CN112004825A - 细胞周期蛋白a1特异性t细胞受体及其用途 - Google Patents
细胞周期蛋白a1特异性t细胞受体及其用途 Download PDFInfo
- Publication number
- CN112004825A CN112004825A CN201980025483.1A CN201980025483A CN112004825A CN 112004825 A CN112004825 A CN 112004825A CN 201980025483 A CN201980025483 A CN 201980025483A CN 112004825 A CN112004825 A CN 112004825A
- Authority
- CN
- China
- Prior art keywords
- amino acid
- seq
- acid sequence
- domain
- chain
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 108091008874 T cell receptors Proteins 0.000 title claims description 365
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 title claims description 363
- 102000008160 Cyclin A1 Human genes 0.000 title description 21
- 108010060267 Cyclin A1 Proteins 0.000 title description 21
- 108091008324 binding proteins Proteins 0.000 claims abstract description 179
- 239000000427 antigen Substances 0.000 claims abstract description 67
- 108091007433 antigens Proteins 0.000 claims abstract description 64
- 102000036639 antigens Human genes 0.000 claims abstract description 64
- 101000934314 Homo sapiens Cyclin-A1 Proteins 0.000 claims abstract description 56
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 39
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 35
- 201000010099 disease Diseases 0.000 claims abstract description 32
- 102100025176 Cyclin-A1 Human genes 0.000 claims abstract description 25
- 239000000203 mixture Substances 0.000 claims abstract description 22
- 201000011510 cancer Diseases 0.000 claims abstract description 20
- 102000054377 human CCNA1 Human genes 0.000 claims abstract description 12
- 102100025191 Cyclin-A2 Human genes 0.000 claims abstract description 7
- 101000934320 Homo sapiens Cyclin-A2 Proteins 0.000 claims abstract description 7
- 102000023732 binding proteins Human genes 0.000 claims abstract 63
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 634
- 210000004027 cell Anatomy 0.000 claims description 196
- 108090000623 proteins and genes Proteins 0.000 claims description 186
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 132
- 238000000034 method Methods 0.000 claims description 87
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 86
- 230000027455 binding Effects 0.000 claims description 85
- 239000013598 vector Substances 0.000 claims description 77
- 102000040430 polynucleotide Human genes 0.000 claims description 66
- 108091033319 polynucleotide Proteins 0.000 claims description 66
- 239000002157 polynucleotide Substances 0.000 claims description 66
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 64
- 235000001014 amino acid Nutrition 0.000 claims description 63
- 230000014509 gene expression Effects 0.000 claims description 54
- 150000001576 beta-amino acids Chemical group 0.000 claims description 52
- 229920001184 polypeptide Polymers 0.000 claims description 47
- 210000002865 immune cell Anatomy 0.000 claims description 45
- 238000006467 substitution reaction Methods 0.000 claims description 45
- 229940024606 amino acid Drugs 0.000 claims description 38
- 150000001413 amino acids Chemical class 0.000 claims description 37
- 241000282414 Homo sapiens Species 0.000 claims description 35
- 239000003112 inhibitor Substances 0.000 claims description 29
- 102000004127 Cytokines Human genes 0.000 claims description 28
- 108090000695 Cytokines Proteins 0.000 claims description 28
- 238000012217 deletion Methods 0.000 claims description 27
- 230000037430 deletion Effects 0.000 claims description 27
- 238000003780 insertion Methods 0.000 claims description 23
- 230000037431 insertion Effects 0.000 claims description 23
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 22
- 239000012634 fragment Substances 0.000 claims description 22
- 108020004705 Codon Proteins 0.000 claims description 16
- 210000003958 hematopoietic stem cell Anatomy 0.000 claims description 16
- 239000013603 viral vector Substances 0.000 claims description 15
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 claims description 13
- 235000018417 cysteine Nutrition 0.000 claims description 13
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 claims description 13
- 230000035772 mutation Effects 0.000 claims description 13
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 12
- 101000844027 Homo sapiens Probable non-functional T cell receptor beta variable 7-3 Proteins 0.000 claims description 12
- 102100032176 Probable non-functional T cell receptor beta variable 7-3 Human genes 0.000 claims description 12
- 230000001506 immunosuppresive effect Effects 0.000 claims description 11
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 claims description 10
- 239000000556 agonist Substances 0.000 claims description 10
- 230000001225 therapeutic effect Effects 0.000 claims description 10
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 9
- 210000000265 leukocyte Anatomy 0.000 claims description 9
- 210000003071 memory t lymphocyte Anatomy 0.000 claims description 9
- 101000795989 Homo sapiens T cell receptor alpha variable 10 Proteins 0.000 claims description 8
- 101000772143 Homo sapiens T cell receptor alpha variable 17 Proteins 0.000 claims description 8
- 101000772105 Homo sapiens T cell receptor alpha variable 24 Proteins 0.000 claims description 8
- 101000606214 Homo sapiens T cell receptor beta variable 5-6 Proteins 0.000 claims description 8
- 108010002350 Interleukin-2 Proteins 0.000 claims description 8
- 102100031333 T cell receptor alpha variable 10 Human genes 0.000 claims description 8
- 102100029306 T cell receptor alpha variable 17 Human genes 0.000 claims description 8
- 102100029484 T cell receptor alpha variable 24 Human genes 0.000 claims description 8
- 102100039749 T cell receptor beta variable 5-6 Human genes 0.000 claims description 8
- 108020001507 fusion proteins Proteins 0.000 claims description 8
- 102000037865 fusion proteins Human genes 0.000 claims description 8
- 230000003463 hyperproliferative effect Effects 0.000 claims description 8
- 210000003289 regulatory T cell Anatomy 0.000 claims description 8
- 230000004044 response Effects 0.000 claims description 8
- 230000004936 stimulating effect Effects 0.000 claims description 7
- 230000005867 T cell response Effects 0.000 claims description 6
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 claims description 6
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 claims description 6
- 210000004443 dendritic cell Anatomy 0.000 claims description 6
- 239000012636 effector Substances 0.000 claims description 6
- 230000001400 myeloablative effect Effects 0.000 claims description 6
- 229960003301 nivolumab Drugs 0.000 claims description 6
- 150000003839 salts Chemical class 0.000 claims description 6
- 238000001356 surgical procedure Methods 0.000 claims description 6
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 5
- 208000002250 Hematologic Neoplasms Diseases 0.000 claims description 5
- 102000037982 Immune checkpoint proteins Human genes 0.000 claims description 5
- 108091008036 Immune checkpoint proteins Proteins 0.000 claims description 5
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 5
- 229940126546 immune checkpoint molecule Drugs 0.000 claims description 5
- 239000003018 immunosuppressive agent Substances 0.000 claims description 5
- 238000001959 radiotherapy Methods 0.000 claims description 5
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 claims description 4
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 claims description 4
- 102100024263 CD160 antigen Human genes 0.000 claims description 4
- 201000009030 Carcinoma Diseases 0.000 claims description 4
- 206010009944 Colon cancer Diseases 0.000 claims description 4
- 206010014759 Endometrial neoplasm Diseases 0.000 claims description 4
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 claims description 4
- 101000772141 Homo sapiens T cell receptor alpha variable 19 Proteins 0.000 claims description 4
- 101000772121 Homo sapiens T cell receptor alpha variable 30 Proteins 0.000 claims description 4
- 101000658398 Homo sapiens T cell receptor beta variable 19 Proteins 0.000 claims description 4
- 101000658410 Homo sapiens T cell receptor beta variable 2 Proteins 0.000 claims description 4
- 101000606219 Homo sapiens T cell receptor beta variable 6-6 Proteins 0.000 claims description 4
- 101000844026 Homo sapiens T cell receptor beta variable 7-2 Proteins 0.000 claims description 4
- 101000844040 Homo sapiens T cell receptor beta variable 9 Proteins 0.000 claims description 4
- 201000003793 Myelodysplastic syndrome Diseases 0.000 claims description 4
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 claims description 4
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 4
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 4
- 102100029307 T cell receptor alpha variable 19 Human genes 0.000 claims description 4
- 102100029314 T cell receptor alpha variable 30 Human genes 0.000 claims description 4
- 102100034884 T cell receptor beta variable 19 Human genes 0.000 claims description 4
- 102100034891 T cell receptor beta variable 2 Human genes 0.000 claims description 4
- 102100039785 T cell receptor beta variable 6-6 Human genes 0.000 claims description 4
- 102100032177 T cell receptor beta variable 7-2 Human genes 0.000 claims description 4
- 102100032166 T cell receptor beta variable 9 Human genes 0.000 claims description 4
- 208000021668 chronic eosinophilic leukemia Diseases 0.000 claims description 4
- 230000009368 gene silencing by RNA Effects 0.000 claims description 4
- 210000000822 natural killer cell Anatomy 0.000 claims description 4
- 229960002621 pembrolizumab Drugs 0.000 claims description 4
- 239000004475 Arginine Substances 0.000 claims description 3
- 108010074708 B7-H1 Antigen Proteins 0.000 claims description 3
- 239000002126 C01EB10 - Adenosine Substances 0.000 claims description 3
- 102100038078 CD276 antigen Human genes 0.000 claims description 3
- 101710185679 CD276 antigen Proteins 0.000 claims description 3
- 102000053642 Catalytic RNA Human genes 0.000 claims description 3
- 108090000994 Catalytic RNA Proteins 0.000 claims description 3
- 102100031351 Galectin-9 Human genes 0.000 claims description 3
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 claims description 3
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 claims description 3
- 101000658376 Homo sapiens T cell receptor alpha variable 12-2 Proteins 0.000 claims description 3
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 claims description 3
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 claims description 3
- 108010043610 KIR Receptors Proteins 0.000 claims description 3
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 claims description 3
- KCWZGJVSDFYRIX-YFKPBYRVSA-N N(gamma)-nitro-L-arginine methyl ester Chemical compound COC(=O)[C@@H](N)CCCN=C(N)N[N+]([O-])=O KCWZGJVSDFYRIX-YFKPBYRVSA-N 0.000 claims description 3
- 108091034117 Oligonucleotide Proteins 0.000 claims description 3
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 claims description 3
- 101710089372 Programmed cell death protein 1 Proteins 0.000 claims description 3
- 206010039491 Sarcoma Diseases 0.000 claims description 3
- 102100034847 T cell receptor alpha variable 12-2 Human genes 0.000 claims description 3
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 claims description 3
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 claims description 3
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 claims description 3
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 claims description 3
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 claims description 3
- 239000002253 acid Substances 0.000 claims description 3
- 229960005305 adenosine Drugs 0.000 claims description 3
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 claims description 3
- 210000002443 helper t lymphocyte Anatomy 0.000 claims description 3
- 238000002650 immunosuppressive therapy Methods 0.000 claims description 3
- 201000000050 myeloid neoplasm Diseases 0.000 claims description 3
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 3
- 108091092562 ribozyme Proteins 0.000 claims description 3
- ZADWXFSZEAPBJS-JTQLQIEISA-N 1-methyl-L-tryptophan Chemical compound C1=CC=C2N(C)C=C(C[C@H](N)C(O)=O)C2=C1 ZADWXFSZEAPBJS-JTQLQIEISA-N 0.000 claims description 2
- 102000004452 Arginase Human genes 0.000 claims description 2
- 108700024123 Arginases Proteins 0.000 claims description 2
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 claims description 2
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 claims description 2
- 229940125565 BMS-986016 Drugs 0.000 claims description 2
- 206010005003 Bladder cancer Diseases 0.000 claims description 2
- 206010005949 Bone cancer Diseases 0.000 claims description 2
- 208000018084 Bone neoplasm Diseases 0.000 claims description 2
- 208000003174 Brain Neoplasms Diseases 0.000 claims description 2
- 206010006187 Breast cancer Diseases 0.000 claims description 2
- 208000026310 Breast neoplasm Diseases 0.000 claims description 2
- HFOBENSCBRZVSP-LKXGYXEUSA-N C[C@@H](O)[C@H](NC(=O)N[C@@H](CC(N)=O)c1nc(no1)[C@@H](N)CO)C(O)=O Chemical compound C[C@@H](O)[C@H](NC(=O)N[C@@H](CC(N)=O)c1nc(no1)[C@@H](N)CO)C(O)=O HFOBENSCBRZVSP-LKXGYXEUSA-N 0.000 claims description 2
- 206010008342 Cervix carcinoma Diseases 0.000 claims description 2
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 2
- 206010052360 Colorectal adenocarcinoma Diseases 0.000 claims description 2
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 2
- DYEFUKCXAQOFHX-UHFFFAOYSA-N Ebselen Chemical compound [se]1C2=CC=CC=C2C(=O)N1C1=CC=CC=C1 DYEFUKCXAQOFHX-UHFFFAOYSA-N 0.000 claims description 2
- 206010014733 Endometrial cancer Diseases 0.000 claims description 2
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 2
- 208000009849 Female Genital Neoplasms Diseases 0.000 claims description 2
- 101100229077 Gallus gallus GAL9 gene Proteins 0.000 claims description 2
- 208000032320 Germ cell tumor of testis Diseases 0.000 claims description 2
- 201000010915 Glioblastoma multiforme Diseases 0.000 claims description 2
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 claims description 2
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 claims description 2
- 101000884270 Homo sapiens Natural killer cell receptor 2B4 Proteins 0.000 claims description 2
- 101000844038 Homo sapiens T cell receptor beta variable 10-2 Proteins 0.000 claims description 2
- 101001102797 Homo sapiens Transmembrane protein PVRIG Proteins 0.000 claims description 2
- 239000004201 L-cysteine Substances 0.000 claims description 2
- 102000017578 LAG3 Human genes 0.000 claims description 2
- 102100020943 Leukocyte-associated immunoglobulin-like receptor 1 Human genes 0.000 claims description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 2
- 206010027406 Mesothelioma Diseases 0.000 claims description 2
- 208000034578 Multiple myelomas Diseases 0.000 claims description 2
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 claims description 2
- FQWRAVYMZULPNK-BYPYZUCNSA-N N(5)-[(hydroxyamino)(imino)methyl]-L-ornithine Chemical compound OC(=O)[C@@H](N)CCCNC(=N)NO FQWRAVYMZULPNK-BYPYZUCNSA-N 0.000 claims description 2
- 101150065403 NECTIN2 gene Proteins 0.000 claims description 2
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 claims description 2
- 102100035488 Nectin-2 Human genes 0.000 claims description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 2
- 206010033128 Ovarian cancer Diseases 0.000 claims description 2
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 claims description 2
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 claims description 2
- 206010060862 Prostate cancer Diseases 0.000 claims description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 2
- 108091030071 RNAI Proteins 0.000 claims description 2
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 2
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 2
- 208000032383 Soft tissue cancer Diseases 0.000 claims description 2
- 208000021712 Soft tissue sarcoma Diseases 0.000 claims description 2
- 208000000102 Squamous Cell Carcinoma of Head and Neck Diseases 0.000 claims description 2
- 102100032167 T cell receptor beta variable 10-2 Human genes 0.000 claims description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 2
- 102100039630 Transmembrane protein PVRIG Human genes 0.000 claims description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 2
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 claims description 2
- 208000002495 Uterine Neoplasms Diseases 0.000 claims description 2
- 239000000074 antisense oligonucleotide Substances 0.000 claims description 2
- 238000012230 antisense oligonucleotides Methods 0.000 claims description 2
- 201000009036 biliary tract cancer Diseases 0.000 claims description 2
- 208000020790 biliary tract neoplasm Diseases 0.000 claims description 2
- 210000000988 bone and bone Anatomy 0.000 claims description 2
- 201000010881 cervical cancer Diseases 0.000 claims description 2
- 208000029742 colonic neoplasm Diseases 0.000 claims description 2
- 239000003246 corticosteroid Substances 0.000 claims description 2
- 208000035250 cutaneous malignant susceptibility to 1 melanoma Diseases 0.000 claims description 2
- 239000003085 diluting agent Substances 0.000 claims description 2
- 239000003937 drug carrier Substances 0.000 claims description 2
- 229950010033 ebselen Drugs 0.000 claims description 2
- 229940056913 eftilagimod alfa Drugs 0.000 claims description 2
- 201000004101 esophageal cancer Diseases 0.000 claims description 2
- 201000006585 gastric adenocarcinoma Diseases 0.000 claims description 2
- 208000005017 glioblastoma Diseases 0.000 claims description 2
- 201000000459 head and neck squamous cell carcinoma Diseases 0.000 claims description 2
- 229940121569 ieramilimab Drugs 0.000 claims description 2
- 229960004942 lenalidomide Drugs 0.000 claims description 2
- GOTYRUGSSMKFNF-UHFFFAOYSA-N lenalidomide Chemical compound C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O GOTYRUGSSMKFNF-UHFFFAOYSA-N 0.000 claims description 2
- 201000007270 liver cancer Diseases 0.000 claims description 2
- 208000014018 liver neoplasm Diseases 0.000 claims description 2
- 201000005202 lung cancer Diseases 0.000 claims description 2
- 208000020816 lung neoplasm Diseases 0.000 claims description 2
- 201000001441 melanoma Diseases 0.000 claims description 2
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 claims description 2
- 231100000782 microtubule inhibitor Toxicity 0.000 claims description 2
- 229960000951 mycophenolic acid Drugs 0.000 claims description 2
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 claims description 2
- 201000008968 osteosarcoma Diseases 0.000 claims description 2
- 201000008129 pancreatic ductal adenocarcinoma Diseases 0.000 claims description 2
- 229960000688 pomalidomide Drugs 0.000 claims description 2
- UVSMNLNDYGZFPF-UHFFFAOYSA-N pomalidomide Chemical compound O=C1C=2C(N)=CC=CC=2C(=O)N1C1CCC(=O)NC1=O UVSMNLNDYGZFPF-UHFFFAOYSA-N 0.000 claims description 2
- 229940002612 prodrug Drugs 0.000 claims description 2
- 239000000651 prodrug Substances 0.000 claims description 2
- 201000009410 rhabdomyosarcoma Diseases 0.000 claims description 2
- 201000000849 skin cancer Diseases 0.000 claims description 2
- 229940126625 tavolimab Drugs 0.000 claims description 2
- 208000002918 testicular germ cell tumor Diseases 0.000 claims description 2
- 201000002510 thyroid cancer Diseases 0.000 claims description 2
- 206010044412 transitional cell carcinoma Diseases 0.000 claims description 2
- 229950007217 tremelimumab Drugs 0.000 claims description 2
- 229950005972 urelumab Drugs 0.000 claims description 2
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 2
- 206010046766 uterine cancer Diseases 0.000 claims description 2
- 208000037965 uterine sarcoma Diseases 0.000 claims description 2
- 229940121351 vopratelimab Drugs 0.000 claims description 2
- 229940125721 immunosuppressive agent Drugs 0.000 claims 4
- 239000002552 dosage form Substances 0.000 claims 2
- 239000007787 solid Substances 0.000 claims 2
- 102100023990 60S ribosomal protein L17 Human genes 0.000 claims 1
- 208000035657 Abasia Diseases 0.000 claims 1
- 108091023037 Aptamer Proteins 0.000 claims 1
- 101000840545 Bacillus thuringiensis L-isoleucine-4-hydroxylase Proteins 0.000 claims 1
- 208000032612 Glial tumor Diseases 0.000 claims 1
- 206010018338 Glioma Diseases 0.000 claims 1
- 206010066476 Haematological malignancy Diseases 0.000 claims 1
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 claims 1
- 101001037256 Homo sapiens Indoleamine 2,3-dioxygenase 1 Proteins 0.000 claims 1
- 101001138062 Homo sapiens Leukocyte-associated immunoglobulin-like receptor 1 Proteins 0.000 claims 1
- 102100040061 Indoleamine 2,3-dioxygenase 1 Human genes 0.000 claims 1
- 102000002698 KIR Receptors Human genes 0.000 claims 1
- YGACXVRLDHEXKY-WXRXAMBDSA-N O[C@H](C[C@H]1c2c(cccc2F)-c2cncn12)[C@H]1CC[C@H](O)CC1 Chemical compound O[C@H](C[C@H]1c2c(cccc2F)-c2cncn12)[C@H]1CC[C@H](O)CC1 YGACXVRLDHEXKY-WXRXAMBDSA-N 0.000 claims 1
- 208000008900 Pancreatic Ductal Carcinoma Diseases 0.000 claims 1
- 101001037255 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Indoleamine 2,3-dioxygenase Proteins 0.000 claims 1
- 208000033781 Thyroid carcinoma Diseases 0.000 claims 1
- 229960000548 alemtuzumab Drugs 0.000 claims 1
- 230000003140 astrocytic effect Effects 0.000 claims 1
- 229940046731 calcineurin inhibitors Drugs 0.000 claims 1
- 238000002512 chemotherapy Methods 0.000 claims 1
- 229960001334 corticosteroids Drugs 0.000 claims 1
- 229940096118 ella Drugs 0.000 claims 1
- 201000005787 hematologic cancer Diseases 0.000 claims 1
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 claims 1
- CGIGDMFJXJATDK-UHFFFAOYSA-N indomethacin Chemical compound CC1=C(CC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(Cl)C=C1 CGIGDMFJXJATDK-UHFFFAOYSA-N 0.000 claims 1
- 229960005386 ipilimumab Drugs 0.000 claims 1
- 230000001737 promoting effect Effects 0.000 claims 1
- ZADWXFSZEAPBJS-UHFFFAOYSA-N racemic N-methyl tryptophan Natural products C1=CC=C2N(C)C=C(CC(N)C(O)=O)C2=C1 ZADWXFSZEAPBJS-UHFFFAOYSA-N 0.000 claims 1
- 150000003384 small molecules Chemical class 0.000 claims 1
- 208000013077 thyroid gland carcinoma Diseases 0.000 claims 1
- 101150095421 tig gene Proteins 0.000 claims 1
- OOLLAFOLCSJHRE-ZHAKMVSLSA-N ulipristal acetate Chemical compound C1=CC(N(C)C)=CC=C1[C@@H]1C2=C3CCC(=O)C=C3CC[C@H]2[C@H](CC[C@]2(OC(C)=O)C(C)=O)[C@]2(C)C1 OOLLAFOLCSJHRE-ZHAKMVSLSA-N 0.000 claims 1
- 150000007523 nucleic acids Chemical class 0.000 abstract description 65
- 102000039446 nucleic acids Human genes 0.000 abstract description 63
- 108020004707 nucleic acids Proteins 0.000 abstract description 63
- 230000009870 specific binding Effects 0.000 abstract description 21
- 208000035475 disorder Diseases 0.000 abstract description 3
- 102000014914 Carrier Proteins Human genes 0.000 description 116
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 description 88
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 description 88
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 87
- 102000004169 proteins and genes Human genes 0.000 description 47
- 235000018102 proteins Nutrition 0.000 description 45
- 108020004414 DNA Proteins 0.000 description 30
- 102000053602 DNA Human genes 0.000 description 30
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 23
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 23
- 230000000694 effects Effects 0.000 description 22
- 108050006400 Cyclin Proteins 0.000 description 19
- 102000016736 Cyclin Human genes 0.000 description 18
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 17
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 17
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 13
- 108060003951 Immunoglobulin Proteins 0.000 description 11
- 108020004459 Small interfering RNA Proteins 0.000 description 11
- 241000700605 Viruses Species 0.000 description 11
- 230000000890 antigenic effect Effects 0.000 description 11
- 108010077245 asparaginyl-proline Proteins 0.000 description 11
- 150000001875 compounds Chemical class 0.000 description 11
- -1 glycopolypeptide Proteins 0.000 description 11
- 102000018358 immunoglobulin Human genes 0.000 description 11
- 230000036961 partial effect Effects 0.000 description 11
- PRXCTTWKGJAPMT-ZLUOBGJFSA-N Cys-Ala-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O PRXCTTWKGJAPMT-ZLUOBGJFSA-N 0.000 description 10
- 239000003795 chemical substances by application Substances 0.000 description 10
- 108010050848 glycylleucine Proteins 0.000 description 10
- 241000880493 Leptailurus serval Species 0.000 description 9
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 9
- 108010093581 aspartyl-proline Proteins 0.000 description 9
- 239000013604 expression vector Substances 0.000 description 9
- 238000000684 flow cytometry Methods 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 108010078144 glutaminyl-glycine Proteins 0.000 description 9
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 9
- 230000028993 immune response Effects 0.000 description 9
- 210000000987 immune system Anatomy 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 239000013612 plasmid Substances 0.000 description 9
- 238000011282 treatment Methods 0.000 description 9
- 230000003612 virological effect Effects 0.000 description 9
- 241000214054 Equine rhinitis A virus Species 0.000 description 8
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 8
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 8
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 108010015792 glycyllysine Proteins 0.000 description 8
- 239000003550 marker Substances 0.000 description 8
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 7
- 108091026890 Coding region Proteins 0.000 description 7
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 7
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 7
- 102000025850 HLA-A2 Antigen Human genes 0.000 description 7
- 108010074032 HLA-A2 Antigen Proteins 0.000 description 7
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 7
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 7
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 7
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 7
- 239000004480 active ingredient Substances 0.000 description 7
- 125000000539 amino acid group Chemical group 0.000 description 7
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 7
- 108010092854 aspartyllysine Proteins 0.000 description 7
- 108010016616 cysteinylglycine Proteins 0.000 description 7
- 108010077515 glycylproline Proteins 0.000 description 7
- 238000001727 in vivo Methods 0.000 description 7
- 239000000463 material Substances 0.000 description 7
- 125000003729 nucleotide group Chemical group 0.000 description 7
- 108010090894 prolylleucine Proteins 0.000 description 7
- 230000000069 prophylactic effect Effects 0.000 description 7
- 102000005962 receptors Human genes 0.000 description 7
- 108020003175 receptors Proteins 0.000 description 7
- 230000010076 replication Effects 0.000 description 7
- GGNHBHYDMUDXQB-KBIXCLLPSA-N Ala-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)N GGNHBHYDMUDXQB-KBIXCLLPSA-N 0.000 description 6
- ZBYLEBZCVKLPCY-FXQIFTODSA-N Asp-Ser-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZBYLEBZCVKLPCY-FXQIFTODSA-N 0.000 description 6
- 102100036301 C-C chemokine receptor type 7 Human genes 0.000 description 6
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 6
- IHSGESFHTMFHRB-GUBZILKMSA-N Gln-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(N)=O IHSGESFHTMFHRB-GUBZILKMSA-N 0.000 description 6
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 6
- 101000716065 Homo sapiens C-C chemokine receptor type 7 Proteins 0.000 description 6
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 6
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 6
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 6
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 6
- 108010079364 N-glycylalanine Proteins 0.000 description 6
- FNGOXVQBBCMFKV-CIUDSAMLSA-N Pro-Ser-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O FNGOXVQBBCMFKV-CIUDSAMLSA-N 0.000 description 6
- JEHPKECJCALLRW-CUJWVEQBSA-N Ser-His-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEHPKECJCALLRW-CUJWVEQBSA-N 0.000 description 6
- ROLGIBMFNMZANA-GVXVVHGQSA-N Val-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N ROLGIBMFNMZANA-GVXVVHGQSA-N 0.000 description 6
- UQMPYVLTQCGRSK-IFFSRLJSSA-N Val-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N)O UQMPYVLTQCGRSK-IFFSRLJSSA-N 0.000 description 6
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 6
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 6
- 210000000612 antigen-presenting cell Anatomy 0.000 description 6
- 239000002246 antineoplastic agent Substances 0.000 description 6
- 108010038633 aspartylglutamate Proteins 0.000 description 6
- 238000010494 dissociation reaction Methods 0.000 description 6
- 230000005593 dissociations Effects 0.000 description 6
- 108010049041 glutamylalanine Proteins 0.000 description 6
- 108010089804 glycyl-threonine Proteins 0.000 description 6
- 108010010147 glycylglutamine Proteins 0.000 description 6
- 238000009169 immunotherapy Methods 0.000 description 6
- 210000004698 lymphocyte Anatomy 0.000 description 6
- 239000002773 nucleotide Substances 0.000 description 6
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 6
- 210000000130 stem cell Anatomy 0.000 description 6
- 230000000638 stimulation Effects 0.000 description 6
- 230000004083 survival effect Effects 0.000 description 6
- 210000001519 tissue Anatomy 0.000 description 6
- 238000013518 transcription Methods 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- WQVYAWIMAWTGMW-ZLUOBGJFSA-N Ala-Asp-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N WQVYAWIMAWTGMW-ZLUOBGJFSA-N 0.000 description 5
- BFDDUDQCPJWQRQ-IHRRRGAJSA-N Arg-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O BFDDUDQCPJWQRQ-IHRRRGAJSA-N 0.000 description 5
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 5
- 241000710198 Foot-and-mouth disease virus Species 0.000 description 5
- CKNUKHBRCSMKMO-XHNCKOQMSA-N Gln-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O CKNUKHBRCSMKMO-XHNCKOQMSA-N 0.000 description 5
- RSUVOPBMWMTVDI-XEGUGMAKSA-N Glu-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCC(O)=O)C)C(O)=O)=CNC2=C1 RSUVOPBMWMTVDI-XEGUGMAKSA-N 0.000 description 5
- YKLNMGJYMNPBCP-ACZMJKKPSA-N Glu-Asn-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YKLNMGJYMNPBCP-ACZMJKKPSA-N 0.000 description 5
- SFKMXFWWDUGXRT-NWLDYVSISA-N Glu-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N)O SFKMXFWWDUGXRT-NWLDYVSISA-N 0.000 description 5
- WNZOCXUOGVYYBJ-CDMKHQONSA-N Gly-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)CN)O WNZOCXUOGVYYBJ-CDMKHQONSA-N 0.000 description 5
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 5
- 241000282412 Homo Species 0.000 description 5
- 101001043809 Homo sapiens Interleukin-7 receptor subunit alpha Proteins 0.000 description 5
- 101001018097 Homo sapiens L-selectin Proteins 0.000 description 5
- 241000725303 Human immunodeficiency virus Species 0.000 description 5
- 102100021593 Interleukin-7 receptor subunit alpha Human genes 0.000 description 5
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 5
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 5
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 5
- 102100033467 L-selectin Human genes 0.000 description 5
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 5
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 5
- 241000699670 Mus sp. Species 0.000 description 5
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 5
- 108010029485 Protein Isoforms Proteins 0.000 description 5
- 102000001708 Protein Isoforms Human genes 0.000 description 5
- 108010003201 RGH 0205 Proteins 0.000 description 5
- JPIDMRXXNMIVKY-VZFHVOOUSA-N Ser-Ala-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPIDMRXXNMIVKY-VZFHVOOUSA-N 0.000 description 5
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 5
- TYIHBQYLIPJSIV-NYVOZVTQSA-N Ser-Trp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)NC(=O)[C@H](CO)N TYIHBQYLIPJSIV-NYVOZVTQSA-N 0.000 description 5
- 241000700584 Simplexvirus Species 0.000 description 5
- GARULAKWZGFIKC-RWRJDSDZSA-N Thr-Gln-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GARULAKWZGFIKC-RWRJDSDZSA-N 0.000 description 5
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 5
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 5
- 108010005233 alanylglutamic acid Proteins 0.000 description 5
- 108010008355 arginyl-glutamine Proteins 0.000 description 5
- 229960001230 asparagine Drugs 0.000 description 5
- 230000001580 bacterial effect Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 239000012472 biological sample Substances 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 229940127089 cytotoxic agent Drugs 0.000 description 5
- 238000011161 development Methods 0.000 description 5
- 239000003814 drug Substances 0.000 description 5
- 108010037850 glycylvaline Proteins 0.000 description 5
- 238000010348 incorporation Methods 0.000 description 5
- 230000002401 inhibitory effect Effects 0.000 description 5
- 108010012058 leucyltyrosine Proteins 0.000 description 5
- 208000032839 leukemia Diseases 0.000 description 5
- 108010005942 methionylglycine Proteins 0.000 description 5
- 238000002703 mutagenesis Methods 0.000 description 5
- 231100000350 mutagenesis Toxicity 0.000 description 5
- 238000003752 polymerase chain reaction Methods 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 108010070643 prolylglutamic acid Proteins 0.000 description 5
- 108010026333 seryl-proline Proteins 0.000 description 5
- 238000002560 therapeutic procedure Methods 0.000 description 5
- 108010061238 threonyl-glycine Proteins 0.000 description 5
- 238000012546 transfer Methods 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 238000011269 treatment regimen Methods 0.000 description 5
- 108010038745 tryptophylglycine Proteins 0.000 description 5
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 4
- WNHNMKOFKCHKKD-BFHQHQDPSA-N Ala-Thr-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O WNHNMKOFKCHKKD-BFHQHQDPSA-N 0.000 description 4
- ISCYZXFOCXWUJU-KZVJFYERSA-N Ala-Thr-Met Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O ISCYZXFOCXWUJU-KZVJFYERSA-N 0.000 description 4
- JJHBEVZAZXZREW-LFSVMHDDSA-N Ala-Thr-Phe Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](Cc1ccccc1)C(O)=O JJHBEVZAZXZREW-LFSVMHDDSA-N 0.000 description 4
- 108700028369 Alleles Proteins 0.000 description 4
- VBFJESQBIWCWRL-DCAQKATOSA-N Arg-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCNC(N)=N VBFJESQBIWCWRL-DCAQKATOSA-N 0.000 description 4
- QIWYWCYNUMJBTC-CIUDSAMLSA-N Arg-Cys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIWYWCYNUMJBTC-CIUDSAMLSA-N 0.000 description 4
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 4
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 4
- VYLVOMUVLMGCRF-ZLUOBGJFSA-N Asn-Asp-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VYLVOMUVLMGCRF-ZLUOBGJFSA-N 0.000 description 4
- JGIAYNNXZKKKOW-KKUMJFAQSA-N Asn-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N JGIAYNNXZKKKOW-KKUMJFAQSA-N 0.000 description 4
- QXOPPIDJKPEKCW-GUBZILKMSA-N Asn-Pro-Arg Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O QXOPPIDJKPEKCW-GUBZILKMSA-N 0.000 description 4
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 4
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 4
- JGLWFWXGOINXEA-YDHLFZDLSA-N Asp-Val-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 JGLWFWXGOINXEA-YDHLFZDLSA-N 0.000 description 4
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 4
- RRIJEABIXPKSGP-FXQIFTODSA-N Cys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CS RRIJEABIXPKSGP-FXQIFTODSA-N 0.000 description 4
- KXUKWRVYDYIPSQ-CIUDSAMLSA-N Cys-Leu-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUKWRVYDYIPSQ-CIUDSAMLSA-N 0.000 description 4
- 108010092160 Dactinomycin Proteins 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- BTSPOOHJBYJRKO-CIUDSAMLSA-N Gln-Asp-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BTSPOOHJBYJRKO-CIUDSAMLSA-N 0.000 description 4
- ORYMMTRPKVTGSJ-XVKPBYJWSA-N Gln-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O ORYMMTRPKVTGSJ-XVKPBYJWSA-N 0.000 description 4
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 4
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 4
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 4
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 4
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 4
- AYUOWUNWZGTNKB-ULQDDVLXSA-N His-Phe-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AYUOWUNWZGTNKB-ULQDDVLXSA-N 0.000 description 4
- KMBPQYKVZBMRMH-PEFMBERDSA-N Ile-Gln-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O KMBPQYKVZBMRMH-PEFMBERDSA-N 0.000 description 4
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 4
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 4
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 4
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 4
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 4
- HVHRPWQEQHIQJF-AVGNSLFASA-N Leu-Lys-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HVHRPWQEQHIQJF-AVGNSLFASA-N 0.000 description 4
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 4
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 4
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 4
- 108091054437 MHC class I family Proteins 0.000 description 4
- 241000699666 Mus <mouse, genus> Species 0.000 description 4
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 4
- 108700026244 Open Reading Frames Proteins 0.000 description 4
- OCSACVPBMIYNJE-GUBZILKMSA-N Pro-Arg-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O OCSACVPBMIYNJE-GUBZILKMSA-N 0.000 description 4
- KIGGUSRFHJCIEJ-DCAQKATOSA-N Pro-Asp-His Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O KIGGUSRFHJCIEJ-DCAQKATOSA-N 0.000 description 4
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 4
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 4
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 4
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 4
- XYEXCEPTALHNEV-RCWTZXSCSA-N Thr-Arg-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XYEXCEPTALHNEV-RCWTZXSCSA-N 0.000 description 4
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 4
- SSNGFWKILJLTQM-QEJZJMRPSA-N Trp-Gln-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SSNGFWKILJLTQM-QEJZJMRPSA-N 0.000 description 4
- BXPOOVDVGWEXDU-WZLNRYEVSA-N Tyr-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BXPOOVDVGWEXDU-WZLNRYEVSA-N 0.000 description 4
- UDNYEPLJTRDMEJ-RCOVLWMOSA-N Val-Asn-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N UDNYEPLJTRDMEJ-RCOVLWMOSA-N 0.000 description 4
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 4
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 4
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 4
- 238000007792 addition Methods 0.000 description 4
- 108010039538 alanyl-glycyl-aspartyl-valine Proteins 0.000 description 4
- 235000009582 asparagine Nutrition 0.000 description 4
- 230000004663 cell proliferation Effects 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 230000002759 chromosomal effect Effects 0.000 description 4
- 230000003247 decreasing effect Effects 0.000 description 4
- 230000004069 differentiation Effects 0.000 description 4
- 229940088598 enzyme Drugs 0.000 description 4
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 4
- 230000036541 health Effects 0.000 description 4
- 108010018006 histidylserine Proteins 0.000 description 4
- 230000002163 immunogen Effects 0.000 description 4
- 230000001976 improved effect Effects 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 230000002147 killing effect Effects 0.000 description 4
- 239000003446 ligand Substances 0.000 description 4
- 108010054155 lysyllysine Proteins 0.000 description 4
- 238000004519 manufacturing process Methods 0.000 description 4
- 108020004999 messenger RNA Proteins 0.000 description 4
- 244000005700 microbiome Species 0.000 description 4
- 238000010369 molecular cloning Methods 0.000 description 4
- 239000008194 pharmaceutical composition Substances 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 4
- 210000001236 prokaryotic cell Anatomy 0.000 description 4
- 230000035755 proliferation Effects 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 108010048818 seryl-histidine Proteins 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 108010051110 tyrosyl-lysine Proteins 0.000 description 4
- 241001430294 unidentified retrovirus Species 0.000 description 4
- 108010009962 valyltyrosine Proteins 0.000 description 4
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 3
- NOGFDULFCFXBHB-CIUDSAMLSA-N Ala-Leu-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N NOGFDULFCFXBHB-CIUDSAMLSA-N 0.000 description 3
- CHFFHQUVXHEGBY-GARJFASQSA-N Ala-Lys-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CHFFHQUVXHEGBY-GARJFASQSA-N 0.000 description 3
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 3
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 3
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 3
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 3
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 3
- LFFOJBOTZUWINF-ZANVPECISA-N Ala-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O)=CNC2=C1 LFFOJBOTZUWINF-ZANVPECISA-N 0.000 description 3
- TVUFMYKTYXTRPY-HERUPUMHSA-N Ala-Trp-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O TVUFMYKTYXTRPY-HERUPUMHSA-N 0.000 description 3
- PTVGLOCPAVYPFG-CIUDSAMLSA-N Arg-Gln-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PTVGLOCPAVYPFG-CIUDSAMLSA-N 0.000 description 3
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 3
- JEOCWTUOMKEEMF-RHYQMDGZSA-N Arg-Leu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JEOCWTUOMKEEMF-RHYQMDGZSA-N 0.000 description 3
- QQEWINYJRFBLNN-DLOVCJGASA-N Asn-Ala-Phe Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QQEWINYJRFBLNN-DLOVCJGASA-N 0.000 description 3
- BHQQRVARKXWXPP-ACZMJKKPSA-N Asn-Asp-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N BHQQRVARKXWXPP-ACZMJKKPSA-N 0.000 description 3
- PAXHINASXXXILC-SRVKXCTJSA-N Asn-Asp-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)O PAXHINASXXXILC-SRVKXCTJSA-N 0.000 description 3
- COWITDLVHMZSIW-CIUDSAMLSA-N Asn-Lys-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O COWITDLVHMZSIW-CIUDSAMLSA-N 0.000 description 3
- YXVAESUIQFDBHN-SRVKXCTJSA-N Asn-Phe-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O YXVAESUIQFDBHN-SRVKXCTJSA-N 0.000 description 3
- XTMZYFMTYJNABC-ZLUOBGJFSA-N Asn-Ser-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N XTMZYFMTYJNABC-ZLUOBGJFSA-N 0.000 description 3
- QQXOYLWJQUPXJU-WHFBIAKZSA-N Asp-Cys-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O QQXOYLWJQUPXJU-WHFBIAKZSA-N 0.000 description 3
- YRBGRUOSJROZEI-NHCYSSNCSA-N Asp-His-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O YRBGRUOSJROZEI-NHCYSSNCSA-N 0.000 description 3
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 3
- YTXCCDCOHIYQFC-GUBZILKMSA-N Asp-Met-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTXCCDCOHIYQFC-GUBZILKMSA-N 0.000 description 3
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 3
- WOPJVEMFXYHZEE-SRVKXCTJSA-N Asp-Phe-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O WOPJVEMFXYHZEE-SRVKXCTJSA-N 0.000 description 3
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 3
- GGBQDSHTXKQSLP-NHCYSSNCSA-N Asp-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N GGBQDSHTXKQSLP-NHCYSSNCSA-N 0.000 description 3
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 3
- PLBJMUUEGBBHRH-ZLUOBGJFSA-N Cys-Ala-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O PLBJMUUEGBBHRH-ZLUOBGJFSA-N 0.000 description 3
- HJXSYJVCMUOUNY-SRVKXCTJSA-N Cys-Ser-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N HJXSYJVCMUOUNY-SRVKXCTJSA-N 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 108010042634 F2A4-K-NS peptide Proteins 0.000 description 3
- 241000713800 Feline immunodeficiency virus Species 0.000 description 3
- 241001663880 Gammaretrovirus Species 0.000 description 3
- FFVXLVGUJBCKRX-UKJIMTQDSA-N Gln-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCC(=O)N)N FFVXLVGUJBCKRX-UKJIMTQDSA-N 0.000 description 3
- ZVQZXPADLZIQFF-FHWLQOOXSA-N Gln-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CCC(N)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 ZVQZXPADLZIQFF-FHWLQOOXSA-N 0.000 description 3
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 3
- JILRMFFFCHUUTJ-ACZMJKKPSA-N Gln-Ser-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O JILRMFFFCHUUTJ-ACZMJKKPSA-N 0.000 description 3
- QXQDADBVIBLBHN-FHWLQOOXSA-N Gln-Tyr-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QXQDADBVIBLBHN-FHWLQOOXSA-N 0.000 description 3
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 3
- WLIPTFCZLHCNFD-LPEHRKFASA-N Glu-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O WLIPTFCZLHCNFD-LPEHRKFASA-N 0.000 description 3
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 3
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 3
- ZHNHJYYFCGUZNQ-KBIXCLLPSA-N Glu-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O ZHNHJYYFCGUZNQ-KBIXCLLPSA-N 0.000 description 3
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 3
- VNCNWQPIQYAMAK-ACZMJKKPSA-N Glu-Ser-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O VNCNWQPIQYAMAK-ACZMJKKPSA-N 0.000 description 3
- BDISFWMLMNBTGP-NUMRIWBASA-N Glu-Thr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O BDISFWMLMNBTGP-NUMRIWBASA-N 0.000 description 3
- ZALGPUWUVHOGAE-GVXVVHGQSA-N Glu-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZALGPUWUVHOGAE-GVXVVHGQSA-N 0.000 description 3
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 3
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 3
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 3
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 3
- VBOBNHSVQKKTOT-YUMQZZPRSA-N Gly-Lys-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O VBOBNHSVQKKTOT-YUMQZZPRSA-N 0.000 description 3
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 3
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 3
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 3
- PFOUFRJYHWZJKW-NKIYYHGXSA-N His-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O PFOUFRJYHWZJKW-NKIYYHGXSA-N 0.000 description 3
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 3
- ODPKZZLRDNXTJZ-WHOFXGATSA-N Ile-Gly-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ODPKZZLRDNXTJZ-WHOFXGATSA-N 0.000 description 3
- PWUMCBLVWPCKNO-MGHWNKPDSA-N Ile-Leu-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PWUMCBLVWPCKNO-MGHWNKPDSA-N 0.000 description 3
- 108010065920 Insulin Lispro Proteins 0.000 description 3
- 108090000174 Interleukin-10 Proteins 0.000 description 3
- 108090000978 Interleukin-4 Proteins 0.000 description 3
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 3
- 241000713666 Lentivirus Species 0.000 description 3
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 3
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 3
- VJGQRELPQWNURN-JYJNAYRXSA-N Leu-Tyr-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJGQRELPQWNURN-JYJNAYRXSA-N 0.000 description 3
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 3
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 3
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 3
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 3
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 3
- OWRUUFUVXFREBD-KKUMJFAQSA-N Lys-His-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O OWRUUFUVXFREBD-KKUMJFAQSA-N 0.000 description 3
- WVJNGSFKBKOKRV-AJNGGQMLSA-N Lys-Leu-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVJNGSFKBKOKRV-AJNGGQMLSA-N 0.000 description 3
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 3
- YSPZCHGIWAQVKQ-AVGNSLFASA-N Lys-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN YSPZCHGIWAQVKQ-AVGNSLFASA-N 0.000 description 3
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 3
- 108091054438 MHC class II family Proteins 0.000 description 3
- 102000043131 MHC class II family Human genes 0.000 description 3
- JPCHYAUKOUGOIB-HJGDQZAQSA-N Met-Glu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPCHYAUKOUGOIB-HJGDQZAQSA-N 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 3
- OJUMUUXGSXUZJZ-SRVKXCTJSA-N Phe-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OJUMUUXGSXUZJZ-SRVKXCTJSA-N 0.000 description 3
- UEHNWRNADDPYNK-DLOVCJGASA-N Phe-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N UEHNWRNADDPYNK-DLOVCJGASA-N 0.000 description 3
- UMKYAYXCMYYNHI-AVGNSLFASA-N Phe-Gln-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N UMKYAYXCMYYNHI-AVGNSLFASA-N 0.000 description 3
- NPLGQVKZFGJWAI-QWHCGFSZSA-N Phe-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O NPLGQVKZFGJWAI-QWHCGFSZSA-N 0.000 description 3
- SCKXGHWQPPURGT-KKUMJFAQSA-N Phe-Lys-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O SCKXGHWQPPURGT-KKUMJFAQSA-N 0.000 description 3
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 3
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 3
- UMIHVJQSXFWWMW-JBACZVJFSA-N Phe-Trp-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UMIHVJQSXFWWMW-JBACZVJFSA-N 0.000 description 3
- GCFNFKNPCMBHNT-IRXDYDNUSA-N Phe-Tyr-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)NCC(=O)O)N GCFNFKNPCMBHNT-IRXDYDNUSA-N 0.000 description 3
- IFMDQWDAJUMMJC-DCAQKATOSA-N Pro-Ala-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O IFMDQWDAJUMMJC-DCAQKATOSA-N 0.000 description 3
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 3
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 3
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 3
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 3
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- SRTCFKGBYBZRHA-ACZMJKKPSA-N Ser-Ala-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SRTCFKGBYBZRHA-ACZMJKKPSA-N 0.000 description 3
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 3
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 3
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 3
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 3
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 3
- KCNSGAMPBPYUAI-CIUDSAMLSA-N Ser-Leu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KCNSGAMPBPYUAI-CIUDSAMLSA-N 0.000 description 3
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 3
- KJKQUQXDEKMPDK-FXQIFTODSA-N Ser-Met-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O KJKQUQXDEKMPDK-FXQIFTODSA-N 0.000 description 3
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 3
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 3
- WUXCHQZLUHBSDJ-LKXGYXEUSA-N Ser-Thr-Asp Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O WUXCHQZLUHBSDJ-LKXGYXEUSA-N 0.000 description 3
- VEVYMLNYMULSMS-AVGNSLFASA-N Ser-Tyr-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEVYMLNYMULSMS-AVGNSLFASA-N 0.000 description 3
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 3
- ODRUTDLAONAVDV-IHRRRGAJSA-N Ser-Val-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ODRUTDLAONAVDV-IHRRRGAJSA-N 0.000 description 3
- 241000713311 Simian immunodeficiency virus Species 0.000 description 3
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 3
- SKHPKKYKDYULDH-HJGDQZAQSA-N Thr-Asn-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SKHPKKYKDYULDH-HJGDQZAQSA-N 0.000 description 3
- PZVGOVRNGKEFCB-KKHAAJSZSA-N Thr-Asn-Val Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N)O PZVGOVRNGKEFCB-KKHAAJSZSA-N 0.000 description 3
- GNHRVXYZKWSJTF-HJGDQZAQSA-N Thr-Asp-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O GNHRVXYZKWSJTF-HJGDQZAQSA-N 0.000 description 3
- JXKMXEBNZCKSDY-JIOCBJNQSA-N Thr-Asp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O JXKMXEBNZCKSDY-JIOCBJNQSA-N 0.000 description 3
- KCRQEJSKXAIULJ-FJXKBIBVSA-N Thr-Gly-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O KCRQEJSKXAIULJ-FJXKBIBVSA-N 0.000 description 3
- ZTPXSEUVYNNZRB-CDMKHQONSA-N Thr-Gly-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ZTPXSEUVYNNZRB-CDMKHQONSA-N 0.000 description 3
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 3
- ADPHPKGWVDHWML-PPCPHDFISA-N Thr-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N ADPHPKGWVDHWML-PPCPHDFISA-N 0.000 description 3
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 3
- VEIKMWOMUYMMMK-FCLVOEFKSA-N Thr-Phe-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 VEIKMWOMUYMMMK-FCLVOEFKSA-N 0.000 description 3
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 3
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 3
- JTMZSIRTZKLBOA-NWLDYVSISA-N Trp-Thr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O JTMZSIRTZKLBOA-NWLDYVSISA-N 0.000 description 3
- RPTAWXPQXXCUGL-OYDLWJJNSA-N Trp-Trp-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O RPTAWXPQXXCUGL-OYDLWJJNSA-N 0.000 description 3
- YLRLHDFMMWDYTK-KKUMJFAQSA-N Tyr-Cys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 YLRLHDFMMWDYTK-KKUMJFAQSA-N 0.000 description 3
- UPODKYBYUBTWSV-BZSNNMDCSA-N Tyr-Phe-Cys Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CS)C(O)=O)C1=CC=C(O)C=C1 UPODKYBYUBTWSV-BZSNNMDCSA-N 0.000 description 3
- RZAGEHHVNYESNR-RNXOBYDBSA-N Tyr-Trp-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RZAGEHHVNYESNR-RNXOBYDBSA-N 0.000 description 3
- JXGWQYWDUOWQHA-DZKIICNBSA-N Val-Gln-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N JXGWQYWDUOWQHA-DZKIICNBSA-N 0.000 description 3
- HQYVQDRYODWONX-DCAQKATOSA-N Val-His-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N HQYVQDRYODWONX-DCAQKATOSA-N 0.000 description 3
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 3
- GBIUHAYJGWVNLN-AEJSXWLSSA-N Val-Ser-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N GBIUHAYJGWVNLN-AEJSXWLSSA-N 0.000 description 3
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 3
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 3
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 3
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 3
- 108010081404 acein-2 Proteins 0.000 description 3
- 229930183665 actinomycin Natural products 0.000 description 3
- 230000000735 allogeneic effect Effects 0.000 description 3
- 230000000340 anti-metabolite Effects 0.000 description 3
- 230000001028 anti-proliverative effect Effects 0.000 description 3
- 229940100197 antimetabolite Drugs 0.000 description 3
- 239000002256 antimetabolite Substances 0.000 description 3
- 108010091092 arginyl-glycyl-proline Proteins 0.000 description 3
- 235000003704 aspartic acid Nutrition 0.000 description 3
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 3
- 210000001185 bone marrow Anatomy 0.000 description 3
- 229960004630 chlorambucil Drugs 0.000 description 3
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 229960000975 daunorubicin Drugs 0.000 description 3
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 210000003162 effector t lymphocyte Anatomy 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 229960005420 etoposide Drugs 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 239000003102 growth factor Substances 0.000 description 3
- 108010092114 histidylphenylalanine Proteins 0.000 description 3
- 102000006639 indoleamine 2,3-dioxygenase Human genes 0.000 description 3
- 108020004201 indoleamine 2,3-dioxygenase Proteins 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 229960000310 isoleucine Drugs 0.000 description 3
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 3
- 238000005304 joining Methods 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 210000002540 macrophage Anatomy 0.000 description 3
- 230000003211 malignant effect Effects 0.000 description 3
- 229960004961 mechlorethamine Drugs 0.000 description 3
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 3
- 230000002018 overexpression Effects 0.000 description 3
- 238000004806 packaging method and process Methods 0.000 description 3
- 108010012581 phenylalanylglutamate Proteins 0.000 description 3
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 108010031719 prolyl-serine Proteins 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000001105 regulatory effect Effects 0.000 description 3
- 230000001177 retroviral effect Effects 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 210000001541 thymus gland Anatomy 0.000 description 3
- 230000002463 transducing effect Effects 0.000 description 3
- 108010020532 tyrosyl-proline Proteins 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- PUPZLCDOIYMWBV-UHFFFAOYSA-N (+/-)-1,3-Butanediol Chemical compound CC(O)CCO PUPZLCDOIYMWBV-UHFFFAOYSA-N 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 2
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 2
- 101150051188 Adora2a gene Proteins 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 2
- DECCMEWNXSNSDO-ZLUOBGJFSA-N Ala-Cys-Ala Chemical compound C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O DECCMEWNXSNSDO-ZLUOBGJFSA-N 0.000 description 2
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 2
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 2
- 241000710929 Alphavirus Species 0.000 description 2
- DFCIPNHFKOQAME-FXQIFTODSA-N Arg-Ala-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFCIPNHFKOQAME-FXQIFTODSA-N 0.000 description 2
- JVMKBJNSRZWDBO-FXQIFTODSA-N Arg-Cys-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O JVMKBJNSRZWDBO-FXQIFTODSA-N 0.000 description 2
- MZRBYBIQTIKERR-GUBZILKMSA-N Arg-Glu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MZRBYBIQTIKERR-GUBZILKMSA-N 0.000 description 2
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 2
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 2
- VRTWYUYCJGNFES-CIUDSAMLSA-N Arg-Ser-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O VRTWYUYCJGNFES-CIUDSAMLSA-N 0.000 description 2
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 2
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 2
- DDPXDCKYWDGZAL-BQBZGAKWSA-N Asn-Gly-Arg Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N DDPXDCKYWDGZAL-BQBZGAKWSA-N 0.000 description 2
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 2
- ZJIFRAPZHAGLGR-MELADBBJSA-N Asn-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZJIFRAPZHAGLGR-MELADBBJSA-N 0.000 description 2
- XEGZSHSPQNDNRH-JRQIVUDYSA-N Asn-Tyr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XEGZSHSPQNDNRH-JRQIVUDYSA-N 0.000 description 2
- PQKSVQSMTHPRIB-ZKWXMUAHSA-N Asn-Val-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O PQKSVQSMTHPRIB-ZKWXMUAHSA-N 0.000 description 2
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 2
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 2
- CJUKAWUWBZCTDQ-SRVKXCTJSA-N Asp-Leu-Lys Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O CJUKAWUWBZCTDQ-SRVKXCTJSA-N 0.000 description 2
- HICVMZCGVFKTPM-BQBZGAKWSA-N Asp-Pro-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HICVMZCGVFKTPM-BQBZGAKWSA-N 0.000 description 2
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 2
- UTLCRGFJFSZWAW-OLHMAJIHSA-N Asp-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O UTLCRGFJFSZWAW-OLHMAJIHSA-N 0.000 description 2
- BJDHEININLSZOT-KKUMJFAQSA-N Asp-Tyr-Lys Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(O)=O BJDHEININLSZOT-KKUMJFAQSA-N 0.000 description 2
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- 241000713704 Bovine immunodeficiency virus Species 0.000 description 2
- 102000008203 CTLA-4 Antigen Human genes 0.000 description 2
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 2
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 2
- 108010077544 Chromatin Proteins 0.000 description 2
- 108020004638 Circular DNA Proteins 0.000 description 2
- 108091028075 Circular RNA Proteins 0.000 description 2
- PTOAARAWEBMLNO-KVQBGUIXSA-N Cladribine Chemical compound C1=NC=2C(N)=NC(Cl)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 PTOAARAWEBMLNO-KVQBGUIXSA-N 0.000 description 2
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 2
- NOCCABSVTRONIN-CIUDSAMLSA-N Cys-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CS)N NOCCABSVTRONIN-CIUDSAMLSA-N 0.000 description 2
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 2
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 2
- ABLQPNMKLMFDQU-BIIVOSGPSA-N Cys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CS)N)C(=O)O ABLQPNMKLMFDQU-BIIVOSGPSA-N 0.000 description 2
- ZLFRUAFDAIFNHN-LKXGYXEUSA-N Cys-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N)O ZLFRUAFDAIFNHN-LKXGYXEUSA-N 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 229920002307 Dextran Polymers 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 102100031780 Endonuclease Human genes 0.000 description 2
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 2
- 241000713730 Equine infectious anemia virus Species 0.000 description 2
- 241000283073 Equus caballus Species 0.000 description 2
- 108700024394 Exon Proteins 0.000 description 2
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 2
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 2
- 102000004961 Furin Human genes 0.000 description 2
- 108090001126 Furin Proteins 0.000 description 2
- LPYPANUXJGFMGV-FXQIFTODSA-N Gln-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LPYPANUXJGFMGV-FXQIFTODSA-N 0.000 description 2
- NSORZJXKUQFEKL-JGVFFNPUSA-N Gln-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)N)N)C(=O)O NSORZJXKUQFEKL-JGVFFNPUSA-N 0.000 description 2
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 2
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 2
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 2
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 2
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 2
- VLOLPWWCNKWRNB-LOKLDPHHSA-N Gln-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O VLOLPWWCNKWRNB-LOKLDPHHSA-N 0.000 description 2
- ATRHMOJQJWPVBQ-DRZSPHRISA-N Glu-Ala-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ATRHMOJQJWPVBQ-DRZSPHRISA-N 0.000 description 2
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 2
- LXAUHIRMWXQRKI-XHNCKOQMSA-N Glu-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O LXAUHIRMWXQRKI-XHNCKOQMSA-N 0.000 description 2
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 2
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 2
- YPHPEHMXOYTEQG-LAEOZQHASA-N Glu-Val-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O YPHPEHMXOYTEQG-LAEOZQHASA-N 0.000 description 2
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 2
- GWCRIHNSVMOBEQ-BQBZGAKWSA-N Gly-Arg-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O GWCRIHNSVMOBEQ-BQBZGAKWSA-N 0.000 description 2
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 2
- HFXJIZNEXNIZIJ-BQBZGAKWSA-N Gly-Glu-Gln Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFXJIZNEXNIZIJ-BQBZGAKWSA-N 0.000 description 2
- YYPFZVIXAVDHIK-IUCAKERBSA-N Gly-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN YYPFZVIXAVDHIK-IUCAKERBSA-N 0.000 description 2
- JSNNHGHYGYMVCK-XVKPBYJWSA-N Gly-Glu-Val Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JSNNHGHYGYMVCK-XVKPBYJWSA-N 0.000 description 2
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 2
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 2
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 2
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 2
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 2
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 2
- DKJWUIYLMLUBDX-XPUUQOCRSA-N Gly-Val-Cys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O DKJWUIYLMLUBDX-XPUUQOCRSA-N 0.000 description 2
- AFMOTCMSEBITOE-YEPSODPASA-N Gly-Val-Thr Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AFMOTCMSEBITOE-YEPSODPASA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 2
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 2
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- BXOLYFJYQQRQDJ-MXAVVETBSA-N His-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CN=CN1)N BXOLYFJYQQRQDJ-MXAVVETBSA-N 0.000 description 2
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 2
- 101000851181 Homo sapiens Epidermal growth factor receptor Proteins 0.000 description 2
- 101000772110 Homo sapiens T cell receptor alpha variable 21 Proteins 0.000 description 2
- 101000662909 Homo sapiens T cell receptor beta constant 1 Proteins 0.000 description 2
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 description 2
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 2
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 2
- UAELWXJFLZBKQS-WHOFXGATSA-N Ile-Phe-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)NCC(O)=O UAELWXJFLZBKQS-WHOFXGATSA-N 0.000 description 2
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 2
- YKZAMJXNJUWFIK-JBDRJPRFSA-N Ile-Ser-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)O)N YKZAMJXNJUWFIK-JBDRJPRFSA-N 0.000 description 2
- FXJLRZFMKGHYJP-CFMVVWHZSA-N Ile-Tyr-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FXJLRZFMKGHYJP-CFMVVWHZSA-N 0.000 description 2
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 2
- 108090000176 Interleukin-13 Proteins 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- 102100033627 Killer cell immunoglobulin-like receptor 3DL1 Human genes 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 2
- WUFYAPWIHCUMLL-CIUDSAMLSA-N Leu-Asn-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O WUFYAPWIHCUMLL-CIUDSAMLSA-N 0.000 description 2
- VCSBGUACOYUIGD-CIUDSAMLSA-N Leu-Asn-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VCSBGUACOYUIGD-CIUDSAMLSA-N 0.000 description 2
- MDVZJYGNAGLPGJ-KKUMJFAQSA-N Leu-Asn-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MDVZJYGNAGLPGJ-KKUMJFAQSA-N 0.000 description 2
- YSKSXVKQLLBVEX-SZMVWBNQSA-N Leu-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 YSKSXVKQLLBVEX-SZMVWBNQSA-N 0.000 description 2
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 2
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 2
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 2
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 2
- XQXGNBFMAXWIGI-MXAVVETBSA-N Leu-His-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 XQXGNBFMAXWIGI-MXAVVETBSA-N 0.000 description 2
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 2
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 2
- ZGUMORRUBUCXEH-AVGNSLFASA-N Leu-Lys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZGUMORRUBUCXEH-AVGNSLFASA-N 0.000 description 2
- YWKNKRAKOCLOLH-OEAJRASXSA-N Leu-Phe-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CC1=CC=CC=C1 YWKNKRAKOCLOLH-OEAJRASXSA-N 0.000 description 2
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 2
- FPFOYSCDUWTZBF-IHPCNDPISA-N Leu-Trp-Leu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H]([NH3+])CC(C)C)C(=O)N[C@@H](CC(C)C)C([O-])=O)=CNC2=C1 FPFOYSCDUWTZBF-IHPCNDPISA-N 0.000 description 2
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 2
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 2
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 2
- GRADYHMSAUIKPS-DCAQKATOSA-N Lys-Glu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRADYHMSAUIKPS-DCAQKATOSA-N 0.000 description 2
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 2
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 2
- DRRXXZBXDMLGFC-IHRRRGAJSA-N Lys-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN DRRXXZBXDMLGFC-IHRRRGAJSA-N 0.000 description 2
- HDNOQCZWJGGHSS-VEVYYDQMSA-N Met-Asn-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HDNOQCZWJGGHSS-VEVYYDQMSA-N 0.000 description 2
- 102000029749 Microtubule Human genes 0.000 description 2
- 108091022875 Microtubule Proteins 0.000 description 2
- 229930192392 Mitomycin Natural products 0.000 description 2
- 241000714177 Murine leukemia virus Species 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- 108010047562 NGR peptide Proteins 0.000 description 2
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 2
- 101710153660 Nuclear receptor corepressor 2 Proteins 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 108010067902 Peptide Library Proteins 0.000 description 2
- 241000009328 Perro Species 0.000 description 2
- WKLMCMXFMQEKCX-SLFFLAALSA-N Phe-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O WKLMCMXFMQEKCX-SLFFLAALSA-N 0.000 description 2
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 2
- YMIZSYUAZJSOFL-SRVKXCTJSA-N Phe-Ser-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O YMIZSYUAZJSOFL-SRVKXCTJSA-N 0.000 description 2
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 2
- VFDRDMOMHBJGKD-UFYCRDLUSA-N Phe-Tyr-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N VFDRDMOMHBJGKD-UFYCRDLUSA-N 0.000 description 2
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 2
- GDXZRWYXJSGWIV-GMOBBJLQSA-N Pro-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 GDXZRWYXJSGWIV-GMOBBJLQSA-N 0.000 description 2
- DIFXZGPHVCIVSQ-CIUDSAMLSA-N Pro-Gln-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DIFXZGPHVCIVSQ-CIUDSAMLSA-N 0.000 description 2
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 2
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 2
- QCMYJBKTMIWZAP-AVGNSLFASA-N Pro-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 QCMYJBKTMIWZAP-AVGNSLFASA-N 0.000 description 2
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 2
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 2
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 2
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 2
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 2
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 2
- BYIROAKULFFTEK-CIUDSAMLSA-N Ser-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO BYIROAKULFFTEK-CIUDSAMLSA-N 0.000 description 2
- OLIJLNWFEQEFDM-SRVKXCTJSA-N Ser-Asp-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLIJLNWFEQEFDM-SRVKXCTJSA-N 0.000 description 2
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 2
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 2
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 2
- SQBLRDDJTUJDMV-ACZMJKKPSA-N Ser-Glu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQBLRDDJTUJDMV-ACZMJKKPSA-N 0.000 description 2
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 2
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 2
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 2
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 2
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 2
- RRVFEDGUXSYWOW-BZSNNMDCSA-N Ser-Phe-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RRVFEDGUXSYWOW-BZSNNMDCSA-N 0.000 description 2
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 2
- FZXOPYUEQGDGMS-ACZMJKKPSA-N Ser-Ser-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZXOPYUEQGDGMS-ACZMJKKPSA-N 0.000 description 2
- QYBRQMLZDDJBSW-AVGNSLFASA-N Ser-Tyr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYBRQMLZDDJBSW-AVGNSLFASA-N 0.000 description 2
- SGZVZUCRAVSPKQ-FXQIFTODSA-N Ser-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N SGZVZUCRAVSPKQ-FXQIFTODSA-N 0.000 description 2
- 102100029487 T cell receptor alpha variable 21 Human genes 0.000 description 2
- 102100037272 T cell receptor beta constant 1 Human genes 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 description 2
- 206010043376 Tetanus Diseases 0.000 description 2
- WYURNTSHIVDZCO-UHFFFAOYSA-N Tetrahydrofuran Chemical compound C1CCOC1 WYURNTSHIVDZCO-UHFFFAOYSA-N 0.000 description 2
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 2
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 2
- RCEHMXVEMNXRIW-IRIUXVKKSA-N Thr-Gln-Tyr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N)O RCEHMXVEMNXRIW-IRIUXVKKSA-N 0.000 description 2
- SLUWOCTZVGMURC-BFHQHQDPSA-N Thr-Gly-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O SLUWOCTZVGMURC-BFHQHQDPSA-N 0.000 description 2
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 2
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 2
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 2
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 2
- XIHGJKFSIDTDKV-LYARXQMPSA-N Thr-Phe-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XIHGJKFSIDTDKV-LYARXQMPSA-N 0.000 description 2
- GFRIEEKFXOVPIR-RHYQMDGZSA-N Thr-Pro-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O GFRIEEKFXOVPIR-RHYQMDGZSA-N 0.000 description 2
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 2
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 2
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 108700019146 Transgenes Proteins 0.000 description 2
- MEZCXKYMMQJRDE-PMVMPFDFSA-N Trp-Leu-Tyr Chemical compound C([C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)CC(C)C)C(O)=O)C1=CC=C(O)C=C1 MEZCXKYMMQJRDE-PMVMPFDFSA-N 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- 102100040403 Tumor necrosis factor receptor superfamily member 6 Human genes 0.000 description 2
- DXYWRYQRKPIGGU-BPNCWPANSA-N Tyr-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DXYWRYQRKPIGGU-BPNCWPANSA-N 0.000 description 2
- HKIUVWMZYFBIHG-KKUMJFAQSA-N Tyr-Arg-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O HKIUVWMZYFBIHG-KKUMJFAQSA-N 0.000 description 2
- IMXAAEFAIBRCQF-SIUGBPQLSA-N Tyr-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N IMXAAEFAIBRCQF-SIUGBPQLSA-N 0.000 description 2
- KCPFDGNYAMKZQP-KBPBESRZSA-N Tyr-Gly-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O KCPFDGNYAMKZQP-KBPBESRZSA-N 0.000 description 2
- JJNXZIPLIXIGBX-HJPIBITLSA-N Tyr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JJNXZIPLIXIGBX-HJPIBITLSA-N 0.000 description 2
- AVIQBBOOTZENLH-KKUMJFAQSA-N Tyr-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AVIQBBOOTZENLH-KKUMJFAQSA-N 0.000 description 2
- OKDNSNWJEXAMSU-IRXDYDNUSA-N Tyr-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 OKDNSNWJEXAMSU-IRXDYDNUSA-N 0.000 description 2
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 2
- XUIOBCQESNDTDE-FQPOAREZSA-N Tyr-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XUIOBCQESNDTDE-FQPOAREZSA-N 0.000 description 2
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 2
- VLDMQVZZWDOKQF-AUTRQRHGSA-N Val-Glu-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VLDMQVZZWDOKQF-AUTRQRHGSA-N 0.000 description 2
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 2
- BZMIYHIJVVJPCK-QSFUFRPTSA-N Val-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N BZMIYHIJVVJPCK-QSFUFRPTSA-N 0.000 description 2
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 2
- FEXILLGKGGTLRI-NHCYSSNCSA-N Val-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N FEXILLGKGGTLRI-NHCYSSNCSA-N 0.000 description 2
- GVJUTBOZZBTBIG-AVGNSLFASA-N Val-Lys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N GVJUTBOZZBTBIG-AVGNSLFASA-N 0.000 description 2
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 2
- WHNSHJJNWNSTSU-BZSNNMDCSA-N Val-Val-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 WHNSHJJNWNSTSU-BZSNNMDCSA-N 0.000 description 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 108010087924 alanylproline Proteins 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 229940045799 anthracyclines and related substance Drugs 0.000 description 2
- 230000001093 anti-cancer Effects 0.000 description 2
- 230000002927 anti-mitotic effect Effects 0.000 description 2
- 230000030741 antigen processing and presentation Effects 0.000 description 2
- 108010060035 arginylproline Proteins 0.000 description 2
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 229960001561 bleomycin Drugs 0.000 description 2
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 229940127093 camptothecin Drugs 0.000 description 2
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 2
- 229960004562 carboplatin Drugs 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 210000003483 chromatin Anatomy 0.000 description 2
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 2
- 229960004316 cisplatin Drugs 0.000 description 2
- 238000002648 combination therapy Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 229960004397 cyclophosphamide Drugs 0.000 description 2
- 238000002784 cytotoxicity assay Methods 0.000 description 2
- 231100000263 cytotoxicity test Toxicity 0.000 description 2
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 2
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 241001493065 dsRNA viruses Species 0.000 description 2
- 230000002357 endometrial effect Effects 0.000 description 2
- 229960001904 epirubicin Drugs 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 210000003754 fetus Anatomy 0.000 description 2
- 229940126864 fibroblast growth factor Drugs 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 238000001415 gene therapy Methods 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- TZBJGXHYKVUXJN-UHFFFAOYSA-N genistein Natural products C1=CC(O)=CC=C1C1=COC2=CC(O)=CC(O)=C2C1=O TZBJGXHYKVUXJN-UHFFFAOYSA-N 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 2
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 108010020688 glycylhistidine Proteins 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 108010045383 histidyl-glycyl-glutamic acid Proteins 0.000 description 2
- 239000000710 homodimer Substances 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 239000005556 hormone Chemical class 0.000 description 2
- 102000045108 human EGFR Human genes 0.000 description 2
- 210000005260 human cell Anatomy 0.000 description 2
- 229960000908 idarubicin Drugs 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 239000000411 inducer Substances 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 230000010354 integration Effects 0.000 description 2
- 201000010260 leiomyoma Diseases 0.000 description 2
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 2
- 108010087810 leucyl-seryl-glutamyl-leucine Proteins 0.000 description 2
- 238000012417 linear regression Methods 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 210000001165 lymph node Anatomy 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 229960001924 melphalan Drugs 0.000 description 2
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 2
- 108010056582 methionylglutamic acid Proteins 0.000 description 2
- 108091070501 miRNA Proteins 0.000 description 2
- 238000000520 microinjection Methods 0.000 description 2
- 210000004688 microtubule Anatomy 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 210000000581 natural killer T-cell Anatomy 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 230000001613 neoplastic effect Effects 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 238000011275 oncology therapy Methods 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 230000001124 posttranscriptional effect Effects 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 2
- 229960004618 prednisone Drugs 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 2
- 108010029020 prolylglycine Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 150000003212 purines Chemical class 0.000 description 2
- 150000003230 pyrimidines Chemical class 0.000 description 2
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 230000006798 recombination Effects 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- HUJXHFRXWWGYQH-UHFFFAOYSA-O sinapine Chemical compound COC1=CC(\C=C\C(=O)OCC[N+](C)(C)C)=CC(OC)=C1O HUJXHFRXWWGYQH-UHFFFAOYSA-O 0.000 description 2
- 229960002930 sirolimus Drugs 0.000 description 2
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 2
- 125000001424 substituent group Chemical group 0.000 description 2
- 230000002381 testicular Effects 0.000 description 2
- 210000001550 testis Anatomy 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 2
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- 108010044292 tryptophyltyrosine Proteins 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- 229960003048 vinblastine Drugs 0.000 description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 2
- 229960004528 vincristine Drugs 0.000 description 2
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 2
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 210000005253 yeast cell Anatomy 0.000 description 2
- DQJCDTNMLBYVAY-ZXXIYAEKSA-N (2S,5R,10R,13R)-16-{[(2R,3S,4R,5R)-3-{[(2S,3R,4R,5S,6R)-3-acetamido-4,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy}-5-(ethylamino)-6-hydroxy-2-(hydroxymethyl)oxan-4-yl]oxy}-5-(4-aminobutyl)-10-carbamoyl-2,13-dimethyl-4,7,12,15-tetraoxo-3,6,11,14-tetraazaheptadecan-1-oic acid Chemical compound NCCCC[C@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)CC[C@H](C(N)=O)NC(=O)[C@@H](C)NC(=O)C(C)O[C@@H]1[C@@H](NCC)C(O)O[C@H](CO)[C@H]1O[C@H]1[C@H](NC(C)=O)[C@@H](O)[C@H](O)[C@@H](CO)O1 DQJCDTNMLBYVAY-ZXXIYAEKSA-N 0.000 description 1
- AXFMEGAFCUULFV-BLFANLJRSA-N (2s)-2-[[(2s)-1-[(2s,3r)-2-amino-3-methylpentanoyl]pyrrolidine-2-carbonyl]amino]pentanedioic acid Chemical compound CC[C@@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AXFMEGAFCUULFV-BLFANLJRSA-N 0.000 description 1
- ZDSRFXVZVHSYMA-CMOCDZPBSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-4-carboxybutanoyl]amino]pentanedioic acid Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=C(O)C=C1 ZDSRFXVZVHSYMA-CMOCDZPBSA-N 0.000 description 1
- KCEHUPIXDRDKQS-VKHMYHEASA-N (2s)-5-amino-2-hydrazinyl-5-oxopentanoic acid Chemical class NN[C@H](C(O)=O)CCC(N)=O KCEHUPIXDRDKQS-VKHMYHEASA-N 0.000 description 1
- NNRFRJQMBSBXGO-CIUDSAMLSA-N (3s)-3-[[2-[[(2s)-2-amino-5-(diaminomethylideneamino)pentanoyl]amino]acetyl]amino]-4-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-oxobutanoic acid Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NNRFRJQMBSBXGO-CIUDSAMLSA-N 0.000 description 1
- MWWSFMDVAYGXBV-MYPASOLCSA-N (7r,9s)-7-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound Cl.O([C@@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 MWWSFMDVAYGXBV-MYPASOLCSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- IQFYYKKMVGJFEH-OFKYTIFKSA-N 1-[(2r,4s,5r)-4-hydroxy-5-(tritiooxymethyl)oxolan-2-yl]-5-methylpyrimidine-2,4-dione Chemical compound C1[C@H](O)[C@@H](CO[3H])O[C@H]1N1C(=O)NC(=O)C(C)=C1 IQFYYKKMVGJFEH-OFKYTIFKSA-N 0.000 description 1
- 102100025573 1-alkyl-2-acetylglycerophosphocholine esterase Human genes 0.000 description 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 1
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 1
- GEZVQLBTOKKPBO-UHFFFAOYSA-N 2-amino-2-hydroxy-2-phenylacetic acid Chemical compound OC(=O)C(O)(N)C1=CC=CC=C1 GEZVQLBTOKKPBO-UHFFFAOYSA-N 0.000 description 1
- CTRPRMNBTVRDFH-UHFFFAOYSA-N 2-n-methyl-1,3,5-triazine-2,4,6-triamine Chemical compound CNC1=NC(N)=NC(N)=N1 CTRPRMNBTVRDFH-UHFFFAOYSA-N 0.000 description 1
- WYWHKKSPHMUBEB-UHFFFAOYSA-N 6-Mercaptoguanine Natural products N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 1
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical group N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 1
- 208000003200 Adenoma Diseases 0.000 description 1
- 108050000203 Adenosine receptors Proteins 0.000 description 1
- 102000009346 Adenosine receptors Human genes 0.000 description 1
- 108010083528 Adenylate Cyclase Toxin Proteins 0.000 description 1
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 1
- CVGNCMIULZNYES-WHFBIAKZSA-N Ala-Asn-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CVGNCMIULZNYES-WHFBIAKZSA-N 0.000 description 1
- STACJSVFHSEZJV-GHCJXIJMSA-N Ala-Asn-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STACJSVFHSEZJV-GHCJXIJMSA-N 0.000 description 1
- ZIBWKCRKNFYTPT-ZKWXMUAHSA-N Ala-Asn-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZIBWKCRKNFYTPT-ZKWXMUAHSA-N 0.000 description 1
- LZRNYBIJOSKKRJ-XVYDVKMFSA-N Ala-Asp-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LZRNYBIJOSKKRJ-XVYDVKMFSA-N 0.000 description 1
- GWFSQQNGMPGBEF-GHCJXIJMSA-N Ala-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N GWFSQQNGMPGBEF-GHCJXIJMSA-N 0.000 description 1
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 1
- XYTNPQNAZREREP-XQXXSGGOSA-N Ala-Glu-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XYTNPQNAZREREP-XQXXSGGOSA-N 0.000 description 1
- BTBUEVAGZCKULD-XPUUQOCRSA-N Ala-Gly-His Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BTBUEVAGZCKULD-XPUUQOCRSA-N 0.000 description 1
- LMFXXZPPZDCPTA-ZKWXMUAHSA-N Ala-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N LMFXXZPPZDCPTA-ZKWXMUAHSA-N 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- LBFXVAXPDOBRKU-LKTVYLICSA-N Ala-His-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LBFXVAXPDOBRKU-LKTVYLICSA-N 0.000 description 1
- QQACQIHVWCVBBR-GVARAGBVSA-N Ala-Ile-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QQACQIHVWCVBBR-GVARAGBVSA-N 0.000 description 1
- VHVVPYOJIIQCKS-QEJZJMRPSA-N Ala-Leu-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VHVVPYOJIIQCKS-QEJZJMRPSA-N 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- DRARURMRLANNLS-GUBZILKMSA-N Ala-Met-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O DRARURMRLANNLS-GUBZILKMSA-N 0.000 description 1
- BFMIRJBURUXDRG-DLOVCJGASA-N Ala-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 BFMIRJBURUXDRG-DLOVCJGASA-N 0.000 description 1
- BDQNLQSWRAPHGU-DLOVCJGASA-N Ala-Phe-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N BDQNLQSWRAPHGU-DLOVCJGASA-N 0.000 description 1
- CNQAFFMNJIQYGX-DRZSPHRISA-N Ala-Phe-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 CNQAFFMNJIQYGX-DRZSPHRISA-N 0.000 description 1
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 1
- CYBJZLQSUJEMAS-LFSVMHDDSA-N Ala-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C)N)O CYBJZLQSUJEMAS-LFSVMHDDSA-N 0.000 description 1
- YHBDGLZYNIARKJ-GUBZILKMSA-N Ala-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N YHBDGLZYNIARKJ-GUBZILKMSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 1
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 1
- VRTOMXFZHGWHIJ-KZVJFYERSA-N Ala-Thr-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VRTOMXFZHGWHIJ-KZVJFYERSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 1
- LYILPUNCKACNGF-NAKRPEOUSA-N Ala-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)N LYILPUNCKACNGF-NAKRPEOUSA-N 0.000 description 1
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 102000006306 Antigen Receptors Human genes 0.000 description 1
- 108010083359 Antigen Receptors Proteins 0.000 description 1
- 108020004491 Antisense DNA Proteins 0.000 description 1
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 1
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 1
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 1
- JTWOBPNAVBESFW-FXQIFTODSA-N Arg-Cys-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N JTWOBPNAVBESFW-FXQIFTODSA-N 0.000 description 1
- OBFTYSPXDRROQO-SRVKXCTJSA-N Arg-Gln-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCN=C(N)N OBFTYSPXDRROQO-SRVKXCTJSA-N 0.000 description 1
- BEXGZLUHRXTZCC-CIUDSAMLSA-N Arg-Gln-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N BEXGZLUHRXTZCC-CIUDSAMLSA-N 0.000 description 1
- LMPKCSXZJSXBBL-NHCYSSNCSA-N Arg-Gln-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O LMPKCSXZJSXBBL-NHCYSSNCSA-N 0.000 description 1
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 1
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 1
- PNIGSVZJNVUVJA-BQBZGAKWSA-N Arg-Gly-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O PNIGSVZJNVUVJA-BQBZGAKWSA-N 0.000 description 1
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- ZATRYQNPUHGXCU-DTWKUNHWSA-N Arg-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ZATRYQNPUHGXCU-DTWKUNHWSA-N 0.000 description 1
- JTZUZBADHGISJD-SRVKXCTJSA-N Arg-His-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O JTZUZBADHGISJD-SRVKXCTJSA-N 0.000 description 1
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 description 1
- UHFUZWSZQKMDSX-DCAQKATOSA-N Arg-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UHFUZWSZQKMDSX-DCAQKATOSA-N 0.000 description 1
- DNUKXVMPARLPFN-XUXIUFHCSA-N Arg-Leu-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DNUKXVMPARLPFN-XUXIUFHCSA-N 0.000 description 1
- IIAXFBUTKIDDIP-ULQDDVLXSA-N Arg-Leu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O IIAXFBUTKIDDIP-ULQDDVLXSA-N 0.000 description 1
- MJINRRBEMOLJAK-DCAQKATOSA-N Arg-Lys-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N MJINRRBEMOLJAK-DCAQKATOSA-N 0.000 description 1
- FVBZXNSRIDVYJS-AVGNSLFASA-N Arg-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N FVBZXNSRIDVYJS-AVGNSLFASA-N 0.000 description 1
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 1
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 1
- JQHASVQBAKRJKD-GUBZILKMSA-N Arg-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JQHASVQBAKRJKD-GUBZILKMSA-N 0.000 description 1
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 1
- VJIQPOJMISSUPO-BVSLBCMMSA-N Arg-Trp-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VJIQPOJMISSUPO-BVSLBCMMSA-N 0.000 description 1
- NMTANZXPDAHUKU-ULQDDVLXSA-N Arg-Tyr-Lys Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=C(O)C=C1 NMTANZXPDAHUKU-ULQDDVLXSA-N 0.000 description 1
- 229940080328 Arginase inhibitor Drugs 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- HZPSDHRYYIORKR-WHFBIAKZSA-N Asn-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O HZPSDHRYYIORKR-WHFBIAKZSA-N 0.000 description 1
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 1
- WVCJSDCHTUTONA-FXQIFTODSA-N Asn-Asp-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WVCJSDCHTUTONA-FXQIFTODSA-N 0.000 description 1
- QRHYAUYXBVVDSB-LKXGYXEUSA-N Asn-Cys-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QRHYAUYXBVVDSB-LKXGYXEUSA-N 0.000 description 1
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 1
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 1
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 1
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 1
- UDSVWSUXKYXSTR-QWRGUYRKSA-N Asn-Gly-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UDSVWSUXKYXSTR-QWRGUYRKSA-N 0.000 description 1
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 1
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 1
- NCFJQJRLQJEECD-NHCYSSNCSA-N Asn-Leu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O NCFJQJRLQJEECD-NHCYSSNCSA-N 0.000 description 1
- RZNAMKZJPBQWDJ-SRVKXCTJSA-N Asn-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N RZNAMKZJPBQWDJ-SRVKXCTJSA-N 0.000 description 1
- NLDNNZKUSLAYFW-NHCYSSNCSA-N Asn-Lys-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLDNNZKUSLAYFW-NHCYSSNCSA-N 0.000 description 1
- BKFXFUPYETWGGA-XVSYOHENSA-N Asn-Phe-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BKFXFUPYETWGGA-XVSYOHENSA-N 0.000 description 1
- UYCPJVYQYARFGB-YDHLFZDLSA-N Asn-Phe-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O UYCPJVYQYARFGB-YDHLFZDLSA-N 0.000 description 1
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 1
- BYLSYQASFJJBCL-DCAQKATOSA-N Asn-Pro-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BYLSYQASFJJBCL-DCAQKATOSA-N 0.000 description 1
- JPPLRQVZMZFOSX-UWJYBYFXSA-N Asn-Tyr-Ala Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 JPPLRQVZMZFOSX-UWJYBYFXSA-N 0.000 description 1
- NJPLPRFQLBZAMH-IHRRRGAJSA-N Asn-Tyr-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(O)=O NJPLPRFQLBZAMH-IHRRRGAJSA-N 0.000 description 1
- DPWDPEVGACCWTC-SRVKXCTJSA-N Asn-Tyr-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O DPWDPEVGACCWTC-SRVKXCTJSA-N 0.000 description 1
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 1
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 1
- GBAWQWASNGUNQF-ZLUOBGJFSA-N Asp-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N GBAWQWASNGUNQF-ZLUOBGJFSA-N 0.000 description 1
- ZVTDYGWRRPMFCL-WFBYXXMGSA-N Asp-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N ZVTDYGWRRPMFCL-WFBYXXMGSA-N 0.000 description 1
- RGKKALNPOYURGE-ZKWXMUAHSA-N Asp-Ala-Val Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O RGKKALNPOYURGE-ZKWXMUAHSA-N 0.000 description 1
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 1
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 1
- KHBLRHKVXICFMY-GUBZILKMSA-N Asp-Glu-Lys Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O KHBLRHKVXICFMY-GUBZILKMSA-N 0.000 description 1
- DGKCOYGQLNWNCJ-ACZMJKKPSA-N Asp-Glu-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O DGKCOYGQLNWNCJ-ACZMJKKPSA-N 0.000 description 1
- OMMIEVATLAGRCK-BYPYZUCNSA-N Asp-Gly-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)NCC(O)=O OMMIEVATLAGRCK-BYPYZUCNSA-N 0.000 description 1
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 1
- RKNIUWSZIAUEPK-PBCZWWQYSA-N Asp-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)O)N)O RKNIUWSZIAUEPK-PBCZWWQYSA-N 0.000 description 1
- SPKCGKRUYKMDHP-GUDRVLHUSA-N Asp-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N SPKCGKRUYKMDHP-GUDRVLHUSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- OEDJQRXNDRUGEU-SRVKXCTJSA-N Asp-Leu-His Chemical compound N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)O OEDJQRXNDRUGEU-SRVKXCTJSA-N 0.000 description 1
- GKWFMNNNYZHJHV-SRVKXCTJSA-N Asp-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC(O)=O GKWFMNNNYZHJHV-SRVKXCTJSA-N 0.000 description 1
- VMVUDJUXJKDGNR-FXQIFTODSA-N Asp-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N VMVUDJUXJKDGNR-FXQIFTODSA-N 0.000 description 1
- JUWISGAGWSDGDH-KKUMJFAQSA-N Asp-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=CC=C1 JUWISGAGWSDGDH-KKUMJFAQSA-N 0.000 description 1
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- IWLZBRTUIVXZJD-OLHMAJIHSA-N Asp-Thr-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O IWLZBRTUIVXZJD-OLHMAJIHSA-N 0.000 description 1
- NAAAPCLFJPURAM-HJGDQZAQSA-N Asp-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O NAAAPCLFJPURAM-HJGDQZAQSA-N 0.000 description 1
- GXHDGYOXPNQCKM-XVSYOHENSA-N Asp-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GXHDGYOXPNQCKM-XVSYOHENSA-N 0.000 description 1
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 1
- ITGFVUYOLWBPQW-KKHAAJSZSA-N Asp-Thr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ITGFVUYOLWBPQW-KKHAAJSZSA-N 0.000 description 1
- YUELDQUPTAYEGM-XIRDDKMYSA-N Asp-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)O)N YUELDQUPTAYEGM-XIRDDKMYSA-N 0.000 description 1
- 108010024976 Asparaginase Proteins 0.000 description 1
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 239000005552 B01AC04 - Clopidogrel Substances 0.000 description 1
- 239000005528 B01AC05 - Ticlopidine Substances 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 102100027314 Beta-2-microglobulin Human genes 0.000 description 1
- 241000537222 Betabaculovirus Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 101100263837 Bovine ephemeral fever virus (strain BB7721) beta gene Proteins 0.000 description 1
- 108700031361 Brachyury Proteins 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- PWNOXXJWYIYASN-UHFFFAOYSA-L C(C(=O)[O-])(=O)[O-].[Pt+2].CN(C1=NC(=NC(=N1)N(C)C)N(C)C)C Chemical compound C(C(=O)[O-])(=O)[O-].[Pt+2].CN(C1=NC(=NC(=N1)N(C)C)N(C)C)C PWNOXXJWYIYASN-UHFFFAOYSA-L 0.000 description 1
- 101150038349 CCNA1 gene Proteins 0.000 description 1
- 229940121697 CD27 agonist Drugs 0.000 description 1
- 229940123205 CD28 agonist Drugs 0.000 description 1
- 229940123189 CD40 agonist Drugs 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 229940122739 Calcineurin inhibitor Drugs 0.000 description 1
- 101710192106 Calcineurin-binding protein cabin-1 Proteins 0.000 description 1
- 102100024123 Calcineurin-binding protein cabin-1 Human genes 0.000 description 1
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 108090000566 Caspase-9 Proteins 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 229940123587 Cell cycle inhibitor Drugs 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical class C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 244000205754 Colocasia esculenta Species 0.000 description 1
- 235000006481 Colocasia esculenta Nutrition 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000711573 Coronaviridae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 102000002554 Cyclin A Human genes 0.000 description 1
- 108010068192 Cyclin A Proteins 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 229930105110 Cyclosporin A Natural products 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- FMDCYTBSPZMPQE-JBDRJPRFSA-N Cys-Ala-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMDCYTBSPZMPQE-JBDRJPRFSA-N 0.000 description 1
- KKZHXOOZHFABQQ-UWJYBYFXSA-N Cys-Ala-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKZHXOOZHFABQQ-UWJYBYFXSA-N 0.000 description 1
- BIVLWXQGXJLGKG-BIIVOSGPSA-N Cys-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N)C(=O)O BIVLWXQGXJLGKG-BIIVOSGPSA-N 0.000 description 1
- HYKFOHGZGLOCAY-ZLUOBGJFSA-N Cys-Cys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O HYKFOHGZGLOCAY-ZLUOBGJFSA-N 0.000 description 1
- VCIIDXDOPGHMDQ-WDSKDSINSA-N Cys-Gly-Gln Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VCIIDXDOPGHMDQ-WDSKDSINSA-N 0.000 description 1
- LBOLGUYQEPZSKM-YUMQZZPRSA-N Cys-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N LBOLGUYQEPZSKM-YUMQZZPRSA-N 0.000 description 1
- PQHYZJPCYRDYNE-QWRGUYRKSA-N Cys-Gly-Phe Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PQHYZJPCYRDYNE-QWRGUYRKSA-N 0.000 description 1
- OXOQBEVULIBOSH-ZDLURKLDSA-N Cys-Gly-Thr Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O OXOQBEVULIBOSH-ZDLURKLDSA-N 0.000 description 1
- UXIYYUMGFNSGBK-XPUUQOCRSA-N Cys-Gly-Val Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O UXIYYUMGFNSGBK-XPUUQOCRSA-N 0.000 description 1
- VTJLJQGUMBWHBP-GUBZILKMSA-N Cys-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N VTJLJQGUMBWHBP-GUBZILKMSA-N 0.000 description 1
- KCPOQGRVVXYLAC-KKUMJFAQSA-N Cys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CS)N KCPOQGRVVXYLAC-KKUMJFAQSA-N 0.000 description 1
- SRIRHERUAMYIOQ-CIUDSAMLSA-N Cys-Leu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SRIRHERUAMYIOQ-CIUDSAMLSA-N 0.000 description 1
- HJGUQJJJXQGXGJ-FXQIFTODSA-N Cys-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HJGUQJJJXQGXGJ-FXQIFTODSA-N 0.000 description 1
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 1
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 1
- MWVDDZUTWXFYHL-XKBZYTNZSA-N Cys-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CS)N)O MWVDDZUTWXFYHL-XKBZYTNZSA-N 0.000 description 1
- YFKWIIRWHGKSQQ-WFBYXXMGSA-N Cys-Trp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CS)N YFKWIIRWHGKSQQ-WFBYXXMGSA-N 0.000 description 1
- VRJZMZGGAKVSIQ-SRVKXCTJSA-N Cys-Tyr-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VRJZMZGGAKVSIQ-SRVKXCTJSA-N 0.000 description 1
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 239000012623 DNA damaging agent Substances 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 241000450599 DNA viruses Species 0.000 description 1
- 206010059352 Desmoid tumour Diseases 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 101100316840 Enterobacteria phage P4 Beta gene Proteins 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 229910052693 Europium Inorganic materials 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 241000714174 Feline sarcoma virus Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 206010016654 Fibrosis Diseases 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 229940123414 Folate antagonist Drugs 0.000 description 1
- 208000000666 Fowlpox Diseases 0.000 description 1
- 101710121810 Galectin-9 Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- PGPJSRSLQNXBDT-YUMQZZPRSA-N Gln-Arg-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O PGPJSRSLQNXBDT-YUMQZZPRSA-N 0.000 description 1
- DTMLKCYOQKZXKZ-HJGDQZAQSA-N Gln-Arg-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DTMLKCYOQKZXKZ-HJGDQZAQSA-N 0.000 description 1
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 1
- AAOBFSKXAVIORT-GUBZILKMSA-N Gln-Asn-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O AAOBFSKXAVIORT-GUBZILKMSA-N 0.000 description 1
- COYGBRTZEVWZBW-XKBZYTNZSA-N Gln-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(N)=O COYGBRTZEVWZBW-XKBZYTNZSA-N 0.000 description 1
- RRBLZNIIMHSHQF-FXQIFTODSA-N Gln-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N RRBLZNIIMHSHQF-FXQIFTODSA-N 0.000 description 1
- AJDMYLOISOCHHC-YVNDNENWSA-N Gln-Gln-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AJDMYLOISOCHHC-YVNDNENWSA-N 0.000 description 1
- LVNILKSSFHCSJZ-IHRRRGAJSA-N Gln-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LVNILKSSFHCSJZ-IHRRRGAJSA-N 0.000 description 1
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 1
- RBWKVOSARCFSQQ-FXQIFTODSA-N Gln-Gln-Ser Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O RBWKVOSARCFSQQ-FXQIFTODSA-N 0.000 description 1
- UFNSPPFJOHNXRE-AUTRQRHGSA-N Gln-Gln-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UFNSPPFJOHNXRE-AUTRQRHGSA-N 0.000 description 1
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 1
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 1
- XJKAKYXMFHUIHT-AUTRQRHGSA-N Gln-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N XJKAKYXMFHUIHT-AUTRQRHGSA-N 0.000 description 1
- NSNUZSPSADIMJQ-WDSKDSINSA-N Gln-Gly-Asp Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NSNUZSPSADIMJQ-WDSKDSINSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- FTIJVMLAGRAYMJ-MNXVOIDGSA-N Gln-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(N)=O FTIJVMLAGRAYMJ-MNXVOIDGSA-N 0.000 description 1
- HWEINOMSWQSJDC-SRVKXCTJSA-N Gln-Leu-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O HWEINOMSWQSJDC-SRVKXCTJSA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- MLSKFHLRFVGNLL-WDCWCFNPSA-N Gln-Leu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MLSKFHLRFVGNLL-WDCWCFNPSA-N 0.000 description 1
- SXGMGNZEHFORAV-IUCAKERBSA-N Gln-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N SXGMGNZEHFORAV-IUCAKERBSA-N 0.000 description 1
- KSKFIECUYMYWNS-AVGNSLFASA-N Gln-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N KSKFIECUYMYWNS-AVGNSLFASA-N 0.000 description 1
- WHVLABLIJYGVEK-QEWYBTABSA-N Gln-Phe-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WHVLABLIJYGVEK-QEWYBTABSA-N 0.000 description 1
- XZUUUKNKNWVPHQ-JYJNAYRXSA-N Gln-Phe-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O XZUUUKNKNWVPHQ-JYJNAYRXSA-N 0.000 description 1
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 1
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 1
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 1
- OKQLXOYFUPVEHI-CIUDSAMLSA-N Gln-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N OKQLXOYFUPVEHI-CIUDSAMLSA-N 0.000 description 1
- XMWNHGKDDIFXQJ-NWLDYVSISA-N Gln-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O XMWNHGKDDIFXQJ-NWLDYVSISA-N 0.000 description 1
- WBBVTGIFQIZBHP-JBACZVJFSA-N Gln-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CCC(=O)N)N WBBVTGIFQIZBHP-JBACZVJFSA-N 0.000 description 1
- JKDBRTNMYXYLHO-JYJNAYRXSA-N Gln-Tyr-Leu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 JKDBRTNMYXYLHO-JYJNAYRXSA-N 0.000 description 1
- SZXSSXUNOALWCH-ACZMJKKPSA-N Glu-Ala-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O SZXSSXUNOALWCH-ACZMJKKPSA-N 0.000 description 1
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 1
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 1
- RCCDHXSRMWCOOY-GUBZILKMSA-N Glu-Arg-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCCDHXSRMWCOOY-GUBZILKMSA-N 0.000 description 1
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 1
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 1
- WPLGNDORMXTMQS-FXQIFTODSA-N Glu-Gln-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O WPLGNDORMXTMQS-FXQIFTODSA-N 0.000 description 1
- VFZIDQZAEBORGY-GLLZPBPUSA-N Glu-Gln-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VFZIDQZAEBORGY-GLLZPBPUSA-N 0.000 description 1
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 1
- CGOHAEBMDSEKFB-FXQIFTODSA-N Glu-Glu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O CGOHAEBMDSEKFB-FXQIFTODSA-N 0.000 description 1
- ILGFBUGLBSAQQB-GUBZILKMSA-N Glu-Glu-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ILGFBUGLBSAQQB-GUBZILKMSA-N 0.000 description 1
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 1
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 1
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 1
- PXXGVUVQWQGGIG-YUMQZZPRSA-N Glu-Gly-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N PXXGVUVQWQGGIG-YUMQZZPRSA-N 0.000 description 1
- OGNJZUXUTPQVBR-BQBZGAKWSA-N Glu-Gly-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OGNJZUXUTPQVBR-BQBZGAKWSA-N 0.000 description 1
- KRRFFAHEAOCBCQ-SIUGBPQLSA-N Glu-Ile-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KRRFFAHEAOCBCQ-SIUGBPQLSA-N 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 1
- NWOUBJNMZDDGDT-AVGNSLFASA-N Glu-Leu-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 NWOUBJNMZDDGDT-AVGNSLFASA-N 0.000 description 1
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 1
- YKBUCXNNBYZYAY-MNXVOIDGSA-N Glu-Lys-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YKBUCXNNBYZYAY-MNXVOIDGSA-N 0.000 description 1
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 1
- RBXSZQRSEGYDFG-GUBZILKMSA-N Glu-Lys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O RBXSZQRSEGYDFG-GUBZILKMSA-N 0.000 description 1
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 1
- KXTAGESXNQEZKB-DZKIICNBSA-N Glu-Phe-Val Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 KXTAGESXNQEZKB-DZKIICNBSA-N 0.000 description 1
- DCBSZJJHOTXMHY-DCAQKATOSA-N Glu-Pro-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DCBSZJJHOTXMHY-DCAQKATOSA-N 0.000 description 1
- BPLNJYHNAJVLRT-ACZMJKKPSA-N Glu-Ser-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O BPLNJYHNAJVLRT-ACZMJKKPSA-N 0.000 description 1
- WXONSNSSBYQGNN-AVGNSLFASA-N Glu-Ser-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O WXONSNSSBYQGNN-AVGNSLFASA-N 0.000 description 1
- HZISRJBYZAODRV-XQXXSGGOSA-N Glu-Thr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O HZISRJBYZAODRV-XQXXSGGOSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- GPSHCSTUYOQPAI-JHEQGTHGSA-N Glu-Thr-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O GPSHCSTUYOQPAI-JHEQGTHGSA-N 0.000 description 1
- YQAQQKPWFOBSMU-WDCWCFNPSA-N Glu-Thr-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O YQAQQKPWFOBSMU-WDCWCFNPSA-N 0.000 description 1
- HQTDNEZTGZUWSY-XVKPBYJWSA-N Glu-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)NCC(O)=O HQTDNEZTGZUWSY-XVKPBYJWSA-N 0.000 description 1
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 1
- WJZLEENECIOOSA-WDSKDSINSA-N Gly-Asn-Gln Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)O WJZLEENECIOOSA-WDSKDSINSA-N 0.000 description 1
- BGVYNAQWHSTTSP-BYULHYEWSA-N Gly-Asn-Ile Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BGVYNAQWHSTTSP-BYULHYEWSA-N 0.000 description 1
- FZQLXNIMCPJVJE-YUMQZZPRSA-N Gly-Asp-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FZQLXNIMCPJVJE-YUMQZZPRSA-N 0.000 description 1
- MOJKRXIRAZPZLW-WDSKDSINSA-N Gly-Glu-Ala Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MOJKRXIRAZPZLW-WDSKDSINSA-N 0.000 description 1
- HDNXXTBKOJKWNN-WDSKDSINSA-N Gly-Glu-Asn Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O HDNXXTBKOJKWNN-WDSKDSINSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- SOEATRRYCIPEHA-BQBZGAKWSA-N Gly-Glu-Glu Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SOEATRRYCIPEHA-BQBZGAKWSA-N 0.000 description 1
- QPTNELDXWKRIFX-YFKPBYRVSA-N Gly-Gly-Gln Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O QPTNELDXWKRIFX-YFKPBYRVSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- TVDHVLGFJSHPAX-UWVGGRQHSA-N Gly-His-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 TVDHVLGFJSHPAX-UWVGGRQHSA-N 0.000 description 1
- VAXIVIPMCTYSHI-YUMQZZPRSA-N Gly-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN VAXIVIPMCTYSHI-YUMQZZPRSA-N 0.000 description 1
- QSVMIMFAAZPCAQ-PMVVWTBXSA-N Gly-His-Thr Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QSVMIMFAAZPCAQ-PMVVWTBXSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 1
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 1
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 1
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 1
- GAFKBWKVXNERFA-QWRGUYRKSA-N Gly-Phe-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 GAFKBWKVXNERFA-QWRGUYRKSA-N 0.000 description 1
- HJARVELKOSZUEW-YUMQZZPRSA-N Gly-Pro-Gln Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJARVELKOSZUEW-YUMQZZPRSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- OCPPBNKYGYSLOE-IUCAKERBSA-N Gly-Pro-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN OCPPBNKYGYSLOE-IUCAKERBSA-N 0.000 description 1
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 1
- JNGHLWWFPGIJER-STQMWFEESA-N Gly-Pro-Tyr Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 JNGHLWWFPGIJER-STQMWFEESA-N 0.000 description 1
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- FKYQEVBRZSFAMJ-QWRGUYRKSA-N Gly-Ser-Tyr Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FKYQEVBRZSFAMJ-QWRGUYRKSA-N 0.000 description 1
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- FOKISINOENBSDM-WLTAIBSBSA-N Gly-Thr-Tyr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O FOKISINOENBSDM-WLTAIBSBSA-N 0.000 description 1
- NWOSHVVPKDQKKT-RYUDHWBXSA-N Gly-Tyr-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O NWOSHVVPKDQKKT-RYUDHWBXSA-N 0.000 description 1
- DUAWRXXTOQOECJ-JSGCOSHPSA-N Gly-Tyr-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O DUAWRXXTOQOECJ-JSGCOSHPSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102000002068 Glycopeptides Human genes 0.000 description 1
- 108010015899 Glycopeptides Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 108060005986 Granzyme Proteins 0.000 description 1
- 102000001398 Granzyme Human genes 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- PROLDOGUBQJNPG-RWMBFGLXSA-N His-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O PROLDOGUBQJNPG-RWMBFGLXSA-N 0.000 description 1
- FLYSHWAAHYNKRT-JYJNAYRXSA-N His-Gln-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FLYSHWAAHYNKRT-JYJNAYRXSA-N 0.000 description 1
- JCOSMKPAOYDKRO-AVGNSLFASA-N His-Glu-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N JCOSMKPAOYDKRO-AVGNSLFASA-N 0.000 description 1
- HAPWZEVRQYGLSG-IUCAKERBSA-N His-Gly-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O HAPWZEVRQYGLSG-IUCAKERBSA-N 0.000 description 1
- RGPWUJOMKFYFSR-QWRGUYRKSA-N His-Gly-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O RGPWUJOMKFYFSR-QWRGUYRKSA-N 0.000 description 1
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 1
- JMSONHOUHFDOJH-GUBZILKMSA-N His-Ser-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 JMSONHOUHFDOJH-GUBZILKMSA-N 0.000 description 1
- SYPULFZAGBBIOM-GVXVVHGQSA-N His-Val-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N SYPULFZAGBBIOM-GVXVVHGQSA-N 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 101100383038 Homo sapiens CD19 gene Proteins 0.000 description 1
- 101100273713 Homo sapiens CD2 gene Proteins 0.000 description 1
- 101100220044 Homo sapiens CD34 gene Proteins 0.000 description 1
- 101000737793 Homo sapiens Cerebellar degeneration-related antigen 1 Proteins 0.000 description 1
- 101100395310 Homo sapiens HLA-A gene Proteins 0.000 description 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 1
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000662902 Homo sapiens T cell receptor beta constant 2 Proteins 0.000 description 1
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 1
- 101000801254 Homo sapiens Tumor necrosis factor receptor superfamily member 16 Proteins 0.000 description 1
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 1
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 1
- 241000713340 Human immunodeficiency virus 2 Species 0.000 description 1
- 241000714192 Human spumaretrovirus Species 0.000 description 1
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 1
- FVEWRQXNISSYFO-ZPFDUUQYSA-N Ile-Arg-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N FVEWRQXNISSYFO-ZPFDUUQYSA-N 0.000 description 1
- LVQDUPQUJZWKSU-PYJNHQTQSA-N Ile-Arg-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LVQDUPQUJZWKSU-PYJNHQTQSA-N 0.000 description 1
- RSDHVTMRXSABSV-GHCJXIJMSA-N Ile-Asn-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N RSDHVTMRXSABSV-GHCJXIJMSA-N 0.000 description 1
- YBJWJQQBWRARLT-KBIXCLLPSA-N Ile-Gln-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O YBJWJQQBWRARLT-KBIXCLLPSA-N 0.000 description 1
- HTDRTKMNJRRYOJ-SIUGBPQLSA-N Ile-Gln-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HTDRTKMNJRRYOJ-SIUGBPQLSA-N 0.000 description 1
- UWLHDGMRWXHFFY-HPCHECBXSA-N Ile-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1CCC[C@@H]1C(=O)O)N UWLHDGMRWXHFFY-HPCHECBXSA-N 0.000 description 1
- TWYOYAKMLHWMOJ-ZPFDUUQYSA-N Ile-Leu-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O TWYOYAKMLHWMOJ-ZPFDUUQYSA-N 0.000 description 1
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 1
- DSDPLOODKXISDT-XUXIUFHCSA-N Ile-Leu-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O DSDPLOODKXISDT-XUXIUFHCSA-N 0.000 description 1
- CKRFDMPBSWYOBT-PPCPHDFISA-N Ile-Lys-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N CKRFDMPBSWYOBT-PPCPHDFISA-N 0.000 description 1
- BKPPWVSPSIUXHZ-OSUNSFLBSA-N Ile-Met-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N BKPPWVSPSIUXHZ-OSUNSFLBSA-N 0.000 description 1
- VOCZPDONPURUHV-QEWYBTABSA-N Ile-Phe-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VOCZPDONPURUHV-QEWYBTABSA-N 0.000 description 1
- KTNGVMMGIQWIDV-OSUNSFLBSA-N Ile-Pro-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O KTNGVMMGIQWIDV-OSUNSFLBSA-N 0.000 description 1
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 1
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 1
- COWHUQXTSYTKQC-RWRJDSDZSA-N Ile-Thr-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N COWHUQXTSYTKQC-RWRJDSDZSA-N 0.000 description 1
- HODVZHLJUUWPKY-STECZYCISA-N Ile-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=C(O)C=C1 HODVZHLJUUWPKY-STECZYCISA-N 0.000 description 1
- DZMWFIRHFFVBHS-ZEWNOJEFSA-N Ile-Tyr-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N DZMWFIRHFFVBHS-ZEWNOJEFSA-N 0.000 description 1
- RQZFWBLDTBDEOF-RNJOBUHISA-N Ile-Val-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N RQZFWBLDTBDEOF-RNJOBUHISA-N 0.000 description 1
- JZBVBOKASHNXAD-NAKRPEOUSA-N Ile-Val-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N JZBVBOKASHNXAD-NAKRPEOUSA-N 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 102100021317 Inducible T-cell costimulator Human genes 0.000 description 1
- 208000022559 Inflammatory bowel disease Diseases 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 description 1
- 108010002386 Interleukin-3 Proteins 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 108010002335 Interleukin-9 Proteins 0.000 description 1
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 1
- 229940125563 LAG3 inhibitor Drugs 0.000 description 1
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 description 1
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 1
- XYUBOFCTGPZFSA-WDSOQIARSA-N Leu-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 XYUBOFCTGPZFSA-WDSOQIARSA-N 0.000 description 1
- DUBAVOVZNZKEQQ-AVGNSLFASA-N Leu-Arg-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CCCN=C(N)N DUBAVOVZNZKEQQ-AVGNSLFASA-N 0.000 description 1
- BAJIJEGGUYXZGC-CIUDSAMLSA-N Leu-Asn-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N BAJIJEGGUYXZGC-CIUDSAMLSA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- JKGHDYGZRDWHGA-SRVKXCTJSA-N Leu-Asn-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JKGHDYGZRDWHGA-SRVKXCTJSA-N 0.000 description 1
- TWQIYNGNYNJUFM-NHCYSSNCSA-N Leu-Asn-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TWQIYNGNYNJUFM-NHCYSSNCSA-N 0.000 description 1
- BPANDPNDMJHFEV-CIUDSAMLSA-N Leu-Asp-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O BPANDPNDMJHFEV-CIUDSAMLSA-N 0.000 description 1
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 1
- FGNQZXKVAZIMCI-CIUDSAMLSA-N Leu-Asp-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N FGNQZXKVAZIMCI-CIUDSAMLSA-N 0.000 description 1
- PJYSOYLLTJKZHC-GUBZILKMSA-N Leu-Asp-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(N)=O PJYSOYLLTJKZHC-GUBZILKMSA-N 0.000 description 1
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- XVSJMWYYLHPDKY-DCAQKATOSA-N Leu-Asp-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O XVSJMWYYLHPDKY-DCAQKATOSA-N 0.000 description 1
- IIKJNQWOQIWWMR-CIUDSAMLSA-N Leu-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N IIKJNQWOQIWWMR-CIUDSAMLSA-N 0.000 description 1
- GZAUZBUKDXYPEH-CIUDSAMLSA-N Leu-Cys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N GZAUZBUKDXYPEH-CIUDSAMLSA-N 0.000 description 1
- HQPHMEPBNUHPKD-XIRDDKMYSA-N Leu-Cys-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N HQPHMEPBNUHPKD-XIRDDKMYSA-N 0.000 description 1
- WCTCIIAGNMFYAO-DCAQKATOSA-N Leu-Cys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O WCTCIIAGNMFYAO-DCAQKATOSA-N 0.000 description 1
- DXYBNWJZJVSZAE-GUBZILKMSA-N Leu-Gln-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N DXYBNWJZJVSZAE-GUBZILKMSA-N 0.000 description 1
- ZTLGVASZOIKNIX-DCAQKATOSA-N Leu-Gln-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N ZTLGVASZOIKNIX-DCAQKATOSA-N 0.000 description 1
- KUEVMUXNILMJTK-JYJNAYRXSA-N Leu-Gln-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KUEVMUXNILMJTK-JYJNAYRXSA-N 0.000 description 1
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 1
- OXRLYTYUXAQTHP-YUMQZZPRSA-N Leu-Gly-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](C)C(O)=O OXRLYTYUXAQTHP-YUMQZZPRSA-N 0.000 description 1
- VBZOAGIPCULURB-QWRGUYRKSA-N Leu-Gly-His Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N VBZOAGIPCULURB-QWRGUYRKSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- XBCWOTOCBXXJDG-BZSNNMDCSA-N Leu-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 XBCWOTOCBXXJDG-BZSNNMDCSA-N 0.000 description 1
- LKXANTUNFMVCNF-IHPCNDPISA-N Leu-His-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LKXANTUNFMVCNF-IHPCNDPISA-N 0.000 description 1
- SGIIOQQGLUUMDQ-IHRRRGAJSA-N Leu-His-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N SGIIOQQGLUUMDQ-IHRRRGAJSA-N 0.000 description 1
- KUIDCYNIEJBZBU-AJNGGQMLSA-N Leu-Ile-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O KUIDCYNIEJBZBU-AJNGGQMLSA-N 0.000 description 1
- QLDHBYRUNQZIJQ-DKIMLUQUSA-N Leu-Ile-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QLDHBYRUNQZIJQ-DKIMLUQUSA-N 0.000 description 1
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 1
- PDQDCFBVYXEFSD-SRVKXCTJSA-N Leu-Leu-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PDQDCFBVYXEFSD-SRVKXCTJSA-N 0.000 description 1
- IFMPDNRWZZEZSL-SRVKXCTJSA-N Leu-Leu-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O IFMPDNRWZZEZSL-SRVKXCTJSA-N 0.000 description 1
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 1
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 1
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 1
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- IZPVWNSAVUQBGP-CIUDSAMLSA-N Leu-Ser-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IZPVWNSAVUQBGP-CIUDSAMLSA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- ODRREERHVHMIPT-OEAJRASXSA-N Leu-Thr-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ODRREERHVHMIPT-OEAJRASXSA-N 0.000 description 1
- LFXSPAIBSZSTEM-PMVMPFDFSA-N Leu-Trp-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=CC=C3)C(=O)O)N LFXSPAIBSZSTEM-PMVMPFDFSA-N 0.000 description 1
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 1
- SEOXPEFQEOYURL-PMVMPFDFSA-N Leu-Tyr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SEOXPEFQEOYURL-PMVMPFDFSA-N 0.000 description 1
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 1
- FMFNIDICDKEMOE-XUXIUFHCSA-N Leu-Val-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMFNIDICDKEMOE-XUXIUFHCSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- 206010024612 Lipoma Diseases 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 1
- WLCYCADOWRMSAJ-CIUDSAMLSA-N Lys-Asn-Cys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(O)=O WLCYCADOWRMSAJ-CIUDSAMLSA-N 0.000 description 1
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 1
- AFAFFVKJJYBBTC-UHFFFAOYSA-N Lys-Gln-Ala-Gly-Asp-Val Chemical compound CC(C)C(C(O)=O)NC(=O)C(CC(O)=O)NC(=O)CNC(=O)C(C)NC(=O)C(CCC(N)=O)NC(=O)C(N)CCCCN AFAFFVKJJYBBTC-UHFFFAOYSA-N 0.000 description 1
- GGNOBVSOZPHLCE-GUBZILKMSA-N Lys-Gln-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GGNOBVSOZPHLCE-GUBZILKMSA-N 0.000 description 1
- MRWXLRGAFDOILG-DCAQKATOSA-N Lys-Gln-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MRWXLRGAFDOILG-DCAQKATOSA-N 0.000 description 1
- HWMZUBUEOYAQSC-DCAQKATOSA-N Lys-Gln-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O HWMZUBUEOYAQSC-DCAQKATOSA-N 0.000 description 1
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 1
- QZONCCHVHCOBSK-YUMQZZPRSA-N Lys-Gly-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O QZONCCHVHCOBSK-YUMQZZPRSA-N 0.000 description 1
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 1
- UETQMSASAVBGJY-QWRGUYRKSA-N Lys-Gly-His Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 UETQMSASAVBGJY-QWRGUYRKSA-N 0.000 description 1
- NKKFVJRLCCUJNA-QWRGUYRKSA-N Lys-Gly-Lys Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN NKKFVJRLCCUJNA-QWRGUYRKSA-N 0.000 description 1
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 1
- OJDFAABAHBPVTH-MNXVOIDGSA-N Lys-Ile-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O OJDFAABAHBPVTH-MNXVOIDGSA-N 0.000 description 1
- IVFUVMSKSFSFBT-NHCYSSNCSA-N Lys-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN IVFUVMSKSFSFBT-NHCYSSNCSA-N 0.000 description 1
- OVAOHZIOUBEQCJ-IHRRRGAJSA-N Lys-Leu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OVAOHZIOUBEQCJ-IHRRRGAJSA-N 0.000 description 1
- ONPDTSFZAIWMDI-AVGNSLFASA-N Lys-Leu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ONPDTSFZAIWMDI-AVGNSLFASA-N 0.000 description 1
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 1
- LJADEBULDNKJNK-IHRRRGAJSA-N Lys-Leu-Val Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LJADEBULDNKJNK-IHRRRGAJSA-N 0.000 description 1
- PYFNONMJYNJENN-AVGNSLFASA-N Lys-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PYFNONMJYNJENN-AVGNSLFASA-N 0.000 description 1
- ZCWWVXAXWUAEPZ-SRVKXCTJSA-N Lys-Met-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZCWWVXAXWUAEPZ-SRVKXCTJSA-N 0.000 description 1
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 1
- QVTDVTONTRSQMF-WDCWCFNPSA-N Lys-Thr-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CCCCN QVTDVTONTRSQMF-WDCWCFNPSA-N 0.000 description 1
- VVURYEVJJTXWNE-ULQDDVLXSA-N Lys-Tyr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O VVURYEVJJTXWNE-ULQDDVLXSA-N 0.000 description 1
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102000043129 MHC class I family Human genes 0.000 description 1
- 231100000002 MTT assay Toxicity 0.000 description 1
- 238000000134 MTT assay Methods 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 201000005505 Measles Diseases 0.000 description 1
- 229920000877 Melamine resin Polymers 0.000 description 1
- 102000012750 Membrane Glycoproteins Human genes 0.000 description 1
- 108010090054 Membrane Glycoproteins Proteins 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- VTKPSXWRUGCOAC-GUBZILKMSA-N Met-Ala-Met Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCSC VTKPSXWRUGCOAC-GUBZILKMSA-N 0.000 description 1
- AHZNUGRZHMZGFL-GUBZILKMSA-N Met-Arg-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCNC(N)=N AHZNUGRZHMZGFL-GUBZILKMSA-N 0.000 description 1
- NKDSBBBPGIVWEI-RCWTZXSCSA-N Met-Arg-Thr Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NKDSBBBPGIVWEI-RCWTZXSCSA-N 0.000 description 1
- XOMXAVJBLRROMC-IHRRRGAJSA-N Met-Asp-Phe Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOMXAVJBLRROMC-IHRRRGAJSA-N 0.000 description 1
- OFNCSQNBSWGGNV-DCAQKATOSA-N Met-Cys-His Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 OFNCSQNBSWGGNV-DCAQKATOSA-N 0.000 description 1
- VZBXCMCHIHEPBL-SRVKXCTJSA-N Met-Glu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN VZBXCMCHIHEPBL-SRVKXCTJSA-N 0.000 description 1
- MVBZBRKNZVJEKK-DTWKUNHWSA-N Met-Gly-Pro Chemical compound CSCC[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N MVBZBRKNZVJEKK-DTWKUNHWSA-N 0.000 description 1
- SXWQMBGNFXAGAT-FJXKBIBVSA-N Met-Gly-Thr Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O SXWQMBGNFXAGAT-FJXKBIBVSA-N 0.000 description 1
- HOLJKDOBVJDHCA-DCAQKATOSA-N Met-His-Cys Chemical compound N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CS)C(O)=O HOLJKDOBVJDHCA-DCAQKATOSA-N 0.000 description 1
- WPTDJKDGICUFCP-XUXIUFHCSA-N Met-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CCSC)N WPTDJKDGICUFCP-XUXIUFHCSA-N 0.000 description 1
- SODXFJOPSCXOHE-IHRRRGAJSA-N Met-Leu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O SODXFJOPSCXOHE-IHRRRGAJSA-N 0.000 description 1
- USBFEVBHEQBWDD-AVGNSLFASA-N Met-Leu-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O USBFEVBHEQBWDD-AVGNSLFASA-N 0.000 description 1
- HAQLBBVZAGMESV-IHRRRGAJSA-N Met-Lys-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O HAQLBBVZAGMESV-IHRRRGAJSA-N 0.000 description 1
- SMVTWPOATVIXTN-NAKRPEOUSA-N Met-Ser-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SMVTWPOATVIXTN-NAKRPEOUSA-N 0.000 description 1
- YIGCDRZMZNDENK-UNQGMJICSA-N Met-Thr-Phe Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YIGCDRZMZNDENK-UNQGMJICSA-N 0.000 description 1
- 101150076359 Mhc gene Proteins 0.000 description 1
- 108700011259 MicroRNAs Proteins 0.000 description 1
- 229940122255 Microtubule inhibitor Drugs 0.000 description 1
- 108020005196 Mitochondrial DNA Proteins 0.000 description 1
- 241000713869 Moloney murine leukemia virus Species 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101100096028 Mus musculus Smok1 gene Proteins 0.000 description 1
- 210000004460 N cell Anatomy 0.000 description 1
- FBKMWOJEPMPVTQ-UHFFFAOYSA-N N'-(3-bromo-4-fluorophenyl)-N-hydroxy-4-[2-(sulfamoylamino)ethylamino]-1,2,5-oxadiazole-3-carboximidamide Chemical compound NS(=O)(=O)NCCNC1=NON=C1C(=NO)NC1=CC=C(F)C(Br)=C1 FBKMWOJEPMPVTQ-UHFFFAOYSA-N 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- 108010066427 N-valyltryptophan Proteins 0.000 description 1
- 108700019961 Neoplasm Genes Proteins 0.000 description 1
- 102000048850 Neoplasm Genes Human genes 0.000 description 1
- KYRVNWMVYQXFEU-UHFFFAOYSA-N Nocodazole Chemical compound C1=C2NC(NC(=O)OC)=NC2=CC=C1C(=O)C1=CC=CS1 KYRVNWMVYQXFEU-UHFFFAOYSA-N 0.000 description 1
- KOBHCUDVWOTEKO-VKHMYHEASA-N Nomega-hydroxy-nor-l-arginine Chemical compound OC(=O)[C@@H](N)CCNC(=N)NO KOBHCUDVWOTEKO-VKHMYHEASA-N 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 208000012868 Overgrowth Diseases 0.000 description 1
- 240000007019 Oxalis corniculata Species 0.000 description 1
- 239000012270 PD-1 inhibitor Substances 0.000 description 1
- 239000012668 PD-1-inhibitor Substances 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- KHGNFPUMBJSZSM-UHFFFAOYSA-N Perforine Natural products COC1=C2CCC(O)C(CCC(C)(C)O)(OC)C2=NC2=C1C=CO2 KHGNFPUMBJSZSM-UHFFFAOYSA-N 0.000 description 1
- YMORXCKTSSGYIG-IHRRRGAJSA-N Phe-Arg-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N YMORXCKTSSGYIG-IHRRRGAJSA-N 0.000 description 1
- XWBJLKDCHJVKAK-KKUMJFAQSA-N Phe-Arg-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N XWBJLKDCHJVKAK-KKUMJFAQSA-N 0.000 description 1
- LGBVMDMZZFYSFW-HJWJTTGWSA-N Phe-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC1=CC=CC=C1)N LGBVMDMZZFYSFW-HJWJTTGWSA-N 0.000 description 1
- HTKNPQZCMLBOTQ-XVSYOHENSA-N Phe-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N)O HTKNPQZCMLBOTQ-XVSYOHENSA-N 0.000 description 1
- RIYZXJVARWJLKS-KKUMJFAQSA-N Phe-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RIYZXJVARWJLKS-KKUMJFAQSA-N 0.000 description 1
- ALHULIGNEXGFRM-QWRGUYRKSA-N Phe-Cys-Gly Chemical compound OC(=O)CNC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=CC=C1 ALHULIGNEXGFRM-QWRGUYRKSA-N 0.000 description 1
- LLGTYVHITPVGKR-RYUDHWBXSA-N Phe-Gln-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O LLGTYVHITPVGKR-RYUDHWBXSA-N 0.000 description 1
- ABQFNJAFONNUTH-FHWLQOOXSA-N Phe-Gln-Tyr Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N ABQFNJAFONNUTH-FHWLQOOXSA-N 0.000 description 1
- CSDMCMITJLKBAH-SOUVJXGZSA-N Phe-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O CSDMCMITJLKBAH-SOUVJXGZSA-N 0.000 description 1
- BFYHIHGIHGROAT-HTUGSXCWSA-N Phe-Glu-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFYHIHGIHGROAT-HTUGSXCWSA-N 0.000 description 1
- JJHVFCUWLSKADD-ONGXEEELSA-N Phe-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O JJHVFCUWLSKADD-ONGXEEELSA-N 0.000 description 1
- WPTYDQPGBMDUBI-QWRGUYRKSA-N Phe-Gly-Asn Chemical compound N[C@@H](Cc1ccccc1)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O WPTYDQPGBMDUBI-QWRGUYRKSA-N 0.000 description 1
- KPEIBEPEUAZWNS-ULQDDVLXSA-N Phe-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KPEIBEPEUAZWNS-ULQDDVLXSA-N 0.000 description 1
- YCCUXNNKXDGMAM-KKUMJFAQSA-N Phe-Leu-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YCCUXNNKXDGMAM-KKUMJFAQSA-N 0.000 description 1
- JKJSIYKSGIDHPM-WBAXXEDZSA-N Phe-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1ccccc1)C(O)=O JKJSIYKSGIDHPM-WBAXXEDZSA-N 0.000 description 1
- IWZRODDWOSIXPZ-IRXDYDNUSA-N Phe-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 IWZRODDWOSIXPZ-IRXDYDNUSA-N 0.000 description 1
- GPLWGAYGROGDEN-BZSNNMDCSA-N Phe-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GPLWGAYGROGDEN-BZSNNMDCSA-N 0.000 description 1
- DSXPMZMSJHOKKK-HJOGWXRNSA-N Phe-Phe-Tyr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O DSXPMZMSJHOKKK-HJOGWXRNSA-N 0.000 description 1
- AAERWTUHZKLDLC-IHRRRGAJSA-N Phe-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O AAERWTUHZKLDLC-IHRRRGAJSA-N 0.000 description 1
- NJJBATPLUQHRBM-IHRRRGAJSA-N Phe-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CO)C(=O)O NJJBATPLUQHRBM-IHRRRGAJSA-N 0.000 description 1
- BONHGTUEEPIMPM-AVGNSLFASA-N Phe-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O BONHGTUEEPIMPM-AVGNSLFASA-N 0.000 description 1
- APXXVISUHOLGEE-ILWGZMRPSA-N Phe-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC4=CC=CC=C4)N)C(=O)O APXXVISUHOLGEE-ILWGZMRPSA-N 0.000 description 1
- APECKGGXAXNFLL-RNXOBYDBSA-N Phe-Trp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 APECKGGXAXNFLL-RNXOBYDBSA-N 0.000 description 1
- QTDBZORPVYTRJU-KKXDTOCCSA-N Phe-Tyr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O QTDBZORPVYTRJU-KKXDTOCCSA-N 0.000 description 1
- FRMKIPSIZSFTTE-HJOGWXRNSA-N Phe-Tyr-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FRMKIPSIZSFTTE-HJOGWXRNSA-N 0.000 description 1
- ZOGICTVLQDWPER-UFYCRDLUSA-N Phe-Tyr-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O ZOGICTVLQDWPER-UFYCRDLUSA-N 0.000 description 1
- 235000014676 Phragmites communis Nutrition 0.000 description 1
- 102000013566 Plasminogen Human genes 0.000 description 1
- 108010051456 Plasminogen Proteins 0.000 description 1
- 108010001014 Plasminogen Activators Proteins 0.000 description 1
- 102000001938 Plasminogen Activators Human genes 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 241001505332 Polyomavirus sp. Species 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 1
- CYQQWUPHIZVCNY-GUBZILKMSA-N Pro-Arg-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CYQQWUPHIZVCNY-GUBZILKMSA-N 0.000 description 1
- XWYXZPHPYKRYPA-GMOBBJLQSA-N Pro-Asn-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O XWYXZPHPYKRYPA-GMOBBJLQSA-N 0.000 description 1
- MLQVJYMFASXBGZ-IHRRRGAJSA-N Pro-Asn-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O MLQVJYMFASXBGZ-IHRRRGAJSA-N 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 1
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 1
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 1
- FEVDNIBDCRKMER-IUCAKERBSA-N Pro-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEVDNIBDCRKMER-IUCAKERBSA-N 0.000 description 1
- UREQLMJCKFLLHM-NAKRPEOUSA-N Pro-Ile-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UREQLMJCKFLLHM-NAKRPEOUSA-N 0.000 description 1
- FXGIMYRVJJEIIM-UWVGGRQHSA-N Pro-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FXGIMYRVJJEIIM-UWVGGRQHSA-N 0.000 description 1
- FYPGHGXAOZTOBO-IHRRRGAJSA-N Pro-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FYPGHGXAOZTOBO-IHRRRGAJSA-N 0.000 description 1
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 1
- INDVYIOKMXFQFM-SRVKXCTJSA-N Pro-Lys-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O INDVYIOKMXFQFM-SRVKXCTJSA-N 0.000 description 1
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 1
- XZBYTHCRAVAXQQ-DCAQKATOSA-N Pro-Met-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XZBYTHCRAVAXQQ-DCAQKATOSA-N 0.000 description 1
- KDBHVPXBQADZKY-GUBZILKMSA-N Pro-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KDBHVPXBQADZKY-GUBZILKMSA-N 0.000 description 1
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 1
- GZNYIXWOIUFLGO-ZJDVBMNYSA-N Pro-Thr-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZNYIXWOIUFLGO-ZJDVBMNYSA-N 0.000 description 1
- QHSSUIHLAIWXEE-IHRRRGAJSA-N Pro-Tyr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O QHSSUIHLAIWXEE-IHRRRGAJSA-N 0.000 description 1
- BXHRXLMCYSZSIY-STECZYCISA-N Pro-Tyr-Ile Chemical compound CC[C@H](C)[C@H](NC(=O)[C@H](Cc1ccc(O)cc1)NC(=O)[C@@H]1CCCN1)C(O)=O BXHRXLMCYSZSIY-STECZYCISA-N 0.000 description 1
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 1
- VDHGTOHMHHQSKG-JYJNAYRXSA-N Pro-Val-Phe Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O VDHGTOHMHHQSKG-JYJNAYRXSA-N 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 241000125945 Protoparvovirus Species 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 201000004681 Psoriasis Diseases 0.000 description 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 206010037742 Rabies Diseases 0.000 description 1
- 241000711798 Rabies lyssavirus Species 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 241000712909 Reticuloendotheliosis virus Species 0.000 description 1
- 241000712907 Retroviridae Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 1
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- MMGJPDWSIOAGTH-ACZMJKKPSA-N Ser-Ala-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MMGJPDWSIOAGTH-ACZMJKKPSA-N 0.000 description 1
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- WXUBSIDKNMFAGS-IHRRRGAJSA-N Ser-Arg-Tyr Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 WXUBSIDKNMFAGS-IHRRRGAJSA-N 0.000 description 1
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 1
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 1
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 1
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 1
- AEGUWTFAQQWVLC-BQBZGAKWSA-N Ser-Gly-Arg Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O AEGUWTFAQQWVLC-BQBZGAKWSA-N 0.000 description 1
- IXCHOHLPHNGFTJ-YUMQZZPRSA-N Ser-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N IXCHOHLPHNGFTJ-YUMQZZPRSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- CAOYHZOWXFFAIR-CIUDSAMLSA-N Ser-His-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CAOYHZOWXFFAIR-CIUDSAMLSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- XXNYYSXNXCJYKX-DCAQKATOSA-N Ser-Leu-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O XXNYYSXNXCJYKX-DCAQKATOSA-N 0.000 description 1
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 1
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 1
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 1
- BYCVMHKULKRVPV-GUBZILKMSA-N Ser-Lys-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYCVMHKULKRVPV-GUBZILKMSA-N 0.000 description 1
- QJKPECIAWNNKIT-KKUMJFAQSA-N Ser-Lys-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QJKPECIAWNNKIT-KKUMJFAQSA-N 0.000 description 1
- JAWGSPUJAXYXJA-IHRRRGAJSA-N Ser-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=CC=C1 JAWGSPUJAXYXJA-IHRRRGAJSA-N 0.000 description 1
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 1
- BUYHXYIUQUBEQP-AVGNSLFASA-N Ser-Phe-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CO)N BUYHXYIUQUBEQP-AVGNSLFASA-N 0.000 description 1
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 1
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- FLONGDPORFIVQW-XGEHTFHBSA-N Ser-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FLONGDPORFIVQW-XGEHTFHBSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 1
- YXGCIEUDOHILKR-IHRRRGAJSA-N Ser-Tyr-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CO)N YXGCIEUDOHILKR-IHRRRGAJSA-N 0.000 description 1
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 1
- SYCFMSYTIFXWAJ-DCAQKATOSA-N Ser-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N SYCFMSYTIFXWAJ-DCAQKATOSA-N 0.000 description 1
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 241000256251 Spodoptera frugiperda Species 0.000 description 1
- 108010023197 Streptokinase Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- 102100037298 T cell receptor beta constant 2 Human genes 0.000 description 1
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 1
- 230000029662 T-helper 1 type immune response Effects 0.000 description 1
- 101150053558 TRBC1 gene Proteins 0.000 description 1
- 101150117561 TRBC2 gene Proteins 0.000 description 1
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- BPEGJWRSRHCHSN-UHFFFAOYSA-N Temozolomide Chemical compound O=C1N(C)N=NC2=C(C(N)=O)N=CN21 BPEGJWRSRHCHSN-UHFFFAOYSA-N 0.000 description 1
- IGROJMCBGRFRGI-YTLHQDLWSA-N Thr-Ala-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O IGROJMCBGRFRGI-YTLHQDLWSA-N 0.000 description 1
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 1
- CAGTXGDOIFXLPC-KZVJFYERSA-N Thr-Arg-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CCCN=C(N)N CAGTXGDOIFXLPC-KZVJFYERSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- VFEHSAJCWWHDBH-RHYQMDGZSA-N Thr-Arg-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VFEHSAJCWWHDBH-RHYQMDGZSA-N 0.000 description 1
- JBHMLZSKIXMVFS-XVSYOHENSA-N Thr-Asn-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JBHMLZSKIXMVFS-XVSYOHENSA-N 0.000 description 1
- XDARBNMYXKUFOJ-GSSVUCPTSA-N Thr-Asp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDARBNMYXKUFOJ-GSSVUCPTSA-N 0.000 description 1
- WLDUCKSCDRIVLJ-NUMRIWBASA-N Thr-Gln-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O WLDUCKSCDRIVLJ-NUMRIWBASA-N 0.000 description 1
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- UDQBCBUXAQIZAK-GLLZPBPUSA-N Thr-Glu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDQBCBUXAQIZAK-GLLZPBPUSA-N 0.000 description 1
- SHOMROOOQBDGRL-JHEQGTHGSA-N Thr-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SHOMROOOQBDGRL-JHEQGTHGSA-N 0.000 description 1
- VYEHBMMAJFVTOI-JHEQGTHGSA-N Thr-Gly-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VYEHBMMAJFVTOI-JHEQGTHGSA-N 0.000 description 1
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 1
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 1
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 1
- TZJSEJOXAIWOST-RHYQMDGZSA-N Thr-Lys-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N TZJSEJOXAIWOST-RHYQMDGZSA-N 0.000 description 1
- SCSVNSNWUTYSFO-WDCWCFNPSA-N Thr-Lys-Glu Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O SCSVNSNWUTYSFO-WDCWCFNPSA-N 0.000 description 1
- WNQJTLATMXYSEL-OEAJRASXSA-N Thr-Phe-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O WNQJTLATMXYSEL-OEAJRASXSA-N 0.000 description 1
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 1
- QJIODPFLAASXJC-JHYOHUSXSA-N Thr-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O QJIODPFLAASXJC-JHYOHUSXSA-N 0.000 description 1
- IJKNKFJZOJCKRR-GBALPHGKSA-N Thr-Trp-Ser Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 IJKNKFJZOJCKRR-GBALPHGKSA-N 0.000 description 1
- JNKAYADBODLPMQ-HSHDSVGOSA-N Thr-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)=CNC2=C1 JNKAYADBODLPMQ-HSHDSVGOSA-N 0.000 description 1
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 1
- 229940122388 Thrombin inhibitor Drugs 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- MDDYTWOFHZFABW-SZMVWBNQSA-N Trp-Gln-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 MDDYTWOFHZFABW-SZMVWBNQSA-N 0.000 description 1
- HQJOVVWAPQPYDS-ZFWWWQNUSA-N Trp-Gly-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQJOVVWAPQPYDS-ZFWWWQNUSA-N 0.000 description 1
- JVTHMUDOKPQBOT-NSHDSACASA-N Trp-Gly-Gly Chemical compound C1=CC=C2C(C[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O)=CNC2=C1 JVTHMUDOKPQBOT-NSHDSACASA-N 0.000 description 1
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 1
- SLOYNOMYOAOUCX-BVSLBCMMSA-N Trp-Phe-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SLOYNOMYOAOUCX-BVSLBCMMSA-N 0.000 description 1
- ARKBYVBCEOWRNR-UBHSHLNASA-N Trp-Ser-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O ARKBYVBCEOWRNR-UBHSHLNASA-N 0.000 description 1
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 1
- XKTWZYNTLXITCY-QRTARXTBSA-N Trp-Val-Asn Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O)=CNC2=C1 XKTWZYNTLXITCY-QRTARXTBSA-N 0.000 description 1
- BABINGWMZBWXIX-BPUTZDHNSA-N Trp-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BABINGWMZBWXIX-BPUTZDHNSA-N 0.000 description 1
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 1
- IELISNUVHBKYBX-XDTLVQLUSA-N Tyr-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IELISNUVHBKYBX-XDTLVQLUSA-N 0.000 description 1
- YLHFIMLKNPJRGY-BVSLBCMMSA-N Tyr-Arg-Trp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O YLHFIMLKNPJRGY-BVSLBCMMSA-N 0.000 description 1
- WAPFQMXRSDEGOE-IHRRRGAJSA-N Tyr-Glu-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O WAPFQMXRSDEGOE-IHRRRGAJSA-N 0.000 description 1
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 1
- DMWNPLOERDAHSY-MEYUZBJRSA-N Tyr-Leu-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DMWNPLOERDAHSY-MEYUZBJRSA-N 0.000 description 1
- JAGGEZACYAAMIL-CQDKDKBSSA-N Tyr-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JAGGEZACYAAMIL-CQDKDKBSSA-N 0.000 description 1
- BYAKMYBZADCNMN-JYJNAYRXSA-N Tyr-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYAKMYBZADCNMN-JYJNAYRXSA-N 0.000 description 1
- GYKDRHDMGQUZPU-MGHWNKPDSA-N Tyr-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CC=C(C=C1)O)N GYKDRHDMGQUZPU-MGHWNKPDSA-N 0.000 description 1
- FMXFHNSFABRVFZ-BZSNNMDCSA-N Tyr-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FMXFHNSFABRVFZ-BZSNNMDCSA-N 0.000 description 1
- FWOVTJKVUCGVND-UFYCRDLUSA-N Tyr-Met-Phe Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N FWOVTJKVUCGVND-UFYCRDLUSA-N 0.000 description 1
- CGWAPUBOXJWXMS-HOTGVXAUSA-N Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 CGWAPUBOXJWXMS-HOTGVXAUSA-N 0.000 description 1
- VXFXIBCCVLJCJT-JYJNAYRXSA-N Tyr-Pro-Pro Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N1CCC[C@H]1C(O)=O VXFXIBCCVLJCJT-JYJNAYRXSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- JHDZONWZTCKTJR-KJEVXHAQSA-N Tyr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JHDZONWZTCKTJR-KJEVXHAQSA-N 0.000 description 1
- GZWPQZDVTBZVEP-BZSNNMDCSA-N Tyr-Tyr-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O GZWPQZDVTBZVEP-BZSNNMDCSA-N 0.000 description 1
- AGDDLOQMXUQPDY-BZSNNMDCSA-N Tyr-Tyr-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O AGDDLOQMXUQPDY-BZSNNMDCSA-N 0.000 description 1
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 1
- 206010046798 Uterine leiomyoma Diseases 0.000 description 1
- 206010046865 Vaccinia virus infection Diseases 0.000 description 1
- CVUDMNSZAIZFAE-TUAOUCFPSA-N Val-Arg-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N CVUDMNSZAIZFAE-TUAOUCFPSA-N 0.000 description 1
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 1
- VMRFIKXKOFNMHW-GUBZILKMSA-N Val-Arg-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N VMRFIKXKOFNMHW-GUBZILKMSA-N 0.000 description 1
- DNOOLPROHJWCSQ-RCWTZXSCSA-N Val-Arg-Thr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DNOOLPROHJWCSQ-RCWTZXSCSA-N 0.000 description 1
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 1
- QGFPYRPIUXBYGR-YDHLFZDLSA-N Val-Asn-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N QGFPYRPIUXBYGR-YDHLFZDLSA-N 0.000 description 1
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- ZXAGTABZUOMUDO-GVXVVHGQSA-N Val-Glu-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZXAGTABZUOMUDO-GVXVVHGQSA-N 0.000 description 1
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 1
- BEGDZYNDCNEGJZ-XVKPBYJWSA-N Val-Gly-Gln Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O BEGDZYNDCNEGJZ-XVKPBYJWSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 1
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 1
- AGXGCFSECFQMKB-NHCYSSNCSA-N Val-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N AGXGCFSECFQMKB-NHCYSSNCSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- BZOSBRIDWSSTFN-AVGNSLFASA-N Val-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N BZOSBRIDWSSTFN-AVGNSLFASA-N 0.000 description 1
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 1
- WBAJDGWKRIHOAC-GVXVVHGQSA-N Val-Lys-Gln Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O WBAJDGWKRIHOAC-GVXVVHGQSA-N 0.000 description 1
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 1
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 1
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 1
- HPOSMQWRPMRMFO-GUBZILKMSA-N Val-Pro-Cys Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N HPOSMQWRPMRMFO-GUBZILKMSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- GUIYPEKUEMQBIK-JSGCOSHPSA-N Val-Tyr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)NCC(O)=O GUIYPEKUEMQBIK-JSGCOSHPSA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 1
- 241000711975 Vesicular stomatitis virus Species 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 108020005202 Viral DNA Proteins 0.000 description 1
- 108020000999 Viral RNA Proteins 0.000 description 1
- 241000713325 Visna/maedi virus Species 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 229960000446 abciximab Drugs 0.000 description 1
- 229960001138 acetylsalicylic acid Drugs 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 230000033289 adaptive immune response Effects 0.000 description 1
- 238000011467 adoptive cell therapy Methods 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 229960000473 altretamine Drugs 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000013103 analytical ultracentrifugation Methods 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 1
- 229940125364 angiotensin receptor blocker Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000001772 anti-angiogenic effect Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 230000006023 anti-tumor response Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000003146 anticoagulant agent Substances 0.000 description 1
- 229940127219 anticoagulant drug Drugs 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- 229940045719 antineoplastic alkylating agent nitrosoureas Drugs 0.000 description 1
- 229940127218 antiplatelet drug Drugs 0.000 description 1
- 239000003816 antisense DNA Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000007900 aqueous suspension Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010013835 arginine glutamate Proteins 0.000 description 1
- 108010089975 arginyl-glycyl-aspartyl-serine Proteins 0.000 description 1
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 229940046844 aromatase inhibitors Drugs 0.000 description 1
- 239000002473 artificial blood Substances 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 229950002916 avelumab Drugs 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 108010081355 beta 2-Microglobulin Proteins 0.000 description 1
- 229960000997 bicalutamide Drugs 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 229910021538 borax Inorganic materials 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 239000006172 buffering agent Substances 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- 235000019437 butane-1,3-diol Nutrition 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000005859 cell recognition Effects 0.000 description 1
- 239000002458 cell surface marker Substances 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 229960002436 cladribine Drugs 0.000 description 1
- GKTWGGQPFAXNFI-HNNXBMFYSA-N clopidogrel Chemical compound C1([C@H](N2CC=3C=CSC=3CC2)C(=O)OC)=CC=CC=C1Cl GKTWGGQPFAXNFI-HNNXBMFYSA-N 0.000 description 1
- 229960003009 clopidogrel Drugs 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000011443 conventional therapy Methods 0.000 description 1
- 230000000139 costimulatory effect Effects 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 108010004073 cysteinylcysteine Proteins 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 210000000172 cytosol Anatomy 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 229960000640 dactinomycin Drugs 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000002074 deregulated effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 201000006827 desmoid tumor Diseases 0.000 description 1
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- XYYVYLMBEZUESM-UHFFFAOYSA-N dihydrocodeine Natural products C1C(N(CCC234)C)C2C=CC(=O)C3OC2=C4C1=CC=C2OC XYYVYLMBEZUESM-UHFFFAOYSA-N 0.000 description 1
- PGUYAANYCROBRT-UHFFFAOYSA-N dihydroxy-selanyl-selanylidene-lambda5-phosphane Chemical compound OP(O)([SeH])=[Se] PGUYAANYCROBRT-UHFFFAOYSA-N 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 229960002768 dipyridamole Drugs 0.000 description 1
- IZEKFCXSFNUWAM-UHFFFAOYSA-N dipyridamole Chemical compound C=12N=C(N(CCO)CCO)N=C(N3CCCCC3)C2=NC(N(CCO)CCO)=NC=1N1CCCCC1 IZEKFCXSFNUWAM-UHFFFAOYSA-N 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 208000037765 diseases and disorders Diseases 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 229950009791 durvalumab Drugs 0.000 description 1
- 229940009662 edetate Drugs 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000003114 enzyme-linked immunosorbent spot assay Methods 0.000 description 1
- 229930013356 epothilone Natural products 0.000 description 1
- HESCAJZNRMSMJG-KKQRBIROSA-N epothilone A Chemical class C/C([C@@H]1C[C@@H]2O[C@@H]2CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 HESCAJZNRMSMJG-KKQRBIROSA-N 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- 235000020774 essential nutrients Nutrition 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- OGPBJKLSAFTDLK-UHFFFAOYSA-N europium atom Chemical compound [Eu] OGPBJKLSAFTDLK-UHFFFAOYSA-N 0.000 description 1
- 230000017188 evasion or tolerance of host immune response Effects 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 210000004700 fetal blood Anatomy 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 239000003527 fibrinolytic agent Substances 0.000 description 1
- 230000004761 fibrosis Effects 0.000 description 1
- 229960000961 floxuridine Drugs 0.000 description 1
- ODKNJVUHOIMIIZ-RRKCRQDMSA-N floxuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(F)=C1 ODKNJVUHOIMIIZ-RRKCRQDMSA-N 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 239000004052 folic acid antagonist Substances 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 201000003444 follicular lymphoma Diseases 0.000 description 1
- 238000010230 functional analysis Methods 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 229940045109 genistein Drugs 0.000 description 1
- 235000006539 genistein Nutrition 0.000 description 1
- ZCOLJUOHXJRHDI-CMWLGVBASA-N genistein 7-O-beta-D-glucoside Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1OC1=CC(O)=C2C(=O)C(C=3C=CC(O)=CC=3)=COC2=C1 ZCOLJUOHXJRHDI-CMWLGVBASA-N 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 108010008237 glutamyl-valyl-glycine Proteins 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 125000003712 glycosamine group Chemical group 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 1
- 108010023364 glycyl-histidyl-arginine Proteins 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 230000003394 haemopoietic effect Effects 0.000 description 1
- 201000011066 hemangioma Diseases 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 230000007446 host cell death Effects 0.000 description 1
- 230000005745 host immune response Effects 0.000 description 1
- 102000052073 human NGFR Human genes 0.000 description 1
- LLPOLZWFYMWNKH-CMKMFDCUSA-N hydrocodone Chemical compound C([C@H]1[C@H](N(CC[C@@]112)C)C3)CC(=O)[C@@H]1OC1=C2C3=CC=C1OC LLPOLZWFYMWNKH-CMKMFDCUSA-N 0.000 description 1
- 229960000240 hydrocodone Drugs 0.000 description 1
- OROGSEYTTFOCAN-UHFFFAOYSA-N hydrocodone Natural products C1C(N(CCC234)C)C2C=CC(O)C3OC2=C4C1=CC=C2OC OROGSEYTTFOCAN-UHFFFAOYSA-N 0.000 description 1
- 229960001101 ifosfamide Drugs 0.000 description 1
- HOMGKSMUEGBAAB-UHFFFAOYSA-N ifosfamide Chemical compound ClCCNP1(=O)OCCCN1CCCl HOMGKSMUEGBAAB-UHFFFAOYSA-N 0.000 description 1
- 230000005934 immune activation Effects 0.000 description 1
- 230000002998 immunogenetic effect Effects 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 230000001024 immunotherapeutic effect Effects 0.000 description 1
- 210000003000 inclusion body Anatomy 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 230000004068 intracellular signaling Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 229940043355 kinase inhibitor Drugs 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 229960003881 letrozole Drugs 0.000 description 1
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 description 1
- 108010077158 leucinyl-arginyl-tryptophan Proteins 0.000 description 1
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010025001 leukocyte-associated immunoglobulin-like receptor 1 Proteins 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 229950011263 lirilumab Drugs 0.000 description 1
- 210000004185 liver Anatomy 0.000 description 1
- 210000003738 lymphoid progenitor cell Anatomy 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 108010064235 lysylglycine Proteins 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 229940124302 mTOR inhibitor Drugs 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 210000003593 megakaryocyte Anatomy 0.000 description 1
- 230000031355 meiotic cell cycle Effects 0.000 description 1
- JDSHMPZPIAZGSV-UHFFFAOYSA-N melamine Chemical compound NC1=NC(N)=NC(N)=N1 JDSHMPZPIAZGSV-UHFFFAOYSA-N 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 108010068488 methionylphenylalanine Proteins 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 235000010755 mineral Nutrition 0.000 description 1
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 1
- 230000004065 mitochondrial dysfunction Effects 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 210000001616 monocyte Anatomy 0.000 description 1
- 229960004866 mycophenolate mofetil Drugs 0.000 description 1
- RTGDFNSFWBGLEC-SYZQJQIISA-N mycophenolate mofetil Chemical compound COC1=C(C)C=2COC(=O)C=2C(O)=C1C\C=C(/C)CCC(=O)OCCN1CCOCC1 RTGDFNSFWBGLEC-SYZQJQIISA-N 0.000 description 1
- 210000003643 myeloid progenitor cell Anatomy 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical group FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- XWXYUMMDTVBTOU-UHFFFAOYSA-N nilutamide Chemical compound O=C1C(C)(C)NC(=O)N1C1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 XWXYUMMDTVBTOU-UHFFFAOYSA-N 0.000 description 1
- 229960002653 nilutamide Drugs 0.000 description 1
- 239000002840 nitric oxide donor Substances 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 229950006344 nocodazole Drugs 0.000 description 1
- 239000003865 nucleic acid synthesis inhibitor Substances 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 201000008482 osteoarthritis Diseases 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 229940121655 pd-1 inhibitor Drugs 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- 229930192851 perforin Natural products 0.000 description 1
- 210000004976 peripheral blood cell Anatomy 0.000 description 1
- 239000010451 perlite Substances 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-N phosphoramidic acid Chemical compound NP(O)(O)=O PTMHPRAIXMAOOB-UHFFFAOYSA-N 0.000 description 1
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 229950010773 pidilizumab Drugs 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229940127126 plasminogen activator Drugs 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 239000000106 platelet aggregation inhibitor Substances 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 229960003171 plicamycin Drugs 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000006555 post-translational control Effects 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 229960000624 procarbazine Drugs 0.000 description 1
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000007420 radioactive assay Methods 0.000 description 1
- 229940121896 radiopharmaceutical Drugs 0.000 description 1
- 239000012217 radiopharmaceutical Substances 0.000 description 1
- 230000002799 radiopharmaceutical effect Effects 0.000 description 1
- 230000022983 regulation of cell cycle Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 208000037803 restenosis Diseases 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 238000009781 safety test method Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- JRPHGDYSKGJTKZ-UHFFFAOYSA-K selenophosphate Chemical compound [O-]P([O-])([O-])=[Se] JRPHGDYSKGJTKZ-UHFFFAOYSA-K 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 108010071207 serylmethionine Proteins 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 230000007781 signaling event Effects 0.000 description 1
- 230000037432 silent mutation Effects 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- HELHAJAZNSDZJO-OLXYHTOASA-L sodium L-tartrate Chemical compound [Na+].[Na+].[O-]C(=O)[C@H](O)[C@@H](O)C([O-])=O HELHAJAZNSDZJO-OLXYHTOASA-L 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 235000011083 sodium citrates Nutrition 0.000 description 1
- 239000001433 sodium tartrate Substances 0.000 description 1
- 229960002167 sodium tartrate Drugs 0.000 description 1
- 235000011004 sodium tartrates Nutrition 0.000 description 1
- 235000010339 sodium tetraborate Nutrition 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 230000021595 spermatogenesis Effects 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000003637 steroidlike Effects 0.000 description 1
- 239000002731 stomach secretion inhibitor Substances 0.000 description 1
- 229960005202 streptokinase Drugs 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 210000001179 synovial fluid Anatomy 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- 229960004964 temozolomide Drugs 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- YLQBMQCUIZJEEH-UHFFFAOYSA-N tetrahydrofuran Natural products C=1C=COC=1 YLQBMQCUIZJEEH-UHFFFAOYSA-N 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 1
- 239000003868 thrombin inhibitor Substances 0.000 description 1
- 229960005001 ticlopidine Drugs 0.000 description 1
- PHWBOXQYWZNQIN-UHFFFAOYSA-N ticlopidine Chemical compound ClC1=CC=CC=C1CN1CC(C=CS2)=C2CC1 PHWBOXQYWZNQIN-UHFFFAOYSA-N 0.000 description 1
- 229960003087 tioguanine Drugs 0.000 description 1
- MNRILEROXIRVNJ-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=NC=N[C]21 MNRILEROXIRVNJ-UHFFFAOYSA-N 0.000 description 1
- 231100000041 toxicology testing Toxicity 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- LLPOLZWFYMWNKH-UHFFFAOYSA-N trans-dihydrocodeinone Natural products C1C(N(CCC234)C)C2CCC(=O)C3OC2=C4C1=CC=C2OC LLPOLZWFYMWNKH-UHFFFAOYSA-N 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 230000014616 translation Effects 0.000 description 1
- 108091007466 transmembrane glycoproteins Proteins 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- 238000011277 treatment modality Methods 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- BSVBQGMMJUBVOD-UHFFFAOYSA-N trisodium borate Chemical compound [Na+].[Na+].[Na+].[O-]B([O-])[O-] BSVBQGMMJUBVOD-UHFFFAOYSA-N 0.000 description 1
- 230000029069 type 2 immune response Effects 0.000 description 1
- 108010068794 tyrosyl-tyrosyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 229960005356 urokinase Drugs 0.000 description 1
- 208000007089 vaccinia Diseases 0.000 description 1
- 108010073969 valyllysine Proteins 0.000 description 1
- 210000003501 vero cell Anatomy 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
Images



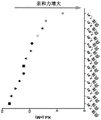



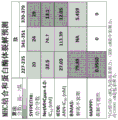
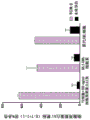

Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/2013—IL-2
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4632—T-cell receptors [TCR]; antibody T-cell receptor constructs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464448—Regulators of development
- A61K39/464449—Cell cycle regulated proteins, e.g. cyclin, CDC, CDK or INK-CCR
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4738—Cell cycle regulated proteins, e.g. cyclin, CDC, INK-CCR
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70514—CD4
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70517—CD8
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2833—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against MHC-molecules, e.g. HLA-molecules
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/58—Medicinal preparations containing antigens or antibodies raising an immune response against a target which is not the antigen used for immunisation
- A61K2039/585—Medicinal preparations containing antigens or antibodies raising an immune response against a target which is not the antigen used for immunisation wherein the target is cancer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/50—Cell markers; Cell surface determinants
- C12N2501/515—CD3, T-cell receptor complex
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Medicinal Chemistry (AREA)
- Cell Biology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Engineering & Computer Science (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- Mycology (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Gastroenterology & Hepatology (AREA)
- Wood Science & Technology (AREA)
- Toxicology (AREA)
- Hematology (AREA)
- General Engineering & Computer Science (AREA)
- Virology (AREA)
- Oncology (AREA)
- Developmental Biology & Embryology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Physics & Mathematics (AREA)
- Plant Pathology (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
本发明提供了特异性结合人细胞周期蛋白A1(CCNA1)的包含TCR的结合蛋白、表达这种抗原特异性结合蛋白的宿主细胞、编码这种结合蛋白的核酸、以及用于治疗细胞过度表达CCNA1的疾病或病症(例如癌症)的组合物。
Description
关于序列表的陈述
与本申请相关联的序列表以文本格式代替纸质副本提供,并且在此通过引用结合到说明书中。包含序列表的文本文件的名称为360056_460WO_SEQUENCE_LISTING.txt。文本文件为269KB,创建于2019年2月10日,正在通过EFS-Web电子提交。
背景技术
涉及离体细胞扩增和输注肿瘤反应性T细胞的过继免疫疗法是一种新兴的治疗方式,特别是在常规治疗失败的患者中(Stromnes等,Immunol.版本号257:145-64,2014)。在一些情况下,肿瘤反应性T细胞包含对肿瘤特异或在肿瘤上过表达的抗原具有特异性的内源性、外源性和/或工程化的受体。
癌症-睾丸抗原细胞周期蛋白A1(CCNA1)是一种替代性的A型细胞周期蛋白,由于其在急性髓细胞白血病(AML)和许多上皮癌(包含睾丸癌、子宫内膜癌和卵巢癌)中过度表达,因此是治疗各种癌症的有吸引力的靶标。细胞周期蛋白A1被认为促进细胞增殖和存活,已被证明在小鼠中是致白血病的,并且在超过50%的AML患者的白血病干细胞中被检测到。
本文提供了鉴定与细胞周期蛋白A1反应的肿瘤反应性T细胞的方法、鉴定对细胞周期蛋白A1特异的T细胞受体(TCR)的方法、以及使用本文描述的方法鉴定的特异性TCR。
附图说明
图1描绘了针对HLA-A2限制性表位的细胞周期蛋白A1 TCR发现方案。示出了HLA-A2前导肽227-235(SEQ ID NO:1)、341-351(SEQ ID NO:2)和370-379(SEQ ID NO:3)在细胞周期蛋白A1蛋白序列(SEQ ID NO:4)的位置。
图2示出了用细胞周期蛋白A1重叠肽库刺激CD8+ T细胞导致抗原特异性细胞系的产生。
图3A-图3B示出了通过计算单个T细胞克隆的四聚体解离常数(Kd)来鉴定高亲和力HLA-A2:01/细胞周期蛋白A1 TCR。
图4示出了用于分离、鉴定和表达选自高亲和力克隆的高亲和力TCR的示意图。
图5A-图5D示出了HLA-A2:01/细胞周期蛋白A1 TCR识别肽脉冲靶标并杀死HLA匹配的细胞周期蛋白A1+白血病细胞系和原代AML细胞。
图6示出了用于体内安全性测试的顶部HLA-A2:01/细胞周期蛋白A1 TCR候选物的诱变示意图。
具体实施方式
在某些方面,本公开提供了细胞周期蛋白A1特异性的结合蛋白(例如,T细胞受体(TCR)),其与主要组织相容性复合物(MHC)(例如,人白细胞抗原(HLA))有关,用于例如过继免疫疗法来治疗癌症。
在某些实施例中,本文所述的组合物和方法将具有治疗效用,用于治疗与CCNA1过表达(例如,以统计学上显著的方式,可检测到的CCNA1表达的水平大于在正常或无病的细胞中可检测到的CCNA-l的表达水平)相关的疾病和病症。此类疾病包含各种形式的过度增殖性疾病,例如急性髓细胞性白血病。这些和相关用途的非限制性实例在本文中进行了描述,包含体外、离体和体内刺激CCNA1抗原特异性T细胞反应,例如通过使用表达对CCNA1肽具有特异性的TCR的重组T细胞(例如,FLDRFLSCM(SEQ ID NO:1)、SLIAAAAFCLA(SEQ ID NO:2)或YSLSEIVPCL(SEQ ID NO:3))。
在更详细地阐述本公开之前,提供在本文中使用的某些术语的定义可能有助于理解本公开。贯穿本公开阐述了附加定义。
在本说明书中,除非另有说明,否则任何浓度范围、百分比范围、比率范围或整数范围应理解为包含所述范围内的任何整数的值并且在适当的时候包含其分数(例如,整数的十分之一和十分之一)。同样,除非另有说明,否则本文所叙述的与任何物理特征,例如聚合物亚基、尺寸或厚度有关的任何数值范围应理解为包含所叙述的范围内的任何整数。如本文所用,除非另外指出,否则术语“大约”是指所指示的范围、值或结构的±20%。应当理解,本文所用的术语“一个”和“一种”是指所列举的组分中的“一个或多个”。替代方案(例如“或”)的使用应理解为是指替代方案之一、两者或它们的任意组合。如本文所用,术语“包括(include)”、“具有”和“包含(comprise)”是同义使用的,这些术语和其变体旨在被解释为非限制性的。
另外,应当理解,本申请公开了衍生自本文所述的结构和取代基的各种组合的单个化合物或化合物组,其程度与单独阐述每种化合物或化合物组的程度相同。因此,特定结构或特定取代基的选择在本公开的范围内。
术语“基本上由...组成”将权利要求的范围限制为指定的材料或步骤,或者限制为实质上不影响要求保护的发明的基本特征的材料或步骤。例如,当结构域、区域、模块或蛋白质的氨基酸序列包含其延伸、删除、突变或其组合(例如,氨基酸或羧基末端或结构域之间的氨基酸),其共同起作用时贡献结构域、区域、模块或蛋白质的长度的最多20%(例如,15%、14%、13%、12%、11%、10%、9%、8%、7%、6%、5%、4%、3%、2%或1%),并且基本上不会影响结构域、区域、模块或蛋白质的活性(例如,结合蛋白的靶结合亲和力)(即,将活性降低的幅度不超过50%,例如不超过40%、30%、25%、20%、15%、10%、5%或1%)时,蛋白质结构域、区域或模块(例如,结合结构域、铰链区、接头模块)或蛋白质(可以具有一个或多个结构域、区域或模块)“基本上由特定氨基酸序列组成”。
如本文所用,“免疫系统细胞”是指源自骨髓的造血干细胞的免疫系统的任何细胞,其产生两个主要谱系,即髓系祖细胞(其产生诸如单核细胞、巨噬细胞、树突状细胞、巨核细胞和粒细胞)和淋巴样祖细胞(会产生淋巴样细胞,例如T细胞、B细胞和自然杀伤(NK)细胞)。示例性的免疫系统细胞包含CD4+ T细胞、CD8+ T细胞、CD4-CD8-双重阴性T细胞、gdT细胞、调节性T细胞、天然杀伤细胞和树突状细胞。巨噬细胞和树突状细胞可以称为“抗原呈递细胞”或“APC”,它们是当与肽复合的APC表面上的主要组织相容性复合物(MHC)受体与T细胞表面上的TCR相互作用时可以激活T细胞的专门细胞。
如本文所用,“造血祖干细胞”是指未分化的造血细胞,其能够在体内自我更新,在体外基本上无限制地繁殖,并且能够分化为其他细胞类型,包括T细胞谱系的细胞。造血干细胞可以为例如但不限于从胎儿肝脏、骨髓、脐带血分离。
如本文所用,“造血祖细胞”是可以衍生自造血干细胞或胎儿组织并且能够进一步分化成成熟细胞类型(例如免疫系统细胞)的细胞。示例性的造血祖细胞包含具有CD24LoLin-CD117+表型或在胸腺中发现的那些(称为祖细胞)。
如本文所用,术语“宿主”是指以异源或外源核酸分子进行遗传修饰以产生目的多肽(例如,高亲和力或增强亲和力的抗CCNA-l TCR)的细胞(例如,T细胞)或微生物。在某些实施例中,宿主细胞可任选地具有或被修饰以包含赋予与异源或外源蛋白质的生物合成相关或不相关的所需特性的其他遗传修饰(例如,包含可检测的标记;删除、改变或截短的内源TCR;增加的共刺激因子表达)。在某些实施例中,宿主细胞是用编码CCNA-1抗原肽特异的TCRΒβ、TCRα链或两者的异源或外源核酸分子转导的人造血祖细胞。在某些实施例中,宿主细胞是自体的、同种异体的或同基因的,以使其接受包含编码本发明的结合蛋白的多核苷酸的宿主细胞。
“T细胞”或“T淋巴细胞”是在胸腺中成熟并产生T细胞受体(TCR)的免疫系统细胞,其可以从例如外周血单核细胞(PBMC)中获得(富集或分离)并且在本文中被称为“块(bulk)”T细胞。分离T细胞后,可以在扩增之前或之后将细胞毒性(CD8+)和辅助(CD4+)T细胞分为幼稚T细胞亚群、记忆T细胞亚群和效应T细胞亚群。T细胞可以是幼稚的(不暴露于抗原;与TCM相比,CD62L、CCR7、CD28、CD3、CD127和CD45RA的表达增加,而CD45RO的表达减少),记忆T细胞(TM)(经历过抗原性和长寿的)和效应细胞(经历过抗原的和有细胞毒性的)。TM可以进一步分为中央记忆T细胞(与幼稚T细胞相比,TCM、CD62L、CCR7、CD28、CD127、CD45RO和CD95的表达增加,而CD54RA的表达减少)和效应记忆T细胞(TEM,与幼稚T细胞或TCM相比,CD62L、CCR7、CD28、CD45RA的表达减少,而CD127的表达增加)。效应T细胞(TE)是指经历过抗原的CD8+细胞毒性T淋巴细胞,与TCM相比,其CD62L、CCR7、CD28的表达降低,并且颗粒酶和穿孔素呈阳性。辅助T细胞(TH)为CD4+细胞,其通过释放细胞因子来影响其他免疫细胞的活性。CD4+ T细胞可以激活和抑制适应性免疫应答,而诱导哪种作用将取决于其他细胞和信号的存在。可以根据已知技术收集T细胞,并且可以通过已知技术,例如通过与抗体的亲和力结合、流式细胞术或免疫磁选择来富集和耗尽各种亚群及其组合。其他示例性T细胞包含调节性T细胞,例如CD4+CD25+(Foxp3+)调节性T细胞和Treg17细胞,以及Tr1、Th3、CD8+CD28+和Qa-1限制性T细胞。
“T细胞受体”(TCR)是指免疫球蛋白超家族成员(具有可变的结合结构域、恒定结构域、跨膜区域和短的细胞质尾巴;参见,例如,Janeway el al.,Immunobiology:TheImmune System in Health and Disease,3rd Ed.,Current Biology Publications,p.4:33,1997),其能够特异性结合与MHC受体结合的抗原肽。TCR可以发现在细胞表面或呈可溶性形式,通常由具有阿α和β链(分别称为TCRα和TCRβ)或γ链和δ链(也称为TCRγ和TCRδ)的异二聚体组成。与免疫球蛋白一样,TCR链的细胞外部分(例如,α链、β链)包含两个免疫球蛋白结构域、位于N端的可变结构域(例如,α链可变结构域或Vα,β链可变结构域或Vβ;通常基于Kabat编号的氨基酸1至116,Rabat et al.,"Sequences of Proteins ofImmunological Interest,US Dept.Health and Human Services,Public HealthService National Institutes of Health,1991,5th ed.)和与细胞膜相邻的一个恒定域(例如,α链恒定域或Cα,通常是基于Rabat的氨基酸117至259,β链恒定结构域或Cβ,通常是基于Rabat的氨基酸117至295)。同样与免疫球蛋白类似,可变结构域包含由构架区(FR)隔开的互补决定区(CDR)(Jores et al.,Proc.Nat’l Acad.Sci.U.S.A.87:9138,1990;Chothia et al.,EMBO J.7:3745,1988;也参见Lefranc et al.,Dev.Comp.Immunol.27:55,2003)。在某些实施例中,TCR在T细胞(或T淋巴细胞)的表面上发现并与CD3复合物缔合。如本公开中使用的TCR的来源可以来自各种动物物种,诸如人、小鼠、大鼠、兔或其他哺乳动物。
术语“可变区”或“可变结构域”是指和TCR与抗原的结合相关的TCRα链或β链(或γδTCR的γ链和δ链)的结构域。幼稚TCR的α链和β链(分别为Vα和Vβ)的可变结构域通常具有相似的结构,每个结构域包含四个保守框架区(FR)和三个CDR。Vα结构域由两个独立的DNA片段(可变基因片段和连接基因片段(V-J))编码;Vβ结构域由三个独立的DNA片段(可变基因片段、多样性基因片段和连接基因片段(V-D-J))编码。
与“高变区”或“HVR”同义的术语“互补决定区”和“CDR”在本领域中已知是指赋予抗原特异性和/或结合亲和力的TCR可变区内的氨基酸的非连续序列。通常,在每个α链可变区(αCDR1、αCDR2、αCDR3)中存在三个CDR,在每个β链可变区(βCDR1、βCDR2、βCDR3)中存在三个CDR。CDR3被认为是负责识别经处理抗原的主要CDR。CDR1和CDR2主要与MHC相互作用。但是,也已示出α链和β链的CDR1环分别与抗原肽的N末端和C末端相互作用,并且可能有助于肽特异性和MHC结合。
如本文所用,“TCR复合物”是指通过CD3与TCR的缔合形成的复合物。例如,TCR复合物可以由CD3γ链、CD3δ链、两条CD3ε链、CD3ζ链的同二聚体、TCRα链和TCRβ链组成。或者,TCR复合物可以由CD3γ链、CD3δ链、两条CD3ε链、CD3ζ链的同二聚体、TCRγ链和TCRδ链组成。
如本文所用、“TCR复合物的组分”是指TCR链(即TCRα、TCRβ、TCRγ或TCRδ)、CD3链(即CD3γ、CD3δ、CD3ε或CD3ζ)或由两条或更多条TCR链或CD3链(例如TCRα和TCRΒ的复合体、TCRγ和TCRδ的复合体、CD3e和CD3δ的复合体、CD3γ和CD3ε的复合体或TCRα、TCRβ、CD3γ、CD3δ和两条CD3ε链的亚TCR复合体)。
如本文所用,“抗原”或“Ag”是指引起免疫应答的免疫原性分子。这种免疫应答可能涉及抗体的产生、特定免疫学上具有活性的细胞(例如,T细胞)的激活或两者。抗原(免疫原性分子)可以是例如肽、糖肽、多肽、糖多肽、多核苷酸、多糖、脂质等。显而易见,抗原可以合成,重组产生或衍生自生物学样品。可以包含一种或多种抗原的示例性生物样品包含组织样品、肿瘤样品、细胞、生物液或其组合。抗原可以由经过修饰或基因工程表达抗原的细胞产生。示例性抗原包含CCNA-1。
术语“表位”或“抗原表位”包含被关联结合分子识别并特异性结合的任何分子、结构、氨基酸序列或蛋白质决定簇,例如免疫球蛋白、T细胞受体(TCR)、嵌合抗原受体、或其他结合分子、结构域或蛋白质。抗原决定簇通常包含分子的化学活性表面基团,例如氨基酸或糖侧链,并且可以具有特定的三维结构特征以及特定的电荷特征。例如,CCNA-1蛋白或其片段可以是包含一个或多个抗原表位的抗原。
“主要组织相容性复合物”(MHC)是指将肽抗原递送至细胞表面的糖蛋白。MHC I类分子是异质二聚体,其具有跨链的膜(具有三个α结构域)和非共价结合的β2微球蛋白。MHCII类分子由两个跨膜糖蛋白α和β组成,两者都跨膜。每个链都有两个结构域。MHC I类分子将起源于细胞液的肽传递到细胞表面,在该细胞表面,肽:MHC复合物被CD8+ T细胞识别出。MHC II类分子将起源于囊泡系统的肽传递到细胞表面,在该细胞表面,它们被CD4+ T细胞识别。人MHC被称为人白细胞抗原(HLA)。
如本文所用,“结合结构域”(也称为“结合区”或“结合部分”)是指具有以下能力的分子或其部分(例如,肽、寡肽、多肽、蛋白质):特异性地且非共价地与靶标(例如,CCNA-1、CCNA-1肽:MHC复合物)缔合、联合或结合。结合结构域包含用于生物分子、分子复合物(即,包含两个或更多个生物分子的复合物)或其他目的靶标的任何天然存在的、合成的、半合成的或重组产生的结合伴侣。示例性结合域包含单链免疫球蛋白可变区(例如scTCR、scFv)、受体胞外域、配体(例如细胞因子、趋化因子)或合成多肽,它们由于其与生物分子、分子复合物或其他目标靶标结合的特异性能力而被选出。
如本文所用,“特异性结合”或“特异性地”是指结合蛋白(例如,TCR受体)或结合结构域(或其融合蛋白)与靶分子(例如,CCNA-1肽)的缔合或结合。HLA或四聚体(例如HLA络合物),其亲和力或Ka(即具有1/M单位的特定结合相互作用的平衡缔合常数)等于或大于105M-1(等于-缔合反应的解离速率[konff]至解离速率[k0ff],而不会与样品中的任何其他分子或组分显著缔合或结合。结合蛋白或结合结构域(或其融合蛋白)可分类为“高亲和力”结合蛋白或结合结构域(或其融合蛋白)或“低亲和力”结合蛋白或结合结构域(或其融合蛋白)。“高亲和力”结合蛋白或结合结构域是指Ka至少为107M-1,至少108M-1,至少109M-1,至少1010M-1,至少1011M-1的那些结合蛋白或结合结构域。,至少1012M-1或至少1013M-1。“低亲和力”结合蛋白或结合结构域是指Ka最高为107M-1,最高为106M-1,最高为105M-1的那些结合蛋白或结合结构域。或者,亲和力可以定义为与M单元(例如105M-1至1013M-1)的特定结合相互作用的平衡解离常数(Kd)。
在某些实施例中,受体或结合结构域可具有“增强的亲和力”,这是指与野生型(或亲本)结合结构域相比对靶抗原具有更强结合的选择或工程化的受体或结合结构域。例如,增强的亲和力可能是由于对靶抗原的Ka(平衡缔合常数)高于野生型结合域,是由于对靶抗原的Kd(解离常数)小于野生型结合域,或是由于靶抗原的解离速率(koff)小于野生型结合域的解离速率(koff),或它们的组合。在某些实施例中,增强的亲和力TCR可以被密码子优化以增强在特定宿主细胞例如T细胞中的表达(Scholten等,Clin.Immunol.119:135,2006)。
已知多种测定法用于鉴定与特定靶标特异性结合的本发明的结合域,以及测定结合域或结合蛋白亲和力,例如蛋白质印迹、ELISA、分析超速离心、光谱法、表面等离振子共振 分析、MHC四聚体分析(参见,例如,Scatchard等,Ann.NY Acad.Sci.57:660,1949;Wilson,Science 295:2103,2002;Wolff等,Cancer Res.53:2560,参见,例如,例如,J.Med.,1993;Altman等人,Science 274:94-96,1996;和美国专利号5,283、173、5,468,614或等效物)。
分析、MHC四聚体分析(参见,例如,Scatchard等,Ann.NY Acad.Sci.57:660,1949;Wilson,Science 295:2103,2002;Wolff等,Cancer Res.53:2560,参见,例如,例如,J.Med.,1993;Altman等人,Science 274:94-96,1996;和美国专利号5,283、173、5,468,614或等效物)。
术语“CCNA-1特异性结合蛋白”是指与CCNA-1或其肽或片段特异性结合的蛋白或多肽。在一些实施例中,蛋白质或多肽以或至少以大约某个特定亲和力结合于例如细胞表面上CCNA-1或其肽,例如与MHC或HLA分子复合的CCNA-1肽。在某些实施例中,CCNA-1特异性结合蛋白以Kd或以亲和力结合CCNA-1衍生的肽:HLA复合物(或CCNA-1衍生的肽:MHC复合物),Kd小于约10-8M、小于约10-9M、小于约10-10M、小于约10-11M、小于约10-12M或小于约10-13M,该亲和力约等于、至少约等于例如通过相同的测定法测定的或大于或等于本文提供的示例性CCNA-1特异性结合蛋白(例如本文提供的任何CCNA-1特异性TCR)所表现出的亲和力。在某些实施例中,CCNA-1特异性结合蛋白包含CCNA-1特异性免疫球蛋白超家族结合蛋白或其结合部分。
评估亲和力或表观亲和力或相对亲和力的测定法是已知的。在某些实例中,通过评估与各种浓度的四聚体的结合来测量对TCR的表观亲和力,例如,通过使用标记的四聚体的流式细胞术。在某些实例中,TCR的表观KD使用标记的四聚体在一定浓度范围内的2倍稀释度进行测量,然后通过非线性回归确定结合曲线,表观KD被确定为产生最大半结合的配体的浓度。
术语“CCNA-1结合结构域”或“CCNA-1结合片段”是指负责特异性CCNA-1结合的CCNA-1特异性结合蛋白的结构域或部分。单独的CCNA-1特异性结合域(即,没有CCNA-1特异性结合蛋白的任何其他部分)可以是可溶的,并且可以以Kd与CCNA-1结合,Kd小于约10-8M、小于约10-9M、小于约10-10M、小于约10-11M、小于约10-12M或小于约10-13M。示例性CCNA-1特异性结合域包括CCNA-1特异性scTCR(例如单链αβTCR蛋白,例如Vα-L-Vβ、Vβ-L-Vα、Vα-Cα-L-Vβ或VαL-Vβ-Cβ,其中Vα和Vβ分别是TCRα和β可变结构域,Cα和Cβ分别是TCRα和β恒定结构域,并且L是本文所述的接头和scFv片段,其可以衍生自抗CCNA-1TCR或抗体。
抗原呈递细胞(APC)(例如树突状细胞、巨噬细胞、淋巴细胞或其他细胞类型)进行抗原加工的原理,以及APC向T细胞呈递抗原的原理,包括主要的组织相容性复合物(MHC)在免疫相容性APC和T细胞之间的受限呈递(例如,至少共享与抗原呈递相关的MHC基因的一种等位基因形式)已经建立(参见例如Murphy,Janeway's Immunobiology(8th Ed。)2011Garland Science,NY;第6、9和16章)。例如,起源于细胞质的加工抗原肽(例如肿瘤抗原、细胞内病原体)的长度通常为约7个氨基酸至约11个氨基酸,并将与I类MHC分子缔合,而在囊泡系统中加工的肽(例如细菌,病毒)的长度将在约10个氨基酸至约25个氨基酸之间变化并且与II类MHC分子缔合。
“细胞周期蛋白A1”或“CCNA-1”是指属于细胞周期蛋白家族的蛋白,其参与雄性生殖系减数分裂细胞周期的细胞周期控制。细胞周期蛋白A1在睾丸以外的正常组织中最少表达,在许多癌症中过表达,包括急性髓细胞性白血病(AML)和许多上皮癌,包括睾丸癌,子宫内膜癌和卵巢癌。在某些实施例中,CCNA1指蛋白质的同工型3,其与同工型1的区别在于氨基酸1-44缺失。在一个特定的实施例中,CCNA1包含SEQ ID NO:4所示的氨基酸序列。
“CCNA-1抗原”或“CCNA-1肽抗原”是指CCNA-1蛋白的天然或合成产生的部分,其长度为约7个氨基酸至约15个氨基酸,其可以与MHC(例如,HLA)分子形成复合物并且这种复合物可以与对CCNA-1肽:MHC(例如,HLA)复合物具有特异性的TCR结合。CCNA-1抗原肽在I类MHC的背景下呈现。在特定实施例中,CCNA-1肽是FLDRFLSCM(SEQ ID NO:1)、SLIAAAAFCLA(SEQ ID NO:2)或YSLSEIVPCL(SEQ ID NO:3),其与人I类HLA缔合,并且更具体地,与等位基因HLA-A*02:0l缔合。
“接头”是指连接两个蛋白质、多肽、肽、结构域、区域或基序的氨基酸序列,并且可以提供与两个亚结合域的相互作用相容的间隔子功能,从而使得所得的多肽保留特异性结合。对靶分子的亲和力(例如,scTCR)或保留信号传导活性(例如,TCR复合物)。在某些实施例中,接头包含例如约2至约35个氨基酸、或约4至约20个氨基酸或约8至约15个氨基酸或约15至约25个氨基酸。
“连接氨基酸”或“连接氨基酸残基”是指多肽的两个相邻基序,区域或结构域之间的一个或多个(例如,约2-10个)氨基酸残基,例如在结合结构域和相邻常数之间。结构域或TCR链和相邻的自我切割肽之间。连接氨基酸可以由结合蛋白的构建体设计产生(例如,在编码结合蛋白的核酸分子的构建过程中使用限制酶位点产生的氨基酸残基)。
“改变的结构域”或“改变的蛋白质”是指基序、区域、结构域、肽、多肽或蛋白质,其与野生型基序、区域、域、肽、多肽或蛋白质(例如,野生型TCRα链、TCR链、TCRα恒定域、TCRβ恒定域)至少为85%(例如86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%、100%)的同一性。
如本文所用,“核酸”或“核酸分子”是指例如通过聚合酶链反应(PCR)或DNA产生的脱氧核糖核酸(DNA)、核糖核酸(RNA)、寡核苷酸、多核苷酸、其片段中的任何一种。通过体外转录,以及通过连接、切割、核酸内切酶作用或核酸外切酶作用产生的片段。在某些实施例中,本公开的核酸通过PCR产生。核酸可以由天然存在的核苷酸的单体(例如脱氧核糖核苷酸和核糖核苷酸)、天然存在的核苷酸的类似物(例如天然存在的核苷酸的α-对映体形式)或两者的组合组成。修饰的核苷酸可以对糖部分、嘧啶或嘌呤碱基部分进行修饰或替代。核酸单体可以通过磷酸二酯键或这种连接的类似物连接。磷酸二酯键的类似物包括硫代磷酸酯、二硫代磷酸酯、亚硒代磷酸酯、二硒代磷酸酯、苯硫代磷酸酯、苯胺基磷酸酯、氨基磷酸酯等。核酸分子可以是单链或双链的。
术语“分离的”是指将材料从其原始环境(例如,如果是天然存在的自然环境)中除去。例如,没有分离出存在于活体动物中的天然存在的核酸或多肽,而是分离了与天然系统中的一些或全部共存物质分离的相同核酸或多肽。这样的核酸可以是载体的一部分和/或这样的核酸或多肽可以是组合物(例如,细胞裂解物)的一部分,并且仍然被分离,因为这样的载体或组合物不是天然环境核酸或多肽的一部分。术语“基因”是指与产生多肽链有关的DNA片段;它包括编码区之前和之后的区域(“前导区和尾区”)以及各个编码段(外显子)之间的插入序列(内含子)。
术语“构建体”是指含有重组核酸分子的任何多核苷酸。构建体可以存在于载体(例如细菌载体、病毒载体)中或可以整合到基因组中。
“载体”是能够转运另一种核酸的核酸分子。载体可以是例如质粒、粘粒、病毒、噬菌体、RNA载体或线性或环状DNA或RNA分子,其可以包括染色体、非染色体、半合成或合成核酸分子。示例性载体是那些能够自主复制的载体(附加载体)或表达与其连接的核酸分子的载体(表达载体)。
“逆转录病毒”是具有RNA基因组的病毒。“γ逆转录病毒”是指逆转录病毒科的属。γ逆转录病毒的例子包括小鼠干细胞病毒、鼠白血病病毒、猫白血病病毒、猫肉瘤病毒和禽网状内皮病病毒。
“慢病毒”是指能够感染分裂细胞和非分裂细胞的逆转录病毒属。慢病毒的几个例子包括HIV(人类免疫缺陷病毒:包括1型和2型HIV);马传染性贫血病毒;猫免疫缺陷病毒(FIV);牛免疫缺陷病毒(BIV);和猿猴免疫缺陷病毒(SIV)。
如本文所用,“慢病毒载体”是指用于基因递送的基于HIV的慢病毒载体,其可以是整合的或非整合的、具有相对大的包装能力、并且可以转导多种不同的细胞类型。慢病毒载体通常是在三个(包装、包膜和转移)或更多质粒瞬时转染到生产细胞后产生的。像HIV一样,慢病毒载体通过病毒表面糖蛋白与细胞表面受体的相互作用进入靶细胞。进入时,病毒RNA进行逆转录,该逆转录由病毒逆转录酶复合体介导。逆转录产物是双链线性病毒DNA,它是病毒整合到感染细胞DNA中的底物。
术语“可操作地连接”是指单个核酸片段上两个或更多个核酸分子的缔合,从而一个的功能受到另一个的影响。例如,当启动子能够影响该编码序列的表达时(即,该编码序列在该启动子的转录控制下),该启动子与该编码序列可操作地连接。“未连锁”是指相关的遗传要素彼此之间不紧密关联,并且其中一个的功能不影响另一个。
如本文所用,术语“表达”是指基于核酸分子例如基因的编码序列产生多肽的过程。该过程可以包括转录、转录后控制、转录后修饰、翻译、翻译后控制、翻译后修饰或其任意组合。
如本文所用,“表达载体”是指包含核酸分子的DNA构建体,该核酸分子可操作地连接至能够影响核酸分子在合适宿主中表达的合适控制序列。此类控制序列包括实现转录的启动子,控制此类转录的任选操纵子序列,编码合适的mRNA核糖体结合位点的序列以及控制转录和翻译终止的序列。载体可以是质粒、噬菌体颗粒、病毒或仅是潜在的基因组插入物。一旦转化为合适的宿主,载体就可以独立于宿主基因组复制和发挥作用,或者在某些情况下可以整合到基因组本身中。在本说明书中,“质粒”、“表达质粒”、“病毒”和“载体”经常互换使用。
在将核酸分子插入细胞中的上下文中的术语“引入”是指“转染”或“转化”或“转导”,并且包括提及将核酸分子掺入真核或原核细胞中,其中核酸分子可以掺入细胞的基因组(例如,染色体、质粒、质体或线粒体DNA)中、转化为自主复制子、或瞬时表达(例如,转染的mRNA)。
如本文所用,“异源”核酸分子,构建体或序列是指不是宿主细胞天然的但可以与核酸分子或核酸的一部分同源的核酸分子或核酸分子的一部分。来自宿主细胞的酸性分子。异源核酸分子、构建体或序列的来源可以来自不同的属或种。在某些实施例中,通过例如缀合、转化、转染、转导、电穿孔等将异源核酸分子添加至宿主细胞或宿主基因组(即,不是内源的或天然的),其中添加的分子可以整合入宿主基因组或作为染色体外遗传物质存在(例如,作为质粒或其他形式的自我复制载体),并可以多拷贝形式存在。另外,“异源”是指由导入宿主细胞的非内源性核酸分子编码的非天然酶、蛋白质或其他活性,即使宿主细胞编码同源蛋白质或活性也是如此。
术语“同源的”或“同源”是指在宿主细胞,物种或菌株中发现或衍生自宿主细胞、物种或菌株的分子或活性。例如,异源分子或编码该分子的基因可以分别与天然宿主或宿主细胞分子或编码该分子的基因同源,并且可以任选地具有改变的结构、序列、表达水平或其组合。
如本文所用,术语“内源的”或“幼稚”是指通常存在于宿主或宿主细胞中的基因、蛋白质、化合物、分子或活性。此外,与亲本基因、蛋白质或活性相比,突变、过度表达、改组、复制或以其他方式改变的基因、蛋白质或活性仍被认为是该特定宿主细胞的内源性或天然性。例如,来自第一基因的内源控制序列(例如,启动子、翻译衰减序列)可用于改变或调节第二天然基因或核酸分子的表达,其中第二天然基因的表达或调控或核酸分子不同于亲代细胞中的正常表达或调控。
如本文所用,术语“工程化的”、“重组的”、“修饰的”或“非天然的”是指已通过引入异源核酸分子而被修饰的生物、微生物、细胞、核酸分子或载体,或指通过人为干预进行了基因工程改造的细胞或微生物,即通过引入异源核酸分子进行修饰的细胞或微生物,或指经过改变使得内源核酸分子或基因是受控的、失控的或组成型的,其中这种改变或修饰可以通过基因工程引入。人类产生的遗传改变可以包括,例如,引入核酸分子的修饰(其可以包括表达控制元件,例如启动子),所述核酸分子编码一种或多种蛋白质,结合蛋白或酶,或其他核酸分子的添加,缺失细胞遗传物质的替代,替代或其他功能破坏或增加。示例性修饰包括来自参考或亲本分子的异源或同源多肽的编码区或其功能片段中的修饰。其他示例性修饰包括例如非编码调控区中的修饰,其中所述修饰改变基因或操纵子的表达。
如本文所用,“突变”是指分别与参考或野生型核酸分子或多肽分子相比,核酸分子或多肽分子的序列变化。突变可导致几种不同类型的序列变化,包括核苷酸或氨基酸的取代、插入或缺失。
在本领域中,“保守取代”被认为是一个氨基酸被具有相似特性的另一氨基酸取代。示例性的保守取代是本领域众所周知的(参见,例如,WO 97/09433,第10页;Lehninger,生物化学,第二版;Worth Publishers,Inc.NY,NY,第71-77页,1975;Lewin,Genes IV,纽约牛津大学出版社,细胞出版社,马萨诸塞州剑桥,1990年第8页)。
如本文所用,“序列同一性”是指在比对序列并引入缺口以达到最大百分比序列后,一个序列中与另一参考多肽序列中的氨基酸残基相同的氨基酸残基的百分比。同一性,并且不考虑将任何保守取代作为序列同一性的一部分。序列同一性百分比值可以使用Altschul等人定义的NCBI BLAST 2.0软件生成,如由Altschul et al.(1997),Nucl.AcidsRes.25:3389-3402所限定的,其中参数设置为默认值。
如本文所用,“过度增殖性疾病”是指与正常或未患病的细胞相比过度生长或增殖。示例性的过度增殖性疾病包括肿瘤、癌症、血液系统恶性肿瘤、赘生性组织、癌、肉瘤、恶性细胞、恶性前细胞、以及非肿瘤性或非恶性过度增殖性疾病(例如、腺瘤、纤维瘤、脂肪瘤、平滑肌瘤、血管瘤、纤维化、再狭窄以及自身免疫性疾病、例如类风湿性关节炎、骨关节炎、牛皮癣、炎症性肠病等)。在某些实施例中,过度增殖性疾病是急性骨髓性白血病。
“过继细胞免疫疗法”或“过继免疫疗法”是指施用天然存在或基因工程的疾病抗原特异性免疫细胞(例如,T细胞)。过继细胞免疫疗法可以是自体的(免疫细胞来自受体)、同种异体的(免疫细胞来自相同物种的供体)或同基因的(免疫细胞来自与受体基因上相同的供体)。
“治疗(treat)”或“治疗(treatment)”或“改善”是指对受试者(例如人类或非人类哺乳动物,例如灵长类、马、狗、小鼠、大鼠)的疾病、病症或病状的医学管理。通常,以足以引起治疗或预防益处的量施用包含表达本公开内容的CCNA1特异性结合蛋白的宿主细胞的合适剂量或治疗方案。治疗或预防/预防益处包括改善临床预后;减轻或减轻与疾病有关的症状;减少症状的发生;改善生活质量;更长的无病状态;疾病程度的减少,疾病状态的稳定;疾病进展延迟;缓解;生存;延长生存期或其任意组合。
表达本公开内容的结合蛋白或细胞的“治疗有效量”或“有效量”是指足以在统计上改善所治疗疾病的一种或多种症状的化合物或细胞的量。重要的方式。当涉及单独施用的单个活性成分或表达单一活性成分的细胞时,治疗有效剂量是指该成分或单独表达该成分的细胞的作用。当提及组合时,治疗有效剂量是指活性成分或辅助活性成分与表达导致治疗效果的细胞的组合的组合量,无论是连续施用还是同时施用。另一种组合可以是表达一种以上活性成分的细胞,例如两种不同的结合蛋白或其他相关治疗剂。
CCNA-1特异性结合蛋白
细胞周期蛋白A1是指由CCNA1基因编码的蛋白质。CCNA1是细胞周期蛋白家族的成员,其表达通常限于睾丸,在睾丸中它参与调节精子发生。CCNA1在白血病细胞和其他恶性肿瘤中高表达,并可能促进细胞增殖和存活。已知CCNA1蛋白的几种肽是与肿瘤相关的抗原肽,它们是HLAA*02:0l限制性抗原。由于这些特性,CCNA1蛋白是临床开发的诱人靶标。
在某些方面,本公开提供特异性结合CCNA1肽FLDRFLSCM(SEQ ID NO:1)、CCNA1肽SLIAAAAFCLA(SEQ ID NO:2)或CCNA1肽YSLSEIVPCL(SEQ ID NO:3)的结合蛋白(例如,免疫球蛋白超家族结合蛋白或其部分)。
一方面,本公开提供了结合蛋白(例如免疫球蛋白超家族结合蛋白或其部分),其包含:(a)T细胞受体(TCR)α链可变(Vα)域,其包含SEQ ID NO:5、7、9、11、13、15、15、17和19中任何一个所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:5、7、9、11、13、15、17和19中任何一个所示的且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列,以及TCRβ链可变(Vβ)域;(b)TCR Vα结构域和TCR Vβ结构域,TCR Vβ包含SEQ ID NO:6、8、10、12、14、16、16、18、20和189中任一项所示的CDR3氨基酸序列,或SEQ ID NO:6、8、10、12、14、16、18、20和189中任一项所述的且具有最多五个氨基酸取代、插入和/或缺失CDR3氨基酸序列;或(c)(a)的Vα结构域和(b)的Vβ结构域,其中结合蛋白能够特异性结合人细胞周期蛋白A1(CCNA1)肽227-235FLDRFLSCM(SEQ ID NO:1):人白细胞抗原(HLA)复合物。
在某些实施例中,(a)Vα结构域包含SEQ ID NO:5的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:6的CDR3氨基酸序列;(b)Vα结构域包含SEQ ID NO:7的CDR3氨基酸序列,并且Vβ结构域包含SEQ ID NO:8的CDR3氨基酸序列;(c)Vα结构域包含SEQ ID NO:9的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:10的CDR3氨基酸序列;(d)Vα结构域包含SEQ ID NO:11的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:12的CDR3氨基酸序列;(e)Vα结构域包含SEQ ID NO:13的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:14的CDR3氨基酸序列;(f)Vα结构域包含SEQ ID NO:15的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:16的CDR3氨基酸序列;(g)Vα结构域包含SEQ ID NO:17的CDR3氨基酸序列,Vβ结构域包含SEQ ID NO:18的CDR3氨基酸序列;(h)Vα结构域包含SEQ ID NO:19的CDR3氨基酸序列,而Vβ结构域包含SEQID NO:20的CDR3氨基酸序列;或(i)Vα结构域包含SEQ ID NO:7的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:189的CDR3氨基酸序列。
一方面,本公开提供了结合蛋白(例如,免疫球蛋白超家族结合蛋白或其部分),其包括:(a)T细胞受体(TCR)α链可变(Vα)结构域以及TCRβ链可变(Vβ)结构域,Vα结构域包含SEQ ID NO:89、97、105、113、119、127、133和137中任一个的互补决定区3(CDR3)氨基酸序列,或SEQ ID NO:89、97、105、113、119、127、133和137中任一个所示且具有多达五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;(b)TCR Vα结构域和TCR Vβ结构域,Vβ结构域包含SEQ ID NO:93、101、109、117、123、129、140和190中任一个所示的CDR3氨基酸序列,或SEQID NO:93、101、109、117、123、129、140和190中任一个所示且具有多达五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;或(c)(a)的Vα结构域和(b)的Vβ结构域,其中结合蛋白能够特异性结合人细胞周期蛋白A1(CCNA1)肽227-235FLDRFLSCM(SEQ ID NO:1):人白细胞抗原(HLA)复合物。
在某些实施例中,(a)Vα结构域包含SEQ ID NO:89的CDR3氨基酸序列,并且Vβ结构域包含SEQ ID NO:93的CDR3氨基酸序列;(b)Vα结构域包含SEQ ID NO:97的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:101的CDR3氨基酸序列;(c)Vα结构域包含SEQ ID NO:105的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:109的CDR3氨基酸序列;(d)Vα结构域包含SEQID NO:113的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:117的CDR3氨基酸序列;(e)Vα结构域包含SEQ ID NO:119的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:123的CDR3氨基酸序列;(f)Vα结构域包含SEQ ID NO:127的CDR3氨基酸序列,并且Vβ结构域包含SEQ ID NO:129的CDR3氨基酸序列;(g)Vα结构域包含SEQ ID NO:133的CDR3氨基酸序列,Vβ结构域包含SEQ ID NO:129的CDR3氨基酸序列;(h)Vα结构域包含SEQ ID NO:137的CDR3氨基酸序列,并且Vβ结构域包含SEQ ID NO:140的CDR3氨基酸序列;(i)Vα结构域包含SEQ ID NO:97的CDR3氨基酸序列,而Vβ结构域包含SEQ ID NO:190的CDR3氨基酸序列。
肽-MHC复合物,例如CCNA1肽:MHC复合物,可被TCR Vα和TCR Vβ结构域识别并结合。在淋巴细胞发育过程中,Vα外显子由不同的可变和连接基因区段(V-J)组装而成,Vβ外显子由不同的可变的多样性和连接基因区段(V-D-J)组装而成。TCRα染色体基因座具有70-80个可变基因区段和61个连接基因区段。TCRβ染色体基因座具有52个可变基因区段,并且两个单独的簇包含单个多样性基因区段,以及六个或七个连接基因区段。功能性Vα和Vβ基因外显子是通过可变基因区段与Vα的连接基因区段以及可变基因区段与Vβ的多样性基因区段和连接基因区段的重组产生的。
Vα和Vβ结构域各自包含三个高变环,也称为接触肽-MHC复合物的互补决定区(CDR)。CDR1和CDR2编码在可变基因区段内,而CDR3通过跨越Vα的可变和连接区段的区域编码或者通过跨院Vβ的可变的多样性和连接区段的区域编码。因此,如果已知Vα或Vβ的可变基因区段的身份,则可以推导其相应的CDR1和CDR2的序列。与CDR1和CDR2相比,由于重组过程中核苷酸的添加和丢失,CDR3的多样性大大提高。
TCR可变结构域序列可以与编号方案(国际免疫遗传学信息系统(IMGT)和Aho)对齐,从而可以使用抗原受体编号和受体分类(ANARCI)软件工具对等效残基位置进行注释并比较不同的分子(2016,Bioinformatics 15:298-300)。编号方案提供了TCR可变结构域中框架区和CDR的标准化描述。
表1提供了包含CDR3的TCR Vα的可变基因区段和连接基因区段的身份,该CDR3包含SEQ ID NO:5、7、9、11、13、15、17、19、21和23的任一个所示的氨基酸序列,以及包含CDR3的TCR Vβ的可变基因区段和连接基因区段的身份,该CDR3包含SEQ ID NO:6、8、10、12、14、16、18、20、22、24和189的任一个所示的氨基酸序列。因此,可以从相应的可变基因片段推导Vα和Vβ结构域的CDR1和CDR2序列。
在一些实施例中,(a)Vβ结构域包含由TRBV9*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV30*01基因编码的CDR1氨基酸序列;(b)Vβ结构域包含由TRBV2*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV10*01基因编码的CDR1氨基酸序列;(c)Vβ结构域包含由TRBV6-6*01基因编码的CDR1氨基酸序列;二Vα结构域包含TRAV24*01基因编码的CDR1氨基酸序列;(d)Vβ结构域包含由TRBV5-6*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV21*01基因编码的CDR1氨基酸序列;(e)Vβ结构域包含由TRBV7-3*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV2l*02基因编码的CDR1氨基酸序列;(f)Vβ结构域包含由TRBV7-3*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAVl2-2*02基因编码的CDR1氨基酸序列;(g)Vβ结构域包含由TRBV7-3*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV17*01基因编码的CDR1氨基酸序列;(h)Vβ结构域包含由TRBV7-2*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV17*01基因编码的CDR1氨基酸序列;或者(i)Vβ结构域包含由TRB VI 0-2*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV10*01基因编码的CDR1氨基酸序列。
在一些实施例中,(a)Vβ结构域包含SEQ ID NO:91的CDR1氨基酸序列,并且Vα结构域包含SEQ ID NO:87的CDR1氨基酸序列;(b)Vβ结构域包含SEQ ID NO:99的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:95的CDR1氨基酸序列;(c)Vβ结构域包含SEQ ID NO:107的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:103的CDR1氨基酸序列;(d)Vβ结构域包含SEQID NO:115的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:111的CDR1氨基酸序列;(e)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:111的CDR1氨基酸序列;(f)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:125的CDR1氨基酸序列;(g)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:131的CDR1氨基酸序列;(h)Vβ结构域包含SEQ ID NO:167的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:95的CDR1氨基酸序列。
在一些实施例中,(a)Vβ结构域包含由TRBV9*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV30*01基因编码的CDR2氨基酸序列;(b)Vβ结构域包含由TRBV2*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV10*01基因编码的CDR2氨基酸序列;(c)Vβ结构域包含由TRBV6-6*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV24*01基因编码的CDR2氨基酸序列;(d)Vβ结构域包含由TRBV5-6*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV21*01基因编码的CDR2氨基酸序列;(e)Vβ结构域包含由TRBV7-3*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV2l*02基因编码的CDR2氨基酸序列;(f)Vβ结构域包含由TRBV7-3*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV12-2*02基因编码的CDR2氨基酸序列;(g)Vβ结构域包含由TRBV7-3*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV17*01基因编码的CDR2氨基酸序列;(h)Vβ结构域包含由TRBV7-2*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV17*01基因编码的CDR2氨基酸序列;或者(i)Vβ结构域包含由TRB V10-2*01基因编码的CDR2氨基酸序列;而Vα结构域包含TRAV10*01基因编码的CDR2氨基酸序列。
在一些实施例中,(a)Vβ结构域包含SEQ ID NO:92的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:88的CDR2氨基酸序列;(b)Vβ结构域包含SEQ ID NO:100的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:96的CDR2氨基酸序列;(c)Vβ结构域包含SEQ ID NO:108的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:104的CDR2氨基酸序列;(d)Vβ结构域包含SEQID NO:116的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:112的CDR2氨基酸序列;(e)Vβ结构域包含SEQ ID NO:122的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:112的CDR2氨基酸序列;(f)Vβ结构域包含SEQ ID NO:122的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:126的CDR2氨基酸序列;(g)Vβ结构域包含SEQ ID NO:122的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:132的CDR2氨基酸序列;(h)Vβ结构域包含SEQ ID NO:129的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:132的CDR2氨基酸序列;或(i)Vβ结构域包含SEQ ID NO:168的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:96的CDR2氨基酸序列。
因此,在某些实施例中,(a)Vβ结构域包含SEQ ID NO:6或93的CDR3氨基酸序列以及由TRBV9*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:5或89的CDR3氨基酸序列和TRAV30*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(b)Vβ结构域包含SEQ ID NO:8或190的CDR3氨基酸序列和由TRBV2*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:7或97的CDR3氨基酸序列和TRAV10*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(c)Vβ结构域包含SEQ ID NO:10或109的CDR3氨基酸序列以及由TRBV6-6*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:9或105的CDR3氨基酸序列以及TRAV24*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(d)Vβ结构域包含SEQ ID NO:12或117的CDR3氨基酸序列和由TRBV5-6*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:11或113的CDR3氨基酸序列以及TRAV2l*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(e)Vβ结构域包含SEQ ID NO:14或123的CDR3氨基酸序列以及由TRBV7-3*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:13或119的CDR3氨基酸序列以及TRAV2l*02基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(f)Vβ结构域包含SEQ ID NO:16或129的CDR3氨基酸序列以及由TRBV7-3*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:15或127的CDR3氨基酸序列以及TRAV12-2*02基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(g)Vβ结构域包含SEQ ID NO:18或129的CDR3氨基酸序列以及由TRBV7-3*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:17或133的CDR3氨基酸序列以及TRAV17*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(h)Vβ结构域包含SEQ ID NO:20或140的CDR3氨基酸序列以及由TRBV7-2*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:19或137的CDR3氨基酸序列和TRAV17*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;或者(i)Vβ结构域包含SEQID NO:189或101的CDR3氨基酸序列和由TRBV10-2*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;而Vα结构域包含SEQ ID NO:7或97的CDR3氨基酸序列和TRAV10*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列。
在某些实施例中,(a)Vβ结构域包含SEQ ID NO:91的CDR1氨基酸序列,SEQ ID NO:92的CDR2氨基酸序列和SEQ ID NO:6或93的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:87的CDR1氨基酸序列,SEQ ID NO:88的CDR2氨基酸序列和SEQ ID NO:5或89的CDR3氨基酸序列;(b)Vβ结构域包含SEQ ID NO:99的CDR1氨基酸序列,SEQ ID NO:100的CDR2氨基酸序列和SEQ ID NO:189或101的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:95的CDR1氨基酸序列,SEQ ID NO:96的CDR2氨基酸序列和SEQ ID NO:7或97的CDR3氨基酸序列;(c)Vβ结构域包含SEQ ID NO:107的CDR1氨基酸序列,SEQ ID NO:108的CDR2氨基酸序列和SEQ ID NO:10或109的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:103的CDR1氨基酸序列,SEQ IDNO:104的CDR2氨基酸序列和SEQ ID NO:9或105的CDR3氨基酸序列;(d)Vβ结构域包含SEQID NO:115的CDR1氨基酸序列,SEQ ID NO:116的CDR2氨基酸序列和SEQ ID NO:12或117的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:111的CDR1氨基酸序列,SEQ ID NO:112的CDR2氨基酸序列和SEQ ID NO:11或113的CDR3氨基酸序列;(e)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,SEQ ID NO:122的CDR2氨基酸序列和SEQ ID NO:14或123的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:111的CDR1氨基酸序列,SEQ ID NO:112的CDR2氨基酸序列和SEQ ID NO:13或119的CDR3氨基酸序列;(f)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,SEQ ID NO:122的CDR2氨基酸序列和SEQ ID NO:16或129的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:125的CDR1氨基酸序列,SEQ ID NO:126的CDR2氨基酸序列和SEQ ID NO:15或127的CDR3氨基酸序列;(g)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,SEQ ID NO:122的CDR2氨基酸序列和SEQ ID NO:18或129的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:131的CDR1氨基酸序列,SEQ ID NO:132的CDR2氨基酸序列和SEQ ID NO:17或133的CDR3氨基酸序列;(h)Vβ结构域包含SEQ ID NO:121的CDR1氨基酸序列,SEQ IDNO:139的CDR2氨基酸序列和SEQ ID NO:20或140的CDR3氨基酸序列;而Vα结构域包含SEQID NO:131的CDR1氨基酸序列,SEQ ID NO:132的CDR2氨基酸序列和SEQ ID NO:19或137的CDR3氨基酸序列;或(i)Vβ结构域包含SEQ ID NO:167的CDR1氨基酸序列,SEQ ID NO:168的CDR2氨基酸序列和SEQ ID NO:8或190的CDR3氨基酸序列;而Vα结构域包含SEQ ID NO:95的CDR1氨基酸序列,SEQ ID NO:96的CDR2氨基酸序列和SEQ ID NO:7或97的CDR3氨基酸序列。
在某些实施例中,结合蛋白包含:(a)与SEQ ID NO:36、38、40、42、44、86、49、51、53、57、59、63、65、67、81和83中任何一个所含的Vα氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同一性的Vα结构域;(b)与SEQ ID NO:36、38、40、42、46、86、49、51、55、57、61、63、67、81和83中任何一个所含的Vβ氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同一性的Vβ结构域;(c)(a)的Vα结构域和(b)的Vβ;其中至少三个或四个CDR没有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或缺失。此类变体Vα和Vβ可用于本文所述的结合蛋白中,条件是结合蛋白保留或基本上保留特异性结合CCNA1肽(SEQ ID NO:1):HLA复合物的能力。
在其他实施例中,结合蛋白包含:(a)Vα结构域,其包含或由SEQ ID NO:36、38、40、42、44、44、86、49、51、53、57、59、63、65、67、81、83、162、165、170、172、174、176、178、180和186中任一个所包含的Vα氨基酸序列组成;(b)Vβ结构域,其包含或由SEQ ID NO:36、38、40、42、46、86、49、51、55、57、61、63、67、81、83、162、165、170、172、174、176、178、180和186中任一个的Vβ氨基酸组成;(c)(a)的Vα结构域和(b)的Vβ。
在一些实施例中,结合蛋白包含:(a)与SEQ ID NO:90、98、106、114、120、128、134和138中任一个的氨基酸序列具有至少约75%、80%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同一性的Vα结构域;(b)与SEQID NO:94、102、110、118、124、130、136、141和166中任一个的氨基酸序列具有至少约75%、80%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vβ结构域;(c)(a)的Vα结构域和(b)的Vβ结构域,其中至少三个或四个CDR没有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或缺失。此类变体Vα和Vβ可用于本文所述的结合蛋白中,条件是结合蛋白保留或基本上保留特异性结合CCNA1肽(SEQ ID NO:1):HLA复合物的能力。
在一些实施例中,结合蛋白包含:(a)Vα结构域,其包含或由SEQ ID NO:90、98、106、114、120、128,134和138中任一个的氨基酸序列组成;或(b)Vβ结构域,其包含或由SEQID NO:94、102、110、118、124、130、136、141和166中任一个的Vβ氨基酸序列组成;(c)(a)的Vα结构域和(b)的Vβ。
示例性的结合蛋白包括:(a)包含SEQ ID NO:36中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:36中包含的Vβ氨基酸序列的Vβ结构域;(b)包含SEQ ID NO:38中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:38中包含的Vβ氨基酸序列的Vβ结构域;(c)包含SEQ ID NO:40中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:40中包含的Vβ氨基酸序列的Vβ结构域;(d)包含SEQ ID NO:42中包含的Vα氨基酸序列的Vα结构域和包含SEQID NO:42中包含的Vβ氨基酸序列的Vβ结构域;(e)包含SEQ ID NO:44中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:46中包含的Vβ氨基酸序列的Vβ结构域;(f)包含SEQ IDNO:86中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:86中包含的Vβ氨基酸序列的Vβ结构域;(g)包含SEQ ID NO:49中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:49中包含的Vβ氨基酸序列的Vβ结构域;(h)包含SEQ ID NO:51中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:51中包含的Vβ氨基酸序列的Vβ结构域;(i)包含SEQ ID NO:53中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:55中包含的Vβ氨基酸序列的Vβ结构域;(j)包含SEQ ID NO:57中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:57中包含的Vβ氨基酸序列的Vβ结构域;(k)包含SEQ ID NO:59中包含的Vα氨基酸序列的Vα结构域和包含SEQID NO:6l中包含的Vβ氨基酸序列的Vβ结构域;(l)包含SEQ ID NO:63中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:63中包含的Vβ氨基酸序列的Vβ结构域;(m)包含SEQ IDNO:65中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:67中包含的Vβ氨基酸序列的Vβ结构域;(n)包含SEQ ID NO:67中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:67中包含的Vβ氨基酸序列的Vβ结构域;(o)包含SEQ ID NO:81的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:81的Vβ氨基酸序列的Vβ结构域;(p)包含SEQ ID NO:83中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:83中包含的Vβ氨基酸序列的Vβ结构域;(q)包含SEQ IDNO:162中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:162中包含的Vβ氨基酸序列的Vβ结构域;(r)包含SEQ ID NO:165中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:165中包含的Vβ氨基酸序列的Vβ结构域;(s)包含SEQ ID NO:170中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:170中包含的Vβ氨基酸序列的Vβ结构域;(t)包含SEQ ID NO:172中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:172中包含的Vβ氨基酸序列的Vβ结构域;(u)包含SEQ ID NO:174中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:174中包含的Vβ氨基酸序列的Vβ结构域;(v)包含SEQ ID NO:176中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:176中包含的Vβ氨基酸序列的Vβ结构域;(w)包含SEQ ID NO:178中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:178中包含的Vβ氨基酸序列的Vβ结构域;(x)包含SEQ ID NO:180中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:180中包含的Vβ氨基酸序列的Vβ结构域;或(y)包含SEQ ID NO:186中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:186中包含的Vβ氨基酸序列的Vβ结构域。
示例性结合蛋白包括:(a)包含SEQ ID NO:90的氨基酸序列的Vα结构域和包含SEQID NO:94的氨基酸序列的Vβ结构域;(b)包含SEQ ID NO:98的氨基酸序列的Vα结构域和包含SEQ ID NO:102的氨基酸序列的Vβ结构域;(c)包含SEQ ID NO:106的氨基酸序列的Vα结构域和包含SEQ ID NO:110的氨基酸序列的Vβ结构域;(d)包含SEQ ID NO:114的氨基酸序列的Vα结构域和包含SEQ ID NO:118的氨基酸序列的Vβ结构域;(e)包含SEQ ID NO:120的氨基酸序列的Vα结构域和包含SEQ ID NO:124的氨基酸序列的Vβ结构域;(f)包含SEQ IDNO:128的氨基酸序列的Vα结构域和包含SEQ ID NO:130的氨基酸序列的Vβ结构域;(g)包含SEQ ID NO:134的氨基酸序列的Vα结构域和包含SEQ ID NO:136的氨基酸序列的Vβ结构域;(h)包含SEQ ID NO:138的氨基酸序列的Vα结构域和包含SEQ ID NO:141的氨基酸序列的Vβ结构域;或(i)具有氨基酸序列SEQ ID NO:98的Vα结构域和具有氨基酸序列SEQ ID NO:166的Vβ结构域。
在另一方面,本公开提供了结合蛋白(例如,免疫球蛋白超家族结合蛋白或其部分),其包含:(a)T细胞受体(TCR)α链可变(Vα)结构域,其包含互补决定区3(CDR3)SEQ IDNO:2l或143中列出的氨基酸序列,或SEQ ID NO:2l或143中列出的CDR3氨基酸序列,具有最多五个氨基酸取代、插入和/或缺失以及TCRβ链变量(Vβ)域;(b)TCR Vα结构域和TCR Vβ结构域,其包含SEQ ID NO:22或147所示的CDR3氨基酸序列或SEQ ID NO:22或147所示的CDR3氨基酸序列,且具有最多五个氨基酸取代、插入和/或缺失;或(c)(a)的Vα结构域和(b)的Vβ结构域,其中结合蛋白能够与人细胞周期蛋白A1(CCNA1)肽341-351SLIAAAAFCLA(SEQ IDNO:2):人特异性结合白细胞抗原(HLA)复合物。在特定实施例中,Vα结构域包含SEQ ID NO:21或143的CDR3氨基酸序列,并且Vβ结构域包含SEQ ID NO:22或147的CDR3氨基酸序列。
在一些实施例中,(a)Vβ结构域包含由TRBV19*01基因编码的CDR1氨基酸序列;Vα结构域包含TRAV24*01基因编码的CDR1氨基酸序列。在一些实施例中,(a)Vβ结构域包含SEQID NO:145的CDR1氨基酸序列,并且Vα结构域包含SEQ ID NO:103的CDR1氨基酸序列。
在一些实施例中,(a)Vβ结构域包含由TRBV19*01基因编码的CDR2氨基酸序列;Vα结构域包含TRAV24*01基因编码的CDR2氨基酸序列。在一些实施例中,(a)Vβ结构域包含SEQID NO:146的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:142的CDR2氨基酸序列。
在某些实施例中,Vβ结构域包含:(a)SEQ ID NO:22或147的CDR3氨基酸序列以及由TRBV19*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(b)Vα结构域包含SEQ ID NO:21或143的CDR3氨基酸序列以及由TRAV24*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;或(a)和(b)两者。
在某些实施例中,(a)Vβ结构域包含SEQ ID NO:145的CDR1氨基酸序列,SEQ IDNO:146的CDR2氨基酸序列和SEQ ID NO:147的CDR3氨基酸序列;而Vα结构域包含SEQ IDNO:103的CDR1氨基酸序列,SEQ ID NO:142的CDR2氨基酸序列和SEQ ID NO:143的CDR3氨基酸序列。
在某些实施例中,结合蛋白包含(a)与SEQ ID NO:69或包含在SEQ ID NO:73或182中的Vα氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同一性的Vα结构域;(b)与SEQ ID NO:71或包含在SEQ ID NO:73或182中的Vβ氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同一性的Vβ结构域;或(c)(a)的Vα结构域和(b)的Vβ结构;其中至少三个或四个CDR没有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或或缺失。此类变体Vα和Vβ结构域可用于本文所述的结合蛋白中,条件是结合蛋白保留或基本上保留特异性结合CCNA1肽(SEQ ID NO:2):HLA复合物的能力。
在一些实施例中,结合蛋白包含:(a)与SEQ ID NO:144的氨基酸序列具有至少约75%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vα结构域;(b)与SEQ ID NO:148的氨基酸序列具有至少约75%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vβ结构域;(c)(a)的Vα结构域和(b)的Vβ。
在一些实施例中,结合蛋白包含:(a)Vα结构域,其包含SEQ ID NO:144的氨基酸序列或由其组成;(b)Vβ,其包含或由SEQ ID NO:148的氨基酸序列组成;(c)(a)的Vα结构域和(b)的Vβ。在一些方面,示例性结合蛋白包含包含SEQ ID NO:144的氨基酸序列的Vα结构域和包含SEQ ID NO:148的氨基酸序列的Vβ结构域。
在某些实施例中,结合蛋白包含:(a)Vα结构域,其包含SEQ ID NO:69或SEQ IDNO:73的Vα氨基酸序列或由其组成;或(b)Vβ结构域,其包含SEQ ID NO:71或SEQ ID NO:73的Vβ氨基酸序列或由其组成;(c)(a)的Vα结构域和(b)的Vβ。在具体的实施例中,结合蛋白包含:(a)包含SEQ ID NO:69的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:71的Vβ氨基酸序列的Vβ结构域;或(b)包含SEQ ID NO:73中的Vα氨基酸序列的Vα结构域和包含SEQ IDNO:73中的Vβ氨基酸序列的Vβ结构域。
在另一方面,本公开提供了结合蛋白(例如,免疫球蛋白超家族结合蛋白或其部分),其包含:(a)T细胞受体(TCR)α链可变(Vα)结构域,其包含SEQ ID NO:23或151中列出的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:23或151中列出的具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列,以及TCRβ链变量(Vβ)域;(b)TCR Vα结构域和TCR Vβ结构域,TCR Vβ结构域包含SEQ ID NO:24或153所示的CDR3氨基酸序列或SEQ ID NO:24或153所示的CDR3氨基酸序列,且最多五个氨基酸取代、插入和/或缺失;或(c)(a)的Vα结构域和(b)的Vβ结构域,其中结合蛋白能够与人细胞周期蛋白A1(CCNA1)肽370-379YSLSEIVPCL(SEQ ID NO:3):人特异性结合白细胞抗原(HLA)复合物。
在某些实施例中,Vα结构域包含SEQ ID NO:23或151的CDR3氨基酸序列,并且Vβ结构域包含SEQ ID NO:24或153的CDR3氨基酸序列。
在一些实施例中,(a)Vβ结构域包含由TRBV5-6*01基因编码的CDR1氨基酸序列;而Vα结构域包含TRAV19*01基因编码的CDR1氨基酸序列。在一些实施例中,(a)Vβ结构域包含SEQ ID NO:115的CDR1氨基酸序列,而Vα结构域包含SEQ ID NO:149的CDR1氨基酸序列。
在一些实施例中,(a)Vβ结构域包含由TRBV5-6*01基因编码的CDR2氨基酸序列;而Vα结构域包括TRAV19*01基因编码的CDR2氨基酸序列。在一些实施例中,(a)Vβ结构域包含SEQ ID NO:116的CDR2氨基酸序列,而Vα结构域包含SEQ ID NO:150的CDR2氨基酸序列。
在某些实施例中,(a)Vβ结构域包含SEQ ID NO:24或153的CDR3氨基酸序列以及由TRBV5-6*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;(b)Vα结构域包含SEQ ID NO:23或151的CDR3氨基酸序列以及由TRAV19*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;或(a)和(b)两者。
在某些实施例中,(a)Vβ结构域包含SEQ ID NO:115的CDR1氨基酸序列、SEQ IDNO:116的CDR2氨基酸序列和SEQ ID NO:153的CDR3氨基酸序列;所述Vα结构域包含SEQ IDNO:149的CDR1氨基酸序列、SEQ ID NO:150的CDR2氨基酸序列和SEQ ID NO:151的CDR3氨基酸序列。
在某些实施例中,结合蛋白包含:(a)与SEQ ID NO:75、79或184中包含的Vα氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vα结构域;(b)与SEQ ID NO:77、79或184中包含的Vβ氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vβ结构域;或(c)(a)的Vα结构域和(b)的Vβ;其中至少三个或四个CDR没有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或缺失。此类变体Vα和Vβ结构域可用于本文所述的结合蛋白中,条件是结合蛋白保留或基本上保留特异性结合CCNA1肽(SEQ ID NO:3):HLA复合物的能力。
在一些实施例中,结合蛋白包含:(a)与SEQ ID NO:152的氨基酸序列具有至少约75%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vα结构域;(b)与SEQ ID NO:154的氨基酸序列具有至少约75%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的Vβ结构域;(c)(a)的Vα结构域和(b)的Vβ。在一些实施例中,结合蛋白包含:(a)Vα结构域,其包含或由SEQ ID NO:152的氨基酸序列组成;(b)Vβ结构域,其包含或由SEQ ID NO:154的氨基酸序列组成;(c)(a)的Vα结构域和(b)的Vβ。在一些方面,示例性结合蛋白包含包含SEQ ID NO:152的氨基酸序列的Vα结构域和包含SEQ ID NO:154的氨基酸序列的Vβ结构域。
在某些实施例中,结合蛋白包含:(a)Vα结构域,其包含或由SEQ ID NO:75、79或184中包含的Vα氨基酸序列组成;或(b)Vβ结构域,其包含或由SEQ ID NO:77、79或184中包含的Vβ氨基酸序列组成;(c)(a)的Vα结构域和(b)的Vβ。在特定的实施例中,结合蛋白包含:(a)包含SEQ ID NO:75中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:77中包含的Vβ氨基酸序列的Vβ结构域;(b)包含SEQ ID NO:79中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:79中包含的Vβ氨基酸序列的Vβ结构域;(c))包含SEQ ID NO:184中包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:184中包含的Vβ氨基酸序列的Vβ结构域。
在另一方面,本公开提供了能够特异性结合CCNA1肽YSLSEIVPCL(SEQ ID NO:3)的结合蛋白。在某些实施例中,结合蛋白能够结合CCNA1肽YSLSEIVPCL(SEQ ID NO:3):HLA复合物。
鉴定TCR Vα和Vβ结构域的结合对的方法是本领域已知的,并且包括,例如,PCT专利公开号WO 2016/161273;和PCT公开号WO2016/161273.Redmond等,2016,Genome Med.8:80;Munson等人,2016,美国国家科学院院刊.Natl.学院科学113:8272-7;Kim et al.,2012,PLoS ONE 7:e37338(每种方法的全部内容都通过引用结合到本文中)。因此,本文所述的用于CCNA1特异性Vβ结构域(例如,包含如SEQ ID NO:6、8、10、12、14、16、18、20、22、24、93、101、109、117、123、129、140、147、153、189或190中任一个所示的CDR3的Vβ结构域)的Vα结构域,反之亦然(例如,包含SEQ ID NO:5、7、9、11、13、15、17、19、21、23、89、97、105、113、119、127、133、137、143或151中任意一个所示的CDR3的Vα结构域),可以使用本领域已知方法进行识别。
氨基酸的保守取代是众所周知的,并且可以天然发生,或者可以在重组产生结合蛋白或TCR时引入。可以使用本领域已知的诱变方法将氨基酸取代、缺失和添加引入蛋白质中(参见,例如,Sambrook等,分子克隆:实验室手册,第3版,冷泉港实验室出版社,纽约,2001)。寡核苷酸定向的位点特异性(或片段特异性)诱变方法可用于提供改变的多核苷酸,其具有根据所需的取代、缺失或插入而改变的特定密码子。或者,可以使用随机或饱和诱变技术,例如丙氨酸扫描诱变、易错聚合酶链反应诱变和寡核苷酸定向诱变来制备免疫原多肽变体(参见,例如,Sambrook等,同上)。
本领域技术人员已知的多种标准表明在肽或多肽的特定位置被取代的氨基酸是否是保守的(或相似的)。例如,相似氨基酸或保守氨基酸取代是其中氨基酸残基被具有相似侧链的氨基酸残基取代的氨基酸。相似的氨基酸可包括在以下类别中:具有碱性侧链的氨基酸(例如赖氨酸、精氨酸、组氨酸);具有酸性侧链的氨基酸(例如天冬氨酸、谷氨酸);具有不带电荷的极性侧链的氨基酸(例如甘氨酸、天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸、酪氨酸、半胱氨酸、组氨酸);具有非极性侧链的氨基酸(例如丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、蛋氨酸、色氨酸);具有β支链侧链的氨基酸(例如苏氨酸、缬氨酸、异亮氨酸)和具有芳香族侧链的氨基酸(例如酪氨酸、苯丙氨酸、色氨酸)。被认为更难以分类的脯氨酸与具有脂族侧链的氨基酸(例如亮氨酸、缬氨酸、异亮氨酸和丙氨酸)具有相同的特性。在某些情况下,可以认为谷氨酰胺代替谷氨酸或天冬酰胺代替天冬氨酸,因为谷氨酰胺和天冬酰胺分别是谷氨酸和天冬氨酸的酰胺衍生物。如本领域中所理解的,两个多肽之间的“相似性”是通过比较该多肽的氨基酸序列和保守的氨基酸替代物与第二个多肽的序列来确定的(例如,使用GENEWORKS,Align,BLAST算法或其他方法)本文所述和本领域中实践的算法)。
在某些实施例中,本公开中提供的CCNA1特异性结合蛋白能够以HLA*02:01限制性方式特异性结合CCNA1肽。
本公开的示例性结合蛋白包括TCR,TCR的抗原结合片段和嵌合抗原受体。示例性的TCR包括ab TCR、gd TCR、单链TCR(scTCR)、可溶性TCR和单结构域TCR。本公开的结合蛋白可以是嵌合的、人源化的或人的。
另一示例性结合蛋白是TCR-CAR。TCR-CAR是异源二聚体融合蛋白,通常包含可溶性TCR(VαCα多肽链和VβCβ多肽链),其中VβCβ多肽链与跨膜结构域和细胞内信号传导成分(例如,包含含ITAM的T细胞活化域和任选的共刺激信号传导域)(参见例如Walseng等人,2017Scientific Reports 7:10713,通过引用整体并入)。
在本文所述的任何实施例中,本发明的结合蛋白,例如TCR,可以进一步包含TCR恒定结构域,该TCR恒定结构域例如连接至Vα结构域、Vβ结构域或两者的C末端。TCRβ链恒定结构域可以由TRBC1基因或TRBC2基因编码。示例性的TCRβ链恒定结构域(Cβ)是与SEQ ID NO:34的氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的TRBC1恒定结构域,或与SEQ ID NO:84的氨基酸序列具有至少约75%、80%、85%、90%、91%、92%93%、94%、95%、96%、97%、98%、99%或100%的同一性的TRBC2恒定域。TCRα链恒定域(Cα)可以由TRAC基因编码。示例性的TCRα链恒定结构域是包含至少约75%,80%,85%,90%,91%,92%,93%,94%,95%,96%,97%,与SEQ ID NO:33、156或157的氨基酸序列具有98%,99%或100%的同一性。
在某些实施例中,TCR Cα结构域、Cβ结构域或两者包含半胱氨酸取代,以在恒定结构域半胱氨酸残基之间产生天然TCR中不存在的链间二硫键。在特定实施例中,结合蛋白包含:(a)在对应于SEQ ID NO:33的位置49的位置、在对应于SEQ ID NO:156的位置48的位置处、在对应于SEQ ID NO:157(Thr→Cys)的位置47的位置处包含半胱氨酸取代的Cα结构域,(b)在对应于SEQ ID NO:34的位置57的位置处或SEQ ID NO:84的位置56(Ser→Cys)的位置处包含半胱氨酸取代的Cβ结构域,或(c)(a)和(b)两者。
在本文所述的任何实施例中,本发明的结合蛋白,例如TCR,可以进一步包含TCR恒定结构域,该TCR恒定结构域例如连接至Vα结构域、Vβ结构域或两者的C末端。示例性的TCRβ链恒定域(CQ)是与SEQ ID NO:155的氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的TRBC1恒定域、或与SEQID NO:135的氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的TRBC2恒定域。TCRα链恒定域(Cα)可以是由TRAC基因编码。示例性的TCRα链恒定结构域与SEQ ID NO:158、159或160的氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性。
在某些实施例中,TCR Cα结构域是截短的TCR Cα结构域。在特定的实施例中,截短的TCRα链恒定结构域在其C末端被截短。在一些实施例中,截短的TCRα链恒定结构域可在其C末端具有1、2、3、4或更多个氨基酸的截短,其对应于SEQ ID NO:33的氨基酸序列。在一个特定的实施例中,截短的TCRα链恒定结构域在其N末端被截短。在一些实施例中,截短的TCRα链恒定结构域可在其N端具有与SEQ ID NO:33的氨基酸序列相对应的1、2、3、4或更多个氨基酸的截短。
在某些实施例中,TCR Cβ结构域是截短的TCR Cβ结构域。在特定的实施例中,截短的TCRβ链恒定结构域在其C末端被截短。在一些实施例中,截短的TCRα链恒定结构域可在其C末端具有1、2、3、4或更多个氨基酸的截短,其对应于SEQ ID NO:34或84的氨基酸序列。在特定实施例中,截短的TCRβ链恒定结构域在其N末端被截短。在一些实施例中,截短的TCRβ链恒定结构域可在其N端具有1、2、3、4或更多个氨基酸的截短,其对应于SEQ ID NO:34或84的氨基酸序列。
在一些实施例中,本公开的结合蛋白是TCR,其包含:(a)与SEQ ID NO:36、38、40、42、44、86、49、51、53、57、59、63、65、67、81、83、162、165、170、172、174、176、178、180和186中任一个所含的α链氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性的α链;(b)与SEQ ID NO:36、38、40、42、46、86、49、51、55、57、61、63、67、81、83、162、165、170、172、174、176、178、180和186中任一个所含的β链氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100的同一性的β链;或(c)(a)的α链和(b)的β链,其中结合蛋白能够特异性结合人CCNA1肽FLDRFLSCM(SEQ ID NO:1):HLA复合物。
示例性的TCR包括TCR,其包括:(a)包含SEQ ID NO:36中包含的链氨基酸序列的TCRα链和包含SEQ ID NO:36中的β链氨基酸序列的TCRβ链;(b)包含SEQ ID NO:38中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:38中包含的β链氨基酸序列的TCRβ链;(c)包含SEQ ID NO:40中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:40中包含的β链氨基酸序列的TCRβ链;(d)包含SEQ ID NO:42中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:42中包含的β链氨基酸序列的TCRβ链;(e)包含氨基酸序列SEQ ID NO:44的TCRα链和包含氨基酸序列SEQ ID NO:46的TCRβ链;(f)包含SEQ ID NO:86中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:86中包含的β链氨基酸序列的TCRβ链;(g)包含SEQ ID NO:49中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:49中包含的β链氨基酸序列的TCRβ链;(h)包含SEQ ID NO:51中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:51中包含的β链氨基酸序列的TCRβ链;(i)包含氨基酸序列SEQ ID NO:53的TCRα链和包含氨基酸序列SEQ ID NO:55的TCRβ链;(j)包含SEQ ID NO:57中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:57中包含的β链氨基酸序列的TCRβ链;(k)包含氨基酸序列SEQ ID NO:59的TCRα链和包含氨基酸序列SEQ ID NO:6l的TCRβ链;(l)包含SEQ ID NO:63中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:63中包含的β链氨基酸序列的TCRβ链;(m)包含SEQ ID NO:65中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:67中包含的β链氨基酸序列的TCRβ链;(n)包含SEQID NO:67中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:67中包含的β链氨基酸序列的TCRβ链;(o)包含SEQ ID NO:81中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:81中包含的β链氨基酸序列的TCRβ链;(p)包含SEQ ID NO:83中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:83中包含的β链氨基酸序列的TCRβ链;(q)包含SEQ ID NO:162中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:162中包含的β链氨基酸序列的TCRβ链;(r)包含SEQ ID NO:165中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:165中包含的β链氨基酸序列的TCRβ链;(s)包含SEQ ID NO:170中包含的α链氨基酸序列的TCRα链和包含SEQ IDNO:170中包含的β链氨基酸序列的TCRβ链;(t)包含SEQ ID NO:172中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:172中包含的β链氨基酸序列的TCRβ链;(u)包含SEQ ID NO:174中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:174中包含的β链氨基酸序列的TCRβ链;(v)包含SEQ ID NO:176中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:176中包含的β链氨基酸序列的TCRβ链;(w)包含SEQ ID NO:178中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:178中包含的β链氨基酸序列的TCRβ链;(x)包含SEQ ID NO:180中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:180中包含的β链氨基酸序列的TCRβ链;或(y)包含SEQ ID NO:186中包含的α链氨基酸序列的TCRα链和包含SEQ ID NO:186中包含的β链氨基酸序列的TCRβ链。
在其他实施例中,本公开的结合蛋白是TCR,其包含:(a)α链,与SEQ ID NO:69的氨基酸序列或SEQ ID NO:73或182中包含的α氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性;(b)α、β链,与SEQ IDNO:71的氨基酸序列或SEQ ID NO:73或182中包含的β链氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性;或(c)(a)的α链和(b)的β链,其中所述结合蛋白能够特异性结合人CCNA1肽SLIAAAAFCLA(SEQ IDNO:2):HLA复合物。
示例性的TCR包括:(a)包含SEQ ID NO:69的氨基酸序列TCRα链和包含SEQ ID NO:71的氨基酸序列的TCRβ链;(b)包含SEQ ID NO:73中包含的氨基酸序列的TCRα链和包含SEQID NO:73中包含的氨基酸序列的TCRβ链;(c)包含SEQ ID NO:182的氨基酸序列TCRα链和包含SEQ ID NO:182的氨基酸序列的TCRβ链。
在另外的实施例中,本公开的结合蛋白是TCR,其包含:(a)α链,与SEQ ID NO:75的氨基酸序列或SEQ ID NO:79或184中包含的α链氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性;(b)α、β链,与SEQ ID NO:77的氨基酸序列或SEQ ID NO:79或184中所包含的β链氨基酸序列具有至少约75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的同一性;或(c)(a)的α链和(b)的β链,其中所述结合蛋白能够与人CCNA1肽YSLSEIVPCL(SEQ IDNO:3):HLA复合物特异性结合。
示例性的TCR包括:(a)包含SEQ ID NO:75的氨基酸序列的TCRα链和包含SEQ IDNO:77的氨基酸序列分TCRβ链;(b)包含SEQ ID NO:79中包含的氨基酸序列的TCRα链和包含SEQ ID NO:79中包含的氨基酸序列的TCRβ链;(c)包含SEQ ID NO:184中包含的氨基酸序列的TCRα链和包含SEQ ID NO:184中包含的氨基酸序列的TCRβ链。
多核苷酸、载体和宿主细胞
在某些方面,提供了编码本文所述的任何一种或多种结合蛋白的核酸分子。
在另一方面,本公开提供了编码结合蛋白的多核苷酸,其包含T细胞受体(TCR)α链可变(Vα)结构域和TCRβ链可变(Vβ)结构域,其中编码的结合蛋白能够特异性与人细胞周期蛋白A1(CCNA1)肽YSLSEIVPCL(SEQ ID NO:3)结合,其中所述异源多核苷酸经密码子优化以在宿主细胞中表达。
在某些实施例中,编码TCRα链或其部分的多核苷酸和编码TCRβ链或其部分的多核苷酸包含在工程宿主细胞(例如,免疫细胞)所包含的单个开放阅读框中,其中单个开放阅读框进一步包含编码自切割多肽的多核苷酸,该自切割多肽位于编码α链的多核苷酸和编码β链的多核苷酸之间。在某些实施例中,自切割多肽选自内部核糖体进入位点(IRES)、弗林蛋白酶切割位点、病毒2A肽或其任意组合。示例性的病毒自我切割多肽包括来自猪破伤风病毒-1(P2A)、Thosea asigna病毒(T2A)、马鼻炎A病毒(E2A)、口蹄疫病毒(F2A)或其变体的病毒2A肽。在某些实施例中,示例性的T2A肽序列包含SEQ ID NO:16的氨基酸序列。其他示例性的核酸和氨基酸序列例如Kim等人(PLOS One 6:el8556,2011,其2A核酸和氨基酸序列通过引用整体并入本文)中阐述。示例性的P2A肽包含SEQ ID NO:29的氨基酸序列。示例性的T2A肽包含SEQ ID NO:30的氨基酸序列。示例性的E2A肽包含SEQ ID NO:31的氨基酸序列。示例性的F2A肽包含SEQ ID NO:32的氨基酸序列。
编码所需结合蛋白的多核苷酸可通过使用本领域已知的任何合适的分子生物学工程技术来完成,包括使用限制性核酸内切酶消化、连接、转化、质粒纯化和DNA测序,例如Sambrook等人(1989年和2001年版;《分子克隆:实验室手册》,冷泉港实验室出版社,纽约)和Ausubel等人(分子生物学的当前方案,2003)所述。或者,可以合成产生目的序列。
本公开内容的核酸可以指任何形式的单链或双链DNA、cDNA或RNA,并且可以包括彼此互补的核酸的正链和负链,包括反义DNA、cDNA和RNA。还包括siRNA、microRNA、RNA-DNA杂种、核酶以及其他各种天然或合成形式的DNA或RNA。
在某些实施例中,编码TCRα链的异源多核苷酸和编码TCRβ链的异源多核苷酸包含在工程免疫细胞中包含的单个开放阅读框中,其中该单个开放阅读框还包含编码自切割多肽的多核苷酸,自切割多肽位于编码α链的多核苷酸和编码β链的多核苷酸之间。
在本文所述的任何实施例中,可以对本公开内容的多核苷酸进行密码子优化以在包含多核苷酸的宿主细胞(例如免疫细胞)中有效表达(参见例如Scholten等,Clin.Immunol.779:135-145(2006))。如本文所用,“密码子优化的”多核苷酸包括异源多核苷酸,所述异源多核苷酸具有经沉默突变修饰的密码子,所述沉默突变对应于目的宿主细胞中tRNA水平的丰度。
根据本文公开的任何实施例,单个多核苷酸分子可以编码一个、两个或多个结合蛋白。编码多于一个转录物的多核苷酸可包含位于每个转录物之间的用于多顺反子表达的序列(例如,病毒2A肽)。
在某些实施例中,本公开的结合蛋白可以可操作地连接至载体的某些元件。例如,可以操作地连接实现多核苷酸序列所连接的编码序列的表达和加工所需的多核苷酸序列。表达控制序列可包括适当的转录起始、终止、启动子和增强子序列;有效的RNA处理信号,例如剪接和聚腺苷酸化信号;稳定细胞质mRNA的序列;增强翻译效率的序列(即Kozak共有序列);增强蛋白质稳定性的序列;以及可能的增强蛋白质分泌的序列。如果表达控制序列与目的基因和表达控制序列邻接,则它们可被有效连接,所述表达控制序列以反式或远距离作用来控制目的基因。
某些实施例包括载体中包含的本公开的多核苷酸。本领域技术人员可以容易地确定适用于本文公开的某些实施例的载体。示例性载体可包含能够转运与其连接的另一核酸分子或能够在宿主生物中复制的核酸分子。载体的一些实例包括质粒、病毒载体、粘粒和其他。一些载体可能能够在引入它们的宿主细胞中自主复制(例如,具有细菌复制起点的细菌载体和附加型哺乳动物载体),而其他载体可能整合到多核苷酸的宿主细胞的基因组中或促进其整合,多核苷酸在引入宿主细胞时插入并且从而与宿主基因组(例如慢病毒载体)一起复制。另外,一些载体能够指导与其可操作连接的基因的表达(这些载体可以称为“表达载体”)。根据相关实施例,还应理解,如果将一种或多种试剂(例如,如本文所述的编码结合蛋白的多核苷酸)共同施用给受试者,则每种试剂可存在于分开的或相同的载体中,并且多种载体(各自包含不同的试剂或相同的试剂)可以包含在细胞或细胞群中或施用于受试者。
载体可以是例如质粒、粘粒、病毒、RNA载体或线性或环状DNA或RNA分子,其可以包括染色体、非染色体、半合成或合成的核酸分子。示例性载体是那些能够自主复制的载体(附加载体)或能够表达与其连接的核酸分子的载体(表达载体)。
病毒载体包括逆转录病毒、腺病毒、细小病毒(例如腺相关病毒)、冠状病毒、负链RNA病毒(例如正粘液病毒(例如流感病毒)、弹状病毒(例如狂犬病和水疱性口炎病毒)、副粘病毒(例如麻疹和仙台)、正链RNA病毒(例如小瘤病毒和alpha病毒)以及双链DNA病毒、包括腺病毒、疱疹病毒(例如1型和2型单纯疱疹病毒、EB病毒、巨细胞病毒)和痘病毒(例如痘苗、鸡痘和金丝雀痘)。其他病毒包括诺沃克病毒、披膜病毒、黄病毒、呼肠孤病毒、巴波病毒、肝炎病毒和肝炎病毒。逆转录病毒的实例包括禽白血病肉瘤、哺乳动物C型、B型病毒、D型病毒、HTLV-BLV组、慢病毒、泡沫病毒(Coffin,J.M.,逆转录病毒:病毒及其复制,《基础病毒学》第三版,BN Fields等编辑,Lippincott-Raven Publishers,费城,1996)。
在某些实施例中,病毒载体可以是γ逆转录病毒,例如莫洛尼氏鼠白血病病毒(MLV)衍生的载体。在其他实施例中,病毒载体可以是更复杂的逆转录病毒来源的载体,例如慢病毒来源的载体。HIV-1衍生的载体属于这一类。其他实例包括源自HIV-2、FIV、马传染性贫血病毒、SIV和Maedi-Visna病毒(绵羊慢病毒)的慢病毒载体。使用逆转录病毒和慢病毒载体和包装细胞以用含有转基因的病毒颗粒转导哺乳动物宿主细胞的方法是本领域已知的,并且先前已在例如美国专利8,119,772;Walchli等人,PLoS One 6:327930,2011;Zhao等,J.Immunol.174:4415,2005;恩格斯等,Hum.Gene Ther.14:1155,2003;Frecha等人,Mol.Ther.18:1748,2010;和Verhoeyen等人,Methods Mol.Biol.506:91,2009中描述。逆转录病毒和慢病毒载体构建体和表达系统也是可商购的。其他病毒载体也可用于多核苷酸递送,包括DNA病毒载体,包括例如基于腺病毒的载体和基于腺伴随病毒(AAV)的载体;源自单纯疱疹病毒(HSV)的载体,包括扩增子载体、复制缺陷型HSV和减毒的HSV(Krisky等,Gene Ther.5:1517,1998)。
最近开发的用于基因治疗用途的其他载体也可以与本公开的组合物和方法一起使用。这样的载体包括衍生自杆状病毒和α-病毒的那些(Jolly,DJ.1999.FriedmannT.ed.Emerging Viral Vectors pp 209-40,Development of HumanGene Therapy。纽约:冷泉港实验室),或质粒载体(例如睡美人或其他转座子载体)。
用于基因工程和产生目的结合蛋白的表达载体的构建可以通过使用本领域已知的任何合适的分子生物学工程技术来完成。为了获得有效的转录和翻译,每个重组表达构建体中的多核苷酸包括至少一个合适的表达控制序列(也称为调节序列),例如与编码结合蛋白的核苷酸序列可操作(即可操作地)连接的前导序列,特别是启动子。
有时使用标记以鉴定或监测异源多核苷酸的转导宿主细胞表达,或检测表达目的结合蛋白的细胞。在某些实施例中,多核苷酸还包含编码标记的多核苷酸。标记可以是赋予抗药性的选择标记,也可以是可通过诸如流式细胞术之类的方法检测的可检测标记,例如荧光标记或细胞表面蛋白。在某些实施例中,编码标记的多核苷酸位于编码结合蛋白的多核苷酸的3'。在其他实施例中,编码标记的多核苷酸位于编码结合蛋白的多核苷酸的5'。示例性标记包括绿色荧光蛋白(GFP)、人CD2的胞外域、截短的人EGFR(huEGFRt;参见Wang等,Blood 118:1255(2011))、截短的人CD 19(huCD19t),截短的人CD34(huCD34t)或截短的人NGFR(huNGFRt)。在某些实施例中,编码的标记物包括EGFRt、CD19t、CD34t或NGFRt。示例性的截短的人EGFR序列包含SEQ ID NO:85的氨基酸序列。
在某些实施例中,载体可以进一步包含自杀基因,其中自杀基因的表达导致包含载体的宿主细胞死亡。例如,在某些情况下,本发明结合蛋白的延长表达是不希望的。载体中包含自杀基因允许对受试者中结合蛋白表达的更好控制。在某些实施例中,自杀基因的表达是可诱导的,例如通过使用调节自杀基因表达的诱导型启动子。在一个具体的实施例中,自杀基因是诱导型胱天蛋白酶9基因(参见美国专利公开号2013/0071414,通过引用整体并入)。
当病毒载体基因组在单个转基因内包含多个多核苷酸以作为分离的蛋白质在宿主细胞中表达时,病毒载体还可在两个(或更多个)多核苷酸之间包含允许双顺反子或多顺反子表达的其他序列。病毒载体中使用的此类序列的实例包括内部核糖体进入位点(IRES)、弗林蛋白酶切割位点、病毒2A肽或其任意组合。
在本文描述的任何实施例中,多核苷酸可进一步包含编码自切割多肽的多核苷酸,其中编码自切割多肽的多核苷酸位于编码结合蛋白的多核苷酸和编码标记的多核苷酸之间。
在某些实施例中,自切割多肽包含来自猪破伤风病毒-1(P2A)、Thosea asigna病毒(T2A)、马鼻炎A病毒(E2A)、口蹄疫病毒(F2A)或其变体。在某些实施例中,示例性的T2A肽序列包含SEQ ID NO:16的氨基酸序列。2A肽的进一步的示例性核酸和氨基酸序列在例如Kim等人(PLOS One 6:el8556,2011,其2A核酸和氨基酸序列通过引用整体并入本文)中描述。示例性的P2A肽包含SEQ ID NO:29的氨基酸序列。示例性的T2A肽包含SEQ ID NO:30的氨基酸序列。示例性的E2A肽包含SEQ ID NO:31的氨基酸序列。示例性的F2A肽包含SEQ IDNO:32的氨基酸序列。
在某些方面,本发明的结合蛋白可以在宿主细胞的表面上表达或由宿主细胞分泌或从宿主细胞分离。宿主细胞可以包括可以接受载体或掺入核酸或表达蛋白质的任何单个细胞或细胞培养物。该术语还涵盖宿主细胞的后代,无论在遗传上还是在表型上相同或不同。合适的宿主细胞可以取决于载体,并且可以包括哺乳动物细胞、动物细胞、人细胞、猿猴细胞、昆虫细胞、酵母细胞和细菌细胞。可以通过使用病毒载体、通过磷酸钙沉淀的转化、DEAE-葡聚糖、电穿孔、显微注射或其他方法诱导这些细胞掺入载体或其他材料。参见,例如,Sambrook等人,Molecular Cloning第2版.(冷泉港实验室,1989年)。
除载体外,某些实施例还涉及经修饰(即,基因改造)以包含目前公开的编码结合蛋白(例如,TCR)的异源多核苷酸的宿主细胞或包括编码结合蛋白(例如,TCR)的异源多核苷酸的载体。包含编码至少一种结合蛋白的异源多核苷酸的修饰的或基因工程的宿主细胞在其细胞表面上表达本发明的至少一种结合蛋白。修饰的宿主细胞可表达本公开的单一类型的结合蛋白或两种或更多种不同类型的结合蛋白。宿主细胞可以离体或体内修饰。宿主细胞可以包括可以接受载体或核酸或蛋白质掺入的任何单个细胞或细胞培养物以及任何子代细胞。该术语还涵盖宿主细胞的后代,无论在遗传上还是在表型上相同或不同。合适的宿主细胞可以取决于载体,并且可以包括哺乳动物细胞、动物细胞、人细胞、猿猴细胞、昆虫细胞、酵母细胞和细菌细胞。可以通过使用病毒载体、通过磷酸钙沉淀的转化、DEAE-葡聚糖、电穿孔、显微注射或其他方法诱导这些细胞掺入载体或其他材料。参见例如,Sambrook等,Molecular Cloning第2版.(冷泉港实验室,1989年)。在任何上述实施例中,包含编码本公开内容的结合蛋白的多核苷酸的宿主细胞由与例如在过继免疫疗法程序中接受修饰的宿主细胞的受试者自体、异源或同基因的细胞组成。
在某些实施例中,转导以表达本公开内容的结合蛋白的宿主细胞是造血祖细胞或人免疫系统细胞。如本文所用,“造血祖细胞”是可以衍生自造血干细胞或胎儿组织并且能够进一步分化成成熟细胞类型(例如免疫系统细胞)的细胞。示例性的造血祖细胞包括具有CD24Lo Lin-CD117+表型的那些或在胸腺中发现的那些(称为祖细胞)。
在某些实施例中,宿主细胞是免疫系统细胞,包括B细胞、CD4+ T细胞、CD8+ T细胞、CD4-CD8-双阴性T细胞、gdT细胞、调节性T细胞、天然杀伤细胞(例如,NK细胞或NK-T细胞)和树突状细胞。
在某些实施例中,宿主细胞是T细胞。T细胞可以是幼稚T细胞、记忆T细胞(TM)、辅助T细胞(TH)、效应T细胞(TE)、γδT细胞、调节性T细胞(Treg)、自然杀伤性T细胞(NKT)或其任意组合。TM可以进一步分为中央记忆T细胞(与幼稚T细胞相比,TCM、CD62L、CCR7、CD28、CD127、CD45RO和CD95的表达增加,而CD54RA的表达减少)和效应记忆T细胞(TEM,与幼稚T细胞或TCM相比,CD62L、CCR7、CD28、CD45RA的表达降低,而CD127的表达增加)。
可以使用已知技术收集T细胞,并且可以通过已知技术,例如通过与抗体的亲和结合、流式细胞术或免疫磁选择来富集或消除各种亚群或其组合。
用所需核酸转染/转导T细胞的方法已经描述(例如,在美国专利申请公开号US2004/0087025;美国专利号6,410,319;PCT公开号WO2014/031687;Brentjens等人,2007,Clin.Cancer Res.13:5426中)为使用具有期望靶特异性的T细胞的过继转移程序(例如,Schmitt等,Hum.Gen.20:1240,2009;Dosse.tt等,Mol.Ther.17:742,2009;Till等人,Blood112:2261,2008;Wang等人,Hum.Gene Ther.18:712,2007;Kuball等人,Blood 109:2331,2007;US 2011/0243972;Leen等人,Ann.Rev.Immunol.25:243,2007;Kalos等人,SciTransl.Med.3:95ra73,2011;Porter等人,201l,N.Engl.J.Med.365:725-33,2011),从而基于本文的教导,包括针对本发明结合蛋白的那些,构想了将这些方法应用于当前公开的实施例。
当包含根据本发明的多核苷酸、载体或蛋白质时,作为本发明的一个方面考虑的真核宿主细胞除人类免疫细胞(例如人类患者自身的免疫细胞)外,还包括VERO细胞、希拉细胞、中国人仓鼠卵巢(CHO)细胞系(包括能够修饰表达的多价结合分子的糖基化模式的修饰CHO细胞,请参见美国专利申请公开号2003/0115614)、COS细胞(例如COS-7)、W138、BEK、HepG2、3T3、RIN、MDCK、A549、PC12、K562、HEK293细胞、HepG2细胞、N细胞、3T3细胞、草地贪夜蛾细胞(例如Sf9细胞)、酿酒酵母细胞和本领域已知的任何其他真核细胞可用于表达和任选地分离根据本公开的蛋白质或肽。还考虑了原核细胞,包括大肠杆菌、枯草芽孢杆菌、鼠伤寒沙门氏菌、链霉菌或本领域已知适合表达和任选分离根据本公开的蛋白质或肽的任何原核细胞。特别地,在从原核细胞中分离蛋白质或肽时,可以考虑使用本领域已知的从包涵体提取蛋白质的技术。考虑了糖基化本公开的结合蛋白的宿主细胞。
根据常规方法,在含有营养物质和所选宿主细胞生长所需的其他成分的培养基中培养转化或转染的宿主细胞。多种合适的介质,包括确定的介质和复合介质,在本领域中是已知的,并且通常包括碳源、氮源、必需氨基酸、维生素和矿物质。根据需要,培养基还可以包含诸如生长因子或血清的成分。生长培养基通常将通过例如药物选择或必需营养素的缺乏来选择含有异源多核苷酸的细胞,所述必需营养素由表达载体上携带的或共同转染到宿主细胞中的选择标记来补充。
在某些实施例中,本公开的结合蛋白在宿主细胞的表面上表达,使得与靶抗原的结合引起来自宿主细胞的活性或应答。可以根据许多本领域公认的用于测定宿主细胞(例如T细胞)活性的方法来对这类表达的蛋白质进行功能表征,所述方法包括确定T细胞结合、激活或诱导,还包括确定抗原特异性的T细胞反应。实例包括确定T细胞增殖、T细胞细胞因子释放、抗原特异性T细胞刺激、MHC限制性T细胞刺激、CTL活性(例如,通过检测从预载靶细胞的51Cr或Europium释放)、T细胞表型变化标记表达和其他T细胞功能指标。例如,可以在Lefkovits(Immunology Methods Manual:Technical Sourcebook of Techniques,1998)中找到进行这些和类似测定的程序。还参见,Current Protocols in Immunology;Weir,Handbook of Experimental Immunology,Blackwell Scientific,Boston,MA(1986);Mishell and Shigii(ed.)Selected Methods n Cellular Immunology,FreemanPublishing,San Francisco,CA(1979);Green and Reed,Science 281:1309(1998)及其中引用的参考文献。
可以根据本文所述和本领域中实践的方法确定细胞因子的水平,包括例如ELISA、ELISPOT、细胞内细胞因子染色和流式细胞术及其组合(例如,细胞内细胞因子染色和流式细胞术)。可以通过分离淋巴细胞,例如外周血细胞样本中的循环淋巴细胞或淋巴结细胞中的循环淋巴细胞,用抗原刺激细胞并测量抗原,来确定由抗原特异性引发或刺激免疫应答引起的免疫细胞增殖和克隆扩增。细胞因子的产生、细胞增殖和/或细胞活力,例如通过掺入氚化的胸腺嘧啶核苷或非放射性测定,例如MTT测定等。可以例如通过确定Th1细胞因子(例如IFN-γ、IL-12、IL-2和TNF-β)和2型细胞因子(例如IL-4、IL-5、IL-9、IL-10和IL-13)的水平来检查本文所述的免疫原对Th1免疫应答和Th2免疫应答之间的平衡的作用。
在其他方面,提供了试剂盒,其包含(a)如本文所述的载体或表达构建体和用于将载体或表达构建体转导至宿主细胞中的任选试剂,和(b)(i)本文公开的结合蛋白、分离的多核苷酸、载体或表达载体,和(ii)用于将多核苷酸或表达载体转导到宿主细胞中的任选试剂,和(c)本公开的宿主细胞。
使用方法
在某些方面,本公开中提供的组合物可以用于治疗以过度表达CCNA-1为特征的过度增殖性疾病或病症的方法,所述方法包括向有需要的受试者施用结合蛋白、包含编码结合蛋白的多核苷酸的载体、表达结合蛋白的修饰宿主细胞或其药物组合物。在某些实施例中,该疾病是癌症。
如本文所用,术语“癌症”包括实体瘤和血液系统恶性肿瘤(例如,白血病)。可以治疗的示例性癌症包括胆道癌、膀胱癌、骨和软组织癌、脑肿瘤、乳腺癌、宫颈癌、结肠癌、结肠直肠腺癌、结肠直肠癌、桥粒状肿瘤、胚胎癌、子宫内膜癌、食道癌、胃癌癌症、胃腺癌、多形性胶质母细胞瘤、妇科肿瘤、头颈鳞状细胞癌、肝癌、肺癌、间皮瘤、恶性黑色素瘤、骨肉瘤、卵巢癌、胰腺癌、胰腺导管腺癌、原发性星形细胞肿瘤、原发性甲状腺癌、前列腺癌癌、肾癌、肾细胞癌、横纹肌肉瘤、皮肤癌、软组织肉瘤、睾丸生殖细胞肿瘤、尿路上皮癌、子宫肉瘤和子宫癌。
典型的血液系统恶性肿瘤包括急性淋巴细胞白血病(ALL)、急性髓细胞性白血病(AML)、慢性粒细胞性白血病(CML)、慢性嗜酸性粒细胞白血病(CEL)、骨髓增生异常综合症(MDS)、霍奇金淋巴瘤、非霍奇金淋巴瘤(NHL)(滤泡性淋巴瘤、弥漫性大B细胞淋巴瘤或慢性淋巴细胞性白血病)、骨髓瘤和多发性骨髓瘤(MM)。
在某些实施例中,受试者是人类或非人类动物,例如非人类灵长类动物、牛、马、绵羊、猪、猫、狗、山羊、小鼠、大鼠、兔或豚鼠。在一个实施例中,受试者是人,例如成人、青少年、儿童或婴儿。
在某些实施例中,给予受试者的修饰的宿主细胞是自体的、同种异体的或同基因的。
CTL免疫应答的水平可以通过本文所述和本领域常规实践的多种免疫学方法中的任何一种来确定。可以在施用由例如T细胞表达的本文描述的任何CCNA1特异性结合蛋白之前和之后确定CTL免疫应答的水平。可以使用本领域常规实践的几种技术和方法中的任何一种来进行用于确定CTL活性的细胞毒性测定(参见例如Henkart等人,“Cytotoxic T-Lymphocytes”in Fundamental Immunology,Paul(ed.)(2003Lippincott,Williams&Wilkins,Philadelphia,PA),第1127-50页,以及其中引用的参考文献)。
抗原特异性T细胞可以通过根据本文所述的任何T细胞功能参数(例如,增殖、细胞因子释放、CTL活性、改变的细胞表面标志物表型等)通过比较观察到的T细胞反应来确定。在适当情况下暴露于同源抗原的T细胞(例如,当由免疫相容性抗原呈递细胞呈递时用于引发或激活T细胞的抗原)与来自相同来源群体的T细胞之间的接触结构上不同或无关的对照抗原。具有统计学显著性的对同源抗原的应答大于对对照抗原的应答表示抗原特异性。
可以从受试者获得生物学样品,用于确定对疾病抗原肽的免疫应答的存在和水平。如本文所用,“生物样品”可以是血液样品(可以从中制备血清或血浆)、活检样品、体液(例如,肺灌洗、腹水、粘膜洗涤液、滑液)、骨髓、淋巴结、组织外植体、器官培养物或受试者或生物学来源的任何其他组织或细胞制剂。也可以在接受任何免疫原性组合物之前从受试者获得生物样品,该生物样品可用作建立基线(即免疫前治疗)数据的对照。
本文所述的结合蛋白、多核苷酸、载体或修饰的宿主细胞可以在药学或生理学上可接受或合适的赋形剂或载体中施用于受试者。药学上可接受的赋形剂是生物相容性载体,例如生理盐水,其在本文中更详细地描述,其适合于施用于人类或其他非人类哺乳动物受试者。在过继细胞疗法的上下文中,治疗有效剂量是在治疗的人类或非人类哺乳动物中能够以统计学上显著的方式产生临床上期望的结果(例如,细胞毒性T细胞应答)的过继转移中使用的宿主细胞(表达根据本发明的结合蛋白)的量。如医学领域所公知的,任何一位患者的剂量取决于许多因素,包括患者的身材、体重、体表面积、年龄、所要施用的特定疗法、性别、施用时间和途径、总体健康状况以及同时在服用的其他药物。剂量会变化,但是施用包含本文所述的重组表达载体的宿主细胞的优选剂量为约107细胞/m2、约5×107细胞/m2、约108细胞/m2、约5×108细胞/m2、大约109细胞/m2、大约5x 109细胞/m2、大约1010细胞/m2、大约5x 1010细胞/m2或大约1011细胞/m2。
如医学领域技术人员所确定的,可以以适合于待治疗(或预防)的疾病或状况的方式施用药物组合物。组合物的合适剂量以及合适的持续时间和施用频率将由诸如患者的健康状况、患者的大小(即重量、体重或体表面积)、患者疾病的类型和严重程度、活性成分的特定形式以及给药方法等因素来确定。通常,合适的剂量和治疗方案以足以提供治疗和/或预防益处的量提供组合物(例如本文所述,包括改善的临床结果,例如更频繁的完全或部分缓解、或更长无疾病和/或总体生存率、或症状严重程度的减轻)。为了预防使用,剂量应足以预防、延迟与疾病或病症相关的疾病的发作或减轻其严重性。可以通过进行临床前(包括体外和体内动物研究)和临床研究,并分析通过适当的统计学、生物学和临床方法及技术从中获得的数据,来确定根据本文所述方法施用的免疫治疗组合物的预防益处,所有这些都可以由本领域技术人员容易地实践。
本文描述的药物组合物可以存在于单位剂量或多剂量容器中,例如密封的安瓿或小瓶中。这样的容器可以冷冻以保持制剂的稳定性直到使用。在某些实施例中,单位剂量包含本文所述的重组宿主细胞,其剂量为约107细胞/m2至约1011细胞/m2。本领域技术人员可以确定在各种治疗方案中使用本文所述的特定组合物的合适的剂量和治疗方案(包括例如肠胃外或静脉内给药或制剂)的开发。
如果本发明的组合物肠胃外给药,则该组合物还可包含无菌的水性或油性溶液或悬浮液。合适的无毒胃肠外可接受的稀释剂或溶剂包括水、林格氏溶液、等渗盐溶液、1,3-丁二醇、乙醇、丙二醇或聚乙二醇与水的混合物。水溶液或悬浮液可进一步包含一种或多种缓冲剂,例如乙酸钠、柠檬酸钠、硼酸钠或酒石酸钠。当然,用于制备任何剂量单位制剂的任何材料应该是药学上纯的,并且在使用量上基本上是无毒的。另外,可以将活性化合物掺入缓释制剂和制剂中。如本文所用,剂量单位形式是指物理上离散的单位,其适合于作为待治疗对象的单位剂量。每个单元可以包含预定量的重组细胞或活性化合物,所述重组细胞或活性化合物经计算可与合适的药物载体结合产生期望的治疗效果。
通常,适当的剂量和治疗方案以足以提供治疗或预防益处的量提供活性分子或细胞。与未治疗的受试者相比,可以通过在治疗的受试者中建立改善的临床结局(例如,更频繁的缓解、完全或部分或更长的无病生存期)来监测这种反应。预先存在的针对肿瘤蛋白的免疫反应的增加通常与改善的临床结果相关。通常可以使用标准增殖、细胞毒性或细胞因子测定法来评估这种免疫应答,其可以使用在治疗之前和之后从受试者获得的样品来进行。
在某些实施例中,治疗疾病的方法包括与一种或多种其他试剂组合施用修饰的免疫细胞。
在某些实施例中,将本公开的修饰的免疫细胞与免疫抑制组分的抑制剂一起施用于受试者。
如本文所用,术语“免疫抑制成分”或“免疫抑制组分”是指提供抑制信号以帮助控制或抑制免疫应答的一种或多种细胞、蛋白质、分子、化合物或复合物。例如,免疫抑制成分包括部分或全部阻断免疫刺激;减少、预防或延迟免疫激活;或增加、激活或上调免疫抑制的分子。示例性免疫抑制组分靶标在本文中进一步详细描述,并且包括免疫检查点分子,例如PD-1、PD-L1、PD-L2、CD80、CD86、B7-H3、B7-H4、HVEM、腺苷、GAL9、VISTA、CEACAM-1、PVRL2、CTLA-4、BTLA、KIR、LAG3、TIM3、A2aR、CD244/2B4、CD 160、TIGIT、LAIR-1、PVRIG/CD112R;代谢酶,例如精氨酸酶、吲哚胺2、3-二加氧酶(IDO);免疫抑制细胞因子,例如IL-10、IL-4、IL-1RA、IL-35;Treg细胞,或其任意组合。
免疫抑制成分的抑制剂可以是化合物、抗体、抗体片段或融合多肽(例如Fc融合物,例如CTLA4-Fc或LAG3-Fc)、反义分子、核酶或RNAi分子、或低分子量有机分子。在本文公开的任何实施例中,方法可以包括将修饰的免疫细胞与以下免疫抑制组分中的任一种的一种或多种抑制剂单独或以任意组合给予。
在某些实施例中,修饰的免疫细胞与PD-1抑制剂(例如PD-1特异性抗体或其结合片段)组合使用,所述抗体例如是pidilizumab、nivolumab(Keytruda,以前称为MDX-1106)、pembrolizumab(Opdivo,以前称为MK-3475)、MEDI0680(以前称为AMP-514)、AMP-224、BMS-936558或其任意组合。
在某些实施例中,修饰的免疫细胞与PD-L1特异性抗体或其结合片段组合使用,例如BMS-936559、德瓦鲁单抗(MEDI4736)、阿特朱单抗(RG7446)、avelumab(MSB0010718C)、MPDL3280A或其任意组合。
在某些实施例中,修饰的免疫细胞与LAG3抑制剂例如LAG525、IMP321、IMP701、9H12、BMS-986016或其任意组合组合使用。
在某些实施例中,修饰的免疫细胞与CTLA4的抑制剂组合使用。在特定的实施例中,修饰的免疫细胞与CTLA4特异性抗体或其结合片段结合使用,所述抗体或其结合片段例如易普利姆玛、tremelimumab、CTLA4-Ig融合蛋白(例如ababatcept、贝拉西普)或其任意组合。
在某些实施例中,修饰的免疫细胞与B7-H3特异性抗体或其结合片段,例如依诺妥珠单抗(MGA271)、376.96或两者结合使用。
在某些实施例中,修饰的免疫细胞与B7-H4特异性抗体或其结合片段,例如scFv或其融合蛋白结合使用,如在例如Dangaj等,Cancer Res.73:4820,2013,以及美国专利第9,574,000号和PCT专利公开号WO2016/40724和WO 2013/025779中所述。
在一些实施例中,修饰的免疫细胞与CD244的抑制剂组合使用。
在某些实施例中,修饰的免疫细胞与BLTA、HVEM、CD 160或其任意组合的抑制剂组合使用。抗CD-160抗体在例如PCT公开号WO2010/084158中描述。
在更多的实施例中,修饰的免疫细胞与TIM3的抑制剂组合使用。
在更多实施例中,修饰的免疫细胞与Gal9的抑制剂组合使用。
在某些实施例中,修饰的免疫细胞与腺苷信号传导抑制剂如诱饵腺苷受体组合使用。
在某些实施例中,修饰的免疫细胞与A2aR抑制剂组合使用。
在某些实施例中,修饰的免疫细胞与KIR抑制剂,例如lirilumab(BMS-986015)组合使用。
在某些实施例中,修饰的免疫细胞与抑制性细胞因子(通常是除TGFβ以外的细胞因子)或Treg发育或活性的抑制剂组合使用。
在某些实施例中,修饰的免疫细胞与IDO抑制剂例如左旋-1-甲基色氨酸、依帕克司他(INCB024360;Liu等人,Blood 115:3520-30,2010)、ebselen(Terentis等人,Biochem.49:591-600,2010)、吲哚莫德、NLG919(Mautino等人,美国癌症研究协会第104届年会2013;2013年4月6-10日)、1-甲基色氨酸(1-MT)-tira-pazamine或其任意组合组合使用。
在某些实施例中,修饰的免疫细胞与精氨酸酶抑制剂组合使用,所述精氨酸酶抑制剂例如N(ω)-硝基-L-精氨酸甲酯(L-NAME)、N-ω-羟基-nor-1-精氨酸(nor-NOHA)、L-NOHA、2(S)-氨基-6-硼代己酸(ABH)、S-(2-硼代乙基)-L-半胱氨酸(BEC)或其任意组合。
在某些实施例中,修饰的免疫细胞与VISTA的抑制剂例如CA-170(Curis,Lexington,MA)组合使用。
在某些实施例中,修饰的免疫细胞与LAIR1抑制剂组合使用。
在某些实施例中,修饰的免疫细胞与CEACAM-1、CEACAM-3、CEACAM-5或其任意组合的抑制剂组合使用。
在某些实施例中,修饰的免疫细胞与增加刺激性免疫检查点分子的活性的试剂(即,激动剂)组合使用。例如,修饰的免疫细胞可以与CD137(4-1BB)激动剂(例如urelumab)、CD134(OX-40)激动剂(例如MEDI6469、MEDI6383、或MEDI0562)、来那度胺、泊马利度胺、CD27激动剂(例如CDX-1127)、CD28激动剂(例如TGN1412、CD80或CD86)、CD40激动剂(例如,CP-870,893、rhuCD40L或SGN-40)、CD122激动剂(例如IL-2)、GITR激动剂(例如PCT专利公开No.WO 2016/054638)、ICOS(CD278)的激动剂(例如GSK3359609、mAb 88.2、JTX-2011、Icos145-1或Icos 314-8)或其任意组合。在本文公开的任何实施例中,一种方法可以包括将修饰的免疫细胞与一种或多种刺激性免疫检查点分子(包括上述任何一种)的激动剂单独或任意组合施用。
在其他实施例中,本公开的方法进一步包括给予包括以下中的一种或多种的次级疗法:对由所靶向的癌细胞表达的癌症抗原具有特异性的抗体或抗原结合片段;化学治疗剂;手术;放射治疗;细胞因子;RNA干扰疗法,或其任意组合。
可用于癌症治疗的示例性单克隆抗体包括例如在Galluzzi等人,Oncotarget 5(24):12472-12508,2014中描述的单克隆抗体,这些抗体通过引用整体并入本文。
在某些实施例中,联合治疗方法包括向受试者施用修饰的免疫细胞并进一步进行放射治疗或手术。放射疗法包括X射线疗法(例如γ射线)和放射性药物疗法。适用于治疗给定的癌症或非发炎的实体瘤的手术和外科技术可以与本公开的修饰的免疫细胞组合用于受试者。
在某些实施例中,组合疗法方法包括将修饰的免疫细胞和化学治疗剂给予受试者。化学治疗剂包括但不限于染色质功能抑制剂、拓扑异构酶抑制剂、微管抑制药物、DNA损伤剂、抗代谢物(例如叶酸拮抗剂、嘧啶类似物、嘌呤类似物和糖修饰的类似物)、DNA合成抑制剂、DNA交互作用剂(例如嵌入剂)和DNA修复抑制剂。示例性化学治疗剂包括但不限于以下组:抗代谢物/抗癌剂,例如嘧啶类似物(5-氟尿嘧啶、氟尿苷、卡培他滨、吉西他滨和阿糖胞苷)和嘌呤类似物、叶酸拮抗剂和相关抑制剂(巯基嘌呤、硫鸟嘌呤、喷司他丁和2-氯脱氧腺苷(克拉屈滨));抗增殖/抗有丝分裂剂包括长春花生物碱(长春碱、长春新碱和长春瑞滨)、微管干扰物、如紫杉烷(紫杉醇、多西紫杉醇)、长春新碱、长春花碱、诺考达唑、埃博霉素和萘韦尔滨、表鬼臼毒素(鬼臼乙叉甙、依托泊苷、氨苄青霉素、蒽环类、博来霉素、白消安、喜树碱、卡铂、苯丁酸氮芥、顺铂、环磷酰胺、环磷酰胺、放线菌素、柔红霉素、阿霉素、表柔比星、六甲基三聚氰胺草酸铂、异磷酰胺、美育素、三聚氰胺、三聚氰胺、三聚氰胺、四氢呋喃、四氢呋喃替莫唑胺、替尼泊苷、三亚乙基硫代磷酰胺和依托泊苷(VP 16));抗生素、如放线菌素(放线菌素D)、柔红霉素、阿霉素(阿霉素)、伊达比星、蒽环类、米托蒽醌、博来霉素、普卡霉素(线霉素)和丝裂霉素;酶(L-天冬酰胺酶可全身性代谢L-天冬酰胺、并剥夺没有能力合成其自身天冬酰胺的细胞);抗血小板药;抗增殖/抗有丝分裂的烷基化剂、例如氮芥子碱(甲氯乙胺、环磷酰胺及其类似物、美法仑、苯丁酸氮芥)、亚乙基亚胺和甲基三聚氰胺(六甲基三聚氰胺和噻替帕)、烷基磺酸盐-白硫丹、亚硝基脲(卡莫司汀(BCNU)和类似物、链脲佐星—(DTIC);抗增殖/抗有丝分裂抗代谢物、例如叶酸类似物(甲氨蝶呤);铂配位配合物(顺铂、卡铂)、丙卡巴嗪、羟基脲、米托坦、氨基谷氨酰胺;激素、激素类似物(雌激素、他莫昔芬、戈舍瑞林、比卡鲁胺、尼鲁米特)和芳香酶抑制剂(来曲唑、阿那曲唑);抗凝剂(肝素、合成肝素盐和其他凝血酶抑制剂);纤维蛋白溶解剂(例如组织纤溶酶原激活剂、链激酶和尿激酶)、阿司匹林、双嘧达莫、噻氯匹定、氯吡格雷、阿昔单抗;抗转移剂;抗分泌剂(breveldin);免疫抑制剂(环孢霉素、他克莫司(FK-506)、西罗莫司(雷帕霉素)、硫唑嘌呤、霉酚酸酯);抗血管生成化合物(TNP470、染料木黄酮)和生长因子抑制剂(血管内皮生长因子(VEGF)抑制剂、成纤维细胞生长因子(FGF)抑制剂);血管紧张素受体阻滞剂;一氧化氮供体;反义寡核苷酸;抗体(曲妥珠单抗、利妥昔单抗);嵌合抗原受体;细胞周期抑制剂和分化诱导剂(维甲酸);mTOR抑制剂、拓扑异构酶抑制剂(阿霉素(阿霉素)、氨水扁桃碱、喜树碱、柔红霉素、放线菌素、依尼泊苷、表柔比星、依托泊苷、伊达柔比星、伊立替康(CPT-11)和米托蒽醌、氢可酮、甾体酮、可替康可、依地替康、依地替康甲基pednisolone、泼尼松和泼尼松);生长因子信号转导激酶抑制剂线粒体功能障碍诱导剂、霍乱毒素、蓖麻毒蛋白、假单胞菌外毒素、百日咳博德特氏菌腺苷酸环化酶毒素或白喉毒素等毒素、以及胱天蛋白酶激活剂;和染色质破坏剂。
细胞因子可用于操纵宿主针对抗癌活性的免疫反应。参见例如Floros和Tarhini,Semin.Oncol.42,539,2015。可用于促进抗癌或抗肿瘤反应的细胞因子包括,例如IFN-α、IL-2、IL-3、IL-4、IL-10、IL-12、IL-13、IL-15、IL-16、IL-17、IL-18、IL-21、IL-24和GM-CSF可以单独使用或组合使用。
另一种癌症治疗方法涉及减少癌基因以及癌细胞生长、维持、增殖和免疫逃避所需的其他基因的表达。RNA干扰,尤其是microRNA(miRNA)小型抑制性RNA(siRNA)的使用提供了一种降低癌症基因表达的方法。参见例如,Larsson等,Cancer Treat.Rev.16:128,2017。
在本文公开的任何实施例中,任何治疗剂(例如,修饰的免疫细胞、免疫抑制成分的抑制剂、刺激性免疫检查点分子的激动剂、化学治疗剂、放射疗法、外科手术、细胞因子或抑制性RNA)可以在治疗过程中一次或多次施用于受试者,并且可以以任何顺序(例如,同时、并发或以任何顺序)组合施用于受试者或任意组合。组合物的合适剂量、合适的持续时间和施用频率将由诸如患者的状况;肿瘤或癌症的大小、类型、扩散、生长和严重性;活性成分的特定形式;和施用方法等因素来确定。
在某些实施例中,向受试者施用多种剂量的本文所述的修饰的免疫细胞,其可以在约两周至约四周的施用之间的间隔内施用。在进一步的实施例中,依序给予细胞因子(例如IL-2、IL-15、IL-21),条件是在给予细胞因子之前至少向受试者给予重组宿主细胞至少三或四次。在某些实施例中,细胞因子与宿主细胞同时施用。在某些实施例中,皮下施用细胞因子。
在另外的实施例中,被治疗的受试者进一步接受免疫抑制疗法,例如钙调神经磷酸酶抑制剂、皮质类固醇、微管抑制剂、低剂量的霉酚酸前药或其任意组合。在另外的实施例中,被治疗的受试者已经接受了非清髓性或造血性造血细胞移植,其中可以在所述非清髓性的造血细胞移植后至少两至至少三个月施用所述治疗。
如本文所述,治疗或药物组合物的有效量是指在所需剂量和所需时间段内足以达到所需临床结果或有益治疗的量。有效量可以一次或多次给药方式递送。如果对已知或已确认患有某种疾病或疾病状态的受试者给药,则术语“治疗量”可以用于治疗,而“预防有效量”可以用于描述对作为预防性过程易感或有患疾病或疾病状态(例如复发)的风险的受试者的给予的有效量。
示例
示例1:
细胞周期蛋白Al TCR
选择最保守的细胞周期蛋白A1同工型的人细胞周期蛋白A1同工型3的蛋白质序列(SEQ ID NO:4),以最大化癌症表达目标表位的机会。通过用跨越整个CCNA1蛋白序列的重叠肽库刺激供体CD8+ T细胞来发现细胞周期蛋白A1特异性TCR,所述重叠肽库被设计为覆盖所有可能的MHC-1表位。当在大约3轮肽刺激后观察到针对完整肽库的反应性T细胞时,通过用表达单个目标HLA等位基因的单个肽和细胞系进行筛选来确定最小的肽表位和呈递的HLA等位基因(参见图1)。
在对几种不同的HLA-A2+供体细胞进行3轮刺激后,检测到细胞周期蛋白A1(227-235)特异性T细胞反应。通过用HLA-A2/细胞周期蛋白A1(227-235)荧光标记的多聚体标记来检测抗原特异性应答(图2第一行)。通过将T细胞与转导表达细胞周期蛋白A1的721.221白血病细胞系以及作为阴性对照的HLA-A1(图2的第二行)或HLA-A2(图2的第三行)一起培养(incubate)来确认HLA限制和效应子功能)。将游离肽作为阳性对照添加至T细胞(图2的第4行)。在高尔基抑制剂存在下共同培养4小时后,固定T细胞并使其通透,然后用抗IFNγ抗体标记并通过流式细胞仪进行分析。几种T细胞系不仅表现出抗原特异性(通过四聚体结合),而且对表达肿瘤抗原和HLA等位基因正确组合的细胞系所呈现的游离肽和天然加工的肽都具有效应子功能。
HLA-A2/细胞周期蛋白A1(227-235)特异性T细胞系按其四聚体结合亲和力排名,以选择最高亲和力的TCR进行进一步分析。在一系列单独的实验中,从12个不同的供体中产生了大约150个不同的T细胞系或克隆。这些的子集如图3A-3B示出。仔细计数T细胞,并用递减浓度的HLA-A2/细胞周期蛋白A1(227-235)荧光标记的多聚体标记来自每个T细胞系的相等数目的T细胞。将每条线的多聚体染色的平均荧光强度相对于四聚体浓度作图(图3A)。从该图进行线性回归分析以确定最大结合系数,将其应用于原始数据以生成每条线的相对解离常数(Kd),即提供50%最大结合的四聚体浓度。这些值与TCR亲和力成反比,其中最低的Kd对应于最高的预测亲和力(图3B)。在不同的供体和测试的T细胞系之间,MHC-肽多聚体具有一系列不同的亲和力。选择了10种最佳候选基因用于RACE PCR、TCR测序和慢病毒TCR基因转移载体的产生。
图4示出了如何从供体CD8+ T细胞中分离、鉴定和表达预测具有高亲和力TCR的高亲和力抗原特异性T细胞系的TCR,并在功能上进行比较。在测试的10个HLA-A2/细胞周期蛋白A1(227-235)特异性TCR中,有5个成功克隆到慢病毒载体中,在CD8+ T细胞中表达,并与MHC-CCNA1肽多聚体结合。包括一个先前生成的HLA-A2/细胞周期蛋白Al(227-235)特异性TCR#4进行比较,以及HLA-A2/细胞周期蛋白Al(341-35l),TCR#7和HLA-A2/细胞周期蛋白A1(370-379),TCR#8另外两个特有的TCR也被克隆、表达和测试。将成功转导的CD8+ T细胞与相关的MHC-肽多聚体进 行分选,并在进行功能分析之前进行扩增。表1提供了CDR3序列以及T细胞受体α和β基因的使用。
表1.细胞周期蛋白A1特异性TCR


TCR#5、9、6、1、2、3、10、11和4对与HLA*02:0l复合的细胞周期蛋白A1(227-235)FLDRFLSCM肽(SEQ ID NO:1)具有特异性。TCR#7特异于与HLA*02:0l复合的细胞周期蛋白A1(341-351)SLIAAAAFCLA(SEQ ID NO:2)。TCR#8特异于与HLA*02:0l复合的细胞周期蛋白A1(370-379)。
在高尔基抑制剂存在下,将第一T细胞与不同浓度的特定肽配体培养4小时,然后固定T细胞并使其通透并用抗IFNγ抗体标记,以进行流式细胞术分析(图5A)。然后,通过将T细胞与HLA-A2+细胞周期蛋白A1+KCL22白血病细胞靶标以不同比例共培养,来测试TCR转导的T细胞的细胞毒性功能。用荧光染料标记靶标,并与抗原阴性对照细胞等比例混合(图5B)。在6小时的培养结束时,通过流式细胞术确定剩余的标记靶的频率(相对于对照细胞),并从该数据计算抗原特异性杀伤的百分比。使用几种开放获取在线算法预测了不同肽表位与HLA-A2的结合强度以及这些表位将由全长蛋白的蛋白质体加工产生的可能性(图5C)。如图5B所示,进行了第二次细胞毒性试验,但是这次比较了最有希望的细胞周期蛋白A1(227-235)特异性TCR(#3)杀死肽负载的T2靶细胞HLA-A2+细胞周期蛋白A1+AML细胞系(ML1)和HLA-A2+细胞周期蛋白A1+原发性AML样品的能力(图5D)。将未转导的T细胞与相同靶标在单独的孔中培养,以控制杀伤的特异性。
图5A显示当用低剂量的游离肽刺激时,识别肽341和370的TCR优于227特异性TCR。在图5B中,使用内源性表达细胞周期蛋白A1蛋白的靶细胞进行的杀伤测定通过227特定的TCR中的至少一个表现出优异的杀伤力,该细胞周期蛋白A1蛋白经蛋白质组加工,装载到MHC分子上并转运到细胞表面以被T细胞识别。这表明,与其他表位相比,肿瘤细胞系可能更有效地处理227肽,而当作为游离配体引入时,341和370可能在溶液中更稳定或与MHC结合更牢固,从而导致卓越的T细胞功能。图5C显示,有一些生物信息学数据表明,肽370确实比肽227更牢固地结合HLA-A2,但该227是预测的三种CCNA1肽中预计将被细胞的一般蛋白体加工机制切割的仅有的一种。该信息支持肽227是癌症治疗的良好靶标。图5D显示表现最佳的227TCR候选物能够杀死载有肽的靶细胞,表达细胞周期蛋白A1的AML细胞系和主要AML样品,尽管肿瘤细胞表面的肽浓度可能比载肽的情况低得多。
由于细胞周期蛋白A1蛋白序列在人和小鼠中高度保守,并且小鼠和人在肺和大脑中均显示低水平的CCNA1 mRNA表达(通过qPCR),因此小鼠是测试细胞周期蛋白A1特异性安全性的良好模型体内TCR。为了使人类HLA*A02:01限制性TCRs在小鼠中识别其同源抗原,已进行基因工程改造以表达HLA*A0:012分子的转基因小鼠用于体内测试。因此,人TCR可变结构域维持其识别肽和呈递的MHC分子的能力。为了在小鼠T细胞表面上有效表达人TCR,已设计了鼠类TCR恒定域来代替人TCR的人TCR恒定域,从而使小鼠TCR发挥正常功能(请参见图6)。
可以将上述各种实施例组合以提供其他实施例。本说明书中提及和/或在应用数据表中列出的所有美国专利、美国专利申请出版物、美国专利申请、外国专利、外国专利申请和非专利出版物的全部内容通过引用合并于此,包括2018年2月12日提交的美国临时专利申请号62/629,648,2018年2月13日提交的美国临时专利申请号62/630,198和2018年5月4日提交的美国临时专利申请号62/667,207。如果需要采用各种专利、申请和出版物的理念以提供进一步的实施例,则可以修改实施例的各方面。
可以根据以上详细描述对实施例进行这些和其他改变。通常,在以下权利要求书中,所使用的术语不应解释为将权利要求书限制为说明书和权利要求书中公开的特定实施例,而是应解释为包括所有可能的实施例以及权利要求等同物的全部范围。因此,权利要求不受公开内容的限制。
序列表
<110> 弗雷德哈钦森癌症研究中心
R·佩雷特
P·D·格林伯格
<120> 细胞周期蛋白A1特异性T细胞受体及其用途
<130> 360056.460WO
<140> PCT
<141> 2019-02-12
<150> US 62/667,207
<151> 2018-05-04
<150> US 62/630,198
<151> 2018-02-13
<150> US 62/629,648
<151> 2018-02-12
<160> 190
<170> FastSEQ for Windows Version 4.0
<210> 1
<211> 9
<212> PRT
<213> 智人
<220>
<223> CCNA1 227-235肽
<400> 1
Phe Leu Asp Arg Phe Leu Ser Cys Met
1 5
<210> 2
<211> 11
<212> PRT
<213> 智人
<220>
<223> CCNA1 341-351肽
<400> 2
Ser Leu Ile Ala Ala Ala Ala Phe Cys Leu Ala
1 5 10
<210> 3
<211> 10
<212> PRT
<213> 智人
<220>
<223> CCNA1 370-379肽
<400> 3
Tyr Ser Leu Ser Glu Ile Val Pro Cys Leu
1 5 10
<210> 4
<211> 421
<212> PRT
<213> 智人
<220>
<223> CCNA1蛋白同工型3
<400> 4
Met His Cys Ser Asn Pro Lys Ser Gly Val Val Leu Ala Thr Val Ala
1 5 10 15
Arg Gly Pro Asp Ala Cys Gln Ile Leu Thr Arg Ala Pro Leu Gly Gln
20 25 30
Asp Pro Pro Gln Arg Thr Val Leu Gly Leu Leu Thr Ala Asn Gly Gln
35 40 45
Tyr Arg Arg Thr Cys Gly Gln Gly Ile Thr Arg Ile Arg Cys Tyr Ser
50 55 60
Gly Ser Glu Asn Ala Phe Pro Pro Ala Gly Lys Lys Ala Leu Pro Asp
65 70 75 80
Cys Gly Val Gln Glu Pro Pro Lys Gln Gly Phe Asp Ile Tyr Met Asp
85 90 95
Glu Leu Glu Gln Gly Asp Arg Asp Ser Cys Ser Val Arg Glu Gly Met
100 105 110
Ala Phe Glu Asp Val Tyr Glu Val Asp Thr Gly Thr Leu Lys Ser Asp
115 120 125
Leu His Phe Leu Leu Asp Phe Asn Thr Val Ser Pro Met Leu Val Asp
130 135 140
Ser Ser Leu Leu Ser Gln Ser Glu Asp Ile Ser Ser Leu Gly Thr Asp
145 150 155 160
Val Ile Asn Val Thr Glu Tyr Ala Glu Glu Ile Tyr Gln Tyr Leu Arg
165 170 175
Glu Ala Glu Ile Arg His Arg Pro Lys Ala His Tyr Met Lys Lys Gln
180 185 190
Pro Asp Ile Thr Glu Gly Met Arg Thr Ile Leu Val Asp Trp Leu Val
195 200 205
Glu Val Gly Glu Glu Tyr Lys Leu Arg Ala Glu Thr Leu Tyr Leu Ala
210 215 220
Val Asn Phe Leu Asp Arg Phe Leu Ser Cys Met Ser Val Leu Arg Gly
225 230 235 240
Lys Leu Gln Leu Val Gly Thr Ala Ala Met Leu Leu Ala Ser Lys Tyr
245 250 255
Glu Glu Ile Tyr Pro Pro Glu Val Asp Glu Phe Val Tyr Ile Thr Asp
260 265 270
Asp Thr Tyr Thr Lys Arg Gln Leu Leu Lys Met Glu His Leu Leu Leu
275 280 285
Lys Val Leu Ala Phe Asp Leu Thr Val Pro Thr Thr Asn Gln Phe Leu
290 295 300
Leu Gln Tyr Leu Arg Arg Gln Gly Val Cys Val Arg Thr Glu Asn Leu
305 310 315 320
Ala Lys Tyr Val Ala Glu Leu Ser Leu Leu Glu Ala Asp Pro Phe Leu
325 330 335
Lys Tyr Leu Pro Ser Leu Ile Ala Ala Ala Ala Phe Cys Leu Ala Asn
340 345 350
Tyr Thr Val Asn Lys His Phe Trp Pro Glu Thr Leu Ala Ala Phe Thr
355 360 365
Gly Tyr Ser Leu Ser Glu Ile Val Pro Cys Leu Ser Glu Leu His Lys
370 375 380
Ala Tyr Leu Asp Ile Pro His Arg Pro Gln Gln Ala Ile Arg Glu Lys
385 390 395 400
Tyr Lys Ala Ser Lys Tyr Leu Cys Val Ser Leu Met Glu Pro Pro Ala
405 410 415
Val Leu Leu Leu Gln
420
<210> 5
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vα CDR3
<400> 5
Cys Gly Thr Glu Glu Ala Asn Asp Tyr Lys Leu Ser Phe
1 5 10
<210> 6
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vβ CDR3
<400> 6
Cys Ala Ser Ser Val Gly Gln Gly Ser Ser Tyr Glu Gln Tyr Phe
1 5 10 15
<210> 7
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号和TCR 11号Vα CDR3
<400> 7
Cys Val Val Trp Gly Gly Asp Thr Asp Lys Leu Ile Phe
1 5 10
<210> 8
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号Vβ CDR3
<400> 8
Cys Ala Ile Leu Asp Gly Glu Gly Ser Pro Leu His Phe
1 5 10
<210> 9
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vα CDR3
<400> 9
Cys Ala Leu Gly Pro Tyr Asn Asp Tyr Lys Leu Ser Phe
1 5 10
<210> 10
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vβ CDR3
<400> 10
Cys Ala Ser Ser Asp Arg Ser Asn Thr Gly Glu Leu Phe Phe
1 5 10
<210> 11
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号Vα CDR3
<400> 11
Cys Ala Val Glu Gly Asp Ser Ser Tyr Lys Leu Ile Phe
1 5 10
<210> 12
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号Vβ CDR3
<400> 12
Cys Ala Ser Ser Phe Phe Ser Gln Glu Thr Gln Tyr Phe
1 5 10
<210> 13
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号Vα CDR3
<400> 13
Cys Ala Val Ile Gly Glu Gln Asn Phe Val Phe
1 5 10
<210> 14
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号Vβ CDR3
<400> 14
Cys Ala Ser Ser Leu Ser Gly Leu Gly Ser Gly Ala Asn Val Leu Thr
1 5 10 15
Phe
<210> 15
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vα CDR3
<400> 15
Cys Ala Val Asp Ser Gly Gly Tyr Gln Lys Val Thr Phe
1 5 10
<210> 16
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vβ CDR3
<400> 16
Cys Ala Ser Ser Leu Asn Met Asn Thr Glu Ala Phe Phe
1 5 10
<210> 17
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号Vα CDR3
<400> 17
Cys Ala Thr Asp Glu Ser Ser Asn Tyr Lys Leu Thr Phe
1 5 10
<210> 18
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号Vβ CDR3
<400> 18
Cys Ala Ser Ser Leu Asn Met Asn Thr Glu Ala Phe Phe
1 5 10
<210> 19
<211> 17
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vα CDR3
<400> 19
Cys Ala Thr Asp Ala Trp Glu Ser Asn Phe Gly Asn Glu Lys Leu Thr
1 5 10 15
Phe
<210> 20
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vβ CDR3
<400> 20
Cys Ala Ser Ser Leu Val Val Gly Ser Tyr Glu Gln Tyr Phe
1 5 10
<210> 21
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vα CDR3
<400> 21
Cys Ala Tyr Leu Gly Ala Gly Asn Gln Phe Tyr Phe
1 5 10
<210> 22
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vβ CDR3
<400> 22
Cys Ala Ser Ser Leu Asn Arg Gly Arg Tyr Gly Tyr Thr Phe
1 5 10
<210> 23
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vα CDR3
<400> 23
Cys Ala Leu Ser Glu Leu Ala Ser Gly Gly Ser Tyr Ile Pro Thr Phe
1 5 10 15
<210> 24
<211> 18
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vβ CDR3
<400> 24
Cys Ala Ser Ser Phe Arg Leu Ala Gly Gly Pro Ser Thr Asp Thr Gln
1 5 10 15
Tyr Phe
<210> 25
<211> 66
<212> DNA
<213> 人工序列
<220>
<223> P2A肽编码核酸
<400> 25
ggttccggag ccacgaactt ctctctgtta aagcaagcag gagacgtgga agaaaacccc 60
ggtccc 66
<210> 26
<211> 63
<212> DNA
<213> 人工序列
<220>
<223> T2A肽编码核酸
<400> 26
ggaagcggag agggcagagg aagtctgcta acatgcggtg acgtcgagga gaatcctgga 60
cct 63
<210> 27
<211> 69
<212> DNA
<213> 人工序列
<220>
<223> E2A肽编码核酸
<400> 27
ggaagcggac agtgtactaa ttatgctctc ttgaaattgg ctggagatgt tgagagcaac 60
cctggacct 69
<210> 28
<211> 75
<212> DNA
<213> 人工序列
<220>
<223> F2A肽编码核酸
<400> 28
ggaagcggag tgaaacagac tttgaatttt gaccttctca agttggcggg agacgtggag 60
tccaaccctg gacct 75
<210> 29
<211> 22
<212> PRT
<213> 人工序列
<220>
<223> P2A肽
<400> 29
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<210> 30
<211> 21
<212> PRT
<213> 人工序列
<220>
<223> T2A肽
<400> 30
Gly Ser Gly Glu Gly Arg Gly Ser Leu Leu Thr Cys Gly Asp Val Glu
1 5 10 15
Glu Asn Pro Gly Pro
20
<210> 31
<211> 23
<212> PRT
<213> 人工序列
<220>
<223> E2A肽
<400> 31
Gly Ser Gly Gln Cys Thr Asn Tyr Ala Leu Leu Lys Leu Ala Gly Asp
1 5 10 15
Val Glu Ser Asn Pro Gly Pro
20
<210> 32
<211> 25
<212> PRT
<213> 人工序列
<220>
<223> F2A肽
<400> 32
Gly Ser Gly Val Lys Gln Thr Leu Asn Phe Asp Leu Leu Lys Leu Ala
1 5 10 15
Gly Asp Val Glu Ser Asn Pro Gly Pro
20 25
<210> 33
<211> 142
<212> PRT
<213> 人工序列
<220>
<223> TCRα恒定结构域多肽
<400> 33
Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser
1 5 10 15
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln
20 25 30
Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys
35 40 45
Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val
50 55 60
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
65 70 75 80
Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
85 90 95
Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
100 105 110
Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val
115 120 125
Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 34
<211> 177
<212> PRT
<213> 人工序列
<220>
<223> TCRβ1恒定结构域多肽
<400> 34
Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro
1 5 10 15
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu
20 25 30
Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn
35 40 45
Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys
50 55 60
Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu
65 70 75 80
Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys
85 90 95
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp
100 105 110
Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg
115 120 125
Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln Gly Val Leu Ser
130 135 140
Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
145 150 155 160
Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp
165 170 175
Phe
<210> 35
<211> 1821
<212> DNA
<213> 人工序列
<220>
<223> TCR 5号构建体; β链-P2A-α链
<400> 35
atgggcttca ggctcctctg ctgtgtggcc ttttgtctcc tgggagcagg cccagtggat 60
tctggagtca cacaaacccc aaagcacctg atcacagcaa ctggacagcg agtgacgctg 120
agatgctccc ctaggtctgg agacctctct gtgtactggt accaacagag cctggaccag 180
ggcctccagt tcctcattca gtattataat ggagaagaga gagcaaaagg aaacattctt 240
gaacgattct ccgcacaaca gttccctgac ttgcactctg aactaaacct gagctctctg 300
gagctggggg actcagcttt gtatttctgt gccagcagcg tagggcaggg gtcctcctac 360
gagcagtact tcgggccggg caccaggctc acggtcacag aggacctgaa aaacgtgttc 420
ccacccgagg tcgctgtgtt tgagccatca gaagcagaga tctcccacac ccaaaaggcc 480
acactggtgt gcctggccac aggcttctac cccgaccacg tggagctgag ctggtgggtg 540
aatgggaagg aggtgcacag tggggtcagc acagacccgc agcccctcaa ggagcagccc 600
gccctcaatg actccagata ctgcctgagc agccgcctga gggtctcggc caccttctgg 660
cagaaccccc gcaaccactt ccgctgtcaa gtccagttct acgggctctc ggagaatgac 720
gagtggaccc aggatagggc caaacctgtc acccagatcg tcagcgccga ggcctggggt 780
agagcagact gtggcttcac ctccgagtct taccagcaag gggtcctgtc tgccaccatc 840
ctctatgaga tcttgctagg gaaggccacc ttgtatgccg tgctggtcag tgccctcgtg 900
ctgatggcca tggtcaagag aaaggattcc agaggcggtt ccggagccac gaacttctct 960
ctgttaaagc aagcaggaga cgtggaagaa aaccccggtc ccatggagac tctcctgaaa 1020
gtgctttcag gcaccttgtt gtggcagttg acctgggtga gaagccaaca accagtgcag 1080
agtcctcaag ccgtgatcct ccgagaaggg gaagatgctg tcatcaactg cagttcctcc 1140
aaggctttat attctgtaca ctggtacagg cagaagcatg gtgaagcacc cgtcttcctg 1200
atgatattac tgaagggtgg agaacagaag ggtcatgaaa aaatatctgc ttcatttaat 1260
gaaaaaaagc agcaaagctc cctgtacctt acggcctccc agctcagtta ctcaggaacc 1320
tacttctgcg gcacagagga agctaacgac tacaagctca gctttggagc cggaaccaca 1380
gtaactgtaa gagcaaatat ccagaaccct gaccctgccg tgtaccagct gagagactct 1440
aaatccagtg acaagtctgt ctgcctattc accgattttg attctcaaac aaatgtgtca 1500
caaagtaagg attctgatgt gtatatcaca gacaaaactg tgctagacat gaggtctatg 1560
gacttcaaga gcaacagtgc tgtggcctgg agcaacaaat ctgactttgc atgtgcaaac 1620
gccttcaaca acagcattat tccagaagac accttcttcc ccagcccaga aagttcctgt 1680
gatgtcaagc tggtcgagaa aagctttgaa acagatacga acctaaactt tcaaaacctg 1740
tcagtgattg ggttccgaat cctcctcctg aaagtggccg ggtttaatct gctcatgacg 1800
ctgcggctgt ggtccagctg a 1821
<210> 36
<211> 606
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号构建体; β链-P2A-α链
<400> 36
Met Gly Phe Arg Leu Leu Cys Cys Val Ala Phe Cys Leu Leu Gly Ala
1 5 10 15
Gly Pro Val Asp Ser Gly Val Thr Gln Thr Pro Lys His Leu Ile Thr
20 25 30
Ala Thr Gly Gln Arg Val Thr Leu Arg Cys Ser Pro Arg Ser Gly Asp
35 40 45
Leu Ser Val Tyr Trp Tyr Gln Gln Ser Leu Asp Gln Gly Leu Gln Phe
50 55 60
Leu Ile Gln Tyr Tyr Asn Gly Glu Glu Arg Ala Lys Gly Asn Ile Leu
65 70 75 80
Glu Arg Phe Ser Ala Gln Gln Phe Pro Asp Leu His Ser Glu Leu Asn
85 90 95
Leu Ser Ser Leu Glu Leu Gly Asp Ser Ala Leu Tyr Phe Cys Ala Ser
100 105 110
Ser Val Gly Gln Gly Ser Ser Tyr Glu Gln Tyr Phe Gly Pro Gly Thr
115 120 125
Arg Leu Thr Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val
130 135 140
Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala
145 150 155 160
Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu
165 170 175
Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp
180 185 190
Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys
195 200 205
Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg
210 215 220
Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp
225 230 235 240
Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala
245 250 255
Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln
260 265 270
Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys
275 280 285
Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met
290 295 300
Val Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser
305 310 315 320
Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu
325 330 335
Thr Leu Leu Lys Val Leu Ser Gly Thr Leu Leu Trp Gln Leu Thr Trp
340 345 350
Val Arg Ser Gln Gln Pro Val Gln Ser Pro Gln Ala Val Ile Leu Arg
355 360 365
Glu Gly Glu Asp Ala Val Ile Asn Cys Ser Ser Ser Lys Ala Leu Tyr
370 375 380
Ser Val His Trp Tyr Arg Gln Lys His Gly Glu Ala Pro Val Phe Leu
385 390 395 400
Met Ile Leu Leu Lys Gly Gly Glu Gln Lys Gly His Glu Lys Ile Ser
405 410 415
Ala Ser Phe Asn Glu Lys Lys Gln Gln Ser Ser Leu Tyr Leu Thr Ala
420 425 430
Ser Gln Leu Ser Tyr Ser Gly Thr Tyr Phe Cys Gly Thr Glu Glu Ala
435 440 445
Asn Asp Tyr Lys Leu Ser Phe Gly Ala Gly Thr Thr Val Thr Val Arg
450 455 460
Ala Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser
465 470 475 480
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln
485 490 495
Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys
500 505 510
Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val
515 520 525
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
530 535 540
Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
545 550 555 560
Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
565 570 575
Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val
580 585 590
Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 37
<211> 1493
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 5号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 37
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggcttc agactgttgt 60
gttgcgtggc cttttgcctt cttggagctg gacctgtgga ttctggagtt acacagaccc 120
ctaagcacct gattacagcc acaggacaga gagtgaccct gagatgtagc cctagaagcg 180
gagatctgag cgtgtattgg taccagcaga gcctggatca aggactccag tttctgatcc 240
agtactacaa cggcgaggag agagccaagg gcaatattct ggagaggttt tctgcccagc 300
agttccctga tctgcactct gaactgaacc tgtctagcct ggaactggga gattctgccc 360
tgtacttttg tgcctctagc gttggacagg gcagctctta tgagcagtac tttggacctg 420
gcaccagact gacagtgaca gaagacctga agaacgtgtt ccccccagag gtggccgtgt 480
tcgagcctag cgaggccgag atcagccaca cccagaaagc caccctcgtg tgcctggcca 540
ccggctttta ccccgaccac gtggaactgt cttggtgggt caacggcaaa gaggtgcaca 600
gcggcgtctg caccgacccc cagcccctga aagagcagcc cgccctgaac gacagccggt 660
actgtctgag cagcagactg agagtgtccg ccaccttctg gcagaacccc cggaaccact 720
tcagatgcca ggtgcagttc tacggcctga gcgagaacga cgagtggacc caggaccggg 780
ccaagcccgt gacccagatc gtgtctgctg aggcctgggg cagagccgat tgcggcttca 840
ccagcgagag ctaccagcag ggcgtgctga gcgccaccat cctgtacgag atcctgctgg 900
gcaaggccac cctgtacgcc gtgctggtgt ccgccctggt gctgatggcc atggtcaagc 960
ggaaggacag ccggggcggt tccggagcca cgaacttctc tctgttaaag caagcaggag 1020
acgtggaaga aaaccccggt cccatggaaa ccctgctgaa agtgctgagc ggaacactgt 1080
tatggcagct tacatgggtg aggtctcagc aacctgtgca atctccacag gccgttatcc 1140
tgagagaagg agaagatgcc gtgatcaact gctctagctc taaagccctg tacagcgtgc 1200
actggtacag acagaaacac ggagaagctc ccgtgttcct gatgattctg ctgaaaggag 1260
gcgagcagaa gggacacgag aagatttctg ccagcttcaa cgagaagaag cagcagtcta 1320
gcctgtacct gacagcttct cagctgagct atagcggcac ctacttttgt ggcacagagg 1380
aagccaacga ctacaaactg agctttggag ccggcacaac agtgacagtt agagccaata 1440
tccagaaccc cgatcctgct gtgtaccagc tgcgggacag caagagcagc gac 1493
<210> 38
<211> 495
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 5号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 38
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Phe Arg Leu
1 5 10 15
Leu Cys Cys Val Ala Phe Cys Leu Leu Gly Ala Gly Pro Val Asp Ser
20 25 30
Gly Val Thr Gln Thr Pro Lys His Leu Ile Thr Ala Thr Gly Gln Arg
35 40 45
Val Thr Leu Arg Cys Ser Pro Arg Ser Gly Asp Leu Ser Val Tyr Trp
50 55 60
Tyr Gln Gln Ser Leu Asp Gln Gly Leu Gln Phe Leu Ile Gln Tyr Tyr
65 70 75 80
Asn Gly Glu Glu Arg Ala Lys Gly Asn Ile Leu Glu Arg Phe Ser Ala
85 90 95
Gln Gln Phe Pro Asp Leu His Ser Glu Leu Asn Leu Ser Ser Leu Glu
100 105 110
Leu Gly Asp Ser Ala Leu Tyr Phe Cys Ala Ser Ser Val Gly Gln Gly
115 120 125
Ser Ser Tyr Glu Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr Val Thr
130 135 140
Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro
145 150 155 160
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu
165 170 175
Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn
180 185 190
Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys
195 200 205
Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu
210 215 220
Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys
225 230 235 240
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp
245 250 255
Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg
260 265 270
Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser
275 280 285
Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
290 295 300
Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp
305 310 315 320
Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
325 330 335
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Thr Leu Leu Lys Val
340 345 350
Leu Ser Gly Thr Leu Leu Trp Gln Leu Thr Trp Val Arg Ser Gln Gln
355 360 365
Pro Val Gln Ser Pro Gln Ala Val Ile Leu Arg Glu Gly Glu Asp Ala
370 375 380
Val Ile Asn Cys Ser Ser Ser Lys Ala Leu Tyr Ser Val His Trp Tyr
385 390 395 400
Arg Gln Lys His Gly Glu Ala Pro Val Phe Leu Met Ile Leu Leu Lys
405 410 415
Gly Gly Glu Gln Lys Gly His Glu Lys Ile Ser Ala Ser Phe Asn Glu
420 425 430
Lys Lys Gln Gln Ser Ser Leu Tyr Leu Thr Ala Ser Gln Leu Ser Tyr
435 440 445
Ser Gly Thr Tyr Phe Cys Gly Thr Glu Glu Ala Asn Asp Tyr Lys Leu
450 455 460
Ser Phe Gly Ala Gly Thr Thr Val Thr Val Arg Ala Asn Ile Gln Asn
465 470 475 480
Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490 495
<210> 39
<211> 1813
<212> DNA
<213> 人工序列
<220>
<223> TCR 11号构建体; β链-P2A-α
链
<400> 39
atgggcacca ggctcttctt ctatgtggcc ctttgtctgc tgtgggcagg acacagggat 60
gctggaatca cccagagccc aagatacaag atcacagaga caggaaggca ggtgaccttg 120
atgtgtcacc agacttggag ccacagctat atgttctggt atcgacaaga cctgggacat 180
gggctgaggc tgatctatta ctcagcagct gctgatatta cagataaagg agaagtcccc 240
gatggctatg ttgtctccag atccaagaca gagaatttcc ccctcactct ggagtcagct 300
acccgctccc agacatctgt gtatttctgc gccagcagtg acgggggcgg gcagtacttc 360
gggccgggca ccaggctcac ggtcacagag gacctgaaaa acgtgttccc acccgaggtc 420
gctgtgtttg agccatcaga agcagagatc tcccacaccc aaaaggccac actggtgtgc 480
ctggccacag gcttctaccc cgaccacgtg gagctgagct ggtgggtgaa tgggaaggag 540
gtgcacagtg gggtcagcac agacccgcag cccctcaagg agcagcccgc cctcaatgac 600
tccagatact gcctgagcag ccgcctgagg gtctcggcca ccttctggca gaacccccgc 660
aaccacttcc gctgtcaagt ccagttctac gggctctcgg agaatgacga gtggacccag 720
gatagggcca aacctgtcac ccagatcgtc agcgccgagg cctggggtag agcagactgt 780
ggcttcacct ccgagtctta ccagcaaggg gtcctgtctg ccaccatcct ctatgagatc 840
ttgctaggga aggccacctt gtatgccgtg ctggtcagtg ccctcgtgct gatggccatg 900
gtcaagagaa aggattccag aggcggttcc ggagccacga acttctctct gttaaagcaa 960
gcaggagacg tggaagaaaa ccccggtccc atgaaaaagc atctgacgac cttcttggtg 1020
attttgtggc tttattttta tagggggaat ggcaaaaacc aagtggagca gagtcctcag 1080
tccctgatca tcctggaggg aaagaactgc actcttcaat gcaattatac agtgagcccc 1140
ttcagcaact taaggtggta taagcaagat actgggagag gtcctgtttc cctgacaatc 1200
atgactttca gtgagaacac aaagtcgaac ggaagatata cagcaactct ggatgcagac 1260
acaaagcaaa gctctctgca catcacagcc tcccagctca gcgattcagc ctcctacatc 1320
tgtgtggtgt ggggggggga caccgacaag ctcatctttg ggactgggac cagattacaa 1380
gtctttccaa atatccagaa ccctgaccct gccgtgtacc agctgagaga ctctaaatcc 1440
agtgacaagt ctgtctgcct attcaccgat tttgattctc aaacaaatgt gtcacaaagt 1500
aaggattctg atgtgtatat cacagacaaa actgctagac atgaggtcta tggacttcaa 1560
gagcaacagt gctgtggcct ggagcaacaa atctgacttt gcatgtgcaa acgccttcaa 1620
caacagcatt attccagaag acaccttctt ccccagccca gaaagttcct gtgatgtcaa 1680
gctggtcgag aaaagctttg aaacagatac gaacctaaac tttcaaaacc tgtcagtgat 1740
tgggttccga atcctcctcc tgaaagtggc cgggtttaat ctgctcatga cgctgcggct 1800
gtggtccagc tga 1813
<210> 40
<211> 531
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号构建体; β链-P2A-α
链
<400> 40
Met Gly Thr Arg Leu Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Ala
1 5 10 15
Gly His Arg Asp Ala Gly Ile Thr Gln Ser Pro Arg Tyr Lys Ile Thr
20 25 30
Glu Thr Gly Arg Gln Val Thr Leu Met Cys His Gln Thr Trp Ser His
35 40 45
Ser Tyr Met Phe Trp Tyr Arg Gln Asp Leu Gly His Gly Leu Arg Leu
50 55 60
Ile Tyr Tyr Ser Ala Ala Ala Asp Ile Thr Asp Lys Gly Glu Val Pro
65 70 75 80
Asp Gly Tyr Val Val Ser Arg Ser Lys Thr Glu Asn Phe Pro Leu Thr
85 90 95
Leu Glu Ser Ala Thr Arg Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser
100 105 110
Ser Asp Gly Gly Gly Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr Val
115 120 125
Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu
130 135 140
Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys
145 150 155 160
Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val
165 170 175
Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu
180 185 190
Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg
195 200 205
Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg
210 215 220
Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln
225 230 235 240
Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly
245 250 255
Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu
260 265 270
Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr
275 280 285
Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys
290 295 300
Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln
305 310 315 320
Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Lys Lys His Leu Thr
325 330 335
Thr Phe Leu Val Ile Leu Trp Leu Tyr Phe Tyr Arg Gly Asn Gly Lys
340 345 350
Asn Gln Val Glu Gln Ser Pro Gln Ser Leu Ile Ile Leu Glu Gly Lys
355 360 365
Asn Cys Thr Leu Gln Cys Asn Tyr Thr Val Ser Pro Phe Ser Asn Leu
370 375 380
Arg Trp Tyr Lys Gln Asp Thr Gly Arg Gly Pro Val Ser Leu Thr Ile
385 390 395 400
Met Thr Phe Ser Glu Asn Thr Lys Ser Asn Gly Arg Tyr Thr Ala Thr
405 410 415
Leu Asp Ala Asp Thr Lys Gln Ser Ser Leu His Ile Thr Ala Ser Gln
420 425 430
Leu Ser Asp Ser Ala Ser Tyr Ile Cys Val Val Trp Gly Gly Asp Thr
435 440 445
Asp Lys Leu Ile Phe Gly Thr Gly Thr Arg Leu Gln Val Phe Pro Asn
450 455 460
Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser
465 470 475 480
Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn
485 490 495
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr Ala
500 505 510
Arg His Glu Val Tyr Gly Leu Gln Glu Gln Gln Cys Cys Gly Leu Glu
515 520 525
Gln Gln Ile
530
<210> 41
<211> 1484
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 11号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 41
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggcaca cggcttttct 60
tctacgttgc cctttgcctg ctgtgggctg gacatagaga tgctggaatc acacagagcc 120
ccaggtacaa gatcacagag acaggaagac aggtgaccct gatgtgtcac caaacatgga 180
gccacagcta catgttctgg tacagacagg atctgggaca cggactgaga ctgatctact 240
attctgctgc cgccgacatc accgataaag gagaagttcc tgacggctac gtggtgtcta 300
gaagcaaaac cgagaacttc cccctgacac tggaatctgc cacaagatct cagaccagcg 360
tgtacttttg cgcctcttct gatggaggag gccagtattt tccaggcaca agactgacag 420
tgaccgagga cctgaagaac gtgttccccc cagaggtggc cgtgttcgag cctagcgagg 480
ccgagatcag ccacacccag aaagccaccc tcgtgtgcct ggccaccggc ttttaccccg 540
accacgtgga actgtcttgg tgggtcaacg gcaaagaggt gcacagcggc gtctgcaccg 600
acccccagcc cctgaaagag cagcccgccc tgaacgacag ccggtactgt ctgagcagca 660
gactgagagt gtccgccacc ttctggcaga acccccggaa ccacttcaga tgccaggtgc 720
agttctacgg cctgagcgag aacgacgagt ggacccagga ccgggccaag cccgtgaccc 780
agatcgtgtc tgctgaggcc tggggcagag ccgattgcgg cttcaccagc gagagctacc 840
agcagggcgt gctgagcgcc accatcctgt acgagatcct gctgggcaag gccaccctgt 900
acgccgtgct ggtgtccgcc ctggtgctga tggccatggt caagcggaag gacagccggg 960
gcggttccgg agccacgaac ttctctctgt taaagcaagc aggagacgtg gaagaaaacc 1020
ccggtcccat gaagaagcac ctgaccacgt tcctggtgat tctttggctg tacttctacc 1080
ggggcaacgg caaaaatcag gtggaacaaa gcccccagag cctgattatt ctggagggca 1140
agaactgcac cctccagtgt aattacaccg tgagcccttt cagcaacctg agatggtaca 1200
agcaggatac cggaagagga cctgtgtctc tgaccatcat gacctttagc gagaacacca 1260
agagcaacgg caggtataca gccacactgg atgccgatac caagcagtct tctctgcaca 1320
ttaccgcctc tcagctgtct gattctgcca gctacatctg tgtggtgtgg ggaggagata 1380
ccgataagct gatctttggc acaggcacca gactgcaagt gttccctaac atccagaacc 1440
ctgatcctgc cgtgtaccag ctgcgggaca gcaagagcag cgac 1484
<210> 42
<211> 492
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 11号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 42
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Thr Arg Leu
1 5 10 15
Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Ala Gly His Arg Asp Ala
20 25 30
Gly Ile Thr Gln Ser Pro Arg Tyr Lys Ile Thr Glu Thr Gly Arg Gln
35 40 45
Val Thr Leu Met Cys His Gln Thr Trp Ser His Ser Tyr Met Phe Trp
50 55 60
Tyr Arg Gln Asp Leu Gly His Gly Leu Arg Leu Ile Tyr Tyr Ser Ala
65 70 75 80
Ala Ala Asp Ile Thr Asp Lys Gly Glu Val Pro Asp Gly Tyr Val Val
85 90 95
Ser Arg Ser Lys Thr Glu Asn Phe Pro Leu Thr Leu Glu Ser Ala Thr
100 105 110
Arg Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser Ser Asp Gly Gly Gly
115 120 125
Gln Tyr Phe Pro Gly Thr Arg Leu Thr Val Thr Glu Asp Leu Lys Asn
130 135 140
Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile
145 150 155 160
Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr
165 170 175
Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His
180 185 190
Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu
195 200 205
Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr
210 215 220
Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr
225 230 235 240
Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val
245 250 255
Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe
260 265 270
Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr
275 280 285
Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala
290 295 300
Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly Gly Ser
305 310 315 320
Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu
325 330 335
Asn Pro Gly Pro Met Lys Lys His Leu Thr Thr Phe Leu Val Ile Leu
340 345 350
Trp Leu Tyr Phe Tyr Arg Gly Asn Gly Lys Asn Gln Val Glu Gln Ser
355 360 365
Pro Gln Ser Leu Ile Ile Leu Glu Gly Lys Asn Cys Thr Leu Gln Cys
370 375 380
Asn Tyr Thr Val Ser Pro Phe Ser Asn Leu Arg Trp Tyr Lys Gln Asp
385 390 395 400
Thr Gly Arg Gly Pro Val Ser Leu Thr Ile Met Thr Phe Ser Glu Asn
405 410 415
Thr Lys Ser Asn Gly Arg Tyr Thr Ala Thr Leu Asp Ala Asp Thr Lys
420 425 430
Gln Ser Ser Leu His Ile Thr Ala Ser Gln Leu Ser Asp Ser Ala Ser
435 440 445
Tyr Ile Cys Val Val Trp Gly Gly Asp Thr Asp Lys Leu Ile Phe Gly
450 455 460
Thr Gly Thr Arg Leu Gln Val Phe Pro Asn Ile Gln Asn Pro Asp Pro
465 470 475 480
Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490
<210> 43
<211> 828
<212> DNA
<213> 人工序列
<220>
<223> TCR 6号α链
<400> 43
atggagaaga atcctttggc agccccatta ctaatcctct ggtttcatct tgactgcgtg 60
agcagcatac tgaacgtgga acaaagtcct cagtcactgc atgttcagga gggagacagc 120
accaatttca cctgcagctt cccttccagc aatttttatg ccttacactg gtacagatgg 180
gaaactgcaa aaagccccga ggccttgttt gtaatgactt taaatgggga tgaaaagaag 240
aaaggacgaa taagtgccac tcttaatacc aaggagggtt acagctattt gtacatcaaa 300
ggatcccagc ctgaagactc agccacatac ctctgtgcct tagggcctta taacgactac 360
aagctcagct ttggagccgg aaccacagta actgtaagag caaatatcca gaaccctgac 420
cctgccgtgt accagctgag agactctaaa tccagtgaca agtctgtctg cctattcacc 480
gattttgatt ctcaaacaaa tgtgtcacaa agtaaggatt ctgatgtgta tatcacagac 540
aaaactgtgc tagacatgag gtctatggac ttcaagagca acagtgctgt ggcctggagc 600
aacaaatctg actttgcatg tgcaaacgcc ttcaacaaca gcattattcc agaagacacc 660
ttcttcccca gcccagaaag ttcctgtgat gtcaagctgg tcgagaaaag ctttgaaaca 720
gatacgaacc taaactttca aaacctgtca gtgattgggt tccgaatcct cctcctgaaa 780
gtggccgggt ttaatctgct catgacgctg cggctgtggt ccagctga 828
<210> 44
<211> 275
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号α链
<400> 44
Met Glu Lys Asn Pro Leu Ala Ala Pro Leu Leu Ile Leu Trp Phe His
1 5 10 15
Leu Asp Cys Val Ser Ser Ile Leu Asn Val Glu Gln Ser Pro Gln Ser
20 25 30
Leu His Val Gln Glu Gly Asp Ser Thr Asn Phe Thr Cys Ser Phe Pro
35 40 45
Ser Ser Asn Phe Tyr Ala Leu His Trp Tyr Arg Trp Glu Thr Ala Lys
50 55 60
Ser Pro Glu Ala Leu Phe Val Met Thr Leu Asn Gly Asp Glu Lys Lys
65 70 75 80
Lys Gly Arg Ile Ser Ala Thr Leu Asn Thr Lys Glu Gly Tyr Ser Tyr
85 90 95
Leu Tyr Ile Lys Gly Ser Gln Pro Glu Asp Ser Ala Thr Tyr Leu Cys
100 105 110
Ala Leu Gly Pro Tyr Asn Asp Tyr Lys Leu Ser Phe Gly Ala Gly Thr
115 120 125
Thr Val Thr Val Arg Ala Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr
130 135 140
Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr
145 150 155 160
Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val
165 170 175
Tyr Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys
180 185 190
Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
195 200 205
Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser
210 215 220
Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr
225 230 235 240
Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile
245 250 255
Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu
260 265 270
Trp Ser Ser
275
<210> 45
<211> 936
<212> DNA
<213> 人工序列
<220>
<223> TCR 6号β链
<400> 45
atgagcatca gcctcctgtg ctgtgcagcc tttcctctcc tgtgggcagg tccagtgaat 60
gctggtgtca ctcagacccc aaaattccgc atcctgaaga taggacagag catgacactg 120
cagtgtaccc aggatatgaa ccataactac atgtactggt atcgacaaga cccaggcatg 180
gggctgaagc tgatttatta ttcagttggt gctggtatca ctgataaagg agaagtcccg 240
aatggctaca acgtctccag atcaaccaca gaggatttcc cgctcaggct ggagttggct 300
gctccctccc agacatctgt gtacttctgt gccagcagtg acaggtctaa caccggggag 360
ctgttttttg gagaaggctc taggctgacc gtactggagg acctgaaaaa cgtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttctacccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtcagcaca gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acctgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gcttcacctc cgagtcttac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatct tgctagggaa ggccaccttg tatgccgtgc tggtcagtgc cctcgtgctg 900
atggccatgg tcaagagaaa ggattccaga ggctag 936
<210> 46
<211> 311
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号β链
<400> 46
Met Ser Ile Ser Leu Leu Cys Cys Ala Ala Phe Pro Leu Leu Trp Ala
1 5 10 15
Gly Pro Val Asn Ala Gly Val Thr Gln Thr Pro Lys Phe Arg Ile Leu
20 25 30
Lys Ile Gly Gln Ser Met Thr Leu Gln Cys Thr Gln Asp Met Asn His
35 40 45
Asn Tyr Met Tyr Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Lys Leu
50 55 60
Ile Tyr Tyr Ser Val Gly Ala Gly Ile Thr Asp Lys Gly Glu Val Pro
65 70 75 80
Asn Gly Tyr Asn Val Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg
85 90 95
Leu Glu Leu Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser
100 105 110
Ser Asp Arg Ser Asn Thr Gly Glu Leu Phe Phe Gly Glu Gly Ser Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Ser Arg Gly
305 310
<210> 47
<211> 1499
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 6号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 47
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgagcatc agcctcctgt 60
gctgtgcagc ctttcctctc ctgtgggcag gtccagtgaa tgctggtgtc actcagaccc 120
caaaattccg catcctgaag ataggacaga gcatgacact gcagtgtacc caggatatga 180
accataacta catgtactgg tatcgacaag acccaggcat ggggctgaag ctgatttatt 240
attcagttgg tgctggtatc actgataaag gagaagtccc gaatggctac aacgtctcca 300
gatcaaccac agaggatttc ccgctcaggc tggagttggc tgctccctcc cagacatctg 360
tgtacttctg tgccagcagt gacaggtcta acaccgggga gctgtttttt ggagaaggct 420
ctaggctgac cgtactggag gacctgaaaa acgtgttccc acccgaggtc gctgtgtttg 480
agccatcaga agcagagatc tcccacaccc aaaaggccac actggtgtgc ctggccacag 540
gcttctaccc cgaccacgtg gagctgagct ggtgggtgaa tgggaaggag gtgcacagtg 600
gggtcagcac agacccgcag cccctcaagg agcagcccgc cctcaatgac tccagatact 660
gcctgagcag ccgcctgagg gtctcggcca ccttctggca gaacccccgc aaccacttcc 720
gctgtcaagt ccagttctac gggctctcgg agaatgacga gtggacccag gatagggcca 780
aacctgtcac ccagatcgtc agcgccgagg cctggggtag agcagactgt ggcttcacct 840
ccgagtctta ccagcaaggg gtcctgtctg ccaccatcct ctatgagatc ttgctaggga 900
aggccacctt gtatgccgtg ctggtcagtg ccctcgtgct gatggccatg gtcaagagaa 960
aggattccag aggcggttcc ggagccacga acttctctct gttaaagcaa gcaggagacg 1020
tggaagaaaa ccccggtccc atggagaaga atcctttggc agccccatta ctaatcctct 1080
ggtttcatct tgactgcgtg agcagcatac tgaacgtgga acaaagtcct cagtcactgc 1140
atgttcagga gggagacagc accaatttca cctgcagctt cccttccagc aatttttatg 1200
ccttacactg gtacagatgg gaaactgcaa aaagccccga ggccttgttt gtaatgactt 1260
taaatgggga tgaaaagaag aaaggacgaa taagtgccac tcttaatacc aaggagggtt 1320
acagctattt gtacatcaaa ggatcccagc ctgaagactc agccacatac ctctgtgcct 1380
tagggcctta taacgactac aagctcagct ttggagccgg aaccacagta actgtaagag 1440
caaatatcca gaaccctgac cctgccgtgt accagctgcg ggacagcaag agcagcgac 1499
<210> 48
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> TCR 1号构建体; β链-P2A-α链
<400> 48
atgggccccg ggctcctctg ctgggcactg ctttgtctcc tgggagcagg cttagtggac 60
gctggagtca cccaaagtcc cacacacctg atcaaaacga gaggacagca agtgactctg 120
agatgctctc ctaagtctgg gcatgacact gtgtcctggt accaacaggc cctgggtcag 180
gggccccagt ttatctttca gtattatgag gaggaagaga gacagagagg caacttccct 240
gatcgattct caggtcacca gttccctaac tatagctctg agctgaatgt gaacgccttg 300
ttgctggggg actcggccct ctatctctgt gccagcagct tcttcagcca agagacccag 360
tacttcgggc caggcacgcg gctcctggtg ctcgaggacc tgaaaaacgt gttcccaccc 420
gaggtcgctg tgtttgagcc atcagaagca gagatctccc acacccaaaa ggccacactg 480
gtgtgcctgg ccacaggctt ctaccccgac cacgtggagc tgagctggtg ggtgaatggg 540
aaggaggtgc acagtggggt cagcacagac ccgcagcccc tcaaggagca gcccgccctc 600
aatgactcca gatactgcct gagcagccgc ctgagggtct cggccacctt ctggcagaac 660
ccccgcaacc acttccgctg tcaagtccag ttctacgggc tctcggagaa tgacgagtgg 720
acccaggata gggccaaacc tgtcacccag atcgtcagcg ccgaggcctg gggtagagca 780
gactgtggct tcacctccga gtcttaccag caaggggtcc tgtctgccac catcctctat 840
gagatcttgc tagggaaggc caccttgtat gccgtgctgg tcagtgccct cgtgctgatg 900
gccatggtca agagaaagga ttccagaggc ggttccggag ccacgaactt ctctctgtta 960
aagcaagcag gagacgtgga agaaaacccc ggtcccatgg agaccctctt gggcctgctt 1020
atcctttggc tgcagctgca atgggtgagc agcaaacagg aggtgacaca gattcctgca 1080
gctctgagtg tcccagaagg agaaaacttg gttctcaact gcagtttcac tgatagcgct 1140
atttacaacc tccagtggtt taggcaggac cctgggaaag gtctcacatc tctgttgctt 1200
attcagtcaa gtcagagaga gcaaacaagt ggaagactta atgcctcgct ggataaatca 1260
tcaggacgta gtactttata cattgcagct tctcagcctg gtgactcagc cacctacctc 1320
tgtgccgtgg agggggatag cagctataaa ttgatcttcg ggagtgggac cagactgctg 1380
gtcaggcctg atatccagaa ccctgaccct gccgtgtacc agctgagaga ctctaaatcc 1440
agtgacaagt ctgtctgcct attcaccgat tttgattctc aaacaaatgt gtcacaaagt 1500
aaggattctg atgtgtatat cacagacaaa actgtgctag acatgaggtc tatggacttc 1560
aagagcaaca gtgctgtggc ctggagcaac aaatctgact ttgcatgtgc aaacgccttc 1620
aacaacagca ttattccaga agacaccttc ttccccagcc cagaaagttc ctgtgatgtc 1680
aagctggtcg agaaaagctt tgaaacagat acgaacctaa actttcaaaa cctgtcagtg 1740
attgggttcc gaatcctcct cctgaaagtg gccgggttta atctgctcat gacgctgcgg 1800
ctgtggtcca gctga 1815
<210> 49
<211> 604
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号构建体; β链-P2A-α链
<400> 49
Met Gly Pro Gly Leu Leu Cys Trp Ala Leu Leu Cys Leu Leu Gly Ala
1 5 10 15
Gly Leu Val Asp Ala Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys
20 25 30
Thr Arg Gly Gln Gln Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His
35 40 45
Asp Thr Val Ser Trp Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe
50 55 60
Ile Phe Gln Tyr Tyr Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro
65 70 75 80
Asp Arg Phe Ser Gly His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn
85 90 95
Val Asn Ala Leu Leu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser
100 105 110
Ser Phe Phe Ser Gln Glu Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu
115 120 125
Leu Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val
130 135 140
Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu
145 150 155 160
Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp
165 170 175
Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln
180 185 190
Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser
195 200 205
Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His
210 215 220
Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp
225 230 235 240
Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala
245 250 255
Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly
260 265 270
Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr
275 280 285
Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
290 295 300
Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu
305 310 315 320
Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Thr Leu
325 330 335
Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp Val Ser Ser Lys
340 345 350
Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val Pro Glu Gly Glu
355 360 365
Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn Leu
370 375 380
Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr Ser Leu Leu Leu
385 390 395 400
Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala Ser
405 410 415
Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser Gln
420 425 430
Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Glu Gly Asp Ser Ser
435 440 445
Tyr Lys Leu Ile Phe Gly Ser Gly Thr Arg Leu Leu Val Arg Pro Asp
450 455 460
Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser
465 470 475 480
Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn
485 490 495
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr Val
500 505 510
Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
515 520 525
Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile
530 535 540
Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val
545 550 555 560
Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln
565 570 575
Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly
580 585 590
Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600
<210> 50
<211> 1487
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 1号构建体; 在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 50
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggacct ggactgcttt 60
gttgggctct tctgtgtctg cttggagctg gactggttga tgctggagtt acacagagcc 120
ctacacacct gatcaagaca agaggacagc aggtgaccct gagatgtagc cctaaatctg 180
gccacgatac cgtgagctgg tatcaacagg ctctgggaca aggacctcag ttcatcttcc 240
agtactacga ggaggaggag agacagagag gcaatttccc tgacaggttt agcggacacc 300
agttccccaa ttacagctct gagctgaacg tgaatgccct tcttctggga gattctgccc 360
tgtatctgtg tgccagcagc ttctttagcc aggaaaccca gtacttcggc ccaggaacaa 420
gactgctggt tcttgaagac ctgaagaacg tgttcccccc agaggtggcc gtgttcgagc 480
ctagcgaggc cgagatcagc cacacccaga aagccaccct cgtgtgcctg gccaccggct 540
tttaccccga ccacgtggaa ctgtcttggt gggtcaacgg caaagaggtg cacagcggcg 600
tctgcaccga cccccagccc ctgaaagagc agcccgccct gaacgacagc cggtactgtc 660
tgagcagcag actgagagtg tccgccacct tctggcagaa cccccggaac cacttcagat 720
gccaggtgca gttctacggc ctgagcgaga acgacgagtg gacccaggac cgggccaagc 780
ccgtgaccca gatcgtgtct gctgaggcct ggggcagagc cgattgcggc ttcaccagcg 840
agagctacca gcagggcgtg ctgagcgcca ccatcctgta cgagatcctg ctgggcaagg 900
ccaccctgta cgccgtgctg gtgtccgccc tggtgctgat ggccatggtc aagcggaagg 960
acagccgggg cggttccgga gccacgaact tctctctgtt aaagcaagca ggagacgtgg 1020
aagaaaaccc cggtcccatg gaaaccctgt taggcctgct cattctgtgg ttacagctcc 1080
aatgggtgag cagcaaacag gaagtgaccc agattcctgc tgccttatct gtgcctgaag 1140
gcgaaaatct ggtgctgaat tgcagcttca ccgattctgc catctacaac ctccagtggt 1200
tcagacagga tccaggaaaa ggcctgacat ctcttctgct gatccagtct agccagagag 1260
agcagacaag cggaagactg aatgcctctc tggacaagag cagcggaaga tctaccctgt 1320
atattgccgc ctctcagcct ggagattctg ccacatatct gtgtgccgtg gagggagata 1380
gcagctataa gctgatcttc ggcagcggca caagattact ggtgagacct gacatccaga 1440
accctgatcc tgctgtgtac cagctgcggg acagcaagag cagcgac 1487
<210> 51
<211> 493
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 1号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 51
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Pro Gly Leu
1 5 10 15
Leu Cys Trp Ala Leu Leu Cys Leu Leu Gly Ala Gly Leu Val Asp Ala
20 25 30
Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys Thr Arg Gly Gln Gln
35 40 45
Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His Asp Thr Val Ser Trp
50 55 60
Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe Ile Phe Gln Tyr Tyr
65 70 75 80
Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro Asp Arg Phe Ser Gly
85 90 95
His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn Val Asn Ala Leu Leu
100 105 110
Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser Ser Phe Phe Ser Gln
115 120 125
Glu Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Leu Val Leu Glu Asp
130 135 140
Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser Glu
145 150 155 160
Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala Thr
165 170 175
Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly Lys
180 185 190
Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln
195 200 205
Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val
210 215 220
Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln Val
225 230 235 240
Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala
245 250 255
Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala Asp
260 265 270
Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr
275 280 285
Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu
290 295 300
Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser Arg
305 310 315 320
Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp
325 330 335
Val Glu Glu Asn Pro Gly Pro Met Glu Thr Leu Leu Gly Leu Leu Ile
340 345 350
Leu Trp Leu Gln Leu Gln Trp Val Ser Ser Lys Gln Glu Val Thr Gln
355 360 365
Ile Pro Ala Ala Leu Ser Val Pro Glu Gly Glu Asn Leu Val Leu Asn
370 375 380
Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn Leu Gln Trp Phe Arg Gln
385 390 395 400
Asp Pro Gly Lys Gly Leu Thr Ser Leu Leu Leu Ile Gln Ser Ser Gln
405 410 415
Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala Ser Leu Asp Lys Ser Ser
420 425 430
Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser Gln Pro Gly Asp Ser Ala
435 440 445
Thr Tyr Leu Cys Ala Val Glu Gly Asp Ser Ser Tyr Lys Leu Ile Phe
450 455 460
Gly Ser Gly Thr Arg Leu Leu Val Arg Pro Asp Ile Gln Asn Pro Asp
465 470 475 480
Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490
<210> 52
<211> 813
<212> DNA
<213> 人工序列
<220>
<223> TCR 2号α链
<400> 52
atggagaccc tcttgggcct gcttatcctt tggctgcagc tgcaatgggt gagcagcaaa 60
caggaggtga cgcagattcc tgcagctctg agtgtcccag aaggagaaaa cttggttctc 120
aactgcagtt tcactgatag cgctatttac aacctccagt ggtttaggca ggaccctggg 180
aaaggtctca catctctgtt gcttattcag tcaagtcaga gagagcaaac aagtggaaga 240
cttaatgcct cgctggataa atcatcagga cgtagtactt tatacattgc agcttctcag 300
cctggtgact cagccaccta cctctgtgct gtgatcggcg aacagaattt tgtctttggt 360
cccggaacca gattgtccgt gctgccctat atccagaacc ctgaccctgc cgtgtaccag 420
ctgagagact ctaaatccag tgacaagtct gtctgcctat tcaccgattt tgattctcaa 480
acaaatgtgt cacaaagtaa ggattctgat gtgtatatca cagacaaaac tgtgctagac 540
atgaggtcta tggacttcaa gagcaacagt gctgtggcct ggagcaacaa atctgacttt 600
gcatgtgcaa acgccttcaa caacagcatt attccagaag acaccttctt ccccagccca 660
gaaagttcct gtgatgtcaa gctggtcgag aaaagctttg aaacagatac gaacctaaac 720
tttcaaaacc tgtcagtgat tgggttccga atcctcctcc tgaaagtggc cgggtttaat 780
ctgctcatga cgctgcggct gtggtccagc tga 813
<210> 53
<211> 270
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号α链
<400> 53
Met Glu Thr Leu Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp
1 5 10 15
Val Ser Ser Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val
20 25 30
Pro Glu Gly Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala
35 40 45
Ile Tyr Asn Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr
50 55 60
Ser Leu Leu Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg
65 70 75 80
Leu Asn Ala Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile
85 90 95
Ala Ala Ser Gln Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Ile
100 105 110
Gly Glu Gln Asn Phe Val Phe Gly Pro Gly Thr Arg Leu Ser Val Leu
115 120 125
Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser
130 135 140
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln
145 150 155 160
Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys
165 170 175
Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val
180 185 190
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
195 200 205
Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
210 215 220
Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
225 230 235 240
Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val
245 250 255
Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
260 265 270
<210> 54
<211> 948
<212> DNA
<213> 人工序列
<220>
<223> TCR 2号β链
<400> 54
atgggcacca ggctcctctg ctgggcagcc ctgtgcctcc tgggggcaga tcacacaggt 60
gctggagtct cccagacccc cagtaacaag gtcacagaga agggaaaata tgtagagctc 120
aggtgtgatc caatttcagg tcatactgcc ctttactggt accgacaaag cctggggcag 180
ggcccagagt ttctaattta cttccaaggc acgggtgcgg cagatgactc agggctgccc 240
aacgatcggt tctttgcagt caggcctgag ggatccgtct ctactctgaa gatccagcgc 300
acagagcggg gggactcagc cgtgtatctc tgtgccagca gcttaagtgg gttaggctct 360
ggggccaacg tcctgacttt cggggccggc agcaggctga ccgtgctgga ggacctgaaa 420
aacgtgttcc cacccgaggt cgctgtgttt gagccatcag aagcagagat ctcccacacc 480
caaaaggcca cactggtgtg cctggccaca ggcttctacc ccgaccacgt ggagctgagc 540
tggtgggtga atgggaagga ggtgcacagt ggggtcagca cagacccgca gcccctcaag 600
gagcagcccg ccctcaatga ctccagatac tgcctgagca gccgcctgag ggtctcggcc 660
accttctggc agaacccccg caaccacttc cgctgtcaag tccagttcta cgggctctcg 720
gagaatgacg agtggaccca ggatagggcc aaacctgtca cccagatcgt cagcgccgag 780
gcctggggta gagcagactg tggcttcacc tccgagtctt accagcaagg ggtcctgtct 840
gccaccatcc tctatgagat cttgctaggg aaggccacct tgtatgccgt gctggtcagt 900
gccctcgtgc tgatggccat ggtcaagaga aaggattcca gaggctag 948
<210> 55
<211> 315
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号β链
<400> 55
Met Gly Thr Arg Leu Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Thr Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr
20 25 30
Glu Lys Gly Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His
35 40 45
Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Ile Tyr Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro
65 70 75 80
Asn Asp Arg Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu
85 90 95
Lys Ile Gln Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala
100 105 110
Ser Ser Leu Ser Gly Leu Gly Ser Gly Ala Asn Val Leu Thr Phe Gly
115 120 125
Ala Gly Ser Arg Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro
130 135 140
Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr
145 150 155 160
Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
165 170 175
Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val
180 185 190
Ser Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser
195 200 205
Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
210 215 220
Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
225 230 235 240
Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
245 250 255
Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu
260 265 270
Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
275 280 285
Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
290 295 300
Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly
305 310 315
<210> 56
<211> 1496
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 2号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 56
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggcacc agactgctgt 60
gttgggctgc tctgtgtctg ctgggagccg atcatacagg tgccggtgtc agccagacac 120
ctagcaacaa agtgaccgag aagggcaaat acgtggaact gagatgcgac cccatcagcg 180
gacacacagc cctgtactgg tacagacagt ctctcggcca gggacctgag ttcctgatct 240
acttccaagg caccggcgct gccgatgata gcggcctgcc taacgataga ttcttcgccg 300
tcagacccga gggcagcgtg tccacactga agatccagag aaccgagagg ggcgacagcg 360
ccgtgtatct gtgtgcctct tctctgtctg gcctcggctc tggcgctaac gtgctgacat 420
ttggcgccgg aagcagactg accgtgctgg aagatctgaa gaacgtgttc ccacctgagg 480
tggccgtgtt cgagccttct gaggccgaga tcagccacac acagaaagcc acactcgtgt 540
gtctggccac cggcttctat cccgaccatg tggaactgtc ttggtgggtc aacggcaaag 600
aggtgcacag cggcgtctgt acagatcccc agcctctgaa agaacagccc gctctgaacg 660
acagccggta ctgtctgtcc tccagactga gagtgtccgc caccttctgg cagaacccca 720
gaaaccactt cagatgccag gtgcagttct acggcctgag cgagaacgat gagtggaccc 780
aggatagagc caagcctgtg acacagatcg tgtctgccga agcctggggc agagccgatt 840
gtggctttac cagcgagagc taccagcagg gcgtgctgtc tgccacaatc ctgtacgaga 900
tcctgctggg caaagccact ctgtacgccg tgctggtgtc tgccctggtg ctgatggcca 960
tggtcaagcg gaaggacagc agaggcggtt ccggagccac gaacttctct ctgttaaagc 1020
aagcaggaga cgtggaagaa aaccccggtc ccatggaaac actgctgggc ctgctgatcc 1080
tgtggctgca actgcaatgg gtgtccagca agcaagaagt gacacagatc cctgccgctc 1140
tgtctgtgcc tgagggcgaa aacctggtgc tgaactgcag cttcaccgac agcgccatct 1200
acaacctgca gtggttcaga caggaccccg gcaagggact gacaagcctg ctgctgattc 1260
agagcagcca gagagagcag accagcggca gactgaatgc cagcctggat aagtcctccg 1320
gcagaagcac cctgtatatc gccgcttctc agcctggcga tagcgccaca tatctgtgtg 1380
ccgtgatcgg cgagcagaac ttcgtgtttg gccctggcac aagactgagc gtgctgccct 1440
acattcagaa ccccgatcct gccgtgtacc agctgcggga cagcaagagc agcgac 1496
<210> 57
<211> 496
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 2号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 57
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Thr Arg Leu
1 5 10 15
Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala Asp His Thr Gly Ala
20 25 30
Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr Glu Lys Gly Lys Tyr
35 40 45
Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu Tyr Trp
50 55 60
Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe Leu Ile Tyr Phe Gln
65 70 75 80
Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro Asn Asp Arg Phe Phe
85 90 95
Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu Lys Ile Gln Arg Thr
100 105 110
Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu Ser Gly
115 120 125
Leu Gly Ser Gly Ala Asn Val Leu Thr Phe Gly Ala Gly Ser Arg Leu
130 135 140
Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val
145 150 155 160
Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu
165 170 175
Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp
180 185 190
Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln
195 200 205
Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser
210 215 220
Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His
225 230 235 240
Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp
245 250 255
Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala
260 265 270
Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly
275 280 285
Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr
290 295 300
Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
305 310 315 320
Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu
325 330 335
Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Thr Leu
340 345 350
Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp Val Ser Ser Lys
355 360 365
Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val Pro Glu Gly Glu
370 375 380
Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn Leu
385 390 395 400
Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr Ser Leu Leu Leu
405 410 415
Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala Ser
420 425 430
Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser Gln
435 440 445
Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Ile Gly Glu Gln Asn
450 455 460
Phe Val Phe Gly Pro Gly Thr Arg Leu Ser Val Leu Pro Tyr Ile Gln
465 470 475 480
Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490 495
<210> 58
<211> 825
<212> DNA
<213> 人工序列
<220>
<223> TCR 3号α链
<400> 58
atgatgaaat ccttgagagt tttactagtg atcctgtggc ttcagttgag ctgggtttgg 60
agccaacaga aggaggtgga gcagaattct ggacccctca gtgttccaga gggagccatt 120
gcctctctca actgcactta cagtgaccga ggttcccagt ccttcttctg gtacagacaa 180
tattctggga aaagccctga gttgataatg tccatatact ccaatggtga caaagaagat 240
ggaaggttta cagcacagct caataaagcc agccagtatg tttctctgct catcagagac 300
tcccagccca gtgattcagc cacctacctc tgtgccgtcg attctggggg ttaccagaaa 360
gttacctttg gaactggaac aaagctccaa gtcatcccaa atatccagaa ccctgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
actgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gctga 825
<210> 59
<211> 274
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号α链
<400> 59
Met Met Lys Ser Leu Arg Val Leu Leu Val Ile Leu Trp Leu Gln Leu
1 5 10 15
Ser Trp Val Trp Ser Gln Gln Lys Glu Val Glu Gln Asn Ser Gly Pro
20 25 30
Leu Ser Val Pro Glu Gly Ala Ile Ala Ser Leu Asn Cys Thr Tyr Ser
35 40 45
Asp Arg Gly Ser Gln Ser Phe Phe Trp Tyr Arg Gln Tyr Ser Gly Lys
50 55 60
Ser Pro Glu Leu Ile Met Ser Ile Tyr Ser Asn Gly Asp Lys Glu Asp
65 70 75 80
Gly Arg Phe Thr Ala Gln Leu Asn Lys Ala Ser Gln Tyr Val Ser Leu
85 90 95
Leu Ile Arg Asp Ser Gln Pro Ser Asp Ser Ala Thr Tyr Leu Cys Ala
100 105 110
Val Asp Ser Gly Gly Tyr Gln Lys Val Thr Phe Gly Thr Gly Thr Lys
115 120 125
Leu Gln Val Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser
<210> 60
<211> 930
<212> DNA
<213> 人工序列
<220>
<223> TCR 3号和TCR 10号β链
<400> 60
atgggcacca ggctcctctg ctgggcagcc ctgtgcctcc tgggggcaga tcacacaggt 60
gctggagtct cccagacccc cagtaacaag gtcacagaga agggaaaata tgtagagctc 120
aggtgtgatc caatttcagg tcatactgcc ctttactggt accgacaaag cctggggcag 180
ggcccagagt ttctaattta cttccaaggc acgggtgcgg cagatgactc agggctgccc 240
aacgatcggt tctttgcagt caggcctgag ggatccgtct ctactctgaa gatccagcgc 300
acagagcggg gggactcagc cgtgtatctc tgtgccagca gcttaaatat gaacactgaa 360
gctttctttg gacaaggcac cagactcaca gttgtagagg acctgaacaa ggtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttcttcccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtcagcacg gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acccgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gctttacctc ggtgtcctac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatcc tgctagggaa ggccaccctg tatgctgtgc tggtcagcgc ccttgtgttg 900
atggccatgg tcaagagaaa ggatttctga 930
<210> 61
<211> 309
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号和TCR 10号β链
<400> 61
Met Gly Thr Arg Leu Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Thr Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr
20 25 30
Glu Lys Gly Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His
35 40 45
Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Ile Tyr Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro
65 70 75 80
Asn Asp Arg Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu
85 90 95
Lys Ile Gln Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala
100 105 110
Ser Ser Leu Asn Met Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg
115 120 125
Leu Thr Val Val Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe
305
<210> 62
<211> 1490
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 3号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 62
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggcacc agactgctgt 60
gttgggccgc tctgtgtctg ctgggcgccg atcatacagg cgctggcgtg tcccagaccc 120
ccagcaacaa agtgaccgag aagggcaaat acgtggaact gagatgcgac cccatcagcg 180
gccacaccgc cctgtactgg tacagacagt ctctgggcca gggccccgag ttcctgatat 240
attttcaggg caccggcgct gccgacgaca gcggcctgcc taacgataga ttcttcgccg 300
tgcggcccga gggcagcgtg tccacactga agatccagag aaccgagcgg ggcgacagcg 360
ccgtgtatct gtgtgccagc agcctgaata tgaacaccga ggcattcttt gggcagggca 420
cccggctgac cgtggtggaa gatctgaaca aggtgttccc cccagaggtg gccgtgttcg 480
agccttctga ggccgagatc agccacaccc agaaagccac cctcgtgtgc ctggccaccg 540
gctttttccc cgaccatgtg gaactgtctt ggtgggtcaa cggcaaagag gtgcacagcg 600
gagtgtccac cgaccctcag cccctgaaag aacagcccgc cctgaacgac agccggtact 660
gcctgagcag cagactgaga gtgtccgcca ccttctggca gaacccccgg aaccacttca 720
gatgccaggt gcagttctac ggcctgagcg agaacgacga gtggacccag gacagagcca 780
agcccgtgac ccagatcgtg tctgccgaag cctggggcag agccgattgc ggctttacct 840
ccgtgtccta tcagcagggc gtgctgagcg ccaccatcct gtacgagatc ctgctgggca 900
aggccaccct gtacgccgtg ctggtgtctg ccctggtgct gatggccatg gtcaagcgga 960
aggacttcgg ttccggagcc acgaacttct ctctgttaaa gcaagcagga gacgtggaag 1020
aaaaccccgg tcccatgatg aagtccctgc gggtgctgct cgtgatcctg tggctgcagc 1080
tgtcttgggt gtggtcccag cagaaagagg tggaacagaa cagcggccct ctgagcgtgc 1140
cagagggcgc cattgctagc ctgaattgca cctacagcga ccggggcagc cagagcttct 1200
tctggtatcg gcagtacagc ggcaagagcc ccgagctgat catgagcatc tacagcaacg 1260
gcgacaaaga ggacggccgg ttcaccgccc agctgaacaa agccagccag tacgtgtcac 1320
tgctgatccg ggacagccag cccagcgata gcgccacata cctgtgcgcc gtggatagcg 1380
gcggctacca gaaagtgacc ttcggcaccg gcaccaagct gcaagtgatc cccaacatcc 1440
agaaccccga ccccgctgtg taccagctgc gggacagcaa gagcagcgac 1490
<210> 63
<211> 494
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 3号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 63
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Thr Arg Leu
1 5 10 15
Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala Asp His Thr Gly Ala
20 25 30
Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr Glu Lys Gly Lys Tyr
35 40 45
Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu Tyr Trp
50 55 60
Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe Leu Ile Tyr Phe Gln
65 70 75 80
Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro Asn Asp Arg Phe Phe
85 90 95
Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu Lys Ile Gln Arg Thr
100 105 110
Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu Asn Met
115 120 125
Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg Leu Thr Val Val Glu
130 135 140
Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
145 150 155 160
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
165 170 175
Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
180 185 190
Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys Glu
195 200 205
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
210 215 220
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
225 230 235 240
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
245 250 255
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
260 265 270
Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln Gly Val Leu Ser Ala
275 280 285
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
290 295 300
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Phe
305 310 315 320
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
325 330 335
Glu Glu Asn Pro Gly Pro Met Met Lys Ser Leu Arg Val Leu Leu Val
340 345 350
Ile Leu Trp Leu Gln Leu Ser Trp Val Trp Ser Gln Gln Lys Glu Val
355 360 365
Glu Gln Asn Ser Gly Pro Leu Ser Val Pro Glu Gly Ala Ile Ala Ser
370 375 380
Leu Asn Cys Thr Tyr Ser Asp Arg Gly Ser Gln Ser Phe Phe Trp Tyr
385 390 395 400
Arg Gln Tyr Ser Gly Lys Ser Pro Glu Leu Ile Met Ser Ile Tyr Ser
405 410 415
Asn Gly Asp Lys Glu Asp Gly Arg Phe Thr Ala Gln Leu Asn Lys Ala
420 425 430
Ser Gln Tyr Val Ser Leu Leu Ile Arg Asp Ser Gln Pro Ser Asp Ser
435 440 445
Ala Thr Tyr Leu Cys Ala Val Asp Ser Gly Gly Tyr Gln Lys Val Thr
450 455 460
Phe Gly Thr Gly Thr Lys Leu Gln Val Ile Pro Asn Ile Gln Asn Pro
465 470 475 480
Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490
<210> 64
<211> 819
<212> DNA
<213> 人工序列
<220>
<223> TCR 10号α链
<400> 64
atggaaactc tcctgggagt gtctttggtg attctatggc ttcaactggc tagggtgaac 60
agtcaacagg gagaagagga tcctcaggcc ttgagcatcc aggagggtga aaatgccacc 120
atgaactgca gttacaaaac tagtataaac aatttacagt ggtatagaca aaattcaggt 180
agaggccttg tccacctaat tttaatacgt tcaaatgaaa gagagaaaca cagtggaaga 240
ttaagagtca cgcttgacac ttccaagaaa agcagttcct tgttgatcac ggcttcccgg 300
gcagcagaca ctgcttctta cttctgtgct acggacgaga gtagcaacta taaactgaca 360
tttggaaaag gaactctctt aaccgtgaat ccaaatatcc agaaccctga ccctgccgtg 420
taccagctga gagactctaa atccagtgac aagtctgtct gcctattcac cgattttgat 480
tctcaaacaa atgtgtcaca aagtaaggat tctgatgtgt atatcacaga caaaactgtg 540
ctagacatga ggtctatgga cttcaagagc aacagtgctg tggcctggag caacaaatct 600
gactttgcat gtgcaaacgc cttcaacaac agcattattc cagaagacac cttcttcccc 660
agcccagaaa gttcctgtga tgtcaagctg gtcgagaaaa gctttgaaac agatacgaac 720
ctaaactttc aaaacctgtc agtgattggg ttccgaatcc tcctcctgaa agtggccggg 780
tttaatctgc tcatgacgct gcggctgtgg tccagctga 819
<210> 65
<211> 272
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号α链
<400> 65
Met Glu Thr Leu Leu Gly Val Ser Leu Val Ile Leu Trp Leu Gln Leu
1 5 10 15
Ala Arg Val Asn Ser Gln Gln Gly Glu Glu Asp Pro Gln Ala Leu Ser
20 25 30
Ile Gln Glu Gly Glu Asn Ala Thr Met Asn Cys Ser Tyr Lys Thr Ser
35 40 45
Ile Asn Asn Leu Gln Trp Tyr Arg Gln Asn Ser Gly Arg Gly Leu Val
50 55 60
His Leu Ile Leu Ile Arg Ser Asn Glu Arg Glu Lys His Ser Gly Arg
65 70 75 80
Leu Arg Val Thr Leu Asp Thr Ser Lys Lys Ser Ser Ser Leu Leu Ile
85 90 95
Thr Ala Ser Arg Ala Ala Asp Thr Ala Ser Tyr Phe Cys Ala Thr Asp
100 105 110
Glu Ser Ser Asn Tyr Lys Leu Thr Phe Gly Lys Gly Thr Leu Leu Thr
115 120 125
Val Asn Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
130 135 140
Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp
145 150 155 160
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
165 170 175
Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser
180 185 190
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe
195 200 205
Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
210 215 220
Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn
225 230 235 240
Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu
245 250 255
Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
260 265 270
<210> 66
<211> 1484
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 10号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 66
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggcacc agactgctgt 60
gttgggccgc tctgtgtctg ctgggcgccg atcatacagg cgctggcgtg tcccagaccc 120
ccagcaacaa agtgaccgag aagggcaaat acgtggaact gagatgcgac cccatcagcg 180
gccacaccgc cctgtactgg tacagacagt ctctgggcca gggccccgag ttcctgatat 240
attttcaggg caccggcgct gccgacgaca gcggcctgcc taacgataga ttcttcgccg 300
tgcggcccga gggcagcgtg tccacactga agatccagag aaccgagcgg ggcgacagcg 360
ccgtgtatct gtgtgccagc agcctgaata tgaacaccga ggcattcttt gggcagggca 420
cccggctgac cgtggtggaa gatctgaaca aggtgttccc cccagaggtg gccgtgttcg 480
agccttctga ggccgagatc agccacaccc agaaagccac cctcgtgtgc ctggccaccg 540
gctttttccc cgaccatgtg gaactgtctt ggtgggtcaa cggcaaagag gtgcacagcg 600
gagtgtccac cgaccctcag cccctgaaag aacagcccgc cctgaacgac agccggtact 660
gcctgagcag cagactgaga gtgtccgcca ccttctggca gaacccccgg aaccacttca 720
gatgccaggt gcagttctac ggcctgagcg agaacgacga gtggacccag gacagagcca 780
agcccgtgac ccagatcgtg tctgccgaag cctggggcag agccgattgc ggctttacct 840
ccgtgtccta tcagcagggc gtgctgagcg ccaccatcct gtacgagatc ctgctgggca 900
aggccaccct gtacgccgtg ctggtgtctg ccctggtgct gatggccatg gtcaagcgga 960
aggacttcgg ttccggagcc acgaacttct ctctgttaaa gcaagcagga gacgtggaag 1020
aaaaccccgg tcccatggaa accctgctgg gagtgtccct cgtgatcctg tggctgcagc 1080
tggccagagt gaacagccag cagggggaag aggatcccca ggccctgagc attcaggaag 1140
gcgagaacgc caccatgaac tgcagctaca agaccagcat caacaacctg cagtggtaca 1200
ggcagaacag cggcagaggc ctggtgcacc tgatcctgat cagaagcaac gagagagaga 1260
agcactccgg acggctgaga gtgaccctgg acacctccaa gaagtcctcc agcctgctga 1320
tcaccgccag cagagccgcc gataccgcca gctacttctg cgccacagac gagagcagca 1380
actacaagct gaccttcggc aagggcacac tgctgacagt gaaccccaac atccagaacc 1440
ccgaccccgc tgtgtaccag ctgcgggaca gcaagagcag cgac 1484
<210> 67
<211> 492
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 10号构建体
多肽;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 67
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Thr Arg Leu
1 5 10 15
Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala Asp His Thr Gly Ala
20 25 30
Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr Glu Lys Gly Lys Tyr
35 40 45
Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu Tyr Trp
50 55 60
Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe Leu Ile Tyr Phe Gln
65 70 75 80
Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro Asn Asp Arg Phe Phe
85 90 95
Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu Lys Ile Gln Arg Thr
100 105 110
Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu Asn Met
115 120 125
Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg Leu Thr Val Val Glu
130 135 140
Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
145 150 155 160
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
165 170 175
Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
180 185 190
Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys Glu
195 200 205
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
210 215 220
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
225 230 235 240
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
245 250 255
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
260 265 270
Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln Gly Val Leu Ser Ala
275 280 285
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
290 295 300
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Phe
305 310 315 320
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
325 330 335
Glu Glu Asn Pro Gly Pro Met Glu Thr Leu Leu Gly Val Ser Leu Val
340 345 350
Ile Leu Trp Leu Gln Leu Ala Arg Val Asn Ser Gln Gln Gly Glu Glu
355 360 365
Asp Pro Gln Ala Leu Ser Ile Gln Glu Gly Glu Asn Ala Thr Met Asn
370 375 380
Cys Ser Tyr Lys Thr Ser Ile Asn Asn Leu Gln Trp Tyr Arg Gln Asn
385 390 395 400
Ser Gly Arg Gly Leu Val His Leu Ile Leu Ile Arg Ser Asn Glu Arg
405 410 415
Glu Lys His Ser Gly Arg Leu Arg Val Thr Leu Asp Thr Ser Lys Lys
420 425 430
Ser Ser Ser Leu Leu Ile Thr Ala Ser Arg Ala Ala Asp Thr Ala Ser
435 440 445
Tyr Phe Cys Ala Thr Asp Glu Ser Ser Asn Tyr Lys Leu Thr Phe Gly
450 455 460
Lys Gly Thr Leu Leu Thr Val Asn Pro Asn Ile Gln Asn Pro Asp Pro
465 470 475 480
Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490
<210> 68
<211> 825
<212> DNA
<213> 人工序列
<220>
<223> TCR 7号α链
<400> 68
atggagaaga atcctttggc agccccatta ctaatcctct ggtttcatct tgactgcgtg 60
agcagcatac tgaacgtgga acaaagtcct cagtcactgc atgttcagga gggagacagc 120
accaatttca cctgcagctt cccttccagc aatttttatg ccttacactg gtacagatgg 180
gaaactgcaa aaagccccga ggccttgttt gtaatgactt taaatgggga tgaaaagaag 240
aaaggacgaa taagtgccac tcttaatacc aaggagggtt acagctattt gtacatcaaa 300
ggatcccagc ctgaagactc agccacatac ctctgtgcct atttaggggc cggtaaccag 360
ttctattttg ggacagggac aagtttgacg gtcattccaa atatccagaa ccctgaccct 420
gccgtgtacc agctgagaga ctctaaatcc agtgacaagt ctgtctgcct attcaccgat 480
tttgattctc aaacaaatgt gtcacaaagt aaggattctg atgtgtatat cacagacaaa 540
actgtgctag acatgaggtc tatggacttc aagagcaaca gtgctgtggc ctggagcaac 600
aaatctgact ttgcatgtgc aaacgccttc aacaacagca ttattccaga agacaccttc 660
ttccccagcc cagaaagttc ctgtgatgtc aagctggtcg agaaaagctt tgaaacagat 720
acgaacctaa actttcaaaa cctgtcagtg attgggttcc gaatcctcct cctgaaagtg 780
gccgggttta atctgctcat gacgctgcgg ctgtggtcca gctga 825
<210> 69
<211> 274
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号α链
<400> 69
Met Glu Lys Asn Pro Leu Ala Ala Pro Leu Leu Ile Leu Trp Phe His
1 5 10 15
Leu Asp Cys Val Ser Ser Ile Leu Asn Val Glu Gln Ser Pro Gln Ser
20 25 30
Leu His Val Gln Glu Gly Asp Ser Thr Asn Phe Thr Cys Ser Phe Pro
35 40 45
Ser Ser Asn Phe Tyr Ala Leu His Trp Tyr Arg Trp Glu Thr Ala Lys
50 55 60
Ser Pro Glu Ala Leu Phe Val Met Thr Leu Asn Gly Asp Glu Lys Lys
65 70 75 80
Lys Gly Arg Ile Ser Ala Thr Leu Asn Thr Lys Glu Gly Tyr Ser Tyr
85 90 95
Leu Tyr Ile Lys Gly Ser Gln Pro Glu Asp Ser Ala Thr Tyr Leu Cys
100 105 110
Ala Tyr Leu Gly Ala Gly Asn Gln Phe Tyr Phe Gly Thr Gly Thr Ser
115 120 125
Leu Thr Val Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
130 135 140
Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp
145 150 155 160
Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr
165 170 175
Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser
180 185 190
Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn
195 200 205
Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro
210 215 220
Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp
225 230 235 240
Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu
245 250 255
Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp
260 265 270
Ser Ser
<210> 70
<211> 930
<212> DNA
<213> 人工序列
<220>
<223> TCR 7号β链
<400> 70
atgagcaacc aggtgctctg ctgtgtggtc ctttgtttcc tgggagcaaa caccgtggat 60
ggtggaatca ctcagtcccc aaagtacctg ttcagaaagg aaggacagaa tgtgaccctg 120
agttgtgaac agaatttgaa ccacgatgcc atgtactggt accgacagga cccagggcaa 180
gggctgagat tgatctacta ctcacagata gtaaatgact ttcagaaagg agatatagct 240
gaagggtaca gcgtctctcg ggagaagaag gaatcctttc ctctcactgt gacatcggcc 300
caaaagaacc cgacagcttt ctatctctgt gccagtagcc tcaacagggg ccgctatggc 360
tacaccttcg gttcggggac caggttaacc gttgtagagg acctgaacaa ggtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttcttcccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtcagcacg gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acccgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gctttacctc ggtgtcctac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatcc tgctagggaa ggccaccctg tatgctgtgc tggtcagcgc ccttgtgttg 900
atggccatgg tcaagagaaa ggatttctga 930
<210> 71
<211> 309
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号β链
<400> 71
Met Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys Phe Leu Gly Ala
1 5 10 15
Asn Thr Val Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg
20 25 30
Lys Glu Gly Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His
35 40 45
Asp Ala Met Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu
50 55 60
Ile Tyr Tyr Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala
65 70 75 80
Glu Gly Tyr Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr
85 90 95
Val Thr Ser Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser
100 105 110
Ser Leu Asn Arg Gly Arg Tyr Gly Tyr Thr Phe Gly Ser Gly Thr Arg
115 120 125
Leu Thr Val Val Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe
305
<210> 72
<211> 1490
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 7号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 72
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgagcaac caggtcttgt 60
gctgtgtggt gctgtgcttt cttggcgcca atacagtgga tggcggcatt acacagagcc 120
ctaagtacct gttccggaaa gaaggccaga acgtgacact gtcttgcgag caaaacctga 180
accacgatgc catgtactgg tacagacagg atcctggaca gggacttagg ctgatctact 240
atagccagat cgtgaacgac ttccagaagg gcgatattgc cgagggctat tctgtgtctc 300
gggagaaaaa ggagagcttc cctctgacag tgacatctgc ccagaagaat cctaccgcct 360
tctacctttg tgccagctct ctgaatcggg gcagatacgg atacaccttt ggatctggca 420
ccagactgac agtggtggaa gatctgaaca aggtgttccc cccagaggtg gccgtgttcg 480
agccttctga ggccgagatc tcccacaccc agaaagccac cctcgtgtgc ctggccaccg 540
gctttttccc cgaccacgtg gaactgtctt ggtgggtcaa cggcaaagag gtgcactccg 600
gcgtgtgcac cgatccccag cctctgaaag aacagcccgc cctgaacgac agccggtact 660
gcctgagcag cagactgaga gtgtccgcca ccttctggca gaacccccgg aaccacttca 720
gatgccaggt gcagttctac ggcctgagcg agaacgacga gtggacccag gacagagcca 780
agcccgtgac acagatcgtg tctgccgaag cctggggcag agccgattgc ggctttacct 840
ccgtgtccta tcagcagggc gtgctgagcg ccacaatcct gtacgagatc ctgctgggca 900
aggccaccct gtacgccgtg ctggtgtctg ccctggtgct gatggccatg gtcaagcgga 960
aggacttcgg ttccggagcc acgaacttct ctctgttaaa gcaagcagga gacgtggaag 1020
aaaaccccgg tcccatggag aagaaccccc ttgcagcacc tctgcttatt ctgtggttcc 1080
acctggattg cgtgagctct atcctgaatg tggagcagtc tcctcagtct ctgcatgttc 1140
aggaaggcga tagcaccaac ttcacctgta gctttcccag cagcaacttc tatgccctgc 1200
actggtacag atgggaaaca gccaaaagcc ctgaagccct gttcgtgatg acccttaatg 1260
gcgatgagaa gaagaagggc cggatttctg ccaccctgaa tacaaaagag ggctacagct 1320
acctgtacat caagggatct cagcctgagg atagcgccac atatctgtgt gcctatctgg 1380
gagccggcaa tcagttctat ttcggaacag gcaccagcct gaccgtgatt cctaatatcc 1440
agaaccccga tcctgccgtg taccagctgc gggacagcaa gagcagcgac 1490
<210> 73
<211> 494
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 7号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 73
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Ser Asn Gln Val
1 5 10 15
Leu Cys Cys Val Val Leu Cys Phe Leu Gly Ala Asn Thr Val Asp Gly
20 25 30
Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys Glu Gly Gln Asn
35 40 45
Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met Tyr Trp
50 55 60
Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile Tyr Tyr Ser Gln
65 70 75 80
Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Gly Tyr Ser Val
85 90 95
Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val Thr Ser Ala Gln
100 105 110
Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser Leu Asn Arg Gly
115 120 125
Arg Tyr Gly Tyr Thr Phe Gly Ser Gly Thr Arg Leu Thr Val Val Glu
130 135 140
Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
145 150 155 160
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
165 170 175
Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
180 185 190
Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu
195 200 205
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
210 215 220
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
225 230 235 240
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
245 250 255
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
260 265 270
Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln Gly Val Leu Ser Ala
275 280 285
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
290 295 300
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Phe
305 310 315 320
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
325 330 335
Glu Glu Asn Pro Gly Pro Met Glu Lys Asn Pro Leu Ala Ala Pro Leu
340 345 350
Leu Ile Leu Trp Phe His Leu Asp Cys Val Ser Ser Ile Leu Asn Val
355 360 365
Glu Gln Ser Pro Gln Ser Leu His Val Gln Glu Gly Asp Ser Thr Asn
370 375 380
Phe Thr Cys Ser Phe Pro Ser Ser Asn Phe Tyr Ala Leu His Trp Tyr
385 390 395 400
Arg Trp Glu Thr Ala Lys Ser Pro Glu Ala Leu Phe Val Met Thr Leu
405 410 415
Asn Gly Asp Glu Lys Lys Lys Gly Arg Ile Ser Ala Thr Leu Asn Thr
420 425 430
Lys Glu Gly Tyr Ser Tyr Leu Tyr Ile Lys Gly Ser Gln Pro Glu Asp
435 440 445
Ser Ala Thr Tyr Leu Cys Ala Tyr Leu Gly Ala Gly Asn Gln Phe Tyr
450 455 460
Phe Gly Thr Gly Thr Ser Leu Thr Val Ile Pro Asn Ile Gln Asn Pro
465 470 475 480
Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp
485 490
<210> 74
<211> 837
<212> DNA
<213> 人工序列
<220>
<223> TCR 8号α链
<400> 74
atgctgactg ccagcctgtt gagggcagtc atagcctcca tctgtgttgt atccagcatg 60
gctcagaagg taactcaagc gcagactgaa atttctgtgg tggagaagga ggatgtgacc 120
ttggactgtg tgtatgaaac ccgtgatact acttattact tattctggta caagcaacca 180
ccaagtggag aattggtttt ccttattcgt cggaactctt ttgatgagca aaatgaaata 240
agtggtcggt attcttggaa cttccagaaa tccaccagtt ccttcaactt caccatcaca 300
gcctcacaag tcgtggactc agcagtatac ttctgtgctc tgagtgagct agcatcagga 360
ggaagctaca tacctacatt tggaagagga accagcctta ttgttcatcc gtatatccag 420
aaccctgacc ctgccgtgta ccagctgaga gactctaaat ccagtgacaa gtctgtctgc 480
ctattcaccg attttgattc tcaaacaaat gtgtcacaaa gtaaggattc tgatgtgtat 540
atcacagaca aaactgtgct agacatgagg tctatggact tcaagagcaa cagtgctgtg 600
gcctggagca acaaatctga ctttgcatgt gcaaacgcct tcaacaacag cattattcca 660
gaagacacct tcttccccag cccagaaagt tcctgtgatg tcaagctggt cgagaaaagc 720
tttgaaacag atacgaacct aaactttcaa aacctgtcag tgattgggtt ccgaatcctc 780
ctcctgaaag tggccgggtt taatctgctc atgacgctgc ggctgtggtc cagctga 837
<210> 75
<211> 278
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号α链
<400> 75
Met Leu Thr Ala Ser Leu Leu Arg Ala Val Ile Ala Ser Ile Cys Val
1 5 10 15
Val Ser Ser Met Ala Gln Lys Val Thr Gln Ala Gln Thr Glu Ile Ser
20 25 30
Val Val Glu Lys Glu Asp Val Thr Leu Asp Cys Val Tyr Glu Thr Arg
35 40 45
Asp Thr Thr Tyr Tyr Leu Phe Trp Tyr Lys Gln Pro Pro Ser Gly Glu
50 55 60
Leu Val Phe Leu Ile Arg Arg Asn Ser Phe Asp Glu Gln Asn Glu Ile
65 70 75 80
Ser Gly Arg Tyr Ser Trp Asn Phe Gln Lys Ser Thr Ser Ser Phe Asn
85 90 95
Phe Thr Ile Thr Ala Ser Gln Val Val Asp Ser Ala Val Tyr Phe Cys
100 105 110
Ala Leu Ser Glu Leu Ala Ser Gly Gly Ser Tyr Ile Pro Thr Phe Gly
115 120 125
Arg Gly Thr Ser Leu Ile Val His Pro Tyr Ile Gln Asn Pro Asp Pro
130 135 140
Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys
145 150 155 160
Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp
165 170 175
Ser Asp Val Tyr Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met
180 185 190
Asp Phe Lys Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe
195 200 205
Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe
210 215 220
Phe Pro Ser Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser
225 230 235 240
Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly
245 250 255
Phe Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr
260 265 270
Leu Arg Leu Trp Ser Ser
275
<210> 76
<211> 948
<212> DNA
<213> 人工序列
<220>
<223> TCR 8号β链
<400> 76
atgggccccg ggctcctctg ctgggcactg ctttgtctcc tgggagcagg cttagtggac 60
gctggagtca cccaaagtcc cacacacctg atcaaaacga gaggacagca agtgactctg 120
agatgctctc ctaagtctgg gcatgacact gtgtcctggt accaacaggc cctgggtcag 180
gggccccagt ttatctttca gtattatgag gaggaagaga gacagagagg caacttccct 240
gatcgattct caggtcacca gttccctaac tatagctctg agctgaatgt gaacgccttg 300
ttgctggggg actcggccct ctatctctgt gccagcagct ttaggctagc gggggggcct 360
agcacagata cgcagtattt tggcccaggc acccggctga cagtgctcga ggacctgaaa 420
aacgtgttcc cacccgaggt cgctgtgttt gagccatcag aagcagagat ctcccacacc 480
caaaaggcca cactggtgtg cctggccaca ggcttctacc ccgaccacgt ggagctgagc 540
tggtgggtga atgggaagga ggtgcacagt ggggtcagca cagacccgca gcccctcaag 600
gagcagcccg ccctcaatga ctccagatac tgcctgagca gccgcctgag ggtctcggcc 660
accttctggc agaacccccg caaccacttc cgctgtcaag tccagttcta cgggctctcg 720
gagaatgacg agtggaccca ggatagggcc aaacctgtca cccagatcgt cagcgccgag 780
gcctggggta gagcagactg tggcttcacc tccgagtctt accagcaagg ggtcctgtct 840
gccaccatcc tctatgagat cttgctaggg aaggccacct tgtatgccgt gctggtcagt 900
gccctcgtgc tgatggccat ggtcaagaga aaggattcca gaggctag 948
<210> 77
<211> 315
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号β链
<400> 77
Met Gly Pro Gly Leu Leu Cys Trp Ala Leu Leu Cys Leu Leu Gly Ala
1 5 10 15
Gly Leu Val Asp Ala Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys
20 25 30
Thr Arg Gly Gln Gln Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His
35 40 45
Asp Thr Val Ser Trp Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe
50 55 60
Ile Phe Gln Tyr Tyr Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro
65 70 75 80
Asp Arg Phe Ser Gly His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn
85 90 95
Val Asn Ala Leu Leu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser
100 105 110
Ser Phe Arg Leu Ala Gly Gly Pro Ser Thr Asp Thr Gln Tyr Phe Gly
115 120 125
Pro Gly Thr Arg Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro
130 135 140
Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr
145 150 155 160
Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
165 170 175
Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val
180 185 190
Ser Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser
195 200 205
Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
210 215 220
Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
225 230 235 240
Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
245 250 255
Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu
260 265 270
Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
275 280 285
Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
290 295 300
Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly
305 310 315
<210> 78
<211> 1520
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 8号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 78
ctcaataaaa gagcccacaa cccctcactc ggcgcgccac catgggacct ggactgcttt 60
gttgggctct tctgtgtctg cttggagctg gactggttga tgctggagtt acacagagcc 120
ctacacacct gatcaagaca agaggacagc aggtgaccct gagatgtagc cctaaatctg 180
gccacgatac cgtgagctgg tatcaacagg ctctgggaca aggacctcag ttcatcttcc 240
agtactacga ggaggaggag agacagagag gcaatttccc tgacaggttt agcggacacc 300
agttccccaa ttacagctct gagctgaacg tgaatgccct tcttctggga gattctgccc 360
tgtatctgtg tgccagcagc tttagactgg ctggaggacc tagcaccgat acacagtatt 420
ttggacctgg caccaggctg acagtgttag aagacctgaa gaacgtgttc cccccagagg 480
tggccgtgtt cgagcctagc gaggccgaga tcagccacac ccagaaagcc accctcgtgt 540
gcctggccac cggcttttac cccgaccacg tggaactgtc ttggtgggtc aacggcaaag 600
aggtgcacag cggcgtctgc accgaccccc agcccctgaa agagcagccc gccctgaacg 660
acagccggta ctgtctgagc agcagactga gagtgtccgc caccttctgg cagaaccccc 720
ggaaccactt cagatgccag gtgcagttct acggcctgag cgagaacgac gagtggaccc 780
aggaccgggc caagcccgtg acccagatcg tgtctgctga ggcctggggc agagccgatt 840
gcggcttcac cagcgagagc taccagcagg gcgtgctgag cgccaccatc ctgtacgaga 900
tcctgctggg caaggccacc ctgtacgccg tgctggtgtc cgccctggtg ctgatggcca 960
tggtcaagcg gaaggacagc cggggcggtt ccggagccac gaacttctct ctgttaaagc 1020
aagcaggaga cgtggaagaa aaccccggtc ccatgttgac cgcttctctc ttacgtgccg 1080
tgattgccag catctgtgtg gttagctcta tggcccagaa ggtgacacaa gctcagacag 1140
agatcagcgt ggtggagaaa gaggatgtga ccctggattg cgtgtacgag accagagata 1200
ccacctacta cctgttctgg tacaagcagc ctccttctgg agaactggtg ttcctgatca 1260
gacggaacag cttcgatgag cagaacgaga ttagcggcag gtatagctgg aacttccaga 1320
agagcaccag cagcttcaac ttcaccatca cagcctctca ggtggtggat tctgccgtgt 1380
acttttgtgc cctgtctgaa ctggcctctg gaggaagcta tatccctaca ttcggcagag 1440
gcacaagcct gattgtgcac ccttacatcc agaaccctga tcctgctgtg taccagctgc 1500
gggacagcaa gagcagcgac 1520
<210> 79
<211> 504
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 8号构建体
多肽;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 79
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Gly Pro Gly Leu
1 5 10 15
Leu Cys Trp Ala Leu Leu Cys Leu Leu Gly Ala Gly Leu Val Asp Ala
20 25 30
Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys Thr Arg Gly Gln Gln
35 40 45
Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His Asp Thr Val Ser Trp
50 55 60
Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe Ile Phe Gln Tyr Tyr
65 70 75 80
Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro Asp Arg Phe Ser Gly
85 90 95
His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn Val Asn Ala Leu Leu
100 105 110
Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser Ser Phe Arg Leu Ala
115 120 125
Gly Gly Pro Ser Thr Asp Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu
130 135 140
Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val
145 150 155 160
Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu
165 170 175
Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp
180 185 190
Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln
195 200 205
Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser
210 215 220
Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His
225 230 235 240
Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp
245 250 255
Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala
260 265 270
Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly
275 280 285
Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr
290 295 300
Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
305 310 315 320
Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu
325 330 335
Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Leu Thr Ala
340 345 350
Ser Leu Leu Arg Ala Val Ile Ala Ser Ile Cys Val Val Ser Ser Met
355 360 365
Ala Gln Lys Val Thr Gln Ala Gln Thr Glu Ile Ser Val Val Glu Lys
370 375 380
Glu Asp Val Thr Leu Asp Cys Val Tyr Glu Thr Arg Asp Thr Thr Tyr
385 390 395 400
Tyr Leu Phe Trp Tyr Lys Gln Pro Pro Ser Gly Glu Leu Val Phe Leu
405 410 415
Ile Arg Arg Asn Ser Phe Asp Glu Gln Asn Glu Ile Ser Gly Arg Tyr
420 425 430
Ser Trp Asn Phe Gln Lys Ser Thr Ser Ser Phe Asn Phe Thr Ile Thr
435 440 445
Ala Ser Gln Val Val Asp Ser Ala Val Tyr Phe Cys Ala Leu Ser Glu
450 455 460
Leu Ala Ser Gly Gly Ser Tyr Ile Pro Thr Phe Gly Arg Gly Thr Ser
465 470 475 480
Leu Ile Val His Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln
485 490 495
Leu Arg Asp Ser Lys Ser Ser Asp
500
<210> 80
<211> 1836
<212> DNA
<213> 人工序列
<220>
<223> TCR 4号构建体; β链-P2A-α链
<400> 80
accatgggca ccaggctcct cttctgggtg gccttctgtc tcctgggggc agatcacaca 60
ggagctggag tctcccagtc ccccagtaac aaggtcacag agaagggaaa ggatgtagag 120
ctcaggtgtg atccaatttc aggtcatact gccctttact ggtaccgaca gagcctgggg 180
cagggcctgg agtttttaat ttacttccaa ggcaacagtg caccagacaa atcagggctg 240
cccagtgatc gcttctctgc agagaggact gggggatccg tctccactct gacgatccag 300
cgcacacagc aggaggactc ggccgtgtat ctctgtgcca gcagcttagt ggtcggctcc 360
tacgagcagt acttcgggcc gggcaccagg ctcacggtca cagaggacct gaaaaacgtg 420
ttcccacccg aggtcgctgt gtttgagcca tcagaagcag agatctccca cacccaaaag 480
gccacactgg tgtgcctggc cacaggcttc taccccgacc acgtggagct gagctggtgg 540
gtgaatggga aggaggtgca cagtggggtc agcacagacc cgcagcccct caaggagcag 600
cccgccctca atgactccag atactgcctg agcagccgcc tgagggtctc ggccaccttc 660
tggcagaacc cccgcaacca cttccgctgt caagtccagt tctacgggct ctcggagaat 720
gacgagtgga cccaggatag ggccaaacct gtcacccaga tcgtcagcgc cgaggcctgg 780
ggtagagcag actgtggctt cacctccgag tcttaccagc aaggggtcct gtctgccacc 840
atcctctatg agatcttgct agggaaggcc accttgtatg ccgtgctggt cagtgccctc 900
gtgctgatgg ccatggtcaa gagaaaggat tccagaggcg gttccggagc cacgaacttc 960
tctctgttaa agcaagcagg agacgtggaa gaaaaccccg gtcccatgga aactctcctg 1020
ggagtgtctt tggtgattct atggcttcaa ctggctaggg tgaacagtca acagggagaa 1080
gaggatcctc aggccttgag catccaggag ggtgaaaatg ccaccatgaa ctgcagttac 1140
aaaactagta taaacaattt acagtggtat agacaaaatt caggtagagg ccttgtccac 1200
ctaattttaa tacgttcaaa tgaaagagag aaacacagtg gaagattaag agtcacgctt 1260
gacacttcca agaaaagcag ttccttgttg atcacggctt cccgggcagc agacactgct 1320
tcttacttct gtgctacgga cgcgtgggaa tctaactttg gaaatgagaa attaaccttt 1380
gggactggaa caagactcac catcataccc aatatccaga accctgaccc tgccgtgtac 1440
cagctgagag actctaaatc cagtgacaag tctgtctgcc tattcaccga ttttgattct 1500
caaacaaatg tgtcacaaag taaggattct gatgtgtata tcacagacaa aactgtgcta 1560
gacatgaggt ctatggactt caagagcaac agtgctgtgg cctggagcaa caaatctgac 1620
tttgcatgtg caaacgcctt caacaacagc attattccag aagacacctt cttccccagc 1680
ccagaaagtt cctgtgatgt caagctggtc gagaaaagct ttgaaacaga tacgaaccta 1740
aactttcaaa acctgtcagt gattgggttc cgaatcctcc tcctgaaagt ggccgggttt 1800
aatctgctca tgacgctgcg gctgtggtcc agctga 1836
<210> 81
<211> 611
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号构建体; β链-P2A-α链
<400> 81
Thr Met Gly Thr Arg Leu Leu Phe Trp Val Ala Phe Cys Leu Leu Gly
1 5 10 15
Ala Asp His Thr Gly Ala Gly Val Ser Gln Ser Pro Ser Asn Lys Val
20 25 30
Thr Glu Lys Gly Lys Asp Val Glu Leu Arg Cys Asp Pro Ile Ser Gly
35 40 45
His Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Leu Glu
50 55 60
Phe Leu Ile Tyr Phe Gln Gly Asn Ser Ala Pro Asp Lys Ser Gly Leu
65 70 75 80
Pro Ser Asp Arg Phe Ser Ala Glu Arg Thr Gly Gly Ser Val Ser Thr
85 90 95
Leu Thr Ile Gln Arg Thr Gln Gln Glu Asp Ser Ala Val Tyr Leu Cys
100 105 110
Ala Ser Ser Leu Val Val Gly Ser Tyr Glu Gln Tyr Phe Gly Pro Gly
115 120 125
Thr Arg Leu Thr Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu
130 135 140
Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys
145 150 155 160
Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu
165 170 175
Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr
180 185 190
Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr
195 200 205
Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro
210 215 220
Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn
225 230 235 240
Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser
245 250 255
Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr
260 265 270
Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly
275 280 285
Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala
290 295 300
Met Val Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe
305 310 315 320
Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met
325 330 335
Glu Thr Leu Leu Gly Val Ser Leu Val Ile Leu Trp Leu Gln Leu Ala
340 345 350
Arg Val Asn Ser Gln Gln Gly Glu Glu Asp Pro Gln Ala Leu Ser Ile
355 360 365
Gln Glu Gly Glu Asn Ala Thr Met Asn Cys Ser Tyr Lys Thr Ser Ile
370 375 380
Asn Asn Leu Gln Trp Tyr Arg Gln Asn Ser Gly Arg Gly Leu Val His
385 390 395 400
Leu Ile Leu Ile Arg Ser Asn Glu Arg Glu Lys His Ser Gly Arg Leu
405 410 415
Arg Val Thr Leu Asp Thr Ser Lys Lys Ser Ser Ser Leu Leu Ile Thr
420 425 430
Ala Ser Arg Ala Ala Asp Thr Ala Ser Tyr Phe Cys Ala Thr Asp Ala
435 440 445
Trp Glu Ser Asn Phe Gly Asn Glu Lys Leu Thr Phe Gly Thr Gly Thr
450 455 460
Arg Leu Thr Ile Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr
465 470 475 480
Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr
485 490 495
Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val
500 505 510
Tyr Ile Thr Asp Lys Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys
515 520 525
Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
530 535 540
Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser
545 550 555 560
Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr
565 570 575
Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile
580 585 590
Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu
595 600 605
Trp Ser Ser
610
<210> 82
<211> 1837
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 4号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 82
caccatgggc accagactgc tgttctgggt ggccttctgt ctgctgggcg ccgatcatac 60
aggcgctggc gtgtcccaga gccccagcaa caaagtgacc gagaagggca aggacgtgga 120
actgagatgc gaccccatca gcggccacac cgccctgtac tggtacagac agtctctggg 180
ccagggcctg gaattcctga tatattttca gggcaacagc gcccctgaca agagcggcct 240
gccctccgat agattcagcg ccgagagaac aggcggcagc gtgtccaccc tgaccatcca 300
gagaacccag caggaagata gcgccgtgta cctgtgcgcc agcagcctgg tcgtgggcag 360
ctacgagcag tactttggcc caggcacccg gctgaccgtg accgaggatc tgaagaacgt 420
gttcccccca gaggtggccg tgttcgagcc ttctgaggcc gagatcagcc acacccagaa 480
agccaccctc gtgtgtctgg ccaccggctt ctaccccgac catgtggaac tgtcttggtg 540
ggtcaacggc aaagaggtgc actccggcgt gtgcaccgat ccccagcctc tgaaagaaca 600
gcccgccctg aacgacagcc ggtactgcct gagcagcaga ctgagagtgt ccgccacctt 660
ctggcagaac ccccggaacc acttcagatg ccaggtgcag ttctacggcc tgagcgagaa 720
cgacgagtgg acccaggaca gagccaagcc cgtgacccag atcgtgtctg ccgaagcctg 780
gggcagagcc gattgcggct ttaccagcga gagctaccag cagggcgtgc tgagcgccac 840
catcctgtac gagattctgc tgggaaaggc cacactgtac gccgtgctgg tgtctgccct 900
ggtgctgatg gccatggtca agcggaagga cagcagaggc ggttccggag ccacgaactt 960
ctctctgtta aagcaagcag gagacgtgga agaaaacccc ggtcccatgg aaaccctgct 1020
gggagtgtcc ctcgtgatcc tgtggctgca gctggccaga gtgaacagcc agcaggggga 1080
agaggatcca caggccctga gcattcagga aggcgagaac gccaccatga actgcagcta 1140
caagaccagc atcaacaacc tgcagtggta caggcagaac tccggcagag gcctggtgca 1200
cctgatcctg atcagaagca acgagagaga gaagcacagc ggacggctga gagtgaccct 1260
ggacacctcc aagaagtcca gctccctgct gatcaccgcc agcagagccg ccgataccgc 1320
cagctacttc tgtgccacag acgcctggga gagcaacttc ggcaacgaga agctgacctt 1380
cggcaccggc acaagactga ccatcatccc caacatccag aaccccgacc ccgccgtgta 1440
tcagctgaga gacagcaaga gcagcgacaa gtccgtgtgc ctgttcaccg acttcgacag 1500
ccagaccaat gtgtcccagt ccaaggacag cgacgtgtac atcaccgata agtgcgtgct 1560
ggacatgcgc agcatggact tcaagagcaa ctccgccgtg gcctggtcca acaagagcga 1620
tttcgcctgc gccaacgcct tcaacaacag cattatcccc gaggacacat tcttcccaag 1680
ccccgagagc agctgcgacg tgaagctggt ggaaaagagc ttcgagacag acaccaacct 1740
gaacttccag aacctgagcg tgatcggctt ccggatcctg ctgctgaagg tggccggctt 1800
caacctgctg atgaccctga gactgtggtc cagctga 1837
<210> 83
<211> 611
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 4号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 83
Thr Met Gly Thr Arg Leu Leu Phe Trp Val Ala Phe Cys Leu Leu Gly
1 5 10 15
Ala Asp His Thr Gly Ala Gly Val Ser Gln Ser Pro Ser Asn Lys Val
20 25 30
Thr Glu Lys Gly Lys Asp Val Glu Leu Arg Cys Asp Pro Ile Ser Gly
35 40 45
His Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Leu Glu
50 55 60
Phe Leu Ile Tyr Phe Gln Gly Asn Ser Ala Pro Asp Lys Ser Gly Leu
65 70 75 80
Pro Ser Asp Arg Phe Ser Ala Glu Arg Thr Gly Gly Ser Val Ser Thr
85 90 95
Leu Thr Ile Gln Arg Thr Gln Gln Glu Asp Ser Ala Val Tyr Leu Cys
100 105 110
Ala Ser Ser Leu Val Val Gly Ser Tyr Glu Gln Tyr Phe Gly Pro Gly
115 120 125
Thr Arg Leu Thr Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu
130 135 140
Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys
145 150 155 160
Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu
165 170 175
Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr
180 185 190
Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr
195 200 205
Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro
210 215 220
Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn
225 230 235 240
Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser
245 250 255
Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr
260 265 270
Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly
275 280 285
Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala
290 295 300
Met Val Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe
305 310 315 320
Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met
325 330 335
Glu Thr Leu Leu Gly Val Ser Leu Val Ile Leu Trp Leu Gln Leu Ala
340 345 350
Arg Val Asn Ser Gln Gln Gly Glu Glu Asp Pro Gln Ala Leu Ser Ile
355 360 365
Gln Glu Gly Glu Asn Ala Thr Met Asn Cys Ser Tyr Lys Thr Ser Ile
370 375 380
Asn Asn Leu Gln Trp Tyr Arg Gln Asn Ser Gly Arg Gly Leu Val His
385 390 395 400
Leu Ile Leu Ile Arg Ser Asn Glu Arg Glu Lys His Ser Gly Arg Leu
405 410 415
Arg Val Thr Leu Asp Thr Ser Lys Lys Ser Ser Ser Leu Leu Ile Thr
420 425 430
Ala Ser Arg Ala Ala Asp Thr Ala Ser Tyr Phe Cys Ala Thr Asp Ala
435 440 445
Trp Glu Ser Asn Phe Gly Asn Glu Lys Leu Thr Phe Gly Thr Gly Thr
450 455 460
Arg Leu Thr Ile Ile Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr
465 470 475 480
Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr
485 490 495
Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val
500 505 510
Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys
515 520 525
Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala
530 535 540
Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser
545 550 555 560
Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr
565 570 575
Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile
580 585 590
Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu
595 600 605
Trp Ser Ser
610
<210> 84
<211> 178
<212> PRT
<213> 人工序列
<220>
<223> TCRβ2恒定结构域
<400> 84
Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
1 5 10 15
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
20 25 30
Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
35 40 45
Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys Glu
50 55 60
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
65 70 75 80
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
85 90 95
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
100 105 110
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
115 120 125
Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala
130 135 140
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
145 150 155 160
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser
165 170 175
Arg Gly
<210> 85
<211> 335
<212> PRT
<213> 人工序列
<220>
<223> 截短的EGFR多肽缺乏信号肽
<400> 85
Arg Lys Val Cys Asn Gly Ile Gly Ile Gly Glu Phe Lys Asp Ser Leu
1 5 10 15
Ser Ile Asn Ala Thr Asn Ile Lys His Phe Lys Asn Cys Thr Ser Ile
20 25 30
Ser Gly Asp Leu His Ile Leu Pro Val Ala Phe Arg Gly Asp Ser Phe
35 40 45
Thr His Thr Pro Pro Leu Asp Pro Gln Glu Leu Asp Ile Leu Lys Thr
50 55 60
Val Lys Glu Ile Thr Gly Phe Leu Leu Ile Gln Ala Trp Pro Glu Asn
65 70 75 80
Arg Thr Asp Leu His Ala Phe Glu Asn Leu Glu Ile Ile Arg Gly Arg
85 90 95
Thr Lys Gln His Gly Gln Phe Ser Leu Ala Val Val Ser Leu Asn Ile
100 105 110
Thr Ser Leu Gly Leu Arg Ser Leu Lys Glu Ile Ser Asp Gly Asp Val
115 120 125
Ile Ile Ser Gly Asn Lys Asn Leu Cys Tyr Ala Asn Thr Ile Asn Trp
130 135 140
Lys Lys Leu Phe Gly Thr Ser Gly Gln Lys Thr Lys Ile Ile Ser Asn
145 150 155 160
Arg Gly Glu Asn Ser Cys Lys Ala Thr Gly Gln Val Cys His Ala Leu
165 170 175
Cys Ser Pro Glu Gly Cys Trp Gly Pro Glu Pro Arg Asp Cys Val Ser
180 185 190
Cys Arg Asn Val Ser Arg Gly Arg Glu Cys Val Asp Lys Cys Asn Leu
195 200 205
Leu Glu Gly Glu Pro Arg Glu Phe Val Glu Asn Ser Glu Cys Ile Gln
210 215 220
Cys His Pro Glu Cys Leu Pro Gln Ala Met Asn Ile Thr Cys Thr Gly
225 230 235 240
Arg Gly Pro Asp Asn Cys Ile Gln Cys Ala His Tyr Ile Asp Gly Pro
245 250 255
His Cys Val Lys Thr Cys Pro Ala Gly Val Met Gly Glu Asn Asn Thr
260 265 270
Leu Val Trp Lys Tyr Ala Asp Ala Gly His Val Cys His Leu Cys His
275 280 285
Pro Asn Cys Thr Tyr Gly Cys Thr Gly Pro Gly Leu Glu Gly Cys Pro
290 295 300
Thr Asn Gly Pro Lys Ile Pro Ser Ile Ala Thr Gly Met Val Gly Ala
305 310 315 320
Leu Leu Leu Leu Leu Val Val Ala Leu Gly Ile Gly Leu Phe Met
325 330 335
<210> 86
<211> 497
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 6号构建体;在β和α链恒定结构域(部分序列)中有半胱氨酸取代的β链-P2A-α链
<400> 86
Lys Ser Pro Gln Pro Leu Thr Arg Arg Ala Thr Met Ser Ile Ser Leu
1 5 10 15
Leu Cys Cys Ala Ala Phe Pro Leu Leu Trp Ala Gly Pro Val Asn Ala
20 25 30
Gly Val Thr Gln Thr Pro Lys Phe Arg Ile Leu Lys Ile Gly Gln Ser
35 40 45
Met Thr Leu Gln Cys Thr Gln Asp Met Asn His Asn Tyr Met Tyr Trp
50 55 60
Tyr Arg Gln Asp Pro Gly Met Gly Leu Lys Leu Ile Tyr Tyr Ser Val
65 70 75 80
Gly Ala Gly Ile Thr Asp Lys Gly Glu Val Pro Asn Gly Tyr Asn Val
85 90 95
Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg Leu Glu Leu Ala Ala
100 105 110
Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser Ser Asp Arg Ser Asn
115 120 125
Thr Gly Glu Leu Phe Phe Gly Glu Gly Ser Arg Leu Thr Val Leu Glu
130 135 140
Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
145 150 155 160
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
165 170 175
Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
180 185 190
Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys Glu
195 200 205
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
210 215 220
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
225 230 235 240
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
245 250 255
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
260 265 270
Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala
275 280 285
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
290 295 300
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser
305 310 315 320
Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly
325 330 335
Asp Val Glu Glu Asn Pro Gly Pro Met Glu Lys Asn Pro Leu Ala Ala
340 345 350
Pro Leu Leu Ile Leu Trp Phe His Leu Asp Cys Val Ser Ser Ile Leu
355 360 365
Asn Val Glu Gln Ser Pro Gln Ser Leu His Val Gln Glu Gly Asp Ser
370 375 380
Thr Asn Phe Thr Cys Ser Phe Pro Ser Ser Asn Phe Tyr Ala Leu His
385 390 395 400
Trp Tyr Arg Trp Glu Thr Ala Lys Ser Pro Glu Ala Leu Phe Val Met
405 410 415
Thr Leu Asn Gly Asp Glu Lys Lys Lys Gly Arg Ile Ser Ala Thr Leu
420 425 430
Asn Thr Lys Glu Gly Tyr Ser Tyr Leu Tyr Ile Lys Gly Ser Gln Pro
435 440 445
Glu Asp Ser Ala Thr Tyr Leu Cys Ala Leu Gly Pro Tyr Asn Asp Tyr
450 455 460
Lys Leu Ser Phe Gly Ala Gly Thr Thr Val Thr Val Arg Ala Asn Ile
465 470 475 480
Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser
485 490 495
Asp
<210> 87
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vα CDR1
<400> 87
Lys Ala Leu Tyr Ser
1 5
<210> 88
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vα CDR2
<400> 88
Leu Leu Lys Gly Gly Glu Gln
1 5
<210> 89
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vα CDR3
<400> 89
Gly Thr Glu Glu Ala Asn Asp Tyr Lys Leu Ser
1 5 10
<210> 90
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vα可变区
<400> 90
Gln Gln Pro Val Gln Ser Pro Gln Ala Val Ile Leu Arg Glu Gly Glu
1 5 10 15
Asp Ala Val Ile Asn Cys Ser Ser Ser Lys Ala Leu Tyr Ser Val His
20 25 30
Trp Tyr Arg Gln Lys His Gly Glu Ala Pro Val Phe Leu Met Ile Leu
35 40 45
Leu Lys Gly Gly Glu Gln Lys Gly His Glu Lys Ile Ser Ala Ser Phe
50 55 60
Asn Glu Lys Lys Gln Gln Ser Ser Leu Tyr Leu Thr Ala Ser Gln Leu
65 70 75 80
Ser Tyr Ser Gly Thr Tyr Phe Cys Gly Thr Glu Glu Ala Asn Asp Tyr
85 90 95
Lys Leu Ser Phe Gly Ala Gly Thr Thr Val Thr Val Arg
100 105
<210> 91
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vβ CDR1
<400> 91
Ser Gly Asp Leu Ser
1 5
<210> 92
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vβ CDR2
<400> 92
Tyr Tyr Asn Gly Glu Glu
1 5
<210> 93
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vβ CDR3
<400> 93
Ala Ser Ser Val Gly Gln Gly Ser Ser Tyr
1 5 10
<210> 94
<211> 114
<212> PRT
<213> 人工序列
<220>
<223> TCR 5号Vβ可变区
<400> 94
Asp Ser Gly Val Thr Gln Thr Pro Lys His Leu Ile Thr Ala Thr Gly
1 5 10 15
Gln Arg Val Thr Leu Arg Cys Ser Pro Arg Ser Gly Asp Leu Ser Val
20 25 30
Tyr Trp Tyr Gln Gln Ser Leu Asp Gln Gly Leu Gln Phe Leu Ile Gln
35 40 45
Tyr Tyr Asn Gly Glu Glu Arg Ala Lys Gly Asn Ile Leu Glu Arg Phe
50 55 60
Ser Ala Gln Gln Phe Pro Asp Leu His Ser Glu Leu Asn Leu Ser Ser
65 70 75 80
Leu Glu Leu Gly Asp Ser Ala Leu Tyr Phe Cys Ala Ser Ser Val Gly
85 90 95
Gln Gly Ser Ser Tyr Glu Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr
100 105 110
Val Thr
<210> 95
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号和TCR 11号Vα CDR1
<400> 95
Val Ser Pro Phe Ser Asn
1 5
<210> 96
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号和TCR 11号Vα CDR2
<400> 96
Thr Phe Ser Glu Asn Thr
1 5
<210> 97
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号和TCR 11号Vα CDR3
<400> 97
Val Val Trp Gly Gly Asp Thr Asp Lys Leu Ile
1 5 10
<210> 98
<211> 111
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号和TCR 11号Vα可变
区
<400> 98
Lys Asn Gln Val Glu Gln Ser Pro Gln Ser Leu Ile Ile Leu Glu Gly
1 5 10 15
Lys Asn Cys Thr Leu Gln Cys Asn Tyr Thr Val Ser Pro Phe Ser Asn
20 25 30
Leu Arg Trp Tyr Lys Gln Asp Thr Gly Arg Gly Pro Val Ser Leu Thr
35 40 45
Ile Met Thr Phe Ser Glu Asn Thr Lys Ser Asn Gly Arg Tyr Thr Ala
50 55 60
Thr Leu Asp Ala Asp Thr Lys Gln Ser Ser Leu His Ile Thr Ala Ser
65 70 75 80
Gln Leu Ser Asp Ser Ala Ser Tyr Ile Cys Val Val Trp Gly Gly Asp
85 90 95
Thr Asp Lys Leu Ile Phe Gly Thr Gly Thr Arg Leu Gln Val Phe
100 105 110
<210> 99
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号Vβ CDR1
<400> 99
Trp Ser His Ser Tyr
1 5
<210> 100
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号Vβ CDR2
<400> 100
Ser Ala Ala Ala Asp Ile
1 5
<210> 101
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号Vβ CDR3
<400> 101
Ala Ser Ser Asp Gly Gly Gly Gln Tyr
1 5
<210> 102
<211> 109
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号Vβ可变区
<400> 102
Asp Ala Gly Ile Thr Gln Ser Pro Arg Tyr Lys Ile Thr Glu Thr Gly
1 5 10 15
Arg Gln Val Thr Leu Met Cys His Gln Thr Trp Ser His Ser Tyr Met
20 25 30
Phe Trp Tyr Arg Gln Asp Leu Gly His Gly Leu Arg Leu Ile Tyr Tyr
35 40 45
Ser Ala Ala Ala Asp Ile Thr Asp Lys Gly Glu Val Pro Asp Gly Tyr
50 55 60
Val Val Ser Arg Ser Lys Thr Glu Asn Phe Pro Leu Thr Leu Glu Ser
65 70 75 80
Ala Thr Arg Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser Ser Asp Gly
85 90 95
Gly Gly Gln Tyr Phe Pro Gly Thr Arg Leu Thr Val Thr
100 105
<210> 103
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号和TCR 7号Vα CDR1
<400> 103
Ser Ser Asn Phe Tyr Ala
1 5
<210> 104
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vα CDR2
<400> 104
Met Thr Leu Asn Gly Asp Glu
1 5
<210> 105
<211> 13
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vα CDR3
<400> 105
Cys Ala Leu Gly Pro Tyr Asn Asp Tyr Lys Leu Ser Phe
1 5 10
<210> 106
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vα可变区
<400> 106
Ile Leu Asn Val Glu Gln Ser Pro Gln Ser Leu His Val Gln Glu Gly
1 5 10 15
Asp Ser Thr Asn Phe Thr Cys Ser Phe Pro Ser Ser Asn Phe Tyr Ala
20 25 30
Leu His Trp Tyr Arg Trp Glu Thr Ala Lys Ser Pro Glu Ala Leu Phe
35 40 45
Val Met Thr Leu Asn Gly Asp Glu Lys Lys Lys Gly Arg Ile Ser Ala
50 55 60
Thr Leu Asn Thr Lys Glu Gly Tyr Ser Tyr Leu Tyr Ile Lys Gly Ser
65 70 75 80
Gln Pro Glu Asp Ser Ala Thr Tyr Leu Cys Ala Leu Gly Pro Tyr Asn
85 90 95
Asp Tyr Lys Leu Ser Phe Gly Ala Gly Thr Thr Val Thr Val Arg Ala
100 105 110
<210> 107
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vβ CDR1
<400> 107
Met Asn His Asn Tyr
1 5
<210> 108
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vβ CDR2
<400> 108
Ser Val Gly Ala Gly Ile
1 5
<210> 109
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vβ CDR3
<400> 109
Ala Ser Ser Asp Arg Ser Asn Thr Gly Glu Leu Phe
1 5 10
<210> 110
<211> 113
<212> PRT
<213> 人工序列
<220>
<223> TCR 6号Vβ可变区
<400> 110
Asn Ala Gly Val Thr Gln Thr Pro Lys Phe Arg Ile Leu Lys Ile Gly
1 5 10 15
Gln Ser Met Thr Leu Gln Cys Thr Gln Asp Met Asn His Asn Tyr Met
20 25 30
Tyr Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Lys Leu Ile Tyr Tyr
35 40 45
Ser Val Gly Ala Gly Ile Thr Asp Lys Gly Glu Val Pro Asn Gly Tyr
50 55 60
Asn Val Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg Leu Glu Leu
65 70 75 80
Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser Ser Asp Arg
85 90 95
Ser Asn Thr Gly Glu Leu Phe Phe Gly Glu Gly Ser Arg Leu Thr Val
100 105 110
Leu
<210> 111
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号和TCR 2号Vα CDR1
<400> 111
Asp Ser Ala Ile Tyr Asn
1 5
<210> 112
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号和TCR 2号Vα CDR2
<400> 112
Ile Gln Ser Ser Gln Arg Glu
1 5
<210> 113
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号Vα CDR3
<400> 113
Ala Val Glu Gly Asp Ser Ser Tyr Lys Leu Ile
1 5 10
<210> 114
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号Vα可变区
<400> 114
Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val Pro Glu Gly
1 5 10 15
Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn
20 25 30
Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr Ser Leu Leu
35 40 45
Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala
50 55 60
Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser
65 70 75 80
Gln Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Glu Gly Asp Ser
85 90 95
Ser Tyr Lys Leu Ile Phe Gly Ser Gly Thr Arg Leu Leu Val Arg Pro
100 105 110
<210> 115
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号和TCR 8号Vβ CDR1
<400> 115
Ser Gly His Asp Thr
1 5
<210> 116
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号和TCR 8号Vβ CDR2
<400> 116
Tyr Tyr Glu Glu Glu Glu
1 5
<210> 117
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号Vβ CDR3
<400> 117
Ala Ser Ser Phe Phe Ser Gln Glu Thr Gln Tyr
1 5 10
<210> 118
<211> 112
<212> PRT
<213> 人工序列
<220>
<223> TCR 1号Vβ可变区
<400> 118
Asp Ala Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys Thr Arg Gly
1 5 10 15
Gln Gln Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His Asp Thr Val
20 25 30
Ser Trp Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe Ile Phe Gln
35 40 45
Tyr Tyr Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro Asp Arg Phe
50 55 60
Ser Gly His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn Val Asn Ala
65 70 75 80
Leu Leu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser Ser Phe Phe
85 90 95
Ser Gln Glu Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu Leu Val Leu
100 105 110
<210> 119
<211> 9
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号Vα CDR3
<400> 119
Ala Val Ile Gly Glu Gln Asn Phe Val
1 5
<210> 120
<211> 110
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号Vα可变区
<400> 120
Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val Pro Glu Gly
1 5 10 15
Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn
20 25 30
Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr Ser Leu Leu
35 40 45
Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala
50 55 60
Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser
65 70 75 80
Gln Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Ile Gly Glu Gln
85 90 95
Asn Phe Val Phe Gly Pro Gly Thr Arg Leu Ser Val Leu Pro
100 105 110
<210> 121
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号, TCR 3号,和TCR 10号
Vβ CDR1
<400> 121
Ser Gly His Thr Ala
1 5
<210> 122
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号, TCR 3号,和TCR 10号
Vβ CDR2
<400> 122
Phe Gln Gly Thr Gly Ala
1 5
<210> 123
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号Vβ CDR3
<400> 123
Ala Ser Ser Leu Ser Gly Leu Gly Ser Gly Ala Asn Val Leu Thr
1 5 10 15
<210> 124
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> TCR 2号Vβ可变区
<400> 124
Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr Glu Lys Gly
1 5 10 15
Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu
20 25 30
Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe Leu Ile Tyr
35 40 45
Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro Asn Asp Arg
50 55 60
Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu Lys Ile Gln
65 70 75 80
Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu
85 90 95
Ser Gly Leu Gly Ser Gly Ala Asn Val Leu Thr Phe Gly Ala Gly Ser
100 105 110
Arg Leu Thr Val Leu
115
<210> 125
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vα CDR1
<400> 125
Asp Arg Gly Ser Gln Ser
1 5
<210> 126
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vα CDR2
<400> 126
Ile Tyr Ser Asn Gly Asp
1 5
<210> 127
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vα CDR3
<400> 127
Ala Val Asp Ser Gly Gly Tyr Gln Lys Val Thr
1 5 10
<210> 128
<211> 110
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vα可变区
<400> 128
Gln Lys Glu Val Glu Gln Asn Ser Gly Pro Leu Ser Val Pro Glu Gly
1 5 10 15
Ala Ile Ala Ser Leu Asn Cys Thr Tyr Ser Asp Arg Gly Ser Gln Ser
20 25 30
Phe Phe Trp Tyr Arg Gln Tyr Ser Gly Lys Ser Pro Glu Leu Ile Met
35 40 45
Ser Ile Tyr Ser Asn Gly Asp Lys Glu Asp Gly Arg Phe Thr Ala Gln
50 55 60
Leu Asn Lys Ala Ser Gln Tyr Val Ser Leu Leu Ile Arg Asp Ser Gln
65 70 75 80
Pro Ser Asp Ser Ala Thr Tyr Leu Cys Ala Val Asp Ser Gly Gly Tyr
85 90 95
Gln Lys Val Thr Phe Gly Thr Gly Thr Lys Leu Gln Val Ile
100 105 110
<210> 129
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vβ CDR3
<400> 129
Ala Ser Ser Leu Asn Met Asn Thr Glu Ala Phe
1 5 10
<210> 130
<211> 113
<212> PRT
<213> 人工序列
<220>
<223> TCR 3号Vβ可变区
<400> 130
Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr Glu Lys Gly
1 5 10 15
Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu
20 25 30
Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe Leu Ile Tyr
35 40 45
Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro Asn Asp Arg
50 55 60
Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu Lys Ile Gln
65 70 75 80
Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu
85 90 95
Asn Met Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg Leu Thr Val
100 105 110
Val
<210> 131
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号和TCR 4号Vα CDR1
<400> 131
Thr Ser Ile Asn Asn
1 5
<210> 132
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号和TCR 4号Vα CDR2
<400> 132
Ile Arg Ser Asn Glu Arg Glu
1 5
<210> 133
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号Vα CDR3
<400> 133
Ala Thr Asp Glu Ser Ser Asn Tyr Lys Leu Thr
1 5 10
<210> 134
<211> 110
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号Vα可变区
<400> 134
Ser Gln Gln Gly Glu Glu Asp Pro Gln Ala Leu Ser Ile Gln Glu Gly
1 5 10 15
Glu Asn Ala Thr Met Asn Cys Ser Tyr Lys Thr Ser Ile Asn Asn Leu
20 25 30
Gln Trp Tyr Arg Gln Asn Ser Gly Arg Gly Leu Val His Leu Ile Leu
35 40 45
Ile Arg Ser Asn Glu Arg Glu Lys His Ser Gly Arg Leu Arg Val Thr
50 55 60
Leu Asp Thr Ser Lys Lys Ser Ser Ser Leu Leu Ile Thr Ala Ser Arg
65 70 75 80
Ala Ala Asp Thr Ala Ser Tyr Phe Cys Ala Thr Asp Glu Ser Ser Asn
85 90 95
Tyr Lys Leu Thr Phe Gly Lys Gly Thr Leu Leu Thr Val Asn
100 105 110
<210> 135
<211> 178
<212> PRT
<213> 人工序列
<220>
<223> TCRβ2恒定结构域,半胱氨酸修饰的
<400> 135
Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro Ser
1 5 10 15
Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu Ala
20 25 30
Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn Gly
35 40 45
Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys Glu
50 55 60
Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu Arg
65 70 75 80
Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys Gln
85 90 95
Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp Arg
100 105 110
Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg Ala
115 120 125
Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser Ala
130 135 140
Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala Val
145 150 155 160
Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp Ser
165 170 175
Arg Gly
<210> 136
<211> 113
<212> PRT
<213> 人工序列
<220>
<223> TCR 10号Vβ可变区
<400> 136
Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr Glu Lys Gly
1 5 10 15
Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu
20 25 30
Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe Leu Ile Tyr
35 40 45
Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro Asn Asp Arg
50 55 60
Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu Lys Ile Gln
65 70 75 80
Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu
85 90 95
Asn Met Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg Leu Thr Val
100 105 110
Val
<210> 137
<211> 15
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vα CDR3
<400> 137
Ala Thr Asp Ala Trp Glu Ser Asn Phe Gly Asn Glu Lys Leu Thr
1 5 10 15
<210> 138
<211> 114
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vα可变区
<400> 138
Ser Gln Gln Gly Glu Glu Asp Pro Gln Ala Leu Ser Ile Gln Glu Gly
1 5 10 15
Glu Asn Ala Thr Met Asn Cys Ser Tyr Lys Thr Ser Ile Asn Asn Leu
20 25 30
Gln Trp Tyr Arg Gln Asn Ser Gly Arg Gly Leu Val His Leu Ile Leu
35 40 45
Ile Arg Ser Asn Glu Arg Glu Lys His Ser Gly Arg Leu Arg Val Thr
50 55 60
Leu Asp Thr Ser Lys Lys Ser Ser Ser Leu Leu Ile Thr Ala Ser Arg
65 70 75 80
Ala Ala Asp Thr Ala Ser Tyr Phe Cys Ala Thr Asp Ala Trp Glu Ser
85 90 95
Asn Phe Gly Asn Glu Lys Leu Thr Phe Gly Thr Gly Thr Arg Leu Thr
100 105 110
Ile Ile
<210> 139
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vβ CDR2
<400> 139
Phe Gln Gly Asn Ser Ala
1 5
<210> 140
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vβ CDR3
<400> 140
Ala Ser Ser Leu Val Val Gly Ser Tyr Glu Gln Tyr
1 5 10
<210> 141
<211> 114
<212> PRT
<213> 人工序列
<220>
<223> TCR 4号Vβ可变区
<400> 141
Gly Ala Gly Val Ser Gln Ser Pro Ser Asn Lys Val Thr Glu Lys Gly
1 5 10 15
Lys Asp Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His Thr Ala Leu
20 25 30
Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Leu Glu Phe Leu Ile Tyr
35 40 45
Phe Gln Gly Asn Ser Ala Pro Asp Lys Ser Gly Leu Pro Ser Asp Arg
50 55 60
Phe Ser Ala Glu Arg Thr Gly Gly Ser Val Ser Thr Leu Thr Ile Gln
65 70 75 80
Arg Thr Gln Gln Glu Asp Ser Ala Val Tyr Leu Cys Ala Ser Ser Leu
85 90 95
Val Val Gly Ser Tyr Glu Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr
100 105 110
Val Thr
<210> 142
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vα CDR2
<400> 142
Met Thr Leu Asn Gly Asp Glu
1 5
<210> 143
<211> 10
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vα CDR3
<400> 143
Ala Tyr Leu Gly Ala Gly Asn Gln Phe Tyr
1 5 10
<210> 144
<211> 110
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vα可变区
<400> 144
Ile Leu Asn Val Glu Gln Ser Pro Gln Ser Leu His Val Gln Glu Gly
1 5 10 15
Asp Ser Thr Asn Phe Thr Cys Ser Phe Pro Ser Ser Asn Phe Tyr Ala
20 25 30
Leu His Trp Tyr Arg Trp Glu Thr Ala Lys Ser Pro Glu Ala Leu Phe
35 40 45
Val Met Thr Leu Asn Gly Asp Glu Lys Lys Lys Gly Arg Ile Ser Ala
50 55 60
Thr Leu Asn Thr Lys Glu Gly Tyr Ser Tyr Leu Tyr Ile Lys Gly Ser
65 70 75 80
Gln Pro Glu Asp Ser Ala Thr Tyr Leu Cys Ala Tyr Leu Gly Ala Gly
85 90 95
Asn Gln Phe Tyr Phe Gly Thr Gly Thr Ser Leu Thr Val Ile
100 105 110
<210> 145
<211> 5
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vβ CDR1
<400> 145
Leu Asn His Asp Ala
1 5
<210> 146
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vβ CDR2
<400> 146
Ser Gln Ile Val Asn Asp
1 5
<210> 147
<211> 12
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vβ CDR3
<400> 147
Ala Ser Ser Leu Asn Arg Gly Arg Tyr Gly Tyr Thr
1 5 10
<210> 148
<211> 113
<212> PRT
<213> 人工序列
<220>
<223> TCR 7号Vβ可变区
<400> 148
Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys Glu Gly
1 5 10 15
Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met
20 25 30
Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile Tyr Tyr
35 40 45
Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Gly Tyr
50 55 60
Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val Thr Ser
65 70 75 80
Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser Leu Asn
85 90 95
Arg Gly Arg Tyr Gly Tyr Thr Phe Gly Ser Gly Thr Arg Leu Thr Val
100 105 110
Val
<210> 149
<211> 7
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vα CDR1
<400> 149
Thr Arg Asp Thr Thr Tyr Tyr
1 5
<210> 150
<211> 8
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vα CDR2
<400> 150
Arg Asn Ser Phe Asp Glu Gln Asn
1 5
<210> 151
<211> 14
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vα CDR3
<400> 151
Ala Leu Ser Glu Leu Ala Ser Gly Gly Ser Tyr Ile Pro Thr
1 5 10
<210> 152
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vα可变区
<400> 152
Ala Gln Lys Val Thr Gln Ala Gln Thr Glu Ile Ser Val Val Glu Lys
1 5 10 15
Glu Asp Val Thr Leu Asp Cys Val Tyr Glu Thr Arg Asp Thr Thr Tyr
20 25 30
Tyr Leu Phe Trp Tyr Lys Gln Pro Pro Ser Gly Glu Leu Val Phe Leu
35 40 45
Ile Arg Arg Asn Ser Phe Asp Glu Gln Asn Glu Ile Ser Gly Arg Tyr
50 55 60
Ser Trp Asn Phe Gln Lys Ser Thr Ser Ser Phe Asn Phe Thr Ile Thr
65 70 75 80
Ala Ser Gln Val Val Asp Ser Ala Val Tyr Phe Cys Ala Leu Ser Glu
85 90 95
Leu Ala Ser Gly Gly Ser Tyr Ile Pro Thr Phe Gly Arg Gly Thr Ser
100 105 110
Leu Ile Val His Pro
115
<210> 153
<211> 16
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vβ CDR1
<400> 153
Ala Ser Ser Phe Arg Leu Ala Gly Gly Pro Ser Thr Asp Thr Gln Tyr
1 5 10 15
<210> 154
<211> 117
<212> PRT
<213> 人工序列
<220>
<223> TCR 8号Vβ可变区
<400> 154
Asp Ala Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys Thr Arg Gly
1 5 10 15
Gln Gln Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His Asp Thr Val
20 25 30
Ser Trp Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe Ile Phe Gln
35 40 45
Tyr Tyr Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro Asp Arg Phe
50 55 60
Ser Gly His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn Val Asn Ala
65 70 75 80
Leu Leu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser Ser Phe Arg
85 90 95
Leu Ala Gly Gly Pro Ser Thr Asp Thr Gln Tyr Phe Gly Pro Gly Thr
100 105 110
Arg Leu Thr Val Leu
115
<210> 155
<211> 177
<212> PRT
<213> 人工序列
<220>
<223> TCRβ1恒定结构域,半胱氨酸修饰的
<400> 155
Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro
1 5 10 15
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu
20 25 30
Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn
35 40 45
Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys
50 55 60
Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu
65 70 75 80
Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys
85 90 95
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp
100 105 110
Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg
115 120 125
Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln Gly Val Leu Ser
130 135 140
Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
145 150 155 160
Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp
165 170 175
Phe
<210> 156
<211> 141
<212> PRT
<213> 人工序列
<220>
<223> TCRα恒定结构域
<400> 156
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
1 5 10 15
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
20 25 30
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr
35 40 45
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
50 55 60
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
65 70 75 80
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
85 90 95
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
100 105 110
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
115 120 125
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 157
<211> 140
<212> PRT
<213> 人工序列
<220>
<223> TCRα恒定结构域
<400> 157
Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser
1 5 10 15
Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn
20 25 30
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr Val
35 40 45
Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
50 55 60
Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile
65 70 75 80
Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val
85 90 95
Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln
100 105 110
Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly
115 120 125
Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 158
<211> 142
<212> PRT
<213> 人工序列
<220>
<223> TCRα恒定结构域,半胱氨酸修饰的
<400> 158
Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser
1 5 10 15
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln
20 25 30
Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys
35 40 45
Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val
50 55 60
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
65 70 75 80
Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
85 90 95
Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
100 105 110
Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val
115 120 125
Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 159
<211> 141
<212> PRT
<213> 人工序列
<220>
<223> TCRα恒定结构域,半胱氨酸修饰的
<400> 159
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
1 5 10 15
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
20 25 30
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys
35 40 45
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
50 55 60
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
65 70 75 80
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
85 90 95
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
100 105 110
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
115 120 125
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 160
<211> 140
<212> PRT
<213> 人工序列
<220>
<223> TCRα恒定结构域,半胱氨酸修饰的
<400> 160
Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser
1 5 10 15
Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn
20 25 30
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val
35 40 45
Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
50 55 60
Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile
65 70 75 80
Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val
85 90 95
Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln
100 105 110
Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly
115 120 125
Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 161
<211> 1821
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 5号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 161
atgggcttca gactgttgtg ttgcgtggcc ttttgccttc ttggagctgg acctgtggat 60
tctggagtta cacagacccc taagcacctg attacagcca caggacagag agtgaccctg 120
agatgtagcc ctagaagcgg agatctgagc gtgtattggt accagcagag cctggatcaa 180
ggactccagt ttctgatcca gtactacaac ggcgaggaga gagccaaggg caatattctg 240
gagaggtttt ctgcccagca gttccctgat ctgcactctg aactgaacct gtctagcctg 300
gaactgggag attctgccct gtacttttgt gcctctagcg ttggacaggg cagctcttat 360
gagcagtact ttggacctgg caccagactg acagtgacag aagacctgaa gaacgtgttc 420
cccccagagg tggccgtgtt cgagcctagc gaggccgaga tcagccacac ccagaaagcc 480
accctcgtgt gcctggccac cggcttttac cccgaccacg tggaactgtc ttggtgggtc 540
aacggcaaag aggtgcacag cggcgtctgc accgaccccc agcccctgaa agagcagccc 600
gccctgaacg acagccggta ctgtctgagc agcagactga gagtgtccgc caccttctgg 660
cagaaccccc ggaaccactt cagatgccag gtgcagttct acggcctgag cgagaacgac 720
gagtggaccc aggaccgggc caagcccgtg acccagatcg tgtctgctga ggcctggggc 780
agagccgatt gcggcttcac cagcgagagc taccagcagg gcgtgctgag cgccaccatc 840
ctgtacgaga tcctgctggg caaggccacc ctgtacgccg tgctggtgtc cgccctggtg 900
ctgatggcca tggtcaagcg gaaggacagc cggggcggtt ccggagccac gaacttctct 960
ctgttaaagc aagcaggaga cgtggaagaa aaccccggtc ccatggaaac cctgctgaaa 1020
gtgctgagcg gaacactgtt atggcagctt acatgggtga ggtctcagca acctgtgcaa 1080
tctccacagg ccgttatcct gagagaagga gaagatgccg tgatcaactg ctctagctct 1140
aaagccctgt acagcgtgca ctggtacaga cagaaacacg gagaagctcc cgtgttcctg 1200
atgattctgc tgaaaggagg cgagcagaag ggacacgaga agatttctgc cagcttcaac 1260
gagaagaagc agcagtctag cctgtacctg acagcttctc agctgagcta tagcggcacc 1320
tacttttgtg gcacagagga agccaacgac tacaaactga gctttggagc cggcacaaca 1380
gtgacagtta gagccaatat ccagaacccc gatcctgctg tgtaccagct gcgggacagc 1440
aagagcagcg acaagagcgt gtgcctgttc accgacttcg acagccagac caacgtgtcc 1500
cagagcaagg acagcgacgt gtacatcacc gataagtgcg tgctggacat gcggagcatg 1560
gacttcaaga gcaacagcgc cgtggcctgg tccaacaaga gcgacttcgc ctgcgccaac 1620
gccttcaaca acagcattat ccccgaggac acattcttcc caagccccga gagcagctgc 1680
gacgtgaagc tggtggaaaa gagcttcgag acagacacca acctgaactt ccagaacctc 1740
agcgtgatcg gcttccggat cctgctgctg aaggtggccg gcttcaacct gctgatgacc 1800
ctgcggctgt ggtccagctg a 1821
<210> 162
<211> 606
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 5号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 162
Met Gly Phe Arg Leu Leu Cys Cys Val Ala Phe Cys Leu Leu Gly Ala
1 5 10 15
Gly Pro Val Asp Ser Gly Val Thr Gln Thr Pro Lys His Leu Ile Thr
20 25 30
Ala Thr Gly Gln Arg Val Thr Leu Arg Cys Ser Pro Arg Ser Gly Asp
35 40 45
Leu Ser Val Tyr Trp Tyr Gln Gln Ser Leu Asp Gln Gly Leu Gln Phe
50 55 60
Leu Ile Gln Tyr Tyr Asn Gly Glu Glu Arg Ala Lys Gly Asn Ile Leu
65 70 75 80
Glu Arg Phe Ser Ala Gln Gln Phe Pro Asp Leu His Ser Glu Leu Asn
85 90 95
Leu Ser Ser Leu Glu Leu Gly Asp Ser Ala Leu Tyr Phe Cys Ala Ser
100 105 110
Ser Val Gly Gln Gly Ser Ser Tyr Glu Gln Tyr Phe Gly Pro Gly Thr
115 120 125
Arg Leu Thr Val Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val
130 135 140
Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala
145 150 155 160
Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu
165 170 175
Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp
180 185 190
Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys
195 200 205
Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg
210 215 220
Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp
225 230 235 240
Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala
245 250 255
Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln
260 265 270
Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys
275 280 285
Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met
290 295 300
Val Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser
305 310 315 320
Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu
325 330 335
Thr Leu Leu Lys Val Leu Ser Gly Thr Leu Leu Trp Gln Leu Thr Trp
340 345 350
Val Arg Ser Gln Gln Pro Val Gln Ser Pro Gln Ala Val Ile Leu Arg
355 360 365
Glu Gly Glu Asp Ala Val Ile Asn Cys Ser Ser Ser Lys Ala Leu Tyr
370 375 380
Ser Val His Trp Tyr Arg Gln Lys His Gly Glu Ala Pro Val Phe Leu
385 390 395 400
Met Ile Leu Leu Lys Gly Gly Glu Gln Lys Gly His Glu Lys Ile Ser
405 410 415
Ala Ser Phe Asn Glu Lys Lys Gln Gln Ser Ser Leu Tyr Leu Thr Ala
420 425 430
Ser Gln Leu Ser Tyr Ser Gly Thr Tyr Phe Cys Gly Thr Glu Glu Ala
435 440 445
Asn Asp Tyr Lys Leu Ser Phe Gly Ala Gly Thr Thr Val Thr Val Arg
450 455 460
Ala Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser
465 470 475 480
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln
485 490 495
Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys
500 505 510
Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val
515 520 525
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
530 535 540
Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
545 550 555 560
Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
565 570 575
Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val
580 585 590
Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 163
<211> 1818
<212> DNA
<213> 人工序列
<220>
<223> TCR 9号构建体; β链-P2A-α链
<400> 163
atggatacct ggctcgtatg ctgggcaatt tttagtctct tgaaagcagg actcacagaa 60
cctgaagtca cccagactcc cagccatcag gtcacacaga tgggacagga agtgatcttg 120
cgctgtgtcc ccatctctaa tcacttatac ttctattggt acagacaaat cttggggcag 180
aaagtcgagt ttctggtttc cttttataat aatgaaatct cagagaagtc tgaaatattc 240
gatgatcaat tctcagttga aaggcctgat ggatcaaatt tcactctgaa gatccggtcc 300
acaaagctgg aggactcagc catgtacttc tgtgccatcc tggatggaga aggttcaccc 360
ctccactttg ggaatgggac caggctcact gtgacagagg acctgaacaa ggtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttcttccct gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtcagcacg gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acccgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gctttacctc ggtgtcctac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatcc tgctagggaa ggccaccctg tatgctgtgc tggtcagcgc ccttgtgttg 900
atggccatgg tcaagagaaa ggatttcggt tccggagcca cgaacttctc tctgttaaag 960
caagcaggag acgtggaaga aaaccccggt cccatgaaaa agcatctgac gaccttcttg 1020
gtgattttgt ggctttattt ttataggggg aatggcaaaa accaagtgga gcagagtcct 1080
cagtccctga tcatcctgga gggaaagaac tgcactcttc aatgcaatta tacagtgagc 1140
cccttcagca acttaaggtg gtataagcaa gatactggga gaggtcctgt ttccctgaca 1200
atcatgactt tcagtgagaa cacaaagtcg aacggaagat atacagcaac tctggatgca 1260
gacacaaagc aaagctctct gcacatcaca gcctcccagc tcagcgattc agcctcctac 1320
atctgtgtgg tgtggggggg ggacaccgac aagctcatct ttgggactgg gaccagatta 1380
caagtctttc caaatatcca gaaccctgac cctgccgtgt accagctgag agactctaaa 1440
tccagtgaca agtctgtctg cctattcacc gattttgatt ctcaaacaaa tgtgtcacaa 1500
agtaaggatt ctgatgtgta tatcacagac aaaactgtgc tagacatgag gtctatggac 1560
ttcaagagca acagtgctgt ggcctggagc aacaaatctg actttgcatg tgcaaacgcc 1620
ttcaacaaca gcattattcc agaagacacc ttcttcccca gcccagaaag ttcctgtgat 1680
gtcaagctgg tcgagaaaag ctttgaaaca gatacgaacc taaactttca aaacctgtca 1740
gtgattgggt tccgaatcct cctcctgaaa gtggccgggt ttaatctgct catgacgctg 1800
cggctgtggt ccagctga 1818
<210> 164
<400> 164
000
<210> 165
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号构建体; β链-P2A-α链
<400> 165
Met Asp Thr Trp Leu Val Cys Trp Ala Ile Phe Ser Leu Leu Lys Ala
1 5 10 15
Gly Leu Thr Glu Pro Glu Val Thr Gln Thr Pro Ser His Gln Val Thr
20 25 30
Gln Met Gly Gln Glu Val Ile Leu Arg Cys Val Pro Ile Ser Asn His
35 40 45
Leu Tyr Phe Tyr Trp Tyr Arg Gln Ile Leu Gly Gln Lys Val Glu Phe
50 55 60
Leu Val Ser Phe Tyr Asn Asn Glu Ile Ser Glu Lys Ser Glu Ile Phe
65 70 75 80
Asp Asp Gln Phe Ser Val Glu Arg Pro Asp Gly Ser Asn Phe Thr Leu
85 90 95
Lys Ile Arg Ser Thr Lys Leu Glu Asp Ser Ala Met Tyr Phe Cys Ala
100 105 110
Ile Leu Asp Gly Glu Gly Ser Pro Leu His Phe Gly Asn Gly Thr Arg
115 120 125
Leu Thr Val Thr Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
305 310 315 320
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Lys Lys His Leu
325 330 335
Thr Thr Phe Leu Val Ile Leu Trp Leu Tyr Phe Tyr Arg Gly Asn Gly
340 345 350
Lys Asn Gln Val Glu Gln Ser Pro Gln Ser Leu Ile Ile Leu Glu Gly
355 360 365
Lys Asn Cys Thr Leu Gln Cys Asn Tyr Thr Val Ser Pro Phe Ser Asn
370 375 380
Leu Arg Trp Tyr Lys Gln Asp Thr Gly Arg Gly Pro Val Ser Leu Thr
385 390 395 400
Ile Met Thr Phe Ser Glu Asn Thr Lys Ser Asn Gly Arg Tyr Thr Ala
405 410 415
Thr Leu Asp Ala Asp Thr Lys Gln Ser Ser Leu His Ile Thr Ala Ser
420 425 430
Gln Leu Ser Asp Ser Ala Ser Tyr Ile Cys Val Val Trp Gly Gly Asp
435 440 445
Thr Asp Lys Leu Ile Phe Gly Thr Gly Thr Arg Leu Gln Val Phe Pro
450 455 460
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
465 470 475 480
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
485 490 495
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr
500 505 510
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
515 520 525
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
530 535 540
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
545 550 555 560
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
565 570 575
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
580 585 590
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 166
<211> 113
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号Vβ可变区
<400> 166
Glu Pro Glu Val Thr Gln Thr Pro Ser His Gln Val Thr Gln Met Gly
1 5 10 15
Gln Glu Val Ile Leu Arg Cys Val Pro Ile Ser Asn His Leu Tyr Phe
20 25 30
Tyr Trp Tyr Arg Gln Ile Leu Gly Gln Lys Val Glu Phe Leu Val Ser
35 40 45
Phe Tyr Asn Asn Glu Ile Ser Glu Lys Ser Glu Ile Phe Asp Asp Gln
50 55 60
Phe Ser Val Glu Arg Pro Asp Gly Ser Asn Phe Thr Leu Lys Ile Arg
65 70 75 80
Ser Thr Lys Leu Glu Asp Ser Ala Met Tyr Phe Cys Ala Ile Leu Asp
85 90 95
Gly Glu Gly Ser Pro Leu His Phe Gly Asn Gly Thr Arg Leu Thr Val
100 105 110
Thr
<210> 167
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号Vβ CDR1
<400> 167
Ser Asn His Leu Tyr Phe
1 5
<210> 168
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号Vβ CDR2
<400> 168
Phe Tyr Asn Asn Glu Ile
1 5
<210> 169
<211> 1818
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 9号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 169
atggatacct ggctcgtgtg ttgggccatc ttttctctgc tgaaagccgg actgaccgaa 60
cctgaagtta cacaaacccc tagccaccag gtgacacaaa tgggacagga ggtgatcctg 120
agatgtgtgc ctatcagcaa ccacctgtac ttctactggt accggcagat tctgggccag 180
aaagtggagt ttctggtgag cttctacaac aacgagatca gcgagaagag cgagatcttc 240
gatgaccagt tcagcgtgga gagaccagat ggaagcaact ttaccctgaa gatccggagc 300
accaagctgg aagattctgc catgtacttc tgcgccatcc tggatggaga gggatctcct 360
ctgcactttg gcaatggcac aagactgacc gtgacagaag atctgaacaa ggtgttcccc 420
ccagaggtgg ccgtgttcga gccttctgag gccgagatct cccacaccca gaaagccacc 480
ctcgtgtgcc tggccaccgg ctttttcccc gaccacgtgg aactgtcttg gtgggtcaac 540
ggcaaagagg tgcactccgg cgtgtgcacc gatccccagc ctctgaaaga acagcccgcc 600
ctgaacgaca gccggtactg cctgagcagc agactgagag tgtccgccac cttctggcag 660
aacccccgga accacttcag atgccaggtg cagttctacg gcctgagcga gaacgacgag 720
tggacccagg acagagccaa gcccgtgaca cagatcgtgt ctgccgaagc ctggggcaga 780
gccgattgcg gctttacctc cgtgtcctat cagcagggcg tgctgagcgc cacaatcctg 840
tacgagatcc tgctgggcaa ggccaccctg tacgccgtgc tggtgtctgc cctggtgctg 900
atggccatgg tcaagcggaa ggacttcggt tccggagcca cgaacttctc tctgttaaag 960
caagcaggag acgtggaaga aaaccccggt cccatgaaga agcacctgac cacgttcctg 1020
gtgattcttt ggctgtactt ctaccggggc aacggcaaaa atcaggtgga acaaagcccc 1080
cagagcctga ttattctgga gggcaagaac tgcaccctcc agtgtaatta caccgtgagc 1140
cctttcagca acctgagatg gtacaagcag gataccggaa gaggacctgt gtctctgacc 1200
atcatgacct ttagcgagaa caccaagagc aacggcaggt atacagccac actggatgcc 1260
gataccaagc agtcttctct gcacattacc gcctctcagc tgtctgattc tgccagctac 1320
atctgtgtgg tgtggggagg agataccgat aagctgatct ttggcacagg caccagactg 1380
caagtgttcc ctaacatcca gaaccctgat cctgccgtgt accagctgcg ggacagcaag 1440
agcagcgaca agagcgtgtg cctgttcacc gacttcgaca gccagaccaa cgtgtcccag 1500
agcaaggaca gcgacgtgta catcaccgat aagtgcgtgc tggacatgcg gagcatggac 1560
ttcaagagca acagcgccgt ggcctggtcc aacaagagcg acttcgcctg cgccaacgcc 1620
ttcaacaaca gcattatccc cgaggacaca ttcttcccaa gccccgagag cagctgcgac 1680
gtgaagctgg tggaaaagag cttcgagaca gacaccaacc tgaacttcca gaacctcagc 1740
gtgatcggct tccggatcct gctgctgaag gtggccggct tcaacctgct gatgaccctg 1800
cggctgtggt ccagctga 1818
<210> 170
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 9号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 170
Met Asp Thr Trp Leu Val Cys Trp Ala Ile Phe Ser Leu Leu Lys Ala
1 5 10 15
Gly Leu Thr Glu Pro Glu Val Thr Gln Thr Pro Ser His Gln Val Thr
20 25 30
Gln Met Gly Gln Glu Val Ile Leu Arg Cys Val Pro Ile Ser Asn His
35 40 45
Leu Tyr Phe Tyr Trp Tyr Arg Gln Ile Leu Gly Gln Lys Val Glu Phe
50 55 60
Leu Val Ser Phe Tyr Asn Asn Glu Ile Ser Glu Lys Ser Glu Ile Phe
65 70 75 80
Asp Asp Gln Phe Ser Val Glu Arg Pro Asp Gly Ser Asn Phe Thr Leu
85 90 95
Lys Ile Arg Ser Thr Lys Leu Glu Asp Ser Ala Met Tyr Phe Cys Ala
100 105 110
Ile Leu Asp Gly Glu Gly Ser Pro Leu His Phe Gly Asn Gly Thr Arg
115 120 125
Leu Thr Val Thr Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
305 310 315 320
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Lys Lys His Leu
325 330 335
Thr Thr Phe Leu Val Ile Leu Trp Leu Tyr Phe Tyr Arg Gly Asn Gly
340 345 350
Lys Asn Gln Val Glu Gln Ser Pro Gln Ser Leu Ile Ile Leu Glu Gly
355 360 365
Lys Asn Cys Thr Leu Gln Cys Asn Tyr Thr Val Ser Pro Phe Ser Asn
370 375 380
Leu Arg Trp Tyr Lys Gln Asp Thr Gly Arg Gly Pro Val Ser Leu Thr
385 390 395 400
Ile Met Thr Phe Ser Glu Asn Thr Lys Ser Asn Gly Arg Tyr Thr Ala
405 410 415
Thr Leu Asp Ala Asp Thr Lys Gln Ser Ser Leu His Ile Thr Ala Ser
420 425 430
Gln Leu Ser Asp Ser Ala Ser Tyr Ile Cys Val Val Trp Gly Gly Asp
435 440 445
Thr Asp Lys Leu Ile Phe Gly Thr Gly Thr Arg Leu Gln Val Phe Pro
450 455 460
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
465 470 475 480
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
485 490 495
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys
500 505 510
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
515 520 525
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
530 535 540
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
545 550 555 560
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
565 570 575
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
580 585 590
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 171
<211> 1827
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 6号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 171
atgagcatca gcctcctgtg ctgtgcagcc tttcctctcc tgtgggcagg tccagtgaat 60
gctggtgtca ctcagacccc aaaattccgc atcctgaaga taggacagag catgacactg 120
cagtgtaccc aggatatgaa ccataactac atgtactggt atcgacaaga cccaggcatg 180
gggctgaagc tgatttatta ttcagttggt gctggtatca ctgataaagg agaagtcccg 240
aatggctaca acgtctccag atcaaccaca gaggatttcc cgctcaggct ggagttggct 300
gctccctccc agacatctgt gtacttctgt gccagcagtg acaggtctaa caccggggag 360
ctgttttttg gagaaggctc taggctgacc gtactggagg acctgaaaaa cgtgttccca 420
cccgaggtcg ctgtgtttga gccatcagaa gcagagatct cccacaccca aaaggccaca 480
ctggtgtgcc tggccacagg cttctacccc gaccacgtgg agctgagctg gtgggtgaat 540
gggaaggagg tgcacagtgg ggtctgcaca gacccgcagc ccctcaagga gcagcccgcc 600
ctcaatgact ccagatactg cctgagcagc cgcctgaggg tctcggccac cttctggcag 660
aacccccgca accacttccg ctgtcaagtc cagttctacg ggctctcgga gaatgacgag 720
tggacccagg atagggccaa acctgtcacc cagatcgtca gcgccgaggc ctggggtaga 780
gcagactgtg gcttcacctc cgagtcttac cagcaagggg tcctgtctgc caccatcctc 840
tatgagatct tgctagggaa ggccaccttg tatgccgtgc tggtcagtgc cctcgtgctg 900
atggccatgg tcaagagaaa ggattccaga ggcggttccg gagccacgaa cttctctctg 960
ttaaagcaag caggagacgt ggaagaaaac cccggtccca tggagaagaa tcctttggca 1020
gccccattac taatcctctg gtttcatctt gactgcgtga gcagcatact gaacgtggaa 1080
caaagtcctc agtcactgca tgttcaggag ggagacagca ccaatttcac ctgcagcttc 1140
ccttccagca atttttatgc cttacactgg tacagatggg aaactgcaaa aagccccgag 1200
gccttgtttg taatgacttt aaatggggat gaaaagaaga aaggacgaat aagtgccact 1260
cttaatacca aggagggtta cagctatttg tacatcaaag gatcccagcc tgaagactca 1320
gccacatacc tctgtgcctt agggccttat aacgactaca agctcagctt tggagccgga 1380
accacagtaa ctgtaagagc aaatatccag aaccctgacc ctgccgtgta ccagctgcgg 1440
gacagcaaga gcagcgacaa gagcgtgtgc ctgttcaccg acttcgacag ccagaccaac 1500
gtgtcccaga gcaaggacag cgacgtgtac atcaccgata agtgcgtgct ggacatgcgg 1560
agcatggact tcaagagcaa cagcgccgtg gcctggtcca acaagagcga cttcgcctgc 1620
gccaacgcct tcaacaacag cattatcccc gaggacacat tcttcccaag ccccgagagc 1680
agctgcgacg tgaagctggt ggaaaagagc ttcgagacag acaccaacct gaacttccag 1740
aacctcagcg tgatcggctt ccggatcctg ctgctgaagg tggccggctt caacctgctg 1800
atgaccctgc ggctgtggtc cagctga 1827
<210> 172
<211> 608
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 6号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 172
Met Ser Ile Ser Leu Leu Cys Cys Ala Ala Phe Pro Leu Leu Trp Ala
1 5 10 15
Gly Pro Val Asn Ala Gly Val Thr Gln Thr Pro Lys Phe Arg Ile Leu
20 25 30
Lys Ile Gly Gln Ser Met Thr Leu Gln Cys Thr Gln Asp Met Asn His
35 40 45
Asn Tyr Met Tyr Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Lys Leu
50 55 60
Ile Tyr Tyr Ser Val Gly Ala Gly Ile Thr Asp Lys Gly Glu Val Pro
65 70 75 80
Asn Gly Tyr Asn Val Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg
85 90 95
Leu Glu Leu Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser
100 105 110
Ser Asp Arg Ser Asn Thr Gly Glu Leu Phe Phe Gly Glu Gly Ser Arg
115 120 125
Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu
305 310 315 320
Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Lys
325 330 335
Asn Pro Leu Ala Ala Pro Leu Leu Ile Leu Trp Phe His Leu Asp Cys
340 345 350
Val Ser Ser Ile Leu Asn Val Glu Gln Ser Pro Gln Ser Leu His Val
355 360 365
Gln Glu Gly Asp Ser Thr Asn Phe Thr Cys Ser Phe Pro Ser Ser Asn
370 375 380
Phe Tyr Ala Leu His Trp Tyr Arg Trp Glu Thr Ala Lys Ser Pro Glu
385 390 395 400
Ala Leu Phe Val Met Thr Leu Asn Gly Asp Glu Lys Lys Lys Gly Arg
405 410 415
Ile Ser Ala Thr Leu Asn Thr Lys Glu Gly Tyr Ser Tyr Leu Tyr Ile
420 425 430
Lys Gly Ser Gln Pro Glu Asp Ser Ala Thr Tyr Leu Cys Ala Leu Gly
435 440 445
Pro Tyr Asn Asp Tyr Lys Leu Ser Phe Gly Ala Gly Thr Thr Val Thr
450 455 460
Val Arg Ala Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg
465 470 475 480
Asp Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp
485 490 495
Ser Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr
500 505 510
Asp Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser
515 520 525
Ala Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe
530 535 540
Asn Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser
545 550 555 560
Ser Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn
565 570 575
Leu Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu
580 585 590
Lys Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 173
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 1号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 173
atgggacctg gactgctttg ttgggctctt ctgtgtctgc ttggagctgg actggttgat 60
gctggagtta cacagagccc tacacacctg atcaagacaa gaggacagca ggtgaccctg 120
agatgtagcc ctaaatctgg ccacgatacc gtgagctggt atcaacaggc tctgggacaa 180
ggacctcagt tcatcttcca gtactacgag gaggaggaga gacagagagg caatttccct 240
gacaggttta gcggacacca gttccccaat tacagctctg agctgaacgt gaatgccctt 300
cttctgggag attctgccct gtatctgtgt gccagcagct tctttagcca ggaaacccag 360
tacttcggcc caggaacaag actgctggtt cttgaagacc tgaagaacgt gttcccccca 420
gaggtggccg tgttcgagcc tagcgaggcc gagatcagcc acacccagaa agccaccctc 480
gtgtgcctgg ccaccggctt ttaccccgac cacgtggaac tgtcttggtg ggtcaacggc 540
aaagaggtgc acagcggcgt ctgcaccgac ccccagcccc tgaaagagca gcccgccctg 600
aacgacagcc ggtactgtct gagcagcaga ctgagagtgt ccgccacctt ctggcagaac 660
ccccggaacc acttcagatg ccaggtgcag ttctacggcc tgagcgagaa cgacgagtgg 720
acccaggacc gggccaagcc cgtgacccag atcgtgtctg ctgaggcctg gggcagagcc 780
gattgcggct tcaccagcga gagctaccag cagggcgtgc tgagcgccac catcctgtac 840
gagatcctgc tgggcaaggc caccctgtac gccgtgctgg tgtccgccct ggtgctgatg 900
gccatggtca agcggaagga cagccggggc ggttccggag ccacgaactt ctctctgtta 960
aagcaagcag gagacgtgga agaaaacccc ggtcccatgg aaaccctgtt aggcctgctc 1020
attctgtggt tacagctcca atgggtgagc agcaaacagg aagtgaccca gattcctgct 1080
gccttatctg tgcctgaagg cgaaaatctg gtgctgaatt gcagcttcac cgattctgcc 1140
atctacaacc tccagtggtt cagacaggat ccaggaaaag gcctgacatc tcttctgctg 1200
atccagtcta gccagagaga gcagacaagc ggaagactga atgcctctct ggacaagagc 1260
agcggaagat ctaccctgta tattgccgcc tctcagcctg gagattctgc cacatatctg 1320
tgtgccgtgg agggagatag cagctataag ctgatcttcg gcagcggcac aagattactg 1380
gtgagacctg acatccagaa ccctgatcct gctgtgtacc agctgcggga cagcaagagc 1440
agcgacaaga gcgtgtgcct gttcaccgac ttcgacagcc agaccaacgt gtcccagagc 1500
aaggacagcg acgtgtacat caccgataag tgcgtgctgg acatgcggag catggacttc 1560
aagagcaaca gcgccgtggc ctggtccaac aagagcgact tcgcctgcgc caacgccttc 1620
aacaacagca ttatccccga ggacacattc ttcccaagcc ccgagagcag ctgcgacgtg 1680
aagctggtgg aaaagagctt cgagacagac accaacctga acttccagaa cctcagcgtg 1740
atcggcttcc ggatcctgct gctgaaggtg gccggcttca acctgctgat gaccctgcgg 1800
ctgtggtcca gctga 1815
<210> 174
<211> 604
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 1号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链域
<400> 174
Met Gly Pro Gly Leu Leu Cys Trp Ala Leu Leu Cys Leu Leu Gly Ala
1 5 10 15
Gly Leu Val Asp Ala Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys
20 25 30
Thr Arg Gly Gln Gln Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His
35 40 45
Asp Thr Val Ser Trp Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe
50 55 60
Ile Phe Gln Tyr Tyr Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro
65 70 75 80
Asp Arg Phe Ser Gly His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn
85 90 95
Val Asn Ala Leu Leu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser
100 105 110
Ser Phe Phe Ser Gln Glu Thr Gln Tyr Phe Gly Pro Gly Thr Arg Leu
115 120 125
Leu Val Leu Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val
130 135 140
Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu
145 150 155 160
Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp
165 170 175
Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln
180 185 190
Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser
195 200 205
Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His
210 215 220
Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp
225 230 235 240
Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala
245 250 255
Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly
260 265 270
Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr
275 280 285
Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys
290 295 300
Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu
305 310 315 320
Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Thr Leu
325 330 335
Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln Trp Val Ser Ser Lys
340 345 350
Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser Val Pro Glu Gly Glu
355 360 365
Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser Ala Ile Tyr Asn Leu
370 375 380
Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu Thr Ser Leu Leu Leu
385 390 395 400
Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly Arg Leu Asn Ala Ser
405 410 415
Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr Ile Ala Ala Ser Gln
420 425 430
Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val Glu Gly Asp Ser Ser
435 440 445
Tyr Lys Leu Ile Phe Gly Ser Gly Thr Arg Leu Leu Val Arg Pro Asp
450 455 460
Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser
465 470 475 480
Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn
485 490 495
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val
500 505 510
Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
515 520 525
Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile
530 535 540
Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val
545 550 555 560
Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln
565 570 575
Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly
580 585 590
Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600
<210> 175
<211> 1824
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 2号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 175
atgggcacca gactgctgtg ttgggctgct ctgtgtctgc tgggagccga tcatacaggt 60
gccggtgtca gccagacacc tagcaacaaa gtgaccgaga agggcaaata cgtggaactg 120
agatgcgacc ccatcagcgg acacacagcc ctgtactggt acagacagtc tctcggccag 180
ggacctgagt tcctgatcta cttccaaggc accggcgctg ccgatgatag cggcctgcct 240
aacgatagat tcttcgccgt cagacccgag ggcagcgtgt ccacactgaa gatccagaga 300
accgagaggg gcgacagcgc cgtgtatctg tgtgcctctt ctctgtctgg cctcggctct 360
ggcgctaacg tgctgacatt tggcgccgga agcagactga ccgtgctgga agatctgaag 420
aacgtgttcc cacctgaggt ggccgtgttc gagccttctg aggccgagat cagccacaca 480
cagaaagcca cactcgtgtg tctggccacc ggcttctatc ccgaccatgt ggaactgtct 540
tggtgggtca acggcaaaga ggtgcacagc ggcgtctgta cagatcccca gcctctgaaa 600
gaacagcccg ctctgaacga cagccggtac tgtctgtcct ccagactgag agtgtccgcc 660
accttctggc agaaccccag aaaccacttc agatgccagg tgcagttcta cggcctgagc 720
gagaacgatg agtggaccca ggatagagcc aagcctgtga cacagatcgt gtctgccgaa 780
gcctggggca gagccgattg tggctttacc agcgagagct accagcaggg cgtgctgtct 840
gccacaatcc tgtacgagat cctgctgggc aaagccactc tgtacgccgt gctggtgtct 900
gccctggtgc tgatggccat ggtcaagcgg aaggacagca gaggcggttc cggagccacg 960
aacttctctc tgttaaagca agcaggagac gtggaagaaa accccggtcc catggaaaca 1020
ctgctgggcc tgctgatcct gtggctgcaa ctgcaatggg tgtccagcaa gcaagaagtg 1080
acacagatcc ctgccgctct gtctgtgcct gagggcgaaa acctggtgct gaactgcagc 1140
ttcaccgaca gcgccatcta caacctgcag tggttcagac aggaccccgg caagggactg 1200
acaagcctgc tgctgattca gagcagccag agagagcaga ccagcggcag actgaatgcc 1260
agcctggata agtcctccgg cagaagcacc ctgtatatcg ccgcttctca gcctggcgat 1320
agcgccacat atctgtgtgc cgtgatcggc gagcagaact tcgtgtttgg ccctggcaca 1380
agactgagcg tgctgcccta cattcagaac cccgatcctg ccgtgtacca gctgcgggac 1440
agcaagagca gcgacaagag cgtgtgcctg ttcaccgact tcgacagcca gaccaacgtg 1500
tcccagagca aggacagcga cgtgtacatc accgataagt gcgtgctgga catgcggagc 1560
atggacttca agagcaacag cgccgtggcc tggtccaaca agagcgactt cgcctgcgcc 1620
aacgccttca acaacagcat tatccccgag gacacattct tcccaagccc cgagagcagc 1680
tgcgacgtga agctggtgga aaagagcttc gagacagaca ccaacctgaa cttccagaac 1740
ctcagcgtga tcggcttccg gatcctgctg ctgaaggtgg ccggcttcaa cctgctgatg 1800
accctgcggc tgtggtccag ctga 1824
<210> 176
<211> 607
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 2号构建体
多肽;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 176
Met Gly Thr Arg Leu Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Thr Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr
20 25 30
Glu Lys Gly Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His
35 40 45
Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Ile Tyr Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro
65 70 75 80
Asn Asp Arg Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu
85 90 95
Lys Ile Gln Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala
100 105 110
Ser Ser Leu Ser Gly Leu Gly Ser Gly Ala Asn Val Leu Thr Phe Gly
115 120 125
Ala Gly Ser Arg Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro
130 135 140
Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr
145 150 155 160
Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
165 170 175
Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val
180 185 190
Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser
195 200 205
Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
210 215 220
Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
225 230 235 240
Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
245 250 255
Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu
260 265 270
Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
275 280 285
Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
290 295 300
Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr
305 310 315 320
Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly
325 330 335
Pro Met Glu Thr Leu Leu Gly Leu Leu Ile Leu Trp Leu Gln Leu Gln
340 345 350
Trp Val Ser Ser Lys Gln Glu Val Thr Gln Ile Pro Ala Ala Leu Ser
355 360 365
Val Pro Glu Gly Glu Asn Leu Val Leu Asn Cys Ser Phe Thr Asp Ser
370 375 380
Ala Ile Tyr Asn Leu Gln Trp Phe Arg Gln Asp Pro Gly Lys Gly Leu
385 390 395 400
Thr Ser Leu Leu Leu Ile Gln Ser Ser Gln Arg Glu Gln Thr Ser Gly
405 410 415
Arg Leu Asn Ala Ser Leu Asp Lys Ser Ser Gly Arg Ser Thr Leu Tyr
420 425 430
Ile Ala Ala Ser Gln Pro Gly Asp Ser Ala Thr Tyr Leu Cys Ala Val
435 440 445
Ile Gly Glu Gln Asn Phe Val Phe Gly Pro Gly Thr Arg Leu Ser Val
450 455 460
Leu Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp
465 470 475 480
Ser Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser
485 490 495
Gln Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp
500 505 510
Lys Cys Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala
515 520 525
Val Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn
530 535 540
Asn Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser
545 550 555 560
Cys Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu
565 570 575
Asn Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys
580 585 590
Val Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 177
<211> 1818
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 3号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 177
atgggcacca gactgctgtg ttgggccgct ctgtgtctgc tgggcgccga tcatacaggc 60
gctggcgtgt cccagacccc cagcaacaaa gtgaccgaga agggcaaata cgtggaactg 120
agatgcgacc ccatcagcgg ccacaccgcc ctgtactggt acagacagtc tctgggccag 180
ggccccgagt tcctgatata ttttcagggc accggcgctg ccgacgacag cggcctgcct 240
aacgatagat tcttcgccgt gcggcccgag ggcagcgtgt ccacactgaa gatccagaga 300
accgagcggg gcgacagcgc cgtgtatctg tgtgccagca gcctgaatat gaacaccgag 360
gcattctttg ggcagggcac ccggctgacc gtggtggaag atctgaacaa ggtgttcccc 420
ccagaggtgg ccgtgttcga gccttctgag gccgagatca gccacaccca gaaagccacc 480
ctcgtgtgcc tggccaccgg ctttttcccc gaccatgtgg aactgtcttg gtgggtcaac 540
ggcaaagagg tgcacagcgg agtgtgcacc gaccctcagc ccctgaaaga acagcccgcc 600
ctgaacgaca gccggtactg cctgagcagc agactgagag tgtccgccac cttctggcag 660
aacccccgga accacttcag atgccaggtg cagttctacg gcctgagcga gaacgacgag 720
tggacccagg acagagccaa gcccgtgacc cagatcgtgt ctgccgaagc ctggggcaga 780
gccgattgcg gctttacctc cgtgtcctat cagcagggcg tgctgagcgc caccatcctg 840
tacgagatcc tgctgggcaa ggccaccctg tacgccgtgc tggtgtctgc cctggtgctg 900
atggccatgg tcaagcggaa ggacttcggt tccggagcca cgaacttctc tctgttaaag 960
caagcaggag acgtggaaga aaaccccggt cccatgatga agtccctgcg ggtgctgctc 1020
gtgatcctgt ggctgcagct gtcttgggtg tggtcccagc agaaagaggt ggaacagaac 1080
agcggccctc tgagcgtgcc agagggcgcc attgctagcc tgaattgcac ctacagcgac 1140
cggggcagcc agagcttctt ctggtatcgg cagtacagcg gcaagagccc cgagctgatc 1200
atgagcatct acagcaacgg cgacaaagag gacggccggt tcaccgccca gctgaacaaa 1260
gccagccagt acgtgtcact gctgatccgg gacagccagc ccagcgatag cgccacatac 1320
ctgtgcgccg tggatagcgg cggctaccag aaagtgacct tcggcaccgg caccaagctg 1380
caagtgatcc ccaacatcca gaaccccgac cccgctgtgt accagctgcg ggacagcaag 1440
agcagcgaca agagcgtgtg cctgttcacc gacttcgaca gccagaccaa cgtgtcccag 1500
agcaaggaca gcgacgtgta catcaccgat aagtgcgtgc tggacatgcg gagcatggac 1560
ttcaagagca acagcgccgt ggcctggtcc aacaagagcg acttcgcctg cgccaacgcc 1620
ttcaacaaca gcattatccc cgaggacaca ttcttcccaa gccccgagag cagctgcgac 1680
gtgaagctgg tggaaaagag cttcgagaca gacaccaacc tgaacttcca gaacctcagc 1740
gtgatcggct tccggatcct gctgctgaag gtggccggct tcaacctgct gatgaccctg 1800
cggctgtggt ccagctga 1818
<210> 178
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 3号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 178
Met Gly Thr Arg Leu Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Thr Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr
20 25 30
Glu Lys Gly Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His
35 40 45
Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Ile Tyr Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro
65 70 75 80
Asn Asp Arg Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu
85 90 95
Lys Ile Gln Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala
100 105 110
Ser Ser Leu Asn Met Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg
115 120 125
Leu Thr Val Val Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
305 310 315 320
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Met Lys Ser Leu
325 330 335
Arg Val Leu Leu Val Ile Leu Trp Leu Gln Leu Ser Trp Val Trp Ser
340 345 350
Gln Gln Lys Glu Val Glu Gln Asn Ser Gly Pro Leu Ser Val Pro Glu
355 360 365
Gly Ala Ile Ala Ser Leu Asn Cys Thr Tyr Ser Asp Arg Gly Ser Gln
370 375 380
Ser Phe Phe Trp Tyr Arg Gln Tyr Ser Gly Lys Ser Pro Glu Leu Ile
385 390 395 400
Met Ser Ile Tyr Ser Asn Gly Asp Lys Glu Asp Gly Arg Phe Thr Ala
405 410 415
Gln Leu Asn Lys Ala Ser Gln Tyr Val Ser Leu Leu Ile Arg Asp Ser
420 425 430
Gln Pro Ser Asp Ser Ala Thr Tyr Leu Cys Ala Val Asp Ser Gly Gly
435 440 445
Tyr Gln Lys Val Thr Phe Gly Thr Gly Thr Lys Leu Gln Val Ile Pro
450 455 460
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
465 470 475 480
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
485 490 495
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys
500 505 510
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
515 520 525
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
530 535 540
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
545 550 555 560
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
565 570 575
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
580 585 590
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 179
<211> 1812
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 10号构建体;在β和α链恒定结构域中有半胱氨酸取代的β
链-P2A-α链
<400> 179
atgggcacca gactgctgtg ttgggccgct ctgtgtctgc tgggcgccga tcatacaggc 60
gctggcgtgt cccagacccc cagcaacaaa gtgaccgaga agggcaaata cgtggaactg 120
agatgcgacc ccatcagcgg ccacaccgcc ctgtactggt acagacagtc tctgggccag 180
ggccccgagt tcctgatata ttttcagggc accggcgctg ccgacgacag cggcctgcct 240
aacgatagat tcttcgccgt gcggcccgag ggcagcgtgt ccacactgaa gatccagaga 300
accgagcggg gcgacagcgc cgtgtatctg tgtgccagca gcctgaatat gaacaccgag 360
gcattctttg ggcagggcac ccggctgacc gtggtggaag atctgaacaa ggtgttcccc 420
ccagaggtgg ccgtgttcga gccttctgag gccgagatca gccacaccca gaaagccacc 480
ctcgtgtgcc tggccaccgg ctttttcccc gaccatgtgg aactgtcttg gtgggtcaac 540
ggcaaagagg tgcacagcgg agtgtgcacc gaccctcagc ccctgaaaga acagcccgcc 600
ctgaacgaca gccggtactg cctgagcagc agactgagag tgtccgccac cttctggcag 660
aacccccgga accacttcag atgccaggtg cagttctacg gcctgagcga gaacgacgag 720
tggacccagg acagagccaa gcccgtgacc cagatcgtgt ctgccgaagc ctggggcaga 780
gccgattgcg gctttacctc cgtgtcctat cagcagggcg tgctgagcgc caccatcctg 840
tacgagatcc tgctgggcaa ggccaccctg tacgccgtgc tggtgtctgc cctggtgctg 900
atggccatgg tcaagcggaa ggacttcggt tccggagcca cgaacttctc tctgttaaag 960
caagcaggag acgtggaaga aaaccccggt cccatggaaa ccctgctggg agtgtccctc 1020
gtgatcctgt ggctgcagct ggccagagtg aacagccagc agggggaaga ggatccccag 1080
gccctgagca ttcaggaagg cgagaacgcc accatgaact gcagctacaa gaccagcatc 1140
aacaacctgc agtggtacag gcagaacagc ggcagaggcc tggtgcacct gatcctgatc 1200
agaagcaacg agagagagaa gcactccgga cggctgagag tgaccctgga cacctccaag 1260
aagtcctcca gcctgctgat caccgccagc agagccgccg ataccgccag ctacttctgc 1320
gccacagacg agagcagcaa ctacaagctg accttcggca agggcacact gctgacagtg 1380
aaccccaaca tccagaaccc cgaccccgct gtgtaccagc tgcgggacag caagagcagc 1440
gacaagagcg tgtgcctgtt caccgacttc gacagccaga ccaacgtgtc ccagagcaag 1500
gacagcgacg tgtacatcac cgataagtgc gtgctggaca tgcggagcat ggacttcaag 1560
agcaacagcg ccgtggcctg gtccaacaag agcgacttcg cctgcgccaa cgccttcaac 1620
aacagcatta tccccgagga cacattcttc ccaagccccg agagcagctg cgacgtgaag 1680
ctggtggaaa agagcttcga gacagacacc aacctgaact tccagaacct cagcgtgatc 1740
ggcttccgga tcctgctgct gaaggtggcc ggcttcaacc tgctgatgac cctgcggctg 1800
tggtccagct ga 1812
<210> 180
<211> 603
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 10号构建体; 在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 180
Met Gly Thr Arg Leu Leu Cys Trp Ala Ala Leu Cys Leu Leu Gly Ala
1 5 10 15
Asp His Thr Gly Ala Gly Val Ser Gln Thr Pro Ser Asn Lys Val Thr
20 25 30
Glu Lys Gly Lys Tyr Val Glu Leu Arg Cys Asp Pro Ile Ser Gly His
35 40 45
Thr Ala Leu Tyr Trp Tyr Arg Gln Ser Leu Gly Gln Gly Pro Glu Phe
50 55 60
Leu Ile Tyr Phe Gln Gly Thr Gly Ala Ala Asp Asp Ser Gly Leu Pro
65 70 75 80
Asn Asp Arg Phe Phe Ala Val Arg Pro Glu Gly Ser Val Ser Thr Leu
85 90 95
Lys Ile Gln Arg Thr Glu Arg Gly Asp Ser Ala Val Tyr Leu Cys Ala
100 105 110
Ser Ser Leu Asn Met Asn Thr Glu Ala Phe Phe Gly Gln Gly Thr Arg
115 120 125
Leu Thr Val Val Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
305 310 315 320
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Thr Leu Leu
325 330 335
Gly Val Ser Leu Val Ile Leu Trp Leu Gln Leu Ala Arg Val Asn Ser
340 345 350
Gln Gln Gly Glu Glu Asp Pro Gln Ala Leu Ser Ile Gln Glu Gly Glu
355 360 365
Asn Ala Thr Met Asn Cys Ser Tyr Lys Thr Ser Ile Asn Asn Leu Gln
370 375 380
Trp Tyr Arg Gln Asn Ser Gly Arg Gly Leu Val His Leu Ile Leu Ile
385 390 395 400
Arg Ser Asn Glu Arg Glu Lys His Ser Gly Arg Leu Arg Val Thr Leu
405 410 415
Asp Thr Ser Lys Lys Ser Ser Ser Leu Leu Ile Thr Ala Ser Arg Ala
420 425 430
Ala Asp Thr Ala Ser Tyr Phe Cys Ala Thr Asp Glu Ser Ser Asn Tyr
435 440 445
Lys Leu Thr Phe Gly Lys Gly Thr Leu Leu Thr Val Asn Pro Asn Ile
450 455 460
Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser
465 470 475 480
Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn Val
485 490 495
Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val Leu
500 505 510
Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp Ser
515 520 525
Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile
530 535 540
Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val Lys
545 550 555 560
Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln Asn
565 570 575
Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly Phe
580 585 590
Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600
<210> 181
<211> 1818
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 7号构建体; 在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 181
atgagcaacc aggtcttgtg ctgtgtggtg ctgtgctttc ttggcgccaa tacagtggat 60
ggcggcatta cacagagccc taagtacctg ttccggaaag aaggccagaa cgtgacactg 120
tcttgcgagc aaaacctgaa ccacgatgcc atgtactggt acagacagga tcctggacag 180
ggacttaggc tgatctacta tagccagatc gtgaacgact tccagaaggg cgatattgcc 240
gagggctatt ctgtgtctcg ggagaaaaag gagagcttcc ctctgacagt gacatctgcc 300
cagaagaatc ctaccgcctt ctacctttgt gccagctctc tgaatcgggg cagatacgga 360
tacacctttg gatctggcac cagactgaca gtggtggaag atctgaacaa ggtgttcccc 420
ccagaggtgg ccgtgttcga gccttctgag gccgagatct cccacaccca gaaagccacc 480
ctcgtgtgcc tggccaccgg ctttttcccc gaccacgtgg aactgtcttg gtgggtcaac 540
ggcaaagagg tgcactccgg cgtgtgcacc gatccccagc ctctgaaaga acagcccgcc 600
ctgaacgaca gccggtactg cctgagcagc agactgagag tgtccgccac cttctggcag 660
aacccccgga accacttcag atgccaggtg cagttctacg gcctgagcga gaacgacgag 720
tggacccagg acagagccaa gcccgtgaca cagatcgtgt ctgccgaagc ctggggcaga 780
gccgattgcg gctttacctc cgtgtcctat cagcagggcg tgctgagcgc cacaatcctg 840
tacgagatcc tgctgggcaa ggccaccctg tacgccgtgc tggtgtctgc cctggtgctg 900
atggccatgg tcaagcggaa ggacttcggt tccggagcca cgaacttctc tctgttaaag 960
caagcaggag acgtggaaga aaaccccggt cccatggaga agaaccccct tgcagcacct 1020
ctgcttattc tgtggttcca cctggattgc gtgagctcta tcctgaatgt ggagcagtct 1080
cctcagtctc tgcatgttca ggaaggcgat agcaccaact tcacctgtag ctttcccagc 1140
agcaacttct atgccctgca ctggtacaga tgggaaacag ccaaaagccc tgaagccctg 1200
ttcgtgatga cccttaatgg cgatgagaag aagaagggcc ggatttctgc caccctgaat 1260
acaaaagagg gctacagcta cctgtacatc aagggatctc agcctgagga tagcgccaca 1320
tatctgtgtg cctatctggg agccggcaat cagttctatt tcggaacagg caccagcctg 1380
accgtgattc ctaatatcca gaaccccgat cctgccgtgt accagctgcg ggacagcaag 1440
agcagcgaca agagcgtgtg cctgttcacc gacttcgaca gccagaccaa cgtgtcccag 1500
agcaaggaca gcgacgtgta catcaccgat aagtgcgtgc tggacatgcg gagcatggac 1560
ttcaagagca acagcgccgt ggcctggtcc aacaagagcg acttcgcctg cgccaacgcc 1620
ttcaacaaca gcattatccc cgaggacaca ttcttcccaa gccccgagag cagctgcgac 1680
gtgaagctgg tggaaaagag cttcgagaca gacaccaacc tgaacttcca gaacctcagc 1740
gtgatcggct tccggatcct gctgctgaag gtggccggct tcaacctgct gatgaccctg 1800
cggctgtggt ccagctga 1818
<210> 182
<211> 605
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 7号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 182
Met Ser Asn Gln Val Leu Cys Cys Val Val Leu Cys Phe Leu Gly Ala
1 5 10 15
Asn Thr Val Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg
20 25 30
Lys Glu Gly Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His
35 40 45
Asp Ala Met Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu
50 55 60
Ile Tyr Tyr Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala
65 70 75 80
Glu Gly Tyr Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr
85 90 95
Val Thr Ser Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser
100 105 110
Ser Leu Asn Arg Gly Arg Tyr Gly Tyr Thr Phe Gly Ser Gly Thr Arg
115 120 125
Leu Thr Val Val Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala
130 135 140
Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr
145 150 155 160
Leu Val Cys Leu Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser
165 170 175
Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro
180 185 190
Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu
195 200 205
Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn
210 215 220
His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu
225 230 235 240
Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu
245 250 255
Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln
260 265 270
Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala
275 280 285
Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val
290 295 300
Lys Arg Lys Asp Phe Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys
305 310 315 320
Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Glu Lys Asn Pro
325 330 335
Leu Ala Ala Pro Leu Leu Ile Leu Trp Phe His Leu Asp Cys Val Ser
340 345 350
Ser Ile Leu Asn Val Glu Gln Ser Pro Gln Ser Leu His Val Gln Glu
355 360 365
Gly Asp Ser Thr Asn Phe Thr Cys Ser Phe Pro Ser Ser Asn Phe Tyr
370 375 380
Ala Leu His Trp Tyr Arg Trp Glu Thr Ala Lys Ser Pro Glu Ala Leu
385 390 395 400
Phe Val Met Thr Leu Asn Gly Asp Glu Lys Lys Lys Gly Arg Ile Ser
405 410 415
Ala Thr Leu Asn Thr Lys Glu Gly Tyr Ser Tyr Leu Tyr Ile Lys Gly
420 425 430
Ser Gln Pro Glu Asp Ser Ala Thr Tyr Leu Cys Ala Tyr Leu Gly Ala
435 440 445
Gly Asn Gln Phe Tyr Phe Gly Thr Gly Thr Ser Leu Thr Val Ile Pro
450 455 460
Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys
465 470 475 480
Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr
485 490 495
Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys
500 505 510
Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala
515 520 525
Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser
530 535 540
Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp
545 550 555 560
Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe
565 570 575
Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala
580 585 590
Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600 605
<210> 183
<211> 1848
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 8号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 183
atgggacctg gactgctttg ttgggctctt ctgtgtctgc ttggagctgg actggttgat 60
gctggagtta cacagagccc tacacacctg atcaagacaa gaggacagca ggtgaccctg 120
agatgtagcc ctaaatctgg ccacgatacc gtgagctggt atcaacaggc tctgggacaa 180
ggacctcagt tcatcttcca gtactacgag gaggaggaga gacagagagg caatttccct 240
gacaggttta gcggacacca gttccccaat tacagctctg agctgaacgt gaatgccctt 300
cttctgggag attctgccct gtatctgtgt gccagcagct ttagactggc tggaggacct 360
agcaccgata cacagtattt tggacctggc accaggctga cagtgttaga agacctgaag 420
aacgtgttcc ccccagaggt ggccgtgttc gagcctagcg aggccgagat cagccacacc 480
cagaaagcca ccctcgtgtg cctggccacc ggcttttacc ccgaccacgt ggaactgtct 540
tggtgggtca acggcaaaga ggtgcacagc ggcgtctgca ccgaccccca gcccctgaaa 600
gagcagcccg ccctgaacga cagccggtac tgtctgagca gcagactgag agtgtccgcc 660
accttctggc agaacccccg gaaccacttc agatgccagg tgcagttcta cggcctgagc 720
gagaacgacg agtggaccca ggaccgggcc aagcccgtga cccagatcgt gtctgctgag 780
gcctggggca gagccgattg cggcttcacc agcgagagct accagcaggg cgtgctgagc 840
gccaccatcc tgtacgagat cctgctgggc aaggccaccc tgtacgccgt gctggtgtcc 900
gccctggtgc tgatggccat ggtcaagcgg aaggacagcc ggggcggttc cggagccacg 960
aacttctctc tgttaaagca agcaggagac gtggaagaaa accccggtcc catgttgacc 1020
gcttctctct tacgtgccgt gattgccagc atctgtgtgg ttagctctat ggcccagaag 1080
gtgacacaag ctcagacaga gatcagcgtg gtggagaaag aggatgtgac cctggattgc 1140
gtgtacgaga ccagagatac cacctactac ctgttctggt acaagcagcc tccttctgga 1200
gaactggtgt tcctgatcag acggaacagc ttcgatgagc agaacgagat tagcggcagg 1260
tatagctgga acttccagaa gagcaccagc agcttcaact tcaccatcac agcctctcag 1320
gtggtggatt ctgccgtgta cttttgtgcc ctgtctgaac tggcctctgg aggaagctat 1380
atccctacat tcggcagagg cacaagcctg attgtgcacc cttacatcca gaaccctgat 1440
cctgctgtgt accagctgcg ggacagcaag agcagcgaca agagcgtgtg cctgttcacc 1500
gacttcgaca gccagaccaa cgtgtcccag agcaaggaca gcgacgtgta catcaccgat 1560
aagtgcgtgc tggacatgcg gagcatggac ttcaagagca acagcgccgt ggcctggtcc 1620
aacaagagcg acttcgcctg cgccaacgcc ttcaacaaca gcattatccc cgaggacaca 1680
ttcttcccaa gccccgagag cagctgcgac gtgaagctgg tggaaaagag cttcgagaca 1740
gacaccaacc tgaacttcca gaacctcagc gtgatcggct tccggatcct gctgctgaag 1800
gtggccggct tcaacctgct gatgaccctg cggctgtggt ccagctga 1848
<210> 184
<211> 615
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 8号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 184
Met Gly Pro Gly Leu Leu Cys Trp Ala Leu Leu Cys Leu Leu Gly Ala
1 5 10 15
Gly Leu Val Asp Ala Gly Val Thr Gln Ser Pro Thr His Leu Ile Lys
20 25 30
Thr Arg Gly Gln Gln Val Thr Leu Arg Cys Ser Pro Lys Ser Gly His
35 40 45
Asp Thr Val Ser Trp Tyr Gln Gln Ala Leu Gly Gln Gly Pro Gln Phe
50 55 60
Ile Phe Gln Tyr Tyr Glu Glu Glu Glu Arg Gln Arg Gly Asn Phe Pro
65 70 75 80
Asp Arg Phe Ser Gly His Gln Phe Pro Asn Tyr Ser Ser Glu Leu Asn
85 90 95
Val Asn Ala Leu Leu Leu Gly Asp Ser Ala Leu Tyr Leu Cys Ala Ser
100 105 110
Ser Phe Arg Leu Ala Gly Gly Pro Ser Thr Asp Thr Gln Tyr Phe Gly
115 120 125
Pro Gly Thr Arg Leu Thr Val Leu Glu Asp Leu Lys Asn Val Phe Pro
130 135 140
Pro Glu Val Ala Val Phe Glu Pro Ser Glu Ala Glu Ile Ser His Thr
145 150 155 160
Gln Lys Ala Thr Leu Val Cys Leu Ala Thr Gly Phe Tyr Pro Asp His
165 170 175
Val Glu Leu Ser Trp Trp Val Asn Gly Lys Glu Val His Ser Gly Val
180 185 190
Cys Thr Asp Pro Gln Pro Leu Lys Glu Gln Pro Ala Leu Asn Asp Ser
195 200 205
Arg Tyr Cys Leu Ser Ser Arg Leu Arg Val Ser Ala Thr Phe Trp Gln
210 215 220
Asn Pro Arg Asn His Phe Arg Cys Gln Val Gln Phe Tyr Gly Leu Ser
225 230 235 240
Glu Asn Asp Glu Trp Thr Gln Asp Arg Ala Lys Pro Val Thr Gln Ile
245 250 255
Val Ser Ala Glu Ala Trp Gly Arg Ala Asp Cys Gly Phe Thr Ser Glu
260 265 270
Ser Tyr Gln Gln Gly Val Leu Ser Ala Thr Ile Leu Tyr Glu Ile Leu
275 280 285
Leu Gly Lys Ala Thr Leu Tyr Ala Val Leu Val Ser Ala Leu Val Leu
290 295 300
Met Ala Met Val Lys Arg Lys Asp Ser Arg Gly Gly Ser Gly Ala Thr
305 310 315 320
Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly
325 330 335
Pro Met Leu Thr Ala Ser Leu Leu Arg Ala Val Ile Ala Ser Ile Cys
340 345 350
Val Val Ser Ser Met Ala Gln Lys Val Thr Gln Ala Gln Thr Glu Ile
355 360 365
Ser Val Val Glu Lys Glu Asp Val Thr Leu Asp Cys Val Tyr Glu Thr
370 375 380
Arg Asp Thr Thr Tyr Tyr Leu Phe Trp Tyr Lys Gln Pro Pro Ser Gly
385 390 395 400
Glu Leu Val Phe Leu Ile Arg Arg Asn Ser Phe Asp Glu Gln Asn Glu
405 410 415
Ile Ser Gly Arg Tyr Ser Trp Asn Phe Gln Lys Ser Thr Ser Ser Phe
420 425 430
Asn Phe Thr Ile Thr Ala Ser Gln Val Val Asp Ser Ala Val Tyr Phe
435 440 445
Cys Ala Leu Ser Glu Leu Ala Ser Gly Gly Ser Tyr Ile Pro Thr Phe
450 455 460
Gly Arg Gly Thr Ser Leu Ile Val His Pro Tyr Ile Gln Asn Pro Asp
465 470 475 480
Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser Asp Lys Ser Val
485 490 495
Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn Val Ser Gln Ser Lys
500 505 510
Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val Leu Asp Met Arg Ser
515 520 525
Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp Ser Asn Lys Ser Asp
530 535 540
Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile Pro Glu Asp Thr
545 550 555 560
Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val Lys Leu Val Glu Lys
565 570 575
Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln Asn Leu Ser Val Ile
580 585 590
Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly Phe Asn Leu Leu Met
595 600 605
Thr Leu Arg Leu Trp Ser Ser
610 615
<210> 185
<211> 1815
<212> DNA
<213> 人工序列
<220>
<223> TCR 11号构建体; β链-P2A-α
链
<400> 185
atgggcacca ggctcttctt ctatgtggcc ctttgtctgc tgtgggcagg acacagggat 60
gctggaatca cccagagccc aagatacaag atcacagaga caggaaggca ggtgaccttg 120
atgtgtcacc agacttggag ccacagctat atgttctggt atcgacaaga cctgggacat 180
gggctgaggc tgatctatta ctcagcagct gctgatatta cagataaagg agaagtcccc 240
gatggctatg ttgtctccag atccaagaca gagaatttcc ccctcactct ggagtcagct 300
acccgctccc agacatctgt gtatttctgc gccagcagtg acgggggcgg gcagtacttc 360
gggccgggca ccaggctcac ggtcacagag gacctgaaaa acgtgttccc acccgaggtc 420
gctgtgtttg agccatcaga agcagagatc tcccacaccc aaaaggccac actggtgtgc 480
ctggccacag gcttctaccc cgaccacgtg gagctgagct ggtgggtgaa tgggaaggag 540
gtgcacagtg gggtcagcac agacccgcag cccctcaagg agcagcccgc cctcaatgac 600
tccagatact gcctgagcag ccgcctgagg gtctcggcca ccttctggca gaacccccgc 660
aaccacttcc gctgtcaagt ccagttctac gggctctcgg agaatgacga gtggacccag 720
gatagggcca aacctgtcac ccagatcgtc agcgccgagg cctggggtag agcagactgt 780
ggcttcacct ccgagtctta ccagcaaggg gtcctgtctg ccaccatcct ctatgagatc 840
ttgctaggga aggccacctt gtatgccgtg ctggtcagtg ccctcgtgct gatggccatg 900
gtcaagagaa aggattccag aggcggttcc ggagccacga acttctctct gttaaagcaa 960
gcaggagacg tggaagaaaa ccccggtccc atgaaaaagc atctgacgac cttcttggtg 1020
attttgtggc tttattttta tagggggaat ggcaaaaacc aagtggagca gagtcctcag 1080
tccctgatca tcctggaggg aaagaactgc actcttcaat gcaattatac agtgagcccc 1140
ttcagcaact taaggtggta taagcaagat actgggagag gtcctgtttc cctgacaatc 1200
atgactttca gtgagaacac aaagtcgaac ggaagatata cagcaactct ggatgcagac 1260
acaaagcaaa gctctctgca catcacagcc tcccagctca gcgattcagc ctcctacatc 1320
tgtgtggtgt ggggggggga caccgacaag ctcatctttg ggactgggac cagattacaa 1380
gtctttccaa atatccagaa ccctgaccct gccgtgtacc agctgagaga ctctaaatcc 1440
agtgacaagt ctgtctgcct attcaccgat tttgattctc aaacaaatgt gtcacaaagt 1500
aaggattctg atgtgtatat cacagacaaa acttggctag acatgaggtc tatggacttc 1560
aagagcaaca gtgctgtggc ctggagcaac aaatctgact ttgcatgtgc aaacgccttc 1620
aacaacagca ttattccaga agacaccttc ttccccagcc cagaaagttc ctgtgatgtc 1680
aagctggtcg agaaaagctt tgaaacagat acgaacctaa actttcaaaa cctgtcagtg 1740
attgggttcc gaatcctcct cctgaaagtg gccgggttta atctgctcat gacgctgcgg 1800
ctgtggtcca gctga 1815
<210> 186
<211> 604
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号构建体; β链-P2A-α
链
<400> 186
Met Gly Thr Arg Leu Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Ala
1 5 10 15
Gly His Arg Asp Ala Gly Ile Thr Gln Ser Pro Arg Tyr Lys Ile Thr
20 25 30
Glu Thr Gly Arg Gln Val Thr Leu Met Cys His Gln Thr Trp Ser His
35 40 45
Ser Tyr Met Phe Trp Tyr Arg Gln Asp Leu Gly His Gly Leu Arg Leu
50 55 60
Ile Tyr Tyr Ser Ala Ala Ala Asp Ile Thr Asp Lys Gly Glu Val Pro
65 70 75 80
Asp Gly Tyr Val Val Ser Arg Ser Lys Thr Glu Asn Phe Pro Leu Thr
85 90 95
Leu Glu Ser Ala Thr Arg Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser
100 105 110
Ser Asp Gly Gly Gly Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr Val
115 120 125
Thr Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu
130 135 140
Pro Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys
145 150 155 160
Leu Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val
165 170 175
Asn Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu
180 185 190
Lys Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg
195 200 205
Leu Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg
210 215 220
Cys Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln
225 230 235 240
Asp Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly
245 250 255
Arg Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu
260 265 270
Ser Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr
275 280 285
Ala Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys
290 295 300
Asp Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln
305 310 315 320
Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Lys Lys His Leu Thr
325 330 335
Thr Phe Leu Val Ile Leu Trp Leu Tyr Phe Tyr Arg Gly Asn Gly Lys
340 345 350
Asn Gln Val Glu Gln Ser Pro Gln Ser Leu Ile Ile Leu Glu Gly Lys
355 360 365
Asn Cys Thr Leu Gln Cys Asn Tyr Thr Val Ser Pro Phe Ser Asn Leu
370 375 380
Arg Trp Tyr Lys Gln Asp Thr Gly Arg Gly Pro Val Ser Leu Thr Ile
385 390 395 400
Met Thr Phe Ser Glu Asn Thr Lys Ser Asn Gly Arg Tyr Thr Ala Thr
405 410 415
Leu Asp Ala Asp Thr Lys Gln Ser Ser Leu His Ile Thr Ala Ser Gln
420 425 430
Leu Ser Asp Ser Ala Ser Tyr Ile Cys Val Val Trp Gly Gly Asp Thr
435 440 445
Asp Lys Leu Ile Phe Gly Thr Gly Thr Arg Leu Gln Val Phe Pro Asn
450 455 460
Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser
465 470 475 480
Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn
485 490 495
Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Thr Trp
500 505 510
Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp
515 520 525
Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile
530 535 540
Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val
545 550 555 560
Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln
565 570 575
Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly
580 585 590
Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600
<210> 187
<211> 1812
<212> DNA
<213> 人工序列
<220>
<223> 密码子优化的TCR 11号构建体;在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 187
atgggcacac ggcttttctt ctacgttgcc ctttgcctgc tgtgggctgg acatagagat 60
gctggaatca cacagagccc caggtacaag atcacagaga caggaagaca ggtgaccctg 120
atgtgtcacc aaacatggag ccacagctac atgttctggt acagacagga tctgggacac 180
ggactgagac tgatctacta ttctgctgcc gccgacatca ccgataaagg agaagttcct 240
gacggctacg tggtgtctag aagcaaaacc gagaacttcc ccctgacact ggaatctgcc 300
acaagatctc agaccagcgt gtacttttgc gcctcttctg atggaggagg ccagtatttt 360
ccaggcacaa gactgacagt gaccgaggac ctgaagaacg tgttcccccc agaggtggcc 420
gtgttcgagc ctagcgaggc cgagatcagc cacacccaga aagccaccct cgtgtgcctg 480
gccaccggct tttaccccga ccacgtggaa ctgtcttggt gggtcaacgg caaagaggtg 540
cacagcggcg tctgcaccga cccccagccc ctgaaagagc agcccgccct gaacgacagc 600
cggtactgtc tgagcagcag actgagagtg tccgccacct tctggcagaa cccccggaac 660
cacttcagat gccaggtgca gttctacggc ctgagcgaga acgacgagtg gacccaggac 720
cgggccaagc ccgtgaccca gatcgtgtct gctgaggcct ggggcagagc cgattgcggc 780
ttcaccagcg agagctacca gcagggcgtg ctgagcgcca ccatcctgta cgagatcctg 840
ctgggcaagg ccaccctgta cgccgtgctg gtgtccgccc tggtgctgat ggccatggtc 900
aagcggaagg acagccgggg cggttccgga gccacgaact tctctctgtt aaagcaagca 960
ggagacgtgg aagaaaaccc cggtcccatg aagaagcacc tgaccacgtt cctggtgatt 1020
ctttggctgt acttctaccg gggcaacggc aaaaatcagg tggaacaaag cccccagagc 1080
ctgattattc tggagggcaa gaactgcacc ctccagtgta attacaccgt gagccctttc 1140
agcaacctga gatggtacaa gcaggatacc ggaagaggac ctgtgtctct gaccatcatg 1200
acctttagcg agaacaccaa gagcaacggc aggtatacag ccacactgga tgccgatacc 1260
aagcagtctt ctctgcacat taccgcctct cagctgtctg attctgccag ctacatctgt 1320
gtggtgtggg gaggagatac cgataagctg atctttggca caggcaccag actgcaagtg 1380
ttccctaaca tccagaaccc tgatcctgcc gtgtaccagc tgcgggacag caagagcagc 1440
gacaagagcg tgtgcctgtt caccgacttc gacagccaga ccaacgtgtc ccagagcaag 1500
gacagcgacg tgtacatcac cgataagtgc gtgctggaca tgcggagcat ggacttcaag 1560
agcaacagcg ccgtggcctg gtccaacaag agcgacttcg cctgcgccaa cgccttcaac 1620
aacagcatta tccccgagga cacattcttc ccaagccccg agagcagctg cgacgtgaag 1680
ctggtggaaa agagcttcga gacagacacc aacctgaact tccagaacct cagcgtgatc 1740
ggcttccgga tcctgctgct gaaggtggcc ggcttcaacc tgctgatgac cctgcggctg 1800
tggtccagct ga 1812
<210> 188
<211> 603
<212> PRT
<213> 人工序列
<220>
<223> 密码子优化的TCR 11号构建体; 在β和α链恒定结构域中有半胱氨酸取代的β链-P2A-α链
<400> 188
Met Gly Thr Arg Leu Phe Phe Tyr Val Ala Leu Cys Leu Leu Trp Ala
1 5 10 15
Gly His Arg Asp Ala Gly Ile Thr Gln Ser Pro Arg Tyr Lys Ile Thr
20 25 30
Glu Thr Gly Arg Gln Val Thr Leu Met Cys His Gln Thr Trp Ser His
35 40 45
Ser Tyr Met Phe Trp Tyr Arg Gln Asp Leu Gly His Gly Leu Arg Leu
50 55 60
Ile Tyr Tyr Ser Ala Ala Ala Asp Ile Thr Asp Lys Gly Glu Val Pro
65 70 75 80
Asp Gly Tyr Val Val Ser Arg Ser Lys Thr Glu Asn Phe Pro Leu Thr
85 90 95
Leu Glu Ser Ala Thr Arg Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser
100 105 110
Ser Asp Gly Gly Gly Gln Tyr Phe Pro Gly Thr Arg Leu Thr Val Thr
115 120 125
Glu Asp Leu Lys Asn Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro
130 135 140
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu
145 150 155 160
Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn
165 170 175
Gly Lys Glu Val His Ser Gly Val Cys Thr Asp Pro Gln Pro Leu Lys
180 185 190
Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu
195 200 205
Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys
210 215 220
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp
225 230 235 240
Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg
245 250 255
Ala Asp Cys Gly Phe Thr Ser Glu Ser Tyr Gln Gln Gly Val Leu Ser
260 265 270
Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
275 280 285
Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp
290 295 300
Ser Arg Gly Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
305 310 315 320
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Lys Lys His Leu Thr Thr
325 330 335
Phe Leu Val Ile Leu Trp Leu Tyr Phe Tyr Arg Gly Asn Gly Lys Asn
340 345 350
Gln Val Glu Gln Ser Pro Gln Ser Leu Ile Ile Leu Glu Gly Lys Asn
355 360 365
Cys Thr Leu Gln Cys Asn Tyr Thr Val Ser Pro Phe Ser Asn Leu Arg
370 375 380
Trp Tyr Lys Gln Asp Thr Gly Arg Gly Pro Val Ser Leu Thr Ile Met
385 390 395 400
Thr Phe Ser Glu Asn Thr Lys Ser Asn Gly Arg Tyr Thr Ala Thr Leu
405 410 415
Asp Ala Asp Thr Lys Gln Ser Ser Leu His Ile Thr Ala Ser Gln Leu
420 425 430
Ser Asp Ser Ala Ser Tyr Ile Cys Val Val Trp Gly Gly Asp Thr Asp
435 440 445
Lys Leu Ile Phe Gly Thr Gly Thr Arg Leu Gln Val Phe Pro Asn Ile
450 455 460
Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser Lys Ser Ser
465 470 475 480
Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln Thr Asn Val
485 490 495
Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys Cys Val Leu
500 505 510
Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val Ala Trp Ser
515 520 525
Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn Ser Ile Ile
530 535 540
Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys Asp Val Lys
545 550 555 560
Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn Phe Gln Asn
565 570 575
Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly Phe
580 585 590
Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
595 600
<210> 189
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 11号Vβ CDR3
<400> 189
Cys Ala Ser Ser Asp Gly Gly Gly Gln Tyr Phe
1 5 10
<210> 190
<211> 11
<212> PRT
<213> 人工序列
<220>
<223> TCR 9号Vβ CDR3
<400> 190
Ala Ile Leu Asp Gly Glu Gly Ser Pro Leu His
1 5 10
Claims (82)
1.一种结合蛋白,包含:
(a)T细胞受体(TCR)α链可变(Vα)结构域以及TCRβ链可变(Vβ)结构域,所述TCR Vα结构域包含SEQ ID NO:5、7、9、11、11、13、15、17和19中任一项所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:5、7、9、11、13、15、17和19中任一项所示的并且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;
(b)TCR Vα结构域和TCR Vβ结构域,所述TCR Vβ结构域包含SEQ ID NO:6、8、10、12、14、16、18、20和189中任一项所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:6、8、10、12、14、16、18、20和189中任一项所示的并且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;或者
(c)(a)的Vα结构域和(b)的Vβ,
其中所述结合蛋白能够特异性结合人细胞周期蛋白A1(CCNA1)肽FLDRFLSCM(SEQ IDNO:1):人白细胞抗原(HLA)复合物。
2.根据权利要求1所述的结合蛋白,其中:
(a)所述Vα结构域包含SEQ ID NO:5的CDR3氨基酸序列,并且所述Vβ结构域包含SEQ IDNO:6的CDR3氨基酸序列;
(b)所述Vα结构域包含SEQ ID NO:7的CDR3氨基酸序列,并且所述Vβ结构域包含SEQ IDNO:8的CDR3氨基酸序列;
(c)所述Vα结构域包含SEQ ID NO:9的CDR3氨基酸序列,并且所述Vβ结构域包含SEQ IDNO:10的CDR3氨基酸序列;
(d)所述Vα结构域包含SEQ ID NO:11的CDR3氨基酸序列,并且所述Vβ结构域包含SEQID NO:12的CDR3氨基酸序列;
(e)所述Vα结构域包含SEQ ID NO:13的CDR3氨基酸序列,并且所述Vβ结构域包含SEQID NO:14的CDR3氨基酸序列;
(f)所述Vα结构域包含SEQ ID NO:15的CDR3氨基酸序列,并且所述Vβ结构域包含SEQID NO:16的CDR3氨基酸序列;
(g)所述Vα结构域包含SEQ ID NO:17的CDR3氨基酸序列,并且所述Vβ结构域包含SEQID NO:18的CDR3氨基酸序列;
(h)所述Vα结构域包含SEQ ID NO:19的CDR3氨基酸序列,并且所述Vβ结构域包含SEQID NO:20的CDR3氨基酸序列;或者
(i)所述Vα结构域包含SEQ ID NO:7的CDR3氨基酸序列,并且所述Vβ结构域包含SEQ IDNO:189的CDR3氨基酸序列。
3.根据权利要求1所述的结合蛋白,其中:
(a)所述Vβ结构域包含SEQ ID NO:6的CDR3氨基酸序列和由TRBV9*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:5的CDR3氨基酸序列和由TRAV30*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(b)所述Vβ结构域包含SEQ ID NO:8的CDR3氨基酸序列和由TRBV2*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:7的CDR3氨基酸序列和由TRAV10*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(c)所述Vβ结构域包含SEQ ID NO:10的CDR3氨基酸序列和由TRBV6-6*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:9的CDR3氨基酸序列和由TRAV24*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(d)所述Vβ结构域包含SEQ ID NO:12的CDR3氨基酸序列和由TRBV5-6*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:11的CDR3氨基酸序列和由TRAV2l*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(e)所述Vβ结构域包含SEQ ID NO:14的CDR3氨基酸序列和由TRBV7-3*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:13的CDR3氨基酸序列和由TRAV2l*02基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(f)所述Vβ结构域包含SEQ ID NO:16的CDR3氨基酸序列和由TRBV7-3*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:15的CDR3氨基酸序列和由TRAV12-2*02基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(g)所述Vβ结构域包含SEQ ID NO:18的CDR3氨基酸序列和由TRBV7-3*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:17的CDR3氨基酸序列和由TRAV17*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;
(h)所述Vβ结构域包含SEQ ID NO:20的CDR3氨基酸序列和由TRBV7-2*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:19的CDR3氨基酸序列和由TRAV17*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;或者
(i)所述Vβ结构域包含SEQ ID NO:189或101的CDR3氨基酸序列和TRBV10-2*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且所述Vα结构域包含SEQ ID NO:7或97的CDR3氨基酸序列和由TRAV10*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列。
4.根据权利要求1或2所述的结合蛋白,其中,所述结合蛋白包含:
(a)与SEQ ID NO:36、38、40、42、44、86、49、51、53、57、59、63、65、67、81、83、162、165、170、172、174、176、178、180和186中任一项所包含的Vα氨基酸序列至少约90%相同的Vα结构域;
(b)与SEQ ID NO:36、38、40、42、46、86、49、51、55、57、61、63、67、81、83、162、165、170、172、174、176、178、180和186任一项所包含的Vβ氨基酸序列至少约90%相同的Vβ结构域;或者
(c)(a)的Vα结构域和(b)的Vβ;
其中所述CDR中的至少三个或四个不具有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或缺失。
5.根据权利要求4所述的结合蛋白,其中,所述结合蛋白包含:
(a)Vα结构域,其包含或由SEQ ID NO:36、38、40、42、44、86、49、51、53、57、59、63、65、67、81、83、162、165、170、172、174、176、178、180和186中任一项所包含的Vα氨基酸序列组成;
(b)Vβ结构域,其包含或由SEQ ID NO:36、38、40、42、46、86、49、51、55、57、61、63、67、81、83、162、165、170、172、174、176、178、180和186中任一项所包含的Vβ氨基酸序列组成;或者
(c)(a)的Vα结构域和(b)的Vβ。
6.根据权利要求5所述的结合蛋白,其中,所述结合蛋白包含:
(a)包含SEQ ID NO:36中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:36中所包含的Vβ氨基酸序列的Vβ结构域;
(b)包含SEQ ID NO:38中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:38中所包含的Vβ氨基酸序列的Vβ结构域;
(c)包含SEQ ID NO:40中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:40中所包含的Vβ氨基酸序列的Vβ结构域;
(d)包含SEQ ID NO:42中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:42中所包含的Vβ氨基酸序列的Vβ结构域;
(e)包含SEQ ID NO:44中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:46中所包含的Vβ氨基酸序列的Vβ结构域;
(f)包含SEQ ID NO:86中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:86中所包含的Vβ氨基酸序列的Vβ结构域;
(g)包含SEQ ID NO:49中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:49中所包含的Vβ氨基酸序列的Vβ结构域;
(h)包含SEQ ID NO:51中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:51中所包含的Vβ氨基酸序列的Vβ结构域;
(i)包含SEQ ID NO:53中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:55中所包含的Vβ氨基酸序列的Vβ结构域;
(j)包含SEQ ID NO:57中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:57中所包含的Vβ氨基酸序列的Vβ结构域;
(k)包含SEQ ID NO:59中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:6l中所包含的Vβ氨基酸序列的Vβ结构域;
(l)包含SEQ ID NO:63中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:63中所包含的Vβ氨基酸序列的Vβ结构域;
(m)包含SEQ ID NO:65中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:67中所包含的Vβ氨基酸序列的Vβ结构域;
(n)包含SEQ ID NO:67中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:67中所包含的Vβ氨基酸序列的Vβ结构域;
(o)包含在SEQ ID NO:81中所包含的Vα氨基酸序列的Vα结构域和包含在SEQ ID NO:81中所包含的Vβ氨基酸序列的Vβ结构域;
(p)包含SEQ ID NO:83中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:83中所包含的Vβ氨基酸序列的Vβ结构域;
(q)包含SEQ ID NO:162中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:162中所包含的Vβ氨基酸序列的Vβ结构域;
(r)包含SEQ ID NO:165中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:165中所包含的Vβ氨基酸序列的Vβ结构域;
(s)包含SEQ ID NO:170中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:170中所包含的Vβ氨基酸序列的Vβ结构域;
(t)包含SEQ ID NO:172中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:172中所包含的Vβ氨基酸序列的Vβ结构域;
(u)包含SEQ ID NO:174中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:174中所包含的Vβ氨基酸序列的Vβ结构域;
(v)包含SEQ ID NO:176中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:176中所包含的Vβ氨基酸序列的Vβ结构域;
(w)包含SEQ ID NO:178中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:178中所包含的Vβ氨基酸序列的Vβ结构域;
(x)包含SEQ ID NO:180中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:180中所包含的Vβ氨基酸序列的Vβ结构域;或者
(y)包含SEQ ID NO:186中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:186中所包含的Vβ氨基酸序列的Vβ结构域。
7.一种结合蛋白,包含:
(a)T细胞受体(TCR)α链可变(Vα)结构域以及TCRβ链可变(Vβ)结构域,所述TCR Vα结构域包含SEQ ID NO:21所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:21所示的并且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;
(b)TCR Vα结构域和TCR Vβ结构域,所述TCR Vβ结构域包含SEQ ID NO:22所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:22所示的并且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;或者
(c)(a)的Vα结构域和(b)的Vβ,
其中所述结合蛋白能够特异性结合人细胞周期蛋白A1(CCNA1)肽SLIAAAAFCLA(SEQ IDNO:2):人白细胞抗原(HLA)复合物。
8.根据权利要求7所述的结合蛋白,其中,所述Vα结构域包含SEQ ID NO:21的CDR3氨基酸序列,并且所述Vβ结构域包含SEQ ID NO:22的CDR3氨基酸序列。
9.根据权利要求7或8所述的结合蛋白,其中:
所述Vβ结构域包含SEQ ID NO:22的CDR3氨基酸序列和由TRBV19*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序;并且
所述Vα结构域包含SEQ ID NO:21的CDR3氨基酸序列和由TRAV24*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序列。
10.根据权利要求7-9中任一项所述的结合蛋白,其中,所述结合蛋白包含:
(a)与SEQ ID NO:69或73中所包含的Vα氨基酸序列至少约90%相同的Vα结构域;
(b)与SEQ ID NO:71或73中所包含的Vβ氨基酸序列至少约90%相同的Vβ结构域;或者
(c)(a)的Vα结构域和(b)的Vβ;
其中所述CDR中的至少三个或四个不具有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或缺失。
11.根据权利要求10所述的结合蛋白,其中,所述结合蛋白包含:
(a)Vα结构域,其包含或由SEQ ID NO:69或73中所包含的Vα氨基酸序列组成;
(b)Vβ结构域,其包含或由SEQ ID NO:71或73所示的氨基酸序列组成;或者
(c)(a)的Vα结构域和(b)的Vβ。
12.根据权利要求11所述的结合蛋白,其中,所述结合蛋白包含:
(a)包含SEQ ID NO:69中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:71中所包含的Vβ氨基酸序列的Vβ结构域;或者
(b)包含SEQ ID NO:73中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:73中所包含的Vβ氨基酸序列的Vβ结构域。
13.一种结合蛋白,包含:
(a)T细胞受体(TCR)α链可变(Vα)结构域以及TCRβ链可变(Vβ)结构域,所述TCR Vα结构域包含SEQ ID NO:23所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:23所示的并且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;
(b)TCR Vα结构域和TCR Vβ结构域,所述TCR Vβ结构域包含SEQ ID NO:24所示的互补决定区3(CDR3)氨基酸序列或SEQ ID NO:24所示的并且具有最多五个氨基酸取代、插入和/或缺失的CDR3氨基酸序列;或者
(c)(a)的Vα结构域和(b)的Vβ,
其中所述结合蛋白能够特异性结合人细胞周期蛋白A1(CCNA1)肽YSLSEIVPCL(SEQ IDNO:3):人白细胞抗原(HLA)复合物。
14.根据权利要求13所述的结合蛋白,其中,所述Vα结构域包含SEQ ID NO:23的CDR3氨基酸序列,并且所述Vβ结构域包含SEQ ID NO:24的CDR3氨基酸序列。
15.根据权利要求13或14所述的结合蛋白,其中:
所述Vβ结构域包含SEQ ID NO:24的CDR3氨基酸序列和由TRBV5-6*01基因编码的CDR1氨基酸序列和CDR2氨基酸序列;并且
所述Vα结构域包含SEQ ID NO:23的CDR3氨基酸序列和由TRAV19*0l基因编码的CDR1氨基酸序列和CDR2氨基酸序列。
16.根据权利要求13-15中任一项所述的结合蛋白,其中,所述结合蛋白包含:
(a)与SEQ ID NO:75或79中所包含的Vα氨基酸序列至少约90%相同的Vα结构域;
(b)与SEQ ID NO:77或79中所包含的Vβ氨基酸序列至少约90%相同的Vβ结构域;或者
(c)(a)的Vα结构域和(b)的Vβ;
其中所述CDR中的至少三个或四个不具有突变,而具有突变的CDR具有三个或更少的氨基酸取代、插入和/或缺失。
17.根据权利要求16所述的结合蛋白,其中,所述结合蛋白包含:
(a)Vα结构域,其包含或由SEQ ID NO:75或79中所包含的Vα氨基酸序列组成;
(b)Vβ结构域,其包含或由SEQ ID NO:77或79中所包含的Vβ氨基酸序列组成;或者
(c)(a)的Vα结构域和(b)的Vβ。
18.根据权利要求17所述的结合蛋白,其中,所述结合蛋白包含:
(a)包含SEQ ID NO:75中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:77中所包含的Vβ氨基酸序列的Vβ结构域;或者
(b)包含SEQ ID NO:79中所包含的Vα氨基酸序列的Vα结构域和包含SEQ ID NO:79中所包含的Vβ氨基酸序列的Vβ结构域。
19.根据权利要求1至18中任一项所述的结合蛋白,其中,所述结合蛋白为TCR、TCR的抗原结合片段或嵌合抗原受体。
20.根据权利要求19所述的结合蛋白,其中,所述TCR的抗原结合片段包含单链TCR(scTCR)。
21.根据权利要求19所述的结合蛋白,其中,所述结合蛋白是TCR。
22.根据权利要求21所述的结合蛋白,其中,所述TCR包含α链恒定(Cα)结构域,所述Cα结构域与SEQ ID NO:33的氨基酸序列具有至少90%的序列同一性。
23.根据权利要求22所述的结合蛋白,其中,所述Cα结构域包含SEQ ID NO:33的氨基酸序列。
24.根据权利要求21所述的结合蛋白,其中,所述TCR包含截短的Cα结构域。
25.根据权利要求24所述的结合蛋白,其中,所述截短的Cα结构域在其N末端、C末端或两者处包含与SEQ ID NO:33的氨基酸序列对应的1、2、3、4或更多个氨基酸的截短。
26.根据权利要求19至25中任一项所述的结合蛋白,其中,所述TCR包含β链恒定(Cβ)结构域,所述Cβ结构域与SEQ ID NO:34或SEQ ID NO:84的氨基酸序列具有至少90%的序列同一性。
27.根据权利要求26所述的结合蛋白,其中,所述Cβ结构域包含SEQ ID NO:34或SEQ IDNO:84的氨基酸序列。
28.根据权利要求19-27中任一项所述的结合蛋白,其中,所述TCR包含:
(a)Cα结构域,其在SEQ ID NO:33的位置49处包含半胱氨酸取代,
(b)Cβ结构域,其在SEQ ID NO:34的位置57处或在SEQ ID NO:84的位置56处包含半胱氨酸取代,或者
(c)(a)和(b)两者。
29.根据权利要求21所述的结合蛋白,其中,所述TCR包含:
(a)与SEQ ID NO:36、38、40、42、44、86、49、51、53、57、59、63、65、67、81、83、162、165、170、172、174、176、178、180和186中任一项所包含的链氨基酸序列具有至少90%序列同一性的α链;
(b)与SEQ ID NO:36、38、40、42、46、86、49、51、55、57、61,63、67、81、83、162、165、170、172、174、176、178、180和186中任一项所包含的链氨基酸序列具有至少90%序列同一性的β链;或者
(c)(a)的α链和(b)的β链。
30.根据权利要求29所述的结合蛋白,其中,所述TCR包含:
(a)包含SEQ ID NO:36中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:36中所包含的β链氨基酸序列的所述TCR β链;
(b)包含SEQ ID NO:38中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:38中所包含的β链氨基酸序列的所述TCR β链;
(c)包含SEQ ID NO:40中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:40中所包含的β链氨基酸序列的所述TCR β链;
(d)包含SEQ ID NO:42中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:42中所包含的β链氨基酸序列的所述TCR β链;
(e)包含SEQ ID NO:44中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:46中所包含的β链氨基酸序列的所述TCR β链;
(f)包含SEQ ID NO:86中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:86中所包含的β链氨基酸序列的所述TCR β链;
(g)包含SEQ ID NO:49中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:49中所包含的β链氨基酸序列的所述TCR β链;或者
(h)包含SEQ ID NO:51中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:51中所包含的β链氨基酸序列的所述TCR β链;
(i)包含SEQ ID NO:53中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:55中所包含的β链氨基酸序列的所述TCR β链;
(j)包含SEQ ID NO:57中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:57中所包含的β链氨基酸序列的所述TCR β链;
(k)包含SEQ ID NO:59中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:61中所包含的β链氨基酸序列的所述TCR β链;
(l)包含SEQ ID NO:63中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:63中所包含的β链氨基酸序列的所述TCR β链;
(m)包含SEQ ID NO:65中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:67中所包含的β链氨基酸序列的所述TCR β链;
(n)包含SEQ ID NO:67中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:67中所包含的β链氨基酸序列的所述TCR β链;
(o)包含SEQ ID NO:81中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:81中所包含的β链氨基酸序列的所述TCR β链;
(p)包含SEQ ID NO:83中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:83中所包含的β链氨基酸序列的所述TCR β链;
(q)包含SEQ ID NO:162中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:162中所包含的β链氨基酸序列的所述TCR β链;
(r)包含SEQ ID NO:165中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:165中所包含的β链氨基酸序列的所述TCR β链;
(s)包含SEQ ID NO:170中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:170中所包含的β链氨基酸序列的所述TCR β链;
(t)包含SEQ ID NO:172中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:172中所包含的β链氨基酸序列的所述TCR β链;
(u)包含SEQ ID NO:174中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:174中所包含的β链氨基酸序列的所述TCR β链;
(v)包含SEQ ID NO:176中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:176中所包含的β链氨基酸序列的所述TCR β链;
(w)包含SEQ ID NO:178中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:178中所包含的β链氨基酸序列的所述TCR β链;
(x)包含SEQ ID NO:180中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:180中所包含的β链氨基酸序列的所述TCR β链;或者
(y)包含SEQ ID NO:186中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:186中所包含的β链氨基酸序列的所述TCR β链。
31.根据权利要求21所述的结合蛋白,其中,所述TCR包含:
(a)与SEQ ID NO:69的氨基酸序列或SEQ ID NO:73中所包含的α链氨基酸序列具有至少90%序列同一性的α链;
(b)与SEQ ID NO:71的氨基酸序列或SEQ ID NO:73中所包含的α链氨基酸序列具有至少90%的序列同一性的β链;或者
(c)(a)的α链和(b)的β链。
32.根据权利要求31所述的结合蛋白,其中,所述TCR包含:
(a)包含SEQ ID NO:69中所包含的氨基酸序列的所述TCRα链以及包含SEQ ID NO:71中所包含的氨基酸序列的所述TCRβ链;
(b)包含SEQ ID NO:73中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:73中所包含的β链氨基酸序列的所述TCR β链;或者
(c)包含SEQ ID NO:182中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:182中所包含的β链氨基酸序列的所述TCR β链。
33.根据权利要求21所述的结合蛋白,其中,所述TCR包含:
(a)与SEQ ID NO:75的氨基酸序列或SEQ ID NO:79中所包含的α链氨基酸序列具有至少90%序列同一性的α链;
(b)与SEQ ID NO:77的氨基酸序列或SEQ ID NO:79中所包含的α链氨基酸序列具有至少90%的序列同一性的β链;或者
(c)(a)的α链和(b)的β链。
34.权利要求33的结合蛋白,其中所述TCR包含:
(a)包含SEQ ID NO:75中所包含的氨基酸序列的所述TCR α链以及包含SEQ ID NO:77中所包含的氨基酸序列的所述TCRβ链;
(b)包含SEQ ID NO:79中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ ID NO:79中所包含的β链氨基酸序列的所述TCR β链;或者
(c)包含SEQ ID NO:184中所包含的α链氨基酸序列的所述TCR α链以及包含SEQ IDNO:184中所包含的β链氨基酸序列的所述TCR β链。
35.权利要求1-34中任一项的结合蛋白,其中,所述HLA包含HLA-A*02:0l。
36.权利要求1-35中任一项的结合蛋白,其中,所述结合蛋白是嵌合、人源化或人TCR,TCR的抗原结合片段或嵌合抗原受体。
37.一种多核苷酸,其编码包含T细胞受体(TCR)、α链可变(Vα)结构域和TCRβ链可变(Vβ)结构域的结合蛋白,其中编码的结合蛋白能够特异性结合人细胞周期蛋白A1(CCNA1)肽YSLSEIVPCL(SEQ ID NO:3),其中多核苷酸经密码子优化以在宿主细胞中表达。
38.根据权利要求37所述的多核苷酸,其中,所述编码的结合蛋白能够特异性结合CCNA1肽YSLSEIVPCL(SEQ ID NO:3):HLA复合物。
39.根据权利要求38所述的多核苷酸,其中,所述ELLA包含HLA-A*02:0l。
40.一种多核苷酸,其编码权利要求1-36中任一项的结合蛋白。
41.根据权利要求40所述的多核苷酸,其中,编码所述结合蛋白的所述多核苷酸经密码子优化以在目的宿主细胞中表达。
42.一种载体,其包含权利要求37-41中任一项的多核苷酸。
43.根据权利要求42所述的载体,其中,所述载体是病毒载体。
44.根据权利要求43所述的载体,其中,所述病毒载体是慢病毒载体或γ-逆转录病毒载体。
45.一种宿主细胞,其包含权利要求37-41中任一项的多核苷酸或权利要求42-44中任一项的载体,其中所述宿主细胞在其细胞表面上表达由所述多核苷酸编码的结合蛋白。
46.根据权利要求45所述的宿主细胞,其中,所述宿主细胞是造血祖细胞或免疫细胞。
47.根据权利要求46所述的宿主细胞,其中,所述免疫细胞是CD4+T细胞、CD8+T细胞、CD4-CD8-T细胞、γδT细胞、天然杀伤细胞、树突状细胞或其任意组合。
48.根据权利要求46所述的宿主细胞,其中,所述免疫细胞是T细胞。
49.根据权利要求48所述的宿主细胞,其中,所述T细胞是幼稚T细胞、中央记忆T细胞、效应子记忆T细胞或其任意组合。
50.根据权利要求45-49中任一项所述的宿主细胞,其中,所述宿主细胞是人。
51.一种组合物,其包含权利要求45-50中任一项的宿主细胞以及药学上可接受的载体、稀释剂或赋形剂。
52.一种治疗过度增殖性疾病的方法,所述方法包括向有需要的受试者施用组合物,所述组合物包含对权利要求1-36中任一项的对CCNA1肽具有特异性的结合蛋白、权利要求37-41中任一项的编码对CCNA1肽具有特异性的结合蛋白的多核苷酸、权利要求42-44中任一项的载体、权利要求45-50中任一项的宿主细胞或权利要求51的组合物。
53.根据权利要求52所述的方法,其中,所述过度增殖性疾病是血液系统恶性肿瘤或实体癌。
54.根据权利要求53所述的方法,其中,所述血液恶性肿瘤选自急性淋巴细胞白血病(ALL)、急性髓细胞性白血病(AML)、慢性粒细胞性白血病(CML)、慢性嗜酸性粒细胞白血病(CEL)、骨髓增生异常综合症(MDS)、非霍奇金氏病淋巴瘤(NHL)和多发性骨髓瘤(MM)。
55.根据权利要求53所述的方法,其中,所述实体癌选自胆道癌、膀胱癌、骨和软组织癌、脑肿瘤、乳腺癌、宫颈癌、结肠癌、结肠直肠腺癌、结肠直肠癌、类胶质瘤、胚胎癌、子宫内膜癌、食道癌、胃癌、胃腺癌、多形性胶质母细胞瘤、妇科肿瘤、头颈鳞状细胞癌、肝癌、肺癌、间皮瘤、恶性黑色素瘤、骨肉瘤、卵巢癌、胰腺癌、胰腺导管癌、原发性星形细胞癌、原发性甲状腺癌、前列腺癌、肾癌、肾细胞癌、横纹肌肉瘤、皮肤癌、软组织肉瘤、睾丸生殖细胞肿瘤、尿路上皮癌、子宫肉瘤或子宫癌。
56.根据权利要求52-55中任一项所述的方法,其中,所述结合蛋白能够以I类HLA限制的方式促进针对人细胞周期蛋白A1的抗原特异性T细胞应答。
57.根据权利要求56所述的方法,其中,所述抗原特异性T细胞应答包含CD4+辅助性T淋巴细胞(Th)应答和CD8+细胞毒性T淋巴细胞(CTL)应答中的至少一种。
58.根据权利要求57所述的方法,其中,所述CTL应答针对CCNA1过表达的细胞。
59.根据权利要求52-58中任一项的方法,其中,所述宿主细胞是肠外给药的。
60.根据权利要求52-59中任一项所述的方法,其中,所述方法包括向所述受试者施用多个剂量的所述宿主细胞。
61.根据权利要求60所述的方法,其中,所述多个剂量在大约两周至大约四周的施用之间的间隔内被施用。
62.根据权利要求52-61中任一项所述的方法,其中,以大约107细胞/m2到大约1011细胞/m2的剂量向所述受试者施用所述宿主细胞。
63.根据权利要求52-62中任一项所述的方法,其中,所述方法进一步包括向所述受试者施用细胞因子。
64.根据权利要求63所述的方法,其中,所述细胞因子是IL-2、IL-15、IL-21或其任意组合。
65.根据权利要求64所述的方法,其中,所述细胞因子是IL-2并且与所述宿主细胞同时或相继施用。
66.根据权利要求65所述的方法,其中,所述细胞因子是连续施用的,条件是所述受试者在施用细胞因子之前被施用了至少三或四次所述宿主细胞。
67.根据权利要求63-66中任一项的方法,其中,所述细胞因子是IL-2并且是皮下给药的。
68.根据权利要求52-67中任一项所述的方法,其中,所述受试者进一步接受免疫抑制疗法。
69.根据权利要求68所述的方法,其中,所述免疫抑制疗法选自钙调神经磷酸酶抑制剂、皮质类固醇、微管抑制剂、低剂量的霉酚酸前药或其任意组合。
70.根据权利要求52-69中任一项所述的方法,其中,所述受试者已经接受了非清髓性或清髓性造血细胞移植。
71.根据权利要求70所述的方法,其中,在所述非清髓性造血细胞移植后至少三个月向所述受试者施用所述宿主细胞。
72.根据权利要求71所述的方法,其中,在清髓性造血细胞移植后至少两个月向受试者施用宿主细胞。
73.根据权利要求51-72中任一项所述的方法,其进一步包括向所述受试者施用免疫抑制剂的抑制剂。
74.根据权利要求73所述的方法,其中,所述免疫抑制剂的抑制剂抑制PD-1、PD-L1、PD-L2、LAG3、CTLA4、B7-H3、B7-H4、CD244/2B4、HVEM、BTLA、CD160、TIM3、GAL9、腺苷、A2aR、免疫抑制性细胞因子、IDO、精氨酸酶、VISTA、TIGIT、PVRIG、PVRL2、KIR、LAIR1、CEACAM-1、CEACAM-3、CEACAM-5、CD160、Treg细胞或其任意组合。
75.根据权利要求73或74所述的方法,其中,所述免疫抑制剂的抑制剂选自抗体或其抗原结合片段、融合蛋白、小分子、RNAi分子、核酶、适体、反义寡核苷酸或其任意组合。
76.根据权利要求75所述的方法,其中,所述免疫抑制剂的抑制剂包含吡吡珠单抗、尼武单抗、派姆单抗、MEDI0680、AMP-224、BMS-936558、BMS-936559、德瓦鲁单抗、阿特朱单抗、阿维鲁单抗、MPDL3280A、LAG525、IMP321、IMP701、9H12、BMS-986016、伊匹单抗、tremelimumab、阿巴西普、贝拉西普、enoblituzumab、376.96、抗B7-H4抗体或抗原结合片段、lirilumab、左旋1-甲基色氨酸、依帕妥司他、依布硒仑、吲哚莫德、NLG919、1-甲基-色氨酸(l-MT)-替拉-扎明、N(ω)-硝基-L-精氨酸甲酯(L-NAME)、N-ω-羟基-nor-l-精氨酸(nor-NOHA)、L-NOHA、2(S)-氨基-6-硼己酸(ABH)、S-(2-硼乙基)-L-半胱氨酸(BEC)、CA-170、COM902、COM701或其抗原结合片段、或其任意组合。
77.根据权利要求52-76中任一项所述的方法,其进一步包括向所述受试者施用治疗有效量的刺激性免疫检查点分子的激动剂。
78.根据权利要求77所述的方法,其中,所述激动剂选自urelumab、MEDI6469、MEDI6383、MEDI0562、来那度胺、泊马利度胺、CDX-1127、TGN1412、CD80、CD86、CP-870893、rhuCD40L、SGN-40、IL-2、GSK3359609、mAb 88.2、JTX-2011、Icos 145-1、Icos 314-8或其任意组合。
79.根据权利要求52-78中任一项所述的方法,其进一步包括向所述受试者施用以下一种或多种:治疗性抗体、化学疗法、放射疗法、手术或其任意组合。
80.根据权利要求52-79中任一项的方法,其中所述受试者是人类。
81.一种单位剂型,其包含权利要求45-50中任一项的宿主细胞。
82.根据权利要求81所述的单位剂型,其中,所述宿主细胞的剂量为大约107细胞/m2到大约1011细胞/m2。
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862629648P | 2018-02-12 | 2018-02-12 | |
| US62/629,648 | 2018-02-12 | ||
| US201862630198P | 2018-02-13 | 2018-02-13 | |
| US62/630,198 | 2018-02-13 | ||
| US201862667207P | 2018-05-04 | 2018-05-04 | |
| US62/667,207 | 2018-05-04 | ||
| PCT/US2019/017708 WO2019157524A1 (en) | 2018-02-12 | 2019-02-12 | Cyclin a1 specific t cell receptors and uses thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112004825A true CN112004825A (zh) | 2020-11-27 |
Family
ID=65767286
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980025483.1A Pending CN112004825A (zh) | 2018-02-12 | 2019-02-12 | 细胞周期蛋白a1特异性t细胞受体及其用途 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US20200405762A1 (zh) |
| EP (1) | EP3752525A1 (zh) |
| JP (2) | JP2021512637A (zh) |
| CN (1) | CN112004825A (zh) |
| AU (1) | AU2019218397A1 (zh) |
| BR (1) | BR112020016330A8 (zh) |
| CA (1) | CA3090700A1 (zh) |
| IL (1) | IL276556A (zh) |
| MX (1) | MX2020008403A (zh) |
| SG (1) | SG11202007660UA (zh) |
| WO (1) | WO2019157524A1 (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022156687A1 (en) * | 2021-01-19 | 2022-07-28 | Wuxi Biologics (Shanghai) Co., Ltd. | Polypeptide complexes with improved stability and expression |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113321725B (zh) * | 2020-02-28 | 2024-06-11 | 香雪生命科学技术(广东)有限公司 | 一种识别afp的t细胞受体 |
| CN113880953A (zh) * | 2020-07-01 | 2022-01-04 | 华夏英泰(北京)生物技术有限公司 | T细胞抗原受体、其多聚体复合物及其制备方法和应用 |
| WO2022022696A1 (zh) * | 2020-07-30 | 2022-02-03 | 香雪生命科学技术(广东)有限公司 | 一种识别afp的高亲和力tcr |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104080797A (zh) * | 2011-11-11 | 2014-10-01 | 弗雷德哈钦森癌症研究中心 | 针对癌症的靶向细胞周期蛋白a1的t细胞免疫疗法 |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5283173A (en) | 1990-01-24 | 1994-02-01 | The Research Foundation Of State University Of New York | System to detect protein-protein interactions |
| US7067318B2 (en) | 1995-06-07 | 2006-06-27 | The Regents Of The University Of Michigan | Methods for transfecting T cells |
| GB9518220D0 (en) | 1995-09-06 | 1995-11-08 | Medical Res Council | Checkpoint gene |
| AU2472400A (en) | 1998-10-20 | 2000-05-08 | City Of Hope | CD20-specific redirected T cells and their use in cellular immunotherapy of CD20+ malignancies |
| US6946292B2 (en) | 2000-10-06 | 2005-09-20 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions with increased antibody dependent cytotoxic activity |
| WO2006076678A2 (en) | 2005-01-13 | 2006-07-20 | The Johns Hopkins University | Prostate stem cell antigen vaccines and uses thereof |
| US8119772B2 (en) | 2006-09-29 | 2012-02-21 | California Institute Of Technology | MART-1 T cell receptors |
| EP2210903A1 (en) | 2009-01-21 | 2010-07-28 | Monoclonal Antibodies Therapeutics | Anti-CD160 monoclonal antibodies and uses thereof |
| EP2258719A1 (en) | 2009-05-19 | 2010-12-08 | Max-Delbrück-Centrum für Molekulare Medizin (MDC) | Multiple target T cell receptor |
| US20130071414A1 (en) | 2011-04-27 | 2013-03-21 | Gianpietro Dotti | Engineered cd19-specific t lymphocytes that coexpress il-15 and an inducible caspase-9 based suicide gene for the treatment of b-cell malignancies |
| JP6120848B2 (ja) | 2011-08-15 | 2017-04-26 | メディミューン,エルエルシー | 抗b7−h4抗体およびその使用 |
| US10780118B2 (en) | 2012-08-20 | 2020-09-22 | Fred Hutchinson Cancer Research Center | Method and compositions for cellular immunotherapy |
| RU2015129551A (ru) | 2012-12-19 | 2017-01-25 | Эмплиммьюн, Инк. | Антитела к в7-н4 человека и их применение |
| WO2016040724A1 (en) | 2014-09-12 | 2016-03-17 | Genentech, Inc. | Anti-b7-h4 antibodies and immunoconjugates |
| EP3201232A1 (en) | 2014-10-03 | 2017-08-09 | Dana-Farber Cancer Institute, Inc. | Glucocorticoid-induced tumor necrosis factor receptor (gitr) antibodies and methods of use thereof |
| WO2016161273A1 (en) | 2015-04-01 | 2016-10-06 | Adaptive Biotechnologies Corp. | Method of identifying human compatible t cell receptors specific for an antigenic target |
| GB201516272D0 (en) * | 2015-09-15 | 2015-10-28 | Adaptimmune Ltd And Immunocore Ltd | TCR Libraries |
| GB201604494D0 (en) * | 2016-03-16 | 2016-04-27 | Immatics Biotechnologies Gmbh | Transfected T-Cells and T-Cell receptors for use in immunotherapy against cancers |
-
2019
- 2019-02-12 SG SG11202007660UA patent/SG11202007660UA/en unknown
- 2019-02-12 CA CA3090700A patent/CA3090700A1/en active Pending
- 2019-02-12 EP EP19711182.6A patent/EP3752525A1/en active Pending
- 2019-02-12 MX MX2020008403A patent/MX2020008403A/es unknown
- 2019-02-12 AU AU2019218397A patent/AU2019218397A1/en not_active Abandoned
- 2019-02-12 BR BR112020016330A patent/BR112020016330A8/pt unknown
- 2019-02-12 CN CN201980025483.1A patent/CN112004825A/zh active Pending
- 2019-02-12 JP JP2020543065A patent/JP2021512637A/ja active Pending
- 2019-02-12 WO PCT/US2019/017708 patent/WO2019157524A1/en unknown
- 2019-02-12 US US16/968,547 patent/US20200405762A1/en active Pending
-
2020
- 2020-08-06 IL IL276556A patent/IL276556A/en unknown
-
2023
- 2023-08-02 JP JP2023126157A patent/JP2023133505A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104080797A (zh) * | 2011-11-11 | 2014-10-01 | 弗雷德哈钦森癌症研究中心 | 针对癌症的靶向细胞周期蛋白a1的t细胞免疫疗法 |
| CN107011426A (zh) * | 2011-11-11 | 2017-08-04 | 弗雷德哈钦森癌症研究中心 | 针对癌症的靶向细胞周期蛋白a1的t细胞免疫疗法 |
Non-Patent Citations (1)
| Title |
|---|
| RACHEL PERRET ET AL: "Expanding the scope of WT1- and cyclin A1-specific TCR gene therapy for AML and other cancers", THE JOURNAL OF IMMUNOLOGY, vol. 196, pages 143, XP055591199 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022156687A1 (en) * | 2021-01-19 | 2022-07-28 | Wuxi Biologics (Shanghai) Co., Ltd. | Polypeptide complexes with improved stability and expression |
Also Published As
| Publication number | Publication date |
|---|---|
| IL276556A (en) | 2020-09-30 |
| CA3090700A1 (en) | 2019-08-15 |
| BR112020016330A2 (pt) | 2020-12-15 |
| BR112020016330A8 (pt) | 2023-04-18 |
| JP2023133505A (ja) | 2023-09-22 |
| AU2019218397A1 (en) | 2020-10-01 |
| EP3752525A1 (en) | 2020-12-23 |
| MX2020008403A (es) | 2020-09-25 |
| SG11202007660UA (en) | 2020-09-29 |
| JP2021512637A (ja) | 2021-05-20 |
| US20200405762A1 (en) | 2020-12-31 |
| WO2019157524A1 (en) | 2019-08-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110582299A (zh) | 高亲和力mage-a1特异性tcr及其用途 | |
| EP3877054B1 (en) | Process for producing genetically engineered t cells | |
| KR20190062505A (ko) | Hpv-특이적 결합 분자 | |
| CN114026116A (zh) | Ras新抗原特异性结合蛋白及其用途 | |
| JP2023120386A (ja) | T細胞療法とbtk阻害剤との併用療法 | |
| KR20210019993A (ko) | Τ 세포 수용체 및 이를 발현하는 조작된 세포 | |
| KR20200089285A (ko) | Bcma-표적화 키메라 항원 수용체, cd19-표적화 키메라 항원 수용체, 및 병용 요법 | |
| AU2016321256A1 (en) | NY-ESO-1 specific TCRs and methods of use thereof | |
| CN113227358A (zh) | 选择并刺激细胞的方法及用于所述方法的设备 | |
| CN112004825A (zh) | 细胞周期蛋白a1特异性t细胞受体及其用途 | |
| BR112020001719A2 (pt) | reagentes para expansão de células que expressam receptores recombinantes | |
| WO2020068702A1 (en) | Chimeric receptor proteins and uses thereof | |
| EP3664820B1 (en) | Methods for producing genetically engineered cell compositions and related compositions | |
| CN111051349A (zh) | Strep-tag特异性嵌合受体及其用途 | |
| KR20220034782A (ko) | 세포 매개 세포 독성 요법 및 친생존 bcl2 패밀리 단백질 억제제의 병용 요법 | |
| WO2019200347A1 (en) | Methods for adoptive cell therapy targeting ror1 | |
| KR20220101641A (ko) | 세포 선택 및/또는 자극 장치 및 사용 방법 | |
| WO2023288281A2 (en) | Chimeric polypeptides | |
| KR20200097253A (ko) | T 세포 조성물의 생산방법 | |
| KR20230022868A (ko) | 재조합 수용체를 발현하는 공여자-배치 세포의 제조 방법 | |
| CN113286815A (zh) | 间皮素特异性t细胞受体及其在免疫治疗中的应用 | |
| CN114555790A (zh) | Wt-1特异性t细胞免疫疗法 | |
| CN117795082A (zh) | 抗EGFRviii抗体、多肽、表达前述多肽的细胞、包含前述细胞的医药组合物、前述细胞的制造方法、及包含编码前述多肽的碱基序列的多核苷酸或载体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information | ||
| CB02 | Change of applicant information |
Address after: Washington State Applicant after: Fred Hutchinson Cancer Center Address before: Washington State Applicant before: Seattle Cancer Care Alliance |
|
| TA01 | Transfer of patent application right | ||
| TA01 | Transfer of patent application right |
Effective date of registration: 20220923 Address after: Washington State Applicant after: Seattle Cancer Care Alliance Address before: Washington State Applicant before: FRED HUTCHINSON CANCER RESEARCH CENTER |