WO2022154116A1 - 化合物またはその塩、およびそれらにより得られる抗体 - Google Patents
化合物またはその塩、およびそれらにより得られる抗体 Download PDFInfo
- Publication number
- WO2022154116A1 WO2022154116A1 PCT/JP2022/001358 JP2022001358W WO2022154116A1 WO 2022154116 A1 WO2022154116 A1 WO 2022154116A1 JP 2022001358 W JP2022001358 W JP 2022001358W WO 2022154116 A1 WO2022154116 A1 WO 2022154116A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- linker
- salt
- indicates
- group
- antibody
- Prior art date
Links
- 150000003839 salts Chemical class 0.000 title claims abstract description 238
- 150000001875 compounds Chemical class 0.000 title claims abstract description 197
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 253
- 230000027455 binding Effects 0.000 claims abstract description 127
- 238000009739 binding Methods 0.000 claims abstract description 127
- 125000004429 atom Chemical group 0.000 claims abstract description 108
- 239000000126 substance Substances 0.000 claims abstract description 98
- 229910052717 sulfur Inorganic materials 0.000 claims abstract description 91
- 108060003951 Immunoglobulin Proteins 0.000 claims abstract description 88
- 102000018358 immunoglobulin Human genes 0.000 claims abstract description 88
- 125000004434 sulfur atom Chemical group 0.000 claims abstract description 58
- 125000004430 oxygen atom Chemical group O* 0.000 claims abstract description 56
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 claims description 99
- -1 pentafluorophenyloxy group Chemical group 0.000 claims description 98
- 125000001424 substituent group Chemical group 0.000 claims description 94
- 125000004435 hydrogen atom Chemical group [H]* 0.000 claims description 52
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 claims description 42
- 239000003153 chemical reaction reagent Substances 0.000 claims description 40
- 125000003396 thiol group Chemical group [H]S* 0.000 claims description 40
- 238000003776 cleavage reaction Methods 0.000 claims description 38
- 125000000623 heterocyclic group Chemical group 0.000 claims description 37
- 125000000539 amino acid group Chemical group 0.000 claims description 31
- 125000003277 amino group Chemical group 0.000 claims description 31
- 229910052760 oxygen Inorganic materials 0.000 claims description 31
- 150000007970 thio esters Chemical class 0.000 claims description 31
- 238000000034 method Methods 0.000 claims description 28
- 238000004519 manufacturing process Methods 0.000 claims description 27
- 229910052721 tungsten Inorganic materials 0.000 claims description 27
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 claims description 18
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 17
- 125000005843 halogen group Chemical group 0.000 claims description 17
- 229910052727 yttrium Inorganic materials 0.000 claims description 13
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 12
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 claims description 9
- 238000001212 derivatisation Methods 0.000 claims description 8
- 229910052757 nitrogen Inorganic materials 0.000 claims description 8
- 125000004433 nitrogen atom Chemical group N* 0.000 claims description 8
- 125000002887 hydroxy group Chemical group [H]O* 0.000 claims description 7
- 125000001433 C-terminal amino-acid group Chemical group 0.000 claims description 4
- 125000000729 N-terminal amino-acid group Chemical group 0.000 claims description 4
- 229910052731 fluorine Inorganic materials 0.000 claims description 3
- 125000001153 fluoro group Chemical group F* 0.000 claims description 3
- 229910052746 lanthanum Inorganic materials 0.000 claims 11
- 125000003275 alpha amino acid group Chemical group 0.000 claims 8
- 125000001183 hydrocarbyl group Chemical group 0.000 claims 3
- 125000005647 linker group Chemical group 0.000 description 149
- 125000004432 carbon atom Chemical group C* 0.000 description 109
- 229960000575 trastuzumab Drugs 0.000 description 107
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 87
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical compound CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 78
- 230000004048 modification Effects 0.000 description 73
- 238000012986 modification Methods 0.000 description 73
- 150000003573 thiols Chemical group 0.000 description 68
- 238000004458 analytical method Methods 0.000 description 64
- 238000001269 time-of-flight mass spectrometry Methods 0.000 description 60
- 239000000543 intermediate Substances 0.000 description 56
- 150000001413 amino acids Chemical group 0.000 description 55
- 239000000243 solution Substances 0.000 description 55
- 238000006243 chemical reaction Methods 0.000 description 52
- 239000000047 product Substances 0.000 description 48
- 150000002430 hydrocarbons Chemical group 0.000 description 42
- 239000000562 conjugate Substances 0.000 description 38
- 125000000217 alkyl group Chemical group 0.000 description 34
- 238000012790 confirmation Methods 0.000 description 34
- 102000004196 processed proteins & peptides Human genes 0.000 description 33
- 239000003814 drug Substances 0.000 description 32
- 239000002994 raw material Substances 0.000 description 31
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 30
- 229940079593 drug Drugs 0.000 description 30
- 125000006615 aromatic heterocyclic group Chemical group 0.000 description 28
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 27
- ZMXDDKWLCZADIW-UHFFFAOYSA-N N,N-Dimethylformamide Chemical compound CN(C)C=O ZMXDDKWLCZADIW-UHFFFAOYSA-N 0.000 description 26
- 229910052799 carbon Inorganic materials 0.000 description 26
- 102000004169 proteins and genes Human genes 0.000 description 26
- 108090000623 proteins and genes Proteins 0.000 description 26
- 238000010586 diagram Methods 0.000 description 25
- 108090000631 Trypsin Proteins 0.000 description 24
- 102000004142 Trypsin Human genes 0.000 description 24
- 235000018102 proteins Nutrition 0.000 description 24
- 239000012588 trypsin Substances 0.000 description 24
- 239000000203 mixture Substances 0.000 description 23
- 239000000872 buffer Substances 0.000 description 22
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 21
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 21
- 230000015572 biosynthetic process Effects 0.000 description 21
- RMVRSNDYEFQCLF-UHFFFAOYSA-N thiophenol Substances SC1=CC=CC=C1 RMVRSNDYEFQCLF-UHFFFAOYSA-N 0.000 description 21
- 239000012190 activator Substances 0.000 description 20
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 19
- 238000003786 synthesis reaction Methods 0.000 description 19
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 18
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 18
- 125000004122 cyclic group Chemical group 0.000 description 18
- 125000000753 cycloalkyl group Chemical group 0.000 description 18
- 239000011259 mixed solution Substances 0.000 description 18
- 230000007017 scission Effects 0.000 description 17
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 16
- 239000007864 aqueous solution Substances 0.000 description 16
- 238000004587 chromatography analysis Methods 0.000 description 16
- 239000000611 antibody drug conjugate Substances 0.000 description 15
- 229940049595 antibody-drug conjugate Drugs 0.000 description 15
- 238000004949 mass spectrometry Methods 0.000 description 15
- 239000003960 organic solvent Substances 0.000 description 14
- 238000012510 peptide mapping method Methods 0.000 description 12
- 238000001228 spectrum Methods 0.000 description 12
- 125000003710 aryl alkyl group Chemical group 0.000 description 11
- PGLTVOMIXTUURA-UHFFFAOYSA-N iodoacetamide Chemical compound NC(=O)CI PGLTVOMIXTUURA-UHFFFAOYSA-N 0.000 description 11
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 10
- USFZMSVCRYTOJT-UHFFFAOYSA-N Ammonium acetate Chemical compound N.CC(O)=O USFZMSVCRYTOJT-UHFFFAOYSA-N 0.000 description 10
- 239000005695 Ammonium acetate Substances 0.000 description 10
- 239000007995 HEPES buffer Substances 0.000 description 10
- 102000035195 Peptidases Human genes 0.000 description 10
- 108091005804 Peptidases Proteins 0.000 description 10
- 239000004365 Protease Substances 0.000 description 10
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 10
- 235000019257 ammonium acetate Nutrition 0.000 description 10
- 229940043376 ammonium acetate Drugs 0.000 description 10
- 125000003118 aryl group Chemical group 0.000 description 10
- 239000000460 chlorine Substances 0.000 description 10
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 9
- 230000021615 conjugation Effects 0.000 description 9
- 201000010099 disease Diseases 0.000 description 9
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 9
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 9
- 125000000732 arylene group Chemical group 0.000 description 8
- 239000007795 chemical reaction product Substances 0.000 description 8
- 125000000524 functional group Chemical group 0.000 description 8
- 230000014509 gene expression Effects 0.000 description 8
- 125000003342 alkenyl group Chemical group 0.000 description 7
- 125000002947 alkylene group Chemical group 0.000 description 7
- 125000000304 alkynyl group Chemical group 0.000 description 7
- 235000018417 cysteine Nutrition 0.000 description 7
- 230000029087 digestion Effects 0.000 description 7
- 238000001962 electrophoresis Methods 0.000 description 7
- 229930195733 hydrocarbon Natural products 0.000 description 7
- 238000005259 measurement Methods 0.000 description 7
- 239000012071 phase Substances 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 6
- 108010033276 Peptide Fragments Proteins 0.000 description 6
- 102000007079 Peptide Fragments Human genes 0.000 description 6
- 101710118538 Protease Proteins 0.000 description 6
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 6
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 6
- 239000000427 antigen Substances 0.000 description 6
- 108091007433 antigens Proteins 0.000 description 6
- 102000036639 antigens Human genes 0.000 description 6
- 125000002029 aromatic hydrocarbon group Chemical group 0.000 description 6
- 239000003431 cross linking reagent Substances 0.000 description 6
- 125000000392 cycloalkenyl group Chemical group 0.000 description 6
- 239000000945 filler Substances 0.000 description 6
- IXCSERBJSXMMFS-UHFFFAOYSA-N hydrogen chloride Substances Cl.Cl IXCSERBJSXMMFS-UHFFFAOYSA-N 0.000 description 6
- 229910000041 hydrogen chloride Inorganic materials 0.000 description 6
- 150000002500 ions Chemical class 0.000 description 6
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 6
- 125000002950 monocyclic group Chemical group 0.000 description 6
- 102000039446 nucleic acids Human genes 0.000 description 6
- 108020004707 nucleic acids Proteins 0.000 description 6
- 150000007523 nucleic acids Chemical class 0.000 description 6
- 230000035484 reaction time Effects 0.000 description 6
- 239000000741 silica gel Substances 0.000 description 6
- 229910002027 silica gel Inorganic materials 0.000 description 6
- 239000003381 stabilizer Substances 0.000 description 6
- 239000004215 Carbon black (E152) Substances 0.000 description 5
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 5
- 108090000317 Chymotrypsin Proteins 0.000 description 5
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 5
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 5
- 108050003558 Interleukin-17 Proteins 0.000 description 5
- 102000013691 Interleukin-17 Human genes 0.000 description 5
- 238000005481 NMR spectroscopy Methods 0.000 description 5
- 125000004450 alkenylene group Chemical group 0.000 description 5
- 125000004419 alkynylene group Chemical group 0.000 description 5
- 235000001014 amino acid Nutrition 0.000 description 5
- 229940024606 amino acid Drugs 0.000 description 5
- 239000002246 antineoplastic agent Substances 0.000 description 5
- 229960002376 chymotrypsin Drugs 0.000 description 5
- 125000000118 dimethyl group Chemical group [H]C([H])([H])* 0.000 description 5
- 230000000694 effects Effects 0.000 description 5
- 238000004128 high performance liquid chromatography Methods 0.000 description 5
- 229910052739 hydrogen Inorganic materials 0.000 description 5
- 239000001257 hydrogen Substances 0.000 description 5
- 239000008194 pharmaceutical composition Substances 0.000 description 5
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 5
- 125000003367 polycyclic group Chemical group 0.000 description 5
- 238000004007 reversed phase HPLC Methods 0.000 description 5
- VCQURUZYYSOUHP-UHFFFAOYSA-N (2,3,4,5,6-pentafluorophenyl) 2,2,2-trifluoroacetate Chemical compound FC1=C(F)C(F)=C(OC(=O)C(F)(F)F)C(F)=C1F VCQURUZYYSOUHP-UHFFFAOYSA-N 0.000 description 4
- 102100037241 Endoglin Human genes 0.000 description 4
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- JGFZNNIVVJXRND-UHFFFAOYSA-N N,N-Diisopropylethylamine (DIPEA) Chemical compound CCN(C(C)C)C(C)C JGFZNNIVVJXRND-UHFFFAOYSA-N 0.000 description 4
- 241000209094 Oryza Species 0.000 description 4
- 235000007164 Oryza sativa Nutrition 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- WYURNTSHIVDZCO-UHFFFAOYSA-N Tetrahydrofuran Chemical compound C1CCOC1 WYURNTSHIVDZCO-UHFFFAOYSA-N 0.000 description 4
- HEDRZPFGACZZDS-MICDWDOJSA-N Trichloro(2H)methane Chemical compound [2H]C(Cl)(Cl)Cl HEDRZPFGACZZDS-MICDWDOJSA-N 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- 238000001042 affinity chromatography Methods 0.000 description 4
- 125000002723 alicyclic group Chemical group 0.000 description 4
- 238000001641 gel filtration chromatography Methods 0.000 description 4
- 238000004255 ion exchange chromatography Methods 0.000 description 4
- 238000002372 labelling Methods 0.000 description 4
- 125000006239 protecting group Chemical group 0.000 description 4
- 235000009566 rice Nutrition 0.000 description 4
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 4
- 125000000341 threoninyl group Chemical group [H]OC([H])(C([H])([H])[H])C([H])(N([H])[H])C(*)=O 0.000 description 4
- 239000003053 toxin Substances 0.000 description 4
- 231100000765 toxin Toxicity 0.000 description 4
- 108700012359 toxins Proteins 0.000 description 4
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 4
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 3
- 108010090849 Amyloid beta-Peptides Proteins 0.000 description 3
- 102000013455 Amyloid beta-Peptides Human genes 0.000 description 3
- 102100034608 Angiopoietin-2 Human genes 0.000 description 3
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 3
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 3
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 3
- 101150013553 CD40 gene Proteins 0.000 description 3
- 108010036395 Endoglin Proteins 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 description 3
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 description 3
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 3
- 101000924533 Homo sapiens Angiopoietin-2 Proteins 0.000 description 3
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 3
- 101000914321 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 7 Proteins 0.000 description 3
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 3
- 101000617725 Homo sapiens Pregnancy-specific beta-1-glycoprotein 2 Proteins 0.000 description 3
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 description 3
- 108010001127 Insulin Receptor Proteins 0.000 description 3
- 102100036721 Insulin receptor Human genes 0.000 description 3
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 3
- 239000004472 Lysine Substances 0.000 description 3
- 101001018085 Lysobacter enzymogenes Lysyl endopeptidase Proteins 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 125000001429 N-terminal alpha-amino-acid group Chemical group 0.000 description 3
- 206010028980 Neoplasm Diseases 0.000 description 3
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 3
- 229920002472 Starch Polymers 0.000 description 3
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 description 3
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N aspartic acid group Chemical group N[C@@H](CC(=O)O)C(=O)O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- 230000033228 biological regulation Effects 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 239000007853 buffer solution Substances 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- 235000015165 citric acid Nutrition 0.000 description 3
- 238000004440 column chromatography Methods 0.000 description 3
- 239000013078 crystal Substances 0.000 description 3
- 238000004925 denaturation Methods 0.000 description 3
- 230000036425 denaturation Effects 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- 235000019253 formic acid Nutrition 0.000 description 3
- 238000004108 freeze drying Methods 0.000 description 3
- 235000013922 glutamic acid Nutrition 0.000 description 3
- 239000004220 glutamic acid Substances 0.000 description 3
- 125000005842 heteroatom Chemical group 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 3
- 150000007522 mineralic acids Chemical class 0.000 description 3
- 238000002715 modification method Methods 0.000 description 3
- 125000001624 naphthyl group Chemical group 0.000 description 3
- 150000007524 organic acids Chemical class 0.000 description 3
- 239000012044 organic layer Substances 0.000 description 3
- 125000004437 phosphorous atom Chemical group 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 239000002504 physiological saline solution Substances 0.000 description 3
- 239000003755 preservative agent Substances 0.000 description 3
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 3
- 239000011347 resin Substances 0.000 description 3
- 229920005989 resin Polymers 0.000 description 3
- UQDJGEHQDNVPGU-UHFFFAOYSA-N serine phosphoethanolamine Chemical compound [NH3+]CCOP([O-])(=O)OCC([NH3+])C([O-])=O UQDJGEHQDNVPGU-UHFFFAOYSA-N 0.000 description 3
- 235000019698 starch Nutrition 0.000 description 3
- 239000008107 starch Substances 0.000 description 3
- 238000003756 stirring Methods 0.000 description 3
- 229960001612 trastuzumab emtansine Drugs 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 2
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 2
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 2
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 description 2
- VHYFNPMBLIVWCW-UHFFFAOYSA-N 4-Dimethylaminopyridine Chemical compound CN(C)C1=CC=NC=C1 VHYFNPMBLIVWCW-UHFFFAOYSA-N 0.000 description 2
- 102100022464 5'-nucleotidase Human genes 0.000 description 2
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 2
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical group [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 2
- 102100026882 Alpha-synuclein Human genes 0.000 description 2
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 2
- 229910000013 Ammonium bicarbonate Inorganic materials 0.000 description 2
- 108091023037 Aptamer Proteins 0.000 description 2
- 101100296075 Arabidopsis thaliana PLL4 gene Proteins 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- 208000023275 Autoimmune disease Diseases 0.000 description 2
- 108010028006 B-Cell Activating Factor Proteins 0.000 description 2
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 2
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- 108010074708 B7-H1 Antigen Proteins 0.000 description 2
- ZOXJGFHDIHLPTG-UHFFFAOYSA-N Boron Chemical group [B] ZOXJGFHDIHLPTG-UHFFFAOYSA-N 0.000 description 2
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 2
- 108010056102 CD100 antigen Proteins 0.000 description 2
- 102100038078 CD276 antigen Human genes 0.000 description 2
- 101710185679 CD276 antigen Proteins 0.000 description 2
- 108010065524 CD52 Antigen Proteins 0.000 description 2
- 102100025221 CD70 antigen Human genes 0.000 description 2
- VTYYLEPIZMXCLO-UHFFFAOYSA-L Calcium carbonate Chemical compound [Ca+2].[O-]C([O-])=O VTYYLEPIZMXCLO-UHFFFAOYSA-L 0.000 description 2
- 208000035473 Communicable disease Diseases 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- VZCYOOQTPOCHFL-OWOJBTEDSA-N Fumaric acid Chemical compound OC(=O)\C=C\C(O)=O VZCYOOQTPOCHFL-OWOJBTEDSA-N 0.000 description 2
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 2
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 102100039939 Growth/differentiation factor 8 Human genes 0.000 description 2
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000678236 Homo sapiens 5'-nucleotidase Proteins 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 2
- 101100334515 Homo sapiens FCGR3A gene Proteins 0.000 description 2
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 description 2
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 description 2
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 2
- 101000845170 Homo sapiens Thymic stromal lymphopoietin Proteins 0.000 description 2
- CPELXLSAUQHCOX-UHFFFAOYSA-N Hydrogen bromide Chemical compound Br CPELXLSAUQHCOX-UHFFFAOYSA-N 0.000 description 2
- WTDHULULXKLSOZ-UHFFFAOYSA-N Hydroxylamine hydrochloride Chemical compound Cl.ON WTDHULULXKLSOZ-UHFFFAOYSA-N 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 208000026350 Inborn Genetic disease Diseases 0.000 description 2
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 2
- 102000014429 Insulin-like growth factor Human genes 0.000 description 2
- 108090000176 Interleukin-13 Proteins 0.000 description 2
- 102000003816 Interleukin-13 Human genes 0.000 description 2
- 108010065637 Interleukin-23 Proteins 0.000 description 2
- 102000017578 LAG3 Human genes 0.000 description 2
- 101150030213 Lag3 gene Proteins 0.000 description 2
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 2
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 2
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 description 2
- 101710150918 Macrophage colony-stimulating factor 1 receptor Proteins 0.000 description 2
- 208000024556 Mendelian disease Diseases 0.000 description 2
- 208000012902 Nervous system disease Diseases 0.000 description 2
- 208000025966 Neurological disease Diseases 0.000 description 2
- 108091008606 PDGF receptors Proteins 0.000 description 2
- 102000011653 Platelet-Derived Growth Factor Receptors Human genes 0.000 description 2
- 239000002202 Polyethylene glycol Substances 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 2
- ODHCTXKNWHHXJC-GSVOUGTGSA-N Pyroglutamic acid Natural products OC(=O)[C@H]1CCC(=O)N1 ODHCTXKNWHHXJC-GSVOUGTGSA-N 0.000 description 2
- 208000035977 Rare disease Diseases 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- 102100027744 Semaphorin-4D Human genes 0.000 description 2
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical group [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 2
- UIIMBOGNXHQVGW-UHFFFAOYSA-M Sodium bicarbonate Chemical compound [Na+].OC([O-])=O UIIMBOGNXHQVGW-UHFFFAOYSA-M 0.000 description 2
- 229930006000 Sucrose Natural products 0.000 description 2
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 2
- 102100031294 Thymic stromal lymphopoietin Human genes 0.000 description 2
- DTQVDTLACAAQTR-UHFFFAOYSA-M Trifluoroacetate Chemical compound [O-]C(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-M 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 2
- 102100036922 Tumor necrosis factor ligand superfamily member 13B Human genes 0.000 description 2
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 2
- 102100039037 Vascular endothelial growth factor A Human genes 0.000 description 2
- NLMBVBUNULOTNS-HOKPPMCLSA-N [4-[[(2s)-5-(carbamoylamino)-2-[[(2s)-2-[6-(2,5-dioxopyrrol-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl n-[(2s)-1-[[(2s)-1-[[(3r,4s,5s)-1-[(2s)-2-[(1r,2r)-3-[[(1s,2r)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-o Chemical compound C1([C@H](O)[C@@H](C)NC(=O)[C@H](C)[C@@H](OC)[C@@H]2CCCN2C(=O)C[C@H]([C@H]([C@@H](C)CC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCC=2C=CC(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN3C(C=CC3=O)=O)C(C)C)=CC=2)C(C)C)OC)=CC=CC=C1 NLMBVBUNULOTNS-HOKPPMCLSA-N 0.000 description 2
- 235000011054 acetic acid Nutrition 0.000 description 2
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 2
- ODHCTXKNWHHXJC-UHFFFAOYSA-N acide pyroglutamique Natural products OC(=O)C1CCC(=O)N1 ODHCTXKNWHHXJC-UHFFFAOYSA-N 0.000 description 2
- 230000002378 acidificating effect Effects 0.000 description 2
- WNLRTRBMVRJNCN-UHFFFAOYSA-N adipic acid Chemical compound OC(=O)CCCCC(O)=O WNLRTRBMVRJNCN-UHFFFAOYSA-N 0.000 description 2
- 108090000185 alpha-Synuclein Proteins 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 235000012538 ammonium bicarbonate Nutrition 0.000 description 2
- 239000001099 ammonium carbonate Substances 0.000 description 2
- 239000003963 antioxidant agent Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 210000000988 bone and bone Anatomy 0.000 description 2
- 229910052796 boron Inorganic materials 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 239000003054 catalyst Substances 0.000 description 2
- 210000004027 cell Anatomy 0.000 description 2
- 239000001913 cellulose Substances 0.000 description 2
- 229920002678 cellulose Polymers 0.000 description 2
- 229960004106 citric acid Drugs 0.000 description 2
- 238000005520 cutting process Methods 0.000 description 2
- 125000004093 cyano group Chemical group *C#N 0.000 description 2
- 229940127089 cytotoxic agent Drugs 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 239000002612 dispersion medium Substances 0.000 description 2
- 239000012153 distilled water Substances 0.000 description 2
- 125000003438 dodecyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 2
- 239000003937 drug carrier Substances 0.000 description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 2
- 125000000816 ethylene group Chemical group [H]C([H])([*:1])C([H])([H])[*:2] 0.000 description 2
- 208000030533 eye disease Diseases 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 102000006815 folate receptor Human genes 0.000 description 2
- 108020005243 folate receptor Proteins 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 2
- 208000014951 hematologic disease Diseases 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 230000007062 hydrolysis Effects 0.000 description 2
- 238000006460 hydrolysis reaction Methods 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 150000007529 inorganic bases Chemical class 0.000 description 2
- 108010024069 integrin alpha9 Proteins 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 229910052740 iodine Inorganic materials 0.000 description 2
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 230000014759 maintenance of location Effects 0.000 description 2
- 102000006240 membrane receptors Human genes 0.000 description 2
- 108020004084 membrane receptors Proteins 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 150000002739 metals Chemical class 0.000 description 2
- 229920000609 methyl cellulose Polymers 0.000 description 2
- 239000001923 methylcellulose Substances 0.000 description 2
- 235000010981 methylcellulose Nutrition 0.000 description 2
- LXCFILQKKLGQFO-UHFFFAOYSA-N methylparaben Chemical compound COC(=O)C1=CC=C(O)C=C1 LXCFILQKKLGQFO-UHFFFAOYSA-N 0.000 description 2
- 239000012046 mixed solvent Substances 0.000 description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 2
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 2
- 235000015205 orange juice Nutrition 0.000 description 2
- 150000007530 organic bases Chemical class 0.000 description 2
- 230000000399 orthopedic effect Effects 0.000 description 2
- CTSLXHKWHWQRSH-UHFFFAOYSA-N oxalyl chloride Chemical compound ClC(=O)C(Cl)=O CTSLXHKWHWQRSH-UHFFFAOYSA-N 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 230000000149 penetrating effect Effects 0.000 description 2
- 108010091748 peptide A Proteins 0.000 description 2
- 229920001223 polyethylene glycol Polymers 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- 125000004805 propylene group Chemical group [H]C([H])([H])C([H])([*:1])C([H])([H])[*:2] 0.000 description 2
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 2
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical compound C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 229910052710 silicon Inorganic materials 0.000 description 2
- 239000005720 sucrose Substances 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-L sulfate group Chemical group S(=O)(=O)([O-])[O-] QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 2
- 125000000542 sulfonic acid group Chemical group 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 239000000375 suspending agent Substances 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 239000000454 talc Substances 0.000 description 2
- 229910052623 talc Inorganic materials 0.000 description 2
- 102000013498 tau Proteins Human genes 0.000 description 2
- 108010026424 tau Proteins Proteins 0.000 description 2
- JOXIMZWYDAKGHI-UHFFFAOYSA-N toluene-4-sulfonic acid Chemical compound CC1=CC=C(S(O)(=O)=O)C=C1 JOXIMZWYDAKGHI-UHFFFAOYSA-N 0.000 description 2
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- GETQZCLCWQTVFV-UHFFFAOYSA-N trimethylamine Chemical compound CN(C)C GETQZCLCWQTVFV-UHFFFAOYSA-N 0.000 description 2
- NOOLISFMXDJSKH-UTLUCORTSA-N (+)-Neomenthol Chemical compound CC(C)[C@@H]1CC[C@@H](C)C[C@@H]1O NOOLISFMXDJSKH-UTLUCORTSA-N 0.000 description 1
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 1
- BJEPYKJPYRNKOW-REOHCLBHSA-N (S)-malic acid Chemical compound OC(=O)[C@@H](O)CC(O)=O BJEPYKJPYRNKOW-REOHCLBHSA-N 0.000 description 1
- PJOHVEQSYPOERL-SHEAVXILSA-N (e)-n-[(4r,4as,7ar,12br)-3-(cyclopropylmethyl)-9-hydroxy-7-oxo-2,4,5,6,7a,13-hexahydro-1h-4,12-methanobenzofuro[3,2-e]isoquinoline-4a-yl]-3-(4-methylphenyl)prop-2-enamide Chemical compound C1=CC(C)=CC=C1\C=C\C(=O)N[C@]1(CCC(=O)[C@@H]2O3)[C@H]4CC5=CC=C(O)C3=C5[C@]12CCN4CC1CC1 PJOHVEQSYPOERL-SHEAVXILSA-N 0.000 description 1
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- DHBXNPKRAUYBTH-UHFFFAOYSA-N 1,1-ethanedithiol Chemical compound CC(S)S DHBXNPKRAUYBTH-UHFFFAOYSA-N 0.000 description 1
- 125000001989 1,3-phenylene group Chemical group [H]C1=C([H])C([*:1])=C([H])C([*:2])=C1[H] 0.000 description 1
- VXNZUUAINFGPBY-UHFFFAOYSA-N 1-Butene Chemical group CCC=C VXNZUUAINFGPBY-UHFFFAOYSA-N 0.000 description 1
- BJHCYTJNPVGSBZ-YXSASFKJSA-N 1-[4-[6-amino-5-[(Z)-methoxyiminomethyl]pyrimidin-4-yl]oxy-2-chlorophenyl]-3-ethylurea Chemical compound CCNC(=O)Nc1ccc(Oc2ncnc(N)c2\C=N/OC)cc1Cl BJHCYTJNPVGSBZ-YXSASFKJSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- 125000000094 2-phenylethyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])([H])* 0.000 description 1
- BZSVVCFHMVMYCR-UHFFFAOYSA-N 2-pyridin-2-ylpyridine;ruthenium Chemical compound [Ru].N1=CC=CC=C1C1=CC=CC=N1.N1=CC=CC=C1C1=CC=CC=N1.N1=CC=CC=C1C1=CC=CC=N1 BZSVVCFHMVMYCR-UHFFFAOYSA-N 0.000 description 1
- BOLMDIXLULGTBD-UHFFFAOYSA-N 3,4-dihydro-2h-oxazine Chemical compound C1CC=CON1 BOLMDIXLULGTBD-UHFFFAOYSA-N 0.000 description 1
- 229960000549 4-dimethylaminophenol Drugs 0.000 description 1
- 108010068327 4-hydroxyphenylpyruvate dioxygenase Proteins 0.000 description 1
- 125000002373 5 membered heterocyclic group Chemical group 0.000 description 1
- 125000004070 6 membered heterocyclic group Chemical group 0.000 description 1
- FHVDTGUDJYJELY-UHFFFAOYSA-N 6-{[2-carboxy-4,5-dihydroxy-6-(phosphanyloxy)oxan-3-yl]oxy}-4,5-dihydroxy-3-phosphanyloxane-2-carboxylic acid Chemical compound O1C(C(O)=O)C(P)C(O)C(O)C1OC1C(C(O)=O)OC(OP)C(O)C1O FHVDTGUDJYJELY-UHFFFAOYSA-N 0.000 description 1
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 1
- 244000215068 Acacia senegal Species 0.000 description 1
- 241000589291 Acinetobacter Species 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 101710092462 Alpha-hemolysin Proteins 0.000 description 1
- 101710197219 Alpha-toxin Proteins 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 102100025668 Angiopoietin-related protein 3 Human genes 0.000 description 1
- 102100027203 B-cell antigen receptor complex-associated protein beta chain Human genes 0.000 description 1
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 1
- 208000035143 Bacterial infection Diseases 0.000 description 1
- 231100000699 Bacterial toxin Toxicity 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 108010049974 Bone Morphogenetic Protein 6 Proteins 0.000 description 1
- 206010005949 Bone cancer Diseases 0.000 description 1
- 102100022525 Bone morphogenetic protein 6 Human genes 0.000 description 1
- 208000018084 Bone neoplasm Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- WKBOTKDWSSQWDR-UHFFFAOYSA-N Bromine atom Chemical group [Br] WKBOTKDWSSQWDR-UHFFFAOYSA-N 0.000 description 1
- 102100036848 C-C motif chemokine 20 Human genes 0.000 description 1
- 102100036166 C-X-C chemokine receptor type 1 Human genes 0.000 description 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 1
- 102100026094 C-type lectin domain family 12 member A Human genes 0.000 description 1
- 108700012439 CA9 Proteins 0.000 description 1
- 102100024210 CD166 antigen Human genes 0.000 description 1
- 102100027207 CD27 antigen Human genes 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 102000000905 Cadherin Human genes 0.000 description 1
- 108050007957 Cadherin Proteins 0.000 description 1
- 102100024155 Cadherin-11 Human genes 0.000 description 1
- 102100038518 Calcitonin Human genes 0.000 description 1
- 108090000932 Calcitonin Gene-Related Peptide Proteins 0.000 description 1
- 108010078311 Calcitonin Gene-Related Peptide Receptors Proteins 0.000 description 1
- 102000014468 Calcitonin Gene-Related Peptide Receptors Human genes 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 102100033868 Cannabinoid receptor 1 Human genes 0.000 description 1
- 101710187010 Cannabinoid receptor 1 Proteins 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 102100036369 Carbonic anhydrase 6 Human genes 0.000 description 1
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 208000024172 Cardiovascular disease Diseases 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 102100023126 Cell surface glycoprotein MUC18 Human genes 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 108010082548 Chemokine CCL11 Proteins 0.000 description 1
- 108700022831 Clostridium difficile toxB Proteins 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 102000001189 Cyclic Peptides Human genes 0.000 description 1
- 108010069514 Cyclic Peptides Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- NOOLISFMXDJSKH-UHFFFAOYSA-N DL-menthol Natural products CC(C)C1CCC(C)CC1O NOOLISFMXDJSKH-UHFFFAOYSA-N 0.000 description 1
- 239000012623 DNA damaging agent Substances 0.000 description 1
- 230000007018 DNA scission Effects 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 241000417321 Daemonorops aurea Species 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 102100033553 Delta-like protein 4 Human genes 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- 206010012689 Diabetic retinopathy Diseases 0.000 description 1
- 102100030074 Dickkopf-related protein 1 Human genes 0.000 description 1
- 101710099518 Dickkopf-related protein 1 Proteins 0.000 description 1
- BUDQDWGNQVEFAC-UHFFFAOYSA-N Dihydropyran Chemical compound C1COC=CC1 BUDQDWGNQVEFAC-UHFFFAOYSA-N 0.000 description 1
- SNRUBQQJIBEYMU-UHFFFAOYSA-N Dodecane Natural products CCCCCCCCCCCC SNRUBQQJIBEYMU-UHFFFAOYSA-N 0.000 description 1
- 102100029722 Ectonucleoside triphosphate diphosphohydrolase 1 Human genes 0.000 description 1
- 102100023688 Eotaxin Human genes 0.000 description 1
- 108010055196 EphA2 Receptor Proteins 0.000 description 1
- 108010055191 EphA3 Receptor Proteins 0.000 description 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 description 1
- 102100030324 Ephrin type-A receptor 3 Human genes 0.000 description 1
- 102100033942 Ephrin-A4 Human genes 0.000 description 1
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 1
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 101000740462 Escherichia coli Beta-lactamase TEM Proteins 0.000 description 1
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 1
- 101710089384 Extracellular protease Proteins 0.000 description 1
- 108010048049 Factor IXa Proteins 0.000 description 1
- 108010014173 Factor X Proteins 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 102100024802 Fibroblast growth factor 23 Human genes 0.000 description 1
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 description 1
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 description 1
- 102100027844 Fibroblast growth factor receptor 4 Human genes 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 102100020997 Fractalkine Human genes 0.000 description 1
- 102000001002 Frizzled-7 Human genes 0.000 description 1
- 108050007985 Frizzled-7 Proteins 0.000 description 1
- 101710198884 GATA-type zinc finger protein 1 Proteins 0.000 description 1
- 102100025101 GATA-type zinc finger protein 1 Human genes 0.000 description 1
- 102100038904 GPI inositol-deacylase Human genes 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 101710088083 Glomulin Proteins 0.000 description 1
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 239000004378 Glycyrrhizin Substances 0.000 description 1
- 102000010956 Glypican Human genes 0.000 description 1
- 108050001154 Glypican Proteins 0.000 description 1
- 108050007237 Glypican-3 Proteins 0.000 description 1
- 101150112082 Gpnmb gene Proteins 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- 102100034221 Growth-regulated alpha protein Human genes 0.000 description 1
- 102100040896 Growth/differentiation factor 15 Human genes 0.000 description 1
- 229920000084 Gum arabic Polymers 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 1
- 102100021866 Hepatocyte growth factor Human genes 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101000693085 Homo sapiens Angiopoietin-related protein 3 Proteins 0.000 description 1
- 101000914491 Homo sapiens B-cell antigen receptor complex-associated protein beta chain Proteins 0.000 description 1
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 1
- 101000713099 Homo sapiens C-C motif chemokine 20 Proteins 0.000 description 1
- 101000947174 Homo sapiens C-X-C chemokine receptor type 1 Proteins 0.000 description 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 1
- 101000912622 Homo sapiens C-type lectin domain family 12 member A Proteins 0.000 description 1
- 101000980840 Homo sapiens CD166 antigen Proteins 0.000 description 1
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 1
- 101000714525 Homo sapiens Carbonic anhydrase 6 Proteins 0.000 description 1
- 101000623903 Homo sapiens Cell surface glycoprotein MUC18 Proteins 0.000 description 1
- 101000872077 Homo sapiens Delta-like protein 4 Proteins 0.000 description 1
- 101001012447 Homo sapiens Ectonucleoside triphosphate diphosphohydrolase 1 Proteins 0.000 description 1
- 101000881679 Homo sapiens Endoglin Proteins 0.000 description 1
- 101000925259 Homo sapiens Ephrin-A4 Proteins 0.000 description 1
- 101001051973 Homo sapiens Fibroblast growth factor 23 Proteins 0.000 description 1
- 101000917134 Homo sapiens Fibroblast growth factor receptor 4 Proteins 0.000 description 1
- 101000854520 Homo sapiens Fractalkine Proteins 0.000 description 1
- 101001099051 Homo sapiens GPI inositol-deacylase Proteins 0.000 description 1
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 1
- 101001069921 Homo sapiens Growth-regulated alpha protein Proteins 0.000 description 1
- 101000893549 Homo sapiens Growth/differentiation factor 15 Proteins 0.000 description 1
- 101000886562 Homo sapiens Growth/differentiation factor 8 Proteins 0.000 description 1
- 101000898034 Homo sapiens Hepatocyte growth factor Proteins 0.000 description 1
- 101001019455 Homo sapiens ICOS ligand Proteins 0.000 description 1
- 101000606465 Homo sapiens Inactive tyrosine-protein kinase 7 Proteins 0.000 description 1
- 101001103039 Homo sapiens Inactive tyrosine-protein kinase transmembrane receptor ROR1 Proteins 0.000 description 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 1
- 101000852965 Homo sapiens Interleukin-1 receptor-like 2 Proteins 0.000 description 1
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 1
- 101000998120 Homo sapiens Interleukin-3 receptor subunit alpha Proteins 0.000 description 1
- 101001076408 Homo sapiens Interleukin-6 Proteins 0.000 description 1
- 101001055222 Homo sapiens Interleukin-8 Proteins 0.000 description 1
- 101000945490 Homo sapiens Killer cell immunoglobulin-like receptor 3DL2 Proteins 0.000 description 1
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 description 1
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 1
- 101001024703 Homo sapiens Nck-associated protein 5 Proteins 0.000 description 1
- 101001103036 Homo sapiens Nuclear receptor ROR-alpha Proteins 0.000 description 1
- 101000589873 Homo sapiens Parathyroid hormone/parathyroid hormone-related peptide receptor Proteins 0.000 description 1
- 101001001487 Homo sapiens Phosphatidylinositol-glycan biosynthesis class F protein Proteins 0.000 description 1
- 101000595923 Homo sapiens Placenta growth factor Proteins 0.000 description 1
- 101000994669 Homo sapiens Potassium voltage-gated channel subfamily A member 3 Proteins 0.000 description 1
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000835984 Homo sapiens SLIT and NTRK-like protein 6 Proteins 0.000 description 1
- 101000709472 Homo sapiens Sialic acid-binding Ig-like lectin 15 Proteins 0.000 description 1
- 101000868152 Homo sapiens Son of sevenless homolog 1 Proteins 0.000 description 1
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 description 1
- 101000669447 Homo sapiens Toll-like receptor 4 Proteins 0.000 description 1
- 101000801433 Homo sapiens Trophoblast glycoprotein Proteins 0.000 description 1
- 101000610604 Homo sapiens Tumor necrosis factor receptor superfamily member 10B Proteins 0.000 description 1
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 1
- 101000685848 Homo sapiens Zinc transporter ZIP6 Proteins 0.000 description 1
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 1
- 208000031226 Hyperlipidaemia Diseases 0.000 description 1
- 102100034980 ICOS ligand Human genes 0.000 description 1
- 229940099539 IL-36 receptor antagonist Drugs 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 102100039813 Inactive tyrosine-protein kinase 7 Human genes 0.000 description 1
- 102100039615 Inactive tyrosine-protein kinase transmembrane receptor ROR1 Human genes 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 108010041012 Integrin alpha4 Proteins 0.000 description 1
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102100036697 Interleukin-1 receptor-like 2 Human genes 0.000 description 1
- 102000003812 Interleukin-15 Human genes 0.000 description 1
- 108090000172 Interleukin-15 Proteins 0.000 description 1
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 description 1
- 102100030703 Interleukin-22 Human genes 0.000 description 1
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 1
- 102000017761 Interleukin-33 Human genes 0.000 description 1
- 108010067003 Interleukin-33 Proteins 0.000 description 1
- 102000004388 Interleukin-4 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 description 1
- 102100026236 Interleukin-8 Human genes 0.000 description 1
- 102000036770 Islet Amyloid Polypeptide Human genes 0.000 description 1
- 108010041872 Islet Amyloid Polypeptide Proteins 0.000 description 1
- 108020003285 Isocitrate lyase Proteins 0.000 description 1
- 241000701460 JC polyomavirus Species 0.000 description 1
- 101150069255 KLRC1 gene Proteins 0.000 description 1
- 208000008839 Kidney Neoplasms Diseases 0.000 description 1
- 102100034840 Killer cell immunoglobulin-like receptor 3DL2 Human genes 0.000 description 1
- 241000588748 Klebsiella Species 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 102000057248 Lipoprotein(a) Human genes 0.000 description 1
- 108010033266 Lipoprotein(a) Proteins 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 208000019693 Lung disease Diseases 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- 102100033486 Lymphocyte antigen 75 Human genes 0.000 description 1
- 101710157884 Lymphocyte antigen 75 Proteins 0.000 description 1
- 108010009254 Lysosomal-Associated Membrane Protein 1 Proteins 0.000 description 1
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 1
- 101100404845 Macaca mulatta NKG2A gene Proteins 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 229930126263 Maytansine Natural products 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 102100034256 Mucin-1 Human genes 0.000 description 1
- 101100262697 Mus musculus Axl gene Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- 108010056852 Myostatin Proteins 0.000 description 1
- 102100022682 NKG2-A/NKG2-B type II integral membrane protein Human genes 0.000 description 1
- 102100036946 Nck-associated protein 5 Human genes 0.000 description 1
- 102100035486 Nectin-4 Human genes 0.000 description 1
- 101710043865 Nectin-4 Proteins 0.000 description 1
- 102000015336 Nerve Growth Factor Human genes 0.000 description 1
- 108010025020 Nerve Growth Factor Proteins 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 102000001759 Notch1 Receptor Human genes 0.000 description 1
- 108010029755 Notch1 Receptor Proteins 0.000 description 1
- 102000001756 Notch2 Receptor Human genes 0.000 description 1
- 108010029751 Notch2 Receptor Proteins 0.000 description 1
- 102000001760 Notch3 Receptor Human genes 0.000 description 1
- 108010029756 Notch3 Receptor Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 1
- 102100032256 Parathyroid hormone/parathyroid hormone-related peptide receptor Human genes 0.000 description 1
- 208000018737 Parkinson disease Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 101710124951 Phospholipase C Proteins 0.000 description 1
- 102100035194 Placenta growth factor Human genes 0.000 description 1
- 231100000742 Plant toxin Toxicity 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 102000007584 Prealbumin Human genes 0.000 description 1
- 108010071690 Prealbumin Proteins 0.000 description 1
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 1
- 108010002519 Prolactin Receptors Proteins 0.000 description 1
- 102100029000 Prolactin receptor Human genes 0.000 description 1
- 102100023832 Prolyl endopeptidase FAP Human genes 0.000 description 1
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 1
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 206010037549 Purpura Diseases 0.000 description 1
- 241001672981 Purpura Species 0.000 description 1
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 101100437153 Rattus norvegicus Acvr2b gene Proteins 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 1
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 206010038389 Renal cancer Diseases 0.000 description 1
- 201000007737 Retinal degeneration Diseases 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 108091006976 SLC40A1 Proteins 0.000 description 1
- 102100025504 SLIT and NTRK-like protein 6 Human genes 0.000 description 1
- 229910052772 Samarium Inorganic materials 0.000 description 1
- 102100034201 Sclerostin Human genes 0.000 description 1
- 108050006698 Sclerostin Proteins 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 102100034361 Sialic acid-binding Ig-like lectin 15 Human genes 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- PMZURENOXWZQFD-UHFFFAOYSA-L Sodium Sulfate Chemical compound [Na+].[Na+].[O-]S([O-])(=O)=O PMZURENOXWZQFD-UHFFFAOYSA-L 0.000 description 1
- DWAQJAXMDSEUJJ-UHFFFAOYSA-M Sodium bisulfite Chemical compound [Na+].OS([O-])=O DWAQJAXMDSEUJJ-UHFFFAOYSA-M 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 101000874347 Streptococcus agalactiae IgA FC receptor Proteins 0.000 description 1
- 241000193998 Streptococcus pneumoniae Species 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 108010021188 Superoxide Dismutase-1 Proteins 0.000 description 1
- 102100038836 Superoxide dismutase [Cu-Zn] Human genes 0.000 description 1
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 1
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- 102000007000 Tenascin Human genes 0.000 description 1
- 108010008125 Tenascin Proteins 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 208000024770 Thyroid neoplasm Diseases 0.000 description 1
- 102100030859 Tissue factor Human genes 0.000 description 1
- 102100030951 Tissue factor pathway inhibitor Human genes 0.000 description 1
- 102100039360 Toll-like receptor 4 Human genes 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 102100030742 Transforming growth factor beta-1 proprotein Human genes 0.000 description 1
- GSEJCLTVZPLZKY-UHFFFAOYSA-N Triethanolamine Chemical compound OCCN(CCO)CCO GSEJCLTVZPLZKY-UHFFFAOYSA-N 0.000 description 1
- RHQDFWAXVIIEBN-UHFFFAOYSA-N Trifluoroethanol Chemical compound OCC(F)(F)F RHQDFWAXVIIEBN-UHFFFAOYSA-N 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 102100033579 Trophoblast glycoprotein Human genes 0.000 description 1
- 102000004243 Tubulin Human genes 0.000 description 1
- 108090000704 Tubulin Proteins 0.000 description 1
- 102100040112 Tumor necrosis factor receptor superfamily member 10B Human genes 0.000 description 1
- 102100029690 Tumor necrosis factor receptor superfamily member 13C Human genes 0.000 description 1
- 101710178300 Tumor necrosis factor receptor superfamily member 13C Proteins 0.000 description 1
- 101710187743 Tumor necrosis factor receptor superfamily member 1A Proteins 0.000 description 1
- 102100033732 Tumor necrosis factor receptor superfamily member 1A Human genes 0.000 description 1
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 1
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 1
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- 108010053096 Vascular Endothelial Growth Factor Receptor-1 Proteins 0.000 description 1
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 1
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 1
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 1
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- VWQVUPCCIRVNHF-OUBTZVSYSA-N Yttrium-90 Chemical compound [90Y] VWQVUPCCIRVNHF-OUBTZVSYSA-N 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 102100023144 Zinc transporter ZIP6 Human genes 0.000 description 1
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 1
- 235000010489 acacia gum Nutrition 0.000 description 1
- 239000000205 acacia gum Substances 0.000 description 1
- 229960000583 acetic acid Drugs 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 125000002252 acyl group Chemical group 0.000 description 1
- 229960002964 adalimumab Drugs 0.000 description 1
- 239000001361 adipic acid Substances 0.000 description 1
- 229960000250 adipic acid Drugs 0.000 description 1
- 235000011037 adipic acid Nutrition 0.000 description 1
- 229940072056 alginate Drugs 0.000 description 1
- 235000010443 alginic acid Nutrition 0.000 description 1
- 229920000615 alginic acid Polymers 0.000 description 1
- 229910052783 alkali metal Inorganic materials 0.000 description 1
- 150000001340 alkali metals Chemical class 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 150000001342 alkaline earth metals Chemical class 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 125000004453 alkoxycarbonyl group Chemical group 0.000 description 1
- 125000004448 alkyl carbonyl group Chemical group 0.000 description 1
- 150000001350 alkyl halides Chemical class 0.000 description 1
- IYABWNGZIDDRAK-UHFFFAOYSA-N allene Chemical group C=C=C IYABWNGZIDDRAK-UHFFFAOYSA-N 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 239000002776 alpha toxin Substances 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- BJEPYKJPYRNKOW-UHFFFAOYSA-N alpha-hydroxysuccinic acid Natural products OC(=O)C(O)CC(O)=O BJEPYKJPYRNKOW-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- CEGOLXSVJUTHNZ-UHFFFAOYSA-K aluminium tristearate Chemical compound [Al+3].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CEGOLXSVJUTHNZ-UHFFFAOYSA-K 0.000 description 1
- 229940063655 aluminum stearate Drugs 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- PLOPBXQQPZYQFA-AXPWDRQUSA-N amlintide Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H]1NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)CSSC1)[C@@H](C)O)C(C)C)C1=CC=CC=C1 PLOPBXQQPZYQFA-AXPWDRQUSA-N 0.000 description 1
- 150000003863 ammonium salts Chemical class 0.000 description 1
- 239000003945 anionic surfactant Substances 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 229940125644 antibody drug Drugs 0.000 description 1
- 229940041181 antineoplastic drug Drugs 0.000 description 1
- 229940045985 antineoplastic platinum compound Drugs 0.000 description 1
- 125000005161 aryl oxy carbonyl group Chemical group 0.000 description 1
- 125000004104 aryloxy group Chemical group 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 108010044540 auristatin Proteins 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- 208000037979 autoimmune inflammatory disease Diseases 0.000 description 1
- OSNDUYDDOHEKEE-UHFFFAOYSA-N azepane-2,7-dione Chemical compound O=C1CCCCC(=O)N1 OSNDUYDDOHEKEE-UHFFFAOYSA-N 0.000 description 1
- 125000002393 azetidinyl group Chemical group 0.000 description 1
- 125000004069 aziridinyl group Chemical group 0.000 description 1
- JSMWYJGCNSFQDN-UHFFFAOYSA-N azonane-2,9-dione Chemical compound O=C1CCCCCCC(=O)N1 JSMWYJGCNSFQDN-UHFFFAOYSA-N 0.000 description 1
- 208000022362 bacterial infectious disease Diseases 0.000 description 1
- 239000000688 bacterial toxin Substances 0.000 description 1
- 239000002585 base Substances 0.000 description 1
- SRSXLGNVWSONIS-UHFFFAOYSA-N benzenesulfonic acid Chemical compound OS(=O)(=O)C1=CC=CC=C1 SRSXLGNVWSONIS-UHFFFAOYSA-N 0.000 description 1
- 229940092714 benzenesulfonic acid Drugs 0.000 description 1
- 125000003236 benzoyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)=O 0.000 description 1
- AGEZXYOZHKGVCM-UHFFFAOYSA-N benzyl bromide Chemical compound BrCC1=CC=CC=C1 AGEZXYOZHKGVCM-UHFFFAOYSA-N 0.000 description 1
- 125000000051 benzyloxy group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])O* 0.000 description 1
- 125000001584 benzyloxycarbonyl group Chemical group C(=O)(OCC1=CC=CC=C1)* 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 229910052797 bismuth Inorganic materials 0.000 description 1
- JCXGWMGPZLAOME-UHFFFAOYSA-N bismuth atom Chemical compound [Bi] JCXGWMGPZLAOME-UHFFFAOYSA-N 0.000 description 1
- 230000008499 blood brain barrier function Effects 0.000 description 1
- 210000001218 blood-brain barrier Anatomy 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 1
- 239000004327 boric acid Substances 0.000 description 1
- 229960003735 brodalumab Drugs 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 125000004744 butyloxycarbonyl group Chemical group 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 229910000019 calcium carbonate Inorganic materials 0.000 description 1
- FNAQSUUGMSOBHW-UHFFFAOYSA-H calcium citrate Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O.[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O FNAQSUUGMSOBHW-UHFFFAOYSA-H 0.000 description 1
- 239000001354 calcium citrate Substances 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical class C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- XYXGFHALMTXBQX-UHFFFAOYSA-N carboxyoxy hydrogen carbonate Chemical compound OC(=O)OOC(O)=O XYXGFHALMTXBQX-UHFFFAOYSA-N 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 206010008118 cerebral infarction Diseases 0.000 description 1
- 208000026106 cerebrovascular disease Diseases 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 125000001309 chloro group Chemical group Cl* 0.000 description 1
- 239000007979 citrate buffer Substances 0.000 description 1
- 229940110456 cocoa butter Drugs 0.000 description 1
- 235000019868 cocoa butter Nutrition 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 238000006482 condensation reaction Methods 0.000 description 1
- 150000001923 cyclic compounds Chemical class 0.000 description 1
- 125000001047 cyclobutenyl group Chemical group C1(=CCC1)* 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000004976 cyclobutylene group Chemical group 0.000 description 1
- 125000004977 cycloheptylene group Chemical group 0.000 description 1
- 125000000596 cyclohexenyl group Chemical group C1(=CCCCC1)* 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000004956 cyclohexylene group Chemical group 0.000 description 1
- 125000004978 cyclooctylene group Chemical group 0.000 description 1
- 125000002433 cyclopentenyl group Chemical group C1(=CCCC1)* 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000004979 cyclopentylene group Chemical group 0.000 description 1
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 1
- 125000004980 cyclopropylene group Chemical group 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 125000002704 decyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 230000007850 degeneration Effects 0.000 description 1
- 229960001251 denosumab Drugs 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- LSXWFXONGKSEMY-UHFFFAOYSA-N di-tert-butyl peroxide Chemical compound CC(C)(C)OOC(C)(C)C LSXWFXONGKSEMY-UHFFFAOYSA-N 0.000 description 1
- 239000012969 di-tertiary-butyl peroxide Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- ZBCBWPMODOFKDW-UHFFFAOYSA-N diethanolamine Chemical compound OCCNCCO ZBCBWPMODOFKDW-UHFFFAOYSA-N 0.000 description 1
- 102000038379 digestive enzymes Human genes 0.000 description 1
- 108091007734 digestive enzymes Proteins 0.000 description 1
- 208000010643 digestive system disease Diseases 0.000 description 1
- 125000004852 dihydrofuranyl group Chemical group O1C(CC=C1)* 0.000 description 1
- 125000005043 dihydropyranyl group Chemical group O1C(CCC=C1)* 0.000 description 1
- 125000005053 dihydropyrimidinyl group Chemical group N1(CN=CC=C1)* 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- LRPQMNYCTSPGCX-UHFFFAOYSA-N dimethyl pimelimidate Chemical compound COC(=N)CCCCCC(=N)OC LRPQMNYCTSPGCX-UHFFFAOYSA-N 0.000 description 1
- 229960004497 dinutuximab Drugs 0.000 description 1
- 150000002009 diols Chemical class 0.000 description 1
- 125000005879 dioxolanyl group Chemical group 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229950003468 dupilumab Drugs 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 210000001163 endosome Anatomy 0.000 description 1
- 230000006862 enzymatic digestion Effects 0.000 description 1
- 239000002532 enzyme inhibitor Substances 0.000 description 1
- 108010087914 epidermal growth factor receptor VIII Proteins 0.000 description 1
- UFNVPOGXISZXJD-XJPMSQCNSA-N eribulin Chemical compound C([C@H]1CC[C@@H]2O[C@@H]3[C@H]4O[C@H]5C[C@](O[C@H]4[C@H]2O1)(O[C@@H]53)CC[C@@H]1O[C@H](C(C1)=C)CC1)C(=O)C[C@@H]2[C@@H](OC)[C@@H](C[C@H](O)CN)O[C@H]2C[C@@H]2C(=C)[C@H](C)C[C@H]1O2 UFNVPOGXISZXJD-XJPMSQCNSA-N 0.000 description 1
- 229960003649 eribulin Drugs 0.000 description 1
- 125000005677 ethinylene group Chemical group [*:2]C#C[*:1] 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 125000003983 fluorenyl group Chemical group C1(=CC=CC=2C3=CC=CC=C3CC12)* 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 239000001530 fumaric acid Substances 0.000 description 1
- 235000011087 fumaric acid Nutrition 0.000 description 1
- 125000002541 furyl group Chemical group 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 230000009368 gene silencing by RNA Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-L glutamate group Chemical group N[C@@H](CCC(=O)[O-])C(=O)[O-] WHUUTDBJXJRKMK-VKHMYHEASA-L 0.000 description 1
- JFCQEDHGNNZCLN-UHFFFAOYSA-N glutaric acid Chemical compound OC(=O)CCCC(O)=O JFCQEDHGNNZCLN-UHFFFAOYSA-N 0.000 description 1
- VANNPISTIUFMLH-UHFFFAOYSA-N glutaric anhydride Chemical compound O=C1CCCC(=O)O1 VANNPISTIUFMLH-UHFFFAOYSA-N 0.000 description 1
- YPZRWBKMTBYPTK-BJDJZHNGSA-N glutathione disulfide Chemical group OC(=O)[C@@H](N)CCC(=O)N[C@H](C(=O)NCC(O)=O)CSSC[C@@H](C(=O)NCC(O)=O)NC(=O)CC[C@H](N)C(O)=O YPZRWBKMTBYPTK-BJDJZHNGSA-N 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- LPLVUJXQOOQHMX-UHFFFAOYSA-N glycyrrhetinic acid glycoside Natural products C1CC(C2C(C3(CCC4(C)CCC(C)(CC4C3=CC2=O)C(O)=O)C)(C)CC2)(C)C2C(C)(C)C1OC1OC(C(O)=O)C(O)C(O)C1OC1OC(C(O)=O)C(O)C(O)C1O LPLVUJXQOOQHMX-UHFFFAOYSA-N 0.000 description 1
- 229960004949 glycyrrhizic acid Drugs 0.000 description 1
- UYRUBYNTXSDKQT-UHFFFAOYSA-N glycyrrhizic acid Natural products CC1(C)C(CCC2(C)C1CCC3(C)C2C(=O)C=C4C5CC(C)(CCC5(C)CCC34C)C(=O)O)OC6OC(C(O)C(O)C6OC7OC(O)C(O)C(O)C7C(=O)O)C(=O)O UYRUBYNTXSDKQT-UHFFFAOYSA-N 0.000 description 1
- 235000019410 glycyrrhizin Nutrition 0.000 description 1
- LPLVUJXQOOQHMX-QWBHMCJMSA-N glycyrrhizinic acid Chemical compound O([C@@H]1[C@@H](O)[C@H](O)[C@H](O[C@@H]1O[C@@H]1C([C@H]2[C@]([C@@H]3[C@@]([C@@]4(CC[C@@]5(C)CC[C@@](C)(C[C@H]5C4=CC3=O)C(O)=O)C)(C)CC2)(C)CC1)(C)C)C(O)=O)[C@@H]1O[C@H](C(O)=O)[C@@H](O)[C@H](O)[C@H]1O LPLVUJXQOOQHMX-QWBHMCJMSA-N 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 229960001743 golimumab Drugs 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 239000005090 green fluorescent protein Substances 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 125000003187 heptyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 150000002391 heterocyclic compounds Chemical class 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229910000042 hydrogen bromide Inorganic materials 0.000 description 1
- 239000001341 hydroxy propyl starch Substances 0.000 description 1
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 1
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 1
- 235000013828 hydroxypropyl starch Nutrition 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 125000002632 imidazolidinyl group Chemical group 0.000 description 1
- 125000002883 imidazolyl group Chemical group 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 125000001041 indolyl group Chemical group 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 229960000598 infliximab Drugs 0.000 description 1
- 208000037797 influenza A Diseases 0.000 description 1
- 208000037798 influenza B Diseases 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 108010021315 integrin beta7 Proteins 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 108040006870 interleukin-10 receptor activity proteins Proteins 0.000 description 1
- 108040001304 interleukin-17 receptor activity proteins Proteins 0.000 description 1
- 102000053460 interleukin-17 receptor activity proteins Human genes 0.000 description 1
- 108010074108 interleukin-21 Proteins 0.000 description 1
- 108040006859 interleukin-5 receptor activity proteins Proteins 0.000 description 1
- 108040006858 interleukin-6 receptor activity proteins Proteins 0.000 description 1
- 108040006861 interleukin-7 receptor activity proteins Proteins 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000000752 ionisation method Methods 0.000 description 1
- 229960005386 ipilimumab Drugs 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 125000002183 isoquinolinyl group Chemical group C1(=NC=CC2=CC=CC=C12)* 0.000 description 1
- 125000001786 isothiazolyl group Chemical group 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 239000003350 kerosene Substances 0.000 description 1
- 201000010982 kidney cancer Diseases 0.000 description 1
- 208000017169 kidney disease Diseases 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 201000010901 lateral sclerosis Diseases 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 108010013555 lipoprotein-associated coagulation inhibitor Proteins 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000004811 liquid chromatography Methods 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000019423 liver disease Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 230000000938 luteal effect Effects 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 210000003712 lysosome Anatomy 0.000 description 1
- 230000001868 lysosomic effect Effects 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 229950001474 maitansine Drugs 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 1
- 239000001630 malic acid Substances 0.000 description 1
- 235000011090 malic acid Nutrition 0.000 description 1
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 1
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 229940041616 menthol Drugs 0.000 description 1
- 229960005108 mepolizumab Drugs 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- 239000004292 methyl p-hydroxybenzoate Substances 0.000 description 1
- 235000010270 methyl p-hydroxybenzoate Nutrition 0.000 description 1
- 229960002216 methylparaben Drugs 0.000 description 1
- 239000010445 mica Substances 0.000 description 1
- 229910052618 mica group Inorganic materials 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 125000002757 morpholinyl group Chemical group 0.000 description 1
- 208000005264 motor neuron disease Diseases 0.000 description 1
- 230000003387 muscular Effects 0.000 description 1
- 125000004370 n-butenyl group Chemical group [H]\C([H])=C(/[H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 238000005319 nano flow HPLC Methods 0.000 description 1
- 125000004957 naphthylene group Chemical group 0.000 description 1
- 125000004998 naphthylethyl group Chemical group C1(=CC=CC2=CC=CC=C12)CC* 0.000 description 1
- 125000004923 naphthylmethyl group Chemical group C1(=CC=CC2=CC=CC=C12)C* 0.000 description 1
- 229960000513 necitumumab Drugs 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 125000001400 nonyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 125000002347 octyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- 229950008516 olaratumab Drugs 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 201000008482 osteoarthritis Diseases 0.000 description 1
- 108010000953 osteoblast cadherin Proteins 0.000 description 1
- 235000006408 oxalic acid Nutrition 0.000 description 1
- 125000000160 oxazolidinyl group Chemical group 0.000 description 1
- 125000002971 oxazolyl group Chemical group 0.000 description 1
- 125000003566 oxetanyl group Chemical group 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 125000001820 oxy group Chemical group [*:1]O[*:2] 0.000 description 1
- 125000005740 oxycarbonyl group Chemical group [*:1]OC([*:2])=O 0.000 description 1
- 201000002528 pancreatic cancer Diseases 0.000 description 1
- 208000008443 pancreatic carcinoma Diseases 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- RXNXLAHQOVLMIE-UHFFFAOYSA-N phenyl 10-methylacridin-10-ium-9-carboxylate Chemical compound C12=CC=CC=C2[N+](C)=C2C=CC=CC2=C1C(=O)OC1=CC=CC=C1 RXNXLAHQOVLMIE-UHFFFAOYSA-N 0.000 description 1
- 125000000843 phenylene group Chemical group C1(=C(C=CC=C1)*)* 0.000 description 1
- 125000004592 phthalazinyl group Chemical group C1(=NN=CC2=CC=CC=C12)* 0.000 description 1
- 125000004193 piperazinyl group Chemical group 0.000 description 1
- 125000003386 piperidinyl group Chemical group 0.000 description 1
- 239000003123 plant toxin Substances 0.000 description 1
- 150000003058 platinum compounds Chemical class 0.000 description 1
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 1
- SXYFKXOFMCIXQW-UHFFFAOYSA-N propanedioyl dichloride Chemical compound ClC(=O)CC(Cl)=O SXYFKXOFMCIXQW-UHFFFAOYSA-N 0.000 description 1
- 125000004368 propenyl group Chemical group C(=CC)* 0.000 description 1
- 229940043274 prophylactic drug Drugs 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 125000002572 propoxy group Chemical group [*]OC([H])([H])C(C([H])([H])[H])([H])[H] 0.000 description 1
- 239000004405 propyl p-hydroxybenzoate Substances 0.000 description 1
- 235000010232 propyl p-hydroxybenzoate Nutrition 0.000 description 1
- QQONPFPTGQHPMA-UHFFFAOYSA-N propylene Natural products CC=C QQONPFPTGQHPMA-UHFFFAOYSA-N 0.000 description 1
- AOHJOMMDDJHIJH-UHFFFAOYSA-N propylenediamine Chemical compound CC(N)CN AOHJOMMDDJHIJH-UHFFFAOYSA-N 0.000 description 1
- 229960003415 propylparaben Drugs 0.000 description 1
- 125000002568 propynyl group Chemical group [*]C#CC([H])([H])[H] 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000008213 purified water Substances 0.000 description 1
- 125000003373 pyrazinyl group Chemical group 0.000 description 1
- 125000003226 pyrazolyl group Chemical group 0.000 description 1
- 125000004076 pyridyl group Chemical group 0.000 description 1
- 125000000714 pyrimidinyl group Chemical group 0.000 description 1
- 125000000719 pyrrolidinyl group Chemical group 0.000 description 1
- 125000000168 pyrrolyl group Chemical group 0.000 description 1
- 125000002294 quinazolinyl group Chemical group N1=C(N=CC2=CC=CC=C12)* 0.000 description 1
- 125000002943 quinolinyl group Chemical group N1=C(C=CC2=CC=CC=C12)* 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 1
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 1
- 108010054624 red fluorescent protein Proteins 0.000 description 1
- 238000006722 reduction reaction Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012827 research and development Methods 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- KZUNJOHGWZRPMI-UHFFFAOYSA-N samarium atom Chemical compound [Sm] KZUNJOHGWZRPMI-UHFFFAOYSA-N 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 239000012488 sample solution Substances 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 229960003323 siltuximab Drugs 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000007974 sodium acetate buffer Substances 0.000 description 1
- WXMKPNITSTVMEF-UHFFFAOYSA-M sodium benzoate Chemical compound [Na+].[O-]C(=O)C1=CC=CC=C1 WXMKPNITSTVMEF-UHFFFAOYSA-M 0.000 description 1
- 239000004299 sodium benzoate Substances 0.000 description 1
- 235000010234 sodium benzoate Nutrition 0.000 description 1
- 229960003885 sodium benzoate Drugs 0.000 description 1
- 235000017557 sodium bicarbonate Nutrition 0.000 description 1
- 229910000030 sodium bicarbonate Inorganic materials 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 229960001790 sodium citrate Drugs 0.000 description 1
- 235000011083 sodium citrates Nutrition 0.000 description 1
- 229940079827 sodium hydrogen sulfite Drugs 0.000 description 1
- 235000010267 sodium hydrogen sulphite Nutrition 0.000 description 1
- 229910052938 sodium sulfate Inorganic materials 0.000 description 1
- 229960003010 sodium sulfate Drugs 0.000 description 1
- 235000011152 sodium sulphate Nutrition 0.000 description 1
- CIJQGPVMMRXSQW-UHFFFAOYSA-M sodium;2-aminoacetic acid;hydroxide Chemical compound O.[Na+].NCC([O-])=O CIJQGPVMMRXSQW-UHFFFAOYSA-M 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- 229940031000 streptococcus pneumoniae Drugs 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 101150047061 tag-72 gene Proteins 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 125000005931 tert-butyloxycarbonyl group Chemical group [H]C([H])([H])C(OC(*)=O)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- YLQBMQCUIZJEEH-UHFFFAOYSA-N tetrahydrofuran Natural products C=1C=COC=1 YLQBMQCUIZJEEH-UHFFFAOYSA-N 0.000 description 1
- 125000003718 tetrahydrofuranyl group Chemical group 0.000 description 1
- 125000001412 tetrahydropyranyl group Chemical group 0.000 description 1
- 125000003507 tetrahydrothiofenyl group Chemical group 0.000 description 1
- RAOIDOHSFRTOEL-UHFFFAOYSA-N tetrahydrothiophene Chemical compound C1CCSC1 RAOIDOHSFRTOEL-UHFFFAOYSA-N 0.000 description 1
- 125000004632 tetrahydrothiopyranyl group Chemical group S1C(CCCC1)* 0.000 description 1
- 125000000383 tetramethylene group Chemical group [H]C([H])([*:1])C([H])([H])C([H])([H])C([H])([H])[*:2] 0.000 description 1
- 150000003536 tetrazoles Chemical class 0.000 description 1
- 125000003831 tetrazolyl group Chemical group 0.000 description 1
- 229940126585 therapeutic drug Drugs 0.000 description 1
- 125000000335 thiazolyl group Chemical group 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 125000001544 thienyl group Chemical group 0.000 description 1
- 125000002053 thietanyl group Chemical group 0.000 description 1
- 125000004149 thio group Chemical group *S* 0.000 description 1
- 125000002813 thiocarbonyl group Chemical group *C(*)=S 0.000 description 1
- 125000004568 thiomorpholinyl group Chemical group 0.000 description 1
- 230000002992 thymic effect Effects 0.000 description 1
- 201000002510 thyroid cancer Diseases 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- ZGYICYBLPGRURT-UHFFFAOYSA-N tri(propan-2-yl)silicon Chemical compound CC(C)[Si](C(C)C)C(C)C ZGYICYBLPGRURT-UHFFFAOYSA-N 0.000 description 1
- 125000004306 triazinyl group Chemical group 0.000 description 1
- 150000003852 triazoles Chemical class 0.000 description 1
- 125000001425 triazolyl group Chemical group 0.000 description 1
- 235000013337 tricalcium citrate Nutrition 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 125000000430 tryptophan group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C2=C([H])C([H])=C([H])C([H])=C12 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 108010047303 von Willebrand Factor Proteins 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Images


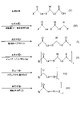






























Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/001—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof by chemical synthesis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6889—Conjugates wherein the antibody being the modifying agent and wherein the linker, binder or spacer confers particular properties to the conjugates, e.g. peptidic enzyme-labile linkers or acid-labile linkers, providing for an acid-labile immuno conjugate wherein the drug may be released from its antibody conjugated part in an acidic, e.g. tumoural or environment
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/65—Peptidic linkers, binders or spacers, e.g. peptidic enzyme-labile linkers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68031—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being an auristatin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/6811—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
- A61K47/6855—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell the tumour determinant being from breast cancer cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/107—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides
- C07K1/1072—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides by covalent attachment of residues or functional groups
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/107—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides
- C07K1/1072—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides by covalent attachment of residues or functional groups
- C07K1/1077—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length by chemical modification of precursor peptides by covalent attachment of residues or functional groups by covalent attachment of residues other than amino acids or peptide residues, e.g. sugars, polyols, fatty acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
Definitions
- the present invention relates to a compound or a salt thereof, an antibody obtained by the compound, and the like.
- ADC antibody-drug conjugates
- ADC is a drug in which a drug (eg, an anticancer drug) is conjugated to an antibody, and has a direct cell-killing activity against cancer cells and the like.
- a typical ADC is T-DM1 (trade name: Kadcyla (registered trademark)) jointly developed by Immunogene and Roche.
- ADCs such as T-DM1
- DAR Drug Antibody Ratio
- a C-CAP (Chemical Conjugation by Affinity Peptide) method that enables regioselective modification of an antibody by a chemically synthesized method (Patent Document 1).
- This method has succeeded in position-selective modification of an antibody by reacting an affinity peptide with a peptide reagent in which an NHS-activated ester and a drug are linked to the antibody.
- the ADC produced by this method the antibody and the drug are bound via a linker containing a peptide moiety.
- the peptide moiety has potential immunogenicity and is susceptible to hydrolysis in the blood. Therefore, the ADC produced by this method has room for improvement in that it contains a peptide moiety in the linker.
- an antibody having a functional substance (eg, a drug) that does not contain a peptide portion as a linker and has a functional substance (eg, a drug) in a position-selective manner is obtained by a chemical synthesis method using a predetermined compound containing an affinity peptide.
- Techniques that can be prepared have been reported (Patent Documents 2 to 6). Avoiding the use of linkers containing peptide moieties is desirable in clinical applications.
- An object of the present invention is to regioselectively modify an antibody with a functional substance and control the binding ratio between the antibody and the functional substance within a desired range.
- the present inventors have selected the lysine residue at position 288/290 of the heavy chain in the immunoglobulin unit as the modification position of the antibody, and made it possible to modify the lysine residue in a position-specific manner.
- the antibody can be position-selectively modified with a functional substance, and the average ratio of binding between the immunoglobulin unit and the functional substance (number of functional substances / immunoglobulin unit) is desired. It was found that it becomes easy to control highly to the range (1.5 to 2.5) of.
- the total number of atoms constituting the main chain and the number of atoms constituting the main chain in the second linker are 5 to 7).
- the present inventors have succeeded in developing a compound represented by the formula (I) or a salt thereof, and a reagent for antibody derivatization containing them.
- the present inventors also use a compound represented by the formula (I) or a salt thereof to selectively modify a specific antibody, that is, the lysine residue at position 288/290 in the antibody with a modifying group.
- an antibody antibody intermediate, thiol group introduction
- an antibody in which the average ratio of binding between immunoglobulin units and modifying groups (number of modifying groups / immunoglobulin units) is highly controlled within a desired range (1.5 to 2.5).
- [1] A compound represented by the formula (I) or a salt thereof.
- [2] The compound of [1] or a salt thereof, wherein the leaving group is selected from the following: (A) RS (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent. , S represents a sulfur atom.); (B) RO (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent.
- O represents an oxygen atom.
- RA- ( RB- ) N (where RA and RB each have a hydrogen atom and a substituent independently of each other.) It represents a monovalent hydrocarbon group, or a monovalent heterocyclic group which may have a substituent, where N represents a nitrogen atom.); Or (d) a halogen atom.
- the compound of [1] or [2] or a salt thereof, wherein the immunoglobulin unit is a human immunoglobulin unit.
- affinity peptide is as follows: (A) Affinity peptide containing the amino acid sequence of CQRRFYEALHDPNLNEEQRNARIRSIKDDC (SEQ ID NO: 1); An affinity peptide comprising an amino acid sequence containing a variation of selected 1-5 amino acid residues, where the lysine residue at position 27 and the two cysteine residues at positions 1 and 30 are maintained.
- the affinity peptide of (B) is selected from the group consisting of the following, the compound of [6] or a salt thereof: (A) Affinity peptide containing the amino acid sequence of FNMQCQRRFYEALHDPNLNEEQRNARIRSIKDDC (SEQ ID NO: 2); (B) Affinity peptide containing the amino acid sequence of FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEDC (SEQ ID NO: 3); (C) Affinity peptide containing the amino acid sequence of FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC (SEQ ID NO: 4); (D) Affinity peptide containing the amino acid sequence of NMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC (SEQ ID NO: 5); (E) Affinity peptide comprising the amino acid sequence of MQCQRRFYEALHDPNLNEEQRNARIRSIKEEC (SEQ ID NO: 6);
- the N-terminal and C-terminal amino acid residues in the affinity peptide may be protected, and the two thiol groups in the side chains of the two cysteine residues (C) in the affinity peptide are disulfide bonds.
- the compound represented by the formula (I) is the compound represented by the formula (I') or a salt thereof according to any one of [1] to [8].
- the compound represented by the formula (I') is the compound represented by the formula (I'') or a salt thereof.
- a reagent for antibody derivatization which comprises a compound represented by the formula (I) or a salt thereof.
- the reagent of [12], wherein the compound represented by the formula (I') is represented by the formula (I'').
- the antibody intermediate of [14] or a salt thereof, wherein the antibody intermediate is a human antibody intermediate.
- the antibody intermediate of [14] or [15] or a salt thereof, wherein the antibody intermediate is a human IgG intermediate.
- [25] The conjugate of [24] or a salt thereof, wherein a specific amino acid residue other than the lysine residue present at the 288/290 position in the two heavy chains is further modified.
- [26] The conjugate of [25] or a salt thereof, wherein the specific amino acid residue is a lysine residue present at position 246/248 in two heavy chains.
- [27] The conjugate of any one of [24] to [26] or a salt thereof, wherein the structural unit represented by the formula (IV) is represented by the formula (IV').
- [28] The conjugate of [27] or a salt thereof, wherein the structural unit represented by the formula (IV') is represented by the formula (IV ′′).
- a compound represented by the formula (V) or a salt thereof is the compound represented by the formula (V') or a salt thereof.
- the compound represented by the formula (V') is the compound represented by the formula (V'') or a salt thereof.
- the compound of [31] or a salt thereof, wherein the compound represented by the formula (V'') is represented by the formula (V''-1) or (V''-2).
- the leaving group having a higher ability to eliminate than the leaving group X is a pentafluorophenyloxy group, a tetrafluorophenyloxy group, a paranitrophenyloxy group, or an N-succinimidyloxy group.
- the compound represented by the formula (VI) is the compound of the formula [33] or [34] or a salt thereof, which is represented by the formula (VI').
- the compound represented by the formula (VI') is the compound represented by the formula (VI'') or a salt thereof.
- a method for producing a thiol group-introduced antibody derivative or a salt thereof comprising reacting a compound represented by the formula (I) or a salt thereof with an antibody containing an immunoglobulin unit.
- the antibody intermediate or a salt thereof is subjected to a cleavage reaction of a thioester to produce a thiol group-introduced antibody derivative or a salt thereof containing a structural unit represented by the formula (III); and (3) thiol.
- a group-introduced antibody derivative or a salt thereof is reacted with a functional substance to form a conjugate of the antibody and the functional substance or a salt thereof, which comprises a structural unit represented by the formula (IV).
- a method for producing a conjugate of a functional substance or a salt thereof is reacted with a functional substance to form a conjugate of the antibody and the functional substance or a salt thereof, which comprises a structural unit represented by the formula (IV).
- the compound represented by the formula (VI) or a salt thereof is reacted with an affinity peptide having a binding region to the CH2 domain in the immunoglobulin unit containing two heavy chains and two light chains to react with the formula (').
- a method for producing the represented compound or a salt thereof is reacted with an affinity peptide having a binding region to the CH2 domain in the immunoglobulin unit containing two heavy chains and two light chains.
- a thiol group-introduced antibody derivative or a salt thereof containing a structural unit represented by the formula (II) is subjected to a cleavage reaction of a thioester to contain the structural unit represented by the formula (III).
- a method for producing a thiol group-introduced antibody derivative or a salt thereof which comprises producing the salt thereof.
- a method for producing a conjugate of an antibody and a functional substance or a salt thereof which comprises producing a conjugate of the sex substance or a salt thereof.
- the average ratio of the bonds between the immunoglobulin unit and the affinity peptide-containing group is in a desired range (1.5 to 2).
- the lysine residue at position 288/290 of the heavy chain in the immunoglobulin unit can be specifically and highly modified so as to be .5). Therefore, the compound represented by the formula (I) or a salt thereof is useful as a reagent for antibody derivatization.
- the lysine residue at position 288/290 of the heavy chain in the immunoglobulin unit is specifically modified with an affinity peptide-containing group
- the antibody intermediate represented by the formula (II) or an antibody intermediate thereof in which the average ratio of the bonds between the immunoglobulin unit and the affinity peptide-containing group (affinity peptide-containing group number / immunoglobulin unit) is highly controlled within a desired range. Salt can be provided.
- an antibody prepared by using the antibody intermediate represented by the formula (II) or a salt thereof as a raw material can inherit the regioselectivity and the average ratio of binding of the antibody intermediate or the salt thereof.
- a thiol group-introduced antibody derivative represented by the formula (III) or a salt thereof which has the above regioselectivity and an average ratio of binding, and a conjugation of the antibody and the functional substance represented by the formula (IV).
- a gate or salt thereof can be provided.
- compounds represented by formulas (V) and (VI) or salts thereof which are synthetic intermediates that enable efficient production of compounds represented by formula (I) or salts thereof.
- FIG. 1 is a schematic diagram (No. 1) showing the concept of modification of immunoglobulin units with the compound of the present invention represented by the formula (I) or a salt thereof.
- the compound of the present invention represented by the formula (I) or a salt thereof associates with the CH2 domain in the immunoglobulin unit via the affinity peptide (Y).
- the compound of the present invention represented by the formula (I) or a salt thereof is a side chain of a specific amino acid residue in the CH2 domain via an activated carbonyl group having a elimination group (X) (Fig.). In it, it reacts with an amino group in the side chain of a lysine residue to produce an antibody intermediate or a salt thereof.
- FIG. 2 is a schematic diagram (No.
- FIG. 3 is a schematic diagram (No. 3) showing the concept of modification of immunoglobulin units with the compound of the present invention represented by the formula (I) or a salt thereof.
- the reaction of a thiol group with a functional substance (Z) in a thiol group-introduced antibody derivative or a salt thereof produces a conjugate of the antibody and the functional substance or a salt thereof.
- FIG. 4 is a diagram showing an outline of an embodiment of the present invention.
- FIG. 5 is a diagram showing an outline of a preferred embodiment of the present invention.
- FIG. 6 is a diagram showing an outline of a more preferable embodiment of the present invention.
- FIG. 7 is a diagram showing ESI-TOFMS analysis of specific modification (number of introduced binding peptides) of trastuzumab (anti-HER2 IgG antibody) (Example 1).
- FIG. 8 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 1).
- FIG. 9 is a diagram showing (1) the amino acid sequence of the heavy chain of trastuzumab (SEQ ID NO: 8) and (2) the amino acid sequence of the light chain of trastuzumab (SEQ ID NO: 9).
- FNWYVDGVEVHNAKTTKPR SEQ ID NO: 10
- a peptide consisting of 18 amino acid residues containing a site of modification of trussumab to a lysine residue by trypsin digestion (a thiol-introduced product (+145.09 Da) subjected to carbamidometry with iodoacetamide).
- MS spectrum measured value: m / z 577.03606, theoretical value: 577.03557, tetravalent
- FIG. 11 shows the modification of the lysine residue at position 288/290 of the human IgG heavy chain in EU numbering, which is a product ion of m / z 682.13 (theoretical value: 682.01) corresponding to trivalent y16. It is a figure which shows the CID spectrum (Example 1-9-4).
- FIG. 12 shows the results of searching for a peptide fragment containing a lysine residue-modified thiol-introduced product (+145.09Da) modified to a lysine residue (Carbamidemethylized with iodoacetamide) in a trypsin digested product of trastuzumab using BioPharma Finder.
- FIG. 13 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 2).
- FIG. 14 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 2).
- FNWYVDGVEVHNAKTTKPR SEQ ID NO: 10
- a peptide consisting of 18 amino acid residues containing a site of modification of trussumab to a lysine residue by trypsin digestion a thiol-introduced product (+145.09 Da) subjected to carbamidometry with iodoacetamide.
- MS spectrum measured value: m / z 577.03571, theoretical value: 577.03557, tetravalent
- FIG. 16 shows the modification of the lysine residue at position 288/290 of the human IgG heavy chain in EU numbering, which is a product ion of m / z 682.41 (theoretical value: 682.01) corresponding to trivalent y16. It is a figure which shows the CID spectrum (Example 2-7-4).
- FIG. 17 shows the results of searching for a peptide fragment containing a lysine residue-modified thiol-introduced product (+145.09Da) modified to a lysine residue by using a BioPharma Finder for a trypsin digest of trastuzumab. It is a figure (Example 2-7-4).
- FIG. 18 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 3).
- FIG. 19 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 3).
- FIG. 20 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 4).
- FIG. 21 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 4).
- FIG. 18 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 3).
- FIG. 19 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example
- FIG. 22 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 5).
- FIG. 23 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 5).
- FIG. 24 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 6).
- FIG. 25 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 6).
- FIG. 23 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 5).
- FIG. 24 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides)
- FIG. 26 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 7).
- FIG. 27 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 7).
- FIG. 28 shows FNWYVDGVEVHNAKTTKPR (SEQ ID NO: 10), a peptide consisting of 18 amino acid residues containing a site of modification of trussumab to a lysine residue by trypsin digestion (a thiol-introduced product (+145.09 Da) subjected to carbamidometry with iodoacetamide).
- FIG. 29 shows the modification of the lysine residue at position 288/290 of the human IgG heavy chain in EU numbering, showing the modification of the product ion of m / z 1022.21 (theoretical value: 1022.51) corresponding to divalent y16. It is a figure which shows the CID spectrum (Example 7-6-4).
- FIG. 30 shows the results of searching for a peptide fragment containing a modification to a lysine residue (a thiol-introduced product (+145.09Da) subjected to Carbamidemethylization with iodoacetamide) in a trypsin digested product of trastuzumab using BioPharma Finder. It is a figure (Example 7-6-4). The horizontal axis shows the identified lysine residue, and the vertical axis shows the Integrity.
- FIG. 31 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 8).
- FIG. 32 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 8).
- FIG. 33 is a diagram showing ESI-TOFMS analysis of specific modification of trastuzumab (number of introduced binding peptides) (Example 9).
- FIG. 34 is a diagram showing ESI-TOFMS analysis of specific modification (heavy chain selectivity) of trastuzumab (Example 9).
- the term "antibody” is as follows.
- the term "immunoglobulin unit” corresponds to a divalent monomeric unit which is a basic component of such an antibody, and is a unit containing two heavy chains and two light chains. .. Therefore, for immunoglobulin units, definitions, examples, and preferred examples of their origin, type (polyclonal or monoclonal, isotype, and full-length antibody or antibody fragment), antigen, lysine residue position, and regioselectivity are given below. Similar to that of the antibody described.
- the origin of the antibody is not particularly limited, and may be derived from an animal such as a mammal, a bird (eg, a chicken), for example.
- the immunoglobulin unit is derived from a mammal.
- mammals include, for example, primates (eg, humans, monkeys, chimpanzees), rodents (eg, mice, rats, guinea pigs, hamsters, rabbits), pet animals (eg, dogs, cats), domestic animals. (Eg, cows, pigs, goats), servants (eg, horses, sheep), preferably primates or rodents, more preferably humans.
- the type of antibody may be a polyclonal antibody or a monoclonal antibody.
- the antibody may also be a divalent antibody (eg, IgG, IgD, IgE) or a tetravalent or higher valent antibody (eg, IgA antibody, IgM antibody).
- the antibody is a monoclonal antibody.
- the monoclonal antibody is modified so as to have, for example, a chimeric antibody, a humanized antibody, a human antibody, or an antibody to which a predetermined sugar chain is added (eg, a sugar chain binding consensus sequence such as an N-type sugar chain binding consensus sequence).
- Antibodies bispecific antibodies, Fc region proteins, Fc fusion proteins.
- Isotypes of monoclonal antibodies include, for example, IgG (eg, IgG1, IgG2, IgG3, IgG4), IgM, IgA, IgD, IgE, and IgY.
- a full-length antibody or an antibody fragment containing a variable region and CH1 domain and CH2 domain can be used as the monoclonal antibody, but a full-length antibody is preferable.
- the antibody is preferably a human IgG monoclonal antibody, more preferably a human IgG full-length monoclonal antibody.
- any antigen can be used as the antigen of the antibody.
- antigens include proteins [oligopeptides, polypeptides. It may be a protein modified with a biomolecule such as sugar (eg, glycoprotein)], sugar chains, nucleic acids, small molecule compounds.
- the antibody may be an antibody that uses a protein as an antigen.
- proteins include cell membrane receptors, cell membrane proteins other than cell membrane receptors (eg, extracellular substrate proteins), ligands, and soluble receptors.
- the protein that is the antigen of the antibody may be a disease target protein.
- diseases target proteins include the following.
- Amyloid AL Hereditary / rare diseases Amyloid AL, SEMA4D (CD100), insulin receptor, ANGPTL3, IL4, IL13, FGF23, corticostimulatory hormone, transthyretin, huntingtin
- monoclonal antibodies include specific chimeric antibodies (eg, rituximab, baciliximab, infliximab, cetuximab, siltuximab, dinutuximab, altertoximab), specific humanized antibodies (eg, dacrizumab, paribizumab, trastuzumab, allenzumab, allenzumab).
- specific chimeric antibodies eg, rituximab, baciliximab, infliximab, cetuximab, siltuximab, dinutuximab, altertoximab
- specific humanized antibodies eg, dacrizumab, paribizumab, trastuzumab, allenzumab, allenzumab.
- Efarizumab Efarizumab, Bebashizumab, Natarizumab (IgG4), Toshirizumab, Ekurizumab (IgG2), Mogamurizumab, Pertsuzumab, Obinutsuzumab, Bedorizumab, Penproridumab (IgG4), Mepolizumab, Erotsumub Human antibodies (eg, adalimumab (IgG1), panitumumab, golimumab, ustequinumab, canaquinumab, ofatumumab, denosumab (IgG2), ipilimumab, berimumab, rapiximab, lambsilmab, nibolumab, dupilumab (IgG4) Necitumumab, Brodalumab (IgG2), Oralatumab) can be mentioned (if the IgG subtype is
- the lysine residue at position 288 corresponds to the 58th residue in the human IgG CH2 region
- the lysine residue at position 290 corresponds to the residue at position 60 in the human IgG CH2 region.
- the notation at position 288/290 indicates that the lysine residue at position 288 or 290 is the subject.
- the lysine residue at position 288/290 in the antibody can be regioselectively modified.
- regioselective or “regioselectivity” refers to binding to a specific amino acid residue in an antibody even though the specific amino acid residue is not unevenly distributed in a specific region in the antibody. It means that a predetermined structural unit that can be formed is unevenly distributed in a specific region in an antibody. Therefore, expressions related to regioselectivity, such as “regioselectively possessed”, “regioselectively bound”, and “regioselectively bound”, are target regions containing one or more specific amino acid residues.
- the retention or binding rate of a given structural unit in the target region is significantly higher than the retention or binding rate of the structural unit in a non-target region containing a plurality of amino acid residues that are the same species as the specific amino acid residue in the target region. It means that it is high at a high level.
- Such regioselectivity is 50% or more, preferably 60% or more, more preferably 70% or more, even more preferably 80% or more, particularly preferably 90% or more, 95% or more, 96% or more, It may be 97% or more, 98% or more, 99% or more, 99.5% or more, or 100%.
- the lysine residue at position 288/290 can be regioselectively modified without utilizing a linker containing a peptide.
- the peptide moiety has potential immunogenicity and is susceptible to hydrolysis in the blood. Therefore, avoiding the use of linkers containing peptide moieties is desirable in clinical applications.
- a specific amino acid residue at another position may be further regioselectively modified.
- methods for regioselectively modifying a particular amino acid residue at a given position in an antibody are described in WO/2018/199337, WO 2019/240288, WO 2019/240287, and International. It is described in Publication No. 2020/090979.
- Such specific amino acid residues include amino acid residues (eg, lysine residue, aspartic acid residue) having side chains that are easily modified (eg, amino group, carboxy group, amide group, hydroxy group, thiol group).
- Glutamic acid residue asparagine residue, glutamine residue, threonine residue, serine residue, tyrosine residue, cysteine residue
- a lysine residue having a side chain containing an amino group hydroxy A tyrosine residue having a side chain containing a group, a serine residue, and a threonine residue, or a cysteine residue having a side chain containing a thiol group, more preferably a lysine residue, and even more preferably.
- It is a lysine residue at position 246/248 or a lysine residue at position 317, and is particularly preferably a lysine residue at position 246/248.
- the notation at position 246/248 indicates that the lysine residue at position 246 or 248 is the subject.
- salt includes, for example, a salt with an inorganic acid, a salt with an organic acid, a salt with an inorganic base, a salt with an organic base, and a salt with an amino acid.
- the salt with the inorganic acid include salts with hydrogen chloride, hydrogen bromide, phosphoric acid, sulfuric acid, and nitric acid.
- salts with organic acids include formic acid, acetic acid, trifluoroacetic acid, lactic acid, tartaric acid, fumaric acid, oxalic acid, maleic acid, citric acid, succinic acid, malic acid, benzenesulfonic acid, and p-toluenesulfonic acid. Salt is mentioned.
- Salts with inorganic bases include, for example, alkali metals (eg, sodium, potassium), alkaline earth metals (eg, calcium, magnesium), and other metals such as zinc, aluminum, and salts with ammonium. ..
- Examples of the salt with an organic base include salts with trimethylamine, triethylamine, propylenediamine, ethylenediamine, pyridine, ethanolamine, monoalkylethanolamine, dialkylethanolamine, diethanolamine, and triethanolamine.
- salts with amino acids include salts with basic amino acids (eg, arginine, histidine, lysine, ornithine) and acidic amino acids (eg, aspartic acid, glutamic acid).
- the salt is preferably a salt with an inorganic acid (eg, hydrogen chloride) or a salt with an organic acid (eg, trifluoroacetic acid).
- the present invention provides a compound represented by the following formula (I) or a salt thereof.
- X indicates a leaving group
- Y represents an affinity peptide having a binding region to the CH2 domain in an immunoglobulin unit containing two heavy chains and two light chains.
- O indicates an oxygen atom
- S represents a sulfur atom
- W represents an oxygen atom or a sulfur atom
- La indicates the first linker
- Lb indicates a second linker
- the total number of atoms constituting the main chain in the first linker and the number of atoms constituting the main chain in the second linker are 5 to 7.
- the leaving group represented by X is a group that can be eliminated by a reaction between a carbon atom of a carbonyl group adjacent to X and an amino group.
- Those skilled in the art can appropriately set such a leaving group.
- Examples of such leaving groups include: (A) RS (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent. , S represents a sulfur atom.); (B) RO (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent.
- O represents an oxygen atom.
- C RA- ( RB- ) N
- RA and RB are independent hydrogen atoms, monovalent hydrocarbon groups which may have substituents, or substituents, respectively. Indicates a monovalent heterocyclic group which may have, where N represents a nitrogen atom.
- the leaving group represented by X may be: (A) RS (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent. , S represents a sulfur atom.); (B) RO (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent. , O represent an oxygen atom.); Or (c) RA- ( RB- ) N (where RA and RB each independently have a hydrogen atom and a substituent. It may be a monovalent hydrocarbon group, or a monovalent heterocyclic group which may have a substituent.);
- the leaving group represented by X may be: (A) RS (where R represents a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a monovalent heterocyclic group which may have a substituent. , S represents a sulfur atom.); Or (b) RO (where R has a hydrogen atom, a monovalent hydrocarbon group which may have a substituent, or a substituent. It represents a monovalent heterocyclic group which may be present, and O represents an oxygen atom.)
- the leaving group represented by X may be: (A) RS (where R is a monovalent aromatic hydrocarbon group which may have a substituent or a monovalent aromatic heterocyclic group which may have a substituent. Shown, S represents a sulfur atom.).
- the leaving group represented by X may be: (A') RS (where R represents a monovalent aromatic hydrocarbon group (eg, phenyl) which may have a substituent and S represents a sulfur atom).
- halogen atom examples include a fluorine atom, a chlorine atom, a bromine atom, and an iodine atom.
- Examples of the monovalent hydrocarbon group include a monovalent chain hydrocarbon group, a monovalent alicyclic hydrocarbon group, and a monovalent aromatic hydrocarbon group.
- the monovalent chain hydrocarbon group means a hydrocarbon group composed of only a chain structure and does not contain a cyclic structure in the main chain. However, the chain structure may be linear or branched. Examples of the monovalent chain hydrocarbon group include alkyl, alkenyl and alkynyl. Alkyl, alkenyl, and alkynyl may be linear or branched.
- alkyl an alkyl having 1 to 12 carbon atoms is preferable, an alkyl having 1 to 6 carbon atoms is more preferable, and an alkyl having 1 to 4 carbon atoms is further preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent.
- alkyl having 1 to 12 carbon atoms include methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl, isobutyl, t-butyl, pentyl, hexyl, heptyl, octyl, nonyl, and decyl. , Dodecyl.
- an alkenyl having 2 to 12 carbon atoms is preferable, an alkenyl having 2 to 6 carbon atoms is more preferable, and an alkenyl having 2 to 4 carbon atoms is further preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent. Examples of the alkenyl having 2 to 12 carbon atoms include vinyl, propenyl, and n-butenyl.
- alkynyl having 2 to 12 carbon atoms is preferable, alkynyl having 2 to 6 carbon atoms is more preferable, and alkynyl having 2 to 4 carbon atoms is even more preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent. Examples of alkynyl having 2 to 12 carbon atoms include ethynyl, propynyl, and n-butynyl.
- alkyl is preferable.
- the monovalent alicyclic hydrocarbon group means a hydrocarbon group containing only an alicyclic hydrocarbon as a ring structure and not containing an aromatic ring, and the alicyclic hydrocarbon is either monocyclic or polycyclic. It may be. However, it does not have to be composed only of alicyclic hydrocarbons, and a chain structure may be contained in a part thereof.
- Examples of the monovalent alicyclic hydrocarbon group include cycloalkyl, cycloalkenyl, and cycloalkynyl, which may be monocyclic or polycyclic.
- cycloalkyl a cycloalkyl having 3 to 12 carbon atoms is preferable, a cycloalkyl having 3 to 6 carbon atoms is more preferable, and a cycloalkyl having 5 to 6 carbon atoms is further preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent.
- Examples of cycloalkyl having 3 to 12 carbon atoms include cyclopropyl, cyclobutyl, cyclopentyl, and cyclohexyl.
- cycloalkenyl a cycloalkenyl having 3 to 12 carbon atoms is preferable, a cycloalkenyl having 3 to 6 carbon atoms is more preferable, and a cycloalkenyl having 5 to 6 carbon atoms is further preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent.
- examples of the cycloalkenyl having 3 to 12 carbon atoms include cyclopropenium, cyclobutenyl, cyclopentenyl, and cyclohexenyl.
- cycloalkynyl having 3 to 12 carbon atoms is preferable, cycloalkynyl having 3 to 6 carbon atoms is more preferable, and cycloalkynyl having 5 to 6 carbon atoms is even more preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent.
- Examples of cycloalkynyl having 3 to 12 carbon atoms include cyclopropynyl, cyclobutynyl, cyclopentinyl, and cyclohexynyl.
- cycloalkyl is preferable.
- the monovalent aromatic hydrocarbon group means a hydrocarbon group containing an aromatic ring structure. However, it does not have to be composed of only an aromatic ring, and a chain structure or an alicyclic hydrocarbon may be contained in a part thereof, and the aromatic ring may be either a monocyclic ring or a polycyclic ring. good.
- the monovalent aromatic hydrocarbon group an aryl having 6 to 12 carbon atoms is preferable, an aryl having 6 to 10 carbon atoms is more preferable, and an aryl having 6 carbon atoms is further preferable.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent. Examples of the aryl having 6 to 12 carbon atoms include phenyl and naphthyl.
- Phenyl is preferable as the monovalent aromatic hydrocarbon group.
- alkyl, cycloalkyl, and aryl are preferable as the monovalent hydrocarbon group.
- a monovalent heterocyclic group is a group obtained by removing one hydrogen atom from the heterocycle of a heterocyclic compound.
- the monovalent heterocyclic group is a monovalent aromatic heterocyclic group or a monovalent non-aromatic heterocyclic group.
- the hetero atom constituting the heterocyclic group preferably contains at least one selected from the group consisting of an oxygen atom, a sulfur atom, a nitrogen atom, a phosphorus atom, a boron atom and a silicon atom, and preferably contains an oxygen atom, a sulfur atom and a nitrogen atom. It is more preferable to include one or more selected from the group consisting of atoms.
- an aromatic heterocyclic group having 1 to 15 carbon atoms is preferable, an aromatic heterocyclic group having 1 to 9 carbon atoms is more preferable, and an aromatic heterocyclic group having 1 to 6 carbon atoms is more preferable.
- Group heterocyclic groups are more preferred.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent.
- Examples of the monovalent aromatic heterocyclic group include pyrrolyl, furanyl, thiophenyl, pyridinyl, pyrariainyl, pyrimidinyl, pyrazinyl, triazinyl, pyrazolyl, imidazolyl, thiazolyl, isothiazolyl, oxazolyl, isooxazolyl, triazolyl, tetrazolyl, indolyl, prynyl and anthraquinolyl. , Carbazonyl, fluorenyl, quinolinyl, isoquinolinyl, quinazolinyl, and phthalazinyl.
- a non-aromatic heterocyclic group having 2 to 15 carbon atoms is preferable, a non-aromatic heterocyclic group having 2 to 9 carbon atoms is more preferable, and a non-aromatic heterocyclic group having 2 to 9 carbon atoms is more preferable.
- the non-aromatic heterocyclic group of 6 is more preferred.
- the carbon atom number of the substituent does not include the carbon atom number of the substituent.
- Examples of the monovalent non-aromatic heterocyclic group include oxylanyl, aziridinyl, azetidinyl, oxetanyl, thietanyl, pyrrolidinyl, dihydrofuranyl, tetrahydrofuranyl, dioxolanyl, tetrahydrothiophenyl, pyrolinyl, imidazolidinyl, oxazolidinyl, piperidinyl and dihydropyranyl.
- Tetrahydropyranyl Tetrahydropyranyl, tetrahydrothiopyranyl, morpholinyl, thiomorpholinyl, piperazinyl, dihydrooxadinyl, tetrahydrooxadinyl, dihydropyrimidinyl, and tetrahydropyrimidinyl.
- a 5-membered or 6-membered heterocyclic group is preferable.
- halogen atoms, monovalent hydrocarbon groups, and monovalent heterocyclic groups in the substituents are the monovalent hydrocarbons described in R , RA , and RB, respectively. It is similar to that of a group and a monovalent heterocyclic group.
- Arylkill means arylalkyl. Definitions, examples and preferred examples of aryl and alkyl in arylalkyl are as described above.
- aralkyl aralkyl having 3 to 15 carbon atoms is preferable. Examples of such aralkyl include benzoyl, phenethyl, naphthylmethyl, and naphthylethyl.
- the affinity peptide indicated by Y has a binding region in the CH2 domain in the immunoglobulin unit containing two heavy chains and two light chains.
- any peptide having a binding region in the CH2 domain in the immunoglobulin unit can be used.
- Amino acid residues eg, lysine residues, proline residues, etc.
- are amino acid residues containing a side chain containing a moiety (eg, amino group, hydroxy group) capable of binding to a carbonyl group (C O) adjacent to Y.
- affinity peptides include International Publication No. 2016/186206, International Publication No. 2018/199337, International Publication No. 2009240288, International Publication No. 2019/240287, and International Publication No. 2020/090979.
- affinity peptides disclosed in the literature cited in these international publications can be used.
- the affinity peptide may be: (A) Affinity peptide containing the amino acid sequence of CQRRFYEALHDPNLNEEQRNARIRSIKDDC (SEQ ID NO: 1); Amino acid sequences containing variations of 1 to 5 selected amino acid residues (ie, 1, 2, 3, 4, or 5) (where the lysine residue at position 27, as well as the 1 and 1 and Affinity peptide containing (the two cysteine residues at position 30 are maintained). Since the affinity peptide containing the amino acid sequence of SEQ ID NO: 1 is a suitable peptide having a binding region in the CH2 domain in the immunoglobulin unit, it is preferable to use such an affinity peptide in the present invention.
- the N-terminal and C-terminal amino acid residues of the affinity peptide may be protected. Further, the thiol groups of the side chains of the two cysteine residues (C) in the affinity peptide may be linked by a disulfide bond or via a linker.
- the affinity peptide of (B) may be selected from the group consisting of: (A) Affinity peptide containing the amino acid sequence of FNMQCQRRFYEALHDPNLNEEQRNARIRSIKDDC (SEQ ID NO: 2); (B) Affinity peptide containing the amino acid sequence of FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEDC (SEQ ID NO: 3); (C) Affinity peptide containing the amino acid sequence of FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC (SEQ ID NO: 4); (D) Affinity peptide containing the amino acid sequence of NMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC (SEQ ID NO: 5); (E) Affinity peptide comprising the amino acid sequence of MQCQRRFYEALHDPNLNEEQRNARIRSIKEEC (SEQ ID NO: 6); and (f) Affinity peptide containing
- the N-terminal and C-terminal amino acid residues of the affinity peptide may be protected. Further, the thiol groups of the side chains of the two cysteine residues (C) in the affinity peptide may be linked by a disulfide bond or via a linker.
- At least two separated cysteine residues in each amino acid sequence of the affinity peptide can form a cyclic peptide by a disulfide bond.
- the thiol groups in the two cysteine residues may be linked by a carbonyl group-containing linker represented by the following.
- the broken line portion of the carbonyl group-containing linker represented above means the bonding portion with the thiol group.
- the linker is more stable to reduction reactions and the like than ordinary disulfide bonds.
- Such peptides can be prepared, for example, by the methods described in WO 2016/186206.
- the amino acids constituting the affinity peptide may be either L-form or D-form, but L-form is preferable (in the examples, all the amino acid residues constituting the peptide are L-form).
- the affinity peptide may be linked to the compound of formula (I) or a salt thereof by modifying a specific amino acid residue with a cross-linking agent. Examples of such a specific amino acid residue include a lysine residue, an aspartic acid residue, and a glutamate residue, but a lysine residue is preferable.
- cross-linking agent for example, a cross-linking agent containing two or more succinimidyl groups such as DSG (disuccinidily glutarate, disuccinimidyl sulrate) and DSS (disuccinidily sublate), DMA (dimethylate).
- DSG disuccinidily glutarate, disuccinimidyl sulrate
- DSS disuccinidily sublate
- DMA dimethylate
- Imidic acid moieties such as 2HCl, dimethyl dihydrochloride adipimide), DMP (dimethyl pimelimidate 2 HCl, dimethyl dimethylidate pimellimidate), and DMS (dimethyl suberimide 2 HCl, dimethyl dihydrochloride suberimide) are preferred.
- Cross-linking agent containing 2 or more and DTBP (dimethyl 3,3'-dithiobispropionimide ⁇ 2HCl, 3,3'-dithiobispropionimide acid dimethyl dihydrochloride) and DSP (dithiobis (succinimimidyl tropionate), dithiobiscus cinmidyl).
- DTBP dimethyl 3,3'-dithiobispropionimide ⁇ 2HCl, 3,3'-dithiobispropionimide acid dimethyl dihydrochloride
- DSP dithiobis (succinimimidyl tropionate), dithiobiscus cinmidyl).
- cross-linking agents having SS bonds such as (acid) (eg, International Publication No. 2016/186206).
- the affinity peptide may have an amino group and a carboxy group at the ends protected.
- the protective group for the N-terminal amino group include an alkylcarbonyl group (acyl group) (eg, a butoxycarbonyl group such as an acetyl group, a propoxy group, a tert-butoxycarbonyl group) and an alkyloxycarbonyl group (eg, fluore).
- Nylmethoxycarbonyl group aryloxycarbonyl group, arylalkyl (aralkyl) oxycarbonyl group (eg, benzyloxycarbonyl group).
- an acetyl group is preferable.
- the protected N-terminal glutamic acid may have a cyclic structure of pyroglutamic acid. Further, when the N-terminal amino acid is glutamine, the protected N-terminal glutamine may have a pyroglutamic acid type cyclic structure.
- Protecting groups for the C-terminal carboxy group include, for example, groups capable of forming esters or amides.
- Groups capable of forming esters or amides include, for example, alkyloxy groups (eg, methyloxy, ethyloxy, propyloxy, butyloxy, pentyloxy, hexyloxy), aryloxy groups (eg, phenyloxy, naphthyloxy), aralkyl. Examples include an oxy group (eg, benzyloxy) and an amino group. As the protecting group for the C-terminal carboxy group, an amino group is preferable.
- the first and second linkers are divalent groups, as can be seen from the chemical structure of formula (I).
- the total number of atoms constituting the main chain in the first linker and the number of atoms constituting the main chain in the second linker are 5 to 7.
- the lysine residue at the 288/290 position of the heavy chain in the immunoglobulin unit can be position-selectively modified with an affinity peptide-containing group, and the antibody. It becomes easy to highly control the average ratio of the binding between the antibody and the affinity peptide-containing group to a desired range (1.5 to 2.5).
- the average ratio of the binding between the antibody and a predetermined group eg, affinity peptide-containing group
- the number of atoms constituting the main chain in the first linker is The number of atoms is 1 to 6, and the number of atoms constituting the main chain in the second linker is 1 to 6. More specifically, the relationship between the number of atoms constituting the main chain in the first linker and the second linker is as follows.
- the main chains in the first linker and the second linker are composed of a chain structure, a cyclic structure, or a structure containing a combination thereof.
- the number of atoms in the main chain can be determined by counting the number of atoms in the chain structure.
- the main chain has a structure including a cyclic structure, it can be determined by counting a predetermined number of atoms constituting the cyclic structure as the number of atoms in the main chain.
- the number of atoms in the main chain in the cyclic structure can be determined by counting the number of atoms in the shortest path connecting the two bonds in the cyclic structure (for example, (a) to (d) below). ) Bold route).
- the main chain is a structure containing a combination of a chain structure and a cyclic structure
- the number of atoms in the main chain communicates the number of atoms in the chain structure not including the cyclic structure with the two bonds in the cyclic structure. It can be determined by adding up with the number of atoms in the shortest path. ⁇ Is a bond.
- the divalent linear hydrocarbon group is a linear alkylene, a linear alkenylene, or a linear alkynylene.
- the linear alkylene is a linear alkylene having 1 to 6 carbon atoms, and a linear alkylene having 1 to 4 carbon atoms is preferable.
- Examples of the linear alkylene include methylene, ethylene, n-propylene, n-butylene, n-pentylene and n-hexylene.
- the linear alkenylene is a linear alkenylene having 2 to 6 carbon atoms, and a linear alkenylene having 2 to 4 carbon atoms is preferable.
- linear alkenylene examples include ethyleneylene, n-propinylene, n-butenylene, n-pentenylene, and n-hexenylene.
- the linear alkynylene is a linear alkynylene having 2 to 6 carbon atoms, and a linear alkynylene having 2 to 4 carbon atoms is preferable.
- Examples of the linear alkynylene include ethynylene, n-propinylene, n-butynylene, n-pentinylene, and n-hexinylene.
- divalent linear hydrocarbon group a linear alkylene is preferable.
- the divalent cyclic hydrocarbon group is an arylene or a divalent non-aromatic cyclic hydrocarbon group.
- a divalent cyclic hydrocarbon group By appropriately setting two bonds in such a divalent cyclic hydrocarbon group, it is possible to set the number of atoms constituting the main chain as described above to be 1 to 6 (hereinafter, described below). The same applies to groups having a cyclic structure).
- the arylene an arylene having 6 to 14 carbon atoms is preferable, an arylene having 6 to 10 carbon atoms is more preferable, and an arylene having 6 carbon atoms is particularly preferable.
- the arylene include phenylene, naphthylene, and anthraceneylene.
- divalent non-aromatic cyclic hydrocarbon group a monocyclic or polycyclic divalent non-aromatic cyclic hydrocarbon group having 3 to 12 carbon atoms is preferable, and a simple monocyclic hydrocarbon group having 4 to 10 carbon atoms is preferable.
- a divalent non-aromatic cyclic hydrocarbon group having a cyclic or polycyclic type is more preferable, and a divalent non-aromatic cyclic hydrocarbon group having a monocyclic number of 5 to 8 carbon atoms is particularly preferable.
- divalent non-aromatic cyclic hydrocarbon group examples include cyclopropylene, cyclobutylene, cyclopentylene, cyclohexylene, cycloheptylene and cyclooctylene.
- divalent cyclic hydrocarbon group arylene is preferable.
- the divalent heterocyclic group is a divalent aromatic heterocyclic group or a divalent non-aromatic heterocyclic group.
- the hetero atom constituting the heterocycle preferably contains at least one selected from the group consisting of an oxygen atom, a sulfur atom, a nitrogen atom, a phosphorus atom, a boron atom and a silicon atom, and preferably contains an oxygen atom, a sulfur atom and a nitrogen atom. It is more preferable to include one or more selected from the group consisting of.
- a divalent aromatic heterocyclic group having 3 to 15 carbon atoms is preferable, a divalent aromatic heterocyclic group having 3 to 9 carbon atoms is more preferable, and a carbon atom.
- a divalent aromatic heterocyclic group having the number 3 to 6 is particularly preferable.
- the divalent aromatic heterocyclic group include pyrrol diyl, frangyl, thiophene diyl, pyridine diyl, pyridazine diyl, pyrimidine diyl, pyrazine diyl, triazine diyl, pyrazole diyl, imidazole diyl, thiazole diyl, isothiazole diyl, and oxazole diyl.
- Isoxazole diyl triazole diyl, tetrazole diyl, indole diyl, purine diyl, anthraquinone diyl, carbazole diyl, full orange yl, quinoline diyl, isoquinolin diyl, quinazoline diyl, and phthalazine diyl.
- a non-aromatic heterocyclic group having 3 to 15 carbon atoms is preferable, a non-aromatic heterocyclic group having 3 to 9 carbon atoms is more preferable, and a non-aromatic heterocyclic group having 3 to 9 carbon atoms is more preferable.
- the non-aromatic heterocyclic group of 6 is particularly preferred.
- divalent non-aromatic heterocyclic group examples include pyrroldionediyl, pyrrolinedionediyl, oxylandiyl, aziridinediyl, azetidinediyl, oxetandiyl, thietandiyl, pyrrolidinediyl, dihydrofurandiyl, tetrahydrofurandiyl, dioxorandiyl and tetrahydrothiophene.
- Diyl Pyrroline Diyl, Imidazolidine Diyl, Oxazolidine Diyl, Piperidine Diyl, Dihydropyran Diyl, Tetrahydropyran Diyl, Tetrahydropyran Diyl, Morpholine Diyl, Thiomorpholindiyl, Piperazine Diyl, Dihydrooxazine Diyl, Tetrahydropyran Diyl, Dihydropyrandiyl, And tetrahydropyrandiyl.
- a divalent aromatic heterocyclic group is preferable.
- W represents an oxygen atom or a sulfur atom, preferably an oxygen atom.
- La and Lb indicate a first linker and a second linker, respectively.
- the main chain in the first linker and the second linker may be composed of only carbon atoms, or may be composed of a combination of carbon atoms and heteroatoms (eg, oxygen atom, nitrogen atom, sulfur atom). However, from the viewpoint of easiness of organic synthesis and improvement of stability, it may be composed of only carbon atoms.
- the main chain in the first linker represented by La is preferably set so that the number of atoms constituting the main chain as described above is 2 to 4.
- the main chain in the second linker represented by Lb is preferably set so that the number of atoms constituting the main chain as described above is 1 to 5.
- the main chain in the first linker represented by La is preferably set so that the number of atoms constituting the main chain as described above is two.
- the main chain in the second linker represented by Lb is preferably set so that the number of atoms constituting the main chain as described above is 3 to 5.
- La is a portion contained in the thiol group-introduced antibody derivative and has a low steric hindrance so as not to interfere with the reaction between the thiol group of the thiol group-introduced antibody derivative and the functional substance, and organic synthesis is carried out.
- the main chain in the first linker represented by La is composed of a divalent linear hydrocarbon group having 2 to 4 carbon atoms.
- the main chain in the first linker represented by La is even more preferably an ethylene group, a propylene group, or a butylene group, and particularly preferably an ethylene group.
- this second linker can be decomposed in the production without any problem. That is, the main chain in the second linker is different from the main chain in the first linker, and its stability is less likely to be a problem.
- the number of atoms constituting the main chain in the second linker is preferably 1 to 5, and more preferably 3 to 5.
- the number of atoms constituting the main chain in the second linker is preferably 1 to 5, and more preferably 3 to 5.
- the number of atoms constituting the main chain in the second linker is preferably 1 to 5, and more preferably 3 to 5.
- the number of atoms constituting the main chain in the second linker is preferably 1 to 5, and more preferably 3 to 5.
- the main chain in the second linker represented by Lb may be propylene or m-phenylene.
- the groups constituting the main chain in the first linker and the second linker may have, for example, 1 to 5, preferably 1 to 3, and more preferably 1 or 2 substituents. Further, the Rd, which is one of the groups constituting the main chain in the first linker and the second linker, may indicate a substituent as described above.
- halogen atoms examples, and preferred examples of halogen atoms, monovalent hydrocarbon groups, aralkyl, and monovalent heterocyclic groups in the substituents are R , RA , and RB, respectively, and (i) to (i) above. This is similar to that of the halogen atom, monovalent hydrocarbon group, aralkyl, and monovalent heterocyclic group described in (iv).
- the compound represented by the formula (I) may be a compound represented by the following formula (I').
- X, Y, O, S and W are the same as those in formula (I).
- Lb represents a second linker having 3 to 5 atoms constituting the main chain.
- R 1 , R 2 , R 3 and R 4 each independently represent a hydrogen atom or substituent.
- examples and preferred examples of substituents represented by R1 , R2 , R3 , and R4 in formula (I') may be possessed by the groups that make up the backbone of the first linker. It is the same as that of the above-mentioned substituent.
- the compound represented by the formula (I') may be a compound represented by the following formula (I ′′).
- X, Y, O, S and W are the same as those in formula (I).
- Lb is the same as that of the formula (I').
- the compound of the present invention represented by the formulas (I) to (I ′′) or a salt thereof is, for example, the Y portion of the compound represented by the formulas (I) to (I ′′) or a salt thereof is eliminated.
- Obtained by synthesizing a compound or a salt thereof substituted with a group (a leaving group having a higher leaving ability than X), and then reacting the synthesized compound or a salt thereof with an affinity peptide. can be done.
- a reaction can be carried out in a suitable reaction system (eg, in an organic solvent or aqueous solution or a mixed solvent thereof) at a suitable temperature (eg, about 15 to 200 ° C.).
- the reaction system may include a suitable catalyst.
- the reaction time is, for example, 1 minute to 20 hours, preferably 10 minutes to 15 hours, more preferably 20 minutes to 10 hours, and even more preferably 30 minutes to 8 hours.
- the Y moiety is replaced with a leaving group (a leaving group having a higher ability to remove than X) or a compound thereof.
- the salt may be a compound represented by the following formula (VI) or a salt thereof.
- O indicates an oxygen atom
- S represents a sulfur atom
- W represents an oxygen atom or a sulfur atom
- La indicates the first linker
- Lb indicates a second linker
- the total number of atoms constituting the main chain in the first linker and the number of atoms constituting the main chain in the second linker are 5 to 7.
- the leaving group represented by X' which has a higher leaving ability than the leaving group X, is not particularly limited as long as it is a leaving group having a higher leaving ability than the leaving group X, for example, pentafluoro. Examples thereof include a phenyloxy group, a tetrafluorophenyloxy group, a paranitrophenyloxy group, and an N-succinimidyloxy group.
- the compound represented by the formula (VI) or a salt thereof is useful as, for example, a synthetic intermediate for efficiently producing the compound represented by the formula (I) or a salt thereof.
- the compound represented by the formula (VI) may be a compound represented by the following formula (VI').
- X, X', O, S and W are the same as those of equation (VI) and Lb represents a second linker having 3 to 5 atoms constituting the main chain.
- R 1 , R 2 , R 3 and R 4 each independently represent a hydrogen atom or substituent.
- the compound represented by the formula (VI') may be a compound represented by the following formula (VI ′′).
- X, X', O, S and W are the same as those of equation (VI) and Lb is the same as that of the formula (VI').
- the compound represented by the formula (VI ′′) may be a compound represented by the following formula (VI ′′ -1) or (VI ′′ -2).
- O, S and W are the same as those of equation (VI) and F is a fluorine atom.
- the compound represented by the formula (VI) or a salt thereof can be produced from the compound represented by the following formula (V) or a salt thereof.
- X indicates a leaving group
- O indicates an oxygen atom
- OH indicates a hydroxy group
- S represents a sulfur atom
- W represents an oxygen atom or a sulfur atom
- La indicates the first linker
- Lb indicates a second linker
- the total number of atoms constituting the main chain in the first linker and the number of atoms constituting the main chain in the second linker are 5 to 7.
- the compound represented by the formula (VI) or a salt thereof can be obtained by reacting the compound represented by the formula (V) or a salt thereof with a carboxyl group modifying reagent.
- carboxyl group modifying reagent include a pentafluorophenylation reagent (eg, pentafluorophenyl trifluoroacetate), a tetrafluorophenylation reagent (eg, trifluoroacetate tetrafluorophenyl), and a paranitrophenylation reagent (eg, tri).
- N-succinimidylating reagent eg, trifluoroacetate N-succinimidyl
- a suitable temperature eg, about
- a suitable organic solvent system eg, an organic solvent containing an alkyl halide (eg, methyl halide) such as CH 2 Cl 2 and an amine such as triethylamine.
- the reaction time is, for example, 1 minute to 20 hours, preferably 10 minutes to 15 hours, more preferably 20 minutes to 10 hours, and even more preferably 30 minutes to 8 hours.
- the compound represented by the formula (V) or a salt thereof is useful as, for example, a synthetic intermediate for efficiently producing the compound represented by the formula (VI) or a salt thereof.
- the compound represented by the formula (V) may be a compound represented by the following formula (V').
- V' represents a second linker having 3 to 5 atoms constituting the main chain.
- R 1 , R 2 , R 3 and R 4 each independently represent a hydrogen atom or substituent.
- the compound represented by the formula (V') may be a compound represented by the following formula (V ′′).
- V ′′ a compound represented by the following formula (V ′′).
- the compound represented by the formula (V ′′) may be a compound represented by the following formula (V ′′ -1) or (V ′′ -2). [During the ceremony, O, OH, S and W are the same as those of the formula (V). ]
- the present invention provides an antibody intermediate or a salt thereof containing a structural unit represented by the following formula (II).
- Ig represents an immunoglobulin unit containing two heavy chains and two light chains, and is an amino in the side chain of a lysine residue present at position 288/290 in the two heavy chains according to Eunumbering. An amide bond is formed with the carbonyl group adjacent to Ig via the group.
- Y represents an affinity peptide having a binding region to the CH2 domain in the immunoglobulin unit.
- O indicates an oxygen atom
- S represents a sulfur atom
- W represents an oxygen atom or a sulfur atom
- La indicates the first linker
- Lb indicates a second linker
- the total number of atoms constituting the main chain in the first linker and the number of atoms constituting the main chain in the second linker are 5 to 7.
- the average ratio r of the amide bonds per two heavy chains is 1.5 to 2.5. ]
- the immunoglobulin unit indicated by Ig is as described above. Definitions, examples, and preferred examples of symbols, terms and expressions such as Y (affinity peptide), W (oxygen atom or sulfur atom), La (first linker), Lb (second linker) in formula (II) , The same as that of the above formula.
- the average ratio (r) of the amide bond per two heavy chains is the average ratio of the bonds between the immunoglobulin unit and the affinity peptide-containing group (affinity peptide-containing group number / immunoglobulin unit). Is shown. Such an average ratio is 1.5 to 2.5. Such an average ratio may be preferably 1.6 or more, more preferably 1.7 or more, even more preferably 1.8 or more, and particularly preferably 1.9 or more. Such an average ratio may also be preferably 2.4 or less, more preferably 2.3 or less, even more preferably 2.2 or less, and particularly preferably 2.1 or less. More specifically, such an average ratio is preferably 1.6 to 2.4, more preferably 1.7 to 2.3, even more preferably 1.8 to 2.2, and particularly preferably 1. It may be .9 to 2.1.
- the structural unit represented by the formula (II) may be the structural unit represented by the following formula (II').
- Ig, Y, O, S, W and r are the same as those of formula (II).
- Lb represents a second linker having 3 to 5 atoms constituting the main chain.
- R 1 , R 2 , R 3 and R 4 each independently represent a hydrogen atom or substituent.
- It may be a structural unit represented by.
- the structural unit represented by the formula (II') may be a structural unit represented by the following formula (II ′′).
- Ig, Y, O, S, W and r are the same as those of formula (II).
- Lb is the same as that of formula (II').
- the antibody intermediate of the present invention or a salt thereof can be obtained by reacting the compound of the present invention or a salt thereof with an antibody containing the above-mentioned immunoglobulin unit.
- the compound of the present invention or a salt thereof is mixed with the antibody. This allows the compounds of the invention or salts thereof to associate with the antibody via an affinity peptide that has an affinity for the antibody.
- the amino group and the carbon atom of the carbonyl group are bonded, and the leaving group (X) is eliminated from the carbonyl group to obtain the antibody intermediate of the present invention or a salt thereof.
- the molar ratio of the compound of the present invention or a salt thereof (the compound of the present invention or a salt thereof / antibody) to the antibody in the reaction varies depending on factors such as the compound of the present invention or a salt thereof and the type of antibody. Although not particularly limited, for example, it is 1 to 100, preferably 2 to 80, more preferably 4 to 60, even more preferably 5 to 50, and particularly preferably 6 to 30.
- Such a reaction can be appropriately carried out under conditions (mild conditions) that cannot cause protein denaturation / decomposition (eg, cleavage of amide bond).
- a reaction can be carried out at room temperature (eg, about 15-30 ° C.) in a suitable reaction system, eg buffer.
- the pH of the buffer is, for example, 5 to 9, preferably 5.5 to 8.5, and more preferably 6.0 to 8.0.
- the buffer may contain a suitable catalyst.
- the reaction time is, for example, 1 minute to 20 hours, preferably 10 minutes to 15 hours, more preferably 20 minutes to 10 hours, and even more preferably 30 minutes to 8 hours.
- Confirmation of the formation of an antibody intermediate or a salt thereof depends on the specific raw material and the molecular weight of the product, but for example, electrophoresis, chromatography (eg, gel filtration chromatography, ion exchange chromatography, reverse phase). It can be done by column chromatography, HPLC), or mass spectrometry. Confirmation of regioselectivity can be performed, for example, by peptide mapping. Peptide mapping can be performed, for example, by protease treatment and mass spectrometry. As the protease, endoprotease is preferable.
- affinity peptides introduced can be confirmed, for example, by electrophoresis, chromatography, or mass spectrometry, preferably mass spectrometry.
- the antibody intermediate or a salt thereof can be appropriately purified by any method such as chromatography (eg, chromatography described above, and affinity chromatography).
- a thiol group-introduced antibody derivative or a salt thereof which comprises a structural unit represented by the following formula (III).
- Ig represents an immunoglobulin unit containing two heavy chains and two light chains, and is an amino in the side chain of a lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the group.
- O indicates an oxygen atom
- SH indicates a thiol group
- La indicates the first linker
- the number of atoms constituting the main chain in the first linker is 2 to 4, and the number of atoms is 2 to 4.
- the average ratio r of the amide bonds per two heavy chains is 1.5 to 2.5.
- the immunoglobulin unit indicated by Ig is as described above. Definitions, examples, and preferred examples of symbols, terms and expressions such as La (first linker) in formula (III) are the same as those in the above formula.
- the average ratio (r) of the amide bond per two heavy chains indicates the average ratio of the bonds between the immunoglobulin unit and the thiol-containing group (thiol-containing group number / immunoglobulin unit).
- Such an average ratio is 1.5 to 2.5.
- Such an average ratio may be preferably 1.6 or more, more preferably 1.7 or more, even more preferably 1.8 or more, and particularly preferably 1.9 or more.
- Such an average ratio may also be preferably 2.4 or less, more preferably 2.3 or less, even more preferably 2.2 or less, and particularly preferably 2.1 or less. More specifically, such an average ratio is preferably 1.6 to 2.4, more preferably 1.7 to 2.3, even more preferably 1.8 to 2.2, and particularly preferably 1. It may be .9 to 2.1.
- the structural unit represented by the formula (III) may be the structural unit represented by the following formula (III').
- Ig, O, SH and r are the same as those of formula (III).
- R 1 , R 2 , R 3 and R 4 each independently represent a hydrogen atom or substituent.
- examples and preferred examples of substituents represented by R1 , R2 , R3, and R4 in formula ( III ') may be possessed by the groups that make up the backbone of the first linker. It is the same as that of the above-mentioned substituent.
- the structural unit represented by the formula (III') may be the structural unit represented by the following formula (III ′′). [During the ceremony, Ig, O, SH and r are the same as those in formula (III). ]
- the thiol group-introduced antibody derivative of the present invention or a salt thereof can be obtained by subjecting the antibody intermediate of the present invention or a salt thereof to a thioester cleavage reaction.
- the thioester cleavage reaction can be carried out under conditions that cannot cause denaturation / degradation of proteins (immunoglobulin / antibody) (eg, cleavage of amide bonds) (mild conditions as described above). More specifically, it can be cleaved by stirring for 1 hour in a hydroxylamine hydrochloride solution in the range of pH 4.0 to pH 8.0, 10 mM to 10 M (eg, Vance, Net al., Bioconjugate Chem. 2019, 30, 148-160.).
- Confirmation of the formation of a thiol group-introduced antibody derivative or a salt thereof depends on the specific raw material and the molecular weight of the product, and is, for example, electrophoresis, chromatography (eg, gel filtration chromatography, ion exchange chromatography, etc.). It can be done by reverse phase column chromatography, HPLC), or mass spectrometry, preferably by mass spectrometry.
- Confirmation of regioselectivity can be performed, for example, by peptide mapping.
- Peptide mapping can be performed, for example, by protease (eg, trypsin, chymotrypsin) treatment and mass spectrometry. As the protease, endoprotease is preferable.
- Examples of such an endoprotease include trypsin, chymotrypsin, Glu-C, Lys-N, Lys-C, and Asp-N.
- the number of thiol groups introduced can be confirmed, for example, by electrophoresis, chromatography, or mass spectrometry, preferably by mass spectrometry.
- the thiol group-introduced antibody derivative or a salt thereof can be appropriately purified by any method such as chromatography (eg, chromatography described above, and affinity chromatography).
- conjugates of antibodies and functional substances or salts thereof which contain structural units represented by the following formula (IV).
- Ig represents an immunoglobulin unit containing two heavy chains and two light chains, and is an amino in the side chain of a lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the group.
- O indicates an oxygen atom
- S represents a sulfur atom
- Z indicates a functional substance
- La indicates the first linker
- the number of atoms constituting the main chain in the first linker is 2 to 4, and the number of atoms is 2 to 4.
- the average ratio r of the amide bonds per two heavy chains is 1.5 to 2.5.
- the immunoglobulin unit indicated by Ig is as described above. Definitions, examples, and preferred examples of symbols, terms and expressions such as La (first linker) in formula (IV) are similar to those in formula (IV) above.
- the functional substance is not particularly limited as long as it is a substance that imparts an arbitrary function to the antibody, and examples thereof include a drug, a labeling substance, and a stabilizer, but a drug or a labeling substance is preferable.
- the functional substance may also be a single functional substance or a substance in which two or more functional substances are linked.
- the drug may be a drug for any disease.
- diseases include, for example, cancers (eg, lung cancer, gastric cancer, colon cancer, pancreatic cancer, kidney cancer, liver cancer, thyroid cancer, prostate cancer, bladder cancer, ovarian cancer, uterine cancer, bone cancer, skin cancer, etc.
- Brain tumor, melanoma autoimmune and inflammatory diseases (eg, allergic disease, rheumatoid arthritis, systemic erythematosus), neurological diseases (eg, cerebral infarction, Alzheimer's disease, Parkinson's disease, muscular atrophic lateral sclerosis), Infectious diseases (eg, bacterial infections, viral infections), hereditary and rare diseases (eg, hereditary globular erythropathy, non-dystrophic myotension), eye diseases (eg, age-related luteal degeneration, diabetic retinopathy, etc.) Retinal pigment degeneration), diseases in the field of bone and orthopedics (eg, osteoarthritis), blood diseases (eg, leukemia, purpura), and other diseases (eg, diabetes, hyperlipidemia, etc.) , Liver disease, kidney disease, lung disease, cardiovascular disease, digestive system disease).
- the drug may be a prophylactic or therapeutic drug for a disease or a palliative drug for side effects.
- the drug is an anti-cancer agent.
- Anti-cancer agents include, for example, chemotherapeutic agents, toxins, radioisotopes or substances containing them.
- Chemotherapeutic agents include, for example, DNA damaging agents, metabolic antagonists, enzyme inhibitors, DNA intercalating agents, DNA cleavage agents, topoisomerase inhibitors, DNA binding inhibitors, tubulin binding inhibitors, cytotoxic nucleosides, etc. Platinum compounds can be mentioned.
- Examples of toxins include bacterial toxins (eg, diphtheria toxins) and plant toxins (eg, ricin).
- Radioisotopes include, for example, a radioisotope of a hydrogen atom (eg, 3H ), a radioisotope of a carbon atom (eg, 14C ), a radioisotope of a phosphorus atom (eg, 32P ), and a sulfur atom.
- Radioisotopes eg, 35 S
- yttrium radioisotopes eg 90 Y
- technetium radioisotopes eg 99 MTc
- indium radioisotopes eg 111 In
- iodine atom radioactivity Isotopes eg 123 I, 125 I, 129 I, 131 I
- samarium radioisotopes eg 153 Sm
- renium radioisotopes eg 186 Re
- asstatin radioisotopes eg 156 Re
- 211 At a radioisotope of bismuth
- a radioisotope of bismuth eg, 212 Bi
- auristatin MMAE, MMAF
- maitansine DM1, DM4
- PBD pyrrolobenzodiazepine
- IGN camptothecin analog
- calicheamicin duocalmycin
- eribulin anthracycline
- dmDNA31 tubricin.
- the labeling substance is a substance that enables detection of a target (eg, tissue, cell, substance).
- Labeling substances include, for example, enzymes (eg, peroxidase, alkaline phosphatase, luciferase, ⁇ -galactosidase), affinity substances (eg, streptavidin, biotin, digoxygenin, aptamer), fluorescent substances (eg, fluorescein, fluorescein isothiocyanate, rhodamine).
- Green fluorescent protein Green fluorescent protein, red fluorescent protein
- luminescent substances eg, luciferin, equolin, acridinium ester, tris (2,2'-bipyridyl) ruthenium, luminol
- radioactive isotopes eg, those mentioned above
- examples include substances containing it.
- Stabilizer is a substance that enables the stabilization of antibodies.
- Stabilizers include, for example, diols, glycerin, nonionic surfactants, anionic surfactants, natural surfactants, saccharides, and polyols.
- Functional substances may also be peptides, proteins, nucleic acids, small molecule organic compounds, sugar chains, lipids, high molecular polymers, metals (eg gold), killer.
- the peptide include a cell membrane penetrating peptide, a blood-brain barrier penetrating peptide, and a peptide drug.
- proteins include enzymes, cytokines, fragment antibodies, lectins, interferons, serum albumin, and antibodies.
- nucleic acids include DNA, RNA, and artificial nucleic acids. Nucleic acids also include, for example, RNA interference-inducing nucleic acids (eg, siRNA), aptamers, antisense.
- small molecule organic compounds include proteolysis-inducing chimeric molecules, dyes, and photodegradable compounds.
- the functional substance may be derivatized so as to have such a functional group.
- Derivatization is common technical knowledge in the art (eg, International Publication No. 2004/010957, US Patent Application Publication No. 2006/0074008, US Patent Application Publication No. 2005/02386649).
- derivatization may be carried out using any cross-linking agent.
- the derivatization may be carried out using a specific linker having the desired functional group.
- such a linker may be one in which the functional substance and the antibody can be separated by cleavage of the linker in an appropriate environment (eg, intracellular or extracellular).
- linkers include, for example, peptidyl linkers that are degraded by specific proteases [eg, intracellular proteases (eg, proteases present in lysosomes, or endosomes), extracellular proteases (eg, secretory proteases)].
- proteases eg, intracellular proteases (eg, proteases present in lysosomes, or endosomes), extracellular proteases (eg, secretory proteases)
- a linker that can be cleaved at a locally acidic site present in the living body eg, US Pat. No. 5, US Pat. No. 5).
- the linker may be self-destructive (eg, WO 02/083180, WO 04/043493, WO 05/1192919).
- the derivatized functional substance is also simply referred to as "functional substance”.
- the average ratio (r) of the amide bond per two heavy chains is the average ratio of the bonds between the immunoglobulin unit and the functional substance-containing group (functional substance-containing group number / immunoglobulin unit). Is shown. Such an average ratio is 1.5 to 2.5. Such an average ratio may be preferably 1.6 or more, more preferably 1.7 or more, even more preferably 1.8 or more, and particularly preferably 1.9 or more. Such an average ratio may also be preferably 2.4 or less, more preferably 2.3 or less, even more preferably 2.2 or less, and particularly preferably 2.1 or less. More specifically, such an average ratio is preferably 1.6 to 2.4, more preferably 1.7 to 2.3, even more preferably 1.8 to 2.2, and particularly preferably 1. It may be .9 to 2.1.
- the structural unit represented by the formula (IV) may be the structural unit represented by the following formula (IV').
- formula (IV') [During the ceremony, Ig, O, S, Z and r are the same as those of formula (IV).
- R 1 , R 2 , R 3 and R 4 each independently represent a hydrogen atom or substituent. ]
- the structural unit represented by the formula (IV') may be the structural unit represented by the following formula (IV ′′). [During the ceremony, Ig, O, S, Z and r are the same as those of formula (IV). ]
- the conjugate of the present invention or a salt thereof can be obtained by reacting the thiol group-introduced antibody derivative of the present invention or a salt thereof with a functional substance.
- a reaction can be carried out under conditions that cannot cause denaturation / degradation of a protein (immunoglobulin / antibody) (eg, cleavage of an amide bond) (mild conditions as described above).
- a functional substance a substance having an arbitrary functional group capable of reacting with a thiol group under mild conditions can be used, but it is preferable to use a functional group that easily reacts with the thiol group.
- a functional group examples include a maleimide group, a disulfide group, an ⁇ -haloketone, an ⁇ -haloamide, a benzyl bromide, and an iodoalkyl group.
- the functional substance derivatized as described above can be used.
- the molar ratio of the functional substance to the thiol group-introduced antibody derivative or its salt is determined by the type of the thiol group-introduced antibody derivative or its salt and the functional substance.
- reaction time since it varies depending on factors such as reaction time, it is not particularly limited, but is, for example, 2 or more, preferably 3 or more, and more preferably 5 or more.
- a sufficient amount (eg, excess amount) of the functional substance with respect to the thiol group-introduced antibody derivative or a salt thereof is used. be able to.
- Confirmation of the formation of a conjugate or salt thereof depends on the specific raw material and the molecular weight of the product, but for example, electrophoresis, chromatography (eg, gel filtration chromatography, ion exchange chromatography, reverse phase column). It can be done by chromatography, HPLC), or mass spectrometry, preferably by mass spectrometry.
- Confirmation of regioselectivity can be performed, for example, by peptide mapping.
- Peptide mapping can be performed, for example, by protease (eg, trypsin, chymotrypsin) treatment and mass spectrometry. As the protease, endoprotease is preferable.
- Examples of such an endoprotease include trypsin, chymotrypsin, Glu-C, Lys-N, Lys-C, and Asp-N.
- the number of functional substances introduced can be confirmed by, for example, electrophoresis, chromatography, or mass spectrometry, preferably mass spectrometry.
- the conjugate or salt thereof can be appropriately purified by any method such as chromatography (eg, chromatography described above, and affinity chromatography).
- the compounds of the present invention or salts thereof can, for example, regioselectively modify the lysine residue at position 288/29 of an antibody. Therefore, the present invention provides a reagent for antibody derivatization, which comprises the compound of the present invention or a salt thereof.
- the reagent of the present invention may be provided in the form of a composition further containing other components.
- other components include solutions, stabilizers (eg, antioxidants, preservatives).
- an aqueous solution is preferable.
- the aqueous solution include water (eg, distilled water, sterile distilled water, purified water, physiological saline), buffer solution (eg, phosphoric acid aqueous solution, Tris-hydrochloride buffer solution, carbonic acid-bicarbonate buffer solution, boric acid aqueous solution). , Glycine-sodium hydroxide buffer, citrate buffer), but a buffer is preferred.
- the pH of the solution is, for example, 5.0 to 9.0, preferably 5.5 to 8.5.
- the reagents of the present invention can be provided in liquid or powder form (eg, lyophilized powder).
- the antibody intermediate of the present invention or a salt thereof, and the thiol group-introduced antibody derivative of the present invention or a salt thereof are useful as, for example, a conjugate of an antibody and a functional substance or an intermediate for preparing a salt thereof.
- the conjugate of the present invention or a salt thereof is useful as, for example, a drug or a reagent (eg, a diagnostic agent, a reagent for research).
- the present invention is regioselectively modified with a functional substance, and the average ratio of binding between the antibody and the functional substance is highly controlled within a desired range (1.5 to 2.5).
- the conjugate or salt thereof is useful as a medicine. It has been reported that changing the number and position of binding of a drug in an antibody-drug conjugate (ADC) changes the pharmacokinetics, the release rate of the drug, and the effect. For these reasons, next-generation ADCs are required to control the number and position of drugs to be conjugated. It is thought that if the number and position are constant, the problems of efficacy, variation of conjugation drug, and lot difference, so-called regulation, as expected will be solved. Therefore, the conjugates of the present invention or salts thereof can solve such regulation problems.
- ADC antibody-drug conjugate
- the conjugate of the present invention or a salt thereof may be provided in the form of a pharmaceutical composition.
- a pharmaceutical composition may contain a pharmaceutically acceptable carrier in addition to the conjugate of the present invention or a salt thereof.
- Pharmaceutically acceptable carriers include, for example, excipients such as sucrose, starch, mannit, sorbit, lactose, glucose, cellulose, talc, calcium phosphate, calcium carbonate, cellulose, methyl cellulose, hydroxypropyl cellulose, polypropylpyrrolidone.
- Gelatin gum arabic, polyethylene glycol, sucrose, starch and other binders, starch, carboxymethyl cellulose, hydroxypropyl starch, sodium hydrogen carbonate, calcium phosphate, calcium citrate and other disintegrants, magnesium stearate, aerodyl, talc, lauryl Lubricants such as sodium sulfate, citric acid, menthol, glycyrrhizin / ammonium salt, glycine, fragrances such as orange powder, preservatives such as sodium benzoate, sodium hydrogen sulfite, methylparaben, propylparaben, citric acid, sodium citrate, acetic acid Stabilizers such as, methyl cellulose, polyvinylpyrrolidone, suspending agents such as aluminum stearate, dispersants such as surfactants, diluents such as water, physiological saline, orange juice, cocoa butter, polyethylene glycol, white kerosene, etc.
- examples include,
- Suitable formulations for oral administration are solutions in which an effective amount of ligand is dissolved in a diluted solution such as water, physiological saline, or orange juice, capsules containing an effective amount of ligand as solids or granules, sachets, or sachets.
- a diluted solution such as water, physiological saline, or orange juice
- capsules containing an effective amount of ligand as solids or granules, sachets, or sachets include tablets, suspensions in which an effective amount of the active ingredient is suspended in an appropriate dispersion medium, and emulsions in which a solution in which an effective amount of the active ingredient is dissolved is dispersed in an appropriate dispersion medium and emulsified.
- the pharmaceutical composition is suitable for parenteral administration (eg, intravenous injection, subcutaneous injection, intramuscular injection, local injection, intraperitoneal administration).
- Pharmaceutical compositions suitable for such parenteral administration include aqueous and non-aqueous isotonic sterile injectable solutions, which include antioxidants, buffers, antibacterial agents, isotonic agents. Etc. may be included. Examples thereof include aqueous and non-aqueous sterile suspensions, which may include suspending agents, solubilizers, thickeners, stabilizers, preservatives and the like.
- the dose of the pharmaceutical composition varies depending on the type / activity of the active ingredient, the severity of the disease, the animal species to be administered, the drug acceptability of the administration target, the body weight, the age, etc., but can be appropriately set.
- Example 1 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis]
- (1-1) Synthesis of IgG1 Fc-binding peptide
- As the peptide synthesizer Liberty Blue manufactured by CEM was used.
- a 2M aqueous trifluoroacetic acid solution was added to the reaction solution to stop the reaction, this was dissolved in a 0.05% aqueous trifluoroacetic acid solution, and subjected to reverse phase high-speed liquid chromatography using octadodecyl group chemically bound silica gel as a filler. , Elution with a mixed solution of water containing 0.05% trifluoroacetic acid and acetonitrile, and each fraction was confirmed by LC-MS. The fraction containing the product was collected and concentrated under reduced pressure to remove acetonitrile, and then freeze-dried to obtain the desired product (20.0 mg, 4.70 ⁇ mol).
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 2. The average ratio r of the amide bonds per two heavy chains is 2.0.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- the average ratio r of the amide bonds per two heavy chains is 2.0.
- the heavy chain VH domain and the number on the light chain are the numbers in the sequence (that is, the N-terminal amino acid is the first; the same applies hereinafter), and the heavy chains CH1, CH2, and CH3 are used. On the domain, it is described using EU numbering.
- (1) and (2) shown in FIG. 9 were used as the data of the amino acid sequence to be searched for the modification site.
- Example 2 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis]
- (2-1) Synthesis of thioester linker (2-1-1)
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 2. The average ratio r of the amide bonds per two heavy chains is 2.0.
- Example 3 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis] (3-1) Synthesis of thioester linker (3-1-1)
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 2. The average ratio r of the amide bonds per two heavy chains is 1.9.
- Example 4 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis] (4-1) Synthesis of thioester linker (4-1-1)
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 2. The average ratio r of the amide bonds per two heavy chains is 1.8.
- Example 5 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis]
- (5-1) Binding of peptide and linker
- Both of the above two amino acid sequences are the amino acid sequences of SEQ ID NO: 3.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 3. The average ratio r of the amide bonds per two heavy chains is 2.0.
- Example 6 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis] (6-1) Binding of peptide and linker Both of the above two amino acid sequences are the amino acid sequences of SEQ ID NO: 4.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 4. The average ratio r of the amide bonds per two heavy chains is 2.0.
- Example 7 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis] (7-1) Binding of peptide and linker Both of the above two amino acid sequences are the amino acid sequences of SEQ ID NO: 5.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 5. The average ratio r of the amide bonds per two heavy chains is 2.0.
- Example 8 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis] (8-1) Binding of peptide and linker Both of the above two amino acid sequences are the amino acid sequences of SEQ ID NO: 6.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 6. The average ratio r of the amide bonds per two heavy chains is 2.0.
- Example 9 Synthesis of a compound having an affinity substance for a soluble protein, a cleaving moiety and a reactive group (peptide thioester linker conjugate-thiophenol activator), and modification of the anti-HER2 antibody trastuzumab using the compound. And its analysis] (9-1) Binding of peptide and linker Both of the above two amino acid sequences are the amino acid sequences of SEQ ID NO: 7.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- Y represents the affinity peptide represented by the amino acid sequence of SEQ ID NO: 7. The average ratio r of the amide bonds per two heavy chains is 2.0.
- the total number of atoms constituting the main chain in the first linker and the number of atoms constituting the main chain in the second linker correspond to less than 4 or 9 or more atoms. Showed an average PAR of 0.5 or less.
- Example 10 Regioselective modification of different target regions of IgG1 Fc with IgG1 Fc-affinity peptide reagent, and synthesis of antibody-drug conjugate] (10-1) Production of thiol group-introduced antibody derivative by cleavage of thioester group following position-selective modification of anti-HER2 antibody trastuzumab The following peptide reagent described in the previous report (WO2019 / 240287A1) was dissolved in dimethylformamide to obtain 10 mM.
- Anti-HER2 antibody trastuzumab (Chugai Pharmaceutical) 500 ⁇ g is dissolved in 20 mM sodium acetate buffer (pH 5.5) 200 ⁇ L (20 ⁇ M), and 10 mM of the above peptide reagent is added 3.38 ⁇ L (10 equivalents to the antibody) at room temperature. The mixture was stirred for 1 hour. Subsequently, a hydroxylamine solution was added according to the previous report (WO2019 / 240287A1), and the mixture was allowed to stand at room temperature for 1 hour. When the mass of the obtained thiol-introduced antibody was measured by ESI-TOFMS, a peak was confirmed at 148760 where the cleavage reaction by hydroxylamine proceeded.
- the following peptide reagent is a reagent that enables modification of the lysine residue at position 246/248 of the IgG heavy chain
- the lysine residue at position 246/248 of the IgG heavy chain is modified with the following peptide reagent. It is thought that it was.
- the amino acid sequence is the amino acid sequence of SEQ ID NO: 11.
- Ig represents an immunoglobulin unit (IgG) containing two heavy chains and two light chains, and the lysine residue present at position 288/290 in the two heavy chains according to Eunumbering.
- An amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the group.
- an amide bond is formed with the carbonyl group adjacent to Ig via the amino group in the side chain of the lysine residue present at the 246/248 position in the two heavy chains according to Eunumbering.
- the average ratios r (288/290 positions) and n (246/248 positions) of the amide bonds per two heavy chains were 1.9 and 2.0, respectively, as a result of evaluation.
Abstract
Description
〔1〕式(I)で表される化合物またはその塩。
〔2〕脱離基が以下から選ばれる、〔1〕の化合物またはその塩:
(a)R-S(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Sは、硫黄原子を示す。);
(b)R-O(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Oは、酸素原子を示す。);または
(c)RA-(RB-)N(ここで、RAおよびRBは、それぞれ独立して、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Nは、窒素原子を示す。);または
(d)ハロゲン原子。
〔3〕イムノグロブリン単位がヒトイムノグロブリン単位である、〔1〕または〔2〕の化合物またはその塩。
〔4〕イムノグロブリン単位がヒトIgGである、〔1〕~〔3〕のいずれかの化合物またはその塩。
〔5〕親和性ペプチドがリジン残基を含み、かつリジン残基の側鎖中のアミノ基を介して、Yに隣接するカルボニル基(C=O)とアミド結合を形成している、〔1〕~〔4〕のいずれかの化合物またはその塩。
〔6〕親和性ペプチドが以下である、〔1〕~〔5〕のいずれかの化合物またはその塩:
(A)CQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号1)のアミノ酸配列を含む親和性ペプチド;または
(B)CQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号1)のアミノ酸配列において、アミノ酸残基の置換、挿入、欠失、および付加からなる群より選ばれる1~5個のアミノ酸残基の変異を含むアミノ酸配列(ここで、27位のリジン残基、ならびに1位および30位の2つのシステイン残基は維持される)を含む親和性ペプチド。
〔7〕(B)の親和性ペプチドが、以下からなる群より選ばれる、〔6〕の化合物またはその塩:
(a)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号2)のアミノ酸配列を含む親和性ペプチド;
(b)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEDC(配列番号3)のアミノ酸配列を含む親和性ペプチド;
(c)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号4)のアミノ酸配列を含む親和性ペプチド;
(d)NMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号5)のアミノ酸配列を含む親和性ペプチド;
(e)MQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号6)のアミノ酸配列を含む親和性ペプチド;および
(f)QCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号7)のアミノ酸配列を含む親和性ペプチド。
〔8〕親和性ペプチドにおけるN末端およびC末端アミノ酸残基が、保護されていてもよく、かつ
親和性ペプチドにおける2つのシステイン残基(C)の側鎖中の2つのチオール基が、ジスルフィド結合により、またはリンカーを介して連結されていてもよい、〔6〕または〔7〕の化合物またはその塩。
〔9〕式(I)で表される化合物が、式(I’)で表される、〔1〕~〔8〕のいずれかの化合物またはその塩。
〔10〕式(I’)で表される化合物が、式(I’’)で表される、〔9〕の化合物またはその塩。
〔11〕式(I)で表される化合物またはその塩を含む、抗体誘導体化用試薬。
〔12〕式(I)で表される化合物が、式(I’)で表される、〔11〕の試薬。
〔13〕式(I’)で表される化合物が、式(I’’)で表される、〔12〕の試薬。
〔14〕式(II)で表される構造単位を含む抗体中間体またはその塩。
〔15〕抗体中間体がヒト抗体中間体である、〔14〕の抗体中間体またはその塩。
〔16〕抗体中間体がヒトIgG中間体である、〔14〕または〔15〕の抗体中間体またはその塩。
〔17〕式(II)で表される構造単位が、式(II’)で表される、〔14〕~〔16〕のいずれかの抗体中間体またはその塩。
〔18〕式(II’)で表される構造単位が、式(II’’)で表される、〔17〕の抗体中間体またはその塩。
〔19〕式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩。
〔20〕前記2個の重鎖中の288/290位に存在するリジン残基以外の特定アミノ酸残基がさらに修飾されている、〔19〕のチオール基導入抗体誘導体またはその塩。
〔21〕前記特定アミノ酸残基が、2個の重鎖中の246/248位に存在するリジン残基である、〔20〕のチオール基導入抗体誘導体またはその塩。
〔22〕式(III)で表される構造単位が、式(III’)で表される、〔19〕~〔21〕のいずれかのチオール基導入抗体誘導体またはその塩。
〔23〕式(III’)で表される構造単位が、式(III’’)で表される、〔22〕のチオール基導入抗体誘導体またはその塩。
〔24〕式(IV)で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩。
〔25〕前記2個の重鎖中の288/290位に存在するリジン残基以外の特定アミノ酸残基がさらに修飾されている、〔24〕のコンジュゲートまたはその塩。
〔26〕前記特定アミノ酸残基が、2個の重鎖中の246/248位に存在するリジン残基である、〔25〕のコンジュゲートまたはその塩。
〔27〕式(IV)で表される構造単位が、式(IV’)で表される、〔24〕~〔26〕のいずれかのコンジュゲートまたはその塩。
〔28〕式(IV’)で表される構造単位が、式(IV’’)で表される、〔27〕のコンジュゲートまたはその塩。
〔29〕式(V)で表される化合物またはその塩。
〔30〕式(V)で表される化合物が、式(V’)で表される、〔29〕の化合物またはその塩。
〔31〕式(V’)で表される化合物が、式(V’’)で表される、〔30〕の化合物またはその塩。
〔32〕式(V’’)で表される化合物が、式(V’’-1)または(V’’-2)で表される、〔31〕の化合物またはその塩。
〔33〕式(VI)で表される化合物またはその塩。
〔34〕脱離基Xよりも脱離する能力が高い脱離基が、ペンタフルオロフェニルオキシ基、テトラフルオロフェニルオキシ基、パラニトロフェニルオキシ基、またはN-スクシンイミジルオキシ基である、〔33〕の化合物またはその塩。
〔35〕式(VI)で表される化合物が、式(VI’)で表される、〔33〕または〔34〕の化合物またはその塩。
〔36〕式(VI’)で表される化合物が、式(VI’’)で表される、〔35〕の化合物またはその塩。
〔37〕式(VI’’)で表される化合物が、式(VI’’-1)または(VI’’-2)で表される、〔36〕の化合物またはその塩。
〔38〕式(I)で表される化合物またはその塩を、イムノグロブリン単位を含む抗体と反応させて、式(II)で表される構造単位を含む抗体中間体またはその塩を生成することを含む、抗体中間体またはその塩の製造方法。
〔39〕(1)式(I)で表される化合物またはその塩を、イムノグロブリン単位を含む抗体と反応させて、式(II)で表される構造単位を含む抗体中間体またはその塩を生成すること;ならびに
(2)抗体中間体またはその塩を、チオエステルの切断反応に供して、式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成することを含む、チオール基導入抗体誘導体またはその塩の製造方法。
〔40〕(1)式(I)で表される化合物またはその塩を、イムノグロブリン単位を含む抗体と反応させて、式(II)で表される構造単位を含む、抗体中間体またはその塩を生成すること;
(2)抗体中間体またはその塩を、チオエステルの切断反応に供して、式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成すること;ならびに
(3)チオール基導入抗体誘導体またはその塩を、機能性物質と反応させて、式(IV)で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を生成することを含む、抗体および機能性物質のコンジュゲートまたはその塩の製造方法。
〔41〕式(VI)で表される化合物またはその塩を、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドと反応させて、式(I)で表される化合物またはその塩を生成することをさらに含む、〔38〕~〔40〕のいずれかの方法。
〔42〕(1’)式(V)で表される化合物またはその塩を、カルボキシル基修飾試薬と反応させて、式(VI)で表される化合物またはその塩を生成すること;ならびに
(2’)式(VI)で表される化合物またはその塩を、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドと反応させて、式(I)で表される化合物またはその塩を生成することをさらに含む、〔38〕~〔40〕のいずれかの方法。
〔43〕式(V)で表される化合物またはその塩を、カルボキシル基修飾試薬と反応させて、式(VI)で表される化合物またはその塩を生成することを含む、式(VI)で表される化合物またはその塩の製造方法。
〔44〕式(II)で表される構造単位を含む抗体中間体またはその塩を、チオエステルの切断反応に供して、式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成することを含む、チオール基導入抗体誘導体またはその塩の製造方法。
〔45〕(1)式(II)で表される構造単位を含む、抗体中間体またはその塩を、チオエステルの切断反応に供して、式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成すること;ならびに
(2)チオール基導入抗体誘導体またはその塩を、機能性物質と反応させて、式(IV)で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を生成することを含む、抗体および機能性物質のコンジュゲートまたはその塩の製造方法。
〔46〕式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を、機能性物質と反応させて、式(IV)で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を生成することを含む、抗体および機能性物質のコンジュゲートまたはその塩の製造方法。
また、式(I)で表される化合物またはその塩によれば、イムノグロブリン単位中の重鎖の288/290位のリジン残基が親和性ペプチド含有基で特異的に修飾されており、かつイムノグロブリン単位と親和性ペプチド含有基との結合の平均比率(親和性ペプチド含有基数/イムノグロブリン単位)が所望の範囲に高度に制御された、式(II)で表される抗体中間体またはその塩を提供することができる。
さらに、式(II)で表される抗体中間体またはその塩を原料として使用して作製された抗体は、当該抗体中間体またはその塩の位置選択性および結合の平均比率を引き継ぐことができる。したがって、上記のような位置選択性および結合の平均比率を有する、式(III)で表されるチオール基導入抗体誘導体またはその塩、ならびに式(IV)で表される抗体および機能性物質のコンジュゲートまたはその塩を提供することができる。
また、式(I)で表される化合物またはその塩の効率的な製造を可能にする合成中間体である式(V)および(VI)で表される化合物またはその塩が提供される。
本発明において、用語「抗体」は、以下のとおりである。また、用語「イムノグロブリン単位」は、このような抗体の基本構成要素である2価の単量体単位に対応するものであり、2個の重鎖および2個の軽鎖を含む単位である。したがって、イムノグロブリン単位について、その由来、種類(ポリクローナルもしくはモノクローナル、アイソタイプ、および全長抗体もしくは抗体断片)、抗原、リジン残基の位置、および位置選択性の定義、例、および好ましい例は、以下に説明する抗体のものと同様である。
PD-L1、GD2、PDGFRα(血小板由来成長因子受容体)、CD22、HER2、ホスファチジルセリン(PS)、EpCAM、フィブロネクチン、PD-1、VEGFR-2、CD33、HGF、gpNMB、CD27、DEC-205、葉酸受容体、CD37、CD19、Trop2、CEACAM5、S1P、HER3、IGF-1R、DLL4、TNT-1/B、CPAAs、PSMA、CD20、CD105(エンドグリン)、ICAM-1、CD30、CD16A、CD38、MUC1、EGFR、KIR2DL1,2,、NKG2A、tenascin-C、IGF(Insulin-like growth factor)、CTLA-4、mesothelin、CD138、c-Met、Ang2、VEGF-A、CD79b、ENPD3、葉酸受容体α、TEM-1、GM2、グリピカン3、macrophage inhibitory factor、CD74、Notch1、Notch2、Notch3、CD37、TLR-2、CD3、CSF-1R、FGFR2b、HLA-DR、GM-CSF、EphA3、B7-H3、CD123、gpA33、Frizzled7受容体、DLL4、VEGF、RSPO、LIV-1、SLITRK6、Nectin-4、CD70、CD40、CD19、SEMA4D(CD100)、CD25、MET、Tissue Factor、IL-8、EGFR、cMet、KIR3DL2、Bst1(CD157)、P-カドヘリン、CEA、GITR、TAM(tumor associated macrophage)、CEA、DLL4、Ang2、CD73、FGFR2、CXCR4、LAG-3、GITR、Fucosyl GM1、IGF-1、Angiopoietin 2、CSF-1R、FGFR3、OX40、BCMA、ErbB3、CD137(4-1BB)、PTK7、EFNA4、FAP、DR5、CEA、Ly6E、CA6、CEACAM5、LAMP1、tissue factor、EPHA2、DR5、B7-H3、FGFR4、FGFR2、α2-PI、A33、GDF15、CAIX、CD166、ROR1、GITR、BCMA、TBA、LAG-3、EphA2、TIM-3、CD-200、EGFRvIII、CD16A、CD32B、PIGF、Axl、MICA/B、Thomsen-Friedenreich、CD39、CD37、CD73、CLEC12A、Lgr3、トランスフェリン受容体、TGFβ、IL-17、5T4、RTK、Immune Suppressor Protein、NaPi2b、ルイス血液型B抗原、A34、Lysil-Oxidase、DLK-1、TROP-2、α9インテグリン、TAG-72(CA72-4)、CD70
IL-17、IL-6R、IL-17R、INF-α、IL-5R、IL-13、IL-23、IL-6、ActRIIB、β7-Integrin、IL-4αR、HAS、Eotaxin-1、CD3、CD19、TNF-α、IL-15、CD3ε、Fibronectin、IL-1β、IL-1α、IL-17、TSLP(Thymic Stromal Lymphopoietin)、LAMP(Alpha4 Beta 7 Integrin)、IL-23、GM-CSFR、TSLP、CD28、CD40、TLR-3、BAFF-R、MAdCAM、IL-31R、IL-33、CD74、CD32B、CD79B、IgE(免疫グロブリンE)、IL-17A、IL-17F、C5、FcRn、CD28、TLR4、MCAM、B7RP1、CXCR1,2 Ligands、IL-21、Cadherin-11、CX3CL1、CCL20、IL-36R、IL-10R、CD86、TNF-α、IL-7R、Kv1.3、α9インテグリン、LIFHT
CGRP、CD20、βアミロイド、βアミロイドプロトフィブリン、Calcitonin Gene-Related Peptide Receptor、LINGO(Ig Domain Containing1)、αシヌクレイン、細胞外tau、CD52、インスリン受容体、tauタンパク、TDP-43、SOD1、TauC3、JCウイルス
Clostridium Difficile toxin B、サイトメガロウイルス、RSウイルス、LPS、S.Aureus Alpha-toxin、M2eタンパク、Psl、PcrV、S.Aureus toxin、インフルエンザA、Alginate、黄色ブドウ球菌、PD-L1、インフルエンザB、アシネトバクター、F-protein、Env、CD3、病原性大腸菌、クレブシエラ、肺炎球菌
アミロイドAL、SEMA4D(CD100)、インスリン受容体、ANGPTL3、IL4、IL13、FGF23、副腎皮質刺激ホルモン、トランスサイレチン、ハンチンチン
Factor D、IGF-1R、PGDFR、Ang2、VEGF-A、CD-105(Endoglin)、IGF-1R、βアミロイド
Sclerostin、Myostatin、Dickkopf-1、GDF8、RNAKL、HAS、Siglec-15
vWF、Factor IXa、Factor X、IFNγ、C5、BMP-6、Ferroportin、TFPI
BAFF(B cell activating factor)、IL-1β、PCSK9、NGF、CD45、TLR-2、GLP-1、TNFR1、C5、CD40、LPA、プロラクチン受容体、VEGFR-1、CB1、Endoglin、PTH1R、CXCL1、CXCL8、IL-1β、AT2-R、IAPP
本発明は、下記式(I)で表される化合物またはその塩を提供する。

Xは、脱離基を示し、
Yは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕
(a)R-S(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Sは、硫黄原子を示す。);
(b)R-O(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Oは、酸素原子を示す。);
(c)RA-(RB-)N(ここで、RAおよびRBは、それぞれ独立して、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Nは、窒素原子を示す。);または
(d)ハロゲン原子。
(a)R-S(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Sは、硫黄原子を示す。);
(b)R-O(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Oは、酸素原子を示す。);または
(c)RA-(RB-)N(ここで、RAおよびRBは、それぞれ独立して、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示す。);であってもよい。
(a)R-S(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Sは、硫黄原子を示す。);または
(b)R-O(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Oは、酸素原子を示す。)。
(a)R-S(ここで、Rは、置換基を有していてもよい1価の芳香族炭化水素基、または置換基を有していてもよい1価の芳香族複素環基を示し、Sは、硫黄原子を示す。)。
(a’)R-S(ここで、Rは、置換基を有していてもよい1価の芳香族炭化水素基(例、フェニル)を示し、Sは、硫黄原子を示す。)。
(i)ハロゲン原子;
(ii)1価の炭化水素基;
(iii)1価の複素環基;
(iv)アラルキル;
(v)Ra-O-、Ra-C(=O)-、Ra-O-C(=O)-、もしくはRa-C(=O)-O-(Raは、水素原子、もしくは1価の炭化水素基を示す。);または
(vi)NRbRc-、NRbRc-C(=O)-、NRbRc-C(=O)-O-、もしくはRb-C(=O)-NRc-(RbおよびRcは、同一もしくは異なって、水素原子、もしくは1価の炭化水素基を示す。);
(vii)ニトロ基、硫酸基、スルホン酸基、シアノ基、およびカルボキシル基。
(i)ハロゲン原子;
(ii)炭素原子数1~12のアルキル、フェニル、もしくはナフチル;
(iii)炭素原子数3~15のアラルキル;
(iv)5員または6員の複素環;
(v)Ra-O-、Ra-C(=O)-、Ra-O-C(=O)-、もしくはRa-C(=O)-O-(Raは、水素原子、もしくは炭素原子数1~12のアルキルを示す。);
(vi)NRbRc-、NRbRc-C(=O)-、NRbRc-C(=O)-O-、もしくはRb-C(=O)-NRc-(RbおよびRcは、同一もしくは異なって、水素原子、もしくは炭素原子数1~12のアルキルを示す。);または
(vii)上記(vii)で列挙したものと同じ基。
(i)ハロゲン原子;
(ii)炭素原子数1~12のアルキル;
(iii)Ra-O-、Ra-C(=O)-、Ra-O-C(=O)-、もしくはRa-C(=O)-O-(Raは、水素原子、もしくは炭素原子数1~12のアルキルを示す。);
(iv)NRbRc-、NRbRc-C(=O)-、NRbRc-C(=O)-O-、もしくはRb-C(=O)-NRc-(RbおよびRcは、同一もしくは異なって、水素原子、もしくは炭素原子数1~12のアルキルを示す。);または
(v)上記(vii)で列挙したものと同じ基。
(i)ハロゲン原子;
(ii)炭素原子数1~6のアルキル;
(iii)Ra-O-、Ra-C(=O)-、Ra-O-C(=O)-、もしくはRa-C(=O)-O-(Raは、水素原子、もしくは炭素原子数1~6のアルキルを示す。);
(iv)NRbRc-、NRbRc-C(=O)-、NRbRc-C(=O)-O-、もしくはRb-C(=O)-NRc-(RbおよびRcは、同一もしくは異なって、水素原子、もしくは炭素原子数1~6のアルキルを示す。);または
(v)上記(vii)で列挙したものと同じ基。
(i)ハロゲン原子;
(ii)炭素原子数1~4のアルキル;
(iii)Ra-O-、Ra-C(=O)-、Ra-O-C(=O)-、もしくはRa-C(=O)-O-(Raは、水素原子、もしくは炭素原子数1~4のアルキルを示す。);
(iv)NRbRc-、NRbRc-C(=O)-、NRbRc-C(=O)-O-、もしくはRb-C(=O)-NRc-(RbおよびRcは、同一もしくは異なって、水素原子、もしくは炭素原子数1~4のアルキルを示す。);または
(v)上記(vii)で列挙したものと同じ基。
(A)CQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号1)のアミノ酸配列を含む親和性ペプチド;または
(B)CQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号1)のアミノ酸配列において、アミノ酸残基の置換、挿入、欠失、および付加からなる群より選ばれる1~5個(すなわち、1個、2個、3個、4個、または5個)のアミノ酸残基の変異を含むアミノ酸配列(ここで、27位のリジン残基、ならびに1位および30位の2つのシステイン残基は維持される)を含む親和性ペプチド。
配列番号1のアミノ酸配列を含む親和性ペプチドは、イムノグロブリン単位におけるCH2ドメインに結合領域を有する好適なペプチドであるため、本発明では、このような親和性ペプチドの使用が好ましい。
上記親和性ペプチドのN末端およびC末端アミノ酸残基は、保護されていてもよい。また、上記親和性ペプチドにおける2つのシステイン残基(C)の側鎖のチオール基は、ジスルフィド結合により、またはリンカーを介して連結されていてもよい。
(a)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号2)のアミノ酸配列を含む親和性ペプチド;
(b)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEDC(配列番号3)のアミノ酸配列を含む親和性ペプチド;
(c)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号4)のアミノ酸配列を含む親和性ペプチド;
(d)NMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号5)のアミノ酸配列を含む親和性ペプチド;
(e)MQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号6)のアミノ酸配列を含む親和性ペプチド;および
(f)QCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号7)のアミノ酸配列を含む親和性ペプチド。
上記親和性ペプチドのN末端およびC末端アミノ酸残基は、保護されていてもよい。また、上記親和性ペプチドにおける2つのシステイン残基(C)の側鎖のチオール基は、ジスルフィド結合により、またはリンカーを介して連結されていてもよい。



(a)の場合、最短経路は太字経路であるため、主鎖の原子数として数えられる2価の環状構造中の原子数は、2である。
(b)の場合、最短経路は太字経路であるため、主鎖の原子数として数えられる2価の環状構造中の原子数は、3である。
(c)の場合、いずれの経路も最短経路(等距離)であるため、主鎖の原子数として数えられる2価の環状構造中の原子数は、4である。
(d)の場合、縮合部位の経路が最短経路であるため、主鎖の原子数として数えられる2価の環状構造中の原子数は、4である。
直鎖アルキレンは、炭素原子数1~6の直鎖アルキレンであり、炭素原子数1~4の直鎖アルキレンが好ましい。直鎖アルキレンとしては、例えば、メチレン、エチレン、n-プロピレン、n-ブチレン、n-ペンチレン、n-へキシレンが挙げられる。
直鎖アルケニレンは、炭素原子2~6の直鎖アルケニレンであり、炭素原子数2~4の直鎖アルケニレンが好ましい。直鎖アルケニレンとしては、例えば、エチレニレン、n-プロピニレン、n-ブテニレン、n-ペンテニレン、n-へキセニレンが挙げられる。
直鎖アルキニレンは、炭素原子数2~6の直鎖アルキニレンであり、炭素原子数2~4の直鎖アルキニレンが好ましい。直鎖アルキニレンとしては、例えば、エチニレン、n-プロピニレン、n-ブチニレン、n-ペンチニレン、n-へキシニレンが挙げられる。
2価の直鎖炭化水素基としては、直鎖アルキレンが好ましい。
アリーレンとしては、炭素原子数6~14のアリーレンが好ましく、炭素原子数6~10のアリーレンがより好ましく、炭素原子数6のアリーレンが特に好ましい。アリーレンとしては、例えば、フェニレン、ナフチレン、アントラセニレンが挙げられる。
2価の非芳香族環状炭化水素基としては、炭素原子数3~12の単環式または多環式である2価の非芳香族環状炭化水素基が好ましく、炭素原子数4~10の単環式または多環式である2価の非芳香族環状炭化水素基がより好ましく、炭素原子数5~8の単環式である2価の非芳香族環状炭化水素基が特に好ましい。2価の非芳香族環状炭化水素基としては、例えば、シクロプロピレン、シクロブチレン、シクロペンチレン、シクロへキシレン、シクロへプチレン、シクロオクチレンが挙げられる。
2価の環状炭化水素基としては、アリーレンが好ましい。
2価の芳香族複素環基としては、炭素原子数3~15の2価の芳香族複素環基が好ましく、炭素原子数3~9の2価の芳香族複素環基がより好ましく、炭素原子数3~6の2価の芳香族複素環基が特に好ましい。2価の芳香族複素環基としては、例えば、ピロールジイル、フランジイル、チオフェンジイル、ピリジンジイル、ピリダジンジイル、ピリミジンジイル、ピラジンジイル、トリアジンジイル、ピラゾールジイル、イミダゾールジイル、チアゾールジイル、イソチアゾールジイル、オキサゾールジイル、イソオキサゾールジイル、トリアゾールジイル、テトラゾールジイル、インドールジイル、プリンジイル、アントラキノンジイル、カルバゾールジイル、フルオレンジイル、キノリンジイル、イソキノリンジイル、キナゾリンジイル、およびフタラジンジイルが挙げられる。
2価の非芳香族複素環基としては、炭素原子数3~15の非芳香族複素環基が好ましく、炭素原子数3~9の非芳香族複素環基がより好ましく、炭素原子数3~6の非芳香族複素環基が特に好ましい。2価の非芳香族複素環基としては、例えば、ピロールジオンジイル、ピロリンジオンジイル、オキシランジイル、アジリジンジイル、アゼチジンジイル、オキセタンジイル、チエタンジイル、ピロリジンジイル、ジヒドロフランジイル、テトラヒドロフランジイル、ジオキソランジイル、テトラヒドロチオフェンジイル、ピロリンジイル、イミダゾリジンジイル、オキサゾリジンジイル、ピペリジンジイル、ジヒドロピランジイル、テトラヒドロピランジイル、テトラヒドロチオピランジイル、モルホリンジイル、チオモルホリンジイル、ピペラジンジイル、ジヒドロオキサジンジイル、テトラヒドロオキサジンジイル、ジヒドロピリミジンジイル、およびテトラヒドロピリミジンジイルが挙げられる。
2価の複素環基としては、2価の芳香族複素環基が好ましい。
(i’)ハロゲン原子;
(ii’)1価の炭化水素基;
(iii’)アラルキル;
(iv’)1価の複素環基;
(v’)Re-O-、Re-C(=O)-、Re-O-C(=O)-、もしくはRe-C(=O)-O-(Reは、水素原子、もしくは1価の炭化水素基を示す。);または
(vi’)NRfRg-、NRfRg-C(=O)-、NRfRg-C(=O)-O-、もしくはRf-C(=O)-NRg-(RfおよびRgは、同一もしくは異なって、水素原子、もしくは1価の炭化水素基を示す。);
(vii’)ニトロ基、硫酸基、スルホン酸基、シアノ基、およびカルボキシル基。
(i’)ハロゲン原子;
(ii’)炭素原子数1~12のアルキル、フェニル、もしくはナフチル;
(iii’)炭素原子数3~15のアラルキル;
(iv’)5員または6員の複素環;
(v’)Re-O-、Re-C(=O)-、Re-O-C(=O)-、もしくはRe-C(=O)-O-(Reは、水素原子、もしくは炭素原子数1~12のアルキルを示す。);
(vi’)NRfRg-、NRfRg-C(=O)-、NRfRg-C(=O)-O-、もしくはRf-C(=O)-NRg-(RfおよびRgは、同一もしくは異なって、水素原子、もしくは炭素原子数1~12のアルキルを示す。);または
(vii’)上記(vii’)で列挙したものと同じ基。
(i’)ハロゲン原子;
(ii’)炭素原子数1~12のアルキル;
(iii’)Re-O-、Re-C(=O)-、Re-O-C(=O)-、もしくはRe-C(=O)-O-(Reは、水素原子、もしくは炭素原子数1~12のアルキルを示す。);
(iv’)NRfRg-、NRfRg-C(=O)-、NRfRg-C(=O)-O-、もしくはRf-C(=O)-NRg-(RfおよびRgは、同一もしくは異なって、水素原子、もしくは炭素原子数1~12のアルキルを示す。);または
(v’)上記(vii’)で列挙したものと同じ基。
(i’)ハロゲン原子;
(ii’)炭素原子数1~6のアルキル;
(iii’)Re-O-、Re-C(=O)-、Re-O-C(=O)-、もしくはRe-C(=O)-O-(Reは、水素原子、もしくは炭素原子数1~6のアルキルを示す。);
(iv’)NRfRg-、NRfRg-C(=O)-、NRfRg-C(=O)-O-、もしくはRf-C(=O)-NRg-(RfおよびRgは、同一もしくは異なって、水素原子、もしくは炭素原子数1~6のアルキルを示す。);または
(v’)上記(vii’)で列挙したものと同じ基。
(i’)ハロゲン原子;
(ii’)炭素原子数1~4のアルキル;
(iii’)Re-O-、Re-C(=O)-、Re-O-C(=O)-、もしくはRe-C(=O)-O-(Reは、水素原子、もしくは炭素原子数1~4のアルキルを示す。);
(iv’)NRfRg-、NRfRg-C(=O)-、NRfRg-C(=O)-O-、もしくはRf-C(=O)-NRg-(RfおよびRgは、同一もしくは異なって、水素原子、もしくは炭素原子数1~4のアルキルを示す。);または
(v’)上記(vii’)で列挙したものと同じ基。

X、Y、O、SおよびWは、式(I)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕

X、Y、O、SおよびWは、式(I)のものと同じであり、
Lbは、式(I’)のものと同じである。〕

Xは、脱離基を示し、
X’は、脱離基Xよりも脱離する能力が高い脱離基を示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕

X、X’、O、SおよびWは、式(VI)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕

X、X’、O、SおよびWは、式(VI)のものと同じであり、
Lbは、式(VI’)のものと同じである。〕

O、SおよびWは、式(VI)のものと同じであり、
Fは、フッ素原子である。〕

Xは、脱離基を示し、
Oは、酸素原子を示し、
OHは、ヒドロキシ基を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕

X、O、OH、SおよびWは、式(V)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕

X、O、OH、SおよびWは、式(V)のものと同じであり、
Lbは、式(V’)のものと同じである。〕

O、OH、SおよびWは、式(V)のものと同じである。〕
本発明は、下記式(II)で表される構造単位を含む抗体中間体またはその塩を提供する。

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Yは、イムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個であり、
2個の重鎖あたりの上記アミド結合の平均比率rは、1.5~2.5である。〕

Ig、Y、O、S、Wおよびrは、式(II)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される構造単位であってもよい。

Ig、Y、O、S、Wおよびrは、式(II)のものと同じであり、
Lbは、式(II’)のものと同じである。〕
本発明は、下記式(III)で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を提供する。

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Oは、酸素原子を示し、
SHは、チオール基を示し、
Laは、第1リンカーを示し、
第1リンカーにおける主鎖を構成する原子数が2~4個であり、
2個の重鎖あたりの上記アミド結合の平均比率rは、1.5~2.5である。〕

Ig、O、SHおよびrは、式(III)のものと同じであり、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕

Ig、O、SHおよびrは、式(III)のものと同じである。〕
本発明は、下記式(IV)で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を提供する。

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Zは、機能性物質を示し、
Laは、第1リンカーを示し、
第1リンカーにおける主鎖を構成する原子数が2~4個であり、
2個の重鎖あたりの上記アミド結合の平均比率rは、1.5~2.5である。〕

Ig、O、S、Zおよびrは、式(IV)のものと同じであり、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕

Ig、O、S、Zおよびrは、式(IV)のものと同じである。〕
本発明の化合物またはその塩は、例えば、抗体の288/29位のリジン残基を位置選択的に修飾することができる。したがって、本発明は、本発明の化合物またはその塩を含む、抗体誘導体化用試薬を提供する。
(1-1)IgG1 Fc結合性ペプチドの合成
可溶性タンパク質に対する親和性物質であるAc-FNMQCQRRFYEALHDPNLNEEQRNARIRSIKDDC-NH2(配列番号2)のペプチドをFmoc固相合成法により合成した。ペプチド合成装置はCEM社製Liberty Blueを使用した。試薬は全て渡辺化学工業製のものを使用した。ResinはFmoc-NH-SAL-PEG Resin,HL、アルギニン(R)、システイン(C)、ヒスチジン(H)はダブルカップリングを行った。Resinからの切り出しはトリフルオロ酢酸:水:トリイソプロピルシラン:エタンジチオール=94:2.5:1.0:2.5の溶液中3時間攪拌の条件で行った。切り出し後Resinをフィルトレーションにより除去し、トリフルオロ酢酸を除去した。生成した結晶中にジエチルエーテルを加えエーテル沈殿を行い、生成した白色結晶をフィルトレーションにより回収した。これを0.1%トリフルオロ酢酸水溶液に溶解し、オクタドデシル基化学結合型シリカゲルを充填剤とする逆相高速液体クロマトグラフィーに付し、トリフルオロ酢酸を0.1%含有する水とアセトニトリルの混合溶液で溶出し、各フラクションをLC-MSにより確認した。生成物が含まれるフラクションを回収し、減圧下濃縮することによりアセトニトリルのみ除去した後、凍結乾燥を行った。
(1-1)で合成したペプチドをDMSOに溶解し、0.1M Tris-HCl pH 8.0を加えた。この溶液にグルタチオン酸化型を加えて室温で20時間攪拌した。反応溶液に2Mトリフルオロ酢酸水溶液を加え反応を停止し、これを0.05%トリフルオロ酢酸水溶液に溶解し、オクタドデシル基化学結合型シリカゲルを充填剤とする逆相高速液体クロマトグラフィーに付し、トリフルオロ酢酸0.05%を含有する水とアセトニトリルの混合溶液で溶出し、各フラクションをLC-MSにより確認した。生成物が含まれるフラクションを回収し、減圧下濃縮することによりアセトニトリルを除去した後、凍結乾燥を行い、目的物(20.0mg,4.70μmol)を得た。
(1-3-1)




1H NMR (400 MHz, Chloroform-d) δ = 7.44 (s, 5H), 3.23 (t, J=6.9, 2H), 3.01 (t, J=6.9, 2H), 2.77 (dt, J=14.5, 7.3, 4H), 2.16 (t, J=7.3, 2H).

(1-4)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgをHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換し、ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。生成物は結合性ペプチドが1個導入された152660、結合性ペプチドが2個導入された157093、3個導入された161528のピークが確認された(図7)。
(1-5)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測され、生成物は重鎖にリンカーが1個導入された55033、軽鎖に原料と同じ23439にピークが観測された(図8)。
(1-5)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表2に示す。表2のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号2のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

(1-7)で得られた抗体中間体に対し、既報(WO2019/240287A1)に従いヒドロキシルアミン溶液を加え、室温で1時間静置した。2時間後、20mM PBSバッファー、10mM EDTA(pH7.4)へと置換し、チオール基導入抗体誘導体を得た。ESI-TOFMSにより質量を測定したところ、切断反応が進行した148409にピークが確認された。

2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕
(1-8)で得られたトラスツズマブ・チオール導入体について、下記工程でペプチドマッピングを行った。
1.5mL低吸着マイクロテストチューブにサンプル溶液を10μL、50mM炭酸水素アンモニウム緩衝液、40%トリフルオロエタノールに溶解した20mMのジチオトレイトール水溶液10μLを加えて65℃で1時間加温後、50mMのヨードアセトアミド水溶液10μLを添加し、遮光下室温で30分間反応させた。反応後、50mM炭酸水素アンモニウム緩衝液を40μL加えて撹拌し、20ng/μLのトリプシン水溶液を10μL添加して37℃で16時間酵素消化した。消化後、20%トリフルオロ酢酸水溶液を2μL添加し反応を止め、LC-MS/MS測定を実施した。
(分析装置)
ナノHPLC:EASY-nLC 1000(サーモフィッシャーサイエンティフィック社)
質量分析計:トライブリッド質量分析計Orbitrap Fusion(サーモフィッシャーサイエンティフィック社)
トラップカラム:Acclaim PepMap(登録商標) 100,75μmx2cm(サーモフィッシャーサイエンティフィック社)
分析カラム:ESI-column(NTCC-360/75-3-125,75μm×12.5cm,3μm(日京テクノス社))
移動相A:0.1%ギ酸水溶液
移動相B:0.1%ギ酸、アセトニトリル溶液
ローディング溶液:0.1%トリフルオロ酢酸水溶液
流速:300nL/min
サンプル注入量:1μL
グラジエント条件(B%):2%(0.0-0.5分)、2%→30%(0.5-23.5分)、30%→75%(23.5-25.5分)、75%(25.5-35.0分)
イオン化法:ESI, Positiveモード
スキャンタイプ:Data Dependent Aquisition
Activation Type:Collision Induced Dissociation(CID)
データの取得は付属ソフトであるXcalibur 3.0(サーモフィッシャーサイエンティフィック社)およびThermo Orbitrap Fusion Tune Application 2.0(サーモフィッシャーサイエンティフィック社)を用いて行った。
LC-MS/MS測定結果に対する修飾部位解析については、BioPharma Finder 3.0(サーモフィッシャーサイエンティフィック社)を用いて行った。
BioPharma Finderでの解析は、S/N Thresholdを1、MS Noise Levelをピークトップの強度の0.01%となるように設定して実施した。また、消化酵素をTrypsinに、SpecificityをHighに設定した。Static Modificationにはヨードアセトアミドによるシステイン残基の修飾として、Carbamidomethyl(+57.021Da)を設定した。Dynamic Modificationsについては、メチオニン残基の酸化(+15.995Da)およびリジン残基への修飾体(ヨードアセトアミドによるCarbamidomethyl化を受けたチオール導入体(+145.019Da))を設定した。また、Confidence Scoreが80以上、ペプチド同定時のMass Accuracyが5ppm以内、MS/MSが観測できているもののみとなるようフィルターを設定した。なお、リジン残基の残基番号に関して、重鎖VHドメインおよび軽鎖上については配列中の番号(すなわち、N末のアミノ酸を1番目とする。以下同様)で、重鎖CH1、CH2、CH3ドメイン上についてはEU numberingを用いて表記した。
また、修飾部位の検索対象のアミノ酸配列のデータとして、図9に示される(1)および(2)を用いた。
LC-MS/MSを用いた解析の結果、トラスツズマブのトリプシン消化によるリジン残基への修飾部位(ヨードアセトアミドによるCarbamidomethyl化を受けたチオール導入体(+145.019Da))を含むアミノ酸18残基からなるペプチド、FNWYVDGVEVHNAKTKPR(配列番号10)のペプチドフラグメントのMSスペクトル(実測値:m/z 577.03606、理論値:577.03557、4価)が観測され(図10)、CIDスペクトルより重鎖のEU numberingにおける288位もしくは290位のリジン残基の修飾を示す、3価のy16に相当するm/z 682.13(理論値:682.01)のプロダクトイオンが確認された(図11)。また、BioPharma Finderでの解析により、288位もしくは290位のリジン残基への修飾が高選択的に起こっていることが示された(図12)。
この結果より、上記(1-8)で得られたトラスツズマブ・チオール導入体では、抗体の重鎖上、EU numberingにおけるLys288およびLys290に位置選択的にコンジュゲーションが進行していることが分かった。
(2-1)チオエステルリンカーの合成
(2-1-1)



1H NMR (400 MHz, Chloroform-d) δ = 8.79 (t, J=1.8, 1H), 8.43 (dt, J=7.8, 1.5, 1H), 8.30 (dt, J=7.9, 1.5, 1H), 7.70 (t, J=7.8, 1H), 7.45 (s, 4H), 3.45 (t, J=6.9, 2H), 3.14 (t, J=6.9, 2H).

(2-2)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152691、結合性ペプチドが2個導入された157163、3個導入された161634のピークが確認された(図13)。
(2-3)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された55067、軽鎖に原料と同じ23439にピークが観測された(図14)。
(2-3)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表3に示す。表3のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号2のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

チオール基導入抗体誘導体は、(2-5)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(2-6)で得られたトラスツズマブ・チオール導入体について、下記工程でペプチドマッピングを行った。
(1-9-1)と同様にして(2-6)で得られたトラスツズマブ・チオール導入体のトリプシン処理を行った。
(1-9-2)と同様の条件でLC-MS/MS測定を行った。
(1-9-3)と同様に解析を行った。
LC-MS/MSを用いた解析の結果、トラスツズマブのトリプシン消化によるリジン残基への修飾部位(ヨードアセトアミドによるCarbamidomethyl化を受けたチオール導入体(+145.019Da))を含むアミノ酸18残基からなるペプチド、FNWYVDGVEVHNAKTKPR(配列番号10)のペプチドフラグメントのMSスペクトル(実測値:m/z 577.03571、理論値:577.03557、4価)が観測され(図15)、CIDスペクトルより重鎖のEU numberingにおける288位もしくは290位のリジン残基の修飾を示す、3価のy16に相当するm/z 682.41(理論値:682.01)のプロダクトイオンが確認された(図16)。また、BioPharma Finderでの解析により、288位もしくは290位のリジン残基への修飾が高選択的に起こっていることが示された(図17)。
この結果より、上記(2-6)で得られたトラスツズマブ・チオール導入体では、抗体の重鎖上、EU numberingにおけるLys288およびLys290に位置選択的にコンジュゲーションが進行していることが分かった。
(3-1)チオエステルリンカーの合成
(3-1-1)


1H NMR (400 MHz, Chloroform-d) δ = 7.44 (s, 5H), 3.20 (t, J=7.0, 2H), 3.00 (t, J=6.9, 2H), 2.66 (dt, J=28.3, 7.4, 5H), 1.79 (ddt, J=20.4, 15.2, 7.5, 5H), 1.57 - 1.38 (m, 3H).

(3-2)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152676、結合性ペプチドが2個導入された157126、3個導入された161572のピークが確認された(図18)。
(3-3)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された55048、軽鎖に原料と同じ23439にピークが観測された(図19)。
(3-3)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表4に示す。表4のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は1.9となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 1.9)の生成が確認された。

Yは、配列番号2のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、1.9である。〕

チオール基導入抗体誘導体は、(3-5)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(4-1)チオエステルリンカーの合成
(4-1-1)



1H NMR (400 MHz, Chloroform-d) δ = 3.84 (s, 2H), 3.28 (t, J=6.9, 2H), 3.19 (t, J=6.8, 2H), 3.00 (t, J=6.8, 2H), 2.74 (t, J=6.8, 2H).

(4-2)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152722、結合性ペプチドが2個導入された157215、3個導入された161708のピークが確認された(図20)。
(4-3)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50594に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された55091、軽鎖に原料と同じ23439にピークが観測された(図21)。
(4-3)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表5に示す。表5のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は1.8となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 1.8)の生成が確認された。

Yは、配列番号2のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、1.8である。〕

チオール基導入抗体誘導体は、(4-5)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(5-1)ペプチドとリンカーの結合

(5-1)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152707、結合性ペプチドが2個導入された157188、3個導入された161676のピークが確認された(図22)。
(5-2)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された55077、軽鎖に原料と同じ23439にピークが観測された(図23)。
(5-2)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表6に示す。表6のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号3のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

チオール基導入抗体誘導体は、(5-4)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(6-1)ペプチドとリンカーの結合

(6-1)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152720、結合性ペプチドが2個導入された157216、3個導入された161716のピークが確認された(図24)。
(6-2)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された55091、軽鎖に原料と同じ23439にピークが観測された(図25)。
(6-2)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表7に示す。表7のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号4のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

チオール基導入抗体誘導体は、(6-4)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(7-1)ペプチドとリンカーの結合

(7-1)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152573、結合性ペプチドが2個導入された156927のピークが確認された(図26)。
(7-2)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された54942、軽鎖に原料と同じ23439にピークが観測された(図27)。
(7-2)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表8に示す。表8のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号5のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

チオール基導入抗体誘導体は、(7-4)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(7-5)で得られたトラスツズマブ・チオール導入体について、下記工程でペプチドマッピングを行った。
(1-9-1)と同様にして(7-5)で得られたトラスツズマブ・チオール導入体のトリプシン処理を行った。
(1-9-2)と同様の条件でLC-MS/MS測定を行った。
(1-9-3)と同様に解析を行った。
LC-MS/MSを用いた解析の結果、トラスツズマブのトリプシン消化によるリジン残基への修飾部位(ヨードアセトアミドによるCarbamidomethyl化を受けたチオール導入体(+145.019Da))を含むアミノ酸18残基からなるペプチド、FNWYVDGVEVHNAKTKPR(配列番号10)のペプチドフラグメントのMSスペクトル(実測値:m/z 769.04506、理論値:769.04482、3価)が観測され(図28)、CIDスペクトルより重鎖のEU numberingにおける288位もしくは290位のリジン残基の修飾を示す、2価のy16に相当するm/z 1022.71(理論値:1022.51)のプロダクトイオンが確認された(図29)。また、BioPharma Finderでの解析により、288位もしくは290位のリジン残基への修飾が高選択的に起こっていることが示された(図30)。
この結果より、上記(7-5)で得られたトラスツズマブ・チオール導入体では、抗体の重鎖上、EU numberingにおけるLys288およびLys290に位置選択的にコンジュゲーションが進行していることが分かった。
(8-1)ペプチドとリンカーの結合

(8-1)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152457、結合性ペプチドが2個導入された156692、3個導入された160929のピークが確認された(図31)。
(8-2)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された54829、軽鎖に原料と同じ23439にピークが観測された(図32)。
(8-2)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表9に示す。表9のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号6のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

チオール基導入抗体誘導体は、(8-4)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
(9-1)ペプチドとリンカーの結合

(9-1)で合成したペプチドリンカー連結物はジメチルスルホキシドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを50mMのHEPESバッファー(pH8.2)200μL(20μM)に溶解させ、10mMのペプチド試薬を3.38μL(抗体に対して10等量)加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは148223にピークが観測された。結合性ペプチドが1個導入された152236、結合性ペプチドが2個導入された156430、3個導入された160541のピークが確認された(図33)。
(9-2)で生成した抗体・ペプチド複合体に100mMトリス(2-カルボキシエチル)ホスフィン塩酸塩溶液2μL(抗体に対して等量)を加えて、室温で15分攪拌した。ESI-TOFMSにより質量を測定したところ、原料のトラスツズマブは50596に重鎖ピーク、23439に軽鎖ピークが観測された。反応物は重鎖にリンカーが1個導入された54698、軽鎖に原料と同じ23439にピークが観測された(図34)。
(9-2)で解析したMSデータについて、DAR calculator(Agilent社ソフト)によりペプチド/抗体結合比の確認を行った結果を表10に示す。表10のDAR peakと%Areaから算出された平均のペプチド/抗体結合比は2.0となった。したがって、下記構造式で表される抗体中間体(平均のペプチド/抗体結合比 2.0)の生成が確認された。

Yは、配列番号7のアミノ酸配列で表される親和性ペプチドを示し、
2個の重鎖あたりの上記アミド結合の平均比率rは、2.0である。〕

チオール基導入抗体誘導体は、(9-4)で得られた抗体中間体を、(1-8)に記載されるチオエステル基の切断反応に供することにより、(1-8)に記載されるチオール基導入抗体誘導体を得た。
実施例化合物におけるリンカー長とペプチド/抗体結合比(PAR)の関係を検討した。その結果、イムノグロブリン単位中の重鎖の288/290位のリジン残基との反応性部分〔X(脱離基)-C=O〕と、親和性ペプチドとの結合部分〔O=C-Y(親和性ペプチド)〕とを連結する主鎖を構成する原子数であるリンカー長が7~9個である化合物(式(I)で表される化合物において、第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が5~7個の原子数に相当するもの)は、所望の範囲(1.5~2.0)の平均PARを示した。

2)結合比:ペプチドと抗体との結合比(ペプチド/抗体)
(以下同様)

上記実施例を参考に以下のペプチドチオエステルリンカー連結物-NHS活性化体もしくはペプチドチオエステルリンカー連結物-チオフェノール活性化体の合成を行い、抗HER2抗体トラスツズマブの特異的修飾とESI-TOFMSによる解析を行った。また、実施例と同様に、トラスツズマブの特異的修飾体のDAR calculatorによるペプチド/抗体結合比(PAR)の確認を行ったところ、リンカー長が6個以下または11個以上の原子数である化合物(式(I)で表される化合物において、第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が4個未満または9個以上の原子数に相当するもの)は、0.5以下の平均PARを示した。

(10-1)抗HER2抗体トラスツズマブの位置選択的修飾に続く、チオエステル基の切断によるチオール基導入抗体誘導体の製造
既報(WO2019/240287A1)記載の下記ペプチド試薬をジメチルホルムアミドに溶解し10mMとした。抗HER2抗体トラスツズマブ(中外製薬)500μgを20mMの酢酸ナトリウムバッファー(pH5.5)200μL(20μM)に溶解させ、10mMの上記ペプチド試薬を3.38μL(抗体に対して10当量)加えて、室温で1時間攪拌した。続いて既報(WO2019/240287A1)に従いヒドロキシルアミン溶液を加え、室温で1時間静置した。得られたチオール導入抗体について、ESI-TOFMSにより質量を測定したところ、ヒドロキシルアミンによる切断反応が進行した148760にピークが確認された。下記ペプチド試薬が、IgG重鎖の246/248位のリジン残基の修飾を可能にする試薬であることを考慮すると、IgG重鎖の246/248位のリジン残基が下記ペプチド試薬で修飾されたと考えられる。

(10-1)で合成したチオール導入抗体溶液を50mMのHEPESバッファー(pH8.2)に置換した。この溶液に対して、(3-2)で合成したペプチドリンカー連結物のジメチルホルムアミド溶液を抗体に対して10当量加えて、室温で1時間攪拌した。反応液を20mM酢酸アンモニウムバッファーに置換した。得られた抗体について、ESI-TOFMSにより質量を測定したところ、(3-2)で合成したチオール導入抗体に対して結合性ペプチドが2個導入された157531のピークが確認された。
(10-2)で得られた抗体中間体に対し、既報(WO2019/240287A1)に従いヒドロキシルアミン溶液を加え、室温で1時間静置した。2時間後、20mM PBSバッファー、10mM EDTA(pH7.4)へと置換し、チオール基導入抗体誘導体を得た。ESI-TOFMSにより質量を測定したところ、切断反応が進行した148760にピークが確認された。よって、得られたチオール基導入抗体誘導体は、下記構造を有することが確認された。

(10-3)で得られたチオール基導入抗体のbuffer(pH7.4PBSバッファー)溶液(20μM)に既報(Org. Process Res.Dev.2019,23,12,2647-2654)のMC-VC-PAB-MMAEのDMF溶液(1.25mM)を10当量加え、室温にて2時間静置後、NAP-5 Columns(GEヘルスケア社製)を用いて精製して、ADCを得た。ESI-TOFMSにより質量を測定したところ、MC-VC-PAB-MMAEが4つ導入された154029にピークが確認された。

Claims (46)
- 下記式(I):

Xは、脱離基を示し、
Yは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩。 - 脱離基が以下から選ばれる、請求項1記載の化合物またはその塩:
(a)R-S(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Sは、硫黄原子を示す。);
(b)R-O(ここで、Rは、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Oは、酸素原子を示す。);
(c)RA-(RB-)N(ここで、RAおよびRBは、それぞれ独立して、水素原子、置換基を有していてもよい1価の炭化水素基、または置換基を有していてもよい1価の複素環基を示し、Nは、窒素原子を示す。);または
(d)ハロゲン原子。 - 前記イムノグロブリン単位がヒトイムノグロブリン単位である、請求項1または2記載の化合物またはその塩。
- 前記イムノグロブリン単位がヒトIgGである、請求項1~3のいずれか一項記載の化合物またはその塩。
- 前記親和性ペプチドがリジン残基を含み、かつ前記リジン残基の側鎖中のアミノ基を介して、Yに隣接するカルボニル基(C=O)とアミド結合を形成している、請求項1~4のいずれか一項記載の化合物またはその塩。
- 前記親和性ペプチドが以下である、請求項1~5のいずれか一項記載の化合物またはその塩:
(A)CQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号1)のアミノ酸配列を含む親和性ペプチド;または
(B)CQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号1)のアミノ酸配列において、アミノ酸残基の置換、挿入、欠失、および付加からなる群より選ばれる1~5個のアミノ酸残基の変異を含むアミノ酸配列(ここで、27位のリジン残基、ならびに1位および30位の2つのシステイン残基は維持される)を含む親和性ペプチド。 - 前記(B)の親和性ペプチドが、以下からなる群より選ばれる、請求項6記載の化合物またはその塩:
(a)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKDDC(配列番号2)のアミノ酸配列を含む親和性ペプチド;
(b)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEDC(配列番号3)のアミノ酸配列を含む親和性ペプチド;
(c)FNMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号4)のアミノ酸配列を含む親和性ペプチド;
(d)NMQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号5)のアミノ酸配列を含む親和性ペプチド;
(e)MQCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号6)のアミノ酸配列を含む親和性ペプチド;および
(f)QCQRRFYEALHDPNLNEEQRNARIRSIKEEC(配列番号7)のアミノ酸配列を含む親和性ペプチド。 - 前記親和性ペプチドにおけるN末端およびC末端アミノ酸残基が、保護されていてもよく、かつ
前記親和性ペプチドにおける2つのシステイン残基(C)の側鎖中の2つのチオール基が、ジスルフィド結合により、またはリンカーを介して連結されていてもよい、請求項6または7記載の化合物またはその塩。 - 前記式(I)で表される化合物が、下記式(I’):

X、Y、O、SおよびWは、前記式(I)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項1~8のいずれか一項記載の化合物またはその塩。 - 前記式(I’)で表される化合物が、下記式(I’’):

X、Y、O、SおよびWは、前記式(I)のものと同じであり、
Lbは、前記式(I’)のものと同じである。〕で表される、請求項9記載の化合物またはその塩。 - 下記式(I):

Xは、脱離基を示し、
Yは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を含む、抗体誘導体化用試薬。 - 前記式(I)で表される化合物が、下記式(I’):

X、Y、O、SおよびWは、前記式(I)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項11記載の試薬。 - 前記式(I’)で表される化合物が、下記式(I’’):

X、Y、O、SおよびWは、前記式(I)のものと同じであり、
Lbは、前記式(I’)のものと同じである。〕で表される、請求項12記載の試薬。 - 下記式(II):

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Yは、前記イムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個であり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む抗体中間体またはその塩。 - 抗体中間体がヒト抗体中間体である、請求項14記載の抗体中間体またはその塩。
- 抗体中間体がヒトIgG中間体である、請求項14または15記載の抗体中間体またはその塩。
- 前記式(II)で表される構造単位が、下記式(II’):

Ig、Y、O、S、Wおよびrは、前記式(II)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項14~16のいずれか一項記載の抗体中間体またはその塩。 - 前記式(II’)で表される構造単位が、下記式(II’’):

Ig、Y、O、S、Wおよびrは、前記式(II)のものと同じであり、
Lbは、前記式(II’)のものと同じである。〕で表される、請求項17記載の抗体中間体またはその塩。 - 下記式(III):

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Oは、酸素原子を示し、
SHは、チオール基を示し、
Laは、第1リンカーを示し、
第1リンカーにおける主鎖を構成する原子数が2~4個であり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む、チオール基導入抗体誘導体またはその塩。 - 前記2個の重鎖中の288/290位に存在するリジン残基以外の特定アミノ酸残基がさらに修飾されている、請求項19記載のチオール基導入抗体誘導体またはその塩。
- 前記特定アミノ酸残基が、2個の重鎖中の246/248位に存在するリジン残基である、請求項20記載のチオール基導入抗体誘導体またはその塩。
- 前記式(III)で表される構造単位が、下記式(III’):

Ig、O、SHおよびrは、前記式(III)のものと同じであり、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項19~21のいずれか一項記載のチオール基導入抗体誘導体またはその塩。 - 前記式(III’)で表される構造単位が、下記式(III’’):

Ig、O、SHおよびrは、前記式(III)のものと同じである。〕で表される、請求項22記載のチオール基導入抗体誘導体またはその塩。 - 下記式(IV):

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Zは、機能性物質を示し、
Laは、第1リンカーを示し、
第1リンカーにおける主鎖を構成する原子数が2~4個であり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩。 - 前記2個の重鎖中の288/290位に存在するリジン残基以外の特定アミノ酸残基がさらに修飾されている、請求項24記載のコンジュゲートまたはその塩。
- 前記特定アミノ酸残基が、2個の重鎖中の246/248位に存在するリジン残基である、請求項25記載のコンジュゲートまたはその塩。
- 前記式(IV)で表される構造単位が、下記式(IV’):

Ig、O、S、Zおよびrは、前記式(IV)のものと同じであり、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項24~26のいずれか一項記載のコンジュゲートまたはその塩。 - 前記式(IV’)で表される構造単位が、下記式(IV’’):

Ig、O、S、Zおよびrは、前記式(IV)のものと同じである。〕で表される、請求項27記載のコンジュゲートまたはその塩。 - 下記式(V):

Xは、脱離基を示し、
Oは、酸素原子を示し、
OHは、ヒドロキシ基を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩。 - 前記式(V)で表される化合物が、下記式(V’):

X、O、OH、SおよびWは、前記式(V)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項29記載の化合物またはその塩。 - 前記式(V’)で表される化合物が、下記式(V’’):

X、O、OH、SおよびWは、前記式(V)のものと同じであり、
Lbは、前記式(V’)のものと同じである。〕で表される、請求項30記載の化合物またはその塩。 - 前記式(V’’)で表される化合物が、下記式(V’’-1)または(V’’-2):

O、OH、SおよびWは、前記式(V)のものと同じである。〕で表される、請求項31記載の化合物またはその塩。 - 下記式(VI):

Xは、脱離基を示し、
X’は、脱離基Xよりも脱離する能力が高い脱離基を示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩。 - 脱離基Xよりも脱離する能力が高い脱離基が、ペンタフルオロフェニルオキシ基、テトラフルオロフェニルオキシ基、パラニトロフェニルオキシ基、またはN-スクシンイミジルオキシ基である、請求項33記載の化合物またはその塩。
- 前記式(VI)で表される化合物が、下記式(VI’):

X、X’、O、SおよびWは、前記式(VI)のものと同じであり、
Lbは、主鎖を構成する原子数が3~5個である第2リンカーを示し、
R1、R2、R3、およびR4は、各々独立して、水素原子、または置換基を示す。〕で表される、請求項33または34記載の化合物またはその塩。 - 前記式(VI’)で表される化合物が、下記式(VI’’):

X、X’、O、SおよびWは、前記式(VI)のものと同じであり、
Lbは、前記式(VI’)のものと同じである。〕で表される、請求項35記載の化合物またはその塩。 - 前記式(VI’’)で表される化合物が、下記式(VI’’-1)または(VI’’-2):

O、SおよびWは、前記式(VI)のものと同じであり、
Fは、フッ素原子である。〕で表される、請求項36記載の化合物またはその塩。 - 下記式(I):

Xは、脱離基を示し、
Yは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を、前記イムノグロブリン単位を含む抗体と反応させて、
下記式(II):

Igは、前記イムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Y、O、S、W、La、およびLbは、前記式(I)のものと同じであり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む抗体中間体またはその塩を生成することを含む、抗体中間体またはその塩の製造方法。 - (1)下記式(I):

Xは、脱離基を示し、
Yは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を、前記イムノグロブリン単位を含む抗体と反応させて、
下記式(II):

Igは、前記イムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Y、O、S、W、La、およびLbは、前記式(I)のものと同じであり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む抗体中間体またはその塩を生成すること;ならびに
(2)前記抗体中間体またはその塩を、チオエステルの切断反応に供して、
下記式(III):

SHは、チオール基を示し、
Ig、Laおよびrは、前記式(II)のものと同じである。〕で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成することを含む、チオール基導入抗体誘導体またはその塩の製造方法。 - (1)下記式(I):

Xは、脱離基を示し、
Yは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を、前記イムノグロブリン単位を含む抗体と反応させて、
下記式(II):

Igは、前記イムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Y、O、S、W、La、およびLbは、前記式(I)のものと同じであり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む、抗体中間体またはその塩を生成すること;
(2)前記抗体中間体またはその塩を、チオエステルの切断反応に供して、
下記式(III):

SHは、チオール基を示し、
Ig、O、Laおよびrは、前記式(II)のものと同じである。〕で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成すること;ならびに
(3)前記チオール基導入抗体誘導体またはその塩を、機能性物質と反応させて、
下記式(IV):

Sは、硫黄原子を示し、
Zは、機能性物質を示し、
Ig、O、Laおよびrは、前記式(III)のものと同じである。〕で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を生成することを含む、抗体および機能性物質のコンジュゲートまたはその塩の製造方法。 - 下記式(VI):

Xは、脱離基を示し、
X’は、脱離基Xよりも脱離する能力が高い脱離基を示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドと反応させて、
前記式(I)で表される化合物またはその塩を生成することをさらに含む、請求項38~40のいずれか一項記載の方法。 - (1’)下記式(V):

Xは、脱離基を示し、
Oは、酸素原子を示し、
OHは、ヒドロキシ基を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を、カルボキシル基修飾試薬と反応させて、
下記式(VI):

X、O、S、W、LaおよびLbは、前記式(V)のものと同じであり、
X’は、脱離基Xよりも脱離する能力が高い脱離基を示す。〕で表される化合物またはその塩を生成すること;ならびに
(2’)前記式(VI)で表される化合物またはその塩を、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドと反応させて、
前記式(I)で表される化合物またはその塩を生成することをさらに含む、請求項38~40のいずれか一項記載の方法。 - 下記式(V):

Xは、脱離基を示し、
Oは、酸素原子を示し、
OHは、ヒドロキシ基を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個である。〕で表される化合物またはその塩を、カルボキシル基修飾試薬と反応させて、
下記式(VI):

X、O、S、W、LaおよびLbは、前記式(V)のものと同じであり、
X’は、脱離基Xよりも脱離する能力が高い脱離基を示す。〕で表される化合物またはその塩を生成することを含む、式(VI)で表される化合物またはその塩の製造方法。 - 下記式(II):

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Yは、前記イムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個であり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む抗体中間体またはその塩を、チオエステルの切断反応に供して、
下記式(III):

SHは、チオール基を示し、
Ig、O、Laおよびrは、前記式(II)のものと同じである。〕で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成することを含む、チオール基導入抗体誘導体またはその塩の製造方法。 - (1)下記式(II):

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Yは、前記イムノグロブリン単位におけるCH2ドメインに結合領域を有する親和性ペプチドを示し、
Oは、酸素原子を示し、
Sは、硫黄原子を示し、
Wは、酸素原子または硫黄原子を示し、
Laは、第1リンカーを示し、
Lbは、第2リンカーを示し、
第1リンカーにおける主鎖を構成する原子数、および第2リンカーにおける主鎖を構成する原子数の合計が、5~7個であり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む、抗体中間体またはその塩を、チオエステルの切断反応に供して、
下記式(III):

SHは、チオール基を示し、
Ig、O、Laおよびrは、前記式(II)のものと同じである。〕で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を生成すること;ならびに
(2)前記チオール基導入抗体誘導体またはその塩を、機能性物質と反応させて、
下記式(IV):

Sは、硫黄原子を示し、
Zは、機能性物質を示し、
Ig、O、Laおよびrは、前記式(III)のものと同じである。〕で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を生成することを含む、抗体および機能性物質のコンジュゲートまたはその塩の製造方法。 - 下記式(III):

Igは、2個の重鎖および2個の軽鎖を含むイムノグロブリン単位を示し、かつ、Eu numberingに従う2個の重鎖中の288/290位に存在するリジン残基の側鎖中のアミノ基を介して、Igに隣接するカルボニル基とアミド結合を形成しており、
Oは、酸素原子を示し、
SHは、チオール基を示し、
Laは、第1リンカーを示し、
第1リンカーにおける主鎖を構成する原子数が2~4個であり、
2個の重鎖あたりの前記アミド結合の平均比率rは、1.5~2.5である。〕で表される構造単位を含む、チオール基導入抗体誘導体またはその塩を、機能性物質と反応させて、
下記式(IV):

Sは、硫黄原子を示し、
Zは、機能性物質を示し、
Ig、O、Laおよびrは、前記式(III)のものと同じである。〕で表される構造単位を含む、抗体および機能性物質のコンジュゲートまたはその塩を生成することを含む、抗体および機能性物質のコンジュゲートまたはその塩の製造方法。
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202280010420.0A CN116829573A (zh) | 2021-01-18 | 2022-01-17 | 化合物或其盐、及由它们得到的抗体 |
| JP2022575662A JPWO2022154116A1 (ja) | 2021-01-18 | 2022-01-17 | |
| CA3208296A CA3208296A1 (en) | 2021-01-18 | 2022-01-17 | Compound or salt thereof, and antibody obtained by using the same |
| EP22739521.7A EP4279500A1 (en) | 2021-01-18 | 2022-01-17 | Compound or salt thereof, and antibody produced using same |
| KR1020237024074A KR20230133294A (ko) | 2021-01-18 | 2022-01-17 | 화합물 또는 그 염, 및 그것들에 의해 얻어지는 항체 |
| AU2022208654A AU2022208654A1 (en) | 2021-01-18 | 2022-01-17 | Compound or salt thereof, and antibody produced using same |
| US18/354,436 US20240000965A1 (en) | 2021-01-18 | 2023-07-18 | Compound or salt thereof, and antibody obtained by using the same |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021005762 | 2021-01-18 | ||
| JP2021-005762 | 2021-01-18 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/354,436 Continuation US20240000965A1 (en) | 2021-01-18 | 2023-07-18 | Compound or salt thereof, and antibody obtained by using the same |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022154116A1 true WO2022154116A1 (ja) | 2022-07-21 |
Family
ID=82448186
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2022/001358 WO2022154116A1 (ja) | 2021-01-18 | 2022-01-17 | 化合物またはその塩、およびそれらにより得られる抗体 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20240000965A1 (ja) |
| EP (1) | EP4279500A1 (ja) |
| JP (1) | JPWO2022154116A1 (ja) |
| KR (1) | KR20230133294A (ja) |
| CN (1) | CN116829573A (ja) |
| AU (1) | AU2022208654A1 (ja) |
| CA (1) | CA3208296A1 (ja) |
| WO (1) | WO2022154116A1 (ja) |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5122368A (en) | 1988-02-11 | 1992-06-16 | Bristol-Myers Squibb Company | Anthracycline conjugates having a novel linker and methods for their production |
| US5622929A (en) | 1992-01-23 | 1997-04-22 | Bristol-Myers Squibb Company | Thioether conjugates |
| US5824805A (en) | 1995-12-22 | 1998-10-20 | King; Dalton | Branched hydrazone linkers |
| US6214345B1 (en) | 1993-05-14 | 2001-04-10 | Bristol-Myers Squibb Co. | Lysosomal enzyme-cleavable antitumor drug conjugates |
| WO2002083180A1 (en) | 2001-03-23 | 2002-10-24 | Syntarga B.V. | Elongated and multiple spacers in activatible prodrugs |
| WO2004010957A2 (en) | 2002-07-31 | 2004-02-05 | Seattle Genetics, Inc. | Drug conjugates and their use for treating cancer, an autoimmune disease or an infectious disease |
| WO2004043493A1 (en) | 2002-11-14 | 2004-05-27 | Syntarga B.V. | Prodrugs built as multiple self-elimination-release spacers |
| US20050238649A1 (en) | 2003-11-06 | 2005-10-27 | Seattle Genetics, Inc. | Monomethylvaline compounds capable of conjugation to ligands |
| WO2005119291A1 (de) | 2004-05-28 | 2005-12-15 | Atlas Elektronik Gmbh | Prüfverfahren für ein verfahren zur passiven gewinnung von zielparametern |
| WO2016186206A1 (ja) | 2015-05-20 | 2016-11-24 | 国立大学法人鹿児島大学 | IgG結合ペプチドによる抗体の特異的修飾 |
| WO2018199337A1 (ja) | 2017-04-28 | 2018-11-01 | 味の素株式会社 | 可溶性タンパク質に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 |
| WO2019240288A1 (ja) | 2018-06-14 | 2019-12-19 | 味の素株式会社 | 抗体に対する親和性物質、および生体直交性官能基を有する化合物またはその塩 |
| WO2019240287A1 (ja) | 2018-06-14 | 2019-12-19 | 味の素株式会社 | 抗体に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 |
| WO2020009165A1 (ja) | 2018-07-03 | 2020-01-09 | 味の素株式会社 | 修飾抗体およびその製造方法 |
| WO2020090979A1 (ja) | 2018-10-31 | 2020-05-07 | 味の素株式会社 | 抗体に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5827769B1 (ja) | 2015-03-27 | 2015-12-02 | 義徳 川窪 | 掃除装置 |
| JP6581254B1 (ja) | 2018-07-09 | 2019-09-25 | セイコーソリューションズ株式会社 | クロック調整装置及びプログラム |
| JP6677281B2 (ja) | 2018-08-23 | 2020-04-08 | ブラザー工業株式会社 | インクジェット記録装置、及びプログラム |
| JP7110955B2 (ja) | 2018-12-04 | 2022-08-02 | トヨタ自動車株式会社 | インホイールモータ |
-
2022
- 2022-01-17 JP JP2022575662A patent/JPWO2022154116A1/ja active Pending
- 2022-01-17 AU AU2022208654A patent/AU2022208654A1/en active Pending
- 2022-01-17 EP EP22739521.7A patent/EP4279500A1/en active Pending
- 2022-01-17 CN CN202280010420.0A patent/CN116829573A/zh active Pending
- 2022-01-17 CA CA3208296A patent/CA3208296A1/en active Pending
- 2022-01-17 WO PCT/JP2022/001358 patent/WO2022154116A1/ja active Application Filing
- 2022-01-17 KR KR1020237024074A patent/KR20230133294A/ko unknown
-
2023
- 2023-07-18 US US18/354,436 patent/US20240000965A1/en active Pending
Patent Citations (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5122368A (en) | 1988-02-11 | 1992-06-16 | Bristol-Myers Squibb Company | Anthracycline conjugates having a novel linker and methods for their production |
| US5622929A (en) | 1992-01-23 | 1997-04-22 | Bristol-Myers Squibb Company | Thioether conjugates |
| US6214345B1 (en) | 1993-05-14 | 2001-04-10 | Bristol-Myers Squibb Co. | Lysosomal enzyme-cleavable antitumor drug conjugates |
| US5824805A (en) | 1995-12-22 | 1998-10-20 | King; Dalton | Branched hydrazone linkers |
| WO2002083180A1 (en) | 2001-03-23 | 2002-10-24 | Syntarga B.V. | Elongated and multiple spacers in activatible prodrugs |
| US20060074008A1 (en) | 2002-07-31 | 2006-04-06 | Senter Peter D | Drug conjugates and their use for treating cancer, an autoimmune disease or an infectious disease |
| WO2004010957A2 (en) | 2002-07-31 | 2004-02-05 | Seattle Genetics, Inc. | Drug conjugates and their use for treating cancer, an autoimmune disease or an infectious disease |
| WO2004043493A1 (en) | 2002-11-14 | 2004-05-27 | Syntarga B.V. | Prodrugs built as multiple self-elimination-release spacers |
| US20050238649A1 (en) | 2003-11-06 | 2005-10-27 | Seattle Genetics, Inc. | Monomethylvaline compounds capable of conjugation to ligands |
| WO2005119291A1 (de) | 2004-05-28 | 2005-12-15 | Atlas Elektronik Gmbh | Prüfverfahren für ein verfahren zur passiven gewinnung von zielparametern |
| WO2016186206A1 (ja) | 2015-05-20 | 2016-11-24 | 国立大学法人鹿児島大学 | IgG結合ペプチドによる抗体の特異的修飾 |
| WO2018199337A1 (ja) | 2017-04-28 | 2018-11-01 | 味の素株式会社 | 可溶性タンパク質に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 |
| WO2019240288A1 (ja) | 2018-06-14 | 2019-12-19 | 味の素株式会社 | 抗体に対する親和性物質、および生体直交性官能基を有する化合物またはその塩 |
| WO2019240287A1 (ja) | 2018-06-14 | 2019-12-19 | 味の素株式会社 | 抗体に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 |
| WO2020009165A1 (ja) | 2018-07-03 | 2020-01-09 | 味の素株式会社 | 修飾抗体およびその製造方法 |
| WO2020090979A1 (ja) | 2018-10-31 | 2020-05-07 | 味の素株式会社 | 抗体に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 |
Non-Patent Citations (7)
| Title |
|---|
| B. G. DEVICES ET AL., NAT. COMMUN, vol. 5, 2014, pages 4740 |
| DUBOWCHIK ET AL., PHARMA. THERAPEUTICS, vol. 83, 1999, pages 67 - 123 |
| G.I.J.L. BERNARDES ET AL., CHEM. REV., vol. 115, 2015, pages 2174 |
| J.L. BERNARDES ET AL., CHEM. ASIAN. J, vol. 4, 2009, pages 630 |
| ORG. PROCESS RES. DEV, vol. 23, no. 12, 2019, pages 2647 - 2654 |
| VANCE, NET, BIOCONJUGATE CHEM, vol. 30, 2019, pages 148 - 160 |
| WAGNER ET AL., BIOCONJUGATE. CHEM, vol. 25, 2014, pages 825 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2022208654A1 (en) | 2023-08-03 |
| EP4279500A1 (en) | 2023-11-22 |
| CA3208296A1 (en) | 2022-07-21 |
| CN116829573A (zh) | 2023-09-29 |
| US20240000965A1 (en) | 2024-01-04 |
| JPWO2022154116A1 (ja) | 2022-07-21 |
| KR20230133294A (ko) | 2023-09-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7413999B2 (ja) | 抗体に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 | |
| AU2021203889B2 (en) | Novel method for producing antibody-drug conjugate | |
| JP7222347B2 (ja) | 可溶性タンパク質に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 | |
| JPWO2020090979A1 (ja) | 抗体に対する親和性物質、切断性部分および反応性基を有する化合物またはその塩 | |
| JPWO2019240288A1 (ja) | 抗体に対する親和性物質、および生体直交性官能基を有する化合物またはその塩 | |
| TW201905000A (zh) | 含有抗globo h抗體之抗體-藥物共軛物及其用途 | |
| TW202241522A (zh) | 免疫刺激化合物及結合物 | |
| WO2022154116A1 (ja) | 化合物またはその塩、およびそれらにより得られる抗体 | |
| WO2022191283A1 (ja) | 化合物またはその塩、およびそれらにより得られる抗体 | |
| WO2022154127A1 (ja) | 化合物またはその塩、およびそれらにより得られる抗体 | |
| WO2023054706A1 (ja) | 抗体および機能性物質のコンジュゲートまたはその塩、ならびにその製造に用いられる抗体誘導体および化合物またはそれらの塩 | |
| WO2023054714A1 (ja) | 抗体および機能性物質の位置選択的なコンジュゲートまたはその塩、ならびにその製造に用いられる抗体誘導体および化合物またはそれらの塩 | |
| WO2022255425A1 (ja) | 抗体および機能性物質のコンジュゲートまたはその塩、ならびにその製造に用いられる化合物またはその塩 | |
| JP2024010532A (ja) | 化合物またはその塩 | |
| WO2023234416A1 (ja) | 親和性物質、化合物、抗体およびそれらの塩 | |
| CN117412774A (zh) | 抗体和功能性物质的缀合物或其盐、以及其制造中使用的化合物或其盐 | |
| TW202024043A (zh) | 妥布賴森(tubulysins)及其中間體之製備之替代方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 22739521 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022575662 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 3208296 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202280010420.0 Country of ref document: CN |
|
| ENP | Entry into the national phase |
Ref document number: 2022208654 Country of ref document: AU Date of ref document: 20220117 Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2022739521 Country of ref document: EP Effective date: 20230818 |