WO2018015995A1 - 長鎖一本鎖dnaを調製する方法 - Google Patents
長鎖一本鎖dnaを調製する方法 Download PDFInfo
- Publication number
- WO2018015995A1 WO2018015995A1 PCT/JP2016/071138 JP2016071138W WO2018015995A1 WO 2018015995 A1 WO2018015995 A1 WO 2018015995A1 JP 2016071138 W JP2016071138 W JP 2016071138W WO 2018015995 A1 WO2018015995 A1 WO 2018015995A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- recognition site
- dna
- strand
- stranded dna
- nicking endonuclease
- Prior art date
Links
Images














Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1003—Extracting or separating nucleic acids from biological samples, e.g. pure separation or isolation methods; Conditions, buffers or apparatuses therefor
- C12N15/1006—Extracting or separating nucleic acids from biological samples, e.g. pure separation or isolation methods; Conditions, buffers or apparatuses therefor by means of a solid support carrier, e.g. particles, polymers
- C12N15/101—Extracting or separating nucleic acids from biological samples, e.g. pure separation or isolation methods; Conditions, buffers or apparatuses therefor by means of a solid support carrier, e.g. particles, polymers by chromatography, e.g. electrophoresis, ion-exchange, reverse phase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/64—General methods for preparing the vector, for introducing it into the cell or for selecting the vector-containing host
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/686—Polymerase chain reaction [PCR]
Definitions
- the present invention relates to a method for preparing a long single-stranded DNA. Specifically, the present invention relates to a method for preparing a long single-stranded DNA by cleaving the recognition site using a vector having a nicking endonuclease recognition site or a target DNA strand.
- Single-stranded DNA is used in many molecular biological experiments such as DNA sequence, SNP analysis, DNA chip, SSCP analysis SELEX.
- Several methods are used for the preparation, and four types of methods are known.
- the first is chemical synthesis. In recent years, chemical synthesis methods for DNA have been improved, and single-stranded DNA can be produced at low cost (Non-patent Document 1).
- the second is a method using ⁇ exonuclease, in which phosphoric acid is introduced only at the 5 ′ end of one strand by PCR reaction using phosphorylated DNA oligomer, and only one strand phosphorylated by ⁇ exonuclease is used.
- Non-patent Document 2 By decomposing, the other single-stranded DNA remaining without being decomposed can be obtained (Non-patent Document 2).
- the third is a technique using biotin, in which biotin is introduced into only one strand by PCR reaction using a biotinylated DNA oligomer, and after alkali denaturation, only the target strand can be recovered with avidin-coated magnetic beads (non-contained) Patent Document 3).
- the fourth is a technique using RNA. After obtaining single-stranded DNA using reverse transcriptase using RNA as a starting material, single-stranded DNA can be obtained by degrading RNA with RNase (non-patented). Reference 4).
- Non-Patent Document 1 the length of bases that can be synthesized is limited to about 200 bases (Non-Patent Document 1), and this length is the entire length of a gene having a general size. It is too short to encode (around 1,000 bases) (Non-patent Document 5).
- Chemical synthesis is known to have a very high error rate, and the error rate of prokaryotic and eukaryotic replication mechanisms is 10 ⁇ 7 to 10 ⁇ 8.
- the error rate of the artificial gene is 10 ⁇ 2 to 10 ⁇ 3 (Non-patent Document 6).
- the target single strand accompanying the PCR is performed. Mutation is introduced into DNA, ⁇ exonuclease side reaction causes degradation of the target single-stranded DNA, and ⁇ exonuclease reaction is not completed, and double-stranded DNA remains. (Non-Patent Document 2).
- Non-patent Document 4 In recent years, with the development of genome editing technology, there is an increasing demand for long single-stranded DNA that cannot be obtained by the above-described method (Non-patent Document 4).
- CRISPR-CAS or TALEN is used to destroy a specific position on a genome or a specific gene (knockout), or even ssODN
- a donor By using (single-strand oligodeoxynucleotide) as a donor, accurate modification and introduction (knock ⁇ ⁇ in) in a small region such as base substitution and SNP mutation is performed.
- a larger region that is, to introduce an entire specific gene, or to introduce an entire gene such as GFP or Cre recombinase for functional analysis.
- Non-Patent Document 5 when knocking in the target DNA by genome editing, it is pointed out that double-stranded DNA is incorporated into a place other than the target position on the genome if double-stranded DNA is mixed.
- the introduction efficiency is about 10% to 20% at the highest, and when using a fertilized egg, it takes 1 to 2 months to obtain an individual. . Moreover, since it deals with an individual rather than a cell, it takes extra time. Therefore, if a high percentage of mutations or deletions have occurred in the single-stranded DNA that should serve as the basis for genome editing using fertilized eggs, a large amount of labor will be expended to obtain accurate knockin individuals. It will end up.
- the present invention has been made in view of such a situation, and is used extensively in molecular biological experiments by using a nicking endonuclease recognition site when preparing a long single-stranded DNA, It is an object of the present invention to provide a method for preparing an accurate long single-stranded DNA that is also desired in the field of genome editing.
- the present inventors examined whether a target long-chain single-stranded DNA can be prepared based on double-stranded DNA.
- double-stranded DNA was denatured or separated by introducing a nick into the vector in which double-stranded DNA having the desired single-stranded DNA was cloned, using nicking endonuclease. It was found that a long single-stranded DNA can be prepared.
- a method for preparing a long single-stranded DNA comprising: (1) (a) at least one nicking endonuclease at each end of the cloning site.
- a method for preparing a long-stranded single-stranded DNA comprising: (1) (a) an object having at least one nicking endonuclease recognition site at each end; A DNA strand that is cleaved by the nicking endonuclease that recognizes the nicking endonuclease recognition site, or (b) at least one nicking endonuclease recognition site at one end and at least at the other end A step of cloning a target DNA strand having one sequence-specific double-strand break endonuclease recognition site into a vector; and (2) the target DNA strand of (a) was cloned by the nicking endonuclease.
- a single-stranded DNA having a uniform length of up to several thousand bases without any mutation or terminal deletion, having an accurate sequence, and without mixing double-stranded DNA. can be provided.
- the target DNA strand is preferably 200 bases or more.
- the target DNA strand has at least 300 bases, at least 400 bases, at least 500 bases, at least 600 bases, at least 700 bases, at least 800 bases, at least 900 bases, or At least 1000 bases.
- the arbitrary separation means is gel electrophoresis.
- gel electrophoresis includes non-denaturing agarose gel electrophoresis without denaturing agent, denaturing agarose gel electrophoresis with denaturing agent, non-denaturing acrylamide gel electrophoresis without denaturing agent, or denaturing acrylamide with denaturing agent. Gel electrophoresis is preferred.
- the optional separation means is gel column chromatography.
- the gel column chromatography is preferably gel filtration column chromatography, ion exchange gel column chromatography, or affinity gel column chromatography.
- the number of bases of the nicking endonuclease recognition site is at least 3 bases. According to another embodiment of the present invention, the number of bases of the nicking endonuclease recognition site is preferably 3, 4, 5, 6, or 7 bases.
- the nicking endonuclease includes Nb. BbvCI, Nb. BsmI, Nb. BtsI, Nb. BsrDI, Nt. BspQI, Nt. BbvCI, Nt. AlwI, Nt. BsmAI, Nt. BstNBI, Nt. CviPII, Nb. Mva 1269I, Nt. Bpu10I, or Nb. BssSI is preferred.
- a guide RNA can be bound to the nicking endonuclease recognition site.
- the nicking endonuclease is preferably a Cas10 D10A mutant.
- the sequence-specific double-strand break endonuclease recognition site is an enzyme selected from the group consisting of a restriction enzyme and a meganuclease, or a TALEN recognition site. Can do.
- the meganuclease is preferably I-CeuI, I-SceI, PI-PspI, or PI-SceI.
- guide RNA or guide DNA can be bound to the sequence-specific double-strand break endonuclease recognition site.
- the sequence-specific double-strand break endonuclease is preferably Cas9 or Argonaut.
- the denaturing agent is formamide, glycerol, urea, thiourea, ethylene glycol, or sodium hydroxide.
- the denaturing agent is preferably formamide or glycerol.
- kits for use in the method of the first or second main aspect of the present invention described above (a) at least one each at both ends of the cloning site.
- at least one vector selected from vectors having at least one sequence-specific double-strand break endonuclease recognition site at the other end of the cloning site (a) at least one each at both ends of the cloning site.
- kits further comprising a reagent containing a denaturing agent for denaturing DNA.
- kits for use in the method according to the second main aspect of the present invention which has a vector that does not contain a nicking endonuclease recognition site. Is done.
- kits further comprising a reagent containing a denaturing agent for denaturing DNA.
- FIG. 1 is a conceptual schematic diagram of a method according to an embodiment of the present invention.
- FIG. 2 shows a plasmid map (FIG. 2A) of a vector used in the method according to an embodiment of the present invention, a multi-cloning site (FIG. 2B) in the vector, and an enzyme used for cloning to obtain single-stranded DNA.
- FIG. 2C is a schematic diagram showing the combination (FIG. 2C) and the entire sequence (FIG. 2D, sequence ID number 1).
- FIG. 3 shows the sequence of a target DNA fragment derived from ⁇ phage DNA (1,500 bp, SEQ ID NO: 2) used in the method according to one embodiment of the present invention.
- FIG. 1 is a conceptual schematic diagram of a method according to an embodiment of the present invention.
- FIG. 2 shows a plasmid map (FIG. 2A) of a vector used in the method according to an embodiment of the present invention, a multi-cloning site (FIG
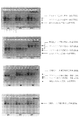
- FIG. 4 shows the result of electrophoresis obtained using the method according to one embodiment of the present invention.
- Formamide is added to the pLSODN-1 (1.5 kb fragment) plasmid introduced with two nicks, heat-denatured, and electrophoresed on a 1.2% non-denaturing agarose gel using 1 ⁇ TAE buffer as the electrophoresis solution did.
- Lane 1 was loaded with 10 ⁇ g and Lane 2 with 5 ⁇ g of plasmid.
- FIG. 5 shows the result of electrophoresis obtained using the method according to one embodiment of the present invention.
- FIG. 6 shows a plasmid map (FIG. 6A) of the cloning vector pETUK (del) used in the method according to one embodiment of the present invention (FIG. 6A), the sequence of the multiple cloning site (FIG. 6B), and the entire sequence (FIG. 6C, SEQ ID NO. 3) is shown.
- FIG. 7 shows the entire sequence of the GFP gene (720 bases, SEQ ID NO: 4).
- FIG. 8 shows the result of electrophoresis obtained using the method according to one embodiment of the present invention.
- Formamide was added to the pETUK (GFP-Tyr) plasmid into which two nicks were introduced, and after heat denaturation, electrophoresis was similarly carried out on a 4 M urea agarose gel of 1.0% concentration using the 4 M urea 1 ⁇ TAE buffer as an electrophoresis solution.
- Lane 1 is DynaMarker DNA High
- lane 2 is pETUK (GFP-Tyr) not treated with endonuclease
- lane 3 is pETUK (GFP-Tyr) treated with endonuclease.
- FIG. 9 shows the results of electrophoresis of purified long-stranded single-stranded DNA (759 bases, 100 ng) of the GFP gene obtained by using the method according to one embodiment of the present invention.
- FIG. 10 shows the result of electrophoresis on a non-denaturing gel of a plasmid into which two nicks were introduced when various denaturants were used in one embodiment of the present invention.
- the method for preparing a long single-stranded DNA includes a nicking endonuclease recognition site, or a nicking endonuclease recognition site and a sequence-specific double-strand cleavage endonuclease recognition site.
- the target DNA is cloned using the vector it contains, cleaved with an appropriate enzyme, electrophoresed, and then the desired long single-stranded DNA is prepared by cutting out a gel containing the desired single-stranded DNA. To do.
- the method for preparing a long single-stranded DNA has a nicking endonuclease recognition site, or a nicking endonuclease recognition site and a sequence-specific double-strand cleavage endonuclease recognition site.
- the target DNA is cloned into a cloning vector, cleaved with an appropriate enzyme, electrophoresed, and then a gel containing the target single-stranded DNA is cut out to obtain the target long-stranded single-stranded DNA. adjust.
- the problems of the above-mentioned four conventional methods for preparing single-stranded DNA can be summarized as follows: (1) difficulty in obtaining long single-stranded DNA, (2) sequence such as internal mutation and terminal deletion Problems of accuracy and size heterogeneity, (3) problems of double-stranded DNA contamination, and (4) problems of complicated operation steps. According to the method according to the present invention, it can be easily understood that all are superior to the conventional methods as follows.
- nicking endonuclease or three types having different molecular weights depending on nicking endonuclease and sequence-specific double-strand cleavage endonuclease
- the target long-stranded single-stranded DNA can be prepared by generating a DNA molecule of ⁇ RTIgt;, ⁇ / RTI> followed by denaturation or separation.
- the size of the target long single-stranded DNA is preferably about half that of the vector. That is, the target long single-stranded DNA flows to the tip of the gel during electrophoresis, and a sufficient distance from other DNA molecules can be obtained so that only the target band can be cut out. Even if there is such a length restriction, for example, when a vector of about 12,000 bases is used, a single-stranded DNA having a length of about 6,000 to 7,000 bases can be prepared.
- Such a length of single-stranded DNA is a length that cannot be obtained by the above-described conventional method, and is a length sufficient as a sequence encoding one structural gene.
- a cosmid vector (30 kbp to 45 kbp), a BAC vector (up to 300 kbp), or a YAC vector (several Mbp)
- a larger long single-stranded DNA can be obtained by the method according to the present invention. Can be prepared.
- the error rate of the biological replication mechanism is about 10 ⁇ 7 to 10 ⁇ 8 and is negligibly small for normal use of single-stranded DNA (Non-patent Document 6).
- single-stranded DNA prepared by the method according to the present invention is prepared by a sequence-specific double-strand cleavage endonuclease such as a restriction enzyme with high base recognition accuracy or a nicking endonuclease derived from a restriction enzyme. Therefore, mutations and terminal heterogeneity are negligible for ordinary experiments.
- the size of the target single-stranded DNA is about half that of the vector during electrophoresis, and If the molecular weight of the target single-stranded DNA is adjusted so that the single-stranded DNA flows to the tip of the gel and electrophoresis is performed so that the target single-stranded DNA and other DNA are sufficiently separated, Contamination of the double stranded DNA does not occur.
- the method according to the present invention uses a very simple principle. Therefore, according to the present invention, as long as it is cloned into a vector, nicking is possible.
- the steps from endonuclease cleavage to electrophoresis and band excision extraction can be completed in half a day or at most one day.
- FIG. 1 is a schematic diagram showing a series of flows of a method according to an embodiment of the present invention.
- a vector DNA having a nicking endonuclease recognition site in a direction capable of cutting the same strand side is arranged with a target DNA to be a long single-stranded DNA, and the nicking endonuclease recognition sites are arranged at both ends thereof.
- the nicking endonuclease recognition site and the sequence-specific double-strand cleavage endonuclease recognition site are respectively cloned at both ends.
- the vector DNA may have recognition sites for a plurality of nicking endonucleases or sequence-specific double-strand cleavage endonucleases at both ends of the cloning site.
- the recognition sites for the nicking endonuclease or the sequence-specific double-strand break endonuclease can be provided at both ends of the target DNA to be cloned instead of the vector DNA.
- the vector in which the target DNA is cloned is cleaved using the nicking endonuclease of the vector DNA or the target DNA, or the nicking endonuclease and the sequence-specific double-strand cleavage endonuclease. .
- the vector in which the target DNA is cloned is cleaved using the nicking endonuclease of the vector DNA or the target DNA, or the nicking endonuclease and the sequence-specific double-strand cleavage endonuclease. .
- three single-stranded DNAs having different molecular weights are generated.
- two linear sequences and one circular sequence were generated, and nicking endonuclease and sequence-specific double-strand cleavage endonuclease were used. In some cases, three linear sequences will be produced.
- Examples of “appropriate treatment” include heat treatment, incubation, and standing still overnight. If three single-stranded DNAs having different molecular weights are denatured or separated by a denaturant, these may be used. It is not limited. After separating three single-stranded DNAs having different molecular weights in this way, the target single-stranded DNA can be prepared by cutting out and extracting the gel piece containing the band of the desired single-stranded DNA. (FIG. 1D). As is clear from FIG.
- the target single-stranded DNA when three single-stranded DNAs having different molecular weights are generated according to the present invention, the target single-stranded DNA always has the smallest molecular weight, so that the gel is cut out after electrophoresis. Cut out the band that has flowed to the bottom.
- the “nicking endonuclease” is an endonuclease having nicking activity, which recognizes a specific nucleotide sequence and cleaves only one strand of a double-stranded nucleic acid having the nucleotide sequence. Say what you can. This nicking endonuclease cleaves the phosphodiester bond of one strand of double-stranded DNA. Many endonucleases exhibiting such activity are known together with their recognition sequences, and those skilled in the art can appropriately select from these endonucleases and use them in the present invention. In the present specification, the nicking endonuclease is sometimes referred to as “nicking enzyme” or “nickase”.
- the number of recognition sites of the nicking endonuclease is at least 3 bases, and may be 4 bases, 5 bases, 6 bases, or 7 bases.
- Examples of such endonucleases include Nb. BbvCI (recognition site base number 7: 5′-GC / TGAGG-3 ′), Nb. BsmI (base number of recognition site 6: 5′-NG / CATTC-3 ′), Nb. BtsI (recognition site base number 6: 5′-NN / CACTGC-3 ′), Nb. BsrDI (recognition site base number 6: 5′-NN / CATTGC-3 ′), Nt.
- BspQI (recognition site base number 7: 5'-GCTCTTCN / -3 '), Nt.
- BbvCI (recognition site base number 7: 5′-CC / TCAGC-3 ′), Nt. AlwI (recognition site base number 5: 5′-GGATCNNNN / N-3 ′), Nt.
- BsmAI (recognition site base number 5: 5′-GTCTCN / N-3 ′), Nt.
- BstNBI base number of recognition site 5: 5′-GAGTCNNNN / N-3 ′
- CviPII (base number of recognition site 3: 5 '-/ CCD-3'), Nb.
- Mva1269I base number of recognition site 6: 5′-G / CATTC-3 ′
- Nt. Bpu10I recognition site base number 7: 5'-CC / TNAGC-3 '
- Nb. BsSI recognition site base number 6: 5'-C / TCGTG-3 '
- “/” indicates a cleavage site
- N indicates any nucleotide of A, T, G, or C
- D indicates any nucleotide of A, T, or G, respectively.
- CAS910D10A nickase has been developed by introducing D10A mutation into CAS9 protein used for genome editing as a new artificial nicking endonuclease (Ran FA, Hsu PD, Lin CY, Gootenberg JS, Konermann S, Trevino AE, Scott DA, Inoue A, Matoba S, Zhang Y, Zhang F. (2013) Double nicking by RNA-guided CRISPR Cas9 for enhanced genome editing specificity. Cell. 12; 154 (6): 1380-9.).
- such artificially produced nickase can also be used.
- the characteristics of the CAS9 D10A mutant which cuts only one strand and inserts a nick without cutting the DNA double strand, Double-stranded DNA can be prepared.
- a guide RNA having a sequence complementary to the base sequence can be bound to the “nicking endonuclease recognition site”.
- the complex of the guide RNA and CAS9 D10A mutant recognizes one strand of the double-stranded DNA via the guide RNA and nicks it.
- the length of the guide RNA recognition sequence is at least 5 bases, preferably about 20 bases.
- the “sequence-specific double-strand cleavage endonuclease” may be any one that can recognize a specific DNA sequence and cleave the double-strand.
- a protein having endonuclease activity can be used.
- disconnection aspect may produce
- the “sequence-specific double-strand break endonuclease” includes various restriction enzymes and meganucleases such as I-CeuI, I-SceI, PI-PspI, or PI-SceI.
- TALEN transcription activator-like effector nuclease
- FokI restriction enzyme
- a restriction enzyme as a DNA cleavage domain
- TALE restriction enzyme
- sequence-specific double-strand break endonuclease a protein that has only DNA cleavage ability and functions with other molecules having DNA binding ability can also be used.
- CAS9 protein Jinek M1, Chylinski K, Fonfara I, Hauer M, Doudna JA, Charpentier E. (2012) A programmable dual-RNA-guided DNA endonuclease in adaptive bacterialcience bacterial enceity.
- the length of the guide RNA or guide DNA recognition sequence is at least 5 bases, preferably about 20 bases.
- the nicking endonuclease as described above or a combination of nicking endonuclease and sequence-specific double-strand cleavage endonuclease is used to cleave the vector in which the DNA strand of interest is cloned, and the molecular weight At least three different types of single-stranded DNA can be produced.
- the recognition site for the nicking endonuclease or the sequence-specific double-strand break endonuclease may be present on either the vector side or the target DNA side.
- target DNA strand”, “target single-stranded DNA”, or “long single-stranded DNA” refers to a sequence having at least 200 bases.
- the “target DNA strand”, “target single strand DNA”, or “long single strand DNA” is at least 300 bases, at least 400 bases, at least 500 bases, At least 600 bases, at least 700 bases, at least 800 bases, at least 900 bases, at least 1,000 bases, at least 1,500 bases, at least 2,000 bases, at least 2,500 bases, at least 3,000 bases, at least 3,500 Base, at least 4,000 base, at least 4,500 base, at least 5,000 base, at least 5,500 base, at least 6,000 base, at least 6,500 base, at least 7,000 base, at least 7,500 base, At least 8,000 bases, less Even 8,500 bases, at least 9,000 bases, at least 9,500 bases can be at least 10,000 bases.
- arbitrary separation means means that at least three types of single-stranded DNAs having different molecular weights are denatured, and then the denatured at least three types of single-stranded DNAs are converted into individual single-stranded DNAs.
- optional separation means include, but are not limited to, gel electrophoresis and gel column chromatography.
- gel electrophoresis may or may not contain a denaturant in the gel or buffer.
- gel electrophoresis used in one embodiment of the present invention includes non-denaturing agarose gel electrophoresis without denaturing agents, denaturing agarose gel electrophoresis with denaturing agents, and non-denaturing acrylamide gel electrophoresis without denaturing agents.
- modified acrylamide gel electrophoresis containing a denaturing agent but is not limited thereto.
- double-stranded DNA having a size of several thousand bases is heat-denatured by adding a physical denaturant that lowers Tm, so that it becomes a single-stranded DNA state.
- the DNA can be electrophoresed while being maintained in a single-stranded state simply by separation and loading onto a normal non-denaturing gel.
- double-stranded DNA of 4,751 bases is used.
- the present inventors have confirmed that even when 9,547-base double-stranded DNA is used, the prepared single-stranded DNA can be electrophoresed in a single-stranded state. .
- the concentration of the plasmid loaded on the electrophoresis gel is as high as 1 ⁇ g / ⁇ l, it can be denatured into single strands and can be separated with sufficient resolution by the difference in molecular weight.
- gel column chromatography when gel column chromatography is used as “arbitrary separation means”, any gel column chromatography can be used.
- gel column chromatography used in one embodiment of the present invention includes, but is not limited to, gel filtration column chromatography, ion exchange gel column chromatography, or affinity gel column chromatography.
- the “denaturing agent” refers to a reagent having an action of cleaving a hydrogen bond of double-stranded DNA by a physical or chemical action and causing it to dissociate into a single strand.
- a sample obtained by treating a vector using a nicking endonuclease or a combination of a nicking endonuclease and a sequence-specific double-strand break endonuclease is nicked. However, it is not separated into complete single-stranded DNA. Therefore, a denaturing agent is added to the nicked vector in order to separate the three types of single-stranded DNA having different molecular weights.
- the physical denaturing agent includes, for example, formamide, glycerol, urea, or the like that lowers the polarity of the solvent and weakens hydrophobic interactions such as stacking of the base portion of the nucleic acid, or base deprotonation.
- examples include, but are not limited to, sodium hydroxide, which is an alkaline reagent that induces inhibition of hydrogen bond formation by crystallization.
- examples of the chemical denaturing agent include formaldehyde and glyoxal that form a Schiff base with a nucleic acid, but are not limited thereto.
- thiourea, ethylene glycol, or the like can be used as a denaturing agent in electrophoresis.
- RNA in the case of electrophoresis of long RNA, after denaturation with a physical denaturant such as formamide, the denaturation state is covalently immobilized with a chemical denaturant such as formaldehyde or glyoxal, Similarly, electrophoresis is performed in an agarose gel containing formaldehyde. That is, in order to maintain a denatured state, it is necessary to expose RNA to a chemical denaturing agent not only in the loading buffer but also in the gel.
- a non-denaturing gel it is preferable to perform gel electrophoresis using
- the single-stranded DNA in the well of the electrophoresis gel leaves the physical denaturing agent contained in the loading buffer when electrophoresis is started.
- the present inventors have discovered that single-stranded DNA after entering a non-denaturing gel does not reanneal with complementary strands as easily as previously thought. That is, the present inventors have obtained the knowledge that the denatured single-stranded DNA is stably electrophoresed as a single strand even in a non-denaturing gel.
- the present inventors also migrated single-stranded DNA electrophoresed in a non-denaturing gel based on the molecular weight, and the resolution is necessary for the use of the present invention for the preparation of single-stranded DNA.
- the knowledge that it is enough is acquired. That is, single-stranded DNA in the gel is not a stable structure, as is the case with double-stranded DNA and RNA that has been denatured by a chemical denaturant, so it forms a secondary structure in the gel. It should be. Therefore, although a simple and accurate proportional relationship between the mobility of electrophoresis and the logarithmic value of molecular weight (log 10 M) does not hold, the present invention does not analyze a subtle difference in molecular weight. Such precise mathematical relationships are not necessary.
- the kit for carrying out the method according to an embodiment of the present invention includes (a) a vector having at least one nicking endonuclease recognition site at both ends of the cloning site, and the nicking endonuclease recognition site. And (b) at least one nicking endonuclease recognition site at one end of the cloning site and at least one sequence-specific duplex at the other end of the cloning site. At least one vector selected from vectors having a cleavage endonuclease recognition site is included.
- the cloned two-dimensional DNA that is the origin of the target single-stranded DNA may or may not have a nicking endonuclease recognition site.
- a recognition site for a nicking endonuclease or a sequence-specific double-strand cleavage endonuclease is provided at both ends of the target DNA to be cloned instead of the vector DNA.
- the vector included in the kit is preferably one that does not contain a nicking endonuclease recognition site.
- the above-described kit may contain a denaturing agent for denaturing DNA.
- Example 1 the cloning procedure of the target DNA using a cloning vector in which a nicking endonuclease recognition site is arranged at the multicloning site is used.
- Example 2 the digestion procedure of the vector in which the target DNA is cloned by nicking endonuclease ( In FIG. 1B), in Example 3, a vector obtained by cloning the target DNA treated with nicking endonuclease was heat denatured with a denaturing agent, and subjected to agarose gel electrophoresis under non-denaturing conditions to extract the target long single-stranded DNA.
- the procedure (FIGS. 1C and 1D) until purification is shown.
- Example 4 shows an example in which a long single-stranded DNA containing the entire GFP gene was prepared using a vector in which the nicking endonuclease recognition site was removed from the entire region.
- Example 5 shows the effect of denaturation of pLSODN-1 (1.5 Kb fragment) plasmid introduced with two nicks with various denaturants.
- Example 1 Cloning of target DNA into cloning vector
- a 1.5 kb DNA fragment derived from ⁇ phage ( ⁇ phage DNA 38,951-40,450, FIG. 3) was used as a model DNA fragment for preparing long single-stranded DNA. It was.
- pLSODN-1 As a cloning vector, pLSODN-1 in which a plurality of nicking endonuclease recognition sites were arranged at a multicloning site was used.
- 2A shows the plasmid map of the cloning vector pLSODN-1
- FIG. 2B shows the sequence of the multicloning site
- FIG. 2C shows the combination of enzymes used for cloning to obtain single-stranded DNA
- the site indicated by the box is a nicking endonuclease site, and the nick introduction position is indicated by an arrow.
- four types of Nb-type nicking endonuclease sites and one type of Nt-type nicking endonuclease site are arranged in the center so as to face each other so that the DNA strands on the same side can be cleaved.
- a 6-base or 8-base recognition restriction enzyme site that produces a 5 ′ overhang sticky end is located upstream of the Nb type nicking enzyme site, and a 3 ′ overhang sticky end is located downstream of the Nt type nicking enzyme site.
- a 6-base recognition restriction enzyme site is generated.
- the target DNA fragment for obtaining long single-stranded DNA is either between two nicking enzyme sites of Nb type and Nt type (circle numeral 1, center diagram) or Nt type. Between the nicking enzyme site and the 6-base recognition restriction enzyme site that produces a 5 'overhang sticky end (circled number 2, left figure), the restriction of 6 base recognition that produces a sticky end of the Nb type nicking enzyme and 3' overhang Cloning was performed between the enzyme sites (circled number 3, right figure).
- two nicking endonuclease sites, Nb.BsrDI and Nt.BspQI were used.
- the cloning vector pLSODN-1 was subjected to PCR using two synthetic DNA oligomers having the sequences shown below to obtain a linear cloning vector pLSODN-1.
- the underlined portion in the following sequence is a homology sequence with the target DNA introduced for cloning the target DNA into a vector.
- the above-mentioned two synthetic DNA oligomers were added to 400 ng of the cloning vector pLSODN-1, 80 pmol each, 1 ⁇ GXL buffer (Takara Bio Inc.), 5 units PrimeSTAR GXL DNA polymerase (Takara Bio Inc.), respectively.
- PCR was performed in a total of 400 ⁇ l of a reaction solution to which 80 nmol of dATP, dGTP, dTTP, and dCTP was added.
- the reaction temperature and time are first 95 ° C for 1 minute, then 95 ° C for 1 minute, 55 ° C for 1 minute, 72 ° C for 6 minutes in this order 16 times each, and finally 72 ° C for 10 minutes. .
- This PCR reaction was donated to 0.8% agarose gel electrophoresis containing 1.6 ⁇ g / ml Crystal® Violet. After electrophoresis, a 3.2 kb DNA band stained blue was excised with a razor, purified with Qiaquick Gel Extraction Kit (Qiagen), dissolved in 50 ⁇ l of 10 mM Tris-HCl (pH 8.0), It was stored as a linear cloning vector pLSODN-1.
- target DNA for obtaining long single-stranded DNA was obtained from ⁇ phage DNA by performing PCR using two synthetic DNA oligomers having the sequences shown below.
- the underlined portion in the following sequence is a homology sequence with the vector introduced for cloning the target DNA into the vector.
- the sequence of the target DNA derived from ⁇ phage DNA is shown in FIG.
- the above-mentioned two synthetic DNA oligomers are each 80 pmol, 1 ⁇ GXL buffer (Takara Bio Inc.), 5 units PrimeSTAR GXL DNA polymerase (Takara Bio Inc.) in 400 ng ⁇ phage DNA (Promega).
- PCR was performed in a total of 400 ⁇ l of a reaction solution to which 80 nmol of dATP, dGTP, dTTP, and dCTP were added.
- the reaction temperature and time are 95 ° C for 1 minute, then 95 ° C for 1 minute, 55 ° C for 1 minute, 72 ° C for 3 minutes in this order 16 times each, and finally 72 ° C for 10 minutes. .
- This PCR reaction was donated to 0.8% agarose gel electrophoresis containing 1.6 ⁇ g / ml Crystal® Violet. After electrophoresis, a 1.5 kb DNA band stained blue was excised with a razor, purified with Qiaquick Gel Extraction Kit (Qiagen), dissolved in 50 ⁇ l of 10 mM Tris-HCl (pH 8.0), It was stored as the target DNA for obtaining long single-stranded DNA.
- Qiaquick Gel Extraction Kit Qiagen
- a linear cloning vector pLSODN-1 obtained by PCR amplification and a 1.5 kb target DNA derived from ⁇ phage DNA were used based on the homology sequence at the end introduced by the synthetic DNA oligomer used in the PCR reaction. Connected.
- the 40 ng linear cloning vector pLSODN-1 obtained by PCR amplification was similarly added to 75 ng of 1.5 kb target DNA derived from ⁇ phage DNA obtained by PCR amplification, 0.5 ⁇ l of 1 x Cloning EZ Buffer (Genescript) and 0.5 ⁇ l of Clone EZ Enzyme (Genescript) were added, respectively, in a total of 5 ⁇ l of reaction solution at 22 ° C. for 20 minutes, and then left on ice for 5 minutes. To complete the ligation reaction.
- a competent cell (Jet® Competent® Cell, Biodynamics Laboratories, Inc.) as follows. First, freeze frozen competent cells (25 ⁇ l) on ice and immediately thaw, then immediately add 1 ⁇ l of ligation solution to the competent cells, and after 5 minutes, 0.25 ml of room temperature Recovery Medium (included with JetJCompetent Cell) Moved the competent cell. Then, after leaving still for 5 minutes, the bacterial solution suspended in RecoveryumMedium was inoculated on an LB agar plate (diameter: 8.5 cm, agar medium amount: 25 ml) containing 50 mg / ml ampicillin. Keep warm for hours.
- a competent cell Jet® Competent® Cell, Biodynamics Laboratories, Inc.
- E. coli colonies formed on the LB agar plate by this culture were taken out, inoculated into 3 ml of LB liquid medium containing 50 mg / ml ampicillin, and cultured with shaking at 37 ° C. for 18 hours.
- a plasmid was prepared from the cells obtained by this shaking culture by Qiagen Plasmid Purification Kit (Qiagen).
- the plasmid obtained as described above was digested with BsrDI and BspQI, and a target DNA fragment derived from a 1.5 kb ⁇ phage was inserted by agarose gel electrophoresis analysis, and ABI PRISM Genetic Analyzer (Applied Biosystems Japan Co., Ltd.) By examining the nucleotide sequence by the company), a product having a sequence in which a DNA strand was correctly inserted between the BsrDI site and the BspQI site of the pLSODN-1 vector was selected. This selected plasmid was designated as pLSODN-1 (1.5 Kb fragment) plasmid.
- the plasmid pLSODN-1 (1.5 Kb fragment) prepared in Example 1 is digested with nicking endonuclease to obtain the above-mentioned plasmid having a circular double-stranded DNA structure.
- the nick was introduced by cleaving only the strands on both ends and one side of the 1.5 Kb fragment which is the target DNA derived from ⁇ phage.
- plasmid pLSODN-1 (1.5 Kb fragment) was added with 1 x 3.1 NEBuffer (New England Biolabs), 50 units of Nt.BspQI, and 50 units of Nb.BsrDI.
- the reaction was carried out in 50 ⁇ l of the reaction solution at 50 ° C. for 60 minutes and subsequently at 60 ° C. for 60 minutes. After the reaction, ethanol precipitation was performed as a desalting operation.
- a gel piece containing the target 1.5 kb single-stranded DNA band with the lowest molecular weight at the tip of the three appearing bands was cut out. Since it is at the tip, there is no possibility that other bands are mixed.
- the target 1.5 kb single-stranded DNA was extracted using QIAquick Gel Extraction Kit (Qiagen). The yield of the target 1.5 kb single-stranded DNA was about 30%.
- Purified 1.5 kb single-stranded DNA is subjected to non-denaturing agarose gel electrophoresis on an analytical scale in the same manner as described above, and has a high degree of purification without contamination of other bands. Was confirmed (FIG. 5).
- Example 4 Cloning of GFP gene into cloning vector pETUK (del)
- a vector pETUK (del) having no nicking enzyme recognition site at the multicloning site in addition to the vector backbone was used.
- a nicking endonuclease recognition site was introduced into both sides of the target DNA fragment by incorporating a nicking endonuclease recognition site into a synthetic DNA oligomer used when the vector and the target DNA fragment were amplified by PCR.
- a single-stranded DNA encoding the entire GFP gene was prepared.
- a homology arm consisting of 19 bases upstream and 20 bases downstream of the target site of knockin to the rat tyrosinase (Tyr) gene by genome editing is bound.
- a urea agarose gel which is a denaturing gel, was used for separation and preparation of single-stranded DNA.
- FIG. 6A shows the plasmid map of the cloning vector pETUK (del)
- FIG. 6B shows the sequence of the multicloning site
- FIG. 6C shows the entire base sequence.
- two nicking enzyme sites Nb.BsrDI and Nt.BspQI, were used for the preparation of a single long-chain DNA.
- the multicloning site of the vector itself does not have this nicking endonuclease site.
- linear cloning vector pETUK (del) was obtained by performing PCR using the cloning vector pETUK (del) as a template and two synthetic DNA oligomers having the sequences shown below.
- the underlined portion of the following sequence is a homology sequence with the target DNA introduced for cloning the target DNA into a vector.
- the sequence surrounded by a box is a recognition sequence for nicking endonucleases Nb.BsrDI and Nt.BspQI introduced on both sides of the target DNA.
- the 400 ng cloning vector pETUK80 (del) was mixed with the above two synthetic DNA oligomers at 80 pmol each, 1 ⁇ GXL buffer (Takara Bio Inc.), 5 units PrimeSTAR GXL DNA polymerase (Takara Bio Inc.), Each was added with 80 nmol of dATP, dGTP, dTTP, and dCTP, and PCR was performed in a total of 400 ⁇ l of the reaction solution.
- the reaction temperature and time are first 95 ° C for 1 minute, then 95 ° C for 1 minute, 55 ° C for 1 minute, 72 ° C for 6 minutes in this order 16 times each, and finally 72 ° C for 10 minutes. .
- This PCR reaction was donated to 0.8% agarose gel electrophoresis containing 1.6 ⁇ g / ml Crystal® Violet. After electrophoresis, a 2.67 kb DNA band stained in blue was excised with a razor, purified with Qiaquick Gel Extraction Kit (Qiagen), dissolved in 50 ⁇ l of 10 mM Tris-HCl (pH 8.0), It was stored as a linear cloning vector pETUK (del).
- the target GFP gene for obtaining long single-stranded DNA is subjected to PCR from pCMV-GFP-LC3 Expression Vector (Cell Biolabs. Inc) using two synthetic DNA oligomers having the sequences shown below. Obtained by.
- the underlined portion in the following sequence is a homology sequence with the vector side introduced for cloning the GFP gene into the vector.
- the GFP gene fragment is cloned between the BamHI site and NotI site of the multicloning site of the vector.
- the sequence of the GFP gene derived from pCMV-GFP-LC3 Expression Vector is shown in FIG. Moreover, the part enclosed with the box is the start codon and end codon of GFP protein, respectively.
- the above-mentioned two synthetic DNA oligomers are each 80 pmol, 1 ⁇ GXL buffer (Takara Bio Inc.), and 5 units of PrimeSTAR® GXL DNA Polymerase (Takara Bio Inc.) in 400 ng of pCMV-GFP-LC3® Expression® Vector.
- PCR was performed in a total of 400 ⁇ l of a reaction solution to which 80 nmol of dATP, dGTP, dTTP, and dCTP were added.
- the reaction temperature and time were first repeated at 95 ° C for 1 minute, then 95 ° C for 1 minute, 55 ° C for 1 minute, 72 ° C for 3 minutes in this order 16 times each, and finally at 72 ° C for 10 minutes. is there.
- This PCR reaction was donated to 0.8% agarose gel electrophoresis containing 1.6 ⁇ g / ml Crystal® Violet. After electrophoresis, the blue-stained 0.75 kb DNA band was excised with a razor, purified with Qiaquick Gel Extraction Kit (Qiagen), dissolved in 50 ⁇ l of 10 mM Tris-HCl (pH 8.0), It was stored as a whole GFP gene DNA fragment for obtaining single-stranded DNA.
- Qiaquick Gel Extraction Kit Qiagen
- linear cloning vector pETUK (del) fragment obtained by PCR amplification and the GFP gene entire region DNA fragment were ligated based on the homology sequence at the end introduced by the synthetic DNA oligomer used in the PCR reaction.
- a 40 ng linear cloning vector pETUK (del) obtained by PCR amplification was added to a 75 ng GFP gene obtained by PCR amplification in the same manner, 0.5 ⁇ l of 1 ⁇ xCloning EZ Buffer (Genescript) ), 0.5 ⁇ l of Clone EZ Enzyme (Genescript Co., Ltd.) was added, and the reaction was performed at 22 ° C. for 20 minutes in a total of 5 ⁇ l of the reaction solution, and then allowed to stand on ice for 5 minutes to complete the ligation reaction.
- a competent cell (Jet® Competent® Cell, Biodynamics Laboratories, Inc.) as follows. First, freeze frozen competent cells (25 ⁇ l) on ice and immediately thaw, then immediately add 1 ⁇ l of ligation solution to the competent cells, and after 5 minutes, 0.25 ml of room temperature Recovery Medium (included with JetJCompetent Cell) Moved the competent cell. Then, after leaving still for 5 minutes, the bacterial solution suspended in RecoveryumMedium was inoculated on an LB agar plate (diameter: 8.5 cm, agar medium amount: 25 ml) containing 50 mg / ml ampicillin. Keep warm for hours.
- a competent cell Jet® Competent® Cell, Biodynamics Laboratories, Inc.
- E. coli colonies formed on the LB agar plate by this culture were taken out, inoculated into 3 ml of LB liquid medium containing 50 mg / ml ampicillin, and cultured with shaking at 37 ° C. for 18 hours. Plasmids were prepared from the cells obtained by this shaking culture using Qiagen Plasmid Purification Kit (Qiagen).
- the plasmid obtained as described above was digested with BsrDI and BspQI, a GFP base DNA fragment of 759 bases was inserted by agarose gel electrophoresis analysis, and ABI PRISM Genetic Analyzer (Applied Biosystems Japan) The nucleotide sequence was examined, and a pETUK (del) vector having a sequence in which the GFP gene was correctly inserted with the BsrDI site and the BspQI site was selected. This selected plasmid was designated as pETUK (GFP-Tyr) plasmid.
- the pETUK (GFP-Tyr) plasmid was digested with two nicking endonucleases (Nb.BsrDI and Nt.BspQI), and nicks were introduced into only one strand at both ends of the GFP gene.
- 100 ⁇ g of plasmid pETUK (GFP-Tyr) was added with 1 x 3.1 NEBuffer (New England Biolabs), 50 units of Nt.BspQI, and 50 units of Nb.BsrDI, for a total reaction of 50 ⁇ l.
- the reaction was carried out at 50 ° C. for 60 minutes and then at 60 ° C. for 60 minutes. After the reaction, ethanol precipitation was performed as a desalting operation.
- PETUK (GFP-Tyr) that introduced two nicks that were desalted by removing the supernatant from the tube, applying the tube to a vacuum evaporator, drying, and adding 50 ⁇ l of sterilized water to change the buffer. A plasmid was obtained.
- the gel was removed from the apparatus, stained with ethidium bromide, and photographed under ultraviolet light (FIG. 8). Since it was confirmed that there was no problem in analytical electrophoresis, the remaining total amount was subjected to 4M urea agarose gel electrophoresis. After electrophoresis, it was stained with ethidium bromide, and the gel piece containing the band of the target 759-base GFP single-stranded DNA having the lowest molecular weight at the tip of the three appearing bands was cut out. Since it is at the tip, there is no possibility that other bands are mixed.
- the target 759-base GFP single-stranded DNA was extracted using QIAquick Gel Extraction Kit (Qiagen). The yield of the target 759-base GFP single-stranded DNA was about 30%.
- the purified 759 single-stranded DNA was electrophoresed on a 4M urea agarose gel in the same manner, and it was confirmed that there was no contamination with other bands and a high degree of purification (FIG. 9). .
- pLSODN-1 1.5 kb fragment
- pLSODN-1 1.5 kb fragment plasmid introduced with two nicks at various concentrations was mixed with various concentrations of formamide, glycerol, urea, or sucrose.
- pLSODN-1 1.5 kb fragment
- glycerol glycerol
- urea urea
- sucrose sucrose
- Formamide completely denatures the pLSODN-1 (1.5 kb fragment) plasmid introduced with two nicks at a concentration of 25% even at a high concentration of 1 ⁇ g / ⁇ l. Single stranded DNA was given. Glycerol was found to be capable of completely denaturing the plasmid at concentrations of 50% and higher. Urea was able to denature 0.25 ⁇ g / ⁇ l of plasmid at 6 M concentration, but was limited for plasmids at concentrations of 0.5 ⁇ g / ⁇ l or higher. Sucrose had no denaturing effect.
- the present invention can be variously modified, and is not limited to the above-described embodiment, and can be variously modified without changing the gist of the invention.
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Analytical Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Plant Pathology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Immunology (AREA)
- Crystallography & Structural Chemistry (AREA)
- Cell Biology (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
【課題】 内部の変異や末端の欠失を含まない正確な配列を有し、均一であり、かつ二本鎖DNAが混入しない長鎖一本鎖DNAを調製する方法を提供すること。 【解決手段】 ニッキングエンドヌクレアーゼ認識部位、またはニッキングエンドヌクレアーゼ認識部位および配列特異的二本鎖切断エンドヌクレアーゼ認識部位を有するベクターを用いて目的DNAをクローニングし、適切な酵素を用いて切断し、電気泳動し、その後、目的の一本鎖DNAを含むゲルを切り出すことにより、目的の長鎖一本鎖DNAを調整する。
Description
本発明は、長鎖の一本鎖DNAを調製する方法に関する。具体的には、本発明は、ニッキングエンドヌクレアーゼ認識部位を有するベクターまたは目的のDNA鎖を用いて、当該認識部位を切断することにより、長鎖の一本鎖DNAを調製する方法に関する。
一本鎖DNAは、DNAシークエンス、SNP解析、DNAチップ、SSCP分析SELEXなど、多くの分子生物学的実験に用いられている。その調製にはいくつかの手法が用いられており、大別して4種類の手法が知られている。1つ目は化学合成であり、近年、DNAの化学合成法が改善され、一本鎖のDNAも安価に作成できるようになっている(非特許文献1)。2つ目はλエキソヌクレアーゼを用いる手法であり、リン酸化DNAオリゴマーを用いたPCR反応によって一方の鎖の5’末端のみにリン酸を導入し、λエキソヌクレアーゼによって当該リン酸化した一方の鎖のみを分解することにより、分解されずに残ったもう一方の一本鎖DNAを取得できる(非特許文献2)。3つ目はビオチンを用いる手法であり、ビオチン化DNAオリゴマーを用いたPCR反応によって一方の鎖のみにビオチンを導入し、アルカリ変性した後、アビジン被覆磁性ビーズで目的の鎖のみを回収できる(非特許文献3)。4つ目はRNAを用いる手法であり、RNAを出発材料にして、逆転写酵素によって一本鎖DNAを取得した後、RNAをRNaseで分解することにより、一本鎖DNAを取得できる(非特許文献4)。
しかし、上述の各手法には、実際の分子生物学的実験に用いる際にいくつかの問題点があった。例えば、1つ目の化学合成を用いた場合には、合成可能な塩基の長さは200塩基程度が限界であり(非特許文献1)、この長さは、一般的な大きさの遺伝子全体(1,000塩基前後)をコードさせるには短すぎる(非特許文献5)。また、化学合成はエラー率が非常に高いことが知られており、原核生物や真核生物の複製機構のエラー率は10-7~10-8であるものの、化学合成で作成した典型的な人工遺伝子のエラー率は10-2~10-3である(非特許文献6)。この値から計算すると、生物が200塩基の2本鎖DNAを作った場合は、99.998%~99.9998%が正しい配列であるが、同じく200塩基の2本鎖DNAを化学合成オリゴマーから作成した場合には、正しい配列を持つものはわずか13.4%~81.9%しかない。また、この人工合成遺伝子のエラー率は、現在用いることのできる種々のエラー除去技術を駆使した上での結果であり、単純に200塩基の長鎖一本鎖DNAを化学合成した場合には、この数値よりも高いエラー率となってしまう(非特許文献6)。
また、2つ目のλエキソヌクレアーゼを用いる手法では、上記のとおり正確性の高いわけではない合成DNAオリゴマーを用いなくてはならないことに加えて、PCRを行うことに伴って目的の一本鎖DNAに変異が導入されてしまう、λエキソヌクレアーゼの副反応によって目的の一本鎖DNAも分解を受けてしまう、及びλエキソヌクレアーゼの反応が完結せずに2本鎖DNAが残存してしまうなどの問題がある(非特許文献2)。
3つ目のビオチンを用いる方法では、2つ目の手法と同様に、正確性の高いわけではない合成DNAオリゴマーを用いなくてはならないことに加えて、PCRを行うことに伴って目的の一本鎖DNAに変異が導入されてしまう可能性があり、また、アルカリ変性後のアビジン被覆磁性ビーズで目的の鎖のみを回収する際に、変性が十分ではなく2本鎖DNAが残存してしまうなどの問題がある(非特許文献3)。
4つ目のRNAを用いる手法でも、上記の手法と同様に、正確性の高いわけではない合成DNAオリゴマーを逆転写反応のプライマーとして用いなくてはならないことに加えて、逆転写酵素による逆転写反応の正確性は、Taq DNA ploymeraseを用いた場合の正確性と同程度であり、決して高いものではなく、変異が導入されてしまう可能性があり、また、その全体の工程は、転写によるRNAの取得、逆転写酵素によるcDNAの作出、及びRNaseによるRNAの分解となっており、複雑かつ煩雑な手順が必要となっており、その工程の途中において、逆転写反応が完結せずに途中で止まってしまったもの、すなわち5’末端に欠失を有するものができあがってしまい、正常なものと欠失を有するものとの混合物になるなどの問題があった(非特許文献4)。
Kosuri S, Church GM (2014) Large-scale de novo DNA synthesis: technologies and applications. Nat Methods. 11(5):499-507.
Wakimoto Y, Jiang J, Wakimoto H. (2014) Isolation of single-stranded DNA. Curr Protoc Mol Biol. 1;107:2.15.1-9.
Avci-Adali M, Paul A, Wilhelm N, Ziemer G, Wendel HP. (2009) Upgrading SELEX technology by using lambda exonuclease digestion for single-stranded DNA generation. Molecules. 24;15(1):1-11.
Miura H, Gurumurthy CB, Sato T, Sato M, Ohtsuka M. (2015) CRISPR/Cas9-based generation of knockdown mice by intronic insertion of artificial microRNA using longer single-stranded DNA. Sci Rep. 10.1038/srep12799.
Mashiko D1, Young SA, Muto M, Kato H, Nozawa K, Ogawa M, Noda T, Kim YJ, Satouh Y, Fujihara Y, Ikawa M. (2014) Feasibility for a large scale mouse mutagenesis by injecting CRISPR/Cas plasmid into zygotes. Dev Growth Differ. 56(1):122-9
Ma S, Saaem I, Tian J. (2012) Error correction in gene synthesis technology. Trends Biotechnol. 30(3):147-54.
ところで、近年、ゲノム編集技術の発展に伴い、上述の手法では取得できない長鎖の一本鎖DNAの需要が高まっている(非特許文献4)。例えば、ラットやマウスを含む動物の受精卵を用いたゲノム編集においては、CRISPR-CASまたはTALENを用いて、ゲノム上の特定の位置や特定の遺伝子を破壊(knock out)したり、さらにはssODN(single-strand oligodeoxynucleotide; 短鎖一本鎖DNA)をドナーとして用いることによって、塩基置換やSNP変異などの小さな領域における正確な改変や導入(knock in)が行われるようになっている。その一方で、より大きな領域の改変、すなわち特定の遺伝子全体を導入したり、機能解析のためのGFPやCreリコンビナーゼなどの遺伝子全体を導入したいといった要望も存在している。
受精卵を用いたゲノム編集の場合、細胞を用いたゲノム編集の場合のような薬剤による選択を行うことができないことから、効率よくゲノム編集を行うためには、knock in自体の効率を上げる必要がある。しかし、従来のssODNをドナーとして用いる方法は、確かに二本鎖DNAをドナーとして用いる方法に比べて導入効率が非常に高く、有用であるものの、上述のように200塩基以上の長さの一本鎖DNAを正確に作製することは技術的に困難であるため(非特許文献4)。そのため、仮に200塩基以上の長さの一本鎖DNAを作成できたとしても、二本鎖DNAが混入していたり、末端や内部に変異が導入されていたり、不均一なものであったりと、受精卵に導入するためには質的な問題を乗り越える必要があった。
また、ゲノム編集によって目的のDNAをknock inする場合、二本鎖DNAが混入していると、ゲノム上の目的箇所以外の場所への二本鎖DNAの組み込みが起こってしまうという問題が指摘されている(非特許文献5)。
さらに、ゲノム編集によって目的のDNAをknock inする場合、その導入効率は高くても10%~20%程度であり、受精卵を用いる場合には、個体を得るのに1ヶ月~2ヵ月を要する。また、細胞ではなく個体を扱うものであるため、手間も余計にかかってしまう。したがって、受精卵を用いたゲノム編集の基礎となるはずの一本鎖DNAに高い割合で変異や欠失が起きてしまっていては、正確なknock in個体を得るためには、大きな労力を費やしてしまうことになる。
そのため、正確な配列を有し、均一かつ二本鎖DNAが混入しない、長鎖一本鎖DNAを調製する方法が望まれていた。
本発明は、このような状況を鑑みてなされたものであり、長鎖一本鎖DNAを調製する際に、ニッキングエンドヌクレアーゼ認識部位を用いることにより、分子生物学的実験において多用され、また、ゲノム編集の分野でも望まれている正確な長鎖一本鎖DNAを調製する方法を提供することを目的とする。
本発明者らは、このような課題を解決するために、二本鎖DNAを元にして目的の長鎖一本鎖DNAを調製できるかどうかを検討した。そして鋭意研究を重ねた結果、目的の一本鎖DNAを有する二本鎖DNAをクローニングしたベクターに、ニッキングエンドヌクレアーゼを用いてニックを導入することにより、二本鎖DNAを変性ないし分離させて目的の長鎖一本鎖DNAを調製することができることを見出した。
具体的には、本発明の第一の主要な観点によれば、長鎖一本鎖DNAを調製する方法であって、(1)(a)クローニング部位の両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有するベクターであって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断されるベクター、または(b)クローニング部位の一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、前記クローニング部位の他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有するベクターに、目的のDNA鎖をクローニングする工程と、(2)前記ニッキングエンドヌクレアーゼによって、前記目的のDNA鎖がクローニングされた(a)のベクターを切断し、または前記ニッキングエンドヌクレアーゼ及び前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位を認識する配列特異的二本鎖切断エンドヌクレアーゼによって、前記目的のDNA鎖がクローニングされた(b)のベクターを切断し、分子量の異なる少なくとも3種類の一本鎖DNAを生成する工程と、(3)前記少なくとも3種類の一本鎖DNAに適当量の変性剤を添加して、前記一本鎖DNAを変性させる工程と、
(4)前記変性させた少なくとも3種類の一本鎖DNAを任意の分離手段によって分離させ、目的の一本鎖DNAを調製する工程とを有する、方法が提供される。
(4)前記変性させた少なくとも3種類の一本鎖DNAを任意の分離手段によって分離させ、目的の一本鎖DNAを調製する工程とを有する、方法が提供される。
また、本願発明の第二の主要な観点によれば、長鎖一本鎖DNAを調製する方法であって、(1)(a)両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有する目的のDNA鎖であって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断される目的のDNA鎖、または(b)一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有する目的のDNA鎖を、ベクターにクローニングする工程と、(2)前記ニッキングエンドヌクレアーゼによって、(a)の目的のDNA鎖がクローニングされたベクターを切断し、または前記ニッキングエンドヌクレアーゼ及び前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位を認識する配列特異的二本鎖切断エンドヌクレアーゼによって、(b)の目的のDNA鎖がクローニングされたベクターを切断し、分子量の異なる少なくとも3種類の一本鎖DNAを生成する工程と、(3)前記少なくとも3種類の一本鎖DNAに適当量の変性剤を添加して、前記一本鎖DNAを変性させる工程と、(4)前記変性させた少なくとも3種類の一本鎖DNAを任意の分離手段によって分離させ、目的の一本鎖DNAを調製する工程とを有する、方法が提供される。
このような構成によれば、変異や末端の欠失がなく、正確な配列を有し、二本鎖DNAを混入することなく、数千塩基までの均一の長さの形の一本鎖DNAを提供することができる。
また、本願発明の一実施形態によれば、上述の方法において、前記目的のDNA鎖が200塩基以上であることが好ましい。また、本発明の他の一実施形態によれば、前記目的のDNA鎖は、少なくとも300塩基、少なくとも400塩基、少なくとも500塩基、少なくとも600塩基、少なくとも700塩基、少なくとも800塩基、少なくとも900塩基、または少なくとも1000塩基である。
また、本願発明の別の一実施形態によれば、前記任意の分離手段はゲル電気泳動である。この場合、ゲル電気泳動としては、変性剤を含まない非変性アガロースゲル電気泳動、変性剤を含む変性アガロースゲル電気泳動、変性剤を含まない非変性アクリルアミドゲル電気泳動、または変性剤を含む変性アクリルアミドゲル電気泳動が好ましい。
さらに、本発明の別の一実施形態によれば、前記任意の分離手段はゲルカラムクロマトグラフィーである。この場合、本発明の一実施形態によれば、ゲルカラムクロマトグラフィーとしては、ゲル濾過カラムクロマトグラフィー、イオン交換ゲルカラムクロマトグラフィー、またはアフィニティーゲルカラムクロマトグラフィーが好ましい。
また、本発明の一実施形態によれば、前記ニッキングエンドヌクレアーゼ認識部位の塩基数は、少なくとも3塩基である。また、本発明の他の一実施形態によれば、前記ニッキングエンドヌクレアーゼ認識部位の塩基数は、3塩基、4塩基、5塩基、6塩基、または7塩基が好ましい。この場合、本発明の一実施形態によれば、ニッキングエンドヌクレアーゼとしては、Nb.BbvCI、Nb.BsmI、Nb.BtsI、Nb.BsrDI、Nt.BspQI、Nt.BbvCI、Nt.AlwI、Nt.BsmAI、Nt.BstNBI、Nt.CviPII、Nb.Mva1269I、Nt.Bpu10I、またはNb.BssSIが好ましい。
また、本発明の他の一実施形態によれば、前記ニッキングエンドヌクレアーゼ認識部位には、ガイドRNAが結合することができる。この場合、前記ニッキングエンドヌクレアーゼは、Cas9のD10A変異体であることが好ましい。
さらに、本発明の他の一実施形態によれば、前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位は、制限酵素およびメガヌクレアーゼからなる群から選択される酵素、またはTALENの認識部位とすることができる。この場合、前記メガヌクレアーゼは、I-CeuI、I-SceI、PI-PspI、またはPI-SceIであることが好ましい。
さらに、本発明の他の一実施形態によれば、前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位には、ガイドRNAまたはガイドDNAが結合することができる。この場合、
前記配列特異的二本鎖切断エンドヌクレアーゼは、Cas9またはArgonauteであることが好ましい。
前記配列特異的二本鎖切断エンドヌクレアーゼは、Cas9またはArgonauteであることが好ましい。
また、本発明の別の一実施形態によれば、前記変性剤は、ホルムアミド、グリセロール、ウレア、チオウレア、エチレングリコール、または水酸化ナトリウムである。また、この場合、前記変性剤は、ホルムアミドまたはグリセロールが好ましい。
また、本願発明の第三の主要な観点によれば、上述の本願発明の第一または第二の主要な観点の方法に用いるキットであって、(a)クローニング部位の両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有するベクターであって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断されるベクター、及び(b)クローニング部位の一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、前記クローニング部位の他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有するベクターから選択される少なくとも1つのベクターを有する、キットが提供される。
また、本願発明の一実施形態によれば、上述のキットであって、さらに、DNAの変性のための変性剤を含有する試薬を有する、キットが提供される。
さらに、本願発明の第四の主要な観点によれば、上述の本願発明の第二の主要な観点の方法に用いるキットであって、ニッキングエンドヌクレアーゼ認識部位を含まないベクターを有する、キットが提供される。
また、本願発明の別の一実施形態によれば、上述のキットであって、さらに、DNAの変性のための変性剤を含有する試薬を有する、キットが提供される。
なお、上記した以外の本発明の特徴及び顕著な作用・効果は、次の発明の実施形態の項及び図面を参照することで、当業者にとって明確となる。
以下に、本願発明に係る一実施形態および実施例を、図面を参照して説明する。
本願発明の一実施形態に係る長鎖一本鎖DNAを調製する方法は、上述したように、ニッキングエンドヌクレアーゼ認識部位、またはニッキングエンドヌクレアーゼ認識部位および配列特異的二本鎖切断エンドヌクレアーゼ認識部位を有するベクターを用いて目的DNAをクローニングし、適切な酵素を用いて切断し、電気泳動し、その後、目的の一本鎖DNAを含むゲルを切り出すことにより、目的の長鎖一本鎖DNAを調整する。
本願発明の一実施形態に係る長鎖一本鎖DNAを調製する方法は、上述したように、ニッキングエンドヌクレアーゼ認識部位、またはニッキングエンドヌクレアーゼ認識部位および配列特異的二本鎖切断エンドヌクレアーゼ認識部位を有するベクターを用いて目的DNAをクローニングし、適切な酵素を用いて切断し、電気泳動し、その後、目的の一本鎖DNAを含むゲルを切り出すことにより、目的の長鎖一本鎖DNAを調整する。
また、本願発明の他の一実施形態に係る長鎖一本鎖DNAを調製する方法では、ニッキングエンドヌクレアーゼ認識部位、またはニッキングエンドヌクレアーゼ認識部位および配列特異的二本鎖切断エンドヌクレアーゼ認識部位を有する目的DNAを用いて、クローニングベクターにクローニングし、適切な酵素を用いて切断し、電気泳動し、その後、目的の一本鎖DNAを含むゲルを切り出すことにより、目的の長鎖一本鎖DNAを調整する。
上述の従来の一本鎖DNA調製の4種類の手法の問題点を整理すると、(1)長鎖一本鎖DNAの取得の困難さの問題、(2)内部変異や末端の欠失など配列の正確性とサイズの不均一性の問題、(3)二本鎖DNAの混入の問題、(4)操作工程の煩雑さの問題、が挙げられる。本願発明に係る方法よれば、以下のように、いずれも従来の手法よりも優れたものであることが容易に理解できる。
まず、(1)の一本鎖DNAの長さの問題については、本願発明に係る方法では、ニッキングエンドヌクレアーゼ、またはニッキングエンドヌクレアーゼと配列特異的二本鎖切断エンドヌクレアーゼとにより分子量の異なる3種類のDNA分子を生成し、その後、変性ないし分離することよって、目的の長鎖一本鎖DNAの調製を可能にしている。そして、後述の問題(3)のとおり、本願発明に係る方法では、目的の長鎖一本鎖DNAに他のDNA分子が混入することを防ぐため、分離のためにゲル電気泳動を用いる場合、目的の長鎖一本鎖DNAの大きさは、ベクターの約半分程度の大きさとすることが好ましい。すなわち、目的の長鎖一本鎖DNAが電気泳動の際にゲルの先端まで流れ、他のDNA分子と十分な距離が得られるようにして、目的のバンドのみを切り出すことを可能にしている。このような長さの制約があったとしても、例えば1万2千塩基程度のベクターを使用する場合、6千~7千塩基程度の長さの一本鎖DNAを調製することができる。このような長さの一本鎖DNAは、上述の従来の方法では得られない長さであり、また1つの構造遺伝子をコードする配列として充分な長さである。また理論的には、コスミドベクター(30kbp~45kbp)、BACベクター(~300kbp)、またはYACベクター(数Mbp)を使用する場合には、本願発明に係る方法によって、より大きな長鎖一本鎖DNAを調製することができる。
次に、(2)の内部変異や末端の欠失の問題について、本願発明に係る方法によって調製される一本鎖DNAは、ベクターにクローニングされたDNA由来であるため、そのエラー率は、原核生物の複製機構のエラー率10-7~10-8と同程度であり、一本鎖DNAの通常の使用には無視できるほど小さい(非特許文献6)。また、本願発明に係る方法によって調製される一本鎖DNAが、塩基認識の正確性の高い制限酵素などの配列特異的二本鎖切断エンドヌクレアーゼや、制限酵素に由来するニッキングエンドヌクレアーゼによって調製されるものであるため、変異や末端の不均一性も通常の実験には無視できる範囲である。
また、(3)の二本鎖DNAの混入の問題については、本願発明に係る方法によれば、電気泳動に際して、目的の一本鎖DNAの大きさをベクターの半分程度の大きさとし、かつ目的の一本鎖DNAがゲルの先端まで流れるように目的の一本鎖DNAの分子量を調製し、目的の一本鎖DNAと他のDNAとが充分に分離するように電気泳動を行えば、二本鎖DNAの混入は起こらない。
そして、(4)の操作工程の煩雑さの問題については、本願発明に係る方法は非常に単純な原理を利用するものあるため、本願発明によれば、ベクターにクローニングさえされていれば、ニッキングエンドヌクレアーゼによる切断から電気泳動、バンドの切り出し抽出までを、半日、長くても一日で終えることができる。
本願発明の一実施形態に係る方法の一連の流れを示す模式図を図1に示した。まず、図1Aにおいて、同一鎖側を切断できる向きでニッキングエンドヌクレアーゼ認識部位を有するベクターDNAに、長鎖一本鎖DNAとなる目的のDNAを、その両端に前記ニッキングエンドヌクレアーゼ認識部位が配置されるようにクローニングし、または同一鎖側を切断できる向きでニッキングエンドヌクレアーゼ認識部位および配列特異的二本鎖切断エンドヌクレアーゼ認識部位を有するベクターDNAに、長鎖一本鎖DNAとなる目的のDNAを、その両端に前記ニッキングエンドヌクレアーゼ認識部位および配列特異的二本鎖切断エンドヌクレアーゼ認識部位がそれぞれ配置されるようにクローニングする。この際、ベクターDNAは、そのクローニング部位の両端に、複数のニッキングエンドヌクレアーゼまたは配列特異的二本鎖切断エンドヌクレアーゼの認識部位を有していてもよい。
また、本願発明の一実施形態において、ニッキングエンドヌクレアーゼまたは配列特異的二本鎖切断エンドヌクレアーゼの認識部位は、ベクターDNAの代わりに、クローニングされる目的のDNAの両端に備えるようにすることもできる。
続いて、図1Bにおいて、ベクターDNAまたは目的のDNAが有するニッキングエンドヌクレアーゼ、またはニッキングエンドヌクレアーゼ及び配列特異的二本鎖切断エンドヌクレアーゼを用いて、上述の目的のDNAがクローニングされたベクターを切断する。これにより、分子量の異なる3つの一本鎖DNAが生成される。なお、切断のための酵素としてニッキングエンドヌクレアーゼのみを用いた場合には2つの直鎖状配列および1つの環状配列が生成され、ニッキングエンドヌクレアーゼと配列特異的二本鎖切断エンドヌクレアーゼとを用いた場合には3つの直鎖状配列が生成されることになる。
ニッキングエンドヌクレアーゼや配列特異的二本鎖切断エンドヌクレアーゼを用いてベクターを切断しただけでは、その切断された配列は完全な一本鎖の状態になっているわけではなく、その相補鎖と水素結合によって結合している状態である。そのため、ニッキングエンドヌクレアーゼや配列特異的二本鎖切断エンドヌクレアーゼを用いてベクターを処理した後、上記のようにして得た試料に変性剤を加え、適当な処理を行い変性させて完全な一本鎖DNAの状態にさせる。そして、分子量の異なる3つの一本鎖DNAをアガロースゲル電気泳動に供し、分子量によって分離させる(図1C)。この際、「適当な処理」としては、熱処理、インキュベーション、オーバーナイトで静置などが挙げられるが、変性剤によって分子量の異なる3つの一本鎖DNAが変性ないし分離するものであれば、これらに限られるものではない。このようにして分子量の異なる3つの一本鎖DNAを分離させた後、目的の一本鎖DNAのバンドを含むゲル片を切り出し、抽出することによって目的の一本鎖DNAを調製することができる(図1D)。図1Bからも明らかなとおり、本願発明によって分子量の異なる3つの一本鎖DNAを生成すると、目的の一本鎖DNAは、必ず一番分子量の小さい配列となるため、電気泳動後のゲルの切り出しは、一番下まで流れてきたバンドを切り出せばよい。
本願発明において、「ニッキングエンドヌクレアーゼ」とは、ニッキング活性を有するエンドヌクレアーゼであって、特定のヌクレオチド配列を認識して、当該ヌクレオチド配列を有する二本鎖核酸のいずれか一方の鎖のみを切断することができるものをいう。このニッキングエンドヌクレアーゼにより、二本鎖DNAの一方の鎖のホスホジエステル結合が開裂する。このような活性を示す多くのエンドヌクレアーゼは、その認識配列とともに知られており、当業者であれば、これらのエンドヌクレアーゼの中から適宜選択して本願発明に使用することができる。なお、本願明細書では、ニッキングエンドヌクレアーゼを「ニッキング酵素」または「ニッカーゼ」と呼ぶことがあるが、いずれも同意である。
本願発明の一実施形態において、ニッキングエンドヌクレアーゼの認識部位の塩基数は、少なくとも3塩基であり、4塩基、5塩基、6塩基、7塩基であっても良い。このようなエンドヌクレアーゼとしては、例えば、Nb.BbvCI(認識部位の塩基数7:5'-GC/TGAGG-3')、Nb.BsmI(認識部位の塩基数6:5'-NG/CATTC-3')、Nb.BtsI(認識部位の塩基数6:5'-NN/CACTGC-3')、Nb.BsrDI(認識部位の塩基数6:5'-NN/CATTGC-3')、Nt.BspQI(認識部位の塩基数7:5'-GCTCTTCN/-3')、Nt.BbvCI(認識部位の塩基数7:5'-CC/TCAGC-3')、Nt.AlwI(認識部位の塩基数5:5'-GGATCNNNN/N-3')、Nt.BsmAI(認識部位の塩基数5:5'-GTCTCN/N-3')、Nt.BstNBI(認識部位の塩基数5:5'-GAGTCNNNN/N-3')、Nt.CviPII(認識部位の塩基数3:5'-/CCD-3')、Nb.Mva1269I(認識部位の塩基数6:5'-G/CATTC-3')、Nt.Bpu10I(認識部位の塩基数7:5'-CC/TNAGC-3')、及びNb.BssSI(認識部位の塩基数6:5'-C/TCGTG-3')が挙げられるが(括弧内に認識部位の塩基数、およびその配列を示した。)、これらの酵素に限られるものではない。ここで、「/」は切断箇所を、「N」はA、T、G、またはCのいずれかのヌクレオチドを、「D」はA、T、またはGのいずれかのヌクレオチドを、それぞれ示す。
また、近年、新たに人工的なニッキングエンドヌクレアーゼとしてゲノム編集に用いられるCAS9タンパク質にD10A変異を導入した、CAS9 D10Aニッカーゼが開発された(Ran FA, Hsu PD, Lin CY, Gootenberg JS, Konermann S, Trevino AE, Scott DA, Inoue A, Matoba S, Zhang Y, Zhang F.(2013)Double nicking by RNA-guided CRISPR Cas9 for enhanced genome editing specificity. Cell. 12;154(6):1380-9.)。本願発明の一実施形態においては、このような人工的に作製されたニッカーゼ(ニッキングエンドヌクレアーゼ)も用いることができる。
ニッキングエンドヌクレアーゼとしてCAS9のD10A変異型を用いる場合、DNA二本鎖を切断することなく、一本鎖のみを切断してニックを入れるというCAS9のD10A変異型の特性を利用して、目的の一本鎖DNAを調製できる。また、CAS9のD10A変異型を用いる場合、「ニッキングエンドヌクレアーゼ認識部位」には、その塩基配列と相補的な配列を有するガイドRNAが結合することができる。そして、ガイドRNAとCAS9のD10A変異型との複合体が、ガイドRNAを介して二本鎖DNAの一方の鎖を認識してニックを入れる。本願発明の一実施形態において、ガイドRNAの認識配列の長さは少なくとも5塩基であり、好ましくは約20塩基である。
また、本願発明において、「配列特異的二本鎖切断エンドヌクレアーゼ」とは、特定のDNAの配列を認識して二本鎖を切断させることができるものであれば良く、種々の既知の酵素や、エンドヌクレアーゼ活性を有するタンパク質を用いることができる。また、その切断の態様は、粘着末端および平滑末端のいずれを生成するものであっても良い。例えば、本願発明の一実施形態において、「配列特異的二本鎖切断エンドヌクレアーゼ」としては、種々の制限酵素や、I-CeuI、I-SceI、PI-PspI、またはPI-SceIなどのメガヌクレアーゼ、または制限酵素であるFokIをDNA切断ドメインとし、かつTALEタンパク質をDNA結合ドメインとして融合させた人工ヌクレアーゼであるTALEN(転写活性化因子様エフェクターヌクレアーゼ)(Cermak T1, Doyle EL, Christian M, Wang L, Zhang Y, Schmidt C, Baller JA, Somia NV, Bogdanove AJ, Voytas DF. (2011) Efficient design and assembly of custom TALEN and other TAL effector-based constructs for DNA targeting. Nucleic Acids Res. Jul;39(12):e82.)を用いることができ、これらに限られるものではない。
さらに、本願発明の一実施形態においては、「配列特異的二本鎖切断エンドヌクレアーゼ」として、DNA切断能のみを有し、DNA結合能を有する他の分子とともに機能するタンパク質を用いることもできる。例えば、DNA結合能をガイドRNAに依存するCAS9タンパク質(Jinek M1, Chylinski K, Fonfara I, Hauer M, Doudna JA, Charpentier E. (2012) A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science. 17;337(6096):816-21.)や、DNA結合能をガイドDNAに依存するArgonauteタンパク質(Gao F, Shen XZ, Jiang F, Wu Y, Han C (2016) DNA-guided genome editing using the Natronobacterium gregoryi Argonaute. Nat Biotechnol. 34(7):768-73.)なども用いることができるが、これらに限られるものではない。また、本願発明の一実施形態において、ガイドRNAまたはガイドDNAの認識配列の長さは少なくとも5塩基であり、好ましくは約20塩基である。
本願発明においては、上述のようなニッキングエンドヌクレアーゼを用いて、またはニッキングエンドヌクレアーゼ及び配列特異的二本鎖切断エンドヌクレアーゼの組み合せを用いて、目的のDNA鎖がクローニングされたベクターを切断し、分子量の異なる少なくとも3種類の一本鎖DNAを生成することができる。この際、ニッキングエンドヌクレアーゼまたは配列特異的二本鎖切断エンドヌクレアーゼの認識部位は、ベクター側、または目的のDNA側のいずれに存在していても良い。
本願発明の一実施形態において、「目的のDNA鎖」、「目的の一本鎖DNA」、または「長鎖一本鎖DNA」とは、少なくとも200塩基を有する配列をいう。また、本願発明の一実施形態において、「目的のDNA鎖」、「目的の一本鎖DNA」、または「長鎖一本鎖DNA」としては、少なくとも300塩基、少なくとも400塩基、少なくとも500塩基、少なくとも600塩基、少なくとも700塩基、少なくとも800塩基、少なくとも900塩基、少なくとも1,000塩基、少なくとも1,500塩基、少なくとも2,000塩基、少なくとも2,500塩基、少なくとも3,000塩基、少なくとも3,500塩基、少なくとも4,000塩基、少なくとも4,500塩基、少なくとも5,000塩基、少なくとも5,500塩基、少なくとも6,000塩基、少なくとも6,500塩基、少なくとも7,000塩基、少なくとも7,500塩基、少なくとも8,000塩基、少なくとも8,500塩基、少なくとも9,000塩基、少なくとも9,500塩基、少なくとも10,000塩基とすることができる。
本願発明において、「任意の分離手段」とは、分子量の異なる少なくとも3種類の一本鎖DNAを変性させた後に、当該変性した少なくとも3種類の一本鎖DNAを、個々の一本鎖DNAに分離し得る任意の手段を指す。例えば、任意の分離手段としては、ゲル電気泳動およびゲルカラムクロマトグラフィーが挙げられるが、これに限られるものではない。
また、本願発明の一実施形態において、ゲル電気泳動は、ゲルやバッファーに変性剤を含んでいても良く、また含まなくても良い。例えば、本願発明の一実施形態において用いられるゲル電気泳動としては、変性剤を含まない非変性アガロースゲル電気泳動、変性剤を含む変性アガロースゲル電気泳動、変性剤を含まない非変性アクリルアミドゲル電気泳動、または変性剤を含む変性アクリルアミドゲル電気泳動が挙げられるが、これに限られるものではない。
本願発明の一実施形態において、ゲル電気泳動を用いる場合、数千塩基もの大きさの二本鎖DNAに、Tmを低下させる物理的変性剤を加えて加熱変性させ、一本鎖DNAの状態に分離させ、通常の非変性ゲルにロードするだけで、DNAを一本鎖の状態に維持したまま電気泳動することができる。例えば、後述の実施例では、4,751塩基の二本鎖DNAを用いている。また、本発明者らは、9,547塩基の二本鎖DNAを用いた場合にも、調製された一本鎖DNAが、一本鎖の状態で電気泳動可能であることを確認している。この際、電気泳動ゲルにロードするプラスミドの濃度は、1μg/μlという高い濃度であっても、一本鎖に変性し、充分な解像度をもって、分子量の違いによって分離可能である。
本願発明の一実施形態において、「任意の分離手段」としてゲルカラムクロマトグラフィーを用いる場合、ゲルカラムクロマトグラフィーは、任意のものを使用することができる。例えば、本願発明の一実施形態において用いられるゲルカラムクロマトグラフィーとしては、ゲル濾過カラムクロマトグラフィー、イオン交換ゲルカラムクロマトグラフィー、またはアフィニティーゲルカラムクロマトグラフィーが挙げられるが、これに限られるものではない。
また、本願発明の一実施形態において、「変性剤」とは、物理的または化学的作用によって二本鎖DNAの水素結合を切断し、一本鎖へ乖離させる作用をもつ試薬を指す。本願発明においては、上述したように、ニッキングエンドヌクレアーゼを用いて、またはニッキングエンドヌクレアーゼ及び配列特異的二本鎖切断エンドヌクレアーゼの組み合せを用いてベクターを処理して得た試料は、ニックが入っているものの、完全な一本鎖DNAに分離しているわけではない。そのため、分子量の異なる3種類の一本鎖DNAに個々に分離させるため、ニックを入れたベクターに変性剤を加える。本願発明の一実施形態において、物理的変性剤としては、例えば、溶媒の極性を下げ、核酸の塩基部分のスタッキング等の疎水性相互作用を弱めるホルムアミド、グリセロール、若しくはウレアなど、または塩基の脱プロトン化による水素結合形成の阻害を誘導するアルカリ性試薬である水酸化ナトリウムなどが挙げられるが、これに限られるものではない。また、本願発明の一実施形態において、化学的変性剤としては、例えば、核酸とシッフ塩基を形成するホルムアルデヒドやグリオキサールなどが挙げられるが、これに限られるものではない。さらに、本願発明の一実施形態において、電気泳動の際の変性剤としては、チオウレアやエチレングリコールなども使用することが可能である。
ここで、長鎖のRNAの電気泳動の場合は、ホルムアミドなどの物理的変性剤で変性させた後、ホルムアルデヒドやグリオキサールなどの化学的変性剤によって、変性状態を共有結合的に固定化してから、同じくホルムアルデヒドを含むアガロースゲル中で電気泳動を行う。すなわち、変性状態を維持するためローディングバッファー中ばかりでなく、ゲル中でも、RNAを化学的変性剤に暴露しておく必要がある。このRNAの電気泳動の場合から推測すると、一本鎖DNAの変性ゲル電気泳動においても、電気泳動前に化学的変性剤によって変性を固定化した後、同じ化学的変性剤を加えたアガロースゲルを用いないと、相補鎖との再アニールを防ぎ、一本鎖状態を保ったままで電気泳動することはできないと考えられる。しかしながら、共有結合性の変性剤は、可逆的に結合を外すことはできるが、何らかの副反応を伴う可能性が否定できない。すなわち、化学的な変性剤を用いると、DNA中に変異を起こさせる可能性を排除できない。また、これらの化学的変性剤は極めて毒性や刺激性が強く、実際に実験を行う際には、扱いに注意が必要であり、危険かつ簡便性に欠ける。
以上によれば、安全性、簡便性、およびDNAの損傷を防ぐという観点から、本願発明の一実施形態において、物理的変性剤のみによって長鎖一本鎖DNAを変性させた後、非変性ゲルを用いてゲル電気泳動することが好ましい。
物理的変性剤を用いて電気泳動を行う場合、電気泳動ゲルのウエル中にある一本鎖DNAは、電気泳動が開始されると、ローディングバッファーに含まれている物理的変性剤の元を離れて、非変性ゲルの中に入っていく。本願発明者らは、非変性ゲル中に入った後の一本鎖DNAが、従来考えられていたほど容易には相補鎖と再アニールすることはないということを発見している。つまり、本発明者らは、変性した一本鎖DNAは、非変性ゲル中においても、一本鎖のまま安定的に電気泳動されるという知見を得ている。
また、本発明者らは、非変性ゲル中で電気泳動される一本鎖DNAも、分子量に基づいて泳動され、その解像度は、一本鎖DNAの調製という本発明の用途としては、必要かつ充分であるという知見を得ている。すなわち、ゲル中の一本鎖DNAは、二本鎖DNAや化学的変性剤によって変性が固定化したRNAと同様に、安定した構造ではないことから、ゲル中で二次的な構造を形成するはずである。そのため、電気泳動の移動度と分子量の対数値(log10 M)との間にある単純で正確な比例関係は成立しないものの、本願発明は微妙な分子量の違いを分析するものではないため、そのような精緻な数学的関係性までは必要としない。
また、本願発明の一実施形態に係る方法を実施するためのキットには、(a)クローニング部位の両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有するベクターであって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断されるベクター、及び(b)クローニング部位の一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、前記クローニング部位の他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有するベクターから選択される少なくとも1つのベクターが包含される。すなわち、上述の(a)及び(b)のいずれのベクターも、ベクター自体に少なくとも1つのニッキングエンドヌクレアーゼ認識部位が存在しているため、目的の一本鎖DNAの元となる、クローニングされる二本鎖DNAにはニッキングエンドヌクレアーゼ認識部位があってもなくても良い。
一方で、本願発明の一実施形態においては、上述のとおり、ニッキングエンドヌクレアーゼまたは配列特異的二本鎖切断エンドヌクレアーゼの認識部位を、ベクターDNAの代わりに、クローニングされる目的のDNAの両端に備えるようにすることもでき、この場合、キットに包含されるベクターとしては、ニッキングエンドヌクレアーゼ認識部位を含まないものが好ましい。
また、本願発明の一実施形態において、上述のキットにはDNAの変性のための変性剤を含有することもできる。
以下に、実施例を用いて、本発明をより詳細に説明するが、本発明はこれらの実施例に限定されるものではない。
後述の実施例1ではマルチクローニングサイトにニッキングエンドヌクレアーゼ認識部位を配置したクローニングベクターを用いた場合の目的DNAのクローニング手順を、実施例2は目的DNAをクローニングしたベクターのニッキングエンドヌクレアーゼによる消化手順(図1B)を、実施例3はニッキングエンドヌクレアーゼ処理した目的DNAをクローニングしたベクターを、変性剤により加熱変性し、非変性条件でのアガロースゲル電気泳動を行い、目的長鎖一本鎖DNAの抽出精製までの手順(図1C及び図1D)を、それぞれ示す。実施例4では、全域からニッキングエンドヌクレアーゼ認識部位を除いたベクターを用いて、GFP遺伝子全域を含む長鎖一本鎖DNAの調製を行った例を示す。実施例5では、2ヶ所のニックを導入したpLSODN-1(1.5Kb断片)プラスミドの種々の変性剤による変性の効果を示す。
クローニングベクターへの目的DNAのクローニング
実施例1では、長鎖一本鎖DNAを調製するためのモデルDNA断片としてλファージ由来の1.5kb DNA断片(λファージDNA 38,951-40,450、図3)を用いた。クローニングベクターとしてはマルチクローニングサイトに複数のニッキングエンドヌクレアーゼ認識部位を配置したpLSODN-1を用いた。図2AにクローニングベクターpLSODN-1のプラスミドマップを、図2Bにマルチクローニングサイトの配列を、図2Cに一本鎖DNAを取得するためのクローニングの際の酵素の組合せを、図2Dに全域の塩基配列を示す。図2Bでは、ボックスで示すサイトがニッキングエンドヌクレアーゼサイトであり、そのニック導入位置を矢印で示す。図2Bに示すように、中央に4種類のNbタイプのニッキングエンドヌクレアーゼサイトと1種のNtタイプのニッキングエンドヌクレアーゼサイトが、同一側のDNA鎖を切断できるように、向き合う形で配置してある。Nbタイプのニッキング酵素サイトの外側上流には、5’オーバーハング粘着末端を生じる6塩基または8塩基認識の制限酵素サイトが、Ntタイプのニッキング酵素サイトの外側下流には3’オーバーハングの粘着末端を生じる6塩基認識の制限酵素サイトが配置してある。図2Cに示すように、長鎖一本鎖DNAを取得するための目的のDNA断片は、NbタイプとNtタイプの二つのニッキング酵素サイトの間(丸数字1、中央図)か、Ntタイプのニッキング酵素サイトと5’オーバーハング粘着末端を生じる6塩基認識の制限酵素サイトの間(丸数字2、左図)、Nbタイプのニッキング酵素と3’オーバーハングの粘着末端を生じる6塩基認識の制限酵素サイトの間(丸数字3、右図)にクローニングした。ここでは、Nb.BsrDIとNt.BspQIの2つのニッキングエンドヌクレアーゼサイトを利用した。
実施例1では、長鎖一本鎖DNAを調製するためのモデルDNA断片としてλファージ由来の1.5kb DNA断片(λファージDNA 38,951-40,450、図3)を用いた。クローニングベクターとしてはマルチクローニングサイトに複数のニッキングエンドヌクレアーゼ認識部位を配置したpLSODN-1を用いた。図2AにクローニングベクターpLSODN-1のプラスミドマップを、図2Bにマルチクローニングサイトの配列を、図2Cに一本鎖DNAを取得するためのクローニングの際の酵素の組合せを、図2Dに全域の塩基配列を示す。図2Bでは、ボックスで示すサイトがニッキングエンドヌクレアーゼサイトであり、そのニック導入位置を矢印で示す。図2Bに示すように、中央に4種類のNbタイプのニッキングエンドヌクレアーゼサイトと1種のNtタイプのニッキングエンドヌクレアーゼサイトが、同一側のDNA鎖を切断できるように、向き合う形で配置してある。Nbタイプのニッキング酵素サイトの外側上流には、5’オーバーハング粘着末端を生じる6塩基または8塩基認識の制限酵素サイトが、Ntタイプのニッキング酵素サイトの外側下流には3’オーバーハングの粘着末端を生じる6塩基認識の制限酵素サイトが配置してある。図2Cに示すように、長鎖一本鎖DNAを取得するための目的のDNA断片は、NbタイプとNtタイプの二つのニッキング酵素サイトの間(丸数字1、中央図)か、Ntタイプのニッキング酵素サイトと5’オーバーハング粘着末端を生じる6塩基認識の制限酵素サイトの間(丸数字2、左図)、Nbタイプのニッキング酵素と3’オーバーハングの粘着末端を生じる6塩基認識の制限酵素サイトの間(丸数字3、右図)にクローニングした。ここでは、Nb.BsrDIとNt.BspQIの2つのニッキングエンドヌクレアーゼサイトを利用した。
まず、クローニングベクターpLSODN-1を、以下に示した配列から成る2つの合成DNAオリゴマーを用いてPCRを行うことによって、直鎖状のクローニングベクターpLSODN-1を取得した。以下の配列における下線部分は、目的DNAをベクターにクローニングするために導入した目的DNAとのホモロジー配列である。

具体的には、400ngのクローニングベクターpLSODN-1に、上記2つの合成DNAオリゴマーを各80pmol、1×GXLバッファー(タカラバイオ株式会社)、5ユニットのPrimeSTAR GXL DNA polymerase(タカラバイオ株式会社)、それぞれ80nmolのdATP、dGTP、dTTP、dCTPを加えた、計400μlの反応液中で、PCRを行った。反応温度及び時間は、最初に95℃で1分、次に95℃で1分、55℃で1分、72℃で6分をこの順にそれぞれ16回繰り返し、最後に72℃で10分である。このPCR反応物を、1.6μg/mlのCrystal Violetを含む0.8%のアガロースゲル電気泳動に供与した。電気泳動後、青色に染まった3.2kbのDNAのバンドをカミソリで切り出し、Qiaquick Gel Extraction Kit(株式会社キアゲン)にて精製し、50μlの10mMトリス塩酸(pH8.0)に溶解し、これを直鎖状のクローニングベクターpLSODN-1として保存した。
一方、長鎖一本鎖DNAを取得するための目的DNAは、λファージDNAから、以下に示した配列から成る2つの合成DNAオリゴマーを用いてPCRを行うことによって取得した。以下の配列における下線部分は、目的DNAをベクターにクローニングするために導入したベクターとのホモロジー配列である。λファージDNA由来の目的DNAの配列を図3に示す。

具体的には、400ngのλファージDNA(プロメガ社)に、上記2つの合成DNAオリゴマーを各80pmol、1×GXLバッファー(タカラバイオ株式会社)、5ユニットのPrimeSTAR GXL DNA polymerase(タカラバイオ株式会社)、それぞれ80nmolのdATP、dGTP、dTTP、dCTPを加えた、計400μlの反応液中で、PCRを行った。反応温度及び時間は、最初に95℃で1分、次に95℃で1分、55℃で1分、72℃で3分をこの順にそれぞれ16回繰り返し、最後に72℃で10分である。このPCR反応物を、1.6μg/mlのCrystal Violetを含む0.8%のアガロースゲル電気泳動に供与した。電気泳動後、青色に染まった1.5kbのDNAのバンドをカミソリで切り出し、Qiaquick Gel Extraction Kit(株式会社キアゲン)にて精製し、50μlの10mMトリス塩酸(pH8.0)に溶解し、これを長鎖一本鎖DNAを取得するための目的DNAとして保存した。
次に、PCR増幅によって得られた直鎖状クローニングベクターpLSODN-1とλファージDNA由来の1.5kbの目的DNAを、PCR反応に用いた合成DNAオリゴマーによって導入した末端のホモロジー配列をもとに連結した。
具体的には、PCR増幅によって得られた40ngの直鎖状クローニングベクターpLSODN-1に、同様にPCR増幅によって得られたλファージDNA由来の75ngの1.5kbの目的DNA、0.5μlの1 x Cloning EZ Buffer(ジーンスクリプト社)、0.5μlのClone EZ Enzyme(ジーンスクリプト社)、をそれぞれ加えた、計5μlの反応液中で22℃で20分間反応させた後、氷上に5分間静置し、連結反応を完結させた。
続いて、連結反応液を1μl用いて、以下のようにコンピテントセル(Jet Competent Cell、株式会社バイオダイナミクス研究所)の形質転換操作を行った。まず、凍結コンピテントセル(25μl)を氷上に置いて融解した後、直ちに1μlの連結反応溶液をコンピテントセルに加え、5分後、室温の0.25mlのRecovery Medium(Jet Competent Cellに付属)にコンピテントセルを移した。そして、5分間このまま静置した後、Recovery Mediumに懸濁された菌液を、50mg/mlのアンピシリンを含むLB寒天プレート(直径8.5cm、寒天培地量25ml)に接種し、37℃で18時間、保温した。この培養によって上記LB寒天プレート上に生じた大腸菌コロニーを取り出し、50mg/mlのアンピシリンを含む3mlのLB液体培地に接種し、37℃で18時間振盪培養した。この振盪培養によって得られた菌体からQiagen Plasmid Purification Kit(株式会社キアゲン)によってプラスミドを調製した。
上述のようにして得られたプラスミドをBsrDIおよびBspQIで消化し、アガロースゲル電気泳動分析にて1.5kbのλファージ由来の目的DNA断片が挿入され、かつABI PRISM Genetic Analyzer(アプライドバイオシステムジャパン株式会社)によりその塩基配列を調べることによりpLSODN-1ベクターのBsrDIサイトとBspQIサイトの間に正しくDNA鎖が挿入された配列を有するものを選んだ。この選択されたプラスミドを、pLSODN-1(1.5Kb断片)プラスミドとした。
目的DNAをクローニングしたベクターのニッキング酵素による消化
実施例1で作成したプラスミドpLSODN-1(1.5Kb断片)を、ニッキングエンドヌクレアーゼで消化することによって、環状二本鎖DNAの構造を持つ上記プラスミド上の、λファージ由来の目的DNAである1.5Kb断片の両端かつ一方の側の鎖のみを切断しニックを導入した。
実施例1で作成したプラスミドpLSODN-1(1.5Kb断片)を、ニッキングエンドヌクレアーゼで消化することによって、環状二本鎖DNAの構造を持つ上記プラスミド上の、λファージ由来の目的DNAである1.5Kb断片の両端かつ一方の側の鎖のみを切断しニックを導入した。
具体的には、100μlのプラスミドpLSODN-1(1.5Kb断片)に、1 x 3.1 NEBuffer (ニュー・イングランド・バイオラブズ社)、50ユニットのNt.BspQI、50ユニットのNb.BsrDIを加えた、計50μlの反応液中で50℃で60分間、続けて60℃で60分間反応させた。反応後は脱塩操作としてエタノール沈殿を行った。
具体的には、2ヶ所のニックを導入した50μlのpLSODN-1(1.5Kb断片)プラスミド反応溶液に、125μlのエタノールを加えて混合した。そして、この混合液を微量高速遠心分離機にセットし、15,000rpm、10分、4℃で回転させ、沈殿させた。チューブから上清を除去した後、沈殿物に500μlの70%冷エタノールを加え、ボルテックスし、再び微量高速遠心分離機を用いて、15,000rpm、10分、4℃で回転させ、再び沈殿させた。チューブから上精を吸引除去し、さらにチューブをバキュームエバポレーターにかけ、乾固させた後、50μlの滅菌水を加えて、バッファー交換し、脱塩した2ヶ所のニックを導入したpLSODN-1(1.5Kb断片)プラスミドを得た。
変性剤による加熱変性と非変性アガロースゲル電気泳動による分離、ゲルからの抽出精製
実施例2で得られた、2ヶ所のニックを導入した20μgのpLSODN-1(1.5Kb断片)プラスミドを含む10μl水溶液に、30μlのブロモフェノールブルーを含む95%ホルムアミドを加え、終濃度71%ホルムアミド溶液とした。これを70℃で5分間熱処理した後、直ちに氷上に置き急冷した。1分間氷上に置いた後、20μl(10μg)と10μl(5μg)を1.2%濃度の非変性のアガロースゲルで1×TAE緩衝液を泳動液として電気泳動を行った。ここにおいて、ウレアやホルムアミドを含む変性アガロースゲルを用いる必要はないことに留意したい。電気泳動はブロモフェノールブルー色素が、ゲル中で適当な位置まで移動したところで止めた。電気泳動後は装置からゲルを取り出し、臭化エチジウムで染色し、紫外線下で撮影した(図4)。撮影後、3本現れるバンドのうち、先端にくる最も分子量の小さい目的の1.5kbの一本鎖DNAのバンドを含むゲル片を切り出した。先端にあることから、他のバンドが混入している可能性はない。ゲル片の重量を測定した後、QIAquick Gel Extraction Kit(キアゲン社)を用いて目的の1.5kb一本鎖DNAを抽出した。目的の1.5kb一本鎖DNAの収率は約30%であった。精製した1.5kb一本鎖DNAは、その少量を同様の方法にて、分析スケールでの非変性アガロースゲル電気泳動を行い、他のバンドの混入はなく、高い精製度を有していることが確認された(図5)。
実施例2で得られた、2ヶ所のニックを導入した20μgのpLSODN-1(1.5Kb断片)プラスミドを含む10μl水溶液に、30μlのブロモフェノールブルーを含む95%ホルムアミドを加え、終濃度71%ホルムアミド溶液とした。これを70℃で5分間熱処理した後、直ちに氷上に置き急冷した。1分間氷上に置いた後、20μl(10μg)と10μl(5μg)を1.2%濃度の非変性のアガロースゲルで1×TAE緩衝液を泳動液として電気泳動を行った。ここにおいて、ウレアやホルムアミドを含む変性アガロースゲルを用いる必要はないことに留意したい。電気泳動はブロモフェノールブルー色素が、ゲル中で適当な位置まで移動したところで止めた。電気泳動後は装置からゲルを取り出し、臭化エチジウムで染色し、紫外線下で撮影した(図4)。撮影後、3本現れるバンドのうち、先端にくる最も分子量の小さい目的の1.5kbの一本鎖DNAのバンドを含むゲル片を切り出した。先端にあることから、他のバンドが混入している可能性はない。ゲル片の重量を測定した後、QIAquick Gel Extraction Kit(キアゲン社)を用いて目的の1.5kb一本鎖DNAを抽出した。目的の1.5kb一本鎖DNAの収率は約30%であった。精製した1.5kb一本鎖DNAは、その少量を同様の方法にて、分析スケールでの非変性アガロースゲル電気泳動を行い、他のバンドの混入はなく、高い精製度を有していることが確認された(図5)。
クローニングベクターpETUK (del)へのGFP遺伝子のクローニング
実施例4では、ベクター骨格に加えてマルチクローニングサイトにもニッキング酵素認識部位を持たないベクターpETUK (del)を用いた。ここでは、ベクターと目的DNA断片をPCRで増幅する際に用いる合成DNAオリゴマー内にニッキングエンドヌクレアーゼ認識部位を組み込むことによって、目的のDNA断片の両側にニッキングエンドヌクレアーゼ認識部位を導入した。また、本施例では、GFP遺伝子全体をコードする一本鎖DNAを調製した。このGFP遺伝子には、ゲノム編集によるラットのチロシナーゼ(Tyr)遺伝子へのknock inの目的箇所の上流側19塩基および下流側20塩基から成るホモロジーアームが結合する。また、本実施例では一本鎖DNAの分離調製には変性ゲルであるウレアアガロースゲルを用いた。
実施例4では、ベクター骨格に加えてマルチクローニングサイトにもニッキング酵素認識部位を持たないベクターpETUK (del)を用いた。ここでは、ベクターと目的DNA断片をPCRで増幅する際に用いる合成DNAオリゴマー内にニッキングエンドヌクレアーゼ認識部位を組み込むことによって、目的のDNA断片の両側にニッキングエンドヌクレアーゼ認識部位を導入した。また、本施例では、GFP遺伝子全体をコードする一本鎖DNAを調製した。このGFP遺伝子には、ゲノム編集によるラットのチロシナーゼ(Tyr)遺伝子へのknock inの目的箇所の上流側19塩基および下流側20塩基から成るホモロジーアームが結合する。また、本実施例では一本鎖DNAの分離調製には変性ゲルであるウレアアガロースゲルを用いた。
図6Aに、クローニングベクターpETUK (del)のプラスミドマップを、図6Bにマルチクローニングサイトの配列を、図6Cに全塩基配列を示した。ここでは、長鎖一本DNAの調製にはNb.BsrDIとNt.BspQIの2つのニッキング酵素サイトを利用したが、前述したようにベクター自体のマルチクローニングサイトにはこのニッキングエンドヌクレアーゼサイトがないものを用いて、PCRを行う際に用いる合成DNAオリゴマーの中に組み込むことによって、目的DNAの両側にニッキング酵素認識部位を導入した。
まず、クローニングベクターpETUK (del)をテンプレートとして、以下に示した配列から成る2つの合成DNAオリゴマーを用いてPCRを行うことによって、直鎖状のクローニングベクターpETUK (del)を取得した。下記配列の下線部分は、目的DNAをベクターにクローニングするために導入した目的DNAとのホモロジー配列である。また、ボックスで囲った配列が、目的DNAの両側に導入されるニッキングエンドヌクレアーゼNb.BsrDIとNt.BspQIの認識配列である。

具体的には、400ngのクローニングベクターpETUK (del)に、上記2つの合成DNAオリゴマーを各80pmol、1×GXLバッファー(タカラバイオ株式会社)、5ユニットのPrimeSTAR GXL DNA polymerase(タカラバイオ株式会社)、それぞれ80nmolのdATP、dGTP、dTTP、dCTPを加え、計400μlの反応液中で、PCRを行った。反応温度及び時間は、最初に95℃で1分、次に95℃で1分、55℃で1分、72℃で6分をこの順にそれぞれ16回繰り返し、最後に72℃で10分である。このPCR反応物を、1.6μg/mlのCrystal Violetを含む0.8%のアガロースゲル電気泳動に供与した。電気泳動後、青色に染まった2.67kbのDNAのバンドをカミソリで切り出し、Qiaquick Gel Extraction Kit(株式会社キアゲン)で精製し、50μlの10mMトリス塩酸(pH8.0)に溶解し、これを直鎖状のクローニングベクターpETUK (del)として保存した。
一方、長鎖一本鎖DNAを取得するための目的GFP遺伝子をpCMV-GFP-LC3 Expression Vector (Cell Biolabs. Inc)から、以下に示した配列から成る2つの合成DNAオリゴマーを用いてPCRを行うことによって取得した。以下の配列における下線部分は、GFP遺伝子をベクターにクローニングするために導入したベクター側とのホモロジー配列である。GFP遺伝子断片はベクターのマルチクローニングサイトのBamHIサイトとNotIサイトとの間にクローニングする。pCMV-GFP-LC3 Expression Vector由来のGFP遺伝子の配列を図7に示した。また、ボックスで囲った部分は、それぞれGFPタンパク質の開始コドンと終始コドンである。

具体的には、400ngのpCMV-GFP-LC3 Expression Vectorに、上記2つの合成DNAオリゴマーを各80pmol、1×GXLバッファー(タカラバイオ株式会社)、5ユニットのPrimeSTAR GXL DNA polymerase(タカラバイオ株式会社)、それぞれ80nmolのdATP、dGTP、dTTP、dCTPを加えた、計400μlの反応液中で、PCRを行った。反応温度及び時間は、最初に95℃で1分、次に、95℃で1分、55℃で1分、72℃で3分をこの順にそれぞれ16回繰り返し、最後に72℃で10分である。このPCR反応物を、1.6μg/mlのCrystal Violetを含む0.8%のアガロースゲル電気泳動に供与した。電気泳動後、青色に染まった0.75kbのDNAのバンドをカミソリで切り出し、Qiaquick Gel Extraction Kit(株式会社キアゲン)で精製し、50μlの10mMトリス塩酸(pH8.0)に溶解し、これを長鎖一本鎖DNAを取得するための目的GFP遺伝子全域DNA断片として保存した。
次に、上記PCR増幅によって得られた直鎖状クローニングベクターpETUK (del)断片とGFP遺伝子全域DNA断片を、PCR反応に用いた合成DNAオリゴマーによって導入した末端のホモロジー配列をもとに連結した。
具体的には、PCR増幅によって得られた40ngの直鎖状クローニングベクターpETUK (del)に、同様にPCR増幅によって得られた75ngのGFP遺伝子、0.5μlの1 x Cloning EZ Buffer(ジーンスクリプト社)、0.5μlのClone EZ Enzyme(ジーンスクリプト社)を加えた、計5μlの反応液中で22℃で20分間反応後、氷上で5分間静置し、連結反応を完結させた。
続いて、連結反応液を1μl用いて、以下のようにコンピテントセル(Jet Competent Cell、株式会社バイオダイナミクス研究所)の形質転換操作を行った。まず、凍結コンピテントセル(25μl)を氷上に置いて融解した後、直ちに1μlの連結反応溶液をコンピテントセルに加え、5分後、室温の0.25mlのRecovery Medium(Jet Competent Cellに付属)にコンピテントセルを移した。そして、5分間このまま静置した後、Recovery Mediumに懸濁された菌液を、50mg/mlのアンピシリンを含むLB寒天プレート(直径8.5cm、寒天培地量25ml)に接種し、37℃で18時間、保温した。この培養によって上記LB寒天プレート上に生じた大腸菌コロニーを取り出し、50mg/mlのアンピシリンを含む3mlのLB液体培地に接種し、37℃で18時間振盪培養した。この振盪培養によって得られた菌体からQiagen Plasmid Purification Kit(株式会社キアゲン)によりプラスミドを調製した。
上述のようにして得られたプラスミドについてBsrDIおよびBspQIで消化し、アガロースゲル電気泳動分析にて759塩基の目的GFP遺伝子DNA断片が挿入され、かつABI PRISM Genetic Analyzer(アプライドバイオシステムジャパン株式会社)によりその塩基配列を調べ、pETUK(del)ベクターにBsrDIサイトとBspQIサイトと伴にGFP遺伝子が正しく挿入された配列を有するものを選んだ。この選択されたプラスミドを、pETUK(GFP-Tyr)プラスミドとした。
次に、pETUK(GFP-Tyr)プラスミドを2つのニッキングエンドヌクレアーゼ(Nb.BsrDIおよびNt.BspQI)で消化し、GFP遺伝子の両端において、一方の側の鎖のみにニックを導入した。具体的には、100μgのプラスミドpETUK(GFP-Tyr)に、1 x 3.1 NEBuffer (ニュー・イングランド・バイオラブズ社)、50ユニットのNt.BspQI、及び50ユニットのNb.BsrDIを加えた、計50μl反応液中で、50℃で60分、続けて60℃で60分反応させた。反応後は脱塩操作としてエタノール沈殿を行った。
具体的には、2ヶ所のニックを導入した50μlのpETUK(GFP-Tyr)プラスミド反応溶液に、125μlのエタノールを加えて混合した。そして、この混合液を微量高速遠心分離機にセットし、15,000rpm、10分、4℃で回転させ、沈殿させた。チューブから上清を除去した後、沈殿物に500μlの70%冷エタノールを加え、ボルテックスし、再び微量高速遠心分離機で、15,000rpm、10分、4℃で回転させ、再び沈殿させた。チューブから上精を吸引除去し、さらにチューブをバキュームエバポレーターにかけ、乾固させた後、50μlの滅菌水を加えて、バッファー交換し、脱塩した2ヶ所のニックを導入したpETUK(GFP-Tyr)プラスミドを得た。
2ヶ所のニックを導入した20μgのpETUK(GFP-Tyr)プラスミドを含む10μl水溶液に、30μlのブロモフェノールブルーを含む95%ホルムアミドを加え、終濃度71%ホルムアミド溶液とした。これを70℃で5分間熱処理した後、直ちに氷上に置き急冷した。1分間氷上に置いた後、その一部である100ngについて、1.0%濃度の4Mウレアアガロースゲルで、4Mウレア含有1×TAE緩衝液を泳動液として分析を目的とした電気泳動を行った。電気泳動はブロモフェノールブルー色素が、ゲル中で適当な位置まで移動したところで止めた。電気泳動後は装置からゲルを取り出し、臭化エチジウムで染色し、紫外線下で撮影した(図8)。分析的電気泳動で問題なく分離されることが確認されたことから、残りの全量を4Mウレアアガロースゲル電気泳動に供した。電気泳動後、臭化エチジウムで染色し、3本現れるバンドのうち、先端にくる最も分子量の小さい目的の759塩基のGFP一本鎖DNAのバンドを含むゲル片を切り出した。先端にあることから、他のバンドが混入している可能性はない。ゲル片の重量を測定した後、QIAquick Gel Extraction Kit(キアゲン社)を用いて目的の759塩基のGFP一本鎖DNAを抽出した。目的の759塩基のGFP一本鎖DNAの収率は約30%であった。精製した759一本鎖DNAは、同様の方法にて4Mウレアアガロースゲルにて電気泳動を行い、他のバンドの混入はなく、高い精製度を有していることが確認された(図9)。
種々の変性剤を用いた場合の、2ヶ所のニックを導入したpLSODN-1(1.5kb断片)プラスミドの変性ゲルおよび非変性ゲルでの電気泳動による個々の一本鎖DNAの分離
以下に、いくつかの物理的変性剤による、ニックを導入したpLSODN-1(1.5kb断片)プラスミドの変性および非変性ゲルでの電気泳動による一本鎖DNAの出現および分離の例を示す。物理的な変性剤としてホルムアミド、グリセロール、及びウレアの例を、対照としてスクロースの場合を示す。ホルムアミド、グリセロール、及びウレアは、核酸の電気泳動用変性剤として通常用いられる試薬である。
以下に、いくつかの物理的変性剤による、ニックを導入したpLSODN-1(1.5kb断片)プラスミドの変性および非変性ゲルでの電気泳動による一本鎖DNAの出現および分離の例を示す。物理的な変性剤としてホルムアミド、グリセロール、及びウレアの例を、対照としてスクロースの場合を示す。ホルムアミド、グリセロール、及びウレアは、核酸の電気泳動用変性剤として通常用いられる試薬である。
具体的には、種々の濃度の、2ヶ所のニックを導入したpLSODN-1(1.5kb断片)プラスミドを、種々の濃度のホムアミド、グリセロール、ウレア、またはスクロースと混合した。次に70℃で5分加熱後、氷上にて急冷した。氷上で1分間放置した後、1.2%非変性アガロースゲル電気泳動に供した。電気泳動後は、ゲルを取出し、1.6% Crystal Violetで一晩振盪染色した。図10にその結果を示した。
ホルムアミドは、25%の濃度で、2ヶ所のニックを導入したpLSODN-1(1.5kb断片)プラスミドを、1μg/μlの高濃度のプラスミドであっても完全に変性させ、1.5kbの目的一本鎖DNAを与えた。グリセロールは、50%以上の濃度で、プラスミドを完全に変性させる能力があることがわかった。ウレアは6M濃度で、0.25μg/μl濃度のプラスミドを変性させることができたが、0.5μg/μl以上の濃度のプラスミドに関しては限定的であった。スクロースでは、全く変性の効果はなかった。
その他、本発明は、さまざまに変形可能であることは言うまでもなく、上述した一実施形態に限定されず、発明の要旨を変更しない範囲で種々変形可能である。
Claims (24)
- 長鎖一本鎖DNAを調製する方法であって、
(1)(a)クローニング部位の両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有するベクターであって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断されるベクター、または(b)クローニング部位の一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、前記クローニング部位の他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有するベクターに、目的のDNA鎖をクローニングする工程と、
(2)前記ニッキングエンドヌクレアーゼによって、前記目的のDNA鎖がクローニングされた(a)のベクターを切断し、または前記ニッキングエンドヌクレアーゼ及び前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位を認識する配列特異的二本鎖切断エンドヌクレアーゼによって、前記目的のDNA鎖がクローニングされた(b)のベクターを切断し、分子量の異なる少なくとも3種類の一本鎖DNAを生成する工程と、
(3)前記少なくとも3種類の一本鎖DNAに適当量の変性剤を添加して、前記一本鎖DNAを変性させる工程と、
(4)前記変性させた少なくとも3種類の一本鎖DNAを任意の分離手段によって分離させ、目的の一本鎖DNAを調製する工程と
を有する、方法。 - 長鎖一本鎖DNAを調製する方法であって、
(1)(a)両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有する目的のDNA鎖であって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断される目的のDNA鎖、または(b)一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有する目的のDNA鎖を、ベクターにクローニングする工程と、
(2)前記ニッキングエンドヌクレアーゼによって、(a)の目的のDNA鎖がクローニングされたベクターを切断し、または前記ニッキングエンドヌクレアーゼ及び前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位を認識する配列特異的二本鎖切断エンドヌクレアーゼによって、(b)の目的のDNA鎖がクローニングされたベクターを切断し、分子量の異なる少なくとも3種類の一本鎖DNAを生成する工程と、
(3)前記少なくとも3種類の一本鎖DNAに適当量の変性剤を添加して、前記一本鎖DNAを変性させる工程と、
(4)前記変性させた少なくとも3種類の一本鎖DNAを任意の分離手段によって分離させ、目的の一本鎖DNAを調製する工程と
を有する、方法。 - 請求項1または2記載の方法において、前記目的のDNA鎖が200塩基以上である、方法。
- 請求項1または2記載の方法において、前記任意の分離手段がゲル電気泳動である、方法。
- 請求項4記載の方法において、前記ゲル電気泳動が、変性剤を含まない非変性アガロースゲル電気泳動、変性剤を含む変性アガロースゲル電気泳動、変性剤を含まない非変性アクリルアミドゲル電気泳動、または変性剤を含む変性アクリルアミドゲル電気泳動である、方法。
- 請求項5記載の方法において、前記ゲル電気泳動が、変性剤を含まない非変性アガロースゲル電気泳動である、方法。
- 請求項1または2記載の方法において、前記任意の分離手段が、ゲルカラムクロマトグラフィーである、方法。
- 請求項7記載の方法において、前記ゲルカラムクロマトグラフィーが、ゲル濾過カラムクロマトグラフィー、イオン交換ゲルカラムクロマトグラフィー、またはアフィニティーゲルカラムクロマトグラフィーである、方法。
- 請求項1または2記載の方法において、前記ニッキングエンドヌクレアーゼ認識部位の塩基数は、少なくとも3塩基である、方法。
- 請求項9記載の方法において、前記ニッキングエンドヌクレアーゼ認識部位が、Nb.BbvCI、Nb.BsmI、Nb.BtsI、Nb.BsrDI、Nt.BspQI、Nt.BbvCI、Nt.AlwI、Nt.BsmAI、Nt.BstNBI、Nt.CviPII、Nb.Mva1269I、Nt.Bpu10I、及びNb.BssSIからなる群から選択されるニッキングエンドヌクレアーゼの認識部位である、方法。
- 請求項10記載の方法において、前記ニッキングエンドヌクレアーゼ認識部位の塩基数は、6塩基または7塩基である、方法。
- 請求項11記載の方法において、前記ニッキングエンドヌクレアーゼ認識部位が、Nb.BbvCI、Nb.BsmI、Nb.BtsI、Nb.BsrDI、Nb.BssSI、Nt.BspQI、Nb.Mva1269I、Nt.Bpu10I、及びNt.BbvCIからなる群から選択されるニッキングエンドヌクレアーゼの認識部位である、方法。
- 請求項1または2記載の方法において、前記ニッキングエンドヌクレアーゼ認識部位に、ガイドRNAが結合する、方法。
- 請求項13記載の方法において、前記ニッキングエンドヌクレアーゼは、Cas9のD10A変異体である、方法。
- 請求項1または2記載の方法において、前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位が、制限酵素およびメガヌクレアーゼからなる群から選択される酵素、またはTALENの認識部位である、方法。
- 請求項15記載の方法において、前記メガヌクレアーゼが、I-CeuI、I-SceI、PI-PspI、またはPI-SceIである、方法。
- 請求項1または2記載の方法において、前記配列特異的二本鎖切断エンドヌクレアーゼ認識部位に、ガイドRNAまたはガイドDNAが結合する、方法。
- 請求項17記載の方法において、前記配列特異的二本鎖切断エンドヌクレアーゼは、Cas9またはArgonauteである、方法。
- 請求項1または2記載の方法において、前記変性剤が、ホルムアミド、グリセロール、ウレア、チオウレア、エチレングリコール、または水酸化ナトリウムである、方法。
- 請求項19記載の方法において、前記変性剤が、ホルムアミドまたはグリセロールである、方法。
- 請求項1または2記載の方法に用いるキットであって、(a)クローニング部位の両端にそれぞれ少なくとも1つのニッキングエンドヌクレアーゼ認識部位を有するベクターであって、前記ニッキングエンドヌクレアーゼ認識部位を認識するニッキングエンドヌクレアーゼによって同一鎖が切断されるベクター、及び(b)クローニング部位の一端に少なくとも1つのニッキングエンドヌクレアーゼ認識部位と、前記クローニング部位の他端に少なくとも1つの配列特異的二本鎖切断エンドヌクレアーゼ認識部位とを有するベクターから選択される少なくとも1つのベクターを有する、キット。
- 請求項21記載の方法に用いるキットであって、さらに、DNAの変性のための変性剤を含有する試薬を有する、キット。
- 請求項2記載の方法に用いるキットであって、ニッキングエンドヌクレアーゼ認識部位を含まないベクターを有する、キット。
- 請求項23記載のキットであって、さらに、DNAの変性のための変性剤を含有する試薬を有する、キット。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018528117A JP7004651B2 (ja) | 2016-07-19 | 2016-07-19 | 長鎖一本鎖dnaを調製する方法 |
| US16/318,832 US20190309283A1 (en) | 2016-07-19 | 2016-07-19 | Method for preparing long-chain single-stranded dna |
| PCT/JP2016/071138 WO2018015995A1 (ja) | 2016-07-19 | 2016-07-19 | 長鎖一本鎖dnaを調製する方法 |
| JP2022000190A JP7305812B2 (ja) | 2016-07-19 | 2022-01-04 | 長鎖一本鎖dnaを調製する方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2016/071138 WO2018015995A1 (ja) | 2016-07-19 | 2016-07-19 | 長鎖一本鎖dnaを調製する方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018015995A1 true WO2018015995A1 (ja) | 2018-01-25 |
Family
ID=60992370
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/071138 WO2018015995A1 (ja) | 2016-07-19 | 2016-07-19 | 長鎖一本鎖dnaを調製する方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20190309283A1 (ja) |
| JP (1) | JP7004651B2 (ja) |
| WO (1) | WO2018015995A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111909927A (zh) * | 2019-05-09 | 2020-11-10 | 苏州金唯智生物科技有限公司 | 一种dna产物的脱盐处理方法及单链dna的制备和制备试剂盒 |
| CN114990144A (zh) * | 2022-05-13 | 2022-09-02 | 华南农业大学 | 一种由特异核苷酸序列引导的缺刻酶介导的dna组装载体及其应用 |
Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005518202A (ja) * | 2002-02-25 | 2005-06-23 | ライフインド・イーエイチエフ | 非環状核酸を二次元コンホメーション依存分離するための方法 |
| JP2008523796A (ja) * | 2004-12-17 | 2008-07-10 | アンスティテュ ナシオナル ドゥ ラ ルシェルシュ アグロノミック‐インラ | 標的ゲノム改変を有する卵母細胞または卵細胞のインビトロでの作成方法 |
| JP2009225682A (ja) * | 2008-03-19 | 2009-10-08 | National Institute Of Agrobiological Sciences | 外来dna断片由来の逆方向反復配列を含む組換えベクター及びその作製方法 |
| JP2013523143A (ja) * | 2010-04-08 | 2013-06-17 | キアゲン ゲーエムベーハー | 核酸を単離および精製するための方法 |
| JP2013528786A (ja) * | 2010-04-08 | 2013-07-11 | キアゲン ゲーエムベーハー | 核酸を単離および精製するためのクロマトグラフィーデバイスおよび方法 |
| JP2013535210A (ja) * | 2010-08-04 | 2013-09-12 | タッチライト ジェネティックス リミテッド | パリンドローム配列を用いた閉鎖型直鎖状dnaの生成 |
| WO2015006290A1 (en) * | 2013-07-09 | 2015-01-15 | President And Fellows Of Harvard College | Multiplex rna-guided genome engineering |
| JP2016027807A (ja) * | 2012-10-23 | 2016-02-25 | ツールゲン インコーポレイテッド | 標的dnaに特異的なガイドrnaおよびcasタンパク質コード核酸またはcasタンパク質を含む、標的dnaを切断するための組成物、ならびにその使用 |
| JP2016103986A (ja) * | 2014-12-01 | 2016-06-09 | 国立大学法人 東京大学 | 複数のユニットが多重に連結したdnaカセットおよび該カセットを含むベクターの製造方法 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030138443A1 (en) * | 1993-03-08 | 2003-07-24 | Noteborn Mathews H.M. | Cloning of chicken anemia virus DNA |
| US8697359B1 (en) * | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| US12054771B2 (en) * | 2014-02-18 | 2024-08-06 | Bionano Genomics, Inc. | Methods of determining nucleic acid structural information |
-
2016
- 2016-07-19 US US16/318,832 patent/US20190309283A1/en active Pending
- 2016-07-19 JP JP2018528117A patent/JP7004651B2/ja active Active
- 2016-07-19 WO PCT/JP2016/071138 patent/WO2018015995A1/ja active Application Filing
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005518202A (ja) * | 2002-02-25 | 2005-06-23 | ライフインド・イーエイチエフ | 非環状核酸を二次元コンホメーション依存分離するための方法 |
| JP2008523796A (ja) * | 2004-12-17 | 2008-07-10 | アンスティテュ ナシオナル ドゥ ラ ルシェルシュ アグロノミック‐インラ | 標的ゲノム改変を有する卵母細胞または卵細胞のインビトロでの作成方法 |
| JP2009225682A (ja) * | 2008-03-19 | 2009-10-08 | National Institute Of Agrobiological Sciences | 外来dna断片由来の逆方向反復配列を含む組換えベクター及びその作製方法 |
| JP2013523143A (ja) * | 2010-04-08 | 2013-06-17 | キアゲン ゲーエムベーハー | 核酸を単離および精製するための方法 |
| JP2013528786A (ja) * | 2010-04-08 | 2013-07-11 | キアゲン ゲーエムベーハー | 核酸を単離および精製するためのクロマトグラフィーデバイスおよび方法 |
| JP2013535210A (ja) * | 2010-08-04 | 2013-09-12 | タッチライト ジェネティックス リミテッド | パリンドローム配列を用いた閉鎖型直鎖状dnaの生成 |
| JP2016027807A (ja) * | 2012-10-23 | 2016-02-25 | ツールゲン インコーポレイテッド | 標的dnaに特異的なガイドrnaおよびcasタンパク質コード核酸またはcasタンパク質を含む、標的dnaを切断するための組成物、ならびにその使用 |
| WO2015006290A1 (en) * | 2013-07-09 | 2015-01-15 | President And Fellows Of Harvard College | Multiplex rna-guided genome engineering |
| JP2016103986A (ja) * | 2014-12-01 | 2016-06-09 | 国立大学法人 東京大学 | 複数のユニットが多重に連結したdnaカセットおよび該カセットを含むベクターの製造方法 |
Non-Patent Citations (3)
| Title |
|---|
| BIODYNAMICS LABORATORY INC.: "Idenshi Knock.in ni Yuyo na Chosa Ipponsa DNA Chosei Kit, Long ssDNA (LsODN) Preparation Kit, Seizo Page Bango:64803", FUNAKOSHI NEWS, no. 612, 1 June 2016 (2016-06-01), pages 9 * |
| MASHIMO, TOMOJI: "Chosa no Ipponsa DNA(LsODN) de Hirogaru Genome Henshu no Kanosei", FUNAKOSHI NEWS, no. 609, 15 April 2016 (2016-04-15), pages 3, 32 * |
| YOSHIMI K. ET AL.: "ssODN-mediated knock-in with CRISPR-Cas for large genomic regions in zygotes", NATURE COMMUNICATIONS, vol. 7, 20 January 2016 (2016-01-20), pages 10431 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111909927A (zh) * | 2019-05-09 | 2020-11-10 | 苏州金唯智生物科技有限公司 | 一种dna产物的脱盐处理方法及单链dna的制备和制备试剂盒 |
| WO2020224228A1 (zh) * | 2019-05-09 | 2020-11-12 | 苏州金唯智生物科技有限公司 | 一种dna产物的脱盐处理方法及单链dna的制备和制备试剂盒 |
| CN114990144A (zh) * | 2022-05-13 | 2022-09-02 | 华南农业大学 | 一种由特异核苷酸序列引导的缺刻酶介导的dna组装载体及其应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20190309283A1 (en) | 2019-10-10 |
| JPWO2018015995A1 (ja) | 2019-05-09 |
| JP7004651B2 (ja) | 2022-02-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106957830B (zh) | 一种Cas9核酸酶ΔF916及其用途 | |
| AU2017308889B2 (en) | Programmable Cas9-recombinase fusion proteins and uses thereof | |
| CN106947750B (zh) | 一种Cas9核酸酶Q920P及其用途 | |
| CN106939303B (zh) | 一种Cas9核酸酶R919P及其用途 | |
| CN106957831B (zh) | 一种Cas9核酸酶K918A及其用途 | |
| CN106967697B (zh) | 一种Cas9核酸酶G915F及其用途 | |
| US11845928B2 (en) | Methods and kits for fragmenting DNA | |
| EP3536796A1 (en) | Gene knockout method | |
| CN112029787A (zh) | 核酸酶介导的dna组装 | |
| US20240301374A1 (en) | Systems and methods for transposing cargo nucleotide sequences | |
| EP4428233A9 (en) | C2c9 nuclease-based novel genome editing system and application thereof | |
| WO2018015995A1 (ja) | 長鎖一本鎖dnaを調製する方法 | |
| EP4217499A1 (en) | Systems and methods for transposing cargo nucleotide sequences | |
| JP7305812B2 (ja) | 長鎖一本鎖dnaを調製する方法 | |
| EP3666898A1 (en) | Gene knockout method | |
| JP2023115236A (ja) | 長鎖一本鎖dnaを調製する方法 | |
| CN112111528B (zh) | 一种内含子异常剪接的修复方法 | |
| WO2024055664A1 (zh) | 一种优化的向导RNA、CRISPR/AcC2C9基因编辑系统及基因编辑方法 | |
| US20240336912A1 (en) | In vivo dna assembly and analysis | |
| WO2023029492A1 (zh) | 一种外源基因定点整合的系统及方法 | |
| Penewit et al. | Recombineering in Staphylococcus aureus | |
| CN107119077B (zh) | CtIP抑制剂的新用途及一种精准的基因组DNA片段编辑方法 | |
| Jiang et al. | An in situ cut-and-paste genome editing platform mediated by CRISPR/Cas9 or Cas12a | |
| JP2024543186A (ja) | C2c9ヌクレアーゼに基づく新規なゲノム編集システムおよびその使用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16909470 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2018528117 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 16909470 Country of ref document: EP Kind code of ref document: A1 |