JP4875911B2 - コンテンツ特定方法及び装置 - Google Patents
コンテンツ特定方法及び装置 Download PDFInfo
- Publication number
- JP4875911B2 JP4875911B2 JP2006076501A JP2006076501A JP4875911B2 JP 4875911 B2 JP4875911 B2 JP 4875911B2 JP 2006076501 A JP2006076501 A JP 2006076501A JP 2006076501 A JP2006076501 A JP 2006076501A JP 4875911 B2 JP4875911 B2 JP 4875911B2
- Authority
- JP
- Japan
- Prior art keywords
- keyword
- content
- data
- user
- registered user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images





















Description
g(t)=f(n)+ρt-ρg(τ)
J(W,V)=(W∩V)/(W∪V)
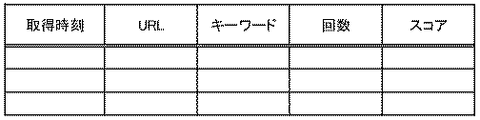
なお、J(W,V)は周知のJaccard Coefficientである。Wは、ステップS61で生成され且つステップS65で特定されたキーワードグループであり、Vは、トピックDB23内の特定のURLのキーワードグループである。従って、分母はW∪Vのキーワード数、分子はW∩Vのキーワード数である。
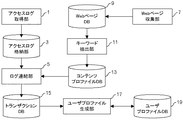
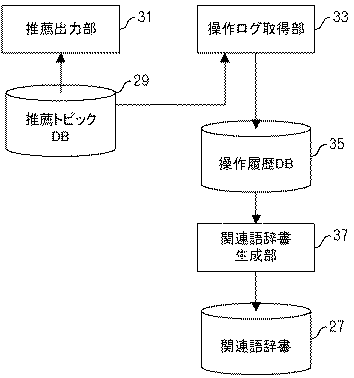
5 ログ連結部 7 Webページ収集部
9 WebページDB 11 キーワード抽出部
13 コンテンツプロファイルDB
15 トランザクションDB 17 ユーザプロファイル生成部
19 ユーザプロファイルDB
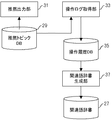
21 コンテンツ選別部 23 トピックDB
25 マッチング部 27 関連語辞書
29 推薦トピックDB 31 推薦出力部
33 操作取得部 35 操作履歴DB
37 関連語辞書生成部
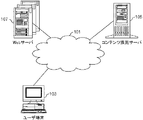
101 ネットワーク 103 ユーザ端末
105 コンテンツ推薦サーバ 107 Webサーバ
Claims (6)
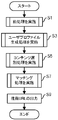
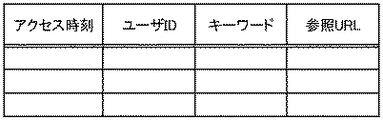
- 登録ユーザがコンテンツにアクセスした時刻であるアクセス時刻を含む、当該登録ユーザのアクセスログを格納するアクセスログ格納部と収集したコンテンツ中のキーワードに関するデータを格納するコンテンツプロファイル・データベースとに格納されているデータから、アクセス時刻及び前記キーワードに関する情報と登録ユーザとの関係を表すトランザクション・データを生成し、トランザクション・データベースに登録するステップと、
前記トランザクション・データベースに格納された未処理のトランザクション・データに係る特定の登録ユーザに関連し且つ当該未処理のトランザクション・データに含まれるキーワードの、アクセス時刻における評価値と、登録ユーザとキーワードとのこれまでの関連度を表すデータを格納するユーザプロファイル・データベースに格納されているデータから前記特定の登録ユーザに関連するキーワードにつき前記アクセス時刻における減衰された関連度とを算出して、前記特定の登録ユーザに関連するキーワードについて前記評価値及び前記減衰された関連度から前記アクセス時刻における関連度を算出し、前記ユーザプロファイル・データベースを更新する更新ステップと、
前記アクセスログ格納部に格納されているデータを用いて、所定の基準を超えてアクセスが増加したコンテンツを特定し、当該特定されたコンテンツについてのデータを前記コンテンツプロファイル・データベースから抽出し、トピック・データベースに登録する登録ステップと、
前記ユーザプロファイル・データベースに格納されている、前記特定の登録ユーザについての前記関連度が上位のキーワードと所定の類似性を有し且つ前記トピック・データベースに登録されているキーワードが出現するコンテンツを特定し、当該特定されたコンテンツの識別情報を前記特定の登録ユーザに対応して推薦トピック・データベースに登録するコンテンツ特定ステップと、
を含み、
前記トランザクション・データベースに格納された前記キーワードに関するデータが、当該キーワードの提示回数kを含み、
前記更新ステップが、
前記未処理のトランザクション・データに含まれるキーワードの提示回数kと所定の減衰係数ρによって、前記キーワードの前記評価値を(1−ρ k )/(1−ρ)として算出するステップ、
を含み、コンピュータにより実行されるコンテンツ特定方法。 - 前記コンテンツ特定ステップが、
関連語辞書から、前記ユーザプロファイル・データベースに格納されている、前記特定の登録ユーザについての前記関連度が上位のキーワードに対応して登録されている関連キーワードを抽出するステップと、
前記特定の登録ユーザについての特定のキーワードと当該特定のキーワードに対応し且つ抽出された前記関連キーワードとを含む第1のセットと、前記トピック・データベースに登録されている前記キーワードをコンテンツ毎にまとめた第2のセットとの類似度を前記コンテンツ毎に算出するステップと、
を含む請求項1記載のコンテンツ特定方法。 - 前記ユーザプロファイル・データベースには、キーワード毎に処理基準日時のデータが登録されており
前記更新ステップが、
前記処理基準日時から前記アクセス時刻までの単位時間数tと所定減衰係数ρと前記これまでの関連度gとによって、前記アクセス時刻における減衰された関連度をρtgとして算出するステップ、
を含む請求項1又は2記載のコンテンツ特定方法。 - 前記登録ステップが、
各前記コンテンツにつき、処理基準時刻のアクセスユーザ数の、1単位時間前までのアクセスユーザ数の平均からの上方乖離度を算出するステップと、
前記上方乖離度が上位所定数内のコンテンツを特定するステップと、
を含む請求項1乃至3のいずれか1つ記載のコンテンツ特定方法。 - 請求項1乃至4のいずれか1つ記載のコンテンツ特定方法をコンピュータに実行させるためのプログラム。
- 登録ユーザがコンテンツにアクセスした時刻であるアクセス時刻を含む、当該登録ユーザのアクセスログを格納するアクセスログ格納部と収集したコンテンツ中のキーワードに関するデータを格納するコンテンツプロファイル・データベースとに格納されているデータから、アクセス時刻及び前記キーワードに関する情報と登録ユーザとの関係を表すトランザクション・データを生成し、トランザクション・データベースに登録する手段と、
前記トランザクション・データベースに格納された未処理のトランザクション・データに係る特定の登録ユーザに関連し且つ当該未処理のトランザクション・データに含まれるキーワードの、アクセス時刻における評価値と、登録ユーザとキーワードとのこれまでの関連度を表すデータを格納するユーザプロファイル・データベースに格納されているデータから前記特定の登録ユーザに関連するキーワードにつき前記アクセス時刻における減衰された関連度とを算出して、前記特定の登録ユーザに関連するキーワードについて前記評価値及び前記減衰された関連度から前記アクセス時刻における関連度を算出し、前記ユーザプロファイル・データベースを更新する更新手段と、
前記アクセスログ格納部に格納されているデータを用いて、所定の基準を超えてアクセスが増加したコンテンツを特定し、当該特定されたコンテンツについてのデータを前記コンテンツプロファイル・データベースから抽出し、トピック・データベースに登録する手段と、
前記ユーザプロファイル・データベースに格納されている、前記特定の登録ユーザについての前記関連度が上位のキーワードと所定の類似性を有し且つ前記トピック・データベースに登録されているキーワードが出現するコンテンツを特定し、当該特定されたコンテンツの識別情報を前記特定の登録ユーザに対応して推薦トピック・データベースに登録する手段と、
を有し、
前記トランザクション・データベースに格納された前記キーワードに関するデータが、当該キーワードの提示回数kを含み、
前記更新手段が、
前記未処理のトランザクション・データに含まれるキーワードの提示回数kと所定の減衰係数ρによって、前記キーワードの前記評価値を(1−ρ k )/(1−ρ)として算出する
コンテンツ特定装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006076501A JP4875911B2 (ja) | 2006-03-20 | 2006-03-20 | コンテンツ特定方法及び装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006076501A JP4875911B2 (ja) | 2006-03-20 | 2006-03-20 | コンテンツ特定方法及び装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007256992A JP2007256992A (ja) | 2007-10-04 |
| JP4875911B2 true JP4875911B2 (ja) | 2012-02-15 |
Family
ID=38631231
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006076501A Expired - Fee Related JP4875911B2 (ja) | 2006-03-20 | 2006-03-20 | コンテンツ特定方法及び装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4875911B2 (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2927183B1 (fr) * | 2008-01-31 | 2010-02-26 | Alcatel Lucent | Procede de generation de donnees permettant la recherche de complements de contenus, systeme, terminal et serveur pour la mise en oeuvre du procede |
| AU2010201495B2 (en) * | 2009-04-16 | 2012-04-12 | Accenture Global Services Limited | Touchpoint customization system |
| JP5435731B2 (ja) * | 2010-04-21 | 2014-03-05 | 日本電信電話株式会社 | コンシェルジュ装置、コンシェルジュサービスの提供方法及びコンシェルジュプログラム |
| JP5741242B2 (ja) * | 2011-06-21 | 2015-07-01 | コニカミノルタ株式会社 | プロファイル更新装置およびその制御方法、ならびに、プロファイル更新用プログラム |
| US9779385B2 (en) | 2011-06-24 | 2017-10-03 | Facebook, Inc. | Inferring topics from social networking system communications |
| JP5673520B2 (ja) * | 2011-12-20 | 2015-02-18 | 株式会社Jvcケンウッド | 情報処理装置、情報処理方法、及び情報処理プログラム |
| TW201709122A (zh) * | 2012-07-19 | 2017-03-01 | 菲絲博克公司 | 以計算機實現的方法及計算機程式產品 |
| US20140052540A1 (en) * | 2012-08-20 | 2014-02-20 | Giridhar Rajaram | Providing content using inferred topics extracted from communications in a social networking system |
| CN111399756B (zh) * | 2019-09-29 | 2024-01-02 | 杭州海康威视系统技术有限公司 | 一种数据存储方法、数据下载方法及装置 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH10326289A (ja) * | 1997-03-28 | 1998-12-08 | Nippon Telegr & Teleph Corp <Ntt> | 情報提供方法、システムおよびそのプログラムを格納した記憶媒体 |
| US7440943B2 (en) * | 2000-12-22 | 2008-10-21 | Xerox Corporation | Recommender system and method |
| JP2003173351A (ja) * | 2001-12-05 | 2003-06-20 | Nippon Telegr & Teleph Corp <Ntt> | 情報解析、収集、検索方法、装置、プログラム、および記録媒体 |
| JP2003173352A (ja) * | 2001-12-05 | 2003-06-20 | Nippon Telegr & Teleph Corp <Ntt> | 検索ログ解析方法および装置、文書情報検索方法および装置、検索ログ解析プログラム、文書情報検索プログラム、および記録媒体 |
| JP4535765B2 (ja) * | 2004-04-23 | 2010-09-01 | 富士通株式会社 | コンテンツナビゲーションプログラム、コンテンツナビゲーション方法及びコンテンツナビゲーション装置 |
-
2006
- 2006-03-20 JP JP2006076501A patent/JP4875911B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2007256992A (ja) | 2007-10-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4875911B2 (ja) | コンテンツ特定方法及び装置 | |
| KR101171405B1 (ko) | 검색 결과에서 배치 내용 정렬의 맞춤화 | |
| JP4350744B2 (ja) | 地域情報検索結果の提供方法およびシステム | |
| CN1858733B (zh) | 信息检索系统和检索方法 | |
| US8738654B2 (en) | Objective and subjective ranking of comments | |
| US7698626B2 (en) | Enhanced document browsing with automatically generated links to relevant information | |
| US8812505B2 (en) | Method for recommending best information in real time by appropriately obtaining gist of web page and user's preference | |
| KR100645608B1 (ko) | 사용자 방문 유알엘 로그를 이용한 정보 검색 서비스 제공 서버 및 그 방법 | |
| KR20070039072A (ko) | 검색 엔진에서의 결과물 기반의 광고 개인화 | |
| JP5084858B2 (ja) | サマリ作成装置、サマリ作成方法及びプログラム | |
| JP2008538149A (ja) | 格付け方法、検索結果組織化方法、格付けシステム及び検索結果組織化システム | |
| JP2010506335A (ja) | 場所に関するサイトの識別 | |
| KR20080096887A (ko) | 사용자 관심도를 반영한 정보검색 랭킹 시스템 및 그 방법 | |
| JP2007334502A (ja) | 検索装置、方法およびプログラム | |
| JP2011154467A (ja) | 検索結果順位付け方法および検索結果順位付けシステム | |
| TWI417751B (zh) | Information providing device, information providing method, information application program, and information recording medium | |
| JP5313295B2 (ja) | 文書探索サービス提供方法及びシステム | |
| TWI399657B (zh) | A provider, a method of providing information, a program, and an information recording medium | |
| KR100900467B1 (ko) | 개인 미디어 검색 서비스 시스템 및 방법 | |
| KR101132431B1 (ko) | 관심 정보 제공 시스템 및 방법 | |
| JP2008204198A (ja) | 情報提供システム、及び、情報提供プログラム | |
| US20020062341A1 (en) | Interested article serving system and interested article serving method | |
| KR101020895B1 (ko) | 지역 정보 검색 결과 제공 방법 및 시스템 | |
| JP2009187384A (ja) | 検索装置、検索方法、検索プログラム、および、記録媒体 | |
| JP2003173351A (ja) | 情報解析、収集、検索方法、装置、プログラム、および記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20081202 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20110106 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110118 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20111108 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20111128 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20141202 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313115 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |