KR20220002859A - T 세포 림프종 및 백혈병에 대한 cd2/5/7 녹-아웃 항-cd2/5/7 키메라 항원 수용체 t 세포의 용도 - Google Patents
T 세포 림프종 및 백혈병에 대한 cd2/5/7 녹-아웃 항-cd2/5/7 키메라 항원 수용체 t 세포의 용도 Download PDFInfo
- Publication number
- KR20220002859A KR20220002859A KR1020217022614A KR20217022614A KR20220002859A KR 20220002859 A KR20220002859 A KR 20220002859A KR 1020217022614 A KR1020217022614 A KR 1020217022614A KR 20217022614 A KR20217022614 A KR 20217022614A KR 20220002859 A KR20220002859 A KR 20220002859A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- gly
- leu
- thr
- ala
- Prior art date
Links
- 206010042971 T-cell lymphoma Diseases 0.000 title claims abstract description 24
- 208000000389 T-cell leukemia Diseases 0.000 title claims abstract description 23
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 title claims abstract description 17
- 208000028530 T-cell lymphoblastic leukemia/lymphoma Diseases 0.000 title claims abstract description 15
- 108091007741 Chimeric antigen receptor T cells Proteins 0.000 title abstract description 143
- 210000004027 cell Anatomy 0.000 claims abstract description 311
- 238000000034 method Methods 0.000 claims abstract description 141
- 239000000203 mixture Substances 0.000 claims abstract description 38
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 claims description 268
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 210
- 239000000427 antigen Substances 0.000 claims description 187
- 108091007433 antigens Proteins 0.000 claims description 187
- 102000036639 antigens Human genes 0.000 claims description 187
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 158
- 230000027455 binding Effects 0.000 claims description 151
- 101000934341 Homo sapiens T-cell surface glycoprotein CD5 Proteins 0.000 claims description 120
- 102100025244 T-cell surface glycoprotein CD5 Human genes 0.000 claims description 120
- 150000007523 nucleic acids Chemical group 0.000 claims description 106
- 108090000623 proteins and genes Proteins 0.000 claims description 101
- 108091033409 CRISPR Proteins 0.000 claims description 88
- 206010028980 Neoplasm Diseases 0.000 claims description 68
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 claims description 66
- 102000039446 nucleic acids Human genes 0.000 claims description 64
- 108020004707 nucleic acids Proteins 0.000 claims description 64
- 230000003834 intracellular effect Effects 0.000 claims description 53
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 52
- 102000004169 proteins and genes Human genes 0.000 claims description 44
- 238000010354 CRISPR gene editing Methods 0.000 claims description 38
- 239000013598 vector Substances 0.000 claims description 38
- 102100027208 T-cell antigen CD7 Human genes 0.000 claims description 36
- 239000002773 nucleotide Substances 0.000 claims description 34
- 125000003729 nucleotide group Chemical group 0.000 claims description 34
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 30
- -1 MN-CA IX Proteins 0.000 claims description 29
- 201000011510 cancer Diseases 0.000 claims description 20
- 108091027544 Subgenomic mRNA Proteins 0.000 claims description 15
- 230000008685 targeting Effects 0.000 claims description 15
- 101150026580 CD5 gene Proteins 0.000 claims description 13
- 108010072866 Prostate-Specific Antigen Proteins 0.000 claims description 12
- 102100038358 Prostate-specific antigen Human genes 0.000 claims description 12
- 102000013529 alpha-Fetoproteins Human genes 0.000 claims description 10
- 108010026331 alpha-Fetoproteins Proteins 0.000 claims description 10
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 claims description 10
- 208000009052 Precursor T-Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 9
- 208000029052 T-cell acute lymphoblastic leukemia Diseases 0.000 claims description 9
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 8
- 101150047061 tag-72 gene Proteins 0.000 claims description 8
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 claims description 7
- 101150069832 CD2 gene Proteins 0.000 claims description 7
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 claims description 7
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 claims description 6
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 claims description 6
- 102100038080 B-cell receptor CD22 Human genes 0.000 claims description 6
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 claims description 6
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 claims description 6
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 5
- 108090001061 Insulin Proteins 0.000 claims description 5
- 102000004877 Insulin Human genes 0.000 claims description 5
- 239000003102 growth factor Substances 0.000 claims description 5
- 229940125396 insulin Drugs 0.000 claims description 5
- LKKMLIBUAXYLOY-UHFFFAOYSA-N 3-Amino-1-methyl-5H-pyrido[4,3-b]indole Chemical compound N1C2=CC=CC=C2C2=C1C=C(N)N=C2C LKKMLIBUAXYLOY-UHFFFAOYSA-N 0.000 claims description 4
- WEVYNIUIFUYDGI-UHFFFAOYSA-N 3-[6-[4-(trifluoromethoxy)anilino]-4-pyrimidinyl]benzamide Chemical compound NC(=O)C1=CC=CC(C=2N=CN=C(NC=3C=CC(OC(F)(F)F)=CC=3)C=2)=C1 WEVYNIUIFUYDGI-UHFFFAOYSA-N 0.000 claims description 4
- 102100030310 5,6-dihydroxyindole-2-carboxylic acid oxidase Human genes 0.000 claims description 4
- 101710163881 5,6-dihydroxyindole-2-carboxylic acid oxidase Proteins 0.000 claims description 4
- 101710163573 5-hydroxyisourate hydrolase Proteins 0.000 claims description 4
- 102100030840 AT-rich interactive domain-containing protein 4B Human genes 0.000 claims description 4
- 101710145634 Antigen 1 Proteins 0.000 claims description 4
- 102100035526 B melanoma antigen 1 Human genes 0.000 claims description 4
- 108060000903 Beta-catenin Proteins 0.000 claims description 4
- 102000015735 Beta-catenin Human genes 0.000 claims description 4
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 claims description 4
- 108010051152 Carboxylesterase Proteins 0.000 claims description 4
- 102000013392 Carboxylesterase Human genes 0.000 claims description 4
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 claims description 4
- 108010025464 Cyclin-Dependent Kinase 4 Proteins 0.000 claims description 4
- 102100036252 Cyclin-dependent kinase 4 Human genes 0.000 claims description 4
- 108010072210 Cyclophilin C Proteins 0.000 claims description 4
- 101150029707 ERBB2 gene Proteins 0.000 claims description 4
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 claims description 4
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 claims description 4
- 102100028073 Fibroblast growth factor 5 Human genes 0.000 claims description 4
- 108090000380 Fibroblast growth factor 5 Proteins 0.000 claims description 4
- 101710113436 GTPase KRas Proteins 0.000 claims description 4
- 102100040510 Galectin-3-binding protein Human genes 0.000 claims description 4
- 101710197901 Galectin-3-binding protein Proteins 0.000 claims description 4
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 claims description 4
- 101000792935 Homo sapiens AT-rich interactive domain-containing protein 4B Proteins 0.000 claims description 4
- 101000874316 Homo sapiens B melanoma antigen 1 Proteins 0.000 claims description 4
- 101100165850 Homo sapiens CA9 gene Proteins 0.000 claims description 4
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 claims description 4
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 claims description 4
- 101001014223 Homo sapiens MAPK/MAK/MRK overlapping kinase Proteins 0.000 claims description 4
- 101000934372 Homo sapiens Macrosialin Proteins 0.000 claims description 4
- 101000655352 Homo sapiens Telomerase reverse transcriptase Proteins 0.000 claims description 4
- 101000847107 Homo sapiens Tetraspanin-8 Proteins 0.000 claims description 4
- 101000671653 Homo sapiens U3 small nucleolar RNA-associated protein 14 homolog A Proteins 0.000 claims description 4
- 108010052919 Hydroxyethylthiazole kinase Proteins 0.000 claims description 4
- 108010027436 Hydroxymethylpyrimidine kinase Proteins 0.000 claims description 4
- 108010031794 IGF Type 1 Receptor Proteins 0.000 claims description 4
- 102000048143 Insulin-Like Growth Factor II Human genes 0.000 claims description 4
- 108090001117 Insulin-Like Growth Factor II Proteins 0.000 claims description 4
- 108010030506 Integrin alpha6beta4 Proteins 0.000 claims description 4
- 102100034872 Kallikrein-4 Human genes 0.000 claims description 4
- 102100031413 L-dopachrome tautomerase Human genes 0.000 claims description 4
- 101710093778 L-dopachrome tautomerase Proteins 0.000 claims description 4
- 108010028275 Leukocyte Elastase Proteins 0.000 claims description 4
- 102100031520 MAPK/MAK/MRK overlapping kinase Human genes 0.000 claims description 4
- 108010046938 Macrophage Colony-Stimulating Factor Proteins 0.000 claims description 4
- 102100028123 Macrophage colony-stimulating factor 1 Human genes 0.000 claims description 4
- 102100025136 Macrosialin Human genes 0.000 claims description 4
- 102000003735 Mesothelin Human genes 0.000 claims description 4
- 108090000015 Mesothelin Proteins 0.000 claims description 4
- 102100034256 Mucin-1 Human genes 0.000 claims description 4
- 102100033174 Neutrophil elastase Human genes 0.000 claims description 4
- 102100024968 Peptidyl-prolyl cis-trans isomerase C Human genes 0.000 claims description 4
- 101710173693 Short transient receptor potential channel 1 Proteins 0.000 claims description 4
- 101710173694 Short transient receptor potential channel 2 Proteins 0.000 claims description 4
- 101150031162 TM4SF1 gene Proteins 0.000 claims description 4
- 108010017842 Telomerase Proteins 0.000 claims description 4
- 102100034902 Transmembrane 4 L6 family member 1 Human genes 0.000 claims description 4
- LVTKHGUGBGNBPL-UHFFFAOYSA-N Trp-P-1 Chemical compound N1C2=CC=CC=C2C2=C1C(C)=C(N)N=C2C LVTKHGUGBGNBPL-UHFFFAOYSA-N 0.000 claims description 4
- 102000003425 Tyrosinase Human genes 0.000 claims description 4
- 108060008724 Tyrosinase Proteins 0.000 claims description 4
- 102100040099 U3 small nucleolar RNA-associated protein 14 homolog A Human genes 0.000 claims description 4
- 230000000968 intestinal effect Effects 0.000 claims description 4
- 108010024383 kallikrein 4 Proteins 0.000 claims description 4
- 238000012737 microarray-based gene expression Methods 0.000 claims description 4
- 238000012243 multiplex automated genomic engineering Methods 0.000 claims description 4
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 claims description 4
- 108010020589 trehalose-6-phosphate synthase Proteins 0.000 claims description 4
- 102000004641 Fetal Proteins Human genes 0.000 claims description 3
- 108010003471 Fetal Proteins Proteins 0.000 claims description 3
- 102100039717 G antigen 1 Human genes 0.000 claims description 3
- 208000032612 Glial tumor Diseases 0.000 claims description 3
- 206010018338 Glioma Diseases 0.000 claims description 3
- 101000886137 Homo sapiens G antigen 1 Proteins 0.000 claims description 3
- 101000578784 Homo sapiens Melanoma antigen recognized by T-cells 1 Proteins 0.000 claims description 3
- 101001062222 Homo sapiens Receptor-binding cancer antigen expressed on SiSo cells Proteins 0.000 claims description 3
- 101000973629 Homo sapiens Ribosome quality control complex subunit NEMF Proteins 0.000 claims description 3
- 102100028389 Melanoma antigen recognized by T-cells 1 Human genes 0.000 claims description 3
- 206010060862 Prostate cancer Diseases 0.000 claims description 3
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 3
- 102100029165 Receptor-binding cancer antigen expressed on SiSo cells Human genes 0.000 claims description 3
- 102100022213 Ribosome quality control complex subunit NEMF Human genes 0.000 claims description 3
- 108010034949 Thyroglobulin Proteins 0.000 claims description 3
- 102000009843 Thyroglobulin Human genes 0.000 claims description 3
- 102000002287 alpha Subunit Glycoprotein Hormones Human genes 0.000 claims description 3
- 108010000732 alpha Subunit Glycoprotein Hormones Proteins 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 3
- 229940084986 human chorionic gonadotropin Drugs 0.000 claims description 3
- 229960002175 thyroglobulin Drugs 0.000 claims description 3
- 102000012406 Carcinoembryonic Antigen Human genes 0.000 claims description 2
- 102000038455 IGF Type 1 Receptor Human genes 0.000 claims 2
- 101000654734 Homo sapiens Septin-4 Proteins 0.000 claims 1
- 102100032743 Septin-4 Human genes 0.000 claims 1
- 108020004414 DNA Proteins 0.000 description 60
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 55
- 108090000765 processed proteins & peptides Proteins 0.000 description 45
- 230000014509 gene expression Effects 0.000 description 44
- 235000018102 proteins Nutrition 0.000 description 41
- 230000011664 signaling Effects 0.000 description 39
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 37
- 238000000338 in vitro Methods 0.000 description 32
- 102000004196 processed proteins & peptides Human genes 0.000 description 30
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 26
- 230000006870 function Effects 0.000 description 26
- 108010001064 glycyl-glycyl-glycyl-glycine Proteins 0.000 description 26
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 22
- 108091008874 T cell receptors Proteins 0.000 description 22
- 230000000694 effects Effects 0.000 description 21
- 229920001184 polypeptide Polymers 0.000 description 21
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 20
- 101100273210 Arabidopsis thaliana CAR5 gene Proteins 0.000 description 19
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 description 19
- 101100004996 Mus musculus Ca5a gene Proteins 0.000 description 19
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 19
- 230000004913 activation Effects 0.000 description 19
- 238000001727 in vivo Methods 0.000 description 19
- 239000003446 ligand Substances 0.000 description 19
- 108060003951 Immunoglobulin Proteins 0.000 description 18
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 18
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 18
- 235000001014 amino acid Nutrition 0.000 description 18
- 108010060035 arginylproline Proteins 0.000 description 18
- 102000018358 immunoglobulin Human genes 0.000 description 18
- 238000003752 polymerase chain reaction Methods 0.000 description 18
- 238000013518 transcription Methods 0.000 description 18
- 230000035897 transcription Effects 0.000 description 18
- 108020005004 Guide RNA Proteins 0.000 description 17
- 238000004520 electroporation Methods 0.000 description 17
- 108020004999 messenger RNA Proteins 0.000 description 17
- 102000040430 polynucleotide Human genes 0.000 description 17
- 108091033319 polynucleotide Proteins 0.000 description 17
- 239000002157 polynucleotide Substances 0.000 description 17
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 15
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 15
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 15
- 229940024606 amino acid Drugs 0.000 description 15
- 108010068380 arginylarginine Proteins 0.000 description 15
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 15
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 14
- 238000010453 CRISPR/Cas method Methods 0.000 description 14
- 241000880493 Leptailurus serval Species 0.000 description 14
- 241000699670 Mus sp. Species 0.000 description 14
- 150000001413 amino acids Chemical class 0.000 description 14
- 230000000259 anti-tumor effect Effects 0.000 description 14
- 230000001086 cytosolic effect Effects 0.000 description 14
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 14
- 230000002147 killing effect Effects 0.000 description 14
- 239000013612 plasmid Substances 0.000 description 14
- 108020003589 5' Untranslated Regions Proteins 0.000 description 13
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 13
- 108010087924 alanylproline Proteins 0.000 description 13
- 230000015572 biosynthetic process Effects 0.000 description 13
- 238000003776 cleavage reaction Methods 0.000 description 13
- 238000012258 culturing Methods 0.000 description 13
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 13
- 239000000463 material Substances 0.000 description 13
- 230000004048 modification Effects 0.000 description 13
- 238000012986 modification Methods 0.000 description 13
- 230000007017 scission Effects 0.000 description 13
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 12
- 101710163270 Nuclease Proteins 0.000 description 12
- 239000003795 chemical substances by application Substances 0.000 description 12
- 108010078144 glutaminyl-glycine Proteins 0.000 description 12
- 108010015792 glycyllysine Proteins 0.000 description 12
- 230000001939 inductive effect Effects 0.000 description 12
- 239000002609 medium Substances 0.000 description 12
- 230000004936 stimulating effect Effects 0.000 description 12
- 108020005345 3' Untranslated Regions Proteins 0.000 description 11
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 11
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 11
- 108010024755 CTL019 chimeric antigen receptor Proteins 0.000 description 11
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 11
- 241001465754 Metazoa Species 0.000 description 11
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 11
- 238000013459 approach Methods 0.000 description 11
- 238000003556 assay Methods 0.000 description 11
- 201000010099 disease Diseases 0.000 description 11
- 108010089804 glycyl-threonine Proteins 0.000 description 11
- 108010050848 glycylleucine Proteins 0.000 description 11
- 150000002632 lipids Chemical class 0.000 description 11
- 210000004698 lymphocyte Anatomy 0.000 description 11
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 11
- 238000012360 testing method Methods 0.000 description 11
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 10
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 10
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 10
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 10
- 230000028993 immune response Effects 0.000 description 10
- 238000009169 immunotherapy Methods 0.000 description 10
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 10
- 239000002502 liposome Substances 0.000 description 10
- 230000004044 response Effects 0.000 description 10
- 238000002560 therapeutic procedure Methods 0.000 description 10
- 238000001890 transfection Methods 0.000 description 10
- 238000013519 translation Methods 0.000 description 10
- 238000011282 treatment Methods 0.000 description 10
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 9
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 9
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 9
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 9
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 9
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 9
- 230000000295 complement effect Effects 0.000 description 9
- 150000001875 compounds Chemical class 0.000 description 9
- 230000000139 costimulatory effect Effects 0.000 description 9
- 239000012636 effector Substances 0.000 description 9
- 239000013604 expression vector Substances 0.000 description 9
- 238000000684 flow cytometry Methods 0.000 description 9
- 238000004519 manufacturing process Methods 0.000 description 9
- 230000001404 mediated effect Effects 0.000 description 9
- 210000001519 tissue Anatomy 0.000 description 9
- 210000004881 tumor cell Anatomy 0.000 description 9
- 239000013603 viral vector Substances 0.000 description 9
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 8
- LWWILHPVAKKLQS-QXEWZRGKSA-N Ile-Gly-Met Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N LWWILHPVAKKLQS-QXEWZRGKSA-N 0.000 description 8
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 8
- 241000713666 Lentivirus Species 0.000 description 8
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 8
- 108060001084 Luciferase Proteins 0.000 description 8
- 239000005089 Luciferase Substances 0.000 description 8
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 8
- BLPYXIXXCFVIIF-FXQIFTODSA-N Ser-Cys-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N)CN=C(N)N BLPYXIXXCFVIIF-FXQIFTODSA-N 0.000 description 8
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 8
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 8
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 8
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 8
- LDKDSFQSEUOCOO-RPTUDFQQSA-N Tyr-Thr-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LDKDSFQSEUOCOO-RPTUDFQQSA-N 0.000 description 8
- 108010081404 acein-2 Proteins 0.000 description 8
- 238000002474 experimental method Methods 0.000 description 8
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 8
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 8
- 108010057952 lysyl-phenylalanyl-lysine Proteins 0.000 description 8
- 230000035755 proliferation Effects 0.000 description 8
- 108010029020 prolylglycine Proteins 0.000 description 8
- 108010000998 wheylin-2 peptide Proteins 0.000 description 8
- PIDRBUDUWHBYSR-UHFFFAOYSA-N 1-[2-[[2-[(2-amino-4-methylpentanoyl)amino]-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O PIDRBUDUWHBYSR-UHFFFAOYSA-N 0.000 description 7
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 7
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 7
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 7
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 7
- WOZDCBHUGJVJPL-AVGNSLFASA-N Arg-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WOZDCBHUGJVJPL-AVGNSLFASA-N 0.000 description 7
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 7
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 7
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 7
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 7
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 7
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 7
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 7
- XXGQRGQPGFYECI-WDSKDSINSA-N Gly-Cys-Glu Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(O)=O XXGQRGQPGFYECI-WDSKDSINSA-N 0.000 description 7
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 7
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 7
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 7
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 7
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 7
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 7
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 7
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 7
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 7
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 7
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 7
- YLLWCSDBVGZLOW-CIUDSAMLSA-N Met-Gln-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O YLLWCSDBVGZLOW-CIUDSAMLSA-N 0.000 description 7
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 7
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 7
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 7
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 7
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 7
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 7
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 7
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 7
- YDWLCDQXLCILCZ-BWAGICSOSA-N Thr-His-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YDWLCDQXLCILCZ-BWAGICSOSA-N 0.000 description 7
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 7
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 7
- RYSNTWVRSLCAJZ-RYUDHWBXSA-N Tyr-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RYSNTWVRSLCAJZ-RYUDHWBXSA-N 0.000 description 7
- BYAKMYBZADCNMN-JYJNAYRXSA-N Tyr-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYAKMYBZADCNMN-JYJNAYRXSA-N 0.000 description 7
- 108091023045 Untranslated Region Proteins 0.000 description 7
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 7
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 7
- 210000003719 b-lymphocyte Anatomy 0.000 description 7
- 239000011324 bead Substances 0.000 description 7
- 229940000406 drug candidate Drugs 0.000 description 7
- 230000008014 freezing Effects 0.000 description 7
- 238000007710 freezing Methods 0.000 description 7
- 108010079547 glutamylmethionine Proteins 0.000 description 7
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 7
- 238000001802 infusion Methods 0.000 description 7
- 108010057821 leucylproline Proteins 0.000 description 7
- 108010003700 lysyl aspartic acid Proteins 0.000 description 7
- 108010051242 phenylalanylserine Proteins 0.000 description 7
- 108010026333 seryl-proline Proteins 0.000 description 7
- 241000894007 species Species 0.000 description 7
- 108010020532 tyrosyl-proline Proteins 0.000 description 7
- 108010073969 valyllysine Proteins 0.000 description 7
- 230000003612 virological effect Effects 0.000 description 7
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 6
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 6
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 6
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 6
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 6
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 6
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 6
- HEDRZPFGACZZDS-UHFFFAOYSA-N Chloroform Chemical compound ClC(Cl)Cl HEDRZPFGACZZDS-UHFFFAOYSA-N 0.000 description 6
- 108091026890 Coding region Proteins 0.000 description 6
- WDQXKVCQXRNOSI-GHCJXIJMSA-N Cys-Asp-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WDQXKVCQXRNOSI-GHCJXIJMSA-N 0.000 description 6
- PGBLJHDDKCVSTC-CIUDSAMLSA-N Cys-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O PGBLJHDDKCVSTC-CIUDSAMLSA-N 0.000 description 6
- 102000004127 Cytokines Human genes 0.000 description 6
- 108090000695 Cytokines Proteins 0.000 description 6
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 6
- UTKICHUQEQBDGC-ACZMJKKPSA-N Glu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N UTKICHUQEQBDGC-ACZMJKKPSA-N 0.000 description 6
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 6
- ZSESFIFAYQEKRD-CYDGBPFRSA-N Ile-Val-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(=O)O)N ZSESFIFAYQEKRD-CYDGBPFRSA-N 0.000 description 6
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 6
- VPKIQULSKFVCSM-SRVKXCTJSA-N Leu-Gln-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPKIQULSKFVCSM-SRVKXCTJSA-N 0.000 description 6
- KYIIALJHAOIAHF-KKUMJFAQSA-N Leu-Leu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KYIIALJHAOIAHF-KKUMJFAQSA-N 0.000 description 6
- SXOFUVGLPHCPRQ-KKUMJFAQSA-N Leu-Tyr-Cys Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(O)=O SXOFUVGLPHCPRQ-KKUMJFAQSA-N 0.000 description 6
- 108010052285 Membrane Proteins Proteins 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 6
- 108010079364 N-glycylalanine Proteins 0.000 description 6
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 6
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 6
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 6
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 6
- NUQZCPSZHGIYTA-HKUYNNGSSA-N Tyr-Trp-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N NUQZCPSZHGIYTA-HKUYNNGSSA-N 0.000 description 6
- CVUDMNSZAIZFAE-UHFFFAOYSA-N Val-Arg-Pro Natural products NC(N)=NCCCC(NC(=O)C(N)C(C)C)C(=O)N1CCCC1C(O)=O CVUDMNSZAIZFAE-UHFFFAOYSA-N 0.000 description 6
- APQIVBCUIUDSMB-OSUNSFLBSA-N Val-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N APQIVBCUIUDSMB-OSUNSFLBSA-N 0.000 description 6
- 108010047495 alanylglycine Proteins 0.000 description 6
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 108010093581 aspartyl-proline Proteins 0.000 description 6
- 108010068265 aspartyltyrosine Proteins 0.000 description 6
- 230000034994 death Effects 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 239000012634 fragment Substances 0.000 description 6
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 6
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 6
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 6
- 108010049041 glutamylalanine Proteins 0.000 description 6
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 6
- 108010037850 glycylvaline Proteins 0.000 description 6
- 108010018006 histidylserine Proteins 0.000 description 6
- 230000001965 increasing effect Effects 0.000 description 6
- 230000000977 initiatory effect Effects 0.000 description 6
- 229920000642 polymer Polymers 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 238000012546 transfer Methods 0.000 description 6
- 238000011144 upstream manufacturing Methods 0.000 description 6
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 5
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 5
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 5
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 5
- BIVYLQMZPHDUIH-WHFBIAKZSA-N Asp-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)O BIVYLQMZPHDUIH-WHFBIAKZSA-N 0.000 description 5
- QCVXMEHGFUMKCO-YUMQZZPRSA-N Asp-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O QCVXMEHGFUMKCO-YUMQZZPRSA-N 0.000 description 5
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 5
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 5
- 102100024633 Carbonic anhydrase 2 Human genes 0.000 description 5
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- 108010042407 Endonucleases Proteins 0.000 description 5
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 5
- SXFPZRRVWSUYII-KBIXCLLPSA-N Gln-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N SXFPZRRVWSUYII-KBIXCLLPSA-N 0.000 description 5
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 5
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 5
- MFVQGXGQRIXBPK-WDSKDSINSA-N Gly-Ala-Glu Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O MFVQGXGQRIXBPK-WDSKDSINSA-N 0.000 description 5
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 5
- SWBUZLFWGJETAO-KKUMJFAQSA-N His-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N)O SWBUZLFWGJETAO-KKUMJFAQSA-N 0.000 description 5
- 101000760643 Homo sapiens Carbonic anhydrase 2 Proteins 0.000 description 5
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 5
- LRAUKBMYHHNADU-DKIMLUQUSA-N Ile-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=CC=C1 LRAUKBMYHHNADU-DKIMLUQUSA-N 0.000 description 5
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 5
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 5
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 5
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 5
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 5
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 5
- NCTDKZKNBDZDOL-GARJFASQSA-N Lys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O NCTDKZKNBDZDOL-GARJFASQSA-N 0.000 description 5
- UETQMSASAVBGJY-QWRGUYRKSA-N Lys-Gly-His Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 UETQMSASAVBGJY-QWRGUYRKSA-N 0.000 description 5
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 5
- WRODMZBHNNPRLN-SRVKXCTJSA-N Lys-Leu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O WRODMZBHNNPRLN-SRVKXCTJSA-N 0.000 description 5
- 102000018697 Membrane Proteins Human genes 0.000 description 5
- GPVLSVCBKUCEBI-KKUMJFAQSA-N Met-Gln-Phe Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O GPVLSVCBKUCEBI-KKUMJFAQSA-N 0.000 description 5
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 5
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 description 5
- 208000027190 Peripheral T-cell lymphomas Diseases 0.000 description 5
- NAXPHWZXEXNDIW-JTQLQIEISA-N Phe-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 NAXPHWZXEXNDIW-JTQLQIEISA-N 0.000 description 5
- 108091036407 Polyadenylation Proteins 0.000 description 5
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 5
- HVKMTOIAYDOJPL-NRPADANISA-N Ser-Gln-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVKMTOIAYDOJPL-NRPADANISA-N 0.000 description 5
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 5
- 208000031672 T-Cell Peripheral Lymphoma Diseases 0.000 description 5
- BZTSQFWJNJYZSX-JRQIVUDYSA-N Thr-Tyr-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O BZTSQFWJNJYZSX-JRQIVUDYSA-N 0.000 description 5
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 5
- VPEFOFYNHBWFNQ-UFYCRDLUSA-N Tyr-Pro-Tyr Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 VPEFOFYNHBWFNQ-UFYCRDLUSA-N 0.000 description 5
- QFXVAFIHVWXXBJ-AVGNSLFASA-N Tyr-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O QFXVAFIHVWXXBJ-AVGNSLFASA-N 0.000 description 5
- QPPZEDOTPZOSEC-RCWTZXSCSA-N Val-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](C(C)C)N)O QPPZEDOTPZOSEC-RCWTZXSCSA-N 0.000 description 5
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 5
- 241000700605 Viruses Species 0.000 description 5
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 5
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 5
- 108010047857 aspartylglycine Proteins 0.000 description 5
- 230000010261 cell growth Effects 0.000 description 5
- 230000007969 cellular immunity Effects 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 5
- 208000015181 infectious disease Diseases 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 230000000670 limiting effect Effects 0.000 description 5
- 208000020968 mature T-cell and NK-cell non-Hodgkin lymphoma Diseases 0.000 description 5
- 239000002953 phosphate buffered saline Substances 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 102000005962 receptors Human genes 0.000 description 5
- 108020003175 receptors Proteins 0.000 description 5
- 230000001105 regulatory effect Effects 0.000 description 5
- 210000002966 serum Anatomy 0.000 description 5
- 230000001225 therapeutic effect Effects 0.000 description 5
- 108010038745 tryptophylglycine Proteins 0.000 description 5
- 239000004474 valine Substances 0.000 description 5
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 4
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 4
- LBYMZCVBOKYZNS-CIUDSAMLSA-N Ala-Leu-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O LBYMZCVBOKYZNS-CIUDSAMLSA-N 0.000 description 4
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 4
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 4
- 102000006306 Antigen Receptors Human genes 0.000 description 4
- 108010083359 Antigen Receptors Proteins 0.000 description 4
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 4
- XPSGESXVBSQZPL-SRVKXCTJSA-N Arg-Arg-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XPSGESXVBSQZPL-SRVKXCTJSA-N 0.000 description 4
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 4
- YKBHOXLMMPZPHQ-GMOBBJLQSA-N Arg-Ile-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O YKBHOXLMMPZPHQ-GMOBBJLQSA-N 0.000 description 4
- PNHQRQTVBRDIEF-CIUDSAMLSA-N Asn-Leu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(=O)N)N PNHQRQTVBRDIEF-CIUDSAMLSA-N 0.000 description 4
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 4
- KYQNAIMCTRZLNP-QSFUFRPTSA-N Asp-Ile-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O KYQNAIMCTRZLNP-QSFUFRPTSA-N 0.000 description 4
- WMLFFCRUSPNENW-ZLUOBGJFSA-N Asp-Ser-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O WMLFFCRUSPNENW-ZLUOBGJFSA-N 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- 108091033380 Coding strand Proteins 0.000 description 4
- AMRLSQGGERHDHJ-FXQIFTODSA-N Cys-Ala-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMRLSQGGERHDHJ-FXQIFTODSA-N 0.000 description 4
- JTNKVWLMDHIUOG-IHRRRGAJSA-N Cys-Arg-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JTNKVWLMDHIUOG-IHRRRGAJSA-N 0.000 description 4
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 4
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 4
- MFNUFCFRAZPJFW-JYJNAYRXSA-N Glu-Lys-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFNUFCFRAZPJFW-JYJNAYRXSA-N 0.000 description 4
- OCQUNKSFDYDXBG-QXEWZRGKSA-N Gly-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OCQUNKSFDYDXBG-QXEWZRGKSA-N 0.000 description 4
- BULIVUZUDBHKKZ-WDSKDSINSA-N Gly-Gln-Asn Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BULIVUZUDBHKKZ-WDSKDSINSA-N 0.000 description 4
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 4
- FGPLUIQCSKGLTI-WDSKDSINSA-N Gly-Ser-Glu Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O FGPLUIQCSKGLTI-WDSKDSINSA-N 0.000 description 4
- ZKJZBRHRWKLVSJ-ZDLURKLDSA-N Gly-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN)O ZKJZBRHRWKLVSJ-ZDLURKLDSA-N 0.000 description 4
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 4
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 4
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 4
- 241000701806 Human papillomavirus Species 0.000 description 4
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 4
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 4
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 4
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 4
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 4
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 4
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 4
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 4
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 4
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 4
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 4
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 4
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 4
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 4
- 108010038807 Oligopeptides Proteins 0.000 description 4
- 102000015636 Oligopeptides Human genes 0.000 description 4
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 4
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 4
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 4
- FKYKZHOKDOPHSA-DCAQKATOSA-N Pro-Leu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FKYKZHOKDOPHSA-DCAQKATOSA-N 0.000 description 4
- DSGSTPRKNYHGCL-JYJNAYRXSA-N Pro-Phe-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O DSGSTPRKNYHGCL-JYJNAYRXSA-N 0.000 description 4
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 4
- AIOWVDNPESPXRB-YTWAJWBKSA-N Pro-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2)O AIOWVDNPESPXRB-YTWAJWBKSA-N 0.000 description 4
- 108091034057 RNA (poly(A)) Proteins 0.000 description 4
- 108010025216 RVF peptide Proteins 0.000 description 4
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 4
- GZBKRJVCRMZAST-XKBZYTNZSA-N Ser-Glu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZBKRJVCRMZAST-XKBZYTNZSA-N 0.000 description 4
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 4
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 4
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 description 4
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 4
- BIBYEFRASCNLAA-CDMKHQONSA-N Thr-Phe-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=CC=C1 BIBYEFRASCNLAA-CDMKHQONSA-N 0.000 description 4
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 4
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 4
- LGEYOIQBBIPHQN-UWJYBYFXSA-N Tyr-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 LGEYOIQBBIPHQN-UWJYBYFXSA-N 0.000 description 4
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 4
- LQGDFDYGDQEMGA-PXDAIIFMSA-N Tyr-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N LQGDFDYGDQEMGA-PXDAIIFMSA-N 0.000 description 4
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 4
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 4
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 4
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 4
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 4
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 4
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 230000000735 allogeneic effect Effects 0.000 description 4
- 230000000890 antigenic effect Effects 0.000 description 4
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 4
- 108010062796 arginyllysine Proteins 0.000 description 4
- 108010092854 aspartyllysine Proteins 0.000 description 4
- 210000004369 blood Anatomy 0.000 description 4
- 239000008280 blood Substances 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 238000003501 co-culture Methods 0.000 description 4
- 230000000875 corresponding effect Effects 0.000 description 4
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 description 4
- 108010016616 cysteinylglycine Proteins 0.000 description 4
- 230000000779 depleting effect Effects 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 208000035475 disorder Diseases 0.000 description 4
- 239000003814 drug Substances 0.000 description 4
- 108020001507 fusion proteins Proteins 0.000 description 4
- 102000037865 fusion proteins Human genes 0.000 description 4
- 238000010362 genome editing Methods 0.000 description 4
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 4
- 108010010147 glycylglutamine Proteins 0.000 description 4
- 230000036541 health Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 238000001990 intravenous administration Methods 0.000 description 4
- 108010034529 leucyl-lysine Proteins 0.000 description 4
- 238000004020 luminiscence type Methods 0.000 description 4
- 210000001616 monocyte Anatomy 0.000 description 4
- 201000005962 mycosis fungoides Diseases 0.000 description 4
- 230000009826 neoplastic cell growth Effects 0.000 description 4
- 239000008194 pharmaceutical composition Substances 0.000 description 4
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 description 4
- 108010090894 prolylleucine Proteins 0.000 description 4
- 230000028327 secretion Effects 0.000 description 4
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 230000000638 stimulation Effects 0.000 description 4
- 239000000126 substance Substances 0.000 description 4
- 238000006467 substitution reaction Methods 0.000 description 4
- 230000004083 survival effect Effects 0.000 description 4
- 230000009258 tissue cross reactivity Effects 0.000 description 4
- 108010003137 tyrosyltyrosine Proteins 0.000 description 4
- 108010027345 wheylin-1 peptide Proteins 0.000 description 4
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 3
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 3
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 3
- RWCLSUOSKWTXLA-FXQIFTODSA-N Arg-Asp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RWCLSUOSKWTXLA-FXQIFTODSA-N 0.000 description 3
- JCROZIFVIYMXHM-GUBZILKMSA-N Arg-Met-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CCCN=C(N)N JCROZIFVIYMXHM-GUBZILKMSA-N 0.000 description 3
- XSPKAHFVDKRGRL-DCAQKATOSA-N Arg-Pro-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XSPKAHFVDKRGRL-DCAQKATOSA-N 0.000 description 3
- FXGMURPOWCKNAZ-JYJNAYRXSA-N Arg-Val-Phe Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FXGMURPOWCKNAZ-JYJNAYRXSA-N 0.000 description 3
- QIRJQYQOIKBPBZ-IHRRRGAJSA-N Asn-Tyr-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QIRJQYQOIKBPBZ-IHRRRGAJSA-N 0.000 description 3
- LIVXPXUVXFRWNY-CIUDSAMLSA-N Asp-Lys-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O LIVXPXUVXFRWNY-CIUDSAMLSA-N 0.000 description 3
- FQHBAQLBIXLWAG-DCAQKATOSA-N Asp-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N FQHBAQLBIXLWAG-DCAQKATOSA-N 0.000 description 3
- BRRPVTUFESPTCP-ACZMJKKPSA-N Asp-Ser-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O BRRPVTUFESPTCP-ACZMJKKPSA-N 0.000 description 3
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 3
- BYLPQJAWXJWUCJ-YDHLFZDLSA-N Asp-Tyr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O BYLPQJAWXJWUCJ-YDHLFZDLSA-N 0.000 description 3
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 3
- 101150013553 CD40 gene Proteins 0.000 description 3
- 102100035793 CD83 antigen Human genes 0.000 description 3
- 101100315624 Caenorhabditis elegans tyr-1 gene Proteins 0.000 description 3
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 3
- GEEXORWTBTUOHC-FXQIFTODSA-N Cys-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N GEEXORWTBTUOHC-FXQIFTODSA-N 0.000 description 3
- 241000702421 Dependoparvovirus Species 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 102100031780 Endonuclease Human genes 0.000 description 3
- TWHDOEYLXXQYOZ-FXQIFTODSA-N Gln-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N TWHDOEYLXXQYOZ-FXQIFTODSA-N 0.000 description 3
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 3
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 3
- LGIKBBLQVSWUGK-DCAQKATOSA-N Gln-Leu-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LGIKBBLQVSWUGK-DCAQKATOSA-N 0.000 description 3
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 3
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 3
- MQJDLNRXBOELJW-KKUMJFAQSA-N Gln-Pro-Phe Chemical compound N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O MQJDLNRXBOELJW-KKUMJFAQSA-N 0.000 description 3
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 3
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 3
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 3
- FMNHBTKMRFVGRO-FOHZUACHSA-N Gly-Asn-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)CN FMNHBTKMRFVGRO-FOHZUACHSA-N 0.000 description 3
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 3
- MHZXESQPPXOING-KBPBESRZSA-N Gly-Lys-Phe Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MHZXESQPPXOING-KBPBESRZSA-N 0.000 description 3
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 3
- FCPSGEVYIVXPPO-QTKMDUPCSA-N His-Thr-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FCPSGEVYIVXPPO-QTKMDUPCSA-N 0.000 description 3
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 description 3
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 3
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 description 3
- PARSHQDZROHERM-NHCYSSNCSA-N Ile-Lys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)O)N PARSHQDZROHERM-NHCYSSNCSA-N 0.000 description 3
- GVEODXUBBFDBPW-MGHWNKPDSA-N Ile-Tyr-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 GVEODXUBBFDBPW-MGHWNKPDSA-N 0.000 description 3
- NXRNRBOKDBIVKQ-CXTHYWKRSA-N Ile-Tyr-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N NXRNRBOKDBIVKQ-CXTHYWKRSA-N 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 3
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 3
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 3
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 3
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 3
- WTZUSCUIVPVCRH-SRVKXCTJSA-N Lys-Gln-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N WTZUSCUIVPVCRH-SRVKXCTJSA-N 0.000 description 3
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 3
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 3
- RMKJOQSYLQQRFN-KKUMJFAQSA-N Lys-Tyr-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O RMKJOQSYLQQRFN-KKUMJFAQSA-N 0.000 description 3
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- CXMSESHALPOLRE-MEYUZBJRSA-N Phe-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N)O CXMSESHALPOLRE-MEYUZBJRSA-N 0.000 description 3
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 3
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 3
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 3
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 3
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 3
- KMWFXJCGRXBQAC-CIUDSAMLSA-N Ser-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N KMWFXJCGRXBQAC-CIUDSAMLSA-N 0.000 description 3
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 3
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 3
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 3
- LRZLZIUXQBIWTB-KATARQTJSA-N Ser-Lys-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LRZLZIUXQBIWTB-KATARQTJSA-N 0.000 description 3
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 3
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 3
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 3
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 3
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 3
- ZSPQUTWLWGWTPS-HJGDQZAQSA-N Thr-Lys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZSPQUTWLWGWTPS-HJGDQZAQSA-N 0.000 description 3
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 3
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 3
- QJIODPFLAASXJC-JHYOHUSXSA-N Thr-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O QJIODPFLAASXJC-JHYOHUSXSA-N 0.000 description 3
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 3
- 239000004473 Threonine Substances 0.000 description 3
- SVGAWGVHFIYAEE-JSGCOSHPSA-N Trp-Gly-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 SVGAWGVHFIYAEE-JSGCOSHPSA-N 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 3
- PEVVXUGSAKEPEN-AVGNSLFASA-N Tyr-Asn-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PEVVXUGSAKEPEN-AVGNSLFASA-N 0.000 description 3
- CDKZJGMPZHPAJC-ULQDDVLXSA-N Tyr-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CDKZJGMPZHPAJC-ULQDDVLXSA-N 0.000 description 3
- LABUITCFCAABSV-UHFFFAOYSA-N Val-Ala-Tyr Natural products CC(C)C(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-UHFFFAOYSA-N 0.000 description 3
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 3
- WSUWDIVCPOJFCX-TUAOUCFPSA-N Val-Met-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N1CCC[C@@H]1C(=O)O)N WSUWDIVCPOJFCX-TUAOUCFPSA-N 0.000 description 3
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 3
- GQLCLPLEEOUJQC-ZTQDTCGGSA-N [(1r)-3-(3,4-dimethoxyphenyl)-1-[3-[2-[2-[[2-[3-[(1r)-3-(3,4-dimethoxyphenyl)-1-[(2s)-1-[(2s)-2-(3,4,5-trimethoxyphenyl)butanoyl]piperidine-2-carbonyl]oxypropyl]phenoxy]acetyl]amino]ethylamino]-2-oxoethoxy]phenyl]propyl] (2s)-1-[(2s)-2-(3,4,5-trimethoxyph Chemical compound C([C@@H](OC(=O)[C@@H]1CCCCN1C(=O)[C@@H](CC)C=1C=C(OC)C(OC)=C(OC)C=1)C=1C=C(OCC(=O)NCCNC(=O)COC=2C=C(C=CC=2)[C@@H](CCC=2C=C(OC)C(OC)=CC=2)OC(=O)[C@H]2N(CCCC2)C(=O)[C@@H](CC)C=2C=C(OC)C(OC)=C(OC)C=2)C=CC=1)CC1=CC=C(OC)C(OC)=C1 GQLCLPLEEOUJQC-ZTQDTCGGSA-N 0.000 description 3
- 238000002679 ablation Methods 0.000 description 3
- 238000007792 addition Methods 0.000 description 3
- 108010070783 alanyltyrosine Proteins 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 210000000612 antigen-presenting cell Anatomy 0.000 description 3
- 230000006907 apoptotic process Effects 0.000 description 3
- 108010008355 arginyl-glutamine Proteins 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 239000012472 biological sample Substances 0.000 description 3
- 238000005415 bioluminescence Methods 0.000 description 3
- 230000029918 bioluminescence Effects 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 230000016396 cytokine production Effects 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000006471 dimerization reaction Methods 0.000 description 3
- 231100000371 dose-limiting toxicity Toxicity 0.000 description 3
- 230000003828 downregulation Effects 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 230000004927 fusion Effects 0.000 description 3
- 108010020688 glycylhistidine Proteins 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 3
- 229960000310 isoleucine Drugs 0.000 description 3
- 208000032839 leukemia Diseases 0.000 description 3
- 238000001638 lipofection Methods 0.000 description 3
- 230000007774 longterm Effects 0.000 description 3
- 229920002521 macromolecule Polymers 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 238000012544 monitoring process Methods 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 210000005259 peripheral blood Anatomy 0.000 description 3
- 239000011886 peripheral blood Substances 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 238000010837 poor prognosis Methods 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 108020001580 protein domains Proteins 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 231100000419 toxicity Toxicity 0.000 description 3
- 230000001988 toxicity Effects 0.000 description 3
- 108010058119 tryptophyl-glycyl-glycine Proteins 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 241001430294 unidentified retrovirus Species 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 230000003442 weekly effect Effects 0.000 description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- 102100023990 60S ribosomal protein L17 Human genes 0.000 description 2
- 208000016683 Adult T-cell leukemia/lymphoma Diseases 0.000 description 2
- 241000059559 Agriotes sordidus Species 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 2
- QDRGPQWIVZNJQD-CIUDSAMLSA-N Ala-Arg-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QDRGPQWIVZNJQD-CIUDSAMLSA-N 0.000 description 2
- WJRXVTCKASUIFF-FXQIFTODSA-N Ala-Cys-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WJRXVTCKASUIFF-FXQIFTODSA-N 0.000 description 2
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 2
- TZDNWXDLYFIFPT-BJDJZHNGSA-N Ala-Ile-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O TZDNWXDLYFIFPT-BJDJZHNGSA-N 0.000 description 2
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 2
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 2
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 2
- DYXOFPBJBAHWFY-JBDRJPRFSA-N Ala-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N DYXOFPBJBAHWFY-JBDRJPRFSA-N 0.000 description 2
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 2
- XKXAZPSREVUCRT-BPNCWPANSA-N Ala-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=C(O)C=C1 XKXAZPSREVUCRT-BPNCWPANSA-N 0.000 description 2
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 2
- DEAGTWNKODHUIY-MRFFXTKBSA-N Ala-Tyr-Trp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DEAGTWNKODHUIY-MRFFXTKBSA-N 0.000 description 2
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 2
- 206010073478 Anaplastic large-cell lymphoma Diseases 0.000 description 2
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 2
- YHQGEARSFILVHL-HJGDQZAQSA-N Arg-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O YHQGEARSFILVHL-HJGDQZAQSA-N 0.000 description 2
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 2
- GXXWTNKNFFKTJB-NAKRPEOUSA-N Arg-Ile-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O GXXWTNKNFFKTJB-NAKRPEOUSA-N 0.000 description 2
- SSZGOKWBHLOCHK-DCAQKATOSA-N Arg-Lys-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N SSZGOKWBHLOCHK-DCAQKATOSA-N 0.000 description 2
- YCYXHLZRUSJITQ-SRVKXCTJSA-N Arg-Pro-Pro Chemical compound NC(=N)NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 YCYXHLZRUSJITQ-SRVKXCTJSA-N 0.000 description 2
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 2
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 2
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 2
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 2
- VPPXTHJNTYDNFJ-CIUDSAMLSA-N Asp-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N VPPXTHJNTYDNFJ-CIUDSAMLSA-N 0.000 description 2
- CXBOKJPLEYUPGB-FXQIFTODSA-N Asp-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(=O)O)N CXBOKJPLEYUPGB-FXQIFTODSA-N 0.000 description 2
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 2
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 2
- LTCKTLYKRMCFOC-KKUMJFAQSA-N Asp-Phe-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LTCKTLYKRMCFOC-KKUMJFAQSA-N 0.000 description 2
- GGRSYTUJHAZTFN-IHRRRGAJSA-N Asp-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O GGRSYTUJHAZTFN-IHRRRGAJSA-N 0.000 description 2
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 2
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 2
- 108091008875 B cell receptors Proteins 0.000 description 2
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 description 2
- 208000025321 B-lymphoblastic leukemia/lymphoma Diseases 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 2
- 102100027207 CD27 antigen Human genes 0.000 description 2
- 238000010446 CRISPR interference Methods 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 2
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 2
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 208000035865 Chronic mast cell leukemia Diseases 0.000 description 2
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 2
- BCFXQBXXDSEHRS-FXQIFTODSA-N Cys-Ser-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O BCFXQBXXDSEHRS-FXQIFTODSA-N 0.000 description 2
- 108010053770 Deoxyribonucleases Proteins 0.000 description 2
- 102000016911 Deoxyribonucleases Human genes 0.000 description 2
- 102000004533 Endonucleases Human genes 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 241001200922 Gagata Species 0.000 description 2
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 2
- QKCZZAZNMMVICF-DCAQKATOSA-N Gln-Leu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O QKCZZAZNMMVICF-DCAQKATOSA-N 0.000 description 2
- YPMDZWPZFOZYFG-GUBZILKMSA-N Gln-Leu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YPMDZWPZFOZYFG-GUBZILKMSA-N 0.000 description 2
- HSHCEAUPUPJPTE-JYJNAYRXSA-N Gln-Leu-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HSHCEAUPUPJPTE-JYJNAYRXSA-N 0.000 description 2
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 2
- XZLLTYBONVKGLO-SDDRHHMPSA-N Gln-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XZLLTYBONVKGLO-SDDRHHMPSA-N 0.000 description 2
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- VEYGCDYMOXHJLS-GVXVVHGQSA-N Gln-Val-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VEYGCDYMOXHJLS-GVXVVHGQSA-N 0.000 description 2
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 2
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 2
- PXHABOCPJVTGEK-BQBZGAKWSA-N Glu-Gln-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O PXHABOCPJVTGEK-BQBZGAKWSA-N 0.000 description 2
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 2
- IQACOVZVOMVILH-FXQIFTODSA-N Glu-Glu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O IQACOVZVOMVILH-FXQIFTODSA-N 0.000 description 2
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 2
- KXRORHJIRAOQPG-SOUVJXGZSA-N Glu-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O KXRORHJIRAOQPG-SOUVJXGZSA-N 0.000 description 2
- LSYFGBRDBIQYAQ-FHWLQOOXSA-N Glu-Tyr-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LSYFGBRDBIQYAQ-FHWLQOOXSA-N 0.000 description 2
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 2
- BRFJMRSRMOMIMU-WHFBIAKZSA-N Gly-Ala-Asn Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O BRFJMRSRMOMIMU-WHFBIAKZSA-N 0.000 description 2
- LJPIRKICOISLKN-WHFBIAKZSA-N Gly-Ala-Ser Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O LJPIRKICOISLKN-WHFBIAKZSA-N 0.000 description 2
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 2
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 2
- QCTLGOYODITHPQ-WHFBIAKZSA-N Gly-Cys-Ser Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O QCTLGOYODITHPQ-WHFBIAKZSA-N 0.000 description 2
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 2
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 2
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 2
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 2
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 2
- AYBKPDHHVADEDA-YUMQZZPRSA-N Gly-His-Asn Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O AYBKPDHHVADEDA-YUMQZZPRSA-N 0.000 description 2
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 2
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 2
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 2
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 2
- VNNRLUNBJSWZPF-ZKWXMUAHSA-N Gly-Ser-Ile Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNNRLUNBJSWZPF-ZKWXMUAHSA-N 0.000 description 2
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- FFALDIDGPLUDKV-ZDLURKLDSA-N Gly-Thr-Ser Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O FFALDIDGPLUDKV-ZDLURKLDSA-N 0.000 description 2
- UIQGJYUEQDOODF-KWQFWETISA-N Gly-Tyr-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 UIQGJYUEQDOODF-KWQFWETISA-N 0.000 description 2
- KOYUSMBPJOVSOO-XEGUGMAKSA-N Gly-Tyr-Ile Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KOYUSMBPJOVSOO-XEGUGMAKSA-N 0.000 description 2
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 2
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 2
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 2
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 2
- OQDLKDUVMTUPPG-AVGNSLFASA-N His-Leu-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OQDLKDUVMTUPPG-AVGNSLFASA-N 0.000 description 2
- CSRRMQFXMBPSIL-SIXJUCDHSA-N His-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CN=CN3)N CSRRMQFXMBPSIL-SIXJUCDHSA-N 0.000 description 2
- FOCSWPCHUDVNLP-PMVMPFDFSA-N His-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC4=CN=CN4)N FOCSWPCHUDVNLP-PMVMPFDFSA-N 0.000 description 2
- ISQOVWDWRUONJH-YESZJQIVSA-N His-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O ISQOVWDWRUONJH-YESZJQIVSA-N 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 2
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 2
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 2
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 2
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 2
- 101001109503 Homo sapiens NKG2-C type II integral membrane protein Proteins 0.000 description 2
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 2
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 2
- AQTWDZDISVGCAC-CFMVVWHZSA-N Ile-Asp-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N AQTWDZDISVGCAC-CFMVVWHZSA-N 0.000 description 2
- KUHFPGIVBOCRMV-MNXVOIDGSA-N Ile-Gln-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(C)C)C(=O)O)N KUHFPGIVBOCRMV-MNXVOIDGSA-N 0.000 description 2
- NHJKZMDIMMTVCK-QXEWZRGKSA-N Ile-Gly-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N NHJKZMDIMMTVCK-QXEWZRGKSA-N 0.000 description 2
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 2
- KBDIBHQICWDGDL-PPCPHDFISA-N Ile-Thr-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N KBDIBHQICWDGDL-PPCPHDFISA-N 0.000 description 2
- JTBFQNHKNRZJDS-SYWGBEHUSA-N Ile-Trp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](C)C(=O)O)N JTBFQNHKNRZJDS-SYWGBEHUSA-N 0.000 description 2
- HQLSBZFLOUHQJK-STECZYCISA-N Ile-Tyr-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HQLSBZFLOUHQJK-STECZYCISA-N 0.000 description 2
- 206010061598 Immunodeficiency Diseases 0.000 description 2
- 208000029462 Immunodeficiency disease Diseases 0.000 description 2
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 102000003812 Interleukin-15 Human genes 0.000 description 2
- 108090000172 Interleukin-15 Proteins 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- 108010002386 Interleukin-3 Proteins 0.000 description 2
- 108010002586 Interleukin-7 Proteins 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 2
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 2
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 2
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 2
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 2
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 2
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 2
- LLBQJYDYOLIQAI-JYJNAYRXSA-N Leu-Glu-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LLBQJYDYOLIQAI-JYJNAYRXSA-N 0.000 description 2
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 2
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 2
- ZJZNLRVCZWUONM-JXUBOQSCSA-N Leu-Thr-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O ZJZNLRVCZWUONM-JXUBOQSCSA-N 0.000 description 2
- FBNPMTNBFFAMMH-UHFFFAOYSA-N Leu-Val-Arg Natural products CC(C)CC(N)C(=O)NC(C(C)C)C(=O)NC(C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-UHFFFAOYSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 239000000232 Lipid Bilayer Substances 0.000 description 2
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 2
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 2
- NFLFJGGKOHYZJF-BJDJZHNGSA-N Lys-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN NFLFJGGKOHYZJF-BJDJZHNGSA-N 0.000 description 2
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 2
- WBSCNDJQPKSPII-KKUMJFAQSA-N Lys-Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O WBSCNDJQPKSPII-KKUMJFAQSA-N 0.000 description 2
- ODTZHNZPINULEU-KKUMJFAQSA-N Lys-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N ODTZHNZPINULEU-KKUMJFAQSA-N 0.000 description 2
- AZOFEHCPMBRNFD-BZSNNMDCSA-N Lys-Phe-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=CC=C1 AZOFEHCPMBRNFD-BZSNNMDCSA-N 0.000 description 2
- JMNRXRPBHFGXQX-GUBZILKMSA-N Lys-Ser-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JMNRXRPBHFGXQX-GUBZILKMSA-N 0.000 description 2
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 2
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 2
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 2
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 2
- 108010010995 MART-1 Antigen Proteins 0.000 description 2
- 102000016200 MART-1 Antigen Human genes 0.000 description 2
- 102000043129 MHC class I family Human genes 0.000 description 2
- 108091054437 MHC class I family Proteins 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 2
- ONGCSGVHCSAATF-CIUDSAMLSA-N Met-Ala-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O ONGCSGVHCSAATF-CIUDSAMLSA-N 0.000 description 2
- ZAJNRWKGHWGPDQ-SDDRHHMPSA-N Met-Arg-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N ZAJNRWKGHWGPDQ-SDDRHHMPSA-N 0.000 description 2
- GXYYFDKJHLRNSI-SRVKXCTJSA-N Met-Gln-His Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O GXYYFDKJHLRNSI-SRVKXCTJSA-N 0.000 description 2
- SJDQOYTYNGZZJX-SRVKXCTJSA-N Met-Glu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SJDQOYTYNGZZJX-SRVKXCTJSA-N 0.000 description 2
- ABHVWYPPHDYFNY-WDSOQIARSA-N Met-His-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CN=CN1 ABHVWYPPHDYFNY-WDSOQIARSA-N 0.000 description 2
- JHDNAOVJJQSMMM-GMOBBJLQSA-N Met-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCSC)N JHDNAOVJJQSMMM-GMOBBJLQSA-N 0.000 description 2
- NLDXSXDCNZIQCN-ULQDDVLXSA-N Met-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CCSC)CC1=CC=CC=C1 NLDXSXDCNZIQCN-ULQDDVLXSA-N 0.000 description 2
- PCTFVQATEGYHJU-FXQIFTODSA-N Met-Ser-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O PCTFVQATEGYHJU-FXQIFTODSA-N 0.000 description 2
- 241001024304 Mino Species 0.000 description 2
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 2
- 102100022683 NKG2-C type II integral membrane protein Human genes 0.000 description 2
- MDHZEOMXGNBSIL-DLOVCJGASA-N Phe-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N MDHZEOMXGNBSIL-DLOVCJGASA-N 0.000 description 2
- LBSARGIQACMGDF-WBAXXEDZSA-N Phe-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 LBSARGIQACMGDF-WBAXXEDZSA-N 0.000 description 2
- NOFBJKKOPKJDCO-KKXDTOCCSA-N Phe-Ala-Tyr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NOFBJKKOPKJDCO-KKXDTOCCSA-N 0.000 description 2
- OQTDZEJJWWAGJT-KKUMJFAQSA-N Phe-Lys-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O OQTDZEJJWWAGJT-KKUMJFAQSA-N 0.000 description 2
- MJAYDXWQQUOURZ-JYJNAYRXSA-N Phe-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O MJAYDXWQQUOURZ-JYJNAYRXSA-N 0.000 description 2
- PEFJUUYFEGBXFA-BZSNNMDCSA-N Phe-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 PEFJUUYFEGBXFA-BZSNNMDCSA-N 0.000 description 2
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 2
- XNQMZHLAYFWSGJ-HTUGSXCWSA-N Phe-Thr-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XNQMZHLAYFWSGJ-HTUGSXCWSA-N 0.000 description 2
- GNRMAQSIROFNMI-IXOXFDKPSA-N Phe-Thr-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GNRMAQSIROFNMI-IXOXFDKPSA-N 0.000 description 2
- YFXXRYFWJFQAFW-JHYOHUSXSA-N Phe-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YFXXRYFWJFQAFW-JHYOHUSXSA-N 0.000 description 2
- 102100034937 Poly(A) RNA polymerase, mitochondrial Human genes 0.000 description 2
- 101710124239 Poly(A) polymerase Proteins 0.000 description 2
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 2
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 2
- HFZNNDWPHBRNPV-KZVJFYERSA-N Pro-Ala-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O HFZNNDWPHBRNPV-KZVJFYERSA-N 0.000 description 2
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 2
- VPVHXWGPALPDGP-GUBZILKMSA-N Pro-Asn-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPVHXWGPALPDGP-GUBZILKMSA-N 0.000 description 2
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 2
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 2
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 2
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 2
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 2
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 2
- GOMUXSCOIWIJFP-GUBZILKMSA-N Pro-Ser-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GOMUXSCOIWIJFP-GUBZILKMSA-N 0.000 description 2
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 2
- LNICFEXCAHIJOR-DCAQKATOSA-N Pro-Ser-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LNICFEXCAHIJOR-DCAQKATOSA-N 0.000 description 2
- CWZUFLWPEFHWEI-IHRRRGAJSA-N Pro-Tyr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O CWZUFLWPEFHWEI-IHRRRGAJSA-N 0.000 description 2
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 2
- 230000004570 RNA-binding Effects 0.000 description 2
- 238000003559 RNA-seq method Methods 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- NLQUOHDCLSFABG-GUBZILKMSA-N Ser-Arg-Arg Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NLQUOHDCLSFABG-GUBZILKMSA-N 0.000 description 2
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 2
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 2
- MESDJCNHLZBMEP-ZLUOBGJFSA-N Ser-Asp-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MESDJCNHLZBMEP-ZLUOBGJFSA-N 0.000 description 2
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 2
- OLIJLNWFEQEFDM-SRVKXCTJSA-N Ser-Asp-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OLIJLNWFEQEFDM-SRVKXCTJSA-N 0.000 description 2
- KCFKKAQKRZBWJB-ZLUOBGJFSA-N Ser-Cys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O KCFKKAQKRZBWJB-ZLUOBGJFSA-N 0.000 description 2
- BQWCDDAISCPDQV-XHNCKOQMSA-N Ser-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CO)N)C(=O)O BQWCDDAISCPDQV-XHNCKOQMSA-N 0.000 description 2
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 2
- OHKFXGKHSJKKAL-NRPADANISA-N Ser-Glu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OHKFXGKHSJKKAL-NRPADANISA-N 0.000 description 2
- IOVHBRCQOGWAQH-ZKWXMUAHSA-N Ser-Gly-Ile Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IOVHBRCQOGWAQH-ZKWXMUAHSA-N 0.000 description 2
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 2
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 2
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 2
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 2
- ADJDNJCSPNFFPI-FXQIFTODSA-N Ser-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO ADJDNJCSPNFFPI-FXQIFTODSA-N 0.000 description 2
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 2
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 2
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 2
- HAUVENOGHPECML-BPUTZDHNSA-N Ser-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CO)=CNC2=C1 HAUVENOGHPECML-BPUTZDHNSA-N 0.000 description 2
- BIWBTRRBHIEVAH-IHPCNDPISA-N Ser-Tyr-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O BIWBTRRBHIEVAH-IHPCNDPISA-N 0.000 description 2
- UKKROEYWYIHWBD-ZKWXMUAHSA-N Ser-Val-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UKKROEYWYIHWBD-ZKWXMUAHSA-N 0.000 description 2
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 2
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- 239000004098 Tetracycline Substances 0.000 description 2
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 2
- DGDCHPCRMWEOJR-FQPOAREZSA-N Thr-Ala-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DGDCHPCRMWEOJR-FQPOAREZSA-N 0.000 description 2
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 2
- LYGKYFKSZTUXGZ-ZDLURKLDSA-N Thr-Cys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)NCC(O)=O LYGKYFKSZTUXGZ-ZDLURKLDSA-N 0.000 description 2
- OYTNZCBFDXGQGE-XQXXSGGOSA-N Thr-Gln-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O OYTNZCBFDXGQGE-XQXXSGGOSA-N 0.000 description 2
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 2
- KZSYAEWQMJEGRZ-RHYQMDGZSA-N Thr-Leu-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O KZSYAEWQMJEGRZ-RHYQMDGZSA-N 0.000 description 2
- XIHGJKFSIDTDKV-LYARXQMPSA-N Thr-Phe-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O XIHGJKFSIDTDKV-LYARXQMPSA-N 0.000 description 2
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 2
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 2
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 2
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 2
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 2
- 108700019146 Transgenes Proteins 0.000 description 2
- VZBWRZGNEPBRDE-HZUKXOBISA-N Trp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N VZBWRZGNEPBRDE-HZUKXOBISA-N 0.000 description 2
- NAQBQJOGGYGCOT-QEJZJMRPSA-N Trp-Asn-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O NAQBQJOGGYGCOT-QEJZJMRPSA-N 0.000 description 2
- YXONONCLMLHWJX-SZMVWBNQSA-N Trp-Glu-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 YXONONCLMLHWJX-SZMVWBNQSA-N 0.000 description 2
- KIMOCKLJBXHFIN-YLVFBTJISA-N Trp-Ile-Gly Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O)=CNC2=C1 KIMOCKLJBXHFIN-YLVFBTJISA-N 0.000 description 2
- ILDJYIDXESUBOE-HSCHXYMDSA-N Trp-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N ILDJYIDXESUBOE-HSCHXYMDSA-N 0.000 description 2
- CCZXBOFIBYQLEV-IHPCNDPISA-N Trp-Leu-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O CCZXBOFIBYQLEV-IHPCNDPISA-N 0.000 description 2
- KCZGSXPFPNKGLE-WDSOQIARSA-N Trp-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N KCZGSXPFPNKGLE-WDSOQIARSA-N 0.000 description 2
- PWPJLBWYRTVYQS-PMVMPFDFSA-N Trp-Phe-Leu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PWPJLBWYRTVYQS-PMVMPFDFSA-N 0.000 description 2
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 2
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 2
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 2
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 2
- XHALUUQSNXSPLP-UFYCRDLUSA-N Tyr-Arg-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 XHALUUQSNXSPLP-UFYCRDLUSA-N 0.000 description 2
- BEIGSKUPTIFYRZ-SRVKXCTJSA-N Tyr-Asp-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O BEIGSKUPTIFYRZ-SRVKXCTJSA-N 0.000 description 2
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 2
- YRBHLWWGSSQICE-IHRRRGAJSA-N Tyr-Asp-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O YRBHLWWGSSQICE-IHRRRGAJSA-N 0.000 description 2
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 2
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 2
- AXWBYOVVDRBOGU-SIUGBPQLSA-N Tyr-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AXWBYOVVDRBOGU-SIUGBPQLSA-N 0.000 description 2
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 2
- MVFQLSPDMMFCMW-KKUMJFAQSA-N Tyr-Leu-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O MVFQLSPDMMFCMW-KKUMJFAQSA-N 0.000 description 2
- AVIQBBOOTZENLH-KKUMJFAQSA-N Tyr-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AVIQBBOOTZENLH-KKUMJFAQSA-N 0.000 description 2
- OLYXUGBVBGSZDN-ACRUOGEOSA-N Tyr-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 OLYXUGBVBGSZDN-ACRUOGEOSA-N 0.000 description 2
- XDGPTBVOSHKDFT-KKUMJFAQSA-N Tyr-Met-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(O)=O XDGPTBVOSHKDFT-KKUMJFAQSA-N 0.000 description 2
- XYNFFTNEQDWZNY-ULQDDVLXSA-N Tyr-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N XYNFFTNEQDWZNY-ULQDDVLXSA-N 0.000 description 2
- KZOZXAYPVKKDIO-UFYCRDLUSA-N Tyr-Met-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KZOZXAYPVKKDIO-UFYCRDLUSA-N 0.000 description 2
- YOTRXXBHTZHKLU-BVSLBCMMSA-N Tyr-Trp-Met Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCSC)C(O)=O)C1=CC=C(O)C=C1 YOTRXXBHTZHKLU-BVSLBCMMSA-N 0.000 description 2
- ABZWHLRQBSBPTO-RNXOBYDBSA-N Tyr-Trp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CC4=CC=C(C=C4)O)N ABZWHLRQBSBPTO-RNXOBYDBSA-N 0.000 description 2
- JRMCISZDVLOTLR-BVSLBCMMSA-N Tyr-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N JRMCISZDVLOTLR-BVSLBCMMSA-N 0.000 description 2
- BUPRFDPUIJNOLS-UFYCRDLUSA-N Tyr-Tyr-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(O)=O BUPRFDPUIJNOLS-UFYCRDLUSA-N 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- LABUITCFCAABSV-BPNCWPANSA-N Val-Ala-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-BPNCWPANSA-N 0.000 description 2
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 2
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 2
- XTAUQCGQFJQGEJ-NHCYSSNCSA-N Val-Gln-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XTAUQCGQFJQGEJ-NHCYSSNCSA-N 0.000 description 2
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 2
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 2
- ZXAGTABZUOMUDO-GVXVVHGQSA-N Val-Glu-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N ZXAGTABZUOMUDO-GVXVVHGQSA-N 0.000 description 2
- JTWIMNMUYLQNPI-WPRPVWTQSA-N Val-Gly-Arg Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N JTWIMNMUYLQNPI-WPRPVWTQSA-N 0.000 description 2
- PMDOQZFYGWZSTK-LSJOCFKGSA-N Val-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C PMDOQZFYGWZSTK-LSJOCFKGSA-N 0.000 description 2
- DAVNYIUELQBTAP-XUXIUFHCSA-N Val-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N DAVNYIUELQBTAP-XUXIUFHCSA-N 0.000 description 2
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 2
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 2
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 2
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 2
- PGQUDQYHWICSAB-NAKRPEOUSA-N Val-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N PGQUDQYHWICSAB-NAKRPEOUSA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 2
- UJMCYJKPDFQLHX-XGEHTFHBSA-N Val-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N)O UJMCYJKPDFQLHX-XGEHTFHBSA-N 0.000 description 2
- LMVWCLDJNSBOEA-FKBYEOEOSA-N Val-Tyr-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N LMVWCLDJNSBOEA-FKBYEOEOSA-N 0.000 description 2
- 241000021375 Xenogenes Species 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 229960005305 adenosine Drugs 0.000 description 2
- 201000006966 adult T-cell leukemia Diseases 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 206010002449 angioimmunoblastic T-cell lymphoma Diseases 0.000 description 2
- 239000003963 antioxidant agent Substances 0.000 description 2
- 238000002617 apheresis Methods 0.000 description 2
- 239000012736 aqueous medium Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 108010077245 asparaginyl-proline Proteins 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 210000001772 blood platelet Anatomy 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 230000032823 cell division Effects 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 230000004663 cell proliferation Effects 0.000 description 2
- 230000007541 cellular toxicity Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 2
- 210000000805 cytoplasm Anatomy 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 238000002784 cytotoxicity assay Methods 0.000 description 2
- 231100000263 cytotoxicity test Toxicity 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 210000004443 dendritic cell Anatomy 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- RNPXCFINMKSQPQ-UHFFFAOYSA-N dicetyl hydrogen phosphate Chemical compound CCCCCCCCCCCCCCCCOP(O)(=O)OCCCCCCCCCCCCCCCC RNPXCFINMKSQPQ-UHFFFAOYSA-N 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 241001493065 dsRNA viruses Species 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 210000003743 erythrocyte Anatomy 0.000 description 2
- 210000004700 fetal blood Anatomy 0.000 description 2
- 238000009472 formulation Methods 0.000 description 2
- 238000012239 gene modification Methods 0.000 description 2
- 238000001415 gene therapy Methods 0.000 description 2
- 230000005017 genetic modification Effects 0.000 description 2
- 235000013617 genetically modified food Nutrition 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 2
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 2
- 108010087823 glycyltyrosine Proteins 0.000 description 2
- 210000003714 granulocyte Anatomy 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 108010025306 histidylleucine Proteins 0.000 description 2
- 230000013632 homeostatic process Effects 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 210000004408 hybridoma Anatomy 0.000 description 2
- 238000006460 hydrolysis reaction Methods 0.000 description 2
- 230000036039 immunity Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 238000007918 intramuscular administration Methods 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 231100000518 lethal Toxicity 0.000 description 2
- 230000001665 lethal effect Effects 0.000 description 2
- 210000000265 leukocyte Anatomy 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 210000001165 lymph node Anatomy 0.000 description 2
- 108010038320 lysylphenylalanine Proteins 0.000 description 2
- 230000036210 malignancy Effects 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000000693 micelle Substances 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 230000001613 neoplastic effect Effects 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- MXHCPCSDRGLRER-UHFFFAOYSA-N pentaglycine Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)NCC(O)=O MXHCPCSDRGLRER-UHFFFAOYSA-N 0.000 description 2
- 108010024607 phenylalanylalanine Proteins 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 108040000983 polyphosphate:AMP phosphotransferase activity proteins Proteins 0.000 description 2
- 208000017426 precursor B-cell acute lymphoblastic leukemia Diseases 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010070643 prolylglutamic acid Proteins 0.000 description 2
- 230000000284 resting effect Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 230000002483 superagonistic effect Effects 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 229960002180 tetracycline Drugs 0.000 description 2
- 229930101283 tetracycline Natural products 0.000 description 2
- 235000019364 tetracycline Nutrition 0.000 description 2
- 150000003522 tetracyclines Chemical class 0.000 description 2
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- 238000003151 transfection method Methods 0.000 description 2
- 108010080629 tryptophan-leucine Proteins 0.000 description 2
- 108010009962 valyltyrosine Proteins 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- SGKRLCUYIXIAHR-AKNGSSGZSA-N (4s,4ar,5s,5ar,6r,12ar)-4-(dimethylamino)-1,5,10,11,12a-pentahydroxy-6-methyl-3,12-dioxo-4a,5,5a,6-tetrahydro-4h-tetracene-2-carboxamide Chemical compound C1=CC=C2[C@H](C)[C@@H]([C@H](O)[C@@H]3[C@](C(O)=C(C(N)=O)C(=O)[C@H]3N(C)C)(O)C3=O)C3=C(O)C2=C1O SGKRLCUYIXIAHR-AKNGSSGZSA-N 0.000 description 1
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 1
- 108010082808 4-1BB Ligand Proteins 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 108020005176 AU Rich Elements Proteins 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 1
- OMMDTNGURYRDAC-NRPADANISA-N Ala-Glu-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OMMDTNGURYRDAC-NRPADANISA-N 0.000 description 1
- XZWXFWBHYRFLEF-FSPLSTOPSA-N Ala-His Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 XZWXFWBHYRFLEF-FSPLSTOPSA-N 0.000 description 1
- LBFXVAXPDOBRKU-LKTVYLICSA-N Ala-His-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LBFXVAXPDOBRKU-LKTVYLICSA-N 0.000 description 1
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 1
- KQESEZXHYOUIIM-CQDKDKBSSA-N Ala-Lys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KQESEZXHYOUIIM-CQDKDKBSSA-N 0.000 description 1
- REAQAWSENITKJL-DDWPSWQVSA-N Ala-Met-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O REAQAWSENITKJL-DDWPSWQVSA-N 0.000 description 1
- FVNAUOZKIPAYNA-BPNCWPANSA-N Ala-Met-Tyr Chemical compound CSCC[C@H](NC(=O)[C@H](C)N)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FVNAUOZKIPAYNA-BPNCWPANSA-N 0.000 description 1
- YCRAFFCYWOUEOF-DLOVCJGASA-N Ala-Phe-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 YCRAFFCYWOUEOF-DLOVCJGASA-N 0.000 description 1
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 1
- CREYEAPXISDKSB-FQPOAREZSA-N Ala-Thr-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CREYEAPXISDKSB-FQPOAREZSA-N 0.000 description 1
- GCTANJIJJROSLH-GVARAGBVSA-N Ala-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C)N GCTANJIJJROSLH-GVARAGBVSA-N 0.000 description 1
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 1
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 1
- 206010002961 Aplasia Diseases 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 1
- BIOCIVSVEDFKDJ-GUBZILKMSA-N Arg-Arg-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O BIOCIVSVEDFKDJ-GUBZILKMSA-N 0.000 description 1
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 1
- MFAMTAVAFBPXDC-LPEHRKFASA-N Arg-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O MFAMTAVAFBPXDC-LPEHRKFASA-N 0.000 description 1
- ZZZWQALDSQQBEW-STQMWFEESA-N Arg-Gly-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZZZWQALDSQQBEW-STQMWFEESA-N 0.000 description 1
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 1
- JEXPNDORFYHJTM-IHRRRGAJSA-N Arg-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JEXPNDORFYHJTM-IHRRRGAJSA-N 0.000 description 1
- CZUHPNLXLWMYMG-UBHSHLNASA-N Arg-Phe-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 CZUHPNLXLWMYMG-UBHSHLNASA-N 0.000 description 1
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 1
- PRLPSDIHSRITSF-UNQGMJICSA-N Arg-Phe-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PRLPSDIHSRITSF-UNQGMJICSA-N 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- SLKLLQWZQHXYSV-CIUDSAMLSA-N Asn-Ala-Lys Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O SLKLLQWZQHXYSV-CIUDSAMLSA-N 0.000 description 1
- HUZGPXBILPMCHM-IHRRRGAJSA-N Asn-Arg-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HUZGPXBILPMCHM-IHRRRGAJSA-N 0.000 description 1
- PQAIOUVVZCOLJK-FXQIFTODSA-N Asn-Gln-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PQAIOUVVZCOLJK-FXQIFTODSA-N 0.000 description 1
- WPOLSNAQGVHROR-GUBZILKMSA-N Asn-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N WPOLSNAQGVHROR-GUBZILKMSA-N 0.000 description 1
- UEONJSPBTSWKOI-CIUDSAMLSA-N Asn-Gln-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O UEONJSPBTSWKOI-CIUDSAMLSA-N 0.000 description 1
- GWNMUVANAWDZTI-YUMQZZPRSA-N Asn-Gly-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N GWNMUVANAWDZTI-YUMQZZPRSA-N 0.000 description 1
- KMCRKVOLRCOMBG-DJFWLOJKSA-N Asn-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KMCRKVOLRCOMBG-DJFWLOJKSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- ZJIFRAPZHAGLGR-MELADBBJSA-N Asn-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZJIFRAPZHAGLGR-MELADBBJSA-N 0.000 description 1
- XMHFCUKJRCQXGI-CIUDSAMLSA-N Asn-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O XMHFCUKJRCQXGI-CIUDSAMLSA-N 0.000 description 1
- NCXTYSVDWLAQGZ-ZKWXMUAHSA-N Asn-Ser-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O NCXTYSVDWLAQGZ-ZKWXMUAHSA-N 0.000 description 1
- JBDLMLZNDRLDIX-HJGDQZAQSA-N Asn-Thr-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O JBDLMLZNDRLDIX-HJGDQZAQSA-N 0.000 description 1
- FHCRKXCTKSHNOE-QEJZJMRPSA-N Asn-Trp-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FHCRKXCTKSHNOE-QEJZJMRPSA-N 0.000 description 1
- RDLYUKRPEJERMM-XIRDDKMYSA-N Asn-Trp-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(C)C)C(O)=O RDLYUKRPEJERMM-XIRDDKMYSA-N 0.000 description 1
- YQPSDMUGFKJZHR-QRTARXTBSA-N Asn-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N YQPSDMUGFKJZHR-QRTARXTBSA-N 0.000 description 1
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 1
- FANQWNCPNFEPGZ-WHFBIAKZSA-N Asp-Asp-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O FANQWNCPNFEPGZ-WHFBIAKZSA-N 0.000 description 1
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 1
- BFOYULZBKYOKAN-OLHMAJIHSA-N Asp-Asp-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BFOYULZBKYOKAN-OLHMAJIHSA-N 0.000 description 1
- WBDWQKRLTVCDSY-WHFBIAKZSA-N Asp-Gly-Asp Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O WBDWQKRLTVCDSY-WHFBIAKZSA-N 0.000 description 1
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 1
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 1
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 1
- IOXWDLNHXZOXQP-FXQIFTODSA-N Asp-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N IOXWDLNHXZOXQP-FXQIFTODSA-N 0.000 description 1
- FAUPLTGRUBTXNU-FXQIFTODSA-N Asp-Pro-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O FAUPLTGRUBTXNU-FXQIFTODSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- ITGFVUYOLWBPQW-KKHAAJSZSA-N Asp-Thr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ITGFVUYOLWBPQW-KKHAAJSZSA-N 0.000 description 1
- ZUNMTUPRQMWMHX-LSJOCFKGSA-N Asp-Val-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(O)=O ZUNMTUPRQMWMHX-LSJOCFKGSA-N 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 108010074708 B7-H1 Antigen Proteins 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 102100021663 Baculoviral IAP repeat-containing protein 5 Human genes 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- 102100025221 CD70 antigen Human genes 0.000 description 1
- 102100037904 CD9 antigen Human genes 0.000 description 1
- 101150069031 CSN2 gene Proteins 0.000 description 1
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 102100039510 Cancer/testis antigen 2 Human genes 0.000 description 1
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108090000566 Caspase-9 Proteins 0.000 description 1
- 108020004638 Circular DNA Proteins 0.000 description 1
- 108091062157 Cis-regulatory element Proteins 0.000 description 1
- 206010010144 Completed suicide Diseases 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- QADHATDBZXHRCA-ACZMJKKPSA-N Cys-Gln-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CS)N QADHATDBZXHRCA-ACZMJKKPSA-N 0.000 description 1
- KABHAOSDMIYXTR-GUBZILKMSA-N Cys-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N KABHAOSDMIYXTR-GUBZILKMSA-N 0.000 description 1
- BCWIFCLVCRAIQK-ZLUOBGJFSA-N Cys-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O BCWIFCLVCRAIQK-ZLUOBGJFSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 230000007018 DNA scission Effects 0.000 description 1
- 241000450599 DNA viruses Species 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- GZDFHIJNHHMENY-UHFFFAOYSA-N Dimethyl dicarbonate Chemical compound COC(=O)OC(=O)OC GZDFHIJNHHMENY-UHFFFAOYSA-N 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 102100021579 Enhancer of filamentation 1 Human genes 0.000 description 1
- 241000701867 Enterobacteria phage T7 Species 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 206010051841 Exposure to allergen Diseases 0.000 description 1
- 229920001917 Ficoll Polymers 0.000 description 1
- 102100039554 Galectin-8 Human genes 0.000 description 1
- 241001663880 Gammaretrovirus Species 0.000 description 1
- 208000034951 Genetic Translocation Diseases 0.000 description 1
- YJIUYQKQBBQYHZ-ACZMJKKPSA-N Gln-Ala-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YJIUYQKQBBQYHZ-ACZMJKKPSA-N 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- RGXXLQWXBFNXTG-CIUDSAMLSA-N Gln-Arg-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O RGXXLQWXBFNXTG-CIUDSAMLSA-N 0.000 description 1
- ZPDVKYLJTOFQJV-WDSKDSINSA-N Gln-Asn-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O ZPDVKYLJTOFQJV-WDSKDSINSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 1
- IWUFOVSLWADEJC-AVGNSLFASA-N Gln-His-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IWUFOVSLWADEJC-AVGNSLFASA-N 0.000 description 1
- DFRYZTUPVZNRLG-KKUMJFAQSA-N Gln-Met-Phe Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N DFRYZTUPVZNRLG-KKUMJFAQSA-N 0.000 description 1
- DRNMNLKUUKKPIA-HTUGSXCWSA-N Gln-Phe-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)CCC(N)=O)C(O)=O DRNMNLKUUKKPIA-HTUGSXCWSA-N 0.000 description 1
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 1
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 1
- RDPOETHPAQEGDP-ACZMJKKPSA-N Glu-Asp-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O RDPOETHPAQEGDP-ACZMJKKPSA-N 0.000 description 1
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 1
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 1
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 1
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- FBEJIDRSQCGFJI-GUBZILKMSA-N Glu-Leu-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O FBEJIDRSQCGFJI-GUBZILKMSA-N 0.000 description 1
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 1
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 1
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- DDXZHOHEABQXSE-NKIYYHGXSA-N Glu-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O DDXZHOHEABQXSE-NKIYYHGXSA-N 0.000 description 1
- JVZLZVJTIXVIHK-SXNHZJKMSA-N Glu-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N JVZLZVJTIXVIHK-SXNHZJKMSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 1
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 1
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 1
- DTRUBYPMMVPQPD-YUMQZZPRSA-N Gly-Gln-Arg Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DTRUBYPMMVPQPD-YUMQZZPRSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 1
- VAXIVIPMCTYSHI-YUMQZZPRSA-N Gly-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN VAXIVIPMCTYSHI-YUMQZZPRSA-N 0.000 description 1
- BHPQOIPBLYJNAW-NGZCFLSTSA-N Gly-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN BHPQOIPBLYJNAW-NGZCFLSTSA-N 0.000 description 1
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 1
- LPHQAFLNEHWKFF-QXEWZRGKSA-N Gly-Met-Ile Chemical compound [H]NCC(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LPHQAFLNEHWKFF-QXEWZRGKSA-N 0.000 description 1
- ZWRDOVYMQAAISL-UWVGGRQHSA-N Gly-Met-Lys Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCCN ZWRDOVYMQAAISL-UWVGGRQHSA-N 0.000 description 1
- WMGHDYWNHNLGBV-ONGXEEELSA-N Gly-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 WMGHDYWNHNLGBV-ONGXEEELSA-N 0.000 description 1
- NVTPVQLIZCOJFK-FOHZUACHSA-N Gly-Thr-Asp Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O NVTPVQLIZCOJFK-FOHZUACHSA-N 0.000 description 1
- GNNJKUYDWFIBTK-QWRGUYRKSA-N Gly-Tyr-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O GNNJKUYDWFIBTK-QWRGUYRKSA-N 0.000 description 1
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 1
- IZVICCORZOSGPT-JSGCOSHPSA-N Gly-Val-Tyr Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IZVICCORZOSGPT-JSGCOSHPSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 102100028967 HLA class I histocompatibility antigen, alpha chain G Human genes 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 108010024164 HLA-G Antigens Proteins 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 1
- XJQDHFMUUBRCGA-KKUMJFAQSA-N His-Asn-Phe Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XJQDHFMUUBRCGA-KKUMJFAQSA-N 0.000 description 1
- KNNSUUOHFVVJOP-GUBZILKMSA-N His-Glu-Ser Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N KNNSUUOHFVVJOP-GUBZILKMSA-N 0.000 description 1
- CWSZWFILCNSNEX-CIUDSAMLSA-N His-Ser-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CWSZWFILCNSNEX-CIUDSAMLSA-N 0.000 description 1
- VIJMRAIWYWRXSR-CIUDSAMLSA-N His-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 VIJMRAIWYWRXSR-CIUDSAMLSA-N 0.000 description 1
- 108010033040 Histones Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 1
- 101000738354 Homo sapiens CD9 antigen Proteins 0.000 description 1
- 101000889345 Homo sapiens Cancer/testis antigen 2 Proteins 0.000 description 1
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 1
- 101000983523 Homo sapiens Caspase-9 Proteins 0.000 description 1
- 101000898310 Homo sapiens Enhancer of filamentation 1 Proteins 0.000 description 1
- 101000608769 Homo sapiens Galectin-8 Proteins 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 description 1
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 1
- 101000984189 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 2 Proteins 0.000 description 1
- 101000984186 Homo sapiens Leukocyte immunoglobulin-like receptor subfamily B member 4 Proteins 0.000 description 1
- 101000991061 Homo sapiens MHC class I polypeptide-related sequence B Proteins 0.000 description 1
- 101000615488 Homo sapiens Methyl-CpG-binding domain protein 2 Proteins 0.000 description 1
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 description 1
- 101100207070 Homo sapiens TNFSF8 gene Proteins 0.000 description 1
- 101000597785 Homo sapiens Tumor necrosis factor receptor superfamily member 6B Proteins 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- LNJLOZYNZFGJMM-DEQVHRJGSA-N Ile-His-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N LNJLOZYNZFGJMM-DEQVHRJGSA-N 0.000 description 1
- GVKKVHNRTUFCCE-BJDJZHNGSA-N Ile-Leu-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)O)N GVKKVHNRTUFCCE-BJDJZHNGSA-N 0.000 description 1
- PNTWNAXGBOZMBO-MNXVOIDGSA-N Ile-Lys-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PNTWNAXGBOZMBO-MNXVOIDGSA-N 0.000 description 1
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 1
- VEPIBPGLTLPBDW-URLPEUOOSA-N Ile-Phe-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N VEPIBPGLTLPBDW-URLPEUOOSA-N 0.000 description 1
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 1
- JZNVOBUNTWNZPW-GHCJXIJMSA-N Ile-Ser-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N JZNVOBUNTWNZPW-GHCJXIJMSA-N 0.000 description 1
- WLRJHVNFGAOYPS-HJPIBITLSA-N Ile-Ser-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N WLRJHVNFGAOYPS-HJPIBITLSA-N 0.000 description 1
- REXAUQBGSGDEJY-IGISWZIWSA-N Ile-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N REXAUQBGSGDEJY-IGISWZIWSA-N 0.000 description 1
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 1
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 102100022338 Integrin alpha-M Human genes 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 102000013462 Interleukin-12 Human genes 0.000 description 1
- 108010065805 Interleukin-12 Proteins 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 108020003285 Isocitrate lyase Proteins 0.000 description 1
- 102100020880 Kit ligand Human genes 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- HGCNKOLVKRAVHD-UHFFFAOYSA-N L-Met-L-Phe Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 HGCNKOLVKRAVHD-UHFFFAOYSA-N 0.000 description 1
- PWKSKIMOESPYIA-BYPYZUCNSA-N L-N-acetyl-Cysteine Chemical compound CC(=O)N[C@@H](CS)C(O)=O PWKSKIMOESPYIA-BYPYZUCNSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 1
- OXKYZSRZKBTVEY-ZPFDUUQYSA-N Leu-Asn-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OXKYZSRZKBTVEY-ZPFDUUQYSA-N 0.000 description 1
- JKGHDYGZRDWHGA-SRVKXCTJSA-N Leu-Asn-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JKGHDYGZRDWHGA-SRVKXCTJSA-N 0.000 description 1
- QKIBIXAQKAFZGL-GUBZILKMSA-N Leu-Cys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QKIBIXAQKAFZGL-GUBZILKMSA-N 0.000 description 1
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 1
- MPSBSKHOWJQHBS-IHRRRGAJSA-N Leu-His-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCSC)C(=O)O)N MPSBSKHOWJQHBS-IHRRRGAJSA-N 0.000 description 1
- LKXANTUNFMVCNF-IHPCNDPISA-N Leu-His-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LKXANTUNFMVCNF-IHPCNDPISA-N 0.000 description 1
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 1
- FKQPWMZLIIATBA-AJNGGQMLSA-N Leu-Lys-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FKQPWMZLIIATBA-AJNGGQMLSA-N 0.000 description 1
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 1
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 1
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 1
- SEOXPEFQEOYURL-PMVMPFDFSA-N Leu-Tyr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SEOXPEFQEOYURL-PMVMPFDFSA-N 0.000 description 1
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 1
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 1
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 1
- 102100025583 Leukocyte immunoglobulin-like receptor subfamily B member 2 Human genes 0.000 description 1
- 102100025578 Leukocyte immunoglobulin-like receptor subfamily B member 4 Human genes 0.000 description 1
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 102000018170 Lymphotoxin beta Receptor Human genes 0.000 description 1
- 108010091221 Lymphotoxin beta Receptor Proteins 0.000 description 1
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 1
- VSRXPEHZMHSFKU-IUCAKERBSA-N Lys-Gln-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VSRXPEHZMHSFKU-IUCAKERBSA-N 0.000 description 1
- MQMIRLVJXQNTRJ-SDDRHHMPSA-N Lys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O MQMIRLVJXQNTRJ-SDDRHHMPSA-N 0.000 description 1
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- QQPSCXKFDSORFT-IHRRRGAJSA-N Lys-Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN QQPSCXKFDSORFT-IHRRRGAJSA-N 0.000 description 1
- URGPVYGVWLIRGT-DCAQKATOSA-N Lys-Met-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O URGPVYGVWLIRGT-DCAQKATOSA-N 0.000 description 1
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 1
- LKDXINHHSWFFJC-SRVKXCTJSA-N Lys-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N LKDXINHHSWFFJC-SRVKXCTJSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102100030301 MHC class I polypeptide-related sequence A Human genes 0.000 description 1
- 102100030300 MHC class I polypeptide-related sequence B Human genes 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- QWTGQXGNNMIUCW-BPUTZDHNSA-N Met-Asn-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O QWTGQXGNNMIUCW-BPUTZDHNSA-N 0.000 description 1
- VOOINLQYUZOREH-SRVKXCTJSA-N Met-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N VOOINLQYUZOREH-SRVKXCTJSA-N 0.000 description 1
- VSJAPSMRFYUOKS-IUCAKERBSA-N Met-Pro-Gly Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O VSJAPSMRFYUOKS-IUCAKERBSA-N 0.000 description 1
- MIXPUVSPPOWTCR-FXQIFTODSA-N Met-Ser-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MIXPUVSPPOWTCR-FXQIFTODSA-N 0.000 description 1
- MNGBICITWAPGAS-BPUTZDHNSA-N Met-Ser-Trp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MNGBICITWAPGAS-BPUTZDHNSA-N 0.000 description 1
- RUTZUJXAVNWLQP-BVSLBCMMSA-N Met-Tyr-Trp Chemical compound C([C@H](NC(=O)[C@@H](N)CCSC)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=C(O)C=C1 RUTZUJXAVNWLQP-BVSLBCMMSA-N 0.000 description 1
- GHQFLTYXGUETFD-UFYCRDLUSA-N Met-Tyr-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N GHQFLTYXGUETFD-UFYCRDLUSA-N 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 102100021299 Methyl-CpG-binding domain protein 2 Human genes 0.000 description 1
- 108060004795 Methyltransferase Proteins 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 1
- 101100207071 Mus musculus Tnfsf8 gene Proteins 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 102000004473 OX40 Ligand Human genes 0.000 description 1
- 108010042215 OX40 Ligand Proteins 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 208000037581 Persistent Infection Diseases 0.000 description 1
- LXVFHIBXOWJTKZ-BZSNNMDCSA-N Phe-Asn-Tyr Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O LXVFHIBXOWJTKZ-BZSNNMDCSA-N 0.000 description 1
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 1
- METZZBCMDXHFMK-BZSNNMDCSA-N Phe-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N METZZBCMDXHFMK-BZSNNMDCSA-N 0.000 description 1
- IEOHQGFKHXUALJ-JYJNAYRXSA-N Phe-Met-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IEOHQGFKHXUALJ-JYJNAYRXSA-N 0.000 description 1
- XOHJOMKCRLHGCY-UNQGMJICSA-N Phe-Pro-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOHJOMKCRLHGCY-UNQGMJICSA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- VGTJSEYTVMAASM-RPTUDFQQSA-N Phe-Thr-Tyr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VGTJSEYTVMAASM-RPTUDFQQSA-N 0.000 description 1
- WSAPMHXTQAOAQQ-BVSLBCMMSA-N Phe-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=CC=C3)N WSAPMHXTQAOAQQ-BVSLBCMMSA-N 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 108010039918 Polylysine Proteins 0.000 description 1
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 1
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 1
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 1
- VDGTVWFMRXVQCT-GUBZILKMSA-N Pro-Glu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 VDGTVWFMRXVQCT-GUBZILKMSA-N 0.000 description 1
- VOZIBWWZSBIXQN-SRVKXCTJSA-N Pro-Glu-Lys Chemical compound NCCCC[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O VOZIBWWZSBIXQN-SRVKXCTJSA-N 0.000 description 1
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 1
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 1
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 1
- JDJMFMVVJHLWDP-UNQGMJICSA-N Pro-Thr-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JDJMFMVVJHLWDP-UNQGMJICSA-N 0.000 description 1
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 1
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 1
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 1
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 101800001494 Protease 2A Proteins 0.000 description 1
- 101800001066 Protein 2A Proteins 0.000 description 1
- 102000016971 Proto-Oncogene Proteins c-kit Human genes 0.000 description 1
- 108010014608 Proto-Oncogene Proteins c-kit Proteins 0.000 description 1
- 108010065868 RNA polymerase SP6 Proteins 0.000 description 1
- 230000007022 RNA scission Effects 0.000 description 1
- 239000012979 RPMI medium Substances 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 241000712907 Retroviridae Species 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- QGMLKFGTGXWAHF-IHRRRGAJSA-N Ser-Arg-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QGMLKFGTGXWAHF-IHRRRGAJSA-N 0.000 description 1
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 1
- HBOABDXGTMMDSE-GUBZILKMSA-N Ser-Arg-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O HBOABDXGTMMDSE-GUBZILKMSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 1
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 1
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 1
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 1
- HMRAQFJFTOLDKW-GUBZILKMSA-N Ser-His-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O HMRAQFJFTOLDKW-GUBZILKMSA-N 0.000 description 1
- LQESNKGTTNHZPZ-GHCJXIJMSA-N Ser-Ile-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O LQESNKGTTNHZPZ-GHCJXIJMSA-N 0.000 description 1
- BKZYBLLIBOBOOW-GHCJXIJMSA-N Ser-Ile-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O BKZYBLLIBOBOOW-GHCJXIJMSA-N 0.000 description 1
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 1
- AZWNCEBQZXELEZ-FXQIFTODSA-N Ser-Pro-Ser Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O AZWNCEBQZXELEZ-FXQIFTODSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 1
- YXGCIEUDOHILKR-IHRRRGAJSA-N Ser-Tyr-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CO)N YXGCIEUDOHILKR-IHRRRGAJSA-N 0.000 description 1
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 241000710960 Sindbis virus Species 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 108010039445 Stem Cell Factor Proteins 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- 241000194020 Streptococcus thermophilus Species 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 108010002687 Survivin Proteins 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- 230000005867 T cell response Effects 0.000 description 1
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- GFDUZZACIWNMPE-KZVJFYERSA-N Thr-Ala-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O GFDUZZACIWNMPE-KZVJFYERSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- LKEKWDJCJSPXNI-IRIUXVKKSA-N Thr-Glu-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 LKEKWDJCJSPXNI-IRIUXVKKSA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 1
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 1
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 1
- HUPLKEHTTQBXSC-YJRXYDGGSA-N Thr-Ser-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUPLKEHTTQBXSC-YJRXYDGGSA-N 0.000 description 1
- MFMGPEKYBXFIRF-SUSMZKCASA-N Thr-Thr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFMGPEKYBXFIRF-SUSMZKCASA-N 0.000 description 1
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 1
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- RCMHSGRBJCMFLR-BPUTZDHNSA-N Trp-Met-Asn Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(O)=O)=CNC2=C1 RCMHSGRBJCMFLR-BPUTZDHNSA-N 0.000 description 1
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 1
- UGFOSENEZHEQKX-PJODQICGSA-N Trp-Val-Ala Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](C)C(O)=O UGFOSENEZHEQKX-PJODQICGSA-N 0.000 description 1
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- 102000044209 Tumor Suppressor Genes Human genes 0.000 description 1
- 108700025716 Tumor Suppressor Genes Proteins 0.000 description 1
- 102100032100 Tumor necrosis factor ligand superfamily member 8 Human genes 0.000 description 1
- 102100032101 Tumor necrosis factor ligand superfamily member 9 Human genes 0.000 description 1
- 102100035284 Tumor necrosis factor receptor superfamily member 6B Human genes 0.000 description 1
- JBBYKPZAPOLCPK-JYJNAYRXSA-N Tyr-Arg-Met Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(O)=O JBBYKPZAPOLCPK-JYJNAYRXSA-N 0.000 description 1
- MBFJIHUHHCJBSN-AVGNSLFASA-N Tyr-Asn-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MBFJIHUHHCJBSN-AVGNSLFASA-N 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- FFCRCJZJARTYCG-KKUMJFAQSA-N Tyr-Cys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O FFCRCJZJARTYCG-KKUMJFAQSA-N 0.000 description 1
- RGYDQHBLMMAYNZ-IHRRRGAJSA-N Tyr-Cys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=C(C=C1)O)N RGYDQHBLMMAYNZ-IHRRRGAJSA-N 0.000 description 1
- ZAGPDPNPWYPEIR-SRVKXCTJSA-N Tyr-Cys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O ZAGPDPNPWYPEIR-SRVKXCTJSA-N 0.000 description 1
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 1
- QARCDOCCDOLJSF-HJPIBITLSA-N Tyr-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QARCDOCCDOLJSF-HJPIBITLSA-N 0.000 description 1
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 1
- QPBJXNYYQTUTDD-KKUMJFAQSA-N Tyr-Met-Gln Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QPBJXNYYQTUTDD-KKUMJFAQSA-N 0.000 description 1
- XJPXTYLVMUZGNW-IHRRRGAJSA-N Tyr-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O XJPXTYLVMUZGNW-IHRRRGAJSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- KHPLUFDSWGDRHD-SLFFLAALSA-N Tyr-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O KHPLUFDSWGDRHD-SLFFLAALSA-N 0.000 description 1
- PQPWEALFTLKSEB-DZKIICNBSA-N Tyr-Val-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PQPWEALFTLKSEB-DZKIICNBSA-N 0.000 description 1
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 1
- WBAJDGWKRIHOAC-GVXVVHGQSA-N Val-Lys-Gln Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O WBAJDGWKRIHOAC-GVXVVHGQSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 1
- VPGCVZRRBYOGCD-AVGNSLFASA-N Val-Lys-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O VPGCVZRRBYOGCD-AVGNSLFASA-N 0.000 description 1
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- LGXUZJIQCGXKGZ-QXEWZRGKSA-N Val-Pro-Asn Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N LGXUZJIQCGXKGZ-QXEWZRGKSA-N 0.000 description 1
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 1
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 1
- ATBOMIWRCZXYSZ-XZBBILGWSA-N [1-[2,3-dihydroxypropoxy(hydroxy)phosphoryl]oxy-3-hexadecanoyloxypropan-2-yl] (9e,12e)-octadeca-9,12-dienoate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OCC(O)CO)OC(=O)CCCCCCC\C=C\C\C=C\CCCCC ATBOMIWRCZXYSZ-XZBBILGWSA-N 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 229960004308 acetylcysteine Drugs 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- AWUCVROLDVIAJX-UHFFFAOYSA-N alpha-glycerophosphate Natural products OCC(O)COP(O)(O)=O AWUCVROLDVIAJX-UHFFFAOYSA-N 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 239000000823 artificial membrane Substances 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 239000012298 atmosphere Substances 0.000 description 1
- 210000000649 b-lymphocyte subset Anatomy 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 108010028263 bacteriophage T3 RNA polymerase Proteins 0.000 description 1
- 210000003651 basophil Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 238000010170 biological method Methods 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 239000002458 cell surface marker Substances 0.000 description 1
- 238000002659 cell therapy Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 230000007073 chemical hydrolysis Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 231100000313 clinical toxicology Toxicity 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 238000001246 colloidal dispersion Methods 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 239000003636 conditioned culture medium Substances 0.000 description 1
- 238000010226 confocal imaging Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 101150055601 cops2 gene Proteins 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 230000003436 cytoskeletal effect Effects 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 230000007123 defense Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 229940093541 dicetylphosphate Drugs 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 230000000447 dimerizing effect Effects 0.000 description 1
- BPHQZTVXXXJVHI-UHFFFAOYSA-N dimyristoyl phosphatidylglycerol Chemical compound CCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OCC(O)CO)OC(=O)CCCCCCCCCCCCC BPHQZTVXXXJVHI-UHFFFAOYSA-N 0.000 description 1
- 230000005782 double-strand break Effects 0.000 description 1
- 229960003722 doxycycline Drugs 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 230000005684 electric field Effects 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 230000007071 enzymatic hydrolysis Effects 0.000 description 1
- 238000006047 enzymatic hydrolysis reaction Methods 0.000 description 1
- 230000008029 eradication Effects 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000011124 ex vivo culture Methods 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 210000003754 fetus Anatomy 0.000 description 1
- 229960000390 fludarabine Drugs 0.000 description 1
- GIUYCYHIANZCFB-FJFJXFQQSA-N fludarabine phosphate Chemical compound C1=NC=2C(N)=NC(F)=NC=2N1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@@H]1O GIUYCYHIANZCFB-FJFJXFQQSA-N 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 231100000221 frame shift mutation induction Toxicity 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 230000005021 gait Effects 0.000 description 1
- 210000004475 gamma-delta t lymphocyte Anatomy 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 238000012215 gene cloning Methods 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 238000011223 gene expression profiling Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 1
- 229940029575 guanosine Drugs 0.000 description 1
- 230000003862 health status Effects 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 235000020256 human milk Nutrition 0.000 description 1
- 210000004251 human milk Anatomy 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 230000009610 hypersensitivity Effects 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 239000012642 immune effector Substances 0.000 description 1
- 108091008915 immune receptors Proteins 0.000 description 1
- 102000027596 immune receptors Human genes 0.000 description 1
- 230000006058 immune tolerance Effects 0.000 description 1
- 230000007813 immunodeficiency Effects 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 230000002601 intratumoral effect Effects 0.000 description 1
- FZWBNHMXJMCXLU-BLAUPYHCSA-N isomaltotriose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)[C@@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)O1 FZWBNHMXJMCXLU-BLAUPYHCSA-N 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000004904 long-term response Effects 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 108010054155 lysyllysine Proteins 0.000 description 1
- 108010017391 lysylvaline Proteins 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 210000003071 memory t lymphocyte Anatomy 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 108010068488 methionylphenylalanine Proteins 0.000 description 1
- 239000010445 mica Substances 0.000 description 1
- 229910052618 mica group Inorganic materials 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 210000005087 mononuclear cell Anatomy 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 210000000581 natural killer T-cell Anatomy 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 210000004882 non-tumor cell Anatomy 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 231100000956 nontoxicity Toxicity 0.000 description 1
- 238000011290 novel combination immunotherapy Methods 0.000 description 1
- 238000010899 nucleation Methods 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 206010033675 panniculitis Diseases 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000013610 patient sample Substances 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 230000035699 permeability Effects 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 230000003094 perturbing effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 238000000053 physical method Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920000656 polylysine Polymers 0.000 description 1
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 229940002612 prodrug Drugs 0.000 description 1
- 239000000651 prodrug Substances 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 230000004850 protein–protein interaction Effects 0.000 description 1
- 108010014186 ras Proteins Proteins 0.000 description 1
- 102000016914 ras Proteins Human genes 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 210000003289 regulatory T cell Anatomy 0.000 description 1
- 230000008521 reorganization Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000002629 repopulating effect Effects 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 210000002345 respiratory system Anatomy 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 229950004008 rimiducid Drugs 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 230000008054 signal transmission Effects 0.000 description 1
- 230000007781 signaling event Effects 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 238000012289 standard assay Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 210000001138 tear Anatomy 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 230000005029 transcription elongation Effects 0.000 description 1
- 230000002463 transducing effect Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 238000002054 transplantation Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 238000013024 troubleshooting Methods 0.000 description 1
- 108010044292 tryptophyltyrosine Proteins 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- 210000003954 umbilical cord Anatomy 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 210000002229 urogenital system Anatomy 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
Images


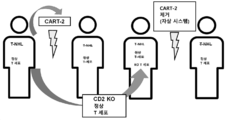





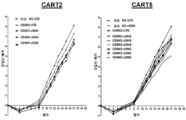







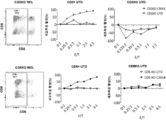


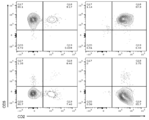
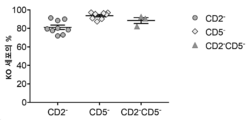




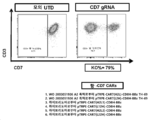
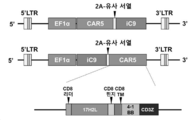
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/0005—Vertebrate antigens
- A61K39/0011—Cancer antigens
- A61K39/001102—Receptors, cell surface antigens or cell surface determinants
- A61K39/001129—Molecules with a "CD" designation not provided for elsewhere
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4631—Chimeric Antigen Receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464429—Molecules with a "CD" designation not provided for elsewhere
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70507—CD2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70578—NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70596—Molecules with a "CD"-designation not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2806—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2896—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against molecules with a "CD"-designation, not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1138—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against receptors or cell surface proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6402—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from non-mammals
- C12N9/6405—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from non-mammals not being snakes
- C12N9/641—Cysteine endopeptidases (3.4.22)
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/515—Animal cells
- A61K2039/5156—Animal cells expressing foreign proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/515—Animal cells
- A61K2039/5158—Antigen-pulsed cells, e.g. T-cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/80—Vaccine for a specifically defined cancer
- A61K2039/804—Blood cells [leukemia, lymphoma]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/38—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the dose, timing or administration schedule
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/46—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the cancer treated
- A61K2239/48—Blood cells, e.g. leukemia or lymphoma
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4748—Tumour specific antigens; Tumour rejection antigen precursors [TRAP], e.g. MAGE
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/522—CH1 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/50—Cell markers; Cell surface determinants
- C12N2501/515—CD3, T-cell receptor complex
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/50—Cell markers; Cell surface determinants
- C12N2501/53—CD2
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2501/00—Active agents used in cell culture processes, e.g. differentation
- C12N2501/50—Cell markers; Cell surface determinants
- C12N2501/599—Cell markers; Cell surface determinants with CD designations not provided for elsewhere
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Biophysics (AREA)
- Cell Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- General Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Toxicology (AREA)
- Mycology (AREA)
- Hematology (AREA)
- Oncology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Developmental Biology & Embryology (AREA)
- Virology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
본 발명은 T 세포 림프종 및 백혈병을 치료하기 위한 조성물 및 방법을 포함한다. 특정 측면에서, 조성물 및 방법은, CD2, CD5 또는 CD7을 표적화하는 CAR T 세포 및 변형 세포를 포함하고, CD2, CD5 또는 CD7은 녹-아웃되어 있다.
Description
관련 출원의 상호-참조
본 출원은, 2018년 12일자로 출원된 미국 가특허출원 제62/782,131호에 대한 35 U.S.C. §119(e)하의 우선권을 갖고, 이는 참조에 의해 그 전체가 본원에 도입된다.
T 세포 림프종 및 백혈병은 T 세포 전구세포(T cell progenitor) 또는 분화된 T 세포로부터 유래하는 침습성 신생물(aggressive neoplasm)이다. 성숙 또는 말초 T 세포 림프종은, 비-호지킨 림프종 전체의 10% 내지 15%, 또는 미국에서는 년간 7,000 내지 10,000 사례를 점유한다. T 세포 림프종 및 백혈병은 예후가 불량하고, 이용가능한 치료법은 거의 없다. 키메라 항원 수용체 T 세포(CART) 요법은, B 세포 신생물에 대한 유효성을 입증하였지만, 대부분의 표적 항원이 정상 세포 및 악성 세포 사이에서 공유되어 CAR T 세포 동족살인을 유도하기 때문에, CAR T 세포의 성공을 T 세포 악성종양까지 확대하는 것은 문제가 있다.
T 세포 림프종 및 백혈병을 치료하기 위한 조성물 및 방법, 뿐만 아니라 CAR T 세포 동족살인을 제거하는 방법에 대한 필요성이 존재한다. 본 발명은 이러한 요구에 대처한다.
본원에 기재된 바와 같이, 본 발명은 CD2, CD5 또는 CD7을 표적화하는 CAR T 세포 및 CD2, CD5 또는 CD7이 녹-아웃(knocked-out)된 변형된 세포를 이용하는 조성물 및 방법에 관한 것이다.
한 가지 측면에서, 본 발명은 이를 필요로 하는 대상체에서 암(cancer)을 치료하는 방법을 포함한다. 상기 방법은, 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포(modified cell)를 대상체에게 투여하는 단계로서, 상기 CAR은 항원 결합 도메인, 막관통 도메인(transmembrane domain) 및 세포내 도메인을 포함하는, 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD5 유전자는 녹-아웃되어 있는, 단계를 포함한다.
또 다른 측면에서, 본 발명은 이를 필요로 하는 대상체에서 암을 치료하는 방법을 포함한다. 상기 방법은, 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 CD2에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD2 유전자는 녹-아웃되어 있는, 단계를 포함한다.
여전히 또 다른 측면에서, 본 발명은 이를 필요로 하는 대상체에서 암을 치료하는 방법을 포함한다. 상기 방법은, CAR을 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 CD5에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD5 유전자가 녹-아웃되어 있는, 단계를 포함한다.
또 다른 측면에서, 본 발명은, 이를 필요로 하는 대상체에서 암을 치료하는 방법으로서, CAR을 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 CD7에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD7 유전자가 녹-아웃되어 있는, 단계를 포함하는, 방법을 포함한다.
본 발명의 또 다른 측면은 CAR을 포함하는 핵산을 포함하고, 여기서 상기 CAR은 CD2에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함한다.
본 발명의 또 다른 측면은 CAR을 포함하는 핵산을 포함하고, 여기서 상기 CAR은 CD5에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함한다.
본 발명의 또 다른 측면은 본원에 개시된 임의의 핵산을 포함하는 벡터(vector)를 포함한다.
다른 측면에서, 본 발명은 본원에 개시된 임의의 핵산 또는 본원에 개시된 임의의 벡터를 포함하는 세포를 포함한다.
또 다른 측면에서, 본 발명은 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 CD2를 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD2 유전자는 녹-아웃되어 있다.
또 다른 측면에서, 본 발명은 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 CD5을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD5 유전자는 녹-아웃되어 있다.
또 다른 측면에서, 본 발명은 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 CD7을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD7 유전자는 녹-아웃되어 있다.
본 발명의 다른 측면은, 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD5 유전자는 녹-아웃되어 있다.
상기 측면 또는 본 발명의 임의의 다른 측면의 다양한 실시양태에서, 내인성 유전자는 CRISPR 방법을 사용하여 녹-아웃된다. 특정 실시양태에서, CRISPR 방법은 CRISPR/Cas9 방법이다. 특정 실시양태에서, CRISPR/Cas9 방법은 서열번호 23의 뉴클레오티드 서열을 포함하는 sgRNA를 이용한다. 특정 실시양태에서, CRISPR/Cas9 방법은 서열번호 22 내지 24로 이루어진 그룹으로부터 선택된 뉴클레오티드 서열을 포함하는 sgRNA를 이용한다.
특정 실시양태에서, CAR의 항원 결합 도메인은, CD5, CD19, CD2, CD7, 종양 특이적 항원(TSA), 종양 관련 항원(TAA), 신경교종 관련 항원, 암배아 항원(CEA), β-인간 융모성 고나도트로핀, 알파페토단백질(AFP), 렉틴-반응성 AFP, 티로글로불린, RAGE-1, MN-CA IX, 인간 텔로머라제 역전사효소, RU1, RU2(AS), 장 카복실 에스테라제, mut hsp70-2, M-CSF, 프로스타제, 전립선-특이적 항원(PSA), PAP, NY-ESO-1, LAGE-la, p53, 프로스테인, PSMA, Her2/neu, 서비빈(survivin), 텔로머라제, 전립선암 종양 항원-1(PCTA-1), MAGE, ELF2M, 호중구 엘라스타제, 에프린B2, CD22,인슐린 성장 인자(IGF)-I, IGF-II, IGF-I 수용체, 메소텔린, MART-1/멜란A(MART-I), gp100(Pmel 17), 티로시나제, TRP-1, TRP-2, MAGE-1, MAGE-3, BAGE, GAGE-1, GAGE-2, pl5, Ras, BCR-ABL, E2A-PRL, H4-RET, IGH-IGK, MYL-RAR, EBVA, HPV 항원 E6, HPV 항원 E7, TSP-180, MAGE-4, MAGE-5, MAGE-6, RAGE, NY-ESO, pl85erbB2, pl80erbB-3, c-met, nm-23H1, PSA, TAG-72, CA 19-9, CA 72-4, CAM 17.1, NuMa, K-ras, 베타-카테닌, CDK4, Mum-1, p15, p16, 43-9F, 5T4, 791Tgp72, 알파-페토단백질, 베타-HCG, BCA225, BTAA, CA 125, CA 15-3\CA 27.29\BCAA, CA 195, CA 242, CA-50, CAM43, CD68\P1, CO-029, FGF-5, G250, Ga733\EpCAM, HTgp-175, M344, MA-50, MG7-Ag, MOV18, NB/70K, NY-CO-1, RCAS1, SDCCAG16, TA-90\Mac-2 결합 단백질\사이클로필린 C-연관 단백질, TAAL6, TAG72, TLP 및 TPS로 이루어진 그룹으로부터 선택된 항원에 결합할 수 있다.
특정 실시양태에서, CAR의 항원 결합 도메인은, 서열번호 31-36, 43-48, 53-58, 65-70, 83-88 및 95-100으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 31-36, 43-48, 53-58 및 65-70으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 83 내지 88 및 95 내지 100으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함한다.
특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 29, 41, 51, 63, 75, 81 및 93으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 30, 42, 52, 64, 76, 82 및 94로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다.
특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 29, 41, 51 및 63으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 30, 42, 52 및 64로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다.
특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 75, 81 및 93으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 76, 82 및 94로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다.
특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 27, 28, 39, 40, 50, 61, 62, 73, 74, 79, 80, 91 및 92로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 27, 28, 39, 40, 50, 61 및 62로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 서열번호 73, 74, 79, 80, 91 및 92로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함한다.
특정 실시양태에서, 상기 CAR은 서열번호 25, 26, 37, 38, 49, 59, 60, 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함한다. 특정 실시양태에서, 상기 CAR은 서열번호 25, 26, 37, 38, 49, 59 및 60으로 이루어진 그룹으로부터 선택되는 아미노산 서열을 포함한다. 특정 실시양태에서, CAR은 서열번호 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 서열번호 1 내지 13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩(encoding)된다. 특정 실시양태에서, CAR은 서열번호 1 내지 7로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩된다. 특정 실시양태에서, CAR은 서열번호 8 내지 13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩된다.
특정 실시양태에서, CAR은 자살 유전자(suicide gene)를 추가로 포함한다. 특정 실시양태에서, 자살 유전자는 iCaspase9이다.
특정 실시양태에서, 제1 및 제2 변형 세포는 T 세포이다.
특정 실시양태에서, 암은 T 세포 림프종 또는 T 세포 백혈병을 포함한다. 특정 실시양태에서, 암은 급성 골수성 백혈병(AML), T-세포 급성 림프구성 백혈병(T-ALL), 급성 림프구성 백혈병(ALL) 및 만성 림프구성 백혈병(CLL)이다.
특정 실시양태에서, 조성물은 약제학적으로 허용되는 담체를 포함한다.
본 발명의 특정 실시양태의 하기 상세한 설명은 첨부된 도면과 함께 판독될 때 보다 잘 이해될 것이다. 본 발명을 설명하기 위해, 예시적 실시양태가 도시되어 있다. 그러나, 본 발명은 도면에 도시된 실시양태의 정확한 배치 및 수단에 한정되지 않는다는 것을 이해해야 한다.
도 1은 T 세포 신생물에 대한 CART 요법에 관한 현재의 문제를 설명하는 개략도이다.
도 2는 혁신적 전략의 개발을 설명하는 개략도이고, 여기서 i. 종양 표적은 유전자-편집을 사용하여 정상 T 세포로부터 제거되고, 이에 의해 제조 중의 동족살인을 회피하고; ii. T 세포 표적이 녹-아웃(KO)되고, 항-T 신생물 CART와 동시 주입되어 CART 사멸에 영향을 받지 않는 T 세포 면역을 제공한 정상 T 세포를 포함하는 제2 T 세포 생성물.
도 3은 T 세포 독성을 유발하지 않으면서 T 세포 림프종을 표적화하기 위한 신규한 접근법을 나타내는 개략도이다. 항-T-NHL(또는 T-ALL) CART(CART2/5/7, 예를 들면, CART2) 및 CD2/5/7 녹-아웃 정상 T 세포를 포함하는 2개의 면역요법이 사용된다. CART는 종양 세포를 파괴하지만, 정상 T 세포를 사멸시킨다. CD2/5/7(또는 다른 종양 표적) KO 정상 T 세포의 주입은 CART 세포가 고갈될 때까지 CART-내성 T 세포 면역을 제공한다.
도 4는 본원에서 사용되는 항-CD2 및 항-CD5 CAR 작제물을 도시한다. 모든 작제물은 렌티바이러스 pTRPE 4-1BB CD3zeta 백본(backbone)을 갖는다.
도 5는 T 세포에서 CART 형질도입 효율을 도시한다. 고(#17), 중(#34) 및 저(#9) 친화성을 갖는 일본쇄 가변 단편(scFv)을 사용하여 6개의 상이한 CAR5 작제물이 생성되었다. T 세포를 항-CD3/CD28 비드(Dynabead)로 활성화시키고, 24시간 후에 렌티바이러스 벡터를 MOI 3에서 첨가했다. 6일차에 Dynabead를 제거했다. 평균 용적이 350 fl 미만으로 되었을 때에 CART 세포를 동결시켰다. CAR 발현(염소-항-마우스 Fab 항체)는 6일차에 시험했다.
도 6은 CD5(또는 CD2, 또는 CD7) KO 제조 프로세스 및 CRISPR-Cas9 KO 효율을 도시한다.
도 7은 몇몇 CART 그룹의 확장 곡선을 도시한다. CD2 KO CART2가 없으면, 세포는 확장하지 않는다. KO CART2 및 CART5의 존재는 약 5-8배 모집단에 도달한다.
도 8은, CD5의 CRISPR-Cas9 KO가 없는 경우, CD5 평균 형광 강도(MFI)가, 대조군 T 세포와 비교하여, CART5에서 10배 작고, CD2 등의 다른 pan T-세포 마커에 변화가 없었다는 발견을 나타낸다.
도 9는 CART2 및 CART5 확장 곡선을 도시한다. T 세포 농도는 콜터 카운터(Coulter Counter)를 사용하여 측정했다.
도 10은 6개의 상이한 CAR2 작제물이, 이들을 루시퍼라제 + Jurkat 세포(T-세포 백혈병 세포주)와 공배양함으로써 시험관내에서 챌린지된 실험으로부터의 결과를 나타낸다. 24시간에에, 총 사멸은 발광의 상대적 감소로 측정되었다. C3029, C3030 및 C3043만이 항-종양 효과를 나타냈다.
도 11은 6개의 상이한 CAR5 작제물이, 이들을 루시퍼라제 + Jurkat 세포(T-세포 백혈병 세포주)와 공배양함으로써 시험관내에서 챌린지된 실험으로부터의 결과를 나타낸다. 24시간에서, 총 사멸은 발광의 상대적 감소로 측정되었다. 모든 CAR5 작제물은 유사한 항-종양 효과를 나타냈다.
도 12는 CART2 및 CART5의 생체내 유효성을 나타낸다. NSG 마우스에 루시페라제 + Jurkat 세포를 이식하고, 마우스를 랜덤화하여, 7일차에 대조군 T 세포 또는 CART2 또는 CART 5(1×l06)를 투여했다. IVIS Xenogen 스펙트럼을 사용하여 마우스를 매주 이미징하고, LivingImage 소프트웨어로 분석했다. CART2 C3043 및 CART5 C3054가 가장 효과적이었다.
도 13은 Jurkat 세포를 상이한 CAR5 작제물(좌측에 제시된 표적 에피토프 및 친화성) 및 GFP-NFAT 리포터로 형질도입시키고, 이어서 CD5 + 종양 세포(또는 대조군)와 24시간 동안 공배양한 실험으로부터 결과를 나타낸다. 리드 CART5(C3054)는 NFAT 활성화의 증가를 나타냈다.
도 14는 Jurkat 세포를 상이한 CAR2 작제물 및 GFP-NFAT 리포터로 형질도입시키고, 이어서 CD2 + 종양 세포(또는 대조군)와 24시간 동안 공배양한 실험으로부터의 결과를 나타낸다. 리드 CART2(C3043)는 NFAT 활성화의 증가를 나타냈다.
도 15는 피부 T 세포 림프종에 대한 CART2 및 CART5 활성을 나타낸다. 24시간 사멸 분석으로부터 결과를 나타냈다. CART2 세포는 일차 세자리(Sezary) 세포(백혈병성 피부 T 세포 림프종) 및 HH 세자리 세포주에 대해 활성이다. 또한, CART5는 HH 세포에 대해 활성이었다.
도 16은 CART2 및 CART5가 정상 T 세포(자가 상부 및 동종이계 하부)를 인식할 수 있고, 이들을 사멸시킬 수 있다는 발견을 도시한다.
도 17은 CAR 표적의 제거가 정상 T 세포를 CART 사멸로부터 보호한다는 발견을 도시한다. CD5 KO는 WT 정상 T 세포에는 없고, CART5 사멸에 내성이 있다. 정상 휴지 T 세포는 CART2(상부) 및 CART5(하부)에 의해 인식되어 사멸된다. CRISPR-Cas9를 사용한 정상 T 세포로부터의 CD2 또는 CD5의 효율적 KO는 각각 CART2 또는 CART5에 대한 내성을 유도한다.
도 18은 CMV-특이적 T 세포가 CD2KO 및 CD5KO 정상 T 세포 생성물에 존재한다는 발견을 나타낸다. CD2 및 CD5 KO 정상 T 세포는 CMV 펩티드를 인식하여 사이토카인을 생산하는 능력을 유지한다. (HLA-A-02:01-CMV PP65 NLVPMVATV 덱스트로머(서열번호 101); CETF 펩티드에 대한 4시간 노출 후의 ICS. CMV-펩티드 펄스 APC에 의한 2차 배양 후).
도 19는 이중 특이적 CAR T 세포의 발달을 나타낸다. P2A 서열에 의해 연결된 CAR5(C3054) 및 CAR2(C3043)를 포함하는 2개의 렌티바이러스 작제물을 생성했다. 유전자 발현은 EF1alpha 프로모터에 의해 유도된다. CAR5 작제물은 4-1BB 공자극 및 CD3zeta 신호전달 도메인을 갖는다.
도 20A 및 20B는 이중 KO CART 세포를 도시한다. 유세포 분석법에 의해 나타낸 바와 같이, 정상 T 세포에서 CD2 및 CD5 둘 모두의 효율적 녹-아웃.
도 21은 생체내에서 CD5 KO CART5가 CD5 + CART5보다 더 효과적이라는 발견을 도시한다. CD5 KO는 CART5의 항종양 효능을 증가시킨다. NSG 마우스를 사용한 Jurkat T-ALL 이종이식 모델에서, CD5 KO CART5(2×l06 세포/마우스)는, WT CART5와 비교하여, 완전한 장기간 완전 반응 및 보다 긴 생존을 유도한다.
도 22는 생체내에서 CD5 KO CART19가 CD5 + CART19보다 더 효과적이라는 발견을 도시한다. CD5 KO는 CART19의 항-종양 효능을 증가시킨다. NALM6 B-ALL 이종이식 모델에서, CD5 KO CART19는, WT CART19와 비교하여, 현저히 높은 종양 제어를 갖는다.
도 23A 및 23B는 CART5 및 CART2가 AML의 20%을 표적화할 수 있다는 발견을 도시한다. 도 23A는 AML에서 CD2 발현을 도시한다. 도 23B는 24시간 사멸 분석으로부터 결과를 나타낸다. CART2 세포를 CD2 + AML 세포와 공배양하고, 24시간에서 유의한 사멸을 나타냈다.
도 24는 CART5가 CLL 및 MCL의 100%를 표적화할 수 있다는 발견을 도시한다. 결과는 CART5 세포가 CD5 + MCL 세포주(Jeko-1 및 Mino)를 인식하여 사멸시킬 수 있다는 것을 나타내는 세포독성 검정으로부터의 것이다.
도 25는 T 세포에서 CD7을 녹-아웃하기 위한 sgRNA의 개발(상부) 및 CD7에 대한 6개의 CAR 작제물의 생성을 도시한다.
도 26은 본원에서 사용되는 Casp9-CAR5 렌티바이러스 작제물을 도시한다. CAR5(C3054), P2A 서열 및 이어서 iCaspase9 자살 유전자(iC9) 또는 iC9-P2A-C3054를 포함하는 2개의 렌티바이러스 작제물을 생성했다. 유전자 발현은 EF1alpha 프로모터에 의해 유도된다. CAR5 작제물은 4-IBB 공자극 및 CD3zeta 신호전달 도메인을 갖는다.
도 1은 T 세포 신생물에 대한 CART 요법에 관한 현재의 문제를 설명하는 개략도이다.
도 2는 혁신적 전략의 개발을 설명하는 개략도이고, 여기서 i. 종양 표적은 유전자-편집을 사용하여 정상 T 세포로부터 제거되고, 이에 의해 제조 중의 동족살인을 회피하고; ii. T 세포 표적이 녹-아웃(KO)되고, 항-T 신생물 CART와 동시 주입되어 CART 사멸에 영향을 받지 않는 T 세포 면역을 제공한 정상 T 세포를 포함하는 제2 T 세포 생성물.
도 3은 T 세포 독성을 유발하지 않으면서 T 세포 림프종을 표적화하기 위한 신규한 접근법을 나타내는 개략도이다. 항-T-NHL(또는 T-ALL) CART(CART2/5/7, 예를 들면, CART2) 및 CD2/5/7 녹-아웃 정상 T 세포를 포함하는 2개의 면역요법이 사용된다. CART는 종양 세포를 파괴하지만, 정상 T 세포를 사멸시킨다. CD2/5/7(또는 다른 종양 표적) KO 정상 T 세포의 주입은 CART 세포가 고갈될 때까지 CART-내성 T 세포 면역을 제공한다.
도 4는 본원에서 사용되는 항-CD2 및 항-CD5 CAR 작제물을 도시한다. 모든 작제물은 렌티바이러스 pTRPE 4-1BB CD3zeta 백본(backbone)을 갖는다.
도 5는 T 세포에서 CART 형질도입 효율을 도시한다. 고(#17), 중(#34) 및 저(#9) 친화성을 갖는 일본쇄 가변 단편(scFv)을 사용하여 6개의 상이한 CAR5 작제물이 생성되었다. T 세포를 항-CD3/CD28 비드(Dynabead)로 활성화시키고, 24시간 후에 렌티바이러스 벡터를 MOI 3에서 첨가했다. 6일차에 Dynabead를 제거했다. 평균 용적이 350 fl 미만으로 되었을 때에 CART 세포를 동결시켰다. CAR 발현(염소-항-마우스 Fab 항체)는 6일차에 시험했다.
도 6은 CD5(또는 CD2, 또는 CD7) KO 제조 프로세스 및 CRISPR-Cas9 KO 효율을 도시한다.
도 7은 몇몇 CART 그룹의 확장 곡선을 도시한다. CD2 KO CART2가 없으면, 세포는 확장하지 않는다. KO CART2 및 CART5의 존재는 약 5-8배 모집단에 도달한다.
도 8은, CD5의 CRISPR-Cas9 KO가 없는 경우, CD5 평균 형광 강도(MFI)가, 대조군 T 세포와 비교하여, CART5에서 10배 작고, CD2 등의 다른 pan T-세포 마커에 변화가 없었다는 발견을 나타낸다.
도 9는 CART2 및 CART5 확장 곡선을 도시한다. T 세포 농도는 콜터 카운터(Coulter Counter)를 사용하여 측정했다.
도 10은 6개의 상이한 CAR2 작제물이, 이들을 루시퍼라제 + Jurkat 세포(T-세포 백혈병 세포주)와 공배양함으로써 시험관내에서 챌린지된 실험으로부터의 결과를 나타낸다. 24시간에에, 총 사멸은 발광의 상대적 감소로 측정되었다. C3029, C3030 및 C3043만이 항-종양 효과를 나타냈다.
도 11은 6개의 상이한 CAR5 작제물이, 이들을 루시퍼라제 + Jurkat 세포(T-세포 백혈병 세포주)와 공배양함으로써 시험관내에서 챌린지된 실험으로부터의 결과를 나타낸다. 24시간에서, 총 사멸은 발광의 상대적 감소로 측정되었다. 모든 CAR5 작제물은 유사한 항-종양 효과를 나타냈다.
도 12는 CART2 및 CART5의 생체내 유효성을 나타낸다. NSG 마우스에 루시페라제 + Jurkat 세포를 이식하고, 마우스를 랜덤화하여, 7일차에 대조군 T 세포 또는 CART2 또는 CART 5(1×l06)를 투여했다. IVIS Xenogen 스펙트럼을 사용하여 마우스를 매주 이미징하고, LivingImage 소프트웨어로 분석했다. CART2 C3043 및 CART5 C3054가 가장 효과적이었다.
도 13은 Jurkat 세포를 상이한 CAR5 작제물(좌측에 제시된 표적 에피토프 및 친화성) 및 GFP-NFAT 리포터로 형질도입시키고, 이어서 CD5 + 종양 세포(또는 대조군)와 24시간 동안 공배양한 실험으로부터 결과를 나타낸다. 리드 CART5(C3054)는 NFAT 활성화의 증가를 나타냈다.
도 14는 Jurkat 세포를 상이한 CAR2 작제물 및 GFP-NFAT 리포터로 형질도입시키고, 이어서 CD2 + 종양 세포(또는 대조군)와 24시간 동안 공배양한 실험으로부터의 결과를 나타낸다. 리드 CART2(C3043)는 NFAT 활성화의 증가를 나타냈다.
도 15는 피부 T 세포 림프종에 대한 CART2 및 CART5 활성을 나타낸다. 24시간 사멸 분석으로부터 결과를 나타냈다. CART2 세포는 일차 세자리(Sezary) 세포(백혈병성 피부 T 세포 림프종) 및 HH 세자리 세포주에 대해 활성이다. 또한, CART5는 HH 세포에 대해 활성이었다.
도 16은 CART2 및 CART5가 정상 T 세포(자가 상부 및 동종이계 하부)를 인식할 수 있고, 이들을 사멸시킬 수 있다는 발견을 도시한다.
도 17은 CAR 표적의 제거가 정상 T 세포를 CART 사멸로부터 보호한다는 발견을 도시한다. CD5 KO는 WT 정상 T 세포에는 없고, CART5 사멸에 내성이 있다. 정상 휴지 T 세포는 CART2(상부) 및 CART5(하부)에 의해 인식되어 사멸된다. CRISPR-Cas9를 사용한 정상 T 세포로부터의 CD2 또는 CD5의 효율적 KO는 각각 CART2 또는 CART5에 대한 내성을 유도한다.
도 18은 CMV-특이적 T 세포가 CD2KO 및 CD5KO 정상 T 세포 생성물에 존재한다는 발견을 나타낸다. CD2 및 CD5 KO 정상 T 세포는 CMV 펩티드를 인식하여 사이토카인을 생산하는 능력을 유지한다. (HLA-A-02:01-CMV PP65 NLVPMVATV 덱스트로머(서열번호 101); CETF 펩티드에 대한 4시간 노출 후의 ICS. CMV-펩티드 펄스 APC에 의한 2차 배양 후).
도 19는 이중 특이적 CAR T 세포의 발달을 나타낸다. P2A 서열에 의해 연결된 CAR5(C3054) 및 CAR2(C3043)를 포함하는 2개의 렌티바이러스 작제물을 생성했다. 유전자 발현은 EF1alpha 프로모터에 의해 유도된다. CAR5 작제물은 4-1BB 공자극 및 CD3zeta 신호전달 도메인을 갖는다.
도 20A 및 20B는 이중 KO CART 세포를 도시한다. 유세포 분석법에 의해 나타낸 바와 같이, 정상 T 세포에서 CD2 및 CD5 둘 모두의 효율적 녹-아웃.
도 21은 생체내에서 CD5 KO CART5가 CD5 + CART5보다 더 효과적이라는 발견을 도시한다. CD5 KO는 CART5의 항종양 효능을 증가시킨다. NSG 마우스를 사용한 Jurkat T-ALL 이종이식 모델에서, CD5 KO CART5(2×l06 세포/마우스)는, WT CART5와 비교하여, 완전한 장기간 완전 반응 및 보다 긴 생존을 유도한다.
도 22는 생체내에서 CD5 KO CART19가 CD5 + CART19보다 더 효과적이라는 발견을 도시한다. CD5 KO는 CART19의 항-종양 효능을 증가시킨다. NALM6 B-ALL 이종이식 모델에서, CD5 KO CART19는, WT CART19와 비교하여, 현저히 높은 종양 제어를 갖는다.
도 23A 및 23B는 CART5 및 CART2가 AML의 20%을 표적화할 수 있다는 발견을 도시한다. 도 23A는 AML에서 CD2 발현을 도시한다. 도 23B는 24시간 사멸 분석으로부터 결과를 나타낸다. CART2 세포를 CD2 + AML 세포와 공배양하고, 24시간에서 유의한 사멸을 나타냈다.
도 24는 CART5가 CLL 및 MCL의 100%를 표적화할 수 있다는 발견을 도시한다. 결과는 CART5 세포가 CD5 + MCL 세포주(Jeko-1 및 Mino)를 인식하여 사멸시킬 수 있다는 것을 나타내는 세포독성 검정으로부터의 것이다.
도 25는 T 세포에서 CD7을 녹-아웃하기 위한 sgRNA의 개발(상부) 및 CD7에 대한 6개의 CAR 작제물의 생성을 도시한다.
도 26은 본원에서 사용되는 Casp9-CAR5 렌티바이러스 작제물을 도시한다. CAR5(C3054), P2A 서열 및 이어서 iCaspase9 자살 유전자(iC9) 또는 iC9-P2A-C3054를 포함하는 2개의 렌티바이러스 작제물을 생성했다. 유전자 발현은 EF1alpha 프로모터에 의해 유도된다. CAR5 작제물은 4-IBB 공자극 및 CD3zeta 신호전달 도메인을 갖는다.
정의
달리 정의되지 않는 한, 본원에서 사용되는 모든 기술적 및 과학적 용어는 본 발명이 속하는 기술분야에서 당업자에 의해 통상적으로 이해되는 것과 동일한 의미를 갖는다. 본원에 기재된 것과 유사하거나 동등한 임의의 방법 및 재료가 본 발명의 시험을 위한 실시에서 사용될 수 있지만, 바람직한 재료 및 방법은 본원에 기재되어 있다. 본 발명을 설명 및 청구하는 경우, 하기의 용어가 사용될 것이다.
또한, 본원에서 사용되는 용어는 특정 실시양태를 설명하기 것을 목적으로 하고, 한정하는 것을 의도하지 않는다는 것을 이해해야 한다.
관사 "a" 및 "an"은 본원에서 관사의 문법적 목적어의 하나 이상(즉, 적어도 하나)를 지칭하기 위해 사용된다. 예로서, "요소"는 하나의 요소 또는 하나 이상의 요소를 의미한다.
양, 시간적 지속기간 등의 측정가능한 값을 지칭할 때에 본원에서 사용되는 "약은 특정 값으로부터 ±20% 또는 ±10%, 보다 바람직하게는 ±5%, 보다 더 바람직하게는 ±1%, 및 더욱 더 바람직하게는 ±0.1%의 변동을 포함하는 것을 의미하고, 이는 이러한 변동이 개시된 방법을 수행하는데 적절하기 때문이다.
본원에서 사용되는 바와 같이, "활성화"는 검출가능한 세포 증식을 유도하기 위해 충분히 자극된 T 세포의 상태를 지칭한다. 활성화는 또한, 유도된 사이토카인 생성, 및 검출가능한 이펙터 기능과 연관될 수 있다. 용어 "활성화된 T 세포"는, 다른 것들 중에서, 세포 분열을 겪는 T 세포를 지칭한다.
본원에 사용된 용어 "항체"는 항원과 특이적으로 결합하는 면역글로불린 분자를 지칭한다. 항체는 천연 공급원 또는 재조합 공급원으로부터 유래하는 무손상 면역글로불린일 수 있고, 무손상 면역글로불린의 면역반응성 부분일 수 있다. 항체는 전형적으로 면역글로불린 분자의 사량체이다. 본 발명의 항체는, 예를 들면, 폴리클로날 항체, 모노클로날 항체, Fv, Fab 및 F(ab)2, 게다가 일본쇄 항체(scFv) 및 인간화 항체를 포함하는 다양한 형태로 존재할 수 있다[참조: Harlow et al., 1999, In: Using Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, NY; Harlow et al., 1989, In: Antibodies: A Laboratory Manual, Cold Spring Harbor, New York; Houston et al., 1988, Proc. Natl. Acad. Sci. USA 85:5879-5883; Bird et al., 1988, Science 242:423-426].
용어 "항체 단편"은 무손상 항체의 일부를 지칭하고, 무손상 항체의 항원 결정 가변 영역을 지칭한다. 항체 단편의 예는 Fab, Fab', F(ab')2 및 Fv 단편, 선형 항체, scFv 항체, 및 항체 단편으로부터 형성된 다중특이적 항체를 포함하지만, 이로 한정되지 않는다.
본원에 사용된 용어 "항체 중쇄"는 자연적으로 발생하는 형태로 모든 항체 분자에 존재하는 2개 유형의 폴리펩티드 쇄를 지칭한다.
본원에서 사용되는 바와 같이, "항체 경쇄"는 자연적으로 발생하는 형태로 모든 항체 분자에 존재하는 2개 유형의 폴리펩티드 쇄 중 더 작은 것을 지칭한다. 카파 및 람다 경쇄는 2개의 주요 항체 경쇄 이소타입을 지칭한다.
본원에 사용된 용어 "합성 항체"는, 예를 들면, 본원에 기재된 바와 같은 박테리오파지에 의해 발현된 항체 등의 재조합 DNA 기술을 사용하여 생성되는 항체를 의미한다. 또한, 상기 용어는, 항체를 코딩하는 DNA 분자의 합성에 의해 생성되고, 이의 DNA 분자가 항체 단백질을 발현하거나, 또는 항체를 특정하는 아미노산 서열을 발현하는 항체를 의미하는 것으로 해석되어야 하고, 여기서 DNA 또는 아미노산 서열은 당해 기술분야에 공지되어 있는 합성 DNA 또는 아미노산 서열 기술을 사용하여 수득되었다.
본원에 사용된 용어 "항원" 또는 "Ag"는 면역 반응을 유발하는 분자로서 정의된다. 이러한 면역 반응은 항체 생산, 또는 특이적 면역학적-경쟁 세포의 활성화, 또는 이들 둘 다를 수반할 수 있다. 당업자는 사실상 모든 단백질 또는 펩티드를 포함하는 임의의 거대분자가 항원으로 작용할 수 있다는 것을 이해할 것이다. 또한, 항원은 재조합 또는 게놈 DNA로부터 유래될 수 있다. 당업자는 면역 반응을 유도하는 단백질을 코딩하는 뉴클레오티드 서열 또는 부분 뉴클레오티드 서열을 포함하는 임의의 DNA가 본원에서 사용되는 용어 "항원"을 코딩한다는 것을 이해할 것이다. 추가로, 당업자는 항원이 유전자의 전장 뉴클레오티드 서열에 의해서만 코딩될 필요가 없다는 것을 이해할 것이다. 본 발명은 하나 이상의 유전자의 부분 뉴클레오티드 서열의 사용을 포함하지만, 이들로 한정되지 않고, 이러한 뉴클레오티드 서열은 다양한 조합으로 배열되어 목적하는 면역 반응을 유발할 수 있다는 것을 용이하게 알 수 있다. 더욱이, 당업자는, 항원이 "유전자"에 의해 코딩될 필요가 전혀 없다는 것을 이해할 것이다. 항원이 합성되거나 생물학적 샘플로부터 유도될 수 있음을 용이하게 알 수 있다. 이러한 생물학적 샘플은 조직 샘플, 종양 샘플, 세포 또는 생물학적 유체를 포함할 수 있지만, 이들로 한정되는 것은 아니다.
본원에 사용된 바와 같이, 용어 "자가"는 이후에 그 개체로 재도입되어야 하는 동일한 개체로부터 유래하는 임의의 물질을 지칭하는 것을 의미한다.
"동종이계"는 동일한 종의 상이한 동물로부터 유래하는 임의의 물질을 지칭한다.
"이종"은 상이한 종의 동물로부터 유래하는 임의의 물질을 지칭한다.
본원에 사용된 용어 "키메라 항원 수용체" 또는 "CAR"은 면역 이펙터 세포 상에서 발현되고, 항원에 특이적으로 결합하도록 조작된 인공 T 세포 수용체를 지칭한다. CAR은 양자 세포 전달에 의한 요법으로서 사용될 수 있다. T 세포는 환자로부터 제거되고, 이들이 특정 형태의 항원에 특이적인 수용체를 발현하도록 변형된다. 일부 실시양태에서, CAR은 선택된 표적, 예를 들면, B 세포 표면 수용체에 대해 특이성을 갖는다. 또한, CAR은 세포내 활성화 도메인, 막관통 도메인 및 종양 관련 항원 결합 영역을 포함하는 세포외 도메인을 포함할 수 있다. 일부 측면에서, CAR은 CD3-제타 막관통 도메인 및 세포내 도메인에 융합된 항-B 세포 결합 도메인을 포함하는 세포외 도메인을 포함한다.
용어 "절단"은 핵산 분자의 골격 등의 공유 결합의 절단 또는 펩티드 결합의 가수분해를 지칭한다. 절단은, 포스포디에스테르 결합의 효소적 또는 화학적 가수분해를 포함하지만 이들로 한정되지 않는 다양한 방법에 의해 개시될 수 있다. 일본쇄 절단 및 이본쇄 절단이 가능하다. 이본쇄 절단은 2개의 상이한 일본쇄 절단 이벤트의 결과로서 발생할 수 있다. DNA 절단은 평활 말단(blunt end) 또는 엇갈린 말단(staggered end)의 생성을 초래할 수 있다. 특정 실시양태에서, 융합 폴리펩티드는 절단된 이본쇄 DNA를 표적화하기 위해 사용될 수 있다.
본원에 사용된 바와 같이, 용어 "보존적 서열 변형"은 아미노산 서열을 함유하는 항체의 결합 특성을 현저하게 영향을 미치거나 변경하지 않는 아미노산 변형을 지칭하는 것으로 의도된다. 이러한 보존적 변형은 아미노산 치환, 부가 및 결실을 포함한다. 변형은 부위-특이적 돌연변이유발(mutagenesis) 및 PCR-매개 돌연변이유발 등의 당해 기술분야에 공지된 표준 기술에 의해 본 발명의 항체에 도입될 수 있다. 보존적 아미노산 치환은 아미노산 잔기가 유사한 측쇄를 갖는 아미노산 잔기로 치환된 것이다. 유사한 측쇄를 갖는 아미노산 잔기의 패밀리(family)는 당해 기술분야에서 정의되어 있다. 이들 패밀리는 염기성 측쇄(예를 들면, 리신, 아르기닌, 히스티딘), 산성 측쇄(예를 들면, 아스파르트산, 글루탐산), 하전되지 않은 극성 측쇄(예를 들면, 글리신, 아스파라긴, 글루타민, 세린, 트레오닌, 티로신, 시스테인, 트립토판), 비극성 측쇄(예를 들면, 알라닌, 발린, 류신, 이소류신, 프롤린, 페닐알라닌, 메티오닌), β-분지 측쇄(예를 들면, 트레오닌, 발린, 이소류신) 및 방향족 측쇄(예를 들면, 티로신, 페닐알라닌, 트립토판, 히스티딘)을 갖는 아미노산을 포함한다. 따라서, 항체의 CDR 영역 내의 하나 이상의 아미노산 잔기는 동일한 측쇄 패밀리로부터 다른 아미노산 잔기로 치환될 수 있고, 변경된 항체는 본원에 기재된 기능성 검정을 사용하여 항원에 결합하는 능력에 대해 시험될 수 있다.
본원에서 사용되는 용어 "공-자극 리간드"는, T 세포 상의 동족 공-자극 분자에 특이적으로 결합하는 항원 제시 세포(예를 들면, aAPC, 수지상 세포, B 세포 등) 상의 분자를 포함하고, 이에 의해, 예를 들면, TCR/CD3 복합체와 펩티드를 로딩한 MHC 분자와의 결합에 의해 제공되는 일차 신호에 추가하여, 증식, 활성화, 분화 등을 포함하지만 이들로 한정되지 않는 T 세포 반응을 매개하는 신호를 제공한다. 공-자극 리간드는 CD7, B7-1(CD80), B7-2(CD86), PD-L1, PD-L2, 4-1BBL, OX40L, 유도성 공자극성 리간드(ICOS-L), 세포간 접착 분자(ICAM), CD30L, CD40, CD70, CD83, HLA-G, MICA, MICB, HVEM, 림포톡신 베타 수용체, 3/TR6, ILT3, ILT4, HVEM, Toll 리간드 수용체와 결합하는 작용제 또는 항체, 및 B7-H3과 특이적으로 결합하는 리간드를 포함하지만, 이들로 한정되지 않는다. 공-자극 리간드는 또한, 특히, CD27, CD28, 4-1BB, 0X40, CD30, CD40, PD-1, ICOS, 림프구 기능 관련 항원-1(LFA-1), CD2, CD7, LIGHT, NKG2C, B7-H3, 및 CD83과 특이적으로 결합하는 리간드(이들로 한정되지 않음)과 같은 T 세포 상에 존재하는 공-자극 분자에 특이적으로 결합하는 항체를 포함한다.
"공-자극 분자"는, 공-자극 리간드와 특이적으로 결합하고, 이에 의해, 증식(이들로 한정되지 않음) 등의, T 세포에 의한 공자극 반응을 매개하는, T 세포 상의 동족 결합 파트너를 지칭한다. 공-자극 분자는 MHC 클래스 I 분자, BTLA 및 톨 리간드 수용체를 포함하지만, 이들로 한정되지 않는다.
본원에서 사용되는 바와 같이, "공-자극성 신호"는 TCR/CD3 결찰 등의 1차 신호와 조합하여, T 세포 증식 및/또는 주요 분자의 상향조절 또는 하향조절을 유도하는 신호를 지칭한다.
"질환"은, 동물이 항상성을 유지할 수 없고, 질환이 개선되지 않는 경우, 동물의 건강이 계속하여 악화되는 동물의 건강 상태이다. 대조적으로, 동물의 "장애"는, 동물이 항상성을 유지할 수 있는 건강 상태이지만, 동물의 건강 상태는 장애가 없는 경우보다 덜 바람직하다. 치료 없이 방치하여도, 장애가 반드시 동물의 건강 상태를 추가로 추가로 저하시키는 것은 아니다.
본원에 사용된 용어 "하향조절"은 하나 이상의 유전자의 유전자 발현의 감소 또는 제거를 지칭한다.
"유효량" 또는 "치료학적 유효량"은 본원에서 상호 교환가능하게 사용되고, 특정 생물학적 결과를 달성하기 위해 또는 치료 또는 예방적 이점을 제공하기 위해 효과적인, 본원에 기재된 바와 같은 화합물, 약제, 재료 또는 조성물의 양을 지칭한다. 이러한 결과는 당해 기술분야에 공지된 임의의 수단에 의해 결정되는 항-종양 활성을 포함할 수 있지만, 이들로 한정되지 않는다.
"코딩하는"은 유전자, 정의된 뉴클레오티드 서열(즉, rRNA, tRNA 및 mRNA) 또는 정의된 아미노산 서열 및 이들로부터 생성되는 생물학적 특성 중의 어느 하나를 갖는 생물학적 프로세스에서 다른 고분자 및 거대분자의 합성을 위한 주형으로서 기능하기 위해, cDNA 또는 mRNA 등의 폴리뉴클레오티드 중의 뉴클레오티드의 특정 서열의 고유 특성을 지칭한다. 따라서, 그 유전자에 대응하는 mRNA의 전사 및 번역이 세포 또는 다른 생물학적 시스템에서 단백질을 생산하는 경우, 그 유전자는 단백질을 코딩한다. 뉴클레오티드 서열이 mRNA 서열과 동일하고 통상의 서열 목록에 제공되는 코딩 가닥(strand), 및 유전자 또는 cDNA의 전사를 위한 주형으로서 사용되는 비-코딩 가닥 둘 다는, 그 유전자 또는 cDNA의 단백질 또는 다른 생성물을 코딩하는 것으로 지칭될 수 있다.
본원에서 사용되는 바와 같이, "내인성"은 생물, 세포, 조직 또는 시스템 내에서 또는 이로부터 생성되는 임의의 물질을 지칭한다.
본원에서 사용되는 바와 같이, 용어 "외인성"은 생물, 세포, 조직 또는 시스템 외부로부터 도입된 또는 그 외부에서 생성된 임의의 물질을 지칭한다.
본원에서 사용되는 용어 "확장"은 T 세포의 수의 증가와 같이, 수를 증가시키는 것을 지칭한다. 한 가지 실시양태에서, 생체외에서 확장된 T 세포는 배양물 중의 최초로 존재하는 수와 비교하여 수가 증가한다. 또 다른 실시양태에서, 생체외에서 확장된 T 세포는 배양물 중의 다른 세포 유형과 비교하여 수가 증가한다. 본원에 사용된 용어 "생체외"는 생물(예를 들면, 인간)로부터 제거되고, 생물의 외부(예를 들면, 배양 접시, 시험 튜브, 또는 생물반응기)에서 증식된 세포를 지칭한다.
본원에 사용된 용어 "발현"은 이의 프로모터에 의해 유도되는 특정 뉴클레오티드 서열의 전사 및/또는 번역으로서 정의된다.
"발현 벡터"는 발현될 뉴클레오티드 서열에 작동적으로 연결된 발현 제어 서열을 포함하는 재조합 폴리뉴클레오티드를 포함하는 벡터를 지칭한다. 발현 벡터는 발현에 충분한 시스-작용 요소를 포함하고; 발현을 위한 다른 요소는 숙주 세포 또는 시험관내 발현 시스템에 의해 공급될 수 있다. 발현 벡터는, 재조합 폴리뉴클레오티드를 도입한 코스미드, 플라스미드(예를 들면, 네이키드 또는 리포좀 내에 함유) 및 바이러스(예를 들면, 센다이 바이러스, 렌티바이러스, 레트로바이러스, 아데노바이러스 및 아데노-관련 바이러스) 등의 당해 기술분야에 공지된 모든 것을 포함한다.
본원에 사용된 바와 같이, "상동성"은 2개의 폴리머 분자 사이, 예를 들면, 2개의 DNA 분자 또는 2개의 RNA 분자 등의 2개의 핵산 분자 사이, 또는 2개의 폴리펩티드 분자 사이의 서브유닛 서열 동일성을 지칭한다. 2개 분자 모두의 서브유닛 위치가 동일한 단량체 서브유닛에 의해 점유되는 경우; 예를 들면, 2개의 DNA 분자 각각의 위치가 아데닌에 의해 점유되는 경우, 이들은 그 위치에서 상동성이다. 2개의 서열 사이의 상동성은, 정합 위치 또는 상동 위치의 수의 직접적 함수이고; 예를 들면, 2개 서열의 위치의 절반(예를 들면, 10개 서브유닛 길이의 폴리머에서 5개 위치)이 상동성인 경우, 2개의 서열은 50% 상동성이고; 위치의 90%(예를 들면, 10개 중의 9개)가 정합하거나 상동성인 경우, 2개의 서열은 90% 상동성이다.
비-인간(예를 들면, 뮤린) 항체의 "인간화" 형태는 키메라 면역글로불린, 면역글로불린 쇄 또는 이들의 단편(예를 들면, Fv, Fab, Fab', F(ab')2 또는 항체의 다른 항원-결합 부분서열)이고, 이들은 비-인간 면역글로불린으로부터 유래하는 최소 서열을 포함한다. 대부분의 경우, 인간화된 항체는 수용자의 상보적-결정 영역(CDR)으로부터의 잔기가, 목적하는 특이성, 친화성 및 능력을 갖는 마우스, 랫트 또는 래빗 등의 비-인간 종(공여체 항체)의 CDR로부터의 잔기에 의해 치환되는 인간 면역글로불린(수용체 항체)이다. 일부 경우에서, 인간 면역글로불린의 Fv 프레임워크 영역(FR) 잔기는 상응하는 비-인간 잔기로 치환된다. 또한, 인간화 항체는 수용자 항체에서도, 수입된 CDR 또는 프레임워크 서열에서도 발견되지 않는 잔기를 포함할 수 있다. 이러한 변형은 항체 성능을 추가로 개선하고 최적화하도록 수행된다. 일반적으로, 인간화 항체는 적어도 하나, 전형적으로 2개의 가변 도메인의 전부 또는 실질적으로 전부를 포함하고, 여기서 CDR 영역의 전부 또는 실질적으로 전부는 비-인간 면역글로불린의 영역에 대응하고, FR 영역의 전부 또는 실질적으로 전부는 인간 면역글로불린 서열의 것이다. 인간화 항체는 또한 최적으로는 면역글로불린 불변 영역(Fc)의 적어도 일부, 전형적으로는 인간 면역글로불린의 것들을 포함한다. 상세에 대해서는 문헌[참조: Jones et al., Nature, 321: 522-525, 1986; Reichmann et al., Nature, 332: 323-329, 1988; Presta, Curr. Op. Struct. Biol., 2: 593-596, 1992]을 참조한다.
"완전 인간"은, 분자 전체가 인간 유래이거나 인간 형태의 항체와 동일한 아미노산 서열로 이루어진, 항체 등의 면역글로불린을 지칭한다.
본원에서 사용되는 바와 같이, "동일성"은, 2개의 폴리머 분자 사이, 특히 2개의 아미노산 분자 사이, 예를 들면, 2개의 폴리펩티드 분자 사이의 서브유닛 서열 동일성을 지칭한다. 2개의 아미노산 서열이 동일한 위치에서 동일한 잔기를 갖는 경우, 예를 들면, 2개의 폴리펩티드 분자 각각의 위치가 아르기닌에 의해 점유되는 경우, 이들은 그 위치에서 동일하다. 2개의 아미노산 서열이 정렬시에 동일한 위치에서 동일한 잔기를 갖는 동일성 또는 정도는 종종 백분율로서 표시된다. 2개의 아미노산 서열 사이의 동일성은 정합 위치 또는 동일한 위치의 수의 직접 함수이고; 예를 들면, 2개 서열의 위치의 절반(예를 들면, 10개 아미노산 길이의 폴리머에서 5개 위치)이 동일한 경우, 2개의 서열은 50% 동일하고; 위치의 90%(예를 들면, 10개 중의 9개)가 정합 또는 동일한 경우, 2개의 아미노산 서열은 90% 동일하다.
본원에 사용된 용어 "면역글로불린" 또는 "Ig"는 항체로서 기능하는 단백질의 클래스로서 정의된다. B 세포에 의해 발현된 항체는 때때로 BCR(B 세포 수용체) 또는 항원 수용체로서 지칭된다. 이 클래스의 단백질에 포함되는 5개의 멤버는 IgA, IgG, IgM, IgD 및 IgE이다. IgA는, 타액, 눈물, 모유, 위장관 분비물 및 호흡기 및 비뇨생식기의 점액 분비물 등의 신체 분비물에 존재하는 1차 항체이다. IgG는 가장 일반적인 순환 항체이다. IgM은 대부분의 대상체에서 1차 면역 반응에서 생성된 주요 면역글로불린이다. 이는, 응집, 보체 결합 및 다른 항체 반응에서 가장 효율적인 면역글로불린이고, 세균 및 바이러스에 대한 방어에서 중요하다. IgD는, 공지된 항체 기능을 갖지 않는 면역글로불린이지만, 항원 수용체로서 기능할 수 있다. IgE는, 알레르겐에 대한 노출시 비만 세포 및 호염기구로부터 매개인자의 방출을 유발함으로써 즉시형 과민증을 매개하는 면역글로불린이다.
본원에 사용된 용어 "면역 반응"은, 림프구가 항원성 분자를 외래물질로서 인식하고, 항원의 형성을 유도하고/하거나 림프구를 활성화하여 항원을 제거할 때에 발생하는 항원에 대한 세포 반응으로서 정의된다.
"면역학적 유효량" 또는 "치료학적 양"을 나타내는 경우, 투여되는 본 발명의 조성물의 정확한 양은 연령, 체중, 종양 크기, 감염 또는 전이의 정도, 및 환자(대상체)의 상태를 고려하여 의사 또는 연구자에 의해 결정될 수 있다.
본원에서 사용되는 바와 같이, "설명 자료"는, 본 발명의 조성물 및 방법의 유용성을 전달하기 위해 사용될 수 있는 출판물, 기록, 다이어그램 또는 기타 임의의 발현 매체를 포함한다. 본 발명의 키트의 설명 자료는, 예를 들면, 본 발명의 핵산, 펩티드 및/또는 조성물을 함유하는 용기에 부착되거나, 핵산, 펩티드를 함유하는 용기와 함께 출하될 수 있다. 대안적으로, 설명 자료 및 화합물이 수령자에 의해 공동으로 사용되는 것을 의도하여, 설명 자료는 용기와 별개로 출하될 수 있다.
"단리된"은, 자연의 상태로부터 변화되거나 제거된 것을 의미한다. 예를 들면, 살아있는 동물에 자연적으로 존재하는 핵산 또는 펩티드는 "단리"되지 않고, 그 천연 상태의 공존 물질로부터 부분적으로 또는 완전히 분리된 동일한 핵산 또는 펩티드는 "단리"된다. 분리된 핵산 또는 단백질은 실질적으로 정제된 형태로 존재할 수 있거나, 예를 들면, 숙주 세포 등의 비-천연 환경에 존재할 수 있다.
본원에 사용된 용어 "녹다운(knockdown)"은 하나 이상의 유전자의 유전자 발현의 감소를 지칭한다.
본원에 사용된 용어 "녹-아웃"은 하나 이상의 유전자의 유전자 발현의 제거를 지칭한다.
본원에서 사용되는 "렌티바이러스"는 레트로비리대(Retroviridae) 과의 속을 지칭한다. 렌티바이러스는 비분열 세포를 감염시킬 수 있다는 점에서 레트로바이러스 중에서도 독특하고; 이들은 숙주 세포의 DNA에 대량의 유전 정보를 전달할 수 있기 때문에, 유전자 전달 벡터의 가장 효율적 방법 중 하나이다. HIV, SIV 및 FIV는 모두 렌티바이러스의 예이다. 렌티바이러스로부터 유래하는 벡터는 생체내에서 유의한 수준의 유전자 전달을 달성하기 위한 수단을 제공한다.
본원에 사용된 용어 "한정 독성"은, 시험관내 또는 생체내에서 건강한 세포, 비-종양 세포, 비-발병 세포, 비-표적 세포 또는 이러한 세포의 모집단에 대한 실질적으로 부정적인 생물학적 효과, 항-종양 효과, 또는 실질적으로 부정적인 생리학적 증상의 결여를 나타내는 본 발명의 펩티드, 폴리펩티드, 세포 및/또는 항체를 지칭한다.
본원에 사용된 용어 "변형된"은, 본 발명의 분자 또는 세포의 변화된 상태 또는 구조를 의미한다. 분자는 화학적, 구조적 및 기능적으로 포함하는 다수의 방법으로 변형될 수 있다. 세포는 핵산의 도입을 통해 변형될 수 있다.
본원에서 사용되는 용어 "조절"은, 치료 또는 화합물의 부재하에 대상체에서 반응 수준과 비교하여 및/또는 그렇지 않으면 동일하지만 무처리된 대상체에서 반응의 수준과 비교하여, 대상체에서 반응의 수준에서의 검출가능한 증가 또는 감소를 매개하는 것을 의미한다. 이 용어는 천연 신호 또는 반응에 섭동 및/또는 영향을 미치고, 이에 의해 대상체, 바람직하게는 인간에서 유익한 치료 반응을 매개하는 것을 포함한다.
본 발명의 문맥에서, 일반적으로 존재하는 핵산 염기에 대한 하기의 약어가 사용된다. "A"는 아데노신을 지칭하고, "C"는 시토신을 지칭하고, "G"는 구아노신을 지칭하고, "T"는 티미딘을 지칭하고, "U"는 우리딘을 지칭한다.
달리 명시되지 않는 한, "아미노산 서열을 코딩하는 뉴클레오티드 서열"은, 서로 축중된 버젼(degenerate version)이고 동일한 아미노산 서열을 코딩하는 모든 뉴클레오티드 서열을 포함한다. 단백질 또는 RNA를 코딩하는 문구 뉴클레오티드 서열은 또한, 단백질을 코딩하는 뉴클레오티드 서열이 일부 버젼에서 인트론(들)을 포함하는 정도까지 인트론을 포함할 수 있다.
용어 "작동적으로 연결된(operably linked)"은 조절 서열 및 이종성 핵산 서열 사이의 기능적 결합을 지칭하고, 이는 후자의 발현을 초래한다. 예를 들면, 제1 핵산 서열이 제2 핵산 서열과 기능적 관계에 있는 경우, 제1 핵산 서열은 제2 핵산 서열과 작동적으로 연결된다. 예를 들면, 프로모터가 코딩 서열의 전사 또는 발현에 영향을 미치는 경우, 프로모터는 코딩 서열에 작동적으로 연결된다. 일반적으로, 작동적으로 연결된 DNA 서열은 연속적이고, 2개의 단백질 코딩 영역을 결합하는데 필요한 경우, 동일한 판독 프레임 내에 존재한다.
용어 "과발현된" 종양 항원 또는 종양 항원의 "과발현"은, 해당 조직 또는 기고나의 정상 세포에서의 발현 수준에 대하여, 환자의 특정 조직 또는 기관 내의 고형 종양과 같은 질환 영역으로부터의 세포에서 종양 항원의 비정상적 발현 수준을 나타내는 것을 의도한다. 고형 종양 또는 종양 항원의 과발현을 특징으로 하는 혈액 악성종양을 갖는 환자는 당해 기술분야에서 공지된 표준 검정에 의해 결정될 수 있다.
면역원성 조성물의 "비경구" 투여는, 예를 들면, 피하(sc), 정맥내(iv), 근육내(im) 또는 흉골내 주입 또는 주입 기술을 포함한다.
본원에 사용된 용어 "폴리뉴클레오티드"는 뉴클레오티드의 쇄로서 정의된다. 추가로, 핵산은 뉴클레오티드의 폴리머이다. 따라서, 본원에 사용된 핵산 및 폴리뉴클레오티드는 상호 교환가능하다. 당업자는, 핵산이 폴리뉴클레오티드이고, 이를 가수분해하여 단량체성 "뉴클레오티드"로 할 수 있다는 일반적 지식을 갖는다. 단량체 뉴클레오티드는 뉴클레오사이드로 가수분해될 수 있다. 본원에 사용된 폴리뉴클레오티드는, 이들로 한정되지 않지만, 통상의 클로닝 기술 및 PCTTM 등을 사용하는 재조합 수단, 즉 재조합 라이브러리 또는 세포로부터의 핵산 서열의 클로닝을 포함하는, 당해 기술분야에서 이용가능한 임의의 수단 및 합성 수단에 의해 수득되는 모든 핵산 서열을 포함한다.
본원에 사용된 바와 같이, 용어 "펩티드", "폴리펩티드", 및 "단백질"은 상호 교환가능하게 사용되고, 펩티드 결합에 의해 공유결합된 아미노산 잔기로 구성된 화합물을 지칭한다. 단백질 또는 펩티드는 적어도 2개의 아미노산을 함유해야 하고, 단백질 또는 펩티드의 서열을 포함할 수 있는 아미노산의 최대 수에 제한은 없다. 폴리펩티드는 펩티드 결합에 의해 서로 결합된 2개 이상의 아미노산을 포함하는 임의의 펩티드 또는 단백질을 포함한다. 본원에서 사용되는 바와 같이, 이 용어는, 예를 들면, 당해 기술분야에 일반적으로 펩티드, 폴리펩티드 및 올리고머로도 불리우는 단쇄, 및 당해 기술분야에서 일반적으로 단백질로 불리우는 보다 긴 쇄의 둘 다를 지칭하고, 다수의 종류가 있다. "폴리펩티드"는, 예를 들면, 생물학적으로 활성인 단편, 실질적으로 상동성인 폴리펩티드, 올리고펩티드, 동종이량체, 헤테로이량체, 폴리펩티드의 변이체, 변형된 폴리펩티드, 유도체, 유사체, 융합 단백질 등을 포함할 수 있다. 폴리펩티드는 천연 펩티드, 재조합 펩티드, 합성 펩티드, 또는 이들의 조합을 포함한다.
본원에 사용된 용어 "프로모터"는 폴리뉴클레오티드 서열의 특정 전사를 개시하는데 필요한, 세포의 합성 기구에 의해 인식되거나, 또는 도입된 합성 기구에 의해 인식되는 DNA 서열로서 정의된다.
"신호 전달 경로"는 세포의 한 부분으로부터 세포의 다른 부분으로 신호의 전달에서 역할을 하는 다양한 신호전달 분자간의 생화학적 관계를 지칭한다. 어구"세포 표면 수용체"는 세포의 원형질막을 가로질러 신호를 수신하고, 신호를 전달할 수 있는 분자 및 분자의 복합체를 포함한다.
항체와 관련하여 본원에 사용된 용어 "특이적으로 결합하는"은, 특정 항원을 인식하지만, 샘플 중의 다른 분자를 실질적으로 인식하거나 결합하지 않는 항체를 의미한다. 예를 들면, 하나의 종으로부터 항원에 특이적으로 결합하는 항체는 또한 하나 이상의 종으로부터 그 항원에 결합할 수 있다. 그러나, 이러한 이종간 반응성은 그 자체가 항체의 특이적 분류를 변경하지 않는다. 또 다른 예에서, 항원에 특이적으로 결합하는 항체는 또한 상이한 대립유전자 형태의 항원에 결합할 수 있다. 그러나, 이러한 교차 반응성은 그 자체가 항체의 특이적 분류를 변경하지 않는다. 일부 경우, 용어 "특이적 결합" 또는 "특이적으로 결합하는"은, 항체, 단백질, 또는 펩티드와 제2 화학종과의 상호작용과 관련하여 사용될 수 있고, 상호작용이 화학 종의 특정 구조(예를 들면, 항원 결정기 또는 에피토프)의 존재에 의존하는 것을 의미하고; 예를 들면, 항체는 일반적으로 단백질이 아닌 특정 단백질 구조를 인식하여 결합한다. 항체가 에피토프 "A"에 특이적인 경우, 표지된 "A" 및 항체를 함유하는 반응에서, 에피토프 A(또는 유리의 비표지된 A)를 함유하는 분자의 존재는 항체에 결합된 표지된 A의 양을 감소시킨다.
용어 "자극"은, 자극성 분자(예를 들면, TCR/CD3 복합체)와 그 동족 리간드와의 결합에 의해 유도된 1차 반응을 의미하고, 이에 의해, 이들로 한정되지 않지만, TCR/CD3 복합체를 통한 신호 전달 등의 신호 전달 이벤트를 매개한다. 자극은 TGF-β의 하향조절 및/또는 세포골격 구조의 재편성 등, 특정 분자의 발현 변화를 매개할 수 있다.
본원에서 사용되는 용어 "자극 분자"는 항원 제시 세포 상에 존재하는 동족체의 자극 리간드와 특이적으로 결합하는 T 세포 상의 분자를 의미한다.
본원에서 사용되는 바와 같은 "자극성 리간드"는, 항원 제시 세포(예를 들면, aAPC, 수지상 세포, B-세포 등)에 존재하는 경우, 동족체 결합 파트너(예를 들면, 본원에서 "자극 분자"로서 지칭됨)에 특이적으로 결합할 수 있는 리간드를 의미하고, 이에 의해 활성화, 면역 반응의 개시, 증식 등을 포함하지만 이들로 한정되지 않는 T 세포에 의한 1차 반응을 매개한다. 자극 리간드는 당해 기술분야에 널리 공지되어 있고, 특히 펩티드, 항-CD3 항체, 수퍼작용제 항-CD28 항체, 및 수퍼작용제 항-CD2 항체가 로딩된 MHC 클래스 I 분자를 포함한다.
용어 "대상체"는 면역 반응이 유발될 수 있는 살아있는 생물(예를 들면, 포유동물)을 포함하는 것으로 의도된다. 본원에서 사용되는 바와 같은, "대상체" 또는 "환자"는 인간 또는 비-인간 포유동물일 수 있다. 비-인간 포유동물은, 예를 들면, 양, 소, 돼지, 개, 고양이 및 뮤린 포유동물 등의 가축 및 애완동물을 포함한다. 바람직하게는, 상기 대상체는 인간이다.
본원에 사용된 바와 같이, "실질적으로 정제된" 세포는 다른 세포 유형을 본질적으로 포함하지 않는 세포이다. 실질적으로 정제된 세포는 또한 자연 발생 상태에서 통상 관련되어 있는 다른 세포 유형으로부터 분리된 세포를 의미한다. 일부 예에서, 실질적으로 정제된 세포의 모집단은 세포의 균질한 모집단을 지칭한다. 다른 예에서, 이 용어는 이들이 자연 상태에서 자연적으로 연관되어 있는 세포로부터 분리된 세포를 단순히 의미한다. 일부 실시양태에서, 세포는 시험관내 배양된다. 다른 실시양태에서, 세포는 시험관내에서 배양되지 않는다.
"표적 부위" 또는 "표적 서열"은, 결합이 발생하기에 충분한 조건하에서 결합 분자가 특이적으로 결합할 수 있는 핵산의 일부를 정의하는 게놈 핵산 서열을 지칭한다.
본원에 사용된 바와 같이, 용어 "T 세포 수용체" 또는 "TCR"은 항원 제시에 응답하여 T 세포의 활성화에 관여하는 막 단백질의 복합체를 지칭한다. TCR은 주요 조직적합성 복합체 분자에 결합된 항원을 인식하는 역할을 한다. TCR은 α(a) 및 β(b) 쇄의 헤테로이량체로 구성되지만, 일부 세포에서 TCR은 감마 및 델타(γ/δ) 쇄로 구성되어 있다. TCR은 알파/베타 및 감마/델타 형태로 존재할 수 있고, 이는 구조적으로 유사하지만 해부학적 위치 및 기능이 상이하다. 각 쇄는 가변 도메인 및 불변 도메인의 2개의 세포외 도메인으로 구성된다. 일부 실시양태에서, TCR은, 예를 들면, 헬퍼 T 세포, 세포독성 T 세포, 메모리 T 세포, 조절성 T 세포, 자연 살해 T 세포 및 감마 델타 T 세포를 포함하는, TCR을 포함하는 임의의 세포 상에서 변형될 수 있다.
본원에 사용된 용어 "치료적"은 치료 및/또는 예방을 의미한다. 치료 효과는 질병 상태의 억제, 관해 또는 근절에 의해 수득된다.
본원에 사용된 용어 "형질감염된" 또는 "형질전환된" 또는 "형질도입된"은 외인성 핵산이 숙주 세포 내로 전달 또는 도입되는 프로세스를 지칭한다. "형질감염"되거나 또는 "형질전환"되거나 "형질도입"된 세포는 외인성 핵산으로 형질감염된, 형질전환된 또는 형질도입된 것이다. 세포는 1차 대상 세포 및 이의 자손을 포함한다.
본원에서 사용되는 용어로서 질환을 "치료하는"은 대상체가 경험하는 질환 또는 장애의 적어도 하나의 징후 또는 증상의 빈도 또는 중증도를 감소시키는 것을 의미한다.
본원에서 사용되는 문구 "전사 제어하에" 또는 "작동적으로 연결된"은 프로모터가 RNA 폴리머라제에 의한 전사의 개시 및 폴리뉴클레오티드의 발현을 제어하기 위해 폴리뉴클레오티드에 대해 정확한 위치 및 배향에 있는 것을 의미한다.
"벡터"는, 단리된 핵산을 포함하고, 단리된 핵산을 세포 내부로 전달하기 위해 사용될 수 있는 물질의 조성물이다. 선형 폴리뉴클레오티드, 이온성 또는 양친매성 화합물과 관련된 폴리뉴클레오티드, 플라스미드 및 바이러스를 포함하지만 이들로 한정되지 않는 다수의 벡터가 당해 기술분야에 공지되어 있다. 따라서, 용어 "벡터"는 자율적으로 복제하는 플라스미드 또는 바이러스를 포함한다. 또한, 상기 용어는, 예를 들면, 폴리리신 화합물, 리포좀 등과 같은 세포 내로의 핵산의 전달을 용이하게 하는 비-플라스미드 및 비-바이러스 화합물을 포함하는 것으로 해석되어야 한다. 바이러스 벡터의 예는 센다이 바이러스 벡터, 아데노바이러스 벡터, 아데노-관련 바이러스 벡터, 레트로바이러스 벡터, 렌티바이러스 벡터 등을 포함하지만, 이들로 한정되지 않는다.
범위: 본 개시 전반에 걸쳐, 본 발명의 다양한 양태들이 범위 형식으로 제시될 수 있다. 범위 형식에서의 설명은 단지 편의성 및 간결성을 위한 것일 뿐이고, 본 발명의 범위에 대한 유연성이 없는 제한으로서 해석되어서는 안된다는 것을 이해해야 한다. 따라서, 범위의 설명은 그 범위 내의 개별 수치 값뿐만 아니라, 모든 가능한 하위 범위를 구체적으로 개시해야 하는 것으로 간주되어야 한다. 예를 들면, 1 내지 6 등의 범위의 설명은 1 내지 3, 1 내지 4, 1 내지 5, 2 내지 4, 2 내지 6, 3 내지 6 등의 하위 범위, 게다가 그 범위 내의 개별 번호, 예를 들면, 1, 2, 2.7, 3, 4, 5, 5.3 및 6를 구체적으로 개시하고 있는 것으로 간주되어야 한다. 이는 범위의 폭과 관계없이 적용된다.
기재
본 개시는, T 세포 신생물을 표적화하는 3개의 키메라 항원 수용체(CAR), 게다가 건강한 T 세포의 동족살인을 방지하는 방법을 기재한다. T 세포 림프종 및 백혈병은 T 세포 전구세포 또는 분화된 T 세포로부터 유래하는 침습성 신생물이다. 성숙한 또는 말초 T-세포 림프종은 모든 비-호지킨 림프종의 10%-15%, 또는 미국에서 연간 7,000 내지 10,000 사례를 점유한다. T 세포 림프종 및 백혈병은 예후가 불량하고, 이용가능한 치료법이 거의 없다. CART 요법은 B-세포 신생물에 대한 유효성을 입증하였지만, 현재까지 키메라 항원 수용체(CAR) T 세포의 성공을 T-세포 악성종양까지 확장하는 것은, 대부분의 표적 항원이 정상 및 악성 세포 사이에서 공유되어 CAR T 세포 동족살인을 유도하기 때문에, 문제가 있었다. 본원에서는 CRISPR-Cas 편집을 사용하여, 건강한 T 세포로부터 표적 항원을 제거하고, CART 세포 치료로부터 이를 보호하고, T 세포 구획의 제거로부터 발생하는 잠재적으로 치명적인 치명적인 면역 억제를 제거한다.
특정 실시양태에서, CAR은 T 세포 항원 CD2, CD5 및 CD7을 표적화한다. 특정 실시양태에서, 건강한 T 세포에서 CD2, CD5 또는 CD7 표적의 CRISPR-Cas 녹-아웃은 제조 및 후속 CART 요법 동안 건강한 T 세포의 사멸을 방지한다.
치료 방법
본 발명은, 이를 필요로 하는 대상체에서 T 세포 림프종 또는 T 세포 백혈병을 치료하는 방법을 포함한다. 또 다른 측면에서, 본 발명은 이를 필요로 하는 대상체에서 CAR T 세포 동족살인을 방지하기 위한 방법을 포함한다.
특정 실시양태에서, 상기 방법은, 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 CD2를 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD2 유전자는 녹-아웃되어 있는 단계를 포함한다.
특정 실시양태에서, 상기 방법은, CAR을 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 CD5를 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD5 유전자는 녹-아웃되어 있는 단계를 포함한다.
특정 실시양태에서, 상기 방법은, CAR을 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 CD7을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD7 유전자는 녹-아웃되어 있는 단계를 포함한다.
특정 실시양태에서, 상기 방법은, 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, 상기 CAR은 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는 단계, 및 제2 변형 세포를 대상체에게 투여하는 단계로서, 상기 내인성 CD5 유전자는 녹-아웃되어 있는 단계를 포함한다.
특정 실시양태에서, 상기 방법은 키메라 항원 수용체(CAR)를 포함하는 변형된 세포를 대상체에게 투여하는 것을 포함하고, 여기서 상기 CAR은 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD5 유전자는 상기 세포에서 녹-아웃되어 있다.
본원에 개시된 방법의 다양한 실시양태에서, 대상체는 본원에 개시된 임의의 CAR을 투여될 수 있다. CAR은 당업자에게 공지된 임의의 종양 관련 항원(TAA) 또는 종양 특이적 항원(TSA)에 특이적일 수 있다.
특정 실시양태에서, CAR은 서열번호 31-36, 43-48, 53-58, 65-70, 83-88 및 95-100으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함한다. 특정 실시양태에서, CAR은, 서열번호 29, 41, 51, 63, 75, 81 및 93으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역 및/또는 서열번호 30, 42, 52, 64, 76, 82 및 94로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는 항원 결합 도메인을 포함한다. 특정 실시양태에서, CAR은, 서열번호 27, 28, 39, 40, 50, 61, 62, 73, 74, 79, 80, 91 및 92로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함한다.
특정 실시양태에서, 대상체는 CAR을 투여하고, 여기서 CAR은 서열번호 1 내지 13 중 어느 하나에 의해 코딩되는 핵산 서열을 포함한다. 특정 실시양태에서, CAR은 서열번호 25, 26, 37, 38, 49, 59, 60, 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함한다.
특정 실시양태에서, 제1 및 제2 변형 세포는 T 세포이다. 특정 실시양태에서, 암은 T 세포 림프종 또는 T 세포 백혈병을 포함한다. 본 발명의 조성물 및 방법에 의해 치료될 수 있는 암의 종류는 비-호지킨(non-Hodgkins) 림프종 및 말초 T-세포 림프종(PTCL), 혈관면역아구성 T-세포 림프종(AITL), 미분화 림프종 키나제(ALK)-음성 미분화 거대 세포 림프종(ALCL, ALK-), 천연 킬러/T-세포 림프종(NKTCL), 성인 T-세포 백혈병/림프종(ATLL), ALCL ALK+, 장병증형 T-세포, 간세포 T-세포, 피하 지방조직염-유사 및 미분류 PTCL을 포함하지만, 이들로 한정되지 않는다.
특정 실시양태에서, 내인성 유전자(예를 들면, CD2, CDS 및 CD7)는 CRISPR/Cas9 방법을 사용하여 녹-아웃된다. 특정 실시양태에서, CRISPR/Cas9 방법은 CD2, CD5 및/또는 CD7을 표적화하는 sgRNA를 이용한다. 특정 실시양태에서, sgRNA는 서열번호 22 내지 24로 이루어진 그룹으로부터 선택된 뉴클레오티드 서열을 포함한다.
특정 실시양태에서, 본 발명의 CAR은 자살 유전자를 추가로 포함한다. 자살 유전자의 하나의 비제한적인 예는 유도성 카스파제 9 유전자(iCaspase9, iCasp9 또는 iC9)이다. iCaspase9 자살 유전자 시스템은 인간 카스파제 9와 변형된 인간 FK-결합 단백질의 융합에 기초하고, 작은 분자 약물(예를 들면, AP1903 등)을 사용하여 조건부 이량체화를 가능하게 한다. 합성 이량체화 약물에 노출되는 경우, iCaspase9는 활성화되어 이 작제물(예를 들면, CAR T 세포)을 발현하는 세포의 신속한 세포자멸사(apoptosis)를 유도한다[참조: Zhou et al. (2015) Methods Mol Biol. 1317: 87-105]. 자살 유전자의 또 다른 예는 HSV-tk 유전자이다[참조: Bordingnon et al. (1995) Human Gene Therapy, vol. 6, no.6., pp 813-819]. HSV-tk 유전자는 CAR T 세포에서 공발현될 수 있고, 발현하면, 무독성 프로드러그 GCV를 GCV-트리포스페이트로 전환시켜 DNA 복제를 중단시킴으로써 세포 사멸을 유도한다.
조성물
본 발명의 한 가지 측면은, 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 CD2을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD2 유전자는 녹-아웃되어 있다.
본 발명의 다른 측면은, CAR을 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 CD5을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD5 유전자는 녹-아웃되어 있다.
본 발명의 또 다른 측면은, CAR을 포함하는 제1 변형 세포 및 제2 변형 세포를 포함하는 조성물을 포함하고, 여기서 상기 CAR은 CD7을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고, 상기 내인성 CD7 유전자는 녹-아웃되어 있다.
특정 실시양태에서, CAR은 서열번호 1-13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩된다. 특정 실시양태에서, 내인성 유전자는 CRISPR/Cas 시스템을 사용하여 녹-아웃되어 있다. 특정 실시양태에서, CRISPR/Cas9 시스템은 서열번호 22 내지 24로 이루어진 그룹으로부터 선택된 핵산 서열을 포함하는 gRNA를 포함한다.
본 발명은 또한 본 발명의 조성물 및 약제학적으로 허용되는 담체를 포함한다.
키메라 항원 수용체(CAR)
본 발명은 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는 키메라 항원 수용체(CAR)를 제공한다. 특정 실시양태에서, 본 발명은 CD2에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는 CAR을 포함한다.
항원 결합 도메인
한 가지 실시양태에서, 본 발명의 CAR은 항원 결합 도메인으로 지칭되는 표적 특이적 결합 요소를 포함한다. 항원 결합 도메인의 선택은 표적 세포의 표면을 정의하는 리간드의 종류 및 개수에 의존한다. 예를 들면, 항원 결합 도메인은 특정 질환 상태(예를 들면, T 세포 림프종 또는 백혈병)와 연관된 표적 세포 상의 세포 표면 마커로서 작용하는 리간드를 인식하도록 선택될 수 있다.
한 가지 실시양태에서, 본 발명의 CAR은 종양 항원을 표적화하도록 조작될 수 있다. 본원에 논의된 항원은 단지 예로서 포함된다. 이 목록은 배타적인 것으로 의도되지 않으며, 추가의 예는 당업자에게 용이하게 명백할 것이다. 종양 항원은 면역 반응, 특히 T-세포 매개된 면역 반응을 유발하는 종양 세포에 의해 생성되는 단백질이다. 본 발명의 항원 결합 도메인의 선택은 치료될 암의 특정 유형에 의존할 것이다. 종양 항원은 당해 기술분야에 널리 공지되어 있고, 예를 들면, 신경교종 관련 항원, 암배아 항원(CEA), β-인간 융모막 고나도트로핀, 알파페토단백질(AFP), 렉틴-반응성 AFP, 티로글로불린, RAGE-1, MN-CA IX, 인간 텔로머라제 역전사효소, RU1, RU2(AS), 장의 카복실 에스테라제, mut hsp70-2, M-CSF, 프로스타제, 전립선-특이적 항원(PSA), PAP, NY-ESO-1, LAGE-1a, p53, 프로스테인, PSMA, Her2/neu, 서비빈 및 텔로머라제, 전립선-암종 종양 항원-1(PCTA-1), MAGE, ELF2M, 호중구 엘라스타아제, 에프린B2, CD22, 인슐린 성장 인자(IGF)-I, IGF-II, IGF-I 수용체 및 메소텔린을 포함하지만, 이들로 한정되지 않는다.
본 발명에서 언급되는 종양 항원의 유형은 또한 종양 특이적 항원(TSA) 또는 종양 관련 항원(TAA)일 수 있다. TSA는 종양 세포에 고유한 것이고, 체내의 다른 세포 상에서는 발생하지 않는다. TAA 관련 항원은 종양 세포에 고유한 것이 아니고, 그 대신에, 항원에 대한 면역 관용의 상태를 유발하지 않는 조건하에서 정상 세포 상에서 발현된다. 종양 상에서의 항원의 발현은 면역 시스템이 항원에 반응하도록 하는 조건하에서 일어날 수 있다. TAA는 면역 시스템이 미성숙 및 응답할 수 없는 태아의 발달 중에 정상 세포에서 발현되는 항원일 수 있거나, 정상 세포에서는 통상 매우 낮은 수준으로 존재하지만, 종양 세포에서는 훨씬 더 높은 수준으로 발현되는 항원일 수 있다.
TSA 또는 TAA 항원의 비제한적 예는 하기를 포함한다:
MART-l/MelanA(MART-I), gp100(Pmel 17), 티로시나제(tyrosinase), TRP-1, TRP-2 등의 분화 항원, 및 MAGE-1, MAGE-3, BAGE, GAGE-1, GAGE-2, p15 등의 종양-특이적 다계통 항원; CEA 등의 과발현된 배성 항원; p53, Ras, HER-2/neu 등의 과발현된 암유전자 및 돌연변이 종양-억제 유전자; 염색체 전좌에 기인하는 독특한 종양 항원, 예컨대, BCR-ABL, E2A-PRL, H4-RET, IGH-IGK, MYL-RAR; 및 엡스타인 바르 바이러스 항원 EBVA 및 인간 파필로마바이러스(HPV) 항원 E6 및 E7 등의 바이러스 항원. 다른 거대 단백질-기반 항원은 TSP-180, MAGE-4, MAGE-5, MAGE-6, RAGE, NY-ESO, pl85erbB2, pl80erbB-3, c-met, nm-23H1, PSA, TAG-72, CA 19-9, CA 72-4, CAM 17.1, NuMa, K-ras, β-카테닌, CDK4, Mum-1, p15, p16, 43-9F, 5T4, 791Tgp72, α-페토단백질, β-HCG, BCA225, BTAA, CA 125, CA 15-3/CA 27.29 /BCAA, CA 195, CA 242, CA-50, CAM43, CD68/P1, CO-029, FGF-5, G250, Ga733/EpCAM, HTgp-175, M344, MA-50, MG7-Ag, MOV18, NB/70K, NY-CO-1, RCAS1, SDCCAG16, TA-90/Mac-2 결합 단백질/사이클로필린 C-관련 단백질, TAAL6, TAG72, TLP 및 TPS를 포함한다.
표적화되는 목적하는 항원에 따라, 본 발명의 CAR은 목적하는 항원 표적에 특이적인 적절한 항원 결합 도메인을 포함하도록 조작될 수 있다. 예를 들면, CD2가 표적화되는 목적하는 항원인 경우, CD2에 대한 항체를 본 발명의 CAR로 도입하기 위한 항원 결합 도메인으로서 사용할 수 있다.
특정 실시양태에서, CAR의 항원 결합 도메인은 CD2를 표적화한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 CD5를 표적화한다. 특정 실시양태에서, CAR의 항원 결합 도메인은 CD7을 표적화한다.
일부 실시양태에서, 본 발명의 CAR에서 항원 결합 도메인은 항-CD2 scFV이다. 일부 실시양태에서, 본 발명의 CAR에서 항원 결합 도메인은 항-CD5 scFV이다. 일부 실시양태에서, 본 발명의 CAR에서 항원 결합 도메인은 항-CD7 scFV이다. 일부 실시양태에서, 항원 결합 도메인은 항-CD2 항체이다. 일부 실시양태에서, 항원 결합 도메인은 항-CD5 항체이다. 일부 실시양태에서, 항원 결합 도메인은 항-CD7 항체이다.
특정 실시양태에서, 항원 결합 도메인은 3개의 중쇄 상보성 결정 영역(HCDR)을 포함하는 중쇄 가변 영역, 및 3개의 경쇄 상보성 결정 영역(LDCR)을 포함하는 경쇄 가변 영역을 포함한다.
특정 실시양태에서, 본 발명은 CD2에 결합할 수 있는 항원 결합 도메인을 포함하는 CAR을 포함하고, 여기서 항원 결합 도메인은 서열번호 31, 32, 33, 34, 35, 36, 43, 44, 45, 46, 47, 48, 53, 54, 55, 56, 57, 58, 65, 66, 67, 68, 69 또는 70 중 어느 하나의 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함한다.
특정 실시양태에서, CAR은 CD2에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 HCDR1은 서열번호 31의 아미노산 서열을 포함하고, HCDR2는 서열번호 33의 아미노산 서열을 포함하고, LCDR1은 서열번호 34의 아미노산 서열을 포함하고, LCDR2는 서열번호 35의 아미노산 서열을 포함하고, LCDR3은 서열번호 36의 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 CD2에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 HCDR1은 서열번호 43의 아미노산 서열을 포함하고, HCDR2는 서열번호 45의 아미노산 서열을 포함하고, LCDR1은 서열번호 46의 아미노산 서열을 포함하고, LCDR2는 서열번호 47의 아미노산 서열을 포함하고, LCDR3은 서열번호 48의 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 CD2에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 HCDR1은 서열번호 65의 아미노산 서열을 포함하고, HCDR2는 서열번호 67의 아미노산 서열을 포함하고, LCDR1은 서열번호 68의 아미노산 서열을 포함하고, LCDR2는 서열번호 69의 아미노산 서열을 포함하고, LCDR3은 서열번호 70의 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 CD2에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 항원 결합 도메인은 서열번호 29의 아미노산 서열을 포함하는 중쇄 가변 영역 및/또는 서열번호 30의 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다. 특정 실시양태에서, 항원 결합 도메인은 서열번호 41의 아미노산 서열을 포함하는 중쇄 가변 영역 및/또는 서열 번호 42의 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다. 특정 실시양태에서, 항원 결합 도메인은 서열번호 51의 아미노산 서열을 포함하는 중쇄 가변 영역 및/또는 서열 52의 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다. 특정 실시양태에서, 항원 결합 도메인은 서열번호 63의 아미노산 서열을 포함하는 중쇄 가변 영역 및/또는 서열번호 64의 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다.
특정 실시양태에서, CAR은 CD2에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 항원 결합 도메인은 서열번호 27, 28, 39, 40, 50, 61 또는 62 중 어느 하나에 기재된 아미노산 서열을 포함하는 scFv이다.
특정 실시양태에서, 본 발명은 CD5에 결합할 수 있는 항원 결합 도메인을 포함하는 CAR을 포함하고, 여기서 항원 결합 도메인은 서열번호 83, 84, 85, 86, 87, 88, 95, 96, 97, 98, 99 또는 100 중 어느 하나의 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함한다.
특정 실시양태에서, CAR은 CD5에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 HCDR1은 서열번호 83의 아미노산 서열을 포함하고, HCDR2는 서열번호 85의 아미노산 서열을 포함하고, LCDR1은 서열번호 86의 아미노산 서열을 포함하고, LCDR2는 서열번호 87의 아미노산 서열을 포함하고, LCDR3은 서열번호 88의 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 CD5에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 HCDR1은 서열번호 95의 아미노산 서열을 포함하고, HCDR2는 서열번호 97의 아미노산 서열을 포함하고, LCDR1은 서열번호 98의 아미노산 서열을 포함하고, LCDR2는 서열번호 99의 아미노산 서열을 포함하고, LCDR3은 서열번호 100의 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 CD5에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 항원 결합 도메인은 서열번호 75의 아미노산 서열을 포함하는 중쇄 가변 영역 및/또는 서열번호 76의 아미노산 서열을 포함하는 경쇄 가변 영역을 포함한다. 특정 실시양태에서, 중쇄 가변 영역은 서열번호 81의 아미노산 서열을 포함하고/하거나, 경쇄 가변 영역은 서열번호 82의 아미노산 서열을 포함한다. 특정 실시양태에서, 중쇄 가변 영역은 서열번호 93의 아미노산 서열을 포함하고/하거나, 경쇄 가변 영역은 서열번호 94의 아미노산 서열을 포함한다.
특정 실시양태에서, CAR은 CD5에 결합할 수 있는 항원 결합 도메인을 포함하고, 여기서 항원 결합 도메인은 서열번호 73, 74, 79, 80, 91 또는 92 중 어느 하나에 기재된 아미노산 서열을 포함하는 scFv이다.
항원 결합 도메인 서열의 허용되는 변화는 당업자에게 공지되어 있다. 예를 들면, 일부 실시양태에서, 항원 결합 도메인은, 서열번호 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 50, 51, 52, 53, 54, 55, 56, 57, 58, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 73, 74, 75, 76, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 91, 92, 93, 94, 95, 96, 97, 98, 99, 또는 100에 기재된 임의의 아미노산 서열과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 81%, 적어도 82%, 적어도 83%, 적어도 84%, 적어도 85%, 적어도 86%, 적어도 87%, 적어도 88%, 적어도 89%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 또는 적어도 99% 서열 동일성을 갖는 아미노산 서열을 포함한다.
막관통 도메인
막관통 도메인과 관련하여, CAR은 CAR의 세포외 도메인에 융합된 막관통 도메인을 포함하도록 설계될 수 있다. 한 가지 실시양태에서, CAR에서 도메인 중 하나와 자연적으로 관련되는 막관통 도메인이 사용된다. 일부 경우에서, 막관통 도메인은 수용체 복합체의 다른 멤버와의 상호작용을 최소화하기 위해, 동일한 또는 상이한 표면 막 단백질의 막관통 도메인에 대한 이러한 도메인의 결합을 회피하기 위해, 아미노산 치환에 의해 선택되거나 변형될 수 있다.
막관통 도메인은 천연 또는 합성 공급원으로부터 유래할 수 있다. 상기 공급원이 천연인 경우, 상기 도메인은 임의의 막-결합 또는 막관통 단백질로부터 유래할 수 있다. 본 발명에서 특히 사용되는 막관통 영역은 T-세포 수용체, CD28, CD3ε, CD45, CD4, CD5, CD8, CD9, CD16, CD22, CD33, CD37, CD64, CD80, CD86, CD134, CD137, CD154의 알파, 베타 또는 제타로부터 유래할 수 있다(즉, 적어도 이의 막관통 영역(들)을 포함). 또는, 막관통 도메인은 합성일 수 있고, 이 경우, 이는 류신 및 발린 등의 주로 소수성 잔기를 포함할 것이다. 바람직하게는, 페닐알라닌, 트립토판 및 발린의 삼중선은 합성 막관통 도메인의 각 말단에서 발견될 것이다. 임의로, 짧은 올리고- 또는 폴리펩티드 링커, 바람직하게는 길이가 2 내지 10개의 아미노산 사이에서, CAR의 막관통 도메인과 세포질 신호전달 도메인 사이의 결합을 형성할 수 있다. 글리신-세린 이중선은 특히 적합한 링커를 제공한다.
한 가지 실시양태에서, 본 발명의 CAR에서 막관통 도메인은 CD8 막관통 도메인이다. 한 가지 실시양태에서, CD8 막관통 도메인은 서열번호 14의 핵산 서열을 포함한다. 한 가지 실시양태에서, CD8 막관통 도메인은 서열번호 15의 아미노산 서열을 코딩하는 핵산 서열을 포함한다. 또 다른 실시양태에서, CD8 막관통 도메인은 서열번호 15의 아미노산 서열을 포함한다.
일부 경우에서, 본 발명의 CAR의 막관통 도메인은 CD8α 힌지 도메인을 포함한다. 한 가지 실시양태에서, CD8 힌지 도메인은 서열번호 16의 핵산 서열을 포함한다. 한 가지 실시양태에서, CD8 힌지 도메인은 서열번호 17의 아미노산 서열을 코딩하는 핵산 서열을 포함한다. 또 다른 실시양태에서, CD8 힌지 도메인은 서열번호 17의 아미노산 서열을 포함한다.
CAR의 항원 결합 도메인과 막관통 도메인 사이, 또는 CAR의 세포내 도메인과 막관통 도메인 사이에, 스페이서 도메인이 도입될 수 있다. 본원에 사용된 바와 같이, 용어 "스페이서 도메인"은 일반적으로 막관통 도메인을 세포외 도메인 또는 폴리펩티드 쇄의 세포질 도메인 중 하나에 연결하도록 기능하는 임의의 올리고- 또는 폴리펩티 드를 의미한다. 스페이서 도메인은 최대 300개 아미노산, 바람직하게는 10 내지 100개 아미노산 및 가장 바람직하게는 25 내지 50개 아미노산을 포함할 수 있다.
세포내 도메인
본 발명의 CAR의 세포내 도메인 또는 다르게는 세포질 도메인은 CAR이 배치된 면역 세포의 정상 이펙터 기능 중 적어도 하나의 활성화에 관여한다. 용어 "이펙터 기능"은 세포의 특화된 기능을 지칭한다. T 세포의 이펙터 기능은, 예를 들면, 세포용해 활성 또는 사이토카인의 분비를 포함하는 헬퍼 활성일 수 있다. 따라서, 용어 "세포내 도메인"은 이펙터 기능 신호를 전달하고, 세포를 특화된 기능을 수행하도록 지시하는 단백질의 일부를 지칭한다. 일반적으로, 세포내 도메인 전체를 사용할 수 있지만, 다수의 경우, 쇄 전체를 사용할 필요는 없다. 세포내 도메인의 절단된 부분이 사용되는 정도까지, 이펙터 기능 신호를 전달하는 한, 이러한 절단된 부분은 무손상 쇄 대신에 사용될 수 있다. 따라서, 용어 세포내 도메인은 이펙터 기능 신호를 전달하기에 충분한 세포내 도메인의 임의의 절단된 부분을 포함하는 것을 의미한다.
본 발명의 CAR에서 사용하기 위한 세포내 도메인의 바람직한 예는 T 세포 수용체(TCR)의 세포질 서열, 및 항원 수용체 관여 후 신호 전달을 개시하도록 협력하여 작용하는 공-수용체, 게다가 이들 서열의 임의의 유도체 또는 변이체 및 동일한 기능적 능력을 갖는 임의의 합성 서열을 포함한다.
TCR 단독을 통해 생성된 신호는 T 세포의 완전한 활성화에 불충분하고, 2차 또는 공-자극 신호가 또한 요구된다는 것이 공지되어 있다. 따라서, T 세포 활성화는, 2개의 상이한 클래스의 세포질 신호전달 서열에 의해 매개된다고 말할 수 있다: TCR(1차 세포질 신호전달 서열)을 통한 항원-의존적 1차 활성화를 개시하는 것, 및 2차 또는 공-자극 신호(2차 세포질 신호전달 서열)를 제공하기 위해 항원-독립적 방식으로 작용하는 것.
1차 세포질 신호전달 서열은 자극적 방식으로 또는 억제적 방식으로 TCR 복합체의 1차 활성화를 조절한다. 자극 방식으로 작용하는 1차 세포질 신호전달 서열은 면역 수용체 티로신-기반 활성화 모티프 또는 ITAM으로 공지되어 있는 신호전달 모티프를 함유할 수 있다.
본 발명에서 특히 사용되는 1차 세포질 신호전달 서열을 함유하는 ITAM의 예는 TCR 제타, FcR 감마, FcR 베타, CD3 감마, CD3 델타, CD3 엡실론, CD5, CD22, CD79a, CD79b 및 CD66d로부터 유래하는 것을 포함한다. 특히, 본 발명의 CAR에서 세포질 신호전달 분자는 CD3 제타로부터 유래하는 세포질 신호전달 서열을 포함한다.
바람직한 실시양태에서, CAR의 세포내 도메인은, 그 자체로 또는 본 발명의 CAR의 문맥에서 유용한 임의의 다른 목적하는 세포내 도메인(들)과 조합하여, CD3-제타 신호전달 도메인을 포함하도록 설계될 수 있다. 예를 들면, CAR의 세포내 도메인은 CD3 제타 쇄 부분 및 공자극 신호전달 영역을 포함할 수 있다. 공자극 신호전달 영역은 공자극 분자의 세포내 도메인을 포함하는 CAR의 일부를 지칭한다. 공자극 분자는 항원에 대한 림프구의 효율적 반응에 필요한, 항원 수용체 또는 이들의 리간드 이외의 세포 표면 분자이다. 이러한 분자의 예는 CD27, CD28, 4-1BB(CD137), 0X40, CD30, CD40, PD-1, ICOS, 림프구 기능-관련 항원-1(LFA-1), CD2, CD7, LIGHT, NKG2C, B7-H3, 및 CD83 등의 특이적으로 결합하는 리간드를 포함하지만, 이들로 한정되지 않는다. 따라서, 본 발명은 공자극 신호전달 요소로서 주로 4-1BB가 예시되어 있지만, 다른 공자극 요소는 본 발명의 범위 내에 있다.
본 발명의 CAR의 세포질 신호전달 부분 내의 세포질 신호전달 서열은 랜덤 또는 특정된 순서로 서로 연결될 수 있다. 임의로, 짧은 올리고- 또는 폴리펩티드 링커, 바람직하게는 길이가 2 내지 10개 아미노산인 결합을 형성할 수 있다. 글리신-세린 이중선은 특히 적합한 링커를 제공한다.
한 가지 실시양태에서, 세포내 도메인은 CD3-제타의 신호전달 도메인 및 CD28의 신호전달 도메인을 포함하도록 설계된다. 다른 실시양태에서, 세포내 도메인은 CD3-제타의 신호전달 도메인 및 4-1BB의 신호전달 도메인을 포함하도록 설계된다. 또 다른 실시양태에서, 세포내 도메인은 CD3-제타의 신호전달 도메인 및 CD28 및 4-1BB의 신호전달 도메인을 포함하도록 설계된다.
한 가지 실시양태에서, 본 발명의 CAR에서 세포내 도메인은 4-IBB의 신호전달 도메인 및 CD3-제타의 신호전달 도메인을 포함하도록 설계되고, 여기서 4-1BB의 신호전달 도메인은 서열번호 18에 기재된 핵산 서열을 포함하고, CD3-제타의 신호전달 도메인은 서열번호 19에 기재된 핵산 서열을 포함한다.
한 가지 실시양태에서, 본 발명의 CAR에서 세포내 도메인은 4-IBB의 신호전달 도메인 및 CD3-제타의 신호전달 도메인을 포함하도록 설계되고, 여기서 4-IBB의 신호전달 도메인은 서열번호 20의 아미노산 서열을 코딩하는 핵산 서열을 포함하고, CD3-제타의 신호전달 도메인은 서열번호 21의 아미노산 서열을 코딩하는 핵산 서열을 포함한다.
한 가지 실시양태에서, 본 발명의 CAR에서 세포내 도메인은 4-IBB의 신호전달 도메인 및 CD3-제타의 신호전달 도메인을 포함하도록 설계되고, 여기서 4-1BB의 신호전달 도메인은 서열번호 20에 기재된 아미노산 서열을 포함하고, CD3-제타의 신호전달 도메인은 서열번호 21에 기재된 아미노산 서열을 포함한다.
한 가지 실시양태에서, 항-CD2 CAR은 서열번호 25, 26, 37, 38, 49, 59 또는 60 중 어느 하나에 기재된 아미노산 서열을 포함한다. 한 가지 실시양태에서, 항-CD2 CAR은 서열번호 1 내지 7로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩된다. 한 가지 실시양태에서, 항-CD5 CAR은 서열번호 71, 72, 77, 78, 89 또는 90 중 어느 하나에 기재된 아미노산 서열을 포함한다. 한 가지 실시양태에서, 항-CD5 CAR은 서열번호 8 내지 13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩된다.
CAR 서열의 허용되는 변이는 당업자에게 공지되어 있다. 예를 들면, 일부 실시양태에서, CAR은, 서열번호 25, 26, 37, 38, 49, 59, 60, 71, 72, 77, 78, 89, 또는 90에 기재된 임의의 아미노산 서열과 적어도 70%, 적어도 75%, 적어도 80%, 적어도 81%, 적어도 82%, 적어도 83%, 적어도 84%, 적어도 85%, 적어도 86%, 적어도 87%, 적어도 88%, 적어도 89%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98% 또는 적어도 99% 서열 동일성을 갖는 아미노산 서열을 포함한다. 일부 실시양태에서, CAR은, 서열번호 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 또는 13에 기재된 핵산 서열과 적어도 60%, 적어도 65%, 적어도 70%, 적어도 75%, 적어도 80%, 적어도 81%, 적어도 82%, 적어도 83%, 적어도 84%, 적어도 85%, 적어도 86%, 적어도 87%, 적어도 88%, 적어도 89%, 적어도 90%, 적어도 91%, 적어도 92%, 적어도 93%, 적어도 94%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99% 서열 동일성을 갖는 핵산 서열에 의해 코딩된다.
본 발명은 CAR, CAR을 코딩하는 핵산, CAR을 코딩하는 핵산을 포함하는 벡터, CAR을 포함하는 세포, CAR을 코딩하는 핵산을 포함하는 세포, 및 CAR을 코딩하는 핵산을 포함하는 벡터를 포함하는 세포 중 어느 하나를 포함하는 것으로 해석되어야 한다.
CD2-MEDI507H2L-3028 CAR (서열번호 1)
ggatccCAAGTCCAACTGGTGCAATCAGGCGCAGAAGTCCAACGACCGGGGGCCAGTGTTAAAGTGTCTTGTAAAGCCTCCGGGTACATTTTTACTGAGTACTATATGTACTGGGTCAGACAGGCCCCAGGGCAAGGTTTGGAACTTGTCGGACGCATAGATCCCGAAGACGGTTCTATAGATTACGTTGAGAAGTTCAAAAAGAAAGTCACACTTACTGCGGACACATCTAGTAGCACCGCATATATGGAACTGAGCAGTCTCACCTCAGACGACACCGCAGTGTACTATTGCGCTCGCGGAAAGTTTAACTATAGGTTCGCGTACTGGGGACAGGGGACACTGGTGACTGTTAGCAGCggtggcggagggagcggcggtggaggaagcggaggcggaggttccGACGTTGTGATGACGCAAAGTCCCCCGTCACTCCTTGTTACTCTCGGCCAGCCAGCGTCTATCTCTTGCCGGTCAAGCCAGAGCTTGCTCCACTCTAGTGGTAACACGTATTTGAACTGGTTGCTGCAAAGGCCTGGACAATCTCCTCAGCCCCTGATCTATTTGGTTAGCAAACTGGAAAGTGGTGTTCCAGACAGATTTTCAGGGTCTGGATCAGGCACTGATTTCACTCTGAAGATCTCCGGGGTAGAGGCCGAGGACGTGGGAGTCTATTACTGCATGCAGTTTACTCACTATCCTTATACCTTTGGTCAAGGGACGAAACTGGAGATCAAAtccgga
CD2-OKT11H2L-3029 CAR (서열번호 2)
ggatccCAAGTTCAGCTTCAGCAACCAGGTGCTGAATTGGTCCGCCCTGGAACTAGCGTTAAACTGTCTTGTAAGGCATCCGGTTATACGTTTACAAGTTATTGGATGCACTGGATTAAGCAAAGGCCCGAACAAGGCCTTGAATGGATTGGGAGAATTGATCCCTACGATAGCGAGACACACTACAATGAAAAATTTAAAGATAAGGCCATCCTCAGCGTAGATAAGAGCAGTTCTACCGCATACATACAGCTCTCAAGCCTGACGTCAGATGACTCAGCCGTTTATTATTGCTCAAGGCGGGACGCTAAATACGACGGCTATGCGCTTGACTACTGGGGACAAGGCACCACTTTGACAGTCTCCAGTggtggcggagggagcggcggtggaggaagcggaggcggaggttccGATATAGTTATGACGCAAGCAGCACCCTCTGTACCTGTGACACCGGGTGAATCCGTTAGTATCTCATGCCGCTCTTCTAAAACCCTCTTGCATTCTAACGGCAATACATATTTGTATTGGTTCCTTCAACGACCAGGACAATCACCGCAAGTGCTTATTTATAGGATGTCTAACTTGGCTAGTGGGGTGCCAAATAGGTTCAGTGGGTCTGGATCTGAGACAACTTTCACGTTGAGAATAAGTAGGGTGGAAGCTGAAGACGTCGGTATATACTACTGTATGCAGCATTTGGAGTACCCTTACACTTTCGGGGGAGGTACTAAGCTCGAAATTAAAtccgga
CD2-OKT11L2H-3030 CAR (서열번호 3)
ggatccGATATAGTTATGACGCAAGCAGCACCCTCTGTACCTGTGACACCGGGTGAATCCGTTAGTATCTCATGCCGCTCTTCTAAAACCCTCTTGCATTCTAACGGCAATACATATTTGTATTGGTTCCTTCAACGACCAGGACAATCACCGCAAGTGCTTATTTATAGGATGTCTAACTTGGCTAGTGGGGTGCCAAATAGGTTCAGTGGGTCTGGATCTGAGACAACTTTCACGTTGAGAATAAGTAGGGTGGAAGCTGAAGACGTCGGTATATACTACTGTATGCAGCATTTGGAGTACCCTTACACTTTCGGGGGAGGTACTAAGCTCGAAATTAAAggtggcggagggagcggcggtggaggaagcggaggcggaggttccCAAGTTCAGCTTCAGCAACCAGGTGCTGAATTGGTCCGCCCTGGAACTAGCGTTAAACTGTCTTGTAAGGCATCCGGTTATACGTTTACAAGTTATTGGATGCACTGGATTAAGCAAAGGCCCGAACAAGGCCTTGAATGGATTGGGAGAATTGATCCCTACGATAGCGAGACACACTACAATGAAAAATTTAAAGATAAGGCCATCCTCAGCGTAGATAAGAGCAGTTCTACCGCATACATACAGCTCTCAAGCCTGACGTCAGATGACTCAGCCGTTTATTATTGCTCAAGGCGGGACGCTAAATACGACGGCTATGCGCTTGACTACTGGGGACAAGGCACCACTTTGACAGTCTCCAGTtccgga
CD2-T11-2-H2L-3031 CAR (서열번호 4)
ggatccCAAGTTCAATTGCAGCAACCGGGTGCCGAGTTGGTAAGGCCCGGTGCGTCAGTCAAACTTAGTTGTAAAGCTAGTGGGTACACTTTTACTACGTTCTGGATGAATTGGGTGAAGCAACGACCAGGCCAAGGTCTGGAATGGATCGGCATGATTGACCCGTCTGACTCAGAAGCTCATTACAACCAGATGTTCAAGGACAAGGCGACTCTGACTGTTGATAAAAGCTCAAGCACCGCCTACATGCAGCTCAGTAGCCTCACATCCGAGGATTCCGCAGTGTACTATTGCGCGAGGGGACGAGGGTATGATGACGGCGATGCGATGGACTATTGGGGACAGGGGACCAGCGTAACAGTCAGTAGTggtggcggagggagcggcggtggaggaagcggaggcggaggttccGATATAGTTATGACCCAGTCTCCCGCCTCTCTGGCCGTTAGCTTGGGACAACGCGCTACCATCTCTTACCGAGCGTCTAAGTCCGTCAGTACAAGCGGTTATAGTTACATGCACTGGAACCAGCAAAAGCCCGGACAACCTCCGAGACTCCTGATTTATTTGGTCTCTAACCTTGAGTCAGGTGTCCCAGCCAGATTCTCCGGCTCTGGAAGCGGCACTGACTTTACATTGAACATTCACCCCGTGGAGGAGGAAGACGCTGCTACCTACTATTGCATGCAATTCACGCACTATCCCTACACATTCGGGGGGGGCACGAAATTGGAAATCAAAtccgga
CD2-TS2-18.1.1-H2L-3032 CAR (서열번호 5)
ggatccGAGGTTCAGCTTGAGGAGAGTGGGGGAGGTTTGGTAATGCCAGGTGGGTCTTTGAAACTCAGTTGCGCGGCGTCAGGCTTCGCATTTTCCTCCTACGATATGTCCTGGGTCAGACAGACACCCGAGAAGCGGCTGGAATGGGTCGCTTACATTTCCGGGGGAGGATTCACGTACTACCCGGATACAGTAAAGGGGAGATTTACTCTGAGCCGGGACAACGCTAAGAATACCCTCTATCTCCAGATGTCCTCTTTGAAGAGTGAAGACACAGCGATGTATTACTGTGCGAGACAAGGGGCCAATTGGGAGCTGGTTTACTGGGGCCAGGGGACGACATTGACGGTTTCTAGCggtggcggagggagcggcggtggaggaagcggaggcggaggttccGACATTGTAATGACACAATCACCTGCTACACTTAGCGTGACTCCAGGTGATCGGGTATTCCTGAGCTGCCGCGCATCACAAAGTATATCCGACTTCCTGCACTGGTATCAGCAGAAATCTCACGAAAGTCCCAGGCTGCTGATTAAATACGCTTCCCAGAGTATTAGTGGTATCCCCTCACGATTTTCTGGCAGCGGGAGCGGTAGTGACTTCACTCTTTCTATAAACTCCGTCGAGCCAGAAGACGTGGGGGTGTATCTTTGCCAAAATGGACACAATTTTCCACCAACCTTTGGTGGGGGCACCAAACTCGAAATAAAGtccgga
CD2-TS2-18.1.1-L2H-3033 CAR (서열번호 6)
ggatccGACATTGTAATGACACAATCACCTGCTACACTTAGCGTGACTCCAGGTGATCGGGTATTCCTGAGCTGCCGCGCATCACAAAGTATATCCGACTTCCTGCACTGGTATCAGCAGAAATCTCACGAAAGTCCCAGGCTGCTGATTAAATACGCTTCCCAGAGTATTAGTGGTATCCCCTCACGATTTTCTGGCAGCGGGAGCGGTAGTGACTTCACTCTTTCTATAAACTCCGTCGAGCCAGAAGACGTGGGGGTGTATCTTTGCCAAAATGGACACAATTTTCCACCAACCTTTGGTGGGGGCACCAAACTCGAAATAAAGggtggcggagggagcggcggtggaggaagcggaggcggaggttccGAGGTTCAGCTTGAGGAGAGTGGGGGAGGTTTGGTAATGCCAGGTGGGTCTTTGAAACTCAGTTGCGCGGCGTCAGGCTTCGCATTTTCCTCCTACGATATGTCCTGGGTCAGACAGACACCCGAGAAGCGGCTGGAATGGGTCGCTTACATTTCCGGGGGAGGATTCACGTACTACCCGGATACAGTAAAGGGGAGATTTACTCTGAGCCGGGACAACGCTAAGAATACCCTCTATCTCCAGATGTCCTCTTTGAAGAGTGAAGACACAGCGATGTATTACTGTGCGAGACAAGGGGCCAATTGGGAGCTGGTTTACTGGGGCCAGGGGACGACATTGACGGTTTCTAGCtccgga
CD2-MEDI507L2H-3043 CAR (서열번호 7)
ggatccGACGTTGTGATGACGCAAAGTCCCCCGTCACTCCTTGTTACTCTCGGCCAGCCAGCGTCTATCTCTTGCCGGTCAAGCCAGAGCTTGCTCCACTCTAGTGGTAACACGTATTTGAACTGGTTGCTGCAAAGGCCTGGACAATCTCCTCAGCCCCTGATCTATTTGGTTAGCAAACTGGAAAGTGGTGTTCCAGACAGATTTTCAGGGTCTGGATCAGGCACTGATTTCACTCTGAAGATCTCCGGGGTAGAGGCCGAGGACGTGGGAGTCTATTACTGCATGCAGTTTACTCACTATCCTTATACCTTTGGTCAAGGGACGAAACTGGAGATCAAAggtggcggagggagcggcggtggaggaagcggaggcggaggttccCAAGTCCAACTGGTGCAATCAGGCGCAGAAGTCCAACGACCGGGGGCCAGTGTTAAAGTGTCTTGTAAAGCCTCCGGGTACATTTTTACTGAGTACTATATGTACTGGGTCAGACAGGCCCCAGGGCAAGGTTTGGAACTTGTCGGACGCATAGATCCCGAAGACGGTTCTATAGATTACGTTGAGAAGTTCAAAAAGAAAGTCACACTTACTGCGGACACATCTAGTAGCACCGCATATATGGAACTGAGCAGTCTCACCTCAGACGACACCGCAGTGTACTATTGCGCTCGCGGAAAGTTTAACTATAGGTTCGCGTACTGGGGACAGGGGACACTGGTGACTGTTAGCAGCtccgga
CD5-17L2H-3045 CAR (서열번호 8)
ggatccAACATTGTACTGACGCAAAGCCCCTCATCTTTGTCTGAGTCACTCGGCGGCAAAGTAACCATCACATGCAAGGCCAGTCAAGACATCAATAAATATATTGCTTGGTATCAGTATAAACCCGGCAAGGGGCCGCGACTGCTGATTCACTACACGAGTACCTTGCAACCGGGCATTCCGAGCCGATTTAGTGGCAGTGGCTCAGGTCGCGATTACTCATTCTCAATAAGTAATCTCGAACCGGAAGACATAGCTACTTATTATTGCTTGCAGTACGATAATTTGTGGACCTTCGGGGGTGGTACAAAGTTGGAAATAAAGggtggcggagggagcggcggtggaggaagcggaggcggaggttccGAGGTCCAACTCGTAGAATCAGGTCCCGGATTGGTGCAACCATCCCAGAGCCTCTCTATTACATGCACGGTCTCTGGATTTAGTCTGACCAATTACGATGTGCATTGGGTGCGCCAGTCTCCCGGCAAGGGGTTGGAATGGCTTGGCGTTATATGGAACTACGGAAATACAGACTATAACGCCGCGTTTATCTCTCGGCTGAGTATACGGAAAGACAGTAGTAAATCCCAGGTCTTTTTTACGATGTCATCCCTGCAAACGCCAGATACCGCAATATATTACTGCGCCAGGAACCACGGTGATGGTTATTATAATTGGTACTTCGATGTGTGGGGTACTGGCACTACAGTCACAGTATCTTCAtctaga
CD5-9H2L-3048 CAR (서열번호 9)
ggatcc CAG GTC CAG CTG AAA GAA AGC GGT CCA GAG CTG GAA AAA CCC GGT GCG AGC GTC AAA ATA TCA TGT AAA GCA AGC GGG TAT TCA TTC ACC GCG TAC TCT ATG AAC TGG GTT AAG CAA AAC AAC GGT ATG TCC TTG GAG TGG ATA GGG TCT ATC GAC CCG TAT TAT GGG GAC ACA AAA TAC GCG CAG AAA TTC AAG GGG AAG GCC ACC CTG ACC GTA GAT AAA GCT AGT TCT ACT GCG TAC TTG CAA CTG AAA AGC CTC ACT TCT GAG GAC TCT GCC GTC TAC TAC TGT GCT CGG CGA ATG ATA ACG ACG GGG GAC TGG TAT TTC GAT GTT TGG GGT ACA GGG ACT ACG GTG ACT GTC AGT AGCggtggcggagggagcggcggtggaggaagcggaggcggaggttcc CAT ATC GTC TTG ACT CAA TCA CCT AGT TCT TTG TCT GCG TCC CTT GGC GAC CGA GTC ACC ATA TCT TGC AGA GCG TCA CAG GAC ATT TCA ACG TAC CTC AAC TGG TAT CAG CAA AAA CCG GAC GGG ACT GTC AAG CTC TTG ATC TTC TAC ACT TCC AGA CTC CAC GCC GGG GTG CCA AGC AGA TTT AGT GGC TCT GGC AGC GGG ACA CAC CAT AGT CTT ACA ATC AGC AAT CTT GAG CAA GAA GAC ATA GCC ACG TAT TTC TGC CAG CAA GGT AAC TCA CTT CCG TTC ACG TTT GGT AGT GGC ACC AAA CTG GAG ATA AAA tccgga
CD5-9L2H-3049 CAR (서열번호 10)
Ggatcc CAT ATC GTC TTG ACT CAA TCA CCT AGT TCT TTG TCT GCG TCC CTT GGC GAC CGA GTC ACC ATA TCT TGC AGA GCG TCA CAG GAC ATT TCA ACG TAC CTC AAC TGG TAT CAG CAA AAA CCG GAC GGG ACT GTC AAG CTC TTG ATC TTC TAC ACT TCC AGA CTC CAC GCC GGG GTG CCA AGC AGA TTT AGT GGC TCT GGC AGC GGG ACA CAC CAT AGT CTT ACA ATC AGC AAT CTT GAG CAA GAA GAC ATA GCC ACG TAT TTC TGC CAG CAA GGT AAC TCA CTT CCG TTC ACG TTT GGT AGT GGC ACC AAA CTG GAG ATA AAA ggtggcggagggagcggcggtggaggaagcggaggcggaggttcc CAG GTC CAG CTG AAA GAA AGC GGT CCA GAG CTG GAA AAA CCC GGT GCG AGC GTC AAA ATA TCA TGT AAA GCA AGC GGG TAT TCA TTC ACC GCG TAC TCT ATG AAC TGG GTT AAG CAA AAC AAC GGT ATG TCC TTG GAG TGG ATA GGG TCT ATC GAC CCG TAT TAT GGG GAC ACA AAA TAC GCG CAG AAA TTC AAG GGG AAG GCC ACC CTG ACC GTA GAT AAA GCT AGT TCT ACT GCG TAC TTG CAA CTG AAA AGC CTC ACT TCT GAG GAC TCT GCC GTC TAC TAC TGT GCT CGG CGA ATG ATA ACG ACG GGG GAC TGG TAT TTC GAT GTT TGG GGT ACA GGG ACT ACG GTG ACT GTC AGT AGC tccgga
CD5-34H2L-3052 CAR (서열번호 11)
ggatccGAGGTTAAACTCGTGGAGAGCGGTGCCGAACTCGTCCGAAGTGGTGCTTCCGTTAAACTCAGTTGTGCCGCGTCAGGATTTAACATAAAAGATTACTACATTCACTGGGTCAAACAGCGCCCGGAGCAGGGGCTTGAATGGATCGGGTGGATTGATCCTGAAAACGGGCGCACCGAATATGCTCCCAAGTTCCAGGGCAAAGCTACTATGACCGCTGACACCTCTAGTAACACTGCCTACCTGCAGTTGAGCTCTCTTACGTCTGAGGATACCGCTGTGTACTACTGTAATAACGGAAATTATGTACGACACTATTACTTCGACTACTGGGGGCAGGGCACTACTGTGACTGTATCTAGCggtggcggagggagcggcggtggaggaagcggaggcggaggttccGATTGGCTCACACAATCCCCTGCAATCCTGAGTGCATCTCCAGGCGAGAAAGTAACTATGACTTGCAGAGCTATAAGCTCTGTGTCCTACATGCACTGGTATCAGCAGAAGCCAGGTTCTTCCCCGAAGCCGTGGATATATGCTACAAGCAATTTGGCATCCGGTGTTCCCGCCCGGTTTAGTGGCTCCGGTTCTGGGACAAGTTACTCCCTCACGATCAGCAGGGTTGAAGCCGAGGACGCTGCCACTTACTATTGCCAACAGTGGTCAAGTAACCCCAGGACTTTCGGGGGAGGAACTAAACTTGAAATCAAAtctaga
CD5-34L2H-3053 CAR (서열번호 12)
Ggatcc GAT TGG CTC ACA CAA TCC CCT GCA ATC CTG AGT GCA TCT CCA GGC GAG AAA GTA ACT ATG ACT TGC AGA GCT ATA AGC TCT GTG TCC TAC ATG CAC TGG TAT CAG CAG AAG CCA GGT TCT TCC CCG AAG CCG TGG ATA TAT GCT ACA AGC AAT TTG GCA TCC GGT GTT CCC GCC CGG TTT AGT GGC TCC GGT TCT GGG ACA AGT TAC TCC CTC ACG ATC AGC AGG GTT GAA GCC GAG GAC GCT GCC ACT TAC TAT TGC CAA CAG TGG TCA AGT AAC CCC AGG ACT TTC GGG GGA GGA ACT AAA CTT GAA ATC AAA
Ggtggcggagggagcggcggtggaggaagcggaggcggaggttcc GAG GTT AAA CTC GTG GAG AGC GGT GCC GAA CTC GTC CGA AGT GGT GCT TCC GTT AAA CTC AGT TGT GCC GCG TCA GGA TTT AAC ATA AAA GAT TAC TAC ATT CAC TGG GTC AAA CAG CGC CCG GAG CAG GGG CTT GAA TGG ATC GGG TGG ATT GAT CCT GAA AAC GGG CGC ACC GAA TAT GCT CCC AAG TTC CAG GGC AAA GCT ACT ATG ACC GCT GAC ACC TCT AGT AAC ACT GCC TAC CTG CAG TTG AGC TCT CTT ACG TCT GAG GAT ACC GCT GTG TAC TAC TGT AAT AAC GGA AAT TAT GTA CGA CAC TAT TAC TTC GAC TAC TGG GGG CAG GGC ACT ACT GTG ACT GTA TCT AGC tCTAGA
CD5-17H2L-3054 CAR (서열번호 13)
ggatccGAGGTCCAACTCGTAGAATCAGGTCCCGGATTGGTGCAACCATCCCAGAGCCTCTCTATTACATGCACGGTCTCTGGATTTAGTCTGACCAATTACGATGTGCATTGGGTGCGCCAGTCTCCCGGCAAGGGGTTGGAATGGCTTGGCGTTATATGGAACTACGGAAATACAGACTATAACGCCGCGTTTATCTCTCGGCTGAGTATACGGAAAGACAGTAGTAAATCCCAGGTCTTTTTTACGATGTCATCCCTGCAAACGCCAGATACCGCAATATATTACTGCGCCAGGAACCACGGTGATGGTTATTATAATTGGTACTTCGATGTGTGGGGTACTGGCACTACAGTCACAGTATCTTCAggtggcggagggagcggcggtggaggaagcggaggcggaggttccAACATTGTACTGACGCAAAGCCCCTCATCTTTGTCTGAGTCACTCGGCGGCAAAGTAACCATCACATGCAAGGCCAGTCAAGACATCAATAAATATATTGCTTGGTATCAGTATAAACCCGGCAAGGGGCCGCGACTGCTGATTCACTACACGAGTACCTTGCAACCGGGCATTCCGAGCCGATTTAGTGGCAGTGGCTCAGGTCGCGATTACTCATTCTCAATAAGTAATCTCGAACCGGAAGACATAGCTACTTATTATTGCTTGCAGTACGATAATTTGTGGACCTTCGGGGGTGGTACAAAGTTGGAAATAAAGtctaga
CD8 막관통 도메인 핵산 서열 (서열번호 14):
atctacatct gggcgccctt ggccgggact tgtggggtcc ttctcctgtc actggttatc
accctttact gc
CD8 막관통 도메인 아미노산 서열 (서열번호 15):
IYIWAPLAGTCGVLLLSLVITLYC
CD8 힌지 도메인 핵산 서열 (서열번호 16):
accacgacgc cagcgccgcg accaccaaca ccggcgccca ccatcgcgtc gcagcccctg
tccctgcgcc cagaggcgtg ccggccagcg gcggggggcg cagtgcacac gagggggctg
gacttcgcct gtgat
CD8 힌지 도메인 아미노산 서열 (서열번호 17):
TTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACD
4-1BB 핵산 서열 (서열번호 18)
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt
gaactg
CD3-제타 핵산 서열 (서열번호 19)
agagtgaagt tcagcaggag cgcagacgcc cccgcgtaca agcagggcca gaaccagctc
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa gagacgtggc
cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg cctgtacaat
gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa aggcgagcgc
cggaggggca aggggcacga tggcctttac cagggtctca gtacagccac caaggacacc
tacgacgccc ttcacatgca ggccctgccc cctcgc
4-1BB 아미노산 서열 (서열번호 20):
KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL
CD3-제타 아미노산 서열 (서열번호 21):
RVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-MEDI507H2L-3028 CAR 아미노산 서열 (서열번호 25)
MALPVTALLLPLALLLHAARPGSQVQLVQSGAEVQRPGASVKVSCKASGYIFTEYYMYWVRQAPGQGLELVGRIDPEDGSIDYVEKFKKKVTLTADTSSSTAYMELSSLTSDDTAVYYCARGKFNYRFAYWGQGTLVTVSSGGGGSGGGGSGGGGSDVVMTQSPPSLLVTLGQPASISCRSSQSLLHSSGNTYLNWLLQRPGQSPQPLIYLVSKLESGVPDRFSGSGSGTDFTLKISGVEAEDVGVYYCMQFTHYPYTFGQGTKLEIKSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-MEDI507L2H-3043 CAR 아미노산 서열 (서열번호 26)
MALPVTALLLPLALLLHAARPGSDVVMTQSPPSLLVTLGQPASISCRSSQSLLHSSGNTYLNWLLQRPGQSPQPLIYLVSKLESGVPDRFSGSGSGTDFTLKISGVEAEDVGVYYCMQFTHYPYTFGQGTKLEIKGGGGSGGGGSGGGGSQVQLVQSGAEVQRPGASVKVSCKASGYIFTEYYMYWVRQAPGQGLELVGRIDPEDGSIDYVEKFKKKVTLTADTSSSTAYMELSSLTSDDTAVYYCARGKFNYRFAYWGQGTLVTVSSSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-MEDI507H2L-3028 scFv 아미노산 서열 (서열번호 27)
GSQVQLVQSGAEVQRPGASVKVSCKASGYIFTEYYMYWVRQAPGQGLELVGRIDPEDGSIDYVEKFKKKVTLTADTSSSTAYMELSSLTSDDTAVYYCARGKFNYRFAYWGQGTLVTVSSGGGGSGGGGSGGGGSDVVMTQSPPSLLVTLGQPASISCRSSQSLLHSSGNTYLNWLLQRPGQSPQPLIYLVSKLESGVPDRFSGSGSGTDFTLKISGVEAEDVGVYYCMQFTHYPYTFGQGTKLEIKSG
CD2-MEDI507L2H-3043 scFv 아미노산 서열 (서열번호 28)
GSDVVMTQSPPSLLVTLGQPASISCRSSQSLLHSSGNTYLNWLLQRPGQSPQPLIYLVSKLESGVPDRFSGSGSGTDFTLKISGVEAEDVGVYYCMQFTHYPYTFGQGTKLEIKGGGGSGGGGSGGGGSQVQLVQSGAEVQRPGASVKVSCKASGYIFTEYYMYWVRQAPGQGLELVGRIDPEDGSIDYVEKFKKKVTLTADTSSSTAYMELSSLTSDDTAVYYCARGKFNYRFAYWGQGTLVTVSSSG
CD2-MEDI507 VH 아미노산 서열 (서열번호 29)
QVQLVQSGAEVQRPGASVKVSCKASGYIFTEYYMYWVRQAPGQGLELVGRIDPEDGSIDYVEKFKKKVTLTADTSSSTAYMELSSLTSDDTAVYYCARGKFNYRFAYWGQGTLVTVSS
CD2-MEDI507 VL 아미노산 서열 (서열번호 30)
DVVMTQSPPSLLVTLGQPASISCRSSQSLLHSSGNTYLNWLLQRPGQSPQPLIYLVSKLESGVPDRFSGSGSGTDFTLKISGVEAEDVGVYYCMQFTHYPYTFGQGTKLEIK
CD2-MEDI507 HCDR1 (서열번호 31)
EYYMY
CD2-MEDI507 HCDR2 (서열번호 32)
RIDPEDGSIDYVEKFKK
CD2-MEDI507 HCDR3 (서열번호 33)
GKFNYRFAY
CD2-MEDI507 LCDR1 (서열번호 34)
RSSQSLLHSSGNTYLN
CD2-MEDI507 LCDR2 (서열번호 35)
LVSKLES
CD2-MEDI507 LCDR3 (서열번호 36)
MQFTHYPYT
CD2-OKT11H2L-3029 CAR 아미노산 서열 (서열번호 37)
MALPVTALLLPLALLLHAARPGSQVQLQQPGAELVRPGTSVKLSCKASGYTFTSYWMHWIKQRPEQGLEWIGRIDPYDSETHYNEKFKDKAILSVDKSSSTAYIQLSSLTSDDSAVYYCSRRDAKYDGYALDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQAAPSVPVTPGESVSISCRSSKTLLHSNGNTYLYWFLQRPGQSPQVLIYRMSNLASGVPNRFSGSGSETTFTLRISRVEAEDVGIYYCMQHLEYPYTFGGGTKLEIKSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-OKT11L2H-3030 CAR 아미노산 서열 (서열번호 38)
MALPVTALLLPLALLLHAARPGSDIVMTQAAPSVPVTPGESVSISCRSSKTLLHSNGNTYLYWFLQRPGQSPQVLIYRMSNLASGVPNRFSGSGSETTFTLRISRVEAEDVGIYYCMQHLEYPYTFGGGTKLEIKGGGGSGGGGSGGGGSQVQLQQPGAELVRPGTSVKLSCKASGYTFTSYWMHWIKQRPEQGLEWIGRIDPYDSETHYNEKFKDKAILSVDKSSSTAYIQLSSLTSDDSAVYYCSRRDAKYDGYALDYWGQGTTLTVSSSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-OKT11H2L-3029 scFv 아미노산 서열 (서열번호 39)
GSQVQLQQPGAELVRPGTSVKLSCKASGYTFTSYWMHWIKQRPEQGLEWIGRIDPYDSETHYNEKFKDKAILSVDKSSSTAYIQLSSLTSDDSAVYYCSRRDAKYDGYALDYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQAAPSVPVTPGESVSISCRSSKTLLHSNGNTYLYWFLQRPGQSPQVLIYRMSNLASGVPNRFSGSGSETTFTLRISRVEAEDVGIYYCMQHLEYPYTFGGGTKLEIKSG
CD2-OKT11L2H-3030 scFv 아미노산 서열 (서열번호 40)
GSDIVMTQAAPSVPVTPGESVSISCRSSKTLLHSNGNTYLYWFLQRPGQSPQVLIYRMSNLASGVPNRFSGSGSETTFTLRISRVEAEDVGIYYCMQHLEYPYTFGGGTKLEIKGGGGSGGGGSGGGGSQVQLQQPGAELVRPGTSVKLSCKASGYTFTSYWMHWIKQRPEQGLEWIGRIDPYDSETHYNEKFKDKAILSVDKSSSTAYIQLSSLTSDDSAVYYCSRRDAKYDGYALDYWGQGTTLTVSSSG
CD2-OKT11 VH 아미노산 서열 (서열번호 41)
QVQLQQPGAELVRPGTSVKLSCKASGYTFTSYWMHWIKQRPEQGLEWIGRIDPYDSETHYNEKFKDKAILSVDKSSSTAYIQLSSLTSDDSAVYYCSRRDAKYDGYALDYWGQGTTLTVSS
CD2-OKT11 VL 아미노산 서열 (서열번호 42)
DIVMTQAAPSVPVTPGESVSISCRSSKTLLHSNGNTYLYWFLQRPGQSPQVLIYRMSNLASGVPNRFSGSGSETTFTLRISRVEAEDVGIYYCMQHLEYPYTFGGGTKLEIK
CD2-OKT11 HCDR1 (서열번호 43)
SYWMH
CD2-OKT11 HCDR2 (서열번호 44)
RIDPYDSETHYNEKFKD
CD2-OKT11 HCDR3 (서열번호 45)
RDAKYDGYALDY
CD2-OKT11 LCDR1 (서열번호 46)
RSSKTLLHSNGNTYLY
CD2-OKT11 LCDR2 (서열번호 47)
RMSNLAS
CD2-OKT11 LCDR3 (서열번호 48)
MQHLEYPYT
CD2-T11-2-H2L-3031 CAR 아미노산 서열 (서열번호 49)
MALPVTALLLPLALLLHAARPGSQVQLQQPGAELVRPGASVKLSCKASGYTFTTFWMNWVKQRPGQGLEWIGMIDPSDSEAHYNQMFKDKATLTVDKSSSTAYMQLSSLTSEDSAVYYCARGRGYDDGDAMDYWGQGTSVTVSSGGGGSGGGGSGGGGSDIVMTQSPASLAVSLGQRATISYRASKSVSTSGYSYMHWNQQKPGQPPRLLIYLVSNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCMQFTHYPYTFGGGTKLEIKSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-T11-2-H2L-3031 scFv 아미노산 서열 (서열번호 50)
GSQVQLQQPGAELVRPGASVKLSCKASGYTFTTFWMNWVKQRPGQGLEWIGMIDPSDSEAHYNQMFKDKATLTVDKSSSTAYMQLSSLTSEDSAVYYCARGRGYDDGDAMDYWGQGTSVTVSSGGGGSGGGGSGGGGSDIVMTQSPASLAVSLGQRATISYRASKSVSTSGYSYMHWNQQKPGQPPRLLIYLVSNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCMQFTHYPYTFGGGTKLEIKSG
CD2-T11-2-H2L-3031 VH 아미노산 서열 (서열번호 51)
QVQLQQPGAELVRPGASVKLSCKASGYTFTTFWMNWVKQRPGQGLEWIGMIDPSDSEAHYNQMFKDKATLTVDKSSSTAYMQLSSLTSEDSAVYYCARGRGYDDGDAMDYWGQGTSVTVSS
CD2-T11-2-H2L-3031 VL 아미노산 서열 (서열번호 52)
DIVMTQSPASLAVSLGQRATISYRASKSVSTSGYSYMHWNQQKPGQPPRLLIYLVSNLESGVPARFSGSGSGTDFTLNIHPVEEEDAATYYCMQFTHYPYTFGGGTKLEIK
CD2-T11-2 HCDR1(서열번호 53)
TFWMN
CD2-T11-2 HCDR2 (서열번호 54)
MIDPSDSEAHYNQMFKD
CD2-T11-2 HCDR3 (서열번호 55)
GRGYDDGDAMDY
CD2-T11-2 LCDR1 (서열번호 56)
RASKSVSTSGYSYMH
CD2-T11-2 LCDR2 (서열번호 57)
LVSNLES
CD2-T11-2 LCDR3 (서열번호 58)
MQFTHYPYT
CD2-TS2-18.1.1-H2L-3032 CAR 아미노산 서열 (서열번호 59)
MALPVTALLLPLALLLHAARPGSEVQLEESGGGLVMPGGSLKLSCAASGFAFSSYDMSWVRQTPEKRLEWVAYISGGGFTYYPDTVKGRFTLSRDNAKNTLYLQMSSLKSEDTAMYYCARQGANWELVYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQSPATLSVTPGDRVFLSCRASQSISDFLHWYQQKSHESPRLLIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYLCQNGHNFPPTFGGGTKLEIKSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-TS2-18.1.1-L2H-3033 CAR 아미노산 서열 (서열번호 60)
MALPVTALLLPLALLLHAARPGSDIVMTQSPATLSVTPGDRVFLSCRASQSISDFLHWYQQKSHESPRLLIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYLCQNGHNFPPTFGGGTKLEIKGGGGSGGGGSGGGGSEVQLEESGGGLVMPGGSLKLSCAASGFAFSSYDMSWVRQTPEKRLEWVAYISGGGFTYYPDTVKGRFTLSRDNAKNTLYLQMSSLKSEDTAMYYCARQGANWELVYWGQGTTLTVSSSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD2-TS2-18.1.1-H2L-3032 scFv 아미노산 서열 (서열번호 61)
GSEVQLEESGGGLVMPGGSLKLSCAASGFAFSSYDMSWVRQTPEKRLEWVAYISGGGFTYYPDTVKGRFTLSRDNAKNTLYLQMSSLKSEDTAMYYCARQGANWELVYWGQGTTLTVSSGGGGSGGGGSGGGGSDIVMTQSPATLSVTPGDRVFLSCRASQSISDFLHWYQQKSHESPRLLIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYLCQNGHNFPPTFGGGTKLEIKSG
CD2-TS2-18.1.1-L2H-3033 scFv 아미노산 서열 (서열번호 62)
GSDIVMTQSPATLSVTPGDRVFLSCRASQSISDFLHWYQQKSHESPRLLIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYLCQNGHNFPPTFGGGTKLEIKGGGGSGGGGSGGGGSEVQLEESGGGLVMPGGSLKLSCAASGFAFSSYDMSWVRQTPEKRLEWVAYISGGGFTYYPDTVKGRFTLSRDNAKNTLYLQMSSLKSEDTAMYYCARQGANWELVYWGQGTTLTVSSSG
CD2-TS2-18.1.1 VH 아미노산 서열 (서열번호 63)
EVQLEESGGGLVMPGGSLKLSCAASGFAFSSYDMSWVRQTPEKRLEWVAYISGGGFTYYPDTVKGRFTLSRDNAKNTLYLQMSSLKSEDTAMYYCARQGANWELVYWGQGTTLTVSS
CD2-TS2-18.1.1 VL 아미노산 서열 (서열번호 64)
DIVMTQSPATLSVTPGDRVFLSCRASQSISDFLHWYQQKSHESPRLLIKYASQSISGIPSRFSGSGSGSDFTLSINSVEPEDVGVYLCQNGHNFPPTFGGGTKLEIK
CD2-TS2-18.1.1 HCDR1 (서열번호 65)
SYDMS
CD2-TS2-18.1.1 HCDR2 (서열번호 66)
YISGGGFTYYPDTVKG
CD2-TS2-18.1.1 HCDR3 (서열번호 67)
QGANWELVY
CD2-TS2-18.1.1 LCDR1 (서열번호 68)
RASQSISDFLH
CD2-TS2-18.1.1 LCDR2 (서열번호 69)
YASQSIS
CD2-TS2-18.1.1 LCDR3 (서열번호 70)
QNGHNFPPT
CD5-17L2H-3045 CAR 아미노산 서열 (서열번호 71)
MALPVTALLLPLALLLHAARPGSNIVLTQSPSSLSESLGGKVTITCKASQDINKYIAWYQYKPGKGPRLLIHYTSTLQPGIPSRFSGSGSGRDYSFSISNLEPEDIATYYCLQYDNLWTFGGGTKLEIKGGGGSGGGGSGGGGSEVQLVESGPGLVQPSQSLSITCTVSGFSLTNYDVHWVRQSPGKGLEWLGVIWNYGNTDYNAAFISRLSIRKDSSKSQVFFTMSSLQTPDTAIYYCARNHGDGYYNWYFDVWGTGTTVTVSSSRTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCHMKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELTSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD5-17H2L-3054 CAR 아미노산 서열 (서열번호 72)
MALPVTALLLPLALLLHAARPGSEVQLVESGPGLVQPSQSLSITCTVSGFSLTNYDVHWVRQSPGKGLEWLGVIWNYGNTDYNAAFISRLSIRKDSSKSQVFFTMSSLQTPDTAIYYCARNHGDGYYNWYFDVWGTGTTVTVSSGGGGSGGGGSGGGGSNIVLTQSPSSLSESLGGKVTITCKASQDINKYIAWYQYKPGKGPRLLIHYTSTLQPGIPSRFSGSGSGRDYSFSISNLEPEDIATYYCLQYDNLWTFGGGTKLEIKSRTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCHMKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELTSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD5-17L2H-3045 scFv 아미노산 서열 (서열번호 73)
NIVLTQSPSSLSESLGGKVTITCKASQDINKYIAWYQYKPGKGPRLLIHYTSTLQPGIPSRFSGSGSGRDYSFSISNLEPEDIATYYCLQYDNLWTFGGGTKLEIKGGGGSGGGGSGGGGSEVQLVESGPGLVQPSQSLSITCTVSGFSLTNYDVHWVRQSPGKGLEWLGVIWNYGNTDYNAAFISRLSIRKDSSKSQVFFTMSSLQTPDTAIYYCARNHGDGYYNWYFDVWGTGTTVTVSS
CD5-17H2L-3054 scFv 아미노산 서열 (서열번호 74)
EVQLVESGPGLVQPSQSLSITCTVSGFSLTNYDVHWVRQSPGKGLEWLGVIWNYGNTDYNAAFISRLSIRKDSSKSQVFFTMSSLQTPDTAIYYCARNHGDGYYNWYFDVWGTGTTVTVSSGGGGSGGGGSGGGGSNIVLTQSPSSLSESLGGKVTITCKASQDINKYIAWYQYKPGKGPRLLIHYTSTLQPGIPSRFSGSGSGRDYSFSISNLEPEDIATYYCLQYDNLWTFGGGTKLEIK
CD5-17 VH 아미노산 서열 (서열번호 75)
EVQLVESGPGLVQPSQSLSITCTVSGFSLTNYDVHWVRQSPGKGLEWLGVIWNYGNTDYNAAFISRLSIRKDSSKSQVFFTMSSLQTPDTAIYYCARNHGDGYYNWYFDVWGTGTTVTVSS
CD5-17 VL 아미노산 서열 (서열번호 76)
NIVLTQSPSSLSESLGGKVTITCKASQDINKYIAWYQYKPGKGPRLLIHYTSTLQPGIPSRFSGSGSGRDYSFSISNLEPEDIATYYCLQYDNLWTFGGGTKLEIK
CD5-9H2L-3048 CAR 아미노산 서열 (서열번호 77)
MALPVTALLLPLALLLHAARPGSQVQLKESGPELEKPGASVKISCKASGYSFTAYSMNWVKQNNGMSLEWIGSIDPYYGDTKYAQKFKGKATLTVDKASSTAYLQLKSLTSEDSAVYYCARRMITTGDWYFDVWGTGTTVTVSSGGGGSGGGGSGGGGSHIVLTQSPSSLSASLGDRVTISCRASQDISTYLNWYQQKPDGTVKLLIFYTSRLHAGVPSRFSGSGSGTHHSLTISNLEQEDIATYFCQQGNSLPFTFGSGTKLEIKSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD5-9L2H-3049 CAR 아미노산 서열 (서열번호 78)
MALPVTALLLPLALLLHAARPGSHIVLTQSPSSLSASLGDRVTISCRASQDISTYLNWYQQKPDGTVKLLIFYTSRLHAGVPSRFSGSGSGTHHSLTISNLEQEDIATYFCQQGNSLPFTFGSGTKLEIKGGGGSGGGGSGGGGSQVQLKESGPELEKPGASVKISCKASGYSFTAYSMNWVKQNNGMSLEWIGSIDPYYGDTKYAQKFKGKATLTVDKASSTAYLQLKSLTSEDSAVYYCARRMITTGDWYFDVWGTGTTVTVSSSGTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYKQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD5-9H2L-3048 scFv 아미노산 서열 (서열번호 79)
GSQVQLKESGPELEKPGASVKISCKASGYSFTAYSMNWVKQNNGMSLEWIGSIDPYYGDTKYAQKFKGKATLTVDKASSTAYLQLKSLTSEDSAVYYCARRMITTGDWYFDVWGTGTTVTVSSGGGGSGGGGSGGGGSHIVLTQSPSSLSASLGDRVTISCRASQDISTYLNWYQQKPDGTVKLLIFYTSRLHAGVPSRFSGSGSGTHHSLTISNLEQEDIATYFCQQGNSLPFTFGSGTKLEIKSG
CD5-9L2H-3049 scFv 아미노산 서열 (서열번호 80)
HIVLTQSPSSLSASLGDRVTISCRASQDISTYLNWYQQKPDGTVKLLIFYTSRLHAGVPSRFSGSGSGTHHSLTISNLEQEDIATYFCQQGNSLPFTFGSGTKLEIKGGGGSGGGGSGGGGSQVQLKESGPELEKPGASVKISCKASGYSFTAYSMNWVKQNNGMSLEWIGSIDPYYGDTKYAQKFKGKATLTVDKASSTAYLQLKSLTSEDSAVYYCARRMITTGDWYFDVWGTGTTVTVSS
CD5-9 VH 아미노산 서열 (서열번호 81)
QVQLKESGPELEKPGASVKISCKASGYSFTAYSMNWVKQNNGMSLEWIGSIDPYYGDTKYAQKFKGKATLTVDKASSTAYLQLKSLTSEDSAVYYCARRMITTGDWYFDVWGTGTTVTVSS
CD5-9 VL 아미노산 서열 (서열번호 82)
HIVLTQSPSSLSASLGDRVTISCRASQDISTYLNWYQQKPDGTVKLLIFYTSRLHAGVPSRFSGSGSGTHHSLTISNLEQEDIATYFCQQGNSLPFTFGSGTKLEIK
CD5-9 HCDR1 (서열번호 83)
AYSMN
CD5-9 HCDR2 (서열번호 84)
SIDPYYGDTKYAQKFKG
CD5-9 HCDR3 (서열번호 85)
RMITTGDWYFDV
CD5-9 LCDR1 (서열번호 86)
RASQDISTYLN
CD5-9 LCDR2 (서열번호 87)
YTSRLHA
CD5-9 LCDR3 (서열번호 88)
QQGNSLPFT
CD5-34H2L-3052 CAR 아미노산 서열 (서열번호 89)
MALPVTALLLPLALLLHAARPGSEVKLVESGAELVRSGASVKLSCAASGFNIKDYYIHWVKQRPEQGLEWIGWIDPENGRTEYAPKFQGKATMTADTSSNTAYLQLSSLTSEDTAVYYCNNGNYVRHYYFDYWGQGTTVTVSSGGGGSGGGGSGGGGSDWLTQSPAILSASPGEKVTMTCRAISSVSYMHWYQQKPGSSPKPWIYATSNLASGVPARFSGSGSGTSYSLTISRVEAEDAATYYCQQWSSNPRTFGGGTKLEIKSRTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCHMKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELTSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD5-34L2H-3053 CAR 아미노산 서열 (서열번호 90)
MALPVTALLLPLALLLHAARPGSDWLTQSPAILSASPGEKVTMTCRAISSVSYMHWYQQKPGSSPKPWIYATSNLASGVPARFSGSGSGTSYSLTISRVEAEDAATYYCQQWSSNPRTFGGGTKLEIKGGGGSGGGGSGGGGSEVKLVESGAELVRSGASVKLSCAASGFNIKDYYIHWVKQRPEQGLEWIGWIDPENGRTEYAPKFQGKATMTADTSSNTAYLQLSSLTSEDTAVYYCNNGNYVRHYYFDYWGQGTTVTVSSSRTTTPAPRPPTPAPTIASQPLSLRPEACRPAAGGAVHTRGLDFACDIYIWAPLAGTCGVLLLSLVITLYCHMKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELTSRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
CD5-34H2L-3052 scFv 아미노산 서열 (서열번호 91)
EVKLVESGAELVRSGASVKLSCAASGFNIKDYYIHWVKQRPEQGLEWIGWIDPENGRTEYAPKFQGKATMTADTSSNTAYLQLSSLTSEDTAVYYCNNGNYVRHYYFDYWGQGTTVTVSSGGGGSGGGGSGGGGSDWLTQSPAILSASPGEKVTMTCRAISSVSYMHWYQQKPGSSPKPWIYATSNLASGVPARFSGSGSGTSYSLTISRVEAEDAATYYCQQWSSNPRTFGGGTKLEIK
CD5-34L2H-3053 scFv 아미노산 서열 (서열번호 92)
DWLTQSPAILSASPGEKVTMTCRAISSVSYMHWYQQKPGSSPKPWIYATSNLASGVPARFSGSGSGTSYSLTISRVEAEDAATYYCQQWSSNPRTFGGGTKLEIKGGGGSGGGGSGGGGSEVKLVESGAELVRSGASVKLSCAASGFNIKDYYIHWVKQRPEQGLEWIGWIDPENGRTEYAPKFQGKATMTADTSSNTAYLQLSSLTSEDTAVYYCNNGNYVRHYYFDYWGQGTTVTVSS
CD5-34 VH 아미노산 서열 (서열번호 93)
EVKLVESGAELVRSGASVKLSCAASGFNIKDYYIHWVKQRPEQGLEWIGWIDPENGRTEYAPKFQGKATMTADTSSNTAYLQLSSLTSEDTAVYYCNNGNYVRHYYFDYWGQGTTVTVSS
CD5-34 VL 아미노산 서열 (서열번호 94)
DWLTQSPAILSASPGEKVTMTCRAISSVSYMHWYQQKPGSSPKPWIYATSNLASGVPARFSGSGSGTSYSLTISRVEAEDAATYYCQQWSSNPRTFGGGTKLEIKSR
CD5-34 HCDR1 (서열번호 95)
DYYIH
CD5-34 HCDR2 (서열번호 96)
WIDPENGRTEYAPKFQG
CD5-34 HCDR3 (서열번호 97)
GNYVRHYYFDY
CD5-34 LCDR1 (서열번호 98)
RAISSVSYMH
CD5-34 LCDR2 (서열번호 99)
ATSNLAS
CD5-34 LCDR3 (서열번호 100)
QQWSSNPRT
CRISPR/Cas
본 발명의 특정 실시양태는 CRISPR/Cas 시스템에 의해 변형된 세포를 포함한다. CRISPR/Cas 시스템은 CRISPR/Cas9 시스템 및 CRISPR/Cpfl 시스템을 포함하지만, 이들로 한정되지 않는다. 특정 실시양태에서, 본 발명은 CRISPR/Cas9 시스템을 사용하여 변형된 세포를 포함한다. 특정 실시양태에서, 변형은 내인성 유전자, 예를 들면, CD2, CD5 또는 CD7을 노킹-아웃(knocking-out) 또는 돌연변이시키는 것을 포함한다.
CRISPK/Cas9 시스템은 표적 유전자 변형을 유발하기 위한 간단하고 효율적인 시스템이다. Cas9 단백질에 의한 표적 인식은 가이드 RNA(gRNA 또는 sgRNA) 내의 "시드" 서열, 및 gRNA-결합 영역의 상류에 있는 프로토스페이서 인접 모티프(PAM) 서열을 함유하는 보존된 트리-뉴클레오티드를 필요로 한다. 따라서, CRISPR/Cas9 시스템은 세포주(293T 세포 등), 1차 세포 및 CAR T 세포에서 사용하기 위해 gRNA를 재설계함으로써 사실상 모든 DNA 서열을 절단하도록 조작될 수 있다. CRISPR/Cas 시스템은 단일 Cas9 단백질을 2개 이상의 gRNA와 공-발현시킴으로써 복수의 게놈 유전자좌를 동시에 표적화할 수 있고, 이 시스템은 복수의 유전자 편집 또는 표적 유전자의 상승적 활성화에 독자적으로 적합하다.
유전자 발현을 억제하는데 사용되는 CRISPR/Cas 시스템의 한 가지 예는 미국 공개 제US2014/0068797호에 기재되어 있고, 이는 참조에 의해 그 전체가 본원에 도입된다. CRISPRi는 RNA-유도 Cas9 엔도뉴클레아제를 이용하여 DNA 이본쇄 절단을 도입하는 영속적 유전자 파괴를 유발하고, 오류-빈발 수복 경로를 유발하여 프레임 시프트 돌연변이를 초래한다. 촉매적으로 사멸 Cas9는 엔도뉴클레아제 활성을 결여한다. 가이드 RNA와 공발현하면, 전사 신장, RNA 폴리머라제 결합, 또는 전사 인자 결합을 특이적으로 방해하는 DNA 인식 복합체가 생성된다. 이 CRISPRi 시스템은 표적화된 유전자의 발현을 효율적으로 억제한다.
CRISPR/Cas 유전자 파괴는 표적 유전자에 특이적인 가이드 핵산 서열 및 Cas 엔도뉴클레아제가 세포에 도입되어, Cas 엔도뉴클레아제가 표적 유전자에서 이본쇄 절단을 도입할 수 있는 복합체를 형성할 때에 발생한다. 특정 실시양태에서, CRISPR 시스템은 pAd5F35-CRISPR 벡터를 포함하지만 이들로 한정되지 않은 발현 벡터를 포함한다. 다른 실시양태에서, Cas 발현 벡터는 Cas9 엔도뉴클레아제의 발현을 유도한다. 다른 엔도뉴클레아제는 Cpf1, T7, Cas3, Cas8a, Cas8b, Cas10d, Cse1, Csy1, Csn2, Cas4, Cas10, Csm2, Cmr5, Fok1, 당해 기술분야에 공지된 다른 뉴클레아제, 및 이들의 임의의 조합을 포함하지만 이들로 한정되지 않는 다른 엔도뉴클레아제를 사용할 수도 있다.
특정 실시양태에서, Cas 발현 벡터를 유도하는 것은 Cas 발현 벡터에서 유도성 프로모터를 활성화시키는 약제에 세포를 노출시키는 것을 포함한다. 이러한 실시양태에서, Cas 발현 벡터는 항생제(예를 들면, 테트라사이클린 또는 테트라사이클린의 유도체, 예를 들면, 독시사이클린)에 노출시킴으로써 유도가능한 것 등의 유도성 프로모터를 포함한다. 그러나, 다른 유도성 프로모터가 사용될 수 있다는 것을 이해해야 한다. 유도제는 유도성 프로모터의 유도를 초래하는 선택적 조건(예를 들면, 약제, 예를 들면, 항생제에 대한 노출)일 수 있다. 이는 Cas 발현 벡터의 발현을 초래한다.
가이드 핵산 서열은 유전자에 특이적이고, Cas 엔도뉴클레아제-유도된 이본쇄 절단을 위해 그 유전자를 표적화한다. 가이드 핵산 서열의 서열은 유전자좌 내에 존재할 수 있다. 한 가지 실시양태에서, 가이드 핵산 서열은 적어도 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40 뉴클레오티드 이상의 길이이다.
가이드 핵산 서열은 임의의 유전자, 예를 들면, CD2, CD5, CD7에 특이적일 수 있다. 가이드 핵산 서열은 RNA 서열, DNA 서열, 이들의 조합(RNA-DNA 조합 서열), 또는 합성 뉴클레오티드를 갖는 서열을 포함한다. 가이드 핵산 서열은 단일 분자 또는 이중 분자일 수 있다. 한 가지 실시양태에서, 가이드 핵산 서열은 단일 가이드 RNA를 포함한다.
CRISPR 복합체의 형성의 문맥에서, "표적 서열"은 가이드 서열이 일부 상보성을 갖도록 설계되는 서열을 지칭하고, 표적 서열 및 가이드 서열 사이의 하이브리드화는 CRISPR 복합체의 형성을 촉진한다. 하이브리드화를 유발하고 CRISPR 복합체의 형성을 촉진하기에 충분한 상보성이 제공되면, 완전한 상보성은 반드시 필요한 것은 아니다. 표적 서열은 DNA 또는 RNA 폴리뉴클레오티드 등의 임의의 폴리뉴클레오티드를 포함할 수 있다. 특정 실시양태에서, 표적 서열은 세포의 핵 또는 세포질에 위치한다. 다른 실시양태에서, 표적 서열은 진핵 세포의 세포 소기관, 예를 들면, 미토콘드리아 또는 핵 내에 존재할 수 있다. 전형적으로, 내인성 CRISPR 시스템의 문맥에서, CRISPR 복합체(표적 서열과 하이브리드화하고, 하나 이상의 Cas 단백질과 복합체화된 가이드 서열을 포함함)의 형성은 표적 서열내 또는 그 근방(예를 들면, 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50 또는 그 이상의 염기쌍내)의 일방 또는 양방의 가닥의 절단을 초래한다. 표적 서열과 같이, 이것이 기능하기에 충분하면, 완전한 상보성은 필요하지 않은 것으로 여겨진다. 특정 실시양태에서, tracr 서열은, 최적으로 정렬되는 경우, tracr 메이트 서열의 길이를 따라 적어도 50%, 60%, 70%, 80%, 90%, 95% 또는 99%의 서열 상보성을 갖는다.
다른 실시양태에서, CRISPR 시스템의 하나 이상의 요소의 발현을 유도하는 하나 이상의 벡터는, CRISPR 시스템의 요소의 발현이 하나 이상의 표적 부위에서의 CRISPR 복합체의 형성을 지시하도록, 숙주 세포 내로 도입된다. 예를 들면, Cas 효소, tracr-메이트 서열에 연결된 가이드 서열, 및 tracr 서열은 각각 별개의 벡터 상의 별개의 조절 요소에 작동적으로 연결될 수 있다. 또는, 동일하거나 상이한 조절 요소로부터 발현되는 2개 이상의 요소를 단일 벡터에 조합시킬 수 있고, 하나 이상의 추가 벡터는 제1 벡터에 포함되지 않은 CRISPR 시스템의 임의의 성분을 제공한다. 단일 벡터에 조합된 CRISPR 시스템 요소는 제2 요소의 ("상류")에 대해 5' 또는 ("하류")에 대해 3'에 위치하는 하나의 요소 등의 임의의 적절한 배향으로 배열될 수 있다. 하나의 요소의 코딩 서열은 제2 요소의 코딩 서열의 동일하거나 반대의 가닥 상에 위치할 수 있고, 동일하거나 반대 방향으로 배향될 수 있다. 특정 실시양태에서, 단일 프로모터는 CRISPR 효소 및 하나 이상의 가이드 서열, tracr 메이트 서열(임의로 가이드 서열에 작동적으로 연결된) 및 하나 이상의 인트론 서열 내에 매립된 tracr 서열(예를 들면, 각각이 상이한 인트론에 있거나, 2개 이상이 적어도 하나의 인트론에 있거나, 모두가 하나의 인트론에 있다)을 코딩하는 전사물의 발현을 유도한다.
특정 실시양태에서, CRISPR 효소는 하나 이상의 이종 단백질 도메인(예를 들면, CRISPR 효소 외에 약 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 또는 그 이상의 도메인)을 포함하는 융합 단백질의 일부이다. CRISPR 효소 융합 단백질은 임의의 추가적인 단백질 서열, 및 임의로 임의의 2개 도메인 사이의 링커 서열을 포함할 수 있다. CRISPR 효소에 융합될 수 있는 단백질 도메인의 예는, 제한 없이, 에피토프 태그, 리포터 유전자 서열, 및 하기 활성 중 하나 이상을 갖는 단백질 도메인을 포함한다: 메틸라제 활성, 데메틸라제 활성, 전사 활성화 활성, 전사 억제 활성, 전사 방출 인자 활성, 히스톤 변형 활성, RNA 절단 활성 및 핵산 결합 활성. CRISPR 효소를 포함하는 융합 단백질의 일부를 형성할 수 있는 추가 도메인은 참조에 의해 본원에 도입되는 US20110059502에 기재되어 있다. 특정 실시양태에서, 태그된 CRISPR 효소는 표적 서열의 위치를 동정하기 위해 사용된다.
종래의 바이러스 및 비-바이러스 기반 유전자 전달 방법을 사용하여, 포유동물 세포 또는 표적 조직에 핵산을 도입할 수 있다. 이러한 방법은 CRISPR 시스템의 성분을 코딩하는 핵산을 배양 중의 세포 또는 숙주 생물에 투여하기 위해 사용될 수 있다. 비-바이러스 벡터 전달 시스템은 DNA 플라스미드, RNA(예를 들면. 본원에 기재된 벡터의 전사물), 네이키드 핵산, 및 리포좀 등의 전달 비히클과 복합체를 형성하는 핵산을 포함한다. CRISPR/Cas9에 대한 또 다른 전달 모드는 RNA와, Cas9-가이드 RNA 리보뉴클레오티드 단백질(RNP) 복합체 형태의 정제된 Cas9 단백질의 조합을 포함한다[참조: Lin et al, 2014, ELife 3:e04766]. 바이러스 벡터 전달 시스템은 세포에의 전달 후에 에피좀 또는 통합 게놈 중 어느 하나를 갖는 DNA 및 RNA 바이러스를 포함한다[참조: Anderson, 1992, Science 256:808-813; and Yu et al., 1994, Gene Therapy 1:13-26].
특정 실시양태에서, CRISPR/Cas는 유형 II CRISPR/Cas 시스템으로부터 유래된다. 다른 실시양태에서, CRISPR/Cas 시스템은 Cas9 단백질로부터 유래된다. Cas9 단백질은 스트렙토코커스 피오게네스(Streptococcus pyogenes), 스트렙토코커스 써모필러스(Streptococcus thermophilus) 또는 다른 종일 수 있다. 특정 실시양태에서, Cas9는 spCas9, Cpfl, CasY, CasX 또는 saCas9를 포함할 수 있다.
일반적으로, CRISPR/Cas 단백질은 적어도 하나의 RNA 인식 및/또는 RNA 결합 도메인을 포함한다. RNA 인식 및/또는 RNA 결합 도메인은 가이드 RNA와 상호작용한다. CRISPR/Cas 단백질은 또한 뉴클레아제 도메인(즉, DNase 또는 RNase 도메인), DNA 결합 도메인, 헬리카제 도메인, RNAase 도메인, 단백질-단백질 상호작용 도메인, 이량체화 도메인, 게다가 기타 도메인을 포함할 수 있다. CRISPR/Cas 단백질은 핵산 결합의 친화성 및/또는 특이성을 증가시키고, 효소 활성을 변경하고/하거나, 단백질의 다른 특성을 변경하도록 변형될 수 있다. 특정 실시양태에서, 융합 단백질의 CRISPR/Cas-유사 단백질은 야생형 Cas9 단백질 또는 이의 단편으로부터 유래할 수 있다. 다른 실시양태에서, CRISPR/Cas는 변형된 Cas9 단백질로부터 유래할 수 있다. 예를 들면, Cas9 단백질의 아미노산 서열은 단백질의 하나 이상의 특성(예를 들면, 뉴클레아제 활성, 친화성, 안정성 등)을 변경하도록 변형될 수 있다. 또는, RNA-유도 절단에 관여하지 않은 Cas9 단백질의 도메인을 단백질로부터 제거하여, 변형된 Cas9 단백질이 야생형 Cas9 단백질보다 작도록 할 수 있다. 일반적으로, Cas9 단백질은 적어도 2개의 뉴클레아제(즉, DNase) 도메인을 포함한다. 예를 들면, Cas9 단백질은 RuvC-유사 뉴클레아제 도메인 및 HNH-유사 뉴클레아제 도메인을 포함할 수 있다. Ruvac 및 HNH 도메인은 함께 일본쇄를 절단하고, DNA에서 이본쇄 절단을 수행한다[참조: Jinek et al., 2012, Science, 337:816-821]. 특정 실시양태에서, Cas9-유래된 단백질은 단지 하나의 기능적 뉴클레아제 도메인(RuvC-유사 또는 HNH-유사 뉴클레아제 도메인)만을 함유하도록 변형될 수 있다. 예를 들면, Cas9-유래된 단백질은 뉴클레아제 도메인 중 하나가 결실 또는 돌연변이되어 더 이상 기능하지 않도록 변형될 수 있다(즉, 뉴클레아제 활성이 존재하지 않는다). 뉴클레아제 도메인들 중 하나가 불활성인 일부 실시양태에서, Cas9-유래된 단백질은 이본쇄 핵산(이러한 단백질은 "닉카제"로 지칭됨)에 닉을 도입할 수 있지만, 이본쇄 DNA를 절단할 수는 없다. 상기 기재된 실시양태에서, 임의의 또는 모든 뉴클레아제 도메인은, 부위-특이적 돌연변이유발, PCR-매개된 돌연변이유발, 및 전체 유전자 합성, 게다가 당해 기술분야에 공지되어 있는 기타 방법 등의 공지된 방법을 사용하여, 하나 이상의 결실 돌연변이, 삽입 돌연변이 및/또는 치환 돌연변이에 의해 불활성화시킬 수 있다,
하나의 비제한적 실시양태에서, 벡터는 CRISPR 시스템의 발현을 유도한다. 당해 기술분야에는 본 발명에 유용한 적절한 벡터가 풍부하다. 사용되는 벡터는 진핵 세포에서의 복제 및 임의로 통합에 적합하다. 전형적 벡터는, 목적하는 핵산 서열의 발현의 조절에 유용한 전사 및 번역 터미네이터, 개시 서열 및 프로모터를 함유한다. 본 발명의 벡터는 또한 핵산 표준 유전자 전달 프로토콜에 사용될 수 있다. 유전자 전달을 위한 방법은 당해 기술분야에 공지되어 있다(미국 특허 제5,399,346호, 제5,580,859호 및 제5,589,466호, 그 전체가 참조에 의해 본원에 도입됨).
또한, 벡터는 바이러스 벡터의 형태로 세포에 제공될 수 있다. 바이러스 벡터 기술은 당해 기술분야에 공지되어 있고, 예를 들면, 문헌[참조: Sambrook et al. (4th Edition, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York, 2012] 및 기타 바이러스학 및 분자생물학 매뉴얼에 기재되어 있다. 벡터로서 유용한 바이러스는 레트로바이러스, 아데노바이러스, 아데노-관련 바이러스, 헤르페스 바이러스, 신드비스 바이러스, 감마레트로바이러스 및 렌티바이러스를 포함하지만, 이들로 한정되지 않는다. 일반적으로, 적합한 벡터는 적어도 하나의 유기체에서 기능적 복제 기점, 프로모터 서열, 편리한 제한 엔도뉴클레아제 부위 및 하나 이상의 선택가능한 마커를 함유한다(예를 들면, WO 01/96584; WO 01/29058; 및 미국 특허 제6,326,193호).
핵산의 도입
핵산을 세포에 도입하는 방법은 물리적, 생물학적 및 화학적 방법을 포함한다. RNA 등의 폴리뉴클레오티드를 숙주 세포에 도입하는 물리적 방법은 칼슘 포스페이트 침전, 리포펙션, 입자 충격, 미세주입, 전기천공 등을 포함한다. RNA는 전기천공(Amaxa Nucleofector-II (Amaxa Biosystems, Cologne, Germany)), (ECM 830 (BTX)(Harvard Instruments, Boston, Mass.), 또는 Gene Pulser II(BioRad, Denver, Colo.), Multiporator(Eppendort, Hamburg Germany)를 포함하는 상업적으로 이용가능한 방법을 사용하여 표적 세포 도입할 수 있다. RNA는 또한 리포펙션을 사용한 양이온성 리포좀 매개 형질감염을 사용하여, 폴리머 캡슐화를 사용하여, 펩티드 매개된 형질감염을 사용하여, 또는 "유전자 총" 등의 생물학적 입자 전달 시스템을 사용하여 세포에 도입할 수 있다[참조: 예를 들면, Nishikawa, et al. Hum Gene Ther., 12(8):861-70 (2001)].
목적의 폴리뉴클레오티드를 숙주 세포에 도입하기 위한 생물학적 방법은 DNA 및 RNA 벡터의 사용을 포함한다. 바이러스 벡터, 및 특히 레트로바이러스 벡터는 포유동물, 예를 들면, 인간 세포에 유전자를 삽입하기 위한 가장 광범위하게 사용되는 방법이다. 다른 바이러스 벡터는 렌티바이러스, 폭스바이러스, 헤르페스 심플렉스 바이러스 I, 아데노바이러스 및 아데노-관련 바이러스 등으로부터 유래할 수 있다[참조: 예를 들면, 미국 특허 제5,350,674호 및 제5,585,36.2호].
폴리뉴클레오티드를 숙주 세포에 도입하기 위한 화학적 수단은 거대분자 복합체, 나노캡슐, 미소구체, 비드 등의 콜로이드성 분산 시스템, 및 수중유 에멀젼, 미셀, 혼합된 미셀 및 리포좀을 포함하는 지질 기반 시스템을 포함한다. 시험관내 및 생체내 전달 비히클로서 사용하기 위한 예시적 콜로이드 시스템은 리포좀(예를 들면, 인공 막 소포)이다.
사용에 적합한 지질은 상업적 공급원으로부터 수득될 수 있다. 예를 들면, 디메리스틸 포스파티딜콜린("DMPC")은 시그마(Sigma, St. Louis, MO)로부터 입수할 수 있고; 디세틸 포스페이트("DCP")는 K&K 라보라토리즈(Plainview, NY)로부터 입수할 수 있고; 콜레스테롤("Choi")은 칼바이오켑-베링(Calbiochem-Behring)으로부터 입수할 수 있고; 디미리스틸 포스파티딜글리세롤("DMPG") 및 기타 지질은 아방티 폴라 리피드스, 인코포레이티드(Avanti Polar Lipids, Inc., Birmingham, AL)로부터 입수할 수 있다. 클로로포름 또는 클로로포름/메탄올중의 지질의 스톡 용액은 약 -20℃에서 저장될 수 있다. 클로로포름은 메탄올보다 더 쉽게 증발되기 때문에 유일한 용매로서 사용된다. 리포좀은, 봉입된 지질 이중층 또는 응집체의 생성에 의해 형성되는 다양한 단일 및 다층 지질 비히클을 포괄하는 총칭이다. 리포좀은 인지질 이중막 및 내부 수성 매체를 구비한 소포 구조를 갖는 것으로 특징지워질 수 있다. 다층 리포좀은 수성 매체에 의해 분리된 복수의 지질층을 갖는다. 이들은 인지질이 과량의 수용액에 현탁될 때에 자발적으로 형성된다. 지질 성분은 폐쇄 구조의 형성 전에 자가-재배열하고, 지질 이중층 사이에 물 및 용해된 용질을 포획할 수 있다[참조: Ghosh et al., 1991 Glycobiology 5: 505-10]. 그러나, 정상 소포 구조로는 용액 중에서 상이한 구조를 갖는 조성물도 포함된다. 예를 들면, 지질은 미셀 구조를 가정하지만, 지질 분자의 불균일한 응집체로서 단순히 존재할 수 있다. 또한, 리포펙타민-핵산 복합체도 고려된다.
외인성 핵산을 숙주 세포에 도입하거나, 그렇지 않으면 세포를 본 발명의 억제제에 노출시키기 위해 사용되는 방법과 무관하게, 숙주 세포에서 핵산의 존재를 확인하기 위해, 다양한 검정을 실시할 수 있다. 이러한 검정에는, 예를 들면, 서던 및 노던 블롯팅, RT-PCR 및 PCR 등의 당업자에게 공지된 "분자 생물학적" 검정; 특정의 펩티드의 존재 또는 부재를 검출하는 등의 "생화학적" 검정, 예를 들면, 면역학적 수단(ELISA 및 웨스턴 블롯) 또는 본 발명의 범위 내에 있는 약제를 동정하기 위한 본원에 기재된 검정에 의한 것을 포함한다.
또한, 핵산은 확장된 T 세포를 형질도입하고, 확장된 T 세포를 형질감염시키고, 확장된 T 세포를 전기천공하는 것 등의 임의의 수단에 의해 도입될 수 있다. 하나의 핵산은 하나의 방법에 의해 도입될 수 있고, 다른 핵산은 다른 방법에 의해 T 세포에 도입될 수 있다.
RNA
한 가지 실시양태에서, T 세포에 도입된 핵산은 RNA이다. 또 다른 실시양태에서, RNA는 시험관내 전사된 RNA 또는 합성 RNA를 포함하는 mRNA이다. RNA는 폴리머라제 연쇄 반응(PCR)-생성된 주형을 사용하여 시험관내 전사에 의해 생성된다. 임의의 공급원으로부터의 목적의 DNA는 적절한 프라이머 및 RNA 폴리머라제를 사용하여, PCR에 의해 시험관내 mRNA 합성용의 주형에 직접 전환될 수 있다. DNA의 공급원은, 예를 들면, 게놈 DNA, 플라스미드 DNA, 파지 DNA, cDNA, 합성 DNA 서열 또는 임의의 다른 적합한 DNA의 공급원일 수 있다. 시험관내 전사를 위한 목적의 주형은 키메라 막 단백질이다. 예로서, 주형은 항체, 항체의 단편 또는 항체의 일부를 코딩한다. 또 다른 예로서, 주형은, 항-CD3 등의 항체의 단일 쇄 가변 도메인을 포함하는 세포외 도메인, 및 공자극 분자의 세포내 도메인을 포함한다. 한 가지 실시양태에서, RNA 키메라 막 단백질을 위한 주형은, 공자극 분자에 대한 항체로부터 유래하는 항원 결합 도메인을 포함하는 세포외 도메인, 및 CD28 및 4-1BB의 세포내 도메인의 일부로부터 유래하는 세포외 도메인을 포함하는 키메라 막 단백질을 코딩한다.
PCR을 사용하여, mRNA의 시험관내 전사를 위한 주형을 생성하고, 이를 세포에 도입할 수 있다. PCR을 실시하기 위한 방법은 당해 기술분야에 공지되어 있다. PCR에 사용하기 위한 프라이머는 PCR에 대한 주형으로서 사용되는 DNA의 영역에 실질적으로 상보적인 영역을 갖도록 설계된다. 본원에 사용된 바와 같이, "실질적으로 상보적"은, 프라이머 서열 중의 염기의 대부분 또는 전부가 상보적이거나, 하나 이상의 염기가 비-상보적이거나, 또는 부정합인 뉴클레오티드의 서열을 지칭한다. 실질적으로 상보적 서열은 PCR에 사용되는 어닐링(annealing) 조건하에서 목적의 DNA 표적과 어닐링 또는 하이브리드화할 수 있다. 프라이머는 DNA 주형의 임의의 부분에 실질적으로 상보적이도록 설계될 수 있다. 예를 들면, 프라이머는 5' 및 3' UTR을 포함하는, 세포 내에서 통상 전사되는 유전자의 일부(개방 판독 프레임)를 증폭하도록 설계될 수 있다. 프라이머는 또한 목적의 특정 도메인을 코딩하는 유전자의 일부를 증폭하도록 설계될 수 있다. 한 가지 실시양태에서, 프라이머는 5' 및 3' UTR의 전부 또는 일부를 포함하는, 인간 cDNA의 코딩 영역을 증폭하도록 설계된다. PCR에 유용한 프라이머는 당해 기술분야에 공지된 합성 방법에 의해 생성된다. "정방향 프라이머"는 증폭될 DNA 서열의 상류에 있는 DNA 주형 상의 뉴클레오티드와 실질적으로 상보적인 뉴클레오티드의 영역을 함유하는 프라이머이다. "상류"는, 본원에서, 코딩 가닥에 대하여 증폭되는 DNA 서열의 위치 5를 지칭하기 위해 사용된다. "역방향 프라이머"는 증폭되는 DNA 서열의 하류에 있는 이본쇄 DNA 주형에 실질적으로 상보적인 뉴클레오티드의 영역을 함유하는 프라이머이다. "하류"는, 본원에서, 코딩 가닥에 대하여 증폭되는 DNA 서열의 3' 위치를 지칭하기 위해 사용된다.
RNA의 안정성 및/또는 번역 효율을 촉진시키는 능력을 갖는 화학 구조도 또한 사용될 수 있다. RNA는 바람직하게는 5' 및 3' UTR을 갖는다. 한 가지 실시양태에서, 5' UTR은 길이가 0 내지 3000 뉴클레오티드이다. 코딩 영역에 추가되는 5' 및 3' UTR 서열의 길이는 UTR의 상이한 영역에 어닐링하는 PCR을 위한 프라이머의 설계를 포함하지만 이들로 한정되지 않는, 상이한 방법에 의해 변경될 수 있다. 이러한 접근법을 사용하여, 당업자는 전사된 RNA의 형질감염 후에 최적의 번역 효율을 달성하는데 필요한 5' 및 3' UTR 길이를 변경할 수 있다.
5' 및 3' UTR은 목적의 유전자의 자연적으로 발생하는 내인성 5' 및 3' UTR일 수 있다. 또는, 목적의 유전자에 대해 내인성이 아닌 UTR 서열은, UTR 서열을 정방향 및 역방향 프라이머에 도입함으로써 또는 주형의 임의의 다른 변형에 의해 추가할 수 있다. 목적의 유전자에 대해 내인성이 아닌 UTR 서열의 사용은 RNA의 안정성 및/또는 번역 효율을 개선하는데 유용할 수 있다. 예를 들면, 3' UTR 서열에서 AU-풍부 요소는 mRNA의 안정성을 저하시킬 수 있다는 것이 공지되어 있다. 따라서, 3' UTR은 당해 기술분야에 공지된 UTR의 특성에 기초하여 전사된 RNA의 안정성을 증가시키도록 선택되거나 설계될 수 있다.
한 가지 실시양태에서, 5' UTR은 내인성 유전자의 코작 서열을 포함할 수 있다. 또는, 목적의 유전자에 대해 내인성이 아닌 5' UTR이 상기한 바와 같이 PCR에 의해 부가되는 경우, 컨센서스 코작 서열은 5' UTR 서열을 부가함으로써 재설계될 수 있다. 코작 서열은 일부 RNA 전사물의 번역 효율을 증가시킬 수 있지만, 효율적인 번역을 가능하게 하기 위해 모든 RNA에 필요한 것은 아니다. 다수의 mRNA에 대한 코작 서열의 요건은 당해 기술분야에 공지되어 있다. 다른 실시양태에서, 5' UTR은 RNA 게놈이 세포 내에서 안정한 RNA 바이러스로부터 유래될 수 있다. 다른 실시양태에서, 다양한 뉴클레오티드 유사체를 3' 또는 5' UTR에서 사용하여, mRNA의 엑소뉴클레아제 분해를 방해할 수 있다.
유전자 클로닝을 필요로 하지 않고서 DNA 주형으로부터 RNA의 합성을 가능하게 하기 위해, 전사 프로모터를 전사되는 서열의 상류의 DNA 주형에 부착하여야 한다. RNA 폴리머라제의 프로모터로서 기능하는 서열이 정방향 프라이머의 5' 말단에 부가되는 경우, RNA 폴리머라제 프로모터는 전사되는 개방 판독 프레임의 상류에 있는 PCR 생성물에 도입된다. 한 가지 실시양태에서, 프로모터는, 본원의 다른 곳에서 기재된 바와 같이, T7 폴리머라제 프로모터이다. 다른 유용한 프로모터는 T3 및 SP6 RNA 폴리머라제 프로모터를 포함하지만, 이들로 한정되지 않는다. T7, T3 및 SP6 프로모터의 컨센서스 뉴클레오티드 서열은 당해 기술분야에 공지되어 있다.
한 가지 실시양태에서, mRNA는, 세포 내의 리포좀 결합, 번역의 개시 및 안정성 mRNA를 결정하는 5' 및 및 3' 폴리(A) 테일의 양방에 캡을 갖는다. 환상 DNA 주형, 예를 들면, 플라스미드 DNA에서, RNA 폴리머라제는 진핵 세포에서의 발현에 적합하지 않은 긴 콘카테머 생성물(concatemeric product)을 생성한다. 3' UTR의 말단에서 선형화된 플라스미드 DNA의 전사는 정상 크기의 mRNA를 초래하고, 이는 전사 후에 폴리아데닐화된 경우에도 진핵생물의 형질감염에는 효과적이지 않다.
선형 DNA 주형에서, 파지 T7 RNA 폴리머라제는 전사물의 3' 말단을 주형의 최후의 염기를 초과하여 신장할 수 있다[참조: Schenborn and Mierendorf, Nuc Acids Res., 13:6223-36 (1985); Nacheva and Berzal-Herranz, Eur. J. Biochem., 270:1485-65 (2003)].
폴리A/T 스트레치를 DNA 주형에 통합하는 종래의 방법은 분자 클로닝이다. 그러나, 플라스미드 DNA에 통합된 폴리A/T 서열은 플라스미드의 불안정성을 야기할 수 있고, 이 때문에, 세균 세포로부터 수득된 플라스미드 DNA 주형은 종종 결실 및 기타 이상으로 고도로 오염된다. 이에 의해, 클로닝 작성 절차가 성가시고 시간 소모적일 뿐만 아니라 종종 신뢰성이 낮아진다. 이 때문에, 클로닝하지 않고서 폴리A/T 3' 스트레치로 DNA 주형을 작제할 수 있는 방법이 매우 바람직한 것이다.
전사 DNA 주형의 폴리A/T 세그먼트는, 100 T 테일(크기는 50 내지 5000T) 등의 폴리 T 테일을 함유하는 역방향 프라이머를 사용함으로써 PCR 중에 생성되거나, 제한 없이, DNA 결찰 또는 시험관내 재조합을 포함하는 임의의 기타 방법에 의해 생성될 수 있다. 폴리(A) 테일은 또한 RNA에 안정성을 제공하고, 이들의 분해를 감소시킨다. 일반적으로, 폴리(A) 테일의 길이는 전사된 RNA의 안정성과 양으로 상관된다. 한 가지 실시양태에서, 폴리(A) 테일은 100 내지 5000 아데노신이다.
RNA의 폴리(A) 테일은 이. 콜라이 폴리A 폴리머라제(E-PAP) 등의 폴리(A) 폴리머라제를 사용하여 시험관내 전사 후에 추가로 확장될 수 있다. 한 가지 실시양태에서, 폴리(A) 테일의 길이를 100개 뉴클레오티드로부터 300 내지 400개 뉴클레오티드로 증가시키면, RNA의 번역 효율이 약 2배 증가된다. 또한, 3' 말단에 대한 상이한 화학 그룹의 부착은 mRNA의 안정성을 증가시킬 수 있다. 이러한 부착은 변형된/인공 뉴클레오티드, 앱타머 및 다른 화합물을 함유할 수 있다. 예를 들면, ATP 유사체는 폴리(A) 폴리머라제를 사용하여 폴리(A) 테일에 도입될 수 있다. ATP 유사체는 RNA의 안정성을 추가로 증가시킬 수 있다.
5' 캡은 또한 RNA 분자에 안정성을 제공한다. 바람직한 실시양태에서, 본원에 개시된 방법에 의해 생성되는 RNA는 5' 캡을 포함한다. 5' 캡은 당해 기술분야에 공지되고 본원에 기재되어 있는 기술을 사용하여 제공된다[참조: Cougot, et al., Trends in Biochem. Sci., 29:436-444 (2001); Stepinski, et al., RNA, 7:1468-95 (2001); Elango, et al., Biochim. Biophys. Res. Commun., 330:958-966 (2005)].
본원에 개시된 방법에 의해 생성된 RNA는 또한 내부 리보솜 진입 부위(IRES) 서열을 포함할 수 있다. IRES 서열은 mRNA에 대한 캡-독립적 리보솜 결합을 개시하고, 번역의 개시를 촉진하는 임의의 바이러스, 염색체 또는 인공적으로 설계된 서열일 수 있다. 당, 펩티드, 지질, 단백질, 산화방지제 및 계면활성제 등, 세포 투과성 및 생존력을 촉진하는 인자를 함유할 수 있는, 세포 전기천공에 적합한 임의의 용질이 포함될 수 있다.
일부 실시양태에서, RNA는 시험관내 전사된 RNA 등의 세포에 전기천공된다.
개시된 방법은, 표적 암 세포를 사멸시키는 유전자 변형된 T 세포의 능력을 포함하여, 암, 줄기 세포, 급성 및 만성 감염, 및 자가면역 질환의 분야에서, 기초 연구 및 치료에서 T 세포 활성의 조절에 적용할 수 있다.
본 방법은 또한, 예를 들면, 프로모터 또는 입력 RNA의 양을 변경시킴으로써 광범위에 걸쳐 발현 수준을 제어하는 능력을 제공하여, 발현 수준을 개별적으로 조절할 수 있다. 또한, mRNA 생성의 PCR-기반 기술은 상이한 구조 및 이들의 도메인의 조합을 갖는 mRNA의 설계를 대폭 촉진시킨다.
본 발명의 RNA 형질감염 방법의 한가지 장점은, RNA 형질감염이 본질적으로 일과성이고, 벡터를 함유하지 않는다는 것이다. RNA 도입유전자는 림프구에 전달되고, 단수한 시험관내 세포 활성화에 계속하여, 추가의 바이러스 서열의 부재하에 최소한의 발현 카세트로서 림프구에서 발현될 수 있다. 이러한 조건하에서, 도입유전자가 숙주 세포 게놈으로 통합하는 가능성은 낮아진다. RNA의 형질감염의 효율과 림프구 모집단 전체를 균일하게 변형시키는 이의 능력으로 인해, 세포의 클로닝은 필요하지 않다.
시험관내 전사된 RNA(IVT-RNA)에 의한 T 세포의 유전자 변형은 2개의 상이한 전략을 이용하고, 이들 둘 다는 다양한 동물 모델에서 연속적으로 시험된다. 세포는 리포펙션 또는 전기천공에 의해 시험관내 전사된 RNA로 형질감염된다. 전달된 IVT-RNA의 연장된 발현을 달성하기 위해, 다양한 변형을 사용하여 IVT-RNA를 안정화시키는 것이 바람직하다.
일부 IVT 벡터는 문헌에 공지되어 있고, 시험관내 전사의 주형으로서 표준화된 방식으로 사용되고, 안정화된 RNA 전사물이 생성되도록 유전적으로 변형되어 있다. 당해 기술분야에서 사용되는 현재 프로토콜은, 하기의 구조를 갖는 플라스미드 벡터에 기초한다: RNA 전사를 가능하게 하는 5' RNA 폴리머라제 프로모터, 이어서 비번역 영역(UTR)에 의해 3' 및/또는 5' 중 어느 하나에 인접하는 목적의 유전자, 및 50-70A 뉴클레오티드를 함유하는 3' 폴리아데닐 카세트. 시험관내 전사의 전에, 환상 플라스미드는 타입 II 제한 효소에 의해 폴리아데닐 카세트의 하류에서 선형화된다(인식 서열은 절단 부위에 대응함). 따라서, 폴리아데닐 카세트는 전사물에서 이후의 폴리(A) 서열에 대응한다. 이 절차의 결과로서, 일부 뉴클레오티드는 선형화 후에 효소 절단 부위의 일부로서 잔류하고, 3' 말단에서 폴리(A) 서열을 확장 또는 마스크한다. 이러한 비생리학적 오버행(overhang)이, 이러한 작제물로부터 세포내에서 생성된 단백질의 양에 영향을 미치는지는 명확하지 않다.
RNA는 종래의 플라스미드 또는 바이러스 접근법에 비해 몇 가지 장점을 갖는다. RNA 공급원으로부터의 유전자 발현은 전사를 필요로 하지 않고, 단백질 생성물은 형질감염 후에 신속하게 생성된다. 또한, RNA는 핵이 아닌 세포질에 접근할 뿐이기 때문에, 일반적 형질감염 방법은 매우 높은 형질감염율을 초래한다. 추가로, 플라스미드 기반 접근법은 목적 유전자의 발현을 유도하는 프로모터가 연구 중의 세포에서 활성화되는 것을 요구한다.
다른 측면에서, RNA 작제물은 전기천공에 의해 세포 내로 전달된다. 예를 들면, US 2004/0014645, US 2005/0052630A1, US 2005/0070841A1, US 2004/0059285A1, US 2004/0092907A1에 교시된 바와 같이, 핵산 작제물을 포유동물 세포로 전기천공하는 제형 및 방법을 참조한다. 임의의 공지된 세포 유형의 전기천공에 필요한 전기장 강도를 포함하는 다양한 파라미터는 관련 연구 문헌에서 공지되어 있고, 이 분야의 다수의 특허 및 응용에서 일반적으로 공지되어 있다. 예를 들면, 미국 특허 제6,678,556호, 미국 특허 제7,171,264호, 및 미국 특허 제7,173,116호를 참조한다. 전기천공의 치료 적용을 위한 장치는 상업적으로 입수가능하고(예를 들면, MedPulserTM DNA 전기천공 요법 시스템)(Inovio/Genetronics, San Diego, Calif.), 미국 특허 제6,567,694호; 미국 특허 제6,516,223호, 미국 특허 제5,993,434호, 미국 특허 제6,181,964호, 미국 특허 제6,241,701호 및 미국 특허 제6,233,482호 등의 특허에 기재되어 있고; 전기천공은 또한, 예를 들면, US20070128708A1에 기재된 바와 같이, 시험관내 세포의 형질감염에 사용될 수 있다. 또한, 전기천공은 시험관내에서 핵산을 세포에 전달하는데 이용될 수 있다. 따라서, 당해 기술분야의 당업자에게 공지된 다수의 이용가능한 장치 및 전기천공 시스템 중 임의의 것을 이용하는 발현 작제물을 포함하는 핵산의 세포 내로의 전기천공-매개 투여는 목적 RNA를 표적 세포에 전달하기 위한 자극적인 새로운 수단을 제공한다.
T 세포의 공급원
특정 실시양태에서, T 세포의 공급원은 대상체로부터 수득된다. 대상의 비제한적인 예는 사람, 개, 고양이, 마우스, 래트 및 이의 트랜스제닉 종을 포함한다. 바람직하게는, 상기 대상체는 인간이다. T 세포는 말초 혈액 단핵 세포, 골수, 림프절 조직, 비장 조직, 제대 및 종양을 포함하는 다수의 공급원으로부터 수득될 수 있다. 특정 실시양태에서, 당해 기술분야에서 이용가능한 임의의 수의 T 세포주를 사용할 수 있다. 특정 실시양태에서, T 세포는 피콜 분리 등의 당업자에게 공지된 임의의 수의 기술을 사용하여, 대상체로부터 수집된 혈액의 단위로부터 수득될 수 있다. 한 가지 실시양태에서, 개체의 순환 혈액으로부터 세포는 아페레시스 또는 백혈구 아페레시스에 의해 수득된다. 아페레시스 생성물은 전형적으로 T 세포, 단핵구, 과립구, B 세포, 기타 유핵 백혈구, 적혈구 및 혈소판을 포함하는 림프구를 포함한다. 아페레시스에 의해 수집된 세포는 혈장 분획을 제거하고, 세포를 인산 완충 생리식염수(PBS) 등의 적절한 완충액 또는 배지에서 배치하기 위해 세척할 수 있거나, 세척 용액은, 후속의 처리 단계를 위해 칼슘을 열여하고, 마그네슘을 결여하거나, 전부는 아니지만 다수의 2가 양이온을 결여할 수 있다. 세척 후, 세포는, 예를 들면, Ca-비함유, Mg-비함유 PBS 등의 다양한 생체적합성 완충액에 재현탁시킬 수 있다. 또는, 아페레시스 샘플의 바람직하지 않은 성분을 제거하고, 세포를 배양 배지에 직접 재현탁시킬 수 있다.
또 다른 실시양태에서, T 세포는 적혈구를 용해시키고, 예를 들면, PERCOLLTM 구배에 의한 원심분리에 의해 단핵구를 고갈시킴으로써 말초혈로부터 단리된다. 또는, T 세포는 제대로부터 단리될 수 있다. 임의의 경우에, T 세포의 특정 아집단은 포지티브 또는 네가티브 선택 기술에 의해 추가로 단리할 수 있다.
이와 같이 단리된 제대혈 단핵 세포는, CD34, CD8, CD14, CD19 및 CD56을 포함하지만 이들로 한정되지 않은 특정 항원을 발현하는 세포를 고갈시킬 수 있다. 이러한 세포의 고갈은, 단리된 항체, 복수 등의 항체, 물리적 지지체에 결합된 항체 및 세포 고갈 항체를 포함하는 생물학적 샘플을 사용하여 달성할 수 있다.
네가티브 선택에 의한 T 세포 모집단의 농후화는, 네가티브로 선택된 세포에 특유한 표면 마커로 지향된 항체의 조합을 사용하여 달성할 수 있다. 바람직한 방법은, 네가티브로 선택된 세포 상에 존재하는 세포 표면 마커로 지향된 모노클로날 항체의 칵테일을 사용하는 네가티브 자기 면역부착 또는 유세포 분석법에 의한 세포 선별 및/또는 선택이다. 예를 들면, 네가티브 선택에 의해 CD4 + 세포를 농후화하기 위해, 모노클로날 항체 칵테일은 통상 CD14, CD20, CDl1b, CD16, HLA-DR 및 CD8에 대한 항체를 포함한다.
포지티브 또는 네가티브 선택에 의한 목적 세포 모집단의 분리를 위해, 세포 및 표면(예를 들면, 비드 등의 입자)의 농도를 변화시킬 수 있다. 특정 실시양태에서, 세포 및 비드의 최대 접촉을 보장하기 위해, 비드 및 세포가 함께 혼합되는 용적을 대폭 감소(즉, 세포의 농도를 증가시킴)시키는 것이 바람직할 수 있다. 예를 들면, 한 가지 실시양태에서, 20억개 세포/ml의 농도가 사용된다. 한 가지 실시양태에서, 10억개 세포/ml의 농도가 사용된다. 추가의 실시양태에서, 1억개 초과의 세포/ml가 사용된다. 또 다른 실시양태에서, 10, 15, 20, 25, 30, 35, 40, 45 또는 50백만 세포/ml의 세포 농도가 사용된다. 또 다른 실시양태에서, 75, 80, 85, 90, 95 또는 100백만 세포/ml의 세포 농도가 사용된다. 추가의 실시양태에서, 125 또는 150백만 세포/ml의 농도가 사용될 수 있다. 고농도를 사용하면, 세포 수율, 세포 활성화 및 세포 확장을 증가시킬 수 있다.
또한, T 세포는 단핵구 제거 단계를 필요로 하지 않는 세척 단계 후에 동결될 수 있다. 이론에 의해 제한되는 것은 아니지만, 동결 및 후속 해동 단계는 세포 모집단의 과립구 및 어느 정도의 단핵구를 제거함으로써 보다 균일한 생성물을 제공한다. 혈장 및 혈소판을 제거하는 세척 단계의 후에, 세포를 동결 용액에 현탁시킬 수 있다. 다수의 동결 용액 및 파라미터가 당해 기술분야에 공지되어 있고, 이러한 문맥에서 유용하지만, 비제한적인 예에서, 한 가지 방법은 20% DMSO 및 8% 인간 혈청 알부민을 함유하는 PBS, 또는 다른 적합한 세포 동결 배지를 사용하는 것을 포함한다. 이어서, 세포를 분당 1℃의 속도로 -80℃로 동결시키고, 액체 질소 저장 탱크의 기상에 저장한다. 제어된 동결의 다른 방법, 뿐만 아니라 -20℃ 또는 액체 질소에서의 제어되지 않은 즉시 동결을 사용할 수도 있다.
한 가지 실시양태에서, T 세포의 모집단은 말초 혈액 단핵 세포, 제대 혈액 세포, 정제된 T 세포의 모집단, 및 T 세포주 등의 세포 내에 포함된다. 다른 실시양태에서, 말초 혈액 단핵 세포는 T 세포의 모집단을 포함한다. 또 다른 실시양태에서, 정제된 T 세포는 T 세포의 모집단을 포함한다.
T 세포의 확장
특정 실시양태에서, 본원에 개시된 T 세포는 약 10배, 20배, 30배, 40배, 50배, 60배, 70배, 80배, 90배, 100배, 200배, 300배, 400배, 500배, 600배, 700배, 800배, 900배, 1000배, 2000배, 3000배, 4000배, 5000배, 6000배, 7000배, 8000배, 9000배, 10,000배, 100,000배, 1,000,000배, 10,000,000배 또는 그 이상, 및 이들 사이의 모든 정수 또는 부분 정수배 증식할 수 있다. 한 가지 실시양태에서, T 세포는 약 20배 내지 약 50배의 범위로 확장한다.
배양 후, T 세포를 배양 장치 내의 세포 배지에서 일정 기간, 또는 세포를 다른 배양 장치로 통과시키기 전에 최적 계대를 위해 세포가 컨플루언시(confluency) 또는 높은 세포 밀도에 도달할 때까지 인큐베이팅(incubating)할 수 있다. 배양 장치는 시험관내에서 세포를 배양하기 위해 일반적으로 사용되는 임의의 배양 장치일 수 있다. 바람직하게는, 컨플루언스 수준은 세포를 다른 배양 장치에 통과시키기 전에 70% 이상이다. 더욱 바람직하게는, 컨플루언스의 수준은 90% 이상이다. 소정 기간은 시험관내에서 세포의 배양에 적합한 임의의 시간일 수 있다. T 세포 배지는 T 세포의 배양 중에 언제든지 교환할 수 있다. 바람직하게는, T 세포 배지는 약 2 내지 3일마다 교환했다. 이어서, T 세포를 배양 장치로부터 회수하고, 이어서 T 세포를 즉시 사용하거나, 이후에 사용하기 위해 저정하기 위해 동결보존할 수 있다. 한 가지 실시양태에서, 본 발명은 확장된 T 세포를 동결보존하는 것을 포함한다. 동결보존된 T 세포는 T 세포에 핵산을 도입하기 전에 해동된다.
또 다른 실시양태에서, 상기 방법은 T 세포를 단리하고, T 세포를 확장시키는 것을 포함한다. 또 다른 실시양태에서, 본 발명은 확장 전에 T 세포를 동결보존하는 것을 추가로 포함한다. 또 다른 실시양태에서, 동결보존된 T 세포는 키메라 막 단백질을 코딩하는 RNA를 사용한 전기천공을 위해 해동된다.
생체외 확장 세포를 위한 또 다른 절차는 미국 특허 제5,199,942호에 기재되어 있다. 미국 특허 제5,199,942호(참조에 의해 본원에 도입됨)에 기재된 것과 같은 확장은 본원에 기재되어 있는 기타 확장 방법의 대안 또는 추가일 수 있다. 요약하면, T 세포의 생체외 배양 및 확장은 미국 특허 제5,199,942호에 기재된 바와 같은 세포 성장 인자, 또는 flt3-L, IL-1, IL-3 및 c-키트 리간드 등의 다른 인자에 대한 첨가를 포함한다. 한 가지 실시양태에서, T 세포를 확장시키는 것은 flt3-L, IL-1, IL-3 및 c-키트 리간드로 이루어진 그룹으로부터 선택된 인자를 사용하여 T 세포를 배양하는 것을 포함한다.
본원에 기재된 배양 단계(본원에 기재된 약제와의 접촉 또는 전기천공후)는 매우 짧고, 예를 들면, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 또는 23시간일 수 있다. 본원에 추가로 기재된 바와 같은 배양 단계는, 예를 들면, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 또는 그 이상의 일일 수 있다.
배양 중의 세포를 설명하기 위해 다양한 용어가 사용된다. 세포 배양은 일반적으로 살아있는 생물체로부터 채취되고, 제어된 조건하에서 성장하는 세포를 지칭한다. 1차 세포 배양은, 최초의 계대 배양 전에, 생물체로부터 직접 채취한 세포, 조직 또는 기관의 배양이다. 세포는, 세포 성장 및/또는 분열을 촉진하는 조건하에서 성장 배지에 배치되면, 배양에서 확장되어, 세포의 더 큰 모집단을 초래한다. 세포가 배양에서 확장되는 경우, 세포 증식의 속도는 통상 세포의 수가 2배로 되는데 필요한 시간(배가 시간으로도 공지되어 있음)에 의해 측정된다.
계대배양의 각 라운드는 계대라고 지칭된다. 세포가 계대배양될 때, 이들은 계대되는 것으로 지칭된다. 세포의 특정 모집단 또는 세포주는 때때로 계대되어 있는 회수를 지칭 또는 특징으로 한다. 예를 들면, 10회 계대된 배양 세포 모집단은 P10 배양으로서 지칭될 수 있다. 초대 배양, 즉 조직으로부터 세포를 단리한 후의 최초의 배양은 P0로 표시된다. 최초 계대배양에 이어서, 세포는 2차 배양(P1 또는 계대 1)으로 기재된다. 2회차 계대배양 후, 세포는 3차 배양(P2 또는 계대 2)으로 된다. 당업자는, 계대 기간 중에 다수의 모집단이 배증할 수 있음을 이해할 것이고; 따라서 배양물의 모집단 배증의 수는 계대 수보다 더 크다. 계대 사이의 기간 중의 세포의 확장(즉, 모집단 배가의 수)은 파종 밀도, 기질, 배지 및 계대 사이의 시간을 포함하지만 이들로 한정되지 않은 다수의 요인에 의존한다.
한 가지 실시양태에서, 세포는 수시간(약 3 시간) 내지 약 14일 또는 그 사이의 임의의 시간 정수 값 동안 배양될 수 있다. T 세포 배양에 적합한 조건은, 혈청(예를 들면, 태소 또는 인간 혈청), 인터류킨-2(IL-2), 인슐린, INF-감마, IL-4, IL-7, GM-CSF, IL-10, IL-12, IL-15, TGF-베타 및 TNF-α, 또는 당업자에게 공지되어 있는 세포의 성장을 위한 기타 첨가물을 포함하여, 증식 및 생존에 필요한 인자를 함유할 수 있는 적절한 배지(예: 최소 필수 배지 또는 RPMI 배지 1640 또는 X-vivo 15(Lonza))를 포함한다. 세포의 성장을 위한 다른 첨가제는 계면활성제, 플라마네이트, 및 N-아세틸-시스테인 및 2-머캅토에탄올 등의 환원제를 포함하지만, 이들로 한정되지 않는다. 매체는 RPMI 1640, AIM-V, DMEM, MEM, α-MEM, F-12, X-Vivo 15, 및 X-Vivo 20, 옵티마이저, 아미노산, 나트륨 피루베이트 및 비타민을 첨가한 것, 무혈청, 또는 적절한 양의 혈청(또는 혈장) 또는 정의된 세트의 호르몬, 및/또는 T 세포의 성장 및 확장에 충분한 양의 사이토카인(들)을 보충한 것을 포함할 수 있다. 페니실린 및 스트렙토마이신 등의 항생물질은 실험 배양물에만 포함되고, 대상체에게 주입되는 세포의 배양물에는 포함되지 않는다. 표적 세포는 성장을 서포트하기 위해 필요한 조건하, 예를 들면, 적절한 온도(예를 들면, 37℃) 및 대기(예를 들면, 공기 + 5% C02)하에서 유지된다.
T 세포를 배양하기 위해 사용되는 배지는 T 세포를 공자극할 수 있는 약제를 포함할 수 있다. 예를 들면, CD3를 자극할 수 있는 약제는 CD3에 대한 항체이고, CD28을 자극할 수 있는 약제는 CD28에 대한 항체이다. 이는, 본원에 개시된 데이터에 의해 입증된 바와 같이, 본원에 개시된 방법에 의해 단리된 세포가 전기천공된 모집단을 배양함으로써 대략 10배, 20배, 30배, 40배, 50배, 60배, 70배, 80배, 90배, 100배, 200배, 300배, 400배, 500배, 600배, 700배, 800배, 900배, 1000배, 2000배, 3000배, 4000배, 5000배, 6000배, 7000배, 8000배, 9000배, 10,000배, 100,000배, 1,000,000배, 10,000,000배 또는 그 이상 확장할 수 있기 때문이다. 한 가지 실시양태에서, T 세포는 전기천공된 모집단을 배양함으로써 약 20배 내지 약 50배, 또는 그 이상의 범위에서 확장한다.
한 가지 실시양태에서, T 세포를 확장시키는 방법은 추가의 적용을 위해 확장된 T 세포를 단리하는 것을 추가로 포함할 수 있다. 또 다른 실시양태에서, 확장하는 방법은 확장된 T 세포의 후속 전기천공 및 이어서 배양을 추가로 포함할 수 있다. 후속 전기천공은, 확장된 T 세포의 형질도입, 확장된 T 세포의 형질감염, 또는 핵산에 의한 확장된 T 세포의 전기천공 등의 약제를 코딩하는 핵산을 T 세포의 확장된 모집단에 도입하는 것을 포함할 수 있고, 여기서 약제는 T 세포를 추가로 자극한다. 제제는 추가 확장, 이펙터 기능, 또는 다른 T 세포 기능을 자극함으로써 T 세포를 자극할 수 있다.
약제학적 조성물
본 발명의 약제학적 조성물은, 하나 이상의 약제학적으로 또는 생리학적으로 허용되는 담체, 희석제 또는 부형제와 조합하여, 본원에 기재된 바와 같은 세포 또는 세포의 모집단을 포함할 수 있다. 이러한 조성물은, 중성 완충 생리식염수, 인산염 완충 생리식염수 등과 같은 완충액; 글루코스, 만노스, 수크로스 또는 덱스트란, 만니톨 등의 탄수화물; 단백질; 폴리펩티드 또는 글리신 등의 아미노산; 산화방지제; EDTA 또는 글루타티온 등의 킬레이트제; 애주번트(adjuvant)(예를 들면. 수산화알루미늄); 및 보존제를 포함할 수 있다. 본 발명의 조성물은 정맥내 투여를 위해 제형화되는 것이 바람직하다.
본 발명의 약제학적 조성물은 치료(또는 방지)될 질환에 적합한 방식으로 투여될 수 있다. 투여량 및 투여 빈도는, 환자의 상태 및 환자의 질환의 유형 및 중증도 등의 요인에 의해 결정될 수 있지만, 적절한 투여량은 임상 시험에 의해 결정될 수 있다.
투여되는 본 발명의 세포는 치료되는 대상체와 관련하여 자가, 동종이계 또는 이종일 수 있다.
본 발명의 세포는, 적절한 전임상 및 임상 실험 및 시험에서 결정되는 투여량 및 경로 및 시간에서 투여될 수 있다. 세포 조성물은 이러한 범위 내의 투여량으로 복수회 투여될 수 있다. 본 발명의 세포의 투여는, 당업자에 의해 결정된 바와 같이, 목적하는 질환 또는 상태를 치료하는데 유용한 다른 방법과 조합될 수 있다.
일반적으로, 본원에 기재된 변형된 T 세포를 포함하는 약제학적 조성물은, 이들 내의 모든 정수 값을 포함하여, 104 내지 109 세포/kg 체중, 일부 경우에 105 내지 106 세포/kg 체중, 일부 경우에 105 내지 106 세포/kg 체중의 용량으로 투여될 수 있는 것으로 일반적으로 언급된다. T 세포 조성물은 또한 이러한 투여량으로 복수회 투여될 수 있다. 세포는 면역요법에서 일반적으로 공지된 주입 기술을 사용하여 투여될 수 있다[참조: 예를 들면, Rosenberg et al., New Eng. J. of Med. 319:1676, 1988]. 특정 환자에 대한 최적의 투여량 및 치료 섭생은, 질환의 징후에 대해 환자를 모니터링하고 그에 따라 치료를 조절함으로써, 의학의 당업자에 의해 용이하게 결정될 수 있다.
본 발명의 변형된 세포의 투여는 당업자에게 공지된 임의의 편리한 방법으로 수행될 수 있다. 본 발명의 세포는 에어로졸 흡입, 주사, 섭취, 수혈, 이식(implantation) 또는 이식(transplantation)에 의해 대상체에게 투여될 수 있다. 본원에 기재된 조성물은 경동맥적, 피하, 피내, 피내, 종양내, 결절내, 골수내, 근육내, 정맥내(i.v.) 주사 또는 복강내로 환자에게 투여될 수 있다. 다른 예에서, 본 발명의 세포는 대상체의 염증 부위, 대상체의 국소 질환 부위, 림프절, 기관, 종양 등에 직접 주사된다.
본 발명에 유용한 방법 및 조성물은 실시예에 기재된 특정 제형에 한정되지 않는다는 것을 이해해야 한다. 하기 실시예는, 당업자에게, 본 발명의 세포의 제조 및 사용 방법, 확장 및 배양 방법, 및 치료 방법의 완전한 개시 및 설명을 제공하기 위해 제시되고, 본 발명자들이 그들의 발명으로 간주하는 것의 범위를 한정하는 것을 의도하는 것은 아니다.
본 발명의 실시는, 달리 지시되지 않는 한, 분자 생물학(재조합 기술 포함), 미생물학, 세포 생물학, 생화학 및 면역학의 기술을 사용하고, 이들은 충분히 당업자의 범위 내에 있다. 이러한 기술은, 예를 들면, 문헌[참조: "Molecular Cloning: A Laboratory Manual", fourth edition (Sambrook, 2012); "Oligonucleotide Synthesis" (Gait, 1984); "Culture of Animal Cells" (Freshney, 2010); "Methods in Enzymology" "Handbook of Experimental Immunology" (Weir, 1997); "Gene Transfer Vectors for Mammalian Cells" (Miller and Calos, 1987); "Short Protocols in Molecular Biology" (Ausubel, 2002); "Polymerase Chain Reaction: Principles, Applications and Troubleshooting", (Babar, 2011); "Current Protocols in Immunology" (Coligan, 2002)]에 상세히 기재되어 있다. 이러한 기술은 본 발명의 폴리뉴클레오티드 및 폴리펩티드의 제조에 적용될 수 있고, 따라서 본 발명의 제조 및 실시에서 고려될 수 있다. 특정 실시양태에 대한 특히 유용한 기술은 하기의 섹션에서 논의될 것이다.
실험예
이어서, 본 발명을 하기 실시예를 참조하여 설명한다. 이들 실시예는 단지 예시를 위해 제공되며, 본 발명은 이들 실시예에 한정되지 않고, 본원에서 제공된 교시의 결과로서 명백한 모든 변형들을 포함한다.
이들 실험에서 사용된 물질 및 방법을 이제 설명한다.

sgRNA는 CD2, CD5 또는 CD7(예를 들면, 각각 서열번호 22-24)를 표적화하도록 설계하고, GeneArt Precision sgRNA 합성 키트를 사용하여 합성했다. Cas9 발현 플라스미드(pGEM-Cas9)를 증폭시키고, 선형화했다. Cas9 RNA는 mMessage mMachine T7 울트라 키트를 사용하여 합성했다. CRISPR 편집은 Jurkat 세포에서 실행했고; CD2/CD5/Cd7 sgRNA 및 Cas9는 전기천공에 의해 Jurkat 세포에 형질감염시켰다. Jurkat 세포에서의 CD2/CD5/CD7의 발현은 유세포 분석에 의해 검출하고, 가장 효과적 CD2/CD5/CD7 sgRNA가 결정되었다. 이어서, 가장 효율적 CD2/CD5/CD7 sgRNA를 사용하여, 초대 인간 T 세포에서 CRISPR 편집을 수행하고; 선택된 sgRNA 및 Cas9 RNA를 초대 인간 T 세포에 전기천공했다. CD2/CD5/CD7의 발현은 녹-아웃/편집 효율을 검증하기 위해 유세포 분석에 의해 초대 인간 T 세포에서 검출했다.
구체적으로는, 신선한 CD4/CD8 T 세포를 취득하고, 0일차에 다이나비드와 함께 인큐베이팅했다. 4일차에, 세포의 비드를 제거하고, Cas9 및 sgRNA를 전기천공했다. 조절된 배지(TCM(X-vivo15, 인간 혈청 5%, 글루타민), IL-7 10ng/ml, 및 IL-15 10ng/ml)를 세포에 첨가했다. 6일차에, 세포에 CAR 렌티바이러스를 형질도입했다. 9일차에, CAR 발현을 평가했다. 세포를 0.8e6/ml까지 공급했다. 용적이 300fl 미만으로 될 때까지 동결시켰다(도 22).
CAR 작제물: 모든 작제물은 렌티바이러스 pTRPE 4-1BB CD3zeta 백본을 사용하여 생성했다. OKT11 CAR 및 TS2/18.1.1 CAR은 ATCC로부터 구입한 하이브리도마(각각 ATCC® CRL-8027™ 및 ATCC® HB-195™)로부터 생성된 항체로부터의 scFv를 사용하여 작제했다. T11-2 CAR은 Ellis Reinherz로부터 제공받은 하이브리도마로부터 생성된 항체로부터의 scFv를 사용하여 작제했다. 모든 CD5 CAR은 WO 제2010/022737 A1호에 공개된 항체 서열로부터의 scFv를 사용하여 작제하고, 이의 내용은 참조에 의해 전체가 본원에 도입된다.
이하에, 실험의 결과를 설명한다.
실시예 1: T 세포 독성을 유발하지 않고서 표적 T 세포 림프종 및 백혈병을 표적화하는 신규한 접근법
T-세포 림프종 및 백혈병은 전체적으로 예후가 매우 불량하고, 이들 환자에게 이용가능한 치료법의 선택지는 거의 없다. 키메라 항원 수용체 T 세포(CART) 면역요법은 CD19+ B-세포 비호지킨 림프종(B-NHL)에서 전례 없는 결과를 유도했다. 여기에서는, 별도의 성공한 "CART19-유사" 생성물이 T-NHL을 표적화하도록 설계되었다. CD19는 T-NHL에서 발현되지 않기 때문에, CD2, CD5, CD7 등의 추가의 표적이 CART 요법에 대해 평가되었다. 그러나, 이들 표적은 모두 정상 T 세포에 의해서도 발현되고, 허용되지 않는 임상 독성(T 세포 형성부전-면역결핍)을 유도한다(도 1). 본원에서, 안전하고 효과적인 CART 전략은 정상 T 세포를 CART 사멸에 내성이도록 편집함으로써 T 세포 림프종의 치료를 위해 개발되었다(도 2). T-세포 림프종 및 백혈병에 대한 CART 요법은 CART 표적(CD2, CD5, CD7)이 정상 T 세포로부터 일시적으로 제거될 때에 실행가능하고, 따라서 CART 매개성 사멸 및 면역결핍을 회피한다(도 2).
실시예 2: 항-CD5 CAR T 세포(CART5) 및 CD5 녹-아웃(KO) 정상 T 세포
항-CD5 CAR T 세포(CART5) 및 CD5 녹-아웃(KO) 정상 T 세포를 포함하는 2면 면역요법이 본원에 개시되어 있다(도 3). CART5는 T 세포 림프종(T-NHL 등) 또는 T 세포 백혈병 세포를 파괴하지만, 정상 T 세포도 사멸시킨다. CD5 KO 정상 T 세포의 주입은, CART5 세포가 고갈할 때까지, 일부 경우에, 자살 유전자(iCasp9, CD20/리툭시맙 등)을 사용하여, CART 내성 T 세포 면역을 제공한다.
CD5는, T-NHL 세포에서의 발현이 높고 T 세포 및 마이너 B 세포 서브세트 이외의 다른 조직에서는 발현이 없기 때문에, T-NHL 표적으로서 선택되었다. 상이한 친화성(각각 고, 중, 저친화성의 #17, #34, #9)을 갖는 일본쇄 가변 단편(scFv)을 사용하여, 6개의 항-CD5 CAR 작제물을 생성했고[참조: Klitgaard JL, et al. (2013) British journal of haematology 163:182-93], T 세포에서 발현시켰다(도 4-5). 흥미롭게도, 항-CD5 CART는, CD5가 100%의 CART 세포에서 발현되는 것에도 불구하고[참조: Mamonkin M, et. al. (2015) Blood 126:983-92], CD5 발현은 대조군 T 세포와 비교하여 낮았지만(도 8), CART5 세포를 제조하기 위해 CD5의 녹아웃을 필요로 하지 않았다. CD5의 CRISPR-Cas9 KO가 없는 경우, CD5의 평균 형광 강도(MFI)는, 대조군 T 세포와 비교하여 CART5에서는 10배 작았지만, CD2 등의 별도의 범 T-세포 마커에서는 변화가 없었다(도 8).
상이한 CART5 작제물의 시험관내 및 생체내 활성을 비교했다. 고친화성 scFv #17로부터 유래하는 작제물 C3054는 최고의 생체내 사멸을 입증했다. Jurkat 세포에 상이한 cAR5 작제물(도 13, 표적 에피토프 및 친화성을 좌측에 제시함) 및 GFP-NFAT 리포터를 형질도입하고, 이어서 CD5+ 종양 세포(또는 대조군)과 24시간 동안 공배양했다. 리드 CART5(C3054)는 NFAT 활성화의 증가를 나타낸다(도 13).
리드 항-CD5 CART는 자살 시스템을 사용하여 실현되고, 그 기능은 시험관내 및 생체내에서 시험되었다. 특정 이론에 얽매이지 않고서, CD5(CRISPR-Cas9 KO)의 제거는 CART5 상의 CAR5와 CD5 사이의 시스 표면 상호작용의 가능성을 제거함으로써 CART 항-종양 효과를 추가로 증가시킨다.
주요 CART5 생성물에서 자살 시스템의 삽입: 주요 후보 CART5(C3054) 생성물은 자살 시스템을 발현하도록 설계되어 있다(도 26). CAR5 및 유도성-caspase9 자살 시스템 둘 다를 코딩하는 P2A 바이시스트론성 벡터[참조: Di Stasi A, et al. (2011) 365:1673-83](iCART5)가 개발되었다. 가장 효율적인 것을 정의하기 위해, 양 배향, CAR5-P2A-iCasp9 및 iCasp9-P2A-CAR5(도 26)을 클로닝했다(안전을 위해, 보다 높은 % 이중-발현 세포 및 보다 낮은 % CAR5+ iCasp9-). iCART5는 임상 등급의 화합물 리미두시드를 사용하여 효율적으로 제거된다[참조: AP1903, Bellicum Pharmaceuticals].
iCART5의 시험관내 시험: 새롭게 생성된 iCART5를 WT CART5와 비교하여, 항원 자극시의 유효성(시험관내 루시퍼라제-기반 사멸) 및 표현형/기능(CD5+ Jurkat T-백혈병 세포)(유세포 분석 표현형, 루미넥스 검정에 의한 30-플렉스 사이토카인 분석, CFSE 증식 및 CD107a 탈과립화)을 확인한다. 중요하게는, 시험관내에서의 고갈은 iCART5를 상이한 농도의 리미두시드(0, 0.03, 0.3, 3, 10nM)과 공배양하고, 15', 30' 및 2, 6, 12 및 24시간에서의 사멸을 확인함으로써 시험한다. iCART5는 초대 CFSE 표지 세자리 세포를 사용한 확립된 사멸 검정을 사용하여 초대 T-NHL 세포에 대해서 또한 시험한다.
iCART의 생체내 시험: 생체내 이종이식 모델[참조: Ruella M, et al. (2016) J Clin Invest][클릭-비틀 그린(CBG) + T-백혈병 세포주 Jurkat 세포주 및 클릭-비틀 레드(CBR)+ iCART5를 사용]을 사용하여, 리미두시드(50㎍/마우스 23)이 iCART5 대 WT CART5를 생체내에서 고갈시키는 능력을 시험한다. NOD SCID 감마-결핍 마우스(NSG) 마우스(그룹당 8마리)에 2×10e6 CART5 세포/마우스를 주사한다. 시간의 경과에 수반하는 종양 부하는 생물발광(CBG)으로서 평가하고, T 세포의 표현형은 유세포 분석에 의해 연구하고, 생물발광(CBR)에 의해 복수의 시점(시간/일)에서 확대한다. 마우스는, 생존 및 재발의 모니터링을 위해 장기간(3 내지 4개월) 사육한다. 인간 T-NHL 이종이식 모델은 이전에 초대 세자리 세포를 정맥내로 주입함으로써 확립했다. 이 모델은, iCART5의 항-종양 효과 및 고갈 효과 둘 다를 시험하기 위해 사용된다.
CART5에서 CD5 KO의 역할의 평가: 예비 데이터는 CD5 CART5가 생체내에서 WT CART5보다도 효과적이라는 것을 나타냈다. CD5는 CRISPR-Cas9를 사용하여 CART5 세포에서 녹-아웃된다. CRISPR-Cas9 CART 확장 프로토콜은 이전에 최적화되었다. 야생형 CART5는, CART5 생존율, 항원 유도된 증식(CFSE 표지를 사용), 사이토카인 생산(30-플렉스 루미넥스에 의해), 탈과립(유세포 분석에 의한 CD107a 평가), 세포독성(루시퍼라제-기반) 및 표현형(메모리 서브세트, Th1/Th2)을 시험함으로써 생체내에서 CD5 KO CART5와 비교한다. 세포주(Jurkat 등) 및 일차 샘플 둘 다가 표적으로서 사용된다. CD5 KO 및 ST CART5(1×10e6 세포/마우스)의 생체내 비교는, Jurkat를 보유하고 10일차 및 14일차에 말초혈의 증식 및 표현형을 모니터링하는 NSG 마우스에서 수행한다.
CD5 KO에 의한 CART5 기능의 강화의 메카니즘: CD5 KO가 CART5 활성을 개선시키는 것으로 증명되었기 때문에, 메카니즘을 이해하기 위해 추가 연구를 수행한다: i. CART5 세포 상의 CAR5 및 CD5의 국재를 분석하기 위한 공초점 이미징; ii. CAR5가 시스에서 CD5에 결합하는 것을 증명하는 단일 분자 이미징(ONI 나노이미저); iii. CD5+ Jurkat에서 CAR5를 발현하고, CD5 에피토프가 (CAR5에 의해) 마스크되어 있기 때문에, CART5가 CAR5+ Jurkat을 사멸할 수 없음을 나타냄; 및 iv. T 세포 활성화의 억제적 역할로서의 CD5로서, CD5의 존재하 또는 부재하에서의 CART5 활성을 연구할 것이다(포스포-유세포 분석).
T 세포 형성부전을 회피하기 위한 CART 내성 정상 T 세포의 생성: CART5는, 둘 다 유사한 수준의 CD5를 발현하기 때문에, 종양성 T 세포 및 정상 T 세포를 구별할 수 없다. CART 내성의 정상 T 세포는 항-T-NHL CART와 동시 주입되도록 개발되어 있고, CART 항-종양 활성 중의 면역을 확보한다. CRISPR-Cas9 유전자 편집은 정상 T 세포의 CD5를 녹-아웃시키기 위해 사용되고, CART5로부터 발견되지 않게 한다. 최적화된 CART 확장 프로토콜을 사용하여, 정상 T 세포에서 CD5의 약 95%를 KO시킬 수 있는 매우 효율적인 CRISPR-Cas9 gRNA(#4)가 생성되었다. 데이터는 CD5 KO T 세포가 CART5에 내성을 나타내고, WT T 세포(CD5+)가 24시간 이내에 강력하게 사멸했음을 나타낸다.
CD5 KO 정사 T 세포의 제조: CD5 KO 정상 T 세포는 Lonza 4D Nucleofector를 사용하여 Cas9 단백질(ThermoFisher v2)와 함께 전기천공되는 고효율의 gRNA(#4)를 사용하여 개발되어 있다. CRISPR-Cas9 KO는 1일차에 실행하고, 세포는 30℃에서 2일간 배양되어 유전자 편집을 증가시키고, 항-CD3/CD28 다이나비드(비드: 1 T 세포)로 활성화시키고, 세포 용적 <300 fl에 도달할 때까지 확장시킨다.
iCART5 사멸에 대한 CD5 KO 정상 T 세포 내성의 시험관내 평가: CD5 KO 정상 T 세포의 CART5에 대한 내성은, 사멸 검정(표적 T 세포의 CFSE 표지)를 실행함으로써 시험관내에서 시험한다. 예비적 결과는, CD5 KO가 내성을 부여하는 것을 나타냈다. 3명의 추가 T 세포 공여자를 시험한다.
자가 이종이식 모델에서 iCART5에 대한 CD5 KO 정상 T 세포 내성의 생체내 평가: NSG 마우스(8마리/그룹)에 루시퍼라제+ CD5 KO 정상 T 세포 또는 WT를 이식하고, 2일 후에 자가 iCART5를 주사한다. CD5 ko 및 WT 정상 T 세포에 대한 iCART5의 효과는 생물발광에 의해 평가한다. WT T 세포가 iCART5(발광)에 의해 완전히 제거되면, 리미두시드(rimiducid)를 투여하여 iCART5를 고갈시킨다. 이어서, WT T 세포를 재주입하여, 정상 T 세포가 숙주를 재증식할 수 있음을 입증한다. CART의 확장을 평가하기 위해, 매주 마우스로부터 채혈한다.
정상 T 세포 기능에 대한 CD5 KO의 역할의 평가: CD5 KO의 역할은 T 세포 이펙터 기능을 주의 깊게 연구함으로써 정상 T 세포에서 조사한다. TCR-특이적 자극(항-CD3/CD28 비드) 후에, 사이토카인 생산(30-플렉스 루미넥스), 증식(CFSE) 및 CD5 KO T 세포 대 WT의 활성화를 측정한다. 또한, 일반적 감염증에 노출될 때에 CD5 KO T 세포를 증식하고, WT와 유사하게 생산하는지의 여부를 시험한다.
임상 사용을 위한 최적 CD5 KO 정상 T 세포 용량의 정의: 인 실리코 및 실험적 접근법(감염성 병원체에 특이적인 TCR의 TCR 서열분석 및 테트라머 염색) 둘 다를 사용하여, 재발 또는 굴절기에 주입되는 세포의 최소 수(r/r) T-NHL 환자는 가장 일반적 감염증에 대한 충분한 T 세포 면역을 보장하기 위해 정의된다.
진행성 T 세포 림프종 환자에서 제1 상 파일롯 임상 시험에서의 iCART5 및 CD5 KO 정상 T 세포의 동시 주입의 시험: 조사 신약(IND) 팩키지를 개발하고, FDA에 제출한다. 환자에서 항-T-NHL CART 접근법을 시험하기 위해, 제1 상 임상 시험을 개시한다. IND 팩키지는, 예비적 결과에 기초하고, 본원에 기재된 실험으로부터의 추가 데이터에 기초한다.
임상 시험 프로토콜 설계: 제1 상 임상 시험에는 3+3 프로토콜 설계를 사용하여 치료되는 r/r T-NHL의 환자가 포함된다. 안일 아페레시스로부터, 농축된 T 세포를 사용하여 2개의 생성물을 생성한다: #1. CRISPR-Cas9 CD5 KO 정상 T 세포 및 #2. CART5. 주입되는 최초의 생성물은 KO 정상 T 세포이고, 다음날 iCART5가 주입된다. 환자의 최초의 코호트는 림프구 고갈[사이클로포스파미드(60mg/kg×2일) 및 플루다라빈(25mg×5일)] 및 생성물 #1을 제공받는다. 용량-제한 독성(DLT)가 관찰되는 경우, 코호트 2는 3일간(총 용량의 10%, 30%, 60%)에 걸쳐 림프구 고갈, 생성물 #1 및 1-5×10e7의 합계 iCART5(생성물 #2)를 제공받고; 1-5×10e7의 합계 CART5는 B-NHL8에서 CART19 실험에 기초하여 최적은 아닌 용량이다. 코호트 2에서 DLT가 관찰되지 않는 경우, 코호트 3은 림프구 고갈, 생성물 #1, 및 1-5×10e8의 합계 CART5(전체 용량)을 제공받는다. 코호트 #1의 환자는, 최초 4주간 이내에 독성이 관찰되지 않는 경우, 코호트 #2로 진행할 수 있다. 종양 클리어런스(및 6개월차에 최대)에 기초하여, iCART5 세포는 이량체화제 리미두시드(NCT0274287)을 사용하여 고갈시켜, 장기적 T 세포 독성의 가능성을 방지한다.
IND 팩키지의 준비 및 FDA 제출: 임상 등급의 제조의 최적화는 임상 백신 및 세포 생산 시설(Clinical Vaccine and Cell Production Facility; CVPF)과 공동으로 실행한다. 기재되어 있는 모든 전임상 실험의 결과는 임상 시험 프로토콜과 함께 IND 적용에 적합하도록 포맷되어 있다. IND 준비의 광범위한 서포트는 CCI 및 ACC 내에서 이용가능하다.
환자의 등록 및 치료: IND의 제출이 성공하고, 모든 규제 당국으로부터 승인된 후, 펜실베니아 대학의 림프종 프로그램 내에서 제1 상 시험이 개시된다[참조: Director: Dr. Stephen Schuster; Scientific Director: Dr. Marco Ruella]. 림프종 프로그램에는 초기 단계의 연구를 관리하는 풍부한 경험을 갖는 전용의 임상 연구 유닛(CRU)가 있다. 루엘라 박사는 이 시험의 주임 연구자이고, 칼 준 박사는 과학 프로토콜 어드바이저이다. 2개 생성물의 제조는 CVPF에서 수행한다.
상관 연구: 환자 샘플(말초혈)을 복수의 시점(아페레시스, 일자 -1, 0, 7, 14, 28, 60, 90)에서 분석하여, CART 확장(qPCR 및 유세포 분석), CART 표현형(CyTOF), CART 유전자 발현 프로파일링(GEP(NanoString, 단일 세포 RNAseq 10× Genomics) 및 혈청중 사이토카인 수준(Luminex, 30-플렉스 어레이)을 시험한다. 가능한 경우, 치료전 및 치료후의 종양 생검에 대해 추가의 연구를 수행한다(종양 미세환경의 RNAseq 및 Hyperion 분석).
이 시험은, 독성을 회피하는 T 세포 비호지킨 림프종을 치료하는 혁신적인 면역요법 접근법을 나타내기 때문에, 신규 병용 면역요법의 개발에서 주요 이정표일 것이다. 항-CD5 CAR T 세포는 종양 T 세포를 사멸시키지만, 유사한 CD5 발현에 기인하여, 필연적으로 정상 T 세포도 사멸한다. 그러나, 본원에 기재된 전략은, CD5용으로 녹-아웃된 정상 T 세포의 동시 주입을 포함하고, 이에 의해 CART5 항종양 활성 중의 T 세포의 면역학적 보호를 보증한다. 이어서, CART5 세포는 자살 시스템을 사용하여 고갈시켜, 정상 면역학적 재구성을 장기적으로 보장한다. 이는 T-NHL의 최초의 CART 시험의 하나이고, 독성의 문제에 대처하는 2개의 접근법을 포함하는 유일한 시험이다. T-NHL의 예후는 매우 불량하고, 현재 이용가능한 능동 면역 요법은 없다. 따라서, 이러한 혁신적 전략의 개발은 혈액학 및 면역요법의 분야에서 수직적 진보를 나타낸다. 제1 상 시험의 임상 결과 및 상관 연구의 결과에 기초하여, 이 전략은, 복수의 표적을 동시 표적화하여, 항원 상실의 회피(CART5+CART7 등)을 회피하거나, CART-매개 사멸을 증강시킬 수 있는 소분자와 CART를 결합하도록 실시할 수 있다.
실시예 3: 항-CD2 CAR T 세포(CART2) 및 CD2 녹-아웃(KO) 정상 T 세포
항-CD2 CAR T 세포(CART2) 및 CD2 녹-아웃(KO) 정상 T 세포를 포함하는 2방향 면역요법 접근법은 본원에 개시되어 있다(도 3). CART2는 T 세포 림프종(T-NHL 등) 또는 T 세포 백혈병 세포를 파괴하지만, 정상 T 세포도 또한 사멸시킨다. CD2 KO 정상 T 세포의 주입은, CART2 세포가 고갈될 때까지, 일부 경우에 자살 유전자(iCasp9 등)을 사용함으로써 CART 내성 T 세포 면역을 제공한다.
가이드 RNA는 CRISPR/Cas9 시스템을 사용하여 CD2 유전자(및 CD5)를 녹-아웃하도록 설계되었다. CD2는 T 세포 모집단의 78%를 효과적으로 녹-아웃시켰다. 제2 세대의 항-CD2 및 항-CD5 CAR(각각 CART2 및 CART5)가 생성되었다(도 4). 녹-아웃 세포(CD2KO 및 CD5KO)를 대응하는 CART 세포(각각 CART2 및 CART5)와 인큐베이팅하고, 자극하고, 모집단의 배가를 측정했다(도 7). gRNA를 포함하지 않는 모의 전기천공된 세포를 비교를 위한 대조군으로 사용했다. CD2 KO가 없으면, CART2 세포는 증식하지 않았다(도 7). KO를 사용하면, CART2 및 CART5는 약 5 내지 8 모집단 배가에 도달한다(도 7).
Jurkat 세포에 상이한 CART2 작제물 및 GFP-NFAT 리포터를 형질도입하고, 이어서 CD2+ 종양 세포(또는 대조군)과 24시간 동안 공-배양했다. 리드 CART2(C3043)은 증가된 NFAT 활성화를 나타낸다(도 14).
CART 확장 프로토콜은, CD2KO 또는 CD5 KO 세포와 인큐베이팅되는 경우, 최적화된 CART2 및 CART가 18일까지 계속 확장했다는 것이다(도 9).
실시예 4: CART2 및 CART5 시험
도 6은 CD5(또는 CD2 또는 CD7) KO 제조 프로세스 및 CRISPR-Cas9 KO 효율을 나타낸다.
6개의 상이한 CAR2 및 6개의 CAR5 작제물을, 루시퍼라제+ Jurkat 세포(T 세포 백혈병 세포주)와 공배양함으로써 시험관내에서 챌린지했다. 24시간 후, 총 사멸을 발광의 상대적 감소로서 측정했다. CART2의 경우, #3029, #3030 및 #3043만이 항종양 효과를 나타낸다(도 10). CART5의 경우, 모든 작제물이 항종양 효과를 나타낸다(도 11). 리드 CART 후보(CART2 C3043 및 CART5 C3054)가 선택되고, 시험되었다. CD2 또는 CD5 녹-아웃이 CART 기능에 미치는 영향을 시험했다. CART2 및 CART5 내성 T 세포는 정상으로 생성되었다. CD5 및 CD2는 정상 T 세포에서 녹-아웃되었다.
피부 T 세포 림프종에 대한 CART2 및 CART5의 활성을 시험했다. 24시간의 사멸 검정을 실시했다. CART2 세포는, 초대 세자리 세포(백혈병 피부 T 세포 림프종) 및 HH 세자리 세포주에 대해 활성이었다(도 15). 또한, CART5는 HH 세포에 대해 활성이었다(도 15).
CART2 및 CART5의 생체내에서의 유효성을 측정했다. NSG 마우스에 루시퍼라제+ Jurkat 세포를 이식하고, 7일차에 대조군 T 세포 또는 CART2 또는 CART5(1×106)을 제공받도록 랜덤화했다. IVIS 제노겐 스펙트럼(Xenogen Spectrum)을 사용하여 마우스를 매주 이미지화하고, LivingImage 소프트웨어로 분석했다. CART2 C3043 및 CART5 C3054가 가장 효과적이었다(도 12).
CART2 및 CART5는 정상 T 세포(자기 및 동종이계)를 인식하고, 각각을 사멸시키는 것으로 입증되었다(도 16).
CAR 표적의 제거가 정상 T 세포를 CART의 사멸로부터 보호하는 것도 또한 입증되었다(도 17). CD5 KO는, WT 정상 T 세포에서는 아니고, CART5 사멸에 내성이 있었다. 정상 휴지 T 세포는, CART2(도 17, 상부) 및 CART5(도 17, 하부)에 의해 인식되고 사멸된다. CRISPR-Cas9를 사용한 정상 T 세포로부터의 CD2 또는 CD5의 효율적 KO는 각각 CART2 또는 CART5의 사멸에 대한 내성을 유도했다(도 17).
CMV 특이적 T 세포는 CD2 KO 및 CD5 KO 정상 T 세포 생성물에 존재했다(도 18). CD2 및 CD5 KO 정상 T 세포는 CMV 펩티드를 인식하여 사이토카인을 생산하는 능력을 유지했다(도 18; HLA-A-02:01 - CMV PP65 NLVPMVATV 덱스트라머(서열번호 101); CETF 펩티드에 대한 4시간 노출 후의 ICS. CMV-펩티드 펄스 APC에 의한 이차 배양 후).
실시예 5: 항-CD7 CAR T 세포(CART7) 및 CD7 녹-아웃(KO) 정상 T 세포
항-CD7 CAR T 세포(CART7) 및 CD7 녹-아웃(KO) 정상 T 세포를 포함하는 2면 면역요법 접근법은 본원에 개시되어 있다. CART7은, T 세포 림프종(예를 들면, T-NHL) 또는 T 세포 백혈병 세포를 파괴하지만, 정상 T 세포도 또한 사멸시킨다. CD7 KO 정상 T 세포의 주입은, CART 세포가 고갈될 때까지, 일부 경우에 자살 유전자(예를 들면, iCasp9)를 사용함으로써 CART-내성 T 세포 면역을 제공한다.
가이드 RNA는 CRISPR/Cas9 시스템을 사용하여 CD7 유전자를 녹-아웃하도록 설계되었다. CD7은 T 세포 모집단의 79%에서 효과적으로 녹-아웃되었다(도 25). 6개의 항-CD7 CAR을 생성했다(도 25)
실시예 6: 이중 특이적 CAR T 세포
P2A 서열에 의해 연결된 CAR5(C3054) 및 CAR2(C3043)를 포함하는 2개의 렌티바이러스 작제물을 생성했다(도 19). 유전자 발현은 EF1alpha 프로모터에 의해 유도되었다. CAR5 작제물은 4-IBB 공자극 및 CD3zeta 신호전달 도메인을 갖는다. 정상 T 세포에서 CD2 및 CD5 모두의 효율적 녹-아웃이 입증되었다(도 20A 내지 20B).
실시예 6: CD5 KO는 CART 면역요법을 증강시킨다
CD5 KO CART5는 생체내에서 CD5 + CART5보다 더 효과적임을 입증했다. CD5 KO는 CART5 항종양 효과를 증가시켰다(도 21). NSG 마우스를 사용한 Jurkat T-ALL 이종이식 모델에서, CD5 KO CART5(2×l06 세포/마우스)는 WT CART 5와 비교하여 완전한 장기간 반응 및 보다 긴 생존율을 유도한다(도 21).
또한, CD5 KO CART19는 생체내에서도 CD5 + CART19보다 더 효과적이었다. CD5 KO는 CART19의 항-종양 효능을 증가시켰다(도 22). NALM6 B-ALL 이종이식 모델 CD5 KO CART19는 WT CART19와 비교하여 현저히 높은 종양 제어를 나타냈다(도 22).
CART5 및 CART2는 또한 20%의 AML를 표적화할 수 있었다. CART2 세포는 CD2 + AML 세포와 공배양하고, 24시간에서 유의한 사멸을 나타냈다(도 23A 내지 23B).
CART5는 또한 CLL 및 MCL의 100%를 표적화한다. 세포독성 검정을 수행하고, CART5 세포가 CD5 + MCL 세포주(Jeko-1 및 Mino)를 인식하여 사멸시킬 수 있다는 것을 입증했다(도 24).
이들 데이터는, 항-CD5 CAR로 처리하는 경우, 또는 놀랍게도 상이한 CAR T 세포(예를 들면, CD19 CART 세포)로 치료하는 경우에, CD5의 녹-아웃이 CART 요법을 증강시킨다는 것을 입증한다.
다른 실시양태
본원에서 변수의 임의의 정의에서 요소의 리스트의 열거는, 수록된 요소의 임의의 단일 요소 또는 조합(또는 서브조합)으로서 그 변수의 정의를 포함한다. 본원에서의 실시양태의 언급은, 임의의 단일 실시양태로서 또는 임의의 다른 실시양태 또는 이의 일부와 조합된 실시양태를 포함한다.
본원에 인용된 각각의 및 모든 특허, 특허 출원 및 간행물의 개시는 참조에 의해 그 전체가 본원에 도입된다. 본 발명은 특정 실시예를 참조하여 개시되었지만, 본 발명의 다른 실시양태 및 변형태는, 본 발명의 진정한 사상 및 범위를 벗어나지 않고 당업자에 의해 고안될 수 있음이 명백하다. 첨부된 특허 청구의 범위는 모든 이러한 실시양태 및 동등한 변형을 포함하는 것으로 해석되는 것을 의도한다.
SEQUENCE LISTING
<110> The Trustees of the University of Pennsylvania
Ruella, Marco
Gill, Saar
June, Carl H.
Posey, Avery D.
Powell, Daniel J.
<120> Use of CD2/5/7 Knock-Out Anti-CD2/5/7 Chimeric Antigen Receptor T
cells Against T Cell Lymphomas and Leukemias
<130> 046483-7224KR1(02616)
<150> 62/782,131
<151> 2018-12-19
<150> PCT/US2019/067613
<151> 2019-12-19
<160> 101
<170> PatentIn version 3.5
<210> 1
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-MEDI507H2L-3028 CAR
<400> 1
ggatcccaag tccaactggt gcaatcaggc gcagaagtcc aacgaccggg ggccagtgtt 60
aaagtgtctt gtaaagcctc cgggtacatt tttactgagt actatatgta ctgggtcaga 120
caggccccag ggcaaggttt ggaacttgtc ggacgcatag atcccgaaga cggttctata 180
gattacgttg agaagttcaa aaagaaagtc acacttactg cggacacatc tagtagcacc 240
gcatatatgg aactgagcag tctcacctca gacgacaccg cagtgtacta ttgcgctcgc 300
ggaaagttta actataggtt cgcgtactgg ggacagggga cactggtgac tgttagcagc 360
ggtggcggag ggagcggcgg tggaggaagc ggaggcggag gttccgacgt tgtgatgacg 420
caaagtcccc cgtcactcct tgttactctc ggccagccag cgtctatctc ttgccggtca 480
agccagagct tgctccactc tagtggtaac acgtatttga actggttgct gcaaaggcct 540
ggacaatctc ctcagcccct gatctatttg gttagcaaac tggaaagtgg tgttccagac 600
agattttcag ggtctggatc aggcactgat ttcactctga agatctccgg ggtagaggcc 660
gaggacgtgg gagtctatta ctgcatgcag tttactcact atccttatac ctttggtcaa 720
gggacgaaac tggagatcaa atccgga 747
<210> 2
<211> 756
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-OKT11H2L-3029
<400> 2
ggatcccaag ttcagcttca gcaaccaggt gctgaattgg tccgccctgg aactagcgtt 60
aaactgtctt gtaaggcatc cggttatacg tttacaagtt attggatgca ctggattaag 120
caaaggcccg aacaaggcct tgaatggatt gggagaattg atccctacga tagcgagaca 180
cactacaatg aaaaatttaa agataaggcc atcctcagcg tagataagag cagttctacc 240
gcatacatac agctctcaag cctgacgtca gatgactcag ccgtttatta ttgctcaagg 300
cgggacgcta aatacgacgg ctatgcgctt gactactggg gacaaggcac cactttgaca 360
gtctccagtg gtggcggagg gagcggcggt ggaggaagcg gaggcggagg ttccgatata 420
gttatgacgc aagcagcacc ctctgtacct gtgacaccgg gtgaatccgt tagtatctca 480
tgccgctctt ctaaaaccct cttgcattct aacggcaata catatttgta ttggttcctt 540
caacgaccag gacaatcacc gcaagtgctt atttatagga tgtctaactt ggctagtggg 600
gtgccaaata ggttcagtgg gtctggatct gagacaactt tcacgttgag aataagtagg 660
gtggaagctg aagacgtcgg tatatactac tgtatgcagc atttggagta cccttacact 720
ttcgggggag gtactaagct cgaaattaaa tccgga 756
<210> 3
<211> 756
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-OKT11L2H-3030 CAR
<400> 3
ggatccgata tagttatgac gcaagcagca ccctctgtac ctgtgacacc gggtgaatcc 60
gttagtatct catgccgctc ttctaaaacc ctcttgcatt ctaacggcaa tacatatttg 120
tattggttcc ttcaacgacc aggacaatca ccgcaagtgc ttatttatag gatgtctaac 180
ttggctagtg gggtgccaaa taggttcagt gggtctggat ctgagacaac tttcacgttg 240
agaataagta gggtggaagc tgaagacgtc ggtatatact actgtatgca gcatttggag 300
tacccttaca ctttcggggg aggtactaag ctcgaaatta aaggtggcgg agggagcggc 360
ggtggaggaa gcggaggcgg aggttcccaa gttcagcttc agcaaccagg tgctgaattg 420
gtccgccctg gaactagcgt taaactgtct tgtaaggcat ccggttatac gtttacaagt 480
tattggatgc actggattaa gcaaaggccc gaacaaggcc ttgaatggat tgggagaatt 540
gatccctacg atagcgagac acactacaat gaaaaattta aagataaggc catcctcagc 600
gtagataaga gcagttctac cgcatacata cagctctcaa gcctgacgtc agatgactca 660
gccgtttatt attgctcaag gcgggacgct aaatacgacg gctatgcgct tgactactgg 720
ggacaaggca ccactttgac agtctccagt tccgga 756
<210> 4
<211> 753
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-T11-2-H2L-3031 CAR
<400> 4
ggatcccaag ttcaattgca gcaaccgggt gccgagttgg taaggcccgg tgcgtcagtc 60
aaacttagtt gtaaagctag tgggtacact tttactacgt tctggatgaa ttgggtgaag 120
caacgaccag gccaaggtct ggaatggatc ggcatgattg acccgtctga ctcagaagct 180
cattacaacc agatgttcaa ggacaaggcg actctgactg ttgataaaag ctcaagcacc 240
gcctacatgc agctcagtag cctcacatcc gaggattccg cagtgtacta ttgcgcgagg 300
ggacgagggt atgatgacgg cgatgcgatg gactattggg gacaggggac cagcgtaaca 360
gtcagtagtg gtggcggagg gagcggcggt ggaggaagcg gaggcggagg ttccgatata 420
gttatgaccc agtctcccgc ctctctggcc gttagcttgg gacaacgcgc taccatctct 480
taccgagcgt ctaagtccgt cagtacaagc ggttatagtt acatgcactg gaaccagcaa 540
aagcccggac aacctccgag actcctgatt tatttggtct ctaaccttga gtcaggtgtc 600
ccagccagat tctccggctc tggaagcggc actgacttta cattgaacat tcaccccgtg 660
gaggaggaag acgctgctac ctactattgc atgcaattca cgcactatcc ctacacattc 720
ggggggggca cgaaattgga aatcaaatcc gga 753
<210> 5
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1-H2L-3032 CAR
<400> 5
ggatccgagg ttcagcttga ggagagtggg ggaggtttgg taatgccagg tgggtctttg 60
aaactcagtt gcgcggcgtc aggcttcgca ttttcctcct acgatatgtc ctgggtcaga 120
cagacacccg agaagcggct ggaatgggtc gcttacattt ccgggggagg attcacgtac 180
tacccggata cagtaaaggg gagatttact ctgagccggg acaacgctaa gaataccctc 240
tatctccaga tgtcctcttt gaagagtgaa gacacagcga tgtattactg tgcgagacaa 300
ggggccaatt gggagctggt ttactggggc caggggacga cattgacggt ttctagcggt 360
ggcggaggga gcggcggtgg aggaagcgga ggcggaggtt ccgacattgt aatgacacaa 420
tcacctgcta cacttagcgt gactccaggt gatcgggtat tcctgagctg ccgcgcatca 480
caaagtatat ccgacttcct gcactggtat cagcagaaat ctcacgaaag tcccaggctg 540
ctgattaaat acgcttccca gagtattagt ggtatcccct cacgattttc tggcagcggg 600
agcggtagtg acttcactct ttctataaac tccgtcgagc cagaagacgt gggggtgtat 660
ctttgccaaa atggacacaa ttttccacca acctttggtg ggggcaccaa actcgaaata 720
aagtccgga 729
<210> 6
<211> 729
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1-L2H-3033 CAR
<400> 6
ggatccgaca ttgtaatgac acaatcacct gctacactta gcgtgactcc aggtgatcgg 60
gtattcctga gctgccgcgc atcacaaagt atatccgact tcctgcactg gtatcagcag 120
aaatctcacg aaagtcccag gctgctgatt aaatacgctt cccagagtat tagtggtatc 180
ccctcacgat tttctggcag cgggagcggt agtgacttca ctctttctat aaactccgtc 240
gagccagaag acgtgggggt gtatctttgc caaaatggac acaattttcc accaaccttt 300
ggtgggggca ccaaactcga aataaagggt ggcggaggga gcggcggtgg aggaagcgga 360
ggcggaggtt ccgaggttca gcttgaggag agtgggggag gtttggtaat gccaggtggg 420
tctttgaaac tcagttgcgc ggcgtcaggc ttcgcatttt cctcctacga tatgtcctgg 480
gtcagacaga cacccgagaa gcggctggaa tgggtcgctt acatttccgg gggaggattc 540
acgtactacc cggatacagt aaaggggaga tttactctga gccgggacaa cgctaagaat 600
accctctatc tccagatgtc ctctttgaag agtgaagaca cagcgatgta ttactgtgcg 660
agacaagggg ccaattggga gctggtttac tggggccagg ggacgacatt gacggtttct 720
agctccgga 729
<210> 7
<211> 747
<212> DNA
<213> Artificial Sequence
<220>
<223> CD2-MEDI507L2H-3043 CAR
<400> 7
ggatccgacg ttgtgatgac gcaaagtccc ccgtcactcc ttgttactct cggccagcca 60
gcgtctatct cttgccggtc aagccagagc ttgctccact ctagtggtaa cacgtatttg 120
aactggttgc tgcaaaggcc tggacaatct cctcagcccc tgatctattt ggttagcaaa 180
ctggaaagtg gtgttccaga cagattttca gggtctggat caggcactga tttcactctg 240
aagatctccg gggtagaggc cgaggacgtg ggagtctatt actgcatgca gtttactcac 300
tatccttata cctttggtca agggacgaaa ctggagatca aaggtggcgg agggagcggc 360
ggtggaggaa gcggaggcgg aggttcccaa gtccaactgg tgcaatcagg cgcagaagtc 420
caacgaccgg gggccagtgt taaagtgtct tgtaaagcct ccgggtacat ttttactgag 480
tactatatgt actgggtcag acaggcccca gggcaaggtt tggaacttgt cggacgcata 540
gatcccgaag acggttctat agattacgtt gagaagttca aaaagaaagt cacacttact 600
gcggacacat ctagtagcac cgcatatatg gaactgagca gtctcacctc agacgacacc 660
gcagtgtact attgcgctcg cggaaagttt aactataggt tcgcgtactg gggacagggg 720
acactggtga ctgttagcag ctccgga 747
<210> 8
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> CD5-17L2H-3045 CAR
<400> 8
ggatccaaca ttgtactgac gcaaagcccc tcatctttgt ctgagtcact cggcggcaaa 60
gtaaccatca catgcaaggc cagtcaagac atcaataaat atattgcttg gtatcagtat 120
aaacccggca aggggccgcg actgctgatt cactacacga gtaccttgca accgggcatt 180
ccgagccgat ttagtggcag tggctcaggt cgcgattact cattctcaat aagtaatctc 240
gaaccggaag acatagctac ttattattgc ttgcagtacg ataatttgtg gaccttcggg 300
ggtggtacaa agttggaaat aaagggtggc ggagggagcg gcggtggagg aagcggaggc 360
ggaggttccg aggtccaact cgtagaatca ggtcccggat tggtgcaacc atcccagagc 420
ctctctatta catgcacggt ctctggattt agtctgacca attacgatgt gcattgggtg 480
cgccagtctc ccggcaaggg gttggaatgg cttggcgtta tatggaacta cggaaataca 540
gactataacg ccgcgtttat ctctcggctg agtatacgga aagacagtag taaatcccag 600
gtctttttta cgatgtcatc cctgcaaacg ccagataccg caatatatta ctgcgccagg 660
aaccacggtg atggttatta taattggtac ttcgatgtgt ggggtactgg cactacagtc 720
acagtatctt catctaga 738
<210> 9
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> CD5-9H2L-3048 CAR
<400> 9
ggatcccagg tccagctgaa agaaagcggt ccagagctgg aaaaacccgg tgcgagcgtc 60
aaaatatcat gtaaagcaag cgggtattca ttcaccgcgt actctatgaa ctgggttaag 120
caaaacaacg gtatgtcctt ggagtggata gggtctatcg acccgtatta tggggacaca 180
aaatacgcgc agaaattcaa ggggaaggcc accctgaccg tagataaagc tagttctact 240
gcgtacttgc aactgaaaag cctcacttct gaggactctg ccgtctacta ctgtgctcgg 300
cgaatgataa cgacggggga ctggtatttc gatgtttggg gtacagggac tacggtgact 360
gtcagtagcg gtggcggagg gagcggcggt ggaggaagcg gaggcggagg ttcccatatc 420
gtcttgactc aatcacctag ttctttgtct gcgtcccttg gcgaccgagt caccatatct 480
tgcagagcgt cacaggacat ttcaacgtac ctcaactggt atcagcaaaa accggacggg 540
actgtcaagc tcttgatctt ctacacttcc agactccacg ccggggtgcc aagcagattt 600
agtggctctg gcagcgggac acaccatagt cttacaatca gcaatcttga gcaagaagac 660
atagccacgt atttctgcca gcaaggtaac tcacttccgt tcacgtttgg tagtggcacc 720
aaactggaga taaaatccgg a 741
<210> 10
<211> 741
<212> DNA
<213> Artificial Sequence
<220>
<223> CD5-9L2H-3049 CAR
<400> 10
ggatcccata tcgtcttgac tcaatcacct agttctttgt ctgcgtccct tggcgaccga 60
gtcaccatat cttgcagagc gtcacaggac atttcaacgt acctcaactg gtatcagcaa 120
aaaccggacg ggactgtcaa gctcttgatc ttctacactt ccagactcca cgccggggtg 180
ccaagcagat ttagtggctc tggcagcggg acacaccata gtcttacaat cagcaatctt 240
gagcaagaag acatagccac gtatttctgc cagcaaggta actcacttcc gttcacgttt 300
ggtagtggca ccaaactgga gataaaaggt ggcggaggga gcggcggtgg aggaagcgga 360
ggcggaggtt cccaggtcca gctgaaagaa agcggtccag agctggaaaa acccggtgcg 420
agcgtcaaaa tatcatgtaa agcaagcggg tattcattca ccgcgtactc tatgaactgg 480
gttaagcaaa acaacggtat gtccttggag tggatagggt ctatcgaccc gtattatggg 540
gacacaaaat acgcgcagaa attcaagggg aaggccaccc tgaccgtaga taaagctagt 600
tctactgcgt acttgcaact gaaaagcctc acttctgagg actctgccgt ctactactgt 660
gctcggcgaa tgataacgac gggggactgg tatttcgatg tttggggtac agggactacg 720
gtgactgtca gtagctccgg a 741
<210> 11
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> CD5-34H2L-3052 CAR
<400> 11
ggatccgagg ttaaactcgt ggagagcggt gccgaactcg tccgaagtgg tgcttccgtt 60
aaactcagtt gtgccgcgtc aggatttaac ataaaagatt actacattca ctgggtcaaa 120
cagcgcccgg agcaggggct tgaatggatc gggtggattg atcctgaaaa cgggcgcacc 180
gaatatgctc ccaagttcca gggcaaagct actatgaccg ctgacacctc tagtaacact 240
gcctacctgc agttgagctc tcttacgtct gaggataccg ctgtgtacta ctgtaataac 300
ggaaattatg tacgacacta ttacttcgac tactgggggc agggcactac tgtgactgta 360
tctagcggtg gcggagggag cggcggtgga ggaagcggag gcggaggttc cgattggctc 420
acacaatccc ctgcaatcct gagtgcatct ccaggcgaga aagtaactat gacttgcaga 480
gctataagct ctgtgtccta catgcactgg tatcagcaga agccaggttc ttccccgaag 540
ccgtggatat atgctacaag caatttggca tccggtgttc ccgcccggtt tagtggctcc 600
ggttctggga caagttactc cctcacgatc agcagggttg aagccgagga cgctgccact 660
tactattgcc aacagtggtc aagtaacccc aggactttcg ggggaggaac taaacttgaa 720
atcaaatcta ga 732
<210> 12
<211> 732
<212> DNA
<213> Artificial Sequence
<220>
<223> CD5-34L2H-3053 CAR
<400> 12
ggatccgatt ggctcacaca atcccctgca atcctgagtg catctccagg cgagaaagta 60
actatgactt gcagagctat aagctctgtg tcctacatgc actggtatca gcagaagcca 120
ggttcttccc cgaagccgtg gatatatgct acaagcaatt tggcatccgg tgttcccgcc 180
cggtttagtg gctccggttc tgggacaagt tactccctca cgatcagcag ggttgaagcc 240
gaggacgctg ccacttacta ttgccaacag tggtcaagta accccaggac tttcggggga 300
ggaactaaac ttgaaatcaa aggtggcgga gggagcggcg gtggaggaag cggaggcgga 360
ggttccgagg ttaaactcgt ggagagcggt gccgaactcg tccgaagtgg tgcttccgtt 420
aaactcagtt gtgccgcgtc aggatttaac ataaaagatt actacattca ctgggtcaaa 480
cagcgcccgg agcaggggct tgaatggatc gggtggattg atcctgaaaa cgggcgcacc 540
gaatatgctc ccaagttcca gggcaaagct actatgaccg ctgacacctc tagtaacact 600
gcctacctgc agttgagctc tcttacgtct gaggataccg ctgtgtacta ctgtaataac 660
ggaaattatg tacgacacta ttacttcgac tactgggggc agggcactac tgtgactgta 720
tctagctcta ga 732
<210> 13
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> CD5-17H2L-3054 CAR
<400> 13
ggatccgagg tccaactcgt agaatcaggt cccggattgg tgcaaccatc ccagagcctc 60
tctattacat gcacggtctc tggatttagt ctgaccaatt acgatgtgca ttgggtgcgc 120
cagtctcccg gcaaggggtt ggaatggctt ggcgttatat ggaactacgg aaatacagac 180
tataacgccg cgtttatctc tcggctgagt atacggaaag acagtagtaa atcccaggtc 240
ttttttacga tgtcatccct gcaaacgcca gataccgcaa tatattactg cgccaggaac 300
cacggtgatg gttattataa ttggtacttc gatgtgtggg gtactggcac tacagtcaca 360
gtatcttcag gtggcggagg gagcggcggt ggaggaagcg gaggcggagg ttccaacatt 420
gtactgacgc aaagcccctc atctttgtct gagtcactcg gcggcaaagt aaccatcaca 480
tgcaaggcca gtcaagacat caataaatat attgcttggt atcagtataa acccggcaag 540
gggccgcgac tgctgattca ctacacgagt accttgcaac cgggcattcc gagccgattt 600
agtggcagtg gctcaggtcg cgattactca ttctcaataa gtaatctcga accggaagac 660
atagctactt attattgctt gcagtacgat aatttgtgga ccttcggggg tggtacaaag 720
ttggaaataa agtctaga 738
<210> 14
<211> 72
<212> DNA
<213> Artificial Sequence
<220>
<223> CD8 transmembrane domain
<400> 14
atctacatct gggcgccctt ggccgggact tgtggggtcc ttctcctgtc actggttatc 60
accctttact gc 72
<210> 15
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> CD8 transmembrane domain
<400> 15
Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu
1 5 10 15
Ser Leu Val Ile Thr Leu Tyr Cys
20
<210> 16
<211> 135
<212> DNA
<213> Artificial Sequence
<220>
<223> CD8 hinge domain
<400> 16
accacgacgc cagcgccgcg accaccaaca ccggcgccca ccatcgcgtc gcagcccctg 60
tccctgcgcc cagaggcgtg ccggccagcg gcggggggcg cagtgcacac gagggggctg 120
gacttcgcct gtgat 135
<210> 17
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> CD8 hinge domain
<400> 17
Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
1 5 10 15
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
20 25 30
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp
35 40 45
<210> 18
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<223> 4-1BB
<400> 18
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa 60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactg 126
<210> 19
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> CD3-zeta
<400> 19
agagtgaagt tcagcaggag cgcagacgcc cccgcgtaca agcagggcca gaaccagctc 60
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa gagacgtggc 120
cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg cctgtacaat 180
gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa aggcgagcgc 240
cggaggggca aggggcacga tggcctttac cagggtctca gtacagccac caaggacacc 300
tacgacgccc ttcacatgca ggccctgccc cctcgc 336
<210> 20
<211> 42
<212> PRT
<213> Artificial Sequence
<220>
<223> 4-1BB
<400> 20
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
35 40
<210> 21
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> CD3-zeta
<400> 21
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<210> 22
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> gRNA
<400> 22
acagctgaca ggctcgacac 20
<210> 23
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> gRNA
<400> 23
cggctcagct ggtatgaccc 20
<210> 24
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> gRNA
<400> 24
ggagcaggtg atgttgacgg 20
<210> 25
<211> 493
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507H2L-3028 CAR
<400> 25
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Gln Val Gln Leu Val Gln Ser Gly Ala
20 25 30
Glu Val Gln Arg Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser
35 40 45
Gly Tyr Ile Phe Thr Glu Tyr Tyr Met Tyr Trp Val Arg Gln Ala Pro
50 55 60
Gly Gln Gly Leu Glu Leu Val Gly Arg Ile Asp Pro Glu Asp Gly Ser
65 70 75 80
Ile Asp Tyr Val Glu Lys Phe Lys Lys Lys Val Thr Leu Thr Ala Asp
85 90 95
Thr Ser Ser Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Thr Ser Asp
100 105 110
Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Lys Phe Asn Tyr Arg Phe
115 120 125
Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Val Val Met
145 150 155 160
Thr Gln Ser Pro Pro Ser Leu Leu Val Thr Leu Gly Gln Pro Ala Ser
165 170 175
Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser Ser Gly Asn Thr
180 185 190
Tyr Leu Asn Trp Leu Leu Gln Arg Pro Gly Gln Ser Pro Gln Pro Leu
195 200 205
Ile Tyr Leu Val Ser Lys Leu Glu Ser Gly Val Pro Asp Arg Phe Ser
210 215 220
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile Ser Gly Val Glu
225 230 235 240
Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Phe Thr His Tyr Pro
245 250 255
Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Ser Gly Thr Thr
260 265 270
Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln
275 280 285
Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala
290 295 300
Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala
305 310 315 320
Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr
325 330 335
Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
340 345 350
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
355 360 365
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
370 375 380
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln
385 390 395 400
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
405 410 415
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
420 425 430
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
435 440 445
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
450 455 460
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
465 470 475 480
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 26
<211> 493
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507L2H-3043 CAR
<400> 26
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Asp Val Val Met Thr Gln Ser Pro Pro
20 25 30
Ser Leu Leu Val Thr Leu Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser
35 40 45
Ser Gln Ser Leu Leu His Ser Ser Gly Asn Thr Tyr Leu Asn Trp Leu
50 55 60
Leu Gln Arg Pro Gly Gln Ser Pro Gln Pro Leu Ile Tyr Leu Val Ser
65 70 75 80
Lys Leu Glu Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
85 90 95
Thr Asp Phe Thr Leu Lys Ile Ser Gly Val Glu Ala Glu Asp Val Gly
100 105 110
Val Tyr Tyr Cys Met Gln Phe Thr His Tyr Pro Tyr Thr Phe Gly Gln
115 120 125
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu
145 150 155 160
Val Gln Arg Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly
165 170 175
Tyr Ile Phe Thr Glu Tyr Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly
180 185 190
Gln Gly Leu Glu Leu Val Gly Arg Ile Asp Pro Glu Asp Gly Ser Ile
195 200 205
Asp Tyr Val Glu Lys Phe Lys Lys Lys Val Thr Leu Thr Ala Asp Thr
210 215 220
Ser Ser Ser Thr Ala Tyr Met Glu Leu Ser Ser Leu Thr Ser Asp Asp
225 230 235 240
Thr Ala Val Tyr Tyr Cys Ala Arg Gly Lys Phe Asn Tyr Arg Phe Ala
245 250 255
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ser Gly Thr Thr
260 265 270
Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln
275 280 285
Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala
290 295 300
Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala
305 310 315 320
Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr
325 330 335
Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
340 345 350
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
355 360 365
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
370 375 380
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln
385 390 395 400
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
405 410 415
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
420 425 430
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
435 440 445
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
450 455 460
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
465 470 475 480
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 27
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507H2L-3028 scFv
<400> 27
Gly Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Gln Arg Pro
1 5 10 15
Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr
20 25 30
Glu Tyr Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu
35 40 45
Leu Val Gly Arg Ile Asp Pro Glu Asp Gly Ser Ile Asp Tyr Val Glu
50 55 60
Lys Phe Lys Lys Lys Val Thr Leu Thr Ala Asp Thr Ser Ser Ser Thr
65 70 75 80
Ala Tyr Met Glu Leu Ser Ser Leu Thr Ser Asp Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Gly Lys Phe Asn Tyr Arg Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Asp Val Val Met Thr Gln Ser Pro Pro
130 135 140
Ser Leu Leu Val Thr Leu Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser
145 150 155 160
Ser Gln Ser Leu Leu His Ser Ser Gly Asn Thr Tyr Leu Asn Trp Leu
165 170 175
Leu Gln Arg Pro Gly Gln Ser Pro Gln Pro Leu Ile Tyr Leu Val Ser
180 185 190
Lys Leu Glu Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
195 200 205
Thr Asp Phe Thr Leu Lys Ile Ser Gly Val Glu Ala Glu Asp Val Gly
210 215 220
Val Tyr Tyr Cys Met Gln Phe Thr His Tyr Pro Tyr Thr Phe Gly Gln
225 230 235 240
Gly Thr Lys Leu Glu Ile Lys Ser Gly
245
<210> 28
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507L2H-3043 scFv
<400> 28
Gly Ser Asp Val Val Met Thr Gln Ser Pro Pro Ser Leu Leu Val Thr
1 5 10 15
Leu Gly Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu
20 25 30
His Ser Ser Gly Asn Thr Tyr Leu Asn Trp Leu Leu Gln Arg Pro Gly
35 40 45
Gln Ser Pro Gln Pro Leu Ile Tyr Leu Val Ser Lys Leu Glu Ser Gly
50 55 60
Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
65 70 75 80
Lys Ile Ser Gly Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met
85 90 95
Gln Phe Thr His Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu
100 105 110
Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Gln Arg Pro Gly
130 135 140
Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Glu
145 150 155 160
Tyr Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Leu
165 170 175
Val Gly Arg Ile Asp Pro Glu Asp Gly Ser Ile Asp Tyr Val Glu Lys
180 185 190
Phe Lys Lys Lys Val Thr Leu Thr Ala Asp Thr Ser Ser Ser Thr Ala
195 200 205
Tyr Met Glu Leu Ser Ser Leu Thr Ser Asp Asp Thr Ala Val Tyr Tyr
210 215 220
Cys Ala Arg Gly Lys Phe Asn Tyr Arg Phe Ala Tyr Trp Gly Gln Gly
225 230 235 240
Thr Leu Val Thr Val Ser Ser Ser Gly
245
<210> 29
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 VH
<400> 29
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Gln Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Glu Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Leu Val
35 40 45
Gly Arg Ile Asp Pro Glu Asp Gly Ser Ile Asp Tyr Val Glu Lys Phe
50 55 60
Lys Lys Lys Val Thr Leu Thr Ala Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Thr Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Lys Phe Asn Tyr Arg Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 30
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 VL
<400> 30
Asp Val Val Met Thr Gln Ser Pro Pro Ser Leu Leu Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Ser Gly Asn Thr Tyr Leu Asn Trp Leu Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Gln Pro Leu Ile Tyr Leu Val Ser Lys Leu Glu Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Gly Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Phe
85 90 95
Thr His Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 31
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 HCDR1
<400> 31
Glu Tyr Tyr Met Tyr
1 5
<210> 32
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 HCDR2
<400> 32
Arg Ile Asp Pro Glu Asp Gly Ser Ile Asp Tyr Val Glu Lys Phe Lys
1 5 10 15
Lys
<210> 33
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 HCDR3
<400> 33
Gly Lys Phe Asn Tyr Arg Phe Ala Tyr
1 5
<210> 34
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 LCDR1
<400> 34
Arg Ser Ser Gln Ser Leu Leu His Ser Ser Gly Asn Thr Tyr Leu Asn
1 5 10 15
<210> 35
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 LCDR2
<400> 35
Leu Val Ser Lys Leu Glu Ser
1 5
<210> 36
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-MEDI507 LCDR3
<400> 36
Met Gln Phe Thr His Tyr Pro Tyr Thr
1 5
<210> 37
<211> 496
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11H2L-3029 CAR
<400> 37
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala
20 25 30
Glu Leu Val Arg Pro Gly Thr Ser Val Lys Leu Ser Cys Lys Ala Ser
35 40 45
Gly Tyr Thr Phe Thr Ser Tyr Trp Met His Trp Ile Lys Gln Arg Pro
50 55 60
Glu Gln Gly Leu Glu Trp Ile Gly Arg Ile Asp Pro Tyr Asp Ser Glu
65 70 75 80
Thr His Tyr Asn Glu Lys Phe Lys Asp Lys Ala Ile Leu Ser Val Asp
85 90 95
Lys Ser Ser Ser Thr Ala Tyr Ile Gln Leu Ser Ser Leu Thr Ser Asp
100 105 110
Asp Ser Ala Val Tyr Tyr Cys Ser Arg Arg Asp Ala Lys Tyr Asp Gly
115 120 125
Tyr Ala Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp
145 150 155 160
Ile Val Met Thr Gln Ala Ala Pro Ser Val Pro Val Thr Pro Gly Glu
165 170 175
Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Thr Leu Leu His Ser Asn
180 185 190
Gly Asn Thr Tyr Leu Tyr Trp Phe Leu Gln Arg Pro Gly Gln Ser Pro
195 200 205
Gln Val Leu Ile Tyr Arg Met Ser Asn Leu Ala Ser Gly Val Pro Asn
210 215 220
Arg Phe Ser Gly Ser Gly Ser Glu Thr Thr Phe Thr Leu Arg Ile Ser
225 230 235 240
Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln His Leu
245 250 255
Glu Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Ser
260 265 270
Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile
275 280 285
Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala
290 295 300
Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr
305 310 315 320
Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu
325 330 335
Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile
340 345 350
Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp
355 360 365
Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
370 375 380
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly
385 390 395 400
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
405 410 415
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
420 425 430
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
435 440 445
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
450 455 460
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
465 470 475 480
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490 495
<210> 38
<211> 496
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11L2H-3030 CAR
<400> 38
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Asp Ile Val Met Thr Gln Ala Ala Pro
20 25 30
Ser Val Pro Val Thr Pro Gly Glu Ser Val Ser Ile Ser Cys Arg Ser
35 40 45
Ser Lys Thr Leu Leu His Ser Asn Gly Asn Thr Tyr Leu Tyr Trp Phe
50 55 60
Leu Gln Arg Pro Gly Gln Ser Pro Gln Val Leu Ile Tyr Arg Met Ser
65 70 75 80
Asn Leu Ala Ser Gly Val Pro Asn Arg Phe Ser Gly Ser Gly Ser Glu
85 90 95
Thr Thr Phe Thr Leu Arg Ile Ser Arg Val Glu Ala Glu Asp Val Gly
100 105 110
Ile Tyr Tyr Cys Met Gln His Leu Glu Tyr Pro Tyr Thr Phe Gly Gly
115 120 125
Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu
145 150 155 160
Leu Val Arg Pro Gly Thr Ser Val Lys Leu Ser Cys Lys Ala Ser Gly
165 170 175
Tyr Thr Phe Thr Ser Tyr Trp Met His Trp Ile Lys Gln Arg Pro Glu
180 185 190
Gln Gly Leu Glu Trp Ile Gly Arg Ile Asp Pro Tyr Asp Ser Glu Thr
195 200 205
His Tyr Asn Glu Lys Phe Lys Asp Lys Ala Ile Leu Ser Val Asp Lys
210 215 220
Ser Ser Ser Thr Ala Tyr Ile Gln Leu Ser Ser Leu Thr Ser Asp Asp
225 230 235 240
Ser Ala Val Tyr Tyr Cys Ser Arg Arg Asp Ala Lys Tyr Asp Gly Tyr
245 250 255
Ala Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Ser
260 265 270
Gly Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile
275 280 285
Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala
290 295 300
Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr
305 310 315 320
Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu
325 330 335
Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile
340 345 350
Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp
355 360 365
Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
370 375 380
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly
385 390 395 400
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
405 410 415
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
420 425 430
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
435 440 445
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
450 455 460
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
465 470 475 480
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490 495
<210> 39
<211> 252
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11H2L-3029 scFv
<400> 39
Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro
1 5 10 15
Gly Thr Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr
20 25 30
Ser Tyr Trp Met His Trp Ile Lys Gln Arg Pro Glu Gln Gly Leu Glu
35 40 45
Trp Ile Gly Arg Ile Asp Pro Tyr Asp Ser Glu Thr His Tyr Asn Glu
50 55 60
Lys Phe Lys Asp Lys Ala Ile Leu Ser Val Asp Lys Ser Ser Ser Thr
65 70 75 80
Ala Tyr Ile Gln Leu Ser Ser Leu Thr Ser Asp Asp Ser Ala Val Tyr
85 90 95
Tyr Cys Ser Arg Arg Asp Ala Lys Tyr Asp Gly Tyr Ala Leu Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
130 135 140
Ala Ala Pro Ser Val Pro Val Thr Pro Gly Glu Ser Val Ser Ile Ser
145 150 155 160
Cys Arg Ser Ser Lys Thr Leu Leu His Ser Asn Gly Asn Thr Tyr Leu
165 170 175
Tyr Trp Phe Leu Gln Arg Pro Gly Gln Ser Pro Gln Val Leu Ile Tyr
180 185 190
Arg Met Ser Asn Leu Ala Ser Gly Val Pro Asn Arg Phe Ser Gly Ser
195 200 205
Gly Ser Glu Thr Thr Phe Thr Leu Arg Ile Ser Arg Val Glu Ala Glu
210 215 220
Asp Val Gly Ile Tyr Tyr Cys Met Gln His Leu Glu Tyr Pro Tyr Thr
225 230 235 240
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Ser Gly
245 250
<210> 40
<211> 252
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11L2H-3030 scFv
<400> 40
Gly Ser Asp Ile Val Met Thr Gln Ala Ala Pro Ser Val Pro Val Thr
1 5 10 15
Pro Gly Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Thr Leu Leu
20 25 30
His Ser Asn Gly Asn Thr Tyr Leu Tyr Trp Phe Leu Gln Arg Pro Gly
35 40 45
Gln Ser Pro Gln Val Leu Ile Tyr Arg Met Ser Asn Leu Ala Ser Gly
50 55 60
Val Pro Asn Arg Phe Ser Gly Ser Gly Ser Glu Thr Thr Phe Thr Leu
65 70 75 80
Arg Ile Ser Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met
85 90 95
Gln His Leu Glu Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu
100 105 110
Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly
130 135 140
Thr Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser
145 150 155 160
Tyr Trp Met His Trp Ile Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp
165 170 175
Ile Gly Arg Ile Asp Pro Tyr Asp Ser Glu Thr His Tyr Asn Glu Lys
180 185 190
Phe Lys Asp Lys Ala Ile Leu Ser Val Asp Lys Ser Ser Ser Thr Ala
195 200 205
Tyr Ile Gln Leu Ser Ser Leu Thr Ser Asp Asp Ser Ala Val Tyr Tyr
210 215 220
Cys Ser Arg Arg Asp Ala Lys Tyr Asp Gly Tyr Ala Leu Asp Tyr Trp
225 230 235 240
Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Ser Gly
245 250
<210> 41
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 VH
<400> 41
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Thr
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Ile Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Tyr Asp Ser Glu Thr His Tyr Asn Glu Lys Phe
50 55 60
Lys Asp Lys Ala Ile Leu Ser Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Ile Gln Leu Ser Ser Leu Thr Ser Asp Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Arg Asp Ala Lys Tyr Asp Gly Tyr Ala Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 42
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 VL
<400> 42
Asp Ile Val Met Thr Gln Ala Ala Pro Ser Val Pro Val Thr Pro Gly
1 5 10 15
Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Thr Leu Leu His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Tyr Trp Phe Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Gln Val Leu Ile Tyr Arg Met Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Asn Arg Phe Ser Gly Ser Gly Ser Glu Thr Thr Phe Thr Leu Arg Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln His
85 90 95
Leu Glu Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 43
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 HCDR1
<400> 43
Ser Tyr Trp Met His
1 5
<210> 44
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 HCDR2
<400> 44
Arg Ile Asp Pro Tyr Asp Ser Glu Thr His Tyr Asn Glu Lys Phe Lys
1 5 10 15
Asp
<210> 45
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 HCDR3
<400> 45
Arg Asp Ala Lys Tyr Asp Gly Tyr Ala Leu Asp Tyr
1 5 10
<210> 46
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 LCDR1
<400> 46
Arg Ser Ser Lys Thr Leu Leu His Ser Asn Gly Asn Thr Tyr Leu Tyr
1 5 10 15
<210> 47
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 LCDR2
<400> 47
Arg Met Ser Asn Leu Ala Ser
1 5
<210> 48
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-OKT11 LCDR3
<400> 48
Met Gln His Leu Glu Tyr Pro Tyr Thr
1 5
<210> 49
<211> 495
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2-H2L-3031 CAR
<400> 49
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala
20 25 30
Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser
35 40 45
Gly Tyr Thr Phe Thr Thr Phe Trp Met Asn Trp Val Lys Gln Arg Pro
50 55 60
Gly Gln Gly Leu Glu Trp Ile Gly Met Ile Asp Pro Ser Asp Ser Glu
65 70 75 80
Ala His Tyr Asn Gln Met Phe Lys Asp Lys Ala Thr Leu Thr Val Asp
85 90 95
Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu
100 105 110
Asp Ser Ala Val Tyr Tyr Cys Ala Arg Gly Arg Gly Tyr Asp Asp Gly
115 120 125
Asp Ala Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp
145 150 155 160
Ile Val Met Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln
165 170 175
Arg Ala Thr Ile Ser Tyr Arg Ala Ser Lys Ser Val Ser Thr Ser Gly
180 185 190
Tyr Ser Tyr Met His Trp Asn Gln Gln Lys Pro Gly Gln Pro Pro Arg
195 200 205
Leu Leu Ile Tyr Leu Val Ser Asn Leu Glu Ser Gly Val Pro Ala Arg
210 215 220
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His Pro
225 230 235 240
Val Glu Glu Glu Asp Ala Ala Thr Tyr Tyr Cys Met Gln Phe Thr His
245 250 255
Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Ser Gly
260 265 270
Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
275 280 285
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
290 295 300
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile
305 310 315 320
Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val
325 330 335
Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe
340 345 350
Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly
355 360 365
Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg
370 375 380
Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln
385 390 395 400
Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp
405 410 415
Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro
420 425 430
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp
435 440 445
Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg
450 455 460
Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
465 470 475 480
Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490 495
<210> 50
<211> 251
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2-H2L-3031 scFv
<400> 50
Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro
1 5 10 15
Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr
20 25 30
Thr Phe Trp Met Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu
35 40 45
Trp Ile Gly Met Ile Asp Pro Ser Asp Ser Glu Ala His Tyr Asn Gln
50 55 60
Met Phe Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr
65 70 75 80
Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Gly Arg Gly Tyr Asp Asp Gly Asp Ala Met Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
130 135 140
Ser Pro Ala Ser Leu Ala Val Ser Leu Gly Gln Arg Ala Thr Ile Ser
145 150 155 160
Tyr Arg Ala Ser Lys Ser Val Ser Thr Ser Gly Tyr Ser Tyr Met His
165 170 175
Trp Asn Gln Gln Lys Pro Gly Gln Pro Pro Arg Leu Leu Ile Tyr Leu
180 185 190
Val Ser Asn Leu Glu Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly
195 200 205
Ser Gly Thr Asp Phe Thr Leu Asn Ile His Pro Val Glu Glu Glu Asp
210 215 220
Ala Ala Thr Tyr Tyr Cys Met Gln Phe Thr His Tyr Pro Tyr Thr Phe
225 230 235 240
Gly Gly Gly Thr Lys Leu Glu Ile Lys Ser Gly
245 250
<210> 51
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2-H2L-3031 VH
<400> 51
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Phe
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Met Ile Asp Pro Ser Asp Ser Glu Ala His Tyr Asn Gln Met Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Arg Gly Tyr Asp Asp Gly Asp Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 52
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2-H2L-3031 VL
<400> 52
Asp Ile Val Met Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Tyr Arg Ala Ser Lys Ser Val Ser Thr Ser
20 25 30
Gly Tyr Ser Tyr Met His Trp Asn Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Arg Leu Leu Ile Tyr Leu Val Ser Asn Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Ala Ala Thr Tyr Tyr Cys Met Gln Phe Thr
85 90 95
His Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 53
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2 HCDR1
<400> 53
Thr Phe Trp Met Asn
1 5
<210> 54
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2 HCDR2
<400> 54
Met Ile Asp Pro Ser Asp Ser Glu Ala His Tyr Asn Gln Met Phe Lys
1 5 10 15
Asp
<210> 55
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2 HCDR3
<400> 55
Gly Arg Gly Tyr Asp Asp Gly Asp Ala Met Asp Tyr
1 5 10
<210> 56
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2 LCDR1
<400> 56
Arg Ala Ser Lys Ser Val Ser Thr Ser Gly Tyr Ser Tyr Met His
1 5 10 15
<210> 57
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2 LCDR2
<400> 57
Leu Val Ser Asn Leu Glu Ser
1 5
<210> 58
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-T11-2 LCDR3
<400> 58
Met Gln Phe Thr His Tyr Pro Tyr Thr
1 5
<210> 59
<211> 487
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1-H2L-3032 CAR
<400> 59
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Glu Val Gln Leu Glu Glu Ser Gly Gly
20 25 30
Gly Leu Val Met Pro Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser
35 40 45
Gly Phe Ala Phe Ser Ser Tyr Asp Met Ser Trp Val Arg Gln Thr Pro
50 55 60
Glu Lys Arg Leu Glu Trp Val Ala Tyr Ile Ser Gly Gly Gly Phe Thr
65 70 75 80
Tyr Tyr Pro Asp Thr Val Lys Gly Arg Phe Thr Leu Ser Arg Asp Asn
85 90 95
Ala Lys Asn Thr Leu Tyr Leu Gln Met Ser Ser Leu Lys Ser Glu Asp
100 105 110
Thr Ala Met Tyr Tyr Cys Ala Arg Gln Gly Ala Asn Trp Glu Leu Val
115 120 125
Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr
145 150 155 160
Gln Ser Pro Ala Thr Leu Ser Val Thr Pro Gly Asp Arg Val Phe Leu
165 170 175
Ser Cys Arg Ala Ser Gln Ser Ile Ser Asp Phe Leu His Trp Tyr Gln
180 185 190
Gln Lys Ser His Glu Ser Pro Arg Leu Leu Ile Lys Tyr Ala Ser Gln
195 200 205
Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Ser
210 215 220
Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Pro Glu Asp Val Gly Val
225 230 235 240
Tyr Leu Cys Gln Asn Gly His Asn Phe Pro Pro Thr Phe Gly Gly Gly
245 250 255
Thr Lys Leu Glu Ile Lys Ser Gly Thr Thr Thr Pro Ala Pro Arg Pro
260 265 270
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
275 280 285
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
290 295 300
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
305 310 315 320
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly
325 330 335
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
340 345 350
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
355 360 365
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
370 375 380
Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
385 390 395 400
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
405 410 415
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
420 425 430
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
435 440 445
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
450 455 460
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
465 470 475 480
Met Gln Ala Leu Pro Pro Arg
485
<210> 60
<211> 487
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1-L2H-3033 CAR
<400> 60
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ala
20 25 30
Thr Leu Ser Val Thr Pro Gly Asp Arg Val Phe Leu Ser Cys Arg Ala
35 40 45
Ser Gln Ser Ile Ser Asp Phe Leu His Trp Tyr Gln Gln Lys Ser His
50 55 60
Glu Ser Pro Arg Leu Leu Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly
65 70 75 80
Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu
85 90 95
Ser Ile Asn Ser Val Glu Pro Glu Asp Val Gly Val Tyr Leu Cys Gln
100 105 110
Asn Gly His Asn Phe Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu
115 120 125
Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Met Pro Gly
145 150 155 160
Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser
165 170 175
Tyr Asp Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp
180 185 190
Val Ala Tyr Ile Ser Gly Gly Gly Phe Thr Tyr Tyr Pro Asp Thr Val
195 200 205
Lys Gly Arg Phe Thr Leu Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
210 215 220
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
225 230 235 240
Ala Arg Gln Gly Ala Asn Trp Glu Leu Val Tyr Trp Gly Gln Gly Thr
245 250 255
Thr Leu Thr Val Ser Ser Ser Gly Thr Thr Thr Pro Ala Pro Arg Pro
260 265 270
Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro
275 280 285
Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu
290 295 300
Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
305 310 315 320
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly
325 330 335
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
340 345 350
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
355 360 365
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
370 375 380
Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
385 390 395 400
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
405 410 415
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
420 425 430
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
435 440 445
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
450 455 460
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
465 470 475 480
Met Gln Ala Leu Pro Pro Arg
485
<210> 61
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1-H2L-3032 scFv
<400> 61
Gly Ser Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Met Pro
1 5 10 15
Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser
20 25 30
Ser Tyr Asp Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu
35 40 45
Trp Val Ala Tyr Ile Ser Gly Gly Gly Phe Thr Tyr Tyr Pro Asp Thr
50 55 60
Val Lys Gly Arg Phe Thr Leu Ser Arg Asp Asn Ala Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr
85 90 95
Cys Ala Arg Gln Gly Ala Asn Trp Glu Leu Val Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ala Thr
130 135 140
Leu Ser Val Thr Pro Gly Asp Arg Val Phe Leu Ser Cys Arg Ala Ser
145 150 155 160
Gln Ser Ile Ser Asp Phe Leu His Trp Tyr Gln Gln Lys Ser His Glu
165 170 175
Ser Pro Arg Leu Leu Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile
180 185 190
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser
195 200 205
Ile Asn Ser Val Glu Pro Glu Asp Val Gly Val Tyr Leu Cys Gln Asn
210 215 220
Gly His Asn Phe Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
225 230 235 240
Lys Ser Gly
<210> 62
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1-L2H-3033 scFv
<400> 62
Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Thr
1 5 10 15
Pro Gly Asp Arg Val Phe Leu Ser Cys Arg Ala Ser Gln Ser Ile Ser
20 25 30
Asp Phe Leu His Trp Tyr Gln Gln Lys Ser His Glu Ser Pro Arg Leu
35 40 45
Leu Ile Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn Ser Val
65 70 75 80
Glu Pro Glu Asp Val Gly Val Tyr Leu Cys Gln Asn Gly His Asn Phe
85 90 95
Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly
100 105 110
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu
115 120 125
Glu Glu Ser Gly Gly Gly Leu Val Met Pro Gly Gly Ser Leu Lys Leu
130 135 140
Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr Asp Met Ser Trp
145 150 155 160
Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val Ala Tyr Ile Ser
165 170 175
Gly Gly Gly Phe Thr Tyr Tyr Pro Asp Thr Val Lys Gly Arg Phe Thr
180 185 190
Leu Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu Gln Met Ser Ser
195 200 205
Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys Ala Arg Gln Gly Ala
210 215 220
Asn Trp Glu Leu Val Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
225 230 235 240
Ser Ser Gly
<210> 63
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 VH
<400> 63
Glu Val Gln Leu Glu Glu Ser Gly Gly Gly Leu Val Met Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ser Tyr
20 25 30
Asp Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Gly Gly Gly Phe Thr Tyr Tyr Pro Asp Thr Val Lys
50 55 60
Gly Arg Phe Thr Leu Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr Leu
65 70 75 80
Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Arg Gln Gly Ala Asn Trp Glu Leu Val Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 64
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 VL
<400> 64
Asp Ile Val Met Thr Gln Ser Pro Ala Thr Leu Ser Val Thr Pro Gly
1 5 10 15
Asp Arg Val Phe Leu Ser Cys Arg Ala Ser Gln Ser Ile Ser Asp Phe
20 25 30
Leu His Trp Tyr Gln Gln Lys Ser His Glu Ser Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Ser Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Pro
65 70 75 80
Glu Asp Val Gly Val Tyr Leu Cys Gln Asn Gly His Asn Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 65
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 HCDR1
<400> 65
Ser Tyr Asp Met Ser
1 5
<210> 66
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 HCDR2
<400> 66
Tyr Ile Ser Gly Gly Gly Phe Thr Tyr Tyr Pro Asp Thr Val Lys Gly
1 5 10 15
<210> 67
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 HCDR3
<400> 67
Gln Gly Ala Asn Trp Glu Leu Val Tyr
1 5
<210> 68
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 LCDR1
<400> 68
Arg Ala Ser Gln Ser Ile Ser Asp Phe Leu His
1 5 10
<210> 69
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 LCDR2
<400> 69
Tyr Ala Ser Gln Ser Ile Ser
1 5
<210> 70
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD2-TS2-18.1.1 LCDR3
<400> 70
Gln Asn Gly His Asn Phe Pro Pro Thr
1 5
<210> 71
<211> 494
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-17L2H-3045 CAR
<400> 71
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Asn Ile Val Leu Thr Gln Ser Pro Ser
20 25 30
Ser Leu Ser Glu Ser Leu Gly Gly Lys Val Thr Ile Thr Cys Lys Ala
35 40 45
Ser Gln Asp Ile Asn Lys Tyr Ile Ala Trp Tyr Gln Tyr Lys Pro Gly
50 55 60
Lys Gly Pro Arg Leu Leu Ile His Tyr Thr Ser Thr Leu Gln Pro Gly
65 70 75 80
Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Arg Asp Tyr Ser Phe
85 90 95
Ser Ile Ser Asn Leu Glu Pro Glu Asp Ile Ala Thr Tyr Tyr Cys Leu
100 105 110
Gln Tyr Asp Asn Leu Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
115 120 125
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Glu Val Gln Leu Val Glu Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
145 150 155 160
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
165 170 175
Asp Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
180 185 190
Gly Val Ile Trp Asn Tyr Gly Asn Thr Asp Tyr Asn Ala Ala Phe Ile
195 200 205
Ser Arg Leu Ser Ile Arg Lys Asp Ser Ser Lys Ser Gln Val Phe Phe
210 215 220
Thr Met Ser Ser Leu Gln Thr Pro Asp Thr Ala Ile Tyr Tyr Cys Ala
225 230 235 240
Arg Asn His Gly Asp Gly Tyr Tyr Asn Trp Tyr Phe Asp Val Trp Gly
245 250 255
Thr Gly Thr Thr Val Thr Val Ser Ser Ser Arg Thr Thr Thr Pro Ala
260 265 270
Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser
275 280 285
Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr
290 295 300
Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala
305 310 315 320
Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys
325 330 335
His Met Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro
340 345 350
Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys
355 360 365
Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Thr Ser Arg Val
370 375 380
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
385 390 395 400
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
405 410 415
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg
420 425 430
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
435 440 445
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
450 455 460
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
465 470 475 480
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 72
<211> 494
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-17H2L-3054 CAR
<400> 72
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Glu Val Gln Leu Val Glu Ser Gly Pro
20 25 30
Gly Leu Val Gln Pro Ser Gln Ser Leu Ser Ile Thr Cys Thr Val Ser
35 40 45
Gly Phe Ser Leu Thr Asn Tyr Asp Val His Trp Val Arg Gln Ser Pro
50 55 60
Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Asn Tyr Gly Asn Thr
65 70 75 80
Asp Tyr Asn Ala Ala Phe Ile Ser Arg Leu Ser Ile Arg Lys Asp Ser
85 90 95
Ser Lys Ser Gln Val Phe Phe Thr Met Ser Ser Leu Gln Thr Pro Asp
100 105 110
Thr Ala Ile Tyr Tyr Cys Ala Arg Asn His Gly Asp Gly Tyr Tyr Asn
115 120 125
Trp Tyr Phe Asp Val Trp Gly Thr Gly Thr Thr Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asn
145 150 155 160
Ile Val Leu Thr Gln Ser Pro Ser Ser Leu Ser Glu Ser Leu Gly Gly
165 170 175
Lys Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr Ile
180 185 190
Ala Trp Tyr Gln Tyr Lys Pro Gly Lys Gly Pro Arg Leu Leu Ile His
195 200 205
Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly Ser
210 215 220
Gly Ser Gly Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro Glu
225 230 235 240
Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asn Leu Trp Thr Phe
245 250 255
Gly Gly Gly Thr Lys Leu Glu Ile Lys Ser Arg Thr Thr Thr Pro Ala
260 265 270
Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser
275 280 285
Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr
290 295 300
Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala
305 310 315 320
Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys
325 330 335
His Met Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro
340 345 350
Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys
355 360 365
Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Thr Ser Arg Val
370 375 380
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
385 390 395 400
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
405 410 415
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg
420 425 430
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
435 440 445
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
450 455 460
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
465 470 475 480
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 73
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-17L2H-3045 scFv
<400> 73
Asn Ile Val Leu Thr Gln Ser Pro Ser Ser Leu Ser Glu Ser Leu Gly
1 5 10 15
Gly Lys Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Ala Trp Tyr Gln Tyr Lys Pro Gly Lys Gly Pro Arg Leu Leu Ile
35 40 45
His Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asn Leu Trp Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly
100 105 110
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
115 120 125
Gly Pro Gly Leu Val Gln Pro Ser Gln Ser Leu Ser Ile Thr Cys Thr
130 135 140
Val Ser Gly Phe Ser Leu Thr Asn Tyr Asp Val His Trp Val Arg Gln
145 150 155 160
Ser Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Asn Tyr Gly
165 170 175
Asn Thr Asp Tyr Asn Ala Ala Phe Ile Ser Arg Leu Ser Ile Arg Lys
180 185 190
Asp Ser Ser Lys Ser Gln Val Phe Phe Thr Met Ser Ser Leu Gln Thr
195 200 205
Pro Asp Thr Ala Ile Tyr Tyr Cys Ala Arg Asn His Gly Asp Gly Tyr
210 215 220
Tyr Asn Trp Tyr Phe Asp Val Trp Gly Thr Gly Thr Thr Val Thr Val
225 230 235 240
Ser Ser
<210> 74
<211> 242
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-17H2L-3054 scFv
<400> 74
Glu Val Gln Leu Val Glu Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Asp Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Asn Tyr Gly Asn Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Leu Ser Ile Arg Lys Asp Ser Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Thr Met Ser Ser Leu Gln Thr Pro Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Asn His Gly Asp Gly Tyr Tyr Asn Trp Tyr Phe Asp Val Trp Gly
100 105 110
Thr Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Asn Ile Val Leu Thr Gln Ser Pro
130 135 140
Ser Ser Leu Ser Glu Ser Leu Gly Gly Lys Val Thr Ile Thr Cys Lys
145 150 155 160
Ala Ser Gln Asp Ile Asn Lys Tyr Ile Ala Trp Tyr Gln Tyr Lys Pro
165 170 175
Gly Lys Gly Pro Arg Leu Leu Ile His Tyr Thr Ser Thr Leu Gln Pro
180 185 190
Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Arg Asp Tyr Ser
195 200 205
Phe Ser Ile Ser Asn Leu Glu Pro Glu Asp Ile Ala Thr Tyr Tyr Cys
210 215 220
Leu Gln Tyr Asp Asn Leu Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu
225 230 235 240
Ile Lys
<210> 75
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-17 VH
<400> 75
Glu Val Gln Leu Val Glu Ser Gly Pro Gly Leu Val Gln Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr
20 25 30
Asp Val His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Asn Tyr Gly Asn Thr Asp Tyr Asn Ala Ala Phe Ile
50 55 60
Ser Arg Leu Ser Ile Arg Lys Asp Ser Ser Lys Ser Gln Val Phe Phe
65 70 75 80
Thr Met Ser Ser Leu Gln Thr Pro Asp Thr Ala Ile Tyr Tyr Cys Ala
85 90 95
Arg Asn His Gly Asp Gly Tyr Tyr Asn Trp Tyr Phe Asp Val Trp Gly
100 105 110
Thr Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 76
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-17 VL
<400> 76
Asn Ile Val Leu Thr Gln Ser Pro Ser Ser Leu Ser Glu Ser Leu Gly
1 5 10 15
Gly Lys Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Lys Tyr
20 25 30
Ile Ala Trp Tyr Gln Tyr Lys Pro Gly Lys Gly Pro Arg Leu Leu Ile
35 40 45
His Tyr Thr Ser Thr Leu Gln Pro Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Arg Asp Tyr Ser Phe Ser Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Asn Leu Trp Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 77
<211> 491
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9H2L-3048 CAR
<400> 77
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Gln Val Gln Leu Lys Glu Ser Gly Pro
20 25 30
Glu Leu Glu Lys Pro Gly Ala Ser Val Lys Ile Ser Cys Lys Ala Ser
35 40 45
Gly Tyr Ser Phe Thr Ala Tyr Ser Met Asn Trp Val Lys Gln Asn Asn
50 55 60
Gly Met Ser Leu Glu Trp Ile Gly Ser Ile Asp Pro Tyr Tyr Gly Asp
65 70 75 80
Thr Lys Tyr Ala Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Val Asp
85 90 95
Lys Ala Ser Ser Thr Ala Tyr Leu Gln Leu Lys Ser Leu Thr Ser Glu
100 105 110
Asp Ser Ala Val Tyr Tyr Cys Ala Arg Arg Met Ile Thr Thr Gly Asp
115 120 125
Trp Tyr Phe Asp Val Trp Gly Thr Gly Thr Thr Val Thr Val Ser Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser His
145 150 155 160
Ile Val Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly Asp
165 170 175
Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Thr Tyr Leu
180 185 190
Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile Phe
195 200 205
Tyr Thr Ser Arg Leu His Ala Gly Val Pro Ser Arg Phe Ser Gly Ser
210 215 220
Gly Ser Gly Thr His His Ser Leu Thr Ile Ser Asn Leu Glu Gln Glu
225 230 235 240
Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Ser Leu Pro Phe Thr
245 250 255
Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Ser Gly Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu
305 310 315 320
Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr
325 330 335
Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe
340 345 350
Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg
355 360 365
Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser
370 375 380
Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr
385 390 395 400
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
405 410 415
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
420 425 430
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
435 440 445
Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
450 455 460
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr
465 470 475 480
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 78
<211> 491
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9L2H-3049 CAR
<400> 78
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser His Ile Val Leu Thr Gln Ser Pro Ser
20 25 30
Ser Leu Ser Ala Ser Leu Gly Asp Arg Val Thr Ile Ser Cys Arg Ala
35 40 45
Ser Gln Asp Ile Ser Thr Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Asp
50 55 60
Gly Thr Val Lys Leu Leu Ile Phe Tyr Thr Ser Arg Leu His Ala Gly
65 70 75 80
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr His His Ser Leu
85 90 95
Thr Ile Ser Asn Leu Glu Gln Glu Asp Ile Ala Thr Tyr Phe Cys Gln
100 105 110
Gln Gly Asn Ser Leu Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu
115 120 125
Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gln Val Gln Leu Lys Glu Ser Gly Pro Glu Leu Glu Lys Pro Gly
145 150 155 160
Ala Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Ala
165 170 175
Tyr Ser Met Asn Trp Val Lys Gln Asn Asn Gly Met Ser Leu Glu Trp
180 185 190
Ile Gly Ser Ile Asp Pro Tyr Tyr Gly Asp Thr Lys Tyr Ala Gln Lys
195 200 205
Phe Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ala Ser Ser Thr Ala
210 215 220
Tyr Leu Gln Leu Lys Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr
225 230 235 240
Cys Ala Arg Arg Met Ile Thr Thr Gly Asp Trp Tyr Phe Asp Val Trp
245 250 255
Gly Thr Gly Thr Thr Val Thr Val Ser Ser Ser Gly Thr Thr Thr Pro
260 265 270
Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu
275 280 285
Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His
290 295 300
Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu
305 310 315 320
Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr
325 330 335
Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe
340 345 350
Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg
355 360 365
Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser
370 375 380
Arg Ser Ala Asp Ala Pro Ala Tyr Lys Gln Gly Gln Asn Gln Leu Tyr
385 390 395 400
Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys
405 410 415
Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn
420 425 430
Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu
435 440 445
Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly
450 455 460
His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr
465 470 475 480
Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 79
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9H2L-3048 scFv
<400> 79
Gly Ser Gln Val Gln Leu Lys Glu Ser Gly Pro Glu Leu Glu Lys Pro
1 5 10 15
Gly Ala Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr
20 25 30
Ala Tyr Ser Met Asn Trp Val Lys Gln Asn Asn Gly Met Ser Leu Glu
35 40 45
Trp Ile Gly Ser Ile Asp Pro Tyr Tyr Gly Asp Thr Lys Tyr Ala Gln
50 55 60
Lys Phe Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ala Ser Ser Thr
65 70 75 80
Ala Tyr Leu Gln Leu Lys Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Arg Met Ile Thr Thr Gly Asp Trp Tyr Phe Asp Val
100 105 110
Trp Gly Thr Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser His Ile Val Leu Thr Gln
130 135 140
Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly Asp Arg Val Thr Ile Ser
145 150 155 160
Cys Arg Ala Ser Gln Asp Ile Ser Thr Tyr Leu Asn Trp Tyr Gln Gln
165 170 175
Lys Pro Asp Gly Thr Val Lys Leu Leu Ile Phe Tyr Thr Ser Arg Leu
180 185 190
His Ala Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr His
195 200 205
His Ser Leu Thr Ile Ser Asn Leu Glu Gln Glu Asp Ile Ala Thr Tyr
210 215 220
Phe Cys Gln Gln Gly Asn Ser Leu Pro Phe Thr Phe Gly Ser Gly Thr
225 230 235 240
Lys Leu Glu Ile Lys Ser Gly
245
<210> 80
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9L2H-3049 scFv
<400> 80
His Ile Val Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Thr Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Phe Tyr Thr Ser Arg Leu His Ala Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr His His Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Ser Leu Pro Phe
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Lys Glu
115 120 125
Ser Gly Pro Glu Leu Glu Lys Pro Gly Ala Ser Val Lys Ile Ser Cys
130 135 140
Lys Ala Ser Gly Tyr Ser Phe Thr Ala Tyr Ser Met Asn Trp Val Lys
145 150 155 160
Gln Asn Asn Gly Met Ser Leu Glu Trp Ile Gly Ser Ile Asp Pro Tyr
165 170 175
Tyr Gly Asp Thr Lys Tyr Ala Gln Lys Phe Lys Gly Lys Ala Thr Leu
180 185 190
Thr Val Asp Lys Ala Ser Ser Thr Ala Tyr Leu Gln Leu Lys Ser Leu
195 200 205
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Arg Met Ile Thr
210 215 220
Thr Gly Asp Trp Tyr Phe Asp Val Trp Gly Thr Gly Thr Thr Val Thr
225 230 235 240
Val Ser Ser
<210> 81
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 VH
<400> 81
Gln Val Gln Leu Lys Glu Ser Gly Pro Glu Leu Glu Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Ala Tyr
20 25 30
Ser Met Asn Trp Val Lys Gln Asn Asn Gly Met Ser Leu Glu Trp Ile
35 40 45
Gly Ser Ile Asp Pro Tyr Tyr Gly Asp Thr Lys Tyr Ala Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ala Ser Ser Thr Ala Tyr
65 70 75 80
Leu Gln Leu Lys Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Met Ile Thr Thr Gly Asp Trp Tyr Phe Asp Val Trp Gly
100 105 110
Thr Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 82
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 VL
<400> 82
His Ile Val Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Gln Asp Ile Ser Thr Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Phe Tyr Thr Ser Arg Leu His Ala Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr His His Ser Leu Thr Ile Ser Asn Leu Glu Gln
65 70 75 80
Glu Asp Ile Ala Thr Tyr Phe Cys Gln Gln Gly Asn Ser Leu Pro Phe
85 90 95
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 83
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 HCDR1
<400> 83
Ala Tyr Ser Met Asn
1 5
<210> 84
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 HCDR2
<400> 84
Ser Ile Asp Pro Tyr Tyr Gly Asp Thr Lys Tyr Ala Gln Lys Phe Lys
1 5 10 15
Gly
<210> 85
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 HCDR3
<400> 85
Arg Met Ile Thr Thr Gly Asp Trp Tyr Phe Asp Val
1 5 10
<210> 86
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 LCDR1
<400> 86
Arg Ala Ser Gln Asp Ile Ser Thr Tyr Leu Asn
1 5 10
<210> 87
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 LCDR2
<400> 87
Tyr Thr Ser Arg Leu His Ala
1 5
<210> 88
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-9 LCDR3
<400> 88
Gln Gln Gly Asn Ser Leu Pro Phe Thr
1 5
<210> 89
<211> 492
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34H2L-3052 CAR
<400> 89
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Glu Val Lys Leu Val Glu Ser Gly Ala
20 25 30
Glu Leu Val Arg Ser Gly Ala Ser Val Lys Leu Ser Cys Ala Ala Ser
35 40 45
Gly Phe Asn Ile Lys Asp Tyr Tyr Ile His Trp Val Lys Gln Arg Pro
50 55 60
Glu Gln Gly Leu Glu Trp Ile Gly Trp Ile Asp Pro Glu Asn Gly Arg
65 70 75 80
Thr Glu Tyr Ala Pro Lys Phe Gln Gly Lys Ala Thr Met Thr Ala Asp
85 90 95
Thr Ser Ser Asn Thr Ala Tyr Leu Gln Leu Ser Ser Leu Thr Ser Glu
100 105 110
Asp Thr Ala Val Tyr Tyr Cys Asn Asn Gly Asn Tyr Val Arg His Tyr
115 120 125
Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Trp
145 150 155 160
Leu Thr Gln Ser Pro Ala Ile Leu Ser Ala Ser Pro Gly Glu Lys Val
165 170 175
Thr Met Thr Cys Arg Ala Ile Ser Ser Val Ser Tyr Met His Trp Tyr
180 185 190
Gln Gln Lys Pro Gly Ser Ser Pro Lys Pro Trp Ile Tyr Ala Thr Ser
195 200 205
Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly
210 215 220
Thr Ser Tyr Ser Leu Thr Ile Ser Arg Val Glu Ala Glu Asp Ala Ala
225 230 235 240
Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Arg Thr Phe Gly Gly
245 250 255
Gly Thr Lys Leu Glu Ile Lys Ser Arg Thr Thr Thr Pro Ala Pro Arg
260 265 270
Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg
275 280 285
Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly
290 295 300
Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr
305 310 315 320
Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys His Met
325 330 335
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
340 345 350
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
355 360 365
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Thr Ser Arg Val Lys Phe
370 375 380
Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu
385 390 395 400
Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp
405 410 415
Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys
420 425 430
Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala
435 440 445
Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys
450 455 460
Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr
465 470 475 480
Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 90
<211> 492
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34L2H-3053 CAR
<400> 90
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Ser Asp Trp Leu Thr Gln Ser Pro Ala Ile
20 25 30
Leu Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Arg Ala Ile
35 40 45
Ser Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Ser Ser
50 55 60
Pro Lys Pro Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile
85 90 95
Ser Arg Val Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp
100 105 110
Ser Ser Asn Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu
130 135 140
Val Lys Leu Val Glu Ser Gly Ala Glu Leu Val Arg Ser Gly Ala Ser
145 150 155 160
Val Lys Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Tyr Tyr
165 170 175
Ile His Trp Val Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile Gly
180 185 190
Trp Ile Asp Pro Glu Asn Gly Arg Thr Glu Tyr Ala Pro Lys Phe Gln
195 200 205
Gly Lys Ala Thr Met Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr Leu
210 215 220
Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys Asn
225 230 235 240
Asn Gly Asn Tyr Val Arg His Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly
245 250 255
Thr Thr Val Thr Val Ser Ser Ser Arg Thr Thr Thr Pro Ala Pro Arg
260 265 270
Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg
275 280 285
Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly
290 295 300
Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr
305 310 315 320
Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys His Met
325 330 335
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
340 345 350
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
355 360 365
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Thr Ser Arg Val Lys Phe
370 375 380
Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu
385 390 395 400
Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp
405 410 415
Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys
420 425 430
Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala
435 440 445
Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys
450 455 460
Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr
465 470 475 480
Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
485 490
<210> 91
<211> 240
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34H2L-3052 scFv
<400> 91
Glu Val Lys Leu Val Glu Ser Gly Ala Glu Leu Val Arg Ser Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Asp Pro Glu Asn Gly Arg Thr Glu Tyr Ala Pro Lys Phe
50 55 60
Gln Gly Lys Ala Thr Met Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Asn Gly Asn Tyr Val Arg His Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Asp Trp Leu Thr Gln Ser Pro Ala Ile
130 135 140
Leu Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Arg Ala Ile
145 150 155 160
Ser Ser Val Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Ser Ser
165 170 175
Pro Lys Pro Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Val Pro
180 185 190
Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile
195 200 205
Ser Arg Val Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp
210 215 220
Ser Ser Asn Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
225 230 235 240
<210> 92
<211> 240
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34L2H-3053 scFv
<400> 92
Asp Trp Leu Thr Gln Ser Pro Ala Ile Leu Ser Ala Ser Pro Gly Glu
1 5 10 15
Lys Val Thr Met Thr Cys Arg Ala Ile Ser Ser Val Ser Tyr Met His
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Pro Trp Ile Tyr Ala
35 40 45
Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly
50 55 60
Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg Val Glu Ala Glu Asp
65 70 75 80
Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Arg Thr Phe
85 90 95
Gly Gly Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly Ser Gly Gly
100 105 110
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Lys Leu Val Glu Ser Gly
115 120 125
Ala Glu Leu Val Arg Ser Gly Ala Ser Val Lys Leu Ser Cys Ala Ala
130 135 140
Ser Gly Phe Asn Ile Lys Asp Tyr Tyr Ile His Trp Val Lys Gln Arg
145 150 155 160
Pro Glu Gln Gly Leu Glu Trp Ile Gly Trp Ile Asp Pro Glu Asn Gly
165 170 175
Arg Thr Glu Tyr Ala Pro Lys Phe Gln Gly Lys Ala Thr Met Thr Ala
180 185 190
Asp Thr Ser Ser Asn Thr Ala Tyr Leu Gln Leu Ser Ser Leu Thr Ser
195 200 205
Glu Asp Thr Ala Val Tyr Tyr Cys Asn Asn Gly Asn Tyr Val Arg His
210 215 220
Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
225 230 235 240
<210> 93
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 VH
<400> 93
Glu Val Lys Leu Val Glu Ser Gly Ala Glu Leu Val Arg Ser Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Ala Ala Ser Gly Phe Asn Ile Lys Asp Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Trp Ile Asp Pro Glu Asn Gly Arg Thr Glu Tyr Ala Pro Lys Phe
50 55 60
Gln Gly Lys Ala Thr Met Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Asn Gly Asn Tyr Val Arg His Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 94
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 VL
<400> 94
Asp Trp Leu Thr Gln Ser Pro Ala Ile Leu Ser Ala Ser Pro Gly Glu
1 5 10 15
Lys Val Thr Met Thr Cys Arg Ala Ile Ser Ser Val Ser Tyr Met His
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Pro Trp Ile Tyr Ala
35 40 45
Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser Gly
50 55 60
Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg Val Glu Ala Glu Asp
65 70 75 80
Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Arg Thr Phe
85 90 95
Gly Gly Gly Thr Lys Leu Glu Ile Lys Ser Arg
100 105
<210> 95
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 HCDR1
<400> 95
Asp Tyr Tyr Ile His
1 5
<210> 96
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 HCDR2
<400> 96
Trp Ile Asp Pro Glu Asn Gly Arg Thr Glu Tyr Ala Pro Lys Phe Gln
1 5 10 15
Gly
<210> 97
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 HCDR3
<400> 97
Gly Asn Tyr Val Arg His Tyr Tyr Phe Asp Tyr
1 5 10
<210> 98
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 LCDR1
<400> 98
Arg Ala Ile Ser Ser Val Ser Tyr Met His
1 5 10
<210> 99
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 LCDR2
<400> 99
Ala Thr Ser Asn Leu Ala Ser
1 5
<210> 100
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CD5-34 LCDR3
<400> 100
Gln Gln Trp Ser Ser Asn Pro Arg Thr
1 5
<210> 101
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> dextramer
<400> 101
Asn Leu Val Pro Met Val Ala Thr Val
1 5
Claims (62)
- 암(cancer)의 치료를 필요로 하는 대상체에서 암을 치료하는 방법으로서, 이러한 방법은
키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포(modified cell)를 대상체에게 투여하는 단계로서, CAR이 항원 결합 도메인, 막관통 도메인(transmembrane domain) 및 세포내 도메인을 포함하는, 단계, 및
제2 변형 세포를 대상체에게 투여하는 단계로서, 내인성 CD5 유전자가 녹-아웃(knocked-out)되어 있는, 단계를 포함하는, 방법. - 제1항에 있어서, 내인성 CD5 유전자가 CRISPR 방법을 사용하여 녹-아웃되어 있는, 방법.
- 제2항에 있어서, CRISPR 방법이 CRISPR/Cas9 방법인, 방법.
- 제3항에 있어서, CRISPR/Cas9 방법이 서열번호 23의 뉴클레오티드 서열을 포함하는 sgRNA를 이용하는, 방법.
- 제1항 내지 제4항 중 어느 한 항에 있어서, CAR의 항원 결합 도메인이, CD5, CD19, CD2, CD7, 종양 특이적 항원(TSA), 종양 관련 항원(TAA), 신경교종 관련 항원, 암배아 항원(CEA), β-인간 융모성 고나도트로핀, 알파페토단백질(AFP), 렉틴-반응성 AFP, 티로글로불린, RAGE-1, MN-CA IX, 인간 텔로머라제 역전사효소, RU1, RU2(AS), 장 카복실 에스테라제, mut hsp70-2, M-CSF, 프로스타제, 전립선-특이적 항원(PSA), PAP, NY-ESO-1, LAGE-la, p53, 프로스테인, PSMA, Her2/neu, 서비빈, 텔로머라제, 전립선암 종양 항원-1(PCTA-1), MAGE, ELF2M, 호중구 엘라스타제, 에프린B2, CD22, 인슐린 성장 인자(IGF)-I, IGF-II, IGF-I 수용체, 메소텔린, MART-1/멜란A(MART-I), gp100(Pmel 17), 티로시나제, TRP-1, TRP-2, MAGE-1, MAGE-3, BAGE, GAGE-1, GAGE-2, pl5, Ras, BCR-ABL, E2A-PRL, H4-RET, IGH-IGK, MYL-RAR, EBVA, HPV 항원 E6, HPV 항원 E7, TSP-180, MAGE-4, MAGE-5, MAGE-6, RAGE, NY-ESO, pl85erbB2, pl80erbB-3, c-met, nm-23H1, PSA, TAG-72, CA 19-9, CA 72-4, CAM 17.1, NuMa, K-ras, 베타-카테닌, CDK4, Mum-1, p15, p16, 43-9F, 5T4, 791Tgp72, 알파-페토단백질, 베타-HCG, BCA225, BTAA, CA 125, CA 15-3\CA 27.29\BCAA, CA 195, CA 242, CA-50, CAM43, CD68\P1, CO-029, FGF-5, G250, Ga733\EpCAM, HTgp-175, M344, MA-50, MG7-Ag, MOV18, NB/70K, NY-CO-1, RCAS1, SDCCAG16, TA-90\Mac-2 결합 단백질\사이클로필린 C-연관 단백질, TAAL6, TAG72, TLP 및 TPS로 이루어진 그룹으로부터 선택되는, 방법.
- 제1항 내지 제5항 중 어느 한 항에 있어서, CAR의 항원 결합 도메인이, 서열번호 31-36, 43-48, 53-58, 65-70, 83-88 및 95-100으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함하는, 방법.
- 제1항 내지 제6항 중 어느 한 항에 있어서, CAR의 항원 결합 도메인이, 서열번호 29, 41, 51, 63, 75, 81 및 93으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 방법.
- 제1항 내지 제7항 중 어느 한 항에 있어서, CAR의 항원 결합 도메인이, 서열번호 30, 42, 52, 64, 76, 82 및 94로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는, 방법.
- 제1항 내지 제8항 중 어느 한 항에 있어서, CAR의 항원 결합 도메인이, 서열번호 27, 28, 39, 40, 50, 61, 62, 73, 74, 79, 80, 91 및 92로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함하는, 방법.
- 제1항 내지 제9항 중 어느 한 항에 있어서, CAR이 서열번호 25, 26, 37, 38, 49, 59, 60, 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는, 방법.
- 제1항 내지 제10항 중 어느 한 항에 있어서, CAR이 서열번호 1 내지 13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩되는(encoding), 방법.
- 제1항 내지 제11항 중 어느 한 항에 있어서, CAR이 자살 유전자(suicide gene)를 추가로 포함하는, 방법.
- 제12항에 있어서, 자살 유전자가 iCaspase9인, 방법.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 제1 및 제2 변형 세포가 T 세포인, 방법.
- 제1항 내지 제14항 중 어느 한 항에 있어서, 암이 T 세포 림프종 또는 T 세포 백혈병을 포함하는, 방법.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 암이 급성 골수성 백혈병(AML), T-세포 급성 림프구성 백혈병(T-ALL), 급성 림프구성 백혈병(ALL) 및 만성 림프구성 백혈병(CLL)으로 이루어진 그룹으로부터 선택되는, 방법.
- 암의 치료를 필요로 하는 대상체에서 암을 치료하는 방법으로서,
키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, CAR은 CD2에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 단계, 및
제2 변형 세포를 대상체에게 투여하는 단계로서, 내인성 CD2 유전자가 녹-아웃되어 있는, 방법. - 제17항에 있어서, CAR의 항원 결합 도메인이 서열번호 31-36, 43-48, 53-58 및 65-70으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함하는, 방법.
- 제18항에 있어서, CAR의 항원 결합 도메인이 서열번호 29, 41, 51 및 63으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 방법.
- 제17항 내지 제19항 중 어느 한 항에 있어서, CAR의 항원 결합 도메인이 서열번호 30, 42, 52 및 64로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는, 방법.
- 제18항에 있어서, CAR의 항원 결합 도메인이 서열번호 27, 28, 39, 40, 50, 61 및 62로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함하는, 방법.
- 제18항에 있어서, CAR이 서열번호 25, 26, 37, 38, 49, 59 및 60으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는, 방법.
- 제18항에 있어서, CAR이 서열번호 1 내지 7로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩되는, 방법.
- 암의 치료를 필요로 하는 대상체에서 암을 치료하는 방법으로서,
CAR을 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, CAR은 CD5에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 단계, 및
제2 변형 세포를 대상체에게 투여하는 단계로서, 내인성 CD5 유전자가 녹-아웃되어 있는, 단계를 포함하는, 방법. - 제24항에 있어서, CAR의 항원 결합 도메인이 서열번호 83-88 및 95-100으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함하는, 방법.
- 제24항에 있어서, CAR의 항원 결합 도메인이 서열번호 75, 81 및 93으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 방법.
- 제24항에 있어서, CAR의 항원 결합 도메인이 서열번호 76, 82 및 94로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는, 방법.
- 제24항에 있어서, CAR의 항원 결합 도메인이 서열번호 73, 74, 79, 80, 91 및 92로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함하는, 방법.
- 제24항에 있어서, CAR이 서열번호 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는, 방법.
- 제18항에 있어서, CAR이 서열번호 8 내지 13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩되는, 방법.
- 암의 치료를 필요로 하는 대상체에서 암을 치료하는 방법으로서,
CAR을 포함하는 제1 변형 세포를 대상체에게 투여하는 단계로서, CAR은 CD7에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 단계, 및
제2 변형 세포를 대상체에게 투여하는 단계로서, 내인성 CD7 유전자가 녹-아웃되어 있는, 단계를 포함하는, 방법. - 제17항 내지 제31항 중 어느 한 항에 있어서, 제1 및 제2 변형 세포가 T 세포인, 방법.
- 제17항 내지 제32항 중 어느 한 항에 있어서, 암이 T 세포 림프종 또는 T 세포 백혈병을 포함하는, 방법.
- 제17항 내지 제32항 중 어느 한 항에 있어서, 암이 급성 골수성 백혈병(AML), T-세포 급성 림프구성 백혈병(T-ALL), 급성 림프구성 백혈병(ALL) 및 만성 림프구성 백혈병(CLL)으로 이루어진 그룹으로부터 선택되는, 방법.
- 제17항 내지 제34항 중 어느 한 항에 있어서, 내인성 유전자가 CRISPR/Cas9 방법을 사용하여 녹-아웃되어 있는, 방법.
- 제35항에 있어서, CRISPR/Cas9 방법이, 서열번호 22 내지 24로 이루어진 그룹으로부터 선택된 뉴클레오티드 서열을 포함하는 sgRNA를 이용하는, 방법.
- 제17항 내지 제36항 중 어느 한 항에 있어서, CAR이 자살 유전자를 추가로 포함하는, 방법.
- 제37항에 있어서, 자살 유전자가 iCaspase9인, 방법.
- CAR을 포함하는 핵산으로서, CAR이, CD2에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 핵산.
- 제39항에 있어서, 항원 결합 도메인이, 서열번호 31-36, 43-48, 53-58 및 65-70으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함하는, 핵산.
- 제39항에 있어서, 항원 결합 도메인이, 서열번호 29, 41, 51 및 63으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 핵산.
- 제39항에 있어서, 항원 결합 도메인이 서열번호 30, 42, 52 및 64로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는, 핵산.
- 제39항에 있어서, CAR의 항원 결합 도메인이, 서열번호 27, 28, 39, 40, 50, 61 및 62로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함하는, 핵산.
- 제39항에 있어서, CAR이 서열번호 25, 26, 37, 38, 49, 59 및 60으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는, 핵산.
- 제39항에 있어서, CAR이 서열번호 1 내지 7로 이루어진 그룹으로부터 선택된 뉴클레오티드 서열에 의해 코딩되는, 핵산.
- CAR을 포함하는 핵산으로서, CAR이 CD5에 결합할 수 있는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하는, 핵산.
- 제46항에 있어서, 항원 결합 도메인이, 서열번호 83-88 및 95-100으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 상보성 결정 영역(CDR)을 포함하는, 핵산.
- 제46항에 있어서, 항원 결합 도메인이, 서열번호 75, 81 및 93으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 중쇄 가변 영역을 포함하는, 핵산.
- 제46항에 있어서, 항원 결합 도메인이, 서열번호 76, 82 및 94로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 경쇄 가변 영역을 포함하는, 핵산.
- 제46항에 있어서, CAR의 항원 결합 도메인이, 서열번호 73, 74, 79, 80, 91 및 92로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는 scFv를 포함하는, 핵산.
- 제46항에 있어서, CAR이 서열번호 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는, 핵산.
- 제46항에 있어서, CAR이 서열번호 8 내지 13으로 이루어진 그룹으로부터 선택된 뉴클레오티드 서열에 의해 코딩되는, 핵산.
- 제39항 내지 제52항 중 어느 한 항의 핵산을 포함하는 벡터(vector).
- 제39항 내지 제52항 중 어느 한 항의 핵산 또는 제53항의 벡터를 포함하는 세포.
- 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포, 및 제2 변형 세포를 포함하는 조성물로서,
CAR은 CD2를 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고,
내인성 CD2 유전자는 녹-아웃되어 있는, 조성물. - 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포, 및 제2 변형 세포를 포함하는 조성물로서,
CAR은 CD5를 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고,
내인성 CD5 유전자는 녹-아웃되어 있는, 조성물. - 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포, 및 제2 변형 세포를 포함하는 조성물로서,
CAR은 CD7을 표적화하는 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고,
내인성 CD7 유전자는 녹-아웃되어 있는, 조성물. - 키메라 항원 수용체(CAR)를 포함하는 제1 변형 세포, 및 제2 변형 세포를 포함하는 조성물로서,
CAR은 항원 결합 도메인, 막관통 도메인 및 세포내 도메인을 포함하고,
내인성 CD5 유전자는 녹-아웃되어 있는, 조성물. - 제58항에 있어서, 항원 결합 도메인이 CD5, CD19, CD2, CD7, 종양 특이적 항원(TSA), 종양 관련 항원(TAA), 신경교종 관련 항원, 암배아 항원(CEA), β-인간 융모성 고나도트로핀, 알파페토단백질(AFP), 렉틴-반응성 AFP, 티로글로불린, RAGE-1, MN-CA IX, 인간 텔로머라제 역전사효소, RU1, RU2(AS), 장 카복실 에스테라제, mut hsp70-2, M-CSF, 프로스타제, 전립선-특이적 항원(PSA), PAP, NY-ESO-1, LAGE-la, p53, 프로스테인, PSMA, Her2/neu, 서비빈, 텔로머라제, 전립선암 종양 항원-1(PCTA-1), MAGE, ELF2M, 호중구 엘라스타제, 에프린B2, CD22, 인슐린 성장 인자(IGF)-I, IGF-II, IGF-I 수용체, 메소텔린, MART-1/멜란A(MART-I), gp100(Pmel 17), 티로시나제, TRP-1, TRP-2, MAGE-1, MAGE-3, BAGE, GAGE-1, GAGE-2, pl5, Ras, BCR-ABL, E2A-PRL, H4-RET, IGH-IGK, MYL-RAR, EBVA, HPV 항원 E6, HPV 항원 E7, TSP-180, MAGE-4, MAGE-5, MAGE-6, RAGE, NY-ESO, pl85erbB2, pl80erbB-3, c-met, nm-23H1, PSA, TAG-72, CA 19-9, CA 72-4, CAM 17.1, NuMa, K-ras, 베타-카테닌, CDK4, Mum-1, p15, p16, 43-9F, 5T4, 791Tgp72, 알파-페토단백질, 베타-HCG, BCA225, BTAA, CA 125, CA 15-3\CA 27.29\BCAA, CA 195, CA 242, CA-50, CAM43, CD68\P1, CO-029, FGF-5, G250, Ga733\EpCAM, HTgp-175, M344, MA-50, MG7-Ag, MOV18, NB/70K, NY-CO-1, RCAS1, SDCCAG16, TA-90\Mac-2 결합 단백질\사이클로필린 C-연관 단백질, TAAL6, TAG72, TLP 및 TPS로 이루어진 그룹으로부터 선택되는, 조성물.
- 제55항 내지 제59항 중 어느 한 항에 따르는 조성물 및 약제학적으로 허용되는 담체.
- 제55항 내지 제60항 중 어느 한 항에 있어서, CAR이 서열번호 1 내지 13으로 이루어진 그룹으로부터 선택된 핵산 서열에 의해 코딩되는, 조성물.
- 제55항 내지 제60항 중 어느 한 항에 있어서, CAR이 서열번호 25, 26, 37, 38, 49, 59, 60, 71, 72, 77, 78, 89 및 90으로 이루어진 그룹으로부터 선택된 아미노산 서열을 포함하는, 조성물.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862782131P | 2018-12-19 | 2018-12-19 | |
| US62/782,131 | 2018-12-19 | ||
| PCT/US2019/067613 WO2020132327A1 (en) | 2018-12-19 | 2019-12-19 | Use of cd2/5/7 knock-out anti-cd2/5/7 chimeric antigen receptor t cells against t cell lymphomas and leukemias |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220002859A true KR20220002859A (ko) | 2022-01-07 |
Family
ID=71102914
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217022614A KR20220002859A (ko) | 2018-12-19 | 2019-12-19 | T 세포 림프종 및 백혈병에 대한 cd2/5/7 녹-아웃 항-cd2/5/7 키메라 항원 수용체 t 세포의 용도 |
Country Status (11)
| Country | Link |
|---|---|
| US (2) | US11673964B2 (ko) |
| EP (1) | EP3898692A4 (ko) |
| JP (1) | JP2022515194A (ko) |
| KR (1) | KR20220002859A (ko) |
| CN (1) | CN113454117A (ko) |
| AU (1) | AU2019404302A1 (ko) |
| CA (1) | CA3124467A1 (ko) |
| IL (1) | IL284196A (ko) |
| MX (1) | MX2021007547A (ko) |
| SG (1) | SG11202106699VA (ko) |
| WO (1) | WO2020132327A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024076121A1 (ko) * | 2022-10-05 | 2024-04-11 | 주식회사 지씨셀 | Cd5를 표적하는 키메라 항원 수용체 및 이를 발현하는 면역세포 |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2013222284A1 (en) * | 2012-02-22 | 2014-08-07 | The Trustees Of The University Of Pennsylvania | Use of the CD2 signaling domain in second-generation chimeric antigen receptors |
| US20170151281A1 (en) | 2015-02-19 | 2017-06-01 | Batu Biologics, Inc. | Chimeric antigen receptor dendritic cell (car-dc) for treatment of cancer |
| US20240033290A1 (en) * | 2020-09-18 | 2024-02-01 | Vor Biopharma Inc. | Compositions and methods for cd7 modification |
| EP4216972A1 (en) * | 2020-09-25 | 2023-08-02 | Beam Therapeutics Inc. | Fratricide resistant modified immune cells and methods of using the same |
| EP4238990A1 (en) * | 2020-11-01 | 2023-09-06 | Nanjing Iaso Biotechnology Co., Ltd. | Fully human antibody targeting cd5, and fully human chimeric antigen receptor (car) and application thereof |
| CA3197423A1 (en) | 2020-11-04 | 2022-05-12 | Daniel Getts | Engineered chimeric fusion protein compositions and methods of use thereof |
| EP4279508A1 (en) * | 2021-01-12 | 2023-11-22 | Nanjing Iaso Biotechnology Co., Ltd. | Cd5-targeting fully humanized antibody |
| CN115044617A (zh) * | 2021-03-08 | 2022-09-13 | 河北森朗生物科技有限公司 | Car t细胞的制备方法、car t细胞及其应用 |
| CN115989244A (zh) * | 2021-08-06 | 2023-04-18 | 上海驯鹿生物技术有限公司 | Cd5和cd7双靶点的全人源嵌合抗原受体(car)及其应用 |
| WO2023114777A2 (en) * | 2021-12-14 | 2023-06-22 | The Trustees Of The University Of Pennsylvania | Cd5 modified cells comprising chimeric antigen receptors (cars) for treatment of solid tumors |
| CN114645022B (zh) * | 2022-05-13 | 2022-09-02 | 首都医科大学宣武医院 | 靶向CD5的CAR-γ δ T细胞及其制备方法与应用 |
| CN117431217A (zh) * | 2022-07-12 | 2024-01-23 | 上海驯鹿生物技术有限公司 | 表达靶向cd5的嵌合抗原受体(car)的细胞及其应用 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5951983A (en) | 1993-03-05 | 1999-09-14 | Universite Catholique De Louvain | Methods of inhibiting T cell mediated immune responses with humanized LO-CD2A-specific antibodies |
| US11047010B2 (en) * | 2014-02-06 | 2021-06-29 | Immunexpress Pty Ltd | Biomarker signature method, and apparatus and kits thereof |
| EP3261651B1 (en) * | 2015-02-27 | 2022-05-04 | iCell Gene Therapeutics LLC | Chimeric antigen receptors (cars) targeting hematologic malignancies, compositions and methods of use thereof |
| US20190112380A1 (en) * | 2016-03-29 | 2019-04-18 | University Of Southern California | Chimeric antigen receptors targeting cancer |
| WO2017189959A1 (en) * | 2016-04-29 | 2017-11-02 | Voyager Therapeutics, Inc. | Compositions for the treatment of disease |
| CN110352068A (zh) * | 2016-12-02 | 2019-10-18 | 南加利福尼亚大学 | 合成的免疫受体及其使用方法 |
| US11690873B2 (en) * | 2017-03-31 | 2023-07-04 | Cellectis Sa | Universal chimeric antigen receptor T cells specific for CD22 |
| CN110770348B (zh) * | 2017-06-01 | 2023-12-15 | 浙江煦顼技术有限公司 | 嵌合抗原受体细胞的制备及其用途 |
-
2019
- 2019-12-19 CA CA3124467A patent/CA3124467A1/en active Pending
- 2019-12-19 MX MX2021007547A patent/MX2021007547A/es unknown
- 2019-12-19 AU AU2019404302A patent/AU2019404302A1/en active Pending
- 2019-12-19 US US17/416,365 patent/US11673964B2/en active Active
- 2019-12-19 WO PCT/US2019/067613 patent/WO2020132327A1/en unknown
- 2019-12-19 SG SG11202106699VA patent/SG11202106699VA/en unknown
- 2019-12-19 CN CN201980092281.9A patent/CN113454117A/zh active Pending
- 2019-12-19 JP JP2021536031A patent/JP2022515194A/ja active Pending
- 2019-12-19 EP EP19898610.1A patent/EP3898692A4/en active Pending
- 2019-12-19 KR KR1020217022614A patent/KR20220002859A/ko unknown
-
2021
- 2021-06-20 IL IL284196A patent/IL284196A/en unknown
-
2023
- 2023-04-21 US US18/304,843 patent/US20230331864A1/en active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024076121A1 (ko) * | 2022-10-05 | 2024-04-11 | 주식회사 지씨셀 | Cd5를 표적하는 키메라 항원 수용체 및 이를 발현하는 면역세포 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019404302A1 (en) | 2021-08-05 |
| CA3124467A1 (en) | 2020-06-25 |
| WO2020132327A1 (en) | 2020-06-25 |
| EP3898692A1 (en) | 2021-10-27 |
| AU2019404302A8 (en) | 2021-08-19 |
| IL284196A (en) | 2021-08-31 |
| MX2021007547A (es) | 2021-10-13 |
| EP3898692A4 (en) | 2022-10-19 |
| JP2022515194A (ja) | 2022-02-17 |
| US20220073639A1 (en) | 2022-03-10 |
| US11673964B2 (en) | 2023-06-13 |
| CN113454117A (zh) | 2021-09-28 |
| SG11202106699VA (en) | 2021-07-29 |
| US20230331864A1 (en) | 2023-10-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11673964B2 (en) | Use of CD2/5/7 knock-out anti-CD2/5/7 chimeric antigen receptor T cells against T cell lymphomas and leukemias | |
| US11597754B2 (en) | Use of the CD2 signaling domain in second-generation chimeric antigen receptors | |
| US11795240B2 (en) | Enhancing activity of CAR T cells by co-introducing a bispecific antibody | |
| US11958892B2 (en) | Use of ICOS-based cars to enhance antitumor activity and car persistence | |
| US20160017286A1 (en) | Ikaros inhibition to augment adoptive t cell transfer | |
| US20210269501A1 (en) | Compositions and methods of nkg2d chimeric antigen receptor t cells for controlling triple-negative breast cancer | |
| US20200080056A1 (en) | CRISPR-Cas9 Knock-out of SHP-1/2 to Reduce T cell Exhaustion in Adoptive Cell Therapy | |
| US20210347845A1 (en) | Compositions and methods for switchable car t cells using surface-bound sortase transpeptidase | |
| WO2023081878A2 (en) | Engineered immune cells and methods for use |