WO2011105604A1 - 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 - Google Patents
情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 Download PDFInfo
- Publication number
- WO2011105604A1 WO2011105604A1 PCT/JP2011/054507 JP2011054507W WO2011105604A1 WO 2011105604 A1 WO2011105604 A1 WO 2011105604A1 JP 2011054507 W JP2011054507 W JP 2011054507W WO 2011105604 A1 WO2011105604 A1 WO 2011105604A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- attribute
- web page
- category
- information processing
- word
- Prior art date
Links
Images























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
Definitions
- the present invention relates to a technical field of an information processing apparatus, an information processing method, a program for an information processing apparatus, and a recording medium for analyzing a web page on the Internet.
- Patent Literature 1 classifies a web page into a content category based on the degree of association between the web page and the content category, matches the classified content category with the advertisement category, and selects advertisement data.
- a category classification method added to the web page is disclosed.
- Patent Document 1 morphological analysis is performed on text data of a web page, and feature words included in the web page based on the appearance frequency of a TF (Term Frequency) / IDF (Inverse Document Frequency) value or the like. And the degree of association between the web page and the content category is calculated based on a keyword similar to the feature word. In such feature word extraction, it has been difficult to obtain feature words with high accuracy on the Internet where the trend is rapidly changing.
- TF Term Frequency
- IDF Inverse Document Frequency
- the present invention has been made in view of such a problem, and an example of the problem is to provide an information processing apparatus and the like that can accurately obtain a feature word of a web page.
- the invention acquires category-related word storage means for storing a category-related word related to a category for classifying an object described in a web page, and acquires a web page.
- Web page acquisition means text data extraction means for extracting text data described in the web page, and linguistic analysis of the extracted text data to extract feature word candidates for the web page
- An extraction unit a search query that uses the feature word candidate as a search keyword, a search result acquisition unit that acquires a search result based on the search query, and the category related word storage unit.
- Search result determining means for determining whether or not the category-related word exists in the snippet; and the category in the snippet. Characterized in that and a feature word determining means for the characteristic word candidate is determined to be characteristic word of the web page when re related term is present.
- the invention according to claim 2 is the information processing apparatus according to claim 1, further comprising noise morpheme storage means for storing noise morphemes, wherein the feature word candidate extraction means refers to the noise morpheme storage means. And a noise removing means for removing a noise morpheme from a morpheme obtained by linguistic analysis of the text data by morphological analysis.
- a third aspect of the present invention is the information processing apparatus according to the first or second aspect, further comprising domain name storage means for storing a domain name of a website, wherein the search result determination means is the category related Referring to the word storage means and the domain name storage means, it is determined whether or not the category related word exists in the snippet of the website related to the domain name in the search result.
- the search query receiving means for receiving a user search query from a user terminal and the user search query are used.
- Web page grouping means for grouping a plurality of web pages for each feature word; and transmission means for sending information on the web page grouped for each feature word to the user terminal as a search result. It is characterized by that.
- the web page acquisition unit acquires a plurality of web pages as the web page, and is described in the web page as initial data.
- Attribute extracting means for extracting the attribute related words
- attribute description pattern extracting means for extracting the attribute description patterns that match the attribute related words from the plurality of web pages, and the web page grouping.
- a plurality of web pages obtained by the user search query based on the feature words and the attribute-related words. Characterized by grouping the di.
- the web page acquisition unit acquires a plurality of web pages as the web page, As data, an attribute-related word related to the attribute of the target, or an initial data acquisition means for acquiring an attribute description pattern used for description of the attribute of the target, and conforming to the attribute description pattern from the plurality of web pages
- Attribute extracting means for extracting attribute-related words of the attribute
- attribute description pattern extracting means for extracting the attribute description patterns that match the attribute-related words from the plurality of web pages, the feature words
- the invention according to claim 7 is the information processing apparatus according to claim 5 or 6, further comprising a repeating unit that alternately repeats the attribute extracting unit and the attribute description pattern extracting unit. To do.
- the invention according to claim 8 is the information processing apparatus according to claim 6 or 7, wherein the attribute extraction unit extracts the attribute name and an attribute value corresponding to the attribute name as the attribute-related word.
- the similar target determination unit has the attribute value that is equal in the attribute value related to the attribute common to the two arbitrary web pages, the target described in the two arbitrary web pages is: It is determined that the objects are similar to each other.
- an attribute list generating unit that generates an attribute list from the extracted attribute-related words is extracted.
- Pattern list generating means for generating a pattern list of the attribute description pattern.
- the invention according to claim 10 is the information processing apparatus according to any one of claims 5 to 9, wherein the attribute scoring means for scoring the attribute-related words, and the attributes in the order of the scores. It further comprises attribute selection means for ranking related words and selecting attribute related words of a predetermined rank or higher.
- the attribute scoring unit performs scoring of the attribute related words based on the number of hits of the search for the attribute related words.
- the attribute-related word appears in a website having a plurality of stores where the attribute scoring means sells the object.
- the attribute related words are scored based on the number of the stores on the web page.
- the attribute-related words appearing in a plurality of web pages belonging to a category different from the category is further characterized by further comprising an attribute filter means for removing.
- the invention according to claim 14 is a category related word storing step of storing a category related word related to a category for classifying a target described in a web page in an information processing method in which an information processing apparatus performs information processing;
- a web page acquisition step for acquiring a web page, a text data extraction step for extracting text data described in the web page, and a linguistic analysis of the extracted text data to obtain feature word candidates for the web page
- a feature word candidate extraction step to extract, a search query using the feature word candidate as a search keyword, a search result acquisition step to acquire a search result based on the search query, and the category related in the snippet of the search result
- a search result determination step for determining whether or not a word exists, and the snippet It characterized by having a a characteristic word determining step of the characteristic word candidate is determined to be characteristic word of the web page when the category related words are present.
- the invention according to claim 15 is a category related word storage means for storing a category related word related to a category for classifying an object described in a web page, a web page acquisition means for acquiring a web page, Text data extraction means for extracting text data described in a web page, linguistic analysis of the extracted text data, feature word candidate extraction means for extracting feature word candidates of the web page, and feature word candidates Create a search query as a search keyword and refer to the search result acquisition means for acquiring a search result based on the search query and the category related word storage means, and the category related word exists in the snippet of the search result Search result determining means for determining whether or not the category-related word is included in the snippet Characterized in that to function the characteristic word candidate feature word determining means for determining the characteristic word of the web page in the case of standing.
- the invention according to claim 16 is a category related word storage means for storing a category related word related to a category for classifying an object described in a web page, a web page acquisition means for acquiring a web page, Text data extraction means for extracting text data described in a web page, linguistic analysis of the extracted text data, feature word candidate extraction means for extracting feature word candidates of the web page, and feature word candidates Create a search query as a search keyword and refer to the search result acquisition means for acquiring a search result based on the search query and the category related word storage means, and the category related word exists in the snippet of the search result Search result determining means for determining whether or not the category-related word is included in the snippet
- the characteristic word candidate program for the information processing apparatus characterized in that to function as a feature word determining means for determining the characteristic word of the web page in the case of standing for recording.
- text data described in a web page is extracted, the text data is subjected to language analysis, feature word candidates of the web page are extracted, and a search query using the feature word candidates as search keywords is created.
- Search results based on the search query determine whether a category-related word exists in the snippet of the search result, and select a feature word candidate when the category-related word exists in the snippet.
- FIG. 17 is a flowchart illustrating an example of an operation for analyzing a web page by extracting feature words of the web page in the web page analysis of FIG. 16. It is a flowchart which shows the operation example which extracts the attribute and attribute value of object from a web page in the web page analysis of FIG. It is a schematic diagram which shows an example of the attribute description pattern memorize
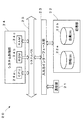
- FIG. 1 is a schematic diagram illustrating a schematic configuration example of an information processing system according to the present embodiment.
- an information processing system 1 includes a web page analysis server (an example of an information processing apparatus) 10 that analyzes a web page, an information providing server 20 that manages a shopping site and a blog, Purchase a search server 30 that provides a web search function for web pages, a store owner terminal 40 of a store owner opening a store on a shopping site, and purchase products (including services provided on the shopping site) at the shopping site. Or a user terminal 45 of a user who posts a blog. Note that a product or a blog is an example of an object described on a web page.
- the web page analysis server 10, the information providing server 20, and the search server 30 are connected by a local area network, the Internet, and the like, and can transmit and receive data to each other, and constitute a server system 5.
- the server system 5, the store owner terminal 40, and the user terminal 45 are connected by the network 3, and can exchange data with each other using, for example, TCP / IP as a communication protocol.
- the network 3 is constructed by, for example, the Internet, a dedicated communication line (for example, a CATV (Community Antenna Television) line), a mobile communication network (including a base station and the like), a gateway, and the like.
- the information processing system 1 functions as a web page analysis system that analyzes a web page or a search system that responds to a search query from the user terminal 45.
- the web page analysis server 10 analyzes a web page registered in the information providing server 20 or the like, extracts feature words from the web page, and calculates a similarity between web pages. Further, the web page analysis server 10 organizes the web pages on the information providing server 20 based on the analysis result, or analyzes the information to the store owner terminal 40 such as the store owner who registered the web page, the user terminal 45, or the like. Notify the result. Further, the web page analysis server 10 receives a search query from the user terminal 45, groups web pages related to similar products based on the analysis result, and transmits the search result to the user terminal 45.
- the information providing server 20 functions as a web server or a database server for selling products on a shopping site, and performs various processes such as acceptance of web page registration, user registration, and purchase procedures for products. .
- the information providing server 20 has web pages classified for each category such as products.
- the information providing server 20 accepts blog posts from users, classifies them by category based on the blog contents, etc., and publishes them on the Internet.
- the search server 30 functions as a search engine on the Internet or the like, and provides a function of a search API (Application Programming Interface) to the web page analysis server 10 or based on a received search query including a search keyword from a terminal. Search a search object such as a page and return search results.
- the search server 30 collects web page information from the information providing server 20 or a website on the Internet (not shown) to construct a search database, analyzes the web page information in advance, Create index information and snippet of search results.
- the snippet is a text such as an explanatory text of each search result, such as a summary of a web page hit by the search or a text including a search keyword described in the web page.
- the store owner terminal 40 used by the store owner is a mobile terminal such as a personal computer, a portable wireless telephone, or a PDA (Personal Digital Assistant).
- the store owner uses the store owner terminal 40 to register or update the web page in the information providing server 20.
- the user terminal 45 used by the user is a portable terminal such as a personal computer, a portable wireless telephone, or a PDA.
- the user uses the user terminal 45 to search for or purchase a product.
- FIG. 2 is a block diagram illustrating an example of a schematic configuration of the web page analysis server 10.
- the web page analysis server 10 that functions as a computer includes a communication unit 11, a storage unit 12, an input / output interface unit 13, and a system control unit 14.
- the system control unit 14 and the input / output interface unit 13 are connected via a system bus 15.
- the communication unit 11 is connected to the network 3 to control the communication state with the user terminal 45 or the like, or connected to the local area network to exchange data with other servers such as the information providing server 20 and the search server 30. To go.
- the storage unit 12 is configured by, for example, a hard disk drive or the like, and stores various programs such as an operating system and a server program, data, and the like. Note that the various programs may be acquired from, for example, another server device via the network 3, or may be recorded on a recording medium and read via a drive device.
- the storage unit 12 includes a category related word database 12a (hereinafter referred to as “category related word DB”) as an example of a category related word storage unit, and a domain name database (hereinafter referred to as “category related word DB”) as an example of a domain name storage unit.
- Domain name DB ) 12b feature word database (hereinafter referred to as" feature word DB ") 12c, attribute description pattern database (hereinafter referred to as” attribute description pattern DB ”) 12d, attributes / attribute values
- a database hereinafter referred to as “attribute / attribute value DB”) 12e and the like is constructed.
- category-related term DB 12a terms are stored for each category such as a product on a website and a blog.
- category related words such as “wine” and “alcohol” are included in the category of “wine”
- category related words such as “golf”, “driver” and “club” are included in the category of “golf driver”.
- category-related terms such as “domestic” and “overseas” are stored in advance.
- the categories have a hierarchical structure. For example, the category of “wine” belongs to the category of “western sake”. These category-related words are stored in association with identifiers corresponding to the respective categories.
- the category-related word DB 12a functions as an example of a category-related word storage unit that stores category-related words related to a category for classifying products.
- category related terms such as “restaurant” and “lunch” are included in the category related to food, and “baseball” and “soccer” are included in categories related to sports. Category related terms such as are stored.
- domain names of websites such as various shopping sites and blog sites on the Internet are stored in advance.
- the feature words of the web page extracted from the web page are stored.
- the feature word is stored in association with the URL (Uniform Resource Locator) of the web page. Further, the feature word DB 12c stores information for removing noise morphemes.
- the attribute description pattern DB 12d stores initial data of attribute description patterns used for describing attributes of products and blogs, and attribute description patterns extracted from web pages. Blog attributes are listed as blog attributes.
- attribute names and attribute values related to attributes of products and the like extracted from the web page are stored.
- attribute-related terms include only attribute names, phrases including attribute names, and combinations of attribute names and attribute values.
- the notation of attribute / attribute value includes a case where an attribute and an attribute value are paired, and specifically includes a case where an attribute name and an attribute value are paired.
- the input / output interface unit 13 performs interface processing between the communication unit 11 and the storage unit 12 and the system control unit 14.
- the system control unit 14 includes a CPU (Central Processing Unit) 14a, a ROM (Read Only Memory) 14b, a RAM (Random Access Memory) 14c, and the like.
- the CPU 14a reads out and executes various programs stored in the ROM 14b and the storage unit 12, thereby extracting attribute names and attribute values that match the attribute description pattern from a plurality of web pages. , Extract feature word candidates for each web page from web page text data, determine feature words from feature word candidates, calculate similarity between web pages based on feature words, multiple web pages Are grouped for each feature word. To do.
- a CPU Central Processing Unit
- ROM Read Only Memory
- RAM Random Access Memory
- FIG. 3 is a block diagram illustrating an example of a schematic configuration of the information providing server 20.
- the information providing server 20 includes a communication unit 21, a storage unit 22, an input / output interface unit 23, and a system control unit 24, and the system control unit 24, the input / output interface unit 23, and the like. Are connected via a system bus 25.
- the configuration and function of the information providing server 20 are substantially the same as the configuration and function of the web page analysis server 10, and therefore, differences in the configuration and functions of the web page analysis server 10 will be mainly described.
- the communication unit 21 controls the communication state with the store owner terminal 40, the user terminal 45, the web page analysis server 10 and the like through the network 3 or the local area network.
- an information database (hereinafter referred to as “information DB”) 22a, a member database (hereinafter referred to as “member DB”) 22b, and the like are constructed.
- the information DB 22a stores information on products, services, blogs, and the like, which are examples of objects described on a web page.
- a product name including a service name
- a type an image of a product
- an image related to a service a specification, a product, and the like
- Product information such as a summary sentence of the introduction, advertisement information, and the like are stored.
- the information DB 22a stores blog articles posted by the user in categories.
- the information DB 22a stores web page files and the like described in a markup language such as HTML (HyperText Markup Language) or XML (Extensible Markup Language).
- user information such as a user ID, a name, an address, a telephone number, and an e-mail address of a registered user (Internet shop user) is registered. Such user information can be determined for each user by the user ID.
- a user ID, a login ID, and a password necessary for a user to log in to the Internet shop site from the user terminal 45 are registered.
- the login ID and the password are login information used for login processing (user authentication processing).
- the system control unit 24 includes a CPU 24a, a ROM 24b, a RAM 24c, and the like.
- the CPU 24a reads out and executes various programs stored in the ROM 24b and the storage unit 22, thereby registering and updating the web page by the store owner, product purchase processing by the user, and product purchase. A history is recorded for each user ID.
- FIG. 4 is a block diagram illustrating an example of a schematic configuration of the search server 30.
- the search server 30 includes a communication unit 31, a storage unit 32, an input / output interface unit 33, and a system control unit 34, and the system control unit 34 and the input / output interface unit 33 are Are connected via a system bus 35.
- the configuration and functions of the search server 30 are almost the same as the configuration and functions of the web page analysis server 10, and therefore, differences in the configurations and functions of the web page analysis server 10 will be mainly described.
- the communication unit 31 controls the communication state with the user terminal 45, the web page analysis server 10 and the like through the network 3 and the local area network.
- search database 32a In the storage unit 32, a search database (hereinafter referred to as “search DB”) 32a and the like are constructed.
- the search DB 32a stores index information generated by the indexer, snippets, and the like.
- the system control unit 34 includes a CPU 34a, a ROM 34b, a RAM 34c, and the like.
- the CPU 34a reads and executes various programs stored in the ROM 34b and the storage unit 32 to collect web page information on the Internet, analyze the web page information in advance, A snippet of information or a search result is created, a search is performed based on a search query from the web page analysis server 10 or the user terminal 45, and a search result is transmitted.
- FIG. 5 is a flowchart showing an operation example of analyzing a web page in the web page analysis server 10.
- FIG. 6 is an explanatory diagram illustrating an example of a web page of the information providing server 20.
- FIG. 7 is an explanatory diagram showing an example of the source code of the web page.
- FIG. 8 is a schematic diagram illustrating an example of an analysis process of text data of a web page.
- FIG. 9 is a schematic diagram illustrating an example of a search result of the search server 30.
- FIG. 10 is a schematic diagram showing an example of the domain name of the website stored in the domain name DB 12b.
- FIG. 11 is a schematic diagram illustrating an example of category-related words stored in the category-related word DB 12a.
- FIG. 12 is a flowchart showing an example of a similarity calculation subroutine in the web page analysis server 10.
- the web page analysis server 10 acquires two web pages (step S1). Specifically, the system control unit 14 of the web page analysis server 10 uses the first web page and the second web for products belonging to the same category (for example, category “wine”) in the information DB 22a. The page is acquired from the information DB 22a through the communication unit 11. These web pages are web pages registered by the store owner or the like through the store owner terminal 40 or web pages of blogs posted from the user terminal 45. As described above, the system control unit 14 and the communication unit 11 of the web page analysis server 10 function as an example of a web page acquisition unit that acquires a web page and acquires a first web page and a second web page.
- the web page analysis server 10 extracts text data from each web page (step S2). Specifically, the system control unit 14 of the web page analysis server 10 extracts text data described in each web page. More specifically, as shown in FIG. 6, the text data of the text portions 51, 52, 53, 54 is extracted from the web page 50. Further, as shown in FIG. 7, the data in the source code described in a markup language such as HTML is also used. For example, text data of the title element portion of the HTML tag is also extracted.
- system control unit 14 of the web page analysis server 10 functions as an example of a text data extracting unit that extracts text data described in each web page.
- the web page analysis server 10 extracts feature word candidates from the extracted text data by morphological analysis, which is an example of language analysis (step S3).
- the system control unit 14 of the web page analysis server 10 uses a morphological analysis program to decompose the extracted text data into morphemes and obtain the part of speech of each phrase.
- a phrase group 53a is obtained.
- the system control unit 14 of the web page analysis server 10 removes noise from the phrase group 53a and extracts the feature word candidate group 53b.
- a part enclosed in parentheses or symbols such as “[]”, a verb phrase, a phrase related to a verb phrase, and the like are removed from the phrase group 53a to obtain a feature word candidate group 53b.
- a part enclosed in parentheses and symbols is often noise, and a verb phrase or a phrase related to a verb phrase is often not a phrase related to a product, service, or blog.
- a general morphological analysis program may be used as the morphological analysis, and there may be a process of forming a compound word when performing the morphological analysis.
- feature word candidates are extracted for the other web page.
- the system control unit 14 of the web page analysis server 10 stores information regarding such noise morphemes in the feature word DB 12c in advance. Further, the system control unit 14 of the web page analysis server 10 may extract not as a feature word candidate but as a feature word.
- the system control unit 14 of the web page analysis server 10 functions as an example of a feature word candidate extracting unit that analyzes the extracted text data and extracts feature word candidates of each web page.
- the system control unit 14 of the web page analysis server 10 functions as an example of a feature word extraction unit that performs language analysis on the extracted text data and extracts a feature word of each web page.
- the system control unit 14 of the web page analysis server 10 functions as an example of a noise morpheme storage unit that stores noise morphemes.
- system control unit 14 of the web page analysis server 10 refers to the noise morpheme storage unit, and is an example of a noise removal unit that removes noise morpheme from morphemes obtained by performing language analysis on text data by morphological analysis. Function as.
- the web page analysis server 10 performs a web search using each feature word candidate (step S4). Specifically, first, the system control unit 14 of the web page analysis server 10 creates each search query using each feature word candidate as a search keyword in order to use the function of the search API provided by the search server 30. . Then, the system control unit 14 of the web page analysis server 10 transmits to the search server 30 through the communication unit 11 and receives a search result for each feature word candidate from the search server 30. As shown in FIG. 9, a search result title part 61 and a snippet part 62 are included for each search result on the search result page 60.
- the system control unit 14 of the web page analysis server 10 functions as an example of a search result acquisition unit that creates a search query using a feature word candidate as a search keyword and acquires a search result based on the search query.
- the web page analysis server 10 determines a feature word candidate when a category-related word is included in the snippet as a feature word (step S6). Specifically, the system control unit 14 of the web page analysis server 10 selects a feature word candidate when a category-related word is included in the snippet of the search result narrowed down in step S5, and this feature word candidate Is determined as a feature word. More specifically, as shown in FIG. 11, when the category is “wine”, the system control unit 14 of the web page analysis server 10 includes the category related word “wine” or “liquor” in the snippet of the search result. A feature word candidate included is selected, and the feature word candidate is determined as a feature word. Then, as shown in FIG. 8, for example, a phrase group 53c is obtained and stored in the feature word DB 12c.
- the system control unit 14 of the web page analysis server 10 refers to the category related word DB 12a as an example of the category related word storage unit and determines whether or not a category related word exists in the snippet of the search result. It functions as an example of search result determination means. Further, the system control unit 14 of the web page analysis server 10 functions as an example of a feature word determining unit that determines a feature word candidate when a category-related word exists in a snippet as a feature word of each web page. Further, the system control unit 14 of the web page analysis server 10 refers to the category-related word storage unit and the domain name storage unit, and the category-related word is present in the snippet of the website related to the domain name in the search result. It functions as an example of search result determination means for determining whether or not.
- the web page analysis server 10 calculates the similarity based on the feature word (step S7). Specifically, the system control unit 14 of the web page analysis server 10 calculates the similarity by a subroutine that calculates the similarity between web pages. The system control unit 14 of the web page analysis server 10 may calculate the similarity based on the feature word candidates extracted in step S.
- the system control unit 14 of the web page analysis server 10 functions as an example of a similarity calculation unit that calculates the similarity between the first web page and the second web page based on the feature word.
- the web page analysis server 10 determines the similarity of the web page based on the similarity (step S8). Specifically, when the similarity calculated by the similarity calculation subroutine is equal to or greater than a predetermined value, the system control unit 14 of the web page analysis server 10 is a web page that handles similar objects such as similar products. It is determined that In addition, when the degree of similarity is higher among the web pages that are determined to be similar objects such as similar products, the web pages may be determined to be the same page that handles the same target such as the same product. . As described above, the system control unit 14 of the web page analysis server 10 determines that the first web page and the second web page are web pages that handle similar objects when the similarity is equal to or greater than a predetermined value. It functions as an example of a similar object determination means for determining.
- the web page database is constructed so that users can browse through the user terminal 45 by collecting web pages that handle the same object or similar objects by using the similarity determination of the web page.
- a GUI Graphic User Interface
- a list of web pages that handle the same object or similar objects can be viewed when the user clicks.
- IDF w is the IDF value of the feature word w
- N is the total number of web pages of a certain shopping site
- N w is the number of web pages in which the feature word w appears on the shopping site (the number of web page appearances).
- the range of web pages for calculating the IDF value may be the number of pages crawled by a search engine, a web page in a certain country, or a plurality of numbers in a certain country.
- Web pages of shopping sites (an example of a website to which each web page belongs), a web page of a higher category in the specified category, or the like.
- the set U 12 is a set in which the feature words of the first web page and the feature words of the second web page are combined. That is, it is the union of the set of feature words of the first web page and the set of feature words of the second web page.
- the set C 12 is a set of characteristic words common to the first web page and the second web page. That is, it is a product set of a set of feature words of the first web page and a set of feature words of the second web page.
- the denominator of Expression (2) is the sum of the IDF values of the feature words that are the elements u of the set U 12
- the numerator of Expression (2) is the IDF of the common feature words that are the elements c of the set C 12. It is the sum of values. As shown in Equation (2), the more common feature words are in the first web page and the second web page, the higher the similarity S 12 is, and the IDF value of the feature words is higher. the higher, the similarity S 12 is high.
- the system control unit 14 of the web page analysis server 10 uses the first web page and the second web page based on the number of web pages that appear in the range of the website to which each web page belongs. It functions as an example of a similarity calculation means for calculating the similarity between.
- the system control unit 14 of the web page analysis server 10 functions as an example of a similarity calculation unit that calculates a similarity based on the number of web page appearances of feature words common to the first web page and the second web page. To do.
- system control unit 14 of the web page analysis server 10 calculates the reverse appearance frequency of the feature word from the number of web pages existing in the range of the website to which each web page belongs and the number of web page appearances, It functions as an example of a similarity calculation unit that calculates the similarity based on the reverse appearance frequency.
- the web page analysis server 10 determines the similarity of the web page in step S8.
- text data such as the text portions 51, 52, and 53 described in the web page 50 is extracted, the text data is subjected to language analysis, and feature word candidates of the web page are extracted.
- a search query using word candidates as a search keyword is created, a search result page 60 based on the search query is acquired, a determination is made as to whether or not a category-related word exists in the snippet of the snippet part 62 of the search result page, and the snippet A feature word candidate when a category-related word exists therein is determined as a feature word of a web page. Therefore, according to the present embodiment, linguistic analysis is performed to extract feature word candidates for the web page, and further, the feature words are determined based on the search query. Therefore, the feature words of the web page can be obtained with high accuracy. it can.
- the present embodiment when narrowing down feature word candidates, by using a snippet obtained by web search, it is possible to reflect the usage status of words on the Internet, and to extract feature words with high accuracy. Furthermore, feature words can be obtained at high speed by limiting to snippets. Furthermore, by using a web search snippet, even if a trend of a product or the like changes, the trend can be followed and an appropriate feature word (for example, a product name or model number) is required. Moreover, the content included in the web page analyzed by language is reflected by determining using the category related word representing the outline of the target included in the web page, such as whether or not the category related word is included in the snippet. The determination for determining an appropriate feature word can be easily performed with high accuracy.
- text data such as the text portions 51, 52, and 53 described in the web page 50 is extracted, the text data is subjected to language analysis, and feature words of the web page are extracted.
- the feature word calculates the similarity between the first web page and the second web page based on the number of appearances of the web page that appears in the range of the website to which each web page belongs, and the similarity is predetermined. If the value is greater than or equal to the value, it is determined that the first web page and the second web page are web pages that deal with similar objects, and linguistic analysis is performed to extract feature words of the web page. Since the similarity is calculated based on the number of appearances of the web page, the similarity of the web page can be obtained.
- the similarity of a web page can be calculated
- the system control unit 14 of the web page analysis server 10 stores the category related words related to the category for classifying the object described in the web page in the category related word DB 12a, and the first web page and the second web page are stored.
- a web page is acquired, the text data of the text portions 51, 52, 53, etc. described in each web page 50 is subjected to language analysis to extract feature word candidates of each web page, and the feature word candidates are used as search keywords.
- the search result page 60 based on the search query is created, a category related word is determined in the snippet of the snippet part 62 of the search result page, and the category related word is included in the snippet.
- a feature word candidate exists, it is determined as a feature word of each web page, and the feature word is the web to which each web page belongs. If the similarity between the first web page and the second web page is calculated based on the number of web pages appearing in the range of the site, and the similarity is equal to or greater than a predetermined value, the first web page And the second web page may be determined to be a web page that deals with a similar target.
- the system control unit 14 of the web page analysis server 10 can reflect the usage status of words on the Internet by using a snippet obtained by a web search, and obtain a highly accurate feature word. Can be extracted. Furthermore, the system control unit 14 of the web page analysis server 10 can obtain feature words at high speed by limiting to snippets. Furthermore, by using the web search snippet, even if the trend of the product or the like changes, the trend can be followed and an appropriate feature word is obtained, and the system control unit 14 of the web page analysis server 10 The similarity can be obtained with high accuracy.
- system control unit 14 of the web page analysis server 10 sets a predetermined range on the Internet as a website to which each web page belongs, calculates the number of web page appearances in which feature words appear, and based on the number of web page appearances When calculating the similarity, the similarity reflecting the website can be calculated.
- the system control unit 14 of the web page analysis server 10 calculates the reverse appearance frequency of the feature word from the number of web pages existing in the range of the website to which each web page belongs and the number of web page appearances, When the similarity is calculated based on the reverse appearance frequency, the feature words can be ranked in descending order of the reverse appearance frequency based on the reverse appearance frequency of the feature words, so that the similarity can be easily determined.
- the system control unit 14 of the web page analysis server 10 calculates the similarity based on the number of web page appearances of the common feature words in the first web page and the second web page, the common feature words The degree of similarity can be calculated accurately.
- the system control unit 14 of the web page analysis server 10 refers to the category related word DB (category related word storage means) 12a, and in the search result, the category related word is included in the snippet of the website related to the domain name.
- category related word DB category related word storage means
- the system control unit 14 of the web page analysis server 10 calculates the similarity between the first web page and the second web page based on the feature word, and the similarity is equal to or greater than a predetermined value. It is determined that the first web page and the second web page are web pages that handle similar objects, and the similarity of products on the web page is obtained, for example, web pages that handle the same object or similar objects. Can be put together, and the convenience of the user can be improved.
- FIG. 13 is a flowchart showing an operation example of grouping web pages in the web page analysis server 10.
- FIG. 14 is a schematic diagram illustrating an example of grouped search results transmitted to the user terminal 45.
- FIG. 15 is a flowchart illustrating an example of a grouping subroutine in the web page analysis server 10.
- the user inputs a keyword such as a product to be searched for in the user terminal 45.
- a search query including the search keyword “white wine” is transmitted to the web page analysis server 10.
- the web page analysis server 10 receives a search query from the user terminal 45 (step S15). Specifically, the system control unit 14 of the web page analysis server 10 receives a search query including a search keyword from the user terminal 45 through the communication unit 11. As described above, the system control unit 14 and the communication unit 11 of the web page analysis server 10 function as an example of a search query receiving unit that receives a user search query from a user terminal.
- the web page analysis server 10 performs a search based on the search query (step S16). Specifically, the system control unit 14 of the web page analysis server 10 searches the information DB 22a for a web page such as a product corresponding to the search keyword.
- the web page analysis server 10 acquires a plurality of web pages based on the search result (step S17). Specifically, the system control unit 14 of the web page analysis server 10 acquires information on a plurality of web pages that handle objects such as products hit by the search keyword in the information DB 22a. These web pages are, for example, a web page registered by the store owner or the like through the store owner terminal 40, or a web page of a blog posted from the user terminal 45. As described above, the system control unit 14 and the communication unit 11 of the web page analysis server 10 function as an example of a web page acquisition unit that acquires a plurality of web pages based on a user search query.
- the web page analysis server 10 extracts text data from each web page (step S18). Specifically, the system control unit 14 of the web page analysis server 10 extracts text data as in step S2.
- the web page analysis server 10 extracts feature word candidates from the extracted text data by morphological analysis, which is an example of language analysis (step S19). Specifically, the system control unit 14 of the web page analysis server 10 extracts feature word candidates as in step S3.
- the web page analysis server 10 performs a web search using each feature word candidate (step S20). Specifically, the system control unit 14 of the web page analysis server 10 performs a web search in the same manner as in step S4.
- the web page analysis server 10 narrows down search results for websites such as shopping sites (step S21). Specifically, the system control unit 14 of the web page analysis server 10 narrows down to search results for websites such as shopping sites as in step S5.
- the web page analysis server 10 determines a feature word candidate when a category-related word is included in the snippet as a feature word (step S22). Specifically, the system control unit 14 of the web page analysis server 10 determines a feature word candidate as a feature word as in step S6.
- the web page analysis server 10 groups a plurality of web pages based on the feature words (step S23). Specifically, the system control unit 14 of the web page analysis server 10 calculates the IDF value of each feature word by a grouping subroutine, and calculates the similarity (any 2) from the IDF value between any two web pages. One example of the second similarity between two web pages) is obtained, and similar web pages are grouped based on the similarity. As shown in FIG. 14, a group name portion 71 is provided for each product in the search result web page 70. In the group name portion 71, specific product names, service names, and feature words from blogs are used. Also, below each group name portion 71, a title portion 72 of web pages belonging to the same grouping and a snippet portion 73 are collected. For example, the title part 72 and the snippet part 73 are listed.
- the system control unit 14 of the web page analysis server 10 uses the second similarity between any two web pages among the plurality of web pages based on the acquired user search query as the similarity based on the feature word. It functions as an example of the similarity calculation means for calculating.
- the web page analysis server 10 transmits the search result to the user terminal (step S24).
- the system control unit 14 of the web page analysis server 10 has transmitted a search query through the communication unit 11 for information such as a markup language such as HTML that displays search results as shown in FIG. It transmits to the user terminal 45.
- the system control unit 14 and the communication unit 11 of the web page analysis server 10 function as an example of a transmission unit that transmits information on web pages grouped for each feature word to the user terminal 45 as a search result.
- the system control unit 14 of the web page analysis server 10 acquires a plurality of web pages related to Bordeaux wine, and sets the characteristic words of each of the plurality of web pages. Those obtained by the above method and having the same or similar feature words may be collected and transmitted to the user terminal 45 as a search result.
- the system control unit 14 of the web page analysis server 10 indicates that the similarity of the combination of AB and the combination of CD is equal to or higher than a predetermined value. If so, grouping may be performed with AB as the first group and CD as the second group. Further, the system control unit 14 of the web page analysis server 10 may group ABCs if the similarity between the web pages of ABC is equal to or greater than a predetermined value.
- the web page analysis server 10 calculates the IDF value of each feature word (step S25). Specifically, the system control unit 14 of the web page analysis server 10 calculates the IDF value of each feature word as in step S10.
- the web page analysis server 10 calculates the similarity based on the IDF value (step S26). Specifically, the system control unit 14 of the web page analysis server 10 calculates a similarity (an example of a second similarity) based on the IDF value, similarly to step S11.
- the web page analysis server 10 groups similar web pages based on the similarity (step S27). Specifically, when the calculated similarity (an example of the second similarity) is equal to or greater than a predetermined value, the system control unit 14 of the web page analysis server 10 is a web page that handles similar objects. And the same group as web pages that handle similar objects. In addition, you may determine with it being a web page which handles the same object, when similarity is still higher among the web pages determined to be a web page which handles a similar object. As described above, the system control unit 14 of the web page analysis server 10 functions as an example of a web page grouping unit that groups web pages when the second similarity is a predetermined value or more. Further, the system control unit 14 of the web page analysis server 10 functions as an example of a web page grouping unit that groups a plurality of web pages for each feature word based on the second similarity.
- the system control unit 14 of the web page analysis server 10 functions as an example of a web page grouping unit that groups a plurality of web
- the system control unit 14 of the web page analysis server 10 When there are a plurality of categories corresponding to the search keyword, the system control unit 14 of the web page analysis server 10 performs the above processing for each category, divides the search result for each category, and displays a group of web pages. To do.
- system control unit 14 of the web page analysis server 10 may group web pages having a predetermined number or more of common feature words.
- the system control unit 14 of the web page analysis server 10 calculates the IDF value of each feature word, sets a rank based on the IDF value for each feature word, and has a predetermined number or more of common feature words each having a predetermined IDF value or more. Pages may be grouped together.
- system control unit 14 of the web page analysis server 10 functions as an example of a web page grouping unit that groups a plurality of web pages obtained by the user search query for each feature word.
- the user search query is received from the user terminal 45, a plurality of web pages based on the user search query are acquired from the web pages, and the text described in each web page 50 is obtained.
- the linguistic analysis of the text data of the sections 51, 52, 53, etc. extracts feature word candidates of each web page, creates a search query using the feature word candidates as search keywords, and obtains a search result page 60 based on the search query.
- a user search query is received from the user terminal 45, a plurality of web pages based on the user search query are acquired, and any two of the plurality of web pages based on the acquired user search query are acquired.
- the second similarity between the two web pages is calculated as a similarity, based on the feature word, the web pages when the second similarity is equal to or greater than a predetermined value are grouped, and information about the grouped web pages is retrieved.
- grouping a plurality of web pages for each feature word to reflect the result in a search result that is easy for the user to see. The convenience can be improved.
- the system control unit 14 of the web page analysis server 10 provides a threshold value for the similarity, it is possible to group web pages uniformly according to the similarity.
- system control unit 14 of the web page analysis server 10 groups a plurality of web pages for each feature word based on the second similarity, it is easy to group the web pages even with a plurality of feature words that differ depending on the similarity. .
- system control unit 14 of the web page analysis server 10 calculates the similarity between any two web pages of the plurality of web pages based on the feature word, and groups the plurality of web pages based on the similarity. In this case, it becomes easy to group web pages even with a plurality of feature words that differ depending on the degree of similarity.
- FIG. 16 is an explanatory diagram showing the overall flow of web page analysis in the web page analysis server 10.
- symbol corresponding to the step of the flowchart mentioned later in the figure was shown.
- the web page analysis server 10 acquires a plurality of web pages from the information DB 22a of the information providing server 20 as an example of a web page acquisition unit.
- the processing of the web page analysis server 10 is divided into two.
- the two processes are a process of extracting a feature word of a web page from the web page and obtaining a similarity between the web pages, and a process of obtaining an attribute / attribute value of a product from the web page.
- the attribute extraction unit and the attribute description pattern extraction unit are repeated a predetermined number of times to constitute a bootstrap method.
- the web page analysis server 10 determines whether or not two web pages are web pages that handle similar objects, based on the similarity and the attribute, as an example of the similarity target determination unit.
- FIG. 17 is a flowchart showing an operation example in which the web page analysis server 10 extracts feature words of the web page and analyzes the web page. *
- the web page analysis server 10 acquires a plurality of web pages (step S30). Specifically, the system control unit 14 of the web page analysis server 10 acquires a plurality of web pages so as to acquire two web pages in step S1.
- the web page analysis server 10 extracts text data from each web page (step S31). Specifically, the system control unit 14 of the web page analysis server 10 extracts text data from each web page as in step S2. *
- the web page analysis server 10 extracts feature word candidates from the extracted text data by morphological analysis as an example of language analysis (step S32). Specifically, the system control unit 14 of the web page analysis server 10 extracts feature word candidates as in step S3.
- the web page analysis server 10 performs a web search using each feature word candidate (step S33). Specifically, first, the system control unit 14 of the web page analysis server 10 performs a web search as in step S4.
- the web page analysis server 10 narrows down search results for websites such as shopping sites (step S34). Specifically, the system control unit 14 of the web page analysis server 10 narrows down the website search results in the same manner as in step S5.
- the web page analysis server 10 determines a feature word candidate when a category-related word is included in the snippet as a feature word (step S35). Specifically, the system control unit 14 of the web page analysis server 10 determines a feature word candidate as a feature word as in step S6.
- the web page analysis server 10 calculates the similarity based on the feature word (step S36). Specifically, the system control unit 14 of the web page analysis server 10 performs the similarity (third similarity between any two web pages among the plurality of obtained web pages) by a subroutine for calculating the similarity as in step S7. Example). As described above, the system control unit 14 of the web page analysis server 10 calculates the similarity based on the feature word using the third similarity between any two web pages of the plurality of acquired web pages as the similarity. Functions as an example.
- the web page analysis server 10 determines the similarity of web pages based on the similarity (step S37). Specifically, the system control unit 14 of the web page analysis server 10 determines the similarity of web pages as in step S8.
- the web page analysis server 10 determines the similarity of the web pages based on the similarity and the attribute (step S38). ). Specifically, the system control unit 14 of the web page analysis server 10 determines whether the two web pages are similar products or the like based on the similarity and the attribute related words common to the two arbitrary web pages. It is determined whether or not the web page handles similar objects. More specifically, the system control unit 14 of the web page analysis server 10 sets the common attribute between any two web pages when the similarity (third similarity) is equal to or greater than a predetermined value.
- the web page analysis server 10 calculates
- the system control unit 14 of the web page analysis server 10 uses the third similarity and the attribute related terms common to any two web pages, and the targets handled by any two web pages are: It functions as an example of a similar object determination unit that determines whether or not the objects are similar to each other.
- system control unit 14 of the web page analysis server 10 has the same attribute value in the attribute value related to the attribute common to any two pages when the third similarity is a predetermined value or more.
- the target handled by any two web pages functions as an example of a similar target determination unit that determines that the target is similar to each other.
- step S37 when the degree of similarity between web pages is not determined to be equal to or greater than a predetermined value (step S37; NO), the web page ends processing because it does not handle similar objects such as similar products.
- FIG. 18 is a flowchart showing an operation example of extracting product attributes / attribute values from a web page in the web page analysis server 10.
- FIG. 19 is a schematic diagram illustrating an example of an attribute description pattern stored in the attribute description pattern DB.
- FIG. 20 is a schematic diagram illustrating an example of how attributes and attribute values are extracted.
- FIG. 21 is a schematic diagram illustrating an example of extracted attributes / attribute values.
- FIG. 22 is a flowchart illustrating an example of an attribute selection subroutine in the web page analysis server 10.
- the web page analysis server 10 obtains an attribute description pattern after obtaining a plurality of web pages in step S30 (step S40). Specifically, the system control unit 14 of the web page analysis server 10 uses the attribute description pattern list in the attribute description pattern DB 12d as the initial data of the bootstrap method in the following steps S41 to S43, as shown in FIG. Get the initial attribute description pattern.
- the attribute description pattern is divided into a front part, a central part, and a rear part. For example, in the case of the attribute description pattern “[::]”, the front part “[”, central part ”: “And rear”] ".
- a phrase between the front part and the middle part is an attribute name
- a phrase between the middle part and the rear part is an attribute value.
- the attribute description pattern may include an HTML tag element.
- the system control unit 14 of the web page analysis server 10 functions as an example of an initial data acquisition unit that acquires, as initial data, an attribute description pattern used to describe a target attribute described in a web page.
- the web page analysis server 10 extracts attributes / attribute values that match the attribute description pattern (step S41). Specifically, the system control unit 14 of the web page analysis server 10 selects a part of a phrase that matches the attribute description pattern 81 or the like (for example, from among a plurality of web pages such as the web page 50) (for example, "[Type: XXX]”) is extracted, and the attribute name "type", the attribute value "XXX” corresponding to the attribute name "type”, and the like are extracted. The extracted attribute name and attribute value are stored in the attribute / attribute value DB 12e as an attribute list.
- a part of a phrase that matches the attribute description pattern 81 or the like for example, from among a plurality of web pages such as the web page 50
- the extracted attribute name and attribute value are stored in the attribute / attribute value DB 12e as an attribute list.
- attributes and attribute values include [accommodation fee: XXX] in the case of travel-related services, and [venue: XXX] in the case of introducing events that are blogs.
- the system control unit 14 of the web page analysis server 10 functions as an example of an attribute extraction unit that extracts attribute-related words having attributes that match the attribute description pattern from a plurality of web pages. Further, the system control unit 14 of the web page analysis server 10 functions as an example of an attribute extraction unit that extracts an attribute name of an attribute as an attribute related word. Further, the system control unit 14 of the web page analysis server 10 functions as an attribute list generating unit that generates an attribute list from the extracted attribute related words.
- the web page analysis server 10 extracts an attribute description pattern that matches the attribute / attribute value (step S42). Specifically, the system control unit 14 of the web page analysis server 10 conforms to the attribute / attribute value 82 (for example, attribute name “product type” and attribute value “XXX”) as shown in FIG. For example, ⁇ td> variety ⁇ / td> ⁇ td> OO ⁇ td>) is taken out, and attribute description patterns are extracted from a plurality of web pages such as the web page 50. The extracted attribute description pattern is added to the attribute description pattern list and stored in the attribute description pattern DB 12d as shown in FIG. For example, as with “capacity * ml”, for the attribute value, a wild card may be used instead of the extracted attribute value itself.
- attribute description pattern DB 12d for example, as with “capacity * ml”, for the attribute value, a wild card may be used instead of the extracted attribute value itself.
- system control unit 14 of the web page analysis server 10 functions as an example of an attribute description pattern extracting unit that extracts attribute description patterns that match attribute related words from a plurality of web pages.
- system control unit 14 of the web page analysis server 10 functions as a pattern list generation unit that generates a pattern list of the extracted attribute description patterns.
- the web page analysis server 10 determines a predetermined number of times (step S43). Specifically, the system control unit 14 of the web page analysis server 10 determines whether or not the number of times of repeatedly executing Step S41 and Step S42 has reached a predetermined number. If the predetermined number of times has not been reached (step S43; NO), the system control unit 14 of the web page analysis server 10 returns to step S41, and extracts new attributes / attribute values from the extracted new attribute description pattern. To do. The system control unit 14 of the web page analysis server 10 repeats step S21 and step S22 until the predetermined number of times is reached.
- system control unit 14 of the web page analysis server 10 determines the number of extracted attributes / attribute values (for example, the number of attribute names, the number of attribute values, the number of combinations of attribute names and attribute values), or the attributes It may be determined whether or not the number of description patterns has reached a predetermined number or more. When the number exceeds the predetermined number, the system control unit 14 of the web page analysis server 10 performs the process of the next step S44.
- the system control unit 14 of the web page analysis server 10 acquires the attribute description pattern acquisition step for acquiring the attribute description pattern used for describing the attribute of the product in steps S40 to S44, and the attribute from the plurality of web pages. Attribute extraction step for extracting attribute-related words of attributes that match the description pattern, and attribute description pattern extraction for further extracting attribute description patterns used in the attribute extraction step from a plurality of web pages based on the extracted attribute-related words And execute steps.
- the system control unit 14 of the web page analysis server 10 functions as an example of a repeating unit that alternately repeats the attribute extracting unit and the attribute description pattern extracting unit.
- the web page analysis server 10 selects an attribute (step S44). Specifically, the system control unit 14 of the web page analysis server 10 selects an attribute from the attribute name and attribute value extracted in step S41 by an attribute selection subroutine. In the attribute selection subroutine, the system control unit 14 of the web page analysis server 10 ranks attributes by ranking, removes noise attributes, and collects synonym attributes (details will be described later). As shown in FIG. 21, in the category “wine”, attribute values are obtained for the attribute names “variety”, “producer”, and the like.
- the attribute name and attribute value selected by extraction are used when the web page analysis server 10 determines the similarity of web pages in step S38.
- the initial attribute / attribute value may be acquired from the attribute / attribute value list of the attribute / attribute value DB 12e as the initial data of the bootstrap method.
- the system control unit 14 of the web page analysis server 10 functions as an example of an initial data acquisition unit that acquires attribute-related words related to a target attribute as initial data.
- the system control unit 14 of the web page analysis server 10 includes an attribute related word acquisition step for acquiring an attribute related word related to the attribute of the product, and an attribute description pattern used for attribute description.
- An attribute description pattern extraction step for extracting an attribute description pattern that matches the attribute-related word from the web page, and attribute-related words used for the attribute description pattern extraction means based on the extracted attribute-related word.
- the web page analysis server 10 scores an attribute (step S50). Specifically, when the shopping site has a plurality of stores that sell products, that is, when a cyber mall is configured, the system control unit 14 of the web page analysis server 10 has a store having a web page in which an attribute name appears. To obtain the attribute score.
- Attribute names of examples of attribute-related words that appear on web pages of various stores are based on the assumption that they are appropriate as attributes. For example, in a wine web page, an appropriate attribute “variety” appears on web pages of various stores. On the other hand, an inappropriate attribute that matches any attribute description turn is often obtained only from a web page of one store, and the attribute score tends to be low.
- the system control unit 14 of the web page analysis server 10 functions as an example of attribute scoring means for scoring attribute related words.
- the system control unit 14 of the web page analysis server 10 determines the attribute based on the number of stores of web pages in which attribute-related words appear in a website having a plurality of stores that sell objects handled by the web page. It functions as an example of attribute scoring means for scoring related terms.
- the web page analysis server 10 selects a higher rank attribute (step S51). Specifically, the system control unit 14 of the web page analysis server 10 ranks attribute names in descending order of attribute scores, and selects attribute names having a predetermined rank or higher. As described above, the system control unit 14 of the web page analysis server 10 functions as an example of an attribute selection unit that ranks attribute related words in order of scores and selects attribute related words of a predetermined rank or higher.
- the web page analysis server 10 performs attribute filtering (step S52). Specifically, the system control unit 14 of the web page analysis server 10 performs attribute filtering using the appearance probability of the attribute name in each category. Attribute filtering is performed based on the assumption that an attribute name as an example of an attribute-related word that appears in other categories is not suitable as an attribute. For example, a phrase such as “free shipping” that is unsuitable as an attribute appears on a large number of web pages, and the appearance probabilities in each category have similar values. On the other hand, the attribute name “variety” often appears on the web page of the wine category, but does not appear in the category of golf drivers, shoes, etc., so the appearance probability in the wine category is the appearance probability in the categories other than wine. Higher than. In this way, the system control unit 14 of the web page analysis server 10 functions as an example of an attribute filter unit that removes attribute-related words that appear in a plurality of web pages belonging to a category different from the category.
- the web page analysis server 10 aggregates synonymous attributes (step S53). Some attributes have the same concept. For example, in the wine category, “variety”, “grape variety”, “grape variety”, “separage”, and “strawberry variety” are synonymous attribute names.
- the system control unit 14 of the web page analysis server 10 uses the synonym dictionary, calculates the degree of similarity between the attribute names, uses the attribute value corresponding to the attribute name, and so on. Aggregate. An attribute name of a similar concept attribute may be used.
- the attribute value that the attribute B has among the attribute values of the attribute A The value obtained by multiplying the ratio of the common attribute and the ratio of the attribute value of the attribute A among the attribute values of the attribute B to the ratio of the common attribute may be used as the degree of similarity.
- the entropy is calculated based on the original value, and the multiplied value may be a similar degree, the Jackard coefficient is very similar, and the number of types of attributes common to attribute A and attribute B is similar. It may be a degree.
- the system control unit 14 of the web page analysis server 10 functions as an example of an attribute name similarity determination unit that determines whether attribute names are similar to each other. Further, the system control unit 14 of the web page analysis server 10 functions as an example of an attribute name aggregation unit that aggregates attribute names determined to be similar by the attribute name similarity determination unit. In addition, the system control unit 14 of the web page analysis server 10 includes an attribute extraction unit that extracts attribute names and attribute values corresponding to the attribute names as attribute-related words, and attribute name aggregation that aggregates attribute names based on the attribute values. It functions as an example of means.
- each web page a plurality of web pages are acquired, and the attribute related words related to the target attribute or the attribute description pattern used to describe the target attribute are used as initial data.
- the attribute related words of the attribute that match the attribute description pattern are extracted from a plurality of web pages, the attribute description pattern that matches the attribute related words is extracted from the plurality of web pages, and the second similarity and attribute
- web pages 70 grouped according to similarity can be further sub-grouped with common attributes, such as web page 90.
- the utility value is increased, for example, by reflecting the result in a search result that is easier for the user to see.
- the feature word is defined as the third similarity between any two web pages among the acquired plurality of web pages.
- the attribute related words related to the target attribute or the attribute description pattern used to describe the target attribute is obtained as initial data, and the attribute matching the attribute description pattern is obtained from multiple web pages. Attribute related words are extracted, attribute description patterns that match the attribute related words are extracted from a plurality of web pages, and based on the third similarity and the attribute related words common between any two web pages.
- a plurality of web pages are acquired as web pages, and attribute-related words related to the attributes of the target described in the web pages or the description of the attributes of the target are acquired as initial data.
- the attribute description pattern used in the above is acquired, the attribute related words of the attribute that match the attribute description pattern are extracted from a plurality of web pages, the attribute description pattern that matches the attribute related words is extracted from the plurality of web pages,
- web pages 70 grouped by feature words can be further sub-grouped by common attributes like web page 90.
- the utility value is increased, for example, by reflecting the results in search results that are easier for the user to see.
- the attribute list or pattern list is expanded by bootstrap, and an attribute other than the attribute given as the initial value is added. Can be extracted. Moreover, the similarity of a web page can be determined by this extracted attribute.
- the system control unit 14 of the web page analysis server 10 extracts an attribute name and an attribute value corresponding to the attribute name as attribute-related words, and is equal in attribute values related to attributes common to any two web pages If there is an object, it is easy to match the attribute value if the object described in any two web pages is similar to each other, so the web page that handles the same or similar object If it is, it becomes easy to determine with high accuracy.
- attribute names are often category-specific, but attribute description patterns are also category-specific, but can be applied to various categories.
- system control unit 14 of the web page analysis server 10 When the system control unit 14 of the web page analysis server 10 generates an attribute list from the extracted attribute-related words and generates a pattern list of the extracted attribute description pattern, an attribute name, an attribute value, etc. Information on attribute-related words and attribute description patterns can be stored.
- the system control unit 14 of the web page analysis server 10 scores attribute-related words, ranks attribute-related words in order of scores, and selects attribute-related words having a predetermined rank or higher, the selected attribute In the related word, the accuracy of the attribute representing the object such as the product is increased.
- the system control unit 14 of the web page analysis server 10 scores attribute related words based on the number of stores of web pages in which attribute related words appear in a website having a plurality of stores selling the target. In this case, when an attribute related word is selected, the accuracy of an attribute representing a target such as a product is increased. For example, if the number of objects (items) or the number of web pages handled varies greatly depending on the store, it will be easily affected by stores that handle objects such as many products, but the attribute-related terms will be scored based on the number of stores. By doing so, the influence of a specific store can be eliminated.
- the system control unit 14 of the web page analysis server 10 removes attribute related words that appear in a plurality of web pages belonging to a category different from the category, the product is obtained by narrowing down to attribute related words specific to the target category. The accuracy of the attribute representing etc. becomes high.
- the system control unit 14 of the web page analysis server 10 extracts the attribute name and the attribute value corresponding to the attribute name as the attribute related word, and the third similarity is equal to or higher than a predetermined value, and any two If there is an attribute value that is the same among the attribute values that are common to two pages, and if it is determined that the targets handled by any two web pages are similar to each other, the attribute value is one if the target is the same. Since it is easy to do, it becomes easy to judge accurately if it is the web page which handles the same or similar object.
- the search server 30 may be a search server of another search site outside the server system 5.
- the web page analysis server 10 transmits a search query and receives a search result through the network 3.
- the web search range for obtaining a snippet may be limited to a web page in the information providing server 20 or may be limited to a web page in a certain country or region.
- selection of attributes and selection of attribute description patterns may be performed in the bootstrap method in step S21 or step S22. In this case, it is possible to prevent the number of extracted attributes / attribute values and attribute description patterns from increasing when the number of bootstraps is increased.
- the attribute score may be the number of web pages in which attribute names appear instead of the number of stores.
- the system control unit 14 of the web page analysis server 10 scores attribute related words as attribute scoring means based on the number of hits of attribute related word searches.
- the present invention can be applied to other than cyber malls where many stores gather.
- FIG. 23 is a schematic diagram showing an example of the grouped search results of FIG.
- FIG. 24 is a schematic diagram showing another modification of the grouped search result of FIG.
- the system control unit 14 of the web page analysis server 10 groups similar web pages based on the degree of similarity, or creates web pages that have a predetermined number or more of common feature words. For example, group name portion 91 is set by a feature word.
- the system control unit 14 of the web page analysis server 10 subgroups each grouped group like the subgroup name unit 94 based on the attribute. Based on the attribute obtained in step S44, the system control unit 14 of the web page analysis server 10 divides the capacity into “750 ml” and “375 ml”, for example, when the attribute name is “capacity”.
- the system control unit 14 of the web page analysis server 10 converts a web page having a common attribute name / attribute value such as “capacity” / “750 ml” or “capacity” / “375 ml” into a feature word (or second similarity). Collect from web pages grouped by degree. Then, in the web page 90, a web page title part 92 and a snippet part 93 are displayed in an area subgrouped by the group name part 91 and the subgroup name part 94.
- the system control unit 14 of the web page analysis server 10 may perform grouping based on attributes such as a group name part 95 “capacity: 750 ml” and “capacity: 375 ml”. .
- the system control unit 14 of the web page analysis server 10 collects web pages having “capacity”, “750 ml”, and the like as attribute names / attribute values. Further, each grouped group is subgrouped as in the subgroup name portion 99 based on the feature words and the similarity.
- the system control unit 14 of the web page analysis server 10 obtains feature words of web pages grouped based on attributes or obtains similarity. Then, the system control unit 14 of the web page analysis server 10 subgroups similar web pages based on the degree of similarity, or web pages having a predetermined number or more of common feature words as in step S27. Or sub-grouping.
- the range of the plurality of web pages required in step S40 may be a range grouped based on feature words, a unit of website, or the same range as that handled in step S40. .
- the system control unit 14 of the web page analysis server 10 functions as an example of a web page grouping unit that groups a plurality of web pages obtained by the user search query based on the feature words and attribute-related words.
- the system control unit 14 of the web page analysis server 10 functions as an example of a web page grouping unit that groups web pages based on the second similarity and attribute-related words.
- the system control unit 14 of the web page analysis server 10 groups web pages based on feature words and attribute-related words, or groups based on second similarity and attribute-related words
- the grouped web pages can be further sub-grouped by a common attribute, or the web pages grouped by a common attribute can be further sub-grouped by a feature word or similarity. Therefore, the utility value is increased, for example, by reflecting the result in a search result that is easier for the user to see.
- the system control unit 14 of the web page analysis server 10 determines whether any two web pages are based on the extracted or determined feature words and the attribute related words common to any two web pages. It may be determined whether the objects to be handled are similar to each other. For example, when there are some common feature words in two web pages, and there are attribute values that are equal in attribute values related to the attributes common between the two web pages, the system control of the web page analysis server 10 The unit 14 determines that the web pages handle objects similar to each other.
- the system control unit 14 of the web page analysis server 10 can determine the similarity of objects such as products handled on the web page. Further, the system control unit 14 of the web page analysis server 10 can collect web pages that handle the same or similar objects. In particular, the determination accuracy is improved by making a determination based on a common attribute-related word in addition to the feature word.
- system control unit 14 of the web page analysis server 10 may create a dictionary in which web pages are organized using feature words as indexes. For example, the system control unit 14 of the web page analysis server 10 groups web pages based on feature words, and collects related web pages using the feature words as an index. Furthermore, the system control unit 14 of the web page analysis server 10 may create a dictionary in which web pages are organized by using attribute names and attribute values as indexes. For example, the system control unit 14 of the web page analysis server 10 groups web pages based on attribute names / attribute values, and collects related web pages using feature words as indexes.
- system control unit 14 of the web page analysis server 10 may combine either one or two, like the same or extremely similar web page or name identification.
- the system control unit 14 of the web page analysis server 10 combines the web pages into one when the similarity is equal to or higher than a predetermined value (for example, a predetermined value higher than that in the case of step S8).
- the present invention is not limited to the above embodiments.
- Each of the embodiments described above is an exemplification, and any configuration that has substantially the same configuration as the technical idea described in the claims of the present invention and has the same operational effects can be used. It is included in the technical scope of the present invention.
- Network 5 Server system 10: Web page analysis server (information processing device) 12a: Category related word DB (category related word storage means) 12b: Domain name DB 12d: attribute description pattern DB 12e: attribute / attribute value DB 20: Information providing server 30: Search server
Abstract
ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶し、ウェブページを取得し(S1)、ウェブページ内に記述されているテキストデータを抽出し(S2)、抽出したテキストデータを言語解析して、ウェブページの特徴語候補を抽出し(S3)、特徴語候補を検索キーワードとする検索クエリを作成し、検索クエリに基づく検索結果を取得し(S4)、検索結果のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補をウェブページの特徴語に決定する(S6)。
Description
本発明は、インターネット上のウェブページを分析する情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体の技術分野に関する。
インターネット上には商品等を販売するためのウェブページや、個人の意見などが書き込まれたブログ(Blog)等のウェブページが存在し、さらに、取り扱われる商品等の内容やブログの内容により、様々なタイプのウェブページが存在する。このような多様なウェブページを分類したり、ウェブページの内容に適合した広告を付加したり等、ウェブページに対して様々な処理がなされている。例えば、特許文献1には、ウェブページとコンテンツカテゴリとの関連度に基づいて、ウェブページをコンテンツカテゴリに分類し、分類されたコンテンツカテゴリと広告カテゴリとをマッチングして、広告データを選択して当該ウェブページに付加するカテゴリ分類方法が開示されている。
しかしながら、特許文献1のような従来技術では、ウェブページのテキストデータを形態素解析し、TF(Term Frequency)・IDF(Inverse Document Frequency)値等の出現頻度に基づいて、ウェブページに含まれる特徴語を抽出して、当該特徴語と類似するキーワードに基づいて、ウェブページとコンテンツカテゴリとの関連度を算出している。このような特徴語の抽出では、流行の変化が激しいインターネット上において、精度の高い特徴語の求めることが難しかった。
本発明は、このような問題に鑑みてなされたものであり、その課題の一例は、ウェブページの特徴語を、精度良く求めることができる情報処理装置等を提供することを目的とする。
上記課題を解決するために、請求項1に記載の発明は、ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段と、ウェブページを取得するウェブページ取得手段と、前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段と、抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出手段と、前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得手段と、前記カテゴリ関連語記憶手段を参照して、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定手段と、前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定手段と、を備えたことを特徴とする。
請求項2に記載の発明は、請求項1に記載の情報処理装置において、ノイズの形態素を記憶するノイズ形態素記憶手段を更に備え、前記特徴語候補抽出手段が、ノイズ形態素記憶手段を参照して、前記テキストデータを形態素解析によって前記言語解析して得られた形態素から、ノイズの形態素を除去するノイズ除去手段を有することを特徴とする。
請求項3に記載の発明は、請求項1または請求項2に記載の情報処理装置において、ウェブサイトのドメイン名を記憶するドメイン名記憶手段を更に備え、前記検索結果判定手段が、前記カテゴリ関連語記憶手段および前記ドメイン名記憶手段を参照して、前記検索結果において、前記ドメイン名に関連したウェブサイトのスニペット中に前記カテゴリ関連語が存在するか否かを判定することを特徴とする。
請求項4に記載の発明は、請求項1から請求項3のいずれか1項に記載の情報処理装置において、ユーザ端末からユーザ検索クエリを受信する検索クエリ受信手段と、前記ユーザ検索クエリによって得られる複数のウェブページを、前記特徴語毎にグルーピングするウェブページ・グルーピング手段と、前記特徴語毎にグルーピングした前記ウェブページに関する情報を検索結果として前記ユーザ端末に送信する送信手段を更に、備えたことを特徴とする。
請求項5に記載の発明は、請求項4に記載の情報処理装置において、前記ウェブページ取得手段が、前記ウェブページとして、複数のウェブページを取得し、初期データとして、ウェブページに記載されている対象の属性に関連した属性関連語、または、当該対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段と、前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段と、前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを、抽出する属性記述パターン抽出手段と、を更に備え、前記ウェブページ・グルーピング手段が、前記特徴語および前記属性関連語に基づき、前記ユーザ検索クエリによって得られる複数のウェブページをグルーピングすることを特徴とする。
請求項6に記載の発明は、請求項1から請求項4のいずれか1項に記載の情報処理装置において、前記ウェブページ取得手段が、前記ウェブページとして、複数のウェブページを取得し、初期データとして、前記対象の属性に関連した属性関連語、または、前記対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段と、前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段と、前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを、抽出する属性記述パターン抽出手段と、前記特徴語と、前記任意の2つのウェブページ間での共通の属性関連語とに基づき、前記任意の2つのウェブページが扱う対象は、互いに類似する対象であるか否かを判定する類似対象判定手段と、を更に備えたことを特徴とする。
請求項7に記載の発明は、請求項5または請求項6に記載の情報処理装置において、前記属性抽出手段および前記属性記述パターン抽出手段を交互に繰り返す繰返手段を更に備えたことを特徴とする。
請求項8に記載の発明は、請求項6または請求項7に記載の情報処理装置において、前記属性抽出手段が、前記属性関連語として、前記属性名および前記属性名に対応する属性値を抽出し、前記類似対象判定手段が、前記任意の2つのウェブページ間で共通の属性に係る前記属性値において等しい前記属性値がある場合に、前記任意の2つのウェブページに記載された対象は、互いに類似する対象であると判定することを特徴とする。
請求項9に記載の発明は、請求項5から請求項8のいずれか1項に記載の情報処理装置において、抽出された前記属性関連語から属性リストを生成する属性リスト生成手段と、抽出された前記属性記述パターンのパターンリストを生成するパターンリスト生成手段と、を更に備えたことを特徴とする。
請求項10に記載の発明は、請求項5から請求項9のいずれか1項に記載の情報処理装置において、前記属性関連語のスコア付けを行う属性スコアリング手段と、前記スコアの順に前記属性関連語のランク付けを行い、所定のランク以上の属性関連語を選択する属性選択手段と、を更に備えたことを特徴とする。
請求項11に記載の発明は、請求項10に記載の情報処理装置において、前記属性スコアリング手段が、前記属性関連語の検索のヒット件数に基づき、前記属性関連語のスコア付けを行うことを特徴とする。
請求項12に記載の発明は、請求項10に記載の情報処理装置において、前記属性スコアリング手段が、前記対象を販売する複数の店舗を有するウェブサイトにおいて、前記属性関連語が出現しているウェブページの前記店舗の数に基づき、前記属性関連語のスコア付けを行うことを特徴とする。
請求項13に記載の発明は、請求項5から請求項12のいずれか1項に記載の情報処理装置において、前記カテゴリとは異なるカテゴリに属している複数のウェブページにおいて出現する前記属性関連語を取り除く属性フィルタ手段を更に備えたことを特徴とする。
請求項14に記載の発明は、情報処理装置が情報処理をする情報処理方法において、ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶ステップと、ウェブページを取得するウェブページ取得ステップと、前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出ステップと、抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出ステップと、前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得ステップと、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定ステップと、前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定ステップと、を有することを特徴とする。
請求項15に記載の発明は、コンピュータを、ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段、ウェブページを取得するウェブページ取得手段、前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段、抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出手段、前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得手段、前記カテゴリ関連語記憶手段を参照して、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定手段、および、前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定手段として機能させることを特徴とする。
請求項16に記載の発明は、コンピュータを、ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段、ウェブページを取得するウェブページ取得手段、前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段、抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出手段、前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得手段、前記カテゴリ関連語記憶手段を参照して、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定手段、および、前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定手段として機能させることを特徴とする情報処理装置用のプログラムを記録する。
本発明によれば、ウェブページ内に記述されているテキストデータを抽出し、テキストデータを言語解析して、ウェブページの特徴語候補を抽出し、特徴語候補を検索キーワードとする検索クエリを作成し、検索クエリに基づく検索結果を取得し、検索結果のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補をウェブページの特徴語に決定することにより、言語解析してウェブページの特徴語候補を抽出し、さらに、検索クエリに基づき特徴語を決定しているため、ウェブページの特徴語を、精度良く求めることができる。
以下、図面を参照して本発明の実施形態について説明する。
(第1実施形態)
(第1実施形態)
[1.情報処理の構成および機能概要]
まず、本発明の第1実施形態に係る情報処理システムの構成および概要機能について、図1を用いて説明する。
まず、本発明の第1実施形態に係る情報処理システムの構成および概要機能について、図1を用いて説明する。
図1は、本実施形態に係る情報処理システムの概要構成例を示す模式図である。
図1に示すように、情報処理システム1は、ウェブページを分析するウェブページ分析サーバ(情報処理装置の一例)10と、ショッピングサイトやブログを運営するための情報提供サーバ20と、インターネット上のウェブページのウェブ検索の機能を提供する検索サーバ30と、ショッピングサイトに出店している店舗主の店舗主端末40と、ショッピングサイトで商品等(ショッピングサイトで提供されているサービスを含む)を購入したり、ブログを投稿するユーザのユーザ端末45と、を備えている。なお、商品等や、ブログは、ウェブページに記載されている対象の一例である。
ウェブページ分析サーバ10と、情報提供サーバ20と、検索サーバ30とは、ローカルエリアネットワークやインターネット等により接続され、相互にデータの送受信が可能になっていて、サーバシステム5を構成している。そして、サーバシステム5と、店舗主端末40と、ユーザ端末45とは、ネットワーク3により接続され、例えば、通信プロトコルにTCP/IP等を用いて相互にデータの送受信が可能になっている。なお、ネットワーク3は、例えば、インターネット、専用通信回線(例えば、CATV(Community Antenna Television)回線)、移動体通信網(基地局等を含む)、およびゲートウェイ等により構築されている。
情報処理システム1は、ウェブページを分析するウェブページ分析システムとして、または、ユーザ端末45から検索クエリに対して応答する検索システムとして機能する。
ウェブページ分析サーバ10は、情報提供サーバ20等に登録されたウェブページを分析して、ウェブページから特徴語を抽出したり、ウェブページ同士の類似度を算出したりする。また、ウェブページ分析サーバ10は、分析結果に基づいて、情報提供サーバ20上のウェブページの整理を行ったり、ウェブページを登録した店舗主等の店舗主端末40や、ユーザ端末45等に分析結果を通知したりする。さらに、ウェブページ分析サーバ10は、ユーザ端末45から検索クエリを受信したり、分析結果に基づき、同じような商品に関するウェブページをグルーピングしたり、ユーザ端末45に検索結果を送信したりする。
情報提供サーバ20は、ショッピングサイトで商品等を販売するためのウェブサーバや、データベースサーバ等として機能し、ウェブページの登録の受け付けや、ユーザ登録や、商品等の購入手続き等の各種処理を行う。また、情報提供サーバ20は、商品等のカテゴリ毎に分類されたウェブページを有している。また、情報提供サーバ20は、ユーザからのブログの投稿を受け付け、ブログの内容等の基づきカテゴリ毎に分類しインターネット上に公開する。
検索サーバ30は、インターネット等上の検索エンジンとして機能し、検索API(Application Programming Interface)の機能を、ウェブページ分析サーバ10に提供したり、端末から検索キーワードを含む受信した検索クエリに基づき、ウェブページ等の検索対象を検索して、検索結果を返したりする。また、検索サーバ30は、検索用のデータベースを構築するために、情報提供サーバ20や、図示しないインターネット上のウェブサイトからウェブページの情報を収集し、ウェブページの情報を予め解析し、検索のためのインデックス情報や検索結果のスニペットを作成する。ここで、スニペットとは、各検索結果の説明文等のテキストであって、検索でヒットしたウェブページの要約や、そのウェブページ内に記述された検索キーワードを含んだ文章等である。
店舗主が使用する店舗主端末40は、パーソナルコンピュータや携帯型無線電話機やPDA(Personal Digital Assistant)等の携帯端末である。店舗主は店舗主端末40を使用して、ウェブページを情報提供サーバ20に登録したり、更新したりする。
ユーザが使用するユーザ端末45は、パーソナルコンピュータや携帯型無線電話機やPDA等の携帯端末である。ユーザはユーザ端末45を使用して、商品の検索や購入等を行う。
[2.各サーバの構成および機能]
(2.1 ウェブページ分析サーバ10の構成および機能)
次に、ウェブページ分析サーバ10の構成および機能について、図2を用いて説明する。
(2.1 ウェブページ分析サーバ10の構成および機能)
次に、ウェブページ分析サーバ10の構成および機能について、図2を用いて説明する。
図2は、ウェブページ分析サーバ10の概要構成の一例を示すブロック図である。
図2に示すように、コンピュータとして機能するウェブページ分析サーバ10は、通信部11と、記憶部12と、入出力インターフェース部13と、システム制御部14と、を備えている。そして、システム制御部14と入出力インターフェース部13とは、システムバス15を介して接続されている。
通信部11は、ネットワーク3に接続してユーザ端末45等との通信状態を制御したり、ローカルエリアネットワークに接続して、情報提供サーバ20や検索サーバ30等の他のサーバとデータの送受信を行ったりする。
記憶部12は、例えば、ハードディスクドライブ等により構成されており、オペレーティングシステムおよびサーバプログラム等の各種プログラムや、データ等を記憶する。なお、各種プログラムは、例えば、他のサーバ装置等からネットワーク3を介して取得されるようにしてもよいし、記録媒体に記録されてドライブ装置を介して読み込まれるようにしてもよい。
また、記憶部12には、カテゴリ関連語記憶手段の一例としてのカテゴリ関連語データベース12a(以下「カテゴリ関連語DB」とする。)や、ドメイン名記憶手段の一例としてのドメイン名データベース(以下「ドメイン名DB」とする。)12bや、特徴語データベース(以下「特徴語DB」とする。)12cや、属性記述パターンデータベース(以下「属性記述パターンDB」とする。)12d、属性・属性値データベース(以下「属性・属性値DB」とする。)12e等が構築されている。
カテゴリ関連語DB12aには、ウェブサイトにおける商品等や、ブログの等のカテゴリ毎に用語が記憶されている。例えば、”ワイン”のカテゴリには、”ワイン”、”お酒”等のカテゴリ関連語が、”ゴルフドライバー”のカテゴリには、”ゴルフ”、”ドライバー”、”クラブ”等のカテゴリ関連語が予め記憶されている。また、”旅行”のカテゴリには、”国内”、”海外”等のカテゴリ関連用語が、予め記憶されている。また、カテゴリは階層構造になっていて、例えば、”ワイン”のカテゴリは、”洋酒”のカテゴリに属する。これらカテゴリ関連語は、各カテゴリに対応する識別子に関連付けられて記憶されている。このように、カテゴリ関連語DB12aは、商品を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段の一例として機能する。なお、カテゴリ関連語DB12aには、ブログためのウェブサイトの場合、食べ物に関するカテゴリには、”レストラン”、”ランチ”等のカテゴリ関連用語が、スポーツに関するカテゴリには、”野球”、”サッカー”等のカテゴリ関連用語が記憶されている。
ドメイン名DB12bには、インターネット上の様々なショッピングサイトやブログサイト等のウェブサイトのドメイン名が予め記憶されている。
特徴語DB12cには、ウェブページ分析サーバ10による分析結果の一例として、ウェブページから、抽出したウェブページの特徴語が記憶されている。特徴語は、ウェブページのURL(Uniform Resource Locator)等に関連付けられて記憶されている。さらに、特徴語DB12cには、ノイズの形態素を除去するための情報が記憶されている。
属性記述パターンDB12dには、商品等やブログの属性の記述に用いられる属性記述パターンの初期データや、ウェブページから抽出した属性記述パターンが記憶されている。なおブログの属性としてブログのカテゴリが挙げられる。
属性・属性値DB12eには、ウェブページから抽出した商品等の属性に関する属性名と属性値とが記憶される。ここで、属性関連語の一例として、属性名のみや、属性名を含む語句や、属性名と属性値との組等が挙げられる。また、属性・属性値という表記は、属性と属性値とが対になっている場合で、具体的に属性名と属性値とが組になった場合も含む。
次に、入出力インターフェース部13は、通信部11および記憶部12とシステム制御部14との間のインターフェース処理を行うようになっている。
システム制御部14は、CPU(Central Processing Unit)14a、ROM(Read Only Memory)14b、RAM(Random Access Memory)14c等により構成されている。そして、システム制御部14は、CPU14aが、ROM14bや記憶部12に記憶された各種プログラムを読み出し実行することにより、複数のウェブページから、属性記述パターンに適合する属性名や属性値を抽出したり、ウェブページのテキストデータから各ウェブページの特徴語候補を抽出したり、特徴語候補から特徴語を決定したり、特徴語に基づき、ウェブページ間の類似度を算出したり、複数のウェブページを特徴語毎にグルーピングしたりする。
する。
する。
(2.2 情報提供サーバ20の構成および機能)
次に、情報提供サーバ20の構成および機能について、図3を用いて説明する。
図3は、情報提供サーバ20の概要構成の一例を示すブロック図である。
次に、情報提供サーバ20の構成および機能について、図3を用いて説明する。
図3は、情報提供サーバ20の概要構成の一例を示すブロック図である。
図3に示すように、情報提供サーバ20は、通信部21と、記憶部22と、入出力インターフェース部23と、システム制御部24と、を備え、システム制御部24と入出力インターフェース部23とは、システムバス25を介して接続されている。なお、情報提供サーバ20の構成および機能は、ウェブページ分析サーバ10の構成および機能とほぼ同じであるので、ウェブページ分析サーバ10の各構成や各機能において、異なるところを中心に説明する。
通信部21は、ネットワーク3やローカルエリアネットワーク等を通して、店舗主端末40やユーザ端末45やウェブページ分析サーバ10等と通信状態を制御等するようになっている。
記憶部22には、情報データベース(以下「情報DB」とする。)22aや、会員データベース(以下「会員DB」とする。)22b等が構築されている。
情報DB22aには、ウェブページに記載されている対象の一例である商品、サービス、および、ブログ等に関する情報が記憶されている。例えば、情報DB22aには、商品等を識別するための識別子である商品IDに関連付けられ、商品名(サービス名を含む)、種類、商品の画像、サービスに関連した画像、スペック、および、商品等の紹介の要約文等の商品情報や、広告情報等が記憶されている。また、情報DB22aには、ユーザが投稿してきたブログの記事がカテゴリ分けされて記憶されている。また、情報DB22aには、HTML(HyperText Markup Language)、XML(Extensible Markup Language)等のマークアップ言語等により記述されたウェブページのファイル等が記憶されている。
会員DB22bには、会員登録されたユーザ(インターネットショップの利用者)のユーザID、名称、住所、電話番号、メールアドレス等のユーザ情報が登録されている。このようなユーザ情報は、ユーザIDによってユーザ毎に判別可能になっている。また、会員DB22bには、ユーザがユーザ端末45からインターネットショップのサイトにログインする際に必要な、ユーザID、ログインID、および、パスワードが登録されている。ここで、ログインIDおよびパスワードは、ログイン処理(ユーザの認証処理)に使用されるログイン情報である。
システム制御部24は、CPU24a、ROM24b、RAM24c等により構成されている。そして、システム制御部24は、CPU24aが、ROM24bや記憶部22に記憶された各種プログラムを読み出し実行することにより、店舗主によるウェブページの登録や更新や、ユーザによる商品購入処理や、商品の購買履歴をユーザID毎に記録させたりする。
(2.3 検索サーバ30の構成および機能)
次に、検索サーバ30の構成および機能について、図4を用いて説明する。
図4は、検索サーバ30の概要構成の一例を示すブロック図である。
次に、検索サーバ30の構成および機能について、図4を用いて説明する。
図4は、検索サーバ30の概要構成の一例を示すブロック図である。
図4に示すように、検索サーバ30は、通信部31と、記憶部32と、入出力インターフェース部33と、システム制御部34と、を備え、システム制御部34と入出力インターフェース部33とは、システムバス35を介して接続されている。なお、検索サーバ30の構成および機能は、ウェブページ分析サーバ10の構成および機能とほぼ同じであるので、ウェブページ分析サーバ10の各構成や各機能において、異なるところを中心に説明する。
通信部31は、ネットワーク3やローカルエリアネットワーク等を通して、ユーザ端末45やウェブページ分析サーバ10等と通信状態を制御等するようになっている。
記憶部32には、検索データベース(以下「検索DB」とする。)32a等が構築されている。
検索DB32aには、インデクサーにより生成されたインデックス情報や、スニペット等が記憶されている。
システム制御部34は、CPU34a、ROM34b、RAM34c等により構成されている。そして、システム制御部34は、CPU34aが、ROM34bや記憶部32に記憶された各種プログラムを読み出し実行することにより、インターネット上のウェブページの情報を収集し、ウェブページの情報を予め解析し、インデックス情報や検索結果のスニペットを作成したり、ウェブページ分析サーバ10やユーザ端末45からの検索クエリに基づき、検索をしたり、検索結果を送信したりする。
[3.第1実施形態のウェブページ分析システムの動作]
次に、本発明の第1実施形態に係る情報処理システム1のウェブページ分析システムとしての動作について図5~図12を用いて説明する。
次に、本発明の第1実施形態に係る情報処理システム1のウェブページ分析システムとしての動作について図5~図12を用いて説明する。
図5は、ウェブページ分析サーバ10においてウェブページを分析する動作例を示すフローチャートである。図6は、情報提供サーバ20のウェブページの一例を示す説明図である。図7は、ウェブページのソースコードの一例を示す説明図である。図8は、ウェブページのテキストデータの分析過程の一例を示す模式図である。図9は、検索サーバ30の検索結果の一例を示す模式図である。図10は、ドメイン名DB12bに記憶されたウェブサイトのドメイン名の一例を示す模式図である。図11は、カテゴリ関連語DB12aに記憶されたカテゴリ関連語の一例を示す模式図である。図12は、ウェブページ分析サーバ10における類似度算出のサブルーチンの一例を示すフローチャートである。
(3.1.ウェブページの分析の流れ)
まず、ウェブページの分析の流れについて、図5を用いて説明する。
まず、ウェブページの分析の流れについて、図5を用いて説明する。
図5に示すように、ウェブページ分析サーバ10は、2つのウェブページを取得する(ステップS1)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、情報DB22aにおいて、同一のカテゴリ(例えば、カテゴリ”ワイン”)に所属している商品に関して、第1のウェブページおよび第2のウェブページを、通信部11を通して情報DB22aから取得する。これらウェブページは、店舗主端末40を通して、店舗主等により登録されたウェブページや、ユーザ端末45から投稿されたブログのウェブページである。このように、ウェブページ分析サーバ10のシステム制御部14および通信部11は、ウェブページを取得する、第1のウェブページおよび第2のウェブページを取得するウェブページ取得手段の一例として機能する。
次に、ウェブページ分析サーバ10は、各ウェブページからテキストデータを抽出する(ステップS2)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、各ウェブページ内に記述されているテキストデータを抽出する。さらに具体的には、図6に示すように、ウェブページ50において、テキスト部51、52、53、54のテキストデータが抽出される。また、図7に示すように、HTML等のマークアップ言語等で記述されたソースコードの中のデータも利用する。例えば、HTMLタグのtitle要素の部分のテキストデータも抽出される。
このように、ウェブページ分析サーバ10のシステム制御部14は、各ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段の一例として機能する。
次に、ウェブページ分析サーバ10は、抽出したテキストデータから言語解析の一例である形態素解析によって特徴語候補を抽出する(ステップS3)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、形態素解析のプログラムを用い、抽出したテキストデータを形態素に分解し、各文節の品詞等を求める。図8に示すように、例えば、語句群53aが得られる。そして、ウェブページ分析サーバ10のシステム制御部14は、語句群53aから、ノイズを除去して、特徴語候補群53bを抽出する。例えば、”[ ]”のように括弧や記号で括られた部分や、動詞句や、動詞句に係る語句等が、語句群53aから取り除かれ、特徴語候補群53bが得られる。ここで、括弧や記号で括られた部分はノイズである場合が多く、また、動詞句や動詞句に係る語句は商品やサービスやブログに関連する語句でないことが多い。
なお、形態素解析として、一般的な形態素解析のプログラムを用いればよく、形態素解析する際、複合語を形成する過程があってもよい。また、他方のウェブページについても、特徴語候補が抽出される。ウェブページ分析サーバ10のシステム制御部14は、このようなノイズの形態素に関する情報を、予め特徴語DB12cに記憶しておく。また、ウェブページ分析サーバ10のシステム制御部14は、特徴語候補としてではなく、特徴語として抽出してもよい。
このようにウェブページ分析サーバ10のシステム制御部14は、抽出したテキストデータを言語解析して、各ウェブページの特徴語候補を抽出する特徴語候補抽出手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、抽出した前記テキストデータを言語解析して、各ウェブページの特徴語を抽出する特徴語抽出手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、ノイズの形態素を記憶するノイズ形態素記憶手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、ノイズ形態素記憶手段を参照して、テキストデータを形態素解析によって言語解析して得られた形態素から、ノイズの形態素を除去するノイズ除去手段の一例として機能する。
次に、ウェブページ分析サーバ10は、各特徴語候補によりウェブ検索を行う(ステップS4)。具体的には、まず、ウェブページ分析サーバ10のシステム制御部14は、検索サーバ30が提供する検索APIの機能を利用するために、各特徴語候補を検索キーワードとする各検索クエリを作成する。そして、ウェブページ分析サーバ10のシステム制御部14は、通信部11を通して、検索サーバ30に送信し、検索サーバ30から特徴語候補毎の検索結果を受信する。図9に示すように、検索結果ページ60の検索結果毎に、検索結果のタイトル部61、スニペット部62が含まれる。なお、使用する検索エンジンによって、タイトル部とスニペット部とに明確に分けられていない場合は、検索結果のテキストデータの一部をスニペットとする。このように、ウェブページ分析サーバ10のシステム制御部14は、特徴語候補を検索キーワードとする検索クエリを作成し、検索クエリに基づく検索結果を取得する検索結果取得手段の一例として機能する。
次に、ウェブページ分析サーバ10は、ショッピングサイト等のウェブサイトの検索結果に絞る(ステップS5)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、検索結果のリンク先のURL(Uniform Resource Locator)において、ショッピングサイト等のウェブサイトのドメイン名を含む検索結果に絞る。さらに具体的には、ウェブページ分析サーバ10のシステム制御部14は、図10のように、ドメイン名DB12bを参照して、上位(例えば30位)の検索結果のうち、HTMLのタグ”<a href=・・・>”の情報やスニペット部62のURL62aの中にショッピングサイト等のウェブサイトのドメイン名を含む検索結果に絞る。なお、ウェブページ分析サーバ10は、ステップS4の検索前に、ドメイン名DB12bを参照してもよい。この場合、検索するドメインを検索APIのパラメータとして、ウェブページ分析サーバ10は、検索を行う。
次に、ウェブページ分析サーバ10は、カテゴリ関連語がスニペットに含まれる場合の特徴語候補を特徴語として決定する(ステップS6)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS5で絞られた検索結果のスニペットの中に、カテゴリ関連語が含まれる場合の特徴語候補を選択し、この特徴語候補を特徴語として決定する。さらに具体的には、図11に示すように、ウェブページ分析サーバ10のシステム制御部14は、カテゴリが”ワイン”の場合、検索結果のスニペットに、カテゴリ関連語”ワイン”または”酒”が含まれる特徴語候補を選択し、特徴語候補を特徴語として決定する。そして、図8に示すように、例えば、語句群53cが得られ、特徴語DB12cに記憶される。
このようにウェブページ分析サーバ10のシステム制御部14は、カテゴリ関連語記憶手段の一例のカテゴリ関連語DB12aを参照して、検索結果のスニペット中にカテゴリ関連語が存在するか否かを判定する検索結果判定手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、スニペット中にカテゴリ関連語が存在する場合の特徴語候補を各ウェブページの特徴語に決定する特徴語決定手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、カテゴリ関連語記憶手段およびドメイン名記憶手段を参照して、検索結果において、ドメイン名に関連したウェブサイトのスニペット中にカテゴリ関連語が存在するか否かを判定する検索結果判定手段の一例として機能する。
次に、ウェブページ分析サーバ10は、特徴語に基づき類似度を算出する(ステップS7)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ウェブページ間の類似度を算出するサブルーチンにより、類似度を算出する。なお、ウェブページ分析サーバ10のシステム制御部14は、ステップSで抽出した特徴語候補に基づき類似度を算出してもよい。
このようにウェブページ分析サーバ10のシステム制御部14は、特徴語に基づき、第1のウェブページと第2のウェブページとの間の類似度を算出する類似度算出手段の一例として機能する。
次に、ウェブページ分析サーバ10は、類似度に基づきウェブページの類似性の判定を行う(ステップS8)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、類似度算出のサブルーチンにより算出した類似度が所定の値以上である場合、ウェブページ同士は類似商品等の類似対象を扱うウェブページであると判定する。なお、類似商品等の類似対象を扱うウェブページであると判定されたウェブページのうち、さらに類似度が高い場合、同一の商品等の同一の対象を扱うウェブページであると判定してもよい。このようにウェブページ分析サーバ10のシステム制御部14は、類似度が所定の値以上である場合、第1のウェブページと第2のウェブページとは類似である対象を扱うウェブページであると判定する類似対象判定手段の一例として機能する。
ウェブページの類似性の判定を利用して、同一の対象や類似の対象を扱うウェブページを集め、ユーザ端末45を通して、ユーザが閲覧できるように、ウェブページのデータベースを構築する。例えば、ウェブページに、ある商品に対するGUI(Graphical User Interface)のボタン等を設け、ユーザがクリックすることにより、同一の対象や類似の対象を扱うウェブページの一覧が見られるようにする。
(3.2.特徴語に基づく類似度の算出)
次に、特徴語に基づく類似度の算出のサブルーチンについて、図12を用いて説明する。
次に、特徴語に基づく類似度の算出のサブルーチンについて、図12を用いて説明する。
図12に示すように、ウェブページ分析サーバ10は、各特徴語のIDF値を算出する(ステップS10)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、各特徴語に対して、下記の式(1)に示すようなIDF(Inverse Document Frequency(逆出現頻度))の値を、算出する。
IDFw=log(N/Nw) ・・・(1)
IDFw=log(N/Nw) ・・・(1)
ここで、IDFwは特徴語wのIDF値であり、Nはあるショッピングサイトの全ウェブページ数であり、Nwは前記ショッピングサイトにおいて特徴語wが出現するウェブページ数(ウェブページ出現数の一例)である。特徴語wのウェブページ数Nwの値が小さいほどIDFwの値が大きくなり、特徴語wは商品を扱うウェブページに特有な語句である可能性が高くなる。なお、IDF値を算出するためのウェブページの範囲(各ウェブページが属するウェブサイトの範囲の一例)は、検索エンジンがクローリングしたページ数でもよいし、ある国のウェブページや、ある国の複数のショッピングサイトのウェブページ(各ウェブページが属するウェブサイトの一例)や、特定しているカテゴリにおける上位のカテゴリのウェブページ等でもよい。
次に、ウェブページ分析サーバ10は、IDF値に基づく類似度を算出する(ステップS11)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、下記の式(2)に示すように、ステップS10で算出したIDF値に基づき、第1のウェブページと第2のウェブページとの類似度S12を算出する。
S12=[Σc∈C12(IDFc)]/[Σu∈U12(IDFu)]・・・(2)
S12=[Σc∈C12(IDFc)]/[Σu∈U12(IDFu)]・・・(2)
ここで、集合U12は、第1のウェブページの特徴語と第2のウェブページの特徴語とを合わせた集合である。すなわち、第1のウェブページの特徴語の集合と、第2のウェブページの特徴語の集合との和集合である。集合C12は、第1のウェブページと第2のウェブページとの共通の特徴語の集合である。すなわち、第1のウェブページの特徴語の集合と、第2のウェブページの特徴語の集合との積集合である。また、式(2)の分母は、集合U12の要素uである特徴語のIDF値の和であり、式(2)の分子は、集合C12の要素cである共通の特徴語のIDF値の和である。式(2)に示すように、第1のウェブページと第2のウェブページとにおいて、共通の特徴語があればあるほど、類似度S12が高くなり、また、その特徴語のIDF値が高いほど、類似度S12が高くなる。
このようにウェブページ分析サーバ10のシステム制御部14は、特徴語が、各ウェブページが属するウェブサイトの範囲において出現するウェブページ出現数に基づき、第1のウェブページと第2のウェブページとの間の類似度を算出する類似度算出手段の一例として機能する。またウェブページ分析サーバ10のシステム制御部14は、第1のウェブページおよび第2のウェブページにおいて共通の特徴語のウェブページ出現数に基づき、類似度を算出する類似度算出手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、各ウェブページが属するウェブサイトの範囲に存在するウェブページの数とウェブページ出現数とから、前記特徴語の逆出現頻度を算出し、当該逆出現頻度に基づき類似度を算出する類似度算出手段の一例として機能する。
この式(2)の類似度に基づき、ステップS8において、ウェブページ分析サーバ10が、ウェブページの類似性の判定を行う。
以上、本実施形態は、ウェブページ50内に記述されているテキスト部51、52、53等のテキストデータを抽出し、テキストデータを言語解析して、ウェブページの特徴語候補を抽出し、特徴語候補を検索キーワードとする検索クエリを作成し、検索クエリに基づく検索結果ページ60を取得し、検索結果ページのスニペット部62のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補をウェブページの特徴語に決定する。従って、本実施形態によれば、言語解析してウェブページの特徴語候補を抽出し、さらに、検索クエリに基づき特徴語を決定しているため、ウェブページの特徴語を、精度良く求めることができる。
また、本実施形態によれば、特徴語候補を絞る際、ウェブ検索により求まるスニペットを使用することにより、インターネット上における語句の使用状況を反映でき、高精度の特徴語を抽出することができる。さらに、スニペットに限ることにより、高速に特徴語を求めることができる。さらにまた、ウェブ検索のスニペットを使用することにより、商品等のトレンドが変化してもトレンドに追随でき、適切な特徴語(例えば、商品名や型番)が求められる。また、カテゴリ関連語がスニペット含まれるか否かのように、ウェブページに含まれる対象の大枠を表すカテゴリ関連語を用いて判定することで、言語解析したウェブページに含まれる内容を反映させた適切な特徴語を決定する判定が精度良く容易にできる。
また、本実施形態によれば、ウェブページ50内に記述されているテキスト部51、52、53等のテキストデータを抽出し、テキストデータを言語解析して、ウェブページの特徴語を抽出し、当該特徴語が、各ウェブページが属するウェブサイトの範囲において出現するウェブページ出現数に基づき、第1のウェブページと第2のウェブページとの間の類似度を算出し、類似度が所定の値以上である場合、第1のウェブページと第2のウェブページとは類似である対象を扱うウェブページであると判定することにより、言語解析してウェブページの特徴語を抽出し、特徴語のウェブページ出現数に基づき類似度を算出しているため、ウェブページの類似性を求めることができる。また、本実施形態によれば、ウェブページの類似度を精度良く求めることができる。さらに、本実施形態によれば、ウェブページで扱われる商品等の対象の類似性を求めて、例えば、同一の対象や類似の対象を扱うウェブページをまとめ上げることができるため、ユーザの利便性の向上を図ることができる。
また、ウェブページ分析サーバ10のシステム制御部14は、ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語をカテゴリ関連語DB12aに記憶し、第1のウェブページおよび第2のウェブページを取得し、各ウェブページ50内に記述されているテキスト部51、52、53等のテキストデータを言語解析して各ウェブページの特徴語候補を抽出し、特徴語候補を検索キーワードとする検索クエリを作成して検索クエリに基づく検索結果ページ60を取得し、検索結果ページのスニペット部62のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補を各ウェブページの特徴語に決定し、当該特徴語が、各ウェブページが属するウェブサイトの範囲において出現するウェブページ出現数に基づき、第1のウェブページと第2のウェブページとの間の類似度を算出し、類似度が所定の値以上である場合、第1のウェブページと第2のウェブページとは類似である対象を扱うウェブページであると判定してもよい。
この場合、ウェブページ分析サーバ10のシステム制御部14は、特徴語候補を絞る際、ウェブ検索により求まるスニペットを使用することにより、インターネット上における語句の使用状況を反映でき、高精度の特徴語を抽出することができる。さらに、ウェブページ分析サーバ10のシステム制御部14は、スニペットに限ることにより、高速に特徴語を求めることができる。さらにまた、ウェブ検索のスニペットを使用することにより、商品等のトレンドが変化してもトレンドに追随でき、適切な特徴語が求められ、ウェブページ分析サーバ10のシステム制御部14は、ウェブページの類似度を精度良く求めることができる。
また、ウェブページ分析サーバ10のシステム制御部14が、インターネットにおける所定の範囲を、各ウェブページが属するウェブサイトとし、特徴語が出現するウェブページ出現数を算出し、当該ウェブページ出現数に基づき、類似度を算出する場合、当該ウェブサイトを反映した類似度を算出できる。
また、ウェブページ分析サーバ10のシステム制御部14が、各ウェブページが属するウェブサイトの範囲に存在するウェブページの数と前記ウェブページ出現数とから、前記特徴語の逆出現頻度を算出し、当該逆出現頻度に基づき前記類似度を算出する場合、特徴語の逆出現頻度により、逆出現頻度が高い順等に特徴語のランク付けができるため、類似性の判断がしやすくなる。
また、ウェブページ分析サーバ10のシステム制御部14が、第1のウェブページおよび第2のウェブページにおいて共通の特徴語のウェブページ出現数に基づき、類似度を算出する場合、共通の特徴語により的確に類似度を算出できる。
また、ウェブページ分析サーバ10のシステム制御部14が、テキストデータを形態素解析して得られた形態素から、ノイズの形態素を除去する場合、的確な特徴語候補を抽出できるため、特徴語の精度が高くなる。
また、ウェブページ分析サーバ10のシステム制御部14が、カテゴリ関連語DB(カテゴリ関連語記憶手段)12aを参照して、検索結果において、ドメイン名に関連したウェブサイトのスニペット中にカテゴリ関連語が存在するか否かを判定する場合、対象の説明がなされているウェブページを多く有するウェブサイトに絞るため、対象を適切に特徴付ける特徴語を抽出でき、特徴語の精度が高くなる。
また、ウェブページ分析サーバ10のシステム制御部14が、特徴語に基づき、第1のウェブページと第2のウェブページとの間の類似度を算出し、類似度が所定の値以上である場合、第1のウェブページと第2のウェブページとは類似対象を扱うウェブページであると判定し、ウェブページの商品の類似性を求めて、例えば、同一の対象や類似の対象を扱うウェブページをまとめ上げることができ、ユーザの利便性の向上を図ることができる。
(第2実施形態)
次に、本発明の第2実施形態に係る情報処理システム1の動作について、図を用いて説明する。なお、前記第1実施形態と同一または対応する部分には、同一の符号を用いて異なる構成および作用のみを説明する。その他の実施形態および変形例も同様とする。
次に、本発明の第2実施形態に係る情報処理システム1の動作について、図を用いて説明する。なお、前記第1実施形態と同一または対応する部分には、同一の符号を用いて異なる構成および作用のみを説明する。その他の実施形態および変形例も同様とする。
[4.第2実施形態に係る検索システムの動作]
次に、本発明の第2実施形態に係る情報処理システム1の検索システムとしての動作について図13~図15を用いて説明する。
次に、本発明の第2実施形態に係る情報処理システム1の検索システムとしての動作について図13~図15を用いて説明する。
図13は、ウェブページ分析サーバ10においてウェブページをグルーピングする動作例を示すフローチャートである。図14は、ユーザ端末45に送信されるグルーピングされた検索結果の一例を示す模式図である。図15は、ウェブページ分析サーバ10におけるグルーピングのサブルーチンの一例を示すフローチャートである。
(4.1.ウェブページのグルーピングの流れ)
ウェブページのグルーピングの流れについて、図13を用いて説明する。
ウェブページのグルーピングの流れについて、図13を用いて説明する。
まず、ユーザはユーザ端末45に、探している商品等のキーワードを入力する。例えば、”白ワイン”と入力し検索を行うと、検索キーワード”白ワイン”を含む検索クエリがウェブページ分析サーバ10に送信される。
次に、図13に示すように、ウェブページ分析サーバ10は、ユーザ端末45から検索クエリを受信する(ステップS15)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、通信部11を通して、ユーザ端末45から検索キーワードを含む検索クエリを受信する。このように、ウェブページ分析サーバ10のシステム制御部14および通信部11は、ユーザ端末からユーザ検索クエリを受信する検索クエリ受信手段の一例として機能する。
次に、ウェブページ分析サーバ10は、検索クエリに基づき検索をする(ステップS16)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、情報DB22aに対して、検索キーワードに対応する商品等のウェブページの検索を行う。
次に、ウェブページ分析サーバ10は、検索結果に基づく複数のウェブページを取得する(ステップS17)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、情報DB22aにおいて、検索キーワードによりヒットした商品等の対象を扱う複数のウェブページの情報を取得する。これらウェブページは、例えば、店舗主端末40を通して、店舗主等により登録されたウェブページや、ユーザ端末45から投稿されたブログのウェブページである。このように、ウェブページ分析サーバ10のシステム制御部14および通信部11は、ユーザ検索クエリに基づく複数のウェブページを取得するウェブページ取得手段の一例として機能する。
次に、ウェブページ分析サーバ10は、各ウェブページからテキストデータを抽出する(ステップS18)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS2と同様にテキストデータを抽出する。
次に、ウェブページ分析サーバ10は、抽出したテキストデータから言語解析の一例である形態素解析によって特徴語候補を抽出する(ステップS19)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS3と同様に、特徴語候補を抽出する。
次に、ウェブページ分析サーバ10は、各特徴語候補によりウェブ検索を行う(ステップS20)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS4と同様にウェブ検索を行う。
次に、ウェブページ分析サーバ10は、ショッピングサイト等のウェブサイトの検索結果に絞る(ステップS21)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS5と同様に、ショッピングサイト等のウェブサイトの検索結果に絞る。
次に、ウェブページ分析サーバ10は、カテゴリ関連語がスニペットに含まれる場合の特徴語候補を特徴語として決定する(ステップS22)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS6と同様に、特徴語候補を特徴語として決定する。
次に、ウェブページ分析サーバ10は、特徴語に基づき複数のウェブページをグルーピングする(ステップS23)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、グルーピングのサブルーチンにより、各特徴語のIDF値を算出し、任意の2つのウェブページ間において、IDF値から類似度(任意の2つのウェブページ間の第2類似度の一例)を求め、類似度に基づき類似のウェブページ同士をグルーピングする。図14に示すように、検索結果のウェブページ70において、商品等毎にグループ名部71が設けられる。グループ名部71には、具体的な商品名やサービス名やブログからの特徴語が利用される。また、各グループ名部71以下に、同じグルーピングに属するウェブページのタイトル部72と、スニペット部73とが、集められる。例えば、タイトル部72およびスニペット部73がリスティングされる。
このようにウェブページ分析サーバ10のシステム制御部14は、取得したユーザ検索クエリに基づく複数のウェブページのうち任意の2つのウェブページ間の第2類似度を、類似度として、特徴語に基づき算出する類似度算出手段の一例として機能する。
次に、ウェブページ分析サーバ10は、ユーザ端末に検索結果を送信する(ステップS24)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、通信部11を通して、図14に示すような検索結果を表示させるHTML等のマークアップ言語等の情報を、検索クエリを送信してきたユーザ端末45に送信する。このように、ウェブページ分析サーバ10のシステム制御部14および通信部11は、特徴語毎にグルーピングしたウェブページに関する情報を検索結果としてユーザ端末45に送信する送信手段の一例として機能する。
なお、例えば「ボルドー ワイン」という語をユーザが検索した場合、ウェブページ分析サーバ10のシステム制御部14は、ボルドー産ワインに関する複数のウェブページを取得し、その複数のウェブページそれぞれの特徴語を上記手法で求め、特徴語が同じまたは類似のもの同士をまとめて、検索結果としてユーザ端末45に送信してもよい。
さらに、例えば、A,B,C,Dの4つのウェブページがある場合に、ウェブページ分析サーバ10のシステム制御部14は、ABの組み合わせ及びCDの組み合わせの類似度が、所定の値以上であれば、ABを第1グループ、CDを第2グループとしたグルーピングを行ってもよい。また、ウェブページ分析サーバ10のシステム制御部14は、ABCの各ウェブページ間の類似度が、所定の値以上ならば、ABCをグルーピングしてもよい。
(4.2.特徴語に基づくグルーピング)
次に、特徴語に基づくグルーピングのサブルーチンについて、図15を用いて説明する。
次に、特徴語に基づくグルーピングのサブルーチンについて、図15を用いて説明する。
図15に示すように、ウェブページ分析サーバ10は、各特徴語のIDF値を算出する(ステップS25)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS10と同様に、各特徴語のIDF値を算出する。
次に、ウェブページ分析サーバ10は、IDF値に基づく類似度を算出する(ステップS26)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS11と同様に、IDF値に基づく類似度(第2類似度の一例)を算出する。
次に、ウェブページ分析サーバ10は、類似度に基づき類似のウェブページ同士をグルーピングする(ステップS27)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、算出した類似度(第2類似度の一例)が所定の値以上である場合、ウェブページ同士は類似対象を扱うウェブページであると判定し、類似の対象を扱うウェブページとして同じグループにする。なお、類似対象を扱うウェブページであると判定されたウェブページのうち、さらに類似度が高い場合、同一の対象を扱うウェブページであると判定してもよい。このようにウェブページ分析サーバ10のシステム制御部14は、第2類似度が所定の値以上である場合のウェブページ同士をグルーピングするウェブページ・グルーピング手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、第2類似度に基づき、複数のウェブページを特徴語毎にグルーピングするウェブページ・グルーピング手段の一例として機能する。
なお、検索キーワードに対応するカテゴリが複数にまたがる場合、ウェブページ分析サーバ10のシステム制御部14は、カテゴリ毎に以上の処理を行い、検索結果をカテゴリ毎に分けて、ウェブページのグループを表示するようにする。
また、ウェブページ分析サーバ10のシステム制御部14は、所定数以上の共通する特徴語を互いに有するウェブページ同士をグルーピングしてもよい。ウェブページ分析サーバ10のシステム制御部14は、各特徴語のIDF値を算出して各特徴語にIDF値によるランクを設け、IDF値が所定以上の共通する特徴語を所定数以上互いに有するウェブページ同士をグルーピングしてもよい。
このようにウェブページ分析サーバ10のシステム制御部14は、ユーザ検索クエリによって得られる複数のウェブページを特徴語毎にグルーピングするウェブページ・グルーピング手段の一例として機能する。
以上、本実施形態によれば、ユーザ端末45からユーザ検索クエリを受信し、ユーザ検索クエリに基づく複数のウェブページを、ウェブページの中から取得し、各ウェブページ50内に記述されているテキスト部51、52、53等のテキストデータを言語解析して各ウェブページの特徴語候補を抽出し、特徴語候補を検索キーワードとする検索クエリを作成して検索クエリに基づく検索結果ページ60を取得し、検索結果ページのスニペット部62のスニペット中にカテゴリ関連語が存在するか否かを判定し、スニペット中にカテゴリ関連語が存在する場合の特徴語候補を各ウェブページの特徴語に決定し、複数のウェブページを特徴語毎にグルーピングし、特徴語毎にグルーピングしたウェブページに関する情報を検索結果(検索結果のウェブページ70)としてユーザ端末45に送信する場合、複数のウェブページを特徴語毎にグルーピングすることにより、ユーザが見やすい検索結果に反映させる等、利用価値が高まり、また、ユーザが見やすい検索結果を提示してユーザの利便性の向上を図ることができる。
また、本実施形態によれば、ユーザ端末45からユーザ検索クエリを受信し、ユーザ検索クエリに基づく複数のウェブページを取得し、当該取得したユーザ検索クエリに基づく複数のウェブページのうち任意の2つのウェブページ間の第2類似度を類似度として、特徴語に基づき算出し、第2類似度が所定の値以上である場合のウェブページ同士をグルーピングし、グルーピングしたウェブページに関する情報を検索結果としてユーザ端末に送信することにより、複数のウェブページを特徴語毎にグルーピングすることにより、ユーザが見やすい検索結果に反映させる等、利用価値が高まり、また、ユーザが見やすい検索結果を提示してユーザの利便性の向上を図ることができる。また、ウェブページ分析サーバ10のシステム制御部14が、類似度に閾値を設けたことにより、類似度により一律に、ウェブページをグルーピングすることができる。
また、ウェブページ分析サーバ10のシステム制御部14が、第2類似度に基づき、複数のウェブページを特徴語毎にグルーピングする場合、類似度により異なる複数の特徴語でもウェブページをグルーピングしやすくなる。
また、ウェブページ分析サーバ10のシステム制御部14が、特徴語に基づき、複数のウェブページのうち任意の2つのウェブページ間の類似度を算出し、類似度に基づき、複数のウェブページをグルーピングする場合、類似度により異なる複数の特徴語でもウェブページをグルーピングしやすくなる。
(第3実施形態)
次に、本発明の第3実施形態に係る情報処理システム1のウェブページ分析システムとしての動作について図16~図22を用いて説明する。
[5.第3実施形態に係るウェブページ分析システムの動作]
次に、本発明の第3実施形態に係る情報処理システム1のウェブページ分析システムとしての動作について図16~図22を用いて説明する。
[5.第3実施形態に係るウェブページ分析システムの動作]
(5.1.ウェブページ分析の全体の流れ)
まず、ウェブページ分析の全体の流れについて、図16を用いて説明する。
図16は、ウェブページ分析サーバ10においてウェブページ分析の全体の流れを示す説明図である。なお、図中に後述するフローチャートのステップに対応する符号を示した。
まず、ウェブページ分析の全体の流れについて、図16を用いて説明する。
図16は、ウェブページ分析サーバ10においてウェブページ分析の全体の流れを示す説明図である。なお、図中に後述するフローチャートのステップに対応する符号を示した。
図16に示すように、まず、ウェブページ分析サーバ10は、ウェブページ取得手段の一例として、情報提供サーバ20の情報DB22aから、複数のウェブページを取得する。
ウェブページを取得した後、ウェブページ分析サーバ10の処理は2つに分かれる。2つの処理は、ウェブページからウェブページの特徴語を抽出してウェブページ間の類似度を求める処理と、ウェブページから商品の属性・属性値を求める処理である。なお、属性抽出手段と、属性記述パターン抽出手段とが所定の回数繰り返され、ブートストラップ法を構成する。
最後に、ウェブページ分析サーバ10は、類似対象判定手段の一例として、類似度と属性とに基づき、2つのウェブページが類似対象を扱うウェブページであるか否かを判定する。
(5.2.ウェブページの特徴語を抽出して分析する流れ)
次に、ウェブページ分析サーバ10においてウェブページの特徴語を抽出してウェブページを分析する流れについて、図17を用いて説明する。
次に、ウェブページ分析サーバ10においてウェブページの特徴語を抽出してウェブページを分析する流れについて、図17を用いて説明する。
図17は、ウェブページ分析サーバ10においてウェブページの特徴語を抽出してウェブページを分析する動作例を示すフローチャートである。
図17に示すように、ウェブページ分析サーバ10は、複数のウェブページを取得する(ステップS30)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS1で2つのウェブページを取得するように、複数のウェブページを取得する。
次に、ウェブページ分析サーバ10は、各ウェブページからテキストデータを抽出する(ステップS31)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS2と同様に各ウェブページからテキストデータを抽出する。
次に、ウェブページ分析サーバ10は、抽出したテキストデータから言語解析の一例として形態素解析によって特徴語候補を抽出する(ステップS32)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS3と同様に特徴語候補を抽出する。
次に、ウェブページ分析サーバ10は、各特徴語候補によりウェブ検索を行う(ステップS33)。具体的には、まず、ウェブページ分析サーバ10のシステム制御部14は、ステップS4と同様に、ウェブ検索を行う。
次に、ウェブページ分析サーバ10は、ショッピングサイト等のウェブサイトの検索結果に絞る(ステップS34)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS5と同様にウェブサイトの検索結果に絞る。
次に、ウェブページ分析サーバ10は、カテゴリ関連語がスニペットに含まれる場合の特徴語候補を特徴語として決定する(ステップS35)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS6と同様に特徴語候補を特徴語として決定する。
次に、ウェブページ分析サーバ10は、特徴語に基づき類似度を算出する(ステップS36)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS7同様に類似度の算出のサブルーチンにより類似度(取得した複数のウェブページのうち任意の2つのウェブページ間の第3類似度の一例)を算出する。このようにウェブページ分析サーバ10のシステム制御部14は、取得した複数のウェブページのうち任意の2つのウェブページ間の第3類似度を類似度として、特徴語に基づき算出する類似度算出手段の一例として機能する。
次に、ウェブページ分析サーバ10は、類似度に基づきウェブページの類似性の判定を行う(ステップS37)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS8と同様にウェブページの類似性の判定を行う。
ウェブページ同士の類似度が所定の値以上と判定された場合(ステップS37;YES)、ウェブページ分析サーバ10は、類似度と属性とに基づき、ウェブページの類似性の判定を行う(ステップS38)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、類似度と、任意の2つのウェブページ間での共通の属性関連語とに基づき、任意の2つのウェブページとは類似商品等の類似対象を扱うウェブページであるか否かを判定する。さらに具体的には、ウェブページ分析サーバ10のシステム制御部14は、類似度(第3類似度)が所定の値以上である場合で、かつ、任意の2つのウェブページ間で共通の属性に係る属性値において等しい属性値がある場合に、任意の2つのウェブページとは類似商品等の類似対象を扱うウェブページであると判定する。また、共通の属性において、属性値が等しい場合の数が、全てである場合や、半数以上の等場合に、同一の商品等の同一対象を扱ったウェブページと判定してもよい。なお、属性関連語等については、図16に示すように、ウェブページ分析サーバ10が別の処理により求める(詳細は後述)。このようにウェブページ分析サーバ10のシステム制御部14は、第3類似度と、任意の2つのウェブページ間での共通の属性関連語とに基づき、任意の2つのウェブページが扱う対象は、互いに類似する対象であるか否かを判定する類似対象判定手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、第3類似度が所定の値以上である場合で、かつ、任意の2つのページ間で共通の属性に係る属性値において等しい属性値がある場合に、任意の2つのウェブページが扱う対象は、互いに類似する対象であると判定する類似対象判定手段の一例として機能する。
次に、ウェブページ同士の類似度が所定の値以上と判定されない場合(ステップS37;NO)、ウェブページは、類似商品等の類似対象を扱っていないとして、処理を終了する。
(5.3.商品の属性・属性値の抽出の流れ)
次に、ウェブページから商品の属性・属性値を抽出する動作の流れについて、図18~図22を用いて説明する。
次に、ウェブページから商品の属性・属性値を抽出する動作の流れについて、図18~図22を用いて説明する。
図18は、ウェブページ分析サーバ10においてウェブページから商品の属性・属性値を抽出する動作例を示すフローチャートである。図19は、属性記述パターンDBに記憶された属性記述パターンの一例を示す模式図である。図20は、属性・属性値の抽出の様子の一例を示す模式図である。図21は、抽出された属性・属性値の一例を示す模式図である。図22は、ウェブページ分析サーバ10における属性選定のサブルーチンの一例を示すフローチャートである。
図18に示すように、ウェブページ分析サーバ10は、ステップS30で、複数のウェブページを取得した後、属性記述パターンを取得する(ステップS40)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、下記のステップS41~S43におけるブートストラップ法の初期データとして、図19に示すように、属性記述パターンDB12dの属性記述パターンリストから、初期の属性記述パターンを取得する。ここで、属性記述パターンは、図19に示すように、前部、中部、および、後部に分かれていて、例えば、属性記述パターン”[ : ]”の場合、前部”[”、中部”:”、および、後部”]”である。前部と中部との間の語句が属性名で、中部と後部との間の語句が属性値である。また、属性記述パターンには、HTMLタグの要素が含まれる場合がある。このようにウェブページ分析サーバ10のシステム制御部14は、初期データとして、ウェブページに記載されている対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段の一例として機能する。
次に、ウェブページ分析サーバ10は、属性記述パターンに適合する属性・属性値を抽出する(ステップS41)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ウェブページ50等の複数のウェブページの中から、図20に示すように、属性記述パターン81等に適合する語句の部分(例えば”[品種:○○○]”)を取り出し、属性名”品種”や、属性名”品種”に対応した属性値”○○○”等を抽出する。そして、抽出した属性名および属性値は、属性リストとして属性・属性値DB12eに記憶される。ここで、どんなパターンにもマッチする特殊文字、すなわち、”*”や”?”等のワイルドカードと属性記述パターンとが用いられて、属性・属性値が抽出される。なお、属性・属性値の例として、旅行関連サービスの場合、[宿泊料金:○○○]、ブログであるイベント紹介をしている場合、[会場:○○○]等が挙げられる。
このようにウェブページ分析サーバ10のシステム制御部14は、複数のウェブページから、属性記述パターンに適合する属性の属性関連語を抽出する属性抽出手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、属性関連語として、属性の属性名を抽出する属性抽出手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、抽出された属性関連語から属性リストを生成する属性リスト生成手段として機能する。
次に、ウェブページ分析サーバ10は、属性・属性値に適合する属性記述パターンを抽出する(ステップS42)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、図20に示すように、属性・属性値82(例えば、属性名”品種”および属性値”○○○”)に適合する(例えば、<td> 品種</td><td>○○○<td>)を取り出し、属性記述パターンをウェブページ50等の複数のウェブページの中から抽出する。そして、抽出した属性記述パターンは、図19に示すように、属性記述パターンリストに追加され、属性記述パターンDB12dに記憶される。なお、例えば、”容量 *ml”のように、属性値に関しては、抽出された属性値自体でなく、ワイルドカードが用いられてもよい。
このようにウェブページ分析サーバ10のシステム制御部14は、複数のウェブページから、属性関連語に適合する属性記述パターンを、抽出する属性記述パターン抽出手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、抽出された属性記述パターンのパターンリストを生成するパターンリスト生成手段として機能する。
次に、ウェブページ分析サーバ10は、所定回数を判定する(ステップS43)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS41およびステップS42を反復実行した回数が所定回数に達しているか否かを判定する。そして、所定回数に達していない場合(ステップS43;NO)、ウェブページ分析サーバ10のシステム制御部14は、ステップS41に戻り、抽出した新たな属性記述パターンにより、新たな属性・属性値を抽出する。ウェブページ分析サーバ10のシステム制御部14は、所定回数に達するまで、ステップS21およびステップS22を繰り返す。なお、ウェブページ分析サーバ10のシステム制御部14は、抽出された属性・属性値の数(例えば、属性名の数や属性値の数や属性名と属性値の組み合わせの数)、または、属性記述パターンの数が、所定数以上になったか否かを判定してもよい。所定数以上になった場合に、ウェブページ分析サーバ10のシステム制御部14は、次のステップS44の処理を行う。
このようにウェブページ分析サーバ10のシステム制御部14は、ステップS40からステップS44において、商品の属性の記述に用いられる属性記述パターンを取得する属性記述パターン取得ステップと、複数のウェブページから、属性記述パターンに適合する属性の属性関連語を抽出する属性抽出ステップと、抽出された属性関連語に基づき、属性抽出ステップで使用する属性記述パターンを、複数のウェブページから更に抽出する属性記述パターン抽出ステップとを実行する。ウェブページ分析サーバ10のシステム制御部14は、属性抽出手段および属性記述パターン抽出手段を交互に繰り返す繰返手段の一例として機能する。
所定回数に達した場合(ステップS43;YES)、ウェブページ分析サーバ10は、属性の選定を行う(ステップS44)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、ステップS41で抽出した属性名および属性値から、属性選定のサブルーチンにより属性を選定する。属性選定のサブルーチンでは、ウェブページ分析サーバ10のシステム制御部14は、属性にスコアを付けてランク付けしたり、ノイズの属性を除去したり、同義語の属性を集約する(詳細は後述)。図21に示すように、カテゴリ”ワインにおいては、属性名”品種”、”生産者”等に対して、それぞれの属性値を得る。
抽出して選定された属性名および属性値は、ステップS38において、ウェブページ分析サーバ10が、ウェブページの類似性を判定する際に利用される。
なお、ブートストラップ法の初期データとして、属性・属性値DB12eの属性・属性値リストから、初期の属性・属性値を取得してもよい。このようにウェブページ分析サーバ10のシステム制御部14は、初期データとして、対象の属性に関連した属性関連語を取得する初期データ取得手段の一例として機能する。
そして、この場合、ウェブページ分析サーバ10のシステム制御部14は、商品の属性に関連した属性関連語を取得する属性関連語取得ステップと、属性の記述に用いられる属性記述パターンであって、複数のウェブページから、属性関連語に適合する属性記述パターンを抽出する属性記述パターン抽出ステップと、抽出された属性関連語に基づき、属性記述パターン抽出手段に使用する属性関連語を、複数のウェブページから更に抽出する属性関連語抽出ステップとを実行する。
(5.4.属性の選定)
次に、属性の選定のサブルーチンについて、図22を用いて説明する。
次に、属性の選定のサブルーチンについて、図22を用いて説明する。
図22に示すように、ウェブページ分析サーバ10は、属性へのスコア付けを行う(ステップS50)。具体的には、ショッピングサイトが商品を販売する複数の店舗を有する場合、すなわち、サイバーモールを構成する場合、ウェブページ分析サーバ10のシステム制御部14は、属性名が出現したウェブページを有する店舗の数を求め、属性のスコアとする。
多種の店舗のウェブページに出現した属性関連語の一例の属性名は、属性として適切であるという仮定に基づいている。例えば、ワインのウェブページにおいて、適切な属性である”品種”という属性は多種の店舗のウェブページに出現する。それに対して、いずれかの属性記述ターンにマッチした不適切な属性は、1店舗のウェブページからしか獲得されないことが多く、属性のスコアが低くなる傾向がある。このようにウェブページ分析サーバ10のシステム制御部14は、属性関連語のスコア付けを行う属性スコアリング手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、ウェブページで扱われる対象を販売する複数の店舗を有するウェブサイトにおいて、属性関連語が出現しているウェブページの店舗の数に基づき、属性関連語のスコア付けを行う属性スコアリング手段の一例として機能する。
次に、ウェブページ分析サーバ10は、上位ランクの属性を選択する(ステップS51)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、属性のスコアの高い順に属性名をランク付けし、所定のランク以上の属性名を選択する。このようにウェブページ分析サーバ10のシステム制御部14は、スコアの順に属性関連語のランク付けを行い、所定のランク以上の属性関連語を選択する属性選択手段の一例として機能する。
次に、ウェブページ分析サーバ10は、属性のフィルタリングを行う(ステップS52)。具体的には、ウェブページ分析サーバ10のシステム制御部14は、各カテゴリにおける属性名の出現確率を用いて、属性のフィルタリングを行う。他のカテゴリにおいても出現する属性関連語の一例の属性名は、属性として不向きであるという仮定に基づいて、属性のフィルタリングが行われている。例えば、属性として不向きな”送料無料”のような語句は、多数のウェブページに出現するため、各カテゴリにおける出現確率が、似通った値になる。一方、”品種”という属性名はワインのカテゴリのウェブページにはよく出現するが、ゴルフドライバーや靴等のカテゴリには出現しないため、ワインのカテゴリにおける出現確率が、ワイン以外のカテゴリにおける出現確率よりも高くなる。このようにウェブページ分析サーバ10のシステム制御部14は、カテゴリとは異なるカテゴリに属している複数のウェブページにおいて出現する属性関連語を取り除く属性フィルタ手段の一例として機能する。
次に、ウェブページ分析サーバ10は、同義の属性を集約する(ステップS53)。属性の中には同じ概念を持つものが存在している。例えば、ワインのカテゴリにおいて、”品種”、”ぶどう品種”、”ブドウ品種”、”セパージュ”、”葡萄品種”は同義の属性名である。ウェブページ分析サーバ10のシステム制御部14は、同義語辞書を用いたり、属性名同士の類似の度合いを算出したり、属性名に対応する属性値を用いたりして、同義の属性の属性名を集約する。なお、類似概念の属性の属性名でもよい。
具体的には、属性名”A”(属性A)と属性名”B”(属性B)との類似の度合いを算出する場合、属性Aの属性値の中で属性Bが持っている属性値と共通なものの割合と、属性Bの属性値の中で属性Aの属性値が持っている属性値と共通なものの割合とを掛け合わせた値を類似の度合いとしてもよいし、これらの割合を元にエントロピーを計算し、掛け合わせた値を類似の度合いとしてもよいし、ジャッカード係数を類似の度合いとてもよいし、属性Aと属性Bの属性値中で共通なものの種類の数を類似の度合いとしてもよい。
このようにウェブページ分析サーバ10のシステム制御部14は、属性名同士が類似であるか否かを判定する属性名類似判定手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、属性名類似判定手段により類似と判定された属性名を集約する属性名集約手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、属性関連語として、属性名および属性名に対応する属性値を抽出する属性抽出手段、および、属性値に基づき属性名を集約する属性名集約手段の一例として機能する。
以上、本実施形態によれば、各ウェブページとして、複数のウェブページを取得し、初期データとして、対象の属性に関連した属性関連語、または、対象の属性の記述に用いられる属性記述パターンを取得し、複数のウェブページから、属性記述パターンに適合する前記属性の属性関連語を抽出し、複数のウェブページから、属性関連語に適合する属性記述パターンを抽出し、第2類似度および属性関連語に基づき、ウェブページをグルーピングすることにより、例えば、類似度によりグルーピングしたウェブページ70をさらに、ウェブページ90のように、共通する属性によりサブグルーピングできる。また、ユーザがより見やすい検索結果に反映させる等、利用価値が高まる。
また、本実施形態によれば、各ウェブページとして、複数のウェブページを取得し、当該取得した複数のウェブページのうち任意の2つのウェブページ間の第3類似度を類似度として、特徴語に基づき算出し、初期データとして、対象の属性に関連した属性関連語、または、対象の属性の記述に用いられる属性記述パターンを取得し、複数のウェブページから、属性記述パターンに適合する属性の属性関連語を抽出し、複数のウェブページから、属性関連語に適合する属性記述パターンを、抽出し、第3類似度と、任意の2つのウェブページ間での共通の属性関連語とに基づき、任意の2つのウェブページが扱う対象は、互いに類似する対象であるか否かを判定することにより、ウェブページで扱われる商品等の対象の類似性を求めることができる。また、本実施形態によれば、同一や類似の対象を扱うウェブページをまとめ上げることができる。特に、類似度の他に、更に共通の属性関連語に基づき判定することにより、判定の精度が向上する。ユーザの利便性も向上させることもできる。
また、本実施形態によれば、ウェブページとして、複数のウェブページを取得し、初期データとして、ウェブページに記載されている対象の属性に関連した属性関連語、または、当該対象の属性の記述に用いられる属性記述パターンを取得し、複数のウェブページから、属性記述パターンに適合する属性の属性関連語を抽出し、複数のウェブページから、属性関連語に適合する属性記述パターンを抽出し、特徴語および属性関連語に基づき、ウェブページをグルーピングすることにより、例えば、特徴語によりグルーピングしたウェブページ70をさらに、ウェブページ90のように、共通する属性によりサブグルーピングできる。また、ユーザがより見やすい検索結果に反映させる等、利用価値が高まる。
ウェブページ分析サーバ10のシステム制御部14が、属性抽出手段および属性記述パターン抽出手段を交互に繰り返す場合、属性リストやパターンリストをブートストラップによって拡張して、初期値として与えた属性以外の属性を抽出することができる。また、この抽出された属性により、ウェブページの類似度が判定できる。
ウェブページ分析サーバ10のシステム制御部14が、属性関連語として、属性名および属性名に対応する属性値を抽出し、任意の2つのウェブページ間で共通の属性に係る属性値において等しい属性値がある場合に、任意の2つのウェブページに記載された対象は、互いに類似する対象であると判定すると、同じ対象であれば属性値が一致しやすいので、同一や類似の対象を扱うウェブページであると精度良く判定しやすくなる。なお、属性名はカテゴリ特有の場合が多いが、属性記述パターンはカテゴリ特有のものもあるが、様々なカテゴリに適用可能である。
ウェブページ分析サーバ10のシステム制御部14が、抽出された属性関連語から属性リストを生成し、抽出された属性記述パターンのパターンリストを生成する場合、カテゴリ毎に、属性名や属性値等の属性関連語や属性記述パターンの情報を蓄積できる。
ウェブページ分析サーバ10のシステム制御部14が、属性関連語のスコア付けを行い、スコアの順に属性関連語のランク付けを行い、所定のランク以上の属性関連語を選択する場合、選択された属性関連語において、商品等の対象を表す属性の精度が高くなる。
ウェブページ分析サーバ10のシステム制御部14が、対象を販売する複数の店舗を有するウェブサイトにおいて、属性関連語が出現しているウェブページの店舗の数に基づき、属性関連語のスコア付けを行う場合、属性関連語を選択する際、商品等の対象を表す属性の精度が高くなる。例えば、店舗により扱う対象(アイテム)の数やウェブページの数が大きく異なる場合、多くの商品等の対象を扱う店舗の影響を受けやすくなるが、店舗の数に基づき属性関連語のスコア付けを行うことにより、ある特定の店舗の影響を解消できる。
ウェブページ分析サーバ10のシステム制御部14が、カテゴリとは異なるカテゴリに属している複数のウェブページにおいて出現する属性関連語を取り除く場合、対象とするカテゴリ固有の属性関連語に絞ることにより、商品等を表す属性の精度が高くなる。
ウェブページ分析サーバ10のシステム制御部14が、属性関連語として、属性名および属性名に対応する属性値を抽出し、第3類似度が所定の値以上である場合で、かつ、任意の2つのページ間で共通の属性に係る属性値において等しい属性値がある場合に、任意の2つのウェブページが扱う対象は、互いに類似する対象であると判定すると、同じ対象であれば属性値が一致しやすいので、同一や類似の対象を扱うウェブページであると精度良く判定しやすくなる。
なお、検索サーバ30は、サーバシステム5外である、他の検索サイトの検索サーバでもよい。この場合、ウェブページ分析サーバ10は、ネットワーク3を通して、検索クエリを送信し、検索結果を受信する。また、スニペットを求める際のウェブ検索する範囲は、情報提供サーバ20内のウェブページに限ったり、ある国や地域のウェブページに限ったりしてもよい。
また、属性の選定や属性記述パターンの選定を、ステップS21やステップS22のブートストラップ法の中で行ってもよい。この場合、ブートストラップの回数を増やした場合に、抽出される属性・属性値や、属性記述パターンが増大することを防止することができる。
ここで、属性記述パターンの選定する場合、属性記述パターンと属性・属性値との共起確率を算出し、共起確率から算出されるエントロピー等を計算して属性記述パターンのスコア付けを行い、スコアに基づき属性記述パターンを選定する。
また、属性のスコアとして、店舗の数でなく、属性名が出現したウェブページの数でもよい。ウェブページ分析サーバ10のシステム制御部14が、属性スコアリング手段として、属性関連語の検索のヒット件数に基づき、属性関連語のスコア付けを行う。この場合、店舗が多く集まるサイバーモール以外にも適用できる。
次に、ウェブページをグルーピングの変形例について図23および図24を用いて説明する。
図23は、図14のグルーピングされた検索結果の一例を示す模式図である。図24は、図14のグルーピングされた検索結果の他の変形例を示す模式図である。
まず、図23に示すように、ウェブページ分析サーバ10のシステム制御部14は、類似度に基づき類似のウェブページ同士をグルーピングしたり、所定数以上の共通する特徴語を互いに有するウェブページ同士にグルーピングしたりして、特徴語によりグループ名部91を設定する。
さらに、ウェブページ分析サーバ10のシステム制御部14は、グルーピングされた各グループを、属性に基づき、サブグループ名部94のように、サブグルーピングをする。ウェブページ分析サーバ10のシステム制御部14は、ステップS44において求めた属性に基づき、例えば、属性名が”容量”に関して、容量が”750ml”と”375ml”とに分けてサブグルーピングする。ウェブページ分析サーバ10のシステム制御部14は、”容量”・”750ml”や”容量”・”375ml”のような共通する属性名・属性値を有するウェブページを、特徴語(または第2類似度)によりグルーピングされたウェブページの中から収集する。そして、ウェブページ90において、グループ名部91およびサブグループ名部94によってサブグループ化された領域に、ウェブページのタイトル部92と、スニペット部93とが表示される。
また、図24に示すように、ウェブページ分析サーバ10のシステム制御部14は、グループ名部95”容量:750ml”、”容量:375ml”のように、属性に基づき、グルーピングを行ってもよい。ウェブページ分析サーバ10のシステム制御部14は、属性名・属性値として、”容量”・”750ml”等を有するウェブページを収集する。さらに、グルーピングされた各グループを、特徴語や類似度に基づき、サブグループ名部99のように、サブグルーピングをする。ウェブページ分析サーバ10のシステム制御部14は、属性に基づきグルーピングされたウェブページの特徴語を求めたり、類似度を求めたりする。そして、ウェブページ分析サーバ10のシステム制御部14は、ステップS27のように、類似度に基づき類似のウェブページ同士をサブグルーピングしたり、所定数以上の共通する特徴語を互いに有するウェブページ同士をサブグルーピングしたりする。
ここで、属性を求める際、ステップS40で必要な複数のウェブページの範囲は、特徴語に基づきグルーピングされた範囲でもよいし、ウェブサイト単位でもよいし、ステップS40で扱うのと同じ範囲でもよい。
このように、ウェブページ分析サーバ10のシステム制御部14は、特徴語および属性関連語に基づき、前記ユーザ検索クエリによって得られる複数のウェブページをグルーピングするウェブページ・グルーピング手段の一例として機能する。また、ウェブページ分析サーバ10のシステム制御部14は、第2類似度および属性関連語に基づき、ウェブページ同士をグルーピングするウェブページ・グルーピング手段の一例として機能する。
ウェブページ分析サーバ10のシステム制御部14が、特徴語および属性関連語に基づき、ウェブページをグルーピングし、または、第2類似度および属性関連語に基づき、グルーピングする場合、特徴語や類似度によりグルーピングしたウェブページをさらに、共通する属性によりサブグルーピングでき、または、共通する属性によりグルーピングしたウェブページをさらに、特徴語や類似度によりサブグルーピングできる。従って、ユーザがより見やすい検索結果に反映させる等、利用価値が高まる。
なお、ウェブページ分析サーバ10のシステム制御部14は、抽出した、または、決定した特徴語と、任意の2つのウェブページ間での共通の属性関連語とに基づき、任意の2つのウェブページが扱う対象は、互いに類似する対象であるか否かを判定してもよい。例えば、2つのウェブページにおいて、共通の特徴語がいくつか存在し、かつ、当該2つのウェブページ間で共通の属性に係る属性値において等しい属性値がある場合、ウェブページ分析サーバ10のシステム制御部14は、互いに類似する対象を扱うウェブページと判定する。
この場合、ウェブページ分析サーバ10のシステム制御部14は、ウェブページで扱われる商品等の対象の類似性を求めることができる。また、ウェブページ分析サーバ10のシステム制御部14は、同一や類似の対象を扱うウェブページをまとめ上げることができる。特に、特徴語の他に、更に共通の属性関連語に基づき判定することにより、判定の精度が向上する。
また、ウェブページ分析サーバ10のシステム制御部14は、特徴語を索引として、ウェブページを整理した辞書を作成してもよい。例えば、ウェブページ分析サーバ10のシステム制御部14は、特徴語に基づき、ウェブページをグルーピングすることで、特徴語を索引として関連したウェブページをまとめる。さらに、ウェブページ分析サーバ10のシステム制御部14は、属性名と属性値を索引として、ウェブページを整理した辞書を作成してもよい。例えば、ウェブページ分析サーバ10のシステム制御部14は、属性名・属性値に基づき、ウェブページをグルーピングすることで、特徴語を索引として関連したウェブページをまとめる。
また、ウェブページ分析サーバ10のシステム制御部14は、同一または極めた類似したウェブページ、名寄せのように、どちらか1つにするか、2つ併せるかして、まとめてもよい。例えば、ウェブページ分析サーバ10のシステム制御部14は、類似度が所定の値(例えば、ステップS8の場合よりさらに高い所定の値)以上の場合、ウェブページを1つにまとめる。
さらに、本発明は、上記各実施形態に限定されるものではない。上記各実施形態は、例示であり、本発明の特許請求の範囲に記載された技術的思想と実質的に同一な構成を有し、同様な作用効果を奏するものは、いかなるものであっても本発明の技術的範囲に包含される。
3:ネットワーク
5:サーバシステム
10:ウェブページ分析サーバ(情報処理装置)
12a:カテゴリ関連語DB(カテゴリ関連語記憶手段)
12b:ドメイン名DB
12d:属性記述パターンDB
12e:属性・属性値DB
20:情報提供サーバ
30:検索サーバ
5:サーバシステム
10:ウェブページ分析サーバ(情報処理装置)
12a:カテゴリ関連語DB(カテゴリ関連語記憶手段)
12b:ドメイン名DB
12d:属性記述パターンDB
12e:属性・属性値DB
20:情報提供サーバ
30:検索サーバ
Claims (16)
- ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段と、
ウェブページを取得するウェブページ取得手段と、
前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段と、
抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出手段と、
前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得手段と、
前記カテゴリ関連語記憶手段を参照して、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定手段と、
前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定手段と、
を備えたことを特徴とする情報処理装置。 - 請求項1に記載の情報処理装置において、
ノイズの形態素を記憶するノイズ形態素記憶手段を更に備え、
前記特徴語候補抽出手段が、ノイズ形態素記憶手段を参照して、前記テキストデータを形態素解析によって前記言語解析して得られた形態素から、ノイズの形態素を除去するノイズ除去手段を有することを特徴とする情報処理装置。 - 請求項1または請求項2に記載の情報処理装置において、
ウェブサイトのドメイン名を記憶するドメイン名記憶手段を更に備え、
前記検索結果判定手段が、前記カテゴリ関連語記憶手段および前記ドメイン名記憶手段を参照して、前記検索結果において、前記ドメイン名に関連したウェブサイトのスニペット中に前記カテゴリ関連語が存在するか否かを判定することを特徴とする情報処理装置。 - 請求項1から請求項3のいずれか1項に記載の情報処理装置において、
ユーザ端末からユーザ検索クエリを受信する検索クエリ受信手段と、
前記ユーザ検索クエリによって得られる複数のウェブページを、前記特徴語毎にグルーピングするウェブページ・グルーピング手段と、
前記特徴語毎にグルーピングした前記ウェブページに関する情報を検索結果として前記ユーザ端末に送信する送信手段を更に、
備えたことを特徴とする情報処理装置。 - 請求項4に記載の情報処理装置において、
前記ウェブページ取得手段が、前記ウェブページとして、複数のウェブページを取得し、
初期データとして、ウェブページに記載されている対象の属性に関連した属性関連語、または、当該対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段と、
前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段と、
前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを、抽出する属性記述パターン抽出手段と、を更に備え、
前記ウェブページ・グルーピング手段が、前記特徴語および前記属性関連語に基づき、前記ユーザ検索クエリによって得られる複数のウェブページをグルーピングすることを特徴とする情報処理装置。 - 請求項1から請求項4のいずれか1項に記載の情報処理装置において、
前記ウェブページ取得手段が、前記ウェブページとして、複数のウェブページを取得し、
初期データとして、前記対象の属性に関連した属性関連語、または、前記対象の属性の記述に用いられる属性記述パターンを取得する初期データ取得手段と、
前記複数のウェブページから、前記属性記述パターンに適合する前記属性の属性関連語を抽出する属性抽出手段と、
前記複数のウェブページから、前記属性関連語に適合する前記属性記述パターンを、抽出する属性記述パターン抽出手段と、
前記特徴語と、前記任意の2つのウェブページ間での共通の属性関連語とに基づき、前記任意の2つのウェブページが扱う対象は、互いに類似する対象であるか否かを判定する類似対象判定手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項5または請求項6に記載の情報処理装置において、
前記属性抽出手段および前記属性記述パターン抽出手段を交互に繰り返す繰返手段を更に備えたことを特徴とする情報処理装置。 - 請求項6または請求項7に記載の情報処理装置において、
前記属性抽出手段が、前記属性関連語として、前記属性名および前記属性名に対応する属性値を抽出し、
前記類似対象判定手段が、前記任意の2つのウェブページ間で共通の属性に係る前記属性値において等しい前記属性値がある場合に、前記任意の2つのウェブページに記載された対象は、互いに類似する対象であると判定することを特徴とする情報処理装置。 - 請求項5から請求項8のいずれか1項に記載の情報処理装置において抽出された前記属性関連語から属性リストを生成する属性リスト生成手段と、
抽出された前記属性記述パターンのパターンリストを生成するパターンリスト生成手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項5から請求項9のいずれか1項に記載の情報処理装置において、
前記属性関連語のスコア付けを行う属性スコアリング手段と、
前記スコアの順に前記属性関連語のランク付けを行い、所定のランク以上の属性関連語を選択する属性選択手段と、
を更に備えたことを特徴とする情報処理装置。 - 請求項10に記載の情報処理装置において、
前記属性スコアリング手段が、前記属性関連語の検索のヒット件数に基づき、前記属性関連語のスコア付けを行うことを特徴とする情報処理装置。 - 請求項10に記載の情報処理装置において、
前記属性スコアリング手段が、前記対象を販売する複数の店舗を有するウェブサイトにおいて、前記属性関連語が出現しているウェブページの前記店舗の数に基づき、前記属性関連語のスコア付けを行うことを特徴とする情報処理装置。 - 請求項5から請求項12のいずれか1項に記載の情報処理装置において、
前記カテゴリとは異なるカテゴリに属している複数のウェブページにおいて出現する前記属性関連語を取り除く属性フィルタ手段を更に備えたことを特徴とする情報処理装置。 - 情報処理装置が情報処理をする情報処理方法において、
ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶ステップと、
ウェブページを取得するウェブページ取得ステップと、
前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出ステップと、
抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出ステップと、
前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得ステップと、
前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定ステップと、
前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定ステップと、
を有することを特徴とする情報処理方法。 - コンピュータを、
ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段、
ウェブページを取得するウェブページ取得手段、
前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段、
抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出手段、
前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得手段、
前記カテゴリ関連語記憶手段を参照して、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定手段、および、
前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定手段として機能させることを特徴とする情報処理装置用のプログラム。 - コンピュータを、
ウェブページに記載されている対象を分類するカテゴリに関連するカテゴリ関連語を記憶するカテゴリ関連語記憶手段、
ウェブページを取得するウェブページ取得手段、
前記ウェブページ内に記述されているテキストデータを抽出するテキストデータ抽出手段、
抽出した前記テキストデータを言語解析して、前記ウェブページの特徴語候補を抽出する特徴語候補抽出手段、
前記特徴語候補を検索キーワードとする検索クエリを作成し、前記検索クエリに基づく検索結果を取得する検索結果取得手段、
前記カテゴリ関連語記憶手段を参照して、前記検索結果のスニペット中に前記カテゴリ関連語が存在するか否かを判定する検索結果判定手段、および、
前記スニペット中に前記カテゴリ関連語が存在する場合の前記特徴語候補を前記ウェブページの特徴語に決定する特徴語決定手段として機能させることを特徴とする情報処理装置用のプログラムを記録したコンピュータ読み取り可能な記録媒体。
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010043392 | 2010-02-26 | ||
| JP2010-043389 | 2010-02-26 | ||
| JP2010043388A JP2013101415A (ja) | 2010-02-26 | 2010-02-26 | 商品ウェブページ分析装置、商品ウェブページ分析方法、および、商品ウェブページ分析装置用のプログラム |
| JP2010-043388 | 2010-02-26 | ||
| JP2010-043392 | 2010-02-26 | ||
| JP2010043389A JP2013101416A (ja) | 2010-02-26 | 2010-02-26 | 検索装置、検索方法、および、検索装置用のプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011105604A1 true WO2011105604A1 (ja) | 2011-09-01 |
Family
ID=44506999
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/054507 WO2011105604A1 (ja) | 2010-02-26 | 2011-02-28 | 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 |
| PCT/JP2011/054509 WO2011105605A1 (ja) | 2010-02-26 | 2011-02-28 | 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2011/054509 WO2011105605A1 (ja) | 2010-02-26 | 2011-02-28 | 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| WO (2) | WO2011105604A1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103530299B (zh) | 2012-07-05 | 2017-04-12 | 阿里巴巴集团控股有限公司 | 一种搜索结果的生成方法及装置 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008269106A (ja) * | 2007-04-17 | 2008-11-06 | Osaka Industrial Promotion Organization | スキーマ抽出方法、情報処理装置、コンピュータプログラム及び記録媒体 |
-
2011
- 2011-02-28 WO PCT/JP2011/054507 patent/WO2011105604A1/ja active Application Filing
- 2011-02-28 WO PCT/JP2011/054509 patent/WO2011105605A1/ja active Application Filing
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008269106A (ja) * | 2007-04-17 | 2008-11-06 | Osaka Industrial Promotion Organization | スキーマ抽出方法、情報処理装置、コンピュータプログラム及び記録媒体 |
Non-Patent Citations (4)
| Title |
|---|
| AKIO KOBAYASHI: "Shopping Site no Shohin Page Title Karano Shohin Kanren Yogo no Chushutsu to Shohin Catalogue eno Shohin Page no Himo Tsuke Shuho", PROCEEDINGS OF THE 16TH ANNUAL MEETING OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, 8 March 2010 (2010-03-08), pages 367 - 370 * |
| CHIKARA HASHIMOTO: "Construction of Domain Dictionary for Fundamental Vocabulary and its Application to Automatic Blog Categorization with the Dynamic Estimation of Unknown Words' Domains", JOURNAL OF NATURAL LANGUAGE PROCESSING, vol. 15, no. 5, 10 October 2008 (2008-10-10), pages 73 - 97 * |
| MASAHIRO KAKIZAKI: "Visualization of search result for improving usability", FIT2008, DAI 7 KAI FORUM ON INFORMATION TECHNOLOGY KOEN RONBUNSHU, vol. 2, 20 August 2008 (2008-08-20), pages 105 - 106 * |
| SATOSHI SEKINE: "Shopping Site ni Okeru Shohin no Doitsusei, Ruijisei no Suitei Shuho", PROCEEDINGS OF THE 16TH ANNUAL MEETING OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, 8 March 2010 (2010-03-08), pages 254 - 257 * |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2011105605A1 (ja) | 2011-09-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5396533B2 (ja) | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム | |
| JP6433614B1 (ja) | チャットボット検索システムおよびプログラム | |
| US8001135B2 (en) | Search support apparatus, computer program product, and search support system | |
| CN102822815B (zh) | 用于利用浏览器历史进行动作建议的方法和系统 | |
| JP5431727B2 (ja) | 関連性判定方法、情報収集方法、オブジェクト組織化方法及び検索システム | |
| CN100403305C (zh) | 包括按子域线索搜索及按子域提供赞助结果的产生搜索结果的系统 | |
| JP5697256B2 (ja) | 検索装置、検索方法、検索プログラム及び記録媒体 | |
| CN107016020A (zh) | 利用垂直建议辅助搜索请求的系统和方法 | |
| JP2013531289A (ja) | 検索におけるモデル情報群の使用 | |
| CN101467147A (zh) | 在竖直区域内执行搜索的系统和方法 | |
| CN101661490B (zh) | 搜索引擎、其客户端及搜索网页的方法 | |
| JP4743766B2 (ja) | 印象判定システム、広告記事生成システム、印象判定方法、広告記事生成方法、印象判定プログラムおよび広告記事生成プログラム | |
| JP2003091552A (ja) | 検索要求情報抽出方法及びその実施システム並びにその処理プログラム | |
| JP2013101416A (ja) | 検索装置、検索方法、および、検索装置用のプログラム | |
| KR20140133633A (ko) | 검색 키워드 분석을 통한 온라인 쇼핑몰의 상품 노출 시스템 및 그 운영방법 | |
| KR20190055963A (ko) | 키워드검색 분석을 통한 온라인 쇼핑몰의 상품 노출 시스템 및 그 운영방법 | |
| JP4728125B2 (ja) | 索引ファイルを用いた文書検索の方法、索引ファイルを用いた文書検索サーバ、及び索引ファイルを用いた文書検索プログラム | |
| WO2011105604A1 (ja) | 情報処理装置、情報処理方法、情報処理装置用のプログラム、および、記録媒体 | |
| JP6960553B2 (ja) | ブランド辞書作成装置、商品等評価装置、ブランド辞書作成方法及びプログラム | |
| JP2013101415A (ja) | 商品ウェブページ分析装置、商品ウェブページ分析方法、および、商品ウェブページ分析装置用のプログラム | |
| JP2001229171A (ja) | 商品検索システム | |
| JP5450135B2 (ja) | 関連度辞書を用いた検索モデリングシステムおよび方法 | |
| WO2019218151A1 (zh) | 一种资料搜寻方法 | |
| JP5155130B2 (ja) | カテゴリ提示装置 | |
| JP6228425B2 (ja) | 広告生成装置および広告生成方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11747558 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 11747558 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |