KR101712208B1 - Pai―1 작용의 치료학적 억제제 및 이의 사용 방법 - Google Patents
Pai―1 작용의 치료학적 억제제 및 이의 사용 방법 Download PDFInfo
- Publication number
- KR101712208B1 KR101712208B1 KR1020107017701A KR20107017701A KR101712208B1 KR 101712208 B1 KR101712208 B1 KR 101712208B1 KR 1020107017701 A KR1020107017701 A KR 1020107017701A KR 20107017701 A KR20107017701 A KR 20107017701A KR 101712208 B1 KR101712208 B1 KR 101712208B1
- Authority
- KR
- South Korea
- Prior art keywords
- leu
- ser
- ala
- val
- gly
- Prior art date
Links
Images













































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/001—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof by chemical synthesis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P7/00—Drugs for disorders of the blood or the extracellular fluid
- A61P7/02—Antithrombotic agents; Anticoagulants; Platelet aggregation inhibitors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/745—Blood coagulation or fibrinolysis factors
- C07K14/75—Fibrinogen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/78—Connective tissue peptides, e.g. collagen, elastin, laminin, fibronectin, vitronectin, cold insoluble globulin [CIG]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/81—Protease inhibitors
- C07K14/8107—Endopeptidase (E.C. 3.4.21-99) inhibitors
- C07K14/811—Serine protease (E.C. 3.4.21) inhibitors
- C07K14/8121—Serpins
- C07K14/8132—Plasminogen activator inhibitors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2451—Glucanases acting on alpha-1,6-glucosidic bonds
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6421—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from mammals
- C12N9/6424—Serine endopeptidases (3.4.21)
- C12N9/6456—Plasminogen activators
- C12N9/6459—Plasminogen activators t-plasminogen activator (3.4.21.68), i.e. tPA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6421—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from mammals
- C12N9/6424—Serine endopeptidases (3.4.21)
- C12N9/6456—Plasminogen activators
- C12N9/6462—Plasminogen activators u-Plasminogen activator (3.4.21.73), i.e. urokinase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y302/00—Hydrolases acting on glycosyl compounds, i.e. glycosylases (3.2)
- C12Y302/01—Glycosidases, i.e. enzymes hydrolysing O- and S-glycosyl compounds (3.2.1)
- C12Y302/01099—Arabinan endo-1,5-alpha-L-arabinosidase (3.2.1.99)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21069—Protein C activated (3.4.21.69)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y304/00—Hydrolases acting on peptide bonds, i.e. peptidases (3.4)
- C12Y304/21—Serine endopeptidases (3.4.21)
- C12Y304/21073—Serine endopeptidases (3.4.21) u-Plasminogen activator (3.4.21.73), i.e. urokinase
Abstract
본 발명은 포유류 PAI-Ⅰ 리간드 및 조절자에 관한 것이다. 특히, 본 발명은 PAI-1의 리간드 및/또는 조절인자인 폴리펩타이드, 폴리펩타이드 조성물 및 폴리펩타이드를 암호화하는 폴리뉴클레오타이드에 관한 것이다. 본 발명은 PAI-Ⅰ 활성을 조절하는 호모폴리리간드 (homopolyligand) 또는 헤테로폴리리간드 (heteropolyligand)인 폴리리간드에 관한 것이다. 본 발명은 또한 세포의 영역에 국재화된 리간드 및 폴리리간드에 관한 것이다. 본 발명은 또한 PAI-Ⅰ 리간드 및 폴리리간드의 공간적 조절을 제공하기 위해 사용될 수 있는 국재화 테터(tether) 및 프로모터 서열에 관한 것이다. 본 발명은 또한 PAI-Ⅰ 리간드 및 폴리리간드의 일시적인 조절을 제공하는데 사용될 수 있는 유도성 유전자 스위치(gene switch)에 관한 것이다. 본 발명은 또한 죽상경화증을 치료 또는 예방하는 방법에 관한 것이다. 본 발명은 또한 섬유증을 치료하거나 예방하는 방법에 관한 것이다.
Description
본 발명은 변형된 PAI-1 단백질 및 핵산에 관한 것이다. 본 발명은 또한 포유동물 PAI-1 리간드 및 조절인자에 관한 것이다. 특히, 본 발명은 PAI-1의 리간드 및/또는 조절인자인 폴리펩타이드, 폴리펩타이드 조성물 및 폴리펩타이드를 암호화하는 폴리뉴클레오타이드에 관한 것이다. 본 발명은 또한 PAI-1 활성을 조절하는 호모폴리리간드(homopolyligand) 또는 헤테로폴리리간드(heteropolyligand)인 폴리리간드에 관한 것이다. 본 발명은 또한 세포의 영역에 국재화된(localized, 局在化) 리간드 및 폴리리간드에 관한 것이다. 본 발명은 또한 PAI-1 리간드 및 폴리리간드의 공간적 조절을 제공하기 위해 사용될 수 있는 국재화 테터(localization tether) 및 프로모터 서열에 관한 것이다. 본 발명은 또한 PAI-1 리간드 및 폴리리간드의 일시적인 조절을 제공하는데 사용될 수 있는 유도성 유전자 스위치(gene switch)에 관한 것이다. 본 발명은 또한 죽상경화증(atherosclerosis)을 치료 또는 예방하는 방법에 관한 것이다. 본 발명은 또한 섬유증(fibrosis)을 치료하거나 예방하는 방법에 관한 것이다.
플라스미노겐 활성인자 억제제-1(PAI-1)은 효소전구체 플라스미노겐을 섬유소용해 효소 플라스민으로 전환시키는 제제인, 조직 플라스미노겐 활성인자(tPA) 및 유로키나제 플라스미노겐 활성인자(uPA)의 세린 프로테아제 억제제이다. PAI-1에 의한 섬유소용해의 조절은, 피브린의 축적이 혈액 응고를 이끌 수 있는 반면, 피브린의 과도한 감소는 출혈을 이끌 수 있으므로, 정상적인 혈관 작용의 중요한 조절 요소이다. PAI-1는 또한 매트릭스 메탈로프로테이나제 및 플라스민 생성을 불활성화시킴으로써 조직 섬유증에 있어서 중요한 역활을 담당하며[참조: Takeshita, K, et al., American Journal of Physiology, 2004(2):449-456], 동물 모델에서 PAI-1 발현을 조절한 연구는 화학적 또는 면역-매개된 손상 후 섬유증의 발병기전에 있어서 PAI-1를 관련시켜 왔다[참조: Weisberg. AD et al., Arterioscler. Thromb. Vase. Biol., 2005, 25:365-371).
PAI-1은 또한 신장, 폐, 심혈관 및 대사 질환[참조: Cale, JM and Lawrence, DA. Curr Drug Targets, 2007, 8(9):971-81], 및 암의 병태생리학과 관련되어 왔다. 다수의 연구는 심장 질환의 발달시 PAI-1에 대한 역활을 지지한다. 예를 들면, PAI-1의 약력학적 억제는 안지오텐신-II-유도된 대동맥 리모델링에 대해 보호하는 것으로 입증되었다[참조: Weisberg. AD et al., Arterioscler. Thromb. Vase. Biol., 2005, 25:365-371]. 또한, 심장 섬유증의 약화된 발달은 야생형과 비교하여 심근경색 후 PAI-결핍 마우스에서 관측되었다[참조: Takesita, K, et al., American Journal of Pathology, 2004, 164(2):449-455]. 몇몇 연구[참조: Sobel, BE et al., Arterioscler. Thromb. Vase. Biol., 2003, 23:1979-1989]는, 혈관 벽에서 PAI-1의 변형된 발현이 심장 죽종형성에 기여할 수 있음을 제안한다.
심장에서 PAI-1 발현을 조절하기 위한 새로운 시약 및 방법은 심장병에서 이의 역활로 연구를 진전시킬 수 있다. 또한, PAI-1 활성을 억제하기 위한 새로운 시약, 치료 및 방법에 대한 당해 분야에서의 필요성이 존재한다.
본 발명의 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 국재화 테터에 연결된 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 조직-특이적인 프로모터에 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 유도성 유전자 스위치(switch)에 연결된 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 리간드, 폴리리간드 및/또는 조절인자를 국재화 테터 또는 조직-특이적인 프로모터에 연결시킴으로써 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자의 공간적인 조절을 달성하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 리간드, 폴리리간드 및/또는 조절인자를 유도성 유전자 스위치에 연결시킴으로써, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자의 일시적인 조절을 달성하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 PAI-1 리간드, 폴리리간드 및/또는 조절인자와 함께 사용되어 공간적 조절을 제공할 수 있는 국제화 테터를 제공하는 것이다.
본 발명의 다른 목적은 PAI-1 리간드, 폴리리간드 및/또는 조절인자와 함께 사용되어 공간적 조절을 제공할 수 있는 조직-특이적인 프로모터를 제공하는 것이다.
본 발명의 다른 목적은 PAI-1 리간드, 폴리리간드 및/또는 조절인자와 함께 사용되어 일시적인 조절을 제공할 수 있는 유도성 유전자 스위치를 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자 및 국재화 테터 또는 조직-특이적인 프로모터를 암호화하는 폴리뉴클레오타이드를 포함하는 유전자 작제물을 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 포함하는 벡터를 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 포함하는 숙주 세포를 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 포함하는 유전자삽입 유기체를 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 사용하여 심혈관병을 치료하거나 예방하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 사용하여 섬유증 상태를 치료하거나 예방하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 심혈관 조직에 전달하는 방법에 관한 것이다.
본 발명의 다른 양태는 불안정한 플라크(plaque)의 형성시 PAI-1의 작용을 평가하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 섬유소용해 경로의 억제제를 발현하도록 변형된 단핵세포를 사용하여 죽상경화증을 치료하거나 예방하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 섬유소용해 경로의 억제제를 발현하도록 변형된 단핵세포를 사용하여 섬유증 상태를 치료하거나 예방하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 데그론에 연결된 PAI-1 단백질을 포함하는 융합 단백질을 제공하는 것이다.
본 발명의 다른 목적은 국재화 시그날에 연결된 PAI-1을 포함하는 융합 단백질을 제공하는 것이다.
본 발명의 다른 목적은 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 제공하는 것이다.
본 발명의 다른 목적은 데그론을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 제공하는 것이다.
본 발명의 다른 목적은 국제화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 제공하는 것이다.
본 발명의 다른 목적은 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 제공하는 것이다.
본 발명의 다른 목적은 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 함유하는 벡터를 제공하는 것이다.
본 발명의 다른 목적은 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 함유하는 벡터를 함유하는 숙주 세포를 제공하는 것이다.
본 발명의 다른 목적은 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자삽입 유기체를 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나, 유도성인 프로모터를 포함하는, 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나, 유도성인 프로모터를 포함하는, 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 함유하는 벡터를 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나, 유도성인 프로모터를 포함하는, 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 함유하는 벡터를 함유하는 숙주 세포를 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나, 유도성인 프로모터를 포함하는, 데그론 및/또는 국재화 시그날을 암호화하는 폴리뉴클레오타이드 서열에 임의 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자 작제물을 함유하는 유전자삽입 유기체를 제공하는 것이다.
본 발명의 다른 목적은 숙주 세포내에서 PAI-1의 발현을 변경시키는 방법을 제공하는 것이다.
본 발명의 다른 목적은 심장 조직에서 PAI-1의 발현을 변경시키는 방법을 제공하는 것이다.
본 발명의 다른 목적은 PAI-1의 발현이 변형된 유전자삽입 대상체를 창조하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 데그론에 연결된 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 국재화 시그날에 연결된 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 제공하는 것이다.
본 발명의 다른 목적은 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 제공하는 것이다.
본 발명의 다른 목적은 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 제공하는 것이다.
본 발명의 다른 목적은 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 함유하는 벡터를 제공하는 것이다.
본 발명의 다른 목적은 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 함유하는 벡터를 함유하는 숙주 세포를 제공하는 것이다.
본 발명의 다른 목적은 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자삽입 유기체를 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나 유도성인 프로모터를 포함하는, 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나 유도성인 프로모터를 포함하는, 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 함유하는 벡터를 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나 유도성인 프로모터를 포함하는, 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 함유하는 벡터를 함유하는 숙주 세포를 제공하는 것이다.
본 발명의 다른 목적은 편재하는, 조직-특이적이거나, 세포-특이적이거나 유도성인 프로모터를 포함하는, 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 임의 연결된, 포유동물 PAI-1 리간드, 폴리리간드 및/또는 조절인자를 암호화하는 폴리뉴클레오타이드를 함유하는 유전자 작제물을 함유하는 유전자삽입 유기체를 제공하는 것이다.
본 발명의 다른 목적은 숙주 세포에서 PAI-1을 억제하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 심장 조직에서 PAI-1을 억제하는 방법을 제공하는 것이다.
본 발명의 다른 목적은 PAI-1 활성이 감소된 유전자삽입 대상체를 창조하는 방법을 제공하는 것이다.
폴리펩타이드 및 폴리뉴클레오타이드 서열의 기술
서열 1 내지 30은 PAI-1 리간드 및 폴리리간드 및 이들을 암호화하는 폴리뉴클레오타이드의 예를 나타낸다. 이들 각각의 펩타이드 성분들의 구조를 나타내는 다음의 리간드 및 폴리리간드 각각의 도해는 도 9에 나타낸다.
상세하게는, 서열 1의 PAI-1 폴리리간드는 서열 2에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 1의 PAI-1 폴리리간드는 호모폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-1로 또한 알려진다.
서열 3의 PAI-1 폴리리간드는 서열 4에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 3의 PAI-1 폴리리간드는 단량체성 리간드의 실시양태이며 본원에서 PAI1-DCY-94-2로 또한 알려진다.
서열 5의 PAI-1 폴리리간드는 서열 6에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 5의 PAI-1 폴리리간드는 호모폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-3으로 또한 알려진다.
서열 7의 PAI-1 폴리리간드는 서열 8에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 7의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-4로 또한 알려진다.
서열 9의 PAI-1 폴리리간드는 서열 10에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 9의 PAI-1 폴리리간드는 단량체성 리간드의 실시양태이며 본원에서 PAI1-DCY-94-5로 또한 알려진다.
서열 11의 PAI-1 폴리리간드는 서열 12에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 11의 PAI-1 폴리리간드는 단량체성 리간드의 양태이며 본원에서 PAI1-DCY-94-6으로 또한 알려진다.
서열 13의 PAI-1 폴리리간드는 서열 14에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 13의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-7로 또한 알려진다.
서열 15의 PAI-1 폴리리간드는 서열 16에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 15의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-8로 또한 알려진다.
서열 17의 PAI-1 폴리리간드는 서열 18에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 17의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-9로 또한 알려진다.
서열 19의 PAI-1 폴리리간드는 서열 20에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 19의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-10으로 또한 알려진다.
서열 21의 PAI-1 폴리리간드는 서열 22에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 21의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-11로 또한 알려진다.
서열 23의 PAI-1 폴리리간드는 서열 24에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 23의 PAI-1 폴리리간드는 헤테로폴리리간드의 양태이며 본원에서 PAI1-DCY-94-12로 또한 알려진다.
서열 25의 PAI-1 폴리리간드는 서열 26에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 25의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-13으로 또한 알려진다.
서열 27의 PAI-1 폴리리간드는 서열 28에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 27의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-14로 또한 알려진다.
서열 29의 PAI-1 폴리리간드는 서열 30에 의해 암호화되며, 여기서, 코돈은 포유동물 발현 및 벡터 삽입용으로 최적화되어 있다. 서열 29의 PAI-1 폴리리간드는 헤테로폴리리간드의 실시양태이며 본원에서 PAI1-DCY-94-15로 또한 알려진다.
서열 31 내지 36은 리간드 및 폴리리간드를 작제하는데 사용된 전장 단백질의 예를 나타낸다. 서열 31은 호모 사피엔스 플라스미노겐 활성인자 억제제 1으로 공지되어 있으며 공공의 수탁 번호 AAA60009를 갖는다. 서열 32는 호모 사피엔스 비트로넥틴으로 알려져 있으며 공공의 수탁 번호 EAW51082를 갖는다. 서열 33은 호모 사피엔스 칼리크레인 2, 전립샘 동형 1으로 알려져 있으며 공공의 수탁 번호 NP_005542를 갖는다. 서열 34는 호모 사피엔스 조직 플라스미노겐 활성인자로 공지되어 있으며 공공의 수탁 번호 BAA00881을 갖는다. 서열 35는 호모 사피엔스 톨-유사 수용체(toll-like receptor) 3으로 알려져 있으며 공공의 수탁 번호 NP_003256을 갖는다. 서열 36은 호모 사피엔스 유로키나제 플라스미노겐 활성인자(uPA)로 알려져 있으며 공공의 수탁 번호 CAA01390을 갖는다.
서열 37 내지 51은 단량체성 리간드 펩타이드의 예를 나타낸다. 서열 37 내지 51 각각은 모 단백질의 명칭 또는 약명, 이어서, 이것이 나타내는 모 단백질의 아미노산 범위, 이어서, 협정: X#Z(여기서, X는 치환될 아미노산의 1 문자 아미노산 코드이고, #는 모 단백질내 아미노산 잔기 위치 또는 번호이며, Z는 새로이 치환되는 아미노산의 1 문자 아미노산 코드이다)으로 나타낸 특정의 아미노산 치환 돌연변이와 함께 도 9에 나타낸다.
서열 37은 서열 31의 일부 서열이며 도 9에서 'PAI1 354-368'로 나타낸다.
서열 38은 서열 31의 일부 서열이며 도 9에서 'PAI1 300-309'로 나타낸다.
서열 39는 서열 31의 일부 서열이며 도 9에서 'PAI1 343-353'으로 나타낸다.
서열 40은 서열 32의 일부 서열이며 도 9에서 '비트로넥틴 20-63'으로 나타낸다.
서열 41은 F32L 치환 돌연변이를 포함하는 서열 32의 일부 서열이며 도 9에서 '비트로넥틴 20-63 F32L'로 나타낸다.
서열 42는 T29A 치환 돌연변이를 포함하는 서열 32의 일부 서열이며 도 9에서 '비트로넥틴 20-63 T29A'로 나타낸다.
서열 43은 E42A 치환 돌연변이를 포함하는 서열 32의 일부 서열이며 도 9에서 '비트로넥틴 20-63 E42a'로 나타낸다.
서열 44는 L43A 치환 돌연변이를 포함하는 서열 32의 일부 서열이며 도 9에서 '비트로넥틴 20-63 L43A'로 나타낸다.
서열 45는 S23F, T52E, D53L, A56Y 및 E57Y 치환 돌연변이를 포함하는 서열 45의 일부 서열이며 도 9에서 '비트로넥틴 20-63 돌연변이체'로 나타낸다.
서열 46은 서열 33의 일부 서열이며 도 9에서 '칼리크레인 2(25-256)'으로 나타낸다.
서열 47은 서열 33의 일부 서열이며 도 9에서 'hK2(25-44)'로 나타낸다.
서열 48은 서열 33의 일부 서열이며 도 9에서 '칼리크레인 2(47-256)'으로 나타낸다.
서열 49는 서열 34의 일부 서열이며 도 9에서 'tPA(301-308)'로 나타낸다.
서열 50은 V55A, N57Y, T59N, S79K, D81K 및 G83E 치환 돌연변이를 포함하는 서열 35의 일부 서열이며 도 9에서 '톨 유사 수용체 3 29-121(V55A, N57Y, T59N, S79K, D81K, G83E)'로 나타낸다.
서열 51은 H224A, D275A 및 S376A 치환 돌연변이를 포함하는 서열 36의 일부 서열이며 도 9에서 '유로키나제 플라스미노겐 활성인자(179-415) H224A, D275A, S376A'로 나타낸다.
서열 52는 천연의 스페이서 단편을 생성하기 위해 사용된 전장 단백질의 예를 나타낸다. 서열 52는 후미콜라 인솔렌스(Humicola insolens) 엑소글루카나제-6A 전구체(엑소셀로바이오하이드롤라제 6A)(1,4-베타-셀로바이오하이드롤라제 6A)(베타-글루칸셀로바이오하이드롤라제 6A)(아비셀라제 2)로 공지되어 있으며 공공의 수탁 번호 Q9C1S9를 갖는다.
서열 53은 천연의 스페이서 단편의 예이다. 서열 53은 서열 52의 일부 서열이며 도 9에서 '16aa 링커'로 나타낸다.
서열 54 내지 56은 인공 스페이서의 예이다.
서열 57 내지 76은 본 발명에서 유용한 제1 부류 국재화 테터 폴리펩타이드의 예를 나타낸다. 이들의 개개의 펩타이드 성분들의 구조를 나타내는 다음의 제1 부류 국재화 테터 폴리펩타이드 각각의 도해는 도 14A 내지 14B에 나타낸다.
서열 57의 제1 부류 국재화 테터는 본원에서 91-1로 또한 알려진다.
서열 58의 제1 부류 국재화 테터는 본원에서 91-2로 또한 알려진다.
서열 59의 제1 부류 국재화 테터는 본원에서 91-3으로 또한 알려진다.
서열 60의 제1 부류 국재화 테터는 본원에서 91-4로 또한 알려진다.
서열 61의 제1 부류 국재화 테터는 본원에서 91-5로 또한 알려진다.
서열 62의 제1 부류 국재화 테터는 본원에서 91-6으로 또한 알려진다.
서열 63의 제1 부류 국재화 테터는 본원에서 91-7로 또한 알려진다.
서열 64의 제1 부류 국재화 테터는 본원에서 91-8로 또한 알려진다.
서열 65의 제1 부류 국재화 테터는 본원에서 91-9로 또한 알려진다.
서열 66의 제1 부류 국재화 테터는 본원에서 91-10으로 또한 알려진다.
서열 67의 제1 부류 국재화 테터는 본원에서 91-11로 또한 알려진다.
서열 68의 제1 부류 국재화 테터는 본원에서 91-12로 또한 알려진다.
서열 69의 제1 부류 국재화 테터는 본원에서 91-13으로 또한 알려진다.
서열 70의 제1 부류 국재화 테터는 본원에서 91-14로 또한 알려진다.
서열 71의 제1 부류 국재화 테터는 본원에서 91-15로 또한 알려진다.
서열 72의 제1 부류 국재화 테터는 본원에서 91-16으로 또한 알려진다.
서열 73의 제1 부류 국재화 테터는 본원에서 91-17로 또한 알려진다.
서열 74의 제1 부류 국재화 테터는 본원에서 91-18로 또한 알려진다.
서열 75의 제1 부류 국재화 테터는 본원에서 91-19로 또한 알려진다.
서열 76의 제1 부류 국재화 테터는 본원에서 91-20으로 또한 알려진다.
서열 77 내지 95는 제1 부류 국재화 테터를 작제하는데 사용된 폴리펩타이드 단편의 예를 나타낸다.
서열 96은 제1 부류 국재화 테터를 작제하기 위한 내부 카고(cargo)로서 사용된 에피토프 태그의 예이며 도 14A 및 14B에 'TAG'로서 나타낸다.
서열 97 내지 99는 제1 부류 국재화 테터를 작제하는데 사용된 스페이서의 예를 나타낸다.
서열 100 내지 111은 본 발명에 유용한 제3 부류 국재화 테터 폴리펩타이드의 예를 나타낸다. 이들의 개개의 펩타이드 성분들의 구조를 나타내는 다음의 제3 부류 국재화 테터 폴리펩타이드 각각의 도해는 도 15에 타나낸다.
서열 100의 제3 부류 국재화 테터는 본원에서 93-1로 또한 알려진다.
서열 101의 제3 부류 국재화 테터는 본원에서 93-2로 또한 알려진다.
서열 102의 제3 부류 국재화 테터는 본원에서 93-3으로 또한 알려진다.
서열 103의 제3 부류 국재화 테터는 본원에서 93-4로 또한 알려진다.
서열 104의 제3 부류 국재화 테터는 본원에서 93-5로 또한 알려진다.
서열 105의 제3 부류 국재화 테터는 본원에서 93-6으로 또한 알려진다.
서열 106의 제3 부류 국재화 테터는 본원에서 93-7로 또한 알려진다.
서열 107의 제3 부류 국재화 테터는 본원에서 93-8로 또한 알려진다.
서열 108의 제3 부류 국재화 테터는 본원에서 93-9로 또한 알려진다.
서열 109의 제3 부류 국재화 테터는 본원에서 93-10으로 또한 알려진다.
서열 110의 제3 부류 국재화 테터는 본원에서 93-11로 또한 알려진다.
서열 111의 제3 부류 국재화 테터는 본원에서 93-12로 또한 알려진다.
서열 112 내지 129는 제3 부류 국재화 테터를 작제하는데 사용된 폴리펩타이드 단편의 예를 나타낸다.
서열 130은 제3 부류 국재화 테터를 작제하기 위한 내부 카고로 사용된 에피토프 태그의 예를 나타내며, 도 15에서 'TAG' 또는 'TAG/IC'로 나타낸다.
서열 131은 제3 부류 국재화 테터를 작제하는데 사용된 합성 TACE/ADAM17 절단 부위의 예를 나타낸다.
서열 32 내지 139는 본 발명에 유용한 조직 특이적인 프로모터 서열의 예를 나타낸다.
서열 132는 인공의 평활근-특이적인 프로모터의 예이며, 본원에서 MOD 5306으로 또한 알려지며, 이의 구조는 도 10에 도식적으로 묘사되어 있다.
서열 133은 합성의 혈관 평활근 세포-특이적인 프로모터의 예이며, 본원에서 MOD 5309로 또한 알려지며, 이의 구조는 도 11A에 도식적으로 묘사되어 있다.
서열 134는 합성의 혈관 평활근 세포-특이적인 프로모터의 예이며, 본원에서 MOD 5312로 또한 알려지며, 이의 구조는 도 11B에 도식적으로 묘사되어 있다.
서열 135는 합성의 혈관 평활근 세포-특이적인 프로모터의 예이며, 본원에서 MOD 5315로 또한 알려지며, 이의 구조는 도 11C에 도식적으로 묘사되어 있다.
서열 136은 내피 세포-특이적인 프로모터의 예이며, 본원에서 MOD 4012-ESM1으로 또한 알려지며, 이의 구조는 도 12A에 도식적으로 묘사되어 있다.
서열 137은 내피 세포-특이적인 프로모터의 예이며, 본원에서 MOD 4399-FLT1으로 또한 알려지며, 이의 구조는 도 12B에 도식적으로 묘사되어 있다.
서열 138은 합성의 내피 세포-특이적인 프로모터의 예이며, 본원에서 MOD 4790으로 또한 알려지며, 이의 구조는 도 13A에 도식적으로 묘사되어 있다.
서열 139는 합성의 내피 세포-특이적인 프로모터의 예이며, 본원에서 MOD 4791로 또한 알려지며, 이의 구조는 도 13B에 도식적으로 묘사되어 있다.
3문자 아미노산 코드 및 1 문자 아미노산 코드는 당해 분야에 일반적으로 알려져 있는 바와 같이 본원에서 사용된다.
발명의 상세한 설명
본 명세서 및 특허청구의 범위에 사용된 용어들은 당해 분야에서 이해되는 통상적인 의미를 갖는다. 예를 들어, 폴리뉴클레오타이드는 핵산과 상호교환적으로 사용되며 일본쇄 또는 이본쇄 DNA, RNA 및 이의 중합체성 유사체를 포함한다.
용어 키메라는 이들의 천연 상태에서 인접하지 않은 단편을 포함함을 의미한다. 예를 들어, 키메라 폴리뉴클레오타이드는 이들의 천연 상태에서 인접하지 않은 단편을 포함하는 폴리뉴클레오타이드를 의미한다.
용어 폴리펩타이드, 펩타이드 및 단백질은 상호교환적으로 사용되며 아미노산의 중합체를 나타낸다.
합성 유전자(또는 유전자의 부분)는 야생형 폴리뉴클레오타이드 서열과는 상이한 비-천연 유전자(또는 유전자의 부분)이다. 합성 유전자(또는 유전자의 부분)는 천연적으로 인접하지 않은 하나 이상의 핵산 서열(키메라 서열)을 함유할 수 있고/있거나 치환, 삽입 및 결실, 및 이들의 조합을 포함할 수 있다.
비-사람 유기체는 비-사람 영장류, 포유동물, 척추동물, 비척추동물, 식물 및 효모 및 점균류를 포함하는 하등 진핵 유기체를 포함한다.
제한 엔도뉴클레아제는 핵산 분자내에 인지 서열에서 핵산을 분해하는 효소이다.
숙주 세포는 ATCC(버지니아주 마나사스 소재)로부터 이용가능한 것들, 영장류 세포 배양물, 줄기 세포, 면역 세포, 혈액 세포, 특정 유기체 또는 조직으로부터의 세포와 같은, 시판 세포주 및 비-시판 세포주를 포함하나, 이에 한정되지 않는다.
벡터는 핵산을 숙주 세포내로 클로닝하고/하거나 전달하기 위한 특정의 비히클을 말한다. 벡터는, 다른 DNA 분절이 부착되어 부착된 분절을 복제하는 레플리콘(replicon)일 수 있다. 레플리콘은 생체내에서 DNA 복제의 자가 단위로 작용하는, 즉, 이의 자체 조절하에 복제할 수 있는, 특정 유전 성분(예를 들면, 플라스미드, 파지, 코스미드, 염색체, 바이러스)를 말한다. 용어 벡터는 시험관내, 생체외 또는 생체내에서 핵산을 세포내로 도입하기 위한 바이러스 및 비바이러스 비히클 둘다를 포함한다. 당해 분야에 공지된 다수의 벡터를 사용하여 핵산을 조작하고 반응 성분 및 프로모터를 유전자 등에 도입할 수 있다. 가능한 벡터는 예를 들면, 플라스미드 또는 예를 들면 람다 유도체와 같은 박테리오파지를 포함하는 변형된 바이러스, 또는 pBR322 또는 pUC 플라스미드 유도체와 같은 플라스미드, 또는 Bluescript 벡터를 포함한다. 본 발명에 유용한 벡터의 다른 예는 본원에 참조로 포함된 국제공개 제2007/038276호에 기술된 바와 같은 UltraVectorTM 생산 시스템[제조원: 인트렉손 코포레이션(Intrexon Corp.), 버지니아주 블랙스부르그 소재]이다. 예를 들면, 반응 성분들 및 프로모터들에 상응하는 DNA 단편의 적합한 벡터내로의 삽입은 적절한 DNA 단편을 상보적인 점착 말단(cohesive terminus)을 갖는 선택된 벡터내로 연결시킴으로써 달성할 수 있다. 달리는, DNA 분자의 말단은 효소적으로 변형시키거나 특정 부위가 뉴클레오타이드 서열(링커)를 DNA 말단에 연결시킴으로써 도입될 수 있다. 이러한 벡터는 마커를 세포 게놈내로 도입시킨 세포의 선택을 위해 제공된 선택성 마커 유전자를 함유하도록 가공할 수 있다. 이러한 마커는 마커에 의해 암호화된 단백질을 도입하여 발현하는 숙주 세포의 확인 및/또는 선택을 허용한다.
바이러스 벡터, 및 특히 레트로바이러스 벡터는 세포 및 살아있는 동물 대상체에서 광범위한 유전자 전달 적용에 사용된다. 사용될 수 있는 바이러스 벡터는 레트로바이러스, 아데노-관련 바이러스, 폭스, 바큘로바이러스, 박시니아, 헤르페스 단성 바이러스, 엡슈타인-바르(Epstein-Barr) 바이러스, 아데노바이러스, 게미니바이러스 및 카울리모바이러스 벡터를 포함할 수 있으나, 이에 한정되지 않는다. 비-바이러스 벡터는 플라스미드, 리포좀, 전기적으로 하전된 지질(사이토펙틴), DNA-단백질 복합체 및 생체중합체를 포함한다. 핵산 외에, 벡터는 또한 하나 이상의 조절 영역 및/또는 핵산 전달 결과(조직 전달, 발현 경과, 등)를 선택하고, 측정하며 모니터링하는에 유용한 선택성 마커를 포함할 수 있다.
용어 플라스미드는 세포의 중심 대사의 일부가 아니며, 일반적으로 환형의 이본쇄 DNA 분자의 형태인 유전자를 흔히 수반하는 염색체-외 성분을 말한다. 이러한 성분들은, 다수의 뉴클레오타이드 서열이 적절한 3' 해독되지 않은 서열과 함께 프로모터 단편 및 선택된 유전자 생성물에 대한 DNA 서열을 세포내로 도입시킬 수 있는 유일한 작제물내로 결합되거나 재조합되어 있는, 어떠한 공급원으로부터도 기원하는 일본쇄- 또는 이본쇄 DNA 또는 RNA의 선형, 환형 또는 슈퍼코일된 자가 복제하는 서열, 게놈 통합 서열, 파지 또는 뉴클레오타이드 서열일 수 있다.
클로닝 벡터는, 다른 핵산 분절이 부착되어 부착된 분절을 복제할 수 있는, 연속적으로 복제하는 단위 길이의 핵산, 바람직하게는 DNA이고 복제 오리진을 포함하는 레플리콘, 예를 들면, 플라스미드, 파지 또는 코스미드를 말한다. 클로닝 벡터는 하나의 세포 유형에서 복제할 수 있고 다른 세포 유형에서 발현할 수 있다(셔틀 벡터). 클로닝 벡터는 목적한 서열의 삽입을 위한 벡터 및/또는 하나 이상의 다수의 클로닝 부위를 포함하는 세포의 선택을 위해 사용될 수 있는 하나 이상의 서열을 포함할 수 있다.
용어 발현 벡터는 삽입된 핵산 서열이 발현 후 숙주내로 형질전활될 수 있도록 설계된 벡터, 플라스미드 또는 비히클을 말한다. 클로닝된 유전자, 즉, 삽입된 핵산 서열은 일반적으로 프로모터, 최소 프로모터, 인핸서 등과 같은 조절 성분의 조절하에 위치한다. 바람직한 숙주 세포에서 핵산의 발현을 구동시키는데 유용한 개시 조절 영역 또는 프로모터는 다수이며 당해 분야의 숙련가에게 익숙하다. 사실상 이들 유전자의 발현을 구동시킬 수 있는 어떠한 프로모터도, 바이러스 프로모터, 세균 프로모터, 동물 프로모터, 포유동물 프로모터, 합성 프로모터, 구성적 프로모터, 조직 특이적인 프로모터, 발병기전 또는 질병 관련 프로모터, 발달 특이적인 프로모터, 유도성 프로모터, 광 조절된 프로모터; CYC1, HIS3, GAL1, GAL4, GAL1O, ADH1, PGK, PHO5, GAPDH, ADC1, TRP1, URA3, LEU2, ENO, TPI, 알칼린 포스파타제 프로모터(사카로마이세스(Saccharomyces)에서 발현용으로 유용); AOX1 프로모터(피키아(Pichia)에서 발현용으로 유용); 베타-락타마제, lac, ara, tet, trp, IPL, IPR, T7, tac, 및 trc 프로모터(에스케리키아 콜라이(Escherichia coli)에서 발현용으로 유용); 광 조절된-, 종자 특이적인-, 수분 특이적인-, 난소 특이적인-, 꽃양배추 모자이크 바이러스 35S, CMV 35S 미니말, 카사바 베인(cassava vein) 모자이크 바이러스(CsVMV), 클로로필 a/b 결합 단백질, 리불로즈 1,5-비스포스페이트 카복실라제, 싹-특이적인, 뿌리-특이적인, 키티나제, 스트레스 유도성, 벼 퉁그로 바실리포름 바이러스(rice tungro bacilliform virus), 식물 슈퍼-프로모터, 감자 루이신 아미노펩티다제, 니트레이트 리덕타제, 만노핀 신타제, 노팔린 신타제, 유비퀴틴, 제인 단백질 및 안토시아닌 프로모터(식물 세포에서 발현용으로 유용); SV40 얼리(early) (SV40e) 프로모터 영역, 로우스 육종 바이러스(Rous sarcoma virus)(RSV)의 3' 긴 말단 반복물(LTR)에 함유된 프로모터, E1A의 프로모터 또는 아데노바이러스(Ad)의 주요 레이트 프로모터(MLP), 사이토메갈로바이러스(CMV) 얼리 프로모터, 헤르페스 단성 바이러스(HSV) 티미딘 키나제(TK) 프로모터, 바큘로바이러스 IE1 프로모터, 연장 인자 1 알파(EF1) 프로모터, 포스포글리세레이트 키나제(PGK) 프로모터, 유비퀴틴(Ubc) 프로모터, 알부민 프로모터, 마우스 메탈로티오네인-L 프로모터의 조절 서열 및 전사 조절 영역, 편재하는 프로모터(HPRT, 비멘틴, 베타-액틴, 부불린 등), 중간 세사(데스민, 신경잔섬유, 케라틴, GFAP 등)의 프로모터, 치료 유전자(MDR, CFTR 또는 인자 VIII형 등)의 프로모터, 발병기전 또는 질병 관련-프로모터, 및 조직 특이성을 나타내며 유전자삽입 동물에서 이용되는 프로모터, 예를 들면, 이자 외분비 세포에서 활성인 엘라스타제 I 유전자 조절 영역을 포함하나, 이에 한정되지 않는 당해 분야에 공지된 동물 및 포유동물 프로모터; 췌장 베타 세포에서 활성인 인슐린 유전자 조절 영역, 림프구 세포에서 활성인 면역글로불린 유전자 조절 영역, 고환, 유방, 림프구 및 유방 세포에서 활성인 마우스 유방 종양 바이러스 조절 영역; 알부민 유전자, 간에서 활성인 Apo AI 및 Apo AII 조절 영역, 간에서 활성인 알파-페로단백질 유전자 조절 영역, 간에서 활성인 알파 1-안티트립신 유전자 조절 영역, 골수 세포에서 활성인 베타-글로빈 유전자 조절 영역, 뇌내 희소돌기아교 세포에서 활성인 수초 염기성 단백질 유전자 조절 영역, 골격근에서 활성인 미오신 경쇄-2 유전자 조절 영역, 및 시상하부에서 활성인 고나도트로핀 방출 호르몬 유전자 조절 영역, 피루베이트 키나제 프로모터, 빌린 프로모터, 지방산 결합 장내 단백질의 프로모터, 평활근 세포 베타-액틴의 프로모터 등을 포함하나, 이에 한정되지 않는 발현 벡터에서 사용될 수 있다. 또한, 이들 발현 서열은 인핸서 또는 조절 서열 등을 첨가함으로써 변형시킬 수 있다.
벡터는 당해 분야에 공지된 방법, 예를 들면, 형질감염, 전기영동(electroporation), 미세주입, 형질유도(transduction), 세포 융합, DEAE 덱스트란, 칼슘 포스페이트 침전, 지질감염(라이소좀 융합), 유전자 건(gene gun)의 사용 또는 DNA 벡터 전달체에 의해 목적한 숙주 세포내로 도입시킬 수 있다[참조: 예를 들면, Wu et al., J. Biol. Chem. 267:963 (1992); Wu et al., J. Biol. Chem. 263:14621 (1988); 및 Hartmut et al., 카나다 특허원 제2,012,311호].
본 발명에 따른 폴리뉴클레오타이드는 지질감염으로 생체내에서 도입시킬 수 있다. 과거 10여년 동안, 시험관내에서 핵산의 봉입(encapsulation) 및 형질감염을 위한 리포좀의 사용이 증가되어 왔다. 리포좀-매개된 형질감염으로 직면하게 되는 장애 및 위험을 제한하도록 설계된 합성 양이온성 지질을 사용하여 마커를 암호화하는 유전자의 생체내 형질감영용 리포좀을 제조할 수 있다[참조: Felgner et al., Proc. Natl. Acad. Sci. USA. 84:7413 (1987); Mackey et al., Proc. Natl. Acad. Sci. USA 85:8027 (1988); 및 Ulmer et al., Science 259:1745 (1993)]. 양이온성 지질의 사용은 음성적으로 하전된 핵산의 봉입을 촉진할 수 있으며, 또한 음성적으로 하전된 세포막과의 융합을 촉진한다[참조: Felgner et al., Science 337:387 (1989)]. 핵산을 전달하기에 특히 유용한 지질 화합물 및 조성물은 국제공개 WO95/18863, WO96/17823 및 미국 특허 제5,459,127호에 기술되어 있다. 생체내에서 특이 유기체내로 외인성 유전자를 도입시키기 위한 지질감염의 사용은 실질적으로 특정의 잇점을 갖는다. 특이 세포에 대한 리포좀의 분자 표적화는 하나의 유리한 영역을 나타낸다. 특수 세포 유형에 대해 형질감염을 지시하는 것이 췌장, 감, 신장 및 뇌와 같은 세포 이질성을 갖는 조직에서 특히 바람직할 수 있다. 지질은 표적화 목적을 위해 다른 분자에 화학적으로 커플링시킬 수 있다(참조: Mackey et al. 1988, 상기 참조). 표적화된 펩타이드, 예를 들면, 호르몬 또는 신경전달인자, 및 항체와 같은 단백질, 또는 비-펩타이드 분자는 리포좀에 화학적으로 커플링시킬 수 있다.
양이온성 올리고펩타이드(예를 들면, 국제공개 WO95/21931), DNA 결합 단백질로부터 기원한 펩타이드(예를 들면, 국제공개 WO96/25508), 또는 양이온성 중합체(예를 들면, WO95/21931)와 같은 다른 분자도 또한 생체내에서 핵산의 형질감염을 촉진시키는데 유용하다.
벡터를 생체내에서 네이크드(naked) DNA 플라스미드로서 도입시키는 것도 또한 가능하다(참조: 미국 특허 제5,693,622호, 제5,589,466호 및 제5,580,859호). 수용체-매개된 DNA 전달 시도 또한 사용될 수 있다[참조: Curiel et al., Hum. Gene Ther. 3:147 (1992); and Wu et al., J. Biol. Chem. 262:4429 (1987)].
용어 "형질감염"은 세포에 의한 외인성 또는 이종 RNA 또는 DNA의 흡수를 말한다. 세포는, 이러한 RNA 또는 DNA가 세포내로 도입되는 경우 외인성 또는 이종 RNA 또는 DNA에 의해 형질감염된다. 세포는, 형질감염된 RNA 또는 DNA가 표현형 변화를 겪는 경우 외인성 또는 이종 RNA 또는 DNA에 의해 형질감염된다. 형질감염 RNA 또는 DNA는 세포의 게놈을 구성하는 염색체 DNA내로 통합(공유 결합)될 수 있다.
형질전환은, 핵산 단편이 숙주 유기체의 게놈내로 전달되어 유전적으로 안정한 유전을 초래하는 것을 말한다. 형질전환된 핵산 단편을 함유하는 숙주 유기체는 유전자삽입 또는 재조합체 또는 형질전환된 유기체로 언급된다.
또한, 본 발명에 따른 폴리뉴클레오타이드를 포함하는 재조합체 벡터는, 이들의 증폭 또는 이들의 발현이 고려되는 세포 숙주내에서 하나 이상의 복제 오리진, 마커 또는 선택성 마커를 포함할 수 있다.
용어 "선택성 마커"는 마커 유전자의 효과, 예를 들면, 항생제에 대한 내성, 제조제에 대한 내성, 비색 마커, 효소, 형광성 마커 등(여기서, 당해 효과는 목적한 핵산의 유전을 추적하고/하거나 목적한 핵산이 유전된 세포 또는 유기체를 확인하는데 사용된다)을 기준으로 하여 선택될 수 있는 확인 인자, 일반적으로 항생제 또는 화학물질 내성 유전자를 말한다. 당해 분야에 알려져 사용되는 선택성 마커 유전자의 예는 암피실린, 스트렙토마이신, 겐타마이신, 가나마이신, 하이그로마이신, 바이알라포스 제초제, 설폰아미드 등에 대한 내성을 제공하는 유전자; 및 표현형 마커로 사용되는 유전자, 즉, 안토시아닌 조절 유전자, 이소펜타닐 트랜스퍼라제 유전자 등을 포함한다.
용어 "리포터 유전자"는 리포터 유전자의 효과를 기준으로 하여 확인가능한 확인 인자를 암호화하는 핵산을 말하며, 여기서, 당해 효과는 목적한 핵산의 유전을 추적하고/하거나, 목적한 핵산을 유전하는 세포 또는 유기체를 확인하고/하거나 유전자 발현 유도 또는 전사를 측정하는데 사용된다. 당해 분야에 공지되고 사용된 리포터 유전자의 예는 루시퍼라제(Luc), 녹색 형광성 단백질(GFP)과 같은 형광성 단백질, 클로람페니콜 아세틸트랜스퍼라제(CAT), 베타-갈락토시다제(LacZ), 베타-글루쿠로니다제(Gus) 등을 포함한다.
프로모터 및 프로모터 서열은 상호교환적으로 사용되며 암호화 서열 또는 작용적 RNA의 발현을 조절할 수 있는 DNA 서열을 말한다. 일반적으로, 암호화 서열은 프로모터 서열에 대해 3'에 위치한다. 프로모터는 천연 유전자로 부터 이들의 전체에서 기원할 수 있거나, 천연에서 발견된 상이한 프로모터로부터 기원한 상이한 성분들로 구성되거나, 심지어 합성 DNA 분절을 포함한다. 당해 분야의 숙련가들은, 상이한 프로모터가 상이한 조직 또는 세포 유형에서, 또는 상이한 발달 단계에서, 또는 상이한 환경 또는 생리학적 상태에 반응하여 유전자의 발현을 지시할 수 있음을 이해한다. 유전자가 대부분의 시간에서 대부분의 세포 유형에서 발현되도록 하는 프로모터는 일반적으로 구성적 프로모터로서 언급된다. 유전자가 특수 세포 유형에서 발현되도록 하는 프로모터는 일반적으로 세포-특이적인 프로모터 또는 조직-특이적인 프로모터로 언급된다. 유전자가 특수한 발달 단계 또는 세포 분화에서 발현되도록 하는 프로모터는 일반적으로 발달적으로-특이적인 프로모터 또는 세포 분화-특이적인 프로모터로 언급된다. 유도되고 유전자가 세포를 프로모터를 유도하는 제제, 생물학적 분자, 화학물질, 리간드, 광 등에 노출 또는 처리 후 발현되도록 하는 프로모터는 일반적으로 유도성 프로모터 또는 조절가능한 프로모터로 언급된다. 대부분의 경우 조절 서열의 정확한 경계는 완전하게 정의되어 있지 않기 때문에, 상이한 길이의 DNA 단편은 확인된 프로모터 활성을 가질수 있는 것으로 또한 인지된다.
프로모터 서열은 통상적으로 전사 개시 부위에 의해 이의 3' 말단에서 결합되며 상부(5' 방향)로 연장되어 배경을 초과하는 검출가능한 수준에서 전사를 개시하는데 필요한 최소 수의 염기 또는 성분들을 포함한다. 프로모터 서열내에서 전사 개시 부위(예를 들면, 뉴클레아제 S1을 사용한 맵핑에 의해 편리하게 정의) 및 RNA 폴리머라제의 결합에 관여하는 단백질 결합 도메인(콘센서스 서열)이 발견될 것이다.
용어 "상동성"(homology)은 2개의 폴리뉴클레오타이드 또는 2개의 폴리펩타이드 잔기사이의 동일성 퍼센트를 말한다. 하나의 잔기로부터 다른 것으로의 서열사이의 상응성은 당해 분야에 알려진 기술로 측정할 수 있다. 예를 들면, 상동성은 서열 정보를 정렬하고 용이하게 이용가능한 컴퓨터 프로그램을 사용함으로써 2개의 폴리펩타이드 분자사이의 서열 정보를 직접 비교함으로써 측정할 수 있다. 달리는, 상동성은 상동인 영역사이에 안정한 이본체를 형성하는 조건하에 폴리뉴클레오타이드를 하이브리드화한 후 일본쇄-특이적인 뉴클레아제(들)로 분해하고 분해된 단편의 크기를 측정함으로써 측정할 수 있다.
본원에 사용된 것으로서, 모든 이의 문법적 형태 및 스펠링 변화에서 용어 상동성은 상과(예를 들면, 면역글로불린 상과)로부터의 단백질 및 상이한 종으로부터의 상동인 단백질(예를 들면, 마이오신 경쇄 등)으로부터의 단백질을 포함하는, 일반적인 진화적 기원을 지닌 단백질 사이의 관계를 말한다[참조: Reeck et al., Cell 50:667 (1987)]. 이러한 단백질(및 이들의 암호화 유전자)는 이들의 고도의 서열 유사성에 의해 반영된 바와 같이, 서열 상동성을 갖는다. 그러나, 일반적인 사용 및 본 출원에서, 용어 상동성은, 고도의와 같은 형용사로 변형되는 경우, 일반적인 유전적 기원이 아닌 서열 유사성을 말할 수 있다.
따라서, 모든 이의 문법적 형태에서 용어 서열 유사성(sequence similarity)은 일반적인 진화 기원을 공유할 수 있거나 공유할 수 없는 단백질의 핵산 또는 아미노산 서열사이의 상동성 또는 상응성의 정도를 말한다[참조: Reeck et al., Cell 50:667 (1987)]. 하나의 양태에서, 2개의 DNA 서열은, 핵산의 적어도 약 50%(예를 들면, 적어도 약 75%, 90%, 또는 95%)가 정의된 길이의 DNA 서열에 걸쳐 일치하는 경우 실질적으로 상동성이거나 실질적으로 유사하다. 실질적으로 상동인 서열은 서열을 서열 데이타 뱅크에서 이용가능한 표준 소프트웨어를 사용하여 비교하거나, 예를 들면, 특수 시스템을 위해 정의된 스트링전트 조건(stringent condition)하에서 서던 하이브리드화 시험에서 서열을 비교함으로써 확인할 수 있다. 적절한 하이브리드화 조건의 정의는 당해 분야의 기술내에 있다9참조: Sambrook et al., 1989, 상기 참조).
본원에 사용되는, "실질적으로 유사한"이란, 하나 이상의 뉴클레오타이드내 변화가 하나 이상의 아미노산의 치환을 초래하지만, DNA 서열에 의해 암호화된 단백질의 작용적 특성에 영향을 미치지 않는 핵산 단편을 말한다. 실질적으로 유사한은, 또한 하나 이상의 뉴클레오타이드 염기가 안티센스 또는 공-제어 기술에 의해 유전자 발현의 변경을 매개하는 핵산 단편의 능력에 영향을 미치지 않는 핵산 단편을 말한다. 실질적으로 유사한은, 또한 수득되는 전사체의 작용적 특성에 실질적으로 영향을 미치지 않는 하나 이상의 뉴클레오타이드 염기의 결실 또는 삽입과 같은 본 발명의 핵산 단편의 변형을 말한다. 따라서, 본 발명이 특수 예시적인 서열 이상을 포함하는 것은 이해된다. 각각의 제안된 변형은 암호화된 생성물의 생물학적 활성의 보유를 측정하는 것과 같이, 당해 분야의 통상의 기술내에 있다.
또한, 숙련가들은, 본 발명에 포함된 실질적으로 유사한 서열이 스트링전트 조건(0.1X SSC, 0.1% SDS, 65℃ 및 2X SSC, 0.1% SDS에 이은 0.1 X SSC, 0.1% SDS를 사용한 세척)하에서 본원에 예시된 서열과 하이브리드화하는 이들의 능력으로 정의된다. 본 발명의 실질적으로 유사한 핵산 단편은, 이의 DNA 서열이 본원에 보고된 핵산 단편의 DNA 서열과 적어도 약 70%, 80%, 90% 또는 95% 동일성인 핵산 단편이다.
용어 "상응하는"은, 본원에서 정확한 위치가 유사성 또는 상동성이 측정되는 분자와 동일하거나 상이한, 유사하거나 상동인 서열을 말한다. 핵산 또는 아미노산 서열 정렬은 스페이스를 포함할 수 있다. 따라서, 용어 "상응하는"은 아미노산 잔기 또는 뉴클레오타이드 염기의 번호매김이 아닌, 서열 유사성을 말한다.
아미노산 또는 뉴클레오타이드 서열의 실질적인 부위는 당해 분야의 숙련가에 의한 서열의 수동 평가에 의해, 또는 컴퓨터-자동화된 서열 비교 및 BLAST[기본적인 국소 정렬 조사 기구(Basic Local Alignment Search Tool); 참조: Altschul et al., J. Mol. Biol. 215:403 (1993)); ncbi.nlm.nih.gov/BLAST/에서 이용가능]와 같은 알고리즘을 사용한 확인에 의해 폴리펩타이드 또는 유전자를 추정적으로 확인하기 위한 충분한 폴리펩타이드의 아미노산 서열 또는 유전자의 뉴클레오타이드 서열을 포함한다. 일반적으로, 10개 이상의 연속된 아미노산 또는 30개 이상의 뉴클레오타이드의 서열이 공지된 단백질 또는 유전자에 대해 상동인 폴리펩타이드 또는 핵산 서열을 추정적으로 확인하기 위해 요구된다. 또한, 뉴클레오타이드 서열과 관련하여, 20 내지 30개의 연속된 뉴클레오타이드를 포함하는 유전자 특이적인 올리고뉴클레오타이드 프로브를 유전자 확인(예를 들면, 서던 하이브리드화) 및 분리(예를 들면, 세균 클론 또는 박테리오파지 플라크의 반응계내 하이브리드화)의 서열-의존적인 방법에 사용할 수 있다. 또한, 12 내지 15개 염기의 짧은 올리고뉴클레오타이드를 PCR에서 증폭 프라이머로 사용하여 프라이머를 포함하는 특수 핵산 단편을 수득할 수 있다. 따라서, 뉴클레오타이드 서열의 실질적인 부분은 서열을 포함하는 핵산 단편을 특이적으로 확인하고/하거나 분리하기에 충분한 서열을 포함한다.
본 발명의 하나의 측면은 데그론에 연결된 PAI-1 단백질을 제공하는 것이다. 데그론은 PAI-1 단백질의 아미노 말단 또는 이의 카복시 말단에 연결될 수 있다. 데그론, 또는 분해-측정 시그날은 당해 분야에서 폴리펩타이드 분해를 유도하는 짧고, 흔히 이동가능한 성분으로 알려져 있으며, 이의 몇 가지 예가 문헌[참조: Garcin, D, et al., Journal of Virology, 2004, 78(16):8799-8811 및 Gardner, RG and Hampton, RY, The EMBO Journal, 1999, 18(21):5994-6004]에 인용되어 있다. 데그론에 연결된 PAI-1의 예는 도 17A, 17B, 17E, I7F, 17G, 및 17H에 나타낸다.
본 발명의 다른 측면은 국재화 시그날에 연결된 PAI-1 단백질을 제공하는 것이다. 세포 국재화 시그날의 비-제한적인 예는 근세포질 세망, 세포질 세망, 세포외 매트릭스, 미토콘드리아, 골지체, 페록시좀, 라이소좀, 핵, 핵소체, 엔도소옴, 엑소소옴, 기타 세포내 소낭, 혈장막, 치근막, 기저측막에 국재화된 시그날이다. 하나의 양태에서, PAI-1은 미국 가특허원 제60/957,328호에 기술된 것들과 같은 비-세포-특이적인 혈장 막을 통해 세포외 표면에 전달된다. 다른 실시양태에서, PAI-1은 섬유아세포, 내피 세포, 평활근 세포, 지방 세포 및 심근 세포의 횡문근형질막에 대해 특이적인 국재화 시그날과 같은 세포-특이적인 국재화 시그날에 접하여 세포외 표면으로 전달된다. 다른 실시양태에서. PAI-1은 콜라겐 결합 단백질과 같은 세포외 연합 도메인을 통해 세포외 매트릭스에, 또는 심근 경색 영역에 풍부한 다른 세포외 성분들에 전달된다. 도 17C 내지 17H는 국재화 시그날에 연결된 PAI-1의 추가의 양태들을 나타낸다. 국재화 시그날은 예로써 제한없이 제공된다.
본 발명의 하나의 측면은 벡터 삽입용으로 최적화된 PAI-1 서열을 제공하는 것이다. 하나의 실시양태에서, 폴리뉴클레오타이드는 ULTRAVECTOR[제조원: 인트렉손 코포레이션(Intrexon Corp.), 버지니아주 블랙스부르그 소재, 제US2004/0185556호)내로의 삽입을 위해 최적화된다. 다른 실시양태에서, 폴리뉴클레오타이드는 다음의 내부 제한 부위의 제거을 통해 벡터 삽입용으로 최적화된다: NgoM FV, Xma I, CIa I, BamH I, BstB I, EcoR I, RcoR V, Pci I, Sac I, Stu I, ApaL I, BgI II, Kpn I, Mfe I, Nde I, Nhe I, Nsi I, Asc I, AsiS I, BsiW I, Fse I, Mlu I, Not I, Pac I, Sal I, Sbf I, SnaB I, Swa I, Rsr III, RsrII2, BstX I, Sap I, BsmB I, Xba I, Xho I, Hpa I, PmI I, Sph I, Aar I, Bgl I, BsmB I, BspM I, BstAP I, BstX I, Dra III, Ear I, Sap I, Blp I, 및 BspE I.
본 발명의 하나의 측면은 데그론 폴리뉴클레오타이드 서열에 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 제공하는 것이다. 하나의 실시양태에서, 데그론 서열은 PAI-1 폴리뉴클레오타이드 서열의 5' 말단에서 연결된다(참조: 예를 들면, 도 18C 및 18H). 본 발명의 다른 실시양태에서, 데그론 서열은 데그론 폴리뉴클레오타이드 서열의 3' 말단에서 연결된다(참조: 예를 들면, 도 18B 및 18F).
본 발명의 다른 측면은 국재화 시그날에 연결된, 벡터 삽입용으로 최적화된 PAI-1 폴리뉴클레오타이드 서열을 제공하는 것이다(참조: 예를 들면, 도 18D 내지 18I).
본 발명의 다른 실시양태는 바람직한 세포, 조직 또는 생리학적 상태에서 벡터 삽입-최적화된 PAI-1 폴리리뉴클레오타이드 서열의 발현을 선택적으로 조절하기 위한 유전자 작제물에 관한 것이다. 유전자 작제물은 데그론 및/또는 국재화 시그날에 임의 연결된 PAI-1 유전자 작제물을 포함할 수 있다. 예시적인 유전자 작제물은 도 13A 내지 13E, 도 23A 내지 23G, 및 도 18A 내지 18I에 나타낸다. 유전자 작제물의 프로모터 부분은 구성적 프로모터, 비-구성적 프로모터, 조직-특이적인 프로모터(구성적 또는 비-구성적) 또는 유도성 프로모터일 수 있다. 본 발명에 유용한 조직-특이적인 프로모터의 비-제한적 예는 내피 세포-특이적인 프로모터[참조: White, SJ, et al., Gene Ther. 2007 Nov 8 [Epub ahead of print]], 혈관 평활근 세포-특이적인 프로모터[참조: Ribault, S, Circ Res., 2001, 88(5):468-75; Appleby, CE, et al., Gene Ther. 2003, 10(18): 1616-22], 심근세포-특이적인 프로모터[참조: Xu, L, et al., J Biol Chem., 2006, 281(45):34430-40], 관상 지방세포-특이적인 프로모터 및 심장 섬유모세포-특이적인 프로모터이다. 심장 및 저산소증-특이적인 프로모터와 같은 조합된 조직 및 상태 특이적인 프로모터[참조: Su, H, et al., Proc Natl. Acad. Sci. U.S.A., 2004, 101(46): 16280-5]가 또한 본 발명에 유용하다. 유도성 프로모터는 약물 또는 기타 인자에 의해 활성화된다. RHEOSWITCH는 본 발명에 유용한 뉴 잉글랜드 바이오랩[New England BioLabs (매사츄세츠주 입스위치 소재)]로부터 시판되는 유도성 프로모터 시스템이다. 본 발명의 양태는 이의 발현이 유도성 프로모터 시스템에 의해 조절되는 PAI-1 유전자 작제물을 포함한다.
본 발명의 다른 측면은 본원에 기술된 바와 같은 포유동물 세포 발현 및 벡터 삽입-최적화된 PAI-1 폴리뉴클레오타이드 서열의 발현을 위한 유전자 작제물을 함유하는 벡터를 제공하는 것이다. 벡터는 본원에 기술된 바와 같이 바이러스 벡터 또는 비-바이러스 벡터일 수 있다. 이러한 벡터의 비-제한적 예는 도 19A 내지 19D에 나타낸다.
도 19A는 벡터 삽입-최적화된 PAI-1 폴리뉴클레오타이드 서열 및 임의의 국재화 시그날 및/또는 데그론을 함유하는 유전 형의 벡터를 나타내며, 여기서, 유전자 작제물은 유전자삽입 동물을 생성하는데 유용한 단위로서 벡터로부터 방출가능하다. 예를 들면, 유전자 작제물 또는 삽입유전자는 제한 엔도뉴클레아제 분해에 의해 벡터 골격으로부터 방출된다. 방출된 삽입유전자는 이후에 마우스 수정란의 전핵내로 주입되거나; 삽입유전자를 사용하여 배아 줄기 세포를 형질감염시킨다. 도 19A의 벡터는 또한 삽입유전자의 일시적인 형질감염에 유용하며, 여기서, 삽입유전자의 프로모터 및 코돈은 포유동물 발현용으로 최적화된다.
도 19B 및 도 19C는 생체내에서 PAI-1 폴리펩타이드 발현을 전달하고 조절하기 위한 유전자 치료요법 벡터의 실시양태를 묘사한다. 도 19B 및 도 19C에서 유전자 작제물에 연결된 폴리뉴클레오타이드 서열은 삽입유전자의 바이러스 게놈 및/또는 숙주 게놈내로의 통합을 촉진시키기 위한 게놈 통합 도메인을 포함한다.
도 19D는 안정한 세포주를 생성하는데 유용한 국재화 시그날 유전자 작제물을 함유하는 벡터를 나타낸다.
본 발명의 다른 측면은 본원에 기술된 바와 같이, 포유동물 세포 발현 및 벡터 삽입-최적화된 PAI-1 폴리뉴클레오타이드 서열의 발현을 위한 유전자 작제물을 함유하는 벡터를 함유하는 숙주 세포를 제공하는 것이다. 하나의 실시양태에서, 숙주 세포는 포유동물 세포이다. 숙주 세포는 사람, 비-사람 영장류, 마우스, 소, 돼지, 양, 말, 랫트, 토끼, 개, 고양이 및 기나아 피그를 포함한다. 숙주 세포의 특수 유형은 심근세포, 섬유모세포, 내피 세포, 평활근 세포 및 지방세포를 포함한다.
본 발명의 다른 측면은 포유동물 세포 발현 및 벡터 삽입-최적화된 PAI-1 폴리뉴클레오타이드 서열을 함유하는 유전자삽입 유기체를 제공하는 것이다. 하나의 실시양태에서, 유전자삽입 숙주는 포유동물이다. 포유동물 유전자삽입 숙주는 비-사람 영장류, 마우스, 소, 돼지, 양, 말, 랫트, 토끼, 개, 고양이 및 기니아 피그를 포함한다. 유전자삽입 유기체는 완성된 삽입유전자를 수정된 난자의 전구핵 또는 배아 줄기 세포내로 주입함으로써 생성시킨다. 완성된 삽입유전자는 본원에 기술된 바와 같은 데그론, 국재화 시그날 또는 구성적 프로모터, 비-구성적 프로모터, 조직-특이적인 프로모터(구성적 또는 비-구성적) 또는 유도성 프로모터에 임의 연결된, 포유동물 세포 발현 및 벡터 삽입-최적화된 PAI-1 폴리뉴클레오타이드 서열을 포함한다. 유전자삽입 유기체는 심장에서 PAI-1의 역활을 정의하기 위한 동물 모델로서 사용될 수 있다.
본 발명의 다른 측면은 PAI-1의 적어도 하나의 카피를 암호화하는 벡터 삽입 최적화된-핵산 분자를 포함하는 벡터를 숙주 세포내로 형질감염시키고 형질감염된 숙주 세포를 PAI-1의 적어도 하나의 카피를 생산하는데 적합한 조건하에서 배양함을 포함하여 숙주 세포에서 PAI-1의 발현을 변경시키는 방법이다.
본 발명의 다른 측면은 PAI-1의 적어도 하나의 카피를 암호화하는 벡터 삽입 최적화된-핵산 분자를 포함하는 벡터를 대상체의 심장 조직내로 주입함을 포함하여 대상체의 심장 조직에서 PAI-1의 발현을 변경시키는 방법이다.
본 발명의 다른 측면은 PAI-1의 적어도 하나의 카피를 암호화하는 벡터 삽입 최적화된-핵산 분자를 포함하는 벡터를 수정란 또는 배아 줄기 세포내로 주입함을 포함하여 PAI-1 발현이 변형된 유전자삽입 대상체를 창조하는 방법이다.
본 발명의 측면은 트렁케이션(truncation) 및/또는 아미노산 치환에 의해 천연 기질 및/또는 조절인자를 변형시킴으로써 PAI-1 활성의 신규 리간드 억제제를 제공하는 것이다.
본 발명의 다른 측면은 신규 억제제 및 이의 변이체를 함께 연결시킴으로써 PAI-1 활성의 모듈러 폴리리간드 억제제를 제공하는 것이다. 본 발명의 추가의 측면은 데그론에 연결시킴으로써 PAI-1 억제제, 리간드 또는 폴리리간드의 활성을 제한하는 것이다. 본 발명의 추가의 측면은 국재화 시그날에 연결시킴에 의한 PAI-1 억제제, 리간드 또는 폴리리간드의 세포 국재화이다.
본 발명의 측면은 심장 조직에서 섬유증을 예방하기 위한 방법으로서 PAI-1의 억제를 포함한다. PAI-1을 억제함으로써, 플라스미노겐 활성인자의 억제가 완화될 것이고, 그 결과 플라스미노겐의 플라스민으로의 활성화 및 피브린의 파괴가 초래될 것이다. 질병이 있는 심장의 피브린 파괴의 증진은 제II형 당뇨병, 고혈당증, 고혈압, 비만, 담배 또는 기타 원인으로 인한 심장근육병증을 치료하거나 예방하기 위한 강력한 시도를 나타낸다.
본 발명의 추가의 측면은 특정 조직에 유용한 PAI-1 억제제를 포함한다.
본 발명의 추가의 실시양태는 세포의 영역에 표적화된 국재화 시그날에 연결시킴으로써 상이한 세포 위치에 국재화된 PAI-1 억제제를 포함한다.
본 발명은 PAI-1용 폴리펩타이드 리간드 및 폴리리간드에 관한 것이다. PAI-1 리간드 및 폴리리간드의 각종 실시양태는 서열 1 내지 30 및 서열 37 내지 51에 나타나 있다. 보다 상세하게는, 본 발명은 서열 37 내지 51 중 어느 하나 또는 그 이상을 포함하는 리간드, 호모폴리리간드 및 헤테로폴리리간드에 관한 것이다. 추가로, 본 발명은 서열 31 내지 36의 하나 이상의 일부 서열(트렁케이션 단편) 또는 이의 특정 부분 포함하는 리간드 및 폴리리간드에 관한 것이다. 또한, 본 발명은 서열 37 내지 51중 하나 이상 또는 이의 특정 부분을 포함하는 폴리리간드에 대해 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 및 99% 서열 동일성을 갖는 폴리리간드에 관한 것이다. 또한 본 발명의 서열 31 내지 36중 하나 이상의 일부 서열을 포함하는 폴리리간드에 대해 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 및 99% 서열 동일성을 갖는 폴리리간드에 관한 것이다.
호모폴리리간드 또는 헤테로폴리리간드일 수 있는 폴리리간드는 2개 이상의 단량체성 폴리펩타이드 리간드로 구성된 키메라 리간드이다. 호모폴리리간드의 예는 도 4A 내지 도 4F에 나타낸다. 헤테로폴리리간드의 예는 도 6A 내지 6J에 나타낸다. 단량체성 리간드의 예는 서열 40으로 나타낸 폴리펩타이드이다. 서열 40은 전장 모 서열 32의 선택된 일부 서열이다. 호모폴리리간드의 예는 서열 37의 이량체 또는 다량체를 포함하는 폴리펩타이드이다. 헤테로폴리리간드의 예는 서열 37 및 서열 38 내지 51 중 하나 이상을 포함하는 폴리펩타이드이다. 서열 37 내지 51중 각각은 단량체 형태의 개개의 폴리펩타이드 리간드를 나타낸다. 서열 37 내지 51은 서열 31 내지 36의 일부 서열의 선택된 예이나, 서열 31 내지 36의 다른 부분 서열을 또한 단량체성 리간드로서 이용할 수 있다. 서열 31 내지 36의 단량체성 일부 서열은 서열 40과 같은 모 폴리펩타이드의 부분과 동일할 수 있다. 또한, 서열 31 내지 36의 단량체성 일부 서열은 서열 41 내지 45와 같은 아미노산 치환을 가질 수 있다. 또한, 단량체성 리간드 및 폴리리간드는 서열 37 내지 51중 하나 이상에서 아미노산 서열을 포함하는 리간드에 대해 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 서열 동일성을 가질 수 있다. 또한, 단량체성 리간드 및 폴리리간드는 서열 31 내지 36의 일부 서열에 대해 적어도 약 80%, 85%, 90%, 95%, 96%, 97%, 98% 및 99% 서열 동일성을 가질 수 있다.
서열 37 내지 51을 동질중합체성 또는 이질중합체성 리간드에 결합시키기 위한 다수의 방법이 존재한다. 또한, 서열 31 내지 36의 추가의 일부 서열을 서로 및 서열 37 내지 51과 결합시켜 중합체성 리간드를 제조하는 다수의 방법이 존재한다. 호모폴리리간드 구조의 비-제한적 예는 도 1A 내지 1F에 나타낸다. 헤테로폴리리간드 구조의 비-제한적 예는 도 2A 내지 2J에 나타낸다. 본 발명은 제한없이, 호모폴리리간드 및 헤테로폴리리간드의 모든 가능한 조합에 관한 것이다. 본 발명의 리간드 및 폴리리간드는 PAI-1의 내인성 효과를 조절하도록 설계된다.
본 발명의 하나의 실시양태에서, 리간드 또는 폴리리간드는 본원에 기술된 PAI-1 리간드 또는 폴리리간드이다.
본 발명의 다른 실시양태에서, 리간드 또는 폴리리간드는 본원에 기술된 PAI-1 리간드 또는 폴리리간드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성을 가진다.
본 발명의 다른 실시양태에서, 리간드 또는 폴리리간드는 하나 이상의 아미노산 결실, 치환, 삽입, 트렁케이션 또는 이의 조합을 포함하도록 변형된, 본원에 기술된 PAI-1 리간드 또는 폴리리간드이다.
본 발명의 다른 실시양태는 서열 1 내지 30중 홀수로 나타낸 폴리펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 폴리펩타이드이다.
본 발명의 다른 실시양태는 서열 1 내지 30중 짝수로 나타낸 폴리뉴클레오타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태에서, PAI-1 리간드 또는 폴리리간드는 서열 37 내지 51중 하나에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 적어도 하나의 펩타이드를 포함한다.
본 발명의 다른 실시양태에서, PAI-1 리간드 또는 폴리리간드는 다음의 억제 메카니즘 중 적어도 하나를 소유한다: 잠복 상태, PA1의 기질로의 전환, tPA 결합에 대한 입체 장애, 내인성 비트로넥틴에 대한 입체 장애 또는 결합 부위에 대한 직접적인 경쟁.
본 발명의 다른 실시양태는 본원에 기술된 PAI-1 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 폴리리간드는 단량체 전, 후 또는 사이에 스페이서 아미노산을 임의로 포함한다(참조: 예시적 구조를 위한 도 ID 내지 IF 및 도 2F 내지 2J).
본 발명은 상기 또는 하기에 기재된 실시예로 제한하지 않는 호모폴리리간드 및 헤테로폴리리간드의 모든 조합을 포함한다. 당해 기술에서, 용어 "리간드(들)"의 사용은 단량체성 리간드, 다량체성 리간드, 동질중합체성 리간드 및/또는 이질중합체성 리간드를 포함한다. 용어 리간드는 또한 용어 디코이(decoy), 억제제 및 조절인자를 포함한다.
단량체성 리간드는, 폴리펩타이드의 적어도 한 부분이 PAI-1에 의해 인지될 수 있는 폴리펩타이드이다. 인지할 수 있는 폴리펩타이드의 부분은 인지 모티프(recognition motif)로 명명된다. 본 발명에서, 인지 모티프는 천연 또는 합성일 수 있다. 인지 모티프의 예는 당해 분야에 잘 공지되어 있으며 천연적으로 존재하는 PAI-1 기질, 슈도기질(pseudosubstrate) 모티프, 및 PAI-1 조절 억제 단백질에 존재하는 상호작용 도메인 및 이의 변형을 포함하나, 이에 한정되지 않는다.
일반적으로, 천연의 PAI-1 상호작용 파트너를 기준으로 한 리간드 단량체는 추정의 PAI-1 상호작용 도메인 인지 모티프를 확인하고 분리함으로써 제조된다. 예시적인 천연의 PAI-1 상호작용 파트너는 당해 분야에 공지되어 있으며, 피브린, 조직 플라스미노겐 활성인자(서열 34로 나타낸 단백질), 유로키나제 플라스미노겐 활성인자(서열 36으로 나타낸 단백질), 및 비트로넥틴(서열 32로 나타낸 단백질)을 포함한다. 추가의 단량체는 PAI-1 인지 모티브 및 PAI-1 상호작용 도메인 인지 모티프의 한쪽 면에 인접하여 연속되는 아미노산을 포함한다. 따라서, 단량체성 리간드는 어떠한 길이일 수 있으며, 단, 단량체는 PAI-1 인지 모티프를 포함한다. 예를 들면, 단량체는 PAI-1 인지 모티프 및 인지 모티프에 인접한 적어도 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 또는 100개 이상의 아미노산을 포함할 수 있다. 또한 설계 고려는 리간드의 3차원 모델화 및 PAI-1과의 결합 상호작용의 모델화로부터 취한다. 리간드 또는 폴리리간드의 주요 서열의 변형이 이러한 모델화를 기준으로 바람직할 수 있다.
예를 들면, 하나의 실시양태에서, 본 발명은
a) 서열 31의 354 내지 368번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
b) 서열 31의 300 내지 309번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
c) 서열 31의 343 내지 353번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
d) 서열 32의 20 내지 63번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
e) 서열 32의 20 내지 63번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 32의 32번 아미노산 잔기에 상응하는 아미노산 잔기는 페닐알라닌으로부터 루이신으로 돌연변이되어 있다);
f) 서열 32의 20 내지 63번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 32의 29번 아미노산 잔기에 상응하는 아미노산 잔기는 트레오닌에서 알라닌으로 돌연변이되어 있다);
g) 서열 32의 20 내지 63번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 32의 42번 아미노산 잔기에 상응하는 아미노산 잔기는 글루탐산에서 알라닌으로 돌연변이되어 있다);
h) 서열 32의 20 내지 63번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 32의 43번 아미노산 잔기에 상응하는 아미노산 잔기는 루이신에서 알라닌으로 돌연변이되어 있다);
i) 서열 32의 20 내지 63번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 32의 23번 아미노산 잔기에 상응하는 아미노산 잔기는 세린에서 페닐알라닌으로 돌연변이되어 있고, 서열 32의 52번 아미노산 잔기에 상응하는 아미노산 잔기는 트레오닌에서 글루탐산으로 돌연변이되어 있고, 서열 32의 53번 아미노산 잔기에 상응하는 아미노산 잔기는 아스파르트산에서 루이신으로 돌연변이되어 있으며, 서열 32의 56번 아미노산 잔기에 상응하는 아미노산 잔기는 알라닌에서 타이로신으로 돌연변이되어 있고; 서열 32의 57번 아미노산 잔기에 상응하는 아미노산 잔기는 글루탐산에서 타이로신으로 돌연변이되어 있다);
j) 서열 33의 25 내지 256번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
k) 서열 33의 25 내지 44번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
l) 서열 33의 47 내지 256번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
m) 서열 34의 301 내지 308번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드;
n) 서열 35의 29 내지 121번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 35의 55번 아미노산 잔기에 상응하는 아미노산 잔기는 발린에서 알라닌으로 돌연변이되어 있고, 서열 35의 57번 아미노산 잔기에 상응하는 아미노산 잔기는 아스파라긴에서 타이로신으로 돌연변이되어 있으며, 서열 35의 59번 아미노산 잔기에 상응하는 아미노산 잔기는 트레오닌에서 아스파라긴으로 돌연변이되어 있고, 서열 35의 79번 아미노산 잔기에 상응하는 아미노산 잔기는 세린에서 라이신으로 돌연변이되어 있으며, 서열 35의 81번 아미노산 잔기에 상응하는 아미노산 잔기는 아스파르트산에서 라이신으로 돌연변이되어 있고, 서열 35의 83번 아미노산 잔기에 상응하는 아미노산 잔기는 글리신에서 글루탐산으로 돌연변이되어 있다); 및
o) 서열 36의 179 내지 415번 아미노산 잔기에 상응하는 아미노산 잔기를 포함하는 펩타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 펩타이드(여기서, 서열 36의 224번 아미노산 잔기에 상응하는 아미노산 잔기는 히스티딘에서 알라닌으로 돌연변이되어 있고, 서열 36의 275번 아미노산 잔기에 상응하는 아미노산 잔기는 아스파르트산에서 알라닌으로 돌연변이되어 있으며, 서열 36의 376번 아미노산 잔기에 상응하는 아미노산 잔기는 세린에서 알라닌으로 돌연변이되어 있다)로 이루어진 그룹 중에서 선택된 펩타이드 중 적어도 하나의 카피를 포함하는 PAI-1의 억제제를 포함한다.
본원에 사용된 것으로서, 용어 "에 상응하다" 및 "에 상응하는"은, 이들이 서열 정렬에 관한 것이므로, 참조 단백질, 예를 들면, (플라스미노겐 활성인자 억제제 1, AAA60009, 서열 31)내 다수의 위치 및 참조 단백질상의 위치와 정렬하는 위치를 의미하는 것으로 의도된다. 따라서, 대상체 펩타이드의 아미노산 서열이 참조 펩타이드의 아미노산 서열, 예를 들면, 서열 31과 정렬하는 경우, 참조 펩타이드 서열의 특정의 다수 위치"에 상응하는" 대상체 펩타이드 서열내 아미노산은 참조 펩타이드 서열의 이러한 위치와 정렬하지만, 참조 서열의 이들 정확한 다수의 위치내에 필수적으로 존재하지 않는 것들이다. 서열간의 상응하는 아미노산을 측정하기위해 서열을 정렬하는 방법은 하기에 기술되어 있다.
다른 실시양태에서, 리간드는 모노클로날 항체 단편, 파지-디스플레이 생성물, PAI-1 합성 억제제 또는 전사 인자 디코이일 수 있다.
단량체성 리간드는, 폴리펩타이드의 적어도 한 부분이 PAI-1에 의해 인지될 수 있는 폴리펩타이드이다. 인지할 수 있는 폴리펩타이드의 부분은 인지 모티프로 명명된다. 본 발명에서, 인지 모티프는 천연 또는 합성일 수 있다. 인지 모티프의 예는 당해 분야에 잘 알려져 있으며 천연적으로 존재하는 PAI-1 기질, 슈도기질 모티프 및 PAI-1 조절성 결합 단백질에 존재하는 상호작용 도메인 및 이의 변형을 포함하나, 이에 한정되지 않는다.
중합체성 리간드(폴리리간드)는 2개 이상의 단량체성 리간드를 포함한다.
동질중합체성 리간드는, 단량체성 리간드 각각이 아미노산 서열에서 동질이고, 단 세린, 트레오닌 또는 타이로신과 같은 탈포스포릴화가능한 잔기가 단량체성 리간드중 하나 이상에서 치환되거나 변형될 수 있는 중합체성 리간드이다. 변형은 슈도포스포릴화된 잔기(산성 아미노산)에 대한 치환 또는 천연 잔기에 대한 치환을 포함하나, 이에 한정되지 않는다.
이질중합체성 리간드는, 단량체성 리간드 중 일부가 동질성인 아미노산 서열을 갖지 않는 중합체성 리간드이다.
본 발명의 리간드는 에피토프 태그, 리포터 및/또는 세포 국재화 시그날을 제공하는 추가의 분자 또는 아미노산에 임의 연결된다. 세포 국재화 시그날은 세포의 영역에 대한 리간드를 표적화한다. 에피토프 태그 및/또는 리포터 및/또는 국재화 시그날은 동일한 분자일 수 있다. 에피토프 태그 및/또는 리포터 및/또는 국재화 시그날은 또한 상이한 분자일 수 있다.
본 발명은 또한 리간드, 호모폴리리간드, 및 헤테로폴리리간드를 암호화하는 뉴클레오타이드 서열을 포함하는 폴리뉴클레오타이드를 포함한다. 본 발명의 핵산은 에피토프 태그, 리포터, 및/또는 세포 국재화 시그날과 같은 추가의 특징을 갖는 폴리펩타이드를 암호화하는 추가의 뉴클레오타이드 서열에 임의 연결된다. 폴리뉴클레오타이드는 제한 엔도뉴클레아제 부위를 포함하는 뉴클레오타이드 서열 및 제한 엔도뉴클레아제 활성에 요구되는 기타 뉴클레오타이드를 포함하는 뉴클레오타이드 서열에 의해 임의 플랭킹된다. 플랭킹 서열은 벡터내에 유일한 클로닝 부위를 임의 제공하며 아서열(subsequence) 클로닝의 방향성을 임의 제공한다. 또한, 본 발명의 핵산은 벡터 폴리뉴클레오타이드내로 임의 혼입된다. 본 발명의 리간드, 폴리리간드 및 폴리뉴클레오타이드는 조사 도구 및/또는 치료제로서의 용도를 지닌다.
본 발명의 추가의 실시양태는 PAI-1에 대한 특정의 추정 또는 실제 상호작용 파트너를 기준으로 위에서 기술한 바와 같은 단량체를 포함한다. 또한, 기질 또는 결합 단백질이 하나 이상의 인지 모티프를 갖는 경우, 하나 이상의 단량체가 여기에서 확인될 수 있다.
본 발명의 다른 실시양태는 리간드 펩타이드의 적어도 하나의 카피를 암호화하는 폴리뉴클레오타이드 서열을 포함하는 핵산 분자이다.
본 발명의 다른 실시양태는, 폴리뉴클레오타이드 서열이 하나 이상의 펩타이드 리간드의 하나 이상의 카피를 암호화하는 핵산 분자이다.
본 발명의 다른 실시양태는, 폴리뉴클레오타이드 서열이 2, 3, 4, 5, 6, 7, 8, 9 또는 10으로 이루어진 그룹 중에서 선택된 펩타이드중 적어도 다수의 카피를 암호화하는 핵산 분자이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드중 적어도 하나의 카피를 암호화하는 핵산 분자를 포함하는 벡터이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드중 적어도 하나의 카피를 암호화하는 핵산 분자를 포함하는 벡터를 포함하는 재조합체 숙주 세포이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드중 적어도 하나의 카피를 암호화하는 핵산 분자를 포함하는 벡터를 숙주 세포내로 형질감염시키고 형질감염된 숙주 세포를 리간드 또는 폴리리간드의 적어도 하나의 카피를 생산하기에 적합한 조건하에서 배양함을 포함하여, 숙주 세포내에서 PAI-1을 억제하는 방법이다.
본 발명의 다른 측면은 PAI-1 리간드 또는 폴리리간드중 적어도 하나의 카피를 암호화하는 핵산 분자를 포함하는 벡터를 대상체의 심장 조직내로 주입함을 포함하여 대상체의 심장 조직에서 PAI-1을 억제하는 방법이다.
본 발명의 다른 측면은 PAI-1 리간드 또는 폴리리간드중 적어도 하나의 카피를 암호화하는 핵산 분자를 포함하는 벡터를 수정란 또는 배아 줄기 세포내로 주입함을 포함하여, PAI-1 활성이 감소된 유전자삽입 대상체를 창조하는 방법이다.
본 발명은 또한 참조 억제제와 적어도 약 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 변형된 억제제에 관한 것이다. "변형된 억제제"는 억제제 단백질 또는 폴리펩타이드의 주요 구조(아미노산 서열)내 하나 이상의 아미노산의 첨가, 결실 또는 치환에 의해 창조될 수 있는 펩타이드를 의미하는데 사용된다. "변형된 인지 모티프"는 모티프의 주요 구조(아미노산 서열)내 하나 이상의 아미노산의 첨가, 결실 또는 치환에 의해 변형된 천연적으로 존재하는 PAI-1 인지 모티프이다. 용어 "단백질" 및 "폴리펩타이드" 및 "펩타이드"는 본원에서 상호교환적으로 사용된다. 참조 억제제는 필수적으로 야생형 단백질 또는 이의 부분이 아니다. 즉, 참조 억제제는, 이의 서열이 야생형 단백질에 걸쳐 이미 변형된 단백질 또는 펩타이드일 수 있다. 참조 억제제는 특수 유기체로부터의 야생형 단백질일 수 있거나 아닐 수 있다.
참조 아미노산 서열에 대해 적어도 예를 들면, 약 95% "동일성"인 아미노산 서열을 갖는 폴리펩타이드는, 펩타이드의 아미노산 서열이 참조 서열과 동일하고 단, 아미노산 서열이 참조 펩타이드를 암호화하는 참조 아미노산 서열중 각 100개의 아미노산당 약 5개까지의 변형을 포함할 수 있음을 의미하는 것으로 이해된다. 다시 말하면, 참조 아미노산 서열에 대해 적어도 약 95% 상동성인 아미노산 서열을 갖는 펩타이드를 수득하기 위해서는, 참조 서열의 아미노산 잔기 중 약 5% 까지가 결실되거나 다른 아미노산으로 치환되거나 또는 참조 서열내 총 아미노산의 약 5% 까지의 아미노산의 수가 참조 서열내로 삽입될 수 있다. 참조 서열의 이러한 변형은 참조 아미노산 서열의 N-말단 또는 C-말단 위치에서 일어날 수 있거나 이들 말단 위치사이 어디에서 일어날 수 있거나, 참조 서열내 아미노산 중에서 개별적으로 산재하거나 또는 참조 서열내 하나 이상의 연속 그룹으로 산재할 수 있다.
본원에 사용된 것으로서, "동일성"(identity)은 참조 뉴클레오타이드 또는 아미노산 서열과 비교된 뉴클레오타이드 서열 또는 아미노산 서열의 상동성의 척도이다. 일반적으로, 서열은, 최대 차수의 조화가 수득되도록 정렬된다. "동일성" 자체는 당해분야에 인지된 의미를 가지며 발표된 기술을 사용하여 계산할 수 있다[참조: 예를 들면, Computational Molecular Biology, Lesk, A. M., ed., Oxford University Press, New York (1988); Biocomputing: Informatics And Genome Projects, Smith, D.W., ed., Academic Press, New York (1993); Computer Analysis of Sequence Data, Part I, Griffin, A. M., and Griffin, H. G., eds., Humana Press, New Jersey (1994); von Heinje, G., Sequence Analysis In Molecular Biology, Academic Press (1987); 및 Sequence Analysis Primer, Gribskov, M. and Devereux, J., eds., M Stockton Press, New York (1991)]. 2개의 폴리뉴클레오타이드 또는 폴리펩타이드 서열사이의 동일성을 측정하기 위한 몇가지 방법이 존재한다고 해도, 용어 "동일성"은 당해 분야의 숙련가에게 잘 알려져 있다[참조: Carillo, H. & Lipton, D., Siam J Applied Math 48:1073 (1988)]. 2개의 서열사이의 동일성 또는 유사성을 측정하기 위해 일반적으로 사용된 방법은 문헌[참조: Guide to Huge Computers, Martin J. Bishop, ed., Academic Press, San Diego (1994) 및 Carillo, H. & Lipton, D., Siam J Applied Math 48:1073 (1988)]에 기술된 것들을 포함하나, 이에 한정되지 않는다. 컴퓨터 프로그램 또한 동일성 및 유사성을 계산하는 방법 및 알고리즘을 포함할 수 있다. 2개의 서열사이의 동일성 및 유사성을 측정하기 위한 컴퓨터 프로그램 방법의 예는 GCG 프로그램 패키지[참조: Devereux, J. et al., Nucleic Acids Research 12(i):387 (1984)], BLASTP, ExPASy, BLASTN, FASTA[참조: Atschul, S. F., et al., J Molex Biol 215:403 (1990)] 및 FASTDB를 포함하나, 이에 한정되지 않는다. 동일성 및 유사성을 측정하는 방법의 예는 참조로 인용된 문헌[참조: Michaels, G. and Garian, R., Current Protocols in Protein Science, Vol 1, John Wiley & Sons, Inc. (2000)]에 논의되어 있다. 본 발명의 하나의 양태에서, 2개 이상의 폴리펩타이드사이에 동일성을 측정하는데 사용된 알고리즘은 BLASTP이다.
본 발명의 다른 실시양태에서, 2개 이상의 폴리펩타이드사이에 동일성을 측정하는데 사용된 알고리즘은 FASTDB이며, 이는 브루틀랙(Brutlag) 등의 알고리즘[참조: 본원에 참조로 포함된 문헌, Comp. App. Biosci. 6:237-245 (1990)]을 기준으로 한다. FASTDB 서열 정렬에서, 의문 및 대상체 서열은 아미노산 서열이다. 서열 정렬의 결과는 동일성 퍼센트이다. 동일성 퍼센트를 계산하기 위한 아미노산 서열의 FASTDB 정렬에 사용될 수 있는 매개변수는 다음을 포함하지만, 이에 한정되지 않는다: 매트릭스=PAM, k-터플(tuple)=2, 미스매치 패널티(Mismatch Penalty)=l, 결합 패널티(Joining Penalty)=20, 무작위 그룹 길이=0, 컷오프 점수(Cutoff Score)=1, 갭 패널티(Gap Penalty)=5, 갭 크기 패널티(Gap Size Penalty) 0.05, 윈도우 크기(Window Size)=500 또는 대상체 아미노산 서열의 길이 중 보다 짧은 것.
대상체 서열이 내부 첨가 또는 결실로 인한 것이 아닌, N-말단 또는 C-말단 첨가 또는 결실로 인해 의문 서열보다 짧거나 긴 경우, FASTDB 프로그램은 상동성 퍼센트를 계산하는 경우에 대상체 서열의 N-말단 및 C-말단 트렁케이션 또는 첨가를 계수하지 않으므로, 수동 교정이 이루어질 수 있다. 의문 서열에 대해 상대적으로, 양쪽 끝에서 트렁케이트된 대상체 서열의 경우, 동일성 퍼센트는 의문 서열의 총 염기의 퍼센트로서, 조화되지 않거나/정렬되지 않은 참조 서열에 대해 N- 및 C-말단인 의문 서열의 염기의 수를 계산함으로써 교정한다. FASTDB 서열 정렬의 결과는 조화/정렬을 측정한다. 이후에 정렬 퍼센트를 규정된 매개변수를 사용하여 상기 FASTDB 프로그램으로 계산된 동일성 퍼센트로부터 감하여, 최종의 동일성 퍼센트 점수에 이른다. 이렇게 교정된 점수는, 정렬이 서로에 대해 "상응하는" 방법 및 동일성 퍼센트를 측정하기 위한 목적으로 사용된다. 참조 또는 대상체 서열의 N- 또는 C-말단을 지나 연장된 의문(대상체) 서열 또는 참조 서열의 잔기 각각은 동일성 퍼센트 점수를 수동으로 조절하기 위한 목적으로 고려될 수 있다. 즉, 비교 서열의 N- 또는 C-말단과 조화하지 않는/정렬되지 않는 잔기는 동일성 퍼센트 점수 또는 정렬 번호매김을 수동으로 조절하는 경우 계수될 수 있다.
예를 들어, 90개 아미노산 잔기 대상체 서열을 100개 잔기 참조 서열과 정렬시켜 동일성 퍼센트를 측정한다. 결실은 대상체 서열의 N-말단에서 발생하므로, FASTDB 정렬은 N-말단에서 처음 10개 잔기의 조화/정렬을 나타내지 않는다. 10개의 쌍을 이루지 않은 잔기는 서열(조화되지 않은 N- 및 C-말단에서 잔기의 수/의문 서열에서 잔기의 총 수)의 10%를 나타내므로, 10%를 FASTDB 프로그램으로 계산한 동일성 퍼센트 점수로부터 감한다. 나머지 90개 잔기가 완벽하게 조화되는 경우, 최종 동일성 퍼센트는 90%가 될 것이다. 다른 예에서, 90개 잔기 대상체 서열을 100개 참조 서열과 비교한다. 이때 결실은 내부 결실이므로, 의문 서열과 조화하지 않는/정렬되지 않는 대상체 서열의 N- 또는 C-말단에서 잔기가 존재하지 않는다. 이 경우에, FASTDB로 계산된 동일성 퍼센트는 수동으로 교정되지 않는다.
본 발명의 폴리리간드는 임의로 단량체 전, 후 또는 사이에 스페이서 아미노산을 포함한다. 스페이서의 길이 및 조성은 변할 수 있다. 스페이서의 예는 글리신, 알라닌, 폴리글리신 또는 폴리알라닌이다. 때때로 폴리펩타이드의 2차 구조를 방해하기 위한 목적으로 스페이서내에 프롤린을 사용하는 것이 바람직하다. 스페이서 아미노산은 임의의 아미노산일 수 있으며 알라닌, 글리신 및 프롤린에 제한되지는 않는다. 예시적인 스페이서는 서열 53 내지 56으로 제공된다. 본 발명은 스페이서가 있거나 없고 상기 또는 하기에 제공된 예들에 제한되지 않는, 호모폴리리간드 및 헤테로폴리리간드의 모든 조합에 관한 것이다.
본 발명의 리간드 및 폴리리간드는 리간드를 세포의 영역에 국재화하는 시그날에 임의 연결된다. 세포 국재화 시그날의 비-제한적 예는 근세포질세망, 세포질세망, 세포외 매트릭스, 미토콘드리아, 골지체, 과산화소체, 라이소좀, 핵, 핵소체, 엔도소옴, 엑소솜, 기타 세포내 소낭, 혈장막, 치근막 및 기저측막에 국재화된 시그날이다. 하나의 양태에서, 리간드 및 폴리리간드는 미국 가특허원 제60/957,328호에 기술된 것과 같은 비-세포-특이적인 혈장막 국재화 시그날을 통해 세포외 표면에 전달된다. 다른 양태에서, 리간드 및 폴리리간드는 섬유모세포, 내피세포, 평활근 세포, 지방세포 및 심근세포의 횡문근형질막에 특이적인 국재화 시그날과 같은 세포-특이적인 국재화 시그날에 접하여 세포외 표면으로 전달된다. 다른 양태에서, 리간드 및 폴리리간드는 콜라겐 결합 단백질과 같은 세포외 연합 도메인을 통해 세포외 매트릭스에, 또는 심근 경색 영역에 풍부한 기타 세포외 성분들에 전달된다. 도 3A 내지 3H, 5A 내지 5I, 11A 내지 11I 및 22A 내지 22F는 국재화 시그날에 연결된 리간드 및 폴리리간드의 예시적인 구조를 나타낸다. 국재화 시그날은 실시예의 방법으로 제한없이 제공된다.
본 발명의 하나의 실시양태는 제1 부류 국재화 테터에 연결된 리간드 또는 폴리리간드이다.
본 발명의 다른 실시양태는 제2 부류 국재화 테터에 연결된 리간드 또는 폴리리간드이다.
본 발명의 다른 실시양태는 제3 부류 국재화 테터에 연결된 리간드 또는 폴리리간드이다.
본 발명의 다른 목적은 본원에 기술된 제1 부류 국재화 테터이다.
본 발명의 다른 실시양태는 본원에 기술된 제1 부류 국재화 테터에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 제1 부류 국재화 테터이다.
본 발명의 다른 실시양태는 하나 이상의 아미노산 결실, 치환, 삽입, 트렁케이션 또는 이의 조합을 포함하도록 변형된, 본원에 기술된 제1 부류 국재화 테터이다.
본 발명의 다른 실시양태는 서열 57 내지 76에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 제1 부류 국재화 테터이다.
본 발명의 다른 실시양태는 서열 77 내지 95중 하나에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 적어도 하나의 펩타이드를 포함하는 제1 부류 국재화 테터이다.
본 발명의 다른 실시양태는 본원에 기술된 제1 부류 국재화 테터를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 본원에 기술된 제2 부류 국재화 테터이다.
본 발명의 다른 실시양태는 본원에 기술된 제2 부류 국재화 테터를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 본원에 기술된 제3 부류 국재화 테터이다.
본 발명의 다른 실시양태는 본원에 기술된 제3 부류 국재화 테터에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동질성인 제3 국제화 테터이다.
본 발명의 다른 실시양태는 하나 이상의 아미노산 결실, 치환, 삽입, 트렁케이션 또는 이의 조합을 포함하도록 변형된 제3 부류 국재화 테터이다.
본 발명의 다른 실시양태는 서열 100 내지 111에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 제3 국제화 테터이다.
본 발명의 다른 실시양태는 서열 112 내지 128에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% 또는 99% 동일성인 적어도 하나의 펩타이드를 포함하는 제3 국제화 테터이다.
본 발명의 다른 실시양태는 본원에 기술된 제3 부류 국재화 테터를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 리간드 및 폴리리간드는 데그론에 연결되어 이들의 활성을 제한할 수 있다. 도 21A 내지 21H 및 22A 내지 22F는 데그론에 연결된 리간드 및 폴리리간드의 몇가지 비-제한 양태를 나타낸다.
또한, 본 발명의 리간드 및 폴리리간드는 에피토프 태그 또는 리포터를 제공하는 추가의 분자 또는 아미노산에 임의 연결된다(참조: 도 4A 내지 4G). 에피토프 태그의 비-제한적 예는 FLAGTM, HA(헤마글루티닌), c-Myc 및 His6이다. 리포터의 비-제한적 예는 알칼린 포스파타제, 갈락토시다제, 퍼옥시다제, 루시퍼라제 및 형광성 단백질이다. 에피토프 및 리포터는 실시예로써 제한없이 제공된다. 에피토프 태그 및/또는 리포터는 동일한 분자일 수 있다. 에피토프 태그 및/또는 리포터는 또한 상이할 분자일 수 있다.
리간드 및 폴리리간드 및 이에 연결된 임의의 아미노산은 당해 분야에 공지된 기술을 사용하여 화학적으로 또는 재조합적으로 합성할 수 있다. 화학적 합성 기술은 자동화된 펩타이드 합성기를 사용하여 흔히 수행되는 펩타이드 합성을 포함하나, 이에 한정되지 않는다. 펩타이드는 또한 당해 분야에 공지된 비-자동화된 펩타이드 합성을 사용하여 합성할 수 있다. 재조합 기술은 리간드-암호화 핵산을 발현 벡터내로 삽입함을 포함하며, 여기서, 핵산 발현 생성물은 세포 인자 및 과정을 사용하여 합성된다.
리간드 또는 폴리리간드에 대한 세포 국재화 시그날, 에피토프 태그, 리포터 또는 데그론의 연결은 리간드에 대한 공유결합적 또는 효소적 연결을 포함할 수 있다. 국재화 시그날이 지질 또는 탄수화물과 같은 폴리펩타이드 외의 물질을 포함하는 경우, 분자를 연결시키는 화학 반응을 이용할 수 있다. 또한, 지질, 탄수화물, 포스페이트 또는 기타 분자로 변형된 비-표준 아미노산 및 아미노산은 펩타이드 합성에 대한 전구체로서 사용할 수 있다. 본 발명의 리간드는 국재화 시그날의 존재 또는 부재하에서 치료학적 용도를 갖는다. 그러나, 국재화 시그날에 연결된 리간드는 아세포 도구 또는 치료제로서의 용도를 갖는다.
도 6A 내지 6E, 13A 내지 13E 및 23A 내지 23G는 PAI-1 리간드-함유 유전자 작제물의 예를 나타낸다. PAI-1 리간드-함유 유전자 작제물은 본원에 기술된 바와 같은 바이러스 또는 비바이러스 벡터를 통해 전달될 수 있다. 도 7B 및 7C는 생체내에서 폴리펩타이드 발현을 전달하고 조절하기 위한 유전자 치료요법 벡터의 양태를 묘사한다. 도 7B 및 7C에서 유전자 작제물에 연결된 폴리뉴클레오타이드 서열은 삽입유전자의 바이러스 게놈 및/또는 숙주 게놈내로의 통합을 촉진하기 위한 게놈 통합 도메인을 포함한다. AttP 및 AttB 서열이 게놈 통합 서열의 비-제한적 예이다.
도 7A는 PAI-1 리간드 유전자 작제물을 함유하는 벡터를 나타내며, 여기서, 리간드 유전자 작제물은 벡터로부터 유전자삽입 동물을 생성하는데 유용한 단위로서 방출가능하다. 예를 들면, 리간드 유전자 작제물 또는 삽입유전자는 제한 엔도뉴클레아제 분해에 의해 벡터 골격으로부터 방출된다. 이후에, 관련된 삽입유전자는 마우스 수정란의 전핵내로 주입되거나; 삽입유전자를 사용하여 배아 줄기 세포를 형질전환시킨다. 도 7A의 리간드 유전자 작제물을 함유하는 벡터는 또한 삽입유전자의 일시적인 형질감염에 유용하며, 여기서, 삽입유전자의 프로모터 및 코돈은 숙주 유기체에 대해 최적화된다. 도 7A의 리간드 유전자 작제물을 함유하는 벡터는 또한 소규모 또는 대규모 생산을 위해 조절가능한 발효 유기체에서 폴리펩타이드의 재조합 발현에 유용하며, 여기서, 삽입유전자의 프로모터 및 코돈은 발효 숙주 유기체에 대해 최적화된다.
도 7D는 안정한 세포주를 생성하는데 유용한 PAI-1 리간드 유전자 작제물을 함유하는 벡터를 나타낸다.
본 발명은 또한 리간드 및 폴리리간드를 암호화하는 뉴클레오타이드 서열을 포함하는 폴리뉴클레오타이드를 포함한다. 본 발명의 폴리뉴클레오타이드는 데그론, 국재화 시그날, 에피토프 또는 리포터를 암호화하는 추가의 뉴클레오타이드 서열에 임의 연결된다. 또한, 본 발명의 핵산은 벡터 폴리뉴클레오타이드내로 임의 혼입된다. 폴리뉴클레오타이드는 제한 엔도뉴클레아제 부위를 포함하는 뉴클레오타이드 서열 및 제한 엔도뉴클레이즈 활성에 요구되는 기타 뉴클레오타이드에 의해 임의로 플랭킹(flanking)된다. 플랭킹 서열은 임의로 벡터내에 클로닝 부위를 제공한다. 제한 부위는 대부분의 시판되는 클로닝 벡터내에서 일반적으로 사용된 부위중 어느 것을 포함하지만, 이에 제한되지는 않는다. 호밍 엔도뉴클레아제(homing endonuclease)를 포함하는 기타 제한 효소에 의한 분해용 부위가 또한 당해 목적에 사용된다. 폴리뉴클레오타이드 플랭킹 서열은 또한 임의로 후속 클로닝의 방향성을 제공한다. 5' 및 3' 제한 엔도뉴클레아제 부위가 서로 상이하여 이본쇄 DNA가 클로닝 벡터의 상응하는 상보성 부위로 방향성으로 클로닝될 수 있는 것이 바람직하다.
데그론, 국재화 시그날, 에피토프 또는 리포터가 있거나 없는 리간드 및 폴리리간드는 재조합 기술로 달리 합성한다. 폴리뉴클레오타이드 발현 작제물은 목적한 성분들을 함유하도록 제조되어 발현 벡터내로 삽입된다. 이후에, 발현 벡터는 세포내로 형질감염되며 폴리펩타이드 생성물이 발현되어 분리된다. 재조합체 DNA 기술에 따라 제조된 리간드는 조사 도구 및/또는 치료제로서의 용도를 갖는다.
다음은, 리간드 및 폴리리간드를 암호화하는 폴리뉴클레오타이드가 생산되는 방법의 예이다. 리간드 및 플랭킹 서열을 암호화하는 상보성 올리고뉴클레오타이드를 합성하여 어닐링한다. 수득되는 이본쇄 DNA 분자를 당해 분야에 공지된 기술을 사용하여 클로닝 벡터내로 삽입한다. 리간드 및 폴리리간드가 단백질 생성물내로 해독되는 유전자삽입 유전자 작제물내 서열에 대해 인접하여 프레임-내(in-frame)에 위치하는 경우, 이들은 세포 또는 유전자삽입 동물에서 발현되는 경우 융합 단백질의 일부를 형성한다.
본 발명의 다른 실시양태는 바람직한 세포, 조직 또는 생리학적 상태에서 PAI-1 리간드 또는 폴리리간드 발현을 선택적으로 조절하기 위한 유전자 작제물에 관한 것이다. 예시적인 유전자 작제물 구조는 도 6A 내지 6E에 나타낸다. 유전자 작제물의 프로모터 부위는 구성적 프로모터, 비-구성적 프로모터, 조직-특이적인 프로모터(구성적 또는 비-구성적) 또는 유도성 프로모터일 수 있다. 본 발명에 유용한 조직-특이적인 프로모터의 비-제한적 예는 내피 세포-특이적인 프로모터[참조: White, SJ, et al., Gene Ther. 2007 Nov 8 [Epub ahead of print]), 혈관 평활근 세포-특이적인 프로모터[참조: Ribault, S, Circ Res., 2001, 88(5):468-75; Appleby, CE, et al., Gene Ther. 2003, 10(18): 1616-22], 심근세포-특이적인 프로모터[참조: Xu, L, et al., J Biol Chem., 2006, 281(45):34430-40], 관상 지방세포-특이적인 프로모터 및 심장 섬유모세포-특이적인 프로모터이다. 심장 및 저산소증-특이적인 프로모터와 같이 조합된 조직 및 상태 특이적인 프로모터[참조: Su, H, et al., Proc Natl Acad Sci U S A, 2004, 101(46): 16280-5]가, 이들이 심근 경색 영역내 리간드 또는 폴리리간드의 발현을 허용하므로 본 발명에 특히 유용하다. 유도성 프로모터는 약물 또는 기타 인자들에 의해 활성화된다. RHEOSWITCH는 본 발명에 유용한 뉴 잉글랜드 바이오랩스(매사츄세츠주 잎스위치 소재)로부터 시판되는 유도성 프로모터 시스템이다. 본 발명의 실시양태는, 이의 발현이 유도성 프로모터 시스템에 의해 조절되는 리간드 또는 폴리리간드 유전자 작제물을 포함한다.
본 발명의 하나의 실시양태는 조직-특이적인 프로모터에 연결된 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 인공 평활근-특이적인 프로모터에 연결된 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 혈관 평활근-특이적인 프로모터에 연결된 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 내피 세포-특이적인 프로모터에 연결된 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 합성의 내피 세포-특이적인 프로모터에 연결된 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 본원에 기술된 조직-특이적인 프로모터를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 하나 이상의 뉴클레오타이드 결실, 치환, 삽입, 트렁케이션 또는 이의 조합을 포함하도록 변형된, 본원에 기술된 조직-특이적인 프로모터를 암호화는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 본원에 기술된 조직-특이적인 프로모터에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 또는 99% 동일성인 조직-특이적인 프로모터를 암호화하는 폴리뉴클레오타이드이다.
본 발명의 다른 실시양태는 서열 132 내지 139에 나타낸 폴리뉴클레오타이드에 대해 적어도 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 또는 99% 동일성인 폴리뉴클레오타이드이다.
폴리리간드는 천연에서 모듈러(modular)이다. 본 발명의 측면은 기술된 폴리리간드의 조합 모듈방식이다. 본 발명의 다른 측면은 이들 모듈러 폴리리간드를 용이하고 편리하게 제조하는 방법이다. 이와 관련하여, 본 발명의 양태는 유전 발현 성분들을 모듈러 클로닝하는 방법을 포함한다. 리간드, 호모폴리리간드, 헤테로폴리리간드 및 임의의 아미노산 발현 성분들을 재조합적으로 합성하는 경우, 각각의 클로닝가능한 성분을 모듈로 고려할 수 있다. 클로닝의 속도 및 편의성을 위하여, 접착성 말단에서 혼용성이고 용이하게 삽입하여 연속적으로 클로닝하기 용이한 모듈러 성분들을 제조하는 것이 바람직하다. 이는 제한 엔도뉴클레아제 부위 인지 및 분해의 천연 특성을 활용하여 달성한다. 본 발명의 하나의 측면은 모듈의 한쪽 말단에서 제한 효소 분해에 한번 이용되고 다른 말단에서 경우에 따라 수회 제한 효소 분해에 이용된 모듈 플랭킹 서열을 포함한다. 다시 말해서, 모듈의 한쪽 말단에서 제한 부위는 모듈 성분들의 연속적인 클로닝을 달성하기 위하여 이용되고 파괴된다. 암호화 영역 모듈을 플랭킹하는 제한 부위의 예는 제한 효소 NgoM IV 및 CIa I; 또는 Xma I 및 CIa I에 의해 인지된 서열이다. 5' NgoM IV 오우버행(overhang) 및 3' CIa I 오우버행을 갖는 선형 DNA를 수득하기 위한 NgoM IV 및 CIa I을 사용한 제1 환형 DNA의 절단; 및 5' CIa I 오우버행 및 3' Xma I 오우버행을 갖는 선형 DNA를 수득하기 위한 Xma I 및 CIa I을 사용한 제2의 환형 DNA의 절단으로 혼용성 점착성 말단을 갖는 제1 및 제2 DNA 단편을 생성한다. 이들 제1 및 제2 DNA 단편을 함께 혼합하고, 어닐링하고, 연결하여 제3의 환형 DNA 단편을 형성시키고, 제1 DNA에 존재하는 NgoM IV 부위 및 제2 DNA에 존재하는 Xma I 부위를 제3의 환형 DNA에서 파괴한다. 이제, 이러한 DNA의 남아있는 영역은 추가의 Xma I 또는 NgoM IV 분해로 보호되나, 제3의 환형 DNA에 남아있는 플랭킹 서열은 여전히 완벽한 5' NgoM IV 및 3' CIa I 부위를 함유한다. 당해 과정을 수회 반복하여 방향성이고, 연속적인, 모듈러 클로닝 현상을 달성할 수 있다. NgoM IV, Xma I, 및 CIa I 엔도뉴클레아제에 의해 인지된 제한 부위는 플랭킹 서열로서 사용된 경우 연속적인 클로닝을 허용하는 부위의 그룹을 나타낸다.
암호화 영역 모듈을 조립하는 다른 방법은 환형 DNA 외에 선형 DNA를 직접 및 연속적으로 사용한다. 예를 들면, 위에서 기술한 연속적인 클로닝 과정과 유사하게, 암호화 영역 모듈을 플랭킹하는 제한 부위는 제한 효소 NgoM IV 및 CIa I; 또는 Xma I 및 CIa I에 의해 인지된 서열이다. 제1의 환형 DNA는 NgoM IV 및 CIa I으로 절단하여 5' NgoM IV 오우버행 및 3' CIa I 오우버행을 갖는 선형 DNA를 수득한다. 제2의 선형 이본쇄 DNA는 PCR 증폭에 의해 또는 상보성 올리고뉴클레오타이드를 합성하고 어닐링함으로써 생성한다. 제2의 선형 DNA는 5' CIa I 오우버행 및 3' Xma I 오우버행을 가지며, 이들은 선형화된 제1 DNA를 갖는 혼용성의 점착성 말단이다. 이들 제1 및 제2의 DNA 단편을 함께 혼합하고, 어닐링하고 연결하여 제3의 환형 DNA 단편을 형성하는 경우, 제1의 DNA에 존재하는 NgoM IV 부위 및 제2의 DNA에 존재하는 Xma I 부위는 제3의 환형 DNA에서 파괴된다. 제3의 환형 DNA에 남아있는 플랭킹 서열은 여전히 완벽한 5' NgoM IV 및 3' CIa I 부위를 함유한다. 당해 과정을 수회 반복하여 방향성이고, 연속적인, 모듈러 클로닝 현상을 달성한다. NgoM IV, Xma I, 및 CIa I 엔도뉴클레아제에 의해 인지된 제한 부위는 플랭킹 서열로서 사용되는 경우 연속적인 클로닝을 허용하는 부위의 그룹을 나타낸다. 당해 과정은 도 8에 묘사한다.
당해 분야의 통상의 기술자는, 다른 제한 부위 그룹이 본원에 기술된 연속적이고, 방향성인 클로닝을 달성할 수 있음을 인지한다. 제한 엔도뉴클레아제 선택에 바람직한 기준은 상용성의 점착성 말단을 생성하지만 이의 부위가 서로 연결시 파괴되는 엔도뉴클레아제의 쌍을 선택하는 것이다. 다른 기준은 처음 2개와 혼용성인 점착성 말단을 생성하지 않는 제3의 엔도뉴클레아제 부위를 선택하는 것이다. 이러한 기준이 연속적이고, 방향성인 클로닝을 위한 시스템으로서 이용되는 경우, 리간드, 폴리리간드 및 기타 암호화 영역 또는 발현 성분들은 바람직하게는 조합적으로 조립될 수 있다. 동일한 연속 과정을 에피토프, 리포터, 데그론 및/또는 국재화 시그날에 이용할 수 있다.
폴리리간드 및 PAI-1 활성을 조절하는 폴리리간드를 제조하는 방법은 기술되어 있다. 치료요법은 국재화 시그날이 있거나 없는 정제된 리간드 또는 폴리리간드를 세포로 전달함을 포함한다. 달리는, 국재화 시그날이 있거나 없는 리간드 및 폴리리간드를 아데노바이러스, 렌티바이러스, 아데노-관련 바이러스 또는 세포에서 단백질 생성물의 발현을 위해 제공하는 기타 바이러스 또는 레트로바이러스 작제물을 사용하는 것과 같은 바이러스 또는 레트로바이러스 작제물을 통해 전달된다.
PAI-1 리간드 또는 폴리리간드, PAI-1 리간드 및 폴리리간드를 암호화하는 핵산, 및 PAI-1 리간드 및 폴리리간드를 암호화하는 핵산을 함유하는 벡터를 사용하여 섬유증 상태에 있는 대상체 또는 섬유증으로 발달될 위험이 있는 대상체를 치료할 수 있다. 대상체는 천연적으로-발생하는 섬유증 상태 또는 수술-유도되거나, 화학물질-유도되거나, 유전적으로-유도되거나, 또는 기타 실험적으로-유도된 섬유증 상태를 지닌 동물일 수 있다. 섬유증 상태는 화학물질 노출, 식이 조절, 유전적 조작, 비만 또는 천연적인 성숙에 의해 유도된 당뇨병 또는 고혈당증으로부터 초래될 수 있다. 섬유증 상태는 또한 고혈압, 허혈, 괴사, 면역-매개된 손상, 담배 연기 노출, 화학물질 노출, 섬유 노출, 바이러스 또는 세균 감염, 또는 특발성 원인으로부터 초래될 수 있다. PAI-1 리간드 또는 폴리리간드, PAI-1 리간드 및 폴리리간드를 암호화하는 핵산, 및 PAI-1 리간드 및 폴리리간드를 암호화하는 핵산을 함유하는 벡터를 사용하여 섬유증 및 심장, 혈액, 신장, 간, 폐 및 난소에서 기타 PAI-1 관련 상태를 치료할 수 있다. PAI-1 리간드 또는 폴리리간드, PAI-1 리간드 및 폴리리간드를 암호화하는 핵산 및 PAI-1 리간드 및 폴리리간드를 암호화하는 핵산을 함유하는 벡터도 또한 PAI-1이 발현되는 각종 암을 치료하는데 유용할 수 있다.
도 1A 내지 1F는, 스페이서가 있거나 없는 호모폴리리간드의 예를 나타낸다.
도 2A 내지 2J는 스페이서있거나 없는 헤테로폴리리간드의 예를 나타낸다.
도 3A 내지 3H는 국재화 시그날에 연결된 리간드 및 폴리리간드의 예를 나타낸다.
도 4A 내지 4G는 에피토프 또는 리포터에 연결된 폴리리간드의 예를 나타낸다.
도 5A 내지 5I는 국재화 시그날 및 에피토프 또는 리포터에 연결된 폴리리간드의 예를 나타낸다.
도 6A 내지 6E는 에피토프, 리포터 및/또는 국재화 시그날에 임의 연결된 리간드 또는 폴리리간드를 포함하는 유전자 작제물의 예를 나타낸다.
도 7A 내지 7D는 리간드 유전자 작제물을 함유하는 벡터의 예를 나타낸다.
도 8은 폴리리간드의 조합 합성에 유용한 일련의 클로닝 과정의 예를 나타낸다.
도 9는 리간드 및 폴리리간드의 예 및 이들의 PAI-1 억제 메카니즘을 나타낸다.
도 10은 인공의 평활근-특이적인 프로모터의 예를 나타낸다.
도 11A 내지 11C는 합성의 혈관 평활근 세포-특이적인 프로모터의 예를 나타낸다.
도 12A 내지 12B는 내피 세포-특이적인 프로모터의 예를 나타낸다.
도 13A 내지 13B는 합성의 내피 세포-특이적인 프로모터의 예를 나타낸다.
도 14A 및 14B는 제1 부류 국재화 테터의 예를 나타낸다.
도 15는 제3 국재화 테터의 예를 나타낸다.
도 16은 PAI-1 리간드 및 폴리리간드의 예시적인 억제 메카니즘을 나타낸다.
도 17A 내지 17H는 데그론 및/또는 국재화 시그날에 연결된 PAI-1의 예를 나타낸다.
도 18A 내지 18I는 데그론 및/또는 국재화 시그날에 임의 연결된, ULTRAVECTOR(UV)-가능한 PAI-1 cDNA를 포함하는 유전자 작제물의 예를 나타낸다.
도 19A 내지 19D는 ULTRAVECTOR(UV)-가능한 PAI-1 유전자 작제물을 함유하는 벡터의 예를 나타낸다.
도 20A 내지 20J는 데그론에 연결된 스페이서가 있거나 없는 리간드 및 호모폴리리간드의 예를 나타낸다.
도 21A 내지 21H는 데그론에 연결된 스페이서가 있거나 없는 헤테로폴리리간드의 예를 나타낸다.
도 22A 내지 22F는 데그론 및/또는 국재화 시그날에 연결된 리간드 및 폴리리간드의 예를 나타낸다.
도 23A 내지 23G는 데그론 및/또는 국재화 시그날에 임의 연결된 리간드 또는 폴리리간드를 포함하는 유전자 작제물의 예를 나타낸다.
도 2A 내지 2J는 스페이서있거나 없는 헤테로폴리리간드의 예를 나타낸다.
도 3A 내지 3H는 국재화 시그날에 연결된 리간드 및 폴리리간드의 예를 나타낸다.
도 4A 내지 4G는 에피토프 또는 리포터에 연결된 폴리리간드의 예를 나타낸다.
도 5A 내지 5I는 국재화 시그날 및 에피토프 또는 리포터에 연결된 폴리리간드의 예를 나타낸다.
도 6A 내지 6E는 에피토프, 리포터 및/또는 국재화 시그날에 임의 연결된 리간드 또는 폴리리간드를 포함하는 유전자 작제물의 예를 나타낸다.
도 7A 내지 7D는 리간드 유전자 작제물을 함유하는 벡터의 예를 나타낸다.
도 8은 폴리리간드의 조합 합성에 유용한 일련의 클로닝 과정의 예를 나타낸다.
도 9는 리간드 및 폴리리간드의 예 및 이들의 PAI-1 억제 메카니즘을 나타낸다.
도 10은 인공의 평활근-특이적인 프로모터의 예를 나타낸다.
도 11A 내지 11C는 합성의 혈관 평활근 세포-특이적인 프로모터의 예를 나타낸다.
도 12A 내지 12B는 내피 세포-특이적인 프로모터의 예를 나타낸다.
도 13A 내지 13B는 합성의 내피 세포-특이적인 프로모터의 예를 나타낸다.
도 14A 및 14B는 제1 부류 국재화 테터의 예를 나타낸다.
도 15는 제3 국재화 테터의 예를 나타낸다.
도 16은 PAI-1 리간드 및 폴리리간드의 예시적인 억제 메카니즘을 나타낸다.
도 17A 내지 17H는 데그론 및/또는 국재화 시그날에 연결된 PAI-1의 예를 나타낸다.
도 18A 내지 18I는 데그론 및/또는 국재화 시그날에 임의 연결된, ULTRAVECTOR(UV)-가능한 PAI-1 cDNA를 포함하는 유전자 작제물의 예를 나타낸다.
도 19A 내지 19D는 ULTRAVECTOR(UV)-가능한 PAI-1 유전자 작제물을 함유하는 벡터의 예를 나타낸다.
도 20A 내지 20J는 데그론에 연결된 스페이서가 있거나 없는 리간드 및 호모폴리리간드의 예를 나타낸다.
도 21A 내지 21H는 데그론에 연결된 스페이서가 있거나 없는 헤테로폴리리간드의 예를 나타낸다.
도 22A 내지 22F는 데그론 및/또는 국재화 시그날에 연결된 리간드 및 폴리리간드의 예를 나타낸다.
도 23A 내지 23G는 데그론 및/또는 국재화 시그날에 임의 연결된 리간드 또는 폴리리간드를 포함하는 유전자 작제물의 예를 나타낸다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드를 본원에 기술된 심혈관 조직으로 전달하는 방법이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오타이드를 아데노바이러스의 국소 주입, 단핵세포의 세포외 형질유도 또는 대동맥내로 직접적인 주입 중 하나를 포함하는 심혈관 조직에 전달하는 방법이다.
본 발명의 다른 실시양태는 본원에 기술된 불안정한 플라크(plaque)의 형성시 PAI-1의 작용을 평가하는 방법이다.
본 발명의 다른 실시양태는 인슐린 내성 마우스 모델을 개발하는 단계를 포함하여 불안정한 플라크의 형성시 PAI-1의 작용을 평가하는 방법이다.
본 발명의 다른 실시양태는 본원에 기술된 리간드 또는 폴리리간드의 공간적 또는 일시적 조절을 달성하는 방법이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드를 조직-특이적인 프로모터에 연결하는 단계를 포함하여 리간드 또는 폴리리간드의 공간적 조절을 달성하는 방법이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드를 국재화 테터에 연결시키는 단게를 포함하여 리간드 또는 폴리리간드의 공간적 조절을 달성하는 방법이다.
본 발명의 다른 실시양태는 리간드 또는 폴리리간드를 유도성 유전자 스위치에 연결하는 단계를 포함하여 리간드 또는 폴리리간드의 일시적 조절을 달성하는 방법이다.
본 발명의 다른 실시양태는
a) 심혈관병 또는 심혈관병에 걸릴 위험이 있는 대상체를 확인하는 단계; 및
b) PAI-1 리간드 또는 폴리리간드를 대상체에게 투여하는 단계를 포함하여, 심혈관병을 치료하거나, 예방하거나 또는 완화시키는 방법이다.
본 발명의 다른 실시양태는
a) 섬유증 상태 또는 섬유증 상태로 발달될 위험이 있는 대상체를 확인하는 단계; 및
b) PAI-1 리간드 또는 폴리리간드를 대상체에게 투여하는 단계를 포함하여, 섬유증 상태를 치료하거나, 예방하거나 또는 완화시키는 방법이다.
정제된 PAI-1 리간드는 경구 또는 비경구 투여, 국소 투여, 또는 정제, 캅셀제 또는 액체형, 비강내 또는 흡입 에어로졸, 피하, 근육내, 복강내 또는 기타 주입; 정맥내 점적주입; 또는 어떠한 다른 투여 경로용으로 제형화될 수 있다. 추가로, 리간드를 암호화하는 뉴클레오타이드 서열은 세포내에서 유전자 생성물을 전달하고 발현하도록 설계된 벡터내로의 혼입을 허용한다. 이러한 벡터는 플라스미드, 코스미드, 인공 염색체 및 변형된 바이러스를 포함한다. 진핵 세포로의 전달은 생체내 또는 생체외에서 달성할 수 있다. 생체외 전달 방법은 의도된 수용체의 세포 또는 공여자 세포의 분리 및 벡터의 이들 세포로의 전달에 이은, 세포를 사용한 수용체의 치료를 포함한다.
본 발명의 다른 측면은
a) 혈관 손상이 있거나 혈관 손상 위험이 있는 대상체를 확인하는 단계;
b) 상기 대상체로부터 단핵세포를 분리하는 단계;
c) 상기 단핵세포내로 프로모터에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입하는 단계; 및
d) 상기 변형된 세포를 상기 대상체에 도입하는 단계를 포함하여, 죽상경화증을 치료하거나 예방하는 방법이다.
본 발명의 다른 실시양태는 대상체의 단핵세포내로 프로모터에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입시켜 변형된 세포를 생산함을 포함하여, 섬유소용해 경로의 폴리펩타이드 조절인자를 상기 대상체에 전달하기 위한 변형된 세포의 제조 방법에 관한 것이다.
본 발명의 하나의 실시양태에서, 프로모터는 유도성 프로모터이다. 본 발명의 다른 양태에서, 프로모터는 대식세포-특이적인 프로모터이다. 본 발명의 다른 실시양태에서, 프로모터는 거품 세포-특이적인 프로모터이다.
본 발명은 내피 및/또는 혈관 평활근 세포로 약물 피복된 스텐트의 카테테르-계 전달 또는 풍선 혈관성형술 매개된 바이러스 전달의 사용과 같은 죽상경화증의 치료를 위한 현재의 국소 전달 방법을 능가하는 몇가지 장점을 갖는다. 장치 매개된 전달 시도와 연관된 챌린지 외에, 혈관 세포 유형은, 세포가 형질유도되기 어려워서 불량한 유전자삽입 발현을 나타내며, 이들 세포로 삽입유전자의 국소 전달을 매우 어렵게 한다. 따라서, 이들 방법들은 다양한 정도의 효율을 갖는다. 본 발명은 혈관 손상의 영역으로 향할 순환하는 세포 유형인, 단핵세포를 이용함으로써, 단백질-계 치료제의 장치 매개된 국소 전달에 대한 요구를 감소시킨다. 단핵세포는 혈관 손상 부위에서 대식세포로 분화한다. 죽종의 국소 환경에서 대식세포는 일단 거품 세포로 추가로 분화할 것이다.
대식세포는 죽상경화증 발달의 대부분의 상에 기여한다. 따라서, 이들은 삽입유전자의 전달, 섬유소용해 경로의 조절인자의 발현을 위한 유용한 세포 유형으로서 죽상경화증성 병변에 국소적으로 존재한다. 이들 병변은 혈관화를 통해 발생할 수 있다. 섬유소용해 경로는 죽상경화증 발달 및 진행에서 중요한 역활을 하는 것으로 밝혀졌으나, 이는 또한 지혈에서도 중요한 역활을 한다. 따라서, 본 발명은, 전신계적 전달이 강력한 원인일 수 있는, 조절되지 않는 출혈과 같은 부작용을 방지하기 위하여, 당해 경로의 조절인자의 시공적 조절을 고려한다.
예를 들어, 본 발명의 다른 측면은
a) 혈관 손상 또는 혈관 손상 위험이 있는 대상체를 확인하는 단계;
b) 상기 대상체로부터 단핵세포를 분리하는 단계;
c) 상기 단핵세포내로 (1) 적어도 하나의 전사 인자 서열(여기서, 상기 적어도 하나의 전사 인자 서열은 화학적 리간드-의존적인 전사 인자를 암호화한다)을 포함하는 유전자 스위치를 암호화하는 폴리뉴클레오타이드, 및 (2) 상기 화학적 리간드-의존적인 전사 인자에 의해 활성화된 프로모터에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입하여 변형된 세포를 생산하는 단계;
d) 상기 변형된 세포를 상기 대상체내로 도입하는 단계; 및
e) 화학적 리간드를 대상체에 도입하여 프로모터를 활성화시키는 단계를 포함하여, 죽상경화증을 치료하거나 예방하는 방법이다.
본 발명의 다른 실시양태는 대상체의 단핵 세포내로 (a) 적어도 하나의 전사 인자 서열(여기서, 상기 적어도 하나의 전사 인자 서열은 화학적 리간드-의존적인 전사 인자를 암호화한다)을 포함하는 유전자 스위치를 암호화하는 폴리뉴클레오타이드, 및 (b) 상기 화학적 리간드-의존적인 전사 인자에 의해 활성화된 프로모터에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입시켜 변형된 세포를 생산함으로 포함하여, 섬유소용해 경로의 폴리펩타이드 조절인자를 상기 대상체에 전달하기 위한 변형된 세포의 제조 방법에 관한 것이다.
하나의 실시양태에서, 섬유소용해 경로의 조절인자는 본원에 기술된 PAI-1 리간드 또는 폴리리간드이다. 그러나, 죽상경화증을 치료하거나 예방하는 방법은 본원에 기술된 PAI-1 리간드 또는 폴리리간드에 한정되지 않으나, 섬유소용해 경로의 특정 폴리펩타이드 조절인자를 사용할 수 있다. 예로서, 본 발명의 방법에 유용한 섬유소용해 경로의 조절인자는 다른 폴리펩타이드 PAI-1 억제제; 미국 특허 제5,830,849호에 기술된 것들과 같은 천연의 플라스미노겐 활성인자; 미국 특허 제5,866,413호에 기술된 것들과 같은 돌연변이체 플라스미노겐 활성인자; 또는 미국 특허 제5,039,791호에 기술된 것들과 같은 플라스미노겐 활성인자 단편을 포함할 수 있다.
본 발명은 또한 대식세포에 대한 삽입유전자 발현을 제한하기 위한 유도성 유전자 스위치를 조절하기 위한 대식세포-특이적인 조절 성분의 사용을 고려한다. 당해 방법에서, 삽입유전자 발현의 공간적이고 일시적인 조절 둘다가 달성될 수 있으므로, 이러한 발현은 죽종내에서 대식세포 및/또는 대식세포 기원 세포에 대해 제한된다. 대식세포-특이적인 조절 성분은 규정된 세포 유형에서, 화학물질의 첨가로 섬유소용해 경로의 조절인자의 발현을 조절할 수 있는 유도성 유전자 스위치 시스템에서 이용된다. 유전자 발현 프로그램은 생체외에서 단핵세포와 같은 대식세포 전구체 세포내로 형질유도되며 죽상경화증의 치료를 위해 체내로 재도입된다. 본 발명에 유용한 대식세포-특이적인 조절 성분의 예는 문헌[참조: Gough, P. J. and E. W. Raines, Blood 101(2): 485-91 (2003)]에 기술된 대식세포-제한된 CD68 유전자로부터의 조절 성분이다.
예를 들면, 본 발명의 다른 측면은
a) 혈관 손상 또는 혈관 손상 위험이 있는 대상체를 확인하는 단계;
b) 상기 대상체로부터 단핵세포를 분리하는 단계;
c) 상기 단핵세포내로 (1) 대식세포-특이적인 조절 성분에 연결된 적어도 하나의 전사 인자 서열(여기서, 적어도 하나의 전사 인자 서열은 화학적 리간드-의존적인 전사 인자를 암호화한다), 및 (2) 상기 화학적 리간드-의존적인 전사 인자에 의해 활성화된 프로모터에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입하여, 변형된 세포를 생산하는 단계;
d) 상기 변형된 세포를 상기 대상체내로 도입하는 단계; 및
e) 화학적 리간드를 대상체에 도입하여 프로모터를 활성화시키는 단계를 포함하여, 죽상경화증을 치료하거나 예방하는 방법이다.
또한, 본 발명의 다른 실시양태는 대상체의 단핵 세포내로 (a) 대식세포-특이적인 조절 성분에 연결된 적어도 하나의 전사 인자 서열(여기서, 적어도 하나의 전사 인자 서열은 화학적 리간드-의존적인 전사 인자를 암호화한다)을 포함하는 유전자 스위치를 암호화하는 폴리뉴클레오타이드, 및 (b) 상기 화학적 리간드-의존적인 전사 인자에 의해 활성화된 프로모터에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입시켜, 변형된 세포를 생산함을 포함하여, 폴리펩타이드 리간드 또는 폴리리간드를 상기 대상체에 전달하기 위한 변형된 세포의 제조 방법에 관한 것이다.
하나의 실시양태에서, 아포지질단백질과 같은 다른 치료학적 단백질을 암호화는 추가의 폴리뉴클레오타이드를 단핵세포내로 도입한다.
본 발명은 다른 대식세포 집단의 표적화를 통하여 다른 조직에서 섬유증을 포함하는 다른 상태의 치료를 고려한다. 예를 들어, 폐포 대식세포와 같은 다른 고정된 대식세포는 폐 섬유증의 강력한 치료를 위한 섬유소용해 조절인자의 발현을 지시하는 특수 프로모터 또는 기타 수단을 통해 표적화될 수 있다. 본 발명의 영역내 속하는 조직내 다른 고정된 대식세포 및 이들의 위치는 연결 조직에서 조직세포, 간에서 쿠퍼 세포(kupffer cell), 신경 조직에서 미세아교 세포, 육아종에서 내피 세포, 골에서 파골세포, 신장내 비장 및 혈관사이 세포에서 굴모양 내층 세포(sinusoidal lining cell)를 포함한다. 본 발명은 섬유소용해 경로의 폴리펩타이드 조절인자의 표적화된 발현을 통해 이들 및 기타 대식세포 아형을 포함하는 특정 섬유소용해 상태의 치료를 고려한다.
본 발명의 다른 측면은
a) 섬유증 상태의 대상체를 확인하는 단계;
b) 상기 대상체로부터 단핵세포를 분리하는 단계;
c) 상기 단핵세포내로 고정된 대식세포 집단에 대해 특이적인 조절 성분에 연결된 섬유소용해 경로의 폴리펩타이드 조절인자를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입하여, 변형된 세포를 생산하는 단계; 및
d) 상기 변형된 세포를 상기 대상체내로 도입하는 단계를 포함하여, 고정된 대식세포 집단을 포함하는 섬유증 상태를 치료하거나, 예방하거나 완화하는 방법이다.
본 발명은 또한 미국 특허 제6,875,612호에 기술된 것들과 같은 단핵세포-특이적인 벡터의 사용을 통해 단핵세포 기원의 세포에 대한 섬유소용해 경로의 폴리펩타이드 조절인자의 표적화된 발현을 위한 생체내 시도를 고려한다.
방법
결과: 심혈관 조직에서 섬유소용해 활성의 성공적인 조절을 입증하는, 시험관내 및 생체내 시험 둘다로부터 수득한, 총체적인 데이타는 질병이 있는 심혈관 조직에서 국재화된 PAI-1 억제의 치료학적 효능을 입증할 것이다. PAI-1 디코이의 발달을 위한 임상적 중요성은, 제II형 당뇨병 환자에서 불안정한 죽상경화판의 형성을 감소시킬 것이다.
목적: 표적화된 목표는 세포외 표면 막 및/또는 질병이 있는 혈관의 세포외 환경에 대해 표적화된 PAI-1 디코이의 유도성의, 조직-특이적인 발현을 사용하는 아데노바이러스 유전자 치료요법을 개발하는 것이다. 당해 치료요법을 구성하는 개개 성분들은 하기에 기술한다.
개개 성분들- PAI-1 디코이: 플라스미노겐 활성인자 억제제-1(PAI1)은 섬유소용해를 조절하는데 관여하는 세린 프로테아제 억제제(세르핀)이다. 이의 표적에는 조직 플라스미노겐 활성인자(tPA) 및 유로키나제 플라스미노겐 활성인자(uPA)가 있다. PAI1은 단지 매우 서서히 분해하는(복합체의 정상적인 정화 이전이 아니다) 중간 상태에서 공유 결합하는, 자살 억제제 반응에서 이의 표적과 결합한다. PAI1 단독은 2시간 미만의 용액내 짧은 반감기를 지닌다. 이는 일시적으로 비-작용성인 잠복기 형태로 구조적으로 이동된다. PAI1과 비트로넥틴의 연합은 분자의 생존 시간을 현저히 증가시킬 수 있고, 비트로넥틴이 다른 ECM 단백질에 대한 결합 도메인을 지니므로, 세포외 매트릭스(ECM)내 특수 위치에 대해 이를 표적화한다. 설계된 디코이는 PAI-1을 억제하기 위한 다수의 방법과 결합하며 분자의 구조적 이동 및 단백질분해를 유발하는 펩타이드를 통한 하향-조절인, 분자의 봉쇄를 포함한다.
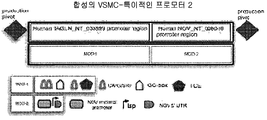
PAI-1 디코이의 공간적이고 일시적인 조절: PAI-1 디코이의 적절한 공간적 국재화는, 조직 및 세포 수준 둘다에서, PAI-1 디코이의 효능을 최대화시키고 독성을 최소화시키기 위해 필수적이다. 조직 수준에서, 이는 PAI-1 디코이 발현을 조절하는 조직 특이적인 프로모터의 사용을 통하여 달성될 것이다. 세포 수준이지만, 이는 PAI-1 디코이에 융합된 국재화 테터의 이용으로 달성될 것이다.
조직 특이적인 프로모터: 표적 기관(들)에 대한 PAI-1 디코이의 발현을 제한하기 위하여, 조직 특이적인 프로모터를 설계하여 혈관 평활근 세포 및 내피 세포를 포함하는, 특수 혈관 세포 유형에 대한 삽입유전자의 발현을 지시한다. 일시적인 조절은 유효한 조직 특이적인 프로모터를 사용하는 유도성 발현용 RheoSwitch 기술을 사용하여 가공될 것이다.
국재화 테터: 세포 수준에서 공간적 조절의 목적을 위해, PAI-1 디코이에 융합되는 경우 이것이 치료학적 잇점을 위한 적절한 부위로 전달할 국재화 테터가 설계되어 왔다. 치료학적 디코이 전달의 일부 생체내 최적화는 죽상경화판에 가장 유익한 결과를 달성하기 위해 요구될 수 있다. 예를 들면, 유전자 치료요법에 의해 표적화된 세포는, 치료학적 디코이의 농도 구배가 얇고 광범위한-아마도 멀리 및 광범위하게 확산하여 심지어 일부 셔틀 엔도크린 효과를 달성하는 경우, 가장 우수한 효과를 달성할 것이다(제2 부류). 다른 한편, 디코이의 농도 구배를 제한함으로써 이것이 주로 형질감염된 세포의 표면에 존재하도록 하는 것이 또한 바람직할 수 있는데; 이러한 시도는 훨씬 작은 영역에 대한 치료요법의 영역을 제한할 수 있다(제1 부류). 본 요약의 요지인 제3 부류는 "중간 과정을 조정하기" 위해 시도하며, 손상 치유중에 있는 상태(즉, 단백질분해 환경)하에 디코이의 주변분비 확산을 가능하도록 한다.
영역: 전임상 연구시 사용하기 위한 유전자 치료제의 개발을 위한 이들 개개 성분들의 성공적인 통합 외에 유효한 디코이, loc 및 프로모터 성분들의 개발. 당해 시험들의 성공적인 완성은, PAI-1의 국재화된 억제에 의한 섬유소용해의 조절이 대사 질병 모델에서, 혈관화시 불안정한 죽상경화판 형성의 형성을 감소시킬 것임을 입증할 것이다.
전임상 모델: 죽상경화증이 발달된 인슐린 내성의 전임상 마우스 모델을 사용하여 불안정한 플라크의 형성시 PAI-1의 작용을 평가할 것이다. 마우스에서 유전자 전달 기술는 표적 조직에 대한 유전자 전달시 사용을 위해 평가될 것이다.
인슐린 내성 마우스 모델- 마우스 모델의 개발을 위한 전체적인 계획: 시험 1) 10주령의, FFA, 트리글리세라이드 및 인슐린의 검정에 의해 입증된 인슐린 내성을 갖는 인슐린 내성 마우스(IRS1+/- ApoE-/- 및 IRS2+/- ApoE-/-), 및 인슐린 및 대조군(C57BL6) 비-인슐린 내성 마우스, 및 인슐린 내성 PAI-1 결핍 마우스(IRS1+/- ApoE-/- PAI-I+/- 및 IRS2+/- ApoE-/- PAI-I+/-)에서 죽상경화증 및 심근 경색의 유도; 동물이 12주 및 16주령인 경우 수축 및 확장 작용을 평가하기 위한 고 성능 초음파 심장 측정(interrogation)의 수행; 및 경색 크기, 섬유증의 정도, 및 10주령시기에 심장 폐색을 경험한 16주령의 마우스의 심장의 좌심방에서 PAI-1의 양 및 국재화의 평가; 2) 다양한 마우스 주에서 경색 크기에 대해 정상화된 좌측 심방 기능의 공오염 손상과 섬유증의 정도사이의 관계를 묘사; 3) 심장 섬유증에 이은 심장 폐색의 생성시 PAI-1의 강력한 역활의 제거 및 PAI-1 결핍 동물을 또한 PAI-1을 과발현하는 인슐린 내성 동물과 교배시키고 상기 1 및 2에 기술된 것들과 동일한 연구를 수행함으로써 경색의 유도; 및 4) 세포 영상 기술을 사용한 대동맥 죽상경화판의 특성화.
심혈관 조직의 유전자 전달: 혈관 조직의 유전자 형질유도에서의 다수 연구가 시도되어 있다고 해도, 이상적인 벡터 및 투여 경로 둘다는 임상적인 유전자 치료요법에 대해 정의되어 있지 않다. 전신계적 전달은 간에서 아데노바이러스의 신속한 정화 및 부착/감염을 초래할 것이다. 심혈관 조직의 국소 형질유도가 보고되어 있다. 심근세포가 아데노바이러스에 의해 용이하게 형질유도될 수 있다 해도, 내피 세포(EC) 및 혈관 평활근 세포(VSMC)는 그렇지 않다. VSMC는 혈청형 2 및 5의 아데노바이러스에 의해 매개된 유전자 전달에 대해 매우 불응성이다. 이는 전통적인 편재하는 프로모터로부터 삽입유전자 자체의 비효율적인 전사 및 불량한 바이러스 도입에 기인한다. 감소된 바이러스 도입은, 동일한 투여량에서 감염된 내피 세포에서 달성된 것보다 현저히 낮은 형질유도 수준을 초래하는, SMC의 표면상에서 콕사키에 아데노바이러스 수용체(CAR)의 제한된 발현으로 잘 설명된다[참조: (Beck, Uramoto et al. 2004) 부착된 문헌 참조].
아데노바이러스의 국소 주입: 하나의 추천은 심장 끝을 통해 좌측 심방의 내강으로 심실내 주입을 수행하는 것이다. 당해 과정은 대동맥 내피에서 삽입유전자 발현을 초래하는 것으로 밝혀졌다(참조: Juan, Lee et al. 2001). 비록 VSMC 발현이 당해 방법을 사용하여 관측된다고 해도, 이는 삽입유전자의 비효율적인 전사에 기인할 수 있다. CMV 매개된 삽입유전자 발현은 VSMC에 비효율적이므로, VSMC 특이적인 프로모터의 봉입은 생체내에서 증가된 발현을 초래하는 것으로 밝혀졌다(참조: Akyurek, Yang et al. 2000; Akyurek, Nallamshetty et al. 2001; Appleby, Kingston et al. 2003). 따라서, 고 역가의 바이러스와 조합된 강력한 VSMC 프로모터의 사용은 당해 기술을 사용하는 VSMC 발현을 초래할 수 있다. 추가로 주입동안 돌출되는 혈관을 클램핑함으로써, 표적세포에 대한 바이러스의 노출을 증가시키는 것이 가능하다. 이는 또한 관상동맥을 통한 심장의 관류를 초래할 것이다(참조: Roth, Lai et al. 2004).
요약- 아데노바이러스의 국소 주입: 당해 방법은 심근세포 및 내피 세포의 생체내 유전자 전달에 적절하다. 그러나, 문헌에 보고된 발견을 바탕으로 하여, VSMC에서 강력한 발현은 EC 장벽 및 낮은 형질유도 효능으로 인해 가능할 것으로 여겨지지 않는다.
단핵세포의 생체외 형질유도: 다른 추천은 생체외 시도를 사용하는 것이다. 대식세포는 혈관벽내에서 죽상경화증 발달의 모든 상에서 작용한다. 단핵세포는 보충되어 혈관 손상 부위에 부착하고 대식세포로 분화한다. 또한, 이들은 높은 생합성 능력을 갖는다(참조: Beck, Uramoto et al. 2004). 골수 세포는 용이하게 분리되어, 형질유도되고 생체외 유전자 전달 시도를 위해 동물내로 다시 위치할 수 있다.
당해 시도는 치료학적 유전자를 죽상경화성 영역에 전달하기 위해 이미 사용되어 왔다. 이러한 시도의 대부분의 예에서, ApoE의 발현이 역 콜레스테롤 수송을 촉진하는데 사용되었다(참조: Hasty, Linton et al. 1999; Van Eck, Herijgers et al. 2000; Ishiguro, Yoshida et al. 2001; Juan, Lee et al. 2001; Yoshida, Hasty et al. 2001; Gough and Raines 2003). 또한, 단핵세포-기원한 대식세포는 MI에 대한 염증 반응에 기여한다. 따라서, 당해 시도는 또한 MI 모델에서 경색시 PAI-1 활성을 감소시키는데 사용될 수 있다.
요약- 단핵세포의 생체외 형질유도: 당해 시도의 주요 단점은, 단핵세포가 Ad5 혈청형에 내해 내성이라는 것이다(참조: Burke, Sumner et al. 2002; Burke 2003). Ad11p 및 Ad35 혈청형 및 렌티바이러스 및 레트로바이러스 벡터는 단핵세포와 같은 골수 세포 유형을 포함하는 조혈 세포 유형을 용이하게 감염시킨다(참조: Segerman, Lindman et al. 2006).
대동맥내로의 직접적인 주입: 다른 시도는 플라크의 부위에서 상행대동맥내로 직접적인 동맥내 주입을 수행하는 것이다. 이는 심근으로의 유전자 전달을 위해 사용된 일반적인 시도이나, 대동맥으로의 유전자 전달을 위한 당해 시도의 실행가능성을 보증하지는 않는다.
전체적인 요약- 심혈관 조직의 유전자 전달: 보고된 각종 유전자 전달 방법의 평가를 기준으로, 좌심방의 내강내로의 주입을 통한, 형질유도된 단핵세포 또는 관상동맥내 전달은, 폐 동맥 및 대동맥을 교차-클램핑한다 해도, 다수의 심혈관 세포 유형에 대한 용이한 유전자 전달 시도를 제공할 것이다.
실험 구성
디코이(Decoys) - 프로젝트 (project) 1
1. PAI-1 생성을 위한 HepG2 세포를 이용한 생체외(in vitro) 확인
a. 항원
b. 활성
2. PAI-1 생성을 위한 VSMC를 이용한 생체외 확인
a. 항원
b. 활성
3. VSMC 이동 분석을 이용한 생체외 확인
a. 인간 VSMC
b. 마우스 VSMC
국재화 범위 - 프로젝트 (project) 2
1. VSMC를 이용한 생체외 확인
a. 배지 대 세포(막) 용해물 중의 항원
b. 형광현미경에 의한 국재화
2. EC를 이용한 생체외 확인
a. 배지 대 세포(막) 용해물 중의 항원
b. 형광현미경에 의한 국재화
3. 단핵구/대식세포 생체외 확인
a. 배지 대 세포(막) 용해물 중의 항원
b. 형광현미경에 의한 국재화
프로모터(promoter) - 프로젝트 (project) 3
4. VSMC를 이용한 생체외(in vitro) 확인
a. VSMC와 비-VSMC에서의 리포터 활성
b. VSMC와 비-VSMC에서의 유도성 리포터 활성
5. EC를 이용한 생체 외 확인
a. EC와 비-EC에서의 리포터 활성
b. EC와 비-EC에서의 유도성 리포터 활성
6. 단핵구/대식세포 생체 외 확인
a. 단핵구/대식세포와 비-단핵구/대식세포 유형에서의 리포터 활성
b. 단핵구/대식세포와 비-단핵구/대식세포 유형에서의 유도성의 리포터 활성
국재화된 유인(Decoys) - 프로젝트 (project) 4
1. 도입된 VSMC (시험 발현과 국재화)를 이용한 생체 외(in vitro) 확인
2. 도입된 EC (시험 발현과 국재화)를 이용한 생체외 확인
3. 도입된 VSMC 이동 분석을 이용한 생체외 확인
a. 인간 VSMC
b. 마우스 VSMC
4. 도입된 단핵구/대식 세포 (시험 발현과 국재화)의 생체외 확인
리포터 (reporter)의 유도성/조직 특이적 발현을 갖는 바이러스 - 프로젝트 (project) 5
1. VSMC 생체외 확인
2. EC 생체외 확인
3. 단핵구/대식세포 생체외 확인
바이러스 유전자 치료 - 프로젝트 (project) 6
1. VSMC (시험 발현과 국재화)를 이용한 생체외 확인
2. 도입된 EC (시험 발현과 국재화)의 생체외 확인
3. 도입된 VSMC 이동 분석을 이용한 생체외 확인
a. 인간 VSMC
b. 마우스 VSMC
4. 도입된 단핵구/대식세포 (시험 발현과 국재화)의 생체외 확인
생체외 자료의 수집된 리포트 - 프로젝트 (project) 7
1. 프로젝트 (project) 1-6로부터 수집된 자료
임상 전 모델 - 프로젝트 (project) 8
1. PAI-1 결핍이 있거나 없는 인슐린 저항성 (IR) 마우스에서의 죽상경화증의 유발
2. PAI-1 존재하지 않는, 인슐린 저항성 (IR) 마우스에서 대동맥의 죽상경화 플라크의 특성화
3. 유전자 전달 모델의 확인
a. 생체 밖의 도입된 단핵구들
b. 나가는 혈관들의 저해가 있거나 없는 심근경색내로의 주입
c. 대동맥으로의 직접 주입
실시예
실시예
:
PAI
-1 디코이 (
Decoys
) 및 억제 방법
PAI-1 디코이에 대한 대표적인 억제 기전(mechanisms)은 도 1에 나타낸다.
대부분의 모든 경우에서, 하기의 대표적인 디코이 설계들은 다수개의 억제 기전들을 포함한다. 각각의 대표적인 디코이 설계 및 그의 억제 기전에 대한 대략적인 개요는 도 9에 나타낸다. 도 9에 도시되고 전술한 실시예에 기재된 디코이 설계들은 본 발명의 예시적인 실시양태로서 작용하는 것을 의도한다. 본 발명은 본 명세서에 기술된 특정한 실시양태로 제한하지 않으며, 또한 광범위한 균등설계들과 억제 방법들이 본 발명의 범위에 속하는 것으로 당업자에 의해 이해될 것이다.
하기의 대표적인 PAI-1 디코이의 상응하는 서열번호들에 대한 "폴리펩타이드 및 폴리뉴클레오티드 서열의 설명" 을 참조.
PAI -1 디코이 1-3: 본래의 PAI1은 용액에서 2시간 미만의 반감기를 가진다. 이것은 자발적으로 비 억제성인 잠복형으로 입체형태적 변위가 일어난다. 단백질 분해 효소 절단 부위 (R346-M347)에 바로 인접한 반응 중심 루프 (RCL) 펩타이드는 잠복형으로 변위에 의해서 PAI1 구조에 현존하는 b-쉬트 내로 삽입이 일어난다. RCL 서열들에 기초가 되는 펩타이드들은 PAI1 단백질 분해 효소 억제 활성을 차단할 수 있다.
이를 기초로 하여, PAI-1 디코이 1-3은 RCL 서열들을 이용하여 본 분자를 억제할 것이다. 본래의 RCL 과 마찬가지로 그러나 짧은 기간에 작용하는, 본 서열에 기초가 되는 재조합 펩타이드들은 PAI1 작용을 억제하는 것으로 나타났다. 개개의 서열들, 다양한 서열들, 간격자 (spacers)에 의해 분리된 (잠재적으로 PAI1 분자들과 다중결합하는)다양한 서열들은 평가될 것이다. 서열들은 본래의 RCL 펩타이드 작용을 모방할 것이다. 본 DCYs는 거의 확실하게 억제할 것이다 - 그 목적은 하기의 다른 설계들과 같이 구성체의 형태는 가장 효과적이고 잠재적으로 결합을 억제할 것으로 확인하는 데 있다.
PAI1 - DCY -94-1: PCL 펩타이드의 4번의 나란한 복제들은 정상의 PAI1 자살 반응을 억제하는데 사용될 것이다. 본 DCY는 상대적인 효율에 대하여 PAI1-DCY-94-2 와 PAI1-DCY-94-3와 비교할 수 있다.
PAI1 - DCY -94-2: 단일 RCL은 정상의 PAI1 자살 반응을 억제하는데 사용될 것이다. 본 DCY는 상대적인 효율에 대하여 PAI1-DCY-94-1 와 PAI1-DCY-94-3와 비교할 수 있다.
PAI1 - DCY -94-3: 다양한 PAI1 분자들과 증강인자 (enhancer) 상호작용으로 간격자에 의해 분리된 PCL 펩타이드의 4번의 나란한 복제들은 정상의 PAI1 자살 반응을 억제하는데 사용될 것이다. 본 DCY는 상대적인 효율에 대하여 PAI1-DCY-94-1 와 PAI1-DCY-94-2와 비교할 수 있다.
PAI -1 디코이 4 및 5: 여러 개의 세린 단백질 분해 효소 (예를 들어 tPA, uPA, 트롬빈)의 어떤 것에 든 결합하기 때문에, PAI1는 자살 억제 반응 끝내는 절단 동안에 인상적인 입체형태적 변위가 일어난다. 실험적인 증거는 구조에서 이러한 재배열은 억제 기전의 중요한 부분이라고 보여준다. 본 입체형태학적 변위를 절단 반응 때문에 연기하는 것은 PAI1을 단지 정상 기질로 바뀔지도 모르는 완성에 이르를 수 있다. 반응 중심 루프 (RCL) 펩타이드는 활성화된 PAI1의 구조들에서 이상을 일으키고 베타 쉬트 내로 삽입한다.
PAI-1 디코이 4 및 5는 염두에 둔 두 개의 가능성이 있는 목표의 어느 쪽이든 - 1)PAI1 구조로 RCL의 느린 삽입과 세린 단백질 분해 효소 표적들에 의해 자연스럽게 분열되는 PAI1을 허락, 또는 2) 완전히 단백질 분해 효소에 결합을 막는 것을 입체적 방해를 통해서 활성화된 pAI1의 RCL 과 상호작용하려고 한다. RCL 펩타이드는 PAI1에서 베타 쉬트와 상호작용한다. 이 쉬트로부터의 서열은 본래의 RCL을 차지하기 위해 채택된다.
PAI1 - DCY -94-4: 본 DCY의 목표는 RCl을 안정시키는 데 있지만 이것은 쉬트와는 독립적이고 분열 반응을 발생 가능하게 하고 있다. RCL 삽입으로 시트의 일부분을 만드는 베타 가닥들은 RCl 펩타이드의 변형된 결합 표면을 제공하는데 사용될 것이다. PAI1의 두 개의 역평행 베타 가닥들은 RCL을 삽입하고 결합하는 본래의 베타 쉬트의 일부분을 만드는데 사용될 것이다. 본 DCY를 만드는 두 개의 가닥들은 서열에서 비연속적이지만, 베타 회전을 형성하는 네 개의 잔기들은 그들을 부착하고 특유의 2차 구조를 가능하게 하는데 사용될 것이다.
PAI1 - DCY -94-5: 본 DCY의 목표는 RCl을 안정시키는 것이지만 이것은 쉬트와는 독립적이고 분열 반응을 진행 가능하게 하고 있다. 사실상 RCL 펩타이드의 삽입은 PAI1 구조에서 평행으로 회전하는 두 개의 베타 가닥들 사이에서 일어난다. 비록 그들이 PAI1에서 이 베타 쉬트의 서열의 구성이지만, 본 두 개의 가닥들은 본연의 구조의 서열에서 연속적이지 않다.
류신 리치 리피트 (leucine rich repeats (LRR))은 세포외 기질 단백질인 데코린(decorin)과 바이글리칸(biglycan), 톨-라이크 수용체 (Toll-like receptors)를 포함하는 여러 개의 단백질에서 발견되는 특색들이다. 본 특색은 베타 가닥들로 구성되었는 약간 오목한 면과 나선형 또는 반-나선형의 구조의 볼록한 면으로 이루어져 있다. 본 특색의 반복된 쌓아올림은 오목한 쉬트를 형성하는 연속된 평행한 베타 가닥과 함께 솔레노이드(solenoid) 구조를 만들어 낸다. 류신은 서열의 결정적인 부분에서 일어나고 바깥으로 향하는 잔기들에서 두드러진 변이성을 가능하게 하는 내부 결합을 제공한다. 특별히 연속하여 반복될 때, 이 특색은 안정된다. 톨-라이크 수용체 3 외부도메인(ectodomain)의 여러 개의 LRRs는 RCL 삽입으로 본연의 쉬트 구조의 단백질을 다시 만드는 골격으로 사용될 것이다. 평행한 가닥들의 쌓아올렸기 때문에 LRR은 PAI1 베타 쉬트 구조의 부분을 모방하는데 이상적이다. PAI1에서 쉬트의 크기 때문에, 그들은 LRR 골격의 두 개의 부분에서 반복될 것이다.
PAI -1 디코이 6 및 7: 칼라크레인 2(hK2, kallikrein 2)는 보통 전립선에서 발현되는 세린 단백질 분해 효소이고 전립선암의 표지자(marker)로 유용하다. 그것은 P1 분열 부위에서 Arg에 강한 특이성을 나타낸다. 그것은 PAI1을 분열할 수 있고 이어서 다른 단백질 분해 효소에 비해서 고효율로 비활성화할 수 있다. 그것의 특이성과 결합시킨 본 단백질의 발현 프로필(profile)은 사실상 PAI1을 분열하고 비활성화할 것인 DCY를 위한 좋은 후보자이다. 만약 PAI1의 표적으로 하는 부위가 존재한다면, 그것은 PAI1을 분열할 수 있어야 하고 그 때문에 효율적으로 비활성화될 수 있어야 한다.
PAI-1 디코이 6 및 7은 활성화된 단백질 분해 효소인 PAI1을 분해하는 칼라크레인 2(hK2)를 사용한다. 그것은 그것의 발현 프로필(profile)에서 특별하고 전립선암의 표지자(marker)로 사용했다. 그것은 그것의 기질에서 특별하고 그것에 의해 억제되는 것과 반대로 PAI1을 분해하는 것으로 특이하게 제시되었다. 본 구성물 중에 하나는 PAI1 결합에서 중요하다고 여겨지는 본연의 tPA 서열을 모방한 하전 고리 (charged loop)를 가지고 있다.
PAI1 - DCY -94-6: 칼라크레인 2에 대한 잠재적인 돌연변이는 결합 특이성을 강화하려고 만들어질 수 있다. tPA에 존재하는 루프는 tPA-PAI1 결합에서 중요한 여러 가지로 하전 된 잔기들을 포함한다. hK2에 상응하는 루프는 본 서열과 대등하게 돌연변이가 될 수 있고 잠재적으로 PAI1에 대한 결합 특이성이 강화될 수 있다.
PAI1 - DCY -94-7: 칼라크레인 2(hK2, kallikrein 2)는 보통 전립선에서 발현되는 세린 단백질 분해 효소이고 전립선암의 표지자로 유용하다. 그것은 P1 분열 부위에서 Arg에 강한 특이성을 나타낸다. 그것은 PAI1을 분열할 수 있고 이어서 다른 단백질 분해 효소에 비해서 고효율로 비활성화할 수 있다. 그것의 서열 특이성과 결합시킨 본 단백질의 발현 프로파일(profile)은 사실상 PAI1을 분열하고 비활성화할 것인 DCY를 위한 좋은 후보자이다.
조직 플라스미노겐 활성인자 (tPA)의 표면 위의 명확하게 하전된 루프는 PAI1 결합에서 중요하다고 제시되었다. 그것은 PAI1의 RCL 펩타이드 근처의 연속된 산성의 잔기들과 상호작용한다고 여겨진다. 본 부위는 hK2에서 존재하는 더 짧은 루프를 되돌려서 획득되었다. 본 서열의 열중(addiction)은 더 높은 친화성 결합과 더 효울적인 분열을 야기할 수 있다.
PAI -1 디코이 8-12: 플라스미노겐 활성인자 억제제-1 (PAI1)은 섬유소용해를 조절하는 것과 관련된 세린 단백질 분해 효소 억제제이다. 그것의 표적들 중에는 조직 플라스미노겐 활성인자 (tPA)와 유로카이네이즈 플라스미노겐 활성인자 (uPA)이 있다. 오직 매우 느리게 분열하는 (복합체의 제거 전에는 분열하지 않는) 아실 효소 중간체와 공유결합으로 결합하는 PAI1은 자살 억제제 반응에서 그것의 표적과 결합한다. PAI1은 용액에서 2시간보다 적은 짧은 반감기를 가진다. 이것은 자연적으로 비 억제하는 잠복형으로 입체형태적 변위가 일어난다. 단백질 분해 효소 절단 부위에 바로 인접한 반응 중심 루프 (RCL, reactive center loop) 펩타이드는 PAI1 구조 상의 b-쉬트내로 삽입이 일어난다. RCL 서열들에 기초가 되는 펩타이드들은 PAI1 단백질 분해 효소 억제 활성을 차단할 수 있다.
바이트로넥틴(vitronectin)은 다양한 ECM 협력자(partner)와 결합하는 세포외 기질 (ECM) 분자이다. tPA와 uPA 그리고 다른 세린 단백질 분해 효소들과 상호작용하고 억제하게 하는, 그것은 높은 친화력으로 PAI1에 결합하고 그것의 반감기는 급격하게 증가한다. PAI1과 상호작용은 바이트로넥틴의 소마토메딘 B (SMB, somatomedin B) 도메인을 통해 일어난다. 이 결합은 특이하고 친화력이 높다 (Kd~1nM).
PAI-1 디코이 8-12은 PAI1과 바이트로넥틴 상호작용의 사용으로 만들어지고 RCL 억제 펩타이드를 그것에 결합한다. 바이트로넥틴의 소마토메딘 B (SMB, somatomedin B) 도메인은 PAI1에 높은 친화력으로 결합하고 그것의 효과적인 반감기를 크게 연장할 수 있다. 여러 개의 논문은 이 결합 면에서 티로신의 돌연변이는 결합을 완전하게 상실할 수 있다고 제시하고 있다. 비록 여기서 우리의 목적은 결합을 파괴하는 것은 아니지만 결합 친화력의 최소 얼마는 유지하면서 SMB 결합의 안정화 효과를 최소화하는 것이다. 연속된 보존 돌연변이는 결합 면을 규명하려고 만들어진다.SMB 돌연변이는 DCYs 위에 많은 억제 특징들을 주는 것인 RCL 펩타이드와 결합하게 된다. 본래의 SMB 도메인이든 돌연변이 구조의 하나이든, 안정을 최소화하면서 결합을 최대화하는 제작물이 발견될 것이다. SMB의 높은 친화 결합은 사실상 RCL 펩타이드를 PAI1에 속박할 것이고 더욱 용이한 상호작용을 촉진할 것이다.
PAI1 - DCY -94-8: DCY는 높은 친화력과 특이성을 가지는 PAI1 결합을 목적으로 하는 바이트로넥틴의 SMB 도메인을 사용할 것이다. SMB 도메인은 PAI1의 RCl을 기본으로 하는 억제 펩타이드의 다수의 반복에 부착될 것이다. 초기의 SMB 결합은 펩타이드를 매우 근접되게 가져올 것이고, 억제와 SMB 도메인의 가능한 유리를 야기하는 b-쉬트 내로 삽입이 일어날 수 있다. 이러한 다양한 결합과 억제 도메인을 가지는 근처 PAI1 분자들에 작용하는 RCL 펩타이드는 시스- 에서든 트랜스- 에서든 잠재적으로 작용할 수 있다.
PAI1 - DCY -94-9: 디코이는 높은 친화력과 특이성을 가지는 PAI1 결합을 목적으로 하는 바이트로넥틴의 SMB 도메인을 사용할 것이다. SMB 도메인은 PAI1의 RCl을 기본으로 하는 억제 펩타이드의 다수의 반복에 부착될 것이다. 초기의 SMB 결합은 펩타이드를 매우 근접되게 가져올 것이고, 억제와 SMB 도메인의 가능한 유리를 야기하는 b-쉬트내로 삽입이 일어날 수 있다. 이러한 다양한 결합과 억제 도메인을 가지는 근처 PAI1 분자들에 작용하는 RCL 펩타이드는 시스- 에서든 트랜스- 에서든 잠재적으로 작용할 수 있다. SMB 도메인은 돌연변이가 될 것이다. 돌연변이는 PAI1에 대한 바이트로넥틴의 안정화를 감소시킬 것이지만 RCL 펩타이드를 표적으로 하는 충분한 친화력은 효과적으로 유지할 것이다.
PAI1 - DCY -94-10: 디코이는 높은 친화력과 특이성을 가지는 PAI1 결합을 목적으로 하는 바이트로넥틴의 SMB 도메인을 사용할 것이다. SMB 도메인은 PAI1의 RCl을 기본으로 하는 억제 펩타이드의 다수의 반복에 부착될 것이다. 초기의 SMB 결합은 펩타이드를 매우 근접되게 가져올 것이고, 억제와 SMB 도메인의 가능한 유리를 야기하는 b-쉬트 내로 삽입이 일어날 수 있다. 이러한 다양한 결합과 억제 도메인을 가지는 근처 PAI1 분자들에 작용하는 RCL 펩타이드는 시스- 에서든 트랜스- 에서든 잠재적으로 작용할 수 있다. SMB 도메인은 돌연변이가 될 것이다. 돌연변이는 PAI1에 대한 바이트로넥틴의 안정화를 감소시킬 것이지만 RCL 펩타이드를 표적으로 하는 충분한 친화력은 효과적으로 유지할 것이다. 몇몇의 연구 논문은 결합이 파괴된 돌연변이, 특히 결합 접촉 면에서 T→A 돌연변이를 증명하였다. 여기서 목적은 결합을 제거하는 것이 아니라 PAI1에 결합하는 바이트로넥틴의 되도록 많이 파생적인 안정화 효과를 제거하는 것이다.
PAI1 - DCY -94-11: 디코이는 높은 친화력과 특이성을 가지는 PAI1 결합을 목적으로 하는 바이트로넥틴의 SMB 도메인을 사용할 것이다. SMB 도메인은 PAI1의 RCl을 기본으로 하는 억제 펩타이드의 다수의 반복에 부착될 것이다. 초기의 SMB 결합은 펩타이드를 매우 근접되게 가져올 것이고, 억제와 SMB 도메인의 가능한 유리를 야기하는 b-쉬트 내로 삽입이 일어날 수 있다. 이러한 다양한 결합과 억제 도메인을 가지는 근처 PAI1 분자들에 작용하는 RCL 펩타이드는 시스- 에서든 트랜스- 에서든 잠재적으로 작용할 수 있다. SMB 도메인은 돌연변이가 될 것이다. 돌연변이는 PAI1에 대한 바이트로넥틴의 안정화를 감소시킬 것이지만 RCL 펩타이드를 표적으로 하는 충분한 친화력은 효과적으로 유지할 것이다.
PAI1 - DCY -94-12: 디코이는 높은 친화력과 특이성을 가지는 PAI1 결합을 목적으로 하는 바이트로넥틴의 SMB 도메인을 사용할 것이다. SMB 도메인은 PAI1의 RCl을 기본으로 하는 억제 펩타이드의 다수의 반복에 부착될 것이다. 초기의 SMB 결합은 펩타이드를 매우 근접되게 가져올 것이고, 억제와 SMB 도메인의 가능한 유리를 야기하는 b-쉬트 내로 삽입이 일어날 수 있다. 이러한 다양한 결합과 억제 도메인을 가지는 근처 PAI1 분자들에 작용하는 RCL 펩타이드는 시스- 에서든 트랜스- 에서든 잠재적으로 작용할 수 있다. SMB 도메인은 돌연변이가 될 것이다. 돌연변이는 PAI1에 대한 바이트로넥틴의 안정화를 감소시킬 것이지만 RCL 펩타이드를 표적으로 하는 충분한 친화력은 효과적으로 유지할 것이다.
PAI -1 디코이 13 및 14: 바이트로넥틴은 다양한 ECM 협력자(partner)와 결합하는 세포외 기질 (ECM) 분자이다. tPA와 uPA 그리고 다른 세린 단백질 분해 효소들과 상호작용하고 억제하게 하는, 그것은 높은 친화력으로 PAI1에 결합하고 그것의 반감기는 인상적으로 증가한다. PAI1과 상호작용은 바이트로넥틴의 소마토메딘 B (SMB) 도메인을 통해 일어난다. 이 결합은 특이하고 친화력이 높다 (Kd~1nM).
칼라크레인 2(hK2, kallikrein 2)는 보통은 전립선에서 발현되는 세린 단백질 분해 효소이고 전립선암의 표지자(marker)로 유용하다. 그것은 P1 분열 부위에서 Arg에 강한 특이성을 나타낸다. 그것은 PAI1을 분열할 수 있고 이어서 다른 단백질 분해 효소에 비해서 고효율로 비활성화할 수 있다. 그것의 서열 특이성과 결합시킨 이 단백질의 발현 프로파일(profile)은 사실상 PAI1을 분열하고 비활성화할 것인 DCY를 위한 좋은 후보자이다.
PAI1에 대해 결합하고 격리할 수 있는 비활성화 단백질 분해 효소나 칼라크레인 2(kallikrein 2) 중 어느 것에 결합하는 경우에는, PAI-1 유인 (Decoys) 13 과 14는 또한 PAI1에 대한 결합 친화력이 증가하는 SMB 도메인을 사용한다.
PAI1 - DCY -94-13: 유로카이네이즈 플라스미노겐 활성인자 (uPA)는 그것의 수용체를 통해서 신호 반응에서 분만 아니라 섬유소용해 경로의 활성과 관련된 세린 단백질 분해 효소이다. uPA는 PAI1의 표적이다. 효소는 오직 촉매 도메인만 포함하도록 끝을 자를 것이고, 촉매 잔기는 활성을 제거하기 위해서 변이될 것이다. 이 비활성 효소는 PAI1에 대한 결합 기반을 제공하는 바이트로넥틴의 SMB 도메인에 부착될 것이다. PAI1은 다른 세린 단백질 분해 효소와 상호작용과 억제로 부터 격리될 것이다. PAI1-DCY-94-7 과 PAI1-DCY-94-14를 비교하면, 이 DCY는 표적 부위로 어떠한 새로운 효소 활성도 전하지 않을 것이다.
PAI1 - DCY -94-14: 디코이는 높은 친화력과 특이성을 가지는 PAI1 결합을 목적으로 하는 바이트로넥틴의 SMB 도메인을 사용할 것이다. SMB 도메인은 높은 친화력과 특이성을 가지는 PAI1을 표적으로 하는 활성화된 칼라크레인 2 분자에 부착되고 분열될 것인데, 그 때문에 비활성화될 것이다.
PAI -1 디코이 15: 바이트로넥틴은 다양한 ECM 협력자(partner)와 결합하는 세포외 기질 (ECM) 분자이다. tPA와 uPA 그리고 다른 세린 단백질 분해 효소들과 상호작용하고 억제하게 하는, 그것은 높은 친화력으로 PAI1에 결합하고 그것의 반감기는 급격하게 증가한다. PAI1과 상호작용은 바이트로넥틴의 소마토메딘 B (SMB) 도메인을 통해 일어난다. 이 결합은 특이하고 친화력이 높다 (Kd~1nM).
PAI-1 디코이 15는 SMB 도메인에 상기의 돌연변이 집합 (set)이다. SMB의 구조는 거의 백본(backbone)을 중심으로 보면 대칭적이다. 그것은 나선과 PAI1 결합 면과 결합 부위 반대 면 모두에서 거의 일치하도록 수정시킨 루프가 있다. 다섯 번의 돌연변이는 SMB 분자에 또 하나의 PAI1 결합 부위를 여러 부위에서 다시 만들 수 있다. 배후 면에 나선과 루프 사이의 공간은 본래의 결합 부위에서보다 약간 작지만, 나선 부위는 어떤 다른 PAI1 분자 친화력을 가지고 결합하는 충분한 상호작용을 제공할 수 있다. RCL 펩타이드들은 만약 실제로 둘이 결합한다면 결합한 PAI1 분자들 모두와 잠재적으로 상호작용하기 위해서 부착될 것이다.
본래의 결합 부위 반대 면은 결합 부위와 비슷한 백본(backbone)을 가지고 있다. 이 면에서의 돌연변이는 PAI1 결합 부위를 불완전하게 재생할 수 있었다. 각각의 돌연변이의 도입은 SMB의 대부분의 PAI1 결합 면을 재현하기 위해서 만들어졌었다. 돌연변이 된 잔기들의 알파 탄소들은 0.99 옹스트롬 RMS 첨가하고 나선 도메인은 알파 탄소들에 0.49 옹스트롬의 RMS을 첨가한다.
이것은 잠재적으로 정면 (face-to-face) 방법으로 PAI1 분자들의 이합체화를 이끌 수도 있다. 최소한 두 개의 가능성이 존재한다- 분자로부터 RCL 펩타이드들은 서로서로 방해할 수도 있고, PAI1 억제 특징에 영향을 줄 수 있는 상당한 입체 방해일 수도 있다. PAI1의 억제를 논증하기 위해서, PAI1에 결합하고 억제하는 외인성의 RCL 펩타이드는 돌연변이 된 SMB 도메인에 테트라머릭 (tetrameric) 반복에 부착될 것이다.
실시예
: 조직-특이적인
촉진자들
(
promoters
)
하기의 대표적인 조직-특이적인 촉진자들의 상응하는 서열번호들에 대한 "폴리펩타이드와 폴리뉴클레오티드 서열의 설명" 을 참조.
MOD 5306 - 동맥 평화근 -특이적인 촉진자 (도 10에 도식적으로 나타냄)- 원리: 데스민(desmin) 유전자는 골격과 심장, 그리고 평활근 세포에 존재하는 인터메디에이트 필라멘트 (intermediate filament) 단백질을 암호화한다. 여기서 사용되는 촉진자 부위는 혈청 반응 인자와 옥트-유사 인자 (Oct-like factor)를 결합할 수 있는 CArG/옥타머 중복 요소를 함유한다. 이것은 또한 (촉진자 예측 기구로 측정시) 최소 촉진자를 함유한다. 이 부분은 동맥 평활근에서 활성화이지만 정맥 평활근 세포에서 또는 생체 내 (in vivo) 심장에서는 그렇지 않다.
합성 촉진자들의 MOD 원리: 혈관 평활근 세포 (VSMC)에서 발현되는 유전자들의 집합의 촉진자 부위의 분석은 VSMC-특이적인 발현과 관련된 각각의 조절 요소들의 목록을 제공한다. 그런 조절 요소들의 한 세트의 결합은 합성 촉진자 작제물로 사용됐다: 평활근 수축 단백질 SM22 알파 유전자 분획은 (Nov) 최소 촉진자 부위가 과발현된 신장모세포종에 융합하였다. SM22 알파는 확립된 VSMC 분화 표시자(marker)이다. 그것의 최소 촉진자는 다른 삽입유전자(transgene)의 동맥 평활근-특이적인 발현을 지시하는 것으로 나타났다. 최근에, 성숙한 래트 대동맥에서 대단히 높은 Nov 발현이 또한 보고되었다.
본 발명의 대표적 합성 혈관 평활근 촉진자들은 MOD 5309 - 합성 VSMC-특이적인 촉진자 1 (도 11A에 도식적으로 나타냄)과 MOD 5312 - 합성 VSMC-특이적인 촉진자 2 (도 11B에 도식적으로 나타냄), 그리고 MOD 5315 - 합성 VSMC-특이적인 촉진자 3 (도 11C에 도식적으로 나타냄)을 포함한다.
MOD 원리: 혈관 평활근 세포 (VSMC)에서 발현되는 유전자들의 집합의 촉진자 부위의 분석은 VSMC-특이적인 발현과 관련된 각각의 조절 요소들의 목록을 제공한다. 그런 조절 요소들의 한 세트의 결합은 합성 촉진자 작제물로 사용됐다: 평활근 수축 단백질 SM22 알파 유전자 절편은 헤비 체인 11 (heavy chain 11)인 인간 굵은 근육 미세섬유 (myosin) 평활근 촉진자 부위와 융합하였다. SM22 알파는 확립된 VSMC 분화 표시자(marker)이다. 래트 최소 촉진자는 다른 삽입유전자의 동맥 평활근-특이적인 발현을 지시하는 것으로 나타났다. 마찬가지로, MYH11은 또한 평활근에 특이적이다.
MOD 4012 - ESM1 , 내피세포-특이적인 촉진자 (도 12A에 도식적으로 나타냄) - Mod 원리: 본 유전자는 주로 내피세포에서 발현되는 분비 단백질을 암호화한다. 본 유전자의 촉진자는 치료/유인 분자의 내피세포-특이적인 발현이 필수적인 유전자 치료 접근법을 위해서 사용될 수도 있다.
MOD 4399 - FLT1 , 내피세포-특이적인 촉진자 (도 12B에 도식적으로 나타냄) - MOD 원리: 인간 막관통 fms-유사 수용체 (transmembrane fms-like receptor) 티로신 카이네이즈 Flt-1은 혈관 내피 성장 인자의 수용체 중에 하나로, 성장 인자는 내피 증식과 혈관 투과성을 유도한다. Flt-1은 특이하게도 내피에서 발현된다. 본 flt-1 촉진자는 내피로 도입된 외인성 유전자의 발현을 목적으로 하는 도구로 사용될 것이다.
MOD 4790 - 합성된 내피세포-특이적인 촉진자 1 (도 13A에 도식적으로 나타냄) - MOD 4791 - 합성된 내피세포-특이적인 촉진자 1 (도 13B에 도식적으로 나타냄) - MOD 원리: 유전자 치료의 주요한 목적은 원하는 세포 유형에 관심 있는 유전자들의 도입이다. 내피세포는 필수적으로 모든 주요 혈관을 채우고 있고 따라서 순환계에 직접 접근할 수 있다. 내피세포를 통해서 전달되는 잠재적인 유전자 생성물은 각각 허혈 (ischemic) 또는 신생혈관(neovscular)의 처리에서 혈관형성(angiogenic) 또는 혈관억제(angiostatic) 분자 뿐만 아니라, 호르몬, 인슐린 같은 혈장에서 찾을 수 있는 단백질 요소들, 성장 호르몬, 인자 Ⅷ을 포함한다. 내피세포-특이적인 유전자의 촉진자 부위의 조사는 대부분 특이적이고 비특이적인 전자 요소들을 모두를 위한 결합 부위가 있는 것을 드러낸다. 본 계획의 목적은 작은 합성 내피세포-특이적인 촉진자를 구성하기 위한 것이었다. 많은 내피세포-특이적인 mRNA 전사의 5`에 위치한 알려진 전사 요소 결합 부위의 서열은 내피세포-특이적인 촉진자 1과 2와 같은 합성물을 생성하기 위해서 인간 ICAM2 최소 촉진자에 연결되어있었다.
실시예
:
국재화
테터
하기의 대표적인 국재화 테터의 상응하는 서열번호들에 대한 "폴리펩타이드및 폴리뉴클레오티드 서열의 설명"을 참조.
국재화 테터 , 종류 1 - 세포외 지질-변형, 원형질막에 필수적인 요소 (도 14A-14B에 도식적으로 나타냄): 국재화 테터, 종류 1은 원형질막의 세포 밖의 표면에서 카고(cargo)에 고정하도록 설계된다. 그들은 심장, 골격 또는 섬유아 세포 조직을 염두에 두고 설계되었다. 구성물의 대부분은 막에 고정하기 위한 글리코실포스페이티딜애노시톨 (GPI) 지질 변형을 이용한다. GPI 합성은 후 번역으로 ER에서 일어난다. 소수성 특색은 단백질의 C-말단 부위에서 인식되고, 그 후에 분열된다. 분열 후에, 완성된 GPI 일부분은 단백질에 삽입된다. GPI 고정은 구조와 구성에서 다양하고 단백질 또는 조직 특이적일 수도 있다. 세포 표면에서 한번, GPI 고정은 인지질 분해효소에 의한 분열을 조건으로 한다. GPI 분열의 동력학은 지질 길이, 막 표면 전하,그리고 막 이중 층 자체의 물리화학적 특색에 의해 결정된다. 따라서, 다른 GPI 고정은 다수의 표면 보유 시간을 제공하는 설계로 사용되었다.
설계 91-1 내지 91-4는 헤모주베린 (HJV, hemojuvelin) GPI-고정 분열/첨가 도메인을 포함한다. HJV는 골격근에서 발현되기 때문에 선택되었고, 만약 정확한 GPI 고정의 첨가가 조직 특이적이라면, 근육조직에서 사용을 위해 도메인 전형을 제공한다. 91-1은 기본적인 신호 펩타이드/카고/GPI 특색 청사진이다. 91-2는 카고 활동의 범위를 늘리는 카고와 지질 고정 사이의 링커(linker)의 첨가를 제공한다. 91-3은 뉴로제닌(neurogenin)에 HJV의 결합을 막는 돌연변이를 포함하는 HJV의 긴 C-말단 부위를 포함하지만 적당히 막으로 수송을 설명하였다. 91-4는 91-2와 같지만 MAGP1 피브릴린(fibrillin)-결합 도메인을 삽입한다. GPI 고정이 분열할 때, 본 구성은 주변 기질 미세원 섬유에 결합하기 위해 계획된다. 이것은 기질 변형 단백질에 아주 근접하여 카고를 유지할 것이다.
설계 91-5 및 91-6은 Thy-1 GPI 분열/첨가 부위로 이용된다. Thy-1은 보유시간이 연구되어 졌고 다른 GPI 고정된 단백질들보다 더 현저하다고 결정되었기 때문에 선택되었다. Thy-1 고정의 구조는 인지질 분해 효소와 함께 입체적 방해의 원인이 될 수도 있고 분열 비율을 감소시킬 수도 있다. 91-7은 테나신-엑스 (TNX, tenascin-X) 기질-결합 도메인의 첨가와 함께 91-6 에 의거해서 세운다. 본 도메인은 분열된 GPI-고정된 단백질을 콜라겐 유형 Ⅰ 미세 원 섬유로 표적를 정해야 한다. 91-8은 또한 기질 결합 도메인을 포함하지만 기질 구조를 표적으로 하기보다는 본 ApoB 도메인은 글리코사미노글리칸(9637699)에 결합하다.
설계 91-9 내지 91-11은 같은 설계원리로 수행하지만, 글리피칸-1 GPI 특색을 이용한다. 글리피칸-1은 rafts와 caveolae에 국한 시키는 GPI-고정된 프로테오글리칸 (proteoglycan)이다. 다른 조직에서 넓게 발현되고 잠재적으로 본 MDR 에서 다른 GPI의 것에 다른 보유 시간을 제공한다. 91-12에서 91-16은 유사한 원리를 따르지만 MT-MMP6 GPI 분열/첨가 부위와 링커와 기질 결합 도메인의 다른 결합을 포함한다.
설계 91-17 및 91-18은 적당히 수송할 것인 간단한 막관통 LOC를 만들어 내고 세포 밖 면에 카고를 나타내려고 한다. MT-MMP C-말단 끝과 막관통 부위는 추정되는 수송 정보 이외에 알려진 기능이 없다. 91-18은 만약 91-17이 막에 존재하지 않는다면 수송을 촉진하는 당화된 외부도메인 (ectodomain)을 추가한다. 91-19와 91-20은 C-말단에 카고 배치를 이룬다. 마트립테이즈(matriptase)는 유형 Ⅱ 세린 단백질 분해 효소이다. 단백질 분해 효소 도메인은 본 구조에서 제거된 C-말단 부위에 있다. 남아있는 부분은 원형질막 전달을 조정하기 위해서 잠재적으로 당질화된다.
전반적으로, 설계 91-9 내지 91-16은 추가된 디코이에 맞는 전형적인 카고 표시를 얻기 위해서 변하는 막 유지 시간을 획득하려고 한다. 어떤 설계들은 전달 위치에서 기질 안에 카고의 활성을 증가하는 기질-결합 도메인을 포함한다. 설계 91-17 내지 91-20은 본래의 활성이 없는 가능한 가장 간단한 설계들을 획득하려고 한다. 모든 설계들의 잠재적인 함정은 원형질막 수송에서 결함이 있다는 것이다.
국재화 테터 , 종류 2 - 분비 그리고-또는 세포 밖, 용해: 본 국재화 구성단위는 조절된 분비 경로나 세포 막에서 세포 밖 공간으로 방출을 위한 구조적인 경로나 어떤 방법에 의해 세포를 통해서 카고를 운반하기 위해서 의도된다. 세포 외부에 한번은, 결합 서열들은 합성된 세포의 원형질막의 외부의 첨판(leaflet)또는 세포 밖 기질에 형성한 단백질에 펩타이드의 접착을 인정할 것이다.
분비를 위해서, 세 가지 전략은 사용되었다. 첫째로, 세포의 조절된 분비 경로는 과립의 안쪽 면에서 지질 또는 단백질에 응집 그리고/또는 결합의 사용을 통해 이용된다. 둘째로, 구조적인 분비 경로는 본 소포로 입장의 보통 신호의 사용을 통해 이용된다. 셋째로, 모든 경로들은 이용된다. 이것은 하나 또는 다른 경로들은 병 상태의 상황에서 "과부하" 가 되는 가능성 때문에 끝났고, 두 개의 기능적으로 다른 신호들의 사용은 전체적으로 펩타이드의 활성의 종료의 방해물로 작용하지 않을 것이다. 분비 과립의 내부 면과 결합이 사용될 때, 세포 표면에서 펩타이드의 배출에 도움이 되는 pH 또는 칼슘 수치 변화에 민감한 결합은 선택되었다.
표면에서 소포로부터 한번 배출되면, 펩타이드는 그 후에 세포의 외부 첨판(leaflet)의 표면에 결합한 단백질들 (다시 말하면, uPAR 또는 아넥신(annexin))이나, 세포 밖 기질을 포함하는 단백질들(다시 말하면, 피브린)에 결합하기를 바라게 된다. 어떤 구성물에서, "감춰진" ECM 결합 특색의 '노출'의 원인인 경색 부위에서 과발현되는 것으로 알려진 그것들의 효소의 단백질 분해 효소 위치들은 사용되었다. 이러한 방법에서, 붙들고 있는 것으로부터 카고와 건강한 조직의 부위 안에 활성에 가까운 단백질들의 방지가 시도된다. 다른 것으로, 위치는 카고는 단지 스스로 세포 밖 기질로 배출되기 위해 국소화 펩타이드의 주요 부에서 배출되는 방법으로 배열된다. ECM에 결합은 카고의 "지구력"을 주려고 기대되지만, 유지되는 막 위 단백질에 결합은 우리의 펩타이드를 회전하게 둘 것이다.
국재화 테터 , 종류 3 - 잠정적으로 용해할 수 있는 세포 밖 (도 15에 도식적으로 나타냄): 본 설계의 기본적인 구성단위의 요소들은 하기와 같다: 잘 알려진 신호 펩타이드로 비교적 활성이 없게 행동할 것으로 예견된 막관통 (transmembrane) 단백질 (또는 전구-단백질)인 지질 막 부착 모티프(motifs) (GPI와 palmitoyl), 그리고 잠정적으로 분열할 수 있는 단백질분해 부위 (TACE/ADAM17, MT1-MMP, uPA/tTPA 또는 다양한 단백질분해효소 절단). 본 구성요소는 17개의 설계와 잠재적인 양성 대조군을 통해서 달라진다. 전체에서 설계 세트는 실험적이고 실질적인 것 모두에서 다른 위험 고려 사항들 사이에서의 균형을 이끌려고 한다.
LOC-93-1은 뛰어나다. 전구-pro-TGF-알파를 기본으로 하지만, 본 설계에서, 분비되고 가공된 성장 인자는 삭제되고 그것 대신에 치료상의 유인, 표지, 또는 형광 단백질이 있다. '작동"에 대한 본 설계을 위해, 디코이는 성숙한 TGF-알파와 아주 흡사하게 가공돼야 한다. 전구-pro-TGF-알파는 주로 TNF-알파와 같은 다양한 프로-염증 사이토카인의 '흘림"과 관련된 종양 괴사 인자 알파 전환 효소 (TACE/ADAM17)에 의해 분열되고 활성화된다. TACE는 프로-염증 환경에 의해 유발되고, 포르볼 에스터 (phorbol ester) 처리에 의해 인위적으로 유도될 수 있다. TACE는 심상 손상과 조직 재형성, 그리고 종양 미세환경 부위에 풍부하고, 분비 소포에서 세포 표면이나 분비 전까지도 활성화될 수 있다. TACE (또는 예견된 TACE 일치) 절단 부위들을 쓰는 본 세트에서 다른 설계들은 LOC-93-2,과 -3, 그리고 -9 이다. 그러나, 본 일치 부위들은 다른 수단을 통해 표면에 국소화하기를 예상된다.
LOC-93-2, -3, -4, -5, -6, -7, 그리고 -12 (대조군) 기능이 알려지지 않은 뇌-특이적인 단백질로 오팔린(Opalin)의 인간 동종인 TM10으로 알려진 다소 모호한 폴리펩타이드을 쓴다. 본 단백질은 EMBL-GFP (Heidelberg, Germany) 국소화 데이터베이스 프로젝트에서 작은(다시 말하면, <200 아마노산) 막관통 단백질들을 조사하면서 확인되었다. 이것은 명백한 신호 펩타이드, 리간드 수용체, 또는 카이네이즈 도메인은 가지고 있지 않고 그것의 141 아미노산 서열의 BLAST 조사는 가까운 동종들은 보이지 않는다. 비록 LOCATE 데이터베이스는 유형 Ⅱ 막 단백질이라고 TM10을 보고하지만, 서열의 다양한 분석은 사실은 예외와 모호없이 (LOCATE을 통해 연결된 분석 부위를 포함) 유형 Ⅰ이라고 나타낸다. 가장 최근에, 본 설계들의 완성 후에, TM10(TMEM10)은 Kippert 등에 (2008.4.25;18439243) 의해서 특성화되었고, 실험적으로 튼튼한 원형질막 국소화와 가능한 액틴(actin) 결합 없이 유형 Ⅰ이라고 증명되었다. 많은 그런 실례들은 규모에서 더 크기 때문에, 작고 조밀한 transmembraneLOCsig의 원리는 거의 그 스스로 증명하고, 치료에서 잠재적인 위험인자인 다면적인 신호에 관여하는 게 더 적당할지도 모른다. 심장-기반 치료에서 희소돌기아교세포(oligodendrocyte)-특이적인 폴리펩타이드를 쓰기 위한 원리는 뇌-특이적인 단백질들이 심장-특이적인 과정을 저해하는데 덜 적당할 것이라는 것이다.
LOC-93-2, -3, 그리고 -4는 실험적인 대조의 동기를 한 데 모아 함께 주제로 다룬다. TAG/DCY와 LOC 사이에 접합부을 형성하도록, 키메라(chimeric) 합성 TACE 기질 (TNF-알파에 두 개의 치환을 더한 TGF-알파 TACE 부위를 기본으로 하는, 짧은 간격자 잔기들 측면에 서서)은 TM10 N-말단과 융합된다. LOC-93-3은 93-2를 EGFR에 n-말단 신호 펩타이드의 포함을 통해 "내부의 카고"로 변환한다; 표면에 전달하는지 안 하는지 본 테스트하는 것은 신호 펩타이드에 의해 증강된다. LOC-93-4는 c-말단 팔미토일 접착 부위를 LOC-93-3에 더한다; 본 첨가로, 차례로 세포 표면 위에 국소화 그리고/또는 보유되는지 안 되는지 테스트하는 것은 c-말단 lipidation을 통해 증강된다.
LOC-93-3, -5, -6, -7은 또한 다른 단백질분해 부위를 비교하기 위해 또 다른 세트와 함께 주제로 다룰지도 모른다. 단백질분해 말단 부위는 TACE/ADAM17, uPA/tTPA, MT1-MMP, 또는 더 불안정하고 많은 단백질분해효소의 표적일 수 있는 부위 (다시 말하면, 알파-2 마크로글로불린)일 것이다.
LOC-93-8, -9, -10, 그리고 -11은 하기와 같이 설계된다. 구성은 내부의 카고를 따르는 신호 펩타이드(pre-Glypican 으로부터)와 추정되는 GPI 고정부위 (MMP25 로부터)를 포함하는 c-말단에서 끝이다. LOC-93-3, -5, -6 그리고 -7같이, 단백질분해효소 절단 부위의 4 가지 가변을 테스트한다. 그러나, 여기서 막 부착의 환경은 막관통을 통해서가 아니라 리피데이션(lipadation)의 단순 방법을 통해서 다르다.
LOC-93-12는 원형질막 국재화에 대한 잠재적인 양성 대조군이고, EMBL-Heidelberg 밖의 GFP-LOC 프로젝트에 의해 특성 지어졌다 - 최근에, Kippert 등 (2008.4.25;18439243)에 의한 논문.
본 발명은 또한 하기의 제한하지 않은 실시형태를 제공한다.
E1. 분리된 폴리펩타이드 리간드, 여기서 상기 리간드는 PAI-1 활성을 변화시킨다.
E2. 분리된 폴리펩타이드 헤테로폴리리간드, 여기서 상기 헤테로폴리리간드는 PAI-1 활성을 변화시킨다.
E3. 분리된 폴리펩타이드 호모폴리리간드, 여기서 상기 호모폴리리간드는 PAI-1 활성을 변화시킨다.
E4. 분리된 융합 단백질, 여기서 상기 융합 단백질은 최소한 하나의 추정되는 PAI-1 상호작용 도메인 인식 모티프(motif)를 가지는 모체 단백질의 하나 또는 그 이상의 절편을 포함한다.
E5. 분리된 E4의 융합 단백질, 여기서 상기 모체 단백질은 섬유소, 조직 플라스미노겐 활성 인자, 유로카이네이즈 플라스미노겐 활성 인자, 또는 바이트로넥틴 (vitronectin)이다.
E6. E1-E5의 폴리펩타이드, 데그론(degron), 국소화 신호, 항원결정인자, 리포터의 하나 또는 그 이상을 상기에 포함
E7. 각각의 E1-E7의 폴리펩타이드를 암호화하는 뉴클레오티드 서열을 포함하는 분리된 폴리뉴클레오티드
E8. E7의 폴리뉴클레오티드를 포함하는 벡터
E9. 폴리뉴클레오티드 E7을 포함하는 숙주세포
E10. E7의 폴리뉴클레오티드를 포함하는 비-인간 유기체
E11. 촉진자에 사용 가능하게 연결된 E7의 폴리뉴클레오티드.
E12. E11의 촉진자에 사용 가능하게 연결된 폴리뉴클레오티드, 여기서 상기 촉진자는 구조 성의 촉진자, 비-특이적인 촉진자, 유도성의 촉진자, 또는 조직-특이적인 촉진자이다.
E13. E12의 촉진자에 사용 가능하게 연결된 폴리뉴클레오티드, 여기서 상기 조직-특이적인 촉진자는 내피세포-특이적인 촉진자, 혈관 평활근세포-특이적인 촉진자, 심장근육세포-특이적인 촉진자, 심장 지방세포-특이적인 촉진자, 또는 심장 섬유모세포-특이적인 촉진자이다.
E14. E9의 숙주세포, 여기서 상기 숙주세포는 포유류 세포이다.
E15. E14의 숙주세포, 여기서 상기 숙주세포는 내피세포, 혈관 평활근 세포, 심장근육세포, 심장 지방세포, 또는 심장 섬유모세포이다.
E16. E10의 비-인간 유기체, 여기서 상기 유기체는 비-인간 영장류, 생쥐, 소, 돼지, 양, 말, 쥐, 토끼, 개, 고양이, 또는 기니 피그이다.
E17. 숙주세포로 E8의 벡터 전달과 폴리펩타이드의 최소한 하나의 복사를 만들수 있는 적당한 상태에서 전달된 숙주세포 배양을 포함하는 세포에서 PAI-1을 억제하는 방법
E18. 대상의 심장 조직으로 E8의 벡터 주입을 포함하는 대상의 심장 조직에서 PAI-1을 억제하는 방법
E19. 수정란으로 E8의 벡터 주입을 포함하는 줄어든 PAI-1 활성을 가지는 유전자 삽입 대상을 만드는 방법
E20. 분리된 융합 단백질, 여기서 상기 융합 단백질은 데그론(degron)과 연결된 PAI-1을 포함한다.
E21. 분리된 융합 단백질, 여기서 상기 융합 단백질은 국소화 신호에 연결된 PAI-1을 포함한다.
E22. 분리된 융합 단백질, 여기서 상기 융합 단백질은 데그론(degron) 및 국소화 신호와 연결된 PAI-1을 포함한다.
E23. 각각의 E20-E22의 폴리펩타이드를 암호화하는 뉴클레오티드 서열을 포함하는 분리된 폴리뉴클레오티드.
E24. 벡터 삽입을 최대한 적합하게 하는 PAI-1을 암호화하는 뉴클레오티드 서열을 포함하는 분리된 폴리뉴클레오티드.
E25. E24의 분리된 폴리펩타이드, 여기서 상기 벡터(vector)는 UTLRAVECTOR이다.
E26. E23-E25의 폴리뉴클레오티드를 포함하는 벡터.
E27. E23-E25의 폴리뉴클레오티드를 포함하는 숙주세포.
E28. E23-E25의 폴리뉴클레오티드를 포함하는 비-인간 유기체.
E29. 촉진자에 사용 가능하게 연결된 E23-E25의 폴리뉴클레오티드.
E30. E29의 촉진자에 사용 가능하게 연결된 폴리뉴클레오티드, 여기서 상기 촉진자는 구조 성의 촉진자, 비-특이적인 촉진자, 유도성의 촉진자, 또는 조직-특이적인 촉진자이다.
E31. E29의 촉진자에 사용가능하게 연결된 폴리뉴클레오티드, 여기서 상기 조직-특이적인 촉진자는 내피세포-특이적인 촉진자, 혈관 평활근세포-특이적인 촉진자, 심장근육세포-특이적인 촉진자, 심장 지방세포-특이적인 촉진자, 또는 심장 섬유모세포-특이적인 촉진자이다.
E32. E27의 숙주세포, 여기서 상기 숙주세포는 포유류 세포이다.
E33. E32의 숙주세포, 여기서 상기 숙주세포는 내피세포, 혈관 평활근 세포, 심장근육세포, 심장 지방세포, 또는 심장 섬유모세포이다.
E34. E28의 비-인간 유기체, 여기서 상기 유기체는 비-인간 영장류, 생쥐, 소, 돼지, 양, 말, 쥐, 토끼, 개, 고양이, 또는 기니 피그이다.
E35. E26의 벡터(vector)를 숙주세포에 전달하고 PAI-1의 적어도 하나의 카피를 만드는데 적합한 상태에서 상기 전달된 숙주세포를 배양함을 포함하는 숙주세포에서 PAI-1의 발현을 변경하는 방법
E36. 대상체의 심장 조직 내로 E26의 벡터(vector)를 주입하는 것을 포함하는 대상체의 심장 조직에서 PAI-1의 발현을 변경하는 방법
E37. E26의 벡터(vector)를 수정난에 주입하는 것을 포함하는 변경된 PAI-1 발현을 가지는 유전자 삽입 대상체를 만드는 방법
상기의 실시예들과 실시양태들은 예시적인 실시양태로서 작용하는 것을 의도한다. 본 발명은 여기에 설명된 특정한 실시양태로 제한하지 않고, 광 범위한 균등한 설계들과 억제 방법들이 본 발명의 범위에 속한다고 당업자들에 의해 이해될 것이다.
참고문헌
Akyurek, L. M., S. Nallamshetty, et al. (2001). "Coexpression of guanylate kinase with thymidine kinase e.lances prodrug cell killing in vitro and suppresses vascular smooth muscle cell proliferation in vivo." MOl Ther 3(5'Pt 1): 779-86.
Akyurek, L. M., Z. Y. Yang, et al. (2000). "SM22a1pha promoter targets gene expression to vascular smooth musc1e cells in vitro and in vivo." MOl Ther 6(11): 983-91.
Appleby, C. E., P. A. Kingston, et al. (2003). "A novel combination of promoter and enhancers increases transgene expression in vascular smooth muscle cells in vitro and coronary .teries in vivo after adenovirus-mediated gene transfer." Gene Ther 10(18): 1616-22.
Beck, C., H. Uramoto, et al. (2004). "Tissue-specific targeting for cardiovascular gene transfer. Potential vectors and future challenges." Curr Gene Ther 4(4): 457-67.
Burke, B. (2003). "Macrophages as novel cellular vehic1es for gene therapy." Exoert Ooin Biol Ther 3(6): 919-24.
Burke, B., S. Sumner, et al. (2002). "Macrophages in gene therapy: cellular delivery vehicles and in vivo targets." J Leukoc Biol 72(3): 417-28.
Gough, P. J. and E. W. Raines (2003). "Gene therapy of apolipoprotein Edeficient mice using a novel macrophage-specific retroviral vector." Blood 101(2): 485-9 1.
Hasty, A. H., M. F. Linton, et al. (1999). "Retroviral gene therapy in ApoEdeficient mice: ApoE expression in the artery wall reduces early foam celllesion formation." Circulation 99(1 9): 2571-6.
Ishiguro, H., H. Y oshida, et a1. (2001). "Retrovirus-mediated expression of apolipoprotein A-I in the macrophage protects against atherosc1erosis in vivo." J Biol Chem 276(39): 36742-8.
Juan, S. H., T. S. Lee, et al. (2001). "Adenovirus-mediated heme oxygenase-l gene transfer inhibits the development of atherosc1erosis in apolipoprotein E-deficient mice." Circulation 104(13): 1519-25.
Lu, Z. Z., F. Ni, et al. (2006). "Efficient gene transfer into hematopoietic cells by a retargeting adenoviral vector system with a chimeric fiber of adenovirus serotype 5 and 11p." Exp Hematol 34(9): 1171-82.
Nilsson, M., S. Karlsson, et al. (2004). "Functionally distinct subpopulations of cord blood CD34+ cells are transduced by adenoviral vectors with serotype 5 or 35 tropism." Mol Ther 9(3): 377-88.
Ophorst, O. J., S. Kostense, et al. (2004). "An adenoviral type 5 vector carrying a type 35 fiber as a vaccine vehic1e: DC targeting, cross neutralization, and immunogenicity." Vaccine 22(23-24): 3035-44.
Roth, D. M., N. C. Lai, et al. (2004). "Indirect intracoronary delivery of adenovirus encoding adenylyl cyc1ase increases left ventricular contractile function in mice." Am J Physiol Heart Circ Phvsiol 287(1): HI72-7.
Segerrnan, A., K. Lindman, et al. (2006). "Adenovirus types IIp and 35 attach to and infect primary lymphocytes and monocytes, but hexon expression in T-cells requires prior activation." Virology 349(1): 96-11 1.
Shayakhmetov, D. M., T. Papayannopoulou, et al. (2000). "Efficient gene
transfer into human CD34(+) cells by a retargeted adenovirus vector." J Virol 74(6): 2567-83.
Van Eck, M., N. Herijgers, et al. (2000). "Effect of macrophage-derived mouse ApoE, human ApoE3-Leiden, and human ApoE2 (ArgI58-->Cys) on cholesterol levels and atherosc1erosis in ApoE-deficient mice." Arteriosc1er Thromb Vasc Biol 20(1): 119-27.
Yoshida, H., A. H. Hasty, et al. (2001). "Isoforrn-specific effects of apolipoprotein E on atherogenesis: gene transduction studies in mice." Circulation 104(23): 2820-5.
<110> Intrexon Corporation
<120> Therapeutic Inhibitors of PAI-1 Function and Methods of Their Use
<130> 2584.070PC02
<150> US 61/020,137
<151> 2008-01-09
<150> US 61/080,640
<151> 2008-07-14
<160> 139
<170> PatentIn version 3.4
<210> 1
<211> 68
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 1
Leu Gln Ile Asp Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile
1 5 10 15
Val Ser Ala Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val
20 25 30
Ser Ala Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser
35 40 45
Ala Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala
50 55 60
Leu Gln Ile Asp
65
<210> 2
<211> 204
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 2
ctgcaaatcg acagcggaac cgtcgcctcc agctccaccg ctgtgattgt gtccgcctcc 60
ggcacagtgg cctcctccag cacagccgtc atcgtcagcg ccagcggcac cgtggccagc 120
agcagcaccg ccgtgatcgt gagcgccagc ggcacagtcg cttcctcctc cacagctgtc 180
attgtctccg ctctccagat tgac 204
<210> 3
<211> 52
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 3
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Leu Gln Ile Asp
50
<210> 4
<211> 156
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 4
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatga gctgtgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacactccag attgac 156
<210> 5
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 5
Leu Gln Ile Asp Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile
1 5 10 15
Val Ser Ala Ser Asp Val Thr Gly Asn Ala Thr Tyr Thr Ile Thr Ser
20 25 30
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Asp
35 40 45
Val Thr Gly Asn Ala Thr Tyr Thr Ile Thr Ser Gly Thr Val Ala Ser
50 55 60
Ser Ser Thr Ala Val Ile Val Ser Ala Ser Asp Val Thr Gly Asn Ala
65 70 75 80
Thr Tyr Thr Ile Thr Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val
85 90 95
Ile Val Ser Ala Leu Gln Ile Asp
100
<210> 6
<211> 312
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 6
ctgcaaatcg acagcggaac cgtcgcctcc agctccaccg ctgtgattgt gtccgccagc 60
gatgtgacag gcaatgccac atacacaatc acatccggca cagtggccag ctccagcaca 120
gccgtcatcg tcagcgcttc cgacgtgacc ggaaacgcta cctataccat taccagcggc 180
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcgacgtgac cggcaacgcc 240
acctacacca tcaccagcgg cacagtcgct tcctcctcca cagctgtcat tgtctccgct 300
ctccagattg ac 312
<210> 7
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 7
Leu Gln Ile Asp Lys Phe Ser Leu Glu Thr Glu Val Asp Leu Asn Pro
1 5 10 15
Ala Gly Ala Leu Gln Lys Val Lys Ile Glu Val Asn Glu Leu Gln Ile
20 25 30
Asp
<210> 8
<211> 99
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 8
ctgcaaatcg acaagtttag cctggagaca gaggtggacc tcaaccctgc cggagccctc 60
cagaaagtga aaatcgaagt gaatgagctg caaattgac 99
<210> 9
<211> 101
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 9
Leu Gln Ile Asp Thr Val Ser His Glu Val Ala Asp Cys Ser His Leu
1 5 10 15
Lys Leu Thr Gln Val Pro Asp Asp Leu Pro Thr Asn Ile Thr Ala Leu
20 25 30
Tyr Leu Asn His Asn Gln Leu Arg Arg Leu Pro Ala Ala Asn Phe Thr
35 40 45
Arg Tyr Ser Gln Leu Thr Lys Leu Lys Val Glu Phe Asn Thr Ile Ser
50 55 60
Lys Leu Glu Pro Glu Leu Cys Gln Lys Leu Pro Met Leu Lys Val Leu
65 70 75 80
Asn Leu Gln His Asn Glu Leu Ser Gln Leu Ser Asp Lys Thr Phe Ala
85 90 95
Phe Leu Gln Ile Asp
100
<210> 10
<211> 303
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 10
ctgcaaatcg acaccgtcag ccatgaggtc gccgattgct cccacctcaa gctgacccag 60
gtgcctgacg atctgcctac caatatcaca gccctctacc tcaaccataa ccaactgagg 120
agactccccg ctgccaattt cacaagatat agccaactga caaagctcaa ggtcgagttt 180
aacacaatct ccaagctgga gcctgagctg tgccaaaagc tccccatgct gaaagtgctc 240
aacctccagc ataacgaact gtcccagctg tccgataaga cattcgcttt cctccagatt 300
gac 303
<210> 11
<211> 240
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 11
Leu Gln Ile Asp Ile Val Gly Gly Trp Glu Cys Glu Lys His Ser Gln
1 5 10 15
Pro Trp Gln Val Ala Val Tyr Ser His Gly Trp Ala His Cys Gly Gly
20 25 30
Val Leu Val His Pro Gln Trp Val Leu Thr Ala Ala His Cys Leu Lys
35 40 45
Lys Asn Ser Gln Val Trp Leu Gly Arg His Asn Leu Phe Glu Pro Glu
50 55 60
Asp Thr Gly Gln Arg Val Pro Val Ser His Ser Phe Pro His Pro Leu
65 70 75 80
Tyr Asn Met Ser Leu Leu Lys His Gln Ser Leu Arg Pro Asp Glu Asp
85 90 95
Ser Ser His Asp Leu Met Leu Leu Arg Leu Ser Glu Pro Ala Lys Ile
100 105 110
Thr Asp Val Val Lys Val Leu Gly Leu Pro Thr Gln Glu Pro Ala Leu
115 120 125
Gly Thr Thr Cys Tyr Ala Ser Gly Trp Gly Ser Ile Glu Pro Glu Glu
130 135 140
Phe Leu Arg Pro Arg Ser Leu Gln Cys Val Ser Leu His Leu Leu Ser
145 150 155 160
Asn Asp Met Cys Ala Arg Ala Tyr Ser Glu Lys Val Thr Glu Phe Met
165 170 175
Leu Cys Ala Gly Leu Trp Thr Gly Gly Lys Asp Thr Cys Gly Gly Asp
180 185 190
Ser Gly Gly Pro Leu Val Cys Asn Gly Val Leu Gln Gly Ile Thr Ser
195 200 205
Trp Gly Pro Glu Pro Cys Ala Leu Pro Glu Lys Pro Ala Val Tyr Thr
210 215 220
Lys Val Val His Tyr Arg Lys Trp Ile Lys Asp Thr Leu Gln Ile Asp
225 230 235 240
<210> 12
<211> 720
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 12
ctgcaaatcg acatcgtcgg cggatgggaa tgcgaaaagc atagccaacc ctggcaagtg 60
gccgtctact cccacggatg ggctcactgt ggcggagtgc tcgtgcatcc ccaatgggtc 120
ctgacagccg ctcactgtct gaaaaagaat agccaagtgt ggctgggcag acacaacctg 180
ttcgagcccg aggacacagg ccaaagagtc cccgtcagcc atagctttcc ccatcccctc 240
tacaatatgt ccctgctcaa gcatcagtcc ctgaggcccg atgaggatag ctcccacgat 300
ctgatgctgc tcagactcag cgaacccgct aagattaccg atgtggtcaa ggtcctggga 360
ctgcctaccc aagagcctgc cctcggcaca acctgttacg ccagcggatg gggaagcatt 420
gagcctgagg agtttctcag acctagatcc ctgcaatgcg tcagcctcca cctcctgtcc 480
aacgatatgt gtgccagggc ctatagcgaa aaggtcaccg agttcatgct gtgtgccgga 540
ctgtggaccg gaggcaaaga cacatgcgga ggcgatagcg gaggccctct ggtctgcaat 600
ggcgtcctgc aaggcattac ctcctgggga cccgaaccct gtgccctccc cgaaaagcct 660
gccgtctaca caaaggtcgt gcattacagg aagtggatca aagacacact ccagattgac 720
720
<210> 13
<211> 254
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 13
Leu Gln Ile Asp Ile Val Gly Gly Trp Glu Cys Glu Lys His Ser Gln
1 5 10 15
Pro Trp Gln Val Ala Val Tyr Ser Lys His Arg Arg Ser Pro Gly Glu
20 25 30
Trp Ala His Cys Gly Gly Val Leu Val His Pro Gln Trp Val Leu Thr
35 40 45
Ala Ala His Cys Leu Lys Lys Asn Ser Gln Val Trp Leu Gly Arg His
50 55 60
Asn Leu Phe Glu Pro Glu Asp Thr Gly Gln Arg Val Pro Val Ser His
65 70 75 80
Ser Phe Pro His Pro Leu Tyr Asn Met Ser Leu Leu Lys His Gln Ser
85 90 95
Leu Arg Pro Asp Glu Asp Ser Ser His Asp Leu Met Leu Leu Arg Leu
100 105 110
Ser Glu Pro Ala Lys Ile Thr Asp Val Val Lys Val Leu Gly Leu Pro
115 120 125
Thr Gln Glu Pro Ala Leu Gly Thr Thr Cys Tyr Ala Ser Gly Trp Gly
130 135 140
Ser Ile Glu Pro Glu Glu Phe Leu Arg Pro Arg Ser Leu Gln Cys Val
145 150 155 160
Ser Leu His Leu Leu Ser Asn Asp Met Cys Ala Arg Ala Tyr Ser Glu
165 170 175
Lys Val Thr Glu Phe Met Leu Cys Ala Gly Leu Trp Thr Gly Gly Lys
180 185 190
Asp Thr Cys Gly Gly Asp Ser Gly Gly Pro Leu Val Cys Asn Gly Val
195 200 205
Leu Gln Gly Ile Thr Ser Trp Gly Pro Glu Pro Cys Ala Leu Pro Glu
210 215 220
Lys Pro Ala Val Tyr Thr Lys Val Val His Tyr Arg Lys Trp Ile Lys
225 230 235 240
Asp Thr Ser Asp Val Thr Gly Asn Ala Thr Tyr Thr Ile Thr
245 250
<210> 14
<211> 762
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 14
ctgcaaatcg acatcgtcgg cggatgggaa tgcgaaaagc atagccaacc ctggcaagtg 60
gccgtctact ccaagcatag aaggagccct ggcgaatggg ctcactgtgg cggagtgctc 120
gtgcatcccc aatgggtcct gacagccgct cactgtctga aaaagaatag ccaagtgtgg 180
ctgggcagac acaacctgtt cgagcccgag gacacaggcc aaagagtccc cgtcagccat 240
agctttcccc atcccctcta caatatgtcc ctgctcaagc atcagtccct gaggcccgat 300
gaggatagct cccacgatct gatgctgctc agactcagcg aacccgctaa gattaccgat 360
gtggtcaagg tcctgggact gcctacccaa gagcctgccc tcggcacaac ctgttacgcc 420
agcggatggg gaagcattga gcctgaggag tttctcagac ctagatccct gcaatgcgtc 480
agcctccacc tcctgtccaa cgatatgtgt gccagggcct atagcgaaaa ggtcaccgag 540
ttcatgctgt gtgccggact gtggaccgga ggcaaagaca catgcggagg cgatagcgga 600
ggccctctgg tctgcaatgg cgtcctgcaa ggcattacct cctggggacc cgaaccctgt 660
gccctccccg aaaagcctgc cgtctacaca aaggtcgtgc attacaggaa gtggatcaaa 720
gacacaagcg atgtgacagg caatgccaca tacacaatca ca 762
<210> 15
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 15
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser
50 55 60
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly
65 70 75 80
Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly Thr
85 90 95
Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Leu Gln Ile Asp
100 105 110
<210> 16
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 16
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatga gctgtgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaagcgga accgtcgcct ccagctccac cgctgtgatt 180
gtgtccgcct ccggcacagt ggcctcctcc agcacagccg tcatcgtcag cgccagcggc 240
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcggcacagt cgcttcctcc 300
tccacagctg tcattgtctc cgctctccag attgac 336
<210> 17
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 17
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Leu Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser
50 55 60
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly
65 70 75 80
Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly Thr
85 90 95
Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Leu Gln Ile Asp
100 105 110
<210> 18
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 18
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgca cagagggact gaatgtggat 60
aagaaatgcc aatgcgatga gctgtgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaagcgga accgtcgcct ccagctccac cgctgtgatt 180
gtgtccgcct ccggcacagt ggcctcctcc agcacagccg tcatcgtcag cgccagcggc 240
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcggcacagt cgcttcctcc 300
tccacagctg tcattgtctc cgctctccag attgac 336
<210> 19
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 19
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Ala Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser
50 55 60
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly
65 70 75 80
Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly Thr
85 90 95
Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Leu Gln Ile Asp
100 105 110
<210> 20
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 20
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgcg ccgagggctt caatgtggat 60
aagaaatgcc aatgcgatga gctgtgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaagcgga accgtcgcct ccagctccac cgctgtgatt 180
gtgtccgcct ccggcacagt ggcctcctcc agcacagccg tcatcgtcag cgccagcggc 240
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcggcacagt cgcttcctcc 300
tccacagctg tcattgtctc cgctctccag attgac 336
<210> 21
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 21
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Ala Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser
50 55 60
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly
65 70 75 80
Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly Thr
85 90 95
Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Leu Gln Ile Asp
100 105 110
<210> 22
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 22
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatgc cctctgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaagcgga accgtcgcct ccagctccac cgctgtgatt 180
gtgtccgcct ccggcacagt ggcctcctcc agcacagccg tcatcgtcag cgccagcggc 240
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcggcacagt cgcttcctcc 300
tccacagctg tcattgtctc cgctctccag attgac 336
<210> 23
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 23
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Ala Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser
50 55 60
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly
65 70 75 80
Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly Thr
85 90 95
Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Leu Gln Ile Asp
100 105 110
<210> 24
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 24
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatga ggcttgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaagcgga accgtcgcct ccagctccac cgctgtgatt 180
gtgtccgcct ccggcacagt ggcctcctcc agcacagccg tcatcgtcag cgccagcggc 240
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcggcacagt cgcttcctcc 300
tccacagctg tcattgtctc cgctctccag attgac 336
<210> 25
<211> 306
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 25
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Thr Ser Thr Thr Ser Thr Ser Ser Ser Ser Thr Thr Ser Arg Ala Thr
50 55 60
Ser Ile Ile Gly Gly Glu Phe Thr Thr Ile Glu Asn Gln Pro Trp Phe
65 70 75 80
Ala Ala Ile Tyr Arg Arg His Arg Gly Gly Ser Val Thr Tyr Val Cys
85 90 95
Gly Gly Ser Leu Ile Ser Pro Cys Trp Val Ile Ser Ala Thr Ala Cys
100 105 110
Phe Ile Asp Tyr Pro Lys Lys Glu Asp Tyr Ile Val Tyr Leu Gly Arg
115 120 125
Ser Arg Leu Asn Ser Asn Thr Gln Gly Glu Met Lys Phe Glu Val Glu
130 135 140
Asn Leu Ile Leu His Lys Asp Tyr Ser Ala Asp Thr Leu Ala His His
145 150 155 160
Asn Ala Ile Ala Leu Leu Lys Ile Arg Ser Lys Glu Gly Arg Cys Ala
165 170 175
Gln Pro Ser Arg Thr Ile Gln Thr Ile Cys Leu Pro Ser Met Tyr Asn
180 185 190
Asp Pro Gln Phe Gly Thr Ser Cys Glu Ile Thr Gly Phe Gly Lys Glu
195 200 205
Asn Ser Thr Asp Tyr Leu Tyr Pro Glu Gln Leu Lys Met Thr Val Val
210 215 220
Lys Leu Ile Ser His Arg Glu Cys Gln Gln Pro His Tyr Tyr Gly Ser
225 230 235 240
Glu Val Thr Thr Lys Met Leu Cys Ala Ala Asp Pro Gln Trp Lys Thr
245 250 255
Asp Ser Cys Gln Gly Asp Ala Gly Gly Pro Leu Val Cys Ser Leu Gln
260 265 270
Gly Arg Met Thr Leu Thr Gly Ile Val Ser Trp Gly Arg Gly Cys Ala
275 280 285
Leu Lys Asp Lys Pro Gly Val Tyr Thr Arg Val Ser His Phe Leu Gln
290 295 300
Ile Asp
305
<210> 26
<211> 918
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 26
ctgcaaattg acgaccaaga gtcctgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatga gctgtgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaacctcc accacaagca caagctccag ctccaccaca 180
agcagggcca caagcatcat tggcggagag tttaccacaa tcgaaaacca accctggttc 240
gctgccattt acaggagaca tagaggaggc tccgtgacat acgtctgcgg aggctccctg 300
attagccctt gctgggtgat tagcgctacc gcttgcttta tcgactaccc taagaaagag 360
gattacattg tgtatctggg aagatccaga ctcaactcca acacacaggg agagatgaag 420
tttgaggtcg agaatctgat tctgcataag gattactccg ccgataccct cgcccatcac 480
aatgccattg ccctcctgaa aatcaggagc aaagagggaa gatgtgccca accctccaga 540
acaatccaaa ccatttgcct cccctccatg tataacgatc cccaattcgg aacctcctgc 600
gaaatcacag gctttggcaa agagaatagc acagactatc tgtatcccga acagctcaag 660
atgaccgtcg tgaaactgat tagccataga gaatgccaac agcctcacta ttacggaagc 720
gaagtgacaa ccaaaatgct ctgcgctgcc gatccccaat ggaaaaccga tagctgtcag 780
ggcgacgccg gaggacccct cgtgtgtagc ctccagggaa gaatgaccct caccggaatc 840
gtcagctggg gcaggggctg tgccctcaag gataagcctg gcgtctacac aagagtcagc 900
catttcctcc agattgac 918
<210> 27
<211> 301
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 27
Leu Gln Ile Asp Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40 45
Thr Ser Thr Thr Ser Thr Ser Ser Ser Ser Thr Thr Ser Arg Ala Thr
50 55 60
Ser Ile Val Gly Gly Trp Glu Cys Glu Lys His Ser Gln Pro Trp Gln
65 70 75 80
Val Ala Val Tyr Ser His Gly Trp Ala His Cys Gly Gly Val Leu Val
85 90 95
His Pro Gln Trp Val Leu Thr Ala Ala His Cys Leu Lys Lys Asn Ser
100 105 110
Gln Val Trp Leu Gly Arg His Asn Leu Phe Glu Pro Glu Asp Thr Gly
115 120 125
Gln Arg Val Pro Val Ser His Ser Phe Pro His Pro Leu Tyr Asn Met
130 135 140
Ser Leu Leu Lys His Gln Ser Leu Arg Pro Asp Glu Asp Ser Ser His
145 150 155 160
Asp Leu Met Leu Leu Arg Leu Ser Glu Pro Ala Lys Ile Thr Asp Val
165 170 175
Val Lys Val Leu Gly Leu Pro Thr Gln Glu Pro Ala Leu Gly Thr Thr
180 185 190
Cys Tyr Ala Ser Gly Trp Gly Ser Ile Glu Pro Glu Glu Phe Leu Arg
195 200 205
Pro Arg Ser Leu Gln Cys Val Ser Leu His Leu Leu Ser Asn Asp Met
210 215 220
Cys Ala Arg Ala Tyr Ser Glu Lys Val Thr Glu Phe Met Leu Cys Ala
225 230 235 240
Gly Leu Trp Thr Gly Gly Lys Asp Thr Cys Gly Gly Asp Ser Gly Gly
245 250 255
Pro Leu Val Cys Asn Gly Val Leu Gln Gly Ile Thr Ser Trp Gly Pro
260 265 270
Glu Pro Cys Ala Leu Pro Glu Lys Pro Ala Val Tyr Thr Lys Val Val
275 280 285
His Tyr Arg Lys Trp Ile Lys Asp Thr Leu Gln Ile Asp
290 295 300
<210> 28
<211> 903
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 28
ctgcaaatcg acgaccaaga gtcctgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatga gctgtgctcc tactatcagt cctgctgtac cgattacaca 120
gccgaatgca aaccccaagt gacaacctcc accacaagca caagctccag ctccaccaca 180
agcagggcca caagcatcgt cggcggatgg gaatgcgaaa agcatagcca accctggcaa 240
gtggccgtct actcccacgg atgggctcac tgtggcggag tgctcgtgca tccccaatgg 300
gtcctgacag ccgctcactg tctgaaaaag aatagccaag tgtggctggg cagacacaac 360
ctgttcgagc ccgaggacac aggccaaaga gtccccgtca gccatagctt tccccatccc 420
ctctacaata tgtccctgct caagcatcag tccctgaggc ccgatgagga tagctcccac 480
gatctgatgc tgctcagact cagcgaaccc gctaagatta ccgatgtggt caaggtcctg 540
ggactgccta cccaagagcc tgccctcggc acaacctgtt acgccagcgg atggggaagc 600
attgagcctg aggagtttct cagacctaga tccctgcaat gcgtcagcct ccacctcctg 660
tccaacgata tgtgtgccag ggcctatagc gaaaaggtca ccgagttcat gctgtgtgcc 720
ggactgtgga ccggaggcaa agacacatgc ggaggcgata gcggaggccc tctggtctgc 780
aatggcgtcc tgcaaggcat tacctcctgg ggacccgaac cctgtgccct ccccgaaaag 840
cctgccgtct acacaaaggt cgtgcattac aggaagtgga tcaaagacac actccagatt 900
gac 903
<210> 29
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 29
Leu Gln Ile Asp Asp Gln Glu Phe Cys Lys Gly Arg Cys Thr Glu Gly
1 5 10 15
Phe Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr
20 25 30
Gln Ser Cys Cys Glu Leu Tyr Thr Tyr Tyr Cys Lys Pro Gln Val Thr
35 40 45
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser
50 55 60
Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly
65 70 75 80
Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Ser Gly Thr
85 90 95
Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala Leu Gln Ile Asp
100 105 110
<210> 30
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 30
ctgcaaatcg acgaccaaga gttttgcaaa ggcagatgca cagagggatt caatgtggat 60
aagaaatgcc aatgcgatga gctttgctcc tactatcagt cctgctgtga gctgtacaca 120
tactattgca aaccccaagt gacaagcgga accgtcgcct ccagctccac cgctgtgatt 180
gtgtccgcct ccggcacagt ggcctcctcc agcacagccg tcatcgtcag cgccagcggc 240
accgtggcca gcagcagcac cgccgtgatc gtgagcgcca gcggcacagt cgcttcctcc 300
tccacagctg tcattgtctc cgctctccag attgac 336
<210> 31
<211> 402
<212> PRT
<213> Homo sapiens
<400> 31
Met Gln Met Ser Pro Ala Leu Thr Cys Leu Val Leu Gly Leu Ala Leu
1 5 10 15
Val Phe Gly Glu Gly Ser Ala Val His His Pro Pro Ser Tyr Val Ala
20 25 30
His Leu Ala Ser Asp Phe Gly Val Arg Val Phe Gln Gln Val Ala Gln
35 40 45
Ala Ser Lys Asp Arg Asn Leu Val Phe Ser Pro Tyr Gly Val Ala Ser
50 55 60
Val Leu Ala Met Leu Gln Leu Thr Thr Gly Gly Glu Thr Gln Gln Gln
65 70 75 80
Ile Gln Ala Ala Met Gly Phe Lys Ile Asp Asp Lys Gly Met Ala Pro
85 90 95
Ala Leu Arg His Leu Tyr Lys Glu Leu Met Gly Pro Trp Asn Lys Asp
100 105 110
Glu Ile Ser Thr Thr Asp Ala Ile Phe Val Gln Arg Asp Leu Lys Leu
115 120 125
Val Gln Gly Phe Met Pro His Phe Phe Arg Leu Phe Arg Ser Thr Val
130 135 140
Lys Gln Val Asp Phe Ser Glu Val Glu Arg Ala Arg Phe Ile Ile Asn
145 150 155 160
Asp Trp Val Lys Thr His Thr Lys Gly Met Ile Ser Asn Leu Leu Gly
165 170 175
Lys Gly Ala Val Asp Gln Leu Thr Arg Leu Val Leu Val Asn Ala Leu
180 185 190
Tyr Phe Asn Gly Gln Trp Lys Thr Pro Phe Pro Asp Ser Ser Thr His
195 200 205
Arg Arg Leu Phe His Lys Ser Asp Gly Ser Thr Val Ser Val Pro Met
210 215 220
Met Ala Gln Thr Asn Lys Phe Asn Tyr Thr Glu Phe Thr Thr Pro Asp
225 230 235 240
Gly His Tyr Tyr Asp Ile Leu Glu Leu Pro Tyr His Gly Asp Thr Leu
245 250 255
Ser Met Phe Ile Ala Ala Pro Tyr Glu Lys Glu Val Pro Leu Ser Ala
260 265 270
Leu Thr Asn Ile Leu Ser Ala Gln Leu Ile Ser His Trp Lys Gly Asn
275 280 285
Met Thr Arg Leu Pro Arg Leu Leu Val Leu Pro Lys Phe Ser Leu Glu
290 295 300
Thr Glu Val Asp Leu Arg Lys Pro Leu Glu Asn Leu Gly Met Thr Asp
305 310 315 320
Met Phe Arg Gln Phe Gln Ala Asp Phe Thr Ser Leu Ser Asp Gln Glu
325 330 335
Pro Leu His Val Ala Gln Ala Leu Gln Lys Val Lys Ile Glu Val Asn
340 345 350
Glu Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala
355 360 365
Arg Met Ala Pro Glu Glu Ile Ile Met Asp Arg Pro Phe Leu Phe Val
370 375 380
Val Arg His Asn Pro Thr Gly Thr Val Leu Phe Met Gly Gln Val Met
385 390 395 400
Glu Pro
<210> 32
<211> 478
<212> PRT
<213> Homo sapiens
<400> 32
Met Ala Pro Leu Arg Pro Leu Leu Ile Leu Ala Leu Leu Ala Trp Val
1 5 10 15
Ala Leu Ala Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly Phe
20 25 30
Asn Val Asp Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr Gln
35 40 45
Ser Cys Cys Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr Arg
50 55 60
Gly Asp Val Phe Thr Met Pro Glu Asp Glu Tyr Thr Val Tyr Asp Asp
65 70 75 80
Gly Glu Glu Lys Asn Asn Ala Thr Val His Glu Gln Val Gly Gly Pro
85 90 95
Ser Leu Thr Ser Asp Leu Gln Ala Gln Ser Lys Gly Asn Pro Glu Gln
100 105 110
Thr Pro Val Leu Lys Pro Glu Glu Glu Ala Pro Ala Pro Glu Val Gly
115 120 125
Ala Ser Lys Pro Glu Gly Ile Asp Ser Arg Pro Glu Thr Leu His Pro
130 135 140
Gly Arg Pro Gln Pro Pro Ala Glu Glu Glu Leu Cys Ser Gly Lys Pro
145 150 155 160
Phe Asp Ala Phe Thr Asp Leu Lys Asn Gly Ser Leu Phe Ala Phe Arg
165 170 175
Gly Gln Tyr Cys Tyr Glu Leu Asp Glu Lys Ala Val Arg Pro Gly Tyr
180 185 190
Pro Lys Leu Ile Arg Asp Val Trp Gly Ile Glu Gly Pro Ile Asp Ala
195 200 205
Ala Phe Thr Arg Ile Asn Cys Gln Gly Lys Thr Tyr Leu Phe Lys Gly
210 215 220
Ser Gln Tyr Trp Arg Phe Glu Asp Gly Val Leu Asp Pro Asp Tyr Pro
225 230 235 240
Arg Asn Ile Ser Asp Gly Phe Asp Gly Ile Pro Asp Asn Val Asp Ala
245 250 255
Ala Leu Ala Leu Pro Ala His Ser Tyr Ser Gly Arg Glu Arg Val Tyr
260 265 270
Phe Phe Lys Gly Lys Gln Tyr Trp Glu Tyr Gln Phe Gln His Gln Pro
275 280 285
Ser Gln Glu Glu Cys Glu Gly Ser Ser Leu Ser Ala Val Phe Glu His
290 295 300
Phe Ala Met Met Gln Arg Asp Ser Trp Glu Asp Ile Phe Glu Leu Leu
305 310 315 320
Phe Trp Gly Arg Thr Ser Ala Gly Thr Arg Gln Pro Gln Phe Ile Ser
325 330 335
Arg Asp Trp His Gly Val Pro Gly Gln Val Asp Ala Ala Met Ala Gly
340 345 350
Arg Ile Tyr Ile Ser Gly Met Ala Pro Arg Pro Ser Leu Ala Lys Lys
355 360 365
Gln Arg Phe Arg His Arg Asn Arg Lys Gly Tyr Arg Ser Gln Arg Gly
370 375 380
His Ser Arg Gly Arg Asn Gln Asn Ser Arg Arg Pro Ser Arg Ala Met
385 390 395 400
Trp Leu Ser Leu Phe Ser Ser Glu Glu Ser Asn Leu Gly Ala Asn Asn
405 410 415
Tyr Asp Asp Tyr Arg Met Asp Trp Leu Val Pro Ala Thr Cys Glu Pro
420 425 430
Ile Gln Ser Val Phe Phe Phe Ser Gly Asp Lys Tyr Tyr Arg Val Asn
435 440 445
Leu Arg Thr Arg Arg Val Asp Thr Val Asp Pro Pro Tyr Pro Arg Ser
450 455 460
Ile Ala Gln Tyr Trp Leu Gly Cys Pro Ala Pro Gly His Leu
465 470 475
<210> 33
<211> 261
<212> PRT
<213> Homo sapiens
<400> 33
Met Trp Asp Leu Val Leu Ser Ile Ala Leu Ser Val Gly Cys Thr Gly
1 5 10 15
Ala Val Pro Leu Ile Gln Ser Arg Ile Val Gly Gly Trp Glu Cys Glu
20 25 30
Lys His Ser Gln Pro Trp Gln Val Ala Val Tyr Ser His Gly Trp Ala
35 40 45
His Cys Gly Gly Val Leu Val His Pro Gln Trp Val Leu Thr Ala Ala
50 55 60
His Cys Leu Lys Lys Asn Ser Gln Val Trp Leu Gly Arg His Asn Leu
65 70 75 80
Phe Glu Pro Glu Asp Thr Gly Gln Arg Val Pro Val Ser His Ser Phe
85 90 95
Pro His Pro Leu Tyr Asn Met Ser Leu Leu Lys His Gln Ser Leu Arg
100 105 110
Pro Asp Glu Asp Ser Ser His Asp Leu Met Leu Leu Arg Leu Ser Glu
115 120 125
Pro Ala Lys Ile Thr Asp Val Val Lys Val Leu Gly Leu Pro Thr Gln
130 135 140
Glu Pro Ala Leu Gly Thr Thr Cys Tyr Ala Ser Gly Trp Gly Ser Ile
145 150 155 160
Glu Pro Glu Glu Phe Leu Arg Pro Arg Ser Leu Gln Cys Val Ser Leu
165 170 175
His Leu Leu Ser Asn Asp Met Cys Ala Arg Ala Tyr Ser Glu Lys Val
180 185 190
Thr Glu Phe Met Leu Cys Ala Gly Leu Trp Thr Gly Gly Lys Asp Thr
195 200 205
Cys Gly Gly Asp Ser Gly Gly Pro Leu Val Cys Asn Gly Val Leu Gln
210 215 220
Gly Ile Thr Ser Trp Gly Pro Glu Pro Cys Ala Leu Pro Glu Lys Pro
225 230 235 240
Ala Val Tyr Thr Lys Val Val His Tyr Arg Lys Trp Ile Lys Asp Thr
245 250 255
Ile Ala Ala Asn Pro
260
<210> 34
<211> 532
<212> PRT
<213> Homo sapiens
<400> 34
Arg Arg Gly Ala Arg Ser Tyr Gln Val Ile Cys Arg Asp Glu Lys Thr
1 5 10 15
Gln Met Ile Tyr Gln Gln His Gln Ser Trp Leu Arg Pro Val Leu Arg
20 25 30
Ser Asn Arg Val Glu Tyr Cys Trp Cys Asn Ser Gly Arg Ala Gln Cys
35 40 45
His Ser Val Pro Val Lys Ser Cys Ser Glu Pro Arg Cys Phe Asn Gly
50 55 60
Gly Thr Cys Gln Gln Ala Leu Tyr Phe Ser Asp Phe Val Cys Gln Cys
65 70 75 80
Pro Glu Gly Phe Ala Gly Lys Cys Cys Glu Ile Asp Thr Arg Ala Thr
85 90 95
Cys Tyr Glu Asp Gln Gly Ile Ser Tyr Arg Gly Thr Trp Ser Thr Ala
100 105 110
Glu Ser Gly Ala Glu Cys Thr Asn Trp Asn Ser Ser Ala Leu Ala Gln
115 120 125
Lys Pro Tyr Ser Gly Arg Arg Pro Asp Ala Ile Arg Leu Gly Leu Gly
130 135 140
Asn His Asn Tyr Cys Arg Asn Pro Asp Arg Asp Ser Lys Pro Trp Cys
145 150 155 160
Tyr Val Phe Lys Ala Gly Lys Tyr Ser Ser Glu Phe Cys Ser Thr Pro
165 170 175
Ala Cys Ser Glu Gly Asn Ser Asp Cys Tyr Phe Gly Asn Gly Ser Ala
180 185 190
Tyr Arg Gly Thr His Ser Leu Thr Glu Ser Gly Ala Ser Cys Leu Pro
195 200 205
Trp Asn Ser Met Ile Leu Ile Gly Lys Val Tyr Thr Ala Gln Asn Pro
210 215 220
Ser Ala Gln Ala Leu Gly Leu Gly Lys His Asn Tyr Cys Arg Asn Pro
225 230 235 240
Asp Gly Asp Ala Lys Pro Trp Cys His Val Leu Lys Asn Arg Arg Leu
245 250 255
Thr Trp Glu Tyr Cys Asp Val Pro Ser Cys Ser Thr Cys Gly Leu Arg
260 265 270
Gln Tyr Ser Gln Pro Gln Phe Arg Ile Lys Gly Gly Leu Phe Ala Asp
275 280 285
Ile Ala Ser His Pro Trp Gln Ala Ala Ile Phe Ala Lys His Arg Arg
290 295 300
Ser Pro Gly Glu Arg Phe Leu Cys Gly Gly Ile Leu Ile Ser Ser Cys
305 310 315 320
Trp Ile Leu Ser Ala Ala His Cys Phe Gln Glu Arg Phe Pro Pro His
325 330 335
His Leu Thr Val Ile Leu Gly Arg Thr Tyr Arg Val Val Pro Gly Glu
340 345 350
Glu Glu Gln Lys Phe Glu Val Glu Lys Tyr Ile Val His Lys Glu Phe
355 360 365
Asp Asp Asp Thr Tyr Asp Asn Asp Ile Ala Leu Leu Gln Leu Lys Ser
370 375 380
Asp Ser Ser Arg Cys Ala Gln Glu Ser Ser Val Val Arg Thr Val Cys
385 390 395 400
Leu Pro Pro Ala Asp Leu Gln Leu Pro Asp Trp Thr Glu Cys Glu Leu
405 410 415
Ser Gly Tyr Gly Lys His Glu Ala Leu Ser Pro Phe Tyr Ser Glu Arg
420 425 430
Leu Lys Glu Ala His Val Arg Leu Tyr Pro Ser Ser Arg Cys Thr Ser
435 440 445
Gln His Leu Leu Asn Arg Thr Val Thr Asp Asn Met Leu Cys Ala Gly
450 455 460
Asp Thr Arg Ser Gly Gly Pro Gln Ala Asn Leu His Asp Ala Cys Gln
465 470 475 480
Gly Asp Ser Gly Gly Pro Leu Val Cys Leu Asn Asp Gly Arg Met Thr
485 490 495
Leu Val Gly Ile Ile Ser Trp Gly Leu Gly Cys Gly Gln Lys Asp Val
500 505 510
Pro Gly Val Tyr Thr Lys Val Thr Asn Tyr Leu Asp Trp Ile Arg Asp
515 520 525
Asn Met Arg Pro
530
<210> 35
<211> 904
<212> PRT
<213> Homo sapiens
<400> 35
Met Arg Gln Thr Leu Pro Cys Ile Tyr Phe Trp Gly Gly Leu Leu Pro
1 5 10 15
Phe Gly Met Leu Cys Ala Ser Ser Thr Thr Lys Cys Thr Val Ser His
20 25 30
Glu Val Ala Asp Cys Ser His Leu Lys Leu Thr Gln Val Pro Asp Asp
35 40 45
Leu Pro Thr Asn Ile Thr Val Leu Asn Leu Thr His Asn Gln Leu Arg
50 55 60
Arg Leu Pro Ala Ala Asn Phe Thr Arg Tyr Ser Gln Leu Thr Ser Leu
65 70 75 80
Asp Val Gly Phe Asn Thr Ile Ser Lys Leu Glu Pro Glu Leu Cys Gln
85 90 95
Lys Leu Pro Met Leu Lys Val Leu Asn Leu Gln His Asn Glu Leu Ser
100 105 110
Gln Leu Ser Asp Lys Thr Phe Ala Phe Cys Thr Asn Leu Thr Glu Leu
115 120 125
His Leu Met Ser Asn Ser Ile Gln Lys Ile Lys Asn Asn Pro Phe Val
130 135 140
Lys Gln Lys Asn Leu Ile Thr Leu Asp Leu Ser His Asn Gly Leu Ser
145 150 155 160
Ser Thr Lys Leu Gly Thr Gln Val Gln Leu Glu Asn Leu Gln Glu Leu
165 170 175
Leu Leu Ser Asn Asn Lys Ile Gln Ala Leu Lys Ser Glu Glu Leu Asp
180 185 190
Ile Phe Ala Asn Ser Ser Leu Lys Lys Leu Glu Leu Ser Ser Asn Gln
195 200 205
Ile Lys Glu Phe Ser Pro Gly Cys Phe His Ala Ile Gly Arg Leu Phe
210 215 220
Gly Leu Phe Leu Asn Asn Val Gln Leu Gly Pro Ser Leu Thr Glu Lys
225 230 235 240
Leu Cys Leu Glu Leu Ala Asn Thr Ser Ile Arg Asn Leu Ser Leu Ser
245 250 255
Asn Ser Gln Leu Ser Thr Thr Ser Asn Thr Thr Phe Leu Gly Leu Lys
260 265 270
Trp Thr Asn Leu Thr Met Leu Asp Leu Ser Tyr Asn Asn Leu Asn Val
275 280 285
Val Gly Asn Asp Ser Phe Ala Trp Leu Pro Gln Leu Glu Tyr Phe Phe
290 295 300
Leu Glu Tyr Asn Asn Ile Gln His Leu Phe Ser His Ser Leu His Gly
305 310 315 320
Leu Phe Asn Val Arg Tyr Leu Asn Leu Lys Arg Ser Phe Thr Lys Gln
325 330 335
Ser Ile Ser Leu Ala Ser Leu Pro Lys Ile Asp Asp Phe Ser Phe Gln
340 345 350
Trp Leu Lys Cys Leu Glu His Leu Asn Met Glu Asp Asn Asp Ile Pro
355 360 365
Gly Ile Lys Ser Asn Met Phe Thr Gly Leu Ile Asn Leu Lys Tyr Leu
370 375 380
Ser Leu Ser Asn Ser Phe Thr Ser Leu Arg Thr Leu Thr Asn Glu Thr
385 390 395 400
Phe Val Ser Leu Ala His Ser Pro Leu His Ile Leu Asn Leu Thr Lys
405 410 415
Asn Lys Ile Ser Lys Ile Glu Ser Asp Ala Phe Ser Trp Leu Gly His
420 425 430
Leu Glu Val Leu Asp Leu Gly Leu Asn Glu Ile Gly Gln Glu Leu Thr
435 440 445
Gly Gln Glu Trp Arg Gly Leu Glu Asn Ile Phe Glu Ile Tyr Leu Ser
450 455 460
Tyr Asn Lys Tyr Leu Gln Leu Thr Arg Asn Ser Phe Ala Leu Val Pro
465 470 475 480
Ser Leu Gln Arg Leu Met Leu Arg Arg Val Ala Leu Lys Asn Val Asp
485 490 495
Ser Ser Pro Ser Pro Phe Gln Pro Leu Arg Asn Leu Thr Ile Leu Asp
500 505 510
Leu Ser Asn Asn Asn Ile Ala Asn Ile Asn Asp Asp Met Leu Glu Gly
515 520 525
Leu Glu Lys Leu Glu Ile Leu Asp Leu Gln His Asn Asn Leu Ala Arg
530 535 540
Leu Trp Lys His Ala Asn Pro Gly Gly Pro Ile Tyr Phe Leu Lys Gly
545 550 555 560
Leu Ser His Leu His Ile Leu Asn Leu Glu Ser Asn Gly Phe Asp Glu
565 570 575
Ile Pro Val Glu Val Phe Lys Asp Leu Phe Glu Leu Lys Ile Ile Asp
580 585 590
Leu Gly Leu Asn Asn Leu Asn Thr Leu Pro Ala Ser Val Phe Asn Asn
595 600 605
Gln Val Ser Leu Lys Ser Leu Asn Leu Gln Lys Asn Leu Ile Thr Ser
610 615 620
Val Glu Lys Lys Val Phe Gly Pro Ala Phe Arg Asn Leu Thr Glu Leu
625 630 635 640
Asp Met Arg Phe Asn Pro Phe Asp Cys Thr Cys Glu Ser Ile Ala Trp
645 650 655
Phe Val Asn Trp Ile Asn Glu Thr His Thr Asn Ile Pro Glu Leu Ser
660 665 670
Ser His Tyr Leu Cys Asn Thr Pro Pro His Tyr His Gly Phe Pro Val
675 680 685
Arg Leu Phe Asp Thr Ser Ser Cys Lys Asp Ser Ala Pro Phe Glu Leu
690 695 700
Phe Phe Met Ile Asn Thr Ser Ile Leu Leu Ile Phe Ile Phe Ile Val
705 710 715 720
Leu Leu Ile His Phe Glu Gly Trp Arg Ile Ser Phe Tyr Trp Asn Val
725 730 735
Ser Val His Arg Val Leu Gly Phe Lys Glu Ile Asp Arg Gln Thr Glu
740 745 750
Gln Phe Glu Tyr Ala Ala Tyr Ile Ile His Ala Tyr Lys Asp Lys Asp
755 760 765
Trp Val Trp Glu His Phe Ser Ser Met Glu Lys Glu Asp Gln Ser Leu
770 775 780
Lys Phe Cys Leu Glu Glu Arg Asp Phe Glu Ala Gly Val Phe Glu Leu
785 790 795 800
Glu Ala Ile Val Asn Ser Ile Lys Arg Ser Arg Lys Ile Ile Phe Val
805 810 815
Ile Thr His His Leu Leu Lys Asp Pro Leu Cys Lys Arg Phe Lys Val
820 825 830
His His Ala Val Gln Gln Ala Ile Glu Gln Asn Leu Asp Ser Ile Ile
835 840 845
Leu Val Phe Leu Glu Glu Ile Pro Asp Tyr Lys Leu Asn His Ala Leu
850 855 860
Cys Leu Arg Arg Gly Met Phe Lys Ser His Cys Ile Leu Asn Trp Pro
865 870 875 880
Val Gln Lys Glu Arg Ile Gly Ala Phe Arg His Lys Leu Gln Val Ala
885 890 895
Leu Gly Ser Lys Asn Ser Val His
900
<210> 36
<211> 431
<212> PRT
<213> Homo sapiens
<400> 36
Met Arg Ala Leu Leu Ala Arg Leu Leu Leu Cys Val Leu Val Val Ser
1 5 10 15
Asp Ser Lys Gly Ser Asn Glu Leu His Gln Val Pro Ser Asn Cys Asp
20 25 30
Cys Leu Asn Gly Gly Thr Cys Val Ser Asn Lys Tyr Phe Ser Asn Ile
35 40 45
His Trp Cys Asn Cys Pro Lys Lys Phe Gly Gly Gln His Cys Glu Ile
50 55 60
Asp Lys Ser Lys Thr Cys Tyr Glu Gly Asn Gly His Phe Tyr Arg Gly
65 70 75 80
Lys Ala Ser Thr Asp Thr Met Gly Arg Pro Cys Leu Pro Trp Asn Ser
85 90 95
Ala Thr Val Leu Gln Gln Thr Tyr His Ala His Arg Ser Asp Ala Leu
100 105 110
Gln Leu Gly Leu Gly Lys His Asn Tyr Cys Arg Asn Pro Asp Asn Arg
115 120 125
Arg Arg Pro Trp Cys Tyr Val Gln Val Gly Leu Lys Pro Leu Val Gln
130 135 140
Glu Cys Met Val His Asp Cys Ala Asp Gly Lys Lys Pro Ser Ser Pro
145 150 155 160
Pro Glu Glu Leu Lys Phe Gln Cys Gly Gln Lys Thr Leu Arg Pro Arg
165 170 175
Phe Lys Ile Ile Gly Gly Glu Phe Thr Thr Ile Glu Asn Gln Pro Trp
180 185 190
Phe Ala Ala Ile Tyr Arg Arg His Arg Gly Gly Ser Val Thr Tyr Val
195 200 205
Cys Gly Gly Ser Leu Ile Ser Pro Cys Trp Val Ile Ser Ala Thr His
210 215 220
Cys Phe Ile Asp Tyr Pro Lys Lys Glu Asp Tyr Ile Val Tyr Leu Gly
225 230 235 240
Arg Ser Arg Leu Asn Ser Asn Thr Gln Gly Glu Met Lys Phe Glu Val
245 250 255
Glu Asn Leu Ile Leu His Lys Asp Tyr Ser Ala Asp Thr Leu Ala His
260 265 270
His Asn Asp Ile Ala Leu Leu Lys Ile Arg Ser Lys Glu Gly Arg Cys
275 280 285
Ala Gln Pro Ser Arg Thr Ile Gln Thr Ile Cys Leu Pro Ser Met Tyr
290 295 300
Asn Asp Pro Gln Phe Gly Thr Ser Cys Glu Ile Thr Gly Phe Gly Lys
305 310 315 320
Glu Asn Ser Thr Asp Tyr Leu Tyr Pro Glu Gln Leu Lys Met Thr Val
325 330 335
Val Lys Leu Ile Ser His Arg Glu Cys Gln Gln Pro His Tyr Tyr Gly
340 345 350
Ser Glu Val Thr Thr Lys Met Leu Cys Ala Ala Asp Pro Gln Trp Lys
355 360 365
Thr Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro Leu Val Cys Ser Leu
370 375 380
Gln Gly Arg Met Thr Leu Thr Gly Ile Val Ser Trp Gly Arg Gly Cys
385 390 395 400
Ala Leu Lys Asp Lys Pro Gly Val Tyr Thr Arg Val Ser His Phe Leu
405 410 415
Pro Trp Ile Arg Ser His Thr Lys Glu Glu Asn Gly Leu Ala Leu
420 425 430
<210> 37
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 37
Ser Gly Thr Val Ala Ser Ser Ser Thr Ala Val Ile Val Ser Ala
1 5 10 15
<210> 38
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 38
Lys Phe Ser Leu Glu Thr Glu Val Asp Leu
1 5 10
<210> 39
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 39
Ala Leu Gln Lys Val Lys Ile Glu Val Asn Glu
1 5 10
<210> 40
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 40
Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly Phe Asn Val Asp
1 5 10 15
Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr Gln Ser Cys Cys
20 25 30
Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40
<210> 41
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 41
Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly Leu Asn Val Asp
1 5 10 15
Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr Gln Ser Cys Cys
20 25 30
Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40
<210> 42
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 42
Asp Gln Glu Ser Cys Lys Gly Arg Cys Ala Glu Gly Phe Asn Val Asp
1 5 10 15
Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr Gln Ser Cys Cys
20 25 30
Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40
<210> 43
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 43
Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly Phe Asn Val Asp
1 5 10 15
Lys Lys Cys Gln Cys Asp Ala Leu Cys Ser Tyr Tyr Gln Ser Cys Cys
20 25 30
Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40
<210> 44
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 44
Asp Gln Glu Ser Cys Lys Gly Arg Cys Thr Glu Gly Phe Asn Val Asp
1 5 10 15
Lys Lys Cys Gln Cys Asp Glu Ala Cys Ser Tyr Tyr Gln Ser Cys Cys
20 25 30
Thr Asp Tyr Thr Ala Glu Cys Lys Pro Gln Val Thr
35 40
<210> 45
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 45
Asp Gln Glu Phe Cys Lys Gly Arg Cys Thr Glu Gly Phe Asn Val Asp
1 5 10 15
Lys Lys Cys Gln Cys Asp Glu Leu Cys Ser Tyr Tyr Gln Ser Cys Cys
20 25 30
Glu Leu Tyr Thr Tyr Tyr Cys Lys Pro Gln Val Thr
35 40
<210> 46
<211> 232
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 46
Ile Val Gly Gly Trp Glu Cys Glu Lys His Ser Gln Pro Trp Gln Val
1 5 10 15
Ala Val Tyr Ser His Gly Trp Ala His Cys Gly Gly Val Leu Val His
20 25 30
Pro Gln Trp Val Leu Thr Ala Ala His Cys Leu Lys Lys Asn Ser Gln
35 40 45
Val Trp Leu Gly Arg His Asn Leu Phe Glu Pro Glu Asp Thr Gly Gln
50 55 60
Arg Val Pro Val Ser His Ser Phe Pro His Pro Leu Tyr Asn Met Ser
65 70 75 80
Leu Leu Lys His Gln Ser Leu Arg Pro Asp Glu Asp Ser Ser His Asp
85 90 95
Leu Met Leu Leu Arg Leu Ser Glu Pro Ala Lys Ile Thr Asp Val Val
100 105 110
Lys Val Leu Gly Leu Pro Thr Gln Glu Pro Ala Leu Gly Thr Thr Cys
115 120 125
Tyr Ala Ser Gly Trp Gly Ser Ile Glu Pro Glu Glu Phe Leu Arg Pro
130 135 140
Arg Ser Leu Gln Cys Val Ser Leu His Leu Leu Ser Asn Asp Met Cys
145 150 155 160
Ala Arg Ala Tyr Ser Glu Lys Val Thr Glu Phe Met Leu Cys Ala Gly
165 170 175
Leu Trp Thr Gly Gly Lys Asp Thr Cys Gly Gly Asp Ser Gly Gly Pro
180 185 190
Leu Val Cys Asn Gly Val Leu Gln Gly Ile Thr Ser Trp Gly Pro Glu
195 200 205
Pro Cys Ala Leu Pro Glu Lys Pro Ala Val Tyr Thr Lys Val Val His
210 215 220
Tyr Arg Lys Trp Ile Lys Asp Thr
225 230
<210> 47
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 47
Ile Val Gly Gly Trp Glu Cys Glu Lys His Ser Gln Pro Trp Gln Val
1 5 10 15
Ala Val Tyr Ser
20
<210> 48
<211> 210
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 48
Trp Ala His Cys Gly Gly Val Leu Val His Pro Gln Trp Val Leu Thr
1 5 10 15
Ala Ala His Cys Leu Lys Lys Asn Ser Gln Val Trp Leu Gly Arg His
20 25 30
Asn Leu Phe Glu Pro Glu Asp Thr Gly Gln Arg Val Pro Val Ser His
35 40 45
Ser Phe Pro His Pro Leu Tyr Asn Met Ser Leu Leu Lys His Gln Ser
50 55 60
Leu Arg Pro Asp Glu Asp Ser Ser His Asp Leu Met Leu Leu Arg Leu
65 70 75 80
Ser Glu Pro Ala Lys Ile Thr Asp Val Val Lys Val Leu Gly Leu Pro
85 90 95
Thr Gln Glu Pro Ala Leu Gly Thr Thr Cys Tyr Ala Ser Gly Trp Gly
100 105 110
Ser Ile Glu Pro Glu Glu Phe Leu Arg Pro Arg Ser Leu Gln Cys Val
115 120 125
Ser Leu His Leu Leu Ser Asn Asp Met Cys Ala Arg Ala Tyr Ser Glu
130 135 140
Lys Val Thr Glu Phe Met Leu Cys Ala Gly Leu Trp Thr Gly Gly Lys
145 150 155 160
Asp Thr Cys Gly Gly Asp Ser Gly Gly Pro Leu Val Cys Asn Gly Val
165 170 175
Leu Gln Gly Ile Thr Ser Trp Gly Pro Glu Pro Cys Ala Leu Pro Glu
180 185 190
Lys Pro Ala Val Tyr Thr Lys Val Val His Tyr Arg Lys Trp Ile Lys
195 200 205
Asp Thr
210
<210> 49
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 49
Lys His Arg Arg Ser Pro Gly Glu
1 5
<210> 50
<211> 93
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 50
Thr Val Ser His Glu Val Ala Asp Cys Ser His Leu Lys Leu Thr Gln
1 5 10 15
Val Pro Asp Asp Leu Pro Thr Asn Ile Thr Ala Leu Tyr Leu Asn His
20 25 30
Asn Gln Leu Arg Arg Leu Pro Ala Ala Asn Phe Thr Arg Tyr Ser Gln
35 40 45
Leu Thr Lys Leu Lys Val Glu Phe Asn Thr Ile Ser Lys Leu Glu Pro
50 55 60
Glu Leu Cys Gln Lys Leu Pro Met Leu Lys Val Leu Asn Leu Gln His
65 70 75 80
Asn Glu Leu Ser Gln Leu Ser Asp Lys Thr Phe Ala Phe
85 90
<210> 51
<211> 237
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 51
Ile Ile Gly Gly Glu Phe Thr Thr Ile Glu Asn Gln Pro Trp Phe Ala
1 5 10 15
Ala Ile Tyr Arg Arg His Arg Gly Gly Ser Val Thr Tyr Val Cys Gly
20 25 30
Gly Ser Leu Ile Ser Pro Cys Trp Val Ile Ser Ala Thr Ala Cys Phe
35 40 45
Ile Asp Tyr Pro Lys Lys Glu Asp Tyr Ile Val Tyr Leu Gly Arg Ser
50 55 60
Arg Leu Asn Ser Asn Thr Gln Gly Glu Met Lys Phe Glu Val Glu Asn
65 70 75 80
Leu Ile Leu His Lys Asp Tyr Ser Ala Asp Thr Leu Ala His His Asn
85 90 95
Ala Ile Ala Leu Leu Lys Ile Arg Ser Lys Glu Gly Arg Cys Ala Gln
100 105 110
Pro Ser Arg Thr Ile Gln Thr Ile Cys Leu Pro Ser Met Tyr Asn Asp
115 120 125
Pro Gln Phe Gly Thr Ser Cys Glu Ile Thr Gly Phe Gly Lys Glu Asn
130 135 140
Ser Thr Asp Tyr Leu Tyr Pro Glu Gln Leu Lys Met Thr Val Val Lys
145 150 155 160
Leu Ile Ser His Arg Glu Cys Gln Gln Pro His Tyr Tyr Gly Ser Glu
165 170 175
Val Thr Thr Lys Met Leu Cys Ala Ala Asp Pro Gln Trp Lys Thr Asp
180 185 190
Ser Cys Gln Gly Asp Ala Gly Gly Pro Leu Val Cys Ser Leu Gln Gly
195 200 205
Arg Met Thr Leu Thr Gly Ile Val Ser Trp Gly Arg Gly Cys Ala Leu
210 215 220
Lys Asp Lys Pro Gly Val Tyr Thr Arg Val Ser His Phe
225 230 235
<210> 52
<211> 476
<212> PRT
<213> Humicola insolens
<400> 52
Met Ala Lys Phe Phe Leu Thr Ala Ala Phe Ala Ala Ala Ala Leu Ala
1 5 10 15
Ala Pro Val Val Glu Glu Arg Gln Asn Cys Ala Pro Thr Trp Gly Gln
20 25 30
Cys Gly Gly Ile Gly Phe Asn Gly Pro Thr Cys Cys Gln Ser Gly Ser
35 40 45
Thr Cys Val Lys Gln Asn Asp Trp Tyr Ser Gln Cys Leu Pro Gly Ser
50 55 60
Gln Val Thr Thr Thr Ser Thr Thr Ser Thr Ser Ser Ser Ser Thr Thr
65 70 75 80
Ser Arg Ala Thr Ser Thr Thr Arg Thr Gly Gly Val Thr Ser Ile Thr
85 90 95
Thr Ala Pro Thr Arg Thr Val Thr Ile Pro Gly Gly Ala Thr Thr Thr
100 105 110
Ala Ser Tyr Asn Gly Asn Pro Phe Glu Gly Val Gln Leu Trp Ala Asn
115 120 125
Asn Tyr Tyr Arg Ser Glu Val His Thr Leu Ala Ile Pro Gln Ile Thr
130 135 140
Asp Pro Ala Leu Arg Ala Ala Ala Ser Ala Val Ala Glu Val Pro Ser
145 150 155 160
Phe Gln Trp Leu Asp Arg Asn Val Thr Val Asp Thr Leu Leu Val Glu
165 170 175
Thr Leu Ser Glu Ile Arg Ala Ala Asn Gln Ala Gly Ala Asn Pro Pro
180 185 190
Tyr Ala Ala Gln Ile Val Val Tyr Asp Leu Pro Asp Arg Asp Cys Ala
195 200 205
Ala Ala Ala Ser Asn Gly Glu Trp Ala Ile Ala Asn Asn Gly Ala Asn
210 215 220
Asn Tyr Lys Gly Tyr Ile Asn Arg Ile Arg Glu Ile Leu Ile Ser Phe
225 230 235 240
Ser Asp Val Arg Thr Ile Leu Val Ile Glu Pro Asp Ser Leu Ala Asn
245 250 255
Met Val Thr Asn Met Asn Val Ala Lys Cys Ser Gly Ala Ala Ser Thr
260 265 270
Tyr Arg Glu Leu Thr Ile Tyr Ala Leu Lys Gln Leu Asp Leu Pro His
275 280 285
Val Ala Met Tyr Met Asp Ala Gly His Ala Gly Trp Leu Gly Trp Pro
290 295 300
Ala Asn Ile Gln Pro Ala Ala Glu Leu Phe Ala Lys Ile Tyr Glu Asp
305 310 315 320
Ala Gly Lys Pro Arg Ala Val Arg Gly Leu Ala Thr Asn Val Ala Asn
325 330 335
Tyr Asn Ala Trp Ser Ile Ser Ser Pro Pro Pro Tyr Thr Ser Pro Asn
340 345 350
Pro Asn Tyr Asp Glu Lys His Tyr Ile Glu Ala Phe Arg Pro Leu Leu
355 360 365
Glu Ala Arg Gly Phe Pro Ala Gln Phe Ile Val Asp Gln Gly Arg Ser
370 375 380
Gly Lys Gln Pro Thr Gly Gln Lys Glu Trp Gly His Trp Cys Asn Ala
385 390 395 400
Ile Gly Thr Gly Phe Gly Met Arg Pro Thr Ala Asn Thr Gly His Gln
405 410 415
Tyr Val Asp Ala Phe Val Trp Val Lys Pro Gly Gly Glu Cys Asp Gly
420 425 430
Thr Ser Asp Thr Thr Ala Ala Arg Tyr Asp Tyr His Cys Gly Leu Glu
435 440 445
Asp Ala Leu Lys Pro Ala Pro Glu Ala Gly Gln Trp Phe Gln Ala Tyr
450 455 460
Phe Glu Gln Leu Leu Arg Asn Ala Asn Pro Pro Phe
465 470 475
<210> 53
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 53
Thr Ser Thr Thr Ser Thr Ser Ser Ser Ser Thr Thr Ser Arg Ala Thr
1 5 10 15
Ser
<210> 54
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 54
Leu Gln Ile Asp
1
<210> 55
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 55
Asn Pro Ala Gly
1
<210> 56
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 56
Ser Asp Val Thr Gly Asn Ala Thr Tyr Thr Ile Thr
1 5 10
<210> 57
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 57
Met Thr Val Ala Arg Pro Ser Val Pro Ala Ala Leu Pro Leu Leu Gly
1 5 10 15
Glu Leu Pro Arg Leu Leu Leu Leu Val Leu Leu Cys Leu Pro Ala Val
20 25 30
Trp Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
35 40 45
Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Val Phe
50 55 60
Asp Val Leu Ile Ser Gly Asp Pro Asn Phe Thr Val Ala Ala Gln Ala
65 70 75 80
Ala Leu Glu Asp Ala Arg Ala Phe Leu Pro Asp Leu Glu Lys Leu His
85 90 95
Leu Phe Pro Ser Asp Ala Gly Val Pro Leu Ser Ser Ala Thr Leu Leu
100 105 110
Ala Pro Leu Leu Ser Gly Leu Phe Val Leu Trp Leu Cys Ile Gln
115 120 125
<210> 58
<211> 135
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 58
Met Thr Val Ala Arg Pro Ser Val Pro Ala Ala Leu Pro Leu Leu Gly
1 5 10 15
Glu Leu Pro Arg Leu Leu Leu Leu Val Leu Leu Cys Leu Pro Ala Val
20 25 30
Trp Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
35 40 45
Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Ser
50 55 60
Pro Lys Pro Pro Glu Ala Val Phe Asp Val Leu Ile Ser Gly Asp Pro
65 70 75 80
Asn Phe Thr Val Ala Ala Gln Ala Ala Leu Glu Asp Ala Arg Ala Phe
85 90 95
Leu Pro Asp Leu Glu Lys Leu His Leu Phe Pro Ser Asp Ala Gly Val
100 105 110
Pro Leu Ser Ser Ala Thr Leu Leu Ala Pro Leu Leu Ser Gly Leu Phe
115 120 125
Val Leu Trp Leu Cys Ile Gln
130 135
<210> 59
<211> 176
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 59
Met Thr Val Ala Arg Pro Ser Val Pro Ala Ala Leu Pro Leu Leu Gly
1 5 10 15
Glu Leu Pro Arg Leu Leu Leu Leu Val Leu Leu Cys Leu Pro Ala Val
20 25 30
Trp Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
35 40 45
Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Asp Leu
50 55 60
Gln Leu Cys Val Gly Val Cys Pro Pro Ser Gln Arg Leu Ser Arg Ser
65 70 75 80
Glu Arg Asn Arg Arg Gly Ala Ile Thr Ile Asp Thr Ala Arg Arg Leu
85 90 95
Cys Lys Glu Gly Leu Pro Val Glu Asp Ala Tyr Phe His Ser Cys Val
100 105 110
Phe Asp Val Leu Ile Ser Gly Asp Pro Asn Phe Thr Val Ala Ala Gln
115 120 125
Ala Ala Leu Glu Asp Ala Arg Ala Phe Leu Pro Asp Leu Glu Lys Leu
130 135 140
His Leu Phe Pro Ser Asp Ala Gly Val Pro Leu Ser Ser Ala Thr Leu
145 150 155 160
Leu Ala Pro Leu Leu Ser Gly Leu Phe Val Leu Trp Leu Cys Ile Gln
165 170 175
<210> 60
<211> 189
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 60
Met Thr Val Ala Arg Pro Ser Val Pro Ala Ala Leu Pro Leu Leu Gly
1 5 10 15
Glu Leu Pro Arg Leu Leu Leu Leu Val Leu Leu Cys Leu Pro Ala Val
20 25 30
Trp Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
35 40 45
Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Ser
50 55 60
Pro Lys Pro Pro Glu Ala Glu Cys Arg Asp Glu Lys Phe Ala Cys Thr
65 70 75 80
Arg Leu Tyr Ser Val His Arg Pro Cys Lys Gln Cys Leu His Gln Ile
85 90 95
Cys Phe Thr Ser Ser Arg Arg Met Tyr Val Ile Asn Asn Glu Ile Cys
100 105 110
Ser Arg Leu Val Cys Lys Glu His Glu Ala Met Lys Val Phe Asp Val
115 120 125
Leu Ile Ser Gly Asp Pro Asn Phe Thr Val Ala Ala Gln Ala Ala Leu
130 135 140
Glu Asp Ala Arg Ala Phe Leu Pro Asp Leu Glu Lys Leu His Leu Phe
145 150 155 160
Pro Ser Asp Ala Gly Val Pro Leu Ser Ser Ala Thr Leu Leu Ala Pro
165 170 175
Leu Leu Ser Gly Leu Phe Val Leu Trp Leu Cys Ile Gln
180 185
<210> 61
<211> 97
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 61
Met Asn Leu Ala Ile Ser Ile Ala Leu Leu Leu Thr Val Leu Gln Val
1 5 10 15
Ser Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro
20 25 30
Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Ser
35 40 45
Pro Pro Ile Ser Ser Gln Asn Val Thr Val Leu Arg Asp Lys Leu Val
50 55 60
Lys Cys Glu Gly Ile Ser Leu Leu Ala Gln Asn Thr Ser Trp Leu Leu
65 70 75 80
Leu Leu Leu Leu Ser Leu Ser Leu Leu Gln Ala Thr Asp Phe Met Ser
85 90 95
Leu
<210> 62
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 62
Met Asn Leu Ala Ile Ser Ile Ala Leu Leu Leu Thr Val Leu Gln Val
1 5 10 15
Ser Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro
20 25 30
Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gln
35 40 45
Lys Gly Ser Val Gly Phe Ala Asp Pro Ser Pro Pro Ile Ser Ser Gln
50 55 60
Asn Val Thr Val Leu Arg Asp Lys Leu Val Lys Cys Glu Gly Ile Ser
65 70 75 80
Leu Leu Ala Gln Asn Thr Ser Trp Leu Leu Leu Leu Leu Leu Ser Leu
85 90 95
Ser Leu Leu Gln Ala Thr Asp Phe Met Ser Leu
100 105
<210> 63
<211> 207
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 63
Met Asn Leu Ala Ile Ser Ile Ala Leu Leu Leu Thr Val Leu Gln Val
1 5 10 15
Ser Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro
20 25 30
Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly
35 40 45
Ser Pro Lys Pro Pro Glu Ala Pro Pro Pro Gln Pro Gly Gly His Thr
50 55 60
Val Gly Ala Gly Val Gly Ser Pro Ser Ser Gln Leu Tyr Glu His Thr
65 70 75 80
Val Glu Gly Gly Glu Lys Gln Val Val Phe Thr His Arg Ile Asn Leu
85 90 95
Pro Pro Ser Thr Gly Cys Gly Cys Pro Pro Gly Thr Glu Pro Pro Val
100 105 110
Leu Ala Ser Glu Val Gln Ala Leu Arg Val Arg Leu Glu Ile Leu Glu
115 120 125
Glu Leu Val Lys Gly Leu Lys Glu Gln Cys Thr Gly Gly Cys Cys Pro
130 135 140
Ala Ser Ala Gln Ala Gly Thr Gly Gln Thr Asp Val Arg Ser Pro Pro
145 150 155 160
Ile Ser Ser Gln Asn Val Thr Val Leu Arg Asp Lys Leu Val Lys Cys
165 170 175
Glu Gly Ile Ser Leu Leu Ala Gln Asn Thr Ser Trp Leu Leu Leu Leu
180 185 190
Leu Leu Ser Leu Ser Leu Leu Gln Ala Thr Asp Phe Met Ser Leu
195 200 205
<210> 64
<211> 167
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 64
Met Asn Leu Ala Ile Ser Ile Ala Leu Leu Leu Thr Val Leu Gln Val
1 5 10 15
Ser Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro
20 25 30
Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Asn
35 40 45
Gln Ser Asp Ile Val Ala His Leu Leu Ser Ser Ser Ser Ser Val Ile
50 55 60
Asp Ala Leu Gln Tyr Lys Leu Glu Gly Thr Thr Arg Leu Thr Arg Lys
65 70 75 80
Arg Gly Leu Lys Leu Ala Thr Ala Leu Ser Leu Ser Asn Lys Phe Val
85 90 95
Glu Gly Ser His Asn Ser Thr Val Ser Leu Thr Thr Lys Asn Met Glu
100 105 110
Val Ser Val Ala Thr Ser Pro Pro Ile Ser Ser Gln Asn Val Thr Val
115 120 125
Leu Arg Asp Lys Leu Val Lys Cys Glu Gly Ile Ser Leu Leu Ala Gln
130 135 140
Asn Thr Ser Trp Leu Leu Leu Leu Leu Leu Ser Leu Ser Leu Leu Gln
145 150 155 160
Ala Thr Asp Phe Met Ser Leu
165
<210> 65
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 65
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Arg Lys Ser Ala Ser Ser Arg Thr Pro Leu Thr His Ala
50 55 60
Leu Pro Gly Leu Ser Glu Arg Glu Gly Gln Gln Thr Ser Ala Ala Ala
65 70 75 80
Pro Thr Pro Pro Gln Ala Ser Pro Leu Leu Leu Leu Gly Leu Ala Leu
85 90 95
Ala Leu Pro Ala Ala Ala Pro Arg Gly Arg
100 105
<210> 66
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 66
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gln Lys Gly Ser Val Gly Phe Ala Asp Pro Arg Lys Ser
50 55 60
Ala Ser Ser Arg Thr Pro Leu Thr His Ala Leu Pro Gly Leu Ser Glu
65 70 75 80
Arg Glu Gly Gln Gln Thr Ser Ala Ala Ala Pro Thr Pro Pro Gln Ala
85 90 95
Ser Pro Leu Leu Leu Leu Gly Leu Ala Leu Ala Leu Pro Ala Ala Ala
100 105 110
Pro Arg Gly Arg
115
<210> 67
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 67
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gln Lys Gly Ser Val Gly Phe Ala Asp Pro Pro Pro Pro
50 55 60
Gln Pro Gly Gly His Thr Val Gly Ala Gly Val Gly Ser Pro Ser Ser
65 70 75 80
Gln Leu Tyr Glu His Thr Val Glu Gly Gly Glu Lys Gln Val Val Phe
85 90 95
Thr His Arg Ile Asn Leu Pro Pro Ser Thr Gly Cys Gly Cys Pro Pro
100 105 110
Gly Thr Glu Pro Pro Val Leu Ala Ser Glu Val Gln Ala Leu Arg Val
115 120 125
Arg Leu Glu Ile Leu Glu Glu Leu Val Lys Gly Leu Lys Glu Gln Cys
130 135 140
Thr Gly Gly Cys Cys Pro Ala Ser Ala Gln Ala Gly Thr Gly Gln Thr
145 150 155 160
Asp Val Arg Arg Lys Ser Ala Ser Ser Arg Thr Pro Leu Thr His Ala
165 170 175
Leu Pro Gly Leu Ser Glu Arg Glu Gly Gln Gln Thr Ser Ala Ala Ala
180 185 190
Pro Thr Pro Pro Gln Ala Ser Pro Leu Leu Leu Leu Gly Leu Ala Leu
195 200 205
Ala Leu Pro Ala Ala Ala Pro Arg Gly Arg
210 215
<210> 68
<211> 103
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 68
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala
50 55 60
Thr Pro Val Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala
65 70 75 80
Ala Gly Arg Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu
85 90 95
Val Gly Gly Val Ala Ser Arg
100
<210> 69
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 69
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gly Thr Ser Leu Pro Val Asp Asn Ala Phe Pro Ala Pro
50 55 60
Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala Thr Pro Val
65 70 75 80
Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala Ala Gly Arg
85 90 95
Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu Val Gly Gly
100 105 110
Val Ala Ser Arg
115
<210> 70
<211> 173
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 70
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Asn Gln Ser Asp Ile Val Ala His Leu Leu Ser Ser Ser
50 55 60
Ser Ser Val Ile Asp Ala Leu Gln Tyr Lys Leu Glu Gly Thr Thr Arg
65 70 75 80
Leu Thr Arg Lys Arg Gly Leu Lys Leu Ala Thr Ala Leu Ser Leu Ser
85 90 95
Asn Lys Phe Val Glu Gly Ser His Asn Ser Thr Val Ser Leu Thr Thr
100 105 110
Lys Asn Met Glu Val Ser Val Ala Thr Pro Ser Ser Gly Pro Arg Ala
115 120 125
Pro Arg Pro Pro Lys Ala Thr Pro Val Ser Glu Thr Cys Asp Cys Gln
130 135 140
Cys Glu Leu Asn Gln Ala Ala Gly Arg Trp Pro Ala Pro Ile Pro Leu
145 150 155 160
Leu Leu Leu Pro Leu Leu Val Gly Gly Val Ala Ser Arg
165 170
<210> 71
<211> 283
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 71
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Asn Gln Ser Asp Ile Val Ala His Leu Leu Ser Ser Ser
50 55 60
Ser Ser Val Ile Asp Ala Leu Gln Tyr Lys Leu Glu Gly Thr Thr Arg
65 70 75 80
Leu Thr Arg Lys Arg Gly Leu Lys Leu Ala Thr Ala Leu Ser Leu Ser
85 90 95
Asn Lys Phe Val Glu Gly Ser His Asn Ser Thr Val Ser Leu Thr Thr
100 105 110
Lys Asn Met Glu Val Ser Val Ala Thr Thr Thr Lys Ala Gln Ile Pro
115 120 125
Ile Leu Arg Met Asn Phe Lys Gln Glu Leu Asn Gly Asn Thr Lys Ser
130 135 140
Lys Pro Thr Val Ser Ser Ser Met Glu Phe Lys Tyr Asp Phe Asn Ser
145 150 155 160
Ser Met Leu Tyr Ser Thr Ala Lys Gly Ala Val Asp His Lys Leu Ser
165 170 175
Leu Glu Ser Leu Thr Ser Tyr Phe Ser Ile Glu Ser Ser Thr Lys Gly
180 185 190
Asp Val Lys Gly Ser Val Leu Ser Arg Glu Tyr Ser Gly Thr Ile Ala
195 200 205
Ser Glu Ala Asn Thr Tyr Leu Asn Ser Lys Ser Thr Gln Ser Ser Val
210 215 220
Lys Leu Gln Gly Thr Ser Lys Pro Ser Ser Gly Pro Arg Ala Pro Arg
225 230 235 240
Pro Pro Lys Ala Thr Pro Val Ser Glu Thr Cys Asp Cys Gln Cys Glu
245 250 255
Leu Asn Gln Ala Ala Gly Arg Trp Pro Ala Pro Ile Pro Leu Leu Leu
260 265 270
Leu Pro Leu Leu Val Gly Gly Val Ala Ser Arg
275 280
<210> 72
<211> 170
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 72
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gly Thr Ser Leu Pro Val Asp Asn Ala Phe Pro Ala Pro
50 55 60
Asp Cys Arg Glu Glu Gln Tyr Pro Cys Thr Arg Leu Tyr Ser Ile His
65 70 75 80
Arg Pro Cys Lys Gln Cys Leu Asn Glu Val Cys Phe Tyr Ser Leu Arg
85 90 95
Arg Val Tyr Val Ile Asn Lys Glu Ile Cys Val Arg Thr Val Cys Ala
100 105 110
His Glu Glu Leu Leu Arg Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro
115 120 125
Pro Lys Ala Thr Pro Val Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu
130 135 140
Asn Gln Ala Ala Gly Arg Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu
145 150 155 160
Pro Leu Leu Val Gly Gly Val Ala Ser Arg
165 170
<210> 73
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 73
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gly Pro Thr Asp Arg Val Lys Glu Gly His Ser Pro Pro
50 55 60
Asp Asp Val Asp Ile Val Ile Lys Leu Asp Asn Thr Ala Ser Thr Val
65 70 75 80
Lys Ala Ile Ala Ile Val Ile Pro Cys Ile Leu Ala Leu Cys Leu Leu
85 90 95
Val Leu Val Tyr Thr Val Phe Gln Phe Lys Arg Lys Gly Thr Pro Arg
100 105 110
His Ala Leu Ala Cys Lys Arg Ser Met Gln Glu Trp Val
115 120 125
<210> 74
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 74
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Thr Cys Glu Gly Arg Asn Ser Cys Val Ser Cys Phe Asn
50 55 60
Val Ser Val Val Asn Thr Thr Cys Phe Trp Ile Glu Cys Lys Asp Glu
65 70 75 80
Ser Asn Thr Ala Ser Thr Val Lys Ala Ile Ala Ile Val Ile Pro Cys
85 90 95
Ile Leu Ala Leu Cys Leu Leu Val Leu Val Tyr Thr Val Phe Gln Phe
100 105 110
Lys Arg Lys Gly Thr Pro Arg His Ala Leu Ala Cys Lys Arg Ser Met
115 120 125
Gln Glu Trp Val
130
<210> 75
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 75
Met Gly Ser Asp Arg Ala Arg Lys Gly Gly Gly Gly Pro Lys Asp Phe
1 5 10 15
Gly Ala Gly Leu Lys Tyr Asn Ser Arg His Glu Lys Val Asn Gly Leu
20 25 30
Glu Glu Gly Val Glu Phe Leu Pro Val Asn Asn Val Lys Lys Val Glu
35 40 45
Lys His Gly Pro Gly Arg Trp Val Val Leu Ala Ala Val Leu Ile Gly
50 55 60
Leu Leu Leu Val Leu Leu Gly Ile Gly Phe Leu Val Trp His Leu Gln
65 70 75 80
Tyr Arg Asp Val Arg Val Gln Lys Val Phe Asn Gly Tyr Met Arg Ile
85 90 95
Thr Asn Glu Asn Phe Val Asp Ala Tyr Glu Asn Ser Asn Ser Thr Glu
100 105 110
Phe Val Ser
115
<210> 76
<211> 142
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 76
Met Leu Leu Leu Phe His Ser Lys Arg Met Pro Val Ala Glu Ala Pro
1 5 10 15
Gln Val Ala Gly Gly Gln Gly Asp Gly Gly Asp Gly Glu Glu Ala Glu
20 25 30
Pro Glu Gly Met Phe Lys Ala Cys Glu Asp Ser Lys Arg Lys Ala Arg
35 40 45
Gly Tyr Leu Arg Leu Val Pro Leu Phe Val Leu Leu Ala Leu Leu Val
50 55 60
Leu Ala Ser Ala Gly Val Leu Leu Trp Tyr Phe Leu Gly Tyr Lys Ala
65 70 75 80
Glu Val Met Val Ser Gln Val Tyr Ser Gly Ser Leu Arg Val Leu Asn
85 90 95
Arg His Phe Ser Gln Asp Leu Thr Arg Arg Glu Ser Ser Ala Phe Arg
100 105 110
Ser Glu Thr Ala Lys Ala Gln Lys Met Leu Lys Glu Leu Ile Thr Ser
115 120 125
Thr Arg Leu Gly Thr Tyr Tyr Asn Ser Ser Ser Val Tyr Ser
130 135 140
<210> 77
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 77
Met Thr Val Ala Arg Pro Ser Val Pro Ala Ala Leu Pro Leu Leu Gly
1 5 10 15
Glu Leu Pro Arg Leu Leu Leu Leu Val Leu Leu Cys Leu Pro Ala Val
20 25 30
Trp Gly
<210> 78
<211> 65
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 78
Val Phe Asp Val Leu Ile Ser Gly Asp Pro Asn Phe Thr Val Ala Ala
1 5 10 15
Gln Ala Ala Leu Glu Asp Ala Arg Ala Phe Leu Pro Asp Leu Glu Lys
20 25 30
Leu His Leu Phe Pro Ser Asp Ala Gly Val Pro Leu Ser Ser Ala Thr
35 40 45
Leu Leu Ala Pro Leu Leu Ser Gly Leu Phe Val Leu Trp Leu Cys Ile
50 55 60
Gln
65
<210> 79
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 79
Asp Leu Gln Leu Cys Val Gly Val Cys Pro Pro Ser Gln Arg Leu Ser
1 5 10 15
Arg Ser Glu Arg Asn Arg Arg Gly Ala Ile Thr Ile Asp Thr Ala Arg
20 25 30
Arg Leu Cys Lys Glu Gly Leu Pro Val Glu Asp Ala Tyr Phe His Ser
35 40 45
Cys Val Phe Asp Val Leu Ile Ser Gly Asp Pro Asn Phe Thr Val Ala
50 55 60
Ala Gln Ala Ala Leu Glu Asp Ala Arg Ala Phe Leu Pro Asp Leu Glu
65 70 75 80
Lys Leu His Leu Phe Pro Ser Asp Ala Gly Val Pro Leu Ser Ser Ala
85 90 95
Thr Leu Leu Ala Pro Leu Leu Ser Gly Leu Phe Val Leu Trp Leu Cys
100 105 110
Ile Gln
<210> 80
<211> 54
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 80
Glu Cys Arg Asp Glu Lys Phe Ala Cys Thr Arg Leu Tyr Ser Val His
1 5 10 15
Arg Pro Cys Lys Gln Cys Leu His Gln Ile Cys Phe Thr Ser Ser Arg
20 25 30
Arg Met Tyr Val Ile Asn Asn Glu Ile Cys Ser Arg Leu Val Cys Lys
35 40 45
Glu His Glu Ala Met Lys
50
<210> 81
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 81
Met Asn Leu Ala Ile Ser Ile Ala Leu Leu Leu Thr Val Leu Gln Val
1 5 10 15
Ser Arg Gly
<210> 82
<211> 50
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 82
Ser Pro Pro Ile Ser Ser Gln Asn Val Thr Val Leu Arg Asp Lys Leu
1 5 10 15
Val Lys Cys Glu Gly Ile Ser Leu Leu Ala Gln Asn Thr Ser Trp Leu
20 25 30
Leu Leu Leu Leu Leu Ser Leu Ser Leu Leu Gln Ala Thr Asp Phe Met
35 40 45
Ser Leu
50
<210> 83
<211> 102
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 83
Pro Pro Pro Gln Pro Gly Gly His Thr Val Gly Ala Gly Val Gly Ser
1 5 10 15
Pro Ser Ser Gln Leu Tyr Glu His Thr Val Glu Gly Gly Glu Lys Gln
20 25 30
Val Val Phe Thr His Arg Ile Asn Leu Pro Pro Ser Thr Gly Cys Gly
35 40 45
Cys Pro Pro Gly Thr Glu Pro Pro Val Leu Ala Ser Glu Val Gln Ala
50 55 60
Leu Arg Val Arg Leu Glu Ile Leu Glu Glu Leu Val Lys Gly Leu Lys
65 70 75 80
Glu Gln Cys Thr Gly Gly Cys Cys Pro Ala Ser Ala Gln Ala Gly Thr
85 90 95
Gly Gln Thr Asp Val Arg
100
<210> 84
<211> 70
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 84
Asn Gln Ser Asp Ile Val Ala His Leu Leu Ser Ser Ser Ser Ser Val
1 5 10 15
Ile Asp Ala Leu Gln Tyr Lys Leu Glu Gly Thr Thr Arg Leu Thr Arg
20 25 30
Lys Arg Gly Leu Lys Leu Ala Thr Ala Leu Ser Leu Ser Asn Lys Phe
35 40 45
Val Glu Gly Ser His Asn Ser Thr Val Ser Leu Thr Thr Lys Asn Met
50 55 60
Glu Val Ser Val Ala Thr
65 70
<210> 85
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 85
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly
20
<210> 86
<211> 55
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 86
Arg Lys Ser Ala Ser Ser Arg Thr Pro Leu Thr His Ala Leu Pro Gly
1 5 10 15
Leu Ser Glu Arg Glu Gly Gln Gln Thr Ser Ala Ala Ala Pro Thr Pro
20 25 30
Pro Gln Ala Ser Pro Leu Leu Leu Leu Gly Leu Ala Leu Ala Leu Pro
35 40 45
Ala Ala Ala Pro Arg Gly Arg
50 55
<210> 87
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 87
Met Arg Leu Arg Leu Arg Leu Leu Ala Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Pro Pro Ala Arg Ala Pro Lys
20
<210> 88
<211> 52
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 88
Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala Thr Pro Val
1 5 10 15
Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala Ala Gly Arg
20 25 30
Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu Val Gly Gly
35 40 45
Val Ala Ser Arg
50
<210> 89
<211> 180
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 89
Asn Gln Ser Asp Ile Val Ala His Leu Leu Ser Ser Ser Ser Ser Val
1 5 10 15
Ile Asp Ala Leu Gln Tyr Lys Leu Glu Gly Thr Thr Arg Leu Thr Arg
20 25 30
Lys Arg Gly Leu Lys Leu Ala Thr Ala Leu Ser Leu Ser Asn Lys Phe
35 40 45
Val Glu Gly Ser His Asn Ser Thr Val Ser Leu Thr Thr Lys Asn Met
50 55 60
Glu Val Ser Val Ala Thr Thr Thr Lys Ala Gln Ile Pro Ile Leu Arg
65 70 75 80
Met Asn Phe Lys Gln Glu Leu Asn Gly Asn Thr Lys Ser Lys Pro Thr
85 90 95
Val Ser Ser Ser Met Glu Phe Lys Tyr Asp Phe Asn Ser Ser Met Leu
100 105 110
Tyr Ser Thr Ala Lys Gly Ala Val Asp His Lys Leu Ser Leu Glu Ser
115 120 125
Leu Thr Ser Tyr Phe Ser Ile Glu Ser Ser Thr Lys Gly Asp Val Lys
130 135 140
Gly Ser Val Leu Ser Arg Glu Tyr Ser Gly Thr Ile Ala Ser Glu Ala
145 150 155 160
Asn Thr Tyr Leu Asn Ser Lys Ser Thr Gln Ser Ser Val Lys Leu Gln
165 170 175
Gly Thr Ser Lys
180
<210> 90
<211> 54
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 90
Asp Cys Arg Glu Glu Gln Tyr Pro Cys Thr Arg Leu Tyr Ser Ile His
1 5 10 15
Arg Pro Cys Lys Gln Cys Leu Asn Glu Val Cys Phe Tyr Ser Leu Arg
20 25 30
Arg Val Tyr Val Ile Asn Lys Glu Ile Cys Val Arg Thr Val Cys Ala
35 40 45
His Glu Glu Leu Leu Arg
50
<210> 91
<211> 74
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 91
Gly Pro Thr Asp Arg Val Lys Glu Gly His Ser Pro Pro Asp Asp Val
1 5 10 15
Asp Ile Val Ile Lys Leu Asp Asn Thr Ala Ser Thr Val Lys Ala Ile
20 25 30
Ala Ile Val Ile Pro Cys Ile Leu Ala Leu Cys Leu Leu Val Leu Val
35 40 45
Tyr Thr Val Phe Gln Phe Lys Arg Lys Gly Thr Pro Arg His Ala Leu
50 55 60
Ala Cys Lys Arg Ser Met Gln Glu Trp Val
65 70
<210> 92
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 92
Thr Cys Glu Gly Arg Asn Ser Cys Val Ser Cys Phe Asn Val Ser Val
1 5 10 15
Val Asn Thr Thr Cys Phe Trp Ile Glu Cys Lys Asp Glu Ser
20 25 30
<210> 93
<211> 51
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 93
Asn Thr Ala Ser Thr Val Lys Ala Ile Ala Ile Val Ile Pro Cys Ile
1 5 10 15
Leu Ala Leu Cys Leu Leu Val Leu Val Tyr Thr Val Phe Gln Phe Lys
20 25 30
Arg Lys Gly Thr Pro Arg His Ala Leu Ala Cys Lys Arg Ser Met Gln
35 40 45
Glu Trp Val
50
<210> 94
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 94
Met Gly Ser Asp Arg Ala Arg Lys Gly Gly Gly Gly Pro Lys Asp Phe
1 5 10 15
Gly Ala Gly Leu Lys Tyr Asn Ser Arg His Glu Lys Val Asn Gly Leu
20 25 30
Glu Glu Gly Val Glu Phe Leu Pro Val Asn Asn Val Lys Lys Val Glu
35 40 45
Lys His Gly Pro Gly Arg Trp Val Val Leu Ala Ala Val Leu Ile Gly
50 55 60
Leu Leu Leu Val Leu Leu Gly Ile Gly Phe Leu Val Trp His Leu Gln
65 70 75 80
Tyr Arg Asp Val Arg Val Gln Lys Val Phe Asn Gly Tyr Met Arg Ile
85 90 95
Thr Asn Glu Asn Phe Val Asp Ala Tyr Glu Asn Ser Asn Ser Thr Glu
100 105 110
Phe Val Ser
115
<210> 95
<211> 142
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 95
Met Leu Leu Leu Phe His Ser Lys Arg Met Pro Val Ala Glu Ala Pro
1 5 10 15
Gln Val Ala Gly Gly Gln Gly Asp Gly Gly Asp Gly Glu Glu Ala Glu
20 25 30
Pro Glu Gly Met Phe Lys Ala Cys Glu Asp Ser Lys Arg Lys Ala Arg
35 40 45
Gly Tyr Leu Arg Leu Val Pro Leu Phe Val Leu Leu Ala Leu Leu Val
50 55 60
Leu Ala Ser Ala Gly Val Leu Leu Trp Tyr Phe Leu Gly Tyr Lys Ala
65 70 75 80
Glu Val Met Val Ser Gln Val Tyr Ser Gly Ser Leu Arg Val Leu Asn
85 90 95
Arg His Phe Ser Gln Asp Leu Thr Arg Arg Glu Ser Ser Ala Phe Arg
100 105 110
Ser Glu Thr Ala Lys Ala Gln Lys Met Leu Lys Glu Leu Ile Thr Ser
115 120 125
Thr Arg Leu Gly Thr Tyr Tyr Asn Ser Ser Ser Val Tyr Ser
130 135 140
<210> 96
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 96
Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val
1 5 10 15
Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp
20 25
<210> 97
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 97
Gly Ser Pro Lys Pro Pro Glu Ala
1 5
<210> 98
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 98
Gln Lys Gly Ser Val Gly Phe Ala Asp Pro
1 5 10
<210> 99
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 99
Gly Thr Ser Leu Pro Val Asp Asn Ala Phe Pro Ala Pro
1 5 10
<210> 100
<211> 156
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 100
Met Val Pro Ser Ala Gly Gln Leu Ala Leu Phe Ala Leu Gly Ile Val
1 5 10 15
Leu Ala Ala Cys Gln Ala Leu Glu Asn Ser Thr Ser Pro Leu Ser Ala
20 25 30
Asp Pro Pro Val Ala Ala Ala Val Val Ser His Phe Asn Asp Arg Ser
35 40 45
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
50 55 60
Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Ala Arg Cys Glu His
65 70 75 80
Ala Asp Leu Leu Ala Val Val Ala Ala Ser Gln Lys Lys Gln Ala Ile
85 90 95
Thr Ala Leu Val Val Val Ser Ile Val Ala Leu Ala Val Leu Ile Ile
100 105 110
Thr Cys Val Leu Ile His Cys Cys Gln Val Arg Lys His Cys Glu Trp
115 120 125
Cys Arg Ala Leu Ile Cys Arg His Glu Lys Pro Ser Ala Leu Leu Lys
130 135 140
Gly Arg Thr Ala Cys Cys His Ser Glu Thr Val Val
145 150 155
<210> 101
<211> 155
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 101
Gly Gly Gly Pro Val Ala Gln Ala Val Val Ser Ser Gly Pro Gly Ser
1 5 10 15
Phe Ser Leu Asn Phe Thr Leu Pro Ala Asn Thr Thr Ser Ser Pro Val
20 25 30
Thr Gly Gly Lys Glu Thr Asp Cys Gly Pro Ser Leu Gly Leu Ala Ala
35 40 45
Gly Ile Pro Leu Leu Val Ala Thr Ala Leu Leu Val Ala Leu Leu Phe
50 55 60
Thr Leu Ile His Arg Arg Arg Ser Ser Ile Glu Ala Met Glu Glu Ser
65 70 75 80
Asp Arg Pro Cys Glu Ile Ser Glu Ile Asp Asp Asn Pro Lys Ile Ser
85 90 95
Glu Asn Pro Arg Arg Ser Pro Thr His Glu Lys Asn Thr Met Gly Ala
100 105 110
Gln Glu Ala His Ile Tyr Val Lys Thr Val Ala Gly Ser Glu Glu Pro
115 120 125
Val His Asp Arg Tyr Arg Pro Thr Ile Glu Met Glu Arg Arg Arg Gly
130 135 140
Leu Trp Trp Leu Val Pro Arg Leu Ser Leu Glu
145 150 155
<210> 102
<211> 213
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 102
Met Arg Pro Ser Gly Thr Ala Gly Ala Ala Leu Leu Ala Leu Leu Ala
1 5 10 15
Ala Leu Cys Pro Ala Ser Arg Ala Leu Glu Glu Lys Lys Val Arg Ser
20 25 30
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
35 40 45
Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Gly Gly Pro Val Ala
50 55 60
Gln Ala Val Val Ser Ser Gly Pro Gly Ser Phe Ser Leu Asn Phe Thr
65 70 75 80
Leu Pro Ala Asn Thr Thr Ser Ser Pro Val Thr Gly Gly Lys Glu Thr
85 90 95
Asp Cys Gly Pro Ser Leu Gly Leu Ala Ala Gly Ile Pro Leu Leu Val
100 105 110
Ala Thr Ala Leu Leu Val Ala Leu Leu Phe Thr Leu Ile His Arg Arg
115 120 125
Arg Ser Ser Ile Glu Ala Met Glu Glu Ser Asp Arg Pro Cys Glu Ile
130 135 140
Ser Glu Ile Asp Asp Asn Pro Lys Ile Ser Glu Asn Pro Arg Arg Ser
145 150 155 160
Pro Thr His Glu Lys Asn Thr Met Gly Ala Gln Glu Ala His Ile Tyr
165 170 175
Val Lys Thr Val Ala Gly Ser Glu Glu Pro Val His Asp Arg Tyr Arg
180 185 190
Pro Thr Ile Glu Met Glu Arg Arg Arg Gly Leu Trp Trp Leu Val Pro
195 200 205
Arg Leu Ser Leu Glu
210
<210> 103
<211> 228
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 103
Met Arg Pro Ser Gly Thr Ala Gly Ala Ala Leu Leu Ala Leu Leu Ala
1 5 10 15
Ala Leu Cys Pro Ala Ser Arg Ala Leu Glu Glu Lys Lys Val Arg Ser
20 25 30
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
35 40 45
Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Gly Gly Pro Val Ala
50 55 60
Gln Ala Val Val Ser Ser Gly Pro Gly Ser Phe Ser Leu Asn Phe Thr
65 70 75 80
Leu Pro Ala Asn Thr Thr Ser Ser Pro Val Thr Gly Gly Lys Glu Thr
85 90 95
Asp Cys Gly Pro Ser Leu Gly Leu Ala Ala Gly Ile Pro Leu Leu Val
100 105 110
Ala Thr Ala Leu Leu Val Ala Leu Leu Phe Thr Leu Ile His Arg Arg
115 120 125
Arg Ser Ser Ile Glu Ala Met Glu Glu Ser Asp Arg Pro Cys Glu Ile
130 135 140
Ser Glu Ile Asp Asp Asn Pro Lys Ile Ser Glu Asn Pro Arg Arg Ser
145 150 155 160
Pro Thr His Glu Lys Asn Thr Met Gly Ala Gln Glu Ala His Ile Tyr
165 170 175
Val Lys Thr Val Ala Gly Ser Glu Glu Pro Val His Asp Arg Tyr Arg
180 185 190
Pro Thr Ile Glu Met Glu Arg Arg Arg Gly Leu Trp Trp Leu Val Pro
195 200 205
Arg Leu Ser Leu Glu Pro Gly Gly Gly Arg Thr Ala Cys Cys His Ser
210 215 220
Glu Thr Val Val
225
<210> 104
<211> 214
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 104
Met Arg Pro Ser Gly Thr Ala Gly Ala Ala Leu Leu Ala Leu Leu Ala
1 5 10 15
Ala Leu Cys Pro Ala Ser Arg Ala Leu Glu Glu Lys Lys Val Arg Ser
20 25 30
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
35 40 45
Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Pro Lys Lys Cys Pro Gly
50 55 60
Arg Val Val Gly Gly Cys Val Ala His Pro Ser Phe Ser Leu Asn Phe
65 70 75 80
Thr Leu Pro Ala Asn Thr Thr Ser Ser Pro Val Thr Gly Gly Lys Glu
85 90 95
Thr Asp Cys Gly Pro Ser Leu Gly Leu Ala Ala Gly Ile Pro Leu Leu
100 105 110
Val Ala Thr Ala Leu Leu Val Ala Leu Leu Phe Thr Leu Ile His Arg
115 120 125
Arg Arg Ser Ser Ile Glu Ala Met Glu Glu Ser Asp Arg Pro Cys Glu
130 135 140
Ile Ser Glu Ile Asp Asp Asn Pro Lys Ile Ser Glu Asn Pro Arg Arg
145 150 155 160
Ser Pro Thr His Glu Lys Asn Thr Met Gly Ala Gln Glu Ala His Ile
165 170 175
Tyr Val Lys Thr Val Ala Gly Ser Glu Glu Pro Val His Asp Arg Tyr
180 185 190
Arg Pro Thr Ile Glu Met Glu Arg Arg Arg Gly Leu Trp Trp Leu Val
195 200 205
Pro Arg Leu Ser Leu Glu
210
<210> 105
<211> 208
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 105
Met Arg Pro Ser Gly Thr Ala Gly Ala Ala Leu Leu Ala Leu Leu Ala
1 5 10 15
Ala Leu Cys Pro Ala Ser Arg Ala Leu Glu Glu Lys Lys Val Arg Ser
20 25 30
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
35 40 45
Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Ala Ser Gln Gly Leu
50 55 60
Leu Asp Arg Lys Ser Phe Ser Leu Asn Phe Thr Leu Pro Ala Asn Thr
65 70 75 80
Thr Ser Ser Pro Val Thr Gly Gly Lys Glu Thr Asp Cys Gly Pro Ser
85 90 95
Leu Gly Leu Ala Ala Gly Ile Pro Leu Leu Val Ala Thr Ala Leu Leu
100 105 110
Val Ala Leu Leu Phe Thr Leu Ile His Arg Arg Arg Ser Ser Ile Glu
115 120 125
Ala Met Glu Glu Ser Asp Arg Pro Cys Glu Ile Ser Glu Ile Asp Asp
130 135 140
Asn Pro Lys Ile Ser Glu Asn Pro Arg Arg Ser Pro Thr His Glu Lys
145 150 155 160
Asn Thr Met Gly Ala Gln Glu Ala His Ile Tyr Val Lys Thr Val Ala
165 170 175
Gly Ser Glu Glu Pro Val His Asp Arg Tyr Arg Pro Thr Ile Glu Met
180 185 190
Glu Arg Arg Arg Gly Leu Trp Trp Leu Val Pro Arg Leu Ser Leu Glu
195 200 205
<210> 106
<211> 226
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 106
Met Arg Pro Ser Gly Thr Ala Gly Ala Ala Leu Leu Ala Leu Leu Ala
1 5 10 15
Ala Leu Cys Pro Ala Ser Arg Ala Leu Glu Glu Lys Lys Val Arg Ser
20 25 30
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
35 40 45
Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp Gly Pro Glu Gly Leu Arg
50 55 60
Val Gly Phe Tyr Glu Ser Asp Val Met Gly Arg Gly His Ala Arg Leu
65 70 75 80
Val His Val Glu Glu Pro Ser Phe Ser Leu Asn Phe Thr Leu Pro Ala
85 90 95
Asn Thr Thr Ser Ser Pro Val Thr Gly Gly Lys Glu Thr Asp Cys Gly
100 105 110
Pro Ser Leu Gly Leu Ala Ala Gly Ile Pro Leu Leu Val Ala Thr Ala
115 120 125
Leu Leu Val Ala Leu Leu Phe Thr Leu Ile His Arg Arg Arg Ser Ser
130 135 140
Ile Glu Ala Met Glu Glu Ser Asp Arg Pro Cys Glu Ile Ser Glu Ile
145 150 155 160
Asp Asp Asn Pro Lys Ile Ser Glu Asn Pro Arg Arg Ser Pro Thr His
165 170 175
Glu Lys Asn Thr Met Gly Ala Gln Glu Ala His Ile Tyr Val Lys Thr
180 185 190
Val Ala Gly Ser Glu Glu Pro Val His Asp Arg Tyr Arg Pro Thr Ile
195 200 205
Glu Met Glu Arg Arg Arg Gly Leu Trp Trp Leu Val Pro Arg Leu Ser
210 215 220
Leu Glu
225
<210> 107
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 107
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gly Pro Glu Gly Leu Arg Val Gly Phe Tyr Glu Ser Asp
50 55 60
Val Met Gly Arg Gly His Ala Arg Leu Val His Val Glu Glu Pro Pro
65 70 75 80
Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala Thr Pro Val Ser
85 90 95
Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala Ala Gly Arg Trp
100 105 110
Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu Val Gly Gly Val
115 120 125
Ala Ser Arg
130
<210> 108
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 108
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Pro Pro Val Ala Ala Ala Val Val Ser His Phe Asn Asp
50 55 60
Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala Thr Pro Val
65 70 75 80
Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala Ala Gly Arg
85 90 95
Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu Val Gly Gly
100 105 110
Val Ala Ser Arg
115
<210> 109
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 109
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Pro Lys Lys Cys Pro Gly Arg Val Val Gly Gly Cys Val
50 55 60
Ala His Pro Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala
65 70 75 80
Thr Pro Val Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala
85 90 95
Ala Gly Arg Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu
100 105 110
Val Gly Gly Val Ala Ser Arg
115
<210> 110
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 110
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly Arg Ser Tyr Pro Tyr Asp Val Pro Asp
20 25 30
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ala Ser Gly Ala Ala
35 40 45
Ala Ile Asp Gly Ala Ser Gln Gly Leu Leu Asp Arg Lys Pro Ser Ser
50 55 60
Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala Thr Pro Val Ser Glu Thr
65 70 75 80
Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala Ala Gly Arg Trp Pro Ala
85 90 95
Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu Val Gly Gly Val Ala Ser
100 105 110
Arg
<210> 111
<211> 143
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 111
Pro Gly Gly Ser Phe Ser Leu Asn Phe Thr Leu Pro Ala Asn Thr Thr
1 5 10 15
Ser Ser Pro Val Thr Gly Gly Lys Glu Thr Asp Cys Gly Pro Ser Leu
20 25 30
Gly Leu Ala Ala Gly Ile Pro Leu Leu Val Ala Thr Ala Leu Leu Val
35 40 45
Ala Leu Leu Phe Thr Leu Ile His Arg Arg Arg Ser Ser Ile Glu Ala
50 55 60
Met Glu Glu Ser Asp Arg Pro Cys Glu Ile Ser Glu Ile Asp Asp Asn
65 70 75 80
Pro Lys Ile Ser Glu Asn Pro Arg Arg Ser Pro Thr His Glu Lys Asn
85 90 95
Thr Met Gly Ala Gln Glu Ala His Ile Tyr Val Lys Thr Val Ala Gly
100 105 110
Ser Glu Glu Pro Val His Asp Arg Tyr Arg Pro Thr Ile Glu Met Glu
115 120 125
Arg Arg Arg Gly Leu Trp Trp Leu Val Pro Arg Leu Ser Leu Glu
130 135 140
<210> 112
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 112
Val Pro Ser Ala Gly Gln Leu Ala Leu Phe Ala Leu Gly Ile Val Leu
1 5 10 15
Ala Ala Cys Gln Ala Leu
20
<210> 113
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 113
Glu Asn Ser Thr Ser Pro Leu Ser Ala Asp
1 5 10
<210> 114
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 114
Pro Pro Val Ala Ala Ala Val Val Ser His Phe Asn Asp
1 5 10
<210> 115
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 115
Gly Ala Arg Cys Glu His Ala Asp Leu Leu Ala Val Val Ala Ala Ser
1 5 10 15
<210> 116
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 116
Gln Lys Lys Gln
1
<210> 117
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 117
Ala Ile Thr Ala Leu Val Val Val Ser Ile Val Ala Leu Ala Val Leu
1 5 10 15
Ile Ile Thr Cys Val Leu Ile His Cys Cys
20 25
<210> 118
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 118
Gln Val Arg Lys His Cys Glu Trp Cys Arg Ala Leu Ile Cys Arg His
1 5 10 15
Glu Lys Pro Ser Ala Leu Leu Lys
20
<210> 119
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 119
Gly Arg Thr Ala Cys Cys His Ser Glu Thr Val Val
1 5 10
<210> 120
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 120
Ser Phe Ser Leu Asn Phe Thr Leu Pro Ala Asn Thr Thr Ser Ser Pro
1 5 10 15
Val Thr Gly Gly Lys Glu Thr Asp Cys Gly Pro Ser
20 25
<210> 121
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 121
Leu Gly Leu Ala Ala Gly Ile Pro Leu Leu Val Ala Thr Ala Leu Leu
1 5 10 15
Val Ala Leu Leu Phe Thr Leu Ile
20
<210> 122
<211> 36
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 122
His Arg Arg Arg Ser Ser Ile Glu Ala Met Glu Glu Ser Asp Arg Pro
1 5 10 15
Cys Glu Ile Ser Glu Ile Asp Asp Asn Pro Lys Ile Ser Glu Asn Pro
20 25 30
Arg Arg Ser Pro
35
<210> 123
<211> 52
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 123
Thr His Glu Lys Asn Thr Met Gly Ala Gln Glu Ala His Ile Tyr Val
1 5 10 15
Lys Thr Val Ala Gly Ser Glu Glu Pro Val His Asp Arg Tyr Arg Pro
20 25 30
Thr Ile Glu Met Glu Arg Arg Arg Gly Leu Trp Trp Leu Val Pro Arg
35 40 45
Leu Ser Leu Glu
50
<210> 124
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 124
Met Arg Pro Ser Gly Thr Ala Gly Ala Ala Leu Leu Ala Leu Leu Ala
1 5 10 15
Ala Leu Cys Pro Ala Ser Arg Ala Leu Glu Glu Lys Lys Val
20 25 30
<210> 125
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 125
Pro Lys Lys Cys Pro Gly Arg Val Val Gly Gly Cys Val Ala His Pro
1 5 10 15
<210> 126
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 126
Gly Ala Ser Gln Gly Leu Leu Asp Arg Lys
1 5 10
<210> 127
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 127
Gly Pro Glu Gly Leu Arg Val Gly Phe Tyr Glu Ser Asp Val Met Gly
1 5 10 15
Arg Gly His Ala Arg Leu Val His Val Glu Glu Pro
20 25
<210> 128
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 128
Met Glu Leu Arg Ala Arg Gly Trp Trp Leu Leu Tyr Ala Ala Ala Val
1 5 10 15
Leu Val Ala Cys Ala Arg Gly
20
<210> 129
<211> 52
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 129
Pro Ser Ser Gly Pro Arg Ala Pro Arg Pro Pro Lys Ala Thr Pro Val
1 5 10 15
Ser Glu Thr Cys Asp Cys Gln Cys Glu Leu Asn Gln Ala Ala Gly Arg
20 25 30
Trp Pro Ala Pro Ile Pro Leu Leu Leu Leu Pro Leu Leu Val Gly Gly
35 40 45
Val Ala Ser Arg
50
<210> 130
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 130
Arg Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val
1 5 10 15
Pro Asp Tyr Ala Ala Ser Gly Ala Ala Ala Ile Asp
20 25
<210> 131
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> synthetic
<400> 131
Gly Gly Gly Pro Val Ala Gln Ala Val Val Ser Ser Gly Pro Gly
1 5 10 15
<210> 132
<211> 785
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 132
gaattccttt ttatgcaaat gagccattcc cagcacccta gccccaccaa tcctgtactc 60
agatagcccc aaccatccct agaggtttag aaaaccttta tagtccaacc cccaactaaa 120
tgtgctactt tctgaatcct gtctcctctc cttccactca cctcatcttg ctcacttgct 180
gcctgaggtc tccatcaccc caatctgtaa gtccagttcc agctgtagac cttcttctgg 240
acttcttgga catccatgtg catccatgga cttcttgtgc atccatttgg ggcacataca 300
tacatacagg caaaacaccc atatatgtaa aataattttt tttttaagat tagcacctta 360
gtttactttt tgacagtttt ttgcttgttt gcttggttag ttggttggtt tggctttttg 420
agataacgtt tctctgtgta gctctggctg tcctgaaatt cactatgtag accaggctag 480
ctttgaaccc acagagatct ggctgcctct gctgggatta aaggcatagg ccaccacgat 540
tggctttgag aagaaataaa ctaataaagc aaataaaggc caattttatg tcactctatt 600
ttataacgat aaaacatgac ttagttatga gggaactgag acaggacact ttctaagaca 660
cctgtgtttc tgacaacagc ttacctcaga gcagcatgta aaatatttta aaaagggaaa 720
aagccaggtg tggtaatgct cacctgtaat cctagccctc tggaagttaa ggcaggaaaa 780
tcatg 785
<210> 133
<211> 458
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 133
ggaaggtttt cgtggtcctg cccataaaag gtttttcccg ccaccctcag caccgccccg 60
ccccaacccc gcagcatctc caaagcatgc agagaatgtc tcgggctgcc cccgacagac 120
tgctccaact tggtgtcttt ccccaaatat ggagcctgtg tggagtgagt ggggcagctg 180
gggcgggtgg ggtggtgtgg gaagccaact aaggagagcg gccttggggc ccatcaccat 240
ggaaaccgcg gagctccttc cacttcccca cccagctgat tcccccaccc catcccctcc 300
tcccagcgca gccaaccggt tttgcgtccc tggagcgcac tataaaactt gcacgggtgg 360
cgctcgctgc tcagccagac ctgggtgaag gggcagtccc gtctccaact ggtaacagcc 420
ccagcaggca gaacatgagc gtcttcctgc gaaagcaa 458
<210> 134
<211> 419
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 134
gtcctgtcca taaaaggctt ttcccgggcc ggctccccgc cggcagcgtg ccccgccccg 60
gcccgctcca tctccaaagc atgcagagaa tgtctcggca gccccggtag actgctccaa 120
cttggtgtct ttccccaaat atggagcctg tgtggagtca ctgggggagc cgggggtggg 180
gagcggagca gccagtcgcc acacacaggc acacgcaggc cccggcgccg cgccctaagg 240
agagcagcac ccacagccaa ttgccatggg ttcgttccac ttccccaccc agccgatctc 300
ccccctcctc cctgcactgc agccaaccgg cttgtgcgcg tcccaggagc gcgctataaa 360
acctgtgctg ggcgtgatcg gcaagcaccg gaccaggggg aaggcgagca gtgccaatc 419
<210> 135
<211> 389
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 135
gtcctgtcca taaaaggctt ttcccgggcc ggctccccgc cggcagcgtg ccccgccccg 60
gcccgctcca tctccaaagc atgcagagaa tgtctcggca gccccggtag actgctccaa 120
cttggtgtct ttccccaaat atggagcctg tgtggagtca ctgggggagc cgggggtggg 180
gagcggagcc ggcgaggggg ccgcgaggga ccctccccaa ctccacccct tcggcctcct 240
cccctttccc agccgcgggc agctccgggt ctataaagag aggcgtccga ggacgcgcag 300
ggagatttgg acgctccggc ctgggaggtg cgtcagatcc gagctcgcca tccagtttcc 360
tctccactag tccccccagt tggagatct 389
<210> 136
<211> 1199
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 136
actcccctct ctcctcttta accttactta ataagaccct ggcacagttg atattttaag 60
agggctactc tgttttccca gagggaccta ggcacggtaa ccctcttagc atgcagacct 120
tgtttcctga ggggtaatgt ttcccttccc tgtgacttgt ttcttggggg ctgtgttctg 180
attttcctgc tgagccactt gttgccttgg gctggctgcc gcgcttggca gtttttagtg 240
agggctctga tagatgccag gaggtgaggg gaagggctct gggtggactc cgtcattgga 300
caagcagact tagtgatgga tgagccttcc cctgaggaag ttttggatca gaagtccaac 360
tgataagttt ttccagaatt gagtaaccca gaagcagtgc cgaaaggatc ttacctctct 420
tgtggctttt tgtattgatt ttaaaagaaa ttctcagagg cagttccaca ttgtactgga 480
agcacagcta tatccacaat aggcttagat atatgtaaca tgaattgctt tagaaataac 540
atttgaggag aggggtgaga ggaaggaaga gagggtctta aaaaatagcc ctatcaaaat 600
attttctttc ttctaagtat tgaaaagaca caatataacc ctttcttctt tcaaatgatc 660
tcatagctat ttgttgaggg gaaataccaa atgtttatta ttttttttga agaagcttct 720
tcggtcctga tgattcatgt tgatatcatt ttcctcctga ctacagaggc tctgagacaa 780
agctacacct caagtgatat gccagggtca gaacaattcc cgtcctgaag gagggtgtgc 840
aaccttcttt atccctcctt cacagacgtc cttgagccct tgagacggat gtgagtgagt 900
ttttcagtcc tcatgcaaaa caaccatcta aacataacag atgacatcag cttgggcttt 960
tcaattcctg gatggcagca gcgtgttaat ccagccttca tcctggattt cataaaccaa 1020
aacaagagag cctggcagga ggacagcgct gctgctgggt tgaggaaatt gatgacgtta 1080
aagcatgcgg gcaacccagt gtataaaact cataaacgtg taggcagagg ctcagctacc 1140
agtttggacg gctgcttccc accagcaaag accacgactg gagagccgag ccggaggca 1199
<210> 137
<211> 958
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 137
cccctgggac ctgagctggt tcgcagtctt cccaaaggtg ccaagcaagc gtcagttccc 60
ctcaggcgct ccaggttcag tgccttgtgc cgagggtctc cggtgccttc ctagacttct 120
cgggacagtc tgaaggggtc aggagcggcg ggacagcgcg ggaagagcag gcaaggggag 180
acagccggac tgcgcctcag tcctccgtgc caagaacacc gtcgcggagg cgcggccagc 240
ttcccttgga tcggactttc cgcccctagg gccaggcggc ggagcttcag ccttgtccct 300
tccccagttt cgggcggccc ccagagctga gtaagccggg tggagggagt ctgcaaggat 360
ttcctgagcg cgatgggcag gaggaggggc aagggcaaga gggcgcggag caaagaccct 420
gaacctgccg gggccgcgct cccgggcccg cgtcgccagc acctccccac gcgcgctcgg 480
ccccgggcca cccgccctcg tcggcccccg cccctctccg tagccgcagg gaagcgagcc 540
tgggaggaag aagagggtag gtggggaggc ggatgagggg tgggggaccc cttgacgtca 600
ccagaaggag gtgccggggt aggaagtggg ctggggaaag gttataaatc gcccccgccc 660
tcggctgctc ttcatcgagg tccgcgggag gctcggagcg cgccaggcgg acactcctct 720
cggctcctcc ccggcagcgg cggcggctcg gagcgggctc cggggctcgg gtgcagcggc 780
cagcgggcgc ctggcggcga ggattacccg gggaagtggt tgtctcctgg ctggagccgc 840
gagacgggcg ctcagggcgc ggggccggcg gcggcgaacg agaggacgga ctctggcggc 900
cgggtcgttg gccgcgggga gcgcgggcac cgggcgagca ggccgcgtcg cgctcacc 958
<210> 138
<211> 178
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 138
ctagaccgcc cctagggaaa gtcccctagg gcgggtctag atagaagact ggtgcacgtg 60
gcttcccaaa gatctctcag ataatgagag gaaatgcagt catcagtttg cagaaggcta 120
gggattctgg gccatagctc agacctgcgc ccaccatctc cctccaggca gcccttgg 178
<210> 139
<211> 298
<212> DNA
<213> Artificial Sequence
<220>
<223> synthetic
<400> 139
ctagaagagg gcctgttgga gcccacgtat gcactgtggc tagggaaagt cccctagctc 60
cagaagcaaa gcaccccatt ggaatgaaaa gtatgaagta cctagccaca gtgcatacgt 120
gggctccaac aggtcctctt catgggtctc ggtctcctag atagaagact ggtgcacgtg 180
gcttcccaaa gatctctcag ataatgagag gaaatgcagt catcagtttg cagaaggcta 240
gggattctgg gccatagctc agacctgcgc ccaccatctc cctccaggca gcccttgg 298
Claims (97)
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 삭제
- 서열 27에 적어도 95% 동일하거나 서열 27과 동일한 아미노산 서열을 포함하는 PAI-1 리간드 또는 폴리리간드.
- 제80항의 PAI-1 리간드 또는 폴리리간드를 암호화하는 분리된 폴리뉴클레오타이드.
- 제81항에 있어서, 서열 28의 핵산 서열을 포함하는 분리된 폴리뉴클레오타이드.
- 서열 57 내지 76 및 100 내지 111로부터 선택되는 아미노산 서열에 연결된 제80항의 PAI-1 리간드 또는 폴리리간드를 포함하는 분리된 폴리펩타이드.
- 제83항의 폴리펩타이드를 암호화하는 분리된 폴리뉴클레오타이드.
- 조직-특이적인 프로모터에 연결된 제81항의 폴리뉴클레오타이드를 포함하는 분리된 폴리뉴클레오타이드.
- 제80항의 PAI-1 리간드 또는 폴리리간드를 포함하는, 심혈관병이 있는 대상체, 심혈관병 발병 위험이 있는 대상체, 섬유증 상태에 있는 대상체 또는 섬유증 상태로의 위험이 있는 대상체에서 심혈관병 또는 섬유증 상태를 치료, 예방 또는 완화하기 위한 약제학적 조성물.
- 프로모터에 연결된 제80항의 리간드 또는 폴리리간드를 암호화하는 적어도 하나의 폴리뉴클레오타이드가 도입된 단핵세포를 포함하는, 혈관 손상이 있는 대상체, 혈관 손상 위험이 있는 대상체, 섬유증 상태에 있는 대상체 또는 섬유증 상태로의 위험이 있는 대상체에서 죽상경화증 또는 섬유증 상태를 치료, 예방 또는 완화하기 위한 약제학적 조성물.
- 대상체의 단핵세포내로 프로모터에 연결된 제80항의 리간드 또는 폴리리간드를 암호화하는 적어도 하나의 폴리뉴클레오타이드를 도입시켜 변형된 세포를 생산함을 포함하는, 상기 대상체에 전달하기 위한 변형된 세포의 제조 방법.
- 제87항에 있어서, 프로모터를 활성확시키기 위한 화학적 리간드를 추가로 포함하는 약제학적 조성물.
- 제88항에 있어서, 상기 폴리뉴클레오타이드가 적어도 하나의 화학적 리간드-의존적인 전사 인자를 암호화하는 폴리뉴클레오타이드를 추가로 포함하는 방법.
- 제81항의 폴리뉴클레오타이드를 포함하는 벡터.
- 제81항의 분리된 폴리뉴클레오타이드를 포함하는 숙주세포.
- 제 92항에 있어서, 숙주세포가 포유동물 세포인 숙주세포.
- 제 81항의 분리된 폴리뉴클레오타이드를 포함하는 비-인간 유기체.
- 제91항의 벡터를 숙주세포 내로 전달한 다음, 상기 전달된 숙주세포를 배양하여 PAI-1 리간드 또는 폴리리간드 폴리펩타이드의 적어도 한 카피를 생성함을 포함하는, PAI-1 리간드 또는 폴리리간드의 생성방법.
- 제91항의 벡터를 포함하는, 심혈관병을 치료, 예방 또는 완화하기 위한 약제학적 조성물.
- 제91항의 벡터를 비-인간 대상체의 수정란 내로 주입하여 PAI-1 리간드 또는 폴리리간드를 암호화하는 폴리뉴클레오티드가 형질전환된 비-인간 대상체를 생성함을 포함하는, 감소된 PAI-1 활성을 갖는 형질전환된(transgenic) 비-인간 대상체의 생성방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US2013708P | 2008-01-09 | 2008-01-09 | |
| US61/020,137 | 2008-01-09 | ||
| US8064008P | 2008-07-14 | 2008-07-14 | |
| US61/080,640 | 2008-07-14 | ||
| PCT/US2009/000155 WO2009089059A2 (en) | 2008-01-09 | 2009-01-09 | Therapeutic inhibitors of pai-1 function methods of their use |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20100129271A KR20100129271A (ko) | 2010-12-08 |
| KR101712208B1 true KR101712208B1 (ko) | 2017-03-03 |
Family
ID=40853701
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020107017701A KR101712208B1 (ko) | 2008-01-09 | 2009-01-09 | Pai―1 작용의 치료학적 억제제 및 이의 사용 방법 |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US8431363B2 (ko) |
| EP (1) | EP2242501A4 (ko) |
| JP (2) | JP2011509093A (ko) |
| KR (1) | KR101712208B1 (ko) |
| CN (1) | CN102123721A (ko) |
| AU (1) | AU2009204464B2 (ko) |
| BR (1) | BRPI0906867A2 (ko) |
| CA (1) | CA2711878A1 (ko) |
| IL (1) | IL206891A0 (ko) |
| MX (1) | MX2010007586A (ko) |
| RU (1) | RU2010133847A (ko) |
| WO (1) | WO2009089059A2 (ko) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011509093A (ja) | 2008-01-09 | 2011-03-24 | イントレキソン コーポレーション | Pai−1機能の治療的阻害因子およびその使用法 |
| CA2872467C (en) * | 2012-05-01 | 2019-05-14 | Fujifilm Corporation | Method of culturing pluripotent stem cell, and polypeptide to be used therefor |
| CN103421781B (zh) * | 2012-07-04 | 2014-12-31 | 华中农业大学 | 猪肌肉组织特异性表达基因myf6启动子及应用 |
| CN105793285A (zh) * | 2013-12-10 | 2016-07-20 | 豪夫迈·罗氏有限公司 | 多亚基结构的亚基的结合结构域用于将药物活性实体靶向递送至多亚基结构的用途 |
| WO2018108161A1 (zh) | 2016-12-15 | 2018-06-21 | 深圳瑞健生命科学研究院有限公司 | 一种预防和治疗肥胖症的方法和药物 |
| WO2018107707A1 (zh) | 2016-12-15 | 2018-06-21 | 深圳瑞健生命科学研究院有限公司 | 一种改善心脏病变的方法 |
| CN110167583A (zh) * | 2016-12-15 | 2019-08-23 | 泰伦基国际有限公司 | 一种治疗冠状动脉粥样硬化及其并发症的方法 |
| US11613744B2 (en) | 2018-12-28 | 2023-03-28 | Vertex Pharmaceuticals Incorporated | Modified urokinase-type plasminogen activator polypeptides and methods of use |
| CN113661239A (zh) | 2018-12-28 | 2021-11-16 | 催化剂生物科学公司 | 经修饰的尿激酶型纤溶酶原激活物多肽和使用方法 |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5639726A (en) * | 1994-09-30 | 1997-06-17 | The Regents Of The University Of Michigan | Peptide mediated enhancement of thrombolysis methods and compositions |
| CA2385703A1 (en) * | 1999-10-07 | 2001-04-12 | Human Genome Sciences, Inc. | Plasminogen-like polynucleotides, polypeptides, and antibodies |
| DE10053251A1 (de) * | 2000-10-26 | 2002-05-08 | Boehringer Ingelheim Pharma | Epitope von PAI-1 |
| US20030211095A1 (en) * | 2002-05-08 | 2003-11-13 | Abd. Al-Roof Higazi | Peptide for regulation of urokinase plasminogen activator and method of optimizing therapeutic efficacy |
| US20030199463A1 (en) * | 2002-04-23 | 2003-10-23 | Silviu Itescu | DNA enzyme to inhibit plasminogen activator inhibitor-1 |
| EP1509236A4 (en) * | 2002-05-13 | 2008-07-30 | Children S Hospital Los Angele | TREATMENT AND PREVENTION OF ABNORMAL SCALING IN KELOIDS AND OTHER SKIN OR INTERNAL WOUNDS OR LESIONS |
| US7241613B1 (en) * | 2002-06-05 | 2007-07-10 | Oscient Pharmaceuticals Corporation | Identification of Candida cell surface proteins and their uses |
| US7785871B2 (en) * | 2002-10-09 | 2010-08-31 | Intrexon Corporation | DNA cloning vector plasmids and methods for their use |
| US20080050808A1 (en) * | 2002-10-09 | 2008-02-28 | Reed Thomas D | DNA modular cloning vector plasmids and methods for their use |
| US7071295B2 (en) * | 2002-12-02 | 2006-07-04 | Intrexon Corporation | Signal for targeting molecules to the sarco(endo)plasmic reticulum |
| US7056943B2 (en) | 2002-12-10 | 2006-06-06 | Wyeth | Substituted indole oxo-acetyl amino acetic acid derivatives as inhibitors of plasminogen activator inhibitor-1 (PAI-1) |
| EP1751298A4 (en) | 2004-05-18 | 2009-11-11 | Intrexon Corp | METHOD FOR DYNAMIC VECTOR ASSEMBLY OF DNA CLONING VECTOR PLASMIDES |
| US8153598B2 (en) | 2005-10-19 | 2012-04-10 | Intrexon Corporation | PKD ligands and polynucleotides encoding PKD ligands |
| WO2007048103A2 (en) | 2006-10-18 | 2007-04-26 | Intrexon Corporation | Pkd ligands and polynucleotides encoding pkd ligands |
| US7943732B2 (en) * | 2006-06-05 | 2011-05-17 | Intrexon Corporation | AKT ligands and polynucleotides encoding AKT ligands |
| US8993263B2 (en) * | 2006-08-07 | 2015-03-31 | Intrexon Corporation | PKA ligands and polynucleotides encoding PKA ligands |
| US8999666B2 (en) * | 2006-08-09 | 2015-04-07 | Intrexon Corporation | PKC ligands and polynucleotides encoding PKC ligands |
| US8283445B2 (en) * | 2006-11-13 | 2012-10-09 | Intrexon Corporation | Extracellular-signal-regulated-kinase (ERK) heteropolyligand polypeptide |
| US8729225B2 (en) * | 2006-11-13 | 2014-05-20 | Intrexon Corporation | Glycogen synthase kinase heteropolyligand polypeptide |
| US7705122B2 (en) * | 2006-12-04 | 2010-04-27 | Intrexon Corporation | mTOR ligands and polynucleotides encoding mTOR ligands |
| JP5611814B2 (ja) | 2007-03-27 | 2014-10-22 | イントレキソン コーポレーション | Mekリガンドおよびmekリガンドをコードするポリヌクレオチド |
| US8211858B2 (en) * | 2007-04-27 | 2012-07-03 | The University Of Toledo | Modified plasminogen activator inhibitor type-1 molecule and methods based thereon |
| JP2011509093A (ja) | 2008-01-09 | 2011-03-24 | イントレキソン コーポレーション | Pai−1機能の治療的阻害因子およびその使用法 |
-
2009
- 2009-01-09 JP JP2010542283A patent/JP2011509093A/ja not_active Withdrawn
- 2009-01-09 WO PCT/US2009/000155 patent/WO2009089059A2/en active Application Filing
- 2009-01-09 AU AU2009204464A patent/AU2009204464B2/en not_active Ceased
- 2009-01-09 BR BRPI0906867A patent/BRPI0906867A2/pt not_active IP Right Cessation
- 2009-01-09 CA CA2711878A patent/CA2711878A1/en not_active Abandoned
- 2009-01-09 RU RU2010133847/10A patent/RU2010133847A/ru not_active Application Discontinuation
- 2009-01-09 EP EP09700772A patent/EP2242501A4/en not_active Withdrawn
- 2009-01-09 KR KR1020107017701A patent/KR101712208B1/ko active IP Right Grant
- 2009-01-09 MX MX2010007586A patent/MX2010007586A/es active IP Right Grant
- 2009-01-09 CN CN2009801088638A patent/CN102123721A/zh active Pending
- 2009-01-09 US US12/812,127 patent/US8431363B2/en not_active Expired - Fee Related
-
2010
- 2010-07-08 IL IL206891A patent/IL206891A0/en unknown
-
2012
- 2012-01-18 JP JP2012008069A patent/JP2012135307A/ja not_active Withdrawn
-
2013
- 2013-02-15 US US13/769,144 patent/US8828686B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US8431363B2 (en) | 2013-04-30 |
| US20130267022A1 (en) | 2013-10-10 |
| US8828686B2 (en) | 2014-09-09 |
| IL206891A0 (en) | 2010-12-30 |
| JP2011509093A (ja) | 2011-03-24 |
| AU2009204464B2 (en) | 2014-12-04 |
| EP2242501A2 (en) | 2010-10-27 |
| WO2009089059A2 (en) | 2009-07-16 |
| JP2012135307A (ja) | 2012-07-19 |
| EP2242501A4 (en) | 2011-10-19 |
| CN102123721A (zh) | 2011-07-13 |
| AU2009204464A1 (en) | 2009-07-16 |
| RU2010133847A (ru) | 2012-05-20 |
| MX2010007586A (es) | 2011-02-22 |
| US20110055940A1 (en) | 2011-03-03 |
| CA2711878A1 (en) | 2009-07-16 |
| BRPI0906867A2 (pt) | 2019-09-24 |
| KR20100129271A (ko) | 2010-12-08 |
| WO2009089059A3 (en) | 2009-09-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101712208B1 (ko) | Pai―1 작용의 치료학적 억제제 및 이의 사용 방법 | |
| JP7418519B2 (ja) | 第ix因子融合タンパク質及びそれらの製造方法及び使用方法 | |
| KR100188302B1 (ko) | 활성화피브린용해성과항-혈전성단백질 | |
| US20030143209A1 (en) | Targeted adenovirus vectors for delivery of heterologous genes | |
| KR20110136825A (ko) | 미락 단백질 | |
| AU2843900A (en) | Proteins that bind angiogenesis-inhibiting proteins, compositions and methods of use thereof | |
| JP2008109938A (ja) | フォンビルブラント因子(vWF)切断酵素 | |
| JPH11509187A (ja) | 内皮細胞増殖の調節 | |
| Xu et al. | An RGD-modified endostatin-derived synthetic peptide shows antitumor activity in vivo | |
| Perez-Mediavilla et al. | Sequence and expression analysis of bovine pigment epithelium-derived factor | |
| JP4754478B2 (ja) | プロテアーゼに対するインヒビタータンパク質およびその利用 | |
| WO2001093897A2 (en) | Angiostatin and endostatin binding proteins and methods of use | |
| EP1088069B1 (en) | Angiostatin-binding protein | |
| KR20190112763A (ko) | 인자 ix 융합 단백질 및 이의 제조 및 사용 방법 | |
| US20050277575A1 (en) | Therapeutic compositions and methods for treating diseases that involve angiogenesis | |
| CA2339529C (en) | Isolated and purified human soluble guanylyl cyclase .alpha.1/.beta.1 (hsgc .alpha.1/.beta.1) | |
| Lee et al. | Cloning of cDNA for a novel fibrinogen/angiopoietin-related protein, FARP | |
| US6908898B1 (en) | Angiogenesis related molecules | |
| JP2002085059A (ja) | 新規なtsp1ドメイン含有ポリペプチド | |
| JP2004105166A (ja) | ネコフォリスタチンおよびその高純度製造方法 | |
| WO2003086447A1 (en) | Methods for modulating neovascularization |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E902 | Notification of reason for refusal | ||
| E90F | Notification of reason for final refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant |