WO2023100944A1 - ランダム領域搭載用フレームワーク配列を有するペプチド及びそのペプチドで構成されるペプチドライブラリ - Google Patents
ランダム領域搭載用フレームワーク配列を有するペプチド及びそのペプチドで構成されるペプチドライブラリ Download PDFInfo
- Publication number
- WO2023100944A1 WO2023100944A1 PCT/JP2022/044235 JP2022044235W WO2023100944A1 WO 2023100944 A1 WO2023100944 A1 WO 2023100944A1 JP 2022044235 W JP2022044235 W JP 2022044235W WO 2023100944 A1 WO2023100944 A1 WO 2023100944A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- amino acid
- seq
- peptide
- acid sequence
- framework
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images













Classifications
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B40/00—Libraries per se, e.g. arrays, mixtures
- C40B40/04—Libraries containing only organic compounds
- C40B40/10—Libraries containing peptides or polypeptides, or derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/005—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies constructed by phage libraries
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/303—Liver or Pancreas
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6803—General methods of protein analysis not limited to specific proteins or families of proteins
- G01N33/6845—Methods of identifying protein-protein interactions in protein mixtures
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Definitions
- the present invention relates to peptides having framework sequences for loading random regions and peptide libraries composed of the peptides.
- the body has a biological defense mechanism that recognizes self and non-self, and that this biological defense mechanism involves cell-mediated immunity and humoral immunity.
- humoral immunity antibodies produced by B cells recognize foreign substances that have invaded the body and specifically bind to antigens (targets) present on the surface of the foreign substances. Then, the foreign matter is removed from the living body.
- the above antibody is a protein called “immunoglobulin” (hereinafter sometimes referred to as "Ig"), and is divided into IgA, IgD, IgE, IgG, and IgM.
- IgG is said to be a general antibody because of its high production amount, and is composed of heavy and light chains in many mammals. However, in camels, alpacas and other camelid animals, or sharks and other cartilaginous fish, it is composed only of heavy chains.
- Such an antibody composed of a single domain consisting of only a heavy chain is called a heavy chain antibody, and is also called a single domain antibody, Nanobody (registered trademark), or VHH because it can bind to an antigen only with the variable region.
- Each VHH has a strictly defined amino acid sequence and can be used as a tool for biochemical analysis such as immunoprecipitation or as a tool for immunohistochemistry, similar to conventional antibodies such as IgG. can do.
- the VHH is known to have a different antigen-binding site from the conventional antibody. Specifically, conventional antibodies bind to convex epitopes of antigens, but the VHHs are known to bind to epitopes forming gaps or crevices in antigens (Prior Art Document 1 See ⁇ 3.). Therefore, in order to develop therapeutic agents that are difficult to develop with conventional antibodies, it is necessary to search for candidate proteins having VHH-binding properties obtained from the above camelids.
- a peptide library can be defined as "a large collection of peptides with systematic combinations of amino acids".
- the above-mentioned peptides include naive peptides obtained from various animals and the like, semi-synthetic peptides modified from naive peptides, and synthetic peptides obtained by chemical synthesis.
- epitope peptide mapping creation of a peptide library for vaccine development, etc. can be performed by screening the synthetic peptide library.
- mRNA display method is an excellent technique in terms of library size.
- the mRNA display method has a problem that the target peptide cannot be stably obtained because the mRNA is easily degraded by RNase in an aqueous solution.
- Conventional technique 2 phage display method
- phage display method is an excellent technique in terms of display stability.
- a construct that expresses the DNA encoding the displayed peptide is prepared, and finally introduced into Escherichia coli or other bacteria for expression. It requires a cell-based translation system. For this reason, there is a problem that the size of the library that can be handled is small, and if the expression of the peptide is harmful or lethal to the host, it cannot be displayed.
- the tertiary structure of a protein or peptide can be predicted to some extent from the secondary structure, it is necessary to predict the binding mode with the target peptide, design such a structure as a binding site, and express it accordingly. There was a problem that it was not possible to
- the FR preferably contains the amino acid sequence represented by SEQ ID NO: 2 as framework 2 (hereinafter referred to as "FR2").
- X in SEQ ID NO: 2 represents an arbitrary amino acid, and is any amino acid selected from the group consisting of tyrosine, valine, phenylalanine, leucine, arginine, glycine and tryptophan from the viewpoint of tertiary structure stability. preferred from [SEQ ID NO: 2] WXRQAPGKGXEXVA
- the FR2 is more preferably any sequence selected from the group consisting of the amino acid sequences represented by SEQ ID NOs: 3 to 6 from the viewpoint of stability of the tertiary structure.
- the FR preferably contains the amino acid sequence represented by SEQ ID NO: 7 as framework 3 (hereinafter referred to as "FR3").
- X in SEQ ID NO: 7 represents any amino acid, preferably any amino acid selected from the group consisting of leucine, valine, alanine (A), arginine (R), and lysine (K). .
- the framework sequence 3 (hereinafter referred to as "FR3") is preferably any sequence selected from the group consisting of the amino acid sequences represented by SEQ ID NOs: 8 to 31 below.
- the FR preferably contains the amino acid sequence represented by SEQ ID NO: 32 in the sequence listing below as framework 4 (hereinafter referred to as "FR4").
- the above FR1-4 are preferably composed of 22-26 amino acids, 12-16 amino acids, 29-33 amino acids, and 9-13 amino acids, respectively. Further, it is more preferable that the above FR1-4 are composed of 25 amino acids, 14 amino acids, 32 amino acids and 11 amino acids, respectively.
- the peptide comprises a complementarity determining region 1 (hereinafter referred to as "CDR1”) composed of 8 to 12 amino acids and a complementarity determining region 2 (hereinafter referred to as “CDR2”) composed of 14 to 18 amino acids. and a complementarity determining region 3 (CDR3) composed of any amino acid sequence selected from the group consisting of 6, 12 and 15 amino acids. More preferably, the peptide comprises CDR1 consisting of 10 amino acids, CDR2 consisting of 16 or 17 amino acids, and CDR3 consisting of 6, 12 or 15 amino acids.
- a second aspect of the present invention is a peptide library composed of the above peptides.
- peptides constituting the peptide library are composed of three complementarity-determining regions and four framework regions, Framework 1 comprises the amino acid sequence shown in SEQ ID NO: 1, framework 2 comprises the amino acid sequence shown in SEQ ID NO: 2; framework 3 comprises the amino acid sequence shown in SEQ ID NO: 7; Framework 4 comprises the amino acid sequence shown in SEQ ID NO: 32;
- Complementarity determining region 1 is an amino acid sequence consisting of 10 amino acids
- Complementarity determining region 2 is an amino acid sequence consisting of 16 or 17 amino acids
- Complementarity determining region 3 is an amino acid sequence consisting of 6, 12, or 15 amino acids
- a peptide library is composed of six 12, or 15 amino acids.
- a particularly preferred peptide library is The peptides constituting the peptide library are composed of three complementarity determining regions and four framework regions, Framework 1 comprises the amino acid sequence shown in SEQ ID NO: 1, Framework 2 comprises an amino acid sequence set forth in any of SEQ ID NOs: 3-6; Framework 3 comprises an amino acid sequence set forth in any of SEQ ID NOs: 8-31; framework 4 comprises the amino acid sequence shown in SEQ ID NO: 32; Complementarity determining region 1 is an amino acid sequence consisting of 10 amino acids, Complementarity determining region 2 is an amino acid sequence consisting of 16 or 17 amino acids, Complementarity determining region 3 is an amino acid sequence consisting of 6, 12, or 15 amino acids, A peptide library.
- the library size of the peptide library is preferably about 10 12 to about 10 14 .
- the above-mentioned next library is preferably single-domain antibodies derived from the above-mentioned heavy-chain antibodies, or multivalent antibodies in which they are combined with each other.
- the polyvalent is any one selected from the group consisting of dimers to pentamers that are mutually linked via a linker.
- a framework sequence having a sequence capable of mounting CDRs of a desired length, and a peptide containing this can be obtained. Furthermore, it is possible to obtain a framework sequence that can be used for efficient screening of single domain antibodies and that can yield peptides having the designed structural properties. Furthermore, a peptide library composed of peptides as described above can be constructed.
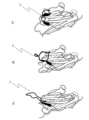
- FIG. 1 is a schematic diagram showing that these were classified into three groups based on the structure of the CDR3 region of the peptides.
- Fig. 1(A) shows an upright type
- Fig. 1(B) shows a half-roll type
- Fig. 1(C) shows a roll type.
- L1 to L3 indicate the CDR3 regions in each molecule.
- FIG. 2 shows the distance between C ⁇ atoms of the peptide (hereinafter sometimes referred to as “C ⁇ distance”) and the pseudo dihedral angle between C ⁇ atoms (hereinafter, “dihedral It is a schematic diagram showing the face angle.
- FIG. 3 is a diagram plotting the C ⁇ distance of VHH and the dihedral angle.
- FIG. 1 is a schematic diagram showing that these were classified into three groups based on the structure of the CDR3 region of the peptides.
- Fig. 1(A) shows an upright type
- Fig. 1(B) shows a half-
- FIG. 3(A) is a diagram showing the distribution of C ⁇ distances and dihedral angles by classifying VHHs into upright type, half-roll type, and roll type.
- FIG. 3(B) is a diagram showing the C ⁇ distance and dihedral angle between VHH and human VH in the same manner as above.
- FIG. 4 is a diagram comparing the amino acid sequences of the upright type and roll type shown in FIG.
- FIG. 5 is a graph showing the CDR3 length distribution of VHHs and human VHs according to the VHH types described above.
- FIG. 6 shows the design of the framework regions of the VHH sublibrary (upright or rolled). Alphabets shown below each amino acid sequence indicate the mutated amino acid and its position.
- FIG. 7 shows the procedure for constructing the DNA sequence of full-length VHHs.
- FIG. 8 is a diagram schematically showing the flow of screening when using the "The Month” platform.
- FIG. 9 shows the properties of anti-GPC3-VHH obtained by screening.
- FIG. 10 shows the properties of VHHs obtained by screening.
- FIG. 10(A) is a graph plotting the relationship between the thermal stability of the obtained VHH and the dissociation constant.
- FIG. 10(C) shows the result of actually measuring the dissociation constant.
- FIG. 10(B) is a graph showing the relationship between the denaturation midpoint temperature (Tm value) and the aggregation initiation temperature (Tagg value).
- FIG. 11 shows the results of flow cytometry analysis evaluating the binding ability of VHHs to target proteins expressed on the cell surface.
- the present invention is a peptide comprising (a) 3 CDRs and 4 FRs and (b) the specific sequences described below as FR1, FR2, FR3 and FR4.
- the peptides constituting FR1 to FR4 can be designed and produced as follows. First, the amino acid sequence of the human framework sequence IGHV3-23*01 DP-47 (FR1 to 4 are shown in Table 1 as SEQ ID NOs: 34 to 37) was used for antigenicity and homology with VHH. Selected as the basic sequence used to design the framework sequences of the invention. Then, taking into account the shape of the finally formed peptide, the FR whose design is to be changed is determined.
- the above FR1-4 are composed of 22-26 amino acids, 12-16 amino acids, 29-33 amino acids, and 9-13 amino acids, respectively, from the viewpoint of stability of the tertiary structure. Further, it is more preferable that the FR1 to FR4 are composed of 24 amino acids, 14 amino acids, 32 amino acids and 11 amino acids, respectively, for the reason of stability of the tertiary structure.
- the sequences of FR1 and FR4 are changed. Instead, the FR2 and FR3 sequences may be altered. In that case, from the viewpoint of the three-dimensional structure of CDR3, amino acids at desired sites in FR2 and FR3 can be substituted with other amino acids as described above.
- the C-terminal amino acid of FR2 of the human framework sequence IGHV3-23*01 DP-47 was changed from serine (S) to alanine (A).
- amino acids at other positions can be substituted with other amino acids.
- tyrosine (Y), valine (V), phenylalanine (F), leucine (L), arginine (R), glycine (G) and tryptophan (W) at the 2nd, 10th or 12th amino acid from the N-terminus ) may be substituted with any amino acid selected from the group consisting of
- FR2 containing the amino acid substituted at the above site can be shown as the amino acid sequence represented by SEQ ID NO: 2 below.
- SEQ ID NO: 2 WXRQAPGKGXEXVA
- the second X from the N-terminus (hereinafter referred to as "X2") is tyrosine, valine (V) and phenylalanine (F), and the tenth X (X10) is arginine (R) or leucine.
- the 12th X (X12) from the N-terminus may be any amino acid selected from the group consisting of tryptophan (W), phenylalanine (F) and glycine (G).
- the above FR2 preferably has a sequence represented by any amino acid sequence selected from the group consisting of SEQ ID NOS:3-6. This is because the three-dimensional structure of the peptide can be controlled to some extent by performing such a substitution.
- the human framework sequence IGHV3-23*01 DP-47 is involved in determining the structure of the VHH CDR3 region and is also a region that can be involved in antigen binding.
- amino acids at other positions can be substituted with other amino acids.
- the 13th, 31st or 32nd amino acids from the N-terminus, the group consisting of leucine (L), valine (V), alanine (A), asparagine (N), lysine (K), and arginine (R) may be substituted with any amino acid selected from
- FR3 containing the amino acid substituted at the above site can be shown as the amino acid sequence represented by SEQ ID NO:7.
- X13 is valine (V) and leucine (L)
- X31 is alanine (A), asparagine (N) or lysine (K)
- X32 is alanine (A), valine (V), arginine (R) and leucine
- It may be any amino acid selected from the group consisting of (L).
- the above FR3 preferably has a sequence represented by any amino acid sequence selected from the group consisting of SEQ ID NOS:8-31. This is because the three-dimensional structure of the peptide can be controlled to some extent by performing such a substitution.
- FR1 to FR4 may be chemically synthesized according to solid-phase synthesis or other conventional methods, or may be outsourced to a company.
- CDR1 to CDR3 (2-1) length of CDR1 to 3
- the peptide consists of three complementarity determining regions (hereinafter , abbreviated as “CDR”), the complementarity determining region 1 (hereinafter referred to as “CDR1”) is composed of 8 to 12 amino acids, and the complementarity determining region 2 (hereinafter referred to as “CDR2”) is composed of It may be composed of 14 to 18 amino acids, and the complementarity determining region 3 (CDR3) may be composed of 6, 12 and 15 amino acids. It is preferable that CDR1 is composed of 10 amino acids, CDR2 is composed of 16 and 17 amino acids, and CDR3 is composed of 6, 12 or 15 amino acids, in order to obtain peptides having the properties described below.
- CDR3 (2-2) Structure and Classification of CDR1-3
- the three structures of CDR3 are the C ⁇ atoms of the amino acid residues at specific positions contained in FR2 and the amino acid residues at specific positions contained in CDR3.
- the distance between the loops, the angle formed by the pseudo-diplane composed of the C ⁇ atoms of the amino acid residues at the end of the CDR3, and the structure of the loop itself are classified as follows ( Figures 1(A)-(B) and Figures 2(A)-(B)). The criteria for this classification are explained below.
- C ⁇ refers to the first carbon adjacent to the functional group. In this specification, the distance between two ⁇ -carbons is called C ⁇ -distance.
- the amino acid at the C-terminus of the CDR3 contained in the above peptide is "n"
- the amino acid residue C ⁇ (n-5) at the n-5th position and the 46th from the N-terminus of this peptide The distance to C ⁇ (46) in the amino acid residue located at is the C ⁇ distance.
- FIG. 1(E) is a diagram of the above peptide viewed from the XY plane.
- the first plane is, for example, when the 102nd amino acid residue from the N-terminus of this peptide is n (H102(n)), the peptide bond contained in H102(n) and its downstream side The plane containing the peptide bond contained in the adjacent amino acid residue (H103(n+1)).
- the second plane is the peptide bond contained in the amino acid residue (H101(n-1)) containing H101 and the amino acid residue (H100(n-2)) adjacent to the downstream side. It refers to the plane containing the peptide bonds involved.
- An angle formed by the first plane and the second plane is called a "dihedral angle".
- the shape of the CDR3 itself is, for example, one extending in the Y direction like L1 in FIG. 1(A), one in a rounded state like L3 in FIG. 1(C), It can be divided into three, such as L2 in FIG. 1(B), which is in the middle state. It should be noted that those with a CDR3 length of less than 6 amino acids are difficult to classify according to the above criteria, and may be conveniently classified as upright from the appearance of their structure.
- the upright shown in Fig. 1(A) has a C ⁇ distance longer than 15 ⁇ , a dihedral angle greater than 140 degrees, and a structure of CDR3 extended. defined as being in good condition.
- the roll shown in FIG. 1(C) is defined as having a C ⁇ distance shorter than 10 ⁇ , a dihedral angle smaller than 140 degrees, and a CDR3 structure in a rounded state.
- the half roll shown in FIG. 1(B) is defined as having an intermediate structure between the upright and the roll.
- VHH By combining the upright type or roll type FR2, FR3, CDR2 and CDR3 shown in Table 1, it is possible to prepare a VHH having a desired structure among the upright type, roll type and half roll type.
- the structures of human VHs can be classified in the same manner as for VHHs.
- the sub-library is a library prepared by selecting clones from the original DNA library under specific conditions according to the purpose of research or the like.
- Source Peptides constituting CDR1-3 can be produced by selecting target peptides.
- structural data of VHH and human VH are obtained from SAbDab database (http://opig.stats.ox.ac.uk/webapps/newsabdab/sabdab/) of Protein Data Bank (PDB).
- PDB Protein Data Bank
- selection criteria can be determined from the information on various VHHs obtained, and VHHs can be selected according to those criteria. Selection criteria for VHHs and human VHs include, for example, those shown in Table 2 below.
- the CDRs of VHHs selected according to the above criteria are determined, for example, by the Kabat method or other conventional methods. Such determinations can also be made automatically using commercially available tools, such as the ANARCI tool (http://opig.stats.ox.ac.uk/webapps/newsabdab/sabpred/anarci/). can be mentioned.
- the obtained amino acid residue information can be used to define variable regions and CDRs, and clustering is performed to group data based on the degree of similarity between variable region (domain) data.
- clustering can be performed using CD-HIT (http://weizhong-lab.ucsd.edu/cd-hit/) or other clustering programs. Redundancy can be removed from the resulting clusters by removing CDRs with 100% similarity (%id) representing perfect matches during clustering. In this specification, the operation of eliminating redundancy as described above is referred to as "curation".
- those containing an amino acid sequence with a sufficient length as an antigen-binding site can be selected. If the length of the resulting sequence is longer than the region determined by the Kabat method, such as CDR1, then the desired region prepared by the Chothia method, such as the sequence of CDR1, is combined with For example, it may be used as CDR1.
- the amino acid sequences of CDR1 and CDR2 can be designed by the following procedure.
- the data obtained by the next-generation sequencer of the naive shuffling library of camelids for example, alpaca (hereinafter sometimes abbreviated as "NGS data")
- NGS data alpaca
- the concentration ratio is not particularly limited, for example, about 0.001% or more is preferable for the reason of data reliability.
- enriched sequences amino acid sequences at the BM positions are used as an index for selecting amino acid sequence candidates for CDR1 and CDR2 from the sequences obtained by concentrating the NGS data. This is for extracting CDR1 and CDR2 of alpaca VHH, which has high structural stability.
- amino acid sequences that match the amino acid sequences at the BM positions from, for example, the VHH sequences of PDB data, and use them as candidate amino acid sequences for CDR1 and CDR2 for reasons of tertiary structural stability.
- the CDR1 and CDR2 amino acid sequence candidates selected as described above are compared with the amino acid sequence of the alpaca germline, for example, up to 2 mismatches for the CDR1 sequence and up to 3 mismatches for the CDR2 sequence. Sequence candidates can be narrowed down by setting criteria such as allowable. These can be used to prepare sets of CDR1 and CDR2.
- a library of desired lengths can be designed for CDR3 sequences based on, for example, CDR3 loop length distribution, correlation between CDR3 length and structural classification, and the like. .
- the CDR3 length may be changed between upright and roll, and may be appropriately selected to match the target peptide.
- uprights may have a CDR3 length of 6 amino acids, 12 amino acids, etc.
- rolls may have a CDR3 length of 12 amino acids, 15 amino acids, etc.
- 17 kinds of amino acids excluding amino acids such as Cys, Met, and Pro can be set to have an equal ratio. This is because these amino acids may cause heterogeneity in the process of formulation of biopharmaceuticals.
- the peptide of the present invention is a humanized camelid or other derived heavy chain antibody, it is necessary to humanize the framework portion.
- the backmutation (BM) positions of the peptide are determined based on the structural information available from databases such as those described above.
- a basic sequence is selected for humanizing the framework region.
- Such sequences can include DP-47, DP-51, DP-29, etc. of the human framework sequence IGHV3-23*01.
- the amino acid sequences of Caplacizumab, Ozoralizmab, Vobaralizmab, and other VHHs that are on the market or used in clinical trials can be referred to.
- a technique for designing a humanized framework sequence for example, the following techniques can be mentioned.
- Peptides from different sources are prepared for comparison of their amino acid sequences. Then, when these amino acid sequences are compared and the same amino acids are assigned to the same positions, it is preferable to assign them as they are to the framework sequence of the present invention because antigenicity is not increased. .
- the above four VHH amino acid sequences are selected for comparison, if the same amino acids are assigned to the same positions, they are also assigned to the same positions in the peptides of the present invention. It is preferable for the design of the humanized framework to determine the amino acids to be assigned by repeating this work.
- the amino acid to be assigned if it is not possible to determine the amino acid to be assigned, the correlation between the structural classification of the CDR3 loop described above and the sequence profile, structural knowledge, knowledge of the human framework sequence, etc. are combined to decide. is preferred.
- a DNA fragment containing each of the CDRs 1 to 3 designed as described above is synthesized by overlap extension PCR, and a library containing the desired full-length peptide can be constructed using restriction enzymes and ligase.
- Restriction enzymes used here include, for example, HphI, FokI, BsmBI, BtgZI and other Type IIS restriction enzymes (recognition and nuclease domains are separated, recognizing asymmetric nucleotide sequences, restriction enzymes that cleave sites), and ligases such as T4 DNA ligase and the like.
- FR1-4 amplification primers can be designed to contain the desired sequence, and the FR4 primer contains the linker hybridization sequence for cDNA display. design is preferred for using cDNA display methods. Desired sequences include, for example, a His tag region, 3'UTR, T7 promoter, SD sequence, 5'UTR, and the like.
- Primers for each sequence may be synthesized according to standard methods, or may be outsourced to a company. Such companies include, for example, Eurofins Genomics Inc., Sigma Aldrich, and the like. From the viewpoint of library diversity, it is preferable to synthesize a large number of CDR1 primers with different CDR1 region sequences and CDR2 primers with different CDR2 region sequences and use them in combination.
- CDR3 primers are preferably designed using trimer oligonucleotides. This is because the appearance frequency of amino acids can be controlled.
- overlap extension PCR is performed under desired conditions to synthesize DNA fragments containing each CDR.
- a reaction solution for overlap extension PCR a solution having the composition shown in Table 3 below can be used, and each synthesized DNA fragment can be purified using, for example, AMPureXP (Beckman).
- the CDR1 fragment and CDR2 fragment are treated with the above restriction enzymes, purified, and ligated together using the above ligase to obtain a ligation product (CDR1-2 fragment).
- the ligation product is purified, eg, by gel electrophoresis, and amplified using the outer primers. After purifying the amplified CDR1-2 fragment, it is treated with a restriction enzyme again.
- CDR3 is treated with restriction enzymes in the same manner as above, purified, and then ligated with the above CDR1-2 fragment with ligase.
- the resulting ligation product (CDR1-2-3 fragment) is purified in the same manner as above to prepare a library.
- the sequence of the CDR1-2-3 fragment obtained as described above is confirmed using, for example, a next-generation sequencer.
- a peptide library can be obtained as described above.
- the target peptide can be obtained by selecting the obtained peptide library by the cDNA display method using the following linker.
- cnvK Linker It is preferable from the viewpoint of reaction efficiency that the sequence of the biotin fragment that forms the main chain has the sequence shown in SEQ ID NO:33.
- BioTEG is bound to the 5' end of the main chain, and N at position 3 in the base sequence represents guanosine.
- This sequence is further bound by CCT via Amino C6-dT.
- Each N at the 12th position represents 3-cyanovinylcarbazole.
- the side chain puromycin segment can have the sequence 5'(5S)TcTCFCZZCC.
- the free terminal P in the side chain sequence represents puromycin as a protein binding site.
- (5S) represents 5' Thiol C6, c represents cytidine, F represents FITC-dT, and Z represents Spacer 18, respectively.
- the above chemical synthesis of the main chain and side chains may be entrusted to Euphofin Genomics, Tsukuba Oligo Service Co., Ltd., or the like.
- the buffer-exchanged reduced puromycin segment solution is mixed with the ethanol precipitation product of the EMCS-modified biotin fragment, and left overnight at 2-6°C. Subsequently, DTT is added to the above reaction solution to a final concentration of 25-74 mM, stirred at room temperature for 15-45 minutes, and ethanol precipitated in the same manner as above.
- the obtained ethanol precipitation product is dissolved in 50 to 150 ⁇ L of Nuclease-free water (manufactured by Nacalai Tesque, Inc.) to obtain a lysate.
- the above-described linker for producing the mRNA/cDNA-protein conjugate and the mRNA having a sequence complementary to the main chain of the linker are combined with T4 RNA at the mRNA ligation site. Ligation is performed by ligase to generate an mRNA-linker conjugate.
- a protein is synthesized from the mRNA in a cell-free translation system, and the synthesized protein is ligated to the protein ligation site in the mRNA-linker conjugate to form the mRNA-linker-protein conjugate.
- the mRNA-linker-protein conjugate is bound to the solid phase via the solid-phase binding site, and the solid phase bound with the mRNA-linker-protein conjugate is washed with the first buffer. Then, using the 3' end of the main chain as the reaction initiation point and the mRNA as a template, a reverse transcription reaction is performed to synthesize a cDNA chain to obtain an mRNA/cDNA-linker-protein conjugate. Then, the solid phase bound with the mRNA/cDNA-linker-protein conjugate is washed with the second buffer solution, and the cleavage site of the main chain is cleaved with the predetermined endoribonuclease.
- the ligation reaction is performed at 20 ⁇ L to 40 ⁇ L from the point of reaction efficiency, and the RNA:linker molar ratio is in the range of 3:1 to 1:6.
- 1:(1-2) (10 pmol to 20 pmol of linker for 10 pmol of mRNA) is recommended.
- the sample solution is warmed on an aluminum block at 90°C for 5 minutes, then transferred to an aluminum block at 70°C for 5 minutes, and then the photocrosslinking reaction between the mRNA and the linker is performed.
- the photocrosslinking reaction is carried out by irradiating UV light at 365 nm for 1 to 5 minutes in 10 mM to 250 mM Tris-HCl buffer (pH 7.0 to 8.0) containing 100 mM to 300 mM NaCl.
- E. coli-derived cell-free protein synthesis system it is preferable to use an E. coli-derived cell-free protein synthesis system as the primary cell-free translation system, and it is more preferable to use a reconstituted E. coli cell-free protein synthesis system.
- a translation reaction can be carried out by adding a reconstituted cell-free protein synthesis system of E. coli and the conjugate.
- the amount of the reconstituted cell-free protein synthesis system of Escherichia coli is about 8.5 ⁇ L to about 17 ⁇ L
- the amount of the conjugate is about 2.4 pmol to about 4 pmol
- the size of the reaction system is about 12.5 ⁇ L to about Make 50 ⁇ L and perform at about 20° C. to about 40° C. for about 10 minutes to about 30 minutes. Translation at about 37°C for about 30 minutes yields high production efficiency and working efficiency.
- the translation product protein and the mRNA-linker conjugate are treated in the presence of, for example, about 0.3 M to about 1.6 M potassium chloride and about 40 mM to about 170 mM magnesium chloride (all concentrations are final concentrations). , at about 27° C. to about 47° C. for about 30 minutes to about 1.5 hours, the protein can be efficiently bound to the conjugate.
- Examples of the solid phase on which the mRNA-linker-protein conjugate is immobilized include beads such as styrene beads, glass beads, agarose beads, sepharose beads, magnetic beads; glass substrates, silicon (quartz) substrates, plastic substrates, and metals. Substrates such as substrates (for example, gold foil substrates); containers such as glass containers and plastic containers; membranes made of materials such as nitrocellulose and polyvinylidene fluoride (PVDF); If the solid phase is composed of a plastic material such as styrene beads or a styrene substrate, a portion of the linker may be covalently bound directly to the solid phase using known techniques ( Qiagen, LiquiChip Applications Handbook, etc.). When biotin or an analogue thereof is bound to the conjugate, the conjugate can be easily bound to the solid phase by binding avidin to the solid phase.
- substrates for example, gold foil substrates
- containers such as glass containers and plastic containers
- membranes made of materials such
- Conjugates that were not bound to the solid phase were isolated from about 0.1 M to about 10 M sodium chloride, about 0.1 mM to about 10 mM EDTA, 1 mM to 100 mM Tris-HCl containing about 0.01% to about 1% detergent. Remove by washing with buffer (pH 7.0-9.0) or phosphate buffer (pH 7.0-9.0). Washing is efficient using 20 mM Tris-HCl buffer (pH 8.0) containing 2 M sodium chloride, 2 mM EDTA, 0.1% Triton X-100.
- a reverse transcription reaction is performed under predetermined conditions to synthesize a cDNA strand.
- an mRNA/cDNA-linker-protein conjugate is obtained.
- the reverse transcription reaction system can be arbitrarily selected, the above-mentioned mRNA-linker protein conjugate, dNTP Mix, DTT, reverse transcriptase, standard solution, and water from which RNase has been removed (hereinafter referred to as "RNase-free water”) are added to prepare a reaction system, and reverse transcription is preferably carried out in this system for 5 to 20 minutes at 30°C to 50°C.
- the linker of the present invention can be used to obtain not only various proteins but also cDNAs corresponding to those proteins.
- the obtained mRNA and linker DNA having puromycin are immobilized on streptavidin-modified magnetic beads using avidin-biotin binding, and the mRNA is converted into We synthesize proteins and synthesize cDNA from mRNA using reverse transcription. Therefore, the protein, which is the phenotype, and the DNA sequence information, which is the genotype, are in a stable one-to-one correspondence on the magnetic beads.
- the affinity of the obtained protein can be used to select mRNA/cDNA-linker-protein conjugates.
- a mutation is introduced into the nucleotide sequence of the selected concatenated product by PCR or the like to carry out an amplification reaction.
- the amplified product is ligated with a double-stranded DNA having a desired promoter sequence by a predetermined method to obtain a first-generation mutant mRNA (hereinafter abbreviated as "mRNA G1").
- mRNA G1 a first-generation mutant mRNA
- Example 1 Structural analysis of VHH CDR3
- the structural data of VHH and human VH were collected from the SAbDab database of the Protein Data Bank (PDB) (http://opig.stats.ox.ac.uk/webapps/newsabdab/ sabdab/).
- the VHHs obtained here were selected according to the criteria shown in Table 2 above, except for those with short CDR structures of less than 5 amino acids.
- CDR information of VHHs obtained from the database was determined by the conventional Kabat method.
- the ANARCI tool http://opig.stats.ox.ac.uk/webapps/newsabdab/sabpred/anarci/
- CD-HIT http://weizhong-lab.ucsd.edu/cd-hit/
- CDR2 H50-H65
- CDR3 H95-H102
- the actual CDR1 antigen-binding site was wider than the region (H31-H35) determined by the Kabat method, so in combination with the CDR1 (H26-H32) prepared by the Chothia method, CDR1 (H26-H35) and bottom.
- FIG. 1 (A) shows the amino acid residues in the vicinity of the antigen in black.
- the three types of loop structures of CDR3 were defined as follows. Those with a C ⁇ distance of 15 ⁇ or more and a dihedral angle of 140 degrees or more are upright type, those with a C ⁇ distance of 10 ⁇ or more and a dihedral angle of 140 degrees or less are roll types, and those with a C ⁇ distance of 15 ⁇ or more and If the dihedral angle was smaller than 140 degrees, or if the C ⁇ distance was larger than 10 ⁇ and the dihedral angle was smaller than 140 degrees, the half-roll type was used.
- FIG. 4 shows the relationship between CDR3 length and its taxonomic type.
- the upright CDR3 tends to include a framework region in the antigen-binding site.
- the role type increases and the inclusion of the framework region in the antigen-binding site decreases.
- the roll structure was stabilized by bringing the framework and CDR3 regions closer together.
- the proportion of CDR3 containing cysteine increases, and the cysteine forms a disulfide bond with the cysteine of CDR2, thereby forming a more stable CDR3.
- the structure of human VH was also classified in the same way as VHH.
- a two-dimensional plot of the C ⁇ distance and the dihedral angle is shown in FIG. 3(B).
- Most of the human VHs were of the half-roll type, with no roll type, and almost no upright type. This suggests that in human antibodies, the presence of the light chain is a steric hindrance and prevents the CDR3 from folding into the above-mentioned roll-type structure.
- Example 2 Construction of an artificial VHH library (2-1) Library design based on analysis data Based on the analysis results of the antigen-binding site, the number of amino acid residues, and the structure of CDR3 described above, Upright6, Upright12, Roll12, and We designed a rational artificial VHH library containing four sub-libraries called Roll15.
- CDR2 of the upright sub-library was composed of 16 amino acid residues
- CDR2 of the roll-type sub-library was composed of 17 amino acid residues. This is because a strong correlation has been confirmed between the number of amino acid residues (16 amino acid residues or 17 amino acid residues) constituting CDR2 and the formation of upright or roll type.
- the amino acid sequences of the CDRs consisted of 150 types of sequence sets for CDR1, 69 or 71 types of sequence sets for CDR2, and 17 types of amino acids excluding methionine, proline and cysteine for CDR3. Designed to be structured. CDR3s longer than 16 amino acids were not designed. This is because the formation of disulfide bonds is undesirable from the pharmaceutical standpoint. Finally, the CDRs 1 to 3 designed as described above were incorporated into the humanized FR as a set.
- VHH framework regions and CDRs contained in this library were defined as follows. FR1(H1-H25), CDR1(H26-H35), FR2(H36-H49), CDR2(H50-H65), FR3(H66-H94), CDR3(H95-H102), FR4(H103-H113). Based on the above definitions, we then designed the framework.
- the undetermined amino acid sequence was determined by combining the structural classification of the CDR3 loop, the correlation with the sequence profile, the structural knowledge, the knowledge of the human framework sequence, etc. (Fig. 6). Additionally, some amino acids were further edited during this humanization process to reduce the frequency of unfavorable amino acids in pharmaceuticals.
- the FR4 primer was designed to contain a His tag region and 3'UTR (including the linker hybridization sequence for cDNA display).
- Primers corresponding to FR1, CDR1, and CDR2 were commissioned to Sigma Aldrich for synthesis.
- the FR1 primer was designed to contain a 5'UTR (T7 promoter and SD sequence).
- Synthesize 150 types of CDR1 primers with different sequences in the CDR1 region, and 140 types of CDR2 primers with different sequences in the CDR2 region (Upright type: 71 types, Roll type: 69 types), and mix these primers. and used.
- Primers corresponding to CDR3 of each library were designed using trimer oligonucleotides to control the frequency of amino acid appearance, and synthesis was commissioned to Ella Biotech.
- the CDR1 fragment and CDR2 fragment were treated with restriction enzymes using BsmBI (NEB) at 55°C for 15 minutes.
- BsmBI BsmBI
- These restriction enzyme-treated DNA fragments were purified according to a conventional method and ligated at 16°C for 16 hours using T4 DNA ligase (Takara Bio Inc.) to obtain the CDR1-CDR2 fragment, which is a ligation product. Synthesized as a ligation product.
- This ligation product was electrophoresed on an 8 M urea PAGE-gel at 200 V for 40 minutes to purify the region of the target product, followed by 10 cycles of PCR amplification using outer primers at an annealing temperature of 62°C.
- the amplified CDR1-2 fragment was purified and then restricted with BtgZ I (NEB) at 60°C for 15 minutes.
- the CDR3 fragment was digested with BsmBI at 55°C for 15 minutes with a restriction enzyme and purified using AMPure XP to obtain a purified CDR3 fragment.
- the purified CDR1-2 fragment and the purified CDR3 fragment were ligated with T4 DNA ligase at 16°C for 16 hours to obtain a full-length VHH sequence.
- the ligation product was recovered by the 8 M urea-denaturing PAGE-gel purification described above, and a library was constructed.
- PCR amplification was performed for each of the above libraries.
- the composition of the reaction solution (25 ⁇ L total) was 12.5 ⁇ L PrimeSTAR MAX PreMIX (2 ⁇ ), 1 ⁇ L library sample, 0.5 ⁇ L each 20 ⁇ M forward/reverse primers (PL_prRd-N4_NL_FW, PL_prRd-N4_NL_RV), and 10.5 ⁇ L of ultrapure water.
- the reaction conditions were the same as in Table 3 above, except that the annealing temperature was 62°C, the extension time was 5 seconds, and the number of cycles for denaturation, etc. was 8 times.
- the resulting PCR product was purified using AMPureXP, and Index PCR was performed using the purified product as a template (the reaction conditions were the same as the above PCR conditions, except that the annealing temperature was changed to 52°C).
- the composition of the reaction solution (25 ⁇ L total) was 12.5 ⁇ L PrimeSTAR MAX PreMIX (2 ⁇ ), 1 ⁇ L PCR product, 2 ⁇ L each 5 ⁇ M forward/reverse primers (Nextera XT Index 1 Primers (N7XX), Nextera XT Index 1 Primers (S5XX)), 7.5 ⁇ L of ultrapure water.
- Index PCR products were purified using AMPure as above and DNA concentrations were measured using NanoPad DS-11. Then, after diluting the Index PCR purified products to a concentration of 10 nM, 5 ⁇ L of each product was collected and mixed in one tube.
- a PhiX library which is a control DNA library, was also prepared in the same manner as a 15 pM library. Finally, 570 ⁇ L of the 15 pM sample library and 30 ⁇ L of the 15 pM PhiX library were mixed, the final NGS sample library was loaded onto the reagent cartridge, the reagent cartridge was set on Miseq, and analysis was performed. Then, by analyzing the obtained data, it was confirmed that each library had the nucleotide sequence as designed.
- cnvK linkers for selection were prepared as follows.
- (1) Preparation of cnvK rC Linker The sequence of the biotin fragment that forms the main chain was the sequence shown in SEQ ID NO: 33 below.
- BioTEG is bound to the 5' end of the biotin fragment (main chain), and N at position 3 in the nucleotide sequence is guanosine, and N at position 12 is 3-cyanovinylcarbazole. respectively.
- CCT was bound to the 3' end of SEQ ID NO: 33 below via Amino C6-dT.
- the side chain puromycin segment has a 5' (5S) TcTCFCZZCCP sequence.
- the free terminal P in the side chain sequence represents puromycin as a protein binding site.
- (5S) represents 5' Thiol C6, c represents cytidine, F represents FITC-dT, and Z represents Spacer 18, respectively.
- the buffer-exchanged reduced puromycin segment solution was mixed with the ethanol precipitation product of the EMCS-modified biotin fragment, and left overnight at 4°C. Subsequently, DTT was added to the reaction solution so that the final concentration was 50 mM, and the mixture was stirred at room temperature for 30 minutes. Thereafter, ethanol precipitation was performed using Quick-Precip Plus Solution (manufactured by Edge BioSystems). The ethanol precipitation product was dissolved in 100 ⁇ L of Nuclease-free water (manufactured by Nacalai Tesque, Inc.).
- the lysate was separated by 12% polyacrylamide gel electrophoresis, and each portion of the cnvK rC Linker was excised.
- the excised gel was crushed using Biomasher II set (Nippi), 500 ⁇ L of Nuclease-free water was added, and the mixture was stirred overnight at 4°C to extract the cnvK rC Linker.
- the stirred solution was transferred to a Costar® Spin-X® centrifugal tube filter, 0.22 ⁇ m cellulose acetate (corning), and centrifuged at 16,000 ⁇ g for 15 minutes to separate the gel and the extract. Thereafter, ethanol precipitation was performed using Quick-Precip Plus Solution to obtain the desired cnvK rC Linker.
- the obtained cnvK rC Linker was dissolved in Nuclease-free water and stored at -20°C.
- VHHs that bind to various antigens can be obtained from the constructed PharmaLogical Library were verified by performing in vitro selection.
- the antigens used as targets this time are HSA (Human Serum Albumin), HER2 (Human Epidermal growth factor receptor 2), GPC3 (Glypican 3), and GPC1 (Glypican 1).
- the selection library used was a mixture of the above-described four types of sub-libraries. Three rounds (four rounds for GPC1) of selection were performed with a series of operations consisting of synthesis of mRNA-linker conjugate, synthesis of cDNA display molecule, in vitro selection, and PCR amplification as one round (FIG. 7).
- RNA concentration was measured using NanoPad DS-11, and the reagents were mixed so that the final concentration was 200 mM NaCl, 50 mM Tris-HCl (pH 7.5), 1 ⁇ M mRNA, and 1 ⁇ M cnvK linker, (s1 ) 90°C for 1 minute, (s2) 70°C for 1 minute, and (s3) 4°C for heat treatment to hybridize the cDNA display synthesis linker to the mRNA.
- the hybridization product of the mRNA and the linker was irradiated with UV at 365 nm using UVP closslinker cl-3000 so that the total energy amount was 406 mJ/cm 2 , thereby photocrosslinking the mRNA and the linker. to create an mRNA-linker conjugate.
- the composition of the reaction solution was 1,600 ⁇ L of Solution I, 160 ⁇ L of each of Solution II and Solution III, 800 ⁇ L of 1 pmol/ ⁇ L Ligation product, 160 ⁇ L of 4-fold diluted DsbC set, 160 ⁇ L of 20 mM GSSG, 160 ⁇ L of ⁇ L of 80 mM GSH was used.
- 1,920 ⁇ L of IVV formation Buffer was added, followed by reaction at 37°C for 30 minutes to covalently bond the translation product to the linker via puromycin.
- 1,280 ⁇ L of 0.5 M EDTA was added and reacted at 4° C. for 10 minutes to release ribosomes from nucleic acids.
- IVV product 6400 ⁇ L of IVV product (mRNA-linker-VHH conjugate) was obtained.
- the resulting IVV product was purified using 3,840 ⁇ L of Dynabeads Streptavidin MyOne C1 (manufactured by Thermo Scientific) according to the attached protocol.
- a reverse transcription reaction solution consisting of 1,280 ⁇ L of 5 ⁇ RT Buffer, 256 ⁇ L of 25 mM dNTPs, 128 ⁇ L of Reverse Transcriptase, and 4736 ⁇ L of ultrapure water was added to the IVV product-bound beads, and allowed to react at 42°C for 1 hour. to synthesize a cDNA display product (cDNA-mRNA-linker-peptide conjugate).
- the cDNA display product obtained as described above was eluted from the beads with 640 ⁇ L of elution buffer containing RNaseT1 (Thermo Scientific), and then cDNA was extracted using 200 ⁇ L of His-Mag Sepharose (Cytiva). The display product was His-tag purified to obtain 200 ⁇ L of cDNA display molecule (cDNA-linker-peptide conjugate).
- the immobilized beads (cDNA display-biotinylated target protein streptavidin-beads) were washed three times with 200 ⁇ L of PBS-T (the tube was exchanged for the third wash). After that, it was eluted twice with 100 ⁇ L of elution buffer, and only the nucleic acid region of the cDNA display molecule that showed binding ability to the target protein was recovered. The resulting eluted samples were purified using AMPure XP.
- PCR Amplification of Selected Sample DNA eluted in the selection was amplified by PCR using PrimeSTAR MAX (Takara Bio Inc.). Quantitative PCR was not performed in the 1st round, and PCR was performed using the entire amount of the eluted sample as a template.
- the composition of the reaction solution (250 ⁇ L total) was 125 ⁇ L PrimeSTAR MAX PreMIX (2 ⁇ ), 100 ⁇ L eluted DNA sample, 5 ⁇ L each 20 ⁇ M forward/reverse primer (PL_T7pro, NewYtag_cnvk-linker), 15 ⁇ L It was made into ultrapure water.
- the PCR program was the same as in Table 3 except that the annealing temperature was 60°C, the extension time was 5 seconds, and the number of cycles of denaturation, etc. was 15 times. PCR products were purified using AMPure XP.
- the composition of the solution used for quantitative PCR was 12.5 ⁇ L THUNDERBIRD qPCR Mix (Toyobo Co., Ltd.), 0.5 ⁇ L each of 20 ⁇ M forward/reverse primer (PL_T7pro, NewYtag_cnvk-linker), 1 ⁇ L of eluted Sample DNA and 10.5 ⁇ L of ultrapure water were used.
- the PCR program consisted of 35 cycles of initial denaturation at 98°C for 30 seconds (denaturation at 98°C for 5 seconds, annealing at 60°C for 10 seconds, extension at 72°C for 35 seconds).
- the composition of the reaction solution (100 ⁇ L total) was 50 ⁇ L PrimeSTAR MAX PreMIX (2 ⁇ ), 25 ⁇ L eluted DNA sample, 2 ⁇ L each 20 ⁇ M forward/reverse primer (PL_T7pro, NewYtag_cnvk-linker), 21 ⁇ L ultrapure water.
- the program was the same as the program shown in Table 3, except that the annealing temperature was 65°C, the extension time was 5 seconds, and the number of cycles for denaturation, etc. was 15 cycles.
- Example 4 Analysis of selection products by NGS (4-1) Preparation of sequence samples
- the reaction mixture (25 ⁇ L total) consisted of 12.5 ⁇ L PrimeSTAR MAX PreMIX (2 ⁇ ), 1 ⁇ L selection product, 0.5 ⁇ L each 20 ⁇ M forward/reverse primers (PL_prRd-N4_NL_FW, PL_prRd-N4_Ytag_RV), 10.5 ⁇ L It was made into ultrapure water.
- the PCR program was the same as in Table 3 except that the annealing temperature was 62°C, the extension time was 5 seconds, and the number of cycles for denaturation, etc. was 8 times.
- the obtained PCR product was purified using AMPure XP, and index PCR was performed using the purified product as a template.
- the composition of the reaction (25 ⁇ L total) was 12.5 ⁇ L PrimeSTAR MAX PreMIX (2 ⁇ ), 1 ⁇ L selection product, 0.5 ⁇ L each 5 ⁇ M forward/reverse primers (Nextera XT Index 1 Primers (N7XX), Nextera XT Index 2 Primers (S5XX)), 10.5 ⁇ L of ultrapure water.
- the PCR program was the same as in Table 3 except that the annealing temperature was 52°C, the extension time was 5 seconds, and the number of cycles for denaturation, etc. was 8 times.
- Index PCR products were similarly purified using AMPure XP and DNA concentrations were measured using NanoPad DS-11. Then, after diluting the Index PCR purified product to 10 nM, 5 ⁇ L of each product was collected and mixed in one tube.
- a 15 pM library was also prepared for the PhiX library, which is a control DNA library, in the same manner. Finally, 570 ⁇ L of 15 pM sample library and 30 ⁇ L of 15 pM PhiX library were mixed to make the final NGS sample library. The final NGS sample library was loaded onto the reagent cartridge, and the reagent cartridge was set on Miseq for analysis. The obtained NGS analysis data were processed to identify binding sequences for each target molecule.
- VHH primary binding evaluation (Example 5) Preparation of VHH expression plasmid library
- the VHH-encoding DNA library selected by the in vitro selection described above was cloned into a plasmid vector for VHH expression.
- a sequence for restriction enzyme treatment was added by PCR to a DNA library obtained by in vitro selection to obtain a PCR product.
- This PCR product and the C. glutamicum expression plasmid vector were treated with the restriction enzyme BamHI at 37°C for 1 hour, and then treated with the restriction enzyme SfiI at 50°C for 1 hour.
- a VHH DNA product to serve as an insert was purified with AMPure XP, and the resulting Vector DNA product was subjected to agarose gel electrophoresis at 100 V for 30 minutes for excision and purification.
- the Vector DNA purified as described above was dephosphorylated at 37°C for 1 hour using the dephosphorylation enzyme FastAP Thermosensitive Alkaline Phosphatase (manufactured by Thermo Scientific). After that, insert DNA and vector DNA were mixed at a molar ratio of 1:10, and ligation reaction was performed overnight at 16°C using Ligation high (Toyobo Co., Ltd.) to introduce the selected VHH library. A plasmid library was obtained.
- Baseline step Measurement for 30 seconds in PBS-T.
- Loading step Measurement for 100 seconds with VHH diluted 50-fold with PBS-T.
- Baseline step Measurement for 30 seconds in PBS-T.
- Association step Measurement for 100 seconds with each target molecule prepared by diluting with PBS-T.
- Example 6 Characterization of VHH clones in vitro (6-1) Obtainment of purified VHH Unique clones identified by the above sequence analysis were precultured overnight at 30°C. Thereafter, this preculture was subcultured in PM1S medium for VHH expression, cultured at 25° C. for 72 hours, and VHH (monomer) was secreted and expressed in the culture supernatant. The culture supernatant was collected by centrifugation to remove the cells from the supernatant.
- Baseline step Measurement for 30 seconds in PBS-T.
- Loading step Measurement for 120 seconds with VHH diluted 50-fold with PBS-T.
- Baseline step Measurement for 30 seconds in PBS-T.
- Association step Measurement for 120 seconds with each target molecule prepared by diluting with PBS-T.
- the denaturation midpoint temperature (Tm value) was calculated based on the decrease in fluorescence intensity from about 330 nm to 350 nm (due to heat denaturation of the protein) and the change in fluorescence spectrum.
- the aggregation initiation temperature (Tagg value) was calculated by measuring the increase in the average molecular weight (aggregation) of the solute due to heat and measuring the change in the intensity of the scattered light at 266 nm (Figs. 9 and 10(B)).
- Example 6 Evaluation of VHH binding ability by flow cytometry In vitro VHH characterization was performed in Example 5 above. However, in vitro binding capacity does not necessarily translate into in vivo binding capacity. Therefore, in order to more accurately evaluate the binding ability of VHHs, the binding ability of VHHs to target proteins (GPC3, HER2) expressed in cells was verified by flow cell cytometry (FCM).
- FCM flow cell cytometry
- hepG2 a hepatocellular carcinoma
- GPC3-expressing cell a hepatocellular carcinoma
- SK-BR-3 a breast cancer cell, as the HER2-expressing cell.
- These cells were cultured (37° C., in a 5% CO 2 incubator, protected from light) until 80% confluency, and harvested with PBS containing 5 mM EDTA.
- the recovered cell sample was washed with 1% BSA/PBS, added with a VHH solution diluted 100-fold with 1% BSA/PBS, and incubated at 4°C for 1 hour.
- the invention of the present application is useful in the field of drug discovery.
- SEQ ID NO: 1 shows the amino acid sequence of FR1.
- SEQ ID NO: 2 shows the amino acid sequence of FR2.
- SEQ ID NO: 3 shows the amino acid sequence of FR2 (Upright type).
- SEQ ID NO: 4 shows the amino acid sequence of FR2 (Upright type).
- SEQ ID NO: 5 shows the amino acid sequence of FR2 (Roll type).
- SEQ ID NO: 6 shows the amino acid sequence of FR2 (Roll type).
- SEQ ID NO: 7 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 8 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 9 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 10 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 11 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 12 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 13 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 14 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 16 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 17 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 18 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 19 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 20 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 21 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 22 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 23 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 25 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 26 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 27 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 28 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 29 shows the amino acid sequence of FR3 (Upright type).
- SEQ ID NO: 30 shows the amino acid sequence of FR3 (Roll/Upright type).
- SEQ ID NO: 31 shows the amino acid sequence of FR3 (Roll/Upright type).
- SEQ ID NO: 32 Shows the amino acid sequence of FR4.
- SEQ ID NO:33 shows the nucleotide sequence of the backbone of the cnvK rC linker
- SEQ ID NO:34 shows the amino acid sequence of FR1 of DP-47.
- SEQ ID NO: 35 Shows the amino acid sequence of FR2 of DP-47.
- SEQ ID NO: 36 Shows the amino acid sequence of FR3 of DP-47.
- SEQ ID NO: 37 Shows the amino acid sequence of FR4 of DP-47.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Molecular Biology (AREA)
- Immunology (AREA)
- Biochemistry (AREA)
- Medicinal Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Cell Biology (AREA)
- Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Oncology (AREA)
- Gastroenterology & Hepatology (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Food Science & Technology (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Virology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Peptides Or Proteins (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023565059A JPWO2023100944A1 (https=) | 2021-12-01 | 2022-11-30 | |
| EP22901376.8A EP4442704A1 (en) | 2021-12-01 | 2022-11-30 | Peptide having framework sequence for random region placement and peptide library composed of said peptide |
| US18/714,591 US20250019460A1 (en) | 2021-12-01 | 2022-11-30 | Peptide having framework sequence for random region placement and peptide library composed of said peptide |
| CN202280079930.3A CN118339180A (zh) | 2021-12-01 | 2022-11-30 | 具有随机区搭载用框架序列的肽以及由该肽构成的肽文库 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021195792 | 2021-12-01 | ||
| JP2021-195792 | 2021-12-01 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023100944A1 true WO2023100944A1 (ja) | 2023-06-08 |
Family
ID=86612245
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/044235 Ceased WO2023100944A1 (ja) | 2021-12-01 | 2022-11-30 | ランダム領域搭載用フレームワーク配列を有するペプチド及びそのペプチドで構成されるペプチドライブラリ |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250019460A1 (https=) |
| EP (1) | EP4442704A1 (https=) |
| JP (1) | JPWO2023100944A1 (https=) |
| CN (1) | CN118339180A (https=) |
| WO (1) | WO2023100944A1 (https=) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003025020A1 (en) | 2001-09-13 | 2003-03-27 | Institute For Antibodies Co., Ltd. | Method of constructing camel antibody library |
| JP2008515446A (ja) * | 2004-10-13 | 2008-05-15 | アブリンクス ナームローゼ フェンノートシャップ | アミロイド−βに対するナノ抗体及びアルツハイマー病のような神経変性疾患の治療のためのナノ抗体TMを含むポリペプチド |
| WO2012145469A1 (en) * | 2011-04-19 | 2012-10-26 | The United States Of America, As Represented By The Secretary, Department Of Health & Human Services | Human monoclonal antibodies specific for glypican-3 and use thereof |
| WO2020076970A1 (en) * | 2018-10-11 | 2020-04-16 | Inhibrx, Inc. | B7h3 single domain antibodies and therapeutic compositions thereof |
| JP2021510521A (ja) * | 2018-01-15 | 2021-04-30 | ナンジン レジェンド バイオテック カンパニー,リミテッドNanjing Legend Biotech Co.,Ltd. | Pd−1に対する単一ドメイン抗体及びその変異体 |
| WO2022194153A1 (zh) * | 2021-03-16 | 2022-09-22 | 中国科学院上海药物研究所 | Pd-l1和tlr7双靶向纳米抗体偶联药物及其在抗肿瘤中的应用 |
-
2022
- 2022-11-30 JP JP2023565059A patent/JPWO2023100944A1/ja active Pending
- 2022-11-30 WO PCT/JP2022/044235 patent/WO2023100944A1/ja not_active Ceased
- 2022-11-30 CN CN202280079930.3A patent/CN118339180A/zh active Pending
- 2022-11-30 EP EP22901376.8A patent/EP4442704A1/en not_active Ceased
- 2022-11-30 US US18/714,591 patent/US20250019460A1/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003025020A1 (en) | 2001-09-13 | 2003-03-27 | Institute For Antibodies Co., Ltd. | Method of constructing camel antibody library |
| JP2008515446A (ja) * | 2004-10-13 | 2008-05-15 | アブリンクス ナームローゼ フェンノートシャップ | アミロイド−βに対するナノ抗体及びアルツハイマー病のような神経変性疾患の治療のためのナノ抗体TMを含むポリペプチド |
| WO2012145469A1 (en) * | 2011-04-19 | 2012-10-26 | The United States Of America, As Represented By The Secretary, Department Of Health & Human Services | Human monoclonal antibodies specific for glypican-3 and use thereof |
| JP2021510521A (ja) * | 2018-01-15 | 2021-04-30 | ナンジン レジェンド バイオテック カンパニー,リミテッドNanjing Legend Biotech Co.,Ltd. | Pd−1に対する単一ドメイン抗体及びその変異体 |
| WO2020076970A1 (en) * | 2018-10-11 | 2020-04-16 | Inhibrx, Inc. | B7h3 single domain antibodies and therapeutic compositions thereof |
| WO2022194153A1 (zh) * | 2021-03-16 | 2022-09-22 | 中国科学院上海药物研究所 | Pd-l1和tlr7双靶向纳米抗体偶联药物及其在抗肿瘤中的应用 |
Non-Patent Citations (2)
| Title |
|---|
| M. ARBABI GHAHROUDI ET AL., FEBS LETTERS, vol. 414, 1997, pages 521 - 526 |
| MARC LAUWEREYS ET AL., EMBO J, vol. 17, no. 13, 1998, pages 3512 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20250019460A1 (en) | 2025-01-16 |
| JPWO2023100944A1 (https=) | 2023-06-08 |
| EP4442704A1 (en) | 2024-10-09 |
| CN118339180A (zh) | 2024-07-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Feng et al. | Construction and next-generation sequencing analysis of a large phage-displayed VNAR single-domain antibody library from six naive nurse sharks | |
| Tiller et al. | A fully synthetic human Fab antibody library based on fixed VH/VL framework pairings with favorable biophysical properties | |
| CN110799532B (zh) | 犬抗体文库 | |
| EP2647704B1 (en) | Polynucleotide construct capable of presenting fab in acellular translation system, and method for manufacturing and screening fab using same | |
| CN102449149B (zh) | 集合及其使用方法 | |
| JP6073038B2 (ja) | 安定化された免疫グロブリン可変ドメイン選別方法及び選別されたドメインの応用 | |
| JP2015531597A5 (https=) | ||
| JP2023518900A (ja) | 抗原特異的結合ポリペプチド遺伝子ディスプレイベクターの構築方法および用途 | |
| US12378696B2 (en) | Antibody library and method | |
| KR102194203B1 (ko) | 항체 나이브 라이브러리의 생성 방법, 상기 라이브러리 및 그 적용(들) | |
| WO2023100944A1 (ja) | ランダム領域搭載用フレームワーク配列を有するペプチド及びそのペプチドで構成されるペプチドライブラリ | |
| KR102216032B1 (ko) | 합성 항체 라이브러리의 생성 방법, 상기 라이브러리 및 그 적용(들) | |
| CN112424221B (zh) | 抗体文库和使用抗体文库的抗体筛选方法 | |
| JP2020534796A (ja) | エピトープ翻訳後修飾状態に特異的な抗体の開発方法及び開発のための組成物 | |
| US20140206579A1 (en) | Dna libraries encoding frameworks with synthetic cdr regions | |
| JP2024075076A (ja) | 新規変異導入方法による進化ライブラリの作成およびそのライブラリを用いたペプチドスクリーニング方法 | |
| EP2027265A1 (en) | Highly diversified antibody libraries | |
| Yang | Phage Display Technology: Design, Library Construction, and Panning Strategies for Antibody Development | |
| JP6293829B2 (ja) | 安定化された免疫グロブリン可変ドメイン選別方法及び選別されたドメインの応用 | |
| CN121717907A (zh) | 人bcma抗体及其应用 | |
| Douthwaite et al. | Accelerated protein evolution using ribosome display | |
| JP2013180966A (ja) | ヒトアルブミン測定用抗体試薬 | |
| HK40039219B (zh) | 抗体文库和使用抗体文库的抗体筛选方法 | |
| HK40022793A (en) | Canine antibody libraries | |
| AU2002353886A1 (en) | Hybridization control of sequence variation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22901376 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023565059 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18714591 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280079930.3 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 11202403262U Country of ref document: SG |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2022901376 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022901376 Country of ref document: EP Effective date: 20240701 |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2022901376 Country of ref document: EP |