KR20140114269A - 표적화된 과가수분해효소 - Google Patents
표적화된 과가수분해효소 Download PDFInfo
- Publication number
- KR20140114269A KR20140114269A KR1020137019093A KR20137019093A KR20140114269A KR 20140114269 A KR20140114269 A KR 20140114269A KR 1020137019093 A KR1020137019093 A KR 1020137019093A KR 20137019093 A KR20137019093 A KR 20137019093A KR 20140114269 A KR20140114269 A KR 20140114269A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- enzyme
- target surface
- group
- fusion protein
- Prior art date
Links
- 102000004190 Enzymes Human genes 0.000 claims abstract description 412
- 108090000790 Enzymes Proteins 0.000 claims abstract description 412
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 232
- 238000000034 method Methods 0.000 claims abstract description 117
- 108020001507 fusion proteins Proteins 0.000 claims abstract description 97
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 97
- 239000000463 material Substances 0.000 claims abstract description 69
- 239000000758 substrate Substances 0.000 claims abstract description 64
- 238000004519 manufacturing process Methods 0.000 claims abstract description 37
- 239000002253 acid Substances 0.000 claims abstract description 32
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 claims abstract description 28
- 229910052760 oxygen Inorganic materials 0.000 claims abstract description 27
- 239000001301 oxygen Substances 0.000 claims abstract description 27
- 238000004659 sterilization and disinfection Methods 0.000 claims abstract description 21
- 238000004332 deodorization Methods 0.000 claims abstract description 10
- 230000002087 whitening effect Effects 0.000 claims abstract description 8
- 238000010612 desalination reaction Methods 0.000 claims abstract description 6
- 229940088598 enzyme Drugs 0.000 claims description 409
- 230000003301 hydrolyzing effect Effects 0.000 claims description 208
- 230000027455 binding Effects 0.000 claims description 197
- 229920002678 cellulose Polymers 0.000 claims description 139
- 239000001913 cellulose Substances 0.000 claims description 138
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 109
- 108010080434 cephalosporin-C deacetylase Proteins 0.000 claims description 102
- 108090000623 proteins and genes Proteins 0.000 claims description 95
- 230000000694 effects Effects 0.000 claims description 85
- -1 polypropylene Polymers 0.000 claims description 82
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 80
- 108010093941 acetylxylan esterase Proteins 0.000 claims description 77
- 108090000371 Esterases Proteins 0.000 claims description 65
- 238000006243 chemical reaction Methods 0.000 claims description 64
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 61
- 150000004965 peroxy acids Chemical class 0.000 claims description 59
- 239000000843 powder Substances 0.000 claims description 59
- 150000001413 amino acids Chemical class 0.000 claims description 58
- 150000001720 carbohydrates Chemical class 0.000 claims description 57
- URAYPUMNDPQOKB-UHFFFAOYSA-N triacetin Chemical compound CC(=O)OCC(OC(C)=O)COC(C)=O URAYPUMNDPQOKB-UHFFFAOYSA-N 0.000 claims description 49
- 239000013077 target material Substances 0.000 claims description 43
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 43
- 125000002887 hydroxy group Chemical group [H]O* 0.000 claims description 42
- 102000004169 proteins and genes Human genes 0.000 claims description 38
- 229920000742 Cotton Polymers 0.000 claims description 32
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 claims description 32
- KFSLWBXXFJQRDL-UHFFFAOYSA-N Peracetic acid Chemical compound CC(=O)OO KFSLWBXXFJQRDL-UHFFFAOYSA-N 0.000 claims description 27
- 230000008901 benefit Effects 0.000 claims description 27
- 108010009043 arylesterase Proteins 0.000 claims description 26
- 102000028848 arylesterase Human genes 0.000 claims description 26
- 125000000229 (C1-C4)alkoxy group Chemical group 0.000 claims description 24
- 125000000217 alkyl group Chemical group 0.000 claims description 24
- 235000013773 glyceryl triacetate Nutrition 0.000 claims description 24
- 125000001072 heteroaryl group Chemical group 0.000 claims description 24
- 229920001184 polypeptide Polymers 0.000 claims description 23
- 229960002622 triacetin Drugs 0.000 claims description 23
- 241000193448 Ruminiclostridium thermocellum Species 0.000 claims description 21
- 239000001087 glyceryl triacetate Substances 0.000 claims description 21
- 125000006850 spacer group Chemical group 0.000 claims description 20
- 239000004743 Polypropylene Substances 0.000 claims description 19
- 229920001131 Pulp (paper) Polymers 0.000 claims description 19
- 229920001155 polypropylene Polymers 0.000 claims description 19
- 125000003118 aryl group Chemical group 0.000 claims description 18
- 244000063299 Bacillus subtilis Species 0.000 claims description 17
- 235000014469 Bacillus subtilis Nutrition 0.000 claims description 17
- 108091005804 Peptidases Proteins 0.000 claims description 17
- 239000004365 Protease Substances 0.000 claims description 17
- 125000004185 ester group Chemical group 0.000 claims description 16
- 239000007788 liquid Substances 0.000 claims description 16
- 241000193830 Bacillus <bacterium> Species 0.000 claims description 15
- 108060003951 Immunoglobulin Proteins 0.000 claims description 15
- 229910052799 carbon Inorganic materials 0.000 claims description 15
- 150000002148 esters Chemical class 0.000 claims description 15
- 102000018358 immunoglobulin Human genes 0.000 claims description 15
- 244000005700 microbiome Species 0.000 claims description 15
- 229920000728 polyester Polymers 0.000 claims description 15
- 241000588724 Escherichia coli Species 0.000 claims description 14
- 239000012634 fragment Substances 0.000 claims description 14
- 230000008569 process Effects 0.000 claims description 14
- 238000004061 bleaching Methods 0.000 claims description 13
- 239000002023 wood Substances 0.000 claims description 13
- 108010059892 Cellulase Proteins 0.000 claims description 12
- 108700016155 Acyl transferases Proteins 0.000 claims description 11
- 241000193403 Clostridium Species 0.000 claims description 11
- 102000004882 Lipase Human genes 0.000 claims description 11
- 108090001060 Lipase Proteins 0.000 claims description 11
- 239000004367 Lipase Substances 0.000 claims description 11
- 239000004793 Polystyrene Substances 0.000 claims description 11
- 125000004432 carbon atom Chemical group C* 0.000 claims description 11
- 229940106157 cellulase Drugs 0.000 claims description 11
- 235000019421 lipase Nutrition 0.000 claims description 11
- 150000002978 peroxides Chemical class 0.000 claims description 11
- 229920001282 polysaccharide Polymers 0.000 claims description 11
- 239000005017 polysaccharide Substances 0.000 claims description 11
- 150000004804 polysaccharides Chemical class 0.000 claims description 11
- 229920002223 polystyrene Polymers 0.000 claims description 11
- 102000057234 Acyl transferases Human genes 0.000 claims description 10
- 229930186147 Cephalosporin Natural products 0.000 claims description 10
- 229940124587 cephalosporin Drugs 0.000 claims description 10
- 150000001780 cephalosporins Chemical class 0.000 claims description 10
- 150000002016 disaccharides Chemical class 0.000 claims description 10
- 230000009467 reduction Effects 0.000 claims description 10
- 238000006722 reduction reaction Methods 0.000 claims description 10
- 230000001954 sterilising effect Effects 0.000 claims description 10
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 9
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 9
- 239000004698 Polyethylene Substances 0.000 claims description 9
- 241000204666 Thermotoga maritima Species 0.000 claims description 9
- 229920002301 cellulose acetate Polymers 0.000 claims description 9
- 238000002156 mixing Methods 0.000 claims description 9
- 229920000573 polyethylene Polymers 0.000 claims description 9
- 239000004952 Polyamide Substances 0.000 claims description 8
- 125000003342 alkenyl group Chemical group 0.000 claims description 8
- 125000002877 alkyl aryl group Chemical group 0.000 claims description 8
- 125000005213 alkyl heteroaryl group Chemical group 0.000 claims description 8
- 125000000304 alkynyl group Chemical group 0.000 claims description 8
- 125000002843 carboxylic acid group Chemical group 0.000 claims description 8
- 229910052739 hydrogen Inorganic materials 0.000 claims description 8
- 229920003229 poly(methyl methacrylate) Polymers 0.000 claims description 8
- 229920002647 polyamide Polymers 0.000 claims description 8
- 239000004926 polymethyl methacrylate Substances 0.000 claims description 8
- 229920000433 Lyocell Polymers 0.000 claims description 7
- 229920000297 Rayon Polymers 0.000 claims description 7
- 239000002964 rayon Substances 0.000 claims description 7
- 101710126783 Acetyl-hydrolase Proteins 0.000 claims description 6
- 230000000249 desinfective effect Effects 0.000 claims description 6
- 229920001343 polytetrafluoroethylene Polymers 0.000 claims description 5
- 239000004810 polytetrafluoroethylene Substances 0.000 claims description 5
- 238000011012 sanitization Methods 0.000 claims description 4
- 241000282832 Camelidae Species 0.000 claims description 3
- 241000894007 species Species 0.000 claims description 3
- 241000178335 Caldicellulosiruptor saccharolyticus Species 0.000 claims description 2
- 230000001877 deodorizing effect Effects 0.000 claims description 2
- 230000008030 elimination Effects 0.000 claims description 2
- 238000003379 elimination reaction Methods 0.000 claims description 2
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 claims 4
- 108010013043 Acetylesterase Proteins 0.000 claims 1
- 208000035484 Cellulite Diseases 0.000 claims 1
- 241000193169 Clostridium cellulovorans Species 0.000 claims 1
- 102000006395 Globulins Human genes 0.000 claims 1
- 108010044091 Globulins Proteins 0.000 claims 1
- 206010049752 Peau d'orange Diseases 0.000 claims 1
- 230000036232 cellulite Effects 0.000 claims 1
- 239000008187 granular material Substances 0.000 claims 1
- 239000000203 mixture Substances 0.000 abstract description 146
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 abstract description 64
- 239000003795 chemical substances by application Substances 0.000 abstract description 24
- 230000008685 targeting Effects 0.000 abstract description 17
- 238000004042 decolorization Methods 0.000 abstract description 12
- 235000010980 cellulose Nutrition 0.000 description 130
- 102000004157 Hydrolases Human genes 0.000 description 90
- 108090000604 Hydrolases Proteins 0.000 description 90
- 210000004027 cell Anatomy 0.000 description 66
- 238000009472 formulation Methods 0.000 description 65
- 150000007523 nucleic acids Chemical group 0.000 description 58
- 150000001733 carboxylic acid esters Chemical class 0.000 description 53
- 235000001014 amino acid Nutrition 0.000 description 52
- 229940024606 amino acid Drugs 0.000 description 51
- 239000003054 catalyst Substances 0.000 description 42
- 108091028043 Nucleic acid sequence Proteins 0.000 description 36
- 235000018102 proteins Nutrition 0.000 description 36
- SCKXCAADGDQQCS-UHFFFAOYSA-N Performic acid Chemical compound OOC=O SCKXCAADGDQQCS-UHFFFAOYSA-N 0.000 description 35
- 230000004927 fusion Effects 0.000 description 34
- 239000004744 fabric Substances 0.000 description 32
- 235000014633 carbohydrates Nutrition 0.000 description 31
- 230000014509 gene expression Effects 0.000 description 30
- 229960002163 hydrogen peroxide Drugs 0.000 description 30
- 239000000243 solution Substances 0.000 description 30
- 239000000872 buffer Substances 0.000 description 29
- 102000039446 nucleic acids Human genes 0.000 description 28
- 108020004707 nucleic acids Proteins 0.000 description 28
- 239000000047 product Substances 0.000 description 28
- 239000002773 nucleotide Substances 0.000 description 26
- 125000003729 nucleotide group Chemical group 0.000 description 26
- 239000000546 pharmaceutical excipient Substances 0.000 description 24
- 239000000835 fiber Substances 0.000 description 21
- 108091026890 Coding region Proteins 0.000 description 20
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 20
- 239000004753 textile Substances 0.000 description 20
- 108020004414 DNA Proteins 0.000 description 19
- 238000006460 hydrolysis reaction Methods 0.000 description 19
- 239000000123 paper Substances 0.000 description 17
- 230000000813 microbial effect Effects 0.000 description 16
- 229920001542 oligosaccharide Polymers 0.000 description 16
- 150000002482 oligosaccharides Chemical class 0.000 description 16
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 15
- 239000000284 extract Substances 0.000 description 15
- 230000007062 hydrolysis Effects 0.000 description 15
- 238000003860 storage Methods 0.000 description 15
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 15
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 14
- 102000035195 Peptidases Human genes 0.000 description 13
- 108700005078 Synthetic Genes Proteins 0.000 description 13
- 125000000539 amino acid group Chemical group 0.000 description 13
- 238000005119 centrifugation Methods 0.000 description 13
- 230000002255 enzymatic effect Effects 0.000 description 13
- 239000000523 sample Substances 0.000 description 13
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 12
- 239000000356 contaminant Substances 0.000 description 12
- 230000001105 regulatory effect Effects 0.000 description 12
- 238000006467 substitution reaction Methods 0.000 description 12
- 229920002994 synthetic fiber Polymers 0.000 description 12
- 108010053835 Catalase Proteins 0.000 description 11
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 11
- UYXTWWCETRIEDR-UHFFFAOYSA-N Tributyrin Chemical compound CCCC(=O)OCC(OC(=O)CCC)COC(=O)CCC UYXTWWCETRIEDR-UHFFFAOYSA-N 0.000 description 11
- 150000007513 acids Chemical class 0.000 description 11
- 238000007792 addition Methods 0.000 description 11
- 102220500059 eIF5-mimic protein 2_S54V_mutation Human genes 0.000 description 11
- 238000004128 high performance liquid chromatography Methods 0.000 description 11
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 11
- 239000000126 substance Substances 0.000 description 11
- 239000013598 vector Substances 0.000 description 11
- 101100166239 Caenorhabditis elegans cbd-1 gene Proteins 0.000 description 10
- 241000589540 Pseudomonas fluorescens Species 0.000 description 10
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 10
- 229920000642 polymer Polymers 0.000 description 10
- 239000011734 sodium Substances 0.000 description 10
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 9
- KMZHZAAOEWVPSE-UHFFFAOYSA-N 2,3-dihydroxypropyl acetate Chemical compound CC(=O)OCC(O)CO KMZHZAAOEWVPSE-UHFFFAOYSA-N 0.000 description 9
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 9
- 102000016938 Catalase Human genes 0.000 description 9
- 108020004705 Codon Proteins 0.000 description 9
- 239000004348 Glyceryl diacetate Substances 0.000 description 9
- 239000007864 aqueous solution Substances 0.000 description 9
- 150000001721 carbon Chemical group 0.000 description 9
- 239000003599 detergent Substances 0.000 description 9
- 235000019443 glyceryl diacetate Nutrition 0.000 description 9
- 210000004209 hair Anatomy 0.000 description 9
- 239000013612 plasmid Substances 0.000 description 9
- 239000007787 solid Substances 0.000 description 9
- JTXMVXSTHSMVQF-UHFFFAOYSA-N 2-acetyloxyethyl acetate Chemical compound CC(=O)OCCOC(C)=O JTXMVXSTHSMVQF-UHFFFAOYSA-N 0.000 description 8
- BVKZGUZCCUSVTD-UHFFFAOYSA-M Bicarbonate Chemical compound OC([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-M 0.000 description 8
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 8
- 239000004599 antimicrobial Substances 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 230000009286 beneficial effect Effects 0.000 description 8
- 239000006172 buffering agent Substances 0.000 description 8
- 230000003197 catalytic effect Effects 0.000 description 8
- 238000004140 cleaning Methods 0.000 description 8
- 238000009396 hybridization Methods 0.000 description 8
- DNIAPMSPPWPWGF-UHFFFAOYSA-N monopropylene glycol Natural products CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 8
- 229920001778 nylon Polymers 0.000 description 8
- 108091033319 polynucleotide Proteins 0.000 description 8
- 102000040430 polynucleotide Human genes 0.000 description 8
- 239000002157 polynucleotide Substances 0.000 description 8
- 238000000746 purification Methods 0.000 description 8
- QZAYGJVTTNCVMB-UHFFFAOYSA-N serotonin Chemical compound C1=C(O)C=C2C(CCN)=CNC2=C1 QZAYGJVTTNCVMB-UHFFFAOYSA-N 0.000 description 8
- 229910052708 sodium Inorganic materials 0.000 description 8
- 239000013076 target substance Substances 0.000 description 8
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 7
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 7
- 239000004677 Nylon Substances 0.000 description 7
- 229910019142 PO4 Inorganic materials 0.000 description 7
- 239000004480 active ingredient Substances 0.000 description 7
- 230000003115 biocidal effect Effects 0.000 description 7
- 235000011180 diphosphates Nutrition 0.000 description 7
- 235000013305 food Nutrition 0.000 description 7
- 235000011187 glycerol Nutrition 0.000 description 7
- 125000001183 hydrocarbyl group Chemical group 0.000 description 7
- 150000002772 monosaccharides Chemical class 0.000 description 7
- 235000021317 phosphate Nutrition 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- 102200025795 rs179363879 Human genes 0.000 description 7
- 239000004094 surface-active agent Substances 0.000 description 7
- 239000012209 synthetic fiber Substances 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 6
- 241000194110 Bacillus sp. (in: Bacteria) Species 0.000 description 6
- 241000894006 Bacteria Species 0.000 description 6
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 6
- 239000007983 Tris buffer Substances 0.000 description 6
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 210000004899 c-terminal region Anatomy 0.000 description 6
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical compound [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- VZCYOOQTPOCHFL-OWOJBTEDSA-L fumarate(2-) Chemical compound [O-]C(=O)\C=C\C([O-])=O VZCYOOQTPOCHFL-OWOJBTEDSA-L 0.000 description 6
- 230000012010 growth Effects 0.000 description 6
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 6
- 230000001965 increasing effect Effects 0.000 description 6
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 6
- 239000003960 organic solvent Substances 0.000 description 6
- 239000008188 pellet Substances 0.000 description 6
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 6
- 239000010452 phosphate Substances 0.000 description 6
- 239000011780 sodium chloride Substances 0.000 description 6
- 210000001519 tissue Anatomy 0.000 description 6
- YZWRNSARCRTXDS-UHFFFAOYSA-N tripropionin Chemical compound CCC(=O)OCC(OC(=O)CC)COC(=O)CC YZWRNSARCRTXDS-UHFFFAOYSA-N 0.000 description 6
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 6
- 229920001221 xylan Polymers 0.000 description 6
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 5
- 239000005913 Maltodextrin Substances 0.000 description 5
- 229920002774 Maltodextrin Polymers 0.000 description 5
- 241000186359 Mycobacterium Species 0.000 description 5
- MLHOXUWWKVQEJB-UHFFFAOYSA-N Propyleneglycol diacetate Chemical compound CC(=O)OC(C)COC(C)=O MLHOXUWWKVQEJB-UHFFFAOYSA-N 0.000 description 5
- 241000589516 Pseudomonas Species 0.000 description 5
- 244000057717 Streptococcus lactis Species 0.000 description 5
- 235000014897 Streptococcus lactis Nutrition 0.000 description 5
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 5
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 5
- 238000004422 calculation algorithm Methods 0.000 description 5
- 230000008859 change Effects 0.000 description 5
- 239000006184 cosolvent Substances 0.000 description 5
- 230000007423 decrease Effects 0.000 description 5
- UYAAVKFHBMJOJZ-UHFFFAOYSA-N diimidazo[1,3-b:1',3'-e]pyrazine-5,10-dione Chemical compound O=C1C2=CN=CN2C(=O)C2=CN=CN12 UYAAVKFHBMJOJZ-UHFFFAOYSA-N 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 238000000855 fermentation Methods 0.000 description 5
- 230000004151 fermentation Effects 0.000 description 5
- CBEQRNSPHCCXSH-UHFFFAOYSA-N iodine monobromide Chemical compound IBr CBEQRNSPHCCXSH-UHFFFAOYSA-N 0.000 description 5
- 229940035034 maltodextrin Drugs 0.000 description 5
- RIEABXYBQSLTFR-UHFFFAOYSA-N monobutyrin Chemical compound CCCC(=O)OCC(O)CO RIEABXYBQSLTFR-UHFFFAOYSA-N 0.000 description 5
- 239000002245 particle Substances 0.000 description 5
- 238000002823 phage display Methods 0.000 description 5
- 159000000001 potassium salts Chemical class 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 229940116423 propylene glycol diacetate Drugs 0.000 description 5
- 239000011541 reaction mixture Substances 0.000 description 5
- 238000011084 recovery Methods 0.000 description 5
- 239000002002 slurry Substances 0.000 description 5
- KDYFGRWQOYBRFD-UHFFFAOYSA-L succinate(2-) Chemical compound [O-]C(=O)CCC([O-])=O KDYFGRWQOYBRFD-UHFFFAOYSA-L 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 150000004823 xylans Chemical class 0.000 description 5
- 125000005023 xylyl group Chemical group 0.000 description 5
- PUPZLCDOIYMWBV-UHFFFAOYSA-N (+/-)-1,3-Butanediol Chemical compound CC(O)CCO PUPZLCDOIYMWBV-UHFFFAOYSA-N 0.000 description 4
- KBPLFHHGFOOTCA-UHFFFAOYSA-N 1-Octanol Chemical compound CCCCCCCCO KBPLFHHGFOOTCA-UHFFFAOYSA-N 0.000 description 4
- KAKZBPTYRLMSJV-UHFFFAOYSA-N Butadiene Chemical compound C=CC=C KAKZBPTYRLMSJV-UHFFFAOYSA-N 0.000 description 4
- 229920003043 Cellulose fiber Polymers 0.000 description 4
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 241000235648 Pichia Species 0.000 description 4
- PXIPVTKHYLBLMZ-UHFFFAOYSA-N Sodium azide Chemical compound [Na+].[N-]=[N+]=[N-] PXIPVTKHYLBLMZ-UHFFFAOYSA-N 0.000 description 4
- 241000204652 Thermotoga Species 0.000 description 4
- LLPWGHLVUPBSLP-IJLUTSLNSA-N [(2r,3r,4r)-3,4-diacetyloxy-3,4-dihydro-2h-pyran-2-yl]methyl acetate Chemical compound CC(=O)OC[C@H]1OC=C[C@@H](OC(C)=O)[C@H]1OC(C)=O LLPWGHLVUPBSLP-IJLUTSLNSA-N 0.000 description 4
- LLPWGHLVUPBSLP-UTUOFQBUSA-N [(2r,3s,4r)-3,4-diacetyloxy-3,4-dihydro-2h-pyran-2-yl]methyl acetate Chemical compound CC(=O)OC[C@H]1OC=C[C@@H](OC(C)=O)[C@@H]1OC(C)=O LLPWGHLVUPBSLP-UTUOFQBUSA-N 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 4
- 239000003139 biocide Substances 0.000 description 4
- 229960000074 biopharmaceutical Drugs 0.000 description 4
- WERYXYBDKMZEQL-UHFFFAOYSA-N butane-1,4-diol Chemical compound OCCCCO WERYXYBDKMZEQL-UHFFFAOYSA-N 0.000 description 4
- 229920001577 copolymer Polymers 0.000 description 4
- 230000001461 cytolytic effect Effects 0.000 description 4
- 238000005202 decontamination Methods 0.000 description 4
- 230000003588 decontaminative effect Effects 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- 239000000645 desinfectant Substances 0.000 description 4
- 238000010494 dissociation reaction Methods 0.000 description 4
- 230000005593 dissociations Effects 0.000 description 4
- 239000013604 expression vector Substances 0.000 description 4
- 239000008103 glucose Substances 0.000 description 4
- 229960001031 glucose Drugs 0.000 description 4
- WQYVRQLZKVEZGA-UHFFFAOYSA-N hypochlorite Chemical compound Cl[O-] WQYVRQLZKVEZGA-UHFFFAOYSA-N 0.000 description 4
- 239000004615 ingredient Substances 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 4
- 239000008363 phosphate buffer Substances 0.000 description 4
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 4
- XAEFZNCEHLXOMS-UHFFFAOYSA-M potassium benzoate Chemical compound [K+].[O-]C(=O)C1=CC=CC=C1 XAEFZNCEHLXOMS-UHFFFAOYSA-M 0.000 description 4
- 235000013772 propylene glycol Nutrition 0.000 description 4
- 229940076279 serotonin Drugs 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 238000009987 spinning Methods 0.000 description 4
- 239000007921 spray Substances 0.000 description 4
- 239000003381 stabilizer Substances 0.000 description 4
- 238000013518 transcription Methods 0.000 description 4
- 230000035897 transcription Effects 0.000 description 4
- 238000011282 treatment Methods 0.000 description 4
- AQLJVWUFPCUVLO-UHFFFAOYSA-N urea hydrogen peroxide Chemical class OO.NC(N)=O AQLJVWUFPCUVLO-UHFFFAOYSA-N 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- KBWFWZJNPVZRRG-UHFFFAOYSA-N 1,3-dibutyrin Chemical compound CCCC(=O)OCC(O)COC(=O)CCC KBWFWZJNPVZRRG-UHFFFAOYSA-N 0.000 description 3
- HMFKFHLTUCJZJO-UHFFFAOYSA-N 2-{2-[3,4-bis(2-hydroxyethoxy)oxolan-2-yl]-2-(2-hydroxyethoxy)ethoxy}ethyl dodecanoate Chemical compound CCCCCCCCCCCC(=O)OCCOCC(OCCO)C1OCC(OCCO)C1OCCO HMFKFHLTUCJZJO-UHFFFAOYSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 3
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 3
- 229940123748 Catalase inhibitor Drugs 0.000 description 3
- 108700010070 Codon Usage Proteins 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 241000588722 Escherichia Species 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- UXDDRFCJKNROTO-UHFFFAOYSA-N Glycerol 1,2-diacetate Chemical compound CC(=O)OCC(CO)OC(C)=O UXDDRFCJKNROTO-UHFFFAOYSA-N 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- 102000016943 Muramidase Human genes 0.000 description 3
- 108010014251 Muramidase Proteins 0.000 description 3
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- 241000316848 Rhodococcus <scale insect> Species 0.000 description 3
- 241000235070 Saccharomyces Species 0.000 description 3
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 3
- 241000999856 Thermotoga maritima MSB8 Species 0.000 description 3
- IHNHAHWGVLXCCI-FDYHWXHSSA-N [(2r,3r,4r,5s)-3,4,5-triacetyloxyoxolan-2-yl]methyl acetate Chemical compound CC(=O)OC[C@H]1O[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@@H]1OC(C)=O IHNHAHWGVLXCCI-FDYHWXHSSA-N 0.000 description 3
- 238000002835 absorbance Methods 0.000 description 3
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 3
- 230000002411 adverse Effects 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- 125000001931 aliphatic group Chemical group 0.000 description 3
- 150000007860 aryl ester derivatives Chemical class 0.000 description 3
- 238000000889 atomisation Methods 0.000 description 3
- 238000002819 bacterial display Methods 0.000 description 3
- 229940098773 bovine serum albumin Drugs 0.000 description 3
- 230000003139 buffering effect Effects 0.000 description 3
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 239000013043 chemical agent Substances 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 125000004122 cyclic group Chemical group 0.000 description 3
- 230000006378 damage Effects 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 239000008367 deionised water Substances 0.000 description 3
- 235000014113 dietary fatty acids Nutrition 0.000 description 3
- 238000002845 discoloration Methods 0.000 description 3
- 235000019441 ethanol Nutrition 0.000 description 3
- 239000000194 fatty acid Substances 0.000 description 3
- 229930195729 fatty acid Natural products 0.000 description 3
- 238000011010 flushing procedure Methods 0.000 description 3
- 238000011065 in-situ storage Methods 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 230000002147 killing effect Effects 0.000 description 3
- 239000004325 lysozyme Substances 0.000 description 3
- 229960000274 lysozyme Drugs 0.000 description 3
- 235000010335 lysozyme Nutrition 0.000 description 3
- 238000002824 mRNA display Methods 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 238000005374 membrane filtration Methods 0.000 description 3
- 230000003647 oxidation Effects 0.000 description 3
- 238000007254 oxidation reaction Methods 0.000 description 3
- 238000004806 packaging method and process Methods 0.000 description 3
- GLOBUAZSRIOKLN-UHFFFAOYSA-N pentane-1,4-diol Chemical compound CC(O)CCCO GLOBUAZSRIOKLN-UHFFFAOYSA-N 0.000 description 3
- 235000013594 poultry meat Nutrition 0.000 description 3
- 238000002818 protein evolution Methods 0.000 description 3
- 239000000376 reactant Substances 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- 238000002702 ribosome display Methods 0.000 description 3
- 102200010049 rs869025189 Human genes 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 238000001694 spray drying Methods 0.000 description 3
- 238000005507 spraying Methods 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 201000008827 tuberculosis Diseases 0.000 description 3
- 235000013311 vegetables Nutrition 0.000 description 3
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 2
- DNIAPMSPPWPWGF-VKHMYHEASA-N (+)-propylene glycol Chemical compound C[C@H](O)CO DNIAPMSPPWPWGF-VKHMYHEASA-N 0.000 description 2
- DNIAPMSPPWPWGF-GSVOUGTGSA-N (R)-(-)-Propylene glycol Chemical compound C[C@@H](O)CO DNIAPMSPPWPWGF-GSVOUGTGSA-N 0.000 description 2
- 229940015975 1,2-hexanediol Drugs 0.000 description 2
- YPFDHNVEDLHUCE-UHFFFAOYSA-N 1,3-propanediol Substances OCCCO YPFDHNVEDLHUCE-UHFFFAOYSA-N 0.000 description 2
- ARXJGSRGQADJSQ-UHFFFAOYSA-N 1-methoxypropan-2-ol Chemical compound COCC(C)O ARXJGSRGQADJSQ-UHFFFAOYSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- DBTMGCOVALSLOR-UHFFFAOYSA-N 32-alpha-galactosyl-3-alpha-galactosyl-galactose Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(OC2C(C(CO)OC(O)C2O)O)OC(CO)C1O DBTMGCOVALSLOR-UHFFFAOYSA-N 0.000 description 2
- ZNBNBTIDJSKEAM-UHFFFAOYSA-N 4-[7-hydroxy-2-[5-[5-[6-hydroxy-6-(hydroxymethyl)-3,5-dimethyloxan-2-yl]-3-methyloxolan-2-yl]-5-methyloxolan-2-yl]-2,8-dimethyl-1,10-dioxaspiro[4.5]decan-9-yl]-2-methyl-3-propanoyloxypentanoic acid Chemical compound C1C(O)C(C)C(C(C)C(OC(=O)CC)C(C)C(O)=O)OC11OC(C)(C2OC(C)(CC2)C2C(CC(O2)C2C(CC(C)C(O)(CO)O2)C)C)CC1 ZNBNBTIDJSKEAM-UHFFFAOYSA-N 0.000 description 2
- HGINCPLSRVDWNT-UHFFFAOYSA-N Acrolein Chemical compound C=CC=O HGINCPLSRVDWNT-UHFFFAOYSA-N 0.000 description 2
- NLHHRLWOUZZQLW-UHFFFAOYSA-N Acrylonitrile Chemical compound C=CC#N NLHHRLWOUZZQLW-UHFFFAOYSA-N 0.000 description 2
- 241000589158 Agrobacterium Species 0.000 description 2
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 2
- 241000228212 Aspergillus Species 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 241000186146 Brevibacterium Species 0.000 description 2
- 101800001415 Bri23 peptide Proteins 0.000 description 2
- 101800000655 C-terminal peptide Proteins 0.000 description 2
- 102400000107 C-terminal peptide Human genes 0.000 description 2
- 101100283604 Caenorhabditis elegans pigk-1 gene Proteins 0.000 description 2
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- NHYCGSASNAIGLD-UHFFFAOYSA-N Chlorine monoxide Chemical compound Cl[O] NHYCGSASNAIGLD-UHFFFAOYSA-N 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- 101710132690 Endo-1,4-beta-xylanase A Proteins 0.000 description 2
- 101710156496 Endoglucanase A Proteins 0.000 description 2
- 108010074124 Escherichia coli Proteins Proteins 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- AALUCPRYHRPMAG-UHFFFAOYSA-N Glycerol 1-propanoate Chemical compound CCC(=O)OCC(O)CO AALUCPRYHRPMAG-UHFFFAOYSA-N 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- KFZMGEQAYNKOFK-UHFFFAOYSA-N Isopropanol Chemical compound CC(C)O KFZMGEQAYNKOFK-UHFFFAOYSA-N 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- 125000000998 L-alanino group Chemical group [H]N([*])[C@](C([H])([H])[H])([H])C(=O)O[H] 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- FEWJPZIEWOKRBE-JCYAYHJZSA-L L-tartrate(2-) Chemical class [O-]C(=O)[C@H](O)[C@@H](O)C([O-])=O FEWJPZIEWOKRBE-JCYAYHJZSA-L 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 229930195725 Mannitol Natural products 0.000 description 2
- 241000187480 Mycobacterium smegmatis Species 0.000 description 2
- MMOXZBCLCQITDF-UHFFFAOYSA-N N,N-diethyl-m-toluamide Chemical compound CCN(CC)C(=O)C1=CC=CC(C)=C1 MMOXZBCLCQITDF-UHFFFAOYSA-N 0.000 description 2
- CBENFWSGALASAD-UHFFFAOYSA-N Ozone Chemical compound [O-][O+]=O CBENFWSGALASAD-UHFFFAOYSA-N 0.000 description 2
- 241001542817 Phaffia Species 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- 229920001214 Polysorbate 60 Polymers 0.000 description 2
- 102000029797 Prion Human genes 0.000 description 2
- 108091000054 Prion Proteins 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- MUPFEKGTMRGPLJ-RMMQSMQOSA-N Raffinose Natural products O(C[C@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](O[C@@]2(CO)[C@H](O)[C@@H](O)[C@@H](CO)O2)O1)[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 MUPFEKGTMRGPLJ-RMMQSMQOSA-N 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 241000607142 Salmonella Species 0.000 description 2
- 238000012300 Sequence Analysis Methods 0.000 description 2
- 241000736131 Sphingomonas Species 0.000 description 2
- 241000187747 Streptomyces Species 0.000 description 2
- PPBRXRYQALVLMV-UHFFFAOYSA-N Styrene Chemical compound C=CC1=CC=CC=C1 PPBRXRYQALVLMV-UHFFFAOYSA-N 0.000 description 2
- 108090000787 Subtilisin Proteins 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- ZIJKGAXBCRWEOL-SAXBRCJISA-N Sucrose octaacetate Chemical compound CC(=O)O[C@H]1[C@H](OC(C)=O)[C@@H](COC(=O)C)O[C@@]1(COC(C)=O)O[C@@H]1[C@H](OC(C)=O)[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@@H](COC(C)=O)O1 ZIJKGAXBCRWEOL-SAXBRCJISA-N 0.000 description 2
- 241001137870 Thermoanaerobacterium Species 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 2
- 241000223259 Trichoderma Species 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- MUPFEKGTMRGPLJ-UHFFFAOYSA-N UNPD196149 Natural products OC1C(O)C(CO)OC1(CO)OC1C(O)C(O)C(O)C(COC2C(C(O)C(O)C(CO)O2)O)O1 MUPFEKGTMRGPLJ-UHFFFAOYSA-N 0.000 description 2
- 240000000851 Vaccinium corymbosum Species 0.000 description 2
- 235000003095 Vaccinium corymbosum Nutrition 0.000 description 2
- 235000017537 Vaccinium myrtillus Nutrition 0.000 description 2
- 239000001083 [(2R,3R,4S,5R)-1,2,4,5-tetraacetyloxy-6-oxohexan-3-yl] acetate Substances 0.000 description 2
- 239000001344 [(2S,3S,4R,5R)-4-acetyloxy-2,5-bis(acetyloxymethyl)-2-[(2R,3R,4S,5R,6R)-3,4,5-triacetyloxy-6-(acetyloxymethyl)oxan-2-yl]oxyoxolan-3-yl] acetate Substances 0.000 description 2
- UAOKXEHOENRFMP-ZJIFWQFVSA-N [(2r,3r,4s,5r)-2,3,4,5-tetraacetyloxy-6-oxohexyl] acetate Chemical compound CC(=O)OC[C@@H](OC(C)=O)[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@@H](OC(C)=O)C=O UAOKXEHOENRFMP-ZJIFWQFVSA-N 0.000 description 2
- 238000010306 acid treatment Methods 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 239000012062 aqueous buffer Substances 0.000 description 2
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 2
- 239000012131 assay buffer Substances 0.000 description 2
- OHDRQQURAXLVGJ-HLVWOLMTSA-N azane;(2e)-3-ethyl-2-[(e)-(3-ethyl-6-sulfo-1,3-benzothiazol-2-ylidene)hydrazinylidene]-1,3-benzothiazole-6-sulfonic acid Chemical compound [NH4+].[NH4+].S/1C2=CC(S([O-])(=O)=O)=CC=C2N(CC)C\1=N/N=C1/SC2=CC(S([O-])(=O)=O)=CC=C2N1CC OHDRQQURAXLVGJ-HLVWOLMTSA-N 0.000 description 2
- 239000012148 binding buffer Substances 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 235000021014 blueberries Nutrition 0.000 description 2
- DKSMCEUSSQTGBK-UHFFFAOYSA-N bromous acid Chemical compound OBr=O DKSMCEUSSQTGBK-UHFFFAOYSA-N 0.000 description 2
- BMRWNKZVCUKKSR-UHFFFAOYSA-N butane-1,2-diol Chemical compound CCC(O)CO BMRWNKZVCUKKSR-UHFFFAOYSA-N 0.000 description 2
- OWBTYPJTUOEWEK-UHFFFAOYSA-N butane-2,3-diol Chemical compound CC(O)C(C)O OWBTYPJTUOEWEK-UHFFFAOYSA-N 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 238000005251 capillar electrophoresis Methods 0.000 description 2
- 229940078916 carbamide peroxide Drugs 0.000 description 2
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 2
- HOKIDJSKDBPKTQ-GLXFQSAKSA-N cephalosporin C Chemical compound S1CC(COC(=O)C)=C(C(O)=O)N2C(=O)[C@@H](NC(=O)CCC[C@@H](N)C(O)=O)[C@@H]12 HOKIDJSKDBPKTQ-GLXFQSAKSA-N 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 238000000576 coating method Methods 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 238000013329 compounding Methods 0.000 description 2
- 238000012136 culture method Methods 0.000 description 2
- JHIVVAPYMSGYDF-UHFFFAOYSA-N cyclohexanone Chemical compound O=C1CCCCC1 JHIVVAPYMSGYDF-UHFFFAOYSA-N 0.000 description 2
- 229910021641 deionized water Inorganic materials 0.000 description 2
- 150000005690 diesters Chemical class 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- OSVXSBDYLRYLIG-UHFFFAOYSA-N dioxidochlorine(.) Chemical compound O=Cl=O OSVXSBDYLRYLIG-UHFFFAOYSA-N 0.000 description 2
- 238000007598 dipping method Methods 0.000 description 2
- 239000002270 dispersing agent Substances 0.000 description 2
- 238000004090 dissolution Methods 0.000 description 2
- 239000011363 dried mixture Substances 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 229960001484 edetic acid Drugs 0.000 description 2
- 235000013399 edible fruits Nutrition 0.000 description 2
- 230000007071 enzymatic hydrolysis Effects 0.000 description 2
- 238000006047 enzymatic hydrolysis reaction Methods 0.000 description 2
- 238000001952 enzyme assay Methods 0.000 description 2
- 238000011067 equilibration Methods 0.000 description 2
- 239000006167 equilibration buffer Substances 0.000 description 2
- LZCLXQDLBQLTDK-UHFFFAOYSA-N ethyl 2-hydroxypropanoate Chemical compound CCOC(=O)C(C)O LZCLXQDLBQLTDK-UHFFFAOYSA-N 0.000 description 2
- OMSUIQOIVADKIM-UHFFFAOYSA-N ethyl 3-hydroxybutyrate Chemical compound CCOC(=O)CC(C)O OMSUIQOIVADKIM-UHFFFAOYSA-N 0.000 description 2
- 235000012055 fruits and vegetables Nutrition 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 238000004817 gas chromatography Methods 0.000 description 2
- 125000003976 glyceryl group Chemical group [H]C([*])([H])C(O[H])([H])C(O[H])([H])[H] 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 238000010438 heat treatment Methods 0.000 description 2
- FHKSXSQHXQEMOK-UHFFFAOYSA-N hexane-1,2-diol Chemical compound CCCCC(O)CO FHKSXSQHXQEMOK-UHFFFAOYSA-N 0.000 description 2
- XXMIOPMDWAUFGU-UHFFFAOYSA-N hexane-1,6-diol Chemical compound OCCCCCCO XXMIOPMDWAUFGU-UHFFFAOYSA-N 0.000 description 2
- OHMBHFSEKCCCBW-UHFFFAOYSA-N hexane-2,5-diol Chemical compound CC(O)CCC(C)O OHMBHFSEKCCCBW-UHFFFAOYSA-N 0.000 description 2
- 229910000378 hydroxylammonium sulfate Inorganic materials 0.000 description 2
- QWPPOHNGKGFGJK-UHFFFAOYSA-N hypochlorous acid Chemical compound ClO QWPPOHNGKGFGJK-UHFFFAOYSA-N 0.000 description 2
- 239000003622 immobilized catalyst Substances 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 238000004900 laundering Methods 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 239000012139 lysis buffer Substances 0.000 description 2
- 239000000594 mannitol Substances 0.000 description 2
- 235000010355 mannitol Nutrition 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- VNWKTOKETHGBQD-UHFFFAOYSA-N methane Chemical compound C VNWKTOKETHGBQD-UHFFFAOYSA-N 0.000 description 2
- VHILIAIEEYLJNA-UHFFFAOYSA-N methyl p-tolyl sulfide Chemical compound CSC1=CC=C(C)C=C1 VHILIAIEEYLJNA-UHFFFAOYSA-N 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 239000004745 nonwoven fabric Substances 0.000 description 2
- 238000007899 nucleic acid hybridization Methods 0.000 description 2
- 235000015097 nutrients Nutrition 0.000 description 2
- 150000002894 organic compounds Chemical class 0.000 description 2
- 150000002927 oxygen compounds Chemical class 0.000 description 2
- 238000010422 painting Methods 0.000 description 2
- 230000001717 pathogenic effect Effects 0.000 description 2
- WCVRQHFDJLLWFE-UHFFFAOYSA-N pentane-1,2-diol Chemical compound CCCC(O)CO WCVRQHFDJLLWFE-UHFFFAOYSA-N 0.000 description 2
- 229920005862 polyol Polymers 0.000 description 2
- 229920000098 polyolefin Polymers 0.000 description 2
- 150000003077 polyols Chemical class 0.000 description 2
- 229920000166 polytrimethylene carbonate Polymers 0.000 description 2
- 229920002635 polyurethane Polymers 0.000 description 2
- 239000004814 polyurethane Substances 0.000 description 2
- 239000008057 potassium phosphate buffer Substances 0.000 description 2
- 244000144977 poultry Species 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 235000004252 protein component Nutrition 0.000 description 2
- MUPFEKGTMRGPLJ-ZQSKZDJDSA-N raffinose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO[C@@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)O)O1 MUPFEKGTMRGPLJ-ZQSKZDJDSA-N 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 108010038196 saccharide-binding proteins Proteins 0.000 description 2
- 238000000527 sonication Methods 0.000 description 2
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 2
- 229960000268 spectinomycin Drugs 0.000 description 2
- 230000002269 spontaneous effect Effects 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- 229940013883 sucrose octaacetate Drugs 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 229940095064 tartrate Drugs 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- RIOQSEWOXXDEQQ-UHFFFAOYSA-N triphenylphosphine Chemical compound C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1 RIOQSEWOXXDEQQ-UHFFFAOYSA-N 0.000 description 2
- 239000012137 tryptone Substances 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- PZSJOBKRSVRODF-UHFFFAOYSA-N vanillin acetate Chemical compound COC1=CC(C=O)=CC=C1OC(C)=O PZSJOBKRSVRODF-UHFFFAOYSA-N 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 239000011534 wash buffer Substances 0.000 description 2
- 239000003643 water by type Substances 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- OMDQUFIYNPYJFM-XKDAHURESA-N (2r,3r,4s,5r,6s)-2-(hydroxymethyl)-6-[[(2r,3s,4r,5s,6r)-4,5,6-trihydroxy-3-[(2s,3s,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]methoxy]oxane-3,4,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O[C@H]2[C@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@H](O)[C@H](O)O1 OMDQUFIYNPYJFM-XKDAHURESA-N 0.000 description 1
- XSYUPRQVAHJETO-WPMUBMLPSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidazol-5-yl)propanoyl]amino]-3-(1h-imidaz Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 XSYUPRQVAHJETO-WPMUBMLPSA-N 0.000 description 1
- PPLUPPGMFOKIQT-UHFFFAOYSA-N (3-hydroxy-2-propanoyloxypropyl) propanoate Chemical compound CCC(=O)OCC(CO)OC(=O)CC PPLUPPGMFOKIQT-UHFFFAOYSA-N 0.000 description 1
- BHQCQFFYRZLCQQ-UHFFFAOYSA-N (3alpha,5alpha,7alpha,12alpha)-3,7,12-trihydroxy-cholan-24-oic acid Natural products OC1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 BHQCQFFYRZLCQQ-UHFFFAOYSA-N 0.000 description 1
- FQVLRGLGWNWPSS-BXBUPLCLSA-N (4r,7s,10s,13s,16r)-16-acetamido-13-(1h-imidazol-5-ylmethyl)-10-methyl-6,9,12,15-tetraoxo-7-propan-2-yl-1,2-dithia-5,8,11,14-tetrazacycloheptadecane-4-carboxamide Chemical compound N1C(=O)[C@@H](NC(C)=O)CSSC[C@@H](C(N)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@@H]1CC1=CN=CN1 FQVLRGLGWNWPSS-BXBUPLCLSA-N 0.000 description 1
- QAVITTVTXPZTSE-UHFFFAOYSA-N (5-formylfuran-2-yl)methyl acetate Chemical compound CC(=O)OCC1=CC=C(C=O)O1 QAVITTVTXPZTSE-UHFFFAOYSA-N 0.000 description 1
- AWHAUPZHZYUHOM-UHFFFAOYSA-N 1,2-dibutyrin Chemical compound CCCC(=O)OCC(CO)OC(=O)CCC AWHAUPZHZYUHOM-UHFFFAOYSA-N 0.000 description 1
- DSVGICPKBRQDDX-UHFFFAOYSA-N 1,3-diacetoxypropane Chemical compound CC(=O)OCCCOC(C)=O DSVGICPKBRQDDX-UHFFFAOYSA-N 0.000 description 1
- LDVVTQMJQSCDMK-UHFFFAOYSA-N 1,3-dihydroxypropan-2-yl formate Chemical compound OCC(CO)OC=O LDVVTQMJQSCDMK-UHFFFAOYSA-N 0.000 description 1
- XUKSWKGOQKREON-UHFFFAOYSA-N 1,4-diacetoxybutane Chemical compound CC(=O)OCCCCOC(C)=O XUKSWKGOQKREON-UHFFFAOYSA-N 0.000 description 1
- RWNUSVWFHDHRCJ-UHFFFAOYSA-N 1-butoxypropan-2-ol Chemical compound CCCCOCC(C)O RWNUSVWFHDHRCJ-UHFFFAOYSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- OAYXUHPQHDHDDZ-UHFFFAOYSA-N 2-(2-butoxyethoxy)ethanol Chemical compound CCCCOCCOCCO OAYXUHPQHDHDDZ-UHFFFAOYSA-N 0.000 description 1
- SBASXUCJHJRPEV-UHFFFAOYSA-N 2-(2-methoxyethoxy)ethanol Chemical compound COCCOCCO SBASXUCJHJRPEV-UHFFFAOYSA-N 0.000 description 1
- CUDYYMUUJHLCGZ-UHFFFAOYSA-N 2-(2-methoxypropoxy)propan-1-ol Chemical compound COC(C)COC(C)CO CUDYYMUUJHLCGZ-UHFFFAOYSA-N 0.000 description 1
- WAEVWDZKMBQDEJ-UHFFFAOYSA-N 2-[2-(2-methoxypropoxy)propoxy]propan-1-ol Chemical compound COC(C)COC(C)COC(C)CO WAEVWDZKMBQDEJ-UHFFFAOYSA-N 0.000 description 1
- MWWXARALRVYLAE-UHFFFAOYSA-N 2-acetyloxybut-3-enyl acetate Chemical compound CC(=O)OCC(C=C)OC(C)=O MWWXARALRVYLAE-UHFFFAOYSA-N 0.000 description 1
- NCKMMSIFQUPKCK-UHFFFAOYSA-N 2-benzyl-4-chlorophenol Chemical compound OC1=CC=C(Cl)C=C1CC1=CC=CC=C1 NCKMMSIFQUPKCK-UHFFFAOYSA-N 0.000 description 1
- WBIQQQGBSDOWNP-UHFFFAOYSA-N 2-dodecylbenzenesulfonic acid Chemical compound CCCCCCCCCCCCC1=CC=CC=C1S(O)(=O)=O WBIQQQGBSDOWNP-UHFFFAOYSA-N 0.000 description 1
- ICPWFHKNYYRBSZ-UHFFFAOYSA-M 2-methoxypropanoate Chemical compound COC(C)C([O-])=O ICPWFHKNYYRBSZ-UHFFFAOYSA-M 0.000 description 1
- CPOBTYJRKAJERX-UHFFFAOYSA-N 3-ethyl-n-[(3-ethyl-1,3-benzothiazol-2-ylidene)amino]-1,3-benzothiazol-2-imine Chemical compound S1C2=CC=CC=C2N(CC)C1=NN=C1SC2=CC=CC=C2N1CC CPOBTYJRKAJERX-UHFFFAOYSA-N 0.000 description 1
- GDBUZIKSJGRBJP-UHFFFAOYSA-N 4-acetoxy benzoic acid Chemical compound CC(=O)OC1=CC=C(C(O)=O)C=C1 GDBUZIKSJGRBJP-UHFFFAOYSA-N 0.000 description 1
- COYZTUXPHRHKGV-UHFFFAOYSA-N 4-methoxy-5-[3-(2-methoxy-4-nitro-5-sulfophenyl)-5-(phenylcarbamoyl)-1h-tetrazol-2-yl]-2-nitrobenzenesulfonic acid Chemical compound COC1=CC([N+]([O-])=O)=C(S(O)(=O)=O)C=C1N1N(C=2C(=CC(=C(C=2)S(O)(=O)=O)[N+]([O-])=O)OC)N=C(C(=O)NC=2C=CC=CC=2)N1 COYZTUXPHRHKGV-UHFFFAOYSA-N 0.000 description 1
- QCVGEOXPDFCNHA-UHFFFAOYSA-N 5,5-dimethyl-2,4-dioxo-1,3-oxazolidine-3-carboxamide Chemical compound CC1(C)OC(=O)N(C(N)=O)C1=O QCVGEOXPDFCNHA-UHFFFAOYSA-N 0.000 description 1
- 101710163881 5,6-dihydroxyindole-2-carboxylic acid oxidase Proteins 0.000 description 1
- PIJBVCVBCQOWMM-UHFFFAOYSA-N 5-acetyloxypentyl acetate Chemical compound CC(=O)OCCCCCOC(C)=O PIJBVCVBCQOWMM-UHFFFAOYSA-N 0.000 description 1
- ODEHMIGXGLNAKK-OESPXIITSA-N 6-kestotriose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)OC[C@@H]1[C@@H](O)[C@H](O)[C@](CO)(O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)O1 ODEHMIGXGLNAKK-OESPXIITSA-N 0.000 description 1
- LPEKGGXMPWTOCB-UHFFFAOYSA-N 8beta-(2,3-epoxy-2-methylbutyryloxy)-14-acetoxytithifolin Natural products COC(=O)C(C)O LPEKGGXMPWTOCB-UHFFFAOYSA-N 0.000 description 1
- 238000010269 ABTS assay Methods 0.000 description 1
- 240000000073 Achillea millefolium Species 0.000 description 1
- 235000007754 Achillea millefolium Nutrition 0.000 description 1
- 241000589291 Acinetobacter Species 0.000 description 1
- 241000588986 Alcaligenes Species 0.000 description 1
- 102100034035 Alcohol dehydrogenase 1A Human genes 0.000 description 1
- 102100036826 Aldehyde oxidase Human genes 0.000 description 1
- 229920001450 Alpha-Cyclodextrin Polymers 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 229920000945 Amylopectin Polymers 0.000 description 1
- 241000192542 Anabaena Species 0.000 description 1
- 108700042778 Antimicrobial Peptides Proteins 0.000 description 1
- 102000044503 Antimicrobial Peptides Human genes 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 241001328122 Bacillus clausii Species 0.000 description 1
- 241000936493 Bacillus clausii KSM-K16 Species 0.000 description 1
- 241000423334 Bacillus halodurans C-125 Species 0.000 description 1
- 239000004342 Benzoyl peroxide Substances 0.000 description 1
- OMPJBNCRMGITSC-UHFFFAOYSA-N Benzoylperoxide Chemical compound C=1C=CC=CC=1C(=O)OOC(=O)C1=CC=CC=C1 OMPJBNCRMGITSC-UHFFFAOYSA-N 0.000 description 1
- 239000002028 Biomass Substances 0.000 description 1
- 208000035985 Body Odor Diseases 0.000 description 1
- DMPSVUHEJJDSCE-UHFFFAOYSA-N Br[Cl](=O)=O Chemical compound Br[Cl](=O)=O DMPSVUHEJJDSCE-UHFFFAOYSA-N 0.000 description 1
- 229910001369 Brass Inorganic materials 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 108010051152 Carboxylesterase Proteins 0.000 description 1
- 102000013392 Carboxylesterase Human genes 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010008885 Cellulose 1,4-beta-Cellobiosidase Proteins 0.000 description 1
- 229920001661 Chitosan Polymers 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- 239000004155 Chlorine dioxide Substances 0.000 description 1
- 241000191366 Chlorobium Species 0.000 description 1
- 239000004380 Cholic acid Substances 0.000 description 1
- 241000190831 Chromatium Species 0.000 description 1
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000605056 Cytophaga Species 0.000 description 1
- GUBGYTABKSRVRQ-CUHNMECISA-N D-Cellobiose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-CUHNMECISA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 125000002353 D-glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- RXVWSYJTUUKTEA-UHFFFAOYSA-N D-maltotriose Natural products OC1C(O)C(OC(C(O)CO)C(O)C(O)C=O)OC(CO)C1OC1C(O)C(O)C(O)C(CO)O1 RXVWSYJTUUKTEA-UHFFFAOYSA-N 0.000 description 1
- 241000238557 Decapoda Species 0.000 description 1
- 241000192093 Deinococcus Species 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 102000002322 Egg Proteins Human genes 0.000 description 1
- 108010000912 Egg Proteins Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000588698 Erwinia Species 0.000 description 1
- 241000190844 Erythrobacter Species 0.000 description 1
- 241000660147 Escherichia coli str. K-12 substr. MG1655 Species 0.000 description 1
- DBVJJBKOTRCVKF-UHFFFAOYSA-N Etidronic acid Chemical compound OP(=O)(O)C(O)(C)P(O)(O)=O DBVJJBKOTRCVKF-UHFFFAOYSA-N 0.000 description 1
- 241000589565 Flavobacterium Species 0.000 description 1
- 206010016818 Fluorosis Diseases 0.000 description 1
- 229920000855 Fucoidan Polymers 0.000 description 1
- 206010017533 Fungal infection Diseases 0.000 description 1
- 101150094690 GAL1 gene Proteins 0.000 description 1
- 101150038242 GAL10 gene Proteins 0.000 description 1
- 229920000926 Galactomannan Polymers 0.000 description 1
- 102100028501 Galanin peptides Human genes 0.000 description 1
- 102100024637 Galectin-10 Human genes 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 241000193385 Geobacillus stearothermophilus Species 0.000 description 1
- 101000892220 Geobacillus thermodenitrificans (strain NG80-2) Long-chain-alcohol dehydrogenase 1 Proteins 0.000 description 1
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 239000004347 Glyceryl monoacetate Substances 0.000 description 1
- 101150009006 HIS3 gene Proteins 0.000 description 1
- 101100246753 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) pyrF gene Proteins 0.000 description 1
- 240000007058 Halophila ovalis Species 0.000 description 1
- 101000780443 Homo sapiens Alcohol dehydrogenase 1A Proteins 0.000 description 1
- 101000928314 Homo sapiens Aldehyde oxidase Proteins 0.000 description 1
- 101100121078 Homo sapiens GAL gene Proteins 0.000 description 1
- 101001046426 Homo sapiens cGMP-dependent protein kinase 1 Proteins 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 102000004195 Isomerases Human genes 0.000 description 1
- 108090000769 Isomerases Proteins 0.000 description 1
- 229930194542 Keto Natural products 0.000 description 1
- 241000588748 Klebsiella Species 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- 125000000510 L-tryptophano group Chemical group [H]C1=C([H])C([H])=C2N([H])C([H])=C(C([H])([H])[C@@]([H])(C(O[H])=O)N([H])[*])C2=C1[H] 0.000 description 1
- 108010029541 Laccase Proteins 0.000 description 1
- JVTAAEKCZFNVCJ-UHFFFAOYSA-M Lactate Chemical compound CC(O)C([O-])=O JVTAAEKCZFNVCJ-UHFFFAOYSA-M 0.000 description 1
- 240000008415 Lactuca sativa Species 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 102000004317 Lyases Human genes 0.000 description 1
- 108090000856 Lyases Proteins 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 229920000057 Mannan Polymers 0.000 description 1
- 241000183011 Melanocarpus Species 0.000 description 1
- 241000589195 Mesorhizobium loti Species 0.000 description 1
- 241000202974 Methanobacterium Species 0.000 description 1
- LDLDJEAVRNAEBW-UHFFFAOYSA-N Methyl 3-hydroxybutyrate Chemical compound COC(=O)CC(C)O LDLDJEAVRNAEBW-UHFFFAOYSA-N 0.000 description 1
- 241000589350 Methylobacter Species 0.000 description 1
- 241000589345 Methylococcus Species 0.000 description 1
- 241000589966 Methylocystis Species 0.000 description 1
- 241001533203 Methylomicrobium Species 0.000 description 1
- 241000589344 Methylomonas Species 0.000 description 1
- 241000589354 Methylosinus Species 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 244000293610 Morus bombycis Species 0.000 description 1
- 208000031888 Mycoses Diseases 0.000 description 1
- 241000863420 Myxococcus Species 0.000 description 1
- 229910019093 NaOCl Inorganic materials 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 101150012394 PHO5 gene Proteins 0.000 description 1
- 241000520272 Pantoea Species 0.000 description 1
- ALQSHHUCVQOPAS-UHFFFAOYSA-N Pentane-1,5-diol Chemical compound OCCCCCO ALQSHHUCVQOPAS-UHFFFAOYSA-N 0.000 description 1
- 108010067902 Peptide Library Proteins 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 1
- 239000005062 Polybutadiene Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 241000762460 Pseudothermotoga lettingae Species 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 241000191025 Rhodobacter Species 0.000 description 1
- 101100394989 Rhodopseudomonas palustris (strain ATCC BAA-98 / CGA009) hisI gene Proteins 0.000 description 1
- 101100434411 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ADH1 gene Proteins 0.000 description 1
- 101001000154 Schistosoma mansoni Phosphoglycerate kinase Proteins 0.000 description 1
- 108010034546 Serratia marcescens nuclease Proteins 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 206010040904 Skin odour abnormal Diseases 0.000 description 1
- 244000061458 Solanum melongena Species 0.000 description 1
- 235000002597 Solanum melongena Nutrition 0.000 description 1
- 206010041349 Somnolence Diseases 0.000 description 1
- UQZIYBXSHAGNOE-USOSMYMVSA-N Stachyose Natural products O(C[C@H]1[C@@H](O)[C@H](O)[C@H](O)[C@@H](O[C@@]2(CO)[C@H](O)[C@@H](O)[C@@H](CO)O2)O1)[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@H](CO[C@@H]2[C@@H](O)[C@@H](O)[C@@H](O)[C@H](CO)O2)O1 UQZIYBXSHAGNOE-USOSMYMVSA-N 0.000 description 1
- 229910000831 Steel Inorganic materials 0.000 description 1
- 108010056079 Subtilisins Proteins 0.000 description 1
- 102000005158 Subtilisins Human genes 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 241000192707 Synechococcus Species 0.000 description 1
- 241000192584 Synechocystis Species 0.000 description 1
- 241000123734 Thermoanaerobacterium sp. Species 0.000 description 1
- 108090001109 Thermolysin Proteins 0.000 description 1
- 241000204664 Thermotoga neapolitana Species 0.000 description 1
- 241000334089 Thermotoga petrophila Species 0.000 description 1
- 241000605118 Thiobacillus Species 0.000 description 1
- RTAQQCXQSZGOHL-UHFFFAOYSA-N Titanium Chemical compound [Ti] RTAQQCXQSZGOHL-UHFFFAOYSA-N 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 241000499912 Trichoderma reesei Species 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- 102000003425 Tyrosinase Human genes 0.000 description 1
- 101150050575 URA3 gene Proteins 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 241000235013 Yarrowia Species 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 1
- 241000588901 Zymomonas Species 0.000 description 1
- IEOLRPPTIGNUNP-RKQHYHRCSA-N [(2r,3r,4s,5r,6r)-3,4,5-triacetyloxy-6-hydroxyoxan-2-yl]methyl acetate Chemical compound CC(=O)OC[C@H]1O[C@@H](O)[C@H](OC(C)=O)[C@@H](OC(C)=O)[C@@H]1OC(C)=O IEOLRPPTIGNUNP-RKQHYHRCSA-N 0.000 description 1
- FEQXFAYSNRWXDW-RKQHYHRCSA-N [(2r,3r,4s,5r,6s)-4,5,6-triacetyloxy-2-(hydroxymethyl)oxan-3-yl] acetate Chemical compound CC(=O)O[C@@H]1O[C@H](CO)[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@H]1OC(C)=O FEQXFAYSNRWXDW-RKQHYHRCSA-N 0.000 description 1
- LPTITAGPBXDDGR-OWYFMNJBSA-N [(2r,3r,4s,5s,6r)-3,4,5,6-tetraacetyloxyoxan-2-yl]methyl acetate Chemical compound CC(=O)OC[C@H]1O[C@H](OC(C)=O)[C@@H](OC(C)=O)[C@@H](OC(C)=O)[C@@H]1OC(C)=O LPTITAGPBXDDGR-OWYFMNJBSA-N 0.000 description 1
- NJVBTKVPPOFGAT-XMTFNYHQSA-N [(2s,3r,4r,5r)-2,3,4,5,6-pentaacetyloxyhexyl] acetate Chemical compound CC(=O)OC[C@@H](OC(C)=O)[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@@H](OC(C)=O)COC(C)=O NJVBTKVPPOFGAT-XMTFNYHQSA-N 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 239000011358 absorbing material Substances 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 150000001242 acetic acid derivatives Chemical class 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 125000003668 acetyloxy group Chemical group [H]C([H])([H])C(=O)O[*] 0.000 description 1
- 108020002494 acetyltransferase Proteins 0.000 description 1
- 102000005421 acetyltransferase Human genes 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 102000045404 acyltransferase activity proteins Human genes 0.000 description 1
- 108700014220 acyltransferase activity proteins Proteins 0.000 description 1
- 101150102866 adc1 gene Proteins 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 238000013019 agitation Methods 0.000 description 1
- 150000001299 aldehydes Chemical class 0.000 description 1
- 239000000956 alloy Substances 0.000 description 1
- 229910045601 alloy Inorganic materials 0.000 description 1
- DBTMGCOVALSLOR-VXXRBQRTSA-N alpha-D-Glcp-(1->3)-alpha-D-Glcp-(1->3)-D-Glcp Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](O)[C@@H](O[C@H]2[C@@H]([C@@H](CO)OC(O)[C@@H]2O)O)O[C@H](CO)[C@H]1O DBTMGCOVALSLOR-VXXRBQRTSA-N 0.000 description 1
- WQZGKKKJIJFFOK-UHFFFAOYSA-N alpha-D-glucopyranose Natural products OCC1OC(O)C(O)C(O)C1O WQZGKKKJIJFFOK-UHFFFAOYSA-N 0.000 description 1
- HFHDHCJBZVLPGP-RWMJIURBSA-N alpha-cyclodextrin Chemical compound OC[C@H]([C@H]([C@@H]([C@H]1O)O)O[C@H]2O[C@@H]([C@@H](O[C@H]3O[C@H](CO)[C@H]([C@@H]([C@H]3O)O)O[C@H]3O[C@H](CO)[C@H]([C@@H]([C@H]3O)O)O[C@H]3O[C@H](CO)[C@H]([C@@H]([C@H]3O)O)O3)[C@H](O)[C@H]2O)CO)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@@H]3O[C@@H]1CO HFHDHCJBZVLPGP-RWMJIURBSA-N 0.000 description 1
- 229940043377 alpha-cyclodextrin Drugs 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 230000006229 amino acid addition Effects 0.000 description 1
- 230000000181 anti-adherent effect Effects 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 239000003911 antiadherent Substances 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- 239000003899 bactericide agent Substances 0.000 description 1
- 235000015278 beef Nutrition 0.000 description 1
- 235000019400 benzoyl peroxide Nutrition 0.000 description 1
- 235000021028 berry Nutrition 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 238000005415 bioluminescence Methods 0.000 description 1
- 230000029918 bioluminescence Effects 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 239000010951 brass Substances 0.000 description 1
- 239000011449 brick Substances 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- NTXGQCSETZTARF-UHFFFAOYSA-N buta-1,3-diene;prop-2-enenitrile Chemical compound C=CC=C.C=CC#N NTXGQCSETZTARF-UHFFFAOYSA-N 0.000 description 1
- BJUFAVXYJRJBLQ-UHFFFAOYSA-N butanoic acid;propane-1,2,3-triol Chemical compound CCCC(O)=O.OCC(O)CO BJUFAVXYJRJBLQ-UHFFFAOYSA-N 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 102220359928 c.229A>G Human genes 0.000 description 1
- 102100022422 cGMP-dependent protein kinase 1 Human genes 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 229940077731 carbohydrate nutrients Drugs 0.000 description 1
- 239000001569 carbon dioxide Substances 0.000 description 1
- 229910002092 carbon dioxide Inorganic materials 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 239000004359 castor oil Substances 0.000 description 1
- 235000019438 castor oil Nutrition 0.000 description 1
- 238000007444 cell Immobilization Methods 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 229920003086 cellulose ether Polymers 0.000 description 1
- 239000000919 ceramic Substances 0.000 description 1
- 235000013339 cereals Nutrition 0.000 description 1
- 230000009920 chelation Effects 0.000 description 1
- 150000005829 chemical entities Chemical class 0.000 description 1
- 230000007073 chemical hydrolysis Effects 0.000 description 1
- 238000000224 chemical solution deposition Methods 0.000 description 1
- 108091006116 chimeric peptides Proteins 0.000 description 1
- 239000000460 chlorine Substances 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 235000019398 chlorine dioxide Nutrition 0.000 description 1
- 235000019416 cholic acid Nutrition 0.000 description 1
- BHQCQFFYRZLCQQ-OELDTZBJSA-N cholic acid Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)[C@@H](O)C1 BHQCQFFYRZLCQQ-OELDTZBJSA-N 0.000 description 1
- 229960002471 cholic acid Drugs 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 229910052804 chromium Inorganic materials 0.000 description 1
- 239000011651 chromium Substances 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 150000001860 citric acid derivatives Chemical class 0.000 description 1
- 235000020971 citrus fruits Nutrition 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 239000003636 conditioned culture medium Substances 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 150000001879 copper Chemical class 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 239000002537 cosmetic Substances 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 244000038559 crop plants Species 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- 239000000287 crude extract Substances 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 108010005400 cutinase Proteins 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- HPXRVTGHNJAIIH-UHFFFAOYSA-N cyclohexanol Chemical compound OC1CCCCC1 HPXRVTGHNJAIIH-UHFFFAOYSA-N 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 1
- 230000006196 deacetylation Effects 0.000 description 1
- 238000003381 deacetylation reaction Methods 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 208000002925 dental caries Diseases 0.000 description 1
- 210000003298 dental enamel Anatomy 0.000 description 1
- 208000004042 dental fluorosis Diseases 0.000 description 1
- 239000002781 deodorant agent Substances 0.000 description 1
- KXGVEGMKQFWNSR-UHFFFAOYSA-N deoxycholic acid Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 KXGVEGMKQFWNSR-UHFFFAOYSA-N 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 229940099371 diacetylated monoglycerides Drugs 0.000 description 1
- GUJOJGAPFQRJSV-UHFFFAOYSA-N dialuminum;dioxosilane;oxygen(2-);hydrate Chemical compound O.[O-2].[O-2].[O-2].[Al+3].[Al+3].O=[Si]=O.O=[Si]=O.O=[Si]=O.O=[Si]=O GUJOJGAPFQRJSV-UHFFFAOYSA-N 0.000 description 1
- 229960001673 diethyltoluamide Drugs 0.000 description 1
- 239000012470 diluted sample Substances 0.000 description 1
- 150000002009 diols Chemical class 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- VTIIJXUACCWYHX-UHFFFAOYSA-L disodium;carboxylatooxy carbonate Chemical compound [Na+].[Na+].[O-]C(=O)OOC([O-])=O VTIIJXUACCWYHX-UHFFFAOYSA-L 0.000 description 1
- 239000012153 distilled water Substances 0.000 description 1
- 229940060296 dodecylbenzenesulfonic acid Drugs 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- ODQWQRRAPPTVAG-GZTJUZNOSA-N doxepin Chemical compound C1OC2=CC=CC=C2C(=C/CCN(C)C)/C2=CC=CC=C21 ODQWQRRAPPTVAG-GZTJUZNOSA-N 0.000 description 1
- 238000001035 drying Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 235000014103 egg white Nutrition 0.000 description 1
- 210000000969 egg white Anatomy 0.000 description 1
- 239000012149 elution buffer Substances 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- AJIPIJNNOJSSQC-NYLIRDPKSA-N estetrol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H]([C@H](O)[C@@H]4O)O)[C@@H]4[C@@H]3CCC2=C1 AJIPIJNNOJSSQC-NYLIRDPKSA-N 0.000 description 1
- ZANNOFHADGWOLI-UHFFFAOYSA-N ethyl 2-hydroxyacetate Chemical compound CCOC(=O)CO ZANNOFHADGWOLI-UHFFFAOYSA-N 0.000 description 1
- JLEKJZUYWFJPMB-UHFFFAOYSA-N ethyl 2-methoxyacetate Chemical compound CCOC(=O)COC JLEKJZUYWFJPMB-UHFFFAOYSA-N 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 229940116333 ethyl lactate Drugs 0.000 description 1
- DEFVIWRASFVYLL-UHFFFAOYSA-N ethylene glycol bis(2-aminoethyl)tetraacetic acid Chemical compound OC(=O)CN(CC(O)=O)CCOCCOCCN(CC(O)=O)CC(O)=O DEFVIWRASFVYLL-UHFFFAOYSA-N 0.000 description 1
- 238000001704 evaporation Methods 0.000 description 1
- 230000008020 evaporation Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000012527 feed solution Substances 0.000 description 1
- 239000000706 filtrate Substances 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 238000005187 foaming Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 235000011389 fruit/vegetable juice Nutrition 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 235000021474 generally recognized As safe (food) Nutrition 0.000 description 1
- 235000021473 generally recognized as safe (food ingredients) Nutrition 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 125000005456 glyceride group Chemical group 0.000 description 1
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 1
- 235000019442 glyceryl monoacetate Nutrition 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 150000002366 halogen compounds Chemical class 0.000 description 1
- 229910052811 halogen oxide Inorganic materials 0.000 description 1
- 150000002367 halogens Chemical class 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 231100000206 health hazard Toxicity 0.000 description 1
- 238000005534 hematocrit Methods 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 238000000265 homogenisation Methods 0.000 description 1
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 229920003063 hydroxymethyl cellulose Polymers 0.000 description 1
- 229940031574 hydroxymethyl cellulose Drugs 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 1
- CUILPNURFADTPE-UHFFFAOYSA-N hypobromous acid Chemical compound BrO CUILPNURFADTPE-UHFFFAOYSA-N 0.000 description 1
- 210000001822 immobilized cell Anatomy 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229910001410 inorganic ion Inorganic materials 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- PNDPGZBMCMUPRI-UHFFFAOYSA-N iodine Chemical compound II PNDPGZBMCMUPRI-UHFFFAOYSA-N 0.000 description 1
- 239000002563 ionic surfactant Substances 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 230000002427 irreversible effect Effects 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- JCQLYHFGKNRPGE-FCVZTGTOSA-N lactulose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 JCQLYHFGKNRPGE-FCVZTGTOSA-N 0.000 description 1
- 229960000511 lactulose Drugs 0.000 description 1
- PFCRQPBOOFTZGQ-UHFFFAOYSA-N lactulose keto form Natural products OCC(=O)C(O)C(C(O)CO)OC1OC(CO)C(O)C(O)C1O PFCRQPBOOFTZGQ-UHFFFAOYSA-N 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 239000007942 layered tablet Substances 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000021374 legumes Nutrition 0.000 description 1
- 231100000636 lethal dose Toxicity 0.000 description 1
- AIHDCSAXVMAMJH-GFBKWZILSA-N levan Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)OC[C@@H]1[C@@H](O)[C@H](O)[C@](CO)(CO[C@@H]2[C@H]([C@H](O)[C@@](O)(CO)O2)O)O1 AIHDCSAXVMAMJH-GFBKWZILSA-N 0.000 description 1
- 239000012669 liquid formulation Substances 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 231100000053 low toxicity Toxicity 0.000 description 1
- 206010025135 lupus erythematosus Diseases 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 229940049920 malate Drugs 0.000 description 1
- BJEPYKJPYRNKOW-UHFFFAOYSA-L malate(2-) Chemical compound [O-]C(=O)C(O)CC([O-])=O BJEPYKJPYRNKOW-UHFFFAOYSA-L 0.000 description 1
- 150000002688 maleic acid derivatives Chemical class 0.000 description 1
- 150000004701 malic acid derivatives Chemical class 0.000 description 1
- FGPATWVHNYVVEE-SKPZHCOCSA-N maltotriulose Chemical compound OC[C@H]1OC(O)(CO)[C@@H](O)[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@@H](CO)O1 FGPATWVHNYVVEE-SKPZHCOCSA-N 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- FYGDTMLNYKFZSV-UHFFFAOYSA-N mannotriose Natural products OC1C(O)C(O)C(CO)OC1OC1C(CO)OC(OC2C(OC(O)C(O)C2O)CO)C(O)C1O FYGDTMLNYKFZSV-UHFFFAOYSA-N 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 238000000691 measurement method Methods 0.000 description 1
- 235000013372 meat Nutrition 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000009988 metabolic benefit Effects 0.000 description 1
- 150000002739 metals Chemical class 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229940057867 methyl lactate Drugs 0.000 description 1
- 239000012569 microbial contaminant Substances 0.000 description 1
- 244000000010 microbial pathogen Species 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 239000011785 micronutrient Substances 0.000 description 1
- 235000013369 micronutrients Nutrition 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000000214 mouth Anatomy 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- QBQNDWBZRZGJTF-JOAYCEEESA-N n-[(2s,3r,4r,5r,6r)-2,4,5-triacetyl-2,4,5-trihydroxy-6-(1-hydroxy-2-oxopropyl)oxan-3-yl]acetamide Chemical compound CC(=O)N[C@H]1[C@@](O)(C(C)=O)O[C@H](C(O)C(C)=O)[C@](O)(C(C)=O)[C@@]1(O)C(C)=O QBQNDWBZRZGJTF-JOAYCEEESA-N 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000001451 organic peroxides Chemical class 0.000 description 1
- 150000002898 organic sulfur compounds Chemical class 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 239000007800 oxidant agent Substances 0.000 description 1
- NRZWYNLTFLDQQX-UHFFFAOYSA-N p-tert-Amylphenol Chemical compound CCC(C)(C)C1=CC=C(O)C=C1 NRZWYNLTFLDQQX-UHFFFAOYSA-N 0.000 description 1
- 239000006174 pH buffer Substances 0.000 description 1
- 238000004091 panning Methods 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 125000000864 peroxy group Chemical group O(O*)* 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 150000002989 phenols Chemical class 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 239000007981 phosphate-citrate buffer Substances 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000029553 photosynthesis Effects 0.000 description 1
- 238000010672 photosynthesis Methods 0.000 description 1
- 239000000049 pigment Substances 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 229920002239 polyacrylonitrile Polymers 0.000 description 1
- 229920002857 polybutadiene Polymers 0.000 description 1
- 229920000139 polyethylene terephthalate Polymers 0.000 description 1
- 239000005020 polyethylene terephthalate Substances 0.000 description 1
- 229920000307 polymer substrate Polymers 0.000 description 1
- 229920000193 polymethacrylate Polymers 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 239000003910 polypeptide antibiotic agent Substances 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 229910052573 porcelain Inorganic materials 0.000 description 1
- 235000015277 pork Nutrition 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000019525 primary metabolic process Effects 0.000 description 1
- WHMQHKUIPUYTKP-UHFFFAOYSA-N propane-1,2,3-triol;propanoic acid Chemical compound CCC(O)=O.OCC(O)CO WHMQHKUIPUYTKP-UHFFFAOYSA-N 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- LLHKCFNBLRBOGN-UHFFFAOYSA-N propylene glycol methyl ether acetate Chemical compound COCC(C)OC(C)=O LLHKCFNBLRBOGN-UHFFFAOYSA-N 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 239000012460 protein solution Substances 0.000 description 1
- 230000012743 protein tagging Effects 0.000 description 1
- 235000021251 pulses Nutrition 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 150000003856 quaternary ammonium compounds Chemical class 0.000 description 1
- 150000003242 quaternary ammonium salts Chemical class 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 230000035484 reaction time Effects 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 102220148016 rs200944017 Human genes 0.000 description 1
- 235000012045 salad Nutrition 0.000 description 1
- 229930195734 saturated hydrocarbon Natural products 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 235000014102 seafood Nutrition 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- UKLNMMHNWFDKNT-UHFFFAOYSA-M sodium chlorite Chemical compound [Na+].[O-]Cl=O UKLNMMHNWFDKNT-UHFFFAOYSA-M 0.000 description 1
- 229960002218 sodium chlorite Drugs 0.000 description 1
- APSBXTVYXVQYAB-UHFFFAOYSA-M sodium docusate Chemical compound [Na+].CCCCC(CC)COC(=O)CC(S([O-])(=O)=O)C(=O)OCC(CC)CCCC APSBXTVYXVQYAB-UHFFFAOYSA-M 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- SUKJFIGYRHOWBL-UHFFFAOYSA-N sodium hypochlorite Chemical compound [Na+].Cl[O-] SUKJFIGYRHOWBL-UHFFFAOYSA-N 0.000 description 1
- 229960001922 sodium perborate Drugs 0.000 description 1
- 229940045872 sodium percarbonate Drugs 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- YKLJGMBLPUQQOI-UHFFFAOYSA-M sodium;oxidooxy(oxo)borane Chemical compound [Na+].[O-]OB=O YKLJGMBLPUQQOI-UHFFFAOYSA-M 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 239000002422 sporicide Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- UQZIYBXSHAGNOE-XNSRJBNMSA-N stachyose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO[C@@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO[C@@H]3[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O3)O)O2)O)O1 UQZIYBXSHAGNOE-XNSRJBNMSA-N 0.000 description 1
- 239000010935 stainless steel Substances 0.000 description 1
- 229910001220 stainless steel Inorganic materials 0.000 description 1
- 239000010421 standard material Substances 0.000 description 1
- 239000010959 steel Substances 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 150000003900 succinic acid esters Chemical class 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 150000003460 sulfonic acids Chemical class 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 150000003899 tartaric acid esters Chemical class 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- AYEKOFBPNLCAJY-UHFFFAOYSA-O thiamine pyrophosphate Chemical compound CC1=C(CCOP(O)(=O)OP(O)(O)=O)SC=[N+]1CC1=CN=C(C)N=C1N AYEKOFBPNLCAJY-UHFFFAOYSA-O 0.000 description 1
- 239000010936 titanium Substances 0.000 description 1
- 229910052719 titanium Inorganic materials 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- WEAPVABOECTMGR-UHFFFAOYSA-N triethyl 2-acetyloxypropane-1,2,3-tricarboxylate Chemical compound CCOC(=O)CC(C(=O)OCC)(OC(C)=O)CC(=O)OCC WEAPVABOECTMGR-UHFFFAOYSA-N 0.000 description 1
- SZYJELPVAFJOGJ-UHFFFAOYSA-N trimethylamine hydrochloride Chemical compound Cl.CN(C)C SZYJELPVAFJOGJ-UHFFFAOYSA-N 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 210000000689 upper leg Anatomy 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 239000012873 virucide Substances 0.000 description 1
- 239000007762 w/o emulsion Substances 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 239000008096 xylene Substances 0.000 description 1
- 150000003738 xylenes Chemical class 0.000 description 1
- FYGDTMLNYKFZSV-BYLHFPJWSA-N β-1,4-galactotrioside Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@H](CO)O[C@@H](O[C@@H]2[C@@H](O[C@@H](O)[C@H](O)[C@H]2O)CO)[C@H](O)[C@H]1O FYGDTMLNYKFZSV-BYLHFPJWSA-N 0.000 description 1
Images

Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/40—Preparation of oxygen-containing organic compounds containing a carboxyl group including Peroxycarboxylic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/18—Carboxylic ester hydrolases (3.1.1)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/16—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from plants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/16—Organic compounds
- C11D3/38—Products with no well-defined composition, e.g. natural products
- C11D3/386—Preparations containing enzymes, e.g. protease or amylase
- C11D3/38636—Preparations containing enzymes, e.g. protease or amylase containing enzymes other than protease, amylase, lipase, cellulase, oxidase or reductase
-
- C—CHEMISTRY; METALLURGY
- C11—ANIMAL OR VEGETABLE OILS, FATS, FATTY SUBSTANCES OR WAXES; FATTY ACIDS THEREFROM; DETERGENTS; CANDLES
- C11D—DETERGENT COMPOSITIONS; USE OF SINGLE SUBSTANCES AS DETERGENTS; SOAP OR SOAP-MAKING; RESIN SOAPS; RECOVERY OF GLYCEROL
- C11D3/00—Other compounding ingredients of detergent compositions covered in group C11D1/00
- C11D3/16—Organic compounds
- C11D3/38—Products with no well-defined composition, e.g. natural products
- C11D3/386—Preparations containing enzymes, e.g. protease or amylase
- C11D3/38681—Chemically modified or immobilised enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2434—Glucanases acting on beta-1,4-glucosidic bonds
- C12N9/2437—Cellulases (3.2.1.4; 3.2.1.74; 3.2.1.91; 3.2.1.150)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/40—Preparation of oxygen-containing organic compounds containing a carboxyl group including Peroxycarboxylic acids
- C12P7/54—Acetic acid
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Biomedical Technology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biophysics (AREA)
- General Chemical & Material Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Botany (AREA)
- Immunology (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Peptides Or Proteins (AREA)
- Cosmetics (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Detergent Compositions (AREA)
- Enzymes And Modification Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
효소에 의한 과산 생성을 표적 표면에 표적화시키기 위한 조성물 및 방법이 제공된다. 표적화된 과가수분해 효소에 의해 생성되는 과산 유익제는 다양한 응용, 예를 들어, 탈색, 미백, 소독, 탈염, 탈취 및 이들의 조합을 위해 사용할 수 있다. 구체적으로, 과가수분해 효소, 및 표적 표면(체표면 및 구강 관리 표면 제외)에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분을 포함하는 융합 단백질은 적절한 기질 및 과산소원과 조합하여 사용하여, 표적 물질의 표면 상에서 또는 그 근처에서 과산을 효소에 의해 생성할 수 있다. 바람직한 태양에서, 표적 표면은 셀룰로스 물질이다.
Description
관련-출원과의 상호 참조
본 출원은 전문이 본 명세서에 참고로 포함되는 미국 가특허 출원 제61/424,916호(출원일: 2010년 12월 20일)의 이익을 주장한다.
본 발명은 효소에 의한 과가수분해 및 표적화된 과산 생성의 분야에 관한 것이다. 표적 표면에 대하여 친화성을 갖는 펩티드 성분에 결합된 과가수분해 효소를 포함하는 융합 단백질을 포함하는 조성물 및 방법이 제공된다. 표적화된 효소에 의한 과산 생성을 위한 세탁 관리 표면에 대하여 친화성을 갖는 펩티드 성분에 결합된 과가수분해 효소를 포함하는 융합 단백질("표적화된 과가수분해효소")이 제공된다. 바람직한 태양에서, 표적화된 과가수분해효소는 과가수분해 활성을 갖는 CE-7 탄수화물 에스테라제를 포함한다.
퍼옥시카르복실산("과산")은 효과적인 항미생물제이다. 원치 않는 미생물 성장에 대하여 경질 표면, 식품, 살아있는 식물 조직 및 의료 장치를 세정하고/거나 소독하고/거나 위생처리하는 방법이 기재되어 있다(예를 들어, 미국 특허 제6,545,047호; 미국 특허 제6,183,807호; 미국 특허 제6,518,307호; 미국 특허 제5,683,724호; 및 미국 특허 제6,635,286호). 또한, 과산은 세탁용 세제 응용을 위한 표백(bleaching) 조성물을 제조하는데 유용한 것으로 보고되어 있다(예를 들어, 미국 특허 제3,974,082호; 미국 특허 제5,296,161호; 및 미국 특허 제5,364,554호).
과가수분해 효소를 사용하여 과산을 생성할 수 있다. 미국 특허 출원 공개 제2008-0176783 A1호; 제2008-0176299 A1호; 제2009-0005590 A1호; 및 제2010-0041752 A1호(디코시모(DiCosimo) 등)에는 카르복실산 에스테르 기질을 (적절한 과산소원, 예컨대 과산화수소의 존재 하에) 소독제 및/또는 탈색제로 사용하기에 충분한 농도로 과산으로 전환시키기 위한 상당한 과가수분해 활성을 특징으로 하는, 구조적으로 탄수화물 에스테라제의 CE-7 패밀리의 구성원으로 분류된 효소(즉, 세팔로스포린 C 데아세틸라제[CAH] 및 아세틸 자일란 에스테라제[AXE])가 개시되어 있다. 탄수화물 에스테라제의 CE-7 패밀리의 일부 구성원은 일단 반응 성분이 혼합되면, 알코올, 다이올 및 글리세롤의 아세틸 에스테르로부터 1분 내에 4000 내지 5000 ppm, 그리고 5분 내지 30분에 최대 9000 rpm의 퍼아세트산을 생성하기에 충분한 과가수분해 활성을 갖는 것으로 입증되었다(DiCosimo et al., 미국 특허 출원 공개 제2009-0005590 A1호). 미국 특허 출원 공개 제2010-0087529 A1호에는 과가수분해 활성이 향상된 변이체 CE-7 효소가 기재되어 있다.
과산은 다양한 물질과 반응할 수 있는 강력한 산화제이다. 이와 같이, 비표적화된 물질의 산화가 바람직하지 않을 수 있는 응용에서 과산을 사용하는 경우에 주의를 해야 한다. 특정 과산 응용은 비표적화된 물질의 원치않는 산화의 최소화를 돕기 위한 표적 표면으로의 조절된 전달로부터 이익을 얻을 수 있다.
과산의 표적 표면으로의 전달을 조절하는 한가지 방법은 과산의 생성을 표적 표면 상에 또는 그 근처에 표적화/국소화시키는 것이다. 표적화된 과산 생성은 비-표적화된 물질의 원치않는 산화의 양을 감소시킬 수 있으며, 원하는 효과(예를 들어, 탈색, 탈염(destaining), 탈취, 살균(sanitizing), 소독(disinfecting) 및 세정)를 달성하는데 필요한 과산(또는 과가수분해효소를 포함하는 과산 생성 성분)을 양을 감소시킬 수 있다.
표적 표면에 대하여 친화성을 갖는 펩티드 친화성 물질(큰 펩티드 물질, 예를 들어, 항체, 항체 단편(Fab), 단쇄 융합된 가변 영역 항체(scFc), 카멜리대(Camelidae) 항체 및 스캐폴드(scaffold) 디스플레이 단백질)을 사용하여 유익제를 표적 표면에 지향시켰다. 전형적으로, 유익제는 표적 표면에 대하여 친화성을 갖는 펩티드 물질에 직접 결합된다. 그러나, 이들 큰 펩티드 친화성 물질의 사용의 비용과 복잡성에 의해, 특정 응용에서의 사용에 대하여 그들이 배제될 수 있다.
유익제를 체표면에 표적화시키기 위한 체표면에 대하여 강력한 친화성을 갖는 더 짧은 펩티드의 이용이 기재되어 있다(미국 특허 제7,220,405호; 제7,309,482호 제7,285,264호 및 제7,807,141호; 미국 특허 출원 공개 제2005-0226839 A1호; 제2007-0196305 A1호; 제2006-0199206 A1호; 제2007-0065387 A1호; 제2008-0107614 A1호; 제2007-0110686 A1호; 제2006-0073111 A1호; 제2010-0158846호; 및 제2010-0158847호; 및 PCT 출원 공개 WO2008/054746호; WO2004/048399호 및 WO2008/073368호). 그러나, 과산 유익제의 생성을 위해 과가수분해 효소 촉매(즉, "표적화된 과가수분해효소")를 표면에 결합시키기 위한, 표적 표면에 대하여 친화성을 갖는 이러한 펩티드 물질의 용도는 기재된 적이 없다.
과산 처리로부터 이익을 얻을 수 있는 일부 표적 표면은 셀룰로스 물질로 이루어질 수 있다. 이와 같이, 셀룰로스 물질에 대하여 친화성을 갖는 물질은 표적화된 과산 처리에 유용할 수 있다. 셀룰로스-결합 도메인(CBD)은 통상 셀룰로스 분해와 관련이 있는 다수의 단백질에서 동정되었다. 톰(Tomme) 등(문헌[J. Chromatogr. B (1998) 7125: 283-296])은 13개 패밀리의 셀룰로스-결합 도메인 및 친화성 정제 응용에서의 그들의 용도를 개시하였다. EP1224270B1호에는 통상 길이가 30개 이하의 아미노산이며, 셀룰로스 물질에 대하여 강력한 친화성을 갖는 합성 "모방(mimic)" 셀룰로스-결합 도메인이 개시되어 있다. WO2005/042735 A1호에는 셀룰로스에 대하여 친화성을 갖는 글루코실 가수분해효소 패밀리 61로부터의 비-촉매적 탄수화물-결합 분자가 개시되어 있다. 한(Han) 등(문헌[Shengwu Huaxue Yu Shengwu Wuli Xuebao 30:263 266 (1998)])은 파지 디스플레이 방법을 사용하여 셀룰로스 매트릭스에 특이적으로 결합하는 펩티드의 동정을 기재한다. 이들 셀룰로스-결합 펩티드의 추정된 아미노산 서열은 보존된 방향족 잔기, 티로신 또는 페닐알라닌을 가지며, 이는 일부 셀룰로스-결합 단백질의 보통의 셀룰로스 결합 도메인과 유사하다.
세탁 관리 응용에서 유익제의 표적화된 전달을 위한 융합 단백질 및 키메라 펩티드 구축물의 생성에서의 셀룰로스-결합 도메인의 사용이 보고되어 있다. 미국 특허 제7,361,487호에는 데님 마무리에서 사용하기 위한 이종 셀룰로스 결합 도메인에 결합된 엔도글루카나제 코어(endoglucanase core)를 포함하는 셀룰라제 융합 단백질이 개시되어 있다. CN101591648A호에는 면 섬유 마무리를 위한 셀룰로스 결합 도메인에 융합된 큐티나제(cutinase)를 포함하는 융합 단백질이 개시되어 있다. 미국 특허 출원 공개 제2006-0246566호에는 멜라노카르푸스(Melanocarpus) 종의 중성의 셀룰라아제 코어 및 트리코데르마 리제이(Trichoderma reesei)의 산 셀로비오하이드롤라제(cellobiohydrolase) I의 링커/셀룰로스 결합 도메인으로 이루어진 테일을 포함하는 셀룰라제 융합 단백질이 개시되어 있다.
WO97/40229호 및 WO97/40127호에는 셀룰라제, 및 페놀 산화 효소 융합형 셀룰로스 결합 도메인을 포함하는 하이브리드 효소를 사용한 패브릭(fabric)의 처리 방법이 개시되어 있다. 미국 특허 제6,017,751호에는 α-아밀라제, 리파제, 퍼옥시다제 또는 라카제(laccase)에 융합된 셀룰로스-결합 도메인을 포함하는 융합 단백질이 개시되어 있다.
미국 특허 제6,586,384호 및 미국 특허 제6,579,842호에는 패브릭 상에 사전-처리된 다중-특이적 결합 분자를 사용하여 사전결정된 활성을 가하는 것에 이어서, 사전-처리된 패브릭과 유익제를 접촉시키는 것을 위한, 유익제를 선택된 패브릭의 영역으로 전달하는 방법이 개시되어 있다. 결합 분자는 유익제에 대하여 친화성을 갖는 제2 부분에 융합된 셀룰로스-결합 도메인을 포함하는 융합 단백질일 수 있다.
미국 특허 제6,919,428호에는 셀룰로스-결합 도메인 및 다른 리간드에 대하여 친화성을 갖는 단백질을 포함하는 융합 단백질, 및 이러한 융합 단백질을 포함하는 세제 조성물이 개시되어 있다. 미국 특허 제7,041,793호에는 다른 리간드에 대하여 친화성을 갖는 항체 또는 항체 단편에 결합된 셀룰로스-결합 도메인을 갖는 융합 단백질을 포함하는 세제 조성물이 개시되어 있다. 미국 특허 제6,410,498호에는 셀룰로스-결합 도메인을 포함하는 변형된 트랜스퍼라제를 포함하는 세탁 세제 및 패브릭 관리 조성물이 개시되어 있다. WO99/57250호에는 비-아미노산 링커를 통해 셀룰로스-결합 도메인을 포함하는 영역에 연결된 촉매적으로 활성인 아미노산 서열을 포함하는 변형된 효소가 개시되어 있다.
미국 특허 제6,465,410호에는 향상된 살균 이익을 위한, 셀룰로스-결합 도메인을 포함하는 아미노산 서열에 결합된 항미생물 펩티드 또는 단백질의 촉매적으로 활성인 아미노산 서열을 갖는 변형된 단백질을 포함하는 세탁 세제 및 패브릭 관리 조성물이 개시되어 있다. 미국 특허 제6,906,024호에는 비-아미노산 링커를 통하여 4개의 특이적 셀룰로스 결합 도메인 중 하나에 결합된 패브릭 유연화(fabric softening) 펩티드를 포함하는 패브릭 관리 조성물이 개시되어 있다.
WO2000/018865호 및 EP1115828B1호에는 세탁 관리 응용에서 사용하기 위한 화학 성분에 결합된 셀룰로스-결합 도메인을 포함하는 화학적 엔티티(entity)가 개시되어 있다. WO2005/051997호에는 진균류 효소로부터의 셀룰로스-결합 도메인 및 유익제를 캡슐화하기 위해 사용되는 멜라민-유형 폴리머 대하여 친화성을 갖는 도메인을 포함하는 융합 단백질이 개시되어 있다.
일부 직물 및 부직물은 합성 물질, 예를 들어, 폴리아미드, 나일론, 폴리우레탄, 폴리아크릴레이트, 폴리에스테르, 폴리올레핀, 폴리락티드 및 반합성 물질, 예를 들어, 셀룰로스 아세테이트로 이루어질 수 있다. 이와 같이, 텍스타일(textile)의 제조에 사용되는 이들 및 기타 합성 또는 반-합성 물질 중 임의의 것에 대하여 친화성을 갖는 펩티드-결합 도메인도 또한 과가수분해 효소의 표적화된 전달에 도움이 될 수 있다.
셀룰로스 및 비-셀룰로스 물질, 예를 들어, 면 패브릭, 폴리에스테르/면 혼방, 셀룰로스 아세테이트, 제지(paper), 폴리메틸 메타크릴레이트, 나일론, 폴리프로필렌, 폴리에틸렌, 폴리스티렌 및 폴리테트라플루오로에틸렌에 대하여 친화성을 갖는 바이오패닝된 펩티드가 보고되어 있다(미국 특허 제7,709,601호; 제7,700,716호; 제7,632,919호; 제7,858,581호; 제7,928,076호; 및 제7,906,617호; 및 미국 특허 출원 공개 제2005-0054752호; 제2010-0310495호; 제2010-0298231호; 제2010-0298240; 제2010-0298241호; 제2010-0298531호; 제2010-0298532호; 제2010-0298533호; 제2010-0298534; 및 제2010-0298535호). 표적화된 과산 생성을 위한 융합 단백질에서의 이러한 펩티드의 용도는 기재된 적이 없다.
WO 01/79479호(Estell et al.)에는 펩티드 라이브러리를 항-표적과 접촉시켜, 항-표적에 결합된 펩티드를 제거한 다음, 비-결합 펩티드를 표적과 접촉시키는 것을 포함하는 변형된 파지 디스플레이 스크리닝 방법이 개시되어 있다. 이러한 방법을 사용하여, 옷깃 오염(collar soil)에 결합하나 폴리에스테르/면에는 결합하지 않는 펩티드 서열 및 폴리우레탄에 결합하나 면, 폴리에스테르, 또는 폴리에스테르/면 패브릭에는 결합하지 않는 펩티드 서열을 동정하였다. 패브릭에 결합하는 펩티드 서열이 상기 개시내용에 보고되어 있지 않다.
해결해야 할 문제는 표적 표면에 과산 기반의 이익을 제공하기 위한 효소에 의한 과산 생성을 표적 물질의 표면에 표적화시키는 조성물 및 방법을 제공하는 것이다.
효소에 의한 과산 생성을 표적 표면에 표적화시키기 위한 조성물 및 방법이 제공된다. 표적 물질의 표면에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분에 결합된 과가수분해 활성을 갖는 효소를 포함하는 융합 단백질이 제공된다. 표적화된 표면은 과가수분해 활성을 갖는 융합 단백질과 접촉되며, 이에 의해, 과가수분해 효소가 표적 표면에 결합된다. 결합된 융합 단백질을 적절한 반응 성분과 배합하여, 표적 표면 상에서 또는 그 근처에서 과산을 효소에 의해 생성할 수 있다.
일 실시형태에서,
1) a) i) 구조
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이며;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 제공하는 단계; 및
1) (1)의 반응 성분을 적절한 반응 조건 하에서 배합하는 단계 - 이에 의해,
a) 융합 단백질이 표적 표면에 결합하고;
b) 적어도 하나의 과산이 효소에 의해 생성되고, 표적 표면과 접촉하며; 이에 의해, 표적 표면에 표백(bleaching), 미백, 소독, 살균(sanitizing), 탈염(destaining), 탈취 및 그들의 조합으로 이루어진 군으로부터 선택되는 과산 기반의 이익이 제공된다 - 를 포함하는 방법이 제공된다.
일 실시형태에서, 본 발명의 방법에 사용되는 과가수분해 활성을 갖는 효소는 프로테아제, 리파제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합이다.
일 실시형태에서, 본 발명의 방법에 사용되는 과가수분해 활성을 갖는 효소는 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처(signature) 모티프를 포함하는 탄수화물 에스테라제이며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다.
다른 실시형태에서, 하기의 일반 구조를 포함하는 융합 단백질이 제공된다:
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
상기 식에서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다.
일 실시형태에서, 과가수분해 활성을 갖는 융합 단백질의 효소 부분은 프로테아제, 리파제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합이다. 다른 실시형태에서, 과가수분해 활성을 갖는 효소 부분은 프로테아제가 아니다.
일 실시형태에서, 융합 단백질은 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖는 탄수화물 에스테라제를 포함하며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다.
일부 실시형태에서, 표적 물질에 대하여 친화성을 갖는 펩티드 성분은 항체, Fab 항체 단편, 단쇄 가변 단편(scFv) 항체, 카멜리대(Camelidae) 항체, 스캐폴드(scaffold) 디스플레이 단백질 또는 면역글로불린 폴드(fold)가 결여된 단쇄 폴리펩티드일 수 있다. 다른 실시형태에서, 표적 물질은 셀룰로스 물질로 이루어질 수 있다. 바람직한 실시형태에서, 표적 물질에 대하여 친화성을 갖는 펩티드 성분은 셀룰로스-결합 도메인 또는 셀룰로스 물질에 대하여 친화성을 갖는 단쇄 펩티드이다.
다른 실시형태에서,
a) i) 구조
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH;
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며; 과가수분해 활성을 갖는 상기 효소가 리파제, 프로테아제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합이고;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이며;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 포함하는 과산 생성 시스템이 제공된다.
일 실시형태에서, 과산 생성 시스템의 융합 단백질 성분은 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖는 탄수화물 에스테라제를 포함하며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다.
다른 실시형태에서, 과산 생성 시스템의 융합 단백질 성분은 서열 번호 162에 대하여 적어도 95% 아미노산 동일성을 갖는 과가수분해 아릴 에스테라제를 포함한다.
다른 실시형태에서,
1) a) i) 구조
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조
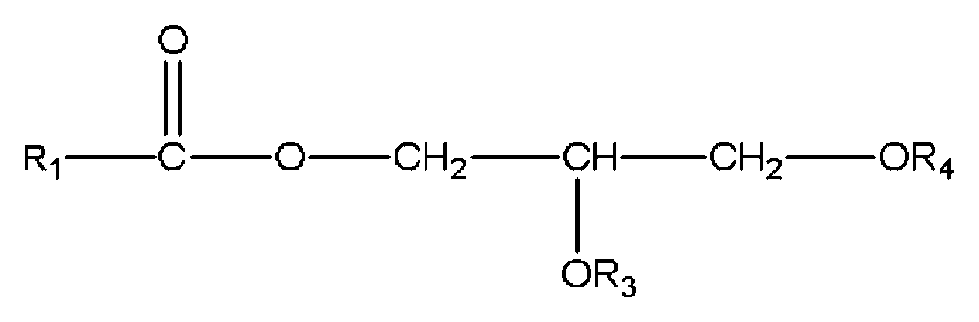
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이며;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 제공하는 단계 - 여기서, 과가수분해 활성을 갖는 효소는 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 포함하며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다 - ;
2) 표적 표면과 과가수분해 활성을 갖는 융합 단백질을 접촉시키는 단계 - 이에 의해, 융합 단백질이 표적 표면에 결합한다 - ;
3) 임의로, 표적 표면을 헹구는 단계; 및
4) 결합된 융합 단백질을 갖는 표적 표면을 상기 적어도 하나의 기질 및 과산소원과 접촉시키는 단계 - 이에 의해, 적어도 하나의 과산이 융합 단백질에 의해, 효소에 의해 생성되고, 이에 의해, 표적 표면에 표백, 미백, 소독, 탈염(destaining), 탈취, 생물막(biofilm)의 감소 또는 제거 및 그들의 조합으로 이루어진 군으로부터 선택되는 과산 기반의 이익이 제공된다 - 를 포함하는 방법이 제공된다.
바람직한 실시형태에서, 표적 표면은 셀룰로스 물질을 포함한다. 다른 실시형태에서, 셀룰로스 물질은 셀룰로스, 목재, 목재 펄프, 제지, 제지 펄프, 면, 레이온, 라이오셀(lyocell) 또는 그들의 임의의 조합을 포함한다.
다른 실시형태에서, 표적 표면은 표적 물질, 예를 들어, 폴리메틸 메타크릴레이트, 폴리프로필렌, 폴리테트라플루오로에틸렌, 폴리에틸렌, 폴리아미드, 폴리에스테르, 폴리스티렌, 셀룰로스 아세테이트 또는 그들의 임의의 조합을 포함한다.
상기의 많은 물질은 섬유, 실, 텍스타일(직물 및 부직물) 및 의류 물품의 제조에서 통상적으로 관찰되며, 여기서, 과산은 탈색, 미백, 세정, 살균, 소독, 탈염, 탈취 및 그들의 조합으로 이루어진 군으로부터 선택되는 이익을 제공할 수 있다.
다른 실시형태에서, 하기의 일반 구조를 갖는 적어도 하나의 융합을 포함하는 세탁 관리 제품이 제공된다:
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH;
상기 식에서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다.
다른 실시형태에서, 융합 단백질이 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖는 CE-7 탄수화물 에스테라제를 포함하는 세탁 관리 제품이 제공되며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다.
다른 실시형태에서, 셀룰로스 물질에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분에 결합된 과가수분해 효소를 포함하는 융합 단백질의 생성 방법이 제공되며, 상기 방법은
a) 융합 단백질을 암호화하는 발현가능한 유전자 구축물을 포함하는 재조합 미생물 숙주 세포를 제공하는 단계 - 상기 융합 단백질은 셀룰로스 물질에 대하여 친화성을 갖는 펩티드 성분에 결합된 과가수분해 활성을 갖는 효소를 포함한다 - ;
b) 재조합 미생물 숙주 세포를 적절한 조건 하에서 성장시키는 단계 - 이에 의해, 융합 단백질이 생성된다 - ; 및
c) 임의로, 융합 단백질을 회수하는 단계를 포함한다.
상기 방법의 일 태양에서, 과가수분해 활성을 갖는 효소는 서열 번호 162와 적어도 95% 동일성을 갖는 아미노산 서열을 포함한다.
상기 방법의 다른 태양에서, 과가수분해 활성을 갖는 효소는 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖는 CE-7 탄수화물 에스테라제를 포함하며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다.
다른 태양에서, 표적 표면의 표백, 미백, 소독, 살균, 탈염 또는 탈취를 위해 유효 농도의 적어도 하나의 과산을 효소에 의해 생성하기 위한, 세탁 제품에서의 본 발명의 하나 이상의 융합 단백질의 용도도 또한 제공된다.
도면의 간단한 설명
도 1. 표적화된 과가수분해효소 및 비표적화된 과가수분해효소에 대한 패브릭 탈색 대 부가되는 효소의 양의 비교
생물학적 서열의 간단한 설명
하기의 서열들은 37 C.F.R. §§ 1.821-1.825("뉴클레오티드 서열 및/또는 아미노산 서열 개시를 포함하는 특허출원에 관한 요건 - 서열 규정")를 따르며 세계지적재산권기구(World Intellectual Property Organization, WIPO) 표준 ST.25(2009), 및 유럽 특허 조약(EPC) 및 특허 협력 조약(PCT)의 서열 목록 요건(규정 5.2 및 49.5(a-bis)) 및 시행세칙의 섹션 208 및 부칙 C에 부합한다. 뉴클레오티드 및 아미노산 서열 데이터에 사용된 기호 및 체제는 37 C.F.R. §1.822에 제시된 규정을 따른다.
서열 번호 1은 바실러스 서브틸리스(Bacillus subtilis) ATCC(등록 상표) 31954(상표명)로부터의 세팔로스포린 X 데아세틸라제를 암호화하는 핵산 서열이다.
서열 번호 2는 바실러스 서브틸리스 ATCC(등록 상표) 31954(상표명)로부터의 세팔로스포린 X 데아세틸라제의 아미노산 서열이다.
서열 번호 3은 바실러스 서브틸리스 아종 서브틸리스 균주 168로부터의 세팔로스포린 C 데아세틸라제를 암호화하는 핵산 서열이다.
서열 번호 4는 바실러스 서브틸리스 아종 서브틸리스 균주 168로부터의 세팔로스포린 C 데아세틸라제의 아미노산 서열이다.
서열 번호 5는 바실러스 서브틸리스 ATCC(등록 상표) 6633(상표명)으로부터의 세팔로스포린 C 데아세틸라제를 암호화하는 핵산 서열이다.
서열 번호 6은 바실러스 서브틸리스 ATCC(등록 상표) 6633(상표명)으로부터의 세팔로스포린 C 데아세틸라제의 아미노산 서열이다.
서열 번호 7은 바실러스 리케니포르미스(B. licheniformis) ATCC(등록 상표) 14580(상표명)으로부터의 세팔로스포린 C 데아세틸라제를 암호화하는 핵산 서열이다.
서열 번호 8은 바실러스 리케니포르미스 ATCC(등록 상표) 14580(상표명)으로부터의 세팔로스포린 C 데아세틸라제의 추정된 아미노산 서열이다.
서열 번호 9는 바실러스 푸밀러스(B. pumilus) PS213으로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 10은 바실러스 푸밀러스 PS213으로부터의 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 11은 클로스트리듐 써모셀룸(Clostridium thermocellum) ATCC(등록 상표) 27405(상표명)로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 12는 클로스트리듐 써모셀룸 ATCC(등록 상표) 27405(상표명)로부터의 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 13은 써모토가 네아폴리타나(Thermotoga neapolitana)로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 14는 써모토가 네아폴리타나로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 15는 써모토가 마리티마(Thermotoga maritima) MSB8로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 16은 써모토가 마리티마 MSB8로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 17은 써모아나에로박테리움(Thermoanaerobacterium) 종 JW/SL YS485로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 18은 써모아나에로박테리움 종 JW/SL YS485로부터의 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 19는 바실러스 종 NRRL B-14911로부터의 세팔로스포린 C 데아세틸라제의 핵산 서열이다. 진뱅크(GENBANK)(등록 상표) 수탁 번호 ZP_01168674에 보고된 바와 같이, 바실러스 종 NRRL B-14911로부터의 세팔로스포린 C 데아세틸라제를 암호화하는 핵산 서열이 다른 세팔로스포린 C 데아세틸라제와의 서열 정렬, 및 보고된 길이(340개 아미노산) 대 다른 CAH 효소의 관찰된 길이(전형적으로, 길이가 318 내지 325개 아미노산; 본 명세서에 참조로 포함되는 미국 특허 출원 공개 제US-2010-0087528-A1호 참조)의 비교에 기초하여, 아마도 부정확할 것 같은 15개 아미노산 N-말단 부가물을 암호화하는 것으로 보이는 것에 주의해야 한다. 이와 같이, 본 명세서에 보고된 바와 같은 핵산 서열은 진뱅크(등록 상표) 수탁 번호 ZP_01168674 하에 보고된 N-말단 15개 아미노산이 없는 바실러스 종 NRRL B-14911로부터의 세팔로스포린 C 데아세틸라제 서열을 암호화한다.
서열 번호 20은 서열 번호 19의 핵산 서열에 의해 암호화되는 바실러스 종 NRRL B-14911로부터의 세팔로스포린 C 데아세틸라제의 추정된 아미노산 서열이다.
서열 번호 21은 바실러스 할로두란스(Bacillus halodurans) C-125로부터의 세팔로스포린 C 데아세틸라제를 암호화하는 핵산 서열이다.
서열 번호 22는 바실러스 할로두란스 C-125로부터의 세팔로스포린 C 데아세틸라제의 추정된 아미노산 서열이다.
서열 번호 23은 바실러스 클라우시이(Bacillus clausii) KSM-K16으로부터의 세팔로스포린 C 데아세틸라제를 암호화하는 핵산 서열이다.
서열 번호 24는 바실러스 클라우시이 KSM-K16으로부터의 세팔로스포린 C 데아세틸라제의 추정된 아미노산 서열이다.
서열 번호 25는 바실러스 서브틸리스 ATCC(등록 상표) 29233(상표명) 세팔로스포린 C 데아세틸라제(CAH)를 암호화하는 핵산 서열이다.
서열 번호 26은 바실러스 서브틸리스 ATCC(등록 상표) 29233(상표명) 세팔로스포린 C 데아세틸라제(CAH)의 추정된 아미노산 서열이다.
서열 번호 27은 미국 특허 출원 공개 제2010-0087529호(본 명세서에 그 전문이 참고로 포함)로부터의 써모토가 네아폴리타나 아세틸 자일란 에스테라제 변이체의 추정된 아미노산 서열(여기서, 위치 277에서의 Xaa 잔기는 Ala, Val, Ser 또는 Thr이다)이다.
서열 번호 28은 미국 특허 출원 공개 제2010-0087529호로부터의 써모토가 마리티마 MSB8 아세틸 자일란 에스테라제 변이체의 추정된 아미노산 서열(여기서, 위치 277에서의 Xaa 잔기는 Ala, Val, Ser 또는 Thr이다)이다.
서열 번호 29는 미국 특허 출원 공개 제2010-0087529호로부터의 써모토가 레틴가에(Thermotoga lettingae) 아세틸 자일란 에스테라제 변이체의 추정된 아미노산 서열(여기서, 위치 277에서의 Xaa 잔기는 Ala, Val, Ser 또는 Thr이다)이다.
서열 번호 30은 미국 특허 출원 공개 제2010-0087529호로부터의 써모토가 페트로필라(Thermotoga petrophila) 아세틸 자일란 에스테라제 변이체의 추정된 아미노산 서열(여기서, 위치 277에서의 Xaa 잔기는 Ala, Val, Ser 또는 Thr이다)이다.
서열 번호 31은 미국 특허 출원 공개 제2010-0087529호로부터의 "RQ2(a)" 유래의 써모토가 종 RQ2 아세틸 자일란 에스테라제 변이체의 추정된 아미노산 서열(여기서, 위치 277에서의 Xaa 잔기는 Ala, Val, Ser 또는 Thr이다)이다.
서열 번호 32는 미국 특허 출원 공개 제2010-0087529호로부터의 "RQ2(b)" 유래의 써모토가 종 RQ2 아세틸 자일란 에스테라제 변이체의 추정된 아미노산 서열(여기서, 위치 278에서의 Xaa 잔기는 Ala, Val, Ser 또는 Thr이다)이다.
서열 번호 33은 써모토가 레틴가에 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 34는 써모토가 페트로필라 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 35는 본 명세서에서 "RQ2(a)"로 기재된 써모토가 종 RQ2로부터의 제1 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 36은 본 명세서에서 "RQ2(b)"로 기재된 써모토가 종 RQ2로부터의 제2 아세틸 자일란 에스테라제의 추정된 아미노산 서열이다.
서열 번호 37은 써모아네아로박테리움 사카롤리티쿰(Thermoanearobacterium saccharolyticum) 세팔로스포린 C 데아세틸라제를 암호화하는 코돈 최적화된 핵산 서열이다.
서열 번호 38은 써모아네아로박테리움 사카롤리티쿰 세팔로스포린 C 데아세틸라제의 추정된 아미노산 서열이다.
서열 번호 39는 락토코커스 락티스(Lactococcus lactis)로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열(진뱅크(등록 상표) 수탁 번호 EU255910)이다.
서열 번호 40은 락토코커스 락티스(진뱅크(등록 상표) 수탁 번호 ABX75634.1)로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 41은 메소리조비움 로티(Mesorhizobium loti)(진뱅크(등록 상표) 수탁 번호 NC_002678.2)로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 42는 메소리조비움 로티(진뱅크(등록 상표) 수탁 번호 BAB53179.1)로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 43은 게오바실러스 스테아로써모필러스(Geobacillus stearothermophilus)(진뱅크(등록 상표) 수탁 번호 AF038547.2)로부터의 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 44는 게오바실러스 스테아로써모필러스(진뱅크(등록 상표) 수탁 번호 AAF70202.1)로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 45는 야생형 써모토가 마리티마 아세틸 자일란 에스테라제 아미노산 서열에 대하여 하기의 치환을 갖는 변이체 아세틸 자일란 에스테라제(변이체 "A3"로 알려져 있는)를 암호화하는 핵산 서열이다: (F24I/S35T/Q179L/N275D/C277S/S308G/F317S).
서열 번호 46은 "A3" 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 47은 N275D/C277S 변이체 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 48은 N275D/C277S 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 49는 C277S/F317S 변이체 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 50은 C277S/F317S 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 51은 S35T/C277S 변이체 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 52는 S35T/C277S 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 53은 Q179/C277S 변이체 아세틸 자일란 에스테라제를 암호화하는 핵산 서열이다.
서열 번호 54는 Q179L/C277S 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 55는 야생형 써모토가 마리티마 아세틸 자일란 에스테라제 아미노산 서열에 대하여 하기의 치환을 갖는 변이체 아세틸 자일란 에스테라제 843H9를 암호화하는 핵산 서열이다: (L8R/L125Q/Q176L/V183D/F247I/C277S/P292L).
서열 번호 56은 843H9 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 57은 야생형 써모토가 마리티마 아세틸 자일란 에스테라제 아미노산 서열에 대하여 하기의 치환을 갖는 변이체 아세틸 자일란 에스테라제 843F12를 암호화하는 핵산 서열이다: K77E/A266E/C277S.
서열 번호 58은 843F12 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 59는 야생형 써모토가 마리티마 아세틸 자일란 에스테라제 아미노산 서열에 대하여 하기의 치환을 갖는 변이체 아세틸 자일란 에스테라제 843C12를 암호화하는 핵산 서열이다: F27Y/I149V/A266V/C277S/I295T/N302S.
서열 번호 60은 843C12 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 61은 야생형 써모토가 마리티마 아세틸 자일란 에스테라제 아미노산 서열에 대하여 하기의 치환을 갖는 변이체 아세틸 자일란 에스테라제 842H3을 암호화하는 핵산 서열이다: L195Q/C277S.
서열 번호 62는 842H3 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 63은 야생형 써모토가 마리티마 아세틸 자일란 에스테라제 아미노산 서열에 대하여 하기의 치환을 갖는 변이체 아세틸 자일란 에스테라제 841A7을 암호화하는 핵산 서열이다: Y110F/C277S.
서열 번호 64는 841A7 변이체 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 65 내지 127은 다양한 폴리머 및 셀룰로스 물질에 대하여 친화성을 갖는 다양한 펩티드의 아미노산 서열이다. 서열 번호 65 내지 79는 폴리메틸 메타크릴레이트에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 80 내지 86은 폴리프로필렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 87 내지 95는 폴리테트라플루오로에틸렌에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 96 내지 102는 폴리에틸렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 103 내지 108은 폴리아미드(나일론)에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 109 내지 111은 폴리스티렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 112 내지 115는 셀룰로스 아세테이트에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 116 및 117은 면에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 116 및 118은 폴리에스테르/면 혼방에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 119 내지 121은 제지에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 122 내지 127은 셀룰로스에 대하여 친화성을 갖는 펩티드의 예이다.
서열 번호 128 내지 140 및 143은 펩티드 링커/스페이서의 아미노산 서열이다.
서열 번호 141은 발현 플라스미드 pLD001의 핵산 서열이다.
서열 번호 142는 써모토가 마리티마 변이체 C277S("PAH")의 아미노산 서열이다.
서열 번호 143은 써모토가 마리티마 변이체 C277S를 결합 도메인 HC263에 연결시키는 가요성 링커의 아미노산 서열이다.
서열 번호 144는 융합 펩티드 C277S-HC263을 암호화하는 핵산 서열이다.
서열 번호 145는 융합 펩티드 C277S-HC263("PAH-HC263")의 아미노산 서열이다.
서열 번호 146은 모발-결합 도메인 HC263의 아미노산이다.
서열 번호 147은 융합 구축물 C277S-CIP를 암호화하는 핵산 서열이다.
서열 번호 148은 융합 펩티드 C277S-CIP의 아미노산 서열이다.
서열 번호 149는 C-말단 His 태그를 갖는 클로스트리듐 써모셀룸의 셀룰로스-결합 도메인 "CIP"의 아미노산 서열이다.
서열 번호 150은 가요성 링커를 통하여 클로스트리듐 셀룰로보란스 CBM17 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 151은 가요성 링커를 통하여 클로스트리듐 셀룰로보란스 CBM17 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소의 아미노산 서열이다.
서열 번호 152는 C-말단 His 태그를 갖는 클로스트리듐 셀룰로보란스 CBM17 셀룰로스-결합 도메인의 아미노산 서열이다.
서열 번호 153은 가요성 링커를 통하여 바실러스 종 CBM28 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 154는 가요성 링커를 통하여 바실러스 종 CBM28 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소의 아미노산 서열이다.
서열 번호 155는 C-말단 His 태그를 갖는 바실러스 종 CBM28 셀룰로스-결합 도메인의 아미노산 서열이다.
서열 번호 156은 가요성 링커를 통하여 써모토가 마리티마 CBM9-2 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 157은 가요성 링커를 통하여 써모토가 마리티마 CBM9-2 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소의 아미노산 서열이다.
서열 번호 158은 써모토가 마리티마 CBM9-2 셀룰로스-결합의 아미노산 서열이다.
서열 번호 159는 가요성 링커를 통하여 칼디셀룰로시룹터 사카로라이티쿠스(Caldicellulosiruptor saccharolyticus) CBD1 셀룰로스-결합 도메인에, 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 160은 가요성 링커를 통하여 칼디셀룰로시룹터 사카로라이티쿠스 CBD1 셀룰로스-결합 도메인에 그의 C-말단에서 융합된 써모토가 마리티마 변이체 C277S 과가수분해효소의 아미노산 서열이다.
서열 번호 161은 칼디셀룰로시룹터 사카로라이티쿠스 CBD1 셀룰로스0결합의 아미노산 서열이다.
서열 번호 162는 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체의 아미노산 서열이다(미국 특허 제7,754,460호; WO2005/056782호; 및 EP1689859 B1호).
서열 번호 163은 슈도모나스 플루오레슨스 에스테라제의 L29P 변이체의 아미노산 서열이다(미국 특허 제7,384,787호).
서열 번호 164는 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 그의 C-말단에 융합된 바실러스 푸밀러스로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 165는 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 융합된 바실러스 푸밀러스로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 166은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 그의 C-말단에서 융합된 락토코커스 락티스 아종 락티스로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 167은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 융합된 락토코커스 락티스 아종 락티스로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 168은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 그의 C-말단에서 융합된 메소리조비움 로티로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴클레오티드 서열이다.
서열 번호 169는 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 융합된 메소리조비움 로티로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 170은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 그의 C-말단에서 융합된 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴레오티드 서열이다.
서열 번호 171은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 172는 가요성 링커를 통하여 칼디셀룰로시룹터 사카로라이티쿠스 CBD1 셀룰로스-결합 도메인에 그의 C-말단에서 융합된 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴레오티드 서열이다.
서열 번호 173은 가요성 링커를 통하여 칼디셀룰로시룹터 사카로라이티쿠스 CBD1 셀룰로스-결합 도메인에 융합된 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 174는 가요성 링커를 통하여 써모토가 마리티마 CBM9-2 셀룰로스-결합 도메인에 그의 C-말단에서 융합된 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴레오티드 서열이다.
서열 번호 175는 가요성 링커를 통하여 써모토가 마리티마 CBM9-2 셀룰로스-결합 도메인에 융합된 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 176은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 그의 C-말단에서 융합된 슈도모나스 플루오레슨스로부터의 가수분해효소의 L29P 변이체로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴레오티드 서열이다.
서열 번호 177은 가요성 링커를 통하여 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(CIP)에 융합된 슈도모나스 플루오레슨스로부터의 가수분해효소의 L29P 변이체로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 178은 가요성 링커를 통하여 써모토가 마리티마 CBM9-2 셀룰로스 결합 도메인에, 그의 C-말단에서 융합된 슈도모나스 플루오레슨스로부터의 가수분해효소의 L29P 변이체로부터의 아세틸 자일란 에스테라제를 암호화하는 합성 유전자의 뉴레오티드 서열이다.
서열 번호 179는 가요성 링커를 통하여 써모토가 마리티마 CBM9-2 셀룰로스-결합 도메인에 융합된 슈도모나스 플루오레슨스로부터의 가수분해효소의 L29P 변이체로부터의 아세틸 자일란 에스테라제의 아미노산 서열이다.
서열 번호 180은 마이코박테리움 스메그마티스로부터의 야생형 아릴 에스테라제의 아미노산 서열이다(미국 특허 제7,754,460호; WO2005/056782호; 및 EP1689859 B1호).
서열 번호 181은 슈도모나스 플루오레슨스 에스테라제의 아미노산 서열이다(미국 특허 제7,384,787호).
본 개시내용에서, 다수의 용어 및 약어가 사용된다. 하기의 정의는 특별히 다르게 언급되지 않는 한 적용된다.
본 명세서에서 사용되는 바와 같이, 본 발명의 요소 또는 성분 앞의 부정 관사("a", "an") 및 정관사("the")는 요소 또는 성분의 경우(즉, 발생)의 수에 관해서는 비제한적인 것으로 의도된다. 따라서, 부정 관사("a", "an") 및 정관사("the")는 하나 또는 적어도 하나를 포함하는 것으로 파악되어야 하며, 요소 또는 성분의 단수형은 그 수가 명백하게 단수임을 의미하는 것이 아니라면 복수형도 포함한다.
본 명세서에 사용되는 바와 같이, 용어 "포함하는"은 특허청구범위에서 인용된 바와 같은 언급된 특징, 정수, 단계, 또는 성분의 존재를 의미하지만, 하나 이상의 다른 특징, 정수, 단계, 성분 또는 그의 그룹의 존재 또는 부가를 배제하지 않는다. 용어 "포함하는"은 용어 "본질적으로 이루어진" 및 "이루어진"에 의해 포함되는 실시형태를 포함하고자 한다. 유사하게, 용어 "본질적으로 이루어진"은 용어 "이루어진"에 의해 포함되는 실시형태를 포함하고자 한다.
본 명세서에 사용되는 바와 같이, 사용되는 성분 또는 반응물질의 양을 수식하는 용어 "약"은 예를 들어, 현장에서 농축물 또는 사용 용액을 제조하는 데 사용되는 전형적인 측정 및 액체 취급 절차를 통해; 이들 과정에서의 우발적인 오차를 통해; 조성물을 제조하거나 방법을 실행하기 위해 적용된 성분의 제조, 공급원 또는 순도의 차이 등을 통해 발생할 수 있는 수치 분량의 변이를 말한다. 용어 "약"은 또한 특정 초기 혼합물로부터 유발되는 조성물에 대한 상이한 평형 조건으로 인해 달라지는 양을 포함한다. 용어 "약"에 의한 수식 여부를 불문하고, 특허청구범위는 분량의 균등물을 포함한다.
모든 범위는 존재하는 경우 포괄적이며 조합가능하다. 예를 들어, "1 내지 5"의 범위가 기재되는 경우, 기재된 범위는 범위 "1 내지 4", "1 내지 3", "1 내지 2", "1 내지 2 및 4 내지 5", "1 내지 3 및 5" 등을 포함하는 것으로 간주되어야 한다.
본 명세서에서 사용되는 "접촉"은 원하는 결과(표적 표면 결합, 과산 기반의 효과 등)를 달성하는데 충분한 기간 동안 조성물을 표적 표면과 접촉하게 배치하는 것을 말한다 조건부로, 표적 표면은 체표면(예를 들어, 모발, 네일, 피부 등) 및 구강 관리 표면(예를 들어, 잇몸, 치아 등)을 포함하지 않는다. 일 실시형태에서, "접촉"은 원하는 결과를 달성하는데 충분한 기간 동안 유효 농도의 과산을 포함하는(또는 이를 생성할 수 있는) 조성물을 표적 표면과 접촉하게 배치하는 것을 말할 수 있다. 다른 실시형태에서, "접촉"은 또한 세탁 관리 조성물의 적어도 하나의 성분, 예를 들어, 효소에 의한 과가수분해에 사용되는 하나 이상의 반응 성분을 표적 표면과 접촉하게 배치하는 것을 말할 수 있다. 접촉은 유효 농도의 과산을 포함하는 과산 용액 또는 조성물, 유효 농도의 과산을 형성하는 용액 또는 조성물, 또는 유효 농도의 과산을 형성하는 조성물의 한 성분을 표적 표면으로의 분무, 처리, 침지, 플러싱(flushing), 그의 위 또는 안으로의 주입, 혼합, 조합, 페인팅, 코팅, 도포, 부착 및 다르게는 전달을 포함한다.
본 명세서에서 사용되는 용어 "기질", "적절한 기질" 및 "카르복실산 에스테르 기질"은 상호교환적으로, 구체적으로
(a) 구조
[X]mR5
(여기서,
X는 화학식 R6C(O)O의 에스테르기이며;
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며, R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고, R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 하나 이상의 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ; 또는
(b) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 하나 이상의 글리세리드;
(c) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 또는
(d) 하나 이상의 아세틸화 단당류, 아세틸화 이당류 또는 아세틸화 다당류; 또는
(e) (a) 내지 (d)의 임의의 조합을 말한다.
본 명세서에서 사용되는 용어 "과산"은 퍼옥시산, 퍼옥시카르복실산, 퍼옥시산, 퍼카르복실산 및 퍼옥소산과 같은 의미이다.
본 명세서에서 사용되는 용어 "과아세트산"은 "PAA"로 약칭되며, 퍼옥시아세트산, 에탄퍼옥소산 및 CAS 등록 번호 79-21-0의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "모노아세틴"은 글리세롤 모노아세테이트, 글리세린 모노아세테이트 및 글리세릴 모노아세테이트와 같은 의미이다.
본 명세서에서 사용되는 용어 "다이아세틴"은 글리세롤 다이아세테이트; 글리세린 다이아세테이트, 글리세릴 다이아세테이트 및 CAS 등록 번호 25395-31-7의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "트라이아세틴"은 글리세린 트라이아세테이트; 글리세롤 트라이아세테이트; 글리세릴 트라이아세테이트, 1,2,3-트라이아세톡시프로판; 1,2,3-프로판트라이올 트라이아세테이트 및 CAS 등록 번호 102-76-1의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "모노부티린"은 글리세롤 모노부티레이트, 글리세린 모노부티레이트 및 글리세릴 모노부티레이트와 같은 의미이다.
본 명세서에서 사용되는 용어 "다이부티린"은 글리세롤 다이부티레이트 및 글리세릴 다이부티레이트와 같은 의미이다.
본 명세서에서 사용되는 용어 "트라이부티린"은 글리세롤 트라이부티레이트, 1,2,3-트라이부티릴글리세롤 및 CAS 등록 번호 60-01-5의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "모노프로피오닌"은 글리세롤 모노프로피오네이트, 글리세린 모노프로피오네이트 및 글리세릴 모노프로피오네이트와 같은 의미이다.
본 명세서에 사용되는 용어 "다이프로피오닌"은 글리세롤 다이프로피오네이트 및 글리세릴 다이프로피오네이트와 같은 의미이다.
본 명세서에서 사용되는 용어 "트라이프로피오닌"은 글리세릴 트라이프로피오네이트, 글리세롤 트라이프로피오네이트, 1,2,3-트라이프로피오닐글리세롤 및 CAS 등록 번호 139-45-7의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "아세틸화 당" 및 "아세틸화 당류"는 적어도 하나의 아세틸기를 포함하는 단당류, 이당류 및 다당류를 말한다. 예에는, 글루코스 펜타아세테이트; 자일로스 테트라아세테이트; 아세틸화 자일란; 아세틸화 자일란 단편; β-D-리보푸라노스-1,2,3,5-테트라아세테이트; 트라이-O-아세틸-D-갈락탈; 및 트라이-O-아세틸-글루칼이 포함되나 이들에 한정되지 않는다.
본 명세서에서 사용되는 용어 "하이드로카르빌", "하이드로카르빌기" 및 "하이드로카르빌 모이어티"는 단일, 이중 또는 삼중 탄소-탄소 결합 및/또는 에테르 결합으로 연결되고, 이에 따라 수소 원자로 치환된 직쇄, 분지쇄 또는 환형 배열의 탄소 원자를 의미한다. 이러한 하이드로카르빌기는 지방족 및/또는 방향족일 수 있다. 하이드로카르빌기의 예에는 메틸, 에틸, 프로필, 아이소프로필, 부틸, 아이소부틸, t-부틸, 사이클로프로필, 사이클로부틸, 펜틸, 사이클로펜틸, 메틸사이클로펜틸, 헥실, 사이클로헥실, 벤질 및 페닐이 포함된다. 바람직한 실시형태에서, 하이드로카르빌 모이어티는 단일 탄소-탄소 결합 및/또는 에테르 결합으로 연결되고 이에 따라 수소 원자로 치환된 직쇄, 분지쇄 또는 환형 배열의 탄소 원자이다.
본 명세서에서 사용되는 용어 1,2-에탄다이올; 1,2-프로판다이올; 1,3-프로판다이올; 1,2-부탄다이올; 1,3-부탄다이올; 2,3-부탄다이올; 1,4-부탄다이올; 1,2-펜탄다이올; 2,5-펜탄다이올; 2,5-펜탄다이올; 1,6-펜탄다이올; 1,2-헥산다이올; 2,5-헥산다이올; 1,6-헥산다이올 및 그들의 혼합물의 "모노에스테르" 및 "다이에스테르"는 화학식 RC(O)O(여기서, R은 C1 내지 C7 선형 하이드로카르빌 모이어티이다)의 적어도 하나의 에스테르기를 포함하는 상기 화합물을 말한다. 일 실시형태에서, 카르복실산 에스테르 기질은 프로필렌 글리콜 다이아세테이트(PGDA), 에틸렌 글리콜 다이아세테이트(EDGA) 및 이들의 혼합물로 이루어진 군으로부터 선택된다.
본 명세서에서 사용되는 용어 "프로필렌 글리콜 다이아세테이트"는 1,2-다이아세톡시프로판, 프로필렌 다이아세테이트, 1,2-프로판다이올 다이아세테이트 및 CAS 등록 번호 623-84-7의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "에틸렌 글리콜 다이아세테이트"는 1,2-다이아세톡시에탄, 에틸렌 다이아세테이트, 글리콜 다이아세테이트 및 CAS 등록 번호 111-55-7의 모든 다른 유의어와 같은 의미이다.
본 명세서에서 사용되는 용어 "적절한 효소적 반응 혼합물", "과산의 동소 생성에 적절한 성분", "적절한 반응 성분", "적절한 수성 반응 혼합물", "반응 혼합물" 및 "과산-생성 성분"은 반응물질 및 과가수분해 효소 촉매가 접촉되는 물질 및 물을 말한다. 과산-생성 성분은 인간 또는 동물 체표면에 표적화되지 않고, 적어도 하나의 적절한 카르복실산 에스테르 기질, 과산소원 및 물(과산소원, 예를 들어, 과산화수소를 포함하는 수용액)인 융합 단백질의 형태의 적어도 하나의 과가수분해효소를 포함할 것이다. 바람직한 태양에서, 과가수분해효소는 비-체표면에 표적화된 융합 단백질의 형태의 CE-7 과가수분해효소이다. 바람직한 실시형태에서, 비-체표면은 세탁 관리 표면이다. 추가의 바람직한 태양에서, 표적 표면은 셀룰로스 및/또는 셀룰로스 물질을 포함한다.
본 명세서에서 사용되는 용어 "과가수분해"는 과산을 형성하기 위한 선택된 기질과 과산화물의 반응으로 정의된다. 전형적으로, 무기 과산화물은 촉매의 존재 하에 선택된 기질과 반응하여, 퍼옥시카르복실산을 생성한다. 본 명세서에 사용되는 용어 "화학적 과가수분해"는 기질(퍼옥시카르복실산 전구체)을 과산화수소원과 배합하는 과가수분해 반응을 포함하며, 퍼옥시카르복실산은 효소 촉매의 부재 하에 형성된다. 본 명세서에서 사용되는 용어 "효소에 의한 과가수분해"는 카르복실산 에스테르 기질(과산 전구체)을 과산화수소원 및 물과 배합하여, 효소 촉매가 과산의 형성을 촉매작용시키는 과가수분해 반응을 포함한다.
본 명세서에서 사용되는 용어 "과가수분해효소 활성"은 단백질, 건조 세포 중량 또는 고정화된 촉매 중량의 단위 질량(예를 들어, 밀리그램)당 촉매 활성을 말한다.
본 명세서에서 사용되는 "효소 활성 1 유닛" 또는 "활성 1 유닛" 또는 "U"는 특정 온도에서 분당 1 μmol의 퍼옥시카르복실산 생성물의 생성에 필요한 과가수분해효소 활성의 양으로 정의된다.
본 명세서에서 사용되는 용어 "효소 촉매" 및 "과가수분해효소 촉매"는 과가수분해 활성을 갖는 효소를 포함하는 촉매를 말하며, 온전한 미생물 세포, 투과화된(permeabilized) 미생물 세포(들), 미생물 세포 추출물의 하나 이상의 세포 성분, 부분 정제된 효소 또는 정제된 효소의 형태일 수 있다. 또한, 효소 촉매는 화학적으로 변형될 수 있다(예를 들어, 페길화(pegylation)에 의하여 또는 가교 결합 시약과의 반응에 의하여). 또한, 과가수분해효소 촉매는 당업자에게 널리 공지되어 있는 방법을 사용하여 용해성 또는 불용성 지지체 상에 고정화될 수 있으며; 예를 들어, 문헌[Immobilization of Enzymes and Cells; Gordon F. Bickerstaff, Editor; Humana Press, Totowa, NJ, USA; 1997]을 참조한다.
본 명세서에 사용되는 "표적화된 과가수분해효소" 또는 "표적화된 과가수분해 효소"는 적어도 과가수분해 활성을 갖는 효소를 갖는 제1 부분 및 조건부로, 인간 모발, 인간 피부, 인간 네일 또는 인간 구강 표면을 포함하지 않는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분을 포함하는 적어도 하나의 제2 부분을 포함하는 과가수분해 융합 단백질을 지칭할 것이다. 개인 관리 응용에서의 사용을 위한 표적화된 과가수분해효소에 관한 공동-계류 중인 출원(공동-소유의, 공동-계류 중인 미국 특허 출원(명칭: "ENZYMATIC PERACID GENERATION FOR USE IN ORAL CARE PRODUCTS" (대리인 문서 번호 CL5256) 및 "ENZYMATIC PERACID GENERATION FOR USE IN HAIR CARE PRODUCTS" (대리인 문서 번호 CL5175)))이 존재하기 때문에, 신체 및 구강 표면을 배제하는 상술된 조건을 포함시켰다. 표적 표면에 대하여 친화성을 갖는 펩티드 성분은 효소에 의한 과산 생성을 표적 표면 상에 또는 그 근처에 국소화시키거나 표적화시키기 위해 선택된다. 일 실시형태에서, 표적 물질은 천연 섬유, 반합성 섬유 또는 합성 섬유 또는 섬유의 혼방을 포함하는 실, 섬유, 텍스타일 또는 패브릭이다. 다른 실시형태에서, 표적 표면은 셀룰로스 물질, 예를 들어, 셀룰로스, 목재, 목재 펄프, 제지, 제지 펄프, 면, 레이온 및 라이오셀(lyocell)을 포함한다. 다른 실시형태에서, 표적 물질은 셀룰로스 물질을 포함하는 섬유, 실, 텍스타일 또는 패브릭(직물 또는 부직물)의 형태이다.
본 명세서에 사용되는 용어 "셀룰로스"는 셀룰로스를 포함하거나 이로부터 유래된 물질을 말한다. 본 명세서에 사용되는 "셀룰로스"는 통상 수백 내지 수천개의 유닛을 포함하는 선형 사슬 β(1→4) 연결된 D-글루코스 유닛으로 이루어진 다당류이다. 셀룰로스 물질의 예는 셀룰로스, 목재, 목재 펄프, 제지, 면, 레이온 및 라이오셀(유기 용매 방사 과정에 의해 수득되는 셀룰로스 섬유)을 포함할 수 있다.
본 명세서에 사용되는 용어 "셀룰로스-결합 도메인"은 많은 셀룰로스 분해 효소에 존재하는 셀룰로스에 대하여 강력한 친화성을 갖는 자연 발생 결합 도메인을 말한다(상기 문헌[Tomme et al.]). 본 명세서에 기재된 비-표적화된 과가수분해 효소는 천연적으로 셀룰로스-결합 도메인을 함유하지 않는다. 이와 같이, 셀룰로스 물질에 대하여 친화성을 갖도록 고안된 표적화된 과가수분해효소는 과가수분해 효소 및 셀룰로스 물질에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분을 포함하는 융합 단백질이다. 일 실시형태에서, 펩티드 성분은 셀룰로스-결합 도메인의 이용을 포함할 수 있다.
본 명세서에서 사용되는 "아세틸 자일란 에스테라제"는 아세틸화 자일란 및 기타 아세틸화 당류의 탈아세틸화를 촉매작용시키는 효소(E.C. 3.1.1.72; AXE)를 말한다. 본 명세서에 예시된 바와 같이, 유의미한 과가수분해 활성을 갖는 아세틸 자일란 에스테라제로 분류되는 몇몇 효소가 제공된다.
본 명세서에 사용되는 용어 "세팔로스포린 C 데아세틸라제" 및 "세팔로스포린 C 아세틸 가수분해효소"는 세팔로스포린, 예를 들어, 세팔로스포린 C 및 7-아미노세팔로스포란산의 탈아세틸화를 촉매작용시키는 효소(E.C. 3.1.1.41)를 말한다(문헌[Mitsushima et al., (1995) Appl . Env . Microbiol. 61(6):2224-2229]). 유의미한 과가수분해 활성을 갖는 몇몇 세팔로스포린 C 데아세틸라제의 아미노산 서열이 본 명세서에 제공된다.
본 명세서에서 사용되는 용어 "바실러스 서브틸리스 ATCC(등록 상표) 31954(상표명) "는 국제 기탁소 수탁 번호가 ATCC(등록 상표) 31954(상표명)인 아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection)(ATCC)에 기탁된 박테리아 세포를 말한다. 바실러스 서브틸리스 ATCC(등록 상표) 31954(상표명)는 2 내지 8개 탄소 아실기를 갖는 글리세롤 에스테르, 특히 다이아세틴을 가수분해시킬 수 있는 에스테르 가수분해효소("다이아세티나제") 활성을 갖는 것으로 보고되었다(미국 특허 제4,444,886호; 본 명세서에 그 전문이 참고로 포함됨). 본 명세서에 기재된 바와 같이, 바실러스 서브틸리스 ATCC(등록 상표) 31954(상표명)로부터의 유의미한 과가수분해효소 활성을 갖는 효소는 서열 번호 2로 제공된다(미국 특허 출원 공개 제2010-0041752호 참조). 분리된 효소의 아미노산 서열은 진뱅크(등록 상표) 수탁 번호 BAA01729.1에 의해 제공되는 세팔로스포린 C 데아세틸라제에 대하여 100% 아미노산 동일성을 갖는다(상기 문헌[Mitsushima et al.]).
본 명세서에 사용되는 용어 "써모토가 마리티마 MSB8"은 아세틸 자일란 에스테라제 활성을 갖는 것으로 보고된 박테리아 세포를 말한다(진뱅크(등록 상표) NP_227893.1; 미국 특허 출원 공개 제2008-0176299호 참조). 써모토가 마리티마 MSB8로부터의 과가수분해효소 활성을 갖는 효소의 아미노산 서열은 서열 번호 16으로 제공되어 있다.
본 명세서에서 사용되는 바와 같은 "분리된 핵산 분자", "분리된 폴리뉴클레오티드" 및 "분리된 핵산 단편"은 상호호환적으로 사용될 것이며, 임의로 합성, 비-천연 또는 변경된 뉴클레오티드 염기를 함유하는 단일 가닥 또는 이중 가닥의 RNA 또는 DNA의 폴리머를 지칭할 것이다. DNA의 폴리머 형태인 분리된 핵산 분자는 cDNA, 게놈 DNA 또는 합성 DNA의 하나 이상의 세그먼트로 이루어질 수 있다.
용어 "아미노산"은 단백질 또는 폴리펩티드의 기본 화학 구조 단위를 지칭한다. 하기의 약어는 특정 아미노산을 확인하기 위해 본 명세서에서 사용된다.

예를 들어, 주어진 부위에 화학적으로 균등한 아미노산의 생성을 유발하면서 암호화된 단백질의 기능적 특성에 영향을 미치지 않는 유전자의 변경이 흔하다는 것은 당업계에 주지되어 있다. 본 발명의 목적상, 치환은 하기 5 개 그룹 중 하나의 그룹 내에서의 교환으로 정의된다:
1. 비극성 또는 약간 극성인 작은 지방족 잔기: Ala, Ser, Thr (Pro, Gly);
2. 극성의, 음성 하전된 잔기 및 그의 아미드: Asp, Asn, Glu, Gln;
3. 양으로 하전된 극성 잔기: His, Arg, Lys;
4. 비극성인 큰 지방족 잔기: Met, Leu, Ile, Val (Cys); 및
큰 방향족 잔기: Phe, Tyr 및 Trp.
따라서, 소수성 아미노산인 아미노산 알라닌에 대한 코돈은 소수성이 보다 낮은 다른 잔기(예를 들어, 글리신) 또는 소수성이 보다 높은 잔기(예를 들어, 발린, 류신 또는 아이소류신)를 암호화하는 코돈으로 치환될 수 있다. 마찬가지로, 음으로 하전된 하나의 잔기로 다른 하나를 치환하거나(예를 들어 글루탐산을 아스파르트산으로) 양으로 하전된 하나의 잔기로 다른 하나를 치환하는(예를 들어, 아르기닌을 라이신으로) 변화도 기능적으로 균등한 생성물을 생성시킬 수 있을 것으로 예상된다. 많은 경우에, 단백질 분자의 N-말단 및 C-말단 부분의 변경을 유발하는 뉴클레오티드 변화도 단백질의 활성을 변경하지 않을 것으로 예상된다. 각각의 제안된 변형은 당업계의 통상적 기술로 충분히 가능하며, 암호화된 생성물의 생물학적 활성의 보유를 결정하는 것도 그러하다.
본 명세서에서 사용되는 용어 "시그니처 모티프" 및 "진단 모티프"는 정의된 활성을 갖는 효소의 패밀리 중에 공유되는 보존된 구조를 지칭한다. 시그니처 모티프를 사용하여, 정의된 기질의 패밀리에 대하여 유사한 효소 활성을 갖는 구조적으로 관련된 효소의 패밀리를 정의하고/거나 동정할 수 있다. 시그니처 모티브는 단일의 연속 아미노산 서열 또는 함께 시그니처 모티프를 형성하는 보존된 불연속 모티프의 집합일 수 있다. 전형적으로, 보존된 모티프(들)는 아미노산 서열로 나타낸다. 바람직한 태양에서, 시그니처 모티프는 "CE-7 시그니처 모티프", "과가수분해 활성"을 갖는 탄수화물 에스테라제 패밀리 7("CE-7 탄수화물 에스테라제")의 구성원에 공유되는 보존된 구조적 모티프이다.
본 명세서에서 사용되는 용어 "코돈 최적화된"은 그것이 다양한 숙주의 형질전환을 위한 핵산 분자의 유전자 또는 암호화 영역을 지칭하기 때문에, DNA가 암호화하는 폴리펩티드를 변경시키지 않고, 숙주 유기체의 전형적인 코돈 사용을 반영하기 위한 핵산 분자의 유전자 또는 암호화 영역에서의 코돈의 변경을 지칭한다.
본 명세서에서 사용되는 "합성 유전자"는 당업자에게 공지되어 있는 절차를 사용하여 화학적으로 합성된 올리고뉴클레오티드 빌딩 블록(building block)으로부터 조립될 수 있다. 이들 빌딩 블록을 라이게이션시키고 어닐링시켜, 유전자 세그먼트를 형성하고, 이어서, 이를 효소에 의해 조립하여 전체 유전자를 구축한다. DNA 서열에 관계된 바와 같은 "화학적으로 합성된"은 뉴클레오티드 성분이 시험관 내에서 조립되는 것을 의미한다. DNA의 수동의 화학적 합성은 널리 확립되어 있는 절차를 사용하여 달성될 수 있거나, 자동화된 화학적 합성은 다수의 상업적으로 입수할 수 있는 장치 중 하나를 사용하여 수행할 수 있다. 따라서, 유전자는 숙주 세포의 코돈 편향을 반영하기 위한 뉴클레오티드 서열의 최적화에 기초하여 최적의 유전자 발현을 위해 맞춤화될 수 있다. 당업자는 코돈 사용이 숙주가 선호하는 코돈에 편향된다면, 성공적인 유전자 발현이 가능함을 인식한다. 바람직한 코돈의 결정은 서열 정보를 이용할 수 있는 숙주 세포 유래의 유전자의 조사에 기초할 수 있다.
본 명세서에서 사용되는 "유전자"는 암호화 서열에 앞서는 조절 서열(5' 비암호화 서열) 및 암호화 서열에 뒤따르는 조절 서열(3' 비암호화 서열)을 포함하는, 특정 단백질을 발현하는 핵산 분자를 말한다. "천연 유전자"는 그 자체의 조절 서열과 함께 자연에서 발견되는 유전자를 지칭한다. "키메라 유전자"는 자연에서 함께 발견되지 않는 조절 및 암호화 서열을 포함하는, 천연 유전자가 아닌 임의의 유전자를 지칭한다. 따라서, 키메라 유전자는 상이한 공급원 유래의 조절 서열과 암호화 서열, 또는 동일한 공급원 유래이지만, 자연에서 발견되는 것과 상이한 방식으로 배열된 조절 서열과 암호화 서열을 포함할 수 있다. "내인성 유전자"는 유기체의 게놈에서 그의 자연적 위치에 있는 천연 유전자를 지칭한다. "외래" 유전자는 숙주 유기체 내에서 정상적으로 발견되는 것이 아니라 유전자 전달에 의해 숙주 유기체 내로 도입된 유전자를 지칭한다. 외래 유전자는 비-천연 유기체 내로 삽입된 천연 유전자, 또는 키메라 유전자를 포함할 수 있다. "트랜스유전자(transgene)"는 형질전환 절차에 의해 게놈 내로 도입된 유전자이다.
본 명세서에 사용되는 "암호화 서열"은 특정 아미노산 서열을 암호화하는 DNA 서열을 말한다. "적절한 조절 서열"은 암호화 서열의 상류(5' 비-암호화 서열), 암호화 서열의 내부 또는 암호화 서열의 하류(3' 비-암호화 서열)에 위치하고, 전사, RNA 프로세싱 또는 안정성 또는 연계된 암호화 서열의 번역에 영향을 미치는 뉴클레오티드 서열을 지칭한다. 조절 서열은 프로모터, 번역 리더 서열(translation leader sequence), RNA 프로세싱 부위, 이펙터(effector) 결합 부위 및 스템-루프 구조(stem-loop structure)를 포함할 수 있다.
본 명세서에 사용되는 용어 "작동가능하게 연결된"은 하나의 기능이 다른 것에 의해 영향을 받게 하는 단일의 핵산 분자 상의 핵산 서열의 회합을 말한다. 예를 들어, 프로모터는 그것이 암호화 서열의 발현에 영향을 미칠 수 있는 경우, 다시 말하면, 암호화 서열이 프로모터의 전사적 제어 하에 있는 경우, 그 암호화 서열과 작동가능하게 연결된다. 암호화 서열은 센스 또는 안티센스 배향으로 조절 서열에 작동가능하게 연결될 수 있다.
본 명세서에 사용되는 용어 "발현"은 본 발명의 핵산 분자로부터 유래된 센스(mRNA) 또는 안티센스 RNA의 전사 및 안정한 축적을 말한다. 또한, 발현은 mRNA의 폴리펩티드로의 번역을 말할 수 있다.
본 명세서에서 사용되는 "형질전환"은 핵산 분자가 숙주 유기체의 게놈으로 전달되어, 유전적으로 안정한 유전성이 야기되는 것을 말한다. 본 발명에서, 숙주 세포의 게놈은 염색체 및 염색체외(예를 들어, 플라스미드) 유전자를 포함한다. 형질전환된 핵산 분자를 포함하는 숙주 유기체는 "트랜스제닉", "재조합" 또는 "형질전환된" 유기체로 지칭된다.
본 명세서에 사용되는 용어 "플라스미드", "벡터" 및 "카세트"는 통상 원형 이중 가닥 DNA 분자의 형태이며, 전형적으로 세포의 중추 대사의 일부가 아닌 유전자를 지니는 염색체외 요소를 말한다. 이러한 요소는 임의의 공급원으로부터 유래되는 자체적으로 복제하는 서열, 게놈 통합 서열, 파지 또는 뉴클레오티드 서열, 선형 또는 환형의 단일- 또는 이중-가닥 DNA 또는 RNA일 수 있으며, 여기서, 다수의 뉴클레오티드 서열은 세포 내로 적절한 3' 미번역 서열과 함께, 프로모터 단편 및 선택된 유전자 산물을 위한 DNA 서열을 도입할 수 있는 독특한 구축물로 결합되거나 재조합된다. "형질전환 카세트"는 외래 유전자를 함유하며, 외래 유전자에 더하여, 특정 숙주 세포의 형질전환을 가능하게 하는 요소를 갖는 특정 벡터를 말한다. "발현 카세트"는 외래 유전자를 함유하며, 외래 유전자에 더하여, 외래 숙주에서 외래 유전자의 발현이 증가되게 하는 요소를 갖는 특정 벡터를 말한다.
본 명세서에서 사용되는 용어 "서열 분석 소프트웨어"는 뉴클레오티드 또는 아미노산 서열을 분석하는데 유용한 임의의 컴퓨터 알고리듬 또는 소프트웨어 프로그램을 지칭한다. "서열 분석 소프트웨어"는 상업적으로 입수할 수 있거나 독립적으로 개발할 수 있다. 통상적인 서열 분석 소프트웨어는 GCG 프로그램 모음(위스콘신 패키지 버전 9.0, 미국 위스콘신주 매디슨 소재의 제네틱스 컴퓨터 그룹(GCG: Genetics Computer Group)), BLASTP, BLASTN, BLASTX(문헌[Altschul et al., J. Mol Biol. 215:403-410 (1990)]) 및 DNASTAR(미국 위스콘신주 53715 파크 스트리트 매디슨 1228 S 소재의 디엔에이스타, 인포레이티드(DNASTAR, Inc.)), 클러스털더블유(예를 들어, 버전 1.83; 문헌[Thompson et al ., Nucleic Acids Research , 22(22):4673-4680 (1994)]) 및 스미스 워터만 알고리듬(Smith-Waterman algorithm)이 통합된 FASTA 프로그램(문헌[W. R. Pearson, Comput. Methods Genome Res ., [Proc. Int. Symp.] (1994), Meeting Date 1992, 111-20. Editor(s): Suhai, Sandor. Publisher: Plenum, New York, NY]), 벡터(Vector) NTI (미국 메릴랜드주 베데스다 소재의 인포맥스(Informax)) 및 시퀀처(Sequencher) v. 4.05를 포함할 것이나 이들에 한정되지 않는다. 본 출원과 관련하여, 서열 분석 소프트웨어가 분석을 위해 사용된 경우에는, 그 분석 결과가 달리 명시되지 않는 한, 참조한 프로그램의 "디폴트 값"에 기초할 것임을 이해할 것이다. 본 명세서에서 사용된 "디폴트 값"은 최초 초기화할 때에 소프트웨어에 원래 로딩된 소프트웨어 제조처에 의해 설정된 임의의 수치 또는 파라미터의 세트를 의미할 것이다.
본 명세서에서 사용되는 용어 "생물학적 오염물질"은 미생물, 포자, 바이러스, 프리온(prion) 및 그들의 혼합물을 포함하나 이들에 한정되지 않는 하나 이상의 원치않고/거나 병원성 생물학적 엔티티(entity)를 지칭한다. 일 실시형태에서, 생물학적 오염물질을 줄이고/거나 그의 존재를 제거하는데 유용한 유효 농도의 적어도 하나의 과산을 효소에 의해 생성하는 방법이 제공된다.
본 명세서에서 사용되는 용어 "소독한다"는 생물학적 오염물질의 파괴 또는 그의 성장의 방지 과정을 말한다. 본 명세서에 사용되는 용어 "소독제"는 생물학적 오염물질을 파괴하거나, 중화시키거나 그의 성장을 억제함으로써 소독하는 제제를 말한다. 본 명세서에 사용되는 용어 "소독"은 소독 행위 또는 과정을 말한다. 본 명세서에 사용되는 용어 "보존제"는 질환-운반형(disease-carrying) 미생물의 성장을 억제하는 화학적 제제를 말한다. 일 태양에서, 생물학적 오염물질은 병원성 미생물이다.
본 명세서에 사용되는 용어 "위생적인"은 전형적으로 건강에 해로울 수 있는 제제를 제거하거나, 방지하거나 조절함에 의한, 건강의 회복 또는 유지를 의미하거나 그와 관련이 있다. 본 명세서에 사용되는 용어 "살균하다"는 위생적이게 만드는 것을 의미한다. 본 명세서에 사용되는 용어 "살균제"는 살균시키는 제제를 말한다. 본 명세서에 사용되는 용어 "살균"은 살균 행위 또는 과정을 말한다.
본 명세서에 사용되는 용어 "살생물제"는 미생물을 불활성화시키거나 파괴시키는 전형적으로 광범위의 화학적 제제를 말한다. 미생물을 불활성화시키거나 파괴하는 능력을 나타내는 화학적 제제는 "살생물" 활성을 갖는 것으로 기재된다. 과산은 살생물 활성을 가질 수 있다. 본 발명에 사용하기에 적절할 수 있는 당업계에 공지되어 있는 대안의 전형적인 살생물제는 예를 들어, 염소, 이산화염소, 클로로아이소시아누레이트, 차아염소산염, 오존, 아크롤레인, 아민, 염화 페놀 화합물, 구리 염, 유기-황 화합물 및 4차 암모늄 염을 포함한다.
본 명세서에 사용되는 어구 "최소 살생물 농도"는 생존가능한 표적화된 미생물의 집단에서 소정의 접촉 시간 동안 목적하는 치사의 비가역적인 감소가 생기게 할 살생물제의 최소 농도를 말한다. 유효성은 처리 후에 생존가능한 미생물의 log10 감소로 측정될 수 있다. 일 태양에서, 처리 후의 생존가능한 미생물의 표적화된 감소는 적어도 3-log10 감소, 더욱 바람직하게는 적어도 4-log10 감소, 가장 바람직하게는 적어도 5-log10 감소이다. 다른 태양에서, 최소의 살생물 농도는 생존가능한 미생물 세포의 적어도 6-log10 감소이다.
본 명세서에 사용되는 용어 "과산소원" 및 "과산소의 공급원"은 과산화수소, 과산화수소 부가물(예를 들어, 우레아-과산화수소 부가물(카르바미드 퍼옥시드)), 과붕산염 및 과탄산염을 포함하나 이들에 한정되지 않는, 수용액에 존재하는 경우 약 1 mM 이상의 농도로 과산화수소를 제공할 수 있는 화합물을 말한다. 본 명세서에 기재된 바와 같이, 수성 반응 제형 중의 과산소 화합물에 의해 제공되는 과산화수소의 농도는 반응 성분의 배합시에 초기에는 적어도 0.1 mM 또는 그 이상이다. 일 실시형태에서, 수성 반응 제형 중의 과산화수소 농도는 적어도 0.5 mM이다. 다른 실시형태에서, 수성 반응 제형 중의 과산화수소 농도는 적어도 10 mM이다. 다른 실시형태에서, 수성 반응 제형 중의 과산화수소 농도는 적어도 100 mM이다. 다른 실시형태에서, 수성 반응 제형 중의 과산화수소 농도는 적어도 200 mM이다. 다른 실시형태에서, 수성 반응 제형 중의 과산화수소 농도는 500 mM 이상이다. 또 다른 실시형태에서, 수성 반응 제형 중의 과산화수소 농도는 1000 mM 이상이다. 수성 반응 제형 중의 과산화수소 대 효소 기질, 예를 들어, 트라이글리세리드, (H2O2:기질)의 몰비는 약 0.002 내지 20, 바람직하게는 약 0.1 내지 10, 가장 바람직하게는 약 0.5 내지 5일 수 있다.
본 명세서에 사용되는 용어 "올리고당"은 글리코시드 결합에 의해 결합되는 2 내지 적어도 24개의 단당류 단위를 함유하는 화합물을 말한다. 용어 "단당류"는 실험식 (CH2O)n(여기서, n은 3 이상이고, 탄소 골격은 비분지형이며, 하나의 탄소 원자를 제외한 각 탄소 원자는 하이드록실기를 함유하고, 나머지 탄소 원자는 탄소 원자 1에서 알데히드 또는 케톤이다)의 화합물을 지칭한다. 또한, 용어 "단당류"는 세포내 환형 헤미아세탈 또는 헤미케탈 형태를 지칭한다.
본 명세서에 사용되는 용어 "부형제"는 제형 중의 활성 성분에 대한 담체로 사용되는 불활성 물질을 말한다. 부형제를 사용하여 활성 성분의 저장 안정성과 같이, 제형 중의 활성 성분을 안정화시킬 수 있다. 또한, 부형제는 때때로 활성 성분을 함유하는 제형의 부피를 늘리기 위해 사용된다. 본 명세서에 기재된 바와 같은 "활성 성분"은 전형적으로 과가수분해 효소에 의해 생성되는 과산이다. 일부 실시형태에서, 활성 성분은 과가수분해 활성을 갖는 효소, 적절한 반응 조건 하에서 과가수분해 효소에 의해 생성되는 과산 또는 그들의 조합일 수 있다.
용어 "실질적으로 물이 없는"은 카르복실산 에스테르에 존재하는 경우 효소 또는 효소 분말의 저장 안정성에 해로운 영향을 주지 않는 제형 중의 물의 농도를 지칭할 것이다. 카르복실산 에스테르는 매우 낮은 농도의 물을 함유할 수 있으며, 예를 들어, 트라이아세틴은 전형적으로 180 ppm 내지 300 ppm의 물을 갖는다. 일 실시형태에서, 과가수분해 효소는 실질적으로 물이 없는 카르복실산 에스테르 기질 중에 저장된다. 추가의 실시형태에서, "실질적으로 물이 없는"은 효소(또는 효소 분말) 및 카르복실산 에스테르를 포함하는 제형 중의 2000 ppm 미만, 바람직하게는 1000 ppm 미만, 더욱 바람직하게는 500 ppm 미만, 더더욱 바람직하게는 250 ppm 미만의 물을 의미할 수 있다. 일 실시형태에서, 과가수분해 효소는 효소가 수용액(예를 들어, 저장 동안 효소에 의해 가수분해될 수 있는 상당한 농도의 카르복실산 에스테르 기질을 함유하지 않는 용액) 중에 안정적이도록 생성 시스템이 고안된다면, 수용액 중에 저장될 수 있다. 일 실시형태에서, 과가수분해 효소는 물 및 하나 이상의 완충제(예를 들어, 바이카르보네이트, 시트레이트, 아세테이트, 포스페이트, 피로포스페이트, 메틸포스포네이트, 석시네이트, 말레이트, 푸마레이트, 타르트레이트 및 말레에이트의 나트륨 및/또는 칼륨 염)가 실질적으로 없는 카르복실산 에스테르 기질을 포함하는 혼합물 중에 저장될 수 있다.
본 명세서에 사용되는 용어 "유익제"는 유용한 이점, 바람직한/목적하는 효과 또는 혜택을 촉진시키거나 증진시키는 물질을 말한다. 본 발명의 표적화된 과가수분해효소 기반의 조성물 및 방법을 사용하여 생성되는 과산 유익제는 표적 물질(경질 표면, 목재 펄프, 제지, 제지 펄프, 섬유, 실, 텍스타일 및 패브릭뿐 아니라, 섬유를 생성하기 위해 사용되는 폴리머 및 코폴리머)에 혜택, 예를 들어, 표적 물질이 인간 또는 동물 체표면(모발, 피부, 네일)뿐 아니라 구강 내의 표면이 아닌 조건과 함께, 소독, 살균, 탈색, 미백, 탈염, 탈취 및 그들의 임의의 조합을 제공한다. 일 실시형태에서, 과산 유익제가 텍스타일 또는 의류 물품 상에서 표적화된 과가수분해효소에 의해 효소적으로 생성되어, 목적하는 혜택, 예를 들어, 소독, 살균, 탈색, 탈염, 탈취 및 그들의 임의의 조합을 달성하는 방법이 제공된다.
과가수분해 활성을 갖는 효소
과가수분해 활성을 갖는 효소는 효소가 본 발명의 하나 이상의 기질에 대하여 과가수분해 활성을 갖는 한, 리파제, 프로테아제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제 및 조합으로 분류된 일부 효소를 포함할 수 있다. 예에는 과가수분해 프로테아제(서브틸리신 칼스버그(subtilisin Carlsberg) 변이체; 미국 특허 제7,510,859호), 과가수분해 아릴 에스테라제(슈도모나스 플루오레슨스; 서열 번호 163[L29P 변이체]; 및 181[야생형]; 미국 특허 제7,384,787호), 마이코박테리움 스메그마티스로부터의 과가수분해 아릴 에스테라제/아실 트랜스퍼라제(서열 번호 162[S54V 변이체] 및 180[야생형]; 미국 특허 제7,754,460호; WO2005/056782호; 및 EP1689859 B1호) 및 과가수분해 탄수화물 에스테라제가 포함될 수 있으나, 이들에 한정되지 않는다. 바람직한 태양에서, 과가수분해 탄수화물 에스테라제는 CE-7 탄수화물 에스테라제이다. 다른 실시형태에서, 과가수분해 효소는 조건부로, 과가수분해 프로테아제를 포함하지 않는다.
일 실시형태에서, 적절한 과가수분해효소는 본 명세서에 기재된 임의의 아미노산 서열에 대하여 적어도 30%, 33%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%의 아미노산 동일성을 갖는 아미노산 서열을 포함하는 효소를 포함할 수 있다.
다른 실시형태에서, 적절한 과가수분해효소는 서열 번호 162, 163, 180 및 181에 대하여 적어도 30%, 33%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 아미노산 동일성을 갖는 아미노산 서열을 포함하는 효소를 포함할 수 있다. 일 실시형태에서, 과가수분해 효소는 서열 번호 162에 대하여 적어도 95% 동일성을 갖는 아미노산 서열을 포함한다.
다른 실시형태에서, 실질적으로 유사한 과가수분해 효소는 매우 엄격한 혼성화 조건(0.1× SSC, 0.1% SDS, 65℃, 및 2× SSC, 0.1% SDS로의 세정에 이은, 0.1× SSC, 0.1% SDS, 65℃의 최종 세정) 하에서 본 발명의 임의의 과가수분해 효소를 암호화하는 폴리뉴클레오티드 서열에 혼성화되는 폴리뉴클레오티드 서열에 의해 암호화되는 것을 포함할 수 있다.
CE-7 과가수분해효소
일 실시형태에서, 본 발명의 조성물 및 방법은 구조적으로 효소의 탄수화물 패밀리 에스테라제 패밀리 7(CE-7 패밀리)의 구성원으로 분류되는 과가수분해 활성을 갖는 적어도 하나의 과가수분해 효소를 갖는 적어도 하나의 융합 단백질을 포함한다(문헌[Coutinho, P.M., Henrissat, B. "Carbohydrate-active enzymes: an integrated database approach" in Recent Advances in Carbohydrate Bioengineering, H.J. Gilbert, G. Davies, B. Henrissat and B. Svensson eds., (1999) The Royal Society of Chemistry, Cambridge, pp. 3-12] 참조). 효소의 CE-7 패밀리는 과산소원과 배합되는 경우 다양한 카르복실산 에스테르 기질로부터 퍼옥시카르복실산을 생성하는데 특히 효과적인 것으로 증명되었다(WO2007/070609호 및 미국 특허 출원 공개 제2008-0176299호, 제2008-176783호, 제2009-0005590호, 제2010-0041752호 및 제2010-0087529호뿐 아니라, 미국 특허 출원 제12/571702호 및 미국 가특허 출원 제61/318016호(DiCosimo et al.); 각각은 본 명세서에 참고로 포함된다).
CE-7 패밀리의 구성원은 세팔로스포린 C 데아세틸라제(CAH; E.C. 3.1.1.41) 및 아세틸 자일란 에스테라제(AXE; E.C. 3.1.1.72)를 포함한다. CE-7 에스테라제 패밀리의 구성원은 보존된 시그니처 모티프를 공유한다(문헌[incent et al., J. Mol. Biol., 330:593-606(2003)]). CE-7 시그니처 모티프를 포함하는 과가수분해효소("CE-7 과가수분해효소") 및/또는 실질적으로 유사한 구조는 본 명세서에 기재된 조성물 및 방법에서 과가수분해 융합 펩티드("표적화된 과가수분해효소")로서의 제조 및 이용에 적절하다. 실질적으로 유사한 생물학적 분자를 동정하는 수단은 당업계에 널리 공지되어 있다(예를 들어, 서열 정렬 프로토콜, 핵산 혼성화 및/또는 보존된 시그니처 모티프의 존재; 조건부로, 과가수분해 효소를 암호화하거나 이와 관련이 있는 실질적으로 유사한 폴리뉴클레오티드 및 폴리펩티드는 표적화된 도메인이 없는 과가수분해 효소와 관련이 있는 서열을 사용하여 동정한다). 일 태양에서, 과가수분해효소는 CE-7 시그니처 모티프, 및 본 명세서에 기재된 서열 중 하나에 대하여 적어도 20%, 바람직하게는 적어도 30%, 더욱 바람직하게는 적어도 33%, 더욱 바람직하게는 적어도 40%, 더욱 바람직하게는 적어도 42%, 더욱 바람직하게는 적어도 50%, 더욱 바람직하게는 적어도 60%, 더욱 바람직하게는 적어도 70%, 더욱 바람직하게는 적어도 80%, 더욱 바람직하게는 적어도 90%, 가장 바람직하게는 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%의 아미노산 동일성을 포함하는 효소를 포함한다.
본 명세서에 사용되는 어구 "효소는 구조적으로 CE-7 효소로 분류된다", "CE-7 과가수분해효소" 또는 "구조적으로 탄수화물 에스테라제 패밀리 7 효소로 분류된"은 구조적으로 CE-7 탄수화물 에스테라제로 분류된 과가수분해 활성을 갖는 효소를 지칭하기 위해 사용될 것이다. 효소의 패밀리는 시그니처 모티프의 존재에 의해 정의될 수 있다(상기 문헌[Vincent et al.]). CE-7 에스테라제에 대한 시그니처 모티프는 3가지 보존된 모티프를 포함한다(서열 번호 2의 참조 서열에 대한 잔기 위치 넘버링; 바실러스 서브틸리스 ATCC(등록 상표) 31954(상표명)로부터의 CE-7 과가수분해효소):
a) Arg118-Gly119-Gln120;
b) Gly179-Xaa180-Ser181-Gln182-Gly183; 및
c) His298-Glu299.
전형적으로, 아미노산 잔기 위치 180에서의 Xaa는 글리신, 알라닌, 프롤린, 트립토판 또는 트레오닌이다. 촉매 트라이아드에 속하는 3개의 아미노산 잔기 중 2개를 볼드체로 나타내었다. 일 실시형태에서, 아미노산 잔기 위치 180에서의 Xaa는 글리신, 알라닌, 프롤린, 트립토판 및 트레오닌으로 이루어진 군으로부터 선택된다.
CE-7 탄수화물 에스테라제 패밀리 내의 보존된 모티프의 추가의 분석에 의해, CE-7 탄수화물 에스테라제 패밀리에 속하는 과가수분해효소를 추가로 정의하기 위해 사용될 수 있는 추가의 보존된 모티프(서열 번호 2의 아미노산 위치 267 내지 269에서의 LXD)의 존재가 나타난다. 추가의 실시형태에서, 상기 정의된 시그니처 모티프는 하기로 정의된 추가의(제4) 보존된 모티프를 포함할 수 있다:
Leu267-Xaa268-Asp269.
아미노산 잔기 위치 268에서의 Xaa는 전형적으로, 아이소류신, 발린 또는 메티오닌이다. 제4 모티프는 촉매 트라이아드(Ser181-Asp269-His298)에 속하는 아스파르트산 잔기(볼드체)를 포함한다.
표적화된 CE-7 과가수분해효소는 적어도 하나의 표적 표면에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분을 갖는 융합 단백질이다. 일 실시형태에서, 표적화된 과가수분해효소(융합 단백질)가 CE-7 시그니처 모티프를 포함하는지 결정하기 위해 사용되는 정렬은 체표면에 대하여 친화성을 갖는 펩티드 성분이 없는 과가수분해 효소의 아미노산 서열에 기초할 것이다.
많은 널리 공지된 전반적인 정렬 알고리듬(즉, 서열 분석 소프트웨어)을 사용하여 과가수분해효소 활성을 갖는 효소를 대표하는 둘 이상의 아미노산 서열을 정렬하여, 효소가 CE-7 시그니처 모티프로 이루어지는지 결정할 수 있다. 정렬된 서열(들)을 참조 서열(서열 번호 2)과 비교하여, 시그니처 모티프의 존재를 결정한다. 일 실시형태에서, 참조 아미노산 서열을 사용하는 클러스털(CLUSTAL) 정렬(예를 들어, 클러스털더블유)(본 명세서에 사용되는 바와 같이, 바실러스 서브틸리스 ATCC(등록 상표) 31954(상표명)로부터의 과가수분해효소 서열(서열 번호 2))을 사용하여 CE-7 에스테라제 패밀리에 속하는 과가수분해효소를 동정한다. 보존된 아미노산 잔기의 상대적 넘버링은 참조 아미노산 서열의 잔기 넘버링에 기초하여, 정렬된 서열 내의 작은 삽입 또는 결실(예를 들어, 전형적으로 5개 이하의 아미노산)을 설명한다.
(참조 서열에 비하여) CE-7 시그니처 모티프를 포함하는 서열을 동정하기 위해 사용될 수 있는 다른 적절한 알고리듬의 예에는 니들만(Needleman) 및 분쉬(Wunsch)(문헌[J. Mol. Biol. 48, 443-453 (1970)]; 전체 정렬 도구) 및 스미스-워터만(Smith-Waterman)(문헌[J. Mol. Biol. 147:195-197 (1981)]; 국소 정렬 도구)이 포함될 수 있으나 이들에 한정되지 않는다. 일 실시형태에서, 스미스-워터만 정렬은 디폴트 파라미터를 사용하여 이행된다. 적절한 디폴트 파라미터의 예에는 블로섬(BLOSUM)62 스코어링 매트릭스(scoring matrix)의 사용이 포함되며, 갭 개방 페널티(GAP open penalty)는 10이고, 갭 연장 페널티(GAP extension penalty)는 0.5이다.
서열 번호 2에 대하여 상대적으로 낮은 전체 아미노산 동일성을 갖는(CE-7 시그니처 모티프를 보유하면서) 효소는 유의미한 과가수분해효소 활성을 나타낼 수 있다. 일 실시형태에서, 적절한 과가수분해효소는 CE-7 시그니처 모티프, 및 서열 번호 2에 대하여 적어도 20%, 바람직하게는 적어도 30%, 33%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99%의 아미노산 동일성을 포함하는 효소를 포함할 수 있다.
과가수분해 활성을 갖는 적절한 CE-7 탄수화물 에스테라제의 예에는 아미노산 서열 예를 들어, 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64를 갖는 효소가 포함되나 이들에 한정되지 않는다. 일 실시형태에서, 효소는 14, 16, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 포함한다.
본 명세서에서 사용되는 용어 "CE-7 변이체", " 변이체 과가수분해효소" 또는 "변이체"는 CE-7 시그니처 모티프 및 관련 과가수분해 활성이 유지되는 한, 변이체가 유래되는 해당하는 효소(전형적으로 야생형 효소)에 비하여, 적어도 하나의 아미노산 부가, 결실 및/또는 치환을 야기하는 유전자 변형을 갖는 CE-7 과가수분해효소를 지칭할 것이다. 또한, CE-7 변이체 과가수분해효소는 본 발명의 조성물 및 방법에서 사용될 수 있다. CE-7 변이체의 예는 서열 번호 27, 28, 29, 30, 31, 32, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 제공된다. 일 실시형태에서, 변이체는 서열 번호 27, 28, 50, 52, 54, 56, 58, 60, 62 및 64를 포함할 수 있다.
당업자는 실질적으로 유사한 CE-7 과가수분해효소 서열(시그니처 모티프 보유)이 또한 본 발명의 조성물 및 방법에 사용될 수 있음을 인식한다. 일 실시형태에서, 실질적으로 유사한 서열은 매우 엄격한 조건 하에서 본 명세서에 예시된 서열과 관련된 핵산 분자와 혼성화하는 그들의 능력에 의해 정의된다. 다른 실시형태에서, 서열 정렬 알고리듬을 사용하여, 본 명세서에 제공되는 DNA 또는 아미노산 서열에 대한 동일성 백분율에 기초하여 실질적으로 유사한 효소를 정의할 수 있다.
본 명세서에서 사용되는 핵산 분자는 제1 분자의 단일의 가닥이 적절한 온도 및 용액 이온 세기의 조건 하에서 다른 분자에 어닐링될 수 있는 경우, 다른 핵산 분자, 예를 들어, cDNA, 게놈 DNA 또는 RNA에 "혼성화가능하다". 혼성화 및 세정 조건은 널리 공지되어 있으며, 문헌[Sambrook, J. and Russell, D., T. Molecular Cloning: A Laboratory Manual, Third Edition, Cold Spring Harbor Laboratory Press, Cold Spring Harbor (2001)]에 예시되어 있다. 온도 및 이온 세기 조건은 혼성화의 "엄격성(stringency)"을 결정한다. 엄격성 조건을 조정하여, 관계가 먼 유기체로부터의 상동 서열과 같은 중등으로 유사한 분자 내지 밀접하게 관련된 유기체로부터의 기능성 효소를 중복시키는 유전자와 같은 고도로 유사한 분자를 스크리닝할 수 있다. 혼성화 후 세정이 전형적으로 엄격성 조건을 결정한다. 한 세트의 바람직한 조건은 실온에서 15분 동안 6× SSC, 0.5% SDS로 시작한 다음, 45℃에서 30분 동안 2× SSC, 0.5% SDS로 반복한 다음, 50℃에서 30분 동안 0.2× SSC, 0.5% SDS로 2회 반복한 일련의 세정을 사용한다. 더욱 바람직한 세트의 조건은 더 높은 온도를 사용하며, 여기서, 세정은 0.2× SSC, 0.5% SDS에서의 최종 2회의 30분 세정의 온도가 60℃로 증가된 것을 제외하고 상기와 동일하다. 다른 바람직한 세트의 고도로 엄격한 혼성화 조건은 0.1× SSC, 0.1% SDS, 65℃이며, 2× SSC, 0.1% SDS로 세정하고, 0.1× SSC, 0.1% SDS, 65℃의 최종 세정으로 이어진다.
혼성화의 엄격성에 따라 염기 간의 미스매치가 가능하지만, 혼성화를 위해서는 2개의 핵산이 상보적 서열을 함유하는 것이 요구된다. 혼성화되는 핵산에 대해 적절한 엄격성은, 당업계에 주지된 변수인 핵산의 길이 및 상보성의 정도에 의존한다. 2개 뉴클레오티드 서열 사이의 유사성 또는 상동성의 정도가 클수록, 이들 서열을 가진 핵산의 하이브리드에 대한 Tm의 값이 커진다. 핵산 혼성화의 상대적 안정성(높은 Tm에 상응함)은 하기의 순서로 감소한다: RNA:RNA, DNA:RNA, DNA:DNA. 100개 뉴클레오티드 길이를 초과하는 하이브리드에 대하여, Tm을 계산하는 수학식이 유도되었다(상기 문헌[Sambrook and Russell]). 더 짧은 핵산, 즉, 올리고뉴클레오티드의 혼성화에 있어서는 미스매치의 위치가 더욱 중요해지며 올리고뉴클레오티드의 길이가 그의 특이성을 결정한다(상기 문헌[Sambrook and Russell]). 일 태양에서, 혼성화가능한 핵산의 길이는 적어도 약 10개 뉴클레오티드이다. 바람직하게는, 혼성화가능한 핵산의 최소의 길이는 적어도 약 15개 뉴클레오티드 길이, 더욱 바람직하게는 적어도 약 20개 뉴클레오티드 길이, 더더욱 바람직하게는 적어도 30개 뉴클레오티드 길이, 더더욱 바람직하게는 적어도 300개 뉴클레오티드 길이, 가장 바람직하게는 적어도 800개 뉴클레오티드 길이이다. 또한, 프로브의 길이와 같은 인자에 따라 필요한 경우에 온도 및 세정 용액 염 농도를 조정할 수 있음을 당업자는 인식할 것이다.
본 명세서에서 사용되는 용어 "동일성 백분율"은 2개 이상의 폴리펩티드 서열 또는 2개 이상의 폴리뉴클레오티드 서열 사이의 관계로서, 서열을 비교함으로써 결정된다. 당업계에서, "동일성"은 또한 경우에 따라서, 서열의 스트링(string) 간의 매치에 의해 결정되는, 폴리펩티드 또는 폴리뉴클레오티드 서열 간의 서열 관련성의 정도를 의미한다. "동일성" 및 "유사성"은 문헌[Computational Molecular Biology (Lesk, A. M., ed.) Oxford University Press, NY (1988)]; 문헌[Biocomputing: Informatics and Genome Projects (Smith, D. W., ed.) Academic Press, NY (1993)]; 문헌[Computer Analysis of Sequence Data, Part I (Griffin, A. M., and Griffin, H. G., eds.) Humana Press, NJ (1994)]; 문헌[Sequence Analysis in Molecular Biology (von Heinje, G., ed.) Academic Press (1987)]; 및 문헌[Sequence Analysis Primer (Gribskov, M. and Devereux, J., eds.) Stockton Press, NY (1991)]. 동일성 및 유사성을 결정하는 방법은 공중에게 이용가능한 컴퓨터 프로그램에 명시되어 있다. 레이저진(LASERGENE) 바이오인포매틱스 컴퓨팅 스위트(bioinformatics computing suite)(미국 위스콘신주 매디슨 소재의 디엔에이스타 인코포레이티드)의 멕얼라인(Megalign) 프로그램, 벡터 NTI v. 7.0(미국 메릴랜드주 베데스다 소재의 인포맥스, 인코포레이티드)의 얼라인엑스(AlignX) 프로그램, 또는 엠보스 오픈 소프트웨어 스위트(EMBOSS Open Software Suite)(EMBL-EBI; 문헌[Rice et al., Trends in Genetics 16, (6):276-277 (2000)])를 사용하여 서열 정렬 및 동일성 백분율 계산을 수행할 수 있다. 서열의 다중의 정렬은 디폴트 파라미터와 함께 클러스털 정렬 방법(예를 들어, 클러스털더블유; 예를 들어, 버전 1.83)(문헌[Higgins and Sharp, CABIOS, 5:151-153 (1989)]; 문헌[Higgins et al., Nucleic Acids Res. 22:4673-4680 (1994)]; 및 문헌[Chenna et al., Nucleic Acids Res 31 (13):3497-500 (2003)], 유럽 바이오인포매틱스 연구소(European Bioinformatics Institute)를 통하여 유럽 분자 생물학 실험실로부터 입수가능함)을 사용하여 수행할 수 있다. 클러스털더블유 단백질 정렬에 적절한 파라미터는 갭 존재 페널티(GAP Existence penalty)=15, 갭 연장=0.2, 매트릭스=고넷(Gonnet)(예를 들어, 고넷250), 단백질 엔드갭(ENDGAP)=-1, 단백질 갭디스트(GAPDIST)=4, 및 KTUPLE=1을 포함한다. 일 실시형태에서, 고속 또는 저속 정렬은 디폴트 설정으로 사용되며, 저속 정렬이 바람직하다. 대안적으로, 클러스털더블유 방법(예를 들어, 버전 1.83)을 사용하는 파라미터는 또한 KTUPLE=1, 갭 페널티=10, 갭 연장=1, 매트릭스=블로섬(예를 들어, 블로섬64), 윈도우(WINDOW)=5 및 탑 디아고날 세이브드(TOP DIAGONALS SAVED)=5를 사용하여 변경될 수 있다.
일 태양에서, 적절한 분리된 핵산 분자는 본 명세서에 기재된 아미노산 서열에 대하여 적어도 약 20%, 바람직하게는 적어도 30%, 33%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는 폴리펩티드를 암호화한다. 다른 태양에서, 적절한 분리된 핵산 분자는 본 명세서에 기재된 아미노산 서열에 대하여 적어도 약 20%, 바람직하게는 적어도 30%, 33%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일한 아미노산 서열을 갖는 폴리펩티드를 암호화하되; 단, 폴리펩티드는 CE-7 시그니처 모티프를 보유한다. 적절한 핵산 분자는 상기 상동성을 가질 뿐 아니라, 또한 전형적으로 약 300 내지 340개 아미노산, 더욱 바람직하게는 약 310 내지 약 330개 아미노산, 가장 바람직하게는 약 318 내지 약 325개 아미노산 길이를 갖는 폴리펩티드를 암호화하며, 각 폴리펩티드는 과가수분해 활성을 갖는 것을 특징으로 한다.
표적 표면에 대하여 친화성을 갖는 단쇄 펩티드
표적 표면에 결합할 수 있는 면역글로불린 폴드가 결여된 단쇄 펩티드는 "표적 표면-결합 펩티드"로 지칭되며, 예를 들어, 임의의 표적 표면에 결합하는 펩티드를 포함할 수 있으며, 조건부로, 표적 표면은 인간 모발, 인간 피부, 인간 네일 또는 인간 구강 표면(예를 들어, 치아 에나멜, 치아 균막, 잇몸 등)을 포함하지 않는다.
적어도 하나의 체표면에 대하여 강력한 친화성을 갖는 짧은 펩티드 또는 유익제가 보고되어 있다(미국 특허 제7,220,405호; 제7,309,482호; 제7,285,264호 및 제7,807,141호; 미국 특허 출원 공개 제2005-0226839호; 제2007-0196305호; 제2006-0199206호; 제2007-0065387호; 제2008-0107614호; 제2007-0110686호; 제2006-0073111호; 제2010-0158846호 및 제2010-0158847호; PCT 출원 공개 WO2008/054746호; WO2004/048399호, 및 WO2008/073368호). 이들 펩티드를 사용하여, 주로 미용 응용에 사용하기 위한, 유익제를 표적 체표면에 결합시킬 수 있는 펩티드계 시약을 구축하였다.
다양한 천연 및 합성 폴리머 물질, 예를 들어, 면 패브릭, 폴리에스테르/면 혼방, 셀룰로스 아세테이트, 제지, 폴리메틸 메타크릴레이트, 폴리에스테르, 예를 들어, 나일론, 폴리프로필렌, 폴리에틸렌, 폴리스티렌 및 폴리테트라플루오로에틸렌에 대하여 친화성을 갖는 바이오패닝된 펩티드가 보고되어 있다(미국 특허 제7,709,601호; 제7,700,716호; 및 제7632919호; 및 미국 특허 출원 공개 제2005-0054752호; 제2007-0265431호; 제2007-0264720호; 제2007-0141628호; 및 제2010-0158823호 및 미국 특허 출원 제12/785694호; 제12/778167호; 제12/778169호; 제12/778174호; 제12/778178호; 제12/778180호; 제12/778186호; 제12/778194호; 및 제12/778199호).
다양한 안료, 폴리머, 셀룰로스 물질 및 인쇄 매체에 대하여 친화성을 갖는 짧은 펩티드도 또한 이중 블록(diblock) 또는 삼중 블록(triblock) 분산제의 생성에서 보고되어 있다(미국 특허 출원 공개 제2005-0054752호). 그러나, 과산 유익제의 생성을 위해 활성 과가수분해효소를 표적 물질 표면에 결합시키기 위한(다시 말하면, "표적화된 과가수분해효소") 이들 펩티드의 이용은 기재된 적이 없다. 바람직한 태양에서, 과산 유익제의 생성을 위해 표적 물질의 표면에 표적화된 CE-7 과가수분해효소의 이용은 기재된 적이 없다.
일부 실시형태에서, 표적 표면-결합 도메인은 길이가 최대 약 60개 아미노산인 표적 표면-결합 펩티드로 이루어진다. 일 실시형태에서, 표적 표면-결합 펩티드는 길이가 5 내지 60개 아미노산이다. 다른 실시형태에서, 표적 표면-결합 펩티드는 길이가 7 내지 50개 아미노산이거나, 길이가 7 내지 30개 아미노산이다. 또 다른 실시형태는 길이가 7 내지 27개 아미노산인 표적 표면-결합 펩티드이다.
일부 실시형태에서, 다수의 표적 표면-결합 펩티드의 사용에 의해, 임의의 개별 표적 표면-결합 펩티드보다 더욱 내구성 있는 펩티드 성분(표적 표면-결합 "도메인")을 제공할 수 있다. 일부 실시형태에서, 표적 표면-결합 도메인은 2 내지 약 50개, 바람직하게는 2 내지 약 25개, 더욱 바람직하게는 2 내지 약 10개, 가장 바람직하게는 2 내지 약 5개의 표적 표면-결합 펩티드를 포함한다.
다중 펩티드 결합 요소는 함께 직접적으로 결합되거나 또는 하나 이상의 펩티드 스페이서/링커를 사용하여 함께 결합될 수 있다. 소정의 펩티드 스페이서는 길이가 1 내지 100개 또는 1 내지 50개 아미노산이다. 일부 실시형태에서, 펩티드 스페이서는 길이가 약 1 내지 약 25개, 3 내지 약 40개, 또는 3 내지 약 30개 아미노산이다. 다른 실시형태에서, 스페이서는 길이가 약 5 내지 약 20개 아미노산이다. 펩티드 링커의 예는 아미노산 서열 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140 및 143에 의해 제공된다. 펩티드 스페이서 링커는 최대 10회 반복될 수 있다.
추가의 표적 표면-결합 도메인 및 그들을 구성하는 더 짧은 표적 표면-결합 펩티드는 예를 들어, 임의의 공지되어 있는 바이오패닝 기술, 예를 들어, 파지 디스플레이, 박테리아 디스플레이, 효모 디스플레이, 리보솜 디스플레이, mRNA 디스플레이 및 그들의 조합을 비롯한 당업계에 공지되어 있는 많은 방법을 사용하여 확인할 수 있다. 전형적으로, 펩티드의 무작위 또는 실질적인 무작위(사건에서 편향이 존재) 라이브러리를 표적 표면에 대하여 바이오패닝하여, 표적 표면에 대하여 친화성을 갖는 라이브러리 내의 펩티드를 확인한다. 짧은 표적 표면-결합 펩티드 및/또는 표적 표면-결합 도메인은 또한 표적 표면에 대한 정전기적 친화성을 갖도록 실험에 의해 생성될 수 있다.
펩티드의 무작위 라이브러리의 생성은 널리 공지되어 있으며, 박테리아 디스플레이(문헌[Kemp, D.J.; Proc. Natl. Acad. Sci. USA 78(7):4520-4524 (1981)] 및 문헌[Helfman et al., Proc. Natl. Acad. Sci. USA 80(1):31-35, (1983)), 효모 디스플레이(문헌[Chien et al., Proc Natl. Acad. Sci. USA 88(21):9578-82 (1991)]), 조합 고체상 펩티드 합성(미국 특허 제5,449,754호, 미국 특허 제5,480,971호, 미국 특허 제5,585,275호, 미국 특허 제5,639,603호) 및 파지 디스플레이 기술(미국 특허 제5,223,409호, 미국 특허 제5,403,484호, 미국 특허 제5,571,698호, 미국 특허 제5,837,500호); 리보솜 디스플레이(미국 특허 제5,643,768호; 미국 특허 제5,658,754호; 및 미국 특허 제7,074,557호),및 mRNA 디스플레이 기술(프로퓨젼(상표명); 미국 특허 제6,258,558호; 제6,518,018호; 제6,281,344호; 제6,214,553호; 제6,261,804호; 제6,207,446호; 제6,846,655호; 제6,312,927호; 제6,602,685호; 제6,416,950호; 제6,429,300호; 제7,078,197호; 및 제6,436,665호 참조)을 포함하는 다양한 기술에 의해 달성될 수 있다.
표적화된 과가수분해효소
본 명세서에 사용되는 용어 "표적화된 과가수분해효소" 및 "과가수분해 활성을 갖는 표적화된 효소"는 표적 물질의 표면에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분에 융합/결합된 적어도 하나의 과가수분해 효소(야생형 또는 그의 변이체)를 포함하는 융합 단백질을 지칭할 것이며; 여기서, 표면은 체표면 또는 구강 표면이 아니다. 바람직한 태양에서, 표적 표면은 하기에 기재된다.
표적화된 과가수분해효소 내의 과가수분해 효소는 임의의 과가수분해 효소일 수 있으며, 효소가 본 발명의 하나 이상의 기질에 대하여 과가수분해 활성을 갖는 한, 리파제, 프로테아제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제 및 조합물을 포함할 수 있다. 예에는 과가수분해 프로테아제(서브틸리신 변이체; 미국 특허 제7,510,859호), 과가수분해 에스테라제(슈도모나스 플루오레슨스; 미국 특허 제7,384,787호; 서열 번호 163 및 181) 및 과가수분해 아릴 에스테라제(마이코박테리움 스메그마티스; 미국 특허 제7,754,460호; WO2005/056782호; 및 EP1689859 B1호; 서열 번호 162[S54V 변이체] 및 180[야생형])가 포함될 수 있으나 이들에 한정되지 않는다.
본 명세서에서 사용되는 용어 "펩티드 성분", "표적 표면에 대하여 친화성을 갖는 펩티드 성분" 및 "TSBD"는 펩티드 결합에 의해 결합된 둘 이상의 아미노산의 적어도 하나의 폴리머를 포함하는 과가수분해 효소의 부분이 아닌 융합 단백질의 성분을 지칭할 것이며; 여기서, 성분은 표적 물질의 표면에 대하여 친화성을 가지며; 여기서, 표면은 체표면 또는 구강 표면이 아니다.
일 실시형태에서, 표적 물질은 목재, 목재 펄프, 섬유, 실, 천연 섬유로부터 제작된 텍스타일 또는 의복, 반합성 섬유, 합성 섬유 또는 섬유 혼방의 표면이다. 일 실시형태에서, 표적 물질은 셀룰로스 물질, 예를 들어, 셀룰로스, 목재, 목재 펄프, 제지, 제지 펄프, 면, 레이온 및 라이오셀(유기 용매 방사 과정에 의해 수득되는 셀룰로스 섬유)이다. 다른 실시형태에서, 표적 물질은 제지, 섬유, 실, 텍스타일(직물 또는 부직물) 또는 의복에 사용될 수 있는 셀룰로스 물질, 폴리머 또는 코폴리머이다. 이들 물질의 예에는 폴리메틸 메타크릴레이트, 폴리프로필렌, 폴리테트라플루오로에틸렌, 폴리에틸렌, 폴리아미드(나일론), 폴리스티렌, 셀룰로스 아세테이트, 면, 폴리에스테르/면 혼방, 목재 퍼프, 제지 및 셀룰로스가 포함될 수 있으나, 이들에 한정되지 않는다.
펩티드 성분은 셀룰로스 물질에 대하여 친화성을 가질 수 있다. 이와 같이, 펩티드 성분은 자연 발생 셀룰로스-결합 도메인(상기 문헌[Tomme et al.]), 자연 발생 셀룰로스-결합 도메인으로부터 유래된 표적-결합 도메인 또는 모방체 셀룰로스 결합 도메인(EP1224270B1)일 수 있다. 셀룰로스-결합 도메인의 예는 다양한 분류 및 패밀리(문헌[Guillen et al., Appl. Microbiol. Biotechnol. (2010) V85 pp. 1241-1249])에 속할 수 있다. 이들은 클로스트리듐 써모셀룸, 클로스트리듐 셀룰로보란스, 바실러스 종, 써모토가 마리티마 및 칼디셀룰로시룹터 사카로라이티쿠스를 포함하나 이들에 한정되지 않는 다양한 미생물로부터 수득될 수 있다. 일 실시형태에서, 셀룰로스-결합 도메인은 클로스트리듐 써모셀룸("CIP", 셀룰로스 결합 도메인의 분류 3 슈퍼패밀리; CBD3), 클로스트리듐 셀룰로보란스(CBM17, 탄수화물 결합 도메인 슈퍼패밀리 17), 바실러스 종(CBM28, 탄수화물 결합 모티프 슈퍼패밀리 28), 써모토가 마리티마(CBM9-2, 셀룰로스 결합 도메인 분류 9; CBM9) 또는 칼디셀룰로시룹터 사카로라이티쿠스(CBD1, 셀룰로스 결합 도메인의 분류 3 슈퍼패밀리; CBD3)로부터 수득된다. 일 실시형태에서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분은 셀룰로스-결합 도메인 패밀리 CBM9, CBM17, CBM28 또는 CBD3에 속하는 셀룰로스-결합 도메인이다. 추가의 실시형태에서, 셀룰로스-결합 도메인은 서열 번호 149, 152, 155, 158 및 161로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 폴리펩티드를 포함하며; 서열 번호 149, 152, 155, 158 및 161은 임의로, 그들의 C-말단 펩티드 링커 및/또는 헥사-his 태그 상에 포함되지 않을 수 있다.
일 실시형태에서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분은 항체, targetFab 항체 단편, 단쇄 가변 단편(scFv) 항체, 카멜리대 항체(문헌[Muyldermans, S., Rev. Mol. Biotechnol. (2001) 74:277-302]), 비-항체 스캐폴드 디스플레이 단백질(다양한 스캐폴드-보조 방법의 검토를 위한 문헌[Hosse et al., Prot. Sci. (2006) 15(1): 14-27 and Binz, H. et al. (2005) Nature Biotechnology 23, 1257-1268]) 또는 면역글로불린 폴드(immunoglobulin fold)가 결여된 단쇄 폴리펩티드일 수 있다. 다른 태양에서, 표적 표면(여기서, 표면은 체표면 또는 구강 표면이 아니다)에 대하여 친화성을 갖는 "펩티드 성분"은 면역글로불린 폴드가 결여된 단쇄 펩티드(다시 말하면, 표적 표면-결합 펩티드 또는 표적 표면에 대하여 친화성을 갖는 적어도 하나의 표적 표면-결합 펩티드를 포함하는 표적 표면-결합 도메인; 여기서, 표면은 체표면 또는 구강 표면이 아니다)이이다. 바람직한 실시형태에서, 펩티드 성분은 표적 표면에 대하여 친화성을 갖는 하나 이상의 표적 표면-결합 펩티드를 포함하는 단쇄 펩티드이다.
표적 표면에 대하여 친화성을 갖는 펩티드 성분은 임의의 펩티드 링커에 의해 과가수분해 효소로부터 분리될 수 있다. 소정의 펩티드 링커/스페이서는 길이가 1 내지 100개 또는 1 내지 50개 아미노산이다. 일부 실시형태에서, 펩티드 스페이서는 길이가 약 1 내지 약 25개, 3 내지 약 40개, 또는 3 내지 약 30개 아미노산이다. 다른 실시형태에서, 스페이서는 길이가 약 5 내지 약 20개 아미노산이다. 다수의 펩티드 링커가 사용될 수 있다. 일 실시형태에서, 적어도 하나의 펩티드 링커가 존재하며, 최대 10번 반복될 수 있다.
일 실시형태에서, 표적화된 과가수분해효소는 하기의 일반 구조를 포함하는 과가수분해 활성을 갖는 융합 단백질이다:
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
상기 식에서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다.
바람직한 태양에서, 표적 물질은 목재, 목재 펄프, 섬유, 실, 천연 섬유로부터 제작된 텍스타일 또는 의복, 반합성 섬유, 합성 섬유 또는 섬유 혼방의 것이다. 일 실시형태에서, 표적 물질은 셀룰로스 물질, 예를 들어 셀룰로스, 목재, 목재 펄프, 제지, 면, 레이온 및 라이오셀(유기 용매 방사 과정에 의해 수득되는 셀룰로스 섬유)이다. 다른 실시형태에서, 표적 물질은 제지, 섬유, 실, 텍스타일(직물 또는 부직물) 또는 의복에 사용될 수 있는 셀룰로스 물질, 폴리머 또는 코폴리머이다.
다양한 물질에 대하여 친화성을 갖는 예시적인 단쇄 펩티드는 이전에 기재된 적이 있다. 예를 들어, 서열 번호 65 내지 127은 다양한 폴리머 및 셀룰로스 물질에 대하여 친화성을 갖는 다양한 펩티드의 아미노산 서열이다. 서열 번호 65 내지 79는 폴리메틸 메타크릴레이트에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 80 내지 86은 폴리프로필렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 87 내지 95는 폴리테트라플루오로에틸렌에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 96 내지 102는 폴리에틸렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 103 내지 108은 폴리아미드(나일론)에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 109 내지 111은 폴리스티렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 112 내지 115는 셀룰로스 아세테이트에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 116 및 117은 면에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 116 및 118은 폴리에스테르/면 혼방에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 119 내지 121은 제지에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 122 내지 127은 셀룰로스에 대하여 친화성을 갖는 펩티드의 예이다.
표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분은 임의의 펩티드 링커에 의해 과가수분해효소로부터 분리될 수 있다. 소정의 펩티드 링커/스페이서는 길이가 1 내지 100개 또는 1 내지 50개 아미노산이다. 일부 실시형태에서, 펩티드 스페이서는 길이가 약 1 내지 약 25개, 3 내지 약 40개, 또는 3 내지 약 30개 아미노산이다. 다른 실시형태에서, 스페이서는 길이가 약 5 내지 약 20개 아미노산이다. 다수의 펩티드 링커가 사용될 수 있다. 일 실시형태에서, 적어도 하나의 펩티드 링커가 존재하며, 최대 10번 반복될 수 있다. 이와 같이, 표적화된 과가수분해효소의 예에는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분에 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 162, 163, 180 및 181로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 임의의 과가수분해효소가 포함될 수 있으나, 이들에 한정되지 않는다.
다른 실시형태에서, 표적화된 과가수분해효소는 하나 이상의 셀룰로스-결합 도메인에 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 162, 163, 180 및 181로 이루어진 군으로부터 선택되는 아미노산 서열을 포함한다. 다른 태양에서, 표적화된 과가수분해효소는 서열 번호 149, 152, 155, 158 및 161로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 하나 이상의 셀룰로스-결합 도메인에 결합된 서열 번호 162, 163, 180 및 181로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 비-CE-7 과가수분해효소를 포함한다. 또 다른 태양에서, 표적화된 과가수분해효소는 서열 번호 148, 151, 154, 157, 160, 165, 167, 169, 171, 173, 175, 177 및 179로 이루어진 군으로부터 선택되는 아미노산 서열을 포함한다. 또 다른 태양에서, 표적화된 과가수분해효소는 서열 번호 171, 173, 175, 177 및 179로 이루어진 군으로부터 선택되는 아미노산 서열을 포함한다.
표적화된 CE-7 과가수분해효소
일 실시형태에서, 표적화된 과가수분해효소는 CE-7 과가수분해효소이다. 본 명세서에 사용되는 용어 "표적화된 CE-7 과가수분해효소" 및 "표적화된 CE-7 탄수화물 에스테라제"는 표적 표면에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분에 융합/결합된 적어도 하나의 CE-7 과가수분해효소(야생형 또는 변이체 과가수분해효소)를 포함하는 융합 단백질을 지칭한다.
일 실시형태에서, 하기의 일반 구조를 포함하는 융합 펩티드가 제공된다:
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH;
상기 식에서,
PAH는 과가수분해 활성을 갖는 CE-7 탄수화물 에스테라제이며; PAH는 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖고, 상기 시그니처 모티프는
i) 서열 번호 2의 아미노산 잔기 118 내지 120과 정렬되는 RGQ 모티프;
ii) 서열 번호 2의 아미노산 잔기 179 내지 183과 정렬되는 GXSQG 모티프; 및
iii) 서열 번호 2의 아미노산 잔기 298 및 299와 정렬되는 HE 모티프를 포함하며,
TSBD는 표적 물질 상의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 여기서, 표적 물질은 인간 모발, 인간 피부, 인간 네일 또는 인간 구강 표면이 아니며;
L은 임의의 펩티드 링커이고;
y는 0 내지 10의 정수이다.
다른 실시형태에서, CE-7 시그니처 모티프는 서열 번호 2의 아미노산 잔기 267 내지 269와 정렬되는 LXD 모티프를 추가로 포함한다.
CE-7 시그니처 모티프의 존재를 결정하기 위한 정렬이 임의의 링커 또는 TSBD 없이 행해지는 것을 주목해야 한다. 일 실시형태에서, 정렬은 클러스털더블유를 사용하여 행한다.
일 실시형태에서, 표적 물질은 목재, 목재 펄프, 섬유, 실, 천연 섬유로부터 제작된 텍스타일 또는 의복, 반합성 섬유, 합성 섬유 또는 섬유 혼방의 표면이다. 일 실시형태에서, 표적 물질은 셀룰로스 물질, 예를 들어, 셀룰로스, 목재, 목재 펄프, 제지, 제지 펄프, 면, 레이온 및 라이오셀(유기 용매 방사 과정에 의해 수득되는 셀룰로스 섬유)이다. 다른 실시형태에서, 표적 물질은 제지, 섬유, 실, 텍스타일(직물 또는 부직물) 또는 의복에 사용될 수 있는 셀룰로스 물질, 폴리머 또는 코폴리머이다. 이들 물질의 예에는 폴리메틸 메타크릴레이트, 폴리프로필렌, 폴리테트라플루오로에틸렌, 폴리에틸렌, 폴리아미드(나일론), 폴리스티렌, 셀룰로스 아세테이트, 면, 폴리에스테르/면 혼방, 목재 퍼프, 제지 및 셀룰로스가 포함될 수 있으나, 이들에 한정되지 않는다.
펩티드 성분은 셀룰로스 물질에 대하여 친화성을 가질 수 있다. 이와 같이, 펩티드 성분은 자연 발생 셀룰로스-결합 도메인(상기 문헌[Tomme et al.]), 자연 발생 셀룰로스-결합 도메인으로부터 유래된 표적-결합 도메인 또는 모방체 셀룰로스 결합 도메인(EP1224270B1)일 수 있다. CE-7 과가수분해효소에 결합될 수 있는 셀룰로스-결합 도메인의 예는 클로스트리듐 써모셀룸, 클로스트리듐 셀룰로보란스, 바실러스 종, 써모토가 마리티마 및 칼디셀룰로시룹터 사카로라이티쿠스를 포함하나 이들에 한정되지 않는 미생물로부터 수득될 수 있다. 일 실시형태에서, 셀룰로스-결합 도메인은 클로스트리듐 써모셀룸(예를 들어, "CIP"), 클로스트리듐 셀룰로보란스 CBM17, 바실러스 종 CBM28, 써모토가 마리티마 CBM9-2 또는 칼디셀룰로시룹터 사카로라이티쿠스 CBD1로부터 수득된다. 추가의 실시형태에서, 셀룰로스-결합 도메인은 서열 번호 149, 152, 155, 158 및 161로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 폴리펩티드를 포함하며; 서열 번호 149, 152, 155, 158 및 161은 임의로, 그들의 C-말단 펩티드 상에 펩티드 링커 및/또는 헥사-his 태그를 포함하지 않을 수 있다.
일 실시형태에서, CE-7 과가수분해효소에 결합된 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분은 항체, Fab 항체 단편, 단쇄 가변 단편(scFv) 항체, 카멜리대 항체(문헌[Muyldermans, S., Rev. Mol. Biotechnol. (2001) 74:277-302]), 비-항체 스캐폴드 디스플레이 단백질(다양한 스캐폴드-보조 방법의 검토를 위한 문헌[Hosse et al., Prot. Sci. (2006) 15(1): 14-27] 및 문헌[Binz, H. et al. (2005) Nature Biotechnology 23, 1257-1268]) 또는 면역글로불린 폴드가 결여된 단쇄 폴리펩티드일 수 있다. 다른 태양에서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분은 면역글로불린 폴드가 결여된 단쇄 펩티드이다(즉, 표적 표면-결합 펩티드 또는 적어도 하나의 표적 표면-결합 펩티드를 포함하는 표적 표면-결합 도메인). 다른 실시형태에서, 펩티드 성분은 표적 물질의 표면에 대하여 친화성을 갖는 하나 이상의 표적 표면-결합 펩티드를 포함하는 단쇄 펩티드이다.
CE-7 과가수분해효소는 표적 물질에 대하여 친화성을 갖는 하나 이상의 단쇄 펩티드에 결합되어, 표적화된 CE-7 과가수분해효소를 생성할 수 있다. 이러한 단쇄 펩티드의 예는 이전에 기재된 적이 있다. 예를 들어, 서열 번호 65 내지 127은 다양한 폴리머 및 셀룰로스 물질에 대하여 친화성을 갖는 다양한 펩티드의 아미노산 서열이다. 서열 번호 65 내지 79는 폴리메틸 메타크릴레이트에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 80 내지 86은 폴리프로필렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 87 내지 95는 폴리테트라플루오로에틸렌에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 96 내지 102는 폴리에틸렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 103 내지 108은 폴리아미드(나일론)에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 109 내지 111은 폴리스티렌에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 112 내지 115는 셀룰로스 아세테이트에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 116 및 117은 면에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 116 및 118은 폴리에스테르/면 혼방에 대하여 친화성을 갖는 펩티드의 예이고, 서열 번호 119 내지 121은 제지에 대하여 친화성을 갖는 펩티드의 예이며, 서열 번호 122 내지 127은 셀룰로스에 대하여 친화성을 갖는 펩티드의 예이다.
표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분은 임의의 펩티드 링커에 의해 CE-7 과가수분해효소로부터 분리될 수 있다. 소정의 펩티드 링커/스페이서는 길이가 1 내지 100개 또는 1 내지 50개 아미노산이다. 일부 실시형태에서, 펩티드 스페이서는 길이가 약 1 내지 약 25개, 3 내지 약 40개, 또는 3 내지 약 30개 아미노산이다. 다른 실시형태에서, 스페이서는 길이가 약 5 내지 약 20개 아미노산이다. 다수의 펩티드 링커가 사용될 수 있다. 이와 같이, 표적화된 과가수분해효소의 예에는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분에 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 임의의 CE-7 과가수분해효소가 포함될 수 있으나, 이들에 한정되지 않는다. 바람직한 실시형태에서, 표적화된 과가수분해효소의 예에는 표적 표면에 대하여 친화성을 갖는 하나 이상의 표적 표면-결합 펩티드에 (임의로 펩티드 스페이서를 통해) 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 임의의 CE-7 과가수분해효소가 포함될 수 있으나, 이들에 한정되지 않는다.
일 실시형태에서, 표적화된 과가수분해효소는 서열 번호 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126 및 127로 이루어진 군으로부터 선택되는 하나 이상의 표적 표면-결합 펩티드에 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 CE-7 과가수분해효소를 포함한다.
다른 실시형태에서, 표적화된 과가수분해효소는 하나 이상의 셀룰로스-결합 도메인에 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 CE-7 과가수분해효소를 포함한다. 다른 태양에서, 표적화된 과가수분해효소는 서열 번호 149, 152, 155, 158 및 161로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 하나 이상의 셀룰로스-결합 도메인에 결합된 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는 CE-7 과가수분해효소를 포함한다. 또 다른 태양에서, 표적화된 과가수분해효소는 서열 번호 148, 151, 154, 157, 160, 165, 167 및 169로 이루어진 군으로부터 선택되는 아미노산 서열을 포함한다.
결합 친화성
표적 표면에 대하여 친화성을 갖는 펩티드 성분은 10-5 몰(M) 이하의 표적 표면에 대한 결합 친화성을 포함한다. 특정 실시형태에서 펩티드 성분은 10-5 몰(M)이하의 결합 친화성을 갖는 하나 이상의 표적 표면-결합 펩티드 및/또는 결합 도메인(들)이다. 일부 실시형태에서, 표적 표면-결합 펩티드 또는 도메인은 적어도 약 50 내지 500 mM 염의 존재 하에 10-5 M 이하의 결합 친화성 값을 가질 것이다. 용어 "결합 친화성"은 결합 펩티드와 그의 각각의 기질의 상호작용의 강도를 말한다. 결합 친화성은 결합 펩티드의 해리 상수("KD") 또는 "MB50"에 관하여 정의되거나 측정될 수 있다.
"KD"는 표적 상의 결합 부위가 절반 점유된, 다시 말하면, 펩티드가 결합된 표적(결합 표적 물질)의 농도가 펩티드가 결합되지 않은 표적의 농도와 같은 경우의 펩티드의 농도에 해당한다. 해리 상수가 더 작을수록, 펩티드가 더욱 단단히 결합된다. 예를 들어, 나노몰(nM) 해리 상수를 갖는 펩티드는 마이크로몰(μM) 해리 상수를 갖는 펩티드보다 더욱 단단히 결합한다. 본 발명의 특정 실시형태는 KD 값이 10-5 이하일 것이다.
"MB50"은 ELISA-기반의 결합 검정법에서 수득되는 최대 신호의 50%의 신호를 제공하는 결합 펩티드의 농도를 말한다. 예를 들어, 본 명세서에 참고로 포함되는 미국 특허 출원 공개 제2005/022683호의 실시예 3을 참고한다. MB50은 복합체의 성분의 결합 상호작용 또는 친화성의 세기의 표시를 제공한다. MB50의 값이 더 낮을수록, 펩티드와 그의 해당하는 기질의 상호작용이 더욱 강력하며, 다시 말하면, 더 낫다. 예를 들어, 나노몰(nM) MB50을 갖는 펩티드는 마이크로몰(μM) MB50을 갖는 펩티드보다 더욱 단단하게 결합한다. 본 발명의 특정 실시형태는 MB50 값이 10-5 M 이하일 것이다.
일부 실시형태에서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분은 KD 또는 MB50 값으로 측정시, 결합 친화성이 약 10-5 M 이하, 약 10-6 M 이하, 약 10-7 M 이하, 약 10-8 M 이하, 약 10-9 M 이하, 또는 약 10-10 M 이하일 수 있다.
본 명세서에서 사용되는 용어 "강력한 친화성"은 KD 또는 MB50 값이 약 10-5 M 이하, 바람직하게는 약 10-6 M 이하, 더욱 바람직하게는 약 10-7 M 이하, 더욱 바람직하게는 약 10-8 M 이하, 약 10-9 M 이하, 또는 가장 바람직하게는 약 10-10 M 이하인 결합 친화성을 지칭할 것이다.
다성분 퍼옥시카르복실산 생성 시스템
다수의 활성 성분을 분리하고 배합하는 시스템 및 수단의 고안은 당업계에 알려져 있으며, 일반적으로 개별 반응 성분의 물리적 형태에 좌우될 것이다. 예를 들어, 다수의 활성 유체(액체-액체) 시스템은 전형적으로 멀티-챔버 디스펜서(multi-chamber dispenser) 병 또는 2상 시스템(예를 들어, 미국 특허 출원 공개 제2005/0139608호; 미국 특허 제5,398,846호; 미국 특허 제5,624,634호; 미국 특허 제6,391,840호; 유럽 특허 제0807156B1호; 미국 특허 출원 공개 제2005/0008526호; 및 PCT 공개 WO 00/61713호), 예컨대 원하는 탈색제가 반응성 유체의 혼합시에 생성되는 일부 탈색 응용에서 관찰되는 것을 사용한다. 퍼옥시카르복실산을 생성하기 위해 사용되는 다른 형태의 다성분 시스템은 하나 이상의 고체 성분 또는 고체-액체 성분의 조합, 예를 들어, 분말(예를 들어, 미국 특허 제5,116,575호), 다층 정제(예를 들어, 미국 특허 제6,210,639호), 다수의 구획을 갖는 수용해성 패킷(packet)(예를 들어, 미국 특허 제6,995,125호) 및 물의 첨가 시에 반응하는 고체 응집체(예를 들어, 미국 특허 제6,319,888호)를 위해 고안된 것들을 포함할 수 있으나, 이들에 한정되지 않는다.
다른 실시형태에서, 제1 성분 중의 카르복실산 에스테르는 모노아세틴, 다이아세틴, 트라이아세틴 및 그들의 조합으로 이루어진 군으로부터 선택된다. 다른 실시형태에서, 제1 성분 중의 카르복실산 에스테르는 아세틸화 당류이다. 다른 실시형태에서, 제1 성분 중의 효소 촉매는 미립자 고체일 수 있다. 다른 실시형태에서, 제1 반응 성분은 고체 정제 또는 분말일 수 있다.
퍼옥시카르복실산은 매우 반응성이 있으며, 일반적으로 시간이 지남에 따라 농도가 감소된다. 이는 특히 종종 장기간 안정성이 결여된 시판용 사전-형성된 퍼옥시카르복실산 조성물에 대하여 그러하다. 또한, 특히 큰 용기 및/또는 매우 농축된 퍼옥시카르복실산 용액을 더 긴 거리로 운송하는 경우, 사전-형성된 퍼옥시카르복실산 수용액은 취급 및/또는 운송의 어려움을 나타낼 수 있다. 추가로, 사전-형성된 퍼옥시카르복실산 용액은 특정 표적 응용을 위해 원하는 농도의 퍼옥시카르복실산을 제공할 수 없을 수 있다. 이와 같이, 특히 액체 제형을 위해 다양한 반응 성분을 분리되게 유지하는 것이 매우 바람직하다.
원하는 퍼옥시카르복실산을 생성하기 위해 배합되는 둘 이상의 성분을 포함하는 다성분 퍼옥시카르복실산 생성 시스템의 이용이 보고되어 있다. 개별 성분은 연장된 기간 동안 안정적이며, 취급하기에 안전해야 한다(다시 말하면, 혼합 시에 생성되는 퍼옥시카르복실산의 농도로 측정시). 일 실시형태에서, 다성분 효소적 퍼옥시카르복실산 생성 시스템의 저장 안정성은 효소 촉매 안정성에 관하여 측정될 수 있다.
표적화된 효소 촉매를 사용하여, 표적 표면 상에 또는 그 근처에 목적하는 퍼옥시카르복실산 농도를 갖는 과산 수용액을 신속하게 생성하는 다성분 퍼옥시카르복실산 생성 제형을 포함하는 제품(예를 들어, 세탁 관리 제품)이 본 명세서에 제공된다. 혼합은 사용 직전에 및/또는 적용 부위(동소)에서 발생할 수 있다. 일 실시형태에서, 제품 제형은 사용될 때까지 분리되어 유지되는 적어도 2개의 성분으로 이루어질 것이다. 성분의 혼합에 의해, 과산 수용액이 신속하게 형성된다. 생성된 과산 수용액이 의도된 최종 용도에 적절한 유효 농도의 과산을 포함하도록 각 성분이 고안된다. 개별 성분의 조성은 (1) 연장된 저장 안정성을 제공하고/거나 (2) 퍼옥시카르복실산으로 이루어진 적절한 수성 반응 제형의 형성을 증진시키는 능력을 제공하도록 고안되어야 한다.
다성분 제형은 적어도 2개의 실질적으로 액체인 성분으로 이루어질 수 있다. 일 실시형태에서, 다성분 제형은 제1 액체 성분 및 제2 액체 성분을 포함하는 2성분 제형일 수 있다. 용어 "제1" 또는 "제2" 액체 성분의 이용은 상대적이되, 단 특정 성분을 포함하는 2가지 상이한 액체 성분은 사용할 때까지 분리되어 유지된다. 최소한도로, 다성분 퍼옥시카르복실산 제형은 (1) 과가수분해 활성을 갖는 융합 단백질(즉, 표적화된 과가수분해효소)을 갖는 적어도 하나의 효소 촉매, (2) 카르복실산 에스테르 기질, 및 (3) 과산소원 및 물을 포함하며, 여기서, 제형은 성분의 배합시에 목적하는 과산을 효소에 의해 생성한다. 일 실시형태에서, 다성분 퍼옥시카르복실산 제형 중의 과가수분해 활성을 갖는 효소는 표적화된 CE-7 과가수분해효소이다.
2성분 제형에 사용되는 다양한 성분의 유형 및 양은 (1) 각 성분의 저장 안정성, 특히 효소 촉매의 과가수분해 활성 및 (2) 용해성 및/또는 목적하는 퍼옥시카르복실산 수용액을 효율적으로 형성하는 능력을 증진시키는 물리적 특성을 제공하도록 조심히 선택되고, 균형을 이루어야 한다(예를 들어, 수성 반응 혼합물 중의 에스테르 기질의 용해성을 증진시키는 성분 및/또는 적어도 하나의 액체 성분의 점도 및/또는 농도를 변경하는 성분[다시 말하면, 효소에 의한 과가수분해 활성에 대한 상당한 역효과를 갖지 않는 적어도 하나의 공용매]).
효소에 의한 과산 생성 시스템의 성능 및/또는 촉매 안정성을 향상시키는 다양한 방법이 개시된다. 미국 특허 출원 공개 제2010-0048448 A1호에는 용해성 및/또는 특정 에스테르 기질의 혼합 특징을 증진시키는 적어도 하나의 공용매의 이용이 기재된다. 또한, 본 발명의 조성물 및 방법은 공용매를 사용할 수 있다. 일 실시형태에서, 카르복실산 에스테르 기질 및 과가수분해효소 촉매를 포함하는 성분은 Log P 값이 약 2 미만인 유기 용매를 포함하며, Log P는 P = [용질]옥탄올/[용질]물로 표현되는 옥탄올과 물 사이의 기질의 분배 계수의 로그로 정의된다. 효소 활성에 대한 유의미한 역효과를 갖지 않는 log P 값이 2 이하인 몇몇 공용매가 기재된다. 다른 실시형태에서, 공용매는 카르복실산 에스테르 기질 및 효소를 포함하는 반응 성분 내에서 약 20 wt% 내지 약 70 wt%이다. 카르복실산 기질 및 효소를 포함하는 반응 성분은 임의로, 하나 이상의 완충제(예를 들어, 바이카르보네이트, 시트레이트, 아세테이트, 포스페이트, 피로포스페이트, 메틸포스포네이트, 석시네이트, 말레이트, 푸마레이트, 타르트레이트 및 말레에이트의 나트륨 및/또는 칼륨 염)를 포함할 수 있다.
미국 특허 출원 공개 제2010-0086534 A1호에는 2성분 시스템의 용도가 기재되어 있으며, 여기서, 제1 성분은 액체 카르복실산 에스테르와 고체 효소 분말의 제형을 포함하며, 상기 효소 분말은 (a) 과가수분해 활성을 갖는 적어도 하나의 CE-7 에스테라제 및 (b) 적어도 하나의 올리고당 부형제의 제형을 포함하며; 제2 성분은 과산소원 및 과산화수소 안정화제를 갖는 물을 포함한다. 본 발명의 조성물 및 방법은 미국 특허 출원 공개 US 2010-0086534 A1호에 기재된 시스템과 유사한 2성분 제형을 사용할 수 있다. 이와 같이, 올리고당 부형제를 사용하여 효소 활성의 안정화를 도울 수 있다. 일 실시형태에서, 올리고당 부형제는 수평균 분자량이 적어도 약 1250일 수 있고, 중량평균 분자량이 적어도 약 9000일 수 있다. 다른 실시형태에서, 올리고당 부형제는 수평균 분자량이 적어도 약 1700이고, 중량평균 분자량이 적어도 약 15000이다. 다른 실시형태에서, 올리고당은 말토덱스트린이다.
또한, 미국 특허 출원 공개 제2010-0086535-A1호에는 2성분 시스템이 기재되어 있으며, 여기서, 제1 성분은 액체 카르복실산 에스테르와 고체 효소 분말의 제형을 포함하며, 상기 제형은 (a) 과가수분해 활성을 갖는 적어도 하나의 CE-7 에스테라제 및 적어도 하나의 올리고당 부형제 및 적어도 하나의 계면활성제를 포함하는 효소 분말; 및 (b) 적어도 하나의 완충제를 포함하고, 바람직한 실시형태에서, 완충제는 분리된(다시 말하면, 효소 분말과 분리된) 불용성 성분으로서 카르복실산 에스테르 기질에 첨가되고; 제2 성분은 과산소원 및 과산화수소 안정화제를 갖는 물을 포함한다. 본 발명의 조성물 및 방법은 미국 특허 출원 공개 US 2010-0086535 A1호에 기재된 시스템과 유사한 2성분 제형을 사용할 수 있다. 일 실시형태에서, 부형제는 수평균 분자량이 적어도 약 1250이고, 중량평균 분자량이 적어도 약 9000인 올리고당 부형제일 수 있다. 다른 실시형태에서, 올리고당 부형제는 수평균 분자량이 적어도 약 1700일 수 있고, 중량평균 분자량이 적어도 약 15000일 수 있다. 다른 실시형태에서, 올리고당은 말토덱스트린이다. 추가의 실시형태에서, pH 완충제는 바이카르보네이트 완충제이다. 추가의 실시형태에서, 과산화수소 안정화제는 터피날(TURPINAL)(등록 상표) SL이다.
효소 분말
일부 실시형태에서, 본 발명의 조성물은 안정화된 효소 분말 형태의 효소 촉매를 사용할 수 있다. 효소 분말을 포함하는 제형을 제조하고 안정화시키는 방법은 미국 특허 출원 공개 제2010-0086534호 및 제2010-0086535호에 기재되어 있다.
일 실시형태에서, 효소는 효소 분말의 건조 중량에 기초하여, 약 5 중량 퍼센트(wt%) 내지 약 75 wt% 범위의 양으로 효소 분말에 존재할 수 있다. 효소 분말/분무-건조된 혼합물 중의 효소의 바람직한 중량% 범위는 약 10 wt% 내지 50 wt%이며, 효소 분말/분무-건조된 혼합물 중의 효소의 더욱 바람직한 중량% 범위는 약 20 wt% 내지 33 wt%이다.
일 실시형태에서, 효소 분말은 부형제를 추가로 포함할 수 있다. 일 태양에서, 부형제는 효소 분말의 건조 중량에 기초하여 약 95 wt% 내지 약 25 wt%의 범위의 양으로 제공된다. 효소 분말 중의 부형제의 바람직한 wt% 범위는 약 90 wt% 내지 50 wt%이며, 효소 분말 중의 부형제의 더욱 바람직한 wt% 범위는 약 80 wt% 내지 67 wt%이다.
일 실시형태에서, 효소 분말을 제조하기 위해 사용되는 부형제는 올리고당 부형제일 수 있다. 일 실시형태에서, 올리고당 부형제는 수평균 분자량이 적어도 약 1250이고, 중량평균 분자량이 적어도 약 9000이다. 일부 실시형태에서, 올리고당 부형제는 수평균 분자량이 적어도 약 1700이고, 중량평균 분자량이 적어도 약 15000이다. 특정 올리고당은 말토덱스트린, 자일란, 만난, 후코이단, 갈락토만난, 키토산, 라피노스, 스타키오스, 펙틴, 인슐린, 레반, 그라미난, 아밀로펙틴, 수크로스, 락툴로스, 락토스, 말토스, 트레할로스, 셀로비오스, 니제로트라이오스(nigerotriose), 말토트라이오스, 멜레지토스, 말토트라이울로스(maltotriulose), 라피노스, 케스토스(kestose) 및 그들의 혼합물을 포함할 수 있으나, 이들에 한정되지 않는다. 바람직한 실시형태에서, 올리고당 부형제는 말토덱스트린이다. 또한, 올리고당계 부형제는 수용성 비이온성 셀룰로스 에테르, 예를 들어, 하이드록시메틸-셀룰로스 및 하이드록시프로필메틸셀룰로스 및 그들의 혼합물을 포함할 수 있지만, 이들에 한정되지 않는다. 추가의 실시형태에서, 부형제는 하기의 화합물 중 하나 이상으로부터 선택될 수 있으나 이들에 한정되지 않는다: 트레할로스, 락토스, 수크로스, 만니톨, 소르비톨, 글루코스, 셀로비오스, α-사이클로덱스트린 및 카르복시메틸셀룰로스.
제형은 적어도 하나의 임의의 계면활성제를 포함할 수 있으며, 여기서, 적어도 하나의 계면활성제의 존재가 바람직하다. 계면활성제는 이온성 및 비이온성 계면활성제 또는 습윤제, 예를 들어, 에톡실화 피마자유, 폴리글리콜화 글리세리드, 아세틸화 모노글리세리드, 소르비탄 지방산 에스테르, 폴록사머, 폴리옥시에틸렌 소르비탄 지방산 에스테르, 폴리옥시에틸렌 유도체, 모노글리세리드 또는 그의 에톡실화 유도체, 다이글리세리드 또는 그의 폴리옥시에틸렌 유도체, 소듐 도쿠세이트, 소듐 라우릴설페이트, 콜린산 또는 그의 유도체, 레시틴, 인지질, 에틸렌 글리콜 및 프로필렌 글리콜의 블록 코폴리머 및 비이온성 유기규소를 포함할 수 있으나, 이들에 한정되지 않는다. 바람직하게는, 계면활성제는 폴리옥시에틸렌 소르비탄 지방산 에스테르이며, 폴리소르베이트 80이 더욱 바람직하다.
제형이 효소 분말을 포함하는 경우, 분말을 제조하는데 사용되는 계면활성제는 효소 분말에 존재하는 단백질의 중량에 기초하여, 약 5 wt% 내지 0.1 wt%, 바람직하게는 효소 분말에 존재하는 단백질의 중량에 기초하여, 약 2 wt% 내지 0.5 wt% 범위의 양으로 존재할 수 있다.
효소 분말은 추가로 1가지 이상의 완충제(예를 들어, 바이카르보네이트, 시트레이트, 아세테이트, 포스페이트, 피로포스페이트, 메틸포스포네이트, 석시네이트, 말레이트, 푸마레이트, 타르트레이트 및 말레에이트의 나트륨 및/또는 칼륨 염), 및 효소 안정화제(예를 들어, 에틸렌다이아민테트라아세트산, (1-하이드록시에틸리덴)비스포스폰산)를 포함할 수 있다.
효소 분말을 형성하기 위한 제형의 분무 건조는 예를 들어, 문헌[Spray Drying Handbook, 5th ed., K. Masters, John Wiley & Sons, Inc., NY, N.Y. (1991)] 및 PCT 특허 출원 공개 WO 97/41833호 및 WO 96/32149호(Platz, R. et al.)에 일반적으로 기재된 바와 같이 수행된다.
일반적으로, 분무 건조는 고도로 이들 분무 건조기 및 특히 분산된 액체와 충분한 양의 고온 공기가 함께 있게 하여 증발을 초래하는 하는 단계 및 액적을 건조시키는 단계로 구성된다. 전형적으로, 공급물은 용매를 증발시키고 건조된 생성물을 수집기로 이동시키는 따뜻한 여과된 공기의 흐름으로 분무된다. 소모된 공기는 이어서 용매와 함께 배기된다. 당업자는 몇몇 상이한 유형의 장치를 사용하여 원하는 제품을 제공할 수 있음을 인식할 것이다. 예를 들어, 부치 리미티드(Buchi Ltd.)(스위스 포스트파치 소재) 또는 지이에이 니로 코포레이션(GEA Niro Corp.)(덴마크 코펜하겐 소재)에 의해 제조되는 시판용 분무 건조기는 원하는 크기의 입자를 효율적으로 생성할 것이다. 이중 노즐 기술을 사용하는 2가지 용액의 동시의 분무와 같은 특정 응용을 위해 이들 분무 건조기 및 특히 그들의 아토마이저(atomizer)가 변경되거나 맞춤화될 수 있음을 추가로 인식할 것이다. 더욱 구체적으로, 유중수형 에멀젼은 하나의 노즐로부터 무화될 수 있으며, 만니톨과 같은 부착-방지제(anti-adherent)를 함유하는 용액을 제2 노즐로부터 공동-무화할 수 있다. 다른 경우에, 고압 액체 크로마토그래피(HPLC) 펌프를 사용하여 맞춤 설계된 노즐을 통해 공급 용액을 밀어내는 것이 바람직할 수 있다. 정확한 형태 및/또는 조성을 포함하는 미세구조체가 생성된다면, 장치의 선택은 중요하지 않으며, 본 명세서의 교시에 비추어 당업자에게 명백할 것이다.
분무된 재료를 건조시키는데 사용되는 기체의 양쪽 입구 및 출구의 온도는 분무된 재료에서 효소의 분해를 야기하지 않는 정도이다. 이러한 온도는 전형적으로 실험에 의해 측정되지만, 일반적으로, 입구 온도는 약 50 ℃ 내지 약 225 ℃ 범위이면서, 출구 온도는 약 30℃ 내지 약 150 ℃ 범위일 것이다. 바람직한 파라미터는 약 0.14 ㎫ 내지 1.03 ㎫(20 내지 150 psi), 바람직하게는 약 0.21-0.28 ㎫ 내지 0.69 ㎫(30-40 내지 100 psi) 범위의 무화 압력을 포함한다. 전형적으로, 사용되는 무화 압력은 다음 중 하나일 것이다(㎫): 0.14, 0.21, 0.28, 0.34, 0.41, 0.48, 0.55, 0.62, 0.69, 0.76, 0.83 또는 그 이상.
효소 분말을 사용하는 경우, 카르복실산 에스테르 중의 효소 분말 또는 효소 분말 제형은 주위 온도에서 저장되는 경우, 연장된 기간 동안 실질적으로 그의 효소적 활성을 유지하는데 필요할 수 있다. 카르복실산 에스테르 중의 효소 분말 또는 효소 분말 제형은 짧은 기간 동안 고온에서 실질적으로 그의 효소적 활성을 유지한다. 일 실시형태에서, "실질적으로 그의 효소적 활성을 유지한다"는 카르복실산 에스테르 중의 효소 분말 또는 효소 분말 제형이 카르복실산 에스테르 및 효소 분말로 이루어진 제형의 제조 전의 효소 분말의 초기 효소 활성에 비하여, 주위 온도에서의 연장된 저장 기간 후에 및/또는 고온(주위 온도 초과)에서의 짧은 저장 기간 후에, 카르복실산 에스테르 및 효소 분말로 이루어진 제형에서의 효소 분말 또는 효소 분말 제형 중의 효소의 효소 활성의 적어도 약 75%를 유지하는 것을 의미한다. 연장된 저장 기간은 주위 온도에서의 약 1년 내지 약 2년의 기간이다. 일 실시형태에서, 고온에서 짧은 저장 기간은 카르복실산 에스테르 및 효소 분말로 이루어진 제형이 40℃에서 생성되는 때로부터 40℃에서 약 8주까지의 기간이다. 다른 실시형태에서, 고온은 약 30℃ 내지 약 52℃의 범위이다. 바람직한 실시형태에서, 고온은 약 30℃ 내지 약 40℃ 범위이다.
일부 실시형태에서, 효소 분말은 40℃에서 카르복실산 에스테르 및 효소 분말로 이루어진 제형의 제조 전의 효소 분말의 초기 효소 활성에 비하여, 40℃에서 8주의 저장 후에 카르복실산 에스테르 및 효소 분말로 이루어진 제형 중에, 효소 활성의 적어도 75%를 유지한다. 다른 실시형태에서, 효소 분말은 40℃에서 카르복실산 에스테르 및 효소 분말로 이루어진 제형의 제조 전의 효소 분말의 초기 효소 활성에 비하여, 40℃에서의 8주의 저장 후에 카르복실산 에스테르 및 효소 분말로 이루어진 제형에서 적어도 하나의 효소의 효소 활성의 적어도 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 또는 100%를 유지한다. 바람직하게는, 과가수분해 활성은 미국 특허 출원 공개 제2010-0086510호의 실시예 8 내지 13에 기재된 바와 같이 측정되나; 과가수분해 활성의 임의의 측정 방법이 사용될 수 있다.
언급된 기간에 걸친 효소 활성의 추가의 향상은 미국 특허 출원 공개 제2010-0086534호에 기재된 바와 같이, 약 5.5 내지 약 9.5의 pH 범위의 완충 능력을 갖는 완충제를 카르복실산 에스테르 및 분무-건조된 효소 분말로 이루어진 제형에 첨가함으로써 달성될 수 있다. 적절한 완충제는 바이카르보네이트, 피로포스페이트, 포스페이트, 메틸포스포네이트, 시트레이트, 아세테이트, 말레이트, 푸마레이트, 타르트레이트, 말레에이트 또는 석시네이트의 나트륨 염, 칼륨 염 또는 나트륨 또는 칼륨 염의 혼합물을 포함할 수 있으나 이들에 한정되지 않는다. 카르복실산 에스테르 및 분무-건조된 효소 분말로 이루어진 제형에서 사용하기에 바람직한 완충제는 바이카르보네이트, 피로포스페이트, 포스페이트, 메틸포스포네이트, 시트레이트, 아세테이트, 말레이트, 푸마레이트, 타르트레이트, 말레에이트, 또는 석시네이트의 나트륨 염, 칼륨 염, 또는 나트륨 또는 칼륨 염의 혼합물을 포함한다. 바람직한 실시형태에서, 완충제는 바이카르보네이트의 나트륨 및/또는 칼륨 염을 포함한다.
완충제가 카르복실산 에스테르 및 효소 분말 제형에 존재할 수 있는 실시형태에서, 완충제는 카르복실산 에스테르 및 효소 분말로 이루어진 제형 중의 카르복실산 에스테르의 중량에 기초하여, 약 0.01 wt% 내지 약 50 wt% 범위의 양으로 존재할 수 있다. 완충제는 카르복실산 에스테르 및 효소 분말로 이루어진 제형 중의 카르복실산 에스테르의 중량에 기초하여, 약 0.10% 내지 약 10%의 더욱 바람직한 범위로 존재할 수 있다. 추가로, 이들 실시형태에서, 효소의 과가수분해 활성 간의 비교는 카르복실산 에스테르, 약 5.5 내지 약 9.5의 pH 범위에서 완충 능력을 갖는 완충제 및 효소 분말로 이루어진 제형의 제조 전의 효소 분말의 초기 과가수분해 활성에 비한, 40℃에서의 8주의 저장 후에 카르복실산 에스테르, 약 5.5 내지 약 9.5의 pH 범위에서 완충 능력을 갖는 완충제 및 효소 분말로 이루어진 제형에서 적어도 하나의 효소의 과가수분해 활성의 적어도 75%를 유지하는 효소 분말 간의 비교로 결정된다.
건조 효소 분말이 적어도 하나의 효소에 대한 기질인 유기 화합물, 예를 들어, 트라이아세틴 중의 제형으로 저장되는 것으로 의도된다. 첨가되는 과산화수소의 부재 하에, 트라이아세틴은 보통 가수분해 효소(예를 들어, CE-7 탄수화물 에스테라제)에 의해 수용액 중에서 가수분해되어, 다이아세틴 및 아세트산을 생성하며, 아세트산의 생성에 의해, 반응 혼합물의 pH의 감소가 야기된다. 트라이아세틴 중의 효소의 장기간 저장 안정성을 위한 하나의 요건은 트라이아세틴 중에 존재할 수 있는 임의의 물과 트라이아세틴의 유의미한 반응이 존재하지 않는 것이며; 하나의 시판용 트라이아세틴(벨기에 브뤼셀 소재의 테센델로 그룹(Tessenderlo Group)에 의해 공급) 중의 수분 함량에 대한 명시는 0.03 wt%의 물(300 ppm)이다. 트라이아세틴 중의 효소의 저장 동안 발생하는 트라이아세틴의 임의의 가수분해에 의해, 아세트산이 생성될 것이며, 이는 CE-7 과가수분해효소의 활성의 감소 또는 CE-7 과가수분해효소의 불활성화를 야기할 수 있고; 과가수분해효소는 전형적으로 pH 5.0 이하에서 불활성화된다(미국 특허 출원 공개 제2009-0005590호(DiCosimo, R., et al) 참조). 본 출원서에서 사용하기 위해 선택된 부형제는 아세트산이 제형 중의 낮은 농도의 물의 존재에 기인하여 생성될 수 있는 조건 하의 효소를 위하여, 유기 기질 중에서의 효소의 안정성을 제공해야 한다. 건조 효소 분말은 적어도 하나의 효소에 대한 기질인 유기 화합물 중의 제형으로 저장될 수 있으며, 여기서, 제형은 추가로 부형제 및 하나 이상의 완충제(예를 들어, 바이카르보네이트, 시트레이트, 아세테이트, 포스페이트, 피로포스페이트, 메틸포스포네이트, 석시네이트, 말레이트, 푸마레이트, 타르트레이트 및 말레에이트의 나트륨 및/또는 칼륨 염)를 포함한다.
표적화된
효소에 의해 촉매작용되는,
카르복실산
에스테르 및 과산화수소로부터의 과산의 제조에 적절한 반응 조건
과가수분해 활성을 갖는 하나 이상의 표적화된 효소를 사용하여, 본 발명의 조성물 및 방법에서, 유효 농도의 목적하는 과산을 생성할 수 있다. 목적하는 과산은 카르복실산 에스테르를 과가수분해 활성을 갖는 융합 단백질을 포함하는 효소 촉매의 존재 하에, 과산화수소, 과붕산나트륨 또는 과탄산나트륨을 포함하나 이에 한정되지 않는 과산소원과 반응시킴으로써 제조될 수 있다.
효소 촉매는 과가수분해 활성을 갖는 적어도 하나의 융합 단백질(표적화된 과가수분해효소)을 포함한다. 일 실시형태에서, 표적화된 과가수분해효소 내의 과가수분해 효소는 임의의 과가수분해 효소일 수 있으며, 효소가 본 발명의 하나 이상의 기질에 대하여 과가수분해 활성을 갖는 한, 리파제, 프로테아제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제 및 조합물을 포함할 수 있다. 예에는 과가수분해 프로테아제(예를 들어, 서브틸리신 변이체; 미국 특허 제7,510,859호), 과가수분해 에스테라제(예를 들어, 슈도모나스 플루오레슨스; 미국 특허 제7,384,787호; 서열 번호 163 및 181) 및 과가수분해 아릴 에스테라제(예를 들어, 마이코박테리움 스메그마티스; 미국 특허 제7,754,460호; WO2005/056782호; 및 EP1689859 B1호; 서열 번호 162[S54V 변이체] 및 180[야생형])가 포함될 수 있으나, 이들에 한정되지 않는다.
다른 실시형태에서, 융합 단백질을 제조하기 위해 사용되는 효소는 구조적으로 CE-7 탄수화물 에스테라제 패밀리의 구성원으로 분류된다(CE-7; 상기 문헌[Coutinho, P.M., and Henrissat, B.] 참조). 다른 실시형태에서, 표적화된 과가수분해효소는 구조적으로 세팔로스포린 C 데아세틸라제로 분류된 과가수분해 효소를 포함한다. 다른 실시형태에서, 표적화된 과가수분해효소는 구조적으로 아세틸 자일란 에스테라제로 분류된 과가수분해 효소를 포함한다. CE-7 아세틸 자일란 에스테라제를 셀룰로스 물질에 표적화시키는 경우, CE-7 아세틸 자일란 에스테라제가 천연적으로 셀룰로스-결합 도메인을 함유하지 않는 것이 이해된다. 이와 같이, 셀룰로스 표면에 표적화된 아세틸 자일란 에스테라제는 셀룰로스에 대하여 친화성을 갖는 추가의 펩티드 성분을 갖도록 고안된 키메라 융합 단백질이다.
일 실시형태에서, 과가수분해효소 촉매는 과가수분해 활성, 및
a) 서열 번호 2의 아미노산 잔기 118 내지 120과 정렬되는 RGQ 모티프;
b) 서열 번호 2의 아미노산 잔기 179 내지 183과 정렬되는 GXSQG 모티프; 및
c) 서열 번호 2의 아미노산 잔기 298 및 299와 정렬되는 HE 모티프를 포함하는 CE-7 시그니처 모티프를 포함한다.
바람직한 실시형태에서, 서열 번호 2의 참조 서열에 대한 정렬은 클러스털더블유를 사용하여 수행된다.
추가의 실시형태에서, 추가의 CE-7 시그니처 모티프가 포함될 수 있으며, 추가의(즉, 제4) 모티프는 서열 번호 2의 참조 서열의 아미노산 잔기 267 내지 269와 정렬되는 LXD 모티프로 정의된다.
다른 실시형태에서, 과가수분해효소 촉매는 과가수분해효소 활성을 갖는 효소를 포함하며, 상기 효소는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 갖는다.
다른 실시형태에서, 과가수분해효소 촉매는 과가수분해효소 활성을 갖는 효소를 포함하며, 상기 효소는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62 및 64로 이루어진 군으로부터 선택되는 아미노산 서열을 가지며, 상기 효소는 시그니처 모티프가 보존되고, 과가수분해효소 활성이 유지되는 한 하나 이상의 부가, 결실 또는 치환을 가질 수 있다.
상술된 바와 같이, CE-7 과가수분해효소는 CE-7 과가수분해효소를 포함하는 제1 부분, 및 과가수분해효소가 표면에 "표적화"되도록 표적 체표면에 대하여 친화성을 갖는 펩티드 성분을 포함하는 제2 부분을 갖는 융합 단백질의 형태로 사용된다. 일 실시형태에서, 임의의 CE-7 과가수분해효소(CE-7 시그니처 모티프의 존재로 정의)는 효소를 표적 표면에 표적화시킬 수 있는 임의의 펩티드 성분/결합 요소에 융합될 수 있다. 일 태양에서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분은 항체, 항체 단편(Fab)뿐 아니라 단쇄 가변 단편(scFv; 면역글로불린의 중쇄(VH) 및 경쇄(VL)의 가변 영역의 융합), 단일 도메인 카멜리드 항체, 스캐폴드 디스플레이 단백질, 셀룰로스-결합 도메인(셀룰로스 물질을 표적화하는 경우) 및 면역글로불린 폴드가 결여된 단쇄 친화성 펩티드를 포함할 수 있다. 항체, 항체 단편 및 다른 면역글로불린-유래의 결합 요소뿐 아니라 라지 스캐폴드 디스플레이 단백질을 포함하는 조성물은 종종 경제적으로 실행가능하지 않다. 이와 같이, 그리고 바람직한 태양에서, 펩티드 성분/결합 요소는 면역글로불린 폴드 및/또는 면역글로불린 도메인이 결여된 단쇄 친화성 펩티드이다.
셀룰로스-결합 도메인은 통상 셀룰로스 분해 효소와 관련이 있다. 12개가 넘는 CBD의 패밀리가 보고되어 있다(상기 문헌[Tomme et al.]). 일 실시형태에서, 셀룰로스-결합 도메인은 CE-7 과가수분해효소를 셀룰로스 물질에 표적화시키기 위한 펩티드 성분으로 사용된다.
짧은 단쇄 체표면-결합 펩티드는 실험에 의해 생성하거나(예를 들어, 음으로 하전된 표면에 표적화된 양으로 하전된 폴리펩티드) 또는 표적 표면에 대한 바이오패닝을 사용하여 생성할 수 있다. 많은 디스플레이 기술(예를 들어, 파지 디스플레이, 효모 디스플레이, 박테리아 디스플레이, 리보솜 디스플레이 및 mRNA 디스플레이)을 사용하여 친화성 펩티드를 동정/수득하는 방법은 당업계에 널리 공지되어 있다. 개별 표적 표면-결합 펩티드는 임의의 스페이서/링커를 통해 함께 결합되어 더 큰 결합 도메인(본 명세서에서 결합 "손(hand)"으로도 지칭)을 형성하여, 과가수분해 효소의 표적 표면으로의 부착/국소화를 증진시킬 수 있다.
또한, 융합 단백질은 CE-7 과가수분해효소를 표적 표면-결합 도메인으로부터 분리하고/거나 상이한 표적 표면-결합 펩티드(예를 들어, 복수의 표적 표면 결합 펩티드가 함께 결합되어 더 큰 표적 표면-결합 도메인을 형성하는 경우) 사이를 분리하는 하나 이상의 펩티드 링커/스페이서를 포함할 수 있다. 일 실시형태에서, 펩티드 스페이서/링커는 최대 10회 반복될 수 있다. 예시적인 펩티드 스페이서의 비제한적인 목록은 서열 번호 128 내지 140 및 143의 아미노산 서열에 의해 제공된다.
적절한 카르복실산 에스테르 기질은 하기의 화학식을 갖는 에스테르를 포함할 수 있다:
(a) 구조
[X]mR5
(여기서,
X는 화학식 R6C(O)O의 에스테르기이며;
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며, R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고, R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 하나 이상의 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ; 또는
(b) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 하나 이상의 글리세리드; 또는
(c) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 또는
(d) 하나 이상의 아세틸화 단당류, 아세틸화 이당류 또는 아세틸화 다당류; 또는
(e) (a) 내지 (d)의 임의의 조합.
또한, 적절한 기질은 아실화 단당류, 이당류 및 다당류로 이루어진 군으로부터 선택되는 하나 이상의 아실화 당류를 포함할 수 있다. 다른 실시형태에서, 아실화 당류는 아세틸화 자일란; 아세틸화 자일란의 단편; 아세틸화 자일로스(예컨대, 자일로스 테트라아세테이트); 아세틸화 글루코스(예컨대, α-D-글루코스 펜타아세테이트; β-D-글루코스 펜타아세테이트; 1-티오-β-D-글루코스-2,3,4,6-테트라아세테이트); β-D-갈락토스 펜타아세테이트;소르비톨 헥사아세테이트; 수크로스 옥타아세테이트; β-D-리보푸라노스-1,2,3,5-테트라아세테이트; β-D-리보푸라노스-1,2,3,4-테트라아세테이트; 트라이-O-아세틸-D-갈락탈; 트라이-O-아세틸-D-글루칼; β-D-자일로푸라노스 테트라아세테이트, α-D-글루코피라노스 펜타아세테이트; β-D-글루코피라노스-1,2,3,4-테트라아세테이트; β-D-글루코피라노스-2,3,4, 6-테트라아세테이트; 2-아세트아미도-2-데옥시-1,3,4,6-테트라아세틸-β-D-글루코피라노스; 2-아세트아미도-2-데옥시-3,4,6-트라이아세틸-1-클로라이드-α-D-글루코피라노스; α-D-만노피라노스 펜타아세테이트 및 아세틸화 셀룰로스로 이루어진 군으부터 선택된다. 바람직한 실시형태에서, 아세틸화 당류는 β-D-리보푸라노스-1,2,3,5-테트라아세테이트; 트라이-O-아세틸-D-갈락탈; 트라이-O-아세틸-D-글루칼; 수크로스 옥타아세테이트; 및 아세틸화 셀룰로스로 이루어진 군으로부터 선택된다.
다른 실시형태에서, 추가의 적절한 기질은 또한 5-아세톡시메틸-2-푸르알데히드; 3,4-다이아세톡시-1-부텐; 4-아세톡시벤조산; 바닐린 아세테이트; 프로필렌 글리콜 메틸 에테르 아세테이트; 메틸 락테이트; 에틸 락테이트; 메틸 글리콜레이트; 에틸 글리콜레이트; 메틸 메톡시아세테이트; 에틸 메톡시아세테이트; 메틸 3-하이드록시부티레이트; 에틸 3-하이드록시부티레이트; 및 트라이에틸 2-아세틸 시트레이트를 포함할 수 있다.
다른 실시형태에서, 적절한 기질은 모노아세틴; 다이아세틴; 트라이아세틴; 모노프로피오닌; 다이프로피오닌; 트라이프로피오닌; 모노부티린; 다이부티린; 트라이부티린; 글루코스 펜타아세테이트; 자일로스 테트라아세테이트; 아세틸화 자일란; 아세틸화 자일란 단편; β-D-리보푸라노스-1,2,3,5-테트라아세테이트; 트라이-O-아세틸-D-갈락탈; 트라이-O-아세틸-D-글루칼; 1,2-에탄다이올; 1,2-프로판다이올; 1,3-프로판다이올; 1,2-부탄다이올; 1,3-부탄다이올; 2,3-부탄다이올; 1,4-부탄다이올; 1,2-펜탄다이올; 2,5-펜탄다이올; 1,5-펜탄다이올; 1,6-펜탄다이올; 1,2-헥산다이올; 2,5-헥산다이올; 1,6-헥산다이올의 모노에스테르 또는 다이에스테르; 및 그들의 혼합물로 이루어진 군으로부터 선택된다. 다른 실시형태에서, 기질은 하나 이상의 에스테르기를 포함하는 C1 내지 C6 폴리올이다. 바람직한 실시형태에서, C1 내지 C6 폴리올 상의 하나 이상의 하이드록실기는 하나 이상의 아세톡시기(예를 들어, 1,3-프로판다이올 다이아세테이트; 1,2-프로판다이올 다이아세테이트; 1,4-부탄다이올 다이아세테이트; 1,5-펜탄다이올 다이아세테이트 등)로 치환된다. 추가의 실시형태에서, 기질은 프로필렌 글리콜 다이아세테이트(PGDA), 에틸렌 글리콜 다이아세테이트(EGDA) 또는 그들의 혼합물이다.
추가의 실시형태에서, 적절한 기질은 모노아세틴, 다이아세틴, 트라이아세틴, 모노프로피오닌, 다이프로피오닌, 트라이프로피오닌, 모노부티린, 다이부티린 및 트라이부티린으로 이루어진 군으로부터 선택된다. 또 다른 태양에서, 기질은 다이아세틴 및 트라이아세틴으로 이루어진 군으로부터 선택된다. 가장 바람직한 실시형태에서, 적절한 기질은 트라이아세틴을 포함한다.
바람직한 실시형태에서, 카르복실산 에스테르는 모노아세틴, 다이아세틴, 트라이아세틴 및 그들의 조합(즉, 혼합물)으로 이루어진 군으로부터 선택되는 액체 기질이다. 카르복실산 에스테르는 효소-촉매작용되는 과가수분해시에 원하는 농도의 퍼옥시카르복실산을 생성하기에 충분한 농도로 반응 제형에 존재한다. 카르복실산 에스테르는 반응 제형 중에서 완전히 용해성일 필요는 없으나, 과가수분해효소 촉매에 의한 에스테르의 상응하는 퍼옥시카르복실산으로의 전환을 가능하게 하기에 충분한 용해성을 갖는다. 카르복실산 에스테르는 반응 제형의 0.05 wt% 내지 40 wt%의 농도, 바람직하게는 반응 제형의 0.1 wt% 내지 20 wt%의 농도, 더욱 바람직하게는 반응 제형의 0.5 wt% 내지 10 wt%의 농도로 반응 제형 중에 존재한다.
과산소원은 과산화수소, 과산화수소 부가물(예를 들어, 우레아-과산화수소 부가물(카르바미드 퍼옥시드)), 과붕산염 및 과탄산염을 포함할 수 있으나 이들에 한정되지 않는다. 반응 제형 중의 과산소 화합물의 농도는 0.0033 wt% 내지 약 50 wt%, 바람직하게는 0.033 wt% 내지 약 40 wt%, 더욱 바람직하게는 0.33 wt% 내지 약 30 wt%의 범위일 수 있다.
많은 과가수분해효소 촉매(전체 세포, 투과화된 전체 세포 및 부분 정제된 전체 세포 추출물)는 카탈라아제 활성(EC 1.11.1.6)을 갖는 것으로 보고되었다. 카탈라아제는 과산화수소의 산소 및 물로의 전환을 촉매작용시킨다. 일 태양에서, 과가수분해 촉매에는 카탈라아제 활성이 결여되어 있다. 다른 태양에서, 카탈라아제 억제제는 반응 제형에 첨가될 수 있다. 카탈라제 억제제의 예에는 나트륨 아지드 및 하이드록실아민 설페이트가 포함되나, 이들에 한정되지 않는다. 당업자는 필요에 따라 카탈라아제 억제제의 농도를 조절할 수 있다. 카탈라제 억제제의 농도는 통상 0.1 mM 내지 약 1 M; 바람직하게는 약 1 mM 내지 약 50 mM; 더욱 바람직하게는 약 1 mM 내지 약 20 mM의 범위이다. 일 태양에서, 나트륨 아지드 농도는 통상 약 20 mM 내지 약 60 mM의 범위인 한편, 하이드록실아민 설페이트 농도는 통상 약 0.5 mM 내지 약 30 mM, 바람직하게는 약 10 mM이다.
다른 실시형태에서, 효소 촉매에는 상당한 카탈라아제 활성이 결여되거나, 카탈라아제 활성을 감소시키거나 제거하도록 엔지니어링될 수 있다. 숙주 세포 내의 카탈라아제 활성은 트랜스포손(transposon) 돌연변이유발, RNA 안티센스 발현, 표적화된 돌연변이유발 및 무작위 돌연변이유발을 포함하나 이에 한정되지 않는 널리 공지되어 있는 기술을 사용하여 카탈라아제 활성을 담당하는 유전자(들)의 발현을 파괴시킴으로써 하향 조절되거나 제거될 수 있다. 바람직한 실시형태에서, 내인성 카탈라아제 활성을 암호화하는 유전자(들)는 하향 조절되거나 파괴된다(즉, 낙-아웃). 본 명세서에 사용되는 "파괴된" 유전자는 변형된 유전자에 의해 암호화된 단백질의 활성 및/또는 기능이 더이상 존재하지 않는 것이다. 유전자를 파괴시키는 수단은 해당 분야에 널리 공지되어 있으며, 해당하는 단백질의 활성 및/또는 기능이 더이상 존재하지 않는 한, 유전자에 대한 삽입, 결실 또는 돌연변이를 포함할 수 있으나, 이들에 한정되지 않는다. 추가의 바람직한 실시형태에서, 생성 숙주는 katG 및 katE로 이루어진 군으로부터 선택되는 파괴된 카탈라아제 유전자를 포함하는 이. 콜라이(E. coli) 생성 숙주이다(미국 특허 출원 공개 제2008-0176299호 참조). 다른 실시형태에서, 생성 숙주는 katG 및 katE 카탈라아제 유전자 둘 모두에서의 하향 조절 및/또는 파괴를 포함하는 에스케리키아 콜라이 균주이다.
수성 반응 제형 중의 촉매의 농도는 촉매의 특정 촉매 활성에 좌우되며, 원하는 반응 속도를 수득하도록 선택된다. 과가수분해 반응물 중의 촉매의 중량은 전형적으로 총 반응 부피 ㎖당 0.0001 ㎎ 내지 10 ㎎, 바람직하게는 ㎖당 0.001 ㎎ 내지 2.0 ㎎ 범위이다. 또한, 촉매는 당업자에게 널리 공지되어 있는 방법을 사용하여 용해성 또는 불용성 지지체 상에 고정화될 수 있으며; 예를 들어, 문헌[Immobilization of Enzymes and Cells; Gordon F. Bickerstaff, Editor; Humana Press, Totowa, NJ, USA; 1997]을 참조한다. 고정화된 촉매의 사용에 의해, 이후의 반응에서 촉매의 회수 및 재사용이 가능하게 된다. 효소 촉매는 전체 미생물 세포, 투과화된 미생물 세포, 미생물 세포 추출물, 부분 정제되거나 정제된 효소 및 그들의 혼합물의 형태일 수 있다.
일 태양에서, 카르복실산 에스테르의 화학적 과가수분해 및 효소에 의한 과가수분해의 조합에 의해 생성되는 퍼옥시카르복실산의 농도는 선택된 응용을 위해 유효 농도의 퍼옥시카르복실산을 제공하기에 충분하다. 다른 태양에서, 본 발명은 효소 및 효소 기질의 조합을 제공하여, 원하는 유효 농도의 퍼옥시카르복실산을 생성하며, 여기서, 첨가되는 효소의 부재 하에서, 유의미하게 더 낮은 농도의 퍼옥시카르복실산의 생성이 존재한다. 일부 경우에, 무기 과산화물과 효소 기질의 직접적인 화학적 반응에 의한 효소 기질의 상당한 화학적 과가수분해가 존재할 수 있지만, 원하는 응용에서 유효 농도의 퍼옥시카르복실산을 제공하기 위해 생성되는 충분한 농도의 퍼옥시카르복실산이 존재하지 않을 수 있으며, 총 퍼옥시카르복실산 농도의 유의미한 증가는 적절한 과가수분해효소 촉매를 반응 제형에 첨가함으로써 달성된다.
적어도 하나의 카르복실산 에스테르의 과가수분해에 의해 생성되는 퍼옥시카르복실산(예를 들어, 퍼아세트산)의 농도는 과가수분해 반응의 개시 10분 내, 바람직하게는 5분 내에 적어도 약 0.1 ppm, 바람직하게는 적어도 0.5 ppm, 1 ppm, 5 ppm, 10 ppm, 20 ppm, 100 ppm, 200 ppm, 300 ppm, 500 ppm, 700 ppm, 1000 ppm, 2000 ppm, 5000 ppm 또는 10,000 ppm의 과산이다. 퍼옥시카르복실산을 포함하는 제품 제형은 임의로, 표적 적용에 대해 원하는 더 낮은 농도의 퍼옥시카르복실산 베이스를 갖는 제형을 생성하도록 물 또는 주로 물로 이루어진 용액으로 희석될 수 있다. 당업자는 반응 성분 및/또는 희석량을 조절하여, 선택된 제품을 위한 목적하는 과산 농도를 달성할 수 있다.
일 태양에서, 원하는 농도의 과산을 생성하는데 필요한 반응 시간은 약 2시간 이하, 바람직하게는 약 30분 이하, 더욱 바람직하게는 약 10분 이하, 가장 바람직하게는 약 5분 이하이다. 다른 태양에서, 표적 표면은 반응 성분의 배합 5분 내에 본 명세서에 기재된 방법에 따라 형성되는 과산과 접촉된다. 일 실시형태에서, 표적 표면은 상기 반응 성분의 배합 약 5분 내지 약 168시간 내에, 또는 상기 반응 성분의 배합 약 5분 내지 약 48시간 내에, 또는 약 5분 내지 2시간 내에, 또는 그 안의 임의의 이러한 시간 간격으로 본 명세서에 기재된 방법에 따라 생성되는 과산과 접촉된다.
본 명세서에 기재된 방법에 따라 형성된 과산은 제품/응용에서 사용되며, 과산은 표적 표면과 접촉하여, 과산 기반의 이익을 표적 물질에 제공한다. 일 실시형태에서, 표적 표면을 위한 과산의 생성 방법은 동소에서 행해진다.
반응의 온도를 선택하여, 반응 속도와 효소 촉매 활성의 안정성 둘 모두를 조절할 수 있다. 반응 온도는 반응 제형의 동결점 바로 위의 온도(대략 0℃) 내지 약 95℃ 범위일 수 있으며, 바람직한 반응 온도 범위는 5℃ 내지 약 75℃이고, 더욱 바람직한 범위는 약 5℃ 내지 약 55℃이다.
퍼옥시카르복실산을 함유하는 최종 반응 제형의 pH는 약 2 내지 약 9, 바람직하게는 약 3 내지 약 8, 더욱 바람직하게는 약 5 내지 약 8, 더더욱 바람직하게는 약 5.5 내지 약 8, 보다 바람직하게는 약 6.0 내지 약 7.5이다. 반응물 및 최종 반응 제형의 pH는 임의로 포스페이트, 피로포스페이트, 바이카르보네이트, 아세테이트 또는 시트레이트를 포함하나 이들에 한정되지 않는 적절한 완충제의 첨가에 의해 조절될 수 있다. 완충제가 사용되는 경우, 완충제의 농도는 전형적으로 0.1 mM 내지 1.0 M, 바람직하게는 1 mM 내지 300 mM, 가장 바람직하게는 10 mM 내지 100 mM이다.
다른 태양에서, 효소에 의한 과가수분해 반응 제형은 분산제로 작용하는 유기 용매를 함유하여, 반응 제형 중의 카르복실산 에스테르의 용해 속도를 증진시킬 수 있다. 이러한 용매는 프로필렌 글리콜 메틸 에테르, 아세톤, 사이클로헥산온, 다이에틸렌 글리콜 부틸 에테르, 트라이프로필렌 글리콜 메틸 에테르, 다이에틸렌 글리콜 메틸 에테르, 프로필렌 글리콜 부틸 에테르, 다이프로필렌 글리콜 메틸 에테르, 사이클로헥산올, 벤질 알코올, 아이소프로판올, 에탄올, 프로필렌 글리콜 및 그들의 혼합물을 포함하나 이들에 한정되지 않는다.
단일 단계 대 다단계 적용 방법
전형적으로, 과산 유익제를 효소에 의해 생성하기 위한 최소 반응 성분 세트는 (1) 표적화된 융합 단백질의 형태의 적어도 하나의 과가수분해효소, (2) 적어도 하나의 적절한 카르복실산 에스테르 기질 및 (3) 과산소원(및 물)을 포함할 것이다.
본 발명의 조성물의 과산 생성 반응 성분은 사용할 때까지 분리되어 유지될 수 있다. 일 실시형태에서, 과산-생성 성분을 배합한 다음, 표적 표면과 접촉시켜, 이에 의해, 생성되는 과산계 유익제가 표적 표면에 이익을 제공한다. 성분을 배합한 다음 표적 표적 표면과 접촉시키거나, 또는 표적 표면 상에서 배합할 수 있다. 일 실시형태에서, 과산-생성 성분은 과산이 동소에서 생성되도록 배합한다.
또한, 다단계 적용이 사용될 수 있다. 효소에 의한 과산 생성에 필요한 나머지 성분을 적용하기 전에, 과산 생성 시스템(즉, 표적 표면 상에서의, 3가지 기본 반응 성분 중 적어도 하나의 순차적 적용) 조성물의 1가지 또는 2가지의 개별 성분을 표적 표면과 접촉시킬 수 있다. 일 실시형태에서, 표적화된 과가수분해 효소는 표면을 카르복실산 에스테르 기질 및/또는 과산소원과 접촉시키기 전에 표적 표면과 접촉시킨다(즉, "2-단계 적용"). 표적화된 과가수분해효소는 표적 표면에 대한 융합 단백질의 비공유 결합을 촉진시키는 적절한 조건 하에서 표적 표면과 접촉한다. 나머지 반응 성분을 배합하기 전에, 임의의 헹굼 단계를 사용하여 과잉의 및/또는 미결합 융합 단백질을 제거할 수 있다.
추가의 실시형태에서, 표적화된 과가수분해 효소 및 카르복실산 에스테르를 과산소원의 첨가 전에 표적 표면에 적용한다.
추가의 실시형태에서, 표적화된 과가수분해 효소 및 과산소원(예를 들어, 과산화수소를 포함하는 수용액)을 카르복실산 에스테르 기질의 첨가 전에 표적 표면에 적용한다.
추가의 실시형태에서, 카르복실산 에스테르 기질 및 과산소원(예를 들어, 과산화수소를 포함하는 수용액)을 표적화된 과가수분해 효소의 첨가 전에 표적 표면에 적용한다.
표적화된 과가수분해효소로 제조되는 퍼옥시카르복실산 조성물의 용도
본 발명의 방법에 따라 생성되는 표적화된 효소 촉매로 생성되는 과산은 생물학적 오염물질의 농도의 감소, 예를 들어, 의료 기구(예를 들어, 내시경), 텍스타일(예를 들어, 의복 및 카페트), 식품 조리 표면, 식품 보관 및 식품-포장 장비, 식품의 포장에 사용되는 물질, 닭 부화장 및 생육 시설, 동물 울타리 및 미생물 및/또는 살바이러스 활성을 갖는 폐가공수(spent process water)의 오염 제거를 위해 다양한 경질 표면/무생물 물체 응용에서 사용될 수 있다. 표적화된 효소로 생성되는 퍼옥시카르복실산은 프리온(예를 들어, 특정 프로테아제)을 불활성화시키도록 고안된 제형에서 사용되어, 추가로 살생 활성을 제공할 수 있다(미국 특허 제7,550,420호(DiCosimo et al) 참조).
일 태양에서, 과산 조성물은 오토클레이브 가능하지 않은(non-autoclavable) 의료 기구 및 식품 포장 장비에 대한 소독제로서 유용하다. 과산-함유 제형이 GRAS 또는 식품-등급 성분(표적화된 과가수분해효소, 효소 기질, 과산화수소 및 완충제)을 사용하여 제조될 수 있음에 따라, 표적화된 과가수분해효소-생성된 과산은 또한 동물 고기덩어리, 고기, 과일 및 야채의 오염 제거 또는 제조된 식품의 오염 제거를 위해 사용될 수 있다. 표적화된 과가수분해효소-생성된 과산이 제품에 혼입될 수 있으며, 제품의 최종 형태는 분말, 액체, 겔, 막, 고체 또는 에어로졸이다. 표적화된 과가수분해효소-생성된 과산을 여전히 유효한 오염 제거를 제공하는 농도로 희석할 수 있다.
과가수분해 효소 및 적어도 하나의 펩티드 성분을 포함하는 융합 단백질을 사용하여, 소독되거나 탈색될 표면 상에서 또는 그 근처에서 유효 농도의 과산을 생성한다. 표적 표면은 생물학적 오염물질, 예를 들어, 병원성 미생물 오염물질로 오염된(또는 오염된 것으로 추정되는) 표면 또는 물체일 수 있다. 일 실시형태에서, 과가수분해 효소를 표적화하기 위해 사용되는 펩티드 성분은 오염된 표면, 오염된 것으로 추정된 표면 또는 실제 오염물질(다시 말하면, 펩티드 성분은 실제 생물학적 오염 물질에 대하여 친화성을 갖는다)에 대하여 친화성을 갖는다.
본 명세서에 사용되는 "접촉"은 유효 농도의 과산(표적화된 과가수분해효소에 의해 생성되는)을 포함하는 소독 조성물을 목적하는 효과를 달성하기에 충분한 기간 동안 표적 표면과 접촉하게 배치하는 것을 말한다. 접촉은 유효 농도의 퍼옥시카르복실산을 형성하는 용액 또는 조성물의 표적 표면으로의 분무, 처리, 침지, 플러싱(flushing), 그의 위 또는 안으로의 주입, 혼합, 조합, 페인팅, 코팅, 도포, 부착 및 다르게는 전달을 포함한다. 표적화된 과가수분해효소를 포함하는 소독 조성물을 세정 조성물과 배합하여, 세정 및 소독 둘 모두를 제공할 수 있다. 대안적으로, 세정제(예를 들어, 계면활성제 또는 세제)를 제형에 혼입시켜, 단일 조성물에서 세정 및 소독 둘 모두를 제공할 수 있다.
또한, 조성물은 적어도 하나의 추가의 항미생물제, 프리온-분해 프로테아제, 살바이러스제(virucide), 살포자제(sporicide) 또는 살생제의 조합을 함유할 수 있다. 청구된 방법에 의해 생성되는 과산과 이들 제제의 병용은 생물학적 오염 물질로 오염된(또는 오염된 것으로 의심되는) 표면 및/또는 물체를 세정하고 소독하기 위해 사용되는 경우 증가된 효과 및/또는 상승 효과를 제공할 수 있다. 적절한 항미생물제에는 원하는 정도의 미생물 보호를 제공하기에 충분한 양의 카르복실산 에스테르(예를 들어, p-하이드록시 알킬 벤조에이트 및 알킬 신나메이트), 설폰산(예를 들어, 도데실벤젠 설폰산), 아이오도-화합물 또는 활성 할로겐 화합물(예를 들어, 원소 할로겐, 할로겐 옥시드(예를 들어, NaOCl, HOCl, HOBr, ClO2), 요오드, 인터할라이드(interhalide)(예를 들어, 일염화요오드, 이염화요오드, 삼염화요오드, 사염화요오드, 염화브롬, 일브롬화요오드 또는 이브롬화요오드), 폴리할라이드, 차아염소산염, 차아염소산, 하이포브롬산염, 하이포브롬산, 클로로- 및 브로모-하이단토인, 이산화염소 및 아염소산나트륨), 유기 과산화물, 예를 들어, 벤조일 퍼옥시드, 알킬 벤조일 퍼옥시드, 오존, 일중항 산소 발생자 및 그들의 혼합물, 페놀 유도체(예를 들어, o-페닐 페닐, o-벤질-p-클로로페놀, tert-아밀 페놀 및 C1-C6 알킬 하이드록시 벤조에이트), 4차 암모늄 화합물(예를 들어, 알킬다이메틸벤질 암모늄 클로라이드, 다이알킬다이메틸 암모늄 클로라이드 및 이들의 혼합물) 및 이러한 항미생물제의 혼합물이 포함된다. 유효량의 항미생물제에는 약 0.001 wt% 내지 약 60 wt% 항미생물제, 약 0.01 wt% 내지 약 15 wt% 항미생물제, 또는 약 0.08 wt% 내지 약 2.5 wt%의 항미생물제가 포함된다.
일 태양에서, 상기 방법에 의해 형성되는 과산을 사용하여, 표적 장소 상에(또는 그 근처에) 효소에 의해 생성되는 경우, 생존가능한 생물학적 오염물질(예를 들어, 미생물 집단)의 농도를 감소시킬 수 있다. 본 명세서에서 사용되는 "장소"는 원하는 과산 기반의 이익에 적절한 표적 표면의 일부 또는 모두를 포함한다. 표적 표면은 잠재적으로 생물학적 오염물질로 오염될 수 있는 모든 표면을 포함할 수 있다. 비제한적인 예에는 식품 또는 음료 산업에서 관찰되는 장비 표면(예를 들어, 탱크, 컨베이어, 바닥, 드레인(drain), 냉각기, 냉동고, 장비 표면, 벽, 밸브, 벨트, 파이프, 드레인, 조인트(joint), 크레바스(crevasse), 이들의 조합 등); 건물 표면(예를 들어, 벽, 바닥 및 창); 수처리 시설, 푸울(pool) 및 스파를 비롯한 비-식품-산업 관련 파이프 및 드레인, 및 발효 탱크; 병원 또는 동물병원 표면(예를 들어, 벽, 바닥, 침대, 장비(예를 들어, 내시경), 병원/동물병원 또는 기타 건강관리 환경에서 입는 의복, 예를 들어, 의복, 스크러브(scrub), 신발 및 기타 병원 또는 동물병원 표면); 식당 표면; 욕실 표면; 화장실; 의복 및 신발; 가축, 예를 들어, 가금류, 소, 젖소, 염소, 말 및 돼지를 위한 곳간 또는 축사의 표면; 가금류 또는 새우를 위한 부화장; 및 약제학적 또는 생물 약제학적 표면(예를 들어, 약제학적 또는 생물 약제학적 제조 장비, 약제학적 또는 생물 약제학적 성분, 약제학적 또는 생물 약제학적 부형제)을 포함한다. 추가의 경질 표면에는 식품, 예를 들어, 소고기, 가금류 고기, 돼지고기, 야채, 과일, 해산물, 이들의 조합 등이 포함된다. 또한, 장소는 물 흡수 물질, 예를 들어, 감염된 린넨 또는 기타 텍스타일을 포함할 수 있다. 또한, 장소는 종자, 옥수수, 덩이줄기, 과일 및 야채, 재배 식물 및 특히 작물 재배 식물, 예를 들어, 곡물, 잎 채소 및 샐러드 작물, 뿌리 채소, 콩과 식물, 장과, 감귤류 및 단단한 과일을 포함하는 수확된 식물 또는 식물 생성물을 포함한다.
경질 표면 물질의 비제한적인 예에는 금속(예를 들어, 강, 스테인리스 강, 크롬, 티탄, 철, 구리, 황동, 알루미늄 및 그들의 합금), 광물(예를 들어, 콘크리트), 폴리머 및 플라스틱(예를 들어, 폴리올레핀, 이를 테면, 폴리에틸렌, 폴리프로필렌, 폴리스티렌, 폴리(메트)아크릴레이트, 폴리아크릴로니트릴, 폴리부타다이엔, 폴리(아크릴로니트릴, 부타디엔, 스티렌), 폴리(아크릴로니트릴, 부타디엔), 아크릴로니트릴 부타디엔; 폴리에스테르, 예를 들어, 폴리에틸렌 테레프탈레이트; 및 폴리아미드, 예를 들어, 나일론)이 포함될 수 있다. 추가의 표면에는 벽돌, 타일, 세라믹, 자기, 목재, 목재 펄프, 제지, 비닐, 리놀륨 및 카페트가 포함된다.
본 발명의 방법에 의해 형성되는 과산을 사용하여, 섬유, 실, 의류 용품 또는 텍스타일에, 소독, 살균, 탈색, 탈염 및 탈취를 포함하나 이들에 한정되지 않는 이익을 제공할 수 있다. 본 발명의 방법에 의해 형성되는 과산은 몇가지만 말하자면, 텍스타일 사전-세정 처리, 세탁 세제, 세탁 세제 또는 첨가제, 염색 제거제, 탈색 조성물, 탈취 조성물 및 헹굼제를 포함하나 이들에 한정되지 않는 많은 세탁 관리 제품에 사용될 수 있다.
본 발명의 방법에 의해 형성되는 과산은 특히 과아세트산이 사용되는 목재 펄프 또는 제지 펄프 탈색/탈리그닌(delignification) 방법의 하나 이상의 단계에 사용될 수 있다(예를 들어, EP1040222 B1호 및 미국 특허 제5,552,018호(Devenyns, J.) 참조).
세탁 관리 조성물
본 발명의 조성물 및 방법은 표적화된 과산 생성을 위해 세탁 관리 응용에 사용될 수 있다. 표적화된 과가수분해효소는 섬유, 실, 텍스타일(직물 또는 부직물), 또는 의류 물품에 표적화될 수 있다. 과산 생성 시스템에 의해 생성되는 과산에 의해, 소독되거나, 살균되거나, 탈색되거나, 탈염되거나, 탈취되거나 또는 이들의 임의의 조합인 표적화된 표면이 야기된다.
과가수분해 활성을 갖는 융합 단백질은 섬유, 실, 텍스타일(직물 또는 부직물) 또는 의류 용품의 제조에 사용되는 표적 물질에 대하여 친화성을 갖도록 고안된다. 표적 물질은 세탁되는 용품의 제조에 사용되는 천연, 반-합성 및 합성 물질을 포함할 수 있다. 표적 물질은 통상 섬유, 실, 텍스타일 및 의류 용품의 제조에 사용되는 폴리머 및 코폴리머를 포함할 수 있다.
표적 물질은 셀룰로스 물질, 비-셀룰로스 물질(예를 들어, 폴리에스테르, 폴리아크릴계 물질) 및 그들의 배합물을 포함할 수 있다. 일 실시형태에서, 표적 표면은 셀룰로스 물질을 포함한다. 이와 같이, 셀룰로스 물질에 대하여 친화성을 갖는 펩티드 성분을 사용하여 표적화된 과가수분해효소를 셀룰로스 물질에 결합시킬 수 있다. 나머지 과산-생성 반응 성분은 표적화된 과가수분해효소를 표적 표면에 결합시키기 전에, 이와 함께, 또는 이후에, 첨가될 수 있다.
과산 유익제의 제2 물질/표면 또는 물체로의 조절된 전달을 위한 제1 물질/표면 또는 물체에 대한 과가수분해효소 표적화
일부 실시형태에서, 과가수분해 효소를 과산계 유익제의 수혜자가 아닌 주요 표적 물질/표면 또는 물체에 표적화시키는 것이 바람직할 수 있다. 예를 들어, 과가수분해 효소를 먼저 주요 물질/표면, 예를 들어, 도구, 기구(utensil), 적용기, 패브릭, 붕대, 스폰지, 대걸레, 비-호흡가능한 입자 등에 표적화시키는 것이 바람직할 수 있으며, 이들은 이후에 세정, 탈색, 미백, 소독, 살균, 탈염, 탈취 또는 이들의 임의의 조합을 위해 제2 물질/표면에 과산 기반의 이익의 전달에 사용된다(예를 들어, 대걸레 헤드에 결합된 과가수분해 융합 단백질은 이후에 바닥과 접촉한다). 다른 태양에서, 표적화된 과가수분해 효소는 이후에 활성 융합 단백질을 위한 전달 비히클로 사용되는 입자에 표적화된다(입자에 대하여 친화성을 갖는 결합 도메인을 사용하여). 추가의 태양에서, 융합 단백질을 포함하는 입자는 호흡가능하지 않으며, 독성이 낮다. 다른 실시형태에서, 입자 또는 표면은 셀룰로스에 대하여 친화성을 갖는 펩티드 성분을 통하여 과가수분해 융합 단백질에 결합할 수 있는 셀룰로스 물질을 포함한다.
퍼옥시카르복실산 및 과산화수소의 농도를 결정하기 위한 HPLC 검정 방법.
적정, 고성능 액체 크로마토그래피(HPLC), 기체 크로마토그래피(GC), 질량 분석기(MS), 모세관 전기영동(CE), 문헌[Pinkernell et al., (Anal . Chem ., 69(17):3623-3627 (1997))]에 기재된 분석 절차, 및 본 실시예에 기재된 바와 같은 2,2'-아지노-비스 (3'-에틸벤조타졸린)-6-설포네이트(ABTS) 검정법(문헌[Pinkernell et . al . Analyst, 122: 567-571, (1997)] 및 문헌[Dinu et . al., Adv. Funct . Mater ., 20: 392-398 (2010)])을 포함하나 이에 한정되지 않는 다양한 분석 방법을 본 발명의 방법에 사용하여 반응물 및 생성물을 분석할 수 있다.
퍼옥시카르복실산의 최소 살생 농도의 결정
특정 개인 관리 응용, 예를 들어, 몇가지만 말하자면, 체취 및 진균 감염, 및 치아 우식증의 발생과 관련된 것과 같은 원치않는 미생물의 제거와 관련이 있을 수 있다. 이와 같이, 표적 개인 관리 응용을 위한 최소 살생 농도를 측정하고자 할 수 있다. 문헌[J. Gabrielson, et al. (J. Microbiol . Methods 50: 63-73 (2002))]에 기재되어 있는 방법은 퍼옥시카르복실산 또는 과산화수소 및 효소 기질의 최소 살생 농도(MBC)의 결정을 위해 사용할 수 있다. 검정 방법은 XTT 환원 억제를 기반으로 하며, 여기서, XTT((2,3-비스[2-메톡시-4-니트로-5-설포페닐]-5-[(페닐아미노)카르보닐]-2H-테트라졸륨, 내염, 모노나트륨 염)는 490 ㎚ 또는 450 ㎚에서 측정한 광학 밀도(OD)의 변화에 의해 미생물 호흡 활성을 나타내는 산화환원 염료이다. 그러나, 플레이트 생존 계수, 직접적인 현미경 계수, 건조 중량, 탁도 측정, 흡광도 및 생물발광을 포함하나 이들에 한정되지 않는 소독제 및 보존제의 활성의 시험에 이용할 수 있는 다양한 다른 방법이 존재한다(예를 들어, 문헌[Brock, Semour S., Disinfection, Sterilization, and Preservation, 5th edition, Lippincott Williams & Wilkins, Philadelphia, PA, USA; 2001] 참조).
재조합 미생물 발현
본 발명의 서열의 유전자 및 유전자 산물은 이종 숙주 세포, 특히 미생물 숙주 세포에서 생성될 수 있다. 본 발명의 유전자 및 핵산 분자의 발현에 바람직한 이종 숙주 세포는 진균 또는 박테리아 패밀리에서 관찰될 수 있고, 넓은 범위의 온도, pH 값 및 용매 용인성에 걸쳐 성장하는 미생물 숙주이다. 예를 들어, 박테리아, 효모 및 사상 진균 중 임의의 것이 본 발명의 핵산 분자의 발현에 적절한 숙주일 수 있는 것으로 고려된다. 과가수분해효소는 세포내, 세포외 또는 세포내와 세포외 둘 모두의 조합에서 발현될 수 있으며, 여기서, 세포외 발현은 발효 생성물로부터의 원하는 단백질의 회수를 세포내 발현에 의해 생성되는 단백질의 회수 방법보다 더 용이하게 한다. 전사, 번역 및 단백질 생합성 장치는 세포 바이오매스를 생성하는데 사용되는 세포 공급원료에 비하여 변함 없이 유지되며; 기능적 유전자는 관련 없이 발현될 것이다. 숙주 균주의 예에는 박테리아, 진균 또는 효모 종, 예를 들어, 아스페르길루스(Aspergillus), 트리코더마(Trichoderma), 사카로마이세스(Saccharomyces), 피키아(Pichia), 파피아(Phaffia), 클루이베로마이세스(Kluyveromyces), 칸디다(Candida), 한세눌라(Hansenula), 야로위아(Yarrowia), 살모넬라(Salmonella), 바실러스(Bacillus), 아키네토박터(Acinetobacter), 자이모모나스(Zymomonas), 아그로박테리움(Agrobacterium), 에리트로박터(Erythrobacter), 클로로븀(Chlorobium), 크로마튬(Chromatium), 플라보박테리움(Flavobacterium), 사이토파가(Cytophaga), 로도박터(Rhodobacter), 로도코커스(Rhodococcus), 스트렙토마이세스(Streptomyces), 브레비박테리움(Brevibacterium), 코리네박테리아(Corynebacteria), 마이코박테리움(Mycobacterium), 데이노코커스(Deinococcus), 에스케리키아(Escherichia), 에르위니아(Erwinia), 판토에아(Pantoea), 슈도모나스(Pseudomonas), 스핑고모나스(Sphingomonas), 메틸로모나스(Methylomonas), 메틸로박터(Methylobacter), 메틸로코커스(Methylococcus), 메틸로시너스(Methylosinus), 메틸로마이크로븀(Methylomicrobium), 메틸로시스티스(Methylocystis), 알칼리게네스(Alcaligenes), 시네코시스티스(Synechocystis), 시네코코커스(Synechococcus), 아나바에나(Anabaena), 티오바실러스(Thiobacillus), 메타노박테리움(Methanobacterium), 클레브시엘라(Klebsiella) 및 마익소코커스(Myxococcus)가 포함되나 이들에 한정되지 않는다. 일 실시형태에서, 박테리아 숙주 스트레인은 에스케리키아, 바실러스, 클루이베로마이세스 및 슈도모나스를 포함한다. 바람직한 실시형태에서, 박테리아 숙주 세포는 바실러스 서브틸리스 또는 에스케리키아 콜라이이다.
대규모 미생물 성장 및 기능적 유전자 발현은 매우 다양한 단순 또는 복합 탄수화물, 유기산 및 알코올 또는 포화 탄화수소, 예를 들어, 메탄 또는 광합성 숙주 또는 화학자가영양(chemoautotrophic) 숙주의 경우에 이산화탄소, 소정의 형태 및 양의 질소, 인, 황, 산소, 탄소, 또는 작은 무기 이온을 포함하는 임의의 미량의 미량영양소를 사용할 수 있다. 성장 속도의 조절은 특정 조절 분자의 배양물로의 첨가 또는 무첨가에 의해 영향을 받을 수 있으며, 통상 영양분 또는 에너지원을 고려하지 않는다.
적절한 숙주 세포의 형질전환에 유용한 벡터 또는 카세트가 당업계에 널리 알려져 있다. 전형적으로, 벡터 또는 카세트는 관련 유전자의 전사 및 번역을 유도하는 서열, 선별가능한 마커, 및 자가 복제 또는 염색체 통합을 허용하는 서열을 포함한다. 적절한 벡터는 전사 개시 제어부를 품고 있는 유전자의 5'의 영역 및 전사 종결을 제어하는 DNA 단편의 3'의 영역을 포함한다. 둘 모두의 제어 영역이 형질전환된 숙주 세포에 대하여 동종의 및/또는 생성 숙주에 대해 천연의 유전자로부터 유래되는 경우가 가장 바람직하지만, 그러한 제어 영역이 그렇게 유래될 필요는 없다.
바람직한 숙주 세포에서 본 발명의 세팔로스포린 C 데아세틸라제 암호화 영역의 발현을 작동시키기에 유용한 개시 제어 영역 또는 프로모터는 많으며, 당업자에게 잘 알려져 있다. 사실상, CYC1, HIS3, GAL1, GAL10, ADH1, PGK, PHO5, GAPDH, ADC1, TRP1, URA3, LEU2, ENO, TPI (사카로마이세스에서의 발현에 유용함); AOX1 (피키아에서의 발현에 유용함); 및 lac, araB, tet, trp, lPL, lPR, T7, tac 및 trc(에스케리키아 콜라이에서의 발현에 유용함)뿐 아니라 amy, apr, npr 프로모터 및 바실러스에서의 발현에 유용한 다양한 파지 프로모터를 포함하나 이들에 한정되지 않는 이들 유전자를 작동시킬 수 있는 임의의 프로모터가 본 발명에 적절하다.
종결 제어 영역은 또한 바람직한 숙주 세포의 다양한 천연의 유전자로부터 유래될 수 있다. 일 실시형태에서, 종결 제어 영역의 포함은 선택적이다. 다른 실시형태에서, 키메라 유전자는 바람직한 숙주 세포 유래의 종결 제어 영역을 포함한다.
산업적 생성
다양한 배양 방법을 적용하여, 과가수분해효소 촉매를 생성할 수 있다. 예를 들어, 재조합 미생물 숙주로부터 과발현되는 특정 유전자 산물의 대규모 생성은 배치식(batch), 유가식(fed-batch) 및 연속식(continuous) 배양 방법에 의해 생성될 수 있다. 배치식 및 유가식 배양 방법은 통상적이며, 해당 분야에 널리 알려져 있으며, 예는 문헌[Thomas D. Brock in Biotechnology: A Textbook of Industrial Microbiology, Second Edition, Sinauer Associates, Inc., Sunderland, MA (1989)] 및 문헌[Deshpande, Mukund V., Appl. Biochem. Biotechnol., 36:227-234 (1992)]에서 찾을 수 있다.
또한, 목적 과가수분해효소 촉매의 상업적 생성은 연속식 배양으로 달성될 수 있다. 연속식 배양은 정의된 배양 배지를 생물반응기에 연속 첨가함과 동시에, 동량의 조절된 배지를 처리를 위해 제거하는 개방형 시스템이다. 연속식 배양은 일반적으로 세포를 고정된 높은 액상 밀도로 유지시키며, 여기서, 세포는 주로 대수기 성장으로 존재한다. 대안적으로, 연속식 배양은 고정화된 세포로 실시될 수 있고, 여기서, 탄소 및 영양분을 지속적으로 공급하고, 가치있는 생성물, 부산물 또는 폐기물을 세포 매스로부터 지속적으로 제거한다. 세포 고정화는 천연 및/또는 합성 재료로 이루어진 매우 다양한 고체 지지체를 사용하여 수행할 수 있다.
배치식 발효, 유가식 발효 또는 연속식 배양으로부터의 목적 과가수분해효소 촉매의 회수는 당업계에 공지되어 있는 임의의 방법에 의해 달성될 수 있다. 예를 들어, 효소 촉매가 세포 내에서 생성되는 경우, 세포 페이스트(paste)를 원심분리 또는 막 여과에 의해 배양 배지로부터 분리하고, 임의로, 물 또는 원하는 pH의 수성 완충제로 세정한 다음, 원하는 pH에서의 수성 완충제 중의 세포 페이스트의 현탁액을 균질화시켜, 원하는 효소 촉매를 함유하는 세포 추출물을 생성한다. 효소 촉매 용액으로부터 원치않는 단백질을 침전시키기 위한 열-처리 단계 전에, 세포 추출물을 임의로, 적절한 여과 조제, 예를 들어 셀라이트 또는 실리카를 통해 여과하여, 세포 데브리스를 제거할 수 있다. 이어서, 원하는 효소 촉매를 함유하는 용액을 막 여과 또는 원심분리에 의하여 침전된 세포 데브리스 및 단백질로부터 분리할 수 있으며, 얻은 부분-정제된 효소 촉매 용액을 추가의 막 여과에 의해 농축시킨 다음, 임의로 적절한 담체(예를 들어, 말토덱스트린, 포스페이트 완충제, 시트레이트 완충제 또는 그들의 혼합물)와 혼합하고, 분무 건조시켜, 원하는 효소 촉매를 함유하는 고체 분말을 생성할 수 있다.
양, 농도, 또는 다른 값 또는 파라미터가 범위, 바람직한 범위 또는 바람직한 상한값 및 바람직한 하한값의 목록으로서 주어지는 경우, 범위가 별도로 개시되는 지에 상관없이 임의의 상한 범위 또는 바람직한 값 및 임의의 하한 범위 또는 바람직한 값의 임의의 쌍으로부터 형성된 모든 범위를 구체적으로 개시하는 것으로 이해되어야 한다. 수치 값의 범위가 본 명세서에서 언급될 경우, 달리 기술되지 않는다면, 그 범위는 그 종점 및 그 범위 내의 모든 정수와 분수를 포함하고자 하는 것이다. 범위를 정의할 때 열거된 특정 값으로 본 발명의 범주를 한정하고자 하는 것은 아니다.
일반 방법
본 발명의 바람직한 태양을 보여주기 위해 하기 실시예가 제공된다. 실시예에 개시된 기술은 본 발명의 실시에서 잘 기능하는 기술을 따르며, 이에 따라, 그의 바람직한 실시 방식을 구성하는 것으로 간주될 수 있음이 당업자에 의해 인식되어야 한다. 그러나, 본 개시내용의 견지에서, 당업자는 개시된 특정 실시형태에서 많은 변경이 이루어질 수 있으며, 여전히 본 명세서에 개시된 방법 및 실시예의 목적 및 범주로부터 벗어남 없이, 비슷하거나 유사한 결과가 수득되는 것을 인식해야 한다.
모든 시약 및 재료는 달리 특정하지 않는 한, 디프코 래보러터리즈(DIFCO Laboratories)(미국 미시간주 디트로이트 소재), GIBCO/BRL(미국 메릴랜드주 개더스버그 소재), 티씨아이 아메리카(TCI America)(미국 오리건주 포틀랜드 소재), 로슈 디아그노스틱스 코포레이션(Roche; Diagnostics Corporation)(미국 인디애나주 인디애나폴리스), 써모 사이언티픽(미국 일리노이주 록포드 소재의 피어스 프로틴 리서츠 프로덕츠(Pierce Protein Research Products)) 또는 시그마-알드리치 케미컬 컴퍼니(Sigma-Aldrich Chemical Company)(미국 미주리주 세인트 루이스 소재)로부터 수득하였다.
설명에서 하기의 약어는 후술되는 바와 같은 측정 유닛, 기술, 특성 또는 화합물에 해당한다: "sec" 또는 "s"는 초를 의미하고, "min"은 분을 의미하며, "h" 또는 "hr"은 시간을 의미하고, "㎕"은 마이크로리터를 의미하며, "㎖"은 밀리리터를 의미하고, "ℓ"은 리터를 의미하며, "mM"은 밀리몰을 의미하고, "M"은 몰을 의미하며, "mmol"은 밀리몰을 의미하고, "ppm"은 백만분율을 의미하며, "wt"는 중량을 의미하고, "wt%"는 중량 백분율을 의미하며, "g"는 그램을 의미하고, "㎎"는 밀리그램을 의미하며, "㎍"는 마이크로그램을 의미하고, "ng"는 나노그램을 의미하며, "g"는 중력을 의미하고, "HPLC"는 고성능 액체 크로마토그래피를 의미하며, "dd H2O"는 증류수 및 탈이온수를 의미하고, "dcw"는 건조 세포 중량을 의미하며, "ATCC" 또는 "ATCC(등록 상표)"는 아메리칸 타입 컬쳐 콜렉션(미국 버지니아주 머내서스 소재)을 의미하고, "U"는 과가수분해효소 활성의 단위를 의미하며, "rpm"은 분당 회전수 의미하고, "PAH"는 과가수분해효소를 의미하고, "EDTA"는 에틸렌다이아민테트라아세트산을 의미한다.
HPLC 과가수분해효소 검정법
반응 혼합물 중의 과아세트산(PAA) 농도의 결정을 문헌[Pinkernell et al.]에 기재된 방법에 따라 수행하였다. 반응 혼합물의 분취액(0.040 ㎖)을 사전결정된 시간에 제거하고, 수 중의 5 mM 인산 0.960 ㎖과 혼합하고; 희석된 시료의 pH의 pH 4 미만으로의 조정에 의해, 반응을 즉시 종결시켰다. 생성된 용액을 12,000 rpm에서 2분 동안의 원심분리에 의하여, 울트라프리(ULTRAFREE)(등록 상표) MC-필터 유닛(30,000 보통 분자량 한계(NMWL), 밀리포어(Millipore) 카탈로그 번호 UFC3LKT 00)을 사용하여 여과하였다. 생성된 여액의 분취액(0.100 ㎖)을 0.300 ㎖의 탈이온수를 함유하는 1.5-㎖ 스크류 캡(screw cap) HPLC 바이얼(vial)(미국 캘리포니아주 팔로 알토 소재의 아질런트 테크놀로지즈(Agilent Technologies); #5182-0715)로 옮긴 다음, 아세토니트릴 중의 20 mM MTS (메틸-p-톨릴-설피드) 0.100 ㎖을 첨가하고, 바이얼을 캡핑하고, 내용물을 광의 부재 하에 약 25℃에서 10분의 인큐베이션 전에 간단히 혼합하였다. 이어서, 각 바이얼에, 0.400 ㎖의 아세토니트릴 및 아세토니트릴 중의 트라이페닐포스핀(TPP, 40 mM) 용액 0.100 ㎖을 첨가하고, 바이얼을 다시 캡핑하고, 생성된 용액을 혼합하고, 광의 부재 하에 약 25℃에서 30분 동안 인큐베이션시켰다. 이어서, 각 바이얼에 0.100 ㎖의 10 mM N,N-다이에틸-m-톨루아미드(DEET; HPLC 외부 표준물질)를 첨가하고, 생성된 용액을 HPLC(워터스 얼라이언스(Waters Alliance) e2695, 미국 매사추세츠주 소재의 워터스 코포레이션(Waters Corporation)으로 분석하였다.
HPLC 방법:
프레컬럼 수펠코 수펠가드 디스커버리(precolumn Supelco Supelguard Discovery) C8(시그마-알드리치; 카탈로그 번호 59590-U)이 있는 수펠코 디스커버리(Supelco Discovery) C8 컬럼(10 ㎝ × 4.0-㎜, 5 ㎛)(카탈로그 번호 569422-U); 10 마이크로리터 주입 부피; 1.0 ㎖/분 및 주위 온도에서 CH3CN(시그마-알드리치; #270717) 및 탈이온수를 사용한 구배 방법:

발현 벡터 pLD001
플라스미드 pLD001(서열 번호 141)은 이전에 에스케리키아 콜라이에 적절한 발현 벡터로 보고되었다(본 명세서에 참고로 포함되는 미국 특허 출원 공개 제2010-0158823 A1호(Wang et al.) 참고).
벡터 pLD001은 상업적으로 입수할 수 있는 벡터 pDEST17(미국 캘리포니아주 칼스배드 소재의 인비트로겐(Invitrogen)) 유래의 것이었다. 이는 상업적으로 입수할 수 있는 벡터 pDEST17(미국 캘리포니아주 캘스배드 소재의 인비트로겐)로부터 유래되며, 효소 케토스테로이드 아이소머라제(KSI)의 단편을 암호화하는 서열을 포함한다.
표준 재조합 DNA 방법을 사용하여, NdeI 및 BamHI 부위에 의해 결합되는 다양한 가수분해효소/과가수분해효소에 대한 암호화 서열을 KSI 단편을 대체하여, pLD001의 NdeI 및 BamHI 부위 사이에 라이게이션시킬 수 있다. 유사하게, BamHI 및 AscI 부위에 의해 결합되는 결합 도메인의 암호화 서열을 pLD001의 BamHI 및 AscI 부위 사이에 라이게이션시킬 수 있다.
실시예 1
면-표적화된 과가수분해효소 융합의 구축
이러한 실시예에는 셀룰로스-결합 서열을 통하여 셀룰로스에 표적화된, 구체적으로 면에 표적화된 과가수분해효소의 생성을 위한 발현 시스템의 고안이 기재되어 있다.
셀룰로스-결합 도메인(각각 서열 번호 148, 151 및 154)으로의 과가수분해효소의 융합을 암호화하는 폴리뉴클레오티드(서열 번호 147, 150 및 153)가 18개 아미노산 가요성 링커(서열 번호 143)를 암호화하는 뉴클레오티드 서열(그 자체는 N-말단에 Met가 있고, C-말단에 His6이 있는 클로스트리듐 써모셀룸(서열 번호 149), 클로스트리듐 셀룰로보란스(서열 번호 152) 및 바실러스 종(서열 번호 155)으로부터의 셀룰라제의 셀룰로스-결합 도메인을 암호화하는 뉴클레오티드 서열에 융합된다)에 3'-말단에서 융합되는 써모토가 마리티마 과가수분해효소의 C277S 변이체(서열 번호 142)의 뉴클레오티드 서열을 갖도록 고안하였다. 유전자를 에스케리키아 콜라이에서의 발현을 위해 코돈 최적화시키고, DNA2.0(미국 캘리포니아주 멘로 파크 소재)에 의해 합성하였다. 암호화 서열을 발현 벡터 pLD001(서열 번호 141) 내에 T7 프로모터 뒤에, NdeI과 AscI 제한 부위 사이에 클로닝하여, 각각 플라스미드 pLR988, pLR1049 및 pLR1050을 제공하였다. 융합 단백질을 발현하기 위하여, 플라스미드는 에스케리키아 콜라이 균주 BL21AI(미국 캘리포니아주 칼스배드 소재의 인비트로겐)으로 옮겨, 각각 균주 LR3310, LR3504 및 LR3505를 생성하였다.
써모토가 마리티카 과가수분해효소(서열 번호 142)의 비-표적화 C277S 변이체를 유사하게 클로닝하였다. 비표적화된 과가수분해효소의 생성은 이전에 미국 특허 출원 공개 제2010-0087529호(DiCosimo et al.)에서 기재되었다.
초기에 모발에 대한 결합을 위해 고안된 다른 과가수분해효소 융합("PAH-HC263"; 서열 번호 145)에 대한 암호화 유전자(서열 번호 144)를 하기의 실험에서 음성 대조군으로 사용하였다(공동-출원되고, 공동-계류 중인 미국 가특허 출원(명칭: "ENZYMATIC PERACID GENERATION FOR USE IN HAIR CARE PRODUCTS"), 대리인 문서 번호 CL5175 US PROV 참조)).
실시예 2
호열성 셀룰로스-결합 도메인에 융합된 과가수분해효소를 포함하는 융합 단백질의 생성
이러한 실시예에는 내열성 셀룰로스-결합 도메인을 통하여 셀룰로스에 표적화된 과가수분해효소의 발현 및 정제가 기재되어 있다.
균주 LR3310을 50 ㎎/ℓ의 스펙티노마이신을 함유하는 1 리터의 자가유도(autoinduction) 배지(10 g/ℓ 트립톤, 5 g/ℓ 효모 추출물, 5 g/ℓ NaCl, 50 mM Na2HPO4, 50 mM KH2PO4, 25 mM (NH4)2SO4, 3 mM MgSO4, 0.75% 글리세롤, 0.075% 글루코스 및 0.05% 아라비노스)에서, 200 rpm 진탕 하에 37℃에서 20시간 동안 성장시켰다. 비-표적화된 써모토가 마리티마 C277S 변이체의 제조 및 재조합 발현이 미국 특허 출원 공개 제2010-0087529호(DiCosimo et al)에서 이전에 보고된 적이 있다.
세포를 8000 rpm 및 4℃에서의 원심분리에 의해 수집하고, 조직 호모지나이저(브린크만 호모지나이저 모델 PCU11)를 사용하여 3500 rpm에서 세포 펠렛을 얼음으로 냉각된 용해 완충제(50 mM Tris pH 7.5, 5 mM EDTA, 100 mM NaCl) 300 ㎖에 재현탁화시킨 다음 원심분리(8000 rpm, 4℃)에 의해 세정하였다. 이어서, 세포를 조직 호모지나이저를 사용하여 75 ㎎의 달걀 흰자 라이소자임(시그마)을 함유하는 냉각된 용해 완충제에서의 재현탁화에 의해 용해시켰다. 세포 현탁액을 조직 호모지나이저를 사용한 주기적인 균질화와 함께, 얼음 위에 3시간 동안 정치되게 하여, 라이소자임에 의한 세포벽의 분해를 가능하게 하였다. 이 단계에서, 추출물의 어떠한 거품 형성도 피하도록 주의하였다. 추출물을 나누고(500-㎖ 병당 150 ㎖), -20℃에서 동결시켰다. 동결된 세포 추출물을 실온(약 22℃)에서 해동시키고, 조직 호모지나이저를 사용하여 균질화시키고, 20% 최대 출력, 1분 동안 2 펄스/초, 1회 반복에서, 5 ㎜ 프로브가 장착된 초음파분해기(브란슨 울트라소닉스 코포레이션(Branson Ultrasonics Corporation); 소니파이어(Sonifier) 모델 450)를 사용하는 초음파분해에 의해 파괴하였다. 용해된 세포 추출물을 4 × 50-㎖ 코니컬(conical) 폴리프로필렌 원심분리용 튜브로 옮긴 다음, 10,000 rpm에서 10분 동안 4℃에서 원심분리하였다. 세포 데브리스(debris)뿐 아니라 파괴되지 않은 세포를 포함하는 펠렛을 동결시켰다. 용해물의 분취액을 15-㎖ 코니컬 폴리프로필렌 튜브(12 × 5-㎖)로 옮기고 15분 동안 60℃로 가열하고, 얼음 위에서 냉각시키고, 4 × 50-㎖ 코니컬 폴리프로필렌 원심분리용 튜브로 모았다. 내열성 효소를 함유하는 가용성 분획 및 침전된 에스케리키아 콜라이 단백질을 10,000 rpm에서 10분 동안 4℃에서의 원심분리에 의해 분리하였다. 세포 파괴가 초음파분해 단계 후에 불완전하였다면, 동결된 펠렛을 다시 해동시키고, 2차의 초음파분해, 원심분리 및 열 처리를 가하였다. 이러한 정제 프로토콜의 산출량은 통상 ㎖당 2 내지 4 ㎎의 단백질을 제공하며, 융합 과가수분해효소의 순도는 폴리아크릴아미드 겔 전기영동(PAGE) 분석에 의해 추정시 90% 내지 75%의 단백질이었다. 표준물질(시그마-알드리치)로서 소 혈청 알부민의 용액을 사용하여 총 단백질을 BCA 검정법(미국 미주리주 세인트 루이스 소재의 시그마-알드리치)에 의해 정량화하였다.
실시예 3
셀룰로스-결합 도메인에 융합된 과가수분해효소를 포함하는 다른 융합 단백질의 생성
이러한 실시예에는 열안정하지 않은 셀룰로스-결합 도메인을 통하여 셀룰로스에 표적화된 과가수분해효소의 발현 및 정제가 기재되어 있다.
균주 LR3504 및 LR3505를 균주 LR3310을 위해 실시예 2에 기재된 바와 같이 1 ℓ의 자가유도 배지에서 성장시켰다. 세포를 수집하고, 전체 세포 추출물을 균주 LR3310의 세포에 대해 기재된 바와 같이 라이소자임/동결-해동 사이클에 의해 제조하였다.
과가수분해효소 융합을 함유하는 용해성 세포 추출물을 금속 킬레이트화 친화성 크로마토그래피로 처리하였다. 5 ㎖의 용해물을 20 ㎖의 평형화/세정 완충제(10 mM Tris HCl pH 7.5, 10% 글리세롤, 150 mM NaCl, 1mM 이미다졸)로 평형화시킨 5-㎖ Co-NTA 크로마토그래피 컬럼(Co-NTA 카탈로그 번호 89965, 미국 일리노이스주 록포드 소재의 써모 사이언티픽(Thermo Scientific)) 상에 로딩하였다. 이어서, 컬럼을 15 ㎖의 평형화/세정 완충제로 세정하고, 결합 융합 단백질을 15 ㎖의 용리 완충제(10 mM Tris HCl pH 7.5, 10% 글리세롤, 150 mM NaCl, 150mM 이미다졸)로 용리시켰다. 과가수분해효소 융합을 추가의 정제 없이 시험하였다.
실시예 4
효소 가수분해효소 활성의 정량화
이러한 실시예에는 비특이적 에스테라제 기질을 사용하는 과가수분해효소의 가수분해효소 활성을 통한 과가수분해효소의 검출 및 정량화 방법이 기재되어 있다.
과가수분해효소 융합의 가수분해효소 활성을 pNPA(p-니트로페닐 아세틸 에스테르)로 결정하였다. 전형적으로, 효소를 가수분해효소 검정 완충제(50 mM KH2PO4, pH 7.2) 중에 1 내지 0.01 ㎍/㎖의 농도로 희석하였다. 25℃ 또는 30℃에서 3 mM(아세토니트릴 중에 용해된 100 mM pNPA 30 ㎕/㎖)의 최종 농도로의 pNPA의 첨가에 의해 반응을 개시하였다. 시간에 따른 400 ㎚에서의 흡광도의 변화를 기록하였다. pNPA의 비-효소적 가수분해의 백그라운드 수준 때문에, 비-효소 대조군을 분석에 포함시켰다. 활성을 Δ400/분(시료) - Δ400/분(비-효소 대조군)으로 측정하고, 가수분해되는 pNPA(μmol)/단백질(㎎) × 분(pNPA 몰 흡수: 10909 M-1)로 전환시켰다. 융합 단백질의 비활성은 통상 10 내지 30 μmol/㎎ × 분이었다.
실시예 5
셀룰로스-표적화 과가수분해효소 융합의 면 패브릭으로의 결합
이러한 실시예에는 셀룰로스-결합 서열의 과가수분해효소로의 융합에 의존적인 방식의, 과가수분해효소의 셀룰로스로의 결합이 기재되어 있다.
면 결합 실험을 위하여, 블루베리 쥬스로 염색된 면 패브을 받은 대로 사용하였다(미국 펜실베이니아주 웨스트 피트슨 소재의 테스트 패브릭스 인코포레이티드(Test Fabrics Inc., West Pittson, PA)). 견본(1 ㎠, 약 27 ㎎)을 1.8-㎖ 원심분리용 튜브에 첨가하였다. 가수분해 검정 완충제(1 ㎖)를 견본에 첨가한 다음, 과가수분해효소를 이 용액에 첨가하였다. 효소를 아담스 뉴테이터(Adams Nutator)(모델 1105, 미국 뉴저지주 프랭클린 레이크스 소재의 벡턴 디킨슨(Becton Dickinson))에서 온건하게 진탕시키면서(24 rpm); 30분 동안 면 견본에 결합되게 하였다. 견본과 함께 또는 모발 없이, 효소 부재 대조군을 pNPA 가수분해효소 시약의 비-효소적 가수분해를 설명하기 위하여 결합 실험에 포함시켰다. 결합 단계 후에, 결합 완충제 0.8 ㎖ 분취액을 9.2 ㎖ 완충제를 포함하는 새로운 튜브로 옮겨, 미결합 효소의 양을 정량화하였다. 추가의 결합 완충제를 제거하고, 견본을 가수분해효소 완충제 중의 1% 트윈(등록 상표)-20, 1 ㎖로 4회 세정하고, 각각 가수분해효소 완충제 중에서의 1 ㎖의 2회의 세정으로 이어졌다. 이어서 견본을 10 ㎖의 가수분해효소 검정법에서 재현탁화시키고, 견본에 계속 결합되는 가수분해효소 활성을 측정하였다. 써모토가 마리티마 과가수분해효소의 C277S 변이체(본 명세서에서 "PAH"로도 지칭; 서열 번호 142)를 대조군(비-표적화 과가수분해효소)으로 사용하였다. 결과는 표 1에 제공되어 있다.

이러한 실험에 의해, CIP 셀룰로스-결합 도메인에 의해 셀룰로스에 표적화된 과가수분해효소 융합이 1% 트윈(등록 상표)-20에서의 광범위한 세정 후에 면 패브릭 상에 유지되는 한편, 비표적화 과가수분해효소 또는 다른 표면에 표적화된 과가수분해효소를 포함하는 융합 단백질은 그렇지 않았음이 입증되었다.
실시예 6
셀룰로스-표적화된 과가수분해 융합의 셀룰로스 물질로의 결합
이러한 실시예에는 셀룰로스-표적화 과가수분해효소 융합의 몇몇 면 혼방 패브릭으로의 결합이 기재된다.
표적화된 과가수분해효소 융합 단백질 C277S-CIP(서열 번호 148), C277S-CBM17(서열 번호 151) 및 C277S-CBM28(서열 번호 154)의 결합을 표 2에 나타낸 면 혼방 패브릭 상에서 시험하였다. 견본(1 ㎠)을 상술된 바와 같은 융합 단백질 용액 1㎖에 노출시켰다. 견본을 상술된 바와 같이 세정하고, 효소를 pNPA 검정법을 사용하여 그의 가수분해효소 활성에 의해 검출하였다.

이러한 실시예에 의해, 셀룰로스계 또는 셀룰로스 함유 패브릭으로의 과가수분해효소의 표적화의 적용가능성 및 유용성이 입증된다.
실시예 7
염색된 면 패브릭 상의 C277S-CIP 셀룰로스-표적화 과가수분해효소의 탈색 활성
이러한 실시예에는 효소가 패브릭으로부터 세정되는 응용에서 염색된 면 패브릭의 탈색에서, 과가수분해효소에 융합된 셀룰로스 표적화 도메인의 이익이 기재되어 있다.
블루베리-염색된 견본(1 ㎠)을 3 ㎖의 PAH 완충제를 함유하는 50-㎖ 폴리프로필렌 튜브(튜브당 3개의 견본)에 배치하였다. 3개의 튜브에는 각각 14 ㎕의 C277S-CIP(4.7 ㎍/㎖), 27 ㎕의 비표적화("비태그화") 써모토가 마리티마 C277S(9 ㎍/㎖)를 제공하고, 효소를 제공하지 않았다.
효소가 온건한 진탕 하에서 30분 동안 결합되게 하였다. 이어서, 견본을 1% 트윈(등록 상표)-20을 함유하는 5 ㎖의 C277S 완충제로 4회 세정하고, C277S 완충제로 2회 이상 세정하였다. 견본을 실온(약 22℃)에서 30분 동안 건조시키고, 그들의 색상을 색도계(SP64 포터블 스피어 스펙트로포토미터(Portable Sphere Spectrophotometer), 모델 SP64, 미국 미시건주 그랜드빌 소재의 엑스-라이트 인코포레이티드(X-Rite Inc.))로 측정하였다(설정: 파장 범위 400 ㎚ 내지 700 ㎚, 매 10 ㎚, 구경 8 ㎜). 2가지 색상 측정은 각 견본의 전방 및 후방 상에서 이루어졌으며, 4개의 값을 평균화하였다.
이어서, 각 견본을 11 mM 과산화수소 + 100 mM 트라이아세틴을 함유하는 1 ㎖의 50 mM Tris pH 7.5 완충제가 있는 1.8-㎖ 원심분리용 튜브에 배치하고, 온건하게 스월링(swirling)시키면서 실온에서 10분 동안 인큐베이션시켰다. 용액을 제거하고, 견본을 50 mM Tris pH 7.5로 세정하고, 대기 건조시키고, 그들의 색상을 색도계를 사용하여 측정하였다.

이러한 실시예는 검정법의 조건 하에서, 표적화된 효소의 존재가 과산화수소 및 트라이아세틴 용액에 의해 제공되는 것보다 탈색을 유의미하게 증진시키는 것을 보여준다. 탈색의 증진은 비표적화된 과가수분해효소에 의해 생성되지 않았으며, 이는 과가수분해효소가 세정 단계 후에 면 패브릭에 결합되지 않음을 나타내며, 이에 따라 과가수분해효소의 표적화의 이점이 면 패브릭 상에 보유되는 것이 입증된다.

이러한 실시예는 과가수분해효소의 셀룰로스로의 표적화 때문에, 다른 셀룰로스-결합 도메인이 과가수분해효소에 융합되는 경우 향상된 탈색이 이행될 수 있음을 보여준다.
실시예 8
과가수분해효소 표적화에 의한 탈색 향상
이러한 실시예에는 효소가 패브릭으로부터 세정되지 않는 응용에서 염색된 면 패브릭의 탈색에서, 과가수분해효소에 융합된 셀룰로스 표적화 도메인의 이익이 기재되어 있다.
이러한 실험에서, 면 패브릭에 결합된 표적화된 과가수분해효소에 의한 과아세트산의 생성에 기인한 탈색을 동일한 총량의 효소의 첨가에서, 비결합 비표적화된 과가수분해효소에 기인한 탈색과 비교하였다. 첨가되는 효소의 총량을 효소의 가수분해효소 활성을 측정함으로써 평가하였다.
블루베리-염색된 면의 견본(1 ㎠)을 1 ㎖의 PAH 완충제를 함유하는 2-㎖ 원심분리용 튜브에 배치하였다. 일련의 튜브에 증가하는 양의 CIP 표적화된 과가수분해효소(C277S-CIP)를 제공하였다: 0, 20, 40 및 80 ㎕의 효소(추정된 90% 순도에서 4 ㎍/㎕의 1:20 희석). 이후에 비표적화된 효소를 제공할 일련의 튜브는 PAH 완충제만을 제공하는 것을 제외하고 동일한 방식으로 제조하였다. 2벌의 튜브를 표적화된 효소 및 이후에 첨가될 비표적화된 효소 둘 모두에 대하여, 하나는 견본 상에 유지되는 효소의 양을 측정하기 위해, 그리고 하나는 탈색을 측정하기 위해, 시험할 각 효소 농도에 대하여 설정하였다. 모든 튜브를 실온(약 22℃)에서 30분 동안 온건하게 진탕시켰다.
모든 C277S-CIP 함유 튜브에 대하여, 0.8 ㎖의 효소 용액을 9.2 ㎖의 PAH-완충제를 함유하는 15-㎖ 폴리프로필렌 튜브로 옮겨, 미결합 효소 분획을 나타내는 가수분해효소 활성을 측정하였다. 견본을 수동으로 진탕시키면서 PAH-완충제 중의 1 ㎖의 1% 트윈(등록 상표)으로 3회 세정하고, 이어서, 1 ㎖의 완충제 PAH-완충제로 2회 세정하였다. 각 C277S-CIP 농도에 대한 하나의 견본을 10 ㎖의 PAH 완충제를 함유하는 15-㎖ 폴리프로필렌 튜브로 옮겨, 결합 가수분해효소 활성을 측정하였다. 각 C277S-CIP(서열 번호 148) 농도에 대한 제2 견본 및 이후에 비표적화 써모토가 마리티마 C277S 효소(서열 번호 142)를 제공하는 모든 다른 견본을 새로운 2-㎖ 원심분리용 튜브로 옮겼다.
C277S-CIP 효소를 제공하지 않은 견본의 절반을 10 ㎖의 PAH-완충제 및 증가하는 양의 비표적화된 효소(추정된 25% 순도에서 0, 10, 20, 30, 40, 50 및 60 ㎕의 13.6 ㎍/㎖ 효소 용액)를 함유하는 15-㎖ 폴리프로필렌 튜브로 옮겨, 결합된 가수분해효소 활성을 측정하였다.
결합된 C277S-CIP 및 미결합 비표적화된 C277S를 갖는 견본의 가수분해효소 활성을 아세토니트릴 중의 100 mM pNPA 300 ㎕를 첨가하고, 시간에 따른 400 ㎚에서의 흡광도의 변화를 모니터링함으로써 측정하였다.
C277S-CIP를 제공하지 않은 제2 세트의 견본에, 증가하는 양의 비표적화된 과가수분해효소를 첨가하였다(추정된 25% 순도에서 0, 10, 20, 30, 40, 50 및 60 ㎕의 13.6 ㎍/㎖ 효소 용액). 이들 견본 및 이전에 표적화된 C277S-CIP에 의해 접촉된 적이 있는 견본에 50 mM Tris pH 7.5 중의 1 ㎖의 11 mM 과산화수소 + 100 mM 트라이아세틴을 제공하여, 과아세트산 생성에 의한 탈색을 평가하였다. 초기의 혼합 후에, 튜브를 실온에 10분 동안 놔두었다. 탈색 반응을 용액의 제거 및 2 × 1-㎖의 50 mM Tris pH 7.5로의 헹굼에 의해 10분 후에 중단시켰다. 견본을 대기 건조시키고, 그들의 색상을 색도계로 측정하였다. 이 실험을 반복하였다. 표 5에 나타낸 바와 같이, 첨가되는 동량의 효소 활성에 대하여, 그리고 동일한 반응 기간에 대하여, 셀룰로스 표적화된 과가수분해효소는 비표적화된 과가수분해효소에 비해 염색된 견본을 탈색시키는데 있어서 더욱 효율적이었다.
이러한 실시예에서는 효소의 효능의 증가를 위한 셀룰로스 기질로의 과가수분해효소의 표적화의 유용성이 입증되었다.

실시예 9
추가의 호열성 셀룰로스 결합 도메인으로의 과가수분해효소 융합의 구축
이러한 실시예에는 셀룰로스-결합 서열을 통하여 셀룰로스에 표적화된, 그리고 구체적으로 면에 표적화된 추가의 과가수분해효소의 생성을 위한 발현 시스템의 고안이 기재되어 있으며, 여기서, 셀룰로스 결합 도메인은 호열성이다.
셀룰로스-결합 도메인(각각 서열 번호 157 및 160)으로의 과가수분해효소의 융합을 암호화하는 폴리뉴클레오티드(서열 번호 156 및 159)가 18개 아미노산 가요성 링커(서열 번호 143)를 암호화하는 뉴클레오티드 서열(그 자체는 N-말단에 Met가 있는 써모토가 마리티마로부터의 엔도-1,4-베타-자일라나제 A의 셀룰로스-결합 도메인 CBM9-2(서열 번호 159) 및 칼디셀룰로시룹터 사카로라이티쿠스로부터의 셀룰라제 A의 CBD1(서열 번호 161)을 암호화하는 뉴클레오티드 서열에 융합된다)에 3'-말단에서 융합되는 써모토가 마리티마 과가수분해효소의 C277S 변이체(서열 번호 142)의 뉴클레오티드 서열을 갖도록 고안하였다. 유전자를 에스케리키아 콜라이에서의 발현을 위해 코돈 최적화시키고, DNA2.0(미국 캘리포니아주 멘로 파크 소재)에 의해 합성하였다. 암호화 서열을 발현 벡터 내에 NdeI 및 AscI 제한 부위를 사용하여 pBAD 프로모터 뒤에 클로닝하여, 각각 플라스미드 pLR1069 및 pLR1071을 제공하였다. 융합 단백질을 발현하기 위하여, 플라스미드를 에스케리키아 콜라이 균주 LR3728(MG1655 araBAD- ackA- pta- msbB- katE- katG-)로 옮겼다.
실시예 10
과가수분해효소 및 호열성 셀룰로스-결합 도메인을 포함하는 융합 단백질의 생성
이러한 실시예에는 내열성 셀룰로스-결합 도메인을 통하여 셀룰로스에 표적화된 과가수분해효소의 발현 및 정제가 기재되어 있다.
써모토가 마리티마 과가수분해효소의 써모토가 마리티마로부터의 엔도-1,4-베타-자일라나제 A의 셀룰로스-결합 도메인 CBM9-2(서열 번호 159) 및 칼디셀룰로시룹터 사카로라이티쿠스로부터의 셀룰라제 A의 CBD1(서열 번호 161)으로의 융합을 암호화하는 유전자를 발현하는 균주를 실시예 2에 기재된 바와 같은 자가유도 배지에서 성장시켰다. 세포를 8000 rpm 및 4℃에서의 원심분리에 의해 수집하고, 세포 펠렛을 10,000 유닛의 벤조나제(미국 미주리주 세인트 루이스 소재의 시그마-알드리치)를 함유하는 300 ㎖의 얼음-냉각된 50 mM KH2PO4, pH 7.2 완충제에서 재현탁화시킴으로써 세정하였다.
세포를 프렌치 압력 셀(French pressure cell)을 통한 2회 통과에 의해 파괴하였다. 용해된 세포 추출물을 4 × 50-㎖ 코니컬 폴리프로필렌 원심분리용 튜브로 옮기고, 10,000 rpm에서 10분 동안 4℃에서 원심분리하였다. 5 ㎖의 용해성 분획을 15-㎖ 코니컬 폴리프로필렌 튜브로 옮기고 15분 동안 80℃로 가열하고, 얼음 위에서 냉각시키고, 4 × 50-㎖ 코니컬 폴리프로필렌 원심분리용 튜브로 모았다. 내열성 효소를 함유하는 가용성 분획 및 침전된 에스케리키아 콜라이 단백질을 10,000 rpm에서 10분 동안 4℃에서의 원심분리에 의해 분리하였다. 이러한 정제 프로토콜의 산출량은 통상 ㎖당 2 내지 4 ㎎의 단백질을 제공하며, 융합 과가수분해효소의 순도는 폴리아크릴아미드 겔 전기영동(PAGE) 분석에 의해 추정시 90% 내지 75%의 단백질이었다. 표준물질(시그마-알드리치)로서 소 혈청 알부민의 용액을 사용하여 총 단백질을 BCA 검정법(미국 미주리주 세인트 루이스 소재의 시그마-알드리치)에 의해 정량화하였다. 과가수분해효소 활성을 ABTS(2,2'-아지노-비스(3-에틸벤조티아졸린)-6-설포네이트)를 사용하여 측정하였다. 융합 과가수분해효소의 비활성은 각각 482 μmol PAA/분/㎎ 및 629 μmol PAA/분/㎎이었다.
호열성 셀룰로스 결합 도메인 둘 모두로의 써모토가 마리티마 과가수분해효소의 융합은 용해성으로 남아있으며, 이는 그들이 비-표적화된 과가수분해효소와 동일한 과정에 의해 생성될 수 있는 것을 나타낸다.
실시예 11
호열성 셀룰로스-결합 도메인에 융합된 과가수분해효소의 작용성의 입증
이러한 실시예에서는 내열성 셀룰로스-결합 도메인을 통하여 셀룰로스에 표적화된 과가수분해효소의 활성뿐 아니라 셀룰로스로의 그들의 결합이 입증된다.
호열성 결합 도메인을 함유하도록 엔지니어링된 과가수분해효소 융합을 셀룰로스 슬러리(아비셀(Avicel)(등록 상표) 미정질 셀룰로스, (미국 펜실베이니아주 필라델피아 소재의 에프엠씨 코포레이션(FMC Corp.)), 1 ㎖의 50 mM 인산칼륨 완충제 pH 7.2 중의 20 ㎎)(2.5 ㎎의 효소/g(셀룰로스))와 접촉시켰다. 30분의 온건한 진탕 후에, 셀룰로스를 원심분리에 의해 펠렛화시켰다. 상층액(미결합 분획)을 새로운 튜브로 옮기고, 셀룰로스는 1 ㎖의 인산염 완충제로 5회 세정하였다. 과가수분해효소 활성을 미결합 분획뿐 아니라 결합 분획(5번째 완충제 세정 후의 셀룰로스 슬러리)에서 측정하였다. 써모토가 CBM9-2 셀룰로스-결합 도메인에 융합된 과가수분해효소의 활성의 96% 및 칼디셀룰로시룹터 CBD-1 셀룰로스-결합 도메인에 융합된 과가수분해효소의 활성의 98%가 셀룰로스 상에 유지되었다. 결합 및 미결합 분획에 존재하는 단백질의 변성 폴리아크릴아미드 겔 전기영동에 의해, 세정된 아비셀(등록 상표) 슬러리에서 융합 과가수분해효소에 해당하는 단백질 밴드가 나타났으며, 비결합 분획에서는 그렇지 않았고, 이에 의해, 과가수분해효소에 융합되는 경우, 셀룰로스에 대한 그들의 결합 및 이에 따른 셀룰로스 결합 도메인의 작용성을 확인하였다.
이러한 실시예에서는 다른 셀룰로스 결합 도메인이 과가수분해효소 결합 도메인에서 엔지니어링될 수 있으며, 과가수분해효소가 그의 활성을 보유하고 셀룰로스에 결합되게 하는 것이 입증된다.
실시예 12
셀룰로스 결합 도메인에 대한 과가수분해효소에 대한 추가의 융합의 구축
이러한 실시예에 의해, 셀룰로스에 표적화된 추가의 과가수분해효소의 생성을 위한 발현 시스템의 고안이 입증된다.

폴리뉴클레오티드 서열(서열 번호 164, 166 및 168)을 바실러스 푸밀러스, 락토코커스 락티스 및 메소리조비움 로티로부터의 자일란 에스테라제(서열 번호 10, 40 및 42)의 18개 아미노산 가요성 링커(서열 번호 143)(그 자체는 CIP 셀룰로스 결합 도메인 클로스트리듐 써모셀룸(서열 번호 149)에 융합된다)로의 융합을 암호화하도록 고안하였다. 이들 효소는 써모토가 마리티마 과가수분해효소가 그러한 것처럼, 가수분해효소의 CE-7 패밀리에 속한다.
폴리뉴클레오티드 서열(서열 번호 170, 172 및 174)을 마이코박테리움 스메그마티스로부터의 아릴 에스테라제의 S54V 변이체(서열 번호 162)의 18개 아미노산 가요성 링커(서열 번호 143)(그 자체는 클로스트리듐 써모셀룸으로부터의 셀룰로스 결합 도메인 CIP(서열 번호 149), 칼디셀룰로시룹터 사카로라이티쿠스로부터의 CBD1(서열 번호 161) 및 써모토가 마리티마로부터의 CBM9-2(서열 번호 158)에 융합된다)로의 융합을 암호화하도록 고안하였다. 마이코박테리움 스메그마티스로부터의 아릴 에스테라제는 써모토가 마리티마 과가수분해효소의 분류와는 상이한 분류의 가수분해 효소에 속한다.
폴리뉴클레오티드 서열(서열 번호 176 및 178)을 슈도모나스 플루오레슨스로부터의 가수분해효소의 L29P 변이체(서열 번호 163)의 18개 아미노산 가요성 링커(서열 번호 143)(그 자체는 클로스트리듐 써모셀룸으로부터의 셀룰로스 결합 도메인 CIP(서열 번호 149) 및 써모토가 마리티마로부터의 CBM9-2(서열 번호 158)에 융합된다)로의 융합을 암호화하도록 고안하였다. 슈도모나스 플루오레슨스로부터의 가수분해효소/에스테라제는 써모토가 마리티마 과가수분해효소의 분류 또는 마이코박테리움 스메그마티스의 분류와는 상이한 분류의 가수분해 효소에 속한다.
유전자를 에스케리키아 콜라이에서의 발현을 위해 코돈 최적화시키고, DNA2.0(미국 캘리포니아주 멘로 파크 소재)에 의해 합성하였다. 암호화 서열을 플라스미드에서, 실시예 1 및 9에 기재된 것과 유사한 방식으로, T7 프로모터 또는 pBAD 프로모터 뒤에 클로닝하였다. 플라스미드를 적절한 발현 숙주에 전달하였다: T7 프로모터 하의 구축물을 위한 에스케리키아 콜라이 균주 BL21AI(미국 캘리포니아주 칼스배드 소재의 인비트로겐) 또는 pBAD 프로모터 하의 구축물을 위한 에스케리키아 콜라이 MG1655의 araBAD 유도균주.
실시예 13
대안적인 에스테라제/과가수분해효소 및 셀룰로스-결합 도메인을 포함하는 융합 단백질의 생성
이러한 실시예에는 셀룰로스에 표적화된 다양한 대안적인 에스테라제/과가수분해효소의 발현 및 정제가 기재되어 있다.
실시예 12의 표 6에서 가수분해효소/과가수분해효소에 대한 융합을 암호화하는 유전자를 발현하는 균주를 200 rpm 진탕 하에서 37℃에서 20시간 동안 50 ㎎/ℓ의 스펙티노마이신을 함유하는 1 ℓ의 자가유도 배지(10 g/ℓ 트립톤, 5 g/ℓ 효모 추출물, 5 g/ℓ NaCl, 50 mM Na2HPO4, 50 mM KH2PO4, 25 mM (NH4)2SO4, 3 mM MgSO4, 0.75% 글리세롤, 0.075% 글루코스 및 0.05% 아라비노스)에서 성장시켰다. 모든 단백질 융합은 에스케리키아 콜라이에서 잘 발현되었다. 세포를 8000 rpm 및 4℃에서의 원심분리에 의해 수집하고, 조직 호모지나이저(브린크만 호모지나이저 모델 PCU11)를 사용하여 3500 rpm에서 세포 펠렛을 얼음으로 냉각된 용해 완충제(50 mM Tris pH 7.5 100 mM NaCl) 300 ㎖에 재현탁화시킨 다음 원심분리(8000 rpm, 4℃)에 의해 세정하였다. 세포를 약 110.32 ㎫(16,000 psi)에서 프렌치 압력 셀을 통한 2회 통과에 의해 파괴하였다. 용해된 세포 추출물을 4 × 50- ㎖ 코니컬 폴리프로필렌 원심분리용 튜브로 옮기고, 10,000 rpm에서 10분 동안 4℃에서 원심분리하였다. 효소를 함유하는 상층액을 새로운 튜브로 옮겼다. 각 추출물 중의 적절한 양의 융합 단백질을 쿠마시(Coomassie) 염색된 PAGE 겔 상의 소 혈청 알부민 표준물질의 밴드와의 비교에 의해 추정하였다.
이러한 실시예에서는 다양한 셀룰로스 결합 도메인에 대한 가수분해효소/과가수분해효소의 다양한 조합의 생성이 입증된다.
실시예 14
셀룰로스-결합 도메인에 융합된 대안적인 과가수분해효소의 과가수분해효소 활성
이러한 실시예에는 셀룰로스에 표적화된 대안적인 에스테라제/과가수분해효소의 활성이 기재되어 있다.
실시예 13에 기재된 바와 같이 생성되는 다양한 표적화 도메인을 갖는 셀룰로스에 표적화된 효소의 과가수분해효소 활성을 ABTS 검정법으로 측정하였다. 결과는 표 7에 보고되어 있으며, 표적화된 CE-7뿐 아니라 비-CE7 가수분해효소가 과가수분해 활성을 갖는 것을 보여준다.

이러한 실시예에서는 CE-7 패밀리로부터의 또는 다른 패밀리로부터의 다른 셀룰로스-표적화된 가수분해효소의 융합이 생성될 수 있으며, 과가수분해 활성을 가지며, 셀룰로스 물질을 수반하는 응용에서 직접적으로 또는 효소 발생 후에 사용될 수 있음이 입증된다.
실시예 15
셀룰로스 결합 도메인에 융합된 대안적인 과가수분해효소의 결합
이러한 실시예에는 셀룰로스에 표적화된 대안적인 에스테라제/과가수분해효소의 활성이 기재되어 있다.
다양한 셀룰로스 결합 도메인에 융합된 가수분해효소/과가수분해효소의 다양한 조합을 발현하는 에스케리키아 콜라이의 미정제 추출물을 셀룰로스 슬러리와 접촉시켰다. 추출물을 과잉으로 로딩하여, 셀룰로스를 포화시켰다(아비셀(등록 상표), 1 ㎖의 50 mM 인산칼륨 완충제 pH7.2 중의 20 ㎎; 과가수분해효소 융합 대략 300 ㎍의 효소/20 ㎎의 셀룰로스). 30분의 온건한 진탕 후에, 셀룰로스를 원심분리에 의해 펠렛화시켰다. 상층액(미결합 분획)을 제거하고, 셀룰로스 펠렛을 1 ㎖의 인산염 완충제로 3회 세정하였다. 제3 세정 후에, 셀룰로스를 1 ㎖의 인산염 완충제 중에 재현탁화시켰다. 20 ㎕의 재현탁화된 슬러리를 20 ㎕의 변성 SDS PAGE 시료 완충제와 혼합하고, 5분 동안 끓였다. 셀룰로스-표적화된 과가수분해효소의 결합을 결합 분획에 존재하는 단백질의 변성 폴리아크릴아미드 겔 전기영동에 의해 평가하였다(레인당 20 ㎕ 샘플 로딩). 모든 융합은 세정된 아비셀(등록 상표) 슬러리에서 융합 과가수분해효소 결합에 해당하는 적절한 크기를 갖는 단백질 밴드를 보였다. 모든 밴드는 모두 유사한 강도를 가졌으며, 이에 따라, 과가수분해효소에 융합되는 경우, 셀룰로스 결합 도메인의 작용성이 입증된다.
이러한 실시예에서는 상이한 가수분해효소 패밀리로부터의 상이한 과가수분해효소가 상이한 셀룰로스 결합 도메인을 통하여 셀룰로스에 표적화될 수 있으며, 셀룰로스 결합 도메인이 써모토가 과가수분해효소 이외의 과가수분해효소로의 융합의 맥락에서 작용성인 것이 입증된다.
SEQUENCE LISTING
<110> E.I. du Pont de Nemours and Company, Inc.
Rouviere, Pierre
Solomon, Linda
Fahnestock, Stephen
Gruber, Tanja
Cunningham, Scott
Payne, Mark
Wang, Hong
DiCosimo, Robert
<120> Targeted Perhydrolases
<130> CL5048 PCT
<150> US 61/424,916
<151> 2010-12-20
<160> 181
<170> PatentIn version 3.5
<210> 1
<211> 960
<212> DNA
<213> Bacillus subtilis
<220>
<221> CDS
<222> (1)..(960)
<400> 1
atg caa cta ttc gat ctg ccg ctc gac caa ttg caa aca tat aag cct 48
Met Gln Leu Phe Asp Leu Pro Leu Asp Gln Leu Gln Thr Tyr Lys Pro
1 5 10 15
gaa aaa aca gca ccg aaa gat ttt tct gag ttt tgg aaa ttg tct ttg 96
Glu Lys Thr Ala Pro Lys Asp Phe Ser Glu Phe Trp Lys Leu Ser Leu
20 25 30
gag gaa ctt gca aaa gtc caa gca gaa cct gat tta cag ccg gtt gac 144
Glu Glu Leu Ala Lys Val Gln Ala Glu Pro Asp Leu Gln Pro Val Asp
35 40 45
tat cct gct gac gga gta aaa gtg tac cgt ctc aca tat aaa agc ttc 192
Tyr Pro Ala Asp Gly Val Lys Val Tyr Arg Leu Thr Tyr Lys Ser Phe
50 55 60
gga aac gcc cgc att acc gga tgg tac gcg gtg cct gac aag caa ggc 240
Gly Asn Ala Arg Ile Thr Gly Trp Tyr Ala Val Pro Asp Lys Gln Gly
65 70 75 80
ccg cat ccg gcg atc gtg aaa tat cat ggc tac aat gca agc tat gat 288
Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
ggt gag att cat gaa atg gta aac tgg gca ctc cat ggc tac gcc gca 336
Gly Glu Ile His Glu Met Val Asn Trp Ala Leu His Gly Tyr Ala Ala
100 105 110
ttc ggc atg ctt gtc cgc ggc cag cag agc agc gag gat acg agt att 384
Phe Gly Met Leu Val Arg Gly Gln Gln Ser Ser Glu Asp Thr Ser Ile
115 120 125
tca ctg cac ggt cac gct ttg ggc tgg atg acg aaa gga att ctt gat 432
Ser Leu His Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Asp
130 135 140
aaa gat aca tac tat tac cgc ggt gtt tat ttg gac gcc gtc cgc gcg 480
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
ctt gag gtc atc agc agc ttc gac gag gtt gac gaa aca agg atc ggt 528
Leu Glu Val Ile Ser Ser Phe Asp Glu Val Asp Glu Thr Arg Ile Gly
165 170 175
gtg aca gga gga agc caa ggc gga ggt tta acc att gcc gca gca gcg 576
Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Thr Ile Ala Ala Ala Ala
180 185 190
ctg tca gac att cca aaa gcc gcg gtt gcc gat tat cct tat tta agc 624
Leu Ser Asp Ile Pro Lys Ala Ala Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
aac ttc gaa cgg gcc att gat gtg gcg ctt gaa cag ccg tac ctt gaa 672
Asn Phe Glu Arg Ala Ile Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
atc aat tcc ttc ttc aga aga aat ggc agc ccg gaa aca gaa gtg cag 720
Ile Asn Ser Phe Phe Arg Arg Asn Gly Ser Pro Glu Thr Glu Val Gln
225 230 235 240
gcg atg aag aca ctt tca tat ttc gat att atg aat ctc gct gac cga 768
Ala Met Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala Asp Arg
245 250 255
gtg aag gtg cct gtc ctg atg tca atc ggc ctg att gac aag gtc acg 816
Val Lys Val Pro Val Leu Met Ser Ile Gly Leu Ile Asp Lys Val Thr
260 265 270
ccg ccg tcc acc gtg ttt gcc gcc tac aat cat ttg gaa aca gag aaa 864
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Glu Lys
275 280 285
gag ctg aag gtg tac cgc tac ttc gga cat gag tat atc cct gct ttt 912
Glu Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Ala Phe
290 295 300
caa acg gaa aaa ctt gct ttc ttt aag cag cat ctt aaa ggc tga taa 960
Gln Thr Glu Lys Leu Ala Phe Phe Lys Gln His Leu Lys Gly
305 310 315
<210> 2
<211> 318
<212> PRT
<213> Bacillus subtilis
<400> 2
Met Gln Leu Phe Asp Leu Pro Leu Asp Gln Leu Gln Thr Tyr Lys Pro
1 5 10 15
Glu Lys Thr Ala Pro Lys Asp Phe Ser Glu Phe Trp Lys Leu Ser Leu
20 25 30
Glu Glu Leu Ala Lys Val Gln Ala Glu Pro Asp Leu Gln Pro Val Asp
35 40 45
Tyr Pro Ala Asp Gly Val Lys Val Tyr Arg Leu Thr Tyr Lys Ser Phe
50 55 60
Gly Asn Ala Arg Ile Thr Gly Trp Tyr Ala Val Pro Asp Lys Gln Gly
65 70 75 80
Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
Gly Glu Ile His Glu Met Val Asn Trp Ala Leu His Gly Tyr Ala Ala
100 105 110
Phe Gly Met Leu Val Arg Gly Gln Gln Ser Ser Glu Asp Thr Ser Ile
115 120 125
Ser Leu His Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Asp
130 135 140
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
Leu Glu Val Ile Ser Ser Phe Asp Glu Val Asp Glu Thr Arg Ile Gly
165 170 175
Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Thr Ile Ala Ala Ala Ala
180 185 190
Leu Ser Asp Ile Pro Lys Ala Ala Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
Asn Phe Glu Arg Ala Ile Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
Ile Asn Ser Phe Phe Arg Arg Asn Gly Ser Pro Glu Thr Glu Val Gln
225 230 235 240
Ala Met Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala Asp Arg
245 250 255
Val Lys Val Pro Val Leu Met Ser Ile Gly Leu Ile Asp Lys Val Thr
260 265 270
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Glu Lys
275 280 285
Glu Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Ala Phe
290 295 300
Gln Thr Glu Lys Leu Ala Phe Phe Lys Gln His Leu Lys Gly
305 310 315
<210> 3
<211> 957
<212> DNA
<213> Bacillus subtilis
<400> 3
atgcaactat tcgatctgcc gctcgaccaa ttgcaaacat ataagcctga aaaaacagca 60
ccgaaagatt tttctgagtt ttggaaattg tctttggagg aacttgcaaa agtccaagca 120
gaacctgatt tacagccggt tgactatcct gctgacggag taaaagtgta ccgtctcaca 180
tataaaagct tcggaaacgc ccgcattacc ggatggtacg cggtgcctga caaggaaggc 240
ccgcatccgg cgatcgtgaa atatcatggc tacaatgcaa gctatgatgg tgagattcat 300
gaaatggtaa actgggcact ccatggctac gccacattcg gcatgcttgt ccgcggccag 360
cagagcagcg aggatacgag tatttcaccg cacggtcacg ctttgggctg gatgacgaaa 420
ggaattcttg ataaagatac atactattac cgcggtgttt atttggacgc cgtccgcgcg 480
cttgaggtca tcagcagctt cgacgaggtt gacgaaacaa ggatcggtgt gacaggagga 540
agccaaggcg gaggtttaac cattgccgca gcagcgctgt cagacattcc aaaagccgcg 600
gttgccgatt atccttattt aagcaacttc gaacgggcca ttgatgtggc gcttgaacag 660
ccgtaccttg aaatcaattc cttcttcaga agaaatggca gcccggaaac agaagtgcag 720
gcgatgaaga cactttcata tttcgatatt atgaatctcg ctgaccgagt gaaggtgcct 780
gtcctgatgt caatcggcct gattgacaag gtcacgccgc cgtccaccgt gtttgccgcc 840
tacaatcatt tggaaacaaa gaaagagctg aaggtgtacc gctacttcgg acatgagtat 900
atccctgctt ttcaaactga aaaacttgct ttctttaagc agcatcttaa aggctga 957
<210> 4
<211> 318
<212> PRT
<213> Bacillus subtilis
<400> 4
Met Gln Leu Phe Asp Leu Pro Leu Asp Gln Leu Gln Thr Tyr Lys Pro
1 5 10 15
Glu Lys Thr Ala Pro Lys Asp Phe Ser Glu Phe Trp Lys Leu Ser Leu
20 25 30
Glu Glu Leu Ala Lys Val Gln Ala Glu Pro Asp Leu Gln Pro Val Asp
35 40 45
Tyr Pro Ala Asp Gly Val Lys Val Tyr Arg Leu Thr Tyr Lys Ser Phe
50 55 60
Gly Asn Ala Arg Ile Thr Gly Trp Tyr Ala Val Pro Asp Lys Glu Gly
65 70 75 80
Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
Gly Glu Ile His Glu Met Val Asn Trp Ala Leu His Gly Tyr Ala Thr
100 105 110
Phe Gly Met Leu Val Arg Gly Gln Gln Ser Ser Glu Asp Thr Ser Ile
115 120 125
Ser Pro His Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Asp
130 135 140
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
Leu Glu Val Ile Ser Ser Phe Asp Glu Val Asp Glu Thr Arg Ile Gly
165 170 175
Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Thr Ile Ala Ala Ala Ala
180 185 190
Leu Ser Asp Ile Pro Lys Ala Ala Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
Asn Phe Glu Arg Ala Ile Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
Ile Asn Ser Phe Phe Arg Arg Asn Gly Ser Pro Glu Thr Glu Val Gln
225 230 235 240
Ala Met Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala Asp Arg
245 250 255
Val Lys Val Pro Val Leu Met Ser Ile Gly Leu Ile Asp Lys Val Thr
260 265 270
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Lys Lys
275 280 285
Glu Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Ala Phe
290 295 300
Gln Thr Glu Lys Leu Ala Phe Phe Lys Gln His Leu Lys Gly
305 310 315
<210> 5
<211> 957
<212> DNA
<213> Bacillus subtilis
<400> 5
atgcaactat tcgatctgcc gctcgaccaa ttgcaaacgt ataagcctga aaaaacaaca 60
ccgaacgatt tttctgagtt ttggaaatcg tctttggacg aacttgcgaa agtcaaagca 120
gcacctgatt tacagctggt tgattatcct gctgatggag tcaaggtgta ccgcctcaca 180
tataaaagct tcggaaacgc ccgcattacc ggatggtacg cagtgcctga caaggaagga 240
ccgcatccgg cgatcgtcaa atatcatggc tacaacgcta gctatgacgg tgagattcat 300
gaaatggtaa actgggcgct ccacggttac gccgcattcg gcatgctagt ccgcggccag 360
cagagcagcg aggatacgag tatttctcca catggccatg ctttgggctg gatgacgaaa 420
ggaatccttg ataaagatac atactattac cggggcgttt atttggacgc tgtccgcgcg 480
cttgaggtca tcagcagctt tgacgaagtt gacgaaacaa gaatcggtgt gacaggcgga 540
agccaaggag gcggcttaac cattgccgca gccgctctgt cagacattcc aaaagccgcg 600
gttgccgatt atccttattt aagcaacttt gaacgggcca ttgatgtggc gcttgaacag 660
ccgtaccttg aaatcaattc cttctttaga agaaatggaa gcccggaaac ggaagagaag 720
gcgatgaaga cactttcata tttcgatatt atgaatctcg ctgaccgagt gaaggtccct 780
gtcctgatgt cgatcggtct gattgacaag gtcacgccgc cgtccaccgt gtttgccgca 840
tacaaccact tggagacaga gaaagagctc aaagtgtacc gctacttcgg gcatgagtat 900
atccctgcct ttcaaacaga aaaacttgct ttctttaagc agcatcttaa aggctga 957
<210> 6
<211> 318
<212> PRT
<213> Bacillus subtilis
<400> 6
Met Gln Leu Phe Asp Leu Pro Leu Asp Gln Leu Gln Thr Tyr Lys Pro
1 5 10 15
Glu Lys Thr Thr Pro Asn Asp Phe Ser Glu Phe Trp Lys Ser Ser Leu
20 25 30
Asp Glu Leu Ala Lys Val Lys Ala Ala Pro Asp Leu Gln Leu Val Asp
35 40 45
Tyr Pro Ala Asp Gly Val Lys Val Tyr Arg Leu Thr Tyr Lys Ser Phe
50 55 60
Gly Asn Ala Arg Ile Thr Gly Trp Tyr Ala Val Pro Asp Lys Glu Gly
65 70 75 80
Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
Gly Glu Ile His Glu Met Val Asn Trp Ala Leu His Gly Tyr Ala Ala
100 105 110
Phe Gly Met Leu Val Arg Gly Gln Gln Ser Ser Glu Asp Thr Ser Ile
115 120 125
Ser Pro His Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Asp
130 135 140
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
Leu Glu Val Ile Ser Ser Phe Asp Glu Val Asp Glu Thr Arg Ile Gly
165 170 175
Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Thr Ile Ala Ala Ala Ala
180 185 190
Leu Ser Asp Ile Pro Lys Ala Ala Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
Asn Phe Glu Arg Ala Ile Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
Ile Asn Ser Phe Phe Arg Arg Asn Gly Ser Pro Glu Thr Glu Glu Lys
225 230 235 240
Ala Met Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala Asp Arg
245 250 255
Val Lys Val Pro Val Leu Met Ser Ile Gly Leu Ile Asp Lys Val Thr
260 265 270
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Glu Lys
275 280 285
Glu Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Ala Phe
290 295 300
Gln Thr Glu Lys Leu Ala Phe Phe Lys Gln His Leu Lys Gly
305 310 315
<210> 7
<211> 957
<212> DNA
<213> Bacillus licheniformis
<400> 7
atgcagcagc cttatgatat gccgcttgaa cagctttatc agtataaacc tgaacggacg 60
gcaccggccg attttaaaga gttctggaag ggttcattgg aggaattggc aaatgaaaaa 120
gcgggaccgc agcttgaacc gcatgaatat ccggctgacg gggtaaaagt ctactggctt 180
acatacagaa gcatcggggg agcgcgaatt aaaggctggt acgcagtacc cgaccgccaa 240
gggcctcatc ctgcgatcgt caaataccac ggctataacg caagctatga cggagacatt 300
cacgatattg tcaattgggc tcttcacggc tatgcggcat tcggtatgct ggtccgcgga 360
cagaacagca gtgaagatac agagatctct catcacggac atgtacccgg ctggatgaca 420
aaaggaatcc tcgatccgaa aacatattac tacagagggg tctatttaga tgccgtacga 480
gcagtcgaag tggtcagcgg ttttgctgaa gtcgatgaaa agcggatcgg ggtgatcggg 540
gcaagccaag gaggcgggct ggccgtcgcg gtttcggcgc tgtccgatat tccaaaagca 600
gccgtgtcag aataccctta tttaagcaat tttcaacgag cgatcgatac agcgatcgac 660
cagccatatc tcgaaatcaa ctcctttttc agaagaaaca ccagtccgga tattgagcag 720
gcggccatgc ataccctgtc ttatttcgat gtcatgaacc ttgcccaatt ggtcaaagcg 780
accgtactca tgtcgatcgg actggttgac accatcactc cgccatccac cgtctttgcg 840
gcttacaatc acttggaaac ggataaagaa ataaaagtgt accgttattt tggacacgaa 900
tacatcccgc cgttccaaac cgaaaagctg gcgtttctga gaaagcatct gaaataa 957
<210> 8
<211> 318
<212> PRT
<213> Bacillus licheniformis
<400> 8
Met Gln Gln Pro Tyr Asp Met Pro Leu Glu Gln Leu Tyr Gln Tyr Lys
1 5 10 15
Pro Glu Arg Thr Ala Pro Ala Asp Phe Lys Glu Phe Trp Lys Gly Ser
20 25 30
Leu Glu Glu Leu Ala Asn Glu Lys Ala Gly Pro Gln Leu Glu Pro His
35 40 45
Glu Tyr Pro Ala Asp Gly Val Lys Val Tyr Trp Leu Thr Tyr Arg Ser
50 55 60
Ile Gly Gly Ala Arg Ile Lys Gly Trp Tyr Ala Val Pro Asp Arg Gln
65 70 75 80
Gly Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr
85 90 95
Asp Gly Asp Ile His Asp Ile Val Asn Trp Ala Leu His Gly Tyr Ala
100 105 110
Ala Phe Gly Met Leu Val Arg Gly Gln Asn Ser Ser Glu Asp Thr Glu
115 120 125
Ile Ser His His Gly His Val Pro Gly Trp Met Thr Lys Gly Ile Leu
130 135 140
Asp Pro Lys Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg
145 150 155 160
Ala Val Glu Val Val Ser Gly Phe Ala Glu Val Asp Glu Lys Arg Ile
165 170 175
Gly Val Ile Gly Ala Ser Gln Gly Gly Gly Leu Ala Val Ala Val Ser
180 185 190
Ala Leu Ser Asp Ile Pro Lys Ala Ala Val Ser Glu Tyr Pro Tyr Leu
195 200 205
Ser Asn Phe Gln Arg Ala Ile Asp Thr Ala Ile Asp Gln Pro Tyr Leu
210 215 220
Glu Ile Asn Ser Phe Phe Arg Arg Asn Thr Ser Pro Asp Ile Glu Gln
225 230 235 240
Ala Ala Met His Thr Leu Ser Tyr Phe Asp Val Met Asn Leu Ala Gln
245 250 255
Leu Val Lys Ala Thr Val Leu Met Ser Ile Gly Leu Val Asp Thr Ile
260 265 270
Thr Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Asp
275 280 285
Lys Glu Ile Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Pro
290 295 300
Phe Gln Thr Glu Lys Leu Ala Phe Leu Arg Lys His Leu Lys
305 310 315
<210> 9
<211> 963
<212> DNA
<213> Bacillus pumilis
<400> 9
atgcaattgt tcgatttatc actagaagag ctaaaaaaat ataaaccaaa gaaaacagca 60
cgtcctgatt tctcagactt ttggaagaaa tcgctcgaag aactgcgcca agtggaggca 120
gagccaacac ttgaatctta tgactatcca gtgaaaggcg tcaaggtgta ccgcctgacg 180
tatcaaagct ttggacattc taaaattgaa ggcttttatg ctgtgcctga tcaaactggt 240
ccgcatccag cgctcgttcg ttttcatggc tataatgcca gctatgacgg cggcattcac 300
gacatcgtca actgggcgct gcacggctat gcaacatttg gtatgctcgt ccgcggtcaa 360
ggtggcagtg aagacacatc agtgacacca ggcgggcatg cattagggtg gatgacaaaa 420
ggcattttat cgaaagatac gtactattat cgaggcgttt atctagatgc tgttcgtgca 480
cttgaagtca ttcagtcttt ccccgaagta gatgaacacc gtatcggcgt gatcggtgga 540
agtcaggggg gtgcgttagc gattgcggcc gcagcccttt cagacattcc aaaagtcgtt 600
gtggcagact atccttactt atcaaatttt gagcgtgcag ttgatgttgc cttggagcag 660
ccttatttag aaatcaattc atactttcgc agaaacagtg atccgaaagt ggaggaaaag 720
gcatttgaga cattaagcta ttttgattta atcaatttag ctggatgggt gaaacagcca 780
acattgatgg cgatcggtct gattgacaaa ataaccccac catctactgt gtttgcggca 840
tacaaccatt tagaaacaga taaagacctg aaagtatatc gctattttgg acacgagttt 900
atccctgctt ttcaaacaga gaagctgtcc tttttacaaa agcatttgct tctatcaaca 960
taa 963
<210> 10
<211> 320
<212> PRT
<213> Bacillus pumilis
<400> 10
Met Gln Leu Phe Asp Leu Ser Leu Glu Glu Leu Lys Lys Tyr Lys Pro
1 5 10 15
Lys Lys Thr Ala Arg Pro Asp Phe Ser Asp Phe Trp Lys Lys Ser Leu
20 25 30
Glu Glu Leu Arg Gln Val Glu Ala Glu Pro Thr Leu Glu Ser Tyr Asp
35 40 45
Tyr Pro Val Lys Gly Val Lys Val Tyr Arg Leu Thr Tyr Gln Ser Phe
50 55 60
Gly His Ser Lys Ile Glu Gly Phe Tyr Ala Val Pro Asp Gln Thr Gly
65 70 75 80
Pro His Pro Ala Leu Val Arg Phe His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
Gly Gly Ile His Asp Ile Val Asn Trp Ala Leu His Gly Tyr Ala Thr
100 105 110
Phe Gly Met Leu Val Arg Gly Gln Gly Gly Ser Glu Asp Thr Ser Val
115 120 125
Thr Pro Gly Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Ser
130 135 140
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
Leu Glu Val Ile Gln Ser Phe Pro Glu Val Asp Glu His Arg Ile Gly
165 170 175
Val Ile Gly Gly Ser Gln Gly Gly Ala Leu Ala Ile Ala Ala Ala Ala
180 185 190
Leu Ser Asp Ile Pro Lys Val Val Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
Asn Phe Glu Arg Ala Val Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
Ile Asn Ser Tyr Phe Arg Arg Asn Ser Asp Pro Lys Val Glu Glu Lys
225 230 235 240
Ala Phe Glu Thr Leu Ser Tyr Phe Asp Leu Ile Asn Leu Ala Gly Trp
245 250 255
Val Lys Gln Pro Thr Leu Met Ala Ile Gly Leu Ile Asp Lys Ile Thr
260 265 270
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Asp Lys
275 280 285
Asp Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Phe Ile Pro Ala Phe
290 295 300
Gln Thr Glu Lys Leu Ser Phe Leu Gln Lys His Leu Leu Leu Ser Thr
305 310 315 320
<210> 11
<211> 963
<212> DNA
<213> Clostridium thermocellum
<400> 11
atggcacaat tatatgatat gcctttggag gaattaaaaa aatataagcc tgcgcttaca 60
aaacagaaag attttgatga gttttgggaa aaaagcctta aagagctggc tgaaattcct 120
ttaaaatatc aacttatacc ttatgatttt ccggcccgga gggtaaaagt tttcagagtt 180
gaatatcttg gttttaaagg tgcaaatatt gaagggtggc ttgccgttcc cgagggagaa 240
gggttgtatc ccgggcttgt acagtttcac ggatacaact gggcgatgga tggatgtgtt 300
cccgatgtgg taaattgggc tttgaatgga tatgccgcat ttcttatgct tgttcgggga 360
cagcagggaa gaagcgtgga caatattgtg cccggcagcg gtcatgcttt gggatggatg 420
tcgaaaggta ttttgtcacc ggaggaatat tattatagag gagtatatat ggatgcggtt 480
cgtgctgttg aaattttggc ttcgcttcct tgtgtggatg aatcgagaat aggagtgaca 540
gggggcagcc agggtggagg acttgcactg gcggtggctg ctctgtccgg cataccgaaa 600
gttgcagccg tgcattatcc gtttctggca cattttgagc gtgccattga cgttgcgccg 660
gacggccctt atcttgaaat taacgaatat ttaagaagaa acagcggtga agaaatagaa 720
agacaggtaa agaaaaccct ttcctatttt gatatcatga atcttgctcc ccgtataaaa 780
tgccgtactt ggatttgcac tggtcttgtg gatgagatta ctcctccgtc aacggttttt 840
gcagtgtaca atcacctcaa atgcccaaag gaaatttcgg tattcagata ttttgggcat 900
gaacatatgc caggaagcgt tgaaatcaag ctgaggatac ttatggatga gctgaatccg 960
taa 963
<210> 12
<211> 320
<212> PRT
<213> Clostridium thermocellum
<400> 12
Met Ala Gln Leu Tyr Asp Met Pro Leu Glu Glu Leu Lys Lys Tyr Lys
1 5 10 15
Pro Ala Leu Thr Lys Gln Lys Asp Phe Asp Glu Phe Trp Glu Lys Ser
20 25 30
Leu Lys Glu Leu Ala Glu Ile Pro Leu Lys Tyr Gln Leu Ile Pro Tyr
35 40 45
Asp Phe Pro Ala Arg Arg Val Lys Val Phe Arg Val Glu Tyr Leu Gly
50 55 60
Phe Lys Gly Ala Asn Ile Glu Gly Trp Leu Ala Val Pro Glu Gly Glu
65 70 75 80
Gly Leu Tyr Pro Gly Leu Val Gln Phe His Gly Tyr Asn Trp Ala Met
85 90 95
Asp Gly Cys Val Pro Asp Val Val Asn Trp Ala Leu Asn Gly Tyr Ala
100 105 110
Ala Phe Leu Met Leu Val Arg Gly Gln Gln Gly Arg Ser Val Asp Asn
115 120 125
Ile Val Pro Gly Ser Gly His Ala Leu Gly Trp Met Ser Lys Gly Ile
130 135 140
Leu Ser Pro Glu Glu Tyr Tyr Tyr Arg Gly Val Tyr Met Asp Ala Val
145 150 155 160
Arg Ala Val Glu Ile Leu Ala Ser Leu Pro Cys Val Asp Glu Ser Arg
165 170 175
Ile Gly Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Ala Leu Ala Val
180 185 190
Ala Ala Leu Ser Gly Ile Pro Lys Val Ala Ala Val His Tyr Pro Phe
195 200 205
Leu Ala His Phe Glu Arg Ala Ile Asp Val Ala Pro Asp Gly Pro Tyr
210 215 220
Leu Glu Ile Asn Glu Tyr Leu Arg Arg Asn Ser Gly Glu Glu Ile Glu
225 230 235 240
Arg Gln Val Lys Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala
245 250 255
Pro Arg Ile Lys Cys Arg Thr Trp Ile Cys Thr Gly Leu Val Asp Glu
260 265 270
Ile Thr Pro Pro Ser Thr Val Phe Ala Val Tyr Asn His Leu Lys Cys
275 280 285
Pro Lys Glu Ile Ser Val Phe Arg Tyr Phe Gly His Glu His Met Pro
290 295 300
Gly Ser Val Glu Ile Lys Leu Arg Ile Leu Met Asp Glu Leu Asn Pro
305 310 315 320
<210> 13
<211> 978
<212> DNA
<213> Thermotoga neapolitana
<400> 13
atggccttct tcgatatgcc ccttgaggaa ctgaaaaagt accggcctga aaggtacgag 60
gagaaagatt tcgatgagtt ctggagggaa acacttaaag aaagcgaagg attccctctg 120
gatcccgtct ttgaaaaggt ggactttcat ctcaaaacgg ttgaaacgta cgatgttact 180
ttctctggat acagggggca gagaataaag ggctggcttc ttgttccgaa gttggcggaa 240
gaaaagcttc catgcgtcgt gcagtacata ggttacaatg gtggaagggg ttttccacac 300
gactggctgt tctggccgtc aatgggttac atctgttttg tcatggacac cagggggcag 360
ggaagcggct ggatgaaggg agacacaccg gattaccctg agggtccagt cgatccacag 420
taccccggat tcatgacgag gggcattctg gatccgggaa cctattacta caggcgagtc 480
ttcgtggatg cggtcagggc ggtggaagca gccatttcct tcccgagagt ggattccagg 540
aaggtggtgg tggccggagg cagtcagggt gggggaatcg cccttgcggt gagtgccctg 600
tcgaacaggg tgaaggctct gctctgcgat gtgccgtttc tgtgccactt cagaagggcc 660
gtgcaacttg tcgacacaca cccatacgtg gagatcacca acttcctcaa aacccacagg 720
gacaaagagg agattgtttt cagaacactt tcctacttcg atggtgtgaa ctttgcagca 780
agggcaaagg tgcccgccct gttttccgtt gggctcatgg acaccatctg tcctccctcg 840
acggtcttcg ccgcttacaa ccactacgcc ggtccaaagg agatcagaat ctatccgtac 900
aacaaccacg aaggtggagg ttctttccag gcaattgagc aggtgaaatt cttgaagaga 960
ctatttgagg aaggctag 978
<210> 14
<211> 325
<212> PRT
<213> Thermotoga neapolitana
<400> 14
Met Ala Phe Phe Asp Met Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Arg Glu Thr Leu
20 25 30
Lys Glu Ser Glu Gly Phe Pro Leu Asp Pro Val Phe Glu Lys Val Asp
35 40 45
Phe His Leu Lys Thr Val Glu Thr Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Ala Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Met Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Gly Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Val Asp Ala Val Arg Ala Val Glu Ala Ala Ile Ser Phe Pro Arg
165 170 175
Val Asp Ser Arg Lys Val Val Val Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Asn Arg Val Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Val Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Val Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Thr Ile Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Ile Glu Gln Val Lys Phe Leu Lys Arg
305 310 315 320
Leu Phe Glu Glu Gly
325
<210> 15
<211> 978
<212> DNA
<213> Thermotoga maritima
<400> 15
atggccttct tcgatttacc actcgaagaa ctgaagaaat atcgtccaga gcggtacgaa 60
gagaaagact tcgatgagtt ctgggaagag acactcgcag agagcgaaaa gttcccctta 120
gaccccgtct tcgagaggat ggagtctcac ctcaaaacag tcgaagcgta cgatgtcacc 180
ttctccggat acaggggaca gaggatcaaa gggtggctcc ttgttccaaa actggaagaa 240
gaaaaacttc cctgcgttgt gcagtacata ggatacaacg gtggaagagg attccctcac 300
gactggctgt tctggccttc tatgggttac atatgtttcg tcatggatac tcgaggtcag 360
ggaagcggct ggctgaaagg agacacaccg gattaccctg agggtcccgt tgaccctcag 420
tatccaggat tcatgacaag aggaatactg gatcccagaa cttactacta cagacgagtc 480
ttcacggacg ctgtcagagc cgttgaagct gctgcttctt ttcctcaggt agatcaagaa 540
agaatcgtga tagctggagg cagtcagggt ggcggaatag cccttgcggt gagcgctctc 600
tcaaagaaag caaaggctct tctgtgcgat gtgccgtttc tgtgtcactt cagaagagca 660
gtacagcttg tggatacgca tccatacgcg gagatcacga actttctaaa gacccacaga 720
gacaaggaag aaatcgtgtt caggactctt tcctatttcg atggagtgaa cttcgcagcc 780
agagcgaaga tccctgcgct gttttctgtg ggtctcatgg acaacatttg tcctccttca 840
acggttttcg ctgcctacaa ttactacgct ggaccgaagg aaatcagaat ctatccgtac 900
aacaaccacg agggaggagg ctctttccaa gcggttgaac aggtgaaatt cttgaaaaaa 960
ctatttgaga aaggctaa 978
<210> 16
<211> 325
<212> PRT
<213> Thermotoga maritima
<400> 16
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 17
<211> 963
<212> DNA
<213> Thermoanaerobacterium sp.
<400> 17
atgggacttt tcgacatgcc attacaaaaa cttagagaat acactggtac aaatccatgc 60
cctgaagatt tcgatgagta ttggaatagg gctttagatg agatgaggtc agttgatcct 120
aaaattgaat tgaaagaaag tagctttcaa gtatcctttg cagaatgcta tgacttgtac 180
tttacaggtg ttcgtggtgc cagaattcat gcaaagtata taaaacctaa gacagaaggg 240
aaacatccag cgttgataag atttcatgga tattcgtcaa attcaggcga ctggaacgac 300
aaattaaatt acgtggcggc aggcttcacc gttgtggcta tggatgtaag aggtcaagga 360
gggcagtctc aagatgttgg cggtgtaact gggaatactt taaatgggca tattataaga 420
gggctagacg atgatgctga taatatgctt ttcaggcata ttttcttaga cactgcccaa 480
ttggctggaa tagttatgaa catgccagaa gttgatgaag atagagtggg agtcatggga 540
ccttctcaag gcggagggct gtcgttggcg tgtgctgcat tggagccaag ggtacgcaaa 600
gtagtatctg aatatccttt tttatctgac tacaagagag tttgggactt agaccttgca 660
aaaaacgcct atcaagagat tacggactat ttcaggcttt ttgacccaag gcatgaaagg 720
gagaatgagg tatttacaaa gcttggatat atagacgtta aaaaccttgc gaaaaggata 780
aaaggcgatg tcttaatgtg cgttgggctt atggaccaag tatgtccgcc atcaactgtt 840
tttgcagcct acaacaacat acagtcaaaa aaagatataa aagtgtatcc tgattatgga 900
catgaaccta tgagaggatt tggagattta gcgatgcagt ttatgttgga actatattca 960
taa 963
<210> 18
<211> 320
<212> PRT
<213> Thermoanaerobacterium sp.
<400> 18
Met Gly Leu Phe Asp Met Pro Leu Gln Lys Leu Arg Glu Tyr Thr Gly
1 5 10 15
Thr Asn Pro Cys Pro Glu Asp Phe Asp Glu Tyr Trp Asn Arg Ala Leu
20 25 30
Asp Glu Met Arg Ser Val Asp Pro Lys Ile Glu Leu Lys Glu Ser Ser
35 40 45
Phe Gln Val Ser Phe Ala Glu Cys Tyr Asp Leu Tyr Phe Thr Gly Val
50 55 60
Arg Gly Ala Arg Ile His Ala Lys Tyr Ile Lys Pro Lys Thr Glu Gly
65 70 75 80
Lys His Pro Ala Leu Ile Arg Phe His Gly Tyr Ser Ser Asn Ser Gly
85 90 95
Asp Trp Asn Asp Lys Leu Asn Tyr Val Ala Ala Gly Phe Thr Val Val
100 105 110
Ala Met Asp Val Arg Gly Gln Gly Gly Gln Ser Gln Asp Val Gly Gly
115 120 125
Val Thr Gly Asn Thr Leu Asn Gly His Ile Ile Arg Gly Leu Asp Asp
130 135 140
Asp Ala Asp Asn Met Leu Phe Arg His Ile Phe Leu Asp Thr Ala Gln
145 150 155 160
Leu Ala Gly Ile Val Met Asn Met Pro Glu Val Asp Glu Asp Arg Val
165 170 175
Gly Val Met Gly Pro Ser Gln Gly Gly Gly Leu Ser Leu Ala Cys Ala
180 185 190
Ala Leu Glu Pro Arg Val Arg Lys Val Val Ser Glu Tyr Pro Phe Leu
195 200 205
Ser Asp Tyr Lys Arg Val Trp Asp Leu Asp Leu Ala Lys Asn Ala Tyr
210 215 220
Gln Glu Ile Thr Asp Tyr Phe Arg Leu Phe Asp Pro Arg His Glu Arg
225 230 235 240
Glu Asn Glu Val Phe Thr Lys Leu Gly Tyr Ile Asp Val Lys Asn Leu
245 250 255
Ala Lys Arg Ile Lys Gly Asp Val Leu Met Cys Val Gly Leu Met Asp
260 265 270
Gln Val Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Asn Ile Gln
275 280 285
Ser Lys Lys Asp Ile Lys Val Tyr Pro Asp Tyr Gly His Glu Pro Met
290 295 300
Arg Gly Phe Gly Asp Leu Ala Met Gln Phe Met Leu Glu Leu Tyr Ser
305 310 315 320
<210> 19
<211> 978
<212> DNA
<213> Bacillus sp.
<220>
<221> CDS
<222> (1)..(978)
<400> 19
atg aac ctt ttt gat atg ccc ctt gag gag ctg cag cat tac aag cct 48
Met Asn Leu Phe Asp Met Pro Leu Glu Glu Leu Gln His Tyr Lys Pro
1 5 10 15
gcc cag acc agg cag gat gat ttt gag tca ttc tgg aaa aag cgg att 96
Ala Gln Thr Arg Gln Asp Asp Phe Glu Ser Phe Trp Lys Lys Arg Ile
20 25 30
gag gag aac agt caa tat ccg ctg aat ata gaa gta atg gag cgg gtt 144
Glu Glu Asn Ser Gln Tyr Pro Leu Asn Ile Glu Val Met Glu Arg Val
35 40 45
tat ccg gtt ccg gga gtg aga gta tat gat att tat ttt gac ggg ttc 192
Tyr Pro Val Pro Gly Val Arg Val Tyr Asp Ile Tyr Phe Asp Gly Phe
50 55 60
cgg aat tcc cgc atc cat ggg gtg tat gtt act cca gaa act ccg gga 240
Arg Asn Ser Arg Ile His Gly Val Tyr Val Thr Pro Glu Thr Pro Gly
65 70 75 80
gcg gac act cct gcg gca gtg att ttt cac ggc tat aac tgg aac acg 288
Ala Asp Thr Pro Ala Ala Val Ile Phe His Gly Tyr Asn Trp Asn Thr
85 90 95
ctg cag ccg cat tac agc ttc aag cac gtg att cag ggg att cct gta 336
Leu Gln Pro His Tyr Ser Phe Lys His Val Ile Gln Gly Ile Pro Val
100 105 110
ctg atg gtg gag gtg cgg gga caa aat ctc ttg tct cca gat aga aat 384
Leu Met Val Glu Val Arg Gly Gln Asn Leu Leu Ser Pro Asp Arg Asn
115 120 125
cat tat ggg aat gga ggt ccg gga ggc tgg atg aca ctc ggc gtg atg 432
His Tyr Gly Asn Gly Gly Pro Gly Gly Trp Met Thr Leu Gly Val Met
130 135 140
gat ccc gat caa tat tat tac agc ctg gta tat atg gac tgc ttc cgc 480
Asp Pro Asp Gln Tyr Tyr Tyr Ser Leu Val Tyr Met Asp Cys Phe Arg
145 150 155 160
agc att gat gct gtc agg gaa ctg tcg agg aag aga agt gtg ttt gtg 528
Ser Ile Asp Ala Val Arg Glu Leu Ser Arg Lys Arg Ser Val Phe Val
165 170 175
gaa ggc gga agc cag gga ggt gca ctg gcg att gcc gca gcc gcc ctg 576
Glu Gly Gly Ser Gln Gly Gly Ala Leu Ala Ile Ala Ala Ala Ala Leu
180 185 190
cag gat gac atc ctg ctt gca ctc gcc gac atc cct ttt ctc acc cat 624
Gln Asp Asp Ile Leu Leu Ala Leu Ala Asp Ile Pro Phe Leu Thr His
195 200 205
ttc aag cgt tcc gtg gag ctt tcc tcg gat gga ccg tat cag gag att 672
Phe Lys Arg Ser Val Glu Leu Ser Ser Asp Gly Pro Tyr Gln Glu Ile
210 215 220
tcc cac tac ttc aaa gtt cat gat cct ctt cat caa acg gaa gag cag 720
Ser His Tyr Phe Lys Val His Asp Pro Leu His Gln Thr Glu Glu Gln
225 230 235 240
gta tat cag acg ctc agc tat gtg gac tgc atg aac atg gcc agc atg 768
Val Tyr Gln Thr Leu Ser Tyr Val Asp Cys Met Asn Met Ala Ser Met
245 250 255
gtt gaa tgt cca gtc ctt ctt tca gcc ggt ctg gaa gac atc gtt tgt 816
Val Glu Cys Pro Val Leu Leu Ser Ala Gly Leu Glu Asp Ile Val Cys
260 265 270
ccc ccg tcc agt gca ttt gca ctg ttc aac cat ctc ggc ggg cca aaa 864
Pro Pro Ser Ser Ala Phe Ala Leu Phe Asn His Leu Gly Gly Pro Lys
275 280 285
gaa ata cgg gcc tat ccg gaa tac gcc cat gaa gta ccg gct gtc cat 912
Glu Ile Arg Ala Tyr Pro Glu Tyr Ala His Glu Val Pro Ala Val His
290 295 300
gaa gag gaa aag ctg aag ttt ata tct tca agg cta aaa aat aga gaa 960
Glu Glu Glu Lys Leu Lys Phe Ile Ser Ser Arg Leu Lys Asn Arg Glu
305 310 315 320
aag agg tgc cgg cca tga 978
Lys Arg Cys Arg Pro
325
<210> 20
<211> 325
<212> PRT
<213> Bacillus sp.
<400> 20
Met Asn Leu Phe Asp Met Pro Leu Glu Glu Leu Gln His Tyr Lys Pro
1 5 10 15
Ala Gln Thr Arg Gln Asp Asp Phe Glu Ser Phe Trp Lys Lys Arg Ile
20 25 30
Glu Glu Asn Ser Gln Tyr Pro Leu Asn Ile Glu Val Met Glu Arg Val
35 40 45
Tyr Pro Val Pro Gly Val Arg Val Tyr Asp Ile Tyr Phe Asp Gly Phe
50 55 60
Arg Asn Ser Arg Ile His Gly Val Tyr Val Thr Pro Glu Thr Pro Gly
65 70 75 80
Ala Asp Thr Pro Ala Ala Val Ile Phe His Gly Tyr Asn Trp Asn Thr
85 90 95
Leu Gln Pro His Tyr Ser Phe Lys His Val Ile Gln Gly Ile Pro Val
100 105 110
Leu Met Val Glu Val Arg Gly Gln Asn Leu Leu Ser Pro Asp Arg Asn
115 120 125
His Tyr Gly Asn Gly Gly Pro Gly Gly Trp Met Thr Leu Gly Val Met
130 135 140
Asp Pro Asp Gln Tyr Tyr Tyr Ser Leu Val Tyr Met Asp Cys Phe Arg
145 150 155 160
Ser Ile Asp Ala Val Arg Glu Leu Ser Arg Lys Arg Ser Val Phe Val
165 170 175
Glu Gly Gly Ser Gln Gly Gly Ala Leu Ala Ile Ala Ala Ala Ala Leu
180 185 190
Gln Asp Asp Ile Leu Leu Ala Leu Ala Asp Ile Pro Phe Leu Thr His
195 200 205
Phe Lys Arg Ser Val Glu Leu Ser Ser Asp Gly Pro Tyr Gln Glu Ile
210 215 220
Ser His Tyr Phe Lys Val His Asp Pro Leu His Gln Thr Glu Glu Gln
225 230 235 240
Val Tyr Gln Thr Leu Ser Tyr Val Asp Cys Met Asn Met Ala Ser Met
245 250 255
Val Glu Cys Pro Val Leu Leu Ser Ala Gly Leu Glu Asp Ile Val Cys
260 265 270
Pro Pro Ser Ser Ala Phe Ala Leu Phe Asn His Leu Gly Gly Pro Lys
275 280 285
Glu Ile Arg Ala Tyr Pro Glu Tyr Ala His Glu Val Pro Ala Val His
290 295 300
Glu Glu Glu Lys Leu Lys Phe Ile Ser Ser Arg Leu Lys Asn Arg Glu
305 310 315 320
Lys Arg Cys Arg Pro
325
<210> 21
<211> 960
<212> DNA
<213> Bacillus halodurans
<400> 21
ttagagatca gataaaaatt gaaaaatccg atcacgatgg cctggcaaat cttcgtgagc 60
aaagtctgga tataactcga tactttttgt cgtcgtgagt ttgttataca tggcaaattg 120
tgtagacggc gggcaaaccg tatccattaa cccaacagca agtaagactt ctccctttac 180
gagtggagca agatgctgaa tatcaatata gcctagcttc gtaaagattt cagcctcacg 240
tcggtgctgt ggatcaaagc gacgaaaata cgtttgcaat tcgtcataag ctttctcggc 300
taaatccatc tcccatacgc gttggtaatc gctaaggaaa ggataaacag gagctacctt 360
tttaattttc ggttccaaag ccgcacaagc aatcgctaag gcccctcctt gtgaccaacc 420
tgtcactgcc acgcgctctt catcgacttc aggaaggttc atcacaatgt tggcaagctg 480
agccgtatca agaaacacat gacggaacaa taattgatca gcattatcat cgagtccgcg 540
tattatatga ccggaatgag tattcccctt cacgcctcct gtgtcttcag acaagcctcc 600
ttgcccgcga acgtccattg caagaacaga atatccgagg gctgcgtaat gaagtaaacc 660
cgtccattcc cccgcattca tcgtatatcc gtgaaaatga ataaccgccg ggtgtgtccc 720
gctcgtgtgt cttgggcgca cgtattttgc gtgaattcta gcacccctaa cccctgtaaa 780
atataggtgg aagcattctg catacgtggt ttgaaaatca ctcggtatga gctctacgtt 840
tggatttacc tttctcatct cttgtaaagc acgatcccaa tactcagtaa agtcatctgg 900
ctttggatta cgtcccatgt actcttttaa ttcggttaac ggcatgtcta ttagtggcat 960
<210> 22
<211> 319
<212> PRT
<213> Bacillus halodurans
<400> 22
Met Pro Leu Ile Asp Met Pro Leu Thr Glu Leu Lys Glu Tyr Met Gly
1 5 10 15
Arg Asn Pro Lys Pro Asp Asp Phe Thr Glu Tyr Trp Asp Arg Ala Leu
20 25 30
Gln Glu Met Arg Lys Val Asn Pro Asn Val Glu Leu Ile Pro Ser Asp
35 40 45
Phe Gln Thr Thr Tyr Ala Glu Cys Phe His Leu Tyr Phe Thr Gly Val
50 55 60
Arg Gly Ala Arg Ile His Ala Lys Tyr Val Arg Pro Arg His Thr Ser
65 70 75 80
Gly Thr His Pro Ala Val Ile His Phe His Gly Tyr Thr Met Asn Ala
85 90 95
Gly Glu Trp Thr Gly Leu Leu His Tyr Ala Ala Leu Gly Tyr Ser Val
100 105 110
Leu Ala Met Asp Val Arg Gly Gln Gly Gly Leu Ser Glu Asp Thr Gly
115 120 125
Gly Val Lys Gly Asn Thr His Ser Gly His Ile Ile Arg Gly Leu Asp
130 135 140
Asp Asn Ala Asp Gln Leu Leu Phe Arg His Val Phe Leu Asp Thr Ala
145 150 155 160
Gln Leu Ala Asn Ile Val Met Asn Leu Pro Glu Val Asp Glu Glu Arg
165 170 175
Val Ala Val Thr Gly Trp Ser Gln Gly Gly Ala Leu Ala Ile Ala Cys
180 185 190
Ala Ala Leu Glu Pro Lys Ile Lys Lys Val Ala Pro Val Tyr Pro Phe
195 200 205
Leu Ser Asp Tyr Gln Arg Val Trp Glu Met Asp Leu Ala Glu Lys Ala
210 215 220
Tyr Asp Glu Leu Gln Thr Tyr Phe Arg Arg Phe Asp Pro Gln His Arg
225 230 235 240
Arg Glu Ala Glu Ile Phe Thr Lys Leu Gly Tyr Ile Asp Ile Gln His
245 250 255
Leu Ala Pro Leu Val Lys Gly Glu Val Leu Leu Ala Val Gly Leu Met
260 265 270
Asp Thr Val Cys Pro Pro Ser Thr Gln Phe Ala Met Tyr Asn Lys Leu
275 280 285
Thr Thr Thr Lys Ser Ile Glu Leu Tyr Pro Asp Phe Ala His Glu Asp
290 295 300
Leu Pro Gly His Arg Asp Arg Ile Phe Gln Phe Leu Ser Asp Leu
305 310 315
<210> 23
<211> 954
<212> DNA
<213> Bacillus clausii
<400> 23
atgccattag tcgatatgcc gttgcgcgag ttgttagctt atgaaggaat aaaccctaaa 60
ccagcagatt ttgaccaata ctggaaccgg gccaaaacgg aaattgaagc gattgatccc 120
gaagtcactc tagtcgaatc ttctttccag tgttcgtttg caaactgtta ccatttctat 180
tatcgaagcg ctggaaatgc aaaaatccat gcgaaatacg tacagccaaa agcaggggag 240
aagacgccag cagtttttat gttccatggg tatggggggc gttcagccga atggagcagc 300
ttgttaaatt atgtagcggc gggtttttct gttttctata tggacgtgcg tggacaaggt 360
ggaacttcag aggatcctgg gggcgtaagg gggaatacat ataggggcca cattattcgc 420
ggcctcgatg ccgggccaga cgcacttttt taccgcagcg ttttcttgga caccgtccaa 480
ttggttcgtg ctgctaaaac attgcctcac atcgataaaa cacggcttat ggccacaggg 540
tggtcgcaag ggggcgcctt aacgcttgcc tgtgctgccc ttgttcctga aatcaagcgt 600
cttgctccag tatacccgtt tttaagcgat tacaagcgag tgtggcaaat ggatttagcg 660
gttcgttcgt ataaagaatt ggctgattat ttccgttcat acgatccgca acataaacgc 720
catggcgaaa tttttgaacg ccttggctac atcgatgtcc agcatcttgc tgaccggatt 780
caaggagatg tcctaatggg agttggttta atggatacag aatgcccgcc gtctacccaa 840
tttgctgctt ataataaaat aaaggctaaa aaatcgtatg agctctatcc tgattttggc 900
catgagcacc ttccaggaat gaacgatcat atttttcgct ttttcactag ttga 954
<210> 24
<211> 317
<212> PRT
<213> Bacillus clausii
<400> 24
Met Pro Leu Val Asp Met Pro Leu Arg Glu Leu Leu Ala Tyr Glu Gly
1 5 10 15
Ile Asn Pro Lys Pro Ala Asp Phe Asp Gln Tyr Trp Asn Arg Ala Lys
20 25 30
Thr Glu Ile Glu Ala Ile Asp Pro Glu Val Thr Leu Val Glu Ser Ser
35 40 45
Phe Gln Cys Ser Phe Ala Asn Cys Tyr His Phe Tyr Tyr Arg Ser Ala
50 55 60
Gly Asn Ala Lys Ile His Ala Lys Tyr Val Gln Pro Lys Ala Gly Glu
65 70 75 80
Lys Thr Pro Ala Val Phe Met Phe His Gly Tyr Gly Gly Arg Ser Ala
85 90 95
Glu Trp Ser Ser Leu Leu Asn Tyr Val Ala Ala Gly Phe Ser Val Phe
100 105 110
Tyr Met Asp Val Arg Gly Gln Gly Gly Thr Ser Glu Asp Pro Gly Gly
115 120 125
Val Arg Gly Asn Thr Tyr Arg Gly His Ile Ile Arg Gly Leu Asp Ala
130 135 140
Gly Pro Asp Ala Leu Phe Tyr Arg Ser Val Phe Leu Asp Thr Val Gln
145 150 155 160
Leu Val Arg Ala Ala Lys Thr Leu Pro His Ile Asp Lys Thr Arg Leu
165 170 175
Met Ala Thr Gly Trp Ser Gln Gly Gly Ala Leu Thr Leu Ala Cys Ala
180 185 190
Ala Leu Val Pro Glu Ile Lys Arg Leu Ala Pro Val Tyr Pro Phe Leu
195 200 205
Ser Asp Tyr Lys Arg Val Trp Gln Met Asp Leu Ala Val Arg Ser Tyr
210 215 220
Lys Glu Leu Ala Asp Tyr Phe Arg Ser Tyr Asp Pro Gln His Lys Arg
225 230 235 240
His Gly Glu Ile Phe Glu Arg Leu Gly Tyr Ile Asp Val Gln His Leu
245 250 255
Ala Asp Arg Ile Gln Gly Asp Val Leu Met Gly Val Gly Leu Met Asp
260 265 270
Thr Glu Cys Pro Pro Ser Thr Gln Phe Ala Ala Tyr Asn Lys Ile Lys
275 280 285
Ala Lys Lys Ser Tyr Glu Leu Tyr Pro Asp Phe Gly His Glu His Leu
290 295 300
Pro Gly Met Asn Asp His Ile Phe Arg Phe Phe Thr Ser
305 310 315
<210> 25
<211> 960
<212> DNA
<213> Bacillus subtilis
<220>
<221> CDS
<222> (1)..(960)
<400> 25
atg caa cta ttc gat ctg ccg ctc gac caa ttg caa aca tat aag cct 48
Met Gln Leu Phe Asp Leu Pro Leu Asp Gln Leu Gln Thr Tyr Lys Pro
1 5 10 15
gaa aaa aca gca ccg aaa gat ttt tct gag ttt tgg aaa ttg tct ttg 96
Glu Lys Thr Ala Pro Lys Asp Phe Ser Glu Phe Trp Lys Leu Ser Leu
20 25 30
gag gaa ctt gca aaa gtc caa gca gaa cct gat cta cag ccg gtt gac 144
Glu Glu Leu Ala Lys Val Gln Ala Glu Pro Asp Leu Gln Pro Val Asp
35 40 45
tat cct gct gac gga gta aaa gtg tac cgt ctc aca tat aaa agc ttc 192
Tyr Pro Ala Asp Gly Val Lys Val Tyr Arg Leu Thr Tyr Lys Ser Phe
50 55 60
gga aac gcc cgc att acc gga tgg tac gcg gtg cct gac aag caa ggc 240
Gly Asn Ala Arg Ile Thr Gly Trp Tyr Ala Val Pro Asp Lys Gln Gly
65 70 75 80
ccg cat ccg gcg atc gtg aaa tat cat ggc tac aat gca agc tat gat 288
Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
ggt gag att cat gaa atg gta aac tgg gca ctc cat ggc tac gcc gca 336
Gly Glu Ile His Glu Met Val Asn Trp Ala Leu His Gly Tyr Ala Ala
100 105 110
ttc ggc atg ctt gtc cgc ggc cag cag agc agc gag gat acg agt att 384
Phe Gly Met Leu Val Arg Gly Gln Gln Ser Ser Glu Asp Thr Ser Ile
115 120 125
tca ccg cac ggt cac gct ttg ggc tgg atg acg aaa gga att ctt gat 432
Ser Pro His Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Asp
130 135 140
aaa gat aca tac tat tac cgc ggt gtt tat ttg gac gcc gtc cgc gcg 480
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
ctt gag gtc atc agc agc ttc gac gag gtt gac gaa aca agg atc ggt 528
Leu Glu Val Ile Ser Ser Phe Asp Glu Val Asp Glu Thr Arg Ile Gly
165 170 175
gtg aca gga gga agc caa ggc gga ggt tta acc att gcc gca gca gcg 576
Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Thr Ile Ala Ala Ala Ala
180 185 190
ctg tca gac att cca aaa gcc gcg gtt gcc gat tat cct tat tta agc 624
Leu Ser Asp Ile Pro Lys Ala Ala Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
aac ttc gaa cgg gcc att gat gtg gcg ctt gaa cag ccg tac ctt gaa 672
Asn Phe Glu Arg Ala Ile Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
atc aat tcc ttc ttc aga aga aat ggc agc ccg gaa aca gaa gtg cag 720
Ile Asn Ser Phe Phe Arg Arg Asn Gly Ser Pro Glu Thr Glu Val Gln
225 230 235 240
gcg atg aag aca ctt tca tat ttc gat att atg aat ctc gct gac cga 768
Ala Met Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala Asp Arg
245 250 255
gtg aag gtg cct gtc ctg atg tca atc ggc ctg att gac aag gtc acg 816
Val Lys Val Pro Val Leu Met Ser Ile Gly Leu Ile Asp Lys Val Thr
260 265 270
ccg cca tcc acc gtg ttt gcc gcc tac aat cat ttg gaa aca gag aaa 864
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Glu Lys
275 280 285
gag ctg aag gtg tac cgc tac ttc gga cat gag tat atc cct gct ttt 912
Glu Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Ala Phe
290 295 300
caa acg gaa aaa ctt gct ttc ttt aag cag cat ctt aaa ggc tga taa 960
Gln Thr Glu Lys Leu Ala Phe Phe Lys Gln His Leu Lys Gly
305 310 315
<210> 26
<211> 318
<212> PRT
<213> Bacillus subtilis
<400> 26
Met Gln Leu Phe Asp Leu Pro Leu Asp Gln Leu Gln Thr Tyr Lys Pro
1 5 10 15
Glu Lys Thr Ala Pro Lys Asp Phe Ser Glu Phe Trp Lys Leu Ser Leu
20 25 30
Glu Glu Leu Ala Lys Val Gln Ala Glu Pro Asp Leu Gln Pro Val Asp
35 40 45
Tyr Pro Ala Asp Gly Val Lys Val Tyr Arg Leu Thr Tyr Lys Ser Phe
50 55 60
Gly Asn Ala Arg Ile Thr Gly Trp Tyr Ala Val Pro Asp Lys Gln Gly
65 70 75 80
Pro His Pro Ala Ile Val Lys Tyr His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
Gly Glu Ile His Glu Met Val Asn Trp Ala Leu His Gly Tyr Ala Ala
100 105 110
Phe Gly Met Leu Val Arg Gly Gln Gln Ser Ser Glu Asp Thr Ser Ile
115 120 125
Ser Pro His Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Asp
130 135 140
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
Leu Glu Val Ile Ser Ser Phe Asp Glu Val Asp Glu Thr Arg Ile Gly
165 170 175
Val Thr Gly Gly Ser Gln Gly Gly Gly Leu Thr Ile Ala Ala Ala Ala
180 185 190
Leu Ser Asp Ile Pro Lys Ala Ala Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
Asn Phe Glu Arg Ala Ile Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
Ile Asn Ser Phe Phe Arg Arg Asn Gly Ser Pro Glu Thr Glu Val Gln
225 230 235 240
Ala Met Lys Thr Leu Ser Tyr Phe Asp Ile Met Asn Leu Ala Asp Arg
245 250 255
Val Lys Val Pro Val Leu Met Ser Ile Gly Leu Ile Asp Lys Val Thr
260 265 270
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Glu Lys
275 280 285
Glu Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Tyr Ile Pro Ala Phe
290 295 300
Gln Thr Glu Lys Leu Ala Phe Phe Lys Gln His Leu Lys Gly
305 310 315
<210> 27
<211> 325
<212> PRT
<213> Thermotoga neapolitana
<220>
<221> MISC_FEATURE
<222> (277)..(277)
<223> Xaa is Ala, Val, Ser, or Thr.
<400> 27
Met Ala Phe Phe Asp Met Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Arg Glu Thr Leu
20 25 30
Lys Glu Ser Glu Gly Phe Pro Leu Asp Pro Val Phe Glu Lys Val Asp
35 40 45
Phe His Leu Lys Thr Val Glu Thr Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Ala Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Met Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Gly Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Val Asp Ala Val Arg Ala Val Glu Ala Ala Ile Ser Phe Pro Arg
165 170 175
Val Asp Ser Arg Lys Val Val Val Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Asn Arg Val Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Val Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Val Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Thr Ile Xaa Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Ile Glu Gln Val Lys Phe Leu Lys Arg
305 310 315 320
Leu Phe Glu Glu Gly
325
<210> 28
<211> 325
<212> PRT
<213> Thermotoga maritima
<220>
<221> MISC_FEATURE
<222> (277)..(277)
<223> Xaa is Ala, Val, Ser, or Thr.
<400> 28
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Xaa Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 29
<211> 326
<212> PRT
<213> Thermotoga lettingae
<220>
<221> MISC_FEATURE
<222> (277)..(277)
<223> Xaa is Ala, Val, Ser, or Thr.
<400> 29
Met Val Tyr Phe Asp Met Pro Leu Glu Asp Leu Arg Lys Tyr Leu Pro
1 5 10 15
Gln Arg Tyr Glu Glu Lys Asp Phe Asp Asp Phe Trp Lys Gln Thr Ile
20 25 30
His Glu Thr Arg Gly Tyr Phe Gln Glu Pro Ile Leu Lys Lys Val Asp
35 40 45
Phe Tyr Leu Gln Asn Val Glu Thr Phe Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Lys Ile Lys Gly Trp Leu Ile Leu Pro Lys Phe Arg Asn
65 70 75 80
Gly Lys Leu Pro Cys Val Val Glu Phe Val Gly Tyr Gly Gly Gly Arg
85 90 95
Gly Phe Pro Tyr Asp Trp Leu Leu Trp Ser Ala Ala Gly Tyr Ala His
100 105 110
Phe Ile Met Asp Thr Arg Gly Gln Gly Ser Asn Trp Met Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Glu Asp Asn Pro Ser Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Leu Thr Lys Gly Val Leu Asn Pro Glu Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Met Asp Ala Phe Met Ala Val Glu Thr Ile Ser Gln Leu Glu Gln
165 170 175
Ile Asp Ser Gln Thr Ile Ile Leu Ser Gly Ala Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Ser Lys Val Met Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Tyr Lys Arg Ala Val Gln Ile Thr
210 215 220
Asp Ser Met Pro Tyr Ala Glu Ile Thr Arg Tyr Cys Lys Thr His Ile
225 230 235 240
Asp Lys Ile Gln Thr Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Cys Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asp Ile Xaa Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Glu Lys Asp Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe His Thr Leu Glu Lys Leu Lys Phe Val Lys Lys
305 310 315 320
Thr Ile Ser Met Arg Glu
325
<210> 30
<211> 325
<212> PRT
<213> Thermotoga petrophilia
<220>
<221> MISC_FEATURE
<222> (277)..(277)
<223> Xaa is Ala, Val, Ser, or Thr.
<400> 30
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Gly Thr Leu
20 25 30
Ala Glu Asn Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Met Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Met Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Asp Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Arg
165 170 175
Val Asp His Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Val Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Xaa Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Ile Glu Gln Val Lys Phe Leu Lys Arg
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 31
<211> 325
<212> PRT
<213> Thermotoga sp.
<220>
<221> MISC_FEATURE
<222> (277)..(277)
<223> Xaa is Ala, Val, Ser, or Thr.
<400> 31
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Lys Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Val Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Asp Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Arg
165 170 175
Val Asp His Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Val Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Xaa Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Ile Glu Gln Val Lys Phe Leu Lys Arg
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 32
<211> 329
<212> PRT
<213> Thermotoga sp.
<220>
<221> MISC_FEATURE
<222> (278)..(278)
<223> Xaa is Ala, Val, Ser, or Thr.
<400> 32
Met Ala Leu Phe Asp Met Pro Leu Glu Lys Leu Arg Ser Tyr Leu Pro
1 5 10 15
Asp Arg Tyr Glu Glu Glu Asp Phe Asp Leu Phe Trp Lys Glu Thr Leu
20 25 30
Glu Glu Ser Arg Lys Phe Pro Leu Asp Pro Ile Phe Glu Arg Val Asp
35 40 45
Tyr Leu Leu Glu Asn Val Glu Val Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Ala Trp Leu Ile Leu Pro Val Val Lys Lys
65 70 75 80
Glu Glu Arg Leu Pro Cys Ile Val Glu Phe Ile Gly Tyr Arg Gly Gly
85 90 95
Arg Gly Phe Pro Phe Asp Trp Leu Phe Trp Ser Ser Ala Gly Tyr Ala
100 105 110
His Phe Val Met Asp Thr Arg Gly Gln Gly Thr Ser Arg Val Lys Gly
115 120 125
Asp Thr Pro Asp Tyr Cys Asp Glu Pro Ile Asn Pro Gln Phe Pro Gly
130 135 140
Phe Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg
145 150 155 160
Val Phe Thr Asp Ala Val Arg Ala Val Glu Thr Ala Ser Ser Phe Pro
165 170 175
Gly Ile Asp Pro Glu Arg Ile Ala Val Val Gly Thr Ser Gln Gly Gly
180 185 190
Gly Ile Ala Leu Ala Val Ala Ala Leu Ser Glu Ile Pro Lys Ala Leu
195 200 205
Val Ser Asn Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Ile
210 215 220
Thr Asp Asn Ala Pro Tyr Ser Glu Ile Val Asn Tyr Leu Lys Val His
225 230 235 240
Arg Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly
245 250 255
Val Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Ala
260 265 270
Leu Met Asp Lys Thr Xaa Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn
275 280 285
His Tyr Ala Gly Pro Lys Glu Ile Lys Val Tyr Pro Phe Asn Glu His
290 295 300
Glu Gly Gly Glu Ser Phe Gln Arg Met Glu Glu Leu Arg Phe Met Lys
305 310 315 320
Arg Ile Leu Lys Gly Glu Phe Lys Ala
325
<210> 33
<211> 326
<212> PRT
<213> Thermotoga lettingae
<400> 33
Met Val Tyr Phe Asp Met Pro Leu Glu Asp Leu Arg Lys Tyr Leu Pro
1 5 10 15
Gln Arg Tyr Glu Glu Lys Asp Phe Asp Asp Phe Trp Lys Gln Thr Ile
20 25 30
His Glu Thr Arg Gly Tyr Phe Gln Glu Pro Ile Leu Lys Lys Val Asp
35 40 45
Phe Tyr Leu Gln Asn Val Glu Thr Phe Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Lys Ile Lys Gly Trp Leu Ile Leu Pro Lys Phe Arg Asn
65 70 75 80
Gly Lys Leu Pro Cys Val Val Glu Phe Val Gly Tyr Gly Gly Gly Arg
85 90 95
Gly Phe Pro Tyr Asp Trp Leu Leu Trp Ser Ala Ala Gly Tyr Ala His
100 105 110
Phe Ile Met Asp Thr Arg Gly Gln Gly Ser Asn Trp Met Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Glu Asp Asn Pro Ser Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Leu Thr Lys Gly Val Leu Asn Pro Glu Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Met Asp Ala Phe Met Ala Val Glu Thr Ile Ser Gln Leu Glu Gln
165 170 175
Ile Asp Ser Gln Thr Ile Ile Leu Ser Gly Ala Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Ser Lys Val Met Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Tyr Lys Arg Ala Val Gln Ile Thr
210 215 220
Asp Ser Met Pro Tyr Ala Glu Ile Thr Arg Tyr Cys Lys Thr His Ile
225 230 235 240
Asp Lys Ile Gln Thr Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Cys Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asp Ile Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Glu Lys Asp Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe His Thr Leu Glu Lys Leu Lys Phe Val Lys Lys
305 310 315 320
Thr Ile Ser Met Arg Glu
325
<210> 34
<211> 325
<212> PRT
<213> Thermotoga petrophilia
<400> 34
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Gly Thr Leu
20 25 30
Ala Glu Asn Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Met Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Met Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Asp Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Arg
165 170 175
Val Asp His Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Val Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Ile Glu Gln Val Lys Phe Leu Lys Arg
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 35
<211> 325
<212> PRT
<213> Thermotoga sp.
<400> 35
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Lys Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Val Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Asp Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Arg
165 170 175
Val Asp His Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Val Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Ile Glu Gln Val Lys Phe Leu Lys Arg
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 36
<211> 329
<212> PRT
<213> Thermotoga sp.
<400> 36
Met Ala Leu Phe Asp Met Pro Leu Glu Lys Leu Arg Ser Tyr Leu Pro
1 5 10 15
Asp Arg Tyr Glu Glu Glu Asp Phe Asp Leu Phe Trp Lys Glu Thr Leu
20 25 30
Glu Glu Ser Arg Lys Phe Pro Leu Asp Pro Ile Phe Glu Arg Val Asp
35 40 45
Tyr Leu Leu Glu Asn Val Glu Val Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Ala Trp Leu Ile Leu Pro Val Val Lys Lys
65 70 75 80
Glu Glu Arg Leu Pro Cys Ile Val Glu Phe Ile Gly Tyr Arg Gly Gly
85 90 95
Arg Gly Phe Pro Phe Asp Trp Leu Phe Trp Ser Ser Ala Gly Tyr Ala
100 105 110
His Phe Val Met Asp Thr Arg Gly Gln Gly Thr Ser Arg Val Lys Gly
115 120 125
Asp Thr Pro Asp Tyr Cys Asp Glu Pro Ile Asn Pro Gln Phe Pro Gly
130 135 140
Phe Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg
145 150 155 160
Val Phe Thr Asp Ala Val Arg Ala Val Glu Thr Ala Ser Ser Phe Pro
165 170 175
Gly Ile Asp Pro Glu Arg Ile Ala Val Val Gly Thr Ser Gln Gly Gly
180 185 190
Gly Ile Ala Leu Ala Val Ala Ala Leu Ser Glu Ile Pro Lys Ala Leu
195 200 205
Val Ser Asn Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Ile
210 215 220
Thr Asp Asn Ala Pro Tyr Ser Glu Ile Val Asn Tyr Leu Lys Val His
225 230 235 240
Arg Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly
245 250 255
Val Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Ala
260 265 270
Leu Met Asp Lys Thr Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn
275 280 285
His Tyr Ala Gly Pro Lys Glu Ile Lys Val Tyr Pro Phe Asn Glu His
290 295 300
Glu Gly Gly Glu Ser Phe Gln Arg Met Glu Glu Leu Arg Phe Met Lys
305 310 315 320
Arg Ile Leu Lys Gly Glu Phe Lys Ala
325
<210> 37
<211> 960
<212> DNA
<213> Thermoanaerobacterium saccharolyticum
<400> 37
atgggtctgt tcgatatgcc actgcaaaaa ctgcgtgaat ataccggtac caacccatgt 60
cctgaggatt tcgatgaata ctgggatcgc gcactggacg aaatgcgtag cgttgatcct 120
aaaatcaaga tgaagaagag ctcctttcaa gttccgttcg cggaatgtta cgatctgtat 180
tttaccggcg ttcgtggtgc ccgcattcac gcgaaataca ttcgtccgaa aaccgaaggc 240
aaacacccgg cgctgattcg cttccatggt tactccagca actctggtga ttggaacgac 300
aagctgaact acgttgcggc tggttttacc gtagtagcga tggacgctcg tggccagggt 360
ggccaatctc aggacgtcgg cggtgttaat ggcaacaccc tgaacggtca catcatccgt 420
ggcctggacg atgatgcaga taacatgctg ttccgtcata ttttcctgga caccgcgcag 480
ctggctggta tcgttatgaa catgccggaa atcgatgagg accgcgtagc tgttatgggt 540
ccgtcccagg gcggcggtct gtccctggcg tgtgcggctc tggaacctaa aatccgtaaa 600
gtagtgtccg aatatccgtt cctgagcgac tacaagcgtg tgtgggatct ggatctggcc 660
aaaaatgcgt accaagaaat cactgactat ttccgtctgt tcgacccacg ccacgaacgt 720
gagaacgagg tttttactaa actgggttac attgacgtaa agaacctggc gaaacgtatc 780
aaaggtgatg ttctgatgtg cgtgggcctg atggatcagg tctgcccgcc gagcaccgta 840
tttgcagcat acaacaacat ccagtccaag aaggacatca aagtctaccc ggactatggt 900
cacgaaccga tgcgtggctt cggtgacctg gctatgcagt tcatgctgga actgtattct 960
<210> 38
<211> 320
<212> PRT
<213> Thermoanaerobacterium saccharolyticum
<400> 38
Met Gly Leu Phe Asp Met Pro Leu Gln Lys Leu Arg Glu Tyr Thr Gly
1 5 10 15
Thr Asn Pro Cys Pro Glu Asp Phe Asp Glu Tyr Trp Asp Arg Ala Leu
20 25 30
Asp Glu Met Arg Ser Val Asp Pro Lys Ile Lys Met Lys Lys Ser Ser
35 40 45
Phe Gln Val Pro Phe Ala Glu Cys Tyr Asp Leu Tyr Phe Thr Gly Val
50 55 60
Arg Gly Ala Arg Ile His Ala Lys Tyr Ile Arg Pro Lys Thr Glu Gly
65 70 75 80
Lys His Pro Ala Leu Ile Arg Phe His Gly Tyr Ser Ser Asn Ser Gly
85 90 95
Asp Trp Asn Asp Lys Leu Asn Tyr Val Ala Ala Gly Phe Thr Val Val
100 105 110
Ala Met Asp Ala Arg Gly Gln Gly Gly Gln Ser Gln Asp Val Gly Gly
115 120 125
Val Asn Gly Asn Thr Leu Asn Gly His Ile Ile Arg Gly Leu Asp Asp
130 135 140
Asp Ala Asp Asn Met Leu Phe Arg His Ile Phe Leu Asp Thr Ala Gln
145 150 155 160
Leu Ala Gly Ile Val Met Asn Met Pro Glu Ile Asp Glu Asp Arg Val
165 170 175
Ala Val Met Gly Pro Ser Gln Gly Gly Gly Leu Ser Leu Ala Cys Ala
180 185 190
Ala Leu Glu Pro Lys Ile Arg Lys Val Val Ser Glu Tyr Pro Phe Leu
195 200 205
Ser Asp Tyr Lys Arg Val Trp Asp Leu Asp Leu Ala Lys Asn Ala Tyr
210 215 220
Gln Glu Ile Thr Asp Tyr Phe Arg Leu Phe Asp Pro Arg His Glu Arg
225 230 235 240
Glu Asn Glu Val Phe Thr Lys Leu Gly Tyr Ile Asp Val Lys Asn Leu
245 250 255
Ala Lys Arg Ile Lys Gly Asp Val Leu Met Cys Val Gly Leu Met Asp
260 265 270
Gln Val Cys Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Asn Ile Gln
275 280 285
Ser Lys Lys Asp Ile Lys Val Tyr Pro Asp Tyr Gly His Glu Pro Met
290 295 300
Arg Gly Phe Gly Asp Leu Ala Met Gln Phe Met Leu Glu Leu Tyr Ser
305 310 315 320
<210> 39
<211> 939
<212> DNA
<213> Lactococcus lactis
<400> 39
atgacaaaaa taaacaattg gcaagattat caaggaagtt cacttaaacc agaggatttt 60
gataaatttt gggatgaaaa aattaatttg gtttcaaatc atcaatttga atttgaatta 120
atagaaaaaa atctttcctc taaggtagtt aacttttatc atttgtggtt tacagctatt 180
gatggagcta aaattcatgc tcagttaatt gttcccaaga atttgaaaga gaaataccca 240
gccatcttac aatttcatgg ttatcattgc gatagtgggg attgggtcga taaaataggg 300
atagttgccg aagggaatgt agttcttgcg cttgattgtc gaggacaagg tggtttaagt 360
caagataata ttcaaactat ggggatgaca atgaagggac tcattgttcg aggaattgat 420
gaagggtatg aaaatctcta ttacgttcgc caatttatgg acttaataac tgcaaccaaa 480
attttatccg agtttgattt tgttgatgaa acaaatataa gtgcacaagg tgcttctcaa 540
ggtggagcgc ttgccgttgc ttgcgccgca ctttctcctc ttataaaaaa ggtgactgcc 600
acttacccct ttctttcaga ttatcgcaaa gcttatgagc ttggtgccga ggaatctgct 660
ttcgaagaac ttccatattg gtttcagttt aaagatccac ttcatctaag agaagactgg 720
ttttttaatc agttggaata cattgatatt caaaatttag caccaagaat taaggctgag 780
gtcatttgga tcctaggcgg caaagatact gttgttcctc cgattacgca aatggcggct 840
tacaataaaa tacaaagtaa aaaatctctc tatgtcttac ctgaatacgg ccatgaatat 900
cttcctaaaa ttagcgactg gttaagagag aatcaataa 939
<210> 40
<211> 312
<212> PRT
<213> Lactococcus lactis
<400> 40
Met Thr Lys Ile Asn Asn Trp Gln Asp Tyr Gln Gly Ser Ser Leu Lys
1 5 10 15
Pro Glu Asp Phe Asp Lys Phe Trp Asp Glu Lys Ile Asn Leu Val Ser
20 25 30
Asn His Gln Phe Glu Phe Glu Leu Ile Glu Lys Asn Leu Ser Ser Lys
35 40 45
Val Val Asn Phe Tyr His Leu Trp Phe Thr Ala Ile Asp Gly Ala Lys
50 55 60
Ile His Ala Gln Leu Ile Val Pro Lys Asn Leu Lys Glu Lys Tyr Pro
65 70 75 80
Ala Ile Leu Gln Phe His Gly Tyr His Cys Asp Ser Gly Asp Trp Val
85 90 95
Asp Lys Ile Gly Ile Val Ala Glu Gly Asn Val Val Leu Ala Leu Asp
100 105 110
Cys Arg Gly Gln Gly Gly Leu Ser Gln Asp Asn Ile Gln Thr Met Gly
115 120 125
Met Thr Met Lys Gly Leu Ile Val Arg Gly Ile Asp Glu Gly Tyr Glu
130 135 140
Asn Leu Tyr Tyr Val Arg Gln Phe Met Asp Leu Ile Thr Ala Thr Lys
145 150 155 160
Ile Leu Ser Glu Phe Asp Phe Val Asp Glu Thr Asn Ile Ser Ala Gln
165 170 175
Gly Ala Ser Gln Gly Gly Ala Leu Ala Val Ala Cys Ala Ala Leu Ser
180 185 190
Pro Leu Ile Lys Lys Val Thr Ala Thr Tyr Pro Phe Leu Ser Asp Tyr
195 200 205
Arg Lys Ala Tyr Glu Leu Gly Ala Glu Glu Ser Ala Phe Glu Glu Leu
210 215 220
Pro Tyr Trp Phe Gln Phe Lys Asp Pro Leu His Leu Arg Glu Asp Trp
225 230 235 240
Phe Phe Asn Gln Leu Glu Tyr Ile Asp Ile Gln Asn Leu Ala Pro Arg
245 250 255
Ile Lys Ala Glu Val Ile Trp Ile Leu Gly Gly Lys Asp Thr Val Val
260 265 270
Pro Pro Ile Thr Gln Met Ala Ala Tyr Asn Lys Ile Gln Ser Lys Lys
275 280 285
Ser Leu Tyr Val Leu Pro Glu Tyr Gly His Glu Tyr Leu Pro Lys Ile
290 295 300
Ser Asp Trp Leu Arg Glu Asn Gln
305 310
<210> 41
<211> 972
<212> DNA
<213> Mesorhizobium loti
<400> 41
atgccgttcc cggatctgat ccagcccgaa ctgggcgctt atgtcagcag tgtcggcatg 60
ccggacgact ttgcccaatt ctggacgtcg accatcgccg aggctcgcca ggccggcggt 120
gaggtcagta tcgtgcaggc gcagacgaca ctgaaggcgg tccagtcctt cgatgtcacg 180
tttccaggat acggcggtca tccaatcaaa ggatggctga tcttgccgac gcaccacaag 240
gggcggcttc ccctcgtcgt gcagtatatc ggctatggcg gcggccgcgg cttggcgcat 300
gagcaactgc attgggcggc gtcaggcttt gcctatttcc gaatggatac acgcgggcag 360
ggaagcgact ggagcgtcgg tgagaccgcc gatcccgtcg gctcgacctc gtccattccc 420
ggctttatga cgcgtggcgt gctggacaag aatgactact attaccggcg cctgttcacc 480
gatgccgtga gggcgataga tgctctgctc ggactggact tcgtcgatcc cgaacgcatc 540
gcggtttgcg gtgacagtca gggaggcggt atttcgctcg ccgttggcgg catcgacccg 600
cgcgtcaagg ccgtaatgcc cgacgttcca tttctgtgcg actttccgcg cgctgtgcag 660
actgccgtgc gcgatcccta tttggaaatc gttcgctttc tggcccagca tcgcgaaaag 720
aaggcggcag tctttgaaac gctcaactat ttcgactgcg tcaacttcgc ccggcggtcc 780
aaggcgccgg cgctgttttc ggtggccctg atggacgaag tctgcccgcc ctctaccgtg 840
tatggcgcat tcaatgccta tgcaggcgaa aagaccatca cagagtacga attcaacaat 900
catgaaggcg ggcaaggcta tcaagagcgc caacagatga cgtggctcag caggctgttc 960
ggtgtcggct ga 972
<210> 42
<211> 323
<212> PRT
<213> Mesorhizobium loit
<400> 42
Met Pro Phe Pro Asp Leu Ile Gln Pro Glu Leu Gly Ala Tyr Val Ser
1 5 10 15
Ser Val Gly Met Pro Asp Asp Phe Ala Gln Phe Trp Thr Ser Thr Ile
20 25 30
Ala Glu Ala Arg Gln Ala Gly Gly Glu Val Ser Ile Val Gln Ala Gln
35 40 45
Thr Thr Leu Lys Ala Val Gln Ser Phe Asp Val Thr Phe Pro Gly Tyr
50 55 60
Gly Gly His Pro Ile Lys Gly Trp Leu Ile Leu Pro Thr His His Lys
65 70 75 80
Gly Arg Leu Pro Leu Val Val Gln Tyr Ile Gly Tyr Gly Gly Gly Arg
85 90 95
Gly Leu Ala His Glu Gln Leu His Trp Ala Ala Ser Gly Phe Ala Tyr
100 105 110
Phe Arg Met Asp Thr Arg Gly Gln Gly Ser Asp Trp Ser Val Gly Glu
115 120 125
Thr Ala Asp Pro Val Gly Ser Thr Ser Ser Ile Pro Gly Phe Met Thr
130 135 140
Arg Gly Val Leu Asp Lys Asn Asp Tyr Tyr Tyr Arg Arg Leu Phe Thr
145 150 155 160
Asp Ala Val Arg Ala Ile Asp Ala Leu Leu Gly Leu Asp Phe Val Asp
165 170 175
Pro Glu Arg Ile Ala Val Cys Gly Asp Ser Gln Gly Gly Gly Ile Ser
180 185 190
Leu Ala Val Gly Gly Ile Asp Pro Arg Val Lys Ala Val Met Pro Asp
195 200 205
Val Pro Phe Leu Cys Asp Phe Pro Arg Ala Val Gln Thr Ala Val Arg
210 215 220
Asp Pro Tyr Leu Glu Ile Val Arg Phe Leu Ala Gln His Arg Glu Lys
225 230 235 240
Lys Ala Ala Val Phe Glu Thr Leu Asn Tyr Phe Asp Cys Val Asn Phe
245 250 255
Ala Arg Arg Ser Lys Ala Pro Ala Leu Phe Ser Val Ala Leu Met Asp
260 265 270
Glu Val Cys Pro Pro Ser Thr Val Tyr Gly Ala Phe Asn Ala Tyr Ala
275 280 285
Gly Glu Lys Thr Ile Thr Glu Tyr Glu Phe Asn Asn His Glu Gly Gly
290 295 300
Gln Gly Tyr Gln Glu Arg Gln Gln Met Thr Trp Leu Ser Arg Leu Phe
305 310 315 320
Gly Val Gly
<210> 43
<211> 990
<212> DNA
<213> Geobacillus stearothermophilus
<400> 43
atgttcgata tgccgttagc acaattacag aaatacatgg ggacaaatcc gaagccggct 60
gattttgctg acttttggag tcgagcgttg gaggaattat ctgcccaatc gttgcattat 120
gagctgattc cggcaacatt tcaaacgaca gtggcgagtt gctaccattt gtatttcacg 180
ggagtcggcg gggctagagt ccattgtcag ttagtaaaac cgagagagca gaagcagaaa 240
ggcccggggt tggtatggtt tcatggctac catacgaata gcggcgattg ggtcgataaa 300
ctggcatatg ctgcggcagg ttttactgta ttggcgatgg attgccgcgg ccaaggagga 360
aaatcagagg ataatttgca agtgaaaggc ccaacattga agggccatat tattcgcgga 420
attgaggatc caaatcctca tcatctttat tatcgaaatg tttttttaga tacagttcag 480
gcggtaagaa ttttatgctc tatggatcat attgatcgtg aacgaattgg tgtatatggc 540
gcttcccaag gaggagcgtt ggcattagcg tgtgctgctc tggaaccatc ggtggtgaaa 600
aaagcggttg tgctctatcc atttttatcg gattataagc gggcgcaaga gttggatatg 660
aaaaataccg cgtatgagga aattcattat tattttcgat ttttagatcc cacacatgag 720
cgggaagaag aagtatttta caaactaggc tatattgata ttcaactctt agccgatcgg 780
atttgtgccg atgttttatg ggctgttgcg ctagaagacc atatttgtcc cccgtccaca 840
caatttgctg tttataataa aattaagtca aaaaaagaca tggttttgtt ttacgagtat 900
ggtcatgagt atttaccgac tatgggagac cgtgcttatc tgtttttttg cccgatcttc 960
tttccaatcc aaaagagaaa cgttaagtaa 990
<210> 44
<211> 329
<212> PRT
<213> Geobacillus stearothermophilus
<400> 44
Met Phe Asp Met Pro Leu Ala Gln Leu Gln Lys Tyr Met Gly Thr Asn
1 5 10 15
Pro Lys Pro Ala Asp Phe Ala Asp Phe Trp Ser Arg Ala Leu Glu Glu
20 25 30
Leu Ser Ala Gln Ser Leu His Tyr Glu Leu Ile Pro Ala Thr Phe Gln
35 40 45
Thr Thr Val Ala Ser Cys Tyr His Leu Tyr Phe Thr Gly Val Gly Gly
50 55 60
Ala Arg Val His Cys Gln Leu Val Lys Pro Arg Glu Gln Lys Gln Lys
65 70 75 80
Gly Pro Gly Leu Val Trp Phe His Gly Tyr His Thr Asn Ser Gly Asp
85 90 95
Trp Val Asp Lys Leu Ala Tyr Ala Ala Ala Gly Phe Thr Val Leu Ala
100 105 110
Met Asp Cys Arg Gly Gln Gly Gly Lys Ser Glu Asp Asn Leu Gln Val
115 120 125
Lys Gly Pro Thr Leu Lys Gly His Ile Ile Arg Gly Ile Glu Asp Pro
130 135 140
Asn Pro His His Leu Tyr Tyr Arg Asn Val Phe Leu Asp Thr Val Gln
145 150 155 160
Ala Val Arg Ile Leu Cys Ser Met Asp His Ile Asp Arg Glu Arg Ile
165 170 175
Gly Val Tyr Gly Ala Ser Gln Gly Gly Ala Leu Ala Leu Ala Cys Ala
180 185 190
Ala Leu Glu Pro Ser Val Val Lys Lys Ala Val Val Leu Tyr Pro Phe
195 200 205
Leu Ser Asp Tyr Lys Arg Ala Gln Glu Leu Asp Met Lys Asn Thr Ala
210 215 220
Tyr Glu Glu Ile His Tyr Tyr Phe Arg Phe Leu Asp Pro Thr His Glu
225 230 235 240
Arg Glu Glu Glu Val Phe Tyr Lys Leu Gly Tyr Ile Asp Ile Gln Leu
245 250 255
Leu Ala Asp Arg Ile Cys Ala Asp Val Leu Trp Ala Val Ala Leu Glu
260 265 270
Asp His Ile Cys Pro Pro Ser Thr Gln Phe Ala Val Tyr Asn Lys Ile
275 280 285
Lys Ser Lys Lys Asp Met Val Leu Phe Tyr Glu Tyr Gly His Glu Tyr
290 295 300
Leu Pro Thr Met Gly Asp Arg Ala Tyr Leu Phe Phe Cys Pro Ile Phe
305 310 315 320
Phe Pro Ile Gln Lys Arg Asn Val Lys
325
<210> 45
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 45
atggcgttct tcgacctgcc tctggaagaa ctgaagaaat accgtccaga gcgttacgaa 60
gagaaggaca tcgacgagtt ctgggaggaa actctggcgg agaccgaaaa gtttccgctg 120
gacccagtgt tcgagcgtat ggaatctcac ctgaaaaccg tggaggcata tgacgttact 180
ttttctggtt accgtggcca gcgtatcaaa ggctggctgc tggttccgaa actggaggaa 240
gaaaaactgc cgtgcgtagt tcagtacatc ggttacaacg gtggccgtgg ctttccgcac 300
gattggctgt tctggccgtc tatgggctac atttgcttcg tcatggatac tcgtggtcag 360
ggttccggct ggctgaaagg cgatactccg gattatccgg agggcccggt agacccgcag 420
taccctggct tcatgacgcg tggtattctg gatccgcgta cctattacta tcgccgcgtt 480
tttaccgatg cagttcgtgc cgtagaggcc gcggcttctt tccctcaggt tgacctggag 540
cgtattgtta tcgctggtgg ctcccagggt ggcggcatcg ccctggcggt atctgcgctg 600
agcaagaaag ctaaggcact gctgtgtgac gtcccgttcc tgtgtcactt ccgtcgcgct 660
gttcagctgg tagataccca tccgtacgcg gagattacta acttcctgaa aactcaccgc 720
gacaaagaag aaatcgtttt ccgcaccctg tcctatttcg acggcgttaa cttcgcggct 780
cgtgcaaaaa ttccggcact gttctctgtt ggtctgatgg acgacatcag ccctccttct 840
accgttttcg cggcatataa ctattatgcg ggtccgaaag aaatccgtat ctatccgtac 900
aacaaccacg aaggcggtgg tggctttcag gctgttgaac aagtgaaatc cctgaagaaa 960
ctgtttgaga agggctaa 978
<210> 46
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 46
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Ile Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Thr Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Leu Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asp Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Gly Phe Gln Ala Val Glu Gln Val Lys Ser Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 47
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 47
atggcgttct tcgacctgcc tctggaagaa ctgaagaaat accgtccaga gcgttacgaa 60
gagaaggact tcgacgagtt ctgggaggaa actctggcgg agagcgaaaa gtttccgctg 120
gacccagtgt tcgagcgtat ggaatctcac ctgaaaaccg tggaggcata tgacgttact 180
ttttctggtt accgtggcca gcgtatcaaa ggctggctgc tggttccgaa actggaggaa 240
gaaaaactgc cgtgcgtagt tcagtacatc ggttacaacg gtggccgtgg ctttccgcac 300
gattggctgt tctggccgtc tatgggctac atttgcttcg tcatggatac tcgtggtcag 360
ggttccggct ggctgaaagg cgatactccg gattatccgg agggcccggt agacccgcag 420
taccctggct tcatgacgcg tggtattctg gatccgcgta cctattacta tcgccgcgtt 480
tttaccgatg cagttcgtgc cgtagaggcc gcggcttctt tccctcaggt tgaccaggag 540
cgtattgtta tcgctggtgg ctcccagggt ggcggcatcg ccctggcggt atctgcgctg 600
agcaagaaag ctaaggcact gctgtgtgac gtcccgttcc tgtgtcactt ccgtcgcgct 660
gttcagctgg tagataccca tccgtacgcg gagattacta acttcctgaa aactcaccgc 720
gacaaagaag aaatcgtttt ccgcaccctg tcctatttcg acggcgttaa cttcgcggct 780
cgtgcaaaaa ttccggcact gttctctgtt ggtctgatgg acgacatcag ccctccttct 840
accgttttcg cggcatataa ctattatgcg ggtccgaaag aaatccgtat ctatccgtac 900
aacaaccacg aaggcggtgg tagctttcag gctgttgaac aagtgaaatt cctgaagaaa 960
ctgtttgaga agggctaa 978
<210> 48
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 48
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asp Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 49
<211> 978
<212> DNA
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 49
atggcgttct tcgacctgcc tctggaagaa ctgaagaaat accgtccaga gcgttacgaa 60
gagaaggact tcgacgagtt ctgggaggaa actctggcgg agagcgaaaa gtttccgctg 120
gacccagtgt tcgagcgtat ggaatctcac ctgaaaaccg tggaggcata tgacgttact 180
ttttctggtt accgtggcca gcgtatcaaa ggctggctgc tggttccgaa actggaggaa 240
gaaaaactgc cgtgcgtagt tcagtacatc ggttacaacg gtggccgtgg ctttccgcac 300
gattggctgt tctggccgtc tatgggctac atttgcttcg tcatggatac tcgtggtcag 360
ggttccggct ggctgaaagg cgatactccg gattatccgg agggcccggt agacccgcag 420
taccctggct tcatgacgcg tggtattctg gatccgcgta cctattacta tcgccgcgtt 480
tttaccgatg cagttcgtgc cgtagaggcc gcggcttctt tccctcaggt tgaccaggag 540
cgtattgtta tcgctggtgg ctcccagggt ggcggcatcg ccctggcggt atctgcgctg 600
agcaagaaag ctaaggcact gctgtgtgac gtcccgttcc tgtgtcactt ccgtcgcgct 660
gttcagctgg tagataccca tccgtacgcg gagattacta acttcctgaa aactcaccgc 720
gacaaagaag aaatcgtttt ccgcaccctg tcctatttcg acggcgttaa cttcgcggct 780
cgtgcaaaaa ttccggcact gttctctgtt ggtctgatgg acaacatcag ccctccttct 840
accgttttcg cggcatataa ctattatgcg ggtccgaaag aaatccgtat ctatccgtac 900
aacaaccacg aaggcggtgg tagctttcag gctgttgaac aagtgaaatc cctgaagaaa 960
ctgtttgaga agggctaa 978
<210> 50
<211> 325
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 50
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Ser Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 51
<211> 978
<212> DNA
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 51
atggcgttct tcgacctgcc tctggaagaa ctgaagaaat accgtccaga gcgttacgaa 60
gagaaggact tcgacgagtt ctgggaggaa actctggcgg agaccgaaaa gtttccgctg 120
gacccagtgt tcgagcgtat ggaatctcac ctgaaaaccg tggaggcata tgacgttact 180
ttttctggtt accgtggcca gcgtatcaaa ggctggctgc tggttccgaa actggaggaa 240
gaaaaactgc cgtgcgtagt tcagtacatc ggttacaacg gtggccgtgg ctttccgcac 300
gattggctgt tctggccgtc tatgggctac atttgcttcg tcatggatac tcgtggtcag 360
ggttccggct ggctgaaagg cgatactccg gattatccgg agggcccggt agacccgcag 420
taccctggct tcatgacgcg tggtattctg gatccgcgta cctattacta tcgccgcgtt 480
tttaccgatg cagttcgtgc cgtagaggcc gcggcttctt tccctcaggt tgaccaggag 540
cgtattgtta tcgctggtgg ctcccagggt ggcggcatcg ccctggcggt atctgcgctg 600
agcaagaaag ctaaggcact gctgtgtgac gtcccgttcc tgtgtcactt ccgtcgcgct 660
gttcagctgg tagataccca tccgtacgcg gagattacta acttcctgaa aactcaccgc 720
gacaaagaag aaatcgtttt ccgcaccctg tcctatttcg acggcgttaa cttcgcggct 780
cgtgcaaaaa ttccggcact gttctctgtt ggtctgatgg acaacatcag ccctccttct 840
accgttttcg cggcatataa ctattatgcg ggtccgaaag aaatccgtat ctatccgtac 900
aacaaccacg aaggcggtgg tagctttcag gctgttgaac aagtgaaatt cctgaagaaa 960
ctgtttgaga agggctaa 978
<210> 52
<211> 325
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 52
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Thr Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 53
<211> 978
<212> DNA
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 53
atggcgttct tcgacctgcc tctggaagaa ctgaagaaat accgtccaga gcgttacgaa 60
gagaaggact tcgacgagtt ctgggaggaa actctggcgg agagcgaaaa gtttccgctg 120
gacccagtgt tcgagcgtat ggaatctcac ctgaaaaccg tggaggcata tgacgttact 180
ttttctggtt accgtggcca gcgtatcaaa ggctggctgc tggttccgaa actggaggaa 240
gaaaaactgc cgtgcgtagt tcagtacatc ggttacaacg gtggccgtgg ctttccgcac 300
gattggctgt tctggccgtc tatgggctac atttgcttcg tcatggatac tcgtggtcag 360
ggttccggct ggctgaaagg cgatactccg gattatccgg agggcccggt agacccgcag 420
taccctggct tcatgacgcg tggtattctg gatccgcgta cctattacta tcgccgcgtt 480
tttaccgatg cagttcgtgc cgtagaggcc gcggcttctt tccctcaggt tgacctggag 540
cgtattgtta tcgctggtgg ctcccagggt ggcggcatcg ccctggcggt atctgcgctg 600
agcaagaaag ctaaggcact gctgtgtgac gtcccgttcc tgtgtcactt ccgtcgcgct 660
gttcagctgg tagataccca tccgtacgcg gagattacta acttcctgaa aactcaccgc 720
gacaaagaag aaatcgtttt ccgcaccctg tcctatttcg acggcgttaa cttcgcggct 780
cgtgcaaaaa ttccggcact gttctctgtt ggtctgatgg acaacatcag ccctccttct 840
accgttttcg cggcatataa ctattatgcg ggtccgaaag aaatccgtat ctatccgtac 900
aacaaccacg aaggcggtgg tagctttcag gctgttgaac aagtgaaatt cctgaagaaa 960
ctgtttgaga agggctaa 978
<210> 54
<211> 325
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 54
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Leu Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 55
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(978)
<400> 55
atg gcg ttc ttc gac ctg cct cgg gaa gaa ctg aag aaa tac cgt cca 48
Met Ala Phe Phe Asp Leu Pro Arg Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
gag cgt tac gaa gag aag gac ttc gac gag ttc tgg gag gaa act ctg 96
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
gcg gag agc gaa aag ttt ccg ctg gac cca gtg ttc gag cgt atg gaa 144
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
tct cac ctg aaa acc gtg gag gca tat gac gtt act ttt tct ggt tac 192
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
cgt ggc cag cgt atc aaa ggc tgg ctg ctg gtt ccg aaa ctg gag gaa 240
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
gaa aaa ctg ccg tgc gta gtt cag tac atc ggt tac aac ggt ggc cgt 288
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
ggc ttt ccg cac gat tgg ctg ttc tgg ccg tct atg ggc tac att tgc 336
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
ttc gtc atg gat act cgt ggt cag ggt tcc ggc tgg cag aaa ggc gat 384
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Gln Lys Gly Asp
115 120 125
act ccg gat tat ccg gag ggc ccg gta gac ccg cag tac cct ggc ttc 432
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
atg acg cgt ggt att ctg gat ccg cgt acc tat tac tat cgc cgc gtt 480
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
ttt acc gat gca gtt cgt gcc gta gag gcc gcg gct tct ttc cct ctg 528
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Leu
165 170 175
gtt gac cag gag cgt att gat atc gct ggt ggc tcc cag ggt ggc ggc 576
Val Asp Gln Glu Arg Ile Asp Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
atc gcc ctg gcg gta tct gcg ctg agc aag aaa gct aag gca ctg ctg 624
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
tgt gac gtc ccg ttc ctg tgt cac ttc cgt cgc gct gtt cag ctg gta 672
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
gat acc cat ccg tac gcg gag att act aac ttc ctg aaa act cac cgc 720
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
gac aaa gaa gaa atc gtt atc cgc acc ctg tcc tat ttc gac ggc gtt 768
Asp Lys Glu Glu Ile Val Ile Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
aac ttc gcg gct cgt gca aaa att ccg gca ctg ttc tct gtt ggt ctg 816
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
atg gac aac atc agc cct cct tct acc gtt ttc gcg gca tat aac tat 864
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
tat gcg ggt ctg aaa gaa atc cgt atc tat ccg tac aac aac cac gaa 912
Tyr Ala Gly Leu Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
ggc ggt ggt agc ttt cag gct gtt gaa caa gtg aaa ttc ctg aag aaa 960
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
ctg ttt gag aag ggc taa 978
Leu Phe Glu Lys Gly
325
<210> 56
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> Synthetic Construct
<400> 56
Met Ala Phe Phe Asp Leu Pro Arg Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Gln Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Leu
165 170 175
Val Asp Gln Glu Arg Ile Asp Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Ile Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Leu Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 57
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(978)
<400> 57
atg gcg ttc ttc gac ctg cct ctg gaa gaa ctg aag aaa tac cgt cca 48
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
gag cgt tac gaa gag aag gac ttc gac gag ttc tgg gag gaa act ctg 96
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
gcg gag agc gaa aag ttt ccg ctg gac cca gtg ttc gag cgt atg gaa 144
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
tct cac ctg aaa acc gtg gag gca tat gac gtt act ttt tct ggt tac 192
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
cgt ggc cag cgt atc aaa ggc tgg ctg ctg gtt ccg gaa ctg gag gaa 240
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Glu Leu Glu Glu
65 70 75 80
gaa aaa ctg ccg tgc gta gtt cag tac atc ggt tac aac ggt ggc cgt 288
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
ggc ttt ccg cac gat tgg ctg ttc tgg ccg tct atg ggc tac att tgc 336
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
ttc gtc atg gat act cgt ggt cag ggt tcc ggc tgg ctg aaa ggc gat 384
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
act ccg gat tat ccg gag ggc ccg gta gac ccg cag tac cct ggc ttc 432
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
atg acg cgt ggt att ctg gat ccg cgt acc tat tac tat cgc cgc gtt 480
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
ttt acc gat gca gtt cgt gcc gta gag gcc gcg gct tct ttc cct cag 528
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
gtt gac cag gag cgt att gtt atc gct ggt ggc tcc cag ggt ggc ggc 576
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
atc gcc ctg gcg gta tct gcg ctg agc aag aaa gct aag gca ctg ctg 624
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
tgt gac gtc ccg ttc ctg tgt cac ttc cgt cgc gct gtt cag ctg gta 672
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
gat acc cat ccg tac gcg gag att act aac ttc ctg aaa act cac cgc 720
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
gac aaa gaa gaa atc gtt ttc cgc acc ctg tcc tat ttc gac ggc gtt 768
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
aac ttc gcg gct cgt gca aaa att ccg gaa ctg ttc tct gtt ggt ctg 816
Asn Phe Ala Ala Arg Ala Lys Ile Pro Glu Leu Phe Ser Val Gly Leu
260 265 270
atg gac aac atc agc cct cct tct acc gtt ttc gcg gca tat aac tat 864
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
tat gcg ggt ccg aaa gaa atc cgt atc tat ccg tac aac aac cac gaa 912
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
ggc ggt ggt agc ttt cag gct gtt gaa caa gtg aaa ttc ctg aag aaa 960
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
ctg ttt gag aag ggc taa 978
Leu Phe Glu Lys Gly
325
<210> 58
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> Synthetic Construct
<400> 58
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Glu Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Glu Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 59
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(978)
<400> 59
atg gcg ttc ttc gac ctg cct ctg gaa gaa ctg aag aaa tac cgt cca 48
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
gag cgt tac gaa gag aag gac ttc gac gag tac tgg gag gaa act ctg 96
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Tyr Trp Glu Glu Thr Leu
20 25 30
gcg gag agc gaa aag ttt ccg ctg gac cca gtg ttc gag cgt atg gaa 144
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
tct cac ctg aaa acc gtg gag gca tat gac gtt act ttt tct ggt tac 192
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
cgt ggc cag cgt atc aaa ggc tgg ctg ctg gtt ccg aaa ctg gag gaa 240
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
gaa aaa ctg ccg tgc gta gtt cag tac atc ggt tac aac ggt ggc cgt 288
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
ggc ttt ccg cac gat tgg ctg ttc tgg ccg tct atg ggc tac att tgc 336
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
ttc gtc atg gat act cgt ggt cag ggt tcc ggc tgg ctg aaa ggc gat 384
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
act ccg gat tat ccg gag ggc ccg gta gac ccg cag tac cct ggc ttc 432
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
atg acg cgt ggt gtt ctg gat ccg cgt acc tat tac tat cgc cgc gtt 480
Met Thr Arg Gly Val Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
ttt acc gat gca gtt cgt gcc gta gag gcc gcg gct tct ttc cct cag 528
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
gtt gac cag gag cgt att gtt atc gct ggt ggc tcc cag ggt ggc ggc 576
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
atc gcc ctg gcg gta tct gcg ctg agc aag aaa gct aag gca ctg ctg 624
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
tgt gac gtc ccg ttc ctg tgt cac ttc cgt cgc gct gtt cag ctg gta 672
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
gat acc cat ccg tac gcg gag att act aac ttc ctg aaa act cac cgc 720
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
gac aaa gaa gaa atc gtt ttc cgc acc ctg tcc tat ttc gac ggc gtt 768
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
aac ttc gcg gct cgt gca aaa att ccg gta ctg ttc tct gtt ggt ctg 816
Asn Phe Ala Ala Arg Ala Lys Ile Pro Val Leu Phe Ser Val Gly Leu
260 265 270
atg gac aac atc agc cct cct tct acc gtt ttc gcg gca tat aac tat 864
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
tat gcg ggt ccg aaa gaa acc cgt atc tat ccg tac aac agc cac gaa 912
Tyr Ala Gly Pro Lys Glu Thr Arg Ile Tyr Pro Tyr Asn Ser His Glu
290 295 300
ggc ggt ggt agc ttt cag gct gtt gaa caa gtg aaa ttc ctg aag aaa 960
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
ctg ttt gag aag ggc taa 978
Leu Phe Glu Lys Gly
325
<210> 60
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> Synthetic Construct
<400> 60
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Tyr Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Val Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Val Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Thr Arg Ile Tyr Pro Tyr Asn Ser His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 61
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(978)
<400> 61
atg gcg ttc ttc gac ctg cct ctg gaa gaa ctg aag aaa tac cgt cca 48
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
gag cgt tac gaa gag aag gac ttc gac gag ttc tgg gag gaa act ctg 96
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
gcg gag agc gaa aag ttt ccg ctg gac cca gtg ttc gag cgt atg gaa 144
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
tct cac ctg aaa acc gtg gag gca tat gac gtt act ttt tct ggt tac 192
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
cgt ggc cag cgt atc aaa ggc tgg ctg ctg gtt ccg aaa ctg gag gaa 240
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
gaa aaa ctg ccg tgc gta gtt cag tac atc ggt tac aac ggt ggc cgt 288
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
ggc ttt ccg cac gat tgg ctg ttc tgg ccg tct atg ggc tac att tgc 336
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
ttc gtc atg gat act cgt ggt cag ggt tcc ggc tgg ctg aaa ggc gat 384
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
act ccg gat tat ccg gag ggc ccg gta gac ccg cag tac cct ggc ttc 432
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
atg acg cgt ggt att ctg gat ccg cgt acc tat tac tat cgc cgc gtt 480
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
ttt acc gat gca gtt cgt gcc gta gag gcc gcg gct tct ttc cct cag 528
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
gtt gac cag gag cgt att gtt atc gct ggt ggc tcc cag ggt ggc ggc 576
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
atc gcc cag gcg gta tct gcg ctg agc aag aaa gct aag gca ctg ctg 624
Ile Ala Gln Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
tgt gac gtc ccg ttc ctg tgt cac ttc cgt cgc gct gtt cag ctg gta 672
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
gat acc cat ccg tac gcg gag att act aac ttc ctg aaa act cac cgc 720
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
gac aaa gaa gaa atc gtt ttc cgc acc ctg tcc tat ttc gac ggc gtt 768
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
aac ttc gcg gct cgt gca aaa att ccg gca ctg ttc tct gtt ggt ctg 816
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
atg gac aac atc agc cct cct tct acc gtt ttc gcg gca tat aac tat 864
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
tat gcg ggt ccg aaa gaa atc cgt atc tat ccg tac aac aac cac gaa 912
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
ggc ggt ggt agc ttt cag gct gtt gaa caa gtg aaa ttc ctg aag aaa 960
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
ctg ttt gag aag ggc taa 978
Leu Phe Glu Lys Gly
325
<210> 62
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> Synthetic Construct
<400> 62
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Gln Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 63
<211> 978
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<220>
<221> CDS
<222> (1)..(978)
<400> 63
atg gcg ttc ttc gac ctg cct ctg gaa gaa ctg aag aaa tac cgt cca 48
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
gag cgt tac gaa gag aag gac ttc gac gag ttc tgg gag gaa act ctg 96
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
gcg gag agc gaa aag ttt ccg ctg gac cca gtg ttc gag cgt atg gaa 144
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
tct cac ctg aaa acc gtg gag gca tat gac gtt act ttt tct ggt tac 192
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
cgt ggc cag cgt atc aaa ggc tgg ctg ctg gtt ccg aaa ctg gag gaa 240
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
gaa aaa ctg ccg tgc gta gtt cag tac atc ggt tac aac ggt ggc cgt 288
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
ggc ttt ccg cac gat tgg ctg ttc tgg ccg tct atg ggc ttc att tgc 336
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Phe Ile Cys
100 105 110
ttc gtc atg gat act cgt ggt cag ggt tcc ggc tgg ctg aaa ggc gat 384
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
act ccg gat tat ccg gag ggc ccg gta gac ccg cag tac cct ggc ttc 432
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
atg acg cgt ggt att ctg gat ccg cgt acc tat tac tat cgc cgc gtt 480
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
ttt acc gat gca gtt cgt gcc gta gag gcc gcg gct tct ttc cct cag 528
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
gtt gac cag gag cgt att gtt atc gct ggt ggc tcc cag ggt ggc ggc 576
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
atc gcc ctg gcg gta tct gcg ctg agc aag aaa gct aag gca ctg ctg 624
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
tgt gac gtc ccg ttc ctg tgt cac ttc cgt cgc gct gtt cag ctg gta 672
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
gat acc cat ccg tac gcg gag att act aac ttc ctg aaa act cac cgc 720
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
gac aaa gaa gaa atc gtt ttc cgc acc ctg tcc tat ttc gac ggc gtt 768
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
aac ttc gcg gct cgt gca aaa att ccg gca ctg ttc tct gtt ggt ctg 816
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
atg gac aac atc agc cct cct tct acc gtt ttc gcg gca tat aac tat 864
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
tat gcg ggt ccg aaa gaa atc cgt atc tat ccg tac aac aac cac gaa 912
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
ggc ggt ggt agc ttt cag gct gtt gaa caa gtg aaa ttc ctg aag aaa 960
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
ctg ttt gag aag ggc taa 978
Leu Phe Glu Lys Gly
325
<210> 64
<211> 325
<212> PRT
<213> artificial sequence
<220>
<223> Synthetic Construct
<400> 64
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Phe Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 65
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 65
Ala Pro Trp His Leu Ser Ser Gln Tyr Ser Gly Thr
1 5 10
<210> 66
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 66
Gly Tyr Cys Leu Arg Val Asp Glu Pro Thr Val Cys Ser Gly
1 5 10
<210> 67
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 67
His Ile His Pro Ser Asp Asn Phe Pro His Lys Asn Arg Thr His
1 5 10 15
<210> 68
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 68
His Thr His His Asp Thr His Lys Pro Trp Pro Thr Asp Asp His Arg
1 5 10 15
Asn Ser Ser Val
20
<210> 69
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 69
Pro Glu Asp Arg Pro Ser Arg Thr Asn Ala Leu His His Asn Ala His
1 5 10 15
His His Asn Ala
20
<210> 70
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 70
Thr Pro His Asn His Ala Thr Thr Asn His His Ala Gly Lys Lys
1 5 10 15
<210> 71
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 71
Glu Met Val Lys Asp Ser Asn Gln Arg Asn Thr Arg Ile Ser Ser
1 5 10 15
<210> 72
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 72
His Tyr Ser Arg Tyr Asn Pro Gly Pro His Pro Leu
1 5 10
<210> 73
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 73
Ile Asp Thr Phe Tyr Met Ser Thr Met Ser His Ser
1 5 10
<210> 74
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 74
Pro Met Lys Glu Ala Thr His Pro Val Pro Pro His Lys His Ser Glu
1 5 10 15
Thr Pro Thr Ala
20
<210> 75
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 75
Tyr Gln Thr Ser Ser Pro Ala Lys Gln Ser Val Gly
1 5 10
<210> 76
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 76
His Leu Pro Ser Tyr Gln Ile Thr Gln Thr His Ala Gln Tyr Arg
1 5 10 15
<210> 77
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 77
Thr Thr Pro Lys Thr Thr Tyr His Gln Ser Arg Ala Pro Val Thr Ala
1 5 10 15
Met Ser Glu Val
20
<210> 78
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 78
Asp Arg Ile His His Lys Ser His His Val Thr Thr Asn His Phe
1 5 10 15
<210> 79
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 79
Trp Ala Pro Glu Lys Asp Tyr Met Gln Leu Met Lys
1 5 10
<210> 80
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 80
Thr Ser Asp Ile Lys Ser Arg Ser Pro His His Arg
1 5 10
<210> 81
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 81
His Thr Gln Asn Met Arg Met Tyr Glu Pro Trp Phe
1 5 10
<210> 82
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 82
Leu Pro Pro Gly Ser Leu Ala
1 5
<210> 83
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 83
Met Pro Ala Val Met Ser Ser Ala Gln Val Pro Arg
1 5 10
<210> 84
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 84
Asn Gln Ser Phe Leu Pro Leu Asp Phe Pro Phe Arg
1 5 10
<210> 85
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 85
Ser Ile Leu Ser Thr Met Ser Pro His Gly Ala Thr
1 5 10
<210> 86
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 86
Ser Met Lys Tyr Ser His Ser Thr Ala Pro Ala Leu
1 5 10
<210> 87
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 87
Glu Ser Ser Tyr Ser Trp Ser Pro Ala Arg Leu Ser
1 5 10
<210> 88
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 88
Gly Pro Leu Lys Leu Leu His Ala Trp Trp Gln Pro
1 5 10
<210> 89
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 89
Asn Ala Leu Thr Arg Pro Val
1 5
<210> 90
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 90
Ser Ala Pro Ser Ser Lys Asn
1 5
<210> 91
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 91
Ser Val Ser Val Gly Met Lys Pro Ser Pro Arg Pro
1 5 10
<210> 92
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 92
Ser Tyr Tyr Ser Leu Pro Pro Ile Phe His Ile Pro
1 5 10
<210> 93
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 93
Thr Phe Thr Pro Tyr Ser Ile Thr His Ala Leu Leu
1 5 10
<210> 94
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 94
Thr Met Gly Phe Thr Ala Pro Arg Phe Pro His Tyr
1 5 10
<210> 95
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 95
Thr Asn Pro Phe Pro Pro Pro Pro Ser Ser Pro Ala
1 5 10
<210> 96
<211> 12
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 96
His Asn Lys Ser Ser Pro Leu Thr Ala Ala Leu Pro
1 5 10
<210> 97
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 97
Leu Pro Pro Trp Lys His Lys Thr Ser Gly Val Ala
1 5 10
<210> 98
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 98
Leu Pro Trp Trp Leu Arg Asp Ser Tyr Leu Leu Pro
1 5 10
<210> 99
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 99
Val Pro Trp Trp Lys His Pro Pro Leu Pro Val Pro
1 5 10
<210> 100
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 100
His His Lys Gln Trp His Asn His Pro His His Ala
1 5 10
<210> 101
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 101
His Ile Phe Ser Ser Trp His Gln Met Trp His Arg
1 5 10
<210> 102
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 102
Trp Pro Ala Trp Lys Thr His Pro Ile Leu Arg Met
1 5 10
<210> 103
<211> 7
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 103
Lys Thr Pro Pro Thr Arg Pro
1 5
<210> 104
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 104
Val Ile Asn Pro Asn Leu Asp
1 5
<210> 105
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 105
Lys Val Trp Ile Val Ser Thr
1 5
<210> 106
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 106
Ala Glu Pro Val Ala Met Leu
1 5
<210> 107
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 107
Ala Glu Leu Val Ala Met Leu
1 5
<210> 108
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 108
His Ser Leu Arg Leu Asp Trp
1 5
<210> 109
<211> 13
<212> PRT
<213> Artificial sequence
<220>
<223> synthetic construct
<400> 109
Thr Ser Thr Ala Ser Pro Thr Met Gln Ser Lys Ile Arg
1 5 10
<210> 110
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 110
Lys Arg Asn His Trp Gln Arg Met His Leu Ser Ala
1 5 10
<210> 111
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 111
Ser His Ala Thr Pro Pro Gln Gly Leu Gly Pro Gln
1 5 10
<210> 112
<211> 20
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 112
Ala Thr Thr Pro Pro Ser Gly Lys Ala Ala Ala His Ser Ala Ala Arg
1 5 10 15
Gln Lys Gly Asn
20
<210> 113
<211> 15
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 113
Asp Thr Ile His Pro Asn Lys Met Lys Ser Pro Ser Ser Pro Leu
1 5 10 15
<210> 114
<211> 20
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 114
Asn Gly Asn Asn His Thr Asp Ile Pro Asn Arg Ser Ser Tyr Thr Gly
1 5 10 15
Gly Ser Phe Ala
20
<210> 115
<211> 15
<212> PRT
<213> ARTIFICIAL SEQUENCE
<220>
<223> synthetic construct
<400> 115
Ser Asp Glu Thr Gly Pro Gln Ile Pro His Arg Arg Pro Thr Trp
1 5 10 15
<210> 116
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 116
Ser Ile Leu Pro Tyr Pro Tyr
1 5
<210> 117
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 117
Ser Thr Ala Ser Tyr Thr Arg
1 5
<210> 118
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 118
Leu Pro Val Arg Pro Trp Thr
1 5
<210> 119
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 119
Gly Asn Thr Pro Ser Arg Ala
1 5
<210> 120
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 120
His Ala Ile Tyr Pro Arg His
1 5
<210> 121
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 121
Tyr Gln Asp Ser Ala Lys Thr
1 5
<210> 122
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 122
Val Pro Arg Val Thr Ser Ile
1 5
<210> 123
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 123
Met Ala Asn His Asn Leu Ser
1 5
<210> 124
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 124
Phe His Glu Asn Trp Pro Ser
1 5
<210> 125
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 125
Thr His Lys Thr Ser Thr Gln Arg Leu Leu Ala Ala
1 5 10
<210> 126
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 126
Lys Cys Cys Tyr Val Asn Val Gly Ser Val Phe Ser
1 5 10
<210> 127
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 127
Ala His Met Gln Phe Arg Thr Ser Leu Thr Pro His
1 5 10
<210> 128
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic construct - caspace 3 cleavable linker
<400> 128
Leu Glu Ser Gly Asp Glu Val Asp
1 5
<210> 129
<211> 37
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 129
Thr Ser Thr Ser Lys Ala Ser Thr Thr Thr Thr Ser Ser Lys Thr Thr
1 5 10 15
Thr Thr Ser Ser Lys Thr Thr Thr Thr Thr Ser Lys Thr Ser Thr Thr
20 25 30
Ser Ser Ser Ser Thr
35
<210> 130
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 130
Gly Gln Gly Gly Tyr Gly Gly Leu Gly Ser Gln Gly Ala Gly Arg Gly
1 5 10 15
Gly Leu Gly Gly Gln Gly
20
<210> 131
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 131
Gly Pro Gly Gly Tyr Gly Pro Gly Gln Gln
1 5 10
<210> 132
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 132
Gly Gly Ser Gly Pro Gly Ser Gly Gly
1 5
<210> 133
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 133
Gly Gly Pro Lys Lys
1 5
<210> 134
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 134
Gly Pro Gly Val Gly
1 5
<210> 135
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 135
Gly Gly Gly Cys Gly Gly Gly
1 5
<210> 136
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 136
Gly Gly Gly Cys
1
<210> 137
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 137
Pro His Met Ala Ser Met Thr Gly Gly Gln Gln Met Gly Ser
1 5 10
<210> 138
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 138
Gly Pro Glu Glu Ala Ala Lys Lys Glu Glu Ala Ala Lys Lys Pro Ala
1 5 10 15
<210> 139
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 139
Gly Ser Gly Gly Gly Gly Ser Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 140
<211> 37
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic construct
<400> 140
Gly Pro Glu Pro Glu Pro Glu Pro Glu Pro Ile Pro Glu Pro Pro Lys
1 5 10 15
Glu Ala Pro Val Val Ile Glu Lys Pro Lys Pro Lys Pro Lys Pro Lys
20 25 30
Pro Lys Pro Pro Ala
35
<210> 141
<211> 6368
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 141
agatctcgat cccgcgaaat taatacgact cactataggg agaccacaac ggtttccctc 60
tagaaataat tttgtttaac tttaagaagg agatatacat atgcacactc cagaacatat 120
caccgcagta gtacagcgtt ttgtggcagc tctgaacgcg ggcgagctgg aaggtattgt 180
ggcgctgttc gcggaagaag ccaccgtgga agaaccggtg ggttctgaac cgcgttccgg 240
caccgcagcc tgccgtgaat tttacgcaaa cagcctgaag ctgccgctgg cggttgaact 300
gacccaagaa tgtcgtgcgg tggctaacga agccgctttc gcgttcaccg tgtccttcga 360
ataccagggt cgtaagaccg ttgtggcgcc atgcgaacac tttcgtttca acggcgcagg 420
caaagtggtt tccatccgcg cactgttcgg tgaaaagaac atccatgctt gtcagggatc 480
cgatccgact ccgccgacga atgtactgat gctggcaacc aaaggcggtg gtacgcattc 540
cacgcacaac catggcagcc cgcgccacac gaatgctgac gcaggcaatc cgggcggcgg 600
caccccacca accaatgtcc tgatgctggc tactaaaggc ggcggcacgc attctaccca 660
caaccatggt agcccgcgcc atactaatgc agatgccggc aacccgggcg gtggtacccc 720
gccaaccaac gttctgatgc tggcgacgaa aggtggcggt acccattcca cgcataatca 780
tggcagccct cgccacacca acgctgatgc tggtaatcct ggtggcggta agaagaaata 840
ataaggcgcg ccgacccagc tttcttgtac aaagtggttg attcgaggct gctaacaaag 900
cccgaaagga agctgagttg gctgctgcca ccgctgagca ataactagca taaccccttg 960
gggcctctaa acgggtcttg aggggttttt tgctgaaagg aggaactata tccggatatc 1020
cacaggacgg gtgtggtcgc catgatcgcg tagtcgatag tggctccaag tagcgaagcg 1080
agcaggactg ggcggcggcc aaagcggtcg gacagtgctc cgagaacggg tgcgcataga 1140
aattgcatca acgcatatag cgctagcagc acgccatagt gactggcgat gctgtcggaa 1200
tggacgatat cccgcaagag gcccggcagt accggcataa ccaagcctat gcctacagca 1260
tccagggtga cggtgccgag gatgacgatg agcgcattgt tagatttcat acacggtgcc 1320
tgactgcgtt agcaatttaa ctgtgataaa ctaccgcatt aaagcttgca gtggcggttt 1380
tcatggcttg ttatgactgt ttttttgggg tacagtctat gcctcgggca tccaagcagc 1440
aagcgcgtta cgccgtgggt cgatgtttga tgttatggag cagcaacgat gttacgcagc 1500
agggcagtcg ccctaaaaca aagttaaaca tcatgaggga agcggtgatc gccgaagtat 1560
cgactcaact atcagaggta gttggcgtca tcgagcgcca tctcgaaccg acgttgctgg 1620
ccgtacattt gtacggctcc gcagtggatg gcggcctgaa gccacacagt gatattgatt 1680
tgctggttac ggtgaccgta aggcttgatg aaacaacgcg gcgagctttg atcaacgacc 1740
ttttggaaac ttcggcttcc cctggagaga gcgagattct ccgcgctgta gaagtcacca 1800
ttgttgtgca cgacgacatc attccgtggc gttatccagc taagcgcgaa ctgcaatttg 1860
gagaatggca gcgcaatgac attcttgcag gtatcttcga gccagccacg atcgacattg 1920
atctggctat cttgctgaca aaagcaagag aacatagcgt tgccttggta ggtccagcgg 1980
cggaggaact ctttgatccg gttcctgaac aggatctatt tgaggcgcta aatgaaacct 2040
taacgctatg gaactcgccg cccgactggg ctggcgatga gcgaaatgta gtgcttacgt 2100
tgtcccgcat ttggtacagc gcagtaaccg gcaaaatcgc gccgaaggat gtcgctgccg 2160
actgggcaat ggagcgcctg ccggcccagt atcagcccgt catacttgaa gctagacagg 2220
cttatcttgg acaagaagaa gatcgcttgg cctcgcgcgc agatcagttg gaagaatttg 2280
tccactacgt gaaaggcgag atcaccaagg tagtcggcaa ataatgtcta acaattcgtt 2340
caagcttatc gatgataagc tgtcaaacat gagaattctt gaagacgaaa gggcctcgtg 2400
atacgcctat ttttataggt taatgtcatg ataataatgg tttcttagac gtcaggtggc 2460
acttttcggg gaaatgtgcg cggaacccct atttgtttat ttttctaaat acattcaaat 2520
atgtatccgc tcatgagaca ataaccctga taaatgcttc aataatattg aaaaaggaag 2580
agtatgagta ttcaacattt ccgtgtcgcc cttattccct tttttgcggc attttgcctt 2640
cctgtttttg ctcacccaga aacgctggtg aaagtaaaag atgctgaaga tcagttgggt 2700
gcacgagtgg gttacatcga actggatctc aacagcggta agatccttga gagttttcgc 2760
cccgaagaac gttttccaat gatgagcact tttaaagttc tgctatgtgg cgcggtatta 2820
tcccgtgttg acgccgggca agagcaactc ggtcgccgca tacactattc tcagaatgac 2880
ttggttgagt actcaccagt cacagaaaag catcttacgg atggcatgac agtaagagaa 2940
ttatgcagtg ctgccataac catgagtgat aacactgcgg ccaacttact tctgacaacg 3000
atcggaggac cgaaggagct aaccgctttt ttgcacaaca tgggggatca tgtaactcgc 3060
cttgatcgtt gggaaccgga gctgaatgaa gccataccaa acgacgagcg tgacaccacg 3120
atgcctgcag caatggcaac aacgttgcgc aaactattaa ctggcgaact acttactcta 3180
gcttcccggc aacaattaat agactggatg gaggcggata aagttgcagg accacttctg 3240
cgctcggccc ttccggctgg ctggtttatt gctgataaat ctggagccgg tgagcgtggg 3300
tctcgcggta tcattgcagc actggggcca gatggtaagc cctcccgtat cgtagttatc 3360
tacacgacgg ggagtcaggc aactatggat gaacgaaata gacagatcgc tgagataggt 3420
gcctcactga ttaagcattg gtaactgtca gaccaagttt actcatatat actttagatt 3480
gatttaaaac ttcattttta atttaaaagg atctaggtga agatcctttt tgataatctc 3540
atgaccaaaa tcccttaacg tgagttttcg ttccactgag cgtcagaccc cgtagaaaag 3600
atcaaaggat cttcttgaga tccttttttt ctgcgcgtaa tctgctgctt gcaaacaaaa 3660
aaaccaccgc taccagcggt ggtttgtttg ccggatcaag agctaccaac tctttttccg 3720
aaggtaactg gcttcagcag agcgcagata ccaaatactg tccttctagt gtagccgtag 3780
ttaggccacc acttcaagaa ctctgtagca ccgcctacat acctcgctct gctaatcctg 3840
ttaccagtgg ctgctgccag tggcgataag tcgtgtctta ccgggttgga ctcaagacga 3900
tagttaccgg ataaggcgca gcggtcgggc tgaacggggg gttcgtgcac acagcccagc 3960
ttggagcgaa cgacctacac cgaactgaga tacctacagc gtgagctatg agaaagcgcc 4020
acgcttcccg aagggagaaa ggcggacagg tatccggtaa gcggcagggt cggaacagga 4080
gagcgcacga gggagcttcc agggggaaac gcctggtatc tttatagtcc tgtcgggttt 4140
cgccacctct gacttgagcg tcgatttttg tgatgctcgt caggggggcg gagcctatgg 4200
aaaaacgcca gcaacgcggc ctttttacgg ttcctggcct tttgctggcc ttttgctcac 4260
atgttctttc ctgcgttatc ccctgattct gtggataacc gtattaccgc ctttgagtga 4320
gctgataccg ctcgccgcag ccgaacgacc gagcgcagcg agtcagtgag cgaggaagcg 4380
gaagagcgcc tgatgcggta ttttctcctt acgcatctgt gcggtatttc acaccgcata 4440
tatggtgcac tctcagtaca atctgctctg atgccgcata gttaagccag tatacactcc 4500
gctatcgcta cgtgactggg tcatggctgc gccccgacac ccgccaacac ccgctgacgc 4560
gccctgacgg gcttgtctgc tcccggcatc cgcttacaga caagctgtga ccgtctccgg 4620
gagctgcatg tgtcagaggt tttcaccgtc atcaccgaaa cgcgcgaggc agctgcggta 4680
aagctcatca gcgtggtcgt gaagcgattc acagatgtct gcctgttcat ccgcgtccag 4740
ctcgttgagt ttctccagaa gcgttaatgt ctggcttctg ataaagcggg ccatgttaag 4800
ggcggttttt tcctgtttgg tcactgatgc ctccgtgtaa gggggatttc tgttcatggg 4860
ggtaatgata ccgatgaaac gagagaggat gctcacgata cgggttactg atgatgaaca 4920
tgcccggtta ctggaacgtt gtgagggtaa acaactggcg gtatggatgc ggcgggacca 4980
gagaaaaatc actcagggtc aatgccagcg cttcgttaat acagatgtag gtgttccaca 5040
gggtagccag cagcatcctg cgatgcagat ccggaacata atggtgcagg gcgctgactt 5100
ccgcgtttcc agactttacg aaacacggaa accgaagacc attcatgttg ttgctcaggt 5160
cgcagacgtt ttgcagcagc agtcgcttca cgttcgctcg cgtatcggtg attcattctg 5220
ctaaccagta aggcaacccc gccagcctag ccgggtcctc aacgacagga gcacgatcat 5280
gcgcacccgt ggccaggacc caacgctgcc cgagatgcgc cgcgtgcggc tgctggagat 5340
ggcggacgcg atggatatgt tctgccaagg gttggtttgc gcattcacag ttctccgcaa 5400
gaattgattg gctccaattc ttggagtggt gaatccgtta gcgaggtgcc gccggcttcc 5460
attcaggtcg aggtggcccg gctccatgca ccgcgacgca acgcggggag gcagacaagg 5520
tatagggcgg cgcctacaat ccatgccaac ccgttccatg tgctcgccga ggcggcataa 5580
atcgccgtga cgatcagcgg tccagtgatc gaagttaggc tggtaagagc cgcgagcgat 5640
ccttgaagct gtccctgatg gtcgtcatct acctgcctgg acagcatggc ctgcaacgcg 5700
ggcatcccga tgccgccgga agcgagaaga atcataatgg ggaaggccat ccagcctcgc 5760
gtcgcgaacg ccagcaagac gtagcccagc gcgtcggccg ccatgccggc gataatggcc 5820
tgcttctcgc cgaaacgttt ggtggcggga ccagtgacga aggcttgagc gagggcgtgc 5880
aagattccga ataccgcaag cgacaggccg atcatcgtcg cgctccagcg aaagcggtcc 5940
tcgccgaaaa tgacccagag cgctgccggc acctgtccta cgagttgcat gataaagaag 6000
acagtcataa gtgcggcgac gatagtcatg ccccgcgccc accggaagga gctgactggg 6060
ttgaaggctc tcaagggcat cggtcgatcg acgctctccc ttatgcgact cctgcattag 6120
gaagcagccc agtagtaggt tgaggccgtt gagcaccgcc gccgcaagga atggtgcatg 6180
caaggagatg gcgcccaaca gtcccccggc cacggggcct gccaccatac ccacgccgaa 6240
acaagcgctc atgagcccga agtggcgagc ccgatcttcc ccatcggtga tgtcggcgat 6300
ataggcgcca gcaaccgcac ctgtggcgcc ggtgatgccg gccacgatgc gtccggcgta 6360
gaggatcg 6368
<210> 142
<211> 325
<212> PRT
<213> Thermotoga maritima
<400> 142
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly
325
<210> 143
<211> 18
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 143
Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly Ser Ala Gly Gly Pro
1 5 10 15
Gly Ser
<210> 144
<211> 1293
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 144
atggcattct tcgacctgcc actggaggag ctgaagaaat atcgtcctga gcgctatgaa 60
gaaaaggatt ttgatgagtt ctgggaggaa actctggcag aaagcgagaa attcccgctg 120
gacccggtgt ttgaacgtat ggagagccat ttgaaaaccg tggaagccta cgatgtgacc 180
tttagcggct atcgtggtca acgcattaaa ggttggctgc tggtgcctaa gctggaagaa 240
gagaagttgc cttgcgtggt gcaatacatt ggttacaacg gtggtcgtgg ttttccgcac 300
gattggttgt tctggccgag catgggttac atttgctttg tgatggatac ccgcggtcaa 360
ggtagcggtt ggctgaaagg cgacaccccg gattacccgg agggtccagt cgacccacag 420
tacccgggtt ttatgacccg tggtatcctt gacccgcgta cctactacta ccgtcgtgtg 480
ttcaccgacg cggtacgtgc agttgaggca gccgcgtcct tcccacaggt tgaccaggaa 540
cgcatcgtga ttgcgggtgg ctcgcaaggt ggtggtatcg cattggcggt tagcgctctg 600
tccaagaaag caaaagcact gctgtgcgac gtgccgtttc tgtgtcactt ccgtcgtgca 660
gttcagctgg ttgatacgca cccttacgcc gaaattacca actttctgaa aacgcaccgc 720
gataaggaag aaatcgtgtt ccgcaccctg agctattttg acggcgtcaa tttcgcagcg 780
cgtgcgaaga ttccagcgtt gttcagcgtt ggtctgatgg ataacatttc cccgccttct 840
accgttttcg cggcctacaa ctactacgca ggcccgaaag agattcgcat ctacccatat 900
aacaaccatg agggtggcgg tagcttccag gcagttgagc aagttaagtt cctgaagaag 960
ctgttcgaaa agggtggtcc gggttcgggt ggtgcgggca gcccgggtag cgccggtggc 1020
cctggatccc ctagcgcaca aagccaactg ccggacaagc atagcggcct gcacgaacgt 1080
gctccgcagc gttacggtcc ggaaccggaa ccggaaccgg agccgatccc agaaccgccg 1140
aaagaggccc cagttgttat tgaaaagccg aagccgaaac cgaagccgaa gccgaagccg 1200
cctgcgcatg atcataagaa tcagaaggaa acccatcagc gtcacgccgc tggttcgggc 1260
ggtggtggta gcccgcacca tcaccaccac cac 1293
<210> 145
<211> 431
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 145
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly
325 330 335
Ser Ala Gly Gly Pro Gly Ser Pro Ser Ala Gln Ser Gln Leu Pro Asp
340 345 350
Lys His Ser Gly Leu His Glu Arg Ala Pro Gln Arg Tyr Gly Pro Glu
355 360 365
Pro Glu Pro Glu Pro Glu Pro Ile Pro Glu Pro Pro Lys Glu Ala Pro
370 375 380
Val Val Ile Glu Lys Pro Lys Pro Lys Pro Lys Pro Lys Pro Lys Pro
385 390 395 400
Pro Ala His Asp His Lys Asn Gln Lys Glu Thr His Gln Arg His Ala
405 410 415
Ala Gly Ser Gly Gly Gly Gly Ser Pro His His His His His His
420 425 430
<210> 146
<211> 88
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 146
Pro Ser Ala Gln Ser Gln Leu Pro Asp Lys His Ser Gly Leu His Glu
1 5 10 15
Arg Ala Pro Gln Arg Tyr Gly Pro Glu Pro Glu Pro Glu Pro Glu Pro
20 25 30
Ile Pro Glu Pro Pro Lys Glu Ala Pro Val Val Ile Glu Lys Pro Lys
35 40 45
Pro Lys Pro Lys Pro Lys Pro Lys Pro Pro Ala His Asp His Lys Asn
50 55 60
Gln Lys Glu Thr His Gln Arg His Ala Ala Gly Ser Gly Gly Gly Gly
65 70 75 80
Ser Pro His His His His His His
85
<210> 147
<211> 1560
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 147
atggcattct tcgacctgcc actggaggag ctgaagaaat atcgtcctga gcgctatgaa 60
gaaaaggatt ttgatgagtt ctgggaggaa actctggcag aaagcgagaa attcccgctg 120
gacccggtgt ttgaacgtat ggagagccat ttgaaaaccg tggaagccta cgatgtgacc 180
tttagcggct atcgtggtca acgcattaaa ggttggctgc tggtgcctaa gctggaagaa 240
gagaagttgc cttgcgtggt gcaatacatt ggttacaacg gtggtcgtgg ttttccgcac 300
gattggttgt tctggccgag catgggttac atttgctttg tgatggatac ccgcggtcaa 360
ggtagcggtt ggctgaaagg cgacaccccg gattacccgg agggtccagt cgacccacag 420
tacccgggtt ttatgacccg tggtatcctt gacccgcgta cctactacta ccgtcgtgtg 480
ttcaccgacg cggtacgtgc agttgaggca gccgcgtcct tcccacaggt tgaccaggaa 540
cgcatcgtga ttgcgggtgg ctcgcaaggt ggtggtatcg cattggcggt tagcgctctg 600
tccaagaaag caaaagcact gctgtgcgac gtgccgtttc tgtgtcactt ccgtcgtgca 660
gttcagctgg ttgatacgca cccttacgcc gaaattacca actttctgaa aacgcaccgc 720
gataaggaag aaatcgtgtt ccgcaccctg agctattttg acggcgtcaa tttcgcagcg 780
cgtgcgaaga ttccagcgtt gttcagcgtt ggtctgatgg ataacatttc cccgccttct 840
accgttttcg cggcctacaa ctactacgca ggcccgaaag agattcgcat ctacccatat 900
aacaaccatg agggtggcgg tagcttccag gcagttgagc aagttaagtt cctgaagaag 960
ctgttcgaaa agggtggtcc gggttcgggt ggtgcgggca gcccgggtag cgccggtggc 1020
cctggatcca tggcgaatac gccggtgtct ggcaatctga aagtggagtt ttacaatagc 1080
aacccgagcg ataccacgaa ttccatcaac ccacaattca aggtgacgaa tacgggcagc 1140
agcgcgattg atctgagcaa attgacgctg cgctattact ataccgttga tggtcagaag 1200
gaccagacct tttgggcgga tcatgcggca atcatcggca gcaatggcag ctacaacggc 1260
attacctcta atgtgaaggg tactttcgtc aaaatgagca gcagcaccaa caacgctgac 1320
acctacctgg aaatcagctt caccggtggc actctggagc cgggtgccca cgtgcagatc 1380
cagggccgtt tcgcgaagaa tgactggtcc aattacaccc aaagcaatga ttacagcttt 1440
aagagccgct cgcaatttgt tgagtgggac caggttaccg cgtatctgaa cggtgtcttg 1500
gtttggggta aagagccagg cggttcggtg gtgggtggcg gtcaccatca ccaccatcac 1560
<210> 148
<211> 520
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 148
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly
325 330 335
Ser Ala Gly Gly Pro Gly Ser Met Ala Asn Thr Pro Val Ser Gly Asn
340 345 350
Leu Lys Val Glu Phe Tyr Asn Ser Asn Pro Ser Asp Thr Thr Asn Ser
355 360 365
Ile Asn Pro Gln Phe Lys Val Thr Asn Thr Gly Ser Ser Ala Ile Asp
370 375 380
Leu Ser Lys Leu Thr Leu Arg Tyr Tyr Tyr Thr Val Asp Gly Gln Lys
385 390 395 400
Asp Gln Thr Phe Trp Ala Asp His Ala Ala Ile Ile Gly Ser Asn Gly
405 410 415
Ser Tyr Asn Gly Ile Thr Ser Asn Val Lys Gly Thr Phe Val Lys Met
420 425 430
Ser Ser Ser Thr Asn Asn Ala Asp Thr Tyr Leu Glu Ile Ser Phe Thr
435 440 445
Gly Gly Thr Leu Glu Pro Gly Ala His Val Gln Ile Gln Gly Arg Phe
450 455 460
Ala Lys Asn Asp Trp Ser Asn Tyr Thr Gln Ser Asn Asp Tyr Ser Phe
465 470 475 480
Lys Ser Arg Ser Gln Phe Val Glu Trp Asp Gln Val Thr Ala Tyr Leu
485 490 495
Asn Gly Val Leu Val Trp Gly Lys Glu Pro Gly Gly Ser Val Val Gly
500 505 510
Gly Gly His His His His His His
515 520
<210> 149
<211> 177
<212> PRT
<213> Clostridium thermocellum
<400> 149
Met Ala Asn Thr Pro Val Ser Gly Asn Leu Lys Val Glu Phe Tyr Asn
1 5 10 15
Ser Asn Pro Ser Asp Thr Thr Asn Ser Ile Asn Pro Gln Phe Lys Val
20 25 30
Thr Asn Thr Gly Ser Ser Ala Ile Asp Leu Ser Lys Leu Thr Leu Arg
35 40 45
Tyr Tyr Tyr Thr Val Asp Gly Gln Lys Asp Gln Thr Phe Trp Ala Asp
50 55 60
His Ala Ala Ile Ile Gly Ser Asn Gly Ser Tyr Asn Gly Ile Thr Ser
65 70 75 80
Asn Val Lys Gly Thr Phe Val Lys Met Ser Ser Ser Thr Asn Asn Ala
85 90 95
Asp Thr Tyr Leu Glu Ile Ser Phe Thr Gly Gly Thr Leu Glu Pro Gly
100 105 110
Ala His Val Gln Ile Gln Gly Arg Phe Ala Lys Asn Asp Trp Ser Asn
115 120 125
Tyr Thr Gln Ser Asn Asp Tyr Ser Phe Lys Ser Arg Ser Gln Phe Val
130 135 140
Glu Trp Asp Gln Val Thr Ala Tyr Leu Asn Gly Val Leu Val Trp Gly
145 150 155 160
Lys Glu Pro Gly Gly Ser Val Val Gly Gly Gly His His His His His
165 170 175
His
<210> 150
<211> 1647
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 150
atggcattct tcgacctgcc actggaggag ctgaagaaat atcgtcctga gcgctatgaa 60
gaaaaggatt ttgatgagtt ctgggaggaa actctggcag aaagcgagaa attcccgctg 120
gacccggtgt ttgaacgtat ggagagccat ttgaaaaccg tggaagccta cgatgtgacc 180
tttagcggct atcgtggtca acgcattaaa ggttggctgc tggtgcctaa gctggaagaa 240
gagaagttgc cttgcgtggt gcaatacatt ggttacaacg gtggtcgtgg ttttccgcac 300
gattggttgt tctggccgag catgggttac atttgctttg tgatggatac ccgcggtcaa 360
ggtagcggtt ggctgaaagg cgacaccccg gattacccgg agggtccagt cgacccacag 420
tacccgggtt ttatgacccg tggtatcctt gacccgcgta cctactacta ccgtcgtgtg 480
ttcaccgacg cggtacgtgc agttgaggca gccgcgtcct tcccacaggt tgaccaggaa 540
cgcatcgtga ttgcgggtgg ctcgcaaggt ggtggtatcg cattggcggt tagcgctctg 600
tccaagaaag caaaagcact gctgtgcgac gtgccgtttc tgtgtcactt ccgtcgtgca 660
gttcagctgg ttgatacgca cccttacgcc gaaattacca actttctgaa aacgcaccgc 720
gataaggaag aaatcgtgtt ccgcaccctg agctattttg acggcgtcaa tttcgcagcg 780
cgtgcgaaga ttccagcgtt gttcagcgtt ggtctgatgg ataacatttc cccgccttct 840
accgttttcg cggcctacaa ctactacgca ggcccgaaag agattcgcat ctacccatat 900
aacaaccatg agggtggcgg tagcttccag gcagttgagc aagttaagtt cctgaagaag 960
ctgttcgaaa agggtggtcc gggttcgggt ggtgcgggca gcccgggtag cgccggtggc 1020
cctggatcca tggcaagcta tgctacccct gttgatccag ttacgaacca gccgacggca 1080
ccgaaagact ttagcagcgg cttttgggac ttcaatgacg gcaccaccca gggttttggc 1140
gtgaatccgg atagcccgat tactgccatt aacgtcgaga acgctaacaa tgcgctgaag 1200
atcagcaacc tgaacagcaa aggtagcaat gatctgtctg aaggcaattt ctgggctaac 1260
gttcgcatca gcgcagacat ctggggtcaa tcgatcaaca tttacggcga taccaagttg 1320
actatggacg tgatcgcgcc gactccggtg aacgtgtcca ttgcagccat cccgcagagc 1380
tccacccacg gctggggtaa tccgacgcgt gcgattcgtg tctggaccaa taacttcgtt 1440
gcgcaaacgg acggtacgta caaagcgacc ctgaccatta gcaccaatga ttccccgaat 1500
ttcaatacca ttgcgacgga tgccgcagac tctgtcgtta ccaacatgat tctgttcgtg 1560
ggtagcaata gcgacaatat cagcctggat aacatcaagt ttacgaaagg tccgtctggt 1620
ccgggtaccc accaccatca ccatcac 1647
<210> 151
<211> 549
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 151
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly
325 330 335
Ser Ala Gly Gly Pro Gly Ser Met Ala Ser Tyr Ala Thr Pro Val Asp
340 345 350
Pro Val Thr Asn Gln Pro Thr Ala Pro Lys Asp Phe Ser Ser Gly Phe
355 360 365
Trp Asp Phe Asn Asp Gly Thr Thr Gln Gly Phe Gly Val Asn Pro Asp
370 375 380
Ser Pro Ile Thr Ala Ile Asn Val Glu Asn Ala Asn Asn Ala Leu Lys
385 390 395 400
Ile Ser Asn Leu Asn Ser Lys Gly Ser Asn Asp Leu Ser Glu Gly Asn
405 410 415
Phe Trp Ala Asn Val Arg Ile Ser Ala Asp Ile Trp Gly Gln Ser Ile
420 425 430
Asn Ile Tyr Gly Asp Thr Lys Leu Thr Met Asp Val Ile Ala Pro Thr
435 440 445
Pro Val Asn Val Ser Ile Ala Ala Ile Pro Gln Ser Ser Thr His Gly
450 455 460
Trp Gly Asn Pro Thr Arg Ala Ile Arg Val Trp Thr Asn Asn Phe Val
465 470 475 480
Ala Gln Thr Asp Gly Thr Tyr Lys Ala Thr Leu Thr Ile Ser Thr Asn
485 490 495
Asp Ser Pro Asn Phe Asn Thr Ile Ala Thr Asp Ala Ala Asp Ser Val
500 505 510
Val Thr Asn Met Ile Leu Phe Val Gly Ser Asn Ser Asp Asn Ile Ser
515 520 525
Leu Asp Asn Ile Lys Phe Thr Lys Gly Pro Ser Gly Pro Gly Thr His
530 535 540
His His His His His
545
<210> 152
<211> 206
<212> PRT
<213> Clostridium cellulovorans
<400> 152
Met Ala Ser Tyr Ala Thr Pro Val Asp Pro Val Thr Asn Gln Pro Thr
1 5 10 15
Ala Pro Lys Asp Phe Ser Ser Gly Phe Trp Asp Phe Asn Asp Gly Thr
20 25 30
Thr Gln Gly Phe Gly Val Asn Pro Asp Ser Pro Ile Thr Ala Ile Asn
35 40 45
Val Glu Asn Ala Asn Asn Ala Leu Lys Ile Ser Asn Leu Asn Ser Lys
50 55 60
Gly Ser Asn Asp Leu Ser Glu Gly Asn Phe Trp Ala Asn Val Arg Ile
65 70 75 80
Ser Ala Asp Ile Trp Gly Gln Ser Ile Asn Ile Tyr Gly Asp Thr Lys
85 90 95
Leu Thr Met Asp Val Ile Ala Pro Thr Pro Val Asn Val Ser Ile Ala
100 105 110
Ala Ile Pro Gln Ser Ser Thr His Gly Trp Gly Asn Pro Thr Arg Ala
115 120 125
Ile Arg Val Trp Thr Asn Asn Phe Val Ala Gln Thr Asp Gly Thr Tyr
130 135 140
Lys Ala Thr Leu Thr Ile Ser Thr Asn Asp Ser Pro Asn Phe Asn Thr
145 150 155 160
Ile Ala Thr Asp Ala Ala Asp Ser Val Val Thr Asn Met Ile Leu Phe
165 170 175
Val Gly Ser Asn Ser Asp Asn Ile Ser Leu Asp Asn Ile Lys Phe Thr
180 185 190
Lys Gly Pro Ser Gly Pro Gly Thr His His His His His His
195 200 205
<210> 153
<211> 1653
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 153
atggcattct tcgacctgcc actggaggag ctgaagaaat atcgtcctga gcgctatgaa 60
gaaaaggatt ttgatgagtt ctgggaggaa actctggcag aaagcgagaa attcccgctg 120
gacccggtgt ttgaacgtat ggagagccat ttgaaaaccg tggaagccta cgatgtgacc 180
tttagcggct atcgtggtca acgcattaaa ggttggctgc tggtgcctaa gctggaagaa 240
gagaagttgc cttgcgtggt gcaatacatt ggttacaacg gtggtcgtgg ttttccgcac 300
gattggttgt tctggccgag catgggttac atttgctttg tgatggatac ccgcggtcaa 360
ggtagcggtt ggctgaaagg cgacaccccg gattacccgg agggtccagt cgacccacag 420
tacccgggtt ttatgacccg tggtatcctt gacccgcgta cctactacta ccgtcgtgtg 480
ttcaccgacg cggtacgtgc agttgaggca gccgcgtcct tcccacaggt tgaccaggaa 540
cgcatcgtga ttgcgggtgg ctcgcaaggt ggtggtatcg cattggcggt tagcgctctg 600
tccaagaaag caaaagcact gctgtgcgac gtgccgtttc tgtgtcactt ccgtcgtgca 660
gttcagctgg ttgatacgca cccttacgcc gaaattacca actttctgaa aacgcaccgc 720
gataaggaag aaatcgtgtt ccgcaccctg agctattttg acggcgtcaa tttcgcagcg 780
cgtgcgaaga ttccagcgtt gttcagcgtt ggtctgatgg ataacatttc cccgccttct 840
accgttttcg cggcctacaa ctactacgca ggcccgaaag agattcgcat ctacccatat 900
aacaaccatg agggtggcgg tagcttccag gcagttgagc aagttaagtt cctgaagaag 960
ctgttcgaaa agggtggtcc gggttcgggt ggtgcgggca gcccgggtag cgccggtggc 1020
cctggatcca tggctagcgg tacggaggtg gaaatcccgg ttgtgcacga tcctaagggc 1080
gaggcggtgt tgccgagcgt ttttgaggac ggcacgcgtc agggttggga ctgggcgggt 1140
gagagcggcg tgaaaacggc gctgaccatt gaagaggcga acggctcgaa cgcactgagc 1200
tgggaatttg gctacccgga ggttaaaccg tccgataact gggcaaccgc cccacgtctg 1260
gatttctgga agtctgacct ggttcgtggt gagaatgact atgtgacgtt cgatttctat 1320
ctggacccgg ttcgcgcaac cgaaggtgcg atgaacatta acctggtctt tcagccgccg 1380
accaatggtt actgggtgca ggcgccgaaa acctatacta tcaatttcga tgaattggaa 1440
gaaccgaatc aagtcaacgg cctgtaccat tacgaggtta agattaacgt ccgtgacatt 1500
accaacatcc aagacgacac gctgctgcgc aatatgatga tcattttcgc ggacgtcgag 1560
agcgatttcg ccggtcgtgt ctttgttgac aatgtccgct ttgagggcgc tgcgggtccg 1620
agcggtcctg gtacccacca ccatcaccat cac 1653
<210> 154
<211> 551
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 154
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly
325 330 335
Ser Ala Gly Gly Pro Gly Ser Met Ala Ser Gly Thr Glu Val Glu Ile
340 345 350
Pro Val Val His Asp Pro Lys Gly Glu Ala Val Leu Pro Ser Val Phe
355 360 365
Glu Asp Gly Thr Arg Gln Gly Trp Asp Trp Ala Gly Glu Ser Gly Val
370 375 380
Lys Thr Ala Leu Thr Ile Glu Glu Ala Asn Gly Ser Asn Ala Leu Ser
385 390 395 400
Trp Glu Phe Gly Tyr Pro Glu Val Lys Pro Ser Asp Asn Trp Ala Thr
405 410 415
Ala Pro Arg Leu Asp Phe Trp Lys Ser Asp Leu Val Arg Gly Glu Asn
420 425 430
Asp Tyr Val Thr Phe Asp Phe Tyr Leu Asp Pro Val Arg Ala Thr Glu
435 440 445
Gly Ala Met Asn Ile Asn Leu Val Phe Gln Pro Pro Thr Asn Gly Tyr
450 455 460
Trp Val Gln Ala Pro Lys Thr Tyr Thr Ile Asn Phe Asp Glu Leu Glu
465 470 475 480
Glu Pro Asn Gln Val Asn Gly Leu Tyr His Tyr Glu Val Lys Ile Asn
485 490 495
Val Arg Asp Ile Thr Asn Ile Gln Asp Asp Thr Leu Leu Arg Asn Met
500 505 510
Met Ile Ile Phe Ala Asp Val Glu Ser Asp Phe Ala Gly Arg Val Phe
515 520 525
Val Asp Asn Val Arg Phe Glu Gly Ala Ala Gly Pro Ser Gly Pro Gly
530 535 540
Thr His His His His His His
545 550
<210> 155
<211> 208
<212> PRT
<213> Bacillus sp.
<400> 155
Met Ala Ser Gly Thr Glu Val Glu Ile Pro Val Val His Asp Pro Lys
1 5 10 15
Gly Glu Ala Val Leu Pro Ser Val Phe Glu Asp Gly Thr Arg Gln Gly
20 25 30
Trp Asp Trp Ala Gly Glu Ser Gly Val Lys Thr Ala Leu Thr Ile Glu
35 40 45
Glu Ala Asn Gly Ser Asn Ala Leu Ser Trp Glu Phe Gly Tyr Pro Glu
50 55 60
Val Lys Pro Ser Asp Asn Trp Ala Thr Ala Pro Arg Leu Asp Phe Trp
65 70 75 80
Lys Ser Asp Leu Val Arg Gly Glu Asn Asp Tyr Val Thr Phe Asp Phe
85 90 95
Tyr Leu Asp Pro Val Arg Ala Thr Glu Gly Ala Met Asn Ile Asn Leu
100 105 110
Val Phe Gln Pro Pro Thr Asn Gly Tyr Trp Val Gln Ala Pro Lys Thr
115 120 125
Tyr Thr Ile Asn Phe Asp Glu Leu Glu Glu Pro Asn Gln Val Asn Gly
130 135 140
Leu Tyr His Tyr Glu Val Lys Ile Asn Val Arg Asp Ile Thr Asn Ile
145 150 155 160
Gln Asp Asp Thr Leu Leu Arg Asn Met Met Ile Ile Phe Ala Asp Val
165 170 175
Glu Ser Asp Phe Ala Gly Arg Val Phe Val Asp Asn Val Arg Phe Glu
180 185 190
Gly Ala Ala Gly Pro Ser Gly Pro Gly Thr His His His His His His
195 200 205
<210> 156
<211> 1599
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 156
atggcattct tcgacctgcc actggaggag ctgaagaaat atcgtcctga gcgctatgaa 60
gaaaaggatt ttgatgagtt ctgggaggaa actctggcag aaagcgagaa attcccgctg 120
gacccggtgt ttgaacgtat ggagagccat ttgaaaaccg tggaagccta cgatgtgacc 180
tttagcggct atcgtggtca acgcattaaa ggttggctgc tggtgcctaa gctggaagaa 240
gagaagttgc cttgcgtggt gcaatacatt ggttacaacg gtggtcgtgg ttttccgcac 300
gattggttgt tctggccgag catgggttac atttgctttg tgatggatac ccgcggtcaa 360
ggtagcggtt ggctgaaagg cgacaccccg gattacccgg agggtccagt cgacccacag 420
tacccgggtt ttatgacccg tggtatcctt gacccgcgta cctactacta ccgtcgtgtg 480
ttcaccgacg cggtacgtgc agttgaggca gccgcgtcct tcccacaggt tgaccaggaa 540
cgcatcgtga ttgcgggtgg ctcgcaaggt ggtggtatcg cattggcggt tagcgctctg 600
tccaagaaag caaaagcact gctgtgcgac gtgccgtttc tgtgtcactt ccgtcgtgca 660
gttcagctgg ttgatacgca cccttacgcc gaaattacca actttctgaa aacgcaccgc 720
gataaggaag aaatcgtgtt ccgcaccctg agctattttg acggcgtcaa tttcgcagcg 780
cgtgcgaaga ttccagcgtt gttcagcgtt ggtctgatgg ataacatttc cccgccttct 840
accgttttcg cggcctacaa ctactacgca ggcccgaaag agattcgcat ctacccatat 900
aacaaccatg agggtggcgg tagcttccag gcagttgagc aagttaagtt cctgaagaag 960
ctgttcgaaa agggtggtcc gggttcgggt ggtgcgggca gcccgggtag cgccggtggc 1020
cctggatccg tggcaactgc taagtatggc acgcctgtta ttgacggcga gattgatgag 1080
atctggaata ccaccgaaga gattgaaacg aaggcagtcg cgatgggttc tttggataag 1140
aatgcgactg cgaaagttcg tgtgctgtgg gacgaaaact acctgtacgt gctggcgatt 1200
gtgaaagatc cggttctgaa caaggataac agcaatccgt gggaacagga ctccgtcgag 1260
attttcattg acgagaacaa tcacaaaacc ggttactatg aggacgacga cgcacagttc 1320
cgcgttaact atatgaacga gcaaaccttt ggtacgggcg gtagcccggc tcgtttcaag 1380
acggccgtta aactgatcga gggcggttac attgtcgaag cggcgatcaa atggaaaacg 1440
atcaaaccaa ccccgaatac cgtcatcggc ttcaatatcc aggtgaatga tgccaatgaa 1500
aagggtcaac gtgtgggcat cattagctgg agcgatccga ccaacaacag ctggcgcgac 1560
ccgagcaagt ttggtaacct gcgtctgatc aaataatga 1599
<210> 157
<211> 531
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 157
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly
325 330 335
Ser Ala Gly Gly Pro Gly Ser Val Ala Thr Ala Lys Tyr Gly Thr Pro
340 345 350
Val Ile Asp Gly Glu Ile Asp Glu Ile Trp Asn Thr Thr Glu Glu Ile
355 360 365
Glu Thr Lys Ala Val Ala Met Gly Ser Leu Asp Lys Asn Ala Thr Ala
370 375 380
Lys Val Arg Val Leu Trp Asp Glu Asn Tyr Leu Tyr Val Leu Ala Ile
385 390 395 400
Val Lys Asp Pro Val Leu Asn Lys Asp Asn Ser Asn Pro Trp Glu Gln
405 410 415
Asp Ser Val Glu Ile Phe Ile Asp Glu Asn Asn His Lys Thr Gly Tyr
420 425 430
Tyr Glu Asp Asp Asp Ala Gln Phe Arg Val Asn Tyr Met Asn Glu Gln
435 440 445
Thr Phe Gly Thr Gly Gly Ser Pro Ala Arg Phe Lys Thr Ala Val Lys
450 455 460
Leu Ile Glu Gly Gly Tyr Ile Val Glu Ala Ala Ile Lys Trp Lys Thr
465 470 475 480
Ile Lys Pro Thr Pro Asn Thr Val Ile Gly Phe Asn Ile Gln Val Asn
485 490 495
Asp Ala Asn Glu Lys Gly Gln Arg Val Gly Ile Ile Ser Trp Ser Asp
500 505 510
Pro Thr Asn Asn Ser Trp Arg Asp Pro Ser Lys Phe Gly Asn Leu Arg
515 520 525
Leu Ile Lys
530
<210> 158
<211> 187
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 158
Val Ala Thr Ala Lys Tyr Gly Thr Pro Val Ile Asp Gly Glu Ile Asp
1 5 10 15
Glu Ile Trp Asn Thr Thr Glu Glu Ile Glu Thr Lys Ala Val Ala Met
20 25 30
Gly Ser Leu Asp Lys Asn Ala Thr Ala Lys Val Arg Val Leu Trp Asp
35 40 45
Glu Asn Tyr Leu Tyr Val Leu Ala Ile Val Lys Asp Pro Val Leu Asn
50 55 60
Lys Asp Asn Ser Asn Pro Trp Glu Gln Asp Ser Val Glu Ile Phe Ile
65 70 75 80
Asp Glu Asn Asn His Lys Thr Gly Tyr Tyr Glu Asp Asp Asp Ala Gln
85 90 95
Phe Arg Val Asn Tyr Met Asn Glu Gln Thr Phe Gly Thr Gly Gly Ser
100 105 110
Pro Ala Arg Phe Lys Thr Ala Val Lys Leu Ile Glu Gly Gly Tyr Ile
115 120 125
Val Glu Ala Ala Ile Lys Trp Lys Thr Ile Lys Pro Thr Pro Asn Thr
130 135 140
Val Ile Gly Phe Asn Ile Gln Val Asn Asp Ala Asn Glu Lys Gly Gln
145 150 155 160
Arg Val Gly Ile Ile Ser Trp Ser Asp Pro Thr Asn Asn Ser Trp Arg
165 170 175
Asp Pro Ser Lys Phe Gly Asn Leu Arg Leu Ile
180 185
<210> 159
<211> 1521
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 159
atggcattct tcgacctgcc actggaggag ctgaagaaat atcgtcctga gcgctatgaa 60
gaaaaggatt ttgatgagtt ctgggaggaa actctggcag aaagcgagaa attcccgctg 120
gacccggtgt ttgaacgtat ggagagccat ttgaaaaccg tggaagccta cgatgtgacc 180
tttagcggct atcgtggtca acgcattaaa ggttggctgc tggtgcctaa gctggaagaa 240
gagaagttgc cttgcgtggt gcaatacatt ggttacaacg gtggtcgtgg ttttccgcac 300
gattggttgt tctggccgag catgggttac atttgctttg tgatggatac ccgcggtcaa 360
ggtagcggtt ggctgaaagg cgacaccccg gattacccgg agggtccagt cgacccacag 420
tacccgggtt ttatgacccg tggtatcctt gacccgcgta cctactacta ccgtcgtgtg 480
ttcaccgacg cggtacgtgc agttgaggca gccgcgtcct tcccacaggt tgaccaggaa 540
cgcatcgtga ttgcgggtgg ctcgcaaggt ggtggtatcg cattggcggt tagcgctctg 600
tccaagaaag caaaagcact gctgtgcgac gtgccgtttc tgtgtcactt ccgtcgtgca 660
gttcagctgg ttgatacgca cccttacgcc gaaattacca actttctgaa aacgcaccgc 720
gataaggaag aaatcgtgtt ccgcaccctg agctattttg acggcgtcaa tttcgcagcg 780
cgtgcgaaga ttccagcgtt gttcagcgtt ggtctgatgg ataacatttc cccgccttct 840
accgttttcg cggcctacaa ctactacgca ggcccgaaag agattcgcat ctacccatat 900
aacaaccatg agggtggcgg tagcttccag gcagttgagc aagttaagtt cctgaagaag 960
ctgttcgaaa agggtggtcc gggttcgggt ggtgcgggca gcccgggtag cgccggtggc 1020
cctggatcca ccccagcgac gtctggtcaa atcaaggttc tgtatgcgaa caaagagact 1080
aattccacca cgaacactat ccgtccgtgg ctgaaagtgg tcaatagcgg tagcagcagc 1140
attgatctga gccgtgtcac gattcgctat tggtacacgg tcgacggcga gcgtgcgcag 1200
agcgcgatct ccgattgggc tcaaattggc gcgtccaacg ttacctttaa gtttgtgaaa 1260
ctgagctcta gcgtgagcgg tgcagactac tatttggaaa ttggtttcaa gagcggtgcc 1320
ggccaactgc agccgggtaa agataccggc gagatccaga tccgtttcaa caaggacgac 1380
tggagcaatt acaatcaggg taatgattgg agctggattc agtcgatgac cagctacggt 1440
gaaaacgaaa aagtgaccgc ctacatcgac ggcgttctgg tttggggtca agagccgagc 1500
ggcaccaccc cggcataatg a 1521
<210> 160
<211> 505
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 160
Met Ala Phe Phe Asp Leu Pro Leu Glu Glu Leu Lys Lys Tyr Arg Pro
1 5 10 15
Glu Arg Tyr Glu Glu Lys Asp Phe Asp Glu Phe Trp Glu Glu Thr Leu
20 25 30
Ala Glu Ser Glu Lys Phe Pro Leu Asp Pro Val Phe Glu Arg Met Glu
35 40 45
Ser His Leu Lys Thr Val Glu Ala Tyr Asp Val Thr Phe Ser Gly Tyr
50 55 60
Arg Gly Gln Arg Ile Lys Gly Trp Leu Leu Val Pro Lys Leu Glu Glu
65 70 75 80
Glu Lys Leu Pro Cys Val Val Gln Tyr Ile Gly Tyr Asn Gly Gly Arg
85 90 95
Gly Phe Pro His Asp Trp Leu Phe Trp Pro Ser Met Gly Tyr Ile Cys
100 105 110
Phe Val Met Asp Thr Arg Gly Gln Gly Ser Gly Trp Leu Lys Gly Asp
115 120 125
Thr Pro Asp Tyr Pro Glu Gly Pro Val Asp Pro Gln Tyr Pro Gly Phe
130 135 140
Met Thr Arg Gly Ile Leu Asp Pro Arg Thr Tyr Tyr Tyr Arg Arg Val
145 150 155 160
Phe Thr Asp Ala Val Arg Ala Val Glu Ala Ala Ala Ser Phe Pro Gln
165 170 175
Val Asp Gln Glu Arg Ile Val Ile Ala Gly Gly Ser Gln Gly Gly Gly
180 185 190
Ile Ala Leu Ala Val Ser Ala Leu Ser Lys Lys Ala Lys Ala Leu Leu
195 200 205
Cys Asp Val Pro Phe Leu Cys His Phe Arg Arg Ala Val Gln Leu Val
210 215 220
Asp Thr His Pro Tyr Ala Glu Ile Thr Asn Phe Leu Lys Thr His Arg
225 230 235 240
Asp Lys Glu Glu Ile Val Phe Arg Thr Leu Ser Tyr Phe Asp Gly Val
245 250 255
Asn Phe Ala Ala Arg Ala Lys Ile Pro Ala Leu Phe Ser Val Gly Leu
260 265 270
Met Asp Asn Ile Ser Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn Tyr
275 280 285
Tyr Ala Gly Pro Lys Glu Ile Arg Ile Tyr Pro Tyr Asn Asn His Glu
290 295 300
Gly Gly Gly Ser Phe Gln Ala Val Glu Gln Val Lys Phe Leu Lys Lys
305 310 315 320
Leu Phe Glu Lys Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly
325 330 335
Ser Ala Gly Gly Pro Gly Ser Thr Pro Ala Thr Ser Gly Gln Ile Lys
340 345 350
Val Leu Tyr Ala Asn Lys Glu Thr Asn Ser Thr Thr Asn Thr Ile Arg
355 360 365
Pro Trp Leu Lys Val Val Asn Ser Gly Ser Ser Ser Ile Asp Leu Ser
370 375 380
Arg Val Thr Ile Arg Tyr Trp Tyr Thr Val Asp Gly Glu Arg Ala Gln
385 390 395 400
Ser Ala Ile Ser Asp Trp Ala Gln Ile Gly Ala Ser Asn Val Thr Phe
405 410 415
Lys Phe Val Lys Leu Ser Ser Ser Val Ser Gly Ala Asp Tyr Tyr Leu
420 425 430
Glu Ile Gly Phe Lys Ser Gly Ala Gly Gln Leu Gln Pro Gly Lys Asp
435 440 445
Thr Gly Glu Ile Gln Ile Arg Phe Asn Lys Asp Asp Trp Ser Asn Tyr
450 455 460
Asn Gln Gly Asn Asp Trp Ser Trp Ile Gln Ser Met Thr Ser Tyr Gly
465 470 475 480
Glu Asn Glu Lys Val Thr Ala Tyr Ile Asp Gly Val Leu Val Trp Gly
485 490 495
Gln Glu Pro Ser Gly Thr Thr Pro Ala
500 505
<210> 161
<211> 162
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 161
Thr Pro Ala Thr Ser Gly Gln Ile Lys Val Leu Tyr Ala Asn Lys Glu
1 5 10 15
Thr Asn Ser Thr Thr Asn Thr Ile Arg Pro Trp Leu Lys Val Val Asn
20 25 30
Ser Gly Ser Ser Ser Ile Asp Leu Ser Arg Val Thr Ile Arg Tyr Trp
35 40 45
Tyr Thr Val Asp Gly Glu Arg Ala Gln Ser Ala Ile Ser Asp Trp Ala
50 55 60
Gln Ile Gly Ala Ser Asn Val Thr Phe Lys Phe Val Lys Leu Ser Ser
65 70 75 80
Ser Val Ser Gly Ala Asp Tyr Tyr Leu Glu Ile Gly Phe Lys Ser Gly
85 90 95
Ala Gly Gln Leu Gln Pro Gly Lys Asp Thr Gly Glu Ile Gln Ile Arg
100 105 110
Phe Asn Lys Asp Asp Trp Ser Asn Tyr Asn Gln Gly Asn Asp Trp Ser
115 120 125
Trp Ile Gln Ser Met Thr Ser Tyr Gly Glu Asn Glu Lys Val Thr Ala
130 135 140
Tyr Ile Asp Gly Val Leu Val Trp Gly Gln Glu Pro Ser Gly Thr Thr
145 150 155 160
Pro Ala
<210> 162
<211> 216
<212> PRT
<213> Mycobacterium smegmatis
<400> 162
Met Ala Lys Arg Ile Leu Cys Phe Gly Asp Ser Leu Thr Trp Gly Trp
1 5 10 15
Val Pro Val Glu Asp Gly Ala Pro Thr Glu Arg Phe Ala Pro Asp Val
20 25 30
Arg Trp Thr Gly Val Leu Ala Gln Gln Leu Gly Ala Asp Phe Glu Val
35 40 45
Ile Glu Glu Gly Leu Val Ala Arg Thr Thr Asn Ile Asp Asp Pro Thr
50 55 60
Asp Pro Arg Leu Asn Gly Ala Ser Tyr Leu Pro Ser Cys Leu Ala Thr
65 70 75 80
His Leu Pro Leu Asp Leu Val Ile Ile Met Leu Gly Thr Asn Asp Thr
85 90 95
Lys Ala Tyr Phe Arg Arg Thr Pro Leu Asp Ile Ala Leu Gly Met Ser
100 105 110
Val Leu Val Thr Gln Val Leu Thr Ser Ala Gly Gly Val Gly Thr Thr
115 120 125
Tyr Pro Ala Pro Lys Val Leu Val Val Ser Pro Pro Pro Leu Ala Pro
130 135 140
Met Pro His Pro Trp Phe Gln Leu Ile Phe Glu Gly Gly Glu Gln Lys
145 150 155 160
Thr Thr Glu Leu Ala Arg Val Tyr Ser Ala Leu Ala Ser Phe Met Lys
165 170 175
Val Pro Phe Phe Asp Ala Gly Ser Val Ile Ser Thr Asp Gly Val Asp
180 185 190
Gly Ile His Phe Thr Glu Ala Asn Asn Arg Asp Leu Gly Val Ala Leu
195 200 205
Ala Glu Gln Val Arg Ser Leu Leu
210 215
<210> 163
<211> 272
<212> PRT
<213> Pseudomonas fluorescens
<400> 163
Met Ser Thr Phe Val Ala Lys Asp Gly Thr Gln Ile Tyr Phe Lys Asp
1 5 10 15
Trp Gly Ser Gly Lys Pro Val Leu Phe Ser His Gly Trp Pro Leu Asp
20 25 30
Ala Asp Met Trp Glu Tyr Gln Met Glu Tyr Leu Ser Ser Arg Gly Tyr
35 40 45
Arg Thr Ile Ala Phe Asp Arg Arg Gly Phe Gly Arg Ser Asp Gln Pro
50 55 60
Trp Thr Gly Asn Asp Tyr Asp Thr Phe Ala Asp Asp Ile Ala Gln Leu
65 70 75 80
Ile Glu His Leu Asp Leu Lys Glu Val Thr Leu Val Gly Phe Ser Met
85 90 95
Gly Gly Gly Asp Val Ala Arg Tyr Ile Ala Arg His Gly Ser Ala Arg
100 105 110
Val Ala Gly Leu Val Leu Leu Gly Ala Val Thr Pro Leu Phe Gly Gln
115 120 125
Lys Pro Asp Tyr Pro Gln Gly Val Pro Leu Asp Val Phe Ala Arg Phe
130 135 140
Lys Thr Glu Leu Leu Lys Asp Arg Ala Gln Phe Ile Ser Asp Phe Asn
145 150 155 160
Ala Pro Phe Tyr Gly Ile Asn Lys Gly Gln Val Val Ser Gln Gly Val
165 170 175
Gln Thr Gln Thr Leu Gln Ile Ala Leu Leu Ala Ser Leu Lys Ala Thr
180 185 190
Val Asp Cys Val Thr Ala Phe Ala Glu Thr Asp Phe Arg Pro Asp Met
195 200 205
Ala Lys Ile Asp Val Pro Thr Leu Val Ile His Gly Asp Gly Asp Gln
210 215 220
Ile Val Pro Phe Glu Thr Thr Gly Lys Val Ala Ala Glu Leu Ile Lys
225 230 235 240
Gly Ala Glu Leu Lys Val Tyr Lys Asp Ala Pro His Gly Phe Ala Val
245 250 255
Thr His Ala Gln Gln Leu Asn Glu Asp Leu Leu Ala Phe Leu Lys Arg
260 265 270
<210> 164
<211> 1545
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 164
atgcagctgt tcgatttgag cctggaagaa ttgaaaaagt acaaaccgaa aaagacggcg 60
cgtccggact tttctgattt ttggaaaaag tctctggagg aactgcgtca ggtcgaggcg 120
gagccgaccc tggaaagcta cgactaccct gtcaagggcg ttaaggtgta ccgcctgacc 180
taccagagct tcggtcatag caaaatcgag ggtttctatg cggtgccgga ccaaaccggt 240
ccgcacccgg cactggttcg tttccacggt tataacgcca gctatgatgg cggtatccat 300
gacatcgtca attgggcact gcatggttac gcaacgtttg gcatgctggt tcgcggccaa 360
ggcggtagcg aggataccag cgttaccccg ggtggccacg cgctgggctg gatgaccaag 420
ggtattctgt ccaaggatac ctattactac cgtggtgtat acttggatgc agttcgtgcg 480
ctggaggtca ttcaaagctt tccggaagtt gacgagcatc gtatcggtgt gattggtggt 540
agccagggtg gcgcgctggc gattgcagct gccgcgttga gcgatattcc gaaagtcgtg 600
gttgcggact atccgtatct gtcgaacttt gagcgcgctg tcgacgtggc actggaacaa 660
ccgtacctgg agattaacag ctacttccgc cgtaatagcg acccgaaagt ggaggagaag 720
gcgtttgaaa ctctgagcta ttttgatctg atcaatctgg cgggttgggt gaaacaaccg 780
accctgatgg ccattggcct gatcgataag atcactccgc cgtctacggt gttcgcggca 840
tataaccacc tggaaaccga caaagacttg aaagtttacc gttatttcgg ccacgagttt 900
atcccagcct tccagacgga aaagttgagc ttcctgcaga aacacctgct gctgagcacg 960
ggtccgggca gcggcggtgc tggttcccct ggcagcgccg gtggtccagg atccatggcg 1020
aatacgccgg tgtctggcaa tctgaaagtg gagttttaca atagcaaccc gagcgatacc 1080
acgaattcca tcaacccaca attcaaggtg acgaatacgg gcagcagcgc gattgatctg 1140
agcaaattga cgctgcgcta ttactatacc gttgatggtc agaaggacca gaccttttgg 1200
gcggatcatg cggcaatcat cggcagcaat ggcagctaca acggcattac ctctaatgtg 1260
aagggtactt tcgtcaaaat gagcagcagc accaacaacg ctgacaccta cctggaaatc 1320
agcttcaccg gtggcactct ggagccgggt gcccacgtgc agatccaggg ccgtttcgcg 1380
aagaatgact ggtccaatta cacccaaagc aatgattaca gctttaagag ccgctcgcaa 1440
tttgttgagt gggaccaggt taccgcgtat ctgaacggtg tcttggtttg gggtaaagag 1500
ccaggcggtt cggtggtggg tggcggtcac catcaccacc atcac 1545
<210> 165
<211> 515
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 165
Met Gln Leu Phe Asp Leu Ser Leu Glu Glu Leu Lys Lys Tyr Lys Pro
1 5 10 15
Lys Lys Thr Ala Arg Pro Asp Phe Ser Asp Phe Trp Lys Lys Ser Leu
20 25 30
Glu Glu Leu Arg Gln Val Glu Ala Glu Pro Thr Leu Glu Ser Tyr Asp
35 40 45
Tyr Pro Val Lys Gly Val Lys Val Tyr Arg Leu Thr Tyr Gln Ser Phe
50 55 60
Gly His Ser Lys Ile Glu Gly Phe Tyr Ala Val Pro Asp Gln Thr Gly
65 70 75 80
Pro His Pro Ala Leu Val Arg Phe His Gly Tyr Asn Ala Ser Tyr Asp
85 90 95
Gly Gly Ile His Asp Ile Val Asn Trp Ala Leu His Gly Tyr Ala Thr
100 105 110
Phe Gly Met Leu Val Arg Gly Gln Gly Gly Ser Glu Asp Thr Ser Val
115 120 125
Thr Pro Gly Gly His Ala Leu Gly Trp Met Thr Lys Gly Ile Leu Ser
130 135 140
Lys Asp Thr Tyr Tyr Tyr Arg Gly Val Tyr Leu Asp Ala Val Arg Ala
145 150 155 160
Leu Glu Val Ile Gln Ser Phe Pro Glu Val Asp Glu His Arg Ile Gly
165 170 175
Val Ile Gly Gly Ser Gln Gly Gly Ala Leu Ala Ile Ala Ala Ala Ala
180 185 190
Leu Ser Asp Ile Pro Lys Val Val Val Ala Asp Tyr Pro Tyr Leu Ser
195 200 205
Asn Phe Glu Arg Ala Val Asp Val Ala Leu Glu Gln Pro Tyr Leu Glu
210 215 220
Ile Asn Ser Tyr Phe Arg Arg Asn Ser Asp Pro Lys Val Glu Glu Lys
225 230 235 240
Ala Phe Glu Thr Leu Ser Tyr Phe Asp Leu Ile Asn Leu Ala Gly Trp
245 250 255
Val Lys Gln Pro Thr Leu Met Ala Ile Gly Leu Ile Asp Lys Ile Thr
260 265 270
Pro Pro Ser Thr Val Phe Ala Ala Tyr Asn His Leu Glu Thr Asp Lys
275 280 285
Asp Leu Lys Val Tyr Arg Tyr Phe Gly His Glu Phe Ile Pro Ala Phe
290 295 300
Gln Thr Glu Lys Leu Ser Phe Leu Gln Lys His Leu Leu Leu Ser Thr
305 310 315 320
Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly Ser Ala Gly Gly Pro
325 330 335
Gly Ser Met Ala Asn Thr Pro Val Ser Gly Asn Leu Lys Val Glu Phe
340 345 350
Tyr Asn Ser Asn Pro Ser Asp Thr Thr Asn Ser Ile Asn Pro Gln Phe
355 360 365
Lys Val Thr Asn Thr Gly Ser Ser Ala Ile Asp Leu Ser Lys Leu Thr
370 375 380
Leu Arg Tyr Tyr Tyr Thr Val Asp Gly Gln Lys Asp Gln Thr Phe Trp
385 390 395 400
Ala Asp His Ala Ala Ile Ile Gly Ser Asn Gly Ser Tyr Asn Gly Ile
405 410 415
Thr Ser Asn Val Lys Gly Thr Phe Val Lys Met Ser Ser Ser Thr Asn
420 425 430
Asn Ala Asp Thr Tyr Leu Glu Ile Ser Phe Thr Gly Gly Thr Leu Glu
435 440 445
Pro Gly Ala His Val Gln Ile Gln Gly Arg Phe Ala Lys Asn Asp Trp
450 455 460
Ser Asn Tyr Thr Gln Ser Asn Asp Tyr Ser Phe Lys Ser Arg Ser Gln
465 470 475 480
Phe Val Glu Trp Asp Gln Val Thr Ala Tyr Leu Asn Gly Val Leu Val
485 490 495
Trp Gly Lys Glu Pro Gly Gly Ser Val Val Gly Gly Gly His His His
500 505 510
His His His
515
<210> 166
<211> 1521
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 166
atgaccaaaa tcaacaattg gcaagactac caaggtagct ctctgaaacc ggaggacttc 60
gataagtttt gggacgagaa aatcaatctg gtgagcaatc atcagtttga gtttgagctg 120
atcgaaaaga acctgagcag caaggttgtg aatttctatc atctgtggtt caccgcaatt 180
gacggtgcaa aaatccacgc gcaattgatc gtcccgaaaa acctgaaaga aaagtatcct 240
gccatcctgc aatttcacgg ttatcactgc gatagcggcg actgggttga caaaattggc 300
atcgtggcgg aaggcaacgt agtgctggca ctggattgtc gcggtcaggg tggcctgagc 360
caagacaata tccagacgat gggtatgact atgaaaggtc tgattgttcg cggcattgac 420
gagggttatg agaacctgta ctacgtccgt caattcatgg atctgatcac cgcgacgaag 480
attctgagcg aattcgattt tgtcgatgaa accaacatca gcgcgcaggg cgccagccaa 540
ggtggtgcgc tggcggttgc gtgcgcggca ctgagcccgc tgattaagaa ggtcacggct 600
acgtacccgt tcttgtccga ctaccgtaaa gcgtacgaac tgggtgccga ggaaagcgcc 660
tttgaggagc tgccatattg gttccagttt aaagacccgt tgcacttgcg tgaggattgg 720
ttcttcaacc agctggaata catcgacatt cagaatctgg ctccgcgtat taaggcagag 780
gttatttgga tcttgggcgg taaagatacc gtggtgccgc cgattaccca aatggctgcg 840
tacaacaaga ttcagtccaa gaaaagcctg tatgttctgc ctgaatacgg ccacgagtat 900
ctgccgaaga tttcggattg gctgcgcgaa aatcagggtc cgggtagcgg cggtgcgggt 960
tctccgggca gcgcaggcgg tccgggatcc atggcgaata cgccggtgtc tggcaatctg 1020
aaagtggagt tttacaatag caacccgagc gataccacga attccatcaa cccacaattc 1080
aaggtgacga atacgggcag cagcgcgatt gatctgagca aattgacgct gcgctattac 1140
tataccgttg atggtcagaa ggaccagacc ttttgggcgg atcatgcggc aatcatcggc 1200
agcaatggca gctacaacgg cattacctct aatgtgaagg gtactttcgt caaaatgagc 1260
agcagcacca acaacgctga cacctacctg gaaatcagct tcaccggtgg cactctggag 1320
ccgggtgccc acgtgcagat ccagggccgt ttcgcgaaga atgactggtc caattacacc 1380
caaagcaatg attacagctt taagagccgc tcgcaatttg ttgagtggga ccaggttacc 1440
gcgtatctga acggtgtctt ggtttggggt aaagagccag gcggttcggt ggtgggtggc 1500
ggtcaccatc accaccatca c 1521
<210> 167
<211> 507
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 167
Met Thr Lys Ile Asn Asn Trp Gln Asp Tyr Gln Gly Ser Ser Leu Lys
1 5 10 15
Pro Glu Asp Phe Asp Lys Phe Trp Asp Glu Lys Ile Asn Leu Val Ser
20 25 30
Asn His Gln Phe Glu Phe Glu Leu Ile Glu Lys Asn Leu Ser Ser Lys
35 40 45
Val Val Asn Phe Tyr His Leu Trp Phe Thr Ala Ile Asp Gly Ala Lys
50 55 60
Ile His Ala Gln Leu Ile Val Pro Lys Asn Leu Lys Glu Lys Tyr Pro
65 70 75 80
Ala Ile Leu Gln Phe His Gly Tyr His Cys Asp Ser Gly Asp Trp Val
85 90 95
Asp Lys Ile Gly Ile Val Ala Glu Gly Asn Val Val Leu Ala Leu Asp
100 105 110
Cys Arg Gly Gln Gly Gly Leu Ser Gln Asp Asn Ile Gln Thr Met Gly
115 120 125
Met Thr Met Lys Gly Leu Ile Val Arg Gly Ile Asp Glu Gly Tyr Glu
130 135 140
Asn Leu Tyr Tyr Val Arg Gln Phe Met Asp Leu Ile Thr Ala Thr Lys
145 150 155 160
Ile Leu Ser Glu Phe Asp Phe Val Asp Glu Thr Asn Ile Ser Ala Gln
165 170 175
Gly Ala Ser Gln Gly Gly Ala Leu Ala Val Ala Cys Ala Ala Leu Ser
180 185 190
Pro Leu Ile Lys Lys Val Thr Ala Thr Tyr Pro Phe Leu Ser Asp Tyr
195 200 205
Arg Lys Ala Tyr Glu Leu Gly Ala Glu Glu Ser Ala Phe Glu Glu Leu
210 215 220
Pro Tyr Trp Phe Gln Phe Lys Asp Pro Leu His Leu Arg Glu Asp Trp
225 230 235 240
Phe Phe Asn Gln Leu Glu Tyr Ile Asp Ile Gln Asn Leu Ala Pro Arg
245 250 255
Ile Lys Ala Glu Val Ile Trp Ile Leu Gly Gly Lys Asp Thr Val Val
260 265 270
Pro Pro Ile Thr Gln Met Ala Ala Tyr Asn Lys Ile Gln Ser Lys Lys
275 280 285
Ser Leu Tyr Val Leu Pro Glu Tyr Gly His Glu Tyr Leu Pro Lys Ile
290 295 300
Ser Asp Trp Leu Arg Glu Asn Gln Gly Pro Gly Ser Gly Gly Ala Gly
305 310 315 320
Ser Pro Gly Ser Ala Gly Gly Pro Gly Ser Met Ala Asn Thr Pro Val
325 330 335
Ser Gly Asn Leu Lys Val Glu Phe Tyr Asn Ser Asn Pro Ser Asp Thr
340 345 350
Thr Asn Ser Ile Asn Pro Gln Phe Lys Val Thr Asn Thr Gly Ser Ser
355 360 365
Ala Ile Asp Leu Ser Lys Leu Thr Leu Arg Tyr Tyr Tyr Thr Val Asp
370 375 380
Gly Gln Lys Asp Gln Thr Phe Trp Ala Asp His Ala Ala Ile Ile Gly
385 390 395 400
Ser Asn Gly Ser Tyr Asn Gly Ile Thr Ser Asn Val Lys Gly Thr Phe
405 410 415
Val Lys Met Ser Ser Ser Thr Asn Asn Ala Asp Thr Tyr Leu Glu Ile
420 425 430
Ser Phe Thr Gly Gly Thr Leu Glu Pro Gly Ala His Val Gln Ile Gln
435 440 445
Gly Arg Phe Ala Lys Asn Asp Trp Ser Asn Tyr Thr Gln Ser Asn Asp
450 455 460
Tyr Ser Phe Lys Ser Arg Ser Gln Phe Val Glu Trp Asp Gln Val Thr
465 470 475 480
Ala Tyr Leu Asn Gly Val Leu Val Trp Gly Lys Glu Pro Gly Gly Ser
485 490 495
Val Val Gly Gly Gly His His His His His His
500 505
<210> 168
<211> 1554
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 168
atgccgtttc cggatctgat ccagccggag ctgggcgcat acgtcagctc cgtcggtatg 60
ccggacgatt tcgctcaatt ctggaccagc accattgccg aagctcgtca ggcaggtggc 120
gaggttagca tcgtccaagc tcagacgact ctgaaagcag tccagagctt cgacgttacc 180
ttcccgggct acggcggtca cccgatcaag ggttggctga tcctgccaac ccaccacaaa 240
ggtcgcctgc cgctggtggt acagtacatt ggttatggcg gtggtcgtgg cttggcgcat 300
gaacagttgc actgggcagc atccggcttt gcgtacttcc gcatggacac ccgtggtcaa 360
ggtagcgatt ggtcggttgg tgagactgcc gacccggttg gtagcaccag cagcatcccg 420
ggctttatga cccgtggtgt gctggataag aatgactact attaccgtcg cttgttcacg 480
gacgcggtcc gtgctattga tgcgctgctg ggtctggact ttgtggaccc ggagcgcatt 540
gccgtctgcg gtgacagcca gggtggcggt atcagcctgg cggttggcgg catcgatccg 600
cgtgttaaag cggttatgcc ggatgtgccg ttcctgtgtg attttccgcg tgccgtccag 660
acggccgttc gcgacccgta cctggagatt gtgcgctttt tggcacaaca ccgtgaaaag 720
aaagcagcgg tgttcgaaac cctgaactat tttgactgtg tgaattttgc gcgtcgtagc 780
aaagcgcctg cgctgtttag cgtggcgctg atggatgaag tgtgcccgcc atctaccgtt 840
tatggtgcct tcaacgcgta tgcgggcgaa aagaccatta cggagtacga gttcaataac 900
cacgagggtg gccaaggcta tcaagaacgt cagcaaatga cgtggctgtc tcgcctgttc 960
ggtgtcggcg gtccgggtag cggtggtgcg ggcagccctg gcagcgcagg tggtccggga 1020
tccatggcga atacgccggt gtctggcaat ctgaaagtgg agttttacaa tagcaacccg 1080
agcgatacca cgaattccat caacccacaa ttcaaggtga cgaatacggg cagcagcgcg 1140
attgatctga gcaaattgac gctgcgctat tactataccg ttgatggtca gaaggaccag 1200
accttttggg cggatcatgc ggcaatcatc ggcagcaatg gcagctacaa cggcattacc 1260
tctaatgtga agggtacttt cgtcaaaatg agcagcagca ccaacaacgc tgacacctac 1320
ctggaaatca gcttcaccgg tggcactctg gagccgggtg cccacgtgca gatccagggc 1380
cgtttcgcga agaatgactg gtccaattac acccaaagca atgattacag ctttaagagc 1440
cgctcgcaat ttgttgagtg ggaccaggtt accgcgtatc tgaacggtgt cttggtttgg 1500
ggtaaagagc caggcggttc ggtggtgggt ggcggtcacc atcaccacca tcac 1554
<210> 169
<211> 518
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 169
Met Pro Phe Pro Asp Leu Ile Gln Pro Glu Leu Gly Ala Tyr Val Ser
1 5 10 15
Ser Val Gly Met Pro Asp Asp Phe Ala Gln Phe Trp Thr Ser Thr Ile
20 25 30
Ala Glu Ala Arg Gln Ala Gly Gly Glu Val Ser Ile Val Gln Ala Gln
35 40 45
Thr Thr Leu Lys Ala Val Gln Ser Phe Asp Val Thr Phe Pro Gly Tyr
50 55 60
Gly Gly His Pro Ile Lys Gly Trp Leu Ile Leu Pro Thr His His Lys
65 70 75 80
Gly Arg Leu Pro Leu Val Val Gln Tyr Ile Gly Tyr Gly Gly Gly Arg
85 90 95
Gly Leu Ala His Glu Gln Leu His Trp Ala Ala Ser Gly Phe Ala Tyr
100 105 110
Phe Arg Met Asp Thr Arg Gly Gln Gly Ser Asp Trp Ser Val Gly Glu
115 120 125
Thr Ala Asp Pro Val Gly Ser Thr Ser Ser Ile Pro Gly Phe Met Thr
130 135 140
Arg Gly Val Leu Asp Lys Asn Asp Tyr Tyr Tyr Arg Arg Leu Phe Thr
145 150 155 160
Asp Ala Val Arg Ala Ile Asp Ala Leu Leu Gly Leu Asp Phe Val Asp
165 170 175
Pro Glu Arg Ile Ala Val Cys Gly Asp Ser Gln Gly Gly Gly Ile Ser
180 185 190
Leu Ala Val Gly Gly Ile Asp Pro Arg Val Lys Ala Val Met Pro Asp
195 200 205
Val Pro Phe Leu Cys Asp Phe Pro Arg Ala Val Gln Thr Ala Val Arg
210 215 220
Asp Pro Tyr Leu Glu Ile Val Arg Phe Leu Ala Gln His Arg Glu Lys
225 230 235 240
Lys Ala Ala Val Phe Glu Thr Leu Asn Tyr Phe Asp Cys Val Asn Phe
245 250 255
Ala Arg Arg Ser Lys Ala Pro Ala Leu Phe Ser Val Ala Leu Met Asp
260 265 270
Glu Val Cys Pro Pro Ser Thr Val Tyr Gly Ala Phe Asn Ala Tyr Ala
275 280 285
Gly Glu Lys Thr Ile Thr Glu Tyr Glu Phe Asn Asn His Glu Gly Gly
290 295 300
Gln Gly Tyr Gln Glu Arg Gln Gln Met Thr Trp Leu Ser Arg Leu Phe
305 310 315 320
Gly Val Gly Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly Ser Ala
325 330 335
Gly Gly Pro Gly Ser Met Ala Asn Thr Pro Val Ser Gly Asn Leu Lys
340 345 350
Val Glu Phe Tyr Asn Ser Asn Pro Ser Asp Thr Thr Asn Ser Ile Asn
355 360 365
Pro Gln Phe Lys Val Thr Asn Thr Gly Ser Ser Ala Ile Asp Leu Ser
370 375 380
Lys Leu Thr Leu Arg Tyr Tyr Tyr Thr Val Asp Gly Gln Lys Asp Gln
385 390 395 400
Thr Phe Trp Ala Asp His Ala Ala Ile Ile Gly Ser Asn Gly Ser Tyr
405 410 415
Asn Gly Ile Thr Ser Asn Val Lys Gly Thr Phe Val Lys Met Ser Ser
420 425 430
Ser Thr Asn Asn Ala Asp Thr Tyr Leu Glu Ile Ser Phe Thr Gly Gly
435 440 445
Thr Leu Glu Pro Gly Ala His Val Gln Ile Gln Gly Arg Phe Ala Lys
450 455 460
Asn Asp Trp Ser Asn Tyr Thr Gln Ser Asn Asp Tyr Ser Phe Lys Ser
465 470 475 480
Arg Ser Gln Phe Val Glu Trp Asp Gln Val Thr Ala Tyr Leu Asn Gly
485 490 495
Val Leu Val Trp Gly Lys Glu Pro Gly Gly Ser Val Val Gly Gly Gly
500 505 510
His His His His His His
515
<210> 170
<211> 1233
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 170
atggcgaaac gcattctgtg cttcggcgac agcctgacct ggggttgggt tccggtcgag 60
gatggcgcac cgacggaacg ttttgcgccg gatgtgcgtt ggacgggtgt gctggctcag 120
caactgggtg ccgattttga ggtcatcgaa gagggtctgg tcgcacgtac gaccaacatt 180
gatgacccga ccgacccgcg tctgaacggc gcaagctatt tgccgagctg tctggcgacc 240
cacctgccgc tggatctggt gattatcatg ttgggcacca atgataccaa agcttatttc 300
cgccgcaccc cgctggacat cgcgctgggc atgagcgtct tggtgacgca ggttctgact 360
agcgctggcg gtgtcggtac tacgtaccct gcgccgaaag tcctggtggt tagcccgcca 420
ccgctggcgc cgatgccgca cccgtggttc caactgattt ttgaaggcgg tgagcaaaag 480
acgaccgagt tggcccgtgt ttacagcgcg ttggcgagct ttatgaaagt tccgtttttc 540
gacgcgggca gcgttattag caccgatggc gtggacggta tccatttcac cgaagcaaat 600
aaccgtgacc tgggtgtggc cctggctgaa caagtgcgca gcctgctggg tccgggctcc 660
ggtggtgccg gttcgccggg tagcgcaggc ggtcctggat ccatggcgaa tacgccggtg 720
tctggcaatc tgaaagtgga gttttacaat agcaacccga gcgataccac gaattccatc 780
aacccacaat tcaaggtgac gaatacgggc agcagcgcga ttgatctgag caaattgacg 840
ctgcgctatt actataccgt tgatggtcag aaggaccaga ccttttgggc ggatcatgcg 900
gcaatcatcg gcagcaatgg cagctacaac ggcattacct ctaatgtgaa gggtactttc 960
gtcaaaatga gcagcagcac caacaacgct gacacctacc tggaaatcag cttcaccggt 1020
ggcactctgg agccgggtgc ccacgtgcag atccagggcc gtttcgcgaa gaatgactgg 1080
tccaattaca cccaaagcaa tgattacagc tttaagagcc gctcgcaatt tgttgagtgg 1140
gaccaggtta ccgcgtatct gaacggtgtc ttggtttggg gtaaagagcc aggcggttcg 1200
gtggtgggtg gcggtcacca tcaccaccat cac 1233
<210> 171
<211> 411
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 171
Met Ala Lys Arg Ile Leu Cys Phe Gly Asp Ser Leu Thr Trp Gly Trp
1 5 10 15
Val Pro Val Glu Asp Gly Ala Pro Thr Glu Arg Phe Ala Pro Asp Val
20 25 30
Arg Trp Thr Gly Val Leu Ala Gln Gln Leu Gly Ala Asp Phe Glu Val
35 40 45
Ile Glu Glu Gly Leu Val Ala Arg Thr Thr Asn Ile Asp Asp Pro Thr
50 55 60
Asp Pro Arg Leu Asn Gly Ala Ser Tyr Leu Pro Ser Cys Leu Ala Thr
65 70 75 80
His Leu Pro Leu Asp Leu Val Ile Ile Met Leu Gly Thr Asn Asp Thr
85 90 95
Lys Ala Tyr Phe Arg Arg Thr Pro Leu Asp Ile Ala Leu Gly Met Ser
100 105 110
Val Leu Val Thr Gln Val Leu Thr Ser Ala Gly Gly Val Gly Thr Thr
115 120 125
Tyr Pro Ala Pro Lys Val Leu Val Val Ser Pro Pro Pro Leu Ala Pro
130 135 140
Met Pro His Pro Trp Phe Gln Leu Ile Phe Glu Gly Gly Glu Gln Lys
145 150 155 160
Thr Thr Glu Leu Ala Arg Val Tyr Ser Ala Leu Ala Ser Phe Met Lys
165 170 175
Val Pro Phe Phe Asp Ala Gly Ser Val Ile Ser Thr Asp Gly Val Asp
180 185 190
Gly Ile His Phe Thr Glu Ala Asn Asn Arg Asp Leu Gly Val Ala Leu
195 200 205
Ala Glu Gln Val Arg Ser Leu Leu Gly Pro Gly Ser Gly Gly Ala Gly
210 215 220
Ser Pro Gly Ser Ala Gly Gly Pro Gly Ser Met Ala Asn Thr Pro Val
225 230 235 240
Ser Gly Asn Leu Lys Val Glu Phe Tyr Asn Ser Asn Pro Ser Asp Thr
245 250 255
Thr Asn Ser Ile Asn Pro Gln Phe Lys Val Thr Asn Thr Gly Ser Ser
260 265 270
Ala Ile Asp Leu Ser Lys Leu Thr Leu Arg Tyr Tyr Tyr Thr Val Asp
275 280 285
Gly Gln Lys Asp Gln Thr Phe Trp Ala Asp His Ala Ala Ile Ile Gly
290 295 300
Ser Asn Gly Ser Tyr Asn Gly Ile Thr Ser Asn Val Lys Gly Thr Phe
305 310 315 320
Val Lys Met Ser Ser Ser Thr Asn Asn Ala Asp Thr Tyr Leu Glu Ile
325 330 335
Ser Phe Thr Gly Gly Thr Leu Glu Pro Gly Ala His Val Gln Ile Gln
340 345 350
Gly Arg Phe Ala Lys Asn Asp Trp Ser Asn Tyr Thr Gln Ser Asn Asp
355 360 365
Tyr Ser Phe Lys Ser Arg Ser Gln Phe Val Glu Trp Asp Gln Val Thr
370 375 380
Ala Tyr Leu Asn Gly Val Leu Val Trp Gly Lys Glu Pro Gly Gly Ser
385 390 395 400
Val Val Gly Gly Gly His His His His His His
405 410
<210> 172
<211> 1188
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 172
atggcgaaac gcattctgtg cttcggcgac agcctgacct ggggttgggt tccggtcgag 60
gatggcgcac cgacggaacg ttttgcgccg gatgtgcgtt ggacgggtgt gctggctcag 120
caactgggtg ccgattttga ggtcatcgaa gagggtctgg tcgcacgtac gaccaacatt 180
gatgacccga ccgacccgcg tctgaacggc gcaagctatt tgccgagctg tctggcgacc 240
cacctgccgc tggatctggt gattatcatg ttgggcacca atgataccaa agcttatttc 300
cgccgcaccc cgctggacat cgcgctgggc atgagcgtct tggtgacgca ggttctgact 360
agcgctggcg gtgtcggtac tacgtaccct gcgccgaaag tcctggtggt tagcccgcca 420
ccgctggcgc cgatgccgca cccgtggttc caactgattt ttgaaggcgg tgagcaaaag 480
acgaccgagt tggcccgtgt ttacagcgcg ttggcgagct ttatgaaagt tccgtttttc 540
gacgcgggca gcgttattag caccgatggc gtggacggta tccatttcac cgaagcaaat 600
aaccgtgacc tgggtgtggc cctggctgaa caagtgcgca gcctgctggg tccgggctcc 660
ggtggtgccg gttcgccggg tagcgcaggc ggtcctggat ccaccccagc gacgtctggt 720
caaatcaagg ttctgtatgc gaacaaagag actaattcca ccacgaacac tatccgtccg 780
tggctgaaag tggtcaatag cggtagcagc agcattgatc tgagccgtgt cacgattcgc 840
tattggtaca cggtcgacgg cgagcgtgcg cagagcgcga tctccgattg ggctcaaatt 900
ggcgcgtcca acgttacctt taagtttgtg aaactgagct ctagcgtgag cggtgcagac 960
tactatttgg aaattggttt caagagcggt gccggccaac tgcagccggg taaagatacc 1020
ggcgagatcc agatccgttt caacaaggac gactggagca attacaatca gggtaatgat 1080
tggagctgga ttcagtcgat gaccagctac ggtgaaaacg aaaaagtgac cgcctacatc 1140
gacggcgttc tggtttgggg tcaagagccg agcggcacca ccccggca 1188
<210> 173
<211> 396
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 173
Met Ala Lys Arg Ile Leu Cys Phe Gly Asp Ser Leu Thr Trp Gly Trp
1 5 10 15
Val Pro Val Glu Asp Gly Ala Pro Thr Glu Arg Phe Ala Pro Asp Val
20 25 30
Arg Trp Thr Gly Val Leu Ala Gln Gln Leu Gly Ala Asp Phe Glu Val
35 40 45
Ile Glu Glu Gly Leu Val Ala Arg Thr Thr Asn Ile Asp Asp Pro Thr
50 55 60
Asp Pro Arg Leu Asn Gly Ala Ser Tyr Leu Pro Ser Cys Leu Ala Thr
65 70 75 80
His Leu Pro Leu Asp Leu Val Ile Ile Met Leu Gly Thr Asn Asp Thr
85 90 95
Lys Ala Tyr Phe Arg Arg Thr Pro Leu Asp Ile Ala Leu Gly Met Ser
100 105 110
Val Leu Val Thr Gln Val Leu Thr Ser Ala Gly Gly Val Gly Thr Thr
115 120 125
Tyr Pro Ala Pro Lys Val Leu Val Val Ser Pro Pro Pro Leu Ala Pro
130 135 140
Met Pro His Pro Trp Phe Gln Leu Ile Phe Glu Gly Gly Glu Gln Lys
145 150 155 160
Thr Thr Glu Leu Ala Arg Val Tyr Ser Ala Leu Ala Ser Phe Met Lys
165 170 175
Val Pro Phe Phe Asp Ala Gly Ser Val Ile Ser Thr Asp Gly Val Asp
180 185 190
Gly Ile His Phe Thr Glu Ala Asn Asn Arg Asp Leu Gly Val Ala Leu
195 200 205
Ala Glu Gln Val Arg Ser Leu Leu Gly Pro Gly Ser Gly Gly Ala Gly
210 215 220
Ser Pro Gly Ser Ala Gly Gly Pro Gly Ser Thr Pro Ala Thr Ser Gly
225 230 235 240
Gln Ile Lys Val Leu Tyr Ala Asn Lys Glu Thr Asn Ser Thr Thr Asn
245 250 255
Thr Ile Arg Pro Trp Leu Lys Val Val Asn Ser Gly Ser Ser Ser Ile
260 265 270
Asp Leu Ser Arg Val Thr Ile Arg Tyr Trp Tyr Thr Val Asp Gly Glu
275 280 285
Arg Ala Gln Ser Ala Ile Ser Asp Trp Ala Gln Ile Gly Ala Ser Asn
290 295 300
Val Thr Phe Lys Phe Val Lys Leu Ser Ser Ser Val Ser Gly Ala Asp
305 310 315 320
Tyr Tyr Leu Glu Ile Gly Phe Lys Ser Gly Ala Gly Gln Leu Gln Pro
325 330 335
Gly Lys Asp Thr Gly Glu Ile Gln Ile Arg Phe Asn Lys Asp Asp Trp
340 345 350
Ser Asn Tyr Asn Gln Gly Asn Asp Trp Ser Trp Ile Gln Ser Met Thr
355 360 365
Ser Tyr Gly Glu Asn Glu Lys Val Thr Ala Tyr Ile Asp Gly Val Leu
370 375 380
Val Trp Gly Gln Glu Pro Ser Gly Thr Thr Pro Ala
385 390 395
<210> 174
<211> 1266
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 174
atggcgaaac gcattctgtg cttcggcgac agcctgacct ggggttgggt tccggtcgag 60
gatggcgcac cgacggaacg ttttgcgccg gatgtgcgtt ggacgggtgt gctggctcag 120
caactgggtg ccgattttga ggtcatcgaa gagggtctgg tcgcacgtac gaccaacatt 180
gatgacccga ccgacccgcg tctgaacggc gcaagctatt tgccgagctg tctggcgacc 240
cacctgccgc tggatctggt gattatcatg ttgggcacca atgataccaa agcttatttc 300
cgccgcaccc cgctggacat cgcgctgggc atgagcgtct tggtgacgca ggttctgact 360
agcgctggcg gtgtcggtac tacgtaccct gcgccgaaag tcctggtggt tagcccgcca 420
ccgctggcgc cgatgccgca cccgtggttc caactgattt ttgaaggcgg tgagcaaaag 480
acgaccgagt tggcccgtgt ttacagcgcg ttggcgagct ttatgaaagt tccgtttttc 540
gacgcgggca gcgttattag caccgatggc gtggacggta tccatttcac cgaagcaaat 600
aaccgtgacc tgggtgtggc cctggctgaa caagtgcgca gcctgctggg tccgggctcc 660
ggtggtgccg gttcgccggg tagcgcaggc ggtcctggat ccgtggcaac tgctaagtat 720
ggcacgcctg ttattgacgg cgagattgat gagatctgga ataccaccga agagattgaa 780
acgaaggcag tcgcgatggg ttctttggat aagaatgcga ctgcgaaagt tcgtgtgctg 840
tgggacgaaa actacctgta cgtgctggcg attgtgaaag atccggttct gaacaaggat 900
aacagcaatc cgtgggaaca ggactccgtc gagattttca ttgacgagaa caatcacaaa 960
accggttact atgaggacga cgacgcacag ttccgcgtta actatatgaa cgagcaaacc 1020
tttggtacgg gcggtagccc ggctcgtttc aagacggccg ttaaactgat cgagggcggt 1080
tacattgtcg aagcggcgat caaatggaaa acgatcaaac caaccccgaa taccgtcatc 1140
ggcttcaata tccaggtgaa tgatgccaat gaaaagggtc aacgtgtggg catcattagc 1200
tggagcgatc cgaccaacaa cagctggcgc gacccgagca agtttggtaa cctgcgtctg 1260
atcaaa 1266
<210> 175
<211> 422
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 175
Met Ala Lys Arg Ile Leu Cys Phe Gly Asp Ser Leu Thr Trp Gly Trp
1 5 10 15
Val Pro Val Glu Asp Gly Ala Pro Thr Glu Arg Phe Ala Pro Asp Val
20 25 30
Arg Trp Thr Gly Val Leu Ala Gln Gln Leu Gly Ala Asp Phe Glu Val
35 40 45
Ile Glu Glu Gly Leu Val Ala Arg Thr Thr Asn Ile Asp Asp Pro Thr
50 55 60
Asp Pro Arg Leu Asn Gly Ala Ser Tyr Leu Pro Ser Cys Leu Ala Thr
65 70 75 80
His Leu Pro Leu Asp Leu Val Ile Ile Met Leu Gly Thr Asn Asp Thr
85 90 95
Lys Ala Tyr Phe Arg Arg Thr Pro Leu Asp Ile Ala Leu Gly Met Ser
100 105 110
Val Leu Val Thr Gln Val Leu Thr Ser Ala Gly Gly Val Gly Thr Thr
115 120 125
Tyr Pro Ala Pro Lys Val Leu Val Val Ser Pro Pro Pro Leu Ala Pro
130 135 140
Met Pro His Pro Trp Phe Gln Leu Ile Phe Glu Gly Gly Glu Gln Lys
145 150 155 160
Thr Thr Glu Leu Ala Arg Val Tyr Ser Ala Leu Ala Ser Phe Met Lys
165 170 175
Val Pro Phe Phe Asp Ala Gly Ser Val Ile Ser Thr Asp Gly Val Asp
180 185 190
Gly Ile His Phe Thr Glu Ala Asn Asn Arg Asp Leu Gly Val Ala Leu
195 200 205
Ala Glu Gln Val Arg Ser Leu Leu Gly Pro Gly Ser Gly Gly Ala Gly
210 215 220
Ser Pro Gly Ser Ala Gly Gly Pro Gly Ser Val Ala Thr Ala Lys Tyr
225 230 235 240
Gly Thr Pro Val Ile Asp Gly Glu Ile Asp Glu Ile Trp Asn Thr Thr
245 250 255
Glu Glu Ile Glu Thr Lys Ala Val Ala Met Gly Ser Leu Asp Lys Asn
260 265 270
Ala Thr Ala Lys Val Arg Val Leu Trp Asp Glu Asn Tyr Leu Tyr Val
275 280 285
Leu Ala Ile Val Lys Asp Pro Val Leu Asn Lys Asp Asn Ser Asn Pro
290 295 300
Trp Glu Gln Asp Ser Val Glu Ile Phe Ile Asp Glu Asn Asn His Lys
305 310 315 320
Thr Gly Tyr Tyr Glu Asp Asp Asp Ala Gln Phe Arg Val Asn Tyr Met
325 330 335
Asn Glu Gln Thr Phe Gly Thr Gly Gly Ser Pro Ala Arg Phe Lys Thr
340 345 350
Ala Val Lys Leu Ile Glu Gly Gly Tyr Ile Val Glu Ala Ala Ile Lys
355 360 365
Trp Lys Thr Ile Lys Pro Thr Pro Asn Thr Val Ile Gly Phe Asn Ile
370 375 380
Gln Val Asn Asp Ala Asn Glu Lys Gly Gln Arg Val Gly Ile Ile Ser
385 390 395 400
Trp Ser Asp Pro Thr Asn Asn Ser Trp Arg Asp Pro Ser Lys Phe Gly
405 410 415
Asn Leu Arg Leu Ile Lys
420
<210> 176
<211> 1401
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 176
atgtccacct tcgttgcgaa agatggcacc cagatttact ttaaagactg gggcagcggc 60
aagccggttc tgtttagcca cggctggccg ctggacgcgg atatgtggga gtatcagatg 120
gagtacctga gcagccgtgg ttaccgtacc atcgccttcg atcgccgtgg ttttggtcgc 180
agcgatcaac cgtggaccgg caatgattat gacacgttcg cagatgacat tgcccagctg 240
atcgagcacc tggacctgaa agaggttacc ctggtcggtt tcagcatggg cggtggtgac 300
gtcgcgcgct acattgcgcg tcatggttcc gctcgtgtgg cgggtctggt cctgctgggt 360
gctgtaacgc cactgtttgg tcaaaagccg gattatccgc agggtgtgcc gttggatgtg 420
tttgcgcgct tcaaaaccga gttgctgaaa gaccgtgcgc aattcatcag cgacttcaac 480
gcaccgtttt acggtatcaa caaaggccaa gttgtcagcc agggcgttca aacgcagacg 540
ctgcagattg cgctgctggc aagcctgaag gcgaccgttg actgcgtgac ggcttttgcg 600
gaaactgatt ttcgtccgga catggcgaag attgatgttc cgaccttggt gattcacggt 660
gacggcgatc agatcgtgcc gttcgaaacc accggtaagg ttgcggccga gctgatcaaa 720
ggtgcggagc tgaaagtgta caaggacgcg cctcacggct tcgcagtcac tcatgcacag 780
caactgaacg aggacttgct ggccttcttg aaacgcggtc cgggctccgg tggcgcaggc 840
agcccgggta gcgcaggtgg tccgggatcc atggcgaata cgccggtgtc tggcaatctg 900
aaagtggagt tttacaatag caacccgagc gataccacga attccatcaa cccacaattc 960
aaggtgacga atacgggcag cagcgcgatt gatctgagca aattgacgct gcgctattac 1020
tataccgttg atggtcagaa ggaccagacc ttttgggcgg atcatgcggc aatcatcggc 1080
agcaatggca gctacaacgg cattacctct aatgtgaagg gtactttcgt caaaatgagc 1140
agcagcacca acaacgctga cacctacctg gaaatcagct tcaccggtgg cactctggag 1200
ccgggtgccc acgtgcagat ccagggccgt ttcgcgaaga atgactggtc caattacacc 1260
caaagcaatg attacagctt taagagccgc tcgcaatttg ttgagtggga ccaggttacc 1320
gcgtatctga acggtgtctt ggtttggggt aaagagccag gcggttcggt ggtgggtggc 1380
ggtcaccatc accaccatca c 1401
<210> 177
<211> 467
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 177
Met Ser Thr Phe Val Ala Lys Asp Gly Thr Gln Ile Tyr Phe Lys Asp
1 5 10 15
Trp Gly Ser Gly Lys Pro Val Leu Phe Ser His Gly Trp Pro Leu Asp
20 25 30
Ala Asp Met Trp Glu Tyr Gln Met Glu Tyr Leu Ser Ser Arg Gly Tyr
35 40 45
Arg Thr Ile Ala Phe Asp Arg Arg Gly Phe Gly Arg Ser Asp Gln Pro
50 55 60
Trp Thr Gly Asn Asp Tyr Asp Thr Phe Ala Asp Asp Ile Ala Gln Leu
65 70 75 80
Ile Glu His Leu Asp Leu Lys Glu Val Thr Leu Val Gly Phe Ser Met
85 90 95
Gly Gly Gly Asp Val Ala Arg Tyr Ile Ala Arg His Gly Ser Ala Arg
100 105 110
Val Ala Gly Leu Val Leu Leu Gly Ala Val Thr Pro Leu Phe Gly Gln
115 120 125
Lys Pro Asp Tyr Pro Gln Gly Val Pro Leu Asp Val Phe Ala Arg Phe
130 135 140
Lys Thr Glu Leu Leu Lys Asp Arg Ala Gln Phe Ile Ser Asp Phe Asn
145 150 155 160
Ala Pro Phe Tyr Gly Ile Asn Lys Gly Gln Val Val Ser Gln Gly Val
165 170 175
Gln Thr Gln Thr Leu Gln Ile Ala Leu Leu Ala Ser Leu Lys Ala Thr
180 185 190
Val Asp Cys Val Thr Ala Phe Ala Glu Thr Asp Phe Arg Pro Asp Met
195 200 205
Ala Lys Ile Asp Val Pro Thr Leu Val Ile His Gly Asp Gly Asp Gln
210 215 220
Ile Val Pro Phe Glu Thr Thr Gly Lys Val Ala Ala Glu Leu Ile Lys
225 230 235 240
Gly Ala Glu Leu Lys Val Tyr Lys Asp Ala Pro His Gly Phe Ala Val
245 250 255
Thr His Ala Gln Gln Leu Asn Glu Asp Leu Leu Ala Phe Leu Lys Arg
260 265 270
Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly Ser Ala Gly Gly Pro
275 280 285
Gly Ser Met Ala Asn Thr Pro Val Ser Gly Asn Leu Lys Val Glu Phe
290 295 300
Tyr Asn Ser Asn Pro Ser Asp Thr Thr Asn Ser Ile Asn Pro Gln Phe
305 310 315 320
Lys Val Thr Asn Thr Gly Ser Ser Ala Ile Asp Leu Ser Lys Leu Thr
325 330 335
Leu Arg Tyr Tyr Tyr Thr Val Asp Gly Gln Lys Asp Gln Thr Phe Trp
340 345 350
Ala Asp His Ala Ala Ile Ile Gly Ser Asn Gly Ser Tyr Asn Gly Ile
355 360 365
Thr Ser Asn Val Lys Gly Thr Phe Val Lys Met Ser Ser Ser Thr Asn
370 375 380
Asn Ala Asp Thr Tyr Leu Glu Ile Ser Phe Thr Gly Gly Thr Leu Glu
385 390 395 400
Pro Gly Ala His Val Gln Ile Gln Gly Arg Phe Ala Lys Asn Asp Trp
405 410 415
Ser Asn Tyr Thr Gln Ser Asn Asp Tyr Ser Phe Lys Ser Arg Ser Gln
420 425 430
Phe Val Glu Trp Asp Gln Val Thr Ala Tyr Leu Asn Gly Val Leu Val
435 440 445
Trp Gly Lys Glu Pro Gly Gly Ser Val Val Gly Gly Gly His His His
450 455 460
His His His
465
<210> 178
<211> 1434
<212> DNA
<213> artificial sequence
<220>
<223> synthetic construct
<400> 178
atgtccacct tcgttgcgaa agatggcacc cagatttact ttaaagactg gggcagcggc 60
aagccggttc tgtttagcca cggctggccg ctggacgcgg atatgtggga gtatcagatg 120
gagtacctga gcagccgtgg ttaccgtacc atcgccttcg atcgccgtgg ttttggtcgc 180
agcgatcaac cgtggaccgg caatgattat gacacgttcg cagatgacat tgcccagctg 240
atcgagcacc tggacctgaa agaggttacc ctggtcggtt tcagcatggg cggtggtgac 300
gtcgcgcgct acattgcgcg tcatggttcc gctcgtgtgg cgggtctggt cctgctgggt 360
gctgtaacgc cactgtttgg tcaaaagccg gattatccgc agggtgtgcc gttggatgtg 420
tttgcgcgct tcaaaaccga gttgctgaaa gaccgtgcgc aattcatcag cgacttcaac 480
gcaccgtttt acggtatcaa caaaggccaa gttgtcagcc agggcgttca aacgcagacg 540
ctgcagattg cgctgctggc aagcctgaag gcgaccgttg actgcgtgac ggcttttgcg 600
gaaactgatt ttcgtccgga catggcgaag attgatgttc cgaccttggt gattcacggt 660
gacggcgatc agatcgtgcc gttcgaaacc accggtaagg ttgcggccga gctgatcaaa 720
ggtgcggagc tgaaagtgta caaggacgcg cctcacggct tcgcagtcac tcatgcacag 780
caactgaacg aggacttgct ggccttcttg aaacgcggtc cgggctccgg tggcgcaggc 840
agcccgggta gcgcaggtgg tccgggatcc gtggcaactg ctaagtatgg cacgcctgtt 900
attgacggcg agattgatga gatctggaat accaccgaag agattgaaac gaaggcagtc 960
gcgatgggtt ctttggataa gaatgcgact gcgaaagttc gtgtgctgtg ggacgaaaac 1020
tacctgtacg tgctggcgat tgtgaaagat ccggttctga acaaggataa cagcaatccg 1080
tgggaacagg actccgtcga gattttcatt gacgagaaca atcacaaaac cggttactat 1140
gaggacgacg acgcacagtt ccgcgttaac tatatgaacg agcaaacctt tggtacgggc 1200
ggtagcccgg ctcgtttcaa gacggccgtt aaactgatcg agggcggtta cattgtcgaa 1260
gcggcgatca aatggaaaac gatcaaacca accccgaata ccgtcatcgg cttcaatatc 1320
caggtgaatg atgccaatga aaagggtcaa cgtgtgggca tcattagctg gagcgatccg 1380
accaacaaca gctggcgcga cccgagcaag tttggtaacc tgcgtctgat caaa 1434
<210> 179
<211> 478
<212> PRT
<213> artificial sequence
<220>
<223> synthetic construct
<400> 179
Met Ser Thr Phe Val Ala Lys Asp Gly Thr Gln Ile Tyr Phe Lys Asp
1 5 10 15
Trp Gly Ser Gly Lys Pro Val Leu Phe Ser His Gly Trp Pro Leu Asp
20 25 30
Ala Asp Met Trp Glu Tyr Gln Met Glu Tyr Leu Ser Ser Arg Gly Tyr
35 40 45
Arg Thr Ile Ala Phe Asp Arg Arg Gly Phe Gly Arg Ser Asp Gln Pro
50 55 60
Trp Thr Gly Asn Asp Tyr Asp Thr Phe Ala Asp Asp Ile Ala Gln Leu
65 70 75 80
Ile Glu His Leu Asp Leu Lys Glu Val Thr Leu Val Gly Phe Ser Met
85 90 95
Gly Gly Gly Asp Val Ala Arg Tyr Ile Ala Arg His Gly Ser Ala Arg
100 105 110
Val Ala Gly Leu Val Leu Leu Gly Ala Val Thr Pro Leu Phe Gly Gln
115 120 125
Lys Pro Asp Tyr Pro Gln Gly Val Pro Leu Asp Val Phe Ala Arg Phe
130 135 140
Lys Thr Glu Leu Leu Lys Asp Arg Ala Gln Phe Ile Ser Asp Phe Asn
145 150 155 160
Ala Pro Phe Tyr Gly Ile Asn Lys Gly Gln Val Val Ser Gln Gly Val
165 170 175
Gln Thr Gln Thr Leu Gln Ile Ala Leu Leu Ala Ser Leu Lys Ala Thr
180 185 190
Val Asp Cys Val Thr Ala Phe Ala Glu Thr Asp Phe Arg Pro Asp Met
195 200 205
Ala Lys Ile Asp Val Pro Thr Leu Val Ile His Gly Asp Gly Asp Gln
210 215 220
Ile Val Pro Phe Glu Thr Thr Gly Lys Val Ala Ala Glu Leu Ile Lys
225 230 235 240
Gly Ala Glu Leu Lys Val Tyr Lys Asp Ala Pro His Gly Phe Ala Val
245 250 255
Thr His Ala Gln Gln Leu Asn Glu Asp Leu Leu Ala Phe Leu Lys Arg
260 265 270
Gly Pro Gly Ser Gly Gly Ala Gly Ser Pro Gly Ser Ala Gly Gly Pro
275 280 285
Gly Ser Val Ala Thr Ala Lys Tyr Gly Thr Pro Val Ile Asp Gly Glu
290 295 300
Ile Asp Glu Ile Trp Asn Thr Thr Glu Glu Ile Glu Thr Lys Ala Val
305 310 315 320
Ala Met Gly Ser Leu Asp Lys Asn Ala Thr Ala Lys Val Arg Val Leu
325 330 335
Trp Asp Glu Asn Tyr Leu Tyr Val Leu Ala Ile Val Lys Asp Pro Val
340 345 350
Leu Asn Lys Asp Asn Ser Asn Pro Trp Glu Gln Asp Ser Val Glu Ile
355 360 365
Phe Ile Asp Glu Asn Asn His Lys Thr Gly Tyr Tyr Glu Asp Asp Asp
370 375 380
Ala Gln Phe Arg Val Asn Tyr Met Asn Glu Gln Thr Phe Gly Thr Gly
385 390 395 400
Gly Ser Pro Ala Arg Phe Lys Thr Ala Val Lys Leu Ile Glu Gly Gly
405 410 415
Tyr Ile Val Glu Ala Ala Ile Lys Trp Lys Thr Ile Lys Pro Thr Pro
420 425 430
Asn Thr Val Ile Gly Phe Asn Ile Gln Val Asn Asp Ala Asn Glu Lys
435 440 445
Gly Gln Arg Val Gly Ile Ile Ser Trp Ser Asp Pro Thr Asn Asn Ser
450 455 460
Trp Arg Asp Pro Ser Lys Phe Gly Asn Leu Arg Leu Ile Lys
465 470 475
<210> 180
<211> 216
<212> PRT
<213> Mycobacterium smegmatis
<400> 180
Met Ala Lys Arg Ile Leu Cys Phe Gly Asp Ser Leu Thr Trp Gly Trp
1 5 10 15
Val Pro Val Glu Asp Gly Ala Pro Thr Glu Arg Phe Ala Pro Asp Val
20 25 30
Arg Trp Thr Gly Val Leu Ala Gln Gln Leu Gly Ala Asp Phe Glu Val
35 40 45
Ile Glu Glu Gly Leu Ser Ala Arg Thr Thr Asn Ile Asp Asp Pro Thr
50 55 60
Asp Pro Arg Leu Asn Gly Ala Ser Tyr Leu Pro Ser Cys Leu Ala Thr
65 70 75 80
His Leu Pro Leu Asp Leu Val Ile Ile Met Leu Gly Thr Asn Asp Thr
85 90 95
Lys Ala Tyr Phe Arg Arg Thr Pro Leu Asp Ile Ala Leu Gly Met Ser
100 105 110
Val Leu Val Thr Gln Val Leu Thr Ser Ala Gly Gly Val Gly Thr Thr
115 120 125
Tyr Pro Ala Pro Lys Val Leu Val Val Ser Pro Pro Pro Leu Ala Pro
130 135 140
Met Pro His Pro Trp Phe Gln Leu Ile Phe Glu Gly Gly Glu Gln Lys
145 150 155 160
Thr Thr Glu Leu Ala Arg Val Tyr Ser Ala Leu Ala Ser Phe Met Lys
165 170 175
Val Pro Phe Phe Asp Ala Gly Ser Val Ile Ser Thr Asp Gly Val Asp
180 185 190
Gly Ile His Phe Thr Glu Ala Asn Asn Arg Asp Leu Gly Val Ala Leu
195 200 205
Ala Glu Gln Val Arg Ser Leu Leu
210 215
<210> 181
<211> 272
<212> PRT
<213> Pseudomonas fluorescens
<400> 181
Met Ser Thr Phe Val Ala Lys Asp Gly Thr Gln Ile Tyr Phe Lys Asp
1 5 10 15
Trp Gly Ser Gly Lys Pro Val Leu Phe Ser His Gly Trp Leu Leu Asp
20 25 30
Ala Asp Met Trp Glu Tyr Gln Met Glu Tyr Leu Ser Ser Arg Gly Tyr
35 40 45
Arg Thr Ile Ala Phe Asp Arg Arg Gly Phe Gly Arg Ser Asp Gln Pro
50 55 60
Trp Thr Gly Asn Asp Tyr Asp Thr Phe Ala Asp Asp Ile Ala Gln Leu
65 70 75 80
Ile Glu His Leu Asp Leu Lys Glu Val Thr Leu Val Gly Phe Ser Met
85 90 95
Gly Gly Gly Asp Val Ala Arg Tyr Ile Ala Arg His Gly Ser Ala Arg
100 105 110
Val Ala Gly Leu Val Leu Leu Gly Ala Val Thr Pro Leu Phe Gly Gln
115 120 125
Lys Pro Asp Tyr Pro Gln Gly Val Pro Leu Asp Val Phe Ala Arg Phe
130 135 140
Lys Thr Glu Leu Leu Lys Asp Arg Ala Gln Phe Ile Ser Asp Phe Asn
145 150 155 160
Ala Pro Phe Tyr Gly Ile Asn Lys Gly Gln Val Val Ser Gln Gly Val
165 170 175
Gln Thr Gln Thr Leu Gln Ile Ala Leu Leu Ala Ser Leu Lys Ala Thr
180 185 190
Val Asp Cys Val Thr Ala Phe Ala Glu Thr Asp Phe Arg Pro Asp Met
195 200 205
Ala Lys Ile Asp Val Pro Thr Leu Val Ile His Gly Asp Gly Asp Gln
210 215 220
Ile Val Pro Phe Glu Thr Thr Gly Lys Val Ala Ala Glu Leu Ile Lys
225 230 235 240
Gly Ala Glu Leu Lys Val Tyr Lys Asp Ala Pro His Gly Phe Ala Val
245 250 255
Thr His Ala Gln Gln Leu Asn Glu Asp Leu Leu Ala Phe Leu Lys Arg
260 265 270
Claims (48)
1) a) i) 구조
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티(moiety)이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해(perhydrolytic) 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 제공하는 단계; 및
2) (1)의 반응 성분을 적절한 반응 조건 하에서 배합하는 단계 - 이에 의해,
a) 융합 단백질이 표적 표면에 결합하고;
b) 적어도 하나의 과산이 효소에 의해 생성되고, 표적 표면과 접촉하며; 이에 의해, 표적 표면에 표백(bleaching), 미백, 소독, 살균(sanitizing), 탈염(destaining), 탈취 및 그들의 조합으로 이루어진 군으로부터 선택되는 과산 기반의 이익이 제공된다 - 를 포함하는 방법.
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티(moiety)이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해(perhydrolytic) 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 제공하는 단계; 및
2) (1)의 반응 성분을 적절한 반응 조건 하에서 배합하는 단계 - 이에 의해,
a) 융합 단백질이 표적 표면에 결합하고;
b) 적어도 하나의 과산이 효소에 의해 생성되고, 표적 표면과 접촉하며; 이에 의해, 표적 표면에 표백(bleaching), 미백, 소독, 살균(sanitizing), 탈염(destaining), 탈취 및 그들의 조합으로 이루어진 군으로부터 선택되는 과산 기반의 이익이 제공된다 - 를 포함하는 방법.
제1항에 있어서, 반응 성분이 표적 표면 상에서 배합되는 방법.
제1항에 있어서, 반응 성분이 표적 표면과의 접촉 전에 배합되는 방법.
제1항에 있어서, 과가수분해 활성을 갖는 융합 단백질이 효소에 의한 과산의 생성 전에 표적 표면 상에 존재하는 방법.
제1항에 있어서, 과가수분해 활성을 갖는 상기 효소가 프로테아제, 리파제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합인 방법.
제5항에 있어서, 아릴 에스테라제가 서열 번호 162에 대하여 적어도 95% 동일성을 갖는 아미노산 서열을 포함하는 방법.
제5항에 있어서, 과가수분해 활성을 갖는 효소가 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처(signature) 모티프를 포함하는 탄수화물 에스테라제이며, 상기 시그니처 모티프가
1) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
2) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
3) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 방법.
1) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
2) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
3) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 방법.
제1항, 제6항 또는 제7항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 항체, Fab 항체 단편, 단쇄 가변 단편(scFv) 항체, 카멜리대(Camelidae) 항체, 스캐폴드(scaffold) 디스플레이 단백질 또는 면역글로불린 폴드(fold)가 결여된 단쇄 폴리펩티드인 방법.
제1항, 제6항 또는 제7항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 셀룰로스-결합 도메인인 방법.
제9항에 있어서, 셀룰로스-결합 도메인이 클로스트리듐 써모셀룸(Clostridium thermocellum), 클로스트리듐 셀룰로보란스(Clostridium cellulovorans), 바실러스(Bacillus) 종, 써모토가 마리티마(Thermotoga maritima) 또는 칼디셀룰로시룹터 사카로라이티쿠스(Caldicellulosiruptor saccharolyticus)로부터의 셀룰로스-결합 효소로부터 수득되는 방법.
제9항에 있어서, 셀룰로스-결합 도메인이 셀룰로스-결합 도메인 패밀리 CBM9, CBM17, CBM28 또는 CBD3의 구성원인 방법.
제8항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 면역글로불린 폴드가 결여된 단쇄 폴리펩티드인 방법.
제12항에 있어서, 단쇄 폴리펩티드는 길이가 5 내지 60개 아미노산 범위인, 표적 표면에 대한 KD 값 또는 MB50 값이 10-5 M 이하인 적어도 하나의 표적 표면-결합 펩티드를 포함하는 방법.
제12항에 있어서, 단쇄 폴리펩티드가 2 내지 50개 표적 표면-결합 펩티드를 포함하며, 표적 표면-결합 펩티드는 독립적으로 그리고 임의로, 길이가 1 내지 100개 아미노산 범위인 펩티드 스페이서(spacer)에 의해 분리되는 방법.
제1항에 있어서, 표적 물질이 셀룰로스 물질을 포함하는 방법.
제15항에 있어서, 셀룰로스 물질이 셀룰로스, 목재, 목재 펄프, 제지, 면(cotton), 레이온, 라이오셀(lyocell) 또는 그들의 임의의 조합을 포함하는 방법.
제1항 또는 제16항에 있어서, 표적 물질이 폴리메틸 메타크릴레이트, 폴리프로필렌, 폴리테트라플루오로에틸렌, 폴리에틸렌, 폴리아미드, 폴리에스테르, 폴리스티렌, 셀룰로스 아세테이트 또는 그들의 임의의 조합을 포함하는 방법.
제1항에 있어서, 과산이 반응 성분의 세트의 배합 5분 내에 500 ppb 내지 10,000 ppm의 농도로 생성되는 방법.
제18항에 있어서, 과산이 1시간 미만 동안 표적 표면과 접촉되는 방법.
제1항, 제18항 또는 제19항에 있어서, 과산이 과아세트산인 방법.
제1항에 있어서, 기질이 트라이아세틴을 포함하는 방법.
하기의 일반 구조를 포함하는 융합 단백질:
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
상기 식에서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다.
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
상기 식에서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이다.
제22항에 있어서, 과가수분해 활성을 갖는 상기 효소가 프로테아제, 리파제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합인 융합 단백질.
제23항에 있어서, 아릴 에스테라제가 서열 번호 162에 대하여 적어도 95% 동일성을 갖는 아미노산 서열을 포함하는 융합 단백질.
제23항에 있어서, 과가수분해 활성을 갖는 효소가 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖는 탄수화물 에스테라제이며, 상기 시그니처 모티프가
1) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
2) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
3) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 융합 단백질.
1) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
2) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
3) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 융합 단백질.
제23항, 제24항 또는 제25항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 항체, Fab 항체 단편, 단쇄 가변 단편(scFv) 항체, 카멜리대 항체, 스캐폴드 디스플레이 단백질 또는 면역글로불린 폴드가 결여된 단쇄 폴리펩티드인 융합 단백질.
제23항, 제24항 또는 제25항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 셀룰로스-결합 도메인인 융합 단백질.
제26항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 면역글로불린 폴드가 결여된 단쇄 폴리펩티드인 융합 단백질.
제28항에 있어서, 상기 적어도 하나의 표적 표면-결합 펩티드는 상기 표적 표면에 대한 KD 값 또는 MB50 값이 10-5 M 이하인 융합 단백질.
제28항에 있어서, 단쇄 폴리펩티드는 길이가 5 내지 60개 아미노산 범위인 적어도 하나의 표적 표면-결합 펩티드를 포함하는 융합 단백질.
제30항에 있어서, 단쇄 폴리펩티드가 2 내지 50개 표적 표면-결합 펩티드를 포함하며, 표적 표면-결합 펩티드는 독립적으로 그리고 임의로, 길이가 1 내지 100개 아미노산 범위인 폴리펩티드 스페이서에 의해 분리되는 융합 단백질.
제22항에 있어서, 펩티드 성분이 200개 이하의 길이의 아미노산을 포함하는 융합 단백질.
1) i) 구조
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
2) 과산소원; 및
3) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며; 과가수분해 활성을 갖는 상기 효소가 리파제, 프로테아제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합이고;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이며; 표면은 체표면 또는 구강 표면이 아니고;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이며;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 포함하는 과산 생성 시스템.
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
2) 과산소원; 및
3) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며; 과가수분해 활성을 갖는 상기 효소가 리파제, 프로테아제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합이고;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이며; 표면은 체표면 또는 구강 표면이 아니고;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이며;
y는 0 또는 1이다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 포함하는 과산 생성 시스템.
제33항에 있어서, 아릴 에스테라제가 서열 번호 162에 대하여 적어도 95% 동일성을 갖는 아미노산 서열을 포함하는 과산 생성 시스템.
제33항에 있어서, 과가수분해 활성을 갖는 탄수화물 에스테라제가 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 갖는 CE-7 탄수화물 에스테라제이고, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 과산 생성 시스템.
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 과산 생성 시스템.
제22항 또는 제23항의 융합 단백질을 포함하는 세탁 관리 제품.
제36항에 있어서, 세탁 관리 제품이 분말, 과립, 페이스트, 겔, 액체, 정제, 헹굼제(rinse) 또는 그들의 임의의 조합의 형태인 세탁 관리 제품.
1) a) i) 구조
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식

(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이며;
과가수분해 활성을 갖는 효소는 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 포함하며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 제공하는 단계;
2) 표적 표면과 과가수분해 활성을 갖는 융합 단백질을 접촉시키는 단계 - 이에 의해, 융합 단백질이 표적 표면에 결합한다 - ;
3) 임의로, 표적 표면을 헹구는 단계; 및
4) 결합된 융합 단백질을 갖는 표적 표면을 상기 적어도 하나의 기질 및 과산소원과 접촉시키는 단계 - 이에 의해, 적어도 하나의 과산이 융합 단백질에 의해, 효소에 의해 생성되고, 이에 의해, 표적 표면에 표백, 미백, 소독, 탈염(destaining), 탈취, 생물막(biofilm)의 감소 또는 제거 및 그들의 조합으로 이루어진 군으로부터 선택되는 과산 기반의 이익이 제공된다 - 를 포함하는 방법.
[X]mR5
(여기서, X는 화학식 R6C(O)O의 에스테르기이며,
R6은 하이드록실기 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 선형, 분지형 또는 환형 하이드로카르빌 모이어티이고, R6은 C2 내지 C7인 R6에 대하여, 하나 이상의 에테르 결합을 임의로 포함하고;
R5는 하이드록실기로 임의로 치환된 C1 내지 C6 선형, 분지형 또는 환형 하이드로카르빌 모이어티 또는 5-원 환형 헤테로방향족 모이어티, 또는 6-원 환형 방향족 또는 헤테로방향족 모이어티이며; R5에서 각 탄소 원자는 각각 1개 이하의 하이드록실기 또는 1개 이하의 에스테르기 또는 카르복실산기를 포함하고; R5는 임의로 하나 이상의 에테르 결합을 포함하며;
m은 1 내지 R5에서의 탄소 원자수 범위의 정수이다)를 갖는 에스테르 - 상기 에스테르는 25℃에서 적어도 5 ppm의 수 용해도를 갖는다 - ;
ii) 구조
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R3 및 R4는 각각 H 또는 R1C(O)이다)를 갖는 글리세리드;
iii) 화학식
(여기서, R1은 하이드록실 또는 C1 내지 C4 알콕시기로 임의로 치환된 C1 내지 C7 직쇄 또는 분지쇄 알킬이며, R2는 C1 내지 C10 직쇄 또는 분지쇄 알킬, 알케닐, 알키닐, 아릴, 알킬아릴, 알킬헤테로아릴, 헤테로아릴, (CH2CH2O)n 또는 (CH2CH(CH3)-O)nH이고, n은 1 내지 10이다)의 하나 이상의 에스테르; 및
iv) 아세틸화 단당류, 아세틸화 이당류 및 아세틸화 다당류로 이루어진 군으로부터 선택되는 아세틸화 당류로 이루어진 군으로부터 선택되는 적어도 하나의 기질;
b) 과산소원; 및
c) 일반 구조
PAH-[L]y-TSBD
또는
TSBD-[L]y-PAH
(여기서,
PAH는 과가수분해 활성을 갖는 효소이며;
TSBD는 표적 물질의 표면에 대하여 친화성을 갖는 펩티드 성분이고; 표면은 체표면 또는 구강 표면이 아니며;
L은 길이가 1 내지 100개 아미노산 범위인 임의의 펩티드 링커이고;
y는 0 또는 1이며;
과가수분해 활성을 갖는 효소는 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 포함하며, 상기 시그니처 모티프는
i) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
ii) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
iii) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함한다)를 포함하는 과가수분해 활성을 갖는 융합 단백질을 포함하는 반응 성분의 세트를 제공하는 단계;
2) 표적 표면과 과가수분해 활성을 갖는 융합 단백질을 접촉시키는 단계 - 이에 의해, 융합 단백질이 표적 표면에 결합한다 - ;
3) 임의로, 표적 표면을 헹구는 단계; 및
4) 결합된 융합 단백질을 갖는 표적 표면을 상기 적어도 하나의 기질 및 과산소원과 접촉시키는 단계 - 이에 의해, 적어도 하나의 과산이 융합 단백질에 의해, 효소에 의해 생성되고, 이에 의해, 표적 표면에 표백, 미백, 소독, 탈염(destaining), 탈취, 생물막(biofilm)의 감소 또는 제거 및 그들의 조합으로 이루어진 군으로부터 선택되는 과산 기반의 이익이 제공된다 - 를 포함하는 방법.
a) 융합 단백질을 암호화하는 발현가능한 유전자 구축물(genetic construct)을 포함하는 재조합 미생물 숙주 세포를 제공하는 단계 - 상기 융합 단백질은 셀룰로스 물질에 대하여 친화성을 갖는 펩티드 성분에 결합된 과가수분해 활성을 갖는 효소를 포함한다 - ;
b) 재조합 미생물 숙주 세포를 적절한 조건 하에서 성장시키는 단계 - 이에 의해, 융합 단백질이 생성된다 - ; 및
c) 임의로, 융합 단백질을 회수하는 단계를 포함하는, 셀룰로스 물질에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분에 결합된 과가수분해 효소를 포함하는 융합 단백질의 생성 방법.
b) 재조합 미생물 숙주 세포를 적절한 조건 하에서 성장시키는 단계 - 이에 의해, 융합 단백질이 생성된다 - ; 및
c) 임의로, 융합 단백질을 회수하는 단계를 포함하는, 셀룰로스 물질에 대하여 친화성을 갖는 적어도 하나의 펩티드 성분에 결합된 과가수분해 효소를 포함하는 융합 단백질의 생성 방법.
제39항에 있어서, 재조합 미생물 숙주 세포가 에스케리키아 콜라이(Escherichia coli) 또는 바실러스 서브틸리스(Bacillus subtilis)인 방법.
제39항에 있어서, 과가수분해 활성을 갖는 상기 효소가 프로테아제, 리파제, 에스테라제, 아실 트랜스퍼라제, 아릴 에스테라제, 탄수화물 에스테라제, 세팔로스포린 아세틸 가수분해효소, 아세틸 자일란 에스테라제 또는 그들의 임의의 조합인 방법.
제41항에 있어서, 아릴 에스테라제가 서열 번호 162에 대하여 적어도 95% 동일성을 갖는 아미노산 서열을 포함하는 방법.
제41항에 있어서, 과가수분해 활성을 갖는 효소가 서열 번호 2의 참조 서열과 정렬되는 CE-7 시그니처 모티프를 포함하는 탄수화물 에스테라제이며, 상기 시그니처 모티프가
1) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
2) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
3) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 방법.
1) 서열 번호 2의 위치 118 내지 120에 해당하는 위치에서 RGQ 모티프;
2) 서열 번호 2의 위치 179 내지 183에 해당하는 위치에서 GXSQG 모티프; 및
3) 서열 번호 2의 위치 298 및 299에 해당하는 위치에서 HE 모티프를 포함하는 방법.
제39항에 있어서, 셀룰로스 물질에 대하여 친화성을 갖는 펩티드 성분이 셀룰로스-결합 도메인인 방법.
제44항에 있어서, 셀룰로스-결합 도메인이 클로스트리듐 써모셀룸, 클로스트리듐 셀룰로보란스, 바실러스 종, 써모토가 마리티마 또는 칼디셀룰로시룹터 사카로라이티쿠스로부터의 셀룰로스-결합 효소로부터 수득되는 방법.
제44항에 있어서, 셀룰로스-결합 도메인이 셀룰로스-결합 도메인 패밀리 CBM9, CBM17, CBM28 또는 CBD3의 구성원인 방법.
제39항에 있어서, 표적 표면에 대하여 친화성을 갖는 펩티드 성분이 면역글로불린 폴드가 결여된 단쇄 폴리펩티드인 방법.
표적 표면의 표백, 미백, 소독, 살균, 탈염 또는 탈취를 위해 유효 농도의 적어도 하나의 과산을 효소에 의해 생성하기 위한, 세탁 제품에서의 제22항, 제23항, 제24항 또는 제25항의 융합 단백질의 용도.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201061424916P | 2010-12-20 | 2010-12-20 | |
| US61/424,916 | 2010-12-20 | ||
| PCT/US2011/065902 WO2012087966A2 (en) | 2010-12-20 | 2011-12-19 | Targeted perhydrolases |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20140114269A true KR20140114269A (ko) | 2014-09-26 |
Family
ID=46314810
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137019093A KR20140114269A (ko) | 2010-12-20 | 2011-12-19 | 표적화된 과가수분해효소 |
Country Status (7)
| Country | Link |
|---|---|
| US (2) | US8652455B2 (ko) |
| EP (1) | EP2655646A4 (ko) |
| KR (1) | KR20140114269A (ko) |
| CN (1) | CN103261430A (ko) |
| AU (1) | AU2011349447A1 (ko) |
| CA (1) | CA2822268A1 (ko) |
| WO (1) | WO2012087966A2 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210117684A (ko) * | 2020-03-20 | 2021-09-29 | (주)코비인터내셔널 | 이색을 갖는 코로조넛 단추의 제조방법 |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9850512B2 (en) | 2013-03-15 | 2017-12-26 | The Research Foundation For The State University Of New York | Hydrolysis of cellulosic fines in primary clarified sludge of paper mills and the addition of a surfactant to increase the yield |
| US9951363B2 (en) | 2014-03-14 | 2018-04-24 | The Research Foundation for the State University of New York College of Environmental Science and Forestry | Enzymatic hydrolysis of old corrugated cardboard (OCC) fines from recycled linerboard mill waste rejects |
| CN105802951B (zh) * | 2014-12-30 | 2021-03-05 | 丰益(上海)生物技术研发中心有限公司 | 固定化脂肪酶及其制备方法和用途 |
| RU2745517C2 (ru) | 2016-12-20 | 2021-03-25 | Колгейт-Палмолив Компани | Композиции для ухода за полостью рта и способы повышения их стабильности |
| DE102018210605A1 (de) * | 2018-06-28 | 2020-01-02 | Henkel Ag & Co. Kgaa | Mittel enthaltend rekombinante Polyesterase |
| CN115099387B (zh) * | 2022-05-26 | 2023-02-03 | 福建天甫电子材料有限公司 | 用于中性清洗剂生产的自动配料系统及其配料方法 |
| CN115806952B (zh) * | 2022-09-14 | 2024-05-03 | 福建师范大学 | 可与葡萄糖氧化酶高效偶联的耻垢分枝杆菌酰基转移酶突变体及其制备方法和应用 |
Family Cites Families (97)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BE498020A (ko) | 1949-09-15 | |||
| US3974082A (en) | 1972-08-21 | 1976-08-10 | Colgate-Palmolive Company | Bleaching compositions |
| JPS526867B2 (ko) | 1972-09-14 | 1977-02-25 | ||
| SE435448B (sv) | 1975-12-24 | 1984-10-01 | Colgate Palmolive Co | I en forpackning innesluten komposition for att forlena har fyllighet eller fasthet |
| US4444886A (en) | 1982-08-11 | 1984-04-24 | Eastman Kodak Company | Diacetinase from Bacillus subtilis |
| US5116575A (en) | 1986-02-06 | 1992-05-26 | Steris Corporation | Powdered anti-microbial composition |
| US5296161A (en) | 1986-06-09 | 1994-03-22 | The Clorox Company | Enzymatic perhydrolysis system and method of use for bleaching |
| US5364554A (en) | 1986-06-09 | 1994-11-15 | The Clorox Company | Proteolytic perhydrolysis system and method of use for bleaching |
| DE69005309T2 (de) | 1989-09-12 | 1994-05-05 | Novonordisk As | Verfahren zur herstellung von peroxykarbonsäuren unter verwendung eines enzymkatalysators. |
| GB9021671D0 (en) | 1990-10-05 | 1990-11-21 | Unilever Plc | Delivery of agents |
| AU642979B2 (en) | 1990-03-21 | 1993-11-04 | Quest International B.V. | Utilization and delivery of enzymes |
| CA2040707C (en) * | 1990-04-27 | 2002-07-09 | Kenji Mitsushima | Cephalosporin acetylhydrolase gene and protein encoded by said gene |
| GB9122048D0 (en) | 1991-10-17 | 1991-11-27 | Interox Chemicals Ltd | Compositions and uses thereof |
| BE1006057A3 (fr) | 1992-07-06 | 1994-05-03 | Solvay Interox | Procede pour la delignification d'une pate a papier chimique. |
| US5683724A (en) | 1993-03-17 | 1997-11-04 | Ecolab Inc. | Automated process for inhibition of microbial growth in aqueous food transport or process streams |
| US5398846A (en) | 1993-08-20 | 1995-03-21 | S. C. Johnson & Son, Inc. | Assembly for simultaneous dispensing of multiple fluids |
| GB2297976A (en) | 1995-02-01 | 1996-08-21 | Reckitt & Colmann Prod Ltd | Improvements in or relating to a bleaching process |
| CZ298690B6 (cs) | 1995-12-27 | 2007-12-27 | Tibotec Pharmaceuticals Ltd. | Bioadhezivní farmaceutická kompozice, dávková forma a suchý zpusob prípravy tablet |
| GB9526633D0 (en) | 1995-12-29 | 1996-02-28 | Procter & Gamble | Hair colouring compositions |
| AU2382197A (en) | 1996-04-19 | 1997-11-12 | Novo Nordisk A/S | Fabric treated with a cellulase and a hybrid enzyme comprising a phenol oxidizing enzyme |
| AU2381297A (en) | 1996-04-19 | 1997-11-12 | Novo Nordisk A/S | Bleaching of fabric with a hybrid enzyme containing a phenol oxidizing enzyme fused to a cellulose binding domain |
| DE19733841A1 (de) | 1997-08-05 | 1999-02-11 | Lothar Dr Till | Mittel zur oxidativen Behandlung menschlichen Haares |
| EP0896998A1 (en) * | 1997-08-14 | 1999-02-17 | The Procter & Gamble Company | Laundry detergent compositions comprising a saccharide gum degrading enzyme |
| US6830745B1 (en) | 1997-10-16 | 2004-12-14 | Pharmacal Biotechnologies, Llc | Compositions for treating biofilm |
| US5871714A (en) | 1997-10-16 | 1999-02-16 | Pharmacal Biotechnologies, Inc. | Compositions for controlling bacterial colonization |
| FI112958B (fi) | 1997-12-19 | 2004-02-13 | Kemira Oyj | Menetelmä kemiallisen massan valkaisemiseksi sekä valkaisuliuoksen käyttö |
| WO1999057250A1 (en) * | 1998-05-01 | 1999-11-11 | The Procter & Gamble Company | Laundry detergent and/or fabric care compositions comprising a modified enzyme |
| US6906024B1 (en) | 1998-05-01 | 2005-06-14 | Procter & Gamble Company | Fabric care compositions comprising cellulose binding domains |
| US6468955B1 (en) | 1998-05-01 | 2002-10-22 | The Proctor & Gamble Company | Laundry detergent and/or fabric care compositions comprising a modified enzyme |
| EP1119613A1 (en) | 1998-09-30 | 2001-08-01 | The Procter & Gamble Company | Laundry detergent and/or fabric care compositions comprising chemical components linked to a cellulose binding domain |
| US6210639B1 (en) | 1998-10-26 | 2001-04-03 | Novartis Ag | Apparatus, method and composition for cleaning and disinfecting |
| EP1169424B1 (en) | 1999-04-12 | 2004-12-15 | Unilever N.V. | Multiple component bleaching compositions |
| US6465410B1 (en) | 1999-04-30 | 2002-10-15 | The Procter & Gamble | Laundry detergent and/or fabric care composition comprising a modified antimicrobial protein |
| US6410498B1 (en) | 1999-04-30 | 2002-06-25 | Procter & Gamble Company | Laundry detergent and/or fabric care compositions comprising a modified transferase |
| AU6373000A (en) | 1999-07-22 | 2001-02-13 | Pericor Science, Inc. | Lysine oxidase linkage of agents to tissue |
| US6245729B1 (en) | 1999-07-27 | 2001-06-12 | Ecolab, Inc. | Peracid forming system, peracid forming composition, and methods for making and using |
| EP1224270B1 (en) | 1999-10-29 | 2005-09-14 | The Procter & Gamble Company | Mimic cellulose binding domain |
| BR0016659A (pt) | 1999-12-22 | 2002-09-03 | Unilever Nv | Método para liberar um agente de benefìcio ao tecido para exercer uma atividade predeterminada, e, composição detergente |
| CA2395138A1 (en) | 1999-12-22 | 2001-06-28 | Unilever Plc | Method of treating fabrics and apparatus used therein |
| DE60036959T2 (de) | 1999-12-22 | 2008-08-07 | Unilever N.V. | Tensidzusammensetzungen, verbesserungsmittel enthaltend |
| US6995125B2 (en) | 2000-02-17 | 2006-02-07 | The Procter & Gamble Company | Detergent product |
| ES2338097T3 (es) | 2000-04-14 | 2010-05-04 | Genencor International, Inc. | Procedimiento de identificacion selectiva. |
| US6635286B2 (en) | 2001-06-29 | 2003-10-21 | Ecolab Inc. | Peroxy acid treatment to control pathogenic organisms on growing plants |
| AU2003222053A1 (en) * | 2002-03-22 | 2003-10-13 | Dow Global Technologies Inc. | Enzymatic resolution of propylene glycol alkyl (or aryl) ethers and ether acetates |
| US7448556B2 (en) | 2002-08-16 | 2008-11-11 | Henkel Kgaa | Dispenser bottle for at least two active fluids |
| US20060171885A1 (en) | 2002-11-25 | 2006-08-03 | Giselle Janssen | Skin or hair binding peptides |
| DE10260903A1 (de) * | 2002-12-20 | 2004-07-08 | Henkel Kgaa | Neue Perhydrolasen |
| DE60320778D1 (de) | 2003-07-08 | 2008-06-19 | Procter & Gamble | Flüssige Bleichaktivatorzusamensetzung |
| US20050054752A1 (en) | 2003-09-08 | 2005-03-10 | O'brien John P. | Peptide-based diblock and triblock dispersants and diblock polymers |
| US8846340B2 (en) | 2003-10-30 | 2014-09-30 | Novozymes A/S | Carbohydrate-binding modules of a new family |
| BRPI0416701A (pt) | 2003-11-27 | 2007-03-06 | Unilever Nv | proteìna de fusão, codificação da seqüência dna, composição detergente, e, processo para o fornecimento de um agente de beneficiamento para um tecido |
| US7754460B2 (en) | 2003-12-03 | 2010-07-13 | Danisco Us Inc. | Enzyme for the production of long chain peracid |
| DK2292743T3 (da) | 2003-12-03 | 2013-11-25 | Danisco Us Inc | Perhydrolase |
| EP1877566B1 (en) | 2005-04-29 | 2009-02-18 | E.I. Du Pont De Nemours And Company | Enzymatic production of peracids using perhydrolytic enzymes |
| US7550420B2 (en) | 2005-04-29 | 2009-06-23 | E. I. Dupont De Nemours And Company | Enzymatic production of peracids using perhydrolytic enzymes |
| US7741093B2 (en) | 2005-04-29 | 2010-06-22 | Ab Enzymes Oy | Cellulases and their uses |
| WO2006133079A2 (en) | 2005-06-06 | 2006-12-14 | Regents Of The University Of Minnesota | Increasing perhydrolase activity in esterases and/or lipases |
| EP1752533A1 (en) * | 2005-08-12 | 2007-02-14 | Institut National de la Recherche Agronomique | Fusion proteins between plant cell-wall degrading enzymes, and their uses |
| US20070082832A1 (en) | 2005-10-06 | 2007-04-12 | Dicosimo Robert | Enzymatic production of peracids from carboxylic acid ester substrates using non-heme haloperoxidases |
| US7563758B2 (en) | 2005-10-06 | 2009-07-21 | E. I. Du Pont De Nemours And Company | Enzymatic production of peracids using Lactobacilli having perhydrolysis activity |
| US7964378B2 (en) | 2005-12-13 | 2011-06-21 | E.I. Du Pont De Nemours And Company | Production of peracids using an enzyme having perhydrolysis activity |
| US7951566B2 (en) * | 2005-12-13 | 2011-05-31 | E.I. Du Pont De Nemours And Company | Production of peracids using an enzyme having perhydrolysis activity |
| US7723083B2 (en) | 2005-12-13 | 2010-05-25 | E.I. Du Pont De Nemours And Company | Production of peracids using an enzyme having perhydrolysis activity |
| US8518675B2 (en) | 2005-12-13 | 2013-08-27 | E. I. Du Pont De Nemours And Company | Production of peracids using an enzyme having perhydrolysis activity |
| US7928076B2 (en) | 2005-12-15 | 2011-04-19 | E. I. Du Pont De Nemours And Company | Polypropylene binding peptides and methods of use |
| US7632919B2 (en) | 2005-12-15 | 2009-12-15 | E.I. Du Pont De Nemours And Company | Polystyrene binding peptides and methods of use |
| US7709601B2 (en) | 2005-12-15 | 2010-05-04 | E. I. Du Pont De Nemours And Company | Nylon binding peptides and methods of use |
| US7700716B2 (en) | 2005-12-15 | 2010-04-20 | E. I. Du Pont De Nemours And Company | Polytetrafluoroethylene binding peptides and methods of use |
| US7906617B2 (en) | 2005-12-15 | 2011-03-15 | E. I. Du Pont De Nemours And Company | Polyethylene binding peptides and methods of use |
| US7858581B2 (en) | 2005-12-15 | 2010-12-28 | E. I. Du Pont De Nemours And Company | PMMA binding peptides and methods of use |
| BRPI0708512A2 (pt) * | 2006-03-03 | 2011-05-31 | Genencor Int | peridrolase para branqueamento de dente |
| US7361487B2 (en) | 2006-04-13 | 2008-04-22 | Ab Enzymes Oy | Enzyme fusion proteins and their use |
| EP1942054B1 (en) | 2007-01-08 | 2013-05-29 | Saab Ab | A method, an electrical system, a digital control module, and an actuator control module in a vehicle |
| WO2008140749A2 (en) * | 2007-05-10 | 2008-11-20 | Novozymes, Inc. | Compositions and methods for enhancing the degradation or conversion of cellulose-containing material |
| US20100189707A1 (en) * | 2007-05-10 | 2010-07-29 | Barnett Christopher C | Stable Enzymatic Peracid Generating Systems |
| EP2331686B1 (en) | 2008-08-13 | 2012-05-09 | E. I. du Pont de Nemours and Company | Control of enzymatic peracid generation |
| CN102239264B (zh) | 2008-10-03 | 2013-11-20 | 纳幕尔杜邦公司 | 含羧酸酯制剂中过水解酶的稳定 |
| US8697654B2 (en) | 2008-12-18 | 2014-04-15 | E I Du Pont De Nemours And Company | Peptide linkers for effective multivalent peptide binding |
| US8206693B2 (en) | 2009-05-20 | 2012-06-26 | E I Du Pont De Nemours And Company | PMMA binding peptides |
| US8389675B2 (en) | 2009-05-20 | 2013-03-05 | E I Du Pont De Nemours And Company | PMMA binding peptides |
| US20100298535A1 (en) | 2009-05-20 | 2010-11-25 | E. I. Du Pont De Nemours And Company | Pmma binding peptides |
| US8263737B2 (en) | 2009-05-20 | 2012-09-11 | E I Du Pont De Nemours And Company | PMMA binding peptides |
| US20100298531A1 (en) | 2009-05-20 | 2010-11-25 | E.I. Du Pont De Nemours And Company | Pmma binding peptides |
| US8455614B2 (en) | 2009-05-20 | 2013-06-04 | E.I. Du Pont De Nemours And Company | PMMA binding peptides |
| US8404214B2 (en) | 2009-05-20 | 2013-03-26 | E I Du Pont De Nemours And Company | PMMA binding peptides |
| US8378065B2 (en) | 2009-05-20 | 2013-02-19 | E I Du Pont De Nemours And Company | PMMA binding peptides |
| CN101591648B (zh) | 2009-06-05 | 2011-04-13 | 江南大学 | 一种耐热角质酶-cbd的制备及其在棉纤维精练中的应用 |
| US20100310495A1 (en) | 2009-06-08 | 2010-12-09 | E. I. Du Pont De Nemours And Company | Peptides having affinity for poly (benzyl methacrylate-co-methacrylic acid) potassium salt copolymers and methods of use |
| US8222012B2 (en) | 2009-10-01 | 2012-07-17 | E. I. Du Pont De Nemours And Company | Perhydrolase for enzymatic peracid production |
| US7927854B1 (en) | 2009-12-07 | 2011-04-19 | E. I. Du Pont De Nemours And Company | Perhydrolase providing improved peracid stability |
| US7910347B1 (en) | 2009-12-07 | 2011-03-22 | E. I. Du Pont De Nemours And Company | Perhydrolase providing improved peracid stability |
| US7932072B1 (en) | 2009-12-07 | 2011-04-26 | E. I. Du Pont De Nemours And Company | Perhydrolase providing improved peracid stability |
| US7960528B1 (en) | 2009-12-07 | 2011-06-14 | E. I. Du Pont De Nemours And Company | Perhydrolase providing improved peracid stability |
| US7923233B1 (en) | 2009-12-07 | 2011-04-12 | E. I. Du Pont De Nemours And Company | Perhydrolase providing improved peracid stability |
| WO2011119703A1 (en) | 2010-03-26 | 2011-09-29 | E.I. Dupont De Nemours And Company | Process for the purification of proteins |
| US8389254B2 (en) | 2010-03-26 | 2013-03-05 | E.I. Du Pont De Nemours And Company | Perhydrolase providing improved specific activity |
| ES2649341T3 (es) | 2011-12-14 | 2018-01-11 | Intel Corporation | Unidad lógica secuencial de múltiples suministros de energía |
-
2011
- 2011-12-19 US US13/330,171 patent/US8652455B2/en not_active Expired - Fee Related
- 2011-12-19 KR KR1020137019093A patent/KR20140114269A/ko not_active Application Discontinuation
- 2011-12-19 WO PCT/US2011/065902 patent/WO2012087966A2/en active Application Filing
- 2011-12-19 AU AU2011349447A patent/AU2011349447A1/en not_active Abandoned
- 2011-12-19 CN CN2011800611264A patent/CN103261430A/zh active Pending
- 2011-12-19 EP EP11851917.2A patent/EP2655646A4/en not_active Withdrawn
- 2011-12-19 CA CA2822268A patent/CA2822268A1/en not_active Abandoned
-
2013
- 2013-11-13 US US14/078,772 patent/US8815550B2/en not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210117684A (ko) * | 2020-03-20 | 2021-09-29 | (주)코비인터내셔널 | 이색을 갖는 코로조넛 단추의 제조방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2011349447A1 (en) | 2013-05-30 |
| EP2655646A4 (en) | 2014-05-21 |
| CN103261430A (zh) | 2013-08-21 |
| US20120321581A1 (en) | 2012-12-20 |
| WO2012087966A2 (en) | 2012-06-28 |
| US20140073029A1 (en) | 2014-03-13 |
| WO2012087966A3 (en) | 2013-01-17 |
| US8652455B2 (en) | 2014-02-18 |
| US8815550B2 (en) | 2014-08-26 |
| EP2655646A2 (en) | 2013-10-30 |
| CA2822268A1 (en) | 2012-06-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20140114269A (ko) | 표적화된 과가수분해효소 | |
| KR20130132936A (ko) | 구강 관리 제품에 사용하기 위한 효소에 의한 과산 생성 | |
| KR20130128442A (ko) | 모발 관리 제품에 사용하기 위한 효소에 의한 과산 생성 | |
| JP2013506421A (ja) | 酵素的な過酸の生成のためのペルヒドロラーゼ | |
| JP6574376B2 (ja) | 過酸生成に有用な酵素 | |
| JP6200485B2 (ja) | 過酸生成に有用な酵素 | |
| EP2831226B1 (en) | Enzymes useful for peracid production | |
| EP2831250B1 (en) | Enzymes useful for peracid production | |
| ES2898699T3 (es) | Lipasas para el uso en detergentes y productos de limpieza | |
| US20130158117A1 (en) | Perhydrolase Variant Providing Improved Specific Activity In the Presence of Surfactant | |
| US20130158115A1 (en) | Perhydrolase Variant Providing Improved Specific Activity In the Presence of Surfactant | |
| US20130158118A1 (en) | Perhydrolase Variant Providing Improved Specific Activity In the Presence of Surfactant | |
| US20130158116A1 (en) | Perhydrolase Variant Providing Improved Specific Activity In the Presence of Surfactant |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |