JPWO2014024751A1 - 音声応答装置 - Google Patents
音声応答装置 Download PDFInfo
- Publication number
- JPWO2014024751A1 JPWO2014024751A1 JP2014529447A JP2014529447A JPWO2014024751A1 JP WO2014024751 A1 JPWO2014024751 A1 JP WO2014024751A1 JP 2014529447 A JP2014529447 A JP 2014529447A JP 2014529447 A JP2014529447 A JP 2014529447A JP WO2014024751 A1 JPWO2014024751 A1 JP WO2014024751A1
- Authority
- JP
- Japan
- Prior art keywords
- voice
- input
- schedule
- unit
- person
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images











Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification
- G10L17/26—Recognition of special voice characteristics, e.g. for use in lie detectors; Recognition of animal voices
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/226—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics
- G10L2015/227—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics of the speaker; Human-factor methodology
Abstract
Description
入力された音声に対する応答を音声で行わせる音声応答装置において、使用者にとってより使い勝手をよくすることが本発明の一側面である。
入力された音声に対する応答を音声で行わせる音声応答装置であって、
入力された音声の特徴を記録する音声特徴記録部と、
入力された音声の特徴が以前に前記音声特徴記録部により記録された音声の特徴と一致するか否かを判定する音声一致判定部と、
前記音声一致判定部により音声の特徴が一致しないと判定された場合、音声の特徴が一致すると判定された場合とは異なる応答を出力させる音声出力部と、
を備えたことを特徴とする。
入力された音声の特徴に基づいて音声を入力した人物を特定する人物特定部と、
入力された音声に従って被制御部を制御する制御部と、を備え、
前記制御部は、異なる人物から矛盾する指示を受けると予め人物毎に設定された優先順位に従って前記優先順位の上位の者による指示を優先して制御を実施するようにしてもよい。
なお、矛盾する指示を受けた場合に、音声による応答で矛盾を指摘する、或いは、代替案を提示するようにしてもよい。この際、代替案を提示する場合には、天候などを加味した応答を出力してもよい。
入力された音声の特徴に基づいて音声を入力した人物を特定する人物特定部と、
入力された音声に基づくスケジュールを前記人物毎に記録するスケジュール記録部と、を備えていてもよい。
なお、本発明において人物特定部を除き、スケジュール記録部を第2局面に係る発明に従属させることができる。また、本発明においては、予定の属性に応じて予定の優先度を変更してもよい。予定の属性とは、例えば、変更できるか否か(相手への影響があるかどうか)などによって区分される。
また、上記音声応答装置においては、第4局面の発明のように、入力された音声が聞き取れない場合(つまり、文字に変換したときに文章として誤りがあると推定できる場合)に所定の連絡先に問い合わせるようにしてもよい。この際、位置情報を利用して問い合わせ元や問い合わせ先を特定するようにしてもよい。
使用者の年齢を推定する際には、例えば、入力された音声の特徴(声の波形、声の高さ等)に応じて推定してもよいし、使用者が音声を入力する際にカメラ等の撮像部によって使用者の顔を撮像することによって推定してもよい。
さらに、現金自動支払機等の対面型の装置に本発明を適用してもよい。この場合、本発明を用いて年齢の認証などの本人確認を行うことができる。
なお、上記発明は音声応答装置として説明したが、入力された音声を認識する構成を備えた音声認識装置として構成してもよい。また、各局面の発明は、他の発明を前提とする必要はなく、可能な限り独立した発明とすることができる。
[本実施形態の構成]
本発明が適用された音声応答システム100は、端末装置1において入力された音声に対して、サーバ90にて適切な応答を生成し、端末装置1で応答を音声で出力するよう構成されたシステムである。また、入力された音声に指令が含まれている場合に、対象となる装置(被制御部95)に対して制御指令を出力する。さらに、使用者のスケジュールを管理する機能も有する。
行動センサユニット10は、周知のMPU31(マイクロプロセッサユニット)、ROM、RAM等のメモリ39、および各種センサを備えており、MPU31は各種センサを構成するセンサ素子が検査対象(湿度、風速等)を良好に検出することができるように、例えば、センサ素子の温度に最適化するためのヒータを駆動させる等の処理を行う。
風速センサ29は、例えば周知の風速センサであって、ヒータ温度を所定温度に維持する際に必要な電力(放熱量)から風速を算出する。
カメラ41は、端末装置1の筐体内において、端末装置1の外部を撮像範囲とするように配置されている。特に、本実施形態においては、端末装置1の使用者を撮像可能な位置にカメラ41が配置されている。
タッチパッド71は、使用者(使用者や使用者の保護者等)により触れられた位置や圧力に応じた信号を出力する。
[本実施形態の処理]
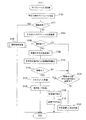
このような音声応答システム100において実施される処理について以下に説明する。
音声入力があれば(S6:YES)、音声をメモリに記録し(S10)、音声の入力が終了したか否かを判定する(S12)。ここでは、音声が一定時間以上途切れた場合や、操作部70を介して音声入力を終了する旨が入力された場合に、音声の入力が終了したと判定する。
また、送信が完了していれば(S16:YES)、後述する音声応答サーバ処理にて送信されるデータ(パケット)を受信したか否かを判定する(S18)。データを受信していなければ(S18:NO)、タイムアウトしたか否かを判定する(S20)。
また、データを受信していれば(S18:YES)、パケットを受信する(S22)。この処理では、文字情報に対する応答を取得する。
タイムアウトしていれば(S26:YES)、エラーが発生した旨を報知部60を介して出力し、音声応答端末処理を終了する。また、タイムアウトしていなければ(S26:NO)、S22の処理に戻る。
この処理では、文章として不具合がある場合(例えば、文法的に誤りがある場合など)には、文章が完成していたとしても認識できなかったものとみなす。文字情報として認識できていなければ(S82:NO)、予め通報先DB117に登録された所定の連絡先(端末装置1毎に設定された連絡先)に、所定の音声(例えば、「以下の言葉が認識できませんでした。録音した音声を再生しますので、正しい文章をお話しください。」といった文章)と、使用者が入力した音声とを送信することで、問い合わせを行う(S84)。
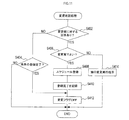
ここで、本処理では、予定について登録する際(S124の処理の際)には、その内容から予定属性を認識し、予定属性についても登録する。また、仮登録された予定についてはこの処理において予定属性を認識する。
また、前後の予定または仮登録した予定を変更可能でなければ(S128:NO)、予定が重複した旨を記録し(S134)、スケジュール入力処理を終了する。
このような変更確認処理が終了すると、図5に戻り、文字情報に類似する文章を入力として応答候補DB105から検索することによって、応答候補DB105から応答を取得する(S56)。ここで、応答候補DB105には、入力となる文字情報と応答となる出力とが一義に対応付けられている。
続いて、会話内容を記録する(S68)。この処理では、入力された文字情報と出力された応答内容を会話内容として学習DB107に記録する。この際、会話内容に含まれるキーワード(音声認識DB102に記録された単語)や発音時の特徴などを学習DB107に記録する。
[本実施形態による効果]
以上のように詳述した音声応答システム100において、サーバ90(演算部101)は、入力された音声の特徴を記録し、入力された音声の特徴が以前に記録された音声の特徴と一致するか否かを判定する。そして、サーバ90は、音声の特徴が一致しないと判定した場合、音声の特徴が一致すると判定した場合とは異なる応答を出力させる。
このような音声応答システム100によれば、人物毎にスケジュールを管理することができる。
さらに、上記音声応答システム100においてサーバ90は、このようにスケジュールを変更する際には、その旨を音声の応答として出力する。このような音声応答システムによれば、スケジュールを変更する際に、使用者に確認を取ることができる。
使用者の年齢を推定する際には、例えば、入力された音声の特徴(声の波形、声の高さ等)に応じて推定してもよいし、使用者が音声を入力する際にカメラ等の撮像部によって使用者の顔を撮像することによって推定する。
このような音声応答システム100によれば、より正確に音声の認識を行うことができる。
本発明の実施の形態は、上記の実施形態に何ら限定されることはなく、本発明の技術的範囲に属する限り種々の形態を採りうる。
そして、変更フラグをONに設定し(S318)、スケジュール入力処理を終了する。また、前後の予定を変更可能でなければ(S314:NO)、予定が重複した旨を記録し(S320)、スケジュール入力処理を終了する。
さらに、操作入力処理においては、図13に示すように、S212およびS214の処理に換えて、天気予報を取得し(S232)、天気予報に応じて代替案を設定してもよい(S234)。例えば、天気予報を取得した結果、これから気温が上がる傾向にある場合には、エアコンの設定温度を下げる案を提案し、これから気温が下がる傾向にある場合には、エアコンの設定温度を上げる案を提案する。また、これから雨が降りそうであれば、窓を閉める提案を行う。
また、上記実施形態においては、文字情報を入力する構成として音声認識を利用したが、音声認識に限らず、キーボードやタッチパネル等の入力手段(操作部70)を利用して入力されてもよい。また、「入力された音声を文字情報に変換」する作動についてはサーバ90で行ったが、端末装置1で行ってもよい。
さらに、上記音声応答システム100においてサーバ90は、応答候補を所定のサーバ、またはインターネット上から取得するようにしてもよい。
さらに、現金自動支払機等の対面型の装置に本発明を適用してもよい。この場合、本発明を用いて年齢の認証などの本人確認を行うことができる。
さらに、音声応答システム100において、発せられる音声に機械音であることを示す音である識別音を含むようにしてもよい。機械音と人が話す声とを識別できるようにするためである。この場合、識別音には何れの装置が発した音声であるかを示す識別子を含むようにするとよく、このようにすると複数種類の機械音の発生元を特定することができる。
さらに、使用者が音声を入力できない場合に備えて、使用者による入力の履歴をディスプレイ上で選択することで音声に代わる入力ができるよう構成してもよい。この場合、単に履歴を新しい順に表示してもよいし、履歴に含まれる入力内容の利用頻度や入力内容が入力された時間帯等を考慮して、利用される可能性が高いと推定される内容から順に表示させるようにしてもよい。
本実施形態における音声応答システム100は、本発明でいう音声応答装置の一例に相当する。また、サーバ90が実行する処理のうち、S74の処理は本発明でいう人物特定部の一例に相当し、S78の処理は本発明でいう音声特徴記録部の一例に相当する。
Claims (3)
- 入力された音声に対する応答を音声で行わせる音声応答装置であって、
入力された音声の特徴を記録する音声特徴記録部と、
入力された音声の特徴が以前に前記音声特徴記録部により記録された音声の特徴と一致するか否かを判定する音声一致判定部と、
前記音声一致判定部により音声の特徴が一致しないと判定された場合、音声の特徴が一致すると判定された場合とは異なる応答を出力させる音声出力部と、
を備えたことを特徴とする音声応答装置。 - 請求項1に記載の音声応答装置において、
入力された音声の特徴に基づいて音声を入力した人物を特定する人物特定部と、
入力された音声に従って被制御部を制御する制御部と、を備え、
前記制御部は、異なる人物から矛盾する指示を受けると予め人物毎に設定された優先順位に従って前記優先順位の上位の者による指示を優先して制御を実施すること
を特徴とする音声応答装置。 - 請求項1に記載の音声応答装置において、
入力された音声の特徴に基づいて音声を入力した人物を特定する人物特定部と、
入力された音声に基づくスケジュールを前記人物毎に記録するスケジュール記録部と、
を備えたことを特徴とする音声応答装置。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012178454 | 2012-08-10 | ||
| JP2012178454 | 2012-08-10 | ||
| PCT/JP2013/070756 WO2014024751A1 (ja) | 2012-08-10 | 2013-07-31 | 音声応答装置 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017182574A Division JP2018036653A (ja) | 2012-08-10 | 2017-09-22 | 音声応答装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JPWO2014024751A1 true JPWO2014024751A1 (ja) | 2016-07-25 |
Family
ID=50067982
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014529447A Pending JPWO2014024751A1 (ja) | 2012-08-10 | 2013-07-31 | 音声応答装置 |
| JP2017182574A Pending JP2018036653A (ja) | 2012-08-10 | 2017-09-22 | 音声応答装置 |
| JP2018206748A Pending JP2019049742A (ja) | 2012-08-10 | 2018-11-01 | 音声応答装置 |
| JP2020133867A Pending JP2020194184A (ja) | 2012-08-10 | 2020-08-06 | 音声応答装置、及び音声応答システム |
Family Applications After (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017182574A Pending JP2018036653A (ja) | 2012-08-10 | 2017-09-22 | 音声応答装置 |
| JP2018206748A Pending JP2019049742A (ja) | 2012-08-10 | 2018-11-01 | 音声応答装置 |
| JP2020133867A Pending JP2020194184A (ja) | 2012-08-10 | 2020-08-06 | 音声応答装置、及び音声応答システム |
Country Status (2)
| Country | Link |
|---|---|
| JP (4) | JPWO2014024751A1 (ja) |
| WO (1) | WO2014024751A1 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017054241A (ja) * | 2015-09-08 | 2017-03-16 | 株式会社東芝 | 表示制御装置、方法及びプログラム |
| EP3460791A4 (en) * | 2016-05-16 | 2019-05-22 | Sony Corporation | INFORMATION PROCESSING DEVICE |
| JP6659514B2 (ja) | 2016-10-12 | 2020-03-04 | 東芝映像ソリューション株式会社 | 電子機器及びその制御方法 |
| KR102170201B1 (ko) * | 2017-10-03 | 2020-10-27 | 구글 엘엘씨 | 센서 기반 검증을 통한 차량 기능 제어 |
| US11328716B2 (en) * | 2017-12-22 | 2022-05-10 | Sony Corporation | Information processing device, information processing system, and information processing method, and program |
| CN111656314A (zh) * | 2018-04-11 | 2020-09-11 | 海信视像科技股份有限公司 | 电子机器及其控制方法 |
| CN109036406A (zh) * | 2018-08-01 | 2018-12-18 | 深圳创维-Rgb电子有限公司 | 一种语音信息的处理方法、装置、设备和存储介质 |
| KR102068422B1 (ko) * | 2018-12-26 | 2020-02-11 | 이청종 | 일정 관리 서비스 시스템 및 방법 |
| CN109960754A (zh) * | 2019-03-21 | 2019-07-02 | 珠海格力电器股份有限公司 | 一种语音设备及其语音交互方法、装置和存储介质 |
| JP7286368B2 (ja) * | 2019-03-27 | 2023-06-05 | 本田技研工業株式会社 | 車両機器制御装置、車両機器制御方法、およびプログラム |
| US11257493B2 (en) * | 2019-07-11 | 2022-02-22 | Soundhound, Inc. | Vision-assisted speech processing |
| CN113096654B (zh) * | 2021-03-26 | 2022-06-24 | 山西三友和智慧信息技术股份有限公司 | 一种基于大数据的计算机语音识别系统 |
| CN114708875A (zh) * | 2022-03-29 | 2022-07-05 | 青岛海尔空调器有限总公司 | 一种音色切换方法及装置 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06186996A (ja) * | 1992-12-18 | 1994-07-08 | Sony Corp | 電子機器 |
| JP2003255991A (ja) * | 2002-03-06 | 2003-09-10 | Sony Corp | 対話制御システム、対話制御方法及びロボット装置 |
| JP2004163541A (ja) * | 2002-11-11 | 2004-06-10 | Mitsubishi Electric Corp | 音声応答装置 |
| JP2004171216A (ja) * | 2002-11-19 | 2004-06-17 | Yamatake Corp | 予定管理装置および方法、プログラム |
| JP2004286805A (ja) * | 2003-03-19 | 2004-10-14 | Sony Corp | 話者識別装置および話者識別方法、並びにプログラム |
| JP2010107614A (ja) * | 2008-10-29 | 2010-05-13 | Mitsubishi Motors Corp | 音声案内応答方法 |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6081782A (en) * | 1993-12-29 | 2000-06-27 | Lucent Technologies Inc. | Voice command control and verification system |
| JPH11259085A (ja) * | 1998-03-13 | 1999-09-24 | Toshiba Corp | 音声認識装置及び認識結果提示方法 |
| US8355912B1 (en) * | 2000-05-04 | 2013-01-15 | International Business Machines Corporation | Technique for providing continuous speech recognition as an alternate input device to limited processing power devices |
| JP2002182895A (ja) * | 2000-12-14 | 2002-06-28 | Sony Corp | 対話方法、情報提供サーバでの対話方法、情報提供サーバ、記憶媒体及びコンピュータプログラム |
| JP2002372991A (ja) * | 2001-06-13 | 2002-12-26 | Olympus Optical Co Ltd | 音声制御装置 |
| JP3715584B2 (ja) * | 2002-03-28 | 2005-11-09 | 富士通株式会社 | 機器制御装置および機器制御方法 |
| JP2004033624A (ja) * | 2002-07-05 | 2004-02-05 | Nti:Kk | ペット型ロボットによる遠隔制御装置 |
| JP2004094077A (ja) * | 2002-09-03 | 2004-03-25 | Nec Corp | 音声認識装置及び制御方法並びにプログラム |
| JP2004212533A (ja) * | 2002-12-27 | 2004-07-29 | Ricoh Co Ltd | 音声コマンド対応機器操作装置、音声コマンド対応機器、プログラム、及び記録媒体 |
| JP3883066B2 (ja) * | 2003-03-07 | 2007-02-21 | 日本電信電話株式会社 | 音声対話システム及び方法、音声対話プログラム並びにその記録媒体 |
| JP2005147925A (ja) * | 2003-11-18 | 2005-06-09 | Hitachi Ltd | 車載端末装置および車両向け情報提示方法 |
| JP2005227510A (ja) * | 2004-02-12 | 2005-08-25 | Ntt Docomo Inc | 音声認識装置及び音声認識方法 |
| US20050229185A1 (en) * | 2004-02-20 | 2005-10-13 | Stoops Daniel S | Method and system for navigating applications |
| JP2005300958A (ja) * | 2004-04-13 | 2005-10-27 | Mitsubishi Electric Corp | 話者照合装置 |
| JP4539149B2 (ja) * | 2004-04-14 | 2010-09-08 | ソニー株式会社 | 情報処理装置および情報処理方法、並びに、プログラム |
| JP4385949B2 (ja) * | 2005-01-11 | 2009-12-16 | トヨタ自動車株式会社 | 車載チャットシステム |
| JP5011686B2 (ja) * | 2005-09-02 | 2012-08-29 | トヨタ自動車株式会社 | 遠隔操作システム |
| US8788589B2 (en) * | 2007-10-12 | 2014-07-22 | Watchitoo, Inc. | System and method for coordinating simultaneous edits of shared digital data |
| JP4869268B2 (ja) * | 2008-03-04 | 2012-02-08 | 日本放送協会 | 音響モデル学習装置およびプログラム |
| JP2010066519A (ja) * | 2008-09-11 | 2010-03-25 | Brother Ind Ltd | 音声対話装置、音声対話方法、および音声対話プログラム |
| EP2485212A4 (en) * | 2009-10-02 | 2016-12-07 | Nat Inst Inf & Comm Tech | LANGUAGE TRANSLATION SYSTEM, FIRST END DEVICE, VOICE RECOGNITION SERVER, TRANSLATION SERVER AND LANGUAGE SYNTHESIS SERV |
| JP2012088370A (ja) * | 2010-10-15 | 2012-05-10 | Denso Corp | 音声認識システム、音声認識端末、およびセンター |
| JP2012141449A (ja) * | 2010-12-28 | 2012-07-26 | Toshiba Corp | 音声処理装置、音声処理システム及び音声処理方法 |
-
2013
- 2013-07-31 WO PCT/JP2013/070756 patent/WO2014024751A1/ja active Application Filing
- 2013-07-31 JP JP2014529447A patent/JPWO2014024751A1/ja active Pending
-
2017
- 2017-09-22 JP JP2017182574A patent/JP2018036653A/ja active Pending
-
2018
- 2018-11-01 JP JP2018206748A patent/JP2019049742A/ja active Pending
-
2020
- 2020-08-06 JP JP2020133867A patent/JP2020194184A/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06186996A (ja) * | 1992-12-18 | 1994-07-08 | Sony Corp | 電子機器 |
| JP2003255991A (ja) * | 2002-03-06 | 2003-09-10 | Sony Corp | 対話制御システム、対話制御方法及びロボット装置 |
| JP2004163541A (ja) * | 2002-11-11 | 2004-06-10 | Mitsubishi Electric Corp | 音声応答装置 |
| JP2004171216A (ja) * | 2002-11-19 | 2004-06-17 | Yamatake Corp | 予定管理装置および方法、プログラム |
| JP2004286805A (ja) * | 2003-03-19 | 2004-10-14 | Sony Corp | 話者識別装置および話者識別方法、並びにプログラム |
| JP2010107614A (ja) * | 2008-10-29 | 2010-05-13 | Mitsubishi Motors Corp | 音声案内応答方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020194184A (ja) | 2020-12-03 |
| JP2018036653A (ja) | 2018-03-08 |
| JP2019049742A (ja) | 2019-03-28 |
| WO2014024751A1 (ja) | 2014-02-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2018036653A (ja) | 音声応答装置 | |
| JP6552123B2 (ja) | 応答要求装置 | |
| CN110288987B (zh) | 用于处理声音数据的系统和控制该系统的方法 | |
| US11004446B2 (en) | Alias resolving intelligent assistant computing device | |
| US20180293221A1 (en) | Speech parsing with intelligent assistant | |
| US20210034192A1 (en) | Systems and methods for identifying users of devices and customizing devices to users | |
| US20190304466A1 (en) | Voice control method, voice control device and computer readable storage medium | |
| CN117577099A (zh) | 设备上的多用户认证的方法、系统和介质 | |
| KR20180070970A (ko) | 음성 인식 방법 및 장치 | |
| BR112015018905B1 (pt) | Método de operação de recurso de ativação por voz, mídia de armazenamento legível por computador e dispositivo eletrônico | |
| CN105580071B (zh) | 用于训练声音识别模型数据库的方法和装置 | |
| US11380325B2 (en) | Agent device, system, control method of agent device, and storage medium | |
| JP2018054866A (ja) | 音声対話装置および音声対話方法 | |
| CN107909995B (zh) | 语音交互方法和装置 | |
| EP4009206A1 (en) | System and method for authenticating a user by voice to grant access to data | |
| CN113574906A (zh) | 信息处理设备、信息处理方法和信息处理程序 | |
| US11398221B2 (en) | Information processing apparatus, information processing method, and program | |
| WO2019024602A1 (zh) | 移动终端及其情景模式的触发方法、计算机可读存储介质 | |
| KR102511517B1 (ko) | 음성 입력 처리 방법 및 이를 지원하는 전자 장치 | |
| JP2017211430A (ja) | 情報処理装置および情報処理方法 | |
| CN108174030B (zh) | 定制化语音控制的实现方法、移动终端及可读存储介质 | |
| KR20200056754A (ko) | 개인화 립 리딩 모델 생성 방법 및 장치 | |
| WO2019118147A1 (en) | Speech parsing with intelligent assistant | |
| US11936718B2 (en) | Information processing device and information processing method | |
| CN111739524B (zh) | 智能体装置、智能体装置的控制方法及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160525 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170704 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170824 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170912 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20180313 |