WO2011105606A1 - 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 - Google Patents
情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 Download PDFInfo
- Publication number
- WO2011105606A1 WO2011105606A1 PCT/JP2011/054510 JP2011054510W WO2011105606A1 WO 2011105606 A1 WO2011105606 A1 WO 2011105606A1 JP 2011054510 W JP2011054510 W JP 2011054510W WO 2011105606 A1 WO2011105606 A1 WO 2011105606A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- attribute
- information processing
- processing apparatus
- web page
- description pattern
- Prior art date
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
- G06F16/254—Extract, transform and load [ETL] procedures, e.g. ETL data flows in data warehouses
Definitions
- the present invention relates to a technical field of an information processing apparatus, an information processing method, a program for an information processing apparatus, and a recording medium for analyzing a web page on the Internet.
- Patent Document 1 devises a method for creating a 6-digit integer classification code table by limiting the search by product category to a three-level search by category, which is searched in order of major classification, middle classification, and minor classification.
- Product classification code table and store classification code table are created using this classification code table creation method, these classification code tables are provided in the Internet shopping mall, and the shop can easily register the product and store information, and the user can easily
- the search system in the shopping mall which can search goods and a store is disclosed.
- the present invention has been made in view of such problems, and an object of the present invention is to provide an information processing apparatus and the like that automatically acquire attributes such as products from a web page.
- the invention described in claim 1 includes a web page obtaining unit that obtains a plurality of web pages having the same category for classifying an object described in a web page, and initial data, An attribute-related word related to the attribute of the target described in the web page, or an initial data acquisition means for acquiring an attribute description pattern used to describe the attribute of the target; and the attribute from the plurality of web pages
- Attribute extraction means for extracting attribute-related words of the attribute that match the description pattern
- attribute description pattern extraction means for extracting the attribute description pattern that matches the attribute-related word from the plurality of web pages. It is characterized by that.
- the invention described in claim 2 is the information processing apparatus according to claim 1, further comprising a repeating unit that alternately repeats the attribute extracting unit and the attribute description pattern extracting unit.
- the invention according to claim 3 is the information processing apparatus according to claim 1 or 2, wherein the attribute extraction unit extracts an attribute name of the attribute as the attribute-related word.
- an attribute list generating unit that generates an attribute list from the extracted attribute-related words is extracted.
- Pattern list generating means for generating a pattern list of the attribute description pattern.
- the attribute scoring means for scoring the attribute-related words, and the attributes in the order of the scores. It further comprises attribute selection means for ranking related words and selecting attribute related words of a predetermined rank or higher.
- the attribute scoring unit performs scoring of the attribute related word based on the number of hits of the attribute related word search.
- the attribute-related word appears in a website having a plurality of stores where the attribute scoring means sells the object.
- the attribute related words are scored based on the number of the stores on the web page.
- the invention according to claim 8 is the information processing apparatus according to any one of claims 1 to 7, wherein the attribute-related word appears in a plurality of web pages belonging to a category different from the category. It is further characterized by further comprising an attribute filter means for removing.
- the invention according to claim 9 is the information processing apparatus according to any one of claims 1 to 8, wherein the attribute description pattern scoring means for scoring the attribute description pattern; It further comprises attribute description pattern selection means for sequentially ranking the attribute description patterns and selecting attribute description patterns of a predetermined rank or higher.
- the attribute description pattern scoring means is configured to determine whether the attribute related word and the attribute description pattern appear together based on the number of co-occurrence. The attribute description pattern is scored.
- the invention according to claim 11 is the information processing apparatus according to any one of claims 1 to 10, wherein the attribute name similarity determination unit determines whether the attribute names are similar to each other; Attribute name aggregation means for aggregating attribute names determined to be similar by the attribute name similarity determination means.
- the invention according to claim 12 is the information processing apparatus according to claim 11, wherein the attribute extraction unit extracts the attribute name and an attribute value corresponding to the attribute name as the attribute-related word, and the attribute A name aggregating unit aggregates the attribute names based on the attribute values.
- the web page acquisition unit acquires a web page of the target supply source, and the initial stage
- the data acquisition means, the attribute extraction means, and the attribute description pattern extraction means extract a supply source target attribute related word from the web page of the target supply source, and the supply source target attribute related word and the attribute related word Further, an attribute related word comparison unit is provided.
- a catalog in which the attribute related words are described is generated based on the extracted attribute related words.
- the apparatus further comprises catalog generating means for performing the above-described operation.
- a web page in which the number of appearances of the attribute-related word is a predetermined number or less from the plurality of web pages is a predetermined number or less from the plurality of web pages.
- Web page extraction means for extracting Is further provided.
- the web page extracting means extracts a web page in which the number of appearances of the attribute related word is zero.
- a web page / attribute grouping unit that groups the plurality of web pages based on the attribute-related words.
- the invention according to claim 18 is an information processing method in which the information processing apparatus performs information processing, a web page acquisition step of acquiring a plurality of web pages having the same category for classifying objects described in the web page; An attribute description pattern acquisition step for acquiring an attribute description pattern used to describe an attribute of a target described in the web page, and attribute related words of the attribute that match the attribute description pattern from the plurality of web pages And an attribute description pattern extraction step of further extracting the attribute description pattern used in the attribute extraction step from the plurality of web pages based on the extracted attribute related words. It is characterized by that.
- the invention according to claim 19 is a web page acquisition step of acquiring a plurality of web pages having the same category for classifying objects described in a web page in an information processing method in which the information processing apparatus performs information processing;
- An attribute-related word acquisition step for acquiring an attribute-related word related to the target attribute described in the web page, and an attribute description pattern used for describing the attribute, from the plurality of web pages,
- An attribute description pattern extraction step for extracting the attribute description pattern that matches the attribute related word, and an attribute related word used in the attribute description pattern extraction step based on the extracted attribute related word from the plurality of web pages
- an attribute-related word extracting step for further extraction.
- the invention described in claim 20 is described in the web page as initial data, web page acquisition means for acquiring a plurality of web pages having the same category for classifying the object described in the web page.
- an attribute description pattern extracting means for extracting the attribute description pattern that matches the attribute related word from the plurality of web pages.
- the invention described in claim 21 is described in the web page as initial data, web page acquisition means for acquiring a plurality of web pages having the same category for classifying the object described in the web page.
- Attribute extraction means for extracting the attribute related words, and an information description apparatus for functioning as attribute description pattern extracting means for extracting the attribute description patterns that match the attribute related words from the plurality of web pages Record the program for
- a plurality of web pages having the same category for classifying the target described in the web page are acquired, and the attribute-related terms related to the target attribute described in the web page are used as initial data.
- obtain the attribute description pattern used to describe the target attribute extract the attribute related words of the attribute that match the attribute description pattern from the multiple web pages, and convert the attribute related words from the multiple web pages to the attribute related words.
- Extract attribute-related terms from multiple web pages belonging to the same category by extracting matching attribute description patterns, or extract attribute description patterns, or extract attribute description patterns and attribute-related Since words are extracted, attributes included in the same category can be acquired with high accuracy.
- FIG. 15 is a flowchart illustrating an example of an attribute / attribute value extraction subroutine of FIG.
- FIG. 14; 15 is a flowchart illustrating an example of an attribute description pattern extraction subroutine of FIG. 14.
- 3 is a flowchart illustrating an operation example of determining an attribute / attribute value in the information processing server of FIG. 1. It is explanatory drawing which shows an example of the web page of suppliers, such as goods. It is a schematic diagram which shows an example of the produced
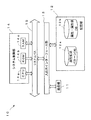
- FIG. 1 is a schematic diagram illustrating a schematic configuration example of an information processing system 1 according to the present embodiment.
- an information processing system 1 includes an information processing server (an example of an information processing apparatus) 10 that generates a catalog of products and the like from a web page and extracts a web page registered in an incorrect category.
- the information providing server 20 the store owner terminal 30 of the store owner opening a store on the shopping site, goods etc. on the shopping site (including services provided on the shopping site)
- a user terminal 35 of a user who posts a blog is an example of an object described on a web page.
- the information processing server 10 and the information providing server 20 are connected by a local area network or the like, and are capable of transmitting and receiving data to each other, and constitute a server system 5.
- the server system 5, the store owner terminal 30, and the user terminal 35 are connected by the network 3, and can exchange data with each other using, for example, TCP / IP as a communication protocol.
- the network 3 is constructed by, for example, the Internet, a dedicated communication line (for example, a CATV (Community Antenna Television) line), a mobile communication network (including a base station and the like), a gateway, and the like.
- the information processing system 1 functions as a catalog generation system that generates a catalog from a web page, or as a web page extraction system that extracts a web page registered in an incorrect category.
- the information processing server 10 generates a catalog of products or the like from a web page registered in the information providing server 20 or the like, or makes it possible to browse the catalog from the user terminal 35 or the like. Further, the information processing server 10 extracts web pages registered in the wrong category from the web pages registered in the information providing server 20 or the like, and organizes the web pages on the information providing server 20 based on the extraction result. Or notification of the extraction result to the store owner terminal 30 or the like such as the store owner who registered the web page.
- the information providing server 20 functions as a web server or a database server for selling products on a shopping site, and performs various processes such as acceptance of web page registration, user registration, and purchase procedures for products. .
- the information providing server 20 has web pages classified for each category such as products.
- the information providing server 20 accepts blog posts from users, classifies them by category based on the blog contents, etc., and publishes them on the Internet.
- the store owner terminal 30 used by the store owner is a portable terminal such as a personal computer, a portable wireless telephone, or a PDA (Personal Digital Assistant).
- the store owner uses the store owner terminal 30 to register or update the web page in the information providing server 20.
- the user terminal 35 used by the user is a portable terminal such as a personal computer, a portable wireless telephone, or a PDA.
- the user uses the user terminal 35 to search for products, purchase products, and the like.
- FIG. 2 is a block diagram illustrating an example of a schematic configuration of the information processing server 10.
- the information processing server 10 that functions as a computer includes a communication unit 11, a storage unit 12, an input / output interface unit 13, and a system control unit 14.
- the system control unit 14 and the input / output interface unit 13 are connected via a system bus 15.
- the communication unit 11 connects to the network 3 to control the communication state with the user terminal 35 or the like, or connects to the local area network and transmits / receives data to / from other servers such as the information providing server 20.
- the storage unit 12 is configured by, for example, a hard disk drive or the like, and stores various programs such as an operating system and a server program, data, and the like. Note that the various programs may be acquired from, for example, another server device via the network 3, or may be recorded on a recording medium and read via a drive device.
- attribute description pattern database 12a an attribute description pattern database (hereinafter referred to as “attribute description pattern DB”) 12a, an attribute / attribute value database (hereinafter referred to as “attribute / attribute value DB”) 12b, and the like are constructed in the storage unit 12. Yes.
- the attribute description pattern DB 12a stores initial data of attribute description patterns used for describing attributes of products and blogs, and attribute description patterns extracted from web pages. Blog attributes are listed as blog attributes.
- attribute / attribute value DB 12b as an example of processing by the information processing server 10, an attribute name and an attribute value related to attributes such as a product extracted from a web page are stored.
- attribute-related terms include only attribute names, phrases including attribute names, and combinations of attribute names and attribute values.
- the notation of attribute / attribute value includes a case where an attribute and an attribute value are paired, and specifically includes a case where an attribute name and an attribute value are paired.
- the input / output interface unit 13 performs interface processing between the communication unit 11 and the storage unit 12 and the system control unit 14.
- the system control unit 14 includes a CPU (Central Processing Unit) 14a, a ROM (Read Only Memory) 14b, a RAM (Random Access Memory) 14c, and the like.
- the CPU 14a reads out and executes various programs stored in the ROM 14b and the storage unit 12, thereby extracting attribute names and attribute values that match the attribute description pattern from a plurality of web pages.
- a catalog of products and the like is generated from the extracted attribute names and attribute values.
- the system control unit 14 extracts, from a plurality of web pages, a web page in which the number of appearances of the attribute name of the attribute is a predetermined number or less as a web page registered in the wrong category.
- FIG. 3 is a block diagram illustrating an example of a schematic configuration of the information providing server 20.
- the information providing server 20 includes a communication unit 21, a storage unit 22, an input / output interface unit 23, and a system control unit 24, and the system control unit 24, the input / output interface unit 23, and the like. Are connected via a system bus 25.
- the configuration and function of the information providing server 20 are substantially the same as the configuration and function of the information processing server 10, and therefore, differences will be mainly described in each configuration and function of the information processing server 10.
- the communication unit 21 controls the communication state with the store owner terminal 30, the user terminal 35, the information processing server 10, and the like through the network 3 and the local area network.
- the storage unit 22 includes a product database (hereinafter referred to as “information DB”) 22a, a member database (hereinafter referred to as “member DB”) 22b, and a product catalog database (hereinafter referred to as “product catalog DB”). ) 22c etc. are constructed.
- information DB product database
- member DB member database
- product catalog DB product catalog database
- the information DB 22a stores information on products, services, blogs, and the like, which are examples of objects described on a web page.
- a product name including a service name
- a type an image of a product
- an image related to a service a specification, a product, and the like
- Product information such as a summary sentence of the introduction, advertisement information, and the like are stored.
- the information DB 22a stores blog articles posted by the user in categories.
- the information DB 22a stores web page files and the like described in a markup language such as HTML (HyperText Markup Language) or XML (Extensible Markup Language).
- the information DB 22a stores information on commodity suppliers such as manufacturer information (including the manufacturer domain) and distributor information (including the distributor domain), and the product ID of each product includes the official information of each product.
- the URL Uniform Resource Locator
- user information such as a user ID, a name, an address, a telephone number, and an e-mail address of a registered user (Internet shop user) is registered. Such user information can be determined for each user by the user ID.
- a user ID, a login ID, and a password necessary for the user to log in to the Internet shop site from the user terminal 35 are registered.
- the login ID and the password are login information used for login processing (user authentication processing).
- the product catalog DB 22c stores a product catalog generated by the information processing server 10 for each product category and each product.
- the system control unit 24 includes a CPU 24a, a ROM 24b, a RAM 24c, and the like.
- the CPU 24a reads out and executes various programs stored in the ROM 24b and the storage unit 22, thereby registering and updating the web page by the store owner, product purchase processing by the user, and product purchase.
- a history is recorded for each user ID.
- information on a product catalog is transmitted.
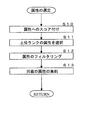
- FIG. 4 is a flowchart showing an operation example of extracting a web page in the information processing server 10.
- FIG. 5 is an explanatory diagram illustrating an example of a web page of the information providing server 20.
- FIG. 6 is an explanatory diagram showing an example of the source code of the web page.
- FIG. 7 is a schematic diagram illustrating an example of an attribute description pattern stored in the attribute description pattern DB.
- FIG. 8 is a schematic diagram illustrating an example of how attributes and attribute values are extracted.
- FIG. 9 is a schematic diagram illustrating an example of extracted attributes / attribute values.
- FIG. 10 is a schematic diagram showing an example of the generated product catalog.
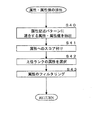
- FIG. 11 is a flowchart illustrating an example of an attribute selection subroutine in the information processing server 10.
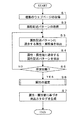
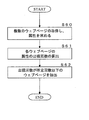
- the information processing server 10 acquires a plurality of web pages (step S1). Specifically, the system control unit 14 of the information processing server 10 sends all web pages in this category through the communication unit 11 for products belonging to the same category of the shopping site operated by the information providing server 20. Obtained from the information DB 22a. More specifically, as shown in FIG. 5, a web page 50 including text data of text portions 51, 52, 53, 54 is acquired. Further, the source code of the web page 50 is described in a markup language such as HTML as shown in FIG. As described above, the system control unit 14 and the communication unit 11 of the information processing server 10 acquire a web page that acquires a plurality of web pages belonging to the same category in the category for classifying the target described in the web page. It functions as an example of means.
- the information processing server 10 acquires an attribute description pattern (step S2). Specifically, the system control unit 14 of the information processing server 10 uses the attribute description pattern list of the attribute description pattern DB 12a as the initial data of the bootstrap method in the following steps S3 to S5, as shown in FIG. Get attribute description pattern.
- the attribute description pattern is divided into a front part, a central part, and a rear part.
- the front part “[”, central part ”: "And rear”] ".
- a phrase between the front part and the middle part is an attribute name
- a phrase between the middle part and the rear part is an attribute value.
- the attribute description pattern may include an HTML tag element.
- the system control unit 14 of the information processing server 10 functions as an example of an initial data acquisition unit that acquires, as initial data, an attribute description pattern used to describe a target attribute described in a web page.
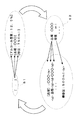
- the information processing server 10 extracts attributes / attribute values that match the attribute description pattern (step S3). Specifically, the system control unit 14 of the information processing server 10 selects a part of a phrase that matches the attribute description pattern 61 or the like (for example, "" from among a plurality of web pages such as the web page 50) as shown in FIG. [Type: XXX] ”) is extracted, and the attribute name“ type ”, the attribute value“ XXX ”corresponding to the attribute name“ type ”, and the like are extracted. The extracted attribute name and attribute value are stored in the attribute / attribute value DB 12b as an attribute list.
- attributes and attribute values include [accommodation fee: XXX] in the case of travel-related services, and [venue: XXX] in the case of introducing events that are blogs.
- the system control unit 14 of the information processing server 10 functions as an example of an attribute extraction unit that extracts attribute-related words having attributes that match the attribute description pattern from a plurality of web pages. Further, the system control unit 14 of the information processing server 10 functions as an example of an attribute extraction unit that extracts an attribute name of an attribute as an attribute related word. Further, the system control unit 14 of the information processing server 10 functions as an attribute list generation unit that generates an attribute list from the extracted attribute-related words.
- the information processing server 10 extracts an attribute description pattern that matches the attribute / attribute value (step S4).
- the system control unit 14 of the information processing server 10 conforms to the attribute / attribute value 62 (for example, the attribute name “product type” and the attribute value “XXX”) (for example, , ⁇ Td> varieties ⁇ / td> ⁇ td> OO ⁇ td>), and attribute description patterns are extracted from a plurality of web pages such as the web page 50.
- the extracted attribute description pattern is added to the attribute description pattern list and stored in the attribute description pattern DB 12a as shown in FIG. For example, as with “capacity * ml”, for the attribute value, a wild card may be used instead of the extracted attribute value itself.
- the system control unit 14 of the information processing server 10 functions as an example of an attribute description pattern extracting unit that extracts an attribute description pattern that matches an attribute-related word from a plurality of web pages.
- the system control unit 14 of the information processing server 10 functions as a pattern list generation unit that generates a pattern list of the extracted attribute description patterns.
- the information processing server 10 determines a predetermined number of times (step S5). Specifically, the system control unit 14 of the information processing server 10 determines whether or not the number of times of repeatedly executing Step S3 and Step S4 has reached a predetermined number. If the predetermined number of times has not been reached (step S5; NO), the system control unit 14 of the information processing server 10 returns to step S3 and extracts new attributes / attribute values based on the extracted new attribute description pattern. . The system control unit 14 of the information processing server 10 repeats step S3 and step S4 until the predetermined number of times is reached.
- the system control unit 14 of the information processing server 10 performs the attribute description pattern acquisition step for acquiring the attribute description pattern used for describing the attribute of the product in steps S2 to S4, and the attribute description from the plurality of web pages.
- the system control unit 14 of the information processing server 10 functions as an example of a repeating unit that alternately repeats the attribute extracting unit and the attribute description pattern extracting unit.
- step S6 the information processing server 10 selects an attribute (step S6). Specifically, the system control unit 14 of the information processing server 10 selects an attribute from the attribute name and attribute value extracted in step S3 by an attribute selection subroutine. In the attribute selection subroutine, the system control unit 14 of the information processing server 10 ranks the attributes by ranking, removes noise attributes, and collects synonym attributes (details will be described later). As shown in FIG. 9, in the category “wine”, attribute values are obtained for the attribute names “variety”, “producer”, and the like.
- the information processing server 10 generates a product catalog based on the attributes and attribute values (step S7). Specifically, as illustrated in FIG. 10, the system control unit 14 of the information processing server 10 arranges attribute names for each product, and generates a product catalog by combining the attribute name and the attribute value. In addition, as shown in FIG. 10, you may add the image of goods to a goods catalog. The order of the attribute names may be determined based on attribute scores to be described later.
- the system control unit 14 of the information processing server 10 functions as an example of a catalog generating unit that generates a product catalog in which attribute related words are described based on the extracted attribute related words.
- the system control unit 14 of the information processing server 10 applies the steps S1 to S7 to web pages of other categories to generate a product catalog. Then, the system control unit 14 of the information processing server 10 transmits the generated product catalog information to the information providing server 20 and stores it in the product catalog DB 22c.
- the information processing server 10 scores an attribute (step S10). Specifically, when the shopping site has a plurality of stores that sell products, that is, when a cyber mall is configured, the system control unit 14 of the information processing server 10 determines the store having the web page in which the attribute name appears. The number is obtained and used as the attribute score.
- Attribute names of examples of attribute-related words that appear on web pages of various stores are based on the assumption that they are appropriate as attributes. For example, in a wine web page, an appropriate attribute “variety” appears on web pages of various stores. On the other hand, an inappropriate attribute that matches any attribute description turn is often obtained only from a web page of one store, and the attribute score tends to be low.
- the system control unit 14 of the information processing server 10 functions as an example of attribute scoring means for scoring attribute-related words. Further, the system control unit 14 of the information processing server 10 is based on the number of stores of web pages in which attribute-related words appear in a website having a plurality of stores that sell the target described in the web page. It functions as an example of attribute scoring means for scoring attribute related words.
- the information processing server 10 selects an attribute with a higher rank (step S11). Specifically, the system control unit 14 of the information processing server 10 ranks attribute names in descending order of attribute scores, and selects attribute names having a predetermined rank or higher. As described above, the system control unit 14 of the information processing server 10 functions as an example of an attribute selection unit that ranks attribute related words in order of scores and selects attribute related words of a predetermined rank or higher.
- the information processing server 10 performs attribute filtering (step S12). Specifically, the system control unit 14 of the information processing server 10 performs attribute filtering using the appearance probability of the attribute name in each category. Attribute filtering is performed based on the assumption that attribute names that appear in other categories are not suitable as attributes. For example, a phrase such as “free shipping” that is unsuitable as an attribute appears on a large number of web pages, and the appearance probabilities in each category have similar values. On the other hand, the attribute name “variety” often appears on the web page of the wine category, but does not appear in the category of golf drivers, shoes, etc., so the appearance probability in the wine category is the appearance probability in the categories other than wine. Higher than. Thus, the system control unit 14 of the information processing server 10 functions as an example of an attribute filter unit that removes attribute-related words that appear in a plurality of web pages belonging to a category different from the category.
- the information processing server 10 aggregates synonymous attributes (step S13).
- Some attributes have the same concept. For example, in the wine category, “variety”, “grape variety”, “grape variety”, “separage”, and “strawberry variety” are synonymous attribute names.
- the system control unit 14 of the information processing server 10 uses the synonym dictionary, calculates the degree of similarity between the attribute names, or uses the attribute value corresponding to the attribute name to determine the attribute name of the synonymous attribute. Summarize. Instead of aggregating attribute names of synonymous attributes, attribute names of attributes of similar concepts may be aggregated.
- the attribute that the attribute B has A value obtained by multiplying the ratio of the attribute value common to the value and the ratio of the attribute value common to the attribute value of the attribute A among the attribute values of the attribute B is set to a similar degree, or based on these ratios.
- a value obtained by calculating and multiplying entropy is set as a similarity degree
- a Jackard coefficient is set as a similarity degree
- the number of types of common attribute values of attribute A and attribute B is set as a similarity degree.
- the system control unit 14 of the information processing server 10 functions as an example of an attribute name similarity determination unit that determines whether or not the attribute names are similar.
- the system control unit 14 of the information processing server 10 functions as an example of an attribute name aggregation unit that aggregates attribute names determined to be similar by the attribute name similarity determination unit.
- the system control unit 14 of the information processing server 10 includes an attribute extraction unit that extracts an attribute name and an attribute value corresponding to the attribute name as an attribute-related word, and an attribute name aggregation unit that collects the attribute name based on the attribute value Functions as an example.
- a plurality of web pages having the same category for classifying the target described in the web page is acquired, and the attribute association related to the target attribute described in the web page is used as initial data.
- the attribute description pattern used to describe the word or attribute of interest extract attribute-related words of attributes that match the attribute description pattern from multiple web pages, and attribute-related words from multiple web pages.
- the attribute list and the pattern list are expanded by bootstrap to extract attributes other than the attribute given as the initial value can do. Moreover, the similarity of a web page can be determined by this extracted attribute. Moreover, it becomes easy for a user to reach a desired product by using a product catalog related to a web page, and the convenience of the user can be improved.
- system control unit 14 of the information processing server 10 when the system control unit 14 of the information processing server 10 generates an attribute list from the extracted attribute-related words and generates a pattern list of the extracted attribute description pattern, an attribute name, an attribute value, etc. for each category Attribute related words and attribute description pattern information can be stored.
- system control unit 14 of the information processing server 10 scores attribute related words and selects an attribute related word of a higher rank, an attribute representing a product or the like in the selected attribute related word or a blog Increases attribute accuracy.
- the system control unit 14 of the information processing server 10 scores attribute-related words based on the number of stores of web pages in which attribute-related words appear in a website having a plurality of stores selling the target.
- the precision of the attribute showing goods etc. becomes high. For example, if the number of products handled by stores and the number of web pages differ greatly, it will be easily affected by stores that handle many products, but by assigning attribute-related terms based on the number of stores, The influence of a specific store can be eliminated.
- system control unit 14 of the information processing server 10 removes attribute-related words that appear in a plurality of web pages belonging to other categories, by narrowing down to attribute-related words specific to the target category, The accuracy of the attribute to represent and the attribute of the blog increases.
- system control unit 14 of the information processing server 10 extracts an attribute name of an attribute as an attribute-related word, it is possible to accurately acquire an attribute / attribute name included in the same category. Also, web pages registered in the wrong category can be extracted by the attribute name.
- system control unit 14 of the information processing server 10 determines whether or not the attribute names are similar and aggregates the attribute names determined to be similar, the duplicate attribute names are removed, and the attribute name is It becomes easy to use.
- system control unit 14 of the information processing server 10 extracts attribute names and attribute values corresponding to the attribute names as attribute-related words and aggregates the attribute names based on the attribute values, the attribute value directly connected to the attribute name This makes it easier to aggregate attribute names.
- the system control unit 14 of the information processing server 10 acquires the target supply source web page, and the initial data acquisition means, attribute extraction means, and attribute description pattern extraction means from the target supply source web page.
- the supplier target attribute related words are extracted and the source target attribute related words are compared with the attribute related words, attributes included in the same category can be acquired with higher accuracy.
- it is possible to improve the reliability of the catalog by taking in the official object information regarding the object such as a product and determining the accuracy of the generated catalog.
- the system control unit 14 of the information processing server 10 when the system control unit 14 of the information processing server 10 generates a catalog in which attribute-related words are described based on the extracted attribute-related words, the user uses the catalog related to the web page to select a desired product, etc. It is easy to reach the target of the user, and the convenience of the user can be improved.
- FIG. 12 is a flowchart showing an operation example of the first modified example of catalog generation of products and the like.
- FIG. 13 is a schematic diagram illustrating an example of how attributes and attribute values are extracted according to the first modification.
- the present modification is that the initial data in the bootstrap method is not attribute description patterns but attributes / attribute values.
- Steps S22 to S24 are different steps from the above embodiment.
- the attribute / attribute value DB 12b stores initial data of attributes / attribute values.
- the information processing server 10 acquires a plurality of web pages as in step S1 (step S21).
- the information processing server 10 acquires the attribute / attribute value (step S22). Specifically, the system control unit 14 of the information processing server 10 uses the attribute / attribute value list of the attribute / attribute value DB 12b as the initial data of the bootstrap method in the following steps S23 to S25 as shown in FIG. The initial attribute / attribute value 66 is acquired. As described above, the system control unit 14 of the information processing server 10 functions as an example of an initial data acquisition unit that acquires attribute-related words related to the product attributes as initial data.
- the information processing server 10 extracts an attribute description pattern that matches the attribute / attribute value (step S23). Specifically, the system control unit 14 of the information processing server 10 selects a part of a phrase that matches the attribute / attribute value 66 or the like (for example, from among a plurality of web pages such as the web page 50) as shown in FIG. “[Product: XXX]”) is extracted, and attribute description pattern “[:]”, etc. is extracted. The extracted attribute description pattern is stored in the attribute description pattern DB 12a as an attribute description pattern list. Here, the attribute description pattern is extracted using the wild card and the attribute / attribute value.
- the information processing server 10 extracts attributes / attribute values that match the attribute description pattern (step S24). Specifically, as shown in FIG. 13, the system control unit 14 of the information processing server 10 generates an attribute description pattern 67 (for example, front part “[”, middle part “:”, rear part “]” of the attribute description pattern). For example, “[alcohol content: 12.5%”] is extracted, and attributes / attribute values are extracted from a plurality of web pages such as the web page 50. The extracted attribute / attribute value is added to the attribute / attribute value list and stored in the attribute / attribute value DB 12b.
- an attribute description pattern 67 for example, front part “[”, middle part “:”, rear part “]” of the attribute description pattern.
- attributes / attribute values are extracted from a plurality of web pages such as the web page 50.
- the extracted attribute / attribute value is added to the attribute / attribute value list and stored in the attribute / attribute value DB 12b.
- steps S25 to S28 are the same as steps S5 to S8.
- step S22 to step S24 the system control unit 14 of the information processing server 10 acquires a plurality of web pages belonging to the same category in the category for classifying the product, and An attribute related word acquisition step for acquiring an attribute related word related to a product attribute, and an attribute description pattern used to describe the attribute, and extracting an attribute description pattern that matches the attribute related word from a plurality of web pages An attribute description pattern extraction step and an attribute related word extraction step of further extracting attribute related words used for the attribute description pattern extraction means from a plurality of web pages based on the extracted attribute related words are executed.
- a category for classifying a product a plurality of web pages belonging to the same category are acquired, attribute related words related to the attribute of the product are acquired from the attribute / attribute value DB 12b, Attribute description pattern used for description, which extracts attribute description patterns that match attribute-related words from multiple web pages. Based on the extracted attribute-related words, attribute-related words used for attribute description pattern extraction , By further extracting from a plurality of web pages and generating a product catalog describing attribute related words based on the extracted attribute related words, the user can use the product catalog related to web pages to It becomes easier to reach the product, and the convenience of the user can be improved.
- FIG. 14 is a flowchart showing an operation example of the second modified example of catalog generation of products and the like.
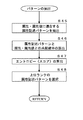
- FIG. 15 is a flowchart illustrating an example of an attribute / attribute value extraction subroutine.
- FIG. 16 is a flowchart illustrating an example of a subroutine for attribute description pattern extraction.
- the information processing server 10 acquires a plurality of web pages (step S31) and acquires an attribute description pattern (step S32), similarly to step S1 and step S2.
- the information processing server 10 extracts attributes / attribute values based on the attribute description pattern (step S33). Specifically, the system control unit 14 of the information processing server 10 extracts attributes / attribute values by an attribute / attribute value extraction subroutine. In the attribute / attribute value extraction subroutine, the system control unit 14 of the information processing server 10 extracts attributes / attribute values that match the attribute description pattern, scores attributes, and assigns attributes of higher ranks. Select or filter attributes.
- the information processing server 10 extracts an attribute description pattern based on the attribute / attribute value (step S34). Specifically, the system control unit 14 of the information processing server 10 extracts an attribute description pattern by an attribute description pattern extraction subroutine. In the attribute description pattern extraction subroutine, the system control unit 14 of the information processing server 10 extracts an attribute description pattern that matches the attribute / attribute value, or calculates a co-occurrence probability between the attribute description pattern and the attribute / attribute value. Or calculating a score or selecting an attribute description pattern of a higher rank.
- the information processing server 10 determines the predetermined number of times similarly to step S5 (step S35).
- the information processing server 10 aggregates synonymous attributes (step S36). Specifically, the system control unit 14 of the information processing server 10 aggregates the attribute names having the same attributes with respect to the attribute names obtained by the bootstrap method in steps S33 to S35, as in step S13. .
- step S37 the information processing server 10 generates a product catalog based on attributes and attribute values (step S37).
- the information processing server 10 extracts attributes / attribute values that match the attribute description pattern (step S40). Specifically, the system control unit 14 of the information processing server 10 extracts attributes / attribute values that match the attribute description pattern, as in step S3.
- the information processing server 10 performs scoring on the attribute (step S41) in the same manner as steps S10 to S12 in the attribute selection subroutine, selects an attribute with a higher rank (step S42), and sets the attribute. Filtering is performed (step S43).
- the information processing server 10 extracts an attribute description pattern that matches the attribute / attribute value in the same manner as in step S4 (step S45).
- I is a set of attribute / attribute value pairs having an attribute / attribute value set i as an element
- T is an attribute description pattern set having an attribute description pattern t as an element.
- the information processing server 10 selects the attribute description pattern of the higher score (step S48). Specifically, the system control unit 14 of the information processing server 10 ranks attribute description patterns having a high entropy H (t) as a score, and selects attribute description patterns having a predetermined rank or higher. As described above, the system control unit 14 of the information processing server 10 functions as an example of an attribute description pattern scoring unit that scores an attribute description pattern. The system control unit 14 of the information processing server 10 functions as an example of an attribute description pattern selection unit that ranks attribute description patterns in order of scores and selects attribute description patterns having a predetermined rank or higher. Further, the system control unit 14 of the information processing server 10 functions as an example of an attribute description pattern scoring unit that scores an attribute description pattern based on the number of co-occurrence in which an attribute related word and an attribute description pattern appear together. .
- steps S46 to S48 are used as a step for selecting an attribute description pattern with respect to the attribute description pattern list obtained up to step S5, and unnecessary attribute description patterns can be omitted.
- the system control unit 14 of the information processing server 10 scores the attribute description pattern and selects an attribute description pattern having a higher rank, the accuracy of the attribute description pattern for extracting the attribute / attribute value is high. Become.
- system control unit 14 of the information processing server 10 scores an attribute description pattern based on the number of co-occurrence in which both attribute-related words and attribute description patterns appear, a score for selecting the attribute description pattern The accuracy of.
- the attribute score may be the number of web pages in which attribute names appear instead of the number of stores.
- the system control unit 14 of the information processing server 10 scores attribute-related words based on the number of hits of attribute-related word searches as attribute scoring means.
- the present invention can be applied to other than cyber malls where many stores gather.
- the accuracy of the attribute / attribute value of the product catalog is determined based on this attribute / attribute value. Good. In this case, the reliability of the product catalog can be improved by incorporating official product information about the product and determining the accuracy of the generated product catalog.
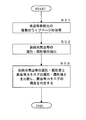
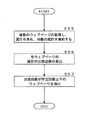
- the information processing server 10 acquires a web page of a target supply source such as a manufacturer or import sales source of a product or the like through a communication unit (step S51).
- the system control unit 14 of the information processing server 10 refers to the URL stored in the information DB 22a and the web page of the supply source corresponding to the product ID of each product as shown in FIG. To get.
- the product ID may be a product ID preliminarily attached to the web page or a product ID extracted from the text data of the web page in the shopping site.
- the system control unit 14 and the communication unit 11 of the information processing server 10 function as an example of a web page acquisition unit that acquires a web page of a target supply source such as a product.
- the information processing server 10 extracts the attribute / attribute value of the supplier product (step S52). Specifically, the system control unit 14 of the information processing server 10 supplies the product from the web page of the product supply source in steps S2 to S6, steps S22 to S26, and steps S32 to S36. Extract attributes and attribute values for the original web page.
- the information processing server 10 compares the attribute / attribute value of the supply target such as the supplier product with the attribute / attribute value of the product catalog to determine the accuracy of the product catalog. Specifically, the system control unit 14 of the information processing server 10 determines whether or not there is an attribute name of a supply source target such as a supply source product in the attribute name of the product etc. catalog, and if there is an attribute name, Compare whether the attribute values match. Then, when there are few identical attribute names or attribute values do not match, it is determined that the accuracy of the generated product catalog is low. If the attribute values do not match, it can be considered an input error on the store side.
- a supply source target such as a supply source product in the attribute name of the product etc. catalog
- the system control unit 14 and the communication unit 11 of the information processing server 10 can supply the supply source from the web page of the supply source of the product or the like by the initial data acquisition unit, the attribute extraction unit, and the attribute description pattern extraction unit. It functions as an example of attribute-related word comparison means that extracts a target attribute-related word and compares the supplier-target attribute-related word with the attribute-related word.
- FIG. 19 is a schematic diagram illustrating an example of a generated product catalog.
- the attribute name “production year” is grouped by the attribute value “1995” and the attribute value “1996”.
- the system control unit 14 of the information processing server 10 obtains an attribute related word in step S6, step S26, step S36, etc.
- a web page having the attribute name “production year” and the attribute value “1995” are collected, and information on a plurality of web pages is grouped based on attribute-related words.
- the product names of the products and other attributes are grouped by the attribute value for the attribute name “production year”.
- the web pages can be grouped according to common attributes.
- the utility value is increased by reflecting the result in a search result that is easy for the user to see.
- FIG. 20 is a flowchart illustrating an operation example of extracting a web page in the information processing system according to the second embodiment.
- the information processing server 10 acquires a plurality of web pages and obtains attributes (step S60). Specifically, the system control unit 14 of the information processing server 10 acquires a plurality of web pages as in steps S1 to S6, and obtains the attribute name and attribute value of the selected attribute. Alternatively, the system control unit 14 of the information processing server 10 acquires a plurality of web pages as in steps S21 to S26, and obtains the attribute name and attribute value of the selected attribute. *
- the information processing server 10 calculates the number of appearances of each web page attribute (step S61). Specifically, the system control unit 14 of the information processing server 10 calculates the number of appearances of the attribute name of the selected attribute on each web page acquired in step S60. Note that the number of appearances is calculated in consideration of synonyms of the aggregated attribute names.
- the information processing server 10 extracts web pages whose number of appearances is a predetermined number or less (step S62). Specifically, the system control unit 14 of the information processing server 10 is the web page acquired in step S60, and the number of appearances of the attribute name of the selected attribute is zero, that is, the web page in which the attribute name of the selected attribute does not appear To extract. When there are a plurality of attribute names, a web page in which no attribute name appears is extracted. The system control unit 14 of the information processing server 10 determines that the extracted web page is a web page registered in an incorrect category.
- the system control unit 14 of the information processing server 10 functions as an example of a web page extracting unit that extracts a web page in which the number of appearances of attribute-related words is a predetermined number or less from a plurality of web pages.
- the system control unit 14 of the information processing server 10 functions as an example of a web page extracting unit that extracts a web page in which the number of appearances of attribute-related words is zero.
- the system control unit 14 of the information processing server 10 applies steps S60 to S62 to web pages of other categories, and extracts web pages registered in the wrong category. And the system control part 14 of the information processing server 10 transmits the information regarding the extracted web page to the shop owner terminal 30 in order to notify the shop owner, or moves the extracted web page to the correct category.
- a plurality of web pages having the same category for classifying the target described in the web page is acquired, and the attribute association related to the target attribute described in the web page is used as initial data.
- the attribute description pattern used to describe the word or attribute of interest, extract attribute-related words of attributes that match the attribute description pattern from multiple web pages, and attribute-related words from multiple web pages The attribute description pattern that conforms to the above is extracted, and a web page registered in the wrong category is extracted from a plurality of web pages by extracting a web page in which the number of appearances of attribute-related words is a predetermined number or less. it can.
- FIG. 21 is a flowchart showing an operation example of the first modification of web page extraction.
- the information processing server 10 acquires a plurality of web pages, obtains attributes, and aggregates synonymous attributes (step S65), as in steps S31 to S36.
- step S66 the information processing server 10 calculates the number of appearances of the attribute name of each web page attribute (step S66), and extracts a web page with the number of appearances equal to or less than the predetermined number (step S66). Step S67).
- the system control unit 14 of the information processing server 10 scores the attribute description pattern and selects an attribute description pattern having a higher rank, the accuracy of the attribute description pattern for extracting the attribute / attribute value is high. Become.
- the system control unit 14 of the information processing server 10 scores the attribute description pattern based on the number of co-occurrence of the attribute related word and the attribute description pattern, the accuracy of the score for selecting the attribute description pattern is high. Get higher.
- the attribute score may be the number of web pages in which attribute names appear instead of the number of stores.
- the system control unit 14 of the information processing server 10 scores attribute-related words based on the number of hits of attribute-related word searches as attribute scoring means.
- the present invention can be applied to other than cyber malls where many stores gather.
- system control unit 14 of the information processing server 10 may extract, as a web page extracting unit, a web page in which a ratio of the number of occurrences of the attribute related word is zero or more in a plurality of attribute related words. Further, the number of appearances of attribute-related words may not be zero, but may be based on the number of occurrences of a small number.
- the present invention is not limited to the above embodiments.
- Each of the embodiments described above is an exemplification, and any configuration that has substantially the same configuration as the technical idea described in the claims of the present invention and has the same operational effects can be used. It is included in the technical scope of the present invention.
- Network 5 Server system 10: Information processing server (information processing apparatus) 12a: attribute description pattern DB 12b: attribute / attribute name DB 20: Information providing server 22c: Product catalog DB
Abstract
Description
を更に備えたことを特徴とする。
(第1実施形態)
まず、本発明の第1実施形態に係る情報処理システムの構成および概要機能について、図1を用いて説明する。
(2.1 情報処理サーバ10の構成および機能)
次に、情報処理サーバ10の構成および機能について、図2を用いて説明する。
次に、情報提供サーバ20の構成および機能について、図3を用いて説明する。
図3は、情報提供サーバ20の概要構成の一例を示すブロック図である。
次に、本発明の一実施形態に係る情報処理システム1のカタログ生成システムとしての動作について図4~図11を用いて説明する。
まず、商品等のカタログ生成の流れについて、図4を用いて説明する。
次に、属性の選定のサブルーチンについて、図11を用いて説明する。
次に、商品等のカタログ生成システムの動作の第1変形例について図12および図13に基づきについて説明する。
次に、商品等のカタログ生成システムの動作の第2変形例について図14~図16に基づきについて説明する。本変形例では、ブートストラップ法のステップにおいて、属性の選定を行ったり、属性記述パターンの選定を行ったりしている。
まず、図14に示すように、情報処理サーバ10は、ステップS1およびステップS2と同様に、複数のウェブページを取得し(ステップS31)、属性記述パターンを取得する(ステップS32)。
次に、属性・属性値抽出のサブルーチンについて、図15を用いて説明する。
次に、属性記述パターン抽出のサブルーチンについて、図16を用いて説明する。
Pt(i)=f(i,t)/Nt ・・・(1)
ここで、Ntは、抽出した属性記述パターンtの数である。
H(t)=-Σi∈IPt(i)×log2Pt(i) ・・・(2)
図19は、生成された商品等カタログの一例を示す模式図である。
次に、本発明の第2実施形態に係る情報処理システム1の動作について、図を用いて説明する。なお、前記第1実施形態と同一または対応する部分には、同一の符号を用いて異なる構成および作用のみを説明する。その他の実施形態および変形例も同様とする。
次に、本発明の第2実施形態に係る情報処理システム1のウェブページ抽出システムとしての動作について図20を用いて説明する。
まず、ウェブページの抽出の流れについて、図20を用いて説明する。
図20は、第2実施形態に係る情報処理システムにおいてウェブページを抽出する動作例を示すフローチャートである。
次に、ウェブページ抽出システムの動作の第1変形例について図21を用いて説明する。本変形例では、ブートストラップ法のステップにおいて、属性の選定を行ったり、属性記述パターンの選定を行ったりしている。
まず、図21に示すように、情報処理サーバ10は、ステップS31~ステップS36と同様に、複数のウェブページを取得し、属性を求め、同義の属性を集約する(ステップS65)。
5:サーバシステム
10:情報処理サーバ(情報処理装置)
12a:属性記述パターンDB
12b:属性・属性名DB
20:情報提供サーバ
22c:商品等カタログDB
Claims (21)
- ウェブページに記載されている対象を分類するカテゴリが同一である複数のウェブページを取得するウェブページ取得手段と、
初期データとして、前記ウェブページに記載されている対象の属性に関連した属性関連語、または、当該対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段と、
前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段と、
前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを抽出する属性記述パターン抽出手段と、
を備えたことを特徴とする情報処理装置。 - 請求項1に記載の情報処理装置において、
前記属性抽出手段および前記属性記述パターン抽出手段を交互に繰り返す繰返手段を更に備えたことを特徴とする情報処理装置。 - 請求項1または請求項2に記載の情報処理装置において、
前記属性抽出手段が、前記属性関連語として、前記属性の属性名を抽出することを特徴とする情報処理装置。 - 請求項1から請求項3のいずれか1項に記載の情報処理装置において、
抽出された前記属性関連語から属性リストを生成する属性リスト生成手段と、
抽出された前記属性記述パターンのパターンリストを生成するパターンリスト生成手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項1から請求項4のいずれか1項に記載の情報処理装置において、
前記属性関連語のスコア付けを行う属性スコアリング手段と、
前記スコアの順に前記属性関連語のランク付けを行い、所定のランク以上の属性関連語を選択する属性選択手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項5に記載の情報処理装置において、
前記属性スコアリング手段が、前記属性関連語の検索のヒット件数に基づき、前記属性関連語のスコア付けを行うことを特徴とする情報処理装置。 - 請求項5に記載の情報処理装置において、
前記属性スコアリング手段が、前記対象を販売する複数の店舗を有するウェブサイトにおいて、前記属性関連語が出現しているウェブページの前記店舗の数に基づき、前記属性関連語のスコア付けを行うことを特徴とする情報処理装置。 - 請求項1から請求項7のいずれか1項に記載の情報処理装置において、
前記カテゴリとは異なるカテゴリに属している複数のウェブページにおいて出現する前記属性関連語を取り除く属性フィルタ手段を更に備えたことを特徴とする情報処理装置。 - 請求項1から請求項8のいずれか1項に記載の情報処理装置において、
前記属性記述パターンのスコア付けを行う属性記述パターン・スコアリング手段と、
前記スコアの順に前記属性記述パターンのランク付けを行い、所定のランク以上の属性記述パターンを選択する属性記述パターン選択手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項9に記載の情報処理装置において、
前記属性記述パターン・スコアリング手段が、前記属性関連語と前記属性記述パターンとが共に出現する共起数に基づき前記属性記述パターンのスコア付けを行うことを特徴とする情報処理装置。 - 請求項1から請求項10のいずれか1項に記載の情報処理装置において、
前記属性名同士が類似であるか否かを判定する属性名類似判定手段と、
前記属性名類似判定手段により類似と判定された属性名を集約する属性名集約手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項11に記載の情報処理装置において、
前記属性抽出手段が、前記属性関連語として、前記属性名および前記属性名に対応する属性値を抽出し、
前記属性名集約手段が、前記属性値に基づき前記属性名を集約することを特徴とする情報処理装置。 - 請求項1から請求項10のいずれか1項に記載の情報処理装置において、
前記ウェブページ取得手段が、前記対象の供給元のウェブページを取得し、
前記初期データ取得手段、前記属性抽出手段、および、前記属性記述パターン抽出手段により、前記対象の供給元のウェブページから供給元対象属性関連語を抽出し、前記供給元対象属性関連語と前記属性関連語とを比較する属性関連語比較手段を更に備えたことを特徴とする情報処理装置。 - 請求項1から請求項13のいずれか1項に記載の情報処理装置において、
抽出された前記属性関連語に基づき、前記属性関連語が記載されたカタログを生成するカタログ生成手段を更に備えたことを特徴とする情報処理装置。 - 請求項1から請求項14のいずれか1項に記載の情報処理装置において、
前記複数のウェブページから、前記属性関連語の出現回数が所定回数以下のウェブページを抽出するウェブページ抽出手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項15に記載の情報処理装置において、
前記ウェブページ抽出手段が、前記属性関連語の出現回数がゼロのウェブページを抽出することを特徴とする情報処理装置。 - 請求項1から請求項16のいずれか1項に記載の情報処理装置において、
前記属性関連語に基づき、前記複数のウェブページをグルーピングするウェブページ・属性グルーピング手段を更に備えたことを特徴とする情報処理装置。 - 情報処理装置が情報処理をする情報処理方法において、
ウェブページに記載されている対象を分類するカテゴリが同一である複数のウェブページを取得するウェブページ取得ステップと、
前記ウェブページに記載されている対象の属性の記述に用いられる属性記述パターンを取得する属性記述パターン取得ステップと、
前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出ステップと、
抽出された前記属性関連語に基づき、前記属性抽出ステップで使用する前記属性記述パターンを、前記複数のウェブページから、更に抽出する属性記述パターン抽出ステップと、
を有することを特徴とする情報処理方法。 - 情報処理装置が情報処理をする情報処理方法において、
ウェブページに記載されている対象を分類するカテゴリが同一である複数のウェブページを取得するウェブページ取得ステップと、
前記ウェブページに記載されている対象の属性に関連した属性関連語を取得する属性関連語取得ステップと、
前記属性の記述に用いられる属性記述パターンであって、前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを抽出する属性記述パターン抽出ステップと、
抽出された前記属性関連語に基づき、前記属性記述パターン抽出ステップで使用する属性関連語を、前記複数のウェブページから、更に抽出する属性関連語抽出ステップと、
を有することを特徴とする情報処理方法。 - コンピュータを、
ウェブページに記載されている対象を分類するカテゴリが同一である複数のウェブページを取得するウェブページ取得手段、
初期データとして、前記ウェブページに記載されている対象の属性に関連した属性関連語、または、当該対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段、
前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段、および、
前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを抽出する属性記述パターン抽出手段として機能させることを特徴とする情報処理装置用のプログラム。 - コンピュータを、
ウェブページに記載されている対象を分類するカテゴリが同一である複数のウェブページを取得するウェブページ取得手段、
初期データとして、前記ウェブページに記載されている対象の属性に関連した属性関連語、または、当該対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段、
前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段、および、
前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを抽出する属性記述パターン抽出手段として機能させることを特徴とする情報処理装置用のプログラムを記録したコンピュータ読み取り可能な記録媒体。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP11747560.8A EP2466499A4 (en) | 2010-02-26 | 2011-02-28 | INFORMATION PROCESSING DEVICE, INFORMATION PROCESSING METHOD, INFORMATION PROCESSING DEVICE PROGRAM, AND RECORDING MEDIUM |
| CN201180009354.7A CN102859518B (zh) | 2010-02-26 | 2011-02-28 | 信息处理装置、信息处理方法 |
| US13/503,591 US9514202B2 (en) | 2010-02-26 | 2011-02-28 | Information processing apparatus, information processing method, program for information processing apparatus and recording medium |
| JP2012501906A JP5396533B2 (ja) | 2010-02-26 | 2011-02-28 | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム |
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010043390 | 2010-02-26 | ||
| JP2010043391 | 2010-02-26 | ||
| JP2010043392 | 2010-02-26 | ||
| JP2010-043391 | 2010-02-26 | ||
| JP2010-043392 | 2010-02-26 | ||
| JP2010-043390 | 2010-02-26 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011105606A1 true WO2011105606A1 (ja) | 2011-09-01 |
Family
ID=44507000
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/054510 WO2011105606A1 (ja) | 2010-02-26 | 2011-02-28 | 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9514202B2 (ja) |
| EP (1) | EP2466499A4 (ja) |
| JP (1) | JP5396533B2 (ja) |
| CN (1) | CN102859518B (ja) |
| WO (1) | WO2011105606A1 (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013122205A1 (ja) * | 2012-02-15 | 2013-08-22 | 楽天株式会社 | 辞書生成装置、辞書生成方法、辞書生成プログラム、及びそのプログラムを記憶するコンピュータ読取可能な記録媒体 |
| JP2014507716A (ja) * | 2011-01-25 | 2014-03-27 | アリババ・グループ・ホールディング・リミテッド | 分類された誤配置の識別 |
| JP2015035082A (ja) * | 2013-08-08 | 2015-02-19 | 株式会社日立製作所 | 商品購入情報作成支援システム |
| JP5887031B1 (ja) * | 2015-05-29 | 2016-03-16 | 楽天株式会社 | 商品特定装置、商品特定方法及び商品特定プログラム |
| JP2020046896A (ja) * | 2018-09-19 | 2020-03-26 | Zホールディングス株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP2021149560A (ja) * | 2020-03-19 | 2021-09-27 | ヤフー株式会社 | 情報処理装置、情報処理システム、情報処理方法、およびプログラム |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2916238A4 (en) * | 2012-10-19 | 2016-06-15 | Rakuten Inc | CORPUS CREATIVE DEVICE, CORPUSED CREATION PROCESS AND CORPUSED CREATING PROGRAM |
| IL224482B (en) | 2013-01-29 | 2018-08-30 | Verint Systems Ltd | System and method for keyword spotting using representative dictionary |
| IL226056A (en) * | 2013-04-28 | 2017-06-29 | Verint Systems Ltd | Keyword Finding Systems and Methods by Adaptive Management of Multiple Template Matching Algorithms |
| CN103617192B (zh) * | 2013-11-07 | 2017-06-16 | 北京奇虎科技有限公司 | 一种数据对象的聚类方法和装置 |
| US9317566B1 (en) | 2014-06-27 | 2016-04-19 | Groupon, Inc. | Method and system for programmatic analysis of consumer reviews |
| US11250450B1 (en) | 2014-06-27 | 2022-02-15 | Groupon, Inc. | Method and system for programmatic generation of survey queries |
| US9444797B2 (en) * | 2014-07-10 | 2016-09-13 | Empire Technology Development Llc | Protection of private data |
| US10878017B1 (en) * | 2014-07-29 | 2020-12-29 | Groupon, Inc. | System and method for programmatic generation of attribute descriptors |
| US20160092519A1 (en) | 2014-09-26 | 2016-03-31 | Wal-Mart Stores, Inc. | System and method for capturing seasonality and newness in database searches |
| US9965788B2 (en) | 2014-09-26 | 2018-05-08 | Wal-Mart Stores, Inc. | System and method for prioritized product index searching |
| US10977667B1 (en) | 2014-10-22 | 2021-04-13 | Groupon, Inc. | Method and system for programmatic analysis of consumer sentiment with regard to attribute descriptors |
| JP6389141B2 (ja) * | 2015-04-07 | 2018-09-12 | 東芝テック株式会社 | サーバおよびプログラム |
| IL242219B (en) | 2015-10-22 | 2020-11-30 | Verint Systems Ltd | System and method for keyword searching using both static and dynamic dictionaries |
| IL242218B (en) | 2015-10-22 | 2020-11-30 | Verint Systems Ltd | A system and method for maintaining a dynamic dictionary |
| CN108431585B (zh) * | 2015-12-25 | 2021-09-14 | 富士胶片株式会社 | 信息处理装置及信息处理方法 |
| JP6756224B2 (ja) * | 2016-10-03 | 2020-09-16 | 富士通株式会社 | ネットワーク監視装置、ネットワーク監視プログラム及びネットワーク監視方法 |
| JP6703017B2 (ja) * | 2018-01-22 | 2020-06-03 | ファナック株式会社 | 計測結果分析装置、計測結果分析方法及びプログラム |
| US11615586B2 (en) * | 2020-11-06 | 2023-03-28 | Adobe Inc. | Modifying light sources within three-dimensional environments by utilizing control models based on three-dimensional interaction primitives |
| US11423607B2 (en) | 2020-11-20 | 2022-08-23 | Adobe Inc. | Generating enriched light sources utilizing surface-centric representations |
| US11551409B2 (en) | 2020-12-01 | 2023-01-10 | Institut Mines Telecom | Rendering portions of a three-dimensional environment with different sampling rates utilizing a user-defined focus frame |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002236694A (ja) | 2001-02-07 | 2002-08-23 | Shikoku Kikaku:Kk | ショッピングモールにおける検索システム,分類コード表作成方法,検索方法,商品購入方法 |
| JP2008269106A (ja) * | 2007-04-17 | 2008-11-06 | Osaka Industrial Promotion Organization | スキーマ抽出方法、情報処理装置、コンピュータプログラム及び記録媒体 |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1008262A2 (en) * | 1997-01-17 | 2000-06-14 | The Board Of Regents Of The University Of Washington | Method and apparatus for accessing on-line stores |
| AU1523400A (en) * | 1998-11-12 | 2000-05-29 | Ac Properties B.V. | A system, method and article of manufacture for advanced mobile bargain shopping |
| US7461022B1 (en) * | 1999-10-20 | 2008-12-02 | Yahoo! Inc. | Auction redemption system and method |
| US20020178072A1 (en) * | 2001-05-24 | 2002-11-28 | International Business Machines Corporation | Online shopping mall virtual association |
| JP2004062446A (ja) * | 2002-07-26 | 2004-02-26 | Ibm Japan Ltd | 情報収集システム、アプリケーションサーバ、情報収集方法、およびプログラム |
| US7536323B2 (en) * | 2003-03-26 | 2009-05-19 | Victor Hsieh | Online intelligent multilingual comparison-shop agents for wireless networks |
| US20100174739A1 (en) * | 2007-03-30 | 2010-07-08 | Albert Mons | System and Method for Wikifying Content for Knowledge Navigation and Discovery |
-
2011
- 2011-02-28 US US13/503,591 patent/US9514202B2/en active Active
- 2011-02-28 JP JP2012501906A patent/JP5396533B2/ja active Active
- 2011-02-28 WO PCT/JP2011/054510 patent/WO2011105606A1/ja active Application Filing
- 2011-02-28 EP EP11747560.8A patent/EP2466499A4/en not_active Ceased
- 2011-02-28 CN CN201180009354.7A patent/CN102859518B/zh active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002236694A (ja) | 2001-02-07 | 2002-08-23 | Shikoku Kikaku:Kk | ショッピングモールにおける検索システム,分類コード表作成方法,検索方法,商品購入方法 |
| JP2008269106A (ja) * | 2007-04-17 | 2008-11-06 | Osaka Industrial Promotion Organization | スキーマ抽出方法、情報処理装置、コンピュータプログラム及び記録媒体 |
Non-Patent Citations (3)
| Title |
|---|
| HIROKI SAKACHI: "Shohin Page Karano Zokusei Zokuseichi Chushutsu to Doitsu Shohin Clustering Shuho", PROCEEDINGS OF THE 16TH ANNUAL MEETING OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, 8 March 2010 (2010-03-08), pages 371 - 374, XP008160570 * |
| SATOSHI SEKINE: "Shopping Site ni Okeru Shohin no Doitsusei, Ruijisei no Suitei Shuho", PROCEEDINGS OF THE 16TH ANNUAL MEETING OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, 8 March 2010 (2010-03-08), pages 254 - 257, XP008160537 * |
| See also references of EP2466499A4 * |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014507716A (ja) * | 2011-01-25 | 2014-03-27 | アリババ・グループ・ホールディング・リミテッド | 分類された誤配置の識別 |
| WO2013122205A1 (ja) * | 2012-02-15 | 2013-08-22 | 楽天株式会社 | 辞書生成装置、辞書生成方法、辞書生成プログラム、及びそのプログラムを記憶するコンピュータ読取可能な記録媒体 |
| JP5567749B2 (ja) * | 2012-02-15 | 2014-08-06 | 楽天株式会社 | 辞書生成装置、辞書生成方法、辞書生成プログラム、及びそのプログラムを記憶するコンピュータ読取可能な記録媒体 |
| JPWO2013122205A1 (ja) * | 2012-02-15 | 2015-05-18 | 楽天株式会社 | 辞書生成装置、辞書生成方法、辞書生成プログラム、及びそのプログラムを記憶するコンピュータ読取可能な記録媒体 |
| JP2015035082A (ja) * | 2013-08-08 | 2015-02-19 | 株式会社日立製作所 | 商品購入情報作成支援システム |
| JP5887031B1 (ja) * | 2015-05-29 | 2016-03-16 | 楽天株式会社 | 商品特定装置、商品特定方法及び商品特定プログラム |
| WO2016194062A1 (ja) * | 2015-05-29 | 2016-12-08 | 楽天株式会社 | 商品特定装置、商品特定方法及び商品特定プログラム |
| JP2020046896A (ja) * | 2018-09-19 | 2020-03-26 | Zホールディングス株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP6998282B2 (ja) | 2018-09-19 | 2022-01-18 | ヤフー株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP2021149560A (ja) * | 2020-03-19 | 2021-09-27 | ヤフー株式会社 | 情報処理装置、情報処理システム、情報処理方法、およびプログラム |
| JP7197531B2 (ja) | 2020-03-19 | 2022-12-27 | ヤフー株式会社 | 情報処理装置、情報処理システム、情報処理方法、およびプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US20120209828A1 (en) | 2012-08-16 |
| CN102859518A (zh) | 2013-01-02 |
| CN102859518B (zh) | 2017-03-08 |
| JP5396533B2 (ja) | 2014-01-22 |
| US9514202B2 (en) | 2016-12-06 |
| JPWO2011105606A1 (ja) | 2013-06-20 |
| EP2466499A4 (en) | 2016-10-26 |
| EP2466499A1 (en) | 2012-06-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5396533B2 (ja) | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム | |
| JP5493267B2 (ja) | 商品検索装置および商品検索方法 | |
| KR100834360B1 (ko) | 적응형 카탈로그 페이지 디스플레이 | |
| JP5721818B2 (ja) | 検索におけるモデル情報群の使用 | |
| US8073865B2 (en) | System and method for content extraction from unstructured sources | |
| US20160086239A1 (en) | Method and system for determining allied products | |
| US20100306249A1 (en) | Social network systems and methods | |
| US9697282B2 (en) | Search apparatus, search method, search program, and recording medium | |
| JP2010224873A (ja) | 商品検索サーバ、商品検索方法、プログラム、および記録媒体 | |
| CN106997390A (zh) | 一种设备配件或零部件商品交易信息搜索方法 | |
| US8909558B1 (en) | Appraising a domain name using keyword monetary value data | |
| JP5395195B2 (ja) | サーバシステム、商品レコメンド方法、商品レコメンドプログラムおよびコンピュータプログラムを記録したコンピュータ読み取り可能な記録媒体 | |
| JP2003091552A (ja) | 検索要求情報抽出方法及びその実施システム並びにその処理プログラム | |
| CN111428100A (zh) | 一种数据检索方法、装置、电子设备及计算机可读存储介质 | |
| CN111654714B (zh) | 信息处理方法、装置、电子设备和存储介质 | |
| KR101091991B1 (ko) | 광고 제공 장치 및 방법 | |
| JP6960253B2 (ja) | 商品等評価装置、商品等評価方法、およびプログラム | |
| JP2013101416A (ja) | 検索装置、検索方法、および、検索装置用のプログラム | |
| JP6568284B1 (ja) | 提供装置、提供方法及び提供プログラム | |
| JP2019056962A (ja) | 情報処理装置、情報処理方法および情報処理プログラム | |
| JP2002014994A (ja) | ウェブページ属性管理装置およびウェブページ属性管理方法 | |
| TWI509440B (zh) | An information processing apparatus, an information processing method, an information processing apparatus program, and a recording medium | |
| JP6894875B2 (ja) | ブランド辞書作成装置、商品等評価装置、ブランド辞書作成方法及びプログラム。 | |
| JP5228683B2 (ja) | 商品検索装置および商品検索方法 | |
| WO2011105604A1 (ja) | 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201180009354.7 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11747560 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2012501906 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2011747560 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13503591 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |