KR20230156945A - 백신 조성물 및 이의 사용 방법 - Google Patents
백신 조성물 및 이의 사용 방법 Download PDFInfo
- Publication number
- KR20230156945A KR20230156945A KR1020237035159A KR20237035159A KR20230156945A KR 20230156945 A KR20230156945 A KR 20230156945A KR 1020237035159 A KR1020237035159 A KR 1020237035159A KR 20237035159 A KR20237035159 A KR 20237035159A KR 20230156945 A KR20230156945 A KR 20230156945A
- Authority
- KR
- South Korea
- Prior art keywords
- protein
- polynucleotide
- seq
- polynucleotide encoding
- acid sequence
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 111
- 229960005486 vaccine Drugs 0.000 title claims abstract description 92
- 239000000203 mixture Substances 0.000 title claims abstract description 63
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 576
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 576
- 239000002157 polynucleotide Substances 0.000 claims abstract description 576
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 316
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 302
- 239000003623 enhancer Substances 0.000 claims abstract description 189
- 108091007433 antigens Proteins 0.000 claims abstract description 176
- 102000036639 antigens Human genes 0.000 claims abstract description 176
- 230000003612 virological effect Effects 0.000 claims abstract description 166
- 239000002245 particle Substances 0.000 claims abstract description 42
- 241000709664 Picornaviridae Species 0.000 claims abstract description 22
- 238000004519 manufacturing process Methods 0.000 claims abstract description 17
- 239000013598 vector Substances 0.000 claims description 284
- 230000014509 gene expression Effects 0.000 claims description 209
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 197
- 210000004027 cell Anatomy 0.000 claims description 138
- 238000004806 packaging method and process Methods 0.000 claims description 115
- 150000007523 nucleic acids Chemical group 0.000 claims description 86
- 241000710886 West Nile virus Species 0.000 claims description 78
- 101710198474 Spike protein Proteins 0.000 claims description 73
- 230000006337 proteolytic cleavage Effects 0.000 claims description 73
- 229940096437 Protein S Drugs 0.000 claims description 71
- 102100031673 Corneodesmosin Human genes 0.000 claims description 69
- 101710139375 Corneodesmosin Proteins 0.000 claims description 69
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 66
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 claims description 61
- 101710141454 Nucleoprotein Proteins 0.000 claims description 61
- 101710204837 Envelope small membrane protein Proteins 0.000 claims description 57
- 101001065501 Escherichia phage MS2 Lysis protein Proteins 0.000 claims description 57
- 101710145006 Lysis protein Proteins 0.000 claims description 57
- 101710085938 Matrix protein Proteins 0.000 claims description 47
- 101710127721 Membrane protein Proteins 0.000 claims description 47
- 241000700605 Viruses Species 0.000 claims description 47
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 39
- 241000711573 Coronaviridae Species 0.000 claims description 38
- 230000003472 neutralizing effect Effects 0.000 claims description 37
- 241001678559 COVID-19 virus Species 0.000 claims description 36
- 230000028993 immune response Effects 0.000 claims description 29
- 239000002671 adjuvant Substances 0.000 claims description 24
- 241000008904 Betacoronavirus Species 0.000 claims description 18
- 201000003176 Severe Acute Respiratory Syndrome Diseases 0.000 claims description 12
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 12
- 101710121417 Envelope glycoprotein Proteins 0.000 claims description 11
- 150000001413 amino acids Chemical class 0.000 claims description 11
- 229940035032 monophosphoryl lipid a Drugs 0.000 claims description 11
- 238000007918 intramuscular administration Methods 0.000 claims description 10
- 239000012528 membrane Substances 0.000 claims description 10
- 230000004044 response Effects 0.000 claims description 10
- 101800001127 Protein prM Proteins 0.000 claims description 9
- 239000003937 drug carrier Substances 0.000 claims description 9
- 230000000069 prophylactic effect Effects 0.000 claims description 9
- 241000127282 Middle East respiratory syndrome-related coronavirus Species 0.000 claims description 8
- 101710172711 Structural protein Proteins 0.000 claims description 8
- 241000700721 Hepatitis B virus Species 0.000 claims description 7
- 238000007920 subcutaneous administration Methods 0.000 claims description 7
- 101710132601 Capsid protein Proteins 0.000 claims description 6
- 230000001939 inductive effect Effects 0.000 claims description 6
- 230000001225 therapeutic effect Effects 0.000 claims description 5
- 229940037003 alum Drugs 0.000 claims description 4
- 230000036755 cellular response Effects 0.000 claims description 4
- 210000000447 Th1 cell Anatomy 0.000 claims description 3
- 108700010900 influenza virus proteins Proteins 0.000 claims description 3
- 102100021696 Syncytin-1 Human genes 0.000 claims 1
- 239000000427 antigen Substances 0.000 description 158
- 239000013612 plasmid Substances 0.000 description 121
- 108020004414 DNA Proteins 0.000 description 46
- 102000053602 DNA Human genes 0.000 description 46
- 102100034349 Integrase Human genes 0.000 description 46
- 101710091045 Envelope protein Proteins 0.000 description 36
- 101710188315 Protein X Proteins 0.000 description 36
- 238000002965 ELISA Methods 0.000 description 34
- 108090001074 Nucleocapsid Proteins Proteins 0.000 description 33
- 108010067390 Viral Proteins Proteins 0.000 description 32
- 108090000765 processed proteins & peptides Proteins 0.000 description 32
- 229920002477 rna polymer Polymers 0.000 description 32
- 108010052285 Membrane Proteins Proteins 0.000 description 27
- 108700010904 coronavirus proteins Proteins 0.000 description 27
- 102000018697 Membrane Proteins Human genes 0.000 description 26
- 230000015572 biosynthetic process Effects 0.000 description 24
- 239000007924 injection Substances 0.000 description 24
- 238000002347 injection Methods 0.000 description 24
- 239000002953 phosphate buffered saline Substances 0.000 description 23
- 230000027455 binding Effects 0.000 description 22
- 210000002966 serum Anatomy 0.000 description 20
- 238000001890 transfection Methods 0.000 description 20
- 238000004113 cell culture Methods 0.000 description 17
- 241000701806 Human papillomavirus Species 0.000 description 16
- 239000012228 culture supernatant Substances 0.000 description 16
- 102000004196 processed proteins & peptides Human genes 0.000 description 16
- 241000699666 Mus <mouse, genus> Species 0.000 description 15
- 241000315672 SARS coronavirus Species 0.000 description 15
- 101000629318 Severe acute respiratory syndrome coronavirus 2 Spike glycoprotein Proteins 0.000 description 15
- 210000001744 T-lymphocyte Anatomy 0.000 description 15
- 238000010790 dilution Methods 0.000 description 15
- 239000012895 dilution Substances 0.000 description 15
- 238000002474 experimental method Methods 0.000 description 15
- 230000002163 immunogen Effects 0.000 description 14
- 229920001184 polypeptide Polymers 0.000 description 14
- 230000028327 secretion Effects 0.000 description 14
- 108010061994 Coronavirus Spike Glycoprotein Proteins 0.000 description 13
- 241000701022 Cytomegalovirus Species 0.000 description 13
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 13
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 13
- 241000699670 Mus sp. Species 0.000 description 13
- 230000000890 antigenic effect Effects 0.000 description 13
- 238000003556 assay Methods 0.000 description 13
- 239000002609 medium Substances 0.000 description 13
- 238000004458 analytical method Methods 0.000 description 12
- 230000005847 immunogenicity Effects 0.000 description 12
- 238000001262 western blot Methods 0.000 description 12
- 108700002099 Coronavirus Nucleocapsid Proteins Proteins 0.000 description 11
- 241000710188 Encephalomyocarditis virus Species 0.000 description 11
- 238000003776 cleavage reaction Methods 0.000 description 11
- 102000039446 nucleic acids Human genes 0.000 description 11
- 108020004707 nucleic acids Proteins 0.000 description 11
- 230000007017 scission Effects 0.000 description 11
- 230000005875 antibody response Effects 0.000 description 10
- -1 e.g. Proteins 0.000 description 10
- 239000006228 supernatant Substances 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 238000011725 BALB/c mouse Methods 0.000 description 9
- 241000725303 Human immunodeficiency virus Species 0.000 description 9
- 108091006197 SARS-CoV-2 Nucleocapsid Protein Proteins 0.000 description 9
- 230000024932 T cell mediated immunity Effects 0.000 description 9
- 230000030833 cell death Effects 0.000 description 9
- 239000012634 fragment Substances 0.000 description 9
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 210000004379 membrane Anatomy 0.000 description 9
- 238000006386 neutralization reaction Methods 0.000 description 9
- 238000010186 staining Methods 0.000 description 9
- 238000006467 substitution reaction Methods 0.000 description 9
- 241000712461 unidentified influenza virus Species 0.000 description 9
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 8
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 8
- 238000011161 development Methods 0.000 description 8
- 238000003114 enzyme-linked immunosorbent spot assay Methods 0.000 description 8
- 230000002068 genetic effect Effects 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- 108010061238 threonyl-glycine Proteins 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- 238000002255 vaccination Methods 0.000 description 8
- 108090000978 Interleukin-4 Proteins 0.000 description 7
- 102000004388 Interleukin-4 Human genes 0.000 description 7
- 241001465754 Metazoa Species 0.000 description 7
- 108010087302 Viral Structural Proteins Proteins 0.000 description 7
- 238000000749 co-immunoprecipitation Methods 0.000 description 7
- 230000000694 effects Effects 0.000 description 7
- 238000000338 in vitro Methods 0.000 description 7
- 208000015181 infectious disease Diseases 0.000 description 7
- 108010057821 leucylproline Proteins 0.000 description 7
- 108020003175 receptors Proteins 0.000 description 7
- 102000005962 receptors Human genes 0.000 description 7
- 239000000523 sample Substances 0.000 description 7
- 108700003471 Coronavirus 3C Proteases Proteins 0.000 description 6
- 108700002673 Coronavirus M Proteins Proteins 0.000 description 6
- 238000012286 ELISA Assay Methods 0.000 description 6
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 6
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 6
- 102100037850 Interferon gamma Human genes 0.000 description 6
- 108010074328 Interferon-gamma Proteins 0.000 description 6
- 108010079364 N-glycylalanine Proteins 0.000 description 6
- 229920001213 Polysorbate 20 Polymers 0.000 description 6
- 101000667982 Severe acute respiratory syndrome coronavirus 2 Envelope small membrane protein Proteins 0.000 description 6
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 6
- 229930006000 Sucrose Natural products 0.000 description 6
- 238000003917 TEM image Methods 0.000 description 6
- NLSNVZAREYQMGR-HJGDQZAQSA-N Thr-Asp-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NLSNVZAREYQMGR-HJGDQZAQSA-N 0.000 description 6
- 238000002835 absorbance Methods 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 238000001514 detection method Methods 0.000 description 6
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 6
- 238000012744 immunostaining Methods 0.000 description 6
- 150000002632 lipids Chemical class 0.000 description 6
- 108010056582 methionylglutamic acid Proteins 0.000 description 6
- 125000003729 nucleotide group Chemical group 0.000 description 6
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 6
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 6
- 239000005720 sucrose Substances 0.000 description 6
- 238000012360 testing method Methods 0.000 description 6
- UAIUNKRWKOVEES-UHFFFAOYSA-N 3,3',5,5'-tetramethylbenzidine Chemical compound CC1=C(N)C(C)=CC(C=2C=C(C)C(N)=C(C)C=2)=C1 UAIUNKRWKOVEES-UHFFFAOYSA-N 0.000 description 5
- 108090000975 Angiotensin-converting enzyme 2 Proteins 0.000 description 5
- 102100035765 Angiotensin-converting enzyme 2 Human genes 0.000 description 5
- 241000283707 Capra Species 0.000 description 5
- 208000001528 Coronaviridae Infections Diseases 0.000 description 5
- 102000004190 Enzymes Human genes 0.000 description 5
- 108090000790 Enzymes Proteins 0.000 description 5
- 102000004961 Furin Human genes 0.000 description 5
- 108090001126 Furin Proteins 0.000 description 5
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 5
- 101710125418 Major capsid protein Proteins 0.000 description 5
- 208000025370 Middle East respiratory syndrome Diseases 0.000 description 5
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 5
- 208000036142 Viral infection Diseases 0.000 description 5
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 239000012141 concentrate Substances 0.000 description 5
- 108020001507 fusion proteins Proteins 0.000 description 5
- 102000037865 fusion proteins Human genes 0.000 description 5
- 108091006104 gene-regulatory proteins Proteins 0.000 description 5
- 102000034356 gene-regulatory proteins Human genes 0.000 description 5
- 108010078144 glutaminyl-glycine Proteins 0.000 description 5
- 108010089804 glycyl-threonine Proteins 0.000 description 5
- 230000028996 humoral immune response Effects 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 5
- 210000000723 mammalian artificial chromosome Anatomy 0.000 description 5
- 239000002773 nucleotide Substances 0.000 description 5
- 230000010076 replication Effects 0.000 description 5
- 239000011347 resin Substances 0.000 description 5
- 229920005989 resin Polymers 0.000 description 5
- 230000003248 secreting effect Effects 0.000 description 5
- 210000004988 splenocyte Anatomy 0.000 description 5
- 239000012089 stop solution Substances 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- 238000003146 transient transfection Methods 0.000 description 5
- 241000701161 unidentified adenovirus Species 0.000 description 5
- 230000009385 viral infection Effects 0.000 description 5
- JQSWHKKUZMTOIH-QWRGUYRKSA-N Asn-Gly-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N JQSWHKKUZMTOIH-QWRGUYRKSA-N 0.000 description 4
- SFJUYBCDQBAYAJ-YDHLFZDLSA-N Asp-Val-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SFJUYBCDQBAYAJ-YDHLFZDLSA-N 0.000 description 4
- 238000011740 C57BL/6 mouse Methods 0.000 description 4
- XEEIQMGZRFFSRD-XVYDVKMFSA-N Cys-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CS)N XEEIQMGZRFFSRD-XVYDVKMFSA-N 0.000 description 4
- 108010041986 DNA Vaccines Proteins 0.000 description 4
- 229940021995 DNA vaccine Drugs 0.000 description 4
- 238000011510 Elispot assay Methods 0.000 description 4
- GTBXHETZPUURJE-KKUMJFAQSA-N Gln-Tyr-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GTBXHETZPUURJE-KKUMJFAQSA-N 0.000 description 4
- NUSWUSKZRCGFEX-FXQIFTODSA-N Glu-Glu-Cys Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O NUSWUSKZRCGFEX-FXQIFTODSA-N 0.000 description 4
- CGWHAXBNGYQBBK-JBACZVJFSA-N Glu-Trp-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CCC(O)=O)N)C(O)=O)C1=CC=C(O)C=C1 CGWHAXBNGYQBBK-JBACZVJFSA-N 0.000 description 4
- SOYWRINXUSUWEQ-DLOVCJGASA-N Glu-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O SOYWRINXUSUWEQ-DLOVCJGASA-N 0.000 description 4
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- 241000700588 Human alphaherpesvirus 1 Species 0.000 description 4
- XVSJMWYYLHPDKY-DCAQKATOSA-N Leu-Asp-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O XVSJMWYYLHPDKY-DCAQKATOSA-N 0.000 description 4
- QRHWTCJBCLGYRB-FXQIFTODSA-N Met-Ala-Cys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(O)=O QRHWTCJBCLGYRB-FXQIFTODSA-N 0.000 description 4
- HUKLXYYPZWPXCC-KZVJFYERSA-N Met-Ala-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HUKLXYYPZWPXCC-KZVJFYERSA-N 0.000 description 4
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 4
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 4
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 4
- YAZNFQUKPUASKB-DCAQKATOSA-N Pro-Lys-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O YAZNFQUKPUASKB-DCAQKATOSA-N 0.000 description 4
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 4
- 101000953880 Severe acute respiratory syndrome coronavirus 2 Membrane protein Proteins 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- MCDVZTRGHNXTGK-HJGDQZAQSA-N Thr-Met-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O MCDVZTRGHNXTGK-HJGDQZAQSA-N 0.000 description 4
- YGKVNUAKYPGORG-AVGNSLFASA-N Tyr-Asp-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YGKVNUAKYPGORG-AVGNSLFASA-N 0.000 description 4
- 230000010530 Virus Neutralization Effects 0.000 description 4
- 210000004436 artificial bacterial chromosome Anatomy 0.000 description 4
- 210000004507 artificial chromosome Anatomy 0.000 description 4
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 4
- 108010077245 asparaginyl-proline Proteins 0.000 description 4
- 210000004369 blood Anatomy 0.000 description 4
- 239000008280 blood Substances 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 4
- 108010060199 cysteinylproline Proteins 0.000 description 4
- UQLDLKMNUJERMK-UHFFFAOYSA-L di(octadecanoyloxy)lead Chemical compound [Pb+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O UQLDLKMNUJERMK-UHFFFAOYSA-L 0.000 description 4
- 230000002458 infectious effect Effects 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 239000007927 intramuscular injection Substances 0.000 description 4
- 238000002955 isolation Methods 0.000 description 4
- 108010027338 isoleucylcysteine Proteins 0.000 description 4
- 229930027917 kanamycin Natural products 0.000 description 4
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 4
- 229960000318 kanamycin Drugs 0.000 description 4
- 229930182823 kanamycin A Natural products 0.000 description 4
- 108010003700 lysyl aspartic acid Proteins 0.000 description 4
- 108020004999 messenger RNA Proteins 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 238000012986 modification Methods 0.000 description 4
- 230000035772 mutation Effects 0.000 description 4
- 239000000546 pharmaceutical excipient Substances 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 239000013641 positive control Substances 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- 238000002360 preparation method Methods 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 239000013049 sediment Substances 0.000 description 4
- 238000000926 separation method Methods 0.000 description 4
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 4
- 210000000952 spleen Anatomy 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 238000012384 transportation and delivery Methods 0.000 description 4
- 108010020532 tyrosyl-proline Proteins 0.000 description 4
- 241001515965 unidentified phage Species 0.000 description 4
- 239000003981 vehicle Substances 0.000 description 4
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 3
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 3
- 239000012103 Alexa Fluor 488 Substances 0.000 description 3
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 3
- 241001580388 Cardiovirus B Species 0.000 description 3
- 241000588724 Escherichia coli Species 0.000 description 3
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 3
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 3
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 3
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- ZYVTXBXHIKGZMD-QSFUFRPTSA-N Ile-Val-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ZYVTXBXHIKGZMD-QSFUFRPTSA-N 0.000 description 3
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 3
- ZGUMORRUBUCXEH-AVGNSLFASA-N Leu-Lys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZGUMORRUBUCXEH-AVGNSLFASA-N 0.000 description 3
- XWEVVRRSIOBJOO-SRVKXCTJSA-N Leu-Pro-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O XWEVVRRSIOBJOO-SRVKXCTJSA-N 0.000 description 3
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 3
- VLMNBMFYRMGEMB-QWRGUYRKSA-N Lys-His-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CNC=N1 VLMNBMFYRMGEMB-QWRGUYRKSA-N 0.000 description 3
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 3
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 3
- 239000012124 Opti-MEM Substances 0.000 description 3
- HHOOEUSPFGPZFP-QWRGUYRKSA-N Phe-Asn-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HHOOEUSPFGPZFP-QWRGUYRKSA-N 0.000 description 3
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 108091005774 SARS-CoV-2 proteins Proteins 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 3
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 3
- 101000779242 Severe acute respiratory syndrome coronavirus 2 ORF3a protein Proteins 0.000 description 3
- 101710137500 T7 RNA polymerase Proteins 0.000 description 3
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 3
- ICPRIGUXAFULPH-ILWGZMRPSA-N Trp-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CNC4=CC=CC=C43)N)C(=O)O ICPRIGUXAFULPH-ILWGZMRPSA-N 0.000 description 3
- 108010047495 alanylglycine Proteins 0.000 description 3
- 239000003146 anticoagulant agent Substances 0.000 description 3
- 229940127219 anticoagulant drug Drugs 0.000 description 3
- 108010047857 aspartylglycine Proteins 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 210000000349 chromosome Anatomy 0.000 description 3
- 238000000576 coating method Methods 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 201000010099 disease Diseases 0.000 description 3
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 235000011187 glycerol Nutrition 0.000 description 3
- 238000003384 imaging method Methods 0.000 description 3
- 238000002649 immunization Methods 0.000 description 3
- 230000003053 immunization Effects 0.000 description 3
- 238000010166 immunofluorescence Methods 0.000 description 3
- 239000003547 immunosorbent Substances 0.000 description 3
- 238000010255 intramuscular injection Methods 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 230000004807 localization Effects 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 230000015654 memory Effects 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 230000006849 nucleocytoplasmic transport Effects 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 3
- 108010051242 phenylalanylserine Proteins 0.000 description 3
- PHEDXBVPIONUQT-RGYGYFBISA-N phorbol 13-acetate 12-myristate Chemical compound C([C@]1(O)C(=O)C(C)=C[C@H]1[C@@]1(O)[C@H](C)[C@H]2OC(=O)CCCCCCCCCCCCC)C(CO)=C[C@H]1[C@H]1[C@]2(OC(C)=O)C1(C)C PHEDXBVPIONUQT-RGYGYFBISA-N 0.000 description 3
- 230000004481 post-translational protein modification Effects 0.000 description 3
- 230000037452 priming Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000012846 protein folding Effects 0.000 description 3
- 230000001177 retroviral effect Effects 0.000 description 3
- 210000003705 ribosome Anatomy 0.000 description 3
- 108010026333 seryl-proline Proteins 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 2
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 2
- 241000701386 African swine fever virus Species 0.000 description 2
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 2
- LBJYAILUMSUTAM-ZLUOBGJFSA-N Ala-Asn-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O LBJYAILUMSUTAM-ZLUOBGJFSA-N 0.000 description 2
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 2
- PCIFXPRIFWKWLK-YUMQZZPRSA-N Ala-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N PCIFXPRIFWKWLK-YUMQZZPRSA-N 0.000 description 2
- KTXKIYXZQFWJKB-VZFHVOOUSA-N Ala-Thr-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O KTXKIYXZQFWJKB-VZFHVOOUSA-N 0.000 description 2
- 239000012109 Alexa Fluor 568 Substances 0.000 description 2
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 2
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 2
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 2
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 description 2
- JOADBFCFJGNIKF-GUBZILKMSA-N Arg-Met-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O JOADBFCFJGNIKF-GUBZILKMSA-N 0.000 description 2
- JOTRDIXZHNQYGP-DCAQKATOSA-N Arg-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JOTRDIXZHNQYGP-DCAQKATOSA-N 0.000 description 2
- WOZDCBHUGJVJPL-AVGNSLFASA-N Arg-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WOZDCBHUGJVJPL-AVGNSLFASA-N 0.000 description 2
- IARGXWMWRFOQPG-GCJQMDKQSA-N Asn-Ala-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IARGXWMWRFOQPG-GCJQMDKQSA-N 0.000 description 2
- KXFCBAHYSLJCCY-ZLUOBGJFSA-N Asn-Asn-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O KXFCBAHYSLJCCY-ZLUOBGJFSA-N 0.000 description 2
- GJFYPBDMUGGLFR-NKWVEPMBSA-N Asn-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC(=O)N)N)C(=O)O GJFYPBDMUGGLFR-NKWVEPMBSA-N 0.000 description 2
- RAQMSGVCGSJKCL-FOHZUACHSA-N Asn-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(N)=O RAQMSGVCGSJKCL-FOHZUACHSA-N 0.000 description 2
- IBLAOXSULLECQZ-IUKAMOBKSA-N Asn-Ile-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC(N)=O IBLAOXSULLECQZ-IUKAMOBKSA-N 0.000 description 2
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 2
- XOQYDFCQPWAMSA-KKHAAJSZSA-N Asn-Val-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOQYDFCQPWAMSA-KKHAAJSZSA-N 0.000 description 2
- FRSGNOZCTWDVFZ-ACZMJKKPSA-N Asp-Asp-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O FRSGNOZCTWDVFZ-ACZMJKKPSA-N 0.000 description 2
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 2
- PAYPSKIBMDHZPI-CIUDSAMLSA-N Asp-Leu-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PAYPSKIBMDHZPI-CIUDSAMLSA-N 0.000 description 2
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 2
- 108091033409 CRISPR Proteins 0.000 description 2
- 241000710190 Cardiovirus Species 0.000 description 2
- 108010039939 Cell Wall Skeleton Proteins 0.000 description 2
- 241001502567 Chikungunya virus Species 0.000 description 2
- 208000035473 Communicable disease Diseases 0.000 description 2
- 241000725619 Dengue virus Species 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- 241001115402 Ebolavirus Species 0.000 description 2
- 241000991587 Enterovirus C Species 0.000 description 2
- 241000702191 Escherichia virus P1 Species 0.000 description 2
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 2
- PNENQZWRFMUZOM-DCAQKATOSA-N Gln-Glu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O PNENQZWRFMUZOM-DCAQKATOSA-N 0.000 description 2
- GURIQZQSTBBHRV-SRVKXCTJSA-N Gln-Lys-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GURIQZQSTBBHRV-SRVKXCTJSA-N 0.000 description 2
- HLRLXVPRJJITSK-IFFSRLJSSA-N Gln-Thr-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HLRLXVPRJJITSK-IFFSRLJSSA-N 0.000 description 2
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 2
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 2
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 2
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 2
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 2
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 2
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 2
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 2
- AAHSHTLISQUZJL-QSFUFRPTSA-N Gly-Ile-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O AAHSHTLISQUZJL-QSFUFRPTSA-N 0.000 description 2
- PCPOYRCAHPJXII-UWVGGRQHSA-N Gly-Lys-Met Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O PCPOYRCAHPJXII-UWVGGRQHSA-N 0.000 description 2
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 2
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 2
- 208000005176 Hepatitis C Diseases 0.000 description 2
- 208000005331 Hepatitis D Diseases 0.000 description 2
- 241000709715 Hepatovirus Species 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- NQKRILCJYCASDV-QWRGUYRKSA-N His-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CN=CN1 NQKRILCJYCASDV-QWRGUYRKSA-N 0.000 description 2
- NDKSHNQINMRKHT-PEXQALLHSA-N His-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N NDKSHNQINMRKHT-PEXQALLHSA-N 0.000 description 2
- 241000701074 Human alphaherpesvirus 2 Species 0.000 description 2
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 2
- 241000701828 Human papillomavirus type 11 Species 0.000 description 2
- QICVAHODWHIWIS-HTFCKZLJSA-N Ile-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N QICVAHODWHIWIS-HTFCKZLJSA-N 0.000 description 2
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 2
- UMYZBHKAVTXWIW-GMOBBJLQSA-N Ile-Asp-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UMYZBHKAVTXWIW-GMOBBJLQSA-N 0.000 description 2
- MQFGXJNSUJTXDT-QSFUFRPTSA-N Ile-Gly-Ile Chemical compound N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)O MQFGXJNSUJTXDT-QSFUFRPTSA-N 0.000 description 2
- UAQSZXGJGLHMNV-XEGUGMAKSA-N Ile-Gly-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N UAQSZXGJGLHMNV-XEGUGMAKSA-N 0.000 description 2
- YSGBJIQXTIVBHZ-AJNGGQMLSA-N Ile-Lys-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O YSGBJIQXTIVBHZ-AJNGGQMLSA-N 0.000 description 2
- QHUREMVLLMNUAX-OSUNSFLBSA-N Ile-Thr-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)O)N QHUREMVLLMNUAX-OSUNSFLBSA-N 0.000 description 2
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 2
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- 241000880493 Leptailurus serval Species 0.000 description 2
- FIJMQLGQLBLBOL-HJGDQZAQSA-N Leu-Asn-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FIJMQLGQLBLBOL-HJGDQZAQSA-N 0.000 description 2
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 2
- FOEHRHOBWFQSNW-KATARQTJSA-N Leu-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N)O FOEHRHOBWFQSNW-KATARQTJSA-N 0.000 description 2
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 2
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 2
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 2
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 2
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 2
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 2
- AEIIJFBQVGYVEV-YESZJQIVSA-N Lys-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCCN)N)C(=O)O AEIIJFBQVGYVEV-YESZJQIVSA-N 0.000 description 2
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 2
- OGAZPKJHHZPYFK-GARJFASQSA-N Met-Glu-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGAZPKJHHZPYFK-GARJFASQSA-N 0.000 description 2
- YAWKHFKCNSXYDS-XIRDDKMYSA-N Met-Glu-Trp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N YAWKHFKCNSXYDS-XIRDDKMYSA-N 0.000 description 2
- RDLSEGZJMYGFNS-FXQIFTODSA-N Met-Ser-Asp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RDLSEGZJMYGFNS-FXQIFTODSA-N 0.000 description 2
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 2
- 108091061960 Naked DNA Proteins 0.000 description 2
- 108700001237 Nucleic Acid-Based Vaccines Proteins 0.000 description 2
- 102000010292 Peptide Elongation Factor 1 Human genes 0.000 description 2
- 108010077524 Peptide Elongation Factor 1 Proteins 0.000 description 2
- 108091093037 Peptide nucleic acid Proteins 0.000 description 2
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 2
- RMKGXGPQIPLTFC-KKUMJFAQSA-N Phe-Lys-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O RMKGXGPQIPLTFC-KKUMJFAQSA-N 0.000 description 2
- 108010039918 Polylysine Proteins 0.000 description 2
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 2
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 2
- ZTHYODDOHIVTJV-UHFFFAOYSA-N Propyl gallate Chemical compound CCCOC(=O)C1=CC(O)=C(O)C(O)=C1 ZTHYODDOHIVTJV-UHFFFAOYSA-N 0.000 description 2
- 108700008625 Reporter Genes Proteins 0.000 description 2
- 241000055391 Saffold virus Species 0.000 description 2
- BCKYYTVFBXHPOG-ACZMJKKPSA-N Ser-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N BCKYYTVFBXHPOG-ACZMJKKPSA-N 0.000 description 2
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 2
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 2
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 2
- RXSWQCATLWVDLI-XGEHTFHBSA-N Ser-Met-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RXSWQCATLWVDLI-XGEHTFHBSA-N 0.000 description 2
- 241000713880 Spleen focus-forming virus Species 0.000 description 2
- 241000256251 Spodoptera frugiperda Species 0.000 description 2
- RAHZWNYVWXNFOC-UHFFFAOYSA-N Sulphur dioxide Chemical compound O=S=O RAHZWNYVWXNFOC-UHFFFAOYSA-N 0.000 description 2
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 2
- JMZKMSTYXHFYAK-VEVYYDQMSA-N Thr-Arg-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O JMZKMSTYXHFYAK-VEVYYDQMSA-N 0.000 description 2
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 2
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 2
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 2
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 2
- 102000002689 Toll-like receptor Human genes 0.000 description 2
- 108020000411 Toll-like receptor Proteins 0.000 description 2
- 229920004890 Triton X-100 Polymers 0.000 description 2
- 239000013504 Triton X-100 Substances 0.000 description 2
- UEFHVUQBYNRNQC-SFJXLCSZSA-N Trp-Phe-Thr Chemical compound C([C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=CC=C1 UEFHVUQBYNRNQC-SFJXLCSZSA-N 0.000 description 2
- UGFOSENEZHEQKX-PJODQICGSA-N Trp-Val-Ala Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](C)C(O)=O UGFOSENEZHEQKX-PJODQICGSA-N 0.000 description 2
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 2
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 2
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 2
- XNLUVJPMPAZHCY-JYJNAYRXSA-N Val-Val-Phe Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 XNLUVJPMPAZHCY-JYJNAYRXSA-N 0.000 description 2
- 241000725110 Vilyuisk human encephalomyelitis virus Species 0.000 description 2
- 241000269368 Xenopus laevis Species 0.000 description 2
- 241000907316 Zika virus Species 0.000 description 2
- 239000003070 absorption delaying agent Substances 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 230000002411 adverse Effects 0.000 description 2
- 239000000443 aerosol Substances 0.000 description 2
- 108010005233 alanylglutamic acid Proteins 0.000 description 2
- 108010044940 alanylglutamine Proteins 0.000 description 2
- 108010087924 alanylproline Proteins 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 108010028263 bacteriophage T3 RNA polymerase Proteins 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 229960000074 biopharmaceutical Drugs 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 239000001506 calcium phosphate Substances 0.000 description 2
- 229910000389 calcium phosphate Inorganic materials 0.000 description 2
- 235000011010 calcium phosphates Nutrition 0.000 description 2
- 229920006317 cationic polymer Polymers 0.000 description 2
- 210000004520 cell wall skeleton Anatomy 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 229960004926 chlorobutanol Drugs 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 239000000412 dendrimer Substances 0.000 description 2
- 229920000736 dendritic polymer Polymers 0.000 description 2
- 108010054813 diprotin B Proteins 0.000 description 2
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 2
- 238000010828 elution Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 2
- CBOQJANXLMLOSS-UHFFFAOYSA-N ethyl vanillin Chemical compound CCOC1=CC(C=O)=CC=C1O CBOQJANXLMLOSS-UHFFFAOYSA-N 0.000 description 2
- 239000013604 expression vector Substances 0.000 description 2
- 230000005714 functional activity Effects 0.000 description 2
- 108010073628 glutamyl-valyl-phenylalanine Proteins 0.000 description 2
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 2
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 2
- 108010050848 glycylleucine Proteins 0.000 description 2
- 108010087823 glycyltyrosine Proteins 0.000 description 2
- 108010037850 glycylvaline Proteins 0.000 description 2
- 208000006454 hepatitis Diseases 0.000 description 2
- 231100000283 hepatitis Toxicity 0.000 description 2
- 208000005252 hepatitis A Diseases 0.000 description 2
- 208000002672 hepatitis B Diseases 0.000 description 2
- 201000010284 hepatitis E Diseases 0.000 description 2
- 108010028295 histidylhistidine Proteins 0.000 description 2
- 206010022000 influenza Diseases 0.000 description 2
- PGHMRUGBZOYCAA-UHFFFAOYSA-N ionomycin Natural products O1C(CC(O)C(C)C(O)C(C)C=CCC(C)CC(C)C(O)=CC(=O)C(C)CC(C)CC(CCC(O)=O)C)CCC1(C)C1OC(C)(C(C)O)CC1 PGHMRUGBZOYCAA-UHFFFAOYSA-N 0.000 description 2
- PGHMRUGBZOYCAA-ADZNBVRBSA-N ionomycin Chemical compound O1[C@H](C[C@H](O)[C@H](C)[C@H](O)[C@H](C)/C=C/C[C@@H](C)C[C@@H](C)C(/O)=C/C(=O)[C@@H](C)C[C@@H](C)C[C@@H](CCC(O)=O)C)CC[C@@]1(C)[C@@H]1O[C@](C)([C@@H](C)O)CC1 PGHMRUGBZOYCAA-ADZNBVRBSA-N 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 108010034529 leucyl-lysine Proteins 0.000 description 2
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 108010044348 lysyl-glutamyl-aspartic acid Proteins 0.000 description 2
- 108010009298 lysylglutamic acid Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 108010054155 lysyllysine Proteins 0.000 description 2
- 108010017391 lysylvaline Proteins 0.000 description 2
- 108010026228 mRNA guanylyltransferase Proteins 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000002105 nanoparticle Substances 0.000 description 2
- 230000009871 nonspecific binding Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 229960003742 phenol Drugs 0.000 description 2
- 108010089198 phenylalanyl-prolyl-arginine Proteins 0.000 description 2
- 238000013492 plasmid preparation Methods 0.000 description 2
- 229920000656 polylysine Polymers 0.000 description 2
- 239000011148 porous material Substances 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 210000002345 respiratory system Anatomy 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 108010007375 seryl-seryl-seryl-arginine Proteins 0.000 description 2
- 238000001542 size-exclusion chromatography Methods 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 235000010199 sorbic acid Nutrition 0.000 description 2
- 229940075582 sorbic acid Drugs 0.000 description 2
- 239000004334 sorbic acid Substances 0.000 description 2
- 229940031439 squalene Drugs 0.000 description 2
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 208000024891 symptom Diseases 0.000 description 2
- 231100000419 toxicity Toxicity 0.000 description 2
- 230000001988 toxicity Effects 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 238000011282 treatment Methods 0.000 description 2
- XETCRXVKJHBPMK-MJSODCSWSA-N trehalose 6,6'-dimycolate Chemical compound C([C@@H]1[C@H]([C@H](O)[C@@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](COC(=O)C(CCCCCCCCCCC3C(C3)CCCCCCCCCCCCCCCCCC)C(O)CCCCCCCCCCCCCCCCCCCCCCCCC)O2)O)O1)O)OC(=O)C(C(O)CCCCCCCCCCCCCCCCCCCCCCCCC)CCCCCCCCCCC1CC1CCCCCCCCCCCCCCCCCC XETCRXVKJHBPMK-MJSODCSWSA-N 0.000 description 2
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- 241000701447 unidentified baculovirus Species 0.000 description 2
- 241001529453 unidentified herpesvirus Species 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- 108010009962 valyltyrosine Proteins 0.000 description 2
- 210000003501 vero cell Anatomy 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- 239000011800 void material Substances 0.000 description 2
- 230000003442 weekly effect Effects 0.000 description 2
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- CWFMWBHMIMNZLN-NAKRPEOUSA-N (2s)-1-[(2s)-2-[[(2s,3s)-2-amino-3-methylpentanoyl]amino]propanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CWFMWBHMIMNZLN-NAKRPEOUSA-N 0.000 description 1
- RRBGTUQJDFBWNN-MUGJNUQGSA-N (2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-2,6-diaminohexanoyl]amino]hexanoyl]amino]hexanoyl]amino]hexanoic acid Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O RRBGTUQJDFBWNN-MUGJNUQGSA-N 0.000 description 1
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 1
- CHHHXKFHOYLYRE-UHFFFAOYSA-M 2,4-Hexadienoic acid, potassium salt (1:1), (2E,4E)- Chemical compound [K+].CC=CC=CC([O-])=O CHHHXKFHOYLYRE-UHFFFAOYSA-M 0.000 description 1
- JKXYOQDLERSFPT-UHFFFAOYSA-N 2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-(2-octadecoxyethoxy)ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethanol Chemical compound CCCCCCCCCCCCCCCCCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO JKXYOQDLERSFPT-UHFFFAOYSA-N 0.000 description 1
- DQVAZKGVGKHQDS-UHFFFAOYSA-N 2-[[1-[2-[(2-amino-4-methylpentanoyl)amino]-4-methylpentanoyl]pyrrolidine-2-carbonyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(=O)NC(CC(C)C)C(O)=O DQVAZKGVGKHQDS-UHFFFAOYSA-N 0.000 description 1
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 1
- WXNZTHHGJRFXKQ-UHFFFAOYSA-N 4-chlorophenol Chemical compound OC1=CC=C(Cl)C=C1 WXNZTHHGJRFXKQ-UHFFFAOYSA-N 0.000 description 1
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 1
- DKJPOZOEBONHFS-ZLUOBGJFSA-N Ala-Ala-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O DKJPOZOEBONHFS-ZLUOBGJFSA-N 0.000 description 1
- LGQPPBQRUBVTIF-JBDRJPRFSA-N Ala-Ala-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LGQPPBQRUBVTIF-JBDRJPRFSA-N 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- UGLPMYSCWHTZQU-AUTRQRHGSA-N Ala-Ala-Tyr Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UGLPMYSCWHTZQU-AUTRQRHGSA-N 0.000 description 1
- WRDANSJTFOHBPI-FXQIFTODSA-N Ala-Arg-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N WRDANSJTFOHBPI-FXQIFTODSA-N 0.000 description 1
- JAMAWBXXKFGFGX-KZVJFYERSA-N Ala-Arg-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JAMAWBXXKFGFGX-KZVJFYERSA-N 0.000 description 1
- XEXJJJRVTFGWIC-FXQIFTODSA-N Ala-Asn-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XEXJJJRVTFGWIC-FXQIFTODSA-N 0.000 description 1
- XQGIRPGAVLFKBJ-CIUDSAMLSA-N Ala-Asn-Lys Chemical compound N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)O XQGIRPGAVLFKBJ-CIUDSAMLSA-N 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 1
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 1
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 1
- AWAXZRDKUHOPBO-GUBZILKMSA-N Ala-Gln-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O AWAXZRDKUHOPBO-GUBZILKMSA-N 0.000 description 1
- JPGBXANAQYHTLA-DRZSPHRISA-N Ala-Gln-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JPGBXANAQYHTLA-DRZSPHRISA-N 0.000 description 1
- ZDYNWWQXFRUOEO-XDTLVQLUSA-N Ala-Gln-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDYNWWQXFRUOEO-XDTLVQLUSA-N 0.000 description 1
- NJPMYXWVWQWCSR-ACZMJKKPSA-N Ala-Glu-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NJPMYXWVWQWCSR-ACZMJKKPSA-N 0.000 description 1
- PAIHPOGPJVUFJY-WDSKDSINSA-N Ala-Glu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PAIHPOGPJVUFJY-WDSKDSINSA-N 0.000 description 1
- BVSGPHDECMJBDE-HGNGGELXSA-N Ala-Glu-His Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N BVSGPHDECMJBDE-HGNGGELXSA-N 0.000 description 1
- LJFNNUBZSZCZFN-WHFBIAKZSA-N Ala-Gly-Cys Chemical compound N[C@@H](C)C(=O)NCC(=O)N[C@@H](CS)C(=O)O LJFNNUBZSZCZFN-WHFBIAKZSA-N 0.000 description 1
- BTBUEVAGZCKULD-XPUUQOCRSA-N Ala-Gly-His Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CN=CN1 BTBUEVAGZCKULD-XPUUQOCRSA-N 0.000 description 1
- SMCGQGDVTPFXKB-XPUUQOCRSA-N Ala-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N SMCGQGDVTPFXKB-XPUUQOCRSA-N 0.000 description 1
- FAJIYNONGXEXAI-CQDKDKBSSA-N Ala-His-Phe Chemical compound C([C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CNC=N1 FAJIYNONGXEXAI-CQDKDKBSSA-N 0.000 description 1
- PNALXAODQKTNLV-JBDRJPRFSA-N Ala-Ile-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O PNALXAODQKTNLV-JBDRJPRFSA-N 0.000 description 1
- YHKANGMVQWRMAP-DCAQKATOSA-N Ala-Leu-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YHKANGMVQWRMAP-DCAQKATOSA-N 0.000 description 1
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 1
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 1
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 1
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 1
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 1
- MLNSNVLOEIYJIU-ZUDIRPEPSA-N Ala-Leu-Thr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLNSNVLOEIYJIU-ZUDIRPEPSA-N 0.000 description 1
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 1
- XRUJOVRWNMBAAA-NHCYSSNCSA-N Ala-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 XRUJOVRWNMBAAA-NHCYSSNCSA-N 0.000 description 1
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 1
- YCRAFFCYWOUEOF-DLOVCJGASA-N Ala-Phe-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 YCRAFFCYWOUEOF-DLOVCJGASA-N 0.000 description 1
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 1
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 1
- DCVYRWFAMZFSDA-ZLUOBGJFSA-N Ala-Ser-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DCVYRWFAMZFSDA-ZLUOBGJFSA-N 0.000 description 1
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 1
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 1
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 1
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- VRTOMXFZHGWHIJ-KZVJFYERSA-N Ala-Thr-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VRTOMXFZHGWHIJ-KZVJFYERSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 1
- 108010011170 Ala-Trp-Arg-His-Pro-Gln-Phe-Gly-Gly Proteins 0.000 description 1
- MTDDMSUUXNQMKK-BPNCWPANSA-N Ala-Tyr-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N MTDDMSUUXNQMKK-BPNCWPANSA-N 0.000 description 1
- AOAKQKVICDWCLB-UWJYBYFXSA-N Ala-Tyr-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N AOAKQKVICDWCLB-UWJYBYFXSA-N 0.000 description 1
- BGGAIXWIZCIFSG-XDTLVQLUSA-N Ala-Tyr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O BGGAIXWIZCIFSG-XDTLVQLUSA-N 0.000 description 1
- XAXMJQUMRJAFCH-CQDKDKBSSA-N Ala-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 XAXMJQUMRJAFCH-CQDKDKBSSA-N 0.000 description 1
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 1
- XSLGWYYNOSUMRM-ZKWXMUAHSA-N Ala-Val-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XSLGWYYNOSUMRM-ZKWXMUAHSA-N 0.000 description 1
- LYILPUNCKACNGF-NAKRPEOUSA-N Ala-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C)N LYILPUNCKACNGF-NAKRPEOUSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- SGYSTDWPNPKJPP-GUBZILKMSA-N Arg-Ala-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SGYSTDWPNPKJPP-GUBZILKMSA-N 0.000 description 1
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 1
- DCGLNNVKIZXQOJ-FXQIFTODSA-N Arg-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N DCGLNNVKIZXQOJ-FXQIFTODSA-N 0.000 description 1
- JSHVMZANPXCDTL-GMOBBJLQSA-N Arg-Asp-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JSHVMZANPXCDTL-GMOBBJLQSA-N 0.000 description 1
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 1
- MFAMTAVAFBPXDC-LPEHRKFASA-N Arg-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O MFAMTAVAFBPXDC-LPEHRKFASA-N 0.000 description 1
- JTWOBPNAVBESFW-FXQIFTODSA-N Arg-Cys-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N JTWOBPNAVBESFW-FXQIFTODSA-N 0.000 description 1
- OANWAFQRNQEDSY-DCAQKATOSA-N Arg-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N OANWAFQRNQEDSY-DCAQKATOSA-N 0.000 description 1
- OBFTYSPXDRROQO-SRVKXCTJSA-N Arg-Gln-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCN=C(N)N OBFTYSPXDRROQO-SRVKXCTJSA-N 0.000 description 1
- KRQSPVKUISQQFS-FJXKBIBVSA-N Arg-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N KRQSPVKUISQQFS-FJXKBIBVSA-N 0.000 description 1
- FRMQITGHXMUNDF-GMOBBJLQSA-N Arg-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N FRMQITGHXMUNDF-GMOBBJLQSA-N 0.000 description 1
- UAOSDDXCTBIPCA-QXEWZRGKSA-N Arg-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UAOSDDXCTBIPCA-QXEWZRGKSA-N 0.000 description 1
- HJDNZFIYILEIKR-OSUNSFLBSA-N Arg-Ile-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HJDNZFIYILEIKR-OSUNSFLBSA-N 0.000 description 1
- CZUHPNLXLWMYMG-UBHSHLNASA-N Arg-Phe-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 CZUHPNLXLWMYMG-UBHSHLNASA-N 0.000 description 1
- VEAIMHJZTIDCIH-KKUMJFAQSA-N Arg-Phe-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEAIMHJZTIDCIH-KKUMJFAQSA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 1
- JQHASVQBAKRJKD-GUBZILKMSA-N Arg-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N JQHASVQBAKRJKD-GUBZILKMSA-N 0.000 description 1
- BECXEHHOZNFFFX-IHRRRGAJSA-N Arg-Ser-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BECXEHHOZNFFFX-IHRRRGAJSA-N 0.000 description 1
- AUZAXCPWMDBWEE-HJGDQZAQSA-N Arg-Thr-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O AUZAXCPWMDBWEE-HJGDQZAQSA-N 0.000 description 1
- RYQSYXFGFOTJDJ-RHYQMDGZSA-N Arg-Thr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RYQSYXFGFOTJDJ-RHYQMDGZSA-N 0.000 description 1
- MOGMYRUNTKYZFB-UNQGMJICSA-N Arg-Thr-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MOGMYRUNTKYZFB-UNQGMJICSA-N 0.000 description 1
- VJIQPOJMISSUPO-BVSLBCMMSA-N Arg-Trp-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VJIQPOJMISSUPO-BVSLBCMMSA-N 0.000 description 1
- CTAPSNCVKPOOSM-KKUMJFAQSA-N Arg-Tyr-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O CTAPSNCVKPOOSM-KKUMJFAQSA-N 0.000 description 1
- QTAIIXQCOPUNBQ-QXEWZRGKSA-N Arg-Val-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QTAIIXQCOPUNBQ-QXEWZRGKSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- YNDLOUMBVDVALC-ZLUOBGJFSA-N Asn-Ala-Ala Chemical compound C[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC(=O)N)N YNDLOUMBVDVALC-ZLUOBGJFSA-N 0.000 description 1
- NUHQMYUWLUSRJX-BIIVOSGPSA-N Asn-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N NUHQMYUWLUSRJX-BIIVOSGPSA-N 0.000 description 1
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 1
- YNSCBOUZTAGIGO-ZLUOBGJFSA-N Asn-Asn-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)C(=O)N YNSCBOUZTAGIGO-ZLUOBGJFSA-N 0.000 description 1
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 1
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 1
- XSGBIBGAMKTHMY-WHFBIAKZSA-N Asn-Asp-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O XSGBIBGAMKTHMY-WHFBIAKZSA-N 0.000 description 1
- UGXVKHRDGLYFKR-CIUDSAMLSA-N Asn-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(N)=O UGXVKHRDGLYFKR-CIUDSAMLSA-N 0.000 description 1
- HLTLEIXYIJDFOY-ZLUOBGJFSA-N Asn-Cys-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O HLTLEIXYIJDFOY-ZLUOBGJFSA-N 0.000 description 1
- CZIXHXIJJZLYRJ-SRVKXCTJSA-N Asn-Cys-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CZIXHXIJJZLYRJ-SRVKXCTJSA-N 0.000 description 1
- XWFPGQVLOVGSLU-CIUDSAMLSA-N Asn-Gln-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N XWFPGQVLOVGSLU-CIUDSAMLSA-N 0.000 description 1
- AYKKKGFJXIDYLX-ACZMJKKPSA-N Asn-Gln-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AYKKKGFJXIDYLX-ACZMJKKPSA-N 0.000 description 1
- WPOLSNAQGVHROR-GUBZILKMSA-N Asn-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N WPOLSNAQGVHROR-GUBZILKMSA-N 0.000 description 1
- QNJIRRVTOXNGMH-GUBZILKMSA-N Asn-Gln-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC(N)=O QNJIRRVTOXNGMH-GUBZILKMSA-N 0.000 description 1
- QPTAGIPWARILES-AVGNSLFASA-N Asn-Gln-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QPTAGIPWARILES-AVGNSLFASA-N 0.000 description 1
- KUYKVGODHGHFDI-ACZMJKKPSA-N Asn-Gln-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O KUYKVGODHGHFDI-ACZMJKKPSA-N 0.000 description 1
- QYXNFROWLZPWPC-FXQIFTODSA-N Asn-Glu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QYXNFROWLZPWPC-FXQIFTODSA-N 0.000 description 1
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- UYXXMIZGHYKYAT-NHCYSSNCSA-N Asn-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)N)N UYXXMIZGHYKYAT-NHCYSSNCSA-N 0.000 description 1
- NKLRWRRVYGQNIH-GHCJXIJMSA-N Asn-Ile-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O NKLRWRRVYGQNIH-GHCJXIJMSA-N 0.000 description 1
- ANPFQTJEPONRPL-UGYAYLCHSA-N Asn-Ile-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O ANPFQTJEPONRPL-UGYAYLCHSA-N 0.000 description 1
- SPCONPVIDFMDJI-QSFUFRPTSA-N Asn-Ile-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O SPCONPVIDFMDJI-QSFUFRPTSA-N 0.000 description 1
- ZMUQQMGITUJQTI-CIUDSAMLSA-N Asn-Leu-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZMUQQMGITUJQTI-CIUDSAMLSA-N 0.000 description 1
- UHGUKCOQUNPSKK-CIUDSAMLSA-N Asn-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)N)N UHGUKCOQUNPSKK-CIUDSAMLSA-N 0.000 description 1
- FHETWELNCBMRMG-HJGDQZAQSA-N Asn-Leu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FHETWELNCBMRMG-HJGDQZAQSA-N 0.000 description 1
- NCFJQJRLQJEECD-NHCYSSNCSA-N Asn-Leu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O NCFJQJRLQJEECD-NHCYSSNCSA-N 0.000 description 1
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 1
- KSGAFDTYQPKUAP-GMOBBJLQSA-N Asn-Met-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KSGAFDTYQPKUAP-GMOBBJLQSA-N 0.000 description 1
- OROMFUQQTSWUTI-IHRRRGAJSA-N Asn-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N OROMFUQQTSWUTI-IHRRRGAJSA-N 0.000 description 1
- BSBNNPICFPXDNH-SRVKXCTJSA-N Asn-Phe-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)N)N BSBNNPICFPXDNH-SRVKXCTJSA-N 0.000 description 1
- PPCORQFLAZWUNO-QWRGUYRKSA-N Asn-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N PPCORQFLAZWUNO-QWRGUYRKSA-N 0.000 description 1
- YXVAESUIQFDBHN-SRVKXCTJSA-N Asn-Phe-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O YXVAESUIQFDBHN-SRVKXCTJSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- YUOXLJYVSZYPBJ-CIUDSAMLSA-N Asn-Pro-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O YUOXLJYVSZYPBJ-CIUDSAMLSA-N 0.000 description 1
- VHQSGALUSWIYOD-QXEWZRGKSA-N Asn-Pro-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O VHQSGALUSWIYOD-QXEWZRGKSA-N 0.000 description 1
- HPNDKUOLNRVRAY-BIIVOSGPSA-N Asn-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N)C(=O)O HPNDKUOLNRVRAY-BIIVOSGPSA-N 0.000 description 1
- SNYCNNPOFYBCEK-ZLUOBGJFSA-N Asn-Ser-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O SNYCNNPOFYBCEK-ZLUOBGJFSA-N 0.000 description 1
- QYRMBFWDSFGSFC-OLHMAJIHSA-N Asn-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QYRMBFWDSFGSFC-OLHMAJIHSA-N 0.000 description 1
- BCADFFUQHIMQAA-KKHAAJSZSA-N Asn-Thr-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BCADFFUQHIMQAA-KKHAAJSZSA-N 0.000 description 1
- KTDWFWNZLLFEFU-KKUMJFAQSA-N Asn-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O KTDWFWNZLLFEFU-KKUMJFAQSA-N 0.000 description 1
- DATSKXOXPUAOLK-KKUMJFAQSA-N Asn-Tyr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O DATSKXOXPUAOLK-KKUMJFAQSA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 1
- HBUJSDCLZCXXCW-YDHLFZDLSA-N Asn-Val-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HBUJSDCLZCXXCW-YDHLFZDLSA-N 0.000 description 1
- WQAOZCVOOYUWKG-LSJOCFKGSA-N Asn-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CC(=O)N)N WQAOZCVOOYUWKG-LSJOCFKGSA-N 0.000 description 1
- KRXIWXCXOARFNT-ZLUOBGJFSA-N Asp-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O KRXIWXCXOARFNT-ZLUOBGJFSA-N 0.000 description 1
- IXIWEFWRKIUMQX-DCAQKATOSA-N Asp-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O IXIWEFWRKIUMQX-DCAQKATOSA-N 0.000 description 1
- CNKAZIGBGQIHLL-GUBZILKMSA-N Asp-Arg-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)O)N CNKAZIGBGQIHLL-GUBZILKMSA-N 0.000 description 1
- CELPEWWLSXMVPH-CIUDSAMLSA-N Asp-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O CELPEWWLSXMVPH-CIUDSAMLSA-N 0.000 description 1
- SVFOIXMRMLROHO-SRVKXCTJSA-N Asp-Asp-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SVFOIXMRMLROHO-SRVKXCTJSA-N 0.000 description 1
- FTNVLGCFIJEMQT-CIUDSAMLSA-N Asp-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N FTNVLGCFIJEMQT-CIUDSAMLSA-N 0.000 description 1
- DZQKLNLLWFQONU-LKXGYXEUSA-N Asp-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)O DZQKLNLLWFQONU-LKXGYXEUSA-N 0.000 description 1
- PZXPWHFYZXTFBI-YUMQZZPRSA-N Asp-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PZXPWHFYZXTFBI-YUMQZZPRSA-N 0.000 description 1
- ICZWAZVKLACMKR-CIUDSAMLSA-N Asp-His-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CN=CN1 ICZWAZVKLACMKR-CIUDSAMLSA-N 0.000 description 1
- GBSUGIXJAAKZOW-GMOBBJLQSA-N Asp-Ile-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O GBSUGIXJAAKZOW-GMOBBJLQSA-N 0.000 description 1
- KQBVNNAPIURMPD-PEFMBERDSA-N Asp-Ile-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KQBVNNAPIURMPD-PEFMBERDSA-N 0.000 description 1
- SPKCGKRUYKMDHP-GUDRVLHUSA-N Asp-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N SPKCGKRUYKMDHP-GUDRVLHUSA-N 0.000 description 1
- KLYPOCBLKMPBIQ-GHCJXIJMSA-N Asp-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N KLYPOCBLKMPBIQ-GHCJXIJMSA-N 0.000 description 1
- SPWXXPFDTMYTRI-IUKAMOBKSA-N Asp-Ile-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SPWXXPFDTMYTRI-IUKAMOBKSA-N 0.000 description 1
- XSXVLWBWIPKUSN-UHFFFAOYSA-N Asp-Leu-Glu-Asp Chemical compound OC(=O)CC(N)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(O)=O)C(O)=O XSXVLWBWIPKUSN-UHFFFAOYSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- UJGRZQYSNYTCAX-SRVKXCTJSA-N Asp-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UJGRZQYSNYTCAX-SRVKXCTJSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- MYOHQBFRJQFIDZ-KKUMJFAQSA-N Asp-Leu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYOHQBFRJQFIDZ-KKUMJFAQSA-N 0.000 description 1
- XWSIYTYNLKCLJB-CIUDSAMLSA-N Asp-Lys-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O XWSIYTYNLKCLJB-CIUDSAMLSA-N 0.000 description 1
- RXBGWGRSWXOBGK-KKUMJFAQSA-N Asp-Lys-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RXBGWGRSWXOBGK-KKUMJFAQSA-N 0.000 description 1
- BWJZSLQJNBSUPM-FXQIFTODSA-N Asp-Pro-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O BWJZSLQJNBSUPM-FXQIFTODSA-N 0.000 description 1
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 1
- QTIZKMMLNUMHHU-DCAQKATOSA-N Asp-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QTIZKMMLNUMHHU-DCAQKATOSA-N 0.000 description 1
- XUVTWGPERWIERB-IHRRRGAJSA-N Asp-Pro-Phe Chemical compound N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O XUVTWGPERWIERB-IHRRRGAJSA-N 0.000 description 1
- KGHLGJAXYSVNJP-WHFBIAKZSA-N Asp-Ser-Gly Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O KGHLGJAXYSVNJP-WHFBIAKZSA-N 0.000 description 1
- DRCOAZZDQRCGGP-GHCJXIJMSA-N Asp-Ser-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DRCOAZZDQRCGGP-GHCJXIJMSA-N 0.000 description 1
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- LEYKQPDPZJIRTA-AQZXSJQPSA-N Asp-Trp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LEYKQPDPZJIRTA-AQZXSJQPSA-N 0.000 description 1
- NJLLRXWFPQQPHV-SRVKXCTJSA-N Asp-Tyr-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJLLRXWFPQQPHV-SRVKXCTJSA-N 0.000 description 1
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 1
- PLOKOIJSGCISHE-BYULHYEWSA-N Asp-Val-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PLOKOIJSGCISHE-BYULHYEWSA-N 0.000 description 1
- RKXVTTIQNKPCHU-KKHAAJSZSA-N Asp-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O RKXVTTIQNKPCHU-KKHAAJSZSA-N 0.000 description 1
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 1
- 241000351920 Aspergillus nidulans Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 241001408568 Bovine rhinitis A virus Species 0.000 description 1
- 241001671987 Bovine rhinitis B virus Species 0.000 description 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 1
- 238000010354 CRISPR gene editing Methods 0.000 description 1
- 102000000584 Calmodulin Human genes 0.000 description 1
- 108010041952 Calmodulin Proteins 0.000 description 1
- 244000197813 Camelina sativa Species 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- 241000222122 Candida albicans Species 0.000 description 1
- 108090000565 Capsid Proteins Proteins 0.000 description 1
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 1
- 241001580405 Cardiovirus A Species 0.000 description 1
- 102000005600 Cathepsins Human genes 0.000 description 1
- 108010084457 Cathepsins Proteins 0.000 description 1
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 1
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 241000282552 Chlorocebus aethiops Species 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 1
- WXKWQSDHEXKKNC-ZKWXMUAHSA-N Cys-Asp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N WXKWQSDHEXKKNC-ZKWXMUAHSA-N 0.000 description 1
- ATPDEYTYWVMINF-ZLUOBGJFSA-N Cys-Cys-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O ATPDEYTYWVMINF-ZLUOBGJFSA-N 0.000 description 1
- GUKYYUFHWYRMEU-WHFBIAKZSA-N Cys-Gly-Asp Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O GUKYYUFHWYRMEU-WHFBIAKZSA-N 0.000 description 1
- SKSJPIBFNFPTJB-NKWVEPMBSA-N Cys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CS)N)C(=O)O SKSJPIBFNFPTJB-NKWVEPMBSA-N 0.000 description 1
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 1
- UCSXXFRXHGUXCQ-SRVKXCTJSA-N Cys-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N UCSXXFRXHGUXCQ-SRVKXCTJSA-N 0.000 description 1
- QQOWCDCBFFBRQH-IXOXFDKPSA-N Cys-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CS)N)O QQOWCDCBFFBRQH-IXOXFDKPSA-N 0.000 description 1
- KVCJEMHFLGVINV-ZLUOBGJFSA-N Cys-Ser-Asn Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(N)=O KVCJEMHFLGVINV-ZLUOBGJFSA-N 0.000 description 1
- JLZCAZJGWNRXCI-XKBZYTNZSA-N Cys-Thr-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O JLZCAZJGWNRXCI-XKBZYTNZSA-N 0.000 description 1
- QUQHPUMRFGFINP-BPUTZDHNSA-N Cys-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CS)N QUQHPUMRFGFINP-BPUTZDHNSA-N 0.000 description 1
- JRZMCSIUYGSJKP-ZKWXMUAHSA-N Cys-Val-Asn Chemical compound SC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O JRZMCSIUYGSJKP-ZKWXMUAHSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 241000214054 Equine rhinitis A virus Species 0.000 description 1
- 241000214056 Equine rhinitis B virus 1 Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 241000710831 Flavivirus Species 0.000 description 1
- 241000710198 Foot-and-mouth disease virus Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- KWUSGAIFNHQCBY-DCAQKATOSA-N Gln-Arg-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O KWUSGAIFNHQCBY-DCAQKATOSA-N 0.000 description 1
- INFBPLSHYFALDE-ACZMJKKPSA-N Gln-Asn-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O INFBPLSHYFALDE-ACZMJKKPSA-N 0.000 description 1
- TWHDOEYLXXQYOZ-FXQIFTODSA-N Gln-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N TWHDOEYLXXQYOZ-FXQIFTODSA-N 0.000 description 1
- LMPBBFWHCRURJD-LAEOZQHASA-N Gln-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N LMPBBFWHCRURJD-LAEOZQHASA-N 0.000 description 1
- ULXXDWZMMSQBDC-ACZMJKKPSA-N Gln-Asp-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ULXXDWZMMSQBDC-ACZMJKKPSA-N 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 1
- ZDJZEGYVKANKED-NRPADANISA-N Gln-Cys-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O ZDJZEGYVKANKED-NRPADANISA-N 0.000 description 1
- KDXKFBSNIJYNNR-YVNDNENWSA-N Gln-Glu-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KDXKFBSNIJYNNR-YVNDNENWSA-N 0.000 description 1
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 1
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 1
- VGTDBGYFVWOQTI-RYUDHWBXSA-N Gln-Gly-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VGTDBGYFVWOQTI-RYUDHWBXSA-N 0.000 description 1
- NROSLUJMIQGFKS-IUCAKERBSA-N Gln-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N NROSLUJMIQGFKS-IUCAKERBSA-N 0.000 description 1
- FTIJVMLAGRAYMJ-MNXVOIDGSA-N Gln-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(N)=O FTIJVMLAGRAYMJ-MNXVOIDGSA-N 0.000 description 1
- VZRAXPGTUNDIDK-GUBZILKMSA-N Gln-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N VZRAXPGTUNDIDK-GUBZILKMSA-N 0.000 description 1
- VUVKKXPCKILIBD-AVGNSLFASA-N Gln-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N VUVKKXPCKILIBD-AVGNSLFASA-N 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- MLSKFHLRFVGNLL-WDCWCFNPSA-N Gln-Leu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MLSKFHLRFVGNLL-WDCWCFNPSA-N 0.000 description 1
- HPCOBEHVEHWREJ-DCAQKATOSA-N Gln-Lys-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O HPCOBEHVEHWREJ-DCAQKATOSA-N 0.000 description 1
- JNVGVECJCOZHCN-DRZSPHRISA-N Gln-Phe-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O JNVGVECJCOZHCN-DRZSPHRISA-N 0.000 description 1
- QBEWLBKBGXVVPD-RYUDHWBXSA-N Gln-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N QBEWLBKBGXVVPD-RYUDHWBXSA-N 0.000 description 1
- MQJDLNRXBOELJW-KKUMJFAQSA-N Gln-Pro-Phe Chemical compound N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O MQJDLNRXBOELJW-KKUMJFAQSA-N 0.000 description 1
- UWMDGPFFTKDUIY-HJGDQZAQSA-N Gln-Pro-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O UWMDGPFFTKDUIY-HJGDQZAQSA-N 0.000 description 1
- DCWNCMRZIZSZBL-KKUMJFAQSA-N Gln-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)N)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O DCWNCMRZIZSZBL-KKUMJFAQSA-N 0.000 description 1
- KUBFPYIMAGXGBT-ACZMJKKPSA-N Gln-Ser-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KUBFPYIMAGXGBT-ACZMJKKPSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- GHAXJVNBAKGWEJ-AVGNSLFASA-N Gln-Ser-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GHAXJVNBAKGWEJ-AVGNSLFASA-N 0.000 description 1
- DYVMTEWCGAVKSE-HJGDQZAQSA-N Gln-Thr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O DYVMTEWCGAVKSE-HJGDQZAQSA-N 0.000 description 1
- NHMRJKKAVMENKJ-WDCWCFNPSA-N Gln-Thr-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NHMRJKKAVMENKJ-WDCWCFNPSA-N 0.000 description 1
- XFHMVFKCQSHLKW-HJGDQZAQSA-N Gln-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O XFHMVFKCQSHLKW-HJGDQZAQSA-N 0.000 description 1
- ARYKRXHBIPLULY-XKBZYTNZSA-N Gln-Thr-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ARYKRXHBIPLULY-XKBZYTNZSA-N 0.000 description 1
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 1
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 1
- SDSMVVSHLAAOJL-UKJIMTQDSA-N Gln-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N SDSMVVSHLAAOJL-UKJIMTQDSA-N 0.000 description 1
- MXOODARRORARSU-ACZMJKKPSA-N Glu-Ala-Ser Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N MXOODARRORARSU-ACZMJKKPSA-N 0.000 description 1
- DIXKFOPPGWKZLY-CIUDSAMLSA-N Glu-Arg-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O DIXKFOPPGWKZLY-CIUDSAMLSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- FKGNJUCQKXQNRA-NRPADANISA-N Glu-Cys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O FKGNJUCQKXQNRA-NRPADANISA-N 0.000 description 1
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 1
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 1
- AIGROOHQXCACHL-WDSKDSINSA-N Glu-Gly-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O AIGROOHQXCACHL-WDSKDSINSA-N 0.000 description 1
- KRGZZKWSBGPLKL-IUCAKERBSA-N Glu-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N KRGZZKWSBGPLKL-IUCAKERBSA-N 0.000 description 1
- ZWQVYZXPYSYPJD-RYUDHWBXSA-N Glu-Gly-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZWQVYZXPYSYPJD-RYUDHWBXSA-N 0.000 description 1
- RAUDKMVXNOWDLS-WDSKDSINSA-N Glu-Gly-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O RAUDKMVXNOWDLS-WDSKDSINSA-N 0.000 description 1
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 1
- KRRFFAHEAOCBCQ-SIUGBPQLSA-N Glu-Ile-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KRRFFAHEAOCBCQ-SIUGBPQLSA-N 0.000 description 1
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 1
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 1
- SWRVAQHFBRZVNX-GUBZILKMSA-N Glu-Lys-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O SWRVAQHFBRZVNX-GUBZILKMSA-N 0.000 description 1
- LKOAAMXDJGEYMS-ZPFDUUQYSA-N Glu-Met-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LKOAAMXDJGEYMS-ZPFDUUQYSA-N 0.000 description 1
- FQFWFZWOHOEVMZ-IHRRRGAJSA-N Glu-Phe-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FQFWFZWOHOEVMZ-IHRRRGAJSA-N 0.000 description 1
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 1
- WIKMTDVSCUJIPJ-CIUDSAMLSA-N Glu-Ser-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WIKMTDVSCUJIPJ-CIUDSAMLSA-N 0.000 description 1
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 1
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 1
- SYAYROHMAIHWFB-KBIXCLLPSA-N Glu-Ser-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYAYROHMAIHWFB-KBIXCLLPSA-N 0.000 description 1
- IDEODOAVGCMUQV-GUBZILKMSA-N Glu-Ser-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IDEODOAVGCMUQV-GUBZILKMSA-N 0.000 description 1
- QOXDAWODGSIDDI-GUBZILKMSA-N Glu-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N QOXDAWODGSIDDI-GUBZILKMSA-N 0.000 description 1
- MWTGQXBHVRTCOR-GLLZPBPUSA-N Glu-Thr-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MWTGQXBHVRTCOR-GLLZPBPUSA-N 0.000 description 1
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- OVSKVOOUFAKODB-UWVGGRQHSA-N Gly-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OVSKVOOUFAKODB-UWVGGRQHSA-N 0.000 description 1
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 1
- SUDUYJOBLHQAMI-WHFBIAKZSA-N Gly-Asp-Cys Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CS)C(O)=O SUDUYJOBLHQAMI-WHFBIAKZSA-N 0.000 description 1
- QSTLUOIOYLYLLF-WDSKDSINSA-N Gly-Asp-Glu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QSTLUOIOYLYLLF-WDSKDSINSA-N 0.000 description 1
- XBWMTPAIUQIWKA-BYULHYEWSA-N Gly-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN XBWMTPAIUQIWKA-BYULHYEWSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- NMROINAYXCACKF-WHFBIAKZSA-N Gly-Cys-Cys Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(O)=O NMROINAYXCACKF-WHFBIAKZSA-N 0.000 description 1
- XLFHCWHXKSFVIB-BQBZGAKWSA-N Gly-Gln-Gln Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLFHCWHXKSFVIB-BQBZGAKWSA-N 0.000 description 1
- NPSWCZIRBAYNSB-JHEQGTHGSA-N Gly-Gln-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NPSWCZIRBAYNSB-JHEQGTHGSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 1
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 1
- SWQALSGKVLYKDT-ZKWXMUAHSA-N Gly-Ile-Ala Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SWQALSGKVLYKDT-ZKWXMUAHSA-N 0.000 description 1
- DGKBSGNCMCLDSL-BYULHYEWSA-N Gly-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN DGKBSGNCMCLDSL-BYULHYEWSA-N 0.000 description 1
- LUJVWKKYHSLULQ-ZKWXMUAHSA-N Gly-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN LUJVWKKYHSLULQ-ZKWXMUAHSA-N 0.000 description 1
- XVYKMNXXJXQKME-XEGUGMAKSA-N Gly-Ile-Tyr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 XVYKMNXXJXQKME-XEGUGMAKSA-N 0.000 description 1
- YIFUFYZELCMPJP-YUMQZZPRSA-N Gly-Leu-Cys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O YIFUFYZELCMPJP-YUMQZZPRSA-N 0.000 description 1
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 1
- UUYBFNKHOCJCHT-VHSXEESVSA-N Gly-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN UUYBFNKHOCJCHT-VHSXEESVSA-N 0.000 description 1
- LHYJCVCQPWRMKZ-WEDXCCLWSA-N Gly-Leu-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LHYJCVCQPWRMKZ-WEDXCCLWSA-N 0.000 description 1
- PTIIBFKSLCYQBO-NHCYSSNCSA-N Gly-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)CN PTIIBFKSLCYQBO-NHCYSSNCSA-N 0.000 description 1
- CVFOYJJOZYYEPE-KBPBESRZSA-N Gly-Lys-Tyr Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CVFOYJJOZYYEPE-KBPBESRZSA-N 0.000 description 1
- SJLKKOZFHSJJAW-YUMQZZPRSA-N Gly-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)CN SJLKKOZFHSJJAW-YUMQZZPRSA-N 0.000 description 1
- IBYOLNARKHMLBG-WHOFXGATSA-N Gly-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 IBYOLNARKHMLBG-WHOFXGATSA-N 0.000 description 1
- QAMMIGULQSIRCD-IRXDYDNUSA-N Gly-Phe-Tyr Chemical compound C([C@H](NC(=O)C[NH3+])C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C([O-])=O)C1=CC=CC=C1 QAMMIGULQSIRCD-IRXDYDNUSA-N 0.000 description 1
- HFPVRZWORNJRRC-UWVGGRQHSA-N Gly-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN HFPVRZWORNJRRC-UWVGGRQHSA-N 0.000 description 1
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 1
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- RHRLHXQWHCNJKR-PMVVWTBXSA-N Gly-Thr-His Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 RHRLHXQWHCNJKR-PMVVWTBXSA-N 0.000 description 1
- HUFUVTYGPOUCBN-MBLNEYKQSA-N Gly-Thr-Ile Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HUFUVTYGPOUCBN-MBLNEYKQSA-N 0.000 description 1
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 1
- WTUSRDZLLWGYAT-KCTSRDHCSA-N Gly-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN WTUSRDZLLWGYAT-KCTSRDHCSA-N 0.000 description 1
- UMBDRSMLCUYIRI-DVJZZOLTSA-N Gly-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)CN)O UMBDRSMLCUYIRI-DVJZZOLTSA-N 0.000 description 1
- OCRQUYDOYKCOQG-IRXDYDNUSA-N Gly-Tyr-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 OCRQUYDOYKCOQG-IRXDYDNUSA-N 0.000 description 1
- FNXSYBOHALPRHV-ONGXEEELSA-N Gly-Val-Lys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN FNXSYBOHALPRHV-ONGXEEELSA-N 0.000 description 1
- BNMRSWQOHIQTFL-JSGCOSHPSA-N Gly-Val-Phe Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 BNMRSWQOHIQTFL-JSGCOSHPSA-N 0.000 description 1
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 1
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 241000282575 Gorilla Species 0.000 description 1
- 241000709721 Hepatovirus A Species 0.000 description 1
- 241000217238 Hepatovirus B Species 0.000 description 1
- KZTLOHBDLMIFSH-XVYDVKMFSA-N His-Ala-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O KZTLOHBDLMIFSH-XVYDVKMFSA-N 0.000 description 1
- HTZKFIYQMHJWSQ-INTQDDNPSA-N His-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N HTZKFIYQMHJWSQ-INTQDDNPSA-N 0.000 description 1
- PDSUIXMZYNURGI-AVGNSLFASA-N His-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC1=CN=CN1 PDSUIXMZYNURGI-AVGNSLFASA-N 0.000 description 1
- RAVLQPXCMRCLKT-KBPBESRZSA-N His-Gly-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RAVLQPXCMRCLKT-KBPBESRZSA-N 0.000 description 1
- ZUPVLBAXUUGKKN-VHSXEESVSA-N His-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC2=CN=CN2)N)C(=O)O ZUPVLBAXUUGKKN-VHSXEESVSA-N 0.000 description 1
- NTXIJPDAHXSHNL-ONGXEEELSA-N His-Gly-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NTXIJPDAHXSHNL-ONGXEEELSA-N 0.000 description 1
- VTZYMXGGXOFBMX-DJFWLOJKSA-N His-Ile-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O VTZYMXGGXOFBMX-DJFWLOJKSA-N 0.000 description 1
- SKYULSWNBYAQMG-IHRRRGAJSA-N His-Leu-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SKYULSWNBYAQMG-IHRRRGAJSA-N 0.000 description 1
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 1
- MJUUWJJEUOBDGW-IHRRRGAJSA-N His-Leu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 MJUUWJJEUOBDGW-IHRRRGAJSA-N 0.000 description 1
- BZAQOPHNBFOOJS-DCAQKATOSA-N His-Pro-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O BZAQOPHNBFOOJS-DCAQKATOSA-N 0.000 description 1
- CHIAUHSHDARFBD-ULQDDVLXSA-N His-Pro-Tyr Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CN=CN1 CHIAUHSHDARFBD-ULQDDVLXSA-N 0.000 description 1
- ILUVWFTXAUYOBW-CUJWVEQBSA-N His-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CN=CN1)N)O ILUVWFTXAUYOBW-CUJWVEQBSA-N 0.000 description 1
- UWSMZKRTOZEGDD-CUJWVEQBSA-N His-Thr-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O UWSMZKRTOZEGDD-CUJWVEQBSA-N 0.000 description 1
- HIJIJPFILYPTFR-ACRUOGEOSA-N His-Tyr-Tyr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HIJIJPFILYPTFR-ACRUOGEOSA-N 0.000 description 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 1
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 description 1
- 101000713602 Homo sapiens T-box transcription factor TBX21 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 1
- SACHLUOUHCVIKI-GMOBBJLQSA-N Ile-Arg-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SACHLUOUHCVIKI-GMOBBJLQSA-N 0.000 description 1
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 1
- CWJQMCPYXNVMBS-STECZYCISA-N Ile-Arg-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N CWJQMCPYXNVMBS-STECZYCISA-N 0.000 description 1
- NCSIQAFSIPHVAN-IUKAMOBKSA-N Ile-Asn-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NCSIQAFSIPHVAN-IUKAMOBKSA-N 0.000 description 1
- NBJAAWYRLGCJOF-UGYAYLCHSA-N Ile-Asp-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N NBJAAWYRLGCJOF-UGYAYLCHSA-N 0.000 description 1
- HVWXAQVMRBKKFE-UGYAYLCHSA-N Ile-Asp-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N HVWXAQVMRBKKFE-UGYAYLCHSA-N 0.000 description 1
- RGSOCXHDOPQREB-ZPFDUUQYSA-N Ile-Asp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N RGSOCXHDOPQREB-ZPFDUUQYSA-N 0.000 description 1
- GYAFMRQGWHXMII-IUKAMOBKSA-N Ile-Asp-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N GYAFMRQGWHXMII-IUKAMOBKSA-N 0.000 description 1
- LLHYWBGDMBGNHA-VGDYDELISA-N Ile-Cys-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LLHYWBGDMBGNHA-VGDYDELISA-N 0.000 description 1
- DURWCDDDAWVPOP-JBDRJPRFSA-N Ile-Cys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N DURWCDDDAWVPOP-JBDRJPRFSA-N 0.000 description 1
- VQUCKIAECLVLAD-SVSWQMSJSA-N Ile-Cys-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N VQUCKIAECLVLAD-SVSWQMSJSA-N 0.000 description 1
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 1
- ODPKZZLRDNXTJZ-WHOFXGATSA-N Ile-Gly-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ODPKZZLRDNXTJZ-WHOFXGATSA-N 0.000 description 1
- VOBYAKCXGQQFLR-LSJOCFKGSA-N Ile-Gly-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O VOBYAKCXGQQFLR-LSJOCFKGSA-N 0.000 description 1
- APDIECQNNDGFPD-PYJNHQTQSA-N Ile-His-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N APDIECQNNDGFPD-PYJNHQTQSA-N 0.000 description 1
- WIZPFZKOFZXDQG-HTFCKZLJSA-N Ile-Ile-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O WIZPFZKOFZXDQG-HTFCKZLJSA-N 0.000 description 1
- KYLIZSDYWQQTFM-PEDHHIEDSA-N Ile-Ile-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N KYLIZSDYWQQTFM-PEDHHIEDSA-N 0.000 description 1
- AXNGDPAKKCEKGY-QPHKQPEJSA-N Ile-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N AXNGDPAKKCEKGY-QPHKQPEJSA-N 0.000 description 1
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 1
- GVKKVHNRTUFCCE-BJDJZHNGSA-N Ile-Leu-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)O)N GVKKVHNRTUFCCE-BJDJZHNGSA-N 0.000 description 1
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 1
- RMNMUUCYTMLWNA-ZPFDUUQYSA-N Ile-Lys-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N RMNMUUCYTMLWNA-ZPFDUUQYSA-N 0.000 description 1
- CEPIAEUVRKGPGP-DSYPUSFNSA-N Ile-Lys-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 CEPIAEUVRKGPGP-DSYPUSFNSA-N 0.000 description 1
- XLXPYSDGMXTTNQ-DKIMLUQUSA-N Ile-Phe-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CC(C)C)C(O)=O XLXPYSDGMXTTNQ-DKIMLUQUSA-N 0.000 description 1
- XLXPYSDGMXTTNQ-UHFFFAOYSA-N Ile-Phe-Leu Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(CC(C)C)C(O)=O)CC1=CC=CC=C1 XLXPYSDGMXTTNQ-UHFFFAOYSA-N 0.000 description 1
- KTNGVMMGIQWIDV-OSUNSFLBSA-N Ile-Pro-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O KTNGVMMGIQWIDV-OSUNSFLBSA-N 0.000 description 1
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 1
- RQJUKVXWAKJDBW-SVSWQMSJSA-N Ile-Ser-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N RQJUKVXWAKJDBW-SVSWQMSJSA-N 0.000 description 1
- CNMOKANDJMLAIF-CIQUZCHMSA-N Ile-Thr-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O CNMOKANDJMLAIF-CIQUZCHMSA-N 0.000 description 1
- YCKPUHHMCFSUMD-IUKAMOBKSA-N Ile-Thr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCKPUHHMCFSUMD-IUKAMOBKSA-N 0.000 description 1
- RTSQPLLOYSGMKM-DSYPUSFNSA-N Ile-Trp-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(C)C)C(=O)O)N RTSQPLLOYSGMKM-DSYPUSFNSA-N 0.000 description 1
- ZUWSVOYKBCHLRR-MGHWNKPDSA-N Ile-Tyr-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZUWSVOYKBCHLRR-MGHWNKPDSA-N 0.000 description 1
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 1
- ZSESFIFAYQEKRD-CYDGBPFRSA-N Ile-Val-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N ZSESFIFAYQEKRD-CYDGBPFRSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102100025305 Integrin alpha-2 Human genes 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- 241000235058 Komagataella pastoris Species 0.000 description 1
- CZCSUZMIRKFFFA-CIUDSAMLSA-N Leu-Ala-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O CZCSUZMIRKFFFA-CIUDSAMLSA-N 0.000 description 1
- KVRKAGGMEWNURO-CIUDSAMLSA-N Leu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N KVRKAGGMEWNURO-CIUDSAMLSA-N 0.000 description 1
- MJOZZTKJZQFKDK-GUBZILKMSA-N Leu-Ala-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(N)=O MJOZZTKJZQFKDK-GUBZILKMSA-N 0.000 description 1
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- XIRYQRLFHWWWTC-QEJZJMRPSA-N Leu-Ala-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XIRYQRLFHWWWTC-QEJZJMRPSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 1
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 1
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 1
- VCSBGUACOYUIGD-CIUDSAMLSA-N Leu-Asn-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VCSBGUACOYUIGD-CIUDSAMLSA-N 0.000 description 1
- RFUBXQQFJFGJFV-GUBZILKMSA-N Leu-Asn-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RFUBXQQFJFGJFV-GUBZILKMSA-N 0.000 description 1
- KKXDHFKZWKLYGB-GUBZILKMSA-N Leu-Asn-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKXDHFKZWKLYGB-GUBZILKMSA-N 0.000 description 1
- POJPZSMTTMLSTG-SRVKXCTJSA-N Leu-Asn-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N POJPZSMTTMLSTG-SRVKXCTJSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- TWQIYNGNYNJUFM-NHCYSSNCSA-N Leu-Asn-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O TWQIYNGNYNJUFM-NHCYSSNCSA-N 0.000 description 1
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 1
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 1
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 1
- IIKJNQWOQIWWMR-CIUDSAMLSA-N Leu-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)N IIKJNQWOQIWWMR-CIUDSAMLSA-N 0.000 description 1
- GZAUZBUKDXYPEH-CIUDSAMLSA-N Leu-Cys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N GZAUZBUKDXYPEH-CIUDSAMLSA-N 0.000 description 1
- HUEBCHPSXSQUGN-GARJFASQSA-N Leu-Cys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N HUEBCHPSXSQUGN-GARJFASQSA-N 0.000 description 1
- PNUCWVAGVNLUMW-CIUDSAMLSA-N Leu-Cys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O PNUCWVAGVNLUMW-CIUDSAMLSA-N 0.000 description 1
- WCTCIIAGNMFYAO-DCAQKATOSA-N Leu-Cys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O WCTCIIAGNMFYAO-DCAQKATOSA-N 0.000 description 1
- DLCXCECTCPKKCD-GUBZILKMSA-N Leu-Gln-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DLCXCECTCPKKCD-GUBZILKMSA-N 0.000 description 1
- ZYLJULGXQDNXDK-GUBZILKMSA-N Leu-Gln-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ZYLJULGXQDNXDK-GUBZILKMSA-N 0.000 description 1
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 1
- KVMULWOHPPMHHE-DCAQKATOSA-N Leu-Glu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KVMULWOHPPMHHE-DCAQKATOSA-N 0.000 description 1
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 1
- HMDDEJADNKQTBR-BZSNNMDCSA-N Leu-His-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMDDEJADNKQTBR-BZSNNMDCSA-N 0.000 description 1
- SGIIOQQGLUUMDQ-IHRRRGAJSA-N Leu-His-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C(C)C)C(=O)O)N SGIIOQQGLUUMDQ-IHRRRGAJSA-N 0.000 description 1
- DBSLVQBXKVKDKJ-BJDJZHNGSA-N Leu-Ile-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O DBSLVQBXKVKDKJ-BJDJZHNGSA-N 0.000 description 1
- AVEGDIAXTDVBJS-XUXIUFHCSA-N Leu-Ile-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AVEGDIAXTDVBJS-XUXIUFHCSA-N 0.000 description 1
- ORWTWZXGDBYVCP-BJDJZHNGSA-N Leu-Ile-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC(C)C ORWTWZXGDBYVCP-BJDJZHNGSA-N 0.000 description 1
- LIINDKYIGYTDLG-PPCPHDFISA-N Leu-Ile-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LIINDKYIGYTDLG-PPCPHDFISA-N 0.000 description 1
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 1
- PPQRKXHCLYCBSP-IHRRRGAJSA-N Leu-Leu-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N PPQRKXHCLYCBSP-IHRRRGAJSA-N 0.000 description 1
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 1
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 1
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 1
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 1
- RRVCZCNFXIFGRA-DCAQKATOSA-N Leu-Pro-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RRVCZCNFXIFGRA-DCAQKATOSA-N 0.000 description 1
- KWLWZYMNUZJKMZ-IHRRRGAJSA-N Leu-Pro-Leu Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O KWLWZYMNUZJKMZ-IHRRRGAJSA-N 0.000 description 1
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 1
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 1
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 1
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 1
- ICYRCNICGBJLGM-HJGDQZAQSA-N Leu-Thr-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O ICYRCNICGBJLGM-HJGDQZAQSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 1
- VHTIZYYHIUHMCA-JYJNAYRXSA-N Leu-Tyr-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VHTIZYYHIUHMCA-JYJNAYRXSA-N 0.000 description 1
- VJGQRELPQWNURN-JYJNAYRXSA-N Leu-Tyr-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O VJGQRELPQWNURN-JYJNAYRXSA-N 0.000 description 1
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 1
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 1
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 1
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- VHXMZJGOKIMETG-CQDKDKBSSA-N Lys-Ala-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CCCCN)N VHXMZJGOKIMETG-CQDKDKBSSA-N 0.000 description 1
- VHNOAIFVYUQOOY-XUXIUFHCSA-N Lys-Arg-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VHNOAIFVYUQOOY-XUXIUFHCSA-N 0.000 description 1
- WALVCOOOKULCQM-ULQDDVLXSA-N Lys-Arg-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WALVCOOOKULCQM-ULQDDVLXSA-N 0.000 description 1
- ZQCVMVCVPFYXHZ-SRVKXCTJSA-N Lys-Asn-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN ZQCVMVCVPFYXHZ-SRVKXCTJSA-N 0.000 description 1
- KPJJOZUXFOLGMQ-CIUDSAMLSA-N Lys-Asp-Asn Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N KPJJOZUXFOLGMQ-CIUDSAMLSA-N 0.000 description 1
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 1
- QIJVAFLRMVBHMU-KKUMJFAQSA-N Lys-Asp-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QIJVAFLRMVBHMU-KKUMJFAQSA-N 0.000 description 1
- DZQYZKPINJLLEN-KKUMJFAQSA-N Lys-Cys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)O DZQYZKPINJLLEN-KKUMJFAQSA-N 0.000 description 1
- MRWXLRGAFDOILG-DCAQKATOSA-N Lys-Gln-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MRWXLRGAFDOILG-DCAQKATOSA-N 0.000 description 1
- RZHLIPMZXOEJTL-AVGNSLFASA-N Lys-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N RZHLIPMZXOEJTL-AVGNSLFASA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- NNKLKUUGESXCBS-KBPBESRZSA-N Lys-Gly-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NNKLKUUGESXCBS-KBPBESRZSA-N 0.000 description 1
- SLQJJFAVWSZLBL-BJDJZHNGSA-N Lys-Ile-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN SLQJJFAVWSZLBL-BJDJZHNGSA-N 0.000 description 1
- XREQQOATSMMAJP-MGHWNKPDSA-N Lys-Ile-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XREQQOATSMMAJP-MGHWNKPDSA-N 0.000 description 1
- VMTYLUGCXIEDMV-QWRGUYRKSA-N Lys-Leu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCCN VMTYLUGCXIEDMV-QWRGUYRKSA-N 0.000 description 1
- ALGGDNMLQNFVIZ-SRVKXCTJSA-N Lys-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ALGGDNMLQNFVIZ-SRVKXCTJSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- ATNKHRAIZCMCCN-BZSNNMDCSA-N Lys-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N ATNKHRAIZCMCCN-BZSNNMDCSA-N 0.000 description 1
- YDDDRTIPNTWGIG-SRVKXCTJSA-N Lys-Lys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O YDDDRTIPNTWGIG-SRVKXCTJSA-N 0.000 description 1
- JYVCOTWSRGFABJ-DCAQKATOSA-N Lys-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCCN)N JYVCOTWSRGFABJ-DCAQKATOSA-N 0.000 description 1
- TWPCWKVOZDUYAA-KKUMJFAQSA-N Lys-Phe-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O TWPCWKVOZDUYAA-KKUMJFAQSA-N 0.000 description 1
- LECIJRIRMVOFMH-ULQDDVLXSA-N Lys-Pro-Phe Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LECIJRIRMVOFMH-ULQDDVLXSA-N 0.000 description 1
- GHKXHCMRAUYLBS-CIUDSAMLSA-N Lys-Ser-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O GHKXHCMRAUYLBS-CIUDSAMLSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- UWHCKWNPWKTMBM-WDCWCFNPSA-N Lys-Thr-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWHCKWNPWKTMBM-WDCWCFNPSA-N 0.000 description 1
- RMOKGALPSPOYKE-KATARQTJSA-N Lys-Thr-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMOKGALPSPOYKE-KATARQTJSA-N 0.000 description 1
- FPQMQEOVSKMVMA-ACRUOGEOSA-N Lys-Tyr-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)NC(=O)[C@H](CCCCN)N)O FPQMQEOVSKMVMA-ACRUOGEOSA-N 0.000 description 1
- QFSYGUMEANRNJE-DCAQKATOSA-N Lys-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N QFSYGUMEANRNJE-DCAQKATOSA-N 0.000 description 1
- 241000282553 Macaca Species 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 241000344351 Marmota himalayana Species 0.000 description 1
- 241000710185 Mengo virus Species 0.000 description 1
- VHGIWFGJIHTASW-FXQIFTODSA-N Met-Ala-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O VHGIWFGJIHTASW-FXQIFTODSA-N 0.000 description 1
- GAELMDJMQDUDLJ-BQBZGAKWSA-N Met-Ala-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O GAELMDJMQDUDLJ-BQBZGAKWSA-N 0.000 description 1
- OSOLWRWQADPDIQ-DCAQKATOSA-N Met-Asp-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OSOLWRWQADPDIQ-DCAQKATOSA-N 0.000 description 1
- WVTYEEPGEUSFGQ-LPEHRKFASA-N Met-Cys-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N WVTYEEPGEUSFGQ-LPEHRKFASA-N 0.000 description 1
- KLFPZIUIXZNEKY-DCAQKATOSA-N Met-Gln-Met Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O KLFPZIUIXZNEKY-DCAQKATOSA-N 0.000 description 1
- HUURTRNKPBHHKZ-JYJNAYRXSA-N Met-Phe-Val Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=CC=C1 HUURTRNKPBHHKZ-JYJNAYRXSA-N 0.000 description 1
- XPVCDCMPKCERFT-GUBZILKMSA-N Met-Ser-Arg Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O XPVCDCMPKCERFT-GUBZILKMSA-N 0.000 description 1
- LXCSZPUQKMTXNW-BQBZGAKWSA-N Met-Ser-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O LXCSZPUQKMTXNW-BQBZGAKWSA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- OOXVBECOTYHTCK-WDSOQIARSA-N Met-Trp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCSC)N OOXVBECOTYHTCK-WDSOQIARSA-N 0.000 description 1
- SQPZCTBSLIIMBL-BPUTZDHNSA-N Met-Trp-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CO)C(=O)O)N SQPZCTBSLIIMBL-BPUTZDHNSA-N 0.000 description 1
- LIIXIZKVWNYQHB-STECZYCISA-N Met-Tyr-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LIIXIZKVWNYQHB-STECZYCISA-N 0.000 description 1
- PNHRPOWKRRJATF-IHRRRGAJSA-N Met-Tyr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 PNHRPOWKRRJATF-IHRRRGAJSA-N 0.000 description 1
- IIHMNTBFPMRJCN-RCWTZXSCSA-N Met-Val-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IIHMNTBFPMRJCN-RCWTZXSCSA-N 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101001026869 Mus musculus F-box/LRR-repeat protein 3 Proteins 0.000 description 1
- 101001002703 Mus musculus Interleukin-4 Proteins 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- XZFYRXDAULDNFX-UHFFFAOYSA-N N-L-cysteinyl-L-phenylalanine Natural products SCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XZFYRXDAULDNFX-UHFFFAOYSA-N 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 1
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 101710193592 ORF3a protein Proteins 0.000 description 1
- 239000005642 Oleic acid Substances 0.000 description 1
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 239000002033 PVDF binder Substances 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241000282520 Papio Species 0.000 description 1
- 229930040373 Paraformaldehyde Natural products 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- BJEYSVHMGIJORT-NHCYSSNCSA-N Phe-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 BJEYSVHMGIJORT-NHCYSSNCSA-N 0.000 description 1
- FPTXMUIBLMGTQH-ONGXEEELSA-N Phe-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 FPTXMUIBLMGTQH-ONGXEEELSA-N 0.000 description 1
- AGYXCMYVTBYGCT-ULQDDVLXSA-N Phe-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O AGYXCMYVTBYGCT-ULQDDVLXSA-N 0.000 description 1
- YYRCPTVAPLQRNC-ULQDDVLXSA-N Phe-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CC1=CC=CC=C1 YYRCPTVAPLQRNC-ULQDDVLXSA-N 0.000 description 1
- LJUUGSWZPQOJKD-JYJNAYRXSA-N Phe-Arg-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)Cc1ccccc1)C(O)=O LJUUGSWZPQOJKD-JYJNAYRXSA-N 0.000 description 1
- KAHUBGWSIQNZQQ-KKUMJFAQSA-N Phe-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 KAHUBGWSIQNZQQ-KKUMJFAQSA-N 0.000 description 1
- AWAYOWOUGVZXOB-BZSNNMDCSA-N Phe-Asn-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 AWAYOWOUGVZXOB-BZSNNMDCSA-N 0.000 description 1
- WMGVYPPIMZPWPN-SRVKXCTJSA-N Phe-Asp-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WMGVYPPIMZPWPN-SRVKXCTJSA-N 0.000 description 1
- OMHMIXFFRPMYHB-SRVKXCTJSA-N Phe-Cys-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OMHMIXFFRPMYHB-SRVKXCTJSA-N 0.000 description 1
- ALHULIGNEXGFRM-QWRGUYRKSA-N Phe-Cys-Gly Chemical compound OC(=O)CNC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=CC=C1 ALHULIGNEXGFRM-QWRGUYRKSA-N 0.000 description 1
- LXUJDHOKVUYHRC-KKUMJFAQSA-N Phe-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N LXUJDHOKVUYHRC-KKUMJFAQSA-N 0.000 description 1
- PSBJZLMFFTULDX-IXOXFDKPSA-N Phe-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N)O PSBJZLMFFTULDX-IXOXFDKPSA-N 0.000 description 1
- IDUCUXTUHHIQIP-SOUVJXGZSA-N Phe-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC2=CC=CC=C2)N)C(=O)O IDUCUXTUHHIQIP-SOUVJXGZSA-N 0.000 description 1
- UAMFZRNCIFFMLE-FHWLQOOXSA-N Phe-Glu-Tyr Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N UAMFZRNCIFFMLE-FHWLQOOXSA-N 0.000 description 1
- JJHVFCUWLSKADD-ONGXEEELSA-N Phe-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O JJHVFCUWLSKADD-ONGXEEELSA-N 0.000 description 1
- QPVFUAUFEBPIPT-CDMKHQONSA-N Phe-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QPVFUAUFEBPIPT-CDMKHQONSA-N 0.000 description 1
- PMKIMKUGCSVFSV-CQDKDKBSSA-N Phe-His-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC2=CC=CC=C2)N PMKIMKUGCSVFSV-CQDKDKBSSA-N 0.000 description 1
- KRYSMKKRRRWOCZ-QEWYBTABSA-N Phe-Ile-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KRYSMKKRRRWOCZ-QEWYBTABSA-N 0.000 description 1
- WEMYTDDMDBLPMI-DKIMLUQUSA-N Phe-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N WEMYTDDMDBLPMI-DKIMLUQUSA-N 0.000 description 1
- OSBADCBXAMSPQD-YESZJQIVSA-N Phe-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N OSBADCBXAMSPQD-YESZJQIVSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- OQTDZEJJWWAGJT-KKUMJFAQSA-N Phe-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O OQTDZEJJWWAGJT-KKUMJFAQSA-N 0.000 description 1
- IWZRODDWOSIXPZ-IRXDYDNUSA-N Phe-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 IWZRODDWOSIXPZ-IRXDYDNUSA-N 0.000 description 1
- GPLWGAYGROGDEN-BZSNNMDCSA-N Phe-Phe-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O GPLWGAYGROGDEN-BZSNNMDCSA-N 0.000 description 1
- RVEVENLSADZUMS-IHRRRGAJSA-N Phe-Pro-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RVEVENLSADZUMS-IHRRRGAJSA-N 0.000 description 1
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 1
- BSKMOCNNLNDIMU-CDMKHQONSA-N Phe-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O BSKMOCNNLNDIMU-CDMKHQONSA-N 0.000 description 1
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 1
- YFXXRYFWJFQAFW-JHYOHUSXSA-N Phe-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YFXXRYFWJFQAFW-JHYOHUSXSA-N 0.000 description 1
- QTDBZORPVYTRJU-KKXDTOCCSA-N Phe-Tyr-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O QTDBZORPVYTRJU-KKXDTOCCSA-N 0.000 description 1
- KIQUCMUULDXTAZ-HJOGWXRNSA-N Phe-Tyr-Tyr Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O KIQUCMUULDXTAZ-HJOGWXRNSA-N 0.000 description 1
- XALFIVXGQUEGKV-JSGCOSHPSA-N Phe-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 XALFIVXGQUEGKV-JSGCOSHPSA-N 0.000 description 1
- JTKGCYOOJLUETJ-ULQDDVLXSA-N Phe-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 JTKGCYOOJLUETJ-ULQDDVLXSA-N 0.000 description 1
- IEIFEYBAYFSRBQ-IHRRRGAJSA-N Phe-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N IEIFEYBAYFSRBQ-IHRRRGAJSA-N 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- DBALDZKOTNSBFM-FXQIFTODSA-N Pro-Ala-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DBALDZKOTNSBFM-FXQIFTODSA-N 0.000 description 1
- AJLVKXCNXIJHDV-CIUDSAMLSA-N Pro-Ala-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O AJLVKXCNXIJHDV-CIUDSAMLSA-N 0.000 description 1
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- GRIRJQGZZJVANI-CYDGBPFRSA-N Pro-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 GRIRJQGZZJVANI-CYDGBPFRSA-N 0.000 description 1
- WWAQEUOYCYMGHB-FXQIFTODSA-N Pro-Asn-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 WWAQEUOYCYMGHB-FXQIFTODSA-N 0.000 description 1
- ILMLVTGTUJPQFP-FXQIFTODSA-N Pro-Asp-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ILMLVTGTUJPQFP-FXQIFTODSA-N 0.000 description 1
- KPDRZQUWJKTMBP-DCAQKATOSA-N Pro-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 KPDRZQUWJKTMBP-DCAQKATOSA-N 0.000 description 1
- XKHCJJPNXFBADI-DCAQKATOSA-N Pro-Asp-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O XKHCJJPNXFBADI-DCAQKATOSA-N 0.000 description 1
- YFNOUBWUIIJQHF-LPEHRKFASA-N Pro-Asp-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O YFNOUBWUIIJQHF-LPEHRKFASA-N 0.000 description 1
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 1
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 1
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 1
- VDGTVWFMRXVQCT-GUBZILKMSA-N Pro-Glu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 VDGTVWFMRXVQCT-GUBZILKMSA-N 0.000 description 1
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- VWXGFAIZUQBBBG-UWVGGRQHSA-N Pro-His-Gly Chemical compound C([C@@H](C(=O)NCC(=O)[O-])NC(=O)[C@H]1[NH2+]CCC1)C1=CN=CN1 VWXGFAIZUQBBBG-UWVGGRQHSA-N 0.000 description 1
- BBFRBZYKHIKFBX-GMOBBJLQSA-N Pro-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@@H]1CCCN1 BBFRBZYKHIKFBX-GMOBBJLQSA-N 0.000 description 1
- HFNPOYOKIPGAEI-SRVKXCTJSA-N Pro-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 HFNPOYOKIPGAEI-SRVKXCTJSA-N 0.000 description 1
- FYPGHGXAOZTOBO-IHRRRGAJSA-N Pro-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2 FYPGHGXAOZTOBO-IHRRRGAJSA-N 0.000 description 1
- XYSXOCIWCPFOCG-IHRRRGAJSA-N Pro-Leu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XYSXOCIWCPFOCG-IHRRRGAJSA-N 0.000 description 1
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 1
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 1
- INDVYIOKMXFQFM-SRVKXCTJSA-N Pro-Lys-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O INDVYIOKMXFQFM-SRVKXCTJSA-N 0.000 description 1
- ABSSTGUCBCDKMU-UWVGGRQHSA-N Pro-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 ABSSTGUCBCDKMU-UWVGGRQHSA-N 0.000 description 1
- KLOQCCRTPHPIFN-DCAQKATOSA-N Pro-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@@H]1CCCN1 KLOQCCRTPHPIFN-DCAQKATOSA-N 0.000 description 1
- ZUZINZIJHJFJRN-UBHSHLNASA-N Pro-Phe-Ala Chemical compound C([C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 ZUZINZIJHJFJRN-UBHSHLNASA-N 0.000 description 1
- MLKVIVZCFYRTIR-KKUMJFAQSA-N Pro-Phe-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLKVIVZCFYRTIR-KKUMJFAQSA-N 0.000 description 1
- AJBQTGZIZQXBLT-STQMWFEESA-N Pro-Phe-Gly Chemical compound C([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H]1NCCC1)C1=CC=CC=C1 AJBQTGZIZQXBLT-STQMWFEESA-N 0.000 description 1
- DWPXHLIBFQLKLK-CYDGBPFRSA-N Pro-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 DWPXHLIBFQLKLK-CYDGBPFRSA-N 0.000 description 1
- WVXQQUWOKUZIEG-VEVYYDQMSA-N Pro-Thr-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O WVXQQUWOKUZIEG-VEVYYDQMSA-N 0.000 description 1
- IURWWZYKYPEANQ-HJGDQZAQSA-N Pro-Thr-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IURWWZYKYPEANQ-HJGDQZAQSA-N 0.000 description 1
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 1
- CNUIHOAISPKQPY-HSHDSVGOSA-N Pro-Thr-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O CNUIHOAISPKQPY-HSHDSVGOSA-N 0.000 description 1
- DIDLUFMLRUJLFB-FKBYEOEOSA-N Pro-Trp-Tyr Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CC4=CC=C(C=C4)O)C(=O)O DIDLUFMLRUJLFB-FKBYEOEOSA-N 0.000 description 1
- LZHHZYDPMZEMRX-STQMWFEESA-N Pro-Tyr-Gly Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O LZHHZYDPMZEMRX-STQMWFEESA-N 0.000 description 1
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 108010066124 Protein S Proteins 0.000 description 1
- 102000029301 Protein S Human genes 0.000 description 1
- 108010065868 RNA polymerase SP6 Proteins 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108010055591 SARS coronavirus 3C-like protease Proteins 0.000 description 1
- 108091005634 SARS-CoV-2 receptor-binding domains Proteins 0.000 description 1
- 241001089247 Saffold virus 2 Species 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- MWMKFWJYRRGXOR-ZLUOBGJFSA-N Ser-Ala-Asn Chemical compound N[C@H](C(=O)N[C@H](C(=O)N[C@H](C(=O)O)CC(N)=O)C)CO MWMKFWJYRRGXOR-ZLUOBGJFSA-N 0.000 description 1
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 1
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 1
- NLQUOHDCLSFABG-GUBZILKMSA-N Ser-Arg-Arg Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NLQUOHDCLSFABG-GUBZILKMSA-N 0.000 description 1
- FCRMLGJMPXCAHD-FXQIFTODSA-N Ser-Arg-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O FCRMLGJMPXCAHD-FXQIFTODSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 1
- UCXDHBORXLVBNC-ZLUOBGJFSA-N Ser-Asn-Cys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(O)=O UCXDHBORXLVBNC-ZLUOBGJFSA-N 0.000 description 1
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- SNNSYBWPPVAXQW-ZLUOBGJFSA-N Ser-Cys-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N)O SNNSYBWPPVAXQW-ZLUOBGJFSA-N 0.000 description 1
- RNFKSBPHLTZHLU-WHFBIAKZSA-N Ser-Cys-Gly Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N)O RNFKSBPHLTZHLU-WHFBIAKZSA-N 0.000 description 1
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 1
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 1
- LALNXSXEYFUUDD-GUBZILKMSA-N Ser-Glu-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LALNXSXEYFUUDD-GUBZILKMSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- CXBFHZLODKPIJY-AAEUAGOBSA-N Ser-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N CXBFHZLODKPIJY-AAEUAGOBSA-N 0.000 description 1
- HZNFKPJCGZXKIC-DCAQKATOSA-N Ser-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N HZNFKPJCGZXKIC-DCAQKATOSA-N 0.000 description 1
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 1
- BYCVMHKULKRVPV-GUBZILKMSA-N Ser-Lys-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYCVMHKULKRVPV-GUBZILKMSA-N 0.000 description 1
- SRKMDKACHDVPMD-SRVKXCTJSA-N Ser-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N SRKMDKACHDVPMD-SRVKXCTJSA-N 0.000 description 1
- OCWWJBZQXGYQCA-DCAQKATOSA-N Ser-Lys-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O OCWWJBZQXGYQCA-DCAQKATOSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- VIIJCAQMJBHSJH-FXQIFTODSA-N Ser-Met-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CO)C(O)=O VIIJCAQMJBHSJH-FXQIFTODSA-N 0.000 description 1
- XVWDJUROVRQKAE-KKUMJFAQSA-N Ser-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CC=CC=C1 XVWDJUROVRQKAE-KKUMJFAQSA-N 0.000 description 1
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 1
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 1
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 1
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 1
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 1
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- DYEGLQRVMBWQLD-IXOXFDKPSA-N Ser-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CO)N)O DYEGLQRVMBWQLD-IXOXFDKPSA-N 0.000 description 1
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 1
- FRPNVPKQVFHSQY-BPUTZDHNSA-N Ser-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CO)N FRPNVPKQVFHSQY-BPUTZDHNSA-N 0.000 description 1
- VEVYMLNYMULSMS-AVGNSLFASA-N Ser-Tyr-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VEVYMLNYMULSMS-AVGNSLFASA-N 0.000 description 1
- HKHCTNFKZXAMIF-KKUMJFAQSA-N Ser-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CC=C(O)C=C1 HKHCTNFKZXAMIF-KKUMJFAQSA-N 0.000 description 1
- ZVBCMFDJIMUELU-BZSNNMDCSA-N Ser-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CO)N ZVBCMFDJIMUELU-BZSNNMDCSA-N 0.000 description 1
- OSFZCEQJLWCIBG-BZSNNMDCSA-N Ser-Tyr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OSFZCEQJLWCIBG-BZSNNMDCSA-N 0.000 description 1
- PMTWIUBUQRGCSB-FXQIFTODSA-N Ser-Val-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O PMTWIUBUQRGCSB-FXQIFTODSA-N 0.000 description 1
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 1
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 1
- ODRUTDLAONAVDV-IHRRRGAJSA-N Ser-Val-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ODRUTDLAONAVDV-IHRRRGAJSA-N 0.000 description 1
- 101000667983 Severe acute respiratory syndrome coronavirus Envelope small membrane protein Proteins 0.000 description 1
- 101001024647 Severe acute respiratory syndrome coronavirus Nucleoprotein Proteins 0.000 description 1
- 101001039853 Sonchus yellow net virus Matrix protein Proteins 0.000 description 1
- 102100025750 Sphingosine 1-phosphate receptor 1 Human genes 0.000 description 1
- 101710155454 Sphingosine 1-phosphate receptor 1 Proteins 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- 102100036840 T-box transcription factor TBX21 Human genes 0.000 description 1
- 241000710209 Theiler's encephalomyelitis virus Species 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- WFUAUEQXPVNAEF-ZJDVBMNYSA-N Thr-Arg-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)O)C(O)=O)CCCN=C(N)N WFUAUEQXPVNAEF-ZJDVBMNYSA-N 0.000 description 1
- TZKPNGDGUVREEB-FOHZUACHSA-N Thr-Asn-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O TZKPNGDGUVREEB-FOHZUACHSA-N 0.000 description 1
- CTONFVDJYCAMQM-IUKAMOBKSA-N Thr-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H]([C@@H](C)O)N CTONFVDJYCAMQM-IUKAMOBKSA-N 0.000 description 1
- OJRNZRROAIAHDL-LKXGYXEUSA-N Thr-Asn-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OJRNZRROAIAHDL-LKXGYXEUSA-N 0.000 description 1
- PQLXHSACXPGWPD-GSSVUCPTSA-N Thr-Asn-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PQLXHSACXPGWPD-GSSVUCPTSA-N 0.000 description 1
- LMMDEZPNUTZJAY-GCJQMDKQSA-N Thr-Asp-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O LMMDEZPNUTZJAY-GCJQMDKQSA-N 0.000 description 1
- MFEBUIFJVPNZLO-OLHMAJIHSA-N Thr-Asp-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O MFEBUIFJVPNZLO-OLHMAJIHSA-N 0.000 description 1
- QILPDQCTQZDHFM-HJGDQZAQSA-N Thr-Gln-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QILPDQCTQZDHFM-HJGDQZAQSA-N 0.000 description 1
- ZQUKYJOKQBRBCS-GLLZPBPUSA-N Thr-Gln-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O ZQUKYJOKQBRBCS-GLLZPBPUSA-N 0.000 description 1
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 1
- UHBPFYOQQPFKQR-JHEQGTHGSA-N Thr-Gln-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UHBPFYOQQPFKQR-JHEQGTHGSA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- SHOMROOOQBDGRL-JHEQGTHGSA-N Thr-Glu-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SHOMROOOQBDGRL-JHEQGTHGSA-N 0.000 description 1
- JMGJDTNUMAZNLX-RWRJDSDZSA-N Thr-Glu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JMGJDTNUMAZNLX-RWRJDSDZSA-N 0.000 description 1
- IGGFFPOIFHZYKC-PBCZWWQYSA-N Thr-His-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O IGGFFPOIFHZYKC-PBCZWWQYSA-N 0.000 description 1
- LCCSEJSPBWKBNT-OSUNSFLBSA-N Thr-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N LCCSEJSPBWKBNT-OSUNSFLBSA-N 0.000 description 1
- GXUWHVZYDAHFSV-FLBSBUHZSA-N Thr-Ile-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GXUWHVZYDAHFSV-FLBSBUHZSA-N 0.000 description 1
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 1
- ODXKUIGEPAGKKV-KATARQTJSA-N Thr-Leu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N)O ODXKUIGEPAGKKV-KATARQTJSA-N 0.000 description 1
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 1
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 1
- HPQHHRLWSAMMKG-KATARQTJSA-N Thr-Lys-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O)N)O HPQHHRLWSAMMKG-KATARQTJSA-N 0.000 description 1
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 1
- MGJLBZFUXUGMML-VOAKCMCISA-N Thr-Lys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MGJLBZFUXUGMML-VOAKCMCISA-N 0.000 description 1
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 1
- NZRUWPIYECBYRK-HTUGSXCWSA-N Thr-Phe-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O NZRUWPIYECBYRK-HTUGSXCWSA-N 0.000 description 1
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 1
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 1
- NWECYMJLJGCBOD-UNQGMJICSA-N Thr-Phe-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O NWECYMJLJGCBOD-UNQGMJICSA-N 0.000 description 1
- GFRIEEKFXOVPIR-RHYQMDGZSA-N Thr-Pro-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O GFRIEEKFXOVPIR-RHYQMDGZSA-N 0.000 description 1
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 1
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 1
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- VUXIQSUQQYNLJP-XAVMHZPKSA-N Thr-Ser-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N)O VUXIQSUQQYNLJP-XAVMHZPKSA-N 0.000 description 1
- GJOBRAHDRIDAPT-NGTWOADLSA-N Thr-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H]([C@@H](C)O)N GJOBRAHDRIDAPT-NGTWOADLSA-N 0.000 description 1
- KVEWWQRTAVMOFT-KJEVXHAQSA-N Thr-Tyr-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O KVEWWQRTAVMOFT-KJEVXHAQSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- 241000255993 Trichoplusia ni Species 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- IBBBOLAPFHRDHW-BPUTZDHNSA-N Trp-Asn-Arg Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N IBBBOLAPFHRDHW-BPUTZDHNSA-N 0.000 description 1
- ADBFWLXCCKIXBQ-XIRDDKMYSA-N Trp-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N ADBFWLXCCKIXBQ-XIRDDKMYSA-N 0.000 description 1
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 1
- AWYXDHQQFPZJNE-QEJZJMRPSA-N Trp-Gln-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N AWYXDHQQFPZJNE-QEJZJMRPSA-N 0.000 description 1
- YTCNLMSUXPCFBW-SXNHZJKMSA-N Trp-Ile-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O YTCNLMSUXPCFBW-SXNHZJKMSA-N 0.000 description 1
- YDTKYBHPRULROG-LTHWPDAASA-N Trp-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N YDTKYBHPRULROG-LTHWPDAASA-N 0.000 description 1
- CMXACOZDEJYZSK-XIRDDKMYSA-N Trp-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N CMXACOZDEJYZSK-XIRDDKMYSA-N 0.000 description 1
- UKWSFUSPGPBJGU-VFAJRCTISA-N Trp-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O UKWSFUSPGPBJGU-VFAJRCTISA-N 0.000 description 1
- UQHPXCFAHVTWFU-BVSLBCMMSA-N Trp-Phe-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O UQHPXCFAHVTWFU-BVSLBCMMSA-N 0.000 description 1
- BIBZRFIKOLGWFQ-XIRDDKMYSA-N Trp-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O BIBZRFIKOLGWFQ-XIRDDKMYSA-N 0.000 description 1
- OJKVFAWXPGCJMF-BPUTZDHNSA-N Trp-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)N[C@@H](CO)C(=O)O OJKVFAWXPGCJMF-BPUTZDHNSA-N 0.000 description 1
- GBEAUNVBIMLWIB-IHPCNDPISA-N Trp-Ser-Phe Chemical compound C([C@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=CC=C1 GBEAUNVBIMLWIB-IHPCNDPISA-N 0.000 description 1
- UIRVSEPRMWDVEW-RNXOBYDBSA-N Trp-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CNC4=CC=CC=C43)N UIRVSEPRMWDVEW-RNXOBYDBSA-N 0.000 description 1
- WTXQBCCKXIKKHB-JYJNAYRXSA-N Tyr-Arg-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WTXQBCCKXIKKHB-JYJNAYRXSA-N 0.000 description 1
- ADBDQGBDNUTRDB-ULQDDVLXSA-N Tyr-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O ADBDQGBDNUTRDB-ULQDDVLXSA-N 0.000 description 1
- PEVVXUGSAKEPEN-AVGNSLFASA-N Tyr-Asn-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PEVVXUGSAKEPEN-AVGNSLFASA-N 0.000 description 1
- SCCKSNREWHMKOJ-SRVKXCTJSA-N Tyr-Asn-Ser Chemical compound N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O SCCKSNREWHMKOJ-SRVKXCTJSA-N 0.000 description 1
- NRFTYDWKWGJLAR-MELADBBJSA-N Tyr-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O NRFTYDWKWGJLAR-MELADBBJSA-N 0.000 description 1
- CGDZGRLRXPNCOC-SRVKXCTJSA-N Tyr-Cys-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CGDZGRLRXPNCOC-SRVKXCTJSA-N 0.000 description 1
- IWRMTNJCCMEBEX-AVGNSLFASA-N Tyr-Glu-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)O IWRMTNJCCMEBEX-AVGNSLFASA-N 0.000 description 1
- CNLKDWSAORJEMW-KWQFWETISA-N Tyr-Gly-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(=O)N[C@@H](C)C(O)=O CNLKDWSAORJEMW-KWQFWETISA-N 0.000 description 1
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 1
- WVGKPKDWYQXWLU-BZSNNMDCSA-N Tyr-His-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CCCCN)C(=O)O)N)O WVGKPKDWYQXWLU-BZSNNMDCSA-N 0.000 description 1
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 1
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 1
- MXFPBNFKVBHIRW-BZSNNMDCSA-N Tyr-Lys-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O MXFPBNFKVBHIRW-BZSNNMDCSA-N 0.000 description 1
- FMXFHNSFABRVFZ-BZSNNMDCSA-N Tyr-Lys-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FMXFHNSFABRVFZ-BZSNNMDCSA-N 0.000 description 1
- XDGPTBVOSHKDFT-KKUMJFAQSA-N Tyr-Met-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XDGPTBVOSHKDFT-KKUMJFAQSA-N 0.000 description 1
- CDBXVDXSLPLFMD-BPNCWPANSA-N Tyr-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDBXVDXSLPLFMD-BPNCWPANSA-N 0.000 description 1
- BIWVVOHTKDLRMP-ULQDDVLXSA-N Tyr-Pro-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O BIWVVOHTKDLRMP-ULQDDVLXSA-N 0.000 description 1
- RCMWNNJFKNDKQR-UFYCRDLUSA-N Tyr-Pro-Phe Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 RCMWNNJFKNDKQR-UFYCRDLUSA-N 0.000 description 1
- RWOKVQUCENPXGE-IHRRRGAJSA-N Tyr-Ser-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RWOKVQUCENPXGE-IHRRRGAJSA-N 0.000 description 1
- TYFLVOUZHQUBGM-IHRRRGAJSA-N Tyr-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TYFLVOUZHQUBGM-IHRRRGAJSA-N 0.000 description 1
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 1
- XFEMMSGONWQACR-KJEVXHAQSA-N Tyr-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O XFEMMSGONWQACR-KJEVXHAQSA-N 0.000 description 1
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 1
- KHPLUFDSWGDRHD-SLFFLAALSA-N Tyr-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O KHPLUFDSWGDRHD-SLFFLAALSA-N 0.000 description 1
- NWEGIYMHTZXVBP-JSGCOSHPSA-N Tyr-Val-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O NWEGIYMHTZXVBP-JSGCOSHPSA-N 0.000 description 1
- RVGVIWNHABGIFH-IHRRRGAJSA-N Tyr-Val-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O RVGVIWNHABGIFH-IHRRRGAJSA-N 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- FZSPNKUFROZBSG-ZKWXMUAHSA-N Val-Ala-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O FZSPNKUFROZBSG-ZKWXMUAHSA-N 0.000 description 1
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 1
- RUCNAYOMFXRIKJ-DCAQKATOSA-N Val-Ala-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN RUCNAYOMFXRIKJ-DCAQKATOSA-N 0.000 description 1
- UUYCNAXCCDNULB-QXEWZRGKSA-N Val-Arg-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O UUYCNAXCCDNULB-QXEWZRGKSA-N 0.000 description 1
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 1
- LIQJSDDOULTANC-QSFUFRPTSA-N Val-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LIQJSDDOULTANC-QSFUFRPTSA-N 0.000 description 1
- ISERLACIZUGCDX-ZKWXMUAHSA-N Val-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N ISERLACIZUGCDX-ZKWXMUAHSA-N 0.000 description 1
- KXUKIBHIVRYOIP-ZKWXMUAHSA-N Val-Asp-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N KXUKIBHIVRYOIP-ZKWXMUAHSA-N 0.000 description 1
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 1
- DLYOEFGPYTZVSP-AEJSXWLSSA-N Val-Cys-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N DLYOEFGPYTZVSP-AEJSXWLSSA-N 0.000 description 1
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 1
- VLDMQVZZWDOKQF-AUTRQRHGSA-N Val-Glu-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VLDMQVZZWDOKQF-AUTRQRHGSA-N 0.000 description 1
- ZXAGTABZUOMUDO-GVXVVHGQSA-N Val-Glu-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZXAGTABZUOMUDO-GVXVVHGQSA-N 0.000 description 1
- XWYUBUYQMOUFRQ-IFFSRLJSSA-N Val-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N)O XWYUBUYQMOUFRQ-IFFSRLJSSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- URIRWLJVWHYLET-ONGXEEELSA-N Val-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C URIRWLJVWHYLET-ONGXEEELSA-N 0.000 description 1
- BVWPHWLFGRCECJ-JSGCOSHPSA-N Val-Gly-Tyr Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N BVWPHWLFGRCECJ-JSGCOSHPSA-N 0.000 description 1
- CPGJELLYDQEDRK-NAKRPEOUSA-N Val-Ile-Ala Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C)C(O)=O CPGJELLYDQEDRK-NAKRPEOUSA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- AEMPCGRFEZTWIF-IHRRRGAJSA-N Val-Leu-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O AEMPCGRFEZTWIF-IHRRRGAJSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- WBAJDGWKRIHOAC-GVXVVHGQSA-N Val-Lys-Gln Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O WBAJDGWKRIHOAC-GVXVVHGQSA-N 0.000 description 1
- CXWJFWAZIVWBOS-XQQFMLRXSA-N Val-Lys-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CXWJFWAZIVWBOS-XQQFMLRXSA-N 0.000 description 1
- MJFSRZZJQWZHFQ-SRVKXCTJSA-N Val-Met-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N MJFSRZZJQWZHFQ-SRVKXCTJSA-N 0.000 description 1
- LJSZPMSUYKKKCP-UBHSHLNASA-N Val-Phe-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 LJSZPMSUYKKKCP-UBHSHLNASA-N 0.000 description 1
- VNGKMNPAENRGDC-JYJNAYRXSA-N Val-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 VNGKMNPAENRGDC-JYJNAYRXSA-N 0.000 description 1
- MHHAWNPHDLCPLF-ULQDDVLXSA-N Val-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 MHHAWNPHDLCPLF-ULQDDVLXSA-N 0.000 description 1
- USLVEJAHTBLSIL-CYDGBPFRSA-N Val-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C USLVEJAHTBLSIL-CYDGBPFRSA-N 0.000 description 1
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 1
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 1
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 1
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 1
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 1
- DFQZDQPLWBSFEJ-LSJOCFKGSA-N Val-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N DFQZDQPLWBSFEJ-LSJOCFKGSA-N 0.000 description 1
- AOILQMZPNLUXCM-AVGNSLFASA-N Val-Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN AOILQMZPNLUXCM-AVGNSLFASA-N 0.000 description 1
- 108010052104 Viral Regulatory and Accessory Proteins Proteins 0.000 description 1
- 241000235015 Yarrowia lipolytica Species 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 235000010419 agar Nutrition 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010039538 alanyl-glycyl-aspartyl-valine Proteins 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 229940050528 albumin Drugs 0.000 description 1
- NWMHDZMRVUOQGL-CZEIJOLGSA-N almurtide Chemical compound OC(=O)CC[C@H](C(N)=O)NC(=O)[C@H](C)NC(=O)CO[C@@H]([C@H](O)[C@H](O)CO)[C@@H](NC(C)=O)C=O NWMHDZMRVUOQGL-CZEIJOLGSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 108010008355 arginyl-glutamine Proteins 0.000 description 1
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 1
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 1
- 108010059459 arginyl-threonyl-phenylalanine Proteins 0.000 description 1
- 108010062796 arginyllysine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 108010068265 aspartyltyrosine Proteins 0.000 description 1
- 238000003149 assay kit Methods 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 239000002585 base Substances 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 235000011089 carbon dioxide Nutrition 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 230000004186 co-expression Effects 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 210000000795 conjunctiva Anatomy 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 108010016616 cysteinylglycine Proteins 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 108010054812 diprotin A Proteins 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 241001493065 dsRNA viruses Species 0.000 description 1
- 239000003480 eluent Substances 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 201000002491 encephalomyelitis Diseases 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 244000309457 enveloped RNA virus Species 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- 229940073505 ethyl vanillin Drugs 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000000763 evoking effect Effects 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 238000012268 genome sequencing Methods 0.000 description 1
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 1
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 108010079547 glutamylmethionine Proteins 0.000 description 1
- 229960005150 glycerol Drugs 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 108010090037 glycyl-alanyl-isoleucine Proteins 0.000 description 1
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010033719 glycyl-histidyl-glycine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 230000036449 good health Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 108010025306 histidylleucine Proteins 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 238000003365 immunocytochemistry Methods 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 230000009851 immunogenic response Effects 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 230000006054 immunological memory Effects 0.000 description 1
- 238000000530 impalefection Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 208000037798 influenza B Diseases 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000017730 intein-mediated protein splicing Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 210000004347 intestinal mucosa Anatomy 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 239000002555 ionophore Substances 0.000 description 1
- 230000000236 ionophoric effect Effects 0.000 description 1
- FZWBNHMXJMCXLU-BLAUPYHCSA-N isomaltotriose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)O1 FZWBNHMXJMCXLU-BLAUPYHCSA-N 0.000 description 1
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 1
- GZQKNULLWNGMCW-PWQABINMSA-N lipid A (E. coli) Chemical compound O1[C@H](CO)[C@@H](OP(O)(O)=O)[C@H](OC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCCCC)[C@@H](NC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCC)[C@@H]1OC[C@@H]1[C@@H](O)[C@H](OC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](NC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](OP(O)(O)=O)O1 GZQKNULLWNGMCW-PWQABINMSA-N 0.000 description 1
- 230000029226 lipidation Effects 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 239000006193 liquid solution Substances 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 230000005923 long-lasting effect Effects 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- ZLNQQNXFFQJAID-UHFFFAOYSA-L magnesium carbonate Chemical compound [Mg+2].[O-]C([O-])=O ZLNQQNXFFQJAID-UHFFFAOYSA-L 0.000 description 1
- 239000001095 magnesium carbonate Substances 0.000 description 1
- 229910000021 magnesium carbonate Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 102000006240 membrane receptors Human genes 0.000 description 1
- 108020004084 membrane receptors Proteins 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- JMUHBNWAORSSBD-WKYWBUFDSA-N mifamurtide Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@@H](OC(=O)CCCCCCCCCCCCCCC)COP(O)(=O)OCCNC(=O)[C@H](C)NC(=O)CC[C@H](C(N)=O)NC(=O)[C@H](C)NC(=O)[C@@H](C)O[C@H]1[C@H](O)[C@@H](CO)OC(O)[C@@H]1NC(C)=O JMUHBNWAORSSBD-WKYWBUFDSA-N 0.000 description 1
- 229960005225 mifamurtide Drugs 0.000 description 1
- 210000002200 mouth mucosa Anatomy 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 239000002077 nanosphere Substances 0.000 description 1
- 210000001989 nasopharynx Anatomy 0.000 description 1
- 210000004492 nuclear pore Anatomy 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 150000003833 nucleoside derivatives Chemical class 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 229920002113 octoxynol Polymers 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 210000000287 oocyte Anatomy 0.000 description 1
- 210000003300 oropharynx Anatomy 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 239000006179 pH buffering agent Substances 0.000 description 1
- 229940090668 parachlorophenol Drugs 0.000 description 1
- 229920002866 paraformaldehyde Polymers 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- 239000000816 peptidomimetic Substances 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- IYDGMDWEHDFVQI-UHFFFAOYSA-N phosphoric acid;trioxotungsten Chemical compound O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.O=[W](=O)=O.OP(O)(O)=O IYDGMDWEHDFVQI-UHFFFAOYSA-N 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 238000013439 planning Methods 0.000 description 1
- 210000004180 plasmocyte Anatomy 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 1
- 235000010241 potassium sorbate Nutrition 0.000 description 1
- 239000004302 potassium sorbate Substances 0.000 description 1
- 229940069338 potassium sorbate Drugs 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000009021 pre-vaccination Methods 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 108010020432 prolyl-prolylisoleucine Proteins 0.000 description 1
- 108010079317 prolyl-tyrosine Proteins 0.000 description 1
- 108010004914 prolylarginine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010015796 prolylisoleucine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 239000000473 propyl gallate Substances 0.000 description 1
- 229940075579 propyl gallate Drugs 0.000 description 1
- 235000010388 propyl gallate Nutrition 0.000 description 1
- 230000004845 protein aggregation Effects 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 238000011158 quantitative evaluation Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012827 research and development Methods 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- CVHZOJJKTDOEJC-UHFFFAOYSA-N saccharin Chemical compound C1=CC=C2C(=O)NS(=O)(=O)C2=C1 CVHZOJJKTDOEJC-UHFFFAOYSA-N 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 229940044609 sulfur dioxide Drugs 0.000 description 1
- 235000010269 sulphur dioxide Nutrition 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 229940033663 thimerosal Drugs 0.000 description 1
- 231100000607 toxicokinetics Toxicity 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000004627 transmission electron microscopy Methods 0.000 description 1
- 238000005829 trimerization reaction Methods 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 108010029384 tryptophyl-histidine Proteins 0.000 description 1
- 108010084932 tryptophyl-proline Proteins 0.000 description 1
- 238000005199 ultracentrifugation Methods 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 210000003708 urethra Anatomy 0.000 description 1
- 239000012646 vaccine adjuvant Substances 0.000 description 1
- 229940124931 vaccine adjuvant Drugs 0.000 description 1
- 229940125575 vaccine candidate Drugs 0.000 description 1
- 210000001215 vagina Anatomy 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
Images
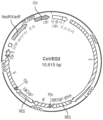

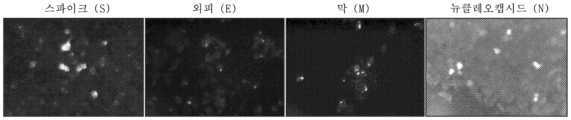

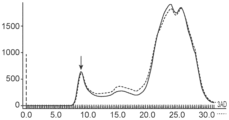
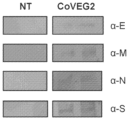



















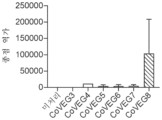












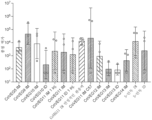











Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/713—Double-stranded nucleic acids or oligonucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
- A61K39/145—Orthomyxoviridae, e.g. influenza virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
- A61K39/215—Coronaviridae, e.g. avian infectious bronchitis virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
- A61K39/29—Hepatitis virus
- A61K39/292—Serum hepatitis virus, hepatitis B virus, e.g. Australia antigen
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/525—Virus
- A61K2039/5258—Virus-like particles
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/53—DNA (RNA) vaccination
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55505—Inorganic adjuvants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55572—Lipopolysaccharides; Lipid A; Monophosphoryl lipid A
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/57—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2
- A61K2039/572—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2 cytotoxic response
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/57—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2
- A61K2039/575—Medicinal preparations containing antigens or antibodies characterised by the type of response, e.g. Th1, Th2 humoral response
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/60—Medicinal preparations containing antigens or antibodies characteristics by the carrier linked to the antigen
- A61K2039/6031—Proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2730/00—Reverse transcribing DNA viruses
- C12N2730/00011—Details
- C12N2730/10011—Hepadnaviridae
- C12N2730/10111—Orthohepadnavirus, e.g. hepatitis B virus
- C12N2730/10122—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2730/00—Reverse transcribing DNA viruses
- C12N2730/00011—Details
- C12N2730/10011—Hepadnaviridae
- C12N2730/10111—Orthohepadnavirus, e.g. hepatitis B virus
- C12N2730/10134—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2730/00—Reverse transcribing DNA viruses
- C12N2730/00011—Details
- C12N2730/10011—Hepadnaviridae
- C12N2730/10111—Orthohepadnavirus, e.g. hepatitis B virus
- C12N2730/10151—Methods of production or purification of viral material
- C12N2730/10152—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2730/00—Reverse transcribing DNA viruses
- C12N2730/00011—Details
- C12N2730/10011—Hepadnaviridae
- C12N2730/10111—Orthohepadnavirus, e.g. hepatitis B virus
- C12N2730/10171—Demonstrated in vivo effect
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2760/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses negative-sense
- C12N2760/00011—Details
- C12N2760/16011—Orthomyxoviridae
- C12N2760/16022—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2760/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses negative-sense
- C12N2760/00011—Details
- C12N2760/16011—Orthomyxoviridae
- C12N2760/16034—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2760/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses negative-sense
- C12N2760/00011—Details
- C12N2760/16011—Orthomyxoviridae
- C12N2760/16051—Methods of production or purification of viral material
- C12N2760/16052—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2760/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses negative-sense
- C12N2760/00011—Details
- C12N2760/16011—Orthomyxoviridae
- C12N2760/16071—Demonstrated in vivo effect
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/20011—Coronaviridae
- C12N2770/20022—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/20011—Coronaviridae
- C12N2770/20023—Virus like particles [VLP]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/20011—Coronaviridae
- C12N2770/20034—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/20011—Coronaviridae
- C12N2770/20051—Methods of production or purification of viral material
- C12N2770/20052—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/20011—Coronaviridae
- C12N2770/20071—Demonstrated in vivo effect
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
- C12N2770/24122—New viral proteins or individual genes, new structural or functional aspects of known viral proteins or genes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
- C12N2770/24123—Virus like particles [VLP]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
- C12N2770/24134—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
- C12N2770/24151—Methods of production or purification of viral material
- C12N2770/24152—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
- C12N2770/24171—Demonstrated in vivo effect
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Virology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- Epidemiology (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Communicable Diseases (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Pulmonology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Oncology (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본 개시내용은 하나 이상의 바이러스 항원 단백질 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는, 백신에서 사용하기 위한 조성물 및 방법을 제공하며, 인핸서 단백질은 피코르나바이러스 리더(L) 또는 이의 기능성 변이체이다. 본원에 제공된 조성물 및 방법은 기능성 바이러스 유사 입자(VLP)의 생산을 개선할 수 있다.
Description
관련 출원의 교차 참조
본 출원은 2021년 3월 17일자로 출원된 미국 임시 특허 출원 번호 제63/162,496호의 우선권을 주장하며, 이는 그 전체 내용이 본원에 인용되어 포함된다.
서열 목록의 포함
이와 함께 전자적으로 제출된 텍스트 파일은 그 전체 내용이 본원에 인용되어 포함된다: 서열 목록의 컴퓨터 판독 가능한 포맷 사본(파일명: EXCI_003_03WO_SeqList_ST25, 기록일: 2022년 3월 17일, 파일 크기: 266 킬로바이트).
바이러스 감염 질환, 예를 들어, 독감은 매우 널리 퍼져 있으며 종종 전염성이 있다. 바이러스 질환은 바이러스 감염 유형 및 개인의 연령 및 전반적인 건강 등을 비롯한 다른 요인에 따라 특징 및 중증도가 달라지는 매우 다양한 증상을 일으킨다. 바이러스 감염은 바이러스 유형 및 다른 요인에 따라 다양한 정도의 성공으로 치료될 수 있다. 때로는 치료는 증상 관리만 포함할 수 있다.
바이러스 감염을 방지하는 가장 효과적인 방식은 백신 접종을 사용하는 것이며, 이는 추후 감염을 방지하는 전체론적 세포 및/또는 체액 면역 반응을 유도할 수 있다. 예방 접종은 바이러스 감염의 발생을 예방하거나 중증도를 최소화함으로써 엄청난 공중 보건 및 경제적 이익을 제공한다. 바이러스 감염을 포함하여 20개 초과의 생명을 위협하는 질환을 예방하기 위한 백신이 입수 가능하지만, 새로운 감염성 바이러스, 예를 들어, SARS CoV2의 출현으로 인해 새로운 바이러스 표적에 대한 백신의 신속한 연구 및 개발이 필요할 수 있다. 그러나, 최신 게놈 서열분석(sequencing) 및 다른 기술 발전에도 불구하고 백신 개발은 여전히 시간이 많이 걸리고 비용이 많이 든다.
따라서 다양한 바이러스를 표적으로 하는 백신 개발에 신속하게 적용할 수 있는 범용성(versatility)을 갖는 방법 및 조성물이 필요하다.
도면의 간단한 설명
도 1a 및 도 1b는 CoVEG2(도 1a) 및 CoVEG1(도 1b)의 플라스미드 맵을 나타낸다. 거대세포바이러스(CMV: cytomegalovirus) 인핸서 및 프로모터 및 시미안 바이러스 40 Poly A(SV40PA: Simian virus 40 Poly A)의 상대 위치를 또한 나타낸다.
도 2는 HEK293 세포에서 CoVEG2로부터의 SARS-CoV-2 S 단백질, SARS-CoV-2 M 단백질, SARS-CoV-2 E 단백질 및 SARS-CoV-2 N 단백질의 발현을 나타낸다.
도 3은 CoVEG2로부터 발현된 SARS-CoV-2 S, N, M 및 E 단백질이 VLP로 조립될 수 있고 세포로부터 분비된다는 것을 나타낸다. 실시예 3을 참조한다. 도 3a는 크기 배제 크로마토그래피 공극 샘플에서 S, N, M, 및 E 단백질 밴드를 나타낸 SDS PAGE 실험으로부터의 결과를 나타낸다. 도 3b는 크기 배제 VLP 단리 전개의 크로마토그램을 나타내는 반면 VLP를 함유하는 공극 부피 피크는 화살표로 표시된다. 도 3c는 크기 배제 크로마토그래피 공극 샘플에서 S, N, M, 및 E 단백질 밴드를 나타낸 웨스턴 블로팅 실험으로부터의 결과를 나타낸다. E: 외피 단백질; M: 막 단백질; N: 뉴클레오캡시드 단백질; S: 스파이크 단백질; NT: 형질주입되지 않음.
도 4는 마우스에서 CoVEG1 및 CoVEG2 플라스미드의 면역원성을 시험하기 위한 연구 설계를 나타낸다.
도 5a 내지 도 5o는 각각 CoVEG 3 내지 CoVEG17 각각의 플라스미드 맵을 나타낸다. 도 5p는 대조군 S 단독 플라스미드의 플라스미드 맵을 나타낸다. CMV: 거대세포바이러스; SV40PA: 시미안 바이러스 40 Poly A.
도 6은 CoVEG3 내지 CoVEG17 각각에서 발현 카세트의 개략도를 나타낸다. 플라스미드 CoVEG 3 내지 CoVEG17 각각은 암호화된 유전자, 유전자 요소의 순서 및 조절 요소, 예를 들어, 바이러스 패키징 신호(viral packaging signal)의 존재 또는 부재가 달라진다. "M", "S", "N" 및 "E"로 표시된 상자는 각각 막 단백질, 스파이크 단백질, 뉴클레오캡시드 단백질 및 외피 단백질을 암호화한 유전자를 나타낸다. "L"로 표시된 상자는 L 인핸서 단백질을 암호화하는 유전자를 지칭한다. "S (Mut)"는 내부 내인성 푸린 절단 부위가 다음 아미노산 치환: R682G, R683S, R685S을 포함하도록 돌연변이되고; 2개의 아미노산 치환인 K986P 및 V987P를 더 갖는 주입전 입체배좌 안정화된 스파이크 단백질 돌연변이체를 나타낸다.
도 7은 다른 바이러스 단백질(M, N 또는 E)이 없는 S 단백질만을 발현하는 대조군 플라스미드 또는 제시된 플라스미드 각각으로 형질주입된 HEK293T 세포의 항-스파이크(S) 단백질 항체 면역염색으로부터의 영상을 나타낸다. 영상은 이들 세포에서 S 단백질의 발현을 확인해 준다.
도 8은 제시된 CoVEG 작제물이 일시적으로 형질주입되는 경우 세포 배양 상청액으로부터 단리된 바이러스 유사 입자(VLP: viral-like particle)의 제제의 웨스턴 블롯 분석으로부터의 결과를 나타낸다. "S"는 다른 바이러스 단백질(M, N 또는 E)이 없는 S 단백질만을 발현하는 대조군 플라스미드로의 일시적인 형질주입을 나타낸다. 항-RBD 항체(좌측) 및 항-N 단백질 항체(우측)로의 염색은 시험된 플라스미드가 VLP로서 바이러스 구조 단백질을 발현하고 이를 세포 배양 상청액으로 분비할 수 있다는 것을 나타낸다. 적색 화살표는 전장 단백질을 나타낸다.
도 9a는 56일 후 제시된 CoVEG 플라스미드 각각이 주사된 BALB/c 마우스로부터의 1:500으로 희석된 혈청 샘플을 사용하여 ELISA 분석으로부터 입수한 전체 신호 값을 나타낸다. 도 9b는 56일 후 제시된 CoVEG 플라스미드 각각이 주사된 BALB/c 마우스로부터의 혈청 샘플을 사용하여 ELISA 분석으로부터 입수한 종점 역가 값을 나타낸다. 종점 역가는 ELISA 신호(450 nm에서의 흡광도)가 배경 신호의 3 표준 편차를 초과하는 상호 최대 항체 희석을 지칭한다.
도 10은 상업적인 cPass™ 중화 검정(GenScript)을 사용하여 제시된 각각의 플라스미드가 주사된 마우스로부터 입수한 혈청 샘플에 의한 ACE2 수용체에 대한 스파이크 단백질 수용체 결합 도메인(RBD)의 시험관 내 결합의 저해 백분율(%)을 나타낸다. 결과는 CoVEG5 및 CoVEG8-주사 마우스로부터 입수한 혈청 샘플이 중화 항체를 가짐을 나타낸다. 양성 대조군 및 음성 대조군은 cPass 중화 검정 키트의 검정 대조군이고, 각각 알려진 양의 SARS-CoV-2 중화 항체 또는 혈청음성 샘플을 함유하며, 제조사의 프로토콜에 따라 사용된다.
도 11은 제시된 CoVEG 작제물이 일시적으로 형질주입되는 경우 세포 배양 상청액으로부터 단리된 바이러스 유사 입자(VLP) 제제의 웨스턴 블롯 분석으로부터의 결과를 나타낸다. 항-RBD 항체(좌측) 및 항-N 단백질 항체(우측)로의 염색은 시험된 플라스미드가 VLP로서 바이러스 구조 단백질을 발현하고 이를 다양한 효율로 세포 배양 상청액으로 분비할 수 있다는 것을 나타낸다.
도 12는 제시된 CoVEG 작제물이 일시적으로 형질주입되는 경우 세포 배양 상청액으로부터 단리된 바이러스 유사 입자(VLP) 제제의 웨스턴 블롯 분석으로부터의 결과를 나타낸다. 항-RBD 항체(좌측) 및 항-N 단백질 항체(우측)로의 염색은 시험된 플라스미드가 VLP로서 바이러스 구조 단백질을 발현하고 이를 다양한 효율로 세포 배양 상청액으로 분비할 수 있다는 것을 나타낸다.
도 13은 15일 후에 제시된 CoVEG 플라스미드 각각을 피부내(ID: intradermally) 또는 근육내(IM: intramuscularly) 주사한 BALB/c 마우스로부터의 ELISA 분석으로부터 입수한 총 신호 값을 나타낸다. "S-only"는 스파이크 단백질의 단독 투여를 나타낸다.
도 14a는 인핸서 단백질(EMCV L1 단백질)과 함께 웨스트 나일 바이러스 단백질, preM 단백질 및 외피 단백질을 암호화하는 플라스미드의 맵을 나타낸다. 도 14b는 웨스트 나일 바이러스 단백질, preM 단백질 및 외피 단백질 CMV: 거대세포바이러스; SV40PA: 시미안 바이러스 40 Poly A만을 암호화하는 대조군 플라스미드의 맵을 나타낸다.
도 15a 및 도 15b는 HEK293 세포에서 VLP 분비의 ELISA 분석으로부터 입수한 총 신호 값을 나타낸다. 도 15a는 항스파이크(S 단백질) 항체를 사용하여 수행된 VLP 분비의 ELISA 분석을 나타낸다. 도 15b는 항-뉴클레오캡시드(N 단백질) 항체를 사용하여 수행된 VLP 분비의 ELISA 분석을 나타낸다.
도 16은 CoVEG10 및 CoVEG20 단백질 발현의 투과 전자 현미경(TEM: transmission electron micrographs)을 나타낸다. 도 16, 좌측은 L 조절 단백질을 함유하는 CoVEG10의 TEM을 나타낸다. 도 16, 우측은 L 조절 단백질이 결여된 CoVEG20의 TEM을 나타낸다.
도 17은 제시된 플라스미드 각각이 형질주입된 HEK293T 세포의 항-뉴클레오캡시드(N) 단백질 항체 면역염색으로부터의 영상을 나타낸다.
도 18은 제시된 CoVEG 작제물이 일시적으로 형질주입되는 경우 세포 배양 상청액으로부터 단리된 바이러스 유사 입자(VLP) 제제의 웨스턴 블롯 분석으로부터의 결과를 나타낸다. 항-RBD 항체(좌측) 및 항-N 단백질 항체(우측)로의 염색은 시험된 플라스미드가 VLP로서 바이러스 구조 단백질을 발현하고 이를 다양한 효율로 세포 배양 상청액으로 분비할 수 있다는 것을 나타낸다.
도 19는 CoVEG10 플라스미드의 동시면역침전 실험의 웨스턴 블롯 결과를 나타낸다. (좌측) N 단백질의 수용체 결합 도메인(RBD) 풀-다운 신호는 N 단백질이 입자 내에 유지되었음을 나타낸다. (우측) 항-RBD 항체 없이 co-IP를 수행하였는데, 이는 N 단백질이 침전 수지에 비특이적으로 결합하지 않았음을 입증한다.
도 20은 C57BL/6 마우스에서 근육내(IM) 또는 피부내(ID) 주사 후 CoVEG5 및 CoVEG9 내지 CoVEG14 플라스미드뿐만 아니라 스파이크(S) 단백질 단독 함유 플라스미드로부터의 항체 결합 역가를 나타낸다.
도 21은 도 20에 도시된 샘플로부터의 중화 항체의 ELISA 분석을 나타낸다.
도 22는 C57BL/6 마우스에서 근육내(IM) 또는 피부내(ID) 주사 후 CoVEG9, CoVEG10 및 CoVEG18 내지 CoVEG20 플라스미드뿐만 아니라 스파이크(S) 단백질 단독 함유 플라스미드로부터의 항체 결합 역가를 나타낸다.
도 23은 C57BL/6 마우스에서 CoVEG9, CoVEG10 및 CoVEG20 플라스미드 근육내(IM) 또는 피부내(ID) 주사에 응답하여 생산된 중화 항체의 ELISA 분석을 나타낸다.
도 24a 및 도 24b는 CoVEG10 및 CoVEG20의 T-세포 분석 결과를 나타낸다. 도 24a는 CoVEG10의 T-세포 분석 결과를 나타낸다. 도 24b는 CoVEG20의 T-세포 분석 결과를 나타낸다.
도 25는 인핸서 단백질이 있는 단리되고 재현탁된 웨스트나일 바이러스(WNV: West-Nile Virus) 작제물(WNV + EG, 원) 및 인핸서 단백질이 없는 단리되고 재현탁된 웨스트나일 바이러스(WNV) 작제물(WNC, 사각형)이 형질주입된 HEK293T 세포의 세포 배양 상청액으로부터 정제된 VLP의 ELISA 분석을 나타낸다. ELISA의 특이성을 특이적 ELISA 검정에서 신호를 제공하지 않는 GFP를 함유한 플라스미드에 대해 시험하였다. ELISA 분석은, 인핸서 단백질을 첨가한 초원심분리에 의한 VLP의 단리가 인핸서 단백질이 없을 때보다 더 많은 활성 VLP를 함유하였다는 것을 나타내었다. 이는, 인핸서 단백질의 부재 하에서 생산된 단백질의 총량이 더 높았기 때문에 특히 놀라운 것이었고, 인핸서 단백질의 첨가가 발현된 표적 단백질의 품질을 증가시켰다는 것을 더 입증하였다.
도 26a 및 도 26b는 인핸서 단백질이 있는 과발현된 웨스트나일 바이러스(WNV) 작제물(WNV + L) 및 인핸서 단백질이 없는 과발현된 웨스트나일 바이러스(WNV) 작제물(WNV)을 함유한 상청액을 과발현하는 HEK293T 세포로부터 입수한 세포 배양 상청액의 시간 경과 분석을 나타낸다. 도 26a는 WNV + L(좌측) 작제물에서 VLP 농도가 형질주입 후 72시간에 최고조에 달했고 그 후 점차적으로 감소했음을 입증하는 ELISA 분석을 나타낸다. 발현 프로파일이 일시적인 형질주입으로부터 예상되는 VLP 생산 및 관련 VLP 입자 반감기에 따랐기 때문에, 이는 건강한 세포로부터의 VLP 분비의 증거였다. 대조적으로, 인핸서 단백질이 없는 WNV 작제물은 상청액에서 VLP의 지속적인 증가를 나타내었는데(우측), 이는 활성 분비보다는 세포 사멸 중에 세포로부터의 단백질의 비특이적 방출과 더 일치한다. 도 26b는 세포 영상으로 ELISA 분석을 확인하였다. WNV +L 세포 영상(좌측)은 세포 사멸이 거의 또는 전혀 나타나지 않은 반면, WNV 세포 영상은 형질주입 후 72시간에 시작하여 세포 사멸의 가시적인 징후를 나타내었다(우측, 검은 별표로 표시된 세포 사멸).
도 27a 및 도 27b는 마우스의 면역화 후 제42일 및 제70일에 CoVEG9, 인핸서 단백질이 있는 스파이크 작제물(스파이크 + L) 및 인핸서 단백질이 없는 스파이크 작제물(스파이크)의 중화 항체 분석을 나타낸다. 중화 항체의 존재는 상업적인 cPass™ SARS-CoV-2 대용체 바이러스 중화 시험(sVNT: Surrogate Virus Neutralization Test) 키트(GenScript)를 사용하여 검출하였다. 분석은, 모든 작제물이 시간 경과에 따라 일부 중화 능력을 손실하지만 인핸서 단백질의 첨가는 시험된 동물의 혈청에서 목적하는 중화 항체(CoVEG9 및 스파이크 + L)의 존재가 연장되는 것을 나타내었다. 도 27a는 제42일 및 제70일에 군별 개별 동물을 나타낸다. 도 27b는 동일한 데이터의 각각의 치료군에서의 중화 항체 수준 중앙값을 나타낸다.
도 28은 인핸서 단백질이 있는 웨스트나일 바이러스(WNV) 작제물(WNV + L, 좌측) 또는 인핸서 단백질이 없는 웨스트나일 바이러스(WNV) 작제물(WNV, 우측)을 과발현하는 세포로부터의 면역형광 영상을 나타낸다. 다른 실시예에서 관찰된 바와 같이, WNV(우측)와 비교하여 면역염색에 사용된 2차 항체의 더 약한 Alexa Fluor 488 Fluor 신호에 의해서 나타난 바와 같이(WNV + L, 좌측), 인핸서 단백질을 첨가하는 경우 단백질의 총량이 감소하였다. 그러나, 인핸서 단백질의 부재는 발현된 단백질의 응집 또는 잘못된 접힘과 일치하는 핵 초점의 형성으로 이어졌는데, 이는 인핸서 단백질이 있는 작제물(WNV + L)에 비해서 더 낮은 품질의 발현 단백질을 나타낸다.
본 개시내용은 바이러스 단백질을 암호화하는 폴리뉴클레오티드 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는, 백신으로서 사용하기 위한 조성물을 제공한다. 일부 실시형태에서, 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체이다. 일부 실시형태에서, 인핸서 단백질의 아미노산 서열은 서열번호 1과 적어도 95%의 동일성 또는 서열번호 2와 적어도 95%의 동일성을 갖는다. 일부 실시형태에서, 인핸서 단백질의 아미노산 서열은 서열번호 1, 또는 서열번호 2이다. 일부 실시형태에서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드는 내부 리보솜 유입 부위(IRES: internal ribosome entry site)를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된다. 일부 실시형태에서, IRES를 암호화하는 폴리뉴클레오티드는 서열번호 24이다.
일부 실시형태에서, 바이러스 단백질은 바이러스 항원이다. 일부 실시형태에서, 바이러스 단백질은 코로나바이러스, 인플루엔자 바이러스, B형 간염 바이러스, 인간 파필로마 바이러스(HPV: Human Papilloma virus), 웨스트나일 바이러스, 및 인간 면역결핍 바이러스(HIV: Human Immunodeficiency Virus) 바이러스 벡터로 이루어진 군으로부터 선택된 바이러스로부터 유래된다. 일부 실시형태에서, 바이러스 단백질은 코로나바이러스로부터 유래된다. 일부 실시형태에서, 코로나바이러스는 베타코로나바이러스이다. 일부 실시형태에서, 베타코로나바이러스는 중증 급성 호흡기 증후군(SARS) 바이러스이다. 일부 실시형태에서, SARS 바이러스는 SARS-CoV-2 바이러스이다. 일부 실시형태에서, 베타코로나바이러스는 중동 호흡기 증후군(MERS) 바이러스이다.
일부 실시형태에서, 코로나바이러스 단백질은 코로나바이러스 스파이크 단백질이다. 일부 실시형태에서, 스파이크 단백질은 서열번호 13과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유한다. 일부 실시형태에서, 스파이크 단백질은 서열번호 13이다. 일부 실시형태에서, 코로나바이러스 단백질은 코로나바이러스 막(M) 단백질이다. 일부 실시형태에서, M 단백질은 서열번호 33과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유한다. 일부 실시형태에서, M 단백질은 서열번호 33이다. 일부 실시형태에서, 코로나바이러스 단백질은 코로나바이러스 외피(E) 단백질이다. 일부 실시형태에서, E 단백질은 서열번호 22와 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유한다. 일부 실시형태에서, E 단백질은 서열번호 22이다. 일부 실시형태에서, 코로나바이러스 단백질은 코로나바이러스 뉴클레오캡시드(N) 단백질이다. 일부 실시형태에서, N 단백질은 서열번호 20과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유한다. 일부 실시형태에서, N 단백질은 서열번호 20이다. 일부 실시형태에서, 코로나바이러스 단백질은 바이러스 유사 입자(VLP)를 형성한다.
일부 실시형태에서, 바이러스 단백질은 웨스트나일 바이러스로부터 유래된다. 일부 실시형태에서, 바이러스 단백질은 전구체 막 단백질(preM), 외피 당단백질(E), 또는 이의 조합물이다.
본 개시내용은 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는, 백신으로 사용하기 위한 벡터를 제공하며, 여기서 폴리뉴클레오티드는 서열번호 30의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함한다. 일부 실시형태에서, 폴리뉴클레오티드는 서열번호 30의 핵산 서열을 포함한다.
본 개시내용은 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는, 백신으로서 사용하기 위한 벡터를 제공하며, 여기서 폴리뉴클레오티드는 서열번호 31의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함한다. 일부 실시형태에서, 폴리뉴클레오티드는 서열번호 31의 핵산 서열을 포함한다.
본 개시내용은 서열번호 35 내지 서열번호 49, 서열번호 55 및 서열번호 62로 이루어진 군으로부터 선택된 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는, 백신으로서 사용하기 위한 벡터를 제공한다.
일부 실시형태에서, 벡터는 네이키드 폴리뉴클레오티드이다. 일부 실시형태에서, 벡터는 데옥시리보핵산(DNA) 폴리뉴클레오티드이다. 일부 실시형태에서, 벡터는 리보핵산(RNA) 폴리뉴클레오티드이다. 일부 실시형태에서, 벡터는 플라스미드를 포함한다. 일부 실시형태에서, 벡터는 선형 DNA를 포함한다. 벡터는 플라스미드, 바이러스, 박테리오파지, 프로-바이러스, 파지미드, 트랜스포존, 인공 염색체 등을 포함하며, 일부 경우에는 자율적으로 복제할 수 있거나 숙주 세포의 염색체에 통합될 수 있다. 벡터는 또한 자율적으로 복제되지 않는 네이키드 RNA 폴리뉴클레오티드, 네이키드 DNA 폴리뉴클레오티드, 동일한 가닥 내의 DNA 및 RNA 둘 다로 구성된 폴리뉴클레오티드, 폴리-라이신-접합 DNA 또는 RNA, 펩티드-접합 DNA 또는 RNA, 리포솜-접합 DNA 등일 수 있다.
일부 실시형태에서, 벡터는 아데노 연관 바이러스(AAV: adeno-associated virus) 벡터, 렌티바이러스 벡터, 레트로바이러스 벡터, 복제 가능 아데노바이러스 벡터, 복제 결핍 아데노바이러스 벡터, 헤르페스 바이러스 벡터, 바큘로바이러스 벡터, 비바이러스 플라스미드, 바이러스 벡터, 플라스미드, 파지, 파지미드, 코스미드, 포스미드, 박테리오파지, 인공 염색체, 또는 아데노바이러스 벡터이다. 일부 실시형태에서, 벡터는 박테리아 인공 염색체(BAC: bacterial artificial chromosome), 플라스미드, 박테리오파지 P1-유래 벡터(PAC: bacteriophage P1-derived vector), 효모 인공 염색체(YAC: yeast artificial chromosome), 또는 포유동물 인공 염색체(MAC: mammalian artificial chromosome)이다.
일부 실시형태에서, 발현 카세트는 발현 카세트의 폴리뉴클레오티드 서열 각각에 작동 가능하게 연결된 프로모터를 포함한다. 일부 실시형태에서, 벡터는 DNA 폴리뉴클레오티드를 포함하고, 상기 DNA 폴리뉴클레오티드는 바이러스 패키징 신호를 암호화한다. 일부 실시형태에서, 바이러스 패키징 신호는 RNA 폴리뉴클레오티드이다. 일부 실시형태에서, 바이러스 패키징 신호는 코로나바이러스로부터 유래된다.
본 개시내용은 본원에 개시된 벡터 중 임의의 하나, 및 약제학적으로 허용 가능한 담체를 포함하는 백신 조성물을 제공한다. 일부 실시형태에서, 백신 조성물은 아주반트를 포함한다. 일부 실시형태에서, 아주반트는 명반(alum)이다. 일부 실시형태에서, 아주반트는 모노포스포릴 지질 A(MPL: monophosphoryl lipid A)이다.
본 개시내용은 세포를 본원에 개시된 벡터 중 임의의 하나와 접촉시키는 것을 포함하는, 진핵 세포에서 바이러스 항원을 발현시키는 방법을 제공한다. 일부 실시형태에서, 세포를 벡터와 접촉시키는 것은, 인핸서 단백질이 없는 벡터보다 (i)더 높은 발현 수준에서의 항원의 발현; 및/또는 (ii)더 긴 시간 기간 동안의 항원의 발현; 및/또는 (iii)더 양호한 단백질 품질을 갖는 항원의 발현을 일으킨다. 일부 실시형태에서, 세포를 벡터와 접촉시키는 것은, 인핸서 단백질이 없는 벡터보다 (i)더 높은 발현 수준에서의 항원을 포함하는 바이러스 유사 입자(VLP)의 발현; 및/또는 (ii)더 긴 시간 기간 동안의 항원을 포함하는 VLP의 발현; 및/또는 (iii)더 양호한 단백질 품질을 갖는 항원을 포함하는 VLP의 발현을 일으킨다.
일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드를 포함하며, 세포를 벡터와 접촉시키는 것은 바이러스 패키징 신호의 발현을 일으키고, VLP는 바이러스 패키징 신호를 캡시드화한다. 일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드가 없는 대조군 벡터와 비교할 때, 더 많은 수의 VLP의 형성을 일으킨다.
본 개시내용은 본원에 개시된 백신 조성물 중 임의의 하나의 유효랑을 대상체에게 투여하는 것을 포함하는, 대상체에서 면역 반응을 유발하는 방법을 제공한다. 일부 실시형태에서, 대상체의 투여 부위의 조직은 항원 및/또는 항원을 포함하는 VLP를 발현한다. 일부 실시형태에서, 대상체의 투여 부위의 조직은 인핸서 단백질이 없는 벡터가 투여되는 경우보다 (i)항원 및/또는 항원을 포함하는 VLP를 더 높은 발현 수준으로 발현하고; 그리고/또는 (ii)항원 및/또는 항원을 포함하는 VLP을 더 긴 시간 기간 동안 발현하고; 그리고/또는 (iii)더 양호한 단백질 품질을 갖는 항원 및/또는 항원을 포함하는 VLP를 발현한다. 일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드를 포함하며, 대상체의 투여 부위의 조직은 바이러스 패키징 신호를 발현하고, VLP는 바이러스 패키징 신호를 캡시드화한다. 일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드가 없는 대조군 벡터와 비교할 때, 더 많은 수의 VLP의 발현을 일으킨다. 일부 실시형태에서, 바이러스 패키징 신호를 캡시드화하는 VLP는 항원을 포함하지만 바이러스 패키징 신호가 없는 대조군 VLP보다 더 양호한 면역원성이다.
일부 실시형태에서, 방법은 대상체에서 항체 반응을 유발한다. 일부 실시형태에서, 항체 반응은 중화 항체 반응이다. 일부 실시형태에서, 방법은 세포 면역 반응을 유발한다. 일부 실시형태에서, 방법은 대상체에서 예방학적, 예방적 및/또는 치료적 면역 반응을 유발한다. 일부 실시형태에서, 투여는 피부내 투여, 근육내 투여, 피하 투여, 또는 비강내 투여이다.
본 개시내용은 코로나바이러스 단백질을 암호화하는 폴리뉴클레오티드 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는 폴리뉴클레오티드를 제공하며, 여기서 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체이다. 일부 실시형태에서, 인핸서 단백질의 아미노산 서열은 서열번호 1과 적어도 95%의 동일성 또는 서열번호 2와 적어도 95%의 동일성을 갖는다. 일부 실시형태에서, 인핸서 단백질의 아미노산 서열은 서열번호 1, 또는 서열번호 2이다.
일부 실시형태에서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드는 내부 리보솜 유입 부위(IRES)를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된다. 일부 실시형태에서, IRES를 암호화하는 폴리뉴클레오티드는 서열번호 24이다. 일부 실시형태에서, 코로나바이러스 단백질은 바이러스 유사 입자(VLP)를 형성한다.
본 개시내용은 서열번호 30의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는 폴리뉴클레오티드를 제공한다. 일부 실시형태에서, 폴리뉴클레오티드는 서열번호 30의 핵산 서열을 포함한다. 본 개시내용은 서열번호 31의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는 폴리뉴클레오티드를 제공한다. 일부 실시형태에서, 폴리뉴클레오티드는 서열번호 31의 핵산 서열을 포함한다.
일부 실시형태에서, 폴리뉴클레오티드는 네이키드 폴리뉴클레오티드이다. 일부 실시형태에서, 폴리뉴클레오티드는 데옥시리보핵산(DNA) 폴리뉴클레오티드이다. 일부 실시형태에서, 폴리뉴클레오티드는 리보핵산(RNA) 폴리뉴클레오티드이다. 일부 실시형태에서, 발현 카세트는 발현 카세트의 폴리뉴클레오티드 서열 각각에 작동 가능하게 연결된 프로모터를 포함한다.
본 개시내용은 벡터를 포함하는 키트를 제공하며, 여기서 벡터는 코로나바이러스 단백질을 암호화하는 폴리뉴클레오티드 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하며, 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체이다.
본 개시내용은 발현 카세트를 포함하는 벡터를 제공하며, 상기 발현 카세트는 표적 유전자에 연결된 프로모터를 포함하고, 벡터는 바이러스 패키징 요소를 암호화하는 핵산 서열을 포함한다. 일부 실시형태에서, 바이러스 패키징 요소는 RNA 폴리뉴클레오티드이다. 일부 실시형태에서, 바이러스 패키징 요소는 코로나바이러스로부터 유래된다. 일부 실시형태에서, 바이러스 패키징 요소는 SARS-CoV2로부터 유래된다. 일부 실시형태에서, 바이러스 패키징 요소를 암호화하는 핵산 서열은 서열번호 34의 핵산 서열과 적어도 약 70%의 동일성을 갖는다.
본 개시내용은 세포를 본원에 개시된 벡터 중 임의의 하나와 접촉시키는 것을 포함하는, 진핵 세포에서 표적 단백질을 발현시키는 방법을 제공한다. 일부 실시형태에서, 세포를 벡터와 접촉시키는 것은 표적 단백질의 바이러스 유사 입자(VLP)의 형성을 일으킨다. 일부 실시형태에서, 세포를 벡터와 접촉시키는 것은 발현 카세트를 포함하지만 바이러스 패키징 요소를 암호화하는 핵산 서열이 없는 대조군 벡터와 비교할 때 더 많은 수의 표적 단백질을 포함하는 바이러스 유사 입자(VLP)의 형성을 일으킨다. 일부 실시형태에서, 바이러스 패키징 요소를 암호화하는 핵산 서열은 서열번호 34의 핵산 서열과 적어도 약 70%의 동일성을 갖는다.
본 개시내용은 발현 카세트를 포함하는, 백신으로 사용하기 위한 벡터를 제공하며, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드 제1 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 제2 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 제3 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 및 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드.
본 개시내용은 또한 발현 카세트를 포함하는, 백신으로서 사용하기 위한 벡터를 제공하며, 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드 또는 이와 적어도 95% 동일한 아미노산 서열, 제1 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 제2 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드.
본 개시내용은 또한 백신으로 사용하기 위한 벡터를 제공하며, 이 벡터는 발현 카세트를 포함하고, 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 및 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드.
본 개시내용은 백신으로 사용하기 위한 벡터를 제공하며, 이 벡터는 발현 카세트를 포함하고, 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, IRES 서열은 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드 .
바이러스 유사 입자(VLP)는 바이러스 구조 단백질로 구성된다. VLP는 면역원성이지만, 이들은 비감염원성이다. 따라서 VLP는 백신 개발에 사용할 수 있는 엄청난 잠재력을 가지고 있다. VLP는 시험관 내에서 생산된 후 면역화가 필요한 대상체에게 투여될 수 있다. 대안적으로, VLP는 대상체의 생체 내에서 생산될 수 있다.
VLP의 생산은 주로 보통 하나 초과의 플라스미드로부터의 하나 초과의 구조 단백질의 발현을 요구하기 때문에 어려움이 있다. 일부 경우에, VLP의 형성을 지원하기 위해 상이한 구조 단백질을 운반하는 몇몇 플라스미드를 정의된 비율로 숙주 세포에 도입해야 할 수도 있다. 이 과정은 신뢰할 수 없으며 보통 필요한 품질의 충분한 수준의 VLP를 생산하지 못한다. VLP의 형성에 필요한 여러 구조 단백질이 단일 플라스미드 또는 단일 RNA 전사체로부터 발현될 수 있는 경우, VLP 제조 과정이 상당히 단순화되어 VLP를 포함하는 백신 개발에 상당한 도움을 줄 수 있다.
본원에 개시된 조성물 및 방법은 생체 내에서 높은 수준의 VLP의 신뢰할 수 있는 형성을 가능하게 하고, 따라서 VLP 상의 바이러스 항원에 대한 면역 반응의 강력한 유도를 가능하게 한다. 또한, 이러한 조성물 및 방법은 상이한 바이러스, 예를 들어, 코로나바이러스(예를 들어, SARS CoV-2), 인플루엔자 바이러스 및 웨스트나일 바이러스에 대한 면역 반응을 유도하는 데 사용될 수 있다.
정의
본원 및 첨부된 청구범위에서 사용된, 단수 형태("a", "an" 및 "the")는 문맥 상 명백하게 다르게 지시되지 않는 한 복수의 대상을 포함한다. 따라서, 예를 들어, "항원"에 대한 언급은 하나 이상의 항원을 지칭할 수 있고, "방법"에 대한 언급은 당업자에게 알려진 동등한 단계 및/또는 방법 등에 대한 언급을 포함한다.
본원에서 사용되는, 용어 "약" 또는 "대략"은 수치 앞에 존재하는 경우 10% 범위의 플러스 또는 마이너스 값을 나타낸다. 예를 들어 "약 100"은 90 및 110을 포함한다.
본원에서 사용되는, 뉴클레오티드 서열은 달리 명시되지 않는 한 5'에서 3' 방향으로 나열되고, 아미노산 서열은 N-말단에서 C-말단 방향으로 나열된다.
용어 "폴리펩티드", "펩티드" 및 "단백질"은 임의의 길이의 아미노산 중합체를 지칭하기 위해 본원에서 상호교환적으로 사용된다. 중합체는 선형 또는 분지형일 수 있고, 이것은 변형된 아미노산을 포함할 수 있으며, 이것은 비아미노산이 개재될 수 있다. 이 용어는 또한 변형된 아미노산 중합체를 포함하며; 변형은 예를 들어, 이황화 결합 형성, 글리코실화, 지질화, 아세틸화, 인산화, 또는 임의의 다른 조작, 예를 들어 표지 성분과의 접합을 포함한다. 본원에서 사용되는, 용어 "아미노산"은 글리신 및 D 또는 L 광학 이성질체 둘 다, 그리고 아미노산 유사체 및 펩티드모방체를 포함하는 자연 및/또는 비자연 또는 합성 아미노산을 포함한다.
본원에서 사용되는, 용어 "대상체"는 인간 및 기타 동물을 포함한다. 전형적으로 대상체는 인간이다. 예를 들어, 대상체는 성인, 청소년, 아동(2세 내지 14세), 유아(1개월 내지 24개월), 신생아(1개월 까지)일 수 있다. 일부 실시형태에서, 성인은 약 65세 이상, 또는 약 60세 이상의 노인이다. 일부 실시형태에서, 대상체는 임신한 여성 또는 임신 계획 중인 여성이다. 다른 실시형태에서, 대상체는 인간이 아니며; 예를 들어, 비인간 영장류; 예를 들어, 개코원숭이, 침팬지, 고릴라 또는 마카크이다. 특정 실시형태에서, 대상체는 애완동물, 예를 들어, 개 또는 고양이일 수 있다.
본원에서 사용되는, 용어 "면역원", "항원" 및 "에피토프"는 면역 반응을 유발할 수 있는 물질, 예를 들어, 당단백질을 비롯한 단백질 및 펩티드를 지칭한다.
본원에서 사용되는, 대상체에서의 "면역원성 반응"은 항원에 대한 체액 및/또는 세포 면역 반응의 대상체에서의 발달을 일으킨다.
용어 "유효량" 또는 "치료적 유효량"은 결과를 달성하는 데, 예를 들어, 유익하거나 원하는 결과에 영향을 미치기에 충분한 작용제의 양을 지칭한다. 치료적 유효량은 치료될 대상체 및 질환 상태, 대상체의 체중 및 연령, 질환 상태의 중증도, 투여 방식 등 중 하나 이상에 따라 달라질 수 있으며, 이는 당업자에 의해서 쉽게 결정될 수 있다. 특정 용량은 선택된 특정 작용제, 따라야 할 투여 요법, 다른 화합물과 병용하여 투여되는지의 여부, 투여 시기, 투여되는 조직 및 운반되는 물리적 전달 시스템 중 하나 이상에 따라 달라질 수 있다.
본원에서 사용되는, 용어 "바이러스 유사 입자"(VLP)는 적어도 하나의 속성이 바이러스와 유사하지만 감염성이 입증되지 않은 구조를 지칭한다. 본 개시내용에 따른 바이러스 유사 입자는 바이러스 유사 입자의 단백질을 암호화하는 유전 정보를 전달하지 않는다. 일반적으로, 바이러스 유사 입자는 바이러스 게놈이 없기 때문에 비감염성이다. 또한, 바이러스 유사 입자는 보통 이종 발현에 의해 대량으로 생산될 수 있고 쉽게 정제될 수 있다.
본원에서 사용되는, 아미노산 대체라고 상호교환적으로 지칭되는, 단백질 서열상의 특정 위치에서의 아미노산 치환은 본원에서 다음과 같은 방식으로 표시된다: "WT 아미노산 잔기의 한 글자 코드 - 아미노산 위치 - 이러한 WT 잔기를 대체하는 아미노산 잔기의 한 글자 코드". 예를 들어, R682G 돌연변이체인 스파이크(S) 단백질은 682번째 아미노산 위치의 야생형 잔기(R 또는 아르기닌)가 G 또는 글리신으로 대체된 S 단백질을 지칭한다.
벡터
본 개시내용은 항원을 암호화하는 폴리뉴클레오티드 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는 벡터를 제공한다. 일부 실시형태에서, 벡터는 백신으로 사용되거나 백신 조성물의 일부로 사용된다.
용어 "벡터"는 핵산이 유기체, 세포 또는 세포 성분 사이에서 전파 및/또는 전달될 수 있는 수단을 지칭한다. 본 개시내용에 따라 사용하기 위한 벡터는 당업계에 알려진 임의의 벡터를 포함할 수 있다. 벡터는 플라스미드, 바이러스, 박테리오파지, 프로-바이러스, 파지미드, 트랜스포존, 인공 염색체 등을 포함하며, 자율적으로 복제할 수 있거나 숙주 세포의 염색체에 통합될 수 있다. 벡터는 또한 자율적으로 복제되지 않는 네이키드 RNA 폴리뉴클레오티드, 네이키드 DNA 폴리뉴클레오티드, 동일한 가닥 내의 DNA 및 RNA 둘 다로 구성된 폴리뉴클레오티드, 폴리-라이신-접합 DNA 또는 RNA, 펩티드-접합 DNA 또는 RNA, 리포솜-접합 DNA 등일 수 있다.
일부 실시형태에서, 벡터는 아데노-연관 바이러스(AAV) 벡터, 렌티바이러스 벡터, 레트로바이러스 벡터, 복제 가능 아데노바이러스 벡터, 복제 결핍 아데노바이러스 벡터, 헤르페스 바이러스 벡터, 바큘로바이러스 벡터, 비바이러스 플라스미드, 바이러스 벡터, 플라스미드, 파지, 파지미드, 코스미드, 포스미드, 박테리오파지, 인공 염색체, 또는 아데노바이러스 벡터이다. 일부 실시형태에서, 벡터는 박테리아 인공 염색체(BAC), 플라스미드, 박테리오파지 P1-유래 벡터(PAC), 효모 인공 염색체(YAC), 또는 포유동물 인공 염색체(MAC)이다. 일부 실시형태에서, 벡터는 네이키드 폴리뉴클레오티드이다. 일부 실시형태에서, 벡터는 데옥시리보핵산(DNA) 폴리뉴클레오티드이다. 일부 실시형태에서, 벡터는 리보핵산(RNA) 폴리뉴클레오티드이다.
일부 실시형태에서, 벡터는 제1 항원을 암호화하는 폴리뉴클레오티드 및 제2 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 벡터는 도 1a 또는 도 1b에 도시된 바와 같은 설계를 갖는다. 일부 실시형태에서, 벡터는 CoVEG1이다. 일부 실시형태에서, 벡터는 CoVEG2이다.
표 1은 CoVEG1 및 CoVEG2의 중요한 영역의 핵산 서열, 및 이들 영역에 의해서 암호화된 아미노산 서열을 나타낸다.
[표 1]
i)
발현 카세트
본원에 개시된 벡터는 하나 이상의 발현 카세트를 포함할 수 있다. 본원에서 사용되는 어구 "발현 카세트"는 또 다른 핵산 또는 해당 핵산 분자에 의해 암호화된 단백질의 생산에 필요한 최소 요소를 포함하는 핵산 분자의 정의된 분절을 지칭한다. 일부 실시형태에서, 발현 카세트는 프로모터를 포함한다. 일부 실시형태에서, 프로모터는 발현 카세트의 폴리뉴클레오티드 서열 각각에 작동 가능하게 연결된다.
일부 실시형태에서, 벡터는 발현 카세트를 포함할 수 있고, 발현 카세트는 제1 항원을 암호화하는 폴리뉴클레오티드, 및 제2 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 발현 카세트는 제1 폴리뉴클레오티드에 작동 가능하게 연결된 제1 프로모터; 및 제2 폴리뉴클레오티드에 작동 가능하게 연결된 제2 프로모터를 포함한다. 일부 실시형태에서, 발현 카세트는 제1 폴리뉴클레오티드 및 제2 폴리뉴클레오티드 둘 다에 작동 가능하게 연결된 공유된 프로모터를 포함한다.
일부 실시형태에서, 발현 카세트는 분리 요소(예를 들어, 리보솜 스키핑 부위 또는 2A 요소)를 암호화하는 폴리뉴클레오티드에 의해 연결된 제1 폴리뉴클레오티드 및 제2 폴리뉴클레오티드를 포함하는 코딩 폴리뉴클레오티드를 포함하며, 코딩 폴리뉴클레오티드는 공유된 프로모터에 작동 가능하게 연결된다.
일부 실시형태에서, 발현 카세트는 코딩 폴리뉴클레오티드를 포함하고, 코딩 폴리뉴클레오티드는 분리 요소(예를 들어, 리보솜 스키핑 부위 또는 2A 요소)에 의해서 연결된 인핸서 단백질 및 항원을 암호화하고, 코딩 폴리뉴클레오티드는 공유된 프로모터에 의해서 작동 가능하게 연결된다.
일부 실시형태에서, 발현 카세트는 분리 요소(예를 들어, 리보솜 스키핑 부위 또는 2A 요소)에 의해 연결된 항원 및 인핸서 단백질 둘 다를 암호화하는 단일 메신저 RNA의 전사를 위해 구성되며; 여기서 메신저 RNA의 번역은 항원 및 인핸서 단백질(예를 들어, L 단백질)을 별개의 폴리펩티드로서 발현시킨다. 일부 실시형태에서, 본원에 개시된 발현 카세트는 하나 이상의 단백질분해 절단 부위, 예를 들어, 1, 2, 3, 4, 또는 5개의 단백질분해 절단 부위를 포함한다. 일부 실시형태에서, 단백질분해 절단 부위는 제1 항원을 암호화하는 폴리뉴클레오티드와 제2 항원을 암호화하는 또 다른 폴리뉴클레오티드 사이에 위치된다. 일부 실시형태에서, 단백질분해 절단 부위는 항원을 암호화하는 폴리뉴클레오티드와 인핸서 단백질을 암호화하는 폴리뉴클레오티드 사이에 위치된다. 일부 실시형태에서, 단백질분해 절단 부위는 서열번호 50의 핵산 서열을 포함한다. 일부 실시형태에서, 단백질분해 절단 부위는 푸린 절단 부위이다.
일부 실시형태에서, 본원에 개시된 발현 카세트는 바이러스 액세서리 단백질, 예를 들어 ORF3a 단백질을 암호화하는 핵산 서열을 포함한다. 일부 실시형태에서, ORF3 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 54의 핵산 서열과 적어도 70%의 서열 동일성 - 예를 들어, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, ORF3 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 54의 핵산 서열을 갖는다. 일부 실시형태에서, ORF3 단백질은 서열번호 53의 아미노산 서열과 적어도 70%의 서열 동일성 - 예를 들어, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 아미노산 서열을 갖는다. 일부 실시형태에서, ORF3 단백질은 서열번호 53의 아미노산 서열을 갖는다.
일부 실시형태에서, 벡터는 CoVEG3 내지 CoVEG17로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 벡터는 서열번호 35 내지 서열번호 49로 이루어진 군으로부터 선택된 핵산 서열과 적어도 약 70%의 동일성, 적어도 약 75%, 적어도 약 80%, 적어도 약 85%, 적어도 약 90%, 적어도 약 95%, 적어도 약 96%, 적어도 약 97%, 적어도 약 98%, 적어도 약 99%, 적어도 약 99.5% 또는 약 100%의 동일성을 갖는 핵산 서열을 포함한다. 일부 실시형태에서, 벡터는 서열번호 35 내지 서열번호 49로 이루어진 군으로부터 선택된 핵산 서열과 적어도 70%(예를 들어, 약 75%, 약 80%, 약 85%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 약 99.5%, 또는 약 100%) 동일성을 갖는 핵산 서열을 포함한다.
본원의 CoVEG3 내지 CoVEG17의 발현 카세트 및 유전 요소의 핵산 서열은 표 2에 열거되어 있다.
[표 2]
일부 실시형태에서, 본원에 개시된 벡터는 SARS CoV2 스파이크 단백질을 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 본원에 개시된 벡터는 SARS CoV2 막 단백질을 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 본원에 개시된 벡터는 SARS CoV2 외피 단백질을 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 본원에 개시된 벡터는 SARS CoV2 뉴클레오캡시드 단백질을 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 본원에 개시된 벡터는 EMCV L 단백질을 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 본원에 개시된 벡터는 내부 리보솜 유입 부위(IRES)를 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다. 일부 실시형태에서, 본원에 개시된 벡터는 바이러스 패키징 신호를 암호화하는 CoVEG1 내지 CoVEG17 중 임의의 하나로부터의 폴리뉴클레오티드를 포함한다.
ii)
폴리뉴클레오티드
본 개시내용의 폴리뉴클레오티드는 DNA, RNA 및 DNA-RNA 하이브리드 분자를 포함할 수 있다. 일부 실시형태에서, 폴리뉴클레오티드는 자연 공급원으로부터 단리되거나; 예를 들어, PCR 증폭 또는 화학적 합성과 같은 기술을 사용하여 시험관 내에서 제조되거나; 예를 들어, 재조합 DNA 기술을 통해 생체 내에서 제조되거나; 또는 임의의 적절한 방법으로 제조되거나 입수된다. 일부 실시형태에서, 폴리뉴클레오티드는 임의의 형상(선형, 원형 등) 또는 토폴로지(단일-가닥, 이중-가닥, 선형, 원형, 슈퍼코일형, 비틀림형(torsional), 니킹(nicked) 등)를 갖는다. 폴리뉴클레오티드는 또한 핵산 유도체, 예를 들어, 펩티드 핵산(PNAS) 및 폴리펩티드-핵산 접합체; 적어도 하나의 화학적으로 변형된 당 잔기, 골격, 뉴클레오티드간 연결, 염기, 뉴클레오티드, 뉴클레오시드 또는 뉴클레오티드 유사체 또는 유도체를 갖는 핵산; 뿐만 아니라 화학적으로 변형된 5' 또는 3' 단부를 갖는 핵산; 및 이러한 변형 중 2개 이상을 갖는 핵산을 포함한다. 폴리뉴클레오티드의 모든 연결이 동일할 필요는 없다.
폴리뉴클레오티드는, 그것이 단백질의 아미노산 서열에 상응하는 아미노산 서열을 생산하기 위해서 전사 및 번역(예를 들어, DNA→RNA→단백질) 또는 번역(RNA→단백질)될 수 있는 핵산 서열을 포함하는 경우 단백질을 "암호화한다"라고 한다. 생체 내(예를 들어, 진핵 세포 내에서) 전사 및/또는 번역은 내인성 또는 외인성 효소에 의해서 수행된다. 일부 실시형태에서, 본 개시내용의 폴리뉴클레오티드의 전사는 진핵 세포의 내인성 중합효소 II(polII: polymerase II)에 의해서 수행된다. 일부 실시형태에서, 외인성 RNA 중합효소는 동일하거나 상이한 벡터상에 제공된다. 일부 실시형태에서, 바이러스 중합효소가 대안적으로 또는 추가로 사용될 수 있다. 일부 실시형태에서, 바이러스 프로모터는 하나 이상의 바이러스 중합효소와 조합하여 사용된다. 일부 실시형태에서, RNA 중합효소는 T3 RNA 중합효소, T5 RNA 중합효소, T7 RNA 중합효소, H8 RNA 중합효소, EMCV RNA 중합효소, HIV RNA 중합효소, 인플루엔자 RNA 중합효소, SP6 RNA 중합효소, CMV RNA 중합효소, T3 RNA 중합효소, T1 RNA 중합효소, SP01 RNA 중합효소, SP2 RNA 중합효소, Phi15 RNA 중합효소 등으로부터 선택된다. 바이러스 중합효소는 RNA 프라이밍 또는 캡핑 중합효소이다. 일부 실시형태에서, IRES 요소는 바이러스 중합효소와 함께 사용된다.
본원에 개시된 폴리뉴클레오티드는 하나 이상의 항원; 및/또는 하나 이상의 인핸서 단백질을 암호화할 수 있다. 일부 실시형태에서, 폴리뉴클레오티드는 하나의 항원을 암호화한다. 일부 실시형태에서, 폴리뉴클레오티드는 하나의 인핸서 단백질을 암호화한다. 일부 실시형태에서, 폴리뉴클레오티드는 하나 초과의 항원; 하나 초과의 인핸서 단백질, 및/또는 하나 이상의 분리 요소를 암호화한다.
일부 실시형태에서, 폴리뉴클레오티드는 항원성이 아닌 폴리펩티드를 암호화할 수 있다. 일부 실시형태에서, 항원성이 아닌 폴리펩티드는 VLP의 일부를 형성할 수 있다. 따라서, 본 개시내용은 하나 이상의 항원을 암호화하는 폴리뉴클레오티드, 및/또는 하나 이상의 비항원성 폴리펩티드를 암호화하는 폴리뉴클레오티드, 및/또는 하나 이상의 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 벡터를 제공한다. 일부 실시형태에서, 하나 이상의 항원 및 하나 이상의 비항원성 폴리펩티드는 바이러스 유사 입자(VLP)를 형성할 수 있다. 일부 실시형태에서, 하나 이상의 항원은 제1 바이러스의 하나 이상의 단백질로부터 유래될 수 있고, 하나 이상의 비항원성 폴리펩티드는 제2 바이러스의 하나 이상의 단백질로부터 유래될 수 있다.
iii)
분리 요소
일부 실시형태에서, 본 개시내용에 따른 항원(들) 및 인핸서 단백질(들)은 동일한 벡터상에 암호화된다. 일부 실시형태에서, 본 개시내용에 따른 항원(들) 및 인핸서 단백질(들)은 별도의 벡터상에 암호화된다. 일부 실시형태에서, 하나 이상의 항원 및 하나 이상의 인핸서 단백질을 암호화하는 핵산 서열이 동일한 벡터에 존재하는 경우, 벡터는 단백질의 개별 발현을 위한 분리 요소를 포함할 수 있다. 일부 실시형태에서, 벡터는 바이시스트론성 벡터 또는 폴리시스트론성 벡터이다. 분리 요소는 내부 리보솜 유입 부위(IRES) 또는 2A 요소일 수 있다. 일부 실시형태에서, 벡터는 2A 요소를 암호화하는 핵산, 또는 IRES를 암호화하는 핵산을 포함할 수 있다.
일부 실시형태에서, 제1 폴리뉴클레오티드 또는 제2 폴리뉴클레오티드, 또는 둘 다는 2A 요소를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된다. 일부 실시형태에서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드 및/또는 항원을 암호화하는 폴리뉴클레오티드는 2A 요소를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된다. 2A 요소의 비제한적인 예는 P2A, E2A, F2A, 및 T2A를 포함한다. 일부 실시형태에서, 2A 펩티드의 아미노산 서열은 서열번호 17과 적어도 80%의 서열 동일성(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%(이들 사이의 임의의 값 및 하위 범위 포함)) 동일성을 갖는다. 일부 실시형태에서, 2A 펩티드의 아미노산 서열은 서열번호 17이다.
일부 실시형태에서, 2A 펩티드를 암호화하는 핵산 서열은 서열번호 18 또는 69와 적어도 80%의 서열 동일성(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%(이들 사이의 임의의 값 및 하위 범위 포함))을 갖는다. 일부 실시형태에서, 2A 펩티드를 암호화하는 핵산 서열은 서열번호 18 또는 69이다.
일부 실시형태에서, 제1 폴리뉴클레오티드 또는 제2 폴리뉴클레오티드, 또는 둘 다는 내부 리보솜 유입 부위(IRES)를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된다. 일부 실시형태에서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드 및/또는 항원을 암호화하는 폴리뉴클레오티드는 IRES를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된다. 일부 실시형태에서, IRES 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 24 또는 67의 핵산 서열과 적어도 80%의 서열 동일성(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%(이들 사이의 임의의 값 및 하위 범위 포함))을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, IRES를 암호화하는 폴리뉴클레오티드는 서열번호 24 또는 67의 핵산 서열을 갖는다.
일부 실시형태에서, 항원 및 인핸서 단백질은 단일 융합 단백질에 포함된다. 일부 실시형태에서, 융합 단백질은 연결 요소를 포함할 수 있다. 일부 실시형태에서, 연결 요소는 시스 또는 트랜스의 효소적 절단을 위한 절단 부위(예를 들어 푸린, 카텝신 또는 인테인 절단 부위)를 포함할 수 있다. 다른 실시형태에서, 융합 단백질 또는 연결 요소는 절단 부위를 포함하지 않으며 발현된 융합 단백질은 표적 단백질 및 인핸서 단백질 둘 다를 포함한다. 일부 실시형태에서, 연결 요소는 2A 요소이다.
iv)
프로모터
본 개시내용에 따른 벡터는 하나 이상의 프로모터를 포함할 수 있다. 용어 "프로모터"는 전사를 개시하기 위한 RNA 중합효소 및 다른 단백질의 인식 및 결합에 관여하는 전사 시작으로부터 상류 또는 하류에 위치한 영역 또는 서열을 지칭한다. 본 개시내용에 따른 폴리뉴클레오티드(들) 또는 벡터(들)는 하나 이상의 프로모터를 포함할 수 있다. 프로모터는 당업계에 알려진 임의의 프로모터일 수 있다. 프로모터는 순방향 프로모터 또는 역방향 프로모터일 수 있다. 일부 실시형태에서, 프로모터는 포유동물 프로모터이다. 일부 실시형태에서, 하나 이상의 프로모터는 천연 프로모터이다. 일부 실시형태에서, 하나 이상의 프로모터는 비천연 프로모터이다. 일부 실시형태에서, 하나 이상의 프로모터는 비포유동물 프로모터이다. 개시된 조성물 및 방법에 사용하기 위한 RNA 프로모터의 비제한적인 예는 U1, 인간 연장 인자-1 알파(EF-1 알파), 거대세포바이러스(CMV), 인간 유비퀴틴, 비장 병소 형성 바이러스(SFFV: spleen focus-forming virus), U6, H1, tRNALys, tRNASer 및 tRNAArg, CAG, PGK, TRE, UAS, UbC, SV40, T7, Sp6, lac, araBad, trp, 및 Ptac 프로모터를 포함한다.
본원에서 사용되는 용어 "작동 가능하게 연결된"은 물리적 위치가 아닌 작동 능력에 의해 연결된 핵산 서열의 요소 또는 구조를 지칭한다. 요소 또는 구조는 원하는 작동을 달성할 수 있거나 달성함으로써 특정될 수 있다. 핵산 서열 내의 요소 또는 구조가 작동 가능하게 연결되기 위해 직렬 또는 인접한 순서로 존재할 필요는 없다는 것이 당업자에 의해 인식된다.
일부 실시형태에서, 본 개시내용에 따른 벡터에 포함된 프로모터는 유도성 프로모터이다.
일부 실시형태에서, 본 개시내용에 따른 벡터는 중합효소를 암호화하는 폴리뉴클레오티드 서열을 더 포함할 수 있다. 일부 실시형태에서, 중합효소는 바이러스 중합효소이다. 일부 실시형태에서, 본원에 개시된 벡터는 T7 RNA 중합효소를 암호화하는 폴리뉴클레오티드 서열을 포함한다. 일부 실시형태에서, 예를 들어, 벡터는 항원을 암호화하는 폴리뉴클레오티드와 T7 RNA 중합효소로 제2 인핸서 단백질을 암호화하는 폴리뉴클레오티드 중 어느 하나 또는 둘 다의 전사를 위해서 구성된 T7 프로모터를 포함할 수 있다.
항원
일부 실시형태에서, 항원의 발현 또는 품질은 예를 들어, 하나 이상의 인핸서 단백질과 함께, 개시된 방법에 따른 발현에 의해서 상당히 개선된다. 일부 실시형태에서, 항원은 단일 단백질로부터 유래된다. 일부 실시형태에서, 항원은 다수의 단백질로부터 유래된다. 일부 실시형태에서, 항원은 하나 이상의 단백질로부터의 아미노산 서열을 포함하는 키메라 항원이다.
일부 실시형태에서, 항원은 바이러스 항원이다. 바이러스 항원은 제한 없이 임의의 바이러스 단백질로부터 유래된 아미노산 서열의 전체 또는 일부를 포함할 수 있다. 일부 실시형태에서, 바이러스 항원은 바이러스 단백질이다. 일부 실시형태에서, 바이러스 단백질의 아미노산 서열은 바이러스의 구조 단백질 또는 다수의 구조 단백질의 전체 또는 일부이다. 일부 실시형태에서, 항원 또는 항원은 VLP로 조립되고 발현 세포로부터 방출된다.
일부 실시형태에서, 바이러스 항원은 제한 없이 임의의 코로나바이러스 단백질의 전체 또는 항원 단편을 포함한다. 일부 실시형태에서, 코로나바이러스는 베타코로나바이러스이다. 일부 실시형태에서, 베타코로나바이러스는 중증 급성 호흡기 증후군(SARS) 바이러스이다. 일부 실시형태에서, 베타코로나바이러스는 중동 호흡기 증후군(MERS) 바이러스, OC43, 또는 HKU1이다. 일부 실시형태에서, SARS 바이러스는 SARS-CoV-1이다. 일부 실시형태에서, SARS 바이러스는 SARS-CoV-2이다.
일부 실시형태에서, 바이러스 항원은 다음 단백질 중 임의의 하나 이상의 전체 또는 항원 단편을 포함한다: 코로나바이러스 스파이크 단백질, 코로나바이러스 M 단백질, 코로나바이러스 N 단백질, 및 코로나바이러스 E 단백질.
일부 실시형태에서, 코로나바이러스 스파이크 단백질은 SARS-Cov-2 스파이크 단백질, 중동 호흡기 증후군(MERS) 스파이크 단백질, 및 SARS-CoV 스파이크 단백질로 이루어진 군으로부터 선택된다. 일부 실시형태에서, 코로나바이러스 M 단백질은 SARS-Cov-2 M 단백질, MERS M 단백질 및 SARS-CoV M 단백질로부터 선택된다. 일부 실시형태에서, 코로나바이러스 N 단백질은 SARS-Cov-2 N 단백질, MERS N 단백질, 및 SARS-CoV N 단백질로부터 선택된다. 일부 실시형태에서, 코로나바이러스 E 단백질은 SARS-Cov-2 E 단백질, MERS E 단백질, 및 SARS-CoV E 단백질로부터 선택된다.
일부 실시형태에서, 코로나바이러스 스파이크 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 14 또는 서열번호 70의 핵산 서열과 적어도 70%의 서열 동일성 - 예를 들어, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 코로나바이러스 스파이크 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 14 또는 서열번호 70의 핵산 서열을 갖는다.
일부 실시형태에서, 코로나바이러스 스파이크 단백질의 아미노산 서열은 서열번호 13의 아미노산 서열과 적어도 70%의 서열 동일성 - 예를 들어, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는다. 일부 실시형태에서, 코로나바이러스 스파이크 단백질의 아미노산 서열은 서열번호 13이다.
일부 실시형태에서, SARS-Cov-2 스파이크 단백질은 서열번호 13과 비교할 때 하나 이상의 아미노산 돌연변이를 포함하는 돌연변이체 S 단백질("S (Mut)"라고도 지칭됨)이다. 일부 실시형태에서, 돌연변이체 S 단백질은 야생형 S 단백질과 비교할 때 더 높은 수준으로 발현된다. 일부 실시형태에서, 돌연변이체 S 단백질은 융합전(prefusion) 입체배좌-안정화된 스파이크 단백질이다. 일부 실시형태에서, S 단백질에서의 돌연변이는 S 단백질의 삼량체 상태를 안정화시킨다. 일부 실시형태에서, 돌연변이체 S 단백질은 S 단백질의 내부 내인성 단백질분해 절단 부위에 하나 이상의 돌연변이를 포함한다. 일부 실시형태에서, 돌연변이체 S 단백질은 S 단백질의 내부 내인성 단백질분해 절단 부위의 결실을 포함한다. 일부 실시형태에서, S 단백질의 단백질분해 절단 부위 내의 하나 이상의 돌연변이는 조립 과정 동안 S 단백질의 절단을 저해한다. 일부 실시형태에서, 본원에 개시된 돌연변이체 S 단백질 중 임의의 하나 이상을 포함하는 VLP는 야생형 S 단백질, 예를 들어, 서열번호 13의 아미노산 서열을 포함하는 S 단백질을 포함하는 VLP보다 더 면역원성이다.
일부 실시형태에서, 돌연변이체 S 단백질은 서열번호 13에 R682, R683, A684, R685, K986, 및 V987로 이루어진 군으로부터 선택된 적어도 하나의 아미노산 잔기의 변형(예를 들어, 치환)을 포함한다. 일부 실시형태에서, 돌연변이체 S 단백질은 서열번호 13에 R682G, R683S, R685S, K986P, 및 V987P로 이루어진 군으로부터 선택된 적어도 하나의 아미노산 치환을 포함한다. 일부 실시형태에서, 돌연변이 S 단백질은 서열번호 13에 아미노산 치환, R682G, R683S, R685S, K986P, 및 V987P를 포함한다. 일부 실시형태에서, 돌연변이체 S 단백질은 내부 내인성 푸린 절단 부위에 다음 아미노산 치환을 포함한다: R682G, R683S, R685S. 즉, 일부 실시형태에서, 돌연변이체 S 단백질은 내부 내인성 푸린 절단 부위에 다음 아미노산을 포함한다: 아미노산 잔기 682에서의 G, 아미노산 잔기 683에서의 S, 아미노산 잔기 684에서의 A, 및 아미노산 잔기 685에서의 S.
일부 실시형태에서, 돌연변이체 S 단백질은 서열번호 51의 아미노산 서열과 적어도 70%의 서열 동일성 - 예를 들어, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는다. 일부 실시형태에서, 돌연변이체 S 단백질의 아미노산 서열은 서열번호 51이다.
일부 실시형태에서, 돌연변이체 S 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 52의 핵산 서열과 적어도 70%의 서열 동일성 - 예를 들어, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 코로나바이러스 스파이크 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 52의 핵산 서열을 갖는다.
일부 실시형태에서, 코로나바이러스 M 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 19 또는 서열번호 66의 핵산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 코로나바이러스 M 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 19 또는 서열번호 66의 핵산 서열을 갖는다.
일부 실시형태에서, 코로나바이러스 M 단백질의 아미노산 서열은 서열번호 33의 아미노산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는다. 일부 실시형태에서, 코로나바이러스 M 단백질의 아미노산 서열은 서열번호 33이다.
일부 실시형태에서, 코로나바이러스 N 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 21 또는 서열번호 71의 핵산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 코로나바이러스 N 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 21 또는 서열번호 71의 핵산 서열을 갖는다.
일부 실시형태에서, 코로나바이러스 N 단백질의 아미노산 서열은 서열번호 20의 아미노산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는다. 일부 실시형태에서, 코로나바이러스 N 단백질의 아미노산 서열은 서열번호 20이다.
일부 실시형태에서, 코로나바이러스 E 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 23 또는 서열번호 72의 핵산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 코로나바이러스 E 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 23 또는 서열번호 72의 핵산 서열을 갖는다.
일부 실시형태에서, 코로나바이러스 E 단백질의 아미노산 서열은 서열번호 22의 아미노산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는다. 일부 실시형태에서, 코로나바이러스 E 단백질의 아미노산 서열은 서열번호 22이다.
일부 실시형태에서, 바이러스 단백질은 볼티모어 분류(Baltimore classification)에 따른 바이러스의 군 I, II, III, IV, V, VI, 또는 VII 중 임의의 하나로부터 유래된다. 일부 실시형태에서, 바이러스 단백질은 외피 음성 센스, 단일 가닥, 분절화 RNA 바이러스(예를 들어, 인플루엔자 바이러스)로부터 유래된다. 일부 실시형태에서, 바이러스 단백질은 외피 DNA 바이러스(예를 들어, B형 간염 바이러스)로부터 유래된다. 일부 실시형태에서, 바이러스 단백질은 비외피 DNA 바이러스(예를 들어, 인간 파필로마바이러스)로부터 유래된다. 일부 실시형태에서, 바이러스 단백질은 양성 가닥 외피 RNA 바이러스(예를 들어, 코로나바이러스, 예를 들어, SARS CoV2, 및 플라비바이러스, 예를 들어, 웨스트나일 바이러스)로부터 유래된다. 일부 실시형태에서, 바이러스 항원은 SARS-CoV-1, MERS-CoV, 치쿤구니아(chikungunya) 바이러스, 아프리카 돼지 열병 바이러스, 뎅기 바이러스, 지카 바이러스, 인플루엔자 바이러스(예를 들어, A, B, C), 인간 면역결핍 바이러스(HIV), 에볼라 바이러스, 간염 바이러스(예를 들어, 간염 A, B형 간염, 간염 C, 간염 D, 및 간염 E), 단순 포진 바이러스 타입 1(HSV-1: herpes simplex virus type 1), 단순 포진 바이러스 타입 2(HSV-2: herpes simplex virus type 1), 웨스트나일 바이러스, 및 인간 파필로마바이러스로 이루어진 군으로부터 선택된 바이러스로부터 유래된 임의의 단백질의 전체 또는 항원 단편을 포함한다.
일부 실시형태에서, 바이러스 항원은 웨스트나일 바이러스로부터 유래된 임의의 단백질의 전체 또는 항원 단편을 포함한다. 일부 실시형태에서, 웨스트 나일 바이러스 단백질은 전구체 막(prM), 외피 당단백질(E), 또는 이의 조합물이다. 일부 실시형태에서, 하나 이상의 웨스트나일 바이러스 단백질, 예를 들어, prM 및/또는 E 단백질을 암호화하는 벡터는 도 14a에 도시된 바와 같은 웨스트나일 바이러스 최소 플라스미드(WNV 최소 플라스미드) 또는 도 14b에 도시된 바와 같은 웨스트나일 바이러스 표준 플라스미드(WNV 표준 플라스미드)이다. 일부 실시형태에서, 하나 이상의 웨스트나일 바이러스 단백질, 예를 들어, prM 및/또는 E 단백질을 암호화하는 벡터는 서열번호 55와 적어도 70%(예를 들어, 약 75%, 약 80%, 약 85%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 약 99.5%, 또는 약 100%)의 동일성을 갖는 핵산 서열을 포함한다. 일부 실시형태에서, 하나 이상의 웨스트나일 바이러스 단백질, 예를 들어 prM 및/또는 E 단백질을 암호화하는 벡터는 서열번호 64와 적어도 70%(예를 들어, 약 75%, 약 80%, 약 85%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 약 99.5%, 또는 약 100%)의 동일성을 갖는 핵산 서열을 갖는 발현 카세트를 포함한다.
일부 실시형태에서, 웨스트나일 바이러스 E 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 60의 핵산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 웨스트나일 바이러스 E 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 60의 핵산 서열을 갖는다.
일부 실시형태에서, 웨스트나일 바이러스 prM 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 59의 핵산 서열과 적어도 80%의 서열 동일성 - 예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5%이고, 이들 사이의 임의의 값 및 하위 범위를 포함하는 - 을 갖는 핵산 서열을 갖는다. 일부 실시형태에서, 웨스트나일 바이러스 prM 단백질을 암호화하는 폴리뉴클레오티드는 서열번호 59의 핵산 서열을 갖는다.
본원에 개시된 웨스트 나일 바이러스 항원, 및 그 안의 유전 요소를 암호화하는 벡터의 핵산 서열을 하기 표 3에 열거한다.
[표 3]
일부 실시형태에서, 바이러스 항원은 인플루엔자 바이러스로부터 유래된 임의의 단백질의 전체 또는 항원 단편을 포함한다. 인플루엔자 바이러스의 균주는 제한되지 않으며, 현재 알려지거나 추후에 발견될 임의의 균주, 예를 들어, H1N1, H3N2, 또는 인플루엔자 B 균주일 수 있다. 일부 실시형태에서, 인플루엔자 바이러스 단백질은 HA 단백질, NA 단백질, M1 단백질, M2 단백질, 또는 이의 임의의 조합이다. 일부 실시형태에서, 바이러스 항원은 B형 간염 바이러스로부터 유래된 임의의 단백질의 전체 또는 항원 단편을 포함한다. 일부 실시형태에서, B형 간염 바이러스 단백질은 sAg(S 단백질), sAg(M 단백질), sAg(L 단백질), preS1, preS2, cAg(코어 항원), 또는 이의 임의의 조합이다. 일부 실시형태에서, 바이러스 항원은 인간 파필로마 바이러스로부터 유래된 임의의 단백질의 전체 또는 항원 단편을 포함한다. 일부 실시형태에서, 인간 파필로마 바이러스 단백질은 HPV 6의 L1 단백질, HPV 11의 L1 단백질, HPV 16의 L1 단백질, HPV 18의 L1 단백질, 또는 이의 임의의 조합이다.
일부 실시형태에서, 바이러스 항원은 하기 표 4에 열거된 바이러스 각각으로부터 유래된 단백질 중 임의의 하나 이상의 전체 또는 항원 단편을 포함한다. 예를 들어, 일부 실시형태에서, 바이러스 항원은 조류 인플루엔자 바이러스(H5N3)로부터 유래된 임의의 단백질의 전체 또는 항원 단편을 포함할 수 있다.
[표 4]
인핸서 단백질
어떠한 이론에도 얽매이고자 함은 아니지만, 인핸서 단백질과 항원의 공동 발현은 수율, 품질, 접힘, 번역 후 변형, 활성, 국재화 및 하류 활성을 포함하지만 이에 제한되지 않는 항원 발현의 하나 이상의 양 개선할 수 있거나, 잘못 접힘, 활성 변형, 잘못된 번역 후 변형 및/또는 독성 중 하나 이상을 감소시킬 수 있다.
일부 실시형태에서, 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체이다. 일부 실시형태에서, 피코르나바이러스 리더(L) 단백질은 핵공을 차단함으로써, 핵세포질간 수송(NCT: nucleocytoplasmic transport)을 저해할 수 있다. 본원에서 사용되는, 용어 "기능성 변이체"는 피코르나바이러스 리더(L) 단백질과 상동이고/이거나 피코르나바이러스 리더(L) 단백질과 실질적인 서열 유사성(예를 들어, 30%, 40%, 50%, 60%, 70%, 80%, 85% 90%, 95%, 또는 99% 초과의 서열 동일성)을 공유하는 단백질을 지칭한다. 일부 실시형태에서, 기능성 변이체는 피코르나바이러스 리더(L) 단백질의 하나 이상의 기능성 특징을 공유한다. 예를 들어, 일부 실시형태에서, 피코르나바이러스 리더(L) 단백질의 기능성 변이체는 NCT를 저해하는 능력을 유지한다.
일부 실시형태에서, 피코르나바이러스 리더(L) 단백질은 카디오바이러스, 헤파토바이러스, 또는 아프토바이러스 속으로부터의 L 단백질이다. 예를 들어, 인핸서 단백질은 소 비염 A 바이러스, 소 비염 B 바이러스, 말 비염 A 바이러스, 구제역 바이러스, 헤파토바이러스 A, 헤파토바이러스 B, 마모타 히말라야나(Marmota himalayana) 헤파토바이러스, 포피바이러스, 카디오바이러스 A, 카디오바이러스 B, 테일러 뮤린 뇌척수염 바이러스 바이러스(TMEV: Theiler's Murine encephalomyelitis), 빌류이스크 인간 뇌척수염 바이러스(VHEV: Vilyuisk human encephalomyelitis virus), 테일러 유사 래트 바이러스(TRV: Theiler-like rat virus), 또는 새폴드 바이러스(SAF-V: Saffold virus)로부터 유래될 수 있다.
일부 실시형태에서, 피코르나바이러스 리더(L) 단백질은 테일러 바이러스의 L 단백질 또는 이의 기능성 변이체이다. 일부 실시형태에서, L 단백질은 서열번호 1과 적어도 90%의 동일성을 공유한다. 일부 실시형태에서, 인핸서 단백질은 서열번호 1을 포함하거나 이들로 이루어질 수 있다. 일부 실시형태에서, 인핸서 단백질은 서열번호 1과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100%의 동일성을 공유할 수 있다.
일부 실시형태에서, 피코르나바이러스 리더(L) 단백질은 뇌심근염 바이러스(EMCV: Encephalomyocarditis virus)의 L 단백질 또는 이의 기능성 변이체이다. 일부 실시형태에서, L 단백질은 서열번호 2와 적어도 90%의 동일성을 공유할 수 있다. 일부 실시형태에서, 인핸서 단백질은 서열번호 2를 포함하거나 이것으로 이루어질 수 있다. 일부 실시형태에서, 인핸서 단백질은 서열번호 2와 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100%의 동일성을 공유할 수 있다.
일부 실시형태에서, 인핸서 단백질을 암호화하는 핵산 서열은 서열번호 68을 포함하거나 이것으로 이루어질 수 있다. 일부 실시형태에서, 인핸서 단백질을 암호화하는 핵산 서열은 서열번호 68과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100%의 동일성을 공유할 수 있다.
일부 실시형태에서, 피코르나바이러스 리더(L) 단백질은 폴리오바이러스의 L 단백질, HRV16의 L 단백질, 멩고 바이러스(mengo virus)의 L 단백질, 및 새폴드 바이러스(Saffold virus) 2의 L 단백질 또는 이의 기능성 변이체로 이루어진 군으로부터 선택된다.
일부 실시형태에서, 피코르나바이러스 리더(L) 단백질은 표 5에 열거된 단백질 또는 이의 기능성 변이체로부터 선택된다. 피코르나바이러스 리더(L) 단백질을 암호화하는 폴리뉴클레오티드는 표 2에 열거된 아미노산 서열과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일한 아미노산 서열을 암호화할 수 있다. 피코르나바이러스 리더(L) 단백질의 아미노산 서열은 표 2에 열거된 아미노산 서열과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일할 수 있다. 피코르나바이러스 리더(L) 단백질의 아미노산 서열은 서열번호 1, 2, 3, 4, 5, 6, 또는 12의 아미노산 서열과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 98%, 적어도 99% 또는 100% 동일할 수 있다. 일부 실시형태에서, 인핸서 단백질은 표 2에 열거된 아미노산 서열 중 하나를 포함하거나 이것으로 이루어진 아미노산 서열을 가질 수 있다. 일부 실시형태에서, 인핸서 단백질은 서열번호 1, 2, 3, 4, 5, 6, 또는 12의 아미노산 서열을 포함하거나 이것으로 이루어진 아미노산 서열을 가질 수 있다.
[표 5]
항원, 인핸서 단백질, 및/또는 융합 단백질, 또는 이를 암호화하는 폴리뉴클레오티드는 하나 이상의 마커, 표지, 또는 태그를 포함하도록 변형될 수 있다. 예를 들어, 일부 실시형태에서, 본 개시내용의 단백질은 이의 검출을 가능하게 하는 임의의 표지, 예를 들어, 방사성표지, 형광제, 비오틴, 펩티드 태그, 효소 단편 등으로 표지될 수 있다. 단백질은 친화성 태그, 예를 들어, His-태그, GST-태그, Strep-태그, 비오틴-태그, 면역글로불린 결합 도메인, 예를 들어, IgG 결합 도메인, 칼모둘린 결합 펩티드 등을 포함할 수 있다. 일부 실시형태에서, 본 개시내용의 폴리뉴클레오티드는 선택 가능한 마커, 예를 들어, 항생제 저항성 마커를 포함한다.
바이러스 패키징 신호
일부 실시형태에서, 본원에 개시된 벡터는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드 서열(본원에서 "바이러스 패키징 서열" 또는 패키징 신호" 또는 "psi 서열"이라고 상호 교환 가능하게 지칭됨)을 포함한다. 일부 실시형태에서, 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드 서열은 DNA 폴리뉴클레오티드, RNA 폴리뉴클레오티드, 또는 이의 조합이다. 일부 실시형태에서, 바이러스 패키징 신호는 RNA 폴리뉴클레오티드이다. 일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드 서열의 하나 초과의 카피, 예를 들어, 폴리뉴클레오티드 서열의 2, 3, 4 또는 5개의 카피를 포함한다.
바이러스 패키징 신호는 임의의 바이러스로부터 유래될 수 있다. 일부 실시형태에서, 바이러스 패키징 신호는 벡터로부터 발현되는 항원과 동일한 바이러스로부터 유래된다. 일부 실시형태에서, 바이러스 패키징 신호는 벡터로부터 발현되는 항원과 상이한 바이러스로부터 유래된다. 일부 실시형태에서, 바이러스 패키징 신호는 SARS-CoV-2, SARS-CoV-1, MERS-CoV, 치쿤구니아(chikungunya) 바이러스, 아프리카 돼지 열병 바이러스, 뎅기 바이러스, 지카 바이러스, 인플루엔자 바이러스(예를 들어, A, B, C), 인간 면역결핍 바이러스(HIV), 에볼라 바이러스, 간염 바이러스(예를 들어, 간염 A, B형 간염, 간염 C, 간염 D, 및 간염 E), 단순 포진 바이러스 타입 1(HSV-1), 단순 포진 바이러스 타입 2(HSV-2), 웨스트나일 바이러스, 및 인간 파필로마바이러스로 이루어진 군으로부터 선택된 바이러스로부터 유래된다.
일부 실시형태에서, 바이러스 패키징 요소를 암호화하는 폴리뉴클레오티드는 서열번호 34의 폴리뉴클레오티드와 적어도 약 70%의 동일성(예를 들어, 약 75%, 약 80%, 약 85%, 약 90%, 약 95%, 약 96%, 약 97%, 약 98%, 약 99%, 약 99.5%, 또는 약 100%)을 가지고, 이들 사이의 모든 값 및 하위범위를 포함한다.
벡터상의 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드의 위치는 제한되지 않는다. 일부 실시형태에서, 벡터상의 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드의 위치는 바이러스 항원을 암호화하는 핵산 서열 모두에 대해서 5'일 수 있다. 일부 실시형태에서, 벡터상의 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드의 위치는 바이러스 항원을 암호화하는 핵산 서열 모두에 대해서 3'일 수 있다. 일부 실시형태에서, 벡터상의 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드의 하나의 카피의 위치는 바이러스 항원을 암호화하는 핵산 서열 모두에 대해서 5'이고, 바이러스 항원을 암호화하는 폴리뉴클레오티드의 다른 카피의 위치는 바이러스 항원을 암호화하는 핵산 서열 모두에 대해서 3'이다. 또한, 바이러스 패키징 신호의 크기는 제한되지 않고, 약 50 bp부터, 약 3 kb, 예를 들어, 약 100 bp, 약 200 bp, 약 300 bp, 약 400 bp, 약 500 bp, 약 550 bp, 약 600 bp, 약 650 bp, 약 700 bp, 약 800, bp, 약 900 bp, 약 1 kb, 약 2 kb, 또는 약 3 kb이고, 이들 사이의 모든 값 및 하위범위를 포함하는 범위일 수 있다. 일부 실시형태에서, 바이러스 패키징 신호의 크기는 약 600 bp 내지 약 700 bp, 예를 들어, 약 650 bp이다. 일부 실시형태에서, 바이러스 패키징 신호의 크기는 약 661 bp이다.
본 개시내용은 발현 카세트를 포함하는 벡터를 더 제공하며, 상기 발현 카세트는 표적 유전자에 연결된 프로모터를 포함하고, 여기서 벡터는 본원에 개시된 바이러스 패키징 요소 중 임의의 하나를 암호화하는 폴리뉴클레오티드를 포함한다.
발현 카세트에서 유전 요소의 순서
본원에 개시된 벡터에서, 하나 이상의 바이러스 항원을 암호화하는 폴리뉴클레오티드 서열, 및 인핸서를 암호화하는 폴리뉴클레오티드 서열, 및/또는 하나 이상의 조절 요소(예를 들어, IRES 서열을 암호화하는 폴리뉴클레오티드, CMV 단백질, 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드, 및 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드)는 임의의 가능한 조합으로 정렬될 수 있다. 예를 들어, 발현 카세트에서 요소의 순서는 도 6의 플라스미드 CoVEG3 내지 CoVEG17 중 임의의 하나에 대해서 도시된 바와 같을 수 있다. 이론에 얽매이고자 함은 아니지만, 발현 카세트에서 요소의 순서는 벡터에 의해서 암호화된 항원의 발현 및/또는 VLP의 형성에 관련될 수 있다고 생각된다. 또한, 발현 카세트가 5'에서 3'로 - M, N, S, 및 E - 의 순서로 유전자를 포함하는 경우 그것은 더 높은 단백질 발현 및 더 안정적인 VLP 형성을 일으킬 수 있다고 생각된다.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 이는 CoVEG3과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트틀 포함하고, 이는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 제1 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 제2 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 제2 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG4와 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG5와 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 및 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG6과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG7과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG8과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG9와 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG10과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징을 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG11과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징을 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG12와 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 이는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG13과 동일한 5'에서 3' 순서로 요소를포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG14와 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징을 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 53 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 ORF3a를 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG15와 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG16과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 53 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 ORF3a를 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드.
일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 CoVEG17과 동일한 5'에서 3' 순서로 요소를 포함한다. 일부 실시형태에서, 벡터는 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 53을 포함하는 ORF3a를 암호화하는 폴리뉴클레오티드 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드.
세포에서 항원 및 VLP의 발현
본 개시내용은 세포를 본원에 개시된 벡터 중 임의의 하나와 접촉시키는 것을 포함하는, 진핵 세포에서 항원을 발현시키는 방법을 제공한다. 일부 실시형태에서, 벡터는 시험관 내, 생체 외 또는 생체 내에서 세포와 접촉된다. 일부 실시형태에서, 벡터는 대상체에서 세포(생체 내)와 접촉된다.
일부 실시형태에서, 하나 이상의 항원의 발현은 바이러스 유사 입자(VLP)의 형성을 초래한다. 일부 실시형태에서, VLP는 면역원성이다. 일부 실시형태에서, VLP는 대상체에서 면역 반응을 유발할 수 있다. 일부 실시형태에서, VLP는 외피로 싸여 있다. 일부 실시형태에서, VLP는 외피로 싸여 있지 않다. VLP에 존재하는 항원의 수는 제한되지 않는다. 일부 실시형태에서, VLP는 1개의 항원, 2개의 항원, 3개의 항원, 4개의 항원, 5개의 항원, 6개의 항원, 7개의 항원, 8개의 항원, 9개의 항원, 10개의 항원, 또는 더 많은 수의 항원을 포함한다. 일부 실시형태에서, VLP는 3개의 항원을 포함한다. 일부 실시형태에서, VLP는 4개의 항원을 포함한다. 일부 실시형태에서, VLP를 형성하는 구조 단백질 및 VLP의 일부인 면역원성 바이러스 항원은 동일한 바이러스(즉, 천연 VLP)로부터 유래된다. 일부 실시형태에서, VLP를 형성하는 구조 바이러스 단백질은 하나의 바이러스로부터 유래되고 상기 VLP에 혼입되는 면역원성 바이러스 항원은 또 다른 바이러스로부터 유래된다(즉, 키메라 VLP). 일부 실시형태에서, 바이러스 단백질은 VLP 조립, VLP 분비 및/또는 상기 VLP에 대한 면역원성 항원 또는 항원의 로딩을 향상시키도록 돌연변이된다.
일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드를 포함하여, 세포와 벡터의 접촉은 바이러스 패키징 신호의 발현을 일으킨다. 일부 실시형태에서, VLP는 바이러스 패키징 신호를 캡시드화한다. 일부 실시형태에서, 바이러스 패키징 신호의 발현은 VLP의 형성을 증가시키거나 촉진시킨다. 일부 실시형태에서, 바이러스 패키징 신호의 부재 하에서와 비교할 때 바이러스 패키징 신호의 존재 하에서 더 많은 수의 VLP가 형성된다. 일부 실시형태에서, 세포와 바이러스 패키징 신호를 암호화하는 개시된 벡터 중 임의의 하나의 접촉은 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드가 없는 대조군 벡터와 비교할 때 더 많은 수의 VLP의 발현을 일으킨다. 일부 실시형태에서, 세포와 바이러스 패키징 신호를 암호화하는 개시된 벡터 중 임의의 하나의 접촉은 VLP 내에서 바이러스 패키징 신호의 패키징을 일으키는데, 이것은 결국 개선된 아주베이팅(adjuvating) 특징 또는 다른 기전으로 인해서 향상된 면역 반응으로 이어진다. 일부 실시형태에서, 패키징 신호 및 단백질은 VLP가 형성되는 동일한 바이러스로부터 유래된다(즉, 천연 패키징). 일부 실시형태에서, 패키징 신호 및 단백질은 알려진 패키징 기전(즉, 키메라 패키징)을 갖는 또 다른 바이러스로부터 유래된다.
일부 실시형태에서, 발현 카세트는 제1 항원, 제2 항원, 제3 항원, 제4 항원, 또는 이의 조합을 암호화하는 폴리뉴클레오티드 서열을 포함한다. 일부 실시형태에서, 발현 카세트는 제1 항원, 제2 항원, 및 제3 항원을 암호화하는 폴리뉴클레오티드 서열을 포함한다. 일부 실시형태에서, 발현 카세트는 제1 항원, 제2 항원, 제3 항원, 및 제4 항원을 암호화하는 폴리뉴클레오티드 서열을 포함한다.
일부 실시형태에서, 제1 항원은 코로나바이러스 스파이크 단백질이고, 제2 항원은 코로나바이러스 막(M) 단백질이며, 제3 항원은 코로나바이러스 외피(E) 단백질이다. 일부 실시형태에서, 제1 항원은 코로나바이러스 스파이크 단백질이고, 제2 항원은 코로나바이러스 막(M) 단백질이며, 제3 항원은 코로나바이러스 외피(E) 단백질이고, 제4 항원은 코로나바이러스 뉴클레오캡시드(N) 단백질이다.
일부 실시형태에서, 벡터는 인핸서 단백질이 없는 벡터와 비교할 때 (i)더 높은 발현 수준에서의 항원의 발현; 및/또는 (ii)더 긴 시간 기간 동안의 발현; 및/또는 (iii)더 양호한 단백질 품질을 갖는 항원의 발현을 일으킨다. 일부 실시형태에서, 벡터는 인핸서 단백질이 없는 벡터보다 (i)더 높은 발현 수준에서의 항원을 포함하는 바이러스 유사 입자(VLP)의 발현; 및/또는 (ii)더 긴 시간 기간 동안의 항원을 포함하는 VLP의 발현; 및/또는 (iii)더 양호한 단백질 품질을 갖는 항원을 포함하는 VLP의 발현을 일으킨다. 본원에서 사용되는, "단백질 품질"은 비제한적으로 단백질 접힘, 번역 후 변형, 기능성 활성, 국재화 및 하류 활성을 지칭할 수 있다. 따라서, 일부 실시형태에서, 본원에 개시된 방법 또는 벡터 또는 조성물 중 임의의 것을 사용하여 인핸서 단백질과 함께 공동 발현되는 항원은 인핸서 단백질과 함께 공동 발현되지 않은 항원과 비교할 때 개선된 단백질 접힘, 개선된 번역 후 변형, 개선된 기능성 활성, 개선된 국재화 및 개선된 하류 활성을 가질 수 있다.
본원에서 사용되는, 용어 "형질주입", "형질도입" 및 "형질전환"은 핵산을 세포(예컨대, 진핵 세포) 내로 도입하는 과정을 지칭한다. 본원에 개시된 벡터는 당업계에 알려진 임의의 방법을 사용하여 세포(예를 들어, 진핵 세포) 내로 도입될 수 있다. 예를 들어, 벡터는 화학적, 물리적, 생물학적 또는 바이러스 수단을 사용하여 세포 내로 도입될 수 있다. 벡터를 세포 내로 도입하는 방법은, 인산칼슘, 덴드리머, 양이온성 중합체, 리포펙션, 푸진(fugene), 세포 투과 펩티드, 펩티드 덴드리머, 전기천공, 세포 압착, 초음파천공(sonoporation), 광학 형질주입, 원형질체 융합, 임페일펙션(impalefection), 유체역학적 전달, 유전자 총, 마그네토펙션(magnetofection), 입자 충격, 뉴클레오펙션, 바이러스 형질도입, 주입, 형질전환, 형질주입, 직접 흡수, 발사체 충격(projectile bombardment) 및 리포솜을 포함하지만 이에 제한되지 않는다. 방법의 다른 비제한적인 예는 바이러스 형질주입, 직접 흡수, 발사체 충격, 전기천공/초음파천공을 사용하거나 사용하지 않는 직접 주입을 포함하며 이들은 양이온성 중합체, 지질, 지질 제형 및 제트 유전자 장치를 사용하거나 또는 사용하지 않는다. 항원 및 인핸서 단백질은 발현 벡터를 사용하여 세포에서 안정적으로 또는 일시적으로 발현될 수 있다. 진핵 세포에서의 발현 기술은 당업자에게 잘 알려져 있다. (문헌[Current Protocols in Human Genetics: Chapter 12 "Vector Therapy" & Chapter 13 "Delivery Systems for Gene Therapy"] 참조).
일부 실시형태에서, 벡터는 선택적으로 렌티바이러스 형질주입, 포유동물 세포 내로의 바큘로바이러스 유전자 전달(BacMam), 레트로바이러스 형질주입, CRISPR/Cas9 및/또는 트랜스포존의 사용을 통해, 안정적인 세포주를 생산하기 위한 표준 방법을 사용하여 게놈 내로 삽입됨으로써 숙주 세포 내로 도입될 수 있다. 일부 실시형태에서, 폴리뉴클레오티드 또는 벡터는 일시적인 형질주입을 위해 숙주 세포 내로 도입될 수 있다. 일부 실시형태에서, 일시적인 형질주입은 바이러스 벡터, 헬퍼 지질, 예를 들어, PEI, Lipofectamine 및/또는 Fectamine 293의 사용을 통해 수행될 수 있다. 유전 요소는, 예를 들어, 벡터상의 DNA로서 또는 예를 들어, PCR로부터의 RNA로서 암호화될 수 있다. 유전 요소는 상이한 벡터에서 분리되거나 동일한 벡터상에서 조합될 수 있다.
항원 및 인핸서 단백질을 발현시키기 위해서 사용되는 숙주 세포는 제한되지 않으며, 원핵생물 숙주(예를 들어, 이. 콜라이(E. coli)) 또는 진핵생물 숙주(예를 들어, 사카로마이세스 세레비지애(Saccharomyces cerevisiae), 곤충 세포, 예를 들어, Sf21 세포, 또는 포유동물 세포주 및 1차 세포, 예를 들어, NIH 3T3, HeLa, COS 세포)를 포함할 수 있다. 이러한 세포는 광범위한 공급원(예를 들어, American Type Culture Collection(미국 메릴랜드주 록랜드 소재); 예를 들어, 상기 문헌[Ausubel et al.] 참조)으로부터 입수될 수 있다. 곤충 세포의 비제한적인 예는 스포도프테라 프루기페르다(Spodoptera frugiperda)(SI) 세포, 예를 들어, Sf9, Sf21, 트리코플루지아 니(Trichoplusia ni) 세포, 예를 들어, 하이 파이브(High Five) 세포, 및 드로소필라(Drosophila) S2 세포이다. (효모를 포함하는) 진균 숙주 세포의 예는 S 세레비지애, 클루이베로마이세스 락티스(K lactis: Kluyveromyces lactis), 칸디다 알비칸스(C. albicans) 및 칸디다 글라브라타(C. glabrata)를 포함하는 칸디다 종, 아스퍼길루스 니둘란스(Aspergillus nidulans), 쉬조사카로마이세스 폼베(S. pombe: Schizosaccharomyces pombe), 피키아 파스토리스(Pichia pastoris), 및 야로위아 리폴라이티카(Yarrowia lipolytica)이다. 포유동물 세포의 예는 COS 세포, 새끼 햄스터 신장 세포, 마우스 L 세포, LNCaP 세포, 중국 햄스터 난소(CHO: Chinese hamster ovary) 세포, 인간 배아 신장(HEK: human embryonic kidney) 세포, 아프리카 녹색 원숭이 세포, CV1 세포, HeLa 세포, MDCK 세포, Vero 및 Hep-2 세포이다. 아프리카발톱개구리(Xenopus laevis) 난모세포, 또는 양서류 유래의 다른 세포도 사용될 수 있다. 원핵생물 숙주 세포는 박테리아 세포, 예를 들어, 이. 콜라이, 바실러스 서브틸리스(B. subtilis) 및 마이코박테리아를 포함한다.
백신 조성물
본 개시내용은 본원에 개시된 벡터 중 임의의 하나, 및 적어도 하나의 약제학적으로 허용 가능한 담체, 부형제, 및/또는 비히클, 예를 들어, 용매, 완충액, 용액, 분산 배지, 코팅, 항박테리아 및 항진균제, 등장 및 흡수 지연제를 포함하는 백신 조성물을 제공한다. 본원에서 사용되는, 용어 "약제학적으로 허용 가능한"은 포유동물, 보다 특별하게는 인간에서 사용하기 위해 연방 또는 주 정부의 규제 기관에 의해 승인되거나 미국 약전, 유럽 약전 또는 기타 일반적으로 인정되는 약전에 열거되어 있음을 의미한다. 일부 실시형태에서, 약제학적으로 허용 가능한 담체, 부형제 및/또는 비히클은 식염수, 완충 식염수, 덱스트로스, 물, 글리세롤, 멸균 등장성 수성 완충액 및 이의 조합을 포함할 수 있다. 일부 실시형태에서, 약제학적으로 허용 가능한 담체, 부형제 및/또는 비히클은 인산염 완충 식염수, 멸균 식염수, 락토스, 수크로스, 인산칼슘, 덱스트란, 한천, 펙틴, 땅콩유, 참깨유, 약제학적 등급의 만니톨, 락토스, 전분, 스테아르산마그네슘, 사카린나트륨, 셀룰로스, 탄산마그네슘, 폴리올(예를 들어, 글리세롤, 프로필렌 글리콜 및 액체 폴리에틸렌 글리콜 등) 또는 이의 적합한 혼합물을 포함한다. 일부 실시형태에서, 본원에 개시된 조성물은 소량의 유화제 또는 습윤제, 또는 pH 완충제를 더 포함한다.
일부 실시형태에서, 조성물은 고체 형태, 예를 들어, 재구성에 적합한 동결건조 분말, 액체 용액, 현탁액, 에멀젼, 정제, 환제, 캡슐, 지속 방출형 제형 또는 분말이다. 일부 실시형태에서, 전달 비히클, 예를 들어, 리포솜, 나노캡슐, 나노입자, 미세입자, 미세구, 지질 입자, 소포, 중합체, 펩티드 등이 본원에 개시된 벡터 및 백신 조성물을 적합한 숙주 세포 내로 도입하기 위해 사용될 수 있다. 일부 실시형태에서, 본원에 개시된 벡터 및 백신 조성물은 지질 입자, 리포솜, 소포, 나노구, 또는 나노입자 등에 캡슐화되어 전달되도록 제형화될 수 있다.
일부 실시형태에서, 본원에 개시된 조성물은 다른 종래의 약제학적 성분, 예를 들어, 보존제 또는 화학적 안정제(예를 들어, 클로로부탄올, 소르빈산칼륨, 소르브산, 이산화황, 프로필 갈레이트, 파라벤, 에틸 바닐린, 글리세린, 페놀, 파라클로로페놀 또는 알부민을 포함한다. 일부 실시형태에서, 본원에 개시된 조성물은 항박테리아 및 항진균제, 예를 들어, 파라벤, 클로로부탄올, 페놀, 소르브산 또는 티메로살; 등장화제, 예를 들어, 당 또는 염화나트륨 및/또는 흡수 지연제, 예를 들어, 알루미늄 모노스테아레이트 및 젤라틴을 포함한다.
일부 실시형태에서, 백신 조성물은 아주반트를 포함한다. 본원에서 사용되는, 용어 "아주반트"는 면역원과 조합하여 사용될 때 면역원에 대해 유도된 면역 반응을 증가시키거나 달리 변경 또는 변형시키는 화합물을 지칭한다. 면역 반응의 변형은 항체 및 세포 면역 반응 중 하나 또는 둘 다의 특이성을 강화하거나 확대하는 것을 포함할 수 있다.
일부 실시형태에서, 아주반트는 명반이다. 일부 실시형태에서, 아주반트는 모노포스포릴 지질 A(MPL)이다. 일부 실시형태에서, 다른 아주반트가 추가로 또는 대안으로서 사용될 수 있다. 사실상 그 전체 내용이 본원에 인용되어 포함된 문헌[Vogel et al., "A Compendium of Vaccine Adjuvants and Excipients (2nd Edition)"]에 기재된 임의의 아주반트의 포함은 본 개시내용의 범주 내에서 예상된다. 다른 아주반트는 완전 Freund 아주반트(사멸된 마이코박테리움 투베르쿨로시스(Mycobacterium tuberculosis)를 함유하는 면역 반응의 비특이적 자극인자), 불완전 Freund 아주반트 및 수산화알루미늄 아주반트, GMCSP, BCG, MDP 화합물, 예를 들어, thur-MDP 및 nor-MDP, CGP(MTP-PE), 지질 A, 및 모노포스포릴 지질 A(MPL), MF-59, RIBI를 포함하며, 이것은 2% 스쿠알렌/트윈(Tween)® 80 에멀젼에서 박테리아, MPL, 트레할로스 디미콜레이트(TDM: trehalose dimycolate) 및 세포벽 골격(CWS: cell wall skeleton)으로부터 추출된 3개의 성분을 함유한다. 일부 실시형태에서, 아주반트는 파우시라멜라(paucilamellar) 지질 소포; 예를 들어, Novasomes®일 수 있다. Novasomes®은 약 100 nm 내지 약 500 nm 범위의 파우시라멜라 비인지질 소포이다. 이것은 Brij 72, 콜레스테롤, 올레산 및 스쿠알렌을 포함한다. Novasomes은 효과적인 아주반트인 것으로 나타났다(미국 특허 제5,629,021호, 제6,387,373호 및 제4,911,928호 참조). 일부 실시형태에서, 조성물은 첨가된 아주반트가 없을 수 있다. 강력한 면역 반응을 유도하는 명반 무함유 조성물이 60세 이상의 성인에서 특히 유용하다.
대상체에서 면역 반응을 유빌하는 방법
본 개시내용은 본원에 개시된 백신 조성물 중 임의의 하나의 유효량을 대상체에게 투여하는 것을 포함하는, 대상체에서 면역 반응을 유발하는 방법을 더 제공한다. 일부 실시형태에서, 대상체의 투여 부위의 조직은 항원 및/또는 항원을 포함하는 VLP를 발현한다. 일부 실시형태에서, 대상체의 투여 부위의 조직은 인핸서 단백질이 없는 벡터가 투여되는 경우와 비교할 때 (i)항원 및/또는 항원을 포함하는 VLP를 더 높은 발현 수준으로 발현하고; 그리고/또는 (ii)항원 및/또는 항원을 포함하는 VLP을 더 긴 시간 기간 동안 발현하고; 그리고/또는 (iii)더 양호한 단백질 품질을 갖는 항원 및/또는 항원을 포함하는 VLP를 발현한다.
일부 실시형태에서, 방법은 대상체에서 항체 반응을 유발한다. 일부 실시형태에서, 항체 반응은 중화 항체 반응이다. 일부 실시형태에서, 방법은 세포 면역 반응을 유발한다. 일부 실시형태에서, 방법은 대상체에서 예방학적, 예방적 및/또는 치료적 면역 반응을 유발한다.
일부 실시형태에서, 벡터는 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드를 포함하여, 대상체의 투여 부위의 조직은 바이러스 패키징 신호를 발현한다. 일부 실시형태에서, VLP는 바이러스 패키징 신호를 캡시드화한다. 일부 실시형태에서, VLP는 바이러스 패키징 신호를 포함하는 폴리뉴클레오티드를 캡시드화한다. 일부 실시형태에서, VLP는 바이러스 패키징 신호로 이루어진 폴리뉴클레오티드를 캡시드화한다. 일부 실시형태에서, 바이러스 패키징 신호를 캡시드화하는 VLP는 항원을 포함하지만 바이러스 패키징 신호가 없는 대조군 VLP보다 더 양호한 면역원성이다. 이론에 얽매이고자 함은 아니지만, 바이러스 패키징 신호의 부재 하에서와 비교할 때 바이러스 패키징 신호의 존재 하에서 더 많은 수의 VLP가 형성될 수 있다고 생각된다. 따라서, 일부 실시형태에서, 바이러스 패키징 신호를 암호화하는 개시된 벡터는 바이러스 패키징 신호를 암호화하지 않는 대조군 벡터와 비교할 때, 더 많은 수의 VLP의 형성을 촉진한다. 이론에 얽매이고자 함은 아니지만, RNA 바이러스 패키징 신호는 또한 톨 유사 수용체(TLR: Toll-like Receptor)의 효능제로서 작용함으로써 아주반트로서 작용할 수 있다고 생각된다.
본원에 개시된 조성물 또는 벡터 중 임의의 하나를 투여하는 방법은 비경구 투여(예를 들어, 피부내, 근육내, 정맥내 및 피하), 경막외 및 점막(예를 들어, 비강내 및 경구 또는 폐 경로 또는 좌제에 의해서), 피부하 및 복강내를 포함하지만 이에 제한되지 않는다. 일부 실시형태에서, 본 발명의 조성물은 근육내, 정맥내, 피하, 경피 또는 피부내로 투여된다. 조성물 또는 벡터는 임의의 편리한 경로로, 예를 들어, 주입 또는 볼러스 주사로, 상피 또는 점막피부 내막(mucocutaneous lining)(예를 들어, 구강 점막, 결장, 결막, 비인두, 구인두, 질, 요도, 방광 및 장점막 등)을 통한 흡수로 투여될 수 있고, 다른 생물학적 활성제와 함께 투여될 수 있다. 일부 실시형태에서, 투여는 피부내 투여이다. 일부 실시형태에서, 투여는 근육내 투여이다. 일부 실시형태에서, 투여는 피하 투여이다. 일부 실시형태에서, 투여는 비강내 투여이다. 일부 실시형태에서, 본원에 개시된 조성물 또는 벡터는 주사에 의해서 투여된다. 일부 실시형태에서, 주사는 바늘, 주사기, 미세바늘 또는 무바늘 장치를 사용하여 수행된다. 일부 실시형태에서, 본원에 개시된 조성물 또는 벡터는 점적액, 큰 입자 에어로졸(약 10 미크론 초과)에 의해서 비강내로 투여되거나 또는 상기도 내로 스프레이되거나 또는 작은 입자 에어로졸(10 미크론 미만) 또는 하기도 내로의 스프레이에 의해서 투여된다. 일부 실시형태에서, 주사 이후에 전기천공이 이어진다.
본원에 개시된 벡터 또는 백신 조성물은 단회 투여 일정 또는 다회 투여 일정으로 투여될 수 있다. 다회 투여는 1차 면역화 일정 또는 부스터 면역화 일정으로 사용될 수 있다. 다회 투여 일정에서 다양한 용량이 동일한 경로 또는 상이한 경로, 예를 들어, 비경구 프라임과 점막 부스트, 점막 프라임과 비경구 부스트 등으로 제공될 수 있다. 일부 양태에서, 이전 용량 후 약 1시간 내지 약 수 년(예를 들어, 약 12시간, 약 1일, 약 2일, 약 5일, 약 1주, 약 2주, 약 3주, 약 4주, 약 5주, 약 6주, 약 1개월, 약 6개월, 약 1년, 약 2년이고, 이들 사이의 모든 값 및 하위범위를 포함하는) 기간 이내에 후속 부스트 용량이 투여된다.
면역원성 효과
일부 실시형태에서, 하나 이상의 바이러스 항원 단백질을 암호화하는 폴리뉴클레오티드에 인핸서 단백질을 포함시키는 것은 인핸서 단백질이 없는 폴리뉴클레오티드에 비해서 기능성 바이러스 유사 입자(VLP) 생산을 증가시킨다. 일부 실시형태에서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 벡터에 비해서 기능성 VLP 생산을 약 10%, 약 20%, 약 30%, 약 40%, 약 50%, 약 60%, 약 70%, 약 80%, 약 90%, 약 100%, 약 125%, 약 150%, 약 175%, 약 200%, 약 250%, 약 300%, 약 350%, 약 400%, 약 500%, 또는 약 1000% 증가시킨다. 본원에서 사용되는 기능성 VLP 생산은 단백질 응집 수준, 생체 내에서 중화 항체의 역가, 유도된 Th1 반응, VLP 반감기에 대한 시간 경과에 따른 VLP의 양, 및/또는 잘못 접힌 VLP와 연관된 세포 사멸을 포함하지만 이들로 제한되지 않는, 당업계에 알려진 방법에 의해서 측정될 수 있다.
일부 실시형태에서, 하나 이상의 바이러스 항원 단백질을 암호화하는 폴리뉴클레오티드에 인핸서 단백질을 포함시키는 것은 인핸서 단백질이 없는 백신 조성물에 비해서 대상체에서 중화 항체의 기간 또는 양을 증가시킨다. 일부 실시형태에서 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 대상체에서 중화 항체의 기간 또는 양을 약 2배, 약 3배, 약 4배, 약 5배, 약 6배, 약 7배, 약 8배, 약 9배, 또는 약 10배 증가시킨다.
일부 실시형태에서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 Th1 세포 반응을 증가시킨다. 일부 실시형태에서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 Th1 반응을 약 25%, 약 50%, 약 100%, 약 200%, 약 300%, 약 400%, 약 500%, 또는 약 1000% 증가시킨다.
키트 및 제조 물품
본 개시내용은 본원에 개시된 벡터 중 임의의 하나 이상을 포함하는 키트를 제공한다. 본 개시내용은 본원에 개시된 폴리뉴클레오티드 중 임의의 하나 이상을 포함하는 키트를 더 제공한다. 본 개시내용은 또한 본원에 개시된 백신 조성물 중 임의의 하나 이상을 포함하는 키트를 제공한다. 본원에 개시된 키트는 개시된 방법을 수행하거나 이의 성능을 보조하는 데 유용하다. 일부 실시형태에서, 키트는 약제학적으로 허용 가능한 담체를 포함한다. 일부 실시형태에서, 키트는 제품 또는 제형의 적절한 사용 및 안전성 정보에 대한 설명서를 포함한다. 일부 실시형태에서, 키트는 의사에 의해서 결정되는 적용 및 투여 방법에 기초한 투여량 정보를 포함한다.
본 출원은 또한 본원에 기재된 백신 조성물 또는 키트 중 임의의 하나를 포함하는 제조 물품을 제공한다. 제조 물품의 예는 바이알(예를 들어, 밀봉된 멸균 바이알)을 포함한다.
일부 실시형태에서, 키트는 본원에 개시된 백신 조성물의 성분 중 하나 이상으로 충전된 하나 이상의 용기 또는 바이알을 포함한다. 일부 실시형태에서, 키트는 2개의 용기를 포함하는데, 하나는 본원에 개시된 벡터, 또는 폴리뉴클레오티드, 또는 백신 조성물을 함유하고, 나머지는 아주반트를 함유한다. 일부 실시형태에서, 키트는 인간 투여를 위한 제조, 사용 또는 판매에 대한 정부 기관의 승인을 반영하는 통지를 더 포함한다.
본 발명은 제한으로 해석되어서는 안 되는 다음 추가 실시예에 의해 더 설명된다. 당업자는, 본 개시내용에 비추어, 개시된 특정 실시형태에 대해 많은 변경이 이루어질 수 있고 본 발명의 사상 및 범주를 벗어나지 않고 여전히 같거나 유사한 결과를 얻을 수 있음을 이해할 수 있을 것이다.
실시예
실시예 1: SARS-CoV-2 및 L 단백질을 암호화하는 폴리뉴클레오티드의 작제
CoVEG1 및 CoVEG2 플라스미드는 SARS-CoV-2 및 L 인핸서 단백질을 암호화한다.
플라스미드 CoVEG1은 SARS-CoV-2의 전장 S 단백질(서열번호 14), M 단백질(서열번호 19), 및 E 단백질(서열번호 23)의 바이러스 단백질을 암호화하는 폴리뉴클레오티드를 포함한다. 플라스미드 CoVEG2는 SARS-CoV-2의 전장 S 단백질, M 단백질, N 단백질(서열번호 21) 및 E 단백질의 바이러스 단백질을 암호화하는 폴리뉴클레오티드를 포함한다. CoVEG1 및 CoVEG2 플라스미드의 골격은 도 1에 도시되어 있다. 추가로, CoVEG1 및 CoVEG2 플라스미드는 또한 EMCV로부터의 L 단백질을 암호화하는 폴리뉴클레오티드(서열번호 16)를 포함한다.
CoVEG2 내의 완전한 삽입물의 핵산 서열이 서열번호 30에 나타나 있다. 표 1을 참조한다. 이 작제물의 발현은 3개의 폴리펩티드, 즉, 서열번호 13의 아미노산 서열을 갖는 SARS-CoV-2 스파이크 단백질, 서열번호 25의 아미노산 서열을 갖는 CoVEG2 폴리펩티드 1, 및 서열번호 26의 아미노산 서열을 갖는 CoVEG2 폴리펩티드 2를 생성시킨다. CoVEG1 내의 삽입물의 핵산 서열이 서열번호 31에 나타나 있다. 이 작제물의 발현은 2개의 폴리펩티드, 즉, 서열번호 13의 아미노산 서열을 갖는 SARS-CoV-2 스파이크 단백질, 및 서열번호 32의 아미노산 서열을 갖는 CoVEG1 폴리펩티드를 생성시킨다. 표 1을 참조한다.
두 플라스미드에 대한 플라스미드 골격(pVax1 플라스미드의 설계 원칙에 기초함) 및 삽입물은 유전자 합성을 사용하여 생성하였고 어떠한 동물 또는 인간 기원의 물질도 함유하지 않는다. 플라스미드 골격은 카나마이신 내성 유전자, ColE1 복제 기점, 인간 거대세포바이러스 극초기 프로모터 및 시미안 바이러스(SV40) Poly A 신호로 이루어진다. 바이러스 단백질을 암호화하는 폴리뉴클레오티드를 CMV 프로모터와 SV40 PolyA 신호 사이에 클로닝하였다. 유전자 합성과 플라스미드 제조 후에, 플라스미드를 클로닝을 위해서 이. 콜라이로 형질전환시키고, 그 다음 카나마이신을 사용하여 스크리닝하였다. 대표적인 콜로니를 선택하고, 이의 플라스미드 서열을 검증하여 추가 개발을 위한 공급원 플라스미드로 사용하였다. 전사 후, 바이러스 단백질을 단일 폴리시스트론성 mRNA로부터 발현시켰다.
어떠한 특정 이론에도 얽매이고자 함이 아니지만, 공동 발현되는 경우 S, E 및 M 단백질은 VLP로 조립되고 발현 세포에 의해 분비되는 것으로 생각되며; N 단백질이 S, E 및 M 단백질과 함께 발현되는 경우 VLP 분비가 유의하게 증가된다고 생각된다.
실시예 2: 면역형광에 의해서 관찰된 진핵 세포에서 SARS-CoV-2 S, E, M, 및 N 단백질의 발현
HEK 293(진핵생물) 세포에 pCoVEG2 플라스미드를 형질주입시켰다. 24시간 후, 세포를 고정하고, 투과화시키고, 검출을 위해 상용 Alexa Fluor 568로형광 표지된 2차 항체를 사용하여 면역세포화학으로 분석하였다. 도 2는 HEK 293 세포에서 S, M, N 및 E 단백질의 발현을 나타내는데, 이는 본원에 개시된 pCoVEG2가 세포에서 바이러스 항원을 발현한다는 것을 입증한다.
실시예 3: SDS-PAGE 및 웨스턴 블롯에 의해서 관찰된 SARS-CoV-2 S, E, M, 및 N 단백질의 발현
HEK 293 세포에 pCoVEG2 플라스미드를 형질주입시키고 96시간 동안 인큐베이션시켰다. 그 후, 세포 배양 상청액을 수거하고 농축하였다. PBS를 용리액으로 사용하여 Tricorn 10/300 컬럼에 패킹된 Superose 6 GL 수지 위에서 농축물을 전개시켰다. 분비된 VLP를 함유하는 공극 분획을 소듐 도데실 설페이트 폴리-아크릴아미드 겔 전기영동(SDS-PAGE: sodium dodecyl sulfate poly-acrylamide gel electrophoresis) 및/또는 S, N, M 또는 E에 대한 단클론성 항체를 사용한 웨스턴 블로팅으로 분석하여 S, N, M 및 E 단백질의 존재를 입증하였다. 도 3을 참조한다
이들 데이터는, 본원에 개시된 DNA 벡터 CoVEG2가 HEK 293 세포에서 모든 SARS-CoV-2 바이러스 구조 단백질(S, M, E 및 N 단백질)을 발현하고 분비된 VLP 성분이 세포 배양 상청액에서 검출될 수 있다는 것을 입증한다. 이러한 결과는 CoVEG1 및 CoVEG2 플라스미드가 잠재적으로 SARS-CoV-2에 대한 매우 효과적인 DNA 백신으로 사용될 수 있음을 시사한다.
실시예 4: 폴리뉴클레오티드 백신의 면역원성
CoVEG1 및 CoVEG2의 면역원성을 결정하기 위해서, 이 플라스미드를 6주령 BALB/c 마우스에게 2주 간격으로 제1일, 제15일, 제29일에 총 3회 주사로 피부내 주사하였다. 유발된 체액성 면역 반응[각각의 효소 결합 면역흡착 검정(ELISA)을 사용한 항-S 항체의 역가]뿐만 아니라 세포 면역 반응[각각의 IFN-γ 및 IL-4 효소 결합 면역 흡수 스팟(Dual color ELISpot) 검정을 사용하는 항원 반응성 T 세포의 존재]을 측정한다. 중화 대 총 항체를 측정하기 위해서, 시험관 내 바이러스 중화 검정을 수행한다. 이를 위해, 제43일에 단리된 혈청을 희석하고 SARS-CoV-2 라이프 바이러스(life virus)와 함께 인큐베이션시킨 후 VERO 세포에 첨가한다. 바이러스 단리는 천연 바이러스와 비교하여 세포의 성공적인 감염의 부재에 의해서 결정된다.
항-S 단백질 항체 ELISA 검정을 포함하는 항-SARS-CoV-2 항체 분석은 상업적으로 입수 가능한 물질에 기초하여 수행된다. 대안적으로, 인하우스 개발 세포 기반 및 VLP 기반 ELISA 분석이 사용된다. ELISpot 분석을 위해서, 비장을 수집하고 T 세포를 단리한다. ELISpot 평가는 Miltenyi Biotec Peptivator SARS-CoV-2 펩티드 풀로 T 세포를 프라이밍하여 SARS-CoV-2 반응성 T 세포를 활성화함으로써 수행된다. 또한, 플라스미드의 독성동태학적 및 약력학적 특징을 결정한다. 도 4를 참조한다.
체중이 15 g 내지 25 g인 암컷 BALB/c 마우스(6주 내지 8주령)를 각각의 군에 10마리의 동물이 포함된 4개의 군으로 무작위 배정한다. CMV 프로모터 제어 하에 인핸서 단백질(들)을 암호화하는 참조 항목 EG-BB인 비히클-PBS과, 1 μg과 25 μg의 CoVEG1 및 CoVEG2 2개 용량을 마우스에게 피부내로 투여한다. 마우스의 사망률 및 빈사 상태를 매일 2회 평가한다. 임상 관찰 및 체중을 제-1주에서 시작하여 매주 수집하고, 그 후 연구 기간 동안 적어도 2주마다 수집한다.
투여된 마우스는 투여 전 미리 정의된 시점에 채혈하고 원심분리에 의해 혈청을 분리한다. 이어서, 입수된 혈청 샘플을 하기 표 3에 나타낸 바와 같이 정량적 ELISA를 사용하여 전장 재조합 S 단백질(S1+S2)에 대한 항체에 대해 분석한다.
[표 3]
제43일 시점에, 생성된 혈청을 2개의 대략적으로 동일한 분취량으로 나누고; 첫 번째 분취물은 항-백신 항체(AVA: anti-vaccine antibody) 분석에 사용할 것이고 두 번째 분취물은 중화 항체 시험용으로 보관할 것이다. 분취물을 드라이아이스 위에서 즉시 냉동하거나 -80℃를 유지하도록 설정된 냉동고에서 냉동한다.
연구 완료 시에, 모든 동물을 안락사시킨다. 비장을 ELISpot에 의한 IFN-γ 및 IL-4 평가를 위한 세포 배양 세척 절차를 사용하여 수집한다.
T-세포 매개 독성 평가를 위해서, ELISpot 검정을 사용하여 정량적 평가를 수행한다. 수거된 비장으로부터의 비장세포를 S, M 및 N SARS-CoV-2 단백질의 서열을 포괄하는 Miltenyi Biotec의 SARS-CoV-2 PepTivator 펩티드 풀로 자극한다. 비장세포를 음성(배지) 및 양성 대조군(포르볼 미리스테이트 아세테이트/이오노마이신) 외에 3개의 상이한 SARS-CoV-2 펩티드 풀의 2개 농도에서 시험한다.
실시예
5: 인간에서 폴리뉴클레오티드 백신의 면역원성
CoVEG1 및 CoVEG2의 안전성, 반응원성(reactogenicity) 및 면역원성을 평가하기 위해서, 공개, 다기관, 용량 범위 연구(open-label, multi-center, dose-ranging study)를 건강 상태가 양호하고 모든 자격 기준을 충족하는 18세 이상의 남성과 임신하지 않은 여성에서 수행하였다. 대략 45명의 대상체를 3개 코호트(1 μg, 25 μg 및 200 μg) 중 하나에 등록한다. 대상체에게 제1일 및 제29일에 CoVEG1 및 CoVEG2를 피부내 주사(100 μl)로 제공하고, 두 번째 백신접종 후 12개월(제394일) 동안 추적 관찰하였다. 추적 관찰 방문은 각각의 백신접종 후 제1주, 제2주, 제4주(제8일, 제15일, 제29일, 제36일, 제57일)뿐만 아니라 두 번째 백신접종 후 제3개월, 제6개월, 제12개월(제119일, 제209일, 제394일)에 한다.
건강한 성인의 2회 용량에 걸쳐 28일 간격으로 제공되는 피부내 주사로 투여되는 CoVEG1 및 CoVEG2의 2회 용량 백신접종 일정의 안전성 및 반응원성을 이상 반응(AE: Adverse Event)이 있는 참가자의 백분율, 투여(주사) 부위 반응을 갖는 참가자의 백분율 및 특별 관심 이상 반응(AESI: Adverse Events of Special Interest)을 갖는 참가자의 백분율에 기초하여 평가한다.
면역원성을 평가하기 위해, CoVEG1 및 CoVEG2의 2회 용량 백신접종 일정에 따라 제15일, 제29일(두 번째 용량 전) 및 제57일에 다음 매개변수를 평가한다:
(a)
검증된 ELISA 방법에 의한 S 항체에 대한 IgG, IgM 및/또는 IgA ELISA;
(b)
면역 기억 징후를 제15일, 제29일, 제57일, 제180일, 제270일 및/또는 제394일에 CD49b+T-bet+ 휴면 기억 Th 세포 전구체 및 CXCR4+ S1P1+ 기억 형질 세포 전구체 세포에 초점을 맞춘 유세포 분석법 및 검증된 ELISpot 검정에 의해서 면역 표현형 분석 PBMC로 평가한다. 측정은 다음을 포함한다: 기준선(제1일 내지 제394일)으로부터의 IgG, IgM 및/또는 IgA 역가의 기하 평균 배수 상승(GMFR: geometric mean fold rise); 항체의 기하 평균 역가(GMT: geometric mean titer)(제15일, 제29일, 제57일, 제180일, 제270일 및 제394일); 및 혈청전환된 대상체의 백분율(제1일 내지 제15일, 제29일, 제57일, 제180일, 제270일 및 제394일). 혈청전환은 기준선으로부터의 항체 역가의 4배 변화로 정의됨; 및
(c)
CD8 T 세포 반응의 척도로서의 IFN-γ 반응 및 기억 면역 세포의 표현형은 검증된 ELISpot 검정에 의해 대상체로부터 단리된 PBMC에서 측정될 것이다. PBMC를 제15일, 제29일, 제57일, 제180일, 제270일, 제394일에 단리할 것이다.
실시예 6: 인핸서 단백질이 있는 또는 인핸서 단백질이 없는 SARS-CoV-2 S, E, M, 및 N 단백질 및 돌연변이체의 발현을 위한 추가의 폴리뉴클레오티드의 설계
플라스미드 CoVEG3 내지 CoVEG17은 도 6에 제시된 순서로 상이한 바이러스 단백질을 암호화하는 발현 카세트를 포함한다. 플라스미드에 대한 플라스미드 골격(pVax1 플라스미드의 설계 원칙에 기초함) 및 삽입물을 유전자 합성을 사용하여 생성하였다. 플라스미드 골격은 카나마이신 내성 유전자, ColE1 복제 기점, 인간 거대세포바이러스 극초기 프로모터 및 시미안 바이러스(SV40) Poly A 신호로 이루어진다. 바이러스 단백질을 암호화하는 폴리뉴클레오티드를 CMV 프로모터와 SV40 PolyA 신호 사이에 클로닝하였다. 유전자 합성 및 플라스미드 제조 후에, 플라스미드를 클로닝을 위해서 이. 콜라이로 형질전환시키고, 그 다음 카나마이신을 사용하여 스크리닝하였다. 대표적인 콜로니를 선택하고, 이의 플라스미드 서열을 검증하여 추가 개발을 위한 공급원 플라스미드로 사용하였다. 전사 후, 바이러스 단백질을 단일 폴리시스트론성 mRNA로부터 발현시켰다.
실시예 7: 면역형광에 의해서 관찰된 SARS-CoV-2 S 및 N 단백질의 발현
HEK293T 세포를 형질주입 24시간 전에 24웰에 40,000개 세포/웰로 시딩하였다. 제조업체의 설명에 따라 PEI 복합체를 사용하여 세포에 pCoVEG3 내지 pCoVEG20 플라스미드를 형질주입시켰다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃, 5% CO2에서 48시간 동안 인큐베이션시켰다. 세포 배지를 제거하고, 세포를 10분 동안 PBS 중의 0.2% Triton X-100으로 투과시킨 후 10분 동안 10% 중성 완충 포르말린으로 고정하였다. 면역염색을 수행하기 전에 EZ 블록(SCYTEK)을 첨가하여 비특이적 결합을 차단하였다. 수용체 결합 도메인(RBD)에 결합하는 항-스파이크(S) 단백질 항체를 갖는 염색 - 본원에서 "항-RBD"라고도 지칭 -을 1:500으로 희석하여 첨가하고 실온에서 1시간 동안 인큐베이션시켰다. 염색을 제거하고, 세포를 세척하고, 2차 항체(Alexa Fluor 568 형광 표지된 2차 항토끼, 1:1000 희석)를 첨가하였다. 염색을 제거하고 세척하기 전에 염색을 실온에서 1시간 동안 인큐베이션시켰다. 세포를 EVOS 세포 영상화 시스템을 사용하여 영상화하였다. 도 7은 HEK293 세포에서의 S 단백질의 발현을 나타내는데, 이는 시험된 모든 CoVEG 플라스미드가 스파이크 단백질을 발현할 수 있음을 입증한다.
또한, VLP의 발현을 확인하기 위해서, 면역형광 염색을 사용하여 세포를 뉴클레오캡시드(N) 단백질의 발현에 대해서 분석하였다. 이 실험을 위해서, HEK293T 세포를 형질주입 24시간 전에 24웰 플레이트에 40,000개 세포/웰로 시딩하였다. 제조업체의 설명에 따라 PEI 복합체를 사용하여 세포에 5, 9 내지 12, 및 14 내지 20 플라스미드를 형질주입시켰다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃, 5% CO2에서 48시간 동안 인큐베이션시켰다. 세포 배지를 제거하고, 세포를 10분 동안 PBS 중의 0.2% Triton X-100으로 투과시킨 후 10분 동안 10% 중성 완충 포르말린으로 고정하였다. 면역염색 전에 EZ 블록(SCYTEK)을 첨가하여 비특이적 결합을 차단하였다. 항-뉴클레오캡시드(N) 단백질 항체를 갖는 염색을 1:1000으로 희석하여 첨가하고 실온에서 1시간 동안 인큐베이션시켰다. 염색을 제거하고, 세포를 세척하고, 2차 항체(Alexa Fluor 488 형광 표지된 2차 항-마우스, 1:1000 희석)를 첨가하였다. 염색을 제거하고 세척하기 전에 2차 항체를 실온에서 1시간 동안 인큐베이션시켰다. 세포를 EVOS 세포 영상화 시스템을 사용하여 영상화하였다. 도 17은 HEK293 세포에서의 N 단백질의 발현을 나타내는데, 이는 시험된 모든 CoVEG 플라스미드가 뉴클레오캡시드 단백질을 발현할 수 있음을 입증한다.
실시예 8: 검출 가능한 SARS-CoV-2 VLP 형성을 위해서 필요한 L 단백질
온전한 바이러스 유사 입자(VLP)를 단리하기 위해, 제조업체 설명에 따라 PEI 복합체를 사용하여 150 mm 접시에서 4 x 106개 HEK293 세포에 pCoVEG3 내지 pCoVEG20 플라스미드를 형질주입시켰다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃, 5% CO2에서 72시간 동안 인큐베이션시켰다. VLP 함유 상청액을 수거하고, 스핀 다운(1,500 x g, 15분)시키고, Amicon 원심분리 필터 장치(100 kDa 컷오프)를 사용하여 농축하였다. 농축물을 스핀 다운(4,500 x g, 15분)시켜 침전물을 제거하고 VLP를 20% 수크로스 쿠션을 통해 펠릿화하였다(100,000 x g, 1.5시간). VLP를 PBS에 재현탁시키고, 도 8에 도시된 바와 같이 웨스턴 블롯으로 분석하였다. 도 8은 CoVEG3 내지 CoVEG8 플라스미드가 S 단백질을 발현할 수 있었고 CoVEG3 및 CoVEG5 내지 CoVEG8 플라스미드가 N 단백질을 발현할 수 있었음을 나타낸다. 이들 데이터는, 본원에 개시된 DNA 벡터 CoVEG3 및 CoVEG5 내지 CoVEG8이 HEK 293 세포에서 VLP 형성에 필요한 SARS-CoV-2 바이러스 구조 단백질을 발현하고 분비된 VLP 성분이 세포 배양 상청액에서 검출될 수 있다는 것을 입증한다.
도 11은 CoVEG5, CoVEG9, CoVEG11, CoVEG16, CoVEG10 및 CoVEG15 플라스미드로부터의 S 단백질 및 N 단백질의 발현을 나타낸다. 결과는 (CoVEG9, CoVEG11, CoVEG10 및 CoVEG15로부터) 돌연변이체 S 단백질을 발현시키면 VLP에서 발현되고 제시되는 스파이크 단백질의 양이 증가한다는 것을 나타내었다. (CoVEG16으로부터) ORF3 단백질의 발현은 VLP에서 S 및 N 단백질의 양을 감소시키는 것으로 나타났다. CoVEG15 플라스미드의 발현 시 인핸서 L 단백질의 부재는 S 단백질의 양은 유사하지만 N 단백질의 양은 훨씬 더 많아지게 하였다. 이론에 얽매이고자 함은 아니지만, 인핸서 L 단백질의 부재 시에 더 많은 양의 N 단백질이 발현되어 불균형적인 VLP 형성을 일으킨다고 생각된다.
도 12는 CoVEG5, CoVEG12, CoVEG14, CoVEG13, CoVEG10, CoVEG9 및 CoVEG11 플라스미드로부터의 S 단백질 및 N 단백질의 발현을 나타낸다. 이러한 데이터는, (CoVEG9, CoVEG10 및 CoVEG11 플라스미드로부터) 돌연변이체 S 단백질의 발현이 야생형 S 단백질을 발현한 비교 플라스미드와 비교할 때 VLP 상에서 발현되고 제시된 스파이크 단백질의 양을 증가시킨 반면 N의 양은 플라스미드 전체에서 일정하게 나타났다는 것을 입증한다.
도 18은 CoVEG5, CoVEG8, CoVEG9, CoVEG10, CoVEG15, CoVEG16, CoVEG17 및 CoVEG20 플라스미드로부터의 S 단백질 및 N 단백질의 발현을 나타낸다. 특히, 예를 들어, 도 18에서 CoVEG10(L 단백질) 대 CoVEG20(L 단백질 없음) S 및 N 웨스턴 블로팅에 의해 나타난 바와 같이 인핸서 L 단백질의 존재가 상이한 S 및 N 단백질 발현 비율이 나타나게 했다.
분비된 VLP의 존재가 또한 ELISA에 의해서 확인되었다. 이 실험을 위해, 24,000개의 HEK293 세포에 pCoVEG5 및 pCoVEG9 내지 pCoVEG14 플라스미드 또는 대조군으로서 스파이크 단백질 또는 뉴클레오캡시드 단백질을 함유하는 플라스미드를 형질주입시켰다. 제조업체의 설명에 따라 PEI 복합체를 사용하여 24웰 플레이트에서 실험을 수행하였다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃ 및 5% CO2에서 72시간 동안 인큐베이션시켰다. VLP 함유 상청액을 수거하고, 스핀 다운시키고(1,500 x g, 15분), 75 μl의 투명해진 상청액을 사용하여 4℃에서 밤새 ELISA 플레이트를 코팅하였다. 인큐베이션 후, 플레이트를 PBS 중의 0.05% Twen-20으로 2회 세척하고, 웰을 EZ 블록을 사용하여 차단하였다(37℃에서 2시간). 플레이트를 PBS 중의 0.05% Tween-20으로 2회 세척하였다. 코팅 물질에서 VLP를 검출하기 위해서, 항-RBD(Sino Biological, 마우스 항-RBD SARS-CoV-2(2019-nCoV) 스파이크 중화 항체, Mouse Mab, 40592-MM57 SARS-CoV-2, EZ 블록에서 1:500 희석) 또는 항-N(Novus Biologicals, 마우스 항-SARS-CoV-2 뉴클레오캡시드, 클론: B3449M, N2787B09, EZ 블록에서 1:1000 희석)을 웰에 첨가하였다. 항체를 실온에서 1시간 동안 인큐베이션시킨 후 PBS 중의 0.05% Tween-20으로 3회 세척하고, 75 μl의 2차 항체(염소-항-마우스, HRP-접합체, 1:2,000 희석, Southern Biotech, 염소 항-마우스 IgG(H+L), 호스래디쉬 퍼옥시다제(HRP: horseradish peroxidase), 다클론성, OB103405)를 첨가하고, 1시간 동안 실온에서 인큐베이션시켰다시켰다. 웰을 철저하게 세척하고(PBS 중의 0.05% Tween-20으로 5회), 75 μl의 3,3',5,5'-테트라메틸벤지딘(TMB) 기질(Surmodisc Inc TMB One Component HRP Microwell Substrate)을 사용하여 결합을 현상시켰다. 75 μl Stop Solution(Surmodisc Inc 450 NM LIQ STOP REAGENT)을 사용하여 30분 동안 반응을 수행하였고, 450 nm에서 흡광도를 측정하였다.
도 15는 단일 단백질 S 및 N 발현 벡터와 비교하여 CoVEG5 및 CoVEG9 내지 CoVEG14 플라스미드의 VLP 분비로부터의 ELISA 결과를 나타낸다. 스파이크와 뉴클레오캡시드 단백질 둘 다는 HEK293 세포로부터 분비되었다. 그러나, S 단백질은 단일 단백질 발현에 비해 높은 ELISA VLP 신호를 나타낸 반면, N 단백질은 단일 단백질 발현에 비해 현저히 낮은 VLP 신호를 나타내었다. N 단백질이 VLP 내부에 존재하고 항체에 접근할 수 없기 때문에 VLP에서 N 신호는 VLP에서 S 신호보다 낮을 수 있다.
SARS-CoV2로부터 발현된 구조 단백질이 온전한 VLP를 형성하는지를 더 확인하기 위해서, 제조업체 설명에 따라 PEI 복합체를 사용하여 5 mm 내지 150 mm 접시에 20 x 106개 HEK293 세포에 pCoVEG10 플라스미드를 형질주입시켰다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃, 5% CO2에서 72시간 동안 인큐베이션시켰다. VLP 함유 상청액을 수거하고, 스핀 다운(1,500 x g, 15분)시키고, Amicon 원심분리 필터 장치(100 kDa 컷오프)를 사용하여 농축하였다. 농축물을 스핀 다운(4,500 x g, 15분)시켜 침전물을 제거하고 VLP를 20% 수크로스 쿠션을 통해 펠릿화하였다(100,000 x g, 1.5시간). VLP를 PBS에 재현탁시키고, 공동 면역침전(co-IP)을 위해서 사용하였다. co-IP의 경우 재현탁된 VLP를 항-S RBD 항체(Sino Biological, 마우스 항-RBD SARS-CoV-2(2019-nCoV) 스파이크 중화 항체, Mouse Mab, 40592-MM57 SARS-CoV-2)와 함께 60분 동안 인큐베이션시킨 후 100 μl의 세척된 단백질 A/G 아가로스 수지(Thermo Fisher scientific)를 첨가하였다. 수지를 120분 동안 인큐베이션시킨 후 0.1 M 글리신 pH 2로 용출시켰다. 5배 부피의 1 M Tris pH 8.0을 첨가하여 용출액을 즉시 중화시켰다. 분획을 항-N 항체(Novus Biologicals, 마우스 항-SARS-CoV-2 뉴클레오캡시드, 클론: B3449M, N2787B09)를 사용하여 웨스턴 블롯으로 N 단백질의 존재를 분석하였다.
도 19는 CoVEG10 플라스미드의 co-IP 실험의 웨스턴 블롯 결과를 나타낸다. N-단백질은 RBD와 함께 인큐베이션 후 용출 분획에 N-신호가 존재하는 것으로 입증된 바와 같이 온전한 VLP에 패킹되어 있다(좌측, 화살표). 세척 분획에 신호가 없는 것과 비교하여 이 신호는 N 단백질이 입자 내에 유지되어 있음을 나타낸다. 비-특이적 N 단백질이 입자 외부에 결합할 가능성에 대한 대조군으로서, 항-RBD 항체 없이 co-IP를 병렬로 실행하였다(우측). N 단백질 신호는 용출 분획에서 검출되지 않았으며, 이는 N 단백질이 수지에 비특이적으로 결합하지 않았음을 입증한다.
분비된 VLP를 시각화하기 위해서, PEI 복합체를 사용하고 제조업체의 설명에 따라 5 x 150 mm 접시에서 20 x 106개의 HEK293 세포에 pCoVEG10 및 pCoVEG20 플라스미드를 형질주입시켰다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃, 5% CO2에서 72시간 동안 인큐베이션시켰다. VLP 함유 상청액을 수거하고, 스핀 다운(1,500 x g, 15분)시키고, Amicon 100 kDa 원심분리 필터 장치를 사용하여 농축하였다. 농축물을 스핀 다운(4,500 x g, 15분)시켜 침전물을 제거하고 VLP를 20% 수크로스 쿠션을 통해 펠릿화하였다(100,000 x g, 1.5시간). VLP를 PBS에 재현탁시키고, 급속 냉동하고, 투과 전자 현미경(TEM)에 사용할 때까지 -80℃에서 보관하였다.
TEM 실험을 위해서, VLP를 TLS-55(Optima TLX Ultracentrifuge, Beckman)를 사용하여 20% 수크로스 쿠션에서 25000 g로 2시간 동안 초원심분리하였다. 10 μl를 현미경 구리 그리드(Sigma Aldrich) 위에 놓고 2%(v/v) 파라포름알데히드로 5분 동안 고정하였다. 그런 다음 샘플을 5 mL의 인텅스텐산(Sigma Aldrich)으로 음성 염색하였다. 그리드를 100 KeV에서 작동하는 Hitachi HT7700 TEM을 사용하여 조사하였다.
도 16은 CoVEG10에 대한 단리된 물질에 VLP의 존재를 나타낸다. CoVEG10에 대해 명확한 스파이크 삼량체화 표면을 갖는 더 큰 입자의 존재가 관찰될 수 있었다(확대 삽도 참조). L 조절 단백질의 존재를 제외하고 CoVEG10과 동일한 CoVEG20은 인식 가능한 VLP를 생성하지 못했다.
온전한 면역원성 VLP는 모든 VLP 형성 단백질의 비율에 상당히 의존적이다. 여기서 L 단백질은 모든 VLP 형성 단백질의 발현 및 VLP의 정확한 형성을 제어한다는 것이 입증되었다.
실시예 9: L 단백질은 생체 내에서 SARS -CoV-2 단백질에 대한 중화 항체를 증가시켰고 Th1 반응에 필요하였다.
플라스미드 CoVEG3 μ내지 CoVEG8의 면역원성을 결정하기 위해서, 플라스미드를 PBS에 1 mg/ml로 희석하고 50 l를 6주령의 BALB/c 마우스에게 2주 간격으로 제1일 및 제15일에 총 2회 주사로 근육내 주사하였다. 제14일, 제28일, 제42일, 제56일에 혈액을 수집하고, 혈청을 단리하고, 항응고제 존재 하에 급속 냉동시켰다.
플라스미드 CoVEG5, CoVEG8 및 CoVEG9 내지 CoVEG14뿐만 아니라 S-단독 플라스미드의 면역원성을 결정하기 위해서, 플라스미드를 PBS에 2 mg/ml 또는 0.5 mg/ml로 희석하고 50 μl를 6주령의 BALB/c 마우스에게 2주 간격으로 제1일 및 제15일에 총 2회 주사로 근육내(2 mg/ml) 또는 피부내(0.5 mg/ml)로 주사하였다. 제14일, 제28일, 제42일, 제56일에 혈액을 수집하고, 혈청을 단리하고, 항응고제 존재하에 급속 냉동시켰다.
플라스미드 CoVEG9, CoVEG10 및 CoVEG20뿐만 아니라 인핸서 단백질이 있는 또는 인핸서 단백질이 없는 S 단독 플라스미드의 면역원성을 결정하기 위해서, 플라스미드를 PBS에 2 mg/ml 또는 0.2 mg/ml로 희석하고, 50 μl를 6주령의 C57BL/6 마우스에게 2주 간격으로 제1일, 제15일 및 제29일에 총 1회 내지 3회 주사로 근육내 주사하였다. 제0일, 제14일, 제28일, 제42일, 제56일 및 제70일에 혈액을 수집하고, 혈청을 단리하고, 항응고제 존재하에 급속 냉동시켰다. 결합 항체 농도, 즉, 유발된 체액성 면역 반응을 측정하기 위해서, 코팅 물질로서 정제된 SARS-CoV-2 스파이크 RBD 단백질(Creative Diagnostics® DAGC149 재조합 SARS-CoV-2 스파이크 단백질 수용체 결합 도메인 [His])을 사용하여 효소 결합 면역흡착 검정(ELISA)을 수행하였다. 이 실험을 위해서, 고결합 96웰 플레이트를 2 μg/ml SARS-CoV-2-스파이크 RBD 용액 75 μl로 코팅하고, 플레이트를 4℃에서 밤새 인큐베이션시켰다. 인큐베이션 후, 플레이트를 PBS 중의 0.05% Twen-20으로 2회 세척하고, 웰을 EZ 블록을 사용하여 차단하였다(37℃에서 2시간). 플레이트를 PBS 중의 0.05% Tween-20으로 2회 세척하였다. 56일 후에 마우스로부터 혈청을 수집하여 웰에 첨가하였다(결합 항체 검출을 위해 1:500 희석, 종점 역가 측정을 위해 1:100 내지 1:7812500). 혈청을 실온에서 1시간 동안 인큐베이션시킨 후 PBS 중의 0.05% Tween-20으로 3회 세척하고, 75 μl의 2차 항체(염소-항-토끼, HRP-접합체, 1:4,000 희석)를 첨가하고, 실온에서 1시간 동안 인큐베이션시켰다. 웰을 철저하게 세척하고(PBS 중의 0.05% Tween-20으로 5회), 75 μl의 3,3',5,5'-테트라메틸벤지딘(TMB) 기질(Surmodisc Inc TMB One Component HRP Microwell Substrate)을 사용하여 결합을 현상시켰다. 75 μl Stop Solution(Surmodisc Inc 450 NM LIQ STOP REAGENT)을 사용하여 30분 동안 반응을 수행하였다. 흡광도를 450 nm에서 측정하였다.
도 9a는 ELISA를 사용하여 측정한 전체 결합 항체를 나타내고, 도 9b는 측정된 종점 역가를 나타낸다. 이러한 결과는 CoVEG3 내지 CoVEG8 플라스미드가 마우스에 주사되는 경우 강력한 면역 반응을 유발하여 항-SARS CoV2 항체를 생산할 수 있음을 입증한다. CoVEG8은 이들 마우스에서 강력한 면역 반응을 유도할 수 있다는 점에서 특히 우수한 것으로 확인되었다. 이러한 결과는 본원에 개시된 플라스미드가 SARS-CoV-2에 대해 매우 효과적인 DNA 백신임을 입증한다.
도 13은 CoVEG5, CoVEG9, CoVEG11, CoVEG10, CoVEG12, CoVEG13, CoVEG8 및 CoVEG14 플라스미드를 근육내(IM) 또는 피부내(ID) 주사한 ELISA 결과를 나타낸다. 놀랍게도, CoVEG10의 근육내 주사는 스파이크 단백질 단독 주사와 비교할 때 훨씬 더 높은 면역 반응을 유도하였다. CoVEG5, CoVEG9, CoVEG11의 근육내 주사 또한 S 단백질 단독 주사에 비해 더 높은 면역 반응을 유도하였다. 이들 결과는 본원에 개시된 플라스미드가 스파이크 단백질 단독을 발현하는 백신보다 성능이 더 우수한 SARS CoV2에 대해 매우 효과적인 DNA 백신이라는 것을 더 입증한다.
도 20 및 도 22는 IM 또는 ID 주사 후 제42일에 CoVEG5 및 CoVEG9 내지 CoVEG14, CoVEG18, CoVEG19 및 CoVEG20 플라스미드뿐만 아니라 S 단독으로부터의 항체 결합 역가를 나타낸다. 흥미롭게도, 시험된 모든 CoVEG는 면역 반응을 유도할 수 있었으며 CoVEG9가 가장 효능이 있었다. 특히, VLP 형성 CoVEG9는 스파이크 단백질 단독보다 더 양호한 성능을 나타내었다.
또한, IFN-γ 및 IL-4 효소 결합 면역 흡수 스팟(ELISpot) 분석을 사용하여 항원 반응성 T 세포의 존재를 사용하여 세포 면역 반응을 측정하였다. ELISpot 분석을 위해서, 비장을 수집하고 T 세포를 단리하였다. Miltenyi Biotec Peptivator SARS-CoV-2 펩티드 풀로 T 세포를 프라이밍하여 SARS-CoV-2 반응성 T 세포를 활성화함으로써 ELISpot 평가를 수행하였다. 분석을 위해, Mouse IL-4 Single color ELISPOT 및 Mouse INF-γ Single color ELISPOT(Immunospot, Cellular Technology Limited)를 제조업체의 설명서에 따라 사용하였다. 약술하자면, 96웰 PVDF 막 플레이트를 IL-4 또는 INF-γ 포획 항체로 코팅하고 4℃에서 밤새 인큐베이션시켰다. 세척 후, 100 μl의 CTL 시험 배지 중의 150,000개의 비장세포를 미리 코팅된 플레이트에 시딩하고, 37℃ 및 4% CO2에서 15분 동안 인큐베이션시켰다. 세포를 PMA/이오노포어(양성 대조군) 또는 웰당 0.6 μl의 재구성된 Miltenyi Biotec Peptivator SARS-CoV-2 펩티드 풀(S, N 또는 M)을 사용하여 활성화시켰다. ImmunoSpot 분석기(CTL)를 사용하여 현상 및 계수하기 전에 반응을 24시간 동안 인큐베이션시켰다.
도 24는 CoVEG10 및 CoVEG20의 T-세포 분석 결과를 나타낸다. 중요한 것은, 호흡기 바이러스, 예를 들어, SARS-CoV-2에 대한 성공적인 백신을 생성하기 위해서, Th1 선호도(INF-γ) 또는 적어도 균형 잡힌 Th1/Th2 반응이 필요하다는 것이다. 놀랍게도, CoVEG10에 L 조절 단백질을 첨가하면 INF-γ(Th1) 반응을 선호하는 T 세포 면역 반응에 영향을 미쳤다. 특히, CoVEG20에 조절 단백질이 없으면 IL4(Th2)에 대한 세포 반응이 역전되었다. Th1 반응은 바이러스에 대한 오래 지속되는 면역 반응을 생성하는 데 필요하다.
혈청이 스파이크 단백질에 결합하는 SARS CoV2에 대한 중화 항체를 갖는지를 시험하기 위해서, 제조업체의 설명서에 따라 cPass™ 중화 검정(GenScript)을 사용한 시험관 내 바이러스 중화 검정을 수행하였다. cPass™은 시험관 내에서 바이러스와 숙주 세포 사이의 상호작용을 모방함으로써 샘플에서 총 중화 항체를 검출할 수 있다. 검정에서, 중화 항체가 시험될 샘플에 존재하는 경우, 숙주 세포막 수용체인 ACE2에 대한 수용체 결합 도메인(RBD)의 결합이 저해된다. 그러나, 중화 항체가 샘플에 존재하지 않는 경우 RBD가 ACE2에 결합할 수 있다. 도 10은 ACE2 수용체에 대한 RBD 결합의 저해 백분율(%)을 나타낸다. ACE2에 대한 RBD 결합의 저해가 30%를 초과하면(빨간색 점선), 샘플은 중화 항체를 갖는 것으로 식별된다. 도 10에 도시된 바와 같이, COVEG5 및 COVEG8이 주사된 마우스로부터 입수된 혈청 샘플은 높은 억제 비율을 나타내고, 따라서, 중화 항체를 생성하였다. 이러한 결과는 개시된 플라스미드가 SARS-CoV-2에 대해 매우 효과적인 DNA 백신이라는 점을 더 강조한다.
도 21은 도 20에 도시된 샘플의 중화 항체를 도시한다. 이러한 데이터는 생성된 모든 항체가 중화 능력을 보유하는 것은 아니라는 것을 나타낸다. 이 검정에서 더 낮은 신호는 음성 대조군(점선)의 70% 미만의 신호로 정의된 중화를 확인해 주었다. 음성 대조군의 30% 미만의 신호는 강력하게 중화되는 것으로 확인되었다. 시험된 CoVEG는 설계 및 주사 부위에 따라 다르게 수행되었다. 놀랍게도, ID 주사는 강한 중화 항체를 유도하지 못한 반면, IM 주사는 강한 중화 항체를 유도하였다. 또한 CoVEG13 및 CoVEG14는 중화 기준을 충족하지 못했다. 그러나, CoVEG9는 S 스파이크 단백질 단독 작제물을 포함하여 시험된 모든 작제물 중 가장 높은 중화를 나타냈는데, 이는 VLP 접근법이 소단위 S 스파이크 단독 백신보다 더 강력한 백신을 제공한다는 것을 다시 입증한다.
도 23은 CoVEG9, CoVEG10 및 CoVEG20 플라스미드의 중화 항체를 나타내는데, 여기서 플라스미드 20은 인핸서 L 단백질의 부재에 대한 대조군이다. CoVEG20은 T-세포 분석에서 입증된 바와 같이 중화 가능한 Th2 오버행을 나타내었지만, 이것은 백신에 대한 실행 가능한 옵션은 아니다.
또한, 시간 경과에 따른 인핸서 단백질 유무에 따른 중화 능력을 cPass™로 분석하였다. SARS-CoV-2 대용체 바이러스 중화 시험(sVNT) 키트. 이를 위해, 면역화된 동물(CoVEG9, 스파이크 + 인핸서 단백질 L 및 인핸서가 없는 스파이크로 면역화됨)로부터의 혈청 샘플을 제42일 및 제70일에 수집하고 상기에 기재된 바와 같이 cPass™를 수행하였다.
도 27a는 분석된 혈청 샘플의 개별 값을 나타내고, 도 27b는 요약과 동일한 데이터의 중앙값을 나타낸다. 흥미롭게도, 인핸서 단백질의 첨가는 시간 경과에 따라 중화 항체의 이점을 명확히 나타내었다. 첫째로, 인핸서 단백질 L(CoVEG9 및 스파이크 + L)을 갖는 두 작제물 모두는 더 높은 중앙값 중화 값을 나타내었다(도 27b, CoVEG9 원, 스파이크 + L 사각형). 둘째, 중화 항체의 수준은 인핸서 단백질이 없는 작제물과 비교하여 주사 70일 후에도 높게 유지되었다(도 27b 스파이크 삼각형).
이는 백신 후보에 인핸서 단백질을 첨가하는 이점을 더 입증하였다.
실시예 10: WNV E 및 M 단백질과 공동 발현되는 경우 L 단백질은 기능성 웨스트나일 바이러스(WNV) VLP 생산을 증가시켰다.
WNV의 NY99 균주의 전구체 막 단백질(prM), 외피 당단백질(E) 및 인핸서 단백질을 암호화하는 플라스미드를 실시예 6에 기재된 바와 같이 작제하였다(도 14a, 서열번호 55 참조). 또한, WNV의 NY99 균주의 전구체 막 단백질(prM) 및 외피 당단백질(E)만을 암호화하는 대조군 플라스미드를 작제하였다(도 11b). HEK293T 세포를 10% FBS가 보충된 DMEM에서 37℃, 5% CO2에서 배양하였다. 제1일에, 세포를 24웰 플레이트에 웰당 20,000개의 세포로 시딩하고 밤새 성장시켰다. 제2일에, 24웰 플레이트에 시딩된 세포에 전구체 막 단백질(prM), WNV의 NY99 균주의 외피 당단백질(E) 및 인핸서 단백질을 암호화하는 플라스미드를 일시적으로 형질주입시켰다. 모든 실험에 WNV의 NY99 균주의 전구체 막 단백질(prM) 및 외피 당단백질(E)만을 암호화하고 인핸서 단백질은 암호화하지 않는 대조군 플라스미드를 사용하였다.
24웰 플레이트의 각각의 웰을 플라스미드/PEI 복합체를 사용하여 형질주입시켰고 이는 50 μl의 Opti-MEM에서 0.5 ug의 상응하는 플라스미드 및 1 ug의 PEI를 사용하여 형성되었다. 플라스미드/PEI 혼합물을 실온에서 30분 동안 인큐베이션시킴으로써 복합체를 형성하였다. 24웰 플레이트에서 세포 배지를 새로운 Opti-MEM으로 교체하고 복합체를 웰에 첨가하였다. 제3일에, 복합체를 형질주입된 세포로부터 제거하고, 새로운 Opti-MEM으로 교체하였다.
제4일에, 세포 배양 상청액을 수집하고, 500xg에서 5분 동안 원심분리하여 세포 잔해로부터 제거하고, ELISA에 의한 하류 분석을 위해 저장하였다. 세포를 250 μl의 10% 중성 완충 포르말린(실온에서 10분)을 사용하여 고정하고, 0.2% Triton-X 100(실온에서 10분)을 사용하여 투과화시키고, 세척하였다.
형광 현미경을 사용하여 다음과 같이 세포에서 단백질 발현을 시각화하였다. 세포를 마우스 항-WNV_E 및 토끼 항-WNV_M 1차 항체(PBS에서 1:500 희석, 실온에서 1시간)를 사용하여 염색하고, 세척하고, 염소 항-마우스 Alexa Fluor 488 2차 항체(PBS에서 1:1000 희석, 실온에서 1시간)로 현상시키고, 세척하고, 형광 현미경을 사용하여 영상화하였다.
면역염색 실험 결과를 도 28에 나타내었다. 본원에 기재된 다른 실험에서 관찰된 바와 같이, WNV + 인핸서 단백질(EG)의 양은 인핸서 단백질이 없는 WNV의 양과 비교하여 더 낮았다. 그러나, 핵의 형성에 의해서 관찰된 바와 같이 인핸서 단백질이 존재하는 경우 품질이 더 높은 것으로 보였다(도 28, 우측, 화살표로 표시). 이들 데이터는, 본원에 제공된 조성물 및 방법으로 발현된 단백질의 품질이 더 높다는 것을 입증한다.
발현된 항원의 분비를 입증하기 위해 ELISA 검정을 사용하였다. 이를 위해, 형질주입된 세포로부터의 상청액을 제4일(형질주입 후 48시간), 제5일(72시간), 제6일(96시간), 제7일(120시간) 및 제8일(144시간)에 수집하였다. 고결합 96웰 플레이트를 웰당 75 μl의 세포 배양 상청액을 사용하여 세포 배양 상청액으로 코팅하고 +4℃에서 밤새 인큐베이션시켰다. 다음날 코팅된 웰을 PBST 완충액을 사용하여 세척하고, 웰당 200 μl의 EZ Block™ 시약(Scytek Laboratories)을 사용하여 +37℃에서 2시간 동안 차단하였다. 웰을 PBST로 3회 세척하고, 1차 항체(마우스 항-WNV_E, EZ 블록에서 1:1000 희석, 웰당 75 μl)와 함께 실온에서 1시간 동안 인큐베이션시켰다. 그 다음 웰을 PBST로 3회 세척하고, EZ 블록 시약(웰당 75 μl)에 1:1000으로 희석된 염소 항-마우스 HRP 2차 항체와 함께 실온에서 1시간 동안 인큐베이션시켰다. 그 다음 PBST를 사용하여 웰을 5회 세척하고, 각각의 웰에 TMB 기질 75 μl를 첨가하고, 실온에서 30분 동안 인큐베이션시킨 후 정지 용액 75 μl를 첨가하고 플레이트 리더를 사용하여 450 nm에서 흡광도를 측정하였다. 추가적으로, VLP 분비가 세포 사멸 및 세포내 단백질의 비특이적 방출에 의해 유발되지 않았음을 입증하기 위해서, 매일 세포를 영상화하고 ELISA 결과를 영상과 비교하였다.
도 26a는 ELISA에 의해 측정된 바와 같은 시간 경과에 따른 형질주입된 세포로부터의 VLP의 분비를 도시한다. 인핸서 단백질이 있는 WNV 작제물은 온전한 VLP 및 건강한 세포에 대해 예상된 바와 같이 형질주입 72시간 후에 가장 높은 분비를 나타낸 반면, 인핸서 단백질이 없는 WNV 작제물은 시간 경과에 따라 분비 물질의 꾸준한 증가를 나타내었다. 후자는 세포 사멸의 증가 및 VLP가 완전히 형성되지 않았을 가능성이 높은 단백질 물질의 비특이적 방출과 더 일치하였다. 결과는 상청액으로부터 수거 당시 촬영된 세포 영상의 분석에 의해서 확인되었다. 인핸서 단백질을 갖는 WNV는 실험 기간 동안 세포 사멸이 거의 또는 전혀 나타나지 않은 반면(별표로 표시), 인핸서 단백질이 없는 WNV는 눈에 띄는 세포 사멸을 나타냈으며(별표로 표시), 72시간 후에는 실험 기간 전체에서 점점 더 뚜렷해졌다. 세포 영상은 인핸서 단백질이 없는 WNV로부터 방출된 물질이 VLP의 조절된 분비보다는 세포 사멸로부터의 단백질 방출로 인한 것일 가능성이 가장 높다는 추가 증거이다.
본 실시예는 본 개시내용의 방법 및 조성물이 생산된 항원의 품질을 향상시킨다는 것을 더 입증한다.
실시예 11: WNV E 및 M 단백질과 공동 발현되는 경우 L 단백질은 총 웨스트나일 바이러스(WNV) VLP 생산을 증가시켰다.
온전한 VLP를 단리하기 위해, 150 mm 접시에서 4 x 106개의 HEK293 세포에 WNV의 NY99 균주의 전구체 막 단백질(prM) 및 외피 당단백질(E) 및 인핸서 단백질을 암호화하는 플라스미드를 형질주입시켰다. 모든 실험에 WNV의 NY99 균주의 전구체 막 단백질(prM) 및 외피 당단백질(E)만을 암호화하고 인핸서 단백질은 암호화하지 않는 대조군 플라스미드를 사용하였다. 형질주입은 150 mm 접시당 40 μg의 플라스미드 및 80 μg의 PEI 복합체를 사용하여 제조업체 설명에 따라 PEI 복합체를 사용하여 수행하였다. 형질주입 12시간 후에 배지를 교체하고 세포를 37℃, 5% CO2에서 72시간 동안 인큐베이션시켰다. VLP 함유 상청액을 수거하고, 스핀 다운(1,500 x g, 15분)시키고, Amicon 초원심분리 필터 장치(100 kDa 컷오프)를 사용하여 농축하였다. 농축물을 스핀 다운(4,500 x g, 15분)시켜 침전물을 제거하고 VLP를 1.5시간 동안 100,000 x g에서 20% 수크로스 쿠션을 통해 펠릿화하였다. VLP를 PBS에 재현탁시키고 ELISA로 분석하였다.
ELISA를 상기 기재된 바와 같이 그리고 예를 들어, 문헌[Cold Spring Harb Protoc; doi:10.1101/pdb.prot093708]에 기재된 바와 같이 그리고 당업계에 알려진 바와 같이 수행하였다. 약술하자면, 1:20에서 1:72,000까지 연속 희석으로 PBS에 재현탁된 VLP를 사용하여 고결합 96웰 플레이트를 코팅하여 인핸서 단백질이 있는 작제물과 인핸서 단백질이 없는 작제물 간의 발현량 차이를 시각화하고 4℃에서 밤새 인큐베이션시켰다. 플레이트를 세척하고 EZ 블록(Scytek Laboratories)으로 37℃에서 2시간 동안 차단하였다. 항-웨스트나일 바이러스 항체, 클론 E16을 EZ 블록(1:5,000)에 희석하고 플레이트를 실온에서 1시간 동안 인큐베이션시켰다. 웰을 세척하고 염소 항-마우스 HRP 표지된 검출 항체(Southern Biotech)를 검출을 위해 첨가한 후 세척하고 TMB 기질 및 정지 용액과 함께 인큐베이션팅했다. 플레이트 판독기를 사용하여 신호를 450 nm에서의 흡광도로 판독하였다.
도 25는 인핸서 단백질이 있는 있는 웨스트나일 작제물 및 인핸서 단백질이 없는 웨스트나일 바이러스 작제물의 전체 발현과 분비 사이의 차이를 입증한다. 도시된 바와 같이, 인핸서 단백질의 첨가(원)는 인핸서 단백질이 없는 작제물(사각형)에 비해 웨스트나일 바이러스 입자의 더 높은 발현으로 이어졌다. 이는 본 개시내용의 조성물 및 방법이 WNV VLP 백신 생산에 유익하다는 것을 입증한다.
실시예 12: 마우스에서 L 인핸서 단백질과 공동 발현된 웨스트나일 바이러스 단백질의 면역원성
WNV의 전구체 막(prM), 외피 당단백질(E) 및 인핸서 단백질을 암호화하는 플라스미드로의 백신 접종 시 생체 내에서 면역 반응을 일으키는 능력을 BALB/c 마우스를 사용하여 다음과 같이 평가한다. 6주령 암컷 BALB/c 마우스를 체중에 기초하여 군으로 무작위 배정하였다. 제1일과 제21일에 피부내 또는 근육내 주사를 사용하여 마우스에게 플라스미드를 투여한다. 제1일(백신접종 전), 제21일(부스트 전) 및 제42일에 마우스 혈청 샘플을 수집한다. 제42일에 마우스를 희생시키고 비장세포를 단리한다.
각각의 효소 결합 면역흡착 검정(ELISA)을 사용하여 항-M 및 항-E 항체의 역가를 평가함으로써 유발된 체액성 면역 반응을 측정한다. 추가로, 각각의 IFN-γ 및 IL-4 효소 결합 면역 흡수 스팟(Dual color ELISpot) 검정을 사용하여 항원 반응성 T 세포의 존재를 평가함으로써 세포 면역 반응을 측정한다.
ELISA를 본원에 기재된 바와 같이 그리고 예를 들어, 문헌[Cold Spring Harb Protoc; doi:10.1101/pdb.prot093708]에 기재된 바와 같이 그리고 당업계에 알려진 바와 같이 수행한다. 약술하자면, 고결합 96웰 플레이트를 재조합 prM 및 E 단백질(Abcam)을 사용하여 2 μg/ml 농도로 코팅하고 차단한다. 혈청 샘플을 EZ 블록 시약으로 연속 희석하고, 사전 코팅된 웰에 첨가하고, 세척하고, 염소 항-마우스 HRP 표지 검출 항체를 사용하여 검출한 다음, 세척하고, TMB 기질 및 정지 용액과 함께 인큐베이션시킨다. 종점 역가는 ELISA 신호(450 nm에서의 흡광도)가 배경 신호의 3 표준 편차를 초과하는 상호 최대 항체 희석으로 정의된다.
Dual color ELISpot 검정을 본원에 기재된 바와 같이 그리고, 예를 들어, 문헌[Cold Spring Harb Protoc 2010 doi:10.1101/pdb.prot5369]에 기재된 바와 같이 그리고 당업계에 알려진 바와 같이 수행한다. 약술하자면, 제42일에 비장세포를 단리하고 각각의 prM 또는 E 펩티드 어레이(Biodefense and Emerging Infections Research Resources Repository)로 자극하고, 미리 준비된 ELISpot 마이크로플레이트에 첨가한다. 음성(배지) 및 양성 대조군(포르볼 미리스테이트 아세테이트/이오노마이신)을 검정에 포함시킨다. 항원-반응성 IFN-감마 및 IL-4 분비 T 세포의 수를 ELISpot 판독기를 사용하여 계수한다.
마지막으로, 상이한 시점(상기 참조)에서 단리된 마우스 혈청 내 WNV 중화 항체의 존재를 본원에 기재된 바와 같이 그리고 문헌[The Journal of Infectious Diseases, Volume 196, Issue 12, 15 December 2007, Pages 1732-1740] 및 문헌[Virology, Volume 346, Issue 1, 1 March 2006, Pages 53-65]에 기재된 바와 같이 평가한다. 약술하자면, WNV 리포터-바이러스 입자(RVP: reporter-virus particles)를 일시적으로 형질주입된 리포터-레플리콘(루시퍼라제) 및 일시적으로 형질주입된 캡시드 단백질이 보충된, WNV prM 및 E 단백질(하위바이러스 입자라고도 알려진 바이러스 유사 입자를 형성하기 위해)을 일시적으로 형질주입시켜 HEK293T 세포에서 생성시킨다. 단리된 RVP를 상이한 연속 희석으로 마우스 혈청 샘플과 함께 인큐베이션시키고, 미리 플레이팅된 PHK-21 세포에 첨가하고, 2일 동안 인큐베이션시킨 후, 마이크로플레이트 판독기를 사용하여 리포터 유전자 활성을 측정한다. 리포터 유전자 활성의 감소는 마우스 혈청에서 WNV 중화 항체 수준을 반영한다.
실시예 13: 추가적인 폴리뉴클레오티드 작제물의 발현 및 면역원성
다른 바이러스, 예를 들어, 인플루엔자 바이러스 단백질(예를 들어, HA, NA, M1, M2, 또는 이의 임의의 조합), B형 간염 바이러스 단백질(예를 들어, sAg(S 단백질), sAg(M 단백질), sAg(L 단백질), preS1, preS2, cAg(코어 항원), 또는 이의 임의의 조합), 인간 파필로마바이러스(예를 들어, HPV 6의 L1 단백질, HPV 11의 L1 단백질, HPV 16의 L1 단백질, HPV 18의 L1 단백질, 또는 이의 임의의 조합)로부터 유래된 바이러스 단백질을 암호화하는 플라스미드의 작제를 실시예 6에 기재된 방법을 사용하여 수행한다. HEK293T 세포에서 이들 단백질의 상이한 조합의 발현 및 VLP의 단리를 실시예 7, 실시예 8, 실시예 10 및 실시예 11에 기재된 방법을 사용하여 수행한다. 이들 단백질을 암호화하는 플라스미드의 면역원성을 실시예 9 및 실시예 12에 기재된 방법을 사용하여 시험한다.
인용에 의한 포함
본 명세서에 인용된 모든 참고문헌, 기사, 간행물, 특허, 특허 간행물 및 특허 출원은 사실상 전체 내용이 참조에 의해 포함된다. 그러나 본원에 인용된 참고문헌, 기사, 간행물, 특허, 특허 간행물 및 특허 출원의 언급은, 그것이 유효한 선행 기술을 구성하거나 세계 모든 나라에서 공통적인 일반적인 지식의 일부를 형성한다는 것을 인정하거나 어떠한 형태로든 시사하는 것으로 받아들여지지 않고 받아들여져서는 안 된다.
번호를 붙인 실시형태
실시형태 1. 백신으로 사용하기 위한 벡터로서, 바이러스 단백질을 암호화하는 폴리뉴클레오티드 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하고, 여기서 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체인, 벡터.
실시형태 2. 실시형태 1에 있어서, 인핸서 단백질의 아미노산 서열은 서열번호 1과 적어도 95%의 동일성, 또는 서열번호 2와 적어도 95%의 동일성을 갖는, 벡터.
실시형태 3. 실시형태 1 또는 실시형태 2에 있어서, 인핸서 단백질의 아미노산 서열은 서열번호 1, 또는 서열번호 2인, 벡터.
실시형태 4. 실시형태 1 내지 실시형태 3 중 어느 하나에 있어서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드는 내부 리보솜 유입 부위(IRES)를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된, 벡터.
실시형태 5. 실시형태 4에 있어서, IRES를 암호화하는 폴리뉴클레오티드는 서열번호 24인, 벡터.
실시형태 6. 실시형태 1 내지 실시형태 5 중 어느 하나에 있어서, 바이러스 단백질은 바이러스 항원인, 벡터.
실시형태 6.1. 실시형태 1 내지 실시형태 6 중 어느 하나에 있어서, 바이러스 단백질은 코로나바이러스, 인플루엔자 바이러스, B형 간염 바이러스, 인간 파필로마 바이러스(HPV), 웨스트나일 바이러스, 및 인간 면역결핍 바이러스(HIV) 바이러스 벡터로 이루어진 군으로부터 선택된 바이러스로부터 유래되는, 벡터.
실시형태 6.2. 실시형태 6.1에 있어서, 바이러스 단백질은 코로나바이러스로부터 유래되는, 벡터.
실시형태 7. 실시형태 1 내지 실시형태 6.2 중 어느 하나에 있어서, 코로나바이러스는 베타코로나바이러스인, 벡터.
실시형태 8. 실시형태 7에 있어서, 베타코로나바이러스는 중증 급성 호흡기 증후군(SARS) 바이러스인, 벡터.
실시형태 9. 실시형태 8에 있어서, SARS 바이러스는 SARS-CoV-2 바이러스인, 벡터.
실시형태 10. 실시형태 7에 있어서, 베타코로나바이러스는 중동 호흡기 증후군(MERS) 바이러스인, 벡터.
실시형태 11. 실시형태 1 내지 실시형태 10 중 어느 한 항에 있어서, 코로나바이러스 단백질은 코로나바이러스 스파이크 단백질인, 벡터.
실시형태 12. 실시형태 11에 있어서, 스파이크 단백질은 서열번호 13과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 벡터.
실시형태 13. 실시형태 12에 있어서, 스파이크 단백질은 서열번호 13인, 벡터.
실시형태 13.1. 실시형태 11에 있어서, 스파이크 단백질은 돌연변이체 스파이크 단백질인, 벡터.
실시형태 13.2. 실시형태 13.1에 있어서, 돌연변이체 스파이크 단백질은 서열번호 13에 아미노산 치환인 R682G, R683S, R685S, K986P, 및 V987P를 포함하는, 벡터.
실시형태 13.3. 실시형태 13.1에 있어서, 돌연변이체 스파이크 단백질은 서열번호 51의 아미노산 서열을 포함하는, 벡터.
실시형태 14. 실시형태 1 내지 실시형태 13.3 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 막(M) 단백질인, 벡터.
실시형태 15. 실시형태 14에 있어서, M 단백질은 서열번호 33과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 벡터.
실시형태 16. 실시형태 14 또는 실시형태 15에 있어서, M 단백질은 서열번호 33인, 벡터.
실시형태 17. 실시형태 1 내지 실시형태 16 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 외피(E) 단백질인, 벡터.
실시형태 18. 실시형태 17에 있어서, E 단백질은 서열번호 22와 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 벡터.
실시형태 19. 실시형태 17 또는 실시형태 18에 있어서, E 단백질은 서열번호 22인, 벡터.
실시형태 20. 실시형태 1 내지 실시형태 19 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 뉴클레오캡시드(N) 단백질인, 벡터.
실시형태 21. 실시형태 20에 있어서, N 단백질은 서열번호 20과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 벡터.
실시형태 22. 실시형태 20 또는 실시형태 21에 있어서, N 단백질은 서열번호 20인, 벡터.
실시형태 23. 실시형태 1 내지 실시형태 22 중 어느 하나에 있어서, 코로나바이러스 단백질은 바이러스 유사 입자(VLP)를 형성하는, 벡터.
실시형태 23.1. 실시형태 6.1에 있어서, 바이러스 단백질은 웨스트나일 바이러스로부터 유래되는, 벡터.
실시형태 23.2. 실시형태 23.1에 있어서, 바이러스 단백질은 전구체 막 단백질(preM), 외피 당단백질(E), 또는 이의 조합물인, 벡터.
실시형태 24. 백신으로 사용하기 위한 벡터로서, 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하고, 폴리뉴클레오티드는 서열번호 30의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는, 백신으로 사용하기 위한 벡터.
실시형태 25. 실시형태 24에 있어서, 폴리뉴클레오티드는 서열번호 30의 핵산 서열을 포함하는, 벡터.
실시형태 26. 백신으로 사용하기 위한 벡터로서, 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는, 폴리뉴클레오티드는 서열번호 31의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는, 백신으로 사용하기 위한 벡터.
실시형태 27. 실시형태 26에 있어서, 폴리뉴클레오티드는 서열번호 31의 핵산 서열을 포함하는, 벡터.
실시형태 27.1. 백신으로 사용하기 위한 벡터로서, 서열번호 35 내지 서열번호 49, 및 서열번호 55로 이루어진 군으로부터 선택된 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는, 백신으로 사용하기 위한 벡터.
실시형태 28. 실시형태 1 내지 실시형태 27.1 중 어느 하나에 있어서, 네이키드 폴리뉴클레오티드인 벡터.
실시형태 29. 실시형태 1 내지 실시형태 28 중 어느 하나에 있어서, 데옥시리보핵산(DNA) 폴리뉴클레오티드인 벡터.
실시형태 30. 실시형태 1 내지 실시형태 28 중 어느 하나에 있어서, 리보핵산(RNA) 폴리뉴클레오티드인 벡터.
실시형태 31. 실시형태 1 내지 실시형태 30 중 어느 하나에 있어서, 플라스미드를 포함하는 벡터.
실시형태 32. 실시형태 1 내지 실시형태 30 중 어느 하나에 있어서, 선형 DNA를 포함하는 벡터.
실시형태 33. 실시형태 1 내지 실시형태 32 중 어느 하나에 있어서, 발현 카세트는 발현 카세트의 폴리뉴클레오티드 서열 각각에 작동 가능하게 연결된 프로모터를 포함하는, 벡터.
실시형태 33.1. 실시형태 1 내지 실시형태 33 중 어느 하나에 있어서, DNA 폴리뉴클레오티드를 포함하고, 상기 DNA 폴리뉴클레오티드는 바이러스 패키징 신호를 암호화하는 벡터.
실시형태 33.2. 실시형태 33.1에 있어서, 바이러스 패키징 신호는 RNA 폴리뉴클레오티드인, 벡터.
실시형태 33.3. 실시형태 33.2에 있어서, 바이러스 패키징 신호는 코로나바이러스로부터 유래되는, 벡터.
실시형태 34. 백신 조성물로서, 실시형태 1 내지 실시형태 33.3 중 어느 하나의 벡터 및 약제학적으로 허용 가능한 담체를 포함하는 백신 조성물.
실시형태 35. 실시형태 34에 있어서, 아주반트를 포함하는 백신 조성물.
실시형태 36. 실시형태 35에 있어서, 아주반트는 명반인, 백신 조성물.
실시형태 37. 실시형태 35에 있어서, 아주반트는 모노포스포릴 지질 A(MPL)인, 백신 조성물.
실시형태 38. 진핵 세포에서 바이러스 항원을 발현시키는 방법으로서, 세포를 실시형태 1 내지 실시형태 33.3 중 어느 하나의 벡터와 접촉시키는 것을 포함하는 방법.
실시형태 39. 실시형태 38에 있어서, 세포를 벡터와 접촉시키는 것은: 인핸서 단백질이 없는 벡터보다 (i) 더 높은 발현 수준에서의 항원의 발현; 및/또는 (ii) 더 긴 시간 기간 동안의 항원의 발현; 및/또는 (iii) 더 양호한 단백질 품질을 갖는 항원의 발현을 일으키는, 방법.
실시형태 40. 실시형태 38 또는 실시형태 39에 있어서, 세포를 벡터와 접촉시키는 것은: 인핸서 단백질이 없는 벡터보다 (i) 더 높은 발현 수준에서의 항원을 포함하는 바이러스 유사 입자(VLP)의 발현; 및/또는 (ii) 더 긴 시간 기간 동안의 항원을 포함하는 VLP의 발현; 및/또는 (iii) 더 양호한 단백질 품질을 갖는 항원을 포함하는 VLP의 발현을 일으키는, 방법.
실시형태 40.1. 실시형태 40에 있어서, 벡터는 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드를 포함하며, 세포를 벡터와 접촉시키는 것은 바이러스 패키징 신호의 발현을 일으키고, VLP는 바이러스 패키징 신호를 캡시드화시키는, 방법.
실시형태 40.2. 실시형태 40.1에 있어서, 벡터는 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드가 없는 대조군 벡터와 비교할 때, 더 많은 수의 VLP의 형성을 일으키는, 방법.
실시형태 41. 대상체에서 면역 반응을 유발하는 방법으로서, 실시형태 34 내지 실시형태 37 중 어느 하나의 백신 조성물의 유효량을 대상체에게 투여하는 것을 포함하는 방법.
실시형태 42. 실시형태 41에 있어서, 대상체의 투여 부위의 조직은 항원 및/또는 항원을 포함하는 VLP를 발현하는, 방법.
실시형태 43. 실시형태 42에 있어서, 대상체의 투여 부위의 조직은 인핸서 단백질이 없는 벡터가 투여되는 경우보다 (i)항원 및/또는 항원을 포함하는 VLP를 더 높은 발현 수준으로 발현하고; 그리고/또는 (ii)항원 및/또는 항원을 포함하는 VLP를 더 긴 시간 기간 동안 발현하고; 그리고/또는 (iii)더 양호한 단백질 품질을 갖는 항원 및/또는 항원을 포함하는 VLP를 발현하는, 방법.
실시형태 43.1. 실시형태 41 내지 실시형태 43 중 어느 하나에 있어서, 벡터는 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드를 포함하며, 대상체의 투여 부위의 조직은 바이러스 패키징 신호를 발현하고, VLP는 바이러스 패키징 신호를 캡시드화하는, 방법.
실시형태 43.2. 실시형태 43 또는 실시형태 43.1에 있어서, 벡터는 바이러스 패키징 신호를 암호화하는 DNA 폴리뉴클레오티드가 없는 대조군 벡터와 비교할 때, 더 많은 수의 VLP의 발현을 일으키는, 방법.
실시형태 43.3. 실시형태 43 내지 실시형태 43.2 중 어느 하나에 있어서, 바이러스 패키징 신호를 캡시드화하는 VLP는 항원을 포함하지만 바이러스 패키징 신호가 없는 대조군 VLP보다 더 양호한 면역원성인, 방법.
실시형태 44. 실시형태 41 내지 실시형태 43 중 어느 하나에 있어서, 대상체에서 항체 반응을 유발하는 방법.
실시형태 45. 실시형태 44에 있어서, 항체 반응은 중화 항체 반응인, 방법.
실시형태 46. 실시형태 41 내지 실시형태 43 중 어느 하나에 있어서, 세포 면역 반응을 유발하는 방법.
실시형태 47. 실시형태 41 내지 실시형태 46 중 어느 하나에 있어서, 대상체에서 예방학적, 예방적 및/또는 치료적 면역 반응을 유발하는 방법.
실시형태 48. 실시형태 41 내지 실시형태 47 중 어느 하나에 있어서, 투여는 피부내 투여, 근육내 투여, 피하 투여, 또는 비강내 투여인, 방법.
실시형태 49. 코로나바이러스 단백질을 암호화하는 폴리뉴클레오티드와 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하는 폴리뉴클레오티드로서, 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체인, 발현 카세트를 포함하는 폴리뉴클레오티드.
실시형태 50. 실시형태 49에 있어서, 인핸서 단백질의 아미노산 서열은 서열번호 1과 적어도 95%의 동일성, 또는 서열번호 2와 적어도 95%의 동일성을 갖는, 폴리뉴클레오티드.
실시형태 51. 실시형태 49 또는 실시형태 50에 있어서, 인핸서 단백질의 아미노산 서열은 서열번호 1, 또는 서열번호 2인, 폴리뉴클레오티드.
실시형태 52. 실시형태 49 내지 실시형태 51 중 어느 하나에 있어서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드는 내부 리보솜 유입 부위(IRES)를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된, 폴리뉴클레오티드.
실시형태 53. 실시형태 52에 있어서, IRES를 암호화하는 폴리뉴클레오티드는 서열번호 24인, 폴리뉴클레오티드.
실시형태 54. 실시형태 49 내지 실시형태 53 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 항원인, 폴리뉴클레오티드.
실시형태 55. 실시형태 49 내지 실시형태 54 중 어느 하나에 있어서, 코로나바이러스는 베타코로나바이러스인, 폴리뉴클레오티드.
실시형태 56. 실시형태 55에 있어서, 베타코로나바이러스는 중증 급성 호흡기 증후군(SARS) 바이러스인, 폴리뉴클레오티드.
실시형태 57. 실시형태 56에 있어서, SARS 바이러스는 SARS-CoV-2 바이러스인, 폴리뉴클레오티드.
실시형태 58. 실시형태 55에 있어서, 베타코로나바이러스는 중동 호흡기 증후군(MERS) 바이러스인, 폴리뉴클레오티드.
실시형태 59. 실시형태 49 내지 실시형태 58 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 스파이크 단백질인, 폴리뉴클레오티드.
실시형태 60. 실시형태 59에 있어서, 스파이크 단백질은 서열번호 13과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 폴리뉴클레오티드.
실시형태 61. 실시형태 59 또는 실시형태 60에 있어서, 스파이크 단백질은 서열번호 13인, 폴리뉴클레오티드.
실시형태 62. 실시형태 49 내지 실시형태 61 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 막(M) 단백질인, 폴리뉴클레오티드.
실시형태 63. 실시형태 62에 있어서, M 단백질은 서열번호 33과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 폴리뉴클레오티드.
실시형태 64. 실시형태 62 또는 실시형태 63에 있어서, M 단백질은 서열번호 33인, 폴리뉴클레오티드.
실시형태 65. 실시형태 49 내지 실시형태 64 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 외피(E) 단백질인, 폴리뉴클레오티드.
실시형태 66. 실시형태 65에 있어서, E 단백질은 서열번호 22와 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 폴리뉴클레오티드.
실시형태 67. 실시형태 65 또는 실시형태 66에 있어서, E 단백질은 서열번호 22인, 폴리뉴클레오티드.
실시형태 68. 실시형태 49 내지 실시형태 67 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 뉴클레오캡시드(N) 단백질인, 폴리뉴클레오티드.
실시형태 69. 실시형태 68에 있어서, N 단백질은 서열번호 20과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 폴리뉴클레오티드.
실시형태 70. 실시형태 68 또는 실시형태 69에 있어서, N 단백질은 서열번호 20인, 폴리뉴클레오티드.
실시형태 71. 실시형태 49 내지 실시형태 70 중 어느 하나에 있어서, 코로나바이러스 단백질은 바이러스 유사 입자(VLP)를 형성하는, 폴리뉴클레오티드.
실시형태 72. 서열번호 30의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는 폴리뉴클레오티드.
실시형태 73. 실시형태 72에 있어서, 서열번호 30의 핵산 서열을 포함하는 폴리뉴클레오티드.
실시형태 74. 서열번호 31의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는 폴리뉴클레오티드.
실시형태 75. 실시형태 74에 있어서, 서열번호 31의 핵산 서열을 포함하는 폴리뉴클레오티드.
실시형태 76. 실시형태 49 내지 실시형태 75 중 어느 하나에 있어서, 네이키드 폴리뉴클레오티드인 폴리뉴클레오티드.
실시형태 77. 실시형태 49 내지 실시형태 76 중 어느 하나에 있어서, 데옥시리보핵산(DNA) 폴리뉴클레오티드인 폴리뉴클레오티드.
실시형태 78. 실시형태 49 내지 실시형태 76 중 어느 하나에 있어서, 리보핵산(RNA) 폴리뉴클레오티드인 폴리뉴클레오티드.
실시형태 79. 실시형태 49 내지 실시형태 78 중 어느 하나에 있어서, 발현 카세트는 발현 카세트의 폴리뉴클레오티드 서열 각각에 작동 가능하게 연결된 프로모터를 포함하는, 폴리뉴클레오티드.
실시형태 80. 벡터를 포함하는 키트로서, 벡터는 코로나바이러스 단백질을 암호화하는 폴리뉴클레오티드 및 인핸서 단백질을 암호화하는 폴리뉴클레오티드를 포함하는 발현 카세트를 포함하며, 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체인, 벡터를 포함하는 키트.
실시형태 81. 실시형태 80에 있어서, 인핸서 단백질의 아미노산 서열은 서열번호 1과 적어도 95%의 동일성, 또는 서열번호 2와 적어도 95%의 동일성을 갖는, 키트.
실시형태 82. 실시형태 80 또는 실시형태 81에 있어서, 인핸서 단백질을 암호화하는 폴리뉴클레오티드는 내부 리보솜 유입 부위(IRES)를 암호화하는 폴리뉴클레오티드에 작동 가능하게 연결된, 키트.
실시형태 83. 실시형태 82에 있어서, IRES를 암호화하는 폴리뉴클레오티드는 서열번호 24인, 키트.
실시형태 84. 실시형태 80 내지 실시형태 83 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 항원인, 키트.
실시형태 85. 실시형태 80 내지 실시형태 84 중 어느 하나에 있어서, 코로나바이러스는 베타코로나바이러스인, 키트.
실시형태 86. 실시형태 85에 있어서, 베타코로나바이러스는 중증 급성 호흡기 증후군(SARS) 바이러스인, 키트.
실시형태 87. 실시형태 86에 있어서, SARS 바이러스는 SARS-CoV-2 바이러스인, 키트.
실시형태 88. 실시형태 85에 있어서, 베타코로나바이러스는 중동 호흡기 증후군(MERS) 바이러스인, 키트.
실시형태 89. 실시형태 80 내지 실시형태 88 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 스파이크 단백질인, 키트.
실시형태 90. 실시형태 89에 있어서, 스파이크 단백질은 서열번호 13과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 키트.
실시형태 91. 실시형태 90에 있어서, 스파이크 단백질은 서열번호 13인, 키트.
실시형태 92. 실시형태 80 내지 실시형태 91 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 막(M) 단백질인, 키트.
실시형태 93. 실시형태 92에 있어서, M 단백질은 서열번호 33과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 키트.
실시형태 94. 실시형태 92 또는 실시형태 93에 있어서, M 단백질은 서열번호 33인, 키트.
실시형태 95. 실시형태 80 내지 실시형태 94 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 외피(E) 단백질인, 키트.
실시형태 96. 실시형태 95에 있어서, E 단백질은 서열번호 22와 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 키트.
실시형태 97. 실시형태 95 또는 실시형태 96에 있어서, E 단백질은 서열번호 22인, 키트.
실시형태 98. 실시형태 80 내지 실시형태 97 중 어느 하나에 있어서, 코로나바이러스 단백질은 코로나바이러스 뉴클레오캡시드(N) 단백질인, 키트.
실시형태 99. 실시형태 98에 있어서, N 단백질은 서열번호 20과 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 공유하는, 키트.
실시형태 100. 실시형태 98 또는 실시형태 99에 있어서, N 단백질은 서열번호 20인, 키트.
실시형태 101. 실시형태 80에 있어서, 발현 카세트는 서열번호 30의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는 폴리뉴클레오티드를 포함하는, 키트.
실시형태 102. 실시형태 80에 있어서, 발현 카세트는 서열번호 31의 핵산 서열과 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 적어도 99.5% 또는 100%의 동일성을 갖는 핵산 서열을 포함하는 폴리뉴클레오티드를 포함하는, 키트.
실시형태 103. 실시형태 80 내지 실시형태 102 중 어느 하나에 있어서, 키트는 약제학적으로 허용 가능한 담체를 포함하는, 키트.
실시형태 104. 벡터로서, 발현 카세트를 포함하며, 상기 발현 카세트는 표적 유전자에 연결된 프로모터를 포함하고, 바이러스 패키징 요소를 암호화하는 핵산 서열을 포함하는 벡터.
실시형태 105. 실시형태 104에 있어서, 바이러스 패키징 요소는 RNA 폴리뉴클레오티드인, 벡터.
실시형태 106. 실시형태 104 또는 실시형태 105에 있어서, 바이러스 패키징 요소는 코로나바이러스로부터 유래되는, 벡터.
실시형태 107. 실시형태 106에 있어서, 바이러스 패키징 요소는 SARS-CoV2로부터 유래되는, 벡터.
실시형태 108. 실시형태 104 내지 실시형태 107 중 어느 하나에 있어서, 바이러스 패키징 요소를 암호화하는 핵산 서열은 서열번호 34의 핵산 서열과 적어도 약 70%의 동일성을 갖는, 벡터.
실시형태 109. 진핵 세포에서 표적 단백질을 발현시키는 방법으로서, 세포를 실시형태 104 내지 실시형태 108 중 어느 하나의 벡터와 접촉시키는 것을 포함하는, 방법.
실시형태 110. 실시형태 109에 있어서, 세포를 벡터와 접촉시키는 것은 표적 단백질의 바이러스 유사 입자(VLP)의 형성을 일으키는, 방법.
실시형태 111. 실시형태 110에 있어서, 세포를 벡터와 접촉시키는 것은 발현 카세트를 포함하지만 바이러스 패키징 요소를 암호화하는 핵산 서열이 없는 대조군 벡터와 비교할 때 더 많은 수의 표적 단백질을 포함하는 바이러스 유사 입자(VLP)의 형성을 일으키는, 방법.
실시형태 112. 실시형태 33.1 내지 실시형태 33.3 중 어느 하나의 벡터, 또는 실시형태 40.1, 실시형태 40.2, 실시형태 43.1 내지 실시형태 43.3 중 어느 하나의 방법으로서, 바이러스 패키징 요소를 암호화하는 핵산 서열은 서열번호 34의 핵산 서열과 적어도 약 70%의 동일성을 갖는, 방법.
실시형태 113. 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33(M 단백질)을 암호화하는 폴리뉴클레오티드, 제1 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20(N 단백질)을 암호화하는 폴리뉴클레오티드, 제2 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13(S 단백질)을 암호화하는 폴리뉴클레오티드, 제3 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22(E 단백질)를 암호화하는 폴리뉴클레오티드, 서열번호 24(IRES)를 암호화하는 폴리뉴클레오티드, 및 서열번호 2(인핸서 L 단백질)를 암호화하는 폴리뉴클레오티드.
실시형태 114. 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33(M 단백질)을 암호화하는 폴리뉴클레오티드, 제1 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13(S 단백질)을 암호화하는 폴리뉴클레오티드, 제2 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22(E 단백질)를 암호화하는 폴리뉴클레오티드, 서열번호 24(IRES)를 암호화하는 폴리뉴클레오티드, 서열번호 2(인핸서 L 단백질)를 암호화하는 폴리뉴클레오티드, 서열번호 20(N 단백질)을 암호화하는 폴리뉴클레오티드, 및 서열번호 34(바이러스 패키징 신호)를 암호화하는 폴리뉴클레오티드.
실시형태 115. 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 및 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드.
실시형태 116. 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로 다음 요소를 포함한다:: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES를 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드.
SEQUENCE LISTING
<110> Excepgen Inc.
<120> VACCINE COMPOSITIONS AND METHODS OF USE THEREOF
<130> EXCI-003/03WO 336721-2012
<150> US 63/162,496
<151> 2021-03-17
<160> 72
<170> PatentIn version 3.5
<210> 1
<211> 71
<212> PRT
<213> Cardiovirus Theiler's-like virus
<400> 1
Met Ala Cys Lys His Gly Tyr Pro Leu Met Cys Pro Leu Cys Thr Ala
1 5 10 15
Leu Asp Lys Thr Ser Asp Gly Leu Phe Thr Leu Leu Phe Asp Asn Glu
20 25 30
Trp Tyr Pro Thr Asp Leu Leu Thr Val Asp Leu Glu Asp Glu Val Phe
35 40 45
Tyr Pro Asp Asp Pro His Met Glu Trp Thr Asp Leu Pro Leu Ile Gln
50 55 60
Asp Ile Glu Met Glu Pro Gln
65 70
<210> 2
<211> 67
<212> PRT
<213> Cardiovirus Encephalomyocarditis virus
<400> 2
Met Ala Thr Thr Met Glu Gln Glu Thr Cys Ala His Ser Leu Thr Phe
1 5 10 15
Glu Glu Cys Pro Lys Cys Ser Ala Leu Gln Tyr Arg Asn Gly Phe Tyr
20 25 30
Leu Leu Lys Tyr Asp Glu Glu Trp Tyr Pro Glu Glu Leu Leu Thr Asp
35 40 45
Gly Glu Asp Asp Val Phe Asp Pro Glu Leu Asp Met Glu Val Val Phe
50 55 60
Glu Leu Gln
65
<210> 3
<211> 127
<212> PRT
<213> Enterovirus Enterovirus C
<400> 3
Asn Tyr His Leu Ala Thr Gln Asp Asp Leu Gln Asn Ala Val Asn Val
1 5 10 15
Met Trp Ser Arg Asp Leu Leu Val Thr Glu Ser Arg Ala Gln Gly Thr
20 25 30
Asp Ser Ile Ala Arg Cys Asn Cys Asn Ala Gly Val Tyr Tyr Cys Glu
35 40 45
Ser Arg Arg Lys Tyr Tyr Pro Val Ser Phe Val Gly Pro Thr Phe Gln
50 55 60
Tyr Met Glu Ala Asn Asn Tyr Tyr Pro Ala Arg Tyr Gln Ser His Met
65 70 75 80
Leu Ile Gly His Gly Phe Ala Ser Pro Gly Asp Cys Gly Gly Ile Leu
85 90 95
Arg Cys His His Gly Val Ile Gly Ile Ile Thr Ala Gly Gly Glu Gly
100 105 110
Leu Val Ala Phe Ser Asp Ile Arg Asp Leu Tyr Ala Tyr Glu Glu
115 120 125
<210> 4
<211> 219
<212> PRT
<213> Erbovirus Equine rhinitis B virus 1
<400> 4
Met Val Thr Met Ala Gly Asn Met Ile Cys Asn Val Phe Ala Gly Leu
1 5 10 15
Ala Thr Glu Ile Cys Ser Pro Lys Gln Gly Pro Leu Leu Asp Asn Glu
20 25 30
Leu Pro Leu Pro Leu Glu Leu Ala Glu Phe Pro Asn Lys Asp Asn Asn
35 40 45
Cys Trp Val Ala Ala Leu Ser His Tyr Tyr Thr Leu Cys Asp Val Thr
50 55 60
Asn His Val Thr Lys Val Thr Pro Thr Thr Ser Gly Ile Arg Tyr Tyr
65 70 75 80
Leu Thr Ala Trp Gln Ser Ile Leu Gln Thr Asp Leu Phe Asn Gly Tyr
85 90 95
Tyr Pro Ala Ala Phe Ala Val Glu Thr Gly Leu Cys His Gly Pro Phe
100 105 110
Pro Met Gln Gln His Gly Tyr Val Arg Asn Ala Thr Ser His Pro Tyr
115 120 125
Asn Phe Cys Leu Cys Ser Glu Pro Val Pro Gly Glu Asp Tyr Trp His
130 135 140
Ala Val Val Lys Val Asp Leu Ser Arg Thr Glu Ala Arg Val Asp Lys
145 150 155 160
Trp Leu Cys Ile Asp Asp Asp Arg Met Tyr Leu Ser Gly Pro Pro Thr
165 170 175
Arg Val Lys Leu Ala Ser Ser Tyr Lys Ile Pro Thr Trp Ile Glu Ser
180 185 190
Leu Ala Gln Phe Cys Leu Gln Leu His Pro Val Gln His Arg Arg Thr
195 200 205
Leu Ala Asn Ser Leu Arg Asn Glu Gln Cys Arg
210 215
<210> 5
<211> 67
<212> PRT
<213> Cardiovirus Encephalomyocarditis virus
<400> 5
Met Ala Thr Thr Met Glu Gln Glu Ile Cys Ala His Ser Met Thr Phe
1 5 10 15
Glu Glu Cys Pro Lys Cys Ser Ala Leu Gln Tyr Arg Asn Gly Phe Tyr
20 25 30
Leu Leu Lys Tyr Asp Glu Glu Trp Tyr Pro Glu Glu Ser Leu Thr Asp
35 40 45
Gly Glu Asp Asp Val Phe Asp Pro Asp Leu Asp Met Glu Val Val Phe
50 55 60
Glu Thr Gln
65
<210> 6
<211> 71
<212> PRT
<213> Cardiovirus Cardiovirus B
<400> 6
Met Ala Cys Lys His Gly Tyr Pro Phe Leu Cys Pro Leu Cys Thr Ala
1 5 10 15
Ile Asp Thr Thr His Asp Gly Ser Phe Thr Leu Leu Ile Asp Asn Glu
20 25 30
Trp Tyr Pro Thr Asp Leu Leu Thr Val Asp Leu Asp Asp Asp Val Phe
35 40 45
His Pro Asp Asp Ser Val Met Glu Trp Thr Asp Leu Pro Leu Ile Gln
50 55 60
Asp Val Val Met Glu Pro Gln
65 70
<210> 7
<400> 7
000
<210> 8
<400> 8
000
<210> 9
<400> 9
000
<210> 10
<400> 10
000
<210> 11
<400> 11
000
<210> 12
<211> 76
<212> PRT
<213> Cardiovirus Cardiovirus B
<400> 12
Met Ala Cys Lys His Gly Tyr Pro Asp Val Cys Pro Ile Cys Thr Ala
1 5 10 15
Val Asp Ala Thr Pro Gly Phe Glu Tyr Leu Leu Met Ala Asp Gly Glu
20 25 30
Trp Tyr Pro Thr Asp Leu Leu Cys Val Asp Leu Asp Asp Asp Val Phe
35 40 45
Trp Pro Ser Asp Thr Ser Asn Gln Ser Gln Thr Met Asp Trp Thr Asp
50 55 60
Val Pro Leu Ile Arg Asp Ile Val Met Glu Pro Gln
65 70 75
<210> 13
<211> 1273
<212> PRT
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 Spike
<400> 13
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Asp Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Pro Arg Arg Ala Arg Ser Val Ala
675 680 685
Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu Asn Ser
690 695 700
Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe Thr Ile
705 710 715 720
Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr Ser Val
725 730 735
Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser Asn Leu
740 745 750
Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala Leu Thr
755 760 765
Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe Ala Gln
770 775 780
Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly Gly Phe
785 790 795 800
Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys Arg Ser
805 810 815
Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp Ala Gly
820 825 830
Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala Arg Asp
835 840 845
Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro Pro Leu
850 855 860
Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu Ala Gly
865 870 875 880
Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu Gln Ile
885 890 895
Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly Val Thr
900 905 910
Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln Phe Asn
915 920 925
Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr Ala Ser Ala
930 935 940
Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala Gln Ala Leu Asn
945 950 955 960
Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly Ala Ile Ser Ser Val
965 970 975
Leu Asn Asp Ile Leu Ser Arg Leu Asp Lys Val Glu Ala Glu Val Gln
980 985 990
Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser Leu Gln Thr Tyr Val
995 1000 1005
Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg Ala Ser Ala Asn
1010 1015 1020
Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly Gln Ser Lys
1025 1030 1035
Arg Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser Phe Pro
1040 1045 1050
Gln Ser Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr Val
1055 1060 1065
Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His
1070 1075 1080
Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val Phe Val Ser Asn
1085 1090 1095
Gly Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln
1100 1105 1110
Ile Ile Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys Asp Val
1115 1120 1125
Val Ile Gly Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln Pro
1130 1135 1140
Glu Leu Asp Ser Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn
1145 1150 1155
His Thr Ser Pro Asp Val Asp Leu Gly Asp Ile Ser Gly Ile Asn
1160 1165 1170
Ala Ser Val Val Asn Ile Gln Lys Glu Ile Asp Arg Leu Asn Glu
1175 1180 1185
Val Ala Lys Asn Leu Asn Glu Ser Leu Ile Asp Leu Gln Glu Leu
1190 1195 1200
Gly Lys Tyr Glu Gln Tyr Ile Lys Trp Pro Trp Tyr Ile Trp Leu
1205 1210 1215
Gly Phe Ile Ala Gly Leu Ile Ala Ile Val Met Val Thr Ile Met
1220 1225 1230
Leu Cys Cys Met Thr Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys
1235 1240 1245
Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp Asp Ser Glu Pro
1250 1255 1260
Val Leu Lys Gly Val Lys Leu His Tyr Thr
1265 1270
<210> 14
<211> 3822
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 Spike
<400> 14
atgtttgttt ttcttgtttt attgccacta gtctctagtc agtgtgttaa tcttacaacc 60
agaactcaat taccccctgc atacactaat tctttcacac gtggtgttta ttaccctgac 120
aaagttttca gatcctcagt tttacattca actcaggact tgttcttacc tttcttttcc 180
aatgttactt ggttccatgc tatacatgtc tctgggacca atggtactaa gaggtttgat 240
aaccctgtcc taccatttaa tgatggtgtt tattttgctt ccactgagaa gtctaacata 300
ataagaggct ggatttttgg tactacttta gattcgaaga cccagtccct acttattgtt 360
aataacgcta ctaatgttgt tattaaagtc tgtgaatttc aattttgtaa tgatccattt 420
ttgggtgttt attaccacaa aaacaacaaa agttggatgg aaagtgagtt cagagtttat 480
tctagtgcga ataattgcac ttttgaatat gtctctcagc cttttcttat ggaccttgaa 540
ggaaaacagg gtaatttcaa aaatcttagg gaatttgtgt ttaagaatat tgatggttat 600
tttaaaatat attctaagca cacgcctatt aatttagtgc gtgatctccc tcagggtttt 660
tcggctttag aaccattggt agatttgcca ataggtatta acatcactag gtttcaaact 720
ttacttgctt tacatagaag ttatttgact cctggtgatt cttcttcagg ttggacagct 780
ggtgctgcag cttattatgt gggttatctt caacctagga cttttctatt aaaatataat 840
gaaaatggaa ccattacaga tgctgtagac tgtgcacttg accctctctc agaaacaaag 900
tgtacgttga aatccttcac tgtagaaaaa ggaatctatc aaacttctaa ctttagagtc 960
caaccaacag aatctattgt tagatttcct aatattacaa acttgtgccc ttttggtgaa 1020
gtttttaacg ccaccagatt tgcatctgtt tatgcttgga acaggaagag aatcagcaac 1080
tgtgttgctg attattctgt cctatataat tccgcatcat tttccacttt taagtgttat 1140
ggagtgtctc ctactaaatt aaatgatctc tgctttacta atgtctatgc agattcattt 1200
gtaattagag gtgatgaagt cagacaaatc gctccagggc aaactggaaa gattgctgat 1260
tataattata aattaccaga tgattttaca ggctgcgtta tagcttggaa ttctaacaat 1320
cttgattcta aggttggtgg taattataat tacctgtata gattgtttag gaagtctaat 1380
ctcaaacctt ttgagagaga tatttcaact gaaatctatc aggccggtag cacaccttgt 1440
aatggtgttg aaggttttaa ttgttacttt cctttacaat catatggttt ccaacccact 1500
aatggtgttg gttaccaacc atacagagta gtagtacttt cttttgaact tctacatgca 1560
ccagcaactg tttgtggacc taaaaagtct actaatttgg ttaaaaacaa atgtgtcaat 1620
ttcaacttca atggtttaac aggcacaggt gttcttactg agtctaacaa aaagtttctg 1680
cctttccaac aatttggcag agacattgct gacactactg atgctgtccg tgatccacag 1740
acacttgaga ttcttgacat tacaccatgt tcttttggtg gtgtcagtgt tataacacca 1800
ggaacaaata cttctaacca ggttgctgtt ctttatcagg atgttaactg cacagaagtc 1860
cctgttgcta ttcatgcaga tcaacttact cctacttggc gtgtttattc tacaggttct 1920
aatgtttttc aaacacgtgc aggctgttta ataggggctg aacatgtcaa caactcatat 1980
gagtgtgaca tacccattgg tgcaggtata tgcgctagtt atcagactca gactaattct 2040
cctcggcggg cacgtagtgt agctagtcaa tccatcattg cctacactat gtcacttggt 2100
gcagaaaatt cagttgctta ctctaataac tctattgcca tacccacaaa ttttactatt 2160
agtgttacca cagaaattct accagtgtct atgaccaaga catcagtaga ttgtacaatg 2220
tacatttgtg gtgattcaac tgaatgcagc aatcttttgt tgcaatatgg cagtttttgt 2280
acacaattaa accgtgcttt aactggaata gctgttgaac aagacaaaaa cacccaagaa 2340
gtttttgcac aagtcaaaca aatttacaaa acaccaccaa ttaaagattt tggtggtttt 2400
aatttttcac aaatattacc agatccatca aaaccaagca agaggtcatt tattgaagat 2460
ctacttttca acaaagtgac acttgcagat gctggcttca tcaaacaata tggtgattgc 2520
cttggtgata ttgctgctag agacctcatt tgtgcacaaa agtttaacgg ccttactgtt 2580
ttgccacctt tgctcacaga tgaaatgatt gctcaataca cttctgcact gttagcgggt 2640
acaatcactt ctggttggac ctttggtgca ggtgctgcat tacaaatacc atttgctatg 2700
caaatggctt ataggtttaa tggtattgga gttacacaga atgttctcta tgagaaccaa 2760
aaattgattg ccaaccaatt taatagtgct attggcaaaa ttcaagactc actttcttcc 2820
acagcaagtg cacttggaaa acttcaagat gtggtcaacc aaaatgcaca agctttaaac 2880
acgcttgtta aacaacttag ctccaatttt ggtgcaattt caagtgtttt aaatgatatc 2940
ctttcacgtc ttgacaaagt tgaggctgaa gtgcaaattg ataggttgat cacaggcaga 3000
cttcaaagtt tgcagacata tgtgactcaa caattaatta gagctgcaga aatcagagct 3060
tctgctaatc ttgctgctac taaaatgtca gagtgtgtac ttggacaatc aaaaagagtt 3120
gatttttgtg gaaagggcta tcatcttatg tccttccctc agtcagcacc tcatggtgta 3180
gtcttcttgc atgtgactta tgtccctgca caagaaaaga acttcacaac tgctcctgcc 3240
atttgtcatg atggaaaagc acactttcct cgtgaaggtg tctttgtttc aaatggcaca 3300
cactggtttg taacacaaag gaatttttat gaaccacaaa tcattactac agacaacaca 3360
tttgtgtctg gtaactgtga tgttgtaata ggaattgtca acaacacagt ttatgatcct 3420
ttgcaacctg aattagactc attcaaggag gagttagata aatattttaa gaatcataca 3480
tcaccagatg ttgatttagg tgacatctct ggcattaatg cttcagttgt aaacattcaa 3540
aaagaaattg accgcctcaa tgaggttgcc aagaatttaa atgaatctct catcgatctc 3600
caagaacttg gaaagtatga gcagtatata aaatggccat ggtacatttg gctaggtttt 3660
atagctggct tgattgccat agtaatggtg acaattatgc tttgctgtat gaccagttgc 3720
tgtagttgtc tcaagggctg ttgttcttgt ggatcctgct gcaaatttga tgaagacgac 3780
tctgagccag tgctcaaagg agtcaaatta cattacacat aa 3822
<210> 15
<400> 15
000
<210> 16
<211> 201
<212> DNA
<213> Artificial Sequence
<220>
<223> L protein from EMCV
<400> 16
atggccacaa ccatggaaca agagacttgc gcgcactctc tcacttttga ggaatgccca 60
aaatgctctg ctctacaata ccgtaatgga ttttacctgc taaagtatga tgaagaatgg 120
tacccagagg agttattgac tgatggagag gatgatgtct ttgatcccga attagacatg 180
gaagtcgttt tcgagttaca g 201
<210> 17
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> 2A site
<400> 17
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<210> 18
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<223> 2A site
<400> 18
ggaagcggag ctactaactt cagcctgctg aagcaggctg gagatgtgga ggagaaccct 60
ggacct 66
<210> 19
<211> 669
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 M protein
<400> 19
atggcagatt ccaacggtac tattaccgtt gaagagctta aaaagctcct tgaacaatgg 60
aacctagtaa taggtttcct attccttaca tggatttgtc ttctacaatt tgcctatgcc 120
aacaggaata ggtttttgta tataattaag ttaattttcc tctggctgtt atggccagta 180
actttagctt gttttgtgct tgctgctgtt tacagaataa attggatcac cggtggaatt 240
gctatcgcaa tggcttgtct tgtaggcttg atgtggctca gctacttcat tgcttctttc 300
agactgtttg cgcgtacgcg ttccatgtgg tcattcaatc cagaaactaa cattcttctc 360
aacgtgccac tccatggcac tattctgacc agaccgcttc tagaaagtga actcgtaatc 420
ggagctgtga tccttcgtgg acatcttcgt attgctggac accatctagg acgctgtgac 480
atcaaggacc tgcctaaaga aatcactgtt gctacatcac gaacgctttc ttattacaaa 540
ttgggagctt cgcagcgtgt agcaggtgac tcaggttttg ctgcatacag tcgctacagg 600
attggcaact ataaattaaa cacagaccat tccagtagca gtgacaatat tgctttgctt 660
gtacagtaa 669
<210> 20
<211> 419
<212> PRT
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 N protein
<400> 20
Met Ser Asp Asn Gly Pro Gln Asn Gln Arg Asn Ala Pro Arg Ile Thr
1 5 10 15
Phe Gly Gly Pro Ser Asp Ser Thr Gly Ser Asn Gln Asn Gly Glu Arg
20 25 30
Ser Gly Ala Arg Ser Lys Gln Arg Arg Pro Gln Gly Leu Pro Asn Asn
35 40 45
Thr Ala Ser Trp Phe Thr Ala Leu Thr Gln His Gly Lys Glu Asp Leu
50 55 60
Lys Phe Pro Arg Gly Gln Gly Val Pro Ile Asn Thr Asn Ser Ser Pro
65 70 75 80
Asp Asp Gln Ile Gly Tyr Tyr Arg Arg Ala Thr Arg Arg Ile Arg Gly
85 90 95
Gly Asp Gly Lys Met Lys Asp Leu Ser Pro Arg Trp Tyr Phe Tyr Tyr
100 105 110
Leu Gly Thr Gly Pro Glu Ala Gly Leu Pro Tyr Gly Ala Asn Lys Asp
115 120 125
Gly Ile Ile Trp Val Ala Thr Glu Gly Ala Leu Asn Thr Pro Lys Asp
130 135 140
His Ile Gly Thr Arg Asn Pro Ala Asn Asn Ala Ala Ile Val Leu Gln
145 150 155 160
Leu Pro Gln Gly Thr Thr Leu Pro Lys Gly Phe Tyr Ala Glu Gly Ser
165 170 175
Arg Gly Gly Ser Gln Ala Ser Ser Arg Ser Ser Ser Arg Ser Arg Asn
180 185 190
Ser Ser Arg Asn Ser Thr Pro Gly Ser Ser Arg Gly Thr Ser Pro Ala
195 200 205
Arg Met Ala Gly Asn Gly Gly Asp Ala Ala Leu Ala Leu Leu Leu Leu
210 215 220
Asp Arg Leu Asn Gln Leu Glu Ser Lys Met Ser Gly Lys Gly Gln Gln
225 230 235 240
Gln Gln Gly Gln Thr Val Thr Lys Lys Ser Ala Ala Glu Ala Ser Lys
245 250 255
Lys Pro Arg Gln Lys Arg Thr Ala Thr Lys Ala Tyr Asn Val Thr Gln
260 265 270
Ala Phe Gly Arg Arg Gly Pro Glu Gln Thr Gln Gly Asn Phe Gly Asp
275 280 285
Gln Glu Leu Ile Arg Gln Gly Thr Asp Tyr Lys His Trp Pro Gln Ile
290 295 300
Ala Gln Phe Ala Pro Ser Ala Ser Ala Phe Phe Gly Met Ser Arg Ile
305 310 315 320
Gly Met Glu Val Thr Pro Ser Gly Thr Trp Leu Thr Tyr Thr Gly Ala
325 330 335
Ile Lys Leu Asp Asp Lys Asp Pro Asn Phe Lys Asp Gln Val Ile Leu
340 345 350
Leu Asn Lys His Ile Asp Ala Tyr Lys Thr Phe Pro Pro Thr Glu Pro
355 360 365
Lys Lys Asp Lys Lys Lys Lys Ala Asp Glu Thr Gln Ala Leu Pro Gln
370 375 380
Arg Gln Lys Lys Gln Gln Thr Val Thr Leu Leu Pro Ala Ala Asp Leu
385 390 395 400
Asp Asp Phe Ser Lys Gln Leu Gln Gln Ser Met Ser Ser Ala Asp Ser
405 410 415
Thr Gln Ala
<210> 21
<211> 1257
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 N protein
<400> 21
atgtctgata atggacccca aaatcagcga aatgcacccc gcattacgtt tggtggaccc 60
tcagattcaa ctggcagtaa ccagaatgga gaacgcagtg gggcgcgatc aaaacaacgt 120
cggccccaag gtttacccaa taatactgcg tcttggttca ccgctctcac tcaacatggc 180
aaggaagacc ttaaattccc tcgaggacaa ggcgttccaa ttaacaccaa tagcagtcca 240
gatgaccaaa ttggctacta ccgaagagct accagacgaa ttcgtggtgg tgacggtaaa 300
atgaaagatc tcagtccaag atggtatttc tactacctag gaactgggcc agaagctgga 360
cttccctatg gtgctaacaa agacggcatc atatgggttg caactgaggg agccttgaat 420
acaccaaaag atcacattgg cacccgcaat cctgctaaca atgctgcaat cgtgctacaa 480
cttcctcaag gaacaacatt gccaaaaggc ttctacgcag aagggagcag aggcggcagt 540
caagcctctt ctcgttcctc atcacgtagt cgcaacagtt caagaaattc aactccaggc 600
agcagtaggg gaacttctcc tgctagaatg gctggcaatg gcggtgatgc tgctcttgct 660
ttgctgctgc ttgacagatt gaaccagctt gagagcaaaa tgtctggtaa aggccaacaa 720
caacaaggcc aaactgtcac taagaaatct gctgctgagg cttctaagaa gcctcggcaa 780
aaacgtactg ccactaaagc atacaatgta acacaagctt tcggcagacg tggtccagaa 840
caaacccaag gaaattttgg ggaccaggaa ctaatcagac aaggaactga ttacaaacat 900
tggccgcaaa ttgcacaatt tgcccccagc gcttcagcgt tcttcggaat gtcgcgcatt 960
ggcatggaag tcacaccttc gggaacgtgg ttgacctaca caggtgccat caaattggat 1020
gacaaagatc caaatttcaa agatcaagtc attttgctga ataagcatat tgacgcatac 1080
aaaacattcc caccaacaga gcctaaaaag gacaaaaaga agaaggctga tgaaactcaa 1140
gccttaccgc agagacagaa gaaacagcaa actgtgactc ttcttcctgc tgcagatttg 1200
gatgatttct ccaaacaatt gcaacaatcc atgagcagtg ctgactcaac tcaggcc 1257
<210> 22
<211> 75
<212> PRT
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 E protein
<400> 22
Met Tyr Ser Phe Val Ser Glu Glu Thr Gly Thr Leu Ile Val Asn Ser
1 5 10 15
Val Leu Leu Phe Leu Ala Phe Val Val Phe Leu Leu Val Thr Leu Ala
20 25 30
Ile Leu Thr Ala Leu Arg Leu Cys Ala Tyr Cys Cys Asn Ile Val Asn
35 40 45
Val Ser Leu Val Lys Pro Ser Phe Tyr Val Tyr Ser Arg Val Lys Asn
50 55 60
Leu Asn Ser Ser Arg Val Pro Asp Leu Leu Val
65 70 75
<210> 23
<211> 228
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 E protein
<400> 23
atgtactcat tcgtttcgga agagacaggt acgttaatag ttaatagcgt acttcttttt 60
cttgctttcg tggtattctt gctagttaca ctagccatcc ttactgcgct tcgattgtgt 120
gcgtactgct gcaatattgt taacgtgagt cttgtaaaac cttcttttta cgtttactct 180
cgtgttaaaa atctgaattc ttctagagtt cctgatcttc tggtctaa 228
<210> 24
<211> 565
<212> DNA
<213> Artificial Sequence
<220>
<223> IRES
<400> 24
tccccccccc ctaacgttac tggccgaagc cgcttggaat aaggccggtg tgcgtttgtc 60
tatatgttat tttccaccat attgccgtct tttggcaatg tgagggcccg gaaacctggc 120
cctgtcttct tgacgagcat tcctaggggt ctttcccctc tcgccaaagg aatgcaaggt 180
ctgttgaatg tcgtgaagga agcagttcct ctggaagctt cttgaagaca aacaacgtct 240
gtagcgaccc tttgcaggca gcggaacccc ccacctggcg acaggtgcct ctgcggccaa 300
aagccacgtg tataagatac acctgcaaag gcggcacaac cccagtgcca cgttgtgagt 360
tggatagttg tggaaagagt caaatggctc tcctcaagcg tattcaacaa ggggctgaag 420
gatgcccaga aggtacccca ttgtatggga tctgatctgg ggcctcggtg cacatgcttt 480
acatgtgttt agtcgaggtt aaaaaaacgt ctaggccccc cgaaccacgg ggacgtggtt 540
ttcctttgaa aaacacgatg ataat 565
<210> 25
<211> 311
<212> PRT
<213> Artificial Sequence
<220>
<223> CoVEG2 polypeptide 1 (fusion of EMCV L protein, 2A site, M protein)
<400> 25
Met Ala Thr Thr Met Glu Gln Glu Thr Cys Ala His Ser Leu Thr Phe
1 5 10 15
Glu Glu Cys Pro Lys Cys Ser Ala Leu Gln Tyr Arg Asn Gly Phe Tyr
20 25 30
Leu Leu Lys Tyr Asp Glu Glu Trp Tyr Pro Glu Glu Leu Leu Thr Asp
35 40 45
Gly Glu Asp Asp Val Phe Asp Pro Glu Leu Asp Met Glu Val Val Phe
50 55 60
Glu Leu Gln Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
65 70 75 80
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ala Asp Ser Asn Gly Thr
85 90 95
Ile Thr Val Glu Glu Leu Lys Lys Leu Leu Glu Gln Trp Asn Leu Val
100 105 110
Ile Gly Phe Leu Phe Leu Thr Trp Ile Cys Leu Leu Gln Phe Ala Tyr
115 120 125
Ala Asn Arg Asn Arg Phe Leu Tyr Ile Ile Lys Leu Ile Phe Leu Trp
130 135 140
Leu Leu Trp Pro Val Thr Leu Ala Cys Phe Val Leu Ala Ala Val Tyr
145 150 155 160
Arg Ile Asn Trp Ile Thr Gly Gly Ile Ala Ile Ala Met Ala Cys Leu
165 170 175
Val Gly Leu Met Trp Leu Ser Tyr Phe Ile Ala Ser Phe Arg Leu Phe
180 185 190
Ala Arg Thr Arg Ser Met Trp Ser Phe Asn Pro Glu Thr Asn Ile Leu
195 200 205
Leu Asn Val Pro Leu His Gly Thr Ile Leu Thr Arg Pro Leu Leu Glu
210 215 220
Ser Glu Leu Val Ile Gly Ala Val Ile Leu Arg Gly His Leu Arg Ile
225 230 235 240
Ala Gly His His Leu Gly Arg Cys Asp Ile Lys Asp Leu Pro Lys Glu
245 250 255
Ile Thr Val Ala Thr Ser Arg Thr Leu Ser Tyr Tyr Lys Leu Gly Ala
260 265 270
Ser Gln Arg Val Ala Gly Asp Ser Gly Phe Ala Ala Tyr Ser Arg Tyr
275 280 285
Arg Ile Gly Asn Tyr Lys Leu Asn Thr Asp His Ser Ser Ser Ser Asp
290 295 300
Asn Ile Ala Leu Leu Val Gln
305 310
<210> 26
<211> 605
<212> PRT
<213> Artificial Sequence
<220>
<223> CoVEG2 polypeptide 2 (fusion of EMCV L protein, 2A site, N protein, 2A site and E protein)
<400> 26
Met Ala Thr Thr Met Glu Gln Glu Thr Cys Ala His Ser Leu Thr Phe
1 5 10 15
Glu Glu Cys Pro Lys Cys Ser Ala Leu Gln Tyr Arg Asn Gly Phe Tyr
20 25 30
Leu Leu Lys Tyr Asp Glu Glu Trp Tyr Pro Glu Glu Leu Leu Thr Asp
35 40 45
Gly Glu Asp Asp Val Phe Asp Pro Glu Leu Asp Met Glu Val Val Phe
50 55 60
Glu Leu Gln Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
65 70 75 80
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ser Asp Asn Gly Pro Gln
85 90 95
Asn Gln Arg Asn Ala Pro Arg Ile Thr Phe Gly Gly Pro Ser Asp Ser
100 105 110
Thr Gly Ser Asn Gln Asn Gly Glu Arg Ser Gly Ala Arg Ser Lys Gln
115 120 125
Arg Arg Pro Gln Gly Leu Pro Asn Asn Thr Ala Ser Trp Phe Thr Ala
130 135 140
Leu Thr Gln His Gly Lys Glu Asp Leu Lys Phe Pro Arg Gly Gln Gly
145 150 155 160
Val Pro Ile Asn Thr Asn Ser Ser Pro Asp Asp Gln Ile Gly Tyr Tyr
165 170 175
Arg Arg Ala Thr Arg Arg Ile Arg Gly Gly Asp Gly Lys Met Lys Asp
180 185 190
Leu Ser Pro Arg Trp Tyr Phe Tyr Tyr Leu Gly Thr Gly Pro Glu Ala
195 200 205
Gly Leu Pro Tyr Gly Ala Asn Lys Asp Gly Ile Ile Trp Val Ala Thr
210 215 220
Glu Gly Ala Leu Asn Thr Pro Lys Asp His Ile Gly Thr Arg Asn Pro
225 230 235 240
Ala Asn Asn Ala Ala Ile Val Leu Gln Leu Pro Gln Gly Thr Thr Leu
245 250 255
Pro Lys Gly Phe Tyr Ala Glu Gly Ser Arg Gly Gly Ser Gln Ala Ser
260 265 270
Ser Arg Ser Ser Ser Arg Ser Arg Asn Ser Ser Arg Asn Ser Thr Pro
275 280 285
Gly Ser Ser Arg Gly Thr Ser Pro Ala Arg Met Ala Gly Asn Gly Gly
290 295 300
Asp Ala Ala Leu Ala Leu Leu Leu Leu Asp Arg Leu Asn Gln Leu Glu
305 310 315 320
Ser Lys Met Ser Gly Lys Gly Gln Gln Gln Gln Gly Gln Thr Val Thr
325 330 335
Lys Lys Ser Ala Ala Glu Ala Ser Lys Lys Pro Arg Gln Lys Arg Thr
340 345 350
Ala Thr Lys Ala Tyr Asn Val Thr Gln Ala Phe Gly Arg Arg Gly Pro
355 360 365
Glu Gln Thr Gln Gly Asn Phe Gly Asp Gln Glu Leu Ile Arg Gln Gly
370 375 380
Thr Asp Tyr Lys His Trp Pro Gln Ile Ala Gln Phe Ala Pro Ser Ala
385 390 395 400
Ser Ala Phe Phe Gly Met Ser Arg Ile Gly Met Glu Val Thr Pro Ser
405 410 415
Gly Thr Trp Leu Thr Tyr Thr Gly Ala Ile Lys Leu Asp Asp Lys Asp
420 425 430
Pro Asn Phe Lys Asp Gln Val Ile Leu Leu Asn Lys His Ile Asp Ala
435 440 445
Tyr Lys Thr Phe Pro Pro Thr Glu Pro Lys Lys Asp Lys Lys Lys Lys
450 455 460
Ala Asp Glu Thr Gln Ala Leu Pro Gln Arg Gln Lys Lys Gln Gln Thr
465 470 475 480
Val Thr Leu Leu Pro Ala Ala Asp Leu Asp Asp Phe Ser Lys Gln Leu
485 490 495
Gln Gln Ser Met Ser Ser Ala Asp Ser Thr Gln Ala Gly Ser Gly Ala
500 505 510
Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro
515 520 525
Gly Pro Met Tyr Ser Phe Val Ser Glu Glu Thr Gly Thr Leu Ile Val
530 535 540
Asn Ser Val Leu Leu Phe Leu Ala Phe Val Val Phe Leu Leu Val Thr
545 550 555 560
Leu Ala Ile Leu Thr Ala Leu Arg Leu Cys Ala Tyr Cys Cys Asn Ile
565 570 575
Val Asn Val Ser Leu Val Lys Pro Ser Phe Tyr Val Tyr Ser Arg Val
580 585 590
Lys Asn Leu Asn Ser Ser Arg Val Pro Asp Leu Leu Val
595 600 605
<210> 27
<211> 380
<212> DNA
<213> Artificial Sequence
<220>
<223> CMV enhancer
<400> 27
gacattgatt attgactagt tattaatagt aatcaattac ggggtcatta gttcatagcc 60
catatatgga gttccgcgtt acataactta cggtaaatgg cccgcctggc tgaccgccca 120
acgacccccg cccattgacg tcaataatga cgtatgttcc catagtaacg ccaataggga 180
ctttccattg acgtcaatgg gtggagtatt tacggtaaac tgcccacttg gcagtacatc 240
aagtgtatca tatgccaagt acgcccccta ttgacgtcaa tgacggtaaa tggcccgcct 300
ggcattatgc ccagtacatg accttatggg actttcctac ttggcagtac atctacgtat 360
tagtcatcgc tattaccatg 380
<210> 28
<211> 204
<212> DNA
<213> Artificial Sequence
<220>
<223> CMV promoter
<400> 28
gtgatgcggt tttggcagta catcaatggg cgtggatagc ggtttgactc acggggattt 60
ccaagtctcc accccattga cgtcaatggg agtttgtttt ggcaccaaaa tcaacgggac 120
tttccaaaat gtcgtaacaa ctccgcccca ttgacgcaaa tgggcggtag gcgtgtacgg 180
tgggaggtct atataagcag agct 204
<210> 29
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<223> Cloning site
<400> 29
ggtttagtga accgtcagat ccgctagcgc taccggactc agatctcgag ctcaagcttc 60
gaattctgca gtcgacggta ccgcgggccc gggatccacc ggtcgccacg 110
<210> 30
<211> 8399
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG2 insert sequence
<400> 30
gacattgatt attgactagt tattaatagt aatcaattac ggggtcatta gttcatagcc 60
catatatgga gttccgcgtt acataactta cggtaaatgg cccgcctggc tgaccgccca 120
acgacccccg cccattgacg tcaataatga cgtatgttcc catagtaacg ccaataggga 180
ctttccattg acgtcaatgg gtggagtatt tacggtaaac tgcccacttg gcagtacatc 240
aagtgtatca tatgccaagt acgcccccta ttgacgtcaa tgacggtaaa tggcccgcct 300
ggcattatgc ccagtacatg accttatggg actttcctac ttggcagtac atctacgtat 360
tagtcatcgc tattaccatg gtgatgcggt tttggcagta catcaatggg cgtggatagc 420
ggtttgactc acggggattt ccaagtctcc accccattga cgtcaatggg agtttgtttt 480
ggcaccaaaa tcaacgggac tttccaaaat gtcgtaacaa ctccgcccca ttgacgcaaa 540
tgggcggtag gcgtgtacgg tgggaggtct atataagcag agctggttta gtgaaccgtc 600
agatccgcta gcgctaccgg actcagatct cgagctcaag cttcgaattc tgcagtcgac 660
ggtaccgcgg gcccgggatc caccggtcgc cacgatgttt gtttttcttg ttttattgcc 720
actagtctct agtcagtgtg ttaatcttac aaccagaact caattacccc ctgcatacac 780
taattctttc acacgtggtg tttattaccc tgacaaagtt ttcagatcct cagttttaca 840
ttcaactcag gacttgttct tacctttctt ttccaatgtt acttggttcc atgctataca 900
tgtctctggg accaatggta ctaagaggtt tgataaccct gtcctaccat ttaatgatgg 960
tgtttatttt gcttccactg agaagtctaa cataataaga ggctggattt ttggtactac 1020
tttagattcg aagacccagt ccctacttat tgttaataac gctactaatg ttgttattaa 1080
agtctgtgaa tttcaatttt gtaatgatcc atttttgggt gtttattacc acaaaaacaa 1140
caaaagttgg atggaaagtg agttcagagt ttattctagt gcgaataatt gcacttttga 1200
atatgtctct cagccttttc ttatggacct tgaaggaaaa cagggtaatt tcaaaaatct 1260
tagggaattt gtgtttaaga atattgatgg ttattttaaa atatattcta agcacacgcc 1320
tattaattta gtgcgtgatc tccctcaggg tttttcggct ttagaaccat tggtagattt 1380
gccaataggt attaacatca ctaggtttca aactttactt gctttacata gaagttattt 1440
gactcctggt gattcttctt caggttggac agctggtgct gcagcttatt atgtgggtta 1500
tcttcaacct aggacttttc tattaaaata taatgaaaat ggaaccatta cagatgctgt 1560
agactgtgca cttgaccctc tctcagaaac aaagtgtacg ttgaaatcct tcactgtaga 1620
aaaaggaatc tatcaaactt ctaactttag agtccaacca acagaatcta ttgttagatt 1680
tcctaatatt acaaacttgt gcccttttgg tgaagttttt aacgccacca gatttgcatc 1740
tgtttatgct tggaacagga agagaatcag caactgtgtt gctgattatt ctgtcctata 1800
taattccgca tcattttcca cttttaagtg ttatggagtg tctcctacta aattaaatga 1860
tctctgcttt actaatgtct atgcagattc atttgtaatt agaggtgatg aagtcagaca 1920
aatcgctcca gggcaaactg gaaagattgc tgattataat tataaattac cagatgattt 1980
tacaggctgc gttatagctt ggaattctaa caatcttgat tctaaggttg gtggtaatta 2040
taattacctg tatagattgt ttaggaagtc taatctcaaa ccttttgaga gagatatttc 2100
aactgaaatc tatcaggccg gtagcacacc ttgtaatggt gttgaaggtt ttaattgtta 2160
ctttccttta caatcatatg gtttccaacc cactaatggt gttggttacc aaccatacag 2220
agtagtagta ctttcttttg aacttctaca tgcaccagca actgtttgtg gacctaaaaa 2280
gtctactaat ttggttaaaa acaaatgtgt caatttcaac ttcaatggtt taacaggcac 2340
aggtgttctt actgagtcta acaaaaagtt tctgcctttc caacaatttg gcagagacat 2400
tgctgacact actgatgctg tccgtgatcc acagacactt gagattcttg acattacacc 2460
atgttctttt ggtggtgtca gtgttataac accaggaaca aatacttcta accaggttgc 2520
tgttctttat caggatgtta actgcacaga agtccctgtt gctattcatg cagatcaact 2580
tactcctact tggcgtgttt attctacagg ttctaatgtt tttcaaacac gtgcaggctg 2640
tttaataggg gctgaacatg tcaacaactc atatgagtgt gacataccca ttggtgcagg 2700
tatatgcgct agttatcaga ctcagactaa ttctcctcgg cgggcacgta gtgtagctag 2760
tcaatccatc attgcctaca ctatgtcact tggtgcagaa aattcagttg cttactctaa 2820
taactctatt gccataccca caaattttac tattagtgtt accacagaaa ttctaccagt 2880
gtctatgacc aagacatcag tagattgtac aatgtacatt tgtggtgatt caactgaatg 2940
cagcaatctt ttgttgcaat atggcagttt ttgtacacaa ttaaaccgtg ctttaactgg 3000
aatagctgtt gaacaagaca aaaacaccca agaagttttt gcacaagtca aacaaattta 3060
caaaacacca ccaattaaag attttggtgg ttttaatttt tcacaaatat taccagatcc 3120
atcaaaacca agcaagaggt catttattga agatctactt ttcaacaaag tgacacttgc 3180
agatgctggc ttcatcaaac aatatggtga ttgccttggt gatattgctg ctagagacct 3240
catttgtgca caaaagttta acggccttac tgttttgcca cctttgctca cagatgaaat 3300
gattgctcaa tacacttctg cactgttagc gggtacaatc acttctggtt ggacctttgg 3360
tgcaggtgct gcattacaaa taccatttgc tatgcaaatg gcttataggt ttaatggtat 3420
tggagttaca cagaatgttc tctatgagaa ccaaaaattg attgccaacc aatttaatag 3480
tgctattggc aaaattcaag actcactttc ttccacagca agtgcacttg gaaaacttca 3540
agatgtggtc aaccaaaatg cacaagcttt aaacacgctt gttaaacaac ttagctccaa 3600
ttttggtgca atttcaagtg ttttaaatga tatcctttca cgtcttgaca aagttgaggc 3660
tgaagtgcaa attgataggt tgatcacagg cagacttcaa agtttgcaga catatgtgac 3720
tcaacaatta attagagctg cagaaatcag agcttctgct aatcttgctg ctactaaaat 3780
gtcagagtgt gtacttggac aatcaaaaag agttgatttt tgtggaaagg gctatcatct 3840
tatgtccttc cctcagtcag cacctcatgg tgtagtcttc ttgcatgtga cttatgtccc 3900
tgcacaagaa aagaacttca caactgctcc tgccatttgt catgatggaa aagcacactt 3960
tcctcgtgaa ggtgtctttg tttcaaatgg cacacactgg tttgtaacac aaaggaattt 4020
ttatgaacca caaatcatta ctacagacaa cacatttgtg tctggtaact gtgatgttgt 4080
aataggaatt gtcaacaaca cagtttatga tcctttgcaa cctgaattag actcattcaa 4140
ggaggagtta gataaatatt ttaagaatca tacatcacca gatgttgatt taggtgacat 4200
ctctggcatt aatgcttcag ttgtaaacat tcaaaaagaa attgaccgcc tcaatgaggt 4260
tgccaagaat ttaaatgaat ctctcatcga tctccaagaa cttggaaagt atgagcagta 4320
tataaaatgg ccatggtaca tttggctagg ttttatagct ggcttgattg ccatagtaat 4380
ggtgacaatt atgctttgct gtatgaccag ttgctgtagt tgtctcaagg gctgttgttc 4440
ttgtggatcc tgctgcaaat ttgatgaaga cgactctgag ccagtgctca aaggagtcaa 4500
attacattac acataatccc ccccccctaa cgttactggc cgaagccgct tggaataagg 4560
ccggtgtgcg tttgtctata tgttattttc caccatattg ccgtcttttg gcaatgtgag 4620
ggcccggaaa cctggccctg tcttcttgac gagcattcct aggggtcttt cccctctcgc 4680
caaaggaatg caaggtctgt tgaatgtcgt gaaggaagca gttcctctgg aagcttcttg 4740
aagacaaaca acgtctgtag cgaccctttg caggcagcgg aaccccccac ctggcgacag 4800
gtgcctctgc ggccaaaagc cacgtgtata agatacacct gcaaaggcgg cacaacccca 4860
gtgccacgtt gtgagttgga tagttgtgga aagagtcaaa tggctctcct caagcgtatt 4920
caacaagggg ctgaaggatg cccagaaggt accccattgt atgggatctg atctggggcc 4980
tcggtgcaca tgctttacat gtgtttagtc gaggttaaaa aaacgtctag gccccccgaa 5040
ccacggggac gtggttttcc tttgaaaaac acgatgataa tatggccaca accatggaac 5100
aagagacttg cgcgcactct ctcacttttg aggaatgccc aaaatgctct gctctacaat 5160
accgtaatgg attttacctg ctaaagtatg atgaagaatg gtacccagag gagttattga 5220
ctgatggaga ggatgatgtc tttgatcccg aattagacat ggaagtcgtt ttcgagttac 5280
agggaagcgg agctactaac ttcagcctgc tgaagcaggc tggagatgtg gaggagaacc 5340
ctggacctat ggcagattcc aacggtacta ttaccgttga agagcttaaa aagctccttg 5400
aacaatggaa cctagtaata ggtttcctat tccttacatg gatttgtctt ctacaatttg 5460
cctatgccaa caggaatagg tttttgtata taattaagtt aattttcctc tggctgttat 5520
ggccagtaac tttagcttgt tttgtgcttg ctgctgttta cagaataaat tggatcaccg 5580
gtggaattgc tatcgcaatg gcttgtcttg taggcttgat gtggctcagc tacttcattg 5640
cttctttcag actgtttgcg cgtacgcgtt ccatgtggtc attcaatcca gaaactaaca 5700
ttcttctcaa cgtgccactc catggcacta ttctgaccag accgcttcta gaaagtgaac 5760
tcgtaatcgg agctgtgatc cttcgtggac atcttcgtat tgctggacac catctaggac 5820
gctgtgacat caaggacctg cctaaagaaa tcactgttgc tacatcacga acgctttctt 5880
attacaaatt gggagcttcg cagcgtgtag caggtgactc aggttttgct gcatacagtc 5940
gctacaggat tggcaactat aaattaaaca cagaccattc cagtagcagt gacaatattg 6000
ctttgcttgt acagtaaccc ccccccctaa cgttactggc cgaagccgct tggaataagg 6060
ccggtgtgcg tttgtctata tgttattttc caccatattg ccgtcttttg gcaatgtgag 6120
ggcccggaaa cctggccctg tcttcttgac gagcattcct aggggtcttt cccctctcgc 6180
caaaggaatg caaggtctgt tgaatgtcgt gaaggaagca gttcctctgg aagcttcttg 6240
aagacaaaca acgtctgtag cgaccctttg caggcagcgg aaccccccac ctggcgacag 6300
gtgcctctgc ggccaaaagc cacgtgtata agatacacct gcaaaggcgg cacaacccca 6360
gtgccacgtt gtgagttgga tagttgtgga aagagtcaaa tggctctcct caagcgtatt 6420
caacaagggg ctgaaggatg cccagaaggt accccattgt atgggatctg atctggggcc 6480
tcggtgcaca tgctttacat gtgtttagtc gaggttaaaa aaacgtctag gccccccgaa 6540
ccacggggac gtggttttcc tttgaaaaac acgatgataa tatggccaca accatggaac 6600
aagagacttg cgcgcactct ctcacttttg aggaatgccc aaaatgctct gctctacaat 6660
accgtaatgg attttacctg ctaaagtatg atgaagaatg gtacccagag gagttattga 6720
ctgatggaga ggatgatgtc tttgatcccg aattagacat ggaagtcgtt ttcgagttac 6780
agggaagcgg agctactaac ttcagcctgc tgaagcaggc tggagatgtg gaggagaacc 6840
ctggacctat gtctgataat ggaccccaaa atcagcgaaa tgcaccccgc attacgtttg 6900
gtggaccctc agattcaact ggcagtaacc agaatggaga acgcagtggg gcgcgatcaa 6960
aacaacgtcg gccccaaggt ttacccaata atactgcgtc ttggttcacc gctctcactc 7020
aacatggcaa ggaagacctt aaattccctc gaggacaagg cgttccaatt aacaccaata 7080
gcagtccaga tgaccaaatt ggctactacc gaagagctac cagacgaatt cgtggtggtg 7140
acggtaaaat gaaagatctc agtccaagat ggtatttcta ctacctagga actgggccag 7200
aagctggact tccctatggt gctaacaaag acggcatcat atgggttgca actgagggag 7260
ccttgaatac accaaaagat cacattggca cccgcaatcc tgctaacaat gctgcaatcg 7320
tgctacaact tcctcaagga acaacattgc caaaaggctt ctacgcagaa gggagcagag 7380
gcggcagtca agcctcttct cgttcctcat cacgtagtcg caacagttca agaaattcaa 7440
ctccaggcag cagtagggga acttctcctg ctagaatggc tggcaatggc ggtgatgctg 7500
ctcttgcttt gctgctgctt gacagattga accagcttga gagcaaaatg tctggtaaag 7560
gccaacaaca acaaggccaa actgtcacta agaaatctgc tgctgaggct tctaagaagc 7620
ctcggcaaaa acgtactgcc actaaagcat acaatgtaac acaagctttc ggcagacgtg 7680
gtccagaaca aacccaagga aattttgggg accaggaact aatcagacaa ggaactgatt 7740
acaaacattg gccgcaaatt gcacaatttg cccccagcgc ttcagcgttc ttcggaatgt 7800
cgcgcattgg catggaagtc acaccttcgg gaacgtggtt gacctacaca ggtgccatca 7860
aattggatga caaagatcca aatttcaaag atcaagtcat tttgctgaat aagcatattg 7920
acgcatacaa aacattccca ccaacagagc ctaaaaagga caaaaagaag aaggctgatg 7980
aaactcaagc cttaccgcag agacagaaga aacagcaaac tgtgactctt cttcctgctg 8040
cagatttgga tgatttctcc aaacaattgc aacaatccat gagcagtgct gactcaactc 8100
aggccggaag cggagctact aacttcagcc tgctgaagca ggctggagat gtggaggaga 8160
accctggacc tatgtactca ttcgtttcgg aagagacagg tacgttaata gttaatagcg 8220
tacttctttt tcttgctttc gtggtattct tgctagttac actagccatc cttactgcgc 8280
ttcgattgtg tgcgtactgc tgcaatattg ttaacgtgag tcttgtaaaa ccttcttttt 8340
acgtttactc tcgtgttaaa aatctgaatt cttctagagt tcctgatctt ctggtctaa 8399
<210> 31
<211> 6308
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG1 insert sequence
<400> 31
gacattgatt attgactagt tattaatagt aatcaattac ggggtcatta gttcatagcc 60
catatatgga gttccgcgtt acataactta cggtaaatgg cccgcctggc tgaccgccca 120
acgacccccg cccattgacg tcaataatga cgtatgttcc catagtaacg ccaataggga 180
ctttccattg acgtcaatgg gtggagtatt tacggtaaac tgcccacttg gcagtacatc 240
aagtgtatca tatgccaagt acgcccccta ttgacgtcaa tgacggtaaa tggcccgcct 300
ggcattatgc ccagtacatg accttatggg actttcctac ttggcagtac atctacgtat 360
tagtcatcgc tattaccatg gtgatgcggt tttggcagta catcaatggg cgtggatagc 420
ggtttgactc acggggattt ccaagtctcc accccattga cgtcaatggg agtttgtttt 480
ggcaccaaaa tcaacgggac tttccaaaat gtcgtaacaa ctccgcccca ttgacgcaaa 540
tgggcggtag gcgtgtacgg tgggaggtct atataagcag agctggttta gtgaaccgtc 600
agatccgcta gcgctaccgg actcagatct cgagctcaag cttcgaattc tgcagtcgac 660
ggtaccgcgg gcccgggatc caccggtcgc cacgatgttt gtttttcttg ttttattgcc 720
actagtctct agtcagtgtg ttaatcttac aaccagaact caattacccc ctgcatacac 780
taattctttc acacgtggtg tttattaccc tgacaaagtt ttcagatcct cagttttaca 840
ttcaactcag gacttgttct tacctttctt ttccaatgtt acttggttcc atgctataca 900
tgtctctggg accaatggta ctaagaggtt tgataaccct gtcctaccat ttaatgatgg 960
tgtttatttt gcttccactg agaagtctaa cataataaga ggctggattt ttggtactac 1020
tttagattcg aagacccagt ccctacttat tgttaataac gctactaatg ttgttattaa 1080
agtctgtgaa tttcaatttt gtaatgatcc atttttgggt gtttattacc acaaaaacaa 1140
caaaagttgg atggaaagtg agttcagagt ttattctagt gcgaataatt gcacttttga 1200
atatgtctct cagccttttc ttatggacct tgaaggaaaa cagggtaatt tcaaaaatct 1260
tagggaattt gtgtttaaga atattgatgg ttattttaaa atatattcta agcacacgcc 1320
tattaattta gtgcgtgatc tccctcaggg tttttcggct ttagaaccat tggtagattt 1380
gccaataggt attaacatca ctaggtttca aactttactt gctttacata gaagttattt 1440
gactcctggt gattcttctt caggttggac agctggtgct gcagcttatt atgtgggtta 1500
tcttcaacct aggacttttc tattaaaata taatgaaaat ggaaccatta cagatgctgt 1560
agactgtgca cttgaccctc tctcagaaac aaagtgtacg ttgaaatcct tcactgtaga 1620
aaaaggaatc tatcaaactt ctaactttag agtccaacca acagaatcta ttgttagatt 1680
tcctaatatt acaaacttgt gcccttttgg tgaagttttt aacgccacca gatttgcatc 1740
tgtttatgct tggaacagga agagaatcag caactgtgtt gctgattatt ctgtcctata 1800
taattccgca tcattttcca cttttaagtg ttatggagtg tctcctacta aattaaatga 1860
tctctgcttt actaatgtct atgcagattc atttgtaatt agaggtgatg aagtcagaca 1920
aatcgctcca gggcaaactg gaaagattgc tgattataat tataaattac cagatgattt 1980
tacaggctgc gttatagctt ggaattctaa caatcttgat tctaaggttg gtggtaatta 2040
taattacctg tatagattgt ttaggaagtc taatctcaaa ccttttgaga gagatatttc 2100
aactgaaatc tatcaggccg gtagcacacc ttgtaatggt gttgaaggtt ttaattgtta 2160
ctttccttta caatcatatg gtttccaacc cactaatggt gttggttacc aaccatacag 2220
agtagtagta ctttcttttg aacttctaca tgcaccagca actgtttgtg gacctaaaaa 2280
gtctactaat ttggttaaaa acaaatgtgt caatttcaac ttcaatggtt taacaggcac 2340
aggtgttctt actgagtcta acaaaaagtt tctgcctttc caacaatttg gcagagacat 2400
tgctgacact actgatgctg tccgtgatcc acagacactt gagattcttg acattacacc 2460
atgttctttt ggtggtgtca gtgttataac accaggaaca aatacttcta accaggttgc 2520
tgttctttat caggatgtta actgcacaga agtccctgtt gctattcatg cagatcaact 2580
tactcctact tggcgtgttt attctacagg ttctaatgtt tttcaaacac gtgcaggctg 2640
tttaataggg gctgaacatg tcaacaactc atatgagtgt gacataccca ttggtgcagg 2700
tatatgcgct agttatcaga ctcagactaa ttctcctcgg cgggcacgta gtgtagctag 2760
tcaatccatc attgcctaca ctatgtcact tggtgcagaa aattcagttg cttactctaa 2820
taactctatt gccataccca caaattttac tattagtgtt accacagaaa ttctaccagt 2880
gtctatgacc aagacatcag tagattgtac aatgtacatt tgtggtgatt caactgaatg 2940
cagcaatctt ttgttgcaat atggcagttt ttgtacacaa ttaaaccgtg ctttaactgg 3000
aatagctgtt gaacaagaca aaaacaccca agaagttttt gcacaagtca aacaaattta 3060
caaaacacca ccaattaaag attttggtgg ttttaatttt tcacaaatat taccagatcc 3120
atcaaaacca agcaagaggt catttattga agatctactt ttcaacaaag tgacacttgc 3180
agatgctggc ttcatcaaac aatatggtga ttgccttggt gatattgctg ctagagacct 3240
catttgtgca caaaagttta acggccttac tgttttgcca cctttgctca cagatgaaat 3300
gattgctcaa tacacttctg cactgttagc gggtacaatc acttctggtt ggacctttgg 3360
tgcaggtgct gcattacaaa taccatttgc tatgcaaatg gcttataggt ttaatggtat 3420
tggagttaca cagaatgttc tctatgagaa ccaaaaattg attgccaacc aatttaatag 3480
tgctattggc aaaattcaag actcactttc ttccacagca agtgcacttg gaaaacttca 3540
agatgtggtc aaccaaaatg cacaagcttt aaacacgctt gttaaacaac ttagctccaa 3600
ttttggtgca atttcaagtg ttttaaatga tatcctttca cgtcttgaca aagttgaggc 3660
tgaagtgcaa attgataggt tgatcacagg cagacttcaa agtttgcaga catatgtgac 3720
tcaacaatta attagagctg cagaaatcag agcttctgct aatcttgctg ctactaaaat 3780
gtcagagtgt gtacttggac aatcaaaaag agttgatttt tgtggaaagg gctatcatct 3840
tatgtccttc cctcagtcag cacctcatgg tgtagtcttc ttgcatgtga cttatgtccc 3900
tgcacaagaa aagaacttca caactgctcc tgccatttgt catgatggaa aagcacactt 3960
tcctcgtgaa ggtgtctttg tttcaaatgg cacacactgg tttgtaacac aaaggaattt 4020
ttatgaacca caaatcatta ctacagacaa cacatttgtg tctggtaact gtgatgttgt 4080
aataggaatt gtcaacaaca cagtttatga tcctttgcaa cctgaattag actcattcaa 4140
ggaggagtta gataaatatt ttaagaatca tacatcacca gatgttgatt taggtgacat 4200
ctctggcatt aatgcttcag ttgtaaacat tcaaaaagaa attgaccgcc tcaatgaggt 4260
tgccaagaat ttaaatgaat ctctcatcga tctccaagaa cttggaaagt atgagcagta 4320
tataaaatgg ccatggtaca tttggctagg ttttatagct ggcttgattg ccatagtaat 4380
ggtgacaatt atgctttgct gtatgaccag ttgctgtagt tgtctcaagg gctgttgttc 4440
ttgtggatcc tgctgcaaat ttgatgaaga cgactctgag ccagtgctca aaggagtcaa 4500
attacattac acataatccc ccccccctaa cgttactggc cgaagccgct tggaataagg 4560
ccggtgtgcg tttgtctata tgttattttc caccatattg ccgtcttttg gcaatgtgag 4620
ggcccggaaa cctggccctg tcttcttgac gagcattcct aggggtcttt cccctctcgc 4680
caaaggaatg caaggtctgt tgaatgtcgt gaaggaagca gttcctctgg aagcttcttg 4740
aagacaaaca acgtctgtag cgaccctttg caggcagcgg aaccccccac ctggcgacag 4800
gtgcctctgc ggccaaaagc cacgtgtata agatacacct gcaaaggcgg cacaacccca 4860
gtgccacgtt gtgagttgga tagttgtgga aagagtcaaa tggctctcct caagcgtatt 4920
caacaagggg ctgaaggatg cccagaaggt accccattgt atgggatctg atctggggcc 4980
tcggtgcaca tgctttacat gtgtttagtc gaggttaaaa aaacgtctag gccccccgaa 5040
ccacggggac gtggttttcc tttgaaaaac acgatgataa tatggccaca accatggaac 5100
aagagacttg cgcgcactct ctcacttttg aggaatgccc aaaatgctct gctctacaat 5160
accgtaatgg attttacctg ctaaagtatg atgaagaatg gtacccagag gagttattga 5220
ctgatggaga ggatgatgtc tttgatcccg aattagacat ggaagtcgtt ttcgagttac 5280
agggaagcgg agctactaac ttcagcctgc tgaagcaggc tggagatgtg gaggagaacc 5340
ctggacctat ggcagattcc aacggtacta ttaccgttga agagcttaaa aagctccttg 5400
aacaatggaa cctagtaata ggtttcctat tccttacatg gatttgtctt ctacaatttg 5460
cctatgccaa caggaatagg tttttgtata taattaagtt aattttcctc tggctgttat 5520
ggccagtaac tttagcttgt tttgtgcttg ctgctgttta cagaataaat tggatcaccg 5580
gtggaattgc tatcgcaatg gcttgtcttg taggcttgat gtggctcagc tacttcattg 5640
cttctttcag actgtttgcg cgtacgcgtt ccatgtggtc attcaatcca gaaactaaca 5700
ttcttctcaa cgtgccactc catggcacta ttctgaccag accgcttcta gaaagtgaac 5760
tcgtaatcgg agctgtgatc cttcgtggac atcttcgtat tgctggacac catctaggac 5820
gctgtgacat caaggacctg cctaaagaaa tcactgttgc tacatcacga acgctttctt 5880
attacaaatt gggagcttcg cagcgtgtag caggtgactc aggttttgct gcatacagtc 5940
gctacaggat tggcaactat aaattaaaca cagaccattc cagtagcagt gacaatattg 6000
ctttgcttgt acagggaagc ggagctacta acttcagcct gctgaagcag gctggagatg 6060
tggaggagaa ccctggacct atgtactcat tcgtttcgga agagacaggt acgttaatag 6120
ttaatagcgt acttcttttt cttgctttcg tggtattctt gctagttaca ctagccatcc 6180
ttactgcgct tcgattgtgt gcgtactgct gcaatattgt taacgtgagt cttgtaaaac 6240
cttcttttta cgtttactct cgtgttaaaa atctgaattc ttctagagtt cctgatcttc 6300
tggtctaa 6308
<210> 32
<211> 408
<212> PRT
<213> Artificial Sequence
<220>
<223> CoVEG1 polypeptide (fusion of EMCV L protein, 2A site, M protein, 2A site and E protein)
<400> 32
Met Ala Thr Thr Met Glu Gln Glu Thr Cys Ala His Ser Leu Thr Phe
1 5 10 15
Glu Glu Cys Pro Lys Cys Ser Ala Leu Gln Tyr Arg Asn Gly Phe Tyr
20 25 30
Leu Leu Lys Tyr Asp Glu Glu Trp Tyr Pro Glu Glu Leu Leu Thr Asp
35 40 45
Gly Glu Asp Asp Val Phe Asp Pro Glu Leu Asp Met Glu Val Val Phe
50 55 60
Glu Leu Gln Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
65 70 75 80
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Ala Asp Ser Asn Gly Thr
85 90 95
Ile Thr Val Glu Glu Leu Lys Lys Leu Leu Glu Gln Trp Asn Leu Val
100 105 110
Ile Gly Phe Leu Phe Leu Thr Trp Ile Cys Leu Leu Gln Phe Ala Tyr
115 120 125
Ala Asn Arg Asn Arg Phe Leu Tyr Ile Ile Lys Leu Ile Phe Leu Trp
130 135 140
Leu Leu Trp Pro Val Thr Leu Ala Cys Phe Val Leu Ala Ala Val Tyr
145 150 155 160
Arg Ile Asn Trp Ile Thr Gly Gly Ile Ala Ile Ala Met Ala Cys Leu
165 170 175
Val Gly Leu Met Trp Leu Ser Tyr Phe Ile Ala Ser Phe Arg Leu Phe
180 185 190
Ala Arg Thr Arg Ser Met Trp Ser Phe Asn Pro Glu Thr Asn Ile Leu
195 200 205
Leu Asn Val Pro Leu His Gly Thr Ile Leu Thr Arg Pro Leu Leu Glu
210 215 220
Ser Glu Leu Val Ile Gly Ala Val Ile Leu Arg Gly His Leu Arg Ile
225 230 235 240
Ala Gly His His Leu Gly Arg Cys Asp Ile Lys Asp Leu Pro Lys Glu
245 250 255
Ile Thr Val Ala Thr Ser Arg Thr Leu Ser Tyr Tyr Lys Leu Gly Ala
260 265 270
Ser Gln Arg Val Ala Gly Asp Ser Gly Phe Ala Ala Tyr Ser Arg Tyr
275 280 285
Arg Ile Gly Asn Tyr Lys Leu Asn Thr Asp His Ser Ser Ser Ser Asp
290 295 300
Asn Ile Ala Leu Leu Val Gln Gly Ser Gly Ala Thr Asn Phe Ser Leu
305 310 315 320
Leu Lys Gln Ala Gly Asp Val Glu Glu Asn Pro Gly Pro Met Tyr Ser
325 330 335
Phe Val Ser Glu Glu Thr Gly Thr Leu Ile Val Asn Ser Val Leu Leu
340 345 350
Phe Leu Ala Phe Val Val Phe Leu Leu Val Thr Leu Ala Ile Leu Thr
355 360 365
Ala Leu Arg Leu Cys Ala Tyr Cys Cys Asn Ile Val Asn Val Ser Leu
370 375 380
Val Lys Pro Ser Phe Tyr Val Tyr Ser Arg Val Lys Asn Leu Asn Ser
385 390 395 400
Ser Arg Val Pro Asp Leu Leu Val
405
<210> 33
<211> 222
<212> PRT
<213> Artificial Sequence
<220>
<223> SARS-CoV-2 M protein
<400> 33
Met Ala Asp Ser Asn Gly Thr Ile Thr Val Glu Glu Leu Lys Lys Leu
1 5 10 15
Leu Glu Gln Trp Asn Leu Val Ile Gly Phe Leu Phe Leu Thr Trp Ile
20 25 30
Cys Leu Leu Gln Phe Ala Tyr Ala Asn Arg Asn Arg Phe Leu Tyr Ile
35 40 45
Ile Lys Leu Ile Phe Leu Trp Leu Leu Trp Pro Val Thr Leu Ala Cys
50 55 60
Phe Val Leu Ala Ala Val Tyr Arg Ile Asn Trp Ile Thr Gly Gly Ile
65 70 75 80
Ala Ile Ala Met Ala Cys Leu Val Gly Leu Met Trp Leu Ser Tyr Phe
85 90 95
Ile Ala Ser Phe Arg Leu Phe Ala Arg Thr Arg Ser Met Trp Ser Phe
100 105 110
Asn Pro Glu Thr Asn Ile Leu Leu Asn Val Pro Leu His Gly Thr Ile
115 120 125
Leu Thr Arg Pro Leu Leu Glu Ser Glu Leu Val Ile Gly Ala Val Ile
130 135 140
Leu Arg Gly His Leu Arg Ile Ala Gly His His Leu Gly Arg Cys Asp
145 150 155 160
Ile Lys Asp Leu Pro Lys Glu Ile Thr Val Ala Thr Ser Arg Thr Leu
165 170 175
Ser Tyr Tyr Lys Leu Gly Ala Ser Gln Arg Val Ala Gly Asp Ser Gly
180 185 190
Phe Ala Ala Tyr Ser Arg Tyr Arg Ile Gly Asn Tyr Lys Leu Asn Thr
195 200 205
Asp His Ser Ser Ser Ser Asp Asn Ile Ala Leu Leu Val Gln
210 215 220
<210> 34
<211> 661
<212> DNA
<213> Artificial Sequence
<220>
<223> Viral packaging signal (CoVEG8)
<400> 34
gtgtcaaagc gcgaggaact gttcaccgga gttttgccca tcctggtcga gctggacggc 60
gatgtgaacg gccacaagtt cagcgtttct ggcgagggtg agctttgggc taagcgcaac 120
attaaaccag taccagaggt gaaaatactc aataatttgg gtgtggacat tgctgctaat 180
actgtgatct gggactacaa aagagatgct ccagcacata tatctactat tggtgtttgt 240
tctatgactg acatagccaa gaaaccaact gaaacgattt gtgcaccact cactgtcttt 300
tttgatggta gagttgatgg tcaagtagac ttatttagaa atgcccgtaa tggtgttctt 360
attacagaag gtagtgttaa aggtttacaa ccatctgtag gtcccaaaca agctagtctt 420
aatggagtca cattaattgg agaagccgta aaaacacagt tcaattatta taagaaagtt 480
gatggtgttg tccaacaatt acctgaaact tactttactc agagtagaaa tttacaagaa 540
tttaaaccca ggagtcaaat ggaaattgat ttcttagaat tagctatgga tgaattcatt 600
gaacggtata aattagaagg ctatgccttc gaacatatcg tttatggaga ttttagtcat 660
a 661
<210> 35
<211> 7705
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG3 Expression Cassette
<400> 35
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagtaat cccccccccc taacgttact ggccgaagcc gcttggaata aggccggtgt 720
gcgtttgtct atatgttatt ttccaccata ttgccgtctt ttggcaatgt gagggcccgg 780
aaacctggcc ctgtcttctt gacgagcatt cctaggggtc tttcccctct cgccaaagga 840
atgcaaggtc tgttgaatgt cgtgaaggaa gcagttcctc tggaagcttc ttgaagacaa 900
acaacgtctg tagcgaccct ttgcaggcag cggaaccccc cacctggcga caggtgcctc 960
tgcggccaaa agccacgtgt ataagataca cctgcaaagg cggcacaacc ccagtgccac 1020
gttgtgagtt ggatagttgt ggaaagagtc aaatggctct cctcaagcgt attcaacaag 1080
gggctgaagg atgcccagaa ggtaccccat tgtatgggat ctgatctggg gcctcggtgc 1140
acatgcttta catgtgttta gtcgaggtta aaaaaacgtc taggcccccc gaaccacggg 1200
gacgtggttt tcctttgaaa aacacgatga taatatggcc acaaccatgg aacaagagac 1260
ttgcgcgcac tctctcactt ttgaggaatg cccaaaatgc tctgctctac aataccgtaa 1320
tggattttac ctgctaaagt atgatgaaga atggtaccca gaggagttat tgactgatgg 1380
agaggatgat gtctttgatc ccgaattaga catggaagtc gttttcgagt tacagggaag 1440
cggagctact aacttcagcc tgctgaagca ggctggagat gtggaggaga accctggacc 1500
tatgttcgtg ttcctggtgc tgctgcctct ggtcagctcc cagtgtgtga acctgaccac 1560
cagaacccag ctgccacctg cttatacaaa ctccttcact cggggggtat actaccccga 1620
caaggtgttc agatctagcg tgctgcattc tacacaagac ctgttcctgc ccttcttcag 1680
caacgtgacc tggttccacg ccatccacgt gtctggaacc aacggaacca agagattcga 1740
caaccccgtg ctgcctttca acgacggcgt gtacttcgcc agcaccgaga agtccaacat 1800
catcagagga tggattttcg gcaccacact ggacagcaaa acccagagcc tgctgatcgt 1860
gaacaacgcc accaacgtgg tgatcaaggt gtgcgagttc cagttctgca atgatccctt 1920
cctgggcgtg tactaccaca agaacaacaa gtcttggatg gaaagcgagt tcagagtgta 1980
ttccagcgcc aacaattgca ccttcgagta cgtgagccaa ccctttctga tggaccttga 2040
aggcaagcag ggcaacttca aaaatctgcg agaatttgtg ttcaagaaca tcgacggata 2100
cttcaagatc tactctaagc acacgccaat caacctggtg agagatctgc cccagggctt 2160
tagcgctttg gaacctctgg tggacctgcc tatcggaatc aacatcacca gatttcaaac 2220
tctcctggcc ctgcacagat cttatctgac ccctggggac agtagtagcg gctggacagc 2280
cggcgccgcc gcctactacg tgggatacct gcagcctaga acattcctgc tgaagtacaa 2340
tgagaacgga acaatcacag acgccgtgga ctgcgccctg gatcctttga gcgagacaaa 2400
gtgcaccctg aagtcgttca ccgtcgaaaa aggcatctac cagaccagca acttccgcgt 2460
gcagcctacg gaatctatcg tgcggttccc caacatcacc aacctgtgcc ctttcggcga 2520
ggtgtttaac gctacaaggt tcgccagcgt gtatgcctgg aacagaaaga gaatcagcaa 2580
ttgcgtggcc gattatagcg ttctgtacaa cagcgcttcc ttcagcacct tcaagtgcta 2640
cggcgtgtct ccaaccaagc tgaacgacct ctgcttcacc aatgtctacg ctgactcttt 2700
cgtgattaga ggcgatgagg ttagacagat cgcacctggc cagaccggca aaatcgctga 2760
ctacaactac aagctgcctg atgacttcac aggctgtgtc attgcctgga actcaaataa 2820
cctggactct aaagtgggcg gcaactacaa ctacctgtac cggctgttcc ggaagagcaa 2880
tctgaaacct tttgagcggg acatctctac agagatctac caggccggca gcacaccctg 2940
caacggcgtt gagggcttca actgctactt ccctctgcag agctacggct ttcagccaac 3000
aaatggagtg ggctaccagc cgtacagagt ggtggtgctg agcttcgaac tgctgcatgc 3060
cccagccaca gtgtgtggac ctaagaagtc taccaacctg gtgaagaaca agtgcgtgaa 3120
ctttaacttt aacggcctga ccggcacagg cgtgctgacc gaatccaaca aaaagttcct 3180
gcccttccaa cagttcggca gagacatcgc cgatacaacc gatgccgtgc gggaccccca 3240
gaccttagaa atcctagata tcaccccgtg cagcttcggc ggagtctctg ttattactcc 3300
tggcaccaac accagcaacc aagtggctgt tctgtaccaa ggcgtgaact gcaccgaagt 3360
gcctgtggct atccacgccg atcagctgac cccaacctgg cgggtgtata gcaccggctc 3420
taacgtgttc cagacccggg ctggctgcct gatcggcgcc gaacacgtca acaactccta 3480
tgaatgtgac atccccatcg gggctggcat ctgcgccagt taccagacac agacaaatag 3540
ccctagacgg gccagaagcg tggcctccca gagtatcatt gcctacacca tgagcctggg 3600
cgccgagaac agcgtggcct attctaacaa tagcatcgca atccctacca actttaccat 3660
ctctgtgaca accgagatcc tgcctgtgag catgaccaaa accagcgtgg actgcacgat 3720
gtacatctgt ggcgacagca cagaatgcag taatctgttg ctgcagtacg gcagcttttg 3780
cacccagttg aatagagccc tgaccggaat cgccgtagag caggacaaaa atacccagga 3840
ggtgttcgcc caggtgaaac agatctacaa gacacctccc attaaggact tcggaggttt 3900
taacttcagc cagatcctgc ccgacccttc caagcctagc aaacgctcct tcatcgagga 3960
cctgctcttc aacaaggtga cactggctga tgccggcttc atcaagcagt acggagattg 4020
tctgggagac atcgccgcta gagatctgat ctgcgcccaa aagttcaacg gcctgaccgt 4080
gctgcctcct ctgcttacag acgagatgat cgcccagtac accagcgccc tgctggctgg 4140
caccatcaca agcggctgga ccttcggagc cggagccgct ctgcaaatcc cctttgccat 4200
gcagatggcc taccggttca acggcatcgg cgtgacacag aatgtgctgt acgagaacca 4260
gaagctgatc gctaaccagt ttaacagcgc tatcggcaag atccaggact cgctgagtag 4320
caccgcctct gccctgggca agctgcagga cgtcgtgaac cagaacgccc aagccctgaa 4380
cacactggtg aaacagctga gcagcaactt cggcgccatc agctctgtgc tgaacgatat 4440
cctgagcaga ctggacaagg tggaagccga ggtccagatc gacagactga tcacaggaag 4500
actgcagagc ctgcaaacgt acgtgacaca gcagctgatc cgggcagccg aaatccgggc 4560
cagcgccaat ctggccgcta ccaagatgag cgagtgcgtg ttaggccaga gcaagcgggt 4620
ggatttctgc ggtaagggat accacctgat gagctttccc cagagcgctc ctcacggcgt 4680
ggtgtttctg cacgtgacct acgttcctgc ccaggaaaag aacttcacca ccgcccctgc 4740
tatctgccac gatggcaagg cccacttccc tagagagggc gttttcgtgt ctaacggcac 4800
acactggttt gtgacccaga gaaacttcta cgagcctcag atcatcacca cagacaacac 4860
ctttgtgagc ggcaattgcg acgtggtgat cggaattgtt aataataccg tgtacgaccc 4920
tctgcagcct gagctcgaca gcttcaagga agagctggac aagtacttca agaaccacac 4980
ctccccagat gtggacctgg gcgatatttc aggcatcaac gcctccgtcg tgaatatcca 5040
gaaggagatc gaccggctca acgaggtggc caagaacctt aacgagagcc tgatcgacct 5100
gcaggaactg ggcaaatatg agcagtacat caagtggcct tggtacatct ggctgggctt 5160
tatcgcaggc ctgatcgcta tcgtgatggt gaccattatg ctgtgttgta tgaccagctg 5220
ttgtagttgt ctgaagggct gctgttcttg cggcagctgc tgcaagttcg acgaagacga 5280
ctcagagccc gtgctgaaag gcgtgaagct gcactacacc taaccccccc ccctaacgtt 5340
actggccgaa gccgcttgga ataaggccgg tgtgcgtttg tctatatgtt attttccacc 5400
atattgccgt cttttggcaa tgtgagggcc cggaaacctg gccctgtctt cttgacgagc 5460
attcctaggg gtctttcccc tctcgccaaa ggaatgcaag gtctgttgaa tgtcgtgaag 5520
gaagcagttc ctctggaagc ttcttgaaga caaacaacgt ctgtagcgac cctttgcagg 5580
cagcggaacc ccccacctgg cgacaggtgc ctctgcggcc aaaagccacg tgtataagat 5640
acacctgcaa aggcggcaca accccagtgc cacgttgtga gttggatagt tgtggaaaga 5700
gtcaaatggc tctcctcaag cgtattcaac aaggggctga aggatgccca gaaggtaccc 5760
cattgtatgg gatctgatct ggggcctcgg tgcacatgct ttacatgtgt ttagtcgagg 5820
ttaaaaaaac gtctaggccc cccgaaccac ggggacgtgg ttttcctttg aaaaacacga 5880
tgataatatg gccacaacca tggaacaaga gacttgcgcg cactctctca cttttgagga 5940
atgcccaaaa tgctctgctc tacaataccg taatggattt tacctgctaa agtatgatga 6000
agaatggtac ccagaggagt tattgactga tggagaggat gatgtctttg atcccgaatt 6060
agacatggaa gtcgttttcg agttacaggg aagcggagct actaacttca gcctgctgaa 6120
gcaggctgga gatgtggagg agaaccctgg acctatgagc gacaacggcc ctcaaaacca 6180
gagaaatgcc cctcggatca catttggcgg acctagcgac agcaccggca gcaaccagaa 6240
tggagaaaga agcggcgcca gatccaagca gcggagacct cagggactgc ccaacaacac 6300
cgctagctgg ttcaccgccc tgacccaaca cggcaaggaa gatctgaagt tccccagagg 6360
ccagggcgtg cctatcaaca caaactcttc tcccgacgac cagatcggat actatagacg 6420
ggccactcgg agaattcggg gcggcgacgg aaaaatgaag gacctttctc caagatggta 6480
cttctactac ctcggcacag gccctgaggc cggcctgcct tacggcgcca acaaggatgg 6540
catcatctgg gtcgccaccg agggcgccct gaacacccct aaggaccaca tcggcacaag 6600
aaaccccgct aacaacgccg caatcgtgct gcagctgcct cagggcacca ccctgcccaa 6660
gggcttctac gccgagggct ctagaggtgg ctcccaggct tctagccgct cctccagccg 6720
cagcagaaac agcagcagga acagcacccc cggcagctcc cggggcacca gccccgccag 6780
aatggccgga aatggcggcg atgccgccct ggccctgctc ctgctggaca gactgaatca 6840
gctggaaagc aagatgagcg gcaaaggaca gcagcagcaa ggccagaccg tgaccaagaa 6900
aagcgctgct gaagcctcca agaaacctag acaaaagcgg accgccacaa aggcctacaa 6960
cgtgacccaa gcctttggaa gaagaggccc cgagcagaca cagggcaatt tcggcgacca 7020
ggagctgatc cggcagggaa ccgactacaa gcactggcct cagatcgccc agttcgcccc 7080
tagcgccagc gccttcttcg gcatgagcag aatcggcatg gaagtgaccc cttctggcac 7140
ctggctgacc tacaccggcg ctatcaagct ggacgataag gatcctaact tcaaggacca 7200
agtgatcctg ctgaacaagc atatcgacgc ctataagacc tttccaccta cagagcctaa 7260
gaaagataag aagaagaaag ccgacgagac acaggccctg cctcagagac agaaaaagca 7320
gcagacagtg acactgctgc cagccgctga cctggatgac ttcagcaagc agctgcagca 7380
gagcatgtct tctgctgata gcacccaggc cggaagcgga gctactaact tcagcctgct 7440
gaagcaggct ggagatgtgg aggagaaccc tggacctatg tattcttttg tgtccgagga 7500
aaccggcaca ctgatcgtta atagcgtgct gctcttcctg gccttcgtgg tgttcctgct 7560
ggtgaccctg gctatcctga ccgccctgag actgtgtgcc tactgctgca acatcgtgaa 7620
cgtgtctctg gtcaagccta gcttctacgt gtacagccgg gtgaagaacc tgaacagcag 7680
cagagtgccc gacctgctgg tgtga 7705
<210> 36
<211> 5656
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG4 expression cassette
<400> 36
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgttcg tgttcctggt gctgctgcct 780
ctggtcagct cccagtgtgt gaacctgacc accagaaccc agctgccacc tgcttataca 840
aactccttca ctcggggggt atactacccc gacaaggtgt tcagatctag cgtgctgcat 900
tctacacaag acctgttcct gcccttcttc agcaacgtga cctggttcca cgccatccac 960
gtgtctggaa ccaacggaac caagagattc gacaaccccg tgctgccttt caacgacggc 1020
gtgtacttcg ccagcaccga gaagtccaac atcatcagag gatggatttt cggcaccaca 1080
ctggacagca aaacccagag cctgctgatc gtgaacaacg ccaccaacgt ggtgatcaag 1140
gtgtgcgagt tccagttctg caatgatccc ttcctgggcg tgtactacca caagaacaac 1200
aagtcttgga tggaaagcga gttcagagtg tattccagcg ccaacaattg caccttcgag 1260
tacgtgagcc aaccctttct gatggacctt gaaggcaagc agggcaactt caaaaatctg 1320
cgagaatttg tgttcaagaa catcgacgga tacttcaaga tctactctaa gcacacgcca 1380
atcaacctgg tgagagatct gccccagggc tttagcgctt tggaacctct ggtggacctg 1440
cctatcggaa tcaacatcac cagatttcaa actctcctgg ccctgcacag atcttatctg 1500
acccctgggg acagtagtag cggctggaca gccggcgccg ccgcctacta cgtgggatac 1560
ctgcagccta gaacattcct gctgaagtac aatgagaacg gaacaatcac agacgccgtg 1620
gactgcgccc tggatccttt gagcgagaca aagtgcaccc tgaagtcgtt caccgtcgaa 1680
aaaggcatct accagaccag caacttccgc gtgcagccta cggaatctat cgtgcggttc 1740
cccaacatca ccaacctgtg ccctttcggc gaggtgttta acgctacaag gttcgccagc 1800
gtgtatgcct ggaacagaaa gagaatcagc aattgcgtgg ccgattatag cgttctgtac 1860
aacagcgctt ccttcagcac cttcaagtgc tacggcgtgt ctccaaccaa gctgaacgac 1920
ctctgcttca ccaatgtcta cgctgactct ttcgtgatta gaggcgatga ggttagacag 1980
atcgcacctg gccagaccgg caaaatcgct gactacaact acaagctgcc tgatgacttc 2040
acaggctgtg tcattgcctg gaactcaaat aacctggact ctaaagtggg cggcaactac 2100
aactacctgt accggctgtt ccggaagagc aatctgaaac cttttgagcg ggacatctct 2160
acagagatct accaggccgg cagcacaccc tgcaacggcg ttgagggctt caactgctac 2220
ttccctctgc agagctacgg ctttcagcca acaaatggag tgggctacca gccgtacaga 2280
gtggtggtgc tgagcttcga actgctgcat gccccagcca cagtgtgtgg acctaagaag 2340
tctaccaacc tggtgaagaa caagtgcgtg aactttaact ttaacggcct gaccggcaca 2400
ggcgtgctga ccgaatccaa caaaaagttc ctgcccttcc aacagttcgg cagagacatc 2460
gccgatacaa ccgatgccgt gcgggacccc cagaccttag aaatcctaga tatcaccccg 2520
tgcagcttcg gcggagtctc tgttattact cctggcacca acaccagcaa ccaagtggct 2580
gttctgtacc aaggcgtgaa ctgcaccgaa gtgcctgtgg ctatccacgc cgatcagctg 2640
accccaacct ggcgggtgta tagcaccggc tctaacgtgt tccagacccg ggctggctgc 2700
ctgatcggcg ccgaacacgt caacaactcc tatgaatgtg acatccccat cggggctggc 2760
atctgcgcca gttaccagac acagacaaat agccctagac gggccagaag cgtggcctcc 2820
cagagtatca ttgcctacac catgagcctg ggcgccgaga acagcgtggc ctattctaac 2880
aatagcatcg caatccctac caactttacc atctctgtga caaccgagat cctgcctgtg 2940
agcatgacca aaaccagcgt ggactgcacg atgtacatct gtggcgacag cacagaatgc 3000
agtaatctgt tgctgcagta cggcagcttt tgcacccagt tgaatagagc cctgaccgga 3060
atcgccgtag agcaggacaa aaatacccag gaggtgttcg cccaggtgaa acagatctac 3120
aagacacctc ccattaagga cttcggaggt tttaacttca gccagatcct gcccgaccct 3180
tccaagccta gcaaacgctc cttcatcgag gacctgctct tcaacaaggt gacactggct 3240
gatgccggct tcatcaagca gtacggagat tgtctgggag acatcgccgc tagagatctg 3300
atctgcgccc aaaagttcaa cggcctgacc gtgctgcctc ctctgcttac agacgagatg 3360
atcgcccagt acaccagcgc cctgctggct ggcaccatca caagcggctg gaccttcgga 3420
gccggagccg ctctgcaaat cccctttgcc atgcagatgg cctaccggtt caacggcatc 3480
ggcgtgacac agaatgtgct gtacgagaac cagaagctga tcgctaacca gtttaacagc 3540
gctatcggca agatccagga ctcgctgagt agcaccgcct ctgccctggg caagctgcag 3600
gacgtcgtga accagaacgc ccaagccctg aacacactgg tgaaacagct gagcagcaac 3660
ttcggcgcca tcagctctgt gctgaacgat atcctgagca gactggacaa ggtggaagcc 3720
gaggtccaga tcgacagact gatcacagga agactgcaga gcctgcaaac gtacgtgaca 3780
cagcagctga tccgggcagc cgaaatccgg gccagcgcca atctggccgc taccaagatg 3840
agcgagtgcg tgttaggcca gagcaagcgg gtggatttct gcggtaaggg ataccacctg 3900
atgagctttc cccagagcgc tcctcacggc gtggtgtttc tgcacgtgac ctacgttcct 3960
gcccaggaaa agaacttcac caccgcccct gctatctgcc acgatggcaa ggcccacttc 4020
cctagagagg gcgttttcgt gtctaacggc acacactggt ttgtgaccca gagaaacttc 4080
tacgagcctc agatcatcac cacagacaac acctttgtga gcggcaattg cgacgtggtg 4140
atcggaattg ttaataatac cgtgtacgac cctctgcagc ctgagctcga cagcttcaag 4200
gaagagctgg acaagtactt caagaaccac acctccccag atgtggacct gggcgatatt 4260
tcaggcatca acgcctccgt cgtgaatatc cagaaggaga tcgaccggct caacgaggtg 4320
gccaagaacc ttaacgagag cctgatcgac ctgcaggaac tgggcaaata tgagcagtac 4380
atcaagtggc cttggtacat ctggctgggc tttatcgcag gcctgatcgc tatcgtgatg 4440
gtgaccatta tgctgtgttg tatgaccagc tgttgtagtt gtctgaaggg ctgctgttct 4500
tgcggcagct gctgcaagtt cgacgaagac gactcagagc ccgtgctgaa aggcgtgaag 4560
ctgcactaca cccgaaaacg gcgcggaagc ggaggaagcg gagctactaa cttcagcctg 4620
ctgaagcagg ctggagatgt ggaggagaac cctggaccta tgtattcttt tgtgtccgag 4680
gaaaccggca cactgatcgt taatagcgtg ctgctcttcc tggccttcgt ggtgttcctg 4740
ctggtgaccc tggctatcct gaccgccctg agactgtgtg cctactgctg caacatcgtg 4800
aacgtgtctc tggtcaagcc tagcttctac gtgtacagcc gggtgaagaa cctgaacagc 4860
agcagagtgc ccgacctgct ggtgtaatcc ccccccccta acgttactgg ccgaagccgc 4920
ttggaataag gccggtgtgc gtttgtctat atgttatttt ccaccatatt gccgtctttt 4980
ggcaatgtga gggcccggaa acctggccct gtcttcttga cgagcattcc taggggtctt 5040
tcccctctcg ccaaaggaat gcaaggtctg ttgaatgtcg tgaaggaagc agttcctctg 5100
gaagcttctt gaagacaaac aacgtctgta gcgacccttt gcaggcagcg gaacccccca 5160
cctggcgaca ggtgcctctg cggccaaaag ccacgtgtat aagatacacc tgcaaaggcg 5220
gcacaacccc agtgccacgt tgtgagttgg atagttgtgg aaagagtcaa atggctctcc 5280
tcaagcgtat tcaacaaggg gctgaaggat gcccagaagg taccccattg tatgggatct 5340
gatctggggc ctcggtgcac atgctttaca tgtgtttagt cgaggttaaa aaaacgtcta 5400
ggccccccga accacgggga cgtggttttc ctttgaaaaa cacgatgata atatggccac 5460
aaccatggaa caagagactt gcgcgcactc tctcactttt gaggaatgcc caaaatgctc 5520
tgctctacaa taccgtaatg gattttacct gctaaagtat gatgaagaat ggtacccaga 5580
ggagttattg actgatggag aggatgatgt ctttgatccc gaattagaca tggaagtcgt 5640
tttcgagtta cagtaa 5656
<210> 37
<211> 7000
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG5 Expression cassette
<400> 37
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgagcg acaacggccc tcaaaaccag 780
agaaatgccc ctcggatcac atttggcgga cctagcgaca gcaccggcag caaccagaat 840
ggagaaagaa gcggcgccag atccaagcag cggagacctc agggactgcc caacaacacc 900
gctagctggt tcaccgccct gacccaacac ggcaaggaag atctgaagtt ccccagaggc 960
cagggcgtgc ctatcaacac aaactcttct cccgacgacc agatcggata ctatagacgg 1020
gccactcgga gaattcgggg cggcgacgga aaaatgaagg acctttctcc aagatggtac 1080
ttctactacc tcggcacagg ccctgaggcc ggcctgcctt acggcgccaa caaggatggc 1140
atcatctggg tcgccaccga gggcgccctg aacaccccta aggaccacat cggcacaaga 1200
aaccccgcta acaacgccgc aatcgtgctg cagctgcctc agggcaccac cctgcccaag 1260
ggcttctacg ccgagggctc tagaggtggc tcccaggctt ctagccgctc ctccagccgc 1320
agcagaaaca gcagcaggaa cagcaccccc ggcagctccc ggggcaccag ccccgccaga 1380
atggccggaa atggcggcga tgccgccctg gccctgctcc tgctggacag actgaatcag 1440
ctggaaagca agatgagcgg caaaggacag cagcagcaag gccagaccgt gaccaagaaa 1500
agcgctgctg aagcctccaa gaaacctaga caaaagcgga ccgccacaaa ggcctacaac 1560
gtgacccaag cctttggaag aagaggcccc gagcagacac agggcaattt cggcgaccag 1620
gagctgatcc ggcagggaac cgactacaag cactggcctc agatcgccca gttcgcccct 1680
agcgccagcg ccttcttcgg catgagcaga atcggcatgg aagtgacccc ttctggcacc 1740
tggctgacct acaccggcgc tatcaagctg gacgataagg atcctaactt caaggaccaa 1800
gtgatcctgc tgaacaagca tatcgacgcc tataagacct ttccacctac agagcctaag 1860
aaagataaga agaagaaagc cgacgagaca caggccctgc ctcagagaca gaaaaagcag 1920
cagacagtga cactgctgcc agccgctgac ctggatgact tcagcaagca gctgcagcag 1980
agcatgtctt ctgctgatag cacccaggcc cgaaaacggc gcggaagcgg aggaagcgga 2040
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 2100
ttcgtgttcc tggtgctgct gcctctggtc agctcccagt gtgtgaacct gaccaccaga 2160
acccagctgc cacctgctta tacaaactcc ttcactcggg gggtatacta ccccgacaag 2220
gtgttcagat ctagcgtgct gcattctaca caagacctgt tcctgccctt cttcagcaac 2280
gtgacctggt tccacgccat ccacgtgtct ggaaccaacg gaaccaagag attcgacaac 2340
cccgtgctgc ctttcaacga cggcgtgtac ttcgccagca ccgagaagtc caacatcatc 2400
agaggatgga ttttcggcac cacactggac agcaaaaccc agagcctgct gatcgtgaac 2460
aacgccacca acgtggtgat caaggtgtgc gagttccagt tctgcaatga tcccttcctg 2520
ggcgtgtact accacaagaa caacaagtct tggatggaaa gcgagttcag agtgtattcc 2580
agcgccaaca attgcacctt cgagtacgtg agccaaccct ttctgatgga ccttgaaggc 2640
aagcagggca acttcaaaaa tctgcgagaa tttgtgttca agaacatcga cggatacttc 2700
aagatctact ctaagcacac gccaatcaac ctggtgagag atctgcccca gggctttagc 2760
gctttggaac ctctggtgga cctgcctatc ggaatcaaca tcaccagatt tcaaactctc 2820
ctggccctgc acagatctta tctgacccct ggggacagta gtagcggctg gacagccggc 2880
gccgccgcct actacgtggg atacctgcag cctagaacat tcctgctgaa gtacaatgag 2940
aacggaacaa tcacagacgc cgtggactgc gccctggatc ctttgagcga gacaaagtgc 3000
accctgaagt cgttcaccgt cgaaaaaggc atctaccaga ccagcaactt ccgcgtgcag 3060
cctacggaat ctatcgtgcg gttccccaac atcaccaacc tgtgcccttt cggcgaggtg 3120
tttaacgcta caaggttcgc cagcgtgtat gcctggaaca gaaagagaat cagcaattgc 3180
gtggccgatt atagcgttct gtacaacagc gcttccttca gcaccttcaa gtgctacggc 3240
gtgtctccaa ccaagctgaa cgacctctgc ttcaccaatg tctacgctga ctctttcgtg 3300
attagaggcg atgaggttag acagatcgca cctggccaga ccggcaaaat cgctgactac 3360
aactacaagc tgcctgatga cttcacaggc tgtgtcattg cctggaactc aaataacctg 3420
gactctaaag tgggcggcaa ctacaactac ctgtaccggc tgttccggaa gagcaatctg 3480
aaaccttttg agcgggacat ctctacagag atctaccagg ccggcagcac accctgcaac 3540
ggcgttgagg gcttcaactg ctacttccct ctgcagagct acggctttca gccaacaaat 3600
ggagtgggct accagccgta cagagtggtg gtgctgagct tcgaactgct gcatgcccca 3660
gccacagtgt gtggacctaa gaagtctacc aacctggtga agaacaagtg cgtgaacttt 3720
aactttaacg gcctgaccgg cacaggcgtg ctgaccgaat ccaacaaaaa gttcctgccc 3780
ttccaacagt tcggcagaga catcgccgat acaaccgatg ccgtgcggga cccccagacc 3840
ttagaaatcc tagatatcac cccgtgcagc ttcggcggag tctctgttat tactcctggc 3900
accaacacca gcaaccaagt ggctgttctg taccaaggcg tgaactgcac cgaagtgcct 3960
gtggctatcc acgccgatca gctgacccca acctggcggg tgtatagcac cggctctaac 4020
gtgttccaga cccgggctgg ctgcctgatc ggcgccgaac acgtcaacaa ctcctatgaa 4080
tgtgacatcc ccatcggggc tggcatctgc gccagttacc agacacagac aaatagccct 4140
ggcagcgcca gcagcgtggc ctcccagagt atcattgcct acaccatgag cctgggcgcc 4200
gagaacagcg tggcctattc taacaatagc atcgcaatcc ctaccaactt taccatctct 4260
gtgacaaccg agatcctgcc tgtgagcatg accaaaacca gcgtggactg cacgatgtac 4320
atctgtggcg acagcacaga atgcagtaat ctgttgctgc agtacggcag cttttgcacc 4380
cagttgaata gagccctgac cggaatcgcc gtagagcagg acaaaaatac ccaggaggtg 4440
ttcgcccagg tgaaacagat ctacaagaca cctcccatta aggacttcgg aggttttaac 4500
ttcagccaga tcctgcccga cccttccaag cctagcaaac gctccttcat cgaggacctg 4560
ctcttcaaca aggtgacact ggctgatgcc ggcttcatca agcagtacgg agattgtctg 4620
ggagacatcg ccgctagaga tctgatctgc gcccaaaagt tcaacggcct gaccgtgctg 4680
cctcctctgc ttacagacga gatgatcgcc cagtacacca gcgccctgct ggctggcacc 4740
atcacaagcg gctggacctt cggagccgga gccgctctgc aaatcccctt tgccatgcag 4800
atggcctacc ggttcaacgg catcggcgtg acacagaatg tgctgtacga gaaccagaag 4860
ctgatcgcta accagtttaa cagcgctatc ggcaagatcc aggactcgct gagtagcacc 4920
gcctctgccc tgggcaagct gcaggacgtc gtgaaccaga acgcccaagc cctgaacaca 4980
ctggtgaaac agctgagcag caacttcggc gccatcagct ctgtgctgaa cgatatcctg 5040
agcagactgg accctcccga agccgaggtc cagatcgaca gactgatcac aggaagactg 5100
cagagcctgc aaacgtacgt gacacagcag ctgatccggg cagccgaaat ccgggccagc 5160
gccaatctgg ccgctaccaa gatgagcgag tgcgtgttag gccagagcaa gcgggtggat 5220
ttctgcggta agggatacca cctgatgagc tttccccaga gcgctcctca cggcgtggtg 5280
tttctgcacg tgacctacgt tcctgcccag gaaaagaact tcaccaccgc ccctgctatc 5340
tgccacgatg gcaaggccca cttccctaga gagggcgttt tcgtgtctaa cggcacacac 5400
tggtttgtga cccagagaaa cttctacgag cctcagatca tcaccacaga caacaccttt 5460
gtgagcggca attgcgacgt ggtgatcgga attgttaata ataccgtgta cgaccctctg 5520
cagcctgagc tcgacagctt caaggaagag ctggacaagt acttcaagaa ccacacctcc 5580
ccagatgtgg acctgggcga tatttcaggc atcaacgcct ccgtcgtgaa tatccagaag 5640
gagatcgacc ggctcaacga ggtggccaag aaccttaacg agagcctgat cgacctgcag 5700
gaactgggca aatatgagca gtacatcaag tggccttggt acatctggct gggctttatc 5760
gcaggcctga tcgctatcgt gatggtgacc attatgctgt gttgtatgac cagctgttgt 5820
agttgtctga agggctgctg ttcttgcggc agctgctgca agttcgacga agacgactca 5880
gagcccgtgc tgaaaggcgt gaagctgcac tacacccgaa aacggcgcgg aagcggagga 5940
agcggagcta ctaacttcag cctgctgaag caggctggag atgtggagga gaaccctgga 6000
cctatgtatt cttttgtgtc cgaggaaacc ggcacactga tcgttaatag cgtgctgctc 6060
ttcctggcct tcgtggtgtt cctgctggtg accctggcta tcctgaccgc cctgagactg 6120
tgtgcctact gctgcaacat cgtgaacgtg tctctggtca agcctagctt ctacgtgtac 6180
agccgggtga agaacctgaa cagcagcaga gtgcccgacc tgctggtgta atcccccccc 6240
cctaacgtta ctggccgaag ccgcttggaa taaggccggt gtgcgtttgt ctatatgtta 6300
ttttccacca tattgccgtc ttttggcaat gtgagggccc ggaaacctgg ccctgtcttc 6360
ttgacgagca ttcctagggg tctttcccct ctcgccaaag gaatgcaagg tctgttgaat 6420
gtcgtgaagg aagcagttcc tctggaagct tcttgaagac aaacaacgtc tgtagcgacc 6480
ctttgcaggc agcggaaccc cccacctggc gacaggtgcc tctgcggcca aaagccacgt 6540
gtataagata cacctgcaaa ggcggcacaa ccccagtgcc acgttgtgag ttggatagtt 6600
gtggaaagag tcaaatggct ctcctcaagc gtattcaaca aggggctgaa ggatgcccag 6660
aaggtacccc attgtatggg atctgatctg gggcctcggt gcacatgctt tacatgtgtt 6720
tagtcgaggt taaaaaaacg tctaggcccc ccgaaccacg gggacgtggt tttcctttga 6780
aaaacacgat gataatatgg ccacaaccat ggaacaagag acttgcgcgc actctctcac 6840
ttttgaggaa tgcccaaaat gctctgctct acaataccgt aatggatttt acctgctaaa 6900
gtatgatgaa gaatggtacc cagaggagtt attgactgat ggagaggatg atgtctttga 6960
tcccgaatta gacatggaag tcgttttcga gttacagtaa 7000
<210> 38
<211> 7705
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG6 expression cassette
<400> 38
atgttcgtgt tcctggtgct gctgcctctg gtcagctccc agtgtgtgaa cctgaccacc 60
agaacccagc tgccacctgc ttatacaaac tccttcactc ggggggtata ctaccccgac 120
aaggtgttca gatctagcgt gctgcattct acacaagacc tgttcctgcc cttcttcagc 180
aacgtgacct ggttccacgc catccacgtg tctggaacca acggaaccaa gagattcgac 240
aaccccgtgc tgcctttcaa cgacggcgtg tacttcgcca gcaccgagaa gtccaacatc 300
atcagaggat ggattttcgg caccacactg gacagcaaaa cccagagcct gctgatcgtg 360
aacaacgcca ccaacgtggt gatcaaggtg tgcgagttcc agttctgcaa tgatcccttc 420
ctgggcgtgt actaccacaa gaacaacaag tcttggatgg aaagcgagtt cagagtgtat 480
tccagcgcca acaattgcac cttcgagtac gtgagccaac cctttctgat ggaccttgaa 540
ggcaagcagg gcaacttcaa aaatctgcga gaatttgtgt tcaagaacat cgacggatac 600
ttcaagatct actctaagca cacgccaatc aacctggtga gagatctgcc ccagggcttt 660
agcgctttgg aacctctggt ggacctgcct atcggaatca acatcaccag atttcaaact 720
ctcctggccc tgcacagatc ttatctgacc cctggggaca gtagtagcgg ctggacagcc 780
ggcgccgccg cctactacgt gggatacctg cagcctagaa cattcctgct gaagtacaat 840
gagaacggaa caatcacaga cgccgtggac tgcgccctgg atcctttgag cgagacaaag 900
tgcaccctga agtcgttcac cgtcgaaaaa ggcatctacc agaccagcaa cttccgcgtg 960
cagcctacgg aatctatcgt gcggttcccc aacatcacca acctgtgccc tttcggcgag 1020
gtgtttaacg ctacaaggtt cgccagcgtg tatgcctgga acagaaagag aatcagcaat 1080
tgcgtggccg attatagcgt tctgtacaac agcgcttcct tcagcacctt caagtgctac 1140
ggcgtgtctc caaccaagct gaacgacctc tgcttcacca atgtctacgc tgactctttc 1200
gtgattagag gcgatgaggt tagacagatc gcacctggcc agaccggcaa aatcgctgac 1260
tacaactaca agctgcctga tgacttcaca ggctgtgtca ttgcctggaa ctcaaataac 1320
ctggactcta aagtgggcgg caactacaac tacctgtacc ggctgttccg gaagagcaat 1380
ctgaaacctt ttgagcggga catctctaca gagatctacc aggccggcag cacaccctgc 1440
aacggcgttg agggcttcaa ctgctacttc cctctgcaga gctacggctt tcagccaaca 1500
aatggagtgg gctaccagcc gtacagagtg gtggtgctga gcttcgaact gctgcatgcc 1560
ccagccacag tgtgtggacc taagaagtct accaacctgg tgaagaacaa gtgcgtgaac 1620
tttaacttta acggcctgac cggcacaggc gtgctgaccg aatccaacaa aaagttcctg 1680
cccttccaac agttcggcag agacatcgcc gatacaaccg atgccgtgcg ggacccccag 1740
accttagaaa tcctagatat caccccgtgc agcttcggcg gagtctctgt tattactcct 1800
ggcaccaaca ccagcaacca agtggctgtt ctgtaccaag gcgtgaactg caccgaagtg 1860
cctgtggcta tccacgccga tcagctgacc ccaacctggc gggtgtatag caccggctct 1920
aacgtgttcc agacccgggc tggctgcctg atcggcgccg aacacgtcaa caactcctat 1980
gaatgtgaca tccccatcgg ggctggcatc tgcgccagtt accagacaca gacaaatagc 2040
cctagacggg ccagaagcgt ggcctcccag agtatcattg cctacaccat gagcctgggc 2100
gccgagaaca gcgtggccta ttctaacaat agcatcgcaa tccctaccaa ctttaccatc 2160
tctgtgacaa ccgagatcct gcctgtgagc atgaccaaaa ccagcgtgga ctgcacgatg 2220
tacatctgtg gcgacagcac agaatgcagt aatctgttgc tgcagtacgg cagcttttgc 2280
acccagttga atagagccct gaccggaatc gccgtagagc aggacaaaaa tacccaggag 2340
gtgttcgccc aggtgaaaca gatctacaag acacctccca ttaaggactt cggaggtttt 2400
aacttcagcc agatcctgcc cgacccttcc aagcctagca aacgctcctt catcgaggac 2460
ctgctcttca acaaggtgac actggctgat gccggcttca tcaagcagta cggagattgt 2520
ctgggagaca tcgccgctag agatctgatc tgcgcccaaa agttcaacgg cctgaccgtg 2580
ctgcctcctc tgcttacaga cgagatgatc gcccagtaca ccagcgccct gctggctggc 2640
accatcacaa gcggctggac cttcggagcc ggagccgctc tgcaaatccc ctttgccatg 2700
cagatggcct accggttcaa cggcatcggc gtgacacaga atgtgctgta cgagaaccag 2760
aagctgatcg ctaaccagtt taacagcgct atcggcaaga tccaggactc gctgagtagc 2820
accgcctctg ccctgggcaa gctgcaggac gtcgtgaacc agaacgccca agccctgaac 2880
acactggtga aacagctgag cagcaacttc ggcgccatca gctctgtgct gaacgatatc 2940
ctgagcagac tggacaaggt ggaagccgag gtccagatcg acagactgat cacaggaaga 3000
ctgcagagcc tgcaaacgta cgtgacacag cagctgatcc gggcagccga aatccgggcc 3060
agcgccaatc tggccgctac caagatgagc gagtgcgtgt taggccagag caagcgggtg 3120
gatttctgcg gtaagggata ccacctgatg agctttcccc agagcgctcc tcacggcgtg 3180
gtgtttctgc acgtgaccta cgttcctgcc caggaaaaga acttcaccac cgcccctgct 3240
atctgccacg atggcaaggc ccacttccct agagagggcg ttttcgtgtc taacggcaca 3300
cactggtttg tgacccagag aaacttctac gagcctcaga tcatcaccac agacaacacc 3360
tttgtgagcg gcaattgcga cgtggtgatc ggaattgtta ataataccgt gtacgaccct 3420
ctgcagcctg agctcgacag cttcaaggaa gagctggaca agtacttcaa gaaccacacc 3480
tccccagatg tggacctggg cgatatttca ggcatcaacg cctccgtcgt gaatatccag 3540
aaggagatcg accggctcaa cgaggtggcc aagaacctta acgagagcct gatcgacctg 3600
caggaactgg gcaaatatga gcagtacatc aagtggcctt ggtacatctg gctgggcttt 3660
atcgcaggcc tgatcgctat cgtgatggtg accattatgc tgtgttgtat gaccagctgt 3720
tgtagttgtc tgaagggctg ctgttcttgc ggcagctgct gcaagttcga cgaagacgac 3780
tcagagcccg tgctgaaagg cgtgaagctg cactacacct aatccccccc ccctaacgtt 3840
actggccgaa gccgcttgga ataaggccgg tgtgcgtttg tctatatgtt attttccacc 3900
atattgccgt cttttggcaa tgtgagggcc cggaaacctg gccctgtctt cttgacgagc 3960
attcctaggg gtctttcccc tctcgccaaa ggaatgcaag gtctgttgaa tgtcgtgaag 4020
gaagcagttc ctctggaagc ttcttgaaga caaacaacgt ctgtagcgac cctttgcagg 4080
cagcggaacc ccccacctgg cgacaggtgc ctctgcggcc aaaagccacg tgtataagat 4140
acacctgcaa aggcggcaca accccagtgc cacgttgtga gttggatagt tgtggaaaga 4200
gtcaaatggc tctcctcaag cgtattcaac aaggggctga aggatgccca gaaggtaccc 4260
cattgtatgg gatctgatct ggggcctcgg tgcacatgct ttacatgtgt ttagtcgagg 4320
ttaaaaaaac gtctaggccc cccgaaccac ggggacgtgg ttttcctttg aaaaacacga 4380
tgataatatg gccacaacca tggaacaaga gacttgcgcg cactctctca cttttgagga 4440
atgcccaaaa tgctctgctc tacaataccg taatggattt tacctgctaa agtatgatga 4500
agaatggtac ccagaggagt tattgactga tggagaggat gatgtctttg atcccgaatt 4560
agacatggaa gtcgttttcg agttacaggg aagcggagct actaacttca gcctgctgaa 4620
gcaggctgga gatgtggagg agaaccctgg acctatggcc gacagcaacg gcacaatcac 4680
cgtggaagag ctgaagaaac tgctggaaca gtggaacctg gtcatcggct tcctgtttct 4740
gacctggatc tgtctgctgc agttcgctta tgccaatcgg aacagattcc tgtacatcat 4800
caagctgatc ttcctgtggc tgctgtggcc tgtgaccctg gcttgcttcg tgctggccgc 4860
tgtgtaccgg atcaactgga tcacaggcgg aatcgccatc gccatggcct gcctggtggg 4920
cctgatgtgg ctgagctact tcatcgcttc tttcagactg ttcgccagaa cccggagcat 4980
gtggtccttc aaccccgaga caaacatcct gctgaacgtg cctctgcacg gcaccatcct 5040
gacaagacct ctgctcgaga gcgagctggt gattggcgca gtgattctga gaggccatct 5100
gaggatcgcc ggacaccacc tgggcagatg cgacatcaag gaccttccaa aggaaatcac 5160
cgttgccacc agccggaccc tgtcctacta caaactgggc gccagccaaa gagtggccgg 5220
cgatagcggc tttgccgcct acagcagata ccgcatcgga aattacaagc tcaacaccga 5280
ccacagcagc tcttctgata acatcgccct gctggtgcag taaccccccc ccctaacgtt 5340
actggccgaa gccgcttgga ataaggccgg tgtgcgtttg tctatatgtt attttccacc 5400
atattgccgt cttttggcaa tgtgagggcc cggaaacctg gccctgtctt cttgacgagc 5460
attcctaggg gtctttcccc tctcgccaaa ggaatgcaag gtctgttgaa tgtcgtgaag 5520
gaagcagttc ctctggaagc ttcttgaaga caaacaacgt ctgtagcgac cctttgcagg 5580
cagcggaacc ccccacctgg cgacaggtgc ctctgcggcc aaaagccacg tgtataagat 5640
acacctgcaa aggcggcaca accccagtgc cacgttgtga gttggatagt tgtggaaaga 5700
gtcaaatggc tctcctcaag cgtattcaac aaggggctga aggatgccca gaaggtaccc 5760
cattgtatgg gatctgatct ggggcctcgg tgcacatgct ttacatgtgt ttagtcgagg 5820
ttaaaaaaac gtctaggccc cccgaaccac ggggacgtgg ttttcctttg aaaaacacga 5880
tgataatatg gccacaacca tggaacaaga gacttgcgcg cactctctca cttttgagga 5940
atgcccaaaa tgctctgctc tacaataccg taatggattt tacctgctaa agtatgatga 6000
agaatggtac ccagaggagt tattgactga tggagaggat gatgtctttg atcccgaatt 6060
agacatggaa gtcgttttcg agttacaggg aagcggagct actaacttca gcctgctgaa 6120
gcaggctgga gatgtggagg agaaccctgg acctatgagc gacaacggcc ctcaaaacca 6180
gagaaatgcc cctcggatca catttggcgg acctagcgac agcaccggca gcaaccagaa 6240
tggagaaaga agcggcgcca gatccaagca gcggagacct cagggactgc ccaacaacac 6300
cgctagctgg ttcaccgccc tgacccaaca cggcaaggaa gatctgaagt tccccagagg 6360
ccagggcgtg cctatcaaca caaactcttc tcccgacgac cagatcggat actatagacg 6420
ggccactcgg agaattcggg gcggcgacgg aaaaatgaag gacctttctc caagatggta 6480
cttctactac ctcggcacag gccctgaggc cggcctgcct tacggcgcca acaaggatgg 6540
catcatctgg gtcgccaccg agggcgccct gaacacccct aaggaccaca tcggcacaag 6600
aaaccccgct aacaacgccg caatcgtgct gcagctgcct cagggcacca ccctgcccaa 6660
gggcttctac gccgagggct ctagaggtgg ctcccaggct tctagccgct cctccagccg 6720
cagcagaaac agcagcagga acagcacccc cggcagctcc cggggcacca gccccgccag 6780
aatggccgga aatggcggcg atgccgccct ggccctgctc ctgctggaca gactgaatca 6840
gctggaaagc aagatgagcg gcaaaggaca gcagcagcaa ggccagaccg tgaccaagaa 6900
aagcgctgct gaagcctcca agaaacctag acaaaagcgg accgccacaa aggcctacaa 6960
cgtgacccaa gcctttggaa gaagaggccc cgagcagaca cagggcaatt tcggcgacca 7020
ggagctgatc cggcagggaa ccgactacaa gcactggcct cagatcgccc agttcgcccc 7080
tagcgccagc gccttcttcg gcatgagcag aatcggcatg gaagtgaccc cttctggcac 7140
ctggctgacc tacaccggcg ctatcaagct ggacgataag gatcctaact tcaaggacca 7200
agtgatcctg ctgaacaagc atatcgacgc ctataagacc tttccaccta cagagcctaa 7260
gaaagataag aagaagaaag ccgacgagac acaggccctg cctcagagac agaaaaagca 7320
gcagacagtg acactgctgc cagccgctga cctggatgac ttcagcaagc agctgcagca 7380
gagcatgtct tctgctgata gcacccaggc cggaagcgga gctactaact tcagcctgct 7440
gaagcaggct ggagatgtgg aggagaaccc tggacctatg tattcttttg tgtccgagga 7500
aaccggcaca ctgatcgtta atagcgtgct gctcttcctg gccttcgtgg tgttcctgct 7560
ggtgaccctg gctatcctga ccgccctgag actgtgtgcc tactgctgca acatcgtgaa 7620
cgtgtctctg gtcaagccta gcttctacgt gtacagccgg gtgaagaacc tgaacagcag 7680
cagagtgccc gacctgctgg tgtga 7705
<210> 39
<211> 6976
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG7 Expression cassette
<400> 39
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgttcg tgttcctggt gctgctgcct 780
ctggtcagct cccagtgtgt gaacctgacc accagaaccc agctgccacc tgcttataca 840
aactccttca ctcggggggt atactacccc gacaaggtgt tcagatctag cgtgctgcat 900
tctacacaag acctgttcct gcccttcttc agcaacgtga cctggttcca cgccatccac 960
gtgtctggaa ccaacggaac caagagattc gacaaccccg tgctgccttt caacgacggc 1020
gtgtacttcg ccagcaccga gaagtccaac atcatcagag gatggatttt cggcaccaca 1080
ctggacagca aaacccagag cctgctgatc gtgaacaacg ccaccaacgt ggtgatcaag 1140
gtgtgcgagt tccagttctg caatgatccc ttcctgggcg tgtactacca caagaacaac 1200
aagtcttgga tggaaagcga gttcagagtg tattccagcg ccaacaattg caccttcgag 1260
tacgtgagcc aaccctttct gatggacctt gaaggcaagc agggcaactt caaaaatctg 1320
cgagaatttg tgttcaagaa catcgacgga tacttcaaga tctactctaa gcacacgcca 1380
atcaacctgg tgagagatct gccccagggc tttagcgctt tggaacctct ggtggacctg 1440
cctatcggaa tcaacatcac cagatttcaa actctcctgg ccctgcacag atcttatctg 1500
acccctgggg acagtagtag cggctggaca gccggcgccg ccgcctacta cgtgggatac 1560
ctgcagccta gaacattcct gctgaagtac aatgagaacg gaacaatcac agacgccgtg 1620
gactgcgccc tggatccttt gagcgagaca aagtgcaccc tgaagtcgtt caccgtcgaa 1680
aaaggcatct accagaccag caacttccgc gtgcagccta cggaatctat cgtgcggttc 1740
cccaacatca ccaacctgtg ccctttcggc gaggtgttta acgctacaag gttcgccagc 1800
gtgtatgcct ggaacagaaa gagaatcagc aattgcgtgg ccgattatag cgttctgtac 1860
aacagcgctt ccttcagcac cttcaagtgc tacggcgtgt ctccaaccaa gctgaacgac 1920
ctctgcttca ccaatgtcta cgctgactct ttcgtgatta gaggcgatga ggttagacag 1980
atcgcacctg gccagaccgg caaaatcgct gactacaact acaagctgcc tgatgacttc 2040
acaggctgtg tcattgcctg gaactcaaat aacctggact ctaaagtggg cggcaactac 2100
aactacctgt accggctgtt ccggaagagc aatctgaaac cttttgagcg ggacatctct 2160
acagagatct accaggccgg cagcacaccc tgcaacggcg ttgagggctt caactgctac 2220
ttccctctgc agagctacgg ctttcagcca acaaatggag tgggctacca gccgtacaga 2280
gtggtggtgc tgagcttcga actgctgcat gccccagcca cagtgtgtgg acctaagaag 2340
tctaccaacc tggtgaagaa caagtgcgtg aactttaact ttaacggcct gaccggcaca 2400
ggcgtgctga ccgaatccaa caaaaagttc ctgcccttcc aacagttcgg cagagacatc 2460
gccgatacaa ccgatgccgt gcgggacccc cagaccttag aaatcctaga tatcaccccg 2520
tgcagcttcg gcggagtctc tgttattact cctggcacca acaccagcaa ccaagtggct 2580
gttctgtacc aaggcgtgaa ctgcaccgaa gtgcctgtgg ctatccacgc cgatcagctg 2640
accccaacct ggcgggtgta tagcaccggc tctaacgtgt tccagacccg ggctggctgc 2700
ctgatcggcg ccgaacacgt caacaactcc tatgaatgtg acatccccat cggggctggc 2760
atctgcgcca gttaccagac acagacaaat agccctagac gggccagaag cgtggcctcc 2820
cagagtatca ttgcctacac catgagcctg ggcgccgaga acagcgtggc ctattctaac 2880
aatagcatcg caatccctac caactttacc atctctgtga caaccgagat cctgcctgtg 2940
agcatgacca aaaccagcgt ggactgcacg atgtacatct gtggcgacag cacagaatgc 3000
agtaatctgt tgctgcagta cggcagcttt tgcacccagt tgaatagagc cctgaccgga 3060
atcgccgtag agcaggacaa aaatacccag gaggtgttcg cccaggtgaa acagatctac 3120
aagacacctc ccattaagga cttcggaggt tttaacttca gccagatcct gcccgaccct 3180
tccaagccta gcaaacgctc cttcatcgag gacctgctct tcaacaaggt gacactggct 3240
gatgccggct tcatcaagca gtacggagat tgtctgggag acatcgccgc tagagatctg 3300
atctgcgccc aaaagttcaa cggcctgacc gtgctgcctc ctctgcttac agacgagatg 3360
atcgcccagt acaccagcgc cctgctggct ggcaccatca caagcggctg gaccttcgga 3420
gccggagccg ctctgcaaat cccctttgcc atgcagatgg cctaccggtt caacggcatc 3480
ggcgtgacac agaatgtgct gtacgagaac cagaagctga tcgctaacca gtttaacagc 3540
gctatcggca agatccagga ctcgctgagt agcaccgcct ctgccctggg caagctgcag 3600
gacgtcgtga accagaacgc ccaagccctg aacacactgg tgaaacagct gagcagcaac 3660
ttcggcgcca tcagctctgt gctgaacgat atcctgagca gactggacaa ggtggaagcc 3720
gaggtccaga tcgacagact gatcacagga agactgcaga gcctgcaaac gtacgtgaca 3780
cagcagctga tccgggcagc cgaaatccgg gccagcgcca atctggccgc taccaagatg 3840
agcgagtgcg tgttaggcca gagcaagcgg gtggatttct gcggtaaggg ataccacctg 3900
atgagctttc cccagagcgc tcctcacggc gtggtgtttc tgcacgtgac ctacgttcct 3960
gcccaggaaa agaacttcac caccgcccct gctatctgcc acgatggcaa ggcccacttc 4020
cctagagagg gcgttttcgt gtctaacggc acacactggt ttgtgaccca gagaaacttc 4080
tacgagcctc agatcatcac cacagacaac acctttgtga gcggcaattg cgacgtggtg 4140
atcggaattg ttaataatac cgtgtacgac cctctgcagc ctgagctcga cagcttcaag 4200
gaagagctgg acaagtactt caagaaccac acctccccag atgtggacct gggcgatatt 4260
tcaggcatca acgcctccgt cgtgaatatc cagaaggaga tcgaccggct caacgaggtg 4320
gccaagaacc ttaacgagag cctgatcgac ctgcaggaac tgggcaaata tgagcagtac 4380
atcaagtggc cttggtacat ctggctgggc tttatcgcag gcctgatcgc tatcgtgatg 4440
gtgaccatta tgctgtgttg tatgaccagc tgttgtagtt gtctgaaggg ctgctgttct 4500
tgcggcagct gctgcaagtt cgacgaagac gactcagagc ccgtgctgaa aggcgtgaag 4560
ctgcactaca cccgaaaacg gcgcggaagc ggaggaagcg gagctactaa cttcagcctg 4620
ctgaagcagg ctggagatgt ggaggagaac cctggaccta tgtattcttt tgtgtccgag 4680
gaaaccggca cactgatcgt taatagcgtg ctgctcttcc tggccttcgt ggtgttcctg 4740
ctggtgaccc tggctatcct gaccgccctg agactgtgtg cctactgctg caacatcgtg 4800
aacgtgtctc tggtcaagcc tagcttctac gtgtacagcc gggtgaagaa cctgaacagc 4860
agcagagtgc ccgacctgct ggtgtaatcc ccccccccta acgttactgg ccgaagccgc 4920
ttggaataag gccggtgtgc gtttgtctat atgttatttt ccaccatatt gccgtctttt 4980
ggcaatgtga gggcccggaa acctggccct gtcttcttga cgagcattcc taggggtctt 5040
tcccctctcg ccaaaggaat gcaaggtctg ttgaatgtcg tgaaggaagc agttcctctg 5100
gaagcttctt gaagacaaac aacgtctgta gcgacccttt gcaggcagcg gaacccccca 5160
cctggcgaca ggtgcctctg cggccaaaag ccacgtgtat aagatacacc tgcaaaggcg 5220
gcacaacccc agtgccacgt tgtgagttgg atagttgtgg aaagagtcaa atggctctcc 5280
tcaagcgtat tcaacaaggg gctgaaggat gcccagaagg taccccattg tatgggatct 5340
gatctggggc ctcggtgcac atgctttaca tgtgtttagt cgaggttaaa aaaacgtcta 5400
ggccccccga accacgggga cgtggttttc ctttgaaaaa cacgatgata atatggccac 5460
aaccatggaa caagagactt gcgcgcactc tctcactttt gaggaatgcc caaaatgctc 5520
tgctctacaa taccgtaatg gattttacct gctaaagtat gatgaagaat ggtacccaga 5580
ggagttattg actgatggag aggatgatgt ctttgatccc gaattagaca tggaagtcgt 5640
tttcgagtta cagggaagcg gagctactaa cttcagcctg ctgaagcagg ctggagatgt 5700
ggaggagaac cctggaccta tgagcgacaa cggccctcaa aaccagagaa atgcccctcg 5760
gatcacattt ggcggaccta gcgacagcac cggcagcaac cagaatggag aaagaagcgg 5820
cgccagatcc aagcagcgga gacctcaggg actgcccaac aacaccgcta gctggttcac 5880
cgccctgacc caacacggca aggaagatct gaagttcccc agaggccagg gcgtgcctat 5940
caacacaaac tcttctcccg acgaccagat cggatactat agacgggcca ctcggagaat 6000
tcggggcggc gacggaaaaa tgaaggacct ttctccaaga tggtacttct actacctcgg 6060
cacaggccct gaggccggcc tgccttacgg cgccaacaag gatggcatca tctgggtcgc 6120
caccgagggc gccctgaaca cccctaagga ccacatcggc acaagaaacc ccgctaacaa 6180
cgccgcaatc gtgctgcagc tgcctcaggg caccaccctg cccaagggct tctacgccga 6240
gggctctaga ggtggctccc aggcttctag ccgctcctcc agccgcagca gaaacagcag 6300
caggaacagc acccccggca gctcccgggg caccagcccc gccagaatgg ccggaaatgg 6360
cggcgatgcc gccctggccc tgctcctgct ggacagactg aatcagctgg aaagcaagat 6420
gagcggcaaa ggacagcagc agcaaggcca gaccgtgacc aagaaaagcg ctgctgaagc 6480
ctccaagaaa cctagacaaa agcggaccgc cacaaaggcc tacaacgtga cccaagcctt 6540
tggaagaaga ggccccgagc agacacaggg caatttcggc gaccaggagc tgatccggca 6600
gggaaccgac tacaagcact ggcctcagat cgcccagttc gcccctagcg ccagcgcctt 6660
cttcggcatg agcagaatcg gcatggaagt gaccccttct ggcacctggc tgacctacac 6720
cggcgctatc aagctggacg ataaggatcc taacttcaag gaccaagtga tcctgctgaa 6780
caagcatatc gacgcctata agacctttcc acctacagag cctaagaaag ataagaagaa 6840
gaaagccgac gagacacagg ccctgcctca gagacagaaa aagcagcaga cagtgacact 6900
gctgccagcc gctgacctgg atgacttcag caagcagctg cagcagagca tgtcttctgc 6960
tgatagcacc caggcc 6976
<210> 40
<211> 7640
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG8 expression cassette
<400> 40
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgttcg tgttcctggt gctgctgcct 780
ctggtcagct cccagtgtgt gaacctgacc accagaaccc agctgccacc tgcttataca 840
aactccttca ctcggggggt atactacccc gacaaggtgt tcagatctag cgtgctgcat 900
tctacacaag acctgttcct gcccttcttc agcaacgtga cctggttcca cgccatccac 960
gtgtctggaa ccaacggaac caagagattc gacaaccccg tgctgccttt caacgacggc 1020
gtgtacttcg ccagcaccga gaagtccaac atcatcagag gatggatttt cggcaccaca 1080
ctggacagca aaacccagag cctgctgatc gtgaacaacg ccaccaacgt ggtgatcaag 1140
gtgtgcgagt tccagttctg caatgatccc ttcctgggcg tgtactacca caagaacaac 1200
aagtcttgga tggaaagcga gttcagagtg tattccagcg ccaacaattg caccttcgag 1260
tacgtgagcc aaccctttct gatggacctt gaaggcaagc agggcaactt caaaaatctg 1320
cgagaatttg tgttcaagaa catcgacgga tacttcaaga tctactctaa gcacacgcca 1380
atcaacctgg tgagagatct gccccagggc tttagcgctt tggaacctct ggtggacctg 1440
cctatcggaa tcaacatcac cagatttcaa actctcctgg ccctgcacag atcttatctg 1500
acccctgggg acagtagtag cggctggaca gccggcgccg ccgcctacta cgtgggatac 1560
ctgcagccta gaacattcct gctgaagtac aatgagaacg gaacaatcac agacgccgtg 1620
gactgcgccc tggatccttt gagcgagaca aagtgcaccc tgaagtcgtt caccgtcgaa 1680
aaaggcatct accagaccag caacttccgc gtgcagccta cggaatctat cgtgcggttc 1740
cccaacatca ccaacctgtg ccctttcggc gaggtgttta acgctacaag gttcgccagc 1800
gtgtatgcct ggaacagaaa gagaatcagc aattgcgtgg ccgattatag cgttctgtac 1860
aacagcgctt ccttcagcac cttcaagtgc tacggcgtgt ctccaaccaa gctgaacgac 1920
ctctgcttca ccaatgtcta cgctgactct ttcgtgatta gaggcgatga ggttagacag 1980
atcgcacctg gccagaccgg caaaatcgct gactacaact acaagctgcc tgatgacttc 2040
acaggctgtg tcattgcctg gaactcaaat aacctggact ctaaagtggg cggcaactac 2100
aactacctgt accggctgtt ccggaagagc aatctgaaac cttttgagcg ggacatctct 2160
acagagatct accaggccgg cagcacaccc tgcaacggcg ttgagggctt caactgctac 2220
ttccctctgc agagctacgg ctttcagcca acaaatggag tgggctacca gccgtacaga 2280
gtggtggtgc tgagcttcga actgctgcat gccccagcca cagtgtgtgg acctaagaag 2340
tctaccaacc tggtgaagaa caagtgcgtg aactttaact ttaacggcct gaccggcaca 2400
ggcgtgctga ccgaatccaa caaaaagttc ctgcccttcc aacagttcgg cagagacatc 2460
gccgatacaa ccgatgccgt gcgggacccc cagaccttag aaatcctaga tatcaccccg 2520
tgcagcttcg gcggagtctc tgttattact cctggcacca acaccagcaa ccaagtggct 2580
gttctgtacc aaggcgtgaa ctgcaccgaa gtgcctgtgg ctatccacgc cgatcagctg 2640
accccaacct ggcgggtgta tagcaccggc tctaacgtgt tccagacccg ggctggctgc 2700
ctgatcggcg ccgaacacgt caacaactcc tatgaatgtg acatccccat cggggctggc 2760
atctgcgcca gttaccagac acagacaaat agccctagac gggccagaag cgtggcctcc 2820
cagagtatca ttgcctacac catgagcctg ggcgccgaga acagcgtggc ctattctaac 2880
aatagcatcg caatccctac caactttacc atctctgtga caaccgagat cctgcctgtg 2940
agcatgacca aaaccagcgt ggactgcacg atgtacatct gtggcgacag cacagaatgc 3000
agtaatctgt tgctgcagta cggcagcttt tgcacccagt tgaatagagc cctgaccgga 3060
atcgccgtag agcaggacaa aaatacccag gaggtgttcg cccaggtgaa acagatctac 3120
aagacacctc ccattaagga cttcggaggt tttaacttca gccagatcct gcccgaccct 3180
tccaagccta gcaaacgctc cttcatcgag gacctgctct tcaacaaggt gacactggct 3240
gatgccggct tcatcaagca gtacggagat tgtctgggag acatcgccgc tagagatctg 3300
atctgcgccc aaaagttcaa cggcctgacc gtgctgcctc ctctgcttac agacgagatg 3360
atcgcccagt acaccagcgc cctgctggct ggcaccatca caagcggctg gaccttcgga 3420
gccggagccg ctctgcaaat cccctttgcc atgcagatgg cctaccggtt caacggcatc 3480
ggcgtgacac agaatgtgct gtacgagaac cagaagctga tcgctaacca gtttaacagc 3540
gctatcggca agatccagga ctcgctgagt agcaccgcct ctgccctggg caagctgcag 3600
gacgtcgtga accagaacgc ccaagccctg aacacactgg tgaaacagct gagcagcaac 3660
ttcggcgcca tcagctctgt gctgaacgat atcctgagca gactggacaa ggtggaagcc 3720
gaggtccaga tcgacagact gatcacagga agactgcaga gcctgcaaac gtacgtgaca 3780
cagcagctga tccgggcagc cgaaatccgg gccagcgcca atctggccgc taccaagatg 3840
agcgagtgcg tgttaggcca gagcaagcgg gtggatttct gcggtaaggg ataccacctg 3900
atgagctttc cccagagcgc tcctcacggc gtggtgtttc tgcacgtgac ctacgttcct 3960
gcccaggaaa agaacttcac caccgcccct gctatctgcc acgatggcaa ggcccacttc 4020
cctagagagg gcgttttcgt gtctaacggc acacactggt ttgtgaccca gagaaacttc 4080
tacgagcctc agatcatcac cacagacaac acctttgtga gcggcaattg cgacgtggtg 4140
atcggaattg ttaataatac cgtgtacgac cctctgcagc ctgagctcga cagcttcaag 4200
gaagagctgg acaagtactt caagaaccac acctccccag atgtggacct gggcgatatt 4260
tcaggcatca acgcctccgt cgtgaatatc cagaaggaga tcgaccggct caacgaggtg 4320
gccaagaacc ttaacgagag cctgatcgac ctgcaggaac tgggcaaata tgagcagtac 4380
atcaagtggc cttggtacat ctggctgggc tttatcgcag gcctgatcgc tatcgtgatg 4440
gtgaccatta tgctgtgttg tatgaccagc tgttgtagtt gtctgaaggg ctgctgttct 4500
tgcggcagct gctgcaagtt cgacgaagac gactcagagc ccgtgctgaa aggcgtgaag 4560
ctgcactaca cccgaaaacg gcgcggaagc ggaggaagcg gagctactaa cttcagcctg 4620
ctgaagcagg ctggagatgt ggaggagaac cctggaccta tgtattcttt tgtgtccgag 4680
gaaaccggca cactgatcgt taatagcgtg ctgctcttcc tggccttcgt ggtgttcctg 4740
ctggtgaccc tggctatcct gaccgccctg agactgtgtg cctactgctg caacatcgtg 4800
aacgtgtctc tggtcaagcc tagcttctac gtgtacagcc gggtgaagaa cctgaacagc 4860
agcagagtgc ccgacctgct ggtgtaatcc ccccccccta acgttactgg ccgaagccgc 4920
ttggaataag gccggtgtgc gtttgtctat atgttatttt ccaccatatt gccgtctttt 4980
ggcaatgtga gggcccggaa acctggccct gtcttcttga cgagcattcc taggggtctt 5040
tcccctctcg ccaaaggaat gcaaggtctg ttgaatgtcg tgaaggaagc agttcctctg 5100
gaagcttctt gaagacaaac aacgtctgta gcgacccttt gcaggcagcg gaacccccca 5160
cctggcgaca ggtgcctctg cggccaaaag ccacgtgtat aagatacacc tgcaaaggcg 5220
gcacaacccc agtgccacgt tgtgagttgg atagttgtgg aaagagtcaa atggctctcc 5280
tcaagcgtat tcaacaaggg gctgaaggat gcccagaagg taccccattg tatgggatct 5340
gatctggggc ctcggtgcac atgctttaca tgtgtttagt cgaggttaaa aaaacgtcta 5400
ggccccccga accacgggga cgtggttttc ctttgaaaaa cacgatgata atatggccac 5460
aaccatggaa caagagactt gcgcgcactc tctcactttt gaggaatgcc caaaatgctc 5520
tgctctacaa taccgtaatg gattttacct gctaaagtat gatgaagaat ggtacccaga 5580
ggagttattg actgatggag aggatgatgt ctttgatccc gaattagaca tggaagtcgt 5640
tttcgagtta cagggaagcg gagctactaa cttcagcctg ctgaagcagg ctggagatgt 5700
ggaggagaac cctggaccta tgagcgacaa cggccctcaa aaccagagaa atgcccctcg 5760
gatcacattt ggcggaccta gcgacagcac cggcagcaac cagaatggag aaagaagcgg 5820
cgccagatcc aagcagcgga gacctcaggg actgcccaac aacaccgcta gctggttcac 5880
cgccctgacc caacacggca aggaagatct gaagttcccc agaggccagg gcgtgcctat 5940
caacacaaac tcttctcccg acgaccagat cggatactat agacgggcca ctcggagaat 6000
tcggggcggc gacggaaaaa tgaaggacct ttctccaaga tggtacttct actacctcgg 6060
cacaggccct gaggccggcc tgccttacgg cgccaacaag gatggcatca tctgggtcgc 6120
caccgagggc gccctgaaca cccctaagga ccacatcggc acaagaaacc ccgctaacaa 6180
cgccgcaatc gtgctgcagc tgcctcaggg caccaccctg cccaagggct tctacgccga 6240
gggctctaga ggtggctccc aggcttctag ccgctcctcc agccgcagca gaaacagcag 6300
caggaacagc acccccggca gctcccgggg caccagcccc gccagaatgg ccggaaatgg 6360
cggcgatgcc gccctggccc tgctcctgct ggacagactg aatcagctgg aaagcaagat 6420
gagcggcaaa ggacagcagc agcaaggcca gaccgtgacc aagaaaagcg ctgctgaagc 6480
ctccaagaaa cctagacaaa agcggaccgc cacaaaggcc tacaacgtga cccaagcctt 6540
tggaagaaga ggccccgagc agacacaggg caatttcggc gaccaggagc tgatccggca 6600
gggaaccgac tacaagcact ggcctcagat cgcccagttc gcccctagcg ccagcgcctt 6660
cttcggcatg agcagaatcg gcatggaagt gaccccttct ggcacctggc tgacctacac 6720
cggcgctatc aagctggacg ataaggatcc taacttcaag gaccaagtga tcctgctgaa 6780
caagcatatc gacgcctata agacctttcc acctacagag cctaagaaag ataagaagaa 6840
gaaagccgac gagacacagg ccctgcctca gagacagaaa aagcagcaga cagtgacact 6900
gctgccagcc gctgacctgg atgacttcag caagcagctg cagcagagca tgtcttctgc 6960
tgatagcacc caggcctaag tgtcaaagcg cgaggaactg ttcaccggag ttttgcccat 7020
cctggtcgag ctggacggcg atgtgaacgg ccacaagttc agcgtttctg gcgagggtga 7080
gctttgggct aagcgcaaca ttaaaccagt accagaggtg aaaatactca ataatttggg 7140
tgtggacatt gctgctaata ctgtgatctg ggactacaaa agagatgctc cagcacatat 7200
atctactatt ggtgtttgtt ctatgactga catagccaag aaaccaactg aaacgatttg 7260
tgcaccactc actgtctttt ttgatggtag agttgatggt caagtagact tatttagaaa 7320
tgcccgtaat ggtgttctta ttacagaagg tagtgttaaa ggtttacaac catctgtagg 7380
tcccaaacaa gctagtctta atggagtcac attaattgga gaagccgtaa aaacacagtt 7440
caattattat aagaaagttg atggtgttgt ccaacaatta cctgaaactt actttactca 7500
gagtagaaat ttacaagaat ttaaacccag gagtcaaatg gaaattgatt tcttagaatt 7560
agctatggat gaattcattg aacggtataa attagaaggc tatgccttcg aacatatcgt 7620
ttatggagat tttagtcata 7640
<210> 41
<211> 7000
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG9 expression cassette
<400> 41
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgagcg acaacggccc tcaaaaccag 780
agaaatgccc ctcggatcac atttggcgga cctagcgaca gcaccggcag caaccagaat 840
ggagaaagaa gcggcgccag atccaagcag cggagacctc agggactgcc caacaacacc 900
gctagctggt tcaccgccct gacccaacac ggcaaggaag atctgaagtt ccccagaggc 960
cagggcgtgc ctatcaacac aaactcttct cccgacgacc agatcggata ctatagacgg 1020
gccactcgga gaattcgggg cggcgacgga aaaatgaagg acctttctcc aagatggtac 1080
ttctactacc tcggcacagg ccctgaggcc ggcctgcctt acggcgccaa caaggatggc 1140
atcatctggg tcgccaccga gggcgccctg aacaccccta aggaccacat cggcacaaga 1200
aaccccgcta acaacgccgc aatcgtgctg cagctgcctc agggcaccac cctgcccaag 1260
ggcttctacg ccgagggctc tagaggtggc tcccaggctt ctagccgctc ctccagccgc 1320
agcagaaaca gcagcaggaa cagcaccccc ggcagctccc ggggcaccag ccccgccaga 1380
atggccggaa atggcggcga tgccgccctg gccctgctcc tgctggacag actgaatcag 1440
ctggaaagca agatgagcgg caaaggacag cagcagcaag gccagaccgt gaccaagaaa 1500
agcgctgctg aagcctccaa gaaacctaga caaaagcgga ccgccacaaa ggcctacaac 1560
gtgacccaag cctttggaag aagaggcccc gagcagacac agggcaattt cggcgaccag 1620
gagctgatcc ggcagggaac cgactacaag cactggcctc agatcgccca gttcgcccct 1680
agcgccagcg ccttcttcgg catgagcaga atcggcatgg aagtgacccc ttctggcacc 1740
tggctgacct acaccggcgc tatcaagctg gacgataagg atcctaactt caaggaccaa 1800
gtgatcctgc tgaacaagca tatcgacgcc tataagacct ttccacctac agagcctaag 1860
aaagataaga agaagaaagc cgacgagaca caggccctgc ctcagagaca gaaaaagcag 1920
cagacagtga cactgctgcc agccgctgac ctggatgact tcagcaagca gctgcagcag 1980
agcatgtctt ctgctgatag cacccaggcc cgaaaacggc gcggaagcgg aggaagcgga 2040
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 2100
ttcgtgttcc tggtgctgct gcctctggtc agctcccagt gtgtgaacct gaccaccaga 2160
acccagctgc cacctgctta tacaaactcc ttcactcggg gggtatacta ccccgacaag 2220
gtgttcagat ctagcgtgct gcattctaca caagacctgt tcctgccctt cttcagcaac 2280
gtgacctggt tccacgccat ccacgtgtct ggaaccaacg gaaccaagag attcgacaac 2340
cccgtgctgc ctttcaacga cggcgtgtac ttcgccagca ccgagaagtc caacatcatc 2400
agaggatgga ttttcggcac cacactggac agcaaaaccc agagcctgct gatcgtgaac 2460
aacgccacca acgtggtgat caaggtgtgc gagttccagt tctgcaatga tcccttcctg 2520
ggcgtgtact accacaagaa caacaagtct tggatggaaa gcgagttcag agtgtattcc 2580
agcgccaaca attgcacctt cgagtacgtg agccaaccct ttctgatgga ccttgaaggc 2640
aagcagggca acttcaaaaa tctgcgagaa tttgtgttca agaacatcga cggatacttc 2700
aagatctact ctaagcacac gccaatcaac ctggtgagag atctgcccca gggctttagc 2760
gctttggaac ctctggtgga cctgcctatc ggaatcaaca tcaccagatt tcaaactctc 2820
ctggccctgc acagatctta tctgacccct ggggacagta gtagcggctg gacagccggc 2880
gccgccgcct actacgtggg atacctgcag cctagaacat tcctgctgaa gtacaatgag 2940
aacggaacaa tcacagacgc cgtggactgc gccctggatc ctttgagcga gacaaagtgc 3000
accctgaagt cgttcaccgt cgaaaaaggc atctaccaga ccagcaactt ccgcgtgcag 3060
cctacggaat ctatcgtgcg gttccccaac atcaccaacc tgtgcccttt cggcgaggtg 3120
tttaacgcta caaggttcgc cagcgtgtat gcctggaaca gaaagagaat cagcaattgc 3180
gtggccgatt atagcgttct gtacaacagc gcttccttca gcaccttcaa gtgctacggc 3240
gtgtctccaa ccaagctgaa cgacctctgc ttcaccaatg tctacgctga ctctttcgtg 3300
attagaggcg atgaggttag acagatcgca cctggccaga ccggcaaaat cgctgactac 3360
aactacaagc tgcctgatga cttcacaggc tgtgtcattg cctggaactc aaataacctg 3420
gactctaaag tgggcggcaa ctacaactac ctgtaccggc tgttccggaa gagcaatctg 3480
aaaccttttg agcgggacat ctctacagag atctaccagg ccggcagcac accctgcaac 3540
ggcgttgagg gcttcaactg ctacttccct ctgcagagct acggctttca gccaacaaat 3600
ggagtgggct accagccgta cagagtggtg gtgctgagct tcgaactgct gcatgcccca 3660
gccacagtgt gtggacctaa gaagtctacc aacctggtga agaacaagtg cgtgaacttt 3720
aactttaacg gcctgaccgg cacaggcgtg ctgaccgaat ccaacaaaaa gttcctgccc 3780
ttccaacagt tcggcagaga catcgccgat acaaccgatg ccgtgcggga cccccagacc 3840
ttagaaatcc tagatatcac cccgtgcagc ttcggcggag tctctgttat tactcctggc 3900
accaacacca gcaaccaagt ggctgttctg taccaaggcg tgaactgcac cgaagtgcct 3960
gtggctatcc acgccgatca gctgacccca acctggcggg tgtatagcac cggctctaac 4020
gtgttccaga cccgggctgg ctgcctgatc ggcgccgaac acgtcaacaa ctcctatgaa 4080
tgtgacatcc ccatcggggc tggcatctgc gccagttacc agacacagac aaatagccct 4140
ggcagcgcca gcagcgtggc ctcccagagt atcattgcct acaccatgag cctgggcgcc 4200
gagaacagcg tggcctattc taacaatagc atcgcaatcc ctaccaactt taccatctct 4260
gtgacaaccg agatcctgcc tgtgagcatg accaaaacca gcgtggactg cacgatgtac 4320
atctgtggcg acagcacaga atgcagtaat ctgttgctgc agtacggcag cttttgcacc 4380
cagttgaata gagccctgac cggaatcgcc gtagagcagg acaaaaatac ccaggaggtg 4440
ttcgcccagg tgaaacagat ctacaagaca cctcccatta aggacttcgg aggttttaac 4500
ttcagccaga tcctgcccga cccttccaag cctagcaaac gctccttcat cgaggacctg 4560
ctcttcaaca aggtgacact ggctgatgcc ggcttcatca agcagtacgg agattgtctg 4620
ggagacatcg ccgctagaga tctgatctgc gcccaaaagt tcaacggcct gaccgtgctg 4680
cctcctctgc ttacagacga gatgatcgcc cagtacacca gcgccctgct ggctggcacc 4740
atcacaagcg gctggacctt cggagccgga gccgctctgc aaatcccctt tgccatgcag 4800
atggcctacc ggttcaacgg catcggcgtg acacagaatg tgctgtacga gaaccagaag 4860
ctgatcgcta accagtttaa cagcgctatc ggcaagatcc aggactcgct gagtagcacc 4920
gcctctgccc tgggcaagct gcaggacgtc gtgaaccaga acgcccaagc cctgaacaca 4980
ctggtgaaac agctgagcag caacttcggc gccatcagct ctgtgctgaa cgatatcctg 5040
agcagactgg accctcccga agccgaggtc cagatcgaca gactgatcac aggaagactg 5100
cagagcctgc aaacgtacgt gacacagcag ctgatccggg cagccgaaat ccgggccagc 5160
gccaatctgg ccgctaccaa gatgagcgag tgcgtgttag gccagagcaa gcgggtggat 5220
ttctgcggta agggatacca cctgatgagc tttccccaga gcgctcctca cggcgtggtg 5280
tttctgcacg tgacctacgt tcctgcccag gaaaagaact tcaccaccgc ccctgctatc 5340
tgccacgatg gcaaggccca cttccctaga gagggcgttt tcgtgtctaa cggcacacac 5400
tggtttgtga cccagagaaa cttctacgag cctcagatca tcaccacaga caacaccttt 5460
gtgagcggca attgcgacgt ggtgatcgga attgttaata ataccgtgta cgaccctctg 5520
cagcctgagc tcgacagctt caaggaagag ctggacaagt acttcaagaa ccacacctcc 5580
ccagatgtgg acctgggcga tatttcaggc atcaacgcct ccgtcgtgaa tatccagaag 5640
gagatcgacc ggctcaacga ggtggccaag aaccttaacg agagcctgat cgacctgcag 5700
gaactgggca aatatgagca gtacatcaag tggccttggt acatctggct gggctttatc 5760
gcaggcctga tcgctatcgt gatggtgacc attatgctgt gttgtatgac cagctgttgt 5820
agttgtctga agggctgctg ttcttgcggc agctgctgca agttcgacga agacgactca 5880
gagcccgtgc tgaaaggcgt gaagctgcac tacacccgaa aacggcgcgg aagcggagga 5940
agcggagcta ctaacttcag cctgctgaag caggctggag atgtggagga gaaccctgga 6000
cctatgtatt cttttgtgtc cgaggaaacc ggcacactga tcgttaatag cgtgctgctc 6060
ttcctggcct tcgtggtgtt cctgctggtg accctggcta tcctgaccgc cctgagactg 6120
tgtgcctact gctgcaacat cgtgaacgtg tctctggtca agcctagctt ctacgtgtac 6180
agccgggtga agaacctgaa cagcagcaga gtgcccgacc tgctggtgta atcccccccc 6240
cctaacgtta ctggccgaag ccgcttggaa taaggccggt gtgcgtttgt ctatatgtta 6300
ttttccacca tattgccgtc ttttggcaat gtgagggccc ggaaacctgg ccctgtcttc 6360
ttgacgagca ttcctagggg tctttcccct ctcgccaaag gaatgcaagg tctgttgaat 6420
gtcgtgaagg aagcagttcc tctggaagct tcttgaagac aaacaacgtc tgtagcgacc 6480
ctttgcaggc agcggaaccc cccacctggc gacaggtgcc tctgcggcca aaagccacgt 6540
gtataagata cacctgcaaa ggcggcacaa ccccagtgcc acgttgtgag ttggatagtt 6600
gtggaaagag tcaaatggct ctcctcaagc gtattcaaca aggggctgaa ggatgcccag 6660
aaggtacccc attgtatggg atctgatctg gggcctcggt gcacatgctt tacatgtgtt 6720
tagtcgaggt taaaaaaacg tctaggcccc ccgaaccacg gggacgtggt tttcctttga 6780
aaaacacgat gataatatgg ccacaaccat ggaacaagag acttgcgcgc actctctcac 6840
ttttgaggaa tgcccaaaat gctctgctct acaataccgt aatggatttt acctgctaaa 6900
gtatgatgaa gaatggtacc cagaggagtt attgactgat ggagaggatg atgtctttga 6960
tcccgaatta gacatggaag tcgttttcga gttacagtaa 7000
<210> 42
<211> 7661
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG10 expression cassette
<400> 42
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgagcg acaacggccc tcaaaaccag 780
agaaatgccc ctcggatcac atttggcgga cctagcgaca gcaccggcag caaccagaat 840
ggagaaagaa gcggcgccag atccaagcag cggagacctc agggactgcc caacaacacc 900
gctagctggt tcaccgccct gacccaacac ggcaaggaag atctgaagtt ccccagaggc 960
cagggcgtgc ctatcaacac aaactcttct cccgacgacc agatcggata ctatagacgg 1020
gccactcgga gaattcgggg cggcgacgga aaaatgaagg acctttctcc aagatggtac 1080
ttctactacc tcggcacagg ccctgaggcc ggcctgcctt acggcgccaa caaggatggc 1140
atcatctggg tcgccaccga gggcgccctg aacaccccta aggaccacat cggcacaaga 1200
aaccccgcta acaacgccgc aatcgtgctg cagctgcctc agggcaccac cctgcccaag 1260
ggcttctacg ccgagggctc tagaggtggc tcccaggctt ctagccgctc ctccagccgc 1320
agcagaaaca gcagcaggaa cagcaccccc ggcagctccc ggggcaccag ccccgccaga 1380
atggccggaa atggcggcga tgccgccctg gccctgctcc tgctggacag actgaatcag 1440
ctggaaagca agatgagcgg caaaggacag cagcagcaag gccagaccgt gaccaagaaa 1500
agcgctgctg aagcctccaa gaaacctaga caaaagcgga ccgccacaaa ggcctacaac 1560
gtgacccaag cctttggaag aagaggcccc gagcagacac agggcaattt cggcgaccag 1620
gagctgatcc ggcagggaac cgactacaag cactggcctc agatcgccca gttcgcccct 1680
agcgccagcg ccttcttcgg catgagcaga atcggcatgg aagtgacccc ttctggcacc 1740
tggctgacct acaccggcgc tatcaagctg gacgataagg atcctaactt caaggaccaa 1800
gtgatcctgc tgaacaagca tatcgacgcc tataagacct ttccacctac agagcctaag 1860
aaagataaga agaagaaagc cgacgagaca caggccctgc ctcagagaca gaaaaagcag 1920
cagacagtga cactgctgcc agccgctgac ctggatgact tcagcaagca gctgcagcag 1980
agcatgtctt ctgctgatag cacccaggcc cgaaaacggc gcggaagcgg aggaagcgga 2040
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 2100
ttcgtgttcc tggtgctgct gcctctggtc agctcccagt gtgtgaacct gaccaccaga 2160
acccagctgc cacctgctta tacaaactcc ttcactcggg gggtatacta ccccgacaag 2220
gtgttcagat ctagcgtgct gcattctaca caagacctgt tcctgccctt cttcagcaac 2280
gtgacctggt tccacgccat ccacgtgtct ggaaccaacg gaaccaagag attcgacaac 2340
cccgtgctgc ctttcaacga cggcgtgtac ttcgccagca ccgagaagtc caacatcatc 2400
agaggatgga ttttcggcac cacactggac agcaaaaccc agagcctgct gatcgtgaac 2460
aacgccacca acgtggtgat caaggtgtgc gagttccagt tctgcaatga tcccttcctg 2520
ggcgtgtact accacaagaa caacaagtct tggatggaaa gcgagttcag agtgtattcc 2580
agcgccaaca attgcacctt cgagtacgtg agccaaccct ttctgatgga ccttgaaggc 2640
aagcagggca acttcaaaaa tctgcgagaa tttgtgttca agaacatcga cggatacttc 2700
aagatctact ctaagcacac gccaatcaac ctggtgagag atctgcccca gggctttagc 2760
gctttggaac ctctggtgga cctgcctatc ggaatcaaca tcaccagatt tcaaactctc 2820
ctggccctgc acagatctta tctgacccct ggggacagta gtagcggctg gacagccggc 2880
gccgccgcct actacgtggg atacctgcag cctagaacat tcctgctgaa gtacaatgag 2940
aacggaacaa tcacagacgc cgtggactgc gccctggatc ctttgagcga gacaaagtgc 3000
accctgaagt cgttcaccgt cgaaaaaggc atctaccaga ccagcaactt ccgcgtgcag 3060
cctacggaat ctatcgtgcg gttccccaac atcaccaacc tgtgcccttt cggcgaggtg 3120
tttaacgcta caaggttcgc cagcgtgtat gcctggaaca gaaagagaat cagcaattgc 3180
gtggccgatt atagcgttct gtacaacagc gcttccttca gcaccttcaa gtgctacggc 3240
gtgtctccaa ccaagctgaa cgacctctgc ttcaccaatg tctacgctga ctctttcgtg 3300
attagaggcg atgaggttag acagatcgca cctggccaga ccggcaaaat cgctgactac 3360
aactacaagc tgcctgatga cttcacaggc tgtgtcattg cctggaactc aaataacctg 3420
gactctaaag tgggcggcaa ctacaactac ctgtaccggc tgttccggaa gagcaatctg 3480
aaaccttttg agcgggacat ctctacagag atctaccagg ccggcagcac accctgcaac 3540
ggcgttgagg gcttcaactg ctacttccct ctgcagagct acggctttca gccaacaaat 3600
ggagtgggct accagccgta cagagtggtg gtgctgagct tcgaactgct gcatgcccca 3660
gccacagtgt gtggacctaa gaagtctacc aacctggtga agaacaagtg cgtgaacttt 3720
aactttaacg gcctgaccgg cacaggcgtg ctgaccgaat ccaacaaaaa gttcctgccc 3780
ttccaacagt tcggcagaga catcgccgat acaaccgatg ccgtgcggga cccccagacc 3840
ttagaaatcc tagatatcac cccgtgcagc ttcggcggag tctctgttat tactcctggc 3900
accaacacca gcaaccaagt ggctgttctg taccaaggcg tgaactgcac cgaagtgcct 3960
gtggctatcc acgccgatca gctgacccca acctggcggg tgtatagcac cggctctaac 4020
gtgttccaga cccgggctgg ctgcctgatc ggcgccgaac acgtcaacaa ctcctatgaa 4080
tgtgacatcc ccatcggggc tggcatctgc gccagttacc agacacagac aaatagccct 4140
ggcagcgcca gcagcgtggc ctcccagagt atcattgcct acaccatgag cctgggcgcc 4200
gagaacagcg tggcctattc taacaatagc atcgcaatcc ctaccaactt taccatctct 4260
gtgacaaccg agatcctgcc tgtgagcatg accaaaacca gcgtggactg cacgatgtac 4320
atctgtggcg acagcacaga atgcagtaat ctgttgctgc agtacggcag cttttgcacc 4380
cagttgaata gagccctgac cggaatcgcc gtagagcagg acaaaaatac ccaggaggtg 4440
ttcgcccagg tgaaacagat ctacaagaca cctcccatta aggacttcgg aggttttaac 4500
ttcagccaga tcctgcccga cccttccaag cctagcaaac gctccttcat cgaggacctg 4560
ctcttcaaca aggtgacact ggctgatgcc ggcttcatca agcagtacgg agattgtctg 4620
ggagacatcg ccgctagaga tctgatctgc gcccaaaagt tcaacggcct gaccgtgctg 4680
cctcctctgc ttacagacga gatgatcgcc cagtacacca gcgccctgct ggctggcacc 4740
atcacaagcg gctggacctt cggagccgga gccgctctgc aaatcccctt tgccatgcag 4800
atggcctacc ggttcaacgg catcggcgtg acacagaatg tgctgtacga gaaccagaag 4860
ctgatcgcta accagtttaa cagcgctatc ggcaagatcc aggactcgct gagtagcacc 4920
gcctctgccc tgggcaagct gcaggacgtc gtgaaccaga acgcccaagc cctgaacaca 4980
ctggtgaaac agctgagcag caacttcggc gccatcagct ctgtgctgaa cgatatcctg 5040
agcagactgg accctcccga agccgaggtc cagatcgaca gactgatcac aggaagactg 5100
cagagcctgc aaacgtacgt gacacagcag ctgatccggg cagccgaaat ccgggccagc 5160
gccaatctgg ccgctaccaa gatgagcgag tgcgtgttag gccagagcaa gcgggtggat 5220
ttctgcggta agggatacca cctgatgagc tttccccaga gcgctcctca cggcgtggtg 5280
tttctgcacg tgacctacgt tcctgcccag gaaaagaact tcaccaccgc ccctgctatc 5340
tgccacgatg gcaaggccca cttccctaga gagggcgttt tcgtgtctaa cggcacacac 5400
tggtttgtga cccagagaaa cttctacgag cctcagatca tcaccacaga caacaccttt 5460
gtgagcggca attgcgacgt ggtgatcgga attgttaata ataccgtgta cgaccctctg 5520
cagcctgagc tcgacagctt caaggaagag ctggacaagt acttcaagaa ccacacctcc 5580
ccagatgtgg acctgggcga tatttcaggc atcaacgcct ccgtcgtgaa tatccagaag 5640
gagatcgacc ggctcaacga ggtggccaag aaccttaacg agagcctgat cgacctgcag 5700
gaactgggca aatatgagca gtacatcaag tggccttggt acatctggct gggctttatc 5760
gcaggcctga tcgctatcgt gatggtgacc attatgctgt gttgtatgac cagctgttgt 5820
agttgtctga agggctgctg ttcttgcggc agctgctgca agttcgacga agacgactca 5880
gagcccgtgc tgaaaggcgt gaagctgcac tacacccgaa aacggcgcgg aagcggagga 5940
agcggagcta ctaacttcag cctgctgaag caggctggag atgtggagga gaaccctgga 6000
cctatgtatt cttttgtgtc cgaggaaacc ggcacactga tcgttaatag cgtgctgctc 6060
ttcctggcct tcgtggtgtt cctgctggtg accctggcta tcctgaccgc cctgagactg 6120
tgtgcctact gctgcaacat cgtgaacgtg tctctggtca agcctagctt ctacgtgtac 6180
agccgggtga agaacctgaa cagcagcaga gtgcccgacc tgctggtgta atcccccccc 6240
cctaacgtta ctggccgaag ccgcttggaa taaggccggt gtgcgtttgt ctatatgtta 6300
ttttccacca tattgccgtc ttttggcaat gtgagggccc ggaaacctgg ccctgtcttc 6360
ttgacgagca ttcctagggg tctttcccct ctcgccaaag gaatgcaagg tctgttgaat 6420
gtcgtgaagg aagcagttcc tctggaagct tcttgaagac aaacaacgtc tgtagcgacc 6480
ctttgcaggc agcggaaccc cccacctggc gacaggtgcc tctgcggcca aaagccacgt 6540
gtataagata cacctgcaaa ggcggcacaa ccccagtgcc acgttgtgag ttggatagtt 6600
gtggaaagag tcaaatggct ctcctcaagc gtattcaaca aggggctgaa ggatgcccag 6660
aaggtacccc attgtatggg atctgatctg gggcctcggt gcacatgctt tacatgtgtt 6720
tagtcgaggt taaaaaaacg tctaggcccc ccgaaccacg gggacgtggt tttcctttga 6780
aaaacacgat gataatatgg ccacaaccat ggaacaagag acttgcgcgc actctctcac 6840
ttttgaggaa tgcccaaaat gctctgctct acaataccgt aatggatttt acctgctaaa 6900
gtatgatgaa gaatggtacc cagaggagtt attgactgat ggagaggatg atgtctttga 6960
tcccgaatta gacatggaag tcgttttcga gttacagtaa gtgtcaaagc gcgaggaact 7020
gttcaccgga gttttgccca tcctggtcga gctggacggc gatgtgaacg gccacaagtt 7080
cagcgtttct ggcgagggtg agctttgggc taagcgcaac attaaaccag taccagaggt 7140
gaaaatactc aataatttgg gtgtggacat tgctgctaat actgtgatct gggactacaa 7200
aagagatgct ccagcacata tatctactat tggtgtttgt tctatgactg acatagccaa 7260
gaaaccaact gaaacgattt gtgcaccact cactgtcttt tttgatggta gagttgatgg 7320
tcaagtagac ttatttagaa atgcccgtaa tggtgttctt attacagaag gtagtgttaa 7380
aggtttacaa ccatctgtag gtcccaaaca agctagtctt aatggagtca cattaattgg 7440
agaagccgta aaaacacagt tcaattatta taagaaagtt gatggtgttg tccaacaatt 7500
acctgaaact tactttactc agagtagaaa tttacaagaa tttaaaccca ggagtcaaat 7560
ggaaattgat ttcttagaat tagctatgga tgaattcatt gaacggtata aattagaagg 7620
ctatgccttc gaacatatcg tttatggaga ttttagtcat a 7661
<210> 43
<211> 7893
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG11 expression cassette
<400> 43
aaaaaaaaaa attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc 60
ttgtagatct gttctctaaa cgaactttaa aatctgtgtg gctgtcactc ggctgcatgc 120
ttagtgcact cacgcagtat aattaataac taattactgt cgttgacagg acacgagtaa 180
ctcgtctatc ttctgcaggc tgcttacggt ttcgtccgtg ttgcagccga tcatcagcac 240
atctaggttt cgtccgggtg tgaccgaaag gtaagatggc cgacagcaac ggcacaatca 300
ccgtggaaga gctgaagaaa ctgctggaac agtggaacct ggtcatcggc ttcctgtttc 360
tgacctggat ctgtctgctg cagttcgctt atgccaatcg gaacagattc ctgtacatca 420
tcaagctgat cttcctgtgg ctgctgtggc ctgtgaccct ggcttgcttc gtgctggccg 480
ctgtgtaccg gatcaactgg atcacaggcg gaatcgccat cgccatggcc tgcctggtgg 540
gcctgatgtg gctgagctac ttcatcgctt ctttcagact gttcgccaga acccggagca 600
tgtggtcctt caaccccgag acaaacatcc tgctgaacgt gcctctgcac ggcaccatcc 660
tgacaagacc tctgctcgag agcgagctgg tgattggcgc agtgattctg agaggccatc 720
tgaggatcgc cggacaccac ctgggcagat gcgacatcaa ggaccttcca aaggaaatca 780
ccgttgccac cagccggacc ctgtcctact acaaactggg cgccagccaa agagtggccg 840
gcgatagcgg ctttgccgcc tacagcagat accgcatcgg aaattacaag ctcaacaccg 900
accacagcag ctcttctgat aacatcgccc tgctggtgca gcgaaaacgg cgcggaagcg 960
gaggaagcgg agctactaac ttcagcctgc tgaagcaggc tggagatgtg gaggagaacc 1020
ctggacctat gagcgacaac ggccctcaaa accagagaaa tgcccctcgg atcacatttg 1080
gcggacctag cgacagcacc ggcagcaacc agaatggaga aagaagcggc gccagatcca 1140
agcagcggag acctcaggga ctgcccaaca acaccgctag ctggttcacc gccctgaccc 1200
aacacggcaa ggaagatctg aagttcccca gaggccaggg cgtgcctatc aacacaaact 1260
cttctcccga cgaccagatc ggatactata gacgggccac tcggagaatt cggggcggcg 1320
acggaaaaat gaaggacctt tctccaagat ggtacttcta ctacctcggc acaggccctg 1380
aggccggcct gccttacggc gccaacaagg atggcatcat ctgggtcgcc accgagggcg 1440
ccctgaacac ccctaaggac cacatcggca caagaaaccc cgctaacaac gccgcaatcg 1500
tgctgcagct gcctcagggc accaccctgc ccaagggctt ctacgccgag ggctctagag 1560
gtggctccca ggcttctagc cgctcctcca gccgcagcag aaacagcagc aggaacagca 1620
cccccggcag ctcccggggc accagccccg ccagaatggc cggaaatggc ggcgatgccg 1680
ccctggccct gctcctgctg gacagactga atcagctgga aagcaagatg agcggcaaag 1740
gacagcagca gcaaggccag accgtgacca agaaaagcgc tgctgaagcc tccaagaaac 1800
ctagacaaaa gcggaccgcc acaaaggcct acaacgtgac ccaagccttt ggaagaagag 1860
gccccgagca gacacagggc aatttcggcg accaggagct gatccggcag ggaaccgact 1920
acaagcactg gcctcagatc gcccagttcg cccctagcgc cagcgccttc ttcggcatga 1980
gcagaatcgg catggaagtg accccttctg gcacctggct gacctacacc ggcgctatca 2040
agctggacga taaggatcct aacttcaagg accaagtgat cctgctgaac aagcatatcg 2100
acgcctataa gacctttcca cctacagagc ctaagaaaga taagaagaag aaagccgacg 2160
agacacaggc cctgcctcag agacagaaaa agcagcagac agtgacactg ctgccagccg 2220
ctgacctgga tgacttcagc aagcagctgc agcagagcat gtcttctgct gatagcaccc 2280
aggcccgaaa acggcgcgga agcggaggaa gcggagctac taacttcagc ctgctgaagc 2340
aggctggaga tgtggaggag aaccctggac ctatgttcgt gttcctggtg ctgctgcctc 2400
tggtcagctc ccagtgtgtg aacctgacca ccagaaccca gctgccacct gcttatacaa 2460
actccttcac tcggggggta tactaccccg acaaggtgtt cagatctagc gtgctgcatt 2520
ctacacaaga cctgttcctg cccttcttca gcaacgtgac ctggttccac gccatccacg 2580
tgtctggaac caacggaacc aagagattcg acaaccccgt gctgcctttc aacgacggcg 2640
tgtacttcgc cagcaccgag aagtccaaca tcatcagagg atggattttc ggcaccacac 2700
tggacagcaa aacccagagc ctgctgatcg tgaacaacgc caccaacgtg gtgatcaagg 2760
tgtgcgagtt ccagttctgc aatgatccct tcctgggcgt gtactaccac aagaacaaca 2820
agtcttggat ggaaagcgag ttcagagtgt attccagcgc caacaattgc accttcgagt 2880
acgtgagcca accctttctg atggaccttg aaggcaagca gggcaacttc aaaaatctgc 2940
gagaatttgt gttcaagaac atcgacggat acttcaagat ctactctaag cacacgccaa 3000
tcaacctggt gagagatctg ccccagggct ttagcgcttt ggaacctctg gtggacctgc 3060
ctatcggaat caacatcacc agatttcaaa ctctcctggc cctgcacaga tcttatctga 3120
cccctgggga cagtagtagc ggctggacag ccggcgccgc cgcctactac gtgggatacc 3180
tgcagcctag aacattcctg ctgaagtaca atgagaacgg aacaatcaca gacgccgtgg 3240
actgcgccct ggatcctttg agcgagacaa agtgcaccct gaagtcgttc accgtcgaaa 3300
aaggcatcta ccagaccagc aacttccgcg tgcagcctac ggaatctatc gtgcggttcc 3360
ccaacatcac caacctgtgc cctttcggcg aggtgtttaa cgctacaagg ttcgccagcg 3420
tgtatgcctg gaacagaaag agaatcagca attgcgtggc cgattatagc gttctgtaca 3480
acagcgcttc cttcagcacc ttcaagtgct acggcgtgtc tccaaccaag ctgaacgacc 3540
tctgcttcac caatgtctac gctgactctt tcgtgattag aggcgatgag gttagacaga 3600
tcgcacctgg ccagaccggc aaaatcgctg actacaacta caagctgcct gatgacttca 3660
caggctgtgt cattgcctgg aactcaaata acctggactc taaagtgggc ggcaactaca 3720
actacctgta ccggctgttc cggaagagca atctgaaacc ttttgagcgg gacatctcta 3780
cagagatcta ccaggccggc agcacaccct gcaacggcgt tgagggcttc aactgctact 3840
tccctctgca gagctacggc tttcagccaa caaatggagt gggctaccag ccgtacagag 3900
tggtggtgct gagcttcgaa ctgctgcatg ccccagccac agtgtgtgga cctaagaagt 3960
ctaccaacct ggtgaagaac aagtgcgtga actttaactt taacggcctg accggcacag 4020
gcgtgctgac cgaatccaac aaaaagttcc tgcccttcca acagttcggc agagacatcg 4080
ccgatacaac cgatgccgtg cgggaccccc agaccttaga aatcctagat atcaccccgt 4140
gcagcttcgg cggagtctct gttattactc ctggcaccaa caccagcaac caagtggctg 4200
ttctgtacca aggcgtgaac tgcaccgaag tgcctgtggc tatccacgcc gatcagctga 4260
ccccaacctg gcgggtgtat agcaccggct ctaacgtgtt ccagacccgg gctggctgcc 4320
tgatcggcgc cgaacacgtc aacaactcct atgaatgtga catccccatc ggggctggca 4380
tctgcgccag ttaccagaca cagacaaata gccctggcag cgccagcagc gtggcctccc 4440
agagtatcat tgcctacacc atgagcctgg gcgccgagaa cagcgtggcc tattctaaca 4500
atagcatcgc aatccctacc aactttacca tctctgtgac aaccgagatc ctgcctgtga 4560
gcatgaccaa aaccagcgtg gactgcacga tgtacatctg tggcgacagc acagaatgca 4620
gtaatctgtt gctgcagtac ggcagctttt gcacccagtt gaatagagcc ctgaccggaa 4680
tcgccgtaga gcaggacaaa aatacccagg aggtgttcgc ccaggtgaaa cagatctaca 4740
agacacctcc cattaaggac ttcggaggtt ttaacttcag ccagatcctg cccgaccctt 4800
ccaagcctag caaacgctcc ttcatcgagg acctgctctt caacaaggtg acactggctg 4860
atgccggctt catcaagcag tacggagatt gtctgggaga catcgccgct agagatctga 4920
tctgcgccca aaagttcaac ggcctgaccg tgctgcctcc tctgcttaca gacgagatga 4980
tcgcccagta caccagcgcc ctgctggctg gcaccatcac aagcggctgg accttcggag 5040
ccggagccgc tctgcaaatc ccctttgcca tgcagatggc ctaccggttc aacggcatcg 5100
gcgtgacaca gaatgtgctg tacgagaacc agaagctgat cgctaaccag tttaacagcg 5160
ctatcggcaa gatccaggac tcgctgagta gcaccgcctc tgccctgggc aagctgcagg 5220
acgtcgtgaa ccagaacgcc caagccctga acacactggt gaaacagctg agcagcaact 5280
tcggcgccat cagctctgtg ctgaacgata tcctgagcag actggaccct cccgaagccg 5340
aggtccagat cgacagactg atcacaggaa gactgcagag cctgcaaacg tacgtgacac 5400
agcagctgat ccgggcagcc gaaatccggg ccagcgccaa tctggccgct accaagatga 5460
gcgagtgcgt gttaggccag agcaagcggg tggatttctg cggtaaggga taccacctga 5520
tgagctttcc ccagagcgct cctcacggcg tggtgtttct gcacgtgacc tacgttcctg 5580
cccaggaaaa gaacttcacc accgcccctg ctatctgcca cgatggcaag gcccacttcc 5640
ctagagaggg cgttttcgtg tctaacggca cacactggtt tgtgacccag agaaacttct 5700
acgagcctca gatcatcacc acagacaaca cctttgtgag cggcaattgc gacgtggtga 5760
tcggaattgt taataatacc gtgtacgacc ctctgcagcc tgagctcgac agcttcaagg 5820
aagagctgga caagtacttc aagaaccaca cctccccaga tgtggacctg ggcgatattt 5880
caggcatcaa cgcctccgtc gtgaatatcc agaaggagat cgaccggctc aacgaggtgg 5940
ccaagaacct taacgagagc ctgatcgacc tgcaggaact gggcaaatat gagcagtaca 6000
tcaagtggcc ttggtacatc tggctgggct ttatcgcagg cctgatcgct atcgtgatgg 6060
tgaccattat gctgtgttgt atgaccagct gttgtagttg tctgaagggc tgctgttctt 6120
gcggcagctg ctgcaagttc gacgaagacg actcagagcc cgtgctgaaa ggcgtgaagc 6180
tgcactacac ccgaaaacgg cgcggaagcg gaggaagcgg agctactaac ttcagcctgc 6240
tgaagcaggc tggagatgtg gaggagaacc ctggacctat gtattctttt gtgtccgagg 6300
aaaccggcac actgatcgtt aatagcgtgc tgctcttcct ggccttcgtg gtgttcctgc 6360
tggtgaccct ggctatcctg accgccctga gactgtgtgc ctactgctgc aacatcgtga 6420
acgtgtctct ggtcaagcct agcttctacg tgtacagccg ggtgaagaac ctgaacagca 6480
gcagagtgcc cgacctgctg gtgtaatccc ccccccctaa cgttactggc cgaagccgct 6540
tggaataagg ccggtgtgcg tttgtctata tgttattttc caccatattg ccgtcttttg 6600
gcaatgtgag ggcccggaaa cctggccctg tcttcttgac gagcattcct aggggtcttt 6660
cccctctcgc caaaggaatg caaggtctgt tgaatgtcgt gaaggaagca gttcctctgg 6720
aagcttcttg aagacaaaca acgtctgtag cgaccctttg caggcagcgg aaccccccac 6780
ctggcgacag gtgcctctgc ggccaaaagc cacgtgtata agatacacct gcaaaggcgg 6840
cacaacccca gtgccacgtt gtgagttgga tagttgtgga aagagtcaaa tggctctcct 6900
caagcgtatt caacaagggg ctgaaggatg cccagaaggt accccattgt atgggatctg 6960
atctggggcc tcggtgcaca tgctttacat gtgtttagtc gaggttaaaa aaacgtctag 7020
gccccccgaa ccacggggac gtggttttcc tttgaaaaac acgatgataa tatggccaca 7080
accatggaac aagagacttg cgcgcactct ctcacttttg aggaatgccc aaaatgctct 7140
gctctacaat accgtaatgg attttacctg ctaaagtatg atgaagaatg gtacccagag 7200
gagttattga ctgatggaga ggatgatgtc tttgatcccg aattagacat ggaagtcgtt 7260
ttcgagttac agtaagtgtt tacctgttaa tgtagcattt gagctttggg ctaagcgcaa 7320
cattaaacca gtaccagagg tgaaaatact caataatttg ggtgtggaca ttgctgctaa 7380
tactgtgatc tgggactaca aaagagatgc tccagcacat atatctacta ttggtgtttg 7440
ttctatgact gacatagcca agaaaccaac tgaaacgatt tgtgcaccac tcactgtctt 7500
ttttgatggt agagttgatg gtcaagtaga cttatttaga aatgcccgta atggtgttct 7560
tattacagaa ggtagtgtta aaggtttaca accatctgta ggtcccaaac aagctagtct 7620
taatggagtc acattaattg gagaagccgt aaaaacacag ttcaattatt ataagaaagt 7680
tgatggtgtt gtccaacaat tacctgaaac ttactttact cagagtagaa atttacaaga 7740
atttaaaccc aggagtcaaa tggaaattga tttcttagaa ttagctatgg atgaattcat 7800
tgaacggtat aaattagaag gctatgcctt cgaacatatc gtttatggag attttagtca 7860
tagtcagtta ggtggtgcga aattgttgtt gtt 7893
<210> 44
<211> 7618
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG12 expression cassette
<400> 44
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgagcg acaacggccc tcaaaaccag 780
agaaatgccc ctcggatcac atttggcgga cctagcgaca gcaccggcag caaccagaat 840
ggagaaagaa gcggcgccag atccaagcag cggagacctc agggactgcc caacaacacc 900
gctagctggt tcaccgccct gacccaacac ggcaaggaag atctgaagtt ccccagaggc 960
cagggcgtgc ctatcaacac aaactcttct cccgacgacc agatcggata ctatagacgg 1020
gccactcgga gaattcgggg cggcgacgga aaaatgaagg acctttctcc aagatggtac 1080
ttctactacc tcggcacagg ccctgaggcc ggcctgcctt acggcgccaa caaggatggc 1140
atcatctggg tcgccaccga gggcgccctg aacaccccta aggaccacat cggcacaaga 1200
aaccccgcta acaacgccgc aatcgtgctg cagctgcctc agggcaccac cctgcccaag 1260
ggcttctacg ccgagggctc tagaggtggc tcccaggctt ctagccgctc ctccagccgc 1320
agcagaaaca gcagcaggaa cagcaccccc ggcagctccc ggggcaccag ccccgccaga 1380
atggccggaa atggcggcga tgccgccctg gccctgctcc tgctggacag actgaatcag 1440
ctggaaagca agatgagcgg caaaggacag cagcagcaag gccagaccgt gaccaagaaa 1500
agcgctgctg aagcctccaa gaaacctaga caaaagcgga ccgccacaaa ggcctacaac 1560
gtgacccaag cctttggaag aagaggcccc gagcagacac agggcaattt cggcgaccag 1620
gagctgatcc ggcagggaac cgactacaag cactggcctc agatcgccca gttcgcccct 1680
agcgccagcg ccttcttcgg catgagcaga atcggcatgg aagtgacccc ttctggcacc 1740
tggctgacct acaccggcgc tatcaagctg gacgataagg atcctaactt caaggaccaa 1800
gtgatcctgc tgaacaagca tatcgacgcc tataagacct ttccacctac agagcctaag 1860
aaagataaga agaagaaagc cgacgagaca caggccctgc ctcagagaca gaaaaagcag 1920
cagacagtga cactgctgcc agccgctgac ctggatgact tcagcaagca gctgcagcag 1980
agcatgtctt ctgctgatag cacccaggcc cgaaaacggc gcggaagcgg aggaagcgga 2040
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 2100
ttcgtgttcc tggtgctgct gcctctggtc agctcccagt gtgtgaacct gaccaccaga 2160
acccagctgc cacctgctta tacaaactcc ttcactcggg gggtatacta ccccgacaag 2220
gtgttcagat ctagcgtgct gcattctaca caagacctgt tcctgccctt cttcagcaac 2280
gtgacctggt tccacgccat ccacgtgtct ggaaccaacg gaaccaagag attcgacaac 2340
cccgtgctgc ctttcaacga cggcgtgtac ttcgccagca ccgagaagtc caacatcatc 2400
agaggatgga ttttcggcac cacactggac agcaaaaccc agagcctgct gatcgtgaac 2460
aacgccacca acgtggtgat caaggtgtgc gagttccagt tctgcaatga tcccttcctg 2520
ggcgtgtact accacaagaa caacaagtct tggatggaaa gcgagttcag agtgtattcc 2580
agcgccaaca attgcacctt cgagtacgtg agccaaccct ttctgatgga ccttgaaggc 2640
aagcagggca acttcaaaaa tctgcgagaa tttgtgttca agaacatcga cggatacttc 2700
aagatctact ctaagcacac gccaatcaac ctggtgagag atctgcccca gggctttagc 2760
gctttggaac ctctggtgga cctgcctatc ggaatcaaca tcaccagatt tcaaactctc 2820
ctggccctgc acagatctta tctgacccct ggggacagta gtagcggctg gacagccggc 2880
gccgccgcct actacgtggg atacctgcag cctagaacat tcctgctgaa gtacaatgag 2940
aacggaacaa tcacagacgc cgtggactgc gccctggatc ctttgagcga gacaaagtgc 3000
accctgaagt cgttcaccgt cgaaaaaggc atctaccaga ccagcaactt ccgcgtgcag 3060
cctacggaat ctatcgtgcg gttccccaac atcaccaacc tgtgcccttt cggcgaggtg 3120
tttaacgcta caaggttcgc cagcgtgtat gcctggaaca gaaagagaat cagcaattgc 3180
gtggccgatt atagcgttct gtacaacagc gcttccttca gcaccttcaa gtgctacggc 3240
gtgtctccaa ccaagctgaa cgacctctgc ttcaccaatg tctacgctga ctctttcgtg 3300
attagaggcg atgaggttag acagatcgca cctggccaga ccggcaaaat cgctgactac 3360
aactacaagc tgcctgatga cttcacaggc tgtgtcattg cctggaactc aaataacctg 3420
gactctaaag tgggcggcaa ctacaactac ctgtaccggc tgttccggaa gagcaatctg 3480
aaaccttttg agcgggacat ctctacagag atctaccagg ccggcagcac accctgcaac 3540
ggcgttgagg gcttcaactg ctacttccct ctgcagagct acggctttca gccaacaaat 3600
ggagtgggct accagccgta cagagtggtg gtgctgagct tcgaactgct gcatgcccca 3660
gccacagtgt gtggacctaa gaagtctacc aacctggtga agaacaagtg cgtgaacttt 3720
aactttaacg gcctgaccgg cacaggcgtg ctgaccgaat ccaacaaaaa gttcctgccc 3780
ttccaacagt tcggcagaga catcgccgat acaaccgatg ccgtgcggga cccccagacc 3840
ttagaaatcc tagatatcac cccgtgcagc ttcggcggag tctctgttat tactcctggc 3900
accaacacca gcaaccaagt ggctgttctg taccaaggcg tgaactgcac cgaagtgcct 3960
gtggctatcc acgccgatca gctgacccca acctggcggg tgtatagcac cggctctaac 4020
gtgttccaga cccgggctgg ctgcctgatc ggcgccgaac acgtcaacaa ctcctatgaa 4080
tgtgacatcc ccatcggggc tggcatctgc gccagttacc agacacagac aaatagccct 4140
agacgggcca gaagcgtggc ctcccagagt atcattgcct acaccatgag cctgggcgcc 4200
gagaacagcg tggcctattc taacaatagc atcgcaatcc ctaccaactt taccatctct 4260
gtgacaaccg agatcctgcc tgtgagcatg accaaaacca gcgtggactg cacgatgtac 4320
atctgtggcg acagcacaga atgcagtaat ctgttgctgc agtacggcag cttttgcacc 4380
cagttgaata gagccctgac cggaatcgcc gtagagcagg acaaaaatac ccaggaggtg 4440
ttcgcccagg tgaaacagat ctacaagaca cctcccatta aggacttcgg aggttttaac 4500
ttcagccaga tcctgcccga cccttccaag cctagcaaac gctccttcat cgaggacctg 4560
ctcttcaaca aggtgacact ggctgatgcc ggcttcatca agcagtacgg agattgtctg 4620
ggagacatcg ccgctagaga tctgatctgc gcccaaaagt tcaacggcct gaccgtgctg 4680
cctcctctgc ttacagacga gatgatcgcc cagtacacca gcgccctgct ggctggcacc 4740
atcacaagcg gctggacctt cggagccgga gccgctctgc aaatcccctt tgccatgcag 4800
atggcctacc ggttcaacgg catcggcgtg acacagaatg tgctgtacga gaaccagaag 4860
ctgatcgcta accagtttaa cagcgctatc ggcaagatcc aggactcgct gagtagcacc 4920
gcctctgccc tgggcaagct gcaggacgtc gtgaaccaga acgcccaagc cctgaacaca 4980
ctggtgaaac agctgagcag caacttcggc gccatcagct ctgtgctgaa cgatatcctg 5040
agcagactgg acaaggtgga agccgaggtc cagatcgaca gactgatcac aggaagactg 5100
cagagcctgc aaacgtacgt gacacagcag ctgatccggg cagccgaaat ccgggccagc 5160
gccaatctgg ccgctaccaa gatgagcgag tgcgtgttag gccagagcaa gcgggtggat 5220
ttctgcggta agggatacca cctgatgagc tttccccaga gcgctcctca cggcgtggtg 5280
tttctgcacg tgacctacgt tcctgcccag gaaaagaact tcaccaccgc ccctgctatc 5340
tgccacgatg gcaaggccca cttccctaga gagggcgttt tcgtgtctaa cggcacacac 5400
tggtttgtga cccagagaaa cttctacgag cctcagatca tcaccacaga caacaccttt 5460
gtgagcggca attgcgacgt ggtgatcgga attgttaata ataccgtgta cgaccctctg 5520
cagcctgagc tcgacagctt caaggaagag ctggacaagt acttcaagaa ccacacctcc 5580
ccagatgtgg acctgggcga tatttcaggc atcaacgcct ccgtcgtgaa tatccagaag 5640
gagatcgacc ggctcaacga ggtggccaag aaccttaacg agagcctgat cgacctgcag 5700
gaactgggca aatatgagca gtacatcaag tggccttggt acatctggct gggctttatc 5760
gcaggcctga tcgctatcgt gatggtgacc attatgctgt gttgtatgac cagctgttgt 5820
agttgtctga agggctgctg ttcttgcggc agctgctgca agttcgacga agacgactca 5880
gagcccgtgc tgaaaggcgt gaagctgcac tacacccgaa aacggcgcgg aagcggagga 5940
agcggagcta ctaacttcag cctgctgaag caggctggag atgtggagga gaaccctgga 6000
cctatgtatt cttttgtgtc cgaggaaacc ggcacactga tcgttaatag cgtgctgctc 6060
ttcctggcct tcgtggtgtt cctgctggtg accctggcta tcctgaccgc cctgagactg 6120
tgtgcctact gctgcaacat cgtgaacgtg tctctggtca agcctagctt ctacgtgtac 6180
agccgggtga agaacctgaa cagcagcaga gtgcccgacc tgctggtgta atcccccccc 6240
cctaacgtta ctggccgaag ccgcttggaa taaggccggt gtgcgtttgt ctatatgtta 6300
ttttccacca tattgccgtc ttttggcaat gtgagggccc ggaaacctgg ccctgtcttc 6360
ttgacgagca ttcctagggg tctttcccct ctcgccaaag gaatgcaagg tctgttgaat 6420
gtcgtgaagg aagcagttcc tctggaagct tcttgaagac aaacaacgtc tgtagcgacc 6480
ctttgcaggc agcggaaccc cccacctggc gacaggtgcc tctgcggcca aaagccacgt 6540
gtataagata cacctgcaaa ggcggcacaa ccccagtgcc acgttgtgag ttggatagtt 6600
gtggaaagag tcaaatggct ctcctcaagc gtattcaaca aggggctgaa ggatgcccag 6660
aaggtacccc attgtatggg atctgatctg gggcctcggt gcacatgctt tacatgtgtt 6720
tagtcgaggt taaaaaaacg tctaggcccc ccgaaccacg gggacgtggt tttcctttga 6780
aaaacacgat gataatatgg ccacaaccat ggaacaagag acttgcgcgc actctctcac 6840
ttttgaggaa tgcccaaaat gctctgctct acaataccgt aatggatttt acctgctaaa 6900
gtatgatgaa gaatggtacc cagaggagtt attgactgat ggagaggatg atgtctttga 6960
tcccgaatta gacatggaag tcgttttcga gttacagtaa gtgtttacct gttaatgtag 7020
catttgagct ttgggctaag cgcaacatta aaccagtacc agaggtgaaa atactcaata 7080
atttgggtgt ggacattgct gctaatactg tgatctggga ctacaaaaga gatgctccag 7140
cacatatatc tactattggt gtttgttcta tgactgacat agccaagaaa ccaactgaaa 7200
cgatttgtgc accactcact gtcttttttg atggtagagt tgatggtcaa gtagacttat 7260
ttagaaatgc ccgtaatggt gttcttatta cagaaggtag tgttaaaggt ttacaaccat 7320
ctgtaggtcc caaacaagct agtcttaatg gagtcacatt aattggagaa gccgtaaaaa 7380
cacagttcaa ttattataag aaagttgatg gtgttgtcca acaattacct gaaacttact 7440
ttactcagag tagaaattta caagaattta aacccaggag tcaaatggaa attgatttct 7500
tagaattagc tatggatgaa ttcattgaac ggtataaatt agaaggctat gccttcgaac 7560
atatcgttta tggagatttt agtcatagtc agttaggtgg tgcgaaattg ttgttgtt 7618
<210> 45
<211> 7882
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG13 expression cassette
<400> 45
attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc ttgtagatct 60
gttctctaaa cgaactttaa aatctgtgtg gctgtcactc ggctgcatgc ttagtgcact 120
cacgcagtat aattaataac taattactgt cgttgacagg acacgagtaa ctcgtctatc 180
ttctgcaggc tgcttacggt ttcgtccgtg ttgcagccga tcatcagcac atctaggttt 240
cgtccgggtg tgaccgaaag gtaaatggcc gacagcaacg gcacaatcac cgtggaagag 300
ctgaagaaac tgctggaaca gtggaacctg gtcatcggct tcctgtttct gacctggatc 360
tgtctgctgc agttcgctta tgccaatcgg aacagattcc tgtacatcat caagctgatc 420
ttcctgtggc tgctgtggcc tgtgaccctg gcttgcttcg tgctggccgc tgtgtaccgg 480
atcaactgga tcacaggcgg aatcgccatc gccatggcct gcctggtggg cctgatgtgg 540
ctgagctact tcatcgcttc tttcagactg ttcgccagaa cccggagcat gtggtccttc 600
aaccccgaga caaacatcct gctgaacgtg cctctgcacg gcaccatcct gacaagacct 660
ctgctcgaga gcgagctggt gattggcgca gtgattctga gaggccatct gaggatcgcc 720
ggacaccacc tgggcagatg cgacatcaag gaccttccaa aggaaatcac cgttgccacc 780
agccggaccc tgtcctacta caaactgggc gccagccaaa gagtggccgg cgatagcggc 840
tttgccgcct acagcagata ccgcatcgga aattacaagc tcaacaccga ccacagcagc 900
tcttctgata acatcgccct gctggtgcag cgaaaacggc gcggaagcgg aggaagcgga 960
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 1020
agcgacaacg gccctcaaaa ccagagaaat gcccctcgga tcacatttgg cggacctagc 1080
gacagcaccg gcagcaacca gaatggagaa agaagcggcg ccagatccaa gcagcggaga 1140
cctcagggac tgcccaacaa caccgctagc tggttcaccg ccctgaccca acacggcaag 1200
gaagatctga agttccccag aggccagggc gtgcctatca acacaaactc ttctcccgac 1260
gaccagatcg gatactatag acgggccact cggagaattc ggggcggcga cggaaaaatg 1320
aaggaccttt ctccaagatg gtacttctac tacctcggca caggccctga ggccggcctg 1380
ccttacggcg ccaacaagga tggcatcatc tgggtcgcca ccgagggcgc cctgaacacc 1440
cctaaggacc acatcggcac aagaaacccc gctaacaacg ccgcaatcgt gctgcagctg 1500
cctcagggca ccaccctgcc caagggcttc tacgccgagg gctctagagg tggctcccag 1560
gcttctagcc gctcctccag ccgcagcaga aacagcagca ggaacagcac ccccggcagc 1620
tcccggggca ccagccccgc cagaatggcc ggaaatggcg gcgatgccgc cctggccctg 1680
ctcctgctgg acagactgaa tcagctggaa agcaagatga gcggcaaagg acagcagcag 1740
caaggccaga ccgtgaccaa gaaaagcgct gctgaagcct ccaagaaacc tagacaaaag 1800
cggaccgcca caaaggccta caacgtgacc caagcctttg gaagaagagg ccccgagcag 1860
acacagggca atttcggcga ccaggagctg atccggcagg gaaccgacta caagcactgg 1920
cctcagatcg cccagttcgc ccctagcgcc agcgccttct tcggcatgag cagaatcggc 1980
atggaagtga ccccttctgg cacctggctg acctacaccg gcgctatcaa gctggacgat 2040
aaggatccta acttcaagga ccaagtgatc ctgctgaaca agcatatcga cgcctataag 2100
acctttccac ctacagagcc taagaaagat aagaagaaga aagccgacga gacacaggcc 2160
ctgcctcaga gacagaaaaa gcagcagaca gtgacactgc tgccagccgc tgacctggat 2220
gacttcagca agcagctgca gcagagcatg tcttctgctg atagcaccca ggcccgaaaa 2280
cggcgcggaa gcggaggaag cggagctact aacttcagcc tgctgaagca ggctggagat 2340
gtggaggaga accctggacc tatgttcgtg ttcctggtgc tgctgcctct ggtcagctcc 2400
cagtgtgtga acctgaccac cagaacccag ctgccacctg cttatacaaa ctccttcact 2460
cggggggtat actaccccga caaggtgttc agatctagcg tgctgcattc tacacaagac 2520
ctgttcctgc ccttcttcag caacgtgacc tggttccacg ccatccacgt gtctggaacc 2580
aacggaacca agagattcga caaccccgtg ctgcctttca acgacggcgt gtacttcgcc 2640
agcaccgaga agtccaacat catcagagga tggattttcg gcaccacact ggacagcaaa 2700
acccagagcc tgctgatcgt gaacaacgcc accaacgtgg tgatcaaggt gtgcgagttc 2760
cagttctgca atgatccctt cctgggcgtg tactaccaca agaacaacaa gtcttggatg 2820
gaaagcgagt tcagagtgta ttccagcgcc aacaattgca ccttcgagta cgtgagccaa 2880
ccctttctga tggaccttga aggcaagcag ggcaacttca aaaatctgcg agaatttgtg 2940
ttcaagaaca tcgacggata cttcaagatc tactctaagc acacgccaat caacctggtg 3000
agagatctgc cccagggctt tagcgctttg gaacctctgg tggacctgcc tatcggaatc 3060
aacatcacca gatttcaaac tctcctggcc ctgcacagat cttatctgac ccctggggac 3120
agtagtagcg gctggacagc cggcgccgcc gcctactacg tgggatacct gcagcctaga 3180
acattcctgc tgaagtacaa tgagaacgga acaatcacag acgccgtgga ctgcgccctg 3240
gatcctttga gcgagacaaa gtgcaccctg aagtcgttca ccgtcgaaaa aggcatctac 3300
cagaccagca acttccgcgt gcagcctacg gaatctatcg tgcggttccc caacatcacc 3360
aacctgtgcc ctttcggcga ggtgtttaac gctacaaggt tcgccagcgt gtatgcctgg 3420
aacagaaaga gaatcagcaa ttgcgtggcc gattatagcg ttctgtacaa cagcgcttcc 3480
ttcagcacct tcaagtgcta cggcgtgtct ccaaccaagc tgaacgacct ctgcttcacc 3540
aatgtctacg ctgactcttt cgtgattaga ggcgatgagg ttagacagat cgcacctggc 3600
cagaccggca aaatcgctga ctacaactac aagctgcctg atgacttcac aggctgtgtc 3660
attgcctgga actcaaataa cctggactct aaagtgggcg gcaactacaa ctacctgtac 3720
cggctgttcc ggaagagcaa tctgaaacct tttgagcggg acatctctac agagatctac 3780
caggccggca gcacaccctg caacggcgtt gagggcttca actgctactt ccctctgcag 3840
agctacggct ttcagccaac aaatggagtg ggctaccagc cgtacagagt ggtggtgctg 3900
agcttcgaac tgctgcatgc cccagccaca gtgtgtggac ctaagaagtc taccaacctg 3960
gtgaagaaca agtgcgtgaa ctttaacttt aacggcctga ccggcacagg cgtgctgacc 4020
gaatccaaca aaaagttcct gcccttccaa cagttcggca gagacatcgc cgatacaacc 4080
gatgccgtgc gggaccccca gaccttagaa atcctagata tcaccccgtg cagcttcggc 4140
ggagtctctg ttattactcc tggcaccaac accagcaacc aagtggctgt tctgtaccaa 4200
ggcgtgaact gcaccgaagt gcctgtggct atccacgccg atcagctgac cccaacctgg 4260
cgggtgtata gcaccggctc taacgtgttc cagacccggg ctggctgcct gatcggcgcc 4320
gaacacgtca acaactccta tgaatgtgac atccccatcg gggctggcat ctgcgccagt 4380
taccagacac agacaaatag ccctagacgg gccagaagcg tggcctccca gagtatcatt 4440
gcctacacca tgagcctggg cgccgagaac agcgtggcct attctaacaa tagcatcgca 4500
atccctacca actttaccat ctctgtgaca accgagatcc tgcctgtgag catgaccaaa 4560
accagcgtgg actgcacgat gtacatctgt ggcgacagca cagaatgcag taatctgttg 4620
ctgcagtacg gcagcttttg cacccagttg aatagagccc tgaccggaat cgccgtagag 4680
caggacaaaa atacccagga ggtgttcgcc caggtgaaac agatctacaa gacacctccc 4740
attaaggact tcggaggttt taacttcagc cagatcctgc ccgacccttc caagcctagc 4800
aaacgctcct tcatcgagga cctgctcttc aacaaggtga cactggctga tgccggcttc 4860
atcaagcagt acggagattg tctgggagac atcgccgcta gagatctgat ctgcgcccaa 4920
aagttcaacg gcctgaccgt gctgcctcct ctgcttacag acgagatgat cgcccagtac 4980
accagcgccc tgctggctgg caccatcaca agcggctgga ccttcggagc cggagccgct 5040
ctgcaaatcc cctttgccat gcagatggcc taccggttca acggcatcgg cgtgacacag 5100
aatgtgctgt acgagaacca gaagctgatc gctaaccagt ttaacagcgc tatcggcaag 5160
atccaggact cgctgagtag caccgcctct gccctgggca agctgcagga cgtcgtgaac 5220
cagaacgccc aagccctgaa cacactggtg aaacagctga gcagcaactt cggcgccatc 5280
agctctgtgc tgaacgatat cctgagcaga ctggacaagg tggaagccga ggtccagatc 5340
gacagactga tcacaggaag actgcagagc ctgcaaacgt acgtgacaca gcagctgatc 5400
cgggcagccg aaatccgggc cagcgccaat ctggccgcta ccaagatgag cgagtgcgtg 5460
ttaggccaga gcaagcgggt ggatttctgc ggtaagggat accacctgat gagctttccc 5520
cagagcgctc ctcacggcgt ggtgtttctg cacgtgacct acgttcctgc ccaggaaaag 5580
aacttcacca ccgcccctgc tatctgccac gatggcaagg cccacttccc tagagagggc 5640
gttttcgtgt ctaacggcac acactggttt gtgacccaga gaaacttcta cgagcctcag 5700
atcatcacca cagacaacac ctttgtgagc ggcaattgcg acgtggtgat cggaattgtt 5760
aataataccg tgtacgaccc tctgcagcct gagctcgaca gcttcaagga agagctggac 5820
aagtacttca agaaccacac ctccccagat gtggacctgg gcgatatttc aggcatcaac 5880
gcctccgtcg tgaatatcca gaaggagatc gaccggctca acgaggtggc caagaacctt 5940
aacgagagcc tgatcgacct gcaggaactg ggcaaatatg agcagtacat caagtggcct 6000
tggtacatct ggctgggctt tatcgcaggc ctgatcgcta tcgtgatggt gaccattatg 6060
ctgtgttgta tgaccagctg ttgtagttgt ctgaagggct gctgttcttg cggcagctgc 6120
tgcaagttcg acgaagacga ctcagagccc gtgctgaaag gcgtgaagct gcactacacc 6180
cgaaaacggc gcggaagcgg aggaagcgga gctactaact tcagcctgct gaagcaggct 6240
ggagatgtgg aggagaaccc tggacctatg tattcttttg tgtccgagga aaccggcaca 6300
ctgatcgtta atagcgtgct gctcttcctg gccttcgtgg tgttcctgct ggtgaccctg 6360
gctatcctga ccgccctgag actgtgtgcc tactgctgca acatcgtgaa cgtgtctctg 6420
gtcaagccta gcttctacgt gtacagccgg gtgaagaacc tgaacagcag cagagtgccc 6480
gacctgctgg tgtaatcccc cccccctaac gttactggcc gaagccgctt ggaataaggc 6540
cggtgtgcgt ttgtctatat gttattttcc accatattgc cgtcttttgg caatgtgagg 6600
gcccggaaac ctggccctgt cttcttgacg agcattccta ggggtctttc ccctctcgcc 6660
aaaggaatgc aaggtctgtt gaatgtcgtg aaggaagcag ttcctctgga agcttcttga 6720
agacaaacaa cgtctgtagc gaccctttgc aggcagcgga accccccacc tggcgacagg 6780
tgcctctgcg gccaaaagcc acgtgtataa gatacacctg caaaggcggc acaaccccag 6840
tgccacgttg tgagttggat agttgtggaa agagtcaaat ggctctcctc aagcgtattc 6900
aacaaggggc tgaaggatgc ccagaaggta ccccattgta tgggatctga tctggggcct 6960
cggtgcacat gctttacatg tgtttagtcg aggttaaaaa aacgtctagg ccccccgaac 7020
cacggggacg tggttttcct ttgaaaaaca cgatgataat atggccacaa ccatggaaca 7080
agagacttgc gcgcactctc tcacttttga ggaatgccca aaatgctctg ctctacaata 7140
ccgtaatgga ttttacctgc taaagtatga tgaagaatgg tacccagagg agttattgac 7200
tgatggagag gatgatgtct ttgatcccga attagacatg gaagtcgttt tcgagttaca 7260
gtaagtgttt acctgttaat gtagcatttg agctttgggc taagcgcaac attaaaccag 7320
taccagaggt gaaaatactc aataatttgg gtgtggacat tgctgctaat actgtgatct 7380
gggactacaa aagagatgct ccagcacata tatctactat tggtgtttgt tctatgactg 7440
acatagccaa gaaaccaact gaaacgattt gtgcaccact cactgtcttt tttgatggta 7500
gagttgatgg tcaagtagac ttatttagaa atgcccgtaa tggtgttctt attacagaag 7560
gtagtgttaa aggtttacaa ccatctgtag gtcccaaaca agctagtctt aatggagtca 7620
cattaattgg agaagccgta aaaacacagt tcaattatta taagaaagtt gatggtgttg 7680
tccaacaatt acctgaaact tactttactc agagtagaaa tttacaagaa tttaaaccca 7740
ggagtcaaat ggaaattgat ttcttagaat tagctatgga tgaattcatt gaacggtata 7800
aattagaagg ctatgccttc gaacatatcg tttatggaga ttttagtcat agtcagttag 7860
gtggtgcgaa attgttgttg tt 7882
<210> 46
<211> 8773
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG14 expression cassette
<400> 46
attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc ttgtagatct 60
gttctctaaa cgaactttaa aatctgtgtg gctgtcactc ggctgcatgc ttagtgcact 120
cacgcagtat aattaataac taattactgt cgttgacagg acacgagtaa ctcgtctatc 180
ttctgcaggc tgcttacggt ttcgtccgtg ttgcagccga tcatcagcac atctaggttt 240
cgtccgggtg tgaccgaaag gtaaatggcc gacagcaacg gcacaatcac cgtggaagag 300
ctgaagaaac tgctggaaca gtggaacctg gtcatcggct tcctgtttct gacctggatc 360
tgtctgctgc agttcgctta tgccaatcgg aacagattcc tgtacatcat caagctgatc 420
ttcctgtggc tgctgtggcc tgtgaccctg gcttgcttcg tgctggccgc tgtgtaccgg 480
atcaactgga tcacaggcgg aatcgccatc gccatggcct gcctggtggg cctgatgtgg 540
ctgagctact tcatcgcttc tttcagactg ttcgccagaa cccggagcat gtggtccttc 600
aaccccgaga caaacatcct gctgaacgtg cctctgcacg gcaccatcct gacaagacct 660
ctgctcgaga gcgagctggt gattggcgca gtgattctga gaggccatct gaggatcgcc 720
ggacaccacc tgggcagatg cgacatcaag gaccttccaa aggaaatcac cgttgccacc 780
agccggaccc tgtcctacta caaactgggc gccagccaaa gagtggccgg cgatagcggc 840
tttgccgcct acagcagata ccgcatcgga aattacaagc tcaacaccga ccacagcagc 900
tcttctgata acatcgccct gctggtgcag cgaaaacggc gcggaagcgg aggaagcgga 960
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 1020
agcgacaacg gccctcaaaa ccagagaaat gcccctcgga tcacatttgg cggacctagc 1080
gacagcaccg gcagcaacca gaatggagaa agaagcggcg ccagatccaa gcagcggaga 1140
cctcagggac tgcccaacaa caccgctagc tggttcaccg ccctgaccca acacggcaag 1200
gaagatctga agttccccag aggccagggc gtgcctatca acacaaactc ttctcccgac 1260
gaccagatcg gatactatag acgggccact cggagaattc ggggcggcga cggaaaaatg 1320
aaggaccttt ctccaagatg gtacttctac tacctcggca caggccctga ggccggcctg 1380
ccttacggcg ccaacaagga tggcatcatc tgggtcgcca ccgagggcgc cctgaacacc 1440
cctaaggacc acatcggcac aagaaacccc gctaacaacg ccgcaatcgt gctgcagctg 1500
cctcagggca ccaccctgcc caagggcttc tacgccgagg gctctagagg tggctcccag 1560
gcttctagcc gctcctccag ccgcagcaga aacagcagca ggaacagcac ccccggcagc 1620
tcccggggca ccagccccgc cagaatggcc ggaaatggcg gcgatgccgc cctggccctg 1680
ctcctgctgg acagactgaa tcagctggaa agcaagatga gcggcaaagg acagcagcag 1740
caaggccaga ccgtgaccaa gaaaagcgct gctgaagcct ccaagaaacc tagacaaaag 1800
cggaccgcca caaaggccta caacgtgacc caagcctttg gaagaagagg ccccgagcag 1860
acacagggca atttcggcga ccaggagctg atccggcagg gaaccgacta caagcactgg 1920
cctcagatcg cccagttcgc ccctagcgcc agcgccttct tcggcatgag cagaatcggc 1980
atggaagtga ccccttctgg cacctggctg acctacaccg gcgctatcaa gctggacgat 2040
aaggatccta acttcaagga ccaagtgatc ctgctgaaca agcatatcga cgcctataag 2100
acctttccac ctacagagcc taagaaagat aagaagaaga aagccgacga gacacaggcc 2160
ctgcctcaga gacagaaaaa gcagcagaca gtgacactgc tgccagccgc tgacctggat 2220
gacttcagca agcagctgca gcagagcatg tcttctgctg atagcaccca ggcccgaaaa 2280
cggcgcggaa gcggaggaag cggagctact aacttcagcc tgctgaagca ggctggagat 2340
gtggaggaga accctggacc tatgttcgtg ttcctggtgc tgctgcctct ggtcagctcc 2400
cagtgtgtga acctgaccac cagaacccag ctgccacctg cttatacaaa ctccttcact 2460
cggggggtat actaccccga caaggtgttc agatctagcg tgctgcattc tacacaagac 2520
ctgttcctgc ccttcttcag caacgtgacc tggttccacg ccatccacgt gtctggaacc 2580
aacggaacca agagattcga caaccccgtg ctgcctttca acgacggcgt gtacttcgcc 2640
agcaccgaga agtccaacat catcagagga tggattttcg gcaccacact ggacagcaaa 2700
acccagagcc tgctgatcgt gaacaacgcc accaacgtgg tgatcaaggt gtgcgagttc 2760
cagttctgca atgatccctt cctgggcgtg tactaccaca agaacaacaa gtcttggatg 2820
gaaagcgagt tcagagtgta ttccagcgcc aacaattgca ccttcgagta cgtgagccaa 2880
ccctttctga tggaccttga aggcaagcag ggcaacttca aaaatctgcg agaatttgtg 2940
ttcaagaaca tcgacggata cttcaagatc tactctaagc acacgccaat caacctggtg 3000
agagatctgc cccagggctt tagcgctttg gaacctctgg tggacctgcc tatcggaatc 3060
aacatcacca gatttcaaac tctcctggcc ctgcacagat cttatctgac ccctggggac 3120
agtagtagcg gctggacagc cggcgccgcc gcctactacg tgggatacct gcagcctaga 3180
acattcctgc tgaagtacaa tgagaacgga acaatcacag acgccgtgga ctgcgccctg 3240
gatcctttga gcgagacaaa gtgcaccctg aagtcgttca ccgtcgaaaa aggcatctac 3300
cagaccagca acttccgcgt gcagcctacg gaatctatcg tgcggttccc caacatcacc 3360
aacctgtgcc ctttcggcga ggtgtttaac gctacaaggt tcgccagcgt gtatgcctgg 3420
aacagaaaga gaatcagcaa ttgcgtggcc gattatagcg ttctgtacaa cagcgcttcc 3480
ttcagcacct tcaagtgcta cggcgtgtct ccaaccaagc tgaacgacct ctgcttcacc 3540
aatgtctacg ctgactcttt cgtgattaga ggcgatgagg ttagacagat cgcacctggc 3600
cagaccggca aaatcgctga ctacaactac aagctgcctg atgacttcac aggctgtgtc 3660
attgcctgga actcaaataa cctggactct aaagtgggcg gcaactacaa ctacctgtac 3720
cggctgttcc ggaagagcaa tctgaaacct tttgagcggg acatctctac agagatctac 3780
caggccggca gcacaccctg caacggcgtt gagggcttca actgctactt ccctctgcag 3840
agctacggct ttcagccaac aaatggagtg ggctaccagc cgtacagagt ggtggtgctg 3900
agcttcgaac tgctgcatgc cccagccaca gtgtgtggac ctaagaagtc taccaacctg 3960
gtgaagaaca agtgcgtgaa ctttaacttt aacggcctga ccggcacagg cgtgctgacc 4020
gaatccaaca aaaagttcct gcccttccaa cagttcggca gagacatcgc cgatacaacc 4080
gatgccgtgc gggaccccca gaccttagaa atcctagata tcaccccgtg cagcttcggc 4140
ggagtctctg ttattactcc tggcaccaac accagcaacc aagtggctgt tctgtaccaa 4200
ggcgtgaact gcaccgaagt gcctgtggct atccacgccg atcagctgac cccaacctgg 4260
cgggtgtata gcaccggctc taacgtgttc cagacccggg ctggctgcct gatcggcgcc 4320
gaacacgtca acaactccta tgaatgtgac atccccatcg gggctggcat ctgcgccagt 4380
taccagacac agacaaatag ccctagacgg gccagaagcg tggcctccca gagtatcatt 4440
gcctacacca tgagcctggg cgccgagaac agcgtggcct attctaacaa tagcatcgca 4500
atccctacca actttaccat ctctgtgaca accgagatcc tgcctgtgag catgaccaaa 4560
accagcgtgg actgcacgat gtacatctgt ggcgacagca cagaatgcag taatctgttg 4620
ctgcagtacg gcagcttttg cacccagttg aatagagccc tgaccggaat cgccgtagag 4680
caggacaaaa atacccagga ggtgttcgcc caggtgaaac agatctacaa gacacctccc 4740
attaaggact tcggaggttt taacttcagc cagatcctgc ccgacccttc caagcctagc 4800
aaacgctcct tcatcgagga cctgctcttc aacaaggtga cactggctga tgccggcttc 4860
atcaagcagt acggagattg tctgggagac atcgccgcta gagatctgat ctgcgcccaa 4920
aagttcaacg gcctgaccgt gctgcctcct ctgcttacag acgagatgat cgcccagtac 4980
accagcgccc tgctggctgg caccatcaca agcggctgga ccttcggagc cggagccgct 5040
ctgcaaatcc cctttgccat gcagatggcc taccggttca acggcatcgg cgtgacacag 5100
aatgtgctgt acgagaacca gaagctgatc gctaaccagt ttaacagcgc tatcggcaag 5160
atccaggact cgctgagtag caccgcctct gccctgggca agctgcagga cgtcgtgaac 5220
cagaacgccc aagccctgaa cacactggtg aaacagctga gcagcaactt cggcgccatc 5280
agctctgtgc tgaacgatat cctgagcaga ctggacaagg tggaagccga ggtccagatc 5340
gacagactga tcacaggaag actgcagagc ctgcaaacgt acgtgacaca gcagctgatc 5400
cgggcagccg aaatccgggc cagcgccaat ctggccgcta ccaagatgag cgagtgcgtg 5460
ttaggccaga gcaagcgggt ggatttctgc ggtaagggat accacctgat gagctttccc 5520
cagagcgctc ctcacggcgt ggtgtttctg cacgtgacct acgttcctgc ccaggaaaag 5580
aacttcacca ccgcccctgc tatctgccac gatggcaagg cccacttccc tagagagggc 5640
gttttcgtgt ctaacggcac acactggttt gtgacccaga gaaacttcta cgagcctcag 5700
atcatcacca cagacaacac ctttgtgagc ggcaattgcg acgtggtgat cggaattgtt 5760
aataataccg tgtacgaccc tctgcagcct gagctcgaca gcttcaagga agagctggac 5820
aagtacttca agaaccacac ctccccagat gtggacctgg gcgatatttc aggcatcaac 5880
gcctccgtcg tgaatatcca gaaggagatc gaccggctca acgaggtggc caagaacctt 5940
aacgagagcc tgatcgacct gcaggaactg ggcaaatatg agcagtacat caagtggcct 6000
tggtacatct ggctgggctt tatcgcaggc ctgatcgcta tcgtgatggt gaccattatg 6060
ctgtgttgta tgaccagctg ttgtagttgt ctgaagggct gctgttcttg cggcagctgc 6120
tgcaagttcg acgaagacga ctcagagccc gtgctgaaag gcgtgaagct gcactacacc 6180
cgaaaacggc gcggaagcgg aggaagcgga gctactaact tcagcctgct gaagcaggct 6240
ggagatgtgg aggagaaccc tggacctatg tattcttttg tgtccgagga aaccggcaca 6300
ctgatcgtta atagcgtgct gctcttcctg gccttcgtgg tgttcctgct ggtgaccctg 6360
gctatcctga ccgccctgag actgtgtgcc tactgctgca acatcgtgaa cgtgtctctg 6420
gtcaagccta gcttctacgt gtacagccgg gtgaagaacc tgaacagcag cagagtgccc 6480
gacctgctgg tgtaatcccc cccccctaac gttactggcc gaagccgctt ggaataaggc 6540
cggtgtgcgt ttgtctatat gttattttcc accatattgc cgtcttttgg caatgtgagg 6600
gcccggaaac ctggccctgt cttcttgacg agcattccta ggggtctttc ccctctcgcc 6660
aaaggaatgc aaggtctgtt gaatgtcgtg aaggaagcag ttcctctgga agcttcttga 6720
agacaaacaa cgtctgtagc gaccctttgc aggcagcgga accccccacc tggcgacagg 6780
tgcctctgcg gccaaaagcc acgtgtataa gatacacctg caaaggcggc acaaccccag 6840
tgccacgttg tgagttggat agttgtggaa agagtcaaat ggctctcctc aagcgtattc 6900
aacaaggggc tgaaggatgc ccagaaggta ccccattgta tgggatctga tctggggcct 6960
cggtgcacat gctttacatg tgtttagtcg aggttaaaaa aacgtctagg ccccccgaac 7020
cacggggacg tggttttcct ttgaaaaaca cgatgataat atggccacaa ccatggaaca 7080
agagacttgc gcgcactctc tcacttttga ggaatgccca aaatgctctg ctctacaata 7140
ccgtaatgga ttttacctgc taaagtatga tgaagaatgg tacccagagg agttattgac 7200
tgatggagag gatgatgtct ttgatcccga attagacatg gaagtcgttt tcgagttaca 7260
gggaagcgga gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc 7320
tggacctatg gacctgttca tgagaatctt caccatcggc accgtgacac tgaagcaggg 7380
cgagatcaag gatgccaccc ctagcgactt cgtgagagcc accgccacaa ttcctatcca 7440
ggctagcctg ccttttggat ggctgatcgt gggcgtcgcc ctgctcgccg tgttccagag 7500
cgcctctaag atcattacac tgaagaaaag atggcagctg gccctctcca aaggcgtgca 7560
cttcgtgtgt aatctgctgc tgctttttgt gacagtgtac agccacctgc tgctggttgc 7620
tgctggcctg gaagcccctt tcctgtacct gtacgccctg gtctacttcc tgcagtctat 7680
caacttcgtg cggatcatca tgcggctgtg gctgtgctgg aagtgcagaa gcaagaaccc 7740
actgctgtac gacgccaatt acttcctgtg ttggcacacc aactgctacg actactgcat 7800
cccctacaac agcgtgacca gcagcatcgt gatcacctct ggcgacggaa caaccagccc 7860
tatcagcgag catgattacc agatcggcgg atatacagag aagtgggaga gcggcgtgaa 7920
ggactgcgtg gtgctgcaca gctactttac ctccgattac taccaactgt attctaccca 7980
gctgagcacc gacaccggcg tggaacacgt gaccttcttc atctacaaca agatcgtgga 8040
cgagcctgag gaacacgtgc agatccacac tatcgacggc agctctggcg ttgtgaaccc 8100
tgtgatggaa cccatctacg atgagcccac cacaacaacc tccgtgcccc tgtaagtgtt 8160
tacctgttaa tgtagcattt gagctttggg ctaagcgcaa cattaaacca gtaccagagg 8220
tgaaaatact caataatttg ggtgtggaca ttgctgctaa tactgtgatc tgggactaca 8280
aaagagatgc tccagcacat atatctacta ttggtgtttg ttctatgact gacatagcca 8340
agaaaccaac tgaaacgatt tgtgcaccac tcactgtctt ttttgatggt agagttgatg 8400
gtcaagtaga cttatttaga aatgcccgta atggtgttct tattacagaa ggtagtgtta 8460
aaggtttaca accatctgta ggtcccaaac aagctagtct taatggagtc acattaattg 8520
gagaagccgt aaaaacacag ttcaattatt ataagaaagt tgatggtgtt gtccaacaat 8580
tacctgaaac ttactttact cagagtagaa atttacaaga atttaaaccc aggagtcaaa 8640
tggaaattga tttcttagaa ttagctatgg atgaattcat tgaacggtat aaattagaag 8700
gctatgcctt cgaacatatc gtttatggag attttagtca tagtcagtta ggtggtgcga 8760
aattgttgtt gtt 8773
<210> 47
<211> 7677
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG15 expression cassette
<400> 47
attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc ttgtagatct 60
gttctctaaa cgaactttaa aatctgtgtg gctgtcactc ggctgcatgc ttagtgcact 120
cacgcagtat aattaataac taattactgt cgttgacagg acacgagtaa ctcgtctatc 180
ttctgcaggc tgcttacggt ttcgtccgtg ttgcagccga tcatcagcac atctaggttt 240
cgtccgggtg tgaccgaaag gtaaatggcc gacagcaacg gcacaatcac cgtggaagag 300
ctgaagaaac tgctggaaca gtggaacctg gtcatcggct tcctgtttct gacctggatc 360
tgtctgctgc agttcgctta tgccaatcgg aacagattcc tgtacatcat caagctgatc 420
ttcctgtggc tgctgtggcc tgtgaccctg gcttgcttcg tgctggccgc tgtgtaccgg 480
atcaactgga tcacaggcgg aatcgccatc gccatggcct gcctggtggg cctgatgtgg 540
ctgagctact tcatcgcttc tttcagactg ttcgccagaa cccggagcat gtggtccttc 600
aaccccgaga caaacatcct gctgaacgtg cctctgcacg gcaccatcct gacaagacct 660
ctgctcgaga gcgagctggt gattggcgca gtgattctga gaggccatct gaggatcgcc 720
ggacaccacc tgggcagatg cgacatcaag gaccttccaa aggaaatcac cgttgccacc 780
agccggaccc tgtcctacta caaactgggc gccagccaaa gagtggccgg cgatagcggc 840
tttgccgcct acagcagata ccgcatcgga aattacaagc tcaacaccga ccacagcagc 900
tcttctgata acatcgccct gctggtgcag cgaaaacggc gcggaagcgg aggaagcgga 960
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 1020
agcgacaacg gccctcaaaa ccagagaaat gcccctcgga tcacatttgg cggacctagc 1080
gacagcaccg gcagcaacca gaatggagaa agaagcggcg ccagatccaa gcagcggaga 1140
cctcagggac tgcccaacaa caccgctagc tggttcaccg ccctgaccca acacggcaag 1200
gaagatctga agttccccag aggccagggc gtgcctatca acacaaactc ttctcccgac 1260
gaccagatcg gatactatag acgggccact cggagaattc ggggcggcga cggaaaaatg 1320
aaggaccttt ctccaagatg gtacttctac tacctcggca caggccctga ggccggcctg 1380
ccttacggcg ccaacaagga tggcatcatc tgggtcgcca ccgagggcgc cctgaacacc 1440
cctaaggacc acatcggcac aagaaacccc gctaacaacg ccgcaatcgt gctgcagctg 1500
cctcagggca ccaccctgcc caagggcttc tacgccgagg gctctagagg tggctcccag 1560
gcttctagcc gctcctccag ccgcagcaga aacagcagca ggaacagcac ccccggcagc 1620
tcccggggca ccagccccgc cagaatggcc ggaaatggcg gcgatgccgc cctggccctg 1680
ctcctgctgg acagactgaa tcagctggaa agcaagatga gcggcaaagg acagcagcag 1740
caaggccaga ccgtgaccaa gaaaagcgct gctgaagcct ccaagaaacc tagacaaaag 1800
cggaccgcca caaaggccta caacgtgacc caagcctttg gaagaagagg ccccgagcag 1860
acacagggca atttcggcga ccaggagctg atccggcagg gaaccgacta caagcactgg 1920
cctcagatcg cccagttcgc ccctagcgcc agcgccttct tcggcatgag cagaatcggc 1980
atggaagtga ccccttctgg cacctggctg acctacaccg gcgctatcaa gctggacgat 2040
aaggatccta acttcaagga ccaagtgatc ctgctgaaca agcatatcga cgcctataag 2100
acctttccac ctacagagcc taagaaagat aagaagaaga aagccgacga gacacaggcc 2160
ctgcctcaga gacagaaaaa gcagcagaca gtgacactgc tgccagccgc tgacctggat 2220
gacttcagca agcagctgca gcagagcatg tcttctgctg atagcaccca ggcccgaaaa 2280
cggcgcggaa gcggaggaag cggagctact aacttcagcc tgctgaagca ggctggagat 2340
gtggaggaga accctggacc tatgttcgtg ttcctggtgc tgctgcctct ggtcagctcc 2400
cagtgtgtga acctgaccac cagaacccag ctgccacctg cttatacaaa ctccttcact 2460
cggggggtat actaccccga caaggtgttc agatctagcg tgctgcattc tacacaagac 2520
ctgttcctgc ccttcttcag caacgtgacc tggttccacg ccatccacgt gtctggaacc 2580
aacggaacca agagattcga caaccccgtg ctgcctttca acgacggcgt gtacttcgcc 2640
agcaccgaga agtccaacat catcagagga tggattttcg gcaccacact ggacagcaaa 2700
acccagagcc tgctgatcgt gaacaacgcc accaacgtgg tgatcaaggt gtgcgagttc 2760
cagttctgca atgatccctt cctgggcgtg tactaccaca agaacaacaa gtcttggatg 2820
gaaagcgagt tcagagtgta ttccagcgcc aacaattgca ccttcgagta cgtgagccaa 2880
ccctttctga tggaccttga aggcaagcag ggcaacttca aaaatctgcg agaatttgtg 2940
ttcaagaaca tcgacggata cttcaagatc tactctaagc acacgccaat caacctggtg 3000
agagatctgc cccagggctt tagcgctttg gaacctctgg tggacctgcc tatcggaatc 3060
aacatcacca gatttcaaac tctcctggcc ctgcacagat cttatctgac ccctggggac 3120
agtagtagcg gctggacagc cggcgccgcc gcctactacg tgggatacct gcagcctaga 3180
acattcctgc tgaagtacaa tgagaacgga acaatcacag acgccgtgga ctgcgccctg 3240
gatcctttga gcgagacaaa gtgcaccctg aagtcgttca ccgtcgaaaa aggcatctac 3300
cagaccagca acttccgcgt gcagcctacg gaatctatcg tgcggttccc caacatcacc 3360
aacctgtgcc ctttcggcga ggtgtttaac gctacaaggt tcgccagcgt gtatgcctgg 3420
aacagaaaga gaatcagcaa ttgcgtggcc gattatagcg ttctgtacaa cagcgcttcc 3480
ttcagcacct tcaagtgcta cggcgtgtct ccaaccaagc tgaacgacct ctgcttcacc 3540
aatgtctacg ctgactcttt cgtgattaga ggcgatgagg ttagacagat cgcacctggc 3600
cagaccggca aaatcgctga ctacaactac aagctgcctg atgacttcac aggctgtgtc 3660
attgcctgga actcaaataa cctggactct aaagtgggcg gcaactacaa ctacctgtac 3720
cggctgttcc ggaagagcaa tctgaaacct tttgagcggg acatctctac agagatctac 3780
caggccggca gcacaccctg caacggcgtt gagggcttca actgctactt ccctctgcag 3840
agctacggct ttcagccaac aaatggagtg ggctaccagc cgtacagagt ggtggtgctg 3900
agcttcgaac tgctgcatgc cccagccaca gtgtgtggac ctaagaagtc taccaacctg 3960
gtgaagaaca agtgcgtgaa ctttaacttt aacggcctga ccggcacagg cgtgctgacc 4020
gaatccaaca aaaagttcct gcccttccaa cagttcggca gagacatcgc cgatacaacc 4080
gatgccgtgc gggaccccca gaccttagaa atcctagata tcaccccgtg cagcttcggc 4140
ggagtctctg ttattactcc tggcaccaac accagcaacc aagtggctgt tctgtaccaa 4200
ggcgtgaact gcaccgaagt gcctgtggct atccacgccg atcagctgac cccaacctgg 4260
cgggtgtata gcaccggctc taacgtgttc cagacccggg ctggctgcct gatcggcgcc 4320
gaacacgtca acaactccta tgaatgtgac atccccatcg gggctggcat ctgcgccagt 4380
taccagacac agacaaatag ccctagacgg gccagaagcg tggcctccca gagtatcatt 4440
gcctacacca tgagcctggg cgccgagaac agcgtggcct attctaacaa tagcatcgca 4500
atccctacca actttaccat ctctgtgaca accgagatcc tgcctgtgag catgaccaaa 4560
accagcgtgg actgcacgat gtacatctgt ggcgacagca cagaatgcag taatctgttg 4620
ctgcagtacg gcagcttttg cacccagttg aatagagccc tgaccggaat cgccgtagag 4680
caggacaaaa atacccagga ggtgttcgcc caggtgaaac agatctacaa gacacctccc 4740
attaaggact tcggaggttt taacttcagc cagatcctgc ccgacccttc caagcctagc 4800
aaacgctcct tcatcgagga cctgctcttc aacaaggtga cactggctga tgccggcttc 4860
atcaagcagt acggagattg tctgggagac atcgccgcta gagatctgat ctgcgcccaa 4920
aagttcaacg gcctgaccgt gctgcctcct ctgcttacag acgagatgat cgcccagtac 4980
accagcgccc tgctggctgg caccatcaca agcggctgga ccttcggagc cggagccgct 5040
ctgcaaatcc cctttgccat gcagatggcc taccggttca acggcatcgg cgtgacacag 5100
aatgtgctgt acgagaacca gaagctgatc gctaaccagt ttaacagcgc tatcggcaag 5160
atccaggact cgctgagtag caccgcctct gccctgggca agctgcagga cgtcgtgaac 5220
cagaacgccc aagccctgaa cacactggtg aaacagctga gcagcaactt cggcgccatc 5280
agctctgtgc tgaacgatat cctgagcaga ctggacaagg tggaagccga ggtccagatc 5340
gacagactga tcacaggaag actgcagagc ctgcaaacgt acgtgacaca gcagctgatc 5400
cgggcagccg aaatccgggc cagcgccaat ctggccgcta ccaagatgag cgagtgcgtg 5460
ttaggccaga gcaagcgggt ggatttctgc ggtaagggat accacctgat gagctttccc 5520
cagagcgctc ctcacggcgt ggtgtttctg cacgtgacct acgttcctgc ccaggaaaag 5580
aacttcacca ccgcccctgc tatctgccac gatggcaagg cccacttccc tagagagggc 5640
gttttcgtgt ctaacggcac acactggttt gtgacccaga gaaacttcta cgagcctcag 5700
atcatcacca cagacaacac ctttgtgagc ggcaattgcg acgtggtgat cggaattgtt 5760
aataataccg tgtacgaccc tctgcagcct gagctcgaca gcttcaagga agagctggac 5820
aagtacttca agaaccacac ctccccagat gtggacctgg gcgatatttc aggcatcaac 5880
gcctccgtcg tgaatatcca gaaggagatc gaccggctca acgaggtggc caagaacctt 5940
aacgagagcc tgatcgacct gcaggaactg ggcaaatatg agcagtacat caagtggcct 6000
tggtacatct ggctgggctt tatcgcaggc ctgatcgcta tcgtgatggt gaccattatg 6060
ctgtgttgta tgaccagctg ttgtagttgt ctgaagggct gctgttcttg cggcagctgc 6120
tgcaagttcg acgaagacga ctcagagccc gtgctgaaag gcgtgaagct gcactacacc 6180
cgaaaacggc gcggaagcgg aggaagcgga gctactaact tcagcctgct gaagcaggct 6240
ggagatgtgg aggagaaccc tggacctatg tattcttttg tgtccgagga aaccggcaca 6300
ctgatcgtta atagcgtgct gctcttcctg gccttcgtgg tgttcctgct ggtgaccctg 6360
gctatcctga ccgccctgag actgtgtgcc tactgctgca acatcgtgaa cgtgtctctg 6420
gtcaagccta gcttctacgt gtacagccgg gtgaagaacc tgaacagcag cagagtgccc 6480
gacctgctgg tgtaatcccc cccccctaac gttactggcc gaagccgctt ggaataaggc 6540
cggtgtgcgt ttgtctatat gttattttcc accatattgc cgtcttttgg caatgtgagg 6600
gcccggaaac ctggccctgt cttcttgacg agcattccta ggggtctttc ccctctcgcc 6660
aaaggaatgc aaggtctgtt gaatgtcgtg aaggaagcag ttcctctgga agcttcttga 6720
agacaaacaa cgtctgtagc gaccctttgc aggcagcgga accccccacc tggcgacagg 6780
tgcctctgcg gccaaaagcc acgtgtataa gatacacctg caaaggcggc acaaccccag 6840
tgccacgttg tgagttggat agttgtggaa agagtcaaat ggctctcctc aagcgtattc 6900
aacaaggggc tgaaggatgc ccagaaggta ccccattgta tgggatctga tctggggcct 6960
cggtgcacat gctttacatg tgtttagtcg aggttaaaaa aacgtctagg ccccccgaac 7020
cacggggacg tggttttcct ttgaaaaaca cgatgataag tgtttacctg ttaatgtagc 7080
atttgagctt tgggctaagc gcaacattaa accagtacca gaggtgaaaa tactcaataa 7140
tttgggtgtg gacattgctg ctaatactgt gatctgggac tacaaaagag atgctccagc 7200
acatatatct actattggtg tttgttctat gactgacata gccaagaaac caactgaaac 7260
gatttgtgca ccactcactg tcttttttga tggtagagtt gatggtcaag tagacttatt 7320
tagaaatgcc cgtaatggtg ttcttattac agaaggtagt gttaaaggtt tacaaccatc 7380
tgtaggtccc aaacaagcta gtcttaatgg agtcacatta attggagaag ccgtaaaaac 7440
acagttcaat tattataaga aagttgatgg tgttgtccaa caattacctg aaacttactt 7500
tactcagagt agaaatttac aagaatttaa acccaggagt caaatggaaa ttgatttctt 7560
agaattagct atggatgaat tcattgaacg gtataaatta gaaggctatg ccttcgaaca 7620
tatcgtttat ggagatttta gtcatagtca gttaggtggt gcgaaattgt tgttgtt 7677
<210> 48
<211> 8509
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG16 expression cassette
<400> 48
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagcgaa aacggcgcgg aagcggagga agcggagcta ctaacttcag cctgctgaag 720
caggctggag atgtggagga gaaccctgga cctatgagcg acaacggccc tcaaaaccag 780
agaaatgccc ctcggatcac atttggcgga cctagcgaca gcaccggcag caaccagaat 840
ggagaaagaa gcggcgccag atccaagcag cggagacctc agggactgcc caacaacacc 900
gctagctggt tcaccgccct gacccaacac ggcaaggaag atctgaagtt ccccagaggc 960
cagggcgtgc ctatcaacac aaactcttct cccgacgacc agatcggata ctatagacgg 1020
gccactcgga gaattcgggg cggcgacgga aaaatgaagg acctttctcc aagatggtac 1080
ttctactacc tcggcacagg ccctgaggcc ggcctgcctt acggcgccaa caaggatggc 1140
atcatctggg tcgccaccga gggcgccctg aacaccccta aggaccacat cggcacaaga 1200
aaccccgcta acaacgccgc aatcgtgctg cagctgcctc agggcaccac cctgcccaag 1260
ggcttctacg ccgagggctc tagaggtggc tcccaggctt ctagccgctc ctccagccgc 1320
agcagaaaca gcagcaggaa cagcaccccc ggcagctccc ggggcaccag ccccgccaga 1380
atggccggaa atggcggcga tgccgccctg gccctgctcc tgctggacag actgaatcag 1440
ctggaaagca agatgagcgg caaaggacag cagcagcaag gccagaccgt gaccaagaaa 1500
agcgctgctg aagcctccaa gaaacctaga caaaagcgga ccgccacaaa ggcctacaac 1560
gtgacccaag cctttggaag aagaggcccc gagcagacac agggcaattt cggcgaccag 1620
gagctgatcc ggcagggaac cgactacaag cactggcctc agatcgccca gttcgcccct 1680
agcgccagcg ccttcttcgg catgagcaga atcggcatgg aagtgacccc ttctggcacc 1740
tggctgacct acaccggcgc tatcaagctg gacgataagg atcctaactt caaggaccaa 1800
gtgatcctgc tgaacaagca tatcgacgcc tataagacct ttccacctac agagcctaag 1860
aaagataaga agaagaaagc cgacgagaca caggccctgc ctcagagaca gaaaaagcag 1920
cagacagtga cactgctgcc agccgctgac ctggatgact tcagcaagca gctgcagcag 1980
agcatgtctt ctgctgatag cacccaggcc cgaaaacggc gcggaagcgg aggaagcgga 2040
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 2100
ttcgtgttcc tggtgctgct gcctctggtc agctcccagt gtgtgaacct gaccaccaga 2160
acccagctgc cacctgctta tacaaactcc ttcactcggg gggtatacta ccccgacaag 2220
gtgttcagat ctagcgtgct gcattctaca caagacctgt tcctgccctt cttcagcaac 2280
gtgacctggt tccacgccat ccacgtgtct ggaaccaacg gaaccaagag attcgacaac 2340
cccgtgctgc ctttcaacga cggcgtgtac ttcgccagca ccgagaagtc caacatcatc 2400
agaggatgga ttttcggcac cacactggac agcaaaaccc agagcctgct gatcgtgaac 2460
aacgccacca acgtggtgat caaggtgtgc gagttccagt tctgcaatga tcccttcctg 2520
ggcgtgtact accacaagaa caacaagtct tggatggaaa gcgagttcag agtgtattcc 2580
agcgccaaca attgcacctt cgagtacgtg agccaaccct ttctgatgga ccttgaaggc 2640
aagcagggca acttcaaaaa tctgcgagaa tttgtgttca agaacatcga cggatacttc 2700
aagatctact ctaagcacac gccaatcaac ctggtgagag atctgcccca gggctttagc 2760
gctttggaac ctctggtgga cctgcctatc ggaatcaaca tcaccagatt tcaaactctc 2820
ctggccctgc acagatctta tctgacccct ggggacagta gtagcggctg gacagccggc 2880
gccgccgcct actacgtggg atacctgcag cctagaacat tcctgctgaa gtacaatgag 2940
aacggaacaa tcacagacgc cgtggactgc gccctggatc ctttgagcga gacaaagtgc 3000
accctgaagt cgttcaccgt cgaaaaaggc atctaccaga ccagcaactt ccgcgtgcag 3060
cctacggaat ctatcgtgcg gttccccaac atcaccaacc tgtgcccttt cggcgaggtg 3120
tttaacgcta caaggttcgc cagcgtgtat gcctggaaca gaaagagaat cagcaattgc 3180
gtggccgatt atagcgttct gtacaacagc gcttccttca gcaccttcaa gtgctacggc 3240
gtgtctccaa ccaagctgaa cgacctctgc ttcaccaatg tctacgctga ctctttcgtg 3300
attagaggcg atgaggttag acagatcgca cctggccaga ccggcaaaat cgctgactac 3360
aactacaagc tgcctgatga cttcacaggc tgtgtcattg cctggaactc aaataacctg 3420
gactctaaag tgggcggcaa ctacaactac ctgtaccggc tgttccggaa gagcaatctg 3480
aaaccttttg agcgggacat ctctacagag atctaccagg ccggcagcac accctgcaac 3540
ggcgttgagg gcttcaactg ctacttccct ctgcagagct acggctttca gccaacaaat 3600
ggagtgggct accagccgta cagagtggtg gtgctgagct tcgaactgct gcatgcccca 3660
gccacagtgt gtggacctaa gaagtctacc aacctggtga agaacaagtg cgtgaacttt 3720
aactttaacg gcctgaccgg cacaggcgtg ctgaccgaat ccaacaaaaa gttcctgccc 3780
ttccaacagt tcggcagaga catcgccgat acaaccgatg ccgtgcggga cccccagacc 3840
ttagaaatcc tagatatcac cccgtgcagc ttcggcggag tctctgttat tactcctggc 3900
accaacacca gcaaccaagt ggctgttctg taccaaggcg tgaactgcac cgaagtgcct 3960
gtggctatcc acgccgatca gctgacccca acctggcggg tgtatagcac cggctctaac 4020
gtgttccaga cccgggctgg ctgcctgatc ggcgccgaac acgtcaacaa ctcctatgaa 4080
tgtgacatcc ccatcggggc tggcatctgc gccagttacc agacacagac aaatagccct 4140
ggcagcgcca gcagcgtggc ctcccagagt atcattgcct acaccatgag cctgggcgcc 4200
gagaacagcg tggcctattc taacaatagc atcgcaatcc ctaccaactt taccatctct 4260
gtgacaaccg agatcctgcc tgtgagcatg accaaaacca gcgtggactg cacgatgtac 4320
atctgtggcg acagcacaga atgcagtaat ctgttgctgc agtacggcag cttttgcacc 4380
cagttgaata gagccctgac cggaatcgcc gtagagcagg acaaaaatac ccaggaggtg 4440
ttcgcccagg tgaaacagat ctacaagaca cctcccatta aggacttcgg aggttttaac 4500
ttcagccaga tcctgcccga cccttccaag cctagcaaac gctccttcat cgaggacctg 4560
ctcttcaaca aggtgacact ggctgatgcc ggcttcatca agcagtacgg agattgtctg 4620
ggagacatcg ccgctagaga tctgatctgc gcccaaaagt tcaacggcct gaccgtgctg 4680
cctcctctgc ttacagacga gatgatcgcc cagtacacca gcgccctgct ggctggcacc 4740
atcacaagcg gctggacctt cggagccgga gccgctctgc aaatcccctt tgccatgcag 4800
atggcctacc ggttcaacgg catcggcgtg acacagaatg tgctgtacga gaaccagaag 4860
ctgatcgcta accagtttaa cagcgctatc ggcaagatcc aggactcgct gagtagcacc 4920
gcctctgccc tgggcaagct gcaggacgtc gtgaaccaga acgcccaagc cctgaacaca 4980
ctggtgaaac agctgagcag caacttcggc gccatcagct ctgtgctgaa cgatatcctg 5040
agcagactgg accctcccga agccgaggtc cagatcgaca gactgatcac aggaagactg 5100
cagagcctgc aaacgtacgt gacacagcag ctgatccggg cagccgaaat ccgggccagc 5160
gccaatctgg ccgctaccaa gatgagcgag tgcgtgttag gccagagcaa gcgggtggat 5220
ttctgcggta agggatacca cctgatgagc tttccccaga gcgctcctca cggcgtggtg 5280
tttctgcacg tgacctacgt tcctgcccag gaaaagaact tcaccaccgc ccctgctatc 5340
tgccacgatg gcaaggccca cttccctaga gagggcgttt tcgtgtctaa cggcacacac 5400
tggtttgtga cccagagaaa cttctacgag cctcagatca tcaccacaga caacaccttt 5460
gtgagcggca attgcgacgt ggtgatcgga attgttaata ataccgtgta cgaccctctg 5520
cagcctgagc tcgacagctt caaggaagag ctggacaagt acttcaagaa ccacacctcc 5580
ccagatgtgg acctgggcga tatttcaggc atcaacgcct ccgtcgtgaa tatccagaag 5640
gagatcgacc ggctcaacga ggtggccaag aaccttaacg agagcctgat cgacctgcag 5700
gaactgggca aatatgagca gtacatcaag tggccttggt acatctggct gggctttatc 5760
gcaggcctga tcgctatcgt gatggtgacc attatgctgt gttgtatgac cagctgttgt 5820
agttgtctga agggctgctg ttcttgcggc agctgctgca agttcgacga agacgactca 5880
gagcccgtgc tgaaaggcgt gaagctgcac tacacccgaa aacggcgcgg aagcggagga 5940
agcggagcta ctaacttcag cctgctgaag caggctggag atgtggagga gaaccctgga 6000
cctatgtatt cttttgtgtc cgaggaaacc ggcacactga tcgttaatag cgtgctgctc 6060
ttcctggcct tcgtggtgtt cctgctggtg accctggcta tcctgaccgc cctgagactg 6120
tgtgcctact gctgcaacat cgtgaacgtg tctctggtca agcctagctt ctacgtgtac 6180
agccgggtga agaacctgaa cagcagcaga gtgcccgacc tgctggtgta atcccccccc 6240
cctaacgtta ctggccgaag ccgcttggaa taaggccggt gtgcgtttgt ctatatgtta 6300
ttttccacca tattgccgtc ttttggcaat gtgagggccc ggaaacctgg ccctgtcttc 6360
ttgacgagca ttcctagggg tctttcccct ctcgccaaag gaatgcaagg tctgttgaat 6420
gtcgtgaagg aagcagttcc tctggaagct tcttgaagac aaacaacgtc tgtagcgacc 6480
ctttgcaggc agcggaaccc cccacctggc gacaggtgcc tctgcggcca aaagccacgt 6540
gtataagata cacctgcaaa ggcggcacaa ccccagtgcc acgttgtgag ttggatagtt 6600
gtggaaagag tcaaatggct ctcctcaagc gtattcaaca aggggctgaa ggatgcccag 6660
aaggtacccc attgtatggg atctgatctg gggcctcggt gcacatgctt tacatgtgtt 6720
tagtcgaggt taaaaaaacg tctaggcccc ccgaaccacg gggacgtggt tttcctttga 6780
aaaacacgat gataatatgg ccacaaccat ggaacaagag acttgcgcgc actctctcac 6840
ttttgaggaa tgcccaaaat gctctgctct acaataccgt aatggatttt acctgctaaa 6900
gtatgatgaa gaatggtacc cagaggagtt attgactgat ggagaggatg atgtctttga 6960
tcccgaatta gacatggaag tcgttttcga gttacaggga agcggagcta ctaacttcag 7020
cctgctgaag caggctggag atgtggagga gaaccctgga cctatggacc tgttcatgag 7080
aatcttcacc atcggcaccg tgacactgaa gcagggcgag atcaaggatg ccacccctag 7140
cgacttcgtg agagccaccg ccacaattcc tatccaggct agcctgcctt ttggatggct 7200
gatcgtgggc gtcgccctgc tcgccgtgtt ccagagcgcc tctaagatca ttacactgaa 7260
gaaaagatgg cagctggccc tctccaaagg cgtgcacttc gtgtgtaatc tgctgctgct 7320
ttttgtgaca gtgtacagcc acctgctgct ggttgctgct ggcctggaag cccctttcct 7380
gtacctgtac gccctggtct acttcctgca gtctatcaac ttcgtgcgga tcatcatgcg 7440
gctgtggctg tgctggaagt gcagaagcaa gaacccactg ctgtacgacg ccaattactt 7500
cctgtgttgg cacaccaact gctacgacta ctgcatcccc tacaacagcg tgaccagcag 7560
catcgtgatc acctctggcg acggaacaac cagccctatc agcgagcatg attaccagat 7620
cggcggatat acagagaagt gggagagcgg cgtgaaggac tgcgtggtgc tgcacagcta 7680
ctttacctcc gattactacc aactgtattc tacccagctg agcaccgaca ccggcgtgga 7740
acacgtgacc ttcttcatct acaacaagat cgtggacgag cctgaggaac acgtgcagat 7800
ccacactatc gacggcagct ctggcgttgt gaaccctgtg atggaaccca tctacgatga 7860
gcccaccaca acaacctccg tgcccctgta agtgtttacc tgttaatgta gcatttgagc 7920
tttgggctaa gcgcaacatt aaaccagtac cagaggtgaa aatactcaat aatttgggtg 7980
tggacattgc tgctaatact gtgatctggg actacaaaag agatgctcca gcacatatat 8040
ctactattgg tgtttgttct atgactgaca tagccaagaa accaactgaa acgatttgtg 8100
caccactcac tgtctttttt gatggtagag ttgatggtca agtagactta tttagaaatg 8160
cccgtaatgg tgttcttatt acagaaggta gtgttaaagg tttacaacca tctgtaggtc 8220
ccaaacaagc tagtcttaat ggagtcacat taattggaga agccgtaaaa acacagttca 8280
attattataa gaaagttgat ggtgttgtcc aacaattacc tgaaacttac tttactcaga 8340
gtagaaattt acaagaattt aaacccagga gtcaaatgga aattgatttc ttagaattag 8400
ctatggatga attcattgaa cggtataaat tagaaggcta tgccttcgaa catatcgttt 8460
atggagattt tagtcatagt cagttaggtg gtgcgaaatt gttgttgtt 8509
<210> 49
<211> 8773
<212> DNA
<213> Artificial Sequence
<220>
<223> CoVEG17 expression cassette
<400> 49
attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc ttgtagatct 60
gttctctaaa cgaactttaa aatctgtgtg gctgtcactc ggctgcatgc ttagtgcact 120
cacgcagtat aattaataac taattactgt cgttgacagg acacgagtaa ctcgtctatc 180
ttctgcaggc tgcttacggt ttcgtccgtg ttgcagccga tcatcagcac atctaggttt 240
cgtccgggtg tgaccgaaag gtaaatggcc gacagcaacg gcacaatcac cgtggaagag 300
ctgaagaaac tgctggaaca gtggaacctg gtcatcggct tcctgtttct gacctggatc 360
tgtctgctgc agttcgctta tgccaatcgg aacagattcc tgtacatcat caagctgatc 420
ttcctgtggc tgctgtggcc tgtgaccctg gcttgcttcg tgctggccgc tgtgtaccgg 480
atcaactgga tcacaggcgg aatcgccatc gccatggcct gcctggtggg cctgatgtgg 540
ctgagctact tcatcgcttc tttcagactg ttcgccagaa cccggagcat gtggtccttc 600
aaccccgaga caaacatcct gctgaacgtg cctctgcacg gcaccatcct gacaagacct 660
ctgctcgaga gcgagctggt gattggcgca gtgattctga gaggccatct gaggatcgcc 720
ggacaccacc tgggcagatg cgacatcaag gaccttccaa aggaaatcac cgttgccacc 780
agccggaccc tgtcctacta caaactgggc gccagccaaa gagtggccgg cgatagcggc 840
tttgccgcct acagcagata ccgcatcgga aattacaagc tcaacaccga ccacagcagc 900
tcttctgata acatcgccct gctggtgcag cgaaaacggc gcggaagcgg aggaagcgga 960
gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc tggacctatg 1020
agcgacaacg gccctcaaaa ccagagaaat gcccctcgga tcacatttgg cggacctagc 1080
gacagcaccg gcagcaacca gaatggagaa agaagcggcg ccagatccaa gcagcggaga 1140
cctcagggac tgcccaacaa caccgctagc tggttcaccg ccctgaccca acacggcaag 1200
gaagatctga agttccccag aggccagggc gtgcctatca acacaaactc ttctcccgac 1260
gaccagatcg gatactatag acgggccact cggagaattc ggggcggcga cggaaaaatg 1320
aaggaccttt ctccaagatg gtacttctac tacctcggca caggccctga ggccggcctg 1380
ccttacggcg ccaacaagga tggcatcatc tgggtcgcca ccgagggcgc cctgaacacc 1440
cctaaggacc acatcggcac aagaaacccc gctaacaacg ccgcaatcgt gctgcagctg 1500
cctcagggca ccaccctgcc caagggcttc tacgccgagg gctctagagg tggctcccag 1560
gcttctagcc gctcctccag ccgcagcaga aacagcagca ggaacagcac ccccggcagc 1620
tcccggggca ccagccccgc cagaatggcc ggaaatggcg gcgatgccgc cctggccctg 1680
ctcctgctgg acagactgaa tcagctggaa agcaagatga gcggcaaagg acagcagcag 1740
caaggccaga ccgtgaccaa gaaaagcgct gctgaagcct ccaagaaacc tagacaaaag 1800
cggaccgcca caaaggccta caacgtgacc caagcctttg gaagaagagg ccccgagcag 1860
acacagggca atttcggcga ccaggagctg atccggcagg gaaccgacta caagcactgg 1920
cctcagatcg cccagttcgc ccctagcgcc agcgccttct tcggcatgag cagaatcggc 1980
atggaagtga ccccttctgg cacctggctg acctacaccg gcgctatcaa gctggacgat 2040
aaggatccta acttcaagga ccaagtgatc ctgctgaaca agcatatcga cgcctataag 2100
acctttccac ctacagagcc taagaaagat aagaagaaga aagccgacga gacacaggcc 2160
ctgcctcaga gacagaaaaa gcagcagaca gtgacactgc tgccagccgc tgacctggat 2220
gacttcagca agcagctgca gcagagcatg tcttctgctg atagcaccca ggcccgaaaa 2280
cggcgcggaa gcggaggaag cggagctact aacttcagcc tgctgaagca ggctggagat 2340
gtggaggaga accctggacc tatgttcgtg ttcctggtgc tgctgcctct ggtcagctcc 2400
cagtgtgtga acctgaccac cagaacccag ctgccacctg cttatacaaa ctccttcact 2460
cggggggtat actaccccga caaggtgttc agatctagcg tgctgcattc tacacaagac 2520
ctgttcctgc ccttcttcag caacgtgacc tggttccacg ccatccacgt gtctggaacc 2580
aacggaacca agagattcga caaccccgtg ctgcctttca acgacggcgt gtacttcgcc 2640
agcaccgaga agtccaacat catcagagga tggattttcg gcaccacact ggacagcaaa 2700
acccagagcc tgctgatcgt gaacaacgcc accaacgtgg tgatcaaggt gtgcgagttc 2760
cagttctgca atgatccctt cctgggcgtg tactaccaca agaacaacaa gtcttggatg 2820
gaaagcgagt tcagagtgta ttccagcgcc aacaattgca ccttcgagta cgtgagccaa 2880
ccctttctga tggaccttga aggcaagcag ggcaacttca aaaatctgcg agaatttgtg 2940
ttcaagaaca tcgacggata cttcaagatc tactctaagc acacgccaat caacctggtg 3000
agagatctgc cccagggctt tagcgctttg gaacctctgg tggacctgcc tatcggaatc 3060
aacatcacca gatttcaaac tctcctggcc ctgcacagat cttatctgac ccctggggac 3120
agtagtagcg gctggacagc cggcgccgcc gcctactacg tgggatacct gcagcctaga 3180
acattcctgc tgaagtacaa tgagaacgga acaatcacag acgccgtgga ctgcgccctg 3240
gatcctttga gcgagacaaa gtgcaccctg aagtcgttca ccgtcgaaaa aggcatctac 3300
cagaccagca acttccgcgt gcagcctacg gaatctatcg tgcggttccc caacatcacc 3360
aacctgtgcc ctttcggcga ggtgtttaac gctacaaggt tcgccagcgt gtatgcctgg 3420
aacagaaaga gaatcagcaa ttgcgtggcc gattatagcg ttctgtacaa cagcgcttcc 3480
ttcagcacct tcaagtgcta cggcgtgtct ccaaccaagc tgaacgacct ctgcttcacc 3540
aatgtctacg ctgactcttt cgtgattaga ggcgatgagg ttagacagat cgcacctggc 3600
cagaccggca aaatcgctga ctacaactac aagctgcctg atgacttcac aggctgtgtc 3660
attgcctgga actcaaataa cctggactct aaagtgggcg gcaactacaa ctacctgtac 3720
cggctgttcc ggaagagcaa tctgaaacct tttgagcggg acatctctac agagatctac 3780
caggccggca gcacaccctg caacggcgtt gagggcttca actgctactt ccctctgcag 3840
agctacggct ttcagccaac aaatggagtg ggctaccagc cgtacagagt ggtggtgctg 3900
agcttcgaac tgctgcatgc cccagccaca gtgtgtggac ctaagaagtc taccaacctg 3960
gtgaagaaca agtgcgtgaa ctttaacttt aacggcctga ccggcacagg cgtgctgacc 4020
gaatccaaca aaaagttcct gcccttccaa cagttcggca gagacatcgc cgatacaacc 4080
gatgccgtgc gggaccccca gaccttagaa atcctagata tcaccccgtg cagcttcggc 4140
ggagtctctg ttattactcc tggcaccaac accagcaacc aagtggctgt tctgtaccaa 4200
ggcgtgaact gcaccgaagt gcctgtggct atccacgccg atcagctgac cccaacctgg 4260
cgggtgtata gcaccggctc taacgtgttc cagacccggg ctggctgcct gatcggcgcc 4320
gaacacgtca acaactccta tgaatgtgac atccccatcg gggctggcat ctgcgccagt 4380
taccagacac agacaaatag ccctggcagc gccagcagcg tggcctccca gagtatcatt 4440
gcctacacca tgagcctggg cgccgagaac agcgtggcct attctaacaa tagcatcgca 4500
atccctacca actttaccat ctctgtgaca accgagatcc tgcctgtgag catgaccaaa 4560
accagcgtgg actgcacgat gtacatctgt ggcgacagca cagaatgcag taatctgttg 4620
ctgcagtacg gcagcttttg cacccagttg aatagagccc tgaccggaat cgccgtagag 4680
caggacaaaa atacccagga ggtgttcgcc caggtgaaac agatctacaa gacacctccc 4740
attaaggact tcggaggttt taacttcagc cagatcctgc ccgacccttc caagcctagc 4800
aaacgctcct tcatcgagga cctgctcttc aacaaggtga cactggctga tgccggcttc 4860
atcaagcagt acggagattg tctgggagac atcgccgcta gagatctgat ctgcgcccaa 4920
aagttcaacg gcctgaccgt gctgcctcct ctgcttacag acgagatgat cgcccagtac 4980
accagcgccc tgctggctgg caccatcaca agcggctgga ccttcggagc cggagccgct 5040
ctgcaaatcc cctttgccat gcagatggcc taccggttca acggcatcgg cgtgacacag 5100
aatgtgctgt acgagaacca gaagctgatc gctaaccagt ttaacagcgc tatcggcaag 5160
atccaggact cgctgagtag caccgcctct gccctgggca agctgcagga cgtcgtgaac 5220
cagaacgccc aagccctgaa cacactggtg aaacagctga gcagcaactt cggcgccatc 5280
agctctgtgc tgaacgatat cctgagcaga ctggaccctc ccgaagccga ggtccagatc 5340
gacagactga tcacaggaag actgcagagc ctgcaaacgt acgtgacaca gcagctgatc 5400
cgggcagccg aaatccgggc cagcgccaat ctggccgcta ccaagatgag cgagtgcgtg 5460
ttaggccaga gcaagcgggt ggatttctgc ggtaagggat accacctgat gagctttccc 5520
cagagcgctc ctcacggcgt ggtgtttctg cacgtgacct acgttcctgc ccaggaaaag 5580
aacttcacca ccgcccctgc tatctgccac gatggcaagg cccacttccc tagagagggc 5640
gttttcgtgt ctaacggcac acactggttt gtgacccaga gaaacttcta cgagcctcag 5700
atcatcacca cagacaacac ctttgtgagc ggcaattgcg acgtggtgat cggaattgtt 5760
aataataccg tgtacgaccc tctgcagcct gagctcgaca gcttcaagga agagctggac 5820
aagtacttca agaaccacac ctccccagat gtggacctgg gcgatatttc aggcatcaac 5880
gcctccgtcg tgaatatcca gaaggagatc gaccggctca acgaggtggc caagaacctt 5940
aacgagagcc tgatcgacct gcaggaactg ggcaaatatg agcagtacat caagtggcct 6000
tggtacatct ggctgggctt tatcgcaggc ctgatcgcta tcgtgatggt gaccattatg 6060
ctgtgttgta tgaccagctg ttgtagttgt ctgaagggct gctgttcttg cggcagctgc 6120
tgcaagttcg acgaagacga ctcagagccc gtgctgaaag gcgtgaagct gcactacacc 6180
cgaaaacggc gcggaagcgg aggaagcgga gctactaact tcagcctgct gaagcaggct 6240
ggagatgtgg aggagaaccc tggacctatg tattcttttg tgtccgagga aaccggcaca 6300
ctgatcgtta atagcgtgct gctcttcctg gccttcgtgg tgttcctgct ggtgaccctg 6360
gctatcctga ccgccctgag actgtgtgcc tactgctgca acatcgtgaa cgtgtctctg 6420
gtcaagccta gcttctacgt gtacagccgg gtgaagaacc tgaacagcag cagagtgccc 6480
gacctgctgg tgtaatcccc cccccctaac gttactggcc gaagccgctt ggaataaggc 6540
cggtgtgcgt ttgtctatat gttattttcc accatattgc cgtcttttgg caatgtgagg 6600
gcccggaaac ctggccctgt cttcttgacg agcattccta ggggtctttc ccctctcgcc 6660
aaaggaatgc aaggtctgtt gaatgtcgtg aaggaagcag ttcctctgga agcttcttga 6720
agacaaacaa cgtctgtagc gaccctttgc aggcagcgga accccccacc tggcgacagg 6780
tgcctctgcg gccaaaagcc acgtgtataa gatacacctg caaaggcggc acaaccccag 6840
tgccacgttg tgagttggat agttgtggaa agagtcaaat ggctctcctc aagcgtattc 6900
aacaaggggc tgaaggatgc ccagaaggta ccccattgta tgggatctga tctggggcct 6960
cggtgcacat gctttacatg tgtttagtcg aggttaaaaa aacgtctagg ccccccgaac 7020
cacggggacg tggttttcct ttgaaaaaca cgatgataat atggccacaa ccatggaaca 7080
agagacttgc gcgcactctc tcacttttga ggaatgccca aaatgctctg ctctacaata 7140
ccgtaatgga ttttacctgc taaagtatga tgaagaatgg tacccagagg agttattgac 7200
tgatggagag gatgatgtct ttgatcccga attagacatg gaagtcgttt tcgagttaca 7260
gggaagcgga gctactaact tcagcctgct gaagcaggct ggagatgtgg aggagaaccc 7320
tggacctatg gacctgttca tgagaatctt caccatcggc accgtgacac tgaagcaggg 7380
cgagatcaag gatgccaccc ctagcgactt cgtgagagcc accgccacaa ttcctatcca 7440
ggctagcctg ccttttggat ggctgatcgt gggcgtcgcc ctgctcgccg tgttccagag 7500
cgcctctaag atcattacac tgaagaaaag atggcagctg gccctctcca aaggcgtgca 7560
cttcgtgtgt aatctgctgc tgctttttgt gacagtgtac agccacctgc tgctggttgc 7620
tgctggcctg gaagcccctt tcctgtacct gtacgccctg gtctacttcc tgcagtctat 7680
caacttcgtg cggatcatca tgcggctgtg gctgtgctgg aagtgcagaa gcaagaaccc 7740
actgctgtac gacgccaatt acttcctgtg ttggcacacc aactgctacg actactgcat 7800
cccctacaac agcgtgacca gcagcatcgt gatcacctct ggcgacggaa caaccagccc 7860
tatcagcgag catgattacc agatcggcgg atatacagag aagtgggaga gcggcgtgaa 7920
ggactgcgtg gtgctgcaca gctactttac ctccgattac taccaactgt attctaccca 7980
gctgagcacc gacaccggcg tggaacacgt gaccttcttc atctacaaca agatcgtgga 8040
cgagcctgag gaacacgtgc agatccacac tatcgacggc agctctggcg ttgtgaaccc 8100
tgtgatggaa cccatctacg atgagcccac cacaacaacc tccgtgcccc tgtaagtgtt 8160
tacctgttaa tgtagcattt gagctttggg ctaagcgcaa cattaaacca gtaccagagg 8220
tgaaaatact caataatttg ggtgtggaca ttgctgctaa tactgtgatc tgggactaca 8280
aaagagatgc tccagcacat atatctacta ttggtgtttg ttctatgact gacatagcca 8340
agaaaccaac tgaaacgatt tgtgcaccac tcactgtctt ttttgatggt agagttgatg 8400
gtcaagtaga cttatttaga aatgcccgta atggtgttct tattacagaa ggtagtgtta 8460
aaggtttaca accatctgta ggtcccaaac aagctagtct taatggagtc acattaattg 8520
gagaagccgt aaaaacacag ttcaattatt ataagaaagt tgatggtgtt gtccaacaat 8580
tacctgaaac ttactttact cagagtagaa atttacaaga atttaaaccc aggagtcaaa 8640
tggaaattga tttcttagaa ttagctatgg atgaattcat tgaacggtat aaattagaag 8700
gctatgcctt cgaacatatc gtttatggag attttagtca tagtcagtta ggtggtgcga 8760
aattgttgtt gtt 8773
<210> 50
<211> 12
<212> DNA
<213> Artificial Sequence
<220>
<223> Furin cleavage site
<400> 50
cgaaaacggc gc 12
<210> 51
<211> 1273
<212> PRT
<213> Artificial Sequence
<220>
<223> Mutant S protein
<400> 51
Met Phe Val Phe Leu Val Leu Leu Pro Leu Val Ser Ser Gln Cys Val
1 5 10 15
Asn Leu Thr Thr Arg Thr Gln Leu Pro Pro Ala Tyr Thr Asn Ser Phe
20 25 30
Thr Arg Gly Val Tyr Tyr Pro Asp Lys Val Phe Arg Ser Ser Val Leu
35 40 45
His Ser Thr Gln Asp Leu Phe Leu Pro Phe Phe Ser Asn Val Thr Trp
50 55 60
Phe His Ala Ile His Val Ser Gly Thr Asn Gly Thr Lys Arg Phe Asp
65 70 75 80
Asn Pro Val Leu Pro Phe Asn Asp Gly Val Tyr Phe Ala Ser Thr Glu
85 90 95
Lys Ser Asn Ile Ile Arg Gly Trp Ile Phe Gly Thr Thr Leu Asp Ser
100 105 110
Lys Thr Gln Ser Leu Leu Ile Val Asn Asn Ala Thr Asn Val Val Ile
115 120 125
Lys Val Cys Glu Phe Gln Phe Cys Asn Asp Pro Phe Leu Gly Val Tyr
130 135 140
Tyr His Lys Asn Asn Lys Ser Trp Met Glu Ser Glu Phe Arg Val Tyr
145 150 155 160
Ser Ser Ala Asn Asn Cys Thr Phe Glu Tyr Val Ser Gln Pro Phe Leu
165 170 175
Met Asp Leu Glu Gly Lys Gln Gly Asn Phe Lys Asn Leu Arg Glu Phe
180 185 190
Val Phe Lys Asn Ile Asp Gly Tyr Phe Lys Ile Tyr Ser Lys His Thr
195 200 205
Pro Ile Asn Leu Val Arg Asp Leu Pro Gln Gly Phe Ser Ala Leu Glu
210 215 220
Pro Leu Val Asp Leu Pro Ile Gly Ile Asn Ile Thr Arg Phe Gln Thr
225 230 235 240
Leu Leu Ala Leu His Arg Ser Tyr Leu Thr Pro Gly Asp Ser Ser Ser
245 250 255
Gly Trp Thr Ala Gly Ala Ala Ala Tyr Tyr Val Gly Tyr Leu Gln Pro
260 265 270
Arg Thr Phe Leu Leu Lys Tyr Asn Glu Asn Gly Thr Ile Thr Asp Ala
275 280 285
Val Asp Cys Ala Leu Asp Pro Leu Ser Glu Thr Lys Cys Thr Leu Lys
290 295 300
Ser Phe Thr Val Glu Lys Gly Ile Tyr Gln Thr Ser Asn Phe Arg Val
305 310 315 320
Gln Pro Thr Glu Ser Ile Val Arg Phe Pro Asn Ile Thr Asn Leu Cys
325 330 335
Pro Phe Gly Glu Val Phe Asn Ala Thr Arg Phe Ala Ser Val Tyr Ala
340 345 350
Trp Asn Arg Lys Arg Ile Ser Asn Cys Val Ala Asp Tyr Ser Val Leu
355 360 365
Tyr Asn Ser Ala Ser Phe Ser Thr Phe Lys Cys Tyr Gly Val Ser Pro
370 375 380
Thr Lys Leu Asn Asp Leu Cys Phe Thr Asn Val Tyr Ala Asp Ser Phe
385 390 395 400
Val Ile Arg Gly Asp Glu Val Arg Gln Ile Ala Pro Gly Gln Thr Gly
405 410 415
Lys Ile Ala Asp Tyr Asn Tyr Lys Leu Pro Asp Asp Phe Thr Gly Cys
420 425 430
Val Ile Ala Trp Asn Ser Asn Asn Leu Asp Ser Lys Val Gly Gly Asn
435 440 445
Tyr Asn Tyr Leu Tyr Arg Leu Phe Arg Lys Ser Asn Leu Lys Pro Phe
450 455 460
Glu Arg Asp Ile Ser Thr Glu Ile Tyr Gln Ala Gly Ser Thr Pro Cys
465 470 475 480
Asn Gly Val Glu Gly Phe Asn Cys Tyr Phe Pro Leu Gln Ser Tyr Gly
485 490 495
Phe Gln Pro Thr Asn Gly Val Gly Tyr Gln Pro Tyr Arg Val Val Val
500 505 510
Leu Ser Phe Glu Leu Leu His Ala Pro Ala Thr Val Cys Gly Pro Lys
515 520 525
Lys Ser Thr Asn Leu Val Lys Asn Lys Cys Val Asn Phe Asn Phe Asn
530 535 540
Gly Leu Thr Gly Thr Gly Val Leu Thr Glu Ser Asn Lys Lys Phe Leu
545 550 555 560
Pro Phe Gln Gln Phe Gly Arg Asp Ile Ala Asp Thr Thr Asp Ala Val
565 570 575
Arg Asp Pro Gln Thr Leu Glu Ile Leu Asp Ile Thr Pro Cys Ser Phe
580 585 590
Gly Gly Val Ser Val Ile Thr Pro Gly Thr Asn Thr Ser Asn Gln Val
595 600 605
Ala Val Leu Tyr Gln Gly Val Asn Cys Thr Glu Val Pro Val Ala Ile
610 615 620
His Ala Asp Gln Leu Thr Pro Thr Trp Arg Val Tyr Ser Thr Gly Ser
625 630 635 640
Asn Val Phe Gln Thr Arg Ala Gly Cys Leu Ile Gly Ala Glu His Val
645 650 655
Asn Asn Ser Tyr Glu Cys Asp Ile Pro Ile Gly Ala Gly Ile Cys Ala
660 665 670
Ser Tyr Gln Thr Gln Thr Asn Ser Pro Gly Ser Ala Ser Ser Val Ala
675 680 685
Ser Gln Ser Ile Ile Ala Tyr Thr Met Ser Leu Gly Ala Glu Asn Ser
690 695 700
Val Ala Tyr Ser Asn Asn Ser Ile Ala Ile Pro Thr Asn Phe Thr Ile
705 710 715 720
Ser Val Thr Thr Glu Ile Leu Pro Val Ser Met Thr Lys Thr Ser Val
725 730 735
Asp Cys Thr Met Tyr Ile Cys Gly Asp Ser Thr Glu Cys Ser Asn Leu
740 745 750
Leu Leu Gln Tyr Gly Ser Phe Cys Thr Gln Leu Asn Arg Ala Leu Thr
755 760 765
Gly Ile Ala Val Glu Gln Asp Lys Asn Thr Gln Glu Val Phe Ala Gln
770 775 780
Val Lys Gln Ile Tyr Lys Thr Pro Pro Ile Lys Asp Phe Gly Gly Phe
785 790 795 800
Asn Phe Ser Gln Ile Leu Pro Asp Pro Ser Lys Pro Ser Lys Arg Ser
805 810 815
Phe Ile Glu Asp Leu Leu Phe Asn Lys Val Thr Leu Ala Asp Ala Gly
820 825 830
Phe Ile Lys Gln Tyr Gly Asp Cys Leu Gly Asp Ile Ala Ala Arg Asp
835 840 845
Leu Ile Cys Ala Gln Lys Phe Asn Gly Leu Thr Val Leu Pro Pro Leu
850 855 860
Leu Thr Asp Glu Met Ile Ala Gln Tyr Thr Ser Ala Leu Leu Ala Gly
865 870 875 880
Thr Ile Thr Ser Gly Trp Thr Phe Gly Ala Gly Ala Ala Leu Gln Ile
885 890 895
Pro Phe Ala Met Gln Met Ala Tyr Arg Phe Asn Gly Ile Gly Val Thr
900 905 910
Gln Asn Val Leu Tyr Glu Asn Gln Lys Leu Ile Ala Asn Gln Phe Asn
915 920 925
Ser Ala Ile Gly Lys Ile Gln Asp Ser Leu Ser Ser Thr Ala Ser Ala
930 935 940
Leu Gly Lys Leu Gln Asp Val Val Asn Gln Asn Ala Gln Ala Leu Asn
945 950 955 960
Thr Leu Val Lys Gln Leu Ser Ser Asn Phe Gly Ala Ile Ser Ser Val
965 970 975
Leu Asn Asp Ile Leu Ser Arg Leu Asp Pro Pro Glu Ala Glu Val Gln
980 985 990
Ile Asp Arg Leu Ile Thr Gly Arg Leu Gln Ser Leu Gln Thr Tyr Val
995 1000 1005
Thr Gln Gln Leu Ile Arg Ala Ala Glu Ile Arg Ala Ser Ala Asn
1010 1015 1020
Leu Ala Ala Thr Lys Met Ser Glu Cys Val Leu Gly Gln Ser Lys
1025 1030 1035
Arg Val Asp Phe Cys Gly Lys Gly Tyr His Leu Met Ser Phe Pro
1040 1045 1050
Gln Ser Ala Pro His Gly Val Val Phe Leu His Val Thr Tyr Val
1055 1060 1065
Pro Ala Gln Glu Lys Asn Phe Thr Thr Ala Pro Ala Ile Cys His
1070 1075 1080
Asp Gly Lys Ala His Phe Pro Arg Glu Gly Val Phe Val Ser Asn
1085 1090 1095
Gly Thr His Trp Phe Val Thr Gln Arg Asn Phe Tyr Glu Pro Gln
1100 1105 1110
Ile Ile Thr Thr Asp Asn Thr Phe Val Ser Gly Asn Cys Asp Val
1115 1120 1125
Val Ile Gly Ile Val Asn Asn Thr Val Tyr Asp Pro Leu Gln Pro
1130 1135 1140
Glu Leu Asp Ser Phe Lys Glu Glu Leu Asp Lys Tyr Phe Lys Asn
1145 1150 1155
His Thr Ser Pro Asp Val Asp Leu Gly Asp Ile Ser Gly Ile Asn
1160 1165 1170
Ala Ser Val Val Asn Ile Gln Lys Glu Ile Asp Arg Leu Asn Glu
1175 1180 1185
Val Ala Lys Asn Leu Asn Glu Ser Leu Ile Asp Leu Gln Glu Leu
1190 1195 1200
Gly Lys Tyr Glu Gln Tyr Ile Lys Trp Pro Trp Tyr Ile Trp Leu
1205 1210 1215
Gly Phe Ile Ala Gly Leu Ile Ala Ile Val Met Val Thr Ile Met
1220 1225 1230
Leu Cys Cys Met Thr Ser Cys Cys Ser Cys Leu Lys Gly Cys Cys
1235 1240 1245
Ser Cys Gly Ser Cys Cys Lys Phe Asp Glu Asp Asp Ser Glu Pro
1250 1255 1260
Val Leu Lys Gly Val Lys Leu His Tyr Thr
1265 1270
<210> 52
<211> 3819
<212> DNA
<213> Artificial Sequence
<220>
<223> Mutant S gene (CoVEG9)
<400> 52
atgttcgtgt tcctggtgct gctgcctctg gtcagctccc agtgtgtgaa cctgaccacc 60
agaacccagc tgccacctgc ttatacaaac tccttcactc ggggggtata ctaccccgac 120
aaggtgttca gatctagcgt gctgcattct acacaagacc tgttcctgcc cttcttcagc 180
aacgtgacct ggttccacgc catccacgtg tctggaacca acggaaccaa gagattcgac 240
aaccccgtgc tgcctttcaa cgacggcgtg tacttcgcca gcaccgagaa gtccaacatc 300
atcagaggat ggattttcgg caccacactg gacagcaaaa cccagagcct gctgatcgtg 360
aacaacgcca ccaacgtggt gatcaaggtg tgcgagttcc agttctgcaa tgatcccttc 420
ctgggcgtgt actaccacaa gaacaacaag tcttggatgg aaagcgagtt cagagtgtat 480
tccagcgcca acaattgcac cttcgagtac gtgagccaac cctttctgat ggaccttgaa 540
ggcaagcagg gcaacttcaa aaatctgcga gaatttgtgt tcaagaacat cgacggatac 600
ttcaagatct actctaagca cacgccaatc aacctggtga gagatctgcc ccagggcttt 660
agcgctttgg aacctctggt ggacctgcct atcggaatca acatcaccag atttcaaact 720
ctcctggccc tgcacagatc ttatctgacc cctggggaca gtagtagcgg ctggacagcc 780
ggcgccgccg cctactacgt gggatacctg cagcctagaa cattcctgct gaagtacaat 840
gagaacggaa caatcacaga cgccgtggac tgcgccctgg atcctttgag cgagacaaag 900
tgcaccctga agtcgttcac cgtcgaaaaa ggcatctacc agaccagcaa cttccgcgtg 960
cagcctacgg aatctatcgt gcggttcccc aacatcacca acctgtgccc tttcggcgag 1020
gtgtttaacg ctacaaggtt cgccagcgtg tatgcctgga acagaaagag aatcagcaat 1080
tgcgtggccg attatagcgt tctgtacaac agcgcttcct tcagcacctt caagtgctac 1140
ggcgtgtctc caaccaagct gaacgacctc tgcttcacca atgtctacgc tgactctttc 1200
gtgattagag gcgatgaggt tagacagatc gcacctggcc agaccggcaa aatcgctgac 1260
tacaactaca agctgcctga tgacttcaca ggctgtgtca ttgcctggaa ctcaaataac 1320
ctggactcta aagtgggcgg caactacaac tacctgtacc ggctgttccg gaagagcaat 1380
ctgaaacctt ttgagcggga catctctaca gagatctacc aggccggcag cacaccctgc 1440
aacggcgttg agggcttcaa ctgctacttc cctctgcaga gctacggctt tcagccaaca 1500
aatggagtgg gctaccagcc gtacagagtg gtggtgctga gcttcgaact gctgcatgcc 1560
ccagccacag tgtgtggacc taagaagtct accaacctgg tgaagaacaa gtgcgtgaac 1620
tttaacttta acggcctgac cggcacaggc gtgctgaccg aatccaacaa aaagttcctg 1680
cccttccaac agttcggcag agacatcgcc gatacaaccg atgccgtgcg ggacccccag 1740
accttagaaa tcctagatat caccccgtgc agcttcggcg gagtctctgt tattactcct 1800
ggcaccaaca ccagcaacca agtggctgtt ctgtaccaag gcgtgaactg caccgaagtg 1860
cctgtggcta tccacgccga tcagctgacc ccaacctggc gggtgtatag caccggctct 1920
aacgtgttcc agacccgggc tggctgcctg atcggcgccg aacacgtcaa caactcctat 1980
gaatgtgaca tccccatcgg ggctggcatc tgcgccagtt accagacaca gacaaatagc 2040
cctggcagcg ccagcagcgt ggcctcccag agtatcattg cctacaccat gagcctgggc 2100
gccgagaaca gcgtggccta ttctaacaat agcatcgcaa tccctaccaa ctttaccatc 2160
tctgtgacaa ccgagatcct gcctgtgagc atgaccaaaa ccagcgtgga ctgcacgatg 2220
tacatctgtg gcgacagcac agaatgcagt aatctgttgc tgcagtacgg cagcttttgc 2280
acccagttga atagagccct gaccggaatc gccgtagagc aggacaaaaa tacccaggag 2340
gtgttcgccc aggtgaaaca gatctacaag acacctccca ttaaggactt cggaggtttt 2400
aacttcagcc agatcctgcc cgacccttcc aagcctagca aacgctcctt catcgaggac 2460
ctgctcttca acaaggtgac actggctgat gccggcttca tcaagcagta cggagattgt 2520
ctgggagaca tcgccgctag agatctgatc tgcgcccaaa agttcaacgg cctgaccgtg 2580
ctgcctcctc tgcttacaga cgagatgatc gcccagtaca ccagcgccct gctggctggc 2640
accatcacaa gcggctggac cttcggagcc ggagccgctc tgcaaatccc ctttgccatg 2700
cagatggcct accggttcaa cggcatcggc gtgacacaga atgtgctgta cgagaaccag 2760
aagctgatcg ctaaccagtt taacagcgct atcggcaaga tccaggactc gctgagtagc 2820
accgcctctg ccctgggcaa gctgcaggac gtcgtgaacc agaacgccca agccctgaac 2880
acactggtga aacagctgag cagcaacttc ggcgccatca gctctgtgct gaacgatatc 2940
ctgagcagac tggaccctcc cgaagccgag gtccagatcg acagactgat cacaggaaga 3000
ctgcagagcc tgcaaacgta cgtgacacag cagctgatcc gggcagccga aatccgggcc 3060
agcgccaatc tggccgctac caagatgagc gagtgcgtgt taggccagag caagcgggtg 3120
gatttctgcg gtaagggata ccacctgatg agctttcccc agagcgctcc tcacggcgtg 3180
gtgtttctgc acgtgaccta cgttcctgcc caggaaaaga acttcaccac cgcccctgct 3240
atctgccacg atggcaaggc ccacttccct agagagggcg ttttcgtgtc taacggcaca 3300
cactggtttg tgacccagag aaacttctac gagcctcaga tcatcaccac agacaacacc 3360
tttgtgagcg gcaattgcga cgtggtgatc ggaattgtta ataataccgt gtacgaccct 3420
ctgcagcctg agctcgacag cttcaaggaa gagctggaca agtacttcaa gaaccacacc 3480
tccccagatg tggacctggg cgatatttca ggcatcaacg cctccgtcgt gaatatccag 3540
aaggagatcg accggctcaa cgaggtggcc aagaacctta acgagagcct gatcgacctg 3600
caggaactgg gcaaatatga gcagtacatc aagtggcctt ggtacatctg gctgggcttt 3660
atcgcaggcc tgatcgctat cgtgatggtg accattatgc tgtgttgtat gaccagctgt 3720
tgtagttgtc tgaagggctg ctgttcttgc ggcagctgct gcaagttcga cgaagacgac 3780
tcagagcccg tgctgaaagg cgtgaagctg cactacacc 3819
<210> 53
<211> 275
<212> PRT
<213> Artificial Sequence
<220>
<223> ORF3 protein
<400> 53
Met Asp Leu Phe Met Arg Ile Phe Thr Ile Gly Thr Val Thr Leu Lys
1 5 10 15
Gln Gly Glu Ile Lys Asp Ala Thr Pro Ser Asp Phe Val Arg Ala Thr
20 25 30
Ala Thr Ile Pro Ile Gln Ala Ser Leu Pro Phe Gly Trp Leu Ile Val
35 40 45
Gly Val Ala Leu Leu Ala Val Phe Gln Ser Ala Ser Lys Ile Ile Thr
50 55 60
Leu Lys Lys Arg Trp Gln Leu Ala Leu Ser Lys Gly Val His Phe Val
65 70 75 80
Cys Asn Leu Leu Leu Leu Phe Val Thr Val Tyr Ser His Leu Leu Leu
85 90 95
Val Ala Ala Gly Leu Glu Ala Pro Phe Leu Tyr Leu Tyr Ala Leu Val
100 105 110
Tyr Phe Leu Gln Ser Ile Asn Phe Val Arg Ile Ile Met Arg Leu Trp
115 120 125
Leu Cys Trp Lys Cys Arg Ser Lys Asn Pro Leu Leu Tyr Asp Ala Asn
130 135 140
Tyr Phe Leu Cys Trp His Thr Asn Cys Tyr Asp Tyr Cys Ile Pro Tyr
145 150 155 160
Asn Ser Val Thr Ser Ser Ile Val Ile Thr Ser Gly Asp Gly Thr Thr
165 170 175
Ser Pro Ile Ser Glu His Asp Tyr Gln Ile Gly Gly Tyr Thr Glu Lys
180 185 190
Trp Glu Ser Gly Val Lys Asp Cys Val Val Leu His Ser Tyr Phe Thr
195 200 205
Ser Asp Tyr Tyr Gln Leu Tyr Ser Thr Gln Leu Ser Thr Asp Thr Gly
210 215 220
Val Glu His Val Thr Phe Phe Ile Tyr Asn Lys Ile Val Asp Glu Pro
225 230 235 240
Glu Glu His Val Gln Ile His Thr Ile Asp Gly Ser Ser Gly Val Val
245 250 255
Asn Pro Val Met Glu Pro Ile Tyr Asp Glu Pro Thr Thr Thr Thr Ser
260 265 270
Val Pro Leu
275
<210> 54
<211> 828
<212> DNA
<213> Artificial Sequence
<220>
<223> ORF3 gene (CoVEG14)
<400> 54
atggacctgt tcatgagaat cttcaccatc ggcaccgtga cactgaagca gggcgagatc 60
aaggatgcca cccctagcga cttcgtgaga gccaccgcca caattcctat ccaggctagc 120
ctgccttttg gatggctgat cgtgggcgtc gccctgctcg ccgtgttcca gagcgcctct 180
aagatcatta cactgaagaa aagatggcag ctggccctct ccaaaggcgt gcacttcgtg 240
tgtaatctgc tgctgctttt tgtgacagtg tacagccacc tgctgctggt tgctgctggc 300
ctggaagccc ctttcctgta cctgtacgcc ctggtctact tcctgcagtc tatcaacttc 360
gtgcggatca tcatgcggct gtggctgtgc tggaagtgca gaagcaagaa cccactgctg 420
tacgacgcca attacttcct gtgttggcac accaactgct acgactactg catcccctac 480
aacagcgtga ccagcagcat cgtgatcacc tctggcgacg gaacaaccag ccctatcagc 540
gagcatgatt accagatcgg cggatataca gagaagtggg agagcggcgt gaaggactgc 600
gtggtgctgc acagctactt tacctccgat tactaccaac tgtattctac ccagctgagc 660
accgacaccg gcgtggaaca cgtgaccttc ttcatctaca acaagatcgt ggacgagcct 720
gaggaacacg tgcagatcca cactatcgac ggcagctctg gcgttgtgaa ccctgtgatg 780
gaacccatct acgatgagcc caccacaaca acctccgtgc ccctgtaa 828
<210> 55
<211> 5651
<212> DNA
<213> Artificial Sequence
<220>
<223> WNV Minimal plasmid sequence
<400> 55
gactcttcgc gatgtacggg ccagatatac gcgttgacat tgattattga ctagttatta 60
atagtaatca attacggggt cattagttca tagcccatat atggagttcc gcgttacata 120
acttacggta aatggcccgc ctggctgacc gcccaacgac ccccgcccat tgacgtcaat 180
aatgacgtat gttcccatag taacgccaat agggactttc cattgacgtc aatgggtgga 240
ctatttacgg taaactgccc acttggcagt acatcaagtg tatcatatgc caagtacgcc 300
ccctattgac gtcaatgacg gtaaatggcc cgcctggcat tatgcccagt acatgacctt 360
atgggacttt cctacttggc agtacatcta cgtattagtc atcgctatta ccatggtgat 420
gcggttttgg cagtacatca atgggcgtgg atagcggttt gactcacggg gatttccaag 480
tctccacccc attgacgtca atgggagttt gttttggcac caaaatcaac gggactttcc 540
aaaatgtcgt aacaactccg ccccattgac gcaaatgggc ggtaggcgtg tacggtggga 600
ggtctatata agcagagctg gtttagtgaa ccgtcagatc cgctagcgct accggactca 660
gatctcgagc tcaagcttcg aattctgcag tcgacggtac cgcgggcccg ggatccaccg 720
gtcgccacat gggcggcaag acaggcatcg ccgtgatgat cggcctgatc gcctccgtgg 780
gcgccgtgac cctgagcaac ttccagggca aggtgatgat gacagtgaac gccacagatg 840
ttaccgatgt tatcacaatc cctaccgccg ctggaaagaa cttgtgcatc gtacgggcca 900
tggatgtggg gtacatgtgc gacgacacca tcacctacga gtgccctgtg ctgagcgccg 960
gcaatgaccc cgaggacatc gactgctggt gcaccaagtc tgccgtttac gtgagatatg 1020
gcaggtgtac caaaaccaga cacagcagga gatctcggag aagcctgacc gtgcaaacac 1080
acggcgagtc caccctggcc aacaagaagg gcgcatggat ggacagcacc aaggccactc 1140
ggtacctggt gaagaccgag agctggatcc tgagaaaccc tggatacgcc ctggtggccg 1200
ccgtgattgg ctggatgctg ggctctaaca ccatgcagag agtggtgttc gtggtgctac 1260
tgctcctagt ggctcctgct tacagcttca actgcctggg catgtctaac cgggacttcc 1320
tggaaggcgt gtccggcgct acatgggtgg acctggtgct cgagggagat agctgcgtga 1380
ccatcatgtc aaaggacaag cccaccatcg acgtgaaaat gatgaacatg gaagctgcta 1440
atctggccga ggtcagatct tactgctacc tggccacagt gagtgatctg agcacaaagg 1500
ccgcctgccc caccatgggc gaggcccaca acgataagcg ggccgatcct gccttcgtgt 1560
gtagacaggg cgtggtggac cggggatggg gcaacggctg cgggctgttc ggcaagggca 1620
gcatcgatac ctgtgccaaa ttcgcctgta gcaccaaggc catcggccgg accattctga 1680
aagaaaacat caagtacgag gtggctatct tcgtgcatgg ccctaccacc gtcgagagcc 1740
acggcaacta ctccacacag gtgggcgcca cacaggccgg ccgattttct atcacacctg 1800
ccgcccccag ctatacactg aaactgggcg agtacggcga agtgacagtg gattgcgagc 1860
ctagaagcgg catcgacact aacgcctact acgtgatgac cgtgggcaca aaaaccttcc 1920
tggttcacag agagtggttc atggacctga acctgccttg gtccagcgcc ggcagcaccg 1980
tgtggcgcaa tagagagaca ctgatggaat tcgaggaacc tcacgccacc aagcagagcg 2040
tgatcgccct cggtagccag gagggcgccc tgcaccaggc cctggctggc gccatccccg 2100
tggaattctc tagcaacacc gtgaaactga ccagcggcca cctgaagtgc agagtgaaga 2160
tggaaaagct ccaactgaag ggaacaactt acggcgtctg cagcaaggct ttcaagttcc 2220
tgggcacccc tgccgacacc ggacacggaa ccgtcgtgct ggaactgcag tacaccggca 2280
cagacggccc atgtaaagtg cctatcagca gcgtggcctc cctgaacgac ctgacaccag 2340
tgggcagact ggtgaccgtt aatcctttcg tcagcgtggc tactgccaat gccaaggtgc 2400
tgatcgagct ggaacccccc ttcggcgact cttatatcgt ggtgggaaga ggagaacaac 2460
agatcaacca ccactggcac aagagcggtt cgtctatcgg aaaggctttt accaccacac 2520
tgaagggcgc tcagcggctg gccgccctgg gcgacacagc ctgggacttc ggcagcgtgg 2580
gcggagtatt tacgtccgtc ggcaaggccg tccatcaggt gtttggagga gcctttcgga 2640
gcctgttcgg aggcatgagc tggatcaccc agggcctgct gggcgcgctg ctgctgtgga 2700
tgggaattaa cgccagagat agaagcatcg ccctgacatt cctggccgtg ggcggcgtgc 2760
tgctgtttct gtctgtgaac gtgcacgcgt aacccccccc cctaacgtta ctggccgaag 2820
ccgcttggaa taaggccggt gtgcgtttgt ctatatgtta ttttccacca tattgccgtc 2880
ttttggcaat gtgagggccc ggaaacctgg ccctgtcttc ttgacgagca ttcctagggg 2940
tctttcccct ctcgccaaag gaatgcaagg tctgttgaat gtcgtgaagg aagcagttcc 3000
tctggaagct tcttgaagac aaacaacgtc tgtagcgacc ctttgcaggc agcggaaccc 3060
cccacctggc gacaggtgcc tctgcggcca aaagccacgt gtataagata cacctgcaaa 3120
ggcggcacaa ccccagtgcc acgttgtgag ttggatagtt gtggaaagag tcaaatggct 3180
ctcctcaagc gtattcaaca aggggctgaa ggatgcccag aaggtacccc attgtatggg 3240
atctgatctg gggcctcggt gcacatgctt tacatgtgtt tagtcgaggt taaaaaaacg 3300
tctaggcccc ccgaaccacg gggacgtggt tttcctttga aaaacacgat gataatatgg 3360
ccacaaccat ggaacaagag acttgcgcgc actctctcac ttttgaggaa tgcccaaaat 3420
gctctgctct acaataccgt aatggatttt acctgctaaa gtatgatgaa gaatggtacc 3480
cagaggagtt attgactgat ggagaggatg atgtctttga tcccgaatta gacatggaag 3540
tcgttttcga gttacagtaa gcgaaattgt tgttgttaac ttgtttattg cagcttataa 3600
tggttacaaa taaagcaata gcatcacaaa tttcacaaat aaagcatttt tttcactgca 3660
ttctagttgt ggtttgtcca aactcatcaa tgtatcttaa ggcgtcttct actgggcggt 3720
tttatggaca gcaagcgaac cggaattgcc agctggggcg ccctctggta aggttgggaa 3780
gccctgcaaa gtaaactgga tggctttctc gccgccaagg atctgatggc gcaggggatc 3840
aagctctgat caagagacag gatgaggatc gtttcgcatg attgaacaag atggattgca 3900
cgcaggttct ccggccgctt gggtggagag gctattcggc tatgactggg cacaacagac 3960
aatcggctgc tctgatgccg ccgtgttccg gctgtcagcg caggggcgcc cggttctttt 4020
tgtcaagacc gacctgtccg gtgccctgaa tgaactgcaa gacgaggcag cgcggctatc 4080
gtggctggcc acgacgggcg ttccttgcgc agctgtgctc gacgttgtca ctgaagcggg 4140
aagggactgg ctgctattgg gcgaagtgcc ggggcaggat ctcctgtcat ctcaccttgc 4200
tcctgccgag aaagtatcca tcatggctga tgcaatgcgg cggctgcata cgcttgatcc 4260
ggctacctgc ccattcgacc accaagcgaa acatcgcatc gagcgagcac gtactcggat 4320
ggaagccggt cttgtcgatc aggatgatct ggacgaagag catcaggggc tcgcgccagc 4380
cgaactgttc gccaggctca aggcgagcat gcccgacggc gaggatctcg tcgtgaccca 4440
tggcgatgcc tgcttgccga atatcatggt ggaaaatggc cgcttttctg gattcatcga 4500
ctgtggccgg ctgggtgtgg cggaccgcta tcaggacata gcgttggcta cccgtgatat 4560
tgctgaagag cttggcggcg aatgggctga ccgcttcctc gtgctttacg gtatcgccgc 4620
tcccgattcg cagcgcatcg ccttctatcg ccttcttgac gagttcttct gaattattaa 4680
cgcttacaat ttcctgatgc ggtattttct ccttacgcat ctgtgcggta tttcacaccg 4740
catacaggtg gcacttttcg gggaaatgtg cgcggaaccc ctatttgttt atttttctaa 4800
atacattcaa atatgtatcc gctcatgaga caataaccct gataaatgct tcaataatag 4860
cacgtgctaa aacttcattt ttaatttaaa aggatctagg tgaagatcct ttttgataat 4920
ctcatgacca aaatccctta acgtgagttt tcgttccact gagcgtcaga ccccgtagaa 4980
aagatcaaag gatcttcttg agatcctttt tttctgcgcg taatctgctg cttgcaaaca 5040
aaaaaaccac cgctaccagc ggtggtttgt ttgccggatc aagagctacc aactcttttt 5100
ccgaaggtaa ctggcttcag cagagcgcag ataccaaata ctgtccttct agtgtagccg 5160
tagttaggcc accacttcaa gaactctgta gcaccgccta catacctcgc tctgctaatc 5220
ctgttaccag tggctgctgc cagtggcgat aagtcgtgtc ttaccgggtt ggactcaaga 5280
cgatagttac cggataaggc gcagcggtcg ggctgaacgg ggggttcgtg cacacagccc 5340
agcttggagc gaacgaccta caccgaactg agatacctac agcgtgagct atgagaaagc 5400
gccacgcttc ccgaagggag aaaggcggac aggtatccgg taagcggcag ggtcggaaca 5460
ggagagcgca cgagggagct tccaggggga aacgcctggt atctttatag tcctgtcggg 5520
tttcgccacc tctgacttga gcgtcgattt ttgtgatgct cgtcaggggg gcggagccta 5580
tggaaaaacg ccagcaacgc ggccttttta cggttcctgg gcttttgctg gccttttgct 5640
cacatgttct t 5651
<210> 56
<211> 255
<212> DNA
<213> Artificial Sequence
<220>
<223> Origin
<400> 56
ttgagatcct ttttttctgc gcgtaatctg ctgcttgcaa acaaaaaaac caccgctacc 60
agcggtggtt tgtttgccgg atcaagagct accaactctt tttccgaagg taactggctt 120
cagcagagcg cagataccaa atactgtcct tctagtgtag ccgtagttag gccaccactt 180
caagaactct gtagcaccgc ctacatacct cgctctgcta atcctgttac cagtggctgc 240
tgccagtggc gataa 255
<210> 57
<211> 584
<212> DNA
<213> Artificial Sequence
<220>
<223> CMV promoter and enhancer sequence
<400> 57
gacattgatt attgactagt tattaatagt aatcaattac ggggtcatta gttcatagcc 60
catatatgga gttccgcgtt acataactta cggtaaatgg cccgcctggc tgaccgccca 120
acgacccccg cccattgacg tcaataatga cgtatgttcc catagtaacg ccaataggga 180
ctttccattg acgtcaatgg gtggactatt tacggtaaac tgcccacttg gcagtacatc 240
aagtgtatca tatgccaagt acgcccccta ttgacgtcaa tgacggtaaa tggcccgcct 300
ggcattatgc ccagtacatg accttatggg actttcctac ttggcagtac atctacgtat 360
tagtcatcgc tattaccatg gtgatgcggt tttggcagta catcaatggg cgtggatagc 420
ggtttgactc acggggattt ccaagtctcc accccattga cgtcaatggg agtttgtttt 480
ggcaccaaaa tcaacgggac tttccaaaat gtcgtaacaa ctccgcccca ttgacgcaaa 540
tgggcggtag gcgtgtacgg tgggaggtct atataagcag agct 584
<210> 58
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> Signal sequence
<400> 58
ggcggcaaga caggcatcgc cgtgatgatc ggcctgatcg cctccgtggg cgcc 54
<210> 59
<211> 501
<212> DNA
<213> Artificial Sequence
<220>
<223> prM gene
<400> 59
gtgaccctga gcaacttcca gggcaaggtg atgatgacag tgaacgccac agatgttacc 60
gatgttatca caatccctac cgccgctgga aagaacttgt gcatcgtacg ggccatggat 120
gtggggtaca tgtgcgacga caccatcacc tacgagtgcc ctgtgctgag cgccggcaat 180
gaccccgagg acatcgactg ctggtgcacc aagtctgccg tttacgtgag atatggcagg 240
tgtaccaaaa ccagacacag caggagatct cggagaagcc tgaccgtgca aacacacggc 300
gagtccaccc tggccaacaa gaagggcgca tggatggaca gcaccaaggc cactcggtac 360
ctggtgaaga ccgagagctg gatcctgaga aaccctggat acgccctggt ggccgccgtg 420
attggctgga tgctgggctc taacaccatg cagagagtgg tgttcgtggt gctactgctc 480
ctagtggctc ctgcttacag c 501
<210> 60
<211> 1506
<212> DNA
<213> Artificial Sequence
<220>
<223> Envelope gene
<400> 60
ttcaactgcc tgggcatgtc taaccgggac ttcctggaag gcgtgtccgg cgctacatgg 60
gtggacctgg tgctcgaggg agatagctgc gtgaccatca tgtcaaagga caagcccacc 120
atcgacgtga aaatgatgaa catggaagct gctaatctgg ccgaggtcag atcttactgc 180
tacctggcca cagtgagtga tctgagcaca aaggccgcct gccccaccat gggcgaggcc 240
cacaacgata agcgggccga tcctgccttc gtgtgtagac agggcgtggt ggaccgggga 300
tggggcaacg gctgcgggct gttcggcaag ggcagcatcg atacctgtgc caaattcgcc 360
tgtagcacca aggccatcgg ccggaccatt ctgaaagaaa acatcaagta cgaggtggct 420
atcttcgtgc atggccctac caccgtcgag agccacggca actactccac acaggtgggc 480
gccacacagg ccggccgatt ttctatcaca cctgccgccc ccagctatac actgaaactg 540
ggcgagtacg gcgaagtgac agtggattgc gagcctagaa gcggcatcga cactaacgcc 600
tactacgtga tgaccgtggg cacaaaaacc ttcctggttc acagagagtg gttcatggac 660
ctgaacctgc cttggtccag cgccggcagc accgtgtggc gcaatagaga gacactgatg 720
gaattcgagg aacctcacgc caccaagcag agcgtgatcg ccctcggtag ccaggagggc 780
gccctgcacc aggccctggc tggcgccatc cccgtggaat tctctagcaa caccgtgaaa 840
ctgaccagcg gccacctgaa gtgcagagtg aagatggaaa agctccaact gaagggaaca 900
acttacggcg tctgcagcaa ggctttcaag ttcctgggca cccctgccga caccggacac 960
ggaaccgtcg tgctggaact gcagtacacc ggcacagacg gcccatgtaa agtgcctatc 1020
agcagcgtgg cctccctgaa cgacctgaca ccagtgggca gactggtgac cgttaatcct 1080
ttcgtcagcg tggctactgc caatgccaag gtgctgatcg agctggaacc ccccttcggc 1140
gactcttata tcgtggtggg aagaggagaa caacagatca accaccactg gcacaagagc 1200
ggttcgtcta tcggaaaggc ttttaccacc acactgaagg gcgctcagcg gctggccgcc 1260
ctgggcgaca cagcctggga cttcggcagc gtgggcggag tatttacgtc cgtcggcaag 1320
gccgtccatc aggtgtttgg aggagccttt cggagcctgt tcggaggcat gagctggatc 1380
acccagggcc tgctgggcgc gctgctgctg tggatgggaa ttaacgccag agatagaagc 1440
atcgccctga cattcctggc cgtgggcggc gtgctgctgt ttctgtctgt gaacgtgcac 1500
gcgtaa 1506
<210> 61
<211> 563
<212> DNA
<213> Artificial Sequence
<220>
<223> IRES encoding sequence
<400> 61
cccccccccc taacgttact ggccgaagcc gcttggaata aggccggtgt gcgtttgtct 60
atatgttatt ttccaccata ttgccgtctt ttggcaatgt gagggcccgg aaacctggcc 120
ctgtcttctt gacgagcatt cctaggggtc tttcccctct cgccaaagga atgcaaggtc 180
tgttgaatgt cgtgaaggaa gcagttcctc tggaagcttc ttgaagacaa acaacgtctg 240
tagcgaccct ttgcaggcag cggaaccccc cacctggcga caggtgcctc tgcggccaaa 300
agccacgtgt ataagataca cctgcaaagg cggcacaacc ccagtgccac gttgtgagtt 360
ggatagttgt ggaaagagtc aaatggctct cctcaagcgt attcaacaag gggctgaagg 420
atgcccagaa ggtaccccat tgtatgggat ctgatctggg gcctcggtgc acatgcttta 480
catgtgttta gtcgaggtta aaaaaacgtc taggcccccc gaaccacggg gacgtggttt 540
tcctttgaaa aacacgatga taa 563
<210> 62
<211> 204
<212> DNA
<213> Artificial Sequence
<220>
<223> EMCV L protein encoding sequence
<400> 62
atggccacaa ccatggaaca agagacttgc gcgcactctc tcacttttga ggaatgccca 60
aaatgctctg ctctacaata ccgtaatgga ttttacctgc taaagtatga tgaagaatgg 120
tacccagagg agttattgac tgatggagag gatgatgtct ttgatcccga attagacatg 180
gaagtcgttt tcgagttaca gtaa 204
<210> 63
<211> 122
<212> DNA
<213> Artificial Sequence
<220>
<223> SV40 poly A encoding sequence
<400> 63
aacttgttta ttgcagctta taatggttac aaataaagca atagcatcac aaatttcaca 60
aataaagcat ttttttcact gcattctagt tgtggtttgt ccaaactcat caatgtatct 120
ta 122
<210> 64
<211> 2203
<212> DNA
<213> Artificial Sequence
<220>
<223> Expression cassette of WNV standard plasmid
<400> 64
atgggcggca agacaggcat cgccgtgatg atcggcctga tcgcctccgt gggcgccgtg 60
accctgagca acttccaggg caaggtgatg atgacagtga acgccacaga tgttaccgat 120
gttatcacaa tccctaccgc cgctggaaag aacttgtgca tcgtacgggc catggatgtg 180
gggtacatgt gcgacgacac catcacctac gagtgccctg tgctgagcgc cggcaatgac 240
cccgaggaca tcgactgctg gtgcaccaag tctgccgttt acgtgagata tggcaggtgt 300
accaaaacca gacacagcag gagatctcgg agaagcctga ccgtgcaaac acacggcgag 360
tccaccctgg ccaacaagaa gggcgcatgg atggacagca ccaaggccac tcggtacctg 420
gtgaagaccg agagctggat cctgagaaac cctggatacg ccctggtggc cgccgtgatt 480
ggctggatgc tgggctctaa caccatgcag agagtggtgt tcgtggtgct actgctccta 540
gtggctcctg cttacagctt caactgcctg ggcatgtcta accgggactt cctggaaggc 600
gtgtccggcg ctacatgggt ggacctggtg ctcgagggag atagctgcgt gaccatcatg 660
tcaaaggaca agcccaccat cgacgtgaaa atgatgaaca tggaagctgc taatctggcc 720
gaggtcagat cttactgcta cctggccaca gtgagtgatc tgagcacaaa ggccgcctgc 780
cccaccatgg gcgaggccca caacgataag cgggccgatc ctgccttcgt gtgtagacag 840
ggcgtggtgg accggggatg gggcaacggc tgcgggctgt tcggcaaggg cagcatcgat 900
acctgtgcca aattcgcctg tagcaccaag gccatcggcc ggaccattct gaaagaaaac 960
atcaagtacg aggtggctat cttcgtgcat ggccctacca ccgtcgagag ccacggcaac 1020
tactccacac aggtgggcgc cacacaggcc ggccgatttt ctatcacacc tgccgccccc 1080
agctatacac tgaaactggg cgagtacggc gaagtgacag tggattgcga gcctagaagc 1140
ggcatcgaca ctaacgccta ctacgtgatg accgtgggca caaaaacctt cctggttcac 1200
agagagtggt tcatggacct gaacctgcct tggtccagcg ccggcagcac cgtgtggcgc 1260
aatagagaga cactgatgga attcgaggaa cctcacgcca ccaagcagag cgtgatcgcc 1320
ctcggtagcc aggagggcgc cctgcaccag gccctggctg gcgccatccc cgtggaattc 1380
tctagcaaca ccgtgaaact gaccagcggc cacctgaagt gcagagtgaa gatggaaaag 1440
ctccaactga agggaacaac ttacggcgtc tgcagcaagg ctttcaagtt cctgggcacc 1500
cctgccgaca ccggacacgg aaccgtcgtg ctggaactgc agtacaccgg cacagacggc 1560
ccatgtaaag tgcctatcag cagcgtggcc tccctgaacg acctgacacc agtgggcaga 1620
ctggtgaccg ttaatccttt cgtcagcgtg gctactgcca atgccaaggt gctgatcgag 1680
ctggaacccc ccttcggcga ctcttatatc gtggtgggaa gaggagaaca acagatcaac 1740
caccactggc acaagagcgg ttcgtctatc ggaaaggctt ttaccaccac actgaagggc 1800
gctcagcggc tggccgccct gggcgacaca gcctgggact tcggcagcgt gggcggagta 1860
tttacgtccg tcggcaaggc cgtccatcag gtgtttggag gagcctttcg gagcctgttc 1920
ggaggcatga gctggatcac ccagggcctg ctgggcgcgc tgctgctgtg gatgggaatt 1980
aacgccagag atagaagcat cgccctgaca ttcctggccg tgggcggcgt gctgctgttt 2040
ctgtctgtga acgtgcacgc gtaagcgaaa ttgttgttgt taacttgttt attgcagctt 2100
ataatggtta caaataaagc aatagcatca caaatttcac aaataaagca tttttttcac 2160
tgcattctag ttgtggtttg tccaaactca tcaatgtatc tta 2203
<210> 65
<211> 4591
<212> DNA
<213> Artificial Sequence
<220>
<223> Control S only plasmid expression cassette
<400> 65
atgttcgtgt tcctggtgct gctgcctctg gtcagctccc agtgtgtgaa cctgaccacc 60
agaacccagc tgccacctgc ttatacaaac tccttcactc ggggggtata ctaccccgac 120
aaggtgttca gatctagcgt gctgcattct acacaagacc tgttcctgcc cttcttcagc 180
aacgtgacct ggttccacgc catccacgtg tctggaacca acggaaccaa gagattcgac 240
aaccccgtgc tgcctttcaa cgacggcgtg tacttcgcca gcaccgagaa gtccaacatc 300
atcagaggat ggattttcgg caccacactg gacagcaaaa cccagagcct gctgatcgtg 360
aacaacgcca ccaacgtggt gatcaaggtg tgcgagttcc agttctgcaa tgatcccttc 420
ctgggcgtgt actaccacaa gaacaacaag tcttggatgg aaagcgagtt cagagtgtat 480
tccagcgcca acaattgcac cttcgagtac gtgagccaac cctttctgat ggaccttgaa 540
ggcaagcagg gcaacttcaa aaatctgcga gaatttgtgt tcaagaacat cgacggatac 600
ttcaagatct actctaagca cacgccaatc aacctggtga gagatctgcc ccagggcttt 660
agcgctttgg aacctctggt ggacctgcct atcggaatca acatcaccag atttcaaact 720
ctcctggccc tgcacagatc ttatctgacc cctggggaca gtagtagcgg ctggacagcc 780
ggcgccgccg cctactacgt gggatacctg cagcctagaa cattcctgct gaagtacaat 840
gagaacggaa caatcacaga cgccgtggac tgcgccctgg atcctttgag cgagacaaag 900
tgcaccctga agtcgttcac cgtcgaaaaa ggcatctacc agaccagcaa cttccgcgtg 960
cagcctacgg aatctatcgt gcggttcccc aacatcacca acctgtgccc tttcggcgag 1020
gtgtttaacg ctacaaggtt cgccagcgtg tatgcctgga acagaaagag aatcagcaat 1080
tgcgtggccg attatagcgt tctgtacaac agcgcttcct tcagcacctt caagtgctac 1140
ggcgtgtctc caaccaagct gaacgacctc tgcttcacca atgtctacgc tgactctttc 1200
gtgattagag gcgatgaggt tagacagatc gcacctggcc agaccggcaa aatcgctgac 1260
tacaactaca agctgcctga tgacttcaca ggctgtgtca ttgcctggaa ctcaaataac 1320
ctggactcta aagtgggcgg caactacaac tacctgtacc ggctgttccg gaagagcaat 1380
ctgaaacctt ttgagcggga catctctaca gagatctacc aggccggcag cacaccctgc 1440
aacggcgttg agggcttcaa ctgctacttc cctctgcaga gctacggctt tcagccaaca 1500
aatggagtgg gctaccagcc gtacagagtg gtggtgctga gcttcgaact gctgcatgcc 1560
ccagccacag tgtgtggacc taagaagtct accaacctgg tgaagaacaa gtgcgtgaac 1620
tttaacttta acggcctgac cggcacaggc gtgctgaccg aatccaacaa aaagttcctg 1680
cccttccaac agttcggcag agacatcgcc gatacaaccg atgccgtgcg ggacccccag 1740
accttagaaa tcctagatat caccccgtgc agcttcggcg gagtctctgt tattactcct 1800
ggcaccaaca ccagcaacca agtggctgtt ctgtaccaag gcgtgaactg caccgaagtg 1860
cctgtggcta tccacgccga tcagctgacc ccaacctggc gggtgtatag caccggctct 1920
aacgtgttcc agacccgggc tggctgcctg atcggcgccg aacacgtcaa caactcctat 1980
gaatgtgaca tccccatcgg ggctggcatc tgcgccagtt accagacaca gacaaatagc 2040
cctggcagcg ccagcagcgt ggcctcccag agtatcattg cctacaccat gagcctgggc 2100
gccgagaaca gcgtggccta ttctaacaat agcatcgcaa tccctaccaa ctttaccatc 2160
tctgtgacaa ccgagatcct gcctgtgagc atgaccaaaa ccagcgtgga ctgcacgatg 2220
tacatctgtg gcgacagcac agaatgcagt aatctgttgc tgcagtacgg cagcttttgc 2280
acccagttga atagagccct gaccggaatc gccgtagagc aggacaaaaa tacccaggag 2340
gtgttcgccc aggtgaaaca gatctacaag acacctccca ttaaggactt cggaggtttt 2400
aacttcagcc agatcctgcc cgacccttcc aagcctagca aacgctcctt catcgaggac 2460
ctgctcttca acaaggtgac actggctgat gccggcttca tcaagcagta cggagattgt 2520
ctgggagaca tcgccgctag agatctgatc tgcgcccaaa agttcaacgg cctgaccgtg 2580
ctgcctcctc tgcttacaga cgagatgatc gcccagtaca ccagcgccct gctggctggc 2640
accatcacaa gcggctggac cttcggagcc ggagccgctc tgcaaatccc ctttgccatg 2700
cagatggcct accggttcaa cggcatcggc gtgacacaga atgtgctgta cgagaaccag 2760
aagctgatcg ctaaccagtt taacagcgct atcggcaaga tccaggactc gctgagtagc 2820
accgcctctg ccctgggcaa gctgcaggac gtcgtgaacc agaacgccca agccctgaac 2880
acactggtga aacagctgag cagcaacttc ggcgccatca gctctgtgct gaacgatatc 2940
ctgagcagac tggaccctcc cgaagccgag gtccagatcg acagactgat cacaggaaga 3000
ctgcagagcc tgcaaacgta cgtgacacag cagctgatcc gggcagccga aatccgggcc 3060
agcgccaatc tggccgctac caagatgagc gagtgcgtgt taggccagag caagcgggtg 3120
gatttctgcg gtaagggata ccacctgatg agctttcccc agagcgctcc tcacggcgtg 3180
gtgtttctgc acgtgaccta cgttcctgcc caggaaaaga acttcaccac cgcccctgct 3240
atctgccacg atggcaaggc ccacttccct agagagggcg ttttcgtgtc taacggcaca 3300
cactggtttg tgacccagag aaacttctac gagcctcaga tcatcaccac agacaacacc 3360
tttgtgagcg gcaattgcga cgtggtgatc ggaattgtta ataataccgt gtacgaccct 3420
ctgcagcctg agctcgacag cttcaaggaa gagctggaca agtacttcaa gaaccacacc 3480
tccccagatg tggacctggg cgatatttca ggcatcaacg cctccgtcgt gaatatccag 3540
aaggagatcg accggctcaa cgaggtggcc aagaacctta acgagagcct gatcgacctg 3600
caggaactgg gcaaatatga gcagtacatc aagtggcctt ggtacatctg gctgggcttt 3660
atcgcaggcc tgatcgctat cgtgatggtg accattatgc tgtgttgtat gaccagctgt 3720
tgtagttgtc tgaagggctg ctgttcttgc ggcagctgct gcaagttcga cgaagacgac 3780
tcagagcccg tgctgaaagg cgtgaagctg cactacacct aatccccccc ccctaacgtt 3840
actggccgaa gccgcttgga ataaggccgg tgtgcgtttg tctatatgtt attttccacc 3900
atattgccgt cttttggcaa tgtgagggcc cggaaacctg gccctgtctt cttgacgagc 3960
attcctaggg gtctttcccc tctcgccaaa ggaatgcaag gtctgttgaa tgtcgtgaag 4020
gaagcagttc ctctggaagc ttcttgaaga caaacaacgt ctgtagcgac cctttgcagg 4080
cagcggaacc ccccacctgg cgacaggtgc ctctgcggcc aaaagccacg tgtataagat 4140
acacctgcaa aggcggcaca accccagtgc cacgttgtga gttggatagt tgtggaaaga 4200
gtcaaatggc tctcctcaag cgtattcaac aaggggctga aggatgccca gaaggtaccc 4260
cattgtatgg gatctgatct ggggcctcgg tgcacatgct ttacatgtgt ttagtcgagg 4320
ttaaaaaaac gtctaggccc cccgaaccac ggggacgtgg ttttcctttg aaaaacacga 4380
tgataatatg gccacaacca tggaacaaga gacttgcgcg cactctctca cttttgagga 4440
atgcccaaaa tgctctgctc tacaataccg taatggattt tacctgctaa agtatgatga 4500
agaatggtac ccagaggagt tattgactga tggagaggat gatgtctttg atcccgaatt 4560
agacatggaa gtcgttttcg agttacagta a 4591
<210> 66
<211> 669
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS CoV2 M gene
<400> 66
atggccgaca gcaacggcac aatcaccgtg gaagagctga agaaactgct ggaacagtgg 60
aacctggtca tcggcttcct gtttctgacc tggatctgtc tgctgcagtt cgcttatgcc 120
aatcggaaca gattcctgta catcatcaag ctgatcttcc tgtggctgct gtggcctgtg 180
accctggctt gcttcgtgct ggccgctgtg taccggatca actggatcac aggcggaatc 240
gccatcgcca tggcctgcct ggtgggcctg atgtggctga gctacttcat cgcttctttc 300
agactgttcg ccagaacccg gagcatgtgg tccttcaacc ccgagacaaa catcctgctg 360
aacgtgcctc tgcacggcac catcctgaca agacctctgc tcgagagcga gctggtgatt 420
ggcgcagtga ttctgagagg ccatctgagg atcgccggac accacctggg cagatgcgac 480
atcaaggacc ttccaaagga aatcaccgtt gccaccagcc ggaccctgtc ctactacaaa 540
ctgggcgcca gccaaagagt ggccggcgat agcggctttg ccgcctacag cagataccgc 600
atcggaaatt acaagctcaa caccgaccac agcagctctt ctgataacat cgccctgctg 660
gtgcagtaa 669
<210> 67
<211> 565
<212> DNA
<213> Artificial Sequence
<220>
<223> IRES encoding sequence
<400> 67
tccccccccc ctaacgttac tggccgaagc cgcttggaat aaggccggtg tgcgtttgtc 60
tatatgttat tttccaccat attgccgtct tttggcaatg tgagggcccg gaaacctggc 120
cctgtcttct tgacgagcat tcctaggggt ctttcccctc tcgccaaagg aatgcaaggt 180
ctgttgaatg tcgtgaagga agcagttcct ctggaagctt cttgaagaca aacaacgtct 240
gtagcgaccc tttgcaggca gcggaacccc ccacctggcg acaggtgcct ctgcggccaa 300
aagccacgtg tataagatac acctgcaaag gcggcacaac cccagtgcca cgttgtgagt 360
tggatagttg tggaaagagt caaatggctc tcctcaagcg tattcaacaa ggggctgaag 420
gatgcccaga aggtacccca ttgtatggga tctgatctgg ggcctcggtg cacatgcttt 480
acatgtgttt agtcgaggtt aaaaaaacgt ctaggccccc cgaaccacgg ggacgtggtt 540
ttcctttgaa aaacacgatg ataat 565
<210> 68
<211> 201
<212> DNA
<213> Artificial Sequence
<220>
<223> L peptide from ECMV encoding sequence
<400> 68
atggccacaa ccatggaaca agagacttgc gcgcactctc tcacttttga ggaatgccca 60
aaatgctctg ctctacaata ccgtaatgga ttttacctgc taaagtatga tgaagaatgg 120
tacccagagg agttattgac tgatggagag gatgatgtct ttgatcccga attagacatg 180
gaagtcgttt tcgagttaca g 201
<210> 69
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<223> P2A skipping site encoding sequence
<400> 69
ggaagcggag ctactaactt cagcctgctg aagcaggctg gagatgtgga ggagaaccct 60
ggacct 66
<210> 70
<211> 3822
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS CoV2 Spike gene
<400> 70
atgttcgtgt tcctggtgct gctgcctctg gtcagctccc agtgtgtgaa cctgaccacc 60
agaacccagc tgccacctgc ttatacaaac tccttcactc ggggggtata ctaccccgac 120
aaggtgttca gatctagcgt gctgcattct acacaagacc tgttcctgcc cttcttcagc 180
aacgtgacct ggttccacgc catccacgtg tctggaacca acggaaccaa gagattcgac 240
aaccccgtgc tgcctttcaa cgacggcgtg tacttcgcca gcaccgagaa gtccaacatc 300
atcagaggat ggattttcgg caccacactg gacagcaaaa cccagagcct gctgatcgtg 360
aacaacgcca ccaacgtggt gatcaaggtg tgcgagttcc agttctgcaa tgatcccttc 420
ctgggcgtgt actaccacaa gaacaacaag tcttggatgg aaagcgagtt cagagtgtat 480
tccagcgcca acaattgcac cttcgagtac gtgagccaac cctttctgat ggaccttgaa 540
ggcaagcagg gcaacttcaa aaatctgcga gaatttgtgt tcaagaacat cgacggatac 600
ttcaagatct actctaagca cacgccaatc aacctggtga gagatctgcc ccagggcttt 660
agcgctttgg aacctctggt ggacctgcct atcggaatca acatcaccag atttcaaact 720
ctcctggccc tgcacagatc ttatctgacc cctggggaca gtagtagcgg ctggacagcc 780
ggcgccgccg cctactacgt gggatacctg cagcctagaa cattcctgct gaagtacaat 840
gagaacggaa caatcacaga cgccgtggac tgcgccctgg atcctttgag cgagacaaag 900
tgcaccctga agtcgttcac cgtcgaaaaa ggcatctacc agaccagcaa cttccgcgtg 960
cagcctacgg aatctatcgt gcggttcccc aacatcacca acctgtgccc tttcggcgag 1020
gtgtttaacg ctacaaggtt cgccagcgtg tatgcctgga acagaaagag aatcagcaat 1080
tgcgtggccg attatagcgt tctgtacaac agcgcttcct tcagcacctt caagtgctac 1140
ggcgtgtctc caaccaagct gaacgacctc tgcttcacca atgtctacgc tgactctttc 1200
gtgattagag gcgatgaggt tagacagatc gcacctggcc agaccggcaa aatcgctgac 1260
tacaactaca agctgcctga tgacttcaca ggctgtgtca ttgcctggaa ctcaaataac 1320
ctggactcta aagtgggcgg caactacaac tacctgtacc ggctgttccg gaagagcaat 1380
ctgaaacctt ttgagcggga catctctaca gagatctacc aggccggcag cacaccctgc 1440
aacggcgttg agggcttcaa ctgctacttc cctctgcaga gctacggctt tcagccaaca 1500
aatggagtgg gctaccagcc gtacagagtg gtggtgctga gcttcgaact gctgcatgcc 1560
ccagccacag tgtgtggacc taagaagtct accaacctgg tgaagaacaa gtgcgtgaac 1620
tttaacttta acggcctgac cggcacaggc gtgctgaccg aatccaacaa aaagttcctg 1680
cccttccaac agttcggcag agacatcgcc gatacaaccg atgccgtgcg ggacccccag 1740
accttagaaa tcctagatat caccccgtgc agcttcggcg gagtctctgt tattactcct 1800
ggcaccaaca ccagcaacca agtggctgtt ctgtaccaag gcgtgaactg caccgaagtg 1860
cctgtggcta tccacgccga tcagctgacc ccaacctggc gggtgtatag caccggctct 1920
aacgtgttcc agacccgggc tggctgcctg atcggcgccg aacacgtcaa caactcctat 1980
gaatgtgaca tccccatcgg ggctggcatc tgcgccagtt accagacaca gacaaatagc 2040
cctagacggg ccagaagcgt ggcctcccag agtatcattg cctacaccat gagcctgggc 2100
gccgagaaca gcgtggccta ttctaacaat agcatcgcaa tccctaccaa ctttaccatc 2160
tctgtgacaa ccgagatcct gcctgtgagc atgaccaaaa ccagcgtgga ctgcacgatg 2220
tacatctgtg gcgacagcac agaatgcagt aatctgttgc tgcagtacgg cagcttttgc 2280
acccagttga atagagccct gaccggaatc gccgtagagc aggacaaaaa tacccaggag 2340
gtgttcgccc aggtgaaaca gatctacaag acacctccca ttaaggactt cggaggtttt 2400
aacttcagcc agatcctgcc cgacccttcc aagcctagca aacgctcctt catcgaggac 2460
ctgctcttca acaaggtgac actggctgat gccggcttca tcaagcagta cggagattgt 2520
ctgggagaca tcgccgctag agatctgatc tgcgcccaaa agttcaacgg cctgaccgtg 2580
ctgcctcctc tgcttacaga cgagatgatc gcccagtaca ccagcgccct gctggctggc 2640
accatcacaa gcggctggac cttcggagcc ggagccgctc tgcaaatccc ctttgccatg 2700
cagatggcct accggttcaa cggcatcggc gtgacacaga atgtgctgta cgagaaccag 2760
aagctgatcg ctaaccagtt taacagcgct atcggcaaga tccaggactc gctgagtagc 2820
accgcctctg ccctgggcaa gctgcaggac gtcgtgaacc agaacgccca agccctgaac 2880
acactggtga aacagctgag cagcaacttc ggcgccatca gctctgtgct gaacgatatc 2940
ctgagcagac tggacaaggt ggaagccgag gtccagatcg acagactgat cacaggaaga 3000
ctgcagagcc tgcaaacgta cgtgacacag cagctgatcc gggcagccga aatccgggcc 3060
agcgccaatc tggccgctac caagatgagc gagtgcgtgt taggccagag caagcgggtg 3120
gatttctgcg gtaagggata ccacctgatg agctttcccc agagcgctcc tcacggcgtg 3180
gtgtttctgc acgtgaccta cgttcctgcc caggaaaaga acttcaccac cgcccctgct 3240
atctgccacg atggcaaggc ccacttccct agagagggcg ttttcgtgtc taacggcaca 3300
cactggtttg tgacccagag aaacttctac gagcctcaga tcatcaccac agacaacacc 3360
tttgtgagcg gcaattgcga cgtggtgatc ggaattgtta ataataccgt gtacgaccct 3420
ctgcagcctg agctcgacag cttcaaggaa gagctggaca agtacttcaa gaaccacacc 3480
tccccagatg tggacctggg cgatatttca ggcatcaacg cctccgtcgt gaatatccag 3540
aaggagatcg accggctcaa cgaggtggcc aagaacctta acgagagcct gatcgacctg 3600
caggaactgg gcaaatatga gcagtacatc aagtggcctt ggtacatctg gctgggcttt 3660
atcgcaggcc tgatcgctat cgtgatggtg accattatgc tgtgttgtat gaccagctgt 3720
tgtagttgtc tgaagggctg ctgttcttgc ggcagctgct gcaagttcga cgaagacgac 3780
tcagagcccg tgctgaaagg cgtgaagctg cactacacct aa 3822
<210> 71
<211> 1257
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS CoV2 N gene
<400> 71
atgagcgaca acggccctca aaaccagaga aatgcccctc ggatcacatt tggcggacct 60
agcgacagca ccggcagcaa ccagaatgga gaaagaagcg gcgccagatc caagcagcgg 120
agacctcagg gactgcccaa caacaccgct agctggttca ccgccctgac ccaacacggc 180
aaggaagatc tgaagttccc cagaggccag ggcgtgccta tcaacacaaa ctcttctccc 240
gacgaccaga tcggatacta tagacgggcc actcggagaa ttcggggcgg cgacggaaaa 300
atgaaggacc tttctccaag atggtacttc tactacctcg gcacaggccc tgaggccggc 360
ctgccttacg gcgccaacaa ggatggcatc atctgggtcg ccaccgaggg cgccctgaac 420
acccctaagg accacatcgg cacaagaaac cccgctaaca acgccgcaat cgtgctgcag 480
ctgcctcagg gcaccaccct gcccaagggc ttctacgccg agggctctag aggtggctcc 540
caggcttcta gccgctcctc cagccgcagc agaaacagca gcaggaacag cacccccggc 600
agctcccggg gcaccagccc cgccagaatg gccggaaatg gcggcgatgc cgccctggcc 660
ctgctcctgc tggacagact gaatcagctg gaaagcaaga tgagcggcaa aggacagcag 720
cagcaaggcc agaccgtgac caagaaaagc gctgctgaag cctccaagaa acctagacaa 780
aagcggaccg ccacaaaggc ctacaacgtg acccaagcct ttggaagaag aggccccgag 840
cagacacagg gcaatttcgg cgaccaggag ctgatccggc agggaaccga ctacaagcac 900
tggcctcaga tcgcccagtt cgcccctagc gccagcgcct tcttcggcat gagcagaatc 960
ggcatggaag tgaccccttc tggcacctgg ctgacctaca ccggcgctat caagctggac 1020
gataaggatc ctaacttcaa ggaccaagtg atcctgctga acaagcatat cgacgcctat 1080
aagacctttc cacctacaga gcctaagaaa gataagaaga agaaagccga cgagacacag 1140
gccctgcctc agagacagaa aaagcagcag acagtgacac tgctgccagc cgctgacctg 1200
gatgacttca gcaagcagct gcagcagagc atgtcttctg ctgatagcac ccaggcc 1257
<210> 72
<211> 228
<212> DNA
<213> Artificial Sequence
<220>
<223> SARS CoV2 Envelope gene
<400> 72
atgtattctt ttgtgtccga ggaaaccggc acactgatcg ttaatagcgt gctgctcttc 60
ctggccttcg tggtgttcct gctggtgacc ctggctatcc tgaccgccct gagactgtgt 120
gcctactgct gcaacatcgt gaacgtgtct ctggtcaagc ctagcttcta cgtgtacagc 180
cgggtgaaga acctgaacag cagcagagtg cccgacctgc tggtgtga 228
Claims (59)
- 바이러스 항원 단백질 및 인핸서 단백질을 암호화하는, 백신에 사용하기 위한 폴리뉴클레오티드로서, 상기 인핸서 단백질은 피코르나바이러스 리더(L) 단백질 또는 이의 기능성 변이체인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항에 있어서, 서열번호 1과 적어도 95%의 동일성을 갖거나, 서열번호 2와 적어도 95%의 동일성을 갖는 인핸서 단백질 아미노산 서열을 암호화하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 또는 제2항 중 어느 한 항에 있어서, 서열번호 1 또는 서열번호 2의 인핸서 단백질 아미노산 서열을 암호화하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제3항 중 어느 한 항에 있어서,상기 인핸서 단백질에 작동 가능하게 연결된 내부 리보솜 유입 부위(IRES: internal ribosome entry site)를 암호화하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제4항에 있어서, IRES를 암호화하는 폴리뉴클레오티드 서열은 서열번호 24인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 바이러스 항원 단백질은 구조 단백질인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제6항 중 어느 한 항에 있어서, 바이러스 항원 단백질은 코로나바이러스로부터 유래되는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제7항에 있어서, 코로나바이러스는 베타코로나바이러스인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제8항에 있어서, 베타코로나바이러스는 중증 급성 호흡기 증후군(SARS-CoV-2: severe acute respiratory syndrome) 바이러스인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제7항에 있어서, 베타코로나바이러스는 중동 호흡기 증후군(MERS: Middle East respiratory syndrome) 바이러스인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 바이러스 항원 단백질은 스파이크(S) 단백질인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제11항에 있어서, 스파이크 단백질은 서열번호 13 또는 이와 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제11항에 있어서, 스파이크 단백질은 서열번호 51의 돌연변이체 스파이크 단백질 서열 아미노산 서열 또는 이와 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제13항에 있어서, 바이러스 항원 단백질은 막(M) 단백질인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제14항에 있어서, M 단백질은 서열번호 33의 서열 또는 이와 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 바이러스 항원 단백질은 외피(E) 단백질인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제16항에 있어서, E 단백질은 서열번호 22의 아미노산 서열 또는 이와 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제17항 중 어느 한 항에 있어서, 바이러스 항원 단백질은 뉴클레오캡시드(N) 단백질인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제18항에 있어서, N 단백질은 서열번호 20의 서열 또는 이와 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 동일성을 갖는 아미노산 서열을 포함하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제19항 중 어느 한 항에 있어서, 바이러스 항원 단백질은 바이러스 유사 입자(VLP: virus-like particle)를 형성하는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제6항에 있어서, 바이러스 항원 단백질은 웨스트나일 바이러스 단백질인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제21항에 있어서, 바이러스 항원 단백질은 전구체 막 단백질(preM) 및/또는 외피 당단백질(E)인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 백신으로 사용하기 위한 폴리뉴클레오티드로서, 서열번호 30의 서열, 또는 이와 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 서열 동일성을 갖는 핵산 서열을 포함하는, 백신으로 사용하기 위한 폴리뉴클레오티드.
- 백신으로 사용하기 위한 폴리뉴클레오티드로서, 서열번호 31의 서열, 또는 이와 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 서열 동일성을 갖는 핵산 서열을 포함하는, 백신으로 사용하기 위한 폴리뉴클레오티드.
- 백신으로 사용하기 위한 폴리뉴클레오티드로서, 서열번호 35 내지 49, 및 55의 서열, 또는 이와 적어도 70%의 동일성, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99%의 동일성을 갖는 핵산 서열 중 임의의 것을 포함하는, 백신으로 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제25항 중 어느 한 항에 있어서, 발현 카세트는 이 발현 카세트의 폴리뉴클레오티드 서열 각각에 작동 가능하게 연결된 프로모터를 포함하는, 폴리뉴클레오티드.
- 제6항에 있어서, 바이러스 항원 단백질은 인플루엔자 바이러스 단백질로부터 유래되는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제27항에 있어서, 바이러스 항원 단백질은 HA, NA, M1, 및 M2 중 하나 이상인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제6항에 있어서, 바이러스 항원 단백질은 B형 간염 바이러스 단백질로부터 유래되는, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제29항에 있어서, 바이러스 항원 단백질은 sAg(S 단백질), sAg(M 단백질), preS1, preS2, 및 cAg(코어 항원) 중 하나 이상인, 백신에 사용하기 위한 폴리뉴클레오티드.
- 제1항 내지 제30항 중 어느 한 항에 있어서, 바이러스 패키징 신호(viral packaging signal)를 암호화하는, 폴리뉴클레오티드.
- 제31항에 있어서, 바이러스 패키징 신호는 코로나바이러스로부터 유래되는, 폴리뉴클레오티드.
- 제1항 내지 제32항 중 어느 한 항의 폴리뉴클레오티드를 포함하는 벡터.
- 백신 조성물로서, 제33항의 벡터 및 약제학적으로 허용 가능한 담체 및/또는 아주반트를 포함하는 백신 조성물.
- 제34항에 있어서, 아주반트는 명반(alum) 및/또는 모노포스포릴 지질 A(MPL: monophosphoryl lipid A)인, 백신 조성물.
- 진핵 세포에서 바이러스 항원 단백질을 발현시키는 방법으로서, 제33항의 벡터와 세포를 접촉시키는 것을 포함하는 방법.
- 제36항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 벡터에 비해서 기능성 바이러스 유사 입자(VLP) 생산을 증가시키는, 방법.
- 제37항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 벡터에 비해서 기능성 VLP 생산을 약 10%, 약 20%, 약 30%, 약 40%, 약 50%, 약 60%, 약 70%, 약 80%, 약 90%, 약 100%, 약 125%, 약 150%, 약 175%, 약 200%, 약 250%, 약 300%, 약 350%, 약 400%, 약 500%, 또는 약 1000% 증가시키는, 방법.
- 대상체에서 면역 반응을 유발하는 방법으로서, 제34항 또는 제35항의 백신 조성물의 유효량을 대상체에게 투여하는 것을 포함하는 방법.
- 제39항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 대상체에서 중화 항체의 기간을 증가시키는, 방법.
- 제40항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 대상체에서 중화 항체의 기간을 약 2배, 약 3배, 약 4배, 약 5배, 약 6배, 약 7배, 약 8배, 약 9배, 또는 약 10배 증가시키는, 방법.
- 제39항 내지 제41항 중 어느 한 항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 Th1 세포 반응을 증가시키는, 방법.
- 제42항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 Th1 반응을 약 25%, 약 50%, 약 100%, 약 200%, 약 300%, 약 400%, 약 500%, 또는 약 1000% 증가시키는, 방법.
- 제39항 내지 제43항 중 어느 한 항에 있어서, 대상체에서 예방학적(prophylactic) 또는 예방적(preventative) 면역 반응을 유발하는 방법.
- 제39항 내지 제44항 중 어느 한 항에 있어서, 대상체에서 치료적 면역 반응을 유발하는 방법.
- 제39항 내지 제45항 중 어느 한 항에 있어서, 투여는 피부내 투여, 근육내 투여, 피하 투여, 또는 비강내 투여인, 방법.
- 제34항 또는 제35항의 백신 조성물, 하나 이상의 바이알 및 이의 사용 설명서를 포함하는, 키트.
- 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 제1 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 제2 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 제3 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 및 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드를 포함하는, 백신으로 사용하기 위한 벡터.
- 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질 또는 이와 적어도 95% 동일한 아미노산 서열을 암호화하는 폴리뉴클레오티드, 제1 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 13 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 S 단백질을 암호화하는 폴리뉴클레오티드, 제2 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질 또는 이와 적어도 95% 동일한 폴리뉴클레오티 서열을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 폴리뉴클레오티드를 포함하는, 백신으로 사용하기 위한 벡터.
- 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로: 프로모터, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 및 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드를 포함하는, 백신으로 사용하기 위한 벡터.
- 백신으로 사용하기 위한 벡터로서, 발현 카세트를 포함하고, 발현 카세트는 5'에서 3' 순서로: 프로모터, 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제1 폴리뉴클레오티드, 서열번호 33 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 M 단백질을 암호화하는 폴리뉴클레오티드 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 20 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 N 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 51 또는 서열번호 52 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 돌연변이된 S 단백질을 암호화하는 폴리뉴클레오티드, 단백질분해 절단 부위를 암호화하는 폴리뉴클레오티드, 서열번호 22 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 E 단백질을 암호화하는 폴리뉴클레오티드, 서열번호 24 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 IRES 서열을 암호화하는 폴리뉴클레오티드, 서열번호 2 또는 이와 적어도 95% 동일한 아미노산 서열을 포함하는 인핸서 L 단백질을 암호화하는 폴리뉴클레오티드, 및 서열번호 34 또는 이와 적어도 95% 동일한 폴리뉴클레오티드 서열을 포함하는 바이러스 패키징 신호를 암호화하는 제2 폴리뉴클레오티드를 포함하는, 백신으로 사용하기 위한 벡터.
- 백신 조성물로서, 제48항 내지 제51항 중 어느 한 항의 벡터 및 약제학적으로 허용 가능한 담체 및/또는 아주반트를 포함하는 백신 조성물.
- 대상체에서 면역 반응을 유발하는 방법으로서, 제52항의 백신 조성물의 유효량을 대상체에게 투여하는 것을 포함하는 방법.
- 제53항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 대상체에서 중화 항체의 기간을 증가시키는, 방법.
- 제54항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 대상체에서 중화 항체의 기간을 약 2배, 약 3배, 약 4배, 약 5배, 약 6배, 약 7배, 약 8배, 약 9배, 또는 약 10배 증가시키는, 방법.
- 제53항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 Th1 세포 반응을 증가시키는, 방법.
- 제56항에 있어서, 인핸서 단백질의 포함은 인핸서 단백질이 없는 백신 조성물에 비해서 Th1 반응을 약 25%, 약 50%, 약 100%, 약 200%, 약 300%, 약 400%, 약 500%, 또는 약 1000% 증가시키는, 방법.
- 제53항 내지 제57항 중 어느 한 항에 있어서, 대상체에서 예방학적, 예방적 및/또는 치료적 면역 반응을 유발하는 방법.
- 제53항 내지 제57항 중 어느 한 항에 있어서, 투여는 피부내 투여, 근육내 투여, 피하 투여, 또는 비강내 투여인, 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163162496P | 2021-03-17 | 2021-03-17 | |
| US63/162,496 | 2021-03-17 | ||
| PCT/US2022/020774 WO2022197940A1 (en) | 2021-03-17 | 2022-03-17 | Vaccine compositions and methods of use thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230156945A true KR20230156945A (ko) | 2023-11-15 |
Family
ID=83320823
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237035159A KR20230156945A (ko) | 2021-03-17 | 2022-03-17 | 백신 조성물 및 이의 사용 방법 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US20240156948A1 (ko) |
| EP (1) | EP4308129A1 (ko) |
| JP (1) | JP2024511356A (ko) |
| KR (1) | KR20230156945A (ko) |
| CN (1) | CN117279648A (ko) |
| AU (1) | AU2022239561A1 (ko) |
| BR (1) | BR112023018838A2 (ko) |
| CA (1) | CA3212387A1 (ko) |
| IL (1) | IL305819A (ko) |
| MX (1) | MX2023010807A (ko) |
| WO (1) | WO2022197940A1 (ko) |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190382450A1 (en) * | 2018-06-18 | 2019-12-19 | University Of Maryland, College Park | Newcastle disease virus-based vectored vaccine |
| CN111876419B (zh) * | 2020-04-03 | 2022-03-11 | 苏州吉玛基因股份有限公司 | 抑制新型冠状病毒的小干扰核酸及组合物和应用 |
| US11130787B2 (en) * | 2020-06-11 | 2021-09-28 | MBF Therapeutics, Inc. | Alphaherpesvirus glycoprotein d-encoding nucleic acid constructs and methods |
-
2022
- 2022-03-17 AU AU2022239561A patent/AU2022239561A1/en active Pending
- 2022-03-17 WO PCT/US2022/020774 patent/WO2022197940A1/en active Application Filing
- 2022-03-17 JP JP2023557020A patent/JP2024511356A/ja active Pending
- 2022-03-17 IL IL305819A patent/IL305819A/en unknown
- 2022-03-17 KR KR1020237035159A patent/KR20230156945A/ko unknown
- 2022-03-17 MX MX2023010807A patent/MX2023010807A/es unknown
- 2022-03-17 BR BR112023018838A patent/BR112023018838A2/pt unknown
- 2022-03-17 EP EP22772215.4A patent/EP4308129A1/en active Pending
- 2022-03-17 CA CA3212387A patent/CA3212387A1/en active Pending
- 2022-03-17 CN CN202280028754.0A patent/CN117279648A/zh active Pending
-
2023
- 2023-09-13 US US18/466,251 patent/US20240156948A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| CN117279648A (zh) | 2023-12-22 |
| AU2022239561A1 (en) | 2023-10-05 |
| MX2023010807A (es) | 2023-11-24 |
| IL305819A (en) | 2023-11-01 |
| CA3212387A1 (en) | 2022-09-22 |
| AU2022239561A9 (en) | 2024-02-22 |
| EP4308129A1 (en) | 2024-01-24 |
| JP2024511356A (ja) | 2024-03-13 |
| WO2022197940A1 (en) | 2022-09-22 |
| US20240156948A1 (en) | 2024-05-16 |
| BR112023018838A2 (pt) | 2023-12-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2020200303B9 (en) | Novel multivalent nanoparticle-based vaccines | |
| EP0714444B1 (en) | Dampening of an immunodominant epitope of an antigen for use in plant, animal and human vaccines and immunotherapies | |
| US8715695B2 (en) | Polypeptide fragments of the hepatitis E virus, the vaccine composition comprising said fragments and the diagnostic kits | |
| US20190307879A1 (en) | Adenovirus-vectored multivalent vaccine | |
| US20090239265A1 (en) | Virus like particles | |
| DK1893228T3 (en) | CHIMERIC POLYPEPTIDES AND THEIR THERAPEUTIC APPLICATIONS TOWARDS A Flaviviridae INFECTION | |
| KR20170048396A (ko) | 재조합 변형된 백시니아 바이러스 앙카라 (mva) 필로바이러스 백신 | |
| MXPA04010886A (es) | Compuesto de diseno de color digital para utilizarse en vidrio laminado. | |
| JP2009511623A (ja) | レンチウイルスベクターベースのワクチン | |
| CN111194221A (zh) | 优化的核酸抗体构建体 | |
| KR20230025020A (ko) | 인간 시토메갈로바이러스 gB 폴리펩티드 | |
| JPH06509237A (ja) | ワクチンとしてのネコ白血病ウィルスgp70からの融合蛋白質 | |
| EP4313138A1 (en) | Sars-cov-2 subunit vaccine | |
| CN111154778A (zh) | 禽新城疫病毒新型基因工程亚单位疫苗 | |
| US5994516A (en) | Mutated proteins encoded by a lentivirus mutated env gene, peptide fragments and expression vectors | |
| MXPA04010919A (es) | Complejos e hibridos de envoltura de vih-cd4. | |
| JP3809502B2 (ja) | ハンタウィルス抗原蛋白質およびモノクローナル抗体 | |
| KR20230156945A (ko) | 백신 조성물 및 이의 사용 방법 | |
| JPH02211881A (ja) | HIVに対する中和抗体を誘発するかまたはかかる抗体によって認識され得る免疫原配列を含むHBsAg抗原の形態学的特徴を有する組換えハイブリッドHBsAg粒子、かかる粒子をコードするヌクレオチド配列及び核粒子を含むワクチン | |
| CN117321209A (zh) | 用于蛋白质表达的系统和方法 | |
| MXPA02006313A (es) | Vacunacion de acido nucleico. | |
| US10766930B2 (en) | Fusion proteins and use thereof for preparing vaccines | |
| CN113801206A (zh) | 利用受体识别域诱导抗新冠病毒中和抗体的方法 | |
| CN113382748A (zh) | 用于制备和使用病毒样颗粒(vlp)的组合物和方法 | |
| KR102713707B1 (ko) | 신규 다가 나노입자 기반 백신 |