CN116209775A - 甲基化状态的检测 - Google Patents
甲基化状态的检测 Download PDFInfo
- Publication number
- CN116209775A CN116209775A CN202180045918.6A CN202180045918A CN116209775A CN 116209775 A CN116209775 A CN 116209775A CN 202180045918 A CN202180045918 A CN 202180045918A CN 116209775 A CN116209775 A CN 116209775A
- Authority
- CN
- China
- Prior art keywords
- nucleic acid
- sequence
- oligonucleotide
- nucleotide
- interest
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 230000011987 methylation Effects 0.000 title claims description 113
- 238000007069 methylation reaction Methods 0.000 title claims description 113
- 238000001514 detection method Methods 0.000 title description 6
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 412
- 239000002773 nucleotide Substances 0.000 claims abstract description 363
- 150000007523 nucleic acids Chemical group 0.000 claims abstract description 260
- 230000002209 hydrophobic effect Effects 0.000 claims abstract description 229
- 238000000034 method Methods 0.000 claims abstract description 203
- 108091034117 Oligonucleotide Proteins 0.000 claims abstract description 191
- 108091028043 Nucleic acid sequence Proteins 0.000 claims abstract description 145
- 238000002844 melting Methods 0.000 claims abstract description 116
- 230000008018 melting Effects 0.000 claims abstract description 116
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 106
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 106
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 claims abstract description 32
- 230000004049 epigenetic modification Effects 0.000 claims abstract description 28
- 108020004414 DNA Proteins 0.000 claims description 146
- 239000000523 sample Substances 0.000 claims description 121
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 claims description 94
- 230000000295 complement effect Effects 0.000 claims description 71
- 239000003999 initiator Substances 0.000 claims description 70
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 claims description 68
- 230000003321 amplification Effects 0.000 claims description 47
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 47
- 238000000137 annealing Methods 0.000 claims description 43
- 239000000138 intercalating agent Substances 0.000 claims description 41
- 229940104302 cytosine Drugs 0.000 claims description 38
- 239000000178 monomer Substances 0.000 claims description 38
- 125000005647 linker group Chemical group 0.000 claims description 25
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 claims description 22
- 108091029430 CpG site Proteins 0.000 claims description 21
- 238000006243 chemical reaction Methods 0.000 claims description 21
- -1 bromo, fluoro, chloro, iodo, mercapto, thio Chemical group 0.000 claims description 14
- 238000011282 treatment Methods 0.000 claims description 13
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 claims description 12
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 claims description 12
- 239000000872 buffer Substances 0.000 claims description 12
- 230000000694 effects Effects 0.000 claims description 12
- 229910052739 hydrogen Inorganic materials 0.000 claims description 10
- 239000001257 hydrogen Substances 0.000 claims description 10
- 238000003753 real-time PCR Methods 0.000 claims description 9
- 206010028980 Neoplasm Diseases 0.000 claims description 8
- 201000011510 cancer Diseases 0.000 claims description 8
- BBEAQIROQSPTKN-UHFFFAOYSA-N pyrene Chemical compound C1=CC=C2C=CC3=CC=CC4=CC=C1C2=C43 BBEAQIROQSPTKN-UHFFFAOYSA-N 0.000 claims description 8
- 230000002255 enzymatic effect Effects 0.000 claims description 6
- GVEPBJHOBDJJJI-UHFFFAOYSA-N fluoranthene Chemical compound C1=CC(C2=CC=CC=C22)=C3C2=CC=CC3=C1 GVEPBJHOBDJJJI-UHFFFAOYSA-N 0.000 claims description 6
- YNPNZTXNASCQKK-UHFFFAOYSA-N phenanthrene Chemical compound C1=CC=C2C3=CC=CC=C3C=CC2=C1 YNPNZTXNASCQKK-UHFFFAOYSA-N 0.000 claims description 6
- 150000008300 phosphoramidites Chemical class 0.000 claims description 6
- 239000011780 sodium chloride Substances 0.000 claims description 6
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 claims description 5
- UHOVQNZJYSORNB-UHFFFAOYSA-N monobenzene Natural products C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 claims description 5
- YBYIRNPNPLQARY-UHFFFAOYSA-N 1H-indene Chemical compound C1=CC=C2CC=CC2=C1 YBYIRNPNPLQARY-UHFFFAOYSA-N 0.000 claims description 4
- UFWIBTONFRDIAS-UHFFFAOYSA-N Naphthalene Chemical compound C1=CC=CC2=CC=CC=C21 UFWIBTONFRDIAS-UHFFFAOYSA-N 0.000 claims description 4
- MWPLVEDNUUSJAV-UHFFFAOYSA-N anthracene Chemical compound C1=CC=CC2=CC3=CC=CC=C3C=C21 MWPLVEDNUUSJAV-UHFFFAOYSA-N 0.000 claims description 4
- 125000003118 aryl group Chemical group 0.000 claims description 4
- CUFNKYGDVFVPHO-UHFFFAOYSA-N azulene Chemical compound C1=CC=CC2=CC=CC2=C1 CUFNKYGDVFVPHO-UHFFFAOYSA-N 0.000 claims description 4
- NIHNNTQXNPWCJQ-UHFFFAOYSA-N fluorene Chemical compound C1=CC=C2CC3=CC=CC=C3C2=C1 NIHNNTQXNPWCJQ-UHFFFAOYSA-N 0.000 claims description 4
- 208000005017 glioblastoma Diseases 0.000 claims description 4
- 238000009396 hybridization Methods 0.000 claims description 4
- 150000002467 indacenes Chemical class 0.000 claims description 4
- RDOWQLZANAYVLL-UHFFFAOYSA-N phenanthridine Chemical compound C1=CC=C2C3=CC=CC=C3C=NC2=C1 RDOWQLZANAYVLL-UHFFFAOYSA-N 0.000 claims description 4
- GBROPGWFBFCKAG-UHFFFAOYSA-N picene Chemical compound C1=CC2=C3C=CC=CC3=CC=C2C2=C1C1=CC=CC=C1C=C2 GBROPGWFBFCKAG-UHFFFAOYSA-N 0.000 claims description 4
- 108091008146 restriction endonucleases Proteins 0.000 claims description 4
- NQRYJNQNLNOLGT-UHFFFAOYSA-N tetrahydropyridine hydrochloride Natural products C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 claims description 4
- 230000001225 therapeutic effect Effects 0.000 claims description 4
- 238000011269 treatment regimen Methods 0.000 claims description 4
- 125000003342 alkenyl group Chemical group 0.000 claims description 3
- 125000003545 alkoxy group Chemical group 0.000 claims description 3
- 125000000217 alkyl group Chemical group 0.000 claims description 3
- 125000004414 alkyl thio group Chemical group 0.000 claims description 3
- 125000000304 alkynyl group Chemical group 0.000 claims description 3
- 125000003368 amide group Chemical group 0.000 claims description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 3
- 230000002596 correlated effect Effects 0.000 claims description 3
- 125000004093 cyano group Chemical group *C#N 0.000 claims description 3
- 125000001072 heteroaryl group Chemical group 0.000 claims description 3
- 125000000623 heterocyclic group Chemical group 0.000 claims description 3
- 125000002887 hydroxy group Chemical group [H]O* 0.000 claims description 3
- 238000011534 incubation Methods 0.000 claims description 3
- IFLREYGFSNHWGE-UHFFFAOYSA-N tetracene Chemical compound C1=CC=CC2=CC3=CC4=CC=CC=C4C=C3C=C21 IFLREYGFSNHWGE-UHFFFAOYSA-N 0.000 claims description 3
- DXBHBZVCASKNBY-UHFFFAOYSA-N 1,2-Benz(a)anthracene Chemical compound C1=CC=C2C3=CC4=CC=CC=C4C=C3C=CC2=C1 DXBHBZVCASKNBY-UHFFFAOYSA-N 0.000 claims description 2
- ZGEGCLOFRBLKSE-UHFFFAOYSA-N 1-Heptene Chemical group CCCCCC=C ZGEGCLOFRBLKSE-UHFFFAOYSA-N 0.000 claims description 2
- XVEUJPQIDXXNFD-UHFFFAOYSA-N 1h-pyrido[2,3]thieno[2,4-d]pyrimidin-4-one Chemical compound C12=CC=CN=C2SC2=C1N=CNC2=O XVEUJPQIDXXNFD-UHFFFAOYSA-N 0.000 claims description 2
- PZMKGWRBZNOIPQ-UHFFFAOYSA-N 1h-thieno[3,2-d]pyrimidin-4-one Chemical compound OC1=NC=NC2=C1SC=C2 PZMKGWRBZNOIPQ-UHFFFAOYSA-N 0.000 claims description 2
- VEPOHXYIFQMVHW-XOZOLZJESA-N 2,3-dihydroxybutanedioic acid (2S,3S)-3,4-dimethyl-2-phenylmorpholine Chemical compound OC(C(O)C(O)=O)C(O)=O.C[C@H]1[C@@H](OCCN1C)c1ccccc1 VEPOHXYIFQMVHW-XOZOLZJESA-N 0.000 claims description 2
- GDALETGZDYOOGB-UHFFFAOYSA-N Acridone Natural products C1=C(O)C=C2N(C)C3=CC=CC=C3C(=O)C2=C1O GDALETGZDYOOGB-UHFFFAOYSA-N 0.000 claims description 2
- PCNDJXKNXGMECE-UHFFFAOYSA-N Phenazine Natural products C1=CC=CC2=NC3=CC=CC=C3N=C21 PCNDJXKNXGMECE-UHFFFAOYSA-N 0.000 claims description 2
- PJANXHGTPQOBST-VAWYXSNFSA-N Stilbene Natural products C=1C=CC=CC=1/C=C/C1=CC=CC=C1 PJANXHGTPQOBST-VAWYXSNFSA-N 0.000 claims description 2
- XBDYBAVJXHJMNQ-UHFFFAOYSA-N Tetrahydroanthracene Natural products C1=CC=C2C=C(CCCC3)C3=CC2=C1 XBDYBAVJXHJMNQ-UHFFFAOYSA-N 0.000 claims description 2
- CWRYPZZKDGJXCA-UHFFFAOYSA-N acenaphthene Chemical compound C1=CC(CC2)=C3C2=CC=CC3=C1 CWRYPZZKDGJXCA-UHFFFAOYSA-N 0.000 claims description 2
- FZEYVTFCMJSGMP-UHFFFAOYSA-N acridone Chemical compound C1=CC=C2C(=O)C3=CC=CC=C3NC2=C1 FZEYVTFCMJSGMP-UHFFFAOYSA-N 0.000 claims description 2
- 125000002529 biphenylenyl group Chemical group C1(=CC=CC=2C3=CC=CC=C3C12)* 0.000 claims description 2
- 125000004817 pentamethylene group Chemical group [H]C([H])([*:2])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[*:1] 0.000 claims description 2
- XDJOIMJURHQYDW-UHFFFAOYSA-N phenalene Chemical compound C1=CC(CC=C2)=C3C2=CC=CC3=C1 XDJOIMJURHQYDW-UHFFFAOYSA-N 0.000 claims description 2
- CTRLRINCMYICJO-UHFFFAOYSA-N phenyl azide Chemical class [N-]=[N+]=NC1=CC=CC=C1 CTRLRINCMYICJO-UHFFFAOYSA-N 0.000 claims description 2
- 150000004032 porphyrins Chemical class 0.000 claims description 2
- PJANXHGTPQOBST-UHFFFAOYSA-N stilbene Chemical compound C=1C=CC=CC=1C=CC1=CC=CC=C1 PJANXHGTPQOBST-UHFFFAOYSA-N 0.000 claims description 2
- 235000021286 stilbenes Nutrition 0.000 claims description 2
- DGEZNRSVGBDHLK-UHFFFAOYSA-N [1,10]phenanthroline Chemical compound C1=CN=C2C3=NC=CC=C3C=CC2=C1 DGEZNRSVGBDHLK-UHFFFAOYSA-N 0.000 claims 1
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 claims 1
- 150000004056 anthraquinones Chemical class 0.000 claims 1
- 150000001924 cycloalkanes Chemical class 0.000 claims 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 claims 1
- 230000001973 epigenetic effect Effects 0.000 abstract description 12
- 238000003752 polymerase chain reaction Methods 0.000 description 90
- 238000003556 assay Methods 0.000 description 83
- 238000013461 design Methods 0.000 description 19
- 102100025825 Methylated-DNA-protein-cysteine methyltransferase Human genes 0.000 description 15
- CTMZLDSMFCVUNX-VMIOUTBZSA-N cytidylyl-(3'->5')-guanosine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=C(C(N=C(N)N3)=O)N=C2)O)[C@@H](CO)O1 CTMZLDSMFCVUNX-VMIOUTBZSA-N 0.000 description 15
- 108040008770 methylated-DNA-[protein]-cysteine S-methyltransferase activity proteins Proteins 0.000 description 14
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 12
- 230000035945 sensitivity Effects 0.000 description 10
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 8
- 238000002474 experimental method Methods 0.000 description 8
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 7
- 238000002156 mixing Methods 0.000 description 7
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 6
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 6
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 210000004027 cell Anatomy 0.000 description 5
- 239000000203 mixture Substances 0.000 description 5
- 230000035772 mutation Effects 0.000 description 5
- 108091093088 Amplicon Proteins 0.000 description 4
- 241000282414 Homo sapiens Species 0.000 description 4
- 108060004795 Methyltransferase Proteins 0.000 description 4
- 102000016397 Methyltransferase Human genes 0.000 description 4
- 239000012807 PCR reagent Substances 0.000 description 4
- 210000001124 body fluid Anatomy 0.000 description 4
- 239000010839 body fluid Substances 0.000 description 4
- 230000014759 maintenance of location Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- 229940035893 uracil Drugs 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 238000002944 PCR assay Methods 0.000 description 3
- 108091028664 Ribonucleotide Proteins 0.000 description 3
- 230000029936 alkylation Effects 0.000 description 3
- 238000005804 alkylation reaction Methods 0.000 description 3
- 239000005547 deoxyribonucleotide Substances 0.000 description 3
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 125000005462 imide group Chemical group 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 238000011835 investigation Methods 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 108090000623 proteins and genes Proteins 0.000 description 3
- 239000002336 ribonucleotide Substances 0.000 description 3
- 125000002652 ribonucleotide group Chemical group 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 229930024421 Adenine Natural products 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 2
- 230000030933 DNA methylation on cytosine Effects 0.000 description 2
- 101000653374 Homo sapiens Methylcytosine dioxygenase TET2 Proteins 0.000 description 2
- 102100030803 Methylcytosine dioxygenase TET2 Human genes 0.000 description 2
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 description 2
- 230000021736 acetylation Effects 0.000 description 2
- 238000006640 acetylation reaction Methods 0.000 description 2
- 229960000643 adenine Drugs 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 2
- 210000002939 cerumen Anatomy 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 230000033444 hydroxylation Effects 0.000 description 2
- 238000005805 hydroxylation reaction Methods 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 238000006198 methoxylation reaction Methods 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 229910052698 phosphorus Inorganic materials 0.000 description 2
- 238000004393 prognosis Methods 0.000 description 2
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 2
- 230000035484 reaction time Effects 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 229960004964 temozolomide Drugs 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 210000002700 urine Anatomy 0.000 description 2
- 229940083957 1,2-butanediol Drugs 0.000 description 1
- ARXJGSRGQADJSQ-UHFFFAOYSA-N 1-methoxypropan-2-ol Chemical compound COCC(C)O ARXJGSRGQADJSQ-UHFFFAOYSA-N 0.000 description 1
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 1
- 125000002103 4,4'-dimethoxytriphenylmethyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)(C1=C([H])C([H])=C(OC([H])([H])[H])C([H])=C1[H])C1=C([H])C([H])=C(OC([H])([H])[H])C([H])=C1[H] 0.000 description 1
- KBCQTGVVTHNJLV-UHFFFAOYSA-N 4-methyl-4-(propan-2-ylamino)pentanenitrile phosphorous acid Chemical compound OP(O)O.CC(C)NC(C)(C)CCC#N KBCQTGVVTHNJLV-UHFFFAOYSA-N 0.000 description 1
- BLQMCTXZEMGOJM-UHFFFAOYSA-N 5-carboxycytosine Chemical compound NC=1NC(=O)N=CC=1C(O)=O BLQMCTXZEMGOJM-UHFFFAOYSA-N 0.000 description 1
- 101000796998 Bacillus subtilis (strain 168) Methylated-DNA-protein-cysteine methyltransferase, inducible Proteins 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 239000004215 Carbon black (E152) Substances 0.000 description 1
- 206010050337 Cerumen impaction Diseases 0.000 description 1
- 108091029523 CpG island Proteins 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 230000007067 DNA methylation Effects 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- 206010047700 Vomiting Diseases 0.000 description 1
- 238000010306 acid treatment Methods 0.000 description 1
- UHKLOQIARLPINB-UHFFFAOYSA-N anthracene-9,10-dione;pyrene Chemical compound C1=CC=C2C=CC3=CC=CC4=CC=C1C2=C43.C1=CC=C2C(=O)C3=CC=CC=C3C(=O)C2=C1 UHKLOQIARLPINB-UHFFFAOYSA-N 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 210000003756 cervix mucus Anatomy 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- BNIILDVGGAEEIG-UHFFFAOYSA-L disodium hydrogen phosphate Chemical compound [Na+].[Na+].OP([O-])([O-])=O BNIILDVGGAEEIG-UHFFFAOYSA-L 0.000 description 1
- 229910000397 disodium phosphate Inorganic materials 0.000 description 1
- 235000019800 disodium phosphate Nutrition 0.000 description 1
- 210000003060 endolymph Anatomy 0.000 description 1
- 230000008995 epigenetic change Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 150000002219 fluoranthenes Chemical class 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 239000004519 grease Substances 0.000 description 1
- 210000004209 hair Anatomy 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 230000006607 hypermethylation Effects 0.000 description 1
- 238000009830 intercalation Methods 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000010309 melting process Methods 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 238000011369 optimal treatment Methods 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 239000013610 patient sample Substances 0.000 description 1
- 210000004049 perilymph Anatomy 0.000 description 1
- 150000005041 phenanthrolines Chemical class 0.000 description 1
- SXADIBFZNXBEGI-UHFFFAOYSA-N phosphoramidous acid Chemical group NP(O)O SXADIBFZNXBEGI-UHFFFAOYSA-N 0.000 description 1
- 210000004910 pleural fluid Anatomy 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000002203 pretreatment Methods 0.000 description 1
- 125000006239 protecting group Chemical group 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 125000000714 pyrimidinyl group Chemical group 0.000 description 1
- 238000012175 pyrosequencing Methods 0.000 description 1
- 230000014493 regulation of gene expression Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000010839 reverse transcription Methods 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 210000002374 sebum Anatomy 0.000 description 1
- 210000000582 semen Anatomy 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 210000004243 sweat Anatomy 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 210000001138 tear Anatomy 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 230000008673 vomiting Effects 0.000 description 1
- 239000012224 working solution Substances 0.000 description 1
Images




















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6832—Enhancement of hybridisation reaction
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/113—Modifications characterised by incorporating modified backbone
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/117—Modifications characterised by incorporating modified base
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2537/00—Reactions characterised by the reaction format or use of a specific feature
- C12Q2537/10—Reactions characterised by the reaction format or use of a specific feature the purpose or use of
- C12Q2537/164—Methylation detection other then bisulfite or methylation sensitive restriction endonucleases
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2563/00—Nucleic acid detection characterized by the use of physical, structural and functional properties
- C12Q2563/173—Nucleic acid detection characterized by the use of physical, structural and functional properties staining/intercalating agent, e.g. ethidium bromide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/154—Methylation markers
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Immunology (AREA)
- Biotechnology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Pathology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Signal Processing For Digital Recording And Reproducing (AREA)
- Sorption Type Refrigeration Machines (AREA)
- Transition And Organic Metals Composition Catalysts For Addition Polymerization (AREA)
Abstract
本发明涉及一种用于确定目的靶核酸序列中至少一个目的核苷酸(NOI)的表观遗传修饰状态的方法。本发明基于以下发现,即与未修饰的靶核酸相比,某些包含疏水性核苷酸的寡核苷酸在与表观遗传修饰的靶核酸的解链温度方面具有显著差异。所述方法具有多种应用,例如在诊断中。本发明还提供了用于此类方法的寡核苷酸,特别是BasePrimer。
Description
背景技术
甲基化是DNA的表观遗传修饰的例子,其中甲基被添加到四种DNA碱基之一上。最常见的是,甲基被添加到胞嘧啶核碱基的5位上。启动子区的DNA甲基化参与基因表达的调节。
在癌症的进展中,几种基因由于其启动子的过度甲基化而沉默,这导致基因转录的阻遏。特定基因的甲基化不仅可以用作癌症的预后因子,而且可以用于为患者选择最佳治疗。在脑肿瘤胶质母细胞瘤中,MGMT(O6-甲基鸟嘌呤-DNA甲基转移酶)启动子的甲基化与更好的预后和对烷基化化疗(如替莫唑胺(TMZ))的更有效反应相关。因此经常测试患有胶质母细胞瘤的患者的MGMT甲基化。
有几种方法可用于检测甲基化,并且金标准方法需要对DNA进行亚硫酸氢盐预处理。预处理将非甲基化胞嘧啶转化成尿嘧啶,而甲基化胞嘧啶未改变。亚硫酸氢盐处理耗时,需要大量DNA输入,并且易于给出错误结果,因为太短的反应时间将导致非甲基化胞嘧啶的不完全转化,并且太长的反应时间会导致甲基化胞嘧啶的转化。这导致假阳性结果和假阴性结果两者的风险。也已经开发了无亚硫酸氢盐的方法,但是它们都需要替代的转化或者不是基于PCR的。用于亚硫酸氢盐转化的试剂盒是可商购的,但是典型地需要至少15个操作步骤。
疏水性核苷酸(例如嵌入核酸(INATM))包含疏水性部分,如嵌入剂。嵌入剂是平面的共轭的芳族或杂芳族环系,其可以参与DNA或RNA双链体的堆积。疏水性核苷酸不参与沃森克里克碱基配对。当具有掺入的疏水性核苷酸的寡核苷酸与未修饰的DNA序列结合时,疏水性部分将其自身定位于DNA螺旋体的中心。疏水性核苷酸与DNA碱基之间的相互作用导致双链DNA的稳定性增加。
发明内容
用于检测核酸的核碱基的表观遗传修饰的简单方法,如在不转化核酸的情况下分析核碱基的甲基化是有益的,这是由于甲基化核酸的检测更快,在转化步骤期间没有样品损失,并且没有基于转化不完全或非特异性的不确定性。在临床环境中,表观遗传修饰(如甲基化)状态的早期检测可以使得患者更快地诊断,因此使得治疗更早地开始。更好的方法也可以潜在地更好地定量甲基化水平并扩展甲基化状态的用途,例如在癌症的治疗和监测或诊断中。
本发明提供了用于检测核酸中的表观遗传修饰,例如用于检测甲基化DNA的非常快速的方法。所述方法基于以下发现,即包含至少一个疏水性核苷酸的合成寡核苷酸可以根据设计分别对在核碱基中具有表观遗传修饰的DNA和不具有所述表观遗传修饰的DNA具有惊人的高亲和力(解链温度)差异。当疏水性核苷酸在合成寡核苷酸内定位成使得它将嵌入靶核酸上潜在的表观遗传修饰的核苷酸(如甲基化的)与紧邻其3'的核苷酸之间时,情况尤其如此。
尽管本发明的方法可以用于检测任何种类的核酸中的任何核苷酸的表观遗传修饰,但所述方法对于检测DNA中的胞嘧啶甲基化特别有用。在此类情况下,优选以这样的方式设计合成寡核苷酸,使得疏水性核苷酸定位成使得它将嵌入潜在的甲基化胞嘧啶与紧邻其3'的核苷酸(最常见的是鸟嘌呤)之间。
可以利用这种惊人的高解链温度差异,以便使用各种方法容易地检测核酸甲基化状态。例如,核酸甲基化状态可以通过简单的PCR方法来检测。重要的是,本发明的方法不需要对核酸进行预处理。因此,通过设计包含一个或多个疏水性核苷酸的适当引物,可以在一步PCR中检测核酸甲基化。
在本发明的优选实施方案中,使用称为BasePrimer的一类引物进行所述方法,其在下面有更详细的描述。
本发明的一个方面是提供确定目的靶核酸序列中至少一个目的核苷酸(NOI)的甲基化状态的方法,其中所述靶核酸序列包含含有所述NOI的靶锚序列,所述方法包括以下步骤:
a.提供包含锚序列(An)的寡核苷酸,其中所述锚序列是与所述靶锚序列至少50%互补的序列,其中所述锚序列包含至少一个定位在与所述NOI互补的核苷酸与所述寡核苷酸中紧邻其5'的核苷酸之间的疏水性核苷酸(H);
b.在高于当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度的温度下,将所述寡核苷酸与所述目的靶核酸一起孵育,
c.检测所述寡核苷酸是否与所述目的靶核酸退火,
由此确定甲基化状态,
其中
i.所述疏水性核苷酸(H)具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
本发明的一个方面是还提供确定未修饰的目的靶核酸序列中至少一个目的核苷酸(NOI)的甲基化状态的方法,其中所述靶核酸序列包含含有所述NOI的靶锚序列,所述方法包括以下步骤:
a.提供包含锚序列(An)的寡核苷酸,其中所述锚序列是与所述靶锚序列至少50%互补的序列,其中所述锚序列包含至少一个定位在与所述NOI互补的核苷酸与紧邻其5'的核苷酸之间的疏水性核苷酸(H);
b.在高于当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度的温度下,将所述寡核苷酸与所述目的靶核酸一起孵育,
c.检测所述寡核苷酸是否与所述目的靶核酸退火,
由此确定甲基化状态,
其中
i.所述疏水性核苷酸(H)具有以下结构:
X-Y-Q,
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元;
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
ii.所述寡核苷酸具有结构5'-An-Lp-St-3',其中
An是所述锚序列;
Lp是不与所述目的靶核酸序列互补的环序列,其中所述环序列由能够形成突出结构、如环结构或茎结构的单个核酸序列组成,或者由能够至少部分地彼此杂交以形成能够形成突出结构、如环结构或茎结构的复合体的两个或更多个核酸序列组成;
St是能够与靶起始子序列杂交的起始子序列,其中所述靶起始子序列是所述靶核酸序列的定位在所述靶锚序列的5'的序列。
在另一个方面,本发明提供了一种用于确定个体是否患有临床病症的风险或个体患上临床病症的风险的方法,其中所述临床病症与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供从所述个体获得的样品;
b.通过进行如本文公开的方法确定所述样品中所述NOI的甲基化状态,其中所述甲基化状态指示所述临床病症的存在或患上所述临床病症的风险。
在一些方面,本发明提供了一种用于确定有需要的个体的临床病症的治疗效果的可能性的方法,其中所述临床病症的所述治疗的效果与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供从所述个体获得的样品;
b.通过进行如本文公开的方法确定所述样品中所述NOI的甲基化状态,其中所述甲基化状态指示不同治疗方案对所述临床病症的效果。
在一些方面,提供了一种包含以下通用结构或由以下通用结构组成的寡核苷酸:
5'(N)n-HG-(N)m-HG-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸
其中所述疏水性核苷酸具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
在又另一个方面,提供了一种包含以下通用结构或由以下通用结构组成的寡核苷酸:
5'(N)n-CGH-(N)m-CGH-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
C是核苷酸胞嘧啶;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸
其中所述疏水性核苷酸具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
本发明由所附权利要求进一步限定。
附图说明
图1.解链温度(Tm)的确定。加热标记的寡核苷酸及其互补靶标的双链体,当链彼此解离时导致RFU降低(参见实施例1)。黑色圆点标记了解链温度。A)探针/靶标双链体的解链曲线。解链温度是斜率最陡的点。B)A中解链曲线的一阶负导数(-dF/dT)。曲线的最大值是解链温度。
图2.分别地甲基化DNA(mC)和非甲基化DNA(非mC)的ΔCt的展示。分别地对于mCDNA或非mC DNA,将ΔCt计算为参考测定的Ct值与甲基特异性测定的Ct值之间的差异。注意,黑色线是计算值的展示,而不是精确Ct值的标记。
图3.BasePrimer方法的展示。BasePrimer由靶向潜在表观遗传修饰区的包含一个或多个疏水性核苷酸的锚序列(黑色)、环序列(深灰色)和起始子序列(浅灰色)组成。A)如果模板DNA是甲基化的,则锚序列对模板具有高亲和力,并且BasePrimer的锚序列和起始子序列将与模板DNA退火,并且可以发生延伸。B)BasePrimer对非甲基化模板将不具有同样高的亲和力,因此在选定的条件下应当不与非甲基化模板DNA结合。这将确保非甲基化模板不被扩增。注意,深灰色线代表模板链,浅灰色线代表扩增子,并且深色圆圈代表甲基化位点。如果BasePrimer充当引物,则将环序列和锚序列掺入可以起反向引物作用的模板中。使用包含BasePrimer的模板从反向引物延伸通常将在锚序列处终止,因为大多数DNA聚合酶不能连读疏水性核苷酸。在发生甲基特异性扩增之后,环序列和起始子序列可以充当常规引物(由BioRender.com创建)。
图4.当分别与互补的甲基化序列或非甲基化序列杂交时,包含不同设计和疏水性核苷酸的不同类型探针的解链温度差异(ΔTm)的条形图。将探针MGMT_Z、MGMT_E、MGMT_E2、MGMT_E3和MGMT_参考(参见表1中的序列)分别单独地与非甲基化靶标(MGMT_0mC)或完全甲基化靶标(MGMT_1,2,3,4mC)(参见表1中的序列)混合。展示了完全甲基化靶标与非甲基化靶标之间的解链温度差异。每个解链实验重复三次。平均值显示在条上面。
图5.分别与靶标MGMT_1,2,3,4mC和MGMT_0mC杂交的探针MGMT_E和参考探针MGMT_参考(参见表1中的序列)的解链峰(解链曲线的一阶负导数)。可以看出,与参考探针相比,MGMT_E在与甲基化靶标和非甲基化靶标两者杂交时具有更高的解链温度,但同时它们之间的区分度也更好(ΔTm更大)。
图6.图展示,在探针下的甲基化位点的数量与探针的亲和力之间存在相关性。显示了甲基化位点的数量与探针MGMT_E的解链温度之间的线性拟合。线性拟合适用于与以下靶标杂交的探针MGMT_E的解链温度:MGMT_1mC、MGMT_2mC、MGMT_3mC、MGMT_4mC(各自具有1个甲基化胞嘧啶),MGMT_2,3mC和MGMT_1,2,3,4mC(分别具有2个和4个甲基化胞嘧啶)(参见表3中的序列)。每个解链实验重复三次。
图7.AmpliQueen预混液(可从PentaBase获得)中探针MGMT_E的解链峰。与靶标MGMT_1,2,3,4mC和MGMT_0mC中的每一个杂交的探针MGMT_E的解链曲线的一阶负导数。可以看出MGMT_E/MGMT_0mC双链体首先在80℃下完全解离。这表明在大约80℃下,探针MGMT_E可以选择性地结合所述预混液中的甲基化互补序列。
图8.在不同的退火时间和温度下,在BasePrimer与参考引物之间PCR循环中的信号差异(ΔCt)的条形图。使用甲基特异性测定与参考测定之间的ΔCt和甲基化DNA与非甲基化DNA之间的ΔΔCt差异来展示最佳退火条件。退火温度和时间指示于附图中。参考测定使用700nM MGMT_Fw2C和MGMT_Rev2C以及500nM MGMT_探针2E,如在以下实施例中在章节“BasePrimer的设计”中所述。甲基特异性测定使用MGMT_Fw环4C引物而不是MGMT_Fw2C。对于在79℃下的实验,使用1% ZUBR Green而不是MGMT_探针2E。
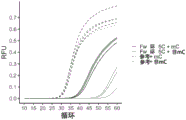
图9.对于甲基化DNA和非甲基化DNA参考测定和甲基特异性测定的PCR曲线。将探针的相对荧光单位(RFU)绘制为循环的函数。使用PCR程序E(参见表10)。所测试的样品是从IDH U87 WT分离的甲基化DNA(mC)和作为对照的来自健康供体的DNA(非mC)。在参考测定(参考)中使用700nM MGMT_Fw2C、700nM MGMT_Rev2C和1% ZUBR Green,并且甲基特异性测定具有700nM MGMT_Fw环4C而不是MGMT_Fw2C。
图10.MGMT_Fw环5C在不同的退火时间和温度下的点图(序列参见表12)。使用甲基特异性测定与参考测定之间的ΔCt和甲基化DNA与非甲基化DNA之间的ΔΔCt差异来展示退火时间和温度改变的影响。A)将退火时间固定为30s并且温度是变化的。B)将退火温度固定为81℃,并且退火时间是变化的。参考测定具有700nM MGMT_Fw2C_suE和MGMT_Rev2C_suE以及1% ZUBR Green。甲基特异性测定包括MGMT_Fw环5C而不是MGMT_Fw2C_suE。
图11.对于甲基化DNA和非甲基化DNA参考测定和甲基特异性测定的PCR曲线。将RFU绘制为循环的函数。使用PCR程序F(参见表15)。在参考测定中使用700nM MGMT_Fw2C_suE、700nM MGMT_Rev2C_suE和1% ZUBR Green,并且甲基特异性测定具有500nM MGMT_Fw环5C而不是MGMT_Fw2C_suE。
图12.参考测定和甲基特异性测定的线性度结果。将Ct绘制为模板输入量的对数[log(q)]的函数。A)参考测定的结果。B)用MGMT_Fw环5C进行的甲基特异性测定的结果。使用PCR程序F。在参考测定中使用700nM MGMT_Fw2C_suE、700nM MGMT_Rev2C_suE和1% ZUBRGreen,并且甲基特异性测定具有500nM MGMT_Fw环5C而不是MGMT_Fw2C_suE。
图13.
在MyGo Pro实时PCR仪器(It-Is lifescience)上的灵敏度研究结果。将ΔCt绘制为甲基化%的函数。使用PCR程序F(参见表15)。在参考测定中使用700nM MGMT_Fw2C_suE、700nM Rev2C和1% ZUBR Green,并且甲基特异性测定具有500nM MGMT_Fw环5C而不是MGMT_Fw2C_suE。
图14.不同类型的突变探针(具有错配的探针)的Tm和ΔTm的条形图。将包含具有(E_M1、E_M2、E_M3、E_M4、E_M5)突变和不具有(E)突变(错配)的E型疏水性核苷酸的MGMT探针分别单独地与非甲基化靶标(0mC)或完全甲基化靶标(1,2,3,4mC)混合。MGMT探针的序列以及所测试的MGMT靶标的序列提供于表20中。展示了甲基化靶标与非甲基化靶标之间的解链温度差异。平均值显示在条上面。
图15.在BaseTyperTM实时PCR仪器上使用在锚序列中具有错配的BasePrimer进行的灵敏度研究。A)将ΔCt绘制为甲基化%的函数。B)将ΔCt绘制为log(甲基化%)的函数。使用PCR程序G(参见表23)。在参考测定中使用700nM MGMT_Fw2C、700nM Rev2E和500nMMGMT_探针2E,并且甲基特异性测定具有700nM MGMT_Fw环5D_M5而不是MGMT_Fw2C。模板是来自MGMT启动子区的人工DNA,其使用CpG甲基转移酶(New England Biolabs Inc,美国马萨诸塞州伊普斯维奇)甲基化。在B)中观察到线性度,表明测定是定量的。
图16.在互补靶序列上在锚序列(An)的3'端与起始子序列(St)的5'端之间具有核苷酸缺口的BasePrimer。展示了具有0个、2个和4个核苷酸的缺口的BasePrimer(用BioRender.com创建)。
图17.在锚序列中具有错配的BasePrimer的ΔCt的条形图。BasePrimer被设计成在互补靶序列上在锚序列的3'端与起始子序列的5'端之间具有核苷酸缺口。使用PCR程序H(参见表25)。对于参考测定,使用700nM MGMT_Fw2C、700nM MGMT_Rev2E和500nM MGMT_探针2E,并且对于甲基特异性测定,使用700nM在表24中列出的BasePrimer而不是MGMT_Fw2C。绘制100%甲基化DNA(100%mC)、10%甲基化DNA(10%mC)和非甲基化DNA(非mC)的ΔCt。模板是来自MGMT启动子区的人工DNA,其使用CpG甲基转移酶(New England Biolabs Inc,美国马萨诸塞州伊普斯维奇)甲基化。
图18.辅助引物复合体的设计方法。辅助引物复合体由两个引物组成。一个称为辅助引物的引物(深灰色)包含与靶DNA互补的锚序列和不与靶序列互补的茎序列。茎序列与第二引物的序列互补。第二引物在引物的3'端具有与靶DNA互补的序列。由此,这两个引物产生三级复合体。A)在选定的条件下,复合体仅在模板DNA被甲基化时才稳定。辅助引物复合体的第二引物用于剩余的PCR循环。B)如果模板DNA没有甲基化,则辅助引物复合体在选定的条件下不稳定,并且不会发生扩增(由BioRender.com创建)。
图19.辅助引物复合体的PCR曲线。将相对荧光单位(RFU)绘制为循环的函数。使用PCR程序H(参见表25)。对于参考测定,使用700nM MGMT_Fw2C、700nM MGMT_Rev2E和500nMMGMT_探针2E,并且对于甲基特异性测定,使用700nM MGMT_引物_1D和50nM MGMT_辅助_1A_E而不是MGMT_Fw2C。模板是来自MGMT启动子区的人工DNA(非mC),并且所述模板使用CpG甲基转移酶(New England Biolabs Inc,美国马萨诸塞州伊普斯维奇)甲基化(mC)。
具体实施方式
定义
术语“锚序列”是指包含在寡核苷酸内、优选在BasePrimer内的序列。锚序列包含一个或多个疏水性核苷酸,其定位成邻近与一个或多个目的核苷酸(NOI)互补的核苷酸。此外,锚序列能够与目的靶核酸序列的称为“靶锚序列”的部分杂交。“锚序列”在本文中缩写为“An”。
如本文所用的术语“BasePrimer”是指包含锚序列(An)、环序列(Lp)和起始子序列(St)或由其组成的寡核苷酸。BasePrimer在下文有更详细的描述。尽管锚序列和起始子序列至少部分地与靶核酸序列互补,因此能够与其杂交,但环序列不与靶核酸序列互补。典型地,环序列和起始子序列都不包含疏水性核苷酸。如果BasePrimer在锚序列与环序列之间包含疏水性核苷酸,则认为这种疏水性核苷酸是锚序列的一部分。术语“环序列”和“突出序列”在本文中可互换地使用。
如本文所用的术语“互补”是指能够通过沃森-克里克碱基对与另一连续核苷酸序列碱基配对的连续核苷酸序列。
如本文所用的术语“疏水性核苷酸”是指下文在章节“疏水性核苷酸”中详细描述的疏水性核苷酸。特别地,根据本发明的疏水性核苷酸含有经由接头连接至核苷酸/核苷酸类似物/骨架单体单元的嵌入剂。
如本文所用的术语“解链温度”表示存在能够形成双链体的50%杂交形式的核酸序列与50%未杂交形式的核酸序列时的以摄氏度计的温度。解链温度也可以被称为(Tm)。核酸的解链是指双链核酸分子中两条链的热分离。优选如以下实施例1中所述确定解链温度。优选的是在用于实施本发明的方法的相同溶液(例如缓冲液)中确定解链温度。
术语“核苷酸的甲基化”或“甲基化核苷酸”是指与所述核苷酸的核碱基中正常存在的(在不具有任何表观遗传修饰的核酸中)相比,所述核碱基被另外的甲基共价修饰。尽管不同的甲基化与本发明相关,但优选的甲基化是胞嘧啶的甲基化。通常,甲基被添加到嘧啶环上的第5个原子上,产生5-甲基胞嘧啶(5-mC):

当胞嘧啶在CpG二核苷酸(其也可以被称为“CpG位点”)中正好位于鸟嘌呤之前时,胞嘧啶的甲基化特别普遍。基因组的某些区域含有大量的CpG位点。此类区域可以被称为“CpG岛”。
如本文所用的术语“核苷酸”是指核苷酸,例如天然存在的核糖核苷酸或脱氧核糖核苷酸,或者核糖核苷酸或脱氧核糖核苷酸的天然存在的衍生物。核苷酸包括包含四种核碱基腺嘌呤(A)、胸腺嘧啶(T)、鸟嘌呤(G)或胞嘧啶(C)之一的脱氧核糖核苷酸,以及包含四种核碱基腺嘌呤(A)、尿嘧啶(U)、鸟嘌呤(G)或胞嘧啶(C)之一的核糖核苷酸。为了简单起见,包含特定核碱基的核苷酸在本文中可以简单地用所述核碱基的名称来提及。举例来说,包含胞嘧啶(C)的核苷酸也可以被称为“胞嘧啶”或“C”。
如本文所用的术语“目的核苷酸”是指这样的核苷酸,其中期望研究所述核苷酸的甲基化状态。目的核苷酸可以是任何核苷酸,但是优选地,目的核苷酸是胞嘧啶(C)。“目的核苷酸”在本文中缩写为“NOI”。
如本文所用的术语“寡核苷酸”是指核苷酸和/或核苷酸类似物和/或疏水性核苷酸的寡聚物。优选地,寡核苷酸是任选地包含一个或多个疏水性核苷酸的核苷酸寡聚物。
术语“目的靶核酸序列”是指包含“靶锚序列”的核酸序列,其中所述“靶锚序列”包含至少一个NOI。
术语“靶锚序列”是指目的靶核酸序列的包含NOI的部分。“锚序列”能够与靶锚序列杂交。
术语“表观遗传改变”是指核酸的核碱基可以天然发生的修饰,假定这种修饰改变核碱基的堆积效率。
如本文所用的术语“表观遗传修饰”是指典型地遗传给子细胞的核碱基的共价修饰。所述表观遗传修饰优选是甲基化,然而它也可以是核碱基的烷基化、乙酰化、羟基化、甲氧基化或其他修饰。
如本文所用的术语“未修饰的”是指目的核酸没有经历修饰或预处理步骤以将非甲基化核苷酸转化成可检测部分和/或将甲基化核苷酸转化成可检测部分。此类修饰或预处理的例子包括亚硫酸氢盐转化、限制性酶切或TET酶促转化。因此,如本文定义的未修饰仅是指核酸处理或修饰的缺乏,所述核酸处理或修饰选择性地作用于甲基化核酸或非甲基化核酸。不能选择性地作用于甲基化核酸或非甲基化核酸或在其间进行辨别的预处理步骤或修饰(如不能辨别甲基化核酸与非甲基化核酸的稀释、DNA纯化或酶促处理)未被如本文所用的术语所涵盖。
靶核酸序列中目的核苷酸的甲基化状态
本发明涉及确定靶核酸序列中至少一个NOI的表观遗传(如甲基化)状态的方法。
所述方法基于使用包含锚序列的寡核苷酸,所述锚序列包含一个或多个疏水性核苷酸。寡核苷酸可以是下文在章节“包含锚序列的寡核苷酸”中描述的任何寡核苷酸。包含锚序列的寡核苷酸对具有所述表观遗传修饰(例如甲基化)的核酸序列的亲和力显著不同于对不具有所述表观遗传修饰的核酸序列的亲和力。例如,与非甲基化核酸相比,包含锚序列的寡核苷酸对甲基化核酸具有显著更高的亲和力。这种亲和力差异可以用于以如下所述的各种方式检测表观遗传修饰,如甲基化。
因此,本发明的方法通常包括步骤b)在高于当所述NOI具有不同于所研究模式的表观遗传修饰模式时在所述寡核苷酸与目的靶核酸序列之间的解链温度的温度下,将所述寡核苷酸与目的靶核酸一起孵育。
优选地,这样选择所述温度,使得所述温度高于当所述NOI未甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度,并且所述温度比当所述NOI甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度高最多2℃、等于或低于所述解链温度。
在一些实施方案中,这样选择所述温度,使得所述温度比当所述NOI未甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度高至少2℃,并且所述温度比当所述NOI甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度高最多2℃、等于或低于所述解链温度。
如本文其他地方所指出,在解链温度下,存在大约50%的杂交形式与大约50%的未杂交形式。因此,在高于解链温度的温度下,典型地仍会发生一些杂交。因此,可以使用略高于解链温度的温度,例如高至多2℃。
亲和力差异以及因此表观遗传状态(如甲基化)差异可以使用各种不同的方法来检测。非常简单地,可以确定在包含锚序列的寡核苷酸与靶核酸序列之间的解链温度,并且可以在此基础上确定表观遗传状态。
优选地,所述方法包括扩增步骤,其中以这样的方式设计所述扩增,使得扩增仅在NOI甲基化时发生,或者可替代地扩增仅在NOI未甲基化时发生。这可以通过设计包括一个或多个步骤的测定来实现,所述步骤使用允许包含锚序列的寡核苷酸与甲基化靶核酸退火、但不允许所述寡核苷酸与非甲基化靶序列退火的温度。
优选的方法是基于PCR的方法,并且特别是下文在章节“PCR”中描述的任何基于PCR的方法。
如上文所解释,本发明的方法的一个优点是所述方法不需要对靶核酸进行预处理以将非甲基化或甲基化核苷酸转化成可检测部分,如亚硫酸氢盐转化、限制性酶切或TET酶促转化。
亚硫酸氢盐将非甲基化胞嘧啶转化成尿嘧啶。5-甲基胞嘧啶保持不变。这产生了取决于甲基化状态的碱基对序列差异,允许诸如通过PCR检测甲基化DNA与非甲基化DNA之间的差异。
甲基化敏感性限制性酶也可以用于确定样品的甲基化状态。通常,甲基化敏感性限制性酶与甲基化不敏感性同切点酶一起使用。这组酶的例子是HpaII和MspI,这两种酶都识别序列CCGG并在CG二核苷酸之前进行切割。HpaII仅切割非甲基化CCGG,并且MspI切割甲基化CCGG位点和非甲基化CCGG位点两者。由此,可以检测甲基化DNA和非甲基化DNA的消化的差异,其可以通过PCR进行分析。
TET酶促转化依赖于两种类型的酶APOBEC和TET2。TET2将5-甲基胞嘧啶转化成5-羧基胞嘧啶。此转化保护5-甲基胞嘧啶免于被APOBEC转化,然后APOBEC仅将非甲基化胞嘧啶脱氨基成尿嘧啶,允许诸如通过PCR检测甲基化DNA与非甲基化DNA之间的差异。
在一些实施方案中,目的靶核酸序列是未修饰的。因此,本发明内包括的是所述方法不包括预处理目的核酸以将非甲基化核苷酸转化成可检测部分和/或将甲基化核苷酸转化成可检测部分的步骤。在一些实施方案中,在进行如本文公开的方法之前,没有对目的靶核酸序列进行包括亚硫酸氢盐转化、限制性酶切或TET酶促转化在内的处理。特别地,优选的是所述方法不包括亚硫酸氢盐转化步骤。
靶核酸序列
靶核酸序列可以是包含至少一个核苷酸(NOI)的任何核酸序列,期望确定所述核苷酸的表观遗传(如甲基化)状态。靶核酸序列典型地是包含较短目的序列(其在本文中被称为“靶锚序列”)的较长核酸序列。靶锚序列包含所述至少一个NOI。
优选地,核酸是DNA,然而核酸也可以是其他种类的核酸,如RNA。在优选的实施方案中,核酸是基因组DNA。本发明方法可以有利地用于确定天然存在序列的表观遗传修饰,特别是胞嘧啶的甲基化。
优选地,表观遗传修饰是甲基化,然而它也可以是核碱基的烷基化、乙酰化、羟基化、甲氧基化或其他修饰。
靶锚序列包含一个或多个NOI。以这样的方式选择本发明的寡核苷酸的锚序列,使得锚序列可以与靶锚序列杂交。典型地,锚序列与靶锚序列至少50%互补。
通常,在靶核酸序列内,可以被修饰(如甲基化)或可以未被修饰的几个NOI定位地紧密邻近。在此类情况下,可能期望确定所有所述核苷酸的总体修饰(甲基化)状态。这可以通过如下所述的本发明的方法,通过使用具有每个NOI包含一个疏水性核苷酸的锚序列的寡核苷酸来进行。本发明内还包括的是仅确定所述NOI中的一个或几个的修饰(甲基化)状态。同样,这可以通过采用具有每个待研究的NOI包含一个疏水性核苷酸的锚序列的寡核苷酸来进行。
在一些实施方案中,靶核酸序列可以是包含一个或多个NOI的核酸序列,所述NOI的表观遗传修饰状态与临床病症相关。例如,所述NOI的甲基化状态可以与临床病症的存在、临床病症的进展、获得临床病症的风险或对某种治疗方法的易感性相关,如下面在章节“临床病症”中更详细地描述的。NOI的甲基化状态与临床病症“相关”并不意味着它是所述临床病症的原因,而是给定的甲基化状态更普遍地与所述临床病症相关。
NOI可以是期望检测表观遗传修饰状态的任何核苷酸。在优选的实施方案中,NOI是胞嘧啶(C),并且甚至更优选地,NOI是定位在CpG位点中的胞嘧啶。在最优选的实施方案中,NOI的表观遗传修饰是CpG位点的甲基化。
靶核酸可以包含在包含所述靶核酸序列的任何组合物中。通常,靶核酸包含在核酸样品内。所述样品可以获自期望确定表观遗传状态(例如甲基化状态)的任何来源。例如,样品可以获自哺乳动物,如人。样品可以是至少部分纯化的,即样品可以包含至少部分纯化的核酸。因此,目的靶核酸序列可以包含在从样品中纯化的DNA中。
如本文其他地方所述,靶锚序列至少部分地与锚序列互补。因此,如果靶核酸是双链核酸,如DNA,则锚序列通常至少部分地与DNA的一条链相同,并且靶锚序列定位在所述DNA的另一条链中。
包含锚序列的寡核苷酸
本发明涉及用于确定至少一个NOI的表观遗传(如甲基化)状态的方法,所述方法采用使用包含锚序列(An)的寡核苷酸,其中锚序列是与靶核酸序列内的在本文中称为“靶锚序列”的包含NOI的部分至少50%互补的序列。锚序列优选包含至少一个定位在与所述NOI互补的核苷酸与寡核苷酸中紧邻其5'的核苷酸之间的疏水性核苷酸(H)。
在本发明的NOI是C的实施方案中,锚序列因此优选包含序列-H-G-,其中所述G与目的C互补。
优选的是锚序列不包含两个相邻的疏水性核苷酸。因此,锚序列可以特别地包含
序列-N-H-G-,其中N可以是任何核苷酸,并且序列-N-G-与目的胞嘧啶及其相邻核苷酸互补。特别地,N可以选自C、G、A和T。
在NOI是位于CpG位点中的C的实施方案中,优选的是锚序列包含序列-C-H-G-。
锚序列可以包含多于一个疏水性核苷酸。因此,锚序列可以包含至少2个、如至少3个、例如至少4个、如在1至10个范围内、例如在2至10个范围内、如在3至10个范围内、例如在4至10个范围内的疏水性核苷酸(H)。
锚序列可以特别地每个NOI包含一个疏水性核苷酸。所述疏水性核苷酸优选全部定位在与NOI互补的核苷酸与寡核苷酸中紧邻其5'的核苷酸之间。此外,锚序列还可以包含另外的疏水性核苷酸。
在本发明的靶核酸序列包含多于一个NOI(其为C)的实施方案中,锚序列因此可以包含多于一个-N-H-G-序列,其中每个N可以单独地是任何核苷酸。优选地,所述锚序列每个NOI(其为C)包含一个-N-H-G-序列,其中每个-N-G-序列与目的胞嘧啶及其相邻核苷酸互补。因此,锚序列可以包含至少2个、如至少3个、例如至少4个、如在2至5个范围内、例如在3至5个范围内、如在4至5个范围内的-N-H-G-序列,其中每个N单独地是任何核苷酸,并且每个序列-N-G-与目的胞嘧啶及其相邻核苷酸互补。特别地,N可以选自C、G、A和T。
在本发明的靶核酸序列包含多于一个NOI(其为定位在CpG位点中的C)的实施方案中,因此锚序列可以每个NOI(其为定位在CpG位点中的C)包含一个-C-H-G-序列。因此,锚序列可以包含至少2个、如至少3个、例如至少4个、如在2至5个范围内、例如在3至5个范围内、如在4至5个范围内的-C-H-G-序列。
在一个实施方案中,寡核苷酸包含由以下通用结构组成的锚序列:
5'(N)n-HG-(N)m-HG-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸,例如下面描述的任何疏水性核苷酸。
在一个实施方案中,寡核苷酸包含由以下通用结构组成的锚序列:
5'(N)n-HG-(N)m-HG-(N)p-HG-(N)q-3',
其中
p≥1;并且
q是≥0的整数。
在一个实施方案中,寡核苷酸包含由以下通用结构组成的锚序列:
5'(N)n-YG-(N)m-YG-(N)p-YG-(N)q-YG-(N)u-3',
其中
q是≥1的整数;并且
u是≥0的整数。
根据扩展IUPAC代码,Y表示C或T。
关于上述寡核苷酸,n可以例如是在0至4范围内的整数,例如n可以是1,m可以例如是在1至8范围内、例如在1至6范围内的整数,p可以例如是在1至50范围内、如在1至30范围内、例如在1至10范围内、例如在1至6范围内的整数,q可以例如是在1至50范围内、如在1至30范围内、例如在1至10范围内、例如在1至6范围内的整数,并且u可以例如是在1至50范围内、如在1至30范围内、例如在1至10范围内、例如在1至6范围内的整数。
在本发明的优选实施方案中,寡核苷酸是如下所述的BasePrimer。在此类实施方案中,锚序列与环序列和起始子序列连接,并且在此类实施方案中,寡核苷酸的3'部分足够长以含有环序列和起始子序列两者。
如上所解释,NOI可以是定位在CpG位点中的胞嘧啶。在此类情况下,优选的是紧邻至少一个H的5'定位的核苷酸是胞嘧啶(C)。如果所有NOI都是定位在CpG位点中的胞嘧啶,则优选的是当H邻近与NOI互补的G时,紧邻所述H的5'定位的所有核苷酸都是胞嘧啶(C)。
与非甲基化靶核酸序列相比,包含锚序列的寡核苷酸以更高的亲和力与甲基化靶核酸序列退火。因此,在所述寡核苷酸与甲基化目的靶核酸序列之间的解链温度通常比在所述寡核苷酸与非甲基化目的靶核酸序列之间的解链温度高至少5℃,例如高至少6℃,如高6℃至15℃的范围,例如高6℃至12℃的范围。
特别地,本发明基于以下发现,即与不包含疏水性核苷酸的类似寡核苷酸相比,本文所述的寡核苷酸在对甲基化靶核酸的亲和力相对于对非甲基化靶核酸的亲和力方面具有更大的差异。这种较大的亲和力差异允许通过简单的方法(如PCR)成功地检测甲基化。在本发明的寡核苷酸与甲基化靶核酸序列之间的解链温度和在本发明的所述寡核苷酸与非甲基化目的靶核酸序列之间的解链温度相比的差异优选比在除了缺少疏水性核苷酸之外具有相同序列的寡核苷酸与所述甲基化靶核酸序列之间的解链温度和在所述除了缺少疏水性核苷酸之外具有相同序列的寡核苷酸与非甲基化靶核酸序列之间的解链温度相比的差异至少高1℃。
NOI甲基化(如胞嘧啶甲基化,即在核酸(如目的靶核酸)中存在一个或多个甲基化胞嘧啶)导致当所述核酸与寡核苷酸杂交时解链温度的差异。所述差异取决于甲基化NOI的数量,并且可能难以检测。与其他方面相同但不包含疏水性核苷酸的寡核苷酸相比,本发明的寡核苷酸的疏水性核苷酸放大了对非甲基化NOI相对于甲基化NOI的亲和力差异。因此,与不包含所述疏水性核苷酸的相同寡核苷酸相比,本发明的寡核苷酸当与目的靶序列杂交时根据甲基化NOI(如甲基化胞嘧啶)的数量提供了更大的解链温度差异,由此有利于检测甲基化NOI的存在。
在一些实施方案中,在以下之间的差异:
A.在以下的解链温度之间的绝对差异:
i.包含一个或多个所述疏水性核苷酸的本发明的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含至少一个甲基化NOI,如至少一个甲基化胞嘧啶;和
ii.包含一个或多个所述疏水性核苷酸的本发明的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶;和
B.在以下的解链温度之间的绝对差异:
i.与A.的寡核苷酸相同、然而不包含一个或多个所述疏水性核苷酸的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含与A.i.中相同数量的甲基化NOI,如与A.i.中相同数量的甲基化胞嘧啶;和
ii.与A.的寡核苷酸相同、然而不包含一个或多个所述疏水性核苷酸的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶,
是每个NOI、如每个胞嘧啶至少0.50℃,如至少0.75℃,优选至少1.0℃,所述NOI在所述目的靶核酸序列中是甲基化的而不是非甲基化的,其中所述差异是A-B,并且其中所述差异是正差异。在优选的实施方案中,解链温度是在包含0.02M Na2HPO4、0.02M NaCl和2mMEDTA的TM缓冲液中测量的。
在一些实施方案中,在以下的解链温度之间的绝对差异:
i.包含所述疏水性核苷酸的本发明的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含至少一个甲基化NOI,如至少一个甲基化胞嘧啶;和
ii.包含所述疏水性核苷酸的本发明的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶;
是每个NOI、如每个胞嘧啶至少1.6℃,如至少1.8℃,如至少2.0℃,如至少2.2℃,优选至少2.4℃,所述NOI在所述目的靶核酸序列中是甲基化的而不是非甲基化的。在优选的实施方案中,解链温度是在包含0.02M Na2HPO4、0.02M NaCl和2mM EDTA的TM缓冲液中测量的。
为了比较,在一些实施方案中,在以下的解链温度之间的绝对差异:
i.与以上段落中描述的寡核苷酸相同、然而不包含所述疏水性核苷酸的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含至少一个甲基化NOI,如至少一个甲基化胞嘧啶;和
ii.与以上段落中描述的寡核苷酸相同、然而不包含所述疏水性核苷酸的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶;
是每个NOI、如每个胞嘧啶至多1.0℃,如至多0.9℃,如至多0.8℃,所述NOI在所述目的靶核酸序列中是甲基化的而不是非甲基化的。在优选的实施方案中,解链温度是在包含0.02M Na2HPO4、0.02M NaCl和2mM EDTA的TM缓冲液中测量的。
优选地,锚序列(An)由在8至30个范围内、例如在8至20个范围内、如在10至20个范围内、例如在15至20个范围内的核苷酸组成,其中所述核苷酸中的一个或多个是一个或多个疏水性核苷酸。
正如所指出,锚序列(An)与靶锚序列至少50%互补,优选地,锚序列(An)与靶锚序列至少85%互补。在一些实施方案中,锚序列可以与靶锚序列100%互补。然而,在优选的实施方案中,锚序列与靶锚序列不是100%互补的。
BasePrimer
本发明涉及用于确定至少一个NOI的表观遗传状态(如甲基化状态)的方法,所述方法采用使用包含锚序列(An)的寡核苷酸。在优选的实施方案中,所述寡核苷酸是如此章节中描述的BasePrimer。
根据本发明的BasePrimer是具有以下结构的寡核苷酸:
5'-An-Lp-St-3',其中
An是锚序列;
Lp是环序列;并且
St是起始子序列。
锚序列(An)优选是与靶核酸序列内的在本文中称为“靶锚序列”的包含NOI的部分至少50%互补的序列。锚序列优选包含至少一个定位在与所述NOI互补的核苷酸与寡核苷酸中紧邻其5'的核苷酸之间的疏水性核苷酸(H)。锚序列可以特别是上文在章节“包含锚序列的寡核苷酸”中描述的任何锚序列。
环序列(Lp)是不与靶核酸序列以任何显著程度杂交的序列。因此,优选地,Lp不与目的核酸序列互补。环序列可以由能够形成突出结构的单个核酸序列组成,或者它可以由能够至少部分地彼此杂交以形成能够形成突出结构的复合体的两个或更多个核酸序列组成。在一些实施方案中,突出结构是环结构。在一些实施方案中,突出结构是茎结构。
在一些实施方案中,本发明的寡核苷酸因此可以由第一核酸序列和第二核酸序列组成,其中第一核酸序列包含与靶DNA互补的锚序列(An)和不与目的靶核酸序列互补的环序列的第一部分,并且第二核酸序列包含能够至少部分地与环序列的第一部分杂交的环序列的第二部分,所述第二核酸序列进一步包含起始子序列(St)。一旦杂交,第一核酸和第二核酸就能够形成突出结构,如茎结构。
在一些实施方案中,本发明的寡核苷酸可以由第一核酸序列、第二核酸序列和第三核酸序列组成,其中第一核酸序列包含与靶DNA互补的锚序列(An)和不与目的靶核酸序列互补的环序列的第一部分,第二核酸序列包含能够至少部分地与环序列的第一部分杂交的环序列的第二部分,所述第二核酸序列进一步包含起始子序列(St),并且所述第三核酸序列能够在第一区域与第一寡核苷酸的3'端的一部分杂交,并且在第二区域与第二寡核苷酸的5'端的一部分杂交。一旦杂交,第一核酸、第二核酸和第三核酸就能够形成突出结构,如环结构。
在一些实施方案中,本发明的寡核苷酸被编码为单个寡核苷酸。在一些实施方案中,本发明的寡核苷酸被编码为两个或更多个单独的寡核苷酸。
起始子序列(St)是可以与靶核酸序列杂交但以低亲和力杂交的序列。因此,在本发明的方法所用的条件下,起始子序列优选不与靶核酸序列退火,除非锚序列也退火。起始子序列(St)可以优选能够被延伸,因此起始子序列应当能够充当引物。因此,起始子序列优选与靶核酸序列的在本文中称为“靶起始子序列”的部分至少90%互补。
靶起始子序列是靶核酸序列的序列,其定位在靶锚序列的5'。靶起始子序列可以紧邻靶锚序列的5'定位,然而,在所述序列之间也可以存在间隔。因此,靶起始子序列可以与靶锚序列隔开在1至20个范围内的核苷酸,如在2至10个范围内的核苷酸,例如在2至5个范围内的核苷酸。
如上所指出,起始子序列与靶起始子序列至少90%互补,但是它也可以与靶起始子序列100%互补。
BasePrimer对于基于PCR的方法特别有用,其中BasePrimer是引物对中的一个引物,其可以用于扩增靶核酸序列。基于锚序列的设计,锚序列将以高亲和力与甲基化靶核酸序列退火,这也允许起始子序列退火。退火之后,可以使用聚合酶,如通过任何常规用于PCR的DNA聚合酶来使BasePrimer延伸。当聚合酶遇到第一个疏水性核苷酸时,第一次逆转录典型地将结束,产物因此将缺少锚序列的至少一部分。然而,下一轮PCR将仍然能够使用BasePrimer作为引物,因为环序列和起始子序列可以与第一轮扩增的产物退火。
由于聚合酶通常在模板包含疏水性核苷酸的位置处停止延伸,因此可以优选的是BasePrimer在锚序列与环序列之间包含疏水性核苷酸。这种疏水性核苷酸被认为是锚序列的一部分。
因此,还优选的是起始子序列和环序列都不包含疏水性核苷酸。然而,如果环序列由两个或更多个核酸序列组成,则一个或多个未共价连接至起始子序列的核酸序列可以包含一个或多个疏水性核苷酸。
环序列和起始子序列充当从靶标开始的第一次扩增之后多轮的引物。因此,环序列和起始子序列一起(-Lp-St-)应当以允许它们作为引物起作用的方式设计。因此,优选的是由Lp-St组成的寡核苷酸与其互补序列的解链温度将为至少50℃,例如至少55℃,如至少65℃。通常,优选的是环序列和起始子序列一起由至少15个核苷酸、例如至少17个核苷酸、如在15至45个范围内的核苷酸、例如在17至35个范围内的核苷酸、如在17至25个范围内的核苷酸组成。
如上所指出,起始子序列应当以低亲和力与靶核酸序列退火。因此,优选的是起始子序列不太长。优选地,起始子序列由在5至15个范围内、如在8至14个范围内、如在10至12个范围内的核苷酸组成。
除了锚序列、环序列和起始子序列之外,BasePrimer还可以包含另外的部分。例如,BasePrimer可以与可检测标记连接。然而,在优选的实施方案中,BasePrimer由锚序列、环序列和起始子序列组成。
其他寡核苷酸
尽管上面描述了根据本发明的优选寡核苷酸,但本发明在一个实施方案中还提供了对甲基化靶核酸序列和非甲基化靶核酸序列具有类似亲和力的寡核苷酸,例如Tm差异至多3℃,如至多2℃。当NOI是定位在CpG位点中的胞嘧啶时,此类寡核苷酸可以包含以下通用结构或由以下通用结构组成:
5'(N)n-CGH-(N)m-CGH-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
C是核苷酸胞嘧啶;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸
其中所述疏水性核苷酸具有以下结构:
X-Y-Q
其中
X、Q和Y可以如本文在章节“疏水性核苷酸”中所述。
寡核苷酸可以特别地具有以下通用结构:
5'(N)n-CGH-(N)m-CGH-(N)p-CGH-(N)q-3',
其中
p≥1;并且
q是≥0的整数。
在一个实施方案中,此类寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-CGH-(N)m-CGH-(N)p-CGH-(N)q-CGH-(N)u-3',
其中
q是≥1的整数;并且
u是≥0的整数。
n、m、p、q和u可以例如如上文在章节“包含锚序列的寡核苷酸”中所述。
疏水性核苷酸
待用于本发明的寡核苷酸包含一个或多个疏水性核苷酸。根据本发明的疏水性核苷酸具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
嵌入剂Q可以是任何嵌入剂。根据本发明,术语嵌入剂涵盖包含至少一个基本上平面的共轭体系的任何分子部分,其能够与核酸的核碱基共堆积。优选地,根据本发明的嵌入剂基本上由至少一个基本上平面的共轭体系组成,其能够与核酸的核碱基共堆积。
嵌入剂包含至少一个π(phi)电子体系,其根据本发明可以与包含π电子体系的其他分子相互作用。这些相互作用可以以正面或负面的方式为所述嵌入剂的疏水相互作用作贡献。Hunter和Sanders(1990)J.Am Chem.Soc.112:5525-5534已经提出两个π电子体系可以彼此积极地相互作用的一系列不同的取向和条件。
嵌入剂可以是在国际专利申请WO 2017/045689中在章节“嵌入剂”中在第30页第26行至第40页第3行中描述的任何嵌入剂。例如,嵌入剂可以具有所述国际专利申请WO2017/045689的第32-39页上描绘的任何结构,将所述国际专利申请的内容通过引用特此并入。
在一个实施方案中,至少一种、如所有嵌入剂Q选自任选地被选自以下的一个或多个取代的多芳烃(polyaromate)和杂多芳烃:羟基、溴、氟、氯、碘、巯基、硫代基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基(carboalkoyl)、烷基、烯基、炔基、硝基、氨基、烷氧基和酰胺基。所述多芳烃或杂多芳烃可以由至少3个环、例如4个环组成。
嵌入剂可以例如选自苯、戊搭烯、茚、萘、薁、不对称引达省、对称引达省、联苯撑、苊、非那烯、庚搭烯、菲蒽烷(phenanthrane)、荧蒽、菲咯啉、吩嗪、菲啶、蒽醌、芘、蒽、环烷烃(napthene)、菲、芴(flurene)、苉、 并四苯(naphtacene)、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素及其衍生物。
并四苯(naphtacene)、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素及其衍生物。
在一个实施方案中,至少一种、如所有嵌入剂Q包含芘或吡啶并[3',2':4,5]噻吩并[3,2-d]嘧啶-4(1H)-酮或7,9-二甲基-吡啶并[3',2',4,5]噻吩并[3,2-d]嘧啶-4(3H)-酮或者由其组成。特别地,至少一种、如所有嵌入剂可以是芘。
根据本发明的核苷酸或核苷酸类似物的骨架单体单元是核苷酸中参与掺入核酸或核酸类似物的骨架中的部分。骨架单体单元(X)优选与接头(Y)共价连接,所述接头与嵌入剂共价连接。可以采用任何合适的骨架单体单元用于将嵌入剂掺入根据本发明的寡核苷酸类似物中。
骨架单体单元可以是在国际专利申请WO 2017/045689中在章节“骨架单体单元”中在第40页第5行至第56页第3行中描述的任何骨架单体单元。骨架单体单元也可以是在国际专利申请WO 03/052132中在章节“骨架单体单元”中在第24页第27行至第43页第14行中描述的任何骨架单体单元。
在本发明的一个特别优选的实施方案中,疏水性核苷酸包含含有亚磷酰胺的骨架单体单元,并且更优选地,骨架单体单元包含三价亚磷酰胺或五价。
合适的三价亚磷酰胺是可以掺入核酸和/或核酸类似物的骨架中的三价或五价亚磷酰胺。通常,亚酰胺基团本身可以不被掺入核酸的骨架中,而是亚酰胺基团或亚酰胺基团的一部分可以充当离去基团和/或保护基团。然而,优选的是骨架单体单位包含亚磷酰胺基团,因为这种基团可以促进骨架单体单位掺入核酸骨架中。
根据本发明的嵌入剂核苷酸的接头是连接所述疏水性核苷酸的嵌入剂与骨架单体、优选共价连接所述嵌入剂与骨架单体单元的部分。接头可以包含一个或多个原子或者原子之间的一个或多个键。
根据上文定义的骨架和嵌入剂的定义,接头是连接骨架与嵌入剂的最短路径。如果嵌入剂与骨架直接连接,则接头是键。
接头通常由原子链或原子支链组成。链可以是饱和的以及不饱和的。接头也可以是具有或不具有共轭键的环结构。
例如,接头可以包含选自C、O、S、N、P、Se、Si、Ge、Sn和Pb,优选选自C、O、S、N和P的原子的链,甚至更优选地,所述原子是C,其中链的一端连接至嵌入剂,并且链的另一端连接至骨架单体单元。
接头可以例如是在国际专利申请WO 2017/045689中在章节“接头”中在第56页第5行至第59页第10行中描述的任何接头。接头也可以是在WO 03/052132中在章节“接头”中在第54页第15行至第58页第7行中描述的任何接头。
PCR
本发明的方法优选包括步骤(b)在高于当所述NOI不包含所研究的表观遗传修饰状态时,例如当所述NOI未甲基化时在本发明的寡核苷酸与目的靶核酸序列之间的解链温度的温度下,将所述寡核苷酸与目的靶核酸一起孵育;以及(c)检测所述寡核苷酸是否与所述目的靶核酸退火。
在优选的实施方案中,所述步骤可以作为聚合酶链式反应(PCR)的一部分进行。所述PCR优选以这样的方式进行,使得PCR的大多数(或甚至所有)步骤在这样的温度下进行,所述温度高于当所述不包含目的表观遗传修饰状态时在所述寡核苷酸与目的靶核酸序列之间的解链温度。甚至更优选地,所述PCR以这样的方式进行,使得PCR的大多数(或甚至所有)步骤在这样的温度下进行,所述温度高于当所述NOI未甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度,但低至足以允许当所述NOI甲基化时在所述寡核苷酸与目的靶核酸序列之间进行扩增。
PCR典型地包括在以下温度下的多个孵育循环:
i.解链温度
ii.退火和延伸温度
退火和延伸温度可以是相同或不同的温度。
优选地,PCR以这样的方式进行,使得在至少第一循环中、优选在所述PCR的一个或多个循环中、如在所述PCR的大多数循环中、例如在所述PCR的所有循环中的退火和延伸温度高于当所述NOI未甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度。此外,可以这样选择所述温度,使得它比当所述NOI甲基化时在所述寡核苷酸与目的靶核酸序列之间的解链温度高或低至多2℃。
所述退火温度取决于具体的寡核苷酸,但是它可以例如在55℃至80℃的范围内。
在本发明的一些实施方案中,PCR的步骤的时长和/或温度在PCR期间改变。特别地,最前面的循环(例如最前面的1至5个循环)可以以这样的方式进行,使得甲基化DNA以更特异的方式扩增。因此,PCR可以包括一个或多个表观遗传修饰特异性扩增循环和一个或多个通用扩增循环,其中一个或多个表观遗传修饰特异性扩增循环包括以下步骤:
a.使核酸解链
b.在表观遗传修饰特异性条件下退火(和延伸)
并且通用扩增循环包括以下步骤:
a.使核酸解链
b.在通用条件下退火(和延伸)
解链包括在解链温度下孵育,所述温度典型地是至少90℃。在表观遗传修饰特异性条件下进行的退火和延伸通常在比在通用条件下进行的退火和延伸高的温度下进行,例如在比用于在通用条件下进行的退火和延伸的温度高至少1℃、如高至少2℃的温度下进行。所述方法可以包括任何合适数量的表观遗传修饰特异性扩增循环,例如在1至100个范围内的表观遗传修饰特异性扩增循环。
在退火(和延伸)温度下孵育的步骤可以进行任何合适的时间量。例如,所述PCR的至少第一循环可以包括在退火温度下孵育在5至120s范围内、如在10至90s范围内的时间。退火也可以例如进行在30至90s范围内、如在45至75s范围内、例如大约60s的时间。
PCR通常涉及使用一组能够扩增目的靶核酸序列的引物。优选地,所述引物之一是根据本发明的寡核苷酸,更优选BasePrimer。如果正向引物是根据本发明的寡核苷酸,例如BasePrimer,则反向引物典型地是常规引物,反之亦然。
技术人员将能够确定待用于PCR的本发明的寡核苷酸的有用浓度。例如,所述浓度可以在300至700nM的范围内,如大约500nM。
PCR可以以技术人员已知的任何合适的方式进行。在一个实施方案中,PCR是实时PCR。实时PCR典型地涉及使用可检测标记,如染料。在一个实施方案中,PCR(例如实时PCR)使用包含可检测标记的探针来检测产物。所述探针可以是能够结合PCR产物的任何寡核苷酸,然而,优选地,探针是能够以至少与每种引物相同的亲和力、优选以比每种引物高的亲和力结合PCR产物的寡核苷酸。因此,探针可以包含与所述PCR反应的产物至少90%互补的寡核苷酸和可检测标记。在优选的实施方案中,所述探针包含一个或多个疏水性核苷酸,因为疏水性核苷酸增加探针的亲和力。
当PCR是实时PCR时,PCR的结果可以确定为Ct。因此,如果Ct低于给定的阈值,则可以认为目的靶核酸是甲基化的。所述阈值可以是预定的或者可以使用相关对照来确定。
除了引物和探针之外,PCR还将含有PCR试剂。技术人员非常了解选择合适的PCR试剂。PCR试剂通常至少包括核苷酸和聚合酶。典型地,PCR试剂还包括合适的盐和缓冲液。
聚合酶可以是任何可用于PCR的聚合酶,例如任何可用于PCR的DNA聚合酶。在一些实施方案中,聚合酶是在模板中的任何疏水性核苷酸处停止延伸的聚合酶。对于大多数常规用于PCR的常规DNA聚合酶,情况如此。
临床病症
本发明的方法可以用于检测NOI的甲基化,NOI的甲基化状态与临床病症相关。
因此,本发明的方法可以用于确定个体是否患有临床病症的风险或个体患上临床病症的风险,其中临床病症与目的核酸中NOI(例如胞嘧啶)的甲基化状态相关。此类方法通常包括以下步骤:
a.提供来自所述个体的样品
b.通过进行本发明的方法确定所述样品中所述NOI的甲基化状态。
在一些方面,提供了用于确定个体是否患有临床病症的风险或个体患上临床病症的风险的方法,其中临床病症与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供从所述个体获得的样品;
b.通过进行根据前述权利要求中任一项所述的方法确定所述样品中所述NOI的甲基化状态,其中所述甲基化状态指示所述临床病症的存在或患上所述临床病症的风险。
本发明的方法还可以用于确定有需要的个体的临床病症的治疗效果的可能性,其中所述临床病症的所述治疗的效果与目的核酸中胞嘧啶的甲基化状态相关。此类方法通常包括以下步骤:
i.提供来自所述个体的样品
ii.通过进行本发明的方法确定所述样品中所述NOI的甲基化状态。
在本发明的一些方面,提供了用于确定有需要的个体的临床病症的治疗效果的可能性的方法,其中所述临床病症的所述治疗的效果与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供从所述个体获得的样品;
b.通过进行如本文公开的方法确定所述样品中所述NOI的甲基化状态,其中所述甲基化状态指示不同治疗方案对所述临床病症的效果。
在一些实施方案中,NOI是胞嘧啶。
已经证明许多临床病症与一个或多个NOI的甲基化相关,所述临床病症如几种类型的癌症(例如乳腺癌、结肠癌和肝癌)以及疾病(如类风湿性关节炎和多发性硬化)。因此,一个或多个NOI的甲基化状态可以指示临床病症的存在、临床病症的进展、临床病症的严重程度、临床病症的预后、获得临床病症的风险等。还已经证明不同治疗方案的效果与一个或多个NOI的甲基化状态相关。因此,本发明的方法可以用于检测所有上述情况。临床病症可以例如是癌症,例如胶质母细胞瘤。
在优选的实施方案中,如上文公开的方法不涉及手术步骤。
在一些实施方案中,如本文公开的方法在从患者分离的样品上进行。在一些实施方案中,所述样品是体液样品。所述体液样品可以是血液、尿液、痰、乳汁、脑脊液、耵聍(cerumen)(耳垢(earwax))、内淋巴液、外淋巴液、胃液、粘液、腹膜液、胸膜液、唾液、皮脂(皮肤油脂)、精液、汗液、泪液、阴道分泌物或者包括其组分或级分的呕吐样品。所述体液样品可以是混合的或合并的。因此,体液样品可以是血液和尿液样品的混合物或血液和脑脊液样品的混合物。所述样品也可以被均化,如通过过滤、稀释和/或离心。在一些实施方案中,样品是皮肤、毛发、细胞或组织。
项目
通过以下项目进一步定义本发明:
1.一种确定目的靶核酸序列中至少一个目的核苷酸(NOI)的甲基化状态的方法,其中所述靶核酸序列包含含有所述NOI的靶锚序列,所述方法包括以下步骤:
a.提供包含锚序列(An)的寡核苷酸,其中所述锚序列是与所述靶锚序列至少50%互补的序列,其中所述锚序列包含至少一个定位在与所述NOI互补的核苷酸与所述寡核苷酸中紧邻其5'的核苷酸之间的疏水性核苷酸(H);
b.在高于当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度的温度下,将所述寡核苷酸与所述目的靶核酸一起孵育,
c.检测所述寡核苷酸是否与所述目的靶核酸退火,
由此确定甲基化状态,
其中所述疏水性核苷酸(H)具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
2.根据项目1所述的方法,其中所述目的靶核酸是DNA。
3.根据前述项目中任一项所述的方法,其中所述NOI是胞嘧啶。
4.根据项目3至4中任一项所述的方法,其中所述胞嘧啶位于CpG位点中,并且其中所述锚序列包含序列-C-H-G-。
5.根据前述项目中任一项所述的方法,其中所述锚序列包含至少2个、如至少3个、例如至少4个、如在2至10个范围内、例如在2至5个范围内、例如在3至5个范围内、如在4至5个范围内的-N-H-G-序列,其中每个N单独地选自C、G、A和T,并且每个序列-N-G-与目的胞嘧啶及其相邻核苷酸互补。
6.根据前述项目中任一项所述的方法,其中步骤b)和c)一起包括进行PCR,其中所述温度用作所述PCR的一个或多个循环中的退火温度。
7.根据前述项目中任一项所述的方法,其中所述寡核苷酸具有结构5'-An-Lp-St-3',其中
An是所述锚序列;
Lp是不与所述目的核酸序列互补的环序列
St是起始子序列,所述序列与靶起始子序列至少90%互补,其中所述靶起始子序列是所述靶核酸序列的定位在所述靶锚序列的5'的序列。
8.根据前述项目中任一项所述的方法,其中所述锚序列(An)由在8至30个范围内、例如在8至20个范围内、如在10至20个范围内、例如在15至20个范围内的核苷酸组成,其中所述核苷酸中的一个或多个是一个或多个疏水性核苷酸。
9.根据前述权利要求中任一项所述的方法,其中所述锚序列包含序列-N-H-G-,其中N选自C、G、A和T,并且序列-N-G-与所述目的胞嘧啶及其相邻核苷酸互补。
10.根据项目8至9中任一项所述的方法,其中Lp和St一起由至少15个核苷酸、例如至少17个核苷酸、如在15至45个范围内的核苷酸、例如在17至35个范围内的核苷酸、如在17至25个范围内的核苷酸组成。
11.根据前述项目中任一项所述的方法,其中目的靶核酸序列包含在从样品中纯化的DNA中。
12.一种用于确定个体是否患有临床病症的风险或个体患上临床病症的风险的方法,其中所述临床病症与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供来自所述个体的样品
b.通过进行根据前述项目中任一项所述的方法确定所述样品中所述NOI的甲基化状态。
13.一种用于确定有需要的个体的临床病症的治疗效果的可能性的方法,其中所述临床病症的所述治疗的效果与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供来自所述个体的样品
b.通过进行根据项目1至10中任一项所述的方法确定所述样品中所述NOI的甲基化状态。
14.根据项目12至13中任一项所述的方法,其中所述临床病症是癌症。
15.一种寡核苷酸,所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-HG-(N)m-HG-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸
其中所述疏水性核苷酸具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
16.根据前述权利要求中任一项所述的方法或寡核苷酸,其中至少一种、如所有嵌入剂Q选自任选地被选自以下的一个或多个取代的多芳烃和杂多芳烃:羟基、溴、氟、氯、碘、巯基、硫代基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基、烷基、烯基、炔基、硝基、氨基、烷氧基和酰胺基。
实施例
通过以下实施例进一步说明本发明,然而,所述实施例不应当被解释为限制本发明。
实施例1
MGMT启动子区
MGMT启动子区的目的序列作为SEQ ID NO:1包含在本文中:
CTCTTGCTTTTCTCAGGTCCTCGGCTCCGCCCCGCTCTAGACCCCGCCCCACGCCGCCATCCCCGTGCCCCTCGGCCCCGCCCCCGCGCCCCGGATATGCTGGGACAGCCCGCGCCCCTAGAACGCTTTGCGTCCCGACGCCCGCAGGTCCTCGCGGTGCGCACCGTTTGCGACTTGGTGAGTGTCTGGGTCGCCTCGCTCCCGGAAGAGTGCGGAGCTCTCCCTCGGGACGGTGGCAGCCTCGAGTGGTCCTGCAGGCGCCCTCA
该序列是129467120-129467385智人(Homo sapiens)10号染色体,GRCh38.p12。SEQ ID NO:1中四个加下划线的CG是CpG位点,设计此测定以分析其甲基化状态。所选的四个CpG位点中的三个通常用于商业试剂盒中的甲基化检测,所述商业试剂盒例如Qiagen的焦磷酸测序试剂盒(Qiagen.(2014). Fast Bisulfite Conversion HandbookFor sample lysis and complete bisulfite Sample&Assay Technologies QIAGENSample and Assay Technologies.Sample&Assay Technologies)。
Fast Bisulfite Conversion HandbookFor sample lysis and complete bisulfite Sample&Assay Technologies QIAGENSample and Assay Technologies.Sample&Assay Technologies)。
PCR测定的通用设置
除了实施例12和13之外,对于所有PCR测定的设置都使用以下设计。体积是针对含有总反应体积为25μL的以下物质的单个PCR管:
1)12.5μL的含有DNA聚合酶、dNTP、MgCl2和缓冲液的2x预混液*(MM)
2)7.5μL的引物/探针(PP)混合物
3)5μL的纯化的基因组DNA
对于实施例12和13,对于PCR测定的设置使用以下设计。体积是针对含有总反应体积为12μL的以下物质的单个PCR管:
1)6μL的含有DNA聚合酶、dNTP、MgCl2和缓冲液的2x预混液*(MM)
2)1μL的引物/探针(PP)混合物
3)5μL的纯化的基因组DNA
*如果没有另外说明,则预混液(MM)由2x Ampliqueen(可从PentaBase ApS获得)组成。在Ampliqueen的工作溶液中MgCl2的浓度为2.25mM。
所有PCR都在MyGo Pro(It-Is Life Science ltd)、BaseCycler或Base Typer(PentaBase ApS)实时PCR仪器上进行。使用所述PCR仪器上的标准设置来确定RFU。
Tm和ΔTm
寡核苷酸的解链温度通过在渐升的温度下将寡核苷酸与其互补靶标一起孵育而实验性地发现。通常,将寡核苷酸以这样的方式用荧光标记进行标记,使得荧光信号取决于结合。例如,寡核苷酸可以在一端与荧光部分连接,并且在另一端与猝灭剂连接。当温度低时,探针与其靶标结合,产生双链体,由此使得能够产生荧光信号,其被测量为RFU。随着温度升高,RFU降低,并且当温度达到双链体的Tm时,可以检测到RFU的突然下降。这展示于图1A中。在Tm下,在解链过程开始时结合的核苷酸中的一半将从靶标解离。可以绘制解链曲线的一阶负导数,并且此曲线的峰(最大值)是探针的解链温度(图1B)。
将Tm差异计算为与一种靶标结合的探针减去与另一种靶标结合的相同探针之间的差异:
ΔTm=Tm.靶标1-Tm.靶标2
ΔCt和ΔΔCt的计算
Ct是指阈值循环,即基于预定的标准检测到产物的PCR循环。通常,Ct是基于荧光阈值确定的。如果没有另外说明,则使用PCR机器MyGo Pro、BaseCycler或BaseTyper及其相关软件的默认设置。阈值设置由软件自动完成。
ΔCt是在参考测定(即使用参考引物的测定)与甲基化敏感性测定(即使用包含疏水性核苷酸的甲基化特异性BasePrimer的测定)之间计算的:
ΔCt=|Ct参考-Ct甲基|
将ΔΔCt计算为当添加非甲基化DNA作为模板时测定的ΔCt与当添加甲基化DNA作为模板时测定的ΔCt之间的差异:
ΔΔCt=|ΔCt非mC-ΔCtmC|
ΔCt非mC因此指示参考测定与当使用非甲基化DNA模板时测试测定之间的Ct差异。ΔCt非mC在本文中也被称为Δ非mC。ΔCt非mC指示测定的特异性,并且优选尽可能地高。
ΔCtmC指示参考测定与使用甲基化DNA模板的甲基化特异性测定之间的Ct差异。ΔCtmC在本文中也被称为ΔmC。ΔCtmC指示测定的灵敏度,优选尽可能地低。
ΔΔCt是ΔCt非mC与ΔCtmC之间的差异,并且这应当优选尽可能地高。
BasePrimer描述
BasePrimer方法基于使用疏水性核苷酸选择性扩增甲基化DNA。该区分可以通过单个引物(在本文中称为BasePrimer)实现。BasePrimer由三部分组成:锚序列、环序列和起始子序列。锚序列含有疏水性核苷酸。与非甲基化DNA相比,当与甲基化DNA结合时,锚序列具有更高的热稳定性。因此,锚序列用于为置于引物的3'端的起始子序列产生稳定性。起始子序列应当具有低热稳定性,因此如果它不能得到来自锚序列的支持,则不能结合到DNA模板上(图4B)。只有当锚序列以高热稳定性结合,从而允许起始子序列结合时,PCR才会开始(图3A,“循环1”)。注意,在PCR期间产生的扩增子将不含任何甲基化核苷酸,因为通常聚合酶在PCR反应中添加具有非甲基化核苷酸的dNTP。
锚序列和起始子序列通过环序列连接。此序列是有益的,因为大多数聚合酶不能连读疏水性核苷酸,因此当反向引物结合并且产生互补链时,锚序列将被切断。起始子序列被设计成具有低热稳定性,因此它无法结合到没有另外序列的扩增子。因此,环序列被掺入引物中,由此允许环序列和起始子序列在甲基特异性扩增的第二循环之后(图3A,“剩余循环”)作为常规引物起作用。
实施例2
对5-甲基胞嘧啶的亲和力
合成与覆盖以上SEQ ID NO:1中标记的四个CpG的区域互补的寡核苷酸。将探针在5'端用FAM荧光团和在3'端用黑洞猝灭剂(BHQ)双重标记。在这些探针中,使用Z型或E型的两种不同的疏水性核苷酸。
Z型疏水性核苷酸的化学名称为3-(1-O-(4,4'-二甲氧基三苯甲基)-2-O-(2-氰乙基二异丙基酰胺基亚磷酸酯)-1,2-丁二醇)-4-N-(7,9-二甲基-3H-吡啶并[3',2':4,5]噻吩并[3,2-d]嘧啶-4-酮的亚磷酰胺。在Z型疏水性核苷酸中,嵌入剂Q具有以下结构:

在本文中,Z型疏水性核苷酸可以简称为“Z”。
E型疏水性核苷酸的化学名称为(S)-1-(4,4'-二甲氧基三苯甲氧基)-3-芘甲氧基-2-丙醇的亚磷酰胺。在此E型疏水性核苷酸中,嵌入剂Q具有以下结构:

在本文中,E型疏水性核苷酸可以简称为“E”。
将Z或E以这样的方式掺入探针中,使得它们定位在SEQ ID NO:1的四个CpG中的C与G之间。这样做是为了测试E和Z中哪一种最能区分甲基化DNA(称为“5-mC”)与非甲基化DNA(称为“非mC”)。
此外,在不同的位置测试E。包含定位在CpG中的C与G之间的E的探针在本文中被称为E型探针。在退火时E紧邻CpG之前定位的探针被称为E2型探针,并且在退火时E紧邻CpG之后定位的探针被称为E3型探针。作为参考,制备不含E和Z的探针。不同探针的序列提供于表1中。
设计并合成了两种人工靶标:一种不含任何甲基化胞嘧啶(mC),并且一种在四个CpG位点处含有mC。序列见表1。

表1.用于分析在不同位置含有E和Z的双重标记的探针对包含5-甲基胞嘧啶(mC)或标准胞嘧啶(C)核碱基的互补靶标的亲和力的探针和靶标序列。
如实施例1中所述确定解链温度。
观察到,与非甲基化靶标(MGMT_0mC)相比,含有E型和Z型疏水性核苷酸的探针当与完全甲基化靶标(MGMT_1,2,3,4mC)结合时具有更高的Tm。对于1,2,3,4mC和0mC的解链温度差异对于探针MGMT_Z是约6.6℃,并且对于探针MGMT_E是约9.6℃。此外,观察到,当与甲基化靶标杂交时,参考探针(MGMT_参考)也具有较高的Tm,其中mC靶标与非mC靶标之间的差异为3.4℃,参见图4和表2。
研究了E型疏水性核苷酸的位置。当E置于CpG中的C与G之间时(探针MGMT_E),出现最佳的区分度。当疏水性核苷酸置于CpG之后时(探针MGMT_E3),观察到比参考探针低的区分度。
MGMT_E和MGMT_参考与甲基化靶标(MGMT_1,2,3,4mC)和非甲基化靶标(MGMT_0mC)的解链的一阶负导数的差异见图5。


表2.MGMT_Z、E、E2、E3和参考与含有0个或4个甲基化位点的靶标解链的解链温度。Avg.=平均值SDV=标准差
实施例3
与5-mC的位置和数量相关的Z和E修饰的探针的亲和力
研究了Z和E修饰的探针与互补靶标的解链温度与所述靶寡核苷酸中5-mC的定位和数量之间的相关性。设计了四种不同的靶标,每种靶标包含一个甲基化CpG位点。
此外,一种靶标被设计成具有两个甲基化CpG位点,并且一种靶标被设计成具有四个甲基化CpG位点。这样做是为了研究5-mC的数量与探针的解链温度之间的相关性。序列见表3。


表3.用于通过改变5-mC的位置分析亲和力的探针和靶标序列。C=非甲基化胞嘧啶。mC=5-甲基胞嘧啶
在甲基化位点在靶标中的位置对解链温度的影响之间没有观察到显著差异。
研究了甲基化位点的数量与探针的解链温度之间的相关性。当排除非甲基化靶标时,线性拟合的R2给出的R2为0.997。这表明当靶标被甲基化时存在线性相关性。非甲基化靶标具有太低以致于无法拟合线性模型的解链温度。绘图示于图6中,并且原始数据呈现在
表4中。

表4.MGMT_E与具有0个、1个、2个和4个甲基化位点的靶标解链的解链温度。
实施例4
在Ampliqueen预混液中的解链研究
已表明与TM缓冲液相比,通过使双链体在1X Ampliqueen(PentaBase ApS)中解链,解链温度降低大约5℃(参见表5)。TM缓冲液包含0.02M Na2HPO4、0.02M NaCl和2mMEDTA。MGMT_E/1,2,3,4mC双链体的解链温度为约78.5℃,并且MGMT_E/0mC双链体的解链温度为约69.7℃。MGMT/0mC双链体首先在80℃下完全解离成两条单链。这可以通过解链峰之后的-dF/dT为0的温度看出,参见图7。

表5.在TM缓冲液和Ampliqueen预混液中MGMT_E与含有0个或4个甲基化位点的靶标解链的Tm。
实施例5
BasePrimer的设计
进行了BasePrimer的四种不同设计(表6)。引物被设计成具有两种不同的环序列和两种不同长度的3'端起始子序列。解链温度是基于环序列和3'端起始子序列的Tm计算的,因为这些序列在环序列已经被掺入扩增子中之后将作为一个引物起作用。

表6.BasePrimer设计。粗体=锚序列。标准字体=环序列。加下划线=3'端起始子序列。

表7.引物和探针
BasePrimer的测试
使用表6的BasePrimer作为正向引物和反向引物MGMT_Rev2C设置PCR(表4)。参考测定使用引物MGMT_Fw2C作为正向引物,并且使用引物MGMT_Rev2C作为反向引物(表7)。
通过将700nM的表7的每种BasePrimer与700nM MGMT_Rev2C和500nM MGMT_探针2E(表7)混合进行甲基特异性测定。通过将700nM MGMT_Fw2C与700nM MGMT_Rev2C和500nMMGMT_探针2E混合进行参考测定。PCR程序提供于表8中,而用于优化PCR程序的优化方案提供于表9中。
在程序优化中仅使用MGMT_Fw环3C和Fw环4C,并且仅在79℃下测试Fw环4C。在此实验中,含有1% ZUBR Green的预混液用于生成信号。对于这些实验,使用1ng/μL来自健康供体的非甲基化DNA和1ng/μL甲基化DNA(从细胞系IDH U87 WT中纯化)。


表8.PCR程序D。*=获取阶段(获取荧光的阶段)

表9.PCR程序D的优化
发现所有BasePrimer都可用于DNA的扩增。发现与参考测定相比,对于甲基特异性测定,MGMT_Fw环3B和Fw环4B具有高Ct值,这意味着这些BasePrimer以低效率扩增甲基化DNA。MGMT_Fw环3C和Fw环4C在甲基化DNA的情况下具有低ΔCt,这意味着这些BasePrimer几乎与参考测定一样有效地扩增甲基化DNA。然而,Fw环3C和Fw环4C不能很好地区分甲基化DNA与非甲基化DNA(ΔΔCt<0.5)。在较短的退火时间和较高的温度下测试这两种BasePrimer,并且区分度改进,参见图8。
对于77℃和79℃的退火温度两者,观察到当退火时间从20s增加到30s时,甲基化DNA和非甲基化DNA两者的ΔCt都降低(图8)。这表明这些BasePrimer需要更多的时间来以高效率与甲基化模板退火。最高ΔΔCt是在79℃下持续30s的情况下,并且为4.46±0.86。
实施例6
甲基特异性预扩增
根据PCR程序用甲基特异性预扩增测试MGMT_Fw环4C(表10)。通过将700nM MGMT_Fw环4C与700nM MGMT_Rev2C混合进行甲基特异性测定。通过将700nM MGMT_Fw2C与700nMRev2C混合进行参考测定。在参考测定和甲基特异性测定两者中都使用含有1% ZUBRGreen的预混液。将结果与用79℃持续20s作为退火设置的常规两步扩增进行比较。使用与以上实施例中相同的实验设置。

表10.PCR程序E。*=获取阶段(获取荧光的阶段)
如以上实施例1中所述确定ΔCt和ΔΔCt。
甲基特异性预扩增循环在甲基特异性测定的情况下对于甲基化DNA给出较低的Ct值,并且对于非甲基化DNA给出较高的Ct值,由此将甲基化的区分度改进到ΔΔCt值为9.93,参见表11。甲基特异性预扩增PCR的PCR曲线见图9。然而,在甲基特异性测定中甲基化DNA的Ct值在预扩增的情况下仍然很高,并且假定环序列和起始子序列在两步非甲基特异性扩增中不能很好地扩增。


表11.甲基特异性预扩增相对于非甲基化特异性预扩增的结果表
实施例7
较高Tm BasePrimer的设计
BasePrimer被设计成具有对互补序列具有较高亲和力的环序列和3'端起始子序列,以在两步扩增中在较高温度下起作用。设计见表12。通过将疏水性核苷酸添加在这些引物的5'端而不是使用常规引物来增加MGMT_Fw2C和MGMT_Rev2C的亲和力。

表12.BasePrimer设计。粗体=锚序列。标准字体=环序列。加下划线=3'端起始子序列。
首先在不进行预扩增的情况下分析新BasePrimer,以找到两步扩增中的最佳退火时间和温度。这些测定如“甲基特异性预扩增”中所述混合,但使用MGMT_Fw环5C作为正向引物代替。根据表13修改PCR程序D。SW1088细胞系用于此实验以及接下来的实验。

表13.PCR程序D的优化
如以上实施例1中所述确定ΔCt和ΔΔCt。
对于BasePrimer MGMT_Fw环5C在不同退火时间和温度下获得的ΔCt和ΔΔCt的结果示于图10中。发现较高的退火温度(时间固定为30s)导致甲基化DNA和非甲基化DNA两者的较差甲基特异性扩增。在80℃下观察到甲基化DNA与非甲基化DNA之间的最佳区分。
实施例8
MGMT_Fw环5C的逐步调整
使用PCR程序E用甲基特异性预扩增测试该BasePrimer,但在预扩增的第二步骤中使用81℃,并且在79℃和80℃两者下测试两步扩增中的第二步骤。

使用PCR程序E,但在预扩增的第二步骤中使用81℃,并且在两步扩增中的第二步骤中使用80℃,在500nM、700nM和900nM的浓度下逐步调整MGMT_Fw环5C。除了变化的浓度之外,如章节“较高Tm BasePrimer的设计”中所述进行测定。
使用甲基特异性预扩增分析MGMT_Fw环5C。500nM Fw环5C是该BasePrimer的最佳浓度。在此,ΔΔCt是12.6,并且甲基化DNA的ΔCt是9.8。较高浓度导致较差的甲基特异性扩增,参见表14中的结果。

表14.MGMT_Fw环5C的逐步调整的结果表。*没有检测到信号
实施例9
一步保持甲基特异性扩增的测试
使用MGMT_Fw环5C来研究一步甲基特异性保持而不是甲基特异性预扩增。如章节“较高Tm BasePrimer的设计”中所述进行测定,其中使用500nM Fw环5C而不是700nM。使用PCR程序F(表15)。在80℃下持续60秒和120秒测试甲基特异性保持时间。

表15.PCR程序F。*=获取阶段(获取荧光的阶段)。
将5个循环的甲基特异性扩增改变成甲基特异性保持以增加该BasePrimer的特异性。发现在80℃下持续60秒(参见图11)优于表14中所示的5个循环的甲基特异性扩增。ΔΔCt从12.6增加到14.8。原始数据呈现于表16中。


表16. 5个循环的甲基特异性扩增相对于一步甲基特异性保持的结果表
实施例10
方法的验证
使用线性度和灵敏度研究并通过评价患者样品进一步验证方法。根据PCR程序F一式两份地测试所有验证样品。通过将500nM MGMT_Fw环5C与700nM MGMT_Rev2C_suE混合进行甲基特异性测定。通过将700nM MGMT_Fw2C_suE与700nM Rev2C_suE混合进行参考测定。在参考测定和甲基特异性测定两者中都使用含有1% ZUBR Green的预混液。
参考测定和甲基特异性测定的线性度
在甲基化模板(从SW1088细胞中纯化的DNA)和非甲基化模板(从健康患者的血液中纯化的DNA)上进行线性度研究。将模板稀释至50、25、12.5、6.25、3.13、1.56、0.78ng/μL的浓度,并且添加到参考测定和甲基特异性测定两者中。将标准曲线拟合为以下等式(Kubista等人,2006):
Ct=k·log(q)+CT(1)
其中k是斜率,q是样品中DNA分子的初始数量。
通过以下等式计算PCR效率(Kubista等人,2006):

与甲基特异性测定相比,参考测定的线性度更好。在参考测定中,非甲基化模板的线性度(R2=0.998)优于甲基化模板(R2=0.98)。对于甲基特异性测定,观察到相反的情况,在甲基特异性测定中,甲基化模板的线性度(R2=0.873)优于非甲基化模板(R2=0.811),参见图12。
对于非甲基化模板,PCR效率大于100%,并且对于甲基化模板,PCR效率低于100%。这解释了参考测定和甲基特异性测定两者(Fw环5C)。结果见表17。


表17.对于甲基化DNA和非甲基化DNA参考测定和Fw环5C测定的PCR效率。
甲基特异性测定的灵敏度
通过将2ng/μL从SW1088中纯化的DNA与2ng/μL从来自健康患者的血液中纯化的DNA混合来分析甲基特异性测定的灵敏度。制备以下浓度:100%、50%、25%、10%、5%、1%和0%甲基化。在MyGo Pro仪器上进行灵敏度测定。
灵敏度为5%,并且甲基化DNA与非甲基化DNA之间的明显差异可以设定在ΔCt=18下。在甲基化%与ΔCt之间没有观察到线性度(参见图13)。
根据结果,可以建议基于ΔCt将患者粗略地分类为高甲基化、低甲基化和非甲基化,参见表18。

表18.基于ΔCt对患者进行分类的建议。
实施例11
突变(错配)探针的解链研究
通过使用MGMT_E探针并在序列中有意添加一些错配核苷酸进行解链研究的扩展。制备含两个突变(导致两个错配)的两个探针,并且制备含一个突变(导致一个错配)的三个探针。序列见表20。实验设置与章节“对5-甲基胞嘧啶的亲和力”中相同。

表20.所测试的具有突变(错配)的探针与具有和不具有甲基化胞嘧啶的靶标。C=未甲基化胞嘧啶。加下划线的单个字母=突变(错配)。加下划线的mC=5-甲基胞嘧啶。
发现具有与靶序列的错配的探针降低了双链体的解链温度,而没有影响对于甲基化DNA相对非甲基化DNA的特异性(ΔTm),除了MGMT_E_M2,其中观察到ΔTm略微降低。结果示于图14中,并且原始数据呈现在表21中。此实验表明,可以降低例如跨越几个高亲和力CpG位点的甲基化特异性引物的亲和力,而不降低特异性。


表21.MGMT_E突变(错配)探针与含有0个和4个甲基化位点的靶标解链的Tm。
实施例12
在锚序列中具有单个错配的BasePrimer的灵敏度
使用在来自MGMT启动子区的合成DNA上进行的灵敏度研究评价在锚序列中具有单个错配的BasePrimer。遵循生产商的方案,使用CpG甲基转移酶(New England BiolabsInc,美国马萨诸塞州伊普斯维奇)将合成DNA甲基化。将浓度为500个拷贝/μL的完全甲基化DNA和非甲基化DNA的稀释液混合以获得100%、50%、25%、12.5%、6.3%、3.1%和0%甲基化模板。对于参考测定,使用700nM MGMT_Fw2C、700nM MGMT_Rev2E和500nM MGMT_探针2E,并且对于甲基特异性测定,使用700nM MGMT_Fw环5D_M5而不是MGMT_Fw2C(序列参见表22)。在BaseTyperTM实时PCR仪器(PentaBase,丹麦欧登塞)上使用PCR程序G(参见表23)进行该研究。

表22.BasePrimer设计。粗体=锚序列。标准字体=环序列。加下划线=3'端起始子序列。粗体且加下划线=错配。

表23.PCR程序G。*=获取阶段(获取荧光的阶段)。
最低检测的样品含有6.3%甲基化DNA,并且在ΔCt与log(甲基化%)之间观察到线性相关性(参见图15)。基于该线性相关性,可以基于ΔCt值定量甲基化程度。
在锚序列与起始子序列之间的碱基对的数量的研究
对于前面提到的BasePrimer,起始子序列与紧接锚序列的3'端的靶序列互补。在锚序列中具有单个错配的新BasePrimer被设计成在互补靶序列上在锚序列的3'端与起始子序列的5'端之间具有核苷酸缺口(参见图16)。这些BasePrimer被设计成具有0个、2个、4个、6个和8个核苷酸的缺口以及两种长度的起始子序列(A和B),参见表24。


表24.BasePrimer设计。粗体=锚序列。标准字体=环序列。加下划线=3'端起始子序列。粗体且加下划线=错配。
对于参考测定,使用700nM MGMT_Fw2C、700nM MGMT_Rev2E和500nM MGMT_探针2E,并且对于甲基特异性测定,使用700nM在表24中列出的BasePrimer而不是MGMT_Fw2C。500个拷贝/μL的非甲基化合成DNA、100%甲基化合成DNA和10%甲基化合成DNA用作模板。使用PCR程序H(参见表25)在BaseTyper上进行PCR。

表25.PCR程序H。*=获取阶段(获取荧光的阶段)。
发现所有设计都可以区分100%mC DNA、10%mC DNA与非mC DNA,除了MGMT_Fw环5B_M5_8A和MGMT_Fw环5B_M5_8B之外(参见图17)。
实施例13
辅助引物复合体
测试了另一种甲基区分性引物设计。甲基区分性引物复合体由包含锚序列和茎序列的辅助引物组成。复合体的另一部分是常规引物,其与辅助引物的茎序列部分互补并且与靶序列部分互补。甲基化DNA相对非甲基化DNA的区分通过与BasePrimer相同的原理进行。然而,在甲基化DNA上开始PCR之后,对于剩余循环使用常规引物。原理展示于图18中。
根据表26中所示的序列测试辅助引物复合体。对于参考测定,使用700nM MGMT_Fw2C、700nM MGMT_Rev2E和500nM MGMT_探针2E,并且对于甲基特异性测定,使用700nMMGMT_引物_1D和50nM MGMT_辅助_1A_E而不是MGMT_Fw2C。500个拷贝/μL的非甲基化合成DNA和100%甲基化合成DNA用作模板。使用PCR程序H(参见表25)在BaseTyper上进行PCR。

表26.辅助引物设计。粗体=锚序列。标准字体=茎序列。加下划线=3'端起始子序列。粗体且加下划线=错配
PCR曲线示于图19中。100%甲基化DNA的ΔCt是5.6,并且非甲基化DNA的ΔCt是9.5,得到ΔΔCt为3.9。
序列表
<110> 潘塔贝斯公司
<120> 甲基化状态的检测
<130> P5659PC00
<160> 42
<170> PatentIn 3.5版
<210> 1
<211> 266
<212> DNA
<213> 智人(Homo sapiens)
<400> 1
ctcttgcttt tctcaggtcc tcggctccgc cccgctctag accccgcccc acgccgccat 60
ccccgtgccc ctcggccccg cccccgcgcc ccggatatgc tgggacagcc cgcgccccta 120
gaacgctttg cgtcccgacg cccgcaggtc ctcgcggtgc gcaccgtttg cgacttggtg 180
agtgtctggg tcgcctcgct cccggaagag tgcggagctc tccctcggga cggtggcagc 240
ctcgagtggt cctgcaggcg ccctca 266
<210> 2
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Z探针
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> Z型疏水性核苷酸
<400> 2
cngtcccnga cngcccng 18
<210> 3
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E探针
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 3
cngtcccnga cngcccng 18
<210> 4
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E2探针
<220>
<221> 尚未归类的特征
<222> (1)..(1)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (7)..(7)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (11)..(11)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (16)..(16)
<223> E型疏水性核苷酸
<400> 4
ncgtccncga ncgccncg 18
<210> 5
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E3探针
<220>
<221> 尚未归类的特征
<222> (3)..(3)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (9)..(9)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (13)..(13)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (18)..(18)
<223> E型疏水性核苷酸
<400> 5
cgntcccgna cgncccgn 18
<210> 6
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_参考探针
<220>
<221> 尚未归类的特征
<222> (1)..(14)
<223> 探针
<400> 6
cgtcccgacg cccg 14
<210> 7
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_0mC靶标
<220>
<221> 尚未归类的特征
<222> (1)..(14)
<223> 靶标
<400> 7
cgggcgtcgg gacg 14
<210> 8
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_1,2,3,4mC靶标
<220>
<221> 尚未归类的特征
<222> (1)..(1)
<223> 甲基化核苷酸
<220>
<221> 尚未归类的特征
<222> (5)..(5)
<223> 甲基化核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> 甲基化核苷酸
<220>
<221> 尚未归类的特征
<222> (13)..(13)
<223> 甲基化核苷酸
<400> 8
cgggcgtcgg gacg 14
<210> 9
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_1mC靶标
<220>
<221> 尚未归类的特征
<222> (1)..(1)
<223> 甲基化核苷酸
<400> 9
cgggcgtcgg gacg 14
<210> 10
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_2mC靶标
<220>
<221> 尚未归类的特征
<222> (5)..(5)
<223> 甲基化核苷酸
<400> 10
cgggcgtcgg gacg 14
<210> 11
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_3mC靶标
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> 甲基化核苷酸
<400> 11
cgggcgtcgg gacg 14
<210> 12
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_4mC靶标
<220>
<221> 尚未归类的特征
<222> (13)..(13)
<223> 甲基化核苷酸
<400> 12
cgggcgtcgg gacg 14
<210> 13
<211> 14
<212> DNA
<213> 人工序列
<220>
<223> MGMT_2,3mC靶标
<220>
<221> 尚未归类的特征
<222> (5)..(5)
<223> 甲基化核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> 甲基化核苷酸
<400> 13
cgggcgtcgg gacg 14
<210> 14
<211> 38
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw环3B BasePrimer
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 14
cngtcccnga cngcccngag gcttctgaca ggtcctcg 38
<210> 15
<211> 40
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw环3C BasePrimer
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 15
cngtcccnga cngcccngag gcttctgaca ggtcctcgcg 40
<210> 16
<211> 40
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw环4B BasePrimer
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 16
cngtcccnga cngcccngag gcttcactga caggtcctcg 40
<210> 17
<211> 42
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw环4C BasePrimer
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 17
cngtcccnga cngcccngag gcttcactga caggtcctcg cg 42
<210> 18
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw2C引物
<220>
<221> 尚未归类的特征
<222> (1)..(24)
<223> 引物
<400> 18
cgcccctaga acgctttgcg tccc 24
<210> 19
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Rev2C引物
<220>
<221> 尚未归类的特征
<222> (1)..(24)
<223> 引物
<400> 19
ggagcgaggc gacccagaca ctca 24
<210> 20
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> MGMT_探针2A
<220>
<221> 尚未归类的特征
<222> (7)..(7)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (14)..(14)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (18)..(18)
<223> Z型疏水性核苷酸
<400> 20
caagtcngca aacnggtng 19
<210> 21
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> MGMT_探针2B
<220>
<221> 尚未归类的特征
<222> (9)..(9)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (14)..(14)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (18)..(18)
<223> Z型疏水性核苷酸
<400> 21
caagtcgcna aacnggtng 19
<210> 22
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> MGMT_探针2D
<220>
<221> 尚未归类的特征
<222> (9)..(9)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (14)..(14)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (20)..(20)
<223> Z型疏水性核苷酸
<400> 22
caagtcgcna aacnggtgcn g 21
<210> 23
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> MGMT_探针2E
<220>
<221> 尚未归类的特征
<222> (9)..(9)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (14)..(14)
<223> Z型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (20)..(20)
<223> Z型疏水性核苷酸
<400> 23
caagtcgcna aacnggtgcn gcac 24
<210> 24
<211> 45
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw环5C BasePrimer
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 24
cngtcccnga cngcccngag cgcttcactg agacaggtcc tcgcg 45
<210> 25
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Fw2C_suE引物
<220>
<221> 尚未归类的特征
<222> (1)..(1)
<223> E型疏水性核苷酸
<400> 25
ncgcccctag aacgctttgc gtccc 25
<210> 26
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> MGMT_Rev2C_suE引物
<220>
<221> 尚未归类的特征
<222> (1)..(1)
<223> E型疏水性核苷酸
<400> 26
nggagcgagg cgacccagac actca 25
<210> 27
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E_M1
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 27
cngacccngt cngcccng 18
<210> 28
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E_M2
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 28
cngtcacnga cngcacng 18
<210> 29
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E_M3
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 29
cngtcacnga cngcccng 18
<210> 30
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E_M4
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 30
cngtcccnga cngcacng 18
<210> 31
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> MGMT_E_M5
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 31
cngacccnga cngcccng 18
<210> 32
<211> 44
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5D_M5
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 32
cngacccnga cngcccngag cgcttcactg agacaggtcc tcgc 44
<210> 33
<211> 23
<212> DNA
<213> 人工
<220>
<223> MGMT_Rev2E
<400> 33
gagcgaggcg acccagacac tca 23
<210> 34
<211> 43
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 34
cngacccnga cngcccngag cgcttcactg agacaggtcc tcg 43
<210> 35
<211> 42
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_2A
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 35
cngacccnga cngcccngag cgcttcactg agaggtcctc gc 42
<210> 36
<211> 41
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_2B
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 36
cngacccnga cngcccngag cgcttcactg agaggtcctc g 41
<210> 37
<211> 42
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_4A
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 37
cngacccnga cngcccngag cgcttcactg agatcctcgc gg 42
<210> 38
<211> 41
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_4B
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 38
cngacccnga cngcccngag cgcttcactg agatcctcgc g 41
<210> 39
<211> 41
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_6A
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 39
cngacccnga cngcccngag cgcttcactg agactcgcgg t 41
<210> 40
<211> 40
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_6B
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 40
cngacccnga cngcccngag cgcttcactg agactcgcgg 40
<210> 41
<211> 39
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_8A
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 41
cngacccnga cngcccngag cgcttcactg agacgcggt 39
<210> 42
<211> 40
<212> DNA
<213> 人工
<220>
<223> MGMT_Fw环5B_M5_8B
<220>
<221> 尚未归类的特征
<222> (2)..(2)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (8)..(8)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (12)..(12)
<223> E型疏水性核苷酸
<220>
<221> 尚未归类的特征
<222> (17)..(17)
<223> E型疏水性核苷酸
<400> 42
cngacccnga cngcccngag cgcttcactg agacgcggtg 40
Claims (71)
1.一种确定未修饰的目的靶核酸序列中至少一个目的核苷酸(NOI)的表观遗传修饰状态、例如甲基化状态的方法,其中所述靶核酸序列包含含有所述NOI的靶锚序列,所述方法包括以下步骤:
a.提供包含锚序列(An)的寡核苷酸,其中所述锚序列是与所述靶锚序列至少50%互补的序列,其中所述锚序列包含至少一个定位在与所述NOI互补的核苷酸与紧邻其5'的核苷酸之间的疏水性核苷酸(H);
b.在高于当所述NOI未被修饰、如未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度的温度下,将所述寡核苷酸与所述目的靶核酸一起孵育,
c.检测所述寡核苷酸是否与所述目的靶核酸退火,
由此确定所述表观遗传修饰状态,例如所述甲基化状态,其中
i.所述疏水性核苷酸(H)具有以下结构:
X-Y-Q,
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元;
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分;并且
ii.所述寡核苷酸具有结构5'-An-Lp-St-3',其中
An是所述锚序列;
Lp是不与所述目的靶核酸序列互补的环序列,其中所述环序列由能够形成突出结构、如环结构或茎结构的单个核酸序列组成,或者由能够至少部分地彼此杂交以形成能够形成突出结构、如环结构或茎结构的复合体的两个或更多个核酸序列组成;
St是能够与靶起始子序列杂交的起始子序列,其中所述靶起始子序列是所述靶核酸序列的定位在所述靶锚序列的5'的序列。
2.根据权利要求1所述的方法,其中所述目的靶核酸是DNA。
3.根据权利要求1所述的方法,其中所述目的靶核酸是RNA。
4.根据前述权利要求中任一项所述的方法,其中在进行所述方法之前,没有对所述未修饰的目的靶核酸序列进行包括亚硫酸氢盐转化、限制性酶切或TET酶促转化在内的处理。
5.根据前述权利要求中任一项所述的方法,其中所述NOI是胞嘧啶。
6.根据前述权利要求中任一项所述的方法,其中在以下之间的差异:
A.在以下的解链温度之间的绝对差异:
i.包含一个或多个所述疏水性核苷酸的所述寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含至少一个甲基化NOI,如至少一个甲基化胞嘧啶;和
ii.包含一个或多个所述疏水性核苷酸的所述寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶;和
B.在以下的解链温度之间的绝对差异:
i.与A.的所述寡核苷酸相同、然而不包含一个或多个所述疏水性核苷酸的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含与A.i.中相同数量的甲基化NOI,如与A.i.中相同数量的甲基化胞嘧啶;和
ii.与A.的所述寡核苷酸相同、然而不包含一个或多个所述疏水性核苷酸的寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶,
是每个NOI、如每个胞嘧啶至少0.50℃,如至少0.75℃,优选至少1.0℃,所述NOI在所述目的靶核酸序列中是甲基化的而不是非甲基化的,其中所述差异是A-B,并且其中所述差异是正差异,并且其中所述解链温度是在包含0.02M Na2HPO4、0.02M NaCl和2mM EDTA的TM缓冲液中测量的。
7.根据前述权利要求中任一项所述的方法,其中在以下的解链温度之间的绝对差异:
i.包含所述疏水性核苷酸的所述寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列包含至少一个甲基化NOI,如至少一个甲基化胞嘧啶;和
ii.包含所述疏水性核苷酸的所述寡核苷酸当与所述目的靶核酸序列杂交时,其中所述目的核酸序列不包含甲基化NOI,如不包含甲基化胞嘧啶,
是每个NOI、如每个胞嘧啶至少1.6℃,如至少1.8℃,如至少2.0℃,如至少2.2℃,优选至少2.4℃,所述NOI在所述目的靶核酸序列中是甲基化的而不是非甲基化的,其中所述解链温度是在包含0.02M Na2HPO4、0.02M NaCl和2mM EDTA的TM缓冲液中测量的。
8.根据前述权利要求中任一项所述的方法,其中所述锚序列包含序列-N-H-G-,其中-G-与目的胞嘧啶互补,并且-N-选自C、G、A和T并且与所述目的胞嘧啶的相邻核苷酸互补。
9.根据权利要求5至8中任一项所述的方法,其中所述胞嘧啶位于CpG位点中,并且其中所述锚序列包含序列-C-H-G-。
10.根据前述权利要求中任一项所述的方法,其中所述锚序列包含至少2个、如至少3个、例如至少4个、如在1至10个范围内、例如在2至10个范围内、如在3至10个范围内、例如在4至10个范围内的疏水性核苷酸(H)。
11.根据前述权利要求中任一项所述的方法,其中所述锚序列包含至少2个、如至少3个、例如至少4个、如在2至10个范围内、例如在2至5个范围内、例如在3至5个范围内、如在4至5个范围内的-N-H-G-序列,其中每个N单独地选自C、G、A和T,并且每个序列-N-G-与目的胞嘧啶及其相邻核苷酸互补。
12.根据前述权利要求中任一项所述的方法,其中2个或更多个NOI定位在CpG位点中,并且所述锚序列包含至少2个、如至少3个、例如至少4个、如在2至5个范围内、例如在3至5个范围内、如在4至5个范围内的-C-H-G-序列。
13.根据前述权利要求中任一项所述的方法,其中步骤b)和c)一起包括进行PCR,其中所述温度用作所述PCR的一个或多个循环中的退火温度。
14.根据前述权利要求中任一项所述的方法,其中所述寡核苷酸被编码为两个或更多个单独的寡核苷酸,如2个、3个或更多个单独的寡核苷酸。
15.根据权利要求1至13中任一项所述的方法,其中所述寡核苷酸被编码为单个寡核苷酸。
16.根据权利要求1至14中任一项所述的方法,其中所述寡核苷酸由第一核酸序列和第二核酸序列组成,其中所述第一核酸序列包含与靶DNA互补的所述锚序列(An)和不与所述目的靶核酸序列互补的环序列的第一部分,并且所述第二核酸序列包含能够至少部分地与所述环序列的第一部分杂交的所述环序列的第二部分,所述第二核酸序列进一步包含所述起始子序列(St),并且其中所述第一核酸和所述第二核酸一旦杂交就能够形成所述突出结构。
17.根据前述权利要求中任一项所述的方法,其中所述锚序列(An)由在8至30个范围内、例如在8至20个范围内、如在10至20个范围内、例如在15至20个范围内的核苷酸组成,其中所述核苷酸中的一个或多个是一个或多个疏水性核苷酸。
18.根据前述权利要求中任一项所述的方法,其中所述锚序列(An)与所述靶锚序列至少85%互补。
19.根据前述权利要求中任一项所述的方法,其中所述起始子序列(St)与靶起始子序列100%互补。
20.根据前述权利要求中任一项所述的方法,其中所述靶锚序列和所述靶起始子序列彼此定位在10个核苷酸内,例如在8个核苷酸内,如在5个核苷酸内。
21.根据前述权利要求中任一项所述的方法,其中这样选择Lp和St,使得由Lp-St组成的寡核苷酸与其互补序列的解链温度为至少50℃,例如至少55℃,如至少65℃。
22.根据前述权利要求中任一项所述的方法,其中Lp和St一起由至少15个核苷酸、例如至少17个核苷酸、如在15至45个范围内的核苷酸、例如在17至35个范围内的核苷酸、如在17至25个范围内的核苷酸组成。
23.根据前述权利要求中任一项所述的方法,其中Lp不包含疏水性核苷酸。
24.根据权利要求1至22中任一项所述的方法,其中Lp由两个或更多个核酸序列组成,并且其中所述一个或多个未共价连接至所述St序列的核酸序列包含一个或多个疏水性核苷酸。
25.根据前述权利要求中任一项所述的方法,其中St不包含疏水性核苷酸。
26.根据前述权利要求中任一项所述的方法,其中在所述寡核苷酸与甲基化目的靶核酸序列之间的解链温度比在所述寡核苷酸与非甲基化目的靶核酸序列之间的解链温度高至少5℃,例如高至少6℃,如高6℃至15℃的范围,例如高6℃至12℃的范围。
27.根据前述权利要求中任一项所述的方法,其中在所述寡核苷酸与所述甲基化靶核酸序列之间的解链温度和在所述寡核苷酸与非甲基化目的靶核酸序列之间的解链温度相比的差异比在除了缺少所述疏水性核苷酸之外具有相同序列的寡核苷酸与所述甲基化靶核酸序列之间的解链温度和在所述除了缺少所述疏水性核苷酸之外具有相同序列的寡核苷酸与非甲基化靶核酸序列之间的解链温度相比的差异至少高1℃。
28.根据前述权利要求中任一项所述的方法,其中步骤b)和c)一起包括进行实时PCR。
29.根据权利要求28所述的方法,其中如果Ct低于使用非甲基化靶核酸序列作为模板进行的对照PCR的Ct,则认为所述目的核酸是甲基化的。
30.根据前述权利要求中任一项所述的方法,其中步骤b)和c)一起包括进行PCR,其中所述PCR的至少第一循环使用这样的退火温度,所述退火温度高于当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度。
31.根据前述权利要求中任一项所述的方法,其中步骤b)的所述温度比当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度高至少2℃。
32.根据前述权利要求中任一项所述的方法,其中步骤b)和c)一起包括进行PCR,其中所述PCR的至少第一循环使用这样的退火温度,所述退火温度高于当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度,并且所述退火温度比当所述NOI甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度高至多4℃、如高至多2℃,与所述解链温度相同或低于所述解链温度。
33.根据前述权利要求中任一项所述的方法,其中步骤b)和c)一起包括进行PCR,其中所述PCR的至少第一循环使用这样的退火温度,所述退火温度高于当所述NOI未甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度,并且所述退火温度比当所述NOI甲基化时在所述寡核苷酸与所述目的靶核酸序列之间的解链温度高至多4℃至低至多4℃。
34.根据前述权利要求中任一项所述的方法,其中步骤b)和c)一起包括进行PCR,其中所述PCR的至少第一循环使用在55℃至80℃范围内的退火温度。
35.根据权利要求34所述的方法,其中所述PCR的至少第一循环包括在所述退火温度下孵育在30至120s范围内的时间。
36.根据前述权利要求中任一项所述的方法,其中在步骤b)期间所述寡核苷酸的浓度在300至700nM的范围内。
37.根据权利要求13至36中任一项所述的方法,其中所述PCR包括一个或多个甲基特异性扩增循环和一个或多个通用扩增循环,其中所述一个或多个甲基特异性扩增循环包括以下步骤:
a.使核酸解链
b.在甲基特异性条件下退火和延伸
并且所述通用扩增循环包括以下步骤:
c.使核酸解链
d.在通用条件下退火和延伸
其中所述解链包括在至少90℃的温度下孵育,并且其中在甲基特异性条件下进行的所述退火和延伸在比在通用条件下进行的退火和延伸高的温度下进行。
38.根据权利要求34至37中任一项所述的方法,其中退火进行在45至90s范围内、如在45至75s范围内、例如大约60s的时间。
39.根据权利要求37至38中任一项所述的方法,其中所述方法包括在1至100个范围内的甲基特异性扩增循环。
40.根据权利要求13至39中任一项所述的方法,其中所述PCR使用所述寡核苷酸作为正向引物来进行,其中所述PCR进一步包括使用与所述目的靶核酸序列下游的序列至少90%相同、例如100%相同的反向引物。
41.根据权利要求13至40中任一项所述的方法,其中所述PCR包括使用可检测探针来检测PCR产物,其中所述探针包含与所述PCR反应的产物至少90%互补的寡核苷酸和可检测标记。
42.根据权利要求41所述的方法,其中所述探针包含一个或多个疏水性核苷酸。
43.根据前述权利要求中任一项所述的方法,其中目的靶核酸序列包含在从样品中纯化的DNA中。
44.根据权利要求43所述的方法,其中所述样品是从患有与所述目的核酸中的甲基化相关的临床病症或有患上所述临床病症的风险的个体获得的样品。
45.根据前述权利要求中任一项所述的方法,其中所述方法不包括预处理目的核酸以将甲基化核苷酸转化成可检测部分的步骤。
46.根据前述权利要求中任一项所述的方法,其中所述方法不包括亚硫酸氢盐转化步骤。
47.一种用于确定个体是否患有临床病症的风险或个体患上临床病症的风险的方法,其中所述临床病症与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供从所述个体获得的样品;
b.通过进行根据前述权利要求中任一项所述的方法确定所述样品中所述NOI的甲基化状态,其中所述甲基化状态指示所述临床病症的存在或患上所述临床病症的风险。
48.一种用于确定有需要的个体的临床病症的治疗效果的可能性的方法,其中所述临床病症的所述治疗的效果与目的核酸中NOI的甲基化状态相关,所述方法包括:
a.提供从所述个体获得的样品;
b.通过进行根据权利要求1至43中任一项所述的方法确定所述样品中所述NOI的甲基化状态,其中所述甲基化状态指示不同治疗方案对所述临床病症的效果。
49.根据权利要求47至48中任一项所述的方法,其中所述临床病症是癌症。
50.根据权利要求49所述的方法,其中所述癌症是胶质母细胞瘤。
51.一种寡核苷酸,所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-HG-(N)m-HG-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸
其中所述疏水性核苷酸具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
52.根据权利要求51所述的寡核苷酸,其中所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-HG-(N)m-HG-(N)p-HG-(N)q-3',
其中
p≥1;并且
q是≥0的整数。
53.根据权利要求51至52中任一项所述的寡核苷酸,其中所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-HG-(N)m-HG-(N)p-HG-(N)q-HG-(N)u-3',
其中
q是≥1的整数;并且
u是≥0的整数。
54.根据权利要求51至53中任一项所述的寡核苷酸,其中n是在0至4范围内的整数,例如n是1。
55.根据权利要求51至54中任一项所述的寡核苷酸,其中m是在1至8范围内、例如在1至6范围内的整数。
56.根据权利要求51至55中任一项所述的寡核苷酸,其中p是在1至50范围内、如在1至30范围内、例如在1至10范围内、例如在1至6范围内的整数。
57.根据权利要求51至56中任一项所述的寡核苷酸,其中q是在1至50范围内、如在1至30范围内、例如在1至10范围内、例如在1至6范围内的整数。
58.根据权利要求51至57中任一项所述的寡核苷酸,其中u是在1至50范围内、如在1至30范围内、例如在1至10范围内、例如在1至6范围内的整数。
59.根据权利要求51至58中任一项所述的寡核苷酸,其中紧邻至少一个H的5'定位的核苷酸是胞嘧啶(C)。
60.根据权利要求51至59中任一项所述的寡核苷酸,其中紧邻H的5'定位的所有核苷酸都是胞嘧啶(C)。
61.根据前述权利要求中任一项所述的方法或寡核苷酸,其中至少一种、如所有嵌入剂Q选自任选地被选自以下的一个或多个取代的多芳烃和杂多芳烃:羟基、溴、氟、氯、碘、巯基、硫代基、氰基、烷硫基、杂环、芳基、杂芳基、羧基、碳烷酰基、烷基、烯基、炔基、硝基、氨基、烷氧基和酰胺基。
62.根据前述权利要求中任一项所述的方法或寡核苷酸,其中所述多芳烃或杂多芳烃由至少3个环、例如4个环组成。
63.根据前述权利要求中任一项所述的方法或寡核苷酸,其中所述嵌入剂选自苯、戊搭烯、茚、萘、薁、不对称引达省、对称引达省、联苯撑、苊、非那烯、庚搭烯、菲蒽烷、荧蒽、菲咯啉、吩嗪、菲啶、蒽醌、芘、蒽、环烷烃、菲、芴、苉、 并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素及其衍生物。
并四苯、吖啶酮、苯并蒽、茋、草酰-吡啶并咔唑、叠氮基苯、卟啉和补骨脂素及其衍生物。
64.根据前述权利要求中任一项所述的方法或寡核苷酸,其中至少一种、如所有嵌入剂Q包含芘或吡啶并[3',2':4,5]噻吩并[3,2-d]嘧啶-4(1H)-酮或7,9-二甲基-吡啶并[3',2',4,5]噻吩并[3,2-d]嘧啶-4(3H)-酮或者由其组成。
65.根据前述权利要求中任一项所述的方法或寡核苷酸,其中至少一个、如所有骨架单体单元选自亚磷酰胺。
66.根据权利要求1至50中任一项所述的方法,其中所述寡核苷酸是根据权利要求43至57中任一项所述的寡核苷酸。
67.一种寡核苷酸,所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-CGH-(N)m-CGH-(N)p-3',
其中N是任何核苷酸或核苷酸类似物;并且
C是核苷酸胞嘧啶;并且
G是核苷酸鸟嘌呤;并且
n是≥0的整数;并且
m是≥1的整数;并且
p是≥0的整数;并且
H是疏水性核苷酸
其中所述疏水性核苷酸具有以下结构:
X-Y-Q
其中
X是核苷酸或核苷酸类似物或者能够被掺入核酸或核酸类似物的骨架中的骨架单体单元,
Q是不参与沃森-克里克氢键合的嵌入剂;并且
Y是连接所述核苷酸或核苷酸类似物或骨架单体单元与所述嵌入剂的接头部分。
68.根据权利要求67所述的寡核苷酸,其中所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-CGH-(N)m-CGH-(N)p-CGH-(N)q-3',
其中
p≥1;并且
q是≥0的整数。
69.根据权利要求67至68中任一项所述的寡核苷酸,其中所述寡核苷酸包含以下通用结构或由以下通用结构组成:
5'(N)n-CGH-(N)m-CGH-(N)p-CGH-(N)q-CGH-(N)u-3',
其中
q是≥1的整数;并且
u是≥0的整数。
70.根据权利要求67至69中任一项所述的寡核苷酸,其中n、m、p、q和u如权利要求54至58中任一项所定义。
71.根据权利要求67至70中任一项所述的寡核苷酸,其中Q和X如权利要求61至65中任一项所定义。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20182947 | 2020-06-29 | ||
| EP20182947.0 | 2020-06-29 | ||
| PCT/EP2021/067880 WO2022002958A1 (en) | 2020-06-29 | 2021-06-29 | Detection of methylation status |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116209775A true CN116209775A (zh) | 2023-06-02 |
Family
ID=71401636
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202180045918.6A Pending CN116209775A (zh) | 2020-06-29 | 2021-06-29 | 甲基化状态的检测 |
Country Status (7)
| Country | Link |
|---|---|
| EP (1) | EP4172361B1 (zh) |
| JP (1) | JP2023540161A (zh) |
| KR (1) | KR20230034959A (zh) |
| CN (1) | CN116209775A (zh) |
| AU (1) | AU2021302551A1 (zh) |
| CA (1) | CA3183054A1 (zh) |
| WO (1) | WO2022002958A1 (zh) |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003052133A2 (en) | 2001-12-18 | 2003-06-26 | Human Genetic Signatures Pty Ltd | Oligonucleotide analogues comprising intercalator pseudonucleotides |
| CN101448957A (zh) * | 2006-03-16 | 2009-06-03 | 潘塔贝斯公司 | 用于检测核酸、核酸的甲基化状态和突变体的包含信号对和疏水性核苷酸、无茎信标的寡核苷酸 |
| GB0714058D0 (en) * | 2007-07-19 | 2007-08-29 | Abertec Ltd | detection of methylation in nucleic acid sequences |
| WO2009105830A1 (en) * | 2008-02-27 | 2009-09-03 | Peter Maccallum Cancer Institute | Analysing methylation specific pcr by amplicon melting |
| US10988810B2 (en) | 2015-09-14 | 2021-04-27 | Pentabase Aps | Methods and materials for detection of mutations |
-
2021
- 2021-06-29 JP JP2022580318A patent/JP2023540161A/ja active Pending
- 2021-06-29 WO PCT/EP2021/067880 patent/WO2022002958A1/en active Search and Examination
- 2021-06-29 KR KR1020227044735A patent/KR20230034959A/ko active Search and Examination
- 2021-06-29 CN CN202180045918.6A patent/CN116209775A/zh active Pending
- 2021-06-29 AU AU2021302551A patent/AU2021302551A1/en active Pending
- 2021-06-29 CA CA3183054A patent/CA3183054A1/en active Pending
- 2021-06-29 EP EP21737437.0A patent/EP4172361B1/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CA3183054A1 (en) | 2022-01-06 |
| EP4172361B1 (en) | 2024-08-07 |
| JP2023540161A (ja) | 2023-09-22 |
| EP4172361C0 (en) | 2024-08-07 |
| EP4172361A1 (en) | 2023-05-03 |
| WO2022002958A1 (en) | 2022-01-06 |
| KR20230034959A (ko) | 2023-03-10 |
| AU2021302551A1 (en) | 2023-01-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7091400B2 (ja) | 核酸の多重検出 | |
| JP6571895B1 (ja) | 核酸プローブ及びゲノム断片検出方法 | |
| CN101889096B (zh) | 核酸扩增 | |
| JP3843215B2 (ja) | 高い特異性を有するプライマー、増幅法およびキット | |
| JP5394937B2 (ja) | 核酸検出 | |
| JP4440469B2 (ja) | 組み込まれたシグナリング系に使用するためのpcrプライマー・コンストラクト | |
| CN112424379B (zh) | 改进的多核苷酸序列检测方法 | |
| EP1071811B1 (en) | A method for the characterisation of nucleic acid molecules involving generation of extendible upstream dna fragments resulting from the cleavage of nucleic acid at an abasic site | |
| EP3152332B1 (en) | Method for methylation analysis | |
| US9863001B2 (en) | Method for the detection of cytosine methylations in DNA | |
| US20190106735A1 (en) | Method for analyzing cancer gene using multiple amplification nested signal amplification and kit | |
| JP2005518217A (ja) | ヘッドループdnaの増幅 | |
| US20180237853A1 (en) | Methods, Compositions and Kits for Detection of Mutant Variants of Target Genes | |
| EP3055430B1 (en) | Method for the detection of target nucleic acid sequences | |
| JP5258760B2 (ja) | メチル化核酸又は非メチル化核酸を増幅する方法 | |
| WO2004113567A9 (en) | Improved heavymethyl assay for the methylation analysis of the gstpi gene | |
| CN116209775A (zh) | 甲基化状态的检测 | |
| JP2019521716A (ja) | 多重増幅二重シグナル増幅によるターゲット核酸配列の検出方法 | |
| EP3971302A1 (en) | Method for detecting 5-hydroxymethylated cytosine | |
| CN114250275A (zh) | 一种荧光定量pcr反应系统、pcr反应试剂盒及核酸定量检测方法 | |
| Whitcombe | 6 Using Scorpion Primers |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |