반적인 CAR-T 표적인 CD19와 관련된 혈액암에 주력하고 있으며, 그 다음으로는 뇌 종양 및 다수의 Her2 양성 암에 특이적인 GD2 및 Her2에 대해 수행되고 있다. 따라서, HCC 및 GC에 대한 CAR-T 면역요법에는 큰 차이가 있다.
오늘날, 제3 세대 GPC3 표적화된 CAR을 발현하는 유전적으로 변형된 T 세포인 KJgpc3-001을 사용하여 진행성 HCC 환자를 치료하기 위한 CAR-T 1상 시험이 유일하게 등록되어 있다. GPC3 (글리피칸-3)은 HCC에서는 고도로 발현되지만, 정상 조직에서는 발현이 제한적으로 일어난다 (63.6% 대 9.2%). 불행하게도, (로슈(Roche)의 자회사인 추가이(Chugai)에 의해 개발된) 항GPC3 mAb GC33에 관한 I상 연구에서는 부분 관해(response) 또는 완전 관해가 관찰되지 않았다. KJgpc3-001은 GC33으로부터 유래된 항GPC3 scFv 및 CD28/4-1BB/CD3ζ로부터 유래된 세포내 신호전달 도메인(signaling domain)을 포함한다. KJgpc3-001은 렌티바이러스 벡터를 이용하여 환자의 T 세포 내로 형질도입되어 간암을 공격할 수 있다. 임상전 연구에서, KJgpc3-001로 처리된 마우스는 모두 60일 초과의 기간 동안 생존한 반면, 염수 처리된 마우스의 생존 기간 중앙값은 33일이었다. KJgpc3-001에 대한 주요 관심사는 정상 조직, 예컨대, 위샘, 신장 세관, 및 생식 세포에서의 GPC3의 발현이다. 앞서, 유방암을 앓는 한 환자는 폐 조직에서의 HER2의 발현에 기인하여 HER2 표적화된 CAR 치료를 받은 후 사망하였다. 환자는 세포 주입 후 15분 이내에 호흡 곤란을 겪었고, 치료 후 5일째 사망하였다. 그러므로, 암 치료를 위한 카드헤린-17 특이적 항체 및 세포독성 세포를 이용한 암 면역요법이 요구되고 있다.
본 개시내용은 카드헤린-17 특이적 항체 및 세포독성 세포를 제공한다.
본 개시내용의 실시양태는 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 70%의 유사성을 가지는 아미노산 서열을 포함하는, 카드헤린-17에 대하여 특이성을 가지는 항체에 관한 것이다.
일부 실시양태에서, 항체는 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 80%의 유사성을 가지는 아미노산 서열을 포함할 수 있다.
일부 실시양태에서, 항체는 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 95%의 유사성을 가지는 아미노산 서열을 포함할 수 있다.
일부 실시양태에서, 모노클로날 항체는 마우스 항체, 인간화 항체, 또는 인간 항체이다. 일부 실시양태에서, 모노클로날 항체는 파지 라이브러리 스크린(phage library screen)으로부터 단리된 인간 항체이다.
일부 실시양태에서, 항체는 경쇄의 가변 영역 (VL), 중쇄의 가변 영역 (VH)을 포함할 수 있고, VL은 서열 번호: 1, 3, 6, 8, 10, 12, 14, 및 16으로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함할 수 있다. 일부 실시양태에서, VH는 서열 번호: 2, 4, 5, 7, 9, 11, 13, 및 15로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함할 수 있다.
일부 실시양태에서, 항체는 접합된 세포독성 모이어티(moiety)를 포함할 수 있다. 일부 실시양태에서, 접합된 세포독성 모이어티는 이리노테칸, 아우리스타틴, PBD, 메이탄신, 아만틴, 스플라이소솜 억제제, 또는 그의 조합을 포함할 수 있다. 일부 실시양태에서, 접합된 세포독성 모이어티는 화학요법제를 포함할 수 있다.
일부 실시양태에서, 항체는 이중특이적 항체이다.
일부 실시양태에서, 항체는 세포독성 T 또는 NK 세포로부터의 세포 수용체에 대한 특이성을 포함할 수 있다. 일부 실시양태에서, 항체는 카드헤린-17 및 CD3 둘 모두에 대하여 특이성을 가지는 이중특이적 항체이다. 일부 실시양태에서, 세포 수용체는 4-1BB, OX40, CD27, CD40, TIM-1, CD28, HVEM, GITR, ICOS, IL12수용체, IL14 수용체, 또는 그의 유도체 또는 조합을 포함할 수 있다.
일부 실시양태에서, 항체는 카드헤린-17에 대하여 특이성을 가지는 제1 단일 쇄 가변 단편 (ScFv) 및 CD3에 대하여 특이성을 가지는 제2 단일 쇄 가변 단편 (ScFv)을 포함할 수 있고, 여기서, 제1 ScFv는 제1 VH 및 제1 VL을 포함할 수 있고, 제2 ScFv는 제2 VH 및 제2 VL을 포함할 수 있다. 일부 실시양태에서, 제1 VH는 서열 번호: 2, 4, 5, 7, 9, 11, 13, 및 15로부터 선택되는 아미노산 서열을 포함할 수 있다. 일부 실시양태에서, 제1 VL은 서열 번호: 1, 3, 6, 8, 10, 12, 14, 및 16으로부터 선택되는 아미노산 서열을 포함할 수 있다.
일부 실시양태에서, 제2 VH는 서열 번호: 18의 아미노산 서열의 상응하는 부분을 포함할 수 있다.
일부 실시양태에서, 제2 VL은 서열 번호: 18의 아미노산 서열의 상응하는 부분을 포함할 수 있다.
일부 실시양태에서, 항체는 면역 체크포인트 억제제에 대한 특이성을 포함할 수 있다. 일부 실시양태에서, 체크포인트 억제제로는 PD-1, TIM-3, LAG-3, TIGIT, CTLA-4, PD-L1, BTLA, VISTA, 또는 그의 조합을 포함할 수 있다.
일부 실시양태에서, 항체는 혈관형성 인자에 대한 특이성을 포함할 수 있다. 일부 실시양태에서, 혈관형성 인자는 VEGF를 포함할 수 있다.
일부 실시양태에서, 항체는 카드헤린-17 도메인 6 중 RGD 부위의 인테그린에의 결합을 길항시키도록 구성된다. 일부 실시양태에서, 인테그린은 알파2베타1을 포함할 수 있다.
일부 실시양태에서, 항체는 모노클로날 항체이다.
본 개시내용의 일부 실시양태는 서열 번호: 2, 4, 5, 7, 9, 11, 13, 및 15로부터 선택되는 서열을 가지는 아미노산 서열을 포함하는, 항체를 위한 IgG 중쇄에 관한 것이다.
본 개시내용의 일부 실시양태는 서열 번호: 1, 3, 6, 8, 10, 12, 14, 및 16으로부터 선택되는 서열을 가지는 아미노산 서열을 포함하는, 항체를 위한 경쇄에 관한 것이다.
본 개시내용의 일부 실시양태는 서열 번호: 1-16으로부터 선택되는 아미노산 서열을 포함하는, 항체를 위한 가변 쇄에 관한 것이다.
본 개시내용의 일부 실시양태는 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함하는, 카드헤린-17에 대하여 특이성을 가지는 scFv 또는 Fab에 관한 것이다.
일부 실시양태에서, scFv 또는 Fab는 세포독성 T 또는 NK 세포로부터의 세포 수용체에 대한 특이성을 포함할 수 있다. 일부 실시양태에서, scFv 또는 Fab는 면역 체크포인트 억제제에 대한 특이성을 포함할 수 있다. 일부 실시양태에서, scFv 또는 Fab는 혈관형성 인자에 대한 특이성을 포함할 수 있다.
본 개시내용의 일부 실시양태는 카드헤린-17에 대하여 특이성을 가지는 T 또는 NK 세포로서, 여기서, T 또는 NK 세포는 키메라 항원 수용체를 포함할 수 있고, 여기서, 키메라 항원 수용체는 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함할 수 있는 것인, T 또는 NK 세포에 관한 것이다.
일부 실시양태에서, 키메라 항원 수용체는 서열 번호: 1-16으로부터 선택되는 아미노산 서열을 포함할 수 있다.
본 개시내용의 일부 실시양태는 상기 기술된 바와 같은 항체, IgG 중쇄, 경쇄, 가변 쇄, 또는 ScFv 또는 Fab를 코딩하는(encoding) 단리된 핵산에 관한 것이다.
본 개시내용의 일부 실시양태는 상기 기술된 것의 단리된 핵산을 포함하는 발현 벡터에 관한 것이다. 일부 실시양태에서, 벡터는 세포에서 발현가능한 것이다.
본 개시내용의 일부 실시양태는 상기 기술된 바와 같은 핵산을 포함하는 숙주 세포에 관한 것이다.
본 개시내용의 일부 실시양태는 상기 기술된 바와 같은 발현 벡터를 포함하는 숙주 세포에 관한 것이다.
일부 실시양태에서, 숙주 세포는 원핵 세포 또는 진핵 세포이다.
본 개시내용의 일부 실시양태는 제1항 내지 제26항 중 어느 한 항의 항체 및 세포독성제를 포함하는 제약 조성물에 관한 것이다.
일부 실시양태에서, 세포독성제로는 시스플라틴, 젬시타빈, 이리노테칸, 또는 항종양 항체를 포함할 수 있다.
일부 실시양태에서, 제약 조성물은 상기 기술된 바와 같은 항체 및 제약상 허용되는 담체를 포함할 수 있다.
본 개시내용의 일부 실시양태는 암을 앓는 대상체(subject)에게 유효량의, 제1항 내지 제26항 중 어느 한 항의 항체, 또는 제34항 또는 제35항의 T 또는 NK 세포를 투여하는 단계를 포함하는, 암을 앓는 대상체를 치료하는 방법에 관한 것이다.
일부 실시양태에서, 암은 간암, 위암, 결장암, 췌장암, 폐암, 또는 그의 조합이다.
본 개시내용의 목적 및 이점은 첨부된 도면과 관련된 그의 바람직한 실시양태에 관한 하기의 상세한 설명으로부터 자명해질 수 있다.
이제, 본 개시내용에 따른 바람직한 실시양태는 도면을 참조로 하여 기술될 수 있고, 여기서, 유사한 참조 숫자는 유사 요소를 나타낸다.
도 1은 Lic3 및 Lic5의 뮤린 VL 및 VH 서열을 보여주는 것이다 (Lic3 서열은 업데이트된 것이며, 즉, prf에서 서열 번호: 1 및 서열 번호: 2는 이에 따라 대체되어야 할 필요가 있다는 것에 주의하여야 한다).
도 2는 인간화를 위한 인간 VL 2-30/J1과의 Lic3 VL 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 3은 인간화를 위한 인간 VL 2-24/J1과의 Lic3 VL 서열의 상동성 및 인간 VH Vk2-29와의 Lic3 Vk 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 4는 인간화를 위한 인간 VH 3-11/J4와의 Lic3 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 5는 인간화를 위한 인간 VH 3-30/J4와의 Lic3 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 6은 인간화를 위한 인간 VL IGKV 2-30과의 Lic5 VL 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 7은 인간화를 위한 인간 VL pdb4X0K와의 Lic5 VL 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 8은 인간화를 위한 인간 VH IGHV3-21과의 Lic5 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 9는 인간화를 위한 인간 VH IGHV3-7과의 Lic5 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 10은, 다수회의 라운드에 걸쳐 수행된 고정화된 CDH17 도메인 1-3에의 결합에 의해 인간 카드헤린-17 특이적 항체를 파지 라이브러리로부터 단리시킨 것인, 항체 파지 라이브러리로부터 인간 카드헤린-17 특이적 항체를 단리시키는 프로세스를 도시한 흐름도를 보여주는 것이다.
도 11은 CDH17에 결합하는, 항체 파지 라이브러리로부터 단리된 인간 항체의 예를 보여주는 그래프이다.
도 12는 파지 라이브러리 스크린으로부터의 인간 CDH17 항체 VL 및 VH 서열을 보여주는 것이다.
도 13은 CDH17 항체 VH 및 VL로부터 생성된, 암 면역요법제를 위한 예시적인 기능적 도메인 형태의 패널을 보여주는 것이다; (a) CDH17 특이적 항체; (b) CDH17 항체 약물 접합체; (c) scFv-Fc 이중특이적 항체 (놉 인 홀(knob in hole)); (d) scFv-Fc 이중특이적 항체 (bite); 및 (e) CAR T 또는 NK 세포.
도 14는 예시적인 CDH17-CD3 이중특이적 항체 (놉 인 홀)의 아미노산 서열을 보여주는 것이다.
도 15는 ELISA에 의해 Lic5 scFv의 CDH17에의 결합을 보여주는 그래프이다.
도 16은 ELISA에 의해 Lic3 scFv의 CDH17에의 결합을 보여주는 그래프이다.
도 17은 ELISA에 의해 측정된 Lic3 및 Lic5 scFv의 친화도를 보여주는 그래프이며, 여기서, scFv lie 3 (kd): 11.88 nM, 및 scFv Iic5: 22.06 nM이다.
도 18은 항체 약물 접합체에 대한 후보로서 Lic5의 인간 위암 세포 내로의 내재화를 보여주는 사진을 보여주는 것이다; (a) 명시된 시점에서의 DAPI (청색) 및 Lic5-FITC (녹색)의 염색을 보여주는 사진; (b) 명시된 시점에서의 DAPI (청색) 및 Lic5-FITC (녹색)의 병합된 염색을 보여주는 사진; 37℃에서 30 min 동안에 걸쳐 Oum1 인간 위암 세포에서의 Lic5-FITC (녹색) 내재화를 공초점 현미경 검사법에 측정하였고; 핵은 DAPI로 염색하였다.
도 19는 ELISA에 의해 측정된 인간화 Lic3의 CDH17에의 결합을 보여주는 것이다.
도 20은 ELISA에 의해 측정된 CDH17 또는 CDH17 말단절단물(truncate)에 결합하는 CDH17 모노클로날 항체를 보여주는 것이다.
도 21은 ELISA에 의해 측정된 종양 세포주에 결합하는 CDH17 모노클로날 항체 및 인간화 Lic3 scFvFc (h3scFv)의 예를 보여주는 것이다. 놀랍게도, 다수의 CDH17 모노클로날 항체가 상이한 CDH17 발현 종양 세포주에 대하여 상이한 결합 패턴을 보였다 (적색 박스).
도 22는 hLic3 CAR7a (서열 번호: 25), hLic3 CAR7b (서열 번호: 26), hLic3 CAR8 (서열 번호: 27), 및 hLic3 CAR9 (서열 번호: 28)의 아미노산 서열을 포함하는, 제2 세대 CAR의 디자인 (a) 및 분석 (b)을 보여주는 것이다.
도 23은 신호전달의 함수로서의 IL2 생산을 보여주는 것이다.
도 24는 Lic3 제2 세대 CAR (Lic3scFv-CD28힌지+TM+엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 19)을 보여주는 것이다.
도 25는 Lic5 제2 세대 CAR (Lic5scFv-CD28힌지+TM+엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 20)을 보여주는 것이다.
도 26은 HLic26 제2 세대 CAR (Lic26scFv-CD28힌지+TM+엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 21)을 보여주는 것이다.
도 27은 Lic3 제3 세대 CAR (Lic3scFv-CD28-4-1BB-CD3제타 엔도)의 아미노산 서열 (서열 번호: 22)을 보여주는 것이다.
도 28은 Lic5 제3 세대 CAR (Lic5scFv-CD28힌지+TM+엔도-4-1BB 엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 23)을 보여주는 것이다.
도 29는 HuLic26 제3 세대 CAR (Lic26scFv-CD28힌지+TM+엔도-4-1BB 엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 24)을 보여주는 것이다.
도 30은 Lic5 정제 및 특성화(characterization)를 보여주는 것이다.
도 31은 Lic5의 화학감작 효과를 보여주는 것이다.
도 32는 Lic5의 경쇄 및 중쇄의 가변 영역의 아미노산 서열을 보여주는 것이다.
도 1은 Lic3 및 Lic5의 뮤린 VL 및 VH 서열을 보여주는 것이다 (Lic3 서열은 업데이트된 것이며, 즉, prf에서 서열 번호: 1 및 서열 번호: 2는 이에 따라 대체되어야 할 필요가 있다는 것에 주의하여야 한다).
도 2는 인간화를 위한 인간 VL 2-30/J1과의 Lic3 VL 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 3은 인간화를 위한 인간 VL 2-24/J1과의 Lic3 VL 서열의 상동성 및 인간 VH Vk2-29와의 Lic3 Vk 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 4는 인간화를 위한 인간 VH 3-11/J4와의 Lic3 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 5는 인간화를 위한 인간 VH 3-30/J4와의 Lic3 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 6은 인간화를 위한 인간 VL IGKV 2-30과의 Lic5 VL 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 7은 인간화를 위한 인간 VL pdb4X0K와의 Lic5 VL 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 8은 인간화를 위한 인간 VH IGHV3-21과의 Lic5 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 9는 인간화를 위한 인간 VH IGHV3-7과의 Lic5 VH 서열의 상동성, 및 Hum으로 표시된 인간화 변이체를 보여주는 것이며, 여기서, 점 표시는 인간 아미노산을 나타내고, 복귀 돌연변이는 단일 아미노산 주석 기호로 표시되어 있다.
도 10은, 다수회의 라운드에 걸쳐 수행된 고정화된 CDH17 도메인 1-3에의 결합에 의해 인간 카드헤린-17 특이적 항체를 파지 라이브러리로부터 단리시킨 것인, 항체 파지 라이브러리로부터 인간 카드헤린-17 특이적 항체를 단리시키는 프로세스를 도시한 흐름도를 보여주는 것이다.
도 11은 CDH17에 결합하는, 항체 파지 라이브러리로부터 단리된 인간 항체의 예를 보여주는 그래프이다.
도 12는 파지 라이브러리 스크린으로부터의 인간 CDH17 항체 VL 및 VH 서열을 보여주는 것이다.
도 13은 CDH17 항체 VH 및 VL로부터 생성된, 암 면역요법제를 위한 예시적인 기능적 도메인 형태의 패널을 보여주는 것이다; (a) CDH17 특이적 항체; (b) CDH17 항체 약물 접합체; (c) scFv-Fc 이중특이적 항체 (놉 인 홀(knob in hole)); (d) scFv-Fc 이중특이적 항체 (bite); 및 (e) CAR T 또는 NK 세포.
도 14는 예시적인 CDH17-CD3 이중특이적 항체 (놉 인 홀)의 아미노산 서열을 보여주는 것이다.
도 15는 ELISA에 의해 Lic5 scFv의 CDH17에의 결합을 보여주는 그래프이다.
도 16은 ELISA에 의해 Lic3 scFv의 CDH17에의 결합을 보여주는 그래프이다.
도 17은 ELISA에 의해 측정된 Lic3 및 Lic5 scFv의 친화도를 보여주는 그래프이며, 여기서, scFv lie 3 (kd): 11.88 nM, 및 scFv Iic5: 22.06 nM이다.
도 18은 항체 약물 접합체에 대한 후보로서 Lic5의 인간 위암 세포 내로의 내재화를 보여주는 사진을 보여주는 것이다; (a) 명시된 시점에서의 DAPI (청색) 및 Lic5-FITC (녹색)의 염색을 보여주는 사진; (b) 명시된 시점에서의 DAPI (청색) 및 Lic5-FITC (녹색)의 병합된 염색을 보여주는 사진; 37℃에서 30 min 동안에 걸쳐 Oum1 인간 위암 세포에서의 Lic5-FITC (녹색) 내재화를 공초점 현미경 검사법에 측정하였고; 핵은 DAPI로 염색하였다.
도 19는 ELISA에 의해 측정된 인간화 Lic3의 CDH17에의 결합을 보여주는 것이다.
도 20은 ELISA에 의해 측정된 CDH17 또는 CDH17 말단절단물(truncate)에 결합하는 CDH17 모노클로날 항체를 보여주는 것이다.
도 21은 ELISA에 의해 측정된 종양 세포주에 결합하는 CDH17 모노클로날 항체 및 인간화 Lic3 scFvFc (h3scFv)의 예를 보여주는 것이다. 놀랍게도, 다수의 CDH17 모노클로날 항체가 상이한 CDH17 발현 종양 세포주에 대하여 상이한 결합 패턴을 보였다 (적색 박스).
도 22는 hLic3 CAR7a (서열 번호: 25), hLic3 CAR7b (서열 번호: 26), hLic3 CAR8 (서열 번호: 27), 및 hLic3 CAR9 (서열 번호: 28)의 아미노산 서열을 포함하는, 제2 세대 CAR의 디자인 (a) 및 분석 (b)을 보여주는 것이다.
도 23은 신호전달의 함수로서의 IL2 생산을 보여주는 것이다.
도 24는 Lic3 제2 세대 CAR (Lic3scFv-CD28힌지+TM+엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 19)을 보여주는 것이다.
도 25는 Lic5 제2 세대 CAR (Lic5scFv-CD28힌지+TM+엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 20)을 보여주는 것이다.
도 26은 HLic26 제2 세대 CAR (Lic26scFv-CD28힌지+TM+엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 21)을 보여주는 것이다.
도 27은 Lic3 제3 세대 CAR (Lic3scFv-CD28-4-1BB-CD3제타 엔도)의 아미노산 서열 (서열 번호: 22)을 보여주는 것이다.
도 28은 Lic5 제3 세대 CAR (Lic5scFv-CD28힌지+TM+엔도-4-1BB 엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 23)을 보여주는 것이다.
도 29는 HuLic26 제3 세대 CAR (Lic26scFv-CD28힌지+TM+엔도-4-1BB 엔도-CD3제타 엔도)의 아미노산 서열 (서열 번호: 24)을 보여주는 것이다.
도 30은 Lic5 정제 및 특성화(characterization)를 보여주는 것이다.
도 31은 Lic5의 화학감작 효과를 보여주는 것이다.
도 32는 Lic5의 경쇄 및 중쇄의 가변 영역의 아미노산 서열을 보여주는 것이다.
본 출원은 카드헤린-17 (CDH17)에 특이적인 항체, 종양 세포를 표적화하는 항체, 및 상기 항체를 사용하는 항종양 면역요법을 제공한다. 상기 면역요법은 상이한 모드의 세포독성 또는 T 또는 NK 세포 세포독성을 자극시키는 키메라 항원 수용체를 가지는 항체를 포함한다.
달리 정의되지 않는 한, 본원에서 사용된 모든 기술 용어 및 과학 용어는 본 개시내용이 속하는 분야의 숙련가가 통상 이해하는 것과 동일한 의미를 가진다. 비록 본원에 기술된 것과 유사하거나, 또는 등가인 임의의 방법 및 물질이 본 개시내용의 실시 또는 시험에서 사용될 수 있기는 하지만, 바람직한 방법 및 물질을 기술한다. 본 개시내용의 목적을 위해 하기 용어들을 하기에서 정의한다.
"하나("a" 및 "an")라는 관사는 본원에서 하나 또는 1개 초과의 (즉, 적어도 하나의) 관사의 문법상 대상을 지칭하는 것으로 사용된다. 예로서, "하나의 요소"란, 1개의 요소 또는 1개 초과의 요소를 의미한다.
"약"이란, 정량, 수준, 값, 개수, 빈도, 백분율, 치수, 크기, 양, 중량 또는 길이가 참조 정량, 수준, 값, 개수, 빈도, 백분율, 치수, 크기, 양, 중량 또는 길이 대비 30, 25, 20, 15, 10, 9, 8, 7, 6, 5, 4, 3, 2 또는 1%만큼 달라질 수 있다는 것을 의미한다.
"코딩 서열"이란, 유전자의 폴리펩티드 생성물을 코딩하는 데 기여하는 임의의 핵산 서열을 의미한다. 그에 반해, "비-코딩 서열"이라는 용어는 유전자의 폴리펩티드 생성물을 코딩하는 데 기여하지 않는 임의의 핵산 서열을 의미한다.
본 명세서 전반에 걸쳐, 문맥상 달리 요구되지 않는 한, "포함하다(comprise)," "포함하다(comprises)," 및 "포함하는"이라는 단어는 임의의 다른 단계 또는 요소 또는 단계들 또는 요소들의 군을 배제시키는 것이 아니라, 언급된 한 단계 또는 요소 또는 단계들 또는 요소들의 군을 포함한다는 것을 암시하는 것으로 이해될 것이다.
"~으로 구성된"이란, "~으로 구성된"이라는 어구 다음에 무엇이 뒤따르든지 간에 그 모두를 포함하고, 그로 제한된다는 것을 의미한다. 따라서, "~으로 구성된"이라는 어구는 열거된 요소가 요구되거나, 또는 필수적인 것이고, 다른 요소는 존재하지 않을 수 있다는 것을 나타낸다.
"본질적으로 ~으로 구성된"이란, 상기 어구 다음에 열거된 임의의 요소들을 포함하고, 상기 열거된 요소들에 대해 본 개시내용에서 명시된 활성 또는 작용을 방해하지 않거나, 또는 그에 기여하지 않는 다른 요소들로 제한된다는 것을 의미한다. 따라서, "본질적으로 ~으로 구성된"이라는 어구는 열거된 요소가 요구되거나, 또는 필수적인 것이지만, 상기 다른 요소들은 임의적이고, 그가 열거된 요소들의 활성 또는 작용에 영향을 미치는지 여부에 따라 존재할 수 있거나, 존재할 수 없다는 것을 나타낸다.
"상보적" 및 "상보성"이라는 용어는 폴리뉴클레오티드 (즉, 뉴클레오티드의 서열)가 염기쌍 형성 법칙에 의한 관계가 있다는 것을 지칭한다. 예를 들어, 서열 "A-G-T"는 서열 "T-C-A"에 상보적이다. 핵산의 염기 중 오직 일부만이 염기쌍 형성 법칙에 따라 매칭될 때 상보성은 "부분적"인 것일 수 있다. 또는, 핵산 사이에 "완전한" 또는 "전체적인" 상보성이 존재할 수 있다. 핵산 가닥 사이의 상보성 정도는 핵산 가닥 사이의 하이브리드화율 및 그의 강도에 유의적인 영향을 미친다.
"~에 상응한다" 또는 "~에 상응하는"이란, (a) 폴리뉴클레오티드가 참조 폴리뉴클레오티드 서열 모두 또는 그의 일부와 실질적으로 동일하거나, 또는 그에 상보적인 뉴클레오티드 서열을 가지거나, 또는 펩티드 또는 단백질 중의 아미노산 서열과 동일한 아미노산 서열을 코딩하거나; 또는 (b) 펩티드 또는 폴리펩티드가 참조 펩티드 또는 단백질 중의 아미노산 서열과 실질적으로 동일한 아미노산 서열을 가지는 것을 의미한다.
본원에서 사용되는 바와 같이, "기능" 및 "기능성"이라는 용어 등은 생물학적, 결합, 또는 치료학적 기능을 지칭한다.
"유전자"란, 염색체 상의 특정 유전자좌를 점유하고, 전사 및/또는 번역 조절 서열 및/또는 코딩 영역 및/또는 비-번역 서열 (즉, 인트론, 5' 및 3' 비번역 서열)로 구성된 유전 단위를 의미한다.
"상동성"이란, 동일하거나 또는 보존적 치환을 구성하는 아미노산 개수의 백분율을 지칭한다. 상동성은 예컨대, GAP (문헌 [Deveraux et al., 1984, Nucleic Acids Research 12, 387-395]) (이는 본원에서 참조로 포함된다)와 같은 서열 비교 프로그램을 사용하여 측정될 수 있다. 이러한 방식으로, 예를 들어, GAP에 의해 사용되는 비교 알고리즘에 의해 결정이 되는 갭(gap)을 정렬 내로 삽입함으로써 본원에서 인용된 것과 유사하거나, 또는 실질적으로 상이한 길이의 서열을 비교할 수 있다.
"숙주 세포"라는 용어는 본 개시내용의 임의의 재조합 벡터(들) 또는 단리된 폴리뉴클레오티드의 수혜자일 수 있거나, 또는 수혜자인, 개별 세포 또는 세포 배양물을 포함한다. 숙주 세포는 단일 숙주 세포의 자손을 포함하고, 자손은 자연, 우발적 또는 고의적 돌연변이 및/또는 변이에 기인하여 원래의 모체 세포와 (형태상으로 또는 전체 DNA 상보성 면에서) 반드시 완전하게 동일하지 않을 수도 있다. 숙주 세포는 생체내 또는 시험관내에서 본 개시내용의 재조합 벡터 또는 폴리뉴클레오티드로 형질감염 또는 감염된 세포를 포함한다. 본 개시내용의 재조합 벡터를 포함하는 숙주 세포는 재조합 숙주 세포이다.
"단리된" 항체는 그의 천연 환경의 성분으로부터 확인되고, 분리 및/또는 회수된 것이다. 그의 천연 환경의 오염 성분은 항체의 진단학적 또는 치료학적 용도를 방해하는 물질이며, 이는 효소, 호르몬, 및 다른 단백질성 또는 비단백질성 용질을 포함할 수 있다.
"단리된" 핵산 분자는 보통은 항체 핵산의 천연 공급원 중에서 확인되고, 그와 회합되어 있는 적어도 하나의 오염 핵산 분자로부터 분리된 핵산 분자이다. 단리된 핵산 분자는 그가 자연에서 발견되는 형태 또는 세팅과는 다른 그 이외의 것이다. 그러므로, 단리된 핵산 분자는 천연 세포에 존재하는 핵산 분자와는 구별된다. 그러나, 단리된 핵산 분자는 보통 항체를 발현하며, 예를 들어, 핵산 분자가 천연 세포의 것과는 다른 염색체 위치에 존재하는 세포에 함유되어 있는 핵산 분자를 포함한다.
"제어 서열"이라는 표현은 특정 숙주 유기체에서 작동가능하게 연결된 코딩 서열의 발현을 위해 필요한 DNA 서열을 지칭한다. 원핵생물에 적합한 제어 서열로는 예를 들어, 프로모터, 임의적으로 오퍼레이터(operator) 서열, 및 리보솜 결합 부위를 포함한다. 진핵 세포는 프로모터, 폴리아데닐화 신호, 및 인핸서(enhancer)를 사용하는 것으로 공지되어 있다.
핵산은 그가 또 다른 핵산 서열과 기능적 관계를 가지고 배치되어 있을 때, "작동가능하게 연결"되어 있는 것이다. 예를 들어, 전구서열 또는 분비 리더에 대한 DNA는 그가 폴리펩티드의 분비에 참여하는 전구단백질로서 발현된다면, 폴리펩티드에 대한 DNA에 작동가능하게 연결되어 있는 것이거나; 프로모터 또는 인핸서는 그가 서열의 전사에 영향을 준다면, 코딩 서열에 작동가능하게 연결되어 있는 것이거나; 또는 리보솜 결합 부위는 그가 번역을 촉진시키기 위해 배치되어 있다면, 코딩 서열에 작동가능하게 연결되어 있는 것이다. 일반적으로, "작동가능하게 연결된"이란, 연결된 DNA 서열이 인접해 있고, 분비 리더인 경우, 인접해 있고, 판독 단계에 있다는 것을 의미한다. 그러나, 인핸서는 인접해 있을 필요는 없다. 연결은 알맞은 제한 부위에서의 라이게이션에 의해 달성된다. 상기 부위가 존재하지 않을 경우, 관행에 따라 합성 올리고뉴클레오티드 어댑터 또는 링커가 사용된다.
본원에서 사용되는 바와 같이, "폴리뉴클레오티드" 또는 "핵산"에 대한 설명은 mRNA, RNA, cRNA, rRNA, cDNA 또는 DNA를 의미하는 것이다. 상기 용어는 전형적으로 길이가 적어도 10개의 염기 길이인 중합체 형태의 뉴클레오티드로서, 리보뉴클레오티드 또는 데옥시뉴클레오티드 중 어느 하나, 또는 어느 한 유형의 뉴클레오티드의 변형된 형태를 지칭한다. 상기 용어는 단일 및 이중 가닥 형태의 DNA 및 RNA를 포함한다.
"폴리뉴클레오티드 변이체" 및 "변이체"라는 용어 등은 참조 폴리뉴클레오티드 서열과 상당한 서열 동일성을 보이는 폴리뉴클레오티드, 또는 하기에서 정의되는 엄격한 조건하에서 참조 서열과 하이브리드화하는 폴리뉴클레오티드를 지칭한다. 상기 용어는 또한 적어도 하나의 뉴클레오티드의 부가, 결실, 또는 치환에 의해 참조 폴리뉴클레오티드와 구별이 되는 폴리뉴클레오티드를 포함한다. 따라서, "폴리뉴클레오티드 변이체" 및 "변이체"라는 용어는 하나 이상의 뉴클레오티드가 부가되거나, 결실되거나, 또는 상이한 뉴클레오티드로 대체된 폴리뉴클레오티드를 포함한다. 이와 관련하여, 참조 폴리뉴클레오티드에 대하여 돌연변이, 부가, 결실, 및 치환을 포함하는 특정 변경이 이루어질 수 있고, 이로써, 변경된 폴리뉴클레오티드는 참조 폴리뉴클레오티드의 생물학적 기능 또는 활성을 유지하거나, 또는 참조 폴리뉴클레오티드와 관련하여 증가된 활성을 가진다는 것 (즉, 최적화되었다는 것)이 당업계에서 널리 이해되고 있다. 폴리뉴클레오티드 변이체는 예를 들어, 본원에 기술된 참조 폴리뉴클레오티드 서열과 적어도 50% (및 적어도 51%, 내지 적어도 99%, 및 그 사이의 모든 정수 백분율, 예컨대, 90%, 95%, 또는 98%)의 서열 동일성을 가지는 폴리뉴클레오티드를 포함한다. "폴리뉴클레오티드 변이체" 및 "변이체"라는 용어는 또한 자연적으로 발생된 대립유전자 변이체 및 상기 효소를 코딩하는 오솔로그(ortholog)를 포함한다.
"폴리펩티드", "폴리펩티드 단편", "펩티드" 및 "단백질"은 본원에서 상호교환적으로 사용되며, 아미노산 잔기의 중합체, 및 상기의 변이체 및 합성 유사체를 지칭한다. 따라서, 상기 용어는 하나 이상의 아미노산 잔기가 합성의 비자연적으로 발생된 아미노산, 예컨대, 상응하는 자연적으로 발생된 아미노산의 화학적 유사체인 것인 아미노산 중합체 뿐만 아니라, 자연적으로 발생된 아미노산 중합체에 적용된다. 특정 측면에서, 폴리펩티드는 전형적으로 다양한 화학 반응을 촉매화하는 (즉, 상기의 반응 속도를 증가시키는) 효소성 폴리펩티드, 또는 "효소"를 포함할 수 있다.
폴리펩티드 "변이체"에 대한 설명은 적어도 하나의 아미노산 잔기의 부가, 결실, 또는 치환에 의해 참조 폴리펩티드 서열과 구별되는 폴리펩티드를 나타낸다. 특정 실시양태에서, 폴리펩티드 변이체는, 보존적 또는 비-보존적일 수 있는 하나 이상의 치환에 의해 참조 폴리펩티드와 구별이 된다. 특정 실시양태에서, 폴리펩티드 변이체는 보존적 치환을 포함하고, 이와 관련하여; 일부 아미노산은 폴리펩티드의 활성의 성질을 변화시키지 않으면서 대체로 유사한 특성을 가진 다른 아미노산으로 변이될 수 있다는 것이 당업계에서 널리 이해되고 있다. 폴리펩티드 변이체는 또한 하나 이상의 아미노산이 부가되거나, 결실되거나, 또는 상이한 아미노산 잔기로 대체된 것인 폴리펩티드를 포함한다.
"참조 서열"이라는 용어는 일반적으로 또 다른 서열의 비교 대상이 되는 핵산 코딩 서열, 또는 아미노산 서열을 지칭한다. 본원에 기술된 모든 폴리펩티드 및 폴리뉴클레오티드 서열은 참조 서열로서 포함된다.
본원에서 사용되는 바와 같이, "서열 동일성" 또는 예를 들어, "~와 50% 동일한 서열"을 포함하는 것에 대한 설명은 서열이 비교창에 걸쳐 뉴클레오티드별로, 또는 아미노산별로 동일한 정도를 나타낸다. 따라서, "서열 동일성(%)"은 최적으로 정렬된 두 서열을 비교창에 걸쳐 비교하고, 두 서열 모두에서 동일한 핵산 염기 (예컨대, A, T, C, G, I) 또는 동일한 아미노산 잔기 (예컨대, Ala, Pro, Ser, Thr, Gly, Val, Leu, Ile, Phe, Tyr, Trp, Lys, Arg, His, Asp, Glu, Asn, Gln, Cys 및 Met)가 존재하는 위치의 개수를 측정하여 매칭되는 위치의 개수를 구하고, 매칭되는 위치의 개수를 비교창 내에 존재하는 위치의 총 개수 (즉, 창 크기)로 나누고, 그 결과에 100을 곱하여 서열 동일성(%)을 구함으로써 산출될 수 있다. 본원에 기술된 참조 서열 (예컨대, 서열 목록 참조) 중 임의의 것과 적어도 약 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 98%, 99%, 또는 100%의 서열 동일성을 가지는 뉴클레오티드 및 폴리펩티드가 포함되며, 전형적으로 여기서, 폴리펩티드 변이체는 참조 폴리펩티드의 적어도 하나의 생물학적 활성을 유지한다.
"통계학상 유의적"이라는 것은 결과가 우연히 발생할 가능성은 없었다는 것을 의미하는 것이다. 통계적 유의도는 당업계에 공지된 임의의 방법에 의해 측정될 수 있다. 통상 사용되는 유의성 척도는, 귀무 가설(null hypothesis)이 진실이라면, 관찰되는 이벤트가 발생하게 될 빈도 또는 확률인 p 값을 포함한다. 수득된 p 값이 유의 수준보다 작다면, 이때 귀무 가설은 기각된다. 간단한 경우에, 유의 수준은 p 값이 0.05 이하인 것으로 정의된다.
"실질적으로" 또는 "본질적으로"라는 것은 거의 전체적으로 또는 완전히라는 것, 예를 들어, 일부 주어진 정량의 95%, 96%, 97%, 98%, 99%, 또는 그 초과라는 것을 의미한다.
"치료하는" 또는 "치료" 또는 "완화"란, 표적화된 병적 상태 또는 장애를 예방하거나, 또는 저속화시키는 (경감시키는) 것을 목적으로 하는 치료학적 치료 및 예방적 또는 예방학적 조치, 둘 모두를 지칭한다. 예를 들어, 암인 경우, 암 세포 개수의 감소 또는 암 세포 부재; 종양 크기 축소; 종양 전이 억제 (즉, 종양 전이를 어느 정도 저속화시키고, 바람직하게는 정지시키는 것); 종양 성장을 어느 정도 억제시키는 것; 관해 기간 연장, 및/또는 특정 암과 연관된 증상들 중 하나 이상의 것을 어느 정도 경감시키는 것; 이환율 및 사망률 감소, 및 삶의 질 문제 개선. 질환의 징후 또는 증상의 감소 또한 환자는 체감할 수 있다. 치료는, 암의 모든 징후가 소멸된 것으로 정의되는 완전 관해, 또는 종양 크기가 축소, 바람직하게는 50% 초과, 더욱 바람직하게, 75%만큼 축소된 것인 부분 관해를 달성할 수 있다. 환자가 안정된 질환을 경험한다면, 환자는 또한 치료된 것으로 간주된다. 바람직한 실시양태에서, 암 환자는 1년 후, 바람직하게, 15개월 후에도 여전히 암 무진행 상태이다. 질환의 성공적인 치료 및 개선을 평가하기 위한 이들 파라미터는 당업계의 적절한 기술을 가진 의사에게 익숙한 통상의 방법에 의해 쉽게 측정가능하다.
"조정하는" 및 "변경시키는"이라는 용어는 전형적으로는 대조군 대비 통계학상 유의적인 양으로 또는 생리학상 유의적인 양으로 "증가시키는" 및 "증진시키는" 것 뿐만 아니라, "감소시키는(decreasing)" 또는 "감소시키는(reducing)" 것을 포함한다. 구체적인 실시양태에서, 혈액 대체제의 이식과 연관된 면역 거부는 비변형된 또는 상이하게 변형된 줄기 세포 대비 적어도 10%, 적어도 15%, 적어도 20%, 적어도 25%, 적어도 30%, 적어도 40%, 적어도 50%, 적어도 60%, 적어도 70%, 적어도 80%, 적어도 90%, 적어도 100%, 적어도 150%, 적어도 200%, 적어도 300%, 적어도 400%, 적어도 500%, 또는 적어도 1000%만큼 감소된다.
"증가된" 또는 "증진된" 양은 전형적으로 "통계학상 유의적인" 양이고, 본원에 기술된 양 또는 수준의 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 30, 40, 또는 50배, 또는 그 초과 (예컨대, 100, 500, 1000배) (그 사이의, 1 초과인 모든 정수 및 십진 소수점이 있는 수, 예컨대, 1.5, 1.6, 1.7. 1.8 등 포함)인 증가를 포함할 수 있다.
"감소된(decreased)" 또는 "감소된(reduced)" 또는 "더 적은" 양은 전형적으로 "통계학상 유의적인" 양이고, 본원에 기술된 양 또는 수준의 약 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2, 2.5, 3, 3.5, 4, 4.5, 5, 6, 7, 8, 9, 10, 15, 20, 30, 40, 50배, 또는 그 초과 (예컨대, 100, 500, 1000배) (그 사이의, 1 초과인 모든 정수 및 십진 소수점이 있는 수, 예컨대, 1.5, 1.6, 1.7. 1.8 등 포함)인 감소를 포함할 수 있다.
"~로부터 수득된"이란, 샘플, 예컨대, 예를 들어, 폴리뉴클레오티드 또는 폴리펩티드가 특정 공급원, 예컨대, 원하는 유기체, 또는 원하는 유기체 내의 특정 조직으로부터 단리되거나, 또는 그로부터 유래된 것임을 의미한다. "~로부터 수득된"이란, 폴리뉴클레오티드 또는 폴리펩티드 서열이 특정 유기체, 또는 유기체 내의 조직으로부터 단리되거나, 또는 그로부터 유래된 것인 상황 또한 지칭할 수 있다. 예를 들어, 본원에 기술된 참조 폴리펩티드를 코딩하는 폴리뉴클레오티드 서열은 다양한 원핵 또는 진핵 유기체로부터, 또는 특정 진핵 유기체 내의 특정 조직 또는 세포로부터 단리될 수 있다. "치료학상 유효량"이란, 대상체에서 질환 또는 장애를 "치료하는 데" 효과적인 항체 또는 약물의 양을 지칭한다. 암인 경우, 치료학상 유효량의 약물은 암 세포 개수를 감소시킬 수 있고/거나, 종양 크기를 축소시킬 수 있고/거나; 암 세포의 말초 기관으로의 침윤을 억제시킬 수 있고/거나 (즉, 그를 어느 정도 저속화 및 바람직하게, 그를 정지시킬 수 있고/거나); 종양 전이를 억제시킬 수 있고/거나 (즉, 그를 어느 정도 저속화 및 바람직하게, 그를 정지시킬 수 있고/거나); 종양 성장을 어느 정도 억제시킬 수 있고/거나; 암과 연관된 증상 중 하나 이상의 것을 어느 정도 경감시킬 수 있다. "치료하는"에 관한 상기 정의를 참조한다.
"만성" 투여란, 연장된 기간 동안 초기의 치료학적 효과 (활성)를 유지시키기 위해, 급성 모드와는 대조되는 연속 모드로 작용제(들)를 투여하는 것을 지칭한다. "간헐적" 투여는 휴지기 없이 연속해서 수행되는 것이 아니라, 사실상 주기적인 치료이다.
"벡터"는 셔틀(shuttle) 및 발현 벡터를 포함한다. 전형적으로, 플라스미드 작제물(construct)은 또한 박테리아에서의 플라스미드의 복제 및 선별을 위해 각각 복제 기점 (예컨대, ColE1 복제 기점) 및 선별가능한 마커 (예컨대, 암피실린 또는 테트라사이클린 내성)를 포함할 것이다. "발현 벡터"란, 박테리아 또는 진핵 세포에서의 본 개시내용의 항체 단편을 포함하는 항체의 발현을 위해 필요한 제어 서열 또는 조절 요소를 함유하는 벡터를 지칭한다. 적합한 벡터는 하기에 개시된다.
"항체"라는 용어는 가장 광범위한 의미로 사용되고, 구체적으로 모노클로날 항체 (전장의 모노클로날 항체 포함), 다중특이적 항체 (예컨대, 이중특이적 항체), 및 원하는 생물학적 활성 또는 기능을 보이는 한, 항체 단편을 포함한다.
"항체 단편"은 전장의 항체의 일부분, 일반적으로, 항체의 항원 결합 또는 가변 영역을 포함한다. 항체 단편의 예로는 Fab, Fab', F(ab')2, 및 Fv 단편; 디아바디(diabody); 선형 항체; 단일 쇄 항체 분자; 및 항체 단편으로부터 형성된 다중특이적 항체를 포함한다.
"Fv"는 완전한 항원 인식 및 결합 부위를 함유하는 최소 항체 단편이다. 상기 단편은 밀착 비-공유적으로 회합되어 있는, 하나의 중쇄 및 하나의 경쇄 가변 영역 도메인으로 이루어진 이량체로 구성되어 있다. 상기 두 도메인의 폴딩(folding)으로부터 항원 결합을 위한 아미노산 잔기에 기여하고, 항체에 대한 항원 결합 특이성을 부여하는 6개의 초가변 루프 (H 및 L 쇄로부터 각각 3개의 루프)가 나온다. 그러나, 비록 전체 결합 부위보다는 친화도가 더 낮기는 하지만, 심지어 단일 가변 도메인 (또는 항원에 특이적인 상보성 결정 영역 (CDR)을 단 3개만을 포함하는 Fv의 절반부)도 항원을 인식하고, 그에 결합하는 능력을 가진다.
본원에서 사용되는 바와 같이, "모노클로날 항체"라는 용어는 실질적으로 균질한 항체 집단으로부터 수득된 항체를 지칭하며, 즉, 상기 집단을 포함하는 개별 항체는 소량으로 존재할 수도 있는, 가능한 자연적으로 발생된 돌연변이를 제외하면 동일하다. 모노클로날 항체는 단일 항원 부위에 대해 작용하며, 고도로 특이적이다. 추가로, 전형적으로 상이한 결정기 (에피토프)에 대해 작용하는 상이한 항체를 포함하는 통상의 (폴리클로날) 항체 제제와 달리, 각각의 모노클로날 항체는 항원 상의 단일 결정기에 대해 작용한다. "모노클로날"이라는 수식어는 실질적으로 균질한 항체 집단으로부터 수득되었다는 항체의 특징을 나타내고, 이는 임의의 특정 방법에 의한 항체 제조가 필요한 것으로 해석되지 않아야 한다. 예를 들어, 본 개시내용에 따라 사용되는 모노클로날 항체는 문헌 [Kohler et al., Nature 256:495 (1975)]에 처음 기술된 하이브리도마 방법에 의해 제조될 수 있거나, 또는 재조합 DNA 방법에 의해 제조될 수 있다 (예컨대, 미국 특허 번호 4,816,567 참조). "모노클로날 항체"는 또한 예를 들어, 문헌 [Clackson et al., Nature 352:624-628 (1991)] 및 [Marks et al., J. Mol. Biol. 222:581-597 (1991)]에 기재된 기술을 사용하여 파지 항체 라이브러리로부터 단리될 수 있다.
"가변"이라는 용어는 가변 도메인 (V 도메인)의 특정 세그먼트가 항체들 사이에서 서열이 크게 상이하다는 사실을 나타낸다. V 도메인은 항원 결합을 매개하고, 그의 특정 항원에 대한 특정 항체의 특이성을 규정한다. 그러나, 가변성은 가변 도메인의 10개의 아미노산 범위에 걸쳐 균등하게 분포되어 있지는 않다. 대신, V 영역은 길이가 각각 9-12개의 아미노산 길이인 "초가변 영역"으로 불리는 가변성이 매우 높은 더 짧은 영역에 의해 분리되어 있는 15-30개의 아미노산으로 이루어진 프레임워크 영역 (FR)으로 불리는 비교적 불변인 스트레치(stretch)로 구성된다. 천연 중쇄 및 경쇄의 가변 도메인은 각각 루프 연결부를 형성하고, 일부 경우에 β-시트 구조의 일부를 형성하는 3개의 초가변 영역에 의해 연결된, 주로 β-시트 입체형태를 취하는 4개의 프레임워크 영역 (FR)을 포함한다. 각 쇄 내의 초가변 영역은 FR에 의해 매우 근접하게 함께 유지되고, 다른 쇄의 초가변 영역과 함께 항체의 항원 결합 부위 형성에 기여한다 (문헌 [Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991)] 참조). 불변 도메인은 항체의 항원에의 결합에 직접 관여하지 않지만, 다양한 이펙터(effector) 기능, 예컨대, 항체 의존성 세포 세포독성 (ADCC)에서의 항체 참여를 나타낸다.
본원에서 사용될 때, "초가변 영역"이라는 용어는 항원 결합을 담당하는 항체의 아미노산 잔기를 지칭한다. 초가변 영역은 일반적으로 CDR로부터의 아미노산 잔기 (예컨대, VL에서 대략 잔기 24-34 (L1), 50-56 (L2) 및 89-97 (L3) 주변, 및 VH에서 대략 31-35B (H1), 50-65 (H2) 및 95-102 (H3) 주변 (문헌 [Kabat et al., Sequences of Proteins of Immunological Interest, 5th Ed. Public Health Service, National Institutes of Health, Bethesda, Md. (1991]) 및/또는 "초가변 루프"로부터의 상기 잔기 (예컨대, VL에서 잔기 26-32 (L1), 50-52 (L2) 및 91-96 (L3), 및 VH에서 26-32 (H1), 52A-55 (H2) 및 96-101 (H3) (문헌 [Chothia and Lesk J. Mol. Biol. 196:901-917 (1987)])를 포함한다.
"키메라" 항체 (면역글로불린)는 특정 종으로부터 유래되거나, 특정 항체 부류 또는 서브부류(subclass)에 속하는 항체 중의 상응하는 서열과 동일하거나, 상동성인 중쇄 및/또는 경쇄의 일부를 가지는 한편, 쇄(들)의 나머지는 또 다른 종으로부터 유래되거나, 또 다른 항체 부류 또는 서브부류에 속하는 항체 뿐만 아니라, 원하는 생물학적 활성을 나타내는 한, 상기 항체의 단편 중의 상응하는 서열과 동일하거나, 상동성이다 (미국 특허 번호 4,816,567; 및 문헌 [Morrison et al. Proc. Natl Acad. Sci. USA 81:6851-6855 (1984)]). 본원에서 사용되는 바와 같이, 인간화 항체는 키메라 항체의 서브세트(subset)이다.
비-인간 (예컨대, 뮤린) 항체의 "인간화" 형태는 비-인간 면역글로불린으로부터 유래된 최소 서열을 함유하는 키메라 항체이다. 일부 실시양태에서, 인간화 항체는 수혜자의 초가변 영역 잔기가 원하는 특이성, 친화도 및 능력을 가지는 비-인간 종 (공여자 항체), 예컨대, 마우스, 래트, 토끼 또는 비-인간 영장류로부터의 초가변 영역 잔기로 대체된 인간 면역글로불린 (수혜자 또는 수용자 항체)이다. 일부 실시양태에서, 인간화 항체는 인간 세포로부터, 또는 인간 항체 유전자를 발현하는 트랜스제닉 동물 (전형적으로 마우스)로부터 유래된 항체이다.
한 측면에서, 본원에서는 CDH-17에 대하여 특이성을 가지는 항체, 또는 그의 항원 결합 단편을 제공한다. 종양 연관 항원은 그의 종양 성장 촉진 활성을 억제시킴으로써 및 종양 세포에 세포독성 활성을 지시함으로써 이루어지는 항종양 면역 요법을 위한 표적으로서 작용할 수 있다. 카드헤린-17은 세포 부착 분자의 카드헤린 슈퍼패밀리에 속하는 클래스 1 원형질 막 당단백질이다. 이는 그의 엑토도메인에 7개의 카드헤린 또는 카드헤린 유사 반복부를 가지는 비-고전적 카드헤린이다. 카드헤린-17 (CDH-17)은 종양 성장에 참여하는 종양 연관 항원이다. 보통 결장, 소장, 및 췌관의 장 상피 세포로 한정된 CDH-17 발현은 결장 선암종, 위 선암종, 간세포 암종 및 췌장 선암종을 비롯한, 수개의 종양 유형에서 과다발현된다. 종양 성장 촉진 활성은 CDH17 도메인 6 중의 RGD 모티프와 인테그린, 예컨대, α2β1 사이의 결합을 포함할 수 있다. 혈중 및 엑소좀 중의 CDH-17 수준의 비정상적인 증가가 예후성 암 마커로서의 역할을 할 수 있다.
본원에서는 프로테오믹스 및 온코제노믹스 접근법을 사용하여, 치료학적 표적인 간-장 카드헤린 또는 카드헤린-17 (CDH17)을 개시한다. 상기 표적은 다수의 위암종 (GC) 및 간세포 암종 (HCC)에서 뿐만 아니라, 췌장암, 결장암, 난소암 및 폐암에서도 과다발현된다. CDH17 유전자의 RNAi 침묵화가 확립된 HCC 마우스 모델 (이종 이식편 및 동소, 둘 모두)에서 종양 성장 및 전이성 확산을 억제시킬 수 있다. 기본적인 항종양 기전은 종양 억제인자 경로 재활성화와 함께 이를 수반하여 Wnt 신호전달의 불활성화에 기초한다.
본 출원에 존재하는 항-CDH17 항체는 간암 및 위암의 시험관내 및 생체내 시스템에서 다중의 항종양 효과를 나타내었다. 상기 항체는 시험관내 및 생체내 정제, 검출, 진단학적 및 치료학적 용도를 가진다. 상기 항체는 종양 세포에 선택적으로 결합하여 항종양 활성을 지원하고, 보체 고정, 항체 의존적 세포독성, 접합된 약물에 의해 매개되는 세포독성, 림프구 매개 세포독성 및 NK 매개 세포독성을 자극하도록 개발될 수 있다. 본원에서는 하기 제공되는 상응하는 서열 번호로서 기재되는 아미노산 서열을 가지는 중쇄 가변 영역을 포함하는 항체 및 인간화 항체, 항원 결합 단편 또는 키메라 항체 단백질을 제공한다.
CDH17 항체 서열은 다양한 유형의 항체, 예컨대, 마우스 항체 (Lic3 및 Lic5; 도 1) 및 그의 인간화 변이체 (도 2-9), 파지 라이브러리 스크린으로부터 단리된 인간 항체 (도 10-12), ADCC, 보체 고정을 지원하는, 이소타입을 포함하는 단일특이적 항체, 및 세포독성 항암 활성을 위한 약물 접합체 (바람직한 접합체 모이어티는 이리노테칸, 아우리스타틴, PBD, 메이탄신, 아만틴, 스플라이소솜 억제제 및 다른 화학요법제이다) (도 13), 각종의 조작된 항체 단편 (Fab, scFv, 디아바디 등)을 포함하는 이중특이적 항체를 포함할 수 있다. 바람직한 형태로는 놉 인투 홀 (knob-into hole) 및 "Bite" (도 14에서 예시적인 서열)를 포함한다.
일부 실시양태에서, 마우스 CDH17 항체, Lic5 scFv 및 Lic3 scFv는 각각 ELISA 검정법에서 CDH17에 결합할 수 있는 그의 능력을 나타낸다 (도 15-16). Lic3 및 Lic5 scFv의 결합 친화도 또한 ELISA에 의해 측정될 수 있으며, scFv lic3 및 scFv lic5의 Kd는 각각 11.88 nM 및 22.06 nM이었다 (도 17).
또 다른 측면에서, 도 18 ((a) 명시된 시점에서의 DAPI (청색) 및 Lic5-FITC (녹색)의 염색을 보여주는 사진; (b) 명시된 시점에서의 DAPI (청색) 및 Lic5-FITC (녹색)의 병합된 염색을 보여주는 사진; 37℃에서 30 min 동안에 걸쳐 Oum1 인간 위암 세포에서의 Lic5-FITC (녹색) 내재화를 공초점 현미경 검사법에 측정하였고; 핵은 DAPI로 염색하였다)에서 나타난 바와 같이, Lic5의 인간 위암 세포 내로의 내재화가 항체 약물 접합체를 위한 후보임을 나타낸다.
일부 실시양태에서, 표준 하이브리도마 기술에 의해 200개 초과의 CDH17 모노클로날 항체를 생성하였다. 4개의 cDNA 발현 작제물 클론 (hL3.1 - 3.4)으로 형질감염된 CHO 세포로부터 인간화 Lic3 scFvFc를 발현시켰다. 형질감염된, 또는 모의 형질감염된 CHO로부터의 배양 배지를 CDH17Fc로 코팅된 96 웰 플레이트에 첨가하였다. 항마우스 Fc HRP 접합체를 사용하여 결합을 측정하였다. 또한 CHO 세포에서 제조된 마우스 Lic3 scFvFc (mLic3 scFv)의 것과 결합을 비교하였다 (도 19).
한 측면에서, 변형된 인간 IgG4 Fc에 융합된, 7개의 카드헤린 반복부 (D1-7)로 이루어진 전체 엑토도메인을 가지는 재조합 CDH17 (CDH17Fc)로 마우스를 면역화시켰다. 하이브리도마 배양 배지는 CDH17Fc에의 결합, 및 IgG4 Fc에의 결합 부재에 대한 스크린이었다. 표준 PCR 방법론에 의해 D1, D1-2, D1-3, D3-4, D6 및 D5-7을 가지는 CDH17Fc 말단절단물을 생성하였다. 각 말단절단물에 특이적으로 결합한 CDH17 항체를 확인하였고, 그 예는 도 20에 제시되어 있다. 13개의 신규한 CDH17 모노클로날 항체로 이루어진 패널을 ELISA에 의해 7개의 엑토도메인 모두를 가지는 CDH17, 또는 도메인 1-2, 도메인 3-4, 도메인 5-6 또는 도메인 6을 가지는 말단절단물에의 결합에 대하여 분석하였다. 항체 에피토프가 상이한 도메인으로 국재화되었다. 놀랍게도, 특정 항체의 결합은 CHO 세포에서 제조된 CDH17로 한정되는 것으로 나타난 반면, 다른 항체의 결합은 293F 세포에서 제조된 CDH17로 한정되는 것으로 나타났다.
또 다른 측면에서, CDH17 의존적 동형 및 이형 상호작용에 연루되어 있는 D1, D6 및 D1 및 D6 도메인에 결합한 항체를 확인하였다. 유세포 분석법에 의해 CDH17 항체의 CDH17 양성 종양 세포주에의 결합으로 예상 밖의 결과를 얻었다 (도 21). 다수의 상이한 결합 프로파일이 관찰되었으며, 이는 세포 유형에 특이적인 방식으로 발현되는 상이한 유형의 CDH17이 존재한다는 것을 제안하는 것이다. 이러한 개념은 293F 세포 대비 CHO 세포에서 제조된 재조합 CDH17에의 CDH17 항체의 차별적인 결합에 의해 추가로 뒷받침된다. 그러므로, 상기 신규한 CDH17 항체는 또 다른 조직이 아닌, 한 조직에서 발현되는 CDH17을 선택적으로 표적화하는 데 사용될 수 있다.
일부 실시양태에서, CAR7, 7b, 8 및 9인 제2 세대 CAR을 디자인하고, 분석하였다. 인간화 Lic3 scFv, CD8 또는 IgG1 힌지, CD8 또는 CD28 막횡단 도메인, CD137 또는 CD28 엔도도메인 및 CD3제타 (이소폼(isoform) 1/2 또는 3/4) 엔도도메인을 이용하여 CAR을 구축하였다 (도 22a). 렌티바이러스 형질도입 후 4일째 Jurkat 세포를 FACS 분석에 의해 분석하였고, 그 결과로 가용성 재조합 CDH17Fc 결합에 의한 GFP 발현 및 CAR 발현이 나타났다 (도 22b). 항Fc 플루오로크롬 접합체를 사용하여 CAR에의 CDH17 결합을 측정하였다. 추가로, 상이한 CAR을 발현하는 Jurkat 세포를 CDH17Fc, EGFRFc (대조군), 또는 단백질이 부재인 것 (NA)으로 코팅된 96 웰 플레이트에 시딩(seeding)하였다. 이뮤노컬트 (CD3-CD28 복합체)를 Jurkat 세포를 함유하는, 일부 비코팅 웰에 첨가하였다. 자극 후 48시간이 경과하였을 때, ELISA에 의해 배양 배지 중의 IL-2 수준을 측정하였고 (도 23), IL2 생산이 신호전달의 함수로서 평가될 수 있다는 것을 나타낸다.
일부 실시양태에서, CDH17 항체는 CDH17 도메인 6 중 RGD 부위의, 알파2베타1을 비롯한 인테그린에의 결합을 길항시킬 수 있다.
또 다른 측면에서, CDH17에 대하여 특이성을 가지는 이중특이적 항체를 개시한다. 이중특이적 항체는 하기 특징들, 제한 없이, 세포 세포독성을 활성화시키는 방식으로 종양 세포 (CDH17)를 세포독성 T 또는 NK 세포 수용체에 연결시킴으로써 (예컨대, CDH17/CD3) 종양 세포를 사멸시키는 특징, 세포독성 또는 케모카인 생산 및 면역 세포 동원을 자극하는 림프구양/NK/단핵구성 세포 활성인자 (예컨대, 4-1BB, OX40, CD27, CD40, TIM-1, CD28, HVEM, GITR, ICOS, IL12 수용체, IL14 수용체)에 결합함으로써 항암 활성을 증가시키는 특징, 면역 체크포인트 억제제 (PD-1, TIM-3, LAG-3, TIGIT, CTLA-4, PD-L1, BTLA, VISTA)를 차단하는 특징, 혈관형성 인자 (예컨대, VEGF)를 차단하는 특징을 포함하는 것들 중 적어도 하나를 가질 수 있다. CDH17은 세포독성 약물 (예컨대, 시스플라틴, 젬시타빈, 이리노테칸) 또는 다른 항종양 항체와 함께 수행되는 조합 치료에서 사용될 수 있다.
일부 실시양태에서, T 및 NK 세포 매개 종양 세포 세포독성을 지원하는 제2 또는 제3 세대 키메라 항원 수용체 (CAR)로서 CDH17 특이적 scFv를 조작한다 (도 24-26에 서열 및 디자인). CDH17 특이적 CAR T 및 CAR NK 세포는 간, 위, 결장, 췌장, 및 폐의 것을 포함하나, 이에 제한되지 않는 상이한 유형의 고형 종양을 사멸시킬 수 있다. 그러므로, CDH17은 예를 들어, 간암 및 위암과 관련된 다양한 병태를 위해 사용될 수 있다.
CDH17은 정상적인 건강한 성체 조직에서가 아닌, 간암 및 위암 둘 모두에서 과다발현되는 두드러진 암 바이오마커이다. CDH17은 암의 전이성 표현형에서 고도로 발현되고, CDH17의 차단은 HCC의 폐 전이를 현저하게 감소시킨다. CDH17 마커를 표적화하는 모노클로날 항체는 간 종양 및 위 종양의 성장을 억제시킬 수 있다. CDH17 인간화 항체는 종양 조직 내에 및/또는 혈청 샘플 중에 CDH17 바이오마커를 나타내는 암 환자를 치료하는 데 임상적으로 사용될 수 있다. 항CDH17 scFv 분자가 개념 입증 생체내 모델 연구를 위해 CAR T 벡터를 생성하기 위해 선택된다.
종양 한정 CDH17 에피토프에 대해 유도되는 특이성을 가지는 항체를 위해 임상 샘플로부터 유래된 종양 항원을 선택하였다. 따라서, Lic5 및 Lic3 mAb 둘 모두 오직 HCC 및 GC의 종양 세포에만 결합하는 것으로 나타났다. (컴퓨터를 이용한 모델링을 통해) 항체 친화도를 저하시키고/거나 변화시킴으로써, CDH17-CAR-T 세포는 종양 세포 표면에 대하여 증진된 차별적인 결합을 보이게 될 것이다.
대부분의 고형 종양은 면역 억제 환경을 특징으로 하는 것인 맥관구조 및 면역 세포로 둘러 싸여져 있다. 암에서 다수의 조절 T 세포의 존재 및 면역 체크포인트 인자 (PD1 및 TIM-3)의 차단은 CAR-T-세포의 유효성에 영향을 줄 수 있는 면역 관용 상태에 유리할 것이다. 이러한 문제를 다루기 위해, CAR-T 비히클 중 항PD1/항Tim3 이중특이적 성분을 생성하여 면역 체크포인트 장벽을 면하였다. 추가로, 일단 상기 항PD1/Tim3 성분이 종양 미세환경에 관여하고 나면, CAR-T 세포의 항종양 세포독성 활성을 전환시켜 효능을 증진시키고, 안전성을 개선시킬 것이다.
인공 T 세포 수용체로도 공지되어 있는 키메라 항원 수용체 (CAR)는 레트로바이러스 벡터에 의해 촉진된 방식으로 T 세포 상에 모노클로날 항체의 특이성을 이식받은 조작된 면역수용체이다. CAR-조작된 T 세포는 암 세포를 인식하고, 사멸시킬 수 있으며, 유의적인 임상적 이익을 입증할 수 있다.
본원에서는 임상적 적용을 위한 키메라 IgG Fc-융합 단백질을 개시한다. 예시적인 키메라 IgG-융합 단백질로는 자가면역 질환 및 바이러스성 감염의 치료학적 개입을 위한 가용성 형태의 ICAM-1 및 ICAM-2를 포함한다. CAR-T 벡터는 mAb로부터 유래된 scFv 도메인, 링커 및 세포질 도메인을 이용하여 구축되며, 여기서, 다른 세대의 CAR-T 벡터는 (활성화 및 공자극성 신호를 위한) 3개의 ITAM을 함유하는 간단한 형태의 CD3-제타로부터 증식/생존 신호를 제공하는 CD28 및 OX40을 함유하는 최근의 제3 세대로 진화하였다. 본원에 개시된 CDH17 특이적 클론 (Lic3 및 Lic5)으로부터, 제3 세대의 렌티바이러스 기반 CAR-T 벡터로 클로닝하기 위한 scFv 세그먼트를 디자인하였다.
실시예
본 개시내용은 하기 실시예를 참조로 하여 추가로 기술된다. 본 실시예는 단지 예시 목적으로 제공되는 것이며, 달리 명시되지 않는 한, 제한하는 것으로 의도되지 않는다. 따라서, 본 개시내용은 어느 방식으로든 하기 실시예로 제한되는 것으로 해석되지 않아야 하며, 오히려 본원에 제공된 교시의 결과로 명백해지는 임의의 모든 변형을 포함하는 것으로 해석되어야 한다.
실시예
1. 연구 디자인 및 방법론
동소 종양 이종 이식 모델을 사용하여 Lic5 단독, 또는 시스플라틴 또는 에피루비신과 조합된 Lic5가 종양 성장 억제 및 동물 생존에 미치는 효과를 시험하였다. 인간 HCC 세포주 MHCC97-L (97L) 및 PLC/PRF/5 (PLC)를 사용하였다. 세포 증식 검정법을 사용하였을 때, 단일 Lic5, 시스플라틴 및 에피루비신 처리가 배양된 HCC 세포의 성장을 억제시켰고, 한편, Lic5와 함께 시스플라틴 또는 에피루비신을 사용하였을 때에 더욱 유의적인 감소가 관찰되었다. 동일한 실험 그룹을 적용시켜 동소 종양 보유 누드 마우스를 처리하였을 때, 유사한 경향의 성장 억제가 관찰되었다.
대조군 군과 비교하였을 때, Lic5 처리가 동소 종양 보유 누드 마우스의 생존을 증진시켰다. 모든 실험군들 중에서 Lic5 및 에피루비신의 조합군이 가장 우수한 생존을 나타내었다. 다음 단계의 항체 인간화를 위해, Lic5의 경쇄 및 중쇄 상의 가변 영역 상의 상보성 결정 영역 (CDR)을 확인하였다. 10% 열 불활성화된 우태아 혈청 (FBS) (라이프 테크놀러지즈(Life Technologies)), 100 유니트/ml 페니실린 및 스트렙토마이신 (라이프 테크놀러지즈)으로 보충된 둘베코스 변형 이글 배지(Dulbecco's Modified Eagle Medium: DMEM) (라이프 테크놀러지즈: 미국 뉴욕주 그랜드아일랜드) 중에서 두 세포주 모두 배양하였다. 배양된 세포를 5% 이산화탄소하에 37℃에서 습윤 대기 중에서 유지시켰다.
실시예
2.
CDH17에
대한 사내
모노클로날
항체인
Lic5
제조 및 특성화
Lic5를 분비하는 사내 하이브리도마 세포주를 기술된 바와 같이 [5] 생성하였다. 10% FBS 및 100 유니트/ml 페니실린 및 스트렙토마이신으로 보충된 DMEM 중에서 하이브리도마 세포를 유지시켰다. Lic5를 수집하기 위해, 하이브리도마 세포를 6일 동안 무혈청 하이브리도마-SFM (라이프 테크놀러지즈) 중에서 배양하였다. 배양된 상청액을 수집하고, 프로테인 G(Protein G) 칼럼 (라이프 테크놀러지즈)을 사용하여 정제하였다. 정제된 Lic5의 농도를 RC DC 프로테인 어세이(RC DC Protein Assay) (바이오-래드(Bio-Rad: 미국 캘리포니아주 허큘리스))를 이용하여 추정하였다. 환원 조건하에서 소듐 도데실 술페이트-폴리아크릴아미드 겔 전기영동 (SDS-PAGE)에 이어서, 쿠마시 블루 염색(Coomassie Blue staining)을 수행함으로써 Lic5의 순도를 평가하였다. 97L 세포 용해물을 사용하여 웨스턴 블롯에 의해, 및 파라핀 포매된 인간 HCC 조직을 사용하여 면역조직화학법에 의해 Lic5의 면역반응성 및 특이성을 확인하였다. 연구를 위한 임상 표본 사용에 관해서는 홍콩 대학교/의원 관리국 홍콩 서 병원 연맹의 기관 감사 위원회(Institutional Review Board of The University of Hong Kong/Hospital Authority Hong Kong West Cluster: HKU/HA HKW IRB)의 승인을 받았다. SDS-PAGE, 쿠마시 블루 염색 및 웨스턴 블롯을 위한 과정은 통상적으로 수행한 반면, 면역조직화학법을 위한 방법은 하기에 기술하였다.
실시예
3.
시험관내
세포 증식 검정법
미리 결정된 개수의 97L 및 PLC 세포를 1일 동안 96 웰 배양 플레이트 상에 시딩하였다. Lic5에 대한 대조군으로서 150 ug/ml 마우스 IgG (시그마-알드리치(Sigma-Aldrich: 미국 미주리주 세인트 루이스)). 처리 후, 처리된 세포의 증식을 셀 증식 키트 I(Cell Proliferation Kit I) (로슈(Roche: 미국 인디애나주 인디애나폴리스))를 사용하여 기술된 바와 같이 측정하였다. 간략하면, MTT 시약을 처리된 세포와 함께 4시간 동안 인큐베이션(incubation)시켰다. 이어서, 10% SDS 첨가 후 비색 신호를 측정하였다. 결과 확인을 위해 비의존적 세포 증식 MTT 검정법을 적어도 2회에 걸쳐 수행하였다.
실시예
4. 동소 종양 이종 이식 모델
홍콩 소재의 홍콩 대학교의 실험 동물 유니트(Laboratory Animal Unit of The University of Hong Kong)로부터 수컷 누드 마우스를 입수하였다. 오토클레이브 처리된 물과 먹이에 자유롭게 접근할 수 있도록 하면서, 12시간 명기/12시간 암기 주기하에 환기가 잘 되는 개별 케이지에서 동물을 하우징(housing)하였다. 본 연구에서 수행된 동물 실험은 본 발명자들의 기관의 교시 및 연구에서 살아있는 동물 사용에 관한 위원회(Committee on the Use of Live Animals in Teaching and Research: CULATR)의 승인을 받았다. 성장하는 동소 간 종양의 생체내 관찰이 이루어질 수 있도록 하기 위해, 앞서 확립된 루시페라제 표지된 97L 세포주를 사용하였다. 5 x 106개의 루시페라제 표지된 97L 세포를 누드 마우스 내로 피하로 주사하여 피하 종양을 성장시켰다. 상기 피하 종양의 크기가 200-300 ㎣에 도달하였을 때, 종양을 수확하고, 표준 방법에 따라 별개의 누드 마우스 군에서 동소 간 종양을 확립시키는 데 종양 시드로서 사용하였다. 동소 종양 이식 후 5일째, 마우스는 3주 동안 주당 3회에 걸쳐 복강내 투여를 통해 하기와 같이 상이한 처리를 받았다 (각 군당 마우스 10-11마리): (1) 6 mg/kg Lic5; (2) 1 mg/kg 시스플라틴; (3) 1 mg/kg 에피루비신; (4) Lic5 및 시스플라틴의 조합 처리; (5) Lic5 및 에피루비신의 조합 처리; (6) Lic5 대조군으로서 6 mg/kg 마우스 IgG. 처리 후 매주, 150 mg/kg 포타슘 루세페린 (골드 바이오테크놀러지(Gold Biotechnology: 미국 미주리주 세인트 루이스))을 복강내 주사한 후 IVIS 100 인 비보 이미징 시스템(IVIS 100 In Vivo Imaging System) (펄킨 엘머(Perkin Elmer: 미국 매사추세츠주 월섬))에서 실시간으로 영상화하여 동소 종양 성장 및 전이를 모니터링하였다. 각 측정을 위해, 각 종양에 대하여 순 광자 계수(net photon count)를 수득하였다. 실험 종료시, 동소 종양을 수집하고, 그에 대해 포르말린 고정 및 파라핀 포매를 수행하였다.
실시예
5. 동물 생존 연구
97L 세포를 사용하여 상기와 같이 동소 간 종양을 확립하였다. 동소 종양 보유 마우스는 3주 동안 주당 3회에 걸쳐 복강내로 하기 처리를 받았다 (각 군당 마우스 11-15마리): (1) 8 mg/kg Lic5; (2) 1 mg/kg 시스플라틴; (3) 1 mg/kg 에피루비신; (4) Lic5 및 시스플라틴의 조합 처리; (5) Lic5 및 에피루비신의 조합 처리; (6) Lic5 대조군으로서 8 mg/kg 마우스 IgG. 처리 후 6주째까지 연속하여 동물 생존을 모니터링하였다.
실시예
6.
면역조직화학법
기술된 바와 같이 파라핀 포매된 동소 종양 이종 이식편 및 인간 HCC 표본에 대해 면역조직화학법을 수행하였다. 간략하면, 파라핀 제거 및 재수화를 위해 6 um 절편을 제조하였다. 항원 회복 및 과산화수소 처리 후, 절편을 3% 우혈청 알부민으로 차단한 후, 4℃에서 밤새도록 알파-카테닌에 대하여 마우스 모노클로날 항체 (1:200; BD 바이오사이언시스(BD Biosciences: 미국 캘리포니아주 산호세)) 및 Lic5 (0.0625 ug/ml)로 염색하였다. 엔비전+ 시스템-HRP 라벨드 폴리머 안티-마우스(EnVision+ System-HRP Labelled Polymer Anti-mouse) (다코(Dako: 미국 캘리포니아주 카핀테리아))를 사용하여 신호를 검출하고, 리퀴드 DAB+ 섭스트레이트 크로모겐 시스템(Liquid DAB+ Substrate Chromogen System) (다코)을 사용하여 시각화하였다. 헤마톡실린을 사용하여 대조염색을 수행하였다. DXM1200F 디지털 카메라(니콘(Nikon: 미국 뉴욕주 멜빌))를 사용하여 영상을 포착하였다.
실시예
7.
Lic5의
가변 영역의
클로닝
TRI졸 시약 (라이프 테크놀러지즈)을 사용하여 Lic5를 분비하는 하이브리도마 세포로부터 전체 RNA를 추출하고, 슈퍼스크립트 III 퍼스트-스트랜드 신테시스 시스템(Superscript III First-Strand Synthesis System) (라이프 테크놀러지즈)을 사용하여 cDNA로 전환시켰다. Ig-프라이머 세트(Ig-Primer Set) (노바겐(Novagen: 독일)) 및 플래티넘 Taq DNA 폴리머라제 하이 피덜리티(Platinum Taq DNA Polymerase High Fidelity) (라이프 테크놀러지즈)를 사용하여 Lic5의 중쇄 및 경쇄로부터의 가변 영역 cDNA 단편을 증폭시켰다. 경쇄의 가변 영역은 불변 영역 상의 5' 가변 영역 프라이머 (5'-ATGGAGACAGACACACTCCTGCTAT-3') 및 3' 프라이머에 의해 증폭시킨 반면, 중쇄의 가변 영역은 불변 영역 상의 5' 가변 영역 프라이머 (5'- ATGAACTTYGGGYTSAGMTTG RTTT-3', 여기서, Y=C/T, S=C/G, M=A/C, 및 R=A/G) 및 3' 프라이머에 의해 수득하였다. 1.5% 아가로스 겔 상에서 분리한 후 PCR 생성물을 정제하고, 서열분석하였다 (BGI: 홍콩).
실시예
8.
Lic5의
CDR
확인
Lic5의 중쇄 및 경쇄의 가변 영역의 뉴클레오티드 서열을 사용하여 아미노산 서열을 도출해내었고, 이어서, 카바트(Kabat) 넘버링 체계에 따라 넘버링하였다. 카바트 정의 (www.bioinf.org.uk)에 따라 CDR을 확인하였다.
실시예
9. 통계학적 분석
SPSS 버전 19 (SPSS 인크.(SPSS Inc.: 미국 일리노이주 시카고))를 사용하여 통계학적 분석을 수행하였다. 막대 차트로 제시된 데이터는 평균 ± SD/SEM로 표시된다. 스튜던츠 t-검정을 사용하여 세포 증식 MTT 검정법 및 동물 종양 이종 이식편 실험, 둘 모두에서의 처리군과 대조군 군 사이의 차이의 유의도를 산출하였다. 생존 분석을 위해서는 카플란-마이어(Kaplan-Meier) 방법을 사용한 반면, 생존 차이는 로그 순위 검정을 사용하여 산출하였다. p 값이 0.05 미만인 것을 통계학상 유의적인 것으로 간주하였다.
실시예
10.
하이브리도마
세포 배양물
상청액으로부터의
다량의
Lic5
확립 및 정제
시험관내 및 생체내 실험을 위해 고순도 및 다량으로 Lic5를 수득하기 위하여, 무혈청 배지 중에서 Lic5를 분비하는 하이브리도마 세포를 배양하였다. Lic5를 정제함으로써 여기까지는 파이프라인을 확립하는 데 우수한 항체 순도 및 수율을 달성하였다. 쿠마시 블루 염색 결과, 6일째 배양물 상청액 상에서 항체의 중쇄 및 경쇄에 상응하는 약 55 및 27 kDa의 뚜렷한 2개의 밴드가 나타났지만, 상기 밴드는 1일째 배양물 상청액에서는 관찰되지 않았다. 검출가능한 수준의 항체의 존재하에서, 6일째 수집된 배양물 상청액에 대해 항체 정제를 위한 프로테인 G 친화성 크로마토그래피를 수행하였다. 6일째 배양물 상청액을 칼럼 상에서 로딩한 후 통과액 중 항체의 존재를 검출하지 않았을 때, 항체가 프로테인 G 칼럼 상에 성공적으로 결합한 것을 확인할 수 있었다. 상이한 분획 (용리제 E1 내지 E4)에 대해 수행된 항체 용출 결과, 두 번째 및 세 번째 용출 분획이 가장 풍부한 항체를 함유한 것으로 나타났다. 항체의 중쇄 및 경쇄에 상응하는 염색된 2개의 밴드는 단백질 겔 상에서 검출된 뚜렷한 밴드이고, 이는 본 발명자들의 항체 순도가 90%를 초과한다는 것을 시사하는 것이다 (도 30(a)). 본 발명자들의 항체 정제 파이프라인을 사용하여, 바람직한 항체는 6일째 수집된 배양물 상청액 1 ℓ당 23.88 ± 6.96 mg Lic5인 양으로 수집되었다.
정제된 Lic5는 CDH17에 대하여 높은 면역반응성을 보였다. Lic5를 웨스턴 블롯을 위한 1차 항체로서 사용하였을 때, CDH17의 겉보기 분자량에 상응하는 약 120 kDa의 단일 밴드는 CDH17 발현 97L 세포에서 검출되었다 (도 30(b)). 인간 HCC 조직에서 CDH17을 검출하기 위하여 Lic5를 면역조직화학법을 위해 사용하였을 때, 별개의 염색이 세포막 및 세포질에서 출현하였다 (도 30(c)). 본 연구에서 Lic5를 사용하여 생성된 면역조직화학적 염색은 면역조직화학법을 위해 CDH17에 대한 상업적 항체를 사용하였을 때의 이전 보고와 유사하였다.
실시예
11.
Lic5의
생존 이익
또 다른 화학요법 약물 에피루비신에 대한 Lic5의 화학감작 효과를 조사하였다. 동소 종양 이종 이식 모델에서 Lic5를 존재 또는 부재하에서 약물 시험을 수행하였다.
정제된 Lic5를 이용하여 동소 종양 보유 마우스를 처리하기 이전에, 배양된 HCC 세포주에서의 Lic5 단독, 또는 시스플라틴 또는 에피루비신과 조합된 Lic5의 항종양 효과를 시험관내에서 세포 증식 MTT 검정법을 이용하여 조사하였다 (도 31(a)). 배양된 97L 세포에 대해 세포 증식 검정법을 수행하였을 때, 2일 동안 시스플라틴 및 에피루비신으로 처리한 결과, 각각 31.6% 및 21.9%의 성장 억제가 일어났다. Lic5와 조합하였을 때에는 시스플라틴의 경우, 1.74배 및 에피루비신의 경우, 1.98배만큼 성장 억제 효과는 추가로 증진되었고, 이로써, 각각 55.1% 및 43.3%의 성장 억제가 일어났다 (도 31(a), 좌측 패널). 배양된 PLC 세포에서도 유사한 성장 억제가 관찰되었으며, 여기서, 시스플라틴으로 처리하였을 때에는 37.6%의 성장 억제가 일어났고, Lic5와 조합하여 처리하였을 때에는 1.73배만큼 (65.2%) 성장 억제가 추가로 증가되었다. 배양된 97L 세포에서의 에피루비신의 유의적인 성장 억제와 달리, 상기 약물은 배양된 PLC 세포의 성장을 단지 8.1%만큼만 억제시켰다. 유사하게, 그와 Lic5와의 조합은 성장 억제를 4.62배만큼 증진시켰고, 37.4%의 유의적인 억제를 유도하였다 (도 31(b), 우측 패널).
프로테인 G 친화성 크로마토그래피를 사용하여 Lic5를 분비하는 하이브리도마 세포주의 배양물 상청액으로부터 Lic5를 정제하였다. 도 31(a)는 쿠마시 블루 염색된 겔 상에서 6일째 (D6)로부터의 배양물 상청액 (배양물 S/N)은 1일째 (D1)보다 더 높은 양으로 항체를 함유하였다는 것을 보여주는 것이다. 항체의 중쇄 및 경쇄에 상응하는 약 55 kDa 및 27 kDa 크기의 염색된 두 밴드가 겔 상에서 시각화되었다. 프로테인 G 칼럼 상에 6일째 배양물 상청액을 통과시킨 후, 통과액 (FT)에서는 어떤 항체도 검출되지 않았다. 4개의 분획 (E1 내지 E4)에 대해 항체 용출을 수행하였다. 가장 풍부한 항체는 분획 E2 및 E3에서 용출되었고, 이를 수집하고, 풀링(pooling)시켰다. 추가로, 도 31(a)는 세포 증식 MTT 검정법에서 마우스 IgG 처리된 세포와 비교하였을 때, 2일 동안의 Lic5, 시스플라틴 또는 에피루비신의 단일 처리가 배양된 97L 및 PLC 세포의 성장을 억제시켰다는 것을 보여주는 것이다. 시스플라틴 또는 에피루비신과의 Lic5의 조합 처리하에서 배양된 세포를 처리하였을 때, 추가의 성장 억제가 관찰되었다. 막대는 평균 ± SD를 나타낸다.
도 31(b)는 97L 세포 용해물에 대한 웨스턴 블롯을 위해 정제된 Lic5를 사용하였을 때, CDH17의 겉보기 분자량에 상응하는 단일 밴드가 나타났다는 것을 보여주는 것이다. 도 31(b)에서, 루시페라제 표지된 97L 세포를 사용하여 누드 마우스에서 동소 종양 이종 이식편을 확립시켰다. 3주 동안 화학요법 약물 시스플라틴 및 에피루비신의 존재 또는 부재하에서의 Lic5 단일 및 조합 처리를 상기 동물에 적용시켰다. 제시된 데이터는 처리 후 3주째 수득된, 대조군 IgG 군 대비의 순 광자 계수이다. 단일 처리 결과, 종양 성장이 억제된 반면, Lic5를 시스플라틴 또는 에피루비신과 조합하였을 때에는 종양 성장이 추가로 감소된 것이 관찰되었다. 막대는 평균 ± SD를 나타낸다.
도 31(c)는 인간 HCC 조직에 대한 면역조직화학법을 위해 정제된 Lic5를 사용하였을 때, CDH17의 막 및 세포질 국재화에 상응하는 별개의 염색이 검출되었다는 것을 보여주는 것이다. 도 31(c)에서, 97L 세포를 사용하여 누드 마우스에서 동소 종양 이종 이식편을 확립시켰다. 상기 동물을 Lic5 및 에피루비신을 단일로 또는 그의 조합 처리로 처리하였다. 카플란-마이어 곡선에서 밝혀진 바와 같이, Lic5 및 에피루비신의 조합 처리가 가장 바람직한 생존을 유도하였다. 조합 처리군을 마우스 IgG 대조군 군과 비교하였을 때, 생존 차이는 통계학상 유의적인 것에 도달하였다 (p = 0.017). 사용된 약어: C, 시스플라틴; E, 에피루비신. **, p < 0.05; ns, 통계학상 비유의적.
세포 증식 MTT 검정법을 사용함으로써 배양된 HCC 세포 상에서의 시스플라틴 및 에피루비신 처리에 대한 Lic5의 화학감작 효과를 확인한 후, 다음 단계는 동물 종양 이종 이식편 실험에 의해 생체내 환경에서 유사한 성장 억제를 관찰할 수 있는지 여부를 조사하는 것이었다. 종양 성장을 실시간으로 모니터링할 수 있게 하는 바, 이에 처리를 위한 동소 종양 이종 이식편을 발생시키는 데 루시페라제 표지된 97L 세포를 사용하였다. IgG 대조군 군과 비교하였을 때, 시스플라틴 처리는 이종 이식편 성장을 48.6%만큼 억제시켰다. Lic5와 조합되었을 때, 상기 처리는 이종 이식편 성장 억제를 79.6%로 1.64배만큼 추가로 증가시켰다. 그러한 억제에도 불구하고, 조합된 처리에 관한 데이터는 대조군 군과 비교하였을 때, 통계학상 유의적인 값을 얻지 못했다 (p = 0.08). 에피루비신의 경우, Lic5와 그의 조합된 처리는 이종 이식편 성장을 단일 에피루비신 처리시에는 37.9%인 것에서부터 86.4%로 (즉, 2.28배) 추가로 감소시킨 것으로 나타났다. 그러나, 상기와 같은 이종 이식편 성장의 하락이 통계학상 유의적인 값에 도달하지는 못했다 (p = 0.07) (도 31(b)). 실험 종료시, CDH17의 하류 분자인 것으로 공지되어 있고, Wnt 신호전달 경로의 중요한 구성원인 알파-카테닌의 발현 및 국재화를 분석하기 위해 동소 종양을 수집하였다. 화학요법 약물의 단일 처리와 비교하였을 때, 시스플라틴 또는 에피루비신과 Lic5의 조합 처리, 둘 모두 알파-카테닌의 전체적인 발현 및 세포질 국재화를 감소시켰다. 그러한 면역조직화학적 결과가 알파-카테닌의 발현 및 국재화를 변경시키는 Lic5의 작용을 통해 이루어지는 그에 의해 매개되는 종양 억제 효과를 추가로 강화시킨다.
도 31(b)에 제시된 바와 같이, 대조군 군과 비교하였을 때, 모든 처리군에 대해서 종양 성장 감소 경향이 관찰되었다. 대조군 군 대비로 각 처리군에 대한 동종 종양 보유 마우스의 생존율을 비교하였다. Lic5 군의 동물 생존율은 63.6%에 도달하였으며, 이는 대조군 군 (26.6%)의 것보다 훨씬 더 높았다 (26.6%). 비록 대조군 군과 에피루비신 군 사이의 생존율이 유사하기는 하였지만 (26.6% 대 25%), 대조군 군과 비교하였을 때, 모든 실험군들 중에서 Lic5 및 에피루비신의 조합 처리가 생존율을 81%까지 가장 유의적으로 증가시켰다 (p = 0.017) (도 31(c)). 그러나, 시스플라틴 군 및 Lic5와의 시스플라틴 군에 대한 생존에 있어서의 상기와 같은 유의적인 차이는 대조군 군과 비교하였을 때, 통계학상 유의적 값에 도달하지는 못했다. 종합해 보면, 상기 동물 실험 세트는 종양 성장 억제 및 생존율 유도에 미치는 특히 에피루비신에 대한 Lic5의 화학감작 효과를 입증하였다.
실시예
13.
Lic5의
가변 영역 상의
CDR
확인
각 모노클로날 항체는 중쇄 및 경쇄 상에 그의 독특한 가변 영역을 가지며, 그들 각각은 상기 항체의 항원 결합 특성을 결정짓는 아미노산 서열로 구성된다. Lic5의 중쇄 및 경쇄로부터 가변 영역 서열을 수득하기 위해, 별개의 프라이머 쌍을 사용하여 각각의 가변 영역을 증폭시켰다 (도 32, 좌측 패널). 증폭된 생성물에 대해 생어(Sanger) 서열분석을 수행한 후, 인 실리코 방법에 의해 뉴클레오티드 서열을 아미노산 서열로 번역시켰다. 카바트 넘버링 체계 및 CDR 정의를 사용하여 도출된 아미노산 서열을 사용함으로써 Lic5의 중쇄 및 경쇄의 가변 영역 상의 3개의 CDR을 확인하였다 (도 32, 우측 패널). PCR, 이어서, 생어 서열분석을 사용하여 Lic5를 분비하는 하이브리도마 세포로부터 제조된 cDNA로부터 Lic5의 경쇄 및 중쇄의 가변 영역 서열을 수득하였다 (도 32, 좌측 패널). 카바트 넘버링 체계 및 CDR 정의에 기초하여, 두 가변 영역 (VL: 서열 번호: 29 및 VH: 서열 번호: 30) 상의 6개의 CDR을 확인하였고, 이를 다른 색상으로 강조 표시하였다 (도 32, 우측 패널).
본 실시예로부터의 결과는 HCC 이종 이식을 치료하는 데 있어서의 Lic5의 항종양 및 화학감작 효과를 입증하였고, 이는 본원에 개시된 모노클로날 항체가 HCC 이외의 다른 암을 치료하는 데에도 유용할 수 있다는 것을 보여주는 것이다. Lic5는 면역원으로서 CDH17의 재조합 엑토도메인 1-2를 사용하여 Lic3과 함께 나란히 제조된 모노클로날 항체였다. Lic5는 CDH17의 세포외 영역을 표적화하고; 이는 치료학적 목적을 위해 사용될 때, 무손상 형태, 또는 CDH17의 카르복실-말단 말단절단된 형태에 결합할 수 있다. 그러므로, Lic5는 CDH17이 과다발현되는 다른 암을 표적화하는 데 사용될 수 있다. HCC 이외에도, 위 선암종, 식도 선암종, 및 결장직장암을 비롯한, 다수의 암이 CDH17을 과다발현하는 것으로 나타나 있다. 이러한 암 유형들 중에서 CDH17 과다발현은 대다수의 결장직장암 및 식도 선암종 암에 존재하였다. 따라서, 이들 CDH17 과다발현 암은 Lic5의 작용에 의해 쉽게 영향을 받을 수 있다. 처리 후 배양된 세포 또는 종양 이종 이식편의 성장이 감소된 것으로 나타난 바와 같이, CDH17 억제를 수행한 수개의 연구는 종양발생을 중화시켰다. 따라서, CDH17을 표적화하여 종양발생을 중화시키는 것이 HCC 이외의, CDH17을 과다발현하는 다른 암에서도 잘 작용한다.
본 실시예로부터의 결과는 CDH17이 α-카테닌-연관 네트워크와 관련이 있는 것으로 보인다는 것을 나타낸다. 한 실시양태에서, Lic5를 사용하여 CDH17을 표적화하는 것이 축 성분, 예컨대, α-카테닌의 발현 및 국재화를 방해함으로써 CDH17/α-카테닌 축을 불활성화시킨다. 또 다른 암 유형에서, CDH17의 내인성 인테그린 결합 친화성에 기인하여 CDH17은 결장직장 종양발생 동안 인테그린 관련 경로로의 가교 역할을 하였다. CDH17은 또한 Ras/Raf/MEK/ERK 및 NFγB와 관련된 2개의 다른 종양발생 경로에 영향을 미치는 바, 이에 그의 억제는 위암에서 상기 경로를 불활성화시켰다. 이러한 관찰결과를 고려해 볼 때, Lic5가 종양발생을 억제시키는 수단으로서 상기 경로를 차단시킬 수 있는지 여부는 여전히 확인되어야 하는 상태 그대로 남아 있다.
Lic5의 항종양 효과를 시험하는 것 이외에도, Lic5의 중쇄 및 경쇄 상의 각 가변 영역 상의 3개의 CDR을 확인하였다. 이들 CDR은 항체 결합 친화도 및 특이성을 결정하는 것을 담당한다.
제약 조성물
"유효량"이라는 용어는 원하는 효과를 달성하는 데, 예컨대, 대상체에서 질환을 호전시키는 데 효과적인 약물의 양을 지칭한다. 질환이 암인 경우, 유효량의 약물은 하기 예시적인 특징들, 제한 없이, 암 세포 성장, 암 세포 증식, 암 세포 이동, 암 세포의 말초 기관으로의 침윤, 종양 전이 및 종양 성장을 포함하는 것들 중 하나 이상의 것을 억제시킬 수 있다 (예를 들어, 그를 어느 정도 저속화시키거나, 억제시키거나, 또는 정지시킬 수 있다). 질환이 암인 경우, 유효량의 약물은 대상체에게 투여되었을 때, 대안적으로, 하기: 종양 성장을 저속화시키거나, 정지시키는 것, 종양 크기 (예를 들어, 부피 또는 질량)을 축소시키는 것, 암과 연관된 증상들 중 하나 이상의 것을 어느 정도 경감시키거나, 무진행 생존을 연장시키는 것, (예를 들어, 부분 관해 또는 완전 관해를 비롯한) 객관적 반응을 일으키는 것, 및 전체 생존 기간을 연장시키는 것 중 하나 이상의 것을 일으킬 수 있다. 약물이 성장을 방해하고/거나, 현존 암 세포를 사멸시킬 수 있는 정도까지 약물은 세포증식억제성이고/거나, 세포독성을 띤다.
대상체, 예컨대, 치료를 필요로 하는 인간 환자에게 투여하는 데 적합한 조성물 제조와 관련하여, 본원에 개시된 항체는 선택된 투여 경로에 따라, 당업계에 공지된 제약상 허용되는 담체와 혼합 또는 조합될 수 있다. 본원에 개시된 항체의 적용 모두에 대해서는 특별한 제한은 없으며, 적합한 투여 경로 및 적합한 조성물의 선택은 과도한 실험 없이 당업계에 공지되어 있다.
비록 다수의 투여 형태가 가능하기는 하지만, 예시적인 투여 형태는 주사용 액제, 특히, 정맥내 또는 동맥내 주사용 액제가 될 것이다. 일반적으로, 주사용으로 적합한 제약 조성물은 제약상 적합한 담체 또는 부형제, 예컨대, 제한 없이, 완충제, 계면활성제, 또는 안정제 제제를 포함할 수 있다. 예시적인 완충제로는 제한 없이, 아세테이트, 포스페이트 또는 시트레이트 완충제를 포함할 수 있다. 예시적인 계면활성제로는 제한 없이, 폴리소르베이트를 포함할 수 있다. 예시적인 안정제로는 제한 없이, 인간 알부민을 포함할 수 있다.
유사하게, 당업자는 병태, 예컨대, 암을 치료하는 데 효과적인, 본원에 개시된 항체의 유효량 또는 농도를 결정할 수 있는 능력을 가진다. 다른 파라미터, 예컨대, 제약 조성물의 다양한 성분들의 비율, 투여 용량 및 빈도는 과도한 실험 없이 당업자에 의해 얻을 수 있다. 예를 들어, 주사용으로 적합한 액제는 제한 없이, 약 1 내지 약 20, 약 1 내지 약 10 mg 항체/ml를 함유할 수 있다. 예시적인 용량은 제한 없이, 약 0.1 내지 약 20, 약 1 내지 약 5 mg/Kg (체중)일 수 있다. 예시적인 투여 빈도는 제한 없이, 1일 1회 또는 주 3회일 수 있다.
본 개시내용은 특정 실시양태 또는 실시예를 참조로 하여 기술되었지만, 실시양태는 예시적인 것이고, 본 개시내용의 범주가 그렇게 제한되는 것은 아니라는 것을 이해할 수 있을 것이다. 본 개시내용의 대안적 실시양태는 본 개시내용과 관련된 기술분야의 숙련가에게 자명해질 수 있다. 상기 대안적 실시양태는 본 개시내용의 범주 내애 포함되는 것으로 간주된다. 따라서, 본 개시내용의 범주는 첨부된 특허청구범위에 의해 정의되고, 상기 설명에 의해 뒷받침된다.
요약하면, 가변 도메인이 CDH17 mAb로부터 유래된 것인 CDH17 항체의 신규한 패널을 통해 암 치료를 위한 독특한 CAR가 생성될 수 있을 것이다. CDH17 항체의 세포 유형 특이성을 통해 정상 세포 또는 조직에서 발현되는 CDH17보다 종양 세포에서 발현하는 CDH17를 표적화하는 데 더욱 큰 특이성을 가질 수 있게 될 것이다. 한 CAR은 종양 세포 상의 CDH17에 대하여 더욱 특이적이고, 제2 CAR은 동일한 종양 세포 상의 종양 연관 항원 (TAA)에 대하여 중간 정도의 특이성을 가지는, 두 CAR을 발현하는 T 세포 또는 NK 세포 또한 생성될 수 있다. 조합적인 특이성을 통해 종양 세포 시그니처를 더욱 선택적으로 표적화할 수 있다. 대안적으로, CDH17 CAR은 상이한 기전을 통해 중간 정도의 특이성을 가지는 종양 특이적 TAA CAR의 더욱 특이적인 표적화를 지원할 수 있다. 예를 들어, 중간 정도의 특이성을 가지는 결장암 또는 위암 TAA CAR을 CD3제타 엔도도메인에 융합시킬 수 있다. 상기 제1 세대 CAR은 강건한 사멸 반응을 지원할 수 없고, 생체내 반감기는 1주 내지 수주로 짧다. 제1 세대 CAR에 강력한 공자극성 신호를 제공하는 CD28 또는 CD28 및 CD137 엔도도메인에 융합된 CDH17 CAR이 공동 발현될 수 있다. CDH17 CAR은 CDH17이 정상적으로 발현되는 결장 및 위에서 결합하고, 강건한 종양 사멸 반응을 활성화시킬 것이다. 공동 발현된 제1 세대 CAR은 결장 또는 위 (또는 CDH17이 정상적으로 발현되는 다른 조직)에서 정상적으로 발현되지 않는 표적에의 결합에 대해 선택될 것이며, 이로써, 선택적으로 활성화되어 결장암 또는 위암 세포를 사멸시키게 될 것이다.
본 개시내용은 특정 실시양태를 참조로 하여 기술되었지만, 실시양태는 예시적인 것이고, 본 개시내용의 범주가 그렇게 제한되는 것은 아니라는 것을 이해할 것이다. 본 개시내용의 대안적 실시양태는 본 개시내용과 관련된 기술분야의 숙련가에게 자명해질 것이다. 상기 대안적 실시양태는 본 개시내용의 범주 내애 포함되는 것으로 간주된다. 따라서, 본 개시내용의 범주는 첨부된 특허청구범위에 의해 정의되고, 상기 설명에 의해 뒷받침된다.
실시양태는 단지 본 개시내용을 예시하기 위한 것이며, 본 개시내용의 범주를 제한하고자 하는 것은 아니다. 특정 변형 및 개선이 이루어질 수 있고, 이는 본 개시내용의 원리로부터 벗어남 없이 본 개시내용의 보호하에 있는 것으로 간주되어야 한다는 것을 본 기술분야의 당업자는 이해하여야 한다.
SEQUENCE LISTING
<110> ARBELE LIMITED
STAUNTON, Donald E.
<120> CADHERIN-17 SPECIFIC ANTIBODIES AND CYTOTOXIC CELLS FOR CANCER TREATMENT
<130> IPA180936-HK
<150> 62/276,855
<151> 2016-01-09
<160> 30
<170> PatentIn version 3.5
<210> 1
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic3 VL
<400> 1
Asp Val Leu Met Thr Gln Ile Pro Leu Ser Leu Thr Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105 110
<210> 2
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic3 VH
<400> 2
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ser Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala
115
<210> 3
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic5 VL
<400> 3
Asp Ile Val Leu Thr Gln Thr Thr Leu Ser Leu Asn Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105 110
Arg Ala Asp
115
<210> 4
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic5 VH
<400> 4
Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Pro Cys Ala Ala Ser Gly Ser Ser Phe Ser Asp Phe
20 25 30
Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala
115
<210> 5
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica26 VH
<400> 5
Ala Glu Val Gln Leu Val Glu Thr Gly Gly Gly Leu Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Ser Arg Phe Gly Met Asp Val Trp Gly Gln Gly Thr
100 105 110
<210> 6
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica26 VL
<400> 6
Met Phe Val Met Ser Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Ser Trp Phe Gln Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Asn Val Phe Asn Arg Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Glu Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly
85 90 95
Thr His Trp Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu
100 105 110
<210> 7
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica30 VH
<400> 7
Ala Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Lys Gly Arg Trp Phe Asp Pro Trp Gly Gln Gly Thr
100 105 110
<210> 8
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica30 VL
<400> 8
Ser Val Val Thr Gln Pro Pro Ser Val Ser Gly Ala Pro Gly Gln Arg
1 5 10 15
Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr
20 25 30
Gly Val Gln Trp Tyr Gln Gln Phe Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Gly Asn Asn Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Asp Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Arg
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Ser Gly Trp Val Phe Gly Gly Gly
100
<210> 9
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica66 VH
<400> 9
Ala Glu Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Gln Gly Ser Gly Trp Tyr Tyr Trp Gly Gln Gly Thr
100 105 110
<210> 10
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica66 VL
<400> 10
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Gly Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Thr Trp Phe Gln Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Lys Val Ser Ser Arg Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Asn Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly
85 90 95
Thr His Trp Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu
100 105 110
<210> 11
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica78 VH
<400> 11
Ala Glu Val Gln Leu Val Glu Ser Gly Ser Glu Leu Lys Lys Pro Gly
1 5 10 15
Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Arg
20 25 30
Tyr Ala Met Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp
35 40 45
Met Gly Trp Ile Asn Thr Asn Thr Gly Asn Pro Thr Tyr Ala Gln Gly
50 55 60
Phe Thr Gly Arg Phe Val Phe Ser Leu Asp Thr Ser Val Ser Thr Ala
65 70 75 80
Tyr Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Gly Arg Arg Gly Ala Phe Asp Ile Trp Gly Gln Gly Thr
100 105 110
<210> 12
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica78 VL
<400> 12
Ile Val Leu Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly Glu
1 5 10 15
Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Arg Asn
20 25 30
Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro
35 40 45
Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro Asp
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Gln Ile Ser
65 70 75 80
Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Ala Leu
85 90 95
Leu Thr Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
<210> 13
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica85 VH
<400> 13
Ala Glu Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Arg Ser Tyr Ser Asn Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
<210> 14
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica85 VL
<400> 14
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Ser Leu Val Tyr Ser
20 25 30
Asp Gly Ser Thr Tyr Leu Asn Trp Tyr Gln Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Ala Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Ala Thr Tyr Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Phe Cys Met Gln Gly
85 90 95
Thr His Trp Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu
100 105 110
<210> 15
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica94 VH
<400> 15
Ala Glu Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Gln Gly Ser Gly Trp Tyr Tyr Trp Gly Gln Gly Thr
100 105 110
<210> 16
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLica94 VL
<400> 16
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Arg Gly Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Thr Trp Phe Gln Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Lys Val Ser Ser Arg Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Asn Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly
85 90 95
Thr His Trp Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu
100 105 110
<210> 17
<211> 485
<212> PRT
<213> Artificial Sequence
<220>
<223> CDH17 arm
<400> 17
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu
130 135 140
Ser Val Thr Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln
145 150 155 160
Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln
165 170 175
Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser Asn Arg
180 185 190
Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr
210 215 220
Tyr Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr
225 230 235 240
Lys Leu Glu Leu Lys Gly Ala Pro Gly Gly Gly Ser Gly Glu Pro Lys
245 250 255
Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
260 265 270
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
275 280 285
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
290 295 300
Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val
305 310 315 320
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser
325 330 335
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
340 345 350
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser
355 360 365
Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
370 375 380
Gln Val Tyr Thr Leu Pro Pro Ser Pro Glu Glu Met Thr Lys Asn Gln
385 390 395 400
Val Ser Leu Tyr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
405 410 415
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
420 425 430
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu
435 440 445
Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser
450 455 460
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
465 470 475 480
Leu Ser Leu Gly Lys
485
<210> 18
<211> 486
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3 arm
<400> 18
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Leu Ile Asn Pro Tyr Lys Gly Val Thr Thr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Val Asp Lys Ser Lys Asn Thr Ala Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Tyr Tyr Gly Asp Ser Asp Trp Tyr Phe Asp Val Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Arg Ala Ser Gln Asp Ile Arg Asn Tyr Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Tyr Thr Ser Arg Leu Glu
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Gly Asn Thr Leu Pro Trp Thr Phe Gly Gln Gly Thr Lys
225 230 235 240
Val Glu Ile Lys Arg Thr Gly Ala Pro Gly Gly Gly Ser Gly Glu Pro
245 250 255
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
260 265 270
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
275 280 285
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
290 295 300
Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
305 310 315 320
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
325 330 335
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
340 345 350
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
355 360 365
Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
370 375 380
Pro Gln Val Tyr Thr Leu Pro Pro Ser Pro Glu Glu Met Thr Lys Asn
385 390 395 400
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
405 410 415
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
420 425 430
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Thr Ser Arg
435 440 445
Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys
450 455 460
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
465 470 475 480
Ser Leu Ser Leu Gly Lys
485
<210> 19
<211> 443
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic2 2nd generation CAR
<400> 19
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ser Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Thr
130 135 140
Val Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser
145 150 155 160
Ile Val His Ser Asn Gly Asn Thr Tyr Leu Gly Trp Tyr Leu Gln Arg
165 170 175
Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe
180 185 190
Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr
210 215 220
Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys
225 230 235 240
Leu Glu Leu Lys Arg Ala Asp Leu Cys Pro Ser Pro Leu Phe Pro Gly
245 250 255
Pro Ser Lys Pro Phe Trp Val Leu Trp Val Gly Gly Val Leu Ala Cys
260 265 270
Tyr Ser Leu Leu Val Thr Val Ala Phe Leu Leu Phe Trp Val Arg Ser
275 280 285
Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg
290 295 300
Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg
305 310 315 320
Asp Phe Ala Ala Tyr Arg Ser Gly Gly Gly Arg Val Lys Phe Ser Arg
325 330 335
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
340 345 350
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
355 360 365
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn
370 375 380
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
385 390 395 400
Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
405 410 415
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr
420 425 430
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 20
<211> 441
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic5 2nd generation CAR
<400> 20
Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Pro Cys Ala Ala Ser Gly Ser Ser Phe Ser Asp Phe
20 25 30
Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr Leu
65 70 75 80
Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Asp Ile Val Leu Thr Gln Thr Thr Leu Ser Leu Asn Val
130 135 140
Ser Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val
145 150 155 160
His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Arg Pro Gly
165 170 175
Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly
180 185 190
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
195 200 205
Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe
210 215 220
Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu
225 230 235 240
Leu Lys Arg Ala Asp Leu Cys Pro Ser Pro Leu Phe Pro Gly Pro Ser
245 250 255
Lys Pro Phe Trp Val Leu Trp Val Gly Gly Val Leu Ala Cys Tyr Ser
260 265 270
Leu Leu Val Thr Val Ala Phe Leu Leu Phe Trp Val Arg Ser Lys Arg
275 280 285
Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro
290 295 300
Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe
305 310 315 320
Ala Ala Tyr Arg Ser Gly Gly Gly Arg Val Lys Phe Ser Arg Ser Ala
325 330 335
Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu
340 345 350
Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly
355 360 365
Arg Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln
370 375 380
Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Val
385 390 395 400
Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp
405 410 415
Gly Leu Val Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala
420 425 430
Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 21
<211> 431
<212> PRT
<213> Artificial Sequence
<220>
<223> HLic26 2nd generation CAR
<400> 21
Ala Glu Val Gln Leu Val Glu Thr Gly Gly Gly Leu Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Val
85 90 95
Cys Ala Ser Arg Phe Gly Met Asp Val Trp Gly Gln Gly Thr Gly Gly
100 105 110
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Met Phe Val
115 120 125
Met Ser Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly Gln Pro Ala
130 135 140
Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser Asp Gly Asn
145 150 155 160
Thr Tyr Leu Ser Trp Phe Gln Gln Arg Pro Gly Gln Ser Pro Arg Arg
165 170 175
Leu Ile Tyr Asn Val Phe Asn Arg Asp Ser Gly Val Pro Asp Arg Phe
180 185 190
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Glu Ile Ser Arg Val
195 200 205
Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly Thr His Trp
210 215 220
Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Leu Cys Pro Ser Pro
225 230 235 240
Leu Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Trp Val Gly Gly
245 250 255
Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Leu Leu Phe
260 265 270
Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn
275 280 285
Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr
290 295 300
Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Gly Gly Gly Arg Val
305 310 315 320
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Val Gln Gln Gly Gln Asn
325 330 335
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Val Asp Val
340 345 350
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln
355 360 365
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp
370 375 380
Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg
385 390 395 400
Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
405 410 415
Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
420 425 430
<210> 22
<211> 488
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic3 3rd generation CAR
<400> 22
Gln Val Gln Leu Gln Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ser Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Asp Ile Val Leu Thr Gln Thr Pro Leu Ser Leu Thr
130 135 140
Val Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser
145 150 155 160
Ile Val His Ser Asn Gly Asn Thr Tyr Leu Gly Trp Tyr Leu Gln Arg
165 170 175
Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe
180 185 190
Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr
210 215 220
Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys
225 230 235 240
Leu Glu Leu Lys Arg Ala Asp Leu Cys Pro Ser Pro Leu Phe Pro Gly
245 250 255
Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala
260 265 270
Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg
275 280 285
Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro
290 295 300
Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro
305 310 315 320
Arg Asp Phe Ala Ala Tyr Arg Ser Gly Gly Gly Arg Gly Arg Lys Lys
325 330 335
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
340 345 350
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
355 360 365
Gly Cys Glu Leu Gly Gly Gly Arg Val Lys Phe Ser Arg Ser Ala Asp
370 375 380
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
385 390 395 400
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
405 410 415
Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu
420 425 430
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
435 440 445
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
450 455 460
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
465 470 475 480
His Met Gln Ala Leu Pro Pro Arg
485
<210> 23
<211> 488
<212> PRT
<213> Artificial Sequence
<220>
<223> Lic5 3rd generation CAR
<400> 23
Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Pro Cys Ala Ala Ser Gly Ser Ser Phe Ser Asp Phe
20 25 30
Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Asp Ile Val Leu Thr Gln Thr Thr Leu Ser Leu Asn
130 135 140
Val Ser Leu Gly Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser
145 150 155 160
Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Arg
165 170 175
Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe
180 185 190
Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe
195 200 205
Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr
210 215 220
Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys
225 230 235 240
Leu Glu Leu Lys Arg Ala Asp Leu Cys Pro Ser Pro Leu Phe Pro Gly
245 250 255
Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala
260 265 270
Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg
275 280 285
Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro
290 295 300
Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro
305 310 315 320
Arg Asp Phe Ala Ala Tyr Arg Ser Gly Gly Gly Arg Gly Arg Lys Lys
325 330 335
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
340 345 350
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
355 360 365
Gly Cys Glu Leu Gly Gly Gly Arg Val Lys Phe Ser Arg Ser Ala Asp
370 375 380
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
385 390 395 400
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
405 410 415
Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu
420 425 430
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
435 440 445
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
450 455 460
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
465 470 475 480
His Met Gln Ala Leu Pro Pro Arg
485
<210> 24
<211> 476
<212> PRT
<213> Artificial Sequence
<220>
<223> HuLic26 3rd generation CAR
<400> 24
Ala Glu Val Gln Leu Val Glu Thr Gly Gly Gly Leu Val Gln Pro Gly
1 5 10 15
Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser
20 25 30
Tyr Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp
35 40 45
Val Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Ser Arg Phe Gly Met Asp Val Trp Gly Gln Gly Thr Gly Gly
100 105 110
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Met Phe Val
115 120 125
Met Ser Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly Gln Pro Ala
130 135 140
Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser Asp Gly Asn
145 150 155 160
Thr Tyr Leu Ser Trp Phe Gln Gln Arg Pro Gly Gln Ser Pro Arg Arg
165 170 175
Leu Ile Tyr Asn Val Phe Asn Arg Asp Ser Gly Val Pro Asp Arg Phe
180 185 190
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Glu Ile Ser Arg Val
195 200 205
Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly Thr His Trp
210 215 220
Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Leu Cys Pro Ser Pro
225 230 235 240
Leu Phe Pro Gly Pro Ser Lys Pro Phe Trp Val Leu Val Val Val Gly
245 250 255
Gly Val Leu Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile
260 265 270
Phe Trp Val Arg Ser Lys Arg Ser Arg Leu Leu His Ser Asp Tyr Met
275 280 285
Asn Met Thr Pro Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro
290 295 300
Tyr Ala Pro Pro Arg Asp Phe Ala Ala Tyr Arg Ser Gly Gly Gly Arg
305 310 315 320
Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro
325 330 335
Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu
340 345 350
Glu Glu Glu Gly Gly Cys Glu Leu Gly Gly Gly Arg Val Lys Phe Ser
355 360 365
Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr
370 375 380
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
385 390 395 400
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys
405 410 415
Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala
420 425 430
Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys
435 440 445
Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr
450 455 460
Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
465 470 475
<210> 25
<211> 472
<212> PRT
<213> Artificial Sequence
<220>
<223> synthesized
<400> 25
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu
130 135 140
Ser Val Thr Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln
145 150 155 160
Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln
165 170 175
Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser Asn Arg
180 185 190
Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr
210 215 220
Tyr Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr
225 230 235 240
Lys Leu Glu Leu Lys Gly Ala Pro Thr Thr Thr Pro Ala Pro Arg Pro
245 250 255
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
260 265 270
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
275 280 285
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
290 295 300
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly
305 310 315 320
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
325 330 335
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
340 345 350
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
355 360 365
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
370 375 380
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
385 390 395 400
Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu
405 410 415
Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser
420 425 430
Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly
435 440 445
Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu
450 455 460
His Met Gln Ala Leu Pro Pro Arg
465 470
<210> 26
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> synthesized
<400> 26
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu
130 135 140
Ser Val Thr Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln
145 150 155 160
Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln
165 170 175
Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser Asn Arg
180 185 190
Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr
210 215 220
Tyr Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr
225 230 235 240
Lys Leu Glu Leu Lys Gly Ala Pro Thr Thr Thr Pro Ala Pro Arg Pro
245 250 255
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
260 265 270
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
275 280 285
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
290 295 300
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly
305 310 315 320
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
325 330 335
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
340 345 350
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
355 360 365
Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
370 375 380
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
385 390 395 400
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
405 410 415
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
420 425 430
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
435 440 445
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
450 455 460
Met Gln Ala Leu Pro Pro Arg
465 470
<210> 27
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> synthesized
<400> 27
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu
130 135 140
Ser Val Thr Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln
145 150 155 160
Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln
165 170 175
Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser Asn Arg
180 185 190
Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr
210 215 220
Tyr Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr
225 230 235 240
Lys Leu Glu Leu Lys Gly Ala Pro Thr Thr Thr Pro Ala Pro Arg Pro
245 250 255
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
260 265 270
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
275 280 285
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
290 295 300
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys
305 310 315 320
Arg Ser Arg Gly Gly His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg
325 330 335
Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp
340 345 350
Phe Ala Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala
355 360 365
Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu
370 375 380
Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp
385 390 395 400
Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu Gly
405 410 415
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
420 425 430
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
435 440 445
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
450 455 460
Met Gln Ala Leu Pro Pro Arg
465 470
<210> 28
<211> 459
<212> PRT
<213> Artificial Sequence
<220>
<223> synthesized
<400> 28
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu
130 135 140
Ser Val Thr Pro Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln
145 150 155 160
Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln
165 170 175
Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Lys Val Ser Asn Arg
180 185 190
Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp
195 200 205
Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr
210 215 220
Tyr Cys Phe Gln Gly Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr
225 230 235 240
Lys Leu Glu Leu Lys Gly Ala Pro Gly Gly Gly Ser Gly Glu Pro Lys
245 250 255
Ser Ser Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
260 265 270
Leu Gly Gly Pro Asp Phe Trp Val Leu Val Val Val Gly Gly Val Leu
275 280 285
Ala Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val
290 295 300
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
305 310 315 320
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
325 330 335
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg
340 345 350
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
355 360 365
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
370 375 380
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Gln Arg Arg Lys Asn
385 390 395 400
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
405 410 415
Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
420 425 430
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr
435 440 445
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
450 455
<210> 29
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> synthesized
<400> 29
Asp Ile Val Leu Thr Gln Thr Thr Leu Ser Leu Asn Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105 110
Arg Ala
<210> 30
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> synthesized
<400> 30
Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Pro Cys Ala Ala Ser Gly Ser Ser Phe Ser Asp Phe
20 25 30
Tyr Met Tyr Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ser Ile Ser Phe Asp Gly Thr Tyr Thr Tyr Tyr Thr Asp Arg Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Asn Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Asp Arg Pro Ala Trp Phe Pro Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala Ala
115
Claims (46)
- 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 70%의 유사성을 가지는 아미노산 서열을 포함하는, 카드헤린-17에 대하여 특이성을 가지는 항체.
- 제1항에 있어서, 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 80%의 유사성을 가지는 아미노산 서열을 포함하는 항체.
- 제1항에 있어서, 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 95%의 유사성을 가지는 아미노산 서열을 포함하는 항체.
- 제1항에 있어서, 모노클로날 항체가 마우스 항체, 인간화 항체, 또는 인간 항체인 것인 항체.
- 제1항에 있어서, 모노클로날 항체가 파지 라이브러리 스크린(phage library screen)으로부터 단리된 인간 항체인 것인 항체.
- 제1항에 있어서, 경쇄의 가변 영역 (VL), 중쇄의 가변 영역 (VH)을 포함하고, 여기서, VL은 서열 번호: 1, 3, 6, 8, 10, 12, 14, 및 16으로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함하는 것인 항체.
- 제6항에 있어서, VH가 서열 번호: 2, 4, 5, 7, 9, 11, 13, 및 15로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함하는 것인 항체.
- 제1항에 있어서, 접합된 세포독성 모이어티(moiety)를 추가로 포함하는 항체.
- 제8항에 있어서, 접합된 세포독성 모이어티가 이리노테칸, 아우리스타틴, PBD, 메이탄신, 아만틴, 스플라이소솜 억제제, 또는 그의 조합을 포함하는 것인 항체.
- 제8항에 있어서, 접합된 세포독성 모이어티가 화학요법제를 포함하는 것인 항체.
- 제1항에 있어서, 항체가 이중특이적 항체인 것인 항체.
- 제11항에 있어서, 세포독성 T 또는 NK 세포로부터의 세포 수용체에 대하여 특이성을 가지는 항체.
- 제12항에 있어서, 항체가 카드헤린-17 및 CD3 둘 모두에 대하여 특이성을 가지는 이중특이적 항체인 것인 항체.
- 제12항에 있어서, 세포 수용체가 4-1BB, OX40, CD27, CD40, TIM-1, CD28, HVEM, GITR, ICOS, IL12수용체, IL14 수용체, 또는 그의 유도체 또는 조합을 포함하는 것인 항체.
- 제12항에 있어서, 카드헤린-17에 대하여 특이성을 가지는 제1 단일 쇄 가변 단편 (ScFv) 및 CD3에 대하여 특이성을 가지는 제2 단일 쇄 가변 단편 (ScFv)을 포함하고, 여기서, 제1 ScFv는 제1 VH 및 제1 VL을 포함하고, 제2 ScFv는 제2 VH 및 제2 VL을 포함하는 것인 항체.
- 제15항에 있어서, 제1 VH가 서열 번호: 2, 4, 5, 7, 9, 11, 13, 및 15로부터 선택되는 아미노산 서열을 포함하는 것인 항체.
- 제15항에 있어서, 제1 VL이 서열 번호: 1, 3, 6, 8, 10, 12, 14, 및 16으로부터 선택되는 아미노산 서열을 포함하는 것인 항체.
- 제15항에 있어서, 제2 VH가 서열 번호: 18의 아미노산 서열의 상응하는 부분을 포함하는 것인 항체.
- 제15항에 있어서, 제2 VL이 서열 번호: 18의 아미노산 서열의 상응하는 부분을 포함하는 것인 항체.
- 제11항에 있어서, 면역 체크포인트 억제제에 대하여 특이성을 가지는 항체.
- 제20항에 있어서, 체크포인트 억제제가 PD-1, TIM-3, LAG-3, TIGIT, CTLA-4, PD-L1, BTLA, VISTA, 또는 그의 조합을 포함하는 것인 항체.
- 제11항에 있어서, 혈관형성 인자에 대하여 특이성을 가지는 항체.
- 제22항에 있어서, 혈관형성 인자가 VEGF를 포함하는 것인 항체.
- 제1항에 있어서, 항체가 카드헤린-17 도메인 6 중 RGD 부위의 인테그린에의 결합을 길항시키도록 구성된 것인 항체.
- 제24항에 있어서, 인테그린이 알파2베타1을 포함하는 것인 항체.
- 제1항에 있어서, 항체가 모노클로날 항체인 것인 항체.
- 서열 번호: 2, 4, 5, 7, 9, 11, 13, 및 15로부터 선택되는 서열을 가지는 아미노산 서열을 포함하는, 항체를 위한 IgG 중쇄.
- 서열 번호: 1, 3, 6, 8, 10, 12, 14, 및 16으로부터 선택되는 서열을 가지는 아미노산 서열을 포함하는, 항체를 위한 경쇄.
- 서열 번호: 1-16으로부터 선택되는 아미노산 서열을 포함하는, 항체를 위한 가변 쇄.
- 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함하는, 카드헤린-17에 대하여 특이성을 가지는 scFv 또는 Fab.
- 제30항에 있어서, 세포독성 T 또는 NK 세포로부터의 세포 수용체에 대하여 특이성을 가지는 scFv 또는 Fab.
- 제30항에 있어서, 면역 체크포인트 억제제에 대하여 특이성을 가지는 scFv 또는 Fab.
- 제30항에 있어서, 혈관형성 인자에 대하여 특이성을 가지는 scFv 또는 Fab.
- 카드헤린-17에 대하여 특이성을 가지는 T 또는 NK 세포로서, 여기서, T 또는 NK 세포는 키메라 항원 수용체를 포함하고, 여기서, 키메라 항원 수용체는 서열 번호: 1-21로부터 선택되는 아미노산 서열과 적어도 90%의 유사성을 가지는 아미노산 서열을 포함하는 것인 T 또는 NK 세포.
- 제34항에 있어서, 키메라 항원 수용체가 서열 번호: 1-16으로부터 선택되는 아미노산 서열을 포함하는 것인 T 또는 NK 세포.
- 제1항 내지 제26항 중 어느 한 항의 항체, 제27항의 IgG 중쇄, 제28항의 경쇄, 제29항의 가변 쇄, 또는 제30항 내지 제33항 중 어느 한 항의 ScFv 또는 Fab를 코딩(encoding)하는 단리된 핵산.
- 제36항의 단리된 핵산을 포함하는 발현 벡터.
- 제37항에 있어서, 벡터가 세포에서 발현가능한 것인 발현 벡터.
- 제36항의 핵산을 포함하는 숙주 세포.
- 제37항의 발현 벡터를 포함하는 숙주 세포.
- 제40항에 있어서, 숙주 세포가 원핵 세포 또는 진핵 세포인 것인 숙주 세포.
- 제1항 내지 제26항 중 어느 한 항의 항체 및 세포독성제를 포함하는 제약 조성물.
- 제42항에 있어서, 세포독성제가 시스플라틴, 젬시타빈, 이리노테칸, 또는 항종양 항체를 포함하는 것인 제약 조성물.
- 제1항 내지 제26항 중 어느 한 항의 항체 및 제약상 허용되는 담체를 포함하는 제약 조성물.
- 암을 앓는 대상체(subject)에게 유효량의, 제1항 내지 제26항 중 어느 한 항의 항체, 또는 제34항 또는 제35항의 T 또는 NK 세포를 투여하는 단계를 포함하는, 암을 앓는 대상체를 치료하는 방법.
- 제45항에 있어서, 암이 간암, 위암, 결장암, 췌장암, 폐암, 또는 그의 조합인 것인 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662276855P | 2016-01-09 | 2016-01-09 | |
| US62/276,855 | 2016-01-09 | ||
| PCT/US2017/012648 WO2017120557A1 (en) | 2016-01-09 | 2017-01-07 | Cadherin-17 specific antibodies and cytotoxic cells for cancer treatment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20180127966A true KR20180127966A (ko) | 2018-11-30 |
Family
ID=59274048
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020187023033A KR20180127966A (ko) | 2016-01-09 | 2017-01-07 | 암 치료를 위한 카드헤린-17 특이적 항체 및 세포독성 세포 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US11207419B2 (ko) |
| EP (1) | EP3400013A4 (ko) |
| JP (3) | JP6974348B2 (ko) |
| KR (1) | KR20180127966A (ko) |
| CN (4) | CN113912725B (ko) |
| AU (1) | AU2017206089B2 (ko) |
| IL (1) | IL260474B (ko) |
| WO (1) | WO2017120557A1 (ko) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210116456A1 (en) * | 2018-05-16 | 2021-04-22 | Arbele Limited | Compositions and methods for diagnosis and treatment of cancer |
| WO2019222428A1 (en) * | 2018-05-16 | 2019-11-21 | Arbele Limited | Composition of bispecific antibodies and method of use thereof |
| TWI717880B (zh) * | 2019-10-24 | 2021-02-01 | 中國醫藥大學附設醫院 | Hla-g特異性嵌合抗原受體、核酸、hla-g特異性嵌合抗原受體表達質體、表達hla-g特異性嵌合抗原受體細胞、其用途以及用於治療癌症之醫藥組合物 |
| CN114786720A (zh) * | 2019-12-05 | 2022-07-22 | 艾贝乐医药科技有限公司 | TriAx抗体的组合物及其制备和使用方法 |
| EP4355778A1 (en) * | 2021-06-17 | 2024-04-24 | Boehringer Ingelheim International GmbH | Novel tri-specific binding molecules |
| WO2023107558A1 (en) * | 2021-12-07 | 2023-06-15 | The Regents Of The University Of California | Cdh17 antibodies and methods of treating cancer |
| CN113999308B (zh) * | 2021-12-30 | 2022-03-11 | 深圳市人民医院 | 靶向钙粘蛋白17的纳米抗体及其应用 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| EP1578799B8 (en) * | 2002-12-02 | 2011-03-23 | Amgen Fremont Inc. | Antibodies directed to tumor necrosis factor and uses thereof |
| EP1914242A1 (en) * | 2006-10-19 | 2008-04-23 | Sanofi-Aventis | Novel anti-CD38 antibodies for the treatment of cancer |
| WO2008072723A1 (ja) * | 2006-12-14 | 2008-06-19 | Forerunner Pharma Research Co., Ltd. | 抗Claudin3モノクローナル抗体およびそれを用いる癌の治療および診断 |
| CN102124105A (zh) * | 2008-02-08 | 2011-07-13 | 伊缪纳斯制药株式会社 | 能够特异性结合Aβ寡聚体的抗体及其应用 |
| BRPI0913656A2 (pt) * | 2008-06-30 | 2019-09-24 | Oncotherapy Science Inc | anticorpos anti-cdh3 marcados com marcador radioisótopo e usos dos mesmos |
| US9207242B2 (en) * | 2008-10-09 | 2015-12-08 | The University Of Hong Kong | Cadherin-17 as diagnostic marker and therapeutic target for liver cancer |
| EA030182B1 (ru) | 2009-04-20 | 2018-07-31 | Оксфорд Байотерепьютикс Лтд. | Антитела, специфические для кадгерина-17 |
| US8815211B2 (en) * | 2010-02-10 | 2014-08-26 | Fujifilm Ri Pharma Co., Ltd. | Radioactive metal-labeled anti-cadherin antibody |
| RS57215B1 (sr) * | 2010-07-15 | 2018-07-31 | Adheron Therapeutics Inc | Humanizovana antitela koja ciljaju ec1 domen kadherina-11 i kompozicije i postupci koji su u vezi sa njima |
| AU2011318574B2 (en) * | 2010-10-20 | 2016-03-03 | Oxford Biotherapeutics Ltd. | Antibodies |
| CN107903325B (zh) * | 2011-05-16 | 2021-10-29 | 埃泰美德(香港)有限公司 | 多特异性fab融合蛋白及其使用方法 |
| JO3519B1 (ar) * | 2013-01-25 | 2020-07-05 | Amgen Inc | تركيبات أجسام مضادة لأجل cdh19 و cd3 |
| WO2014114801A1 (en) * | 2013-01-25 | 2014-07-31 | Amgen Inc. | Antibodies targeting cdh19 for melanoma |
| PE20210107A1 (es) * | 2013-12-17 | 2021-01-19 | Genentech Inc | Anticuerpos anti-cd3 y metodos de uso |
-
2017
- 2017-01-07 EP EP17736491.6A patent/EP3400013A4/en active Pending
- 2017-01-07 CN CN202111238599.9A patent/CN113912725B/zh active Active
- 2017-01-07 AU AU2017206089A patent/AU2017206089B2/en active Active
- 2017-01-07 CN CN202111238485.4A patent/CN113817060B/zh active Active
- 2017-01-07 KR KR1020187023033A patent/KR20180127966A/ko not_active Application Discontinuation
- 2017-01-07 WO PCT/US2017/012648 patent/WO2017120557A1/en active Application Filing
- 2017-01-07 US US16/068,665 patent/US11207419B2/en active Active
- 2017-01-07 JP JP2018554645A patent/JP6974348B2/ja active Active
- 2017-01-07 CN CN201780005758.6A patent/CN108778327B/zh active Active
- 2017-01-07 CN CN202111238201.1A patent/CN113817059B/zh active Active
-
2018
- 2018-07-08 IL IL260474A patent/IL260474B/en active IP Right Grant
-
2021
- 2021-11-04 JP JP2021179905A patent/JP7275232B2/ja active Active
-
2023
- 2023-05-02 JP JP2023075948A patent/JP2023109790A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| AU2017206089A1 (en) | 2018-08-30 |
| CN108778327B (zh) | 2021-11-05 |
| JP7275232B2 (ja) | 2023-05-17 |
| CN113912725A (zh) | 2022-01-11 |
| CN113912725B (zh) | 2024-03-08 |
| EP3400013A1 (en) | 2018-11-14 |
| EP3400013A4 (en) | 2019-09-11 |
| CN113817060B (zh) | 2024-03-08 |
| JP2023109790A (ja) | 2023-08-08 |
| IL260474B (en) | 2020-08-31 |
| WO2017120557A1 (en) | 2017-07-13 |
| CN113817059A (zh) | 2021-12-21 |
| JP2022036939A (ja) | 2022-03-08 |
| US11207419B2 (en) | 2021-12-28 |
| JP2019518721A (ja) | 2019-07-04 |
| JP6974348B2 (ja) | 2021-12-01 |
| CN108778327A (zh) | 2018-11-09 |
| AU2017206089B2 (en) | 2020-04-16 |
| CN113817059B (zh) | 2024-03-08 |
| CN113817060A (zh) | 2021-12-21 |
| US20190046655A1 (en) | 2019-02-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20240018257A1 (en) | Antibodies specific to human poliovirus receptor (pvr) | |
| EP3344658B1 (en) | Antibodies specific to human t-cell immunoglobulin and itim domain (tigit) | |
| JP7275232B2 (ja) | がん処置のためのカドヘリン-17特異的抗体及び細胞傷害性細胞 | |
| CN112512575A (zh) | 双特异性抗体组合物及其使用方法 | |
| JP6649941B2 (ja) | Fstl1を利用した抗がん剤・転移抑制剤およびその併用剤 | |
| CN114040927A (zh) | 结合cd33的多肽及其用途 | |
| WO2021079958A1 (ja) | 抗garp抗体と免疫調節剤の組み合わせ | |
| JP2024517986A (ja) | 抗-CD300c抗体を利用した併用療法 | |
| CA3218832A1 (en) | Combined therapy using anti-cd300c antibody | |
| JPWO2015108203A1 (ja) | 抗slc6a6抗体を用いたがん治療用医薬組成物 | |
| WO2022214681A1 (en) | Methods for the treatment of anaplastic large cell lymphoma | |
| JP2024517985A (ja) | 抗-CD300cモノクローナル抗体及びその癌の予防または治療用バイオマーカー | |
| JP2024515879A (ja) | 抗siglec組成物及びその使用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| N231 | Notification of change of applicant | ||
| E902 | Notification of reason for refusal |