CN106536544B - 艰难梭菌免疫原性组合物 - Google Patents
艰难梭菌免疫原性组合物 Download PDFInfo
- Publication number
- CN106536544B CN106536544B CN201580039744.7A CN201580039744A CN106536544B CN 106536544 B CN106536544 B CN 106536544B CN 201580039744 A CN201580039744 A CN 201580039744A CN 106536544 B CN106536544 B CN 106536544B
- Authority
- CN
- China
- Prior art keywords
- seq
- cdtb
- protein
- cdta
- clostridium difficile
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000000203 mixture Substances 0.000 title claims abstract description 150
- 230000002163 immunogen Effects 0.000 title claims abstract description 104
- 241000193163 Clostridioides difficile Species 0.000 title claims description 85
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 242
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 219
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 46
- 108020001507 fusion proteins Proteins 0.000 claims abstract description 46
- 229960005486 vaccine Drugs 0.000 claims abstract description 35
- 108700012359 toxins Proteins 0.000 claims description 64
- 239000012634 fragment Substances 0.000 claims description 58
- 239000003053 toxin Substances 0.000 claims description 55
- 231100000765 toxin Toxicity 0.000 claims description 54
- 239000002671 adjuvant Substances 0.000 claims description 49
- 101710182532 Toxin a Proteins 0.000 claims description 34
- 101710084578 Short neurotoxin 1 Proteins 0.000 claims description 17
- 238000011282 treatment Methods 0.000 claims description 14
- 108700022831 Clostridium difficile toxB Proteins 0.000 claims description 11
- 230000002265 prevention Effects 0.000 claims description 7
- 238000004519 manufacturing process Methods 0.000 claims description 6
- 239000003814 drug Substances 0.000 claims description 3
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 3
- 230000027455 binding Effects 0.000 abstract description 88
- 108010010925 Clostridium actin-specific ADP-ribosyltransferase Proteins 0.000 abstract description 78
- 108010076504 Protein Sorting Signals Proteins 0.000 abstract description 55
- 102000005962 receptors Human genes 0.000 abstract description 46
- 108020003175 receptors Proteins 0.000 abstract description 46
- 239000011148 porous material Substances 0.000 abstract description 20
- 230000001225 therapeutic effect Effects 0.000 abstract 1
- 235000018102 proteins Nutrition 0.000 description 197
- 235000001014 amino acid Nutrition 0.000 description 151
- 229940024606 amino acid Drugs 0.000 description 151
- 150000001413 amino acids Chemical class 0.000 description 144
- 108090000765 processed proteins & peptides Proteins 0.000 description 131
- 102000004196 processed proteins & peptides Human genes 0.000 description 115
- 229920001184 polypeptide Polymers 0.000 description 113
- 210000004027 cell Anatomy 0.000 description 81
- 230000035772 mutation Effects 0.000 description 75
- 238000000034 method Methods 0.000 description 63
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 62
- 230000014509 gene expression Effects 0.000 description 47
- 230000004927 fusion Effects 0.000 description 41
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 40
- 230000003013 cytotoxicity Effects 0.000 description 37
- 231100000135 cytotoxicity Toxicity 0.000 description 37
- 125000003275 alpha amino acid group Chemical group 0.000 description 34
- 239000013598 vector Substances 0.000 description 34
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 32
- 241000282414 Homo sapiens Species 0.000 description 31
- 239000011780 sodium chloride Substances 0.000 description 31
- 238000000746 purification Methods 0.000 description 28
- 239000013604 expression vector Substances 0.000 description 27
- 239000000427 antigen Substances 0.000 description 26
- 108091007433 antigens Proteins 0.000 description 26
- 102000036639 antigens Human genes 0.000 description 26
- 210000004899 c-terminal region Anatomy 0.000 description 22
- 108091033319 polynucleotide Proteins 0.000 description 22
- 102000040430 polynucleotide Human genes 0.000 description 22
- 239000002157 polynucleotide Substances 0.000 description 22
- 101710182223 Toxin B Proteins 0.000 description 21
- 230000000694 effects Effects 0.000 description 20
- FSVCELGFZIQNCK-UHFFFAOYSA-N N,N-bis(2-hydroxyethyl)glycine Chemical compound OCCN(CCO)CC(O)=O FSVCELGFZIQNCK-UHFFFAOYSA-N 0.000 description 19
- 239000003921 oil Substances 0.000 description 19
- 235000019198 oils Nutrition 0.000 description 19
- 108010070675 Glutathione transferase Proteins 0.000 description 18
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 18
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 description 18
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 18
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 17
- 241000699670 Mus sp. Species 0.000 description 17
- 201000010099 disease Diseases 0.000 description 17
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 17
- 239000007998 bicine buffer Substances 0.000 description 16
- 235000012000 cholesterol Nutrition 0.000 description 16
- 238000010367 cloning Methods 0.000 description 16
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 16
- 239000002953 phosphate buffered saline Substances 0.000 description 16
- 239000000523 sample Substances 0.000 description 16
- 229930182558 Sterol Natural products 0.000 description 15
- 150000007523 nucleic acids Chemical group 0.000 description 15
- 150000003432 sterols Chemical class 0.000 description 15
- 235000003702 sterols Nutrition 0.000 description 15
- 239000002773 nucleotide Substances 0.000 description 14
- 125000003729 nucleotide group Chemical group 0.000 description 14
- 235000010384 tocopherol Nutrition 0.000 description 14
- 229920001213 Polysorbate 20 Polymers 0.000 description 13
- 239000000872 buffer Substances 0.000 description 13
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 13
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 13
- -1 prodomain Proteins 0.000 description 13
- 230000000717 retained effect Effects 0.000 description 13
- 238000006467 substitution reaction Methods 0.000 description 13
- 108010049290 ADP Ribose Transferases Proteins 0.000 description 12
- 102000009062 ADP Ribose Transferases Human genes 0.000 description 12
- 241000588724 Escherichia coli Species 0.000 description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 238000010561 standard procedure Methods 0.000 description 12
- 108090000317 Chymotrypsin Proteins 0.000 description 11
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 11
- 230000001580 bacterial effect Effects 0.000 description 11
- 238000004422 calculation algorithm Methods 0.000 description 11
- 229960002376 chymotrypsin Drugs 0.000 description 11
- 238000013461 design Methods 0.000 description 11
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 11
- 102000039446 nucleic acids Human genes 0.000 description 11
- 108020004707 nucleic acids Proteins 0.000 description 11
- 229930182490 saponin Natural products 0.000 description 11
- 150000007949 saponins Chemical class 0.000 description 11
- 235000017709 saponins Nutrition 0.000 description 11
- 239000000243 solution Substances 0.000 description 11
- SNKAWJBJQDLSFF-NVKMUCNASA-N 1,2-dioleoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCC\C=C/CCCCCCCC SNKAWJBJQDLSFF-NVKMUCNASA-N 0.000 description 10
- 108020004414 DNA Proteins 0.000 description 10
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 10
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 10
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 10
- 230000015572 biosynthetic process Effects 0.000 description 10
- 238000009472 formulation Methods 0.000 description 10
- 235000013922 glutamic acid Nutrition 0.000 description 10
- 239000004220 glutamic acid Substances 0.000 description 10
- 230000005764 inhibitory process Effects 0.000 description 10
- 239000002609 medium Substances 0.000 description 10
- 239000012528 membrane Substances 0.000 description 10
- 238000003752 polymerase chain reaction Methods 0.000 description 10
- 239000001397 quillaja saponaria molina bark Substances 0.000 description 10
- 241000699666 Mus <mouse, genus> Species 0.000 description 9
- 238000007792 addition Methods 0.000 description 9
- 230000003321 amplification Effects 0.000 description 9
- 239000002299 complementary DNA Substances 0.000 description 9
- 238000012217 deletion Methods 0.000 description 9
- 230000037430 deletion Effects 0.000 description 9
- 238000010790 dilution Methods 0.000 description 9
- 239000012895 dilution Substances 0.000 description 9
- 238000002296 dynamic light scattering Methods 0.000 description 9
- 238000010828 elution Methods 0.000 description 9
- 239000003995 emulsifying agent Substances 0.000 description 9
- 239000002502 liposome Substances 0.000 description 9
- 238000003199 nucleic acid amplification method Methods 0.000 description 9
- 239000007764 o/w emulsion Substances 0.000 description 9
- 239000008188 pellet Substances 0.000 description 9
- 238000013519 translation Methods 0.000 description 9
- DFUSDJMZWQVQSF-XLGIIRLISA-N (2r)-2-methyl-2-[(4r,8r)-4,8,12-trimethyltridecyl]-3,4-dihydrochromen-6-ol Chemical compound OC1=CC=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1 DFUSDJMZWQVQSF-XLGIIRLISA-N 0.000 description 8
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 8
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 8
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 8
- 235000004279 alanine Nutrition 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 235000003704 aspartic acid Nutrition 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 8
- 238000011033 desalting Methods 0.000 description 8
- 229930195712 glutamate Natural products 0.000 description 8
- 230000006698 induction Effects 0.000 description 8
- 238000003780 insertion Methods 0.000 description 8
- 230000037431 insertion Effects 0.000 description 8
- 229960000318 kanamycin Drugs 0.000 description 8
- 239000000047 product Substances 0.000 description 8
- 238000012360 testing method Methods 0.000 description 8
- 230000009466 transformation Effects 0.000 description 8
- 108020004705 Codon Proteins 0.000 description 7
- 238000002965 ELISA Methods 0.000 description 7
- 108091005804 Peptidases Proteins 0.000 description 7
- 239000004365 Protease Substances 0.000 description 7
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 7
- 239000012505 Superdex™ Substances 0.000 description 7
- 239000006143 cell culture medium Substances 0.000 description 7
- 230000001413 cellular effect Effects 0.000 description 7
- 210000004922 colonic epithelial cell Anatomy 0.000 description 7
- 230000002950 deficient Effects 0.000 description 7
- 239000002158 endotoxin Substances 0.000 description 7
- 230000028993 immune response Effects 0.000 description 7
- 230000003993 interaction Effects 0.000 description 7
- 229930027917 kanamycin Natural products 0.000 description 7
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 7
- 229930182823 kanamycin A Natural products 0.000 description 7
- 229920006008 lipopolysaccharide Polymers 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 239000000178 monomer Substances 0.000 description 7
- 239000013612 plasmid Substances 0.000 description 7
- 229920000136 polysorbate Polymers 0.000 description 7
- 241000894007 species Species 0.000 description 7
- 241000894006 Bacteria Species 0.000 description 6
- 239000004471 Glycine Substances 0.000 description 6
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 6
- 239000002253 acid Substances 0.000 description 6
- 150000007513 acids Chemical class 0.000 description 6
- 230000004913 activation Effects 0.000 description 6
- 230000003115 biocidal effect Effects 0.000 description 6
- 238000003776 cleavage reaction Methods 0.000 description 6
- 238000009826 distribution Methods 0.000 description 6
- 239000000839 emulsion Substances 0.000 description 6
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 6
- 230000001939 inductive effect Effects 0.000 description 6
- 208000015181 infectious disease Diseases 0.000 description 6
- 229930182817 methionine Natural products 0.000 description 6
- 238000006384 oligomerization reaction Methods 0.000 description 6
- 239000002245 particle Substances 0.000 description 6
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 6
- 229920000053 polysorbate 80 Polymers 0.000 description 6
- 238000002360 preparation method Methods 0.000 description 6
- 230000007017 scission Effects 0.000 description 6
- 230000003612 virological effect Effects 0.000 description 6
- 238000005406 washing Methods 0.000 description 6
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 5
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 5
- 102100021935 C-C motif chemokine 26 Human genes 0.000 description 5
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 5
- 241000196324 Embryophyta Species 0.000 description 5
- 101000897493 Homo sapiens C-C motif chemokine 26 Proteins 0.000 description 5
- 241000124008 Mammalia Species 0.000 description 5
- 101710137500 T7 RNA polymerase Proteins 0.000 description 5
- 241000700605 Viruses Species 0.000 description 5
- 229940009444 amphotericin Drugs 0.000 description 5
- 239000003242 anti bacterial agent Substances 0.000 description 5
- 229940088710 antibiotic agent Drugs 0.000 description 5
- 238000012512 characterization method Methods 0.000 description 5
- 238000011161 development Methods 0.000 description 5
- 239000003623 enhancer Substances 0.000 description 5
- 239000012091 fetal bovine serum Substances 0.000 description 5
- 239000007850 fluorescent dye Substances 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 230000005847 immunogenicity Effects 0.000 description 5
- 150000002632 lipids Chemical class 0.000 description 5
- 239000007788 liquid Substances 0.000 description 5
- 230000036961 partial effect Effects 0.000 description 5
- 230000001681 protective effect Effects 0.000 description 5
- 238000013207 serial dilution Methods 0.000 description 5
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- GEYOCULIXLDCMW-UHFFFAOYSA-N 1,2-phenylenediamine Chemical compound NC1=CC=CC=C1N GEYOCULIXLDCMW-UHFFFAOYSA-N 0.000 description 4
- 241000193738 Bacillus anthracis Species 0.000 description 4
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- 108091060211 Expressed sequence tag Proteins 0.000 description 4
- 102220488184 Olfactory receptor 2A12_Y67A_mutation Human genes 0.000 description 4
- 108091081024 Start codon Proteins 0.000 description 4
- 210000001744 T-lymphocyte Anatomy 0.000 description 4
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 4
- 238000000149 argon plasma sintering Methods 0.000 description 4
- 239000001110 calcium chloride Substances 0.000 description 4
- 235000011148 calcium chloride Nutrition 0.000 description 4
- 229910001628 calcium chloride Inorganic materials 0.000 description 4
- 229910002091 carbon monoxide Inorganic materials 0.000 description 4
- 230000001186 cumulative effect Effects 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 4
- 230000001472 cytotoxic effect Effects 0.000 description 4
- 238000009792 diffusion process Methods 0.000 description 4
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 229940088598 enzyme Drugs 0.000 description 4
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 230000003053 immunization Effects 0.000 description 4
- 238000011068 loading method Methods 0.000 description 4
- 239000012139 lysis buffer Substances 0.000 description 4
- 230000001320 lysogenic effect Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 238000012986 modification Methods 0.000 description 4
- 239000012071 phase Substances 0.000 description 4
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 238000003259 recombinant expression Methods 0.000 description 4
- 238000011084 recovery Methods 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 210000002966 serum Anatomy 0.000 description 4
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 4
- 229940031439 squalene Drugs 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- PIGTXFOGKFOFTO-FVFWYJKVSA-N (2S,3S,4S,5R,6R)-6-[[(3S,4S,4aR,6aR,6bS,8R,8aR,12aS,14aR,14bR)-8a-carboxy-4-formyl-8-hydroxy-4,6a,6b,11,11,14b-hexamethyl-1,2,3,4a,5,6,7,8,9,10,12,12a,14,14a-tetradecahydropicen-3-yl]oxy]-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound O([C@H]1CC[C@]2(C)[C@H]3CC=C4[C@@]([C@@]3(CC[C@H]2[C@@]1(C=O)C)C)(C)C[C@@H](O)[C@]1(CCC(C[C@H]14)(C)C)C(O)=O)[C@@H]1O[C@H](C(O)=O)[C@@H](O)[C@H](O)[C@H]1O PIGTXFOGKFOFTO-FVFWYJKVSA-N 0.000 description 3
- SRSAMLMFVUJPSR-UHFFFAOYSA-N 2-carboxyethylphosphanium;chloride Chemical compound Cl.OC(=O)CCP SRSAMLMFVUJPSR-UHFFFAOYSA-N 0.000 description 3
- 102220485325 ATP-dependent DNA/RNA helicase DHX36_Y69A_mutation Human genes 0.000 description 3
- 102000007469 Actins Human genes 0.000 description 3
- 108010085238 Actins Proteins 0.000 description 3
- 229920001817 Agar Polymers 0.000 description 3
- 241000588832 Bordetella pertussis Species 0.000 description 3
- 241000193449 Clostridium tetani Species 0.000 description 3
- 108091026890 Coding region Proteins 0.000 description 3
- 108010013369 Enteropeptidase Proteins 0.000 description 3
- 102100029727 Enteropeptidase Human genes 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 238000010867 Hoechst staining Methods 0.000 description 3
- 102220475348 Junctional protein associated with coronary artery disease_R255A_mutation Human genes 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- 125000000773 L-serino group Chemical group [H]OC(=O)[C@@]([H])(N([H])*)C([H])([H])O[H] 0.000 description 3
- 108050004171 Lon proteases Proteins 0.000 description 3
- 101710182846 Polyhedrin Proteins 0.000 description 3
- 241001454523 Quillaja saponaria Species 0.000 description 3
- 235000009001 Quillaja saponaria Nutrition 0.000 description 3
- 241000723873 Tobacco mosaic virus Species 0.000 description 3
- 239000008272 agar Substances 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 229960000723 ampicillin Drugs 0.000 description 3
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 230000021615 conjugation Effects 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 238000002784 cytotoxicity assay Methods 0.000 description 3
- 231100000263 cytotoxicity test Toxicity 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 238000010612 desalination reaction Methods 0.000 description 3
- 229940042399 direct acting antivirals protease inhibitors Drugs 0.000 description 3
- 239000012149 elution buffer Substances 0.000 description 3
- 239000013613 expression plasmid Substances 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 3
- 125000000487 histidyl group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C([H])=N1 0.000 description 3
- 238000009396 hybridization Methods 0.000 description 3
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 231100000065 noncytotoxic Toxicity 0.000 description 3
- 230000002020 noncytotoxic effect Effects 0.000 description 3
- 108010003052 omptin outer membrane protease Proteins 0.000 description 3
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 238000002731 protein assay Methods 0.000 description 3
- 238000004062 sedimentation Methods 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 239000011534 wash buffer Substances 0.000 description 3
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 3
- OILXMJHPFNGGTO-UHFFFAOYSA-N (22E)-(24xi)-24-methylcholesta-5,22-dien-3beta-ol Natural products C1C=C2CC(O)CCC2(C)C2C1C1CCC(C(C)C=CC(C)C(C)C)C1(C)CC2 OILXMJHPFNGGTO-UHFFFAOYSA-N 0.000 description 2
- OQMZNAMGEHIHNN-UHFFFAOYSA-N 7-Dehydrostigmasterol Natural products C1C(O)CCC2(C)C(CCC3(C(C(C)C=CC(CC)C(C)C)CCC33)C)C3=CC=C21 OQMZNAMGEHIHNN-UHFFFAOYSA-N 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- 241000024188 Andala Species 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 108010077805 Bacterial Proteins Proteins 0.000 description 2
- 241000193403 Clostridium Species 0.000 description 2
- 206010009657 Clostridium difficile colitis Diseases 0.000 description 2
- IELOKBJPULMYRW-NJQVLOCASA-N D-alpha-Tocopheryl Acid Succinate Chemical compound OC(=O)CCC(=O)OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C IELOKBJPULMYRW-NJQVLOCASA-N 0.000 description 2
- 241000194033 Enterococcus Species 0.000 description 2
- 108010074860 Factor Xa Proteins 0.000 description 2
- 108010084884 GDP-mannose transporter Proteins 0.000 description 2
- 108010024636 Glutathione Proteins 0.000 description 2
- 241000606768 Haemophilus influenzae Species 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- SIKJAQJRHWYJAI-UHFFFAOYSA-N Indole Chemical compound C1=CC=C2NC=CC2=C1 SIKJAQJRHWYJAI-UHFFFAOYSA-N 0.000 description 2
- 241000235058 Komagataella pastoris Species 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 241001092142 Molina Species 0.000 description 2
- 241000588655 Moraxella catarrhalis Species 0.000 description 2
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 2
- 101100301239 Myxococcus xanthus recA1 gene Proteins 0.000 description 2
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 description 2
- 241000588650 Neisseria meningitidis Species 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 102000003992 Peroxidases Human genes 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- 108700011066 PreScission Protease Proteins 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 241000714474 Rous sarcoma virus Species 0.000 description 2
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 2
- 241000256251 Spodoptera frugiperda Species 0.000 description 2
- 241000191967 Staphylococcus aureus Species 0.000 description 2
- 241000191963 Staphylococcus epidermidis Species 0.000 description 2
- 206010043376 Tetanus Diseases 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- UZQJVUCHXGYFLQ-AYDHOLPZSA-N [(2s,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-4-[(2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-6-(hydroxymethyl)-4-[(2s,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxyoxan-2-yl]oxy-3,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-6-(hy Chemical compound O([C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1[C@H](O)[C@@H](CO)O[C@H]([C@@H]1O)O[C@H]1CC[C@]2(C)[C@H]3CC=C4[C@@]([C@@]3(CC[C@H]2[C@@]1(C=O)C)C)(C)CC(O)[C@]1(CCC(CC14)(C)C)C(=O)O[C@H]1[C@@H]([C@@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O[C@H]4[C@@H]([C@@H](O[C@H]5[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O5)O)[C@H](O)[C@@H](CO)O4)O)[C@H](O)[C@@H](CO)O3)O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO)O1)O)[C@@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O UZQJVUCHXGYFLQ-AYDHOLPZSA-N 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 239000008365 aqueous carrier Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 229940065181 bacillus anthracis Drugs 0.000 description 2
- LGJMUZUPVCAVPU-UHFFFAOYSA-N beta-Sitostanol Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(C)CCC(CC)C(C)C)C1(C)CC2 LGJMUZUPVCAVPU-UHFFFAOYSA-N 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 239000007979 citrate buffer Substances 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 2
- 229940099418 d- alpha-tocopherol succinate Drugs 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 206010013023 diphtheria Diseases 0.000 description 2
- 210000001163 endosome Anatomy 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- 230000013595 glycosylation Effects 0.000 description 2
- 238000006206 glycosylation reaction Methods 0.000 description 2
- 101150085823 hsdR gene Proteins 0.000 description 2
- 101150023479 hsdS gene Proteins 0.000 description 2
- 238000002649 immunization Methods 0.000 description 2
- 238000003018 immunoassay Methods 0.000 description 2
- 230000002480 immunoprotective effect Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 230000035800 maturation Effects 0.000 description 2
- 150000004667 medium chain fatty acids Chemical class 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 238000002493 microarray Methods 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 229940035032 monophosphoryl lipid a Drugs 0.000 description 2
- 231100000252 nontoxic Toxicity 0.000 description 2
- 230000003000 nontoxic effect Effects 0.000 description 2
- 101150093139 ompT gene Proteins 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 244000052769 pathogen Species 0.000 description 2
- 238000010647 peptide synthesis reaction Methods 0.000 description 2
- 108040007629 peroxidase activity proteins Proteins 0.000 description 2
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 2
- 229940068968 polysorbate 80 Drugs 0.000 description 2
- 230000001323 posttranslational effect Effects 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 230000000601 reactogenic effect Effects 0.000 description 2
- 239000013074 reference sample Substances 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 229960000984 tocofersolan Drugs 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 230000005945 translocation Effects 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 201000008827 tuberculosis Diseases 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- MYPYJXKWCTUITO-UHFFFAOYSA-N vancomycin Natural products O1C(C(=C2)Cl)=CC=C2C(O)C(C(NC(C2=CC(O)=CC(O)=C2C=2C(O)=CC=C3C=2)C(O)=O)=O)NC(=O)C3NC(=O)C2NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(CC(C)C)NC)C(O)C(C=C3Cl)=CC=C3OC3=CC2=CC1=C3OC1OC(CO)C(O)C(O)C1OC1CC(C)(N)C(O)C(C)O1 MYPYJXKWCTUITO-UHFFFAOYSA-N 0.000 description 2
- 235000015112 vegetable and seed oil Nutrition 0.000 description 2
- 239000008158 vegetable oil Substances 0.000 description 2
- 238000011179 visual inspection Methods 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- RQOCXCFLRBRBCS-UHFFFAOYSA-N (22E)-cholesta-5,7,22-trien-3beta-ol Natural products C1C(O)CCC2(C)C(CCC3(C(C(C)C=CCC(C)C)CCC33)C)C3=CC=C21 RQOCXCFLRBRBCS-UHFFFAOYSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- NWUYHJFMYQTDRP-UHFFFAOYSA-N 1,2-bis(ethenyl)benzene;1-ethenyl-2-ethylbenzene;styrene Chemical compound C=CC1=CC=CC=C1.CCC1=CC=CC=C1C=C.C=CC1=CC=CC=C1C=C NWUYHJFMYQTDRP-UHFFFAOYSA-N 0.000 description 1
- IJFVSSZAOYLHEE-UHFFFAOYSA-N 2,3-di(dodecanoyloxy)propyl 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCC(=O)OCC(COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCC IJFVSSZAOYLHEE-UHFFFAOYSA-N 0.000 description 1
- IAJOBQBIJHVGMQ-UHFFFAOYSA-N 2-amino-4-[hydroxy(methyl)phosphoryl]butanoic acid Chemical compound CP(O)(=O)CCC(N)C(O)=O IAJOBQBIJHVGMQ-UHFFFAOYSA-N 0.000 description 1
- 230000005730 ADP ribosylation Effects 0.000 description 1
- SRNWOUGRCWSEMX-KEOHHSTQSA-N ADP-beta-D-ribose Chemical group C([C@H]1O[C@H]([C@@H]([C@@H]1O)O)N1C=2N=CN=C(C=2N=C1)N)OP(O)(=O)OP(O)(=O)OC[C@H]1O[C@@H](O)[C@H](O)[C@@H]1O SRNWOUGRCWSEMX-KEOHHSTQSA-N 0.000 description 1
- 241000511582 Actinomyces meyeri Species 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 108010024223 Adenine phosphoribosyltransferase Proteins 0.000 description 1
- 102100029457 Adenine phosphoribosyltransferase Human genes 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 235000019737 Animal fat Nutrition 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 241001203868 Autographa californica Species 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 description 1
- GAWIXWVDTYZWAW-UHFFFAOYSA-N C[CH]O Chemical group C[CH]O GAWIXWVDTYZWAW-UHFFFAOYSA-N 0.000 description 1
- 101710132601 Capsid protein Proteins 0.000 description 1
- 241000701489 Cauliflower mosaic virus Species 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 108090000227 Chymases Proteins 0.000 description 1
- 102000003858 Chymases Human genes 0.000 description 1
- 229940122644 Chymotrypsin inhibitor Drugs 0.000 description 1
- 101710137926 Chymotrypsin inhibitor Proteins 0.000 description 1
- 241001522791 Clostridioides difficile R20291 Species 0.000 description 1
- 208000037384 Clostridium Infections Diseases 0.000 description 1
- 241000193155 Clostridium botulinum Species 0.000 description 1
- 206010054236 Clostridium difficile infection Diseases 0.000 description 1
- 101710094648 Coat protein Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 241000186216 Corynebacterium Species 0.000 description 1
- 241000186227 Corynebacterium diphtheriae Species 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- 101150074155 DHFR gene Proteins 0.000 description 1
- 235000001815 DL-alpha-tocopherol Nutrition 0.000 description 1
- 239000011627 DL-alpha-tocopherol Substances 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 102000002322 Egg Proteins Human genes 0.000 description 1
- 108010000912 Egg Proteins Proteins 0.000 description 1
- DNVPQKQSNYMLRS-NXVQYWJNSA-N Ergosterol Natural products CC(C)[C@@H](C)C=C[C@H](C)[C@H]1CC[C@H]2C3=CC=C4C[C@@H](O)CC[C@]4(C)[C@@H]3CC[C@]12C DNVPQKQSNYMLRS-NXVQYWJNSA-N 0.000 description 1
- 241000672609 Escherichia coli BL21 Species 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- 239000005561 Glufosinate Substances 0.000 description 1
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 1
- 241000256257 Heliothis Species 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 101000582320 Homo sapiens Neurogenic differentiation factor 6 Proteins 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 108020005350 Initiator Codon Proteins 0.000 description 1
- 206010022678 Intestinal infections Diseases 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 241000102542 Kara Species 0.000 description 1
- ZQISRDCJNBUVMM-UHFFFAOYSA-N L-Histidinol Natural products OCC(N)CC1=CN=CN1 ZQISRDCJNBUVMM-UHFFFAOYSA-N 0.000 description 1
- ZQISRDCJNBUVMM-YFKPBYRVSA-N L-histidinol Chemical compound OC[C@@H](N)CC1=CNC=N1 ZQISRDCJNBUVMM-YFKPBYRVSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 108091026898 Leader sequence (mRNA) Proteins 0.000 description 1
- 241000006351 Leucophyllum frutescens Species 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 101100261636 Methanothermobacter marburgensis (strain ATCC BAA-927 / DSM 2133 / JCM 14651 / NBRC 100331 / OCM 82 / Marburg) trpB2 gene Proteins 0.000 description 1
- 241000204795 Muraena helena Species 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- 101800000135 N-terminal protein Proteins 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 102100030589 Neurogenic differentiation factor 6 Human genes 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 101710141454 Nucleoprotein Proteins 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 101800001452 P1 proteinase Proteins 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 108010067902 Peptide Library Proteins 0.000 description 1
- 201000005702 Pertussis Diseases 0.000 description 1
- 101100124346 Photorhabdus laumondii subsp. laumondii (strain DSM 15139 / CIP 105565 / TT01) hisCD gene Proteins 0.000 description 1
- 101100525628 Picea mariana SB62 gene Proteins 0.000 description 1
- 101710083689 Probable capsid protein Proteins 0.000 description 1
- 101710194807 Protective antigen Proteins 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 208000003100 Pseudomembranous Enterocolitis Diseases 0.000 description 1
- 206010037128 Pseudomembranous colitis Diseases 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 108020004518 RNA Probes Proteins 0.000 description 1
- 239000003391 RNA probe Substances 0.000 description 1
- 241000220010 Rhode Species 0.000 description 1
- 108010003581 Ribulose-bisphosphate carboxylase Proteins 0.000 description 1
- 235000019774 Rice Bran oil Nutrition 0.000 description 1
- 108010082913 S-layer proteins Proteins 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 241000193998 Streptococcus pneumoniae Species 0.000 description 1
- 102100038014 Succinate dehydrogenase [ubiquinone] cytochrome b small subunit, mitochondrial Human genes 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- 210000000447 Th1 cell Anatomy 0.000 description 1
- 102000002933 Thioredoxin Human genes 0.000 description 1
- 108091036066 Three prime untranslated region Proteins 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 241000255985 Trichoplusia Species 0.000 description 1
- 241000255993 Trichoplusia ni Species 0.000 description 1
- 229940122618 Trypsin inhibitor Drugs 0.000 description 1
- 101710162629 Trypsin inhibitor Proteins 0.000 description 1
- HZYXFRGVBOPPNZ-UHFFFAOYSA-N UNPD88870 Natural products C1C=C2CC(O)CCC2(C)C2C1C1CCC(C(C)=CCC(CC)C(C)C)C1(C)CC2 HZYXFRGVBOPPNZ-UHFFFAOYSA-N 0.000 description 1
- 108091023045 Untranslated Region Proteins 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 108010059993 Vancomycin Proteins 0.000 description 1
- MECHNRXZTMCUDQ-UHFFFAOYSA-N Vitamin D2 Natural products C1CCC2(C)C(C(C)C=CC(C)C(C)C)CCC2C1=CC=C1CC(O)CCC1=C MECHNRXZTMCUDQ-UHFFFAOYSA-N 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- XJLXINKUBYWONI-DQQFMEOOSA-N [[(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-3-hydroxy-4-phosphonooxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [(2s,3r,4s,5s)-5-(3-carbamoylpyridin-1-ium-1-yl)-3,4-dihydroxyoxolan-2-yl]methyl phosphate Chemical compound NC(=O)C1=CC=C[N+]([C@@H]2[C@H]([C@@H](O)[C@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](OP(O)(O)=O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 XJLXINKUBYWONI-DQQFMEOOSA-N 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 102000005421 acetyltransferase Human genes 0.000 description 1
- 108020002494 acetyltransferase Proteins 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 229940087168 alpha tocopherol Drugs 0.000 description 1
- 108010027597 alpha-chymotrypsin Proteins 0.000 description 1
- AZDRQVAHHNSJOQ-UHFFFAOYSA-N alumane Chemical class [AlH3] AZDRQVAHHNSJOQ-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- ILRRQNADMUWWFW-UHFFFAOYSA-K aluminium phosphate Chemical compound O1[Al]2OP1(=O)O2 ILRRQNADMUWWFW-UHFFFAOYSA-K 0.000 description 1
- 229940126575 aminoglycoside Drugs 0.000 description 1
- 238000013103 analytical ultracentrifugation Methods 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 235000010208 anthocyanin Nutrition 0.000 description 1
- 239000004410 anthocyanin Substances 0.000 description 1
- 229930002877 anthocyanin Natural products 0.000 description 1
- 150000004636 anthocyanins Chemical class 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000001147 anti-toxic effect Effects 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 229940076810 beta sitosterol Drugs 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- NJKOMDUNNDKEAI-UHFFFAOYSA-N beta-sitosterol Natural products CCC(CCC(C)C1CCC2(C)C3CC=C4CC(O)CCC4C3CCC12C)C(C)C NJKOMDUNNDKEAI-UHFFFAOYSA-N 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 230000021523 carboxylation Effects 0.000 description 1
- 238000006473 carboxylation reaction Methods 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 235000013339 cereals Nutrition 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 239000003541 chymotrypsin inhibitor Substances 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 239000003240 coconut oil Substances 0.000 description 1
- 235000019864 coconut oil Nutrition 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 210000004292 cytoskeleton Anatomy 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- GVJHHUAWPYXKBD-UHFFFAOYSA-N d-alpha-tocopherol Natural products OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 230000001079 digestive effect Effects 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- 230000006806 disease prevention Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 235000013345 egg yolk Nutrition 0.000 description 1
- 210000002969 egg yolk Anatomy 0.000 description 1
- 230000009881 electrostatic interaction Effects 0.000 description 1
- 238000004945 emulsification Methods 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 231100000174 enterotoxicity Toxicity 0.000 description 1
- 239000006167 equilibration buffer Substances 0.000 description 1
- 229960002061 ergocalciferol Drugs 0.000 description 1
- DNVPQKQSNYMLRS-SOWFXMKYSA-N ergosterol Chemical compound C1[C@@H](O)CC[C@]2(C)[C@H](CC[C@]3([C@H]([C@H](C)/C=C/[C@@H](C)C(C)C)CC[C@H]33)C)C3=CC=C21 DNVPQKQSNYMLRS-SOWFXMKYSA-N 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 229940047650 haemophilus influenzae Drugs 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 208000006454 hepatitis Diseases 0.000 description 1
- 231100000283 hepatitis Toxicity 0.000 description 1
- 230000002363 herbicidal effect Effects 0.000 description 1
- 239000004009 herbicide Substances 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 101150113423 hisD gene Proteins 0.000 description 1
- 238000000265 homogenisation Methods 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- PZOUSPYUWWUPPK-UHFFFAOYSA-N indole Natural products CC1=CC=CC2=C1C=CN2 PZOUSPYUWWUPPK-UHFFFAOYSA-N 0.000 description 1
- RKJUIXBNRJVNHR-UHFFFAOYSA-N indolenine Natural products C1=CC=C2CC=NC2=C1 RKJUIXBNRJVNHR-UHFFFAOYSA-N 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007852 inverse PCR Methods 0.000 description 1
- 239000003456 ion exchange resin Substances 0.000 description 1
- 229920003303 ion-exchange polymer Polymers 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 101150066555 lacZ gene Proteins 0.000 description 1
- GZQKNULLWNGMCW-PWQABINMSA-N lipid A (E. coli) Chemical class O1[C@H](CO)[C@@H](OP(O)(O)=O)[C@H](OC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCCCC)[C@@H](NC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCC)[C@@H]1OC[C@@H]1[C@@H](O)[C@H](OC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](NC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](OP(O)(O)=O)O1 GZQKNULLWNGMCW-PWQABINMSA-N 0.000 description 1
- 230000029226 lipidation Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 108020004999 messenger RNA Proteins 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 150000002739 metals Chemical class 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 229960000282 metronidazole Drugs 0.000 description 1
- VAOCPAMSLUNLGC-UHFFFAOYSA-N metronidazole Chemical compound CC1=NC=C([N+]([O-])=O)N1CCO VAOCPAMSLUNLGC-UHFFFAOYSA-N 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- ZAHQPTJLOCWVPG-UHFFFAOYSA-N mitoxantrone dihydrochloride Chemical compound Cl.Cl.O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO ZAHQPTJLOCWVPG-UHFFFAOYSA-N 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 210000004877 mucosa Anatomy 0.000 description 1
- 238000002887 multiple sequence alignment Methods 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 1
- WWZKQHOCKIZLMA-UHFFFAOYSA-N octanoic acid Chemical compound CCCCCCCC(O)=O WWZKQHOCKIZLMA-UHFFFAOYSA-N 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- 230000020477 pH reduction Effects 0.000 description 1
- 239000003346 palm kernel oil Substances 0.000 description 1
- 235000019865 palm kernel oil Nutrition 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000007030 peptide scission Effects 0.000 description 1
- 101150104606 pgl gene Proteins 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 230000008092 positive effect Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 238000002953 preparative HPLC Methods 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 101150079601 recA gene Proteins 0.000 description 1
- 230000010837 receptor-mediated endocytosis Effects 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000008165 rice bran oil Substances 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 230000000405 serological effect Effects 0.000 description 1
- 239000010686 shark liver oil Substances 0.000 description 1
- 229940069764 shark liver oil Drugs 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- KZJWDPNRJALLNS-VJSFXXLFSA-N sitosterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CC[C@@H](CC)C(C)C)[C@@]1(C)CC2 KZJWDPNRJALLNS-VJSFXXLFSA-N 0.000 description 1
- 229950005143 sitosterol Drugs 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 238000012421 spiking Methods 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- HCXVJBMSMIARIN-PHZDYDNGSA-N stigmasterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)/C=C/[C@@H](CC)C(C)C)[C@@]1(C)CC2 HCXVJBMSMIARIN-PHZDYDNGSA-N 0.000 description 1
- 229940032091 stigmasterol Drugs 0.000 description 1
- 235000016831 stigmasterol Nutrition 0.000 description 1
- BFDNMXAIBMJLBB-UHFFFAOYSA-N stigmasterol Natural products CCC(C=CC(C)C1CCCC2C3CC=C4CC(O)CCC4(C)C3CCC12C)C(C)C BFDNMXAIBMJLBB-UHFFFAOYSA-N 0.000 description 1
- 229940031000 streptococcus pneumoniae Drugs 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000004094 surface-active agent Substances 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 108060008226 thioredoxin Proteins 0.000 description 1
- 229940094937 thioredoxin Drugs 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 238000012090 tissue culture technique Methods 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- 101150081616 trpB gene Proteins 0.000 description 1
- 101150111232 trpB-1 gene Proteins 0.000 description 1
- 239000002753 trypsin inhibitor Substances 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 238000002255 vaccination Methods 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 229960003165 vancomycin Drugs 0.000 description 1
- MYPYJXKWCTUITO-LYRMYLQWSA-N vancomycin Chemical compound O([C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1OC1=C2C=C3C=C1OC1=CC=C(C=C1Cl)[C@@H](O)[C@H](C(N[C@@H](CC(N)=O)C(=O)N[C@H]3C(=O)N[C@H]1C(=O)N[C@H](C(N[C@@H](C3=CC(O)=CC(O)=C3C=3C(O)=CC=C1C=3)C(O)=O)=O)[C@H](O)C1=CC=C(C(=C1)Cl)O2)=O)NC(=O)[C@@H](CC(C)C)NC)[C@H]1C[C@](C)(N)[C@H](O)[C@H](C)O1 MYPYJXKWCTUITO-LYRMYLQWSA-N 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- MECHNRXZTMCUDQ-RKHKHRCZSA-N vitamin D2 Chemical compound C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)/C=C/[C@H](C)C(C)C)=C\C=C1\C[C@@H](O)CCC1=C MECHNRXZTMCUDQ-RKHKHRCZSA-N 0.000 description 1
- 235000001892 vitamin D2 Nutrition 0.000 description 1
- 239000011653 vitamin D2 Substances 0.000 description 1
- 239000010497 wheat germ oil Substances 0.000 description 1
- 239000002076 α-tocopherol Substances 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
Images










Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
- C07K14/33—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria from Clostridium (G)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/02—Bacterial antigens
- A61K39/08—Clostridium, e.g. Clostridium tetani
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/02—Local antiseptics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55555—Liposomes; Vesicles, e.g. nanoparticles; Spheres, e.g. nanospheres; Polymers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55572—Lipopolysaccharides; Lipid A; Monophosphoryl lipid A
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55577—Saponins; Quil A; QS21; ISCOMS
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/70—Multivalent vaccine
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Immunology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Epidemiology (AREA)
- Mycology (AREA)
- Gastroenterology & Hepatology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Engineering & Computer Science (AREA)
- Oncology (AREA)
- Communicable Diseases (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
本发明涉及包含分离的艰难梭菌CDTb的免疫原性组合物。具体而言,所述分离的艰难梭菌CDTb蛋白已被突变以改变孔形成能力,改变七聚化能力,或者其是去除信号肽和前域且还去除受体结合域和/或去除CDTa结合域的截短的CDTb蛋白。本发明还涉及包含CDTa蛋白和CDTb蛋白的融合蛋白。包含此类免疫原性组合物的疫苗及其治疗用途也构成本发明的部分。
Description
背景
艰难梭菌(Clostridium difficile,C.difficile)是医院肠道感染的最重要原因并且是人中假膜性结肠炎的主要原因(Bartlett等 Am. J. Clin.Nutr.11 suppl:2521-6(1980))。感染艰难梭菌的个体的总体相关死亡率在诊断的3个月内计算为5.99%,并且更高的死亡率与高龄相关,在超过80岁的患者中为13.5% (Karas 等 Journal of Infection561:1-9 (2010))。目前对艰难梭菌感染的治疗是施用抗生素(甲硝唑和万古霉素);然而,已经存在对这些抗生素具有抗性的菌株的证据 (Shah等, Expert Rev. AntiInfect.Ther.8(5), 555–564 (2010))。因此,存在对能够诱导针对艰难梭菌的抗体和/或针对艰难梭菌的保护性免疫应答的免疫原性组合物的需求。
艰难梭菌的肠毒性主要由于毒素A和毒素B两种毒素的作用。这些都是有效的细胞毒素(Lyerly等 Current Microbiology 21:29-32 (1990)。
已经表明毒素A的片段具体为C末端结构域的片段能够导致在仓鼠中的保护性免疫应答(Lyerly 等 Current Microbiology 21:29-32 (1990))、WO96/12802和WO00/61762。
一些但不是所有菌株还表达艰难梭菌二元毒素(CDT)。与许多其他二元毒素类似,CDT由两种组分-酶活性组分(“二元毒素A”或“CDTa”)和催化惰性的转运和结合组分(“二元毒素B”或“CDTb”)构成。催化惰性的组分有利于CDTa易位进入靶细胞。
CDTa具有ADP-核糖基化活性,其转移NAD/NADPH的ADP-核糖部分至靶细胞中的单体肌动蛋白(G-肌动蛋白)并因此防止其多聚化为F-肌动蛋白,并导致细胞骨架的瓦解和最终细胞死亡(Sundriyal 等, Protein expression and Purification 74 (2010) 42-48)。
WO2013/112867 (Merck)描述了针对艰难梭菌的疫苗,所述疫苗包含重组艰难梭菌毒素A、毒素B和CDTa蛋白(均包含相对于天然毒素序列描述为实质上降低或消除毒性的具体限定的突变)并组合有二元毒素B(CDTb)。
本发明人已经发现包含这样的突变的CDTb蛋白具有改进的特征,所述突变设计以改变CDTb的孔形成能力或改变CDTb的七聚化(heptamerisation)能力。
发明概述
在本发明的第一方面,提供包含分离的艰难梭菌CDTb蛋白的免疫原性组合物,其中所述分离的艰难梭菌CDTb蛋白已进行突变以改变孔形成能力。
在本发明的第二方面,提供包含分离的艰难梭菌CDTb蛋白的免疫原性组合物,所述分离的艰难梭菌CDTb蛋白是去除信号肽和前域且还去除受体结合域和/或去除CDTa结合域的截短的CDTb蛋白。
在本发明的第三方面,提供包含分离的艰难梭菌CDTb蛋白的免疫原性组合物,其中所述分离的艰难梭菌CDTb蛋白已进行突变以改变七聚化能力。
在本发明的第四方面,提供包含含有全长CDTa蛋白和CDTb蛋白的融合蛋白的免疫原性组合物。
在第五方面,本发明提供包含前四方面中任一方面的免疫原性组合物和药学上可接受的赋形剂的疫苗。
在第六方面,本发明提供前四方面中任一方面的免疫原性组合物或第五方面的疫苗,其用于治疗或预防疾病例如艰难梭菌疾病。
在第七方面,本发明提供前四方面中任一方面的免疫原性组合物或第五方面的疫苗在制备用于预防或治疗疾病例如艰难梭菌疾病的药物中的用途。
在第八方面,本发明提供预防或治疗艰难梭菌疾病的方法,其包括向哺乳动物主体施用前四方面中任一方面的免疫原性组合物或第五方面的疫苗。
在第九方面,本发明提供如本文定义的新的多肽和核苷酸。
在进一步的方面,本发明提供用于治疗或预防完全或部分由艰难梭菌引起的病况或疾病的方法。所述方法包括向有需要的主体施用治疗有效量的如本文所述的蛋白、本发明的免疫原性组合物或本发明的疫苗。
附图简述
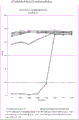
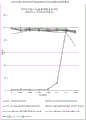
图1-CDTb候选物单独对HT29细胞的细胞毒性:来自实施例7的数据。图1中提及的C37、C123、C124、C126和C128为实施例2、4和6中所述的CDTb蛋白,其序列描述于序列概要中(表A)。
图2-混合有完整CDTa的CDTb候选物对HT29细胞的细胞毒性:来自实施例7的数据。图1中提及的C37、C123、C124、C126和C128为实施例2、4和6中所述的CDTb蛋白,其序列描述于序列概要中(表A)。“完整CDTa (CDTa full)”是CDTa蛋白C34,其序列描述于序列概要中(表A)。
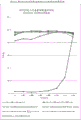
图3:KO孔形成CDTb构建体C123、C126和KO七聚化CDTb构建体C128的流体力学半径的动态光散射测量。平均半径给出样品同质性的指示,而峰1半径为目标蛋白的流体力学半径的估计值。
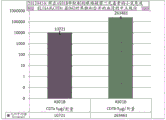
图4:显示用艰难梭菌CDTa或艰难梭菌CDTb(在两种情况下均用佐剂配制)免疫的小鼠中的抗CDTb免疫原性的图。
图5:显示用艰难梭菌CDTa或艰难梭菌CDTb(在两种情况下均用佐剂配制)免疫的小鼠中的抗CDTa免疫原性的图。
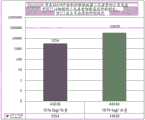
图6:在来自用艰难梭菌CDTa或艰难梭菌CDTb(在两种情况下均用佐剂配制)免疫的小鼠的HCT116细胞中的细胞毒性抑制效价。
图7:在来自用艰难梭菌CDTa或艰难梭菌CDTb(在两种情况下均用佐剂配制)免疫的小鼠的HT29细胞中的细胞毒性抑制效价。
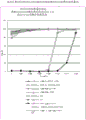
图8:CDTb候选物单独(图8a)或与完整CDTa混合的CDTb候选物(图8b)对HT29细胞的细胞毒性:来自实施例7的数据。C37、C123、C124、C126和C128为实施例2、4和6中所述的CDTb蛋白,其序列描述于序列概要中(表A)。“完整CDTa (CDTa full)”是CDTa蛋白C34,其序列描述于序列概要中(表A)。C149、C152、C164、C166、C116、C117为如实施例4和5所述的CDTb蛋白。
图9:CDTb候选物单独(图9a)或与完整CDTa混合的CDTb候选物(图9b)对HCT116细胞的细胞毒性(如实施例12中所述)。
图10:与完全活化的CDTa混合的CDTa-CDTb融合蛋白对HT29细胞的细胞毒性(如实施例13中所述)。
图11 与完整CDTb混合的CDTa-CDTb融合蛋白对HT29细胞的细胞毒性(如实施例13中所述)。
图12:显示用CDTb蛋白或CDTa-CDTb融合体免疫的小鼠中抗CDTa免疫原性的图(参见实施例14)。
图13:显示用CDTb蛋白或CDTa-CDTb融合体免疫的小鼠中抗CDTb免疫原性的图(参见实施例14)。
图14:用CDTb蛋白或CDTa-CDTb融合体免疫的小鼠,HT29和HCT116细胞中的细胞毒性抑制效价(参见实施例15)。
发明详述
艰难梭菌二元毒素包含两种不同蛋白CDTa和CDTb。CDTa包含两个结构域,C末端结构域负责ADP核糖基转移酶活性而N末端结构域负责与CDTb相互作用。
在感染过程中,CDTb通过由糜蛋白酶样蛋白酶的蛋白酶剪切而活化以产生缺少前域的CDTb(称为CDTb”)。注意CDTb”也缺少CDTb信号序列。缺少信号序列但不缺少前域的CDTb蛋白也称为CDTb’。蛋白水解活化后,CDTb寡聚化并结合CDTa以形成完整的艰难梭菌二元毒素(CDT)。二元毒素结合细胞受体导致受体介导的胞吞作用。由于内体酸化,CDTb结合域经历允许CDTb寡聚物形成孔的构象变化,所述孔形成引起ADP核糖基转移酶结构域(CDTa)易位入靶细胞内。
在一个方面,本发明提供包含分离的艰难梭菌CDTb蛋白的免疫原性组合物,所述分离的艰难梭菌CDTb蛋白已被突变以改变孔形成能力。
术语“已被突变以改变孔形成能力的CDTb蛋白”指已经被突变以改变CDTb蛋白形成孔的能力的CDTb蛋白。
在一个实施方案中,分离的艰难梭菌CDTb蛋白已被突变以降低孔形成能力。
孔形成能力可以根据描述于以下中的方法来分析:The J. of Biol.Chem.2001,vol. 276 :8371-8376、PNAS 2004, vol. 101 :16756-16761、或The J. ofBiol.Chem.2008, vol. 283 :3904-3914。
在该方面,分离的艰难梭菌CDTb蛋白可以已被突变以避免形成β桶状结构,所述β桶状结构由在七聚体(其在CDTb寡聚化后形成)包含的每一CDTb单体共有的β链构成。在该方面,CDTb蛋白可以是去除信号肽的截短的CDTb蛋白。在该方面,CDTb蛋白可以是去除信号肽并去除前域的截短的CDTb蛋白。
术语“去除信号肽的截短的CDTb蛋白”指去除实质上全部信号肽的CDTb蛋白(因此其不包含对应于实质上全部信号肽的氨基酸)。例如,术语“去除信号肽的截短的CDTb蛋白”指去除信号肽的氨基酸中的至少25个的CDTb蛋白。可以保留信号肽的若干氨基酸。例如,可以保留信号肽的2、5、10、15或20个氨基酸。
术语“去除信号肽并去除前域的截短的CDTb蛋白”指去除实质上全部信号肽和前域的CDTb蛋白(因此其不包含对应于实质上全部信号肽和实质上全部前域的氨基酸)。例如,术语“去除信号肽并去除前域的截短的CDTb蛋白”指去除全部信号肽且去除前域的氨基酸中的至少85个的CDTb蛋白。可以保留信号肽和/或前域的若干氨基酸。例如,可以保留信号肽的2、5、10、15或20个氨基酸。例如,可以保留前域的2、5、10、15或20个氨基酸。CDTb的信号肽对应于SEQ ID NO: 3的氨基酸1-48(包括氨基酸1-42)或其在从不同的艰难梭菌菌株中分离的二元毒素蛋白中的等同物,例如来自菌株CD196的CDTb的氨基酸序列的氨基酸1-42 (Perelle, M. 等 Infect.Immun., 65 (1997), 第1402–1407页)。CDTb的前域对应于SEQ ID NO:3的氨基酸48-211(包括氨基酸48-166)或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。
在一个实施方案中,分离的艰难梭菌CDTb蛋白包含SEQ ID NO: 3的位置455处的突变或其在不同的艰难梭菌菌株中的等同物。在该方面的另一个实施方案中,分离的艰难梭菌CDTb蛋白包含SEQ ID NO: 3的位置426处的突变或其在不同的艰难梭菌菌株中的等同物。在该方面的另一个实施方案中,分离的艰难梭菌CDTb蛋白包含SEQ ID NO: 3的位置453处的突变或其在不同的艰难梭菌菌株中的等同物。在该方面的另一个实施方案中,分离的艰难梭菌CDTb蛋白包含SEQ ID NO: 3的位置426处的突变和位置453处的突变或其在不同的艰难梭菌菌株中的等同物。
在一个实施方案中,分离的艰难梭菌CDTb蛋白包含选自F455R、F455G、E426A和D453A的至少一个突变。“F455R”意指SEQ ID NO: 3中的CDTb序列的位置455处的苯丙氨酸(F)突变为精氨酸(R)。“F455G”意指SEQ ID NO: 3中的CDTb序列的位置455处的苯丙氨酸(F)突变为甘氨酸(G)。“E426A”意指SEQ ID NO: 3中的CDTb序列的位置426处的谷氨酸(E)突变为丙氨酸(A)。“D453A”意指SEQ ID NO: 3中的CDTb序列的位置453处的天冬氨酸(D)突变为丙氨酸(A)。在该方面的一个实施方案中,分离的艰难梭菌CDTb蛋白包含突变F455R或其在不同的艰难梭菌菌株中的等同物。在该方面的一个实施方案中,分离的艰难梭菌CDTb蛋白包含突变F455G或其在不同的艰难梭菌菌株中的等同物。在该方面的一个实施方案中,分离的艰难梭菌CDTb蛋白包含突变E426A和D453A或其在不同的艰难梭菌菌株中的等同物。
在一个实施方案中,分离的艰难梭菌CDTb蛋白是或者包含
(i) SEQ ID NO:10或SEQ ID NO:11或SEQ ID NO:25或SEQ ID NO:26;或
(ii) 具有与SEQ ID NO: 10或SEQ ID NO: 11或SEQ ID NO: 25或SEQ ID NO: 26至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体;或
(iii)具有SEQ ID NO: 10或SEQ ID NO: 11或SEQ ID NO: 25或SEQ ID NO: 26的至少30、50、80、100、120、150、200、250或300个邻接氨基酸的CDTb的片段。
在一个实施方案中,分离的艰难梭菌CDTb蛋白是或者包含
(i) SEQ ID NO:43或SEQ ID NO:44;或
(ii) 具有与SEQ ID NO: 43或SEQ ID NO:44至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体;或
(iii)具有SEQ ID NO: 43或SEQ ID NO:44的至少30、50、80、100、120、150、200、250或300个邻接氨基酸的CDTb的片段。
在一个此类方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有与SEQ ID NO: 10或SEQ ID NO: 11或SEQ ID NO: 25或SEQ ID NO: 26至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体。
在一个此类方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有与SEQ ID NO:43或SEQ ID NO: 44至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体。
在另一方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有SEQID NO: 10或SEQ ID NO: 11或SEQ ID NO: 25或SEQ ID NO: 26的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600、650、700、750、800或850个邻接氨基酸的CDTb的片段。
在另一方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有SEQID NO: 43或SEQ ID NO:44的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600或650个邻接氨基酸的CDTb的片段。
本发明还提供包含分离的艰难梭菌CDTb蛋白的免疫原性组合物,所述分离的艰难梭菌CDTb蛋白是去除信号肽和前域且还去除受体结合域和/或去除CDTa结合域的截短的CDTb蛋白。
术语“去除信号肽和前域且还去除受体结合域和/或去除CDTa结合域的截短的CDTb蛋白”意指去除信号肽和前域的截短的CDTb蛋白,其中受体结合域和/或CDTa结合域也已经去除。其指去除实质上全部信号肽和前域(因此其不包含对应于实质上全部信号肽和实质上全部前域的氨基酸)且还去除实质上全部受体结合域和/或去除实质上全部CDTa结合域(因此其不包含对应于实质上全部受体结合域的氨基酸和/或其不包含对应于实质上全部CDTa结合域的氨基酸)的SEQ ID NO: 3或其片段或变体。例如,术语“去除信号肽并去除前域的截短的CDTb蛋白”指去除全部信号肽且去除前域的氨基酸中的至少85个的CDTb蛋白。可以保留信号肽、前域、受体结合域或CDTa结合域的若干氨基酸。例如,可以保留信号肽的2、5、10、15或20个氨基酸。例如,可以保留前域的2、5、10、15或20个氨基酸。例如,可以保留受体结合域的2、5、10、15或20个氨基酸。例如,可以保留CDTa结合域的2、5、10、15或20个氨基酸。
CDTb的信号肽对应于SEQ ID NO: 3的氨基酸1-48(包括氨基酸1-42)或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物,例如来自菌株CD196的CDTb的氨基酸序列的氨基酸1-42 (Perelle, M. 等 Infect. Immun., 65 (1997), 第1402–1407页)。
CDTb的前域对应于SEQ ID NO:3的氨基酸48-211(包括氨基酸48-166)或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。
在一个实施方案中,CDTb的受体结合域对应于SEQ ID NO:3的氨基酸620-876或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。在另一个实施方案中,受体结合域对应于SEQ ID NO:3的氨基酸636-876或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。
CDTb的CDTa结合域对应于SEQ ID NO:3的氨基酸212-296或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。
在该方面的一个实施方案中,免疫原性组合物包含分离的艰难梭菌CDTb蛋白,所述分离的艰难梭菌CDTb蛋白是去除信号肽和前域且还去除受体结合域或去除CDTa结合域的截短的CDTb蛋白。
在该方面的另一个实施方案中,免疫原性组合物包含分离的艰难梭菌CDTb蛋白,所述分离的艰难梭菌CDTb蛋白是去除信号肽和前域且还去除受体结合域和去除CDTa结合域的截短的CDTb蛋白。
合适地,分离的艰难梭菌CDTb蛋白是或者包含
(i) SEQ ID NO:8或SEQ ID NO:9或SEQ ID NO:37;
(ii) 具有与SEQ ID NO: 8或SEQ ID NO: 9或SEQ ID NO: 37至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体;或
(iii) 具有SEQ ID NO: 8或SEQ ID NO: 9或SEQ ID NO: 37的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600、650、700、750或800个邻接氨基酸的CDTb的片段。
合适地,分离的艰难梭菌CDTb蛋白是或者包含
(i) SEQ ID NO:8或SEQ ID NO:9或SEQ ID NO:37;
(ii) 具有与SEQ ID NO: 8或SEQ ID NO: 9或SEQ ID NO: 37至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体;或
(iii)具有SEQ ID NO:8的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸或SEQ ID NO:9的至少30、50、80、100、120、150、200、250、300、350、400、450、500或550个邻接氨基酸或SEQ ID NO:37的至少30、50、80、100、120、150、200、250或300个邻接氨基酸的CDTb的片段。
在一个此类方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有与SEQ ID NO: 8或SEQ ID NO: 9或SEQ ID NO: 37至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体。
在另一方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有SEQID NO: 8或SEQ ID NO: 9或SEQ ID NO:37的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550个邻接氨基酸的CDTb的片段。
在本发明的第三方面,提供包含分离的艰难梭菌CDTb蛋白的免疫原性组合物,其中所述分离的艰难梭菌CDTb蛋白已进行突变以改变七聚化能力。
已进行突变以改变七聚化能力的CDTb蛋白意指所述CDTb蛋白已经进行突变以改变其自装配为七聚折叠(heptameric fold)的能力。该七聚化通过共享来自每一CDTb单体的β链以形成β桶状结构而容许。在该方面,CDTb蛋白可以是去除信号肽的截短的CDTb蛋白。在该方面,CDTb蛋白可以是去除信号肽并去除前域的截短的CDTb蛋白。
在一个实施方案中,分离的艰难梭菌CDTb蛋白已被突变以降低七聚化能力。
CDTb蛋白七聚化的能力可以使用技术诸如动态光散射(DLS)来测量。DLS除了提供关于同质性的信息和检测蛋白样品内高分子量聚集体(诸如七聚体)的存在外,还可用于评估CDTb纯化蛋白的溶液中的流体力学半径。这基于计算通过测量光散射波动获得的不同种类的扩散系数,其取决于蛋白分子大小和形状和样品的其他次要成分。
基于对CDTb获得的3D结构模型的深度分析,寡聚化结构域中的环可能潜在地参与CDTb的七聚化。在该环中,四个氨基酸已经鉴定具有与七聚化CDTb的其他单体中包含的氨基酸的可能静电相互作用。这些残基是SEQ ID NO: 3的Asp537、Glu539、Asp540和Lys541。
在一个实施方案中,分离的艰难梭菌CDTb蛋白包含改变七聚化能力的寡聚化结构域中的至少一个突变和/或截短。
寡聚化结构域对应于SEQ ID NO:3的氨基酸297-619或其在分离自不同的艰难梭菌菌株的CDTb蛋白中的等同物。
在一个实施方案中,分离的艰难梭菌CDTb蛋白包含在含有SEQ ID NO: 3的氨基酸533-542的CDTb的区域或在不同的艰难梭菌菌株中的等同区域中的至少一个突变和/或截短。
在一个实施方案中,分离的艰难梭菌CDTb蛋白包含SEQ ID NO: 3的Asp537、Glu539、Asp540和Lys541处的至少一个突变或其在不同的艰难梭菌菌株中的等同物。在一个实施方案中,合适地,Asp537、Glu539、Asp540和/或Lys541中的任一个或多个突变为Gly或另一个小的残基。
在另一个实施方案中,将寡聚化结构域截短。例如,SEQ ID NO:3的氨基酸533-542或其在分离自不同的艰难梭菌菌株的CDTb蛋白中的等同物可以被缺失并任选地被其他残基例如3、4、5或更多个Gly和/或Ala残基所取代。在一个实施方案中,SEQ ID NO:3的氨基酸533-542或其在分离自不同的艰难梭菌菌株的CDTb蛋白中的等同物可以被缺失并任选地被3个Gly残基或3个Ala残基所取代。
在一个实施方案中,分离的艰难梭菌CDTb蛋白包含四个氨基酸中的突变。例如,CDTb蛋白包含突变D537G-E539G-D540G-K541G或其在不同的艰难梭菌菌株中的等同物。“D537G”意指SEQ ID NO: 3中的CDTb序列的位置537处的天冬氨酸突变为甘氨酸。“E539G”意指SEQ ID NO: 3中的CDTb序列的位置539处的谷氨酸突变为甘氨酸。“D540G”意指SEQ IDNO: 3中的CDTb序列的位置540处的天冬氨酸突变为甘氨酸。“K541G”意指SEQ ID NO: 3中的CDTb序列的位置541处的赖氨酸突变为甘氨酸。
在该方面的另一个实施方案中,分离的艰难梭菌CDTb蛋白包含这样的突变,其中SEQ ID NO:3的氨基酸533-542或其在分离自不同的艰难梭菌菌株的CDTb蛋白中的等同物被3个Gly残基所取代。
在一个实施方案中,分离的艰难梭菌CDTb蛋白是或者包含
(i) SEQ ID NO:12或SEQ ID NO:13;或
(ii) 具有与SEQ ID NO: 12或SEQ ID NO:13至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体;或
(iii)具有SEQ ID NO: 12或SEQ ID NO:13的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600、650、700、750、800或850个邻接氨基酸的CDTb的片段。
在一个此类方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有与SEQ ID NO:12或SEQ ID NO: 13至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体。
在另一方面中,提供免疫原性组合物,其中分离的艰难梭菌CDTb蛋白是具有SEQID NO: 12或SEQ ID NO:13的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600、650、700、750、800或850个邻接氨基酸的CDTb的片段。
CDTb和CDTa蛋白在不同菌株之间在氨基酸序列上不同,由于这一原因,菌株之间的氨基酸编号可能不同。由于这一原因,术语‘不同菌株中的等同物’指这样的氨基酸,其对应于参考菌株(例如艰难梭菌R20291,SEQ ID NO:1和SEQ ID NO:3来自其中)的那些,但其发现于来自不同菌株的毒素中并且可能因此而编号不同。可以通过比对来自不同菌株的毒素的序列来确定‘等同物’氨基酸的区域。艰难梭菌的实例二元毒素产生菌株的实例包括CD196、CCUG 20309、R8637、IS81、IS93、IS51、IS58、R6786、R7605、R10456和R5989。除非另有说明,否则全文中提供的氨基酸编号指参考菌株R20291的那些,如SEQ ID NO: 1 (CDTa)和SEQ ID NO:3 (CDTb)中所述的。
在一个实施方案中,分离的艰难梭菌CDTb蛋白是CDTb的单体。在进一步的实施方案中,分离的艰难梭菌CDTb蛋白是CDTb的多聚体。在进一步的实施方案中,分离的艰难梭菌CDTb蛋白是CDTb的七聚体。
在一个实施方案中,免疫原性组合物不包含/不进一步包含分离的艰难梭菌CDTa蛋白。
本发明提供包含作为单独的艰难梭菌抗原的分离的艰难梭菌CDTb蛋白的免疫原性组合物。如本文所用,术语“作为单独的艰难梭菌抗原”意指免疫原性组合物不再包含另一种来自艰难梭菌的抗原,例如免疫原性组合物不再包含毒素A、毒素B或CDTa蛋白。
在一个实施方案中,免疫原性组合物包含/进一步包含分离的艰难梭菌CDTa蛋白。
合适地,分离的艰难梭菌CDTa蛋白是截短的CDTa蛋白。如本文所用的“截短的CDTa蛋白”意指这样的CDTa蛋白,其未达到其全长或其合适形式,并因此缺失存在于SEQ ID NO:1的全长CDTa或不同菌株中的等同物中的一些氨基酸 残基,并且其不能行使其旨在的功能,因为其结构无法这么做,例如ADP核糖基转移酶活性和/或与CDTb相互作用。ADP核糖基转移酶活性的合适测定描述于PLOS pathogens 2009, vol 5(10) : e1000626。
合适地,分离的艰难梭菌CDTa蛋白是不包含C末端结构域的截短的CDTa蛋白。术语‘不包含C末端结构域的截短的CDTa蛋白’指不包含C末端结构域的实质部分的SEQ ID NO:1的片段或变体,可以保留C末端结构域的几个氨基酸,例如C末端结构域的2、5、10、15、20、25、30、35或50个氨基酸可以保留。C末端结构域对应于SEQ ID NO:1的氨基酸269-463或其在分离自不同的艰难梭菌菌株的CDTa蛋白中的等同物。在该实施方案中,截短的艰难梭菌CDTa蛋白合适地是或者包含
(i) SEQ ID NO:18或SEQ ID NO:19;
(i) 具有与SEQ ID NO: 18或SEQ ID NO:19至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTa的变体;或
(iii)具有SEQ ID NO: 18或SEQ ID NO:19的至少30、50、80、100、120、150或190个邻接氨基酸的CDTa的片段。
在一个实施方案中,不包含C末端结构域的截短的CDTa蛋白是与SEQ ID NO:20具有至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTa的变体。在进一步的实施方案中,不包含C末端结构域的截短的CDTa蛋白是具有SEQ ID NO:20的至少30、50、80、100、120、150、或190个邻接氨基酸的CDTa的变体。
在本发明的任一方面的进一步的实施方案中,分离的艰难梭菌CDTa蛋白合适地含有降低其ADP核糖基转移酶活性的突变。例如,分离的艰难梭菌CDTa蛋白具有在SEQ ID NO:1的位置428处从谷氨酸至另一氨基酸的突变或在艰难梭菌的另一菌株中的等同突变。术语‘具有在位置428处的突变’指在该准确位置处具有突变的CDTa蛋白,但也指从不同菌株中分离并且在等同位置具有突变的CDTa蛋白。CDTa蛋白在不同菌株之间在氨基酸序列上有所不同,由于该原因,氨基酸编号在菌株间可以不同,因而来自不同菌株的CDTa蛋白可以具有不是序列中的第428位的相应谷氨酸。在一个实施方案中,分离的艰难梭菌CDTa蛋白具有在SEQ ID NO: 1的位置428处从谷氨酸至谷氨酰胺的突变。
在本发明的任何方面的进一步的实施方案中,分离的艰难梭菌CDTa蛋白合适地具有在SEQ ID NO: 1的位置430处从谷氨酸至不同氨基酸的突变或在艰难梭菌的另一菌株中的等同突变。术语‘具有在位置430处的突变’指具有该准确位置的蛋白,但也指从不同菌株中分离并且在等同位置具有突变的CDTa蛋白。在一个实施方案中,分离的艰难梭菌CDTa蛋白具有在SEQ ID NO: 1的位置430处从谷氨酸至谷氨酰胺的突变。
在本发明的任一方面的进一步的实施方案中,分离的艰难梭菌CDTa蛋白合适地是或者包含
(i) SEQ ID NO:21;SEQ ID NO:22;SEQ ID NO:23;或SEQ ID NO:24;或
(ii) 具有与SEQ ID NO: 21;SEQ ID NO: 22;SEQ ID NO: 23;或SEQ ID NO: 24至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTa的变体;或
(iii)具有SEQ ID NO: 21;SEQ ID NO: 22;SEQ ID NO: 23;或SEQ ID NO: 24的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸的CDTa的片段。
在本发明的任一方面的进一步的实施方案中,分离的艰难梭菌CDTa蛋白合适地是或者包含
(i) SEQ ID NO:22;或
(ii) 具有与SEQ ID NO:22至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTa的变体;或
(iii)具有SEQ NO:22的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸的CDTa的片段。
包含CDTa蛋白和CDTb蛋白的融合蛋白
在另一方面,本发明提供包含含有全长CDTa蛋白和CDTb蛋白的融合蛋白的免疫原性组合物。在该方面,“全长CDTa”意指SEQ ID NO. 36的全长CDTa或艰难梭菌的另一菌株中的等同物或具有与SEQ ID NO: 36至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTa的变体。
“融合多肽”或“融合蛋白”指具有直接或经氨基酸接头共价连接的至少两个异源多肽(例如至少两个艰难梭菌多肽)的蛋白。其还可以指具有非共价连接的至少两个异源多肽的蛋白。形成融合蛋白的多肽通常连接C末端至N末端,尽管它们还可以连接C末端至C末端、N末端至N末端、或N末端至C末端。融合蛋白的多肽可以以任何顺序。该术语还指保守修饰的变体、多态变体(polymorphic variant)、等位基因、突变体、免疫原性片段和构成融合蛋白的抗原的种间同源物。
术语“融合的”指融合蛋白中的两个多肽之间的键例如共价键。多肽通常经肽键彼此直接或经氨基酸接头连接。任选地,肽可以经本领域技术人员已知的非肽共价键连接。
可以使用肽接头序列来通过足以确保每一多肽折叠成其二级和三级结构的距离分隔开第一和第二多肽组分。使用本领域熟知的标准技术将这样的肽接头序列整合入融合蛋白中。可以根据以下因素选择合适的肽接头序列:(1)它们采用柔性延伸构象的能力;(2)它们采用能够与第一和第二多肽上的功能性表位相互作用的二级结构的能力;和(3)缺少可以与多肽功能性表位反应的疏水性或带电残基。优选的肽接头序列包含Gly、Asn和Ser残基。其他的近中性氨基酸诸如Thr和Ala也可以用于接头序列中。可以有用地用作接头的氨基酸序列包括以下中公开的那些:Maratea 等, Gene 40:39-46 (1985);Murphy 等,Proc.Natl.Acad.Sci.USA 83:8258-8262 (1986);美国专利号4,935,233和美国专利号4,751,180。接头序列可以通常长度为1至约50个氨基酸,例如长度为1、5、10、15、20、25、30、35或40个氨基酸。当第一和第二多肽具有可用于分隔功能结构域并阻止立体干扰(stericinterference)的非必需N末端氨基酸区时,不需要接头序列。
在该方面,融合蛋白可以合适地包含接头。合适的接头的一个实例包括六个连续Gly残基或由其组成。
在该方面,CDTa蛋白合适地在融合体的第一位(first)。这意指CDTa蛋白相对于CDTb蛋白的位置位于融合蛋白的N末端。这改善CDTa-CDTb融合体的加工性。
在一个实施方案中,CDTa蛋白具有在SEQ ID NO: 1的位置45处从半胱氨酸至另一氨基酸或在艰难梭菌的另一菌株中的等同氨基酸的突变。术语‘具有在位置45处的突变’指在SEQ ID NO: 1的该准确位置处具有突变的CDTa蛋白,但也指从不同菌株中分离并且在等同位置具有突变的CDTa蛋白。在一个实施方案中,CDTa蛋白具有在位置45处从半胱氨酸至酪氨酸的突变。进行该突变以防止/避免在两个CDTa蛋白之间形成二硫键。
在一个实施方案中,全长CDTa蛋白包含降低其ADP核糖基转移酶活性的一个或多个突变。
例如,CDTa蛋白可以具有WO2013/112867中公开的突变集合中的任何突变。例如,CDTa蛋白可以包含在位置2、67、69、253、255、258、302、307、342、345、356、359、382、385和387 (对应于本申请的SEQ ID NO: 36的序列的位置3、68、70、254、256、259、303、308、343、346、357、360、383、386和388)处选自以下突变C2A、Y67A、Y69A、Y253A、R255A、Y258A、R302A、Q307E、N342A、S345F、F356A、R359A、Y382A、E385Q、E385A、E387Q、和E387D(如WO2013/112867中所公开)的至少两种突变。“C2A”意指公开于WO2013/112867的CDTb蛋白序列的位置2(对应于本申请的SEQ ID NO:36的位置3)处的半胱氨酸突变为丙氨酸,并且该组中列出的其他突变应类似地理解。在一些实施方案中,CDTa突变选自:C2A、R302A、S345F、E385Q、E385A、E387Q和E387D。在本发明的该方面的实施方案中,CDTa蛋白包含选自以下的一组突变:(a)S345F、E385Q和E387Q;(b) R302A、E385A、E387D;(c) C2A、S345F、E385Q和E387Q;(d)R302A、S345F、E385Q和E387Q;(e) Y67A、Y69A、和R255A;(f) R359A、Y67A和Q307E;(g)Y258A、F356A、S345F;和(h) N342A、Y253A和Y382A。
在一个实施方案中,CDTa蛋白包含降低其ADP核糖基转移酶活性的一个突变。
术语“CDTa蛋白包含降低其ADP核糖基转移酶活性的一个突变”指CDTa蛋白包含在单一位置处的一个突变,所述突变单独旨在降低其ADP核糖基转移酶活性。CDTa蛋白可以任选地包含不具体旨在降低其ADP核糖基转移酶活性的其他突变。具体旨在降低ADP核糖基转移酶活性的突变包括E428Q和E430Q (参考SEQ ID NO:1的氨基酸编号)或如WO2013/112867中公开的C2A、Y67A、Y69A、Y253A、R255A、Y258A、R302A、Q307E、N342A、S345F、F356A、R359A、Y382A、E385Q、E385A、E387Q和E387D(参考SEQ ID NO 36对应于位置3、68、70、254、256、259、303、308、343、346、357、360、383、386和388的氨基酸编号)。
例如,CDTa蛋白具有在SEQ ID NO: 1的位置428处从谷氨酸至另一氨基酸或在艰难梭菌的另一菌株中的等同氨基酸的突变。术语‘具有在位置428处的突变’指在SEQ IDNO: 1的该准确位置处具有突变的CDTa蛋白,但也指从不同菌株中分离并且在等同位置具有突变的CDTa蛋白。CDTa蛋白在不同菌株之间在氨基酸序列上有所不同,由于该原因,氨基酸编号在菌株间可以不同,因而来自不同菌株的CDTa蛋白可以具有不是序列中的第428位的相应谷氨酸。在一个实施方案中,CDTa蛋白具有在位置428处从谷氨酸至谷氨酰胺的突变。在进一步的实施方案中,CDTa蛋白合适地具有在SEQ ID NO: 1的位置430处从谷氨酸至不同氨基酸或在艰难梭菌的另一菌株中的等同氨基酸的突变。术语‘具有在位置430处的突变’指具有该准确位置的蛋白,但也指从不同菌株中分离并且在等同位置具有突变的CDTa蛋白。在一个实施方案中,CDTa蛋白具有在位置430处从谷氨酸至谷氨酰胺的突变。
在一个实施方案中,全长CDTa蛋白合适地是或者包含
(i) SEQ ID NO:39;或
(ii) 具有与SEQ ID NO:39至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的变体CDTa;或
(iii)具有SEQ ID NO:39的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸的CDTa的片段。
在另一个实施方案中,全长CDTa蛋白合适地是或者包含
(i) 如WO2013/112867中SEQ ID NO: 40、42或67中所述的氨基酸序列;或
(ii) 具有与(i)中任何序列至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTa的变体;或
(iii)具有(i)中任何序列的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸的CDTa的片段。
在一个实施方案中,CDTb蛋白是全长CDTb蛋白。在该方面中,“全长CDTb”意指SEQID NO. 7的全长CDTb,即去除前域的CDTb。
在该方面的该实施方案中,包含全长CDTa蛋白和CDTb蛋白的融合蛋白合适地是或者包含
(i) SEQ ID NO:14;或
(ii) 具有与SEQ ID NO:14至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的变体融合蛋白;或
(iii)具有SEQ ID NO: 14的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600、650、700、750、800或850个邻接氨基酸的片段。
在另一实施方案中,CDTb蛋白是去除CDTa结合域的截短的CDTb蛋白。术语“去除CDTa结合域”指去除实质上全部CDTa结合域的SEQ ID NO: 3的片段或变体、或其在艰难梭菌的另一菌株中的等同物(因此其不包含对应于实质上全部CDTa结合域的氨基酸)。例如,术语“去除CDTa结合域的截短的CDTb蛋白”指去除CDTa结合域的氨基酸的至少65个的CDTb蛋白。可以保留CDTa结合域的若干氨基酸。例如,可以保留CDTa结合域的2、5、10、15或20个氨基酸。
CDTb的CDTa结合域对应于SEQ ID NO:3的氨基酸212-295或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。
在该实施方案中,去除CDTa结合域的截短的CDTb蛋白合适地是或者包含
(i) SEQ ID NO:9;或
(ii) 具有与SEQ ID NO:9至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的变体融合蛋白;或
(iii)具有SEQ ID NO:9的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸的片段。
在该实施方案中,包含全长CDTa蛋白和去除CDTa结合域的截短的CDTb蛋白的融合蛋白合适地是或者包含
(i) SEQ ID NO:15;或
(ii) 具有与SEQ ID NO:15至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的变体融合蛋白;或
(iii)具有SEQ ID NO: 15的至少30、50、80、100、120、150、200、250、300、350、400、450、500、550、600、650、700、750、800或850个邻接氨基酸的片段。
在另一实施方案中,CDTb蛋白是包含受体结合域的截短的CDTb蛋白。术语‘包含受体结合域的截短的CDTb蛋白’指去除实质上全部(但排除受体结合域)的SEQ ID NO: 3的片段或变体、或其在艰难梭菌的另一菌株中的等同物(因此其不包含对应于除去受体结合域之外的实质上全部蛋白的氨基酸),除了受体结合域以外还可以保留若干氨基酸,例如除去受体结合域之外的2、5、10、15或20个氨基酸/除了受体结合域以外另外的2、5、10、15或20个氨基酸。在一种版本中,受体结合域对应于SEQ ID NO:3的氨基酸620-876或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。在另一种版本中,受体结合域对应于SEQID NO:3的氨基酸636-876或其在分离自不同的艰难梭菌菌株的二元毒素蛋白中的等同物。
在该实施方案中,CDTb蛋白合适地是或者包含
(i) SEQ ID NO:27或SEQ ID NO:28;或
(i) 具有与SEQ ID NO: 27或SEQ ID NO:28至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的CDTb的变体;或
(iii)具有SEQ ID NO: 27或SEQ ID NO:28的至少30、50、80、100、120、150或200个邻接氨基酸的CDTb的片段。
在该实施方案中,包含全长CDTa蛋白和含有受体结合域的截短的CDTb蛋白的融合蛋白合适地是或者包含
(i) SEQ ID NO:16或SEQ ID NO:17;或
(ii) 具有与SEQ ID NO: 16或SEQ ID NO:17至少80%、85%、88%、90%、92%、95%、98%、99%、100%序列同一性的变体融合蛋白;或
(iii)具有SEQ ID NO: 16或SEQ ID NO:17的至少30、50、80、100、120、150、200、250、300、350或400个邻接氨基酸的片段。
在另一方面,本发明提供如本文定义的新的多肽和核苷酸。
在一个实施方案中,本发明提供包含由SEQ ID NOs 8、9、10、11、12、13、14、15、16、17、25、26、37、43、44、49、50、51、52、53、54、55、56、57、58、66、67或71中任一种所代表的氨基酸序列的多肽。
在本发明的任一方面的一个实施方案中,免疫原性组合物引发中和CDTa或CDTb或两者的抗体。在进一步的实施方案中,组合物引发中和二元毒素的抗体。可以通过用免疫原性组合物免疫小鼠、收集血清并通过使用ELISA分析血清的抗毒素效价来测定组合物是否引发针对毒素的抗体。应该将血清与获取自未进行免疫的小鼠的参考样品进行比较。如果针对多肽的血清产生了高于参考样品超过10%、20%、30%、50%、70%、80%、90%或100%的ELISA读出,则本发明的组合物引发了中和CDTa的抗体。
在进一步的实施方案中,本发明的免疫原性组合物引发了在哺乳动物宿主中针对艰难梭菌菌株的保护性免疫应答。在一个实施方案中,哺乳动物宿主选自小鼠、兔、豚鼠、非人灵长类动物、猴和人。在一个实施方案中,哺乳动物宿主是小鼠。在进一步的实施方案中,哺乳动物宿主是人。
可以使用攻击测定来确定免疫原性组合物是否引发了在哺乳动物宿主中针对艰难梭菌菌株的保护性免疫应答。在此类测定中,将哺乳动物宿主用免疫原性组合物接种并通过暴露于艰难梭菌进行攻击,将哺乳动物在攻击后存活的时间与未曾用免疫原性组合物免疫的参考哺乳动物存活的时间进行比较。如果在用艰难梭菌攻击后,用免疫原性组合物免疫的哺乳动物存活长于未曾免疫的参考哺乳动物至少10%、20%、30%、50%、80%、80%、90%或100%,则免疫原性组合物引发了保护性免疫应答。
毒素A和毒素B
在本发明任一方面的一个实施方案中,本发明的免疫原性组合物进一步包含分离的艰难梭菌毒素A蛋白和/或分离的艰难梭菌毒素B蛋白。
术语‘分离的艰难梭菌毒素A蛋白’指具有SEQ ID NO: 29的氨基酸序列或SEQ IDNO: 29的片段或变体的蛋白。在一个实施方案中,分离的艰难梭菌毒素A蛋白是包含SEQ IDNO:29的50、100、150、200、250、300、500、750、1000、1250、1500、1750、2000或2500个邻接氨基酸的片段。在一个实施方案中,分离的艰难梭菌毒素A蛋白是具有与SEQ ID NO:29的80%、85%、90%、92%、95%、98%、99%或100%同一性的变体。
术语‘分离的艰难梭菌毒素B蛋白’指具有SEQ ID NO: 30的氨基酸序列或SEQ IDNO: 30的片段或变体的蛋白。在一个实施方案中,分离的艰难梭菌毒素B蛋白是包含SEQ IDNO:30的50、100、150、200、250、300、500、750、1000、1250、1500、1750或2000的片段。在一个实施方案中,分离的艰难梭菌毒素B蛋白是具有与SEQ ID NO:30的80%、85%、90%、92%、95%、98%、99%或100%同一性的变体。
在一个实施方案中,分离的艰难梭菌毒素A蛋白包含重复结构域片段。术语‘毒素A重复结构域’指来自艰难梭菌的毒素A蛋白的C末端结构域,其包含重复序列。毒素A重复结构域指来自菌株VPI10463 (ATCC43255)的毒素A的氨基酸1832-2710以及它们在不同菌株中的等同物,来自菌株VPI10463 (ATCC43255)的氨基酸1832-2710的序列对应于SEQ IDNO:29的氨基酸1832-2710。
在进一步的实施方案中,分离的艰难梭菌毒素A蛋白包含毒素A N末端结构域的片段。毒素A N末端结构域指来自菌株VPI10463 (ATCC43255)的毒素A的氨基酸1-1831以及它们在不同菌株中的等同物。来自菌株VPI10463 (ATCC43255)的毒素A的氨基酸1-1831的序列对应于SEQ ID NO:29的氨基酸1-1831。
在一个实施方案中,分离的艰难梭菌毒素B蛋白包含毒素B重复结构域片段。术语‘毒素B重复结构域’指来自艰难梭菌的毒素B蛋白的C末端结构域。该结构域指来自菌株VPI10463 (ATCC43255)的氨基酸1834-2366及其在不同菌株中的等同物。来自菌株VPI10463 (ATCC43255)的氨基酸1834-2366的序列对应于SEQ ID NO: 30的氨基酸1834-2366。
在进一步的实施方案中,分离的艰难梭菌毒素B蛋白包含毒素B N末端结构域的片段。毒素B N末端结构域指来自菌株VBI10463 (ATCC43255)的氨基酸1-1833及其在不同菌株中的等同物。来自菌株VBI10463 (ATCC43255)的毒素B的氨基酸1-1833的序列对应于SEQID NO: 30的氨基酸1-1833。
艰难梭菌毒素A和B是保守蛋白,然而,该序列在菌株间有少量差别,此外,不同菌株中的毒素A和B的氨基酸序列可能在许多氨基酸上有所不同。
因此,术语毒素A重复结构域和/或毒素B重复结构域指这样的序列,其是与SEQ IDNO:29的氨基酸1832-2710具有90%、95%、98%、99%或100%序列同一性的变体或与SEQ ID NO:30的氨基酸1834-2366具有90%、95%、98%、99%或100%序列同一性的变体。类似地,术语毒素AN末端结构域和/或毒素B N末端结构域指这样的序列,其是与SEQ ID NO:29的氨基酸1-1831具有90%、95%、98%、99%或100%序列同一性的变体或与SEQ ID NO:30的氨基酸1-1833具有90%、95%、98%、99%或100%序列同一性的变体。
此外,氨基酸编号可以在来自一种菌株的毒素A(或毒素B)与来自另一种菌株的毒素A(或毒素B)的C末端结构域之间有所不同。由于这一原因,术语‘不同菌株中的等同物’指这样的氨基酸,其对应于参考菌株(例如艰难梭菌VPI10463)的那些,但发现于来自不同菌株的毒素中并且可能因此而编号不同。可以通过比对来自不同菌株的毒素的序列来确定‘等同物’氨基酸的区域。全文中提供的氨基酸编号指菌株VPI10463的那些(且如SEQ IDNO: 29和SEQ ID NO:3中所述的)。
在本发明任一方面的进一步的实施方案中,分离的艰难梭菌毒素A蛋白和分离的艰难梭菌毒素B蛋白形成融合蛋白。在一个实施方案中,融合蛋白与选自SEQ ID NO: 31、32、33、34和35的序列80%、85%、90%、95%、98%、99%或100%相同。在进一步的实施方案中,融合蛋白是选自SEQ ID NO: 31、32、33、34和35的序列至少800、850、900或950个邻接氨基酸的片段。
片段
如本文定义的术语“片段”可以指包含T细胞表位的片段。T细胞表位是由T细胞(例如CD4+ 或CD8+ T 细胞)识别的短的邻接氨基酸片段。T细胞表位的鉴定可以经本领域技术人员熟知的表位作图实验来实现(参见例如Paul, Fundamental Immunology, 第三版,243-247 (1993);Beiβbarth 等 Bioinformatics 2005 21(Suppl. 1):i29-i37)。
当涉及包含组氨酸标签的多肽使用时,术语“片段”包括不具有组氨酸标签的多肽,例如其中组氨酸标签已切除的多肽。例如,包含由序列ID No 5、7-28或36-42(其每一个均包含组氨酸标签)中任一者代表的氨基酸序列的多肽的合适的片段包含由序列ID No47-76所代表的不具有组氨酸标签的对应多肽,如以下词语索引中所记载的:
| 包括his标签的多肽: | 不具有his标签的合适片段: |
| SEQ ID NO:5 | SEQ ID NO:47 |
| SEQ ID NO:7 | SEQ ID NO:48 |
| SEQ ID NO:8 | SEQ ID NO:49 |
| SEQ ID NO:9 | SEQ ID NO:50 |
| SEQ ID NO:10 | SEQ ID NO:51 |
| SEQ ID NO:11 | SEQ ID NO:52 |
| SEQ ID NO:12 | SEQ ID NO:53 |
| SEQ ID NO:13 | SEQ ID NO:54 |
| SEQ ID NO:14 | SEQ ID NO:55 |
| SEQ ID NO:15 | SEQ ID NO:56 |
| SEQ ID NO:16 | SEQ ID NO:57 |
| SEQ ID NO:17 | SEQ ID NO:58 |
| SEQ ID NO:18 | SEQ ID NO:59 |
| SEQ ID NO:19 | SEQ ID NO:60 |
| SEQ ID NO:20 | SEQ ID NO:61 |
| SEQ ID NO:21 | SEQ ID NO:62 |
| SEQ ID NO:22 | SEQ ID NO:63 |
| SEQ ID NO:23 | SEQ ID NO:64 |
| SEQ ID NO:24 | SEQ ID NO:65 |
| SEQ ID NO:25 | SEQ ID NO:66 |
| SEQ ID NO:26 | SEQ ID NO:67 |
| SEQ ID NO:27 | SEQ ID NO:68 |
| SEQ ID NO:28 | SEQ ID NO:69 |
| SEQ ID NO:36 | SEQ ID NO:70 |
| SEQ ID NO:37 | SEQ ID NO:71 |
| SEQ ID NO:38 | SEQ ID NO:72 |
| SEQ ID NO:39 | SEQ ID NO:73 |
| SEQ ID NO:40 | SEQ ID NO:74 |
| SEQ ID NO:41 | SEQ ID NO:75 |
| SEQ ID NO:42 | SEQ ID NO:76 |
合适地,本发明的片段是免疫原性片段。根据本发明的“免疫原性片段”将通常包含来自全长多肽序列的至少9个邻接氨基酸(例如至少10个),诸如至少12个邻接氨基酸(例如至少15个或至少20个邻接氨基酸),尤其是至少50个邻接氨基酸,诸如至少100个邻接氨基酸(例如至少200个邻接氨基酸)。合适地,免疫原性片段将为全长多肽序列的长度的至少20%、诸如至少50%、至少70%或至少80%。
将理解在不同的远交种群(out-bred population)中,诸如人中,不同的HLA型意指特定表位可以不被种群的所有成员识别。因此,为了最大化识别水平和对多肽免疫应答的规模,通常期望免疫原性片段包含来自全长序列的多个表位(合适地所有表位)。
变体
“变体”或“保守修饰的变体”应用于氨基酸和核酸序列两者。关于具体核酸序列,保守修饰的变体指编码相同或基本上相同的氨基酸序列的那些核酸。当核酸不编码氨基酸序列时,“保守修饰的变体”指基本上相同的序列。
关于蛋白序列的变体,技术人员将认识到对多肽单个的取代、缺失或添加(其改变、添加或缺失单个氨基酸或小百分比的氨基酸)是“保守修饰的变体”,其中改变导致氨基酸被功能相似氨基酸取代或实质上不影响变体的生物功能的残基的取代/缺失/添加。
提供功能相似氨基酸的保守取代表是本领域众所周知的。此类保守修饰的变体除了且不排除本发明的多态变体、种间同源物和等位基因。
当相比于参考序列时,本发明的多肽(诸如CDTa蛋白或CDTb蛋白)可以含有多个保守取代(例如,1-50个,诸如1-25个,尤其是1-10个且特别是1个氨基酸残基可以改变)。通常,此类保守取代将落入下文说明的氨基酸分组之一中,尽管在一些情况下其他取代也是可以的且不会实质上影响抗原的免疫原性特性。以下八组各自含有通常彼此保守取代的氨基酸:
1) 丙氨酸 (A), 甘氨酸 (G);
2) 天冬氨酸 (D), 谷氨酸 (E);
3) 天冬酰胺 (N), 谷氨酰胺 (Q);
4) 精氨酸 (R), 赖氨酸 (K);
5) 异亮氨酸 (I), 亮氨酸 (L), 甲硫氨酸 (M), 缬氨酸 (V);
6) 苯丙氨酸 (F), 酪氨酸 (Y), 色氨酸 (W);
7) 丝氨酸 (S), 苏氨酸 (T); 和
8) 半胱氨酸 (C), 甲硫氨酸 (M)
(参见例如, Creighton, Proteins 1984)。
合适地,此类取代不在表位的区域中发生,并且因此不对抗原的免疫原性特性具有显著影响。
多肽变体还可以包括其中相比于参考序列插入额外的氨基酸的那些,例如,此类插入可以在1-10个位置(诸如1-5个位置、合适地1或2个位置,尤其是1个位置)发生,并且例如可以涉及在每一位置处添加50个或更少氨基酸(诸如20个或更少,尤其是10个或更少,特别是5个或更少)。合适地,此类插入不在表位的区域中发生,并且因此不对抗原的免疫原性特性具有显著影响。插入的一个实例包括组氨酸残基的短片段(例如2-6个残基)以帮助所讨论的抗原的表达和/或纯化。
多肽变体包括其中相比于参考序列已缺失氨基酸的那些,例如,此类缺失可以在1-10个位置(诸如1-5个位置、合适地1或2个位置,尤其是1个位置)发生,并且例如可以涉及在每一位置处缺失50个或更少氨基酸(诸如20个或更少,尤其是10个或更少,特别是5个或更少)。合适地,此类缺失不在表位的区域中发生,并且因此不对抗原的免疫原性特性具有显著影响。
技术人员将认识到具体多肽变体可以包含取代、缺失和添加(或其任何组合)。
变体优选展示与相关的参考序列至少约70%同一性,更优选至少约80%同一性且最优选至少约90%同一性(诸如至少约95%,至少约98%或至少约99%)。
术语“相同”或百分比“同一性”在两个或多个核酸或多肽序列的上下文中指两个或多个序列或子序列,当如使用例如序列比较算法或通过手动比对和目检来测量的在比较窗口或指定区域上比较并比对最大对应时,其是相同的或具有相同的氨基酸残基或核苷酸的特定百分比(即,对于特定区域为70%同一性,任选75%、80%、85%、90%、95%、98%或99%同一性)。此类序列随后被称为“实质上相同的”。该定义还指测试序列的互补(compliment)。任选地,同一性在长度为至少约25至约50个氨基酸或核苷酸的区域上存在,或任选在长度为75-100个氨基酸或核苷酸的区域上存在。合适地,在对应于参考序列的整个长度的窗口上进行比较。
对于序列比较,通常一个序列作为参考序列,测试序列与其进行比较。当使用序列比较算法时,将测试和参考序列登入计算机中,指定子序列坐标,如需要,指定序列算法程序参数。可以使用缺省程序参数,或者可以指定可选参数。序列比较算法随后基于程序参数计算测试序列相对于参考序列的百分比序列同一性。
如本文所用“比较窗口”指这样的区段,其中在两条序列最优比对后,序列可以与相同数目的邻接位置的参考序列进行比较。用于比较的序列比对的方法是本领域所熟知的。用于比较的序列最优比对可以如下进行,例如通过Smith & Waterman, Adv. Appl.Math. 2:482 (1981)的局部同源性算法,通过Needleman & Wunsch, J. Mol. Biol. 48:443 (1970)的同源性比对算法,通过Pearson & Lipman, Proc. Nat’l. Acad. Sci. USA85:2444 (1988)的搜索相似性方法,通过这些算法的计算机化实现(GAP、BESTFIT、FASTA、和TFASTA,于 Wisconsin Genetics Software Package中, Genetics Computer Group,575 Science Dr., Madison, WI),或通过手动比对和目检(例如参见, Current Protocols in Molecular Biology (Ausubel 等, 编辑 1995 supplement))。
有用的算法的一个实例是PILEUP。PILEUP使用渐进式两两比对(pairwisealignment)从一组相关序列中产生多序列比对来显示相关性和百分比序列同一性。它还绘制显示用于产生比对的成簇关系的树或系统树图(tree or dendogram)。PILEUP使用Feng& Doolittle, J. Mol. Evol. 35:351-360 (1987)的渐进式比对方法的简化方式。所用的方法与Higgins & Sharp, CABIOS 5:151-153 (1989)所述的方法相似。程序可以比对多至300个序列,其各自最大长度为5,000核苷酸或氨基酸。多重比对程序用两个最相似序列的两两比对开始,产生两个比对的序列的簇。该簇随后比对至所比对序列的下一最相关序列或簇。将两簇序列通过两个单独序列的两两比对的简单延伸(simple extension)来比对。最终比对通过一系列渐进式两两比对来实现。程序通过指定具体序列及其对于序列比对区域的氨基酸或核苷酸坐标并通过指定程序参数来运行。使用PILEUP,使用以下参数将参考序列与其他测试序列比较来确定百分比序列同一性关系:缺省缺口权重(gap weight)(3.00)、缺省缺口长度权重(0.10)和加权的末端缺口(weighted end gaps)。PILEUP可以获自GCG序列分析软件包,例如7.0版本(Devereaux 等, Nuc.Acids Res.12:387-395(1984)。
适合于确定百分比序列同一性和序列相似性的算法的另一实例是BLAST和BLAST2.0算法,其分别描述于Altschul 等, Nuc. Acids Res. 25:3389-3402 (1977)和Altschul 等, J. Mol. Biol. 215:403-410 (1990)。进行BLAST分析的软件从NationalCenter for Biotechnology Information (网址为www.ncbi.nlm.nih.gov/)上是公众可获得的。该算法首先涉及通过鉴定查询序列中长度W的短字符来鉴定高评分序列对(HSPs),当与数据库序列中相同长度的字符比对时,其匹配或满足某些正值的阈值分值T。T称为邻近字符分值阈值(Altschul等, 见上文)。这些初始的邻近字符匹配作为种子用于开始检索以发现包含它们的更长HSPs。字符匹配沿每一序列在两个方向上延伸,远至累积比对分值能够增加。对于核苷酸序列,使用参数M(对匹配残基对的奖励分值;始终>0)和N(对错配残基的惩罚分值;始终<0)计算累积分值。对于氨基酸序列,使用评分矩阵计算累积分值。当出现以下情况时,在每一方向上字符匹配的延伸停止:累积比对分值以数量X从它的最大实现值中掉落;由于积累了一个或多个负评分残基比对,累积分值变为零或低于零;或到达任一序列的末端。BLAST算法参数W、T和X确定了比对的灵敏度和速度。BLASTN程序(用于核苷酸序列)使用字符长(W)为11、期望值(E)为10、M=5、N=-4和两条链的比较作为缺省值。对于氨基酸序列,BLASTP程序使用字符长为3、和期望值(E)为10、和BLOSUM62评分矩阵(参见Henikoff & Henikoff, Proc. Natl. Acad. Sci. USA 89:10915 (1989))比对值(B)为50、期望值(E)为10、M=5、N=-4和比较两条链作为缺省值。
BLAST算法还进行两条序列之间的相似性的统计分析(参见例如, Karlin &Altschul, Proc. Nat’l. Acad. Sci. USA 90:5873-5787 (1993))。由BLAST算法提供的相似性的一种量度是最小和概率(P(N)),其提供概率的指示,通过所述概率指示两个核苷酸或氨基酸序列之间的匹配将偶然发生。例如,如果测试核酸与参考核酸的比较中的最小和概率小于约0.2,更优选小于约0.01且最优选小于约0.001,则认为核酸与参考序列相似。
多核苷酸鉴定和表征
本发明的编码艰难梭菌CDTa、CDTb、毒素A和毒素B蛋白的多核苷酸可以使用多种良好建立的技术的任一种来鉴定、制备和/或操作。例如,可以如下文更详尽所述通过筛选cDNA的微阵列来鉴定多核苷酸。此列筛选例如可以根据制造商说明书(且基本上如Schena等, Proc. Natl. Acad. Sci. USA 93:10614-10619 (1996)和Heller等, Proc. Natl. Acad. Sci. USA 94:2150-2155 (1997)所述)使用Synteni微阵列 (Palo Alto, CA)来进行。可选地,多核苷酸可以从表达本文所述蛋白的细胞例如结核分枝杆菌(M. tuberculosis)细胞制备的cDNA来扩增。此类多核苷酸可以经聚合酶链反应(PCR)进行扩增。对于该方法,序列特异性引物可以基于本文提供的序列进行设计,并可以购买或合成。
多核苷酸的扩增部分可以用于使用众所周知的技术从合适文库(例如结核分枝杆菌cDNA文库)分离全长基因。在此类技术中,使用适合用于扩增的一个或多个多核苷酸探针或引物筛选文库(cDNA或基因组文库)。优选地,将文库大小选择以包括更大的分子。随机引发的文库还可以优选用于鉴定基因的5'和上游区。基因组文库优选用于获得内含子和延伸5'序列。
对于杂交技术,部分序列可以使用熟知的技术进行标记(例如,通过缺口平移或用32P末端标记)。细菌或噬菌体文库随后通常通过用标记的探针杂交含有变性细菌菌落的滤器(或含有噬菌斑的菌苔)进行筛选(参见Sambrook 等, Molecular Cloning: A Laboratory Manual (2000))。选择并扩展杂交菌落或噬菌斑,并分离DNA用于进一步分析。分析cDNA克隆来例如使用来自部分序列的引物和来自载体的引物通过PCR来确定额外序列的量。限制性图谱和部分序列可以生成以鉴定一个或多个重叠克隆。完整序列可以随后使用标准技术(其可以涉及生成一系列缺失克隆)来确定。所得的重叠序列可以随后装配入单一邻接序列中。全长cDNA分子可以通过连接合适片段使用熟知的技术来生成。
可选地,存在大量用于从部分cDNA序列获得全长编码序列的扩增技术。在此类技术内,通常经PCR进行扩增。多种商购试剂盒的任一种均可用于进行扩增步骤。可以使用例如本领域中熟知的软件来设计引物。引物优选长度为22-30个核苷酸,具有至少50%的GC含量,并在约68℃-72℃的温度下退火至靶序列。扩增的区域可以如上所述测序并且重叠序列装配入邻接序列中。
一种此类扩增技术为反向PCR(参见Triglia 等, Nucl.Acids Res.16:8186(1988)),其使用限制酶来生成基因已知区域中的片段。片段随后通过分子内连接环化并用作模板用于使用来源于已知区域的不同引物的PCR。在可选的方法中,邻近部分序列的序列可以用接头序列的引物和对已知区域特异性的引物通过扩增来获得。扩增后的序列通常进行第二轮扩增,使用相同的接头引物和对已知区域特异性的第二引物。该程序的变化描述于WO 96/38591中,其利用从已知序列在相对方向上起始延伸的两条引物。另一种此类技术已知为“cDNA末端快速扩增”或RACE。该技术涉及使用内部引物和外部引物,其杂交至聚腺苷酸(polyA)区域或载体序列,以鉴定已知序列的5'和3'的序列。额外的技术包括捕获PCR(Lagerstrom 等, PCR Methods Applic.1:111-19 (1991))和步行PCR (Parker 等, Nucl.Acids.Res.19:3055-60 (1991))。采用扩增的其他方法也可以采用以获得全长cDNA序列。
在某些情况中,可以获得全长cDNA序列,其通过分析在表达序列标签(EST)数据库中提供的序列,诸如可来自GenBank的序列。搜索重叠EST可以通常使用熟知程序进行(例如NCBI BLAST搜索),并且此类EST可以使用来生成邻接的全长序列。全长DNA序列还可以通过分析基因组片段获得。
宿主细胞中的多核苷酸表达
编码艰难梭菌CDTa、CDTb、毒素A和毒素B蛋白、或其融合蛋白或功能等同物的多核苷酸序列或其片段可以用于重组DNA分子以在合适宿主细胞中直接表达多肽。由于遗传编码的内在简并性,编码实质上相同或功能等同的氨基酸序列的其他DNA序列可以产生并且这些序列可以用于克隆并表达给定多肽。
如本领域技术人员将理解的,在一些情况下有利的是产生具有非天然存在密码子的编码多肽的核苷酸序列。例如,可以选择由具体原核或真核宿主优选的密码子以增加蛋白表达速率或产生具有期望特性(诸如比由天然存在序列生成的转录物的半衰期更长的半衰期)的重组RNA转录物。
此外,多核苷酸序列可以为了多种原因使用本领域通常已知的方法来工程化以改变多肽编码序列,包括但不限于修饰基因产物的克隆、加工和/或表达的改变。例如,可以使用通过随机片段化的DNA改组和基因片段和合成寡核苷酸的PCR重装配来工程化核苷酸序列。此外,可以使用基因定点诱变来插入新的限制位点、变更糖基化模式、改变密码子偏好、产生剪接变体或引入突变等。
天然的、修饰的或重组核酸序列可以连接至异源序列以编码融合蛋白。例如,为了筛选用于多肽活性的抑制剂的肽文库,编码可以由商购抗体识别的嵌合蛋白可能是有用的。融合蛋白还可以进行工程化以包含位于编码多肽的序列和异源蛋白序列之间的切割位点,从而使得多肽可以被切割并从异源部分中纯化出来。
可以使用本领域中熟知的化学方法全部或部分合成编码期望的多肽的序列(见Caruthers, M. H. 等, Nucl.Acids Res.Symp.Ser. pp. 215-223 (1980), Horn 等, Nucl.Acids Res.Symp.Ser. pp. 225-232 (1980))。或者,蛋白本身可以使用合成多肽或其部分的氨基酸序列的化学方法来产生。例如,肽合成可以使用多种固相技术(Roberge等, Science 269:202-204 (1995))进行并且自动合成可以例如使用ABI 431A PeptideSynthesizer (Perkin Elmer, Palo Alto, CA)来实现。
新合成的肽可以通过制备型高效液相层析(例如, Creighton, Proteins, Structures and Molecular Principles (1983))或本领域可用的其他相当的技术来实质上纯化。合成肽的组成可以通过氨基酸分析或测序(例如,Edman降解程序)来确认。此外,多肽的氨基酸序列或其任何部分可以在直接合成过程中改变和/或使用化学方法与来自其他蛋白或其任何部分的序列组合以产生变体多肽。
为了表达期望的多肽,可以将编码多肽或功能等同物的核苷酸序列插入合适的表达载体,即含有所插入的编码序列的转录和翻译的必要元件的载体。本领域技术人员熟知的方法可用于构建含有编码目标多肽的序列和合适的转录和翻译控制元件的表达载体。这些方法包括体外重组DNA技术、合成技术和体内遗传重组。此类技术描述于Sambrook 等, Molecular Cloning, A Laboratory Manual (2000),和Ausubel 等, Current Protocols in Molecular Biology (每年更新)。
多种表达载体/宿主系统可用于包含并表达多核苷酸序列。这些包括但不限于微生物诸如用重组噬菌体、质粒或黏粒DNA表达载体转化的细菌;用酵母表达载体转化的酵母;用病毒表达载体(例如杆状病毒)感染的昆虫细胞系统;用病毒表达载体(例如花椰菜花叶病毒,CaMV;烟草花叶病毒,TMV)或用细菌表达载体(例如Ti或pBR322质粒)转化的植物细胞系统;或动物细胞系统。
存在于表达载体中的“控制元件”或“调控序列”是载体的那些非翻译区域——增强子、启动子、5'和3'非翻译区域——其与宿主细胞蛋白相互作用以进行转录和翻译。此类元件可以在其强度和特异性中不同。取决于所用的载体系统和宿主,可以使用任何数目的合适的转录和翻译元件,包括组成型和诱导型启动子。例如,当克隆在细菌系统中时,可以使用诱导型启动子诸如PBLUESCRIPT 噬菌粒 (Stratagene, La Jolla, Calif.) 或PSPORT1 质粒 (Gibco BRL, Gaithersburg, MD)等的杂合lacZ启动子。在哺乳动物细胞系统中,通常优选来自哺乳动物基因或来自哺乳动物病毒的启动子。如果需要生成含有编码多肽的序列的多个拷贝的细胞系,可以有利地使用基于SV40或EBV的载体与合适的可选择标记物。
在细菌系统中,根据旨在用于表达的多肽的用途,可以选择多种表达载体。例如,当需要大量时,例如用于诱导抗体,可以使用指导容易纯化的融合蛋白的高水平表达的载体。此类载体包括但不限于多功能大肠杆菌克隆和表达载体诸如BLUESCRIPT(Stratagene),其中编码目标多肽的序列可以框内(in frame)连接入具有氨基末端Met和随后的β-半乳糖苷酶的7个残基的序列的载体中使得产生杂合蛋白;pIN载体 (Van Heeke&Schuster, J. Biol. Chem. 264:5503-5509 (1989));等等。pGEX载体(Promega,Madison, Wis; GE Healthcare.)也可以用于表达作为与谷胱甘肽S转移酶(GST)的融合蛋白的外源多肽。通常,此类融合蛋白是可溶的并且可以容易地通过吸附至谷胱甘肽-琼脂糖珠随后在游离谷胱甘肽存在的情况下洗脱而从裂解的细胞中纯化。在此类系统中制备的蛋白可以设计以包括肝素、凝血酶或因子XA蛋白酶切割位点,使得克隆的目标多肽可以随意从GST部分释放。
在酵母中,例如酿酒酵母(Saccharomyces cerevisiae)或毕赤酵母属(Pichia)诸如巴斯德毕赤酵母(Pichia pastoris),多种含有组成型或诱导型启动子诸如α因子、醇氧化酶和PGH的载体可以使用。其他含有组成型或诱导型启动子的载体包括GAP、PGK、GAL和ADH。综述见于Ausubel等(上文) 和 Grant 等, Methods Enzymol.153:516-544 (1987)和 Romas 等Yeast 8 423-88 (1992)。
在其中使用植物表达载体的情况下,编码多肽的序列的表达可以由多种启动子的任一种驱动。例如,病毒启动子诸如CaMV的35S和19S启动子可以单独使用或与来自TMV的ω前导序列(Takamatsu, EMBO J. 6:307-311 (1987))组合使用。可选地,植物启动子诸如RUBISCO的小亚基或热休克启动子可以使用(Coruzzi 等, EMBO J. 3:1671-1680 (1984);Broglie 等, Science 224:838-843 (1984); 和Winter 等, Results Probl.Cell Differ.17:85-105 (1991))。这些构建体可以通过直接DNA转化或病原体介导的转染引入植物细胞。此类技术描述于许多通常可获的综述中(参见例如, Hobbs于McGraw Hill Yearbook of Science and Technology pp. 191-196 (1992))。
还可以使用昆虫系统来表达目标多肽。例如,在一个此类系统中,使用苜蓿银纹夜蛾(Autographa californica)核型多角体病毒(AcNPV)作为载体来在草地贪夜蛾(Spodoptera frugiperda)细胞或在粉夜蛾幼虫(Trichoplusia larvae)中表达外源基因。编码多肽的这些序列可以克隆入病毒的非必要区域,诸如多角体蛋白基因,并置于多角体蛋白启动子的控制下。编码多肽序列的成功插入将使得多角体蛋白基因失活并产生缺少外壳蛋白的重组病毒。重组病毒可以随后用于感染例如草地贪夜蛾细胞或粉夜蛾幼虫,其中目标多肽可以表达(Engelhard 等, Proc.Natl.Acad.Sci.U.S.A.91 :3224-3227(1994))。
在哺乳动物宿主细胞中,多种基于病毒的表达系统通常可用。例如,在其中腺病毒用作表达载体的情况中,编码目标多肽的序列可以连接入由后期启动子和三联前导序列组成的腺病毒转录/翻译复合体中。在病毒基因组的非必需E1或E3区域中插入可以用于获得能够在经感染的宿主细胞中表达多肽的活病毒(Logan & Shenk, Proc.Natl.Acad.Sci.U.S.A.81:3655-3659 (1984))。此外,转录增强子诸如劳斯肉瘤病毒(RSV)增强子可用于增加哺乳动物宿主细胞中的表达。用于操作腺病毒载体的方法和方案综述于Wold, Adenovirus Methods and Protocols, 1998。关于使用腺病毒载体的额外参考可见于Adenovirus:A Medical Dictionary, Bibliography, and Annotated Research Guide to Internet References, 2004。
特异性起始信号还可用于实现编码目标多肽的序列的更有效翻译。此类信号包括ATG起始密码子和邻近序列。在其中编码多肽的序列、其起始密码子和上游序列插入合适的表达载体的情况中,可以不需要额外的转录和翻译控制信号。然而,在其中仅插入编码序列或其部分的情况中,应该提供包括ATG起始密码子的外源翻译控制信号。此外,起始密码子应该在正确的读码框内以确保整个插入序列的翻译。外源翻译元件和起始密码子可以是多种来源,天然的和合成的两者。表达效率可以通过包括对于所用的具体细胞系统合适的增强子而得到增强,诸如文献中描述的那些(Scharf.等, Results Probl.Cell Differ.20:125-162 (1994))。
此外,宿主细胞菌株可以对其调节插入的序列的表达或以期望方式处理所表达的蛋白的能力进行选择。多肽的此类修饰包括但不限于乙酰化、羧基化、糖基化、磷酸化、脂化、和酰化。切割蛋白的“前原(prepro)”形式的翻译后加工也可以用于促进正确插入、折叠和/或行使功能。可以选择不同的宿主细胞诸如CHO、HeLa、MDCK、HEK293和WI38(其对于此类翻译后活性具有特定的细胞机器和特征机制)以确保外源蛋白的正确修饰和加工。
对于长期、高产率生产重组蛋白,通常优选稳定表达。例如,稳定表达目标多核苷酸的细胞系可以使用可在相同的或在分开的载体上含有病毒复制起点和/或内源表达元件和可选择标记物基因的表达载体进行转化。引入载体后,细胞可以允许在富集培养基中生长1-2天,随后将它们转换至选择培养基中。可选择标记物的目的在于赋予抗性进行选择,并且其存在允许成功表达引入的序列的细胞的生长和回收。稳定转染的细胞的抗性克隆可以使用对于细胞类型合适的组织培养技术来增殖。
可以使用任何数目的选择系统来回收转化的细胞系。这些包括但不限于单纯疱疹病毒胸苷激酶(Wigler 等, Cell 11:223-32 (1977))和腺嘌呤磷酸核糖基转移酶(Lowy等, Cell 22:817-23 (1990))基因,其可以分别用于tk.sup.-或aprt.sup.-细胞中。此外,可以将抗代谢物、抗生素或除草剂抗性用作选择基础;例如,赋予对甲氨蝶呤抗性的dhfr(Wigler 等, Proc. Natl. Acad. Sci. U.S.A. 77:3567-70 (1980));npt,其赋予对氨基糖甙类、新霉素和G-418的抗性 (Colbere-Garapin 等, J. Mol. Biol. 150:1-14(1981));和als或pat,其分别赋予对于氯磺隆和草丁膦乙酰转移酶(phosphinotricinacetyltransferase)的抗性(Murry,上文)。已描述额外的可选择基因,例如,trpB,其允许细胞利用吲哚代替色氨酸,或hisD,其允许细胞利用组氨醇(histinol)代替组氨酸(Hartman & Mulligan, Proc.Natl.Acad.Sci.U.S.A.85:8047-51 (1988))。近来,使用可见标记物已得到普及,其中此类标记物如花色素苷、β-葡糖醛酸酶及其底物GUS,和萤光素酶及其底物萤光素广泛地不仅用于鉴定转化子而且还定量归因于特定表达系统的瞬时或稳定蛋白表达的量(Rhodes 等, Methods Mol.Biol.55:121-131 (1995))。
尽管标记物基因表达的存在/不存在暗示目标基因也存在,但目标基因的存在和表达可能需要确证。例如,如果编码多肽的序列插入标记物基因序列中,则含有序列的重组细胞可以通过缺乏标记物基因功能而鉴定。可选地,标记物基因可以与编码多肽的序列串联置于单个启动子的控制下。响应于诱导或选择的标记物基因的表达通常表示串联基因也表达。
可选地,含有且表达期望的多核苷酸序列的宿主细胞可以通过多种本领域技术人员已知的程序来鉴定。这些程序包括但不限于DNA-DNA或DNA-RNA杂交和蛋白生物测定或免疫测定技术,其包括用于检测和/或定量核酸或蛋白的基于膜、溶液或芯片的技术。
用于检测和测量多核苷酸编码的产物的表达的多种方案(其使用对产物特异性的多克隆或单克隆抗体)是本领域已知的。实例包括酶联免疫吸附测定(ELISA)、放射性免疫测定(RIA)和荧光激活细胞分选(FACS)。利用与给定多肽上的两个非干扰表位反应的单克隆抗体的基于两位点、单克隆的免疫测定可以优选用于一些应用,但也可以采用竞争性结合测定。这些和其他测定除此以外描述于Hampton 等, Serological Methods, a Laboratory Manual (1990)和Maddox 等, J. Exp.Med.158:1211-1216 (1983)。
许多种标记和缀合技术是本领域技术人员已知的并可以用于多种核酸和氨基酸测定中。用于产生检测与多核苷酸相关的序列的标记的杂交或PCR探针的方法包括使用标记的核苷酸的寡标记、缺口平移、末端标记或PCR扩增。可选地,序列或其任何部分可以克隆入用于产生mRNA探针的载体内。此类载体是本领域已知的,可商购且可以用于通过添加合适的RNA聚合酶诸如T7、T3或SP6和标记的核苷酸来体外合成RNA探针。这些程序可以使用多种可商购试剂盒来进行。可以使用的合适的报道分子或标记包括放射性核素、酶、荧光剂、化学发光剂或生色剂以及底物、辅因子、抑制剂、磁性颗粒等。
用目标多核苷酸序列转化的宿主细胞可以在适合于从细胞培养物中表达和回收蛋白的条件下进行培养。由重组细胞产生的蛋白可以分泌或包含在胞内,其取决于所用的序列和/或载体。如本领域技术人员将理解的,含有多核苷酸的表达载体可以设计以含有指导所编码的多肽经原核或真核细胞膜分泌的信号序列。其他重组构建可用于将编码目标多肽的序列与编码将利于可溶性蛋白纯化的多肽结构域的核苷酸序列连接。此类利于纯化的结构域包括但不限于金属螯合肽诸如组氨酸-色氨酸模块(其允许在固定的金属上纯化),蛋白A结构域(其允许在固定的免疫球蛋白上纯化),和用于FLAGS延伸/亲和纯化系统(Immunex Corp., Seattle, Wash.)中的结构域。在纯化结构域和编码的多肽之间包括可切割接头序列诸如对于因子XA或肠激酶特异性的那些(Invitrogen. San Diego, Calif.)可用于利于纯化。一种此类表达载体提供含有目标多肽和编码在硫氧还蛋白或肠激酶切割位点前的6个组氨酸残基的核酸的融合蛋白的表达。组氨酸残基促进在IMIAC(固定金属离子亲和层析)上的纯化,如描述于Porath 等, Prot. Exp. Purif. 3:263-281 (1992),而肠激酶切割位点提供从融合蛋白纯化期望的多肽的方法。含有融合蛋白的载体的讨论提供于Kroll 等, DNA Cell Biol.12:441-453 (1993))。
多肽组合物
通常,本发明使用的多肽(例如艰难梭菌CDTa、CDTb、毒素A和毒素B蛋白)将是分离的多肽(即,分离自所述多肽在天然情况下通常发现伴随的那些组分)。
例如,如果天然存在的蛋白分离自天然系统中共存物质的一些或所有中,则其被分离。优选地,此类多肽为至少约90%纯,更优选至少约95%纯,且最优选至少约99%纯。如果例如将多核苷酸克隆入不是天然环境的一部分的载体内,则认为将其分离。
多肽可以使用多种众所周知的技术的任一种来制备。由上文所述的DNA序列编码的重组多肽可以容易地使用本领域普通技术人员已知的多种表达载体的任一种从DNA序列中制备。表达可以在任何已转化有或转染有包含编码重组多肽的DNA分子的表达载体的合适宿主细胞中实现。合适的宿主细胞包括原核生物、酵母、和高等真核细胞,诸如哺乳动物细胞和植物细胞。优选地,采用的宿主细胞是大肠杆菌、酵母或哺乳动物细胞系诸如COS或CHO。来自分泌重组蛋白或多肽至培养基中的合适宿主/载体系统的上清液可使用可商购滤器首先浓缩。浓缩后,浓缩物可以应用到合适的纯化基质诸如亲和基质或离子交换树脂。最后,可以采用一种或多种反相HPLC步骤来进一步纯化重组多肽。
用于本发明的多肽、其免疫原性片段和具有小于约100个氨基酸且通常小于约50个氨基酸的其他变体也可以通过合成方法使用本领域普通技术人员熟知的技术来生成。例如,此类多肽可以使用任何可商购的固相技术诸如Merrifield固相合成方法(其中氨基酸顺序地添加至生长中的氨基酸链)来合成。参见Merrifield, J. Am. Chem.Soc.85:2149-2146 (1963)。自动合成多肽的设备可从供应商诸如Perkin Elmer/Applied BioSystemsDivision (Foster City, CA)进行商购,并可以根据制造商说明书进行操作。
在某些特定的实施方案中,多肽可以是融合蛋白,其包含如本文描述的多个多肽,或者包含至少一个如本文所述的多肽和不相关序列,此类蛋白的实例包括破伤风、结核病和肝炎蛋白(参见例如, Stoute 等,New Engl. J. Med.336:86-91 (1997))。融合配偶体例如可以有助于提供T辅助细胞表位(免疫融合配偶体),优选由人识别的T辅助细胞表位,或者可以有助于以高于天然重组蛋白的产量表达蛋白(表达增强子)。某些优选的融合配偶体是免疫和表达增强的融合配偶体。其他融合配偶体可以选择以增加蛋白的溶解性或使得蛋白能够靶向期望的胞内区室。还进一步的融合配偶体包括亲和标签,其促进蛋白纯化。
融合蛋白可以通常使用标准技术包括化学缀合来制备。优选地,融合蛋白表达为重组蛋白,其允许在表达系统中相对于未融合的蛋白,以提高的水平生产。简言之,编码多肽组分的DNA序列可以分开装配,并连接入合适的表达载体中。用或不用肽接头将编码一种多肽组分的DNA序列的3'末端连接至编码第二多肽组分的DNA序列的5'末端,使得序列的读码框是同相的(in phase)。这允许翻译为单一融合蛋白,其保留了两种组分多肽的生物活性。
可以使用肽接头序列来通过足以确保每一肽折叠成其二级和三级结构的距离分隔开第一和第二多肽组分。使用本领域熟知的标准技术将这样的肽接头序列整合入融合蛋白中。可以根据以下因素选择合适的肽接头序列:(1)它们采用柔性延伸构象的能力;(2)它们采用能够与第一和第二多肽上的功能性表位相互作用的二级结构的能力;和(3)缺少可以与多肽功能性表位反应的疏水性或带电残基。优选的肽接头序列包含Gly、Asn和Ser残基。其他的近中性氨基酸诸如Thr和Ala也可以用于接头序列中。可以有用地用作接头的氨基酸序列包括以下中公开的那些:Maratea 等, Gene 40:39-46 (1985); Murphy 等,Proc.Natl.Acad.Sci.USA 83:8258-8262 (1986); 美国专利号4,935,233和美国专利号4,751,180。接头序列的长度通常可以为1-约50个氨基酸。当第一和第二多肽具有可用于分隔功能结构域并阻止立体干扰(steric interference)的非必需N末端氨基酸区时,不需要接头序列。
佐剂
在本发明任一方面的进一步的实施方案中,免疫原性组合物进一步包含佐剂。在一个实施方案中,佐剂包括氢氧化铝或磷酸铝。可选地,本发明的免疫原性组合物可以包含无铝佐剂,将免疫原性组合物与不含铝或铝盐的佐剂(即无铝佐剂或佐剂系统)配制。
在某些实施方案中,免疫原性组合物与以脂质体形式存在的包含免疫活性皂苷级分的佐剂配制。佐剂可以进一步包含脂多糖。佐剂可以包含QS21。例如,在一个实施方案中,佐剂包含在脂质体制剂中的QS21。在一个实施方案中,佐剂系统包括3D-MPL和QS21。例如,在一个实施方案中,佐剂包含在脂质体制剂中的3D-MPL和QS21。任选地,佐剂系统还包含胆固醇。在一个特定的实施方案中,佐剂包括QS21和胆固醇。任选地,佐剂系统包含1, 2-二油酰基-sn-甘油-3-磷酸胆碱(DOPC)。例如,在一个特定的佐剂系统中,包含胆固醇、DOPC、3D-MPL和QS21。
在一个特定实例中,免疫原性组合物包括以包括以下的剂量配制的佐剂:约0.1至约0.5 mg胆固醇;约0.25至约2 mg DOPC;约10 µg至约100 µg 3D-MPL;和约10 µg至约100µg QS21。在另一个特定实例中,免疫原性组合物包括以包括以下的剂量配制的佐剂:约0.1至约0.5 mg胆固醇;约0.25至约2 mg DOPC;约10 µg至约70 µg 3D-MPL;和约10 µg至约70µg QS21。在一种特定的制剂中,佐剂以单一剂量配制,其包含:约0.25 mg胆固醇;约1.0 mgDOPC;约50 µg 3D-MPL;和约50 µg QS21。在其他实施方案中,免疫原性组合物以分数剂量(它是这样的剂量,其为之前单一剂量制剂的一部分,诸如二分之一的之前量的组分(胆固醇、DOPC、3D-MPL和QS21)、1/4的之前量的组分或另一分数剂量(例如1/3、1/6等)的之前量的组分)配制。
在一个实施方案中,根据本发明的免疫原性组合物包含含有脂多糖和皂树皂甙(Quillaja saponin)的组合的佐剂(其已之前公开于例如EP0671948中)。本专利证明当脂多糖(3D-MPL)与皂树皂苷(QS21)组合时的强协同作用。
佐剂可以进一步包含免疫刺激性寡核苷酸(例如CpG)或载体。
用于本发明的尤其合适的皂苷是Quil A及其衍生物。Quil A是分离自南美树皂皮树(Quillaja Saponaria Molina)的皂苷制剂,并首次由Dalsgaard等于1974年(“Saponinadjuvants”, Archiv. für die gesamte Virusforschung, Vol. 44, Springer Verlag,Berlin, p243-254)描述具有佐剂活性。Quil A的纯化片段已通过HPLC分离,所述纯化片段保留佐剂活性而不具有伴随Quil A的毒性(EP 0 362 278),例如QS7和QS21(也称为QA7和QA21)。QS21是来源于皂皮树的树皮的天然皂苷,其诱导CD8+细胞毒性T细胞(CTLs)、Th1细胞和主要的IgG2a抗体应答,并且是本发明上下文中优选的皂苷。
当佐剂包含以脂质体形式存在的免疫活性皂苷级分时,佐剂可以进一步包含固醇。合适地,固醇以1:1-1:100 w/w、诸如1:1-1:10w/w或1:1-1:5 w/w的皂苷:固醇的比例提供。
在特定的实施方案中,QS21以其更低的反应原性组合物提供,其中其用外源固醇诸如胆固醇猝灭(quenched)。存在几种具体的更低反应原性组合物的形式,其中QS21用外源胆固醇猝灭。在一个特定的实施方案中,皂苷/固醇呈脂质体结构的形式(WO 96/33739,实施例1)。在该实施方案中,脂质体合适地包含中性脂质,例如磷脂酰胆碱,其合适地在室温下是非结晶的,例如卵黄磷脂酰胆碱、二油酰磷脂酰胆碱(DOPC)或二月桂基磷脂酰胆碱。该脂质体还可以包含带电荷的脂质,其增加脂质体-QS21结构对由饱和的脂质构成的脂质体的稳定性。在这些情况中,带电荷的脂质的量合适地为1-20% w/w,优选5-10%。固醇与磷脂的比例为1-50% (mol/mol),合适地为20-25%。
合适的固醇包括β-谷甾醇、豆甾醇、麦角甾醇、麦角钙化醇和胆固醇。在一个具体的实施方案中,佐剂组合物包含胆固醇作为固醇。这些固醇是本领域熟知的,例如胆固醇公开于Merck Index,第11版,第341页,作为动物脂肪中发现的天然存在的固醇。
当活性皂苷级分为QS21时,QS21:固醇的比例将通常在1:100-1:1 (w/w)、合适地在1:10-1:1 (w/w)、且优选地在1:5-1:1 (w/w)的级别(order)中。合适地,过量固醇存在,QS21:固醇的比例为至少1:2 (w/w)。在一个实施方案中,QS21:固醇的比例为1:5 (w/w)。固醇合适地为胆固醇。
在一个实施方案中,本发明提供一剂量的免疫原性组合物,其包含免疫活性的皂苷,优选QS21,以约1-约70 μg/剂量的水平,例如以约50 μg的量。
在一个实施方案中,本发明提供一剂量的免疫原性组合物,其包含免疫活性的皂苷,优选QS21,以60 μg或更低的水平,例如1-60 μg。在一个实施方案中,所述剂量的免疫原性组合物包含以约50 µg左右的水平的QS21,例如45-55 µg,合适地46-54 µg或47-53 µg或48-52 µg或49-51 µg或50 µg。
在另一个实施方案中,所述剂量的免疫原性组合物包含以约25 µg的水平的QS21,例如20-30 µg,合适地21-29 µg或22-28 µg或23-27 µg或24-26 µg或25 µg。
在另一个实施方案中,所述剂量的免疫原性组合物包含以每约10 µg的水平的QS21,例如5-15 µg,合适地6-14 µg,例如7-13 µg或8-12 µg或9-11 µg或10µg。
具体而言,0.5 ml疫苗剂量体积包含每剂量25 µg或50 µg的QS21。具体而言,0.5ml疫苗剂量体积包含每剂量50 µg的QS21。
在包含脂多糖的组合物中,脂多糖可以以约1-约70 µg/剂量的量存在,例如以约50 µg的量。
脂多糖可以是脂质A的无毒衍生物,尤其是单磷酰脂质A或更尤其是3-脱酰单磷酰脂质A (3D – MPL)。
3D-MPL以名称MPL由GlaxoSmithKline Biologicals S.A.销售并且在整个本文件中称为MPL或3D-MPL。例如,参见美国专利号4,436,727; 4,877,611; 4,866,034和4,912,094。3D-MPL主要促进具有IFN-γ (Th1)表型的CD4+ T细胞应答。3D-MPL可以根据GB 2 220211 A中描述的方法产生。在化学上,它是具有3、4、5或6个酰化链的3-脱酰单磷酰脂质A的混合物。优选地,在本发明的组合物中,使用小颗粒3D-MPL。小颗粒3D-MPL具有可以使它经0.22µm滤器无菌过滤的颗粒大小。此类制剂描述于WO 94/21292中。
因此,本发明提供一剂量的免疫原性组合物,其包含脂多糖,优选3D-MPL,以75 μg或更低的水平,例如1-60 μg。
在一个实施方案中,所述剂量的免疫原性组合物包含以约50 µg的水平的3D-MPL,例如45-55 µg,合适地46-54 µg或47-53 µg或48-52 µg或49-51 µg或50 µg。
在一个实施方案中,所述剂量的免疫原性组合物包含以约25 µg的水平的3D-MPL,例如20-30 µg,合适地21-29 µg或22-28 µg或23-27 µg或24-26 µg或25 µg。
在另一个实施方案中,所述剂量的免疫原性组合物包含以约10 µg的水平的3D-MPL,例如5-15 µg,合适地6-14 µg,例如7-13 µg或8-12 µg或9-11 µg或10µg。
在一个实施方案中,剂量体积为0.5 ml。在进一步的实施方案中,免疫原性组合物以适合于体积大于0.5 ml,例如0.6、0.7、0.8、0.9或1 ml的剂量的体积。在进一步的实施方案中,人剂量为1 ml-1.5 ml。
具体而言,0.5 ml疫苗剂量体积包含每剂量25 µg或50 µg的3D-MPL。具体而言,0.5 ml疫苗剂量体积包含每剂量50 µg的3D-MPL。
根据本发明的任一方面的免疫原性组合物的剂量合适地指人剂量。术语“人剂量”表示在适合于人使用的体积中的剂量。通常,这为0.3-1.5 ml。在一个实施方案中,人剂量为0.5 ml。在进一步的实施方案中,人剂量高于0.5 ml,例如0.6、0.7、0.8、0.9或1 ml。在进一步的实施方案中,人剂量为1 ml-1.5 ml。
合适的本发明的组合物是那些组合物,其中最初在无MPL的情况下制备脂质体(如WO 96/33739中所描述),并且随后加入MPL,适合地为小于100 nm颗粒的小颗粒或容易经0.22 µm膜无菌过滤的颗粒。因此MPL不包含在小泡膜内(已知为MPL在外)。其中MPL包含在小泡膜内(已知为MPL在内)的组合物也形成本发明的方面。包含艰难梭菌毒素A片段和/或艰难梭菌毒素B片段的多肽可以包含在小泡膜(vesicle membrane)内或包含在小泡膜外。
在特定的实施方案中,QS21和3D-MPL以相同的每剂量免疫原性组合物最终浓度存在,即QS21:3D-MPL的比率为1:1。在该实施方案中的一个方面中,一剂量的免疫原性组合物包含25 µg的3D-MPL和25 µg的QS21或50 µg的3D-MPL和50 µg的QS21的终水平。
在一个实施方案中,佐剂包括水包油乳状液。在一个实施方案中,佐剂包含水包油乳状液,其中水包油乳状液包含可代谢油、母育酚(tocol)和乳化剂。例如,水包油乳状液可以包含油相,其掺合可代谢油和额外的油相组分诸如母育酚。水包油乳状液还可以包含含水组分,诸如缓冲的盐溶液(例如,磷酸缓冲盐溶液)。此外,水包油乳状液通常包含乳化剂。在一个实施方案中,可代谢油是角鲨烯。在一个实施方案中,母育酚是α生育酚。在一个实施方案中,乳化剂是非离子表面活性剂乳化剂(诸如聚氧乙烯山梨聚糖单油酸酯(polyoxyethethylene sorbitan monooleate)、Polysorbate® 80、TWEEN80™)。在示例性实施方案中,水包油乳状液包含角鲨烯和α生育酚,其以等于或小于1 (w/w)的比率。
水包油乳状液中的可代谢油可以以0.5-10mg的量存在。水包油乳状液中的母育酚可以以0.5-11 mg的量存在。乳化剂可以以0.4-4 mg的量存在。
为了任何水包油组合物适合于人施用,乳状液系统的油相必须包含可代谢油。术语可代谢油的含义是本领域熟知的。可代谢的可以定义为‘能够通过新陈代谢来转化’(Dorland’s Illustrated Medical Dictionary, W.B.Sanders Company, 25th edition(1974))。油可以是任何植物油、鱼油、动物油或合成油,其对于受体是无毒的并且能够通过新陈代谢来转化。坚果、种子和谷物是植物油的常见来源。合成油也是本发明的部分,并且可以包括可商购的油诸如NEOBEE®(使用甘油从植物油来源制备的辛酸甘油三酯/癸酸甘油三酯和从椰子油或棕榈仁油制备的中链脂肪酸(MCT))及其他。特别合适的可代谢油是角鲨烯。角鲨烯(2,6,10,15,19,23-六甲基-2,6,10,14,18,22-二十四碳六烯)是不饱和油,其大量发现于鲨鱼肝油中,以较低量于橄榄油、麦胚芽油、米糠油和酵母中,并且是用于本发明的尤其优选的油。角鲨烯是借助于以下的事实的可代谢油,即其是胆固醇的生物合成的中间体(Merck 索引, 第10版, 登录号8619)。
合适地,可代谢油以0.5-10 mg的量存在于佐剂组合物中,优选1-10、2-10、3-9、4-8、5-7、或5-6 mg (例如 2-3、5-6、或9-10mg),尤其是约5.35 mg或约2.14 mg/剂量。
母育酚是本领域中众所周知的并描述于EP0382271。合适地,母育酚是α生育酚或其衍生物,诸如α生育酚琥珀酸酯(也称为维生素E琥珀酸酯)。所述母育酚合适地以0.5-11mg的量存在,优选1-11、2-10、3-9、4-8、5-7、5-6 mg (例如 10-11、5-6、2.5-3.5或1-3 mg)。在特定的实施方案中,母育酚以约5.94 mg或约2.38 mg/剂量的量存在。
水包油乳状液进一步包含乳化剂。乳化剂可以合适地为聚氧乙烯山梨聚糖单油酸酯。在具体的实施方案中,乳化剂可以为Polysorbate® 80 (聚氧乙烯(20)山梨聚糖单油酸酯)或Tween® 80。
所述乳化剂合适地以0.1-5、0.2-5、0.3-4、0.4-3或2-3 mg (例如0.4-1.2、2-3或4-5 mg)乳化剂的量存在于佐剂组合物中。在特定的实施方案中,乳化剂以约0.97 mg或约2.425 mg的量存在。
在一个实施方案中,组合物中存在的具体组分的量为存在于0.5 ml人剂量中的量。在进一步的实施方案中,免疫原性组合物以适合于体积大于0.5 ml,例如0.6、0.7、0.8、0.9或1 ml的人剂量的体积。在进一步的实施方案中,人剂量为1 ml-1.5 ml。
当佐剂为液体形式并与多肽组合物的液体形式组合时,以人剂量的佐剂组合物将是人剂量的预期终体积的一部分,例如约一半的人剂量的预期终体积,例如对于0.7 ml的预期人剂量为350 µl体积,或对于0.5 ml的预期人剂量为250 µl体积。当与多肽抗原组合物组合时,将佐剂组合物稀释以提供疫苗的最终人剂量。此类剂量的终体积将当然根据佐剂组合物的初始体积和添加至佐剂组合物的多肽抗原组合物的体积而不同。在可选的实施方案中,使用液体佐剂来重构冷冻干燥的多肽组合物。在该实施方案中,佐剂组合物的人剂量约等于人剂量的终体积。将液体佐剂组合物添加至含有冷冻干燥的多肽组合物的小瓶中。最终人剂量可以在0.5-1.5 ml之间变化。
生产水包油乳状液的方法是本领域技术人员熟知的。通常,所述方法包括混合含有母育酚的油相与表面活性剂诸如PBS/聚氧乙烯山梨聚糖单油酸酯溶液,随后使用匀浆器均化。对于本领域技术人员将清楚的是包括将混合物通过注射器针两次的方法将适合于均化小体积的液体。同样,微射流器(microfluidiser)(M110S Microfluidics机, 最大50次通过, 以最大6 bar的压力输入持续2分钟的时期(约850 bar的输出压力))中的乳化过程可以由本领域技术人员适配来产生较小或较大的乳状液体积。适配可以通过例行实验来实现,其包括测量所得的乳状液直至实现具有所需直径的油滴的制剂。
在水包油乳状液中,油和乳化剂应在含水载体中。含水载体可以例如是磷酸缓冲盐溶液。
优选地,本发明的水包油乳状液系统具有亚微米范围的小油滴大小。合适地,微滴大小将在120-750 nm范围中,更优选大小为直径120-600 nm。最优选地,水包油乳状液包含其中以强度(intensity)计至少70%为直径小于500 nm,更优选以强度计至少80%直径小于300 nm,更优选以强度计至少90%直径范围在120-200 nm的油滴。
在一个实施方案中,免疫原性组合物不是组合有佐剂的3μg或10 µg的SEQ IDNos. 1-7中任一种,所述佐剂包含具有0.125 mL SB62乳状液(总体积)、5.35 mg角鲨烯、5.94 mg DL-α-生育酚和2.425 mg聚山梨酯80/0.5 ml剂量的水包油乳状液。在一个实施方案中,免疫原性组合物不是组合有佐剂的3μg或10 µg的SEQ ID Nos. 1-7中任一种,所述佐剂包含5.35 mg角鲨烯、5.94 mg DL-α-生育酚和2.425 mg聚山梨酯80/0.5 ml剂量的水包油乳状液。在一个实施方案中,免疫原性组合物不包含这样的佐剂,所述佐剂含有具有角鲨烯、DL-α-生育酚和聚山梨酯80的水包油乳状液。
本发明的免疫原性组合物和疫苗
在一个实施方案中,免疫原性组合物具有0.5-1.5 ml的体积。
在一个实施方案中,免疫原性组合物还包含额外的抗原。在一个实施方案中,额外抗原是来源于选自以下的细菌的抗原:肺炎链球菌(S.pneumoniae)、流感嗜血杆菌(H.influenzae)、脑膜炎奈瑟氏菌(N.meningitidis)、大肠杆菌(E.coli)、粘膜炎莫拉菌(M.catarrhalis)、破伤风梭菌(Clostridium tetani)(破伤风)、白喉棒状杆菌(Corynebacterium diphtheria)(白喉)、百日咳杆菌(Bordetella pertussis)(百日咳)、表皮葡萄球菌(S.epidermidis)、肠球菌(enterococci)、金黄色葡萄球菌(S.aureus)和铜绿假单胞菌(Pseudomonas aeruginosa)。
在进一步的实施方案中,本发明的免疫原性组合物可以包含来自艰难梭菌的其他抗原,例如S层蛋白(WO01/73030)。任选地,免疫原性组合物还包含来自艰难梭菌的糖。
还提供包含本发明免疫原性组合物和药学上可接受的赋形剂的疫苗。
可以通过经全身或黏膜途径施用包含本发明的免疫原性组合物的疫苗制剂,使用所述疫苗来保护对艰难梭菌感染易感的哺乳动物或治疗患有艰难梭菌感染的哺乳动物。这些施用可以包括经肌内、腹膜内、皮内或皮下途径注射;或经向口腔/消化道、呼吸道、生殖泌尿道的黏膜施用。尽管本发明的疫苗可以作为单一剂量施用,但其组分也可以在同一时间或以不同次数一同共施用(例如,肺炎球菌糖缀合物可以单独、在疫苗的任何细菌蛋白组分施用的同一时间或其后1-2周施用,以协调彼此相关的免疫应答)。除了施用的单一途径之外,可以使用2种不同的施用途径。例如,糖或糖缀合物可以肌内(IM)或皮内(ID)施用,并且细菌蛋白可以鼻内(IN)或皮内(ID)施用。此外,本发明的疫苗可以肌内施用为致敏剂量并且鼻内施用为加强剂量。
疫苗中毒素的含量通常将在1-250μg的范围内,优选5-50μg,最常见在5 - 25μg的范围内。初始接种后,主体可以接受一次或适当分隔开的几次加强免疫。疫苗制剂通常描述于Vaccine Design ("The subunit and adjuvant approach" (Powell M. F.和NewmanM.J.编辑)(1995) Plenum Press New York)中。在脂质体内封装由Fullerton, 美国专利4,235,877描述。
在本发明的一个方面,提供疫苗试剂盒,其包括含有本发明的免疫原性组合物的小瓶,任选以冷冻干燥形式,并且还包括含有如本文描述的佐剂的小瓶。预想在本发明的该方面中,将使用佐剂来重构冷冻干燥的免疫原性组合物。
本发明的进一步的方面是预防或治疗艰难梭菌感染的方法,其包括向宿主施用免疫保护性剂量的本发明的免疫原性组合物或疫苗或试剂盒。在一个实施方案中,提供预防或治疗艰难梭菌感染的原发性和/或复发事件的方法,其包括向宿主施用免疫保护性剂量的本发明的免疫原性组合物或疫苗或试剂盒。
在本发明的一个实施方案中,提供用于治疗或预防由艰难梭菌引起的病况或疾病的本发明的免疫原性组合物或疫苗。“艰难梭菌疾病”意指完全或部分由艰难梭菌引起的疾病。在本发明的进一步的实施方案中,提供本发明的免疫原性组合物或疫苗,其用于治疗或预防完全或部分由选自以下的艰难梭菌的菌株引起的病况或疾病:078、019、023、027、033、034、036、045、058、059、063、066、075、078、080、111、112、203、250和571。优选地,菌株是菌株078。
如本文所用,“治疗”意指预防主体中病况或疾病症状的发生,预防主体中病况或疾病症状的复发,延迟主体中病况或疾病症状的复发,降低主体中病况或疾病症状的严重度或频率,减缓或消除主体中病况的进展和部分或完全消除主体中疾病或病况的症状。
在本发明的进一步的方面中,提供本发明的免疫原性组合物或疫苗在制备用于预防或治疗艰难梭菌疾病的药物中的用途。在进一步的实施方案中,疾病是由选自以下的艰难梭菌的菌株引起的疾病:078、019、023、027、033、034、036、045、058、059、063、066、075、078、080、111、112、203、250和571。优选地,菌株是菌株078。
在本发明的进一步的方面中,提供预防或治疗艰难梭菌疾病的方法,其包括向哺乳动物主体诸如人主体施用本发明的免疫原性组合物或本发明的疫苗。在进一步的实施方案中,疾病是由选自以下的艰难梭菌的菌株引起的疾病:078、019、023、027、033、034、036、045、058、059、063、066、075、078、080、111、112、203、250和571。优选地,菌株是菌株078。
一般内容
将“左右”或“大约”定义为在本发明的目的的给定数值的10%或多或少之内。
术语“包含(comprises)”表示“包括(includes)”。因此,除非上下文另外需要,将理解词语“包含(comprises)”及变化诸如“包含(comprise)”和“包含(comprising)”意指包括陈述的化合物或组合物(例如核酸、多肽、抗原)或步骤,或化合物或步骤的组,但不排除任何其他的化合物、组合物、步骤、或其的组。缩写“例如(e.g.)”来源于拉丁文例如(exempli gratia),并用于本文以表示非限定性实例。因此,缩写“例如(e.g.)”与术语“例如(for example)”同义。
本文使用的氨基酸编号来源于本文分别呈现为SEQ ID NO: 1、SEQ ID NO: 3、SEQID NO: 29和SEQ ID NO: 30(其被认为是这些蛋白的参考序列)的CDTa、CDTb、毒素A和毒素B的序列。
本文中涉及本发明的“疫苗组合物”的实施方案也适用于涉及本发明的“免疫原性组合物”的实施方案,并且反之亦然。
除非另有解释,本文使用的所有技术和科学术语具有如本公开内容所属技术领域的普通技术人员通常理解的相同含义。分子生物学中普通术语的定义可以见于BenjaminLewin, Genes V, 由Oxford University Press出版, 1994 (ISBN 0-19-854287-9);Kendrew等(编辑), The Encyclopedia of Molecular Biology, 由Blackwell ScienceLtd.出版, 1994 (ISBN 0-632-02182-9);和Robert A. Meyers (编辑), Molecular Biology and Biotechnology: a Comprehensive Desk Reference, 由VCH Publishers,Inc.出版, 1995 (ISBN 1-56081-569-8)。
除非上下文明确另有说明,单数术语“一个(a)”、“一个(an)”和“该(the)”包括复数指示物。类似地,除非上下文明确另有说明,词语“或”旨在包括“和”。术语“复数”指两个或更多。还应理解对核酸或多肽给出的所有碱基大小或氨基酸大小、和所有分子量(molecular weight)或分子量(molecular mass)值均是近似的,并且提供用于说明。此外,关于物质诸如抗原的浓度或水平给出的数值界限可以是近似的。
本专利说明书中引用的所有参考文献或专利申请以其整体通过引用并入本文。
为了本发明可以更好地理解,描述以下实施例。这些实施例仅为说明目的,而不应以任何方式解释为限定本发明的范围。
实施例
所指的AS01B佐剂是具有50 µg呈脂质体形式的QS21、50 µg 3D-MPL、0.25 mg胆固醇和1.0 mg DOPC/0.5 ml剂量的佐剂。适合于免疫小鼠的50 µl剂量包含5 µg QS21、 5 µg3D-MPL、0.025 mg胆固醇和0.1 mg DOPC。
实施例1:二元毒素抗原的设计
二元毒素(其他名称:ADP核糖基转移酶毒素)由两种组分构成:酶组分即CDTa和转运和结合组分即CDTb。
基于其他细菌二元毒素的组分可获得的文献数据和信息,CDTb可以分为五个结构域。第一个结构域是前域,其由具有糜蛋白酶活性的酶的切割允许成熟蛋白的七聚化(heptamerisation)。第二个结构域允许结合CDTa。第三个和第四个结构域参与寡聚化和膜插入。最后,最后一个结构域是宿主细胞受体结合域。
CDTb成熟
为了避免在CDTb加工中的糜蛋白酶活化步骤,尝试仅表达成熟CDTb蛋白(无其信号肽和前域)。
在文献(Protein Expression and Purification, 2010, vol. 74 :42-48)中,成熟CDTb描述为在SEQ ID NO: 3的亮氨酸210处开始。该成熟的CDTb命名为CDTb"。
其他实验数据表明活化的CDTb在SEQ ID NO: 3的丝氨酸212处开始。该结果被CDTb的3D模型结构的分析支持。该模型使用SwissModel建立(Bioinformatics, 2006,vol. 22 :195-201)。用于同源建模的模板是炭疽芽孢杆菌(Bacillus anthracis)的B组分,即保护性抗原或PA (Protein Data Bank检索号:3TEW)。
单独的CDTb受体结合域
使用来自炭疽芽孢杆菌的PA抗原对CDTb获得的3D同源结构模型对于CDTb的四个第一结构域而非受体结合域(CDTb和PA的这些结构域非常不同)是准确的。为了设计表达单独的受体结合域的构建体,第四个结构域的C末端部分在3D结构模型上分析以决定最后一个结构域将在哪里开始。
设计了两个版本的CDTb受体结合域。在第一个版本中,该结构域刚好在第四个结构域的模型化的3D结构之后开始。在该版本中,CDTb受体结合域将可能在其N末端部分具有长的柔性肽。受体结合域的第二个版本开始于在CDTb的C末端部分上进行的2D预测结构(使用Psipred程序完成预测,Bioinformatics, 2000, vol. 16 : 404-405)在缺少预测的二级结构后变得更紧密处。这能够说明新的结构域的开始。在该第二个版本中,在分离的CDTb受体结合域的N末端部分处不存在柔性肽。
CDTb Ca2+ 结合基序突变
按照文献信息,在产气荚膜梭菌的ι毒素的B组分(Ib)的Ca2+结合域中的突变消除与该二元毒素的A组分(Ia)的结合。这些突变在疫苗组合物包含成熟CDTb蛋白和野生型CDTa蛋白的混合物的情况下可以是非常有趣的。
使用多蛋白序列比对,这些突变位于CDTb序列上并被突变。它涉及SEQ ID NO: 3的残基Asp220、Asp222 和Asp224。它们被突变为Ala残基。
CDTb前域
为了尝试降低在凝胶中用构建体C55(去除前域的CDTb)观察到的降解问题,评价了一些共表达测试。进行此事的工作假设将改进成熟CDTb的折叠。
提出了前域的两个边界。第一个开始于SEQ ID NO: 3的CDTb(在信号肽切割后)的残基43处,且终止于残基Met211(给定成熟CDTb的实验确定的第一个残基是Ser212)。第二个前域基于CDTb的预测的3D结构进行设计。成熟CDTb蛋白的前域和第一结构域之间存在的接头在该构建体中去除。
实施例2-艰难梭菌CDTb蛋白的克隆、表达和纯化
表达质粒和重组菌株:C37和C55 (如表A中所述)。
使用BamHI/XhoI限制位点用标准方法将编码不具有信号肽(Pro-CDTb`, C37)和C末端的His标签的CDTb截短蛋白的基因克隆入pGEX-6p1表达载体(GE Healthcare)中。该载体包括在CDTb`( GST-Pro-CDTb’)的N末端中的GST(谷胱甘肽-S-转移酶)作为融合配偶体。按照标准方法用CaCl2处理的细胞用重组表达载体通过转化大肠杆菌菌株BL21 (DE3)来生成最终的构建体(Hanahan D. « Plasmid transformation by Simanis. » 于Glover, D.M. (Ed), DNA cloning. IRL Press London. (1985): 第109-135页.)。
使用NdeI/XhoI限制位点用标准方法将编码不具有信号肽和前域(CDTb``: C55)和C末端的His标签的CDTb截短蛋白的基因克隆入pET24b(+)表达载体(Novagen)中。按照标准方法用CaCl2处理的细胞用合适的重组表达载体通过转化大肠杆菌B834 (DE3)修饰的菌株来生成最终的构建体(Hanahan D. « Plasmid transformation by Simanis. » 于Glover, D. M. (Ed), DNA cloning. IRL Press London. (1985): 第109-135页.)。
宿主菌株
BL21(DE3)。BL21(DE3)是B834的无甲硫氨酸营养缺陷型衍生物。具有命名(DE3)的菌株对于包含IPTG诱导型T7 RNA聚合酶的λ原噬菌体是溶原的。设计λ DE3溶原体用于来自pET载体的蛋白表达。该菌株也缺乏lon和ompT蛋白酶。
基因型:大肠杆菌BL21::DE3菌株, F- ompT hsdS B(rB - mB -) gal dcm (DE3)。
B834是BL21的亲本菌株。这些蛋白酶缺乏宿主是甲硫氨酸营养缺陷型。设计λ DE3溶原体用于来自pET载体的蛋白表达。该菌株也缺乏lon和ompT蛋白酶。
修饰:包括PGL基因以避免生物素基因座中的磷酸葡糖酰化(phosphogluconoylation)(菌株是生物素营养缺陷型)。
基因型:B834 ::DE3菌株, F– ompT hsdSB(rB – mB–) gal dcm met (DE3)
修饰:Δ(bioA-bioD)::PGL。
重组蛋白的表达:
从琼脂板上刮下大肠杆菌转化子并用于接种200 ml的LBT培养基± 1% (w/v)葡萄糖±卡那霉素(50 µg/ml)或氨苄青霉素(100 µg/ml),以获得0.1 -0.2之间的O.D.600nm。在37 ℃, 250 RPM下过夜孵育培养物。
在500 ml的含有±卡那霉素(50 µg/ml)或氨苄青霉素(100 µg/ml)的LBT培养基中将过夜培养物稀释至1:20,并且在37℃下以250 rpm的转速生长直到O.D.620达到0.5/0.6。
在600nm处的O.D.为0.6左右时,在加入1 mM异丙基-β-D-1-硫代半乳糖苷(IPTG;EMD Chemicals Inc., 目录号: 5815)诱导重组蛋白的表达之前将培养物冷却下来,并且随后在23 ℃, 250 RPM下过夜孵育。
过夜诱导(16个小时左右)后,评估诱导后的600nm处的O.D.,并且以14 000 RPM将培养物离心15分钟,并将沉淀分别冷冻于-20℃。
纯化
C37 (SEQ ID NO:5)
将细菌沉淀重悬于50mM N,N-二(羟乙基)甘氨酸缓冲液(pH 8.0),所述缓冲液含有500mM NaCl、5mM TCEP (Thermo Scientific Pierce, (2-羧乙基)膦盐酸盐(phosphinehydrochloride)) 和蛋白酶抑制剂的混合物 (Complete, Roche)。使用French Press系统3 X 20 000 PSI裂解细菌。通过离心在4℃下以20 000g持续30分钟分离可溶(上清液)和不可溶(沉淀)组分。
在IMAC上在非变性条件下纯化6-His标签化的蛋白。将可溶组分装载到用用于细菌重悬的相同缓冲液预平衡的5ml GE Histrap柱(GE)上。在柱上装载后,将柱用50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0洗涤, 所述缓冲液含有150mM NaCl、25mM咪唑、1mM TCEP。使用含有150mM NaCl、250mM咪唑、1mM TCEP的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0进行洗脱。
在含有150mM NaCl和1mM TCEP的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0中脱盐步骤(BIORAD Bio-Gel P6 Desalting)后,将产物用PreScission蛋白酶(GE-Healthcare)处理(4℃下过夜)以切割GST标签。过夜处理后,将0.2% Tween 20加入到消化混合物中。
随后将蛋白经过用包含150mM NaCl、1mM TCEP、0.2% tween20和20mM还原的谷胱甘肽(glutation)的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0预平衡的GST亲和柱( GEGSTrap FF),以去除切割的标签、未切割的融合蛋白和PreScission蛋白酶。
在流通物(flow through)中收集无GST的蛋白,并再次装载至用包含150mM NaCl、1mM TCEP、0.2% tween20的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0预平衡的5ml GEHistrap柱(GE)上。在柱上装载后,将柱用50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0洗涤,所述缓冲液含有150mM NaCl、0.2% tween20、1mM TCEP和10mM咪唑。使用含有150mM NaCl、0.2% tween20、1mM TCEP和500mM咪唑的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0进行洗脱。
在包含150 mM NaCl、1mM TCEP和0.2% tween 20的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0中的脱盐步骤(BIORAD Bio-Gel P6 Desalting)后,将产物用α-糜蛋白酶 (来自牛胰- Sigma)处理,随后用胰蛋白酶抑制剂处理(来自蛋白- Sigma)。CDTb由糜蛋白酶的完全活化通过SDS-PAGE监测。
将完全活化的产物装载至SEC层析(SUPERDEX TM 75)上,于含有300mM NaCl、1mMTCEP的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0中。包含CDTb抗原的级分通过SDS-PAGE基于纯度进行选择。使用BioRad的Lowry RC/DC蛋白测定来测定蛋白浓度。纯化的批次(bulk)在0.22 µm上无菌过滤并存储在-80℃。
C55 (SEQ ID NO:7)
将细菌沉淀重悬于50mM N,N-二(羟乙基)甘氨酸缓冲液(pH 8.0),所述缓冲液含有150mM NaCl、5mM TCEP (Thermo Scientific Pierce, (2-羧乙基)膦盐酸盐(phosphinehydrochloride))、0.4% empigen和蛋白酶抑制剂的混合物 (Complete, Roche)。使用French Press系统3 X 20 000 PSI裂解细菌。通过离心在4℃下以20 000g持续30分钟分离可溶(上清液)和不可溶(沉淀)组分。
在IMAC上在非变性条件下纯化6-His标签化的蛋白。将可溶性组分装载至用含有150mM NaCl、0.15% empigen、1mM TCEP的50mM N,N-二(羟乙基)甘氨酸缓冲液(pH 8.0)预平衡的5ml GE Histrap柱(GE)上。在柱上装载后,将柱用50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0洗涤, 所述缓冲液含有150mM NaCl、0.2% tween20、20mM咪唑和1mM TCEP。使用含有150mM NaCl、0.2% tween20、500mM咪唑和1mM TCEP的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0进行洗脱。
在含有300mM NaCl、1mM TCEP的50mM N,N-二(羟乙基)甘氨酸缓冲液pH8.0中脱盐步骤(BIORAD Bio-Gel P6 Desalting)后,将产物装载至相同缓冲液中的SEC层析(SUPERDEX TM 75)上。包含CDTb抗原的级分通过SDS-PAGE基于纯度进行选择。使用BioRad的Lowry RC/DC蛋白测定来测定蛋白浓度。纯化的批次(bulk)在0.22 µm上无菌过滤并存储在-80℃。
实施例3:CDTa蛋白的克隆、表达和纯化
表达质粒和重组菌株:CDTa全长(如表A中所述的C34、C44、C49、C50、C54、C67、C68、
C69、C107、C108、C110)
使用NdeI/XhoI限制位点用标准方法将编码不具有CDTa的信号肽具有和不具有突变(参见表A)和C末端的His标签的全长蛋白的基因克隆入pET24b(+)表达载体(Novagen)中。按照标准方法用CaCl2处理的细胞分别用每一重组表达载体通过转化大肠杆菌菌株HMS174 (DE3)或BLR (DE3) pLysS (C34)来生成最终的构建体(Hanahan D. « Plasmidtransformation by Simanis. » 于Glover, D. M. (Ed), DNA cloning. IRL PressLondon. (1985): 第109-135页.)。
宿主菌株:
HMS 174 (DE3)。HMS174菌株提供在K-12背景中的recA突变。具有命名(DE3)的菌株对于包含IPTG诱导型T7 RNA聚合酶的λ原噬菌体是溶原的。λ DE3溶原体设计用于从pET载体的蛋白表达
基因型:F- recA1 hsdR(rK12 - mK12 +) (Rif R)。
BLR(DE3) pLysS。BLR是BL21的recA衍生物。具有命名(DE3)的菌株对于包含IPTG诱导型T7 RNA聚合酶的λ原噬菌体是溶原的。λ DE3溶原体设计用于从pET载体的蛋白表达。该菌株也缺乏lon和ompT 蛋白酶,pLysS菌株表达T7溶菌酶,其进一步抑制诱导前T7 RNA聚合酶的本底表达。
基因型:大肠杆菌BLR::DE3菌株, F- ompT hsdS B(rB - mB -) gal dcm (DE3) Δ(srl-recA)306::Tn10 pLysS (CamR, TetR)。
重组蛋白的表达:
从琼脂板上刮下大肠杆菌转化子并用于接种200 ml的LBT培养基± 1% (w/v)葡萄糖+卡那霉素(50 µg/ml),以获得0.1 -0.2之间的O.D.600nm。在37 ℃, 250 RPM下过夜孵育培养物。
在500 ml的含有卡那霉素(50 µg/ml)的LBT培养基中将每一过夜培养物稀释至1:20,并且在37℃下以250 rpm的转速生长直到O.D.620达到0.5/0.6。
在O.D.600nm为0.6左右时,在加入1 mM异丙基-β-D-1-硫代半乳糖苷(IPTG;EMDChemicals Inc., 目录号: 5815)诱导重组蛋白的表达之前将培养物冷却下来,并且随后在23 ℃, 250 RPM下过夜孵育。
过夜诱导后(16个小时左右),评估诱导后的O.D.600nm,并且以14 000 RPM将培养物离心15分钟,并将沉淀分别冷冻于-20℃。
表达质粒和重组菌株:CDTa- N-term (如表A中所述的C49和C50)
使用NdeI/XhoI限制位点用标准方法将编码不具有CDTa的信号肽(参见表A)和C末端的His标签的N末端蛋白的基因克隆入pET24b(+)表达载体(Novagen)中。按照标准方法用CaCl2处理的细胞分别用每一重组表达载体通过转化大肠杆菌菌株HMS174 (DE3)来生成最终的构建体(Hanahan D. « Plasmid transformation by Simanis. » 于Glover, D. M.(Ed), DNA cloning. IRL Press London. (1985): 第 109-135页.)。
宿主菌株:
HMS 174 (DE3)。HMS174菌株提供在K-12背景中的recA突变。具有命名(DE3)的菌株对于包含IPTG诱导型T7 RNA聚合酶的λ原噬菌体是溶原的。λ DE3溶原体设计用于从pET载体的蛋白表达
基因型:F- recA1 hsdR(rK12 - mK12 +) (Rif R)。
重组蛋白的表达:
从琼脂板上刮下大肠杆菌转化子并用于接种200 ml的LBT培养基± 1% (w/v)葡萄糖+卡那霉素(50 µg/ml),以获得0.1 -0.2之间的O.D.600nm。在37 ℃, 250 RPM下过夜孵育培养物。
在500 ml的含有卡那霉素(50 µg/ml)的LBT培养基中将该过夜培养物稀释至1:20,并且在37℃下以250 rpm的转速生长直到O.D.620达到0.5/0.6。
在O.D.600nm为0.6左右时,在加入1 mM异丙基-β-D-1-硫代半乳糖苷(IPTG;EMDChemicals Inc., 目录号: 5815)诱导重组蛋白的表达之前将培养物冷却下来,并且随后在23 ℃, 250 RPM下过夜孵育。
过夜诱导后(16个小时左右),评估诱导后的O.D.600nm,并且以14 000 RPM将培养物离心15分钟,并将沉淀分别冷冻于-20℃。
纯化
以下程序用于纯化构建体C34、C44、C49、C50、C54、C67、C69、C107和C110。
将细菌沉淀重悬于20mM或50mM N,N-二(羟乙基)甘氨酸缓冲液(pH 7.5或pH8.0),所述缓冲液含有500mM NaCl、0mM或5mM TCEP (Thermo Scientific Pierce, (2-羧乙基)膦盐酸盐(phosphine hydrochloride)) 和蛋白酶抑制剂的混合物 (Complete,Roche, 无EDTA)。使用French Press系统3 X 20 000 PSI裂解细菌。通过离心在4℃下以20000g持续30分钟分离可溶(上清液)和不可溶(沉淀)组分。
在IMAC上在非变性条件下纯化6-His标签化的蛋白。将可溶组分装载到用用于细菌重悬的相同缓冲液预平衡的5ml GE Histrap柱(GE)上。在柱上装载后,将柱用20mM或50mM N,N-二(羟乙基)甘氨酸缓冲液(pH7.5或pH8.0)洗涤, 所述缓冲液含有500mM NaCl、10mM咪唑、5mM TCEP。洗脱使用50mM N,N-二(羟乙基)甘氨酸缓冲液pH7.6、500mM NaCl、1mM TCEP和咪唑(250mM或500mM)进行。
脱盐( BIORAD Bio-Gel P6 Desalting)和浓缩(Amicon Ultra 10kDa)后,将产物装载在SEC层析 (SUPERDEX TM 75或200)上,于20mM或50mM N,N-二(羟乙基)甘氨酸缓冲液( pH7.5或pH8.0)、150mM NaCl、1mM TCEP中,用于进一步的纯化步骤。
包含CDTa抗原的级分通过SDS-PAGE基于纯度进行选择。使用BioRad的Lowry RC/DC蛋白测定来测定蛋白浓度。纯化的批次(bulk)在0.22 µm上无菌过滤并存储在-80℃。
实施例4:具有改变的孔形成能力的艰难梭菌CDTb蛋白的设计、克隆、表达和纯化。
评估第一策略以降低单独CDTb观察到的细胞毒性:避免对于CDTb改变其在内体中的结构以向该内体的膜内形成孔的可能性。该方法中参考的两种策略基于对于来自炭疽芽孢杆菌(C123和C149)和肉毒梭菌(Clostridium botulinium)(C126、C152、C164和C166)的二元毒素的B组分可获得的公开数据。设计以下CDTb蛋白:
| 名称 | 长度(aa)* | 位置 | 描述 | SEQ ID |
| C123 | pGEX-CDTb -F455R-His | SEQ ID NO:10 | ||
| C126 | pGEX-CdtB-E426A-D453A | SEQ ID NO:11 | ||
| C149 | 841 | SEQ ID NO: 3的CDTb的43-876 | pET24b-Cdtb -F455R-His | SEQ ID NO:25 |
| C152 | 841 | SEQ ID NO: 3的CDTb的43-876 | pET24b-Cdtb-E426A-D453A-His | SEQ ID NO:26 |
| C164 | 672 | SEQ ID NO: 3的CDTb的212-876 | pET24b-Cdtb-无前域-F455R-His | SEQ ID NO:43 |
| C166 | 672 | SEQ ID NO: 3的CDTb的212-876 | pET24b-Cdtb-无前域-E426A-D453A-His | SEQ ID NO:44 |
* 考虑开始的Met密码子和His标签。
克隆和纯化
C末端的His标签/在pGEX-6p1载体的BamH1-Xho1位点克隆/ 菌株B834(DE3): 基因型: 大肠杆菌BL21::DE3菌株, F- ompT hsdSB(rB- mB-) gal dcm (DE3)。
B834是BL2的亲本菌株。这些蛋白酶缺乏宿主是甲硫氨酸营养缺陷型。设计λ DE3溶原体用于从pET和pGEX载体的蛋白表达。该菌株也缺乏lon和ompT蛋白酶。选择抗生素:氨苄青霉素:50µg/ml/在16C产生过夜。
纯化(C123、C126、C149和C152):
弗氏压碎器,用裂解缓冲液:50mM N,N-二(羟乙基)甘氨酸-500mM NaCl、-5mMTCEP、完全- pH8.0
Ni-NTA GE His trap 5ml (profinia) + 脱盐
平衡:50mM N,N-二(羟乙基)甘氨酸 - 500mM NaCl、 1mMTCEP - pH8.0
洗涤:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl 、1mMTCEP - 咪唑 0mM pH8.0
洗脱:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl 、1mMTCEP - 咪唑 250mMpH8.0
脱盐:50mM N,N-二(羟乙基)甘氨酸-150mMNaCl-1mMTCEP pH8.0
Prescission切割(GST标签):
+375µl ( 500UI/250µl) :750 UI
4℃过夜 + 添加Tween 20 0.2%终浓度
GSTrap FF (1ml)
平衡缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP – 0.2%Tween20 pH8.0
保持FT
洗涤缓冲液:与平衡缓冲液相同
洗脱缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP- 0.2%Tween20 -250mM 咪唑, -pH8.0
IMAC GE 5ml + 脱盐
平衡缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP 0.2%Tween20, -pH8.0
洗涤缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP- 10mM 咪唑0.2%Tween20 , -pH8.0
洗脱缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP- 250mM 咪唑 – 0.2%Tween 20, -pH8.0
脱盐缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP – 0.2%Tween20, -pH8.0
RC/DC 剂量
活化:糜蛋白酶处理:
100µg 糜蛋白酶 (1µg/µl)活化1mg蛋白
(42mg + 3.6mg的糜蛋白酶于12.5ml终体积)
RT下50 min
+ 失活 : 糜蛋白酶抑制剂12.6mg
SEC Superdex 200
平衡:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
在IMAC GE 1ml上浓缩 + 脱盐
平衡缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
洗涤缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
洗脱缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP- 250mM 咪唑, -pH8.0
脱盐缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
过滤0.22µm , RC/DC剂量。
C164的纯化按照以下方案1来进行:

方案1。
C166纯化按照以下方案2来进行:

方案2。
表征:
使用动态光散射除了提供关于同质性的信息和检测蛋白样品内高分子量聚集体的存在外,还用来评估CDTb纯化蛋白的溶液中的流体力学半径。这基于计算通过测量光散射波动获得的不同种类的扩散系数,其取决于蛋白分子大小和形状和样品的其他次要成分。
将蛋白样品在Dynapro板读数器(Wyatt technology)上分析,使用在25℃下15秒的五次获取。
a- 缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
结果显示于图3中。
实施例5:去除信号肽和前域且还去除受体结合域和/或去除CDTa结合域的艰难梭
菌CDTb蛋白的设计、克隆、表达和纯化。
表达单独CDTb的不同结构域的推理用来理解哪一个导致降解和聚集问题。使用这一策略来评估两个结构域:分别在构建体C116和C117上去除受体结合域和CDTa结合域。没有分开表达CDTb的“寡聚化”和“膜插入”结构域,因为它们是潜在地结构相关的。设计以下CDTb蛋白:
| 名称 | 长度(aa)* | 位置 | 描述 | SEQ ID |
| C116 | 414 | SEQ ID NO: 3的CDTb的212-616 | pET24b-CDTb ΔRBD-His | SEQ ID NO:8 |
| C117 | 588 | SEQ ID NO: 3的CDTb的296-876 | pET24b-CDTb ΔCDTa bdg-His | SEQ ID NO:9 |
| C118 | 330 | SEQ ID NO: 3的CDTb的296-616 | pET24b-CDTb- ΔRBD-ΔCDTa bdg-His | SEQ ID NO:37 |
* 考虑开始的Met密码子和His标签。
克隆和纯化
C末端中的His标签/在pET24b载体的Nde1-Xho1位点克隆/ 菌株B834(DE3): 基因型: 大肠杆菌BL21::DE3菌株, F- ompT hsdSB(rB- mB-) gal dcm (DE3)。
B834是BL2的亲本菌株。这些蛋白酶缺乏宿主是甲硫氨酸营养缺陷型。设计λ DE3溶原体用于来自pET载体的蛋白表达。该菌株也缺乏lon和ompT蛋白酶。选择抗生素:卡那霉素:50µg/ml/在16C产生过夜。
纯化和表征
C116
弗氏压碎器
裂解缓冲液:50mM N,N-二(羟乙基)甘氨酸-500mM NaCl、- 5mMTCEP、完全- pH8.0
Ni-NTA GE His trap 5ml
平衡:8M 尿素 - 50mM N,N-二(羟乙基)甘氨酸 - 500mM NaCl、 1mMTCEP -pH8.0
洗涤:8M 尿素 -50mM N,N-二(羟乙基)甘氨酸 - 500mM NaCl、1mMTCEP – 5mM 咪唑 - pH8.0
在柱His trap上再折叠
梯度:在1ml/min下100min :8M -50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl -1mM TECP – pH 8.0 1mMTCEP至0M 尿素 50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl -1mM TECP – pH 8.0
洗脱
50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl 、1mMTCEP - 咪唑 500mM pH7.5
SEC :Superdex 200
50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl - 1mMTCEP - pH7.5
0.22µm - 剂量 LowryRCDC
C117
弗氏压碎器
用裂解缓冲液:50mM N,N-二(羟乙基)甘氨酸-500mM NaCl、- 5mMTCEP、完全-pH8.0
Ni-NTA GE His trap 5ml (profinia)
平衡:50mM N,N-二(羟乙基)甘氨酸 - 500mM NaCl、 1mMTCEP - pH8.0
洗涤:50mM N,N-二(羟乙基)甘氨酸 - 500mM NaCl 、1mMTCEP - 咪唑 0mM pH8.0
洗脱:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl 、1mMTCEP - 咪唑 500mMpH7.5
SEC Superdex 200
平衡:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH7.5
过滤0.22µm , RC/DC剂量。
实施例6:具有改变的七聚化能力的艰难梭菌CDTb蛋白的设计、克隆、表达和纯化。
使用第二策略来降低对于单独CDTb所观察到的细胞毒性:避免CDTb的七聚化。设计CDTb的七聚复合体的3D模型。使用该模型,将一个环鉴定为在单体之间可能相互作用。评估两种方法:去除该环(C127)或者突变该环中包含的可能参与单体之间相互作用的残基(C128)。设计以下蛋白:
| 名称 | 长度(aa)* | 位置 | 描述 | SEQ ID |
| C127 | 834 | SEQ ID NO: 3的CDTb的43-876 | pET24b-截短的CDTb-His | SEQ ID NO:12 |
| C128 | 841 | SEQ ID NO: 3的CDTb的43-876 | pET24b-突变的CDTb-His | SEQ ID NO:13 |
* 考虑开始的Met密码子和His标签。
克隆和纯化
C末端中的His标签/在pET24b载体的Nde1-Xho1位点克隆/ 菌株B834(DE3): 基因型: 大肠杆菌BL21::DE3菌株, F- ompT hsdSB(rB- mB-) gal dcm (DE3)。
B834是BL2的亲本菌株。这些蛋白酶缺乏宿主是甲硫氨酸营养缺陷型。设计λ DE3溶原体用于来自pET载体的蛋白表达。该菌株也缺乏lon和ompT蛋白酶。选择抗生素:卡那霉素:50µg/ml/在16C产生过夜。
纯化和表征
弗氏压碎器
用裂解缓冲液:50mM N,N-二(羟乙基)甘氨酸-150mM NaCl- 0.4% Empigen-5mMTCEP - 完全- pH8.0
Ni-NTA GE His trap 1ml (profinia)
平衡:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl -0.15% Empigen - 1mMTCEP- pH8.0
洗涤:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl - 0.2% Tween 20 -1mMTCEP - 咪唑 10mM pH8.0
洗脱:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl - 0.2% Tween 20 -1mMTCEP - 咪唑 500mM pH8.0
脱盐 G-25:50mM N,N-二(羟乙基)甘氨酸 - 150mM NaCl - 0.2% Tween 20 -1mMTCEP - pH8.0
糜蛋白酶活化
SEC :Superdex 200 XK16/60 (120ml)
平衡:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
浓缩:GE-His Trap (1ml) + 脱盐
50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0
0.22µm - 剂量 LowryRCDC。
表征:
使用动态光散射除了提供关于同质性的信息和检测蛋白样品内高分子量聚集体的存在外,还用来评估CdtB纯化蛋白的溶液中的流体力学半径。这基于计算通过测量光散射波动获得的不同种类的扩散系数,其取决于蛋白分子大小和形状和样品的其他次要成分。
将蛋白样品在Dynapro板读数器(Wyatt technology)上分析,使用在25℃下15秒的五次获取。
a- 缓冲液:50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0。
实施例7:CDTb蛋白对HT29细胞的细胞毒性
糜蛋白酶活化的CDTb亚基(C37)单独似乎对HT29细胞是有细胞毒性的。这暗示孔形成可能负责细胞毒性。
已经产生第二代抗原设计以通过破坏单个蛋白的β折叠之间的疏水性相互作用来抑制孔形成步骤。
二元毒素的该二元毒素亚基B(结合细胞部分)单独或与二元毒素亚基A(酶部分)混合添加至人结肠上皮细胞(HT29细胞)以评估其残留的细胞毒性。
检测候选物C123、C126、C128、C164、C166、C116、C117、C149和C152对HT29细胞系的细胞毒性。
二元毒素细胞毒性测定
将人结肠上皮细胞(HT29细胞)在37℃与5%CO2下在DMEM + 10%胎牛血清 + 1%谷氨酰胺 + 1%抗生素(青霉素-链霉素-两性霉素)中培养,并以4 103细胞/孔(对于HT29)的密度接种在96孔黑色组织培养板(Greiner Bio-one, Ref:655090)中。
24小时后,从孔中去除50µl细胞培养基。
将待表征的二元毒素候选物稀释以达到2µg/ml的CDTa和6 µg/ml的CDTb。进一步的三倍稀释在微量板(NUNC, Ref:163320)中进行。将50 µl的二元毒素制备物的连续稀释物加入黑色板中,并将微量板在37℃和5% CO2下孵育6天。
6天后,将二元毒素和培养基的混合物从孔中去除,并将100µl在磷酸缓冲盐溶液(PBS)中1:500稀释的Hoescht 染色剂(BD Pharmingen, Ref. 561908)加入每孔中室温下于黑暗中2小时。
显色后,将Hoechst染色剂从孔中去除并使用Axiovision显微镜测量细胞荧光细胞。
将细胞毒性以每孔中被荧光染色覆盖的表面的百分比来表示。用单独细胞获得无细胞毒性(100%恢复(recovery))作用。并且用完全活化的二元毒素(CDTa C34+ CDTb C37)获得更高水平的细胞毒性。
结果显示于图1、图2和图8中。
实施例8:通过DLS分析CDTb蛋白
使用动态光散射(DLS)除了提供关于同质性的信息和检测蛋白样品内高分子量聚集体的存在外,还用来评估CDTb纯化蛋白C123、C126和C128的溶液中的流体力学半径。这基于计算通过测量光散射波动获得的不同种类的扩散系数,其取决于蛋白分子大小和形状和样品的其他次要成分。
将以下蛋白样品在Dynapro板读数器(Wyatt technology)上分析,使用在25℃下15秒的五次获取。
所有蛋白均在包含50mM N,N-二(羟乙基)甘氨酸 – 150mM NaCl- 1mMTCEP, -pH8.0的缓冲液中。对在4℃下保存的没有冷冻过的经纯化的大批量(bulk)进行测量。
如图3中所示,C126 KO孔形成构建体和C128 KO七聚化构建体两者均具有约3nm的主群体的流体力学半径,其可能与单体一致。发现C123 KO七聚化构建体为同质的高分子量寡聚物或聚集体,具有15.7nm的流体力学半径。
总样品的平均流体力学半径接近主群体的半径连同它们的低多分散性的事实表明C123、C126和C128his标签化的经纯化蛋白均具有均匀的大小分布。
实施例9:包含全长CDTa蛋白和CDTb蛋白的艰难梭菌CDTb融合蛋白的设计、克隆、
表达和纯化
CDTa和CDTb融合体有两大优点:第一个优点是仅一个处理来获得两种蛋白。第二个优点:CDTa比CDTb更易产生 -> 将CDTa作为融合体的第一配偶体能够潜在地对融合体的整体加工性具有积极作用。在C139中,将成熟CDTa(不具有其信号肽)和CDTb(不具有其信号肽且不具有其前域)蛋白融合。
在C139中,将CDTa配偶体在位置428处突变(将谷氨酸突变为谷氨酰胺)以突变CDTa的细胞毒性活性,并且将该融合体的CDTa配偶体在位置45处突变(将Cys突变为Tyr残基)以避免CDTa观察到的二聚化。
在C145中,融合体的CDTa部分与C139的相同。去除CDTb配偶体的CDTa结合域以潜在地避免该结构域与CDTa配偶体之间的相互作用。在两个配偶体之间,加入接头/间隔区(6个Gly残基)以改进配偶体之间的结构柔性并允许两个蛋白的独立正确折叠。
CDTb的受体结合域具有非常好的表达产率,是同质的但比CDTb成熟的免疫原性更低。我们尝试通过将该结构域融合至成熟CDTa配偶体增加其免疫原性。对于该受体结合域设计了两种不同的限制,因此评估了2种融合体。在C155和C156中,CDTa配偶体与C139和C145的相同。在C156中,在融合体的两个配偶体之间,加入间隔区/接头(6个Gly残基)。在C155构建体中不需要该接头,因为C155中使用的CDTb的受体结合域开始于能用作接头/间隔区的长的无结构化的(un-structured)且柔性的肽。
设计以下融合蛋白:

* 考虑开始的Met密码子和His标签。
克隆和纯化
如同实施例5。
实施例10:CDTb和CDTa-CDTb融合构建体的分子量评价
可以使用分析超速离心,通过测定分子响应离心力而移动的速率来确定蛋白样品中不同种类在溶液中的同质性和大小分布。这基于通过沉降速度实验获得的不同种类的沉降系数的计算结果,其依赖于它们的分子形状和质量。
1. AN-60Ti转子已经被平衡至15℃后,将蛋白样品在Beckman-CoulterProteomeLab XL-1分析超速离心机中以8000RPM、25000RPM或42000RPM(取决于目标蛋白大小)离心。
2. 对于数据采集,在280nm处每5分钟记录扫描。
3. 使用程序SEDFIT进行数据分析来测定C(S)分布。用SEDNTERP软件从它们的氨基酸序列进行蛋白的微分比容的测定。Sednterp也可以用于测定缓冲液的粘度和密度。
4. 考虑到原始数据比C(M)分布(浓度相比于分子量)是表征混合物的大小分布的更好代表,所以可以从C(S)分布曲线(浓度相比于沉降系数)中测定不同种类的分子量。
实施例11:用AS01B制剂中的艰难梭菌CDTa和CDTb亚基蛋白免疫小鼠。
小鼠免疫
将25只雌性Balb/C小鼠的组用5 µg的完全CDTa和CDTb二元毒素纯化的亚基在第0、14和28天IM免疫。这些抗原在AS01B制剂中注射。
在第42天(III后14 (Post III 14))收集的个体血清中测定抗CDTa和抗CDTbELISA效价。结果显示于图4-5中。
还在合并的III后血清(第42天)上进行二元毒素细胞毒性抑制。结果显示于图6-7中。
抗CDTa和抗CDTb ELISA应答:方案
完整CDTa (C34)或完整CDTb (C37)亚基以1µg/ml (对于CDTa)或2µg/ml (对于CDTb)在磷酸缓冲盐溶液(PBS)中包被在高结合微量滴定板上(Nunc MAXISORPTM),在4℃过夜。将板用PBS-BSA 1%在RT下摇动封闭30分钟。小鼠抗血清1/500在PBS-BSA0.2%-TWEENTM0.05%中预稀释,随后,在微量滴定板中进行进一步的两倍稀释并在RT下孵育30分钟。洗涤后,将结合的小鼠抗体使用在PBS-BSA0.2%-tween 0.05%中1:5000稀释的JacksonImmunoLaboratories Inc.过氧化酶缀合的抗小鼠(ref: 115-035-003)检测。将检测抗体在室温(RT)下摇动孵育30分钟。在室温下黑暗中使用4 mg O-苯二胺 (OPD) + 5 µl H2O2/10 ml pH4.5 0.1M柠檬酸盐缓冲液显出颜色15分钟。用50 µl HCl终止反应,并在490 nm处读取相对于620 nm的光密度(OD)。
抗CDTa或抗CDTb抗体的水平表示为中点效价。在每一处理组中计算25个样品的GMT。
二元毒素细胞毒性抑制测定
将人结肠上皮细胞(HT29或HCT-116细胞)在37℃与5%CO2下在DMEM +10%胎牛血清+ 1% 谷氨酰胺 +1% 抗生素(青霉素-链霉素-两性霉素)中培养,并以4.104细胞/孔(对于HT29)和1.104细胞/孔(对于HCT116)的密度接种在96孔黑色组织培养板(Greiner Bio-one, Ref : 655090)中。
24小时后,从孔中去除细胞培养基。
将小鼠抗血清在细胞培养基中1:50预稀释,并随后在微量板(NUNC, Ref :163320)中进行进一步的三倍稀释。将50µl系列稀释的小鼠合并的抗血清加入到黑色板中。随后将50µl的CDTa (25ng/ml)和糜蛋白酶活化的CDTb (75 ng/ml)的混合物加入并将黑色板在37℃与5% CO2下孵育6天。
6天后,将抗血清和毒素的混合物从孔中去除,并将100µl在磷酸缓冲盐溶液(PBS)中1:500稀释的Hoescht 染色剂(BD Pharmingen, Ref : 561908)加入每孔中室温下于黑暗中2小时。
显色后,将Hoescht染色剂从孔中去除并使用Axiovision显微镜测量细胞荧光细胞。
在每孔中测定由荧光染色覆盖的表面,并将细胞毒性抑制效价定义为诱导荧光信号的50%抑制的稀释度倒数(reciprocal dilution)。
实施例12:CDTb蛋白对HCT116细胞的细胞毒性
糜蛋白酶活化的CDTb亚基(C37)单独似乎对HCT116细胞是有细胞毒性的。这暗示孔形成可能负责细胞毒性。
已经产生第二代抗原设计以通过破坏单个蛋白的β折叠之间的疏水性相互作用来抑制孔形成步骤。
二元毒素的该二元毒素亚基B(结合细胞部分)单独或与二元毒素亚基A(酶部分)混合添加至人结肠上皮细胞(HCT116)以评估其残留的细胞毒性。
检测候选物C123、C126、C128、C164、C166、C116、C117、C149和C152对HCT116细胞系的细胞毒性。
二元毒素细胞毒性测定
将人结肠上皮细胞(HCT116细胞)在37℃与5%CO2下在DMEM + 10%胎牛血清 + 1%谷氨酰胺 + 1%抗生素(青霉素-链霉素-两性霉素)中培养,并以103细胞/孔(对于HCT116)的密度接种在96孔黑色组织培养板(Greiner Bio-one, Ref:655090)中。
24小时后,从孔中去除50µl细胞培养基。
将待表征的二元毒素候选物稀释以达到2µg/ml的CDTa和6 µg/ml的CDTb。进一步的三倍稀释在微量板(NUNC, Ref:163320)中进行。将50 µl的二元毒素制备物的连续稀释物加入黑色板中,并将微量板在37℃和5% CO2下孵育6天。
6天后,将二元毒素和培养基的混合物从孔中去除,并将100µl在磷酸缓冲盐溶液(PBS)中1:500稀释的Hoescht 染色剂(BD Pharmingen, Ref. 561908)加入每孔中室温下于黑暗中2小时。
显色后,将Hoechst染色剂从孔中去除并使用Axiovision显微镜测量细胞荧光细胞。
将细胞毒性以每孔中被荧光染色覆盖的表面的百分比来表示。用单独细胞获得无细胞毒性(100%恢复)作用。并且用完全活化的二元毒素(CDTa C34+ CDTb C37)获得更高水平的细胞毒性。
结果显示于图9中。
实施例13:CDTa-CDTb融合蛋白对HT29细胞的细胞毒性
测试融合体C139、C145、C155和C156对HT29细胞系的细胞毒性。通过掺有(spikingwith)完整CdtA亚基来评估与CdtB亚基相关的可能残留细胞毒性。通过掺有完整CdtB亚基来评估与CdtA亚基相关的可能残留细胞毒性。使用全长CDTa和全长CDTb作为对照。
二元毒素细胞毒性测定
将人结肠上皮细胞(HT29细胞)在37℃与5%CO2下在DMEM + 10%胎牛血清 + 1%谷氨酰胺 + 1%抗生素(青霉素-链霉素-两性霉素)中培养,并以4 103细胞/孔(对于HT29)的密度接种在96孔黑色组织培养板(Greiner Bio-one, Ref:655090)中。
24小时后,从孔中去除50µl细胞培养基。
将待表征的二元毒素候选物稀释以达到2µg/ml的CDTa和6 µg/ml的CDTb。进一步的三倍稀释在微量板(NUNC, Ref:163320)中进行。将50 µl的二元毒素制备物的连续稀释物加入黑色板中,并将微量板在37℃和5% CO2下孵育6天。
6天后,将二元毒素和培养基的混合物从孔中去除,并将100µl在磷酸缓冲盐溶液(PBS)中1:500稀释的Hoescht 染色剂(BD Pharmingen, Ref. 561908)加入每孔中室温下于黑暗中2小时。
显色后,将Hoechst染色剂从孔中去除并使用Axiovision显微镜测量细胞荧光细胞。
将细胞毒性以每孔中被荧光染色覆盖的表面的百分比来表示。用单独细胞获得无细胞毒性(100%恢复)作用。并且用完全活化的二元毒素(CDTa C34+ CDTb C37)获得更高水平的细胞毒性。
融合体均没有细胞毒性且没有观察到与融合体的CDTb亚基相关的残留细胞毒性。在完整CdtA -完整CdtB 融合体 (C139)中没有观察到与CDTa亚基相关的残留细胞毒性。在不包括全长CdtB的3个融合体(C145、C155、C156)中观察到与CDTa亚基相关的非常低的残留细胞毒性。
结果显示于图10和11中。
实施例14:用AS01B制剂中的艰难梭菌CDTb蛋白或CDTa-CDTb融合体免疫小鼠。
小鼠免疫
将12只雌性Balb/C小鼠的组用1 µg的CDTa和CDTb二元毒素纯化的亚基和用2 µg的CDTa-CDTb融合体在第0、14和28天IM免疫。这些抗原在AS01B制剂中注射。
在第42天(III后14)收集的个体血清中测定抗CDTa和抗CDTb ELISA效价。结果显示于图12-13中。
还对合并的III后血清(第42天)对HT29和HCT116细胞系进行二元毒素细胞毒性抑制测定。结果显示于图14中。
抗CDTa和抗CDTb ELISA应答:方案
E-428突变的CDTa (C44)或未活化的CDTb (C46)亚基以1µg/ml在磷酸缓冲盐溶液(PBS)中包被在高结合微量滴定板上(Nunc MAXISORPTM),在4℃过夜。将板用PBS-BSA 1%在RT下摇动封闭30分钟。小鼠抗血清1/500在PBS-BSA0.2%-TWEENTM 0.05%中预稀释,随后,在微量滴定板中进行进一步的两倍稀释并在RT下孵育30分钟。洗涤后,将结合的小鼠抗体使用在PBS-BSA0.2%-tween 0.05%中1:5000稀释的Jackson ImmunoLaboratories Inc.过氧化酶缀合的抗小鼠(ref: 115-035-003)检测。将检测抗体在室温(RT)下摇动孵育30分钟。在室温下黑暗中使用4 mg O-苯二胺 (OPD) + 5 µl H2O2/10 ml pH4.5 0.1M柠檬酸盐缓冲液显出颜色15分钟。用50 µl HCl终止反应,并在490 nm处读取相对于620 nm的光密度(OD)。
抗CDTa或CDTb抗体的水平表示为中点效价。在每一处理组中计算12个样品的GMT。
获得的抗CdtA抗体效价显示在图12中。
获得的抗CdtB抗体效价显示在图13中。
实施例15:CDTb和CDTa-CDTb融合体细胞毒性抑制测定
二元毒素细胞毒性抑制测定
将人结肠上皮细胞(HT29或HCT-116细胞)在37℃与5%CO2下在DMEM +10%胎牛血清+ 1% 谷氨酰胺 +1% 抗生素(青霉素-链霉素-两性霉素)中培养,并以4.103细胞/孔(对于HT29)和1.103细胞/孔(对于HCT116)的密度接种在96孔黑色组织培养板(Greiner Bio-one, Ref : 655090)中。
24小时后,从孔中去除细胞培养基。
将小鼠抗血清在细胞培养基中1:50预稀释,并随后在微量板(NUNC, Ref :163320)中进行进一步的三倍稀释。将50µl系列稀释的小鼠合并的抗血清加入到黑色板中。随后将50µl的CDTa (25ng/ml)和糜蛋白酶活化的CDTb (75 ng/ml)的混合物加入并将黑色板在37℃与5% CO2下孵育6天。
6天后,将抗血清和毒素的混合物从孔中去除,并将100µl在磷酸缓冲盐溶液(PBS)中1:500稀释的Hoescht 染色剂(BD Pharmingen, Ref : 561908)加入每孔中室温下于黑暗中2小时。
显色后,将Hoescht染色剂从孔中去除并使用Axiovision显微镜测量细胞荧光细胞。
在每孔中测定由荧光染色覆盖的表面,并将细胞毒性抑制效价定义为诱导荧光信号的50%抑制的稀释度倒数(reciprocal dilution)。
结果显示于图14中。
序列概述(表 A)
| 描述 | 构建体参考 | 氨基酸序列 | 多核苷酸序列 |
| CDTa全长(菌株R20291) | N/A | SEQ.I.D.NO:1 | SEQ.I.D.NO:2 |
| CDTb全长(菌株R20291) | N/A | SEQ.I.D.NO:3 | SEQ.I.D.NO:4 |
| 连接至谷胱甘肽-S-转移酶蛋白的CDTb'(减去信号肽(minus signal peptide))(GST下划线)。 | C37 | SEQ.I.D.NO:5 | SEQ.I.D.NO:6 |
| 去除前域的CDTb (CDTb", aa212-876) | C55 | SEQ ID NO:7 | |
| 去除前域和受体结合域的CDTb(对应于SEQ ID NO: 3的aa 212-616),包括his标签 | C116 | SEQ ID NO:8 | |
| 去除前域和CDTa结合域的CDTb(对应于SEQ ID NO: 3的aa296-876),包括his标签 | C117 | SEQ ID NO:9 | |
| CDTb (对应于SEQ ID NO: 3) mut -F455R, His标签 | C123 | SEQ ID NO:10 | |
| CDTb序列(对应于SEQ ID NO: 3),其中残基423(谷氨酸)和453(天冬氨酸)均突变为丙氨酸。 | C126 | SEQ ID NO:11 | |
| CDTb(对应于SEQ ID NO: 3的aa 43-876),其中缺失aa 532至aa 542并被3个Gly残基取代 | C127 | SEQ ID NO:12 | |
| CDTb (对应于SEQ ID NO: 3的aa43-876) mut -D537G-E539G-D540G-K541G, His标签 | C128 | SEQ ID NO:13 | |
| 融合体CdtA-E428Q-Cdtb成熟, his标签 (CDTa: SEQ ID NO: 1的aa44-463;CDTb:SEQ ID NO: 3的aa212-876) | C139 | SEQ ID NO:14 | |
| 去除CdtA bdg结构域的融合体CdtA-E428Q-Cdtb, his标签 (CDTa: SEQ ID NO:1的aa44-463;CDTb: SEQ ID NO: 3的aa296-876) | C145 | SEQ ID NO:15 | |
| 融合体CdtA-E428Q-Cdtb RBD长 (CDTa: SEQ ID NO: 1的aa44-463;CDTb: SEQID NO: 3的aa620-876) | C155 | SEQ ID NO:16 | |
| 融合体CdtA-E428Q-Cdtb RBD短 (CDTa: SEQ ID NO: 1的aa44-463;CDTb: SEQID NO: 3的aa636-876) | C156 | SEQ ID NO:17 | |
| CDTa接头(aa44-268 SEQ ID NO: 1) | C49 | SEQ ID NO:18 | |
| CDTa无接头(aa44-260 SEQ ID NO: 1) | C50 | SEQ ID NO:19 | |
| CDTa N末端结构域(残基44至残基240) | Gulke 等 2001 | SEQ ID NO:20 | |
| CDTa (aa44-463 SEQ ID NO:1) mut E428Q-E430Q | C67 | SEQ ID NO:21 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F-E428Q-E430Q | C69 | SEQ ID NO:22 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F | C107 | SEQ ID NO:23 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F-E430Q | C108 | SEQ ID NO:24 | |
| 具有前域的CDTb, mut F455R | C149 | SEQ ID NO:25 | |
| 具有前域的CDTb, mutE426A-D453A | C152 | SEQ ID NO:26 | |
| 在序列的N末端具有接头的CDTb受体结合域,从aa 620-876 SEQ ID NO: 3 | C52 | SEQ ID NO:27 | |
| 在序列的N末端不具有接头的CDTb受体结合域,从aa 636-876SEQ ID NO: 3 | C53 | SEQ ID NO:28 | |
| 毒素A | SEQ ID NO:29 | ||
| 毒素B | SEQ ID NO:30 | ||
| 融合体1 | F1 | SEQ ID NO:31 | |
| 融合体2 | F2 | SEQ ID NO:32 | |
| 融合体3 | F3 | SEQ ID NO:33 | |
| 融合体4 | F4 | SEQ ID NO:34 | |
| 融合体5 | F5 | SEQ ID NO:35 | |
| CDTa (SEQ ID NO: 1的aa44-463) | C34 | SEQ ID NO:36 | |
| 去除信号肽、前域、受体结合域和CDTa结合域的截短的CDTb蛋白,对应于SEQ ID NO:3的aa296至aa 616 | C118 | SEQ ID NO:37 | |
| CDTb’ (减去信号肽) | C46 | SEQ ID NO:38 | |
| CDTa (aa44-463 SEQ ID NO:1) mut E428Q | C44 | SEQ ID NO:39 | |
| CDTa (aa44-463 SEQ ID NO:1) mut E430Q | C54 | SEQ ID NO:40 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-E428Q-E430Q | C68 | SEQ ID NO:41 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F-E428Q | C110 | SEQ ID NO:42 | |
| 不具有前域的CDTb, mut F455R | C164 | SEQ ID NO:43 | SEQ ID NO:45 |
| 不具有前域的CDTb, mutE426A-D453A | C166 | SEQ ID NO:44 | SEQ ID NO:46 |
| 连接至谷胱甘肽-S-转移酶蛋白的CDTb'(减去信号肽)(GST下划线)(无his标签) | 不具有his标签的C37 | SEQ ID NO:47 | |
| 去除前域的CDTb (CDTb", aa212-876)(无his标签) | 不具有his标签的C55 | SEQ ID NO:48 | |
| 去除前域和受体结合域的CDTb(对应于SEQ ID NO: 3的aa 212-616),不具有his标签 | 不具有his标签的C116 | SEQ ID NO:49 | |
| 去除前域和CDTa结合域的CDTb(对应于SEQ ID NO: 3的aa296-876),不具有his标签 | 不具有his标签的C117 | SEQ ID NO:50 | |
| CDTb (对应于SEQ ID NO: 3) mut -F455R, 不具有His标签 | 不具有his标签的C123 | SEQ ID NO:51 | |
| CDTb序列(对应于SEQ ID NO: 3),其中残基423(谷氨酸)和453(天冬氨酸)均突变为丙氨酸。不具有his标签 | 不具有his标签的C126 | SEQ ID NO:52 | |
| CDTb(对应于SEQ ID NO: 3的aa 43-876),其中缺失aa 532至aa 542并被3个Gly残基取代,不具有his标签 | 不具有his标签的C127 | SEQ ID NO:53 | |
| CDTb (对应于aa43-876 SEQ ID NO: 3) mut -D537G-E539G-D540G-K541G, 不具有his标签 | 不具有his标签的C128 | SEQ ID NO:54 | |
| 融合体CdtA-E428Q-Cdtb成熟, 不具有his标签 (CDTa: SEQ ID NO: 1的aa44-463;CDTb: SEQ ID NO: 3的aa212-876) | 不具有his标签的C139 | SEQ ID NO:55 | |
| 去除CdtA bdg结构域的融合体CdtA-E428Q-Cdtb, 不具有his标签 (CDTa: SEQID NO: 1的aa44-463;CDTb: SEQ ID NO: 3的aa296-876) | 不具有his标签的C145 | SEQ ID NO:56 | |
| 融合体CdtA-E428Q-Cdtb RBD长 (CDTa: SEQ ID NO: 1的aa44-463;CDTb: SEQID NO: 3的aa620-876),不具有his标签 | 不具有his标签的C155 | SEQ ID NO:57 | |
| 融合体CdtA-E428Q-Cdtb RBD短 (CDTa: SEQ ID NO: 1的aa44-463;CDTb: SEQID NO: 3的aa636-876),不具有his标签 | 不具有his标签的C156 | SEQ ID NO:58 | |
| CDTa接头 (aa44-268 SEQ ID NO: 1) 不具有his标签 | 不具有his标签的C49 | SEQ ID NO:59 | |
| 不具有接头的CDTa (aa44-260 SEQ ID NO: 1) 不具有his标签 | 不具有his标签的C50 | SEQ ID NO:60 | |
| CDTa N末端结构域(残基44至残基240),不具有his标签 | Gulke 等 2001,不具有his标签 | SEQ ID NO:61 | |
| CDTa (aa44-463 SEQ ID NO:1) mut E428Q-E430Q 不具有his标签 | 不具有his标签的C67 | SEQ ID NO:62 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F-E428Q-E430Q 不具有his标签 | 不具有his标签的C69 | SEQ ID NO:63 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F 不具有his标签 | 不具有his标签的C107 | SEQ ID NO:64 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F-E430Q不具有his标签 | 不具有his标签的C108 | SEQ ID NO:65 | |
| 具有前域的CDTb, mut F455R 不具有his标签 | 不具有his标签的C149 | SEQ ID NO:66 | |
| 具有前域的CDTb, mutE426A-D453A 不具有his标签 | 不具有his标签的C152 | SEQ ID NO:67 | |
| 在序列的N末端具有接头的CDTb受体结合域,从aa 620-876 SEQ ID NO: 3,不具有his标签 | 不具有his标签的C52 | SEQ ID NO:68 | |
| 在序列的N末端不具有接头的CDTb受体结合域,从aa 636-876SEQ ID NO: 3,不具有his标签 | 不具有his标签的C53 | SEQ ID NO:69 | |
| CDTa (SEQ ID NO: 1的aa44-463) 不具有his标签 | 不具有his标签的C34 | SEQ ID NO:70 | |
| 去除信号肽、前域、受体结合域和CDTa结合域的截短的CDTb蛋白,对应于SEQ ID NO:3的aa296至aa 616,不具有his标签 | 不具有his标签的C118 | SEQ ID NO:71 | |
| CDTb’(减去信号肽),不具有his标签 | 不具有his标签的C46 | SEQ ID NO:72 | |
| CDTa (aa44-463 SEQ ID NO:1) mut E428Q, 不具有his标签 | 不具有his标签的C44 | SEQ ID NO:73 | |
| CDTa (aa44-463 SEQ ID NO:1) mut E430Q, 不具有his标签 | 不具有his标签的C54 | SEQ ID NO:74 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-E428Q-E430Q,不具有his标签 | 不具有his标签的C68 | SEQ ID NO:75 | |
| CDTa (aa44-463 SEQ ID NO:1) mut R345A-Q350A-N385A-R402A-S388F-E428Q,不具有his标签 | 不具有his标签的C110 | SEQ ID NO:76 |
序列表
SEQ ID 1 – CDTa全长多肽序列

SEQ ID 2 – CDTa全长多核苷酸序列


SEQ ID 3 – CDTb全长多肽序列

SEQ ID 4 – CDTb全长多核苷酸序列


SEQ ID 5 – CDTb C37构建体。连接至谷胱甘肽-S-转移酶蛋白的CDTb'(减去信号肽(minus signal peptide))(GST下划线)多肽序列。


SEQ ID 6 – CDTb C37构建体。连接至谷胱甘肽-S-转移酶蛋白的CDTb'(减去前域)(GST下划线)多核苷酸序列。


SEQ ID NO:7 – 去除前域的CDTb的氨基酸序列 (CDTb", aa212-876) (C55)

SEQ ID NO:8 C116


SEQ ID NO:9 C117

SEQ ID NO:10 C123 具有F455R的CDTb序列。

SEQ ID NO:11 C126 CDTb序列,其中残基426(谷氨酸)和453(天冬氨酸)均突变为丙氨酸。

SEQ ID NO:12 C127

SEQ ID NO:13 C128

SEQ ID NO:14 C139







SEQ ID NO:20:CDTa N末端结构域(残基44至残基240)多肽序列。










SEQ ID NO:29 毒素A的氨基酸序列


SEQ ID NO:30 – 毒素B的氨基酸序列









SEQ ID NO:36:CDTa C34构建体多肽序列


SEQ ID NO:37:CDTb C118 构建体。不具有信号肽、不具有前域、不具有CDTa结合域且不具有受体结合域的CDTb

SEQ ID NO:38:CDTb C46 构建体。CDTb’(减去信号肽)多肽序列

SEQ ID NO:39:C44构建体。CDTa突变E428Q多肽序列。


SEQ ID NO:40:C54构建体。CDTa突变E430Q多肽序列。


SEQ ID NO:42:不具有信号肽具有六个突变(R345A、Q350A、N385A、R402A、S388F、E430Q, aa 44-463) 的CDTa的氨基酸序列 (C110

SEQ ID NO:43:C164的氨基酸序列(在不具有前域的CdtB上KO孔形成突变F455R)


SEQ ID NO:44:C166的氨基酸序列(在不具有前域的CdtB上KO孔形成突变E426A-D453A)

SEQ ID NO:45:C164的核酸序列(在不具有前域的CdtB上KO孔形成突变F455R)


SEQ ID NO:46:C166的核酸序列(在不具有前域的CdtB上KO孔形成突变E426A-D453A)


SEQ ID 47 – CDTb C37构建体。连接至谷胱甘肽-S-转移酶蛋白的CDTb'(减去信号肽)(GST下划线)多肽序列,不具有his标签。


SEQ ID NO:48 – 去除前域的CDTb的氨基酸序列 (CDTb", aa212-876) (C55),不具有his标签

SEQ ID NO:49 不具有his标签的C116

SEQ ID NO:50 不具有his标签的C117


SEQ ID NO:51 C123 具有F455R的CDTb序列,不具有his标签。

SEQ ID NO:52 C126 CDTb序列,其中残基426(谷氨酸)和453(天冬氨酸)均突变为丙氨酸,不具有his标签。


SEQ ID NO:53 不具有his标签的C127

SEQ ID NO:54 不具有his标签的C128


SEQ ID NO:55 不具有his标签的C139

SEQ ID NO:56 不具有his标签的C145


SEQ ID NO:57 不具有his标签的C155

SEQ ID NO:58 不具有his标签的C156

SEQ ID NO:59:不具有his标签的C49

SEQ ID NO:60:不具有his标签的C50

SEQ ID NO:61:CDTa N末端结构域(残基44至残基240)多肽序列,不具有his标签。

SEQ ID NO:62:不具有his标签的C67

SEQ ID NO:63:不具有his标签的C69

SEQ ID NO:64:不具有his标签的C107

SEQ ID NO:65:不具有his标签的C108

SEQ ID NO:66:不具有his标签的C149

SEQ ID NO:67:不具有his标签的C152


SEQ ID NO:68:不具有his标签的C52

SEQ ID NO:69:不具有his标签的C53

SEQ ID NO:70:CDTa C34构建体多肽序列,不具有his标签。

SEQ ID NO:71:CDTb C118 构建体。不具有信号肽、不具有前域、不具有CDTa结合域且不具有受体结合域的CDTb,不具有his标签。

SEQ ID NO:72:CDTb C46 构建体。CDTb’(减去信号肽)多肽序列,不具有his标签

SEQ ID NO:73:C44构建体。CDTa突变E428Q多肽序列,不具有his标签。

SEQ ID NO:74:C54构建体。CDTa突变E430Q多肽序列,不具有his标签。

SEQ ID NO:75:不具有his标签的C68

SEQ ID NO:76:不具有信号肽具有六个突变(R345A、Q350A、N385A、R402A、S388F、E430Q, aa 44-463) 的CDTa的氨基酸序列 (C110,不具有his标签)

Claims (9)
1.免疫原性组合物,其包含含有(i)全长CDTa蛋白和(ii)CDTb蛋白的融合蛋白,其中含有全长CDTa蛋白和CDTb蛋白的所述融合蛋白合适地是
(i) SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16或SEQ ID NO:17;或
(ii) SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16或SEQ ID NO:17的变体融合蛋白,其中所述CDTb蛋白是SEQ ID NO:25、SEQ ID NO:26、SEQ ID NO:43或SEQ ID NO:44;或
(iii) 缺少His标签的SEQ ID NO:14、SEQ ID NO:15、SEQ ID NO:16或SEQ ID NO:17的片段,其中所述片段如SEQ ID NO:55、SEQ ID NO:56、SEQ ID NO:57或SEQ ID NO:58所示。
2.权利要求1的免疫原性组合物,其中所述组合物引发中和CDTa或CDTb或两者的抗体。
3.权利要求1的免疫原性组合物,其中所述组合物引发中和二元毒素的抗体。
4.权利要求1的免疫原性组合物,其中所述免疫原性组合物进一步包含分离的艰难梭菌毒素A蛋白和/或分离的艰难梭菌毒素B蛋白。
5.权利要求1的免疫原性组合物,其中所述免疫原性组合物包含分离的艰难梭菌毒素A蛋白和分离的艰难梭菌毒素B蛋白,其中所述分离的艰难梭菌毒素A蛋白和分离的艰难梭菌毒素B蛋白形成融合蛋白。
6.权利要求1的免疫原性组合物,其中所述免疫原性组合物进一步包含佐剂。
7.疫苗,其包含前述权利要求中任一项的免疫原性组合物和药学上可接受的赋形剂。
8.权利要求1-6中任一项的免疫原性组合物或权利要求7的疫苗,其用于治疗或预防艰难梭菌疾病。
9.权利要求1-6中任一项的免疫原性组合物或权利要求7的疫苗在制备用于预防或治疗艰难梭菌疾病的药物中的用途。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB1411306.2 | 2014-06-25 | ||
| GBGB1411306.2A GB201411306D0 (en) | 2014-06-25 | 2014-06-25 | Immunogenic composition |
| GB1411371.6 | 2014-06-26 | ||
| GB201411371A GB201411371D0 (en) | 2014-06-26 | 2014-06-26 | Immunogenic composition |
| PCT/EP2015/064324 WO2015197737A1 (en) | 2014-06-25 | 2015-06-25 | Clostridium difficile immunogenic composition |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN106536544A CN106536544A (zh) | 2017-03-22 |
| CN106536544B true CN106536544B (zh) | 2020-04-07 |
Family
ID=53498986
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201580039744.7A Active CN106536544B (zh) | 2014-06-25 | 2015-06-25 | 艰难梭菌免疫原性组合物 |
Country Status (18)
| Country | Link |
|---|---|
| US (1) | US20170218031A1 (zh) |
| EP (2) | EP3160500B1 (zh) |
| JP (2) | JP6688233B2 (zh) |
| CN (1) | CN106536544B (zh) |
| BE (1) | BE1022949B1 (zh) |
| BR (1) | BR112016030096B1 (zh) |
| CA (1) | CA2952118A1 (zh) |
| CY (1) | CY1122145T1 (zh) |
| DK (1) | DK3160500T3 (zh) |
| ES (1) | ES2749701T3 (zh) |
| HR (1) | HRP20191864T1 (zh) |
| HU (1) | HUE045936T2 (zh) |
| LT (1) | LT3160500T (zh) |
| MX (1) | MX2016017094A (zh) |
| PL (1) | PL3160500T3 (zh) |
| PT (1) | PT3160500T (zh) |
| SI (1) | SI3160500T1 (zh) |
| WO (1) | WO2015197737A1 (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| MX2019010948A (es) * | 2017-03-15 | 2020-01-09 | Novavax Inc | Métodos y composiciones para inducir respuestas inmunitarias contra clostridium difficile. |
| CA3102353A1 (en) | 2018-06-19 | 2019-12-26 | Glaxosmithkline Biologicals Sa | Immunogenic composition |
| GB202205833D0 (en) | 2022-04-21 | 2022-06-08 | Glaxosmithkline Biologicals Sa | Bacteriophage |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005004791A2 (en) * | 2002-11-08 | 2005-01-20 | President And Fellows Of Harvard College | Compounds and methods for the treatment and prevention of bacterial infection |
| WO2013112867A1 (en) * | 2012-01-27 | 2013-08-01 | Merck Sharp & Dohme Corp. | Vaccines against clostridium difficile comprising recombinant toxins |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4235877A (en) | 1979-06-27 | 1980-11-25 | Merck & Co., Inc. | Liposome particle containing viral or bacterial antigenic subunit |
| US4866034A (en) | 1982-05-26 | 1989-09-12 | Ribi Immunochem Research Inc. | Refined detoxified endotoxin |
| US4436727A (en) | 1982-05-26 | 1984-03-13 | Ribi Immunochem Research, Inc. | Refined detoxified endotoxin product |
| US4751180A (en) | 1985-03-28 | 1988-06-14 | Chiron Corporation | Expression using fused genes providing for protein product |
| US4935233A (en) | 1985-12-02 | 1990-06-19 | G. D. Searle And Company | Covalently linked polypeptide cell modulators |
| US4877611A (en) | 1986-04-15 | 1989-10-31 | Ribi Immunochem Research Inc. | Vaccine containing tumor antigens and adjuvants |
| JP2851288B2 (ja) | 1987-06-05 | 1999-01-27 | アメリカ合衆国 | 癌診断および管理における自己分泌運動性因子 |
| US4912094B1 (en) | 1988-06-29 | 1994-02-15 | Ribi Immunochem Research Inc. | Modified lipopolysaccharides and process of preparation |
| ATE115862T1 (de) | 1989-02-04 | 1995-01-15 | Akzo Nobel Nv | Tocole als impfstoffadjuvans. |
| EP0671948B1 (en) | 1992-06-25 | 1997-08-13 | SMITHKLINE BEECHAM BIOLOGICALS s.a. | Vaccine composition containing adjuvants |
| ES2109685T5 (es) | 1993-03-23 | 2005-09-01 | Smithkline Beecham Biologicals S.A. | Composiciones para vacunas que contienen monofosforil-lipido a 3-o-desacilado. |
| HUT78048A (hu) | 1994-10-24 | 1999-07-28 | Ophidian Pharmaceuticals, Inc. | A C. difficile által okozott betegség kezelésére és megelőzésére szolgáló vakcina és antitoxin |
| UA56132C2 (uk) | 1995-04-25 | 2003-05-15 | Смітклайн Бічем Байолоджікалс С.А. | Композиція вакцини (варіанти), спосіб стабілізації qs21 відносно гідролізу (варіанти), спосіб приготування композиції вакцини |
| CA2220530A1 (en) | 1995-06-02 | 1996-12-05 | Incyte Pharmaceuticals, Inc. | Improved method for obtaining full-length cdna sequences |
| AU781175B2 (en) | 1999-04-09 | 2005-05-12 | Intercell Usa, Inc. | Recombinant toxin A/toxin B vaccine against Clostridium Difficile |
| US20020065396A1 (en) | 2000-03-28 | 2002-05-30 | Fei Yang | Compositions and methods of diagnosing, monitoring, staging, imaging and treating colon cancer |
| JP6084631B2 (ja) * | 2011-12-08 | 2017-02-22 | ノバルティス アーゲー | Clostridiumdifficile毒素ベースのワクチン |
| LT3513806T (lt) * | 2012-12-05 | 2023-04-11 | Glaxosmithkline Biologicals Sa | Imunogeninė kompozicija |
| GB201223342D0 (en) * | 2012-12-23 | 2013-02-06 | Glaxosmithkline Biolog Sa | Immunogenic composition |
-
2015
- 2015-06-25 MX MX2016017094A patent/MX2016017094A/es active IP Right Grant
- 2015-06-25 PT PT157334046T patent/PT3160500T/pt unknown
- 2015-06-25 CA CA2952118A patent/CA2952118A1/en active Pending
- 2015-06-25 BE BE2015/5390A patent/BE1022949B1/fr active
- 2015-06-25 EP EP15733404.6A patent/EP3160500B1/en active Active
- 2015-06-25 US US15/320,190 patent/US20170218031A1/en not_active Abandoned
- 2015-06-25 EP EP19192151.9A patent/EP3636278A3/en not_active Withdrawn
- 2015-06-25 LT LT15733404T patent/LT3160500T/lt unknown
- 2015-06-25 ES ES15733404T patent/ES2749701T3/es active Active
- 2015-06-25 CN CN201580039744.7A patent/CN106536544B/zh active Active
- 2015-06-25 DK DK15733404T patent/DK3160500T3/da active
- 2015-06-25 PL PL15733404T patent/PL3160500T3/pl unknown
- 2015-06-25 WO PCT/EP2015/064324 patent/WO2015197737A1/en active Application Filing
- 2015-06-25 HU HUE15733404A patent/HUE045936T2/hu unknown
- 2015-06-25 BR BR112016030096-3A patent/BR112016030096B1/pt active IP Right Grant
- 2015-06-25 SI SI201530954T patent/SI3160500T1/sl unknown
- 2015-06-25 JP JP2016575190A patent/JP6688233B2/ja active Active
-
2019
- 2019-10-09 CY CY20191101061T patent/CY1122145T1/el unknown
- 2019-10-15 HR HRP20191864TT patent/HRP20191864T1/hr unknown
-
2020
- 2020-01-17 JP JP2020005532A patent/JP2020100625A/ja active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005004791A2 (en) * | 2002-11-08 | 2005-01-20 | President And Fellows Of Harvard College | Compounds and methods for the treatment and prevention of bacterial infection |
| WO2013112867A1 (en) * | 2012-01-27 | 2013-08-01 | Merck Sharp & Dohme Corp. | Vaccines against clostridium difficile comprising recombinant toxins |
Non-Patent Citations (2)
| Title |
|---|
| Clostridium botulinum C2 toxin: Identification of the binding site for chloroquine and related compounds and influence of the binding site on properties of the C2II channel;T.neumeyer等;《Journal of biological chemistry》;20071211;第283卷(第7期);全文 * |
| Expression,purification and cell cytotoxicity of actin-modifying binary toxin from clostridium difficile;Sunriyal A等;《Protein expression and purification》;20101101;第74卷(第1期);全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3636278A2 (en) | 2020-04-15 |
| WO2015197737A1 (en) | 2015-12-30 |
| BE1022949B1 (fr) | 2016-10-21 |
| BR112016030096A8 (pt) | 2021-07-06 |
| SI3160500T1 (sl) | 2019-11-29 |
| DK3160500T3 (da) | 2019-11-11 |
| BR112016030096A2 (pt) | 2017-08-22 |
| JP6688233B2 (ja) | 2020-04-28 |
| EP3636278A3 (en) | 2020-07-15 |
| HRP20191864T1 (hr) | 2020-01-10 |
| CY1122145T1 (el) | 2020-11-25 |
| MX2016017094A (es) | 2017-05-03 |
| PT3160500T (pt) | 2019-11-11 |
| EP3160500A1 (en) | 2017-05-03 |
| BR112016030096B1 (pt) | 2023-10-03 |
| CA2952118A1 (en) | 2015-12-30 |
| HUE045936T2 (hu) | 2020-01-28 |
| JP2020100625A (ja) | 2020-07-02 |
| US20170218031A1 (en) | 2017-08-03 |
| LT3160500T (lt) | 2019-10-25 |
| PL3160500T3 (pl) | 2020-02-28 |
| CN106536544A (zh) | 2017-03-22 |
| EP3160500B1 (en) | 2019-08-21 |
| BE1022949A1 (fr) | 2016-10-21 |
| JP2017520573A (ja) | 2017-07-27 |
| ES2749701T3 (es) | 2020-03-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6515036B2 (ja) | C.ディフィシルCDTb及び/又はCDTaタンパク質のエレメントを含む免疫原性組成物 | |
| DK2248822T3 (en) | MENINGOCOKKER ADHESIONS | |
| JP5139618B2 (ja) | Mycobacteriumtuberculosisの融合タンパク質 | |
| JP2009515831A (ja) | ペスト菌(Yersiniapestis)抗原を含む組成物 | |
| JP2020100625A (ja) | クロストリジウム・ディフィシル免疫原性組成物 | |
| JP2015529677A (ja) | ワクチンとしてのClostridiumdifficileポリペプチド | |
| JP2012532626A (ja) | 無毒化されたEscherichiacoli免疫原 | |
| JP2015528457A (ja) | Staphylococcusaureusに対する免疫化のための安定化されたタンパク質 | |
| US9926346B2 (en) | Recombinant mycobacterium encoding a heparin-binding hemagglutinin (HBHA) fusion protein and uses thereof | |
| BE1022553A1 (fr) | Mutants de spy0269 | |
| JP2015532594A (ja) | Staphylococcusaureusに対する免疫化のための安定化されたタンパク質 | |
| BE1022553B1 (fr) | Mutants de spy0269 | |
| EP3840770A1 (en) | Immunogenic proteins and compositions | |
| JP2018134074A (ja) | ヘパリン結合性赤血球凝集素(hbha)融合タンパク質とその用途をコードする組換え型マイコバクテリウム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |