KR20230021699A - 항-nme 항체 및 암 또는 암 전이의 치료 방법 - Google Patents
항-nme 항체 및 암 또는 암 전이의 치료 방법 Download PDFInfo
- Publication number
- KR20230021699A KR20230021699A KR1020237000259A KR20237000259A KR20230021699A KR 20230021699 A KR20230021699 A KR 20230021699A KR 1020237000259 A KR1020237000259 A KR 1020237000259A KR 20237000259 A KR20237000259 A KR 20237000259A KR 20230021699 A KR20230021699 A KR 20230021699A
- Authority
- KR
- South Korea
- Prior art keywords
- nme7
- antibody
- cells
- cancer
- seq
- Prior art date
Links
Images
















































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New breeds of animals
- A01K67/027—New breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/04—Antineoplastic agents specific for metastasis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/001—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof by chemical synthesis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/12—Transferases (2.) transferring phosphorus containing groups, e.g. kinases (2.7)
- C12N9/1229—Phosphotransferases with a phosphate group as acceptor (2.7.4)
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; CARE OF BIRDS, FISHES, INSECTS; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/0331—Animal model for proliferative diseases
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
- A61K2039/507—Comprising a combination of two or more separate antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/35—Valency
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
- C12N2510/02—Cells for production
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y207/00—Transferases transferring phosphorus-containing groups (2.7)
- C12Y207/04—Phosphotransferases with a phosphate group as acceptor (2.7.4)
- C12Y207/04006—Nucleoside-diphosphate kinase (2.7.4.6)
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/90—Enzymes; Proenzymes
- G01N2333/91—Transferases (2.)
- G01N2333/912—Transferases (2.) transferring phosphorus containing groups, e.g. kinases (2.7)
- G01N2333/91205—Phosphotransferases in general
- G01N2333/91235—Phosphotransferases in general with a phosphate group as acceptor (2.7.4)
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/56—Staging of a disease; Further complications associated with the disease
Abstract
본 출원은 항-NME 항체 및 질환의 치료 또는 예방에서의 이의 용도를 개시한다.
Description
본 출원은 NME 단백질, NME 단백질로부터 유래된 펩타이드 및 이의 펩타이드로부터 생성된 항체 또는 상기 펩타이드에 결합하는 능력에 의해 선택되는 항체 또는 항체 단편에 관한 것이다. 본 출원은 또한 환자에서 NME의 발현과 연관된 질환을 치료하거나 예방하는 것에 관한 것이다.
NDPK(뉴클레오사이드 다이포스페이트 단백질 키나제(nucleoside diphosphate protein kinase)) 단백질은, 이들이 모두 NDPK 도메인을 함유하기 때문에 함께 그룹으로 엮인 단백질 패밀리이다. 발견된 첫 번째 NME 단백질은 이전에는 NM23 단백질로 불렸으며, NM23-H1 및 NM23-H2이었다. 수십 년 동안, 이들이 조혈 세포의 분화를 유도하는지 또는 분화를 방지하였는지는 불분명하였다. 본 발명자들은 이전에, NM23-H1이 이량체인 경우 MUC1* 성장 인자 수용체에 결합하여 분화를 방지하지만, 보다 높은 농도에서 NM23-H1은 육량체가 되며, MUC1*에 결합하지 않고, 분화를 유도함을 발견하였다. NM23은 이것이 일부 매우 공격적인 암에서 하향-발현되는 것을 발견하였 때, 전이 억제자로 지칭되었던 적도 있다. 본 발명자들은 이전에, NM23-H1 이량체가 대부분의 암에서 과발현되는 MUC1* 성장 인자 수용체의 세포외 도메인에 결합하여, 이를 이량체화하고, 이러한 결합이 암 세포의 성장을 촉진한다는 것을 발견하였다. 역으로, 보다 고농도에서, NM23은 MUC1*에 결합하지 않는 사량체 및 육량체를 형성하고, 종양 형성을 촉진하지 않는다. 매우 최근에 보다 많은 NME 패밀리 단백질(NME 1 내지 NME 10)이 발견되었지만, 현재까지 이들의 기능은 설명되지 않고 있다. NME7은 새로 발견된 NME 패밀리 단백질이지만, 이의 NDPK 도메인은 다른 NME 패밀리 구성원과는 달리 효소 활성을 갖지 않는다. NME7은 성인 조직에서 전혀 발현되지 않거나 극도로 낮은 수준으로 발현된다.
본 출원은 NME 패밀리의 구성원에 대해서 제조된 항체를 대상체에게 투여하는 단계를 포함하는, 대상체에서 암을 치료하거나 예방하는 방법에 관한 것이다. NME 패밀리는 NME7 패밀리일 수 있다. 항체는 NME7에 결합할 수 있다. NME7AB 또는 NME7AB-유사 단백질에 결합할 수 있다. 항체는 NME7-X1에 결합할 수 있다. 항체는 NME7과 이의 동족 결합 파트너(cognate binding partner) 사이의 결합을 저해할 수 있다. 동족 결합 파트너는 MUC1*일 수 있다. 동족 결합 파트너는 MUC1* 세포외 도메인의 PSMGFR 부분일 수 있다. 일 양상에서, 도 6 내지 도 9에 열거된 것들(서열번호 88 내지 145)로부터 선택되는 펩타이드에 결합하는 항체가 생성되거나, 이러한 능력에 대해 선택될 수 있다. 바람직하게는, 펩타이드는 도 9에 열거된 펩타이드(서열번호 141 내지 145)로부터 선택될 수 있다.
펩타이드는, 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)에 고도로 상동성인 펩타이드, 또는 이러한 펩타이드의 N-말단 또는 C-말단에 7개 이하, 6개 이하, 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개 이하의 아미노산 잔기가 첨가되거나 제거된 펩타이드일 수 있다. 일 양상에서, 항체는 NME1이 아닌 NME7AB 또는 NME7-X1에 결합하는 능력에 대해 선택될 수 있다. 항체는 다클론성 항체, 단클론성 항체, 2가 항체, 1가 항체, 이중특이적 항체, 가변 영역을 함유하는 항체 단편 또는 항체 모방체일 수 있다. 항체는 인간 항체 또는 인간화된 항체일 수 있다. 항체는 단쇄 scFv일 수 있다.
또 다른 양상에서, 본 발명은 NME7AB의 영역에 고도로 상동성이거나 이와 동일한 펩타이드를 대상체에게 투여하는 단계를 포함하는, 대상체의 암을 치료하거나 예방하는 방법에 관한 것이다. 펩타이드는 도 6에 열거된 펩타이드 중 하나 이상과 적어도 80% 상동성일 수 있다. 펩타이드는 도 7에 열거된 펩타이드 중 하나 이상과 적어도 80% 상동성일 수 있다. 펩타이드는 도 8에 열거된 펩타이드 중 하나 이상과 적어도 80% 상동성일 수 있다. 펩타이드는 도 9에 열거된 펩타이드 중 하나 이상과 적어도 80% 상동성일 수 있다. 펩타이드는 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)로부터 선택될 수 있다. 펩타이드는 도 9에 열거된 펩타이드(서열번호 141 내지 145)로부터 선택될 수 있다. 또는, 펩타이드는, 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)에 고도로 상동성인 펩타이드, 또는 이러한 펩타이드의 N-말단 또는 C-말단에 7개 이하, 6개 이하, 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개 이하의 아미노산 잔기가 첨가되거나 제거된 펩타이드일 수 있다. 펩타이드는 스페이서 또는 링커를 통해 또 다른 펩타이드에 연결될 수 있다.
또 다른 양상에서, 본 발명은 암의 치료 또는 예방을 위한 키메라 항원 수용체(CAR)에 관한 것이며, 여기서 CAR의 표적화 세포외 부분은 NME 패밀리의 구성원의 적어도 하나의 펩타이드 단편을 포함한다. NME 패밀리는 NME7 패밀리일 수 있다. NME7 패밀리의 구성원은 NME7일 수 있다. 또는, NME7 패밀리의 구성원은 NME7AB 또는 NME7AB-유사 단백질일 수 있다. NME7 패밀리의 구성원은 또한 NME7-X1일 수 있다. CAR의 표적화 세포외 부분은 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145) 중의 펩타이드를 포함할 수 있다. 펩타이드는 도 9에 열거된 펩타이드(서열번호 141 내지 145)로부터 선택될 수 있다. 펩타이드는, 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)에 고도로 상동성인 펩타이드, 또는 이러한 펩타이드의 N-말단 또는 C-말단에 7개 이하, 6개 이하, 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개 이하의 아미노산 잔기가 첨가되거나 제거된 펩타이드를 포함할 수 있다. 펩타이드는 스페이서 또는 링커를 통해 또 다른 펩타이드에 연결될 수 있다.
또 다른 양상에서, 본 발명은 청구범위 제3항에 따른 키메라 항원 수용체를 면역계 세포 내에서 조작하고, 세포를 이를 필요로 하는 대상체에게 투여하는 단계를 포함하는, 암 또는 암 전이를 치료하거나 예방하는 방법에 관한 것이다.
다른 양상에서, 본 발명은 암의 치료 또는 예방을 위한 키메라 항원 수용체(CAR)에 관한 것이며, 여기서 키메라 항원 수용체의 표적화 세포외 부분은 NME7AB, NME7AB-유사 단백질 또는 NME7-X1에 결합하는 항체의 부분을 포함한다. 항체의 부분은 단쇄 scFv일 수 있거나, 인간 항체 또는 인간화된 항체일 수 있다.
또 다른 양상에서, 본 발명은 NME 패밀리 구성원의 펩타이드 단편으로 인간을 면역화시키는 단계를 포함하는, 인간에게 암 또는 전이성 암에 대한 백신 접종하는 방법에 관한 것이다. NME 패밀리는 NME7 패밀리일 수 있다. NME7 패밀리의 구성원은 NME7 또는 NME7b일 수 있다. NME7 패밀리의 구성원은 NME7AB 또는 NME7AB-유사 단백질일 수 있다. NME7 패밀리는 NME7-X1일 수 있다. 면역화 펩타이드는 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)로부터의 펩타이드일 수 있다. 바람직하게는, 펩타이드는 도 9에 열거된 펩타이드(서열번호 141 내지 145)로부터 선택될 수 있다. 면역화 펩타이드는, 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)에 고도로 상동성인 펩타이드, 또는 이러한 펩타이드의 N-말단 또는 C-말단에 7개 이하, 6개 이하, 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개 이하의 아미노산 잔기가 첨가되거나 제거된 펩타이드를 포함할 수 있다. 면역화 펩타이드는 스페이서 또는 링커를 통해 또 다른 펩타이드에 연결될 수 있다.
추가의 또 다른 양상에서, 본 발명은 NME7, NME7b, NME7AB-유사 단백질 또는 NME7-X1의 발현을 저해하는 핵산을 대상체에게 투여하는 단계를 포함하는, 대상체에서 암을 치료하거나 예방하는 방법에 관한 것이다. 핵산은 NME7, NME7AB-유사 단백질 또는 NME7-X1의 발현을 억제하는 안티-센스 핵산일 수 있다. 핵산은 NME7, NME7AB-유사 단백질 또는 NME7-X1의 발현을 저해하는 저해성 RNA, siRNA, RNAi 또는 shRNA일 수 있다.
또 다른 양상에서, 본 발명은 NME7, NME7b, NME7AB-유사 단백질 또는 NME7-X1의 발현을 저해하는 유전자 편집된 핵산을 대상체에게 투여하는 단계를 포함하는, 대상체에서 암을 치료하거나 예방하는 방법에 관한 것이다. NME7, NME7b, NME7AB-유사 단백질 또는 NME7-X1의 발현을 저해하는 유전자 편집된 핵산은 세포 내로 삽입될 수 있으며, 그 다음, 환자에게 투여될 수 있다. NME7, NME7b, NME7AB-유사 단백질 또는 NME7-X1의 발현을 저해하는 유전자 편집된 핵산은 바이러스 벡터를 사용하여 세포 내로 삽입될 수 있다. 바이러스 벡터는 렌티바이러스 시스템일 수 있다.
또 다른 양상에서, 본 발명은 암 세포를 NME7AB, NME7b, NME7AB-유사 단백질 또는 NME7-X1, 2i 또는 5i와 접촉시키는 단계를 포함하는, 암 세포를 성장시키는 방법에 관한 것이다. 이러한 방법은 NME7AB, NME7b, NME7AB-유사 단백질 또는 NME7-X1, 2i 또는 5i를 함유하는 배지 내에서 세포를 배양하는 단계, 또는 인간 NME7AB, NME7b, NME7AB-유사 단백질 또는 NME7-X1을 발현하는 동물, 또는 NME7AB, NME7b, NME7AB-유사 단백질 또는 NME7-X1이 투여된 동물에서 세포를 성장시키는 단계를 포함할 수 있다. 암 세포는 유방암, 전립선암, 난소암, 결장직장 암, 췌장암, 간암, 흑색종 또는 뇌암 세포일 수 있다. 후보 약물은 세포 상에서 시험될 수 있다. 약물의 효능은, 암 성장을 무-약물(no drug) 대조군과 비교하거나, 전이 마커 또는 줄기세포 마커의 발현 수준을 무-약물 대조군과 비교하거나, 무-약물 대조군과 비교하여 낮은 세포 카피 수(copy number)로부터 동물에서 종양을 형성하는 생성된 세포의 능력을 비교하고, 암 또는 전이 치료용 후보 약물의 효능을 결정함으로써 평가될 수 있다. 세포는 암 치료를 위해 평가되는 환자로부터 얻어질 수 있고, 그 환자에게 효과적일 약물은 전술한 방법을 사용하여 얻은 결과에 기초하여 선택된다. 세포는 암 치료를 위해 평가되는 환자로부터 얻어지지 않을 수 있지만, 그 환자에게 효과적일 약물은 전술한 방법을 사용하여 얻은 결과에 기초하여 선택된다.
다른 양상에서, 본 발명은 NME의 서열로부터 유래되는 서열을 갖는 펩타이드 또는 펩타이드 모방체로부터 항체 또는 항체-유사 분자를 생성시키는 방법에 관한 것이다. NME는 NME7일 수 있다. 펩타이드는 항체 또는 항체-유사 분자를 생성시키기 위한 면역원으로서 사용될 수 있다. 펩타이드는 항-NME7 항체를 생성시키기 위해 동물에게 투여될 수 있다. 펩타이드는 항-NME7 항체를 생성시키기 위해 인간에게 투여될 수 있다. 펩타이드는 도 6 내지 도 9에 열거된 서열(서열번호 88 내지 145)을 가질 수 있다. 바람직하게는, 펩타이드는 도 9에 열거된 펩타이드(서열번호 141 내지 145)로부터 선택될 수 있다. 펩타이드는, 도 6 내지 도 9에 열거된 펩타이드(서열번호 88 내지 145)에 고도로 상동성인 펩타이드, 또는 이러한 펩타이드의 N-말단 또는 C-말단에 7개 이하, 6개 이하, 5개 이하, 4개 이하, 3개 이하, 2개 이하 또는 1개 이하의 아미노산 잔기가 첨가되거나 제거된 펩타이드를 포함할 수 있다.
또 다른 양상에서, 본 발명은 하기를 포함하는, 암의 존재 또는 암의 진행을 검출하는 방법에 관한 것이다:
1) 암 환자 또는 암이 발병할 위험이 있는 환자로부터 샘플을 얻는 단계;
2) 샘플을 NME7 패밀리의 구성원의 수준 또는 NME7 패밀리의 구성원을 암호화하는 핵산의 수준을 검출하거나 측정할 수 있는 검정에 적용하는 단계;
3) 시험 샘플에서 측정된 NME7 패밀리의 구성원 또는 NME7 패밀리의 구성원-암호화 핵산의 수준을 대조군 환자 또는 대조군 세포에서의 수준과 비교하는 단계;
4) NME7 패밀리의 구성원 또는 NME7 패밀리의 구성원을 암호화하는 핵산의 수준이 대조군과 비교하여 상승되는지를 결정하는 단계; 및
5) 시험이 비교되는 대조군이 이전에 암을 진단받은 공여자로부터 유래된 것인 경우, 시험 샘플의 공여자가 암을 가지고 있거나, 암이 진행되었다고 결론 내리는 단계. 이러한 방법에서, 순환계 또는 조직 내에서 NME7 패밀리의 구성원의 검출은 환자에서 암의 지표(indicator)일 수 있다. NME7 패밀리의 구성원은 NME7, NME7b, NME7-X1 또는 NME7AB-유사 단백질일 수 있다.
또 다른 양상에서, 본 발명은 하기 단계를 포함하는 방법에 관한 것이다:
환자에서 NME7 패밀리의 구성원 또는 MUC1*의 존재를 검출하는 단계; 및
항-NME7 항체 또는 항-MUC1*항체 또는 항체들을 NME7 패밀리의 구성원 또는 MUC1* 발현을 나타내는 환자에게 투여하는 단계. NME7 패밀리의 구성원은 NME7, NME7b, NME7-X1 또는 NME7AB-유사 단백질일 수 있다.
또 다른 양상에서, 본 발명은 하기 단계를 포함하는, 암을 치료하거나 예방하는 방법에 관한 것이다:
1) 암이 의심되는 환자, 암이 발병할 위험이 있는 환자 또는 전이성 암이 발병할 위험이 있는 환자로부터 샘플을 얻는 단계;
2) NME7 패밀리의 구성원 또는 NME7 패밀리의 구성원을 암호화하는 핵산의 양을 측정하는 단계로서, 측정된 수준은 대조군 샘플에서 측정된 것보다 상당히 더 높은, 상기 단계;
3) 환자가 암을 가지고 있거나 환자에서 보다 공격적인 암 또는 전이성 암이 발병되었음을 결정하는 단계;
4) NME7 패밀리의 구성원의 발현을 억제하거나, NME7의 절단을 저해하거나, 표적에 대한 NME7의 결합을 저해하는 치료제를 유효량으로 환자에게 투여하는 단계. NME7 패밀리의 구성원의 표적은 MUC1*일 수 있다. NME7 패밀리의 구성원의 표적은 MUC1* 세포외 도메인의 PSMGFR 부분일 수 있다. NME7 패밀리의 구성원은 NME7, NME7b, NME7-X1 또는 NME7AB-유사 단백질일 수 있다.
암에 관한 상기 방법 중 임의의 방법에서, 암은 유방암, 전립선암, 난소암, 결장직장암, 췌장암, 간암, 흑색종 또는 뇌암을 포함할 수 있다.
일 양상에서, 본 발명은 서열번호 145 또는 서열번호 169의 NME7 B3 펩타이드에 결합하는 NME7 특이적 항체 또는 이의 단편에 관한 것이다. 이러한 항체는 단클론성 항체 또는 2가, 1가, Fab 또는 단쇄 가변 단편 항체(scFv)일 수 있다. 항체는 항체 약물 접합체에 연결될 수 있다. 약물은 독소 또는 프로-톡신(pro-toxin)에 연결될 수 있다.
본 발명은 또한 항체를 암호화하는 단리된 핵산에 관한 것이다.
본 발명은 상기에 논의된 단클론성 항체를 발현하는 단리된 하이브리도마에 관한 것이다. 이러한 항체는 NME1이 아닌 NME7AB 또는 NME7-X1에 특이적으로 결합할 수 있다. 이러한 항체는 NME7AB와 MUC1* 세포외 도메인 사이 또는 NME7-X1과 MUC1* 세포외 도메인 사이의 상호작용을 방해할 수 있다. 또는, 이러한 항체는 NME7AB와 PSMGFR 사이 또는 NME7-X1과 PSMGFR 사이의 결합을 방해할 수 있다. 추가로, 이러한 항체는 NME7AB와 N-10 사이 또는 NME7-X1과 N-10 사이의 결합을 방해할 수 있다.
또 다른 양상에서, 이러한 항체는 NME7AB와 MUC1* 세포외 도메인 사이 또는 NME7-X1과 MUC1* 세포외 도메인 사이의 상호작용을 방해할 수 없다. NME7AB 또는 NME7-X1은 N-10 펩타이드(서열번호 170)에 결합할 수 있지만, C-10 펩타이드(서열번호 171)에는 결합하지 않을 수 있다. 특히, 항체는 5A1, 4A3, 5D4 또는 4P3일 수 있다.
항체는 하기를 포함하는 중쇄 가변 영역 내의 아미노산 서열:
CDR1 영역 YTFTNYGMN(서열번호 439);
CDR2 영역 WINTYTGEPTYVDDFKG(서열번호 440); 및
CDR3 영역 LRGIRPGPLAY(서열번호 441); 및
하기를 포함하는 경쇄 가변 영역 내의 아미노산 서열을 포함할 수 있다:
CDR1 영역 SASSSVSYMN(서열번호 444);
CDR2 영역 GISNLAS(서열번호 445); 및
CDR3 영역 QQRSSYPPT(서열번호 446).
이러한 상기 항체의 예는 5A1이다.
또 다른 양상에서, 항체는 하기를 포함하는 중쇄 가변 영역 내의 아미노산 서열:
CDR1 영역 NTFTEYTMH(서열번호 429);
CDR2 영역 GFNPNNGVTNYNQKFKG(서열번호 430); 및
CDR3 영역 RYYHSTYVFYFDS(서열번호 431); 및
하기를 포함하는 경쇄 가변 영역 내의 아미노산 서열을 포함할 수 있다:
CDR1 영역 SASQGISNYLN(서열번호 434);
CDR2 영역 YTSSLHS(서열번호 435); 및
CDR3 영역 QQYSKLPYT(서열번호 436).
이러한 상기 항체의 예는 5D4이다.
또 다른 양상에서, 항체는 하기를 포함하는 중쇄 가변 영역 내의 아미노산 서열:
CDR1 영역 NTFTEYTMH(서열번호 388);
CDR2 영역 GFNPNNGVTNYNQKFKG(서열번호 389); 및
CDR3 영역 RYYHSLYVFYFDY(서열번호 390); 및
하기를 포함하는 경쇄 가변 영역 내의 아미노산 서열을 포함할 수 있다:
CDR1 영역 SASQGISNYLN(서열번호 393);
CDR2 영역 YTSSLHS(서열번호 394); 및
CDR3 영역 QQYSKLPYT(서열번호 395).
이러한 상기 항체의 예는 4A3이다.
또 다른 양상에서, 항체는 하기를 포함하는 중쇄 가변 영역 내의 아미노산 서열:
CDR1 영역 NTFTEYTMH(서열번호 388);
CDR2 영역 GFNPNNGVTNYNQKFKG(서열번호 389); 및
CDR3 영역 RYYHSLYVFYFDY(서열번호 390); 및
하기를 포함하는 경쇄 가변 영역 내의 아미노산 서열을 포함할 수 있다:
CDR1 영역 ITSTDIDDDMN(서열번호);
CDR2 영역 EGNTLRP(서열번호); 및
CDR3 영역 LQSDNLPLT(서열번호).
이러한 상기 항체의 예는 4P3이다.
항체는 인간, 인간화된 또는 조작된 항체 모방체일 수 있다.
항체는 비-인간, 예컨대, 뮤린 또는 낙타과일 수 있다.
본 발명은 또한 환자에게 상기에 기재된 항체를 포함하는 조성물을 투여하는 단계를 포함하는, 암의 예방 또는 치료를 위해서 환자에게 투여하는 것에 관한 것이다.
본 발명은 또한 환자에게 상기에 기재된 항체를 포함하는 조성물을 투여하는 단계를 포함하는, 환자에서 암 전이를 예방 또는 치료하는 방법에 관한 것이다.
본 발명은 또한 환자 시편 및 정상 시편을 상기 항체와 접촉시키는 단계 및 두 시편으로부터의 결과를 비교하는 단계를 포함하는 암 또는 암 전이를 진단하는 방법에 관한 것이며, 여기서 환자 시편 내의 항체에 대한 양성 결합의 존재는 환자에서 암 또는 암 전이의 존재를 나타낸다. 항체는 조영제(imaging agent)에 연결될 수 있다. 환자 시편은 수술 중(intra-operative)을 포함하는 생체내, 시험관내의 혈액, 체액, 조직, 순환 세포일 수 있다.
본 발명은 또한 항-NME7AB 항체 또는 이의 단편을 발현하도록 조작된 세포에 관한 것이다. 이러한 세포는 면역 세포, 예컨대, T 세포 또는 NK 세포, 또는 줄기세포 또는 전구 세포, 바람직하게는 이후에 T 세포가 되도록 분화되는 줄기세포 또는 전구 세포일 수 있다.
세포는 종영 연관 항원을 인식하는 키메라 항원 수용체(CAR)를 포함할 수 있다. 항-NME7 항체의 발현은 유도성일 수 있다. 항-NME7AB 항체를 암호화하는 핵산은 Foxp3 인핸서 또는 프로모터에 삽입될 수 있다. 항-NME7AB 항체는 NFAT-유도성 시스템에 존재할 수 있다. NFATc1 반응 요소는 Foxp3 인핸서 또는 프로모터 영역 내에 삽입된 항체 서열의 상류에 삽입될 수 있다.
항-NME7AB 항체 또는 이의 단편은 NME7 B3 펩타이드에 결합할 수 있거나, MUC1* 세포외 도메인의 PSMGFR 펩타이드에 대한 NME7AB 또는 NME7-X1의 결합을 방해할 수 있다.
CAR은 종양 연관 항원 및 항-NME7 항체를 인식할 수 있다. 종양 연관 항원은 MUC1*일 수 있다.
본 발명은 또한 면역원성 도출 부분으로서 도 6 내지 도 9에 열거된 NME7AB로부터 유래된 1종 이상의 펩타이드 또는 이와 적어도 80%, 85%, 90%, 95%, 97%의 서열 동일성을 갖는 펩타이드를 포함하는 조성물을 포함하는 항암 백신에 관한 것이다. 펩타이드는 서열번호 141 내지 145의 펩타이드 또는 이와 적어도 80%, 85%, 90%, 95%, 97%의 서열 동일성을 갖는 펩타이드일 수 있다. 펩타이드는 서열번호 145의 펩타이드 또는 이와 적어도 80%, 85%, 90%, 95%, 97%의 서열 동일성을 갖는 펩타이드일 수 있다.
또 다른 양상에서, 본 발명은 상기에 기재된 항체를 포함하는 BiTE에 관한 것이다.
추가의 또 다른 양상에서, 본 발명은 항-NME7AB 항체를 생성시키는 방법에 관한 것이며, 여기서 NME7 B3 펩타이드 내의 시스테인 잔기는 이황화 결합을 회피하도록 돌연변이된다.
추가의 또 다른 양상에서, 본 발명은 세포를 NME7AB 또는 NME7-X1과 함께 배양하는 단계를 포함하는, 전이 가능성이 증가된 세포를 생성시키는 방법에 관한 것이다.
본 발명은 또한 NME7AB 또는 NME7-X1을 발현하도록 조작된 세포, NME7AB 또는 NME7-X1을 발현하는 트랜스제닉 동물에 관한 것이며, 여기서 NME7AB 또는 NME7-X1은 인간일 수 있고, 또한 NME7AB 또는 NME7-X1의 발현은 유도성일 수 있다.
특허 또는 출원 파일은 컬러로 실행된 적어도 하나의 도면을 포함한다. 컬러 도면이 포함된 본 특허 또는 특허 출원 간행물의 사본은 요청 및 필요한 수수료 지불 시 특허청에서 제공된다.
본 발명은 본 명세서의 하기에 제공되는 상세한 설명, 및 단지 예시로서 제공되므로 본 발명을 제한하고자 하는 것이 아닌 첨부 도면을 통해서 보다 완전히 이해될 것이다.
도 1은 NME7-AB가 MUC1* 세포외 도메인 펩타이드를 이량체화한다는 것을 나타낸 ELISA 샌드위치 검정으로부터의 HRP 신호의 그래프.
도 2는 전통적인 배지 또는 NME7을 함유하는 배지에서 배양된 후 T47D 암 세포에 대한 줄기세포 마커 및 암 줄기세포 마커에 대한 유전자 발현의 RT-PCR 측정치의 그래프(여기서 비-부착성이 된 세포(부유체(floater))를 부착된 채로 유지된 세포와 별개로 분석하였다.
도 3은 DU145 전립선 암 세포에 대한 다양한 줄기 및 추정 암 줄기세포 마커에 대한 유전자 발현의 RT-PCR 측정치의 그래프. 세포를 전통 배지 또는 NME1 이량체("NM23") 또는 NME7(NME7-AB)을 함유하는 배지에서 배양하였다. Rho 키나제 저해제는 계대 2에 의해서, 세포가 부착된 채로 남아있기 때문에 사용되지 않았다.
도 4는 줄기세포를 보다 미경험 상태로 반전시킨다고 이미 밝혀진 2i 저해제(GSK3-베타 및 MEK 저해제)가 또한 NME7AB만큼은 아니지만 암 세포를 보다 전이성인 상태로 유도한다는 것을 나타낸 전이 마커 및 만능 줄기세포(pluripotent stem cell) 마커의 RT-PCR 측정치의 그래프.
도 5는 인간 NME1과 인간 NME7-A 또는 -B 영역 간의 서열 정렬.
도 6은 NME1과 서열 동일성이 낮고, 암의 치료 또는 예방을 위해 치료용 항-NME7 항체를 생성하는 능력에 대해 선택된, 인간 NME7의 면역원성 펩타이드를 열거한 도면.
도 7은 암의 치료 또는 예방을 위해 치료용 항-NME7 항체를 생성시키는 능력에 대해 선택된, 구조적 온전성 또는 MUC1*에 대한 결합에 중요할 수 있는 인간 NME7의 면역원성 펩타이드를 열거한 도면.
도 8은 암의 치료 또는 예방을 위해 치료용 항-NME7 항체를 생성시키는 능력에 대해 선택된, 구조적 온전성 또는 MUC1*에 대한 결합에 중요할 수 있는 인간 NME1의 면역원성 펩타이드를 열거한 도면.
도 9는 NME1에 대한 낮은 서열 동일성 및 암에 관여하는 박테리아 NME1 단백질에 대한 상동성에 대해 선택된 인간 NME7로부터의 면역원성 펩타이드를 열거한 도면. 이들 펩타이드는 암의 치료 또는 예방을 위한 치료용 항-NME7 항체를 생성시키는 능력 면에서 바람직하다. 본 도면에서 도시된 펩타이드는 C-말단 단부에 공유 결합된 시스테인을 포함하고 첨가한다.
도 10A 내지 도 10B는 NME7-AB(도 10A) 또는 NME1(도 10B)이 플레이트에 흡착된 ELISA 검정의 그래프이고, NME7 펩타이드 A1, A2, B1, B2 및 B3에 의해서 생성된 항-NME7 항체를 NME1이 아닌 NME7에 결합하는 능력에 대해서 시험한다. C20은 항-NME1 항체이다.
도 11은 생성된 항-NME7 항체를 NME1의 결합을 저해하지 않고 표면 고정된 MUC1* 펩타이드에 대한 NME7-AB의 결합을 저해하는 능력에 대해서 시험한 ELISA 검정의 그래프.
도 12는 유방암 세포를 항체를 생성시키거나 선택하는 데 사용된 NME7 항체 또는 NME7로부터 유래된 짧은 펩타이드의 존재 또는 부재 하에서 성장시킨 암 세포 성장 실험의 그래프. 또한 거의 전체 NME7-AB 펩타이드인 아미노산 100 내지 376으로의 면역화에 의해서 생성된 항체가 암 세포 성장을 저해하는 것으로 나타났다.
도 13은 유방암 세포를 항체를 생성시키거나 선택하는 데 사용된 NME7 항체의 조합물 또는 NME7로부터 유래된 짧은 펩타이드의 조합물의 존재 또는 부재 하에서 성장시킨 암 세포 성장 실험의 그래프. 항체 및 이의 면역화 NME7-AB 펩타이드 둘 다 암 세포의 성장을 저해하였다.
도 14A 및 도 14B는 암 세포를 보다 전이성인 상태로 형질전환시킬 수 있는 NME7-AB 또는 2i 저해제에서 그리고 NME7 유래 펩타이드 A1, A2, B1, B2 및 B3의 존재 또는 부재 하에서 암 세포를 성장시켰을 때의 과학자 관찰 표. NME7-AB 펩타이드는 RT-PCR 측정에서 전이 마커, 특히 CXCR4의 발현이 증가된 것으로 나타난 부유체 세포로의 부착성 암 세포의 전이를 저해하였다.
도 15A 내지 도 15C는 각각은 암 세포를 보다 전이성인 상태로 형질전환시키는 NME7-AB 또는 2i 저해제에서 성장한 T47D 유방암 세포에서 CXCR4 및 기타 전이 마커의 발현의 RT-PCR 측정치의 그래프 및 전이성 형질전환에 대한 항-NME7 항체의 저해성 효과의 그래프. 도 15A는 항-NME7 항체의 존재 또는 부재 하에서 NME7AB 또는 2i에서 성장한 T47D 암 세포의 CXCR4 발현의 PCR 그래프를 도시한다. 도 15B는 NME7AB 면역화 펩타이드의 존재 하에서 72시간 또는 144시간 동안 2i 저해제에서 성장시킨 T47D 유방암 세포에서 CXCR4, CHD1 및 SOX2 발현의 RT-PCR 측정치의 그래프를 도시하고, 펩타이드 자체가 전이성 형질전환에 대해서 저해성임을 나타낸다. 도 15A의 저해성 콤보 2 및 3에 사용된 펩타이드 A1, A2 및 B1도 펩타이드로서 저해성이다. 펩타이드 B3이 가장 저해성이며, 이는 도 15A에서 시험된 가장 저해성 항체인 항체 61에 대한 면역화 펩타이드이다. 도 15C는 Y축의 스케일이 감소된 도 15B의 그래프를 도시한다.
도 16은 도 31에서 CXCR4의 RT-PCR 측정에 사용된 샘플에서 기록된 RNA 수준의 표뿐만 아니라 CXCR4 발현 및 대조군 하우스키핑 유전자에 대한 역치 사이클 수를 도시한 도면.
도 17은 인간 줄기 세포 및 암 세포의 패널에서 NME7-X1의 발현의 RT-PCR 측정치의 그래프.
도 18은 인간 줄기 세포 및 암 세포의 패널에서 NME7, NME7a, NME7b 및 NME7-X1의 발현의 RT-PCR 측정치의 그래프. NME7a는 전장 NME7이고, NME7b는 DM10 도메인의 작은 부분이 누락되었으며, NME7-X1은 DM10 도메인 전체 및 제1 NDPK A 도메인의 N-말단의 작은 부분이 누락되었다. NME7으로 표시된 막대는 NME7a 및 NME7b 둘 다를 검출한 프라이머가 사용되었음을 의미한다.
도 19A 내지 19F는 NME7 유래 펩타이드로의 면역화에 의해 생성된 항체를 사용하여 NME7 종의 발현에 대해 다양한 암 세포주가 프로빙된 웨스턴 블롯의 사진. 도 19A는 A1 펩타이드에 결합하는 항체 52가 전장 NME7, NME7AB 또는 NME7-X1의 존재에 대해 세포의 패널을 프로빙하는데 사용된 웨스턴 블롯을 나타낸다. 도 19B는 B1 펩타이드에 결합하는 항체 56이 전장 NME7, NME7AB 또는 NME7-X1의 존재에 대해 세포의 패널을 프로빙하는데 사용된 웨스턴 블롯을 나타낸다. 도 19C는 B3 펩타이드에 결합하는 항체 61이 전장 NME7, NME7AB 또는 NME7-X1의 존재에 대해 세포의 패널을 프로빙하는데 사용된 웨스턴 블롯을 나타낸다. 도 19D는 NME7 A 및 B 도메인 둘 다에 대해 생성된 상업적으로 입수 가능한 다클론성 항체 H278을 사용하여 NME7의 존재에 대해 세포의 패널을 프로빙한 웨스턴 블롯을 나타낸다. 도면에 나타난 바와 같이, 항체 H278은 또한 NME1을 인식한다. 도 19E는 상업적으로 입수 가능한 항-NME7 항체 B9에 대해 웹사이트에 공개된 겔을 나타내는데, 이는 그것이 전장 NME7의 겉보기 분자량을 갖는 종에 결합함을 나타낸다. 도 19F는 본 발명자들이 항-NME7 항체 B9를 사용하여 NME1만 로딩된 겔을 프로빙한 웨스턴 블롯을 나타낸다. 도면에서 인지될 수 있는 바와 같이, 항체 B9는 NME1뿐만 아니라 전장 NME7을 인식한다. 이것은 항체 H278과 같이, B9가 NME1의 A 도메인이 NME7AB의 A 도메인과 고도로 상동성인 NME7의 A 및 B 도메인 둘 다에 대해 발생했기 때문에 놀라운 것이 아니다.
도 20A 내지 도 20C는 표준 배지와 비교하여 NME7-AB를 함유하는 무혈청 배지에서 배양된 후 암 세포에서 전이 마커의 RT-PCR 측정치의 그래프. 도 20A는 MUC1-양성 난소암 세포주인 SK-OV3이 전이 마커 CXCR4, CDH1(일명 E-카드헤린), SOX2 및 NME7-X1의 발현을 증가시켰음을 나타내고; 도 20B는 MUC1-음성 난소암 세포주인 OV-90이 전이 마커 CXCR4 및 NME7-X1의 증가된 발현을 나타내고; 도 20C는 최소 수준의 MUC1을 발현하는 유방암 세포주인 MDA-MB가 전이 마커 CDH1(일명 E-카드헤린) 및 SOX2의 발현을 증가시켰다는 것을 나타낸다.
도 21A 내지 도 21F는 분석된 암 세포주의 웨스턴 블롯의 사진 및 설명을 나타낸다. 도 21A 및 21B에서의 웨스턴 블롯의 경우, 모든 암 샘플을 40ug/㎖의 농도로 겔에 로딩되도록 정규화하였다. 도 21A에서, 다양한 암 세포주를 항-탠덤 반복 단클론성 항체 VU4H5를 사용하여 전장 MUC1의 발현에 대해 프로빙한다. 도 21B에서, 다양한 암 세포주를 다클론성 항-PSMGFR 항체를 사용하여 절단된 형태 MUC1*의 발현에 대해 프로빙한다. 도 21C는 분석된 암 세포주의 설명이다. 도 21D는 "BT474(모세포)"로 표시된 HER2 양성 BT474 유방암 세포가 도면에서 "BTres1"로 표시된 허셉틴 및 기타 화학요법 약물에 대한 내성을 획득할 때까지 MUC1 또는 MUC1*을 거의 또는 전혀 발현하지 않는다는 것을 나타낸다. 모 세포는 허셉틴의 준치사(sub-lethal) 수준에서 세포를 배양함으로써 허셉틴, 탁솔, 옥소루비신 및 사이클로포스파마이드에 내성을 갖도록 만들었다. 도 21D는 세포가 허셉틴에 대한 내성을 획득함에 따라 HER2의 발현 수준은 변하지 않았지만 MUC1*의 발현은 극적으로 증가되었음을 나타낸다. 도 21E는 항-MUC1* Fab의 존재 또는 부재 하에서 허셉틴을 사용한 처리에 반응하여 약물 내성 전이성 세포와 비교한 모 BT474 세포의 성장 그래프를 도시한다. 도면에서 인지할 수 있는 바와 같이, BT474 모 세포는 세포 성장에서 허셉틴 농도 의존적 감소를 나타낸 반면, 2개의 허셉틴 내성 세포주인 BTRes 1과 BTRes2는 허셉틴 처리에 대한 반응으로 암 세포 성장에서 감소를 나타내지 않는다. 그러나, 항-MUC1* Fab로 처리되는 경우, 내성 세포주는 암 세포 성장에서 허셉틴 농도 의존적 감소를 나타낸다. 도 21F는 항-MUC1* Fab의 존재 또는 부재 하에서 탁솔을 사용한 처리에 대한 반응으로, 약물 내성 BTRes1 세포와 비교한 모 BT474 세포의 세포 사멸 백분율의 그래프를 나타낸다.
도 22A 내지 도 22E는 공동 면역침전 실험의 웨스턴 블롯 사진. T47D 유방암 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 2개의 상이한 상업적으로 입수 가능한 항-NME7 항체 B9(도 22A) 및 CF7(도 22B)로 블로팅하였다. 두 겔 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 22C) 및 (도 22D)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7-AB와 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7-AB-유사 종 및 NME7-X1임을 나타낸다(도 22E).
도 23A 내지 도 23C는 공동 면역침전 실험의 웨스턴 블롯 사진. 인간 유도 만능 줄기(human induced pluripotent stem), iPS7 또는 배아 줄기, HES3, 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 상업적으로 입수 가능한 항-NME7 항체 B9로 블로팅하였다(도 23A). 두 세포 유형은 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 23B)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7-AB와 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7-AB-유사 종 및 NME7-X1임을 나타낸다(도 23C).
도 24는 NME7-AB에 결합하는 능력에 대해 새로운 항-NME7 항체를 검정하는 ELISA 실험의 그래프. NME7-AB는 MUC1*의 세포외 도메인에 결합하는 것으로 알려져 있다. 다중-웰 플레이트의 표면을 재조합 NME7-AB로 코팅하였다. 항-NME7-AB 항체를 웰에 별도로 첨가하였다. 표준 세척을 수행하고 HRP-접합 2차 항체를 첨가하여 시각화하였다. 인지될 수 있는 바와 같이, 10개의 새로운 항-NME7 항체 중 7개가 NME7-AB에 강하게 결합하였다.
도 25는 NME1에 결합하는 능력 또는 바람직하게는 무능력에 대해 새로운 항-NME7 항체를 검정하는 ELISA 실험의 그래프. 다중-웰 플레이트의 표면을 MUC1* 세포외 도메인에 결합하는 것으로 또한 알려진 재조합 NME1-S120G 이량체로 코팅하였다. 항-NME7-AB 항체를 웰에 별도로 첨가하였다. 표준 세척을 수행하고 HRP-접합 2차 항체를 첨가하여 시각화하였다. 인지될 수 있는 바와 같이 단지 하나의 항체가 NME1에 대한 최소 결합을 나타내었다.
도 26은 ELISA 경쟁적 저해 검정의 그래프. NME7-AB/항-NME7 항체 복합체는 MUC1* 세포외 도메인 펩타이드인 PSMGFR로 코팅된 다중-웰 플레이트에 첨가하기 전에 제조되었다. NME7-AB는 MUC1* 세포외 도메인에 각각 결합할 수 있는 2개의 유사-동일 도메인 A 및 B가 있음을 상기하기 바란다. B 도메인 내의 NME7 B3 펩타이드에 결합하는 항체는 NME7 A 도메인에 결합하지 않는다. 따라서 NME7-AB/MUC1* 상호작용의 부분적인 저해만이 예상된다.
도 27은 ELISA 변위 검정의 그래프. NME7-AB를 먼저 플레이트 상의 표면 고정된 MUC1* 세포외 도메인 펩타이드에 결합시킨 다음, 항-NME7 항체의 첨가에 의해 파괴시켰다.
도 28은 ELISA 변위 검정의 그래프. 이러한 경우, 다중-웰 플레이트를 PSMGFR 서열이 누락된 10개의 N-말단 아미노산을 갖는 절두된 MUC1* 펩타이드, N-10으로 코팅하였다. NME7-AB는 N-10 펩타이드에 결합하는 것으로 알려져 있다. NME7-AB를 플레이트 상의 표면 고정된 N-10 펩타이드에 결합시킨 다음, 항-NME7 항체의 첨가에 의해 파괴시켰다.
도 29는 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RMPI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포의 샘플에 존재하는 RNA의 양의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 샘플에서 RNA 양의 증가 또는 감소는, 작용제가 생성된 주어진 집단에서 세포 수를 각각 증가시켰거나 감소시켰다는 것을 주장한다.
도 30은 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RPMI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포 중의 전이 마커 CXCR4의 PCR 측정치의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 도면에서 인지될 수 있는 바와 같이, NME7-AB 배지에서의 성장은 세포의 부유체 집단에서 CXCR4를 증가시키고, 항-NME7 B3 항체는 발현을 감소시키는데, 이는 항-NME7 항체가 암 줄기세포의 생성을 감소시켰다고 주장한다.
도 31은 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RMPI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포 중의 줄기세포 마커 및 전이 마커 SOX2의 PCR 측정치의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 도면에서 인지될 수 있는 바와 같이, NME7-AB 배지에서의 성장은 세포의 부유체 집단에서 SOX2 발현을 증가시키고, 항-NME7 B3 항체는 발현을 감소시키는데, 이는 항-NME7 항체가 암 줄기세포의 생성을 감소시켰다고 주장한다.
도 32는 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RMPI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포 중의 줄기세포 마커 및 전이성 성장 인자 수용체 MUC1의 PCR 측정치의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 도면에서 인지될 수 있는 바와 같이, NME7-AB 배지에서의 성장은 세포의 부유체 집단에서 MUC1 발현을 증가시키고, 항-NME7 B3 항체는 발현을 감소시키는데, 이는 항-NME7 항체가 암 줄기세포의 생성을 감소시켰다고 주장한다.
도 33A 내지 도 33B는 암 세포의 꼬리 정맥 주사 후 제6일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 33A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 33B는 최소 배지에서 NME7-AB에서 10일 동안 성장시킨 10,000개의 T47D 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 부유 세포를 수집하였다. 이러한 부유 세포를 본 명세서에서 암 줄기세포, CSC로 지칭한다. 도면에서 인지될 수 있는 바와 같이, 야생형 암 세포를 주사한 마우스는 전이의 징후를 보이지 않는다. 그러나, 암 줄기세포가 아닌, 50배 적은 양의 세포를 주사한 마우스는 주사한 암 세포가 분명히 전이하고 있는 것으로 나타났다.
도 34A 내지 도 34D는 암 세포의 꼬리 정맥 주사 후 제10일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 34A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 34B는 10,000개의 T47D-CSC(암 줄기세포)를 주사한 마우스의 IVIS 사진을 도시한다. 도 34C는 10,000개의 T47D-CSC(암 줄기세포)를 주사하고, 제7일에 항-NME7 항체를 주사한 마우스의 IVIS 사진을 도시한다. 도 34D는 방출된 광자의 IVIS 측정치의 수기 기록을 도시한다. 도면에서 인지될 수 있는 바와 같이, 치료를 위해 선택된 마우스는 비교 가능한 T47D-CSC 마우스보다 더 전이성이다. 제1 항체 주사의 효능은 유리 NME7-AB의 제6일 주사에 의해 차단되었을 수 있다. 500,000개의 T47D-wt 세포를 주사한 대조군 마우스는 배경 또는 생존 암 세포일 수 있는 광자의 약한 방출을 나타낸다.
도 35A 내지 도 35C는 암 세포의 꼬리 정맥 주사 후 제12일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 35A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 35B는 항-NME7 항체로 처리하지 않은 10,000개의 T47D-CSC(암 줄기세포)를 주사한 마우스가 IVIS 사진을 찍을 수 있기 전에 과도한 종양 부하로 사망했음을 도시한다. 도 35C는 10,000개의 T47D-CSC(암 줄기세포)를 주사하고, 제7일 및 제10일에 항-NME7 항체를 주사한 마우스의 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, 항-NME7 항체로 처리한 마우스는 암 전이가 제거되고 있다. 500,000개의 T47D-wt 세포를 주사한 대조군 마우스는 더 약한 광자 방출을 나타내는데, 이는 더 적은 수의 생존 암 세포를 나타내거나 배경일 수 있다.
도 36A 내지 도 36B는 암 세포의 꼬리 정맥 주사 후 제14일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 36A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 36B는 10,000개의 T47D-CSC(암 줄기세포)를 주사하고, 제7일, 제10일 및 제12일에 항-NME7 항체를 주사한 마우스의 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, 항-NME7 항체로 처리한 마우스는 암 세포 전이가 거의 완전이 없다. 500,000개의 T47D-wt 세포를 주사한 대조군 마우스는 광자 방출을 나타내지 않는다.
도 37A 내지 도 37V는 암 세포 꼬리 정맥 주사 후 제6일에서부터 제26일까지 면역 손상된 nu/nu 마우스의 IVIS 사진의 시간 경과를 도시한 도면. 도 37A, 도 37C, 도 37E, 도 37G, 도 37I, 도 37K, 도 37M 및 도 37O는 제0일에 꼬리 정맥에 500,000개의 T47D-wt 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 37B, 도 37D, 도 37F, 도 37H, 도 37J, 도 37L, 도 37N 및 도 37P는 제0일에 10,000개의 T47D 암 줄기세포를 꼬리 정맥에 주사하고, 제7일부터 제17일까지 항-NME7 항체를 투여하고, 그 때 치료를 중단하고, 그 다음 제21일에 재개한 마우스의 IVIS 사진을 도시한다. 도 37Q, 도 37R, 도 37S, 도 37T 및 도 37U는 항-NME7 항체 처리를 중단한 제17일부터, 항체 처리를 재개한 제21일을 지나서, 제26일까지 처리된 마우스의 IVIS 확대 사진을 도시한다. 도 37V는IVIS 측정의 스케일 막대를 나타낸다. 이러한 시간 경과에서 인지될 수 있는 바와 같이, NME7에서 성장한 암 세포는 쉽게 전이되며, 이러한 전이는 NME7에 결합하는 항체를 처리함으로써 효과적으로 치료, 예방 또는 반전될 수 있다.
도 38A 내지 도 38C는 500,000개의 T47D 야생형 유방암 세포 또는 10,000개의 T47D 암 줄기세포를 주사한 후 제6일에서부터 제19일까지 면역 손상된 nu/nu 마우스의 IVIS 사진의 시간 경과를 도시한 도면. 도 38A는 꼬리 정맥(i.v.)에 주사된 마우스를 도시한다. 도 38B는 복강내(i.p.) 주사된 마우스를 도시한다. 도 38C는 피하 주사(s.c.)된 마우스를 도시한다.
도 39A 내지 39C는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 폐 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다.
도 40A 내지 도 40C는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 소장 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다.
도 41A 내지 41D는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 결장 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다.
도 42A 내지 도 42F는 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사하고, 8F9A4A3이라고도 알려진 항-NME7AB 항체 4A3로 처리한 각각 대략 20g의 체중의 암컷 nu/nu 마우스의 사진. 암 세포를 영상화하기 위해, 루시페라제 기질인 루시페린을 IVIS 기기로 촬영하기 10분 전에 복강내에 주사한다. 도 42A 내지 도 42C는 동물을 아래로 향하게 한 IVIS 사진을 도시한다. 도 42D 내지 도 42F는 동물을 위로 향하게 한 IVIS 사진을 도시한다. 도 42A 및 도 42D는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 42B 및 도 42E는 전이성 암 세포를 주사하기 24시간 전에 동물에게 항-NME7AB 항체 4A3을 주사한 후, 22일 동안 총 12회 항체 주사를 위해 대략 격일로 동물에 주사한 예방 모델을 도시한다. 도 42C 및 도 42F는 전이성 암 세포를 주사한 후 24시간 후에 동물에게 항-NME7AB 항체 4A3을 주사하고, 그 다음 20일 동안 총 11회 항체 주사를 위해 대략 격일로 동물에 주사한 반전 모델을 도시한다.
도 43A 내지 도 43F는 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사하고, 8F9A5A1이라고도 알려진 항-NME7AB 항체 5A1 및 5F3A5D4라고도 알려진 5D4로 처리한 각각 대략 20g의 체중의 암컷 nu/nu 마우스의 사진. 암 세포를 영상화하기 위해, 루시페라제 기질인 루시페린을 IVIS 기기로 촬영하기 10분 전에 복강내에 주사한다. 도 43A 내지 도 43C는 동물을 아래로 향하게 한 IVIS 사진을 도시한다. 도 43D 내지 도 43F는 동물을 위로 향하게 한 IVIS 사진을 도시한다. 도 43A 및 도 43D는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 43B, 도 43E, 도 43C 및 도 43F는 전이성 암 세포를 주사하기 24시간 전에 동물에게 항-NME7AB 항체를 주사한 후, 22일 동안 총 12회 항체 주사를 위해 대략 격일로 동물에 주사한 예방 모델을 도시한다. 제27일에 영상을 찍었다.
도 44A 내지 도 44D는 제0일에 32nM의 최종 농도로 NME7AB와 혼합된 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사한 암컷 nu/nu 마우스의 사진. 제1일 및 제2일에 동물에게 본 발명자들이 전이를 증가시키는 것으로 발견한 더 많은 32nM NME7AB를 꼬리 정맥에 주사하였다. 이것은 확립된 전이의 반전을 입증하기 위한 시스템이다. 제7일에, 동물을 개별 항-NME7AB 항체 8F9A5A1, 8F9A4A3 또는 5F3A5D4로 처리하였다. 도 44A는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 44B는 5A1이라고도 알려진 항-NME7AB 단클론성 항체 8F9A5A1로 처리된 동물을 도시한다. 도 44C는 4A3이라고도 알려진 항-NME7AB 단클론성 항체 8F9A4A3으로 처리된 동물을 도시한다. 도 44D는 5D4이라고도 알려진 항-NME7AB 단클론성 항체 5F3A5D4로 처리된 동물을 도시한다. 녹색 화살표는 표시된 기간 동안 낮은 항체 투여량(5 내지 7㎎/㎏)을 나타내고, 적색 화살표는 높은 투여량(15㎎/㎏)을 나타낸다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체로 처리된 동물은, 항체로 처리될 군 내의 다수의 동물이 임의의 처리 전에 더 많은 전이를 가졌음에도 불구하고, 대조군 동물보다 전이가 적다. 높은 농도의 항-NME7AB 항체는 낮은 농도보다 더 효과적이다. 예를 들어, 제11일과 제17일 사이에, 동물을 고용량으로 처리하였고, 처리된 동물의 대부분은 약 제17일까지 전이가 제거되었다. 그러나, 1회의 저용량 항체는 전이 재발을 초래하였다. 동물은 제32일까지 고용량 치료에 다시 반응한다.
도 45A 내지 도 45B는 제0일에 32nM의 최종 농도로 NME7AB와 혼합되고, 그 다음 마트리겔과 1:1 vol:vol로 혼합된, 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 우측 옆구리에 피하 주사한 암컷 nu/nu 마우스의 사진. 종양 생착을 제0일 내지 제6일 진행하도록 하였다. 이어서 동물을 항-NME7AB 항체로 꼬리 정맥 주사에 의해서 정맥내 처리하였다. 대조군 동물에게 PBS를 주사하였다. 도 45A는 대조군 동물의 IVIS 사진을 나타낸다. 도 45B는 15㎎/㎏의 총 농도로 항-NME7AB 항체 5A1, 4A3 및 5D4의 칵테일을 꼬리 정맥에 주사한 동물의 IVIS 사진을 도시한다. 항체 또는 PBS를 제7일과 제18일 사이에 4회 투여하였다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체 처리 동물은 대조군보다 전이가 적었다. 처리된 군에서 5마리의 동물 중 2마리는 대조군보다 더 큰 원발성 종양을 갖는다. 이는 항-NME7AB 항체가 암 세포의 확산을 방지하여 원발성 종양에 집중되어 있기 때문일 수 있다. 본 실험에서, PCR 분석은 NME7AB와 배양한 지 11일 후에 T47D 유방암 세포가 CXCR4를 109배, OCT4를 2배, NANOG를 3.5배, MUC1을 2.7배 상향조절한 것으로 나타났다.
도 46A 내지 도 46Q는 제0일에 32nM의 최종 농도로 NME7AB와 혼합되고, 그 다음 마트리겔과 1:1 vol:vol로 혼합된, 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 우측 옆구리에 피하 주사한 암컷 nu/nu 마우스의 사진. 종양 생착을 제0일 내지 제6일 진행하도록 하였다. 이어서 동물을 항-NME7AB 항체로 꼬리 정맥 주사에 의해서 정맥내 처리하였다. 대조군 동물에게 PBS를 주사하였다. 제38일에, 동물을 희생시키고, 간을 수거하고, 이어서 IVIS로 분석하여 간에 전이된 암 세포를 검출하였다. 도 46A 내지 도 46B는 PBS만을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46C 내지 도 46D는 항-NME7AB 항체 5A1을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46E 도 46F는 항-NME7AB 항체 4A3을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46G 내지 도 46H는 항-NME7AB 항체 5D4를 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46A, 도 46C, 도 46E 및 도 46G는 치료 전 제7일에 촬영한 IVIS 사진이다. 도 46B, 도 46D, 도 46F 및 도 46H는 항-NME7AB 항체 치료 또는 모의 실험 후 제31일에 촬영한 IVIS 사진이다. 도면에서 인지될 수 있는 바와 같이, PBS 대조군의 동물은 전신 IVIS 사진에서 전이(청색점)를 나타낸 반면, 항-NME7AB 항체로 처리한 동물은 그렇지 않았다. 도 46I 내지 도 46P는 희생 후 동물로부터 수거한 간 및 폐의 사진 및 IVIS 사진을 도시한다. 도 46I, 도 46K, 도 46M, 도 46O는 일반 사진이다. 도 46J, 도 46L, 도 46N 및 도 46P는 전이된 암 세포를 나타내는 IVIS 사진이다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체는 유방암 전이의 1차 부위인 간으로의 전이를 크게 저해하였다. 도 46Q는 대조군 동물 대 처리 동물로부터 수거된 간에 대해 IVIS 기기에 의해 방출되고 열거된 측정된 광자의 막대 그래프이다.
도 47A 내지 도 47F는 NME7AB의 존재에 대해 다양한 암 세포주가 염색되는 면역형광 실험의 사진. 도 47A는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 T47D 유방암 세포를 도시한다. 도 47B는 다양한 농도의 항-NME7AB 항체 5D4로 염색된, 1500s라고도 알려진 ZR-75-1 유방암 세포를 도시한다. 도 47C는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 H1975 비소세포 폐암 세포를 도시한다. 도 47D는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 H292 비소세포 폐암 세포를 도시한다. 도 47E는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 HPAFII 췌장암 세포를 도시한다. 도 47F는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 DU145 전립선암 세포를 도시한다. 도면에서 인지될 수 있는 바와 같이, 본 발명자들이 시험한 모든 암 세포주는 NME7AB에 대해 강력하고 막성인 염색을 나타낸다. 본 실험에 사용된 단클론성 항체는 5D4였다. 동시에, NME7AB 항체 5A1 및 4A3을 사용하여 동일한 세포주를 염색하고 동일한 결과를 생성하였다.
도 48A 내지 도 48I는 NME7AB의 존재에 대해 다양한 폐암 세포주가 염색되는 면역형광 실험의 사진. 도 48A 내지 도 48C는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 선암종인 H1975 비소세포 폐암 세포를 도시한다. 도 48A는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48B는 항-NME7AB 염색 단독을 나타낸다. 도 48C는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다. 도 48D 내지 도 48F는 다양한 농도의 항-NME7AB 항체 5D4로 염색된, 점막표피양 폐 암종인 H292 비소세포 폐암 세포를 도시한다. 도 48D는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48E는 항-NME7AB 염색 단독을 나타낸다. 도 48F는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다. 도 48G 내지 도 48I는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 전이성 기관지폐포 암종인 H358 비소세포 폐암 세포를 도시한다. 도 48G는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48H는 항-NME7AB 염색 단독을 나타낸다. 도 48I는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다.
도 49A 내지 도 49I는 NME7AB에서의 배양 전 후의 암 세포주, 유방 T47D, 폐 H1975, 폐 H358 및 췌장 HPAFII의 PCR 그래프. 도 49A는 유방 전이 마커 CXCR4를 측정하였다. 도 49B는 줄기세포 마커 OCT4를 측정하였다. 도 49C는 전이 마커 ALDH1을 측정하였다. 도 49D는 줄기세포 마커 SOX2를 측정하였다. 도 49E는 줄기세포 마커 NANOG를 측정하였다. 도 49F는는 E-카드헤린이라고도 공지된 마커 CDH1을 측정하였다. 도 49G는 전이 마커 CD133을 측정하였다. 도 49H는 줄기세포 마커 ZEB2를 측정하였다. 도 49I는 줄기, 암 및 전이 마커 MUC1을 측정하였다. 종양 구체로도 알려진 부유체 세포는 독립적으로 고정부(anchorage)를 성장시킬 수 있게 되며, 부착 세포보다 더 증가된 전이 마커를 나타낸다. 암 줄기세포를 주사한 동물은 NME7AB 배양 부유체 세포를 주사한 동물이다. 도면에서 인지될 수 있는 바와 같이, 전이 마커, 줄기세포 마커 또는 상피에서 중간엽으로의 전이(epithelial to mesenchymal transition: EMT)의 마커는 NME7AB에서 배양 후 증가하는데, 이는 보다 전이성 상태로의 변화를 나타낸다.
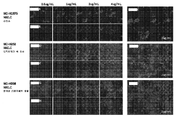
도 50A 내지 도 50D는 NME7AB와의 배양에서 10일 후 NCI-H358 모 세포 또는 NCI-H358 세포인 10,000개의 암 세포를 꼬리 정맥에 주사한 NSG 마우스의 IVIS 사진. 도 50A 및 도 50C는 NME7AB에서 10일 동안 성장시킨 NCI-H358 폐암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 50B 및 도 50D는 모체 NCI-H358 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 50A 및 도 50B는 마우스를 아래로 향하게 하여 영상화한 IVIS 사진을 도시한다. 도 50C 및 도 50D는 마우스를 위로 향하게 하여 영상화한 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, NME7AB 성장 세포는 전이 가능성이 크게 증가하였다.
도 51은 NME1 또는 NME7AB라고도 알려진 이량체 NM23-H1에서 배양물에서 2 또는 3 계대 전 및 후의 MUC1 음성 전립선암주 PC3의 PCR 그래프. 그래프는 줄기세포 마커, 암 세포 마커 및 전이 마커의 배수 차이를 도시한다. 도면에서 인지될 수 있는 바와 같이, NME1 또는 NME7AB의 반복 배양은 줄기, 암 및 전이 마커의 상향조절을 유도하지만, MUC1의 발현도 5 내지 8배 상향조절한다.
본 발명은 본 명세서의 하기에 제공되는 상세한 설명, 및 단지 예시로서 제공되므로 본 발명을 제한하고자 하는 것이 아닌 첨부 도면을 통해서 보다 완전히 이해될 것이다.
도 1은 NME7-AB가 MUC1* 세포외 도메인 펩타이드를 이량체화한다는 것을 나타낸 ELISA 샌드위치 검정으로부터의 HRP 신호의 그래프.
도 2는 전통적인 배지 또는 NME7을 함유하는 배지에서 배양된 후 T47D 암 세포에 대한 줄기세포 마커 및 암 줄기세포 마커에 대한 유전자 발현의 RT-PCR 측정치의 그래프(여기서 비-부착성이 된 세포(부유체(floater))를 부착된 채로 유지된 세포와 별개로 분석하였다.
도 3은 DU145 전립선 암 세포에 대한 다양한 줄기 및 추정 암 줄기세포 마커에 대한 유전자 발현의 RT-PCR 측정치의 그래프. 세포를 전통 배지 또는 NME1 이량체("NM23") 또는 NME7(NME7-AB)을 함유하는 배지에서 배양하였다. Rho 키나제 저해제는 계대 2에 의해서, 세포가 부착된 채로 남아있기 때문에 사용되지 않았다.
도 4는 줄기세포를 보다 미경험 상태로 반전시킨다고 이미 밝혀진 2i 저해제(GSK3-베타 및 MEK 저해제)가 또한 NME7AB만큼은 아니지만 암 세포를 보다 전이성인 상태로 유도한다는 것을 나타낸 전이 마커 및 만능 줄기세포(pluripotent stem cell) 마커의 RT-PCR 측정치의 그래프.
도 5는 인간 NME1과 인간 NME7-A 또는 -B 영역 간의 서열 정렬.
도 6은 NME1과 서열 동일성이 낮고, 암의 치료 또는 예방을 위해 치료용 항-NME7 항체를 생성하는 능력에 대해 선택된, 인간 NME7의 면역원성 펩타이드를 열거한 도면.
도 7은 암의 치료 또는 예방을 위해 치료용 항-NME7 항체를 생성시키는 능력에 대해 선택된, 구조적 온전성 또는 MUC1*에 대한 결합에 중요할 수 있는 인간 NME7의 면역원성 펩타이드를 열거한 도면.
도 8은 암의 치료 또는 예방을 위해 치료용 항-NME7 항체를 생성시키는 능력에 대해 선택된, 구조적 온전성 또는 MUC1*에 대한 결합에 중요할 수 있는 인간 NME1의 면역원성 펩타이드를 열거한 도면.
도 9는 NME1에 대한 낮은 서열 동일성 및 암에 관여하는 박테리아 NME1 단백질에 대한 상동성에 대해 선택된 인간 NME7로부터의 면역원성 펩타이드를 열거한 도면. 이들 펩타이드는 암의 치료 또는 예방을 위한 치료용 항-NME7 항체를 생성시키는 능력 면에서 바람직하다. 본 도면에서 도시된 펩타이드는 C-말단 단부에 공유 결합된 시스테인을 포함하고 첨가한다.
도 10A 내지 도 10B는 NME7-AB(도 10A) 또는 NME1(도 10B)이 플레이트에 흡착된 ELISA 검정의 그래프이고, NME7 펩타이드 A1, A2, B1, B2 및 B3에 의해서 생성된 항-NME7 항체를 NME1이 아닌 NME7에 결합하는 능력에 대해서 시험한다. C20은 항-NME1 항체이다.
도 11은 생성된 항-NME7 항체를 NME1의 결합을 저해하지 않고 표면 고정된 MUC1* 펩타이드에 대한 NME7-AB의 결합을 저해하는 능력에 대해서 시험한 ELISA 검정의 그래프.
도 12는 유방암 세포를 항체를 생성시키거나 선택하는 데 사용된 NME7 항체 또는 NME7로부터 유래된 짧은 펩타이드의 존재 또는 부재 하에서 성장시킨 암 세포 성장 실험의 그래프. 또한 거의 전체 NME7-AB 펩타이드인 아미노산 100 내지 376으로의 면역화에 의해서 생성된 항체가 암 세포 성장을 저해하는 것으로 나타났다.
도 13은 유방암 세포를 항체를 생성시키거나 선택하는 데 사용된 NME7 항체의 조합물 또는 NME7로부터 유래된 짧은 펩타이드의 조합물의 존재 또는 부재 하에서 성장시킨 암 세포 성장 실험의 그래프. 항체 및 이의 면역화 NME7-AB 펩타이드 둘 다 암 세포의 성장을 저해하였다.
도 14A 및 도 14B는 암 세포를 보다 전이성인 상태로 형질전환시킬 수 있는 NME7-AB 또는 2i 저해제에서 그리고 NME7 유래 펩타이드 A1, A2, B1, B2 및 B3의 존재 또는 부재 하에서 암 세포를 성장시켰을 때의 과학자 관찰 표. NME7-AB 펩타이드는 RT-PCR 측정에서 전이 마커, 특히 CXCR4의 발현이 증가된 것으로 나타난 부유체 세포로의 부착성 암 세포의 전이를 저해하였다.
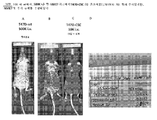
도 15A 내지 도 15C는 각각은 암 세포를 보다 전이성인 상태로 형질전환시키는 NME7-AB 또는 2i 저해제에서 성장한 T47D 유방암 세포에서 CXCR4 및 기타 전이 마커의 발현의 RT-PCR 측정치의 그래프 및 전이성 형질전환에 대한 항-NME7 항체의 저해성 효과의 그래프. 도 15A는 항-NME7 항체의 존재 또는 부재 하에서 NME7AB 또는 2i에서 성장한 T47D 암 세포의 CXCR4 발현의 PCR 그래프를 도시한다. 도 15B는 NME7AB 면역화 펩타이드의 존재 하에서 72시간 또는 144시간 동안 2i 저해제에서 성장시킨 T47D 유방암 세포에서 CXCR4, CHD1 및 SOX2 발현의 RT-PCR 측정치의 그래프를 도시하고, 펩타이드 자체가 전이성 형질전환에 대해서 저해성임을 나타낸다. 도 15A의 저해성 콤보 2 및 3에 사용된 펩타이드 A1, A2 및 B1도 펩타이드로서 저해성이다. 펩타이드 B3이 가장 저해성이며, 이는 도 15A에서 시험된 가장 저해성 항체인 항체 61에 대한 면역화 펩타이드이다. 도 15C는 Y축의 스케일이 감소된 도 15B의 그래프를 도시한다.
도 16은 도 31에서 CXCR4의 RT-PCR 측정에 사용된 샘플에서 기록된 RNA 수준의 표뿐만 아니라 CXCR4 발현 및 대조군 하우스키핑 유전자에 대한 역치 사이클 수를 도시한 도면.
도 17은 인간 줄기 세포 및 암 세포의 패널에서 NME7-X1의 발현의 RT-PCR 측정치의 그래프.
도 18은 인간 줄기 세포 및 암 세포의 패널에서 NME7, NME7a, NME7b 및 NME7-X1의 발현의 RT-PCR 측정치의 그래프. NME7a는 전장 NME7이고, NME7b는 DM10 도메인의 작은 부분이 누락되었으며, NME7-X1은 DM10 도메인 전체 및 제1 NDPK A 도메인의 N-말단의 작은 부분이 누락되었다. NME7으로 표시된 막대는 NME7a 및 NME7b 둘 다를 검출한 프라이머가 사용되었음을 의미한다.
도 19A 내지 19F는 NME7 유래 펩타이드로의 면역화에 의해 생성된 항체를 사용하여 NME7 종의 발현에 대해 다양한 암 세포주가 프로빙된 웨스턴 블롯의 사진. 도 19A는 A1 펩타이드에 결합하는 항체 52가 전장 NME7, NME7AB 또는 NME7-X1의 존재에 대해 세포의 패널을 프로빙하는데 사용된 웨스턴 블롯을 나타낸다. 도 19B는 B1 펩타이드에 결합하는 항체 56이 전장 NME7, NME7AB 또는 NME7-X1의 존재에 대해 세포의 패널을 프로빙하는데 사용된 웨스턴 블롯을 나타낸다. 도 19C는 B3 펩타이드에 결합하는 항체 61이 전장 NME7, NME7AB 또는 NME7-X1의 존재에 대해 세포의 패널을 프로빙하는데 사용된 웨스턴 블롯을 나타낸다. 도 19D는 NME7 A 및 B 도메인 둘 다에 대해 생성된 상업적으로 입수 가능한 다클론성 항체 H278을 사용하여 NME7의 존재에 대해 세포의 패널을 프로빙한 웨스턴 블롯을 나타낸다. 도면에 나타난 바와 같이, 항체 H278은 또한 NME1을 인식한다. 도 19E는 상업적으로 입수 가능한 항-NME7 항체 B9에 대해 웹사이트에 공개된 겔을 나타내는데, 이는 그것이 전장 NME7의 겉보기 분자량을 갖는 종에 결합함을 나타낸다. 도 19F는 본 발명자들이 항-NME7 항체 B9를 사용하여 NME1만 로딩된 겔을 프로빙한 웨스턴 블롯을 나타낸다. 도면에서 인지될 수 있는 바와 같이, 항체 B9는 NME1뿐만 아니라 전장 NME7을 인식한다. 이것은 항체 H278과 같이, B9가 NME1의 A 도메인이 NME7AB의 A 도메인과 고도로 상동성인 NME7의 A 및 B 도메인 둘 다에 대해 발생했기 때문에 놀라운 것이 아니다.
도 20A 내지 도 20C는 표준 배지와 비교하여 NME7-AB를 함유하는 무혈청 배지에서 배양된 후 암 세포에서 전이 마커의 RT-PCR 측정치의 그래프. 도 20A는 MUC1-양성 난소암 세포주인 SK-OV3이 전이 마커 CXCR4, CDH1(일명 E-카드헤린), SOX2 및 NME7-X1의 발현을 증가시켰음을 나타내고; 도 20B는 MUC1-음성 난소암 세포주인 OV-90이 전이 마커 CXCR4 및 NME7-X1의 증가된 발현을 나타내고; 도 20C는 최소 수준의 MUC1을 발현하는 유방암 세포주인 MDA-MB가 전이 마커 CDH1(일명 E-카드헤린) 및 SOX2의 발현을 증가시켰다는 것을 나타낸다.
도 21A 내지 도 21F는 분석된 암 세포주의 웨스턴 블롯의 사진 및 설명을 나타낸다. 도 21A 및 21B에서의 웨스턴 블롯의 경우, 모든 암 샘플을 40ug/㎖의 농도로 겔에 로딩되도록 정규화하였다. 도 21A에서, 다양한 암 세포주를 항-탠덤 반복 단클론성 항체 VU4H5를 사용하여 전장 MUC1의 발현에 대해 프로빙한다. 도 21B에서, 다양한 암 세포주를 다클론성 항-PSMGFR 항체를 사용하여 절단된 형태 MUC1*의 발현에 대해 프로빙한다. 도 21C는 분석된 암 세포주의 설명이다. 도 21D는 "BT474(모세포)"로 표시된 HER2 양성 BT474 유방암 세포가 도면에서 "BTres1"로 표시된 허셉틴 및 기타 화학요법 약물에 대한 내성을 획득할 때까지 MUC1 또는 MUC1*을 거의 또는 전혀 발현하지 않는다는 것을 나타낸다. 모 세포는 허셉틴의 준치사(sub-lethal) 수준에서 세포를 배양함으로써 허셉틴, 탁솔, 옥소루비신 및 사이클로포스파마이드에 내성을 갖도록 만들었다. 도 21D는 세포가 허셉틴에 대한 내성을 획득함에 따라 HER2의 발현 수준은 변하지 않았지만 MUC1*의 발현은 극적으로 증가되었음을 나타낸다. 도 21E는 항-MUC1* Fab의 존재 또는 부재 하에서 허셉틴을 사용한 처리에 반응하여 약물 내성 전이성 세포와 비교한 모 BT474 세포의 성장 그래프를 도시한다. 도면에서 인지할 수 있는 바와 같이, BT474 모 세포는 세포 성장에서 허셉틴 농도 의존적 감소를 나타낸 반면, 2개의 허셉틴 내성 세포주인 BTRes 1과 BTRes2는 허셉틴 처리에 대한 반응으로 암 세포 성장에서 감소를 나타내지 않는다. 그러나, 항-MUC1* Fab로 처리되는 경우, 내성 세포주는 암 세포 성장에서 허셉틴 농도 의존적 감소를 나타낸다. 도 21F는 항-MUC1* Fab의 존재 또는 부재 하에서 탁솔을 사용한 처리에 대한 반응으로, 약물 내성 BTRes1 세포와 비교한 모 BT474 세포의 세포 사멸 백분율의 그래프를 나타낸다.
도 22A 내지 도 22E는 공동 면역침전 실험의 웨스턴 블롯 사진. T47D 유방암 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 2개의 상이한 상업적으로 입수 가능한 항-NME7 항체 B9(도 22A) 및 CF7(도 22B)로 블로팅하였다. 두 겔 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 22C) 및 (도 22D)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7-AB와 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7-AB-유사 종 및 NME7-X1임을 나타낸다(도 22E).
도 23A 내지 도 23C는 공동 면역침전 실험의 웨스턴 블롯 사진. 인간 유도 만능 줄기(human induced pluripotent stem), iPS7 또는 배아 줄기, HES3, 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 상업적으로 입수 가능한 항-NME7 항체 B9로 블로팅하였다(도 23A). 두 세포 유형은 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 23B)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7-AB와 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7-AB-유사 종 및 NME7-X1임을 나타낸다(도 23C).
도 24는 NME7-AB에 결합하는 능력에 대해 새로운 항-NME7 항체를 검정하는 ELISA 실험의 그래프. NME7-AB는 MUC1*의 세포외 도메인에 결합하는 것으로 알려져 있다. 다중-웰 플레이트의 표면을 재조합 NME7-AB로 코팅하였다. 항-NME7-AB 항체를 웰에 별도로 첨가하였다. 표준 세척을 수행하고 HRP-접합 2차 항체를 첨가하여 시각화하였다. 인지될 수 있는 바와 같이, 10개의 새로운 항-NME7 항체 중 7개가 NME7-AB에 강하게 결합하였다.
도 25는 NME1에 결합하는 능력 또는 바람직하게는 무능력에 대해 새로운 항-NME7 항체를 검정하는 ELISA 실험의 그래프. 다중-웰 플레이트의 표면을 MUC1* 세포외 도메인에 결합하는 것으로 또한 알려진 재조합 NME1-S120G 이량체로 코팅하였다. 항-NME7-AB 항체를 웰에 별도로 첨가하였다. 표준 세척을 수행하고 HRP-접합 2차 항체를 첨가하여 시각화하였다. 인지될 수 있는 바와 같이 단지 하나의 항체가 NME1에 대한 최소 결합을 나타내었다.
도 26은 ELISA 경쟁적 저해 검정의 그래프. NME7-AB/항-NME7 항체 복합체는 MUC1* 세포외 도메인 펩타이드인 PSMGFR로 코팅된 다중-웰 플레이트에 첨가하기 전에 제조되었다. NME7-AB는 MUC1* 세포외 도메인에 각각 결합할 수 있는 2개의 유사-동일 도메인 A 및 B가 있음을 상기하기 바란다. B 도메인 내의 NME7 B3 펩타이드에 결합하는 항체는 NME7 A 도메인에 결합하지 않는다. 따라서 NME7-AB/MUC1* 상호작용의 부분적인 저해만이 예상된다.
도 27은 ELISA 변위 검정의 그래프. NME7-AB를 먼저 플레이트 상의 표면 고정된 MUC1* 세포외 도메인 펩타이드에 결합시킨 다음, 항-NME7 항체의 첨가에 의해 파괴시켰다.
도 28은 ELISA 변위 검정의 그래프. 이러한 경우, 다중-웰 플레이트를 PSMGFR 서열이 누락된 10개의 N-말단 아미노산을 갖는 절두된 MUC1* 펩타이드, N-10으로 코팅하였다. NME7-AB는 N-10 펩타이드에 결합하는 것으로 알려져 있다. NME7-AB를 플레이트 상의 표면 고정된 N-10 펩타이드에 결합시킨 다음, 항-NME7 항체의 첨가에 의해 파괴시켰다.
도 29는 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RMPI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포의 샘플에 존재하는 RNA의 양의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 샘플에서 RNA 양의 증가 또는 감소는, 작용제가 생성된 주어진 집단에서 세포 수를 각각 증가시켰거나 감소시켰다는 것을 주장한다.
도 30은 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RPMI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포 중의 전이 마커 CXCR4의 PCR 측정치의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 도면에서 인지될 수 있는 바와 같이, NME7-AB 배지에서의 성장은 세포의 부유체 집단에서 CXCR4를 증가시키고, 항-NME7 B3 항체는 발현을 감소시키는데, 이는 항-NME7 항체가 암 줄기세포의 생성을 감소시켰다고 주장한다.
도 31은 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RMPI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포 중의 줄기세포 마커 및 전이 마커 SOX2의 PCR 측정치의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 도면에서 인지될 수 있는 바와 같이, NME7-AB 배지에서의 성장은 세포의 부유체 집단에서 SOX2 발현을 증가시키고, 항-NME7 B3 항체는 발현을 감소시키는데, 이는 항-NME7 항체가 암 줄기세포의 생성을 감소시켰다고 주장한다.
도 32는 최적인 4nM 또는 8nM에서 성장 인자로서 NME7-AB만을 함유하는 정상 권장 배지인 RMPI, 무혈청 배지 또는 8nM에서 성장 인자로서 NME1 S120G 이량체만을 함유하는 무혈청 배지에서 배양된 T47D 유방암 세포 중의 줄기세포 마커 및 전이성 성장 인자 수용체 MUC1의 PCR 측정치의 그래프를 도시하며; NME1은 동종이량체이고 NME7-AB는 2개의 유사-동일 도메인으로 구성된 단량체이기 때문에 8nM NME1은 4nM NME7-AB의 몰 당량이다. 암 세포를 항-NME7 B3 항체의 존재 또는 부재 하에서 배양하였다. 본 실험에서, 부유 세포를 부착 세포로부터 분리하여 별도로 분석하였다. 중요한 데이터는 부유체 세포가 암 줄기세포라고 주장한다. 도면에서 인지될 수 있는 바와 같이, NME7-AB 배지에서의 성장은 세포의 부유체 집단에서 MUC1 발현을 증가시키고, 항-NME7 B3 항체는 발현을 감소시키는데, 이는 항-NME7 항체가 암 줄기세포의 생성을 감소시켰다고 주장한다.
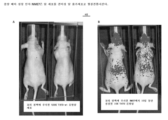
도 33A 내지 도 33B는 암 세포의 꼬리 정맥 주사 후 제6일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 33A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 33B는 최소 배지에서 NME7-AB에서 10일 동안 성장시킨 10,000개의 T47D 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 부유 세포를 수집하였다. 이러한 부유 세포를 본 명세서에서 암 줄기세포, CSC로 지칭한다. 도면에서 인지될 수 있는 바와 같이, 야생형 암 세포를 주사한 마우스는 전이의 징후를 보이지 않는다. 그러나, 암 줄기세포가 아닌, 50배 적은 양의 세포를 주사한 마우스는 주사한 암 세포가 분명히 전이하고 있는 것으로 나타났다.
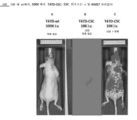
도 34A 내지 도 34D는 암 세포의 꼬리 정맥 주사 후 제10일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 34A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 34B는 10,000개의 T47D-CSC(암 줄기세포)를 주사한 마우스의 IVIS 사진을 도시한다. 도 34C는 10,000개의 T47D-CSC(암 줄기세포)를 주사하고, 제7일에 항-NME7 항체를 주사한 마우스의 IVIS 사진을 도시한다. 도 34D는 방출된 광자의 IVIS 측정치의 수기 기록을 도시한다. 도면에서 인지될 수 있는 바와 같이, 치료를 위해 선택된 마우스는 비교 가능한 T47D-CSC 마우스보다 더 전이성이다. 제1 항체 주사의 효능은 유리 NME7-AB의 제6일 주사에 의해 차단되었을 수 있다. 500,000개의 T47D-wt 세포를 주사한 대조군 마우스는 배경 또는 생존 암 세포일 수 있는 광자의 약한 방출을 나타낸다.
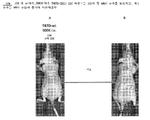
도 35A 내지 도 35C는 암 세포의 꼬리 정맥 주사 후 제12일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 35A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 35B는 항-NME7 항체로 처리하지 않은 10,000개의 T47D-CSC(암 줄기세포)를 주사한 마우스가 IVIS 사진을 찍을 수 있기 전에 과도한 종양 부하로 사망했음을 도시한다. 도 35C는 10,000개의 T47D-CSC(암 줄기세포)를 주사하고, 제7일 및 제10일에 항-NME7 항체를 주사한 마우스의 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, 항-NME7 항체로 처리한 마우스는 암 전이가 제거되고 있다. 500,000개의 T47D-wt 세포를 주사한 대조군 마우스는 더 약한 광자 방출을 나타내는데, 이는 더 적은 수의 생존 암 세포를 나타내거나 배경일 수 있다.
도 36A 내지 도 36B는 암 세포의 꼬리 정맥 주사 후 제14일에 면역 손상된 nu/nu 마우스의 IVIS 사진. 도 36A는 500,000개의 T47D-wt 유방암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 36B는 10,000개의 T47D-CSC(암 줄기세포)를 주사하고, 제7일, 제10일 및 제12일에 항-NME7 항체를 주사한 마우스의 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, 항-NME7 항체로 처리한 마우스는 암 세포 전이가 거의 완전이 없다. 500,000개의 T47D-wt 세포를 주사한 대조군 마우스는 광자 방출을 나타내지 않는다.
도 37A 내지 도 37V는 암 세포 꼬리 정맥 주사 후 제6일에서부터 제26일까지 면역 손상된 nu/nu 마우스의 IVIS 사진의 시간 경과를 도시한 도면. 도 37A, 도 37C, 도 37E, 도 37G, 도 37I, 도 37K, 도 37M 및 도 37O는 제0일에 꼬리 정맥에 500,000개의 T47D-wt 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 37B, 도 37D, 도 37F, 도 37H, 도 37J, 도 37L, 도 37N 및 도 37P는 제0일에 10,000개의 T47D 암 줄기세포를 꼬리 정맥에 주사하고, 제7일부터 제17일까지 항-NME7 항체를 투여하고, 그 때 치료를 중단하고, 그 다음 제21일에 재개한 마우스의 IVIS 사진을 도시한다. 도 37Q, 도 37R, 도 37S, 도 37T 및 도 37U는 항-NME7 항체 처리를 중단한 제17일부터, 항체 처리를 재개한 제21일을 지나서, 제26일까지 처리된 마우스의 IVIS 확대 사진을 도시한다. 도 37V는IVIS 측정의 스케일 막대를 나타낸다. 이러한 시간 경과에서 인지될 수 있는 바와 같이, NME7에서 성장한 암 세포는 쉽게 전이되며, 이러한 전이는 NME7에 결합하는 항체를 처리함으로써 효과적으로 치료, 예방 또는 반전될 수 있다.
도 38A 내지 도 38C는 500,000개의 T47D 야생형 유방암 세포 또는 10,000개의 T47D 암 줄기세포를 주사한 후 제6일에서부터 제19일까지 면역 손상된 nu/nu 마우스의 IVIS 사진의 시간 경과를 도시한 도면. 도 38A는 꼬리 정맥(i.v.)에 주사된 마우스를 도시한다. 도 38B는 복강내(i.p.) 주사된 마우스를 도시한다. 도 38C는 피하 주사(s.c.)된 마우스를 도시한다.
도 39A 내지 39C는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 폐 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다.
도 40A 내지 도 40C는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 소장 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다.
도 41A 내지 41D는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 결장 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다.
도 42A 내지 도 42F는 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사하고, 8F9A4A3이라고도 알려진 항-NME7AB 항체 4A3로 처리한 각각 대략 20g의 체중의 암컷 nu/nu 마우스의 사진. 암 세포를 영상화하기 위해, 루시페라제 기질인 루시페린을 IVIS 기기로 촬영하기 10분 전에 복강내에 주사한다. 도 42A 내지 도 42C는 동물을 아래로 향하게 한 IVIS 사진을 도시한다. 도 42D 내지 도 42F는 동물을 위로 향하게 한 IVIS 사진을 도시한다. 도 42A 및 도 42D는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 42B 및 도 42E는 전이성 암 세포를 주사하기 24시간 전에 동물에게 항-NME7AB 항체 4A3을 주사한 후, 22일 동안 총 12회 항체 주사를 위해 대략 격일로 동물에 주사한 예방 모델을 도시한다. 도 42C 및 도 42F는 전이성 암 세포를 주사한 후 24시간 후에 동물에게 항-NME7AB 항체 4A3을 주사하고, 그 다음 20일 동안 총 11회 항체 주사를 위해 대략 격일로 동물에 주사한 반전 모델을 도시한다.
도 43A 내지 도 43F는 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사하고, 8F9A5A1이라고도 알려진 항-NME7AB 항체 5A1 및 5F3A5D4라고도 알려진 5D4로 처리한 각각 대략 20g의 체중의 암컷 nu/nu 마우스의 사진. 암 세포를 영상화하기 위해, 루시페라제 기질인 루시페린을 IVIS 기기로 촬영하기 10분 전에 복강내에 주사한다. 도 43A 내지 도 43C는 동물을 아래로 향하게 한 IVIS 사진을 도시한다. 도 43D 내지 도 43F는 동물을 위로 향하게 한 IVIS 사진을 도시한다. 도 43A 및 도 43D는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 43B, 도 43E, 도 43C 및 도 43F는 전이성 암 세포를 주사하기 24시간 전에 동물에게 항-NME7AB 항체를 주사한 후, 22일 동안 총 12회 항체 주사를 위해 대략 격일로 동물에 주사한 예방 모델을 도시한다. 제27일에 영상을 찍었다.
도 44A 내지 도 44D는 제0일에 32nM의 최종 농도로 NME7AB와 혼합된 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사한 암컷 nu/nu 마우스의 사진. 제1일 및 제2일에 동물에게 본 발명자들이 전이를 증가시키는 것으로 발견한 더 많은 32nM NME7AB를 꼬리 정맥에 주사하였다. 이것은 확립된 전이의 반전을 입증하기 위한 시스템이다. 제7일에, 동물을 개별 항-NME7AB 항체 8F9A5A1, 8F9A4A3 또는 5F3A5D4로 처리하였다. 도 44A는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 44B는 5A1이라고도 알려진 항-NME7AB 단클론성 항체 8F9A5A1로 처리된 동물을 도시한다. 도 44C는 4A3이라고도 알려진 항-NME7AB 단클론성 항체 8F9A4A3으로 처리된 동물을 도시한다. 도 44D는 5D4이라고도 알려진 항-NME7AB 단클론성 항체 5F3A5D4로 처리된 동물을 도시한다. 녹색 화살표는 표시된 기간 동안 낮은 항체 투여량(5 내지 7㎎/㎏)을 나타내고, 적색 화살표는 높은 투여량(15㎎/㎏)을 나타낸다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체로 처리된 동물은, 항체로 처리될 군 내의 다수의 동물이 임의의 처리 전에 더 많은 전이를 가졌음에도 불구하고, 대조군 동물보다 전이가 적다. 높은 농도의 항-NME7AB 항체는 낮은 농도보다 더 효과적이다. 예를 들어, 제11일과 제17일 사이에, 동물을 고용량으로 처리하였고, 처리된 동물의 대부분은 약 제17일까지 전이가 제거되었다. 그러나, 1회의 저용량 항체는 전이 재발을 초래하였다. 동물은 제32일까지 고용량 치료에 다시 반응한다.
도 45A 내지 도 45B는 제0일에 32nM의 최종 농도로 NME7AB와 혼합되고, 그 다음 마트리겔과 1:1 vol:vol로 혼합된, 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 우측 옆구리에 피하 주사한 암컷 nu/nu 마우스의 사진. 종양 생착을 제0일 내지 제6일 진행하도록 하였다. 이어서 동물을 항-NME7AB 항체로 꼬리 정맥 주사에 의해서 정맥내 처리하였다. 대조군 동물에게 PBS를 주사하였다. 도 45A는 대조군 동물의 IVIS 사진을 나타낸다. 도 45B는 15㎎/㎏의 총 농도로 항-NME7AB 항체 5A1, 4A3 및 5D4의 칵테일을 꼬리 정맥에 주사한 동물의 IVIS 사진을 도시한다. 항체 또는 PBS를 제7일과 제18일 사이에 4회 투여하였다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체 처리 동물은 대조군보다 전이가 적었다. 처리된 군에서 5마리의 동물 중 2마리는 대조군보다 더 큰 원발성 종양을 갖는다. 이는 항-NME7AB 항체가 암 세포의 확산을 방지하여 원발성 종양에 집중되어 있기 때문일 수 있다. 본 실험에서, PCR 분석은 NME7AB와 배양한 지 11일 후에 T47D 유방암 세포가 CXCR4를 109배, OCT4를 2배, NANOG를 3.5배, MUC1을 2.7배 상향조절한 것으로 나타났다.
도 46A 내지 도 46Q는 제0일에 32nM의 최종 농도로 NME7AB와 혼합되고, 그 다음 마트리겔과 1:1 vol:vol로 혼합된, 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 우측 옆구리에 피하 주사한 암컷 nu/nu 마우스의 사진. 종양 생착을 제0일 내지 제6일 진행하도록 하였다. 이어서 동물을 항-NME7AB 항체로 꼬리 정맥 주사에 의해서 정맥내 처리하였다. 대조군 동물에게 PBS를 주사하였다. 제38일에, 동물을 희생시키고, 간을 수거하고, 이어서 IVIS로 분석하여 간에 전이된 암 세포를 검출하였다. 도 46A 내지 도 46B는 PBS만을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46C 내지 도 46D는 항-NME7AB 항체 5A1을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46E 도 46F는 항-NME7AB 항체 4A3을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46G 내지 도 46H는 항-NME7AB 항체 5D4를 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46A, 도 46C, 도 46E 및 도 46G는 치료 전 제7일에 촬영한 IVIS 사진이다. 도 46B, 도 46D, 도 46F 및 도 46H는 항-NME7AB 항체 치료 또는 모의 실험 후 제31일에 촬영한 IVIS 사진이다. 도면에서 인지될 수 있는 바와 같이, PBS 대조군의 동물은 전신 IVIS 사진에서 전이(청색점)를 나타낸 반면, 항-NME7AB 항체로 처리한 동물은 그렇지 않았다. 도 46I 내지 도 46P는 희생 후 동물로부터 수거한 간 및 폐의 사진 및 IVIS 사진을 도시한다. 도 46I, 도 46K, 도 46M, 도 46O는 일반 사진이다. 도 46J, 도 46L, 도 46N 및 도 46P는 전이된 암 세포를 나타내는 IVIS 사진이다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체는 유방암 전이의 1차 부위인 간으로의 전이를 크게 저해하였다. 도 46Q는 대조군 동물 대 처리 동물로부터 수거된 간에 대해 IVIS 기기에 의해 방출되고 열거된 측정된 광자의 막대 그래프이다.
도 47A 내지 도 47F는 NME7AB의 존재에 대해 다양한 암 세포주가 염색되는 면역형광 실험의 사진. 도 47A는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 T47D 유방암 세포를 도시한다. 도 47B는 다양한 농도의 항-NME7AB 항체 5D4로 염색된, 1500s라고도 알려진 ZR-75-1 유방암 세포를 도시한다. 도 47C는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 H1975 비소세포 폐암 세포를 도시한다. 도 47D는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 H292 비소세포 폐암 세포를 도시한다. 도 47E는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 HPAFII 췌장암 세포를 도시한다. 도 47F는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 DU145 전립선암 세포를 도시한다. 도면에서 인지될 수 있는 바와 같이, 본 발명자들이 시험한 모든 암 세포주는 NME7AB에 대해 강력하고 막성인 염색을 나타낸다. 본 실험에 사용된 단클론성 항체는 5D4였다. 동시에, NME7AB 항체 5A1 및 4A3을 사용하여 동일한 세포주를 염색하고 동일한 결과를 생성하였다.
도 48A 내지 도 48I는 NME7AB의 존재에 대해 다양한 폐암 세포주가 염색되는 면역형광 실험의 사진. 도 48A 내지 도 48C는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 선암종인 H1975 비소세포 폐암 세포를 도시한다. 도 48A는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48B는 항-NME7AB 염색 단독을 나타낸다. 도 48C는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다. 도 48D 내지 도 48F는 다양한 농도의 항-NME7AB 항체 5D4로 염색된, 점막표피양 폐 암종인 H292 비소세포 폐암 세포를 도시한다. 도 48D는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48E는 항-NME7AB 염색 단독을 나타낸다. 도 48F는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다. 도 48G 내지 도 48I는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 전이성 기관지폐포 암종인 H358 비소세포 폐암 세포를 도시한다. 도 48G는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48H는 항-NME7AB 염색 단독을 나타낸다. 도 48I는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다.
도 49A 내지 도 49I는 NME7AB에서의 배양 전 후의 암 세포주, 유방 T47D, 폐 H1975, 폐 H358 및 췌장 HPAFII의 PCR 그래프. 도 49A는 유방 전이 마커 CXCR4를 측정하였다. 도 49B는 줄기세포 마커 OCT4를 측정하였다. 도 49C는 전이 마커 ALDH1을 측정하였다. 도 49D는 줄기세포 마커 SOX2를 측정하였다. 도 49E는 줄기세포 마커 NANOG를 측정하였다. 도 49F는는 E-카드헤린이라고도 공지된 마커 CDH1을 측정하였다. 도 49G는 전이 마커 CD133을 측정하였다. 도 49H는 줄기세포 마커 ZEB2를 측정하였다. 도 49I는 줄기, 암 및 전이 마커 MUC1을 측정하였다. 종양 구체로도 알려진 부유체 세포는 독립적으로 고정부(anchorage)를 성장시킬 수 있게 되며, 부착 세포보다 더 증가된 전이 마커를 나타낸다. 암 줄기세포를 주사한 동물은 NME7AB 배양 부유체 세포를 주사한 동물이다. 도면에서 인지될 수 있는 바와 같이, 전이 마커, 줄기세포 마커 또는 상피에서 중간엽으로의 전이(epithelial to mesenchymal transition: EMT)의 마커는 NME7AB에서 배양 후 증가하는데, 이는 보다 전이성 상태로의 변화를 나타낸다.
도 50A 내지 도 50D는 NME7AB와의 배양에서 10일 후 NCI-H358 모 세포 또는 NCI-H358 세포인 10,000개의 암 세포를 꼬리 정맥에 주사한 NSG 마우스의 IVIS 사진. 도 50A 및 도 50C는 NME7AB에서 10일 동안 성장시킨 NCI-H358 폐암 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 50B 및 도 50D는 모체 NCI-H358 세포를 주사한 마우스의 IVIS 사진을 도시한다. 도 50A 및 도 50B는 마우스를 아래로 향하게 하여 영상화한 IVIS 사진을 도시한다. 도 50C 및 도 50D는 마우스를 위로 향하게 하여 영상화한 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, NME7AB 성장 세포는 전이 가능성이 크게 증가하였다.
도 51은 NME1 또는 NME7AB라고도 알려진 이량체 NM23-H1에서 배양물에서 2 또는 3 계대 전 및 후의 MUC1 음성 전립선암주 PC3의 PCR 그래프. 그래프는 줄기세포 마커, 암 세포 마커 및 전이 마커의 배수 차이를 도시한다. 도면에서 인지될 수 있는 바와 같이, NME1 또는 NME7AB의 반복 배양은 줄기, 암 및 전이 마커의 상향조절을 유도하지만, MUC1의 발현도 5 내지 8배 상향조절한다.
정의
본 출원에서, 단수 표현은 단일 대상 및 복수의 대상 둘 다를 지칭하는 데 사용된다.
본 명세서에 사용된 바와 같이, "약" 또는 "실질적으로"는 일반적으로, 정확한 수로 한정되지 않는 재량을 제공한다. 예를 들어, 폴리펩타이드 서열의 길이에 대한 맥락에서 사용된 바와 같이, "약" 또는 "실질적으로"는, 폴리펩타이드가 언급된 수의 아미노산으로 제한되지 않아야 함을 나타낸다. N-말단 또는 C-말단에 첨가되거나 제거된 몇몇 아미노산은, 이의 결합 활성과 같은 기능적 활성이 존재하는 한, 포함될 수 있다.
본 명세서에 사용된 바와 같이, 1종 이상 추가적인 치료제"와 조합한" 투여는 동시(동반되는) 투여 및 임의의 순서의 연속 투여를 포함한다.
본 명세서에 사용된 바와 같이, "아미노산" 및 "아미노산들"은 모든 자연 발생 L-α-아미노산을 지칭한다. 이러한 정의는 노르류신, 오르니틴 및 호모시스테인을 포함한다.
본 명세서에 사용된 바와 같이, 일반적으로, 용어 "아미노산 서열 변이체"는 참조(예를 들어, 천연(천연) 서열) 폴리펩타이드와 비교하여 아미노산 서열이 약간 상이한 분자를 지칭한다. 아미노산 변경은 천연 아미노산 서열에서의 치환, 삽입, 결실 또는 이러한 변화의 임의의 바람직한 조합일 수 있다.
치환 변이체는, 천연 서열에서 적어도 하나의 아미노산 잔기가 제거되고, 동일한 위치에서 이의 자리에 상이한 아미노산이 삽입된 것이다. 치환은 분자에서 단지 하나의 아미노산이 치환된 단일 치환일 수 있거나, 동일한 분자에서 2개 이상의 아미노산이 치환된 다중 치환일 수 있다.
서열 내의 아미노산에 대한 치환기는, 아미노산이 속한 부류의 다른 구성원으로부터 선택될 수 있다. 예를 들어, 비극성(소수성) 아미노산은 알라닌, 류신, 아이소류신, 발린, 프롤린, 페닐알라닌, 트립토판 및 메티오닌을 포함한다. 극성 중성 아미노산은, 글리신, 세린, 트레오닌, 시스테인, 티로신, 아스파라긴 및 글루타민을 포함한다. 양전하성(염기성) 아미노산은 아르기닌, 라이신 및 히스티딘을 포함한다. 음전하성(산성) 아미노산은 아스파트산 및 글루탐산을 포함한다. 동일하거나 유사한 생물학적 활성을 나타내는 단백질, 단편 또는 이들의 유도체, 및 번역 동안 또는 번역 후에 예를 들어, 글리코실화, 단백질분해 절단, 항체 분자 또는 다른 세포성 리간드에 대한 연결 등에 의해 상이하게 변형되는 유도체가 또한 본 발명의 범주 내에 포함된다.
삽입 변이체는, 천연 아미노산 서열 내의 특정 위치에 있는 아미노산에 바로 인접하여 하나 이상의 아미노산이 삽입된 것이다. 아미노산에 바로 인접해 있다는 것은, 아미노산의 α-카복시 또는 α-아미노 작용기에 연결됨을 의미한다.
결실 변이체는, 천연 아미노산 서열에서 하나 이상의 아미노산이 제거된 것이다. 본래, 결실 변이체는 분자의 특정 영역에서 1개 또는 2개의 아미노산이 결실될 것이다.
본 명세서에 사용된 바와 같이, "단편" 또는 "기능적 유도체"는 본 발명의 폴리펩타이드의 생물학적 활성 아미노산 서열 변이체 및 단편, 뿐만 아니라 유기 유도체화제와의 반응, 번역-후 변형, 비-단백질성 중합체를 갖는 유도체 및 면역어드헤신(immunoadhesin)을 포함하는 공유 변형을 지칭한다.
본 명세서에 사용된 바와 같이, "담체"는, 사용되는 투여량 및 농도에서 노출되는 세포 또는 포유동물에 무독성인 약제학적으로 허용 가능한 담체, 부형제 또는 안정화제를 포함한다. 종종, 약제학적으로 허용 가능한 담체는 pH 완충 용액이다. 약제학적으로 허용 가능한 담체의 예는 비제한적으로, 완충제, 예컨대, 포스페이트, 시트레이트 및 다른 유기산; 아스코르브산을 비롯한 항산화제; 저분자량(잔기가 약 10개 미만인) 폴리펩타이드; 단백질, 예컨대, 혈청 알부민, 젤라틴 또는 면역글로불린; 친수성 중합체, 예컨대, 폴리바이닐피롤리돈; 아미노산, 예컨대, 글리신, 글루타민, 아스파라긴, 아르기닌 또는 라이신; 글루코스, 만노스 또는 덱스트린을 비롯한 단당류, 이당류 및 다른 탄수화물; 킬레이트제, 예컨대, EDTA; 당 알코올, 예컨대, 만니톨 또는 솔비톨; 염-형성 반대이온, 예컨대, 나트륨; 및/또는 비이온성 계면활성제, 예컨대, TWEEN®, 폴리에틸렌 글리콜(PEG) 및 PLURONICS® 등을 포함한다.
본 명세서에 사용된 바와 같이, "약제학적으로 허용 가능한 담체 및/또는 희석제"는, 임의의 모든 용매, 분산 배지, 코팅제, 항박테리아제, 항진균제, 등장성제 및 흡수 지연제 등을 포함한다. 약제학적 활성 성분에 대한 이러한 배지 및 작용제의 용도는 당업계에 널리 공지되어 있다. 임의의 통상적인 배지 또는 작용제가 활성 성분과 비융화성인 경우를 제외하고는, 치료 조성물에서 이의 사용이 고려된다. 보조적인 활성 성분이 또한 조성물 내로 혼입될 수 있다.
특히, 투여의 용이성 및 투여량의 균일성을 위해 비경구 조성물을 투여 단위 형태로 제형화하는 것이 유리하다. 본 명세서에 사용된 바와 같이, 투여 단위 형태는 치료될 포유동물 대상체를 위한 일원화된 용량으로서 적합한 물리적 개별 단위를 지칭하며; 각각의 단위는 필요한 약제학적 담체와 연관된 바람직한 치료 효과를 발휘하도록 계산된 활성 물질을 예정된 양으로 함유한다. 본 발명의 투여 단위 형태에 대한 설명은 (a) 활성 물질의 고유한 특징 및 달성되어야 하는 특정 치료 효과, 및 (b) 신체적 건강이 손상된 병변이 있는 병태를 갖는 살아 있는 대상체에서 질환의 치료를 위한 활성 물질과 같은 컴파운딩(compounding) 분야에 내재하는 한계에 의해 설명되며, 이들에 직접 좌우된다.
기본적인 활성 성분은 편리하고, 효과적인 투여를 위해 유효량으로, 투여 단위 형태로 약제학적으로 허용 가능한 적합한 담체와 함께 컴파운딩된다. 단위 투여 형태는 예를 들어, 기본적인 활성 화합물을 0.5㎍ 내지 약 2000㎎ 범위의 양으로 함유할 수 있다. 비율로서 표현하면, 활성 화합물은 일반적으로 담체의 약 0.5㎍/㎖ 로 존재한다. 보조 활성 성분을 함유하는 조성물의 경우, 투여량은 상기 성분의 통상적인 용량 및 투여 방식을 참고하여 결정된다.
본 명세서에 사용된 바와 같이, "벡터", "폴리뉴클레오타이드 벡터", "작제물" 및 "폴리뉴클레오타이드 작제물"은 본 명세서에서 상호 교환 가능하게 사용된다. 본 발명의 폴리뉴클레오타이드 벡터는 RNA, DNA, 레트로바이러스 코트에 캡슐화된 RNA, 아데노바이러스 코트에 캡슐화된 DNA, 또 다른 바이러스 또는 바이러스-유사 형태(예컨대, 헤르페스 심플렉스 및 아데노-구조물, 예컨대, 폴리아마이드)에 패키징된 DNA를 포함하지만 이들로 제한되지 않는 몇몇 형태들 중 임의의 형태로 존재할 수 있다.
본 명세서에 사용된 바와 같이, "숙주 세포"는 본 발명의 벡터의 수여자일 수 있거나 수여자였던 개별 세포 또는 세포 배양물을 포함한다. 숙주 세포는 단일 숙주 세포의 자손을 포함하고, 자손은 본질적으로는, 자연적, 우연적 또는 고의적인 돌연변이 및/또는 변화로 인해 본래 모 세포와 (형태 또는 총 DNA 상보체의 면에서) 완전히 일치하지 않을 수 있다.
본 명세서에 사용된 바와 같이, "대상체"는 척추동물, 바람직하게는 포유동물, 보다 바람직하게는 인간이다.
본 명세서에 사용된 바와 같이, 치료를 위한 "포유동물"는 인간, 가축 및 농장용 동물, 동물원, 스포츠 또는 애완 동물, 예컨대, 개, 고양이, 소, 말, 양, 돼지 등을 비롯하여 포유동물로서 분류되는 임의의 동물을 지칭한다. 바람직하게는, 포유동물은 인간이다.
본 명세서에 사용된 바와 같이, "치료"는 유익하거나 목적하는 임상 결과를 수득하기 위한 접근법이다. 본 발명의 목적에 있어서, 유익하거나 목적하는 임상 결과는, 검출 가능하거나 검출 불가능하든 간에, 증상의 완화, 질환 정도의 감소, 안정화된(즉, 악화되지 않는) 질환 상태, 질환 진행의 지연 또는 서행, 질환 상태의 개선 또는 경감, 및 (부분적이거나 전체적이든지 간에) 차도 등을 포함하지만 이들로 제한되지 않는다. "치료"는 또한 치료를 받지 않을 경우 예상되는 생존율과 비교하여, 생존율을 연장시키는 것을 의미할 수 있다. "치료"는 치유적 치료 및 예방적 또는 방지적 조치 둘 모두를 지칭한다. 치료가 필요한 개체는, 이미 장애를 앓고 있는 개체뿐만 아니라 장애가 예방되어야 하는 개체를 포함한다. 질환의 "경감"은, 질환 상태의 정도 및/또는 바람직하지 못한 임상 징후가 줄어들고/거나 진행 시간이 치료를 받지 않는 상황과 비교하여 둔화되거나 길어지는 것을 의미한다.
본 명세서에 사용된 바와 같이, "A1" 펩타이드, "A2" 펩타이드, "B1" 펩타이드, "B2" 펩타이드 및 "B3" 펩타이드는 인간 NME1에 결합하지 않지만(또는 상당히 적게 결합하나) 인간 NME7AB에 결합하는 항체를 생성하거나 선택하는 데 사용되는 NME7로부터 유래된 펩타이드를 지칭한다. 이들 항체를 생성하는 데 사용되는 펩타이드는 NME7AB 및 NME7-X1 둘 모두에 공통적이며, 하기에 제시되어 있다.
A1은 NME7A 펩타이드 1(A 도메인): MLSRKEALDFHVDHQS(서열번호 141)이고,
A2는 NME7A 펩타이드 2(A 도메인): SGVARTDASES(서열번호 142)이고,
B1은 NME7B 펩타이드 1(B 도메인): DAGFEISAMQMFNMDRVNVE(서열번호 143)이고,
B2는 NME7B 펩타이드 2(B 도메인): EVYKGVVTEYHDMVTE(서열번호 144)이고,
B3은 NME7B 펩타이드 3(B 도메인): AIFGKTKIQNAVHCTDLPEDGLLEVQYFF(서열번호 145)이다.
추가로, 명료화를 위해서, (대문자 "A"를 가진) NME7A는 NME7의 소단위 A 부분을 지칭한다. (소문자 "a"를 가진) NME7a는 본 출원 어디에서든지 기술되는 전장 NME7을 지칭한다. 또한 (대문자 "B"를 가진) NME7B는 NME7의 소단위 B 부분을 지칭한다. (소문자 "b"를 가진) NME7b는 본 출원 어디에서든지 기술되며, DM10 영역을 부분적으로 포함하지 않는 NME7의 종을 지칭한다.
본 명세서에 사용된 바와 같이, 용어 "항체-유사"는, 항체의 일부를 함유하지만 자연에서 자연 발생하는 항체는 아닌 방식으로 조작될 수 있는 분자를 의미한다. 예는, CAR(키메라 항원 수용체) T 세포 기술 및 Ylanthia® 기술 등을 포함하지만, 이들로 제한되지 않는다. CAR 기술은 T 세포의 일부에 융합된 항체 에피토프를 사용하여, 신체의 면역계가 특이적인 표적 단백질 또는 세포를 공격하도록 한다. Ylanthia® 기술은, 이후에, 표적 단백질로부터의 펩타이드 에피토프에 결합하는지에 대해서 스크리닝되는 합성 인간 fab의 컬렉션(collection)인 "항체-유사" 라이브러리로 이루어진다. 그런 다음, 선택된 Fab 영역은 스캐폴드 또는 골격 내로 조작되어, 항체를 닮게 될 수 있다.
본 명세서에 사용된 바와 같이, "NME 패밀리 구성원 단백질을 저해하기 위한 작용제의 유효량"은, 예를 들어, NME 패 밀리 구성원 단백질과 이의 동족 수용체 사이의 활성화 상호작용을 방해하는 데 있어서의 작용제의 유효량을 지칭한다.
본 명세서에 사용된 바와 같이, "NME 유래 단편"은, NME의 단편이거나, NME 단편인 펩타이드 서열에 고도로 상동성인 펩타이드 서열을 지칭한다.
본 명세서에서, "MUC1*" 세포외 도메인은 주로 PSMGFR 서열(GTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA(서열번호 6))에 의해서 정의된다. MUC1 절단의 정확한 부위는 이를 클리핑(clipping)하는 효소에 좌우되고, 절단 효소는 세포 유형, 조직 유형 또는 세포의 진화 시간에 따라 달라지기 때문에, MUC1*세포외 도메인의 정확한 서열은 N-말단에서 달라질 수 있다.
본 명세서에 사용된 바와 같이, 용어 "PSMGFR"은 GTINVHDVETQFNQYKTEAASRYNLTISDVSVSDVPFPFSAQSGA(서열번호 6)로 제시된 바와 같은 MUC1 성장 인자 수용체의 일차 서열에 대한 두문자어이다. 이와 관련하여, "N-10 PSMGFR" 또는 단순히 "N-10", "N-15 PSMGFR" 또는 단순히 "N-15", 또는 "N-20 PSMGFR" 또는 단순히 "N-20"에서와 같이 "N-수"는 PSMGFR의 N-말단에서 결실된 아미노산 잔기의 수를 지칭한다. 마찬가지로, "C-10 PSMGFR", 또는 단순히 "C-10", "C-15 PSMGFR" 또는 단순히 "C-15", "C-20 PSMGFR" 또는 단순히 "C-20"에서와 같이 "C-수"는 PSMGFR의 C-말단에서 결실된 아미노산 잔기의 수를 지칭한다. 결실과 부가의 혼합물이 또한 가능하다. 예를 들어, N+20/C-27은 20개의 아미노산이 N-말단에서 PSMGFR에 부가되고, 27개의 아미노산이 C-말단으로부터 결실되는 야생형 MUC1의 펩타이드 단편을 지칭한다.
본 명세서에서 사용되는 바와 같이, "MUC1*의 세포외 도메인"은 탠덤 반복 도메인을 포함하지 않는 MUC1 단백질의 세포외 부분을 지칭한다. 대부분의 경우, MUC1*은 절단 생성물이며, 여기서, MUC1* 부분은 탠덤 반복부를 포함하지 않는 짧은 세포외 도메인, 막관통 도메인 및 세포질 꼬리로 이루어진다. MUC1이 절단되는 정확한 위치는, MUC1이 하나 초과의 효소에 의해 절단될 수 있는 것으로 보이기 때문에, 아마도 알려져 있지 않다. MUC1*의 세포외 도메인은 PSMGFR 서열 대부분을 포함할 것이지만, 부가적인 10개 내지 20개의 N-말단 아미노산을 가질 수 있다.
본 명세서에서 사용되는 바와 같이, "높은 상동성"은, 임의의 2개의 폴리펩타이드 간의 지정된 중복 영역에서 30% 이상, 35% 이상, 40% 이상, 45% 이상, 50% 이상, 55% 이상, 60% 이상, 65% 이상, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이 상, 95% 이상 또는 97% 이상의 동일성인 것으로 간주된다.
본 명세서에서 사용되는 바와 같이, 수가 1 내지 10인 "NME 패밀리 단백질" 또는 "NME 패밀리 멤버 단백질"은, 이들 모두가 적어도 하나의 NDPK(뉴클레오타이드 다이포스페이트 키나제) 도메인을 갖기 때문에, 함께 단백질로 분류된다. 일부 경우, NDPK 영역은, ATP가 ADP로 전환되는 것을 촉매할 수 있다는 점에서, 기능적이지 않다. NME 단백질은 형식상 H1 및 H2로 넘버링되는 NM23 단백질로서 알려져 있었다. 최근, NME 패밀리 구성원 10개가 식별되어 있다. 본 명세서에 사용된 바와 같이, 용어 NM23 및 NME는 상호 교환 가능하다. 본 명세서에 사용된 바와 같이, 용어 NME1, NME2, NME5, NME6, NME7, NME8 및 NME9은 천연 단백질뿐만 아니라 NME 변이체를 지칭하는 데 사용된다. 일부 경우, 이들 변이체는 천연 서열 단백질보다 용해성이며, 이. 콜라이(E. coli)에서 더 잘 발현되거나 또는 더 용해성이다. 예를 들어, 명세서에서 사용되는 바와 같은 NME7은, 천연 단백질 또는 변이체, 예컨대, 변이가 이, 콜라이에서 용해성의 적절하게 접혀진 단백질을 고 수율로 발현되게 할 수 있기 때문에 우수한 상업적인 이용 가능성을 갖는 NME7AB 의미할 수 있다. NME7AB는 주로 NME7 A 및 NME7 B 도메인으로 이루어지지만, 천연 단백질의 N-말단에 존재하는 DM10 도메인(서열번호 39)을 대부분 포함하지 않는다. 본 명세서에서 지칭되는 바와 같은 "NME1"은 "NM23-H1"과 상호 교환 가능하다. 본 발명은 또한 NME 단백질의 정확한 서열에 의해 제한되지 않는 것으로 의도된다. NM23-S120G로도 지칭되는 돌연변이체 NME1-S120G는 출원 전체에서 상호 교환 가능하게 사용된다. S120G 돌연변이체 및 P96S 돌연변이체는 이들의 이량체 형성 선호도 때문에 바람직하지만, 본 명세서에서 NM23 이량체, NME1 이량체, 이량체 NME1 또는 이량체 NM23으로 지칭될 수 있다.
본 명세서에서 지칭되는 바와 같은 NME7은 분자량이 약 42kDa인 천연 NME7을 의미하도록 의도된다.
"NME7의 패밀리"는 전장 NME7뿐만 아니라, 분자량이 30kDa, 33kDa인 자연 발생 절단된 형태 또는 인공적으로 생성된 절단된 형태, 또는 분자량이 약 25kDa인 절단된 형태, DM10 리더 서열을 포함하지 않거나 부분적으로 포함하지 않는 변이체, 예컨대, NME7b, NME7-X1, NME7AB 또는 재조합 NME7 단백질, 또는 효율적인 발현을 허용하도록 변경될 수 있거나 또는 NME7을 보다 효과적이거나 또는 상업적으로 보다 활력이 있도록 만드는 다른 특징, 용해성 또는 수율을 증가시키도록 변경될 수 있는 이의 변이체를 의미하도록 의도되며, DM10 리더 서열(서열번호 162)은 서열번호 82 또는 147로 표시되는 NME7의 NME7 아미노산 1 내지 91이다. "NME7의 패밀리"는 또한 암 세포에서 발현되는 30kDa 내지 33kDa 범위의 단백질인 "NME7AB-유사" 단백질을 포함할 수 있다.
본 명세서에 사용된 바와 같이, "줄기세포를 미경험 상태로 유지시키거나 프라이밍된(primed) 줄기세포를 미경험 상태로 반전시키는 작용제"는, 단독으로 또는 조합하여, 줄기세포를 미경험 상태로 유지시켜, 세포가 배아의 내부 세포 덩어리를 닮게 만드는 단백질, 작은 분자 또는 핵산을 지칭한다. 예는 인간 NME 단백질, 특히 NME1, NME7, NME7-X1, NME7AB, NME6, 2i(문헌[Silva J et al, 2008; Hanna et al, 2010]), 5i(문헌[Theunissen TW et al, 2014]), 핵산, 예컨대, MBD3, CHD4(문헌[Rais Y1 et al, 2013), BRD4 또는 JMJD6(문헌[Liu W et al 2013])의 발현을 억제시키는 siRNA에 높은 서열 일치성을 갖는 인간 NME1 이량체, 박테리아, 진균, 효모, 바이러스 또는 기생충 NME 단백질 등을 포함하지만 이들로 제한되지 않는다.
본 명세서에서 사용되는 바와 같이, 용어 "NME7AB", "NME7AB" 및 "NME-AB"는 상호 교환 가능하게 사용된다.
본 명세서에 사용된 바와 같이, "전분화능(pluripotency)을 촉진하는 작용제" 또는 "체세포를 줄기-유사 또는 암-유사 상태로 반전시키는 작용제"는, 단독으로 또는 조합하여, 유전적 시그니처가 줄기세포 또는 암 세포를 보다 근접하게 닮은 시그니처로 이동되도록 소정의 유전자의 발현을 유도하거나 발현을 억제하는 단백질, 작은 분자 또는 핵산을 지칭한다. 예는 NME1 이량체, NME7, NME7-X1, NME7AB, 2i, 5i, 핵산, 예컨대, MBD3, CHD4, BRD4 또는 JMJD6의 발현을 억제하는 siRNA, 인간 NME1, NME2, NME5, NME6, NME7, NME8 또는 NME9, 바람직하게는 NDPK 도메인을 갖는 영역에 대해 높은 서열 상동성을 갖는 미생물 NME 단백질 등을 포함하지만 이들로 제한되지 않는다.
본 명세서에서 사용되는 바와 같이, "작은 분자"로 지칭되는 작용에 대한 언급에서, 이는 분자량이 50Da 내지 2000Da, 보다 바람직하게는 150Da 내지 1000Da, 보다 더 바람직하게는 200Da 내지 750Da인 합성 화학 또는 화학적 기반의 분자일 수 있다.
본 명세서에서, "자연 생성물"로 지칭되는 작용제에 대한 언급에서, 이는 분자가 자연에 존재하는 한, 화학적 분자 또는 생물학적 분자일 수 있다.
본 명세서에서 사용되는 바와 같이, FGF, FGF-2 또는 bFGF는 섬유아세포 성장 인자를 지칭한다(문헌[Xu RH et al, 2005; Xu C et al, 2005]).
본 명세서에서 사용되는 바와 같이, "Rho 연관 키나제 저해제"는 소분자, 펩타이드 또는 단백질일 수 있다(문헌[Rath N, et al, 2012]). Rho 키나제 저해제는 본 명세서 및 다른 어디에서도 ROCi 또는 ROCKi 또는 Ri로 약칭된다. 특이적인 rho 키나제 저해제의 사용은 예시적인 것으로 의미되며, 임의의 다른 rho 키나제 저해제를 대체할 수 있다.
본 명세서에서 사용되는 바와 같이, 용어 "암 줄기세포" 또는 "종양 개시 세포"는, 보다 전이적인 상태 또는 보다 공격적인 암과 관련된 유전자의 수준을 발현하는 암 세포를 지칭한다. 용어 "암 줄기세포" 또는 "종양 개시 세포"는 또한 동물에게 이식되는 경우 종양을 발생시키는 데 있어서 훨씬 더 적은 수의 세포가 필요한 암 세포를 지칭할 수 있다. 암 줄기세포 및 종양 개시 세포는 종종 화학요법 약물에 내성이다.
본 명세서에서 사용되는 바와 같이, 용어 "줄기/암", "암-유사", "줄기-유사"는, 세포가 줄기세포 또는 암 세포의 특징을 획득하며, 줄기세포, 암 세포 또는 암 줄기세포의 유전자 발현 프로파일의 중요한 요소를 공유하는 상태를 지칭한다. 줄기-유사 세포는, 덜 성숙한 상태로의 유도를 수행하고 있는, 예컨대, 전분화능 유전자의 발현을 증가시키는 체세포일 수 있다. 줄기-유사 세포는 또한 일부 탈분화를 수행하였거나, 또는 이들이 이들의 말기 분화를 변경할 수 있는 준-안정 상태에 있는 세포를 지칭한다. 암-유사 세포는 아직까지는 완전히 특징규명되지 않았지만 암 세포의 형태 및 특징을 나타내는, 예컨대, 고정부-독립적으로 성장할 수 있거나 또는 동물에서 종양을 발생시킬 수 있는 암 세포일 수 있다.
본 명세서에 사용된 바와 같이, 길이가 서로 다른 "스페이서" 또는 "링커"는 펩타이드 내 어디에서든지 혼입될 수 있다. 스페이서 부착은 통상적으로 아마이드 연결을 통해 이루어지지만, 다른 작용기도 가능하다.
NME, NME7 및 NME7의 단백질 패밀리
본 발명자들은 NME7 및 NME7-X1이 초기 인간 줄기세포 및 또한 대부분의 암 세포에서 고도로 발현됨을 발견하였다(도 17, 도 18, 도 19A 내지 도 19F, 도 22, 도 23, 도 39, 도 40, 도 41, 도 47, 도 48). 도 17은 인간 줄기 세포 및 암 세포의 패널에서 NME7-X1의 발현의 RT-PCR 측정치의 그래프. 도 18은 인간 줄기 세포 및 암 세포의 패널에서 NME7, NME7a, NME7b 및 NME7-X1의 발현의 RT-PCR 측정치의 그래프. NME7a는 전장 NME7이고, NME7b는 DM10 도메인의 작은 부분이 누락되었으며, NME7-X1은 DM10 도메인 전체 및 제1 NDPK A 도메인의 N-말단의 작은 부분이 누락되었다. NME7으로 표시된 막대는 NME7a 및 NME7b 둘 다를 검출한 프라이머가 사용되었음을 의미한다. 도 19A 내지 19F는 NME7 유래 짧은 펩타이드로의 면역화에 의해 생성된 항체를 사용하여 NME7 종의 발현에 대해 다양한 암 세포주가 프로빙된 웨스턴 블롯의 사진. 도 19A는 NME7 유래 펩타이드 A1에 결합하는 본 발명의 항체 #52로 프로빙된 웨스턴을 도시한다. 도 19B는 NME7 유래 펩타이드 B1에 결합하는 본 발명의 항체 #56으로 프로빙된 웨스턴을 도시한다. 도 19C는 NME7 유래 펩타이드 B3에 결합하는 본 발명의 항체 #61로 프로빙된 웨스턴을 도시한다. 도 22A 내지 도 22E는 공동 면역침전 실험의 웨스턴 블롯 사진. T47D 유방암 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 2개의 상이한 상업적으로 입수 가능한 항-NME7 항체 B9(도 22A) 및 CF7(도 22B)로 블로팅하였다. 두 겔 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 22C) 및 (도 22D)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7-AB와 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7-AB-유사 종 및 NME7-X1임을 나타낸다(도 22E). 도 23A 내지 도 23C는 공동 면역침전 실험의 웨스턴 블롯 사진. 인간 유도 만능 줄기, iPS7 또는 배아 줄기, HES3, 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 상업적으로 입수 가능한 항-NME7 항체 B9로 블로팅하였다(도 23A). 두 세포 유형은 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 23B)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7-AB와 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7-AB-유사 종 및 NME7-X1임을 나타낸다(도 23C). 도 39A 내지 39C는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 폐 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다. 도 40A 내지 도 40C는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 소장 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다. 도 41A 내지 41D는 B3 펩타이드에 결합하는 항-NME7 항체로 염색된 인간 결장 조직 시편을 도시한 도면. 도면은 정상 조직에서 NME7 발현의 결여는 종양 등급 및 전이가 증가함에 따라 NME7의 발현이 증가함을 나타낸다. 도 47 및 도 48은 NME7이 광범위한 암 세포주의 세포외 수용체에 의해서 발현되고, 이에 결합한다는 것을 나타낸 면역형광 사진을 도시한 도면을 나타낸다.
추가로, 본 발명자들은, NM23-H1과 유사하게, NME7이 줄기세포 및 암 세포 둘 다 상에 존재하는 MUC1* 성장 인자 수용체에 결합하여, 이를 이량체화한다는 것을 입증하였다(도 1). 도 5는 NME1과 NME7 A 및 NME7 B 도메인의 서열 정렬을 도시한다.
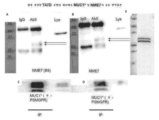
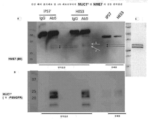
본 발명자들은 최근, NME7이 매우 초기의 배아 줄기세포에서 발현되는 원시 형태의 NME1(NM23-H1)임을 발견하였다. NME7은 성인 조직에서는 전혀 발현되지 않거나, 극도로 낮은 수준을 발현된다. 그러나, 본 발명자들은, NME7이 암성 세포 및 조직에서 높은 수준으로 발현되고, 전이성 암 세포 및 조직에서는 심지어 더 높은 수준으로 발현된다는 것을 발견하였다. 절단된 형태의 NME7은 세포외 수용체에 결합하여 이를 활성화시킬 수 있는 분비된 형태일 수 있다. 본 발명자들은 전장 NME7, MW 42kDa뿐만 아니라 약 33kDa 및 30kDa인 NME7 종을 검출한다. 33kDa 종 및 30kDa 종은 암 세포로부터 분비된다. 웨스턴 블롯은 세포 파쇄물에서 전장 NME7을 검출하지만, 이들의 조건화된 배지에서는 더 작은 30kDa 내지 33kDa NME7 종을 검출한다. NME7을 인식하는 항체 또는 DM10 도메인만을 인식하는 항체를 사용하여 프로빙된 웨스턴 블롯은, 조건화된 배지 내로 분비되는 보다 낮은 분자량의 NME7 종이 DM10 도메인을 포함하지 않는다는 것을 나타낸다. 이들 데이터는, 자연 발생 NME7 종이 본 발명자들이 생성한 재조합 NME7AB와 대등하는 생각과 일치하는데, 그 이유는 이들이 거의 동일한 분자량을 가지며, 둘 다가 분비되고, 둘 다가 단백질을 세포 내에서 보유할 수 있는 DM10 도메인의 91개 아미노산이 존재하지 않기 때문이다.
본 발명자들은 새로운 NME7 아이소폼인 NME7-X1을 발견하였고, 또한 이는 암에서 과발현되며 특히 전립선암에서 과발현됨을 발견하였다(도 17, 도 18, 도 19 및 도 22). 분자량이 약 30kDa인 NME7-X1은 NME7 아미노산 125 내지 376을 포함하는 반면, 본 발명자들이 생성한 분자량이 약 33kDa인 재조합 NME7AB는 아미노산 92 내지 376에 걸쳐 있고, 따라서, 33개보다 많은 N-말단 아미노산을 포함한다. NME7b는 아미노산 37 내지 376에 걸쳐 있고, DM10 도메인의 단지 37개의 아미노산을 포함하지 않으며, 또한 전립선암에서 과발현된다(도 18). 본 발명자들은 인간 재조합 NME7-X1을 생성시켰으며, 이는 자연 발생 약 33kDa NME7 종보다 바로 아래에서 전개되며, 절단 생성물 또는 대안적인 아이소폼인 자연 발생 "NME7AB-유사" 단백질인 것으로 보이는, 암 세포에서 분비되는 30kDa NME7 종임을 나타낸다.
본 발명자들은 암 세포주 패널을 시험하였으며, 암 세포주가 NME7, 및 NME7AB, 예컨대, NME7AB-유사 단백질 또는 대안적인 아이소폼, 예컨대, NME7-X1과 유사한 절두물일 수 있는 보다 낮은 분자량의 종을 높은 수준으로 발현한다는 것을 발견하였다.
NM23-H1(NME1이라고도 함)은 이량체이어야 하는 반면, NME7은 MUC1* 세포외 도메인에 대해 2개의 결합 부위를 가진 단량체이다. 본 발명자들은 DM10 도메인을 포함하지 않는 재조합 인간 NME7을 생성시켰으며, 본 발명자들은 이를 NME7AB로 칭한다. 샌드위치 ELISA 결합 검정은, 재조합 NME7AB가 2개의 PSMGFR 펩타이드에 동시에 결합하며, 여기서, MUC1*의 세포외 도메인이 PSMGFR 서열을 대부분 또는 모두 포함함을 나타낸다(도 1). 나노입자 결합 검정에서, NME7은 또한 MUC1* 세포외 도메인의 PSMGFR 부분에 결합하여 이를 이량체화할 수 있는 것으로 나타났다.
NME7을 불능화시키거나, NME7과 이의 결합 파트너와의 상호작용을 차단하거나 이의 발현을 억제하는 작용제는 강력한 항암 치료제이다. 이러한 작용제는 항체, 소분자 또는 핵산일 수 있다. 이들은 NME7에 직접 작용하거나, NME7 발현을 조절하는 분자, 또는 NME7을 암-촉진 형태로 절단하는 효소에 작용할 수 있다.
본 발명자들은, NM23-H1 이량체와 유사하게, 재조합 NME7AB 단량체가 임의의 다른 성장 인자, 사이토카인 또는 혈청의 부재 하에 전분화능 인간 줄기세포 성장을 완전히 지지할 수 있었음을 발견하였다. 본질적으로 PSMGFR 서열을 포함하며 줄기세포의 분화를 유도하는 NME7과 MUC1* 세포외 도메인 사이의 상호작용을 경쟁적으로 저해하는 것은, NME7과 MUC1*의 상호작용이 줄기세포 성장을 촉진하고, 분화를 저해한다는 것을 나타낸다.
그 다음, 본 발명자들은, NME7AB 단독이 또한 인간 암 세포 성장을 완전히 지지할 수 있음을 나타내었다. NME7AB가 보통의 암 세포 성장 배지에 첨가되었을 때, 이는 암 세포 성장, 특히 MUC1-양성 및 MUC1*-양성 암 세포의 성장을 자극하였다. NME7과 MUC1*의 상호작용을 저해하면, 암 세포 성장을 저해하였다. MUC1* 성장 인자 수용체를 항-MUC1* Fab로 차단하면, 암 세포 성장을 강력하게 저해하였다. 유사하게는, NME7에 결합하는 항체는 암 세포 성장을 저해한다. 항-NME7 항체에 의한 암 성장 저해의 일례에서, 다클론성 항체는 아미노산 100 내지 376에 걸쳐 있는 NME7의 부분을 사용하여 동물을 면역화시킴으로써 생성되었다(도 12 및 도 13). 그러나, 본 발명자들은, NME7AB 또는 NME7-X1로부터의 보다 짧은 펩타이드로부터의 면역화에 의해서 생성된 항체가 또한 암 성장을 저해한다는 것을 발견하였다. 특히, 이들은 MUC1 및 MUC1*-양성 암의 성장을 저해한 다. 본 발명의 항-NME7 항체는, 종양 구체를 형성할 수 있고, 원발성 종양 및 전이로부터 이동할 수 있는 비-부착성 "부유체" 세포의 형성을 저해하였다(도 14, 도 16, 도 29). 본 발명의 항-NME7 항체는 전이 및 현재 전이의 특징이라고 여겨지는 줄기세포 마커의 상향조절을 저해하였다(도 15, 도 30, 도 31, 도 32).
NME7은 암 전이를 유발한다.
추가로, 본 발명자들은, NME7AB를 함유하는 최소 배지에서 암 세포를 배양하는 것은 광범위하게 다양한 암 세포가 보다 전이성 상태로 형질전환되도록 유도하였음을 발견하였다. 이러한 유도된 전이성 상태에 대한 증거는 부착 성 세포 성장으로부터 비-부착성 세포 성장, 즉, "부유체" 세포로의 변화, 및 부유 세포에서 특히 상향조절된 특이적인 전이 마커의 수반되는 상향조절을 포함한다. NME7AB에서 배양된 후 상향조절되는 이들 전이 마커는, CXCR4, CHD1(E-카드헤린이라고도 함), MUC1, ALDH1, CD44 및 만능 줄기세포 마커, 예컨대, OCT4, SOX2, NANOG, KLF2/4, FOXa2, TBX3, ZEB2 및 c-Myc(도 2, 도 3, 도 20, 도 49, 도 51)를 포함하지만 이들로 제한되지 않는다. NME7AB에서 배양된 암 세포는 시험 동물 내로 이종 이식되었을 때 급격하게 더 높은 이식률을 가졌으며, 이러한 이식률은 90%를 초과하였다. 또한 매우 적은 수의 이식된 암 세포로도 시험 동물에서 종양이 형성되었으며, 이는, NME7AB가 이러한 암 세포를 전이성 암 세포로도 알려진 암 줄기세포로 형질전환시켰다는 증거이다. NME7AB에서 배양되고, 에스트로겐 방출 펠릿을 보유하는 NOD/SCID/GAMMA 마우스의 꼬리 정맥에 주입된 암 세포는 일반 배지에서 성장된 모 세포에 비해 적은 수의 세포로부터 동물에서 전이되는 펠릿을 방출한다(도 33 내지 도 38). 암 세포가, 본질적으로 NME7AB와 동등한 NME7 절단 생성물 또는 대체 아이소폼을 만들기 때문에, 본 명세서에 기술된 방법은 NME7AB를 사용하는 것으로 제한되지 않으며; 다른 NME7 종이 마찬가지로 작용할 수 있었다. 예를 들어, 본 발명자들은 또 다른 NME7 아이소폼인 NME7-X1이 암 세포에 의해 발현됨을 발견하였다. 이는, X1 아이소폼이 N-말단으로부터 33개의 아미노산이 누락되었다는 것을 제외하고는, 본 발명자들의 재조합 NME7AB와 동일하다. NME7-X1은 NME7AB와 유사하게 작용하는 것으로 예상된다. "NME7AB-유사" 단백질 또한 암 세포에서 검출되었으며, 이는 약 33Da 종이다.
본 발명자들은, 발명자들의 이전 연구가, NME7AB가 단독이 인간 줄기세포를 보다 조기의 미경험 상태로 반전시킬 수 있음을 나타내었다는 것을 주목한다. 본 발명자들은, 줄기세포를 보다 미경험 상태로 반전시키는 다른 시약의 존재 하에 암 세포를 배양하면, 암 세포를 보다 전이성 상태로 형질전환시킴을 발견하였다. 본 발명자들은, 암 세포 NME7AB(도 2) 또는 키메라 NME1(도 3)에서 또는 "2i" 저해제(도 4)가 각각 보통의 암 세포를 전이성 암 세포로 형질전환시킬 수 있으며, 이들 또한 암 줄기세포 "CSC" 또는 종양 개시 세포 "TIC"로 지칭된다. 그러나, NME7AB는 암 세포를 2i보다 더 양호한 NM23-H1이라고도 공지된 NME1보다 더 양호하게 전이성 상태가 되게 유도하였다.
2i는 연구자들이 인간 줄기세포를 보다 미경험 상태로 반전시키게 하는 것으로 발견한 2개의 생화학적 저해제에 대해 주어진 명칭이다. 2i는 MEK 및 GSK3-베타 저해제 PD0325901 및 CHIR99021이며, 이들은 배양 배지에 각각 약 1mM 및 3mM의 최종 농도로 첨가된다. NME7AB 및 NME7-X1은 암 세포를 전이성 세포로 형질전환시키기 위해 최소 배지의 별개의 배취에 첨가되었을 때, 약 4nM의 최종 농도로 존재하긴 하지만, 보다 낮은 농도 및 보다 높은 농도도 약 1nM 내지 16nM의 범위에서 양호하게 작용한다. 인간 NME1 이량체 또는 박테리아 NME1 이량체는 4nM 내지 32nM의 최종 농도로 사용되며, 16nM이 이들 실험에 전형적으로 사용되고, 여기서, 인간 NME는 S120G 돌연변이를 보유한다. 야생형을 사용하는 경우, 보다 낮은 농도가 필요할 수 있다. 이들 정확한 농도가 중요한 것은 아니다. NME1 단백질이 이량체이고, 이것이 발생하는 농도 범위는 낮은 나노몰 범위로 존재하지만, 특정 돌연변이는 보다 높은 농도에서 이량체로서 유지될 수 있게 하는 것이 중요하다. 유사하게는, NME7 단백질의 농도는 달라질 수 있다. NME7AB 및 NME7-X1은 단량체이고, 암 세포를 전이성 세포로 변환시키는 데 사용된 농도는 단백질을 단량체로 유지시킬 수 있어야 한다.
NME7, NME7AB, NME7-X1, 및 2i 저해제 MEKi 및 GSK3i 외에도, 다른 시약 및 저해제가 줄기세포를 보다 미경험 상태로 반전시키는 것으로 나타났다. 이들 저해제, "i"는 JNKi, p38i, PKCi, ROCKi, BMPi, BRAFi, SRCi뿐만 아니라 성장 활성화 인자 LIF를 포함한다(문헌[afni et al 2013, Chan et al 2013, Valamehr et al 2014, Ware et al 2014, Theunissen et al 2014]. 이들 시약은 또한 암 세포를 보다 전이성 상태로 진행시키는 데 사용될 수 있다. 그런 다음, 줄기세포를 보다 미경험 상태로 반전시키는 임의의 단일 인자, 또는 저해제 또는 성장 인자의 조합물을 사용하여 보다 전이성 상태로 형질전환시키도록 유도되었던 세포는 암 전이를 치료하거나 예방하기 위한 약물을 확인하거나 시험하는 디스커버리 툴로서 사용될 수 있다.
다양한 분자 마커는 전이성 암 세포의 지표로서 제안되었다. 서로 다른 유형의 암들은, 상향조절되는 상이한 분자를 가질 수 있다. 예를 들어, 수용체 CXCR4는 전이성 유방암에서 상향조절되며, 한편, CHD1으로도 알려져 있는 E-카드헤린은 전이성 전립선암에서 더 상향조절된다. 이들 특이적인 전이 마커 외에도, 전분화능에 대한 전형적인 마커, 예컨대, OCT4, SOX2, NANOG 및 KLF4는 암이 전이성으로 됨에 따라 상향조절된다. 출발 암 세포 및 이후의 전이성 암 세포는 이들 유전자의 발현 수준을 측정하기 위해 PCR에 의해 검정된다. 본 발명자들은, 암 세포를 보다 전이성 상태로 형질전환시키는 시약, 예컨대, NME7AB에서 배양된 이들 암 세포가 전이 마커 및 만능 줄기세포 마커의 발현 증가에 의해 입증되는 바와 같이, 전이성 암 세포로서 작용한다는 것을 예증하였다.
암 세포 집단이 전이성인지 아닌지에 대한 기능 시험은, 매우 적은 수, 예를 들어, 200개의 세포를 면역-손상된 마우스에 이식하고, 이들 세포가 종양으로 발병되는지 알아보는 것이다. 전형적으로, 면역-손상된 마우스에서 종양을 형성하기 위해서는 5백만 내지 6백만개의 암 세포가 필요하다. 본 발명자들은, 50개만큼 적은 수의 NME-유도 전이성 암 세포가 마우스에서 종양을 형성하였음을 나타내었다. 또한 시험 기간 전체 동안에 인간 NME7AB, NME1 또는 NME7-X1이 주사된 마우스에서 원거리 전이가 발병되었다.
하나의 특정 시험에서, T47D 인간 유방암 세포를 표준 RPMI 배지에서 14일 동안 배양하였으며, 이때, 배지를 48시간마다 교환하였고, 약 75% 컨플루언트되었을 때, 트립신처리에 의해 계대시켰다. 이어서, 세포를 6-웰 플레이트 내에 플레이팅하고, 4nM NME7AB가 보충된 최소 줄기세포 배지(실시예 1 참조)에서 배양하였다. 배지를 48시간마다 교환하였다. 약 4일까지, 일부 세포는 표면으로부터 탈착되어, 부유한다. "부유체"가 전이 마커의 RT-PCR 측정에 의해 입증되는 바와 같이 가장 높은 전이 잠재력을 갖는 세포이기 때문에, "부유체"를 보유하기 위해 배지를 조심스럽게 교환한다. 7일 또는 8일에, 부유체를 수거하고, 계수한다. RT-PCR 측정을 위해 샘플을 유지한다. 측정된 주요 마커는 CXCR4이며, 이는 NME7AB에서 간단히 배양된 후 40배 내지 200배 상향조절된다.
새로 수거된 부유체 전이성 세포를, 90-일 서방형 에스트로겐 펠릿이 이식되었던 암컷 nu/nu 무흉선 마우스의 옆구리에 이종 이식하였다. 부유체 세포를 각각 10,000개, 1,000개, 100개 또는 50개 세포로 이종 이식하였다. 또한 6마리로 이루어진 각각의 군 내의 마우스 중 절반에는 32 nM NME7AB를 본래 이식 부위 근처에 매일 주사하였다. NME7AB가 없는 RPMI 배지에서 배양된 모 T47D 세포를 또한 대조군으로서 6백만개, 10,000개 또는 100개로 마우스에게 이식하였다. NME7-유도 부유체 세포를 이식한 마우스는 50개만큼 적은 수의 세 포가 이식되었을 때에도 종양이 발병되었다. 부유체 세포를 이식하고, NME7AB를 매일 주사한 마우스에서는 또한 원거리 종양이 발병되거나 다양한 기관에서 원거리 전이가 발병되었다. NME7AB에서 배양된 암 세포를 이식한 후, 인간 NME7AB를 주사한 12마리의 마우스 중 11마리, 또는 92%의 마우스에서 주사 부위에서 종양이 발병되었다. 이식 후 인간 NME7AB를 주사하지 않은 12마리의 마우스 중 단지 7마리 또는 58%의 마우스에서만 종양이 발병되었다. 종양을 나타내고, 인간 NME7AB가 주사된 11마리의 마우스 중 9마리 또는 82%의 마우스에서, 주사 부위로부터 원거리에서 다중 종양이 발병되었다. NME7AB를 주사하지 않은 마우스 중 어떤 마우스에서도 가시적인 다중 종양이 발병되지 않았다.
희생시킨 후, RT-PCR 및 웨스턴 블롯은, NME7AB를 주사한 마우스 상의 원거리 범프(bump)가 사실상 인간 유방 종양이었음을 나타내었다. 이들 기관에 대한 유사한 분석은, 원거리 범프 외에도, 마우스에서, 이식된 인간 유방암 세포의 인간 유방암 특징이 간 및 폐로 무작위로 전이되었음을 나타내었다. 예상된 바와 같이, 6백만개 세포를 이식한 마우스만 종양을 성장시켰다.
본 발명자들은, 인간 재조합 NME7AB가 NME7-X1 및 30kDa 내지 33kDa NME7 절단 생성물과 크기 및 서열 면에서 유사함을 입증하였다. 본 발명자들은, NME7AB가 암성 성장을 촉진하고, 암 세포가 종양 개시 세포(TIC)로도 지칭되는 고도로 전이성인 암 줄기세포(CSC) 상태로 가속화하도록 함을 발견하였다. 따라서, 본 발명자들은, NME7-X1, 및 DM10 도메인을 제거한 NME7 절단 생성물이 또한 암성 성장을 촉진하고, 암 세포가 종양 개시 세포(TIC)로도 지칭되는 고도로 전이성인 암 줄기세포(CSC) 상태로 가속화하도록 한다고 결론 내린다. 일례에서, NME7AB를 임의의 다른 성장 인자 또는 사이토카인의 부재 하에 무혈청 배지 중의 암 세포에 첨가하였다. 7일 내지 10일 이내에, 암 세포는 전이성 암 세포의 지표인 분자 마커, 예컨대, CXCR4의 발현의 100배 초과의 증가에 의해 입증되는 바와 같이, 고도로 전이성인 CSC/TIC로 반전되었다. 일례에서, T47D 유방암 세포를 표준 RPMI 배지 또는 최소 줄기세포 배지(실시예 1)에서 배양하였으며, 이 배지에 재조합 NME7AB를 16nM의 최종 농도로 첨가하였다. 10일 후, 세포를 수집하고, CSC의 분자 마커의 발현에 대해 RT-PCR로 분석하였으며, 이러한 발현은 10배 내지 200배만큼 상승되었다(도 2). 이는, 본 발명자들이 하나의 유형의 암 세포를 보다 전이성 상태로 형질전환시킨 방법을 나타내는 구체적인 상세한 예이다. 이러한 방식으로 형질전환되는 암 세포는 광범위하게 존재하며, 줄기세포를 보다 미경험 상태로 반전시키며 또한 암 세포를 보다 전이성 상태로 진행시키는 시약이 광범위하게 존재하며, 첨가되는 시약이 암 세포를 형질전환시키는 농도도 광범위하기 때문에, 본 발명은 이들 상세한 사항에 의해 제한되지 않아야 한다. 다른 유형의 암 세포는, 전이 마커의 급격한 상향조절 및 이식된 매우 적은 수의 암 세포로부터 종양을 형성하는 능력을 위해서는 NME7AB에서 보다 장기간 동안 배양될 필요가 있었다. 예를 들어, NME7AB, 2i, 인간 NME1, 또는 인간 NME1 또는 인간 NME7에 대해 높은 상동성을 갖는 박테리아 NME1에서 배양된 전립선암 세포는 2회 내지 3회의 계대 후, 전이 마커의 급격한 증가를 나타내었다.
전이 마커 CXCR4는 특히 전이성 유방암 세포에서 상승되는 한편, CHD1은 특히 전이성 전립선암에서 상승된다. 본 명세서에서, 본 발명자들은, 만능 줄기세포 마커, 예컨대, OCT4, SOX2, NANOG, KLF2/4 및 TBX3 또한 암 세포가 보다 전이성 세포로 형질전환될 때 상향조절된다는 것을 발견하였다.
DU145 전립선암 세포를 유사하게 배양하였으며, NME7AB에서 배양된 세포 또한 CSC 마커의 발현의 급격한 증가를 나타내었다(도 3). 전립선암 세포에서, CHD1(즉, E-카드헤린) 및 CXCR4는 다른 만능 줄기세포 마커와 함께, NME7AB에서 성장되지 않은 대조군 암 세포에 비해서 상향조절되었다. 도 20A 내지 도 20C는, 난소 암 세포주 SK-OV3, OV-90 및 유방암 세포주 MDA-MB가 모두 부착성 세포를 비-부착성 부유체 세포로 전이시켰으며, NME7AB와 배양한 지 72시간 또는 144시간 후, 전이 마커의 발현을 증가시켰음을 나타낸다. 난소암 세포, 췌장암 세포 및 흑색종 세포가 또한 NME7AB에서 배양되었으며, 배양 3일 후에 보다 전이성 상태로 형질전환되었다. 도 21은 유방암 세포, 난소암 세포, 췌장암 세포 및 흑색종 세포가 MUC1 및 MUC1*를 발현한다는 것을 나타낸다.
본 명세서에서, 본 발명자들은, NME7AB가 광범위한 암 세포를 보다 전이성 상태로 형질전환시킨다는 것을 발견하였다. 본 발명자들은 또한 암 세포가 재조합 NME7AB 33kDa과 대략 동일한 분자량을 갖는 자연 발생 종을 발현하고(도 17, 도 18), 도 19, 및 도 22), 또한 NME7AB와 유사하게 DM10 도메인을 포함하지 않고, 또한 N-말단에 33개의 아미노산이 누락된 것을 제외하고는 NME7AB와 동일한 서열인 대체 아이소폼 NME7-X1 30kDa을 발현한다는 것을 발견하였다. 공동-면역침전 실험을 T47D 유방암 세포 상에서 수행하였으며, 여기서, 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동-면역침전시켰다. 면역침전된 종을 겔 전기영동에 의해 분리하였다. 겔을 2개의 상이한 상업적으로 입수 가능한 항-NME7 항체로 블로팅하였다. 두 겔 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다(도 22A 및 도 22B). 겔을 제거하고, MUC1*, 항-PSMGFR(도 22C 및 도 22D)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7AB와 본 발명자들이 만든 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7AB-유사 종 및 NME7-X1임을 나타낸다(도 22E). 유사한 실험을 인간 줄기세포에서 수행하였다. 도 23A 내지 도 23C는 공동 면역침전 실험의 웨스턴 블롯 사진. 인간 유도 만능 줄기, iPS7 또는 배아 줄기, HES3, 세포 추출물을 MUC1 세포질 꼬리에 대한 항체인 Ab-5 또는 대조군 항체인 IgG와 함께 인큐베이션시키고, 공동 면역침전시켰다. 겔을 상업적으로 입수 가능한 항-NME7 항체 B9로 블로팅하였다(도 23A). 두 세포 유형은 모두 약 33kDa 및 약 30kDa에서 고유한 NME7 밴드를 나타낸다. 겔을 제거하고, MUC1*, 항-PSMGFR(도 23B)의 세포외 도메인에 대한 항체로 재프로빙하였는데, 이는 NME7 종 및 MUC1*이 상호작용함을 나타낸다. 재조합 NME7AB와 본 발명자들이 만든 재조합 NME7-X1을 함께 혼합하고, 겔에서 전개시킨 다음, 항-NME7 항체로 프로빙하였는데, 이는 유방암 세포에서 자연적으로 발생하고, MUC1*와 상호작용하는 2개의 고유한 NME7 종이 NME7AB-유사 종 및 NME7-X1임을 나타낸다(도 23C). NME7AB가 재조합 단백질이기 때문에, 본 발명자들은 자연 발생 종이 1개 내지 15개의 부가적인 여분의 아미노산을 함유할 수 있는지 또는 동일한 겉보기 분자량으로 전개되지만 재조합 NME7AB보다 1개 내지 15개의 부가적인 아미노산을 포함하지 않을 수 있는지 알지 못한다. "NME7AB-유사"란, 본 발명자들은, 대략 33kDa의 겉보기 분자량으로 전개되는 NME7 종이 암 세포 성장을 자극할 수 있고, 보다 전이성 상태로의 암 세포의 변이를 유도하고, 인간 줄기세포의 전분화능 성장을 전적으로 지지할 수 있다는 점에서, 재조합 NME7AB가 수행하는 방식으로 작용할 수 있음을 의미한다.
본 발명자들은, NME7 및 보다 낮은 분자량의 NME7 종을 발현하는 암 세포주 및 암 세포 집단이, CSC 또는 전이성 암 세포인 일부 암 세포를 함유한다고 결론 내린다. 이들 암은 보다 전이성으로 될 수 있거나, NME7AB, NME7-X1 또는 보다 낮은 분자량의 NME7 종에서 세포를 배양함으로써 전이성 세포 집단을 증가시킬 수 있다. 도 19는 NME7뿐만 아니라 33kDa에서 보다 낮은 분자량을 가진 종인 NME7AB-유사 및 30kDa에서 NME7-X1을 모두 발현하는 암 세포 패널의 웨스턴 블롯을 도시한다. 도 21은, 유방암 세포주 T47D, 전립선암 세포주 PC3 및 DU145, 유방암 세포주 BT-474, 둘 다 흑색종 세포주인 CHL-1 및 A2058, 및 둘 다 췌장 세포주인 CAPAN-2 및 PANC-1이 MUC1 및 MUC1*을 발현함을 나타낸다. 도 21A에서, BT474 세포가 MUC1 또는 MUC1*를 발현하지 않는 것으로 보이지만, 본 발명자들은 이전에(문헌[Fessler et al 2009]), 이들 HER2 양성 유방암 세포가 화학요법 약물에 대해 내성으로 될 때, 즉, 전이성으로 될 때, 이들 세포는 MUC1*의 발현을 증가시킴으로써 이를 수행한다는 것을 나타내었다(도 21D). 항-MUC1* Fab를 사용하여 MUC1*수용체를 차단하는 것은 허셉틴(도 21E), 탁솔(도 21F)뿐만 아니라 다른 화학치료제에 대한 이들의 내성을 반전시켰다. 이들 유형의 암 및 NME7 및 보다 낮은 분자량, 예컨대, 33kDa, 30kDa의 NME7 종을 발현하는 다른 유형의 암은 보다 전이성으로 될 수 있거나, NME7AB, NME7-X1 또는 보다 낮은 분자량의 NME7 종에서 세포를 배양함으로써 전이성 세포 집단을 증가시킬 수 있다.
이에 반해서, 이들 암 및 NME7과 보다 저분자량의 NME7 종, 예컨대, 33kDa 또는 30kDa NME7 종을 발현하는 다른 암 유형의 전이 잠재력은 세포를 항-NME7 항체로 치료함으로써 반전될 수 있다. 항-NME7 항체, 또는 NME7AB 또는 NME7-X1에 결합하는 항체는 유방암, 전립선암, 난소암, 췌장암 및 간암을 비롯한 암의 치료 또는 예방을 위해 환자에게 투여된다. 본 발명자들이, NME7AB가 MUC1* 성장 인자 수용체에 결합하고 이를 활성화시킴으로써 NME7AB의 종양원성 효과를 발휘함을 나타내었기 때문에, 항-NME7 항체는 유방암, 폐암, 간암, 췌장암, 위암, 결장직장암, 전립선암, 뇌암, 흑색종, 신장암 및 다른 암 등을 포함하지만 이들로 제한되지 않는 임의의 MUC1* -양성 암에 대해 효과적일 것이다. 항-NME7 항체, 항-NME7AB 항체 또는 항-NME7-X1 항체는, NME7AB, NME7AB-유사, NME7-X1 양성 또는 MUC1*양성인 암의 치료 또는 예방을 위해 환자에게 투여된다.
효과적인 요법을 위한 환자 암 세포의 시험
NME7AB, NME7-X1뿐만 아니라 2i, 및 줄기세포를 보다 미경험 상태로 반전시키는 다른 시약은 또한 암 세포가 보다 전이성 상태로 형질전환되도록 유도한다. 이들 시약 중 임의의 하나 또는 조합물을 사용한 치료 후, 암 세포는 보다 높은 이식률을 가지며, 시험 동물에서 종양을 형성하는 데 있어서 100,000배까지 더 적은 수의 세포를 필요로 한다. 따라서, 본 개시내용에서 언급되는 방법은 환자의 원발성 종양 세포를 시험 동물 내로 이종 이식시킬 수 있는 데 사용될 수 있다.
그 다음, 후보물질 치료제를 수여자 동물에서 시험할 수 있다. 이러한 방식으로 확인된 효과적인 치료제는 공여자 환자 또는 유사한 암을 가진 다른 환자를 치료하는 데 사용될 수 있다. 일 실시형태에서, 특정 환자 또는 특정 유형의 암에 효과적인 치료제를 확인하는 방법은 하기 단계를 포함한다: 1) 세포주, 환자, 또는 시험될 치료제를 투여될 환자 로부터 암 세포를 얻는 단계; 2) 암 세포를, NME7AB, NME7-X1, 인간 NME1, 인간 NME1 또는 NME7에 대해 높은 상동성을 갖는 박테리아 NME1, 2i, 또는 줄기세포를 보다 미경험 상태로 반전시키는 것으로 공지된 다른 시약 내에서 배양하는 단계; 3) 생성된 암 세포를, 인간 NME7AB, NME7-X1, 인간 NME1, 인간 NME1 또는 NME7에 대해 높은 상동성을 갖는 박테리아 NME1, 2i, 또는 줄기세포를 보다 미경험 상태로 반전시키는 것으로 공개된 다른 시약이 또한 투여될 수 있는 시험 동물 또는 동물이 인간 NME7AB 또는 NME7-X1에 대해서 트랜스제닉인 시험 동물에게 이식하는 단계; 4) 후보물질 항암 치료제를 동물에게 투여하는 단계; 5) 치료제의 효능을 평가하는 단계; 및 6) 효과적인 치료제를 공여자 환자 또는 유사한 암을 가진 또 다른 환자에게 투여하는 단계.
항-NME7 항체
항-NME7 항체는 강력한 항암제이다. NME7은 암 세포의 성장을 촉진하며, 암 세포가 보다 전이성 상태 또는 보다 공격적인 상태로 진행되는 것을 촉진하는 성장 인자이다. NME7 및 절두된 형태의 NME7은 약 33kDa 또는 30kDa이며, 임의의 다른 성장 인자 또는 사이토카인을 포함하지 않는 무혈청 배지에서조차 암 성장을 전적으로 지지하는 것으로 나타났다. 풀-다운 검정, ELISA 및 나노입자 결합 실험에서, 본 발명자들은, 성장 인자 수용체 MUC1*이 NME7 및 NME7AB의 결합 파트너임을 나타내었다. 모든 다른 성장 인자 또는 사이토카인을 제거함으로써 이러한 상호작용을 촉진하는 것은 암 줄기세포 마커의 발현을 증가시켰다. 혈청의 존재 하에서조차 NME7에 특이적으로 결합하는 다클론성 항체를 사용하여 이러한 상호작용을 차단하는 것은 암 세포를 능동적으로 살해하였다. 따라서, 항-NME7 항체 또는 항-NME7AB 항체는 암 치료 또는 예방을 위해 환자에게 투여될 수 있는 강력한 항암제이다. 모든 암들 중 75% 초과는 MUC1* 양성이다. MUC1*는 MUC1의 막투과 절단 생성물이며, 여기서, 대부분의 세포외 도메인은 탈락되었으며, 따라서, 대부분의 PSMGFR 서열을 함유하며, PSMGFR 서열의 경계에 9개 내지 20개의 부가적인 아미노산 N-말단을 함유할 수 있는 세포외 도메인의 일부가 남겨진다.
본 발명의 일 양상은 항-NME7 항체를 유효량으로 대상체에게 투여하는 단계를 포함하는, 대상체에서 암을 치료하거나 예방하는 방법이다. 일례에서, 항-NME7 항체는 NME7AB에 결합할 수 있다. 또 다른 예에서, 항-NME7 항체는 NME7-X1에 결합할 수 있다. 또 다른 예에서, 환자에게 투여되는 항-NME7 항체는 암의 촉진 시 NME7과 이의 표적 사이의 결합을 저해하거나 방지한다. 일례로, 표적은 절단된 MUC1의 세포외 도메인이다. 보다 구체적으로는, 암을 촉진하는 NME7 표적은 MUC1* 세포외 도메인의 PSMGFR 영역이다. 일 양상에서, 효과적인 치료제는 NME7 종과, 주로 MUC1*의 PSMGFR 부분 또는 PSMGFR 펩타이드로 이루어진 MUC1*세포외 도메인 사이의 상호작용을 방해하거나 저해하는 것이다. 암 치료 또는 예방용 작용제는, NME7, NME7AB-유사 절단 생성물, 또는 NME7-X1을 비롯한 대체 아이소폼의 발현 또는 기능을 직접 또는 간접적으로 저해하는 작용제이다. 일례로, 효과적인 항암 치료제는, NME7 종에 결합하거나 이의 종양원성 활성을 불능화시키는 것이다. 암 치료 또는 예방에 효과적인 치료제는, NME7, NME7AB-유사 절단 생성물, 또는 대체 아이소폼 또는 NME7-X1에 결합하거나 이들을 불능화시키는 작용제이다. 일 양상에서, NME7 종에 결합하는 치료제는 항체이다. 항체는 다클론성 항체, 단클론성 항체, 이중특이적 항체, 2가 항체, 1가 항체, 단쇄 항체, scFv, 기원이 동물일 수 있는 항체 모방체, 인간-동물 키메라 항체, 인간화된 항체 또는 인간 항체일 수 있다. 항체는 NME7 종 또는 이의 단편과 함께 인큐베이션되거나 이를 사용하여 면역화됨으로써 생성될 수 있거나, NME7, NME7AB-유사 절단 생성물, 또는 NME7-X1을 비롯한 대체 아이소폼을 비롯한 NME7 종에 결합하는 능력에 대해 예를 들어, 항체 라이브러리 또는 항체 풀로부터 선택될 수 있다.
항-NME7 항체의 생성
항-NME7 항체는 숙주 동물에서와 같이 환자의 외부에서 생성되거나 환자 내에서 생성될 수 있다. 항체는 NME7 또는 NME7 단편의 면역화에 의해 생성되거나, 목적하는 NME7 종, 예컨대, NME7AB 또는 NME7-X1로의 결합 능력에 기초하여 자연 항체, 합성 항체, 전체 항체 또는 항체 단편일 수 있는 항체 라이브러리 또는 항체 풀로부터 선택될 수 있다. 일 양상에서, 항체는 도 6 내지 도 9에 열거된 펩타이드부터 선택되는 펩타이드를 사용한 면역화에 의해 생성되거나, 이러한 펩타이드에 결합하는 능력에 대해 선택된다. 또 다른 양상에서, 항체는 인간 NME1의 서열과 일치하지 않는 서열을 갖는 펩타이드로부터 생성되거나, 항체는 NME7 종에 대한 결합 능력 및 인간 NME1에 대한 결합 불능에 대해서 선택된다.
암 성장을 저해하고 전이로의 전이를 저해하는 항체를 유발하는 NME7 또는 NME7-X1 유래의 펩타이드 또는 그 자체가 저해성인 펩타이드를 식별하는 데 사용되는 하나의 방법은 하기와 같다: 1) 인간 NME1, 인간 NME7, 인간 NME7-X1, 및 인간 NME1 또는 인간 NME7 중 하나에 대해 높은 서열 상동성을 갖는 몇몇 박테리아 또는 진균 NME 단백질의 단백질 서열을 정렬하는 단계; 2) 모든 NME 중에서 높은 서열 상동성을 갖는 영역을 식별하는 단계; 3) NME7 또는 NME7-X1에 고유하지만, 높은 서열 상동성을 갖는 영역에 측접하는 펩타이드 서열을 식별하는 단계. 이어서, 펩타이드를 합성하고, 이를 사용하여 인간 또는 숙주 동물에서 항체를 생성시킨다. 생성된 항체는, 1) 이들이 NME1이 아닌 NME7AB 또는 NME7-X1에 결합하거나; 2) 암 성장을 저해하는 능력을 갖거나; 3) 암 세포가 더 전이성인 상태로 전이되는 것을 저해하는 능력을 갖거나; 4) 생체내에서 전이를 저해하면 치료 용도를 위해서 선택된다. 일부 경우에, 치료용 용도를 위한 항체는 MUC1* 세포외 도메인에 대한, PSMGFR 펩타이드에 대한 또는 N-10 펩타이드에 대한 NME7AB 또는 NME7-X1의 결합을 방해하는 능력에 대해서 선택된다.
암의 치료를 위한 항-NME7 항체의 용도
암 성장 또는 보다 전이성 상태로의 변이를 저해하는 항체는 항암 치료제로서 사용되도록 선택되며, 암의 치료 또는 예방을 위해 환자에게 투여될 수 있다. 선택된 항체는 예를 들어, 인간 키메라 항체 또는 전체 인간 항체를 조작하거나 제조함으로써 추가로 최적화될 수 있다. 이러한 접근법의 효능을 입증하기 위해, 본 발명자들은 암성 기능에 중요한 것으로 의심되는 NME7 영역으로부터 NME7 펩타이드를 선택하였다. 이어서, 본 발명자들은 이들 펩타이드를 사용하여 항체를 생성한 다음, 생성되는 항체뿐만 아니라 면역화 펩타이드 둘 다를 하기 능력에 대해 시험하였다: a) 암성 성장을 저해하는 능력; 및 b) 암 세포로부터 전이성 암 세포로의 유도 전이를 저해하는 능력. NME7 펩타이드를 항체 생성을 위한 면역화 작용제로서, 그리고 그 자체를 저해제로서 선택하였다(도 9 및 실시예 7). 펩타이드 A1(서열번호141), A2(서열번호142), B1(서열번호143), B2(서열번호144) 및 B3(서열번호145), 여기서, A는 펩타이드가 유래되는 도메인, 즉, NDPK A 도메인을 지칭하고, B는 펩타이드가 NDPK B 도메인으로부터 유래됨을 나타낸다(도 5). 각각의 펩타이드는 면역원으로서 사용되었으며, 다클론성 항체의 제조를 위해 2마리의 토끼에게 각각 주사되었다. 면역화된 토끼의 혈액으로부터 수집한 항체를 면역화 펩타이드를 사용하여 유도체화된 칼럼에서 정제하였다. 이어서, 정제된 항체를 인간 NME7로의 결합 능력에 대해 시험하였다. 목적하는 바와 같이 생성된 모든 항체는 인간 NME1이 아니라 인간 NME7에 결합하였다(도 10A 및 도 10B, 실시예 8). 이들 결과는, 서열이 NME1에서 정확하게 일치하지는 않지만 NME7에서 발견되는 펩타이드를 선택함으로써, NME1이 아니라 NME7에 특이적으로 결합하는 항체가 생성된다는 것을 나타낸다. NME1이 건강한 기능을 가지기 때문에, 대부분의 경우, NME1을 방해하지 않는 항체를 생성하는 것이 바람직하다. 항체를 또한 MUC1* 세포외 도메인 펩타이드에 대한 NME7의 결합을 저해하는 능력에 대해 시험하였다. 도 11에 도시된 ELISA 실험은, 항체가, NME1의 결합을 저해했던 것보다 MUC1* 세포외 도메인 펩타이드에 대한 NME7AB의 결합을 훨씬 더 크게 저해하였음을 나타낸다. NME7 A 도메인 및 B 도메인 각각이 PSMGFR 펩타이드에 결합할 수 있다는 것을 상기하기 바란다. 따라서, PSMGFR 펩타이드에 대한 NME7AB 결합의 완전한 저해는 단 하나의 도메인으로부터 유래된 단일 항체 또는 펩타이드로 달성될 수 없다. 이들 항체와 각각의 면역 펩타이드도 암 세포 성장을 저해하였다(도 12 및 도 13). 이 항체는 또한 NME7AB에서 성장하는 암 세포로 인한 비-부착성 "부유체" 세포의 형성을 저해하였다(도 14). 도면에서 인지될 수 있는 바와 같이, B3 펩타이드로의 면역화에 의해서 생성된 다클론성 항체는 전이성 부유체 세포의 수를 95% 감소시켰는데, 이는 B3 펩타이드에 결합하는 항-NME7 항체가 암 전이를 저해하는 데 있어서 가장 효과적임을 나타낸다. 유사하게, 항체는 전이 마커 CXCR4의 발현을 저해하였다(도 15A). 다시 말하지만, B3 항체는 CXCR4의 발현을 억제하는 데 가장 효율적이었고; 막대로 표지된 NME7 FL(NME7 부유체 세포)은 B3 항체 61이 20배로 감소한 CXCR4의 70배 증가를 나타낸다(NME7+61 FL로 표지된 막대). 또한 면역 펩타이드 자체는 T47D 암 세포가 NME7AB 또는 2i에서 성장했을 때 CXCR4 및 기타 전이 마커의 상향 조절을 저해하였다.
그러나, 이는 NME7 및 NME7 종의 암성 기능을 저해하는 항체를 생성하는 펩타이드를 선택하는 일례이다. 인간 NME1, 인간 NME7, 인간 NME7-X1, 및 인간 NME1 또는 NME7에 대해 높은 서열 상동성을 갖는 박테리아 NME 단백질 사이에서의 서열 정렬은 5개의 상동성 영역을 식별하였다. 펩타이드 A1, A2, B1, B2 및 B3가 모두 암 성장 또는 전이성 상태로의 변이를 저해한 항체를 생성하였다는 사실은, 이들 펩타이드가 유래되는 5개의 영역이 암의 촉진에 있어서 이의 기능에 중요한 NME7의 영역임을 의미한다. 이들 영역으로부터의 다른 펩타이드가 또한 암 성장 및 전이를 저해할 항-NME7 항체를 생성할 것이며, 따라서, 강력한 항암 치료제이다. 펩타이드 A1, A2, B1, B2 및 B3로부터 생성된 항체는 암 성장을 저해하는 것으로 나타났으며, 보다 전이성 상태로의 전이를 저해하였다. 동일하거나 유사한 펩타이드를 사용한 면역화에 의해 생성된 단클론성 항체 및 이러한 단클론성 항체의 후속적인 시험은, 당업계에 공지된 인간화 또는 다른 조작 후, 암의 치료 또는 예방을 위해 환자에게 투여될 항체를 식별할 것이다.
특정 실험에서, 펩타이드 A1, A2, B1, B2 및 B3를 사용한 면역화에 의해 생성된 항체뿐만 아니라 면역화 펩타이드 자체를 배양 중인 암 세포에 첨가하여, 항체 또는 면역화 펩타이드의 첨가가 암 세포 성장을 저해할 것인지를 살펴보았다. 낮은 농도에서 개별적으로 첨가되어도, 항체뿐만 아니라 면역화 펩타이드는 암 세포 성장을 저해하였다(일례를 위해서, 도 12). 그러나, 보다 고농도에서 첨가되거나 조합하여 첨가되었을 때, 항체뿐만 아니라 면역화 펩타이드는 암 세포 성장을 강력하게 저해하였다(도 13). 면역화 펩타이드 A1, A2, B1, B2 및 B3의 상응하는 인간 NME7 아미노산 수는 서열번호 82 또는 147을 갖는 인간 전장 NME7으로부터 각각 127 내지 142, 181 내지 191, 263 내지 282, 287 내지 301, 343 내지 371이다.
명확성을 위해서, NME7의 잔기 수가 논의될 때, 이들 수는 서열번호82 또는 147에 표시된 바와 같이 NME7의 잔기 수를 지칭한다.
암 성장 저해 실험에서 사용된 항체 및 도 12에 도시된 항체 중 하나는 NME7의 아미노산 100 내지 376(서열번호 82 또는 147)에 상응하는 NME7 펩타이드를 사용한 면역화에 의해 생성되었다. 보다 높은 친화성이고, 특이적인 항-NME7 항체를 생성시키기 위해서, 하기 단계들이 후속된다: 인간 NME7 아미노산 100 내지 376을 함유하는 펩타이드로 동물을 면역화시키고, 이어서, 1) 인간 NME1에 결합하는 항체를 탈락시키는 단계; 2) NME7AB, 2i 또는 보다 전이성 상태로의 암 세포의 변이를 유도하는 다른 NME를 저해하는 항체를 선택하는 단계; 3) 암 세포의 성장을 저해하는 항체를 선택하는 단계; 4) MUC1* 양성 암 세포의 성장을 저해하는 항체를 선택하는 단계; 5) MUC1* 세포외 도메인으로의 NME7AB 또는 NME7-X1의 결합을 저해하는, 본질적으로 PSMGFR 펩타이드에 대한 결합을 저해하는 항체를 선택하는 단계; 및/또는 6) 도 9에 열거된 펩타이드 - A1, A2, B1, B2 또는 B3 펩타이드 중 하나 이상에 결합하는 항체를 선택하는 단계.
보다 높은 친화성을 가진 단클론성 항체, 또는 더 긴 펩타이드로부터 생성되는 단클론성 항체는 보다 효과 적인 항체 치료제일 수 있다. 대안적으로, 효능을 증가시키기 위해, 항-NME7, 항-NME7AB 또는 항-NME7-X1 항체의 조합물이 환자에게 투여된다.
항-NME7 항체는 암 세포의 전이성 암 세포로의 전이를 저해한다.
항-NME7 항체는 암 줄기세포(CSC) 또는 종양 개시 세포(TIC)라고도 지칭되는 전이성 암 세포로의 암 세포의 전이를 저해한다. 본 발명자들이, NME7AB의 존재 하에 광범위하게 다양한 암 세포를 배양하면, NME7AB가 보통의 암 세포로부터 전이성 CSC 또는 TIC로의 변이를 유발함을 입증하였음을 상기하기 바란다. 따라서, NME7, NME7AB 또는 NME7- X1에 결합하는 항체는 보다 전이성 상태로의 암 세포의 진행을 저해할 것이다.
암 세포는 줄기세포를 보다 미경험 상태로 반전시키는 작용제의 존재 하에 배양되었을 때, 보다 전이성 상태로 형질전환된다. 본 발명자들은, NME7AB, 인간 NME1 이량체, 박테리아 NME1 이량체, 또는 "2i"로 지칭되는 MEK 및 GSK3-베타 저해제에서 암 세포를 배양하면, 세포가 보다 전이성 상태로 된다는 것을 입증하였다. 세포가 보다 전이성 상태로 전이됨에 따라서, 세포는 비-부착성 또는 덜 부착성인 상태가 되고, 배양 플레이트로부터 부유한다. 이들 부유하는 세포인 "부유체"를 부착성인 세포로부터 개별적으로 수집하였으며, 이들은, a) 전이성 유전자를 훨씬 더 높은 수준으로 발현하고; b) 매우 낮은 카피 수로 마우스 내로 이종 이식되었을 때, 종양을 형성하는 것으로 나타났다. RT-PCR 측정값에서, 특이적인 전이 마커, 예컨대, 유방암의 경우 CXCR4, 전립선암의 경우 CHD1, 및 다른 만능 줄기세포 마커, 예컨대, OCT4, SOX2, NANOG, KLF4 및 다른 마커는 NME7AB에서 배양된 암 세포에서 급격하게 과발현되었으며, 본 명세서 및 도면에서 "부유체"로 지칭되는 비-부착성이된 세포에서 극적으로 과발현되었다.
일례에서, NME7-유래 펩타이드 A1, A2, B1, B2 및 B3를 사용한 면역화에 의해 생성된 NME7AB 특이적인 항체뿐만 아니라 면역화 펩타이드 그 자체를 NME7AB 또는 2i와 함께 배지에 첨가하여, 이들이 보통의 암 세포에서 전이성 암 줄기세포로의 형질전환을 저해하였는지 확인하였다. 항체 및 펩타이드를 전이성 변환을 유발하는 작용제 와 함께 개별적으로 첨가하였으며; 이 경우, NME7AB 또는 2i 저해제 PD0325901 및 CHIR99021였다. NME7AB 및 2i를 개별적으로 사용하여, 형질전환되는 암 세포를 보다 공격적인 전이성 상태로 유도하였다. 2i를 사용하여, 배지에 첨가된 항체가 단순히 NME7AB를 모두 흡수하였는지에 대해 논쟁이 없도록 할 수 있었으며, 따라서, 원인 물질(causative agent)은 배지에 효과적으로 존재하지 않았다(실시예 10).
실험이 진행됨에 따라, 2명의 과학자들이 시각적인 관찰을 독립적으로 기록하였다(도 14). 가장 놀라운 관찰은, 항체 및 펩타이드가 부유체 세포의 수를 급격하게 감소시킨 것이며, 이는, 항체 및 펩타이드가 전이성 암 세포로의 형질전환을 저해한다는 제1 지표였다. 특히, B3 펩타이드를 사용한 면역화로부터 항체가 생성된 세포는 임의의 부유체 세포를 거의 생성하지 않았다. mRNA를 부유체 세포, 부착성 세포 및 대조군 암 세포 모두로부터 추출하였다. 세포의 생존력 및 성장을 나타내는 mRNA의 양을 측정하였다. 항체로 처리한 세포는 훨씬 더 적은 양의 mRNA를 가졌으며, 이는 살아있는 분화성 세포가 더 적음을 나타내고(도 16), 이는, 항-NME7AB 항체가 암 세포 성장뿐만 아니라 보다 전이성 상태로의 암 세포의 전이를 저해함을 나타낸다. RT-PCR을 사용하여, CXCR4를 비롯한 전이 마커의 발현 수준을 측정하였다. 항-NME7 항체를 사용한 치료는 전이 마커, 예컨대, CXCR4의 양을 크게 감소시켰으며, 이는, 항-NME7 항체 또는 펩타이드가 전이성 암으로의 전이를 저해한다는 것을 나타낸다(도 15A 내지 도 15C). 이들 결과는, NME7AB에 결합하는 항체가 전이성 암의 치료 또는 예방을 위해 환자에게 투여될 수 있음을 나타낸다.
NME7
AB
또는 NME7-X1 유래의 펩타이드는 온전한 NME7
AB
및 NME7-X1의 결합을 경쟁적으로 저해하고, 항암제이다.
본 발명의 또 다른 양상에서, 암의 치료 또는 예방을 위한 치료제는 NME7 서열 유래의 펩타이드이며, 이는 암의 치료 또는 예방을 위해 환자에게 투여된다. 일 양상에서, 전체 NME7보다 더 짧고, NME7의 발암 활성을 부여할 수 없고, NME7의 표적에 결합하고, 암을 촉진하는 온전한 NME7과 이의 표적과의 상호작용을 경쟁적으로 저해해야 하는 NME7-유래 펩타이드가 환자에게 투여된다. NME7AB가 발암 활성을 완전히 부여할 수 있기 때문에, NME7AB의 서열은 보다 짧은 펩타이드(들)에 대한 공급원으로서 바람직하며, 여기서, 펩타이드 자체는 암성 성장 또는 다른 종양원성 활성 또는 발암 활성을 촉진할 수 없는 것이 확인되어야 한다. 바람직한 실시형태에서, NME7AB의 일부의 서열을 가지며, 바람직하게는 길이가 약 12개 내지 56개 아미노산인 하나 이상의 펩타이드가 환자에게 투여된다. 반감기를 증가시키기 위해, 펩타이드는 펩타이드 모방체, 예컨대, 비자연 골격을 갖는 펩타이드 또는 L에 대한 D-형태 아미노산을 갖는 펩타이드일 수 있다. 또 다른 경우에서, 항암 치료제는 펩타이드 또는 펩타이드 모방체이며, 여기서, 펩타이드는 NME7, NME7AB 또는 NME7-X1, 또는 이의 표적이며, 본 명세서에서 일부 경우에 "FLR"로도 지칭되는 PSMGFR 펩타이드를 포함하는 MUC1* 세포외 도메인의 적어도 하나의 부분과 고도로 상동성인 서열을 갖는다.
도 6 내지 도 9는 NME7과 이의 동족 표적 사이의 결합을 저해하는 것으로 예측되는 바람직한 아미노산 서열의 목록을 제공한다. 추가로 더 바람직한 실시형태에서, 암 환자 또는 암이 발병할 위험이 있는 환자에게 투여하기 위해 선택된 펩타이드는 이들이 NME7 결합 파트너에 결합하고, 그 자체는 종양원성 활성을 부여하지 않기 때문에 선택된다. 추가로 더 바람직한 실시형태에서, NME7 결합 파트너는 MUC1*의 세포외 도메인이다. 추가로 더 바람직한 실시형태에서, NME7 결합 파트너는 PSMGFR 펩타이드이다.
용어 "종양원성 활성 또는 발암 활성을 부여하는"은, 펩타이드 그 자체는 암의 성장을 지지하거나 촉진할 수 없음을 의미한다. NME7로부터 유래된 펩타이드 또는 펩타이드들이 종양 형성을 촉진할 수 있는지의 여부를 시험하는 또 다른 방식은, 펩타이드가 인간 줄기세포의 전분화능 성장을 지지할 수 있는지를 시험하는 것이다. 전분화능 인간 줄기세포 성장을 지지하는 NME 단백질 및 펩타이드는 또한 암 성장을 지지한다. 또 다른 방법에서, 펩타이드가 체세포를 덜 성숙한 상태로 반전시킬 수 있다면 이러한 펩타이드는 탈락된다
NME7AB의 단편은 암 세포 성장 및 보다 전이성 상태로의 암 세포의 전이를 저해한다. 입증된 바와 같이, 개별적으로(도 12) 또는 조합하여(도 13) 첨가된 NME7 펩타이드 A1, A2, B1, B2 및 B3는 암 세포의 성장을 저해한다. 또한 NME7 펩타이드 A1, A2, B1, B2 및 B3는 보다 전이성 상태로의 암 세포의 전이를 저해하였다(도 15).
따라서, NME7에 특이적인 펩타이드 및 NME7AB 또는 NME7-X1에 특이적인 펩타이드를 사용하여 면역화함으로써 생성되는 항체는 NME7 종의 암성 작용을 차단할 것이며, 강력한 항암제일 것이다. 유사하게는, 이들 결과는, NME7에 특이적이고 NME7AB 또는 NME7-X1에 특이적인 펩타이드가 NME7 종의 암성 작용을 차단할 것임을 나타낸다. 본 발명의 일 양상에서, 펩타이드는 도 6에 도시된 목록으로부터 선택된다. 본 발명의 일 양상에서, 펩타이드는 도 7에 도시된 목록으로부터 선택된다. 본 발명의 일 양상에서, 펩타이드는 도 8에 도시된 목록으로부터 선택된다. 본 발명의 추가의 또 다른 양상에서, 펩타이드는 도 9에 도시된 목록으로부터 선택된다. 이들 항체는 면역화에 의해서 생성될 수 있거나 다른 수단에 의해서 생성되거나 선택될 수 있고, 이어서 NME7, NME7AB, NME7-X1 또는 NME7 유래 펩타이드 A1(서열번호 141), A2(서열번호 142), B1(서열번호 143), B2(서열번호 144) 또는 B3(서열번호 145)를 포함하지만 이들로 제한되지 않는 NME7 유래 펩타이드에 결합하는 능력에 대해서 선택될 수 있다. 이러한 항체는 다클론성, 단클론성, 이중특이적, 2가, 1가, 단쇄, scFv, 인간 또는 인간화될 수 있거나 특이적 표적에 결합하는 인식 영역을 제시하는 단백질 스캐폴드와 같은 항체 모방체일 수 있다.
암의 치료 또는 예방에 사용하기 위한 항-NME7 항체는 당업계에 공지된 표준 방법에 의해 생성될 수 있으며, 여기서, 이들 방법은 NME7, NME7AB 또는 보다 짧은 형태의 NME7AB를 인지하는 항체 또는 항체-유사 분자를 생성하는 데 사용되며, 여기서, N-말단을 형성하는 부가적인 10개 내지 25개의 아미노산은 존재하지 않는다. 이러한 항체는 인간 항체 또는 인간화된 항체일 수 있다. 이러한 항체는 다클론성, 단클론성, 이중특이적, 2가, 1가, 단쇄, scFv, 인간 또는 인간화될 수 있거나 특이적 표적에 결합하는 인식 영역을 제시하는 단백질 스캐폴드와 같은 항체 모방체일 수 있다.
NME7 유래 펩타이드 A1(서열번호 141), A2(서열번호 142), B1(서열번호 143), B2(서열번호 144) 또는 B3(서열번호 145)로의 면역화에 의해서 생성된 항-NME7 항체 또는 A1, A2, B1, B2 또는 B3 펩타이드에 결합하는 항체는 NME7AB 및 NME7-X1에 결합하지만 일부 건강한 세포의 기능에 필요할 수 있는 NME1에 대한 결합에 저항하는 항체이다. 이러한 항체는 NME7AB 또는 NME7-X1의 이의 표적 수용체, MUC1*에 대한 결합을 저해한다. A1, A2, B1, B2 또는 B3 펩타이드에 결합하는 항체는 암 또는 전이로 진단되거나 이것이 발병할 위험이 있는 환자에게 투여될 수 있다. 이러한 항체는 인간 항체 또는 인간화된 항체일 수 있다. 이러한 항체는 다클론성, 단클론성, 이중특이적, 2가, 1가, 단쇄, scFv일 수 있거나 특이적 표적에 결합하는 인식 영역을 제시하는 단백질 스캐폴드와 같은 항체 모방체일 수 있다.
B3 펩타이드로의 면역화에 의해서 생성되는 항-NME7 항체 또는 B3 펩타이드에 결합하는 항체는 NME7AB 및 NME7-X1의 인식에 특히 특이적이다. 이러한 항체는 또한 NME7AB 또는 NME7-X1의 이의 표적 수용체, MUC1*에 대한 결합을 저해하는 데 매우 효과적이다. B3 펩타이드에 결합하는 항체는 또한 암 또는 암 전이를 예방, 저해 및 반전시키는데 예외적으로 효과적이다. 이러한 항체는 인간 항체 또는 인간화된 항체일 수 있다. 이러한 항체는 다클론성, 단클론성, 이중특이적, 2가, 1가, 단쇄, scFv일 수 있거나 특이적 표적에 결합하는 인식 영역을 제시하는 단백질 스캐폴드와 같은 항체 모방체일 수 있다.
B3 펩타이드로 면역화된 토끼에서 생성된 다클론성 항체 #61이 전이 마커 CXCR4의 상향조절을 차단하는 항체 #61에 의해서 입증되는 바와 같이 암 세포의 암 줄기세포로의 형질전환을 저해하였다는 것을 주목하기 바란다(도 15).
NME7로부터 유래된 B3 펩타이드(서열번호 145)는 항-NME7 항체의 생성을 복잡하게 만드는 14번 위치에서 시스테인을 갖는다. 본 발명자들은 시스테인 14를 세린으로 돌연변이시켜 AIFGKTKIQNAVHSTDLPEDGLLEVQYFF(서열번호 169)를 만들었고, 동물을 면역화시켜 항-NME7 단클론성 항체를 생성시켰다. 생성된 항체는 천연 B3 서열뿐만 아니라 B3Cys14Ser 펩타이드에 결합한다. 7개의 고 친화성 및 특이적 단클론성 항체를 생성시켰다: 8F9A5A1, 8F9A4A3, 5F3A5D4, 5D9E2B11, 5D9E10E4, 5D9G2C4 및 8H5H5G4. 그러나, 다양한 서열 정렬은 단지 3개의 고유한 서열 항체가 존재함을 나타내었다: 하기에 제시된 바와 같은 8F9A5A1, 8F9A4A3, 8F9A4P3 및 5F3A5D4. 볼드체 및 밑줄친 영역은 CDR 서열을 나타낸다.


단클론성 항체 5D9E2B11, 5D9E10E4, 5D9G2C4 및 8H5H5G4 모두는 5D4라고도 알려진 5F3A5D4와 동일한 서열을 갖는다. 본 명세서에서, 본 발명자들이 5D4라고도 하는 항체 5F3A5D4를 지칭하는 경우, 그것은 5D9E2B11, 5D9E10E4, 5D9G2C4 및 8H5H5G4에 적용된다는 것이 이해된다. 도 24 및 도 25에서 인지될 수 있는 바와 같이, 항-NME7 항체 8F9A5A1, 8F9A4A3 및 5F3A5D4 모두는 NME1이 아닌 NME7AB에 결합한다. 이는 NME7의 A 도메인이 정상 세포 기능에 필요한 NME1과 높은 상동성을 갖기 때문에 중요하다. 항암 치료제 또는 항전이 치료제의 경우 NME7AB를 저해하는 것이 필수적이지만 NME1은 저해하지 않아야 할 것이다.
도 26, 도 27 및 도 28은 이들 항-NME7 항체가 또한 MUC1* PSMGFR 펩타이드 및 N-10 PSMGFR 펩타이드에 대한 NME7AB의 결합을 방해할 수 있음을 나타낸다. 인지될 수 있는 바와 같이, MUC1* 펩타이드로부터 NME7AB의 전체 변위는 존재하지 않는다. 그러나, NME7AB는 각각 MUC1*에 결합할 수 있는 A 도메인과 B 도메인으로 구성된다. 이러한 항체는 MUC1*에 대한 B 도메인의 결합을 방해하도록 설계되었고; NME7AB의 A 도메인은 여전히 플레이트 표면의 MUC1* 펩타이드에 결합할 수 있다. 유용한 치료제의 경우, 항체는 MUC1*에 대한 하나의 도메인의 결합을 방해하기만 하면 되며, 그렇게 함으로써 MUC1* 성장 인자 수용체의 리간드 유도 이량체화 및 활성화가 차단될 것이다. NME7 B3 펩타이드 또는 B3Cys14Ser 펩타이드(서열번호 169)에 결합하는 항체 또는 항체 모방체는 암 또는 전이로 진단되거나 이의 발병 위험이 있는 환자에게 투여될 수 있다.
동물 모델에서 암 세포를 전이시키는 것이 어렵다는 것은 당업계에 널리 공지되어 있다. 인간 종양에서 100,000개 중 1개 또는 심지어 1,000,000개 중 1개 정도의 암 세포가 종양에서 떨어져 나와, 다른 곳에 이식되어 전이를 시작할 수 있는 것으로 추정된다[문헌[Al-Hajj et al., 2003]]. 일부 연구자들은 면역 손상된 마우스에 주입된 T47D 유방암 세포가 약 12주 후에 전이될 것이라고 보고한다[문헌[Harrell et al 2006]]. 다른 연구자들은 AsPC-1 췌장암 세포가 약 4주 후에 전이될 것이라고 보고한다[문헌[Suzuki et al, 2013]].
본 명세서에서, 본 발명자들은 T47D 유방암 세포가 유일한 성장 인자로서 재조합 NME7AB를 함유하는 무혈청 배지에서 10일 동안 성장되었음을 나타낸다. NME7AB에서 성장했을 때 암 세포의 약 25%가 부유하기 시작했고 분열을 멈췄지만 여전히 생존할 수 있는 것으로 관찰되었다. PCR 측정은 이러한 "부유" 세포가 유방암 전이 인자 CXCR4의 발현을 크게 상향조절함을 나타내었다.
본 명세서에 제시된 일부 도면에서, 이들 부유체 세포는 암 줄기 세포(CSC)라고 지칭된다. 면역 손상된 암컷 nu/nu 마우스에게 90일 방출 에스트로겐 펠릿을 이식하였다. 500,000개의 T47D-wt 세포 또는 10,000개의 T47D-CSC(암 줄기세포)를 nu/nu 마우스의 꼬리 정맥(i.v.), 피하(s.c.) 또는 복강내 공간(i.p.)에 주사하였다. 이 암 세포는 루시페라제를 발현하도록 조작되었다. 종양 또는 암 세포를 시각화하기 위해서, 동물에게 루시페린을 주입한 다음, 10분 후 IVIS 기기에서 시각화한다. 도 33A 및 도 33B의 IVIS 측정에서 볼 수 있는 바와 같이, 6일까지 꼬리 정맥에 주입된 500,000개의 T47D-wt 세포는 살아있는 암 세포 또는 암 세포 생착의 징후를 나타내지 않는다.
극명하게 대조적으로, 꼬리 정맥에 주사된 10,000개의 T47D-CSC는 전이되었다. 제6일에 IVIS 측정 전에, T47D-CSC 마우스에게 32nM의 재조합 NME7AB를 주사하였다. 다음날, 두 CSC 마우스 중 하나에 15㎎s/㎏에 해당하는 농도에서 200uL 부피의 항-NME7 단클론성 항체 8F9A5A1, 8F9A4A3 및 5F3A5D4의 칵테일을 주사하였다. NME7AB와 항-NME7 항체의 거의 동시 주사는 항체의 효과를 무효화했을 가능성이 있다. 도 34는 제10일까지 처리된 마우스가 거의 완전히 전이되었음을 나타낸다. 도면에서 인지될 수 있는 바와 같이, 치료를 위해 선택된 마우스는 비교 가능한 T47D-CSC 마우스보다 더 전이성이다.
제10일에 그 동물에게 항-NME7 항체를 다시 주사하였다. 제12일의 IVIS 측정(도 35)은 항체 처리된 마우스가 전이를 제거하기 시작했음을 나타낸다. 제14일까지(도 36) 미처리 마우스는 만연한 전이로 사망하였고, 처리된 마우스는 전이가 없어졌다. 도 37은 500,000개의 T47D-wt 세포를 주사한 마우스와 항-NME7 처리를 제공받은 T47D-CSC를 주사한 마우스에서 항체 처리가 중단된 제17일까지 IVIS 측정의 시간 경과를 나타낸다. 인지될 수 있는 바와 같이, 제17일에 암 세포의 작은 클러스터가 남아 있었고, 제19일에는 더 커졌다. 21일까지 전이가 퍼졌고 항체 치료가 재개되었다. 도면에 나타난 바와 같이, 항-NME7 항체 치료를 재개한 후 동물은 모든 전이가 소실되었으며, 건강에 이상이 없는 것으로 나타났다.
도 38은 피하 또는 복강내 주사된 동물에 대한 IVIS 시간 경과를 나타낸다. 피하 또는 복강내로 CSC가 주사된 동물에 대한 항체 주사에도 항-NME7 항체가 s.c. 또는 i.p로 주사되었다. 이들 동물에서, 항체 주사는 제17일에 중단되었고, 재개되지 않았다. 도 39 내지 도 40은 B3 펩타이드로의 면역화에 의해서 생성된 다클론성 항-NME7 항체가 진행성 암 및 전이성 암을 염색하지만 정상 조직 또는 저등급 암은 염색하지 않는다는 것을 나타내며, 이에 의해서 100,000개 암 세포 중에서 단지 1개 또는 1,000,000개 암 세포 중에서 1개가 전이성 암 세포일 것이다. 종합하면, 이들 데이터는 항-NME7 항체 8F9A5A1, 8F9A4A3 및 5F3A5D4 또는 8F9A5A1, 또는 8F9A4A3, 또는 5F3A5D4를 암으로 진단되거나 이의 발병 위험이 있는 환자에게 투여하면 암 전이를 예방, 저해 또는 반전시킬 수 있음을 나타낸다.
항-NME7AB 항체의 칵테일로 전이성 동물을 치료하는 것 외에도, 본 발명자들은 또한 단클론성 항-NME7AB 항체를 개별적으로 투여하였고, 이들이 암 전이를 예방할 뿐만 아니라 반전시킬 수 있음을 나타내었다. 하나의 입증에서, 각각 대략 20g 체중의 암컷 nu/nu 마우스에게 8 내지 10주령 사이에 90일 에스트로겐 방출 펠릿을 이식했다. 성장 인자 NME7AB가 보충된 무혈청 배지에서 10 내지 15일 동안 배양함으로써 암 세포를 전이성으로 만들었다. 부착성 세포와 부유 세포 둘 다 전이 마커의 상향 조절을 나타내며, 동물에서는 4 내지 7일 이내에 전이할 수 있다. 이 경우, 시험관내 배양 제11일에 부유 세포를 수거하여 실험 동물의 꼬리 정맥에 주사하였다. 예방 모델을 시험하기 위해서, 전이성 암 세포를 주입하기 24시간 전에, 동물의 하나의 군에게 꼬리 정맥으로 항-NME7AB 항체 8F9A4A3 15㎎/㎏을 주사하고, 그 후 대략 48시간마다 동일한 투여량을 주사하였다. 도 42A 내지 도 42F는 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사하고, 8F9A4A3이라고도 알려진 항-NME7AB 항체 4A3로 처리한 암컷 nu/nu 마우스의 사진을 나타낸다. 암 세포를 영상화하기 위해, 루시페라제 기질인 루시페린을 IVIS 기기로 촬영하기 10분 전에 복강내에 주사한다. 도 42A 내지 도 42C는 동물을 아래로 향하게 한 IVIS 사진을 도시한다. 도 42D 내지 도 42F는 동물을 위로 향하게 한 IVIS 사진을 도시한다. 도 42A 및 도 42D는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 42B 및 도 42E는 전이성 암 세포를 주사하기 24시간 전에 동물에게 항-NME7AB 항체 4A3을 주사한 후, 22일 동안 총 12회 항체 주사를 위해 대략 격일로 동물에 주사한 예방 모델을 도시한다. 도 42C 및 도 42F는 전이성 암 세포를 주사한 후 24시간 후에 동물에게 항-NME7AB 항체 4A3을 주사하고, 그 다음 20일 동안 총 11회 항체 주사를 위해 대략 격일로 동물에 주사한 반전 모델을 도시한다. 도면에서 인지할 수 있는 바와 같이, 항-NME7AB 항체 8F9A4A3은 확립된 전이를 예방할 뿐만 아니라 반전시킬 수 있다.
항-NME7AB 항체 5A1 및 5D4를 또한 전이 예방에서 시험하였고, 암 전이를 상당히 저해한다는 것을 발견하였다. 도 43A 내지 도 43F는 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사하고, 8F9A5A1이라고도 알려진 항-NME7AB 항체 5A1 및 5F3A5D4라고도 알려진 5D4로 처리한 각각 대략 20g의 체중의 암컷 nu/nu 마우스의 사진을 도시한다. 암 세포를 영상화하기 위해, 루시페라제 기질인 루시페린을 IVIS 기기로 촬영하기 10분 전에 복강내에 주사한다. 도 43A 내지 도 43C는 동물을 아래로 향하게 한 IVIS 사진을 도시한다. 도 43D 내지 도 43F는 동물을 위로 향하게 한 IVIS 사진을 도시한다. 도 43A 및 도 43D는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 43B, 도 43E, 도 43C 및 도 43F는 전이성 암 세포를 주사하기 24시간 전에 동물에게 항-NME7AB 항체를 15㎎/㎏으로 주사한 후, 22일 동안 총 12회 항체 주사를 위해 대략 격일로 동물에 주사한 예방 모델을 도시한다. 사진은 제24일 또는 제27일에 촬영되었다. 구체적으로, 항체 5A1로 처리된 군의 마우스 #1을 제27일에 촬영하였으며, 마우스 #2 및 #3은 동물이 제26일에 사망했기 때문에 제24일에 촬영하였다.
항-NME7AB 항체 5A1 및 5D4를 또한 전이 반전 모델에서 시험하였고, 확립된 암 전이를 크게 저해하는 것을 발견하였다. 본 실험에서, 동물에게 제0일에 꼬리 정맥으로 32nM의 최종 농도에서 NME7AB와 혼합된 10,000개의 T47D 전이성 암 세포를 주사하였다. 또한 동물을 더 많은 NME7AB로 제3일과 제4일에 2회 주사하였는데, 여기서 본 발명자들의 실험은 전이를 반전시키기가 더 어려워졌다는 것을 나타내었다. 첫 번째 항체 주사는 제7일이었다. 각각의 실험 동물의 전이 정도는 다소 다양하기 때문에, 본 발명자들은 전이성 암 세포의 명백한 제거가 항 NME7AB 치료로 인한 것임을 확인하기를 원했다. 따라서 본 발명자들은 고용량과 저용량을 번갈아 가며 동물을 치료하였다. 도 44에서 명확하게 인지될 수 있는 바와 같이, 고용량 항-NME7AB는 전이를 제거하는데, 이는 완전히 근절되지 않으면 재발하고, 심지어는 더 낮은 투여량으로 증가한다. 본 실험은 NME7-B3 펩타이드에 결합할 수 있는 시험된 3개의 항-NME7AB 항체, 5A1, 4A3 및 5D4 모두가 농도 의존적 방식으로 암 전이를 저해한다는 것을 나타낸다. 도 44A 내지 도 44D는 32nM의 최종 농도로 NME7AB와 혼합된 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 꼬리 정맥에 주사한 암컷 nu/nu 마우스의 사진을 도시한다. 이어서 동물에게 32nM NME7AB를 꼬리 정맥에 주사한 후 개별 항-NME7AB 항체로 치료하였다. 도 44A는 인산염 완충 식염수 용액을 주사한 대조군 동물을 도시한다. 도 44B는 항-NME7AB 단클론성 항체 8F9A5A1로 처리된 동물을 도시한다. 도 44C는 항-NME7AB 단클론성 항체 8F9A4A3으로 처리된 동물을 도시한다. 도 44D는 항-NME7AB 단클론성 항체 5F3A5D4로 처리된 동물을 도시한다. 녹색 화살표는 표시된 기간 동안 낮은 항체 투여량(5 내지 7㎎/㎏)을 나타내고, 적색 화살표는 높은 투여량(15㎎/㎏)을 나타낸다. 도면에서 인지될 수 있는 바와 같이, 항체를 15㎎/㎏으로 투여하는 경우 전이가 상당히 사라진다.
본 발명의 항-NME7AB 항체가 전이를 저해할 수 있음을 입증하는 것에 더하여, 본 발명자들은 암 전이의 생리학을 보다 밀접하게 모방할 원발성 종양으로부터의 전이에 대한 이들의 효과를 시험하였다. 본 발명자들은 NME7AB를 함유하는 최소 무혈청 배지에서 10 내지 15일 동안 암 세포를 배양함으로써 암 줄기 세포(CSC)라고도 공지된 T47D 전이성 유방암 세포를 생성시켰다. 이어서, 이러한 T47D CSC를 90일 에스트로겐 방출 펠릿이 이식된 NSG 마우스의 우측 옆구리에 피하 이식하였다. 이식된 암 세포는 루시페라제 양성이어서, 루시페라제 기질인 루시페린을 주사한 후 암 세포가 광자를 방출하고, IVIS 기기로 촬영하여 이식된 암 세포를 측정하고 위치를 찾아낼 수 있다. 도 45A 내지 도 45B는 제0일에 32nM의 최종 농도로 NME7AB와 혼합되고, 그 다음 마트리겔과 1:1 vol:vol로 혼합된, 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 우측 옆구리에 피하 주사한 암컷 nu/nu 마우스의 사진을 도시한다. 종양 생착을 제0일 내지 제6일 진행하도록 하였다. 이어서 동물을 항-NME7AB 항체로 꼬리 정맥 주사에 의해서 정맥내 처리하였다. 대조군 동물에게 PBS를 주사하였다. 도 45A는 대조군 동물의 IVIS 사진을 나타낸다. 도 45B는 15㎎/㎏의 총 농도로 항-NME7AB 항체 5A1, 4A3 및 5D4의 칵테일을 꼬리 정맥에 주사한 동물의 IVIS 사진을 도시한다. 항체 또는 PBS를 제7일과 제18일 사이에 4회 투여하였다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체 처리 동물은 대조군보다 전이가 적었다(전신의 청색 점). 처리된 군에서 5마리의 동물 중 2마리는 대조군보다 더 큰 원발성 종양을 갖는다. 이는 항-NME7AB 항체가 암 세포의 확산을 방지하여 원발성 종양에 집중되어 있기 때문일 수 있다. 본 실험에서, 암 세포의 주사 전에 수행된 PCR 분석은 NME7AB와 배양한 지 11일 후에 T47D 유방암 세포가 CXCR4를 109배, OCT4를 2배, NANOG를 3.5배, MUC1을 2.7배 상향조절한 것으로 나타났다.
또 다른 실험에서, 본 발명자들은 원발성 종양에서부터 유방암이 전형적으로 전이되는 기관으로의 전이에 대한 본 발명의 항-NME7AB 항체의 효과를 시험하였다. 유방암은 일반적으로 간, 폐, 뼈, 뇌의 순으로 전이된다. 본 발명자들은 NME7AB를 함유하는 최소 무혈청 배지에서 11일 동안 배양함으로써 T47D 전이성 유방암 세포를 생성시켰다. 이어서, 이러한 T47D CSC를 90일 에스트로겐 방출 펠릿이 이식된 NSG 마우스의 우측 옆구리에 피하 이식하였다. 도 46A 내지 도 46P는 제0일에 32nM의 최종 농도로 NME7AB와 혼합되고, 그 다음 마트리겔과 1:1 vol:vol로 혼합된, 10,000개의 루시페라제 양성 T47D 전이성 유방암 줄기세포를 우측 옆구리에 피하 주사한 암컷 nu/nu 마우스의 사진을 도시한다. 종양 생착을 제0일 내지 제6일 진행하도록 하였다. 이어서 동물을 항-NME7AB 항체로 꼬리 정맥 주사에 의해서 정맥내 처리하였다. 대조군 동물에게 PBS를 주사하였다. 제38일에, 동물을 희생시키고, 간을 수거하고, 이어서 IVIS로 분석하여 간에 전이된 암 세포를 검출하였다. 도 46A 내지 도 46B는 PBS만을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46C 내지 도 46D는 항-NME7AB 항체 5A1을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46E 도 46F는 항-NME7AB 항체 4A3을 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46G 내지 도 46H 도 46F는 항-NME7AB 항체 5D4를 주사한 대조군 동물의 전신 IVIS 사진을 도시한다. 도 46A, 도 46C, 도 46E 및 도 46G는 치료 전 제7일에 촬영한 IVIS 사진이다. 도 46B, 도 46D, 도 46F 및 도 46H는 항-NME7AB 항체 치료 또는 모의 실험 후 제31일에 촬영한 IVIS 사진이다. 도면에서 인지될 수 있는 바와 같이, PBS 대조군의 동물은 전신 IVIS 사진에서 전이(청색점)를 나타낸 반면, 항-NME7AB 항체로 처리한 동물은 그렇지 않았다. 도 46I 내지 도 46P는 희생 후 동물로부터 수거한 간 및 폐의 사진 및 IVIS 사진을 도시한다. 도 46I, 도 46K, 도 46M, 도 46O는 일반 사진이다. 도 46J, 도 46L, 도 46N 및 도 46P는 전이된 암 세포를 나타내는 IVIS 사진이다. 도면에서 인지될 수 있는 바와 같이, 항-NME7AB 항체는 유방암 전이의 1차 부위인 간으로의 전이를 크게 저해하였다. 도 46Q는 대조군 동물 대 처리 동물로부터 수거된 간에 대해 IVIS 기기에 의해 방출되고 열거된 측정된 광자의 막대 그래프이다. IVIS 측정치의 삽입 그래프에서 인지될 수 있는 바와 같이, 꼬리 정맥에 세포를 주입했을 때 간으로의 전이의 저해는 전이의 저해 순위를 따르며, 이는 NME7AB-MUC1* 상호작용을 방해할 수 있는 효력의 순위와도 일치한다.
본 발명자들은 배양된 암 세포주가 NME7AB를 발현하는지를 결정하기 위해 많은 암 세포주의 면역형광 영상화를 수행하였다. 도 47A 내지 도 47F 및 도 48A 내지 도 48I가 명확하게 나타내는 바와 같이, 본 발명자들이 시험한 각각의 MUC1 양성 암 세포주는 NME7AB에 대해 양성이고, 이의 결합은 막성이며, NME7AB가 암 세포로부터 분비되어 그것이 MUC1*의 세포외 도메인에 결합하는 것과 일치한다. 도 47A 내지 도 47F는 NME7AB의 존재에 대해 다양한 암 세포주가 염색되는 면역형광 실험의 사진을 도시한다. 도 47A는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 T47D 유방암 세포를 도시한다. 도 47B는 다양한 농도의 항-NME7AB 항체 5D4로 염색된, 1500s라고도 알려진 ZR-75-1 유방암 세포를 도시한다. 도 47C는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 H1975 비소세포 폐암 세포를 도시한다. 도 47D는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 H292 비소세포 폐암 세포를 도시한다. 도 47E는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 HPAFII 췌장암 세포를 도시한다. 도 47F는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 DU145 전립선암 세포를 도시한다. 도면에서 인지될 수 있는 바와 같이, 본 발명자들이 시험한 모든 암 세포주는 NME7AB에 대해 강력하고 막성인 염색을 나타낸다. 본 실험에 사용된 단클론성 항체는 5D4였다. 동시에, NME7AB 항체 5A1 및 4A3을 사용하여 동일한 세포주를 염색하고 동일한 결과를 생성하였다.
도 48A 내지 도 48I는 NME7AB의 존재에 대해 다양한 폐암 세포주가 염색되는 면역형광 실험의 사진을 도시한다. 도 48A 내지 도 48C는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 선암종인 H1975 비소세포 폐암 세포를 도시한다. 도 48A는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48B는 항-NME7AB 염색 단독을 나타낸다. 도 48C는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다. 도 48D 내지 도 48F는 다양한 농도의 항-NME7AB 항체 5D4로 염색된, 점막표피양 폐 암종인 H292 비소세포 폐암 세포를 도시한다. 도 48D는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48E는 항-NME7AB 염색 단독을 나타낸다. 도 48F는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다. 도 48G 내지 도 48I는 다양한 농도의 항-NME7AB 항체 5D4로 염색된 전이성 기관지폐포 암종인 H358 비소세포 폐암 세포를 도시한다. 도 48G는 DAPI 및 항-NME7AB 염색의 오버레이이다. 도 48H는 항-NME7AB 염색 단독을 나타낸다. 도 48I는 DAPI 및 항-NME7AB 염색 오버레이의 확대도이다.
또한 NME7AB를 함유하는 무혈청 배지에서 이들 세포주를 배양하면 줄기세포 및 전이 마커의 발현이 더욱 증가하였다. 특히, 비-부착성이 된 세포(본 명세서에서 부유체라고 지칭됨)는 부착성 대응물보다 줄기세포 및 전이 마커의 발현이 훨씬 더 높다. 도 49A 내지 도 49I는 NME7AB에서의 배양 전 후의 암 세포주, 유방 T47D, 폐 H1975, 폐 H358 및 췌장 HPAFII의 PCR 그래프. 도 49A는 유방 전이 마커 CXCR4를 측정하였다. 도 49B는 줄기세포 마커 OCT4를 측정하였다. 도 49C는 전이 마커 ALDH1을 측정하였다. 도 49D는 줄기세포 마커 SOX2를 측정하였다. 도 49E는 줄기세포 마커 NANOG를 측정하였다. 도 49F는는 E-카드헤린이라고도 공지된 마커 CDH1을 측정하였다. 도 49G는 전이 마커 CD133을 측정하였다. 도 49H는 줄기세포 마커 ZEB2를 측정하였다. 도 49I는 줄기, 암 및 전이 마커 MUC1을 측정하였다. 종양 구체로도 알려진 부유체 세포는 독립적으로 고정부(anchorage)를 성장시킬 수 있게 되며, 부착 세포보다 더 증가된 전이 마커를 나타낸다. 암 줄기세포를 주사한 동물은 NME7AB 배양 부유체 세포를 주사한 동물이다. 도면에서 인지될 수 있는 바와 같이, 전이 마커, 줄기세포 마커 또는 상피에서 중간엽으로의 전이(epithelial to mesenchymal transition: EMT)의 마커는 NME7AB에서 배양 후 증가하는데, 이는 보다 전이성 상태로의 변화를 나타낸다. 도 50은 NME7AB와의 배양에서 10 내지 12일 후 10,000개의 H358 폐암 모 세포 또는 H358 세포를 꼬리 정맥에 주사한 NSG 마우스의 제6일 IVIS 사진을 도시한다. 도면에서 인지될 수 있는 바와 같이, NME7AB에서 배양한 NCI-H358 폐암 세포는 자체적으로 전이성 세포인 것으로 보고된 모 세포에 비해 전이 가능성이 크게 증가하였다. 단지 10,000개 세포로부터의 NCI-H358 NME7AB 전이성 암 줄기세포로부터 6일 동안의 전이의 기능적 증가는 도 49와 일치하며, 이는 H358 세포가 NME7AB에서 배양 후 전이 마커의 발현을 크게 증가시킴을 나타낸다.
도 51은 NME1 또는 NME7AB라고도 알려진 이량체 NM23-H1에서 배양물에서 2 또는 3 계대 전 및 후의 MUC1 음성 전립선암주 PC3의 PCR 그래프를 도시한다. 그래프는 줄기세포 마커, 암 세포 마커 및 전이 마커의 배수 차이를 도시한다. 도면에서 인지될 수 있는 바와 같이, NME1 또는 NME7AB의 반복 배양은 줄기, 암 및 전이 마커의 상향조절을 유도하지만, MUC1의 발현도 5 내지 8배 상향조절한다.
종합적으로, 이러한 데이터는 DM10 도메인이 없는 NME7이 암 세포에 의해 분비되고, 탠덤 반복 도메인이 없는 MUC1의 세포외 도메인에 결합하여, NME7이 MUC1* 세포외 도메인을 이량체화하는데, 이것이 암 세포 성장을 증가시키고, 암 세포의 전이 가능성을 증가시킨다는 것을 입증한다. NME7AB와 MUC1* 세포외 도메인 간의 상호작용을 방해하는 항체가 암 세포 성장을 저해하고, 암 전이를 저해할 것임은 당연하다. 본 명세서에서, 본 발명자들은 NME7AB와 MUC1* 세포외 도메인 간의 상호작용을 저해하는 항-NME7AB 항체가 실제로 암 세포 성장과 암 전이를 저해한다는 것을 나타내었다. 따라서, 항-NME7AB 항체는 암의 치료 또는 예방을 위해 암 또는 전이로 진단되거나 이의 발병할 위험이 있는 환자에게 투여될 수 있다.
NME1은 모든 세포의 세포질에서 발현되고 넉아웃되면 치명적일 수 있고, 중요하게는 NME1 A 도메인이 NME7 A 도메인에 대해 높은 서열 상동성을 갖기 때문에, 치료 용도를 위한 항-NME7AB 항체는 NME1이 아닌 NME7AB 또는 NME7-X1에 결합하는 것이 중요하다. 본 발명의 일 양상에서, 치료 용도에 최적일 항체는 NME7AB 또는 NME7-X1에 고유하고, NME1 서열에 존재하지 않는 펩타이드에 결합하는 능력에 대해 선택되었다. 도 6 내지 도 9는 NME7AB 고유 펩타이드를 열거한다.
바람직한 실시형태에서, 암 또는 암 전이의 치료 또는 예방을 위해 환자에게 투여하기에 적합한 항체는 NME7 B3 펩타이드에 결합하는 항체의 군으로부터 선택된다. 추가로 더 바람직한 실시형태에서, 암 또는 암 전이의 치료 또는 예방을 위해 환자에게 투여하기에 적합한 항체는 NME7 B3 펩타이드에 결합하고, NME7AB에 결합하지만, NME1에 결합하지 않는 항체의 군으로부터 선택된다. 시험관내 및 생체내에서 이러한 항암 활성 및 항전이 활성을 입증한 암 또는 암 전이의 치료 또는 예방을 위한 치료 용도에 적합한 항체의 예는 항-NME7 항체 5A1, 4A3 및 5D4를 포함한다. 이들은 예시일 뿐이며, 본 명세서에 기재된 바와 같이 생성되고, 본 명세서에 기재된 바와 같이 선택된 다른 항체는 동일한 항암 및 항전이 활성을 가질 것이다. 이러한 항체는 scFv 또는 항체 모방체를 포함하는 완전한 항체 또는 이의 단편일 수 있으며, 여기서 항체의 가변 도메인은 항체를 모방하는 단백질 스캐폴드에 혼입된다. 항체는 뮤린, 낙타과, 라마, 인간 또는 인간화를 포함하는 인간 또는 비인간 종의 것일 수 있고, 단클론성, 다클론성, scFv 또는 이의 단편일 수 있다.
암 또는 전이의 치료 또는 예방을 위한 항-NME7 항체는 다수의 상이한 치료 포맷으로 사용될 수 있다. 예를 들어, 본 명세서에 기재된 임의의 항체 또는 이의 단편은 독립형(stand-alone) 항체 또는 항체 단편으로서 환자에게 투여될 수 있거나, 항체 약물 접합체(ADC)와 같은 독소에 부착되거나, 이중특이적 항체 또는 BiTE(이중특이적 T 세포 관여기) 내로 통합되거나, 키메라 항원 수용체(CAR) 내로 통합되거나, CAR을 또한 발현하는 세포에 의해 발현되도록 조작된다. 세포는 면역 세포, T 세포, NK 세포 또는 줄기세포 또는 전구 세포일 수 있으며, 이것은 그 다음 T 세포 또는 NK 세포로 분화될 수 있다.
본 명세서에 기재된 임의의 항체 또는 이의 단편은 암의 지표 또는 암에 대한 감수성일 NME7AB 또는 NME7-X1의 존재에 대해 체액, 세포, 조직 또는 신체 표본을 프로빙하기 위한 진단 시약으로 사용될 수 있다. 진단 용도를 위한 항체는 조영제, 핵산 태그에 연결될 수 있고, 낙타과를 포함한 임의의 종의 것일 수 있고, 시험관내, 생체내 또는 수술 중에 혈액, 세포 또는 조직과 같은 체액 상에서 또는 전신 적용에 사용될 수 있다.
치료적으로 유용하거나 진단적으로 유용한 항-NME7 항체에 대한 선택 기준은 항체가 혼입될 치료 또는 진단의 형식 또는 양식에 좌우된다. 항체 또는 항체 단편이 암 또는 암 전이의 치료 또는 예방을 위한 독립형 작용제로서 환자에게 투여되는 경우, 항체는 i) NME1이 아닌 NME7AB 또는 NME7-X1에 결합하는 능력; ii) PSMGFR 펩타이드에 결합하는 능력; iii) N-10 펩타이드에 결합하는 능력; iv) NME7AB 또는 NME7-X1과 MUC1* 세포외 도메인 사이의 상호작용 또는 NME7AB 또는 NME7-X1과 N-10 펩타이드 사이의 상호작용을 방해하는 능력에 대해서 선택된다. 항체는 또한 NME7 B3 펩타이드에 결합하는 능력에 대해 선택될 수 있다. 이 치료 포맷은 또한 CAR 및 분비된 항-NME7 항체를 발현하도록 조작된 세포를 포함한다.
다른 양식은 항-NME7 항체에 대한 다른 선택 기준을 필요로 한다. 항-NME7 항체가 ADC에 혼입되는 경우, ADC는 표적 세포에 의해 내재화되어 표적 세포의 사멸을 촉발해야 한다. NME7AB 또는 NME7-X1은 MUC1*의 세포외 도메인에 결합될 것이다. 항체가 MUC1* 세포외 도메인에 대한 NME의 결합을 방해하는 경우 독소-접합 항체는 내재화되지 않고 세포가 사멸되지 않을 것이다. 유사하게, 항-NME7 항체가 CAR 또는 BiTE에 혼입되는 경우, NME7AB 또는 NME7-X1 사이의 상호작용이 방해될 수 없거나 면역 세포가 더 이상 이의 사멸제를 암 세포에 지향시킬 수 없게 될 것이다. 항-NME7 항체를 진단 시약으로 사용하는 경우, NME7AB 또는 NME7-X1 간의 상호작용이 방해되거나, 항체 및 연관 표지가 씻겨 나갈 수 없다. 따라서 ADC, CAR T 또는 CAR-NK, BiTE 또는 진단 응용의 경우, 항-NME7 항체는 i) NME1가 아닌 NME7AB 또는 NME7-X1에 결합하는 능력; ii) PSMGFR 펩타이드에 결합하는 능력; iii) N-10 펩타이드에 결합하는 능력, iv) MUC1* 세포외 도메인과의 상호작용 또는 NME7AB 또는 NME7-X1과 N-10 펩타이드 사이의 상호작용을 방해하지 않고 NME7AB 또는 NME7-X1에 결합하는 능력에 대해서 선택된다. 항체는 또한 NME7 B3 펩타이드에 결합하는 능력에 대해 선택될 수 있다.
본 발명의 일 양상에서, 세포는 본 발명의 항-NME7AB 항체 또는 이의 단편을 발현하도록 조작된다. 세포는 T 세포 또는 NK 세포와 같은 면역 세포일 수 있거나, T 세포 또는 NK 세포와 같은 보다 성숙한 면역 세포로 분화될 수 있는 줄기세포 또는 전구 세포일 수 있다. 바람직한 실시형태에서, 항-NME7AB 항체를 발현하도록 조작된 세포는 또한 키메라 항원 수용체(CAR)를 발현하도록 조작된다. 바람직한 실시형태에서, CAR은 종양 연관 항원을 인식한다. 바람직한 실시형태에서, CAR은 MUC1*을 표적화한다. 보다 바람직한 실시형태에서, CAR은 항-MUC1* 항체 MNC2에 의해 종양에 지향된다. 본 발명의 또 다른 양상에서, CAR을 발현하도록 조작된 세포는 또한 항-NME7 항체를 유도 가능하게 발현하도록 조작된다. 일례에서, 항-NME7AB 항체를 암호화하는 핵산은 Foxp3 인핸서 또는 프로모터에 삽입된다. 또 다른 예에서, 항-NME7AB 항체는 NFAT-유도성 시스템에 존재한다. 일 양상에서, NFAT-유도성 시스템은 항-NME7AB 항체 서열의 상류에 삽입된 NFATc1 반응 요소를 혼입한다. 이들은 IL-2 프로모터, Foxp3 인핸서 또는 프로모터 또는 다른 적합한 프로모터 또는 인핸서에 삽입될 수 있다.
본 발명의 또 다른 양상에서, NME7AB 또는 NME7-X1에 고유한 펩타이드는 암 또는 암 전이에 대해 사람을 면역화시키거나 사람에게 백신 접종하는 데 사용되는 실체에 혼입된다. 바람직한 실시형태에서, 펩타이드는 Cys-14-Ser 돌연변이를 갖는 NME7 B3 펩타이드일 수 있는 NME7 B3 펩타이드의 전부 또는 일부를 포함한다.
본 발명의 또 다른 양상은 숙주 동물에서 항-NME7AB 항체를 생성시키는 방법을 포함하며, 여기서 동물은 NME7 B3 펩타이드로 면역화된다. 바람직한 실시형태에서, NME7 B3 펩타이드는 NME7 특이적 항체 생성을 저해하는 이황화 결합 형성을 피하기 위해 세린으로 돌연변이된 시스테인 14(서열번호 169)를 갖는다.
본 발명의 또 다른 양상은 NME7AB 또는 NME7-X1로 세포를 배양하는 것을 포함하는 향상된 전이 가능성을 갖는 세포를 생성시키는 방법을 포함한다. 이러한 세포는 약물 발견의 다수의 양상에서 사용될 수 있다.
본 발명의 또 다른 양상은 NME7AB 또는 NME7-X1을 발현하도록 조작된 세포를 포함한다. NME7AB 또는 NME7-X1은 인간 서열일 수 있다. 이들의 발현은 유도성일 수 있다. 일 양상에서, 세포는 인간 NME7AB 또는 NME7-X1을 발현할 수 있는 트랜스제닉 동물일 수 있는 동물로 이후에 발달되는 난자이다.
NME7은 MUC1* 성장 인자 수용체의 세포외 도메인에 결합하여 이를 이량체화한다. 조직 연구는 종양 등급 및 전이가 증가함에 따라 MUC1*이 증가함을 나타낸다. 본 명세서에서 본 발명자들은 종양 등급 및 전이가 증가함에 따라 NME7 발현이 증가함을 나타내다(도 39 내지 도 41). 본 명세서에서 본 발명자들은 NME7과 MUC1*의 상호작용을 저해하는 항체가 종양 성장 및 전이를 저해한다는 것을 나타내었다.
다른 NME 패밀리 구성원은 MUC1* 성장 인자 수용체의 세포외 도메인에 결합하여 이를 이량체화할 수 있다. 예를 들어, 본 발명자들은 NME1, NME2 및 NME6이 이량체로 존재할 수 있고, MUC1* 세포외 도메인에 결합하여, 이를 이량체화한다는 것을 나타내었다. NME7AB 및 NME7-X1는 MUC1* 세포외 도메인에 결합할 수 있는 두 개의 도메인을 갖고, 단량체로서 이들은 MUC1* 성장 인자 수용체를 이량체화하고, 활성화한다. 본 발명자들은 본 발명에 이르러서 항-NME7 항체가 암 및 암 전이를 저해한다는 것을 나타내었다. 유사하게, 이들 다른 NME 단백질에 결합하는 항체 또는 항체 모방체는 암 또는 전이로 진단되거나 이의 발병 위험이 있는 환자에게 투여될 수 있는 항암 또는 항전이 치료제일 수 있다. 본 발명의 일 양상에서, 암 또는 전이의 치료를 위해 치료용으로 사용될 수 있는 항체는 NME1, NME2, NME3, NME4, NME5, NME6, NME7, NME8, NME9 또는 NME10에 결합하는 항체이다. 본 발명의 한 양상에서, 치료 항체 또는 항체 모방체는 NME 단백질 및 이의 동족 성장 인자 수용체의 결합을 저해한다. 본 발명의 일 양상에서, 치료용 항체 또는 항체 모방체는 MUC1*의 세포외 도메인과 NME 단백질의 상호작용을 저해한다. 본 발명의 또 다른 양상에서, 치료용 항체 또는 항체 모방체는 NME1, NME2, NME3, NME4, NME5, NME6, NME7, NME8, NME9 또는 NME10으로부터 유래된 펩타이드에 결합하고, 여기서 펩타이드는 NME7 A1, A2, B1, B2 또는 B3 펩타이드에 상동성이다.
하기는 NME7과 다른 NME 패밀리 구성원 간의 상동성 및 동일성 정렬을 나타내는 서열 정렬이다. 밑줄 또는 밑줄 및 볼드체 서열은 NME7 펩타이드 A1(서열번호 141), A2(서열번호 142), B1(서열번호 143), B2(서열번호 144) 및 B3(서열번호 145)에 해당한다.











예로서, NME7 상동성 펩타이드("상동성 펩타이드"), 특히 A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 항체 또는 항체 모방체가 암으로 진단되거나 이의 발병 위험이 있는 환자에게 투여될 수 있다.
A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 펩타이드
A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 펩타이드는 하기를 포함하지만 이들로 제한되지 않는 것을 포함할 수 있다:






일부 경우에, 다른 NME 단백질로부터 유래된 펩타이드는 프레임을 이동하거나 확장된 펩타이드가 암 또는 암 전이를 저해하는 항체를 생성하는 NME7 펩타이드에 대해 더욱 상동성이도록 NME7 펩타이드를 확장함으로써 NME7 A1, A2, B1, B2 또는 B3 펩타이드에 더 상동성이도록 만들 수 있다. 또 다른 예로서, NME7 상동성의 연장된 펩타이드("연장된 펩타이드")에 결합하는 항체 또는 항체 모방체가 암으로 진단되거나 이의 발병 위험이 있는 환자에게 투여될 수 있다.
A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 연장된 펩타이드
연장된 펩타이드인 A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 펩타이드는 하기를 포함하지만 이들로 제한되지 않는 것을 포함할 수 있다:





일부 NME 단백질은 정상 세포 성장 또는 발달에 필요한 기능을 발휘한다. 예를 들어, NME1은 정상 세포 기능에 필요하다고 생각된다. 다른 NME 단백질은 기능이 정상 세포 또는 조직에 필요한 촉매 도메인을 갖는다. 이러한 경우에, 치료용 항체는 표적화된 암 연관 NME에 결합하지만 비표적화 NME에는 결합하지 않는 능력을 기반으로 선택될 수 있다. 예를 들어, 본 명세서에 제시된 항-NME7 항체인 8F9A5A1, 8F9A4A3 및 5F3A5D4는 NME7AB에는 결합하지만 NME1에는 결합하지 않는 능력에 대해 선택되었고; 이들은 암 및 암 전이를 저해하는 능력을 기반으로 추가로 선택되었다.
본 발명의 또 다른 양상에서, 항-NME7 항체, 항체 단편, 예를 들어, scFv, 또는 항체 모방체의 단편은 면역 세포에서 발현되도록 조작된 키메라 항원 수용체(CAR) 내에 혼입된다. 면역 세포는 항-NME7 CAR, 항-MUC1* CAR, 또는 둘 다를 발현하도록 조작될 수 있다. CAR 중 하나는 유도성 프로모터로부터 발현될 수 있다. 대안적으로, 면역 세포는 항-MUC1* CAR 및 유도성 항-NME7 항체 또는 항체 단편과 같은 CAR을 발현하도록 조작될 수 있다. 일부 예에서 유도성 프로모터는 NFAT 반응 요소를 함유할 수 있다. 일 양상에서, 이들 조작된 종은 T 세포, NK 세포 또는 수지상 세포에서 발현된다. 면역 세포는 환자 또는 기증자로부터 얻을 수 있다. 일부 경우에, 면역 분자, 예컨대, MHC, 면역관문 저해제 또는 면역관문 저해제에 대한 수용체가 예를 들어, CrisPR 또는 CrisPR-유사 기술을 사용하여 돌연변이되거나 절단된다. 또 다른 양상에서, ITAM 분자, Fos 또는 Jun은 환자 또는 기증자 유래 면역 세포에서 Talens, Sleeping Beauty, CrisPR 또는 CrisPR-유사 기술을 통해 돌연변이되거나 유전적으로 절제된다.
본 발명의 일 양상에서, CAR T 포맷에서 사용하기 위한 항-NME7 항체 또는 항체 모방체는 NME7에 특이적이지만 MUC1*의 세포외 도메인에 대한 NME7의 결합을 방해하지 않는 항체 또는 항체 모방체의 군으로부터 선택된다. 이러한 방식으로, CAR T를 종양에 표적화하는 항-NME7 항체 또는 항체 모방체는 단순히 수용체로부터 리간드를 뽑지 않을 것이고, 따라서 T 세포는 표적 암 세포에 그랜자임 B를 주입할 수 없을 것이다. 이러한 항체 또는 항체 모방체는 동물을 NME7 펩타이드 A1, A2, B1, B2 또는 B3과 같은 NME7 펩타이드로 면역화함으로써 생성되거나 NME7 펩타이드 A1, A2, B1, B2 또는 B3에 결합하는 능력으로 인해 선택된다. 항체 또는 항체 모방체는 NME7에 특이적으로 결합하지만 NME1 또는 NME2에는 결합하지 않는 능력 및 또한 NME7과 MUC1* 세포외 도메인 간의 결합을 방해하는 무능력에 대해 스크리닝될 수 있다. 예를 들어, ELISA 설정에서, PSMGFR 펩타이드는 표면에 고정된다. 표지된 NME7AB는 표면 고정된 MUC1* 세포외 도메인에 결합하도록 허용하고, NME7AB 표지의 검출은 시험 항체 또는 항체 모방체의 존재 또는 부재 하에 측정된다. 본 발명의 일 양상에서, NME7AB와 표면-고정된 MUC1* 세포외 도메인 펩타이드 사이의 결합을 감소시키지 않는 항체는 CAR 내로 혼입되고 면역 세포에서 발현되도록 조작된 항체로서 선택되고, 이어서 암 또는 암 전이의 치료 또는 예방을 위한 환자에게 투여된다.
본 발명의 일 양상에서, 항-NME7 항체 또는 이의 단편은 암 또는 암 전이로 진단되거나 이의 발병 위험이 있는 환자에게 투여된다. 일 양상에서, 항-NME7 항체 또는 항체 단편은 특히 "A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 펩타이드" 및 "A1, A2, B1, B2 또는 B3에 상동성인 확장된 펩타이드" 섹션에서 상기에 논의된 NME 펩타이드에 결합한다.
또 다른 양상에서, 항체, 항체 단편 또는 항체 모방체는 A1, A2, B1, B2 또는 B3(서열번호 141 내지 145) 중에서 선택되는 NME7 유래 펩타이드에 결합한다. 또 다른 양상에서, 항체, 항체 단편 또는 항체 모방체는 B3 펩타이드의 대부분 또는 전부를 포함하는 NME7 펩타이드에 결합한다. 본 발명의 일 양상에서, 항-NME7 항체, 항체 단편 또는 항체 모방체는 하기에 제시된 항-NME7 항체 8F9A4A3("4A3")(서열번호 1001-1015), 8F9A5A1("5A1")(서열번호 1016 - 1030) 또는 8H5H5G4("5G4")(서열번호 1031 - 1045)의 가변 도메인으로부터 유래된 서열을 포함한다.
































본 발명의 또 다른 양상에서, CAR을 발현하도록 조작된 면역 세포는 암 또는 암 전이로 진단되거나 이의 발병 위험이 있는 환자에게 투여되고, 여기서 면역 세포는 또한 유도성 프로모터로부터 발현될 수 있는 항-NME7 항체 또는 항체 단편을 발현하도록 조작된다. 일 양상에서, CAR은 항-MUC1* 항체 단편에 의해서 안내된다. 하나의 경우에, CAR은 huMNC2-CAR44이다. 일 양상에서, 항-NME7 항체 또는 항체 단편은 상기 "A1, A2, B1, B2 또는 B3 펩타이드에 상동성인 펩타이드" 및 "A1, A2, B1, B2 또는 B3에 상동성인 확장된 펩타이드" 섹션에 열거된 NME7 펩타이드에 결합한다. 또 다른 양상에서, 항체 또는 항체 단편은 A1, A2, B1, B2 또는 B3(서열번호 141 내지 145) 중에서 선택되는 NME7 유래 펩타이드에 결합한다. 또 다른 양상에서, 항체, 항체 단편 또는 항체 모방체는 B3 펩타이드를 포함하는 NME7 펩타이드에 결합한다. 본 발명의 일 양상에서, 항-NME7 항체, 항체 단편 또는 항체 모방체는 항-NME7 항체 8F9A4A3, 8F9A5A1 또는 8H5H5G4의 가변 도메인으로부터 유래된 서열을 포함한다.
이러한 항체는 인간 항체 또는 인간화된 항체일 수 있다. 이러한 항체는 다클론성, 단클론성, 이중특이적, 2가, 1가, 단쇄, scFv일 수 있거나 특이적 표적에 결합하는 인식 영역을 제시하는 단백질 스캐폴드와 같은 항체 모방체일 수 있다. 당업자가 인지하는 바와 같이, 항체는 비-인간 기원, 인간 또는 인간화될 수 있다. 항체를 인간화하는 방법은 마우스 가변 영역의 전부 또는 일부를 예를 들어, 서열번호 1001 내지 1045로서 열거된 서열에 제시된 바와 같은 가장 밀접하게 일치하는 인간 항체 서열의 V- 및 J- 영역에 융합시키는 것을 포함한다. 단쇄 작제물이 아닌 전체 항체도 만들 수 있다. 예를 들어, 중쇄 가변 마우스 서열은 인간 V- 및 J- 영역에 융합된 다음 IgG1, IgG2 또는 IgG3의 인간 중쇄 불변 영역에 융합된다. 유사하게, 경쇄 가변 마우스 서열은 인간 V- 및 J- 영역에 융합된 다음 IgG1, IgG2 또는 IgG3의 인간 카파 또는 람다 불변 영역에 융합된다. 플라스미드는 함께 발현되고, 회합하여 완전한 항체(서열번호 1047-1051)를 형성한다.
본 발명의 또 다른 양상에서, 소분자는 NME7, NME7AB 또는 NME7-X1의 종양형성 효과를 저해하는 능력에 대해 선택된 항암제이다. 예를 들어, 고속대량처리(high throughput) 스크린은 암을 치료할 작은 분자를 식별한다. 다중-웰 플레이트에서, NME7AB를 함유하는 배지에서 암 세포가 배양된 웰에 소분자를 별도로 첨가한다. 소분자가 부유체가 되는 세포의 양을 감소시키고/시키거나 전이 마커, 예컨대, CXCR4, CHD1 또는 만능 줄기 세포 마커의 발현을 감소시킨다면, 그 작은 분자는 항암 약물 후보이다. 항암제인 소분자를 식별하는 또 다른 방법은 NME7, NME7AB 또는 NME7-X1에 결합하거나 NME7 종의 발현을 억제하는 소분자를 선택하는 것이다. 또 다른 고속대량처리 스크린은 NME7AB가 MUC1* 세포외 도메인의 PSMGFR 펩타이드에 결합하는 것을 저해하는 소분자를 선택하는 것이며, 이러한 소분자는 항암제가 될 것이다.
NME7AB 및 NME7-X1의 서열은 NME7-X1이 NME7AB가 갖는 N-말단 서열의 일부가 누락되어 있다는 것만 상이하다. 실험은, NME7AB와 거의 동일한 자연 발생 NME7 종이 존재한다는 것을 나타내며, 이를 본 발명자들은 NME7AB-유사 종이라고 부른다. NME7-X1에 결합하는 항체는 항체가 구별할 수 있는 구조적 차이가 없는 한 NME7AB를 모방하는 자연 발생 종에도 결합할 수 있다. 따라서 NME7-X1을 억제하지만 NME7AB-유사 종은 저해하지 않으려는 경우 또는 그 반대의 경우, siRNA, 안티센스 핵산 또는 유전자 편집 기술을 사용하여 하나의 발현을 저해하지만 다른 하나는 저해하지 않을 수 있다.
하나의 경우에, 항암 치료제는 NME7, NME7-X1 또는 NME7AB-유사 종의 특이적 발현을 직접적으로 또는 간접적으로 억제하는 핵산이다. 이러한 핵산은 NME7 종을 직접 억제하는 siRNA, RNAi, 안티센스 핵산 등일 수 있다. 본 발명의 또 다른 양상에서, 핵산은 예를 들어, 이를 조절하는 분자의 발현을 변경함으로써 NME7 종을 간접적으로 억제할 수 있다. 예를 들어, 슈퍼 인핸서 BRD4는 NME7의 발현을 억제한다. 따라서, 암의 치료 또는 예방에 효과적인 치료제는 BRD4의 발현을 증가시키는 작용제이다. 효과적인 치료제는 BRD4의 보조 인자인 JMJD6의 발현을 증가시키는 작용제일 수 있다.
NME7AB 또는 NME7-X1, 또는 전체 단백질로부터 유래된 펩타이드는 동물에서 항-NME7 또는 항-NME7-X1 항체를 생성시키는 데 사용되며, 이는 본 발명자들이 암 성장을 저해하고, 암 세포가 전이성 암 세포로 전이하는 것을 저해하는 것으로 입증한 것이었다. 유사하게, NME7 유래 펩타이드는 암을 치료 또는 예방하거나 암 세포가 전이성 암 세포로 전이하는 것을 저해하는 항체를 생성하도록 인간에게 투여될 수 있다. NME7 펩타이드 또는 단백질은 수여자에서 항-NME7, 항-NME7AB 또는 항-NME7-X1 항체의 생산을 자극하기 위해 하나의 유형의 백신으로 사람에게 투여된다. 도 12 및 도 13에 도시된 결과는 NME7, 특히 NME7-X1 또는 NME7AB 서열에서 유래된 펩타이드 컬렉션으로 사람을 면역시키는 것이 단일 펩타이드로의 면역화 것보다 더 효과적인 백신일 수 있음을 나타낸다. 상기 펩타이드 또는 단백질은 면역 반응의 자극을 돕기 위해 당업자에게 공지된 담체 단백질 또는 기타 보조제에 추가로 접합될 수 있다.
DM10 도메인 외부에 있는 NME7 펩타이드는 암의 치료 또는 예방을 위한 항체를 생성하는 데 바람직하다. 암 또는 전이를 예방하기 위해 환자에게 투여할 수 있는 펩타이드는 도 6 내지 도 9에 열거된 펩타이드의 서열을 함유한다. A1, A2, B1, B2 및 B3은 NME7AB 및 NME7-X1에 결합하는 항체를 생성하는 펩타이드의 예이고, 암의 치료 또는 예방을 위해 환자에게 투여된다. 본 발명은 NME7 또는 NME7-X1에서 자연 발생하는 것과 같은 정확한 서열의 펩타이드에 제한되지 않는다. 당업자에게 공지된 바와 같이, 펩타이드 서열의 여러 아미노산의 치환은 여전히 천연 단백질 서열을 특이적으로 인식하는 항체를 생성시킬 수 있다. 본 발명이 암 성장을 저해하거나 일반 암 세포에서 전이성 암 세포로의 전이를 저해하기 위해 본 명세서에서 입증된 펩타이드로 제한되는 것으로 의도되지 않는다. 펩타이드 A1, A2, B1, B2 및 B3을 식별하기 위해서 본 명세서에서 사용된 방법은 또한 본 명세서에서 입증된 펩타이드와 동등하거나 이보다 더 효과적일 수 있는 다른 펩타이드 서열을 식별하는 데 사용할 수 있다.
인간 NME7AB 또는 NME7-X1의 부분을 포함하거나 NME7AB 또는 NME7-X1에 결합하는 항체 단편을 포함하는 키메라 항원 수용체 분자는 항암 치료제이고, 암 또는 암 전이의 치료 또는 예방을 위해서 환자에게 투여된다.
일례에서, 항-NME7 항체의 인식 단위 또는 가변 영역은 CAR(키메라 항원 수용체) 기술 또는 CAR T 기술로서 공지된 기술을 사용하여 T 세포의 분자에 융합된다. 암을 치료하거나 예방하기 위해 치료용으로 사용될 수 있는 항체 또는 이의 단편의 가장 중요한 특징은, NME7을 인식하고, 암을 촉진하는 표적과 NME7과의 상호작용을 방지하는 항체-유사 가변 영역의 식별이다. 일례로, 표적은 MUC1*의 PSMGFR 영역이다.
항체, 항체 단편 또는 단쇄 항체는 CAR이라도 알려져 있는 키메라 항원 수용체를 비롯한 키메라 분자 내로 조작될 수 있으며, 그런 다음 이러한 분자는 T 세포와 같은 면역계 세포 내로 형질주입되거나 형질도입된 다음, 환자에게 투여된다. 인간화된 항체 또는 항체 단편, 전형적으로 scFv는 CAR의 세포외 도메인의 대부분을 포함한다. 항체 단편은, 막관통 도메인으로서 CD8과 같은 면역계 신호전달 분자 및 세포질 신호전달 모티프, 예컨대, 활성화 도메인으로도 지칭되는 T 세포 수용체 신호전달 분자, 또는 비제한적으로 CD3-제타, CD28, 41bb, OX40을 포함하는 공자극성 도메인에 생화학적으로 융합된다. CAR은 T 세포 또는 다른 세포, 바람직하게는 면역계 세포 내로 형질주입되고, 환자에게 투여될 수 있다. 본 명세서에서, 본 발명자들은, 세포외 부분이 항-NME7, 항NME7AB 또는 항-NME7-X1 항체, 항체 단편 또는 단쇄, scFv 항체 단편을 함유하는 CAR을 기재한다. 바람직한 실시형태에서, 항체 또는 항체 단편은 인간 항체 또는 인간화된 항체이다.
효과적인 항-NME7 항체 또는 항-NME7-X1 항체 또는 단편은 천연 NME7, NME7AB 또는 NME7-X1에 결합하는 능력을 가질 것이다. 실제로, CAR의 세포외 도메인이 조작되는 모 항체는 NME7, NME7AB 또는 NME7-X1 유래 펩타이드를 동물에게 면역화함으로써 생성된다. 본 발명의 일 양상에서, 면역화 펩타이드는 NME7 아미노산 1 내지 376으로 구성된다. 본 발명의 일 양상에서, 면역화 펩타이드는 NME7 아미노산 92 내지 376으로 구성된다. 본 발명의 또 다른 양상에서, 면역화 펩타이드는 NME7 아미노산 125 내지 376으로 구성된다. 본 발명의 또 다른 양상에서, 면역화 펩타이드는 도 6 내지 도 8에 열거된 서열로 제조된다. 본 발명의 다른 양상에서, 면역화 펩타이드는 도 9에 열거된 서열로 제조된다. 대안적으로, 모 항체 또는 항체 단편은 항체 라이브러리 또는 항체 풀로부터 선택되며, 이러한 항체는 자연 항체, 합성 항체 또는 이들의 단편일 수 있으며, 여기서, 이들 항체는 NME7, NME7AB 또는 NME7-X1, 도 6 내지 도 8에 열거된 펩타이드 또는 도 9에 열거된 펩타이드에 대한 결합 능력에 대해 선택된다.
CAR의 표적화 부분은 항체 또는 항체 단편일 필요가 없다. 본 명세서에서, 본 발명자들은, 세포외 도메인이 NME7 단편을 함유하는 CAR을 기재한다. NME7-유래의 펩타이드(들)는 상이한 종류의 CAR 내에서 조작되며, 여기서, 세포외 도메인의 표적화 부분은 항체 또는 항체 단편이기보다는 단백질 단편 또는 펩타이드이다. 펩타이드 CAR은 면역계 세포, 전형적으로 T 세포 내로 형질감염 또는 형질도입된다. NME7 단편 또는 NME7-유래의 펩타이드는 이들의 동족 결합 파트너에의 결합 능력에 대해 선택되지만, 온전한 NME7, NME7AB 또는 NME7-X1로서 작용할 수 없으며, 종양원성 활성을 부여하지 않아야 한다. NME7 단편 또는 NME7-유래의 펩타이드는, 막관통 도메인 CD8과 같은 면역계 신호전달 분자 및 세포질 신호전달 모티프, 예컨대, 활성화 도메인으로도 지칭되는 T 세포 수용체 신호전달 분자, 또는 비제한적으로 CD3-제타, CD28, 41bb, OX40을 포함하는 공자극성 도메인에 생화학적으로 융합된다.
본 발명의 일 양상에서, NME7 단편은 NME7 NDPK B 도메인의 대부분이거나 모두이다. 본 발명의 다른 양상에서, NME7 단편은 도 6 내지 도 9에 열거된 펩타이드 서열 중 하나 이상 함유하는 NME7 펩타이드이다. 실험은, NME7, NME7의 단편, NME7AB 또는 NME7-X1을 조작된 면역 세포 치료제를 위한 키메라 항원 수용체(CAR)의 표적화 부분으로서 사용하는 전략에 있어서, 상당히 큰 NME7AB의 단편 또는 NME7-X1이 더 짧은 펩타이드, 예를 들어, 길이가 15개 아미노산 미만인 펩타이드보다 더 효과적일 것임을 가리킨다. 대안적으로, 각각이 상이한 NME7AB 유래의 펩타이드를 가진 CAR의 컬렉션은 수집해서 면역계 세포 내로 형질감염되거나 형질도입되고, 암의 치료 또는 예방을 위해 환자에게 투여될 수 있다. 도 12 및 도 13에 도시된 실험은 이러한 접근법의 타당성을 뒷받침한다.
NME7 단편을 이의 세포외 도메인에 함유하는 CAR은 면역계 세포, 전형적으로 T 세포 내로 형질주입되거나 형질도입되고, 암의 치료 또는 예방을 위해 환자에게 투여될 수 있다. 일 양상에서, 암은 MUC1*-양성 암이다. 또 다른 양상에서, 암은 전이성 암이다.
NME7을 절단하는 효소를 저해하는 작용제는 암을 치료하거나 예방하는 데 사용될 수 있다. 일부 형태의 NME7은 세포 내에서 격리되며, 따라서, 세포로부터 분비되지 않으며, 이때, 이들은 암을 촉진하는 성장 인자로서 작용할 수 있다. 전장 NME7은 42kDa이다. 그러나, 본 발명자들은, DM10 도메인을 포함하지 않으며 본 발명자들이 생성한 재조합 NME7AB와 본질적으로 일치하는 것으로 보이는 약 33kDa NME7 종이 암 세포 및 줄기세포로부터 분비된다는 것을 발견하였다. 이러한 약 33kDa NME7 종 및 다른 약 25kDa NME7 종은, NME7의 절단을 저해한 작용제에 의해 제거될 절단 생성물일 수 있다.
환자 샘플에서 NME7, 또는 본 발명자들이 NME7AB-유사 종이라고 지칭하는 약 33kDa NME7 종, 또는 NME7-X1의 상승된 수준의 검출은 암의 존재, 또는 보다 공격적인 상태 또는 전이성 상태로의 암의 진행을 나타내는 진단 지표이다. 본 발명자들은, 조기 단계의 미경험 줄기세포 및 암 세포, 특히 MUC1*-양성 암 세포 둘 다가, DM10 도메인을 포함하지 않는 약 33kDa NME7 및 NME7-X1을 높은 수준으로 발현한다는 것을 발견하였다.
NME7-X1은 최근에 NME7의 이론적인 대체 아이소폼으로서 단백질 데이터베이스에 열거되었으나, 이는 조직 또는 세포에서 전혀 검출되지 않았다. 본 발명자들은, PCR에 의해 NME7-X1을 NME7으로부터 구별하는 프라이머를 설계하였다. 인간 NME7, NME7a, NME7b 및 NME7-X1의 발현 수준을, 섬유아세포, 인간 배아 줄기세포, 인간 iPS 세포, T47D 인간 유방암 세포, DU145 인간 전립선암 세포, PC3 인간 전립선암 세포, HEK295 인간 태아 간 세포 및 다른 인간 줄기세포주를 포함하는 세포 패널에서 PCR에 의해 측정하였다. NME7은 줄기세포에서보다 암 세포에서 더 높은 수준으로 발현된다. 특히, NME7-X1은 섬유아세포 또는 줄기세포에서보다 전립선암 세포에서 10배 더 높게 발현되고, 유방암 세포에서 3배 더 높게 발현된다. NME7-X1은 섬유아세포 또는 줄기세포에서보다 HEK293 태아 간 세포에서 약 5배 더 높게 발현되며, 따라서, NME7-X1이 간암에서 상승된다는 것을 예측한다. NME7b는 줄기세포에서보다 전립선암 세포에서 17배 내지 25배 더 높게 발현된다.
환자 샘플에서 NME7 종의 상승된 수준의 검출은, 환자가 암을 갖거나 암 발병 위험이 있을지에 대한 지표일 것이다. NME7 종의 수준은 PCR, 혼성화 계획, 사이클링 표지 기술, FISH, 면역세포화학, IHC, 웨스턴 블롯, 면역침전, 샌드위치 검정, ELISA 검정 등에 의해 측정되거나 평가될 수 있다. 환자 샘플은 체액 샘플, 혈액 샘플, 젖, 소변, 세포, 액체 생검, 생검 등일 수 있다. 암을 진단받은 환자에서, NME7 종의 상승된 수준은 전이 잠재력 증가의 지표이다. NME7-X1의 상승된 수준은 전립선암의 지표이다. 본 발명의 항체는 NME7 종을 검출하고 구별하는 데 사용되며, 진단 도구로서 사용된다.
성체 세포 및 조직은 NME7을 유의미한 수준으로 발현하지 않거나 NME7을 분비하지 않기 때문에, 암을 진단하거나, 보다 공격적이거나 전이성 형태를 진단하거나, 보다 공격적인 형태로의 이동을 진단하기 위한 효과적인 방식은, 환자, 세포 또는 조직 컬렉션, 또는 배양된 세포로부터의 샘플에서 NME7의 수준을, 건강한 샘플 내의 NME7의 수준과 비교하거나, 건강한 성체 세포 또는 조직에 존재하는 것으로 공지된 NME7의 수준과 비교하여 측정하는 것이다. NME7의 증가된 수준은 암의 존재, 전이성 암의 존재 또는 전이의 개시를 나타낸다. NME7의 증가된 수준은 또한 MUC1*-양성 암의 지표이다. NME7의 존재에 대해 분석된 샘플은 배양된 세포주 또는 환자 유래의 세포일 수 있는 세포 컬렉션, 체액, 혈액 샘플, 조직 표본 또는 생검 표본일 수 있다. 따라서, 암의 존재 또는 암의 진행을 검출할 진단 검정은 하기 단계를 포함한다: 1) 암 환자 또는 암이 발병할 위험이 있는 환자로부터 샘플을 얻는 단계; 2) 해당 샘플을, NME7의 수준, 또는 NME7을 암호화하는 핵산의 수준을 검출하거나 측정할 수 있는 검정으로 처리하는 단계; 3) 시험 샘플에서 측정된 NME7 단백질 또는 NME7-암호화 핵산의 수준을 대조군 환자 또는 대조군 세포에서의 수준과 비교하는 단계; 4) NME7 또는 NME7을 암호화하는 핵산의 수준이 대조군과 비교하여 상승되는지 확인하는 단계; 및 5) 시험이 비교되는 대조군이 이전에 암을 진단받은 공여자로부터 유래된 것이라면, 시험 샘플의 공여자가 암을 가지고 있거나, 암이 진행되었다고 결론 내리는 단계.
이러한 검정에서, 시험 샘플이 비교되는 대조군 샘플은 비-암성 세포, 배양된 세포, 건강한 공여자 유래의 샘플, 공여자 유래의 비-암성 샘플, 또는 시험 샘플의 공여자 유래의 샘플일 수 있으며, 여기서, 대조군 샘플은 이전 시점에서 공여자로부터 취하였다. 이러한 샘플의 공급원은 암의 존재 또는 진행에 대해 시험되고 있는 환자로부터 취한 체액, 뇌척수액, 골수 샘플, 혈액, 조직, 세포, 생검 조직 또는 세포, 환자의 세포로부터 유래된 배양된 세포 등을 비롯한 임의의 표본일 수 있다. 시험 샘플이 비교되는 샘플의 공급원은 체액, 뇌척수액, 골수 샘플, 혈액, 조직, 세포, 생검 조직 또는 세포, 또는 건강한 공여자 또는 시험 환자로부터 유래될 수 있는 배양된 세포일 수 있으며, 여기서, 샘플은 이전의 시점에서 취하였다. 시험 샘플이 비교되는 측정된 수준은 이전에 기록된 데이터로부터 유래될 수 있으며, 시험 샘플과의 비교를 위해 목록으로 컴파일링될 수 있다.
치료진단법(theranostics)
이어서, NME7 단백질 또는 NME7을 암호화하는 핵산의 수준이 상승된 것으로 진단받은 환자를, NME7의 발현을 억제하거나, NME7의 절단을 저해하거나, 이러한 상호작용이 암을 촉진하는 표적에 대한 NME7의 결합을 저해하는 치료제로 치료한다. NME7, 또는 NME7의 절단 생성물의 중요한 표적은 MUC1*이다. NME7은 MUC1*의 세포외 도메인에 결합하여, 이를 이량체화한다. 따라서, NME7 수준이 상승된 것으로 진단받은 환자는, NME7을 저해하는 치료제 및/또는 MUC1의 절단된 형태의 이량체화를 저해하는 치료제를 사용한 치료로부터 이득을 얻을 것이며, MUC1의 세포외 도메인은 PSMGFR 서열을 일부 또는 모두 포함한다. 따라서, 암 치료의 적합성, 및 암의 치료 또는 예방을 위한 치료제의 유효량의 투여를 평가하는 것은 하기 단계로 이루어질 것이다: 1) 암이 의심되는 환자, 암이 발병할 위험이 있는 환자, 또는 전이성 암이 발 병할 위험이 있는 환자로부터 샘플을 얻는 단계; 2) NME7, 이의 절단 생성물 또는 NME7을 암호화하는 핵산의 양을 측정하는 단계로서, 측정된 수준이 대조군 샘플에서 측정된 것보다 상당히 더 높은, 상기 단계; 3) 환자가 암을 갖고 있거나 환자에서 보다 공격적인 암 또는 전이성 암이 발병되었음을 확인하는 단계; 4) NME7의 발현을 억제하거나, NME7의 절단을 저해하거나, 표적에 대한 NME7의 결합을 저해하는 치료제를 유효량으로 환자에게 투여하고/투여하거나 MUC1의 발현을 억제하거나, MUC1*로의 MUC1의 절단을 저해하거나, 표적에 대한 MUC1*의 결합을 저해하는 치료제를 유효량으로 환자에게 투여하는 단계. 바람직한 실시형태에서, 표적에 대한 NME7의 결합을 저해하는 치료제는 NME7과 MUC1*와의 상호작용을 저해한다. 더 바람직한 실시형태에서, 이러한 치료제는 이것과 본질적으로 PSMGFR 서열을 포함하는 MUC1*의 세포외 도메인과의 상호작용을 저해한다. 바람직한 실시형태에서, 표적에 대한 MUC1*의 결합을 저해하는 치료제는 MUC1*와 NME7 사이의 상호작용을 저해한다. 더 바람직한 실시형태에서, MUC1*와 NME7 사이의 상호작용을 저해하는 치료제는, 본질적으로 NME7AB의 서열을 포함하는 NME7의 부분에 MUC1*이 결합하는 것을 저해한다.
화학적으로 변형된 펩타이드
폴리펩타이드 또는 항체 치료제는 순환 반감기가 짧고, 단백질용해성 분해되고, 용해도가 낮을 수 있다. 본 발명의 생물약제의 약물동력학 및 약력학을 개선하기 위해서, 면역원성을 감소 또는 증가시키고, 단백질용해성 절단을 감소시키기 위한 아미노산의 조작과 같은 방법이 수행될 수 있으며; 면역글로불린 및 알부민과 같은 혈청 단백질에 대한 펩타이드의 융합 또는 접합이 수행될 수 있으며; 보호 및 서방성을 위해 생물약제, 예컨대, 본 발명의 펩타이드 및 항체용 약물 전달 비히클 내로의 혼입이 또한 수행될 수 있고; 자연 중합체 또는 합성 중합체에 대한 접합이 또한 고려된다. 특히, 합성 중합체 접합을 위해, 페길화(pegylation) 또는 아실화, 예컨대, N-아실화, S-아실화 등이 또한 고려된다.
핵산 작제물
본 발명은 또한 본 명세서에 기술된 바와 같은 핵산 분자를 포함하는 발현 벡터를 제공하며, 여기서, 핵산 분자는 발현 조절 서열에 작동적으로 연결된다. 본 발명은 또한 폴리펩타이드의 제조를 위한 숙주-벡터 시스템을 제공하며, 이러한 시스템은 폴리펩타이드의 발현에 적합한 숙주 세포 내로 도입된 본 발명의 발현 벡터를 포함한다. 적합한 숙주 세포는 박테리아 세포, 예컨대, 이. 콜라이(E. coli), 효모 세포, 예컨대, 피치아 파스토리스(Pichia pastoris), 곤충 세포, 예컨대, 스포돕테라 프루기페르다(Spodoptera frugiperda) 또는 포유동물 세포, 예컨대, COS, HEK 또는 CHO 세포일 수 있다.
본 발명은 또한 폴리펩타이드의 제조를 허용하고 결과적으로 제조된 폴리펩타이드를 회수하는 조건 하에서, 본 명세서에 기재된 숙주-벡터 시스템의 세포를 성장시킴으로써 본 발명의 폴리펩타이드를 제조하는 방법을 제공한다. 본 발명을 실시하는 데 유용한 폴리펩타이드는 원핵 또는 진핵 발현 시스템에서 발현에 의해 제조될 수 있다.
재조합 유전자가 발현되고, 폴리펩타이드는 임의의 수의 방법을 이용하여 정제될 수 있다. 유전자는 예를 들어, 비제한적으로 pZErO와 같은 박테리아 발현 벡터 내로 서브클로닝될 수 있다.
폴리펩타이드는 임의의 기술에 의해 정제되어, 안정한 생물학적 활성 단백질이 후속적으로 형성될 수 있다. 예를 들어, 비제한적으로, 인자들은 세포로부터 가용성 단백질 또는 봉입체(inclusion body)로서 회수될 수 있으며, 이로부터 인자는 8M 구아니디늄 염산염 및 투석에 의해 정량적으로 추출될 수 있다. 인자를 더 정제하기 위해서, 비제한적으로 종래의 이온 교환 크로마토그래피, 친화성 크로마토그래피, 상이한 당 크로마토그래피, 소수성 상호작용 크로마토그래피, 역상 크로마토그래피 또는 겔 여과를 비롯한 임의의 수의 정제 방법이 사용될 수 있다.
본 명세서에서 사용되었을 때, 폴리펩타이드는 기능적으로 동등한 분자를 포함하며, 이 분자에서 서열 내의 잔기에 대해 아미노산 잔기가 치환되어, 침묵 변화 또는 보존 변화가 초래된다. 예를 들어, 서열 내의 하나 이상 아미노산 잔기는 유사한 극성을 가진 또 다른 아미노산에 의해 치환될 수 있으며, 이는 기능적 동등물로서 작용하여, 침묵 변경 또는 보존 변경이 초래된다. 서열 내의 아미노산에 대한 치환기는, 아미노산이 속한 부류의 다른 구성원으로부터 선택될 수 있다. 예를 들어, 비극성(소수성) 아미노산은 알라닌, 류신, 아이소류신, 발린, 프롤린, 페닐알라닌, 트립토판 및 메티오닌을 포함한다. 극성 중성 아미노산은, 글리신, 세린, 트레오닌, 시스테인, 티로신, 아스파라긴 및 글루타민을 포함한다. 양전하성(염기성) 아미노산은 아르기닌, 라이신 및 히스티딘을 포함한다. 음전하성(산성) 아미노산은 아스파트산 및 글루탐산을 포함한다. 잠재적인 글리코실화 아미노산은, 세린, 트레오닌 및 아스파라긴을 포함한다. 동일하거나 유사한 생물학적 활성을 나타내는 단백질, 단편 또는 이들의 유도체, 및 번역 동안 또는 번역 후에 예를 들어, 글리코실화, 단백질분해 절단, 항체 분자 또는 다른 세포성 리간드에 대한 연결 등에 의해 상이하게 변형되는 유도체가 또한 본 발명의 범주 내에 포함된다.
당업자에게 공지된, DNA 단편을 벡터 내로 삽입시키는 임의의 방법이 사용되어, 본 발명의 폴리펩타이드를 암호화하는 발현 벡터를 적절한 전사/번역 조절 신호 및 단백질 암호 서열을 사용하여 작제할 수 있다. 이들 방법은 시험관내 재조합 DNA 및 합성 기술 및 생체내 재조합(유전 재조합)을 포함할 수 있다. 본 발명의 폴리펩타이드를 암호화하는 핵산 서열의 발현은, 폴리펩타이드가 재조합 DNA 분자로 변형된 숙주에서 발현되도록, 제2 핵산 서열에 의해 조절될 수 있다. 예를 들어, 본 명세서에 기재된 폴리펩타이드의 발현은 당업계에 공지된 프로모터/인핸서 요소에 의해 제어될 수 있다. 폴리펩타이드의 발현을 제어하는 데 사용될 수 있는 프로모터는, 문헌[Squinto et al., (1991, Cell 65:1-20)에 기재된 바와 같은 긴 말단 반복부; SV40 조기(early) 프로모터 영역(문헌[Bernoist and Chambon, 1981, Nature 290:304-310], CMV 프로모터, M-MuLV 5' 말단 반복부, 라우스 육종 바이러스의 3' 긴 말단 반복부에 함유된 프로모터(문헌[Yamamoto, et al., 1980, Cell 22:787-797]), 헤르페스 티미딘 키나제 프로모터(문헌[Wagner et al., 1981, Proc. Natl. Acad. Sci. U.S.A. 78:144-1445]), 메탈로티오네인 유전자의 조절 서열(문헌[Brinster et al., 1982, Nature 296:39-42]); 원핵 발현 벡터, 예컨대, β-락타마제 프로모터(문헌[Villa-Kamaroff, et al., 1978, Proc. Natl. Acad. Sci. U.S.A. 75:3727-3731]), 또는 tac 프로모터(문헌[DeBoer, et al., 1983, Proc. Natl. Acad. Sci. U.S.A. 80:21-25]), (또한 문헌["Useful proteins from recombinant bacteria" in Scientific American, 1980, 242:74-94] 참고); 효모 또는 다른 진균 유래의 프로모터 요소, 예컨대, Gal 4 프로모터, ADH(알코올 데하이드로게나제) 프로모터, PGK(포스포글리세롤 키나제) 프로모터, 알칼리 포스파타제 프로모터, 및 조직 특이성을 나타내고 트랜스제닉 동물에 이용되어온 하기 동물 전사 조절 영역: 췌장 선포 세포(acinar cell)에서 활성인 엘라스타제 I 유전자 조절 영역(문헌[Swift et al., 1984, Cell 38:639-646; Ornitz et al., 1986, Cold Spring Harbor Symp. Quant. Biol. 50:399-409; MacDonald, 1987, Hepatology 7:425-515]); 췌장 베타 세포에서 활성인 인슐린 유전자 조절 영역(문헌[Hanahan, 1985, Nature 315:115-122]), 림프모양 세포(lymphoid cell)에서 활성인 면역글로불린 유전자 조절 영역(문헌[Grosschedl et al., 1984, Cell 38:647-658; Adames et al., 1985, Nature 318:533-538; Alexander et al., 1987, Mol. Cell. Biol. 7:1436-1444]), 고환 세포, 유방 세포, 림프모양 세포 및 비만 세포에서 활성인 마우스 유방 종양 바이러스 조절 영역(문헌[Leder et al., 1986, Cell 45:485-495]), 센다이 바이러스, 렌티바이러스, 간에서 활성인 알부민 유전자 조절 영역(문헌[Pinkert et al., 1987, Genes and Devel. 1:268-276]), 간에서 활성인 알파-페토단백질 유전자 조절 영역(문헌[Krumlauf et al., 1985, Mol. Cell. Biol. 5:1639-1648; Hammer et al., 1987, Science 235:53-58]); 간에서 활성인 알파 1-안티트립신 유전자 조절 영역(문헌[Kelsey et al., 1987, Genes and Devel. 1:161-171]), 골수 세포에서 활성인 베타-글로빈 유전자 조절 영역(문헌[Mogram et al., 1985, Nature 315:338-340; Kollias et al., 1986, Cell 46:89-94]); 뇌 내의 희돌기세포에서 활성인 미엘린 베이직 단백질 유전자 조절 영역(문헌[Readhead et al., 1987, Cell 48:703-712]); 골격근에서 활성인 미오신 경쇄-2 유전자 조절 영역(문헌[Shani, 1985, Nature 314:283-286]), 및 시상하부에서 활성인 성선자극 방출 호르몬 유전자 조절 영역(문헌[Mason et al., 1986, Science 234:1372-1378]) 등을 포함하지만 이들로 제한되지 않는다.
따라서, 본 발명에 따르면, 본 명세서에 기재된 바와 같은 폴리펩타이드를 암호화하는 핵산을 포함하며 박테리아 또는 진핵 숙주에서 복제될 수 있는 발현 벡터가 사용되어, 숙주를 형질주입시키고, 이로써, 이러한 핵산이 발현되어 폴리펩타이드가 제조될 수 있게 하며, 이어서, 이러한 폴리펩타이드는 생물학적 활성 형태로 회수될 수 있다. 본 명세서에서 사용되는 바와 같이, 생물학적 활성 형태는 관련 수용체에 결합할 수 있고 분화된 기능을 야기할 수 있고/있거나 수용체를 발현하는 세포의 표현형에 영향을 미칠 수 있는 형태를 포함한다.
핵산 삽입물을 함유하는 발현 벡터는 비제한적으로, 적어도 3개의 일반적인 접근법에 의해 확인될 수 있다: (a) DNA-DNA 혼성화, (b) "마커" 유전자 기능의 존재 또는 부재, 및 (c) 삽입된 서열의 발현. 제1 접근법에서, 발현 벡터 내에 삽입된 외래 핵산의 존재는, 삽입된 핵산 서열에 상동성인 서열을 포함하는 프로브를 사용하여 DNA-DNA 혼성화에 의해 검출될 수 있다. 제2 접근법에서, 재조합 벡터/숙주 시스템은 벡터 내로의 외래 핵산 서열의 삽입에 의해 유발되는 특정 "마커" 유전자 기능(예를 들어, 티미딘 키나제 활성, 항생제에 대한 내성, 형질전환 표현형, 배큘로바이러스(baculovirus)에서의 폐색체(occlusion body) 형성 등)의 존재 또는 부재에 기초하여 식별 및 선택될 수 있다. 예를 들어, efl 핵산 서열이 벡터의 마커 유전자 서열 내에 삽입되면, 삽입체를 함유하는 재조합이 마커 유전자 기능의 부재에 의해 식별될 수 있다. 제3 접근법에서, 재조합 발현 벡터는 재조합 작제물에 의해 발현되는 외래 핵산 생성물을 분석함으로써 식별될 수 있다. 이러한 검정은 예를 들어, 관심대상 핵산 생성물의 물성 또는 기능적 특성을 기초로 할 수 있으며, 예를 들어, 검출 가능한 항체 또는 이의 일부로 태깅될 수 있는 수용체 또는 이의 일부에 대한 리간드의 결합, 또는 관심대상 단백질 또는 이의 일부에 대해 제조된 항체에 대한 결합에 의한 것일 수 있다.
본 발명의 폴리펩타이드, 특히 변형된 폴리펩타이드는 숙주 세포에서 일시적으로, 구성적으로 또는 영구적으로 발현될 수 있다.
본 출원에서 언급되는 질환 또는 장애의 치료에 유용한 유효 용량은 당업자에게 알려진 방법을 사용하여 결정될 수 있다(예를 들어, 문헌[Fingl, et al., The Pharmacological Basis of Therapeutics, Goodman and Gilman, eds. Macmillan Publishing Co, New York, pp. 1-46 (1975)] 참고). 본 발명에 따라 사용하기 위한 약제학적 조성물은, 생체내 투여되기 전에, 담체 또는 표적화 분자(예를 들어, 항체, 호르몬, 성장 인자 등)에 연결되고/연결되거나 리포좀, 미세캡슐 및 제어 방출형 제제 내에 혼입된 전술한 폴리펩타이드를 약물학적으로 허용 가능한 액체, 고체 또는 반고체 담체 형태로 포함한다. 예를 들어, 약제학적 조성물은 수용액, 예컨대, 멸균 물, 식염수, 포스페이트 완충제 또는 덱스트로스 용액 내에 폴리펩타이드를 포함할 수 있다. 대안적으로, 활성제는 이러한 치료가 필요한 환자에 게 이식될 수 있는 고체(예를 들어, 왁스) 또는 반고체(예를 들어, 젤라틴성) 제형에 포함될 수 있다. 투여 경로는 정맥내, 척추강내, 피하, 자궁내, 관련 조직 내로의 주사, 동맥내, 비내, 경구 또는 이식 장치를 통한 것을 포함하지만 이들로 제한되지 않는 당업계에 공지된 임의의 투여 방식일 수 있다.
투여에 의해, 본 발명의 활성제가 신체 전반적으로 또는 국소화된 영역에 분포될 수 있다. 예를 들어, 신경계의 먼 영역을 수반하는 일부 조건에서, 작용제의 정맥내 또는 척추강내 투여가 바람직할 수 있다. 일부 상황에서, 활성제를 함유하는 이식물이 병변 영역 또는 그 부근에 위치될 수 있다. 적합한 이식물은, 젤폼, 왁스, 스프레이 또는 미세입자-기재 이식물 등을 포함하지만 이들로 제한되지 않는다.
본 발명은 또한 본 명세서에 기재된 폴리펩타이드를 약물학적으로 허용 가능한 비히클에 포함하는 약제학적 조성물을 제공한다. 본 조성물은 전신적으로 또는 국소적으로 투여될 수 있다. 정맥내, 척추강내, 동맥내, 비내, 경구, 피하, 복강내 투여, 또는 국소 주사 또는 수술적 이식 등을 포함하지만 이들로 제한되지 않는 당업계에 공지된 임의의 적절한 투여 방식이 사용될 수 있다. 서방형 제형이 또한 제공된다.
유전자 요법
유전자 요법은 발현된 핵산 또는 발현 가능한 핵산을 대상체에게 투여함으로써 수행되는 요법을 지칭한다. 본 발명의 이러한 실시형태에서, 핵산은 치료 효과를 매개하는, 핵산의 암호화된 단백질을 생성한다.
당업자에게 이용가능한 임의의 유전자 치료 방법이 본 발명에 따라 사용될 수 있다. 예시적인 방법이 하기에 기재된다.
유전자 치료 방법에 대한 일반적인 검토에 대해서는 문헌[Goldspiel et al., Clinical Pharmacy 12:488-505 (1993); Wu and Wu, Biotherapy 3:87-95 (1991); Tolstoshev, Ann. Rev. Pharmacol. Toxicol. 32:573-596 (1993); Mulligan, Science 260:926-932 (1993); 및 Morgan and Anderson, Ann. Rev. Biochem. 62:191-217 (1993); May, TIBTECH 11(5):155-215 (1993)]을 참고하기 바란다. 사용될 수 있는 재조합 DNA 기술 분야에 일반적으로 공지된 방법은 문헌[Ausubel et al. (eds.), Current Protocols in Molecular Biology, John Wiley & Sons, NY (1993); 및 Kriegler, Gene Transfer and Expression, A Laboratory Manual, Stockton Press, NY (1990)]에 기재되어 있다.
환자에게 핵산을 전달하는 것은 직접적일 수 있으며, 이 경우 환자는 핵산 또는 핵산-운반 벡터에 직접 노출되며, 또는 전달은 간접적일 수 있고, 이 경우 세포는 우선 시험관내에서 핵산으로 형질전환되고, 이어서 환자에게 이식된다. 이들 2개의 접근법은 각각 생체내 또는 생체외 유전자 요법으로서 알려져 있다.
구체적인 실시형태에서, 핵산 서열은 생체내에서 직접 투여되며, 여기서 핵산 서열이 발현되어, 암호화된 생성물을 생성시킨다. 이는 당업계에 공지된 수많은 방법 중 임의의 방법을 사용하여 달성될 수 있으며, 예를 들어, 이들을 적절한 핵산 발현 벡터의 일부로서 작제하고, 이러한 벡터 일부를 투여하여, 이들이 예를 들어, 결함이 있거나 약화된 레트로바이러스 또는 다른 바이러스 벡터를 사용한 감염에 의해, 또는 네이키드 DNA의 직접 주사에 의해, 또는 지질 또는 세포-표면 수용체 또는 형질주입제로의 코팅, 리포좀, 미세입자 또는 미세캡슐 내에서의 캡슐화에 의해 세포내 성분으로 되거나, 핵에 들어가는 것으로 알려진 펩타이드에 연결된 상태에서의 투여에 의해, 수용체-매개 엔도사이토시스에 적용되는 리간드에 연결된 상태로 대상체에게 투여함으로써 작제될 수 있다(예를 들어, 문헌[Wu and Wu, J. Biol. Chem. 262:4429-4432 (1987)] 참고)(이것은 수용체를 특이적으로 발현하는 세포 유형을 표적으로 하는 데 사용될 수 있음). 다른 실시형태에서, 핵산-리간드 복합체가 형성될 수 있으며, 이 복합체에서, 리간드는 엔도좀을 방해하기 위해 융합생성(fusogenic) 바이러스 펩타이드를 포함하며, 따라서, 핵산은 리포좀 분해를 피할 수 있다. 또 다른 실시형태에서, 핵산은 특정 수용체를 표적화함으로써, 세포 특이적 흡수 및 발현을 위해 생체내에서 표적화될 수 있다. 대안적으로, 핵산은 상동성 재조합에 의해 발현용 숙주 세포 DNA 내에서 세포내로 도입되고 혼입될 수 있다(문헌[Koller and Smithies, Proc. Natl. Acad. Sci. USA 86:8932-8935 (1989); Zijlstra et al., Nature 342:435-438 (1989)]).
구체적인 실시형태에서, 폴리펩타이드를 암호화하는 핵산 서열을 함유하는 바이러스 벡터가 사용된다. 유전자 요법에 사용되어야 하는 폴리펩타이드를 암호화하는 핵산 서열은 하나 이상의 벡터 내로 클로닝되며, 이러한 벡터는 환자에 대한 유전자의 전달을 촉진한다. 렌티바이러스 벡터, 예컨대, 레트로바이러스 벡터 및 다른 벡터, 예컨대, 아데노바이러스 벡터 및 아데노-연관 바이러스는 사용될 수 있는 바이러스 벡터의 예이다. 레트로바이러스 벡터는 바이러스 게놈의 올바른 패키징 및 숙주 세포 DNA 내로의 통합에 필수적인 성분을 함유한다.
아데노바이러스는 특히 경증 질환을 유발하는 호흡기 상피를 자연적으로 감염시키기 때문에, 유전자를 호흡기 상피에 전달하기 위한 매력적인 비히클이다. 아데노바이러스-기재 전달 시스템에 대한 다른 표적은 간, 중추신경계, 내피 세포 및 근육이다. 아데노바이러스는 비-분화성 세포를 감염시킬 수 있는 이점을 갖는다. 또한 아데노-연관 바이러스(AAV) 또한 유전자 요법에서 사용되도록 제안되었다.
유전자 요법에 대한 또 다른 접근법은, 전기천공, 리포펙션, 칼슘 포스페이트 매개 형질감염 또는 바이러스 감염과 같은 방법에 의해, 유전자를 조직 배양 중인 세포 내로 전달하는 단계를 수반한다. 통상적으로, 이송 방법은 선택 마커를 세포에 전달하는 것을 포함한다. 이어서, 세포를 선택되도록 두어, 전달된 유전자를 얻고, 이를 발현하고 있는 세포를 단리시킨다. 그런 다음, 이들 세포를 환자에게 전달한다.
이러한 실시형태에서, 핵산은, 생성되는 재조합 세포의 생체내 투여 전에, 세포 내로 도입된다. 이러한 도입은 당업계에 공지된 임의의 방법에 의해 수행될 수 있으며, 이러한 방법은 형질감염, 전기천공, 미세주사, 핵 산 서열을 함유하는 바이러스 또는 박테리오파지 벡터를 사용한 감염, 세포 융합, 염색체-매개 유전자 이송, 미세세포(micrcell)-매개 유전자 이송, 스페로플라스트(spheroplast) 융합 등을 포함하지만 이들로 제한되지 않는다. 외래 유전자를 세포 내에 도입하는 수많은 기술이 당업계에 공지되어 있으며, 이들 방법은 본 발명에 따라 사용될 수 있되, 단, 수여자 세포의 필수적인 발달 및 생리학적 기능은 방해를 받지 않아야 한다. 이러한 기술은 핵산을 세포에 안정하게 전달하며, 따라서, 핵산은 세포에 의해 발현될 수 있고, 바람직하게는 유전될 수 있고 이의 세포 자손에 의해 발현될 수 있다.
유전자 요법을 위해 핵산이 도입될 수 있는 세포는 임의의 목적하는 이용 가능한 세포 유형을 포함하며, 상피 세포, 내피 세포, 케라틴 생성 세포, 섬유아세포, 근육 세포, 간세포; 혈액 세포, 예컨대, T-림프구, B-림프구, 단핵구, 대식세포, 중성구, 호산구, 거핵세포, 과립세포; 다양한 줄기세포 또는 전구세포, 특히 예를 들어, 골수, 제대혈, 말초 혈액, 태아 간으로부터 얻어지는 조혈 줄기세포 또는 조혈 전구세포 등을 포함하지만 이들로 제한되지 않는다.
바람직한 실시형태에서, 유전자 요법에 사용되는 세포는 환자에서 자가(autologous)이다.
재조합 세포가 유전자 요법에 사용되는 일 실시형태에서, 폴리펩타이드를 암호화하는 핵산 서열은, 이들 서열이 세포 또는 이의 자손에 의해 발현될 수 있도록 세포 내로 도입되며, 그런 다음, 재조합 세포는 치료 효과를 위해 생체내에 투여된다. 구체적인 실시형태에서, 줄기세포 또는 전구세포가 사용된다. 시험관내에서 단리 및 유지될 수 있는 임의의 줄기세포 및/또는 전구세포는 잠재적으로는 본 발명의 이러한 실시형태에 따라 사용될 수 있다.
구체적인 실시형태에서, 유전자 요법을 목적으로 도입되는 핵산은 암호 영역에 작동적으로 연결된 유도성 프로모터를 포함하며, 따라서, 핵산의 발현은 적절한 전사 유도제의 존재 또는 부재를 조절함으로써 조절될 수 있다.
치료 조성물
치료 화합물의 제형화는 일반적으로 당업계에 공지되어 있으며, 편리하게는 문헌[Remington's Pharmaceutical Sciences, 17th ed., Mack Publishing Co., Easton, Pa., USA]를 참고할 수 있다. 예를 들어, 매일 체중 1㎏ 당 약 0.05ng 내지 약 20㎎이 투여될 수 있다. 투여량 치료법은 최적의 치료 반응을 제공하기 위해 조정될 수 있다. 예를 들어, 몇몇 분할 용량이 매일 투여될 수 있거나, 용량은 치료 상황의 긴급성에 의해 지시되는 바와 같이 비례해서 감소될 수 있다. 활성 화합물은 종래의 방식, 예컨대, 경구, 정맥내(수용성인 경우), 근육내, 피하, 비내, 안내, 피내 또는 좌제 경로 또는 이식(예를 들어, 서방형 분자를 복강내 경로에 의해 사용하거나, 시험관 내에서 감작되고 수여자에게 입양 전달되는(adoptively transferred) 단핵구 또는 수지상 세포와 같은 세포를 사용함으로써)에 의해 투여될 수 있다. 투여 경로에 따라, 펩타이드는, 효소, 산 및 상기 성분을 불활성화시킬 수 있는 다른 자연적인 조건의 작용으로부터 펩타이드를 보호하기 위해 물질 내에서 코팅될 필요가 있을 수 있다.
예를 들어, 펩타이드의 낮은 친유성은, 펩타이드 결합을 절단할 수 있는 효소에 의해 위장관에서와 산 가수분해에 의해 위(stomach)에서 펩타이드가 파괴될 수 있게 할 것이다. 비경구 투여 이외의 경로에 의해 펩타이드를 투여하기 위해, 펩타이드는 이의 불활성화를 방지하는 물질에 의해 코팅되거나 이러한 물질과 함께 투여될 것이다. 예를 들어, 펩타이드는 아주반트 내에서 투여되거나, 효소 저해제와 함께 공동-투여되거나 리포좀 내에서 투여될 수 있다. 본 명세서에서 고려되는 아주반트는 레소르시놀, 비-이온성 계면활성제, 예컨대, 폴리옥시에틸렌 올레일 에터 및 n-헥사데실 폴리에틸렌 에터를 포함한다. 효소 저해제는 췌장 트립신 저해제, 다이아이소프로필플루오로포스페이트(DEP) 및 트라실롤을 포함한다. 리포좀은 수-중-유-중-수 CGF 에멀션뿐만 아니라 종래의 리포좀을 포함한다.
활성 화합물은 비경구 또는 복강내로 투여될 수도 있다. 분산액은 또한 글리세롤 액체 폴리에틸렌 글리콜, 이들의 혼합물 및 오일 내에서 제조될 수 있다. 저장 및 사용을 위한 통상적인 조건 하에서, 이들 제제는 미생물의 성장을 방지하기 위해 보존제를 함유한다.
주사용으로 적합한 약제학적 형태는 멸균 수용액(수용성인 경우) 또는 분산액, 및 멸균 주사액 또는 분산액의 즉시 제조를 위한 멸균 분말을 포함한다. 모든 경우, 이러한 형태는 멸균되어야 하고, 용이한 주사기 사용성(syringability)이 존재하는 범위까지 유체성이어야 한다. 이는 제조 및 보관 조건 하에 안정해야 하고, 박테리아 및 진균과 같은 미생물의 오염 작용으로부터 보존되어야 한다. 담체는 예를 들어, 물, 에탄올, 폴리올(예를 들어, 글리세롤, 프로필렌 글리콜 및 액체 폴리에틸렌 글리콜 등), 이들의 적합한 혼합물 및 식물유를 함유하는 용매 또는 분산 매질일 수 있다. 적절한 유동성은 예를 들어, 레시틴과 같은 코팅제의 사용, 분산액의 경우 필요한 입자 크기의 유지 및 계면활성제의 사용에 의해 유지될 수 있다. 미생물 작용의 예방은 다양한 항박테리아제 및 항진균제, 예를 들어, 클로로부탄올, 페놀, 소르브산, 테오머살 등에 의해 유발될 수 있다. 많은 경우, 당 또는 염화나트륨과 같은 등장성제를 포함하는 것이 바람직할 것이다. 주사용 조성물의 흡수 연장은 흡수를 지연시키는 작용제, 예를 들어, 알루미늄 모노스테아레이트 및 젤라틴을 조성물에 사용함으로써 유발될 수 있다.
멸균 주사 용액은, 필요한 양의 활성 화합물을 전술한 다양한 다른 성분과 함께 적절한 용매 내에서 혼입하고, 필요한 경우, 여과 멸균함으로써 제조된다. 일반적으로, 분산액은 다양한 멸균 활성 성분을, 염기성 분산 매질 및 전술한 것으로부터의 필요한 다른 성분을 함유하는 멸균 비히클 내로 혼입함으로써 제조된다. 멸균 주사 용액의 제조용 멸균 분말의 경우, 바람직한 제조 방법은 진공 건조 및 동결-건조 기술이며, 이는 이전에 멸균-여과된 용액으로부터 임의의 부가적인 목적하는 성분이 더해진 활성 성분 분말을 제공한다.
펩타이드가 상기에 기재된 바와 같이 적합하게 보호될 때, 활성 화합물은 예를 들어, 불활성 희석제 또는 동화가능한 식용(assimilable edible) 담체와 함께 경구 투여될 수 있거나, 활성 화합물은 경질 또는 연질 쉘 젤라틴 캡슐 내에 포함될 수 있거나, 정제로 압축될 수 있거나, 식품과 함께 직접 혼입될 수 있다. 경구 치료 투여를 위해, 활성 화합물은 부형제와 함께 혼입되고, 섭취 가능한 정제, 협측 정제(buccal tablet), 트로키, 캡슐, 엘릭시르, 현탁액, 시럽, 웨이퍼 등의 형태로 사용될 수 있다. 이러한 조성물 및 제제는 활성 화합물을 적어도 1중량% 함유해야 한다. 조성물 및 제제의 백분율은 물론 달라질 수 있고, 편리하게는 단위 중량의 약 5% 내지 약 80%일 수 있다. 치료적으로 유용한 이러한 조성물 중의 활성 화합물의 양은, 적합한 용량이 수득될 양이다. 본 발명에 따라 바람직한 조성물 또는 제제는, 경구 투여 단위 형태가 활성 화합물을 0.1㎍ 내지 2000㎎으로 함유하도록 제조된다.
정제, 알약, 캡슐 등은 또한 하기를 함유할 수도 있고: 결합제, 예컨대, 트래거캔스검, 아카시아, 옥수수 전분 또는 젤라틴; 부형제, 예컨대, 다이칼슘 포스페이트; 붕괴제, 예컨대, 옥수수 전분, 감자 전분, 알긴산 등; 윤활제, 예컨대, 마그네슘 스테아레이트; 및 감미제, 예컨대, 수크로스, 락토스 또는 사카린이 첨가될 수 있거나, 풍 미제, 예컨대, 페퍼민트, 윈터그린(wintergreen) 오일 또는 체리향이 첨가될 수 있다. 투여 단위 형태가 캡슐인 경우, 이는 상기 유형의 물질 외에도 액체 담체를 함유할 수 있다. 다양한 다른 물질은 코팅제로서 존재하거나, 그렇지 않으면 투여 단위의 물리적 형태를 변경하기 위해 존재할 수 있다. 예를 들어, 정제, 알약 또는 캡슐은 쉘락, 당 또는 둘 다를 사용하여 코팅될 수 있다. 시럽 또는 엘릭시르는 활성 화합물, 감미제로서 수크로스, 보존제로서 메틸 및 프로필파라벤, 염료 및 풍미제, 예컨대, 체리향 또는 오렌지향을 함유할 수 있다. 물론, 임의의 투여 단위 형태를 제조하는 데 사용되는 임의의 물질은 약제학적으로 순수하고, 이용되는 양에서 실질적으로 무독성이어야 한다. 또한 활성 화합물은 서방형 제제 및 제형 내로 혼입될 수 있다.
전달 시스템
다양한 전달 시스템은 공지되어 있고, 본 발명의 화합물을 투여하는 데 사용될 수 있으며, 예를 들어, 리포좀, 미세입자, 미세캡슐, 화합물을 발현시킬 수 있는 재조합 세포 내에서의 캡슐화, 수용체-매개 엔도사이토시스, 레트로바이러스 또는 다른 벡터의 일부로서의 핵산의 작제 등이 있다. 도입 방법은 피내, 근육내, 복강내, 정맥내, 피하, 비내, 안내, 경막외 및 경구 경로 등을 포함하지만 이들로 제한되지 않는다. 화합물 또는 조성물은 임의의 편리한 경로, 예를 들어, 주입 또는 불러스 주사, 상피 라이닝 또는 점액피부 라이닝(예를 들어, 구강 점막, 직장 및 장 점막 등)을 통한 흡수에 의해 투여될 수 있고, 다른 생물학적 활성제와 함께 투여될 수 있다. 투여는 전신 투여 또는 국소 투여일 수 있다. 또한 본 발명의 약제학적 화합물 또는 조성물을 뇌실내 및 척추강내 주사를 비롯한 임의의 적합한 경로에 의해 중추신경계 내로 도입하는 것이 바람직할 수 있으며; 뇌실내 주사는 예를 들어, 저장소, 예컨대, Ommaya 저장소에 부착된 뇌실내 카테터에 의해 촉진될 수 있다. 예를 들어, 흡입기 또는 네뷸라이저의 사용에 의한 폐 투여가 또한 이용될 수 있으며, 제형은 에어로졸제를 포함한다.
구체적인 실시형태에서, 본 발명의 약제학적 화합물 또는 조성물을 치료가 필요한 영역에 국소 투여하는 것이 바람직할 수 있으며; 이는 비제한적으로 예를 들어, 수술 동안의 국소 주입, 국소 적용, 예를 들어, 수술 후 상처 드레싱과 함께 국소 적용, 주사, 카테터, 좌제, 또는 이식에 의해 달성될 수 있고, 상기 이식은 시알라스틱 막(sialastic membrane)과 같은 막 또는 섬유를 비롯한 다공성, 비-다공성 또는 젤라틴성 물질이다. 바람직하게는, 본 발명의 항체 또는 펩타이드를 비롯한 단백질을 투여할 때, 단백질이 흡수되지 않는 물질을 사용하기 위해서는 주의를 기울여야 한다. 또 다른 실시형태에서, 화합물 또는 조성물은 비히클, 특히 리포좀 내에서 전달될 수 있다. 추가의 다른 실시형태에서, 화합물 또는 조성물은 제어 방출 시스템에서 전달될 수 있다. 일 실시 형태에서, 펌프가 사용될 수 있다. 또 다른 실시형태에서, 중합체 물질이 사용될 수 있다. 추가의 다른 실시형태에서, 제어 방출 시스템은 치료 표적에 근접하여 위치될 수 있으며, 따라서, 전신 용량의 단지 일부가 필요할 수 있다.
서열 목록 프리 텍스트
a, g, c, t 이외의 뉴클레오타이드 부호의 사용과 관련하여, 이들은 WIPO 표준 ST.25, 부록 2, 표 1에 기재되어 있는 관례를 따르며, 여기서, k는 t 또는 g를 나타내며; n은 a, c, t 또는 g를 나타내며; m은 a 또는 c; r은 a 또는 g를 나타내며; s는 c 또는 g를 나타내며; w는 a 또는 t를 나타내고, y는 c 또는 t를 나타낸다.


서열번호 2, 3 및 4는 MUC1 수용체 및 절두된 아이소폼을 세포막 표면으로 안내하기 위한 N-말단 MUC-1 신호전달 서열을 기재한다. 최대 3개의 아미노산 잔기가 서열번호 2, 3 및 4에서의 변이체에 의해서 제시된 바와 같이 C-말단 단부에 존재하지 않을 수 있다.




























실시예
실시예 1 - 최소 무혈청 베이스("MM")(500㎖)의 성분
400㎖ DME/F12/GlutaMAX I(Invitrogen# 10565-018)
100㎖ 넉아웃 혈청 대체물(KO-SR, Invitrogen# 10828-028)
5㎖ 100x MEM 비-필수 아미노산 용액(Invitrogen# 11140-050)
0.9㎖(0.1mM) "β-머캅토에탄올(55 mM 스톡, Invitrogen# 21985-023).
실시예 2 - 단백질 작제물의 생성
재조합 NME7을 생성시키기 위해서, 효율적으로 그리고 가용성 형태로 발현될 수 있는 재조합 NME7을 제조하기 위해, 먼저 작제물을 제조하였다. 제1 접근법은 천연 NME7(a), 또는 N-말단 결실을 갖는 대체 스플라이스 변이체 NME7(b)를 암호화할 작제하는 것이었다. 일부 경우, 작제물은 히스티딘 태그 또는 스트렙(strep) 태그를 가지고 있어서, 정제에 도움이 되었다. NME7-a, 이. 콜라이에서 불량하게 발현되는 전장 NME7 및 NME7-b는 모두 이. 콜라이에서 발현되지 않았다. 그러나, 제조된 신규한 작제물은 DM10 서열이 결실되어 있었으며, NME7은 분자량 계산치가 33kDa인 NDPK A 및 B 도메인을 본질적으로 포함하였다.
이러한 신규 NME7AB는 이. 콜라이에서 매우 양호하게 발현되었으며, 용해성 단백질로서 존재하였다. NME7AB를 먼저 NTA-Ni 칼럼 상에서 정제한 다음, Sephadex 200 칼럼 상의 크기 배제 크로마토그래피(FPLC)에 의해 더 정제하였다. 분획을 수집하고, SDS-PAGE에 의해 시험하여, NME7AB의 가장 높고, 가장 순수한 발현을 갖는 분획을 식별하였다. 가장 순수한 조합 분획에 대한 FPLC 트레이스(trace)를 조합하였다. 이어서, 정제된 NME7AB 단백질을 시험하였고, 이는 인간 줄기세포의 성장을 전적으로 지지하고, 이러한 줄기세포를 가장 미경험 사전-X-불활성화 상태로 반전시키는 것으로 나타났다. 정제된 NME7AB는 또한 암 세포의 성장을 가속화시키는 것으로 나타났다.
실시예 3 - NME7AB 가 2개의 MUC1* 세포외 영역 펩타이드에 동시에 결합한다는 것을 나타낸 ELISA 검정
결과를 도 1에 도시한다. C-말단 시스테인을 보유하는 PSMGFR 펩타이드(PSMGFR-Cys)를 Imject Maleimide 활성화된 BSA 키트(써모 피셔사)를 사용하여 BSA에 공유 커플링시켰다. BSA에 커플링된 PSMGFR-Cys를 0.1M 탄산염/중탄산염 완충제 pH 9.6에서 10ug/㎖로 희석시키고, 50uL를 96웰 플레이트의 각각의 웰에 첨가하였다. 4℃에서 밤새 인큐베이션시킨 후, 플레이트 PBS-T로 2회 세척하고, 3% BSA 용액을 첨가하여, 웰 상에 남아있는 결합 부위를 차단하였다. 실온에서 1시간 후, 플레이트를 PBS-T 및 NME7으로 2회 세척하고, PBS-T + 1% BSA로 희석시키고, 상이한 농도로 첨가하였다. 실온에서 1시간 후, 플레이트를 PBS-T 및 항-NM23-H7(B-9, 산타 크루즈 바이오테크놀로지사)로 3회 세척하고, PBS-T + 1% BSA에서 희석시키고, 1/500의 희석비로 첨가하였다. 실온에서 1시간 후, 플레이트를 PBS-T 및 염소 항 마우스-HRP로 3회 세척하고, PBS-T + 1% BSA에서 희석시키고, 1/3333의 희석비로 첨가하였다. 실온에서 1시간 후, 플레이트를 PBS-T로 3회 세척하고, NME7의 결합을 ABTS 용액(피어스사(Pierce))을 사용해 415nm에서 측정하였다.
ELISA MUC1* 이량체화: NME7 결합에 대한 프로토콜을 사용하였고, NME7을 11.6ug/㎖ 농도로 사용하였다.
실온에서 1시간 후, 플레이트를 PBS-T 및 His-태깅된 PSMGFR 펩타이드(PSMGFR-His) 또는 바이오티닐화된 PSMGFR 펩타이드(PSMGFR-바이오틴)로 3회 세척하고, PBS-T + 1% BSA에서 희석시키고, 상이한 농도로 첨가하였다. 실온에서 1시간 후, 플레이트를 PBS-T 및 항-His태그-HRP(압캠사(Abcam)) 또는 스트렙타비딘-HRP(피어스사(Pierce))로 3회 세척하고, PBS-T + 1% BSA에서 희석시키고, 1/5000의 농도로 첨가하였다. 실온에서 1시간 후, 플레이트를 PBS-T로 3회 세척하고, PSMGFR 펩타이드가, BSA에 커플링된 또 다른 PSMGFR 펩타이드(항-His 항체 또는 스트렙타비딘에 의해 신호를 전달할 수 없었음)에 이미 결합된 NME7에 결합했는지의 여부를 ABTS 용액(피어스사)을 사용하여 415nm에서 측정하였다.
실시예 4 - 인간 재조합 NME7AB 의 기능 시험
전분화능을 유지하고 분화를 저해하는 능력에 대해 재조합 NME7AB를 시험하기 위해, NME7의 가용성 변이체인 NME7AB를 생성시키고, 정제하였다. 인간 줄기세포(iPS cat# SC101a-1, 시스템 바이오사이언시스사(System Biosciences))를 지시서에 따라 마우스 섬유아세포 피더 세포 층 상에서 4ng/㎖ bFGF에서 4회 계대 동안 성장시켰다. 그런 다음, 이들 기원 줄기세포를, 단클론성 항-MUC1*항체인 MN-C3으로 12.5ug/웰로 코팅했던 6-웰 세포 배양 플레이트(VitaTM, 써모 피셔사) 상에 플레이팅하였다. 세포를 웰당 300,000개 세포의 밀도로 플레이팅하였다. 베이스 배지는 하기로 이루어진 최소 줄기세포 배지였다: 400㎖ DME/F12/GlutaMAX I(Invitrogen# 10565-018), 100 ㎖ 넉아웃 혈청 대체물(KO-SR, Invitrogen# 10828-028), 5㎖ 100x MEM 비-필수 아미노산 용액(Invitrogen# 11140-050) 및 0.9㎖(0.1mM) β-머캅토에탄올(55mM 스톡, Invitrogen# 21985-023). 베이스 배지는 임의의 배지일 수 있다. 바람직한 실시형태에서, 베이스 배지는 다른 성장 인자 및 사이토카인을 포함하지 않는다. 베이스 배지에, 안정적인 이량체로서 다시 접혀지고 정제된 8nM NME7AB 또는 8nM NM23-H1을 첨가하였다. 배지를 48시간마다 교환하였고, 플레이팅 3일 후에 수거하고, 계대시켜야 했다. 줄기세포를 NM23-H1 이량체 또는 NME7 단량체에서 성장시켰을 때, 유사한 만능 줄기세포 성장이 달성되었다.
NME7 및 NM23-H1(NME1) 이량체 둘 다 전분화능적으로 성장하였으며, 100% 컨플루언트에 도달할 때에도 분화되지 않았다. 사진에서 인지될 수 있는 바와 같이, NME7 세포는 NM23-H1 이량체에서 성장한 세포보다 더 빠르게 성장하였다. 처음에 수거한 세포 계수치는, NME7에서의 배양이 NM23-H1 이량체에서의 배양보다 세포를 1.4배 더 많이 생성하였음을 확인해 주었다. 전형적인 전분화능 마커에 대한 ICC 염색은, NME7AB가 인간 줄기세포 성장, 전분화능을 전적으로 지지하였으며, 분화를 저지하였음을 확인해 주었다.
약 30kDa 내지 33kDa의 NME7 종은 대체 스플라이스 아이소폼이거나 절단과 같은 번역후 변형된 것일 수 있으며, 이는 세포로부터 분비될 수 있다.
실시예 5 - 줄기세포를 보다 미경험 상태로 반전시키는 조건 하에 세포를 배양함으로써, 암 세포의 전이성 암 세포로 전이의 유도
암 세포를 일반적으로 혈청-함유 배지, 예컨대, RPMI에서 배양한다. 본 발명자들은, 줄기세포를 보다 미경험 상태로 반전시키는 시약의 존재 하에 암 세포를 배양하면, 암 세포를 보다 전이성 상태로 형질전환시킴을 발견하였다.
본 발명자들은, NME7AB, 인간 NME1 이량체, 박테리아 NME1 이량체, NME7-X1 및 "2i" 저해제가 각각 보통의 암 세포를 암 줄기세포 "CSC" 또는 종양 개시 세포 "TIC"라고도 지칭되는 전이성 암 세포로 형질전환시킬 수 있었다는 것을 입증하였다. 2i는 연구자들이 인간 줄기세포를 보다 미경험 상태로 반전시키게 하는 것으로 발견한 2개의 생화학적 저해제에 대해 주어진 명칭이다. 2i는 MEK 및 GSK3-베타 저해제 PD0325901 및 CHIR99021이며, 이들은 배양 배지에 각각 약 1mM 및 3mM의 최종 농도로 첨가된다.
NME7AB 및 NME7-X1은 암 세포를 전이성 세포로 형질전환시키기 위해 최소 배지의 별개의 배취에 첨가되었을 때, 약 4nM의 최종 농도로 존재하긴 하지만, 보다 낮은 농도 및 보다 높은 농도도 약 1nM 내지 16nM의 범위에서 양호하게 작용한다. 인간 NME1 이량체 또는 박테리아 NME1 이량체는 4nM 내지 32nM의 최종 농도로 사용되며, 16nM이 이들 실험에 전형적으로 사용되고, 여기서, 인간 NME는 S120G 돌연변이를 보유한다. 야생형을 사용하는 경우, 보다 낮은 농도가 필요할 수 있다. 이들 정확한 농도가 중요한 것은 아니다. NME1 단백질이 이량체이고, 이것이 발생하는 농도 범위는 낮은 나노몰 범위로 존재하지만, 특정 돌연변이는 보다 높은 농도에서 이량체로서 유지될 수 있게 하는 것이 중요하다.
유사하게는, NME7 단백질의 농도는 달라질 수 있다. NME7AB 및 NME7-X1은 단량체이고, 암 세포를 전이성 세포로 변환시키는 데 사용된 농도는 단백질을 단량체로 유지시킬 수 있어야 한다. 다양한 분자 마커는 전이성 암 세포의 지표로서 제안되었다. 서로 다른 유형의 암들은, 상향조절되는 상이한 분자를 가질 수 있다. 예를 들어, 수용체 CXCR4는 전이성 유방암에서 상향조절되며, 한편, CHD1으로도 알려져 있는 E-카드헤린은 전이성 전립선암에서 더 상향조절된다.
이들 특이적인 전이 마커 외에도, 전분화능에 대한 전형적인 마커, 예컨대, OCT4, SOX2, NANOG 및 KLF4는 암이 전이성으로 됨에 따라 상향조절된다. 출발 암 세포 및 이후의 전이성 암 세포는 이들 유전자의 발현 수준을 측정하기 위해 PCR에 의해 검정될 수 있다.
도 2는, NME7AB를 함유한 배지에서 배양된 T47D 유방암 세포의 RT-PCR 측정 그래프를 도시한다. rho I 키나제 저해제, ROCi, ROCKi 또는 Ri를 첨가하여, 형질전환된 세포가 플레이트로부터 탈착되어 부유하는 것을 방지하였다. 모 세포 및 NME7AB 배양된 세포에 대해서 다양한 전이 마커뿐만 아니라 만능 줄기세포 마커의 발현 수준을 측정하였다. 그 결과는, 부유 세포가 ROCi를 제공받은 세포와 비교하여 전이 마커 및 전분화능 마커를 보다 높은 양으로 발현한다는 것을 나타낸다. 본 발명자들은 이들 측정 결과가, 형질전환되지 않은 세포와, 형질전환되었지만 ROCi가 이들을 부착성으로 유지하는 세포의 평균이었기 때문이라고 생각하였다. 이는 도면에서 명백하게 인지될 수 있고, 여기서, "-Ri"는 ROCi를 제공받지 않은 부착성 세포이며, 따라서, 부유하는 고도로 전이성인 세포와 혼합되지 않았음을 의미한다.
전립선암 세포는 또한 NME1이라고도 하는 NM23 또는 NME7AB를 함유하는 배지에서 배양되었을 때, 보다 전이성 상태로 전이되었다. 본 명세서에서, 본 발명자들은, 지금까지 시험된 모든 세포주에 대해서, NME7AB, 인간 NME1 이량체 또는 인간 NME에 대해 높은 서열 상동성을 갖는 박테리아 NME에서의 배양이 보다 전이성 상태로의 전이를 유도한다는 것을 나타낸다.
도 4는 2i 저해제, NME7AB 또는 둘 다를 함유하는 배지에서 배양된 유방암 세포에 대한 전이 마커 및 전분화능 마커의 발현 수준에 대한 RT-PCR 측정의 그래프를 도시한다. 인지될 수 있는 바와 같이, 2i 저해제는 또한 암 세포의 보다 전이성인 상태로의 전이를 유도할 수 있다. 난소 암 세포주 SK-OV3, OV-90, 췌장암 세포주 CAPAN-2 및 PANC-1, 유방암 세포주 MDA-MB는 모두 NME7AB 및/또는 2i 저해제에서 배양되었을 때, 부착성으로부터 비-부착성으로의 형태학적 전이를 나타내었다.
도 20은 NME7AB에서 72시간 또는 144시간 동안 배양된 다양한 암 세포주에 대한 전이 마커 또는 전분화능 마커의 RT-PCR 측정 그래프를 나타낸다. 도 20A는, SK-OV3 세포가 NME7AB에서 배양되었을 때, 전이 마커 CHD1, SOX2 및 NME7-X1의 발현을 증가시킴을 나타낸다. 도 20B는, OV-90 세포가 NME7AB에서 배양된 후, 전이 마커 CXCR4 및 NME7-X1의 발현을 증가시킴을 나타낸다.
실시예 6 - NME7에서 배양된 암 세포가 전이성이 된다는 것에 대한 입증
암 세포 집단이 전이성인지 아닌지에 대한 기능 시험은, 매우 적은 수, 예를 들어, 200개의 세포를 면역-손상된 마우스에 이식하고, 이들 세포가 종양으로 발병되는지 알아보는 것이다. 전형적으로, 면역-손상된 마우스에서 종양을 형성하기 위해서는 5백만 내지 6백만개의 암 세포가 필요하다. 본 발명자들은, 50개만큼 적은 수의 NME-유도 전이성 암 세포가 마우스에서 종양을 형성하였음을 나타내었다. 또한, 시험 기간 전체 동안에 인간 NME7AB, NME1 또는 NME7-X1이 주사된 마우스에서 원거리 전이가 발병되었다.
T47D 인간 유방암 세포를 표준 RPMI 배지에서 14일 동안 배양하였으며, 이때, 배지를 48시간마다 교환하였고, 약 75% 컨플루언트되었을 때, 트립신처리에 의해 계대시켰다. 이어서, 세포를 6-웰 플레이트 내에 플레이팅하고, 4nM NME7AB가 보충된 최소 줄기세포 배지(실시예 1 참조)에서 배양하였다. 배지를 48시간마다 교환하였다. 약 4일까지, 일부 세포는 표면으로부터 탈착되어, 부유한다. "부유체"가 전이 마커의 RT-PCR 측정에 의해 입증되는 바와 같이 가장 높은 전이 잠재력을 갖는 세포이기 때문에, "부유체"를 보유하기 위해 배지를 조심스럽게 교환한다. 7일 또는 8일에, 부유체를 수거하고, 계수한다. RT-PCR 측정을 위해 샘플을 유지한다. 측정된 주요 마커는 CXCR4이며, 이는 NME7AB에서 간단히 배양된 후 40배 내지 200배 상향조절된다.
새로 수거된 부유체 전이성 세포를, 90-일 서방성 에스트로겐 펠릿이 이식되었던 암컷 nu/nu 무흉선 마우스의 옆구리에 이종 이식하였다. 부유체 세포를 각각 10,000개, 1,000개, 100개 또는 50개 세포로 이종 이식하였다. 또한, 6마리로 이루어진 각각의 군 내의 마우스 중 절반에는 32 nM NME7AB를 본래 이식 부위 근처에 매일 주사하였다. NME7AB가 없는 RPMI 배지에서 배양된 모 T47D 세포를 또한, 대조군으로서 6백만개, 10,000개 또는 100개로 마우스에게 이식하였다. NME7-유도 부유체 세포를 이식한 마우스는 50개만큼 적은 수의 세 포가 이식되었을 때에도 종양이 발병되었다. 부유체 세포를 이식하고, NME7AB를 매일 주사한 마우스에서는 또한 원거리 종양이 발병되거나 다양한 기관에서 원거리 전이가 발병되었다. NME7AB에서 배양된 암 세포를 이식한 후, 인간 NME7AB를 주사한 12마리의 마우스 중 11마리, 또는 92%의 마우스에서 주사 부위에서 종양이 발병되었다. 이식 후 인간 NME7AB를 주사하지 않은 12마리의 마우스 중 단지 7마리 또는 58%의 마우스에서만 종양이 발병되었다. 종양을 나타내고, 인간 NME7AB가 주사된 11마리의 마우스 중 9마리 또는 82%의 마우스에서, 주사 부위로부터 원거리에서 다중 종양이 발병되었다. NME7AB를 주사하지 않은 마우스 중 어떤 마우스에서도 가시적인 다중 종양이 발병되지 않았다.
희생시킨 후, RT-PCR 및 웨스턴 블롯은, NME7AB를 주사한 마우스 상의 원거리 범프(bump)가 사실상 인간 유방 종양이었음을 나타내었다. 이들 기관에 대한 유사한 분석은, 원거리 범프 외에도, 마우스에서, 이식된 인간 유방암 세포의 인간 유방암 특징이 간 및 폐로 무작위로 전이되었음을 나타내었다. 예상된 바와 같이, 6백만개 세포를 이식한 마우스만 종양을 성장시켰다.
상기에 기재된 것과 유사한 몇몇 실험을 수행하였으며, 본질적으로 동일한 결과로 수행되었다. 각각의 실험에서, 모든 적절한 대조군을 비롯하여 24마리 또는 52마리의 마우스가 존재하였다.
실시예 7 - 선택된 펩타이드는 이들의 서열이 NME7, A1, A2, B1, B2 및 B3에 고유하기 때문에, MUC1* 세포외 도메인 펩타이드에 대한 NME7 종의 결합을 저해한다.
NME7 펩타이드를 항체 생성을 위한 면역화 작용제로서 선택하였다. NME7 펩타이드 A1, A2, B1, B2 및 B3(도 9)를, 인간 NME1, 인간 NME7, 및 인간 NME1 또는 인간 NME7에 대해 상동성인 몇몇 박테리아 NME 중에서 서열 정렬 방법을 사용하여 선택하였다. 모두 중에서 높은 서열 상동성을 갖는 5개의 영역을 식별하였다. 그러나, 인간 NME1뿐만 아니라 인간 NME7을 저해할 항체를 생성할 펩타이드의 선택을 방지하기 위해서, 본 발명은 상동성 영역에 인접한 NME7 서열을 선택하였으며, 여기서, 이들 펩타이드는 인간 NME1과 상이한 서열을 가졌다. 본 발명자들은, 펩타이드 자체가 표면 상의 합성 MUC1* 펩타이드에 결합하고, 고정화된 펩타이드에 대한 인간 NME7 또는 인간 NME1의 결합을 저해할 수 있는지 알아보기 위해 ELISA 검정을 수행하였다(도 11). 도 11은, 펩타이드가, 고정화된 펩타이드에 대한 NME7 및 NME1의 결합을 저해하였음을 나타낸다. NME7 A 도메인 및 B 도메인 각각이 PSMGFR 펩타이드에 결합할 수 있다는 것을 상기하기 바란다. 따라서, PSMGFR 펩타이드에 대한 NME7AB 결합의 완전한 저해는 단 하나의 도메인으로부터 유래된 단일 항체 또는 펩타이드로 달성될 수 없다. 이는, 펩타이드가 유래된 영역이 MUC1*와 상호작용하였고, NME7의 영역에 결합하고 MUC1* 수용체에 대한 이의 결합을 저해할 항체를 생성시킬 영역이었음을 나타내었다.
또 다른 실험에서, 유리 펩타이드 A1, A2, B1, B2 및 B3를, NME7AB 또는 2i에서 배양함으로써 보다 전이성 상태로의 전이를 겪고 있는 배양 중인 암 세포에 첨가하였다. 도 14는, 암 세포를 NME7AB 또는 2i 저해제에서 성장시킬 때의 과학자들의 관찰 결과의 표를 나타내며, 유리 펩타이드가 부착성 세포에서 부유 세포로의 형태학적 변화를 저해하였으며, 이러한 형태학적 변화는 유방암 세포의 경우 전이 마커, 특히 CXCR4의 증가된 발현과 직접 상관관계가 있음을 나타낸다. RT-PCR 측정은, NME7AB 펩타이드가 전이 마커 CXCR4의 발현 증가를 저해하였음을 확인시켜 준다.
도 15는 NME7AB 또는 2i 저해제(이들 각각은 암 세포를 보다 전이성 상태로 형질전환시킴)에서 성장시킨 T47D 유방암 세포에서 CXCR4 발현 및 전이성 형질전환에 미치는 NME7-유래의 펩타이드, A1, A2, B1, B2 및 B3의 저해 효과에 대한 RT-PCR 측정 그래프를 나타낸다. 도 32는 도 15에서 CXCR4의 RT-PCR 측정에 사용된 샘플에서 기록된 RNA 수준의 표뿐만 아니라 CXCR4 발현 및 대조군 하우스키핑 유전자에 대한 역치 사이클 수를 도시한다.
실시예 8 - 항-NME7 항체는 인간 NME1이 아닌 인간 NME7에 특이적으로 결합한다.
인간 NME1은 건강한 기능을 가지며, 이를 항체로 차단하는 것이 인간에게 유해할 수 있기 때문에 본 발명자들은 NME7AB 펩타이드 A1, A2, B1, B2 및 B3를 사용한 면역화에 의해 생성한 NME7 항체가 인간 NME1이 아닌 NME7AB에 특이적으로 결합할 것인지 확인하기 위해 표준 ELISA 검정을 수행하였다. 도 24 내지 도 25의 ELISA는, 본 발명자들이 펩타이드 A1, A2, B1, B2 및 B3으로부터 생성된 모든 NME7 항체가 인간 NME1(도 25)이 아닌 인간 NME7AB(도 24)에 결합함을 나타낸다. 이들 항체를 생성하는 데 사용되는 펩타이드는 NME7AB 및 NME7-X1 둘 모두에 공통적이다. 이러한 검정은, 펩타이드 A1, A2, B1, B2 및 B3로부터 생성된 항체가 NME7AB에 특이적으로 결합하며, 확장에 의해서 NME7-X1에도 결합할 것임을 나타낸다.
NME7A 펩타이드 1(A 도메인): MLSRKEALDFHVDHQS(서열번호 141),
NME7A 펩타이드 2(A 도메인): SGVARTDASES(서열번호 142),
NME7B 펩타이드 1(B 도메인): DAGFEISAMQMFNMDRVNVE(서열번호 143),
NME7B 펩타이드 2(B 도메인): EVYKGVVTEYHDMVTE(서열번호 144),
NME7B 펩타이드 3(B 도메인): AIFGKTKIQNAVHCTDLPEDGLLEVQYFF(서열번호 145).
실시예 9 - 항-NME7 특이적 항체 및 이를 생성시킨 펩타이드는 암 세포 성장을 저해한다.
토끼를 NME7 펩타이드 A1, A2, B1, B2 및 B3을 사용하여 면역화시키고, 항체를 생성시키고, 수집하고, 면역화 펩타이드가 접합된 칼럼 상에서 정제시켰다. T47D 유방암 세포를 플레이팅하고, 혈청이 보충된 RPMI 배지에서 ATCC 프로토콜에 따라 배양하였다. 펩타이드 A1, A2, B1, B2 및 B3을 사용한 면역화로부터 생성된 항체를 도 12에 제시된 농도로 첨가하였다. 면역화 펩타이드 A1, A2, B1, B2 및 B3 및 본 명세서에서 "FLR"라고 하는 MUC1*의 PSMGFR 세포외 도메인 펩타이드를 또한 성장 중인 T47D 유방암 세포에 개별적으로 첨가하였다. 탁솔 및 E6 항-MUC1*Fab를 대조군으로서 첨가하였다. 도 12의 그래프는, 생성된 항체뿐만 아니라 유리 펩타이드가 암 세포의 성장을 강력하게 저해하였음을 나타낸다. 건강한 세포 및 암 세포를 유사하게 살해하는 화학치료제인 탁솔을 사용한 저해와의 비교를 주목하기 바란다. 또한 비교를 위해, 아미노산 100 내지 376으로부터의 NME7의 큰 스트레치를 사용하여 생성된 다클론성 항체를 나타낸다. 이러한 항체가 암 성장의 강력한 저해제이긴 하지만, 이는 NME1뿐만 아니라 NME7에도 결합할 수 있기 때문에, 비-특이적 효과를 가질 수 있었다.
유사한 실험에서, 펩타이드 A1, A2, B1, B2 및 B3을 사용한 면역화로부터 생성된 항체뿐만 아니라 펩타이드 자체를 성장 중인 암 세포에 제시된 농도로 첨가하였다. 도 13에 도시된 세포 성장의 그래프는, 항체와 펩타이드의 조합물이 암 세포의 성장을 강력하게 저해하였음을 나타낸다. 이들 2개의 실험에서, 세포는 MUC1* 양성 유방암 세포였다.
실시예 10 - 항-NME7 항체는 암 세포의 전이성 암 세포로의 전이를 저해한다.
암 세포는 줄기세포를 보다 미경험 상태로 반전시키는 작용제의 존재 하에 배양되었을 때, 보다 전이성 상태로 형질전환된다. 본 발명자들은, NME7AB, 인간 NME1 이량체, 박테리아 NME1 이량체, 또는 "2i"로 지칭되는 MEK 및 GSK3-베타 저해제에서 암 세포를 배양하면, 세포가 보다 전이성 상태로 된다는 것을 입증하였다. 세포가 보다 전이성 상태로 전이됨에 따라서, 세포는 비-부착성인 상태가 되고, 배양 플레이트로부터 부유한다. 이들 부유하는 세포인 "부유체"를 부착성인 세포로부터 개별적으로 수집하였으며, 이들은, a) 전이성 유전자를 훨씬 더 높은 수준으로 발현하고; b) 마우스 내로 이종 이식되었을 때, 부유체 세포는 매우 낮은 수로 이식된 경우 종양을 생성시킬 수 있는 것으로 나타났다. RT-PCR 측정값에서, 특이적인 전이 마커, 예컨대, 유방암에서 CXCR4, 전립선암에서 CHD1, 및 다른 만능 줄기세포 마커, 예컨대, OCT4, SOX2, NANOG, KLF4, c-Myc 및 다른 마커는 NME7AB에서 배양된 암 세포에서 급격하게 과발현되었으며, 본 명세서 및 도면에서 "부유체"로 지칭되는 비-부착성이된 세포에서 극적으로 과발현되었다.
본 명세서에서 본 발명자들은, NME7-유래 펩타이드 A1, A2, B1, B2 및 B3을 사용한 면역화에 의해 생성된 NME7-특이적 항체뿐만 아니라 펩타이드 자체가 암 세포에서 전이성 암 세포로의 전이를 저해함을 나타낸다. 이들 실험 중 제1 실험에서, A1, A2, B1, B2 및 B3을 사용한 면역화에 의해 생성된 항체를, T47D 유방암 세포를 NME7AB 또는 2i 저해제에서 배양함으로써 유도되는 전이성 전이를 저해하는 능력에 대해 시험하였다. 가장 놀라운 관찰은, 항체 및 펩타이드가 부유체 세포의 수를 급격하게 감소시킨 것이며, 이는, 항체 및 펩타이드가 전이성 암 세포로의 형질전환을 저해했다는 제1 지표였다. 특히, B3 펩타이드를 사용한 면역화로부터 항체가 생성된 세포는 임의의 부유체 세포를 거의 생성시키지 않았다.
도 14는, 어떠한 항체 치료도 제공받지 않은 대조군 웰과 비교하여, 각각의 항체에 대해 가시적인 부유체 세포의 백분율의 기록된 관찰을 나타낸다. mRNA를 부유체 세포 및 부착성 세포 둘 다로부터 추출하였다. RT-PCR을 사용하여, CXCR4를 비롯한 전이 마커의 발현 수준을 측정하였다. 항-NME7 항체를 사용한 치료는 전이 마커, 예컨대, CXCR4의 양을 크게 감소시켰으며, 이는, 이러한 항체가 전이성 암으로의 전이를 저해했음을 나타낸다(도 15 참고). 주목할 만하게는, 펩타이드 B3를 사용한 면역화에 의해 생성된 항체, 즉, 항체 #61은 보다 전이성 상태로의 전이를 본질적으로 완전히 저해하였다. 도 15B는, NME7AB 펩타이드, A1, A2, B1, B2 및 B3로 처리된 유방암 세포 단독이 2i 저해제를 함유하는 배지에서 세포를 배양함으로써 유도된 보다 전이성 상태로의 전이를 강력하게 저해할 수 있었음을 나타낸다. 이것이 생성한 항체 #61이었기 때문에, 펩타이드 B3이 특히 효과적이었다. 도 15C는 동일한 그래프를 나타내지만, Y-축은 전이 마커의 펩타이드 저해를 보여주기 위해 확대되었다. 세포의 생존력 및 성장을 나타내는 mRNA의 양을 측정하였다. 항체로 처리된 세포는 훨씬 더 적은 양의 mRNA를 가졌는데, 이는 보다 전이성 상태로의 전이를 저해하는 것 외에도, 항-NME7AB 항체가 암 세포의 성장을 저해하였음을 나타낸다. 도 16은 도 15A에서 도시된 저해 실험을 위해 회수된 RNA의 양을 나타낸 표를 도시한다.
실시예 11 - NME7-유래 펩타이드 A1, A2, B1, B2 및 B3을 사용하여 생성된 항-NME7 항체는 임의의 상업적으로 입수 가능한 항체를 사용하여 검출 불가능한 신규 NME7 종을 식별한다.
당업자에게 공지된 바와 같이, 일부 항체는 표적 단백질의 선형 부분을 인지하고, 웨스턴 블롯 검정에서 사용될 수 있으며, 한편, 다른 항체는 비-선형 구조 모티프를 인식하고, 풀-다운 또는 면역침전 검정에서 사용될 수 있다. 본 출원 이전에, 절단된 NME7 또는 아이소폼 NME7-X1은 존재하는 것으로 알려지지 않았다. 출원 시점에서 상업적으로 입수 가능한 항체를 사용하면, 기존의 항체는 이들 중요한 NME7 종을 특이적으로 검출할 수 없었음을 나타낸다. B9(산타 크루즈 바이오테크놀로지사)는 NME7 아미노산 100 내지 376에 대해 생성된 단클론성 항체이다. 도 19D 내지 19F는 이 항체가 전장 42kDa NME7만을 검출함을 나타낸다. 또 다른 상업적으로 입수 가능한 항체인 H278은, NME7에 고유하지 않은 아미노산 서열을 포함하는 NME7 아미노산 100 내지 376에 대해 생성된 토끼 다클론성 항체이다. 도 19D 내지 19F는, 이러한 항체가 또한 17kDa인 NME1뿐만 아니라 전장 NME7, 및 NME7AB에 특이적인 것으로 보이지 않는 다른 밴드를 염색시킴을 나타낸다.
NME7AB 펩타이드 A1, A2, B1, B2 또는 B3를 사용한 면역화에 의해 생성된 NME7 항체는, 전장 42kDa 단백질을 포함하는 새로운 NME7 종, 절단 생성물 또는 대체 아이소폼일 수 있는 약 33kDa NME7 종, 절단 생성물 또는 대체 아이소폼일 수 있는 약 30kDa NME7 종을 식별하며, 여기서, 약 30kDa 종은 NME7-X1인 것으로 보인다. 도 19A 내지 도 19C는, 펩타이드 A1, B1 및 B3에 의해 생성된 항체가 T47D 유방암 세포, PC3 및 DU145 전립선암 세포, HEK293 태아 간 세포 및 백혈병 세포 IM-9, K562 및 MV411을 비롯한 광범위한 암 세포주에서 분비 형태의 NME7, NME7AB 및 NME7-X1을 식별한다는 것을 나타낸다.
실시예 12 - 항-NME7 항체의 생성
*NME7의 B3 영역의 서열, AIFGKTKIQNAVHCTDLPEDGLLEVQYFFC(서열번호)을 갖는 합성 펩타이드를 사용하여 토끼를 면역화시켰다. NME7 펩타이드 B3으로의 면역화로부터 생성된 항체는 MUC1* 양성 암 세포의 성장을 저해하였고, 또한 암 줄기세포의 형성을 저해하였는데, 암 줄기세포의 형성은 전이 마커의 상향조절, 고정부를 독립적으로 성장시키는 능력 및 200개만큼 적은 세포로부터 동물에서 종양을 형성할 수 있는 능력에 의해서 특징규명되는 반면, 보통 암 세포는 종양 생착을 위해서 전형적으로 약 4백만개의 세포의 이식을 필요로 한다.
일부 경우에, NME7 B3 펩타이드는 C14A 또는 C14V 돌연변이로 제조되었다. 이러한 서열은 항-NME7 항체를 보다 재현 가능하게 생성시켰다.
NME7 B3, C14A 돌연변이를 갖는 B3 또는 C14V 돌연변이를 갖는 B3으로의 면역화에 의해서 표준 방법에 따라서 마우스에서 단클론성 항체를 생성시켰다. 열거된 항체는 NME7, NME7-X1, NME7AB에 결합하는 능력으로 인해서 선택되었지만, 중요하게는 NME1에 결합하지 않았는데, 이는 일부 정상 세포 기능에 필요하다고 생각된다. 이들 항체는 또한 NME7 유래 펩타이드 B3, C14A 돌연변이를 갖는 B3, 및 C14V 돌연변이를 갖는 B3에 결합한다.
실험은, 이들 항-NME7 항체가 MUC1* 세포외 도메인에 대한 NME7의 결합을 저해하였지만, MUC1* 세포외 도메인 펩타이드에 대한 NME1의 결합을 차단하지 않았다는 것을 나타내었다. 추가로, 항체는 암 줄기세포의 형성을 저해하였다.
인용 참고문헌 목록



******
당업자는 본 명세서에 구체적으로 기재된 본 발명의 특정 실시형태에 대한 다수의 등가물을 일상적인 실험을 사용하여 인식하거나 확인할 수 있을 것이다. 이러한 등가물은 청구범위의 범주에 포함되도록 의도된다.
SEQUENCE LISTING
<110> Minerva Biotechnologies Corporation
<120> ANTI-NME ANTIBODY AND METHOD OF TREATING CANCER OR CANCER
METASTASIS
<130> 16831-163WO0
<140> PCT/US2021/036500
<141> 2021-06-08
<160> 1051
<170> PatentIn version 3.5
<210> 1
<211> 1255
<212> PRT
<213> Artificial Sequence
<220>
<223> MUC1 Receptor - Mucin 1 precursor, Genbank Accession number:
P15941
<400> 1
Met Thr Pro Gly Thr Gln Ser Pro Phe Phe Leu Leu Leu Leu Leu Thr
1 5 10 15
Val Leu Thr Val Val Thr Gly Ser Gly His Ala Ser Ser Thr Pro Gly
20 25 30
Gly Glu Lys Glu Thr Ser Ala Thr Gln Arg Ser Ser Val Pro Ser Ser
35 40 45
Thr Glu Lys Asn Ala Val Ser Met Thr Ser Ser Val Leu Ser Ser His
50 55 60
Ser Pro Gly Ser Gly Ser Ser Thr Thr Gln Gly Gln Asp Val Thr Leu
65 70 75 80
Ala Pro Ala Thr Glu Pro Ala Ser Gly Ser Ala Ala Thr Trp Gly Gln
85 90 95
Asp Val Thr Ser Val Pro Val Thr Arg Pro Ala Leu Gly Ser Thr Thr
100 105 110
Pro Pro Ala His Asp Val Thr Ser Ala Pro Asp Asn Lys Pro Ala Pro
115 120 125
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
130 135 140
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
145 150 155 160
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
165 170 175
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
180 185 190
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
195 200 205
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
210 215 220
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
225 230 235 240
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
245 250 255
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
260 265 270
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
275 280 285
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
290 295 300
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
305 310 315 320
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
325 330 335
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
340 345 350
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
355 360 365
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
370 375 380
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
385 390 395 400
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
405 410 415
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
420 425 430
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
435 440 445
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
450 455 460
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
465 470 475 480
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
485 490 495
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
500 505 510
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
515 520 525
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
530 535 540
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
545 550 555 560
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
565 570 575
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
580 585 590
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
595 600 605
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
610 615 620
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
625 630 635 640
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
645 650 655
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
660 665 670
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
675 680 685
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
690 695 700
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
705 710 715 720
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
725 730 735
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
740 745 750
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
755 760 765
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
770 775 780
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
785 790 795 800
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
805 810 815
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
820 825 830
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
835 840 845
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr
850 855 860
Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser
865 870 875 880
Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala Pro Pro Ala His
885 890 895
Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro Gly Ser Thr Ala
900 905 910
Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Thr Arg Pro Ala Pro
915 920 925
Gly Ser Thr Ala Pro Pro Ala His Gly Val Thr Ser Ala Pro Asp Asn
930 935 940
Arg Pro Ala Leu Gly Ser Thr Ala Pro Pro Val His Asn Val Thr Ser
945 950 955 960
Ala Ser Gly Ser Ala Ser Gly Ser Ala Ser Thr Leu Val His Asn Gly
965 970 975
Thr Ser Ala Arg Ala Thr Thr Thr Pro Ala Ser Lys Ser Thr Pro Phe
980 985 990
Ser Ile Pro Ser His His Ser Asp Thr Pro Thr Thr Leu Ala Ser His
995 1000 1005
Ser Thr Lys Thr Asp Ala Ser Ser Thr His His Ser Ser Val Pro
1010 1015 1020
Pro Leu Thr Ser Ser Asn His Ser Thr Ser Pro Gln Leu Ser Thr
1025 1030 1035
Gly Val Ser Phe Phe Phe Leu Ser Phe His Ile Ser Asn Leu Gln
1040 1045 1050
Phe Asn Ser Ser Leu Glu Asp Pro Ser Thr Asp Tyr Tyr Gln Glu
1055 1060 1065
Leu Gln Arg Asp Ile Ser Glu Met Phe Leu Gln Ile Tyr Lys Gln
1070 1075 1080
Gly Gly Phe Leu Gly Leu Ser Asn Ile Lys Phe Arg Pro Gly Ser
1085 1090 1095
Val Val Val Gln Leu Thr Leu Ala Phe Arg Glu Gly Thr Ile Asn
1100 1105 1110
Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys Thr Glu Ala
1115 1120 1125
Ala Ser Arg Tyr Asn Leu Thr Ile Ser Asp Val Ser Val Ser Asp
1130 1135 1140
Val Pro Phe Pro Phe Ser Ala Gln Ser Gly Ala Gly Val Pro Gly
1145 1150 1155
Trp Gly Ile Ala Leu Leu Val Leu Val Cys Val Leu Val Ala Leu
1160 1165 1170
Ala Ile Val Tyr Leu Ile Ala Leu Ala Val Cys Gln Cys Arg Arg
1175 1180 1185
Lys Asn Tyr Gly Gln Leu Asp Ile Phe Pro Ala Arg Asp Thr Tyr
1190 1195 1200
His Pro Met Ser Glu Tyr Pro Thr Tyr His Thr His Gly Arg Tyr
1205 1210 1215
Val Pro Pro Ser Ser Thr Asp Arg Ser Pro Tyr Glu Lys Val Ser
1220 1225 1230
Ala Gly Asn Gly Gly Ser Ser Leu Ser Tyr Thr Asn Pro Ala Val
1235 1240 1245
Ala Ala Ala Ser Ala Asn Leu
1250 1255
<210> 2
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> N-terminal MUC-1 signaling sequence
<400> 2
Met Thr Pro Gly Thr Gln Ser Pro Phe Phe Leu Leu Leu Leu Leu Thr
1 5 10 15
Val Leu Thr
<210> 3
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> N-terminal MUC-1 signaling sequence
<400> 3
Met Thr Pro Gly Thr Gln Ser Pro Phe Phe Leu Leu Leu Leu Leu Thr
1 5 10 15
Val Leu Thr Val Val Thr Ala
20
<210> 4
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> N-terminal MUC-1 signaling sequence
<400> 4
Met Thr Pro Gly Thr Gln Ser Pro Phe Phe Leu Leu Leu Leu Leu Thr
1 5 10 15
Val Leu Thr Val Val Thr Gly
20
<210> 5
<211> 146
<212> PRT
<213> Artificial Sequence
<220>
<223> Truncated MUC1 receptor isoform having nat-PSMGFR at its
N-terminus and including the transmembrane and cytoplasmic
sequences of a full-length MUC1 receptor
<400> 5
Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys
1 5 10 15
Thr Glu Ala Ala Ser Arg Tyr Asn Leu Thr Ile Ser Asp Val Ser Val
20 25 30
Ser Asp Val Pro Phe Pro Phe Ser Ala Gln Ser Gly Ala Gly Val Pro
35 40 45
Gly Trp Gly Ile Ala Leu Leu Val Leu Val Cys Val Leu Val Ala Leu
50 55 60
Ala Ile Val Tyr Leu Ile Ala Leu Ala Val Cys Gln Cys Arg Arg Lys
65 70 75 80
Asn Tyr Gly Gln Leu Asp Ile Phe Pro Ala Arg Asp Thr Tyr His Pro
85 90 95
Met Ser Glu Tyr Pro Thr Tyr His Thr His Gly Arg Tyr Val Pro Pro
100 105 110
Ser Ser Thr Asp Arg Ser Pro Tyr Glu Lys Val Ser Ala Gly Asn Gly
115 120 125
Gly Ser Ser Leu Ser Tyr Thr Asn Pro Ala Val Ala Ala Ala Ser Ala
130 135 140
Asn Leu
145
<210> 6
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> PSMGFR sequence
<400> 6
Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys
1 5 10 15
Thr Glu Ala Ala Ser Arg Tyr Asn Leu Thr Ile Ser Asp Val Ser Val
20 25 30
Ser Asp Val Pro Phe Pro Phe Ser Ala Gln Ser Gly Ala
35 40 45
<210> 7
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> PSMGFR sequence
<400> 7
Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys Thr
1 5 10 15
Glu Ala Ala Ser Arg Tyr Asn Leu Thr Ile Ser Asp Val Ser Val Ser
20 25 30
Asp Val Pro Phe Pro Phe Ser Ala Gln Ser Gly Ala
35 40
<210> 8
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> PSMGFR sequence
<400> 8
Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys
1 5 10 15
Thr Glu Ala Ala Ser Pro Tyr Asn Leu Thr Ile Ser Asp Val Ser Val
20 25 30
Ser Asp Val Pro Phe Pro Phe Ser Ala Gln Ser Gly Ala
35 40 45
<210> 9
<211> 44
<212> PRT
<213> Artificial Sequence
<220>
<223> PSMGFR sequence
<400> 9
Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys Thr
1 5 10 15
Glu Ala Ala Ser Pro Tyr Asn Leu Thr Ile Ser Asp Val Ser Val Ser
20 25 30
Asp Val Pro Phe Pro Phe Ser Ala Gln Ser Gly Ala
35 40
<210> 10
<211> 216
<212> DNA
<213> Artificial Sequence
<220>
<223> MUC1 cytoplasmic domain nucleotide sequence
<400> 10
tgtcagtgcc gccgaaagaa ctacgggcag ctggacatct ttccagcccg ggatacctac 60
catcctatga gcgagtaccc cacctaccac acccatgggc gctatgtgcc ccctagcagt 120
accgatcgta gcccctatga gaaggtttct gcaggtaacg gtggcagcag cctctcttac 180
acaaacccag cagtggcagc cgcttctgcc aacttg 216
<210> 11
<211> 72
<212> PRT
<213> Artificial Sequence
<220>
<223> MUC1 cytoplasmic domain amino acid sequence
<400> 11
Cys Gln Cys Arg Arg Lys Asn Tyr Gly Gln Leu Asp Ile Phe Pro Ala
1 5 10 15
Arg Asp Thr Tyr His Pro Met Ser Glu Tyr Pro Thr Tyr His Thr His
20 25 30
Gly Arg Tyr Val Pro Pro Ser Ser Thr Asp Arg Ser Pro Tyr Glu Lys
35 40 45
Val Ser Ala Gly Asn Gly Gly Ser Ser Leu Ser Tyr Thr Asn Pro Ala
50 55 60
Val Ala Ala Ala Ser Ala Asn Leu
65 70
<210> 12
<211> 854
<212> DNA
<213> Artificial Sequence
<220>
<223> NME7 nucleotide sequence (NME7: GENBANK ACCESSION AB209049)
<400> 12
gagatcctga gacaatgaat catagtgaaa gattcgtttt cattgcagag tggtatgatc 60
caaatgcttc acttcttcga cgttatgagc ttttatttta cccaggggat ggatctgttg 120
aaatgcatga tgtaaagaat catcgcacct ttttaaagcg gaccaaatat gataacctgc 180
acttggaaga tttatttata ggcaacaaag tgaatgtctt ttctcgacaa ctggtattaa 240
ttgactatgg ggatcaatat acagctcgcc agctgggcag taggaaagaa aaaacgctag 300
ccctaattaa accagatgca atatcaaagg ctggagaaat aattgaaata ataaacaaag 360
ctggatttac tataaccaaa ctcaaaatga tgatgctttc aaggaaagaa gcattggatt 420
ttcatgtaga tcaccagtca agaccctttt tcaatgagct gatccagttt attacaactg 480
gtcctattat tgccatggag attttaagag atgatgctat atgtgaatgg aaaagactgc 540
tgggacctgc aaactctgga gtggcacgca cagatgcttc tgaaagcatt agagccctct 600
ttggaacaga tggcataaga aatgcagcgc atggccctga ttcttttgct tctgcggcca 660
gagaaatgga gttgtttttt ccttcaagtg gaggttgtgg gccggcaaac actgctaaat 720
ttactaattg tacctgttgc attgttaaac cccatgctgt cagtgaaggt atgttgaata 780
cactatattc agtacatttt gttaatagga gagcaatgtt tattttcttg atgtacttta 840
tgtatagaaa ataa 854
<210> 13
<211> 283
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7 amino acid sequence (NME7: GENBANK ACCESSION AB209049)
<400> 13
Asp Pro Glu Thr Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu
1 5 10 15
Trp Tyr Asp Pro Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe
20 25 30
Tyr Pro Gly Asp Gly Ser Val Glu Met His Asp Val Lys Asn His Arg
35 40 45
Thr Phe Leu Lys Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu
50 55 60
Phe Ile Gly Asn Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile
65 70 75 80
Asp Tyr Gly Asp Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu
85 90 95
Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu
100 105 110
Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys
115 120 125
Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His
130 135 140
Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly
145 150 155 160
Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp
165 170 175
Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala
180 185 190
Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala
195 200 205
Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu
210 215 220
Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe
225 230 235 240
Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
245 250 255
Met Leu Asn Thr Leu Tyr Ser Val His Phe Val Asn Arg Arg Ala Met
260 265 270
Phe Ile Phe Leu Met Tyr Phe Met Tyr Arg Lys
275 280
<210> 14
<211> 534
<212> DNA
<213> Artificial Sequence
<220>
<223> NM23-H1 nucleotide sequence (NM23-H1: GENBANK ACCESSION AF487339)
<400> 14
atggtgctac tgtctacttt agggatcgtc tttcaaggcg aggggcctcc tatctcaagc 60
tgtgatacag gaaccatggc caactgtgag cgtaccttca ttgcgatcaa accagatggg 120
gtccagcggg gtcttgtggg agagattatc aagcgttttg agcagaaagg attccgcctt 180
gttggtctga aattcatgca agcttccgaa gatcttctca aggaacacta cgttgacctg 240
aaggaccgtc cattctttgc cggcctggtg aaatacatgc actcagggcc ggtagttgcc 300
atggtctggg aggggctgaa tgtggtgaag acgggccgag tcatgctcgg ggagaccaac 360
cctgcagact ccaagcctgg gaccatccgt ggagacttct gcatacaagt tggcaggaac 420
attatacatg gcagtgattc tgtggagagt gcagagaagg agatcggctt gtggtttcac 480
cctgaggaac tggtagatta cacgagctgt gctcagaact ggatctatga atga 534
<210> 15
<211> 177
<212> PRT
<213> Artificial Sequence
<220>
<223> NM23-H1 describes amino acid sequence (NM23-H1: GENBANK ACCESSION
AF487339)
<400> 15
Met Val Leu Leu Ser Thr Leu Gly Ile Val Phe Gln Gly Glu Gly Pro
1 5 10 15
Pro Ile Ser Ser Cys Asp Thr Gly Thr Met Ala Asn Cys Glu Arg Thr
20 25 30
Phe Ile Ala Ile Lys Pro Asp Gly Val Gln Arg Gly Leu Val Gly Glu
35 40 45
Ile Ile Lys Arg Phe Glu Gln Lys Gly Phe Arg Leu Val Gly Leu Lys
50 55 60
Phe Met Gln Ala Ser Glu Asp Leu Leu Lys Glu His Tyr Val Asp Leu
65 70 75 80
Lys Asp Arg Pro Phe Phe Ala Gly Leu Val Lys Tyr Met His Ser Gly
85 90 95
Pro Val Val Ala Met Val Trp Glu Gly Leu Asn Val Val Lys Thr Gly
100 105 110
Arg Val Met Leu Gly Glu Thr Asn Pro Ala Asp Ser Lys Pro Gly Thr
115 120 125
Ile Arg Gly Asp Phe Cys Ile Gln Val Gly Arg Asn Ile Ile His Gly
130 135 140
Ser Asp Ser Val Glu Ser Ala Glu Lys Glu Ile Gly Leu Trp Phe His
145 150 155 160
Pro Glu Glu Leu Val Asp Tyr Thr Ser Cys Ala Gln Asn Trp Ile Tyr
165 170 175
Glu
<210> 16
<211> 534
<212> DNA
<213> Artificial Sequence
<220>
<223> NM23-H1 S120G mutant nucleotide sequence (NM23-H1: GENBANK
ACCESSION AF487339)
<400> 16
atggtgctac tgtctacttt agggatcgtc tttcaaggcg aggggcctcc tatctcaagc 60
tgtgatacag gaaccatggc caactgtgag cgtaccttca ttgcgatcaa accagatggg 120
gtccagcggg gtcttgtggg agagattatc aagcgttttg agcagaaagg attccgcctt 180
gttggtctga aattcatgca agcttccgaa gatcttctca aggaacacta cgttgacctg 240
aaggaccgtc cattctttgc cggcctggtg aaatacatgc actcagggcc ggtagttgcc 300
atggtctggg aggggctgaa tgtggtgaag acgggccgag tcatgctcgg ggagaccaac 360
cctgcagact ccaagcctgg gaccatccgt ggagacttct gcatacaagt tggcaggaac 420
attatacatg gcggtgattc tgtggagagt gcagagaagg agatcggctt gtggtttcac 480
cctgaggaac tggtagatta cacgagctgt gctcagaact ggatctatga atga 534
<210> 17
<211> 177
<212> PRT
<213> Artificial Sequence
<220>
<223> NM23-H1 S120G mutant amino acid sequence (NM23-H1: GENBANK
ACCESSION AF487339)
<400> 17
Met Val Leu Leu Ser Thr Leu Gly Ile Val Phe Gln Gly Glu Gly Pro
1 5 10 15
Pro Ile Ser Ser Cys Asp Thr Gly Thr Met Ala Asn Cys Glu Arg Thr
20 25 30
Phe Ile Ala Ile Lys Pro Asp Gly Val Gln Arg Gly Leu Val Gly Glu
35 40 45
Ile Ile Lys Arg Phe Glu Gln Lys Gly Phe Arg Leu Val Gly Leu Lys
50 55 60
Phe Met Gln Ala Ser Glu Asp Leu Leu Lys Glu His Tyr Val Asp Leu
65 70 75 80
Lys Asp Arg Pro Phe Phe Ala Gly Leu Val Lys Tyr Met His Ser Gly
85 90 95
Pro Val Val Ala Met Val Trp Glu Gly Leu Asn Val Val Lys Thr Gly
100 105 110
Arg Val Met Leu Gly Glu Thr Asn Pro Ala Asp Ser Lys Pro Gly Thr
115 120 125
Ile Arg Gly Asp Phe Cys Ile Gln Val Gly Arg Asn Ile Ile His Gly
130 135 140
Gly Asp Ser Val Glu Ser Ala Glu Lys Glu Ile Gly Leu Trp Phe His
145 150 155 160
Pro Glu Glu Leu Val Asp Tyr Thr Ser Cys Ala Gln Asn Trp Ile Tyr
165 170 175
Glu
<210> 18
<211> 459
<212> DNA
<213> Artificial Sequence
<220>
<223> NM23-H2 nucleotide sequence (NM23-H2: GENBANK ACCESSION AK313448)
<400> 18
atggccaacc tggagcgcac cttcatcgcc atcaagccgg acggcgtgca gcgcggcctg 60
gtgggcgaga tcatcaagcg cttcgagcag aagggattcc gcctcgtggc catgaagttc 120
ctccgggcct ctgaagaaca cctgaagcag cactacattg acctgaaaga ccgaccattc 180
ttccctgggc tggtgaagta catgaactca gggccggttg tggccatggt ctgggagggg 240
ctgaacgtgg tgaagacagg ccgagtgatg cttggggaga ccaatccagc agattcaaag 300
ccaggcacca ttcgtgggga cttctgcatt caggttggca ggaacatcat tcatggcagt 360
gattcagtaa aaagtgctga aaaagaaatc agcctatggt ttaagcctga agaactggtt 420
gactacaagt cttgtgctca tgactgggtc tatgaataa 459
<210> 19
<211> 152
<212> PRT
<213> Artificial Sequence
<220>
<223> NM23-H2 amino acid sequence (NM23-H2: GENBANK ACCESSION AK313448)
<400> 19
Met Ala Asn Leu Glu Arg Thr Phe Ile Ala Ile Lys Pro Asp Gly Val
1 5 10 15
Gln Arg Gly Leu Val Gly Glu Ile Ile Lys Arg Phe Glu Gln Lys Gly
20 25 30
Phe Arg Leu Val Ala Met Lys Phe Leu Arg Ala Ser Glu Glu His Leu
35 40 45
Lys Gln His Tyr Ile Asp Leu Lys Asp Arg Pro Phe Phe Pro Gly Leu
50 55 60
Val Lys Tyr Met Asn Ser Gly Pro Val Val Ala Met Val Trp Glu Gly
65 70 75 80
Leu Asn Val Val Lys Thr Gly Arg Val Met Leu Gly Glu Thr Asn Pro
85 90 95
Ala Asp Ser Lys Pro Gly Thr Ile Arg Gly Asp Phe Cys Ile Gln Val
100 105 110
Gly Arg Asn Ile Ile His Gly Ser Asp Ser Val Lys Ser Ala Glu Lys
115 120 125
Glu Ile Ser Leu Trp Phe Lys Pro Glu Glu Leu Val Asp Tyr Lys Ser
130 135 140
Cys Ala His Asp Trp Val Tyr Glu
145 150
<210> 20
<211> 1023
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NM23-H7-2 sequence optimized for E. coli expression
<400> 20
atgcatgacg ttaaaaatca ccgtaccttt ctgaaacgca cgaaatatga taatctgcat 60
ctggaagacc tgtttattgg caacaaagtc aatgtgttct ctcgtcagct ggtgctgatc 120
gattatggcg accagtacac cgcgcgtcaa ctgggtagtc gcaaagaaaa aacgctggcc 180
ctgattaaac cggatgcaat ctccaaagct ggcgaaatta tcgaaattat caacaaagcg 240
ggtttcacca tcacgaaact gaaaatgatg atgctgagcc gtaaagaagc cctggatttt 300
catgtcgacc accagtctcg cccgtttttc aatgaactga ttcaattcat caccacgggt 360
ccgattatcg caatggaaat tctgcgtgat gacgctatct gcgaatggaa acgcctgctg 420
ggcccggcaa actcaggtgt tgcgcgtacc gatgccagtg aatccattcg cgctctgttt 480
ggcaccgatg gtatccgtaa tgcagcacat ggtccggact cattcgcatc ggcagctcgt 540
gaaatggaac tgtttttccc gagctctggc ggttgcggtc cggcaaacac cgccaaattt 600
accaattgta cgtgctgtat tgtcaaaccg cacgcagtgt cagaaggcct gctgggtaaa 660
attctgatgg caatccgtga tgctggcttt gaaatctcgg ccatgcagat gttcaacatg 720
gaccgcgtta acgtcgaaga attctacgaa gtttacaaag gcgtggttac cgaatatcac 780
gatatggtta cggaaatgta ctccggtccg tgcgtcgcga tggaaattca gcaaaacaat 840
gccaccaaaa cgtttcgtga attctgtggt ccggcagatc cggaaatcgc acgtcatctg 900
cgtccgggta ccctgcgcgc aatttttggt aaaacgaaaa tccagaacgc tgtgcactgt 960
accgatctgc cggaagacgg tctgctggaa gttcaatact ttttcaaaat tctggataat 1020
tga 1023
<210> 21
<211> 340
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NM23-H7-2 sequence optimized for E. coli expression
<400> 21
Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys Arg Thr Lys Tyr
1 5 10 15
Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn Lys Val Asn Val
20 25 30
Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp Gln Tyr Thr Ala
35 40 45
Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala Leu Ile Lys Pro
50 55 60
Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala
65 70 75 80
Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu Ser Arg Lys Glu
85 90 95
Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro Phe Phe Asn Glu
100 105 110
Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala Met Glu Ile Leu
115 120 125
Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn
130 135 140
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe
145 150 155 160
Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro Asp Ser Phe Ala
165 170 175
Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys
180 185 190
Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr Cys Cys Ile Val
195 200 205
Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys Ile Leu Met Ala
210 215 220
Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln Met Phe Asn Met
225 230 235 240
Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr Lys Gly Val Val
245 250 255
Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser Gly Pro Cys Val
260 265 270
Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe
275 280 285
Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg Pro Gly Thr
290 295 300
Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val His Cys
305 310 315 320
Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys
325 330 335
Ile Leu Asp Asn
340
<210> 22
<211> 399
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A
<400> 22
atggaaaaaa cgctagccct aattaaacca gatgcaatat caaaggctgg agaaataatt 60
gaaataataa acaaagctgg atttactata accaaactca aaatgatgat gctttcaagg 120
aaagaagcat tggattttca tgtagatcac cagtcaagac cctttttcaa tgagctgatc 180
cagtttatta caactggtcc tattattgcc atggagattt taagagatga tgctatatgt 240
gaatggaaaa gactgctggg acctgcaaac tctggagtgg cacgcacaga tgcttctgaa 300
agcattagag ccctctttgg aacagatggc ataagaaatg cagcgcatgg ccctgattct 360
tttgcttctg cggccagaga aatggagttg tttttttga 399
<210> 23
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A
<400> 23
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe
130
<210> 24
<211> 444
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A1
<400> 24
atggaaaaaa cgctagccct aattaaacca gatgcaatat caaaggctgg agaaataatt 60
gaaataataa acaaagctgg atttactata accaaactca aaatgatgat gctttcaagg 120
aaagaagcat tggattttca tgtagatcac cagtcaagac cctttttcaa tgagctgatc 180
cagtttatta caactggtcc tattattgcc atggagattt taagagatga tgctatatgt 240
gaatggaaaa gactgctggg acctgcaaac tctggagtgg cacgcacaga tgcttctgaa 300
agcattagag ccctctttgg aacagatggc ataagaaatg cagcgcatgg ccctgattct 360
tttgcttctg cggccagaga aatggagttg ttttttcctt caagtggagg ttgtgggccg 420
gcaaacactg ctaaatttac ttga 444
<210> 25
<211> 147
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A1
<400> 25
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr
145
<210> 26
<211> 669
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A2
<400> 26
atgaatcata gtgaaagatt cgttttcatt gcagagtggt atgatccaaa tgcttcactt 60
cttcgacgtt atgagctttt attttaccca ggggatggat ctgttgaaat gcatgatgta 120
aagaatcatc gcaccttttt aaagcggacc aaatatgata acctgcactt ggaagattta 180
tttataggca acaaagtgaa tgtcttttct cgacaactgg tattaattga ctatggggat 240
caatatacag ctcgccagct gggcagtagg aaagaaaaaa cgctagccct aattaaacca 300
gatgcaatat caaaggctgg agaaataatt gaaataataa acaaagctgg atttactata 360
accaaactca aaatgatgat gctttcaagg aaagaagcat tggattttca tgtagatcac 420
cagtcaagac cctttttcaa tgagctgatc cagtttatta caactggtcc tattattgcc 480
atggagattt taagagatga tgctatatgt gaatggaaaa gactgctggg acctgcaaac 540
tctggagtgg cacgcacaga tgcttctgaa agcattagag ccctctttgg aacagatggc 600
ataagaaatg cagcgcatgg ccctgattct tttgcttctg cggccagaga aatggagttg 660
tttttttga 669
<210> 27
<211> 222
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A2
<400> 27
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe
210 215 220
<210> 28
<211> 714
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A3
<400> 28
atgaatcata gtgaaagatt cgttttcatt gcagagtggt atgatccaaa tgcttcactt 60
cttcgacgtt atgagctttt attttaccca ggggatggat ctgttgaaat gcatgatgta 120
aagaatcatc gcaccttttt aaagcggacc aaatatgata acctgcactt ggaagattta 180
tttataggca acaaagtgaa tgtcttttct cgacaactgg tattaattga ctatggggat 240
caatatacag ctcgccagct gggcagtagg aaagaaaaaa cgctagccct aattaaacca 300
gatgcaatat caaaggctgg agaaataatt gaaataataa acaaagctgg atttactata 360
accaaactca aaatgatgat gctttcaagg aaagaagcat tggattttca tgtagatcac 420
cagtcaagac cctttttcaa tgagctgatc cagtttatta caactggtcc tattattgcc 480
atggagattt taagagatga tgctatatgt gaatggaaaa gactgctggg acctgcaaac 540
tctggagtgg cacgcacaga tgcttctgaa agcattagag ccctctttgg aacagatggc 600
ataagaaatg cagcgcatgg ccctgattct tttgcttctg cggccagaga aatggagttg 660
ttttttcctt caagtggagg ttgtgggccg gcaaacactg ctaaatttac ttga 714
<210> 29
<211> 237
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A3
<400> 29
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser
210 215 220
Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr
225 230 235
<210> 30
<211> 408
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B
<400> 30
atgaattgta cctgttgcat tgttaaaccc catgctgtca gtgaaggact gttgggaaag 60
atcctgatgg ctatccgaga tgcaggtttt gaaatctcag ctatgcagat gttcaatatg 120
gatcgggtta atgttgagga attctatgaa gtttataaag gagtagtgac cgaatatcat 180
gacatggtga cagaaatgta ttctggccct tgtgtagcaa tggagattca acagaataat 240
gctacaaaga catttcgaga attttgtgga cctgctgatc ctgaaattgc ccggcattta 300
cgccctggaa ctctcagagc aatctttggt aaaactaaga tccagaatgc tgttcactgt 360
actgatctgc cagaggatgg cctattagag gttcaatact tcttctga 408
<210> 31
<211> 135
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B
<400> 31
Met Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
1 5 10 15
Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile
20 25 30
Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe
35 40 45
Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr
50 55 60
Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn
65 70 75 80
Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile
85 90 95
Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr
100 105 110
Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu
115 120 125
Leu Glu Val Gln Tyr Phe Phe
130 135
<210> 32
<211> 426
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B1
<400> 32
atgaattgta cctgttgcat tgttaaaccc catgctgtca gtgaaggact gttgggaaag 60
atcctgatgg ctatccgaga tgcaggtttt gaaatctcag ctatgcagat gttcaatatg 120
gatcgggtta atgttgagga attctatgaa gtttataaag gagtagtgac cgaatatcat 180
gacatggtga cagaaatgta ttctggccct tgtgtagcaa tggagattca acagaataat 240
gctacaaaga catttcgaga attttgtgga cctgctgatc ctgaaattgc ccggcattta 300
cgccctggaa ctctcagagc aatctttggt aaaactaaga tccagaatgc tgttcactgt 360
actgatctgc cagaggatgg cctattagag gttcaatact tcttcaagat cttggataat 420
tagtga 426
<210> 33
<211> 140
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B1
<400> 33
Met Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
1 5 10 15
Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile
20 25 30
Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe
35 40 45
Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr
50 55 60
Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn
65 70 75 80
Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile
85 90 95
Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr
100 105 110
Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu
115 120 125
Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
130 135 140
<210> 34
<211> 453
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B2
<400> 34
atgccttcaa gtggaggttg tgggccggca aacactgcta aatttactaa ttgtacctgt 60
tgcattgtta aaccccatgc tgtcagtgaa ggactgttgg gaaagatcct gatggctatc 120
cgagatgcag gttttgaaat ctcagctatg cagatgttca atatggatcg ggttaatgtt 180
gaggaattct atgaagttta taaaggagta gtgaccgaat atcatgacat ggtgacagaa 240
atgtattctg gcccttgtgt agcaatggag attcaacaga ataatgctac aaagacattt 300
cgagaatttt gtggacctgc tgatcctgaa attgcccggc atttacgccc tggaactctc 360
agagcaatct ttggtaaaac taagatccag aatgctgttc actgtactga tctgccagag 420
gatggcctat tagaggttca atacttcttc tga 453
<210> 35
<211> 150
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B2
<400> 35
Met Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr
1 5 10 15
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
20 25 30
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
35 40 45
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
50 55 60
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
65 70 75 80
Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala
85 90 95
Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala
100 105 110
Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys
115 120 125
Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu
130 135 140
Glu Val Gln Tyr Phe Phe
145 150
<210> 36
<211> 471
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B3
<400> 36
atgccttcaa gtggaggttg tgggccggca aacactgcta aatttactaa ttgtacctgt 60
tgcattgtta aaccccatgc tgtcagtgaa ggactgttgg gaaagatcct gatggctatc 120
cgagatgcag gttttgaaat ctcagctatg cagatgttca atatggatcg ggttaatgtt 180
gaggaattct atgaagttta taaaggagta gtgaccgaat atcatgacat ggtgacagaa 240
atgtattctg gcccttgtgt agcaatggag attcaacaga ataatgctac aaagacattt 300
cgagaatttt gtggacctgc tgatcctgaa attgcccggc atttacgccc tggaactctc 360
agagcaatct ttggtaaaac taagatccag aatgctgttc actgtactga tctgccagag 420
gatggcctat tagaggttca atacttcttc aagatcttgg ataattagtg a 471
<210> 37
<211> 155
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B3
<400> 37
Met Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr
1 5 10 15
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
20 25 30
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
35 40 45
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
50 55 60
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
65 70 75 80
Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala
85 90 95
Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala
100 105 110
Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys
115 120 125
Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu
130 135 140
Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
145 150 155
<210> 38
<211> 864
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-AB, also known as NME7AB
<400> 38
atggaaaaaa cgctagccct aattaaacca gatgcaatat caaaggctgg agaaataatt 60
gaaataataa acaaagctgg atttactata accaaactca aaatgatgat gctttcaagg 120
aaagaagcat tggattttca tgtagatcac cagtcaagac cctttttcaa tgagctgatc 180
cagtttatta caactggtcc tattattgcc atggagattt taagagatga tgctatatgt 240
gaatggaaaa gactgctggg acctgcaaac tctggagtgg cacgcacaga tgcttctgaa 300
agcattagag ccctctttgg aacagatggc ataagaaatg cagcgcatgg ccctgattct 360
tttgcttctg cggccagaga aatggagttg ttttttcctt caagtggagg ttgtgggccg 420
gcaaacactg ctaaatttac taattgtacc tgttgcattg ttaaacccca tgctgtcagt 480
gaaggactgt tgggaaagat cctgatggct atccgagatg caggttttga aatctcagct 540
atgcagatgt tcaatatgga tcgggttaat gttgaggaat tctatgaagt ttataaagga 600
gtagtgaccg aatatcatga catggtgaca gaaatgtatt ctggcccttg tgtagcaatg 660
gagattcaac agaataatgc tacaaagaca tttcgagaat tttgtggacc tgctgatcct 720
gaaattgccc ggcatttacg ccctggaact ctcagagcaa tctttggtaa aactaagatc 780
cagaatgctg ttcactgtac tgatctgcca gaggatggcc tattagaggt tcaatacttc 840
ttcaagatct tggataatta gtga 864
<210> 39
<211> 286
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-AB, also known as NME7AB
<400> 39
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
145 150 155 160
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe
165 170 175
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
180 185 190
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met
195 200 205
Val Thr Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln
210 215 220
Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro
225 230 235 240
Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly
245 250 255
Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp
260 265 270
Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
275 280 285
<210> 40
<211> 846
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-AB1
<400> 40
atggaaaaaa cgctagccct aattaaacca gatgcaatat caaaggctgg agaaataatt 60
gaaataataa acaaagctgg atttactata accaaactca aaatgatgat gctttcaagg 120
aaagaagcat tggattttca tgtagatcac cagtcaagac cctttttcaa tgagctgatc 180
cagtttatta caactggtcc tattattgcc atggagattt taagagatga tgctatatgt 240
gaatggaaaa gactgctggg acctgcaaac tctggagtgg cacgcacaga tgcttctgaa 300
agcattagag ccctctttgg aacagatggc ataagaaatg cagcgcatgg ccctgattct 360
tttgcttctg cggccagaga aatggagttg ttttttcctt caagtggagg ttgtgggccg 420
gcaaacactg ctaaatttac taattgtacc tgttgcattg ttaaacccca tgctgtcagt 480
gaaggactgt tgggaaagat cctgatggct atccgagatg caggttttga aatctcagct 540
atgcagatgt tcaatatgga tcgggttaat gttgaggaat tctatgaagt ttataaagga 600
gtagtgaccg aatatcatga catggtgaca gaaatgtatt ctggcccttg tgtagcaatg 660
gagattcaac agaataatgc tacaaagaca tttcgagaat tttgtggacc tgctgatcct 720
gaaattgccc ggcatttacg ccctggaact ctcagagcaa tctttggtaa aactaagatc 780
cagaatgctg ttcactgtac tgatctgcca gaggatggcc tattagaggt tcaatacttc 840
ttctga 846
<210> 41
<211> 281
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-AB1
<400> 41
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
145 150 155 160
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe
165 170 175
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
180 185 190
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met
195 200 205
Val Thr Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln
210 215 220
Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro
225 230 235 240
Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly
245 250 255
Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp
260 265 270
Gly Leu Leu Glu Val Gln Tyr Phe Phe
275 280
<210> 42
<211> 399
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A sequence optimized for E. coli expression
<400> 42
atggaaaaaa cgctggccct gattaaaccg gatgcaatct ccaaagctgg cgaaattatc 60
gaaattatca acaaagcggg tttcaccatc acgaaactga aaatgatgat gctgagccgt 120
aaagaagccc tggattttca tgtcgaccac cagtctcgcc cgtttttcaa tgaactgatt 180
caattcatca ccacgggtcc gattatcgca atggaaattc tgcgtgatga cgctatctgc 240
gaatggaaac gcctgctggg cccggcaaac tcaggtgttg cgcgtaccga tgccagtgaa 300
tccattcgcg ctctgtttgg caccgatggt atccgtaatg cagcacatgg tccggactca 360
ttcgcatcgg cagctcgtga aatggaactg tttttctga 399
<210> 43
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A sequence optimized for E. coli expression
<400> 43
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe
130
<210> 44
<211> 444
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A1 sequence optimized for E. coli expression
<400> 44
atggaaaaaa cgctggccct gattaaaccg gatgcaatct ccaaagctgg cgaaattatc 60
gaaattatca acaaagcggg tttcaccatc acgaaactga aaatgatgat gctgagccgt 120
aaagaagccc tggattttca tgtcgaccac cagtctcgcc cgtttttcaa tgaactgatt 180
caattcatca ccacgggtcc gattatcgca atggaaattc tgcgtgatga cgctatctgc 240
gaatggaaac gcctgctggg cccggcaaac tcaggtgttg cgcgtaccga tgccagtgaa 300
tccattcgcg ctctgtttgg caccgatggt atccgtaatg cagcacatgg tccggactca 360
ttcgcatcgg cagctcgtga aatggaactg tttttcccga gctctggcgg ttgcggtccg 420
gcaaacaccg ccaaatttac ctga 444
<210> 45
<211> 147
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A1 sequence optimized for E. coli expression
<400> 45
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr
145
<210> 46
<211> 669
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A2 sequence optimized for E. coli expression
<400> 46
atgaatcact ccgaacgctt tgtttttatc gccgaatggt atgacccgaa tgcttccctg 60
ctgcgccgct acgaactgct gttttatccg ggcgatggta gcgtggaaat gcatgacgtt 120
aaaaatcacc gtacctttct gaaacgcacg aaatatgata atctgcatct ggaagacctg 180
tttattggca acaaagtcaa tgtgttctct cgtcagctgg tgctgatcga ttatggcgac 240
cagtacaccg cgcgtcaact gggtagtcgc aaagaaaaaa cgctggccct gattaaaccg 300
gatgcaatct ccaaagctgg cgaaattatc gaaattatca acaaagcggg tttcaccatc 360
acgaaactga aaatgatgat gctgagccgt aaagaagccc tggattttca tgtcgaccac 420
cagtctcgcc cgtttttcaa tgaactgatt caattcatca ccacgggtcc gattatcgca 480
atggaaattc tgcgtgatga cgctatctgc gaatggaaac gcctgctggg cccggcaaac 540
tcaggtgttg cgcgtaccga tgccagtgaa tccattcgcg ctctgtttgg caccgatggt 600
atccgtaatg cagcacatgg tccggactca ttcgcatcgg cagctcgtga aatggaactg 660
tttttctga 669
<210> 47
<211> 222
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A2 sequence optimized for E. coli expression
<400> 47
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe
210 215 220
<210> 48
<211> 714
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-A3 sequence optimized for E. coli expression
<400> 48
atgaatcact ccgaacgctt tgtttttatc gccgaatggt atgacccgaa tgcttccctg 60
ctgcgccgct acgaactgct gttttatccg ggcgatggta gcgtggaaat gcatgacgtt 120
aaaaatcacc gtacctttct gaaacgcacg aaatatgata atctgcatct ggaagacctg 180
tttattggca acaaagtcaa tgtgttctct cgtcagctgg tgctgatcga ttatggcgac 240
cagtacaccg cgcgtcaact gggtagtcgc aaagaaaaaa cgctggccct gattaaaccg 300
gatgcaatct ccaaagctgg cgaaattatc gaaattatca acaaagcggg tttcaccatc 360
acgaaactga aaatgatgat gctgagccgt aaagaagccc tggattttca tgtcgaccac 420
cagtctcgcc cgtttttcaa tgaactgatt caattcatca ccacgggtcc gattatcgca 480
atggaaattc tgcgtgatga cgctatctgc gaatggaaac gcctgctggg cccggcaaac 540
tcaggtgttg cgcgtaccga tgccagtgaa tccattcgcg ctctgtttgg caccgatggt 600
atccgtaatg cagcacatgg tccggactca ttcgcatcgg cagctcgtga aatggaactg 660
tttttcccga gctctggcgg ttgcggtccg gcaaacaccg ccaaatttac ctga 714
<210> 49
<211> 237
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-A3 sequence optimized for E. coli expression
<400> 49
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser
210 215 220
Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr
225 230 235
<210> 50
<211> 408
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B sequence optimized for E. coli expression
<400> 50
atgaattgta cgtgctgtat tgtcaaaccg cacgcagtgt cagaaggcct gctgggtaaa 60
attctgatgg caatccgtga tgctggcttt gaaatctcgg ccatgcagat gttcaacatg 120
gaccgcgtta acgtcgaaga attctacgaa gtttacaaag gcgtggttac cgaatatcac 180
gatatggtta cggaaatgta ctccggtccg tgcgtcgcga tggaaattca gcaaaacaat 240
gccaccaaaa cgtttcgtga attctgtggt ccggcagatc cggaaatcgc acgtcatctg 300
cgtccgggta ccctgcgcgc aatttttggt aaaacgaaaa tccagaacgc tgtgcactgt 360
accgatctgc cggaagacgg tctgctggaa gttcaatact ttttctga 408
<210> 51
<211> 135
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B sequence optimized for E. coli expression
<400> 51
Met Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
1 5 10 15
Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile
20 25 30
Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe
35 40 45
Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr
50 55 60
Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn
65 70 75 80
Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile
85 90 95
Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr
100 105 110
Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu
115 120 125
Leu Glu Val Gln Tyr Phe Phe
130 135
<210> 52
<211> 423
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B1 sequence optimized for E. coli expression
<400> 52
atgaattgta cgtgctgtat tgtcaaaccg cacgcagtgt cagaaggcct gctgggtaaa 60
attctgatgg caatccgtga tgctggcttt gaaatctcgg ccatgcagat gttcaacatg 120
gaccgcgtta acgtcgaaga attctacgaa gtttacaaag gcgtggttac cgaatatcac 180
gatatggtta cggaaatgta ctccggtccg tgcgtcgcga tggaaattca gcaaaacaat 240
gccaccaaaa cgtttcgtga attctgtggt ccggcagatc cggaaatcgc acgtcatctg 300
cgtccgggta ccctgcgcgc aatttttggt aaaacgaaaa tccagaacgc tgtgcactgt 360
accgatctgc cggaagacgg tctgctggaa gttcaatact ttttcaaaat tctggataat 420
tga 423
<210> 53
<211> 140
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B1 sequence optimized for E. coli expression
<400> 53
Met Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
1 5 10 15
Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile
20 25 30
Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe
35 40 45
Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr
50 55 60
Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn
65 70 75 80
Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile
85 90 95
Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr
100 105 110
Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu
115 120 125
Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
130 135 140
<210> 54
<211> 453
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B2 sequence optimized for E. coli expression
<400> 54
atgccgagct ctggcggttg cggtccggca aacaccgcca aatttaccaa ttgtacgtgc 60
tgtattgtca aaccgcacgc agtgtcagaa ggcctgctgg gtaaaattct gatggcaatc 120
cgtgatgctg gctttgaaat ctcggccatg cagatgttca acatggaccg cgttaacgtc 180
gaagaattct acgaagttta caaaggcgtg gttaccgaat atcacgatat ggttacggaa 240
atgtactccg gtccgtgcgt cgcgatggaa attcagcaaa acaatgccac caaaacgttt 300
cgtgaattct gtggtccggc agatccggaa atcgcacgtc atctgcgtcc gggtaccctg 360
cgcgcaattt ttggtaaaac gaaaatccag aacgctgtgc actgtaccga tctgccggaa 420
gacggtctgc tggaagttca atactttttc tga 453
<210> 55
<211> 150
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B2 sequence optimized for E. coli expression
<400> 55
Met Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr
1 5 10 15
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
20 25 30
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
35 40 45
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
50 55 60
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
65 70 75 80
Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala
85 90 95
Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala
100 105 110
Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys
115 120 125
Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu
130 135 140
Glu Val Gln Tyr Phe Phe
145 150
<210> 56
<211> 468
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-B3 sequence optimized for E. coli expression
<400> 56
atgccgagct ctggcggttg cggtccggca aacaccgcca aatttaccaa ttgtacgtgc 60
tgtattgtca aaccgcacgc agtgtcagaa ggcctgctgg gtaaaattct gatggcaatc 120
cgtgatgctg gctttgaaat ctcggccatg cagatgttca acatggaccg cgttaacgtc 180
gaagaattct acgaagttta caaaggcgtg gttaccgaat atcacgatat ggttacggaa 240
atgtactccg gtccgtgcgt cgcgatggaa attcagcaaa acaatgccac caaaacgttt 300
cgtgaattct gtggtccggc agatccggaa atcgcacgtc atctgcgtcc gggtaccctg 360
cgcgcaattt ttggtaaaac gaaaatccag aacgctgtgc actgtaccga tctgccggaa 420
gacggtctgc tggaagttca atactttttc aaaattctgg ataattga 468
<210> 57
<211> 155
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-B3 sequence optimized for E. coli expression
<400> 57
Met Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr
1 5 10 15
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
20 25 30
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
35 40 45
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
50 55 60
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
65 70 75 80
Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala
85 90 95
Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala
100 105 110
Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys
115 120 125
Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu
130 135 140
Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
145 150 155
<210> 58
<211> 861
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-AB, also known as NME7AB sequence optimized for E.
coli expression
<400> 58
atggaaaaaa cgctggccct gattaaaccg gatgcaatct ccaaagctgg cgaaattatc 60
gaaattatca acaaagcggg tttcaccatc acgaaactga aaatgatgat gctgagccgt 120
aaagaagccc tggattttca tgtcgaccac cagtctcgcc cgtttttcaa tgaactgatt 180
caattcatca ccacgggtcc gattatcgca atggaaattc tgcgtgatga cgctatctgc 240
gaatggaaac gcctgctggg cccggcaaac tcaggtgttg cgcgtaccga tgccagtgaa 300
tccattcgcg ctctgtttgg caccgatggt atccgtaatg cagcacatgg tccggactca 360
ttcgcatcgg cagctcgtga aatggaactg tttttcccga gctctggcgg ttgcggtccg 420
gcaaacaccg ccaaatttac caattgtacg tgctgtattg tcaaaccgca cgcagtgtca 480
gaaggcctgc tgggtaaaat tctgatggca atccgtgatg ctggctttga aatctcggcc 540
atgcagatgt tcaacatgga ccgcgttaac gtcgaagaat tctacgaagt ttacaaaggc 600
gtggttaccg aatatcacga tatggttacg gaaatgtact ccggtccgtg cgtcgcgatg 660
gaaattcagc aaaacaatgc caccaaaacg tttcgtgaat tctgtggtcc ggcagatccg 720
gaaatcgcac gtcatctgcg tccgggtacc ctgcgcgcaa tttttggtaa aacgaaaatc 780
cagaacgctg tgcactgtac cgatctgccg gaagacggtc tgctggaagt tcaatacttt 840
ttcaaaattc tggataattg a 861
<210> 59
<211> 286
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-AB, also known as NME7AB sequence optimized for E.
coli expression
<400> 59
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
145 150 155 160
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe
165 170 175
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
180 185 190
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met
195 200 205
Val Thr Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln
210 215 220
Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro
225 230 235 240
Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly
245 250 255
Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp
260 265 270
Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
275 280 285
<210> 60
<211> 846
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-AB1, also known as NME7AB1 sequence optimized for E.
coli expression
<400> 60
atggaaaaaa cgctggccct gattaaaccg gatgcaatct ccaaagctgg cgaaattatc 60
gaaattatca acaaagcggg tttcaccatc acgaaactga aaatgatgat gctgagccgt 120
aaagaagccc tggattttca tgtcgaccac cagtctcgcc cgtttttcaa tgaactgatt 180
caattcatca ccacgggtcc gattatcgca atggaaattc tgcgtgatga cgctatctgc 240
gaatggaaac gcctgctggg cccggcaaac tcaggtgttg cgcgtaccga tgccagtgaa 300
tccattcgcg ctctgtttgg caccgatggt atccgtaatg cagcacatgg tccggactca 360
ttcgcatcgg cagctcgtga aatggaactg tttttcccga gctctggcgg ttgcggtccg 420
gcaaacaccg ccaaatttac caattgtacg tgctgtattg tcaaaccgca cgcagtgtca 480
gaaggcctgc tgggtaaaat tctgatggca atccgtgatg ctggctttga aatctcggcc 540
atgcagatgt tcaacatgga ccgcgttaac gtcgaagaat tctacgaagt ttacaaaggc 600
gtggttaccg aatatcacga tatggttacg gaaatgtact ccggtccgtg cgtcgcgatg 660
gaaattcagc aaaacaatgc caccaaaacg tttcgtgaat tctgtggtcc ggcagatccg 720
gaaatcgcac gtcatctgcg tccgggtacc ctgcgcgcaa tttttggtaa aacgaaaatc 780
cagaacgctg tgcactgtac cgatctgccg gaagacggtc tgctggaagt tcaatacttt 840
ttctga 846
<210> 61
<211> 281
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-AB1, also known as NME7AB1 sequence optimized for E.
coli expression
<400> 61
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
145 150 155 160
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe
165 170 175
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
180 185 190
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met
195 200 205
Val Thr Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln
210 215 220
Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro
225 230 235 240
Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly
245 250 255
Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp
260 265 270
Gly Leu Leu Glu Val Gln Tyr Phe Phe
275 280
<210> 62
<211> 570
<212> DNA
<213> Artificial Sequence
<220>
<223> Mouse NME6
<400> 62
atgacctcca tcttgcgaag tccccaagct cttcagctca cactagccct gatcaagcct 60
gatgcagttg cccacccact gatcctggag gctgttcatc agcagattct gagcaacaag 120
ttcctcattg tacgaacgag ggaactgcag tggaagctgg aggactgccg gaggttttac 180
cgagagcatg aagggcgttt tttctatcag cggctggtgg agttcatgac aagtgggcca 240
atccgagcct atatccttgc ccacaaagat gccatccaac tttggaggac actgatggga 300
cccaccagag tatttcgagc acgctatata gccccagatt caattcgtgg aagtttgggc 360
ctcactgaca cccgaaatac tacccatggc tcagactccg tggtttccgc cagcagagag 420
attgcagcct tcttccctga cttcagtgaa cagcgctggt atgaggagga ggaaccccag 480
ctgcggtgtg gtcctgtgca ctacagtcca gaggaaggta tccactgtgc agctgaaaca 540
ggaggccaca aacaacctaa caaaacctag 570
<210> 63
<211> 189
<212> PRT
<213> Artificial Sequence
<220>
<223> Mouse NME6
<400> 63
Met Thr Ser Ile Leu Arg Ser Pro Gln Ala Leu Gln Leu Thr Leu Ala
1 5 10 15
Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu Ile Leu Glu Ala Val
20 25 30
His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile Val Arg Thr Arg Glu
35 40 45
Leu Gln Trp Lys Leu Glu Asp Cys Arg Arg Phe Tyr Arg Glu His Glu
50 55 60
Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe Met Thr Ser Gly Pro
65 70 75 80
Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala Ile Gln Leu Trp Arg
85 90 95
Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala Arg Tyr Ile Ala Pro
100 105 110
Asp Ser Ile Arg Gly Ser Leu Gly Leu Thr Asp Thr Arg Asn Thr Thr
115 120 125
His Gly Ser Asp Ser Val Val Ser Ala Ser Arg Glu Ile Ala Ala Phe
130 135 140
Phe Pro Asp Phe Ser Glu Gln Arg Trp Tyr Glu Glu Glu Glu Pro Gln
145 150 155 160
Leu Arg Cys Gly Pro Val His Tyr Ser Pro Glu Glu Gly Ile His Cys
165 170 175
Ala Ala Glu Thr Gly Gly His Lys Gln Pro Asn Lys Thr
180 185
<210> 64
<211> 585
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6
<400> 64
atgacccaga atctggggag tgagatggcc tcaatcttgc gaagccctca ggctctccag 60
ctcactctag ccctgatcaa gcctgacgca gtcgcccatc cactgattct ggaggctgtt 120
catcagcaga ttctaagcaa caagttcctg attgtacgaa tgagagaact actgtggaga 180
aaggaagatt gccagaggtt ttaccgagag catgaagggc gttttttcta tcagaggctg 240
gtggagttca tggccagcgg gccaatccga gcctacatcc ttgcccacaa ggatgccatc 300
cagctctgga ggacgctcat gggacccacc agagtgttcc gagcacgcca tgtggcccca 360
gattctatcc gtgggagttt cggcctcact gacacccgca acaccaccca tggttcggac 420
tctgtggttt cagccagcag agagattgca gccttcttcc ctgacttcag tgaacagcgc 480
tggtatgagg aggaagagcc ccagttgcgc tgtggccctg tgtgctatag cccagaggga 540
ggtgtccact atgtagctgg aacaggaggc ctaggaccag cctga 585
<210> 65
<211> 194
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6
<400> 65
Met Thr Gln Asn Leu Gly Ser Glu Met Ala Ser Ile Leu Arg Ser Pro
1 5 10 15
Gln Ala Leu Gln Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala
20 25 30
His Pro Leu Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys
35 40 45
Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys
50 55 60
Gln Arg Phe Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu
65 70 75 80
Val Glu Phe Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His
85 90 95
Lys Asp Ala Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val
100 105 110
Phe Arg Ala Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly
115 120 125
Leu Thr Asp Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser
130 135 140
Ala Ser Arg Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg
145 150 155 160
Trp Tyr Glu Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val Cys Tyr
165 170 175
Ser Pro Glu Gly Gly Val His Tyr Val Ala Gly Thr Gly Gly Leu Gly
180 185 190
Pro Ala
<210> 66
<211> 525
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 1
<400> 66
atgacccaga atctggggag tgagatggcc tcaatcttgc gaagccctca ggctctccag 60
ctcactctag ccctgatcaa gcctgacgca gtcgcccatc cactgattct ggaggctgtt 120
catcagcaga ttctaagcaa caagttcctg attgtacgaa tgagagaact actgtggaga 180
aaggaagatt gccagaggtt ttaccgagag catgaagggc gttttttcta tcagaggctg 240
gtggagttca tggccagcgg gccaatccga gcctacatcc ttgcccacaa ggatgccatc 300
cagctctgga ggacgctcat gggacccacc agagtgttcc gagcacgcca tgtggcccca 360
gattctatcc gtgggagttt cggcctcact gacacccgca acaccaccca tggttcggac 420
tctgtggttt cagccagcag agagattgca gccttcttcc ctgacttcag tgaacagcgc 480
tggtatgagg aggaagagcc ccagttgcgc tgtggccctg tgtga 525
<210> 67
<211> 174
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 1
<400> 67
Met Thr Gln Asn Leu Gly Ser Glu Met Ala Ser Ile Leu Arg Ser Pro
1 5 10 15
Gln Ala Leu Gln Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala
20 25 30
His Pro Leu Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys
35 40 45
Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys
50 55 60
Gln Arg Phe Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu
65 70 75 80
Val Glu Phe Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His
85 90 95
Lys Asp Ala Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val
100 105 110
Phe Arg Ala Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly
115 120 125
Leu Thr Asp Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser
130 135 140
Ala Ser Arg Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg
145 150 155 160
Trp Tyr Glu Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val
165 170
<210> 68
<211> 468
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 2
<400> 68
atgctcactc tagccctgat caagcctgac gcagtcgccc atccactgat tctggaggct 60
gttcatcagc agattctaag caacaagttc ctgattgtac gaatgagaga actactgtgg 120
agaaaggaag attgccagag gttttaccga gagcatgaag ggcgtttttt ctatcagagg 180
ctggtggagt tcatggccag cgggccaatc cgagcctaca tccttgccca caaggatgcc 240
atccagctct ggaggacgct catgggaccc accagagtgt tccgagcacg ccatgtggcc 300
ccagattcta tccgtgggag tttcggcctc actgacaccc gcaacaccac ccatggttcg 360
gactctgtgg tttcagccag cagagagatt gcagccttct tccctgactt cagtgaacag 420
cgctggtatg aggaggaaga gccccagttg cgctgtggcc ctgtgtga 468
<210> 69
<211> 155
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 2
<400> 69
Met Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu
1 5 10 15
Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile
20 25 30
Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe
35 40 45
Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe
50 55 60
Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala
65 70 75 80
Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala
85 90 95
Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr Asp
100 105 110
Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser Arg
115 120 125
Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg Trp Tyr Glu
130 135 140
Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val
145 150 155
<210> 70
<211> 528
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 3
<400> 70
atgctcactc tagccctgat caagcctgac gcagtcgccc atccactgat tctggaggct 60
gttcatcagc agattctaag caacaagttc ctgattgtac gaatgagaga actactgtgg 120
agaaaggaag attgccagag gttttaccga gagcatgaag ggcgtttttt ctatcagagg 180
ctggtggagt tcatggccag cgggccaatc cgagcctaca tccttgccca caaggatgcc 240
atccagctct ggaggacgct catgggaccc accagagtgt tccgagcacg ccatgtggcc 300
ccagattcta tccgtgggag tttcggcctc actgacaccc gcaacaccac ccatggttcg 360
gactctgtgg tttcagccag cagagagatt gcagccttct tccctgactt cagtgaacag 420
cgctggtatg aggaggaaga gccccagttg cgctgtggcc ctgtgtgcta tagcccagag 480
ggaggtgtcc actatgtagc tggaacagga ggcctaggac cagcctga 528
<210> 71
<211> 175
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 3
<400> 71
Met Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu
1 5 10 15
Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile
20 25 30
Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe
35 40 45
Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe
50 55 60
Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala
65 70 75 80
Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala
85 90 95
Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr Asp
100 105 110
Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser Arg
115 120 125
Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg Trp Tyr Glu
130 135 140
Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val Cys Tyr Ser Pro Glu
145 150 155 160
Gly Gly Val His Tyr Val Ala Gly Thr Gly Gly Leu Gly Pro Ala
165 170 175
<210> 72
<211> 585
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 sequence optimized for E. coli expression
<400> 72
atgacgcaaa atctgggctc ggaaatggca agtatcctgc gctccccgca agcactgcaa 60
ctgaccctgg ctctgatcaa accggacgct gttgctcatc cgctgattct ggaagcggtc 120
caccagcaaa ttctgagcaa caaatttctg atcgtgcgta tgcgcgaact gctgtggcgt 180
aaagaagatt gccagcgttt ttatcgcgaa catgaaggcc gtttctttta tcaacgcctg 240
gttgaattca tggcctctgg tccgattcgc gcatatatcc tggctcacaa agatgcgatt 300
cagctgtggc gtaccctgat gggtccgacg cgcgtctttc gtgcacgtca tgtggcaccg 360
gactcaatcc gtggctcgtt cggtctgacc gatacgcgca ataccacgca cggtagcgac 420
tctgttgtta gtgcgtcccg tgaaatcgcg gcctttttcc cggacttctc cgaacagcgt 480
tggtacgaag aagaagaacc gcaactgcgc tgtggcccgg tctgttattc tccggaaggt 540
ggtgtccatt atgtggcggg cacgggtggt ctgggtccgg catga 585
<210> 73
<211> 194
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 sequence optimized for E. coli expression
<400> 73
Met Thr Gln Asn Leu Gly Ser Glu Met Ala Ser Ile Leu Arg Ser Pro
1 5 10 15
Gln Ala Leu Gln Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala
20 25 30
His Pro Leu Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys
35 40 45
Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys
50 55 60
Gln Arg Phe Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu
65 70 75 80
Val Glu Phe Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His
85 90 95
Lys Asp Ala Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val
100 105 110
Phe Arg Ala Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly
115 120 125
Leu Thr Asp Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser
130 135 140
Ala Ser Arg Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg
145 150 155 160
Trp Tyr Glu Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val Cys Tyr
165 170 175
Ser Pro Glu Gly Gly Val His Tyr Val Ala Gly Thr Gly Gly Leu Gly
180 185 190
Pro Ala
<210> 74
<211> 525
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 1 sequence optimized for E. coli expression
<400> 74
atgacgcaaa atctgggctc ggaaatggca agtatcctgc gctccccgca agcactgcaa 60
ctgaccctgg ctctgatcaa accggacgct gttgctcatc cgctgattct ggaagcggtc 120
caccagcaaa ttctgagcaa caaatttctg atcgtgcgta tgcgcgaact gctgtggcgt 180
aaagaagatt gccagcgttt ttatcgcgaa catgaaggcc gtttctttta tcaacgcctg 240
gttgaattca tggcctctgg tccgattcgc gcatatatcc tggctcacaa agatgcgatt 300
cagctgtggc gtaccctgat gggtccgacg cgcgtctttc gtgcacgtca tgtggcaccg 360
gactcaatcc gtggctcgtt cggtctgacc gatacgcgca ataccacgca cggtagcgac 420
tctgttgtta gtgcgtcccg tgaaatcgcg gcctttttcc cggacttctc cgaacagcgt 480
tggtacgaag aagaagaacc gcaactgcgc tgtggcccgg tctga 525
<210> 75
<211> 174
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 1 sequence optimized for E. coli expression
<400> 75
Met Thr Gln Asn Leu Gly Ser Glu Met Ala Ser Ile Leu Arg Ser Pro
1 5 10 15
Gln Ala Leu Gln Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala
20 25 30
His Pro Leu Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys
35 40 45
Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys
50 55 60
Gln Arg Phe Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu
65 70 75 80
Val Glu Phe Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His
85 90 95
Lys Asp Ala Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val
100 105 110
Phe Arg Ala Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly
115 120 125
Leu Thr Asp Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser
130 135 140
Ala Ser Arg Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg
145 150 155 160
Trp Tyr Glu Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val
165 170
<210> 76
<211> 468
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 2 sequence optimized for E. coli expression
<400> 76
atgctgaccc tggctctgat caaaccggac gctgttgctc atccgctgat tctggaagcg 60
gtccaccagc aaattctgag caacaaattt ctgatcgtgc gtatgcgcga actgctgtgg 120
cgtaaagaag attgccagcg tttttatcgc gaacatgaag gccgtttctt ttatcaacgc 180
ctggttgaat tcatggcctc tggtccgatt cgcgcatata tcctggctca caaagatgcg 240
attcagctgt ggcgtaccct gatgggtccg acgcgcgtct ttcgtgcacg tcatgtggca 300
ccggactcaa tccgtggctc gttcggtctg accgatacgc gcaataccac gcacggtagc 360
gactctgttg ttagtgcgtc ccgtgaaatc gcggcctttt tcccggactt ctccgaacag 420
cgttggtacg aagaagaaga accgcaactg cgctgtggcc cggtctga 468
<210> 77
<211> 155
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 2 sequence optimized for E. coli expression
<400> 77
Met Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu
1 5 10 15
Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile
20 25 30
Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe
35 40 45
Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe
50 55 60
Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala
65 70 75 80
Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala
85 90 95
Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr Asp
100 105 110
Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser Arg
115 120 125
Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg Trp Tyr Glu
130 135 140
Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val
145 150 155
<210> 78
<211> 528
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME6 3 sequence optimized for E. coli expression
<400> 78
atgctgaccc tggctctgat caaaccggac gctgttgctc atccgctgat tctggaagcg 60
gtccaccagc aaattctgag caacaaattt ctgatcgtgc gtatgcgcga actgctgtgg 120
cgtaaagaag attgccagcg tttttatcgc gaacatgaag gccgtttctt ttatcaacgc 180
ctggttgaat tcatggcctc tggtccgatt cgcgcatata tcctggctca caaagatgcg 240
attcagctgt ggcgtaccct gatgggtccg acgcgcgtct ttcgtgcacg tcatgtggca 300
ccggactcaa tccgtggctc gttcggtctg accgatacgc gcaataccac gcacggtagc 360
gactctgttg ttagtgcgtc ccgtgaaatc gcggcctttt tcccggactt ctccgaacag 420
cgttggtacg aagaagaaga accgcaactg cgctgtggcc cggtctgtta ttctccggaa 480
ggtggtgtcc attatgtggc gggcacgggt ggtctgggtc cggcatga 528
<210> 79
<211> 175
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME6 3 sequence optimized for E. coli expression
<400> 79
Met Leu Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu
1 5 10 15
Ile Leu Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile
20 25 30
Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe
35 40 45
Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe
50 55 60
Met Ala Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala
65 70 75 80
Ile Gln Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala
85 90 95
Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr Asp
100 105 110
Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser Arg
115 120 125
Glu Ile Ala Ala Phe Phe Pro Asp Phe Ser Glu Gln Arg Trp Tyr Glu
130 135 140
Glu Glu Glu Pro Gln Leu Arg Cys Gly Pro Val Cys Tyr Ser Pro Glu
145 150 155 160
Gly Gly Val His Tyr Val Ala Gly Thr Gly Gly Leu Gly Pro Ala
165 170 175
<210> 80
<211> 1306
<212> DNA
<213> Artificial Sequence
<220>
<223> OriGene-NME7-1 full length
<400> 80
gacgttgtat acgactccta tagggcggcc gggaattcgt cgactggatc cggtaccgag 60
gagatctgcc gccgcgatcg ccatgaatca tagtgaaaga ttcgttttca ttgcagagtg 120
gtatgatcca aatgcttcac ttcttcgacg ttatgagctt ttattttacc caggggatgg 180
atctgttgaa atgcatgatg taaagaatca tcgcaccttt ttaaagcgga ccaaatatga 240
taacctgcac ttggaagatt tatttatagg caacaaagtg aatgtcttct ctcgacaact 300
ggtattaatt gactatgggg atcaatatac agctcgccag ctgggcagta ggaaagaaaa 360
aacgctagcc ctaattaaac cagatgcaat atcaaaggct ggagaaataa ttgaaataat 420
aaacaaagct ggatttacta taaccaaact caaaatgatg atgctttcaa ggaaagaagc 480
attggatttt catgtagatc accagtcaag accctttttc aatgagctga tccagtttat 540
tacaactggt cctattattg ccatggagat tttaagagat gatgctatat gtgaatggaa 600
aagactgctg ggacctgcaa actctggagt ggcacgcaca gatgcttctg aaagcattag 660
agccctcttt ggaacagatg gcataagaaa tgcagcgcat ggccctgatt cttttgcttc 720
tgcggccaga gaaatggagt tgttttttcc ttcaagtgga ggttgtgggc cggcaaacac 780
tgctaaattt actaattgta cctgttgcat tgttaaaccc catgctgtca gtgaaggact 840
gttgggaaag atcctgatgg ctatccgaga tgcaggtttt gaaatctcag ctatgcagat 900
gttcaatatg gatcgggtta atgttgagga attctatgaa gtttataaag gagtagtgac 960
cgaatatcat gacatggtga cagaaatgta ttctggccct tgtgtagcaa tggagattca 1020
acagaataat gctacaaaga catttcgaga attttgtgga cctgctgatc ctgaaattgc 1080
ccggcattta cgccctggaa ctctcagagc aatctttggt aaaactaaga tccagaatgc 1140
tgttcactgt actgatctgc cagaggatgg cctattagag gttcaatact tcttcaagat 1200
cttggataat acgcgtacgc ggccgctcga gcagaaactc atctcagaag aggatctggc 1260
agcaaatgat atcctggatt acaaggatga cgacgataag gtttaa 1306
<210> 81
<211> 407
<212> PRT
<213> Artificial Sequence
<220>
<223> OriGene-NME7-1 full length
<400> 81
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser
210 215 220
Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr
225 230 235 240
Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys
245 250 255
Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln
260 265 270
Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr
275 280 285
Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser
290 295 300
Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr
305 310 315 320
Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu
325 330 335
Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn
340 345 350
Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln
355 360 365
Tyr Phe Phe Lys Ile Leu Asp Asn Thr Arg Thr Arg Arg Leu Glu Gln
370 375 380
Lys Leu Ile Ser Glu Glu Asp Leu Ala Ala Asn Asp Ile Leu Asp Tyr
385 390 395 400
Lys Asp Asp Asp Asp Lys Val
405
<210> 82
<211> 376
<212> PRT
<213> Artificial Sequence
<220>
<223> Abnova NME7-1 Full length
<400> 82
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser
210 215 220
Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr
225 230 235 240
Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys
245 250 255
Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln
260 265 270
Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr
275 280 285
Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser
290 295 300
Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr
305 310 315 320
Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu
325 330 335
Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn
340 345 350
Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln
355 360 365
Tyr Phe Phe Lys Ile Leu Asp Asn
370 375
<210> 83
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> Abnova Partial NME7-B
<400> 83
Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr Lys Gly Val Val
1 5 10 15
Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser Gly Pro Cys Val
20 25 30
Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe
35 40 45
Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg Pro Gly Thr
50 55 60
Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val His Cys
65 70 75 80
Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys
85 90 95
Ile Leu
<210> 84
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Histidine Tag
<400> 84
ctcgagcacc accaccacca ccactga 27
<210> 85
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Strept II Tag
<400> 85
accggttgga gccatcctca gttcgaaaag taatga 36
<210> 86
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> N-10 peptide
<400> 86
Gln Phe Asn Gln Tyr Lys Thr Glu Ala Ala Ser Arg Tyr Asn Leu Thr
1 5 10 15
Ile Ser Asp Val Ser Val Ser Asp Val Pro Phe Pro Phe Ser Ala Gln
20 25 30
Ser Gly Ala
35
<210> 87
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> C-10 peptide
<400> 87
Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys
1 5 10 15
Thr Glu Ala Ala Ser Arg Tyr Asn Leu Thr Ile Ser Asp Val Ser Val
20 25 30
Ser Asp Val
35
<210> 88
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 88
Leu Ala Leu Ile Lys Pro Asp Ala
1 5
<210> 89
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 89
Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His
1 5 10 15
Gln Ser
<210> 90
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 90
Ala Leu Asp Phe His Val Asp His Gln Ser
1 5 10
<210> 91
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 91
Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu
1 5 10
<210> 92
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 92
Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro
1 5 10
<210> 93
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 93
Arg Asp Asp Ala Ile Cys Glu Trp
1 5
<210> 94
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 94
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe
1 5 10 15
Gly Thr Asp Gly Ile Arg Asn Ala Ala
20 25
<210> 95
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 95
Glu Leu Phe Phe Pro Ser Ser Gly Gly
1 5
<210> 96
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 96
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
1 5 10 15
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala
20 25
<210> 97
<211> 36
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 97
Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln Met
1 5 10 15
Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr Lys
20 25 30
Gly Val Val Thr
35
<210> 98
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 98
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp
1 5 10 15
<210> 99
<211> 43
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 99
Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly
1 5 10 15
Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg
20 25 30
Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala
35 40
<210> 100
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 100
Tyr Ser Gly Pro Cys Val Ala Met
1 5
<210> 101
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 101
Phe Arg Glu Phe Cys Gly Pro
1 5
<210> 102
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 102
Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr
1 5 10 15
Phe Phe Lys Ile Leu Asp Asn
20
<210> 103
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 103
Ile Gln Asn Ala Val His Cys Thr Asp
1 5
<210> 104
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 104
Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys
1 5 10 15
Ile Leu Asp Asn
20
<210> 105
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 105
Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys
1 5 10
<210> 106
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 106
Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
1 5 10
<210> 107
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 107
Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser
1 5 10 15
<210> 108
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 108
Asn Glu Leu Ile Gln Phe Ile Thr Thr
1 5
<210> 109
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 109
Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu
1 5 10
<210> 110
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 110
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe
1 5 10 15
Gly Thr Asp Gly Ile
20
<210> 111
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 111
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser
1 5 10
<210> 112
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 112
Ala Leu Phe Gly Thr Asp Gly Ile
1 5
<210> 113
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 113
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu
1 5 10
<210> 114
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 114
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala
1 5 10
<210> 115
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 115
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
1 5 10 15
<210> 116
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 116
Glu Val Tyr Lys Gly Val Val Thr
1 5
<210> 117
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 117
Glu Tyr His Asp Met Val Thr Glu
1 5
<210> 118
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 118
Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg
1 5 10 15
<210> 119
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 119
Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val
1 5 10
<210> 120
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 120
Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu
1 5 10 15
Asp Asn
<210> 121
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Peptide of NME7AB
<400> 121
Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe
1 5 10 15
Pro
<210> 122
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 122
Ile Cys Glu Trp Lys Arg Leu
1 5
<210> 123
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 123
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala
1 5 10
<210> 124
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 124
His Ala Val Ser Glu Gly Leu Leu Gly Lys
1 5 10
<210> 125
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 125
Val Thr Glu Met Tyr Ser Gly Pro
1 5
<210> 126
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 126
Asn Ala Thr Lys Thr Phe Arg Glu Phe
1 5
<210> 127
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 127
Ala Ile Arg Asp Ala Gly Phe Glu Ile
1 5
<210> 128
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 128
Ala Ile Cys Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn
1 5 10
<210> 129
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 129
Asp His Gln Ser Arg Pro Phe Phe
1 5
<210> 130
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 130
Ala Ile Cys Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn
1 5 10
<210> 131
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 131
Val Asp His Gln Ser Arg Pro Phe
1 5
<210> 132
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 132
Pro Asp Ser Phe Ala Ser
1 5
<210> 133
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME7
<400> 133
Lys Ala Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile
1 5 10 15
Thr Lys
<210> 134
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 134
Met Ala Asn Cys Glu Arg Thr Phe Ile Ala Ile Lys Pro Asp Gly Val
1 5 10 15
Gln Arg Gly Leu Val Gly Glu Ile Ile Lys Arg Phe Glu
20 25
<210> 135
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 135
Val Asp Leu Lys Asp Arg Pro Phe
1 5
<210> 136
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 136
His Gly Ser Asp Ser Val Glu Ser Ala Glu Lys Glu Ile Gly Leu Trp
1 5 10 15
Phe
<210> 137
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 137
Glu Arg Thr Phe Ile Ala Ile Lys Pro Asp Gly Val Gln Arg Gly Leu
1 5 10 15
Val Gly Glu Ile Ile Lys Arg Phe Glu
20 25
<210> 138
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 138
Val Asp Leu Lys Asp Arg Pro Phe Phe Ala Gly Leu Val Lys Tyr Met
1 5 10 15
His Ser Gly Pro Val Val Ala Met Val Trp Glu Gly Leu Asn
20 25 30
<210> 139
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 139
Asn Ile Ile His Gly Ser Asp Ser Val Glu Ser Ala Glu Lys Glu Ile
1 5 10 15
Gly Leu Trp Phe His Pro Glu Glu Leu Val
20 25
<210> 140
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Immunizing peptides derived from human NME1
<400> 140
Lys Pro Asp Gly Val Gln Arg Gly Leu Val Gly Glu Ile Ile
1 5 10
<210> 141
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A peptide 1 (A domain)
<400> 141
Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser
1 5 10 15
<210> 142
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A peptide 2 (A domain)
<400> 142
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser
1 5 10
<210> 143
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B peptide 1 (B domain)
<400> 143
Asp Ala Gly Phe Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg
1 5 10 15
Val Asn Val Glu
20
<210> 144
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B peptide 2 (B domain)
<400> 144
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
1 5 10 15
<210> 145
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B peptide 3 (B domain)
<400> 145
Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp
1 5 10 15
Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe
20 25
<210> 146
<211> 1131
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7 a
<400> 146
atgaatcata gtgaaagatt cgttttcatt gcagagtggt atgatccaaa tgcttcactt 60
cttcgacgtt atgagctttt attttaccca ggggatggat ctgttgaaat gcatgatgta 120
aagaatcatc gcaccttttt aaagcggacc aaatatgata acctgcactt ggaagattta 180
tttataggca acaaagtgaa tgtcttttct cgacaactgg tattaattga ctatggggat 240
caatatacag ctcgccagct gggcagtagg aaagaaaaaa cgctagccct aattaaacca 300
gatgcaatat caaaggctgg agaaataatt gaaataataa acaaagctgg atttactata 360
accaaactca aaatgatgat gctttcaagg aaagaagcat tggattttca tgtagatcac 420
cagtcaagac cctttttcaa tgagctgatc cagtttatta caactggtcc tattattgcc 480
atggagattt taagagatga tgctatatgt gaatggaaaa gactgctggg acctgcaaac 540
tctggagtgg cacgcacaga tgcttctgaa agcattagag ccctctttgg aacagatggc 600
ataagaaatg cagcgcatgg ccctgattct tttgcttctg cggccagaga aatggagttg 660
ttttttcctt caagtggagg ttgtgggccg gcaaacactg ctaaatttac taattgtacc 720
tgttgcattg ttaaacccca tgctgtcagt gaaggactgt tgggaaagat cctgatggct 780
atccgagatg caggttttga aatctcagct atgcagatgt tcaatatgga tcgggttaat 840
gttgaggaat tctatgaagt ttataaagga gtagtgaccg aatatcatga catggtgaca 900
gaaatgtatt ctggcccttg tgtagcaatg gagattcaac agaataatgc tacaaagaca 960
tttcgagaat tttgtggacc tgctgatcct gaaattgccc ggcatttacg ccctggaact 1020
ctcagagcaa tctttggtaa aactaagatc cagaatgctg ttcactgtac tgatctgcca 1080
gaggatggcc tattagaggt tcaatacttc ttcaagatct tggataatta g 1131
<210> 147
<211> 376
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7 a
<400> 147
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser
210 215 220
Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr
225 230 235 240
Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys
245 250 255
Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln
260 265 270
Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr
275 280 285
Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser
290 295 300
Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr
305 310 315 320
Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu
325 330 335
Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn
340 345 350
Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln
355 360 365
Tyr Phe Phe Lys Ile Leu Asp Asn
370 375
<210> 148
<211> 1023
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7 b
<400> 148
atgcatgatg taaagaatca tcgcaccttt ttaaagcgga ccaaatatga taacctgcac 60
ttggaagatt tatttatagg caacaaagtg aatgtctttt ctcgacaact ggtattaatt 120
gactatgggg atcaatatac agctcgccag ctgggcagta ggaaagaaaa aacgctagcc 180
ctaattaaac cagatgcaat atcaaaggct ggagaaataa ttgaaataat aaacaaagct 240
ggatttacta taaccaaact caaaatgatg atgctttcaa ggaaagaagc attggatttt 300
catgtagatc accagtcaag accctttttc aatgagctga tccagtttat tacaactggt 360
cctattattg ccatggagat tttaagagat gatgctatat gtgaatggaa aagactgctg 420
ggacctgcaa actctggagt ggcacgcaca gatgcttctg aaagcattag agccctcttt 480
ggaacagatg gcataagaaa tgcagcgcat ggccctgatt cttttgcttc tgcggccaga 540
gaaatggagt tgttttttcc ttcaagtgga ggttgtgggc cggcaaacac tgctaaattt 600
actaattgta cctgttgcat tgttaaaccc catgctgtca gtgaaggact gttgggaaag 660
atcctgatgg ctatccgaga tgcaggtttt gaaatctcag ctatgcagat gttcaatatg 720
gatcgggtta atgttgagga attctatgaa gtttataaag gagtagtgac cgaatatcat 780
gacatggtga cagaaatgta ttctggccct tgtgtagcaa tggagattca acagaataat 840
gctacaaaga catttcgaga attttgtgga cctgctgatc ctgaaattgc ccggcattta 900
cgccctggaa ctctcagagc aatctttggt aaaactaaga tccagaatgc tgttcactgt 960
actgatctgc cagaggatgg cctattagag gttcaatact tcttcaagat cttggataat 1020
tag 1023
<210> 149
<211> 340
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7 b
<400> 149
Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys Arg Thr Lys Tyr
1 5 10 15
Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn Lys Val Asn Val
20 25 30
Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp Gln Tyr Thr Ala
35 40 45
Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala Leu Ile Lys Pro
50 55 60
Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala
65 70 75 80
Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu Ser Arg Lys Glu
85 90 95
Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro Phe Phe Asn Glu
100 105 110
Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala Met Glu Ile Leu
115 120 125
Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn
130 135 140
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe
145 150 155 160
Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro Asp Ser Phe Ala
165 170 175
Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys
180 185 190
Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr Cys Cys Ile Val
195 200 205
Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys Ile Leu Met Ala
210 215 220
Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln Met Phe Asn Met
225 230 235 240
Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr Lys Gly Val Val
245 250 255
Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser Gly Pro Cys Val
260 265 270
Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe
275 280 285
Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg Pro Gly Thr
290 295 300
Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val His Cys
305 310 315 320
Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys
325 330 335
Ile Leu Asp Asn
340
<210> 150
<211> 861
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-AB also known as NME7AB
<400> 150
atggaaaaaa cgctagccct aattaaacca gatgcaatat caaaggctgg agaaataatt 60
gaaataataa acaaagctgg atttactata accaaactca aaatgatgat gctttcaagg 120
aaagaagcat tggattttca tgtagatcac cagtcaagac cctttttcaa tgagctgatc 180
cagtttatta caactggtcc tattattgcc atggagattt taagagatga tgctatatgt 240
gaatggaaaa gactgctggg acctgcaaac tctggagtgg cacgcacaga tgcttctgaa 300
agcattagag ccctctttgg aacagatggc ataagaaatg cagcgcatgg ccctgattct 360
tttgcttctg cggccagaga aatggagttg ttttttcctt caagtggagg ttgtgggccg 420
gcaaacactg ctaaatttac taattgtacc tgttgcattg ttaaacccca tgctgtcagt 480
gaaggactgt tgggaaagat cctgatggct atccgagatg caggttttga aatctcagct 540
atgcagatgt tcaatatgga tcgggttaat gttgaggaat tctatgaagt ttataaagga 600
gtagtgaccg aatatcatga catggtgaca gaaatgtatt ctggcccttg tgtagcaatg 660
gagattcaac agaataatgc tacaaagaca tttcgagaat tttgtggacc tgctgatcct 720
gaaattgccc ggcatttacg ccctggaact ctcagagcaa tctttggtaa aactaagatc 780
cagaatgctg ttcactgtac tgatctgcca gaggatggcc tattagaggt tcaatacttc 840
ttcaagatct tggataatta g 861
<210> 151
<211> 286
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-AB also known as NME7AB
<400> 151
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
145 150 155 160
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe
165 170 175
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
180 185 190
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met
195 200 205
Val Thr Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln
210 215 220
Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro
225 230 235 240
Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly
245 250 255
Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp
260 265 270
Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
275 280 285
<210> 152
<211> 759
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-X1
<400> 152
atgatgatgc tttcaaggaa agaagcattg gattttcatg tagatcacca gtcaagaccc 60
tttttcaatg agctgatcca gtttattaca actggtccta ttattgccat ggagatttta 120
agagatgatg ctatatgtga atggaaaaga ctgctgggac ctgcaaactc tggagtggca 180
cgcacagatg cttctgaaag cattagagcc ctctttggaa cagatggcat aagaaatgca 240
gcgcatggcc ctgattcttt tgcttctgcg gccagagaaa tggagttgtt ttttccttca 300
agtggaggtt gtgggccggc aaacactgct aaatttacta attgtacctg ttgcattgtt 360
aaaccccatg ctgtcagtga aggactgttg ggaaagatcc tgatggctat ccgagatgca 420
ggttttgaaa tctcagctat gcagatgttc aatatggatc gggttaatgt tgaggaattc 480
tatgaagttt ataaaggagt agtgaccgaa tatcatgaca tggtgacaga aatgtattct 540
ggcccttgtg tagcaatgga gattcaacag aataatgcta caaagacatt tcgagaattt 600
tgtggacctg ctgatcctga aattgcccgg catttacgcc ctggaactct cagagcaatc 660
tttggtaaaa ctaagatcca gaatgctgtt cactgtactg atctgccaga ggatggccta 720
ttagaggttc aatacttctt caagatcttg gataattag 759
<210> 153
<211> 252
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-X1
<400> 153
Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His
1 5 10 15
Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly
20 25 30
Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp
35 40 45
Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala
50 55 60
Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala
65 70 75 80
Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu
85 90 95
Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe
100 105 110
Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
115 120 125
Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile
130 135 140
Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe
145 150 155 160
Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr
165 170 175
Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn
180 185 190
Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile
195 200 205
Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr
210 215 220
Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu
225 230 235 240
Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn
245 250
<210> 154
<211> 1128
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7 a (optimized for E coli expression)
<400> 154
atgaatcact ccgaacgctt tgtttttatc gccgaatggt atgacccgaa tgcttccctg 60
ctgcgccgct acgaactgct gttttatccg ggcgatggta gcgtggaaat gcatgacgtt 120
aaaaatcacc gtacctttct gaaacgcacg aaatatgata atctgcatct ggaagacctg 180
tttattggca acaaagtcaa tgtgttctct cgtcagctgg tgctgatcga ttatggcgac 240
cagtacaccg cgcgtcaact gggtagtcgc aaagaaaaaa cgctggccct gattaaaccg 300
gatgcaatct ccaaagctgg cgaaattatc gaaattatca acaaagcggg tttcaccatc 360
acgaaactga aaatgatgat gctgagccgt aaagaagccc tggattttca tgtcgaccac 420
cagtctcgcc cgtttttcaa tgaactgatt caattcatca ccacgggtcc gattatcgca 480
atggaaattc tgcgtgatga cgctatctgc gaatggaaac gcctgctggg cccggcaaac 540
tcaggtgttg cgcgtaccga tgccagtgaa tccattcgcg ctctgtttgg caccgatggt 600
atccgtaatg cagcacatgg tccggactca ttcgcatcgg cagctcgtga aatggaactg 660
tttttcccga gctctggcgg ttgcggtccg gcaaacaccg ccaaatttac caattgtacg 720
tgctgtattg tcaaaccgca cgcagtgtca gaaggcctgc tgggtaaaat tctgatggca 780
atccgtgatg ctggctttga aatctcggcc atgcagatgt tcaacatgga ccgcgttaac 840
gtcgaagaat tctacgaagt ttacaaaggc gtggttaccg aatatcacga tatggttacg 900
gaaatgtact ccggtccgtg cgtcgcgatg gaaattcagc aaaacaatgc caccaaaacg 960
tttcgtgaat tctgtggtcc ggcagatccg gaaatcgcac gtcatctgcg tccgggtacc 1020
ctgcgcgcaa tttttggtaa aacgaaaatc cagaacgctg tgcactgtac cgatctgccg 1080
gaagacggtc tgctggaagt tcaatacttt ttcaaaattc tggataat 1128
<210> 155
<211> 378
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7 a (optimized for E coli expression)
<400> 155
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala
85 90 95
Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile
100 105 110
Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu
115 120 125
Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro
130 135 140
Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala
145 150 155 160
Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu
165 170 175
Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile
180 185 190
Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro
195 200 205
Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser
210 215 220
Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr
225 230 235 240
Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys
245 250 255
Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln
260 265 270
Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr
275 280 285
Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser
290 295 300
Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr
305 310 315 320
Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu
325 330 335
Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn
340 345 350
Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln
355 360 365
Tyr Phe Phe Lys Ile Leu Asp Asn Thr Gly
370 375
<210> 156
<211> 1020
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7 b (optimized for E coli expression)
<400> 156
atgcatgacg ttaaaaatca ccgtaccttt ctgaaacgca cgaaatatga taatctgcat 60
ctggaagacc tgtttattgg caacaaagtc aatgtgttct ctcgtcagct ggtgctgatc 120
gattatggcg accagtacac cgcgcgtcaa ctgggtagtc gcaaagaaaa aacgctggcc 180
ctgattaaac cggatgcaat ctccaaagct ggcgaaatta tcgaaattat caacaaagcg 240
ggtttcacca tcacgaaact gaaaatgatg atgctgagcc gtaaagaagc cctggatttt 300
catgtcgacc accagtctcg cccgtttttc aatgaactga ttcaattcat caccacgggt 360
ccgattatcg caatggaaat tctgcgtgat gacgctatct gcgaatggaa acgcctgctg 420
ggcccggcaa actcaggtgt tgcgcgtacc gatgccagtg aatccattcg cgctctgttt 480
ggcaccgatg gtatccgtaa tgcagcacat ggtccggact cattcgcatc ggcagctcgt 540
gaaatggaac tgtttttccc gagctctggc ggttgcggtc cggcaaacac cgccaaattt 600
accaattgta cgtgctgtat tgtcaaaccg cacgcagtgt cagaaggcct gctgggtaaa 660
attctgatgg caatccgtga tgctggcttt gaaatctcgg ccatgcagat gttcaacatg 720
gaccgcgtta acgtcgaaga attctacgaa gtttacaaag gcgtggttac cgaatatcac 780
gatatggtta cggaaatgta ctccggtccg tgcgtcgcga tggaaattca gcaaaacaat 840
gccaccaaaa cgtttcgtga attctgtggt ccggcagatc cggaaatcgc acgtcatctg 900
cgtccgggta ccctgcgcgc aatttttggt aaaacgaaaa tccagaacgc tgtgcactgt 960
accgatctgc cggaagacgg tctgctggaa gttcaatact ttttcaaaat tctggataat 1020
<210> 157
<211> 342
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7 b (optimized for E coli expression)
<400> 157
Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys Arg Thr Lys Tyr
1 5 10 15
Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn Lys Val Asn Val
20 25 30
Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp Gln Tyr Thr Ala
35 40 45
Arg Gln Leu Gly Ser Arg Lys Glu Lys Thr Leu Ala Leu Ile Lys Pro
50 55 60
Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala
65 70 75 80
Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu Ser Arg Lys Glu
85 90 95
Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro Phe Phe Asn Glu
100 105 110
Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala Met Glu Ile Leu
115 120 125
Arg Asp Asp Ala Ile Cys Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn
130 135 140
Ser Gly Val Ala Arg Thr Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe
145 150 155 160
Gly Thr Asp Gly Ile Arg Asn Ala Ala His Gly Pro Asp Ser Phe Ala
165 170 175
Ser Ala Ala Arg Glu Met Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys
180 185 190
Gly Pro Ala Asn Thr Ala Lys Phe Thr Asn Cys Thr Cys Cys Ile Val
195 200 205
Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys Ile Leu Met Ala
210 215 220
Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln Met Phe Asn Met
225 230 235 240
Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr Lys Gly Val Val
245 250 255
Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser Gly Pro Cys Val
260 265 270
Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe
275 280 285
Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg Pro Gly Thr
290 295 300
Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val His Cys
305 310 315 320
Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys
325 330 335
Ile Leu Asp Asn Thr Gly
340
<210> 158
<211> 858
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-AB also known as NME7AB (optimized for E coli
expression)
<400> 158
atggaaaaaa cgctggccct gattaaaccg gatgcaatct ccaaagctgg cgaaattatc 60
gaaattatca acaaagcggg tttcaccatc acgaaactga aaatgatgat gctgagccgt 120
aaagaagccc tggattttca tgtcgaccac cagtctcgcc cgtttttcaa tgaactgatt 180
caattcatca ccacgggtcc gattatcgca atggaaattc tgcgtgatga cgctatctgc 240
gaatggaaac gcctgctggg cccggcaaac tcaggtgttg cgcgtaccga tgccagtgaa 300
tccattcgcg ctctgtttgg caccgatggt atccgtaatg cagcacatgg tccggactca 360
ttcgcatcgg cagctcgtga aatggaactg tttttcccga gctctggcgg ttgcggtccg 420
gcaaacaccg ccaaatttac caattgtacg tgctgtattg tcaaaccgca cgcagtgtca 480
gaaggcctgc tgggtaaaat tctgatggca atccgtgatg ctggctttga aatctcggcc 540
atgcagatgt tcaacatgga ccgcgttaac gtcgaagaat tctacgaagt ttacaaaggc 600
gtggttaccg aatatcacga tatggttacg gaaatgtact ccggtccgtg cgtcgcgatg 660
gaaattcagc aaaacaatgc caccaaaacg tttcgtgaat tctgtggtcc ggcagatccg 720
gaaatcgcac gtcatctgcg tccgggtacc ctgcgcgcaa tttttggtaa aacgaaaatc 780
cagaacgctg tgcactgtac cgatctgccg gaagacggtc tgctggaagt tcaatacttt 840
ttcaaaattc tggataat 858
<210> 159
<211> 288
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-AB also known as NME7AB (optimized for E coli
expression)
<400> 159
Met Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala
1 5 10 15
Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys
20 25 30
Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val
35 40 45
Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr
50 55 60
Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys
65 70 75 80
Glu Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr
85 90 95
Asp Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg
100 105 110
Asn Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
Glu Leu Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala
130 135 140
Lys Phe Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser
145 150 155 160
Glu Gly Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe
165 170 175
Glu Ile Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu
180 185 190
Glu Phe Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met
195 200 205
Val Thr Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln
210 215 220
Asn Asn Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro
225 230 235 240
Glu Ile Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly
245 250 255
Lys Thr Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp
260 265 270
Gly Leu Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn Thr Gly
275 280 285
<210> 160
<211> 756
<212> DNA
<213> Artificial Sequence
<220>
<223> Human NME7-X1 (optimized for E coli expression)
<400> 160
atgatgatgc tgagccgtaa agaagccctg gattttcatg tcgaccacca gtctcgcccg 60
tttttcaatg aactgattca attcatcacc acgggtccga ttatcgcaat ggaaattctg 120
cgtgatgacg ctatctgcga atggaaacgc ctgctgggcc cggcaaactc aggtgttgcg 180
cgtaccgatg ccagtgaatc cattcgcgct ctgtttggca ccgatggtat ccgtaatgca 240
gcacatggtc cggactcatt cgcatcggca gctcgtgaaa tggaactgtt tttcccgagc 300
tctggcggtt gcggtccggc aaacaccgcc aaatttacca attgtacgtg ctgtattgtc 360
aaaccgcacg cagtgtcaga aggcctgctg ggtaaaattc tgatggcaat ccgtgatgct 420
ggctttgaaa tctcggccat gcagatgttc aacatggacc gcgttaacgt cgaagaattc 480
tacgaagttt acaaaggcgt ggttaccgaa tatcacgata tggttacgga aatgtactcc 540
ggtccgtgcg tcgcgatgga aattcagcaa aacaatgcca ccaaaacgtt tcgtgaattc 600
tgtggtccgg cagatccgga aatcgcacgt catctgcgtc cgggtaccct gcgcgcaatt 660
tttggtaaaa cgaaaatcca gaacgctgtg cactgtaccg atctgccgga agacggtctg 720
ctggaagttc aatacttttt caaaattctg gataat 756
<210> 161
<211> 254
<212> PRT
<213> Artificial Sequence
<220>
<223> Human NME7-X1 (optimized for E coli expression)
<400> 161
Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His
1 5 10 15
Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly
20 25 30
Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp
35 40 45
Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala
50 55 60
Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala
65 70 75 80
Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu
85 90 95
Phe Phe Pro Ser Ser Gly Gly Cys Gly Pro Ala Asn Thr Ala Lys Phe
100 105 110
Thr Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly
115 120 125
Leu Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile
130 135 140
Ser Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe
145 150 155 160
Tyr Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr
165 170 175
Glu Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn
180 185 190
Ala Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile
195 200 205
Ala Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr
210 215 220
Lys Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu
225 230 235 240
Leu Glu Val Gln Tyr Phe Phe Lys Ile Leu Asp Asn Thr Gly
245 250
<210> 162
<211> 91
<212> PRT
<213> Artificial Sequence
<220>
<223> DM10 domain of NME7
<400> 162
Met Asn His Ser Glu Arg Phe Val Phe Ile Ala Glu Trp Tyr Asp Pro
1 5 10 15
Asn Ala Ser Leu Leu Arg Arg Tyr Glu Leu Leu Phe Tyr Pro Gly Asp
20 25 30
Gly Ser Val Glu Met His Asp Val Lys Asn His Arg Thr Phe Leu Lys
35 40 45
Arg Thr Lys Tyr Asp Asn Leu His Leu Glu Asp Leu Phe Ile Gly Asn
50 55 60
Lys Val Asn Val Phe Ser Arg Gln Leu Val Leu Ile Asp Tyr Gly Asp
65 70 75 80
Gln Tyr Thr Ala Arg Gln Leu Gly Ser Arg Lys
85 90
<210> 163
<211> 43
<212> PRT
<213> Artificial Sequence
<220>
<223> Fragment or variation of PSMGFR peptide
<400> 163
Ser Asn Ile Lys Phe Arg Pro Gly Ser Val Val Val Gln Leu Thr Leu
1 5 10 15
Ala Phe Arg Glu Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe
20 25 30
Asn Gln Tyr Lys Thr Glu Ala Ala Ser Arg Tyr
35 40
<210> 164
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> Fragment or variation of PSMGFR peptide
<400> 164
Ser Val Val Val Gln Leu Thr Leu Ala Phe Arg Glu Gly Thr Ile Asn
1 5 10 15
Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys Thr Glu Ala Ala
20 25 30
Ser Arg Tyr
35
<210> 165
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Fragment or variation of PSMGFR peptide
<400> 165
Val Gln Leu Thr Leu Ala Phe Arg Glu Gly Thr Ile Asn Val His Asp
1 5 10 15
Val Glu Thr Gln Phe Asn Gln Tyr
20
<210> 166
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Fragment or variation of PSMGFR peptide
<400> 166
Ser Asn Ile Lys Phe Arg Pro Gly Ser Val Val Val Gln Leu Thr Leu
1 5 10 15
Ala Phe Arg Glu Gly Thr Ile Asn
20
<210> 167
<211> 38
<212> PRT
<213> Artificial Sequence
<220>
<223> Fragment or variation of PSMGFR peptide
<400> 167
Ser Asn Ile Lys Phe Arg Pro Gly Ser Val Val Val Gln Leu Thr Leu
1 5 10 15
Ala Phe Arg Glu Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe
20 25 30
Asn Gln Tyr Lys Thr Glu
35
<210> 168
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> Fragment or variation of PSMGFR peptide
<400> 168
Val Gln Leu Thr Leu Ala Phe Arg Glu Gly Thr Ile Asn Val His Asp
1 5 10 15
Val Glu Thr Gln Phe Asn Gln Tyr Lys Thr Glu Ala Ala Ser Arg Tyr
20 25 30
Asn Leu Thr Ile Ser Asp Val Ser Val Ser Asp Val Pro
35 40 45
<210> 169
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> Ser of NME7B peptide 3 (B domain)
<400> 169
Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn Ala Val His Ser Thr Asp
1 5 10 15
Leu Pro Glu Asp Gly Leu Leu Glu Val Gln Tyr Phe Phe
20 25
<210> 170
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> N-10 peptide
<400> 170
Gln Phe Asn Gln Tyr Lys Thr Glu Ala Ala Ser Arg Tyr Asn Leu Thr
1 5 10 15
Ile Ser Asp Val Ser Val Ser Asp Val Pro Phe Pro Phe Ser Ala Gln
20 25 30
Ser Gly Ala
35
<210> 171
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> C-10 peptide
<400> 171
Gly Thr Ile Asn Val His Asp Val Glu Thr Gln Phe Asn Gln Tyr Lys
1 5 10 15
Thr Glu Ala Ala Ser Arg Tyr Asn Leu Thr Ile Ser Asp Val Ser Val
20 25 30
Ser Asp Val
35
<210> 172
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A5A1H heavy chain
<400> 172
Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu Thr
1 5 10 15
Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr Gly
20 25 30
Met Asn Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met Gly
35 40 45
Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe Lys
50 55 60
Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Thr Thr Ala Tyr Leu
65 70 75 80
Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ser Thr Tyr Phe Cys Ala
85 90 95
Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 173
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A4A3H heavy chain
<400> 173
Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 174
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E2B11H
<400> 174
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr
115
<210> 175
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E10E4H
<400> 175
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 176
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9G2C4H
<400> 176
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 177
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 5F3A5D4H
<400> 177
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 178
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 8H5H5G4H
<400> 178
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 179
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A4A3H
<400> 179
Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 180
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E2B11H
<400> 180
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr
115
<210> 181
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E10E4H
<400> 181
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 182
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9G2C4H
<400> 182
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 183
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 5F3A5D4H
<400> 183
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 184
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 8H5H5G4H
<400> 184
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 185
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A4A3L
<400> 185
Glu Thr Thr Val Thr Gln Ser Pro Ala Ser Leu Ser Met Ala Ile Gly
1 5 10 15
Glu Lys Val Thr Ile Arg Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Pro Pro Lys Leu Leu Ile
35 40 45
Ser Glu Gly Asn Thr Leu Arg Pro Gly Val Pro Ser Arg Phe Ser Ser
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Val Phe Thr Ile Glu Asn Met Leu Ser
65 70 75 80
Glu Asp Val Ala Asp Tyr Tyr Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 186
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E2B11L
<400> 186
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 187
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E10E4L
<400> 187
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 188
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9G2C4L
<400> 188
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 189
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5F3A5D4L
<400> 189
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 190
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 8H5H5G4L
<400> 190
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 191
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A5A1L
<400> 191
Glu Ile Leu Leu Thr Gln Ser Pro Ala Ile Ile Ala Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Ile Trp Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Phe Ser Phe Thr Ile Asn Ser Met Glu Ala Glu
65 70 75 80
Asp Val Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 192
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E2B11L
<400> 192
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 193
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9E10E4L
<400> 193
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 194
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5D9G2C4L
<400> 194
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 195
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 5F3A5D4L
<400> 195
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 196
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 8H5H5G4L
<400> 196
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 197
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A4A3L
<400> 197
Glu Thr Thr Val Thr Gln Ser Pro Ala Ser Leu Ser Met Ala Ile Gly
1 5 10 15
Glu Lys Val Thr Ile Arg Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Pro Pro Lys Leu Leu Ile
35 40 45
Ser Glu Gly Asn Thr Leu Arg Pro Gly Val Pro Ser Arg Phe Ser Ser
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Val Phe Thr Ile Glu Asn Met Leu Ser
65 70 75 80
Glu Asp Val Ala Asp Tyr Tyr Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 198
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A5A1L
<400> 198
Glu Ile Leu Leu Thr Gln Ser Pro Ala Ile Ile Ala Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Ile Trp Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Phe Ser Phe Thr Ile Asn Ser Met Glu Ala Glu
65 70 75 80
Asp Val Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 199
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 199
Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly
1 5 10 15
Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu
20 25 30
Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp
35 40 45
His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr
50 55 60
Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70 75 80
Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp
85 90 95
Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn
100 105 110
Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu
115 120 125
Leu Phe Phe
130
<210> 200
<211> 152
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2 partial sequence
<400> 200
Met Ala Asn Leu Glu Arg Thr Phe Ile Ala Ile Lys Pro Asp Gly Val
1 5 10 15
Gln Arg Gly Leu Val Gly Glu Ile Ile Lys Arg Phe Glu Gln Lys Gly
20 25 30
Phe Arg Leu Val Ala Met Lys Phe Leu Arg Ala Ser Glu Glu His Leu
35 40 45
Lys Gln His Tyr Ile Asp Leu Lys Asp Arg Pro Phe Phe Pro Gly Leu
50 55 60
Val Lys Tyr Met Asn Ser Gly Pro Val Val Ala Met Val Trp Glu Gly
65 70 75 80
Leu Asn Val Val Lys Thr Gly Arg Val Met Leu Gly Glu Thr Asn Pro
85 90 95
Ala Asp Ser Lys Pro Gly Thr Ile Arg Gly Asp Phe Cys Ile Gln Val
100 105 110
Gly Arg Asn Ile Ile His Gly Ser Asp Ser Val Lys Ser Ala Glu Lys
115 120 125
Glu Ile Ser Leu Trp Phe Lys Pro Glu Glu Leu Val Asp Tyr Lys Ser
130 135 140
Cys Ala His Asp Trp Val Tyr Glu
145 150
<210> 201
<211> 134
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 201
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
1 5 10 15
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
20 25 30
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
35 40 45
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
50 55 60
Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala
65 70 75 80
Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala
85 90 95
Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys
100 105 110
Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu
115 120 125
Glu Val Gln Tyr Phe Phe
130
<210> 202
<211> 152
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2 partial sequence
<400> 202
Met Ala Asn Leu Glu Arg Thr Phe Ile Ala Ile Lys Pro Asp Gly Val
1 5 10 15
Gln Arg Gly Leu Val Gly Glu Ile Ile Lys Arg Phe Glu Gln Lys Gly
20 25 30
Phe Arg Leu Val Ala Met Lys Phe Leu Arg Ala Ser Glu Glu His Leu
35 40 45
Lys Gln His Tyr Ile Asp Leu Lys Asp Arg Pro Phe Phe Pro Gly Leu
50 55 60
Val Lys Tyr Met Asn Ser Gly Pro Val Val Ala Met Val Trp Glu Gly
65 70 75 80
Leu Asn Val Val Lys Thr Gly Arg Val Met Leu Gly Glu Thr Asn Pro
85 90 95
Ala Asp Ser Lys Pro Gly Thr Ile Arg Gly Asp Phe Cys Ile Gln Val
100 105 110
Gly Arg Asn Ile Ile His Gly Ser Asp Ser Val Lys Ser Ala Glu Lys
115 120 125
Glu Ile Ser Leu Trp Phe Lys Pro Glu Glu Leu Val Asp Tyr Lys Ser
130 135 140
Cys Ala His Asp Trp Val Tyr Glu
145 150
<210> 203
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 203
Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly
1 5 10 15
Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu
20 25 30
Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp
35 40 45
His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr
50 55 60
Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70 75 80
Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp
85 90 95
Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn
100 105 110
Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu
115 120 125
Leu Phe Phe
130
<210> 204
<211> 130
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3 partial sequence
<400> 204
Glu Arg Thr Phe Leu Ala Val Lys Pro Asp Gly Val Gln Arg Arg Leu
1 5 10 15
Val Gly Glu Ile Val Arg Arg Phe Glu Arg Lys Gly Phe Lys Leu Val
20 25 30
Ala Leu Lys Leu Val Gln Ala Ser Glu Glu Leu Leu Arg Glu His Tyr
35 40 45
Val Glu Leu Arg Glu Arg Pro Phe Tyr Ser Arg Leu Val Lys Tyr Met
50 55 60
Gly Ser Gly Pro Val Val Ala Met Val Trp Gln Gly Leu Asp Val Val
65 70 75 80
Arg Ala Ser Arg Ala Leu Ile Gly Ala Thr Asp Pro Gly Asp Ala Thr
85 90 95
Pro Gly Thr Ile Arg Gly Asp Phe Cys Val Glu Val Gly Lys Asn Val
100 105 110
Ile His Gly Ser Asp Ser Val Glu Ser Ala Gln Arg Glu Ile Ala Leu
115 120 125
Trp Phe
130
<210> 205
<211> 134
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 205
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
1 5 10 15
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
20 25 30
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
35 40 45
Glu Val Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu
50 55 60
Met Tyr Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala
65 70 75 80
Thr Lys Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala
85 90 95
Arg His Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys
100 105 110
Ile Gln Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu
115 120 125
Glu Val Gln Tyr Phe Phe
130
<210> 206
<211> 169
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3 partial sequence
<400> 206
Met Ile Cys Leu Val Leu Thr Ile Phe Ala Asn Leu Phe Pro Ser Ala
1 5 10 15
Tyr Ser Gly Val Asn Glu Arg Thr Phe Leu Ala Val Lys Pro Asp Gly
20 25 30
Val Gln Arg Arg Leu Val Gly Glu Ile Val Arg Arg Phe Glu Arg Lys
35 40 45
Gly Phe Lys Leu Val Ala Leu Lys Leu Val Gln Ala Ser Glu Glu Leu
50 55 60
Leu Arg Glu His Tyr Val Glu Leu Arg Glu Arg Pro Phe Tyr Ser Arg
65 70 75 80
Leu Val Lys Tyr Met Gly Ser Gly Pro Val Val Ala Met Val Trp Gln
85 90 95
Gly Leu Asp Val Val Arg Ala Ser Arg Ala Leu Ile Gly Ala Thr Asp
100 105 110
Pro Gly Asp Ala Thr Pro Gly Thr Ile Arg Gly Asp Phe Cys Val Glu
115 120 125
Val Gly Lys Asn Val Ile His Gly Ser Asp Ser Val Glu Ser Ala Gln
130 135 140
Arg Glu Ile Ala Leu Trp Phe Arg Glu Asp Glu Leu Leu Cys Trp Glu
145 150 155 160
Asp Ser Ala Gly His Trp Leu Tyr Glu
165
<210> 207
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 207
Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly
1 5 10 15
Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu
20 25 30
Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp
35 40 45
His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr
50 55 60
Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70 75 80
Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp
85 90 95
Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn
100 105 110
Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu
115 120 125
Leu Phe Phe
130
<210> 208
<211> 130
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4 partial sequence
<400> 208
Glu Arg Thr Leu Val Ala Val Lys Pro Asp Gly Val Gln Arg Arg Leu
1 5 10 15
Val Gly Asp Val Ile Gln Arg Phe Glu Arg Arg Gly Phe Thr Leu Val
20 25 30
Gly Met Lys Met Leu Gln Ala Pro Glu Ser Val Leu Ala Glu His Tyr
35 40 45
Gln Asp Leu Arg Arg Lys Pro Phe Tyr Pro Ala Leu Ile Arg Tyr Met
50 55 60
Ser Ser Gly Pro Val Val Ala Met Val Trp Glu Gly Tyr Asn Val Val
65 70 75 80
Arg Ala Ser Arg Ala Met Ile Gly His Thr Asp Ser Ala Glu Ala Ala
85 90 95
Pro Gly Thr Ile Arg Gly Asp Phe Ser Val His Ile Ser Arg Asn Val
100 105 110
Ile His Ala Ser Asp Ser Val Glu Gly Ala Gln Arg Glu Ile Gln Leu
115 120 125
Trp Phe
130
<210> 209
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 209
Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly
1 5 10 15
Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met
20 25 30
Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val
35 40 45
Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr
50 55 60
Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys
65 70 75 80
Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His
85 90 95
Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln
100 105 110
Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val
115 120 125
Gln Tyr Phe Phe
130
<210> 210
<211> 128
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4 partial sequence
<400> 210
Thr Leu Val Ala Val Lys Pro Asp Gly Val Gln Arg Arg Leu Val Gly
1 5 10 15
Asp Val Ile Gln Arg Phe Glu Arg Arg Gly Phe Thr Leu Val Gly Met
20 25 30
Lys Met Leu Gln Ala Pro Glu Ser Val Leu Ala Glu His Tyr Gln Asp
35 40 45
Leu Arg Arg Lys Pro Phe Tyr Pro Ala Leu Ile Arg Tyr Met Ser Ser
50 55 60
Gly Pro Val Val Ala Met Val Trp Glu Gly Tyr Asn Val Val Arg Ala
65 70 75 80
Ser Arg Ala Met Ile Gly His Thr Asp Ser Ala Glu Ala Ala Pro Gly
85 90 95
Thr Ile Arg Gly Asp Phe Ser Val His Ile Ser Arg Asn Val Ile His
100 105 110
Ala Ser Asp Ser Val Glu Gly Ala Gln Arg Glu Ile Gln Leu Trp Phe
115 120 125
<210> 211
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 211
Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly
1 5 10 15
Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu
20 25 30
Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp
35 40 45
His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr
50 55 60
Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70 75 80
Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp
85 90 95
Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn
100 105 110
Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu
115 120 125
Leu Phe Phe
130
<210> 212
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5 partial sequence
<400> 212
Glu Lys Thr Leu Ala Ile Ile Lys Pro Asp Ile Val Asp Lys Glu Glu
1 5 10 15
Glu Ile Gln Asp Ile Ile Leu Arg Ser Gly Phe Thr Ile Val Gln Arg
20 25 30
Arg Lys Leu Arg Leu Ser Pro Glu Gln Cys Ser Asn Phe Tyr Val Glu
35 40 45
Lys Tyr Gly Lys Met Phe Phe Pro Asn Leu Thr Ala Tyr Met Ser Ser
50 55 60
Gly Pro Leu Val Ala Met Ile Leu Ala Arg His Lys Ala Ile Ser Tyr
65 70 75 80
Trp Leu Glu Leu Leu Gly Pro Asn Asn Ser Leu Val Ala Lys Glu Thr
85 90 95
His Pro Asp Ser Leu Arg Ala Ile Tyr Gly Thr Asp Asp Leu Arg Asn
100 105 110
Ala Leu His Gly Ser Asn Asp Phe Ala Ala Ala Glu Arg Glu Ile Arg
115 120 125
Phe Met Phe
130
<210> 213
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 213
Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly
1 5 10 15
Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met
20 25 30
Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val
35 40 45
Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr
50 55 60
Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys
65 70 75 80
Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His
85 90 95
Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln
100 105 110
Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val
115 120 125
Gln Tyr Phe Phe
130
<210> 214
<211> 129
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5 partial sequence
<400> 214
Thr Leu Ala Ile Ile Lys Pro Asp Ile Val Asp Lys Glu Glu Glu Ile
1 5 10 15
Gln Asp Ile Ile Leu Arg Ser Gly Phe Thr Ile Val Gln Arg Arg Lys
20 25 30
Leu Arg Leu Ser Pro Glu Gln Cys Ser Asn Phe Tyr Val Glu Lys Tyr
35 40 45
Gly Lys Met Phe Phe Pro Asn Leu Thr Ala Tyr Met Ser Ser Gly Pro
50 55 60
Leu Val Ala Met Ile Leu Ala Arg His Lys Ala Ile Ser Tyr Trp Leu
65 70 75 80
Glu Leu Leu Gly Pro Asn Asn Ser Leu Val Ala Lys Glu Thr His Pro
85 90 95
Asp Ser Leu Arg Ala Ile Tyr Gly Thr Asp Asp Leu Arg Asn Ala Leu
100 105 110
His Gly Ser Asn Asp Phe Ala Ala Ala Glu Arg Glu Ile Arg Phe Met
115 120 125
Phe
<210> 215
<211> 129
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 215
Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile
1 5 10 15
Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met
20 25 30
Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln
35 40 45
Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro
50 55 60
Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys
65 70 75 80
Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala Ser
85 90 95
Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn Ala Ala
100 105 110
His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu Leu Phe
115 120 125
Phe
<210> 216
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6 partial sequence
<400> 216
Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu Ile Leu
1 5 10 15
Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile Val Arg
20 25 30
Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe Tyr Arg
35 40 45
Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe Met Ala
50 55 60
Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala Ile Gln
65 70 75 80
Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala Arg His
85 90 95
Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr Asp Thr Arg
100 105 110
Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser Arg Glu Ile
115 120 125
Ala Ala Phe Phe
130
<210> 217
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 217
Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly
1 5 10 15
Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met
20 25 30
Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val
35 40 45
Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr
50 55 60
Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys
65 70 75 80
Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His
85 90 95
Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln
100 105 110
Asn Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val
115 120 125
Gln Tyr Phe Phe
130
<210> 218
<211> 132
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6 partial sequence
<400> 218
Thr Leu Ala Leu Ile Lys Pro Asp Ala Val Ala His Pro Leu Ile Leu
1 5 10 15
Glu Ala Val His Gln Gln Ile Leu Ser Asn Lys Phe Leu Ile Val Arg
20 25 30
Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe Tyr Arg
35 40 45
Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe Met Ala
50 55 60
Ser Gly Pro Ile Arg Ala Tyr Ile Leu Ala His Lys Asp Ala Ile Gln
65 70 75 80
Leu Trp Arg Thr Leu Met Gly Pro Thr Arg Val Phe Arg Ala Arg His
85 90 95
Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr Asp Thr Arg
100 105 110
Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser Arg Glu Ile
115 120 125
Ala Ala Phe Phe
130
<210> 219
<211> 131
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 219
Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly
1 5 10 15
Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu
20 25 30
Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp
35 40 45
His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr
50 55 60
Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70 75 80
Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp
85 90 95
Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn
100 105 110
Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met Glu
115 120 125
Leu Phe Phe
130
<210> 220
<211> 133
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8 partial sequence
<400> 220
Glu Lys Thr Leu Ala Leu Leu Arg Pro Asn Leu Phe His Glu Arg Lys
1 5 10 15
Asp Asp Val Leu Arg Ile Ile Lys Asp Glu Asp Phe Lys Ile Leu Glu
20 25 30
Gln Arg Gln Val Val Leu Ser Glu Lys Glu Ala Gln Ala Leu Cys Lys
35 40 45
Glu Tyr Glu Asn Glu Asp Tyr Phe Asn Lys Leu Ile Glu Asn Met Thr
50 55 60
Ser Gly Pro Ser Leu Ala Leu Val Leu Leu Arg Asp Asn Gly Leu Gln
65 70 75 80
Tyr Trp Lys Gln Leu Leu Gly Pro Arg Thr Val Glu Glu Ala Ile Glu
85 90 95
Tyr Phe Pro Glu Ser Leu Cys Ala Gln Phe Ala Met Asp Ser Leu Pro
100 105 110
Val Asn Gln Leu Tyr Gly Ser Asp Ser Leu Glu Thr Ala Glu Arg Glu
115 120 125
Ile Gln His Phe Phe
130
<210> 221
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 221
Glu Lys Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly
1 5 10 15
Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu
20 25 30
Lys Met Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp
35 40 45
His Gln Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr
50 55 60
Gly Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70 75 80
Trp Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp
85 90 95
Ala Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp Gly Ile Arg Asn
100 105 110
Ala Ala His Gly Pro Asp Ser Phe Ala Ser Ala Ala Arg Glu Met
115 120 125
<210> 222
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8 partial sequence
<400> 222
Gln Ser Thr Leu Gly Leu Ile Lys Pro His Ala Thr Ser Glu Gln Arg
1 5 10 15
Glu Gln Ile Leu Lys Ile Val Lys Glu Ala Gly Phe Asp Leu Thr Gln
20 25 30
Val Lys Lys Met Phe Leu Thr Pro Glu Gln Ile Glu Lys Ile Tyr Pro
35 40 45
Lys Val Thr Gly Lys Asp Phe Tyr Lys Asp Leu Leu Glu Met Leu Ser
50 55 60
Val Gly Pro Ser Met Val Met Ile Leu Thr Lys Trp Asn Ala Val Ala
65 70 75 80
Glu Trp Arg Arg Leu Met Gly Pro Thr Asp Pro Glu Glu Ala Lys Leu
85 90 95
Leu Ser Pro Asp Ser Ile Arg Ala Gln Phe Gly Ile Ser Lys Leu Lys
100 105 110
Asn Ile Val His Gly Ala Ser Asn Ala Tyr Glu Ala Lys Glu Val
115 120 125
<210> 223
<211> 63
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 223
Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile
1 5 10 15
Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met
20 25 30
Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln
35 40 45
Ser Arg Pro Phe Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly
50 55 60
<210> 224
<211> 65
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8 partial sequence
<400> 224
Ser Ile Ala Ile Ile Lys Pro Asp Ala Val Ile Ser Lys Lys Val Leu
1 5 10 15
Glu Ile Lys Arg Lys Ile Thr Lys Ala Gly Phe Ile Ile Glu Ala Glu
20 25 30
His Lys Thr Val Leu Thr Glu Glu Gln Val Val Asn Phe Tyr Ser Arg
35 40 45
Ile Ala Asp Gln Cys Asp Phe Glu Glu Phe Val Ser Phe Met Thr Ser
50 55 60
Gly
65
<210> 225
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 225
Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly
1 5 10 15
Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met
20 25 30
Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val
35 40 45
Tyr Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr
50 55 60
Ser Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys
65 70 75 80
Thr Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His
85 90 95
Leu Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln
100 105 110
Asn Ala Val His
115
<210> 226
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8 partial sequence
<400> 226
Thr Leu Gly Leu Ile Lys Pro His Ala Thr Ser Glu Gln Arg Glu Gln
1 5 10 15
Ile Leu Lys Ile Val Lys Glu Ala Gly Phe Asp Leu Thr Gln Val Lys
20 25 30
Lys Met Phe Leu Thr Pro Glu Gln Ile Glu Lys Ile Tyr Pro Lys Val
35 40 45
Thr Gly Lys Asp Phe Tyr Lys Asp Leu Leu Glu Met Leu Ser Val Gly
50 55 60
Pro Ser Met Val Met Ile Leu Thr Lys Trp Asn Ala Val Ala Glu Trp
65 70 75 80
Arg Arg Leu Met Gly Pro Thr Asp Pro Glu Glu Ala Lys Leu Leu Ser
85 90 95
Pro Asp Ser Ile Arg Ala Gln Phe Gly Ile Ser Lys Leu Lys Asn Ile
100 105 110
Val His
<210> 227
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 227
Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln
1 5 10 15
Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr
20 25 30
Lys Gly Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser
35 40 45
Gly Pro Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr
50 55 60
Phe Arg Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu
65 70 75 80
Arg Pro Gly Thr Leu Arg Ala Ile Phe Gly Lys Thr Lys Ile Gln Asn
85 90 95
Ala Val His Cys Thr Asp Leu Pro Glu Asp Gly Leu Leu Glu Val Gln
100 105 110
Tyr Phe Phe
115
<210> 228
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8 partial sequence
<400> 228
Val Leu Arg Ile Ile Lys Asp Glu Asp Phe Lys Ile Leu Glu Gln Arg
1 5 10 15
Gln Val Val Leu Ser Glu Lys Glu Ala Gln Ala Leu Cys Lys Glu Tyr
20 25 30
Glu Asn Glu Asp Tyr Phe Asn Lys Leu Ile Glu Asn Met Thr Ser Gly
35 40 45
Pro Ser Leu Ala Leu Val Leu Leu Arg Asp Asn Gly Leu Gln Tyr Trp
50 55 60
Lys Gln Leu Leu Gly Pro Arg Thr Val Glu Glu Ala Ile Glu Tyr Phe
65 70 75 80
Pro Glu Ser Leu Cys Ala Gln Phe Ala Met Asp Ser Leu Pro Val Asn
85 90 95
Gln Leu Tyr Gly Ser Asp Ser Leu Glu Thr Ala Glu Arg Glu Ile Gln
100 105 110
His Phe Phe
115
<210> 229
<211> 100
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 229
Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys Ile Leu
1 5 10 15
Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln Met Phe
20 25 30
Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val Tyr Lys Gly
35 40 45
Val Val Thr Glu Tyr His Asp Met Val Thr Glu Met Tyr Ser Gly Pro
50 55 60
Cys Val Ala Met Glu Ile Gln Gln Asn Asn Ala Thr Lys Thr Phe Arg
65 70 75 80
Glu Phe Cys Gly Pro Ala Asp Pro Glu Ile Ala Arg His Leu Arg Pro
85 90 95
Gly Thr Leu Arg
100
<210> 230
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8 partial sequence
<400> 230
Ile Ile Lys Pro Asp Ala Val Ile Ser Lys Lys Val Leu Glu Ile Lys
1 5 10 15
Arg Lys Ile Thr Lys Ala Gly Phe Ile Ile Glu Ala Glu His Lys Thr
20 25 30
Val Leu Thr Glu Glu Gln Val Val Asn Phe Tyr Ser Arg Ile Ala Asp
35 40 45
Gln Cys Asp Phe Glu Glu Phe Val Ser Phe Met Thr Ser Gly Leu Ser
50 55 60
Tyr Ile Leu Val Val Ser Gln Gly Ser Lys His Asn Pro Pro Ser Glu
65 70 75 80
Glu Thr Glu Pro Gln Thr Asp Thr Glu Pro Asn Glu Arg Ser Glu Asp
85 90 95
Gln Pro Glu Val Glu Ala Gln Val Thr Pro Gly Met Met Lys
100 105 110
<210> 231
<211> 174
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9
<400> 231
Met Leu Ser Ser Lys Gly Leu Thr Val Val Asp Val Tyr Gln Gly Trp
1 5 10 15
Cys Gly Pro Cys Lys Pro Val Val Ser Leu Phe Gln Lys Met Arg Ile
20 25 30
Glu Val Gly Leu Asp Leu Leu His Phe Ala Leu Ala Glu Ala Asp Arg
35 40 45
Leu Asp Val Leu Glu Lys Tyr Arg Gly Lys Cys Glu Pro Thr Phe Leu
50 55 60
Phe Tyr Ala Ile Lys Asp Glu Ala Leu Ser Asp Glu Asp Glu Cys Val
65 70 75 80
Ser His Gly Lys Asn Asn Gly Glu Asp Glu Asp Met Val Ser Ser Glu
85 90 95
Arg Thr Cys Thr Leu Ala Ile Ile Lys Pro Asp Ala Val Ala His Gly
100 105 110
Lys Thr Asp Glu Ile Ile Met Lys Ile Gln Glu Ala Gly Phe Glu Ile
115 120 125
Leu Thr Asn Glu Glu Arg Thr Met Thr Glu Ala Glu Val Arg Leu Phe
130 135 140
Tyr Gln His Lys Ala Gly Glu Ser Pro Ser Ser Val Arg His Arg Asn
145 150 155 160
Ala Leu Gln Cys Arg Pro Trp Lys Pro Gly Gln Arg Arg Cys
165 170
<210> 232
<211> 58
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 232
Thr Leu Ala Leu Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile
1 5 10 15
Ile Glu Ile Ile Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met
20 25 30
Met Met Leu Ser Arg Lys Glu Ala Leu Asp Phe His Ala Met Glu Ile
35 40 45
Leu Arg Asp Asp Ala Ile Cys Glu Trp Lys
50 55
<210> 233
<211> 60
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9 partial sequence
<400> 233
Thr Leu Ala Ile Ile Lys Pro Asp Ala Val Ala His Gly Lys Thr Asp
1 5 10 15
Glu Ile Ile Met Lys Ile Gln Glu Ala Gly Phe Glu Ile Leu Thr Asn
20 25 30
Glu Glu Arg Thr Met Thr Glu Ala Glu Val Arg Leu Phe Tyr Thr Leu
35 40 45
Ala Ile Ile Lys Pro Asp Ala Val Ala His Gly Lys
50 55 60
<210> 234
<211> 31
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 234
Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly Phe
1 5 10 15
Thr Ile Thr Lys Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala
20 25 30
<210> 235
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9 partial sequence
<400> 235
Ile Gln Glu Ala Gly Phe Glu Ile Leu Thr Asn Glu Glu Arg Thr Met
1 5 10 15
Thr Glu Ala Glu Val Arg Leu Phe Tyr Gln His Lys Ala
20 25
<210> 236
<211> 53
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 236
Asn Cys Thr Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu
1 5 10 15
Leu Gly Lys Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser
20 25 30
Ala Met Gln Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr
35 40 45
Glu Val Tyr Lys Gly
50
<210> 237
<211> 53
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9 partial sequence
<400> 237
Thr Cys Thr Leu Ala Ile Ile Lys Pro Asp Ala Val Ala His Gly Lys
1 5 10 15
Thr Asp Glu Ile Ile Met Lys Ile Gln Glu Ala Gly Phe Glu Ile Leu
20 25 30
Thr Asn Glu Glu Arg Thr Met Thr Glu Ala Glu Val Arg Leu Phe Tyr
35 40 45
Gln His Lys Ala Gly
50
<210> 238
<211> 350
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10
<400> 238
Met Gly Cys Phe Phe Ser Lys Arg Arg Lys Ala Asp Lys Glu Ser Arg
1 5 10 15
Pro Glu Asn Glu Glu Glu Arg Pro Lys Gln Tyr Ser Trp Asp Gln Arg
20 25 30
Glu Lys Val Asp Pro Lys Asp Tyr Met Phe Ser Gly Leu Lys Asp Glu
35 40 45
Thr Val Gly Arg Leu Pro Gly Thr Val Ala Gly Gln Gln Phe Leu Ile
50 55 60
Gln Asp Cys Glu Asn Cys Asn Ile Tyr Ile Phe Asp His Ser Ala Thr
65 70 75 80
Val Thr Ile Asp Asp Cys Thr Asn Cys Ile Ile Phe Leu Gly Pro Val
85 90 95
Lys Gly Ser Val Phe Phe Arg Asn Cys Arg Asp Cys Lys Cys Thr Leu
100 105 110
Ala Cys Gln Gln Phe Arg Val Arg Asp Cys Arg Lys Leu Glu Val Phe
115 120 125
Leu Cys Cys Ala Thr Gln Pro Ile Ile Glu Ser Ser Ser Asn Ile Lys
130 135 140
Phe Gly Cys Phe Gln Trp Tyr Tyr Pro Glu Leu Ala Phe Gln Phe Lys
145 150 155 160
Asp Ala Gly Leu Ser Ile Phe Asn Asn Thr Trp Ser Asn Ile His Asp
165 170 175
Phe Thr Pro Val Ser Gly Glu Leu Asn Trp Ser Leu Leu Pro Glu Asp
180 185 190
Ala Val Val Gln Asp Tyr Val Pro Ile Pro Thr Thr Glu Glu Leu Lys
195 200 205
Ala Val Arg Val Ser Thr Glu Ala Asn Arg Ser Ile Val Pro Ile Ser
210 215 220
Arg Gly Gln Arg Gln Lys Ser Ser Asp Glu Ser Cys Leu Val Val Leu
225 230 235 240
Phe Ala Gly Asp Tyr Thr Ile Ala Asn Ala Arg Lys Leu Ile Asp Glu
245 250 255
Met Val Gly Lys Gly Phe Phe Leu Val Gln Thr Lys Glu Val Ser Met
260 265 270
Lys Ala Glu Asp Ala Gln Arg Val Phe Arg Glu Lys Ala Pro Asp Phe
275 280 285
Leu Pro Leu Leu Asn Lys Gly Pro Val Ile Ala Leu Glu Phe Asn Gly
290 295 300
Asp Gly Ala Val Glu Val Cys Gln Leu Ile Val Asn Glu Ile Phe Asn
305 310 315 320
Gly Thr Lys Met Phe Val Ser Glu Ser Lys Glu Thr Ala Ser Gly Asp
325 330 335
Val Asp Ser Phe Tyr Asn Phe Ala Asp Ile Gln Met Gly Ile
340 345 350
<210> 239
<211> 68
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 239
Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile Ile Asn Lys Ala Gly
1 5 10 15
Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu Ser Arg Lys Glu Ala
20 25 30
Leu Asp Phe His Val Asp His Gln Ser Arg Pro Phe Phe Asn Glu Leu
35 40 45
Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala Met Glu Ile Leu Arg
50 55 60
Asp Asp Ala Ile
65
<210> 240
<211> 63
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10 partial sequence
<400> 240
Thr Ile Ala Asn Ala Arg Lys Leu Ile Asp Glu Met Val Gly Lys Gly
1 5 10 15
Phe Phe Leu Val Gln Thr Lys Glu Val Ser Met Lys Ala Glu Asp Ala
20 25 30
Gln Arg Val Phe Arg Glu Lys Ala Pro Asp Phe Leu Pro Leu Leu Asn
35 40 45
Lys Gly Pro Val Ile Ala Leu Glu Phe Asn Gly Asp Gly Ala Val
50 55 60
<210> 241
<211> 43
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 241
Pro Ile Ile Ala Met Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu Trp
1 5 10 15
Lys Arg Leu Leu Gly Pro Ala Asn Ser Gly Val Ala Arg Thr Asp Ala
20 25 30
Ser Glu Ser Ile Arg Ala Leu Phe Gly Thr Asp
35 40
<210> 242
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10 partial sequence
<400> 242
Pro Ile Pro Thr Thr Glu Glu Leu Lys Ala Val Arg Val Ser Thr Glu
1 5 10 15
Ala Asn Arg Ser Ile Val Pro Ile Ser Arg Gly Gln Arg Gln Lys Ser
20 25 30
Ser Asp Glu Ser Cys Leu Val Val Leu Phe Ala Gly Asp
35 40 45
<210> 243
<211> 74
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7A partial sequence
<400> 243
Ile Lys Pro Asp Ala Ile Ser Lys Ala Gly Glu Ile Ile Glu Ile Ile
1 5 10 15
Asn Lys Ala Gly Phe Thr Ile Thr Lys Leu Lys Met Met Met Leu Ser
20 25 30
Arg Lys Glu Ala Leu Asp Phe His Val Asp His Gln Ser Arg Pro Phe
35 40 45
Phe Asn Glu Leu Ile Gln Phe Ile Thr Thr Gly Pro Ile Ile Ala Met
50 55 60
Glu Ile Leu Arg Asp Asp Ala Ile Cys Glu
65 70
<210> 244
<211> 75
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10 partial sequence
<400> 244
Val Asp Pro Lys Asp Tyr Met Phe Ser Gly Leu Lys Asp Glu Thr Val
1 5 10 15
Gly Arg Leu Pro Gly Thr Val Ala Gly Gln Gln Phe Leu Ile Gln Asp
20 25 30
Cys Glu Asn Cys Asn Ile Tyr Ile Phe Asp His Ser Ala Thr Val Thr
35 40 45
Ile Asp Asp Cys Thr Asn Cys Ile Ile Phe Leu Gly Pro Val Lys Gly
50 55 60
Ser Val Phe Phe Arg Asn Cys Arg Asp Cys Lys
65 70 75
<210> 245
<211> 47
<212> PRT
<213> Artificial Sequence
<220>
<223> NME7B partial sequence
<400> 245
Cys Cys Ile Val Lys Pro His Ala Val Ser Glu Gly Leu Leu Gly Lys
1 5 10 15
Ile Leu Met Ala Ile Arg Asp Ala Gly Phe Glu Ile Ser Ala Met Gln
20 25 30
Met Phe Asn Met Asp Arg Val Asn Val Glu Glu Phe Tyr Glu Val
35 40 45
<210> 246
<211> 51
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10 partial sequence
<400> 246
Cys Cys Ala Thr Gln Pro Ile Ile Glu Ser Ser Ser Asn Ile Lys Phe
1 5 10 15
Gly Cys Phe Gln Trp Tyr Tyr Pro Glu Leu Ala Phe Gln Phe Lys Asp
20 25 30
Ala Gly Leu Ser Ile Phe Asn Asn Thr Trp Ser Asn Ile His Asp Phe
35 40 45
Thr Pro Val
50
<210> 247
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2A1
<400> 247
Arg Ala Ser Glu Glu His Leu Lys Gln His Tyr Ile Asp Leu Lys Asp
1 5 10 15
<210> 248
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2A2
<400> 248
Pro Ala Asp Ser Lys Pro Gly Thr
1 5
<210> 249
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2B1
<400> 249
Gln Lys Gly Phe Arg Leu Val Ala Met Lys Phe Leu Arg Ala Ser Glu
1 5 10 15
Glu His Leu Lys
20
<210> 250
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2B2
<400> 250
Ile Asp Leu Lys Asp Arg Pro Phe Pro Gly Leu Val Lys Tyr
1 5 10
<210> 251
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2B3
<400> 251
Gly Asp Phe Cys Ile Gln Val Gly Arg Asn Ile Ile His Gly Ser Asp
1 5 10 15
Ser Val Lys Ser Ala Glu Lys Glu Ile Ser Leu Trp Phe
20 25
<210> 252
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3A1
<400> 252
Gln Ala Ser Glu Glu Leu Leu Arg Glu His Tyr Val Glu Leu Arg Glu
1 5 10 15
<210> 253
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3A1
<400> 253
Pro Gly Asp Ala Thr Pro Gly Thr
1 5
<210> 254
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3B1
<400> 254
Arg Lys Gly Phe Lys Leu Val Ala Leu Lys Leu Val Gln Ala Ser Glu
1 5 10 15
Glu Leu Leu Arg
20
<210> 255
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3B2
<400> 255
Val Glu Leu Arg Glu Arg Pro Phe Tyr Ser Arg Leu Val Lys Tyr
1 5 10 15
<210> 256
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3B3
<400> 256
Gly Asp Phe Cys Val Glu Val Gly Lys Asn Val Ile His Gly Ser Asp
1 5 10 15
Ser Val Glu Ser Ala Gln Arg Glu Ile Ala Leu Trp Phe
20 25
<210> 257
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4A1
<400> 257
Gln Ala Pro Glu Ser Val Leu Ala Glu His Tyr Gln Asp Leu Arg Arg
1 5 10 15
<210> 258
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4A2
<400> 258
Ser Ala Glu Ala Ala Pro Gly Thr
1 5
<210> 259
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4B1
<400> 259
Arg Arg Gly Phe Thr Leu Val Gly Met Lys Met Leu Gln Ala Pro Glu
1 5 10 15
Ser Val Leu Ala
20
<210> 260
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4B2
<400> 260
Gln Asp Leu Arg Arg Lys Pro Phe Tyr Pro Ala Leu Ile Arg Tyr
1 5 10 15
<210> 261
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4B3
<400> 261
Gly Asp Phe Ser Val His Ile Ser Arg Asn Val Ile His Ala Ser Asp
1 5 10 15
Ser Val Glu Gly Ala Gln Arg Glu Ile Gln Leu Trp Phe
20 25
<210> 262
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5A1
<400> 262
Arg Leu Ser Pro Glu Gln Cys Ser Asn Phe Tyr Val Glu Lys Tyr Gly
1 5 10 15
<210> 263
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5A2
<400> 263
Ser Leu Val Ala Lys Glu Thr His Pro Asp Ser
1 5 10
<210> 264
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5B1
<400> 264
Arg Ser Gly Phe Thr Ile Val Gln Arg Arg Lys Leu Arg Leu Ser Pro
1 5 10 15
Glu Gln Cys Ser
20
<210> 265
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5B2
<400> 265
Val Glu Lys Tyr Gly Lys Met Phe Phe Pro Asn Leu Thr Ala Tyr
1 5 10 15
<210> 266
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5B3
<400> 266
Ala Ile Tyr Gly Thr Asp Asp Leu Arg Asn Ala Leu His Gly Ser Asn
1 5 10 15
Asp Phe Ala Ala Ala Glu Arg Glu Ile Arg Phe Met Phe
20 25
<210> 267
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6A1
<400> 267
Leu Trp Arg Lys Glu Asp Cys Gln Arg Phe Tyr Arg Glu His Glu Gly
1 5 10 15
<210> 268
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6A2
<400> 268
Val Phe Arg Ala Arg His Val Ala Pro Asp Ser
1 5 10
<210> 269
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6B1
<400> 269
Ser Asn Lys Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp Arg Lys
1 5 10 15
Glu Asp Cys Gln
20
<210> 270
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6B2
<400> 270
Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu Phe
1 5 10 15
<210> 271
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6B3
<400> 271
Gly Ser Phe Gly Leu Thr Asp Thr Arg Asn Thr Thr His Gly Ser Asp
1 5 10 15
Ser Val Val Ser Ala Ser Arg Glu Ile Ala Ala Phe Phe
20 25
<210> 272
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A1
<400> 272
Val Leu Ser Glu Lys Glu Ala Gln Ala Leu Cys Lys Glu Tyr Glu Asn
1 5 10 15
<210> 273
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A2
<400> 273
Val Glu Glu Ala Ile Glu Tyr Phe Pro Glu Ser
1 5 10
<210> 274
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A3
<400> 274
Phe Leu Thr Pro Glu Gln Ile Glu Lys Ile Tyr Pro Lys Val Thr Gly
1 5 10 15
<210> 275
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A4
<400> 275
Pro Glu Glu Ala Lys Leu Leu Ser Pro Asp Ser
1 5 10
<210> 276
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A5
<400> 276
Val Leu Thr Glu Glu Gln Val Val Asn Phe Tyr Ser Arg Ile Ala Asp
1 5 10 15
<210> 277
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B1
<400> 277
Glu Ala Gly Phe Asp Leu Thr Gln Val Lys Lys Met Phe Leu Thr Pro
1 5 10 15
Glu Gln Ile Glu
20
<210> 278
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B2
<400> 278
Pro Lys Val Thr Gly Lys Asp Phe Tyr Lys Asp Leu Leu Glu Met
1 5 10 15
<210> 279
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B3
<400> 279
Ala Gln Phe Gly Ile Ser Lys Leu Lys Asn Ile Val His
1 5 10
<210> 280
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B4
<400> 280
Asp Glu Asp Phe Lys Ile Leu Glu Gln Arg Gln Val Val Leu Ser Glu
1 5 10 15
Lys Glu Ala Gln
20
<210> 281
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B5
<400> 281
Lys Glu Tyr Glu Asn Glu Asp Tyr Phe Asn Lys Leu Ile Glu Asn
1 5 10 15
<210> 282
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B6
<400> 282
Ala Gln Phe Ala Met Asp Ser Leu Pro Val Asn Gln Leu Tyr Gly Ser
1 5 10 15
Asp Ser Leu Glu Thr Ala Glu Arg Glu Ile Gln His Phe Phe
20 25 30
<210> 283
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B7
<400> 283
Lys Ala Gly Phe Ile Ile Glu Ala Glu His Lys Thr Val Leu Thr Glu
1 5 10 15
Glu Gln Val Val
20
<210> 284
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B8
<400> 284
Ser Arg Ile Ala Asp Gln Cys Asp Phe Glu Glu Phe Val Ser Phe
1 5 10 15
<210> 285
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9A1
<400> 285
Thr Met Thr Glu Ala Glu Val Arg Leu Phe Tyr
1 5 10
<210> 286
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9B1
<400> 286
Glu Ala Gly Phe Glu Ile Leu Thr Asn Glu Glu Arg Thr Met Thr Glu
1 5 10 15
Ala Glu Val Arg
20
<210> 287
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10A1
<400> 287
Ser Met Lys Ala Glu Asp Ala Gln Arg Val Phe Arg Glu Lys
1 5 10
<210> 288
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10A2
<400> 288
Gly Gln Arg Gln Lys Ser Ser Asp Glu Ser
1 5 10
<210> 289
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10A3
<400> 289
Ile Gln Asp Cys Glu Asn Cys Asn Ile Tyr Ile Phe Asp His Ser Ala
1 5 10 15
<210> 290
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10B1
<400> 290
Glu Leu Ala Phe Gln Phe Lys Asp Ala Gly Leu Ser Ile Phe Asn Asn
1 5 10 15
Thr Trp Ser Asn Ile His
20
<210> 291
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2A1
<400> 291
Arg Ala Ser Glu Glu His Leu Lys Gln His Tyr Ile Asp Leu Lys Asp
1 5 10 15
Arg Pro Phe Phe Pro Gly Leu
20
<210> 292
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2A2
<400> 292
Leu Gly Glu Thr Asn Pro Ala Asp Ser Lys Pro Gly Thr Ile Arg Gly
1 5 10 15
Asp Phe
<210> 293
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2B1
<400> 293
Gly Leu Val Gly Glu Ile Ile Lys Arg Phe Glu Gln Lys Gly Phe Arg
1 5 10 15
Leu Val Ala Met Lys Phe Leu Arg Ala Ser Glu Glu His Leu Lys Gln
20 25 30
His Tyr
<210> 294
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2B2
<400> 294
Tyr Ile Asp Leu Lys Asp Arg Pro Phe Phe Pro Gly Leu Val Lys Tyr
1 5 10 15
Met Asn Ser Gly Pro Val Val Ala Met
20 25
<210> 295
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME2B3
<400> 295
Pro Gly Thr Ile Arg Gly Asp Phe Cys Ile Gln Val Gly Arg Asn Ile
1 5 10 15
Ile His Gly Ser Asp Ser Val Lys Ser Ala Glu Lys Glu Ile Ser Leu
20 25 30
Trp Phe
<210> 296
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3A1
<400> 296
Leu Lys Leu Val Gln Ala Ser Glu Glu Leu Leu Arg Glu His Tyr Val
1 5 10 15
Glu Leu Arg Glu Arg Pro Phe Tyr Ser Arg Leu
20 25
<210> 297
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3A1
<400> 297
Leu Ile Gly Ala Thr Asp Pro Gly Asp Ala Thr Pro Gly Thr Ile Arg
1 5 10 15
Gly Asp Phe
<210> 298
<211> 31
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3B1
<400> 298
Leu Val Gly Glu Ile Val Arg Arg Phe Glu Arg Lys Gly Phe Lys Leu
1 5 10 15
Val Ala Leu Lys Leu Val Gln Ala Ser Glu Glu Leu Leu Arg Glu
20 25 30
<210> 299
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3B2
<400> 299
Glu His Tyr Val Glu Leu Arg Glu Arg Pro Phe Tyr Ser Arg Leu Val
1 5 10 15
Lys Tyr Met Gly Ser Gly Pro Val Val Ala Met
20 25
<210> 300
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME3B3
<400> 300
Pro Gly Thr Ile Arg Gly Asp Phe Cys Val Glu Val Gly Lys Asn Val
1 5 10 15
Ile His Gly Ser Asp Ser Val Glu Ser Ala Gln Arg Glu Ile Ala Leu
20 25 30
Trp Phe
<210> 301
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4A1
<400> 301
Gly Phe Thr Leu Val Gly Met Lys Met Leu Gln Ala Pro Glu Ser Val
1 5 10 15
Leu Ala Glu His Tyr Gln Asp Leu Arg Arg Lys Pro Phe
20 25
<210> 302
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4A2
<400> 302
Gly His Thr Asp Ser Ala Glu Ala Ala Pro Gly Thr Ile Arg Gly Asp
1 5 10 15
Phe
<210> 303
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4B1
<400> 303
Leu Val Gly Asp Val Ile Gln Arg Phe Glu Arg Arg Gly Phe Thr Leu
1 5 10 15
Val Gly Met Lys Met Leu Gln Ala Pro Glu Ser Val Leu Ala Glu His
20 25 30
Tyr
<210> 304
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4B2
<400> 304
Glu His Tyr Gln Asp Leu Arg Arg Lys Pro Phe Tyr Pro Ala Leu Ile
1 5 10 15
Arg Tyr Met Ser Ser Gly Pro Val Val Ala Met
20 25
<210> 305
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME4B3
<400> 305
Pro Gly Thr Ile Arg Gly Asp Phe Ser Val His Ile Ser Arg Asn Val
1 5 10 15
Ile His Ala Ser Asp Ser Val Glu Gly Ala Gln Arg Glu Ile Gln Leu
20 25 30
Trp Phe
<210> 306
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5A1
<400> 306
Gly Phe Thr Ile Val Gln Arg Arg Lys Leu Arg Leu Ser Pro Glu Gln
1 5 10 15
Cys Ser Asn Phe Tyr Val Glu Lys Tyr Gly Lys Met Phe Phe
20 25 30
<210> 307
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5A2
<400> 307
Leu Leu Gly Pro Asn Asn Ser Leu Val Ala Lys Glu Thr His Pro Asp
1 5 10 15
Ser Leu Arg Ala Ile Tyr Gly Thr Asp
20 25
<210> 308
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5B1
<400> 308
Ile Gln Asp Ile Ile Leu Arg Ser Gly Phe Thr Ile Val Gln Arg Arg
1 5 10 15
Lys Leu Arg Leu Ser Pro Glu Gln Cys Ser Asn Phe Tyr
20 25
<210> 309
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5B2
<400> 309
Phe Tyr Val Glu Lys Tyr Gly Lys Met Phe Phe Pro Asn Leu Thr Ala
1 5 10 15
Tyr Met Ser Ser Gly Pro Leu Val Ala Met
20 25
<210> 310
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME5B3
<400> 310
Pro Asp Ser Leu Arg Ala Ile Tyr Gly Thr Asp Asp Leu Arg Asn Ala
1 5 10 15
Leu His Gly Ser Asn Asp Phe Ala Ala Ala Glu Arg Glu Ile Arg Phe
20 25 30
Met Phe
<210> 311
<211> 32
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6A1
<400> 311
Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp Arg Lys Glu Asp Cys
1 5 10 15
Gln Arg Phe Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu
20 25 30
<210> 312
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6A2
<400> 312
Leu Met Gly Pro Thr Arg Val Phe Arg Ala Arg His Val Ala Pro Asp
1 5 10 15
Ser Ile Arg Gly Ser Phe Gly
20
<210> 313
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6B1
<400> 313
Ile Leu Ser Asn Lys Phe Leu Ile Val Arg Met Arg Glu Leu Leu Trp
1 5 10 15
Arg Lys Glu Asp Cys Gln Arg Phe Tyr
20 25
<210> 314
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6B2
<400> 314
Phe Tyr Arg Glu His Glu Gly Arg Phe Phe Tyr Gln Arg Leu Val Glu
1 5 10 15
Phe Met Ala Ser Gly Pro Ile Arg Ala
20 25
<210> 315
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> NME6B3
<400> 315
Ala Arg His Val Ala Pro Asp Ser Ile Arg Gly Ser Phe Gly Leu Thr
1 5 10 15
Asp Thr Arg Asn Thr Thr His Gly Ser Asp Ser Val Val Ser Ala Ser
20 25 30
Arg Glu Ile Ala Ala Phe Phe
35
<210> 316
<211> 33
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A1
<400> 316
Phe Lys Ile Leu Glu Gln Arg Gln Val Val Leu Ser Glu Lys Glu Ala
1 5 10 15
Gln Ala Leu Cys Lys Glu Tyr Glu Asn Glu Asp Tyr Phe Asn Lys Leu
20 25 30
Ile
<210> 317
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A2
<400> 317
Trp Lys Gln Leu Leu Gly Pro Arg Thr Val Glu Glu Ala Ile Glu Tyr
1 5 10 15
Phe Pro Glu Ser Leu Cys Ala Gln Phe Ala Met Asp
20 25
<210> 318
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A3
<400> 318
Ala Gly Phe Asp Leu Thr Gln Val Lys Lys Met Phe Leu Thr Pro Glu
1 5 10 15
Gln Ile Glu Lys Ile Tyr Pro Lys Val Thr Gly Lys Asp Phe Tyr Lys
20 25 30
Asp Leu
<210> 319
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A4
<400> 319
Glu Trp Arg Arg Leu Met Gly Pro Thr Asp Pro Glu Glu Ala Lys Leu
1 5 10 15
Leu Ser Pro Asp Ser Ile Arg Ala Gln Phe Gly
20 25
<210> 320
<211> 34
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8A5
<400> 320
Lys Ala Gly Phe Ile Ile Glu Ala Glu His Lys Thr Val Leu Thr Glu
1 5 10 15
Glu Gln Val Val Asn Phe Tyr Ser Arg Ile Ala Asp Gln Cys Asp Phe
20 25 30
Glu Glu
<210> 321
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B1
<400> 321
Ile Leu Lys Ile Val Lys Glu Ala Gly Phe Asp Leu Thr Gln Val Lys
1 5 10 15
Lys Met Phe Leu Thr Pro Glu Gln Ile Glu Lys Ile Tyr
20 25
<210> 322
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B2
<400> 322
Tyr Pro Lys Val Thr Gly Lys Asp Phe Tyr Lys Asp Leu Leu Glu Met
1 5 10 15
Leu Ser Val Gly Pro
20
<210> 323
<211> 27
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B3
<400> 323
Asp Pro Glu Glu Ala Lys Leu Leu Ser Pro Asp Ser Ile Arg Ala Gln
1 5 10 15
Phe Gly Ile Ser Lys Leu Lys Asn Ile Val His
20 25
<210> 324
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B4
<400> 324
Leu Arg Ile Ile Lys Asp Glu Asp Phe Lys Ile Leu Glu Gln Arg Gln
1 5 10 15
Val Val Leu Ser Glu Lys Glu Ala Gln
20 25
<210> 325
<211> 23
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B5
<400> 325
Lys Glu Tyr Glu Asn Glu Asp Tyr Phe Asn Lys Leu Ile Glu Asn Met
1 5 10 15
Thr Ser Gly Pro Ser Leu Ala
20
<210> 326
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B6
<400> 326
Pro Glu Ser Leu Cys Ala Gln Phe Ala Met Asp Ser Leu Pro Val Asn
1 5 10 15
Gln Leu Tyr Gly Ser Asp Ser Leu Glu Thr Ala Glu Arg Glu Ile Gln
20 25 30
His Phe Phe
35
<210> 327
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B7
<400> 327
Ile Lys Arg Lys Ile Thr Lys Ala Gly Phe Ile Ile Glu Ala Glu His
1 5 10 15
Lys Thr Val Leu Thr Glu Glu Gln Val Val Asn Phe Tyr
20 25
<210> 328
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> NME8B8
<400> 328
Phe Tyr Ser Arg Ile Ala Asp Gln Cys Asp Phe Glu Glu Phe Val Ser
1 5 10 15
Phe Met Thr Ser Gly
20
<210> 329
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9A1
<400> 329
Ala Gly Phe Glu Ile Leu Thr Asn Glu Glu Arg Thr Met Thr Glu Ala
1 5 10 15
Glu Val Arg Leu Phe Tyr
20
<210> 330
<211> 29
<212> PRT
<213> Artificial Sequence
<220>
<223> NME9B1
<400> 330
Ile Ile Met Lys Ile Gln Glu Ala Gly Phe Glu Ile Leu Thr Asn Glu
1 5 10 15
Glu Arg Thr Met Thr Glu Ala Glu Val Arg Leu Phe Tyr
20 25
<210> 331
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10A1
<400> 331
Gly Phe Phe Leu Val Gln Thr Lys Glu Val Ser Met Lys Ala Glu Asp
1 5 10 15
Ala Gln Arg Val Phe Arg Glu Lys Ala Pro
20 25
<210> 332
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10A2
<400> 332
Glu Ala Asn Arg Ser Ile Val Pro Ile Ser Arg Gly Gln Arg Gln Lys
1 5 10 15
Ser Ser Asp Glu Ser Cys Leu Val Val Leu Phe Ala Gly Asp
20 25 30
<210> 333
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10A3
<400> 333
Ile Gln Asp Cys Glu Asn Cys Asn Ile Tyr Ile Phe Asp His Ser Ala
1 5 10 15
<210> 334
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> NME10B1
<400> 334
Glu Leu Ala Phe Gln Phe Lys Asp Ala Gly Leu Ser Ile Phe Asn Asn
1 5 10 15
Thr Trp Ser Asn Ile His Asp Phe Thr Pro Val Asp Cys Thr
20 25 30
<210> 335
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> 8F9A4A3 Heavy chain variable region sequence mouse
<400> 335
gtccagctgc aacagtctgg acctgaactg gtgaagcctg gggcttcagt gaagatatcc 60
tgcaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acggtactac 300
catagtctct acgtgtttta ctttgactac tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 336
<211> 294
<212> DNA
<213> Artificial Sequence
<220>
<223> IGHV1-24*01 V-REGION sequence human (closest match hu antibody
sequence)
<400> 336
caggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg tttccggata caccctcact gaattatcca tgcactgggt gcgacaggct 120
cctggaaaag ggcttgagtg gatgggaggt tttgatcctg aagatggtga aacaatctac 180
gcacagaagt tccagggcag agtcaccatg accgaggaca catctacaga cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aaca 294
<210> 337
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> IGHJ4*01 J-REGION sequence human (closest match hu antibody
sequence)
<400> 337
tactttgact actggggcca aggaaccctg gtcaccgtct cctca 45
<210> 338
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Heavy chain variable region sequence
<400> 338
caggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg tttccggaaa cacattcact gaatacacca tgcactgggt gcgacaggct 120
cctggaaaag ggcttgagtg gatgggaggt tttaatccta acaatggtgt tactaactac 180
aaccagaagt tcaagggcag agtcaccatg accgaggaca catctacaga cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aagacggtac 300
taccatagtc tctacgtgtt ttactttgac tactggggcc aaggaaccct ggtcaccgtc 360
tcctca 366
<210> 339
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Heavy chain variable region sequence (codon
optimized)
<400> 339
caggttcagc tggttcagtc tggcgccgaa gtgaagaaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg tgtccggaaa taccttcacc gagtacacca tgcactgggt ccgacaggcc 120
cctggcaaag gacttgaatg gatgggcggc ttcaacccca acaacggcgt gaccaactac 180
aaccagaaat tcaagggccg cgtgaccatg accgaggaca caagcacaga caccgcctac 240
atggaactga gcagcctgag aagcgaggac accgccgtgt actactgcgc cagaaggtac 300
taccacagcc tgtacgtgtt ctacttcgac tactggggcc agggcaccct ggtcacagtt 360
tcttct 366
<210> 340
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Heavy chain variable region sequence)
<400> 340
caggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg tttccggaaa cacattcact gaatacacca tgcactgggt gcgacaggct 120
cctggaaaag ggcttgagtg gattggaggt tttaatccta acaatggtgt tactaactac 180
aaccagaagt tcaagggcaa agtcaccctg accgtggaca catctagcag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aagacggtac 300
taccatagtc tctacgtgtt ttactttgac tactggggcc aaggaaccct ggtcaccgtc 360
tcctca 366
<210> 341
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Heavy chain variable region sequence
(codon optimized)
<400> 341
caggttcagc tggttcagtc tggcgccgaa gtgaagaaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg tgtccggaaa taccttcacc gagtacacca tgcactgggt ccgacaggcc 120
cctggcaaag gactggaatg gatcggcggc ttcaacccca acaacggcgt gaccaactac 180
aaccagaaat tcaagggcaa agtgaccctg accgtggaca ccagcagcag cacagcctac 240
atggaactga gcagcctgag aagcgaggac accgccgtgt actactgcgc cagaaggtac 300
taccacagcc tgtacgtgtt ctacttcgac tactggggcc agggcaccct ggtcacagtt 360
tcttct 366
<210> 342
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> 8F9A4A3 Light chain variable region sequence mouse
<400> 342
gaaacaactg tgacccagtc tccagcatcc ctgtccatgg ctataggaga aaaagtcacc 60
atcagatgca taaccagcac tgatattgat gatgatatga actggtacca gcagaagcca 120
ggggaacctc ctaagctcct tatttcagaa ggcaatactc ttcgtcctgg agtcccatcc 180
cgattctcca gcagtggcta tggtacagat tttgttttta caattgaaaa catgctctca 240
gaagatgttg cagattacta ctgtttgcaa agtgataact tgcctctcac gttcggctcg 300
gggacaaagt tggaaataaa acgg 324
<210> 343
<211> 264
<212> DNA
<213> Artificial Sequence
<220>
<223> IGKV5-2*01 V-REGION sequence human (closest match hu antibody
sequence)
<400> 343
gaaacgacac tcacgcagtc tccagcattc atgtcagcga ctccaggaga caaagtcaac 60
atctcctgca aagccagcca agacattgat gatgatatga actggtacca acagaaacca 120
ggagaagctg ctattttcat tattcaagaa gctactactc tcgttcctgg aatcccacct 180
cgattcagtg gcagcgggta tggaacagat tttaccctca caattaataa catagaatct 240
gaggatgctg catattactt ctgt 264
<210> 344
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> IGKJ4*02 J-REGION sequence human (closest match hu antibody
sequence)
<400> 344
ctcacgttcg gcggagggac caaggtggag atcaaa 36
<210> 345
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Light chain variable region sequence
<400> 345
gaaacgacac tcacgcagtc tccagcattc atgtcagcga ctccaggaga caaagtcaac 60
atctcctgca taaccagcac tgatattgat gatgatatga actggtacca acagaaacca 120
ggagaagctg ctattttcat tattcaagaa ggcaatactc ttcgtcctgg aatcccacct 180
cgattcagtg gcagcgggta tggaacagat tttaccctca caattaataa catagaatct 240
gaggatgctg catattactt ctgtttgcaa agtgataact tgcctctcac gttcggcgga 300
gggaccaagg tggagatcaa acgg 324
<210> 346
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Light chain variable region sequence (codon
optimized)
<400> 346
gagacaaccc tgacacagag ccctgccttc atgtctgcca cacctggcga caaagtgaac 60
atcagctgca tcaccagcac cgacatcgac gacgacatga actggtatca gcagaagcct 120
ggcgaggccg ccatcttcat catccaagag ggcaacacac tgcggcctgg catccctcct 180
agattttctg gcagcggcta cggcaccgac ttcaccctga ccatcaacaa catcgagagc 240
gaggacgccg cctactactt ctgcctgcaa agcgacaacc tgcctctgac ctttggcgga 300
ggcaccaagg tggaaatcaa gcgg 324
<210> 347
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Light chain variable region sequence
<400> 347
gaaacgacag tgacgcagtc tccagcattc atgtcagcga ctccaggaga caaagtcacc 60
atctcctgca taaccagcac tgatattgat gatgatatga actggtacca acagaaacca 120
ggagaagctg ctattctgct gattagcgaa ggcaatactc ttcgtcctgg aatcccacct 180
cgattcagta gcagcgggta tggaacagat tttaccctca caattaataa catagaatct 240
gaggatgctg catattactt ctgtttgcaa agtgataact tgcctctcac gttcggcgga 300
gggaccaagg tggagatcaa acgg 324
<210> 348
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Light chain variable region sequence
(codon optimized)
<400> 348
gagacaaccg tgacacagag ccctgccttc atgtctgcca cacctggcga caaagtgacc 60
atcagctgca tcaccagcac cgacatcgac gacgacatga actggtatca gcagaagcct 120
ggcgaggccg ccatcctgct tatctctgag ggaaacacac tgcggcctgg catccctcct 180
agattttcca gcagcggcta cggcaccgac ttcaccctga ccatcaacaa catcgagagc 240
gaggacgccg cctactactt ctgcctgcaa agcgacaacc tgcctctgac ctttggcgga 300
ggcaccaagg tggaaatcaa gcgg 324
<210> 349
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 sequence (codon optimized) - humanized
heavy and light chains joined via a flexible linker
<400> 349
caggttcagc tggttcagtc tggcgccgaa gtgaagaaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg tgtccggaaa taccttcacc gagtacacca tgcactgggt ccgacaggcc 120
cctggcaaag gactggaatg gatcggcggc ttcaacccca acaacggcgt gaccaactac 180
aaccagaaat tcaagggcaa agtgaccctg accgtggaca ccagcagcag cacagcctac 240
atggaactga gcagcctgag aagcgaggac accgccgtgt actactgcgc cagaaggtac 300
taccacagcc tgtacgtgtt ctacttcgac tactggggcc agggcaccct ggtcacagtt 360
tcttctggcg gtggcggaag cggaggcggt ggctccggtg gcggaggcag cgaaacgaca 420
gtgacgcagt ctccagcatt catgtcagcg actccaggag acaaagtcac catctcctgc 480
ataaccagca ctgatattga tgatgatatg aactggtacc aacagaaacc aggagaagct 540
gctattctgc tgattagcga aggcaatact cttcgtcctg gaatcccacc tcgattcagt 600
agcagcgggt atggaacaga ttttaccctc acaattaata acatagaatc tgaggatgct 660
gcatattact tctgtttgca aagtgataac ttgcctctca cgttcggcgg agggaccaag 720
gtggagatca aacgg 735
<210> 350
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> 8F9A5A1 Heavy chain variable region sequence
<400> 350
atccagttgg tgcagtctgg acctgagctg aagaagcctg gagagacagt caagatctcc 60
tgcaaggctt ctgggtatac cttcacaaac tatggaatga actgggtgaa gcaggctcca 120
ggaaagggtt taaagtggat gggctggata aacacctaca ctggagagcc aacatatgtt 180
gatgacttca agggacggtt tgccttctct ttggaaacct ctgccaccac tgcctatttg 240
cagatcaaca acctcaaaaa tgaggacacg tctacatatt tctgtgcaag attgaggggg 300
atacgaccgg gtcccttggc ttactggggc caagggactc tggtcactgt ctctgca 357
<210> 351
<211> 294
<212> DNA
<213> Artificial Sequence
<220>
<223> IGHV7-81*01 V-REGION sequence
<400> 351
caggtgcagc tggtgcagtc tggccatgag gtgaagcagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggtta cagtttcacc acctatggta tgaattgggt gccacaggcc 120
cctggacaag ggcttgagtg gatgggatgg ttcaacacct acactgggaa cccaacatat 180
gcccagggct tcacaggacg gtttgtcttc tccatggaca cctctgccag cacagcatac 240
ctgcagatca gcagcctaaa ggctgaggac atggccatgt attactgtgc gaga 294
<210> 352
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> IGHJ4*03 J-REGION sequence
<400> 352
tactttgact actggggcca agggaccctg gtcaccgtct cctca 45
<210> 353
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Heavy chain variable region sequence
<400> 353
caggtgcagc tggtgcagtc tggccatgag gtgaagcagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctgggta taccttcaca aactatggaa tgaactgggt gccacaggcc 120
cctggacaag ggcttgagtg gatgggatgg ataaacacct acactggaga gccaacatat 180
gttgatgact tcaagggacg gtttgtcttc tccatggaca cctctgccag cacagcatac 240
ctgcagatca gcagcctaaa ggctgaggac atggccatgt attactgtgc aagattgagg 300
gggatacgac cgggtccctt ggcttactgg ggccaaggga ccctggtcac cgtctcctca 360
<210> 354
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Heavy chain variable region sequence (codon
optimized)
<400> 354
caggttcagc tggtgcagtc tggccacgaa gtgaaacagc ctggcgcctc tgtgaaggtg 60
tcctgtaaag ccagcggcta cacctttacc aactacggca tgaactgggt gccccaggct 120
cctggacaag gcttggaatg gatgggctgg atcaacacct acaccggcga gcctacctac 180
gtggacgact tcaagggcag attcgtgttc agcatggaca ccagcgccag cacagcctac 240
ctgcagatca gctctctgaa ggccgaggat atggccatgt actactgcgc cagactgaga 300
ggcatcagac ctggacctct ggcctattgg ggacagggca cactggtcac agtgtcctct 360
<210> 355
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Heavy chain variable region sequence
<400> 355
cagatccagc tggtgcagtc tggccccgag gtgaagcagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctgggta taccttcaca aactatggaa tgaactgggt gaagcaggcc 120
cctggacaag ggcttgagtg gatgggatgg ataaacacct acactggaga gccaacatat 180
gttgatgact tcaagggacg gtttgccttc tccatggaca cctctgccag cacagcatac 240
ctgcagatca gcagcctaaa ggctgaggac accgccacct attactgtgc aagattgagg 300
gggatacgac cgggtccctt ggcttactgg ggccaaggga ccctggtcac cgtctcctca 360
<210> 356
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Heavy chain variable region sequence
(codon optimized)
<400> 356
cagattcagc tggtgcagtc tggccccgaa gtgaaacaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg ccagcggcta cacctttacc aactacggca tgaactgggt caagcaggcc 120
cctggacaag gcctggaatg gatgggctgg atcaacacct acaccggcga gcctacctac 180
gtggacgact tcaagggcag attcgccttc agcatggaca ccagcgccag cacagcctac 240
ctgcagatca gctctctgaa ggccgaggac accgccacct actactgtgc cagactgaga 300
ggcatcagac ccggacctct ggcctattgg ggacagggaa cactggtcac cgtgtcctct 360
<210> 357
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> 8F9A5A1 Light chain variable region sequence
<400> 357
gaaattttgc tcacccagtc tccagcaatc atagctgcat ctcctgggga gaaggtcacc 60
atcacctgca gtgccagctc aagtgtaagt tacatgaact ggtaccagca gaaaccagga 120
tcctccccca aaatatggat ttatggtata tccaacctgg cttctggagt tcctgctcgc 180
ttcagtggca gtgggtctgg gacatctttc tctttcacaa tcaacagcat ggaggctgaa 240
gatgttgcca cttattactg tcagcaaagg agtagttacc cacccacgtt cggagggggg 300
accaagctgg aaataaaacg g 321
<210> 358
<211> 279
<212> DNA
<213> Artificial Sequence
<220>
<223> IGKV3D-15*02 V-REGION sequence
<400> 358
gaaatagtga tgatgcagtc tccagccacc ctgtctgtgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcaacttag cctggtacca gcagaaacct 120
ggccaggctc ccaggctcct catctatggt gcatccacca gggccactgg catcccagcc 180
aggttcagtg gcagtgggtc tgggacagag ttcactctca ccatcagcag cctgcagtct 240
gaagattttg cagtttatta ctgtcagcag tataataac 279
<210> 359
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> IGKJ4*02 J-REGION sequence
<400> 359
ctcacgttcg gcggagggac caaggtggag atcaaa 36
<210> 360
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Light chain variable region sequence
<400> 360
gaaatagtga tgatgcagtc tccagccacc ctgtctgtgt ctccagggga aagagccacc 60
ctctcctgca gtgccagctc aagtgtaagt tacatgaact ggtaccagca gaaacctggc 120
caggctccca ggctcctcat ctatggtata tccaacctgg cttctggcat cccagccagg 180
ttcagtggca gtgggtctgg gacagagttc actctcacca tcagcagcct gcagtctgaa 240
gattttgcag tttattactg tcagcaaagg agtagttacc cacccacgtt cggcggaggg 300
accaaggtgg agatcaaacg g 321
<210> 361
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Light chain variable region sequence (codon
optimized)
<400> 361
gagatcgtga tgatgcagag ccccgccaca ctgagtgtgt ctccaggcga aagagccaca 60
ctgtcctgta gcgccagcag cagcgtgtcc tacatgaact ggtatcagca gaagcccgga 120
caggccccta gactgctgat ctacggcatc agcaatctgg ccagcggcat ccctgccaga 180
ttttctggct ctggctccgg caccgagttc accctgacaa tctctagcct gcagagcgag 240
gacttcgccg tgtactactg ccagcagaga agcagctacc ctcctacctt tggcggaggc 300
accaaggtgg aaatcaagcg g 321
<210> 362
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Light chain variable region sequence
<400> 362
gaaatagtgc tgacccagtc tccagccacc ctgtctgtgt ctccagggga aagagccacc 60
ctctcctgca gtgccagctc aagtgtaagt tacatgaact ggtaccagca gaaacctggc 120
caggctccca ggctctggat ctatggtata tccaacctgg cttctggcat cccagccagg 180
ttcagtggca gtgggtctgg gacaagcttc agcctcacca tcagcagcct gcagtctgaa 240
gattttgcag tttattactg tcagcaaagg agtagttacc cacccacgtt cggcggaggg 300
accaaggtgg agatcaaacg g 321
<210> 363
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Light chain variable region sequence
(codon optimized)
<400> 363
gagatcgtgc tgacacagtc tcccgccaca ctgagtgtgt ctccaggcga aagagccaca 60
ctgtcctgta gcgccagcag cagcgtgtcc tacatgaact ggtatcagca gaagcccgga 120
caggccccta gactgtggat ctacggcatc agcaatctgg ccagcggcat ccctgccaga 180
ttttctggct ctggctccgg caccagcttc agcctgacaa tcagcagcct gcagagcgag 240
gacttcgccg tgtactactg ccagcagaga agcagctacc ctcctacctt tggcggaggc 300
accaaggtgg aaatcaagcg g 321
<210> 364
<211> 726
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 scFV sequence (codon optimized)
<400> 364
cagattcagc tggtgcagtc tggccccgaa gtgaaacaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg ccagcggcta cacctttacc aactacggca tgaactgggt caagcaggcc 120
cctggacaag gcctggaatg gatgggctgg atcaacacct acaccggcga gcctacctac 180
gtggacgact tcaagggcag attcgccttc agcatggaca ccagcgccag cacagcctac 240
ctgcagatca gctctctgaa ggccgaggac accgccacct actactgtgc cagactgaga 300
ggcatcagac ccggacctct ggcctattgg ggacagggaa cactggtcac cgtgtcctct 360
ggcggtggcg gaagcggagg cggtggctcc ggtggcggag gcagcgagat cgtgctgaca 420
cagtctcccg ccacactgag tgtgtctcca ggcgaaagag ccacactgtc ctgtagcgcc 480
agcagcagcg tgtcctacat gaactggtat cagcagaagc ccggacaggc ccctagactg 540
tggatctacg gcatcagcaa tctggccagc ggcatccctg ccagattttc tggctctggc 600
tccggcacca gcttcagcct gacaatcagc agcctgcaga gcgaggactt cgccgtgtac 660
tactgccagc agagaagcag ctaccctcct acctttggcg gaggcaccaa ggtggaaatc 720
aagcgg 726
<210> 365
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> 8H5H5G4 Heavy chain variable region sequence
<400> 365
gtccagctgc aacagtctgg acctgatctg gtgaagcctg ggacttcagt gaagatatcc 60
tgtaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acgttactac 300
catagtacct acgtgttcta ctttgactcc tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 366
<211> 294
<212> DNA
<213> Artificial Sequence
<220>
<223> IGHV1-24*01 V-REGION sequence
<400> 366
caggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg tttccggata caccctcact gaattatcca tgcactgggt gcgacaggct 120
cctggaaaag ggcttgagtg gatgggaggt tttgatcctg aagatggtga aacaatctac 180
gcacagaagt tccagggcag agtcaccatg accgaggaca catctacaga cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aaca 294
<210> 367
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> IGHJ4*03 J-REGION sequence
<400> 367
tactttgact actggggcca agggaccctg gtcaccgtct cctca 45
<210> 368
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized 8H5H5G4 Heavy chain variable region sequence
<400> 368
caggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg tttccggaaa cacattcact gaatacacca tgcactgggt gcgacaggct 120
cctggaaaag ggcttgagtg gatgggaggt tttaatccta acaatggtgt tactaactac 180
aaccagaagt tcaagggcag agtcaccatg accgaggaca catctacaga cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aagacgttac 300
taccatagta cctacgtgtt ctactttgac tcctggggcc aagggaccct ggtcaccgtc 360
tcctca 366
<210> 369
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized 8H5H5G4 Heavy chain variable region sequence (codon
optimized)
<400> 369
caggttcagc tggttcagtc tggcgccgaa gtgaagaaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg tgtccggaaa taccttcacc gagtacacca tgcactgggt ccgacaggcc 120
cctggcaaag gacttgaatg gatgggcggc ttcaacccca acaacggcgt gaccaactac 180
aaccagaaat tcaagggccg cgtgaccatg accgaggaca caagcacaga caccgcctac 240
atggaactga gcagcctgag aagcgaggac accgccgtgt actactgcgc cagaaggtac 300
taccacagca cctacgtgtt ctacttcgac agctggggcc agggcacact ggtcacagtt 360
tcttct 366
<210> 370
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified Humanized 8H5H5G4 Heavy chain variable region sequence
<400> 370
caggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg tttccggaaa cacattcact gaatacacca tgcactgggt gcgacaggct 120
cctggaaaag ggcttgagtg gatcggaggt tttaatccta acaatggtgt tactaactac 180
aaccagaagt tcaagggcaa ggtcaccctg accgtggaca catctagcag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc aagacgttac 300
taccatagta cctacgtgtt ctactttgac tcctggggcc aagggaccct ggtcaccgtc 360
tcctca 366
<210> 371
<211> 366
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified Humanized 8H5H5G4 Heavy chain variable region sequence
(codon optimized)
<400> 371
caggttcagc tggttcagtc tggcgccgaa gtgaagaaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg tgtccggaaa taccttcacc gagtacacca tgcactgggt ccgacaggcc 120
cctggcaaag gactggaatg gatcggcggc ttcaacccca acaacggcgt gaccaactac 180
aaccagaaat tcaagggcaa agtgaccctg accgtggaca ccagcagcag cacagcctac 240
atggaactga gcagcctgag aagcgaggac accgccgtgt actactgcgc cagaaggtac 300
taccacagca cctacgtgtt ctacttcgac agctggggcc agggcacact ggtcacagtt 360
tcttct 366
<210> 372
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> 8H5H5G4 Light chain variable region sequence
<400> 372
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtttca gcagaaacca 120
gatggaacta ttaagctcct gatctattac acatcaagtt tacattcagg agtcccatca 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagtaa tgtggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccttacac gttcggaggg 300
gggaccaagc tggagataaa acgg 324
<210> 373
<211> 285
<212> DNA
<213> Artificial Sequence
<220>
<223> IGKV1-27*01 V-REGION sequence
<400> 373
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcgagtca gggcattagc aattatttag cctggtatca gcagaaacca 120
gggaaagttc ctaagctcct gatctatgct gcatccactt tgcaatcagg ggtcccatct 180
cggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagatgttg caacttatta ctgtcaaaag tataacagtg cccct 285
<210> 374
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> IGKJ4*02 J-REGION sequence
<400> 374
ctcacgttcg gcggagggac caaggtggag atcaaa 36
<210> 375
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8H5H5G4 Light chain variable region sequence
<400> 375
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca gtgcaagtca gggcattagc aattatttaa actggtatca gcagaaacca 120
gggaaagttc ctaagctcct gatctattac acatcaagtt tacattcagg ggtcccatct 180
cggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag cctgcagcct 240
gaagatgttg caacttatta ctgtcagcag tatagtaagc ttccttacac gttcggcgga 300
gggaccaagg tggagatcaa acgg 324
<210> 376
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> humanized 8H5H5G4 Light chain variable region sequence (codon
optimized)
<400> 376
gacatccaga tgacacagag ccctagcagc ctgtctgcca gcgtgggaga cagagtgacc 60
atcacatgta gcgccagcca gggcatcagc aactacctga actggtatca gcagaaaccc 120
ggcaaggtgc ccaagctgct gatctactac accagcagcc tgcacagcgg cgtgccaagc 180
agattttctg gcagcggctc tggcaccgac ttcaccctga ccatatctag cctgcagcct 240
gaggacgtgg ccacctacta ctgtcagcag tacagcaagc tgccctacac ctttggcgga 300
ggcaccaagg tggaaatcaa gcgg 324
<210> 377
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8H5H5G4 Light chain variable region sequence
<400> 377
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca gtgcaagtca gggcattagc aattatttaa actggtatca gcagaaacca 120
gggaaagttc ctaagctcct gatctattac acatcaagtt tacattcagg ggtcccatct 180
cggttcagtg gcagtggatc tgggacagat tacactctca ccatcagcag cctgcagcct 240
gaagatgttg caacttatta ctgtcagcag tatagtaagc ttccttacac gttcggcgga 300
gggaccaagg tggagatcaa acgg 324
<210> 378
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8H5H5G4 Light chain variable region sequence
(codon optimized)
<400> 378
gacatccaga tgacacagag ccctagcagc ctgtctgcca gcgtgggaga cagagtgacc 60
atcacatgta gcgccagcca gggcatcagc aactacctga actggtatca gcagaaaccc 120
ggcaaggtgc ccaagctgct gatctactac accagcagcc tgcacagcgg cgtgccaagc 180
agattttctg gcagcggctc tggcaccgac tacaccctga ccatatctag cctgcagcct 240
gaggacgtgg ccacctacta ctgtcagcag tacagcaagc tgccctacac ctttggcgga 300
ggcaccaagg tggaaatcaa gcgg 324
<210> 379
<211> 735
<212> DNA
<213> Artificial Sequence
<220>
<223> Modified humanized 8H5H5G4 scFV sequence (codon optimized)
<400> 379
caggttcagc tggttcagtc tggcgccgaa gtgaagaaac ctggcgcctc tgtgaaggtg 60
tcctgcaagg tgtccggaaa taccttcacc gagtacacca tgcactgggt ccgacaggcc 120
cctggcaaag gactggaatg gatcggcggc ttcaacccca acaacggcgt gaccaactac 180
aaccagaaat tcaagggcaa agtgaccctg accgtggaca ccagcagcag cacagcctac 240
atggaactga gcagcctgag aagcgaggac accgccgtgt actactgcgc cagaaggtac 300
taccacagca cctacgtgtt ctacttcgac agctggggcc agggcacact ggtcacagtt 360
tcttctggcg gtggcggaag cggaggcggt ggctccggtg gcggaggcag cgacatccag 420
atgacacaga gccctagcag cctgtctgcc agcgtgggag acagagtgac catcacatgt 480
agcgccagcc agggcatcag caactacctg aactggtatc agcagaaacc cggcaaggtg 540
cccaagctgc tgatctacta caccagcagc ctgcacagcg gcgtgccaag cagattttct 600
ggcagcggct ctggcaccga ctacaccctg accatatcta gcctgcagcc tgaggacgtg 660
gccacctact actgtcagca gtacagcaag ctgccctaca cctttggcgg aggcaccaag 720
gtggaaatca agcgg 735
<210> 380
<211> 993
<212> DNA
<213> Artificial Sequence
<220>
<223> Human IgG1 heavy chain constant region sequence: (for making full
antibody - pair with either kappa or lambda constant region; 2
plasmids, express together)
<400> 380
gctagcacca agggcccatc ggtcttcccc ctggcaccct cctccaagag cacctctggg 60
ggcacagcgg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgaca gtgccctcca gcagcttggg cacccagacc 240
tacatctgca acgtgaatca caagcccagc aacaccaagg tggacaagaa agttgagccc 300
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga 360
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 420
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 480
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 540
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 600
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 660
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggaggag 720
atgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 780
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 840
ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg 900
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 960
cagaagagcc tctccctgtc tccgggtaaa tga 993
<210> 381
<211> 981
<212> DNA
<213> Artificial Sequence
<220>
<223> Human IgG2 heavy chain constant region sequence: (for making full
antibody - pair with either kappa or lambda constant region; 2
plasmids, express together)
<400> 381
gcctccacca agggcccatc ggtcttcccc ctggcgccct gctccaggag cacctccgag 60
agcacagccg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 120
tggaactcag gcgctctgac cagcggcgtg cacaccttcc cagctgtcct acagtcctca 180
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcaacttcgg cacccagacc 240
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagac agttgagcgc 300
aaatgttgtg tcgagtgccc accgtgccca gcaccacctg tggcaggacc gtcagtcttc 360
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacgtgc 420
gtggtggtgg acgtgagcca cgaagacccc gaggtccagt tcaactggta cgtggacggc 480
gtggaggtgc ataatgccaa gacaaagcca cgggaggagc agttcaacag cacgttccgt 540
gtggtcagcg tcctcaccgt tgtgcaccag gactggctga acggcaagga gtacaagtgc 600
aaggtctcca acaaaggcct cccagccccc atcgagaaaa ccatctccaa aaccaaaggg 660
cagccccgag aaccacaggt gtacaccctg cccccatccc gggaggagat gaccaagaac 720
caggtcagcc tgacctgcct ggtcaaaggc ttctacccca gcgacatcgc cgtggagtgg 780
gagagcaatg ggcagccgga gaacaactac aagaccacac ctcccatgct ggactccgac 840
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 900
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 960
tccctgtctc cgggtaaata g 981
<210> 382
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Human Kappa light chain constant region sequence
<400> 382
aggacggtgg ctgcaccatc tgtcttcatc ttcccgccat ctgatgagca gttgaaatct 60
ggaactgcct ctgttgtgtg cctgctgaat aacttctatc ccagagaggc caaagtacag 120
tggaaggtgg ataacgccct ccaatcgggt aactcccagg agagtgtcac agagcaggac 180
agcaaggaca gcacctacag cctcagcagc accctgacgc tgagcaaagc agactacgag 240
aaacacaaag tctacgcctg cgaagtcacc catcagggcc tgagctcgcc cgtcacaaag 300
agcttcaaca ggggagagtg ttag 324
<210> 383
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Human Lambda light chain constant region sequence
<400> 383
ggtcagccca aggctgcccc ctcggtcact ctgttcccgc cctcctctga ggagcttcaa 60
gccaacaagg ccacactggt gtgtctcata agtgacttct acccgggagc cgtgacagtg 120
gcctggaagg cagatagcag ccccgtcaag gcgggagtgg agaccaccac accctccaaa 180
caaagcaaca acaagtacgc ggccagcagc tatctgagcc tgacgcctga gcagtggaag 240
tcccacagaa gctacagctg ccaggtcacg catgaaggga gcaccgtgga gaagacagtg 300
gcccctacag aatgttcata g 321
<210> 384
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Human IgG1 Fc region sequence: (to be fused to scFv for
homo-dimerizes)
<400> 384
gagcccaaat cttgtgacaa aactcacaca tgcccaccgt gcccagcacc tgaactcctg 60
gggggaccgt cagtcttcct cttcccccca aaacccaagg acaccctcat gatctcccgg 120
acccctgagg tcacatgcgt ggtggtggac gtgagccacg aagaccctga ggtcaagttc 180
aactggtacg tggacggcgt ggaggtgcat aatgccaaga caaagccgcg ggaggagcag 240
tacaacagca cgtaccgtgt ggtcagcgtc ctcaccgtcc tgcaccagga ctggctgaat 300
ggcaaggagt acaagtgcaa ggtctccaac aaagccctcc cagcccccat cgagaaaacc 360
atctccaaag ccaaagggca gccccgagaa ccacaggtgt acaccctgcc cccatcccgg 420
gaggagatga ccaagaacca ggtcagcctg acctgcctgg tcaaaggctt ctatcccagc 480
gacatcgccg tggagtggga gagcaatggg cagccggaga acaactacaa gaccacgcct 540
cccgtgctgg actccgacgg ctccttcttc ctctacagca agctcaccgt ggacaagagc 600
aggtggcagc aggggaacgt cttctcatgc tccgtgatgc atgaggctct gcacaaccac 660
tacacgcaga agagcctctc cctgtctccg ggtaaatga 699
<210> 385
<211> 687
<212> DNA
<213> Artificial Sequence
<220>
<223> Human IgG2 Fc region sequence
<400> 385
gagcgcaaat gttgtgtcga gtgcccaccg tgcccagcac cacctgtggc aggaccgtca 60
gtcttcctct tccccccaaa acccaaggac accctcatga tctcccggac ccctgaggtc 120
acgtgcgtgg tggtggacgt gagccacgaa gaccccgagg tccagttcaa ctggtacgtg 180
gacggcgtgg aggtgcataa tgccaagaca aagccacggg aggagcagtt caacagcacg 240
ttccgtgtgg tcagcgtcct caccgttgtg caccaggact ggctgaacgg caaggagtac 300
aagtgcaagg tctccaacaa aggcctccca gcccccatcg agaaaaccat ctccaaaacc 360
aaagggcagc cccgagaacc acaggtgtac accctgcccc catcccggga ggagatgacc 420
aagaaccagg tcagcctgac ctgcctggtc aaaggcttct accccagcga catcgccgtg 480
gagtgggaga gcaatgggca gccggagaac aactacaaga ccacacctcc catgctggac 540
tccgacggct ccttcttcct ctacagcaag ctcaccgtgg acaagagcag gtggcagcag 600
gggaacgtct tctcatgctc cgtgatgcat gaggctctgc acaaccacta cacgcagaag 660
agcctctccc tgtctccggg taaatag 687
<210> 386
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 - Heavy chain variable region
sequence - H-1,8,9,10,11
<400> 386
gtccagctgc aacagtctgg acctgaactg gtgaagcctg gggcttcagt gaagatatcc 60
tgcaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acggtactac 300
catagtctct acgtgtttta ctttgactac tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 387
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 387
Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 388
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Heavy chain variable region CDR1
<400> 388
Asn Thr Phe Thr Glu Tyr Thr Met His
1 5
<210> 389
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Heavy chain variable region CDR2
<400> 389
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 390
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Heavy chain variable region CDR3
<400> 390
Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr
1 5 10
<210> 391
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Light chain variable region sequence
- K-3,4,9,10,11
<400> 391
gaaacaactg tgacccagtc tccagcatcc ctgtccatgg ctataggaga aaaagtcacc 60
atcagatgca taaccagcac tgatattgat gatgatatga actggtacca gcagaagcca 120
ggggaacctc ctaagctcct tatttcagaa ggcaatactc ttcgtcctgg agtcccatcc 180
cgattctcca gcagtggcta tggtacagat tttgttttta caattgaaaa catgctctca 240
gaagatgttg cagattacta ctgtttgcaa agtgataact tgcctctcac gttcggctcg 300
gggacaaagt tggaaataaa acgg 324
<210> 392
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 392
Glu Thr Thr Val Thr Gln Ser Pro Ala Ser Leu Ser Met Ala Ile Gly
1 5 10 15
Glu Lys Val Thr Ile Arg Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Pro Pro Lys Leu Leu Ile
35 40 45
Ser Glu Gly Asn Thr Leu Arg Pro Gly Val Pro Ser Arg Phe Ser Ser
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Val Phe Thr Ile Glu Asn Met Leu Ser
65 70 75 80
Glu Asp Val Ala Asp Tyr Tyr Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 393
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Light chain variable region CDR1
<400> 393
Ile Thr Ser Thr Asp Ile Asp Asp Asp Met Asn
1 5 10
<210> 394
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Light chain variable region CDR2
<400> 394
Glu Gly Asn Thr Leu Arg Pro
1 5
<210> 395
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A4A3 Light chain variable region CDR3
<400> 395
Leu Gln Ser Asp Asn Leu Pro Leu Thr
1 5
<210> 396
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 - Heavy chain variable region
sequence - H-1,4,7,8,12
<400> 396
gtccagctgc aacagtctgg acctgatctg gtgaagcctg ggacttcagt gaagatatcc 60
tgtaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acgttactac 300
catagtacct acgtgttcta ctttgactcc tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 397
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 397
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 398
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Heavy chain variable region CDR1
<400> 398
Asn Thr Phe Thr Glu Tyr Thr Met His
1 5
<210> 399
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Heavy chain variable region CDR2
<400> 399
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 400
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Heavy chain variable region CDR3
<400> 400
Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser
1 5 10
<210> 401
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Light chain variable region sequence
- K-3,4,5,6,12
<400> 401
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtttca gcagaaacca 120
gatggaacta ttaagctcct gatctattac acatcaagtt tacattcagg agtcccatca 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagtaa tgtggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccttacac gttcggaggg 300
gggaccaagc tggagataaa acgg 324
<210> 402
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Translated protein
<400> 402
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 403
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 403
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 404
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Light chain variable region CDR 1
<400> 404
Ser Ala Ser Gln Gly Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 405
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Light chain variable region CDR2
<400> 405
Tyr Thr Ser Ser Leu His Ser
1 5
<210> 406
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E2B11 Light chain variable region CDR3
<400> 406
Gln Gln Tyr Ser Lys Leu Pro Tyr Thr
1 5
<210> 407
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 - Heavy chain variable region
sequence - H-2,4,7,10,12
<400> 407
gtccagctgc aacagtctgg acctgatctg gtgaagcctg ggacttcagt gaagatatcc 60
tgtaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acgttactac 300
catagtacct acgtgttcta ctttgactcc tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 408
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 408
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 409
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Heavy chain variable region CDR1
<400> 409
Asn Thr Phe Thr Glu Tyr Thr Met His
1 5
<210> 410
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Heavy chain variable region CDR2
<400> 410
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 411
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Heavy chain variable region CDR3
<400> 411
Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser
1 5 10
<210> 412
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Light chain variable region sequence
- K-2,6,8,14,15
<400> 412
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtttca gcagaaacca 120
gatggaacta ttaagctcct gatctattac acatcaagtt tacattcagg agtcccatca 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagtaa tgtggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccttacac gttcggaggg 300
gggaccaagc tggagataaa acgg 324
<210> 413
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 413
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 414
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Light chain variable region CDR 1
<400> 414
Ser Ala Ser Gln Gly Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 415
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Light chain variable region CDR2
<400> 415
Tyr Thr Ser Ser Leu His Ser
1 5
<210> 416
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9E10E4 Light chain variable region CDR3
<400> 416
Gln Gln Tyr Ser Lys Leu Pro Tyr Thr
1 5
<210> 417
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 - Heavy chain variable region
sequence - H-4,9,10,11,13
<400> 417
gtccagctgc aacagtctgg acctgatctg gtgaagcctg ggacttcagt gaagatatcc 60
tgtaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acgttactac 300
catagtacct acgtgttcta ctttgactcc tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 418
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 418
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 419
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Heavy chain variable region CDR1
<400> 419
Asn Thr Phe Thr Glu Tyr Thr Met His
1 5
<210> 420
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Heavy chain variable region CDR2
<400> 420
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 421
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Heavy chain variable region CDR3
<400> 421
Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser
1 5 10
<210> 422
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Light chain variable region sequence
- K-4,6,7,8,10
<400> 422
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtttca gcagaaacca 120
gatggaacta ttaagctcct gatctattac acatcaagtt tacattcagg agtcccatca 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagtaa tgtggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccttacac gttcggaggg 300
gggaccaagc tggagataaa acgg 324
<210> 423
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 423
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 424
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Light chain variable region CDR 1
<400> 424
Ser Ala Ser Gln Gly Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 425
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Light chain variable region CDR2
<400> 425
Tyr Thr Ser Ser Leu His Ser
1 5
<210> 426
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5D9G2C4 Light chain variable region CDR3
<400> 426
Gln Gln Tyr Ser Lys Leu Pro Tyr Thr
1 5
<210> 427
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 - Heavy chain variable region
sequence - H-2,3,4,13,15
<400> 427
gtccagctgc aacagtctgg acctgatctg gtgaagcctg ggacttcagt gaagatatcc 60
tgtaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acgttactac 300
catagtacct acgtgttcta ctttgactcc tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 428
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 428
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 429
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Heavy chain variable region CDR1
<400> 429
Asn Thr Phe Thr Glu Tyr Thr Met His
1 5
<210> 430
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Heavy chain variable region CDR2
<400> 430
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 431
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Heavy chain variable region CDR3
<400> 431
Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser
1 5 10
<210> 432
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Light chain variable region sequence
- K-1,2,3,4,9
<400> 432
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtttca gcagaaacca 120
gatggaacta ttaagctcct gatctattac acatcaagtt tacattcagg agtcccatca 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagtaa tgtggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccttacac gttcggaggg 300
gggaccaagc tggagataaa acgg 324
<210> 433
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 433
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 434
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Light chain variable region CDR1
<400> 434
Ser Ala Ser Gln Gly Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 435
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Light chain variable region CDR2
<400> 435
Tyr Thr Ser Ser Leu His Ser
1 5
<210> 436
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 5F3A5D4 Light chain variable region CDR3
<400> 436
Gln Gln Tyr Ser Lys Leu Pro Tyr Thr
1 5
<210> 437
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 - Heavy chain variable region
sequence - H-3,4,6,10,11
<400> 437
atccagttgg tgcagtctgg acctgagctg aagaagcctg gagagacagt caagatctcc 60
tgcaaggctt ctgggtatac cttcacaaac tatggaatga actgggtgaa gcaggctcca 120
ggaaagggtt taaagtggat gggctggata aacacctaca ctggagagcc aacatatgtt 180
gatgacttca agggacggtt tgccttctct ttggaaacct ctgccaccac tgcctatttg 240
cagatcaaca acctcaaaaa tgaggacacg tctacatatt tctgtgcaag attgaggggg 300
atacgaccgg gtcccttggc ttactggggc caagggactc tggtcactgt ctctgca 357
<210> 438
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 438
Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu Thr
1 5 10 15
Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr Gly
20 25 30
Met Asn Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met Gly
35 40 45
Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe Lys
50 55 60
Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Thr Thr Ala Tyr Leu
65 70 75 80
Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ser Thr Tyr Phe Cys Ala
85 90 95
Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 439
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Heavy chain variable region CDR1
<400> 439
Tyr Thr Phe Thr Asn Tyr Gly Met Asn
1 5
<210> 440
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Heavy chain variable region CDR2
<400> 440
Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe Lys
1 5 10 15
Gly
<210> 441
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Heavy chain variable region CDR3
<400> 441
Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr
1 5 10
<210> 442
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Light chain variable region sequence
- K-1,2,3,4,5
<400> 442
gaaattttgc tcacccagtc tccagcaatc atagctgcat ctcctgggga gaaggtcacc 60
atcacctgca gtgccagctc aagtgtaagt tacatgaact ggtaccagca gaaaccagga 120
tcctccccca aaatatggat ttatggtata tccaacctgg cttctggagt tcctgctcgc 180
ttcagtggca gtgggtctgg gacatctttc tctttcacaa tcaacagcat ggaggctgaa 240
gatgttgcca cttattactg tcagcaaagg agtagttacc cacccacgtt cggagggggg 300
accaagctgg aaataaaacg g 321
<210> 443
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 443
Glu Ile Leu Leu Thr Gln Ser Pro Ala Ile Ile Ala Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Ile Trp Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Phe Ser Phe Thr Ile Asn Ser Met Glu Ala Glu
65 70 75 80
Asp Val Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 444
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Light chain variable region CDR 1
<400> 444
Ser Ala Ser Ser Ser Val Ser Tyr Met Asn
1 5 10
<210> 445
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Light chain variable region CDR2
<400> 445
Gly Ile Ser Asn Leu Ala Ser
1 5
<210> 446
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8F9A5A1 Light chain variable region CDR3
<400> 446
Gln Gln Arg Ser Ser Tyr Pro Pro Thr
1 5
<210> 447
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 - Heavy chain variable region
sequence - H-1,3,5,6,10
<400> 447
gtccagctgc aacagtctgg acctgatctg gtgaagcctg ggacttcagt gaagatatcc 60
tgtaagactt ctggaaacac attcactgaa tacaccatgc actgggtgaa gcagagccat 120
ggaaagagcc ttgagtggat tggaggtttt aatcctaaca atggtgttac taactacaac 180
cagaagttca agggcaaggc cacattgact gtagacaagt cctccagcac agcctacatg 240
gagctccgca gcctgacatc tgaggattct gcagtctatt actgtgcaag acgttactac 300
catagtacct acgtgttcta ctttgactcc tggggccaag gcaccactct cacagtctcc 360
tca 363
<210> 448
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 448
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 449
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Heavy chain variable region CDR1
<400> 449
Asn Thr Phe Thr Glu Tyr Thr Met His
1 5
<210> 450
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Heavy chain variable region CDR2
<400> 450
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 451
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Heavy chain variable region CDR3
<400> 451
Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser
1 5 10
<210> 452
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Light chain variable region sequence
- K-2,5,8,9,15
<400> 452
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtttca gcagaaacca 120
gatggaacta ttaagctcct gatctattac acatcaagtt tacattcagg agtcccatca 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagtaa tgtggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccttacac gttcggaggg 300
gggaccaagc tggagataaa acgg 324
<210> 453
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Translated protein, wherein the
underlined sequence is the complementarity determining region
(CDR)
<400> 453
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 454
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Light chain variable region CDR 1
<400> 454
Ser Ala Ser Gln Gly Ile Ser Asn Tyr Leu Asn
1 5 10
<210> 455
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Light chain variable region CDR2
<400> 455
Tyr Thr Ser Ser Leu His Ser
1 5
<210> 456
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Monoclonal antibody 8H5H5G4 Light chain variable region CDR3
<400> 456
Gln Gln Tyr Ser Lys Leu Pro Tyr Thr
1 5
<210> 457
<400> 457
000
<210> 458
<400> 458
000
<210> 459
<400> 459
000
<210> 460
<400> 460
000
<210> 461
<400> 461
000
<210> 462
<400> 462
000
<210> 463
<400> 463
000
<210> 464
<400> 464
000
<210> 465
<400> 465
000
<210> 466
<400> 466
000
<210> 467
<400> 467
000
<210> 468
<400> 468
000
<210> 469
<400> 469
000
<210> 470
<400> 470
000
<210> 471
<400> 471
000
<210> 472
<400> 472
000
<210> 473
<400> 473
000
<210> 474
<400> 474
000
<210> 475
<400> 475
000
<210> 476
<400> 476
000
<210> 477
<400> 477
000
<210> 478
<400> 478
000
<210> 479
<400> 479
000
<210> 480
<400> 480
000
<210> 481
<400> 481
000
<210> 482
<400> 482
000
<210> 483
<400> 483
000
<210> 484
<400> 484
000
<210> 485
<400> 485
000
<210> 486
<400> 486
000
<210> 487
<400> 487
000
<210> 488
<400> 488
000
<210> 489
<400> 489
000
<210> 490
<400> 490
000
<210> 491
<400> 491
000
<210> 492
<400> 492
000
<210> 493
<400> 493
000
<210> 494
<400> 494
000
<210> 495
<400> 495
000
<210> 496
<400> 496
000
<210> 497
<400> 497
000
<210> 498
<400> 498
000
<210> 499
<400> 499
000
<210> 500
<400> 500
000
<210> 501
<400> 501
000
<210> 502
<400> 502
000
<210> 503
<400> 503
000
<210> 504
<400> 504
000
<210> 505
<400> 505
000
<210> 506
<400> 506
000
<210> 507
<400> 507
000
<210> 508
<400> 508
000
<210> 509
<400> 509
000
<210> 510
<400> 510
000
<210> 511
<400> 511
000
<210> 512
<400> 512
000
<210> 513
<400> 513
000
<210> 514
<400> 514
000
<210> 515
<400> 515
000
<210> 516
<400> 516
000
<210> 517
<400> 517
000
<210> 518
<400> 518
000
<210> 519
<400> 519
000
<210> 520
<400> 520
000
<210> 521
<400> 521
000
<210> 522
<400> 522
000
<210> 523
<400> 523
000
<210> 524
<400> 524
000
<210> 525
<400> 525
000
<210> 526
<400> 526
000
<210> 527
<400> 527
000
<210> 528
<400> 528
000
<210> 529
<400> 529
000
<210> 530
<400> 530
000
<210> 531
<400> 531
000
<210> 532
<400> 532
000
<210> 533
<400> 533
000
<210> 534
<400> 534
000
<210> 535
<400> 535
000
<210> 536
<400> 536
000
<210> 537
<400> 537
000
<210> 538
<400> 538
000
<210> 539
<400> 539
000
<210> 540
<400> 540
000
<210> 541
<400> 541
000
<210> 542
<400> 542
000
<210> 543
<400> 543
000
<210> 544
<400> 544
000
<210> 545
<400> 545
000
<210> 546
<400> 546
000
<210> 547
<400> 547
000
<210> 548
<400> 548
000
<210> 549
<400> 549
000
<210> 550
<400> 550
000
<210> 551
<400> 551
000
<210> 552
<400> 552
000
<210> 553
<400> 553
000
<210> 554
<400> 554
000
<210> 555
<400> 555
000
<210> 556
<400> 556
000
<210> 557
<400> 557
000
<210> 558
<400> 558
000
<210> 559
<400> 559
000
<210> 560
<400> 560
000
<210> 561
<400> 561
000
<210> 562
<400> 562
000
<210> 563
<400> 563
000
<210> 564
<400> 564
000
<210> 565
<400> 565
000
<210> 566
<400> 566
000
<210> 567
<400> 567
000
<210> 568
<400> 568
000
<210> 569
<400> 569
000
<210> 570
<400> 570
000
<210> 571
<400> 571
000
<210> 572
<400> 572
000
<210> 573
<400> 573
000
<210> 574
<400> 574
000
<210> 575
<400> 575
000
<210> 576
<400> 576
000
<210> 577
<400> 577
000
<210> 578
<400> 578
000
<210> 579
<400> 579
000
<210> 580
<400> 580
000
<210> 581
<400> 581
000
<210> 582
<400> 582
000
<210> 583
<400> 583
000
<210> 584
<400> 584
000
<210> 585
<400> 585
000
<210> 586
<400> 586
000
<210> 587
<400> 587
000
<210> 588
<400> 588
000
<210> 589
<400> 589
000
<210> 590
<400> 590
000
<210> 591
<400> 591
000
<210> 592
<400> 592
000
<210> 593
<400> 593
000
<210> 594
<400> 594
000
<210> 595
<400> 595
000
<210> 596
<400> 596
000
<210> 597
<400> 597
000
<210> 598
<400> 598
000
<210> 599
<400> 599
000
<210> 600
<400> 600
000
<210> 601
<400> 601
000
<210> 602
<400> 602
000
<210> 603
<400> 603
000
<210> 604
<400> 604
000
<210> 605
<400> 605
000
<210> 606
<400> 606
000
<210> 607
<400> 607
000
<210> 608
<400> 608
000
<210> 609
<400> 609
000
<210> 610
<400> 610
000
<210> 611
<400> 611
000
<210> 612
<400> 612
000
<210> 613
<400> 613
000
<210> 614
<400> 614
000
<210> 615
<400> 615
000
<210> 616
<400> 616
000
<210> 617
<400> 617
000
<210> 618
<400> 618
000
<210> 619
<400> 619
000
<210> 620
<400> 620
000
<210> 621
<400> 621
000
<210> 622
<400> 622
000
<210> 623
<400> 623
000
<210> 624
<400> 624
000
<210> 625
<400> 625
000
<210> 626
<400> 626
000
<210> 627
<400> 627
000
<210> 628
<400> 628
000
<210> 629
<400> 629
000
<210> 630
<400> 630
000
<210> 631
<400> 631
000
<210> 632
<400> 632
000
<210> 633
<400> 633
000
<210> 634
<400> 634
000
<210> 635
<400> 635
000
<210> 636
<400> 636
000
<210> 637
<400> 637
000
<210> 638
<400> 638
000
<210> 639
<400> 639
000
<210> 640
<400> 640
000
<210> 641
<400> 641
000
<210> 642
<400> 642
000
<210> 643
<400> 643
000
<210> 644
<400> 644
000
<210> 645
<400> 645
000
<210> 646
<400> 646
000
<210> 647
<400> 647
000
<210> 648
<400> 648
000
<210> 649
<400> 649
000
<210> 650
<400> 650
000
<210> 651
<400> 651
000
<210> 652
<400> 652
000
<210> 653
<400> 653
000
<210> 654
<400> 654
000
<210> 655
<400> 655
000
<210> 656
<400> 656
000
<210> 657
<400> 657
000
<210> 658
<400> 658
000
<210> 659
<400> 659
000
<210> 660
<400> 660
000
<210> 661
<400> 661
000
<210> 662
<400> 662
000
<210> 663
<400> 663
000
<210> 664
<400> 664
000
<210> 665
<400> 665
000
<210> 666
<400> 666
000
<210> 667
<400> 667
000
<210> 668
<400> 668
000
<210> 669
<400> 669
000
<210> 670
<400> 670
000
<210> 671
<400> 671
000
<210> 672
<400> 672
000
<210> 673
<400> 673
000
<210> 674
<400> 674
000
<210> 675
<400> 675
000
<210> 676
<400> 676
000
<210> 677
<400> 677
000
<210> 678
<400> 678
000
<210> 679
<400> 679
000
<210> 680
<400> 680
000
<210> 681
<400> 681
000
<210> 682
<400> 682
000
<210> 683
<400> 683
000
<210> 684
<400> 684
000
<210> 685
<400> 685
000
<210> 686
<400> 686
000
<210> 687
<400> 687
000
<210> 688
<400> 688
000
<210> 689
<400> 689
000
<210> 690
<400> 690
000
<210> 691
<400> 691
000
<210> 692
<400> 692
000
<210> 693
<400> 693
000
<210> 694
<400> 694
000
<210> 695
<400> 695
000
<210> 696
<400> 696
000
<210> 697
<400> 697
000
<210> 698
<400> 698
000
<210> 699
<400> 699
000
<210> 700
<400> 700
000
<210> 701
<400> 701
000
<210> 702
<400> 702
000
<210> 703
<400> 703
000
<210> 704
<400> 704
000
<210> 705
<400> 705
000
<210> 706
<400> 706
000
<210> 707
<400> 707
000
<210> 708
<400> 708
000
<210> 709
<400> 709
000
<210> 710
<400> 710
000
<210> 711
<400> 711
000
<210> 712
<400> 712
000
<210> 713
<400> 713
000
<210> 714
<400> 714
000
<210> 715
<400> 715
000
<210> 716
<400> 716
000
<210> 717
<400> 717
000
<210> 718
<400> 718
000
<210> 719
<400> 719
000
<210> 720
<400> 720
000
<210> 721
<400> 721
000
<210> 722
<400> 722
000
<210> 723
<400> 723
000
<210> 724
<400> 724
000
<210> 725
<400> 725
000
<210> 726
<400> 726
000
<210> 727
<400> 727
000
<210> 728
<400> 728
000
<210> 729
<400> 729
000
<210> 730
<400> 730
000
<210> 731
<400> 731
000
<210> 732
<400> 732
000
<210> 733
<400> 733
000
<210> 734
<400> 734
000
<210> 735
<400> 735
000
<210> 736
<400> 736
000
<210> 737
<400> 737
000
<210> 738
<400> 738
000
<210> 739
<400> 739
000
<210> 740
<400> 740
000
<210> 741
<400> 741
000
<210> 742
<400> 742
000
<210> 743
<400> 743
000
<210> 744
<400> 744
000
<210> 745
<400> 745
000
<210> 746
<400> 746
000
<210> 747
<400> 747
000
<210> 748
<400> 748
000
<210> 749
<400> 749
000
<210> 750
<400> 750
000
<210> 751
<400> 751
000
<210> 752
<400> 752
000
<210> 753
<400> 753
000
<210> 754
<400> 754
000
<210> 755
<400> 755
000
<210> 756
<400> 756
000
<210> 757
<400> 757
000
<210> 758
<400> 758
000
<210> 759
<400> 759
000
<210> 760
<400> 760
000
<210> 761
<400> 761
000
<210> 762
<400> 762
000
<210> 763
<400> 763
000
<210> 764
<400> 764
000
<210> 765
<400> 765
000
<210> 766
<400> 766
000
<210> 767
<400> 767
000
<210> 768
<400> 768
000
<210> 769
<400> 769
000
<210> 770
<400> 770
000
<210> 771
<400> 771
000
<210> 772
<400> 772
000
<210> 773
<400> 773
000
<210> 774
<400> 774
000
<210> 775
<400> 775
000
<210> 776
<400> 776
000
<210> 777
<400> 777
000
<210> 778
<400> 778
000
<210> 779
<400> 779
000
<210> 780
<400> 780
000
<210> 781
<400> 781
000
<210> 782
<400> 782
000
<210> 783
<400> 783
000
<210> 784
<400> 784
000
<210> 785
<400> 785
000
<210> 786
<400> 786
000
<210> 787
<400> 787
000
<210> 788
<400> 788
000
<210> 789
<400> 789
000
<210> 790
<400> 790
000
<210> 791
<400> 791
000
<210> 792
<400> 792
000
<210> 793
<400> 793
000
<210> 794
<400> 794
000
<210> 795
<400> 795
000
<210> 796
<400> 796
000
<210> 797
<400> 797
000
<210> 798
<400> 798
000
<210> 799
<400> 799
000
<210> 800
<400> 800
000
<210> 801
<400> 801
000
<210> 802
<400> 802
000
<210> 803
<400> 803
000
<210> 804
<400> 804
000
<210> 805
<400> 805
000
<210> 806
<400> 806
000
<210> 807
<400> 807
000
<210> 808
<400> 808
000
<210> 809
<400> 809
000
<210> 810
<400> 810
000
<210> 811
<400> 811
000
<210> 812
<400> 812
000
<210> 813
<400> 813
000
<210> 814
<400> 814
000
<210> 815
<400> 815
000
<210> 816
<400> 816
000
<210> 817
<400> 817
000
<210> 818
<400> 818
000
<210> 819
<400> 819
000
<210> 820
<400> 820
000
<210> 821
<400> 821
000
<210> 822
<400> 822
000
<210> 823
<400> 823
000
<210> 824
<400> 824
000
<210> 825
<400> 825
000
<210> 826
<400> 826
000
<210> 827
<400> 827
000
<210> 828
<400> 828
000
<210> 829
<400> 829
000
<210> 830
<400> 830
000
<210> 831
<400> 831
000
<210> 832
<400> 832
000
<210> 833
<400> 833
000
<210> 834
<400> 834
000
<210> 835
<400> 835
000
<210> 836
<400> 836
000
<210> 837
<400> 837
000
<210> 838
<400> 838
000
<210> 839
<400> 839
000
<210> 840
<400> 840
000
<210> 841
<400> 841
000
<210> 842
<400> 842
000
<210> 843
<400> 843
000
<210> 844
<400> 844
000
<210> 845
<400> 845
000
<210> 846
<400> 846
000
<210> 847
<400> 847
000
<210> 848
<400> 848
000
<210> 849
<400> 849
000
<210> 850
<400> 850
000
<210> 851
<400> 851
000
<210> 852
<400> 852
000
<210> 853
<400> 853
000
<210> 854
<400> 854
000
<210> 855
<400> 855
000
<210> 856
<400> 856
000
<210> 857
<400> 857
000
<210> 858
<400> 858
000
<210> 859
<400> 859
000
<210> 860
<400> 860
000
<210> 861
<400> 861
000
<210> 862
<400> 862
000
<210> 863
<400> 863
000
<210> 864
<400> 864
000
<210> 865
<400> 865
000
<210> 866
<400> 866
000
<210> 867
<400> 867
000
<210> 868
<400> 868
000
<210> 869
<400> 869
000
<210> 870
<400> 870
000
<210> 871
<400> 871
000
<210> 872
<400> 872
000
<210> 873
<400> 873
000
<210> 874
<400> 874
000
<210> 875
<400> 875
000
<210> 876
<400> 876
000
<210> 877
<400> 877
000
<210> 878
<400> 878
000
<210> 879
<400> 879
000
<210> 880
<400> 880
000
<210> 881
<400> 881
000
<210> 882
<400> 882
000
<210> 883
<400> 883
000
<210> 884
<400> 884
000
<210> 885
<400> 885
000
<210> 886
<400> 886
000
<210> 887
<400> 887
000
<210> 888
<400> 888
000
<210> 889
<400> 889
000
<210> 890
<400> 890
000
<210> 891
<400> 891
000
<210> 892
<400> 892
000
<210> 893
<400> 893
000
<210> 894
<400> 894
000
<210> 895
<400> 895
000
<210> 896
<400> 896
000
<210> 897
<400> 897
000
<210> 898
<400> 898
000
<210> 899
<400> 899
000
<210> 900
<400> 900
000
<210> 901
<400> 901
000
<210> 902
<400> 902
000
<210> 903
<400> 903
000
<210> 904
<400> 904
000
<210> 905
<400> 905
000
<210> 906
<400> 906
000
<210> 907
<400> 907
000
<210> 908
<400> 908
000
<210> 909
<400> 909
000
<210> 910
<400> 910
000
<210> 911
<400> 911
000
<210> 912
<400> 912
000
<210> 913
<400> 913
000
<210> 914
<400> 914
000
<210> 915
<400> 915
000
<210> 916
<400> 916
000
<210> 917
<400> 917
000
<210> 918
<400> 918
000
<210> 919
<400> 919
000
<210> 920
<400> 920
000
<210> 921
<400> 921
000
<210> 922
<400> 922
000
<210> 923
<400> 923
000
<210> 924
<400> 924
000
<210> 925
<400> 925
000
<210> 926
<400> 926
000
<210> 927
<400> 927
000
<210> 928
<400> 928
000
<210> 929
<400> 929
000
<210> 930
<400> 930
000
<210> 931
<400> 931
000
<210> 932
<400> 932
000
<210> 933
<400> 933
000
<210> 934
<400> 934
000
<210> 935
<400> 935
000
<210> 936
<400> 936
000
<210> 937
<400> 937
000
<210> 938
<400> 938
000
<210> 939
<400> 939
000
<210> 940
<400> 940
000
<210> 941
<400> 941
000
<210> 942
<400> 942
000
<210> 943
<400> 943
000
<210> 944
<400> 944
000
<210> 945
<400> 945
000
<210> 946
<400> 946
000
<210> 947
<400> 947
000
<210> 948
<400> 948
000
<210> 949
<400> 949
000
<210> 950
<400> 950
000
<210> 951
<400> 951
000
<210> 952
<400> 952
000
<210> 953
<400> 953
000
<210> 954
<400> 954
000
<210> 955
<400> 955
000
<210> 956
<400> 956
000
<210> 957
<400> 957
000
<210> 958
<400> 958
000
<210> 959
<400> 959
000
<210> 960
<400> 960
000
<210> 961
<400> 961
000
<210> 962
<400> 962
000
<210> 963
<400> 963
000
<210> 964
<400> 964
000
<210> 965
<400> 965
000
<210> 966
<400> 966
000
<210> 967
<400> 967
000
<210> 968
<400> 968
000
<210> 969
<400> 969
000
<210> 970
<400> 970
000
<210> 971
<400> 971
000
<210> 972
<400> 972
000
<210> 973
<400> 973
000
<210> 974
<400> 974
000
<210> 975
<400> 975
000
<210> 976
<400> 976
000
<210> 977
<400> 977
000
<210> 978
<400> 978
000
<210> 979
<400> 979
000
<210> 980
<400> 980
000
<210> 981
<400> 981
000
<210> 982
<400> 982
000
<210> 983
<400> 983
000
<210> 984
<400> 984
000
<210> 985
<400> 985
000
<210> 986
<400> 986
000
<210> 987
<400> 987
000
<210> 988
<400> 988
000
<210> 989
<400> 989
000
<210> 990
<400> 990
000
<210> 991
<400> 991
000
<210> 992
<400> 992
000
<210> 993
<400> 993
000
<210> 994
<400> 994
000
<210> 995
<400> 995
000
<210> 996
<400> 996
000
<210> 997
<400> 997
000
<210> 998
<400> 998
000
<210> 999
<400> 999
000
<210> 1000
<400> 1000
000
<210> 1001
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Anti-NME7 B3 peptide monoclonal antibodies - 8F9A4A3 Heavy chain
variable region sequence mouse
<400> 1001
Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 1002
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> IGHV1-24*01 V-REGION sequence human (closest match hu antibody
sequence)
<400> 1002
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Tyr Thr Leu Thr Glu Leu
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asp Pro Glu Asp Gly Glu Thr Ile Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr
<210> 1003
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> IGHJ4*01 J-REGION sequence human (closest match hu antibody
sequence)
<400> 1003
Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10 15
<210> 1004
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Heavy chain variable region sequence
<400> 1004
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1005
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Heavy chain variable region sequence (codon
optimized)
<400> 1005
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1006
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Heavy chain variable region sequence)
<400> 1006
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Val Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1007
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Heavy chain variable region sequence
(codon optimized)
<400> 1007
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Val Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1008
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A4A3 Light chain variable region sequence mouse
<400> 1008
Glu Thr Thr Val Thr Gln Ser Pro Ala Ser Leu Ser Met Ala Ile Gly
1 5 10 15
Glu Lys Val Thr Ile Arg Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Pro Pro Lys Leu Leu Ile
35 40 45
Ser Glu Gly Asn Thr Leu Arg Pro Gly Val Pro Ser Arg Phe Ser Ser
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Val Phe Thr Ile Glu Asn Met Leu Ser
65 70 75 80
Glu Asp Val Ala Asp Tyr Tyr Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 1009
<211> 88
<212> PRT
<213> Artificial Sequence
<220>
<223> IGKV5-2*01 V-REGION sequence human (closest match hu antibody
sequence)
<400> 1009
Glu Thr Thr Leu Thr Gln Ser Pro Ala Phe Met Ser Ala Thr Pro Gly
1 5 10 15
Asp Lys Val Asn Ile Ser Cys Lys Ala Ser Gln Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Ala Ala Ile Phe Ile Ile
35 40 45
Gln Glu Ala Thr Thr Leu Val Pro Gly Ile Pro Pro Arg Phe Ser Gly
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr Ile Asn Asn Ile Glu Ser
65 70 75 80
Glu Asp Ala Ala Tyr Tyr Phe Cys
85
<210> 1010
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> IGKJ4*02 J-REGION sequence human (closest match hu antibody
sequence)
<400> 1010
Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 1011
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Light chain variable region sequence
<400> 1011
Glu Thr Thr Leu Thr Gln Ser Pro Ala Phe Met Ser Ala Thr Pro Gly
1 5 10 15
Asp Lys Val Asn Ile Ser Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Ala Ala Ile Phe Ile Ile
35 40 45
Gln Glu Gly Asn Thr Leu Arg Pro Gly Ile Pro Pro Arg Phe Ser Gly
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr Ile Asn Asn Ile Glu Ser
65 70 75 80
Glu Asp Ala Ala Tyr Tyr Phe Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1012
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A4A3 Light chain variable region sequence (codon
optimized)
<400> 1012
Glu Thr Thr Leu Thr Gln Ser Pro Ala Phe Met Ser Ala Thr Pro Gly
1 5 10 15
Asp Lys Val Asn Ile Ser Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Ala Ala Ile Phe Ile Ile
35 40 45
Gln Glu Gly Asn Thr Leu Arg Pro Gly Ile Pro Pro Arg Phe Ser Gly
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr Ile Asn Asn Ile Glu Ser
65 70 75 80
Glu Asp Ala Ala Tyr Tyr Phe Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1013
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Light chain variable region sequence
<400> 1013
Glu Thr Thr Val Thr Gln Ser Pro Ala Phe Met Ser Ala Thr Pro Gly
1 5 10 15
Asp Lys Val Thr Ile Ser Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Ala Ala Ile Leu Leu Ile
35 40 45
Ser Glu Gly Asn Thr Leu Arg Pro Gly Ile Pro Pro Arg Phe Ser Ser
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr Ile Asn Asn Ile Glu Ser
65 70 75 80
Glu Asp Ala Ala Tyr Tyr Phe Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1014
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 Light chain variable region sequence
(codon optimized)
<400> 1014
Glu Thr Thr Val Thr Gln Ser Pro Ala Phe Met Ser Ala Thr Pro Gly
1 5 10 15
Asp Lys Val Thr Ile Ser Cys Ile Thr Ser Thr Asp Ile Asp Asp Asp
20 25 30
Met Asn Trp Tyr Gln Gln Lys Pro Gly Glu Ala Ala Ile Leu Leu Ile
35 40 45
Ser Glu Gly Asn Thr Leu Arg Pro Gly Ile Pro Pro Arg Phe Ser Ser
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr Ile Asn Asn Ile Glu Ser
65 70 75 80
Glu Asp Ala Ala Tyr Tyr Phe Cys Leu Gln Ser Asp Asn Leu Pro Leu
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1015
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A4A3 sequence (codon optimized) - humanized
heavy and light chains joined via a flexible linker
<400> 1015
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Val Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Leu Tyr Val Phe Tyr Phe Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Thr Thr Val Thr Gln Ser
130 135 140
Pro Ala Phe Met Ser Ala Thr Pro Gly Asp Lys Val Thr Ile Ser Cys
145 150 155 160
Ile Thr Ser Thr Asp Ile Asp Asp Asp Met Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Glu Ala Ala Ile Leu Leu Ile Ser Glu Gly Asn Thr Leu Arg
180 185 190
Pro Gly Ile Pro Pro Arg Phe Ser Ser Ser Gly Tyr Gly Thr Asp Phe
195 200 205
Thr Leu Thr Ile Asn Asn Ile Glu Ser Glu Asp Ala Ala Tyr Tyr Phe
210 215 220
Cys Leu Gln Ser Asp Asn Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys
225 230 235 240
Val Glu Ile Lys Arg
245
<210> 1016
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A5A1 Heavy chain variable region sequence
<400> 1016
Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu Thr
1 5 10 15
Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr Gly
20 25 30
Met Asn Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met Gly
35 40 45
Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe Lys
50 55 60
Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Thr Thr Ala Tyr Leu
65 70 75 80
Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ser Thr Tyr Phe Cys Ala
85 90 95
Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 1017
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> IGHV7-81*01 V-REGION sequence
<400> 1017
Gln Val Gln Leu Val Gln Ser Gly His Glu Val Lys Gln Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Thr Tyr
20 25 30
Gly Met Asn Trp Val Pro Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Phe Asn Thr Tyr Thr Gly Asn Pro Thr Tyr Ala Gln Gly Phe
50 55 60
Thr Gly Arg Phe Val Phe Ser Met Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Met Ala Met Tyr Tyr Cys
85 90 95
Ala Arg
<210> 1018
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> IGHJ4*03 J-REGION sequence
<400> 1018
Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10 15
<210> 1019
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Heavy chain variable region sequence
<400> 1019
Gln Val Gln Leu Val Gln Ser Gly His Glu Val Lys Gln Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Pro Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe
50 55 60
Lys Gly Arg Phe Val Phe Ser Met Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Met Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1020
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Heavy chain variable region sequence (codon
optimized)
<400> 1020
Gln Val Gln Leu Val Gln Ser Gly His Glu Val Lys Gln Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Pro Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe
50 55 60
Lys Gly Arg Phe Val Phe Ser Met Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Met Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1021
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Heavy chain variable region sequence
<400> 1021
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Val Lys Gln Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Lys Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Met Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1022
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Heavy chain variable region sequence
(codon optimized)
<400> 1022
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Val Lys Gln Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Lys Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Met Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1023
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> 8F9A5A1 Light chain variable region sequence
<400> 1023
Glu Ile Leu Leu Thr Gln Ser Pro Ala Ile Ile Ala Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Ile Trp Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Phe Ser Phe Thr Ile Asn Ser Met Glu Ala Glu
65 70 75 80
Asp Val Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 1024
<211> 93
<212> PRT
<213> Artificial Sequence
<220>
<223> IGKV3D-15*02 V-REGION sequence
<400> 1024
Glu Ile Val Met Met Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Ser
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Asn Asn
85 90
<210> 1025
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> IGKJ4*02 J-REGION sequence
<400> 1025
Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 1026
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Light chain variable region sequence
<400> 1026
Glu Ile Val Met Met Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Ser Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1027
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8F9A5A1 Light chain variable region sequence (codon
optimized)
<400> 1027
Glu Ile Val Met Met Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Ser Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1028
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Light chain variable region sequence
<400> 1028
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Trp Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Phe Ser Leu Thr Ile Ser Ser Leu Gln Ser Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1029
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 Light chain variable region sequence
(codon optimized)
<400> 1029
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Trp Ile Tyr
35 40 45
Gly Ile Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Phe Ser Leu Thr Ile Ser Ser Leu Gln Ser Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Gln Gln Arg Ser Ser Tyr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1030
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8F9A5A1 scFV sequence (codon optimized)
<400> 1030
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Val Lys Gln Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Lys Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Val Asp Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Met Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Ser Ser Leu Lys Ala Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Leu Arg Gly Ile Arg Pro Gly Pro Leu Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Glu Ile Val Leu Thr Gln Ser Pro Ala
130 135 140
Thr Leu Ser Val Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Ser Ala
145 150 155 160
Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln
165 170 175
Ala Pro Arg Leu Trp Ile Tyr Gly Ile Ser Asn Leu Ala Ser Gly Ile
180 185 190
Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Phe Ser Leu Thr
195 200 205
Ile Ser Ser Leu Gln Ser Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln
210 215 220
Arg Ser Ser Tyr Pro Pro Thr Phe Gly Gly Gly Thr Lys Val Glu Ile
225 230 235 240
Lys Arg
<210> 1031
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> 8H5H5G4 Heavy chain variable region sequence
<400> 1031
Val Gln Leu Gln Gln Ser Gly Pro Asp Leu Val Lys Pro Gly Thr Ser
1 5 10 15
Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Phe Thr Glu Tyr Thr
20 25 30
Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly
35 40 45
Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met
65 70 75 80
Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala
85 90 95
Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 1032
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> IGHV1-24*01 V-REGION sequence
<400> 1032
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Tyr Thr Leu Thr Glu Leu
20 25 30
Ser Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asp Pro Glu Asp Gly Glu Thr Ile Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr
<210> 1033
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> IGHJ4*03 J-REGION sequence
<400> 1033
Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10 15
<210> 1034
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized 8H5H5G4 Heavy chain variable region sequence
<400> 1034
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1035
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized 8H5H5G4 Heavy chain variable region sequence (codon
optimized)
<400> 1035
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Glu Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1036
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified Humanized 8H5H5G4 Heavy chain variable region sequence
<400> 1036
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Val Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1037
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified Humanized 8H5H5G4 Heavy chain variable region sequence
(codon optimized)
<400> 1037
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Val Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 1038
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> 8H5H5G4 Light chain variable region sequence
<400> 1038
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Phe Gln Gln Lys Pro Asp Gly Thr Ile Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Val Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Arg
100 105
<210> 1039
<211> 95
<212> PRT
<213> Artificial Sequence
<220>
<223> IGKV1-27*01 V-REGION sequence
<400> 1039
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Ser Thr Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Lys Tyr Asn Ser Ala Pro
85 90 95
<210> 1040
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> IGKJ4*02 J-REGION sequence
<400> 1040
Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 1041
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8H5H5G4 Light chain variable region sequence
<400> 1041
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1042
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> humanized 8H5H5G4 Light chain variable region sequence (codon
optimized)
<400> 1042
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1043
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8H5H5G4 Light chain variable region sequence
<400> 1043
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1044
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8H5H5G4 Light chain variable region sequence
(codon optimized)
<400> 1044
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Val Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 1045
<211> 245
<212> PRT
<213> Artificial Sequence
<220>
<223> Modified humanized 8H5H5G4 scFV sequence (codon optimized)
<400> 1045
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Val Ser Gly Asn Thr Phe Thr Glu Tyr
20 25 30
Thr Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Gly Phe Asn Pro Asn Asn Gly Val Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Val Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Tyr Tyr His Ser Thr Tyr Val Phe Tyr Phe Asp Ser Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser
130 135 140
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
145 150 155 160
Ser Ala Ser Gln Gly Ile Ser Asn Tyr Leu Asn Trp Tyr Gln Gln Lys
165 170 175
Pro Gly Lys Val Pro Lys Leu Leu Ile Tyr Tyr Thr Ser Ser Leu His
180 185 190
Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr
195 200 205
Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Val Ala Thr Tyr Tyr
210 215 220
Cys Gln Gln Tyr Ser Lys Leu Pro Tyr Thr Phe Gly Gly Gly Thr Lys
225 230 235 240
Val Glu Ile Lys Arg
245
<210> 1046
<211> 330
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG1 heavy chain constant region sequence: (for making full
antibody - pair with either kappa or lambda constant region; 2
plasmids, express together)
<400> 1046
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 1047
<211> 326
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG2 heavy chain constant region sequence: (for making full
antibody - pair with either kappa or lambda constant region; 2
plasmids, express together)
<400> 1047
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Asn Phe Gly Thr Gln Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Thr Val Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro
100 105 110
Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
115 120 125
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
130 135 140
Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly
145 150 155 160
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn
165 170 175
Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp
180 185 190
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro
195 200 205
Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu
210 215 220
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn
225 230 235 240
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
245 250 255
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
260 265 270
Thr Pro Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
275 280 285
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
290 295 300
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
305 310 315 320
Ser Leu Ser Pro Gly Lys
325
<210> 1048
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Human Kappa light chain constant region sequence
<400> 1048
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 1049
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Human Lambda light chain constant region sequence
<400> 1049
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 1050
<211> 232
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG1 Fc region sequence: (to be fused to scFv for
homo-dimerizes)
<400> 1050
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
1 5 10 15
Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
20 25 30
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
35 40 45
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
50 55 60
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
65 70 75 80
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
85 90 95
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
100 105 110
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
115 120 125
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr
130 135 140
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
145 150 155 160
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
165 170 175
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
180 185 190
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
195 200 205
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
210 215 220
Ser Leu Ser Leu Ser Pro Gly Lys
225 230
<210> 1051
<211> 228
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG2 Fc region sequence
<400> 1051
Glu Arg Lys Cys Cys Val Glu Cys Pro Pro Cys Pro Ala Pro Pro Val
1 5 10 15
Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu
20 25 30
Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser
35 40 45
His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu
50 55 60
Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr
65 70 75 80
Phe Arg Val Val Ser Val Leu Thr Val Val His Gln Asp Trp Leu Asn
85 90 95
Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ala Pro
100 105 110
Ile Glu Lys Thr Ile Ser Lys Thr Lys Gly Gln Pro Arg Glu Pro Gln
115 120 125
Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys Asn Gln Val
130 135 140
Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val
145 150 155 160
Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro
165 170 175
Pro Met Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr
180 185 190
Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val
195 200 205
Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu
210 215 220
Ser Pro Gly Lys
225
Claims (49)
- NME7 특이적 항체 또는 이의 단편으로서, 서열번호 145 또는 서열번호 169의 NME7 B3 펩타이드에 결합하는, NME7 특이적 항체 또는 이의 단편.
- 제1항에 있어서, 단클론성 항체인, 항체.
- 제1항에 있어서, 2가, 1가, Fab 또는 단쇄 가변 단편 항체(scFv)인, 항체.
- 제1항에 있어서, 항체 약물 접합체에 연결된, 항체.
- 제1항에 있어서, 상기 약물은 독소 또는 프로-톡신에 연결된, 항체.
- 제2항에 따른 단클론성 항체를 암호화하는, 단리된 핵산.
- 제2항에 따른 단클론성 항체를 발현하는, 단리된 하이브리도마.
- 제1항에 있어서, NME7AB 또는 NME7-X1에 특이적으로 결합하지만 NME1에 결합하지 않는, 항체.
- 제1항에 있어서, NME7AB와 MUC1* 세포외 도메인 사이 또는 NME7-X1과 MUC1* 세포외 도메인 사이의 상호작용을 방해하는, 항체.
- 제1항에 있어서, NME7AB와 PSMGFR 사이 또는 NME7-X1과 PSMGFR 사이의 결합을 방해하는, 항체.
- 제1항에 있어서, NME7AB와 N-10 사이 또는 NME7-X1과 N-10 사이의 결합을 방해하는, 항체.
- 제1항에 있어서, NME7AB와 MUC1* 세포외 도메인 사이 또는 NME7-X1과 MUC1* 세포외 도메인 사이의 상호작용을 방해하지 않되, 상기 NME7AB 또는 NME7-X1은 N-10 펩타이드(서열번호 170)에 결합하지만, C-10 펩타이드(서열번호 171)에는 결합하지 않는, 항체.
- 제2항에 있어서, 상기 항체는 5A1, 4A3, 4P3 또는 5D4인, 항체.
- 제2항에 있어서,
CDR1 영역 YTFTNYGMN(서열번호 439);
CDR2 영역 WINTYTGEPTYVDDFKG(서열번호 440); 및
CDR3 영역 LRGIRPGPLAY(서열번호 441)
를 포함하는 중쇄 가변 영역 내의 아미노산 서열; 및
CDR1 영역 SASSSVSYMN(서열번호 444);
CDR2 영역 GISNLAS(서열번호 445); 및
CDR3 영역 QQRSSYPPT(서열번호 446)
를 포함하는 경쇄 가변 영역 내의 아미노산 서열
을 포함하는, 항체. - 제2항에 있어서,
CDR1 영역 NTFTEYTMH(서열번호 388);
CDR2 영역 GFNPNNGVTNYNQKFKG(서열번호 389); 및
CDR3 영역 RYYHSLYVFYFDY(서열번호 390)
를 포함하는 중쇄 가변 영역 내의 아미노산 서열; 및
CDR1 영역 SASQGISNYLN(서열번호 393);
CDR2 영역 YTSSLHS(서열번호 394); 및
CDR3 영역 QQYSKLPYT(서열번호 395)
를 포함하는 경쇄 가변 영역 내의 아미노산 서열
을 포함하는, 항체. - 제2항에 있어서,
CDR1 영역 NTFTEYTMH(서열번호 429);
CDR2 영역 GFNPNNGVTNYNQKFKG(서열번호 430); 및
CDR3 영역 RYYHSTYVFYFDS(서열번호 431)
를 포함하는 중쇄 가변 영역 내의 아미노산 서열; 및
CDR1 영역 SASQGISNYLN(서열번호 434);
CDR2 영역 YTSSLHS(서열번호 435); 및
CDR3 영역 QQYSKLPYT(서열번호 436)
를 포함하는 경쇄 가변 영역 내의 아미노산 서열
을 포함하는, 항체. - 제2항에 있어서,
CDR1 영역 NTFTEYTMH(서열번호 388);
CDR2 영역 GFNPNNGVTNYNQKFKG(서열번호 389); 및
CDR3 영역 RYYHSLYVFYFDY(서열번호 390)
를 포함하는 중쇄 가변 영역 내의 아미노산 서열; 및
CDR1 영역 ITSTDIDDDMN(서열번호);
CDR2 영역 EGNTLRP(서열번호); 및
CDR3 영역 LQSDNLPLT(서열번호)
를 포함하는 경쇄 가변 영역 내의 아미노산 서열
을 포함하는, 항체. - 제1항에 있어서, 인간, 인간화된 또는 조작된 항체 모방체인, 항체.
- 제1항에 있어서, 비-인간인, 항체.
- 제19항에 있어서, 뮤린(murine) 또는 낙타과(camelid)인, 항체.
- 환자에게 암의 치료 또는 예방을 위해서 투여하는 방법으로서, 상기 환자에게 제1항 내지 제17항 중 어느 한 항의 항체를 포함하는 조성물을 투여하는 단계를 포함하는, 투여하는 방법.
- 환자에서 암 전이를 예방 또는 치료하는 방법으로서, 상기 환자에게 제1항 내지 제17항 중 어느 한 항의 항체를 포함하는 조성물을 투여하는 단계를 포함하는, 예방 또는 치료하는 방법.
- 암 또는 암 전이를 진단하는 방법으로서, 환자 시편 및 정상 시편을 제1항 내지 제17항 중 어느 한 항의 항체와 접촉시키는 단계 및 두 시편으로부터의 결과를 비교하는 단계를 포함하되, 상기 환자 시편 내의 항체에 대한 양성 결합의 존재는 상기 환자에서 암 또는 암 전이의 존재를 나타내는, 암 또는 암 전이를 진단하는 방법.
- 제23항에 있어서, 상기 항체는 제12항에 제시된 바와 같은, 암 또는 암 전이를 진단하는 방법.
- 제22항에 있어서, 상기 항체는 조영제(imaging agent)에 연결된, 암 또는 암 전이를 진단하는 방법.
- 제22항에 있어서, 상기 환자 시편은 수술 중(intra-operative)을 포함하는 생체내, 시험관내의 혈액, 체액, 조직, 순환 세포인, 암 또는 암 전이를 진단하는 방법.
- 항-NME7AB 항체 또는 이의 단편을 발현하도록 조작된, 세포.
- 제27항에 있어서, 상기 세포는 면역 세포인, 세포.
- 제27항에 있어서, 상기 면역 세포는 T 세포 또는 NK 세포인, 세포.
- 제27항에 있어서, 상기 세포는 줄기세포 또는 전구 세포인, 세포.
- 제30항에 있어서, 상기 줄기세포 또는 전구 세포는 추후에 분화되어 T 세포가 되는, 세포.
- 제27항에 있어서, 종양 연관 항원을 인식하는, 키메라 항원 수용체(chimeric antigen receptor: CAR)를 포함하는, 세포.
- 제27항에 있어서, 상기 항-NME7 항체의 발현은 유도성인, 세포.
- 제27항에 있어서, 항-NME7AB 항체를 암호화하는 핵산이 Foxp3 인핸서 또는 프로모터에 삽입된, 세포.
- 제27항에 있어서, 항-NME7AB 항체는 NFAT-유도성 시스템에 존재하는, 세포.
- 제35항에 있어서, NFATc1 반응 요소가 Foxp3 인핸서 또는 프로모터 영역에 삽입된 항체 서열의 상류에 삽입된, 세포.
- 제27항에 있어서, 항-NME7AB 항체 또는 이의 단편은 NME7 B3 펩타이드에 결합하거나, MUC1* 세포외 도메인의 PSMGFR 펩타이드에 대한 NME7AB 또는 NME7-X1의 결합을 방해하는, 세포.
- 제28항에 있어서, 종양 연관 항원 및 항-NME7 항체를 인식하는 CAR을 발현하는 것을 포함하는, 면역 세포.
- 제38항에 있어서, 상기 종양 연관 항원은 MUC1*인, 면역 세포.
- 항암 백신으로서, 면역원성 도출 부분으로서 도 6 내지 도 9에 열거된 NME7AB로부터 유래된 1종 이상의 펩타이드 또는 이와 적어도 80%, 85%, 90%, 95%, 97%의 서열 동일성을 갖는 펩타이드를 포함하는 조성물을 포함하는, 항암 백신.
- 제40항에 있어서, 상기 펩타이드는 서열번호 141 내지 145의 펩타이드 또는 이와 적어도 80%, 85%, 90%, 95%, 97%의 서열 동일성을 갖는 펩타이드인, 항암 백신.
- 제41항에 있어서, 상기 펩타이드는 서열번호 145의 펩타이드 또는 이와 적어도 80%, 85%, 90%, 95%, 97%의 서열 동일성을 갖는 펩타이드인, 항암 백신.
- 제1항 내지 제17항의 항체를 포함하는, BiTE.
- 항-NME7AB 항체의 생성 방법으로서, 상기 NME7 B3 펩타이드 내의 시스테인 잔기가 이황화 결합을 회피하도록 돌연변이된, 항-NME7AB 항체의 생성 방법,
- 전이 가능성이 증가된 세포를 생성시키는 방법으로서, 상기 세포를 NME7AB 또는 NME7-X1과 함께 배양하는 단계를 포함하는, 전이 가능성이 증가된 세포를 생성시키는 방법.
- NME7AB 또는 NME7-X1을 발현하도록 조작된, 세포.
- NME7AB 또는 NME7-X1을 발현하는, 트랜스제닉(transgenic) 동물.
- 제47항에 있어서, 상기 NME7AB 또는 NME7-X1이 인간인, 트랜스제닉 동물.
- 제48항에 있어서, NME7AB 또는 NME7-X1의 발현은 유도성인, 트랜스제닉 동물.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063036288P | 2020-06-08 | 2020-06-08 | |
| US63/036,288 | 2020-06-08 | ||
| US202063044670P | 2020-06-26 | 2020-06-26 | |
| US63/044,670 | 2020-06-26 | ||
| US202063046852P | 2020-07-01 | 2020-07-01 | |
| US63/046,852 | 2020-07-01 | ||
| PCT/US2021/036500 WO2021252551A2 (en) | 2020-06-08 | 2021-06-08 | Anti-nme antibody and method of treating cancer or cancer metastasis |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230021699A true KR20230021699A (ko) | 2023-02-14 |
Family
ID=78845867
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237000259A KR20230021699A (ko) | 2020-06-08 | 2021-06-08 | 항-nme 항체 및 암 또는 암 전이의 치료 방법 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US20230279141A1 (ko) |
| EP (1) | EP4161970A2 (ko) |
| JP (1) | JP2023530039A (ko) |
| KR (1) | KR20230021699A (ko) |
| CN (1) | CN116367857A (ko) |
| AU (1) | AU2021289677A1 (ko) |
| CA (1) | CA3181655A1 (ko) |
| IL (1) | IL298780A (ko) |
| WO (1) | WO2021252551A2 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023530039A (ja) * | 2020-06-08 | 2023-07-12 | ミネルバ バイオテクノロジーズ コーポレーション | 抗nme抗体および癌または癌転移の治療方法 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI746420B (zh) * | 2014-04-07 | 2021-11-21 | 美商密內瓦生物技術公司 | 抗nme抗體 |
| WO2018010140A1 (zh) * | 2016-07-14 | 2018-01-18 | 中国科学院生物物理研究所 | I型干扰素受体抗体及其用途 |
| EP3515949A4 (en) * | 2016-09-20 | 2020-10-28 | Wuxi Biologics Ireland Limited. | NEW ANTI-PCSK9 ANTIBODIES |
| US20200390870A1 (en) * | 2017-11-27 | 2020-12-17 | Minerva Biotechnologies Corporation | Humanized anti-muc1* antibodies and direct use of cleavage enzyme |
| CA3128384A1 (en) * | 2019-02-04 | 2020-08-13 | Minerva Biotechnologies Corporation | Anti-nme antibody and method of treating cancer or cancer metastasis |
| JP2023530039A (ja) * | 2020-06-08 | 2023-07-12 | ミネルバ バイオテクノロジーズ コーポレーション | 抗nme抗体および癌または癌転移の治療方法 |
-
2021
- 2021-06-08 JP JP2023519161A patent/JP2023530039A/ja active Pending
- 2021-06-08 CN CN202180056403.6A patent/CN116367857A/zh active Pending
- 2021-06-08 WO PCT/US2021/036500 patent/WO2021252551A2/en unknown
- 2021-06-08 EP EP21822506.8A patent/EP4161970A2/en active Pending
- 2021-06-08 US US18/000,249 patent/US20230279141A1/en active Pending
- 2021-06-08 CA CA3181655A patent/CA3181655A1/en active Pending
- 2021-06-08 IL IL298780A patent/IL298780A/en unknown
- 2021-06-08 KR KR1020237000259A patent/KR20230021699A/ko unknown
- 2021-06-08 AU AU2021289677A patent/AU2021289677A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| JP2023530039A (ja) | 2023-07-12 |
| WO2021252551A3 (en) | 2022-12-08 |
| AU2021289677A1 (en) | 2023-01-19 |
| US20230279141A1 (en) | 2023-09-07 |
| CN116367857A (zh) | 2023-06-30 |
| EP4161970A2 (en) | 2023-04-12 |
| IL298780A (en) | 2023-02-01 |
| WO2021252551A2 (en) | 2021-12-16 |
| CA3181655A1 (en) | 2021-12-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102551365B1 (ko) | 항-ror1 항체 및 그 용도 | |
| RU2755503C2 (ru) | Анти-lag-3 антитела и их композиции | |
| KR102589136B1 (ko) | 항-b7-h3 항체 및 그 용도 | |
| KR20190133160A (ko) | 항-gprc5d 항체 및 항-gprc5d 항체를 포함하는 분자 | |
| CN107207604B (zh) | 抗alk2抗体 | |
| TWI688572B (zh) | 包含dr5-結合結構域的多價分子 | |
| KR102466763B1 (ko) | 항- psma 항체 및 이의 용도 | |
| KR102649788B1 (ko) | 항-트랜스타이레틴 항체 | |
| PT2711375T (pt) | Proteínas humanas de ligação a antigénios que se ligam a beta-klotho, recetores fgf e os seus complexos | |
| TW200924796A (en) | Activin receptor-like kinase-1 compositions and methods of use | |
| KR20170120607A (ko) | 항-트랜스타이레틴 항체 | |
| KR102405278B1 (ko) | Alk7 결합 단백질 및 이들의 용도 | |
| KR20200074956A (ko) | 항-트랜스타이레틴 항체 | |
| KR20160131073A (ko) | Lg4-5에 대해 특이적인 항-라미닌4 항체 | |
| KR20170082495A (ko) | 암 치료용 항-ck8 항체 | |
| CN111704669B (zh) | 一种用于治疗晚期胃癌的抗cldn18全人源化抗体 | |
| JP2024023278A (ja) | Alk7結合タンパク質およびその使用 | |
| KR20210104064A (ko) | 항-il-27 항체 및 그의 용도 | |
| CN114685660A (zh) | 抗cldn18.2抗体及其制备方法和应用 | |
| TW201028165A (en) | Anti-NR10 antibody, and use thereof | |
| KR20160131082A (ko) | Lg1-3에 특이적인 항-라미닌4 항체 | |
| KR20220016802A (ko) | 항-nme 항체 및 암 또는 암 전이의 치료 방법 | |
| KR20230021699A (ko) | 항-nme 항체 및 암 또는 암 전이의 치료 방법 | |
| KR20220107252A (ko) | 생리학적 철분 과다에 대한 치료 | |
| KR20210068065A (ko) | 안타고니스트 |