JP7247060B2 - データの利活用のためのデータ準備を支援するシステム、及び、その方法 - Google Patents
データの利活用のためのデータ準備を支援するシステム、及び、その方法 Download PDFInfo
- Publication number
- JP7247060B2 JP7247060B2 JP2019159980A JP2019159980A JP7247060B2 JP 7247060 B2 JP7247060 B2 JP 7247060B2 JP 2019159980 A JP2019159980 A JP 2019159980A JP 2019159980 A JP2019159980 A JP 2019159980A JP 7247060 B2 JP7247060 B2 JP 7247060B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- analysis
- target data
- user
- reference information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000002360 preparation method Methods 0.000 title claims description 25
- 238000000034 method Methods 0.000 title claims description 17
- 238000004458 analytical method Methods 0.000 claims description 279
- 208000018910 keratinopathic ichthyosis Diseases 0.000 claims description 52
- 238000012545 processing Methods 0.000 claims description 24
- 238000003860 storage Methods 0.000 claims description 24
- 238000004364 calculation method Methods 0.000 claims description 11
- 238000011156 evaluation Methods 0.000 claims description 8
- 239000011159 matrix material Substances 0.000 description 22
- 238000000556 factor analysis Methods 0.000 description 18
- 238000007405 data analysis Methods 0.000 description 14
- 238000000605 extraction Methods 0.000 description 13
- 238000007726 management method Methods 0.000 description 13
- 239000000284 extract Substances 0.000 description 10
- 230000008859 change Effects 0.000 description 9
- 230000008569 process Effects 0.000 description 8
- 238000004220 aggregation Methods 0.000 description 6
- 230000002776 aggregation Effects 0.000 description 6
- 238000000611 regression analysis Methods 0.000 description 6
- 230000007704 transition Effects 0.000 description 6
- 239000002131 composite material Substances 0.000 description 4
- 238000004891 communication Methods 0.000 description 3
- 230000001934 delay Effects 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000001174 ascending effect Effects 0.000 description 2
- 238000013523 data management Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 230000001737 promoting effect Effects 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000002547 anomalous effect Effects 0.000 description 1
- 238000010224 classification analysis Methods 0.000 description 1
- 238000007621 cluster analysis Methods 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000003754 machining Methods 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000013450 outlier detection Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/21—Design, administration or maintenance of databases
- G06F16/217—Database tuning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/221—Column-oriented storage; Management thereof
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/283—Multi-dimensional databases or data warehouses, e.g. MOLAP or ROLAP
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/10—Office automation; Time management
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Business, Economics & Management (AREA)
- General Engineering & Computer Science (AREA)
- Human Resources & Organizations (AREA)
- Entrepreneurship & Innovation (AREA)
- Strategic Management (AREA)
- Software Systems (AREA)
- Economics (AREA)
- Marketing (AREA)
- Operations Research (AREA)
- Quality & Reliability (AREA)
- Tourism & Hospitality (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
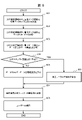
102、103 ユーザ端末
104-106 業務システム
Claims (9)
- データの利活用のためのデータ準備を支援するシステムであって、
処理装置と、
記憶装置と、を備え、
前記処理装置は、前記記憶装置に記録されたプログラムを実行することによって、
複数の業務システムの夫々から業務データを収集し、当該業務データを前記記憶装置に対象データとして少なくとも一時的に蓄積し、
ユーザ端末から前記対象データに対する分析目的を受信し、
前記分析目的と前記対象データとに基づいて、前記分析目的に対して推奨される分析ステップを決定し、
前記推奨される分析ステップに利用可能なデータの組合せを、前記対象データから抽出し、
前記抽出されたデータの組合せの複数の夫々を評価し、
当該評価の結果に基づいて、前記データの組合せの複数を夫々順位付けしたリストを作成し、
当該リストを前記ユーザ端末に出力させ、
ユーザが前記リストから所定のデータの組合せを選択できるようにし、
前記記憶装置は、前記対象データに対する基準情報を備え、
前記処理装置は、
前記推奨される分析ステップを前記基準情報に基づいて決定することと、
前記推奨される分析ステップを決定することを、前記対象データに対する分析の実施段階の複数タイプの中から、いずれかのタイプの分析の実施段階に決定することによって実行することと、
を有し、
前記処理装置は、
前記分析目的が、前記対象データ、又は、当該対象データ及び前記基準情報に適合する程度を算出し、
前記基準情報の前記分析目的に対する有効性の程度を算出し、
両方の算出結果に基づいて、前記いずれかのタイプの分析の実施段階を決定し、
前記分析目的はKPIを含み、
前記基準情報は前記対象データに対する辞書データを含み、
前記処理装置は、
前記分析目的が前記対象データに適合する程度を算出することを、前記KPIと前記対象データのカラム名とを比較することによって行い、
前記分析目的が前記基準情報に適合する程度を算出することを、前記KPIと前記辞書データとを比較することによって行う、
システム。 - 前記分析目的は、前記複数のタイプの分析の実施段階のうち、ユーザが所望する分析の実施段階を含み、
前記処理装置は、
前記両方の算出結果に基づいて、当該ユーザが所望する分析の実施段階を評価し、この評価は当該分析の実施段階を維持するか、又は、他の分析の実施段階に変更することを含み、
前記評価の結果に基づいて、前記ユーザに、前記推奨される分析の実施段階を提示する、
請求項1記載のシステム。 - データの利活用のためのデータ準備を支援するシステムであって、
処理装置と、
記憶装置と、を備え、
前記処理装置は、前記記憶装置に記録されたプログラムを実行することによって、
複数の業務システムの夫々から業務データを収集し、当該業務データを前記記憶装置に対象データとして少なくとも一時的に蓄積し、
ユーザ端末から前記対象データに対する分析目的を受信し、
前記分析目的と前記対象データとに基づいて、前記分析目的に対して推奨される分析ステップを決定し、
前記推奨される分析ステップに利用可能なデータの組合せを、前記対象データから抽出し、
前記抽出されたデータの組合せの複数の夫々を評価し、
当該評価の結果に基づいて、前記データの組合せの複数を夫々順位付けしたリストを作成し、
当該リストを前記ユーザ端末に出力させ、
ユーザが前記リストから所定のデータの組合せを選択できるようにし、
前記記憶装置は、前記対象データに関する基準情報を備え、
前記処理装置は、
前記推奨される分析ステップに利用可能なデータの組合せを、前記対象データから抽出することを、
前記対象データから前記分析目的に該当するデータを抽出することと、そして、
前記対象データから前記基準情報に該当するデータを抽出することと、から実行し、
前記分析目的に該当するデータと、前記基準情報に該当するデータと、に基づいて、前記データの組合せの複数を構成し、
当該データの組合せの複数の夫々を、データ量に基づいて評価し、
前記処理装置は、
前記対象データから前記分析目的に該当するデータを抽出することを、前記分析目的に該当するカラムを前記対象データから抽出することから実行し、
前記対象データから前記基準情報に該当するデータを抽出することを、前記対象データから前記基準情報に該当するカラムを前記対象データから抽出することから実行し、
前記データの組合せとして、前記分析目的に該当するカラムと前記基準情報に該当するカラムの組合せを複数構成し、
前記データ量として、当該複数の組合せ夫々のレコード数を算出する、
システム。 - 前記処理装置は、
前記分析の実施段階の複数タイプ毎に、前記抽出されたデータの組合せの複数の夫々を評価する、
請求項1記載のシステム。 - 前記処理装置は、
前記複数の組合せの夫々について、複数あるデータ値変動パタンのうちどのデータ値変動パタンを備えるかを判定し、
データ値変動パタン毎に前記レコード数を算出する、
請求項3記載のシステム。 - 前記処理装置は、
前記対象データのカラムを前記辞書データの4W情報の夫々に基づいて抽出する、
請求項1記載のシステム。 - ユーザによる分析目的情報の登録に対する、推奨する分析ステップ、または、作業項目に関する情報、さらに各分析ステップにおけるユーザが指定するKPIや着目データ項目に関連する利用可能なデータの組合せに関する情報を、ユーザに提示するための出力装置を有する、請求項1記載のシステム。
- データの利活用のためのデータ準備を支援する方法であって、
コンピュータは、
複数の業務システムの夫々から業務データを収集し、当該業務データを記憶装置に対象データとして少なくとも一時的に蓄積し、
ユーザ端末から前記対象データに対する分析目的を受信し、
前記分析目的と前記対象データとに基づいて、前記分析目的に対して推奨される分析ステップを決定し、
前記推奨される分析ステップに利用可能なデータの組合せを、前記対象データから抽出し、
前記抽出されたデータの組合せの複数の夫々を評価し、
当該評価の結果に基づいて、前記データの組合せの複数を夫々順位付けしたリストを作成し、
当該リストを前記ユーザ端末に出力させ、
ユーザが前記リストから所定のデータの組合せを選択できるようにし、
前記記憶装置は、前記対象データに関する基準情報を備え、
前記コンピュータは、
前記推奨される分析ステップを前記基準情報に基づいて決定することと、
前記推奨される分析ステップを決定することを、前記対象データに対する分析の実施段階の複数タイプの中から、いずれかのタイプの分析の実施段階に決定することによって実行することを有し、
前記コンピュータは、
前記分析目的が、前記対象データ、又は、当該対象データ及び前記基準情報に適合した程度を算出し、
前記基準情報の前記分析目的に対する有効性の程度を算出し、
両方の算出結果に基づいて、前記いずれかのタイプの分析の実施段階を決定し、
前記分析目的はKPIを含み、
前記基準情報は前記対象データに対する辞書データを含み、
前記コンピュータは、
前記分析目的が前記対象データに適した程度を算出することを、前記KPIと前記対象データのカラム名を比較することによって行い、
前記分析目的が前記基準情報に適合する程度を算出することを、前記KPIと前記辞書データとを比較することによって行う、
前記方法。 - データの利活用のためのデータ準備を支援する方法であって、
コンピュータは、
複数の業務システムの夫々から業務データを収集し、当該業務データを記憶装置に対象データとして少なくとも一時的に蓄積し、
ユーザ端末から前記対象データに対する分析目的を受信し、
前記分析目的と前記対象データとに基づいて、前記分析目的に対して推奨される分析ステップを決定し、
前記推奨される分析ステップに利用可能なデータの組合せを、前記対象データから抽出し、
前記抽出されたデータの組合せの複数の夫々を評価し、
当該評価の結果に基づいて、前記データの組合せの複数を夫々順位付けしたリストを作成し、
当該リストを前記ユーザ端末に出力させ、
ユーザが前記リストから所定のデータの組合せを選択できるようにし、
前記記憶装置は、前記対象データに関する基準情報を備え、
前記コンピュータは、
前記推奨される分析ステップに利用可能なデータの組合せを、前記対象データから抽出することを、
前記対象データから前記分析目的に該当するデータを抽出することと、そして、
前記対象データから前記基準情報に該当するデータを抽出することと、から実行し、
前記分析目的に該当するデータと、前記基準情報に該当するデータと、に基づいて、前記データの組合せの複数を構成し、
当該データの組合せの複数の夫々を、データ量に基づいて評価し、
前記コンピュータは、
前記対象データから前記分析目的に該当するデータを抽出することを、前記分析目的に該当するカラムを前記対象データから抽出することから実行し、
前記対象データから前記基準情報に該当するデータを抽出することを、前記対象データから前記基準情報に該当するカラムを前記対象データから抽出することから実行し、
前記データの組合せとして、前記分析目的に該当するカラムと前記基準情報に該当するカラムとの組合せを複数構成し、
前記データ量として、当該複数の組合せ夫々のレコード数を算出する、
前記方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019159980A JP7247060B2 (ja) | 2019-09-02 | 2019-09-02 | データの利活用のためのデータ準備を支援するシステム、及び、その方法 |
| KR1020200023603A KR102345302B1 (ko) | 2019-09-02 | 2020-02-26 | 데이터의 이용·활용을 위한 데이터 준비를 지원하는 시스템, 및 그 방법 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019159980A JP7247060B2 (ja) | 2019-09-02 | 2019-09-02 | データの利活用のためのデータ準備を支援するシステム、及び、その方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2021039523A JP2021039523A (ja) | 2021-03-11 |
| JP2021039523A5 JP2021039523A5 (ja) | 2022-03-25 |
| JP7247060B2 true JP7247060B2 (ja) | 2023-03-28 |
Family
ID=74849117
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019159980A Active JP7247060B2 (ja) | 2019-09-02 | 2019-09-02 | データの利活用のためのデータ準備を支援するシステム、及び、その方法 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7247060B2 (ja) |
| KR (1) | KR102345302B1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2024096635A (ja) * | 2023-01-04 | 2024-07-17 | 富士通株式会社 | 情報処理プログラム、情報処理方法および情報処理装置 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010205218A (ja) | 2009-03-06 | 2010-09-16 | Dainippon Printing Co Ltd | データ分析支援装置、データ分析支援システム、データ分析支援方法、及びプログラム |
| US20160328406A1 (en) | 2015-05-08 | 2016-11-10 | Informatica Llc | Interactive recommendation of data sets for data analysis |
| WO2018159042A1 (ja) | 2017-03-02 | 2018-09-07 | 株式会社日立製作所 | 分析ソフトウェア管理システム及び分析ソフトウェア管理方法 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0877010A (ja) * | 1994-09-07 | 1996-03-22 | Hitachi Ltd | データ分析方法および装置 |
| JP2005190402A (ja) | 2003-12-26 | 2005-07-14 | Hitachi Ltd | リスク評価支援システム、情報処理装置、リスク評価支援方法、及びプログラム |
| JP2013077124A (ja) | 2011-09-30 | 2013-04-25 | Hitachi Ltd | ソフトウェアテストケース生成装置 |
| JP6158623B2 (ja) | 2013-07-25 | 2017-07-05 | 株式会社日立製作所 | データベース分析装置及び方法 |
| JP2016004525A (ja) | 2014-06-19 | 2016-01-12 | 株式会社日立製作所 | データ分析システム及びデータ分析方法 |
| JP5847344B1 (ja) | 2015-03-24 | 2016-01-20 | 株式会社ギックス | データ処理システム、データ処理方法、プログラム及びコンピュータ記憶媒体 |
| JP2019106031A (ja) | 2017-12-13 | 2019-06-27 | 株式会社日立製作所 | データ処理システム及びデータ分析処理方法 |
| JP6903595B2 (ja) | 2018-01-22 | 2021-07-14 | 株式会社日立製作所 | データ分析支援システム及びデータ分析支援方法 |
-
2019
- 2019-09-02 JP JP2019159980A patent/JP7247060B2/ja active Active
-
2020
- 2020-02-26 KR KR1020200023603A patent/KR102345302B1/ko active IP Right Grant
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010205218A (ja) | 2009-03-06 | 2010-09-16 | Dainippon Printing Co Ltd | データ分析支援装置、データ分析支援システム、データ分析支援方法、及びプログラム |
| US20160328406A1 (en) | 2015-05-08 | 2016-11-10 | Informatica Llc | Interactive recommendation of data sets for data analysis |
| WO2018159042A1 (ja) | 2017-03-02 | 2018-09-07 | 株式会社日立製作所 | 分析ソフトウェア管理システム及び分析ソフトウェア管理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102345302B1 (ko) | 2021-12-31 |
| KR20210027024A (ko) | 2021-03-10 |
| JP2021039523A (ja) | 2021-03-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Larco et al. | Managing warehouse efficiency and worker discomfort through enhanced storage assignment decisions | |
| Gozhyj et al. | Web resources management method based on intelligent technologies | |
| Karsak | Robot selection using an integrated approach based on quality function deployment and fuzzy regression | |
| US20130297540A1 (en) | Systems, methods and computer-readable media for generating judicial prediction information | |
| US8015057B1 (en) | Method and system for analyzing service outsourcing | |
| Felfernig et al. | An overview of recommender systems in requirements engineering | |
| Neumann et al. | Simulating operator learning during production ramp-up in parallel vs. serial flow production | |
| JP2012155684A (ja) | 生涯需要予測方法、プログラムおよび生涯需要予測装置 | |
| US20170132555A1 (en) | Semi-automated machine learning process to match work to worker | |
| JP6696568B2 (ja) | アイテム推奨方法、アイテム推奨プログラムおよびアイテム推奨装置 | |
| JP7247060B2 (ja) | データの利活用のためのデータ準備を支援するシステム、及び、その方法 | |
| Jain et al. | Evaluation of flexibility in FMS by VIKOR methodology | |
| Gattermann-Itschert et al. | Using machine learning to include planners’ preferences in railway crew scheduling optimization | |
| JP2008159023A (ja) | 部品の採用決定支援システム、部品の採用決定支援方法、および部品の採用決定支援プログラム | |
| Chan et al. | Comparative performance analysis of a flexible manufacturing system (FMS): a review-period-based control | |
| KR20180035633A (ko) | 인간 의사결정 프로세스의 기계학습에 기초한 의사 결정을 위한 인공지능 | |
| Rahmiati et al. | Ceramic supplier selection using analytical hierarchy process method. | |
| JP5101846B2 (ja) | マーケティング支援システム | |
| JP2011227601A (ja) | 情報提供装置及びそのプログラム | |
| Prakash et al. | Effects of inventory classifications on CONWIP system: a case study | |
| JP2006059195A (ja) | 求職者・求人者マッチングシステムおよび求職者・求人者マッチング方法 | |
| JP7295792B2 (ja) | データ分析装置およびデータ分析方法 | |
| JP5900154B2 (ja) | 商品推薦方法及びサーバ装置 | |
| JP2011227920A (ja) | マーケティング支援システム | |
| Aouadni et al. | Supplier selection: an analytic network process and imprecise goal programming model integrating the decision-maker’s preferences |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220316 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220316 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230227 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230307 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230315 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7247060 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |