WO2018099256A1 - 一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 - Google Patents
一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 Download PDFInfo
- Publication number
- WO2018099256A1 WO2018099256A1 PCT/CN2017/110349 CN2017110349W WO2018099256A1 WO 2018099256 A1 WO2018099256 A1 WO 2018099256A1 CN 2017110349 W CN2017110349 W CN 2017110349W WO 2018099256 A1 WO2018099256 A1 WO 2018099256A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- gene
- plant
- sequence
- deaminase
- promoter
- Prior art date
Links
Images




Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8216—Methods for controlling, regulating or enhancing expression of transgenes in plant cells
- C12N15/8222—Developmentally regulated expression systems, tissue, organ specific, temporal or spatial regulation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8201—Methods for introducing genetic material into plant cells, e.g. DNA, RNA, stable or transient incorporation, tissue culture methods adapted for transformation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2810/00—Vectors comprising a targeting moiety
- C12N2810/10—Vectors comprising a non-peptidic targeting moiety
Definitions
- the present invention relates to the field of biotechnology, and in particular to a CRISPR/nCas9-mediated application of site-directed base substitution in plants.
- CRISPR/Cas9-mediated genome editing technology has become one of the most powerful tools in molecular biology. First discovered in bacteria, it consists of two parts, sgRNA and Cas9 (Jinek et al., 2012). CRISPR/Cas9 causes double-strand breaks (DSBs) of target site DNA sequences through its own endonuclease activity, followed by non-homologous end joining (NHEJ) or homologous recombination Mutations were introduced in two ways, homology-directed repair (HDR).
- DSBs double-strand breaks
- NHEJ non-homologous end joining
- HDR homology-directed repair
- CRISPR/Cas9 Most of the mutations induced by the NHEJ pathway are nucleotide insertions or deletions, resulting in frameshift mutations, while HDR is mediated by homologous donor DNA-mediated fragment insertion or nucleotide modification (Jinek et al., 2012).
- the recognition of the target site by the CRISPR/Cas9 system relies on base-pair pairing between nucleic acids, and can edit any 20 bp target sequence immediately following PAM (NGG), and its target frequency is highly distributed in the genome. Therefore, it is easier to find a suitable target site for a target gene that requires site-specific editing.
- the CRISPR/Cas9 system can simultaneously edit the positions of different sites or multiple genes of the same gene to make it more flexible.
- the CRISPR/Cas9 system is simple and fast to operate, and only needs to replace the 20-30 bp nucleotide sequence on the original vector for each target, which is more suitable for large-scale, high-throughput operation (Cong et al., 2013; Feng et al. , 2014; Gao and Zhao, 2014; Zhou et al., 2014; Lawrenson et al., 2015; Liu et al., 2015; Ma et al., 2015; Wang et al., 2015; Xie et al., 2015 ;Paul III and Qi, 2016).
- CRISPR/Cas9 With the establishment and application of CRISPR/Cas9 technology in human and animal cell lines, the engineered CRISPR/Cas9 system has also been rapidly applied to directed editing of different plant genomes such as Arabidopsis thaliana, tobacco, sorghum, rice, wheat, and corn.
- plant genomes such as Arabidopsis thaliana, tobacco, sorghum, rice, wheat, and corn.
- Puchta and Fauser, 2014 Voytas and Gao, 2014
- Li et al., 2015; Ma et al. , 2015; Svitashev et al., 2015; Endo et al., 2016; Gao et al., 2016; Sun et al., 2016 In the study, and to obtain higher induced mutation rates and stable genetically engineered genome editing plants (Shan et al., 2013; Puchta and Fauser, 2014; Voytas and Gao, 2014; Li et al., 2015; Ma
- CRISPR/Cas9 as a new targeted gene modification technology, has shown broad development potential and application prospects, and has been widely used in crop improvement, it is currently limited to random mutation and knockout of genes. A large number of agronomic traits in crops are caused by single base mutations.
- AID activation-induced cytidine deaminase
- the plant gene expression promoter initiates expression of Cas9 nuclease and cytidine deaminase in the CRISPR/Cas9 system;
- a fusion protein consisting of Cas9 nuclease and cytidine deaminase, to be edited Application of sgRNA and plant gene expression promoters in site-directed editing of plant or crop genes;
- the plant gene expression promoter drives expression of a fusion protein gene consisting of the Cas9 nuclease and the cytidine deaminase;
- the plant gene expression promoter initiates expression of Cas9 nuclease, cytidine deaminase and uracil DNA glycosylase inhibitory protein in the CRISPR/Cas9 system;
- fusion protein consisting of Cas9 nuclease, cytidine deaminase and uracil DNA glycosylase inhibitory protein, sgRNA of a gene to be edited, and a plant gene expression promoter in a site-editing plant or crop gene;
- the plant gene expression promoter drives expression of a gene encoding a fusion protein consisting of the Cas9 nuclease, the cytidine deaminase, and the uracil DNA glycosylase inhibitor protein;
- a fusion protein consisting of a Cas9 nuclease, a deaminase, a linker peptide linked to the Cas9 nuclease to the deaminase, and a uracil DNA glycosylase inhibitory protein, an sgRNA of a gene to be edited, and a plant gene Expression of a promoter in a site-editing plant or crop gene;
- the plant gene expression promoter drives expression of a gene encoding a fusion protein consisting of the Cas9 nuclease, the cytidine deaminase, the linker peptide, and the uracil DNA glycosylase inhibitory protein.
- the cytidine deaminase is APOBEC1, and the coding gene sequence thereof is position 4838-5524 of sequence 1.
- the uracil DNA glycosylase inhibitory protein is Uracil DNA glycosylase inhibitor, and the coding gene sequence thereof is position 429-688 of sequence 1.
- the plant gene expression promoter is the maize Ubiquitin promoter, and the nucleotide sequence thereof is from positions 5545-7535 of sequence 1.
- the Cas9 nuclease is nCas9 (D10A), and the coding gene sequence thereof is position 689-4789 of the sequence 1.
- the coding sequence of the linker peptide is sequence 4790-4837;
- the coding gene sequence of the fusion protein is position 392-5524 of sequence 1;
- the genes to be edited are OsSBEIIb and OsPDS;
- the nucleotide sequence of the sgRNA is position 7875-8268 of sequence 1 or position 7785-8268 of sequence 2 or position 7785-8268 of sequence 3.
- Another object of the present invention is to provide a method of site-editing a plant or crop gene or a method of site-editing a plant or crop nucleic acid molecule.
- the method provided by the present invention is as follows (1) or (2):
- the method comprises the steps of: introducing a Cas9 nuclease encoding gene, a cytidine deaminase encoding gene, a coding gene of a sgRNA of a gene to be edited, and a plant gene promoter into a starting plant to realize a fixed point of a target gene in the starting plant. edit;
- the method comprises the steps of: a Cas9 nuclease encoding gene, a cytidine deaminase encoding gene, a gene encoding a linker peptide of the Cas9 nuclease and the cytidine deaminase, and a uracil DNA sugar
- the coding gene of the enzyme inhibitor protein, the coding gene of the sgRNA of the gene to be edited, and the plant gene promoter are introduced into the starting plant to realize the site-directed editing of the target gene in the starting plant.
- the Cas9 nuclease encoding gene, the cytidine deaminase encoding gene, the coding gene of the sgRNA of the gene to be edited, and the plant gene promoter are introduced into a starting plant through a recombinant plasmid;
- the recombinant plasmid comprises a gene encoding a fusion protein consisting of Cas9 nuclease and cytidine deaminase, a gene encoding the sgRNA of the gene to be edited, and a plant gene promoter;
- the plant gene promoter drives expression of a fusion protein gene consisting of the Cas9 nuclease and the cytidine deaminase;
- the recombinant plasmid includes a gene encoding a fusion protein consisting of a Cas9 nuclease, a cytidine deaminase, a linker peptide linking the Cas9 nuclease to the cytidine deaminase, and a uracil DNA glycosylase inhibitory protein. a gene encoding the sgRNA of the gene to be edited and a plant gene promoter;
- the plant gene promoter drives the Cas9 nuclease, the cytidine deaminase, the linker peptide linking the Cas9 nuclease to the cytidine deaminase, and the uracil DNA sugar Expression of a gene encoding a fusion protein consisting of a protein inhibitor.
- the cytidine deaminase is APOBEC1
- the coding gene sequence thereof is position 4838-5524 of the sequence 1.
- the uracil DNA glycosylase inhibitory protein is Uracil DNA glycosylase inhibitor, and the coding gene sequence thereof is position 429-688 of sequence 1.
- the plant gene expression promoter is a maize Ubiquitin promoter, and the nucleotide sequence thereof is from positions 5545-7535 of the sequence 1.
- the Cas9 nuclease is nCas9 (D10A), and the coding gene sequence thereof is position 689-4789 of the sequence 1.
- the coding gene sequence of the linker peptide is position 4790-4837 of sequence 1;
- the coding gene sequence of the fusion protein is position 392-5524 of sequence 1;
- the genes to be edited are OsSBEIIb and OsPDS;
- the nucleotide sequence of the sgRNA is position 7875-8268 of sequence 1 or position 7785-8268 of sequence 2 or position 7785-8268 of sequence 3.
- nucleotide sequence of the recombinant plasmid is Sequence 1, Sequence 2 or Sequence 3.
- the plant is a monocot or a dicot; the monocot may specifically be rice; and the rice variety may specifically be Kitaake (Oryza sativa L. subsp. japonica).
- Still another object of the present invention is to provide a system for fixed point editing of plant genomes or a system for site editing of plant nucleic acid molecules.
- the system provided by the present invention includes the above recombinant plasmid.
- a final object of the present invention is to provide a novel use of the above recombinant plasmid or the above system.
- the present invention provides the use of the above recombinant plasmid or the above system for site-directed editing of plant or crop genes.
- the fixed point editing is a fixed point base substitution; the substitution is a mutation from C to T, or a mutation of G to A.
- the CRISPR/Cas9 system is a CRISPR/nCas9 system, and the CRISPR/nCas9 system is specifically a CRISPR/nCas9 (D10A) system.
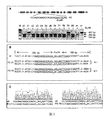
- Figure 1 is a diagram of the pCXUN-BE3 vector framework.
- Figure 2 shows the identification of transgenic plants.
- A is the carrier T-DNA structure map and the location of the primer.
- B, C and D are the detection of Cas9 (D10A), gRNA and hptII genes of P2, S3 and S5 transgenic plants, respectively.
- Figure 3 shows the identification of transgenic plants and sequences of the S5 target of the OsSBEIIb gene.
- A is the schematic diagram of the BE3 fixed point mutation system.
- B is the OsSBEIIb gene structure map and the location of the S5 target, and the PCR product is digested and identified. "+” indicates that the PCR product was cleaved, and "-” indicates that the PCR product was not digested.
- C is the result of cloning and sequencing of PCR products of all plants.
- D is the sequencing map of the genotypes of the two strains S5-17 and S5-26.
- the PAM is represented by blue, and the base to be mutated is expected to be represented by red, and the unintended mutated base is represented by green.
- Figure 4 shows the identification of transgenic plants and sequences of the S3 target of the OsSBEIIb gene.
- A is the OsSBEIIb gene structure map and the location of the S3 target, and the electrophoresis pattern of the PCR product.
- B is the result of cloning and sequencing of PCR products of all plants.
- C is the sequencing map of the genotypes of the two strains S3-1 and S3-18.
- the PAM is represented by blue, and the base to be mutated is expected to be represented by red, and the unintended mutated base is represented by green.
- Figure 5 shows the identification of transgenic plants and sequences of the P2 target of the OsSBEIIb gene.
- A is the OsSBEIIb gene structure map and the location of the P2 target, and the PCR product digestion map. "+” indicates that the PCR product was cleaved, and "-” indicates that the PCR product was not digested.
- C is the result of cloning and sequencing of PCR products of all plants.
- D is a genotype sequencing peak map of two strains of P2-21 and P2-79. The PAM is represented by blue, and the base to be mutated is expected to be represented by red, and the unintended mutated base is represented by green.
- the rice material for rice transformation in the following examples was Kitaake (Oryza sativa L. subsp. japonica), obtained from the Crop Science Research Institute of the Chinese Academy of Agricultural Sciences.
- the pCMV-BE3 vector in the following examples is in the literature "Komor AC, Kim YB, Packer MS, Zuris JA, Liu DR. 2016. Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage. Nature.” Publicly available, the public can Obtained from the Crop Science Institute of the Chinese Academy of Agricultural Sciences.
- endonucleases, kits and PCR enzymes used in the following examples were purchased from the reagent company, and all other reagents were domestically analyzed.
- the AAM medium (pH 5.2) in the following examples is a medium obtained by mixing MS salts & vitamins salt, sucrose, MES, glucose, casein amino acid, acetosyringone and 100 ml of 10 x AA amino acids, each of which The concentration of solute in AAM medium was 4.3 g/L MS salts & vitamins salt, 68.5 g/L sucrose, 0.5 g/L MES, 36 g/L glucose, 500 mg/L casein amino acid, 40 mg/L acetosyringone .
- the above 10x AA amino acids solution is a solution obtained by mixing L-glutamine, L-aspartate, L-arginine, glycine and water, wherein each solute is in a 10x AA amino acid solution.
- concentrations were: 8.76 g/L L-glutamine, 2.66 g/L L-day (-)-Aspartic acid, 1.74 g/L L-arginine, and 75 mg/L glycine.
- the R1 medium (pH 5.8) in the following examples is a medium obtained by mixing MS & Vitamins salt, sucrose, MES, casein amino acid, L-valine, 2,4-D, plant gel and water.
- concentrations of each solute in R1 medium were: 4.3g/L MS& Vitamins salt, 30g/L sucrose, 0.5g/L MES, 300mg/L casein amino acid, 2.8g/L L-valine, 2mg /L 2,4-D, 4 g/L plant gel.
- the R2 medium (pH 5.2) in the following examples is a medium obtained by mixing MS & Vitamins salt, sucrose, MES, casein amino acid, 2,4-D, phytogel, acetosyringone and water, each of which The concentrations of solutes in R2 medium were: 4.3 g/L MS & Vitamins salt, 30 g/L sucrose, 0.5 g/L MES, 300 mg/L casein amino acid, 2 mg/L 2,4-D, 4 g/L plants Gel, 20 mg/ml acetosyringone.
- the R1 screening medium (pH 5.8) in the following examples is a medium obtained by mixing MS & Vitamins salt, sucrose, MES, casein amino acid, L-valine, 2,4-D, plant gel and water. , wherein the concentration of each solute in the R1 screening medium is: 4.3 g / L MS & Vitamins salt, 30 g / L sucrose, 0.5 g / L MES, 300 mg / L casein amino acid, 2.8 g / L L-valine, 2 mg/L 2,4-D, 4 g/L plant gel.
- the R4 differentiation medium (pH 5.8) in the following examples was prepared by mixing MS & Vitamins salt, sucrose, MES, casein amino acid, sorbitol, kinetin, NAA, plant gel and water.
- the medium to which the solute was present in the R4 differentiation medium was: 4.3 g/L MS& Vitamins salt, 30 g/L sucrose, 0.5 g/L MES, 2 g/L casein amino acid, 30 g/L sorbitol 2 mg/L kinetin, 1 mg/L NAA, 4 g/L plant gel.
- the R5 medium (pH 5.8) in the following examples is a medium obtained by mixing MS & Vitamins salt, sucrose, MES, vegetable gel and water, wherein the concentration of each solute in the R5 medium is 2.15 g, respectively. /L MS& Vitamins salt, 15 g/L sucrose, 0.5 g/L MES, 2 g/L plant gel.
- the PAM site is represented by a wavy line
- the deaminase target is represented by a bold black body
- G # and C # # represents the position of the base
- the starting site away from the PAM site is the first base.
- the cleavage site is indicated by an underline.
- the linearized vector obtained in the step (1) and the PCR product obtained in the step (2) were ligated by homologous recombination using the pEASY-Uni Seamless Cloning and Assembly Kit of the full-scale gold company to obtain the vector pCXUN-BE3 ( Figure 1), it can be seen from Figure 1 that the pCXUN-BE3 vector includes an expression cassette, which in turn includes the maize Ubiquitin promoter (Ubi promoter), the coding gene for cytidine deaminase (APOBEC1), and the linkage.
- Ubi promoter maize Ubiquitin promoter
- APOBEC1 coding gene for cytidine deaminase
- the pCXUN-BE3 vector was digested with restriction endonuclease Pme I to obtain a linearized vector;
- PCR amplification was performed using primers S5-F/hrpme-u3R and hrpme-u3F/S5-R, respectively, and the amplified product was mixed 1:1 and used as a template, with primer hrpme. -u3F/hrpme-u3R for amplification, recovery of PCR product;
- step C The linearized vector obtained in step A and the PCR product obtained in step B were ligated by homologous recombination using the pEASY-Uni Seamless Cloning and Assembly Kit of the full-scale gold company, and the positive clone was identified and verified by sequencing to obtain the gRNA of S5.
- nucleotide sequence of the gRNA expression cassette pCXUN-BE3-S5 of S5 was sequence 1, in which position 392-5524 of sequence 1 was composed of nCas9 (D10A) nuclease, deaminase (APOBEC1), and nCas9.
- D10A nuclease and deaminase-linked peptide (XTEN Linker), uracil DNA glycosylase inhibitory protein (UGI) fusion protein BE3 coding gene sequence, 5545-7535 is plant gene expression promoter
- the nucleotide sequence of Ubi, positions 7785-8268 are sgRNA sequences.
- the pCXUN-BE3 vector was digested with restriction endonuclease Pme I to obtain a linearized vector;
- PCR amplification was performed using primers S3-F/hrpme-u3R and hrpme-u3F/S3-R, respectively, and the amplification products were mixed 1:1 and used as a template. Amplification of hrpme-u3F/hrpme-u3R to recover PCR product;
- step C The linearized vector obtained in step A and the PCR product obtained in step B were ligated by homologous recombination using the pEASY-Uni Seamless Cloning and Assembly Kit of the full-scale gold company, and the positive clone was identified and verified by sequencing to obtain the gRNA of S3.
- nucleotide sequence of the gRNA expression cassette pCXUN-BE3-S3 of S3 is sequence 2, wherein position 392-5524 of sequence 2 is composed of nCas9 (D10A) nuclease, deaminase (APOBEC1), and nCas9 (D10A) nuclease and cytidine deaminase-binding peptide (XTEN Linker), uracil DNA glycosylase inhibitory protein (UGI) fusion gene BE3 encoding gene sequence, 5545-7535 for plant gene expression
- the nucleotide sequence of the promoter Ubi, and positions 7785-8268 are sgRNA sequences.
- the pCXUN-BE3 vector was digested with restriction endonuclease Pme I to obtain a linearized vector;
- PCR amplification was performed using primers P2-F/hrpme-u3R and hrpme-u3F/P2-R, respectively, and the amplified product was mixed 1:1 and used as a template, using primer hrpme. -u3F/hrpme-u3R for amplification, recovery of PCR product;
- step C The linearized vector obtained in step A and the PCR product obtained in step B were ligated by homologous recombination using the pEASY-Uni Seamless Cloning and Assembly Kit of the full-scale gold company, and the positive clone was identified and verified by sequencing to obtain the gRNA of P2.
- nucleotide sequence of p2 gRNA expression cassette pCXUN-BE3-P2 was sequence 3, wherein position 392-5524 of sequence 3 was composed of nCas9 (D10A) nuclease, deaminase (APOBEC1), and nCas9 (D10A) nuclease and cytidine deaminase-binding peptide (XTEN Linker), uracil DNA glycosylase inhibitory protein (UGI) fusion gene BE3 encoding gene sequence, 5545-7535 for plant gene expression
- the nucleotide sequence of the promoter Ubi, and positions 7785-8268 are sgRNA sequences.
- the recombinant plasmids pCXUN-BE3-S5, pCXUN-BE3-S3 and pCXUN-BE3-P2 obtained in the first step were introduced into Agrobacterium EHA105, respectively, to obtain recombinant Agrobacterium pCXUN-BE3-S5/EHA105, pCXUN-BE3-S3/EHA105, respectively. And pCXUN-BE3-P2/EHA105.
- the BE3, gRNA and hptII gene primers BE3-F/R, U3-F/R and HPTII-F/R were designed and tested according to the vector sequence, and all T 0 generation S5 rice plants obtained, T 0 generation were obtained.
- Transgenic S3 rice plants and T 0 transgenic P2 rice plants were identified by PCR and statistical results were obtained.
- the primers S5testF/R were used to amplify the genomic DNA of 52 positive T 0 transgenic S5 rice plants obtained in step 3, and the PCR product was obtained.
- the PCR product was digested with BstNI, and the target sequence occurred in the transgenic rice plants of S5. In the expected mutation, the PCR product corresponding to the S5 rice plant will not be digested by the corresponding restriction enzyme BstNI.
- the sequencing results are shown in Figure 3.
- 23 plants with site-directed mutagenesis can be divided into the following three types: the first group has 10 plants, and the fifth and sixth bases are mutated from G to A (G 5 is mutated into A 5 and G 6 is mutated to A 6 ), wherein 3 plants are homozygous (the fifth and sixth bases of both homologous chromosomes are mutated from G to A, S5-17, S5-36, and S5-46), 6 are heterozygous types (S5-1, S5-8, S5-21, S5-33, S5-42, and S5-43), and 1 is a double allele type (S5-34)
- the first category (expected mutation type) accounted for 43% (10/23) of all mutation types, and the efficiency reached 20% (10/52) relative to all transgenic plants; the second category had 8 plants at the same time.
- the fifth and/or sixth bases are mutated from G to A and G to C or T, one of which is homozygous (S5-26) and the other 7 is heterozygous (S5) -10, S5-25, S5-44, S5-45, S5-48, S5-50 and S5-52); there are 5 plants in the third category.
- This type of mutation is a non-expected type, mainly a locus. Insertion and deletion, 3 are biallelic mutations (S5-18, S5-31 and S4-47) and 2 are heterozygous (S5-16 and S5-23).
- Other G was also contained in the S5 target, but no corresponding mutation occurred.
- the sequencing results are shown in Figure 4.
- the sequencing results showed that there were 11 plants with site-directed mutations in 38 positive T 0 transgenic plants.
- 11 plants with site-directed mutagenesis could be divided into the following three categories: the first group contained 4 plants, which were only Contains the expected type of mutation (C mutation to T), which are S3-1, S3-4, S3-26 and S3-29, respectively, wherein S3-1, S3-4 and S3-29 are homozygous plants, S3-26 is a heterozygous plant, and all three target sites on a homologous chromosome of heterozygous S3-26 are mutated (the first, second and seventh bases are all changed from C to T).
- the other three homologous chromosomes are all wild-type; the second type has only one plant, which is S3-6, and the seventh base of a homologous chromosome of S3-6 is mutated from C to T.
- the seventh base of another homologous chromosome is mutated from C to G;
- the third class has 6 plants, all of which are unexpected types, of which 4 are homozygous and the seventh base is C.
- the mutation is G, and the other two plants are one strand.
- the first base and the seventh base are both mutated from C to G, and the other base is only the seventh base is mutated from C to G.
- the primers P2testF/R were used to amplify the genomic DNA of 88 positive T 0 transgenic P2 rice plants, and the PCR product was obtained.
- the PCR product was digested with EcoRI, and the expected mutation occurred in the target sequence in the transgenic P2 rice plant.
- the PCR product corresponding to the transgenic P2 rice plant will not be digested by the corresponding restriction endonuclease BstNI.
- the sequencing results are shown in Figure 5.
- the results showed that both P2-21 and P2-79 were heterozygous.
- a homologous chromosome of P2-21 was mutated from G to A in the eighth and tenth bases of the target sequence, and another homologue.
- the chromosome is wild type.
- a homologous chromosome of P2-79 is mutated from G to C in the eighth base of the target sequence, the tenth base does not change, and the other homologous chromosome is wild type.
- the present invention provides a system for site-directed editing of a plant genome comprising a BE3 plant expression vector expressed by nCas9 (D10A), deaminase (APOBEC1) and uracil DNA glycosylase inhibitory protein (UGI)
- nCas9 D10A
- APOBEC1 deaminase
- UMI uracil DNA glycosylase inhibitory protein
- the fusion protein is composed and the system is verified by rice OsPDS and OsSBEIIb as target genes. The results showed that among the selected three targets, the expected site-directed mutant plants were obtained, and C was mutated to T (or G to A) in the 4-8 position of the target sequence, and was achieved in rice.
Landscapes
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Chemical & Material Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Cell Biology (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
一种CRISPR/nCas9介导的定点碱基替换在植物中的应用。所述定点碱基替换通过定点编辑植物基因组的系统实现,该系统包括BE3植物表达载体,BE3植物表达载体表达由nCas9(D10A)、脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白,并以水稻OsPDS和OsSBEIIb为靶基因对该系统进行验证。结果表明,在所选的3个靶点中,均获得预期定点突变植株,在水稻中实现了碱基的精确的点突变,且效率最高达到20%左右,为农作物育种提供了一种可行的有效的碱基替换方法,在农业育种方面具有强大的应用潜力,为快速改良农作物重要农艺性状提供了基础。
Description
本发明涉及生物技术领域,具体涉及一种CRISPR/nCas9介导的定点碱基替换在植物中的应用。
CRISPR/Cas9介导的基因组编辑技术已经成为分子生物学中最强大的工具之一。首次在细菌中发现,由sgRNA和Cas9两部分组成(Jinek et al.,2012)。CRISPR/Cas9是通过自身的核酸内切酶活性引起靶位点DNA序列双链断裂(double-strand breaks,DSBs),然后通过非同源末端连接(non-homologous end joining,NHEJ)或同源重组介导的修复(homology-directed repair,HDR)两种方式引入突变。NHEJ途径诱导产生的突变大部分为核苷酸的插入或缺失,造成移码突变,而HDR则由同源供体DNA介导片段插入或核苷酸修正(Jinek et al.,2012)。CRISPR/Cas9系统对靶位点的识别依赖于核酸之间碱基互补配对,可对任何紧随PAM(NGG)的20bp的靶点序列进行编辑,且其靶点在基因组中的分布频率很高,因此对于需要定点编辑的靶基因,更容易找到合适的靶位点。另外CRISPR/Cas9系统可同时对同一基因的不同位点或多个基因的位点进行定向编辑,使其运用更加灵活。此外,CRISPR/Cas9系统操作简单快捷,每次打靶只需替换原有载体上20-30bp的核苷酸序列,更适宜规模化,高通量操作(Cong et al.,2013;Feng et al.,2014;Gao and Zhao,2014;Zhou et al.,2014;Lawrenson et al.,2015;Liu et al.,2015;Ma et al.,2015;Wang et al.,2015;Xie et al.,2015;Paul III and Qi,2016)。随着CRISPR/Cas9技术在人类与动物细胞系中建立并应用,经过改造的CRISPR/Cas9系统也迅速地被应用到拟南芥、烟草、高粱、水稻、小麦、玉米等不同植物基因组的定向编辑研究中,并且获得较高的诱导突变率和可稳定遗传的基因组编辑植株(Shan et al.,2013;Puchta and Fauser,2014;Voytas and Gao,2014;Li et al.,2015;Ma et al.,2015;Svitashev et al.,2015;Endo et al.,2016;Gao et al.,2016;Sun et al.,2016)。
尽管CRISPR/Cas9作为一种新的靶向基因修饰技术,展现了广阔的发展潜力和应用前景,并在农作物改良中得到广泛应用,但目前主要局限于基因随机突变和敲除。农作物中含有大量农艺性状是由单碱基的突变导致,传统CRISPR/Cas9技术引入DSB后,与非同源末端连接的随机过程相比,HDR总是以相当低的频率发生,只有少数报道表明CRISPR/Cas9介导的HDR在作物中可行(Li et al.,2015;Svitashev et al.,2015;Endo et al.,2016;Shi et al.,2016;Sun et al.,2016),使得大量农艺性状无法得到快速的改良。
Nishida et al.(2016)将dCas9或nicked-Cas9(nCas9,D10A)与来自七鳃鳗(sea lamprey)免疫系统的激活诱导性胞苷脱氨(activation-induced cytidine deaminase,AID)融合在一起。在正常情况下,这种AID酶在免疫球蛋白和抗体基因中产生突变从而让免疫系统具有多样性。AID作用在单链DNA上,将胞嘧啶(C)替换为尿嘧啶(U),随后在一轮DNA复制中,这种尿嘧啶(U)被转化为胸腺嘧啶(T)。研究结果表明当在向导RNA(gRNA)的引导下,这种蛋白复合物靶向作用于CAN1基因,而且相对于非靶向的选择性标志物,CAN1基因发生突变的频率增加了1000倍。利用全基因组测序,研究人员发现很少的脱靶突变,只比背景突变率略有增加。Komor et al.(2016)将nCas9(D10A)与胞苷脱氨酶融合,在gRNA的指导下,nCas9(D10A)到达指定位点,可作为“单碱基编辑器”将在非目标链的第4-8位目标胞嘧啶定点替换。通过DNA复制或修复后,胞嘧啶被转化成胸腺嘧啶,最终由C突变成T,或者G突变成A。
发明公开
本发明的一个目的是提供如下(1)-(7)中任一种所述的应用:
(1)CRISPR/Cas9系统、胞苷脱氨酶和植物基因表达启动子在定点编辑植物或农作物基因中的应用;
所述植物基因表达启动子启动CRISPR/Cas9系统中Cas9核酸酶和胞苷脱氨酶的表达;
(2)CRISPR/Cas9系统和胞苷脱氨酶在定点编辑植物或农作物基因中的应用;
(3)由Cas9核酸酶和胞苷脱氨酶组成的融合蛋白、待编辑基因的
sgRNA和植物基因表达启动子在定点编辑植物或农作物基因中的应用;
所述植物基因表达启动子驱动由所述Cas9核酸酶和所述胞苷脱氨酶组成的融合蛋白基因的表达;
(4)CRISPR/Cas9系统、胞苷脱氨酶、尿嘧啶DNA糖基化酶抑制蛋白和植物基因表达启动子在定点编辑植物或农作物基因中的应用;
所述植物基因表达启动子启动CRISPR/Cas9系统中Cas9核酸酶、胞苷脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白的表达;
(5)CRISPR/Cas9系统、胞苷脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白在定点编辑植物或农作物基因中的应用;
(6)由Cas9核酸酶、胞苷脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白、待编辑基因的sgRNA和植物基因表达启动子在定点编辑植物或农作物基因中的应用;
所述植物基因表达启动子驱动由所述Cas9核酸酶、所述胞苷脱氨酶和所述尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因的表达;
(7)由Cas9核酸酶、脱氨酶、连接所述Cas9核酸酶与所述脱氨酶的连接肽和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白、待编辑基因的sgRNA和植物基因表达启动子在定点编辑植物或农作物基因中的应用;
所述植物基因表达启动子驱动由所述Cas9核酸酶、所述胞苷脱氨酶、所述连接肽和所述尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因的表达。
上述应用中,所述胞苷脱氨酶为APOBEC1,其编码基因序列为序列1第4838-5524位。
上述应用中,所述尿嘧啶DNA糖基化酶抑制蛋白为Uracil DNA glycosylase inhibitor,其编码基因序列为序列1第429-688位。
上述应用中,所述植物基因表达启动子为玉米Ubiquitin启动子,其核苷酸序列为序列1第5545-7535位。
上述应用中,所述Cas9核酸酶为nCas9(D10A),其编码基因序列为序列1第689-4789位。
上述应用中,所述连接肽的编码基因序列为序列1第4790-4837位;
所述融合蛋白的编码基因序列为序列1第392-5524位;
所述待编辑基因为OsSBEIIb和OsPDS;
所述sgRNA的核苷酸序列为序列1第7785-8268位或序列2第7785-8268位或序列3第7785-8268位。
本发明的另一个目的是提供一种定点编辑植物或农作物基因的方法或一种定点编辑植物或农作物核酸分子的方法。
本发明提供的方法为如下(1)或(2):
(1)所述方法包括如下步骤:将Cas9核酸酶编码基因、胞苷脱氨酶编码基因、待编辑基因的sgRNA的编码基因和植物基因启动子导入出发植物,实现出发植物中靶基因的定点编辑;
(2)所述方法包括如下步骤:将Cas9核酸酶编码基因、胞苷脱氨酶编码基因、连接所述Cas9核酸酶与所述胞苷脱氨酶的连接肽的编码基因、尿嘧啶DNA糖基化酶抑制蛋白的编码基因、待编辑基因的sgRNA的编码基因和植物基因启动子导入出发植物,实现出发植物中靶基因的定点编辑。
上述方法中,
(1)中,所述Cas9核酸酶编码基因、所述胞苷脱氨酶编码基因、所述待编辑基因的sgRNA的编码基因和所述植物基因启动子通过重组质粒导入出发植物中;
所述重组质粒包括由Cas9核酸酶和胞苷脱氨酶组成融合蛋白的编码基因、所述待编辑基因的sgRNA的编码基因和植物基因启动子;
所述植物基因启动子驱动由所述Cas9核酸酶和所述胞苷脱氨酶组成的融合蛋白基因的表达;
(2)中,所述Cas9核酸酶编码基因、所述胞苷脱氨酶编码基因、所述连接所述Cas9核酸酶与所述胞苷脱氨酶的连接肽的编码基因、所述尿嘧啶DNA糖基化酶抑制蛋白基因、所述待编辑基因的sgRNA的编码基因和所述植物基因启动子通过重组质粒导入出发植物中;
所述重组质粒包括由Cas9核酸酶、胞苷脱氨酶、连接所述Cas9核酸酶与所述胞苷脱氨酶的连接肽和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因、所述待编辑基因的sgRNA的编码基因和植物基因启动子;
所述植物基因启动子驱动由所述Cas9核酸酶、所述胞苷脱氨酶、所述连接所述Cas9核酸酶与所述胞苷脱氨酶的连接肽和所述尿嘧啶DNA糖
基化酶抑制蛋白组成的融合蛋白的编码基因的表达。
上述方法中,所述胞苷脱氨酶为APOBEC1,其编码基因序列为序列1第4838-5524位。
上述方法中,所述尿嘧啶DNA糖基化酶抑制蛋白为Uracil DNA glycosylase inhibitor,其编码基因序列为序列1第429-688位。
上述方法中,所述植物基因表达启动子为玉米Ubiquitin启动子,其核苷酸序列为序列1第5545-7535位。
上述方法中,所述Cas9核酸酶为nCas9(D10A),其编码基因序列为序列1第689-4789位。
上述方法中,所述连接肽的编码基因序列为序列1第4790-4837位;
所述融合蛋白的编码基因序列为序列1第392-5524位;
所述待编辑基因为OsSBEIIb和OsPDS;
所述sgRNA的核苷酸序列为序列1第7785-8268位或序列2第7785-8268位或序列3第7785-8268位。
上述方法中,所述重组质粒的核苷酸序列为序列1、序列2或序列3。
上述方法中,所述植物为单子叶植物或双子叶植物;所述单子叶植物具体可为水稻;所述水稻品种具体可为Kitaake(Oryza sativa L.subsp.japonica)。
上述重组质粒也属于本发明的保护范围。
本发明还有一个目的是提供一种定点编辑植物基因组的系统或一种定点编辑植物核酸分子的系统。
本发明提供的系统包括上述重组质粒。
本发明的最后一个目的是提供上述重组质粒或上述系统的新用途。
本发明提供了上述重组质粒或上述系统在定点编辑植物或农作物基因中的应用。
上述应用或方法中,所述定点编辑为定点碱基替换;所述替换为由C突变成T,或者G突变成A。
上述应用或方法中,所述CRISPR/Cas9系统为CRISPR/nCas9系统,所述CRISPR/nCas9系统具体为CRISPR/nCas9(D10A)系统。
图1为pCXUN-BE3载体框架图。
图2为转基因植株的鉴定。注:A为载体T-DNA结构图及引物所在位置。B,C和D分别为P2,S3和S5转基因植株的Cas9(D10A),gRNA及hptII基因的检测。
图3为OsSBEIIb基因S5靶点的转基因植株及序列的鉴定。注:A为BE3定点突变系统原理图。B为OsSBEIIb基因结构图及S5靶点所在位置,PCR产物酶切鉴定图。“+”表示PCR产物经过酶切,“-”表示PCR产物没经过酶切。C为所有植株PCR产物的克隆测序结果。D为S5-17和S5-26两个株系基因型测序峰图。PAM由蓝色表示,预期突变成的碱基由红色表示,非预期的突变碱基由绿色表示。
图4为OsSBEIIb基因S3靶点的转基因植株及序列的鉴定。注:A为OsSBEIIb基因结构图及S3靶点所在位置,PCR产物电泳图。B为所有植株PCR产物的克隆测序结果。C为S3-1和S3-18两个株系基因型测序峰图。PAM由蓝色表示,预期突变成的碱基由红色表示,非预期的突变碱基由绿色表示。
图5为OsSBEIIb基因P2靶点的转基因植株及序列的鉴定。注:A为OsSBEIIb基因结构图及P2靶点所在位置,PCR产物酶切鉴定图。“+”表示PCR产物经过酶切,“-”表示PCR产物没经过酶切。C为所有植株PCR产物的克隆测序结果。D为P2-21和P2-79两个株系基因型测序峰图。PAM由蓝色表示,预期突变成的碱基由红色表示,非预期的突变碱基由绿色表示。
实施发明的最佳方式
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
下述实施例中的定量试验,均设置三次重复实验,结果取平均值。
下述实施例中的用于水稻转化的水稻材料为Kitaake(Oryza sativa L.subsp.japonica),由中国农业科学院作物科学研究所获得。
下述实施例中的pCMV-BE3载体在文献“Komor AC,Kim YB,Packer MS,Zuris JA,Liu DR.2016.Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage.Nature.”中公开过,公众可
以从中国农业科学院作物科学研究所获得。
下述实施例中所用的内切酶、试剂盒和PCR酶均购自试剂公司,其他试剂均为国产分析纯。
下述实施例中的引物和DNA合成及测序均在华大公司完成。
下述实施例中的AAM培养基(pH 5.2)是将MS salts & vitamins盐、蔗糖、MES、葡萄糖、酪蛋白氨基酸、乙酰丁香酮和100ml 10 x AA amino acids混匀得到的培养基,其中各溶质在AAM培养基中的浓度分别为4.3g/L MS salts & vitamins盐、68.5g/L蔗糖、0.5g/L MES、36g/L葡萄糖、500mg/L酪蛋白氨基酸、40mg/L乙酰丁香酮。上述10x AA amino acids溶液为将L-谷氨酰胺、L-天(门)冬氨酸、L-精氨酸、甘氨酸和水混匀得到的溶液,其中各溶质在10x AA amino acids溶液中的浓度分别为:8.76g/L L-谷氨酰胺、2.66g/L L-天(门)冬氨酸、1.74g/L L-精氨酸和75mg/L甘氨酸。
下述实施例中的R1培养基(pH 5.8)是将MS&Vitamins盐、蔗糖、MES、酪蛋白氨基酸、L-脯氨酸、2,4-D、植物凝胶和水混匀得到的培养基,其中各溶质在R1培养基中的浓度分别为:4.3g/L MS& Vitamins盐、30g/L蔗糖、0.5g/L MES、300mg/L酪蛋白氨基酸、2.8g/L L-脯氨酸、2mg/L 2,4-D、4g/L植物凝胶。
下述实施例中的R2培养基(pH 5.2)是将MS&Vitamins盐、蔗糖、MES、酪蛋白氨基酸、2,4-D、植物凝胶、乙酰丁香酮和水混匀得到的培养基,其中各溶质在R2培养基中的浓度分别为:4.3g/L MS& Vitamins盐、30g/L蔗糖、0.5g/L MES、300mg/L酪蛋白氨基酸、2mg/L 2,4-D、4g/L植物凝胶、20mg/ml乙酰丁香酮。
下述实施例中的R1筛选培养基(pH 5.8)是将MS&Vitamins盐、蔗糖、MES、酪蛋白氨基酸、L-脯氨酸、2,4-D、植物凝胶和水混匀得到的培养基,其中各溶质在R1筛选培养基中的浓度为:4.3g/L MS& Vitamins盐、30g/L蔗糖、0.5g/L MES、300mg/L酪蛋白氨基酸、2.8g/L L-脯氨酸、2mg/L 2,4-D、4g/L植物凝胶。
下述实施例中的R4分化培养基(pH 5.8)是将MS& Vitamins盐、蔗糖、MES、酪蛋白氨基酸、山梨醇、激动素、NAA、植物凝胶和水混匀得
到的培养基,其中各溶质在R4分化培养基中的浓度分别为:4.3g/L MS& Vitamins盐、30g/L蔗糖、0.5g/L MES、2g/L酪蛋白氨基酸、30g/L山梨醇、2mg/L激动素、1mg/L NAA、4g/L植物凝胶。
下述实施例中的R5培养基(pH 5.8)是将MS& Vitamins盐、蔗糖、MES、植物凝胶和水混匀得到的培养基,其中各溶质在R5培养基中的浓度分别为:2.15g/L MS& Vitamins盐、15g/L蔗糖、0.5g/L MES、2g/L植物凝胶。
下述实施例中所用的引物如表1所示:
表1、引物序列


下述实施例中靶点位置及序列如表2所示。
表2、靶点位置及序列

注:PAM位点由波浪线表示,脱氨酶靶点由加粗黑体表示,G#和C#,#代表碱基所在位置,远离PAM位点的起始位点为第一个碱基。酶切位点由下划线表示。
实施例1、一种CRISPR/nCas9介导的定点碱基替换在植物中的应用
一、表达载体的构建
1、pCXUN-BE3载体的构建
(1)用限制性内切酶BamHI酶切pCXUN-Cas9载体,得到线性化的载体;
(2)以BE-F/R为引物,pCMV-BE3载体为模板进行PCR扩增,得到PCR产物,该PCR产物的5’和3’最末端的序列分别和线性化载体两末端序列完全一致;
(3)采用全式金公司的pEASY-Uni Seamless Cloning and Assembly Kit将步骤(1)获得的线性化的载体、步骤(2)获得的PCR产物通过同源重组进行连接,获得载体pCXUN-BE3(图1),从图1中可以看出:pCXUN-BE3载体包括表达盒甲,该表达盒甲依次包括玉米Ubiquitin启动子(Ubi启动子)、胞苷脱氨酶(APOBEC1)的编码基因、连接nCas9(D10A)核酸酶和脱氨酶的连接肽(XTEN Linker)、nCas9(D10A)核酸酶的编码基因和尿嘧啶DNA糖基化酶抑制蛋白(UGI)的编码基因。
2、利用重叠PCR方法构建P2、S3及S5的gRNA表达盒pCXUN-BE3-P2、pCXUN-BE3-S3和pCXUN-BE3-S5载体
(1)S5的gRNA表达盒pCXUN-BE3-S5的构建
A、用限制性内切酶Pme I酶切pCXUN-BE3载体,得到线性化的载体;
B、以pOsU3-sgRNA质粒为模板,分别利用引物S5-F/hrpme-u3R和hrpme-u3F/S5-R进行PCR扩增,并将扩增产物1:1混合后做为模板,用引物hrpme-u3F/hrpme-u3R进行扩增,回收PCR产物;
C、采用全式金公司的pEASY-Uni Seamless Cloning and Assembly Kit将步骤A获得的线性化的载体、步骤B获得的PCR产物通过同源重组进行连接,鉴定阳性克隆并测序验证,得到S5的gRNA表达盒pCXUN-BE3-S5。
经过测序验证:S5的gRNA表达盒pCXUN-BE3-S5的核苷酸序列为序列1,其中序列1的第392-5524位为由nCas9(D10A)核酸酶、脱氨酶(APOBEC1)、连接nCas9(D10A)核酸酶和脱氨酶的连接肽(XTEN Linker)、尿嘧啶DNA糖基化酶抑制蛋白(UGI)组成的融合蛋白BE3的编码基因序列、第5545-7535位为植物基因表达启动子Ubi的核苷酸序列,第7785-8268位为sgRNA序列。
(2)S3的gRNA表达盒pCXUN-BE3-S3的构建
A、用限制性内切酶Pme I酶切pCXUN-BE3载体,得到线性化的载体;
B、以pOsU3-sgRNA质粒为模板,分别利用引物S3-F/hrpme-u3R和hrpme-u3F/S3-R进行PCR扩增,并将扩增产物1:1混合后做为模板,用引
物hrpme-u3F/hrpme-u3R进行扩增,回收PCR产物;
C、采用全式金公司的pEASY-Uni Seamless Cloning and Assembly Kit将步骤A获得的线性化的载体、步骤B获得的PCR产物通过同源重组进行连接,鉴定阳性克隆并测序验证,得到S3的gRNA表达盒pCXUN-BE3-S3。
经过测序验证:S3的gRNA表达盒pCXUN-BE3-S3的核苷酸序列为序列2,其中序列2的第392-5524位为由nCas9(D10A)核酸酶、脱氨酶(APOBEC1)、连接nCas9(D10A)核酸酶和胞苷脱氨酶的连接肽(XTEN Linker)、尿嘧啶DNA糖基化酶抑制蛋白(UGI)组成的融合蛋白BE3的编码基因序列、第5545-7535位为植物基因表达启动子Ubi的核苷酸序列,第7785-8268位为sgRNA序列。
(3)P2的gRNA表达盒pCXUN-BE3-P2的构建
A、用限制性内切酶Pme I酶切pCXUN-BE3载体,得到线性化的载体;
B、以pOsU3-sgRNA质粒为模板,分别利用引物P2-F/hrpme-u3R和hrpme-u3F/P2-R进行PCR扩增,并将扩增产物1:1混合后做为模板,用引物hrpme-u3F/hrpme-u3R进行扩增,回收PCR产物;
C、采用全式金公司的pEASY-Uni Seamless Cloning and Assembly Kit将步骤A获得的线性化的载体、步骤B获得的PCR产物通过同源重组进行连接,鉴定阳性克隆并测序验证,得到P2的gRNA表达盒pCXUN-BE3-P2。
经过测序验证:P2的gRNA表达盒pCXUN-BE3-P2的核苷酸序列为序列3,其中序列3的第392-5524位为由nCas9(D10A)核酸酶、脱氨酶(APOBEC1)、连接nCas9(D10A)核酸酶和胞苷脱氨酶的连接肽(XTEN Linker)、尿嘧啶DNA糖基化酶抑制蛋白(UGI)组成的融合蛋白BE3的编码基因序列、第5545-7535位为植物基因表达启动子Ubi的核苷酸序列,第7785-8268位为sgRNA序列。
二、重组菌的构建
分别将步骤一获得的重组质粒pCXUN-BE3-S5、pCXUN-BE3-S3和pCXUN-BE3-P2导入农杆菌EHA105,分别得到重组农杆菌pCXUN-BE3-S5/EHA105、pCXUN-BE3-S3/EHA105和pCXUN-BE3-P2/EHA105。
三、转基因水稻的获得
1、分别将重组农杆菌pCXUN-BE3-S5/EHA105、pCXUN-BE3-S3/EHA105
及pCXUN-BE3-P2/EHA105在LB培养基上培养两天后,收集农杆菌,并用AAM培养基重悬,OD600调到0.3-0.5,分别得到OD600为0.3-0.5的菌液。
2、选取饱满的kitaake水稻种子,剥去种皮,灭菌洗涤后,均匀的点入R1培养基中,28℃持续光照2-3周诱导愈伤组织的形成。将形成的愈伤组织转移到新的R1培养基上培养3-5天,然后分别转移到上述OD600为0.3-0.5的菌液中侵染5分钟,侵染后用滤纸吸干表面菌液并转移到R2培养基上在25℃下培养三天,再转移至含有浓度为50mg/L潮霉素的R1筛选培养基上,在28℃条件下持续光照2周后转移至新的含有浓度为50mg/L潮霉素的R1筛选培养基,在28℃条件下持续光照2周。选取生长良好呈嫩黄色的阳性愈伤组织,用无菌镊子移至含有浓度为50mg/L潮霉素的R4分化培养基中,在28℃条件下持续光照培养。待分化出来的幼苗长至2-5mm时,将幼苗转入不含激素和抗生素的R5培养基中,在28℃条件下持续光照培养2-3周,之后移入土中置于温室中生长(培养条件为:温度28-30℃,光照为16h光照/8h黑暗),分别得到T0代转P2水稻植株、T0代转S3水稻植株和T0代转S5水稻植株。
3、转基因水稻植株的鉴定
根据载体序列分别设计检测BE3、gRNA和hptII基因引物BE3-F/R,U3-F/R和HPTII-F/R(表2),对获得的所有T0代转S5水稻植株、T0代转S3水稻植株和T0代转P2水稻植株进行PCR鉴定并统计结果。
转基因水稻植株的PCR鉴定结果如图2所示。结果表明:共获得52颗阳性T0代转S5水稻植株、38颗阳性T0代转S3水稻植株及88颗阳性T0代转P2水稻植株。
四、定点编辑的检测
1、定点编辑OsSBEIIb的S5靶点的基因型鉴定
利用引物S5testF/R对步骤三获得的52颗阳性T0代转S5水稻植株的基因组DNA进行扩增,得到PCR产物,用BstNI酶切PCR产物,如果转S5水稻植株中的靶点序列发生所期待的突变,则该转S5水稻植株对应的PCR产物将无法被相对应的限制性内切酶BstNI酶切。
酶切鉴定结果表明:52颗阳性T0代转S5水稻植株中共有23颗阳性T0代转S5水稻植株的PCR产物完全不能或者部分不能被BstNI切开,说明
在该酶切位点处发生突变,将上述23颗植株记作定点突变的植株,并对其进行测序。
测序结果如图3所示。根据测序结果可以将23颗定点突变的植株分成如下三类:第一类共有10颗植株,为第五位和第六位碱基由G突变成A(G5突变成A5和G6突变成A6),其中,3颗植株为纯合类型(两条同源染色体的第五位和第六位碱基均由G突变成A,S5-17、S5-36、和S5-46)、6颗为杂合类型(S5-1、S5-8、S5-21、S5-33、S5-42和S5-43),1颗为双等位突变类型(S5-34),第一类(期待突变类型)占所有突变类型的43%(10/23),相对于所有转基因植株而言,效率达到20%(10/52);第二类共有8颗植株,为同时包含第五位和/或第六位碱基由G突变成A及G突变成C或者T,其中,一颗为纯合类型(S5-26),另外7颗为杂合类型(S5-10、S5-25、S5-44、S5-45、S5-48、S5-50和S5-52);第三类共有5颗植株,这一类型突变均为非期待类型,主要是位点的插入和缺失,3颗为双等位突变(S5-18、S5-31和S4-47),2颗为杂合类型(S5-16和S5-23)。在S5靶点内同样含有其他的G,但都没有发生相应的突变。
2、定点编辑OsSBEIIb的S3靶点的基因型鉴定
利用引物S3testF/R对步骤三获得的38颗阳性T0代转S3水稻植株的基因组DNA进行扩增,得到PCR产物,并对PCR扩增产物直接测序。
测序结果如图4所示。测序结果表明,38颗阳性T0代转S3水稻植株中共有11颗定点突变的植株,根据测序结果可以将11颗定点突变的植株分成如下三类:第一类共包含4颗植株,为只含有所期待的突变类型(C突变成T),分别为S3-1,S3-4,S3-26和S3-29,其中,S3-1,S3-4和S3-29为纯合植株,S3-26为杂合型植株,杂合型植株S3-26的一条同源染色体上的三个靶位点均发生突变(第一,第二和第七位碱基均由C突变为T),另外一条同源染色体的三个靶位点均为野生型;第二类只有一颗植株,为S3-6,S3-6的一条同源染色体的第七位碱基由C突变为T,另外一条同源染色体的第七位碱基由C突变为G;第三类共有6颗植株,均为非期待的类型,其中,4颗为纯合类型,为第七位碱基均由C突变为G,另外2颗植株为一条链在第一位碱基和第七位碱基均由C突变成G,另外一条链仅第七位碱基由C突变成G。
3、定点编辑OsPDS的P2靶点的基因型鉴定
利用引物P2testF/R对获得88颗阳性T0代转P2水稻植株的基因组DNA进行扩增,得到PCR产物,用EcoRI酶切PCR产物,如果转P2水稻植株中的靶点序列发生所期待的突变,则该转P2水稻植株对应的PCR产物将无法被相对应的限制性内切酶BstNI酶切。
利用EcoRI酶切T0代转P2水稻植株的PCR产物,结果表明有2颗T0代转P2水稻植株(P2-21和P2-79)的PCR产物为部分切开,说明在该酶切位点处发生突变,将上述2颗植株记作定点突变的植株,并对其进行测序。
测序结果如图5所示。结果表明,P2-21和P2-79均为杂合类型,P2-21的一条同源染色体在靶点序列的第八位和第十位碱基均由G突变成A,另外一条同源染色体为野生型。P2-79的一条同源染色体在靶点序列的第八位碱基由G突变成C,第十位碱基没有发生变化,另外一条同源染色体为野生型。
工业应用
本发明提供了一种定点编辑植物基因组的系统,该系统包括BE3植物表达载体,BE3植物表达载体表达由nCas9(D10A)、脱氨酶(APOBEC1)和尿嘧啶DNA糖基化酶抑制蛋白(UGI)组成的融合蛋白,并以水稻OsPDS和OsSBEIIb为靶基因对该系统进行验证。结果表明,在所选的3个靶点中,均获得预期定点突变植株,既在靶点序列的4-8位置的C突变成T(或G突变成A),在水稻中实现了碱基的精确的点突变,且效率最高达到20%左右,而且该方法操作简单、可行,与构建CRISPR/Cas9并无明显差别,为农作物育种提供了一种可行的有效的碱基替换方法,在农业育种方面具有强大的应用潜力,为快速改良农作物重要农艺性状提供了基础。
Claims (29)
- 如下(1)-(7)中任一种所述的应用:(1)CRISPR/Cas9系统、脱氨酶和植物基因表达启动子在定点编辑植物或农作物基因中的应用;所述植物基因表达启动子启动CRISPR/Cas9系统中Cas9核酸酶和脱氨酶的表达;(2)CRISPR/Cas9系统和脱氨酶在定点编辑植物或农作物基因中的应用;(3)由Cas9核酸酶和脱氨酶组成的融合蛋白、待编辑基因的sgRNA和植物基因表达启动子在定点编辑植物或农作物基因中的应用;所述植物基因表达启动子驱动由所述Cas9核酸酶和所述脱氨酶组成的融合蛋白基因的表达;(4)CRISPR/Cas9系统、脱氨酶、尿嘧啶DNA糖基化酶抑制蛋白和植物基因表达启动子在定点编辑植物或农作物基因中的应用;所述植物基因表达启动子启动CRISPR/Cas9系统中Cas9核酸酶、脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白的表达;(5)CRISPR/Cas9系统、脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白在定点编辑植物或农作物基因中的应用;(6)由Cas9核酸酶、脱氨酶和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白、待编辑基因的sgRNA和植物基因表达启动子在定点编辑植物或农作物基因中的应用;所述植物基因表达启动子驱动由所述Cas9核酸酶、所述脱氨酶和所述尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因的表达;(7)由Cas9核酸酶、脱氨酶、连接所述Cas9核酸酶与所述脱氨酶的连接肽和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白、待编辑基因的sgRNA和植物基因表达启动子在定点编辑植物或农作物基因中的应用;所述植物基因表达启动子驱动由所述Cas9核酸酶、所述脱氨酶、所述连接肽和所述尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因的表达。
- 根据权利要求1所述的应用,其特征在于:所述脱氨酶为APOBEC1。
- 根据权利要求2所述的应用,其特征在于:所述APOBEC1的编码基因序列为序列1第4838-5524位。
- 根据权利要求1所述的应用,其特征在于:所述尿嘧啶DNA糖基化酶抑制蛋白为Uracil DNA glycosylase inhibitor。
- 根据权利要求4所述的应用,其特征在于:所述Uracil DNA glycosylase inhibitor的编码基因序列为序列1第429-688位。
- 根据权利要求1所述的应用,其特征在于:所述Cas9核酸酶为nCas9。
- 根据权利要求6所述的应用,其特征在于:所述nCas9的编码基因序列为序列1第689-4789位。
- 根据权利要求1所述的应用,其特征在于:所述植物基因表达启动子为玉米Ubiquitin启动子。
- 根据权利要求8所述的应用,其特征在于:所述玉米Ubiquitin启动子的核苷酸序列为序列1第5545-7535位。
- 根据权利要求1-9中任一所述的应用,其特征在于:所述连接肽的编码基因序列为序列1第4790-4837位;所述融合蛋白的编码基因序列为序列1第392-5524位。
- 根据权利要求1-9中任一所述的应用,其特征在于:所述待编辑基因为OsSBEIIb和OsPDS;所述sgRNA的核苷酸序列为序列1第7785-8268位或序列2第7785-8268位或序列3第7785-8268位。
- 一种定点编辑植物或农作物基因的方法,为如下(1)或(2):(1)所述方法包括如下步骤:将Cas9核酸酶编码基因、脱氨酶编码基因、待编辑基因的sgRNA的编码基因和植物基因启动子导入出发植物,实现出发植物中靶基因的定点编辑;(2)所述方法包括如下步骤:将Cas9核酸酶编码基因、脱氨酶编码 基因、连接所述Cas9核酸酶与所述脱氨酶的连接肽的编码基因、尿嘧啶DNA糖基化酶抑制蛋白的编码基因、待编辑基因的sgRNA的编码基因和植物基因启动子导入出发植物,实现出发植物中靶基因的定点编辑。
- 根据权利要求12所述的方法,其特征在于:(1)中,所述Cas9核酸酶编码基因、所述脱氨酶编码基因、所述待编辑基因的sgRNA的编码基因和所述植物基因启动子通过重组质粒导入出发植物中;所述重组质粒包括由Cas9核酸酶和脱氨酶组成融合蛋白的编码基因、所述待编辑基因的sgRNA的编码基因和植物基因启动子;所述植物基因启动子驱动由所述Cas9核酸酶和所述脱氨酶组成的融合蛋白基因的表达;(2)中,所述Cas9核酸酶编码基因、所述脱氨酶编码基因、所述连接所述Cas9核酸酶与所述脱氨酶的连接肽的编码基因、所述尿嘧啶DNA糖基化酶抑制蛋白基因、所述待编辑基因的sgRNA的编码基因和所述植物基因启动子通过重组质粒导入出发植物中;所述重组质粒包括由Cas9核酸酶、脱氨酶、连接所述Cas9核酸酶与所述脱氨酶的连接肽和尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因、所述待编辑基因的sgRNA的编码基因和植物基因启动子;所述植物基因启动子驱动由所述Cas9核酸酶、所述脱氨酶、所述连接所述Cas9核酸酶与所述脱氨酶的连接肽和所述尿嘧啶DNA糖基化酶抑制蛋白组成的融合蛋白的编码基因的表达。
- 根据权利要求13所述的方法,其特征在于:所述脱氨酶为APOBEC1。
- 根据权利要求14所述的方法,其特征在于:所述APOBEC1的编码基因序列为序列1第4838-5524位。
- 根据权利要求13所述的方法,其特征在于:所述尿嘧啶DNA糖基化酶抑制蛋白为Uracil DNA glycosylase inhibitor。
- 根据权利要求16所述的方法,其特征在于:所述Uracil DNA glycosylase inhibitor的编码基因序列为序列1 第429-688位。
- 根据权利要求13所述的方法,其特征在于:所述Cas9核酸酶为nCas9。
- 根据权利要求18所述的方法,其特征在于:所述nCas9的编码基因序列为序列1第689-4789位。
- 根据权利要求13所述的方法,其特征在于:所述植物基因表达启动子为玉米Ubiquitin启动子。
- 根据权利要求20所述的方法,其特征在于:所述玉米Ubiquitin启动子的核苷酸序列为序列1第5545-7535位。
- 根据权利要求13所述的方法,其特征在于:所述连接肽的编码基因序列为序列1第4790-4837位;所述融合蛋白的编码基因序列为序列1第392-5524位。
- 根据权利要求13所述的方法,其特征在于:所述待编辑基因为OsSBEIIb和OsPDS;所述sgRNA的核苷酸序列为序列1第7785-8268位或序列2第7785-8268位或序列3第7785-8268位。
- 根据权利要求13所述的方法,其特征在于:所述重组质粒的核苷酸序列为序列1、序列2或序列3。
- 根据权利要求12-24中任一所述的方法,其特征在于:所述植物为单子叶植物或双子叶植物。
- 根据权利要求25所述的方法,其特征在于:所述单子叶植物为水稻。
- 权利要求13中所述的重组质粒。
- 一种定点编辑植物基因组的系统,包括权利要求13中所述的重组质粒。
- 权利要求27所述的重组质粒或权利要求28所述的系统在定点编辑植物或农作物基因中的应用。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201611091107 | 2016-12-01 | ||
| CN201611091107.7 | 2016-12-01 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018099256A1 true WO2018099256A1 (zh) | 2018-06-07 |
Family
ID=59545361
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2017/110349 WO2018099256A1 (zh) | 2016-12-01 | 2017-11-10 | 一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN107043779B (zh) |
| WO (1) | WO2018099256A1 (zh) |
Cited By (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10323236B2 (en) | 2011-07-22 | 2019-06-18 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| US10465176B2 (en) | 2013-12-12 | 2019-11-05 | President And Fellows Of Harvard College | Cas variants for gene editing |
| US10508298B2 (en) | 2013-08-09 | 2019-12-17 | President And Fellows Of Harvard College | Methods for identifying a target site of a CAS9 nuclease |
| CN110878305A (zh) * | 2019-12-09 | 2020-03-13 | 安徽省农业科学院水稻研究所 | 一种高效的宽窗口单碱基编辑基因及其应用和育种方法 |
| US10597679B2 (en) | 2013-09-06 | 2020-03-24 | President And Fellows Of Harvard College | Switchable Cas9 nucleases and uses thereof |
| US10682410B2 (en) | 2013-09-06 | 2020-06-16 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US10704062B2 (en) | 2014-07-30 | 2020-07-07 | President And Fellows Of Harvard College | CAS9 proteins including ligand-dependent inteins |
| US10745677B2 (en) | 2016-12-23 | 2020-08-18 | President And Fellows Of Harvard College | Editing of CCR5 receptor gene to protect against HIV infection |
| US10858639B2 (en) | 2013-09-06 | 2020-12-08 | President And Fellows Of Harvard College | CAS9 variants and uses thereof |
| CN112239756A (zh) * | 2019-07-01 | 2021-01-19 | 科稷达隆生物技术有限公司 | 一组来源于植物的胞嘧啶脱氨酶和其在碱基编辑系统中的应用 |
| US10947530B2 (en) | 2016-08-03 | 2021-03-16 | President And Fellows Of Harvard College | Adenosine nucleobase editors and uses thereof |
| US11046948B2 (en) | 2013-08-22 | 2021-06-29 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| US11214780B2 (en) | 2015-10-23 | 2022-01-04 | President And Fellows Of Harvard College | Nucleobase editors and uses thereof |
| US11268082B2 (en) | 2017-03-23 | 2022-03-08 | President And Fellows Of Harvard College | Nucleobase editors comprising nucleic acid programmable DNA binding proteins |
| CN114317518A (zh) * | 2020-09-30 | 2022-04-12 | 北京市农林科学院 | SpRYn-CBE碱基编辑系统在植物基因组碱基替换中的应用 |
| CN114317590A (zh) * | 2020-09-30 | 2022-04-12 | 北京市农林科学院 | 一种将植物基因组中的碱基c突变为碱基t的方法 |
| US11306324B2 (en) | 2016-10-14 | 2022-04-19 | President And Fellows Of Harvard College | AAV delivery of nucleobase editors |
| US11319532B2 (en) | 2017-08-30 | 2022-05-03 | President And Fellows Of Harvard College | High efficiency base editors comprising Gam |
| US11447770B1 (en) | 2019-03-19 | 2022-09-20 | The Broad Institute, Inc. | Methods and compositions for prime editing nucleotide sequences |
| US11542509B2 (en) | 2016-08-24 | 2023-01-03 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| US11542496B2 (en) | 2017-03-10 | 2023-01-03 | President And Fellows Of Harvard College | Cytosine to guanine base editor |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| US11661590B2 (en) | 2016-08-09 | 2023-05-30 | President And Fellows Of Harvard College | Programmable CAS9-recombinase fusion proteins and uses thereof |
| US11732274B2 (en) | 2017-07-28 | 2023-08-22 | President And Fellows Of Harvard College | Methods and compositions for evolving base editors using phage-assisted continuous evolution (PACE) |
| US11795443B2 (en) | 2017-10-16 | 2023-10-24 | The Broad Institute, Inc. | Uses of adenosine base editors |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| US11912985B2 (en) | 2020-05-08 | 2024-02-27 | The Broad Institute, Inc. | Methods and compositions for simultaneous editing of both strands of a target double-stranded nucleotide sequence |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AR110075A1 (es) * | 2016-11-14 | 2019-02-20 | Inst Genetics & Developmental Biology Cas | Un método para edición basal en plantas |
| CN107043779B (zh) * | 2016-12-01 | 2020-05-12 | 中国农业科学院作物科学研究所 | 一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 |
| CN109295053B (zh) * | 2017-07-25 | 2023-12-22 | 中国科学院上海营养与健康研究所 | 通过诱导剪接位点碱基突变或多聚嘧啶区碱基置换调控rna剪接的方法 |
| CN109321584B (zh) * | 2017-12-27 | 2021-07-16 | 华东师范大学 | 一种简单定性/定量检测单碱基基因编辑技术工作效率的报告系统 |
| AU2019266327A1 (en) * | 2018-05-11 | 2020-11-26 | Beam Therapeutics Inc. | Methods of editing single nucleotide polymorphism using programmable base editor systems |
| CN110835634B (zh) * | 2018-08-15 | 2022-07-26 | 华东师范大学 | 一种新型碱基转换编辑系统及其应用 |
| CN110835632B (zh) * | 2018-08-15 | 2022-01-11 | 华东师范大学 | 新型碱基转换编辑系统用于基因治疗的应用 |
| CN110835629B (zh) * | 2018-08-15 | 2022-07-26 | 华东师范大学 | 一种新型碱基转换编辑系统的构建方法及其应用 |
| CN114045303B (zh) * | 2018-11-07 | 2023-08-29 | 中国农业科学院植物保护研究所 | 一套用于水稻的人工基因编辑系统 |
| CN113473845A (zh) * | 2018-12-04 | 2021-10-01 | 先正达农作物保护股份公司 | 经由基因组编辑进行基因沉默 |
| CN109593781B (zh) * | 2018-12-20 | 2021-02-23 | 华中农业大学 | 陆地棉基因组的精准高效编辑方法 |
| CN109652439A (zh) * | 2018-12-27 | 2019-04-19 | 宜春学院 | 利用CRISPR/Cas9介导的腺嘌呤碱基编辑系统改良水稻稻瘟病广谱抗性的方法 |
| CN109652440A (zh) * | 2018-12-28 | 2019-04-19 | 北京市农林科学院 | VQRn-Cas9&PmCDA1&UGI碱基编辑系统在植物基因编辑中的应用 |
| CN109666693B (zh) * | 2018-12-29 | 2022-08-16 | 北京市农林科学院 | Mg132在碱基编辑系统编辑受体基因组中的应用 |
| CN117264998A (zh) * | 2019-07-10 | 2023-12-22 | 苏州齐禾生科生物科技有限公司 | 双功能基因组编辑系统及其用途 |
| US20220380749A1 (en) * | 2019-08-20 | 2022-12-01 | Tianjin Institute Of Industrial Biotechnology, Chinese Academy Of Sciences | Base editing systems for achieving c to a and c to g base mutation and application thereof |
| CN112779265B (zh) * | 2019-11-11 | 2022-11-08 | 中国科学院遗传与发育生物学研究所 | 一种对植物特定基因进行饱和碱基编辑的育种方法 |
| BR112022017704A2 (pt) * | 2020-03-04 | 2022-11-01 | Suzhou Qi Biodesign Biotechnology Company Ltd | Método e sistema de edição de genoma multiplex |
| CN112538492B (zh) * | 2020-12-14 | 2022-10-11 | 安徽省农业科学院水稻研究所 | 一种识别PAM序列为NRTH的SpCas9n变体及相应碱基编辑系统 |
| CN116262927B (zh) * | 2021-12-13 | 2024-04-26 | 中国科学院微生物研究所 | 基于CRISPR/Cas系统调控基因表达的方法及其应用 |
| CN114591977B (zh) * | 2022-02-28 | 2023-05-16 | 中国农业科学院作物科学研究所 | 通过精准编辑内源epsps基因获得抗草甘膦水稻的方法及其所用系统 |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014186686A2 (en) * | 2013-05-17 | 2014-11-20 | Two Blades Foundation | Targeted mutagenesis and genome engineering in plants using rna-guided cas nucleases |
| WO2015133554A1 (ja) * | 2014-03-05 | 2015-09-11 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換するゲノム配列の改変方法及びそれに用いる分子複合体 |
| CN105934516A (zh) * | 2013-12-12 | 2016-09-07 | 哈佛大学的校长及成员们 | 用于基因编辑的cas变体 |
| WO2017070632A2 (en) * | 2015-10-23 | 2017-04-27 | President And Fellows Of Harvard College | Nucleobase editors and uses thereof |
| CN106609282A (zh) * | 2016-12-02 | 2017-05-03 | 中国科学院上海生命科学研究院 | 一种用于植物基因组定点碱基替换的载体 |
| WO2017090761A1 (ja) * | 2015-11-27 | 2017-06-01 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換する、単子葉植物のゲノム配列の変換方法、及びそれに用いる分子複合体 |
| CN106834341A (zh) * | 2016-12-30 | 2017-06-13 | 中国农业大学 | 一种基因定点突变载体及其构建方法和应用 |
| CN107043779A (zh) * | 2016-12-01 | 2017-08-15 | 中国农业科学院作物科学研究所 | 一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 |
-
2017
- 2017-02-23 CN CN201710098892.7A patent/CN107043779B/zh active Active
- 2017-11-10 WO PCT/CN2017/110349 patent/WO2018099256A1/zh active Application Filing
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014186686A2 (en) * | 2013-05-17 | 2014-11-20 | Two Blades Foundation | Targeted mutagenesis and genome engineering in plants using rna-guided cas nucleases |
| CN105934516A (zh) * | 2013-12-12 | 2016-09-07 | 哈佛大学的校长及成员们 | 用于基因编辑的cas变体 |
| WO2015133554A1 (ja) * | 2014-03-05 | 2015-09-11 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換するゲノム配列の改変方法及びそれに用いる分子複合体 |
| WO2017070632A2 (en) * | 2015-10-23 | 2017-04-27 | President And Fellows Of Harvard College | Nucleobase editors and uses thereof |
| WO2017090761A1 (ja) * | 2015-11-27 | 2017-06-01 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換する、単子葉植物のゲノム配列の変換方法、及びそれに用いる分子複合体 |
| CN107043779A (zh) * | 2016-12-01 | 2017-08-15 | 中国农业科学院作物科学研究所 | 一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 |
| CN106609282A (zh) * | 2016-12-02 | 2017-05-03 | 中国科学院上海生命科学研究院 | 一种用于植物基因组定点碱基替换的载体 |
| CN106834341A (zh) * | 2016-12-30 | 2017-06-13 | 中国农业大学 | 一种基因定点突变载体及其构建方法和应用 |
Non-Patent Citations (1)
| Title |
|---|
| PLOSKY, B. S.: "CRISPR-Mediated Base Editing without DNA Double-Strand Breaks", MOLECULAR CELL, 19 May 2016 (2016-05-19), XP029552452 * |
Cited By (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12006520B2 (en) | 2011-07-22 | 2024-06-11 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| US10323236B2 (en) | 2011-07-22 | 2019-06-18 | President And Fellows Of Harvard College | Evaluation and improvement of nuclease cleavage specificity |
| US11920181B2 (en) | 2013-08-09 | 2024-03-05 | President And Fellows Of Harvard College | Nuclease profiling system |
| US10954548B2 (en) | 2013-08-09 | 2021-03-23 | President And Fellows Of Harvard College | Nuclease profiling system |
| US10508298B2 (en) | 2013-08-09 | 2019-12-17 | President And Fellows Of Harvard College | Methods for identifying a target site of a CAS9 nuclease |
| US11046948B2 (en) | 2013-08-22 | 2021-06-29 | President And Fellows Of Harvard College | Engineered transcription activator-like effector (TALE) domains and uses thereof |
| US10682410B2 (en) | 2013-09-06 | 2020-06-16 | President And Fellows Of Harvard College | Delivery system for functional nucleases |
| US11299755B2 (en) | 2013-09-06 | 2022-04-12 | President And Fellows Of Harvard College | Switchable CAS9 nucleases and uses thereof |
| US10858639B2 (en) | 2013-09-06 | 2020-12-08 | President And Fellows Of Harvard College | CAS9 variants and uses thereof |
| US10912833B2 (en) | 2013-09-06 | 2021-02-09 | President And Fellows Of Harvard College | Delivery of negatively charged proteins using cationic lipids |
| US10597679B2 (en) | 2013-09-06 | 2020-03-24 | President And Fellows Of Harvard College | Switchable Cas9 nucleases and uses thereof |
| US11124782B2 (en) | 2013-12-12 | 2021-09-21 | President And Fellows Of Harvard College | Cas variants for gene editing |
| US11053481B2 (en) | 2013-12-12 | 2021-07-06 | President And Fellows Of Harvard College | Fusions of Cas9 domains and nucleic acid-editing domains |
| US10465176B2 (en) | 2013-12-12 | 2019-11-05 | President And Fellows Of Harvard College | Cas variants for gene editing |
| US11578343B2 (en) | 2014-07-30 | 2023-02-14 | President And Fellows Of Harvard College | CAS9 proteins including ligand-dependent inteins |
| US10704062B2 (en) | 2014-07-30 | 2020-07-07 | President And Fellows Of Harvard College | CAS9 proteins including ligand-dependent inteins |
| US11214780B2 (en) | 2015-10-23 | 2022-01-04 | President And Fellows Of Harvard College | Nucleobase editors and uses thereof |
| US12043852B2 (en) | 2015-10-23 | 2024-07-23 | President And Fellows Of Harvard College | Evolved Cas9 proteins for gene editing |
| US10947530B2 (en) | 2016-08-03 | 2021-03-16 | President And Fellows Of Harvard College | Adenosine nucleobase editors and uses thereof |
| US11999947B2 (en) | 2016-08-03 | 2024-06-04 | President And Fellows Of Harvard College | Adenosine nucleobase editors and uses thereof |
| US11702651B2 (en) | 2016-08-03 | 2023-07-18 | President And Fellows Of Harvard College | Adenosine nucleobase editors and uses thereof |
| US11661590B2 (en) | 2016-08-09 | 2023-05-30 | President And Fellows Of Harvard College | Programmable CAS9-recombinase fusion proteins and uses thereof |
| US11542509B2 (en) | 2016-08-24 | 2023-01-03 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| US12084663B2 (en) | 2016-08-24 | 2024-09-10 | President And Fellows Of Harvard College | Incorporation of unnatural amino acids into proteins using base editing |
| US11306324B2 (en) | 2016-10-14 | 2022-04-19 | President And Fellows Of Harvard College | AAV delivery of nucleobase editors |
| US11820969B2 (en) | 2016-12-23 | 2023-11-21 | President And Fellows Of Harvard College | Editing of CCR2 receptor gene to protect against HIV infection |
| US10745677B2 (en) | 2016-12-23 | 2020-08-18 | President And Fellows Of Harvard College | Editing of CCR5 receptor gene to protect against HIV infection |
| US11898179B2 (en) | 2017-03-09 | 2024-02-13 | President And Fellows Of Harvard College | Suppression of pain by gene editing |
| US11542496B2 (en) | 2017-03-10 | 2023-01-03 | President And Fellows Of Harvard College | Cytosine to guanine base editor |
| US11268082B2 (en) | 2017-03-23 | 2022-03-08 | President And Fellows Of Harvard College | Nucleobase editors comprising nucleic acid programmable DNA binding proteins |
| US11560566B2 (en) | 2017-05-12 | 2023-01-24 | President And Fellows Of Harvard College | Aptazyme-embedded guide RNAs for use with CRISPR-Cas9 in genome editing and transcriptional activation |
| US11732274B2 (en) | 2017-07-28 | 2023-08-22 | President And Fellows Of Harvard College | Methods and compositions for evolving base editors using phage-assisted continuous evolution (PACE) |
| US11319532B2 (en) | 2017-08-30 | 2022-05-03 | President And Fellows Of Harvard College | High efficiency base editors comprising Gam |
| US11932884B2 (en) | 2017-08-30 | 2024-03-19 | President And Fellows Of Harvard College | High efficiency base editors comprising Gam |
| US11795443B2 (en) | 2017-10-16 | 2023-10-24 | The Broad Institute, Inc. | Uses of adenosine base editors |
| US11795452B2 (en) | 2019-03-19 | 2023-10-24 | The Broad Institute, Inc. | Methods and compositions for prime editing nucleotide sequences |
| US11447770B1 (en) | 2019-03-19 | 2022-09-20 | The Broad Institute, Inc. | Methods and compositions for prime editing nucleotide sequences |
| US11643652B2 (en) | 2019-03-19 | 2023-05-09 | The Broad Institute, Inc. | Methods and compositions for prime editing nucleotide sequences |
| CN112239756B (zh) * | 2019-07-01 | 2022-04-19 | 科稷达隆(北京)生物技术有限公司 | 一组来源于植物的胞嘧啶脱氨酶和其在碱基编辑系统中的应用 |
| CN112239756A (zh) * | 2019-07-01 | 2021-01-19 | 科稷达隆生物技术有限公司 | 一组来源于植物的胞嘧啶脱氨酶和其在碱基编辑系统中的应用 |
| CN110878305B (zh) * | 2019-12-09 | 2022-04-12 | 安徽省农业科学院水稻研究所 | 一种宽窗口单碱基编辑基因及其应用和育种方法 |
| CN110878305A (zh) * | 2019-12-09 | 2020-03-13 | 安徽省农业科学院水稻研究所 | 一种高效的宽窗口单碱基编辑基因及其应用和育种方法 |
| US11912985B2 (en) | 2020-05-08 | 2024-02-27 | The Broad Institute, Inc. | Methods and compositions for simultaneous editing of both strands of a target double-stranded nucleotide sequence |
| US12031126B2 (en) | 2020-05-08 | 2024-07-09 | The Broad Institute, Inc. | Methods and compositions for simultaneous editing of both strands of a target double-stranded nucleotide sequence |
| CN114317518A (zh) * | 2020-09-30 | 2022-04-12 | 北京市农林科学院 | SpRYn-CBE碱基编辑系统在植物基因组碱基替换中的应用 |
| CN114317590B (zh) * | 2020-09-30 | 2024-01-16 | 北京市农林科学院 | 一种将植物基因组中的碱基c突变为碱基t的方法 |
| CN114317518B (zh) * | 2020-09-30 | 2024-01-12 | 北京市农林科学院 | SpRYn-CBE碱基编辑系统在植物基因组碱基替换中的应用 |
| CN114317590A (zh) * | 2020-09-30 | 2022-04-12 | 北京市农林科学院 | 一种将植物基因组中的碱基c突变为碱基t的方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN107043779B (zh) | 2020-05-12 |
| CN107043779A (zh) | 2017-08-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2018099256A1 (zh) | 一种CRISPR/nCas9介导的定点碱基替换在植物中的应用 | |
| CN107988229B (zh) | 一种利用CRISPR-Cas修饰OsTAC1基因获得分蘖改变的水稻的方法 | |
| CN108795972B (zh) | 不使用转基因标记序列分离细胞的方法 | |
| Svitashev et al. | Targeted mutagenesis, precise gene editing, and site-specific gene insertion in maize using Cas9 and guide RNA | |
| CN104846010B (zh) | 一种删除转基因水稻筛选标记基因的方法 | |
| CN107267524B (zh) | 用于基因打靶和性状堆叠的工程化转基因整合平台(etip) | |
| Gurushidze et al. | True-breeding targeted gene knock-out in barley using designer TALE-nuclease in haploid cells | |
| CN109652422B (zh) | 高效的单碱基编辑系统OsSpCas9-eCDA及其应用 | |
| CN107012164A (zh) | CRISPR/Cpf1植物基因组定向修饰功能单元、包含该功能单元的载体及其应用 | |
| Shimatani et al. | Inheritance of co-edited genes by CRISPR-based targeted nucleotide substitutions in rice | |
| Lin et al. | Genome editing in plants with MAD7 nuclease | |
| TW201424578A (zh) | 用來產生植物之螢光激活細胞分選富增技術 | |
| WO2018098935A1 (zh) | 一种用于植物基因组定点碱基替换的载体 | |
| Hsu et al. | Application of Cas12a and nCas9-activation-induced cytidine deaminase for genome editing and as a non-sexual strategy to generate homozygous/multiplex edited plants in the allotetraploid genome of tobacco | |
| CN108034671B (zh) | 一种质粒载体及利用其建立植物群体的方法 | |
| CN113801891B (zh) | 甜菜BvCENH3基因单倍体诱导系的构建方法与应用 | |
| Li et al. | TALEN utilization in rice genome modifications | |
| Char et al. | CRISPR/Cas9 for mutagenesis in rice | |
| Rather et al. | Advances in protoplast transfection promote efficient CRISPR/Cas9-mediated genome editing in tetraploid potato | |
| WO2019014917A1 (zh) | 一种基因编辑系统及应用其对植物基因组进行编辑的方法 | |
| CN116732070A (zh) | 一种能够实现碱基颠换的cgbe单碱基编辑器及其应用 | |
| WO2017197588A1 (zh) | 抗草甘膦基因筛选方法、epsps突变基因和缺陷型菌株及应用 | |
| CN112522299A (zh) | 一种利用OsTNC1基因突变获得分蘖增加的水稻的方法 | |
| CN115216488A (zh) | 创制水稻大长粒型新种质或大长粒型矮杆新种质的方法及其应用 | |
| JP2022549430A (ja) | Dna塩基編集のための方法及び組成物 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17877094 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 17877094 Country of ref document: EP Kind code of ref document: A1 |