KR20210086621A - 락테이트 데히드로게나제 (ldha) 유전자 편집을 위한 조성물 및 방법 - Google Patents
락테이트 데히드로게나제 (ldha) 유전자 편집을 위한 조성물 및 방법 Download PDFInfo
- Publication number
- KR20210086621A KR20210086621A KR1020217012025A KR20217012025A KR20210086621A KR 20210086621 A KR20210086621 A KR 20210086621A KR 1020217012025 A KR1020217012025 A KR 1020217012025A KR 20217012025 A KR20217012025 A KR 20217012025A KR 20210086621 A KR20210086621 A KR 20210086621A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- composition
- nos
- guide
- sequence selected
- Prior art date
Links
- 239000000203 mixture Substances 0.000 title claims abstract description 533
- 238000000034 method Methods 0.000 title claims abstract description 455
- 108700023483 L-lactate dehydrogenases Proteins 0.000 title description 33
- 102000003855 L-lactate dehydrogenase Human genes 0.000 title description 32
- 238000010362 genome editing Methods 0.000 title description 6
- 101150041530 ldha gene Proteins 0.000 claims abstract description 60
- 108020005004 Guide RNA Proteins 0.000 claims description 278
- 238000012986 modification Methods 0.000 claims description 259
- 230000004048 modification Effects 0.000 claims description 259
- 125000003729 nucleotide group Chemical group 0.000 claims description 259
- 239000002773 nucleotide Substances 0.000 claims description 244
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 claims description 115
- 230000004568 DNA-binding Effects 0.000 claims description 110
- 108091033409 CRISPR Proteins 0.000 claims description 105
- 239000011230 binding agent Substances 0.000 claims description 103
- 102100034671 L-lactate dehydrogenase A chain Human genes 0.000 claims description 88
- 108020004999 messenger RNA Proteins 0.000 claims description 69
- 210000002700 urine Anatomy 0.000 claims description 65
- 102000039446 nucleic acids Human genes 0.000 claims description 55
- 108020004707 nucleic acids Proteins 0.000 claims description 55
- 150000007523 nucleic acids Chemical class 0.000 claims description 55
- 238000011282 treatment Methods 0.000 claims description 54
- 208000008852 Hyperoxaluria Diseases 0.000 claims description 39
- 210000004185 liver Anatomy 0.000 claims description 37
- AEMRFAOFKBGASW-UHFFFAOYSA-M Glycolate Chemical compound OCC([O-])=O AEMRFAOFKBGASW-UHFFFAOYSA-M 0.000 claims description 35
- 150000002632 lipids Chemical class 0.000 claims description 33
- 210000002966 serum Anatomy 0.000 claims description 32
- -1 cationic lipid Chemical class 0.000 claims description 30
- 210000003734 kidney Anatomy 0.000 claims description 30
- 238000004519 manufacturing process Methods 0.000 claims description 30
- 230000014509 gene expression Effects 0.000 claims description 28
- QXDMQSPYEZFLGF-UHFFFAOYSA-L calcium oxalate Chemical compound [Ca+2].[O-]C(=O)C([O-])=O QXDMQSPYEZFLGF-UHFFFAOYSA-L 0.000 claims description 27
- 208000010444 Acidosis Diseases 0.000 claims description 24
- 230000007950 acidosis Effects 0.000 claims description 24
- 208000026545 acidosis disease Diseases 0.000 claims description 24
- 230000000295 complement effect Effects 0.000 claims description 24
- 230000008021 deposition Effects 0.000 claims description 22
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 claims description 21
- 208000004777 Primary Hyperoxaluria Diseases 0.000 claims description 19
- 230000009467 reduction Effects 0.000 claims description 19
- 208000020832 chronic kidney disease Diseases 0.000 claims description 16
- 201000000523 end stage renal failure Diseases 0.000 claims description 16
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 claims description 16
- 238000009472 formulation Methods 0.000 claims description 15
- 230000001965 increasing effect Effects 0.000 claims description 15
- 101100288581 Homo sapiens LDHA gene Proteins 0.000 claims description 14
- 208000006750 hematuria Diseases 0.000 claims description 14
- 230000002265 prevention Effects 0.000 claims description 13
- 230000003247 decreasing effect Effects 0.000 claims description 11
- 239000002105 nanoparticle Substances 0.000 claims description 10
- 210000000056 organ Anatomy 0.000 claims description 10
- 230000002829 reductive effect Effects 0.000 claims description 10
- 230000001939 inductive effect Effects 0.000 claims description 9
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 claims description 9
- 239000008194 pharmaceutical composition Substances 0.000 claims description 9
- 102100039856 Histone H1.1 Human genes 0.000 claims description 8
- 101001035402 Homo sapiens Histone H1.1 Proteins 0.000 claims description 8
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 8
- 239000003814 drug Substances 0.000 claims description 8
- 230000009885 systemic effect Effects 0.000 claims description 8
- 101001090713 Homo sapiens L-lactate dehydrogenase A chain Proteins 0.000 claims description 7
- 208000028208 end stage renal disease Diseases 0.000 claims description 7
- 230000002459 sustained effect Effects 0.000 claims description 7
- 230000037406 food intake Effects 0.000 claims description 6
- 210000002216 heart Anatomy 0.000 claims description 5
- 230000007935 neutral effect Effects 0.000 claims description 5
- 230000001225 therapeutic effect Effects 0.000 claims description 5
- NRJAVPSFFCBXDT-HUESYALOSA-N 1,2-distearoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCCCC NRJAVPSFFCBXDT-HUESYALOSA-N 0.000 claims description 4
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 4
- 208000000913 Kidney Calculi Diseases 0.000 claims description 4
- 206010029148 Nephrolithiasis Diseases 0.000 claims description 4
- 235000012000 cholesterol Nutrition 0.000 claims description 4
- 210000001508 eye Anatomy 0.000 claims description 4
- 235000012631 food intake Nutrition 0.000 claims description 4
- AJAMRCUNWLZBDF-UHFFFAOYSA-N propyl octadeca-9,12-dienoate Chemical compound CCCCCC=CCC=CCCCCCCCC(=O)OCCC AJAMRCUNWLZBDF-UHFFFAOYSA-N 0.000 claims description 4
- 210000003491 skin Anatomy 0.000 claims description 4
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 claims description 3
- 108700024394 Exon Proteins 0.000 claims description 3
- 239000011575 calcium Substances 0.000 claims description 3
- 229910052791 calcium Inorganic materials 0.000 claims description 3
- AJAMRCUNWLZBDF-MURFETPASA-N propyl linoleate Chemical compound CCCCC\C=C/C\C=C/CCCCCCCC(=O)OCCC AJAMRCUNWLZBDF-MURFETPASA-N 0.000 claims description 3
- 102100023917 Histone H1.10 Human genes 0.000 claims description 2
- 102100039855 Histone H1.2 Human genes 0.000 claims description 2
- 102100027368 Histone H1.3 Human genes 0.000 claims description 2
- 102100027369 Histone H1.4 Human genes 0.000 claims description 2
- 102100022653 Histone H1.5 Human genes 0.000 claims description 2
- 102100033558 Histone H1.8 Human genes 0.000 claims description 2
- 102100023920 Histone H1t Human genes 0.000 claims description 2
- 101000905024 Homo sapiens Histone H1.10 Proteins 0.000 claims description 2
- 101001035375 Homo sapiens Histone H1.2 Proteins 0.000 claims description 2
- 101001009450 Homo sapiens Histone H1.3 Proteins 0.000 claims description 2
- 101001009443 Homo sapiens Histone H1.4 Proteins 0.000 claims description 2
- 101000899879 Homo sapiens Histone H1.5 Proteins 0.000 claims description 2
- 101000872218 Homo sapiens Histone H1.8 Proteins 0.000 claims description 2
- 101000905044 Homo sapiens Histone H1t Proteins 0.000 claims description 2
- 101000897979 Homo sapiens Putative spermatid-specific linker histone H1-like protein Proteins 0.000 claims description 2
- 101000843236 Homo sapiens Testis-specific H1 histone Proteins 0.000 claims description 2
- 102100021861 Putative spermatid-specific linker histone H1-like protein Human genes 0.000 claims description 2
- 102100031010 Testis-specific H1 histone Human genes 0.000 claims description 2
- 239000003937 drug carrier Substances 0.000 claims description 2
- 235000013305 food Nutrition 0.000 claims description 2
- 230000002045 lasting effect Effects 0.000 claims description 2
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 2
- 210000003932 urinary bladder Anatomy 0.000 claims description 2
- 235000006408 oxalic acid Nutrition 0.000 claims 1
- 230000005782 double-strand break Effects 0.000 abstract description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 328
- 101710163270 Nuclease Proteins 0.000 description 130
- 108010088350 Lactate Dehydrogenase 5 Proteins 0.000 description 87
- 210000004027 cell Anatomy 0.000 description 79
- 108020004414 DNA Proteins 0.000 description 66
- 210000003494 hepatocyte Anatomy 0.000 description 50
- 108090000623 proteins and genes Proteins 0.000 description 50
- 102100026842 Serine-pyruvate aminotransferase Human genes 0.000 description 46
- 241000699670 Mus sp. Species 0.000 description 45
- 230000000694 effects Effects 0.000 description 37
- 102000004169 proteins and genes Human genes 0.000 description 36
- 235000018102 proteins Nutrition 0.000 description 35
- 235000000346 sugar Nutrition 0.000 description 35
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 31
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 31
- 108091027544 Subgenomic mRNA Proteins 0.000 description 29
- 108010033918 Alanine-glyoxylate transaminase Proteins 0.000 description 28
- 108010060800 serine-pyruvate aminotransferase Proteins 0.000 description 28
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 27
- 102000004389 Ribonucleoproteins Human genes 0.000 description 20
- 108010081734 Ribonucleoproteins Proteins 0.000 description 20
- 230000008685 targeting Effects 0.000 description 20
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 19
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 19
- 210000002381 plasma Anatomy 0.000 description 19
- 230000002950 deficient Effects 0.000 description 18
- 101000629622 Homo sapiens Serine-pyruvate aminotransferase Proteins 0.000 description 17
- 239000013598 vector Substances 0.000 description 17
- 230000007423 decrease Effects 0.000 description 16
- 238000001727 in vivo Methods 0.000 description 16
- 229940001447 lactate Drugs 0.000 description 16
- 208000000891 primary hyperoxaluria type 1 Diseases 0.000 description 16
- JVTAAEKCZFNVCJ-UHFFFAOYSA-M Lactate Chemical compound CC(O)C([O-])=O JVTAAEKCZFNVCJ-UHFFFAOYSA-M 0.000 description 15
- 108010077850 Nuclear Localization Signals Proteins 0.000 description 15
- 238000006467 substitution reaction Methods 0.000 description 15
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 14
- 108700026244 Open Reading Frames Proteins 0.000 description 14
- 238000004458 analytical method Methods 0.000 description 14
- 238000012217 deletion Methods 0.000 description 14
- 230000037430 deletion Effects 0.000 description 14
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 14
- 238000003780 insertion Methods 0.000 description 14
- 230000037431 insertion Effects 0.000 description 14
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 14
- 210000001519 tissue Anatomy 0.000 description 14
- 230000015572 biosynthetic process Effects 0.000 description 13
- HHLFWLYXYJOTON-UHFFFAOYSA-N glyoxylic acid Chemical compound OC(=O)C=O HHLFWLYXYJOTON-UHFFFAOYSA-N 0.000 description 13
- 238000001638 lipofection Methods 0.000 description 13
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 12
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 12
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 12
- 108020004459 Small interfering RNA Proteins 0.000 description 12
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 12
- 201000010099 disease Diseases 0.000 description 12
- 231100000673 dose–response relationship Toxicity 0.000 description 12
- 230000035772 mutation Effects 0.000 description 12
- 229930024421 Adenine Natural products 0.000 description 11
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 11
- 241000193996 Streptococcus pyogenes Species 0.000 description 11
- 108090000848 Ubiquitin Proteins 0.000 description 11
- 102000044159 Ubiquitin Human genes 0.000 description 11
- 229960000643 adenine Drugs 0.000 description 11
- 235000001014 amino acid Nutrition 0.000 description 11
- 150000001413 amino acids Chemical class 0.000 description 11
- 229920001184 polypeptide Polymers 0.000 description 11
- 108090000765 processed proteins & peptides Proteins 0.000 description 11
- 102000004196 processed proteins & peptides Human genes 0.000 description 11
- 229940076788 pyruvate Drugs 0.000 description 11
- 208000035657 Abasia Diseases 0.000 description 10
- 102000004190 Enzymes Human genes 0.000 description 10
- 108090000790 Enzymes Proteins 0.000 description 10
- 241001465754 Metazoa Species 0.000 description 10
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 10
- 229940088598 enzyme Drugs 0.000 description 10
- 238000000338 in vitro Methods 0.000 description 10
- 238000011534 incubation Methods 0.000 description 10
- 125000003835 nucleoside group Chemical group 0.000 description 10
- 238000010354 CRISPR gene editing Methods 0.000 description 9
- 238000010453 CRISPR/Cas method Methods 0.000 description 9
- 229930185560 Pseudouridine Natural products 0.000 description 9
- PTJWIQPHWPFNBW-UHFFFAOYSA-N Pseudouridine C Natural products OC1C(O)C(CO)OC1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-UHFFFAOYSA-N 0.000 description 9
- WGDUUQDYDIIBKT-UHFFFAOYSA-N beta-Pseudouridine Natural products OC1OC(CN2C=CC(=O)NC2=O)C(O)C1O WGDUUQDYDIIBKT-UHFFFAOYSA-N 0.000 description 9
- 239000003795 chemical substances by application Substances 0.000 description 9
- 239000002609 medium Substances 0.000 description 9
- 239000002777 nucleoside Substances 0.000 description 9
- 239000000047 product Substances 0.000 description 9
- PTJWIQPHWPFNBW-GBNDHIKLSA-N pseudouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-GBNDHIKLSA-N 0.000 description 9
- 238000001262 western blot Methods 0.000 description 9
- 229910019142 PO4 Inorganic materials 0.000 description 8
- 238000003776 cleavage reaction Methods 0.000 description 8
- 238000010874 in vitro model Methods 0.000 description 8
- 235000021317 phosphate Nutrition 0.000 description 8
- 239000000523 sample Substances 0.000 description 8
- 230000007017 scission Effects 0.000 description 8
- 208000024891 symptom Diseases 0.000 description 8
- UVBYMVOUBXYSFV-XUTVFYLZSA-N 1-methylpseudouridine Chemical compound O=C1NC(=O)N(C)C=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 UVBYMVOUBXYSFV-XUTVFYLZSA-N 0.000 description 7
- ZXIATBNUWJBBGT-JXOAFFINSA-N 5-methoxyuridine Chemical compound O=C1NC(=O)C(OC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZXIATBNUWJBBGT-JXOAFFINSA-N 0.000 description 7
- 241000699666 Mus <mouse, genus> Species 0.000 description 7
- 239000006180 TBST buffer Substances 0.000 description 7
- 208000035475 disorder Diseases 0.000 description 7
- 239000006166 lysate Substances 0.000 description 7
- 238000007481 next generation sequencing Methods 0.000 description 7
- 239000010452 phosphate Substances 0.000 description 7
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 7
- 238000011321 prophylaxis Methods 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 238000002098 selective ion monitoring Methods 0.000 description 7
- 150000008163 sugars Chemical class 0.000 description 7
- 238000013518 transcription Methods 0.000 description 7
- 101150077194 CAP1 gene Proteins 0.000 description 6
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 6
- 101100245221 Mus musculus Prss8 gene Proteins 0.000 description 6
- 108091034117 Oligonucleotide Proteins 0.000 description 6
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 6
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 6
- 230000004075 alteration Effects 0.000 description 6
- 230000000692 anti-sense effect Effects 0.000 description 6
- 108010041758 cleavase Proteins 0.000 description 6
- 108091006047 fluorescent proteins Proteins 0.000 description 6
- 102000034287 fluorescent proteins Human genes 0.000 description 6
- 230000000670 limiting effect Effects 0.000 description 6
- 125000005647 linker group Chemical group 0.000 description 6
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- 238000001890 transfection Methods 0.000 description 6
- RKSLVDIXBGWPIS-UAKXSSHOSA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-iodopyrimidine-2,4-dione Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(I)=C1 RKSLVDIXBGWPIS-UAKXSSHOSA-N 0.000 description 5
- 241000180579 Arca Species 0.000 description 5
- 101150014715 CAP2 gene Proteins 0.000 description 5
- 241000282567 Macaca fascicularis Species 0.000 description 5
- 241001529936 Murinae Species 0.000 description 5
- 101100260872 Mus musculus Tmprss4 gene Proteins 0.000 description 5
- FZWGECJQACGGTI-UHFFFAOYSA-N N7-methylguanine Natural products NC1=NC(O)=C2N(C)C=NC2=N1 FZWGECJQACGGTI-UHFFFAOYSA-N 0.000 description 5
- 108091093037 Peptide nucleic acid Proteins 0.000 description 5
- 238000009825 accumulation Methods 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 5
- 210000004369 blood Anatomy 0.000 description 5
- 239000008280 blood Substances 0.000 description 5
- 230000001413 cellular effect Effects 0.000 description 5
- 229940109239 creatinine Drugs 0.000 description 5
- 230000006378 damage Effects 0.000 description 5
- 238000004520 electroporation Methods 0.000 description 5
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 5
- 230000002440 hepatic effect Effects 0.000 description 5
- 102000055848 human LDHA Human genes 0.000 description 5
- 230000002401 inhibitory effect Effects 0.000 description 5
- 239000000178 monomer Substances 0.000 description 5
- 238000010172 mouse model Methods 0.000 description 5
- 239000013612 plasmid Substances 0.000 description 5
- 238000012163 sequencing technique Methods 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 5
- 229940045145 uridine Drugs 0.000 description 5
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- 102000004533 Endonucleases Human genes 0.000 description 4
- 108010042407 Endonucleases Proteins 0.000 description 4
- 108010070675 Glutathione transferase Proteins 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 description 4
- 239000012098 Lipofectamine RNAiMAX Substances 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 4
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical group OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 4
- 238000011374 additional therapy Methods 0.000 description 4
- 125000000217 alkyl group Chemical group 0.000 description 4
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 4
- 230000027455 binding Effects 0.000 description 4
- 238000002306 biochemical method Methods 0.000 description 4
- 229910052799 carbon Inorganic materials 0.000 description 4
- 230000003197 catalytic effect Effects 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- 238000002648 combination therapy Methods 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical group NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- 230000037433 frameshift Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 238000002156 mixing Methods 0.000 description 4
- 210000003205 muscle Anatomy 0.000 description 4
- 230000006780 non-homologous end joining Effects 0.000 description 4
- 150000003833 nucleoside derivatives Chemical class 0.000 description 4
- 150000007524 organic acids Chemical class 0.000 description 4
- 229910052760 oxygen Inorganic materials 0.000 description 4
- 239000001301 oxygen Substances 0.000 description 4
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 4
- 239000002953 phosphate buffered saline Substances 0.000 description 4
- 229910052698 phosphorus Inorganic materials 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 150000003230 pyrimidines Chemical group 0.000 description 4
- 108010054624 red fluorescent protein Proteins 0.000 description 4
- 125000001424 substituent group Chemical group 0.000 description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 4
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 3
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 3
- 238000009010 Bradford assay Methods 0.000 description 3
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 102000016911 Deoxyribonucleases Human genes 0.000 description 3
- 108010053770 Deoxyribonucleases Proteins 0.000 description 3
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 3
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 3
- 101150105486 HAO1 gene Proteins 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 3
- 108020004485 Nonsense Codon Proteins 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- RWRDLPDLKQPQOW-UHFFFAOYSA-N Pyrrolidine Chemical compound C1CCNC1 RWRDLPDLKQPQOW-UHFFFAOYSA-N 0.000 description 3
- 108010083644 Ribonucleases Proteins 0.000 description 3
- 102000006382 Ribonucleases Human genes 0.000 description 3
- 241000191967 Staphylococcus aureus Species 0.000 description 3
- 108091028113 Trans-activating crRNA Proteins 0.000 description 3
- 125000003282 alkyl amino group Chemical group 0.000 description 3
- 230000003321 amplification Effects 0.000 description 3
- 125000001769 aryl amino group Chemical group 0.000 description 3
- 125000003118 aryl group Chemical group 0.000 description 3
- 125000004429 atom Chemical group 0.000 description 3
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 239000013592 cell lysate Substances 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 238000007385 chemical modification Methods 0.000 description 3
- 239000013078 crystal Substances 0.000 description 3
- 125000000753 cycloalkyl group Chemical group 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 125000004663 dialkyl amino group Chemical group 0.000 description 3
- 125000004986 diarylamino group Chemical group 0.000 description 3
- 125000005240 diheteroarylamino group Chemical group 0.000 description 3
- 230000034431 double-strand break repair via homologous recombination Effects 0.000 description 3
- 230000009977 dual effect Effects 0.000 description 3
- 239000012636 effector Substances 0.000 description 3
- 230000002616 endonucleolytic effect Effects 0.000 description 3
- 230000029142 excretion Effects 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 3
- 229910052736 halogen Inorganic materials 0.000 description 3
- 125000005241 heteroarylamino group Chemical group 0.000 description 3
- 125000000623 heterocyclic group Chemical group 0.000 description 3
- 238000011532 immunohistochemical staining Methods 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 238000013059 nephrectomy Methods 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 125000004437 phosphorous atom Chemical group 0.000 description 3
- 229920002401 polyacrylamide Polymers 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 102000040430 polynucleotide Human genes 0.000 description 3
- 108091033319 polynucleotide Proteins 0.000 description 3
- 239000002157 polynucleotide Substances 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 150000003212 purines Chemical class 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 3
- 238000011808 rodent model Methods 0.000 description 3
- 239000011780 sodium chloride Substances 0.000 description 3
- 238000001356 surgical procedure Methods 0.000 description 3
- 229940104230 thymidine Drugs 0.000 description 3
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- 102100038837 2-Hydroxyacid oxidase 1 Human genes 0.000 description 2
- 101150003270 Agxt gene Proteins 0.000 description 2
- 108091093088 Amplicon Proteins 0.000 description 2
- 241000906059 Bacillus pseudomycoides Species 0.000 description 2
- 101710201279 Biotin carboxyl carrier protein Proteins 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 102220605874 Cytosolic arginine sensor for mTORC1 subunit 2_D10A_mutation Human genes 0.000 description 2
- 238000007400 DNA extraction Methods 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 2
- 108010000445 Glycerate dehydrogenase Proteins 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102100030648 Glyoxylate reductase/hydroxypyruvate reductase Human genes 0.000 description 2
- 101710200205 Glyoxylate reductase/hydroxypyruvate reductase Proteins 0.000 description 2
- 101001031589 Homo sapiens 2-Hydroxyacid oxidase 1 Proteins 0.000 description 2
- 101001082063 Homo sapiens Interferon-induced protein with tetratricopeptide repeats 5 Proteins 0.000 description 2
- 101000600434 Homo sapiens Putative uncharacterized protein encoded by MIR7-3HG Proteins 0.000 description 2
- 102100027355 Interferon-induced protein with tetratricopeptide repeats 1 Human genes 0.000 description 2
- 101710166699 Interferon-induced protein with tetratricopeptide repeats 1 Proteins 0.000 description 2
- 102100027356 Interferon-induced protein with tetratricopeptide repeats 5 Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 241000194036 Lactococcus Species 0.000 description 2
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 241000190928 Microscilla marina Species 0.000 description 2
- BAWFJGJZGIEFAR-NNYOXOHSSA-O NAD(+) Chemical compound NC(=O)C1=CC=C[N+]([C@H]2[C@@H]([C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 BAWFJGJZGIEFAR-NNYOXOHSSA-O 0.000 description 2
- 241000167285 Natranaerobius thermophilus Species 0.000 description 2
- 241000588650 Neisseria meningitidis Species 0.000 description 2
- 241000919925 Nitrosococcus halophilus Species 0.000 description 2
- WSDRAZIPGVLSNP-UHFFFAOYSA-N O.P(=O)(O)(O)O.O.O.P(=O)(O)(O)O Chemical compound O.P(=O)(O)(O)O.O.O.P(=O)(O)(O)O WSDRAZIPGVLSNP-UHFFFAOYSA-N 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 241000589516 Pseudomonas Species 0.000 description 2
- 102100037401 Putative uncharacterized protein encoded by MIR7-3HG Human genes 0.000 description 2
- 239000012083 RIPA buffer Substances 0.000 description 2
- 208000001647 Renal Insufficiency Diseases 0.000 description 2
- 108700008625 Reporter Genes Proteins 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 108091006243 SLC7A13 Proteins 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 241000194020 Streptococcus thermophilus Species 0.000 description 2
- 241000203587 Streptosporangium roseum Species 0.000 description 2
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 2
- 241000123710 Sutterella Species 0.000 description 2
- 101710137500 T7 RNA polymerase Proteins 0.000 description 2
- 102100036407 Thioredoxin Human genes 0.000 description 2
- 108091023040 Transcription factor Proteins 0.000 description 2
- 102000040945 Transcription factor Human genes 0.000 description 2
- 101710082247 Ubiquitin-like protein 5 Proteins 0.000 description 2
- 102100030580 Ubiquitin-like protein 5 Human genes 0.000 description 2
- 208000006568 Urinary Bladder Calculi Diseases 0.000 description 2
- 238000002835 absorbance Methods 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 150000001450 anions Chemical class 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 2
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 2
- 125000003710 aryl alkyl group Chemical group 0.000 description 2
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 210000000988 bone and bone Anatomy 0.000 description 2
- 229940098773 bovine serum albumin Drugs 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 125000002091 cationic group Chemical group 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 102000021178 chitin binding proteins Human genes 0.000 description 2
- 108091011157 chitin binding proteins Proteins 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 238000009295 crossflow filtration Methods 0.000 description 2
- 238000002425 crystallisation Methods 0.000 description 2
- 230000008025 crystallization Effects 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 238000003182 dose-response assay Methods 0.000 description 2
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- 108010021843 fluorescent protein 583 Proteins 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 150000002367 halogens Chemical class 0.000 description 2
- 125000001072 heteroaryl group Chemical group 0.000 description 2
- 230000013632 homeostatic process Effects 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 230000015788 innate immune response Effects 0.000 description 2
- 210000005007 innate immune system Anatomy 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 201000006370 kidney failure Diseases 0.000 description 2
- 230000003907 kidney function Effects 0.000 description 2
- KWGKDLIKAYFUFQ-UHFFFAOYSA-M lithium chloride Chemical compound [Li+].[Cl-] KWGKDLIKAYFUFQ-UHFFFAOYSA-M 0.000 description 2
- 210000005228 liver tissue Anatomy 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- 239000002207 metabolite Substances 0.000 description 2
- 210000003470 mitochondria Anatomy 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 2
- 230000037434 nonsense mutation Effects 0.000 description 2
- 230000009437 off-target effect Effects 0.000 description 2
- 235000005985 organic acids Nutrition 0.000 description 2
- 150000003891 oxalate salts Chemical group 0.000 description 2
- 230000000858 peroxisomal effect Effects 0.000 description 2
- 150000004713 phosphodiesters Chemical group 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- 230000017854 proteolysis Effects 0.000 description 2
- LXNHXLLTXMVWPM-UHFFFAOYSA-N pyridoxine Chemical compound CC1=NC=C(CO)C(CO)=C1O LXNHXLLTXMVWPM-UHFFFAOYSA-N 0.000 description 2
- 239000002510 pyrogen Substances 0.000 description 2
- 239000011535 reaction buffer Substances 0.000 description 2
- 230000008439 repair process Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 229910052594 sapphire Inorganic materials 0.000 description 2
- 239000010980 sapphire Substances 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 125000006850 spacer group Chemical group 0.000 description 2
- 238000010186 staining Methods 0.000 description 2
- 238000003860 storage Methods 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 239000011593 sulfur Substances 0.000 description 2
- 239000013589 supplement Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000010381 tandem affinity purification Methods 0.000 description 2
- 108060008226 thioredoxin Proteins 0.000 description 2
- 229940094937 thioredoxin Drugs 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 108091006106 transcriptional activators Proteins 0.000 description 2
- 108091006107 transcriptional repressors Proteins 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- 239000001226 triphosphate Substances 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- 208000019206 urinary tract infection Diseases 0.000 description 2
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 2
- FBOUIAKEJMZPQG-AWNIVKPZSA-N (1E)-1-(2,4-dichlorophenyl)-4,4-dimethyl-2-(1,2,4-triazol-1-yl)pent-1-en-3-ol Chemical compound C1=NC=NN1/C(C(O)C(C)(C)C)=C/C1=CC=C(Cl)C=C1Cl FBOUIAKEJMZPQG-AWNIVKPZSA-N 0.000 description 1
- RRBGTUQJDFBWNN-MUGJNUQGSA-N (2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-2,6-diaminohexanoyl]amino]hexanoyl]amino]hexanoyl]amino]hexanoic acid Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O RRBGTUQJDFBWNN-MUGJNUQGSA-N 0.000 description 1
- 125000003161 (C1-C6) alkylene group Chemical group 0.000 description 1
- AJDIZQLSFPQPEY-UHFFFAOYSA-N 1,1,2-Trichlorotrifluoroethane Chemical compound FC(F)(Cl)C(F)(Cl)Cl AJDIZQLSFPQPEY-UHFFFAOYSA-N 0.000 description 1
- MGAXHFMCFLLMNG-UHFFFAOYSA-N 1h-pyrimidine-6-thione Chemical compound SC1=CC=NC=N1 MGAXHFMCFLLMNG-UHFFFAOYSA-N 0.000 description 1
- YMHOBZXQZVXHBM-UHFFFAOYSA-N 2,5-dimethoxy-4-bromophenethylamine Chemical compound COC1=CC(CCN)=C(OC)C=C1Br YMHOBZXQZVXHBM-UHFFFAOYSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- FZIIBDOXPQOKBP-UHFFFAOYSA-N 2-methyloxetane Chemical compound CC1CCO1 FZIIBDOXPQOKBP-UHFFFAOYSA-N 0.000 description 1
- CYDQOEWLBCCFJZ-UHFFFAOYSA-N 4-(4-fluorophenyl)oxane-4-carboxylic acid Chemical compound C=1C=C(F)C=CC=1C1(C(=O)O)CCOCC1 CYDQOEWLBCCFJZ-UHFFFAOYSA-N 0.000 description 1
- 108010071258 4-hydroxy-2-oxoglutarate aldolase Proteins 0.000 description 1
- XZLIYCQRASOFQM-UHFFFAOYSA-N 5h-imidazo[4,5-d]triazine Chemical compound N1=NC=C2NC=NC2=N1 XZLIYCQRASOFQM-UHFFFAOYSA-N 0.000 description 1
- BXJHWYVXLGLDMZ-UHFFFAOYSA-N 6-O-methylguanine Chemical compound COC1=NC(N)=NC2=C1NC=N2 BXJHWYVXLGLDMZ-UHFFFAOYSA-N 0.000 description 1
- ZAOGIVYOCDXEAK-UHFFFAOYSA-N 6-n-methyl-7h-purine-2,6-diamine Chemical compound CNC1=NC(N)=NC2=C1NC=N2 ZAOGIVYOCDXEAK-UHFFFAOYSA-N 0.000 description 1
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 1
- 230000035495 ADMET Effects 0.000 description 1
- 101001082110 Acanthamoeba polyphaga mimivirus Eukaryotic translation initiation factor 4E homolog Proteins 0.000 description 1
- 241000007910 Acaryochloris marina Species 0.000 description 1
- 241001135192 Acetohalobium arabaticum Species 0.000 description 1
- 241000604451 Acidaminococcus Species 0.000 description 1
- 241000093740 Acidaminococcus sp. Species 0.000 description 1
- 241001464929 Acidithiobacillus caldus Species 0.000 description 1
- 241000605222 Acidithiobacillus ferrooxidans Species 0.000 description 1
- 102100022900 Actin, cytoplasmic 1 Human genes 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 1
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 1
- 241000640374 Alicyclobacillus acidocaldarius Species 0.000 description 1
- 241000190857 Allochromatium vinosum Species 0.000 description 1
- 241000147155 Ammonifex degensii Species 0.000 description 1
- 241000272814 Anser sp. Species 0.000 description 1
- 241000620196 Arthrospira maxima Species 0.000 description 1
- 240000002900 Arthrospira platensis Species 0.000 description 1
- 235000016425 Arthrospira platensis Nutrition 0.000 description 1
- 241001495183 Arthrospira sp. Species 0.000 description 1
- 208000037157 Azotemia Diseases 0.000 description 1
- 108091005950 Azurite Proteins 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 241000823281 Burkholderiales bacterium Species 0.000 description 1
- 241000168061 Butyrivibrio proteoclasticus Species 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- 108091079001 CRISPR RNA Proteins 0.000 description 1
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 description 1
- 101100421200 Caenorhabditis elegans sep-1 gene Proteins 0.000 description 1
- 206010007027 Calculus urinary Diseases 0.000 description 1
- 102000000584 Calmodulin Human genes 0.000 description 1
- 108010041952 Calmodulin Proteins 0.000 description 1
- 102000007590 Calpain Human genes 0.000 description 1
- 108010032088 Calpain Proteins 0.000 description 1
- 241000589875 Campylobacter jejuni Species 0.000 description 1
- 241000589986 Campylobacter lari Species 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- 241001496650 Candidatus Desulforudis Species 0.000 description 1
- 241001040999 Candidatus Methanoplasma termitum Species 0.000 description 1
- 241000243205 Candidatus Parcubacteria Species 0.000 description 1
- 241000223282 Candidatus Peregrinibacteria Species 0.000 description 1
- KXDHJXZQYSOELW-UHFFFAOYSA-M Carbamate Chemical compound NC([O-])=O KXDHJXZQYSOELW-UHFFFAOYSA-M 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 108091005944 Cerulean Proteins 0.000 description 1
- 241000579895 Chlorostilbon Species 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 108091005960 Citrine Proteins 0.000 description 1
- 241000193163 Clostridioides difficile Species 0.000 description 1
- 241000193155 Clostridium botulinum Species 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 241000907165 Coleofasciculus chthonoplastes Species 0.000 description 1
- 102000012422 Collagen Type I Human genes 0.000 description 1
- 108010022452 Collagen Type I Proteins 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- 241000186216 Corynebacterium Species 0.000 description 1
- 241000065716 Crocosphaera watsonii Species 0.000 description 1
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 1
- 108091005943 CyPet Proteins 0.000 description 1
- 241000159506 Cyanothece Species 0.000 description 1
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 1
- 238000007399 DNA isolation Methods 0.000 description 1
- 101001082109 Danio rerio Eukaryotic translation initiation factor 4E-1B Proteins 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 108091005941 EBFP Proteins 0.000 description 1
- 108091005947 EBFP2 Proteins 0.000 description 1
- 108091005942 ECFP Proteins 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 101100176848 Escherichia phage N15 gene 15 gene Proteins 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 241000326311 Exiguobacterium sibiricum Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 241000605896 Fibrobacter succinogenes Species 0.000 description 1
- KRHYYFGTRYWZRS-UHFFFAOYSA-M Fluoride anion Chemical compound [F-] KRHYYFGTRYWZRS-UHFFFAOYSA-M 0.000 description 1
- BDAGIHXWWSANSR-UHFFFAOYSA-M Formate Chemical compound [O-]C=O BDAGIHXWWSANSR-UHFFFAOYSA-M 0.000 description 1
- 241000589602 Francisella tularensis Species 0.000 description 1
- 241000589599 Francisella tularensis subsp. novicida Species 0.000 description 1
- 108091092584 GDNA Proteins 0.000 description 1
- 241000968725 Gammaproteobacteria bacterium Species 0.000 description 1
- KOSRFJWDECSPRO-WDSKDSINSA-N Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(O)=O KOSRFJWDECSPRO-WDSKDSINSA-N 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 1
- 108010038519 Glyoxylate reductase Proteins 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- 208000034596 Gyrate atrophy of choroid and retina Diseases 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 208000032843 Hemorrhage Diseases 0.000 description 1
- 206010019670 Hepatic function abnormal Diseases 0.000 description 1
- 101000662056 Homo sapiens Ubiquitin D Proteins 0.000 description 1
- 101000643925 Homo sapiens Ubiquitin-fold modifier 1 Proteins 0.000 description 1
- 101001057508 Homo sapiens Ubiquitin-like protein ISG15 Proteins 0.000 description 1
- 101000941158 Homo sapiens Ubiquitin-related modifier 1 Proteins 0.000 description 1
- 108010059247 Hydroxypyruvate reductase Proteins 0.000 description 1
- 208000026350 Inborn Genetic disease Diseases 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 102000002227 Interferon Type I Human genes 0.000 description 1
- 108010014726 Interferon Type I Proteins 0.000 description 1
- 241000483399 Ipimorpha retusa Species 0.000 description 1
- 108010044467 Isoenzymes Proteins 0.000 description 1
- 241001430080 Ktedonobacter racemifer Species 0.000 description 1
- 241000904817 Lachnospiraceae bacterium Species 0.000 description 1
- 241000689670 Lachnospiraceae bacterium ND2006 Species 0.000 description 1
- 241000186679 Lactobacillus buchneri Species 0.000 description 1
- 241000186673 Lactobacillus delbrueckii Species 0.000 description 1
- 241000186606 Lactobacillus gasseri Species 0.000 description 1
- 241000186869 Lactobacillus salivarius Species 0.000 description 1
- 241000589902 Leptospira Species 0.000 description 1
- 241001148627 Leptospira inadai Species 0.000 description 1
- 241000186805 Listeria innocua Species 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 241001134698 Lyngbya Species 0.000 description 1
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 1
- FUKDBQGFSJUXGX-RWMBFGLXSA-N Lys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)C(=O)O FUKDBQGFSJUXGX-RWMBFGLXSA-N 0.000 description 1
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 1
- 241000206589 Marinobacter Species 0.000 description 1
- 241000501784 Marinobacter sp. Species 0.000 description 1
- 102100025169 Max-binding protein MNT Human genes 0.000 description 1
- 241000204637 Methanohalobium evestigatum Species 0.000 description 1
- 108060004795 Methyltransferase Proteins 0.000 description 1
- 102000016397 Methyltransferase Human genes 0.000 description 1
- 241000192710 Microcystis aeruginosa Species 0.000 description 1
- 241000542065 Moraxella bovoculi Species 0.000 description 1
- 101100203897 Mus musculus Agxt gene Proteins 0.000 description 1
- 101100288586 Mus musculus Ldha gene Proteins 0.000 description 1
- 208000021642 Muscular disease Diseases 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- 201000009623 Myopathy Diseases 0.000 description 1
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 1
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-KEWYIRBNSA-N N-acetyl-D-galactosamine Chemical group CC(=O)N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-KEWYIRBNSA-N 0.000 description 1
- 108700004934 NEDD8 Proteins 0.000 description 1
- 102000053987 NEDD8 Human genes 0.000 description 1
- 101150107958 NEDD8 gene Proteins 0.000 description 1
- 241000588654 Neisseria cinerea Species 0.000 description 1
- 241000750004 Nestor meridionalis Species 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 241001515112 Nitrosococcus watsonii Species 0.000 description 1
- 241000203619 Nocardiopsis dassonvillei Species 0.000 description 1
- 241001223105 Nodularia spumigena Species 0.000 description 1
- 241000192673 Nostoc sp. Species 0.000 description 1
- 108091007494 Nucleic acid- binding domains Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 102000002488 Nucleoplasmin Human genes 0.000 description 1
- 101100532088 Oryza sativa subsp. japonica RUB2 gene Proteins 0.000 description 1
- 101100532090 Oryza sativa subsp. japonica RUB3 gene Proteins 0.000 description 1
- 241000192520 Oscillatoria sp. Species 0.000 description 1
- 108020002230 Pancreatic Ribonuclease Proteins 0.000 description 1
- 102000005891 Pancreatic ribonuclease Human genes 0.000 description 1
- 241001386755 Parvibaculum lavamentivorans Species 0.000 description 1
- 241000606856 Pasteurella multocida Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 241000142651 Pelotomaculum thermopropionicum Species 0.000 description 1
- 241000009328 Perro Species 0.000 description 1
- 241000983938 Petrotoga mobilis Species 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 241001599925 Polaromonas naphthalenivorans Species 0.000 description 1
- 241001472610 Polaromonas sp. Species 0.000 description 1
- 108010068086 Polyubiquitin Proteins 0.000 description 1
- 102100037935 Polyubiquitin-C Human genes 0.000 description 1
- 241000878522 Porphyromonas crevioricanis Species 0.000 description 1
- 241001135241 Porphyromonas macacae Species 0.000 description 1
- 241001135219 Prevotella disiens Species 0.000 description 1
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 241000590028 Pseudoalteromonas haloplanktis Species 0.000 description 1
- 108010009413 Pyrophosphatases Proteins 0.000 description 1
- 102000009609 Pyrophosphatases Human genes 0.000 description 1
- 230000007022 RNA scission Effects 0.000 description 1
- 108010012974 RNA triphosphatase Proteins 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 206010062237 Renal impairment Diseases 0.000 description 1
- 241000316848 Rhodococcus <scale insect> Species 0.000 description 1
- 241000190984 Rhodospirillum rubrum Species 0.000 description 1
- MEFKEPWMEQBLKI-AIRLBKTGSA-N S-adenosyl-L-methioninate Chemical compound O[C@@H]1[C@H](O)[C@@H](C[S+](CC[C@H](N)C([O-])=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 MEFKEPWMEQBLKI-AIRLBKTGSA-N 0.000 description 1
- 108010034546 Serratia marcescens nuclease Proteins 0.000 description 1
- 241001063963 Smithella Species 0.000 description 1
- 101100166144 Staphylococcus aureus cas9 gene Proteins 0.000 description 1
- 241001501869 Streptococcus pasteurianus Species 0.000 description 1
- 241000194022 Streptococcus sp. Species 0.000 description 1
- 241001518258 Streptomyces pristinaespiralis Species 0.000 description 1
- 241000187191 Streptomyces viridochromogenes Species 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 241000192560 Synechococcus sp. Species 0.000 description 1
- 244000269722 Thea sinensis Species 0.000 description 1
- 241000206213 Thermosipho africanus Species 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 241000589892 Treponema denticola Species 0.000 description 1
- 241000078013 Trichormus variabilis Species 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 102100037932 Ubiquitin D Human genes 0.000 description 1
- 102100021012 Ubiquitin-fold modifier 1 Human genes 0.000 description 1
- 102100027266 Ubiquitin-like protein ISG15 Human genes 0.000 description 1
- 102100031319 Ubiquitin-related modifier 1 Human genes 0.000 description 1
- 206010046865 Vaccinia virus infection Diseases 0.000 description 1
- 241000545067 Venus Species 0.000 description 1
- 241000607479 Yersinia pestis Species 0.000 description 1
- SXEHKFHPFVVDIR-UHFFFAOYSA-N [4-(4-hydrazinylphenyl)phenyl]hydrazine Chemical compound C1=CC(NN)=CC=C1C1=CC=C(NN)C=C1 SXEHKFHPFVVDIR-UHFFFAOYSA-N 0.000 description 1
- 241001673106 [Bacillus] selenitireducens Species 0.000 description 1
- 241001531273 [Eubacterium] eligens Species 0.000 description 1
- AGWRKMKSPDCRHI-UHFFFAOYSA-K [[5-(2-amino-7-methyl-6-oxo-1H-purin-9-ium-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-oxidophosphoryl] [[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-oxidophosphoryl]oxy-5-(6-aminopurin-9-yl)-4-methoxyoxolan-2-yl]methoxy-oxidophosphoryl] phosphate Chemical compound COC1C(OP([O-])(=O)OCC2OC(C(O)C2O)N2C=NC3=C2N=C(N)NC3=O)C(COP([O-])(=O)OP([O-])(=O)OP([O-])(=O)OCC2OC(C(O)C2O)N2C=[N+](C)C3=C2N=C(N)NC3=O)OC1N1C=NC2=C1N=CN=C2N AGWRKMKSPDCRHI-UHFFFAOYSA-K 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 238000010535 acyclic diene metathesis reaction Methods 0.000 description 1
- 229960001570 ademetionine Drugs 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- PPQRONHOSHZGFQ-LMVFSUKVSA-N aldehydo-D-ribose 5-phosphate Chemical group OP(=O)(O)OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PPQRONHOSHZGFQ-LMVFSUKVSA-N 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 125000006350 alkyl thio alkyl group Chemical group 0.000 description 1
- 125000002947 alkylene group Chemical group 0.000 description 1
- 125000000304 alkynyl group Chemical group 0.000 description 1
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 1
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 125000002431 aminoalkoxy group Chemical group 0.000 description 1
- 238000005349 anion exchange Methods 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 229940011019 arthrospira platensis Drugs 0.000 description 1
- 125000004104 aryloxy group Chemical group 0.000 description 1
- 239000012298 atmosphere Substances 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- OWMVSZAMULFTJU-UHFFFAOYSA-N bis-tris Chemical compound OCCN(CCO)C(CO)(CO)CO OWMVSZAMULFTJU-UHFFFAOYSA-N 0.000 description 1
- 230000036765 blood level Effects 0.000 description 1
- 108091005948 blue fluorescent proteins Proteins 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 125000001246 bromo group Chemical group Br* 0.000 description 1
- 239000000337 buffer salt Substances 0.000 description 1
- 125000000480 butynyl group Chemical group [*]C#CC([H])([H])C([H])([H])[H] 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 125000001369 canonical nucleoside group Chemical group 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- 125000002057 carboxymethyl group Chemical group [H]OC(=O)C([H])([H])[*] 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 210000003855 cell nucleus Anatomy 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 125000001309 chloro group Chemical group Cl* 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 239000011035 citrine Substances 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 108091036078 conserved sequence Proteins 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 108010082025 cyan fluorescent protein Proteins 0.000 description 1
- 125000004093 cyano group Chemical group *C#N 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 238000012350 deep sequencing Methods 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 238000000326 densiometry Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000005868 electrolysis reaction Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 239000003480 eluent Substances 0.000 description 1
- 239000010976 emerald Substances 0.000 description 1
- 229910052876 emerald Inorganic materials 0.000 description 1
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000004049 epigenetic modification Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 125000001153 fluoro group Chemical group F* 0.000 description 1
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 1
- 231100000221 frame shift mutation induction Toxicity 0.000 description 1
- 229940118764 francisella tularensis Drugs 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 230000009395 genetic defect Effects 0.000 description 1
- 208000016361 genetic disease Diseases 0.000 description 1
- 238000011773 genetically engineered mouse model Methods 0.000 description 1
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 229940029575 guanosine Drugs 0.000 description 1
- 108010064833 guanylyltransferase Proteins 0.000 description 1
- 150000004820 halides Chemical group 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 125000004435 hydrogen atom Chemical class [H]* 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 238000000126 in silico method Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 125000002346 iodo group Chemical group I* 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 208000017169 kidney disease Diseases 0.000 description 1
- 239000010410 layer Substances 0.000 description 1
- 101150100271 ldhb gene Proteins 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- GZQKNULLWNGMCW-PWQABINMSA-N lipid A (E. coli) Chemical compound O1[C@H](CO)[C@@H](OP(O)(O)=O)[C@H](OC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCCCC)[C@@H](NC(=O)C[C@@H](CCCCCCCCCCC)OC(=O)CCCCCCCCCCC)[C@@H]1OC[C@@H]1[C@@H](O)[C@H](OC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](NC(=O)C[C@H](O)CCCCCCCCCCC)[C@@H](OP(O)(O)=O)O1 GZQKNULLWNGMCW-PWQABINMSA-N 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000012317 liver biopsy Methods 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 229940040511 liver extract Drugs 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 229950009772 lumasiran Drugs 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- HHRZAEJMHSGZNP-UHFFFAOYSA-N mebanazine Chemical compound NNC(C)C1=CC=CC=C1 HHRZAEJMHSGZNP-UHFFFAOYSA-N 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- CAAULPUQFIIOTL-UHFFFAOYSA-N methyl dihydrogen phosphate Chemical compound COP(O)(O)=O CAAULPUQFIIOTL-UHFFFAOYSA-N 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 1
- BOPGDPNILDQYTO-NNYOXOHSSA-N nicotinamide-adenine dinucleotide Chemical compound C1=CCC(C(=O)N)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OC[C@@H]2[C@H]([C@@H](O)[C@@H](O2)N2C3=NC=NC(N)=C3N=C2)O)O1 BOPGDPNILDQYTO-NNYOXOHSSA-N 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 231100001078 no known side-effect Toxicity 0.000 description 1
- 108060005597 nucleoplasmin Proteins 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 229940039748 oxalate Drugs 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- 230000021962 pH elevation Effects 0.000 description 1
- 229940051027 pasteurella multocida Drugs 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 210000002824 peroxisome Anatomy 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 238000005191 phase separation Methods 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-N phosphoramidic acid Chemical compound NP(O)(O)=O PTMHPRAIXMAOOB-UHFFFAOYSA-N 0.000 description 1
- 150000003014 phosphoric acid esters Chemical class 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 238000007747 plating Methods 0.000 description 1
- 231100000857 poor renal function Toxicity 0.000 description 1
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 238000000751 protein extraction Methods 0.000 description 1
- 229940024999 proteolytic enzymes for treatment of wounds and ulcers Drugs 0.000 description 1
- RADKZDMFGJYCBB-UHFFFAOYSA-N pyridoxal hydrochloride Natural products CC1=NC=C(CO)C(C=O)=C1O RADKZDMFGJYCBB-UHFFFAOYSA-N 0.000 description 1
- OYRRZWATULMEPF-UHFFFAOYSA-N pyrimidin-4-amine Chemical compound NC1=CC=NC=N1 OYRRZWATULMEPF-UHFFFAOYSA-N 0.000 description 1
- 125000000714 pyrimidinyl group Chemical group 0.000 description 1
- 238000012797 qualification Methods 0.000 description 1
- 239000000700 radioactive tracer Substances 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000037425 regulation of transcription Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 239000003161 ribonuclease inhibitor Substances 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 101150024074 rub1 gene Proteins 0.000 description 1
- JRPHGDYSKGJTKZ-UHFFFAOYSA-N selenophosphoric acid Chemical class OP(O)([SeH])=O JRPHGDYSKGJTKZ-UHFFFAOYSA-N 0.000 description 1
- 238000012772 sequence design Methods 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 239000002356 single layer Substances 0.000 description 1
- 239000001540 sodium lactate Substances 0.000 description 1
- 229940005581 sodium lactate Drugs 0.000 description 1
- 235000011088 sodium lactate Nutrition 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 230000036319 strand breaking Effects 0.000 description 1
- 125000000547 substituted alkyl group Chemical group 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- PXQLVRUNWNTZOS-UHFFFAOYSA-N sulfanyl Chemical class [SH] PXQLVRUNWNTZOS-UHFFFAOYSA-N 0.000 description 1
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 1
- 108091005946 superfolder green fluorescent proteins Proteins 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 108700029760 synthetic LTSP Proteins 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 125000005309 thioalkoxy group Chemical group 0.000 description 1
- 150000003568 thioethers Chemical class 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 238000011222 transcriptome analysis Methods 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- GWBUNZLLLLDXMD-UHFFFAOYSA-H tricopper;dicarbonate;dihydroxide Chemical compound [OH-].[OH-].[Cu+2].[Cu+2].[Cu+2].[O-]C([O-])=O.[O-]C([O-])=O GWBUNZLLLLDXMD-UHFFFAOYSA-H 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 208000009852 uremia Diseases 0.000 description 1
- 210000001635 urinary tract Anatomy 0.000 description 1
- 201000002327 urinary tract obstruction Diseases 0.000 description 1
- 208000008281 urolithiasis Diseases 0.000 description 1
- 208000007089 vaccinia Diseases 0.000 description 1
- 239000002966 varnish Substances 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 235000019158 vitamin B6 Nutrition 0.000 description 1
- 239000011726 vitamin B6 Substances 0.000 description 1
- 229940011671 vitamin b6 Drugs 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
Images





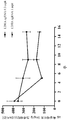













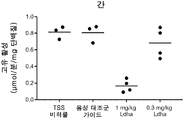




Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1137—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
- A61K48/0025—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid
- A61K48/0033—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition wherein the non-active part clearly interacts with the delivered nucleic acid the non-active part being non-polymeric
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/48—Preparations in capsules, e.g. of gelatin, of chocolate
- A61K9/50—Microcapsules having a gas, liquid or semi-solid filling; Solid microparticles or pellets surrounded by a distinct coating layer, e.g. coated microspheres, coated drug crystals
- A61K9/51—Nanocapsules; Nanoparticles
- A61K9/5107—Excipients; Inactive ingredients
- A61K9/5123—Organic compounds, e.g. fats, sugars
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/02—Drugs for disorders of the urinary system of urine or of the urinary tract, e.g. urine acidifiers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0006—Oxidoreductases (1.) acting on CH-OH groups as donors (1.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y101/00—Oxidoreductases acting on the CH-OH group of donors (1.1)
- C12Y101/01—Oxidoreductases acting on the CH-OH group of donors (1.1) with NAD+ or NADP+ as acceptor (1.1.1)
- C12Y101/01027—L-Lactate dehydrogenase (1.1.1.27)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/12—Type of nucleic acid catalytic nucleic acids, e.g. ribozymes
- C12N2310/122—Hairpin
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/322—2'-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
Abstract
LDHA 유전자 내에 편집, 예를 들어, 이중-가닥 파괴를 도입하기 위한 조성물 및 방법이 제공된다. 고수산뇨증을 가진 대상체를 치료하기 위한 조성물 및 방법이 제공된다.
Description
본 출원은 2018년 9월 28일에 출원된 미국 가특허 출원 번호 제62/738,956호, 2019년 4월 15일에 출원된 미국 가특허 출원 번호 제62/834,334호, 및 2019년 5월 1일에 출원된 미국 가특허 출원 번호 제62/841,740호의 우선권의 이득을 주장하고, 이들 각각의 내용은 모든 목적을 위해 그 전문을 참조로 포함한다.
콩팥에 의해 노폐물로서 소변에서 일반적으로 제거되는 옥살레이트는 고수산뇨증을 가진 대상체에서 상승된다. 고-옥살레이트 식품 섭취와 관련된 원발성 고수산뇨증, 옥살산증, 장성 고수산뇨증, 및 고수산뇨증을 포함한 여러 유형의 고수산뇨증이 있다. 과도한 옥살레이트는 칼슘과 결합하여 콩팥과 다른 기관에서 옥살산칼슘을 형성할 수 있다. 옥살산칼슘의 침착은 옥살산칼슘의 광범위한 침착 (신석회화증) 또는 콩팥 및 방광 결석 형성 (요로 결석)을 생성하여 콩팥 손상을 유발할 수 있다. 고수산뇨증의 일반적인 콩팥 합병증은 소변에서의 혈액 (혈뇨), 요로 감염, 콩팥 손상, 및 말기 신장 질환 (ESRD)을 포함한다. 시간 경과에 따라, 고수산뇨증을 가진 환자의 콩팥은 기능이 저하되기 시작하고, 옥살레이트의 수준은 혈액에서 상승할 수 있다. 전신을 통한 조직에서의 옥살레이트의 침착, 예를 들어, 전신성 옥살산증은 높은 혈액 수준의 옥살레이트로 인해 발생할 수 있고 적어도 뼈, 심장, 피부 및 눈에서 합병증을 유발할 수 있다. 콩팥 부전은 어린이를 포함한 임의의 연령에서, 특히 고수산뇨증을 가진 대상체에서 발생할 수 있다. 유일한 치료 옵션으로서 신장 투석 또는 이중 콩팥/간 기관 이식.
원발성 고수산뇨증 (PH)은 유아부터 노인까지 모든 연령의 대상체에게 영향을 미치는 희귀 유전 장애이다. PH는 세 가지 별개의 단백질의 발현을 변경하는 유전적 결함을 포함하는 세 가지 하위유형을 포함한다. PH1은 알라닌-글리옥실레이트 아미노트랜스퍼라제, 또는 AGT/AGT1을 포함한다. PH2는 글리옥실레이트/하이드록시피루베이트 리덕타제, 또는 GR/HPR을 포함하고, PH3은 4-하이드록시-2-옥소글루타레이트 알돌라제, 또는 HOGA를 포함한다. PH1에서, 돌연변이는 AGXT 유전자에 의해 암호화되는 효소 알라닌 글리옥실레이트 아미노트랜스퍼라제 (AGT 또는 AGT1)에서 발견된다. 일반적으로, AGT는 간 퍼옥시좀에서 글리옥실레이트를 글리신으로 전환시킨다. PH1을 가진 환자에서, 돌연변이 AGT는 글리옥실레이트를 분해할 수 없고, 글리옥실레이트와 이의 대사산물 옥살레이트의 수준이 증가한다. 인간은 옥살레이트를 산화시킬 수 없고, PH1을 가진 대상체에서 높은 수준의 옥살 레이트는 고수산뇨증 야기한다
대상체가 고수산뇨증을 앓고 있는지를 결정하기 위해, 24시간 소변을 수집할 수 있고, 옥살레이트, 글리콜레이트 및 기타 유기산 수준을 측정한다. 유전자 검사 또는 간 생검은 유전적 형태의 고수산뇨증의 확실한 진단을 위해 수행될 수 있다. 예를 들어, 문헌 (Cochat P et al., (2012) Nephrol Dial Transplant 5:1729-36)을 참조한다. 정상적인 건강한 대상체에서, 24시간 소변 옥살레이트 및 글리콜레이트 수준은 45 mg/일 미만이지만, 고수산뇨증 환자에서는, 100 mg/일 초과의 소변 옥살레이트 수준이 전형적이다. 예를 들어, 문헌 (Cochat P. (2013). N Engl J Med 369:649-658)을 참조한다.
정상 대상체에서 혈장 글리콜레이트 수준은 전형적으로 4 내지 8 마이크로 몰이지만, 고수산뇨증 환자에서는 글리콜레이트 수준은 광범위할 수 있고, 고수산뇨증 대상체의 2/3에서 상승한다. 예를 들어, 문헌 (Marangella, M et al. (1992) J. Urol. 148:986-989)을 참조한다. 유전적 형태의 고수산뇨증을 가진 대부분의 환자는 현재 유전자 검사를 통해 진단되지만, 24시간 소변 검사는 고수산뇨증 대상체의 치료 반응을 추적하는 데 사용되는 주요 방법이다. 위와 동일함.
락테이트 데하이드로게나제 (LDH)는 락테이트와 피루베이트의 항상성과 글리옥실레이트와 옥살레이트 대사의 항상성 둘 다를 조절하는 거의 모든 세포에서 발견되는 효소이다. LDH는 4량체를 형성하는 4개의 폴리펩타이드로 구성된다. 이들의 서브유닛 구성요소와 조직 분포가 상이한 LDH의 5개의 아이소자임이 식별되었다. LDH의 2개의 가장 일반적인 형태는 LDHA 유전자에 의해 암호화된 근육 (M) 형태와 LDHB 유전자에 의해 암호화된 심장 (H) 형태이다. 간 세포의 퍼옥시좀에서, LDH는 글리옥살레이트를 옥살레이트로 전환시키는 역할을 하는 핵심 효소로, 이어서 혈장으로 분비되어 콩팥에 의해 배설된다 (Lai et al. (2018) Mol Ther. 26(8):1983-1995)
옥살레이트 생성의 증가는 콩팥 및 신장 질환에서 옥살산칼슘 결정의 침전을 초래한다. 고수산뇨증이 진행됨에 따라, 옥살레이트는 모든 조직에서 침착된다. 유전성 락테이트 데하이드로게나제 M-서브유닛 결핍을 가진 대상체는 손상된 간 기능 또는 간-특이적 표현형을 나타내지 않고, 이는 글리옥실레이트를 옥살레이트로 전환시키는 역할을 하는 제안된 핵심 효소인 간 락테이트 데하이드로게나제 (LDH) 발현 양의 억제 또는 감소는 락테이트 데하이드로게나제 M-서브유닛의 손실로 인한 부작용 없이 고수산뇨증을 가진 대상체에서 옥살레이트의 축적을 방지할 수 있음을 시사한다. 이 가설은 고수산뇨증의 유전자 조작된 뮤린 모델과 고수산뇨증이 에틸렌 글리콜 (EG)로 화학적으로 유도된 뮤린 모델에서 시험되었다. 문헌 (Kanno, T et al. (1988) Clin. Chim. Acta 173, 89-98; Takahashi, Y et al. (1995) Intern. Med. 34, 326-329; and Tsujino, S et al. (1994) Ann. Neurol. 36, 661-665)을 참조한다.
LDH가 옥살레이트 생성의 최종 단계에서 핵심이기 때문에, N-아세틸 갈락토사민 (GalNAc) 잔기와의 접합을 통해 간세포로 유도된 LDHA siRNA를 사용하여 고수산뇨증의 마우스 모델에서 LDHA 사일런싱을 매개하였다. 문헌 (Lai et al. (2018) Mol Ther. 26(8):1983-1995)을 참조한다. 이 LDHA siRNA로 마우스를 처리하면 간 LDH의 감소와 효율적인 옥살레이트 감소가 초래되었고, 유전자 조작된 고수산뇨증 마우스 모델과 화학적으로 유도된 고수산뇨증 마우스 모델 둘 다에서 옥살산칼슘 결정 침착이 방지되었다. 위와 동일함. 마우스에서 간 LDH의 억제는 순환하는 간 효소, 락테이트 산성혈증 또는 운동성 근육병증의 급성 상승을 초래하지 않았다.
LDHA를 억제하여 고수산뇨증을 가진 환자를 치료하는 아이디어는 간이 최대 80%의 인간 간세포로 구성된 인간화된 키메라 마우스와 비인간 영장류 둘 다의 LDHA siRNA 처리에 의해 더 뒷받침된다. 위와 동일함.
따라서, 다음 구현예가 제공된다. 일부 구현예에서, 본원 개시내용은 LDHA 유전자의 발현을 실질적으로 감소 또는 녹아웃시킴으로써 LDH의 생성을 실질적으로 감소 또는 제거하여, 소변 옥살레이트를 감소시키고 혈청 글리콜레이트를 증가시키기 위해 CRISPR/Cas 시스템과 같은 RNA-가이드된 DNA 결합제와 함께 가이드 RNA를 사용하는 조성물 및 방법을 제공한다. LDHA 유전자의 변경을 통한 LDH 생산의 실질적인 감소 또는 제거는 고수산뇨증에 대한 장기적인 또는 영구적인 치료일 될 수 있다.
요약
하기 구현예가 제공된다.
구현예 01
조성물을 세포에 전달하는 단계를 포함하여, LDHA 유전자 내에 이중-가닥 파괴 (DSB) 또는 단일-가닥 파괴 (SSB)를 유도하는 방법으로서, 여기서, 상기 조성물은 다음을 포함하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 02
조성물을 세포에 전달하는 단계를 포함하여 LDHA 유전자의 발현을 감소시키는 방법으로서, 여기서, 상기 조성물은 다음을 포함하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 03
조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하여 고수산뇨증을 치료 또는 예방하는 방법으로서, 여기서, 상기 조성물은 다음을 포함하여 고수산뇨증을 치료 또는 예방하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 04
조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하여 고수산뇨증으로 야기된 말기 신장 질환 (ESRD)을 치료 또는 예방하는 방법으로서, 여기서, 상기 조성물은 다음을 포함하여 고수산뇨증으로 야기된 (ESRD)를 치료 또는 예방하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 05
조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하여 옥살산칼슘 생성 및 침착, 원발성 고수산뇨증 (PH1, PH2, 및 PH3 포함), 옥살산증, 혈뇨 중 임의의 하나를 치료 또는 예방하고, 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는 방법으로서, 여기서, 상기 조성물은 다음을 포함하여 옥살산칼슘 생성 및 침착, 원발성 고수산뇨증, 옥살산증, 혈뇨 중 임의의 하나를 치료 또는 예방하고, 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 06
조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하여, 혈청 글리콜레이트 농도를 증가시키는 방법으로서, 여기서, 상기 조성물은 다음을 포함하여 혈청 글리콜레이트 농도를 증가시키는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 07
조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하여 대상체의 소변에서 옥실레이트를 감소시키는 방법으로서, 여기서, 상기 조성물은 다음을 포함하여 대상체의 소변에서 옥살레이트를 감소시키는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 08
구현예 1 내지 7 중 어느 하나에 있어서, RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산이 투여되는, 방법.
구현예 09
다음을 포함하는 조성물:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 어느 한 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산.
구현예 10
다음을 포함하는 짧은-단일 가이드 RNA (짧은-sgRNA)를 포함하는 조성물:
a. 다음을 포함하는 가이드 서열:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나; 및
b. 헤어핀 영역을 포함하는 sgRNA의 보존된 부분으로서, 여기서, 상기 헤어핀 영역은 적어도 5 내지 10개의 뉴클레오티드가 결여되어 있고 임의로 상기 짧은-sgRNA는 5' 단부 변형 및 3' 단부 변형 중 하나 이상을 포함하는, 보존된 부분.
구현예 11
구현예 10에 있어서, 서열번호 202의 서열을 포함하는, 조성물.
구현예 12
구현예 10 또는 11에 있어서, 5' 단부 변형을 포함하는, 조성물.
구현예 13
구현예 10 내지 12 중 어느 하나에 있어서, 상기 짧은-sgRNA는 3' 단부 변형을 포함하는, 조성물.
구현예 14
구현예 10 내지 13 중 어느 하나에 있어서, 상기 짧은-sgRNA는 5' 단부 변형 및 3' 단부 변형을 포함하는, 조성물.
구현예 15
구현예 10 내지 14중 어느 하나에 있어서, 상기 짧은-sgRNA는 3' 꼬리 (tail)를 포함하는, 조성물.
구현예 16
구현예 15에 있어서, 상기 3' 꼬리는 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 뉴클레오티드를 포함하는, 조성물.
구현예 17
구현예 15에 있어서, 상기 3' 꼬리는 약 1 내지 2개, 1 내지 3개, 1 내지 4개, 1 내지 5개, 1 내지 7개, 1 내지 10개, 적어도 1 내지 2개, 적어도 1 내지 3개, 적어도 1 내지 4개, 적어도 1 내지 5개, 적어도 1 내지 7개, 또는 적어도 1 내지 10개의 뉴클레오티드를 포함하는, 조성물.
구현예 18
구현예 10 내지 17 중 어느 하나에 있어서, 상기 짧은-sgRNA는 3' 꼬리를 포함하지 않는, 조성물.
구현예 19
구현예 10 내지 18 중 어느 하나에 있어서, 상기 헤어핀 영역에서의 변형을 포함하는, 조성물.
구현예 20
구현예 10 내지 19 중 어느 하나에 있어서, 3' 단부 변형, 및 상기 헤어핀 영역에서의 변형을 포함하는, 조성물.
구현예 21
구현예 10 내지 20 중 어느 하나에 있어서, 3' 단부 변형, 상기 헤어핀 영역에서의 변형, 및 5' 단부 변형을 포함하는, 조성물.
구현예 22
구현예 10 내지 21 중 어느 하나에 있어서, 5' 단부 변형, 및 상기 헤어핀 영역에서의 변형을 포함하는, 조성물.
구현예 23
구현예 10 내지 22 중 어느 하나에 있어서, 상기 헤어핀 영역은 적어도 5개의 연속 뉴클레오티드가 결여된 것인, 조성물.
구현예 24
구현예 10 내지 23 중 어느 하나에 있어서, 적어도 5 내지 10개의 결여된 뉴클레오티드는
a. 헤어핀 1 내에 있거나;
b. 헤어핀 1 내에 있고 헤어핀 1과 헤어핀 2 사이의 "N"이거나;
c. 헤어핀 1 내에 있고 헤어핀 1의 3' 바로 인접한 2개의 뉴클레오티드이거나;
d. 헤어핀 1의 적어도 일부를 포함하거나;
e. 헤어핀 2 내에 있거나;
f. 헤어핀 2의 적어도 일부를 포함하거나;
g. 헤어핀 1 및 헤어핀 2 내에 있거나;
h. 헤어핀 1의 적어도 일부를 포함하고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하거나;
i. 헤어핀 2의 적어도 일부를 포함하고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하거나;
j. 헤어핀 1의 적어도 일부를 포함하고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하고 헤어핀 2의 적어도 일부를 포함하거나;
k. 헤어핀 1과 헤어핀 2 사이에 "N"을 임의로 포함하는 헤어핀 1 또는 헤어핀 2 내에 있거나;
l. 연속적이거나;
m. 연속적이고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하거나;
n. 연속적이고 헤어핀 1의 적어도 일부 및 헤어핀 2의 일부에 걸쳐 있거나;
o. 연속적이고 헤어핀 1의 적어도 일부와 헤어핀 1과 헤어핀 2 사이의 "N"에 걸쳐 있거나;
p. 연속적이고 헤어핀 1의 적어도 일부 및 헤어핀 1의 3' 바로 인접한 2개의 뉴클레오티드에 걸쳐 있거나;
q. 5 내지 10개의 뉴클레오티드로 이루어지거나;
r. 6 내지 10개의 뉴클레오티드로 이루어지거나;
s. 5 내지 10개의 연속 뉴클레오티드로 이루어지거나;
t. 6 내지 10개의 연속 뉴클레오티드로 이루어지거나;
u. 서열번호 400의 뉴클레오티드 54 내지 58로 이루어진, 조성물.
구현예 25
구현예 10 내지 24 중 어느 하나에 있어서, 넥서스 영역을 포함하는 sgRNA의 보존된 부분을 포함하며, 여기서, 상기 넥서스 영역은 적어도 하나의 뉴클레오티드가 결여되어 있는, 조성물.
구현예 26
구현예 25에 있어서, 상기 넥서스 영역에 결여된 뉴클레오티드는 다음 중 임의의 하나 이상을 포함하는, 조성물:
a. 상기 넥서스 영역에서 적어도 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 뉴클레오티드;
b. 상기 넥서스 영역에서 적어도 또는 정확히 1 내지 2개의 뉴클레오티드, 1 내지 3개의 뉴클레오티드, 1 내지 4개의 뉴클레오티드, 1 내지 5개의 뉴클레오티드, 1 내지 6개의 뉴클레오티드, 1 내지 10개의 뉴클레오티드, 또는 1 내지 15개의 뉴클레오티드; 및
c. 상기 넥서스 영역에서 각각의 뉴클레오티드.
구현예 27
다음을 포함하는 변형된 단일 가이드 RNA (sgRNA)를 포함하는 조성물:
a. 다음을 포함하는 가이드 서열:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나; 그리고 추가로 포함하는
b. 다음으로부터 선택된 하나 이상의 변형:
1. 하나 이상의 가이드 영역 YA 부위에서의 YA 변형;
2. 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
3. 하나 이상의 가이드 영역 YA 부위 및 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
4. i) 2개 이상의 가이드 영역 YA 부위에서의 YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
5. i) 하나 이상의 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 가이드 영역 YA 부위는 5' 말단의 5' 단부로부터 뉴클레오티드 8에 또는 그 뒤에 있는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및 임의로;
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
6. i) 하나 이상의 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 가이드 영역 YA 부위는 상기 가이드 영역의 3' 말단 뉴클레오티드의 13개의 뉴클레오티드 내에 있는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
7. i) 5' 단부 변형 및 3' 단부 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
8. i) 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 가이드 영역 YA 부위의 변형은 상기 가이드 영역 YA 부위의 5'에 위치한 적어도 하나의 뉴클레오티드가 포함하지 않는 변형을 포함하는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
9. i) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
ii) 보존된 영역 YA 부위 1 및 8에서 YA 변형; 또는
10. i) 하나 이상의 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 YA 부위는 5' 말단으로부터 뉴클레오티드 8에 또는 그 뒤에 있는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) H1-1 및 H2-1 중 하나 이상에서의 변형; 또는
11. i) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형;
ii) 보존된 영역 YA 부위 1, 5, 6, 7, 8, 및 9 중 하나 이상에서의 YA 변형; 및
iii) H1-1 및 H2-1 중 하나 이상에서의 변형; 또는
12. i) 5' 말단으로부터 뉴클레오티드 6에 또는 그 뒤에 위치한 하나 이상의 뉴클레오티드에서 YA 변형과 같은 변형;
ii) 하나 이상의 가이드 서열 YA 부위에서의 YA 변형;
iii) B3, B4, 및 B5 중 하나 이상에서의 변형으로서, 여기서, B6은 2'-OMe 변형을 포함하지 않거나 2'-OMe 이외의 변형을 포함하는, 변형;
iv) LS10에서의 변형으로서, 여기서, LS10은 2'-플루오로 이외의 변형을 포함하는, 변형; 및/또는
v) N2, N3, N4, N5, N6, N7, N10, 또는 N11에서의 변형; 및
여기서, 다음 중 적어도 하나는 참이다:
i. 하나 이상의 가이드 영역 YA 부위에서의 YA 변형;
ii. 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
iii. 하나 이상의 가이드 영역 YA 부위 및 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
iv. 5' 말단의 5' 단부로부터 뉴클레오티드 8 내지 11, 13, 14, 17, 또는 18 중 적어도 하나는 2'-플루오로 변형을 포함하지 않거나;
v. 5' 말단의 5' 단부로부터 뉴클레오티드 6 내지 10 중 적어도 하나는 포스포로티오에이트 연결을 포함하지 않거나;
vi. B2, B3, B4, 또는 B5 중 적어도 하나는 2'-OMe 변형을 포함하지 않거나;
vii. LS1, LS8, 또는 LS10 중 적어도 하나는 2'-OMe 변형을 포함하지 않거나;
viii. N2, N3, N4, N5, N6, N7, N10, N11, N16, 또는 N17 중 적어도 하나는 2'-OMe 변형을 포함하지 않거나;
ix. H1-1은 변형을 포함하거나;
x. H2-1은 변형을 포함하거나;
xi. H1-2, H1-3, H1-4, H1-5, H1-6, H1-7, H1-8, H1-9, H1-10, H2-1, H2-2, H2-3, H2-4, H2-5, H2-6, H2-7, H2-8, H2-9, H2-10, H2-11, H2-12, H2-13, H2-14, 또는 H2-15 중 적어도 하나는 포스포로티오에이트 연결을 포함하지 않는다.
구현예 28
구현예 27에 있어서, 서열번호 450을 포함하는, 조성물.
구현예 29
구현예 9 내지 28 중 어느 하나에 있어서, 세포 또는 대상체에서 LDHA 유전자 내에 이중-가닥 파괴 (DSB) 또는 단일-가닥 파괴 (SSB)를 유도하는데 사용하기 위한, 조성물.
구현예 30
구현예 9 내지 28 중 어느 하나에 있어서, 세포 또는 대상체에서 LDHA 유전자의 발현을 감소시키는데 사용하기 위한, 조성물.
구현예 31
구현예 9 내지 28 중 어느 하나에 있어서, 대상체에서 고수산뇨증을 치료 또는 예방하는 데 사용하기 위한, 조성물.
구현예 32
구현예 9 내지 28 중 어느 하나에 있어서, 대상체에서 혈청 및/또는 혈장 글리콜레이트 농도를 증가시키는 데 사용하기 위한, 조성물.
구현예 33
구현예 9 내지 28 중 어느 하나에 있어서, 대상체에서 소변 옥살레이트 농도를 감소시키는 데 사용하기 위한, 조성물.
구현예 34
구현예 9 내지 28 중 어느 하나에 있어서, 옥살레이트 생성, 기관에서의 옥살산칼슘 침착, 원발성 고수산뇨증, 전신성 옥살산증을 포함한 옥살산증, 혈뇨, 말기 신장 질환 (ESRD)을 치료 또는 예방 및/또는 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는 데 사용하기 위한, 조성물.
구현예 35
구현예 1 내지 8 중 어느 하나에 있어서, 다음을 추가로 포함하는, 방법:
a. 세포 또는 대상체에서 상기 LDHA 유전자 내에 이중-가닥 파괴 (DSB) 유도;
b. 세포 또는 대상체에서 상기 LDHA 유전자의 발현 감소;
c. 대상체에서 고수산뇨증 치료 또는 예방;
d. 대상체에서 원발성 고수산뇨증 치료 또는 예방;
e. 대상체에서 PH1, PH2, 및/또는 PH3 치료 또는 예방;
f. 대상체에서 장성 고수산뇨증 치료 또는 예방;
g. 대상체에서 고-옥살레이트 식품 섭취와 관련된 고수산뇨증 치료 또는 예방;
h. 대상체에서 혈청 및/또는 혈장 글리콜레이트 농도 증가;
i. 대상체에서 소변 옥살레이트 농도 감소;
j. 옥살레이트 생성 감소;
k. 기관에서의 옥살산칼슘 침착 감소;
l. 고수산뇨증 감소;
m. 전신성 옥살산증을 포함한 옥살산증 치료 또는 예방;
n. 혈뇨 치료 또는 예방;
o. 말기 신장 질환 (ESRD) 예방; 및/또는
p. 콩팥 또는 간 이식의 필요성 지연 또는 개선.
구현예 36
구현예 1 내지 8 또는 29 내지 35 중 어느 하나에 있어서, 상기 조성물은 혈청 및/또는 혈장 글리콜레이트 수준을 증가시키는, 방법 또는 조성물.
구현예 37
구현예 1 내지 8 또는 29 내지 35 중 어느 하나에 있어서, 상기 조성물은 상기 LDHA 유전자의 편집을 초래하는, 방법 또는 조성물.
구현예 38
구현예 37에 있어서, 상기 편집이 편집된 집단의 백분율 (퍼센트 편집)로서 계산되는, 방법 또는 조성물.
구현예 39
구현예 38에 있어서, 상기 퍼센트 편집은 상기 집단의 30%와 99% 사이인, 방법 또는 조성물.
구현예 40
구현예 38에 있어서, 상기 퍼센트 편집은 상기 집단의 30%와 35% 사이, 35%와 40% 사이, 40%와 45% 사이, 45%와 50% 사이, 50%와 55% 사이, 55%와 60% 사이, 60%와 65% 사이, 65%와 70% 사이, 70%와 75% 사이, 75%와 80% 사이, 80%와 85% 사이, 85%와 90% 사이, 90%와 95% 사이, 또는 95%와 99% 사이인, 방법 또는 조성물.
구현예 41
구현예 1 내지 8 또는 29 내지 35 중 어느 하나에 있어서, 상기 조성물은 소변 옥살레이트 농도를 감소시키는, 방법 또는 조성물.
구현예 42
구현예 41에 있어서, 소변 옥살레이트의 감소는 콩팥, 간, 방광, 심장, 피부 또는 눈에서 콩팥 결석 및/또는 옥살산칼슘 침착을 감소시키는, 방법 또는 조성물.
구현예 43
구현예 1 내지 42 중 어느 하나에 있어서, 상기 가이드 서열은 다음으로부터 선택되는, 방법 또는 조성물:
a. 서열번호 1 내지 84 및 100 내지 192;
b. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80;
c. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48;
d. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184; 및
e. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123.
구현예 44
구현예 1 내지 43 중 어느 하나에 있어서, 상기 조성물은 다음을 포함하는 sgRNA를 포함하는, 방법 또는 조성물:
a. 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나; 또는
b. 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081 중 임의의 하나; 또는
c. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80으로부터 선택된 가이드 서열; 또는
d. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48로부터 선택된 가이드 서열;
e. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184로부터 선택된 가이드 서열; 및
f. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123으로부터 선택된 가이드 서열.
구현예 45
구현예 1 내지 44 중 어느 하나에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 1 내지 8 중 임의의 하나에 있는, 방법 또는 조성물.
구현예 46
구현예 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 1 또는 2에 있는, 방법 또는 조성물.
구현예 47
구현예 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 3에 있는, 방법 또는 조성물.
구현예 48
구현예 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 4에 있는, 방법 또는 조성물.
구현예 49
구현예 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 5 또는 6에 있는, 방법 또는 조성물.
구현예 50
구현예 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 7 또는 8에 있는, 방법 또는 조성물.
구현예 51
구현예 1 내지 50 중 어느 하나에 있어서, 상기 가이드 서열은 LDHA의 양성 가닥의 표적 서열에 상보적인, 방법 또는 조성물.
구현예 52
구현예 1 내지 50 중 어느 하나에 있어서, 상기 가이드 서열은 LDHA의 음성 가닥의 표적 서열에 상보적인, 방법 또는 조성물.
구현예 53
구현예 1 내지 50 중 어느 하나에 있어서, 상기 제1 가이드 서열은 상기 LDHA 유전자의 양성 가닥에서 제1 표적 서열에 상보적이고, 상기 조성물은 상기 LDHA 유전자의 음성 가닥에서 제2 표적 서열에 상보적인 제2 가이드 서열을 추가로 포함하는, 방법 또는 조성물.
구현예 54
구현예 1 내지 53 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1 내지 84 및 100 내지 192 중 임의의 하나로부터 선택된 가이드 서열을 포함하고, 서열번호 200의 뉴클레오티드 서열을 추가로 포함하고, 서열번호 200의 뉴클레오티드는 이의 3' 단부에서 상기 가이드 서열을 따르는, 방법 또는 조성물.
구현예 55
구현예 1 내지 54 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1 내지 84 및 100 내지 192 중 임의의 하나로부터 선택된 가이드 서열을 포함하고, 서열번호 201, 서열번호 202, 서열번호 203, 또는 서열번호 400 내지 450 중 임의의 하나의 뉴클레오티드 서열을 추가로 포함하고, 여기서, 서열번호 201, 서열번호 202, 서열번호 203의 뉴클레오티드는 이의 3' 단부에서 상기 가이드 서열을 따르는, 방법 또는 조성물.
구현예 56
구현예 1 내지 55 중 어느 하나에 있어서, 상기 가이드 RNA는 단일 가이드 (sgRNA)인, 방법 또는 조성물.
구현예 57
구현예 56에 있어서, 상기 sgRNA는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나를 포함하는 가이드 서열을 포함하는, 방법 또는 조성물.
구현예 58
구현예 56에 있어서, 상기 sgRNA는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나, 또는 이의 변형된 버전을 포함하고, 임의로 상기 변형된 버전은 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081을 포함하는, 방법 또는 조성물.
구현예 59
구현예 1 내지 58 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 300의 패턴에 따라 변형되고, 상기 N은 집합적으로 표 1의 가이드 서열 (서열번호 1 내지 84 및 100 내지 192) 중 임의의 하나인, 방법 또는 조성물.
구현예 60
구현예 59에 있어서, 서열번호 300에서 각각의 N은 임의의 천연 또는 비천연 뉴클레오티드이고, 여기서, 상기 N은 가이드 서열을 형성하고, 상기 가이드 서열은 Cas9를 LDHA 유전자에 표적화하는, 방법 또는 조성물.
구현예 61
구현예 1 내지 60 중 어느 하나에 있어서, 상기 sgRNA는 서열번호 1 내지 84 및 100 내지 192의 가이드 서열 중 임의의 하나 및 서열번호 201, 서열번호 202, 또는 서열번호 203의 뉴클레오티드를 포함하는, 방법 또는 조성물.
구현예 62
구현예 56 내지 61 중 어느 하나에 있어서, 상기 sgRNA는 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열을 포함하는, 방법 또는 조성물.
구현예 63
구현예 62에 있어서, 상기 sgRNA는 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 1081, 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로부터 선택된 서열을 포함하는, 방법 또는 조성물.
구현예 64
구현예 1 내지 63 중 어느 하나에 있어서, 상기 가이드 RNA는 적어도 하나의 변형을 포함하는, 방법 또는 조성물.
구현예 65
구현예 64에 있어서, 상기 적어도 하나의 변형은 2'-O-메틸(2'-O-Me) 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
구현예 66
구현예 64 또는 65에 있어서, 뉴클레오티드 사이에 포스포로티오에이트 (PS) 결합을 포함하는, 방법 또는 조성물.
구현예 67
구현예 64 내지 66 중 어느 하나에 있어서, 2'-플루오로 (2'-F) 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
구현예 68
구현예 64 내지 67 중 어느 하나에 있어서, 상기 가이드 RNA의 5' 단부에서 처음 5개의 뉴클레오티드 중 하나 이상에서 변형을 포함하는, 방법 또는 조성물.
구현예 69
구현예 64 내지 68 중 어느 하나에 있어서, 상기 가이드 RNA의 3' 단부에서 마지막 5개의 뉴클레오티드 중 하나 이상에서 변형을 포함하는, 방법 또는 조성물.
구현예 70
구현예 64 내지 69 중 어느 하나에 있어서, 상기 가이드 RNA의 처음 4개의 뉴클레오티드 사이에 PS 결합을 포함하는, 방법 또는 조성물.
구현예 71
구현예 64 내지 70 중 어느 하나에 있어서, 상기 가이드 RNA의 마지막 4개의 뉴클레오티드 사이에 PS 결합을 포함하는, 방법 또는 조성물.
구현예 72
구현예 64 내지 71 중 어느 하나에 있어서, 상기 가이드 RNA의 5' 단부에서 처음 3개의 뉴클레오티드에서 2'-O-Me 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
구현예 73
구현예 64 내지 72 중 어느 하나에 있어서, 상기 가이드 RNA의 3' 단부에서 마지막 3개의 뉴클레오티드에서 2'-O-Me 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
구현예 74
구현예 64 내지 73 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 300의 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물,
구현예 75
구현예 1 내지 74 중 어느 하나에 있어서, 상기 조성물은 약제학적으로 허용되는 부형제를 추가로 포함하는, 방법 또는 조성물.
구현예 76
구현예 1 내지 75 중 어느 하나에 있어서, 상기 가이드 RNA는 지질 나노입자 (LNP)와 회합되는, 방법 또는 조성물.
구현예 77
구현예 76에 있어서, 상기 LNP는 양이온성 지질을 포함하는, 방법 또는 조성물.
구현예 78
구현예 77에 있어서, 상기 양이온성 지질은 3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 (9Z,12Z)-옥타데카-9,12-디에노에이트로도 불리는 (9Z,12Z)-3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 옥타데카-9,12-디에노에이트인, 방법 또는 조성물.
구현예 79
구현예 76 내지 78 중 어느 하나에 있어서, 상기 LNP는 중성 지질을 포함하는, 방법 또는 조성물.
구현예 80
구현예 79에 있어서, 상기 중성 지질은 DSPC인, 방법 또는 조성물.
구현예 81
구현예 76 내지 80 중 어느 하나에 있어서, 상기 LNP는 헬퍼 (helper) 지질을 포함하는, 방법 또는 조성물.
구현예 82
구현예 81에 있어서, 상기 헬퍼 지질은 콜레스테롤인, 방법 또는 조성물.
구현예 83
구현예 76 내지 82 중 어느 하나에 있어서, 상기 LNP는 스텔스 (stealth) 지질을 포함하는, 방법 또는 조성물.
구현예 84
구현예 83에 있어서, 상기 스텔스 지질은 PEG2k-DMG인, 방법 또는 조성물.
구현예 85
구현예 1 내지 84 중 어느 하나에 있어서, 상기 조성물은 RNA-가이드된 DNA 결합제를 추가로 포함하는, 방법 또는 조성물.
구현예 86
구현예 1 내지 85 중 어느 하나에 있어서, 상기 조성물은 RNA-가이드된 DNA 결합제를 암호화하는 mRNA를 추가로 포함하는, 방법 또는 조성물.
구현예 87
구현예 85 또는 86에 있어서, 상기 RNA-가이드된 DNA 결합제는 Cas9인, 방법 또는 조성물.
구현예 88
구현예 1 내지 87 중 어느 하나에 있어서, 상기 조성물은 약제학적 제형이고, 약제학적으로 허용되는 담체를 추가로 포함하는, 방법 또는 조성물.
구현예 89
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 1인, 방법 또는 조성물.
구현예 90
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 2인, 방법 또는 조성물.
구현예 91
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 3인, 방법 또는 조성물.
구현예 92
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 4인, 방법 또는 조성물.
구현예 93
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 5인, 방법 또는 조성물.
구현예 94
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 6인, 방법 또는 조성물.
구현예 95
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 7인, 방법 또는 조성물.
구현예 96
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 8인, 방법 또는 조성물.
구현예 97
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 9인, 방법 또는 조성물.
구현예 98
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 10인, 방법 또는 조성물.
구현예 99
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 11인, 방법 또는 조성물.
구현예 100
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 12인, 방법 또는 조성물.
구현예 101
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 13인, 방법 또는 조성물.
구현예 102
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 14인, 방법 또는 조성물.
구현예 103
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 15인, 방법 또는 조성물.
구현예 104
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 16인, 방법 또는 조성물.
구현예 105
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 17인, 방법 또는 조성물.
구현예 106
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 18인, 방법 또는 조성물.
구현예 107
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 19인, 방법 또는 조성물.
구현예 108
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 20인, 방법 또는 조성물.
구현예 109
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 21인, 방법 또는 조성물.
구현예 110
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 22인, 방법 또는 조성물.
구현예 111
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 23인, 방법 또는 조성물.
구현예 112
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 24인, 방법 또는 조성물.
구현예 113
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 25인, 방법 또는 조성물.
구현예 114
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 26인, 방법 또는 조성물.
구현예 115
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 27인, 방법 또는 조성물.
구현예 116
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 28인, 방법 또는 조성물.
구현예 117
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 29인, 방법 또는 조성물.
구현예 118
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 30인, 방법 또는 조성물.
구현예 119
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 31인, 방법 또는 조성물.
구현예 120
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 32인, 방법 또는 조성물.
구현예 121
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 33인, 방법 또는 조성물.
구현예 122
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 34인, 방법 또는 조성물.
구현예 123
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 35인, 방법 또는 조성물.
구현예 124
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 36인, 방법 또는 조성물.
구현예 125
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 37인, 방법 또는 조성물.
구현예 126
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 38인, 방법 또는 조성물.
구현예 127
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 39인, 방법 또는 조성물.
구현예 128
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 40인, 방법 또는 조성물.
구현예 129
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 41인, 방법 또는 조성물.
구현예 130
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 42인, 방법 또는 조성물.
구현예 131
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 43인, 방법 또는 조성물.
구현예 132
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 44인, 방법 또는 조성물.
구현예 133
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 45인, 방법 또는 조성물.
구현예 134
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 46인, 방법 또는 조성물.
구현예 135
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 47인, 방법 또는 조성물.
구현예 136
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 48인, 방법 또는 조성물.
구현예 137
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 49인, 방법 또는 조성물.
구현예 138
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 50인, 방법 또는 조성물.
구현예 139
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 51인, 방법 또는 조성물.
구현예 140
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 52인, 방법 또는 조성물.
구현예 141
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 53인, 방법 또는 조성물.
구현예 142
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 54인, 방법 또는 조성물.
구현예 143
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 55인, 방법 또는 조성물.
구현예 144
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 56인, 방법 또는 조성물.
구현예 145
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 57인, 방법 또는 조성물.
구현예 146
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 58인, 방법 또는 조성물.
구현예 147
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 59인, 방법 또는 조성물.
구현예 148
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 60인, 방법 또는 조성물.
구현예 149
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 61인, 방법 또는 조성물.
구현예 150
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 62인, 방법 또는 조성물.
구현예 151
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 63인, 방법 또는 조성물.
구현예 152
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 64인, 방법 또는 조성물.
구현예 153
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 65인, 방법 또는 조성물.
구현예 154
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 66인, 방법 또는 조성물.
구현예 155
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 67인, 방법 또는 조성물.
구현예 156
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 68인, 방법 또는 조성물.
구현예 157
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 69인, 방법 또는 조성물.
구현예 158
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 70인, 방법 또는 조성물.
구현예 159
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 71인, 방법 또는 조성물.
구현예 160
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 72인, 방법 또는 조성물.
구현예 161
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 73인, 방법 또는 조성물.
구현예 162
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 74인, 방법 또는 조성물.
구현예 163
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 75인, 방법 또는 조성물.
구현예 164
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 76인, 방법 또는 조성물.
구현예 165
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 77인, 방법 또는 조성물.
구현예 166
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 78인, 방법 또는 조성물.
구현예 167
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 79인, 방법 또는 조성물.
구현예 168
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 80인, 방법 또는 조성물.
구현예 169
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 81인, 방법 또는 조성물.
구현예 170
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 82인, 방법 또는 조성물.
구현예 171
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 83인, 방법 또는 조성물.
구현예 172
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 84인, 방법 또는 조성물.
구현예 173
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 103인, 방법 또는 조성물.
구현예 174
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 109인, 방법 또는 조성물.
구현예 175
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 123인, 방법 또는 조성물.
구현예 176
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 133인, 방법 또는 조성물.
구현예 177
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 149인, 방법 또는 조성물.
구현예 178
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 156인, 방법 또는 조성물.
구현예 179
구현예 1 내지 88 중 어느 하나에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 166인, 방법 또는 조성물.
구현예 180
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 서열은 서열번호 2, 9, 13, 16, 22, 24, 25, 27, 30, 31, 32, 33, 35, 36, 40, 44, 45, 53, 55, 57, 60, 61-63, 65, 67, 69, 70, 71, 73, 76, 78, 79, 80, 82-84, 103, 109, 123, 133, 149, 156, 및 166 중 임의의 하나를 포함하는, 방법 또는 조성물.
구현예 181
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 서열은 서열번호 100 내지 102, 104 내지 108, 110 내지 122, 124 내지 132, 134 내지 148, 150 내지 155, 157 내지 165, 및 167 내지 192 중 임의의 하나를 포함하는, 방법 또는 조성물.
구현예 182
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 서열은 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는, 방법 또는 조성물.
구현예 183
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 서열은 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는, 방법 또는 조성물.
구현예 184
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 86 내지 90 중 임의의 하나를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 185
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 89를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 186
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1001 또는 2001을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 187
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1005 또는 2005를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 188
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1007 또는 2007을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 189
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1008 또는 2008을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 190
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1014 또는 2014를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 191
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1023 또는 2023을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 192
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1027 또는 2027을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 193
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1032 또는 2032를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 194
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1045 또는 2045를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 195
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1048 또는 2048을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 196
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1063 또는 2063을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 197
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1067 또는 2067을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 198
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1069 또는 2069를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 199
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1071 또는 2071을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 200
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1074 또는 2074를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 201
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1076 또는 2076을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 202
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1077 또는 2077을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 203
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1078 또는 2078을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 204
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1079 또는 2079를 포함하는 sgRNA인, 방법 또는 조성물.
구현예 205
구현예 1 내지 88 중 어느 하나에 있어서, 상기 가이드 RNA는 서열번호 1081 또는 2081을 포함하는 sgRNA인, 방법 또는 조성물.
구현예 206
구현예 1 내지 205 중 어느 하나에 있어서, 상기 조성물은 단일 용량으로 투여되는, 방법 또는 조성물.
구현예 207
구현예 1 내지 206 중 어느 하나에 있어서, 상기 조성물은 1회 투여되는, 방법 또는 조성물.
구현예 208
구현예 206 또는 207에 있어서, 상기 단일 용량 또는 1회 투여는
a. DSB를 유도하고/하거나;
b. LDHA 유전자의 발현을 감소시키고/시키거나;
c. 고수산뇨증을 치료 또는 예방하고/하거나;
d. 고수산뇨증으로 야기된 ESRD의 치료 또는 예방하고/하거나;
e. 옥살산칼슘 생성 및 침착을 치료 또는 예방하고/하거나;
f. 원발성 고수산뇨증 (PH1, PH2, 및 PH3을 포함)을 치료 또는 예방하고/하거나;
g. 옥살산증을 치료 또는 예방하고/하거나;
h. 혈뇨를 치료 및 예방하고/하거나;
i. 장성 고수산뇨증을 치료 또는 예방하고/하거나;
j. 고-옥살레이트 식품 섭취와 관련된 고수산뇨증을 치료 또는 예방하고/하거나;
k. 콩팥 또는 간 이식의 필요성을 지연 또는 개선하고/하거나;
l. 혈청 글리콜레이트 농도를 증가시키고/시키거나;
m. 소변에서 옥살레이트를 감소시키는, 방법 또는 조성물.
구현예 209
구현예 208에 있어서, 상기 단일 용량 또는 1회 투여는 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 또는 15주 동안 a) 내지 m) 중 임의의 하나 이상을 달성하는, 방법 또는 조성물.
구현예 210
구현예 208에 있어서, 상기 단일 용량 또는 1회 투여는 지속 효과를 달성하는, 방법 또는 조성물.
구현예 211
구현예 1 내지 208 중 어느 하나에 있어서, 지속 효과를 달성하는 단계를 추가로 포함하는, 방법 또는 조성물.
구현예 212
구현예 210 또는 211에 있어서, 상기 지속 효과는 적어도 1개월, 적어도 3개월, 적어도 6개월, 적어도 1년, 또는 적어도 5년 지속되는, 방법 또는 조성물.
구현예 213
구현예 1 내지 212 중 어느 하나에 있어서, 상기 조성물의 투여는 치료적으로 관련된 소변 내 옥살레이트의 감소를 초래하는, 방법 또는 조성물.
구현예 214
구현예 1 내지 213 중 어느 하나에 있어서, 상기 조성물의 투여는 치료 범위 내의 소변 옥살레이트 수준을 초래하는, 방법 또는 조성물.
구현예 215
구현예 1 내지 214 중 어느 하나에 있어서, 상기 조성물의 투여는 정상 범위의 100, 120, 또는 150% 내의 옥살레이트 수준을 초래하는, 방법 또는 조성물.
구현예 216
고수산뇨증을 가진 인간 대상체를 치료하기 위한 약제의 제조를 위한 구현예 9 내지 215 중 어느 하나의 조성물 또는 제형의 용도.
또한, 고수산뇨증을 갖는 인간 대상체를 치료하기 위한 약제의 제조를 위한 임의의 전술한 구현예의 조성물 또는 제형의 용도가 개시된다. 또한, 고수산뇨증을 치료하는데 사용하거나 LDHA 유전자를 변형하는데 (예를 들어, 인델 (indel) 형성 또는 프레임 시프트 또는 넌센스 돌연변이 형성) 사용하기 위한 임의의 전술한 조성물 또는 제형이 개시된다.
도 1은 LDHA를 표적화하는 특정 sgRNA의 오프-표적 분석을 나타낸다.
도 2는 PHH에서 LDHA를 표적화하는 특정 sgRNA의 편집 %의 용량 반응 곡선을 나타낸다.
도 3은 PCH에서 LDHA를 표적화하는 특정 sgRNA의 편집 %의 용량 반응 곡선을 나타낸다.
도 4는 PHH에서 LDHA-표적화된 변형된 sgRNA (표 2에 나열됨)의 웨스턴 블롯 분석을 보여준다
도 5는 AGT-결핍 마우스에서 생체내 변형된 sgRNA를 포함하는 LNP로 처리한 후 소변 옥살레이트 수준을 나타낸다.
도 6은 15주 연구에서 AGT-결핍 마우스에서 생체내 변형된 sgRNA를 포함하는 LNP로 처리한 후 소변 옥살레이트 수준을 나타낸다.
도 7은 15주 연구에서 AGT-결핍 마우스에서 생체내 변형된 sgRNA를 포함하는 LNP로 처리한 후 웨스턴 블롯 분석을 나타낸다.
도 8은 AGT-결핍 마우스의 간에서 생체내 LDHA 단백질의 면역조직화학적 염색을 타나내다.
도 9는 표 19에 묘사된 편집 수준과 단백질 수준 사이의 상관관계를 나타낸다.
도 10은 예시적인 sgRNA 서열에서 1 내지 10 (서열번호 2082)의 10개의 보존된 영역 YA 부위를 표지한다. 숫자 25, 45, 50, 56, 64, 67, 및 83은 (N)x로서 나타낸 가이드 영역을 갖는 sgRNA에서 YA 부위 1, 5, 6, 7, 8, 9 및 10의 피리미딘의 위치를 나타내고, 예를 들어, 여기서 x는 임의로 20이다.
도 11은 하단 줄기 (stem), 돌출부 (bulge), 상단 줄기, 넥서스 (이의 뉴클레오티드는 각각 5'에서 3' 방향으로 N1 내지 N18로서 지칭될 수 있음), 헤어핀 1, 및 헤어핀 2 영역을 포함한 sgRNA의 보존된 영역의 개별 뉴클레오티드를 지정하는 라벨을 갖는 가능한 2차 구조의 예시적인 sgRNA (서열번호 401; 모든 변형을 나타내지 않음)를 나타낸다. 헤어핀 1과 헤어핀 2 사이의 뉴클레오티드는 n으로 표지된다. 가이드 영역은 sgRNA 상에 존재할 수 있고, 이 도면에서 sgRNA의 보존된 영역 앞에 "(N)x"로 나타낸다.
도 12a 내지 12c는 일차 사이노몰구스 간세포에서 LDHA를 표적화하는 특정 sgRNA의 퍼센트 편집의 용량 반응 곡선을 나타낸다.
도 13a 및 13b는 1차 인간 및 사이노몰구스 간세포에서 특정 sgRNA를 포함하는 리포펙션 처리 후 LDHA 발현에서 상대적 감소의 용량 반응 곡선을 나타낸다.
도 14a 내지 14c는 AGT-결핍 마우스의 특정 sgRNA를 포함하는 LNP로 처리한 후, 용량-의존적 소변 옥살레이트 수준, 퍼센트 편집 및 소변 옥살레이트 수준과 퍼센트 편집 사이의 상관관계를 각각 나타낸다.
도 15a 및 15b는 실시예 4에 기재된 바와 같이 15주 내구성 연구에서 AGT-결핍 마우스의 특정 sgRNA를 포함하는 LNP로 처리한 후 간 및 근육 샘플에서의 LDHA 활성을 나타낸다.
도 16a 및 16b는 실시예 4에 기재된 바와 같이 15주 지속성 연구에서 AGT-결핍 마우스의 특정 sgRNA를 포함하는 LNP로 처리한 후 간 및 혈장 샘플에서의 피루베이트 수준을 나타낸다.
도 17은 특정 sgRNA를 포함하는 LNP로 처리한 후 5/6 신장절제술 또는 샴 (sham) 수술을 받은 마우스에서 평균 혈장 락테이트 제거율을 나타낸다.
도 2는 PHH에서 LDHA를 표적화하는 특정 sgRNA의 편집 %의 용량 반응 곡선을 나타낸다.
도 3은 PCH에서 LDHA를 표적화하는 특정 sgRNA의 편집 %의 용량 반응 곡선을 나타낸다.
도 4는 PHH에서 LDHA-표적화된 변형된 sgRNA (표 2에 나열됨)의 웨스턴 블롯 분석을 보여준다
도 5는 AGT-결핍 마우스에서 생체내 변형된 sgRNA를 포함하는 LNP로 처리한 후 소변 옥살레이트 수준을 나타낸다.
도 6은 15주 연구에서 AGT-결핍 마우스에서 생체내 변형된 sgRNA를 포함하는 LNP로 처리한 후 소변 옥살레이트 수준을 나타낸다.
도 7은 15주 연구에서 AGT-결핍 마우스에서 생체내 변형된 sgRNA를 포함하는 LNP로 처리한 후 웨스턴 블롯 분석을 나타낸다.
도 8은 AGT-결핍 마우스의 간에서 생체내 LDHA 단백질의 면역조직화학적 염색을 타나내다.
도 9는 표 19에 묘사된 편집 수준과 단백질 수준 사이의 상관관계를 나타낸다.
도 10은 예시적인 sgRNA 서열에서 1 내지 10 (서열번호 2082)의 10개의 보존된 영역 YA 부위를 표지한다. 숫자 25, 45, 50, 56, 64, 67, 및 83은 (N)x로서 나타낸 가이드 영역을 갖는 sgRNA에서 YA 부위 1, 5, 6, 7, 8, 9 및 10의 피리미딘의 위치를 나타내고, 예를 들어, 여기서 x는 임의로 20이다.
도 11은 하단 줄기 (stem), 돌출부 (bulge), 상단 줄기, 넥서스 (이의 뉴클레오티드는 각각 5'에서 3' 방향으로 N1 내지 N18로서 지칭될 수 있음), 헤어핀 1, 및 헤어핀 2 영역을 포함한 sgRNA의 보존된 영역의 개별 뉴클레오티드를 지정하는 라벨을 갖는 가능한 2차 구조의 예시적인 sgRNA (서열번호 401; 모든 변형을 나타내지 않음)를 나타낸다. 헤어핀 1과 헤어핀 2 사이의 뉴클레오티드는 n으로 표지된다. 가이드 영역은 sgRNA 상에 존재할 수 있고, 이 도면에서 sgRNA의 보존된 영역 앞에 "(N)x"로 나타낸다.
도 12a 내지 12c는 일차 사이노몰구스 간세포에서 LDHA를 표적화하는 특정 sgRNA의 퍼센트 편집의 용량 반응 곡선을 나타낸다.
도 13a 및 13b는 1차 인간 및 사이노몰구스 간세포에서 특정 sgRNA를 포함하는 리포펙션 처리 후 LDHA 발현에서 상대적 감소의 용량 반응 곡선을 나타낸다.
도 14a 내지 14c는 AGT-결핍 마우스의 특정 sgRNA를 포함하는 LNP로 처리한 후, 용량-의존적 소변 옥살레이트 수준, 퍼센트 편집 및 소변 옥살레이트 수준과 퍼센트 편집 사이의 상관관계를 각각 나타낸다.
도 15a 및 15b는 실시예 4에 기재된 바와 같이 15주 내구성 연구에서 AGT-결핍 마우스의 특정 sgRNA를 포함하는 LNP로 처리한 후 간 및 근육 샘플에서의 LDHA 활성을 나타낸다.
도 16a 및 16b는 실시예 4에 기재된 바와 같이 15주 지속성 연구에서 AGT-결핍 마우스의 특정 sgRNA를 포함하는 LNP로 처리한 후 간 및 혈장 샘플에서의 피루베이트 수준을 나타낸다.
도 17은 특정 sgRNA를 포함하는 LNP로 처리한 후 5/6 신장절제술 또는 샴 (sham) 수술을 받은 마우스에서 평균 혈장 락테이트 제거율을 나타낸다.
이제 본 발명의 특정 구현예에 대한 참조가 상세하게 이루어질 것이고, 이의 예는 첨부된 도면에 도시되어 있다. 본 발명은 예시된 구현예와 관련하여 설명되지만, 본 발명을 이들 구현예로 제한하려는 의도가 아님을 이해할 것이다. 반대로, 본 발명은 첨부된 청구범위 및 포함된 구현예에 의해 정의된 바와 같이 본 발명 내에 포함될 수 있는 모든 대안, 변형, 및 등가물을 포함하도록 의도된다.
본 교시를 상세하게 설명하기 전에, 개시내용이 특정 조성물 또는 공정 단계로 제한되지 않고, 그 자체가 다양할 수 있음을 이해해야 한다. 본 명세서 및 첨부된 청구범위에서 사용된 바와 같이 "a", "an" "the"는 문맥상 명백히 달리 나타내지 않는 한 복수의 언급을 포함함을 주목해야 한다. 따라서, 예를 들어, "접합체"에 대한 언급은 복수의 접합체를 포함하고 "세포"에 대한 언급은 복수의 세포 등을 포함한다.
숫자 범위는 범위를 정의하는 숫자를 포함한다. 측정 및 측정 가능한 값은 유효 숫자 및 측정과 관련된 오류를 고려하여 근사치로 이해된다. 또한, "포함하다 (comprise)", "포함하다 (comprises)", "포함하는 (comprising)", "함유하다 (contain)", "함유하다 (contains)", "함유하는 (containing)", "포함하다 (include)", "포함하다 (includes)" 및 "포함하는 (including)"의 사용은 제한하려는 의도가 아니다. 전술한 일반적인 설명과 상세한 설명 둘 다는 예시적이고 설명적일 뿐이며 교시를 제한하지 않음을 이해해야 한다.
명세서에서 구체적으로 언급하지 않는 한, 다양한 구성요소를 "포함하는"을 언급하는 명세서에서의 구현예는 또한, 언급된 구성요소의 "이루어진" 또는 "본질적으로 이루어진"으로 고려되고; 다양한 구성요소로 "이루어진"을 언급하는 명세서에서의 구현예는 또한, 언급된 구성요소를 "포함하는" 또는 "본질적으로 이루어진"으로 고려되고; 다양한 구성요소로 "본질적으로 이루어진"을 언급하는 명세서에서의 구현예는 또한, 언급된 구성요소를 "이루는" 또는 "포함하는"으로 고려된다 (이 상호교환성은 청구범위에서 이들 용어의 사용에 적용되지 않음). 용어 "또는"은 포괄적인 의미, 즉 문맥상 명백히 달리 나타내지 않는 한 "및/또는"과 동등한 의미로 사용된다.
본원에 사용된 섹션 제목은 구성 목적으로만 사용되고 어떤 방식으로든 원하는 주제를 제한하는 것으로 해석되어서는 안된다. 참고로 포함된 임의의 자료가 본 명세서에 정의된 임의의 용어 또는 본 명세서의 임의의 다른 표현 내용과 모순되는 경우, 본 명세서가 우선한다. 본 교시가 다양한 구현예와 관련하여 설명되었지만, 본 교시가 그러한 구현예로 제한되는 것으로 의도되지 않는다. 반대로, 본 교시는 당업자에 의해 이해되는 바와 같이, 다양한 대안, 변형 및 등가물을 포함한다.
I. 정의
달리 언급되지 않는 한, 본원에 사용된 다음 용어 및 구는 다음 의미를 갖는 것으로 의도된다:
"폴리뉴클레오티드" 및 "핵산"은 통상적인 RNA, DNA, 혼합 RNA-DNA 및 이들의 유사체인 중합체를 포함한 골격을 따라 함께 연결된 질소성 헤테로사이클릭 염기 또는 염기 유사체를 갖는 뉴클레오시드 또는 뉴클레오시드 유사체를 포함하는 다량체 화합물을 지칭하기 위해 본원에서 사용된다. 핵산 "골격"은 당-포스포디에스테르 연결, 펩타이드-핵산 결합 ("펩타이드 핵산" 또는 PNA; PCT 번호 제WO 95/32305호), 포스포로티오에이트 결합, 메틸포스포네이트 연결, 또는 이들의 조합 중 하나 이상을 포함하는 다양한 연결로 구성될 수 있다. 핵산의 당 모이어티는 리보스, 데옥시리보스 또는 치환, 예를 들어, 2' 메톡시 또는 2' 할라이드 치환을 갖는 유사한 화합물일 수 있다. 질소성 염기는 통상적인 염기 (A, G, C, T, U), 이의 유사체 (예를 들어, 변형된 우리딘, 예컨대 5-메톡시우리딘, 슈도우리딘, 또는 N1-메틸슈도우리딘, 또는 기타); 이노신; 퓨린 또는 피리미딘의 유도체 (예를 들어, N4-메틸 데옥시아노신, 데아자- 또는 아자-퓨린, 데아자- 또는 아자-피리미딘, 5 또는 6 위치에서 치환기를 갖는 피리미딘 염기 (예를 들어, 5-메틸시토신), 2, 6, 또는 8 위치에서 치환기를 갖는 퓨린 염기, 2-아미노-6-메틸아미노퓨린, O6-메틸구아닌, 4-티오-피리미딘, 4-아미노-피리미딘, 4-디메틸하이드라진-피리미딘, 및 O4-알킬-피리미딘; 미국 특허 제5,378,825호 및 PCT 번호 제WO 93/13121호)일 수 있다. 일반적인 논의는 문헌 (The Biochemistry of the Nucleic Acids 5-36, Adams et al., ed., 11th ed., 1992)을 참조한다. 핵산은 골격이 중합체의 위치(들)에 대한 질소성 염기를 포함하지 않는 하나 이상의 "비염기성" 잔기를 포함할 수 있다 (미국 특허 번호 제5,585,481호). 핵산은 통상적인 RNA 또는 DNA 당, 염기 및 연결만을 포함할 수 있거나, 통상적인 구성요소 및 치환 (예를 들어, 2' 메톡시 연결을 갖는 통상적인 염기, 또는 통상적인 염기 및 하나 이상의 염기 유사체를 둘 다 함유하는 중합체)을 둘 다 포함할 수 있다. 핵산은 상보적 RNA 및 DNA 서열에 대한 혼성화 친화성을 향상시키는 당 형태를 모방하는 RNA에 잠금된 바이사이클릭 퓨라노스 단위를 갖는 하나 이상의 LNA 뉴클레오티드 단량체를 함유하는 유사체인 "잠금된 핵산" (LNA: locked nucleic acid)을 포함한다 (Vester 및 Wengel, 2004, Biochemistry 43(42):13233-41). RNA 및 DNA는 상이한 당 모이어티를 가지고, RNA에서 우라실 또는 이의 유사체와 DNA에서 티민 또는 이의 유사체의 존재에 의해 상이할 수 있다.
"가이드 RNA", "gRNA", 및 "가이드"는 crRNA (CRISPR RNA로도 알려짐) 또는 crRNA와 trRNA의 조합 (tracrRNA로도 알려짐)을 지칭하기 위해 본원에서 상호교환적으로 사용된다. crRNA 및 trRNA는 단일 RNA 분자 (단일 가이드 RNA, sgRNA) 또는 2개의 개별 RNA 분자 (이중 가이드 RNA, dgRNA)로서 회합될 수 있다. "가이드 RNA" 또는 "gRNA"는 각 유형을 지칭한다. trRNA는 자연 발생 서열, 또는 자연 발생 서열과 비교하여 변형 또는 변이가 있는 trRNA 서열일 수 있다.
본원에 사용된 바와 같이, "가이드 서열"은 표적 서열에 상보적이고 RNA-가이드된 DNA 결합제에 의한 결합 또는 변형 (예를 들어, 절단)을 위해 가이드 RNA를 표적 서열로 지시하는 기능을 하는 가이드 RNA 내의 서열을 지칭한다. "가이드 서열"은 "표적화 서열" 또는 "스페이서 서열"로도 지칭될 수 있다. 가이드 서열은 스트렙토코커스 피로게네스 (즉, Spy Cas9) 및 관련된 Cas9 상동체/오톨로그의 경우 20개의 염기 쌍 길이일 수 있다. 더 짧거나 더 긴 서열은 또한, 예를 들어, 15-, 16-, 17-, 18-, 19-, 21-, 22-, 23-, 24-, 또는 25-뉴클레오티드 길이인 가이드로서 사용될 수 있다. 예를 들어, 일부 구현예에서, 가이드 서열은 서열 번호 1 내지 84로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드를 포함한다. 일부 구현예에서, 표적 서열은, 예를 들어, 유전자 또는 염색체에 있고 가이드 서열에 상보적이다. 일부 구현예에서, 가이드 서열과 이의 상응하는 표적 서열 사이의 상보성 또는 동일성의 정도는 약 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%일 수 있다. 예를 들어, 일부 구현예에서, 가이드 서열은 서열번호 1 내지 84로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드와 약 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 동일성을 갖는 서열을 포함한다. 일부 구현예에서, 가이드 서열 및 표적 영역은 100% 상보적이거나 동일할 수 있다. 다른 구현예에서, 가이드 서열 및 표적 영역은 적어도 하나의 불일치를 포함할 수 있다. 예를 들어, 가이드 서열 및 표적 서열은 1, 2, 3, 또는 4개의 불일치를 포함할 수 있고, 여기서, 표적 서열의 총 길이는 적어도 17, 18, 19, 20개 이상의 염기 쌍이다. 일부 구현예에서, 가이드 서열 및 표적 영역은 1 내지 4개의 불일치를 포함할 수 있고, 여기서, 가이드 서열은 적어도 17, 18, 19, 20개 이상의 뉴클레오티드를 포함한다. 일부 구현예에서, 가이드 서열 및 표적 영역은 1, 2, 3, 또는 4개의 불일치를 포함할 수 있고, 여기서, 가이드 서열은 20개의 뉴클레오티드를 포함한다.
RNA-가이드된 DNA 결합제에 대한 핵산 기질이 이중 가닥 핵산이므로, RNA-가이드된 DNA 결합제에 대한 표적 서열은 게놈 DNA의 양성 및 음성 가닥 (즉, 주어진 서열 및 서열의 역 보체)을 둘 다 포함한다. 따라서, 가이드 서열이 "표적 서열에 상보적"이라고 언급되는 경우, 가이드 서열은 가이드 RNA가 표적 서열의 역 보체에 결합하도록 지시할 수 있음을 이해해야 한다. 따라서, 일부 구현예에서, 가이드 서열이 표적 서열의 역 보체에 결합하는 경우, 가이드 서열은 가이드 서열에서 T를 U로 치환하는 것을 제외하고는 표적 서열 (예를 들어, PAM을 포함하지 않는 표적 서열)의 특정 뉴클레오티드와 동일하다.
본원에 사용된 바와 같이, "YA 부위"는 5'-피리미딘-아데닌-3' 디뉴클레오티드를 지칭한다. "보존된 영역 YA 부위"는 sgRNA의 보존된 영역에 존재한다. "가이드 영역 YA 부위"는 sgRNA의 가이드 영역에 존재한다. sgRNA에서 비변형된 YA 부위는 RNase-A 유사 엔도뉴클레아제, 예를 들어, RNase A에 의해 절단되기 쉬울 수 있다. 일부 구현예에서, sgRNA는 이의 보존된 영역에서 약 10개의 YA 부위를 포함한다. 일부 구현예에서, sgRNA는 이의 보존된 영역에서 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 YA 부위를 포함한다. 예시적인 보존된 영역 YA 부위는 도 10에 나타낸다. 가이드 영역은 임의의 수의 YA 부위를 포함하여 임의의 서열일 수 있으므로 예시적인 가이드 영역 YA 부위는 도 10에 나타내지 않는다. 일부 구현예에서, sgRNA는 도 10에 나타낸 YA 부위 중 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개를 포함한다. 일부 구현예에서, sgRNA는 다음 위치 또는 이의 서브세트에서 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 YA 부위를 포함한다: LS5-LS6; US3-US4; US9-US10; US12-B3; LS7-LS8; LS12-N1; N6-N7; N14-N15; N17-N18; 및 H2-2 내지 H2-3. 일부 구현예에서, YA 부위는 변형을 포함하고, 이는 YA 부위의 적어도 하나의 뉴클레오티드가 변형됨을 의미한다. 일부 구현예에서, YA 부위의 피리미딘 (피리미딘 위치로도 불림)은 변형 (피리미딘의 당의 3' 바로 인접한 뉴클레오시드간 연결을 변경하는 변형을 포함)을 포함한다. 일부 구현예에서, YA 부위의 아데닌 (아데닌 위치로도 불림)은 변형 (아데닌의 당의 3' 바로 인접한 뉴클레오시드간 연결을 변경하는 변형을 포함)을 포함한다. 일부 구현예에서, YA 부위의 피리미딘 위치 및 아데닌 위치는 변형을 포함한다.
본원에 사용된 바와 같이, "RNA-가이드된 DNA 결합제"는 RNA 및 DNA 결합 활성을 갖는 폴리펩티드 또는 폴리펩티드의 복합체, 또는 그러한 복합체의 DNA-결합 서브유닛을 의미하고, 여기서, DNA 결합 활성은 서열-특이적이고 RNA의 서열에 따라 다르다. 예시적인 RNA-가이드된 DNA 결합제는 Cas 클리바세/닉카제 및 이의 불활성화된 형태 ("dCas DNA 결합제")를 포함한다. 본원에 사용된 바와 같이, "Cas 단백질"로도 불리는 "Cas 뉴클레아제뉴클레아제"는 Cas 클리바세, Cas 닉카제 및 dCas DNA 결합제를 포함한다. Cas 클리바세/닉카제 및 dCas DNA 결합제는 III형 CRISPR 시스템의 Csm 또는 Cmr 복합체, Cas10, Csm1, 또는 이의 Cmr2 서브유닛, I형 CRISPR 시스템의 캐스케이드 복합체, 이의 Cas3 서브유닛, 및 부류 2 Cas 뉴클레아제를 포함한다. 본원에 사용된 바와 같이, "부류 2 Cas 뉴클레아제"는 Cas9 뉴클레아제 또는 Cpf1 뉴클레아제와 같은 RNA-가이드된 DNA 결합 활성을 갖는 단일-사슬 폴리펩타이드이다. 부류 2 Cas 뉴클레아제는 RNA-가이드된 DNA 클리바세 또는 닉카제 활성을 추가로 갖는 부류 2 Cas 클리바세 및 부류 2 Cas 닉카제 (예를 들어, H840A, D10A, 또는 N863A 변이체), 및 클리바세/닉카제 활성이 비활성화된 부류 2 dCas DNA 결합제를 포함한다. 부류 2 Cas 뉴클레아제는, 예를 들어, Cas9, Cpf1, C2c1, C2c2, C2c3, HF Cas9 (예를 들어, N497A, R661A, Q695A, Q926A 변이체), HypaCas9 (예를 들어, N692A, M694A, Q695A, H698A 변이체), eSPCas9(1.0) (예를 들어, K810A, K1003A, R1060A 변이체), 및 eSPCas9(1.1) (예를 들어, K848A, K1003A, R1060A 변이체) 단백질 및 이의 변형을 포함한다. Cpf1 단백질 (Zetsche et al., Cell, 163: 1-13 (2015))은 Cas9와 상동성이고, RuvC-유사 뉴클레아제 도메인을 포함한다. Zetsche의 Cpf1 서열은 그 전체가 본원에 참조로 포함된다. 예를 들어, Zetsche의 표 S1 및 S3을 참조한다. "Cas9"는 Spy Cas9, 본원에 열거된 Cas9의 변이체 및 이의 등가물을 포함한다. 예를 들어, 문헌 (Makarova et al., Nat Rev Microbiol, 13(11): 722-36 (2015); Shmakov et al., Molecular Cell, 60:385-397 (2015))을 참조한다.
본원에 사용된 바와 같이, "리보핵단백질" (RNP) 또는 "RNP 복합체"는 Cas 뉴클레아제, 예를 들어, Cas 클리바세, Cas 닉카제, 또는 dCas DNA 결합제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 결합제와 함께 가이드 RNA를 지칭한다. 일부 구현예에서, 가이드 RNA는 Cas9와 같은 RNA-가이드된 DNA 결합제를 표적 서열로 가이드하고, 가이드 RNA는 표적 서열과 혼성화하고 제제가 표적 서열에 결합한다; 제제가 클리바세 또는 닉카제인 경우, 결합은 절단 또는 닉킹 (nicking)이 뒤따를 수 있다.
본원에 사용된 바와 같이, 제1 서열에 대한 제2 서열의 정렬이 제2 서열의 이의 전체 위치의 X% 이상이 제1 서열과 일치함을 나타내는 경우, 제1 서열은 제2 서열과 "적어도 X% 동일성을 갖는 서열을 포함"하는 것으로 간주된다. 예를 들어, 서열 AAGA는 제2 서열의 3개 위치 모두에 대한 일치가 존재한다는 점에서 정렬이 100% 동일성을 제공하기 때문에 서열 AAG와 100% 동일성을 갖는 서열을 포함한다. RNA와 DNA 사이의 차이 (일반적으로 우리딘을 티미딘으로 또는 그 반대로 교환) 및 변형된 우리딘과 같은 뉴클레오시드 유사체의 존재는, 관련 뉴클레오티드 (예컨대 티미딘, 우리딘, 또는 변형된 우리딘)가 동일한 보체 (예를 들어, 모든 티미딘, 우리딘, 또는 변형된 우리딘에 대한 아데노신; 또 다른 예는 시토신 및 5-메틸시토신이며, 둘 다 보체로서 구아노신 또는 변형된 구아노신을 갖는다)를 갖는 한, 폴리뉴클레오티드 간의 동일성 또는 상보성의 차이에 기여하지 않는다. 따라서, 예를 들어, 슈도우리딘, N1-메틸슈도우리딘, 또는 5-메톡시우리딘과 같은 X가 임의의 변형된 우리딘인 서열 5'-AXG는 둘 다가 동일한 서열 (5'-CAU)에 완벽하게 상보적이라는 점에서 AUG와 100% 동일한 것으로 간주된다. 예시적인 정렬 알고리즘은 당업계에 잘 알려진 Smith-Waterman 및 Needleman-Wunsch 알고리즘이다. 당업자는 어떤 알고리즘과 파라미터 설정의 선택이 정렬된 주어진 서열 쌍에 적절한지를 이해할 것이다; 일반적으로 유사한 길이 및 아미노산의 경우 > 50% 또는 뉴클레오티드의 경우> 75%의 예상 동일성을 갖는 서열의 경우, www.ebi.ac.uk 웹 서버에서 EBI에 의해 제공되는 Needleman-Wunsch 알고리즘 인터페이스의 디폴트 설정을 사용하는 Needleman-Wunsch 알고리즘이 일반적으로 적절하다.
"mRNA"는 RNA 또는 변형된 RNA이고 폴리펩티드로 해독될 수 있는 오픈 리딩 프레임을 포함하는 폴리뉴클레오티드를 지칭하기 위해 본원에서 사용된다 (즉, 리보솜 및 아미노-아실화된 tRNA에 의한 해독을 위한 기질로서 작용할 수 있음). mRNA는 리보스 잔기 또는 이의 유사체, 예를 들어 2'-메톡시 리보스 잔기를 포함하는 포스페이트-당 골격을 포함할 수 있다. 일부 구현예에서, mRNA 포스페이트-당 골격의 당은 본질적으로 리보스 잔기, 2'-메톡시 리보스 잔기 또는 이들의 조합으로 이루어진다.
본원에 기재된 가이드 RNA 조성 및 방법에 유용한 가이드 서열은 표 1 및 출원 전반에 걸쳐 나타낸다.
본원에 사용된 바와 같이, "인델"은 표적 핵산에서 이중-가닥 파괴 (DSB) 부위에 삽입되거나 결실된 다수의 뉴클레오티드로 이루어진 삽입/결실 돌연변이를 지칭한다.
본원에 사용된 바와 같이, "녹다운"은 특정 유전자 산물 (예를 들어, 단백질, mRNA, 또는 둘 다)의 발현의 감소를 지칭한다. 단백질의 녹다운은 관심있는 조직 또는 세포 집단으로부터 단백질의 총 세포 양을 검출하여 측정될 수 있다. mRNA의 녹다운을 측정하는 방법은 알려져 있고, 관심있는 조직 또는 세포 집단으로부터 단리된 mRNA의 서열분석을 포함한다. 일부 구현예에서, "녹다운"은 특정 유전자 산물의 발현의 일부 손실, 예를 들어, 전사된 mRNA 양의 감소 또는 세포 집단에 의해 발현된 단백질 양의 감소를 지칭할 수 있다 (조직에서 발견되는 것들과 같은 생체내 집단을 포함함).
본원에 사용된 바와 같이, "녹아웃"은 세포에서 특정 단백질의 발현 손실을 지칭한다. 녹아웃은 세포, 조직 또는 세포 집단에서 단백질의 총 세포 양을 감지함으로써 측정될 수 있다. 일부 구현예에서, 본 개시내용의 방법은 하나 이상의 세포에서 (예를 들어, 조직에서 발견되는 것들과 같은 생체내 집단을 포함하는 세포 집단에서) LDHA를 "녹아웃"한다. 일부 구현예에서, 녹아웃은, 예를 들어, 인델에 의해 생성된 돌연변이 LDHA 단백질의 형성이 아니라 세포에서 LDH 단백질의 완전한 발현 손실이다. 본원에 사용된 바와 같이, "LDH"는 LDHA 유전자의 유전자 산물인 락테이트 데하이드로게나제를 지칭한다. 인간 야생형 LDHA 서열은 NCBI 유전자 ID: 3939; Ensembl ENSG00000134333에서 가용하다.
"고수산뇨증"은 소변에서 과도한 옥살레이트를 특징으로 하는 병태이다. 고수산뇨증의 예시적인 유형은 원발성 고수산뇨증 (1형 (PH1), 2형 (PH2), 및 3형 (PH3) 포함), 옥살산증, 장성 고수산뇨증, 및 고-옥살레이트 식품 섭취와 관련된 고수산뇨증을 포함한다. 고수산뇨증은 특발성일 수 있다. 높은 옥살레이트 수준은 옥살산칼슘 결석 형성 및 신장 실질 손상을 유발하여 신장 기능의 점진적인 저하를 초래하고 결국 말기 신장 질환을 초래한다. 따라서, 고수산뇨증은 과도한 옥살레이트 생성과 콩팥과 요로에서의 옥살살칼슘 결정의 침착을 초래할 수 있다. 옥살레이트로부터의 신장 손상은 세뇨관 독성, 콩팥에서의 옥살산칼슘 침착, 옥살산칼슘 결석에 의한 소변 폐색의 조합에 의해 야기된다. 과도한 옥살레이트가 더 이상 효과적으로 배설될 수 없기 때문에 손상된 콩팥 기능은 질환을 악화시켜 뼈, 눈, 피부, 및 심장, 및 기타 기관에 옥살레이트의 후속적 축적 및 결정화를 초래하여 심각한 질병과 사망을 야기한다. 신부전 및 말기 신장 질환이 발생할 수 있다. 고수산뇨증에 대한 승인된 약제학적 요법은 없다.
"원발성 고수산뇨증 1형 (PH1)"은 간 퍼옥시좀 알라닌-글리옥실레이트 아미노트랜스퍼라제 (AGT) 효소를 암호화하는 AGXT 유전자의 돌연변이로 인한 상염색체 열성 장애이다. AGT는 글리옥실레이트를 글리신으로 대사한다. AGT 활성이 결여되어 있거나 미토콘드리아에 대한 잘못된 표적화는 글리옥실레이트가 옥살레이트로 산화되어 소변으로만 배설될 수 있도록 한다.
콩팥에 의해 배설되기 전에 글리옥실레이트를 옥실레이트로 전환하는 간 퍼옥시좀 효소인 락테이트 데하이드로게나제 (LDH)를 방해하는 것은 고수산뇨증에서 발생하는 병리를 잠재적으로 예방하기 위해 병든 간에서 옥살레이트 합성을 차단하는 하나의 가능한 메커니즘이다. 락테이트 데하이드로게나제 유전자 (LDHA) 유전자에 의해 암호화된 LDH는 글리옥실레이트로부터 옥살레이트로의 전환을 촉매한다. LDH 활성의 억제는 옥살레이트 생성을 억제하여 소변의 옥살레이트 수준을 감소시키면서 글리옥실레이트 리덕타제/하이드록시피루베이트 리덕타제 (GRHPR)에 의해 글리콜레이트로 전환될 수 있는 글리옥실레이트의 축적을 야기해야 한다. 옥살레이트와 달리, 글리콜레이트는 가용성이며, 소변으로 쉽게 배설된다. 현재 상승된 글리콜레이트 수준의 알려진 부작용은 없다. 따라서, 일부 구현예에서, 일단 억제되면 옥살레이트 생성이 억제되고 글리콜레이트 생성이 증가되는 LDH 활성을 억제하는 방법이 제공된다.
글리옥실레이트의 산화 생성물인 옥살레이트는 소변으로만 배설될 수 있다. 소변에서 높은 수준의 옥살레이트 ("고수산뇨증")는 고수산뇨증의 증상이다. 따라서, 소변 내 증가된 옥살레이트는 고수산뇨증의 증상이다. 옥살레이트는 칼슘과 결합하여 콩팥 및 방광 결석의 주 성분인 옥살산칼슘을 형성할 수 있다. 콩팥 및 기타 조직에 옥살산칼슘의 침착은 소변에서의 혈액 (혈뇨), 요로 감염, 신장 손상, 말기 신장 질환 등을 유발할 수 있다. 시간 경과에 따라, 혈중 옥살레이트 수준이 상승할 수 있고 옥살산칼슘이 신체 전체의 다른 기관에 침착될 수 있다 (옥살산증 또는 전신성 옥살산증).
본원에 사용된 바와 같이, "표적 서열"은 gRNA의 가이드 서열에 상보성을 갖는 표적 유전자의 핵산 서열을 지칭한다. 표적 서열과 가이드 서열의 상호작용은 RNA-가이드된 DNA 결합제가 표적 서열 내에서 결합하고 잠재적으로 닉킹 또는 절단 (작용제의 활성에 따름)하도록 지시한다.
본원에 사용된 바와 같이, "치료"는 대상체에서 질환 또는 장애에 대한 치료제의 임의의 투여 또는 적용을 지칭하고, 질환 억제, 이의 발병 억제, 질환의 하나 이상의 증상 완화, 질환 치료, 또는 질환의 하나 이상의 증상 재발 방지를 포함한다. 예를 들어, 고수산뇨증의 치료는 고수산뇨증의 증상 완화를 포함할 수 있다.
본원에 사용된 "옥살레이트의 치료적으로 관련된 감소" 또는 "치료 범위 내의 옥살레이트 수준"이라는 용어는 기준선과 비교하여 소변 옥살레이트 배설물의 30% 초과의 감소를 의미한다. 문헌 (Leumann and Hoppe (1999) Nephrol Dial Transplant 14:2556-2558 at 2557, second column)을 참조한다. 예를 들어, 치료 범위 내에서 옥살레이트 수준을 달성한다는 것은 기준선으로부터 30% 초과로 소변 옥살레이트를 감소시킴을 의미한다. 일부 구현예에서, "정상 옥살레이트 수준" 또는 "정상 옥살레이트 범위"는 약 80 μg과 약 122 μg 사이의 옥살레이트/mg 크레아티닌이다. 문헌 (Li et al. (2016) Biochim Biophys Acta 1862(2):233-239)을 참조한다. 일부 구현예에서, 치료적으로 관련된 옥살레이트의 감소는 정상의 200%, 150%, 125%, 120%, 115%, 110%, 105%, 또는 100% 미만 또는 그 이내의 수준을 달성한다.
용어 "약" 또는 "대략"은 값이 측정 또는 결정되는 방법에 부분적으로 의존하는 당업자에 의해 결정된 특정 값에 대한 허용 가능한 오류를 의미한다.
II. 조성물
A.
가이드 RNA (gRNA)를 포함하는 조성물
예를 들어, RNA-가이드된 DNA 결합제 (예를 들어, CRISPR/Cas 시스템)와 함께 가이드 RNA를 사용하여 LDHA 유전자 내에서 이중-가닥 파괴 (DSB)를 유도하는 데 유용한 조성물이 본원에서 제공된다. 조성물은 고수산뇨증을 갖거나 가질 것으로 의심되는 대상체에게 투여될 수 있다. 조성물은 증가된 소변 옥살레이트 생산량 또는 감소된 혈청 글리콜레이트 생산량을 갖는 대상체에게 투여될 수 있다. LDHA 유전자를 표적화하는 가이드 서열은 표 1의 서열번호 1 내지 84에 나타낸다.
표 1의 서열번호 1 내지 84 및 100 내지 192에 나타낸 각각의 가이드 서열은 추가 뉴클레오티드를 추가로 포함하여 예를 들어, 이의 3' 단부에서 가이드 서열 뒤에 하기 예시적인 뉴클레오티드 서열과 함께 crRNA를 형성한다: 5'에서 3' 방향으로 GUUUUAGAGCUAUGCUGUUUUG (서열번호 200). sgRNA의 경우, 상기 가이드 서열은 추가 뉴클레오티드를 추가로 포함하여 예를 들어, 가이드 서열의 3' 단부 뒤에 하기 예시적인 뉴클레오티드 서열과 함께 sgRNA를 형성한다: 5'에서 3' 방향으로 GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGCUUUU (서열번호 201) 또는 GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC (서열번호 203, 4개의 말단 U가 없는 서열번호 201). 일부 구현예에서, 서열 번호 201의 4개의 말단 U는 존재하지 않는다. 일부 구현예에서, 서열번호 201의 4개의 말단 U 중 1, 2 또는 3개만이 존재한다.
일부 구현예에서, 본원에 기재된 바와 같은 가이드 서열 및 헤어핀 영역을 포함하는 "sgRNA의 보존된 부분"을 포함하는 LDHA 짧은-단일 가이드 RNA (LDHA 짧은-sgRNA)가 제공되고, 여기서, 헤어핀 영역은 적어도 5 내지 10개의 뉴클레오티드 또는 6 내지 10개의 뉴클레오티드가 결여되어 있다. 특정 구현예에서, LDHA 짧은-단일 가이드 RNA의 헤어핀 영역은 sgRNA의 보존된 부분과 관련하여 5 내지 10개의 뉴클레오티드, 예를 들어, 표 2B에서의 뉴클레오티드 H1-1 내지 H2-15가 결여되어 있다. 특정 구현예에서, LDHA 짧은-단일 가이드 RNA의 헤어핀 1 영역은 sgRNA의 보존된 부분과 관련하여 5 내지 10개의 뉴클레오티드, 예를 들어, 표 2B에서의 뉴클레오티드 H1-1 내지 H1-12가 결여되어 있다.
예시적인 "sgRNA의 보존된 부분"은 에스. 피로게네스 (S. pyogenes) Cas9 ("spyCas9" ("spCas9"로도 지칭됨)) sgRNA의 "보존된 영역"을 나타내는 표 2A에 나타낸다. 제1 행은 뉴클레오티드의 번호매김을 나타내고, 제2 행은 서열 (서열 번호 700)을 나타낸다; 제3 행은 "도메인"을 나타낸다. 문헌 (Briner AE et al., Molecular Cell 56:333-339 (2014))은 표적화를 담당하는 "스페이서" 도메인, "하단 줄기", "돌출부", "상단 줄기" (테트라루프를 포함할 수 있음), "넥서스" 및 "헤어핀 1" 및 "헤어핀 2" 도메인 포함하는, "도메인"으로 본원에서 지칭되는 sgRNA의 기능적 도메인을 설명한다. Briner 등의 334쪽, 도 1a를 참조한다.
표 2B는 본원에 사용된 sgRNA의 도메인의 개략도를 제공한다. 표 2B에서, 영역 사이의 "n"은 뉴클레오티드의 가변 수, 예를 들어, 0 내지 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 이상을 나타낸다. 일부 구현예에서, n은 0과 같다. 일부 구현예에서, n은 1과 같다.
일부 구현예에서, LDHA sgRNA는 에스. 피로겐 (S. pyogene) Cas9 ("spyCas9") 또는 spyCas9 등가물로부터 기원한다. 일부 구현예에서, sgRNA는 에스. 피로겐으로부터 기원하지 않는다 ("비-spyCas9"). 일부 구현예에서, 5 내지 10개의 뉴클레오티드 또는 6 내지 10개의 뉴클레오티드는 연속적이다.
일부 구현예에서, LDHA 짧은-sgRNA는 표 2A에 나타낸 바와 같이 에스. 피로겐 Cas9 ("spyCas9") sgRNA의 보존된 부분의 적어도 뉴클레오티드 54 내지 58 (AAAAA)이 결여되어 있다. 일부 구현예에서, LDHA 짧은-sgRNA는, 예를 들어, 쌍별 또는 구조적 정렬에 의해 결정된 바와 같이 spyCas9의 보존된 부분의 뉴클레오티드 54 내지 58 (AAAAA)에 상응하는 뉴클레오티드가 적어도 결여된 비-spyCas9 sgRNA이다. 일부 구현예에서, 비-spyCas9 sgRNA는 스타필로코커스 아우레우스 (Staphylococcus aureus) Cas9 ("saCas9") sgRNA이다.
일부 구현예에서, LDHA 짧은-sgRNA는 spyCas9 sgRNA의 보존된 부분의 적어도 뉴클레오티드 54 내지 61 (AAAAAGUG)이 결여되어 있다. 일부 구현예에서, LDHA 짧은-sgRNA는 spyCas9 sgRNA의 보존된 부분의 뉴클레오티드 53 내지 60 (GAAAAAGU)이 적어도 결여되어 있다. 일부 구현예에서, LDHA 짧은-sgRNA는 spyCas9 sgRNA의 보존된 부분의 뉴클레오티드 53 내지 60 (GAAAAAGU) 또는 뉴클레오티드 54 내지 61 (AAAAAGUG)의 4, 5, 6, 7, 또는 8개의 뉴클레오티드, 또는, 예를 들어, 쌍별 또는 구조적 정렬에 의해 결정된 바와 같이 비-spyCas9 sgRNA의 보존된 부분의 상응하는 뉴클레오티드가 결여되어 있다.
일부 구현예에서, sgRNA는 서열번호 1 내지 146의 가이드 서열 중 임의의 하나 및 추가 뉴클레오티드를 포함하여 예를 들어, 이의 3' 단부에서 가이드 서열 뒤에 하기 예시적인 뉴클레오티드 서열과 함께 crRNA를 형성한다: 5'에서 3' 방향으로 GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGGCACCGAGUCGGUGC (서열번호 202). 서열번호 202는 야생형 가이드 RNA 보존된 서열과 관련하여 8개의 뉴클레오티드가 결여되어 있다: GUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC (서열번호 203).
[표 1] 인간 및 사이노몰구스 원숭이에 대한 LDHA 표적화된 가이드 서열 및 염색체 좌표









표 2B

일부 구현예에서, 본 발명은 뉴클레아제 (예를 들어, Cas 뉴클레아제, 예컨대 Cas9)일 수 있는 RNA-가이드된 DNA 결합제를 LDHA의 표적 DNA 서열로 지시하는 가이드 서열을 포함하는 하나 이상의 가이드 RNA (gRNA)를 포함하는 조성물을 제공한다. gRNA는 표 1에 나타낸 가이드 서열을 포함하는 crRNA를 포함할 수 있다. gRNA는 표 1에 나타낸 가이드 서열의 17, 18, 19, 또는 20개의 인접 뉴클레오티드를 포함하는 crRNA를 포함할 수 있다. 일부 구현예에서, gRNA는 표 1에 나타낸 가이드 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드와 약 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 동일성을 갖는 서열을 포함하는 crRNA를 포함한다. 일부 구현예에서, gRNA는 표 1에 나타낸 가이드 서열과 약 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100% 동일성을 갖는 서열을 포함하는 crRNA를 포함한다. gRNA는 trRNA를 추가로 포함할 수 있다. 본원에 기재된 각각의 조성물 및 방법 구현예에서, crRNA 및 trRNA는 단일 RNA (sgRNA)로서 회합될 수 있거나, 개별 RNA (dgRNA) 상에 있을 수 있다. sgRNA의 맥락에서, crRNA 및 trRNA 조성은, 예를 들어, 포스포디에스테르 결합 또는 다른 공유 결합을 통해 공유적으로 연결될 수 있다.
본원에 기재된 각각의 조성물, 용도 및 방법 구현예에서, 가이드 RNA는 "이중 가이드 RNA" 또는 "dgRNA"로서 2개의 RNA 분자를 포함할 수 있다. dgRNA 는, 예를 들어, 표 1에 나타낸 가이드 서열을 포함하는 crRNA를 포함하는 제1 RNA 분자 및 trRNA를 포함하는 제2 RNA 분자를 포함한다. 제1 및 제2 RNA 분자는 공유적으로 연결되지 않을 수 있지만 crRNA와 trRNA의 일부 사이의 염기 쌍을 통해 RNA 듀플렉스를 형성할 수 있다.
본원에 기재된 각각의 조성물, 용도 및 방법 구현예에서, 가이드 RNA는 "단일 가이드 RNA" 또는 "sgRNA"로서 단일 RNA 분자를 포함할 수 있다. sgRNA는 trRNA에 공유적으로 연결된 표 1에 나타낸 가이드 서열을 포함하는 crRNA (또는 이의 일부)를 포함할 수 있다. sgRNA는 표 1에 나타낸 가이드 서열의 17, 18, 19, 또는 20개의 인접 뉴클레오티드를 포함할 수 있다. 일부 구현예에서, crRNA 및 trRNA는 링커를 통해 공유적으로 연결된다. 일부 구현예에서, sgRNA는 crRNA와 trRNA 일부 사이의 염기 쌍을 통해 줄기-루프 구조를 형성한다. 일부 구현예에서, crRNA 및 trRNA는 포스포디에스테르 결합이 아닌 하나 이상의 결합을 통해 공유적으로 연결된다..
일부 구현예에서, trRNA는 자연-발생 CRISPR/Cas 시스템으로부터 유래된 trRNA 서열의 전부 또는 일부를 포함할 수 있다. 일부 구현예에서, trRNA는 절단되거나 변형된 야생형 trRNA를 포함한다. trRNA의 길이는 사용된 CRISPR/Cas 시스템에 따라 다르다. 일부 구현예에서, trRNA는 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100, 또는 100개 초과의 뉴클레오티드를 포함하거나 이루어진다. 일부 구현예에서, trRNA는, 예를 들어, 하나 이상의 헤어핀 또는 줄기-루프 구조, 또는 하나 이상의 돌출부 구조와 같은 특정 2차 구조를 포함할 수 있다.
일부 구현예에서, 본 발명은 서열 번호 1 내지 84 중 임의의 하나의 가이드 서열을 포함하는 하나 이상의 가이드 RNA를 포함하는 조성물을 제공한다.
일부 구현예에서, 본 발명은 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나를 포함하는 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 포함하는 조성물을 제공한다.
하나의 양상에서, 본 발명은 서열 번호 1 내지 84의 임의의 핵산과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열을 포함하는 gRNA를 포함하는 조성물을 제공한다.
다른 구현예에서, 상기 조성물은 서열번호 1 내지 84의 가이드 서열 중 임의의 2개 이상으로부터 선택된 가이드 서열을 포함하는 적어도 하나, 예를 들어, 적어도 2개의 gRNA를 포함한다. 일부 구현예에서, 상기 조성물은 서열번호 1 내지 84의 임의의 핵산과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열을 각각 포함하는 적어도 2개의 gRNA를 포함한다.
본 발명의 가이드 RNA 조성물은 LDHA 유전자에서 표적 서열을 인식 (예를 들어, 하이브리드화)하도록 디자인된다. 예를 들어, LDHA 표적 서열은 절단되고 가이드 RNA를 포함하는 제공된 Cas 클리바세에 의해 절단될 수 있다. 일부 구현예에서, RNA-가이드된 DNA 결합제, 예컨대 Cas 클리바세는 가이드 RNA에 의해 LDHA 유전자의 표적 서열로 지시될 수 있고, 여기서, 가이드 RNA의 가이드 서열은 표적 서열과 혼성화하고 RNA-가이드된 DNA 결합제, 예컨대 aCas 클리바세는 표적 서열을 절단한다.
일부 구현예에서, 하나 이상의 가이드 RNA의 선택은 LDHA 유전자 내의 표적 서열에 기반하여 결정된다.
임의의 특정 이론에 얽매이지 않고, 유전자의 특정 영역에서의 돌연변이 (예를 들어, 뉴클레아제-매개된 DSB의 결과로서 발생하는 인델로부터 초래되는 프레임 시프트 돌연변이)는 유전자의 다른 영역에서의 돌연변이보다 덜 관용성일 수 있으므로 DSB의 위치는 결과적으로 발생할 수 있는 단백질 녹다운의 양 또는 유형에서 중요한 요소이다. 일부 구현예에서, LDHA 내의 표적 서열에 상보적이거나 상보성을 갖는 gRNA는 RNA-가이드된 DNA 결합제를 LDHA 유전자의 특정 위치로 지시하는 데 사용된다. 일부 구현예에서, gRNA는 LDHA의 엑손 1, 엑손 2, 엑손 3, 엑손 4, 엑손 5, 엑손 6, 엑손 7 또는 엑손 8에서 표적 서열에 상보적이거나 상보성을 갖는 가이드 서열을 갖도록 디자인된다.
일부 구현예에서, 가이드 서열은 인간 LDHA 유전자에 존재하는 표적 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일하다. 일부 구현예에서, 표적 서열은 가이드 RNA의 가이드 서열에 상보적일 수 있다. 일부 구현예에서, 가이드 RNA의 가이드 서열과 이의 상응하는 표적 서열 사이의 상보성 또는 동일성의 정도는 적어도 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 또는 100%일 수 있다. 일부 구현예에서, gRNA의 표적 서열 및 가이드 서열은 100% 상보적이거나 동일할 수 있다. 다른 구현예에서, gRNA의 표적 서열 및 가이드 서열은 적어도 하나의 불일치를 포함할 수 있다. 예를 들어, gRNA의 표적 서열 및 가이드 서열은 1, 2, 3, 또는 4개의 불일치를 포함할 수 있고, 여기서, 가이드 서열의 총 길이는 20이다. 일부 구현예에서, gRNA의 표적 서열 및 가이드 서열은 1 내지 4개의 불일치를 포함할 수 있고, 여기서, 가이드 서열은 20개의 뉴클레오티드이다.
일부 구현예에서, 본원에 개시된 조성물 또는 제형은 본원에 기재된 Cas 뉴클레아제와 같은 RNA-가이드된 DNA 결합제를 암호화하는 오픈 리딩 프레임 (ORF)을 포함하는 mRNA를 포함한다. 일부 구현예에서, Cas 뉴클레아제와 같은 RNA-가이드된 DNA 결합제를 암호화하는 ORF를 포함하는 mRNA가 제공, 사용 또는 투여된다.
B. 변형된 gRNA 및 mRNA
일부 구현예에서, gRNA는 화학적으로 변형된다. 하나 이상의 변형된 뉴클레오시드 또는 뉴클레오티드를 포함하는 gRNA는 "변형된" gRNA 또는 "화학적으로 변형된" gRNA로 불리고, 표준 (canonical) A, G, C 및 U 잔기 대신에 또는 이에 추가하여 사용되는 하나 이상의 비-천연 및/또는 자연 발생 성분 또는 배열의 존재를 설명한다. 일부 구현예에서, 변형된 gRNA는 비-표준 뉴클레오시드 또는 뉴클레오티드로 합성되며, 본원에서는 "변형된"으로 불린다. 변형된 뉴클레오시드 및 뉴클레오티드는 다음 중 하나 이상을 포함할 수 있다: (i) 포스포디에스테르 골격 연결에서 비-연결 포스페이트 산소 중 하나 또는 둘 다 및/또는 연결 포스페이트 산소 중 하나 이상의 변경, 예를 들어, 대체 (예시적인 골격 변형); (ii) 리보스 당의 구성성분, 예를 들어, 리보스 당 상의 2' 하이드록실의 변경, 예를 들어, 대체 (예시적인 당 변형); (iii) "데포스포" 링커로 포스페이트 모이어티의 대규모 대체 (예시적인 골격 변형); (iv) 비-표준 핵염기를 포함하는 자연 발생 핵염기의 변형 또는 대체 (예시적인 염기 변형); (v) 리보스-포스페이트 골격의 대체 또는 변형 (예시적인 골격 변형); (vi) 올리고뉴클레오티드의 3' 단부 또는 5' 단부의 변형, 예를 들어, 말단 포스페이트 기의 제거, 변형 또는 대체, 또는 모이어티, 캡 또는 링커의 접합 (그러한 3' 또는 5' 캡 변형은 당 및/또는 골격 변형을 포함할 수 있음); 및 (vii) 당의 변형 또는 대체 (예시적인 당 변형).
상기 열거된 것과 같은 화학적 변형을 조합하여 2개, 3개, 4개 또는 그 이상의 변형을 가질 수 있는 뉴클레오시드 및 뉴클레오티드 (집합적으로 "잔기")를 포함하는 변형된 gRNA 및/또는 mRNA를 제공할 수 있다. 예를 들어, 변형된 잔기는 변형된 당 및 변형된 핵염기를 가질 수 있다. 일부 구현예에서, gRNA의 모든 염기는 변형되는데, 예를 들어, 모든 염기는 변형된 포스페이트 기, 예컨대 포스포로티오에이트 기를 갖는다. 특정 구현예에서, gRNA 분자의 포스페이트 기의 전부 또는 실질적으로 전부는 포스포로티오에이트 기로 대체된다. 일부 구현예에서, 변형된 gRNA는 RNA의 5' 단부에 또는 그 근처에 적어도 하나의 변형된 잔기를 포함한다. 일부 구현예에서, 변형된 gRNA는 RNA의 3' 단부에 또는 그 근처에 적어도 하나의 변형된 잔기를 포함한다.
일부 구현예에서, gRNA는 1, 2, 3개 이상의 변형된 잔기를 포함한다. 일부 구현예에서, 변형된 gRNA에서 위치의 적어도 5% (예를 들어, 적어도 5%, 적어도 10%, 적어도 15%, 적어도 20%, 적어도 25%, 적어도 30%, 적어도 35%, 적어도 40%, 적어도 45%, 적어도 50%, 적어도 55%, 적어도 60%, 적어도 65%, 적어도 70%, 적어도 75%, 적어도 80%, 적어도 85%, 적어도 90%, 적어도 95%, 또는 100%)는 변형된 뉴클레오시드 또는 뉴클레오티이다.
비변형된 핵산, 예를 들어, 세포내 뉴클레아제 또는 혈청에서 발견되는 것들에 의해 분해되기 쉬울 수 있다. 예를 들어, 뉴클레아제는 핵산 포스포디에스테르 결합을 가수분해할 수 있다. 따라서, 하나의 양상에서, 본원에 기재된 gRNA는, 예를 들어, 세포내 또는 혈청-기반 뉴클레아제에 대한 안정성을 도입하기 위해 하나 이상의 변형된 뉴클레오시드 또는 뉴클레오티드를 포함할 수 있다. 일부 구현예에서, 본원에 기재된 변형된 gRNA 분자는 생체내 및 생체외 둘 다에서 세포 집단에 도입될 때 감소된 선천적 면역 반응을 나타낼 수 있다. 용어 "선천적 면역 반응"은 사이토카인 발현 및 방출, 특히 인터페론 및 세포 사멸의 유도를 포함하는 단일 가닥 핵산을 포함하는 외인성 핵산에 대한 세포 반응을 포함한다.
골격 변형의 일부 구현예에서, 변형된 잔기의 포스페이트 기는 하나 이상의 산소를 상이한 치환기로 대체함으로써 변형될 수 있다. 또한, 변형된 잔기, 예를 들어, 변형된 핵산에 존재하는 변형된 잔기는 비변형된 포스페이트 모이어티를 본원에 기재된 변형된 포스페이트 기로 대량 대체함을 포함할 수 있다. 일부 구현예에서, 포스페이트 골격의 골격 변형은 비대칭 전하 분포를 갖는 비하전된 링커 또는 하전된 링커를 초래하는 변경을 포함할 수 있다.
변형된 포스페이트 기의 예는 포스포로티오에이트, 포스포로셀레네이트, 보라노 포스페이트, 보라노 포스페이트 에스테르, 수소 포스포네이트, 포스포로아미데이트, 알킬 또는 아릴 포스포네이트 및 포스포트리에스테르를 포함한다. 비변형된 포스페이트 기에서 인 원자는 아키랄이다. 그러나, 비-브릿징 (non-bridging) 산소 중 하나를 상기 원자들 또는 원자들의 기 중 하나로 대체하면 인 원자가 키랄이 되도록 할 수 있다. 입체중심 인 원자는 "R" 배열 (여기서 Rp) 또는 "S" 배열 (여기서 Sp)을 가질 수 있다. 골격은 또한 브릿징 산소 (즉, 포스페이트를 뉴클레오시드에 연결하는 산소)를, 질소 (브릿징된 포스포로아미데이트), 황 (브릿징된 포스포로티오에이트) 및 탄소 (브릿징된 메틸렌포스포네이트)로 대체하여 변형될 수 있다. 대체는 연결 산소 또는 연결 산소 둘 다에서 발생할 수 있다.
포스페이트 기는 특정 골격 변형에서 비-인 함유 커넥터로 대체될 수 있다. 일부 구현예에서, 하전된 포스페이트 기는 중성 모이어티로 대체될 수 있다. 포스페이트 기를 대체할 수 있는 모이어티의 예는, 제한 없이, 예를 들어, 메틸 포스페이트, 하이드록실아미노, 실록산, 카보네이트, 카복시메틸, 카바메이트, 아미드, 티오에테르, 에틸린 옥사이드 링커, 설포네이트, 설폰아미드, 티오포름아세탈, 포름아세탈, 옥심, 메틸렌이미노, 메틸렌메틸이미노, 메틸렌하이드라조, 메틸렌디메틸하이드라조 및 메틸렌옥시메틸이미노를 포함할 수 있다.
포스페이트 링커 및 리보스 당이 뉴클레아제 내성 뉴클레오시드 또는 뉴클레오티드 대용물로 대체되는, 핵산을 모방할 수 있는 스캐폴드도 작제될 수 있다. 그러한 변형은 골격 및 당 변형을 포함할 수 있다. 일부 구현예에서, 핵염기는 대용물 골격에 의해 테더링될 수 있다. 예는, 제한 없이, 모르폴리노, 사이클로부틸, 피롤리딘 및 펩타이드 핵산 (PNA) 뉴클레오시드 대용물을 포함할 수 있다.
변형된 뉴클레오시드 및 변형된 뉴클레오티드는 당 기에 대한 하나 이상의 변형, 즉 당 변형을 포함할 수 있다. 예를 들어, 2' 하이드록실 기 (OH)는 변형될 수 있는데, 예를 들어, 다수의 상이한 "옥시" 또는 "데옥시" 치환기로 대체된다. 일부 구현예에서, 2' 하이드록실 기에 대한 변형은 하이드록실이 더 이상 2'-알콕시드 이온을 형성하기 위해 탈양성자화될 수 없기 때문에 핵산의 안정성을 향상시킬 수 있다.
2' 하이드록실 기 변형의 예는 알콕시 또는 아릴옥시 (또는, 여기서, "R"은, 예를 들어, 알킬, 사이클로알킬, 아릴, 아르알킬, 헤테로아릴 또는 당일 수 있다); 폴리에틸렌글리콜 (PEG), O(CH2CH2O)nCH2CH2OR을 포함할 수 있고, 여기서, R은, 예를 들어, H 또는 임의로 치환된 알킬일 수 있고, n은 0 내지 20 (예를 들어, 0 내지 4, 0 내지 8, 0 내지 10, 0 내지 16, 1 내지 4, 1 내지 8, 1 내지 10, 1 내지 16, 1 내지 20, 2 내지 4, 2 내지 8, 2 내지 10, 2 내지 16, 2 내지 20, 4 내지 8, 4 내지 10, 4 내지 16, 및 4 내지 20)의 정수일 수 있다. 일부 구현예에서, 2' 하이드록실 기 변형은 2'-O-Me일 수 있다. 일부 구현예에서, 2' 하이드록실 기 변형은 2' 하이드록실 기를 플루오라이드로 대체하는 2'-플루오로 변형일 수 있다. 일부 구현예에서, 2' 하이드록실 기 변형은 2' 하이드록실이, 예를 들어, C1-6 알킬렌 또는 C1-6 헤테로알킬렌 브릿지에 의해 동일한 리보스 당의 4' 탄소에 연결될 수 있는 "잠금된" 핵산 (LNA)을 포함할 수 있고, 여기서, 예시적인 브릿지는 메틸렌, 프로필렌, 에테르, 또는 아미노 브릿지; O-아미노 (여기서, 아미노는, 예를 들어, NH2; 알킬아미노, 디알킬아미노, 헤테로사이클릴, 아릴아미노, 디아릴아미노, 헤테로아릴아미노, 또는 디헤테로아릴아미노, 에틸렌디아민, 또는 폴리아미노일 수 있다) 및 아미노알콕시, O(CH2)n-아미노 (여기서, 아미노는, 예를 들어, NH2; 알킬아미노, 디알킬아미노, 헤테로사이클릴, 아릴아미노, 디아릴아미노, 헤테로아릴아미노, 또는 디헤테로아릴아미노, 에틸렌디아민, 또는 폴리아미노일 수 있다)를 포함할 수 있다. 일부 구현예에서, 2' 하이드록실 기 변형은 리보스 고리가 C2'-C3' 결합이 결여된 "비잠금된 (unlocked)" 핵산 (UNA)을 포함할 수 있다. 일부 구현예에서, 2' 하이드록실 기 변형은 메톡시에틸 기 (MOE), (OCH2CH2OCH3, 예를 들어, PEG 유도체)를 포함할 수 있다.
"데옥시" 2' 변형은 수소 (즉, 예를 들어, 부분적으로 dsRNA의 오버행 부분에서의 데옥시리보스 당); 할로 (예를 들어, 브로모, 클로로, 플루오로, 또는 요오도); 아미노 (여기서, 아미노는, 예를 들어, NH2; 알킬아미노, 디알킬아미노, 헤테로사이클릴, 아릴아미노, 디아릴아미노, 헤테로아릴아미노, 디헤테로아릴아미노, 또는 아미노산일 수 있다); NH(CH2CH2NH)nCH2CH2- 아미노 (여기서, 아미노는, 예를 들어, 본원에 기재된 바와 같을 수 있다), -NHC(O)R (여기서, R은, 예를 들어, 알킬, 사이클로알킬, 아릴, 아르알킬, 헤테로아릴 또는 당일 수 있다), 시아노; 머캅토; 알킬-티오-알킬; 티오알콕시; 및 예를 들어, 본원에 기재된 바와 같은 아미노로 임의로 치환될 수 있는 알킬, 사이클로알킬, 아릴, 알케닐 및 알키닐을 포함할 수 있다.
당 변형은 리보스에서 상응하는 탄소의 것과 반대의 입체화학적 배열을 갖는 하나 이상의 탄소를 또한 포함할 수 있는 당 그룹을 포함할 수 있다. 따라서, 변형된 핵산은 당으로서, 예를 들어, 아라비노스를 함유하는 뉴클레오티드를 포함할 수 있다. 변형된 핵산은 또한 무염기 (abasic) 당을 포함할 수 있다. 이들 무염기 당은 또한 구성성분 당 원자 중 하나 이상에서 추가로 변형될 수 있다. 변형된 핵산은 또한 L 형태, 예를 들어 L-뉴클레오시드인 하나 이상의 당을 포함할 수 있다.
변형된 핵산에 통합될 수 있는 본원에 기재된 변형된 뉴클레오시드 및 변형된 뉴클레오티드는 핵염기로도 불리는 변형된 염기를 포함할 수 있다. 핵염기의 예는 아데닌 (A), 구아닌 (G), 시토신 (C), 및 우라실 (U)을 포함하지만 이에 제한되지 않는다. 이들 핵염기는 변형된 핵산에 통합될 수 있는 변형된 잔기를 제공하기 위해 변형되거나 완전히 대체될 수 있다. 뉴클레오티드의 핵염기는 퓨린, 피리미딘, 퓨린 유사체 또는 피리미딘 유사체로부터 독립적으로 선택될 수 있다. 일부 구현예에서, 핵염기는, 예를 들어, 염기의 자연-발생 및 합성 유도체를 포함할 수 있다.
이중 가이드 RNA를 사용하는 구현예에서, crRNA 및 tracr RNA 각각은 변형을 포함할 수 있다. 그러한 변형은 crRNA 및/또는 tracr RNA의 한쪽 또는 양쪽 단부에 있을 수 있다. sgRNA를 포함하는 구현예에서, sgRNA의 한쪽 또는 양쪽 단부에 있는 하나 이상의 잔기는 화학적으로 변형될 수 있고/있거나, 내부 뉴클레오시드가 변형될 수 있고/있거나, 전체 sgRNA가 화학적으로 변형될 수 있다. 특정 구현예는 5' 단부 변형을 포함한다. 특정 구현예는 3' 단부 변형을 포함한다.
일부 구현예에서, 본원에 개시된 가이드 RNA는 "화학적으로 변형된 가이드 RNA"란 명칭으로 2017년 12월 8일에 출원된 제WO2018/107028 A1호에 개시된 변형 패턴 중 하나를 포함하고, 상기 특허의 내용은 그 전체가 본원에 참조로 포함된다. 일부 구현예에서, 본원에 개시된 가이드 RNA는 제US20170114334호에 개시된 구조/변형 패턴 중 하나를 포함하고, 상기 특허의 내용은 그 전체가 본원에 참조로 포함된다. 일부 구현예에서, 본원에 개시된 가이드 RNA는 제WO2017/136794호에 개시된 구조/변형 패턴 중 하나를 포함하고, 상기 특허의 내용은 그 전체가 본원에 참조로 포함된다.
C.
YA 변형
YA 부위에서 변형 (본원에서 "YA 변형"으로도 지칭됨)은 뉴클레오시드간 연결의 변형, 예를 들어, 화학적 변형, 치환, 또는 달리 및/또는 당의 변형 (예를 들어, 2'-O-알킬, 2'-F, 2'-moe, 2'-F 아라비노스, 2'-H (데옥시리보스) 등과 같은 2' 위치에서)에 의한 염기의 변형 (피리미딘 또는 아데닌)일 수 있다. 일부 구현예에서, "YA 변형"은, 예를 들어, RNase에 의한 YA 부위의 인식 또는 절단을 방해하고/하거나 RNase에 대한 절단 부위의 접근성을 감소시키는 RNA 구조 (예를 들어, 2차 구조)를 안정화함으로써 RNA 엔도뉴클레아제 활성을 감소시키기 위해 디뉴클레오티드 모티프의 구조를 변경하는 임의의 변형이다. 문헌 (Peacock et al., J Org Chem. 76: 7295-7300 (2011); Behlke, Oligonucleotides 18:305-320 (2008); Ku et al., Adv. Drug Delivery Reviews 104: 16-28 (2016); Ghidini et al., Chem. Commun., 2013, 49, 9036)을 참조한다. Peacock 등, Belhke, Ku, 및 Ghidini는 YA 변형에 적합한 예시적인 변형을 제공한다. 내핵분해 분해 (endonucleolytic degradation)를 감소시키기 위해 당업자에게 알려진 변형이 포함된다. RNase 절단에 관여하는 2' 하이드록실 기에 영향을 미치는 예시적인 2' 리보스 변형은 2'-H, 및 2'-O-Me를 포함한 2'-O-알킬이다. 변형, 예컨대 바이사이클릭 리보스 유사체, UNA, 및 YA 부위에서 잔기의 변형된 뉴클레오시드간 연결은 YA 변형일 수 있다. RNA 구조를 안정화할 수 있는 예시적인 염기 변형은 슈도우리딘 및 5-메틸시토신이다. 일부 구현예에서, YA 부위의 적어도 하나의 뉴클레오티드가 변형된다. 일부 구현예에서, YA 부위의 피리미딘 ("피리미딘 위치"로도 불림)은 변형 (예를 들어, 이의 2' 위치에서 피리미딘의 당의 3' 바로 인접한 뉴클레오시드간 연결을 변경하는 변형, 피리미딘 염기의 변형, 및 리보스의 변형을 포함함)을 포함한다. 일부 구현예에서, YA 부위의 아데닌 ("아데닌 위치"로도 불림)은 변형 (예를 들어, 이의 2' 위치에서 피리미딘 당의 3' 바로 인접한 뉴클레오시드간 연결을 변경하는 변형, 피리미딘 염기의 변형 및 리보스의 변형을 포함함)을 포함한다. 일부 구현예에서, YA 부위의 피리미딘 및 아데닌은 변형을 포함한다. 일부 구현예에서, YA 변형은 RNA 엔도뉴클레아제 활성을 감소시킨다.
일부 구현예에서, sgRNA는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16개 이상의 YA 부위에서 변형을 포함한다. 일부 구현예에서, YA 부위의 피리미딘은 변형 (피리미딘의 당의 3' 바로 인접한 뉴클레오시드간 연결을 변경하는 변형을 포함함)을 포함한다. 일부 구현예에서, YA 부위의 아데닌은 변형 (피리미딘의 당의 3' 바로 인접한 뉴클레오시드간 연결을 변경하는 변형을 포함함)을 포함한다. 일부 구현예에서, YA 부위의 피리미딘 및 아데닌은 변형, 예컨대 당, 염기, 또는 뉴클레오시드간 연결 변형을 포함한다. YA 변형은 본원에 설명된 임의의 유형의 변형일 수 있다. 일부 구현예에서, YA 변형은 포스포로티오에이트, 2'-OMe, 또는 2'-플루오로 중 하나 이상을 포함한다. 일부 구현예에서, YA 변형은 포스포로티오에이트, 2'-OMe, 또는 2'-플루오로 중 하나 이상을 포함하는 피리미딘 변형을 포함한다. 일부 구현예에서, YA 변형은 하나 이상의 YA 부위를 포함하는 RNA 듀플렉스 영역 내에 바이사이클릭 리보스 유사체 (예를 들어, LNA, BNA, 또는 ENA)를 포함한다. 일부 구현예에서, YA 변형은 YA 부위를 포함하는 RNA 듀플렉스 영역 내에 바이사이클릭 리보스 유사체 (예를 들어, LNA, BNA, 또는 ENA)를 포함하며, 여기서, YA 변형은 YA 부위에 대해 원위에 있다.
일부 구현예에서, sgRNA는 가이드 영역 YA 부위 변형을 포함한다. 일부 구현예에서, 가이드 영역은 YA 변형을 포함할 수 있는 1, 2, 3, 4, 5개 이상의 YA 부위 ("가이드 영역 YA 부위")를 포함한다. 일부 구현예에서, 5' 말단 (여기서, "5-단부" 등은 가이드 영역의 3' 단부, 즉 가이드 영역에서 최외곽 3' 뉴클레오티드에 대한 위치 5를 지칭한다)의 5' 단부로부터 5-단부, 6-단부, 7-단부, 8-단부, 9-단부, 또는 10-단부에 위치하는 하나 이상의 YA 부위는 YA 변형을 포함한다. 일부 구현예에서, 5' 말단의 5' 단부로부터 5-단부, 6-단부, 7-단부, 8-단부, 9-단부, 또는 10-단부에 위치하는 2개 이상의 YA 부위는 YA 변형을 포함한다. 일부 구현예에서, 5' 말단의 5' 단부로부터 5-단부, 6-단부, 7-단부, 8-단부, 9-단부, 또는 10-단부에 위치하는 3개 이상의 YA 부위는 YA 변형을 포함한다. 일부 구현예에서, 5' 말단의 5' 단부로부터 5-단부, 6-단부, 7-단부, 8-단부, 9-단부, 또는 10-단부에 위치하는 4개 이상의 YA 부위는 YA 변형을 포함한다. 일부 구현예에서, 5' 말단의 5' 단부로부터 5-단부, 6-단부, 7-단부, 8-단부, 9-단부, 또는 10-단부에 위치하는 5개 이상의 YA 부위는 YA 변형을 포함한다. 변형된 가이드 영역 YA 부위는 YA 변형을 포함한다.
일부 구현예에서, 변형된 가이드 영역 YA 부위는 가이드 영역의 3' 말단 뉴클레오티드의 17, 16, 15, 14, 13, 12, 11, 10, 또는 9개의 뉴클레오티드 내에 있다. 예를 들어, 변형된 가이드 영역 YA 부위가 가이드 영역의 3' 말단 뉴클레오티드의 10개의 뉴클레오티드 이내이고 가이드 영역의 길이가 20개의 뉴클레오티드인 경우, 변형된 가이드 영역 YA 부위의 변형된 뉴클레오티드는 11 내지 20 위치 중 하나에 위치한다. 일부 구현예에서, YA 변형은 가이드 영역의 3' 말단 뉴클레오티드로부터 YA 부위 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1개의 뉴클레오티드 내에 위치한다. 일부 구현예에서, YA 변형은 가이드 영역의 3' 말단 뉴클레오티드로부터 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 또는 1개의 뉴클레오티드에 위치한다.
일부 구현예에서, 변형된 가이드 영역 YA 부위는 5' 말단의 5' 단부로부터 뉴클레오티드 4, 5, 6, 7, 8, 9, 10, 또는 11에 또는 그 뒤에 있다.
일부 구현예에서, 변형된 가이드 영역 YA 부위는 5' 단부 변형이 아니다. 예를 들어, sgRNA는 본원에 기재된 5' 단부 변형을 포함할 수 있고, 변형된 가이드 영역 YA 부위를 추가로 포함한다. 대안적으로, sgRNA는 비변형된 5' 단부 및 변형된 가이드 영역 YA 부위를 포함할 수 있다. 대안적으로, sgRNA는 변형된 5' 단부 및 비변형된 가이드 영역 YA 부위를 포함할 수 있다.
일부 구현예에서, 변형된 가이드 영역 YA 부위는 가이드 영역 YA 부위의 5'에 위치한 적어도 하나의 뉴클레오티드가 포함하지 않는 변형을 포함한다. 예를 들어, 뉴클레오티드 1 내지 3이 포스포로티오에이트를 포함하고, 뉴클레오티드 4가 2'-OMe 변형만을 포함하고, 뉴클레오티드 5가 YA 부위의 피리미딘이고 포스포로티오에이트를 포함하는 경우, 변형된 가이드 영역 YA 부위는 가이드 영역 YA 부위의 5'에 위치한 적어도 하나의 뉴클레오티드 (뉴클레오티드 4)가 포함하지 않는 변형 (포스포로티오에이트)을 포함한다. 또 다른 예에서, 뉴클레오티드 1 내지 3이 포스포로티오에이트를 포함하고, 뉴클레오티드 4가 YA 부위의 피리미딘이고 2'-OMe를 포함하는 경우, 변형된 가이드 영역 YA 부위는 가이드 영역 YA 부위의 5'에 위치한 적어도 하나의 뉴클레오티드 (뉴클레오티드 1 내지 3 중 임의의 것)가 포함하지 않는 변형 (2'-OMe)을 포함한다. 이 조건은 또한 비변형된 뉴클레오티드가 변형된 가이드 영역 YA 사이트의 5'에 위치하는 경우에도 항상 충족된다.
일부 구현예에서, 변형된 가이드 영역 YA 부위는 상기 YA 부위에 대해 기재된 바와 같은 변형을 포함한다.
가이드 영역 YA 부위 변형의 추가 구현예는 상기 요약에 설명되어 있다. 본 개시내용의 다른 곳에 설명된 임의의 구현예는 전술한 구현예 중 임의의 것과 가능한 정도까지 조합될 수 있다.
일부 구현예에서, sgRNA는 보존된 영역 YA 부위 변형을 포함한다. 보존된 영역 YA 부위 1 내지 10은 도 10에 도시되어 있다. 일부 구현예에서, 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10의 보존된 영역 YA 부위는 변형을 포함한다.
일부 구현예에서, 보존된 영역 YA 부위 1, 8, 또는 1 및 8은 YA 변형을 포함한다. 일부 구현예에서, 보존된 영역 YA 부위 1, 2, 3, 4, 및 10은 YA 변형을 포함한다. 일부 구현예에서, YA 부위 2, 3, 4, 8, 및 10은 YA 변형을 포함한다. 일부 구현예에서, 보존된 영역 YA 부위 1, 2, 3, 및 10은 YA 변형을 포함한다. 일부 구현예에서, YA 부위 2, 3, 8, 및 10은 YA 변형을 포함한다. 일부 구현예에서, YA 부위 1, 2, 3, 4, 8, 및 10은 YA 변형을 포함한다. 일부 구현예에서, 1, 2, 3, 4, 5, 6, 7, 또는 8의 추가 보존된 영역 YA 부위는 YA 변형을 포함한다.
일부 구현예에서, 보존된 영역 YA 부위 2, 3, 4, 및 10의 1, 2, 3, 또는 4는 YA 변형을 포함한다. 일부 구현예에서, 1, 2, 3, 4, 5, 6, 7, 또는 8의 추가 보존된 영역 YA 부위는 YA 변형을 포함한다.
일부 구현예에서, 변형된 보존된 영역 YA 부위는 상기 YA 부위에 대해 기재된 바와 같은 변형을 포함한다.
보존된 영역 YA 부위 변형의 추가 구현예는 상기 요약에 설명되어 있다. 본 개시내용의 다른 곳에 설명된 임의의 구현예는 전술한 구현예 중 임의의 것과 가능한 정도까지 조합될 수 있다.
일부 구현예에서, sgRNA는 표 2 위 또는 표 3 아래에 나타낸 임의의 변형 패턴을 포함하고, 여기서, N은, 존재하는 경우, 임의의 천연 또는 비천연 뉴클레오티드이고, N의 전체는 표 1에 본원에 기재된 바와 같은 LDHA 가이드 서열을 포함한다. 표 3은 sgRNA의 가이드 서열 부분을 묘사하지 않는다. 가이드의 뉴클레오티드에 대한 N의 치환에도 불구하고 변형은 표 3에 나타낸 대로 남아 있다. 즉, 가이드의 뉴클레오티드가 "N"을 대체하더라도, 표 3에 나타낸 바와 같이 뉴클레오티드가 변형된다. 가이드 서열이 5' 단부에 추가되는 경우, 가이드 서열의 5' 단부 (또는 5' 말단)가 변형될 수 있다. 일부 구현예에서, 변형은 2'-O-Me 및/또는 PS-결합을 포함한다. 일부 구현예에서, 2'-O-Me 및/또는 PS-결합은 이의 5' 단부에서 가이드 서열의 처음 1 내지 7, 1 내지 6, 1 내지 5, 1 내지 4, 또는 1 내지 3개의 뉴클레오티드에 있다.
[표 3] LDHA sgRNA 변형 패턴. 가이드 서열은 나타내지 않고 이의 5' 단부에 나타낸 서열을 추가할 것이다.




일부 구현예에서, 변형된 sgRNA는 하기 서열을 포함하고: mN*mN*mN*NNNNNNNNNNNNNNNNNGUUUUAGAmGmCmUmAmGmAmAmAmUmAmGmCAAGUUAAAAUAAGGCUAGUCCGUUAUCAmAmCmUmUmGmAmAmAmAmAmGmUmGmGmCmAmCmCmGmAmGmUmCmGmGmUmGmCmU*mU*mU*mU (서열번호 300), 여기서, "N"은 임의의 천연 또는 비천연 뉴클레오티드일 수 있고, N의 전체는 표 1에 기재된 바와 같은 LDHA 가이드 서열을 포함한다. 예를 들어, 본원에 포함되는 것은 서열번호 300이고, 여기서, N은 표 1에서 본원에 개시된 임의의 가이드 서열로 대체된다 (서열번호 1 내지 84).
아래에 기재된 임의의 변형은 본원에 기재된 gRNA 및 mRNA에 존재할 수 있다.
용어 "mA," "mC," "mU," 또는 "mG"는 2'-O-Me로 변형된 뉴클레오티드를 나타내기 위해 사용될 수 있다.
2'-O-메틸의 변형은 다음과 같이 묘사될 수 있다:

뉴클레오티드 당 고리에 영향을 미치는 것으로 밝혀진 또 다른 화학적 변형은 할로겐 치환이다. 예를 들어, 뉴클레오티드 당 고리에서 2'-플루오로 (2'-F) 치환은 올리고뉴클레오티드 결합 친화도 및 뉴클레아제 안정성을 증가시킬 수 있다.
본 출원에서, 용어 "fA," "fC," "fU," 또는 "fG"는 2'-F로 치환된 뉴클레오티드를 나타내기 위해 사용될 수 있다.
2'-F의 치환은 다음과 같이 묘사될 수 있다:

포스포로티오에이트 (PS) 연결 또는 결합은 포스포디에스테르 결합, 예를 들어, 뉴클레오티드 염기 사이의 결합에서 하나의 비브릿징 포스페이트 산소 대신 황이 대체되는 결합을 지칭한다. 포스포로티오에이트가 올리고뉴클레오티드를 생성하기 위해 사용되는 경우, 변형된 올리고뉴클레오티드는 또한 S-올리고로 지칭될 수 있다.
PS 변형을 나타내지 위해 "*"가 사용될 수 있다. 본 출원에서, 용어 A*, C*, U*, 또는 G*는 PS 결합으로 다음 (예를 들어, 3') 뉴클레오티드에 연결된 뉴클레오티드를 나타내기 위해 사용될 수 있다.
본 출원에서, 용어 "mA*," "mC*," "mU*," 또는 "mG*"는 2'-O-Me로 치환되고 PS 결합으로 다음 (예를 들어, 3') 뉴클레오티드에 연결된 뉴클레오티드를 나타내기 위해 사용될 수 있다.
아래 다이어그램은 포스포디에스테르 결합 대신에 PS 결합을 생성하는 비브릿징 포스페이트 산소로의 S-의 치환을 나타낸다.

비염기성 (abasic) 뉴클레오티드는 질소 염기가 결여된 뉴클레오티드를 지칭한다. 아래 도면은 염기가 결여된 무염기 (아퓨린으로도 알려짐) 부위를 갖는 올리고뉴클레오티드를 나타낸다:

역전된 염기 (inverted base)란 정상적인 5'로부터 3' 연결 (즉, 5'로부터 5' 연결 또는 3'로부터 3' 연결)로 반전된 연결을 가진 염기를 지칭한다. 예를 들어:

비염기성 뉴클레오티드는 역전된 연결로 부착될 수 있다. 예를 들어, 비염기성 뉴클레오티드는 5'로부터 5' 연결을 통해 말단 5' 뉴클레오티드에 부착될 수 있거나, 비염기성 뉴클레오티는 3'로부터 3' 연결을 통해 말단 3' 뉴클레오티드에 부착될 수 있다. 말단 5' 또는 3' 뉴클레오티드에서의 역전된 비염기성 뉴클레오티는 역전된 비염기성 말단 캡으로도 불릴 수 있다.
일부 구현예에서, 5' 말단에서 처음 3개, 4개 또는 5개의 뉴클레오티드 중 하나 이상 및 3' 말단에서 마지막 3개, 4개 또는 5개의 뉴클레오티드 중 하나 이상이 변형된다. 일부 구현예에서, 변형은 2'-O-Me, 2'-F, 역전된 비염기성 뉴클레오티드, PS 결합, 또는 안정성 및/또는 성능을 증가시키기 위해 당업계에 잘 알려진 다른 뉴클레오티드 변형이다.
일부 구현예에서, 5' 말단에서 처음 4개의 뉴클레오티드와 3' 말단에서 마지막 4개의 뉴클레오티드는 포스포로티오에이트 (PS) 결합과 연결되어 있다.
일부 구현예에서, 5' 말단에서 처음 3개의 뉴클레오티드와 3' 말단에서 마지막 3개의 뉴클레오티드는 2'-O-메틸 (2'-O-Me) 변형된 뉴클레오티드를 포함한다. 일부 구현예에서, 5' 말단에서 처음 3개의 뉴클레오티드와 3' 말단에서 마지막 3개의 뉴클레오티드는 2'-플루오로 (2'-F) 변형된 뉴클레오티드를 포함한다. 일부 구현예에서, 5' 말단에서 처음 3개의 뉴클레오티드와 3' 말단에서 마지막 3개의 뉴클레오티드는 역전된 비염기성 뉴클레오티드를 포함한다.
일부 구현예에서, 가이드 RNA는 변형된 sgRNA를 포함한다. 일부 구현예에서, sgRNA는 서열번호 201, 202, 또는 203에 나타낸 변형 패턴을 포함하고, 여기서, N은 임의의 천연 또는 비천연 뉴클레오티드이고, N의 전체는 뉴클레아제를, 예를 들어, 표 1에 나타낸 바와 같이 LDHA의 표적 서열로 지시하는 가이드 서열을 포함한다.
일부 구현예에서, 가이드 RNA는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나로 나타낸 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 포함하는 조성물을 제공한다. 일부 구현예에서, 가이드 RNA는 서열번호 1 내지 84 및 100 내지 192의 가이드 서열 중 임의의 하나 및 서열번호 201, 202, 또는 203의 뉴클레오티드를 포함하는 sgRNA를 포함하고, 여기서, 서열번호 201, 202, 또는 203의 뉴클레오티드는 가이드 서열의 3' 단부에 있고, sgRNA는 표 3 또는 서열번호 300에 나타낸 바와 같이 변형될 수 있다.
상기 언급된 바와 같이, 일부 구현예에서, 본원에 개시된 조성물 또는 제형은 본원에 기재된 Cas 뉴클레아제와 같은 RNA-가이드된 DNA 결합제를 암호화하는 오픈 리딩 프레임 (ORF)을 포함하는 mRNA를 포함한다. 일부 구현예에서, Cas 뉴클레아제와 같은 RNA-가이드된 DNA 결합제를 암호화하는 ORF를 포함하는 mRNA가 제공, 사용 또는 투여된다. 일부 구현예에서, RNA-가이드된 DNA 뉴클레아제를 암호화하는 ORF는 "변형된 RNA-가이드된 DNA 결합제 ORF" 또는 단순히 "변형된 ORF"이고, 이는 ORF가 변형되었음을 나타내는 약어로서 사용된다.
일부 구현예에서, 변형된 ORF는 적어도 하나, 복수 또는 모든 우리 딘 위치에서 변형된 우리딘을 포함할 수 있다. 일부 구현예에서, 변형된 우리딘은 5 위치에서, 예를 들어, 할로겐, 메틸, 또는 에틸로 변형된 우리딘이다. 일부 구현예에서, 변형된 우리딘은 1 위치에서, 예를 들어, 할로겐, 메틸, 또는 에틸로 변형된 슈도우리딘이다. 변형된 우리딘은, 예를 들어, 슈도우리딘, N1-메틸-슈도우리딘, 5-메톡시우리딘, 5-요오도우리딘, 또는 이들의 조합일 수 있다. 일부 구현예에서, 변형된 우리딘은 5-메톡시우리딘이다. 일부 구현예에서, 변형된 우리딘은 5-요오도우리딘이다. 일부 구현예에서, 변형된 우리딘은 슈도우리딘이다. 일부 구현예에서, 변형된 우리딘은 N1-메틸-슈도우리딘이다. 일부 구현예에서, 변형된 우리딘은 슈도우리딘과 N1-메틸-슈도우리딘의 조합이다. 일부 구현예에서, 변형된 우리딘은 슈도우리딘과 5-메톡시우리딘의 조합이다. 일부 구현예에서, 변형된 우리딘은 N1-메틸슈도우리딘과 5-메톡시우리딘의 조합이다. 일부 구현예에서, 변형된 우리딘은 5-요오도우리딘과 N1-메틸-슈도우리딘의 조합이다. 일부 구현예에서, 변형된 우리딘은 슈도우리딘과 5-요오도우리딘의 조합이다. 일부 구현예에서, 변형된 우리딘은 5-요오도우리딘과 5-메톡시우리딘의 조합이다.
일부 구현예에서, 본원에 개시된 mRNA는 Cap0, Cap1, 또는 Cap2와 같은 5' 캡을 포함한다. 5' 캡은 일반적으로 5'-트리포스페이트를 통해 mRNA의 5'-내지-3' 사슬의 제1 뉴클레오티드, 즉 제1 캡-근위 뉴클레오티드의 5' 위치에 연결된 7-메틸구아닌 리보뉴클레오티드 (이는 예를 들어, ARCA와 관련하여 아래에 논의된 바와 같이 추가로 변형될 수 있음)이다. Cap0에서, mRNA의 제1 및 제2 캡-근위 뉴클레오티드의 리보스는 둘 다 2'-하이드록실을 포함한다. Cap1에서, mRNA의 제1 및 제2 전사된 뉴클레오티드의 리보스는 각각 2'-메톡시 및 2'-하이드록실을 포함한다. Cap2에서, mRNA의 제1 및 제2 캡-근위 뉴클레오티드의 리보스는 둘 다 2'-메톡시를 포함한다. 예를 들어, 문헌 (Katibah et al. (2014) Proc Natl Acad Sci USA 111(33):12025-30; Abbas et al. (2017) Proc Natl Acad Sci USA 114(11):E2106-E2115)을 참조한다. 인간 mRNA와 같은 포유류 mRNA를 포함한 대부분의 내인성 고등 진핵 mRNA는 Cap1 또는 Cap2를 포함한다. Cap1 및 Cap2와 상이한 Cap0 및 기타 캡 구조는 IFIT-1 및 IFIT-5와 같은 선천적 면역계의 구성요소에 의해 "비-자기 (non-self)"로 인식되기 때문에 인간과 같은 포유동물에서 면역원성일 수 있고, 이는 I형 인터페론을 포함한 상승된 사이토카인 수준을 초래할 수 있다. IFIT-1 및 IFIT-5와 같은 선천적 면역계의 구성요소는 또한 mRNA의 Cap1 또는 Cap2 이외의 캡과의 결합에 대해 eIF4E와 경쟁하여 잠재적으로 mRNA의 해독을 억제할 수 있다.
캡은 공동-전사로 포함될 수 있다. 예를 들어, ARCA (반-역 캡 유사체; Thermo Fisher Scientific 카탈로그 번호 AM8045)는 시험관내에서 시작시 전사체로 통합될 수 있는 구아닌 리보뉴클레오티드의 5' 위치에 연결된 7-메틸구아닌 3'-메톡시-5'-트리포스페이트를 포함하는 캡 유사체이다. ARCA는 제1 캡-근위 뉴클레오티드의 2' 위치가 하이드록실인 Cap0 캡을 초래한다. 예를 들어, 문헌 (Stepinski et al., (2001) "Synthesis and properties of mRNAs containing the novel 'anti-reverse' cap analogs 7-methyl(3'-O-methyl)GpppG and 7-methyl(3'deoxy)GpppG," RNA 7: 1486-1495)을 참조한다. ARCA 구조는 아래에 나타낸다.

CleanCapTM AG (m7G(5')ppp(5')(2'OMeA)pG; TriLink Biotechnologies 카탈로그 번호 N-7113) 또는 CleanCapTM GG (m7G(5')ppp(5')(2'OMeG)pG; TriLink Biotechnologies 카탈로그 번호 N-7133)를 사용하여 공동-전사로 Cap1 구조를 제공할 수 있다. 3'-O-메틸화된 버전의 CleanCapTM AG 및 CleanCapTM GG는 또한 각각 카탈로그 번호 N-7413 및 N-7433으로서 TriLink Biotechnologies로부터 입수 가능하다. CleanCapTM AG 구조는 아래에 나타낸다.

대안적으로, 캡은 전사 후 RNA에 추가될 수 있다. 예를 들어, 백시니아 캡핑 효소는 상업적으로 입수 가능하고 (New England Biolabs 카탈로그 번호 M2080S), 이의 D1 서브유닛에 의해 제공되는 RNA 트리포스파타제 및 구아닐릴트랜스퍼라제 활성 및 이의 D12 서브유닛에 의해 제공되는 구아닌 메틸트랜스퍼라제를 갖는다. 이와 같이, 7-메틸구아닌을 RNA에 추가하여 S-아데노실 메티오닌 및 GTP의 존재하에 Cap0을 제공할 수 있다. 예를 들어, 문헌 (Guo, P. 및 Moss, B. (1990) Proc. Natl. Acad. Sci. USA 87, 4023-4027; Mao, X. 및 Shuman, S. (1994) J. Biol. Chem. 269, 24472-24479)을 참조한다.
일부 구현예에서, mRNA는 폴리-아데닐화된 (폴리-A) 꼬리를 추가로 포함한다. 일부 구현예에서, 폴리-A 꼬리는 적어도 20, 30, 40, 50, 60, 70, 80, 90, 또는 100개의 아데닌, 임의로 최대 300개의 아데닌을 포함한다. 일부 구현예에서, 폴리-A 꼬리는 95, 96, 97, 98, 99, 또는 100개의 아데닌 뉴클레오티드를 포함한다.
A. 리보핵단백질 복합체
일부 구현예에서, 표 1로부터의 하나 이상의 가이드 서열 또는 표 2로부터의 하나 이상의 sgRNA를 포함하는 하나 이상의 gRNA 및 RNA-가이드된 DNA 결합제, 예를 들어, 뉴클레아제, 예컨대 Cas 뉴클레아제, 예컨대 Cas9를 포함하는 조성물이 포함된다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 클리바세 활성을 가지고, 이는 또한 이중-가닥 엔도뉴클레아제 활성으로 지칭될 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 Cas 뉴클레아제를 포함한다. Cas9 뉴클레아제의 예는 에스. 피로게네스 (S. pyogenes), 에스. 아우레스 (S. aureus) 및 기타 원핵생물 (예를 들어, 다음 단락의 리스트 참조)의 II형 CRISPR 시스템, 및 이의 변형된 (예를 들어, 조작된 또는 돌연변이) 버전의 것들을 포함한다. 예를 들어, 문헌 (US2016/0312198 A1; US 2016/0312199 A1)을 참조한다. Cas 뉴클레아제의 다른 예는 III형 CRISPR 시스템 또는 이의 Cas10, Csm1, 또는 Cmr2 서브유닛의 Csm 또는 Cmr 복합체; 및 I형 CRISPR 시스템 또는 이의 Cas3 서브유닛의 캐스케이드 복합체를 포함한다. 일부 구현예에서, Cas 뉴클레아제는 IIA형, IIB형, 또는 IIC형 시스템으로부터 유래될 수 있다. 다양한 CRISPR 시스템 및 Cas 뉴클레아제에 대한 논의의 경우, 예를 들어, 문헌 (Makarova et al., Nat. Rev. Microbiol. 9:467-477 (2011); Makarova et al., Nat. Rev. Microbiol, 13: 722-36 (2015); Shmakov et al., Molecular Cell, 60:385-397 (2015))을 참조한다.
Cas 뉴클레아제가 유래될 수 있는 비제한적인 예시적인 종은 스트렙토코커스 피로게네스 (Streptococcus pyogenes), 스트렙토코커스 써모필루스 (Streptococcus thermophilus), 스트렙코커스 종 (Streptococcus sp.), 스타필로코커스 아우레우스 (Staphylococcus aureus), 리스테리아 이노쿠아 (Listeria innocua), 락토바실러스 가세리 (Lactobacillus gasseri), 프란시셀라 노비시다 (Francisella novicida), 윌리넬라 숙시노게네 (Wolinella succinogenes), 수테렐라 와즈워텐시스 (Sutterella wadsworthensis), 감마프로테오박테리움 (Gammaproteobacterium), 나이세리아 메닌지티디스 (Neisseria meningitidis), 캄필로벡터 제주니 (Campylobacter jejuni), 파스튜렐라 멀토시다 (Pasteurella multocida), 피브로박터 숙시노게네 (Fibrobacter succinogene), 로도스피릴륨 루브륨 (Rhodospirillum rubrum), 노카르디옵시스 다손빌레이 (Nocardiopsis dassonvillei), 스트렙토마이세스 프리스티네스피랄리스 (Streptomyces pristinaespiralis), 스트렙토마이세스 비리도크로모게네스 (Streptomyces viridochromogenes), 스트렙토마이세스 비리도크로모게네스, 스트렙토스포랑기움 로세움 (Streptosporangium roseum), 스트렙토스포랑기움 로세움, 알리시클로바실러스 아시도칼다리우스 (Alicyclobacillus acidocaldarius), 바실러스 슈도마이코이데스 (Bacillus pseudomycoides), 바실러스 셀레니티레두센스 (Bacillus selenitireducens), 엑시구오박테니움 시비리쿰 (Exiguobacterium sibiricum), 락토바실러스 델브루엑기 (Lactobacillus delbrueckii), 락토바실러스 살리바리우스 (Lactobacillus salivarius), 락투바실러스 부크네리 (Lactobacillus buchneri), 트레포네마 덴티콜라 (Treponema denticola), 미크로스킬라 마리나 (Microscilla marina), 버크홀데리알레스 박테리움 (Burkholderiales bacterium), 폴라로모나스 나프탈레니보란스 (Polaromonas naphthalenivorans), 폴라로모나스 종 (Polaromonas sp.), 크로코스파에라 와트소니아 (Crocosphaera watsonii), 시아노테세 종 (Cyanothece sp.), 마이크로시스티스 애루기노사 (Microcystis aeruginosa), 시네코코커스 종 (Synechococcus sp.), 아세토할로븀 아라바티쿰 (Acetohalobium arabaticum), 암모니펙스 데겐시이 (Ammonifex degensii) 칼디셀룰로시룹터 벡시이 (Caldicelulosiruptor becscii), 칸디다투스 데술포루디스 (Candidatus Desulforudis), 클로스트리디움 보툴리눔 (Clostridium botulinum), 클로스트리디움 디피실 (Clostridium difficile), 피레골디아 마그나 (Finegoldia magna), 나트라나에로비우스 써모필러스 (Natranaerobius thermophilus), 펠로토마쿨룸 써모프로피오니쿰 (Pelotomaculum thermopropionicum), 애시디티오바실러스 칼더스 (Acidithiobacillus caldus), 애시디티오바실러스 페로악시댄스 (Acidithiobacillus ferrooxidans), 알로크로마티움 비노숨 (Allochromatium vinosum), 마리노박터 종 (Marinobacter sp.), 니트로소코커스 할로필러스 (Nitrosococcus halophilus), 니트로소코커스 와트소니 (Nitrosococcus watsoni), 슈도알테로모나스 할로플랭크티스 (Pdeudoalteromonas haloplanktis), 크테도노박터 라세미퍼 (Ktedonobacter racemifer), 메타노할로비움 에베스티가툼 (Methanohalobium evestigatum), 아나베나 바리아빌리스 (Anabaena variabilis), 노둘라리아 스푸미게나 (Nodularia spumigena), 노스톡 종 (Nostoc sp.), 아르트로스피라 막시마 (Arthrospira maxima), 아르토로스피라 플라텐시스 (Arthrospira platensis), 아르트로스피라 종 (Arthrospira sp.), 링비아 종 (Lyngbya sp.), 마이크로콜레우스 크토노플라스테스 (Microcoleus chthonoplastes), 오실라토리아 종 (Oscillatoria sp.), 페트로토가 모빌리스 (Petrotoga mobilis), 서모시포 아프리카누스 (Thermosipho africanus), 스트렙코커스 파스테우리아누스 (Streptococcus pasteurianus), 네이세리아 키네레아 (Neisseria cinerea), 캄필로박터 라리 (Campylobacter lari), 파르비바쿨룸 라바멘티보란스 (Parvibaculum lavamentivorans), 코리네박테니움 디프테리아 (Corynebacterium diphtheria), 액시드아미노코커스 종 (Acidaminococcus sp.), 라크노스피라세아에 박테리움 (Lachnospiraceae bacterium) ND2006, 및 아카리오클로리스 마리나 (Acaryochloris marina)를 포함한다.
일부 구현예에서, Cas 뉴클레아제는 스트렙토코커스 피로게네스로부터의 Cas9 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제는 스트렙코커스 써모필루스로부터의 Cas9 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제는 나이세리아 메닌지티디스로부터의 Cas9 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제는 스타필로코커스 아우레우스로부터의 Cas9 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제는 프란시셀라 노비시다로부터의 Cpf1 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제는 액시드아미노코커스 종으로부터의 Cpf1 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제는 라크노스피라세아에 박테리움 ND2006으로부터의 Cpf1 뉴클레아제이다. 추가의 구현예에서, Cas 뉴클레아제는 프란시셀라 툴라렌시스 (Francisella tularensis), 라크노스피라세아에 박테리움 (Lachnospiraceae bacterium), 부티리비브리오 프로테오클라스티쿠스 (Butyrivibrio proteoclasticus), 페레그리니박테리아 박테리움 (Peregrinibacteria bacterium), 파르쿠박테리아 박테리움 (Parcubacteria bacterium), 스미텔라 (Smithella), 액시드아미노코커스 (Acidaminococcus), 칸디다투스 메타노플라스마 터미툼 (Candidatus Methanoplasma termitum), 유박테리움 엘리겐스 (Eubacterium eligens), 모락셀라 보보쿨리 (Moraxella bovoculi), 렙토스피라 이나다이 (Leptospira inadai), 포르피로모나스 크레비오리카니스 (Porphyromonas crevioricanis), 프레보텔라 디시엔스 (Prevotella disiens), 또는 포르피로모나스 마카카에 (Porphyromonas macacae)로부터의 Cpf1 뉴클레아제이다. 특정 구현예에서, Cas 뉴클레아제는 애시드아미노코커스 또는 라크노스피라세아에로부터의 Cpf1 뉴클레아제이다.
일부 구현예에서, RNA-가이드된 DNA 결합제와 함께 gRNA는 리보핵단백질 복합체 (RNP)로 불린다. 일부 구현예에서, RNA-가이드된 DNA 결합제는 Cas 뉴클레아제이다. 일부 구현예에서, Cas 뉴클레아제와 함께 gRNA는 Cas RNP로 불린다. 일부 구현예에서, RNP는 I형, II형, 또는 III형 구성요소를 포함한다. 일부 구현예에서, Cas 뉴클레아제는 II형 CRISPR/Cas 시스템으로부터의 Cas9 단백질이다. 일부 구현예에서, Cas9와 함께 gRNA는 Cas9 RNP로 불린다.
야생형 Cas9는 두 가지 뉴클레아제 도메인을 갖는다: RuvC 및 HNH. RuvC 도메인은 비-표적 DNA 가닥을 절단하고, HNH 도메인은 DNA의 표적 가닥을 절단한다. 일부 구현예에서, Cas9 단백질은 하나 초과의 RuvC 도메인 및/또는 하나 초과의 HNH 도메인을 포함한다. 일부 구현예에서, Cas9 단백질은 야생형 Cas9이다. 각각의 조성물, 용도, 및 방법 구현예에서, Cas는 표적 DNA에서 이중 가닥 절단을 유도한다.
일부 구현예에서, 키메라 Cas 뉴클레아제가 사용되고, 여기서, 단백질의 하나의 도메인 또는 영역은 상이한 단백질의 일부로 대체된다. 일부 구현예에서, Cas 뉴클레아제 도메인은 Fok1과 같은 상이한 뉴클레아제로부터 도메인으로 대체될 수 있다. 일부 구현예에서, Cas 뉴클레아제는 변형된 뉴클레아제일 수 있다.
다른 구현예에서, Cas 뉴클레아제는 I형 CRISPR/Cas 시스템으로부터 유래될 수 있다. 일부 구현예에서, Cas 뉴클레아제는 I형 CRISPR/Cas 시스템의 캐스케이드 복합체의 구성요소일 수 있다. 일부 구현예에서, Cas 뉴클레아제는 Cas3 단백질일 수 있다. 일부 구현예에서, Cas 뉴클레아제는 III형 CRISPR/Cas 시스템으로부터 유래될 수 있다. 일부 구현예에서, Cas 뉴클레아제는 RNA 절단 활성을 가질 수 있다.
일부 구현예에서, RNA-가이드된 DNA-결합제는 단일-가닥 닉카제 활성을 가지고, 즉, 하나의 DNA 가닥을 절단하여 "닉"으로도 알려진 단일-가닥 절단을 생성할 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 Cas 닉카제를 포함한다. 닉카제는 dsDNA에서 닉을 생성하는 효소인데, 즉, DNA 이중 나선의 한 가닥은 절단하고 다른 가닥은 절단하지 않는다. 일부 구현예에서, Cas 닉카제는, 예를 들어, 촉매 도메인에서 하나 이상의 변경 (예를 들어, 점 돌연변이)에 의해 내핵분해 활성 부위가 비활성화되는 Cas 뉴클레아제 (예를 들어, 상기 논의된 Cas 뉴클레아제)의 버전이다. 예를 들어, Cas 닉카제 및 예시적인 촉매 도메인 변경의 논의에 대해 미국 특허 제8,889,356호를 참조한다. 일부 구현예에서, Cas9 닉카제와 같은 Cas 닉카제는 비활성화된 RuvC 또는 HNH 도메인을 갖는다.
일부 구현예에서, RNA-가이드된 DNA-결합제는 하나의 기능적 뉴클레아제 도메인만을 함유하도록 변형된다. 예를 들어, 작용제 단백질은 이의 핵산 절단 활성을 감소시키기 위해 뉴클레아제 도메인 중 하나가 돌연변이되거나 완전히 또는 부분적으로 결실되도록 변형될 수 있다. 일부 구현예에서, 활성이 감소된 RuvC 도메인을 갖는 닉카제가 사용된다. 일부 구현예에서, 불활성 RuvC 도메인을 갖는 닉카제가 사용된다. 일부 구현예에서, 활성이 감소된 HNH 도메인을 갖는 닉카제가 사용된다. 일부 구현예에서, 불활성 HNH 도메인을 갖는 닉카제가 사용된다.
일부 구현예에서, Cas 단백질 뉴클레아제 도메인 내의 보존된 아미노산은 뉴클레아제 활성을 감소시키거나 변경시키기 위해 치환된다. 일부 구현예에서, Cas 뉴클레아제는 RuvC 또는 RuvC-유사 뉴클레아제 도메인에서 아미노산 치환을 포함할 수 있다. RuvC 또는 RuvC-유사 뉴클레아제 도메인에서 예시적인 아미노산 치환은 D10A (에스. 피로게네스 Cas9 단백질을 기반으로 함)을 포함한다. 예를 들어, 문헌 (Zetsche et al. (2015) Cell Oct 22:163(3): 759-771)을 참조한다. 일부 구현예에서, Cas 뉴클레아제는 HNH 또는 HNH-유사 뉴클레아제 도메인에서 아미노산 치환을 포함할 수 있다. HNH 또는 HNH-유사 뉴클레아제 도메인에서 예시적인 아미노산 치환은 E762A, H840A, N863A, H983A, 및 D986A (에스. 피로게네스 Cas9 단백질을 기반으로 함)를 포함한다. 예를 들어, 문헌 (Zetsche et al. (2015))을 참조한다. 또한, 예시적인 아미노산 치환은 D917A, E1006A, 및 D1255A (프란시셀라 노비시다 U112 Cpf1 (FnCpf1) 서열 (UniProtKB - A0Q7Q2 (CPF1_FRATN)에 기반함)을 포함한다.
일부 구현예에서, 닉카제를 암호화하는 mRNA는 각각 표적 서열의 센스 및 안티센스 가닥에 상보적인 가이드 RNA의 쌍과 조합하여 제공된다. 이 구현예에서, 가이드 RNA는 닉카제를 표적 서열로 지시하고 표적 서열의 반대 가닥에 닉을 생성함으로써 DSB를 도입한다 (즉, 이중 닉킹). 일부 구현예에서, 이중 닉킹의 사용은 특이성을 개선하고 오프-표적 효과를 감소시킬 수 있다. 일부 구현예에서, 닉카제는 표적 DNA에서 이중 닉을 생성하기 위해 DNA의 반대 가닥을 표적화하는 2개의 개별 가이드 RNA와 함께 사용된다. 일부 구현예에서, 닉카제는 표적 DNA에서 이중 닉을 생성하기 위해 매우 근접하도록 선택되는 2개의 개별 가이드 RNA와 함께 사용된다.
일부 구현예에서, RNA-가이드된 DNA-결합제는 클리바세 및 닉카제 활성이 결여되어 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 dCas DNA-결합 폴리펩타이드를 포함한다. dCas 폴리펩타이드는 DNA-결합 활성을 갖지만 본질적으로 촉매 (클리바세/닉카제) 활성이 결여되어 있다. 일부 구현예에서, dCas 폴리펩타이드는 dCas9 폴리펩타이드이다. 일부 구현예에서, 클리바세 및 닉카제 활성이 결여된 RNA-가이드된 DNA-결합제 또는 dCas DNA-결합 폴리펩타이드는 Cas 뉴클레아제 (예를 들어, 상기 논의된 Cas 뉴클레아제)의 한 버전으로, 이의 내핵분해 활성 부위가, 예를 들어, 이의 촉매 도메인에서 하나 이상의 변경 (예를 들어, 점 돌연변이)에 의해 비활성화된다. 예를 들어, 문헌 (US 2014/0186958 A1; US 2015/0166980 A1)을 참조한다.
일부 구현예에서, RNA-가이드된 DNA-결합제는 하나 이상의 이종 기능성 도메인을 포함한다 (예를 들어, 융합 폴리펩타이드이거나 이를 포함한다).
일부 구현예에서, 이종 기능성 도메인은 RNA-가이드된 DNA-결합제의 세포 핵으로의 수송을 촉진할 수 있다. 예를 들어, 이종 기능성 도메인은 핵 위치 신호 (NLS)일 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 1 내지 10개의 NLS(들)와 융합될 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 1 내지 5개의 NLS(들)와 융합될 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 하나의 NLS와 융합될 수 있다. 하나의 NLS가 사용되는 경우, NLS는 RNA-가이드된 DNA-결합제 서열의 N-말단 또는 C-말단에 연결될 수 있다. 또한 RNA-가이드된 DNA 결합제 서열 내에 삽입될 수 있다. 다른 구현예에서, RNA-가이드된 DNA 결합제는 하나 초과의 NLS와 융합될 수 있다. 일부 구현예에서, RNA-가이드된 DNA 결합제는 2, 3, 4 또는 5개의 NLS와 융합될 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 2개의 NLS와 융합될 수 있다. 특정 상황에서, 2개의 NLS는 동일하거나 (예를 들어, 2개의 SV40 NLS) 상이할 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 카복시 말단에 연결된 2개의 SV40 NLS 서열에 융합된다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 2개의 NLS와 융합될 수 있는데, 하나는 N-말단에 연결되고 하나는 C-말단에 연결된다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 3개의 NLS와 융합될 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 NLS 없이 융합될 수 있다. 일부 구현예에서, NLS는, 예를 들어, SV40 NLS, PKKKRKV (서열번호 600) 또는 PKKKRRV (서열번호 601)와 같은 단일분절 (monopartite) 서열일 수 있다. 일부 구현예에서, NLS는 뉴클레오플라스민의 NLS, KRPAATKKAGQAKKKK (서열번호 602)와 같은 이분절 (bipartite) 서열일 수 있다. 특정 구현예에서, 단일 PKKKRKV (서열번호 600) NLS는 RNA-가이드된 DNA-결합제의 C-말단에 연결될 수 있다. 하나 이상의 링커는 임의로 융합 부위에 포함된다.
일부 구현예에서, 이종 기능성 도메인은 RNA-가이드된 DNA 결합제의 세포내 반감기를 변형시킬 수 있다. 일부 구현예에서, RNA-가이드된 DNA 결합제의 반감기가 증가될 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제의 반감기가 감소될 수 있다. 일부 구현예에서, 이종 기능성 도메인은 RNA-가이드된 DNA-결합제의 안정성을 증가시킬 수 있다. 일부 구현예에서, 이종 기능성 도메인은 RNA-가이드된 DNA-결합제의 안정성을 감소시킬 수 있다. 일부 구현예에서, 이종 기능성 도메인은 단백질 분해를 위한 신호 펩타이드로서 작용할 수 있다. 일부 구현예에서, 단백질 분해는, 예를 들어, 프로테아좀, 리소좀 프로테아제 또는 칼파인 프로테아제와 같은 단백질분해 효소에 의해 매개될 수 있다. 일부 구현예에서, 이종 기능성 도메인은 PEST 서열을 포함할 수 있다. 일부 구현예에서, RNA-가이드된 DNA-결합제는 유비퀴틴 또는 폴리유비퀴틴 사슬의 첨가에 의해 변형될 수 있다. 일부 구현예에서, 유비퀴틴은 유비퀴틴-유사 단백질 (UBL)일 수 있다. 유비퀴틴-유사 단백질의 비제한적인 예는 작은 유비퀴틴-유사 변형체 (SUMO), 유비퀴틴 교차반응 단백질 (UCRP, 인터페론-자극 유전자-15 (ISG15)로도 알려져 있음), 유비퀴틴-관련 변형체-1 (URM1), 뉴런-전구체-세포-발현 발달 하향조절된 단백질-8 (NEDD8, 에스. 세레비세에 (S. cerevisiae)에서 Rub1로도 불림), 인간 백혈구 항원 F-연관 (FAT10), 자가포식-8 (ATG8) 및 -12 (ATG12), Fau 유비퀴틴-유사 단백질 (FUB1), 막-고정 UBL (MUB), 유비퀴틴 폴드-변형체-1 (UFM1), 및 유비퀴틴-유사 단백질-5 (UBL5)를 포함한다.
일부 구현예에서, 이종 기능성 도메인은 마커 도메인일 수 있다. 마커 도메인의 비제한적인 예는 형광 단백질, 정제 태그, 에피토프 태그, 및 리포터 유전자 서열을 포함한다. 일부 구현예에서, 마커 도메인은 형광 단백질일 수 있다. 적합한 형광 단백질의 비제한적인 예는 녹색 형광 단백질 (예를 들어, GFP, GFP-2, tagGFP, turboGFP, sfGFP, EGFP, Emerald, Azami Green, Monomeric Azami Green, CopGFP, AceGFP, ZsGreen1), 황색 형광 단백질 (예를 들어, YFP, EYFP, Citrine, Venus, YPet, PhiYFP, ZsYellow1), 청색 형광 단백질 (예를 들어, EBFP, EBFP2, Azurite, mKalamal, GFPuv, Sapphire, T-sapphire), 청록색 형광 단백질 (예를 들어, ECFP, Cerulean, CyPet, AmCyan1, Midoriishi-Cyan), 적색 형광 단백질 (예를 들어, mKate, mKate2, mPlum, DsRed 단량체, mCherry, mRFP1, DsRed-Express, DsRed2, DsRed-단량체, HcRed-Tandem, HcRed1, AsRed2, eqFP611, mRasberry, mStrawberry, Jred), 및 오렌지색 형광 단백질 (mOrange, mKO, Kusabira-Orange, Monomeric Kusabira-Orange, mTangerine, tdTomato) 또는 임의의 다른 적합한 형광 단백질을 포함한다. 다른 구현예에서, 마커 도메인은 정제 태그 및/또는 에피토프 태그일 수 있다. 비제한적인 예시적인 태그는 글루타티온-S-트랜스퍼라제 (GST), 키틴 결합 단백질 (CBP), 말토오스 결합 단백질 (MBP), 티오레독신 (TRX), 폴리(NANP), 직렬 친화성 정제 (TAP) 태그, myc, AcV5, AU1, AU5, E, ECS, E2, FLAG, HA, nus, Softag 1, Softag 3, Strep, SBP, Glu-Glu, HSV, KT3, S, S1, T7, V5, VSV-G, 6xHis, 8xHis, 비오틴 카복실 담체 단백질 (BCCP), 폴리-His, 및 칼모둘린을 포함한다. 비제한적인 예시적인 리포터 유전자는 글루타티온-S-트랜스퍼라제 (GST), 서양고추냉이 퍼옥시다제 (HRP), 클로람페니콜 아세틸트랜스퍼라제 (CAT), 베타-갈락토시다제, 베타-글루쿠로니다제, 루시퍼라제, 또는 형광 단백질을 포함한다.
추가 구현예에서, 이종 기능성 도메인은 RNA-가이드된 DNA-결합제를 특정 세포기관, 세포 유형, 조직, 또는 기관에 표적화할 수 있다. 일부 구현예에서, 이종 기능성 도메인은 RNA-가이드된 DNA-결합제를 미토콘드리아에 표적화할 수 있다.
추가 구현예에서, 이종 기능성 도메인은 이펙터 (effector) 도메인일 수 있다. RNA-가이드된 DNA-결합제가 표적 서열로 지시되는 경우, 예를 들어 Cas 뉴클레아제가 gRNA에 의해 표적 서열로 지시되는 경우, 이펙터 도메인은 표적 서열을 변형하거나 영향을 미칠 수 있다. 일부 구현예에서, 이펙터 도메인은 핵산 결합 도메인, 뉴클레아제 도메인 (예를 들어, 비-Cas 뉴클레아제 도메인), 후성적 변형 도메인, 전사 활성화 도메인, 또는 전사 억제인자 도메인으로부터 선택될 수 있다. 일부 구현예에서, 이종 기능성 도메인은 FokI 뉴클레아제와 같은 뉴클레아제이다. 예를 들어, 미국 특허 제9,023,649호를 참조한다. 일부 구현예에서, 이종 기능성 도메인은 전사 활성화제 또는 억제인자이다. 예를 들어, 문헌 (Qi et al., "Repurposing CRISPR as an RNA-guided platform for sequence-specific control of gene expression," Cell 152:1173-83 (2013); Perez-Pinera et al., "RNA-guided gene activation by CRISPR-Cas9-based transcription factors," Nat. Methods 10:973-6 (2013); Mali et al., "CAS9 transcriptional activators for target specificity screening and paired nickases for cooperative genome engineering," Nat. Biotechnol. 31:833-8 (2013); Gilbert et al., "CRISPR-mediated modular RNA-guided regulation of transcription in eukaryotes," Cell 154:442-51 (2013))을 참조한다. 이와 같이, RNA-가이드된 DNA-결합제는 본질적으로 가이드 RNA를 사용하여 원하는 표적 서열에 결합하도록 지시될 수 있는 전사 인자가 된다.
E.
gRNA의 효능 결정
일부 구현예에서, gRNA의 효능은 RNP를 형성하는 다른 성분과 함께 전달되거나 발현될 때 결정된다. 일부 구현예에서, gRNA는 RNA-가이드된 DNA 결합제, 예컨대 Cas 단백질, 예를 들어, Cas9와 함께 발현된다. 일부 구현예에서, gRNA는 RNA-가이드된 DNA 뉴클레아제, 예컨대 Cas 뉴클레아제 또는 닉카제, 예를 들어, Cas9 뉴클레아제 또는 닉카제를 이미 안정적으로 발현하는 세포주로 전달되거나 세포주에서 발현된다. 일부 구현예에서, gRNA는 RNP의 일부로서 세포에 전달된다. 일부 구현예에서, gRNA는 RNA-가이드된 DNA 뉴클레아제, 예컨대 Cas 뉴클레아제 또는 닉카제, 예를 들어, Cas9 뉴클레아제 또는 닉카제를 암호화하는 mRNA와 함께 세포로 전달된다.
본원에 기재된 바와 같이, 본원에 개시된 RNA-가이드된 DNA 뉴클레아제 및 가이드 RNA의 사용은 DNA에 이중-가닥 파괴를 유발하여 세포 기계에 의한 복구시 삽입/결실 (인델) 돌연변이 형태로 오류를 생성할 수 있다. 인델로 인한 많은 돌연변이는 판독 프레임을 변경하거나 조기 중지 코돈을 도입하여 비-기능적 단백질을 생성한다.
일부 구현예에서, 특정 gRNA의 효능은 시험관내 모델을 기반으로 결정된다. 일부 구현예에서, 시험관내 모델은 Cas9 (HEK293_Cas9)를 안정적으로 발현하는 HEK293 세포이다. 일부 구현예에서, 시험관내 모델은 HUH7 인간 간암종 세포이다. 일부 구현예에서, 시험관내 모델은 HepG2 세포이다. 일부 구현예에서, 시험관내 모델은 1차 인간 간세포이다. 일부 구현예에서, 시험관내 모델은 1차 사이노몰구스 간세포이다. 1차 인간 간세포 사용과 관련하여, 상업적으로 이용 가능한 1차 인간 간세포를 사용하여 실험 간의 일관성을 높일 수 있다. 일부 구현예에서, 시험관내 모델에서 (예를 들어, 1차 인간 간세포에서) 결실 또는 삽입이 발생하는 오프-표적 부위의 수는, 예를 들어, Cas9 mRNA 및 가이드 RNA로 시험관내에서 형질감염된 1차 인간 간세포로부터 게놈 DNA를 분석하여 결정된다. 일부 구현예에서, 그러한 결정은 Cas9 mRNA, 가이드 RNA 및 공여자 올리고뉴클레오티드로 시험관내 형질감염된 1차 인간 간세포로부터의 게놈 DNA를 분석하는 단계를 포함한다. 그러한 결정을 위한 예시적인 절차는 아래 작업 실시예에서 제공된다.
일부 구현예에서, 특정 gRNA의 효능은 gRNA 선택 과정을 위한 다수의 시험관내 세포 모델에 걸쳐 결정된다. 일부 구현예에서, 선택된 gRNA와 데이터의 세포주 비교가 수행된다. 일부 구현예에서, 다중 세포 모델에서의 교차 스크리닝이 수행된다.
일부 구현예에서, 특정 gRNA의 효능은 생체내 모델을 기반으로 결정된다. 일부 구현예에서, 생체내 모델은 설치류 모델이다. 일부 구현예에서, 설치류 모델은 LDHA 유전자를 발현하는 마우스이다. 일부 구현예에서, 설치류 모델은 인간 LDHA 유전자를 발현하는 마우스이다. 일부 구현예에서, 생체내 모델은 비-인간 영장류, 예를 들어, 사이노몰구스 원숭이이다.
일부 구현예에서, 가이드 RNA의 효능은 LDHA의 퍼센트 편집으로 측정된다. 일부 구현예에서, LDHA의 퍼센트 편집은, 예를 들어, 시험관내 모델의 경우 전체 세포 용해물로부터, 생체내 모델의 경우 조직에서 LDHA 단백질의 녹다운을 달성하는 데 필요한 퍼센트 편집과 비교된다.
일부 구현예에서, 가이드 RNA의 효능은 표적 세포 유형의 게놈 내 오프-표적 서열에서 인델의 수 및/또는 빈도에 의해 측정된다. 일부 구현예에서, 세포 집단에서 매우 낮은 빈도 (예를 들어, < 5%)로 및/또는 표적 부위에서 인델 생성 빈도에 비해 오프-표적 부위에서 인델을 생성하는 효과적인 가이드 RNA가 제공된다. 따라서, 본 개시내용은 표적 세포 유형 (예를 들어, 간세포)에서 오프-표적 인델 형성을 나타내지 않거나 세포 집단에서 및/또는 표적 부위에서의 인델 생성 빈도에 비해 < 5%의 오프-표적 인델 형성 빈도를 생성하는 가이드 RNA를 제공한다. 일부 구현예에서, 본 개시내용은 표적 세포 유형 (예를 들어, 간세포)에서 임의의 오프 표적 인델 형성도 나타내지 않는 가이드 RNA를 제공한다. 일부 구현예에서, 예를 들어, 본원에 기재된 하나 이상의 방법에 의해 평가된 바와 같이, 5개 미만의 오프-표적 부위에서 인델을 생성하는 가이드 RNA가 제공된다. 일부 구현예에서, 예를 들어, 본원에 기재된 하나 이상의 방법에 의해 평가된 바와 같이, 4, 3, 2 또는 1개 이하의 오프-표적 부위(들)에서 인델을 생성하는 가이드 RNA가 제공된다. 일부 구현예에서, 오프-표적 부위(들)는 표적 세포 (예를 들어, 간세포) 게놈의 단백질 암호화 영역에서 발생하지 않는다.
일부 구현예에서, 표적 DNA에서 삽입/결실 ("인델") 돌연변이 및 상동성 지시된 복구 (HDR) 이벤트의 형성과 같은 유전자 편집 이벤트를 검출하는 것은 태그된 프라이머를 사용한 선형 증폭을 사용하고 태그된 증폭 산물을 단리한다 (이하, "LAM-PCR" 또는 "선형 증폭 (LA)" 방법으로 지칭됨).
일부 구현예에서, 가이드 RNA의 효능은 체액, 예를 들어, 혈청, 혈장, 혈액 또는 소변과 같은 샘플에서 글리콜레이트 수준 및/또는 옥살레이트 수준을 측정함으로써 측정된다. 일부 구현예에서, 가이드 RNA의 효능은 혈청 또는 혈장 내 글리콜레이트 수준 및/또는 소변 내 옥살레이트 수준을 측정함으로써 측정된다. 혈청 또는 혈장 내 글리콜레이트 수준의 증가 및/또는 소변 내 옥살레이트 수준의 감소는 효과적인 가이드 RNA를 나타낸다. 일부 구현예에서, 소변 옥살레이트는 0.7 mmol/24시간/1.73 m2 미만으로 감소된다. 일부 구현예에서, 글리콜레이트 및 옥살레이트의 수준은 세포 배양 배지 또는 혈청 또는 혈장을 사용한 효소-연결된 면역흡착 검정 (ELISA) 검정을 사용하여 측정된다. 일부 구현예에서, 글리콜레이트 및 옥살레이트의 수준은 편집을 측정하는 데 사용되는 동일한 시험관내 또는 생체내 시스템 또는 모델에서 측정된다. 일부 구현예에서, 글리콜레이트 및 옥살레이트의 수준은 세포, 예를 들어, 1차 인간 간세포에서 측정된다. 일부 구현예에서, 글리콜레이트 및 옥살레이트의 수준은 HUH7 세포에서 측정된다. 일부 구현예에서, 글리콜레이트 및 옥살레이트의 수준은 HepG2 세포에서 측정된다.
II. 치료 방법
본원에 개시된 gRNA 및 관련 방법 및 조성물은 LDHA 유전자 내에 이중-가닥 파괴 (DSB)를 유도하고 LDHA 유전자의 발현을 감소시키는 데 유용하다. 본원에 개시된 gRNA 및 관련 방법 및 조성물은 고수산뇨증의 치료 및 예방 및 고수산뇨증의 증상 예방에 유용하다. 일부 구현예에서, 본원에 개시된 gRNA는 옥살산칼슘 생성, 기관에서의 옥살산칼슘 침착, 원발성 고수산뇨증 (PH1, PH2 및 PH3 포함), 전신성 옥살산증을 포함한 옥살산증 및 혈뇨의 치료 및 예방에 유용하다. 일부 구현예에서, 본원에 개시된 gRNA는 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는데 유용하다. 일부 구현예에서, 본원에 개시된 gRNA는 말기 신장 질환 (ESRD)을 예방하는데 유용하다. 본원에 개시된 gRNA의 투여는 혈청 또는 혈장 글리콜레이트를 증가시키고 옥살레이트 생성 또는 축적을 감소시켜 더 적은 옥살레이트가 소변으로 배설되도록 할 것이다. 따라서, 하나의 양상에서, 치료/예방의 효과는 혈청 또는 혈장 글리콜레이트를 측정하여 평가할 수 있고, 여기서, 글리콜레이트 수준의 증가는 효과를 나타낸다. 일부 구현예에서, 치료/예방의 효과는 소변 옥살레이트와 같은 샘플에서 옥살레이트를 측정하여 평가할 수 있고, 여기서, 소변 옥살레이트의 감소는 효과를 나타낸다.
건강한 대상체의 소변에서 정상적인 1일 옥살레이트 배설물은 약 45 mg 미만이고, 24시간당 약 45 mg을 초과하는 농도는 임상 고수산뇨증으로 간주된다 (예를 들어, 문헌 (Bhasin et al., World J Nephrol 2015 May 6; 4(2): 235-244; and Cochat P., Rumsby G. (2013). N Engl J Med 369:649-658) 참조). 따라서, 일부 구현예에서, 본원에 개시된 gRNA 및 조성물의 투여는 대상체가 임상 고수산뇨증과 관련된 소변 옥살레이트의 수준을 더 이상 나타내지 않도록 옥살레이트의 수준을 감소시키는 데 유용하다. 일부 구현예에서, 본원에 개시된 gRNA 및 조성물의 투여는 대상체의 소변 옥살레이트를 24시간의 기간 내에 약 45 또는 40 mg 미만으로 감소시킨다. 일부 구현예에서, 본원에 개시된 gRNA 및 조성물의 투여는 대상체의 소변 옥살레이트를 24시간의 기간 내에 약 35 mg 미만, 약 30 mg 미만, 약 25 mg 미만, 약 20 mg 미만, 약 15 mg 미만 또는 약 10 mg 미만으로 감소시킨다.
일부 구현예에서, 본원에 기재된 gRNA, 조성물 또는 약제학적 제형 중 임의의 하나 이상은 대상체에서 질환 또는 장애를 치료 또는 예방하기 위한 약제를 제조하는 데 사용하기 위한 것이다. 일부 구현예에서, 치료 및/또는 예방은 약제/조성물의 단일 용량, 예를 들어, 1회 치료로 달성된다. 일부 구현예에서, 질환 또는 장애는 고수산뇨증이다.
일부 구현예에서, 본 발명은 본원에 기재된 gRNA, 조성물 또는 약제 학적 제형 중 임의의 하나 이상을 투여하는 단계 포함하여, 대상체에서 질환 또는 장애를 치료 또는 예방하는 방법을 포함한다. 일부 구현예에서, 질환 또는 장애는 고수산뇨증이다. 일부 구현예에서, 본원에 기재된 gRNA, 조성물 또는 약제학적 제형은, 예를 들어, 단일 용량으로, 1회 투여된다. 일부 구현예에서, 단일 용량은 지속적인 치료 및/또는 예방을 달성한다. 일부 구현예에서, 방법은 지속적인 치료 및/또는 예방을 달성한다. 본원에 사용된 바와 같은 지속적인 치료 및/또는 예방은 적어도 i) 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 또는 15주; ii) 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 18, 24, 30, 또는 36개월; 또는 iii) 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10년에 걸쳐 연장되는 치료 및/또는 예방을 포함한다. 일부 구현예에서, 본원에 기재된 gRNA, 조성물 또는 약제학적 제형의 단일 용량은 대상체의 수명 기간 동안 본원에 기재된 임의의 징후를 치료 및/또는 예방하기에 충분하다.
일부 구현예에서, 본 발명은 본원에 기재된 gRNA, 조성물 또는 약제학적 제형 중 임의의 하나 이상을 포함, 투여 또는 전달하는 단계를 포함하여 표적 DNA를 변형시키는 (예를 들어, 이중 가닥 파괴 생성) 방법 또는 사용을 포함한다. 일부 구현예에서, 표적 DNA는 LDHA 유전자이다. 일부 구현예에서, 표적 DNA는 LDHA 유전자의 엑손에 있다. 일부 구현예에서, 표적 DNA는 LDHA 유전자의 엑손 1, 2, 3, 4, 5, 6, 7, 또는 8에 있다.
일부 구현예에서, 본 발명은 본원에 기재된 gRNA, 조성물 또는 약제학적 제형 중 임의의 하나 이상을 포함, 투여 또는 전달하는 단계를 포함하여 표적 유전자의 조절을 위한 방법 또는 사용을 포함한다. 일부 구현예에서, 조절은 LDHA 표적 유전자의 편집이다. 일부 구현예에서, 조절은 LDHA 표적 유전자에 의해 암호화된 단백질의 발현에서의 변화이다.
일부 구현예에서, 방법 또는 사용은 유전자 편집을 초래한다. 일부 구현예에서, 방법 또는 사용은 표적 LDHA 유전자 내에서 이중-가닥 파괴를 초래한다. 일부 구현예에서, 방법 또는 사용은 DSB의 비-상동성 단부 결합 동안 인델 돌연변이의 형성을 초래한다. 일부 구현예에서, 방법 또는 사용은 표적 LDHA 유전자에서 뉴클레오티드의 삽입 또는 결실을 초래한다. 일부 구현예에서, 표적 LDHA 유전자에서 뉴클레오티드의 삽입 또는 결실은 비-기능적 단백질을 초래하는 프레임 시프트 돌연변이 또는 조기 정지 코돈을 유도한다. 일부 구현예에서, 표적 LDHA 유전자에서 뉴클레오티드의 삽입 또는 결실은 표적 유전자 발현의 녹다운 또는 제거를 유도한다. 일부 구현예에서, 방법 또는 사용은 DSB의 상동성 지시된 복구를 포함한다.
일부 구현예에서, 방법 또는 사용은 LDHA 유전자 조절을 초래한다. 일부 구현예에서, LDHA 유전자 조절은 유전자 발현에서의 감소이다. 일부 구현예에서, 방법 또는 사용은 표적 유전자에 의해 암호화된 단백질의 감소된 발현을 초래한다.
일부 구현예에서, LDHA 유전자 내에 이중-가닥 파괴 (DSB)를 유도하는 방법이 제공되고, 이는 서열번호 1 내지 84의 임의의 하나 이상의 가이드 서열을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 포함하는 조성물을 투여하는 단계를 제공한다. 일부 구현예에서, 서열번호 1 내지 84 및 100 내지 192의 임의의 하나 이상의 가이드 서열을 포함하는 gRNA는 LDHA 유전자에서 DSB를 유도하기 위해 투여된다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, LDHA 유전자를 변형하는 방법이 제공되고, 이는 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 포함하는 조성물을 투여하는 단계를 제공한다. 일부 구현예에서, 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 gRNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전은 LDHA 유전자를 변형시키기 위해 투여된다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, 고수산뇨증을 치료 또는 예방하는 방법이 제공되고, 이는 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 포함하는 조성물을 투여하는 단계를 제공한다. 일부 구현예에서, 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 gRNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전은 고수산뇨증을 치료 또는 예방하기 위해 투여된다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다. 일부 구현예에서, 고수산뇨증은 원발성 고수산뇨증이다. 일부 구현예에서, 원발성 고수산뇨증은 1형 (PH1), 2형 (PH2), 또는 3형 (PH3)이다. 일부 구현예에서, 고수산뇨증 특발성이다.
일부 구현예에서, 옥살산칼슘 생성 및/또는 침착을 감소 또는 제거하는 방법이 제공되고, 이는 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 투여하는 단계를 포함한다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, PH1, PH2, 또는 PH3을 포함하는 원발성 고수산뇨증을 치료 또는 예방하는 방법이 제공되고, 이는 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 투여하는 단계를 포함한다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, 전신성 옥살산증을 포함한 옥살산증을 치료 또는 예방하는 방법이 제공되고, 이는 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 투여하는 단계를 포함한다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, 혈뇨를 치료 또는 예방하는 방법이 제공되고, 이는 서열번호 1 내지 84의 가이드 서열 중 임의의 하나 이상을 포함하는 가이드 RNA, 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전을 투여하는 단계를 포함한다. 가이드 RNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, 서열번호 1 내지 84 및 100 내지 192의 가이드 서열 중 임의의 하나 이상을 포함하는 gRNA 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전은 소변에서 옥살레이트 수준을 감소시키기 위해 투여된다. gRNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, 서열번호 1 내지 84 및 100 내지 192의 가이드 서열 중 임의의 하나 이상을 포함하는 gRNA 또는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081의 임의의 하나 이상의 sgRNA, 또는, 예를 들어, 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로 나타낸 이의 변형된 버전은 혈청 또는 혈장에서 혈청 글리콜레이트를 증가시키기 위해 투여된다. gRNA는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제 또는 Cas 뉴클레아제 (예를 들어, Cas9)와 같은 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA 또는 벡터와 함께 투여될 수 있다.
일부 구현예에서, Cas 뉴클레아제와 같은 RNA-가이드된 DNA 뉴클레아제와 함께 표 1의 가이드 서열을 포함하는 gRNA는 DSB를 유도하고, 복구 동안 비-상동 말단 결합 (NHEJ)은 LDHA 유전자의 돌연변이를 유도한다. 일부 구현예에서, NHEJ는 뉴클레오티드(들)의 결실 또는 삽입을 유발하고, 이는 LDHA 유전자에서 프레임 시프트 또는 넌센스 돌연변이를 유도한다.
일부 구현예에서, 본 발명의 가이드 RNA를 (예를 들어, 본원에 제공된 조성물에서) 투여하면 대상체에서 글리콜레이트의 수준 (예를 들어, 혈청 또는 혈장 수준)이 증가하므로 옥살레이트 축적을 예방한다.
일부 구현예에서, 혈청 글리콜레이트를 증가시키면 소변 옥살레이트의 감소를 초래한다. 일부 구현예에서, 소변 옥살 레이트의 감소는 기관에서의 옥살산칼슘 형성 및 침착을 감소 또는 제거한다.
일부 구현예에서, 대상체는 포유류이다. 일부 구현예에서, 대상체는 인간이다. 일부 구현예에서, 대상체는 소, 돼지, 원숭이, 양, 개, 고양이, 어류 또는 가금류이다.
일부 구현예에서, 표 1의 가이드 서열 중 임의의 하나 이상 또는 표 2로부터의 하나 이상의 sgRNA (예를 들어, 본원에 제공된 조성물에서)를 포함하는 가이드 RNA의 용도는 고수산뇨증을 갖는 인간 대상체를 치료하기 위한 약제의 제조를 위해 제공된다.
일부 구현예에서, 가이드 RNA, 조성물, 및 제형은 정맥내로 투여된다. 일부 구현예에서, 가이드 RNA, 조성물, 및 제형은 간 순환으로 투여된다.
일부 구현예에서, 본원에 제공된 가이드 RNA를 포함하는 조성물의 단일 투여는 돌연변이 단백질의 발현을 녹다운하기에 충분하다. 다른 구현예에서, 본원에 제공된 가이드 RNA를 포함하는 조성물의 1회 초과의 투여는 치료 효과를 최대화하는데 유익할 수 있다.
일부 구현예에서, 치료는 고수산뇨증 질환 진행을 늦추거나 중단시킨다.
일부 구현예에서, 치료는 말기 신장 질환 (ESRD)의 진행을 늦추거나 중단시킨다. 일부 구현예에서, 치료는 콩팥 및/또는 간 이식의 필요성을 늦추거나 중단시킨다. 일부 구현예에서, 치료는 고수산뇨증 증상의 개선, 안정화, 또는 변화를 늦추는 것을 초래한다.
A. 병용 요법
일부 구현예에서, 본 발명은 (예를 들어, 본원에 제공된 조성물에서) 표 1에 개시된 가이드 서열 중 임의의 하나 이상을 포함하는 임의의 하나의 gRNA 를 포함하는 병용 요법을 상기 기재된 바와 같이 고수산뇨증 및 이의 증상을 완화시키는 데 적합한 추가 요법과 함께 포함한다.
일부 구현예에서, 고수산뇨증에 대한 추가 요법은 비타민 B6, 수화, 신장 투석, 또는 간 또는 콩팥 이식이다. 일부 구현예에서, 추가 요법은 LDHA 유전자를 파괴하는 또 다른 제제, 예를 들어 LDHA 유전자에 지시된 siRNA이다. 일부 구현예에서, LDHA 유전자에 지시된 siRNA는 DCR-PHXC이다. 일부 구현예에서, 예컨대 고수산뇨증이 PH1에 의해 야기되는 경우, 추가 요법은, 예를 들어, HAO1 유전자에 지시된 siRNA와 같은 HAO1 유전자를 파괴하는 제제이다. 일부 구현예에서, HAO1 siRNA는 루마시란 (ALN-GO1; Alnylam)이다.
일부 구현예에서, 병용 요법은 HAO1 또는 LDHA를 표적화하는 siRNA와 함께 표 1에 개시된 가이드 서열 중 임의의 하나 이상을 포함하는 임의의 하나의 gRNA를 포함한다. 일부 구현예에서, siRNA는 LDHA의 발현을 추가로 감소 또는 제거할 수 있는 임의의 siRNA이다. 일부 구현예에서, siRNA는 (예를 들어, 본원에 제공된 조성물에서) 표 1에 개시된 가이드 서열 중 임의의 하나 이상을 포함하는 임의의 하나의 gRNA 뒤에 투여된다. 일부 구현예에서, siRNA는 본원에 제공된 임의의 gRNA 조성물로 치료한 후 정기적으로 투여된다.
일부 구현예에서, 병용 요법은 LDHA를 표적화하는 안티센스 뉴클레오티드와 함께 (예를 들어, 본원에 제공된 조성물에서) 표 1에 개시된 가이드 서열 중 임의의 하나 이상을 포함하는 임의의 하나의 gRNA를 포함한다. 일부 구현예에서, 안티센스 뉴클레오티드는 LDHA의 발현을 추가로 감소 또는 제거할 수 있는 임의의 안티센스 뉴클레오티드이다. 일부 구현예에서, 안티센스 뉴클레오티드는 (예를 들어, 본원에 제공된 조성물에서) 표 1에 개시된 가이드 서열 중 임의의 하나 이상을 포함하는 임의의 하나의 gRNA 뒤에 투여된다. 일부 구현예에서, 안티센스 뉴클레오티드는 본원에 제공된 임의의 gRNA 조성물로 처리 후 정기적으로 투여된다.
B. gRNA 조성물의 전달
지질 나노입자 (LNP)는 뉴클레오티드 및 단백질 카고 (cargo)의 전달을 위한 잘 알려진 수단이고, 본원에 개시된 가이드 RNA, 조성물 또는 약제학적 제형의 전달에 사용될 수 있다. 일부 구현예에서, LNP는 핵산, 단백질, 또는 단백질과 함께 핵산을 전달한다.
일부 구현예에서, 본 발명은 본원에 개시된 임의의 하나의 gRNA를 대상체에게 전달하는 방법을 포함하고, 여기서, gRNA는 LNP와 회합된다. 일부 구현예에서, gRNA/LNP는 또한 Cas9 또는 Cas9를 암호화하는 mRNA와 회합된다.
일부 구현예에서, 본 발명은 개시된 임의의 하나의 gRNA 및 LNP를 포함하는 조성물을 포함한다. 일부 구현예에서, 조성물은 Cas9 또는 Cas9를 암호화하는 mRNA를 추가로 포함한다.
일부 구현예에서, LNP는 양이온성 지질을 포함한다. 일부 구현예에서, LNP는 3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 (9Z,12Z)-옥타데카-9,12-디에노에이트)로도 불리는 (9Z,12Z)-3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 옥타데카-9,12-디에노에이트 또는 또 다른 이온화 가능한 지질을 포함한다. 예를 들어, WO/2017/173054 및 본원에 기재된 참조문헌을 참조한다. 일부 구현예에서, LNP는 약 4.5, 5.0, 5.5, 6.0, 또는 6.5의 양이온성 지질 아민 대 RNA 포스페이트 (N:P)의 몰 비를 포함한다. 일부 구현예에서, LNP 지질과 관련하여 용어 양이온성 및 이온화 가능은 상호교환 가능하고, 예를 들어, 이온화 가능한 지질은 pH에 따라 양이온성이다.
일부 구현예에서, 본원에 개시된 gRNA와 회합된 LNP는 질환 또는 장애를 치료하기 위한 약제를 제조하는데 사용하기 위한 것이다.
전기천공은 카고 전달을 위한 잘 알려진 수단이고, 임의의 전기 천공 방법은 본원에 개시된 임의의 하나의 gRNA를 전달을 위해 사용될 수 있다. 일부 구현예에서, 전기천공은 본원에 개시된 임의의 하나의 gRNA 및 Cas9 또는 Cas9를 암호화하는 mRNA를 전달하는 데 사용될 수 있다.
일부 구현예에서, 본 발명은 본원에 개시된 임의의 하나의 gRNA를 생체외 세포에 전달하는 방법을 포함하고, 여기서, gRNA는 LNP와 회합되거나 LNP와 회합되지 않는다. 일부 구현예에서, gRNA/LNP 또는 gRNA는 또한 Cas9 또는 Cas9를 암호화하는 mRNA와 회합된다.
일부 구현예에서, 본원에 기재된 가이드 RNA 조성물은 단독으로 또는 하나 이상의 벡터에서 암호화되고, 지질 나노입자로 제형화되거나 이를 통해 투여된다; 예를 들어, 2017년 3월 30일에 출원되고 2017년 5월 10일에 공개된 "CRISPR/CAS 구성요소를 위한 지질 나노입자 제형"이라는 명칭의 WO/2017/173054를 참조하고, 상기 특허는 그 내용이 그 전체가 본원에 참조로 포함된다.
특정 구현예에서, 본 발명은 본원에 기재된 가이드 서열 중 임의의 하나 이상을 포함하는 임의의 가이드 RNA를 암호화하는 DNA 또는 RNA 벡터를 포함한다. 일부 구현예에서, 가이드 RNA 서열 이외에, 벡터는 가이드 RNA를 암호화하지 않는 핵산을 추가로 포함한다. 가이드 RNA를 암호화하지 않는 핵산은 프로모터, 인핸서, 조절 서열, 및 Cas9와 같은 뉴클레아제일 수 있는 RNA-가이드된 DNA 뉴클레아제를 암호화하는 핵산을 포함하지만 이에 제한되지 않는다. 일부 구현예에서, 벡터는 crRNA, trRNA, 또는 crRNA 및 trRNA를 암호화하는 하나 이상의 뉴클레오티드 서열(들)을 포함한다. 일부 구현예에서, 벡터는 sgRNA를 암호화하는 하나 이상의 뉴클레오티드 서열(들) 및 Cas9 또는 Cpf1과 같은 Cas 뉴클레아제일 수 있는 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA를 포함한다. 일부 구현예에서, 벡터는 crRNA를 암호화하는 하나 이상의 뉴클레오티드 서열(들), trRNA, 및 Cas9와 같은 Cas 단백질일 수 있는 RNA-가이드된 DNA 뉴클레아제를 암호화하는 mRNA를 포함한다. 하나의 구현예에서, Cas9는 스트렙토코커스 피로게네스 (즉, Spy Cas9)로부터 유래된다. 일부 구현예에서, crRNA, trRNA, 또는 crRNA 및 trRNA (sgRNA일 수 있음)를 암호화하는 뉴클레오티드 서열은 자연 발생 CRISPR/Cas 시스템으로부터의 반복 서열의 전부 또는 일부가 측면에 있는 가이드 서열을 포함하거나 이로 이루어진다. crRNA, trRNA, 또는 crRNA 및 trRNA를 포함하거나 이로 이루어진 핵산은 벡터 서열을 추가로 포함할 수 있고, 여기서, 벡터 서열은 crRNA, trRNA 또는 crRNA 및 trRNA와 함께 자연적으로 발견되지 않는 핵산을 포함하거나 이로 이루어진다.
이 설명 및 예시적인 구현예는 제한적인 것으로 간주되어서는 안된다. 이 명세서 및 첨부된 청구범위의 목적을 위해, 달리 나타내지 않는 한, 명세서 및 청구범위에 사용된 수량, 백분율, 또는 비율을 표현하는 모든 숫자 및 기타 수치는 아직 비변형된 범위 내에서 모든 경우에 "약"이라는 용어에 의해 변형된 것으로 이해되어야 한다. 따라서, 반대로 나타내지 않는 한, 하기 명세서 및 첨부된 청구범위에 기재된 수치 파라미터는 얻고자 하는 원하는 성질에 따라 변할 수 있는 근사치이다. 적어도 청구 범위에 대한 등가 원칙의 적용을 제한하려는 시도가 아니라, 각 수치 파라미터는 적어도 보고된 유효 자릿수와 일반적인 반올림 기술을 적용하여 해석되어야 한다.
본 명세서 및 첨부된 청구범위에서 사용된 바와 같이, 단수 형태 "a", "an" 및 "the" 및 임의의 단어의 임의의 단수 사용은 명시적이고 명확하게 하나의 대상으로 제한되지 않는 한 복수 대상을 포함한다는 점에 유의한다. 본원에 사용된 바와 같이, 용어 "포함하다" 및 이의 문법적 변형은 비제한적인 것으로 의도되어, 목록에 있는 항목의 인용이 나열된 항목에 대체되거나 추가될 수 있는 다른 유사한 항목을 배제하지 않도록 한다.
실시예
다음 실시예는 특정 개시된 구현예를 예시하기 위해 제공되고, 어떠한 방식으로든 본 개시내용의 범위를 제한하는 것으로 해석되어서는 안된다.
실시예 1 - 재료 및 방법
뉴클레아제 mRNA의 시험관내 전사 ("IVT")
N1-메틸 슈도-U를 포함하는 캡핑 및 폴리아데닐화 스트렙토코커스 피오게네스 ("Spy") Cas9 mRNA는 선형화된 플라스미드 DNA 주형 및 T7 RNA 폴리머라제를 사용하여 시험관내 전사에 의해 생성되었다. T7 프로모터 및 전사를 위한 서열을 포함하는 플라스미드 DNA (본원에 기재된 mRNA를 포함하는 mRNA를 생성하기 위한) (예시적인 ORF에 대해 아래 표 24의 서열번호 501-515 참조)는 37℃에서 항온처리하여 다음 조건에서 XbaI로 분해를 완료함으로써 선형화되었다: 200 ng/μL 플라스미드, 2 U/μL XbaI (NEB) 및 1x 반응 완충액. 반응을 65℃에서 20분 동안 가열함으로써 XbaI를 비활성화시켰다. 선형화된 플라스미드를 실리카 맥시 스핀 컬럼 (Epoch Life Sciences)을 사용하여 효소 및 완충액 염으로부터 정제하고, 아가로스 겔로 분석하여 선형화를 확인하였다. Cas9 변형된 mRNA를 생성하기 위한 IVT 반응은 다음 조건에서 37℃에서 4시간 동안 항온처리되었다: 50 ng/μL 선형화된 플라스미드; 각각 2 mM의 GTP, ATP, CTP, 및 N1-메틸 슈도-UTP (Trilink); 10 mM ARCA (Trilink); 5 U/μL T7 RNA 폴리머라제 (NEB); 1 U/μL Murine RNase 억제제 (NEB); 0.004 U/μL 무기 이. 콜리 피로포스파타제 (NEB); 및 1x 반응 완충액. 4시간 항온처리 후, TURBO DNase (ThermoFisher)를 최종 농도 0.01 U/μL로 첨가하고, 반응물을 추가 30분 동안 항온처리하여 DNA 주형을 제거하였다. Cas9 mRNA는 제조사의 프로토콜 (ThermoFisher)에 따라 MegaClear 전사 클립-업 키트를 사용하여 효소와 뉴클레오티드로부터 정제되었다. 대안적으로, Cas9 mRNA는 LiCl 침전 방법으로 정제되었고, 일부 경우에는 접선 유동 여과에 의한 추가 정제가 이어졌다. 전사체 농도는 260 nm (Nanodrop)에서 흡광도를 측정하여 결정하고, 전사체는 Bioanlayzer (Agilent)에 의한 모세관 전기영동으로 분석하였다.
실시예에서 사용된 Cas9 mRNA의 전사를 위한 서열은 표 24에 나타낸 바와 같이 서열번호 501 내지 515로부터 선택된 서열을 포함한다.
[표 24] 예시적인 Cas9 mRNA 서열























지질 나노입자 (LNP) 제형
일반적으로, 지질 나노입자 성분은 다양한 몰 비로 100% 에탄올에 용해되었다. RNA 카고 (예를 들어, Cas9 mRNA 및 sgRNA)를 25 mM 시트레이트, 100 mM NaCl, pH 5.0에 용해시켜 대략 0.45 mg/mL의 RNA 카고 농도를 생성하였다. 실시예 2 내지 4에서 사용된 LNP는 3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 (9Z,12Z)-옥타데카-9,12-디에노에이트)로도 불리는 이온화 가능한 지질 ((9Z,12Z)-3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 옥타데카-9,12-디에노에이트, 콜레스테롤, DSPC, 및 PEG2k-DMG를 각각 50:38:9:3 몰 비로 함유하였다. LNP는 지질 아민 대 RNA 포스페이트 (N:P) 몰 비가 약 6이고 gRNA 대 mRNA의 비가 중량 기준으로 1:1로 제형화되었다.
LNP는 2 부피의 RNA 용액 및 1 부피의 물과 함께 에탄올 중에서 지질의 충돌 제트 혼합을 사용하는 교차-유동 기술을 사용하여 준비되었다. 에탄올에서 지질은 2 부피의 RNA 용액과 혼합 교차를 통해 혼합되었다. 제4 스트림의 물은 인라인 티 (inline tee)를 통해 교차의 출구 스트림과 혼합되었다 (WO2016010840 도 2 참조). LNP를 실온에서 1시간 동안 유지하고, 물로 추가로 희석하였다 (대략 1:1 v/v). 희석된 LNP는 평평한 시트 카트리지 (Sartorius, 100kD MWCO)에서 접선 유동 여과를 사용하여 농축한 다음, PD-10 탈염 컬럼 (GE)을 사용하여 50 mM Tris, 45 mM NaCl, 5% (w/v) 수크로스, pH 7.5 (TSS)로 완충액 교환하였다. 이어서, 생성된 혼합물을 0.2 μm 멸균 필터를 사용하여 여과하였다. 최종 LNP는 추가로 사용할 때까지 4℃ 또는 -80℃에서 보관하였다.
인간 LDHA 가이드 디자인 및 사이노몰구스 상동성 가이드 디자인을 사용하는 인간 LDHA
관심 영역에서 PAM을 식별하기 위해 인간 참조 게놈 (예를 들어, hg38) 및 사용자 정의된 관심 게놈 영역 (예를 들어, LDHA 단백질 암호화 엑손)을 사용하여 초기 가이드 선택을 인실리코로 수행하였다. 식별된 각 PAM에 대해, 분석을 수행하고 통계를 보고하였다. gRNA 분자를 추가로 선택하고, 당업계에 알려진 다수의 기준 (예를 들어, GC 함량, 예측된 표적상 (on-target) 활성 및 잠재적인 오프-표적 활성)에 기초하여 순위를 매겼다.
총 84개의 가이드 RNA는 단백질 엑소닉 암호화 영역을 표적화하는 인간 LDHA (ENSG00000134333)에 대해 디자인되었다. 가이드 및 상응하는 게놈 좌표가 상기 제공된다 (표 1). 40개의 가이드 RNA는 사이노몰구스 LDHA와 100% 상동성을 갖는다.
추가 가이드는 드 보노 사이노몰구스 마카크 LDHA 전사체에 대해 디자인되었다. 미가공 (raw) 데이터는 모리셔스-기원 암컷 사이노몰구스 마카크로부터 간 샘플의 공개된 전사체 서열분석으로부터 얻었다 (NCBI SRA ID: SRR1758956; Peng et al. (2015), Nucleic Acids Research, Volume 43, Issue D1, Pages D737-D742). 드 보노 전사체 어셈블리는 Trinity (v2.8.4; Grabherr et al. (2011), Nature Biotechnology, 29: 644-652) 및 SPAdes (v3.13.0; Bankevich et al. (2012), Journal of Computational Biology, 19:5)를 사용하여 수행되었다. 두 방법 모두 LDHA 전사체를 어셈블링할 수 있었는데, 이는 이들의 서열을 LDHA 단백질 (UniProt ID: Q9BE24)과 BLAST (Altschul et al. (1990), Journal of Molecular Biology, 215:3, 403-410)와 비교하여 식별되었다. 시험관내 Cas9 (mRNA/단백질) 및 가이드 RNA 전달.
1차 인간 간 간세포 (PHH) (Gibco, Lot# Hu8298 또는 Hu8296) 및 1차 사이노몰구스 간 간세포 (PCH) (Gibco, Lot# Cy367 또는 In Vitro ADMET Laboratories, Inc. Lot# 10281011)를 해동시키고 보충제 (Gibco, Cat. CM7500)와 함께 간세포 해동 배지에 재현탁시킨 다음, 원심 분리하였다. 상청액을 버리고 펠릿화된 세포를 간세포 플레이팅 배지와 보충 팩 (Invitrogen, Cat. A1217601 및 CM3000)에 재현탁시켰다. 세포를 계수하고, PHH의 경우 33,000개 세포/웰 및 PCH의 경우 50,000개 세포/웰의 밀도로 Bio-coat 콜라겐 I 코팅된 96-웰 플레이트 (ThermoFisher, Cat. 877272)에 플레이팅하였다. 플레이팅된 세포를 37℃ 및 5% CO2 분위기에서 조직 배양 인큐베이터에서 5시간 동안 침강 및 부착되도록 하였다. 항온처리 후, 세포를 단층 형성에 대해 확인하였고, 간세포 배양 배지 (Takara, Cat. Y20020 및/또는 Invitrogen, Cat. A1217601 및 CM4000)로 1회 세척 하였다.
dgRNA를 사용하는 연구를 위해, 개별 crRNA 및 trRNA는 동일한 양의 시약을 혼합하고 95℃에서 2분 동안 항온처리하고 실온으로 냉각시킴으로써 사전- 어닐링되었다. 사전-어닐링된 crRNA 및 trRNA로 이루어진 이중 가이드 (dgRNA)를 Spy Cas9 단백질과 함께 배양하여 리보핵단백질 (RNP) 복합체를 형성하였다. 세포는 제조업체의 프로토콜에 따라 리포펙타민 (Lipofectamine) RNAiMAX (ThermoFisher, Cat. 13778150)로 형질감염시켰다. 세포는 Spy Cas9 (10 nM), 개별 가이드 (10 nM), 트레이서 (tracer) RNA (10 nM), 리포펙타민 RNAiMAX (1.0 μL/웰) 및 OptiMem을 포함하는 RNP로 형질감염시켰다.
sgRNA를 사용하는 연구를 위해, 가이드를 Spy Cas9 단백질과 함께 항온처리하여 리보핵단백질 (RNP) 복합체를 형성하였다. RNP 형질감염을 사용하는 연구에서, 세포는 제조업체의 프로토콜에 따라 리포펙타민 RNAiMAX (ThermoFisher, Cat. 13778150)로 형질감염시켰다. 세포는 Spy Cas9 (10 nM), sgRNA (10 nM), 리포펙타민 RNAiMAX (1.0 μL/웰) 및 OptiMem을 함유하는 RNP로 형질감염시켰다. 전기천공을 이용하는 연구에서, 세포는 Lonza 4D-Nucleofector 코어 유닛 (Cat. AAF-1002X), 96-웰 셔틀 장치 (Shuttle Device) (Cat. AAM 10015), 및 P3 1차 세포 키트 (Cat. V4XP-3960)를 사용하여 Spy Cas9 (2 uM) 및 sgRNA (4 uM)를 함유하는 RNP로 전기천공하였다.
1차 인간 및 사이노몰구스 간세포는 또한 아래에 추가로 설명되는 바와 같이 LNP로 처리되었다. LNP로 처리하기 전에 세포를 37℃, 5% CO2에서 48시간 동안 항온처리하였다. LNP를 3% 사이노몰구스 혈청을 함유하는 배지에서 37℃에서 10분 동안 항온처리하고, 여기에 추가로 제공된 양으로 세포에 투여하였다.
Cas9 mRNA 및 gRNA의 리포펙션은 지질 성분이 50% 지질 A, 9% DSPC, 38% 콜레스테롤 및 3% PEG2k-DMG의 몰 비로 100% 에탄올에서 재구성된 사전-혼합된 지질 제형을 사용하였다. 이어서, 지질 혼합물을 약 6.0의 지질 아민 대 RNA 포스페이트 (N:P) 몰 비로 RNA 카고 (예를 들어, Cas9 mRNA 및 gRNA)와 혼합하였다. 리포펙션은 6% 사이노몰구스 혈청과 gRNA 대 mRNA의 비가 중량 기준으로 1:1로 수행되었다.
게놈 DNA 단리
PHH 및 PCH 형질감염된 세포를 형질감염 후 72 또는 96시간에 수확 하였다. gDNA는 제조업체의 프로토콜에 따라 50 μL/웰 BuccalAmp DNA 추출 용액 (Epicentre, Cat. QE09050)을 사용하여 96-웰 플레이트의 각 웰로부터 추출되었다. 모든 DNA 샘플은 본원에 기재된 바와 같이 PCR 및 후속 NGS로 분석되었다.
표적상 절단 효율을 위한 차세대 서열분석 ("NGS") 및 분석
게놈의 표적 위치에서 편집의 효율을 정량적으로 결정하기 위해, 심층 서열분석을 사용하여 유전자 편집에 의해 도입된 삽입 및 삭제의 존재를 식별하였다. 관심 유전자 (예를 들어, LDHA) 내의 표적 부위 주변에 PCR 프라이머를 디자인하고 관심 게놈 영역을 증폭시켰다. 프라이머 서열 디자인은 현장에서 표준으로 수행되었다.
제조업체의 프로토콜 (Illumina)에 따라 추가 PCR을 수행하여 서열분석을 위한 화학 물질을 추가하였다. 앰플리콘은 Illumina MiSeq 기기에서 서열분석되었다. 판독치는 품질 스코어가 낮은 항목을 제거한 후 참조 게놈 (예를 들어, hg38)에 정렬되었다. 판독치를 포함하는 생성된 파일은 참조 게놈 (BAM 파일)에 매핑되었고, 여기서, 관심 표적 영역과 겹치는 판독치가 선택되었고 야생형 판독치의 수와 삽입 또는 결실을 포함하는 판독치의 수 ("인델")가 계산되었다.
편집 백분율 (예를 들어, "편집 효율" 또는 "편집 퍼센트")은 야생형을 포함한 총 서열 판독치의 수에 대한 삽입 또는 결실 ("인델")이 있는 서열 판독치의 총 수로서 정의된다.
웨스턴 블롯에 의한 락테이트 데하이드로게나제 A (LDHA) 단백질 분석
1차 인간 간세포를 실시예 3에 추가로 기재된 바와 같이 표 1로부터의 선택 가이드로 제형화된 LNP로 처리하였다. LNP는 3% 사이노몰구스 혈청을 함유하는 배지 (Takara, Cat. Y20020)에서 37℃에서 10분 동안 항온처리하였다. 항온처리 후 LNP를 인간 간세포에 첨가하였다. 형질감염 21일 후, 배지를 제거하고, 세포를 50 μL/웰 RIPA 완충액 (Boston Bio Products, Cat. BP-115)과 완전 프로테아제 억제제 칵테일 (Sigma, Cat. 11697498001), 1 mM DTT, 및 250 U/ml 벤조나제 (Benzonase) (EMD Millipore, Cat. 71206-3)로 이루어진 새로 첨가된 프로테아제 억제제 혼합물로 용해시켰다. NaCl (1 M 최종 농도)이 첨가될 때 세포는 30분 동안 얼음에 유지시켰다. 세포 용해물을 완전히 혼합하고, 얼음 위에서 30분 동안 유지하였다. 전체 세포 추출물 ("WCE")을 PCR 플레이트로 옮기고 원심 분리하여 펠렛 파편으로 만들었다. 브래드포드 (Bradford) 검정 (Bio-Rad, Cat. 500-0001)을 사용하여 용해물의 단백질 함량을 평가하였다. 브래드포드 검정 절차는 제조업체의 프로토콜에 따라 완료되었다. 추출물은 사용하기 전에 -20℃에서 보관되었다.
AGT-결핍 마우스는 실시예 4에 추가로 기재된 바와 같이 선택 가이드로 제형화된 LNP로 처리하였다. 치료후 마우스로부터 간을 수확하고 단백질 추출을 위해 60 mg 부분을 사용하였다. 샘플을 비드 튜브 (MP Biomedical, Cat. 6925-500)에 넣고, 600 μL/샘플의 RIPA 완충액 (Boston Bio Products, Cat. BP-115)과 완전 프로테아제 억제제 칵테일 (Sigma, Cat. 116974500)로 이루어진 새로 첨가된 프로테아제 억제제 혼합물로 용해하고 5.0 m/초로 균질화하였다. 이어서, 샘플을 4℃에서 10분 동안 14,000 RPM에서 원심분리하고, 액체를 새 튜브로 옮겼다. 최종 원심분리는 14,000 RPM에서 10분 동안 수행되었고, 샘플은 상기 기재된 바와 같이 브래드포드 검정을 사용하여 정량화되었다.
LDHA 단백질 수준을 평가하기 위해 웨스턴 블롯을 수행하였다. 용해물을 Laemmli 완충액과 혼합하고, 95℃에서 10분 동안 변성시켰다. 블롯은 제조업체의 프로토콜에 따라 10% Bis-Tris 겔 (Thermo Fisher Scientific, Cat. NP0302BOX)에서 NuPage 시스템을 사용하여 실행한 다음, 0.45 μm 니트로셀룰로오스 막 (Bio-Rad, Cat. 1620115) 상에 습식 전달하였다. 전이 막을 물로 완전히 헹구고, Ponceau S 용액 (Boston Bio Products, Cat. ST-180)으로 염색하여 완전하고 균일한 전이를 확인하였다. 블롯은 실온에서 실험실 로커에서 30분 동안 TBS 중 5% 분유를 사용하여 차단되었다. 블롯은 TBST로 헹구고, TBST에서 1:1000으로 토끼 α-LDHA 폴리클로날 항체 (세포 용해물의 경우 Sigma, Cat. SAB2108638 또는 마우스 간 용해물의 경우 Genetex, Cat. GTX101416)로 프로브되었다. 시험관내 세포 용해물을 사용한 블롯의 경우, TBST에서 1:1000으로 로딩 대조군 (Novus, Cat. NB600-501)으로 베타-액틴을 사용하고, LDHA 1차 항체와 동시에 항온처리하였다. 생체내 마우스 간 추출물을 사용한 블롯의 경우, GAPDH를 TBST에서 1:1000으로 로딩 대조군 (Abcam, ab8245)으로서 사용하고, LDHA 1차 항체와 동시에 항온처리하였다. 블롯을 백에 밀봉하고, 실험실 로커에서 4℃에서 밤새 보관하였다. 항온처리 후, 블롯을 TBST에서 각각 5분 동안 3회 헹구고, 실온에서 30분 동안 TBST에서 각각 1:12,500으로 마우스 및 토끼 (Thermo Fisher Scientific, Cat. PI35518 및 PISA535571)에 대한 2차 항체로 프로브되었다. 항온처리 후, 블롯을 TBST에서 각각 5분 동안 3회, PBS로 2회 헹구었다. 블롯을 Licor Odyssey 시스템을 사용하여 시각화하고 분석하였다.
면역조직화학적 염색에 의한 락테이트 데하이드로게나제 A (LDHA) 단백질 분석
마우스 간의 시각적 LDHA 단백질 분석을 위해, 표준 면역조화학적 염색이 Lecia Bond Rxm에서 수행되었다. 항원 복구 (HIER)를 위해, 슬라이드를 94℃에서 25분 동안 pH 9 EDTA-기반 완충액에서 가열한 다음, 1:500에서 30분 항체 항온처리 (Abcam Cat. Ab52488)를 수행하였다. 항체 결합은 HRP-접합된 2차 중합체를 사용하여 검출한 다음, 디아미노벤지딘으로 발색 시각화를 수행하였다.
마우스 근육 및 간으로부터 LDH 활성 측정
락테이트 데하이드로게나제 활성을 위해 생화학적 방법 (예를 들어, Wood KD et al., Biochim Biophys Acta Mol Basis Dis. 2019 Sep 1;1865(9):2203-2209; PMC6613992)이 사용되었다. 락테이트 데하이드로게나제 활성의 측정을 위해, 조직을 빙냉 용해 완충액 (25 mM HEPES, pH 7.3, 0.1% Triton-X-100)에서 프로브 초음파 처리로 균질화하여 10% wt/vol 용해물을 제공하였다. LDH 활성은 락테이트의 존재하에 NAD를 NADH로 감소시키면서 340 nm에서 흡광도의 증가에 의해 측정되었다. LDG의 락테이트 대 피루베이트 활성은 20 mM 락테이트, 100 mM Tris-HCL, pH 9.0, 2 mM NAD+, 0.01% 간 용해물로 측정되었다. 소 혈청 알부민 (BSA)을 표준으로 하는 쿠마시 플러스 (Cooomassie Plus) 단백질 분석 키트 (Pierce, Rockford, IL)를 사용하여 조직 용해물에서 단백질 농도를 측정하였다.
마우스 샘플로부터 옥살레이트, 크레아티닌, 피루베이트, 및 락테이트 측정
옥살레이트 측정을 위해, -80℃에서 저장하기 전에 소변 수집의 일부를 HCl로 1과 2 사이의 pH로 산성화하여 저온 저장 및/또는 알칼리화와 관련된 옥살로겐시스로 발생할 수 있는 임의의 가능한 옥살레이트 결정화를 방지하였다. 남은 산성화되지 않은 소변은 크레아티닌 측정을 위해 -80℃에서 냉동되었다. 질량 분석법 또는 ICMS (Thermo Fisher Scientific Inc., Waltham, MA)와 결합된 이온 크로마토그래피 이전에 거대 분자를 제거하기 위해 10,000 공칭 분자량 한계를 갖는 나노-sep 원심분리 필터 (VWR International, Batavia, IL)를 통해 혈장 제제를 여과하였다. 원심분리 필터는 필터 장치에 포획된 임의의 오염 미량 유기산을 제거하기 위해 샘플 여과 전에 10 mM HCl로 세척되었다. 간 조직은 유기산 분석을 위해 10% (wt/vol) 트리클로로아세트산 (TCA)으로 추출하였다. 이들 유기산은 동일한 부피의 1,1,2-트리클로로트리플루오로에탄 (Freon)-트리옥틸아민 (3:1, vol/vol; Aldrich, Milwaukee, WI)으로 격렬하게 볼텍싱하고, 상 분리를 촉진하기 위해 4℃에서 원심분리하고, 분석을 위해 상부 수성 층을 수집하여 TCA를 제거한 후 ICMS로 측정하였다. 이전에 기재된 바와 같이, 소변 크레아티닌은 화학 분석기로 측정하고, 소변 옥살레이트는 ICMS로 측정하였다.
다음 질량/전하 비 및 콘 전압에서 선택된-이온 모니터링 (SIM)을 사용하여 락테이트 (SIM 89.0, 35V) 및 13C3-락테이트 (SIM 92.0, 35V)를 정량화하였다. 피루베이트 AS11-HC 4 μm, 2 x 150 mm, 30℃의 제어된 온도에서 음이온 교환 컬럼 및 Dionex™ ERS™ 500 음이온 전기분해 재생 억제기를 사용하여 IC/MS로 측정되었다. 0.38 ml/분의 유속에서 60분에 걸쳐 0.5 mM로부터 80 mM 까지 KOH 구배를 사용하여 샘플 음이온을 분리하였다. 질량 분석기 (MSQ-PLUS)는 ESI 네거티브 모드, 니들 전압 1.5 V, 500℃ 소스 온도에서 작동하고, 컬럼 용리액은 MSQ에 들어가기 전에 제로 데드 부피 혼합 티 (tee)를 사용하여 0.38 ml/분에서 50% 아세토니트릴과 혼합하였다. 피루베이트 (SIM 87.0, 30 V)를 위해 다음 질량/충전 비 및 콘 전압에서 선택된-이온 모니터링 (SIM)을 사용하였다.
실시예 2 - 스크리닝 및 가이드 적격성 평가
1차 간세포에서 LDHA 가이드의 교차 스크리닝
인간 LDHA를 표적화하는 가이드 및 사이노몰구스 원숭이에서 상동성을 갖는 가이드를 실시예 1에 기재된 바와 같이 1차 인간 (RNP 형질감염을 통해) 및 사이노몰구스 간세포 (RNP 전기천공을 통해)로 형질감염시켰다. 퍼센트 편집은 각 세포 유형에 걸쳐 각 가이드 서열을 포함하는 sgRNA에 대해 결정되었다. 두 세포주에서 표 1의 가이드 서열에 대한 스크리닝 데이터는 아래에 나열되어 있다 (표 4-5).
표 4는 1차 인간 간세포에 RNP로 형질감염된 LDHA에 대한 % 편집, % 삽입 (Ins) 및 % 결실 (Del)에 대한 중복 샘플의 평균 및 표준 편차를 나타낸다. N = 2.
[표 4]



표 5는 1차 사이노몰구스 간세포에서 RNP로 전기천공된 시험된 LDHA sgRNA에 대한 % 편집, % 삽입 (Ins) 및 % 결실 (Del)에 대한 평균 및 표준 편차를 나타낸다. N = 2.
[표 5]

표 6은 30 nM 농도의 sgRNA에서 리포펙션을 사용하여 1차 사이노몰구스 간세포에서 시험된 LDHA sgRNA에 대한 다중 염색체 위치에 걸친 % 편집에 대한 평균 및 표준 편차를 나타낸다. N = 2.
[표 6]




1차 인간 및 1차 사이노몰구스 간세포 편집 데이터에 기초하여, 가이드 서열의 서브세트가 추가로 평가되었다. 이 서브세트는 표 7 및 8에 제공되고, 1차 간세포 스크린으로부터 상응하는 편집 데이터가 재현된다.
[표 7]

[표 8]

LDHA 가이드의 오프-표적 분석
생화학적 방법 (예를 들어, 문헌 (Cameron et al., Nature Methods. 6, 600-606; 2017) 참조)을 사용하여 LDHA를 표적화하는 Cas9에 의해 절단된 잠재적인 오프-표적 게놈 부위를 결정하였다. 이 실험에서, 인간 LDHA를 표적화하는 10개의 변형된 sgRNA (및 알려진 오프-표적 프로파일을 가진 2개의 대조군 가이드)는 단리된 HEK293 게놈 DNA를 사용하여 스크리닝되었고, 잠재적인 오프-표적 결과는 도 1에 플롯되었다. 검정은 시험된 sgRNA에 대한 잠재적인 오프-표적 부위를 식별하였다.
잠재적인 오프-표적 부위를 검증하기 위한 표적화된 서열분석
상기 사용된 생화학적 방법과 같은 알려진 오프-표적 검출 검정에서, 다수의 잠재적인 오프-표적 부위는 전형적으로 다른 문맥에서, 예를 들어, 관심있는 1차 세포에서 검증될 수 있는 잠재적 부위에 대해 "광범위한 네트를 캐스팅"하기 위해 디자인에 의해 회수된다. 예를 들어, 생화학적 방법은 전형적으로 검정이 세포 환경이 없는 정제된 고분자량 게놈 DNA를 사용하고 사용된 Cas9 RNP의 용량에 따라 달라지므로 잠재적인 오프-표적 부위의 수를 과도하게 나타낸다. 따라서, 이들 방법에 의해 식별된 잠재적인 오프-표적 부위는 식별된 잠재적인 오프-표적 부위의 표적화된 서열분석을 사용하여 검증될 수 있다.
하나의 접근법에서, 1차 간세포는 Cas9 mRNA 및 관심 sgRNA (예를 들어, 평가를 위한 잠재적인 오프-표적 부위를 갖는 sgRNA)를 포함하는 LNP로 처리된다. 이어서, 1차 간세포를 용해하고 잠재적인 오프-표적 부위(들) 측면에 있는 프라이머를 사용하여 NGS 분석을 위한 앰플리콘을 생성한다. 특정 수준에서 인델의 식별은 잠재적인 오프-표적 부위를 검증할 수 있는 반면, 잠재적인 오프-표적 부위에서 발견된 인델의 결핍은 사용되었던 오프-표적 검정에서 위양성을 나타낼 수 있다.
1차 인간 및 사이노몰구스 간세포에서 Spy Cas9 mRNA 및 sgRNA를 포함하는 지질 나노입자 (LNP) 제형의 교차 스크리닝
인간 LDHA를 표적화하는 변형된 sgRNA의 지질 나노입자 (LNP) 제형 및 사이노에서 상동성인 것들은 용량 반응 검정에서 1차 인간 간세포 및 1차 사이노몰구스 간세포에서 시험되었다. LNP는 실시예 1에 기재된 바와 같이 제형화되었다. 1차 인간 및 사이노몰구스 간세포는 실시예 1에 기재된 바와 같이 플레이팅하였다. LNP로 처리하기 전에 두 세포주를 37℃, 5% CO2에서 48시간 동안 항온처리하엿다. LNP는 6% 사이노몰구스 혈청을 포함하는 배지에서 37℃에서 10분 동안 항온처리하였다. 항온처리 후, LNP를 300 ng Cas9 mRNA에서 시작하는 8 포인트 3배 용량 반응 곡선으로 인간 또는 사이노몰구스 간세포에 첨가하였다. 세포를 실시예 1에 기재된 바와 같이 NGS 분석을 위해 처리 96시간 후에 용해시켰다. 두 세포주에서 가이드 서열에 대한 용량 반응 곡선 데이터를 도 2 및 3에 나타낸다. 22 nM 농도에서의 퍼센트 편집은 아래 표 9 및 10에 나열되어 있다.
표 9는 1차 인간 간세포에서 LNP를 통해 Spy Cas9와 함께 전달된 22 nM에서 시험된 LDHA sgRNA에 대한 % 편집, % 삽입 (Ins) 및 % 결실 (Del)에 대한 평균 및 표준 편차를 나타낸다.
[표 9]

표 10은 1차 사이노몰구스 간세포에서 LNP를 통해 Spy Cas9와 함께 전달된 22 nM에서 시험된 LDHA sgRNA에 대한 % 편집, % 삽입 (Ins) 및 % 결실 (Del)에 대한 평균 및 표준 편차를 나타낸다. 이들 샘플은 3회 생성되었다.
[표 10]

리포펙션을 사용하여 1차 사이노몰구스 간세포에서 Spy Cas9 mRNA 및 sgRNA의 교차 스크리닝. LDHA를 표적화하는 변형된 sgRNA는 용량 반응 검정에서 1차 사이노몰구스 간세포에서 시험되었다. 리포펙션 샘플은 실시예 1에 기재된 바와 같이 제조되었다. 1차 사이노몰구스 간세포는 실시예 1에 기재된 바와 같이 플레이팅하였다. 세포는 리포펙션 전에 37℃, 5% CO2에서 48시간 동안 항온처리하였다. 리포펙션 샘플은 6% 사이노몰구스 혈청을 포함하는 배지에서 37℃에서 10분 동안 항온처리하였다. 항온처리 후 리포펙션 샘플을 53 nM sgRNA (n = 2)에서 시작하는 8 포인트 3배 용량 반응 곡선으로 사이노몰구스 간세포에 첨가하였다. 세포는 실시예 1에 기재된 바와 같이 NGS 분석을 위해 처리 96시간 후에 용해시켰다. 가이드 서열에 대한 용량 반응 곡선 데이터는 도 12a 내지 12c에 나타낸다. 53 nM 농도에서의 % 편집은 아래 표 11에 나열되어 있다.
[표 11]

실시예 3. 표현형 분석
세포내 락테이트 데하이드로게나제 A의 웨스턴 블롯 분석
인간 LDHA를 표적화하는 변형된 sgRNA의 지질 나노입자 (LNP) 제형을 1차 인간 간세포에 투여하여 웨스턴 블로팅을 위해 샘플을 생성하였다. LNP는 실시예 1에 기재된 바와 같이 제형화되었다. 1차 인간 간세포를 실시예 1에 기재된 바와 같이 플레이팅 하였다. 세포를 LNP로 처리하기 전에 37℃, 5% CO2에서 48시간 동안 항온처리하였다. LNP는 6% 사이노몰구스 혈청을 포함하는 배지에서 37℃에서 10분 동안 항온처리하였다. 항온처리 후 LNP를 샘플 당 25 nM의 sgRNA 농도로 인간 간세포에 첨가하였다. 형질감염 후 96시간에, 세포의 일부를 수집하고, 실시예 1에 기재된 바와 같이 NGS 서열분석을 위해 처리하였다. 나머지 세포를 형질감염 21일 후 수확하고, 전체 세포 추출물 (WCE)을 제조하고, 실시예 1에 기재된 바와 같이 웨스턴 블롯에 의해 분석하였다.
이들 세포에 대한 편집 데이터는 표 12에 제공된다.
[표 12]

WCE는 LDHA 단백질의 감소를 위해 웨스턴 블롯에 의해 분석되었다. 전장 LDHA 단백질은 332개의 아미노산과 36.6 kD의 예상 분자량을 갖는다. 이 분자량에서의 밴드는 대조군 레인 (미처리된 세포)에서 관찰되었지만 처리된 레인 어디에서도 관찰되지 않았다 (도 4).
락테이트 데하이드로게나제 A의 전사체 분석
LDHA를 표적화하는 선택된 변형된 sgRNA를 리포펙션에 의해 1차 인간 및 사이노몰구스 간세포에 투여하여 qPCR용 샘플을 생성하였다. 리포펙션 샘플은 실시예 1에 기재된 바와 같이 제형화되었다. 1차 간세포는 실시예 1에 기재된 바와 같이 플레팅하였다. 세포는 지질 패킷으로 처리하기 전에 37℃, 5% CO2에서 48시간 동안 항온처리하였다. 리포펙션 샘플은 6% 사이노몰구스 혈청을 포함하는 배지에서 37℃에서 10분 동안 항온처리하였다. 항온처리 후 지질 패킷을 여러 농도로 간세포에 첨가하였다. 리포펙션 96시간 후, 세포를 수집하고, 실시예 1에 기재된 바와 같이 RNA에 대해 처리하였다. 15 nM 가이드에서 1차 인간 및 사이노몰구스 간세포에서의 평균 LDHA 전사체 감소는 아래 표 13에 포함되고, 전체-용량 반응 데이터는 도 13a 및 13b에 표시된다.
[표 13]

실시예 4. PH1의 마우스 모델에서 Ldha의 생체내 편집
야생형 및 AGT 결핍 마우스 (Agxt1 -/-) 둘 다, 예를 들어, 간 AGXT mRNA 및 단백질이 결여된 널 돌연변이 마우스가 이 연구에 사용되었다. AGT-결핍 마우스는 고수산뇨증 및 결정뇨 (crystalluria)를 나타내므로 이전에 문헌 (Salido et al., Proc Natl Acad Sci USA. 2006 Nov 28;103(48):18249-54)에 의해 기재된 바와 같이 PH1의 표현형 모델을 나타낸다. 야생형 마우스를 사용하여 AGT-결핍 마우스에서 시험할 제형을 결정하였다.
LNP를 제형화하기 전에, 뮤린 Ldha를 표적화하는 dgRNA를 포함하는 RNP는 인간 및 사이노몰구스 LDHA-표적화 gRNA에 대해 실시예 2에 기재된 바와 유사하게 편집 효율에 대해 스크리닝되었다. dgRNA 스크린으로부터 활성 gRNA를 식별한 후, 이러한 gRNA를 기반으로 한 더 작은 변형된 sgRNA 세트를 생체내에서 추가 평가를 위해 합성하였다.
그룹 평균 체중을 기준으로 투여 용액을 제조하기 위해, 동물의 체중을 측정하고 체중에 따라 그룹화하였다. 뮤린 Ldha (아래 표 14 참조)를 표적화하는 변형된 sgRNA를 포함하는 LNP는 동물 당 0.2 mL의 부피 (체중 킬로그램 당 대략 10 mL)로 측면 꼬리 정맥을 통해 투여되었다. LNP는 실시예 1에 기재된 바와 같이 제형화되었다. 처리 1주 후, 야생형 마우스를 안락사시키고, 간 조직을 DNA 추출 및 뮤린 Ldha의 편집 분석을 위해 수집하였다. 아래 표 14에 나타낸 바와 같이, 용량-의존적 편집 수준이 처리된 마우스에서 관찰되었다.
[표 14]


LNP가 생체내 마우스 Ldha 유전자를 편집할 수 있음을 확립한 후, G009439를 포함하는 LNP를 총 mRNA 카고에 대한 용량 반응 (0, 0.25, 0.5, 1, 및 2 mpk)으로 AGT-결핍 마우스에 투여하였다. 이들 마우스는 대사 케이지에 수용되었고, 예를 들어, 문헌 (Liebow et al., J Am Soc Nephrol. 2017 Feb;28(2):494-503)에 기재된 바와 같이 옥살레이트 수준에 대해 다양한 시점에서 소변을 수집하였다. Ldha 유전자의 편집과 옥살레이트의 분비는 LNP의 용량이 증가함에 따라 각각 증가 및 감소하는 것으로 나타났다. % 편집 및 배설된 ug 소변 옥살레이트/mg 크레아티닌은 아래 표 15에 포함되고, 도 14a 내지 14c에 표시된다.
[표 15]

LNP가 생체내 옥살레이트 분비를 감소시킬 수 있음을 확립한 후, G009439를 포함하는 LNP를 총 mRNA 카고에 대해 2 mpk의 용량으로 AGT-결핍 마우스에게 투여하였다 (n=4). 도 5에 나타낸 바와 같이, 소변 옥살레이트 수준은 처리 1주 후 감소되었고, 이러한 감소 수준은 연구가 종료된 시점으로부터 투여 후 적어도 5주까지 지속되었다. 대조군 (PBS 주입) 동물 (n=4)에서는 감소가 관찰되지 않았다. 각 처리된 동물의 퍼센트 편집은 표 16에 보고되고, 소변 옥살레이트의 % 감소는 표 18에서 치료후 매주 나타낸다.
동일한 연구에서, AGT-결핍 마우스는 뮤린 Hao1을 표적화하는 sgRNA (G000723)를 포함하는 LNP (2 mpk (n=4)의 용량으로)를 투여하였다. 또한 도 5 및 표 17에 나타낸 바와 같이, 옥살레이트 수준은 이러한 gRNA를 포함하는 LNP로 처리한 1주일 후에 감소되었고, 이러한 감소 수준은 투여 후 적어도 5주까지 지속되었다.
G000723:
mC*mA*mC*GUGAGCCAUGCACUGCAGUUUUAGAmGmCmUmAmGmAmAmAmUmAmGmCAAGUUAAAAUAAGGCUAGUCCGUUAUCAmAmCmUmUmGmAmAmAmAmAmGmUmGmGmCmAmCmCmGmAmGmUmCmGmGmUmGmCmU*mU*mU*mU (서열번호 85) * = PS 연결; 'm' = 2'-O-Me 뉴클레오티드
[표 16]

[표 17]

[표 18]

LNP 치료 후 최대 5주까지 AGT-결핍 마우스에서 지속적인 소변 옥살레이트 감소를 입증한 후, 투여 후 15주 까지 소변 옥살레이트를 추적하기 위한 추가 연구가 수행되었다. G009439를 포함하는 LNP는 0.3 mpk (n=4) 및 1 mpk (n=4)의 용량으로 AGT-결핍 마우스에 투여되었다. 이들 마우스를 대사 케이지에 수용하고 상기 기재된 바와 같이 옥살레이트 수준에 대해 다양한 시점에서 소변을 수집하였다. 표 19는 AGT-결핍 마우스에 대한 편집 결과를 나타낸다. 0.3 mpk 용량에서 달성된 평균 % 편집은 33.42였고, 표준 편차는 11.95였다. 1 mpk 용량에서 달성된 평균 % 편집은 75.68이었고, 표준 편차는 7.35였다. 도 6에 나타낸 바와 같이, 소변 옥살레이트 수준은 처리 후 감소되었고, 이러한 감소 수준은 연구가 종료된 시점으로부터 투여 후 적어도 15주까지 지속되었다. 도 6에 묘사된 데이터는 표 20에 나타낸다. 대조군 (PBS 주입) 동물 (n=3)에서는 감소가 관찰되지 않았다 (데이터는 나타내지 않음).
처리된 마우스로부터의 간 샘플을 처리하고 실시예 1에 기재된 바와 같이 웨스턴 블롯에서 실행하였다. LDHA 단백질의 퍼센트 감소는 Licor Odyssey Image Studio Ver 5.2 소프트웨어를 사용하여 계산되었다. GAPDH는 로딩 대조군으로서 사용되었고, LDHA와 동시에 프로브되었다. LDHA에 대한 밴드를 포함하는 전체 영역과 비교하여 각 샘플 내의 GAPDH에 대한 밀도측정 값에 대한 비를 계산하였다. LDHA 단백질의 퍼센트 감소는 비가 음성 대조군 레인에 대해 표준화된 후에 결정되었다. 결과는 표 19에 나타내고 도 7에 나타내었다.
처리된 마우스와 비처리된 마우스에서 LDHA 단백질은 실시예 1에 기재되고 도 8에 도시된 바와 같이 면역조직화학적 염색을 통해 추가로 특성화되었다. LDHA 염색에서의 점진적 감소는 대조군 마우스와 비교하여 0.3 mpk-투여된 마우스 및 1 mpk-투여된 마우스에서 관찰되었다. 도 9는 표 19의 편집 수준과 단백질 수준 사이의 R2 값이 0.95인 상관관계를 나타낸다.
[표 19]

[표 20]

처리된 마우스로부터의 간 및 근육 샘플을 실시예 1에 기재된 바와 같이 LDH 활성에 대해 처리하였다. 1 mpk의 Ldha LNP로 처리한 마우스로부터의 간 샘플에서 LDH 활성의 감소가 관찰되었다. 처리된 마우스와 대조군 마우스로부터의 고유 활성 (μmol/min/mg 단백질)은 아래 표 21과 도 15a 및 15b에 표시된 데이터에 포함되어 있다.
[표 21]

처리된 마우스로부터의 간 및 혈장 샘플도 실시예 1에 기재된 바와 같이 피루베이트에 대해 분석되었다. 피루베이트는 락테이트 데하이드로게나제에 의해 락테이트로 전환된 대사산물이다 (Urbanska K et al, Int J Mol Sci. 2019 Apr 27;20(9)). 피루베이트 농도는 1 mpk-처리된 마우스로부터 간 샘플에서 상승하는 것으로 입증되었지만, 처리된 마우스와 대조군 마우스 간에 혈장 피루베이트 농도의 차이가 거의 관찰되지 않았다. 이들 데이터는 표 22에 포함되어 있고 도 16a 및 16b에 나타낸다.
[표 22]

LNP 처리 후 최대 15주 까지 AGT-결핍 마우스에서 지속적인 소변 옥살레이트 감소를 입증한 후, LDHA 녹다운 후 락테이트를 제거하는 손상된 신장 기능을 가진 마우스의 능력을 결정하기 위한 추가 연구가 수행되었다. 5/6 신장절제술 또는 샴 수술을 받은 C51Bl6 수컷 마우스는 Jackson Laboratory (Bar Harbor, ME)로부터 입수했다. 수술 1주 후, 동물을 실시예 1에 기재된 바와 같이 기준선 락테이트 수준에 대해 채혈하였다. 이어서, 동물에게 2 mpk (n=6)의 용량으로 G009439를 함유하는 LNP를 투여하였다. 투여 2주 후, 동물에게 복강내 전달된 포스페이트 완충 식염수 (농도 200 mg/mL, ~18 mM) pH 7.4에 용해된 2 g/kg의 락트산나트륨을 포함하는 락테이트 챌린지를 투여하였다 동물은 챌린지 전과 챌린지 후 15, 30, 60 및 180분에 꼬리-출혈이 있었다. 실시예 1에 기재된 바와 같이 혈액 샘플을 락테이트 수준에 대해 분석하였다. 샴 수술 및 비히클 처리 마우스와 비교하여, 신장 절제술 및 LDHA LNP를 받은 마우스에서 락테이트 제거율의 유의한 차이가 관찰되지 않았다. 아래 표 23은 도 17에서도 나타낸 바와 같이 동물 그룹에 걸쳐 평균 혈장 피루베이트를 상세히 보여준다.
[표 23]

SEQUENCE LISTING
<110> INTELLIA THERAPEUTICS, INC.
<120> COMPOSITIONS AND METHODS FOR LACTATE DEHYDROGENASE (LDHA) GENE
EDITING
<130> 01155-0025-00PCT
<150> US 62/738,956
<151> 2018-09-28
<150> US 62/834,334
<151> 2019-04-15
<150> US 62/841,740
<151> 2019-05-01
<160> 2082
<170> PatentIn version 3.5
<210> 1
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1
acauagaccu accuuaauca 20
<210> 2
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2
aaauaacuua ugcuuaccac 20
<210> 3
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 3
augcagucaa aagccucacc 20
<210> 4
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 4
ucagggucuu uacggaauaa 20
<210> 5
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 5
ccuaucauac agugcuuaug 20
<210> 6
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 6
ccgauuccgu uaccuaaugg 20
<210> 7
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 7
uagaccuacc uuaaucaugg 20
<210> 8
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 8
uacagagagu ccaauagccc 20
<210> 9
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 9
cuuuuagugc cuguauggag 20
<210> 10
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 10
cccgauuccg uuaccuaaug 20
<210> 11
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 11
ggcuggggca cgucagcaag 20
<210> 12
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 12
ccccauuagg uaacggaauc 20
<210> 13
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 13
aagcugguca uuaucacggc 20
<210> 14
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 14
uacacuuugg gggauccaaa 20
<210> 15
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 15
auuugauguc uuuuaggacu 20
<210> 16
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 16
cuccaagcug gucauuauca 20
<210> 17
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 17
guccaauaug gcaacucuaa 20
<210> 18
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 18
ggcuacacau ccugggcuau 20
<210> 19
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 19
uaccuucauu aagauacuga 20
<210> 20
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 20
agcccgauuc cguuaccuaa 20
<210> 21
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 21
gccuuucccc cauuagguaa 20
<210> 22
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 22
uacgcuggac caaauuaaga 20
<210> 23
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 23
uauuucuuuu agugccugua 20
<210> 24
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 24
agcuggucau uaucacggcu 20
<210> 25
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 25
gcuggucauu aucacggcug 20
<210> 26
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 26
gcuggggcac gucagcaaga 20
<210> 27
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 27
cuuuaucagu cccuaaaucu 20
<210> 28
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 28
gcccgauucc guuaccuaau 20
<210> 29
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 29
uuucaucuuc agggucuuua 20
<210> 30
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 30
acaacuguaa ucuuauucug 20
<210> 31
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 31
cauuaagaua cugauggcac 20
<210> 32
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 32
uuuagggacu gauaaagaua 20
<210> 33
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 33
cugauaaaga uaaggaacag 20
<210> 34
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 34
uuaccuaaug ggggaaaggc 20
<210> 35
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 35
uggaguggaa ugaauguugc 20
<210> 36
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 36
ucuuuaucag ucccuaaauc 20
<210> 37
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 37
uccguuaccu aaugggggaa 20
<210> 38
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 38
uaucugcacu cuucuucaaa 20
<210> 39
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 39
uaccuaaugg gggaaaggcu 20
<210> 40
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 40
agccgugaua augaccagcu 20
<210> 41
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 41
cccccauuag guaacggaau 20
<210> 42
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 42
uuuaaaauug cagcuccuuu 20
<210> 43
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 43
gcugauuuau aaucuucuaa 20
<210> 44
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 44
acauucauuc cacuccauac 20
<210> 45
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 45
ccuuaaucau gguggaaacu 20
<210> 46
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 46
accuuaauca ugguggaaac 20
<210> 47
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 47
ccuuugccag agacaaucuu 20
<210> 48
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 48
gaaggugacu cugacuucug 20
<210> 49
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 49
uauuggaagc gguugcaauc 20
<210> 50
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 50
aagucagagu caccuucaca 20
<210> 51
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 51
gacucugacu ucugaggaag 20
<210> 52
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 52
ugcaaccgcu uccaauaaca 20
<210> 53
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 53
uauuuucucc uuuuucauag 20
<210> 54
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 54
uuuuuuucau uucaucuuca 20
<210> 55
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 55
accaaaguag ucacuguuca 20
<210> 56
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 56
acgcaguuaa aaggcucacc 20
<210> 57
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 57
uugcuuauug uuucaaaucc 20
<210> 58
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 58
uucccccuau agauuccuuc 20
<210> 59
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 59
ucgagcuuug uggcaguuag 20
<210> 60
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 60
uugggguuaa uaaaccgcga 20
<210> 61
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 61
ugaaggccca uaccuuagcg 20
<210> 62
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 62
cgguuuauua accccaagug 20
<210> 63
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 63
cccauaccuu agcguggaaa 20
<210> 64
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 64
ggcuuuucug cacguaccuc 20
<210> 65
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 65
gaaaaggaau aucgacguuu 20
<210> 66
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 66
accgcgaugg gugagcccuc 20
<210> 67
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 67
gcgguuuauu aaccccaagu 20
<210> 68
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 68
accgcacgcu ucagugccuu 20
<210> 69
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 69
ggaaaaggaa uaucgacguu 20
<210> 70
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 70
guguaaguau agccuccuga 20
<210> 71
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 71
gauauuccuu uuccacgcua 20
<210> 72
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 72
gcgaugggug agcccucagg 20
<210> 73
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 73
ggaaaggcca gccccacuug 20
<210> 74
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 74
caccgcacgc uucagugccu 20
<210> 75
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 75
ugccacaaag cucgagccca 20
<210> 76
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 76
gguguaagua uagccuccug 20
<210> 77
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 77
uccugagggc ucacccaucg 20
<210> 78
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 78
aggaaaggcc agccccacuu 20
<210> 79
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 79
uuauuaaccc caaguggggc 20
<210> 80
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 80
gaggaaaggc cagccccacu 20
<210> 81
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 81
gcucaaagug aucuugucug 20
<210> 82
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 82
ccuggcugug uccuugcugu 20
<210> 83
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 83
cgcgguuuau uaaccccaag 20
<210> 84
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 84
ugggguuaau aaaccgcgau 20
<210> 85
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 85
cacgugagcc augcacugca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 86
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 86
guucacgcgc ugagcuguca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 87
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 87
gggggcccgu cagcaagagg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 88
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 88
guugcaaucu ggauucagcg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 89
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 89
gucauggaag acaaacucaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 90
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 90
acugggcacu gacgcagaca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 91
<400> 91
000
<210> 92
<400> 92
000
<210> 93
<400> 93
000
<210> 94
<400> 94
000
<210> 95
<400> 95
000
<210> 96
<400> 96
000
<210> 97
<400> 97
000
<210> 98
<400> 98
000
<210> 99
<400> 99
000
<210> 100
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 100
uuucccaaaa accguguuau 20
<210> 101
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 101
gaaagagguu cacaagcagg 20
<210> 102
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 102
guggaaagag guucacaagc 20
<210> 103
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 103
gagaugaugg aucuccaaca 20
<210> 104
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 104
uaaggaaaag gcugccaugu 20
<210> 105
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 105
uguaacugca aacuccaagc 20
<210> 106
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 106
cuuccaauaa cacgguuuuu 20
<210> 107
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 107
aaaaaccgug uuauuggaag 20
<210> 108
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 108
guucacccau uaagcuguca 20
<210> 109
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 109
uucacccauu aagcugucau 20
<210> 110
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 110
acccauuaag cugucauggg 20
<210> 111
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 111
uggaaucucc auguucccca 20
<210> 112
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 112
agaguauaau gaagaaucuu 20
<210> 113
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 113
gcugauucau aaucuucuaa 20
<210> 114
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 114
caaauugaag ggagagauga 20
<210> 115
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 115
ucuuuggugu ucuaaggaaa 20
<210> 116
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 116
caauaagcaa cuugcaguuc 20
<210> 117
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 117
acaauaagca acuugcaguu 20
<210> 118
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 118
gcuuauuguu ucaaauccag 20
<210> 119
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 119
acuuccaaua acacgguuuu 20
<210> 120
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 120
cccauuaagc ugucaugggu 20
<210> 121
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 121
uccacuccau acaggcacac 20
<210> 122
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 122
aagacucugc acccagauuu 20
<210> 123
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 123
agacucugca cccagauuua 20
<210> 124
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 124
ccaguuucca ccaugauuaa 20
<210> 125
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 125
accaugauua agggucucua 20
<210> 126
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 126
auagagaccc uuaaucaugg 20
<210> 127
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 127
uccauagaga cccuuaauca 20
<210> 128
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 128
uaagggucuc uauggaauaa 20
<210> 129
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 129
agauaaggaa caguggaaag 20
<210> 130
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 130
cagaauaaga uuacaguugu 20
<210> 131
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 131
agaauaagau uacaguuguu 20
<210> 132
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 132
aacaacugua aucuuauucu 20
<210> 133
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 133
gaauaagauu acaguuguug 20
<210> 134
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 134
caacaacugu aaucuuauuc 20
<210> 135
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 135
aagauuacag uuguuggggu 20
<210> 136
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 136
guuguugggg uuggugcugu 20
<210> 137
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 137
ugccaucagu aucuuaauga 20
<210> 138
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 138
guccuucauu aagauacuga 20
<210> 139
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 139
caguaucuua augaaggacu 20
<210> 140
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 140
ugucaucgaa gacaaauuga 20
<210> 141
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 141
gucaucgaag acaaauugaa 20
<210> 142
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 142
agacaaucuu ugguguucua 20
<210> 143
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 143
agaacaccaa agauugucuc 20
<210> 144
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 144
ggcuggggca cgucaacaag 20
<210> 145
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 145
gcuggggcac gucaacaaga 20
<210> 146
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 146
gggagaaagc cgucuuaauu 20
<210> 147
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 147
uaaagauguu cacguuacgc 20
<210> 148
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 148
gggcuguauu uuacaacauu 20
<210> 149
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 149
uacguggcuu ggaagauaag 20
<210> 150
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 150
acuuaucuuc caagccacgu 20
<210> 151
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 151
ugcaaccacu uccaauaaca 20
<210> 152
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 152
agccagauuc cguuaccuga 20
<210> 153
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 153
gccagauucc guuaccugau 20
<210> 154
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 154
ccagauuccg uuaccugaug 20
<210> 155
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 155
ccccaucagg uaacggaauc 20
<210> 156
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 156
cccacccaug acagcuuaau 20
<210> 157
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 157
acccacccau gacagcuuaa 20
<210> 158
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 158
agcugucaug gguggguccu 20
<210> 159
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 159
gcugucaugg guggguccuu 20
<210> 160
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 160
cugucauggg uggguccuug 20
<210> 161
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 161
gggugggucc uuggggaaca 20
<210> 162
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 162
gagauuccag ugugccugua 20
<210> 163
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 163
uccagugugc cuguauggag 20
<210> 164
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 164
aucugggugc agagucuuca 20
<210> 165
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 165
aaucugggug cagagucuuc 20
<210> 166
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 166
uaugagguga ucaaacucaa 20
<210> 167
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 167
uggacucucu guagcagauu 20
<210> 168
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 168
cccaguuucc accaugauua 20
<210> 169
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 169
ugggguuggu gcuguuggca 20
<210> 170
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 170
gaacaccaaa gauugucucu 20
<210> 171
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 171
cagauuccgu uaccugaugg 20
<210> 172
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 172
uuaccugaug ggggaaagac 20
<210> 173
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 173
gucuuucccc caucagguaa 20
<210> 174
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 174
uaccugaugg gggaaagacu 20
<210> 175
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 175
cucccagucu uucccccauc 20
<210> 176
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 176
aacucaaagg cuacacaucc 20
<210> 177
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 177
acucaaaggc uacacauccu 20
<210> 178
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 178
ggcuacacau ccugggccau 20
<210> 179
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 179
uacagagagu ccaauggccc 20
<210> 180
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 180
aucugcuaca gagaguccaa 20
<210> 181
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 181
cccuuaauca ugguggaaac 20
<210> 182
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 182
ccuugcauuu ugggacagaa 20
<210> 183
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 183
ccauucuguc ccaaaaugca 20
<210> 184
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 184
aguggauauc uugaccuacg 20
<210> 185
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 185
auaucuugac cuacguggcu 20
<210> 186
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 186
uauuggaagu gguugcaauc 20
<210> 187
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 187
ucuuucccag agacaaucuu 20
<210> 188
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 188
ggugguugag agugcuuaug 20
<210> 189
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 189
ccucaguguu ccuugcauuu 20
<210> 190
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 190
cucaguguuc cuugcauuuu 20
<210> 191
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 191
ccaaaaugca aggaacacug 20
<210> 192
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 192
acguagguca agauauccac 20
<210> 193
<400> 193
000
<210> 194
<400> 194
000
<210> 195
<400> 195
000
<210> 196
<400> 196
000
<210> 197
<400> 197
000
<210> 198
<400> 198
000
<210> 199
<400> 199
000
<210> 200
<211> 22
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 200
guuuuagagc uaugcuguuu ug 22
<210> 201
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 201
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 202
<211> 68
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 202
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uuggcaccga 60
gucggugc 68
<210> 203
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 203
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugc 76
<210> 204
<400> 204
000
<210> 205
<400> 205
000
<210> 206
<400> 206
000
<210> 207
<400> 207
000
<210> 208
<400> 208
000
<210> 209
<400> 209
000
<210> 210
<400> 210
000
<210> 211
<400> 211
000
<210> 212
<400> 212
000
<210> 213
<400> 213
000
<210> 214
<400> 214
000
<210> 215
<400> 215
000
<210> 216
<400> 216
000
<210> 217
<400> 217
000
<210> 218
<400> 218
000
<210> 219
<400> 219
000
<210> 220
<400> 220
000
<210> 221
<400> 221
000
<210> 222
<400> 222
000
<210> 223
<400> 223
000
<210> 224
<400> 224
000
<210> 225
<400> 225
000
<210> 226
<400> 226
000
<210> 227
<400> 227
000
<210> 228
<400> 228
000
<210> 229
<400> 229
000
<210> 230
<400> 230
000
<210> 231
<400> 231
000
<210> 232
<400> 232
000
<210> 233
<400> 233
000
<210> 234
<400> 234
000
<210> 235
<400> 235
000
<210> 236
<400> 236
000
<210> 237
<400> 237
000
<210> 238
<400> 238
000
<210> 239
<400> 239
000
<210> 240
<400> 240
000
<210> 241
<400> 241
000
<210> 242
<400> 242
000
<210> 243
<400> 243
000
<210> 244
<400> 244
000
<210> 245
<400> 245
000
<210> 246
<400> 246
000
<210> 247
<400> 247
000
<210> 248
<400> 248
000
<210> 249
<400> 249
000
<210> 250
<400> 250
000
<210> 251
<400> 251
000
<210> 252
<400> 252
000
<210> 253
<400> 253
000
<210> 254
<400> 254
000
<210> 255
<400> 255
000
<210> 256
<400> 256
000
<210> 257
<400> 257
000
<210> 258
<400> 258
000
<210> 259
<400> 259
000
<210> 260
<400> 260
000
<210> 261
<400> 261
000
<210> 262
<400> 262
000
<210> 263
<400> 263
000
<210> 264
<400> 264
000
<210> 265
<400> 265
000
<210> 266
<400> 266
000
<210> 267
<400> 267
000
<210> 268
<400> 268
000
<210> 269
<400> 269
000
<210> 270
<400> 270
000
<210> 271
<400> 271
000
<210> 272
<400> 272
000
<210> 273
<400> 273
000
<210> 274
<400> 274
000
<210> 275
<400> 275
000
<210> 276
<400> 276
000
<210> 277
<400> 277
000
<210> 278
<400> 278
000
<210> 279
<400> 279
000
<210> 280
<400> 280
000
<210> 281
<400> 281
000
<210> 282
<400> 282
000
<210> 283
<400> 283
000
<210> 284
<400> 284
000
<210> 285
<400> 285
000
<210> 286
<400> 286
000
<210> 287
<400> 287
000
<210> 288
<400> 288
000
<210> 289
<400> 289
000
<210> 290
<400> 290
000
<210> 291
<400> 291
000
<210> 292
<400> 292
000
<210> 293
<400> 293
000
<210> 294
<400> 294
000
<210> 295
<400> 295
000
<210> 296
<400> 296
000
<210> 297
<400> 297
000
<210> 298
<400> 298
000
<210> 299
<400> 299
000
<210> 300
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 300
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 301
<400> 301
000
<210> 302
<400> 302
000
<210> 303
<400> 303
000
<210> 304
<400> 304
000
<210> 305
<400> 305
000
<210> 306
<400> 306
000
<210> 307
<400> 307
000
<210> 308
<400> 308
000
<210> 309
<400> 309
000
<210> 310
<400> 310
000
<210> 311
<400> 311
000
<210> 312
<400> 312
000
<210> 313
<400> 313
000
<210> 314
<400> 314
000
<210> 315
<400> 315
000
<210> 316
<400> 316
000
<210> 317
<400> 317
000
<210> 318
<400> 318
000
<210> 319
<400> 319
000
<210> 320
<400> 320
000
<210> 321
<400> 321
000
<210> 322
<400> 322
000
<210> 323
<400> 323
000
<210> 324
<400> 324
000
<210> 325
<400> 325
000
<210> 326
<400> 326
000
<210> 327
<400> 327
000
<210> 328
<400> 328
000
<210> 329
<400> 329
000
<210> 330
<400> 330
000
<210> 331
<400> 331
000
<210> 332
<400> 332
000
<210> 333
<400> 333
000
<210> 334
<400> 334
000
<210> 335
<400> 335
000
<210> 336
<400> 336
000
<210> 337
<400> 337
000
<210> 338
<400> 338
000
<210> 339
<400> 339
000
<210> 340
<400> 340
000
<210> 341
<400> 341
000
<210> 342
<400> 342
000
<210> 343
<400> 343
000
<210> 344
<400> 344
000
<210> 345
<400> 345
000
<210> 346
<400> 346
000
<210> 347
<400> 347
000
<210> 348
<400> 348
000
<210> 349
<400> 349
000
<210> 350
<400> 350
000
<210> 351
<400> 351
000
<210> 352
<400> 352
000
<210> 353
<400> 353
000
<210> 354
<400> 354
000
<210> 355
<400> 355
000
<210> 356
<400> 356
000
<210> 357
<400> 357
000
<210> 358
<400> 358
000
<210> 359
<400> 359
000
<210> 360
<400> 360
000
<210> 361
<400> 361
000
<210> 362
<400> 362
000
<210> 363
<400> 363
000
<210> 364
<400> 364
000
<210> 365
<400> 365
000
<210> 366
<400> 366
000
<210> 367
<400> 367
000
<210> 368
<400> 368
000
<210> 369
<400> 369
000
<210> 370
<400> 370
000
<210> 371
<400> 371
000
<210> 372
<400> 372
000
<210> 373
<400> 373
000
<210> 374
<400> 374
000
<210> 375
<400> 375
000
<210> 376
<400> 376
000
<210> 377
<400> 377
000
<210> 378
<400> 378
000
<210> 379
<400> 379
000
<210> 380
<400> 380
000
<210> 381
<400> 381
000
<210> 382
<400> 382
000
<210> 383
<400> 383
000
<210> 384
<400> 384
000
<210> 385
<400> 385
000
<210> 386
<400> 386
000
<210> 387
<400> 387
000
<210> 388
<400> 388
000
<210> 389
<400> 389
000
<210> 390
<400> 390
000
<210> 391
<400> 391
000
<210> 392
<400> 392
000
<210> 393
<400> 393
000
<210> 394
<400> 394
000
<210> 395
<400> 395
000
<210> 396
<400> 396
000
<210> 397
<400> 397
000
<210> 398
<400> 398
000
<210> 399
<400> 399
000
<210> 400
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 400
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 401
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 401
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 402
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 402
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 403
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 403
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 404
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 404
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 405
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 405
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 406
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 406
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 407
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 407
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 408
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 408
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 409
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 409
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 410
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 410
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 411
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 411
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 412
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 412
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 413
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 413
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 414
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 414
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 415
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 415
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 416
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 416
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 417
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 417
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 418
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 418
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 419
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 419
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 420
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 420
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 421
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 421
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 422
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 422
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 423
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 423
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 424
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 424
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 425
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 425
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 426
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 426
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 427
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 427
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 428
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 428
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 429
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 429
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 430
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 430
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 431
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 431
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 432
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 432
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 433
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 433
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 434
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 434
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 435
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 435
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 436
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 436
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 437
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 437
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 438
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 438
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 439
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 439
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 440
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 440
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 441
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 441
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 442
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 442
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 443
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 443
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 444
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 444
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 445
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 445
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 446
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 446
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 447
<211> 80
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 447
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uugaaaaagu 60
ggcaccgagu cggugcuuuu 80
<210> 448
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 448
nnnnnnnnnn nnnnnnnnnn 20
<210> 449
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<220>
<221> misc_feature
<222> (1)..(20)
<223> n is a, c, g, or u
<400> 449
nnnnnnnnnn nnnnnnnnnn 20
<210> 450
<211> 68
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 450
guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc cguuaucaac uuggcaccga 60
gucggugc 68
<210> 451
<400> 451
000
<210> 452
<400> 452
000
<210> 453
<400> 453
000
<210> 454
<400> 454
000
<210> 455
<400> 455
000
<210> 456
<400> 456
000
<210> 457
<400> 457
000
<210> 458
<400> 458
000
<210> 459
<400> 459
000
<210> 460
<400> 460
000
<210> 461
<400> 461
000
<210> 462
<400> 462
000
<210> 463
<400> 463
000
<210> 464
<400> 464
000
<210> 465
<400> 465
000
<210> 466
<400> 466
000
<210> 467
<400> 467
000
<210> 468
<400> 468
000
<210> 469
<400> 469
000
<210> 470
<400> 470
000
<210> 471
<400> 471
000
<210> 472
<400> 472
000
<210> 473
<400> 473
000
<210> 474
<400> 474
000
<210> 475
<400> 475
000
<210> 476
<400> 476
000
<210> 477
<400> 477
000
<210> 478
<400> 478
000
<210> 479
<400> 479
000
<210> 480
<400> 480
000
<210> 481
<400> 481
000
<210> 482
<400> 482
000
<210> 483
<400> 483
000
<210> 484
<400> 484
000
<210> 485
<400> 485
000
<210> 486
<400> 486
000
<210> 487
<400> 487
000
<210> 488
<400> 488
000
<210> 489
<400> 489
000
<210> 490
<400> 490
000
<210> 491
<400> 491
000
<210> 492
<400> 492
000
<210> 493
<400> 493
000
<210> 494
<400> 494
000
<210> 495
<400> 495
000
<210> 496
<400> 496
000
<210> 497
<400> 497
000
<210> 498
<400> 498
000
<210> 499
<400> 499
000
<210> 500
<400> 500
000
<210> 501
<211> 4411
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 501
gggtcccgca gtcggcgtcc agcggctctg cttgttcgtg tgtgtgtcgt tgcaggcctt 60
attcggatcc gccaccatgg acaagaagta cagcatcgga ctggacatcg gaacaaacag 120
cgtcggatgg gcagtcatca cagacgaata caaggtcccg agcaagaagt tcaaggtcct 180
gggaaacaca gacagacaca gcatcaagaa gaacctgatc ggagcactgc tgttcgacag 240
cggagaaaca gcagaagcaa caagactgaa gagaacagca agaagaagat acacaagaag 300
aaagaacaga atctgctacc tgcaggaaat cttcagcaac gaaatggcaa aggtcgacga 360
cagcttcttc cacagactgg aagaaagctt cctggtcgaa gaagacaaga agcacgaaag 420
acacccgatc ttcggaaaca tcgtcgacga agtcgcatac cacgaaaagt acccgacaat 480
ctaccacctg agaaagaagc tggtcgacag cacagacaag gcagacctga gactgatcta 540
cctggcactg gcacacatga tcaagttcag aggacacttc ctgatcgaag gagacctgaa 600
cccggacaac agcgacgtcg acaagctgtt catccagctg gtccagacat acaaccagct 660
gttcgaagaa aacccgatca acgcaagcgg agtcgacgca aaggcaatcc tgagcgcaag 720
actgagcaag agcagaagac tggaaaacct gatcgcacag ctgccgggag aaaagaagaa 780
cggactgttc ggaaacctga tcgcactgag cctgggactg acaccgaact tcaagagcaa 840
cttcgacctg gcagaagacg caaagctgca gctgagcaag gacacatacg acgacgacct 900
ggacaacctg ctggcacaga tcggagacca gtacgcagac ctgttcctgg cagcaaagaa 960
cctgagcgac gcaatcctgc tgagcgacat cctgagagtc aacacagaaa tcacaaaggc 1020
accgctgagc gcaagcatga tcaagagata cgacgaacac caccaggacc tgacactgct 1080
gaaggcactg gtcagacagc agctgccgga aaagtacaag gaaatcttct tcgaccagag 1140
caagaacgga tacgcaggat acatcgacgg aggagcaagc caggaagaat tctacaagtt 1200
catcaagccg atcctggaaa agatggacgg aacagaagaa ctgctggtca agctgaacag 1260
agaagacctg ctgagaaagc agagaacatt cgacaacgga agcatcccgc accagatcca 1320
cctgggagaa ctgcacgcaa tcctgagaag acaggaagac ttctacccgt tcctgaagga 1380
caacagagaa aagatcgaaa agatcctgac attcagaatc ccgtactacg tcggaccgct 1440
ggcaagagga aacagcagat tcgcatggat gacaagaaag agcgaagaaa caatcacacc 1500
gtggaacttc gaagaagtcg tcgacaaggg agcaagcgca cagagcttca tcgaaagaat 1560
gacaaacttc gacaagaacc tgccgaacga aaaggtcctg ccgaagcaca gcctgctgta 1620
cgaatacttc acagtctaca acgaactgac aaaggtcaag tacgtcacag aaggaatgag 1680
aaagccggca ttcctgagcg gagaacagaa gaaggcaatc gtcgacctgc tgttcaagac 1740
aaacagaaag gtcacagtca agcagctgaa ggaagactac ttcaagaaga tcgaatgctt 1800
cgacagcgtc gaaatcagcg gagtcgaaga cagattcaac gcaagcctgg gaacatacca 1860
cgacctgctg aagatcatca aggacaagga cttcctggac aacgaagaaa acgaagacat 1920
cctggaagac atcgtcctga cactgacact gttcgaagac agagaaatga tcgaagaaag 1980
actgaagaca tacgcacacc tgttcgacga caaggtcatg aagcagctga agagaagaag 2040
atacacagga tggggaagac tgagcagaaa gctgatcaac ggaatcagag acaagcagag 2100
cggaaagaca atcctggact tcctgaagag cgacggattc gcaaacagaa acttcatgca 2160
gctgatccac gacgacagcc tgacattcaa ggaagacatc cagaaggcac aggtcagcgg 2220
acagggagac agcctgcacg aacacatcgc aaacctggca ggaagcccgg caatcaagaa 2280
gggaatcctg cagacagtca aggtcgtcga cgaactggtc aaggtcatgg gaagacacaa 2340
gccggaaaac atcgtcatcg aaatggcaag agaaaaccag acaacacaga agggacagaa 2400
gaacagcaga gaaagaatga agagaatcga agaaggaatc aaggaactgg gaagccagat 2460
cctgaaggaa cacccggtcg aaaacacaca gctgcagaac gaaaagctgt acctgtacta 2520
cctgcagaac ggaagagaca tgtacgtcga ccaggaactg gacatcaaca gactgagcga 2580
ctacgacgtc gaccacatcg tcccgcagag cttcctgaag gacgacagca tcgacaacaa 2640
ggtcctgaca agaagcgaca agaacagagg aaagagcgac aacgtcccga gcgaagaagt 2700
cgtcaagaag atgaagaact actggagaca gctgctgaac gcaaagctga tcacacagag 2760
aaagttcgac aacctgacaa aggcagagag aggaggactg agcgaactgg acaaggcagg 2820
attcatcaag agacagctgg tcgaaacaag acagatcaca aagcacgtcg cacagatcct 2880
ggacagcaga atgaacacaa agtacgacga aaacgacaag ctgatcagag aagtcaaggt 2940
catcacactg aagagcaagc tggtcagcga cttcagaaag gacttccagt tctacaaggt 3000
cagagaaatc aacaactacc accacgcaca cgacgcatac ctgaacgcag tcgtcggaac 3060
agcactgatc aagaagtacc cgaagctgga aagcgaattc gtctacggag actacaaggt 3120
ctacgacgtc agaaagatga tcgcaaagag cgaacaggaa atcggaaagg caacagcaaa 3180
gtacttcttc tacagcaaca tcatgaactt cttcaagaca gaaatcacac tggcaaacgg 3240
agaaatcaga aagagaccgc tgatcgaaac aaacggagaa acaggagaaa tcgtctggga 3300
caagggaaga gacttcgcaa cagtcagaaa ggtcctgagc atgccgcagg tcaacatcgt 3360
caagaagaca gaagtccaga caggaggatt cagcaaggaa agcatcctgc cgaagagaaa 3420
cagcgacaag ctgatcgcaa gaaagaagga ctgggacccg aagaagtacg gaggattcga 3480
cagcccgaca gtcgcataca gcgtcctggt cgtcgcaaag gtcgaaaagg gaaagagcaa 3540
gaagctgaag agcgtcaagg aactgctggg aatcacaatc atggaaagaa gcagcttcga 3600
aaagaacccg atcgacttcc tggaagcaaa gggatacaag gaagtcaaga aggacctgat 3660
catcaagctg ccgaagtaca gcctgttcga actggaaaac ggaagaaaga gaatgctggc 3720
aagcgcagga gaactgcaga agggaaacga actggcactg ccgagcaagt acgtcaactt 3780
cctgtacctg gcaagccact acgaaaagct gaagggaagc ccggaagaca acgaacagaa 3840
gcagctgttc gtcgaacagc acaagcacta cctggacgaa atcatcgaac agatcagcga 3900
attcagcaag agagtcatcc tggcagacgc aaacctggac aaggtcctga gcgcatacaa 3960
caagcacaga gacaagccga tcagagaaca ggcagaaaac atcatccacc tgttcacact 4020
gacaaacctg ggagcaccgg cagcattcaa gtacttcgac acaacaatcg acagaaagag 4080
atacacaagc acaaaggaag tcctggacgc aacactgatc caccagagca tcacaggact 4140
gtacgaaaca agaatcgacc tgagccagct gggaggagac ggaggaggaa gcccgaagaa 4200
gaagagaaag gtctagctag ccatcacatt taaaagcatc tcagcctacc atgagaataa 4260
gagaaagaaa atgaagatca atagcttatt catctctttt tctttttcgt tggtgtaaag 4320
ccaacaccct gtctaaaaaa cataaatttc tttaatcatt ttgcctcttt tctctgtgct 4380
tcaattaata aaaaatggaa agaacctcga g 4411
<210> 502
<211> 4107
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 502
auggacaaga aguacagcau cggacuggac aucggaacaa acagcgucgg augggcaguc 60
aucacagacg aauacaaggu cccgagcaag aaguucaagg uccugggaaa cacagacaga 120
cacagcauca agaagaaccu gaucggagca cugcuguucg acagcggaga aacagcagaa 180
gcaacaagac ugaagagaac agcaagaaga agauacacaa gaagaaagaa cagaaucugc 240
uaccugcagg aaaucuucag caacgaaaug gcaaaggucg acgacagcuu cuuccacaga 300
cuggaagaaa gcuuccuggu cgaagaagac aagaagcacg aaagacaccc gaucuucgga 360
aacaucgucg acgaagucgc auaccacgaa aaguacccga caaucuacca ccugagaaag 420
aagcuggucg acagcacaga caaggcagac cugagacuga ucuaccuggc acuggcacac 480
augaucaagu ucagaggaca cuuccugauc gaaggagacc ugaacccgga caacagcgac 540
gucgacaagc uguucaucca gcugguccag acauacaacc agcuguucga agaaaacccg 600
aucaacgcaa gcggagucga cgcaaaggca auccugagcg caagacugag caagagcaga 660
agacuggaaa accugaucgc acagcugccg ggagaaaaga agaacggacu guucggaaac 720
cugaucgcac ugagccuggg acugacaccg aacuucaaga gcaacuucga ccuggcagaa 780
gacgcaaagc ugcagcugag caaggacaca uacgacgacg accuggacaa ccugcuggca 840
cagaucggag accaguacgc agaccuguuc cuggcagcaa agaaccugag cgacgcaauc 900
cugcugagcg acauccugag agucaacaca gaaaucacaa aggcaccgcu gagcgcaagc 960
augaucaaga gauacgacga acaccaccag gaccugacac ugcugaaggc acuggucaga 1020
cagcagcugc cggaaaagua caaggaaauc uucuucgacc agagcaagaa cggauacgca 1080
ggauacaucg acggaggagc aagccaggaa gaauucuaca aguucaucaa gccgauccug 1140
gaaaagaugg acggaacaga agaacugcug gucaagcuga acagagaaga ccugcugaga 1200
aagcagagaa cauucgacaa cggaagcauc ccgcaccaga uccaccuggg agaacugcac 1260
gcaauccuga gaagacagga agacuucuac ccguuccuga aggacaacag agaaaagauc 1320
gaaaagaucc ugacauucag aaucccguac uacgucggac cgcuggcaag aggaaacagc 1380
agauucgcau ggaugacaag aaagagcgaa gaaacaauca caccguggaa cuucgaagaa 1440
gucgucgaca agggagcaag cgcacagagc uucaucgaaa gaaugacaaa cuucgacaag 1500
aaccugccga acgaaaaggu ccugccgaag cacagccugc uguacgaaua cuucacaguc 1560
uacaacgaac ugacaaaggu caaguacguc acagaaggaa ugagaaagcc ggcauuccug 1620
agcggagaac agaagaaggc aaucgucgac cugcuguuca agacaaacag aaaggucaca 1680
gucaagcagc ugaaggaaga cuacuucaag aagaucgaau gcuucgacag cgucgaaauc 1740
agcggagucg aagacagauu caacgcaagc cugggaacau accacgaccu gcugaagauc 1800
aucaaggaca aggacuuccu ggacaacgaa gaaaacgaag acauccugga agacaucguc 1860
cugacacuga cacuguucga agacagagaa augaucgaag aaagacugaa gacauacgca 1920
caccuguucg acgacaaggu caugaagcag cugaagagaa gaagauacac aggaugggga 1980
agacugagca gaaagcugau caacggaauc agagacaagc agagcggaaa gacaauccug 2040
gacuuccuga agagcgacgg auucgcaaac agaaacuuca ugcagcugau ccacgacgac 2100
agccugacau ucaaggaaga cauccagaag gcacagguca gcggacaggg agacagccug 2160
cacgaacaca ucgcaaaccu ggcaggaagc ccggcaauca agaagggaau ccugcagaca 2220
gucaaggucg ucgacgaacu ggucaagguc augggaagac acaagccgga aaacaucguc 2280
aucgaaaugg caagagaaaa ccagacaaca cagaagggac agaagaacag cagagaaaga 2340
augaagagaa ucgaagaagg aaucaaggaa cugggaagcc agauccugaa ggaacacccg 2400
gucgaaaaca cacagcugca gaacgaaaag cuguaccugu acuaccugca gaacggaaga 2460
gacauguacg ucgaccagga acuggacauc aacagacuga gcgacuacga cgucgaccac 2520
aucgucccgc agagcuuccu gaaggacgac agcaucgaca acaagguccu gacaagaagc 2580
gacaagaaca gaggaaagag cgacaacguc ccgagcgaag aagucgucaa gaagaugaag 2640
aacuacugga gacagcugcu gaacgcaaag cugaucacac agagaaaguu cgacaaccug 2700
acaaaggcag agagaggagg acugagcgaa cuggacaagg caggauucau caagagacag 2760
cuggucgaaa caagacagau cacaaagcac gucgcacaga uccuggacag cagaaugaac 2820
acaaaguacg acgaaaacga caagcugauc agagaaguca aggucaucac acugaagagc 2880
aagcugguca gcgacuucag aaaggacuuc caguucuaca aggucagaga aaucaacaac 2940
uaccaccacg cacacgacgc auaccugaac gcagucgucg gaacagcacu gaucaagaag 3000
uacccgaagc uggaaagcga auucgucuac ggagacuaca aggucuacga cgucagaaag 3060
augaucgcaa agagcgaaca ggaaaucgga aaggcaacag caaaguacuu cuucuacagc 3120
aacaucauga acuucuucaa gacagaaauc acacuggcaa acggagaaau cagaaagaga 3180
ccgcugaucg aaacaaacgg agaaacagga gaaaucgucu gggacaaggg aagagacuuc 3240
gcaacaguca gaaagguccu gagcaugccg caggucaaca ucgucaagaa gacagaaguc 3300
cagacaggag gauucagcaa ggaaagcauc cugccgaaga gaaacagcga caagcugauc 3360
gcaagaaaga aggacuggga cccgaagaag uacggaggau ucgacagccc gacagucgca 3420
uacagcgucc uggucgucgc aaaggucgaa aagggaaaga gcaagaagcu gaagagcguc 3480
aaggaacugc ugggaaucac aaucauggaa agaagcagcu ucgaaaagaa cccgaucgac 3540
uuccuggaag caaagggaua caaggaaguc aagaaggacc ugaucaucaa gcugccgaag 3600
uacagccugu ucgaacugga aaacggaaga aagagaaugc uggcaagcgc aggagaacug 3660
cagaagggaa acgaacuggc acugccgagc aaguacguca acuuccugua ccuggcaagc 3720
cacuacgaaa agcugaaggg aagcccggaa gacaacgaac agaagcagcu guucgucgaa 3780
cagcacaagc acuaccugga cgaaaucauc gaacagauca gcgaauucag caagagaguc 3840
auccuggcag acgcaaaccu ggacaagguc cugagcgcau acaacaagca cagagacaag 3900
ccgaucagag aacaggcaga aaacaucauc caccuguuca cacugacaaa ccugggagca 3960
ccggcagcau ucaaguacuu cgacacaaca aucgacagaa agagauacac aagcacaaag 4020
gaaguccugg acgcaacacu gauccaccag agcaucacag gacuguacga aacaagaauc 4080
gaccugagcc agcugggagg agacuag 4107
<210> 503
<211> 4101
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 503
gacaagaagu acagcaucgg acuggacauc ggaacaaaca gcgucggaug ggcagucauc 60
acagacgaau acaagguccc gagcaagaag uucaaggucc ugggaaacac agacagacac 120
agcaucaaga agaaccugau cggagcacug cuguucgaca gcggagaaac agcagaagca 180
acaagacuga agagaacagc aagaagaaga uacacaagaa gaaagaacag aaucugcuac 240
cugcaggaaa ucuucagcaa cgaaauggca aaggucgacg acagcuucuu ccacagacug 300
gaagaaagcu uccuggucga agaagacaag aagcacgaaa gacacccgau cuucggaaac 360
aucgucgacg aagucgcaua ccacgaaaag uacccgacaa ucuaccaccu gagaaagaag 420
cuggucgaca gcacagacaa ggcagaccug agacugaucu accuggcacu ggcacacaug 480
aucaaguuca gaggacacuu ccugaucgaa ggagaccuga acccggacaa cagcgacguc 540
gacaagcugu ucauccagcu gguccagaca uacaaccagc uguucgaaga aaacccgauc 600
aacgcaagcg gagucgacgc aaaggcaauc cugagcgcaa gacugagcaa gagcagaaga 660
cuggaaaacc ugaucgcaca gcugccggga gaaaagaaga acggacuguu cggaaaccug 720
aucgcacuga gccugggacu gacaccgaac uucaagagca acuucgaccu ggcagaagac 780
gcaaagcugc agcugagcaa ggacacauac gacgacgacc uggacaaccu gcuggcacag 840
aucggagacc aguacgcaga ccuguuccug gcagcaaaga accugagcga cgcaauccug 900
cugagcgaca uccugagagu caacacagaa aucacaaagg caccgcugag cgcaagcaug 960
aucaagagau acgacgaaca ccaccaggac cugacacugc ugaaggcacu ggucagacag 1020
cagcugccgg aaaaguacaa ggaaaucuuc uucgaccaga gcaagaacgg auacgcagga 1080
uacaucgacg gaggagcaag ccaggaagaa uucuacaagu ucaucaagcc gauccuggaa 1140
aagauggacg gaacagaaga acugcugguc aagcugaaca gagaagaccu gcugagaaag 1200
cagagaacau ucgacaacgg aagcaucccg caccagaucc accugggaga acugcacgca 1260
auccugagaa gacaggaaga cuucuacccg uuccugaagg acaacagaga aaagaucgaa 1320
aagauccuga cauucagaau cccguacuac gucggaccgc uggcaagagg aaacagcaga 1380
uucgcaugga ugacaagaaa gagcgaagaa acaaucacac cguggaacuu cgaagaaguc 1440
gucgacaagg gagcaagcgc acagagcuuc aucgaaagaa ugacaaacuu cgacaagaac 1500
cugccgaacg aaaagguccu gccgaagcac agccugcugu acgaauacuu cacagucuac 1560
aacgaacuga caaaggucaa guacgucaca gaaggaauga gaaagccggc auuccugagc 1620
ggagaacaga agaaggcaau cgucgaccug cuguucaaga caaacagaaa ggucacaguc 1680
aagcagcuga aggaagacua cuucaagaag aucgaaugcu ucgacagcgu cgaaaucagc 1740
ggagucgaag acagauucaa cgcaagccug ggaacauacc acgaccugcu gaagaucauc 1800
aaggacaagg acuuccugga caacgaagaa aacgaagaca uccuggaaga caucguccug 1860
acacugacac uguucgaaga cagagaaaug aucgaagaaa gacugaagac auacgcacac 1920
cuguucgacg acaaggucau gaagcagcug aagagaagaa gauacacagg auggggaaga 1980
cugagcagaa agcugaucaa cggaaucaga gacaagcaga gcggaaagac aauccuggac 2040
uuccugaaga gcgacggauu cgcaaacaga aacuucaugc agcugaucca cgacgacagc 2100
cugacauuca aggaagacau ccagaaggca caggucagcg gacagggaga cagccugcac 2160
gaacacaucg caaaccuggc aggaagcccg gcaaucaaga agggaauccu gcagacaguc 2220
aaggucgucg acgaacuggu caaggucaug ggaagacaca agccggaaaa caucgucauc 2280
gaaauggcaa gagaaaacca gacaacacag aagggacaga agaacagcag agaaagaaug 2340
aagagaaucg aagaaggaau caaggaacug ggaagccaga uccugaagga acacccgguc 2400
gaaaacacac agcugcagaa cgaaaagcug uaccuguacu accugcagaa cggaagagac 2460
auguacgucg accaggaacu ggacaucaac agacugagcg acuacgacgu cgaccacauc 2520
gucccgcaga gcuuccugaa ggacgacagc aucgacaaca agguccugac aagaagcgac 2580
aagaacagag gaaagagcga caacgucccg agcgaagaag ucgucaagaa gaugaagaac 2640
uacuggagac agcugcugaa cgcaaagcug aucacacaga gaaaguucga caaccugaca 2700
aaggcagaga gaggaggacu gagcgaacug gacaaggcag gauucaucaa gagacagcug 2760
gucgaaacaa gacagaucac aaagcacguc gcacagaucc uggacagcag aaugaacaca 2820
aaguacgacg aaaacgacaa gcugaucaga gaagucaagg ucaucacacu gaagagcaag 2880
cuggucagcg acuucagaaa ggacuuccag uucuacaagg ucagagaaau caacaacuac 2940
caccacgcac acgacgcaua ccugaacgca gucgucggaa cagcacugau caagaaguac 3000
ccgaagcugg aaagcgaauu cgucuacgga gacuacaagg ucuacgacgu cagaaagaug 3060
aucgcaaaga gcgaacagga aaucggaaag gcaacagcaa aguacuucuu cuacagcaac 3120
aucaugaacu ucuucaagac agaaaucaca cuggcaaacg gagaaaucag aaagagaccg 3180
cugaucgaaa caaacggaga aacaggagaa aucgucuggg acaagggaag agacuucgca 3240
acagucagaa agguccugag caugccgcag gucaacaucg ucaagaagac agaaguccag 3300
acaggaggau ucagcaagga aagcauccug ccgaagagaa acagcgacaa gcugaucgca 3360
agaaagaagg acugggaccc gaagaaguac ggaggauucg acagcccgac agucgcauac 3420
agcguccugg ucgucgcaaa ggucgaaaag ggaaagagca agaagcugaa gagcgucaag 3480
gaacugcugg gaaucacaau cauggaaaga agcagcuucg aaaagaaccc gaucgacuuc 3540
cuggaagcaa agggauacaa ggaagucaag aaggaccuga ucaucaagcu gccgaaguac 3600
agccuguucg aacuggaaaa cggaagaaag agaaugcugg caagcgcagg agaacugcag 3660
aagggaaacg aacuggcacu gccgagcaag uacgucaacu uccuguaccu ggcaagccac 3720
uacgaaaagc ugaagggaag cccggaagac aacgaacaga agcagcuguu cgucgaacag 3780
cacaagcacu accuggacga aaucaucgaa cagaucagcg aauucagcaa gagagucauc 3840
cuggcagacg caaaccugga caagguccug agcgcauaca acaagcacag agacaagccg 3900
aucagagaac aggcagaaaa caucauccac cuguucacac ugacaaaccu gggagcaccg 3960
gcagcauuca aguacuucga cacaacaauc gacagaaaga gauacacaag cacaaaggaa 4020
guccuggacg caacacugau ccaccagagc aucacaggac uguacgaaac aagaaucgac 4080
cugagccagc ugggaggaga c 4101
<210> 504
<211> 4179
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 504
auggacaaga aguacagcau cggacuggac aucggaacaa acagcgucgg augggcaguc 60
aucacagacg aauacaaggu cccgagcaag aaguucaagg uccugggaaa cacagacaga 120
cacagcauca agaagaaccu gaucggagca cugcuguucg acagcggaga aacagcagaa 180
gcaacaagac ugaagagaac agcaagaaga agauacacaa gaagaaagaa cagaaucugc 240
uaccugcagg aaaucuucag caacgaaaug gcaaaggucg acgacagcuu cuuccacaga 300
cuggaagaaa gcuuccuggu cgaagaagac aagaagcacg aaagacaccc gaucuucgga 360
aacaucgucg acgaagucgc auaccacgaa aaguacccga caaucuacca ccugagaaag 420
aagcuggucg acagcacaga caaggcagac cugagacuga ucuaccuggc acuggcacac 480
augaucaagu ucagaggaca cuuccugauc gaaggagacc ugaacccgga caacagcgac 540
gucgacaagc uguucaucca gcugguccag acauacaacc agcuguucga agaaaacccg 600
aucaacgcaa gcggagucga cgcaaaggca auccugagcg caagacugag caagagcaga 660
agacuggaaa accugaucgc acagcugccg ggagaaaaga agaacggacu guucggaaac 720
cugaucgcac ugagccuggg acugacaccg aacuucaaga gcaacuucga ccuggcagaa 780
gacgcaaagc ugcagcugag caaggacaca uacgacgacg accuggacaa ccugcuggca 840
cagaucggag accaguacgc agaccuguuc cuggcagcaa agaaccugag cgacgcaauc 900
cugcugagcg acauccugag agucaacaca gaaaucacaa aggcaccgcu gagcgcaagc 960
augaucaaga gauacgacga acaccaccag gaccugacac ugcugaaggc acuggucaga 1020
cagcagcugc cggaaaagua caaggaaauc uucuucgacc agagcaagaa cggauacgca 1080
ggauacaucg acggaggagc aagccaggaa gaauucuaca aguucaucaa gccgauccug 1140
gaaaagaugg acggaacaga agaacugcug gucaagcuga acagagaaga ccugcugaga 1200
aagcagagaa cauucgacaa cggaagcauc ccgcaccaga uccaccuggg agaacugcac 1260
gcaauccuga gaagacagga agacuucuac ccguuccuga aggacaacag agaaaagauc 1320
gaaaagaucc ugacauucag aaucccguac uacgucggac cgcuggcaag aggaaacagc 1380
agauucgcau ggaugacaag aaagagcgaa gaaacaauca caccguggaa cuucgaagaa 1440
gucgucgaca agggagcaag cgcacagagc uucaucgaaa gaaugacaaa cuucgacaag 1500
aaccugccga acgaaaaggu ccugccgaag cacagccugc uguacgaaua cuucacaguc 1560
uacaacgaac ugacaaaggu caaguacguc acagaaggaa ugagaaagcc ggcauuccug 1620
agcggagaac agaagaaggc aaucgucgac cugcuguuca agacaaacag aaaggucaca 1680
gucaagcagc ugaaggaaga cuacuucaag aagaucgaau gcuucgacag cgucgaaauc 1740
agcggagucg aagacagauu caacgcaagc cugggaacau accacgaccu gcugaagauc 1800
aucaaggaca aggacuuccu ggacaacgaa gaaaacgaag acauccugga agacaucguc 1860
cugacacuga cacuguucga agacagagaa augaucgaag aaagacugaa gacauacgca 1920
caccuguucg acgacaaggu caugaagcag cugaagagaa gaagauacac aggaugggga 1980
agacugagca gaaagcugau caacggaauc agagacaagc agagcggaaa gacaauccug 2040
gacuuccuga agagcgacgg auucgcaaac agaaacuuca ugcagcugau ccacgacgac 2100
agccugacau ucaaggaaga cauccagaag gcacagguca gcggacaggg agacagccug 2160
cacgaacaca ucgcaaaccu ggcaggaagc ccggcaauca agaagggaau ccugcagaca 2220
gucaaggucg ucgacgaacu ggucaagguc augggaagac acaagccgga aaacaucguc 2280
aucgaaaugg caagagaaaa ccagacaaca cagaagggac agaagaacag cagagaaaga 2340
augaagagaa ucgaagaagg aaucaaggaa cugggaagcc agauccugaa ggaacacccg 2400
gucgaaaaca cacagcugca gaacgaaaag cuguaccugu acuaccugca gaacggaaga 2460
gacauguacg ucgaccagga acuggacauc aacagacuga gcgacuacga cgucgaccac 2520
aucgucccgc agagcuuccu gaaggacgac agcaucgaca acaagguccu gacaagaagc 2580
gacaagaaca gaggaaagag cgacaacguc ccgagcgaag aagucgucaa gaagaugaag 2640
aacuacugga gacagcugcu gaacgcaaag cugaucacac agagaaaguu cgacaaccug 2700
acaaaggcag agagaggagg acugagcgaa cuggacaagg caggauucau caagagacag 2760
cuggucgaaa caagacagau cacaaagcac gucgcacaga uccuggacag cagaaugaac 2820
acaaaguacg acgaaaacga caagcugauc agagaaguca aggucaucac acugaagagc 2880
aagcugguca gcgacuucag aaaggacuuc caguucuaca aggucagaga aaucaacaac 2940
uaccaccacg cacacgacgc auaccugaac gcagucgucg gaacagcacu gaucaagaag 3000
uacccgaagc uggaaagcga auucgucuac ggagacuaca aggucuacga cgucagaaag 3060
augaucgcaa agagcgaaca ggaaaucgga aaggcaacag caaaguacuu cuucuacagc 3120
aacaucauga acuucuucaa gacagaaauc acacuggcaa acggagaaau cagaaagaga 3180
ccgcugaucg aaacaaacgg agaaacagga gaaaucgucu gggacaaggg aagagacuuc 3240
gcaacaguca gaaagguccu gagcaugccg caggucaaca ucgucaagaa gacagaaguc 3300
cagacaggag gauucagcaa ggaaagcauc cugccgaaga gaaacagcga caagcugauc 3360
gcaagaaaga aggacuggga cccgaagaag uacggaggau ucgacagccc gacagucgca 3420
uacagcgucc uggucgucgc aaaggucgaa aagggaaaga gcaagaagcu gaagagcguc 3480
aaggaacugc ugggaaucac aaucauggaa agaagcagcu ucgaaaagaa cccgaucgac 3540
uuccuggaag caaagggaua caaggaaguc aagaaggacc ugaucaucaa gcugccgaag 3600
uacagccugu ucgaacugga aaacggaaga aagagaaugc uggcaagcgc aggagaacug 3660
cagaagggaa acgaacuggc acugccgagc aaguacguca acuuccugua ccuggcaagc 3720
cacuacgaaa agcugaaggg aagcccggaa gacaacgaac agaagcagcu guucgucgaa 3780
cagcacaagc acuaccugga cgaaaucauc gaacagauca gcgaauucag caagagaguc 3840
auccuggcag acgcaaaccu ggacaagguc cugagcgcau acaacaagca cagagacaag 3900
ccgaucagag aacaggcaga aaacaucauc caccuguuca cacugacaaa ccugggagca 3960
ccggcagcau ucaaguacuu cgacacaaca aucgacagaa agagauacac aagcacaaag 4020
gaaguccugg acgcaacacu gauccaccag agcaucacag gacuguacga aacaagaauc 4080
gaccugagcc agcugggagg agacggaagc ggaagcccga agaagaagag aaaggucgac 4140
ggaagcccga agaagaagag aaaggucgac agcggauag 4179
<210> 505
<211> 4173
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 505
gacaagaagu acagcaucgg acuggacauc ggaacaaaca gcgucggaug ggcagucauc 60
acagacgaau acaagguccc gagcaagaag uucaaggucc ugggaaacac agacagacac 120
agcaucaaga agaaccugau cggagcacug cuguucgaca gcggagaaac agcagaagca 180
acaagacuga agagaacagc aagaagaaga uacacaagaa gaaagaacag aaucugcuac 240
cugcaggaaa ucuucagcaa cgaaauggca aaggucgacg acagcuucuu ccacagacug 300
gaagaaagcu uccuggucga agaagacaag aagcacgaaa gacacccgau cuucggaaac 360
aucgucgacg aagucgcaua ccacgaaaag uacccgacaa ucuaccaccu gagaaagaag 420
cuggucgaca gcacagacaa ggcagaccug agacugaucu accuggcacu ggcacacaug 480
aucaaguuca gaggacacuu ccugaucgaa ggagaccuga acccggacaa cagcgacguc 540
gacaagcugu ucauccagcu gguccagaca uacaaccagc uguucgaaga aaacccgauc 600
aacgcaagcg gagucgacgc aaaggcaauc cugagcgcaa gacugagcaa gagcagaaga 660
cuggaaaacc ugaucgcaca gcugccggga gaaaagaaga acggacuguu cggaaaccug 720
aucgcacuga gccugggacu gacaccgaac uucaagagca acuucgaccu ggcagaagac 780
gcaaagcugc agcugagcaa ggacacauac gacgacgacc uggacaaccu gcuggcacag 840
aucggagacc aguacgcaga ccuguuccug gcagcaaaga accugagcga cgcaauccug 900
cugagcgaca uccugagagu caacacagaa aucacaaagg caccgcugag cgcaagcaug 960
aucaagagau acgacgaaca ccaccaggac cugacacugc ugaaggcacu ggucagacag 1020
cagcugccgg aaaaguacaa ggaaaucuuc uucgaccaga gcaagaacgg auacgcagga 1080
uacaucgacg gaggagcaag ccaggaagaa uucuacaagu ucaucaagcc gauccuggaa 1140
aagauggacg gaacagaaga acugcugguc aagcugaaca gagaagaccu gcugagaaag 1200
cagagaacau ucgacaacgg aagcaucccg caccagaucc accugggaga acugcacgca 1260
auccugagaa gacaggaaga cuucuacccg uuccugaagg acaacagaga aaagaucgaa 1320
aagauccuga cauucagaau cccguacuac gucggaccgc uggcaagagg aaacagcaga 1380
uucgcaugga ugacaagaaa gagcgaagaa acaaucacac cguggaacuu cgaagaaguc 1440
gucgacaagg gagcaagcgc acagagcuuc aucgaaagaa ugacaaacuu cgacaagaac 1500
cugccgaacg aaaagguccu gccgaagcac agccugcugu acgaauacuu cacagucuac 1560
aacgaacuga caaaggucaa guacgucaca gaaggaauga gaaagccggc auuccugagc 1620
ggagaacaga agaaggcaau cgucgaccug cuguucaaga caaacagaaa ggucacaguc 1680
aagcagcuga aggaagacua cuucaagaag aucgaaugcu ucgacagcgu cgaaaucagc 1740
ggagucgaag acagauucaa cgcaagccug ggaacauacc acgaccugcu gaagaucauc 1800
aaggacaagg acuuccugga caacgaagaa aacgaagaca uccuggaaga caucguccug 1860
acacugacac uguucgaaga cagagaaaug aucgaagaaa gacugaagac auacgcacac 1920
cuguucgacg acaaggucau gaagcagcug aagagaagaa gauacacagg auggggaaga 1980
cugagcagaa agcugaucaa cggaaucaga gacaagcaga gcggaaagac aauccuggac 2040
uuccugaaga gcgacggauu cgcaaacaga aacuucaugc agcugaucca cgacgacagc 2100
cugacauuca aggaagacau ccagaaggca caggucagcg gacagggaga cagccugcac 2160
gaacacaucg caaaccuggc aggaagcccg gcaaucaaga agggaauccu gcagacaguc 2220
aaggucgucg acgaacuggu caaggucaug ggaagacaca agccggaaaa caucgucauc 2280
gaaauggcaa gagaaaacca gacaacacag aagggacaga agaacagcag agaaagaaug 2340
aagagaaucg aagaaggaau caaggaacug ggaagccaga uccugaagga acacccgguc 2400
gaaaacacac agcugcagaa cgaaaagcug uaccuguacu accugcagaa cggaagagac 2460
auguacgucg accaggaacu ggacaucaac agacugagcg acuacgacgu cgaccacauc 2520
gucccgcaga gcuuccugaa ggacgacagc aucgacaaca agguccugac aagaagcgac 2580
aagaacagag gaaagagcga caacgucccg agcgaagaag ucgucaagaa gaugaagaac 2640
uacuggagac agcugcugaa cgcaaagcug aucacacaga gaaaguucga caaccugaca 2700
aaggcagaga gaggaggacu gagcgaacug gacaaggcag gauucaucaa gagacagcug 2760
gucgaaacaa gacagaucac aaagcacguc gcacagaucc uggacagcag aaugaacaca 2820
aaguacgacg aaaacgacaa gcugaucaga gaagucaagg ucaucacacu gaagagcaag 2880
cuggucagcg acuucagaaa ggacuuccag uucuacaagg ucagagaaau caacaacuac 2940
caccacgcac acgacgcaua ccugaacgca gucgucggaa cagcacugau caagaaguac 3000
ccgaagcugg aaagcgaauu cgucuacgga gacuacaagg ucuacgacgu cagaaagaug 3060
aucgcaaaga gcgaacagga aaucggaaag gcaacagcaa aguacuucuu cuacagcaac 3120
aucaugaacu ucuucaagac agaaaucaca cuggcaaacg gagaaaucag aaagagaccg 3180
cugaucgaaa caaacggaga aacaggagaa aucgucuggg acaagggaag agacuucgca 3240
acagucagaa agguccugag caugccgcag gucaacaucg ucaagaagac agaaguccag 3300
acaggaggau ucagcaagga aagcauccug ccgaagagaa acagcgacaa gcugaucgca 3360
agaaagaagg acugggaccc gaagaaguac ggaggauucg acagcccgac agucgcauac 3420
agcguccugg ucgucgcaaa ggucgaaaag ggaaagagca agaagcugaa gagcgucaag 3480
gaacugcugg gaaucacaau cauggaaaga agcagcuucg aaaagaaccc gaucgacuuc 3540
cuggaagcaa agggauacaa ggaagucaag aaggaccuga ucaucaagcu gccgaaguac 3600
agccuguucg aacuggaaaa cggaagaaag agaaugcugg caagcgcagg agaacugcag 3660
aagggaaacg aacuggcacu gccgagcaag uacgucaacu uccuguaccu ggcaagccac 3720
uacgaaaagc ugaagggaag cccggaagac aacgaacaga agcagcuguu cgucgaacag 3780
cacaagcacu accuggacga aaucaucgaa cagaucagcg aauucagcaa gagagucauc 3840
cuggcagacg caaaccugga caagguccug agcgcauaca acaagcacag agacaagccg 3900
aucagagaac aggcagaaaa caucauccac cuguucacac ugacaaaccu gggagcaccg 3960
gcagcauuca aguacuucga cacaacaauc gacagaaaga gauacacaag cacaaaggaa 4020
guccuggacg caacacugau ccaccagagc aucacaggac uguacgaaac aagaaucgac 4080
cugagccagc ugggaggaga cggaagcgga agcccgaaga agaagagaaa ggucgacgga 4140
agcccgaaga agaagagaaa ggucgacagc gga 4173
<210> 506
<211> 4405
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 506
gggtcccgca gtcggcgtcc agcggctctg cttgttcgtg tgtgtgtcgt tgcaggcctt 60
attcggatcc atggacaaga agtacagcat cggactggac atcggaacaa acagcgtcgg 120
atgggcagtc atcacagacg aatacaaggt cccgagcaag aagttcaagg tcctgggaaa 180
cacagacaga cacagcatca agaagaacct gatcggagca ctgctgttcg acagcggaga 240
aacagcagaa gcaacaagac tgaagagaac agcaagaaga agatacacaa gaagaaagaa 300
cagaatctgc tacctgcagg aaatcttcag caacgaaatg gcaaaggtcg acgacagctt 360
cttccacaga ctggaagaaa gcttcctggt cgaagaagac aagaagcacg aaagacaccc 420
gatcttcgga aacatcgtcg acgaagtcgc ataccacgaa aagtacccga caatctacca 480
cctgagaaag aagctggtcg acagcacaga caaggcagac ctgagactga tctacctggc 540
actggcacac atgatcaagt tcagaggaca cttcctgatc gaaggagacc tgaacccgga 600
caacagcgac gtcgacaagc tgttcatcca gctggtccag acatacaacc agctgttcga 660
agaaaacccg atcaacgcaa gcggagtcga cgcaaaggca atcctgagcg caagactgag 720
caagagcaga agactggaaa acctgatcgc acagctgccg ggagaaaaga agaacggact 780
gttcggaaac ctgatcgcac tgagcctggg actgacaccg aacttcaaga gcaacttcga 840
cctggcagaa gacgcaaagc tgcagctgag caaggacaca tacgacgacg acctggacaa 900
cctgctggca cagatcggag accagtacgc agacctgttc ctggcagcaa agaacctgag 960
cgacgcaatc ctgctgagcg acatcctgag agtcaacaca gaaatcacaa aggcaccgct 1020
gagcgcaagc atgatcaaga gatacgacga acaccaccag gacctgacac tgctgaaggc 1080
actggtcaga cagcagctgc cggaaaagta caaggaaatc ttcttcgacc agagcaagaa 1140
cggatacgca ggatacatcg acggaggagc aagccaggaa gaattctaca agttcatcaa 1200
gccgatcctg gaaaagatgg acggaacaga agaactgctg gtcaagctga acagagaaga 1260
cctgctgaga aagcagagaa cattcgacaa cggaagcatc ccgcaccaga tccacctggg 1320
agaactgcac gcaatcctga gaagacagga agacttctac ccgttcctga aggacaacag 1380
agaaaagatc gaaaagatcc tgacattcag aatcccgtac tacgtcggac cgctggcaag 1440
aggaaacagc agattcgcat ggatgacaag aaagagcgaa gaaacaatca caccgtggaa 1500
cttcgaagaa gtcgtcgaca agggagcaag cgcacagagc ttcatcgaaa gaatgacaaa 1560
cttcgacaag aacctgccga acgaaaaggt cctgccgaag cacagcctgc tgtacgaata 1620
cttcacagtc tacaacgaac tgacaaaggt caagtacgtc acagaaggaa tgagaaagcc 1680
ggcattcctg agcggagaac agaagaaggc aatcgtcgac ctgctgttca agacaaacag 1740
aaaggtcaca gtcaagcagc tgaaggaaga ctacttcaag aagatcgaat gcttcgacag 1800
cgtcgaaatc agcggagtcg aagacagatt caacgcaagc ctgggaacat accacgacct 1860
gctgaagatc atcaaggaca aggacttcct ggacaacgaa gaaaacgaag acatcctgga 1920
agacatcgtc ctgacactga cactgttcga agacagagaa atgatcgaag aaagactgaa 1980
gacatacgca cacctgttcg acgacaaggt catgaagcag ctgaagagaa gaagatacac 2040
aggatgggga agactgagca gaaagctgat caacggaatc agagacaagc agagcggaaa 2100
gacaatcctg gacttcctga agagcgacgg attcgcaaac agaaacttca tgcagctgat 2160
ccacgacgac agcctgacat tcaaggaaga catccagaag gcacaggtca gcggacaggg 2220
agacagcctg cacgaacaca tcgcaaacct ggcaggaagc ccggcaatca agaagggaat 2280
cctgcagaca gtcaaggtcg tcgacgaact ggtcaaggtc atgggaagac acaagccgga 2340
aaacatcgtc atcgaaatgg caagagaaaa ccagacaaca cagaagggac agaagaacag 2400
cagagaaaga atgaagagaa tcgaagaagg aatcaaggaa ctgggaagcc agatcctgaa 2460
ggaacacccg gtcgaaaaca cacagctgca gaacgaaaag ctgtacctgt actacctgca 2520
gaacggaaga gacatgtacg tcgaccagga actggacatc aacagactga gcgactacga 2580
cgtcgaccac atcgtcccgc agagcttcct gaaggacgac agcatcgaca acaaggtcct 2640
gacaagaagc gacaagaaca gaggaaagag cgacaacgtc ccgagcgaag aagtcgtcaa 2700
gaagatgaag aactactgga gacagctgct gaacgcaaag ctgatcacac agagaaagtt 2760
cgacaacctg acaaaggcag agagaggagg actgagcgaa ctggacaagg caggattcat 2820
caagagacag ctggtcgaaa caagacagat cacaaagcac gtcgcacaga tcctggacag 2880
cagaatgaac acaaagtacg acgaaaacga caagctgatc agagaagtca aggtcatcac 2940
actgaagagc aagctggtca gcgacttcag aaaggacttc cagttctaca aggtcagaga 3000
aatcaacaac taccaccacg cacacgacgc atacctgaac gcagtcgtcg gaacagcact 3060
gatcaagaag tacccgaagc tggaaagcga attcgtctac ggagactaca aggtctacga 3120
cgtcagaaag atgatcgcaa agagcgaaca ggaaatcgga aaggcaacag caaagtactt 3180
cttctacagc aacatcatga acttcttcaa gacagaaatc acactggcaa acggagaaat 3240
cagaaagaga ccgctgatcg aaacaaacgg agaaacagga gaaatcgtct gggacaaggg 3300
aagagacttc gcaacagtca gaaaggtcct gagcatgccg caggtcaaca tcgtcaagaa 3360
gacagaagtc cagacaggag gattcagcaa ggaaagcatc ctgccgaaga gaaacagcga 3420
caagctgatc gcaagaaaga aggactggga cccgaagaag tacggaggat tcgacagccc 3480
gacagtcgca tacagcgtcc tggtcgtcgc aaaggtcgaa aagggaaaga gcaagaagct 3540
gaagagcgtc aaggaactgc tgggaatcac aatcatggaa agaagcagct tcgaaaagaa 3600
cccgatcgac ttcctggaag caaagggata caaggaagtc aagaaggacc tgatcatcaa 3660
gctgccgaag tacagcctgt tcgaactgga aaacggaaga aagagaatgc tggcaagcgc 3720
aggagaactg cagaagggaa acgaactggc actgccgagc aagtacgtca acttcctgta 3780
cctggcaagc cactacgaaa agctgaaggg aagcccggaa gacaacgaac agaagcagct 3840
gttcgtcgaa cagcacaagc actacctgga cgaaatcatc gaacagatca gcgaattcag 3900
caagagagtc atcctggcag acgcaaacct ggacaaggtc ctgagcgcat acaacaagca 3960
cagagacaag ccgatcagag aacaggcaga aaacatcatc cacctgttca cactgacaaa 4020
cctgggagca ccggcagcat tcaagtactt cgacacaaca atcgacagaa agagatacac 4080
aagcacaaag gaagtcctgg acgcaacact gatccaccag agcatcacag gactgtacga 4140
aacaagaatc gacctgagcc agctgggagg agacggagga ggaagcccga agaagaagag 4200
aaaggtctag ctagccatca catttaaaag catctcagcc taccatgaga ataagagaaa 4260
gaaaatgaag atcaatagct tattcatctc tttttctttt tcgttggtgt aaagccaaca 4320
ccctgtctaa aaaacataaa tttctttaat cattttgcct cttttctctg tgcttcaatt 4380
aataaaaaat ggaaagaacc tcgag 4405
<210> 507
<211> 4140
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 507
atggacaaga agtacagcat cggactggac atcggaacaa acagcgtcgg atgggcagtc 60
atcacagacg aatacaaggt cccgagcaag aagttcaagg tcctgggaaa cacagacaga 120
cacagcatca agaagaacct gatcggagca ctgctgttcg acagcggaga aacagcagaa 180
gcaacaagac tgaagagaac agcaagaaga agatacacaa gaagaaagaa cagaatctgc 240
tacctgcagg aaatcttcag caacgaaatg gcaaaggtcg acgacagctt cttccaccgg 300
ctggaagaaa gcttcctggt cgaagaagac aagaagcacg aaagacaccc gatcttcgga 360
aacatcgtcg acgaagtcgc ataccacgaa aagtacccga caatctacca cctgagaaag 420
aagctggtcg acagcacaga caaggcagac ctgagactga tctacctggc actggcacac 480
atgatcaagt tcagaggaca cttcctgatc gaaggagacc tgaacccgga caacagcgac 540
gtcgacaagc tgttcatcca gctggtccag acatacaacc agctgttcga agaaaacccg 600
atcaacgcaa gcggagtcga cgcaaaggca atcctgagcg caagactgag caagagcaga 660
agactggaaa acctgatcgc acagctgccg ggagaaaaga agaacggact gttcggaaac 720
ctgatcgcac tgagcctggg actgacaccg aacttcaaga gcaacttcga cctggcagaa 780
gacgcaaagc tgcagctgag caaggacaca tacgacgacg acctggacaa cctgctggca 840
cagatcggag accagtacgc agacctgttc ctggcagcaa agaacctgag cgacgcaatc 900
ctgctgagcg acatcctgag agtcaacaca gaaatcacaa aggcaccgct gagcgcaagc 960
atgatcaaga gatacgacga acaccaccag gacctgacac tgctgaaggc actggtcaga 1020
cagcagctgc cggaaaagta caaggaaatc ttcttcgacc agagcaagaa cggatacgca 1080
ggatacatcg acggaggagc aagccaggaa gaattctaca agttcatcaa gccgatcctg 1140
gaaaagatgg acggaacaga agaactgctg gtcaagctga acagagaaga cctgctgaga 1200
aagcagagaa cattcgacaa cggaagcatc ccgcaccaga tccacctggg agaactgcac 1260
gcaatcctga gaagacagga agacttctac ccgttcctga aggacaacag agaaaagatc 1320
gaaaagatcc tgacattcag aatcccgtac tacgtcggac cgctggcaag aggaaacagc 1380
agattcgcat ggatgacaag aaagagcgaa gaaacaatca caccgtggaa cttcgaagaa 1440
gtcgtcgaca agggagcaag cgcacagagc ttcatcgaaa gaatgacaaa cttcgacaag 1500
aacctgccga acgaaaaggt cctgccgaag cacagcctgc tgtacgaata cttcacagtc 1560
tacaacgaac tgacaaaggt caagtacgtc acagaaggaa tgagaaagcc ggcattcctg 1620
agcggagaac agaagaaggc aatcgtcgac ctgctgttca agacaaacag aaaggtcaca 1680
gtcaagcagc tgaaggaaga ctacttcaag aagatcgaat gcttcgacag cgtcgaaatc 1740
agcggagtcg aagacagatt caacgcaagc ctgggaacat accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgaa gaaaacgaag acatcctgga agacatcgtc 1860
ctgacactga cactgttcga agacagagaa atgatcgaag aaagactgaa gacatacgca 1920
cacctgttcg acgacaaggt catgaagcag ctgaagagaa gaagatacac aggatgggga 1980
agactgagca gaaagctgat caacggaatc agagacaagc agagcggaaa gacaatcctg 2040
gacttcctga agagcgacgg attcgcaaac agaaacttca tgcagctgat ccacgacgac 2100
agcctgacat tcaaggaaga catccagaag gcacaggtca gcggacaggg agacagcctg 2160
cacgaacaca tcgcaaacct ggcaggaagc ccggcaatca agaagggaat cctgcagaca 2220
gtcaaggtcg tcgacgaact ggtcaaggtc atgggaagac acaagccgga aaacatcgtc 2280
atcgaaatgg caagagaaaa ccagacaaca cagaagggac agaagaacag cagagaaaga 2340
atgaagagaa tcgaagaagg aatcaaggaa ctgggaagcc agatcctgaa ggaacacccg 2400
gtcgaaaaca cacagctgca gaacgaaaag ctgtacctgt actacctgca aaacggaaga 2460
gacatgtacg tcgaccagga actggacatc aacagactga gcgactacga cgtcgaccac 2520
atcgtcccgc agagcttcct gaaggacgac agcatcgaca acaaggtcct gacaagaagc 2580
gacaagaaca gaggaaagag cgacaacgtc ccgagcgaag aagtcgtcaa gaagatgaag 2640
aactactgga gacagctgct gaacgcaaag ctgatcacac agagaaagtt cgacaacctg 2700
acaaaggcag agagaggagg actgagcgaa ctggacaagg caggattcat caagagacag 2760
ctggtcgaaa caagacagat cacaaagcac gtcgcacaga tcctggacag cagaatgaac 2820
acaaagtacg acgaaaacga caagctgatc agagaagtca aggtcatcac actgaagagc 2880
aagctggtca gcgacttcag aaaggacttc cagttctaca aggtcagaga aatcaacaac 2940
taccaccacg cacacgacgc atacctgaac gcagtcgtcg gaacagcact gatcaagaag 3000
tacccgaagc tggaaagcga attcgtctac ggagactaca aggtctacga cgtcagaaag 3060
atgatcgcaa agagcgaaca ggaaatcgga aaggcaacag caaagtactt cttctacagc 3120
aacatcatga acttcttcaa gacagaaatc acactggcaa acggagaaat cagaaagaga 3180
ccgctgatcg aaacaaacgg agaaacagga gaaatcgtct gggacaaggg aagagacttc 3240
gcaacagtca gaaaggtcct gagcatgccg caggtcaaca tcgtcaagaa gacagaagtc 3300
cagacaggag gattcagcaa ggaaagcatc ctgccgaaga gaaacagcga caagctgatc 3360
gcaagaaaga aggactggga cccgaagaag tacggaggat tcgacagccc gacagtcgca 3420
tacagcgtcc tggtcgtcgc aaaggtcgaa aagggaaaga gcaagaagct gaagagcgtc 3480
aaggaactgc tgggaatcac aatcatggaa agaagcagct tcgaaaagaa cccgatcgac 3540
ttcctggaag caaagggata caaggaagtc aagaaggacc tgatcatcaa gctgccgaag 3600
tacagcctgt tcgaactgga aaacggaaga aagagaatgc tggcaagcgc aggagaactg 3660
cagaagggaa acgaactggc actgccgagc aagtacgtca acttcctgta cctggcaagc 3720
cactacgaaa agctgaaggg aagcccggaa gacaacgaac agaagcagct gttcgtcgaa 3780
cagcacaagc actacctgga cgaaatcatc gaacagatca gcgaattcag caagagagtc 3840
atcctggcag acgcaaacct ggacaaggtc ctgagcgcat acaacaagca cagagacaag 3900
ccgatcagag aacaggcaga aaacatcatc cacctgttca cactgacaaa cctgggagca 3960
ccggcagcat tcaagtactt cgacacaaca atcgacagaa agagatacac aagcacaaag 4020
gaagtcctgg acgcaacact gatccaccag agcatcacag gactgtacga aacaagaatc 4080
gacctgagcc agctgggagg agacggagga ggaagcccga agaagaagag aaaggtctag 4140
<210> 508
<211> 4140
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 508
atggacaaga agtacagcat cggcctggac atcggcacca acagcgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gcccagcaag aagttcaagg tgctgggcaa caccgacaga 120
cacagcatca agaagaacct gatcggcgcc ctgctgttcg acagcggcga gaccgccgag 180
gccaccagac tgaagagaac cgccagaaga agatacacca gaagaaagaa cagaatctgc 240
tacctgcagg agatcttcag caacgagatg gccaaggtgg acgacagctt cttccacaga 300
ctggaggaga gcttcctggt ggaggaggac aagaagcacg agagacaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgagaaag 420
aagctggtgg acagcaccga caaggccgac ctgagactga tctacctggc cctggcccac 480
atgatcaagt tcagaggcca cttcctgatc gagggcgacc tgaaccccga caacagcgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggagaacccc 600
atcaacgcca gcggcgtgga cgccaaggcc atcctgagcg ccagactgag caagagcaga 660
agactggaga acctgatcgc ccagctgccc ggcgagaaga agaacggcct gttcggcaac 720
ctgatcgccc tgagcctggg cctgaccccc aacttcaaga gcaacttcga cctggccgag 780
gacgccaagc tgcagctgag caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttc ctggccgcca agaacctgag cgacgccatc 900
ctgctgagcg acatcctgag agtgaacacc gagatcacca aggcccccct gagcgccagc 960
atgatcaaga gatacgacga gcaccaccag gacctgaccc tgctgaaggc cctggtgaga 1020
cagcagctgc ccgagaagta caaggagatc ttcttcgacc agagcaagaa cggctacgcc 1080
ggctacatcg acggcggcgc cagccaggag gagttctaca agttcatcaa gcccatcctg 1140
gagaagatgg acggcaccga ggagctgctg gtgaagctga acagagagga cctgctgaga 1200
aagcagagaa ccttcgacaa cggcagcatc ccccaccaga tccacctggg cgagctgcac 1260
gccatcctga gaagacagga ggacttctac cccttcctga aggacaacag agagaagatc 1320
gagaagatcc tgaccttcag aatcccctac tacgtgggcc ccctggccag aggcaacagc 1380
agattcgcct ggatgaccag aaagagcgag gagaccatca ccccctggaa cttcgaggag 1440
gtggtggaca agggcgccag cgcccagagc ttcatcgaga gaatgaccaa cttcgacaag 1500
aacctgccca acgagaaggt gctgcccaag cacagcctgc tgtacgagta cttcaccgtg 1560
tacaacgagc tgaccaaggt gaagtacgtg accgagggca tgagaaagcc cgccttcctg 1620
agcggcgagc agaagaaggc catcgtggac ctgctgttca agaccaacag aaaggtgacc 1680
gtgaagcagc tgaaggagga ctacttcaag aagatcgagt gcttcgacag cgtggagatc 1740
agcggcgtgg aggacagatt caacgccagc ctgggcacct accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgag gagaacgagg acatcctgga ggacatcgtg 1860
ctgaccctga ccctgttcga ggacagagag atgatcgagg agagactgaa gacctacgcc 1920
cacctgttcg acgacaaggt gatgaagcag ctgaagagaa gaagatacac cggctggggc 1980
agactgagca gaaagctgat caacggcatc agagacaagc agagcggcaa gaccatcctg 2040
gacttcctga agagcgacgg cttcgccaac agaaacttca tgcagctgat ccacgacgac 2100
agcctgacct tcaaggagga catccagaag gcccaggtga gcggccaggg cgacagcctg 2160
cacgagcaca tcgccaacct ggccggcagc cccgccatca agaagggcat cctgcagacc 2220
gtgaaggtgg tggacgagct ggtgaaggtg atgggcagac acaagcccga gaacatcgtg 2280
atcgagatgg ccagagagaa ccagaccacc cagaagggcc agaagaacag cagagagaga 2340
atgaagagaa tcgaggaggg catcaaggag ctgggcagcc agatcctgaa ggagcacccc 2400
gtggagaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaacggcaga 2460
gacatgtacg tggaccagga gctggacatc aacagactga gcgactacga cgtggaccac 2520
atcgtgcccc agagcttcct gaaggacgac agcatcgaca acaaggtgct gaccagaagc 2580
gacaagaaca gaggcaagag cgacaacgtg cccagcgagg aggtggtgaa gaagatgaag 2640
aactactgga gacagctgct gaacgccaag ctgatcaccc agagaaagtt cgacaacctg 2700
accaaggccg agagaggcgg cctgagcgag ctggacaagg ccggcttcat caagagacag 2760
ctggtggaga ccagacagat caccaagcac gtggcccaga tcctggacag cagaatgaac 2820
accaagtacg acgagaacga caagctgatc agagaggtga aggtgatcac cctgaagagc 2880
aagctggtga gcgacttcag aaaggacttc cagttctaca aggtgagaga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtggtgg gcaccgccct gatcaagaag 3000
taccccaagc tggagagcga gttcgtgtac ggcgactaca aggtgtacga cgtgagaaag 3060
atgatcgcca agagcgagca ggagatcggc aaggccaccg ccaagtactt cttctacagc 3120
aacatcatga acttcttcaa gaccgagatc accctggcca acggcgagat cagaaagaga 3180
cccctgatcg agaccaacgg cgagaccggc gagatcgtgt gggacaaggg cagagacttc 3240
gccaccgtga gaaaggtgct gagcatgccc caggtgaaca tcgtgaagaa gaccgaggtg 3300
cagaccggcg gcttcagcaa ggagagcatc ctgcccaaga gaaacagcga caagctgatc 3360
gccagaaaga aggactggga ccccaagaag tacggcggct tcgacagccc caccgtggcc 3420
tacagcgtgc tggtggtggc caaggtggag aagggcaaga gcaagaagct gaagagcgtg 3480
aaggagctgc tgggcatcac catcatggag agaagcagct tcgagaagaa ccccatcgac 3540
ttcctggagg ccaagggcta caaggaggtg aagaaggacc tgatcatcaa gctgcccaag 3600
tacagcctgt tcgagctgga gaacggcaga aagagaatgc tggccagcgc cggcgagctg 3660
cagaagggca acgagctggc cctgcccagc aagtacgtga acttcctgta cctggccagc 3720
cactacgaga agctgaaggg cagccccgag gacaacgagc agaagcagct gttcgtggag 3780
cagcacaagc actacctgga cgagatcatc gagcagatca gcgagttcag caagagagtg 3840
atcctggccg acgccaacct ggacaaggtg ctgagcgcct acaacaagca cagagacaag 3900
cccatcagag agcaggccga gaacatcatc cacctgttca ccctgaccaa cctgggcgcc 3960
cccgccgcct tcaagtactt cgacaccacc atcgacagaa agagatacac cagcaccaag 4020
gaggtgctgg acgccaccct gatccaccag agcatcaccg gcctgtacga gaccagaatc 4080
gacctgagcc agctgggcgg cgacggcggc ggcagcccca agaagaagag aaaggtgtga 4140
<210> 509
<211> 4411
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 509
gggtcccgca gtcggcgtcc agcggctctg cttgttcgtg tgtgtgtcgt tgcaggcctt 60
attcggatcc gccaccatgg acaagaagta cagcatcggc ctggacatcg gcaccaacag 120
cgtgggctgg gccgtgatca ccgacgagta caaggtgccc agcaagaagt tcaaggtgct 180
gggcaacacc gacagacaca gcatcaagaa gaacctgatc ggcgccctgc tgttcgacag 240
cggcgagacc gccgaggcca ccagactgaa gagaaccgcc agaagaagat acaccagaag 300
aaagaacaga atctgctacc tgcaggagat cttcagcaac gagatggcca aggtggacga 360
cagcttcttc cacagactgg aggagagctt cctggtggag gaggacaaga agcacgagag 420
acaccccatc ttcggcaaca tcgtggacga ggtggcctac cacgagaagt accccaccat 480
ctaccacctg agaaagaagc tggtggacag caccgacaag gccgacctga gactgatcta 540
cctggccctg gcccacatga tcaagttcag aggccacttc ctgatcgagg gcgacctgaa 600
ccccgacaac agcgacgtgg acaagctgtt catccagctg gtgcagacct acaaccagct 660
gttcgaggag aaccccatca acgccagcgg cgtggacgcc aaggccatcc tgagcgccag 720
actgagcaag agcagaagac tggagaacct gatcgcccag ctgcccggcg agaagaagaa 780
cggcctgttc ggcaacctga tcgccctgag cctgggcctg acccccaact tcaagagcaa 840
cttcgacctg gccgaggacg ccaagctgca gctgagcaag gacacctacg acgacgacct 900
ggacaacctg ctggcccaga tcggcgacca gtacgccgac ctgttcctgg ccgccaagaa 960
cctgagcgac gccatcctgc tgagcgacat cctgagagtg aacaccgaga tcaccaaggc 1020
ccccctgagc gccagcatga tcaagagata cgacgagcac caccaggacc tgaccctgct 1080
gaaggccctg gtgagacagc agctgcccga gaagtacaag gagatcttct tcgaccagag 1140
caagaacggc tacgccggct acatcgacgg cggcgccagc caggaggagt tctacaagtt 1200
catcaagccc atcctggaga agatggacgg caccgaggag ctgctggtga agctgaacag 1260
agaggacctg ctgagaaagc agagaacctt cgacaacggc agcatccccc accagatcca 1320
cctgggcgag ctgcacgcca tcctgagaag acaggaggac ttctacccct tcctgaagga 1380
caacagagag aagatcgaga agatcctgac cttcagaatc ccctactacg tgggccccct 1440
ggccagaggc aacagcagat tcgcctggat gaccagaaag agcgaggaga ccatcacccc 1500
ctggaacttc gaggaggtgg tggacaaggg cgccagcgcc cagagcttca tcgagagaat 1560
gaccaacttc gacaagaacc tgcccaacga gaaggtgctg cccaagcaca gcctgctgta 1620
cgagtacttc accgtgtaca acgagctgac caaggtgaag tacgtgaccg agggcatgag 1680
aaagcccgcc ttcctgagcg gcgagcagaa gaaggccatc gtggacctgc tgttcaagac 1740
caacagaaag gtgaccgtga agcagctgaa ggaggactac ttcaagaaga tcgagtgctt 1800
cgacagcgtg gagatcagcg gcgtggagga cagattcaac gccagcctgg gcacctacca 1860
cgacctgctg aagatcatca aggacaagga cttcctggac aacgaggaga acgaggacat 1920
cctggaggac atcgtgctga ccctgaccct gttcgaggac agagagatga tcgaggagag 1980
actgaagacc tacgcccacc tgttcgacga caaggtgatg aagcagctga agagaagaag 2040
atacaccggc tggggcagac tgagcagaaa gctgatcaac ggcatcagag acaagcagag 2100
cggcaagacc atcctggact tcctgaagag cgacggcttc gccaacagaa acttcatgca 2160
gctgatccac gacgacagcc tgaccttcaa ggaggacatc cagaaggccc aggtgagcgg 2220
ccagggcgac agcctgcacg agcacatcgc caacctggcc ggcagccccg ccatcaagaa 2280
gggcatcctg cagaccgtga aggtggtgga cgagctggtg aaggtgatgg gcagacacaa 2340
gcccgagaac atcgtgatcg agatggccag agagaaccag accacccaga agggccagaa 2400
gaacagcaga gagagaatga agagaatcga ggagggcatc aaggagctgg gcagccagat 2460
cctgaaggag caccccgtgg agaacaccca gctgcagaac gagaagctgt acctgtacta 2520
cctgcagaac ggcagagaca tgtacgtgga ccaggagctg gacatcaaca gactgagcga 2580
ctacgacgtg gaccacatcg tgccccagag cttcctgaag gacgacagca tcgacaacaa 2640
ggtgctgacc agaagcgaca agaacagagg caagagcgac aacgtgccca gcgaggaggt 2700
ggtgaagaag atgaagaact actggagaca gctgctgaac gccaagctga tcacccagag 2760
aaagttcgac aacctgacca aggccgagag aggcggcctg agcgagctgg acaaggccgg 2820
cttcatcaag agacagctgg tggagaccag acagatcacc aagcacgtgg cccagatcct 2880
ggacagcaga atgaacacca agtacgacga gaacgacaag ctgatcagag aggtgaaggt 2940
gatcaccctg aagagcaagc tggtgagcga cttcagaaag gacttccagt tctacaaggt 3000
gagagagatc aacaactacc accacgccca cgacgcctac ctgaacgccg tggtgggcac 3060
cgccctgatc aagaagtacc ccaagctgga gagcgagttc gtgtacggcg actacaaggt 3120
gtacgacgtg agaaagatga tcgccaagag cgagcaggag atcggcaagg ccaccgccaa 3180
gtacttcttc tacagcaaca tcatgaactt cttcaagacc gagatcaccc tggccaacgg 3240
cgagatcaga aagagacccc tgatcgagac caacggcgag accggcgaga tcgtgtggga 3300
caagggcaga gacttcgcca ccgtgagaaa ggtgctgagc atgccccagg tgaacatcgt 3360
gaagaagacc gaggtgcaga ccggcggctt cagcaaggag agcatcctgc ccaagagaaa 3420
cagcgacaag ctgatcgcca gaaagaagga ctgggacccc aagaagtacg gcggcttcga 3480
cagccccacc gtggcctaca gcgtgctggt ggtggccaag gtggagaagg gcaagagcaa 3540
gaagctgaag agcgtgaagg agctgctggg catcaccatc atggagagaa gcagcttcga 3600
gaagaacccc atcgacttcc tggaggccaa gggctacaag gaggtgaaga aggacctgat 3660
catcaagctg cccaagtaca gcctgttcga gctggagaac ggcagaaaga gaatgctggc 3720
cagcgccggc gagctgcaga agggcaacga gctggccctg cccagcaagt acgtgaactt 3780
cctgtacctg gccagccact acgagaagct gaagggcagc cccgaggaca acgagcagaa 3840
gcagctgttc gtggagcagc acaagcacta cctggacgag atcatcgagc agatcagcga 3900
gttcagcaag agagtgatcc tggccgacgc caacctggac aaggtgctga gcgcctacaa 3960
caagcacaga gacaagccca tcagagagca ggccgagaac atcatccacc tgttcaccct 4020
gaccaacctg ggcgcccccg ccgccttcaa gtacttcgac accaccatcg acagaaagag 4080
atacaccagc accaaggagg tgctggacgc caccctgatc caccagagca tcaccggcct 4140
gtacgagacc agaatcgacc tgagccagct gggcggcgac ggcggcggca gccccaagaa 4200
gaagagaaag gtgtgactag ccatcacatt taaaagcatc tcagcctacc atgagaataa 4260
gagaaagaaa atgaagatca atagcttatt catctctttt tctttttcgt tggtgtaaag 4320
ccaacaccct gtctaaaaaa cataaatttc tttaatcatt ttgcctcttt tctctgtgct 4380
tcaattaata aaaaatggaa agaacctcga g 4411
<210> 510
<211> 4140
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 510
atggacaaga agtactctat cggtttggac atcggtacca actctgtcgg ttgggccgtc 60
atcaccgacg aatacaaggt cccatctaag aagttcaagg tcttgggtaa caccgacaga 120
cactctatca agaagaactt gatcggtgcc ttgttgttcg actctggtga aaccgccgaa 180
gccaccagat tgaagagaac cgccagaaga agatacacca gaagaaagaa cagaatctgc 240
tacttgcaag aaatcttctc taacgaaatg gccaaggtcg acgactcttt cttccacaga 300
ttggaagaat ctttcttggt cgaagaagac aagaagcacg aaagacaccc aatcttcggt 360
aacatcgtcg acgaagtcgc ctaccacgaa aagtacccaa ccatctacca cttgagaaag 420
aagttggtcg actctaccga caaggccgac ttgagattga tctacttggc cttggcccac 480
atgatcaagt tcagaggtca cttcttgatc gaaggtgact tgaacccaga caactctgac 540
gtcgacaagt tgttcatcca attggtccaa acctacaacc aattgttcga agaaaaccca 600
atcaacgcct ctggtgtcga cgccaaggcc atcttgtctg ccagattgtc taagagcaga 660
agattggaaa acttgatcgc ccaattgcca ggtgaaaaga agaacggttt gttcggtaac 720
ttgatcgcct tgtctttggg tttgacccca aacttcaagt ctaacttcga cttggccgaa 780
gacgccaagt tgcaattgtc taaggacacc tacgacgacg acttggacaa cttgttggcc 840
caaatcggtg accaatacgc cgacttgttc ttggccgcca agaacttgtc tgacgccatc 900
ttgttgtctg acatcttgag agtcaacacc gaaatcacca aggccccatt gtctgcctct 960
atgatcaaga gatacgacga acaccaccaa gacttgacct tgttgaaggc cttggtcaga 1020
caacaattgc cagaaaagta caaggaaatc ttcttcgacc aatctaagaa cggttacgcc 1080
ggttacatcg acggtggtgc ctctcaagaa gaattctaca agttcatcaa gccaatcttg 1140
gaaaagatgg acggtaccga agaattgttg gtcaagttga acagagaaga cttgttgaga 1200
aagcaaagaa ccttcgacaa cggttctatc ccacaccaaa tccacttggg tgaattgcac 1260
gccatcttga gaagacaaga agacttctac ccattcttga aggacaacag agaaaagatc 1320
gaaaagatct tgaccttcag aatcccatac tacgtcggtc cattggccag aggtaacagc 1380
agattcgcct ggatgaccag aaagtctgaa gaaaccatca ccccatggaa cttcgaagaa 1440
gtcgtcgaca agggtgcctc tgcccaatct ttcatcgaaa gaatgaccaa cttcgacaag 1500
aacttgccaa acgaaaaggt cttgccaaag cactctttgt tgtacgaata cttcaccgtc 1560
tacaacgaat tgaccaaggt caagtacgtc accgaaggta tgagaaagcc agccttcttg 1620
tctggtgaac aaaagaaggc catcgtcgac ttgttgttca agaccaacag aaaggtcacc 1680
gtcaagcaat tgaaggaaga ctacttcaag aagatcgaat gcttcgactc tgtcgaaatc 1740
tctggtgtcg aagacagatt caacgcctct ttgggtacct accacgactt gttgaagatc 1800
atcaaggaca aggacttctt ggacaacgaa gaaaacgaag acatcttgga agacatcgtc 1860
ttgaccttga ccttgttcga agacagagaa atgatcgaag aaagattgaa gacctacgcc 1920
cacttgttcg acgacaaggt catgaagcaa ttgaagagaa gaagatacac cggttggggt 1980
agattgagca gaaagttgat caacggtatc agagacaagc aatctggtaa gaccatcttg 2040
gacttcttga agtctgacgg tttcgccaac agaaacttca tgcaattgat ccacgacgac 2100
tctttgacct tcaaggaaga catccaaaag gcccaagtct ctggtcaagg tgactctttg 2160
cacgaacaca tcgccaactt ggccggttct ccagccatca agaagggtat cttgcaaacc 2220
gtcaaggtcg tcgacgaatt ggtcaaggtc atgggtagac acaagccaga aaacatcgtc 2280
atcgaaatgg ccagagaaaa ccaaaccacc caaaagggtc aaaagaacag cagagaaaga 2340
atgaagagaa tcgaagaagg tatcaaggaa ttgggttctc aaatcttgaa ggaacaccca 2400
gtcgaaaaca cccaattgca aaacgaaaag ttgtacttgt actacttgca aaacggtaga 2460
gacatgtacg tcgaccaaga attggacatc aacagattgt ctgactacga cgtcgaccac 2520
atcgtcccac aatctttctt gaaggacgac tctatcgaca acaaggtctt gaccagatct 2580
gacaagaaca gaggtaagtc tgacaacgtc ccatctgaag aagtcgtcaa gaagatgaag 2640
aactactgga gacaattgtt gaacgccaag ttgatcaccc aaagaaagtt cgacaacttg 2700
accaaggccg aaagaggtgg tttgtctgaa ttggacaagg ccggtttcat caagagacaa 2760
ttggtcgaaa ccagacaaat caccaagcac gtcgcccaaa tcttggacag cagaatgaac 2820
accaagtacg acgaaaacga caagttgatc agagaagtca aggtcatcac cttgaagtct 2880
aagttggtct ctgacttcag aaaggacttc caattctaca aggtcagaga aatcaacaac 2940
taccaccacg cccacgacgc ctacttgaac gccgtcgtcg gtaccgcctt gatcaagaag 3000
tacccaaagt tggaatctga attcgtctac ggtgactaca aggtctacga cgtcagaaag 3060
atgatcgcca agtctgaaca agaaatcggt aaggccaccg ccaagtactt cttctactct 3120
aacatcatga acttcttcaa gaccgaaatc accttggcca acggtgaaat cagaaagaga 3180
ccattgatcg aaaccaacgg tgaaaccggt gaaatcgtct gggacaaggg tagagacttc 3240
gccaccgtca gaaaggtctt gtctatgcca caagtcaaca tcgtcaagaa gaccgaagtc 3300
caaaccggtg gtttctctaa ggaatctatc ttgccaaaga gaaactctga caagttgatc 3360
gccagaaaga aggactggga cccaaagaag tacggtggtt tcgactctcc aaccgtcgcc 3420
tactctgtct tggtcgtcgc caaggtcgaa aagggtaagt ctaagaagtt gaagtctgtc 3480
aaggaattgt tgggtatcac catcatggaa agatcttctt tcgaaaagaa cccaatcgac 3540
ttcttggaag ccaagggtta caaggaagtc aagaaggact tgatcatcaa gttgccaaag 3600
tactctttgt tcgaattgga aaacggtaga aagagaatgt tggcctctgc cggtgaattg 3660
caaaagggta acgaattggc cttgccatct aagtacgtca acttcttgta cttggcctct 3720
cactacgaaa agttgaaggg ttctccagaa gacaacgaac aaaagcaatt gttcgtcgaa 3780
caacacaagc actacttgga cgaaatcatc gaacaaatct ctgaattctc taagagagtc 3840
atcttggccg acgccaactt ggacaaggtc ttgtctgcct acaacaagca cagagacaag 3900
ccaatcagag aacaagccga aaacatcatc cacttgttca ccttgaccaa cttgggtgcc 3960
ccagccgcct tcaagtactt cgacaccacc atcgacagaa agagatacac ctctaccaag 4020
gaagtcttgg acgccacctt gatccaccaa tctatcaccg gtttgtacga aaccagaatc 4080
gacttgtctc aattgggtgg tgacggtggt ggttctccaa agaagaagag aaaggtctaa 4140
<210> 511
<211> 4140
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 511
atggacaaga agtactccat cggcctggac atcggcacca actccgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gccctccaag aagttcaagg tgctgggcaa caccgaccgg 120
cactccatca agaagaacct gatcggcgcc ctgctgttcg actccggcga gaccgccgag 180
gccacccggc tgaagcggac cgcccggcgg cggtacaccc ggcggaagaa ccggatctgc 240
tacctgcagg agatcttctc caacgagatg gccaaggtgg acgactcctt cttccaccgg 300
ctggaggagt ccttcctggt ggaggaggac aagaagcacg agcggcaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgcggaag 420
aagctggtgg actccaccga caaggccgac ctgcggctga tctacctggc cctggcccac 480
atgatcaagt tccggggcca cttcctgatc gagggcgacc tgaaccccga caactccgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggagaacccc 600
atcaacgcct ccggcgtgga cgccaaggcc atcctgtccg cccggctgtc caagtcccgg 660
cggctggaga acctgatcgc ccagctgccc ggcgagaaga agaacggcct gttcggcaac 720
ctgatcgccc tgtccctggg cctgaccccc aacttcaagt ccaacttcga cctggccgag 780
gacgccaagc tgcagctgtc caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttc ctggccgcca agaacctgtc cgacgccatc 900
ctgctgtccg acatcctgcg ggtgaacacc gagatcacca aggcccccct gtccgcctcc 960
atgatcaagc ggtacgacga gcaccaccag gacctgaccc tgctgaaggc cctggtgcgg 1020
cagcagctgc ccgagaagta caaggagatc ttcttcgacc agtccaagaa cggctacgcc 1080
ggctacatcg acggcggcgc ctcccaggag gagttctaca agttcatcaa gcccatcctg 1140
gagaagatgg acggcaccga ggagctgctg gtgaagctga accgggagga cctgctgcgg 1200
aagcagcgga ccttcgacaa cggctccatc ccccaccaga tccacctggg cgagctgcac 1260
gccatcctgc ggcggcagga ggacttctac cccttcctga aggacaaccg ggagaagatc 1320
gagaagatcc tgaccttccg gatcccctac tacgtgggcc ccctggcccg gggcaactcc 1380
cggttcgcct ggatgacccg gaagtccgag gagaccatca ccccctggaa cttcgaggag 1440
gtggtggaca agggcgcctc cgcccagtcc ttcatcgagc ggatgaccaa cttcgacaag 1500
aacctgccca acgagaaggt gctgcccaag cactccctgc tgtacgagta cttcaccgtg 1560
tacaacgagc tgaccaaggt gaagtacgtg accgagggca tgcggaagcc cgccttcctg 1620
tccggcgagc agaagaaggc catcgtggac ctgctgttca agaccaaccg gaaggtgacc 1680
gtgaagcagc tgaaggagga ctacttcaag aagatcgagt gcttcgactc cgtggagatc 1740
tccggcgtgg aggaccggtt caacgcctcc ctgggcacct accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgag gagaacgagg acatcctgga ggacatcgtg 1860
ctgaccctga ccctgttcga ggaccgggag atgatcgagg agcggctgaa gacctacgcc 1920
cacctgttcg acgacaaggt gatgaagcag ctgaagcggc ggcggtacac cggctggggc 1980
cggctgtccc ggaagctgat caacggcatc cgggacaagc agtccggcaa gaccatcctg 2040
gacttcctga agtccgacgg cttcgccaac cggaacttca tgcagctgat ccacgacgac 2100
tccctgacct tcaaggagga catccagaag gcccaggtgt ccggccaggg cgactccctg 2160
cacgagcaca tcgccaacct ggccggctcc cccgccatca agaagggcat cctgcagacc 2220
gtgaaggtgg tggacgagct ggtgaaggtg atgggccggc acaagcccga gaacatcgtg 2280
atcgagatgg cccgggagaa ccagaccacc cagaagggcc agaagaactc ccgggagcgg 2340
atgaagcgga tcgaggaggg catcaaggag ctgggctccc agatcctgaa ggagcacccc 2400
gtggagaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaacggccgg 2460
gacatgtacg tggaccagga gctggacatc aaccggctgt ccgactacga cgtggaccac 2520
atcgtgcccc agtccttcct gaaggacgac tccatcgaca acaaggtgct gacccggtcc 2580
gacaagaacc ggggcaagtc cgacaacgtg ccctccgagg aggtggtgaa gaagatgaag 2640
aactactggc ggcagctgct gaacgccaag ctgatcaccc agcggaagtt cgacaacctg 2700
accaaggccg agcggggcgg cctgtccgag ctggacaagg ccggcttcat caagcggcag 2760
ctggtggaga cccggcagat caccaagcac gtggcccaga tcctggactc ccggatgaac 2820
accaagtacg acgagaacga caagctgatc cgggaggtga aggtgatcac cctgaagtcc 2880
aagctggtgt ccgacttccg gaaggacttc cagttctaca aggtgcggga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtggtgg gcaccgccct gatcaagaag 3000
taccccaagc tggagtccga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag 3060
atgatcgcca agtccgagca ggagatcggc aaggccaccg ccaagtactt cttctactcc 3120
aacatcatga acttcttcaa gaccgagatc accctggcca acggcgagat ccggaagcgg 3180
cccctgatcg agaccaacgg cgagaccggc gagatcgtgt gggacaaggg ccgggacttc 3240
gccaccgtgc ggaaggtgct gtccatgccc caggtgaaca tcgtgaagaa gaccgaggtg 3300
cagaccggcg gcttctccaa ggagtccatc ctgcccaagc ggaactccga caagctgatc 3360
gcccggaaga aggactggga ccccaagaag tacggcggct tcgactcccc caccgtggcc 3420
tactccgtgc tggtggtggc caaggtggag aagggcaagt ccaagaagct gaagtccgtg 3480
aaggagctgc tgggcatcac catcatggag cggtcctcct tcgagaagaa ccccatcgac 3540
ttcctggagg ccaagggcta caaggaggtg aagaaggacc tgatcatcaa gctgcccaag 3600
tactccctgt tcgagctgga gaacggccgg aagcggatgc tggcctccgc cggcgagctg 3660
cagaagggca acgagctggc cctgccctcc aagtacgtga acttcctgta cctggcctcc 3720
cactacgaga agctgaaggg ctcccccgag gacaacgagc agaagcagct gttcgtggag 3780
cagcacaagc actacctgga cgagatcatc gagcagatct ccgagttctc caagcgggtg 3840
atcctggccg acgccaacct ggacaaggtg ctgtccgcct acaacaagca ccgggacaag 3900
cccatccggg agcaggccga gaacatcatc cacctgttca ccctgaccaa cctgggcgcc 3960
cccgccgcct tcaagtactt cgacaccacc atcgaccgga agcggtacac ctccaccaag 4020
gaggtgctgg acgccaccct gatccaccag tccatcaccg gcctgtacga gacccggatc 4080
gacctgtccc agctgggcgg cgacggcggc ggctccccca agaagaagcg gaaggtgtga 4140
<210> 512
<211> 4140
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 512
atggacaaga agtacagcat cggcctggac atcggcacca acagcgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gcccagcaag aagttcaagg tgctgggcaa caccgaccgg 120
cacagcatca agaagaacct gatcggcgcc ctgctgttcg acagcggcga gaccgccgag 180
gccacccggc tgaagcggac cgcccggcgg cggtacaccc ggcggaagaa ccggatctgc 240
tacctgcagg agatcttcag caacgagatg gccaaggtgg acgacagctt cttccaccgg 300
ctggaggaga gcttcctggt ggaggaggac aagaagcacg agcggcaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgcggaag 420
aagctggtgg acagcaccga caaggccgac ctgcggctga tctacctggc cctggcccac 480
atgatcaagt tccggggcca cttcctgatc gagggcgacc tgaaccccga caacagcgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggagaacccc 600
atcaacgcca gcggcgtgga cgccaaggcc atcctgagcg cccggctgag caagagccgg 660
cggctggaga acctgatcgc ccagctgccc ggcgagaaga agaacggcct gttcggcaac 720
ctgatcgccc tgagcctggg cctgaccccc aacttcaaga gcaacttcga cctggccgag 780
gacgccaagc tgcagctgag caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttc ctggccgcca agaacctgag cgacgccatc 900
ctgctgagcg acatcctgcg ggtgaacacc gagatcacca aggcccccct gagcgccagc 960
atgatcaagc ggtacgacga gcaccaccag gacctgaccc tgctgaaggc cctggtgcgg 1020
cagcagctgc ccgagaagta caaggagatc ttcttcgacc agagcaagaa cggctacgcc 1080
ggctacatcg acggcggcgc cagccaggag gagttctaca agttcatcaa gcccatcctg 1140
gagaagatgg acggcaccga ggagctgctg gtgaagctga accgggagga cctgctgcgg 1200
aagcagcgga ccttcgacaa cggcagcatc ccccaccaga tccacctggg cgagctgcac 1260
gccatcctgc ggcggcagga ggacttctac cccttcctga aggacaaccg ggagaagatc 1320
gagaagatcc tgaccttccg gatcccctac tacgtgggcc ccctggcccg gggcaacagc 1380
cggttcgcct ggatgacccg gaagagcgag gagaccatca ccccctggaa cttcgaggag 1440
gtggtggaca agggcgccag cgcccagagc ttcatcgagc ggatgaccaa cttcgacaag 1500
aacctgccca acgagaaggt gctgcccaag cacagcctgc tgtacgagta cttcaccgtg 1560
tacaacgagc tgaccaaggt gaagtacgtg accgagggca tgcggaagcc cgccttcctg 1620
agcggcgagc agaagaaggc catcgtggac ctgctgttca agaccaaccg gaaggtgacc 1680
gtgaagcagc tgaaggagga ctacttcaag aagatcgagt gcttcgacag cgtggagatc 1740
agcggcgtgg aggaccggtt caacgccagc ctgggcacct accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgag gagaacgagg acatcctgga ggacatcgtg 1860
ctgaccctga ccctgttcga ggaccgggag atgatcgagg agcggctgaa gacctacgcc 1920
cacctgttcg acgacaaggt gatgaagcag ctgaagcggc ggcggtacac cggctggggc 1980
cggctgagcc ggaagctgat caacggcatc cgggacaagc agagcggcaa gaccatcctg 2040
gacttcctga agagcgacgg cttcgccaac cggaacttca tgcagctgat ccacgacgac 2100
agcctgacct tcaaggagga catccagaag gcccaggtga gcggccaggg cgacagcctg 2160
cacgagcaca tcgccaacct ggccggcagc cccgccatca agaagggcat cctgcagacc 2220
gtgaaggtgg tggacgagct ggtgaaggtg atgggccggc acaagcccga gaacatcgtg 2280
atcgagatgg cccgggagaa ccagaccacc cagaagggcc agaagaacag ccgggagcgg 2340
atgaagcgga tcgaggaggg catcaaggag ctgggcagcc agatcctgaa ggagcacccc 2400
gtggagaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaacggccgg 2460
gacatgtacg tggaccagga gctggacatc aaccggctga gcgactacga cgtggaccac 2520
atcgtgcccc agagcttcct gaaggacgac agcatcgaca acaaggtgct gacccggagc 2580
gacaagaacc ggggcaagag cgacaacgtg cccagcgagg aggtggtgaa gaagatgaag 2640
aactactggc ggcagctgct gaacgccaag ctgatcaccc agcggaagtt cgacaacctg 2700
accaaggccg agcggggcgg cctgagcgag ctggacaagg ccggcttcat caagcggcag 2760
ctggtggaga cccggcagat caccaagcac gtggcccaga tcctggacag ccggatgaac 2820
accaagtacg acgagaacga caagctgatc cgggaggtga aggtgatcac cctgaagagc 2880
aagctggtga gcgacttccg gaaggacttc cagttctaca aggtgcggga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtggtgg gcaccgccct gatcaagaag 3000
taccccaagc tggagagcga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag 3060
atgatcgcca agagcgagca ggagatcggc aaggccaccg ccaagtactt cttctacagc 3120
aacatcatga acttcttcaa gaccgagatc accctggcca acggcgagat ccggaagcgg 3180
cccctgatcg agaccaacgg cgagaccggc gagatcgtgt gggacaaggg ccgggacttc 3240
gccaccgtgc ggaaggtgct gagcatgccc caggtgaaca tcgtgaagaa gaccgaggtg 3300
cagaccggcg gcttcagcaa ggagagcatc ctgcccaagc ggaacagcga caagctgatc 3360
gcccggaaga aggactggga ccccaagaag tacggcggct tcgacagccc caccgtggcc 3420
tacagcgtgc tggtggtggc caaggtggag aagggcaaga gcaagaagct gaagagcgtg 3480
aaggagctgc tgggcatcac catcatggag cggagcagct tcgagaagaa ccccatcgac 3540
ttcctggagg ccaagggcta caaggaggtg aagaaggacc tgatcatcaa gctgcccaag 3600
tacagcctgt tcgagctgga gaacggccgg aagcggatgc tggccagcgc cggcgagctg 3660
cagaagggca acgagctggc cctgcccagc aagtacgtga acttcctgta cctggccagc 3720
cactacgaga agctgaaggg cagccccgag gacaacgagc agaagcagct gttcgtggag 3780
cagcacaagc actacctgga cgagatcatc gagcagatca gcgagttcag caagcgggtg 3840
atcctggccg acgccaacct ggacaaggtg ctgagcgcct acaacaagca ccgggacaag 3900
cccatccggg agcaggccga gaacatcatc cacctgttca ccctgaccaa cctgggcgcc 3960
cccgccgcct tcaagtactt cgacaccacc atcgaccgga agcggtacac cagcaccaag 4020
gaggtgctgg acgccaccct gatccaccag agcatcaccg gcctgtacga gacccggatc 4080
gacctgagcc agctgggcgg cgacggcggc ggcagcccca agaagaagcg gaaggtgtga 4140
<210> 513
<211> 4179
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 513
atggacaaga agtactccat cggcctggac atcggcacca actccgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gccctccaag aagttcaagg tgctgggcaa caccgaccgg 120
cactccatca agaagaacct gatcggcgcc ctgctgttcg actccggcga gaccgccgag 180
gccacccggc tgaagcggac cgcccggcgg cggtacaccc ggcggaagaa ccggatctgc 240
tacctgcagg agatcttctc caacgagatg gccaaggtgg acgactcctt cttccaccgg 300
ctggaggagt ccttcctggt ggaggaggac aagaagcacg agcggcaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgcggaag 420
aagctggtgg actccaccga caaggccgac ctgcggctga tctacctggc cctggcccac 480
atgatcaagt tccggggcca cttcctgatc gagggcgacc tgaaccccga caactccgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggagaacccc 600
atcaacgcct ccggcgtgga cgccaaggcc atcctgtccg cccggctgtc caagtcccgg 660
cggctggaga acctgatcgc ccagctgccc ggcgagaaga agaacggcct gttcggcaac 720
ctgatcgccc tgtccctggg cctgaccccc aacttcaagt ccaacttcga cctggccgag 780
gacgccaagc tgcagctgtc caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttc ctggccgcca agaacctgtc cgacgccatc 900
ctgctgtccg acatcctgcg ggtgaacacc gagatcacca aggcccccct gtccgcctcc 960
atgatcaagc ggtacgacga gcaccaccag gacctgaccc tgctgaaggc cctggtgcgg 1020
cagcagctgc ccgagaagta caaggagatc ttcttcgacc agtccaagaa cggctacgcc 1080
ggctacatcg acggcggcgc ctcccaggag gagttctaca agttcatcaa gcccatcctg 1140
gagaagatgg acggcaccga ggagctgctg gtgaagctga accgggagga cctgctgcgg 1200
aagcagcgga ccttcgacaa cggctccatc ccccaccaga tccacctggg cgagctgcac 1260
gccatcctgc ggcggcagga ggacttctac cccttcctga aggacaaccg ggagaagatc 1320
gagaagatcc tgaccttccg gatcccctac tacgtgggcc ccctggcccg gggcaactcc 1380
cggttcgcct ggatgacccg gaagtccgag gagaccatca ccccctggaa cttcgaggag 1440
gtggtggaca agggcgcctc cgcccagtcc ttcatcgagc ggatgaccaa cttcgacaag 1500
aacctgccca acgagaaggt gctgcccaag cactccctgc tgtacgagta cttcaccgtg 1560
tacaacgagc tgaccaaggt gaagtacgtg accgagggca tgcggaagcc cgccttcctg 1620
tccggcgagc agaagaaggc catcgtggac ctgctgttca agaccaaccg gaaggtgacc 1680
gtgaagcagc tgaaggagga ctacttcaag aagatcgagt gcttcgactc cgtggagatc 1740
tccggcgtgg aggaccggtt caacgcctcc ctgggcacct accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgag gagaacgagg acatcctgga ggacatcgtg 1860
ctgaccctga ccctgttcga ggaccgggag atgatcgagg agcggctgaa gacctacgcc 1920
cacctgttcg acgacaaggt gatgaagcag ctgaagcggc ggcggtacac cggctggggc 1980
cggctgtccc ggaagctgat caacggcatc cgggacaagc agtccggcaa gaccatcctg 2040
gacttcctga agtccgacgg cttcgccaac cggaacttca tgcagctgat ccacgacgac 2100
tccctgacct tcaaggagga catccagaag gcccaggtgt ccggccaggg cgactccctg 2160
cacgagcaca tcgccaacct ggccggctcc cccgccatca agaagggcat cctgcagacc 2220
gtgaaggtgg tggacgagct ggtgaaggtg atgggccggc acaagcccga gaacatcgtg 2280
atcgagatgg cccgggagaa ccagaccacc cagaagggcc agaagaactc ccgggagcgg 2340
atgaagcgga tcgaggaggg catcaaggag ctgggctccc agatcctgaa ggagcacccc 2400
gtggagaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaacggccgg 2460
gacatgtacg tggaccagga gctggacatc aaccggctgt ccgactacga cgtggaccac 2520
atcgtgcccc agtccttcct gaaggacgac tccatcgaca acaaggtgct gacccggtcc 2580
gacaagaacc ggggcaagtc cgacaacgtg ccctccgagg aggtggtgaa gaagatgaag 2640
aactactggc ggcagctgct gaacgccaag ctgatcaccc agcggaagtt cgacaacctg 2700
accaaggccg agcggggcgg cctgtccgag ctggacaagg ccggcttcat caagcggcag 2760
ctggtggaga cccggcagat caccaagcac gtggcccaga tcctggactc ccggatgaac 2820
accaagtacg acgagaacga caagctgatc cgggaggtga aggtgatcac cctgaagtcc 2880
aagctggtgt ccgacttccg gaaggacttc cagttctaca aggtgcggga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtggtgg gcaccgccct gatcaagaag 3000
taccccaagc tggagtccga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag 3060
atgatcgcca agtccgagca ggagatcggc aaggccaccg ccaagtactt cttctactcc 3120
aacatcatga acttcttcaa gaccgagatc accctggcca acggcgagat ccggaagcgg 3180
cccctgatcg agaccaacgg cgagaccggc gagatcgtgt gggacaaggg ccgggacttc 3240
gccaccgtgc ggaaggtgct gtccatgccc caggtgaaca tcgtgaagaa gaccgaggtg 3300
cagaccggcg gcttctccaa ggagtccatc ctgcccaagc ggaactccga caagctgatc 3360
gcccggaaga aggactggga ccccaagaag tacggcggct tcgactcccc caccgtggcc 3420
tactccgtgc tggtggtggc caaggtggag aagggcaagt ccaagaagct gaagtccgtg 3480
aaggagctgc tgggcatcac catcatggag cggtcctcct tcgagaagaa ccccatcgac 3540
ttcctggagg ccaagggcta caaggaggtg aagaaggacc tgatcatcaa gctgcccaag 3600
tactccctgt tcgagctgga gaacggccgg aagcggatgc tggcctccgc cggcgagctg 3660
cagaagggca acgagctggc cctgccctcc aagtacgtga acttcctgta cctggcctcc 3720
cactacgaga agctgaaggg ctcccccgag gacaacgagc agaagcagct gttcgtggag 3780
cagcacaagc actacctgga cgagatcatc gagcagatct ccgagttctc caagcgggtg 3840
atcctggccg acgccaacct ggacaaggtg ctgtccgcct acaacaagca ccgggacaag 3900
cccatccggg agcaggccga gaacatcatc cacctgttca ccctgaccaa cctgggcgcc 3960
cccgccgcct tcaagtactt cgacaccacc atcgaccgga agcggtacac ctccaccaag 4020
gaggtgctgg acgccaccct gatccaccag tccatcaccg gcctgtacga gacccggatc 4080
gacctgtccc agctgggcgg cgacggctcc ggctccccca agaagaagcg gaaggtggac 4140
ggctccccca agaagaagcg gaaggtggac tccggctga 4179
<210> 514
<211> 4179
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 514
atggacaaga agtacagcat cggcctggac atcggcacca acagcgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gcccagcaag aagttcaagg tgctgggcaa caccgaccgg 120
cacagcatca agaagaacct gatcggcgcc ctgctgttcg acagcggcga gaccgccgag 180
gccacccggc tgaagcggac cgcccggcgg cggtacaccc ggcggaagaa ccggatctgc 240
tacctgcagg agatcttcag caacgagatg gccaaggtgg acgacagctt cttccaccgg 300
ctggaggaga gcttcctggt ggaggaggac aagaagcacg agcggcaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgcggaag 420
aagctggtgg acagcaccga caaggccgac ctgcggctga tctacctggc cctggcccac 480
atgatcaagt tccggggcca cttcctgatc gagggcgacc tgaaccccga caacagcgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggagaacccc 600
atcaacgcca gcggcgtgga cgccaaggcc atcctgagcg cccggctgag caagagccgg 660
cggctggaga acctgatcgc ccagctgccc ggcgagaaga agaacggcct gttcggcaac 720
ctgatcgccc tgagcctggg cctgaccccc aacttcaaga gcaacttcga cctggccgag 780
gacgccaagc tgcagctgag caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttc ctggccgcca agaacctgag cgacgccatc 900
ctgctgagcg acatcctgcg ggtgaacacc gagatcacca aggcccccct gagcgccagc 960
atgatcaagc ggtacgacga gcaccaccag gacctgaccc tgctgaaggc cctggtgcgg 1020
cagcagctgc ccgagaagta caaggagatc ttcttcgacc agagcaagaa cggctacgcc 1080
ggctacatcg acggcggcgc cagccaggag gagttctaca agttcatcaa gcccatcctg 1140
gagaagatgg acggcaccga ggagctgctg gtgaagctga accgggagga cctgctgcgg 1200
aagcagcgga ccttcgacaa cggcagcatc ccccaccaga tccacctggg cgagctgcac 1260
gccatcctgc ggcggcagga ggacttctac cccttcctga aggacaaccg ggagaagatc 1320
gagaagatcc tgaccttccg gatcccctac tacgtgggcc ccctggcccg gggcaacagc 1380
cggttcgcct ggatgacccg gaagagcgag gagaccatca ccccctggaa cttcgaggag 1440
gtggtggaca agggcgccag cgcccagagc ttcatcgagc ggatgaccaa cttcgacaag 1500
aacctgccca acgagaaggt gctgcccaag cacagcctgc tgtacgagta cttcaccgtg 1560
tacaacgagc tgaccaaggt gaagtacgtg accgagggca tgcggaagcc cgccttcctg 1620
agcggcgagc agaagaaggc catcgtggac ctgctgttca agaccaaccg gaaggtgacc 1680
gtgaagcagc tgaaggagga ctacttcaag aagatcgagt gcttcgacag cgtggagatc 1740
agcggcgtgg aggaccggtt caacgccagc ctgggcacct accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgag gagaacgagg acatcctgga ggacatcgtg 1860
ctgaccctga ccctgttcga ggaccgggag atgatcgagg agcggctgaa gacctacgcc 1920
cacctgttcg acgacaaggt gatgaagcag ctgaagcggc ggcggtacac cggctggggc 1980
cggctgagcc ggaagctgat caacggcatc cgggacaagc agagcggcaa gaccatcctg 2040
gacttcctga agagcgacgg cttcgccaac cggaacttca tgcagctgat ccacgacgac 2100
agcctgacct tcaaggagga catccagaag gcccaggtga gcggccaggg cgacagcctg 2160
cacgagcaca tcgccaacct ggccggcagc cccgccatca agaagggcat cctgcagacc 2220
gtgaaggtgg tggacgagct ggtgaaggtg atgggccggc acaagcccga gaacatcgtg 2280
atcgagatgg cccgggagaa ccagaccacc cagaagggcc agaagaacag ccgggagcgg 2340
atgaagcgga tcgaggaggg catcaaggag ctgggcagcc agatcctgaa ggagcacccc 2400
gtggagaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaacggccgg 2460
gacatgtacg tggaccagga gctggacatc aaccggctga gcgactacga cgtggaccac 2520
atcgtgcccc agagcttcct gaaggacgac agcatcgaca acaaggtgct gacccggagc 2580
gacaagaacc ggggcaagag cgacaacgtg cccagcgagg aggtggtgaa gaagatgaag 2640
aactactggc ggcagctgct gaacgccaag ctgatcaccc agcggaagtt cgacaacctg 2700
accaaggccg agcggggcgg cctgagcgag ctggacaagg ccggcttcat caagcggcag 2760
ctggtggaga cccggcagat caccaagcac gtggcccaga tcctggacag ccggatgaac 2820
accaagtacg acgagaacga caagctgatc cgggaggtga aggtgatcac cctgaagagc 2880
aagctggtga gcgacttccg gaaggacttc cagttctaca aggtgcggga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtggtgg gcaccgccct gatcaagaag 3000
taccccaagc tggagagcga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag 3060
atgatcgcca agagcgagca ggagatcggc aaggccaccg ccaagtactt cttctacagc 3120
aacatcatga acttcttcaa gaccgagatc accctggcca acggcgagat ccggaagcgg 3180
cccctgatcg agaccaacgg cgagaccggc gagatcgtgt gggacaaggg ccgggacttc 3240
gccaccgtgc ggaaggtgct gagcatgccc caggtgaaca tcgtgaagaa gaccgaggtg 3300
cagaccggcg gcttcagcaa ggagagcatc ctgcccaagc ggaacagcga caagctgatc 3360
gcccggaaga aggactggga ccccaagaag tacggcggct tcgacagccc caccgtggcc 3420
tacagcgtgc tggtggtggc caaggtggag aagggcaaga gcaagaagct gaagagcgtg 3480
aaggagctgc tgggcatcac catcatggag cggagcagct tcgagaagaa ccccatcgac 3540
ttcctggagg ccaagggcta caaggaggtg aagaaggacc tgatcatcaa gctgcccaag 3600
tacagcctgt tcgagctgga gaacggccgg aagcggatgc tggccagcgc cggcgagctg 3660
cagaagggca acgagctggc cctgcccagc aagtacgtga acttcctgta cctggccagc 3720
cactacgaga agctgaaggg cagccccgag gacaacgagc agaagcagct gttcgtggag 3780
cagcacaagc actacctgga cgagatcatc gagcagatca gcgagttcag caagcgggtg 3840
atcctggccg acgccaacct ggacaaggtg ctgagcgcct acaacaagca ccgggacaag 3900
cccatccggg agcaggccga gaacatcatc cacctgttca ccctgaccaa cctgggcgcc 3960
cccgccgcct tcaagtactt cgacaccacc atcgaccgga agcggtacac cagcaccaag 4020
gaggtgctgg acgccaccct gatccaccag agcatcaccg gcctgtacga gacccggatc 4080
gacctgagcc agctgggcgg cgacggcagc ggcagcccca agaagaagcg gaaggtggac 4140
ggcagcccca agaagaagcg gaaggtggac agcggctga 4179
<210> 515
<211> 4107
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 515
atggacaaga agtacagcat cggcctggac atcggcacca acagcgtggg ctgggccgtg 60
atcaccgacg agtacaaggt gcccagcaag aagttcaagg tgctgggcaa caccgaccgg 120
cacagcatca agaagaacct gatcggcgcc ctgctgttcg acagcggcga gaccgccgag 180
gccacccggc tgaagcggac cgcccggcgg cggtacaccc ggcggaagaa ccggatctgc 240
tacctgcagg agatcttcag caacgagatg gccaaggtgg acgacagctt cttccaccgg 300
ctggaggaga gcttcctggt ggaggaggac aagaagcacg agcggcaccc catcttcggc 360
aacatcgtgg acgaggtggc ctaccacgag aagtacccca ccatctacca cctgcggaag 420
aagctggtgg acagcaccga caaggccgac ctgcggctga tctacctggc cctggcccac 480
atgatcaagt tccggggcca cttcctgatc gagggcgacc tgaaccccga caacagcgac 540
gtggacaagc tgttcatcca gctggtgcag acctacaacc agctgttcga ggagaacccc 600
atcaacgcca gcggcgtgga cgccaaggcc atcctgagcg cccggctgag caagagccgg 660
cggctggaga acctgatcgc ccagctgccc ggcgagaaga agaacggcct gttcggcaac 720
ctgatcgccc tgagcctggg cctgaccccc aacttcaaga gcaacttcga cctggccgag 780
gacgccaagc tgcagctgag caaggacacc tacgacgacg acctggacaa cctgctggcc 840
cagatcggcg accagtacgc cgacctgttc ctggccgcca agaacctgag cgacgccatc 900
ctgctgagcg acatcctgcg ggtgaacacc gagatcacca aggcccccct gagcgccagc 960
atgatcaagc ggtacgacga gcaccaccag gacctgaccc tgctgaaggc cctggtgcgg 1020
cagcagctgc ccgagaagta caaggagatc ttcttcgacc agagcaagaa cggctacgcc 1080
ggctacatcg acggcggcgc cagccaggag gagttctaca agttcatcaa gcccatcctg 1140
gagaagatgg acggcaccga ggagctgctg gtgaagctga accgggagga cctgctgcgg 1200
aagcagcgga ccttcgacaa cggcagcatc ccccaccaga tccacctggg cgagctgcac 1260
gccatcctgc ggcggcagga ggacttctac cccttcctga aggacaaccg ggagaagatc 1320
gagaagatcc tgaccttccg gatcccctac tacgtgggcc ccctggcccg gggcaacagc 1380
cggttcgcct ggatgacccg gaagagcgag gagaccatca ccccctggaa cttcgaggag 1440
gtggtggaca agggcgccag cgcccagagc ttcatcgagc ggatgaccaa cttcgacaag 1500
aacctgccca acgagaaggt gctgcccaag cacagcctgc tgtacgagta cttcaccgtg 1560
tacaacgagc tgaccaaggt gaagtacgtg accgagggca tgcggaagcc cgccttcctg 1620
agcggcgagc agaagaaggc catcgtggac ctgctgttca agaccaaccg gaaggtgacc 1680
gtgaagcagc tgaaggagga ctacttcaag aagatcgagt gcttcgacag cgtggagatc 1740
agcggcgtgg aggaccggtt caacgccagc ctgggcacct accacgacct gctgaagatc 1800
atcaaggaca aggacttcct ggacaacgag gagaacgagg acatcctgga ggacatcgtg 1860
ctgaccctga ccctgttcga ggaccgggag atgatcgagg agcggctgaa gacctacgcc 1920
cacctgttcg acgacaaggt gatgaagcag ctgaagcggc ggcggtacac cggctggggc 1980
cggctgagcc ggaagctgat caacggcatc cgggacaagc agagcggcaa gaccatcctg 2040
gacttcctga agagcgacgg cttcgccaac cggaacttca tgcagctgat ccacgacgac 2100
agcctgacct tcaaggagga catccagaag gcccaggtga gcggccaggg cgacagcctg 2160
cacgagcaca tcgccaacct ggccggcagc cccgccatca agaagggcat cctgcagacc 2220
gtgaaggtgg tggacgagct ggtgaaggtg atgggccggc acaagcccga gaacatcgtg 2280
atcgagatgg cccgggagaa ccagaccacc cagaagggcc agaagaacag ccgggagcgg 2340
atgaagcgga tcgaggaggg catcaaggag ctgggcagcc agatcctgaa ggagcacccc 2400
gtggagaaca cccagctgca gaacgagaag ctgtacctgt actacctgca gaacggccgg 2460
gacatgtacg tggaccagga gctggacatc aaccggctga gcgactacga cgtggaccac 2520
atcgtgcccc agagcttcct gaaggacgac agcatcgaca acaaggtgct gacccggagc 2580
gacaagaacc ggggcaagag cgacaacgtg cccagcgagg aggtggtgaa gaagatgaag 2640
aactactggc ggcagctgct gaacgccaag ctgatcaccc agcggaagtt cgacaacctg 2700
accaaggccg agcggggcgg cctgagcgag ctggacaagg ccggcttcat caagcggcag 2760
ctggtggaga cccggcagat caccaagcac gtggcccaga tcctggacag ccggatgaac 2820
accaagtacg acgagaacga caagctgatc cgggaggtga aggtgatcac cctgaagagc 2880
aagctggtga gcgacttccg gaaggacttc cagttctaca aggtgcggga gatcaacaac 2940
taccaccacg cccacgacgc ctacctgaac gccgtggtgg gcaccgccct gatcaagaag 3000
taccccaagc tggagagcga gttcgtgtac ggcgactaca aggtgtacga cgtgcggaag 3060
atgatcgcca agagcgagca ggagatcggc aaggccaccg ccaagtactt cttctacagc 3120
aacatcatga acttcttcaa gaccgagatc accctggcca acggcgagat ccggaagcgg 3180
cccctgatcg agaccaacgg cgagaccggc gagatcgtgt gggacaaggg ccgggacttc 3240
gccaccgtgc ggaaggtgct gagcatgccc caggtgaaca tcgtgaagaa gaccgaggtg 3300
cagaccggcg gcttcagcaa ggagagcatc ctgcccaagc ggaacagcga caagctgatc 3360
gcccggaaga aggactggga ccccaagaag tacggcggct tcgacagccc caccgtggcc 3420
tacagcgtgc tggtggtggc caaggtggag aagggcaaga gcaagaagct gaagagcgtg 3480
aaggagctgc tgggcatcac catcatggag cggagcagct tcgagaagaa ccccatcgac 3540
ttcctggagg ccaagggcta caaggaggtg aagaaggacc tgatcatcaa gctgcccaag 3600
tacagcctgt tcgagctgga gaacggccgg aagcggatgc tggccagcgc cggcgagctg 3660
cagaagggca acgagctggc cctgcccagc aagtacgtga acttcctgta cctggccagc 3720
cactacgaga agctgaaggg cagccccgag gacaacgagc agaagcagct gttcgtggag 3780
cagcacaagc actacctgga cgagatcatc gagcagatca gcgagttcag caagcgggtg 3840
atcctggccg acgccaacct ggacaaggtg ctgagcgcct acaacaagca ccgggacaag 3900
cccatccggg agcaggccga gaacatcatc cacctgttca ccctgaccaa cctgggcgcc 3960
cccgccgcct tcaagtactt cgacaccacc atcgaccgga agcggtacac cagcaccaag 4020
gaggtgctgg acgccaccct gatccaccag agcatcaccg gcctgtacga gacccggatc 4080
gacctgagcc agctgggcgg cgactga 4107
<210> 516
<400> 516
000
<210> 517
<400> 517
000
<210> 518
<400> 518
000
<210> 519
<400> 519
000
<210> 520
<400> 520
000
<210> 521
<400> 521
000
<210> 522
<400> 522
000
<210> 523
<400> 523
000
<210> 524
<400> 524
000
<210> 525
<400> 525
000
<210> 526
<400> 526
000
<210> 527
<400> 527
000
<210> 528
<400> 528
000
<210> 529
<400> 529
000
<210> 530
<400> 530
000
<210> 531
<400> 531
000
<210> 532
<400> 532
000
<210> 533
<400> 533
000
<210> 534
<400> 534
000
<210> 535
<400> 535
000
<210> 536
<400> 536
000
<210> 537
<400> 537
000
<210> 538
<400> 538
000
<210> 539
<400> 539
000
<210> 540
<400> 540
000
<210> 541
<400> 541
000
<210> 542
<400> 542
000
<210> 543
<400> 543
000
<210> 544
<400> 544
000
<210> 545
<400> 545
000
<210> 546
<400> 546
000
<210> 547
<400> 547
000
<210> 548
<400> 548
000
<210> 549
<400> 549
000
<210> 550
<400> 550
000
<210> 551
<400> 551
000
<210> 552
<400> 552
000
<210> 553
<400> 553
000
<210> 554
<400> 554
000
<210> 555
<400> 555
000
<210> 556
<400> 556
000
<210> 557
<400> 557
000
<210> 558
<400> 558
000
<210> 559
<400> 559
000
<210> 560
<400> 560
000
<210> 561
<400> 561
000
<210> 562
<400> 562
000
<210> 563
<400> 563
000
<210> 564
<400> 564
000
<210> 565
<400> 565
000
<210> 566
<400> 566
000
<210> 567
<400> 567
000
<210> 568
<400> 568
000
<210> 569
<400> 569
000
<210> 570
<400> 570
000
<210> 571
<400> 571
000
<210> 572
<400> 572
000
<210> 573
<400> 573
000
<210> 574
<400> 574
000
<210> 575
<400> 575
000
<210> 576
<400> 576
000
<210> 577
<400> 577
000
<210> 578
<400> 578
000
<210> 579
<400> 579
000
<210> 580
<400> 580
000
<210> 581
<400> 581
000
<210> 582
<400> 582
000
<210> 583
<400> 583
000
<210> 584
<400> 584
000
<210> 585
<400> 585
000
<210> 586
<400> 586
000
<210> 587
<400> 587
000
<210> 588
<400> 588
000
<210> 589
<400> 589
000
<210> 590
<400> 590
000
<210> 591
<400> 591
000
<210> 592
<400> 592
000
<210> 593
<400> 593
000
<210> 594
<400> 594
000
<210> 595
<400> 595
000
<210> 596
<400> 596
000
<210> 597
<400> 597
000
<210> 598
<400> 598
000
<210> 599
<400> 599
000
<210> 600
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 600
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 601
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 601
Pro Lys Lys Lys Arg Arg Val
1 5
<210> 602
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 602
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 603
<400> 603
000
<210> 604
<400> 604
000
<210> 605
<400> 605
000
<210> 606
<400> 606
000
<210> 607
<400> 607
000
<210> 608
<400> 608
000
<210> 609
<400> 609
000
<210> 610
<400> 610
000
<210> 611
<400> 611
000
<210> 612
<400> 612
000
<210> 613
<400> 613
000
<210> 614
<400> 614
000
<210> 615
<400> 615
000
<210> 616
<400> 616
000
<210> 617
<400> 617
000
<210> 618
<400> 618
000
<210> 619
<400> 619
000
<210> 620
<400> 620
000
<210> 621
<400> 621
000
<210> 622
<400> 622
000
<210> 623
<400> 623
000
<210> 624
<400> 624
000
<210> 625
<400> 625
000
<210> 626
<400> 626
000
<210> 627
<400> 627
000
<210> 628
<400> 628
000
<210> 629
<400> 629
000
<210> 630
<400> 630
000
<210> 631
<400> 631
000
<210> 632
<400> 632
000
<210> 633
<400> 633
000
<210> 634
<400> 634
000
<210> 635
<400> 635
000
<210> 636
<400> 636
000
<210> 637
<400> 637
000
<210> 638
<400> 638
000
<210> 639
<400> 639
000
<210> 640
<400> 640
000
<210> 641
<400> 641
000
<210> 642
<400> 642
000
<210> 643
<400> 643
000
<210> 644
<400> 644
000
<210> 645
<400> 645
000
<210> 646
<400> 646
000
<210> 647
<400> 647
000
<210> 648
<400> 648
000
<210> 649
<400> 649
000
<210> 650
<400> 650
000
<210> 651
<400> 651
000
<210> 652
<400> 652
000
<210> 653
<400> 653
000
<210> 654
<400> 654
000
<210> 655
<400> 655
000
<210> 656
<400> 656
000
<210> 657
<400> 657
000
<210> 658
<400> 658
000
<210> 659
<400> 659
000
<210> 660
<400> 660
000
<210> 661
<400> 661
000
<210> 662
<400> 662
000
<210> 663
<400> 663
000
<210> 664
<400> 664
000
<210> 665
<400> 665
000
<210> 666
<400> 666
000
<210> 667
<400> 667
000
<210> 668
<400> 668
000
<210> 669
<400> 669
000
<210> 670
<400> 670
000
<210> 671
<400> 671
000
<210> 672
<400> 672
000
<210> 673
<400> 673
000
<210> 674
<400> 674
000
<210> 675
<400> 675
000
<210> 676
<400> 676
000
<210> 677
<400> 677
000
<210> 678
<400> 678
000
<210> 679
<400> 679
000
<210> 680
<400> 680
000
<210> 681
<400> 681
000
<210> 682
<400> 682
000
<210> 683
<400> 683
000
<210> 684
<400> 684
000
<210> 685
<400> 685
000
<210> 686
<400> 686
000
<210> 687
<400> 687
000
<210> 688
<400> 688
000
<210> 689
<400> 689
000
<210> 690
<400> 690
000
<210> 691
<400> 691
000
<210> 692
<400> 692
000
<210> 693
<400> 693
000
<210> 694
<400> 694
000
<210> 695
<400> 695
000
<210> 696
<400> 696
000
<210> 697
<400> 697
000
<210> 698
<400> 698
000
<210> 699
<400> 699
000
<210> 700
<400> 700
000
<210> 701
<400> 701
000
<210> 702
<400> 702
000
<210> 703
<400> 703
000
<210> 704
<400> 704
000
<210> 705
<400> 705
000
<210> 706
<400> 706
000
<210> 707
<400> 707
000
<210> 708
<400> 708
000
<210> 709
<400> 709
000
<210> 710
<400> 710
000
<210> 711
<400> 711
000
<210> 712
<400> 712
000
<210> 713
<400> 713
000
<210> 714
<400> 714
000
<210> 715
<400> 715
000
<210> 716
<400> 716
000
<210> 717
<400> 717
000
<210> 718
<400> 718
000
<210> 719
<400> 719
000
<210> 720
<400> 720
000
<210> 721
<400> 721
000
<210> 722
<400> 722
000
<210> 723
<400> 723
000
<210> 724
<400> 724
000
<210> 725
<400> 725
000
<210> 726
<400> 726
000
<210> 727
<400> 727
000
<210> 728
<400> 728
000
<210> 729
<400> 729
000
<210> 730
<400> 730
000
<210> 731
<400> 731
000
<210> 732
<400> 732
000
<210> 733
<400> 733
000
<210> 734
<400> 734
000
<210> 735
<400> 735
000
<210> 736
<400> 736
000
<210> 737
<400> 737
000
<210> 738
<400> 738
000
<210> 739
<400> 739
000
<210> 740
<400> 740
000
<210> 741
<400> 741
000
<210> 742
<400> 742
000
<210> 743
<400> 743
000
<210> 744
<400> 744
000
<210> 745
<400> 745
000
<210> 746
<400> 746
000
<210> 747
<400> 747
000
<210> 748
<400> 748
000
<210> 749
<400> 749
000
<210> 750
<400> 750
000
<210> 751
<400> 751
000
<210> 752
<400> 752
000
<210> 753
<400> 753
000
<210> 754
<400> 754
000
<210> 755
<400> 755
000
<210> 756
<400> 756
000
<210> 757
<400> 757
000
<210> 758
<400> 758
000
<210> 759
<400> 759
000
<210> 760
<400> 760
000
<210> 761
<400> 761
000
<210> 762
<400> 762
000
<210> 763
<400> 763
000
<210> 764
<400> 764
000
<210> 765
<400> 765
000
<210> 766
<400> 766
000
<210> 767
<400> 767
000
<210> 768
<400> 768
000
<210> 769
<400> 769
000
<210> 770
<400> 770
000
<210> 771
<400> 771
000
<210> 772
<400> 772
000
<210> 773
<400> 773
000
<210> 774
<400> 774
000
<210> 775
<400> 775
000
<210> 776
<400> 776
000
<210> 777
<400> 777
000
<210> 778
<400> 778
000
<210> 779
<400> 779
000
<210> 780
<400> 780
000
<210> 781
<400> 781
000
<210> 782
<400> 782
000
<210> 783
<400> 783
000
<210> 784
<400> 784
000
<210> 785
<400> 785
000
<210> 786
<400> 786
000
<210> 787
<400> 787
000
<210> 788
<400> 788
000
<210> 789
<400> 789
000
<210> 790
<400> 790
000
<210> 791
<400> 791
000
<210> 792
<400> 792
000
<210> 793
<400> 793
000
<210> 794
<400> 794
000
<210> 795
<400> 795
000
<210> 796
<400> 796
000
<210> 797
<400> 797
000
<210> 798
<400> 798
000
<210> 799
<400> 799
000
<210> 800
<400> 800
000
<210> 801
<400> 801
000
<210> 802
<400> 802
000
<210> 803
<400> 803
000
<210> 804
<400> 804
000
<210> 805
<400> 805
000
<210> 806
<400> 806
000
<210> 807
<400> 807
000
<210> 808
<400> 808
000
<210> 809
<400> 809
000
<210> 810
<400> 810
000
<210> 811
<400> 811
000
<210> 812
<400> 812
000
<210> 813
<400> 813
000
<210> 814
<400> 814
000
<210> 815
<400> 815
000
<210> 816
<400> 816
000
<210> 817
<400> 817
000
<210> 818
<400> 818
000
<210> 819
<400> 819
000
<210> 820
<400> 820
000
<210> 821
<400> 821
000
<210> 822
<400> 822
000
<210> 823
<400> 823
000
<210> 824
<400> 824
000
<210> 825
<400> 825
000
<210> 826
<400> 826
000
<210> 827
<400> 827
000
<210> 828
<400> 828
000
<210> 829
<400> 829
000
<210> 830
<400> 830
000
<210> 831
<400> 831
000
<210> 832
<400> 832
000
<210> 833
<400> 833
000
<210> 834
<400> 834
000
<210> 835
<400> 835
000
<210> 836
<400> 836
000
<210> 837
<400> 837
000
<210> 838
<400> 838
000
<210> 839
<400> 839
000
<210> 840
<400> 840
000
<210> 841
<400> 841
000
<210> 842
<400> 842
000
<210> 843
<400> 843
000
<210> 844
<400> 844
000
<210> 845
<400> 845
000
<210> 846
<400> 846
000
<210> 847
<400> 847
000
<210> 848
<400> 848
000
<210> 849
<400> 849
000
<210> 850
<400> 850
000
<210> 851
<400> 851
000
<210> 852
<400> 852
000
<210> 853
<400> 853
000
<210> 854
<400> 854
000
<210> 855
<400> 855
000
<210> 856
<400> 856
000
<210> 857
<400> 857
000
<210> 858
<400> 858
000
<210> 859
<400> 859
000
<210> 860
<400> 860
000
<210> 861
<400> 861
000
<210> 862
<400> 862
000
<210> 863
<400> 863
000
<210> 864
<400> 864
000
<210> 865
<400> 865
000
<210> 866
<400> 866
000
<210> 867
<400> 867
000
<210> 868
<400> 868
000
<210> 869
<400> 869
000
<210> 870
<400> 870
000
<210> 871
<400> 871
000
<210> 872
<400> 872
000
<210> 873
<400> 873
000
<210> 874
<400> 874
000
<210> 875
<400> 875
000
<210> 876
<400> 876
000
<210> 877
<400> 877
000
<210> 878
<400> 878
000
<210> 879
<400> 879
000
<210> 880
<400> 880
000
<210> 881
<400> 881
000
<210> 882
<400> 882
000
<210> 883
<400> 883
000
<210> 884
<400> 884
000
<210> 885
<400> 885
000
<210> 886
<400> 886
000
<210> 887
<400> 887
000
<210> 888
<400> 888
000
<210> 889
<400> 889
000
<210> 890
<400> 890
000
<210> 891
<400> 891
000
<210> 892
<400> 892
000
<210> 893
<400> 893
000
<210> 894
<400> 894
000
<210> 895
<400> 895
000
<210> 896
<400> 896
000
<210> 897
<400> 897
000
<210> 898
<400> 898
000
<210> 899
<400> 899
000
<210> 900
<400> 900
000
<210> 901
<400> 901
000
<210> 902
<400> 902
000
<210> 903
<400> 903
000
<210> 904
<400> 904
000
<210> 905
<400> 905
000
<210> 906
<400> 906
000
<210> 907
<400> 907
000
<210> 908
<400> 908
000
<210> 909
<400> 909
000
<210> 910
<400> 910
000
<210> 911
<400> 911
000
<210> 912
<400> 912
000
<210> 913
<400> 913
000
<210> 914
<400> 914
000
<210> 915
<400> 915
000
<210> 916
<400> 916
000
<210> 917
<400> 917
000
<210> 918
<400> 918
000
<210> 919
<400> 919
000
<210> 920
<400> 920
000
<210> 921
<400> 921
000
<210> 922
<400> 922
000
<210> 923
<400> 923
000
<210> 924
<400> 924
000
<210> 925
<400> 925
000
<210> 926
<400> 926
000
<210> 927
<400> 927
000
<210> 928
<400> 928
000
<210> 929
<400> 929
000
<210> 930
<400> 930
000
<210> 931
<400> 931
000
<210> 932
<400> 932
000
<210> 933
<400> 933
000
<210> 934
<400> 934
000
<210> 935
<400> 935
000
<210> 936
<400> 936
000
<210> 937
<400> 937
000
<210> 938
<400> 938
000
<210> 939
<400> 939
000
<210> 940
<400> 940
000
<210> 941
<400> 941
000
<210> 942
<400> 942
000
<210> 943
<400> 943
000
<210> 944
<400> 944
000
<210> 945
<400> 945
000
<210> 946
<400> 946
000
<210> 947
<400> 947
000
<210> 948
<400> 948
000
<210> 949
<400> 949
000
<210> 950
<400> 950
000
<210> 951
<400> 951
000
<210> 952
<400> 952
000
<210> 953
<400> 953
000
<210> 954
<400> 954
000
<210> 955
<400> 955
000
<210> 956
<400> 956
000
<210> 957
<400> 957
000
<210> 958
<400> 958
000
<210> 959
<400> 959
000
<210> 960
<400> 960
000
<210> 961
<400> 961
000
<210> 962
<400> 962
000
<210> 963
<400> 963
000
<210> 964
<400> 964
000
<210> 965
<400> 965
000
<210> 966
<400> 966
000
<210> 967
<400> 967
000
<210> 968
<400> 968
000
<210> 969
<400> 969
000
<210> 970
<400> 970
000
<210> 971
<400> 971
000
<210> 972
<400> 972
000
<210> 973
<400> 973
000
<210> 974
<400> 974
000
<210> 975
<400> 975
000
<210> 976
<400> 976
000
<210> 977
<400> 977
000
<210> 978
<400> 978
000
<210> 979
<400> 979
000
<210> 980
<400> 980
000
<210> 981
<400> 981
000
<210> 982
<400> 982
000
<210> 983
<400> 983
000
<210> 984
<400> 984
000
<210> 985
<400> 985
000
<210> 986
<400> 986
000
<210> 987
<400> 987
000
<210> 988
<400> 988
000
<210> 989
<400> 989
000
<210> 990
<400> 990
000
<210> 991
<400> 991
000
<210> 992
<400> 992
000
<210> 993
<400> 993
000
<210> 994
<400> 994
000
<210> 995
<400> 995
000
<210> 996
<400> 996
000
<210> 997
<400> 997
000
<210> 998
<400> 998
000
<210> 999
<400> 999
000
<210> 1000
<400> 1000
000
<210> 1001
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1001
acauagaccu accuuaauca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1002
<400> 1002
000
<210> 1003
<400> 1003
000
<210> 1004
<400> 1004
000
<210> 1005
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1005
ccuaucauac agugcuuaug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1006
<400> 1006
000
<210> 1007
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1007
uagaccuacc uuaaucaugg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1008
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1008
uacagagagu ccaauagccc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1009
<400> 1009
000
<210> 1010
<400> 1010
000
<210> 1011
<400> 1011
000
<210> 1012
<400> 1012
000
<210> 1013
<400> 1013
000
<210> 1014
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1014
uacacuuugg gggauccaaa uuuuagagcu agaaauagca aguuaaaaua aggcuagucc 60
guuaucaacu ugaaaaagug gcaccgaguc ggugcuuuu 99
<210> 1015
<400> 1015
000
<210> 1016
<400> 1016
000
<210> 1017
<400> 1017
000
<210> 1018
<400> 1018
000
<210> 1019
<400> 1019
000
<210> 1020
<400> 1020
000
<210> 1021
<400> 1021
000
<210> 1022
<400> 1022
000
<210> 1023
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1023
uauuucuuuu agugccugua guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1024
<400> 1024
000
<210> 1025
<400> 1025
000
<210> 1026
<400> 1026
000
<210> 1027
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1027
cuuuaucagu cccuaaaucu uuuuagagcu agaaauagca aguuaaaaua aggcuagucc 60
guuaucaacu ugaaaaagug gcaccgaguc ggugcuuuu 99
<210> 1028
<400> 1028
000
<210> 1029
<400> 1029
000
<210> 1030
<400> 1030
000
<210> 1031
<400> 1031
000
<210> 1032
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1032
uuuagggacu gauaaagaua uuuuagagcu agaaauagca aguuaaaaua aggcuagucc 60
guuaucaacu ugaaaaagug gcaccgaguc ggugcuuuu 99
<210> 1033
<400> 1033
000
<210> 1034
<400> 1034
000
<210> 1035
<400> 1035
000
<210> 1036
<400> 1036
000
<210> 1037
<400> 1037
000
<210> 1038
<400> 1038
000
<210> 1039
<400> 1039
000
<210> 1040
<400> 1040
000
<210> 1041
<400> 1041
000
<210> 1042
<400> 1042
000
<210> 1043
<400> 1043
000
<210> 1044
<400> 1044
000
<210> 1045
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1045
ccuuaaucau gguggaaacu uuuuagagcu agaaauagca aguuaaaaua aggcuagucc 60
guuaucaacu ugaaaaagug gcaccgaguc ggugcuuuu 99
<210> 1046
<400> 1046
000
<210> 1047
<400> 1047
000
<210> 1048
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1048
gaaggugacu cugacuucug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1049
<400> 1049
000
<210> 1050
<400> 1050
000
<210> 1051
<400> 1051
000
<210> 1052
<400> 1052
000
<210> 1053
<400> 1053
000
<210> 1054
<400> 1054
000
<210> 1055
<400> 1055
000
<210> 1056
<400> 1056
000
<210> 1057
<400> 1057
000
<210> 1058
<400> 1058
000
<210> 1059
<400> 1059
000
<210> 1060
<400> 1060
000
<210> 1061
<400> 1061
000
<210> 1062
<400> 1062
000
<210> 1063
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1063
cgguuuauua accccaagug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1064
<400> 1064
000
<210> 1065
<400> 1065
000
<210> 1066
<400> 1066
000
<210> 1067
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1067
accgcgaugg gugagcccuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1068
<400> 1068
000
<210> 1069
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1069
accgcacgcu ucagugccuu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1070
<400> 1070
000
<210> 1071
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1071
guguaaguau agccuccuga guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1072
<400> 1072
000
<210> 1073
<400> 1073
000
<210> 1074
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1074
ggaaaggcca gccccacuug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1075
<400> 1075
000
<210> 1076
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1076
ugccacaaag cucgagccca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1077
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1077
gguguaagua uagccuccug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1078
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1078
uccugagggc ucacccaucg uuuuagagcu agaaauagca aguuaaaaua aggcuagucc 60
guuaucaacu ugaaaaagug gcaccgaguc ggugcuuuu 99
<210> 1079
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1079
aggaaaggcc agccccacuu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1080
<400> 1080
000
<210> 1081
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 1081
gaggaaaggc cagccccacu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 1082
<400> 1082
000
<210> 1083
<400> 1083
000
<210> 1084
<400> 1084
000
<210> 1085
<400> 1085
000
<210> 1086
<400> 1086
000
<210> 1087
<400> 1087
000
<210> 1088
<400> 1088
000
<210> 1089
<400> 1089
000
<210> 1090
<400> 1090
000
<210> 1091
<400> 1091
000
<210> 1092
<400> 1092
000
<210> 1093
<400> 1093
000
<210> 1094
<400> 1094
000
<210> 1095
<400> 1095
000
<210> 1096
<400> 1096
000
<210> 1097
<400> 1097
000
<210> 1098
<400> 1098
000
<210> 1099
<400> 1099
000
<210> 1100
<400> 1100
000
<210> 1101
<400> 1101
000
<210> 1102
<400> 1102
000
<210> 1103
<400> 1103
000
<210> 1104
<400> 1104
000
<210> 1105
<400> 1105
000
<210> 1106
<400> 1106
000
<210> 1107
<400> 1107
000
<210> 1108
<400> 1108
000
<210> 1109
<400> 1109
000
<210> 1110
<400> 1110
000
<210> 1111
<400> 1111
000
<210> 1112
<400> 1112
000
<210> 1113
<400> 1113
000
<210> 1114
<400> 1114
000
<210> 1115
<400> 1115
000
<210> 1116
<400> 1116
000
<210> 1117
<400> 1117
000
<210> 1118
<400> 1118
000
<210> 1119
<400> 1119
000
<210> 1120
<400> 1120
000
<210> 1121
<400> 1121
000
<210> 1122
<400> 1122
000
<210> 1123
<400> 1123
000
<210> 1124
<400> 1124
000
<210> 1125
<400> 1125
000
<210> 1126
<400> 1126
000
<210> 1127
<400> 1127
000
<210> 1128
<400> 1128
000
<210> 1129
<400> 1129
000
<210> 1130
<400> 1130
000
<210> 1131
<400> 1131
000
<210> 1132
<400> 1132
000
<210> 1133
<400> 1133
000
<210> 1134
<400> 1134
000
<210> 1135
<400> 1135
000
<210> 1136
<400> 1136
000
<210> 1137
<400> 1137
000
<210> 1138
<400> 1138
000
<210> 1139
<400> 1139
000
<210> 1140
<400> 1140
000
<210> 1141
<400> 1141
000
<210> 1142
<400> 1142
000
<210> 1143
<400> 1143
000
<210> 1144
<400> 1144
000
<210> 1145
<400> 1145
000
<210> 1146
<400> 1146
000
<210> 1147
<400> 1147
000
<210> 1148
<400> 1148
000
<210> 1149
<400> 1149
000
<210> 1150
<400> 1150
000
<210> 1151
<400> 1151
000
<210> 1152
<400> 1152
000
<210> 1153
<400> 1153
000
<210> 1154
<400> 1154
000
<210> 1155
<400> 1155
000
<210> 1156
<400> 1156
000
<210> 1157
<400> 1157
000
<210> 1158
<400> 1158
000
<210> 1159
<400> 1159
000
<210> 1160
<400> 1160
000
<210> 1161
<400> 1161
000
<210> 1162
<400> 1162
000
<210> 1163
<400> 1163
000
<210> 1164
<400> 1164
000
<210> 1165
<400> 1165
000
<210> 1166
<400> 1166
000
<210> 1167
<400> 1167
000
<210> 1168
<400> 1168
000
<210> 1169
<400> 1169
000
<210> 1170
<400> 1170
000
<210> 1171
<400> 1171
000
<210> 1172
<400> 1172
000
<210> 1173
<400> 1173
000
<210> 1174
<400> 1174
000
<210> 1175
<400> 1175
000
<210> 1176
<400> 1176
000
<210> 1177
<400> 1177
000
<210> 1178
<400> 1178
000
<210> 1179
<400> 1179
000
<210> 1180
<400> 1180
000
<210> 1181
<400> 1181
000
<210> 1182
<400> 1182
000
<210> 1183
<400> 1183
000
<210> 1184
<400> 1184
000
<210> 1185
<400> 1185
000
<210> 1186
<400> 1186
000
<210> 1187
<400> 1187
000
<210> 1188
<400> 1188
000
<210> 1189
<400> 1189
000
<210> 1190
<400> 1190
000
<210> 1191
<400> 1191
000
<210> 1192
<400> 1192
000
<210> 1193
<400> 1193
000
<210> 1194
<400> 1194
000
<210> 1195
<400> 1195
000
<210> 1196
<400> 1196
000
<210> 1197
<400> 1197
000
<210> 1198
<400> 1198
000
<210> 1199
<400> 1199
000
<210> 1200
<400> 1200
000
<210> 1201
<400> 1201
000
<210> 1202
<400> 1202
000
<210> 1203
<400> 1203
000
<210> 1204
<400> 1204
000
<210> 1205
<400> 1205
000
<210> 1206
<400> 1206
000
<210> 1207
<400> 1207
000
<210> 1208
<400> 1208
000
<210> 1209
<400> 1209
000
<210> 1210
<400> 1210
000
<210> 1211
<400> 1211
000
<210> 1212
<400> 1212
000
<210> 1213
<400> 1213
000
<210> 1214
<400> 1214
000
<210> 1215
<400> 1215
000
<210> 1216
<400> 1216
000
<210> 1217
<400> 1217
000
<210> 1218
<400> 1218
000
<210> 1219
<400> 1219
000
<210> 1220
<400> 1220
000
<210> 1221
<400> 1221
000
<210> 1222
<400> 1222
000
<210> 1223
<400> 1223
000
<210> 1224
<400> 1224
000
<210> 1225
<400> 1225
000
<210> 1226
<400> 1226
000
<210> 1227
<400> 1227
000
<210> 1228
<400> 1228
000
<210> 1229
<400> 1229
000
<210> 1230
<400> 1230
000
<210> 1231
<400> 1231
000
<210> 1232
<400> 1232
000
<210> 1233
<400> 1233
000
<210> 1234
<400> 1234
000
<210> 1235
<400> 1235
000
<210> 1236
<400> 1236
000
<210> 1237
<400> 1237
000
<210> 1238
<400> 1238
000
<210> 1239
<400> 1239
000
<210> 1240
<400> 1240
000
<210> 1241
<400> 1241
000
<210> 1242
<400> 1242
000
<210> 1243
<400> 1243
000
<210> 1244
<400> 1244
000
<210> 1245
<400> 1245
000
<210> 1246
<400> 1246
000
<210> 1247
<400> 1247
000
<210> 1248
<400> 1248
000
<210> 1249
<400> 1249
000
<210> 1250
<400> 1250
000
<210> 1251
<400> 1251
000
<210> 1252
<400> 1252
000
<210> 1253
<400> 1253
000
<210> 1254
<400> 1254
000
<210> 1255
<400> 1255
000
<210> 1256
<400> 1256
000
<210> 1257
<400> 1257
000
<210> 1258
<400> 1258
000
<210> 1259
<400> 1259
000
<210> 1260
<400> 1260
000
<210> 1261
<400> 1261
000
<210> 1262
<400> 1262
000
<210> 1263
<400> 1263
000
<210> 1264
<400> 1264
000
<210> 1265
<400> 1265
000
<210> 1266
<400> 1266
000
<210> 1267
<400> 1267
000
<210> 1268
<400> 1268
000
<210> 1269
<400> 1269
000
<210> 1270
<400> 1270
000
<210> 1271
<400> 1271
000
<210> 1272
<400> 1272
000
<210> 1273
<400> 1273
000
<210> 1274
<400> 1274
000
<210> 1275
<400> 1275
000
<210> 1276
<400> 1276
000
<210> 1277
<400> 1277
000
<210> 1278
<400> 1278
000
<210> 1279
<400> 1279
000
<210> 1280
<400> 1280
000
<210> 1281
<400> 1281
000
<210> 1282
<400> 1282
000
<210> 1283
<400> 1283
000
<210> 1284
<400> 1284
000
<210> 1285
<400> 1285
000
<210> 1286
<400> 1286
000
<210> 1287
<400> 1287
000
<210> 1288
<400> 1288
000
<210> 1289
<400> 1289
000
<210> 1290
<400> 1290
000
<210> 1291
<400> 1291
000
<210> 1292
<400> 1292
000
<210> 1293
<400> 1293
000
<210> 1294
<400> 1294
000
<210> 1295
<400> 1295
000
<210> 1296
<400> 1296
000
<210> 1297
<400> 1297
000
<210> 1298
<400> 1298
000
<210> 1299
<400> 1299
000
<210> 1300
<400> 1300
000
<210> 1301
<400> 1301
000
<210> 1302
<400> 1302
000
<210> 1303
<400> 1303
000
<210> 1304
<400> 1304
000
<210> 1305
<400> 1305
000
<210> 1306
<400> 1306
000
<210> 1307
<400> 1307
000
<210> 1308
<400> 1308
000
<210> 1309
<400> 1309
000
<210> 1310
<400> 1310
000
<210> 1311
<400> 1311
000
<210> 1312
<400> 1312
000
<210> 1313
<400> 1313
000
<210> 1314
<400> 1314
000
<210> 1315
<400> 1315
000
<210> 1316
<400> 1316
000
<210> 1317
<400> 1317
000
<210> 1318
<400> 1318
000
<210> 1319
<400> 1319
000
<210> 1320
<400> 1320
000
<210> 1321
<400> 1321
000
<210> 1322
<400> 1322
000
<210> 1323
<400> 1323
000
<210> 1324
<400> 1324
000
<210> 1325
<400> 1325
000
<210> 1326
<400> 1326
000
<210> 1327
<400> 1327
000
<210> 1328
<400> 1328
000
<210> 1329
<400> 1329
000
<210> 1330
<400> 1330
000
<210> 1331
<400> 1331
000
<210> 1332
<400> 1332
000
<210> 1333
<400> 1333
000
<210> 1334
<400> 1334
000
<210> 1335
<400> 1335
000
<210> 1336
<400> 1336
000
<210> 1337
<400> 1337
000
<210> 1338
<400> 1338
000
<210> 1339
<400> 1339
000
<210> 1340
<400> 1340
000
<210> 1341
<400> 1341
000
<210> 1342
<400> 1342
000
<210> 1343
<400> 1343
000
<210> 1344
<400> 1344
000
<210> 1345
<400> 1345
000
<210> 1346
<400> 1346
000
<210> 1347
<400> 1347
000
<210> 1348
<400> 1348
000
<210> 1349
<400> 1349
000
<210> 1350
<400> 1350
000
<210> 1351
<400> 1351
000
<210> 1352
<400> 1352
000
<210> 1353
<400> 1353
000
<210> 1354
<400> 1354
000
<210> 1355
<400> 1355
000
<210> 1356
<400> 1356
000
<210> 1357
<400> 1357
000
<210> 1358
<400> 1358
000
<210> 1359
<400> 1359
000
<210> 1360
<400> 1360
000
<210> 1361
<400> 1361
000
<210> 1362
<400> 1362
000
<210> 1363
<400> 1363
000
<210> 1364
<400> 1364
000
<210> 1365
<400> 1365
000
<210> 1366
<400> 1366
000
<210> 1367
<400> 1367
000
<210> 1368
<400> 1368
000
<210> 1369
<400> 1369
000
<210> 1370
<400> 1370
000
<210> 1371
<400> 1371
000
<210> 1372
<400> 1372
000
<210> 1373
<400> 1373
000
<210> 1374
<400> 1374
000
<210> 1375
<400> 1375
000
<210> 1376
<400> 1376
000
<210> 1377
<400> 1377
000
<210> 1378
<400> 1378
000
<210> 1379
<400> 1379
000
<210> 1380
<400> 1380
000
<210> 1381
<400> 1381
000
<210> 1382
<400> 1382
000
<210> 1383
<400> 1383
000
<210> 1384
<400> 1384
000
<210> 1385
<400> 1385
000
<210> 1386
<400> 1386
000
<210> 1387
<400> 1387
000
<210> 1388
<400> 1388
000
<210> 1389
<400> 1389
000
<210> 1390
<400> 1390
000
<210> 1391
<400> 1391
000
<210> 1392
<400> 1392
000
<210> 1393
<400> 1393
000
<210> 1394
<400> 1394
000
<210> 1395
<400> 1395
000
<210> 1396
<400> 1396
000
<210> 1397
<400> 1397
000
<210> 1398
<400> 1398
000
<210> 1399
<400> 1399
000
<210> 1400
<400> 1400
000
<210> 1401
<400> 1401
000
<210> 1402
<400> 1402
000
<210> 1403
<400> 1403
000
<210> 1404
<400> 1404
000
<210> 1405
<400> 1405
000
<210> 1406
<400> 1406
000
<210> 1407
<400> 1407
000
<210> 1408
<400> 1408
000
<210> 1409
<400> 1409
000
<210> 1410
<400> 1410
000
<210> 1411
<400> 1411
000
<210> 1412
<400> 1412
000
<210> 1413
<400> 1413
000
<210> 1414
<400> 1414
000
<210> 1415
<400> 1415
000
<210> 1416
<400> 1416
000
<210> 1417
<400> 1417
000
<210> 1418
<400> 1418
000
<210> 1419
<400> 1419
000
<210> 1420
<400> 1420
000
<210> 1421
<400> 1421
000
<210> 1422
<400> 1422
000
<210> 1423
<400> 1423
000
<210> 1424
<400> 1424
000
<210> 1425
<400> 1425
000
<210> 1426
<400> 1426
000
<210> 1427
<400> 1427
000
<210> 1428
<400> 1428
000
<210> 1429
<400> 1429
000
<210> 1430
<400> 1430
000
<210> 1431
<400> 1431
000
<210> 1432
<400> 1432
000
<210> 1433
<400> 1433
000
<210> 1434
<400> 1434
000
<210> 1435
<400> 1435
000
<210> 1436
<400> 1436
000
<210> 1437
<400> 1437
000
<210> 1438
<400> 1438
000
<210> 1439
<400> 1439
000
<210> 1440
<400> 1440
000
<210> 1441
<400> 1441
000
<210> 1442
<400> 1442
000
<210> 1443
<400> 1443
000
<210> 1444
<400> 1444
000
<210> 1445
<400> 1445
000
<210> 1446
<400> 1446
000
<210> 1447
<400> 1447
000
<210> 1448
<400> 1448
000
<210> 1449
<400> 1449
000
<210> 1450
<400> 1450
000
<210> 1451
<400> 1451
000
<210> 1452
<400> 1452
000
<210> 1453
<400> 1453
000
<210> 1454
<400> 1454
000
<210> 1455
<400> 1455
000
<210> 1456
<400> 1456
000
<210> 1457
<400> 1457
000
<210> 1458
<400> 1458
000
<210> 1459
<400> 1459
000
<210> 1460
<400> 1460
000
<210> 1461
<400> 1461
000
<210> 1462
<400> 1462
000
<210> 1463
<400> 1463
000
<210> 1464
<400> 1464
000
<210> 1465
<400> 1465
000
<210> 1466
<400> 1466
000
<210> 1467
<400> 1467
000
<210> 1468
<400> 1468
000
<210> 1469
<400> 1469
000
<210> 1470
<400> 1470
000
<210> 1471
<400> 1471
000
<210> 1472
<400> 1472
000
<210> 1473
<400> 1473
000
<210> 1474
<400> 1474
000
<210> 1475
<400> 1475
000
<210> 1476
<400> 1476
000
<210> 1477
<400> 1477
000
<210> 1478
<400> 1478
000
<210> 1479
<400> 1479
000
<210> 1480
<400> 1480
000
<210> 1481
<400> 1481
000
<210> 1482
<400> 1482
000
<210> 1483
<400> 1483
000
<210> 1484
<400> 1484
000
<210> 1485
<400> 1485
000
<210> 1486
<400> 1486
000
<210> 1487
<400> 1487
000
<210> 1488
<400> 1488
000
<210> 1489
<400> 1489
000
<210> 1490
<400> 1490
000
<210> 1491
<400> 1491
000
<210> 1492
<400> 1492
000
<210> 1493
<400> 1493
000
<210> 1494
<400> 1494
000
<210> 1495
<400> 1495
000
<210> 1496
<400> 1496
000
<210> 1497
<400> 1497
000
<210> 1498
<400> 1498
000
<210> 1499
<400> 1499
000
<210> 1500
<400> 1500
000
<210> 1501
<400> 1501
000
<210> 1502
<400> 1502
000
<210> 1503
<400> 1503
000
<210> 1504
<400> 1504
000
<210> 1505
<400> 1505
000
<210> 1506
<400> 1506
000
<210> 1507
<400> 1507
000
<210> 1508
<400> 1508
000
<210> 1509
<400> 1509
000
<210> 1510
<400> 1510
000
<210> 1511
<400> 1511
000
<210> 1512
<400> 1512
000
<210> 1513
<400> 1513
000
<210> 1514
<400> 1514
000
<210> 1515
<400> 1515
000
<210> 1516
<400> 1516
000
<210> 1517
<400> 1517
000
<210> 1518
<400> 1518
000
<210> 1519
<400> 1519
000
<210> 1520
<400> 1520
000
<210> 1521
<400> 1521
000
<210> 1522
<400> 1522
000
<210> 1523
<400> 1523
000
<210> 1524
<400> 1524
000
<210> 1525
<400> 1525
000
<210> 1526
<400> 1526
000
<210> 1527
<400> 1527
000
<210> 1528
<400> 1528
000
<210> 1529
<400> 1529
000
<210> 1530
<400> 1530
000
<210> 1531
<400> 1531
000
<210> 1532
<400> 1532
000
<210> 1533
<400> 1533
000
<210> 1534
<400> 1534
000
<210> 1535
<400> 1535
000
<210> 1536
<400> 1536
000
<210> 1537
<400> 1537
000
<210> 1538
<400> 1538
000
<210> 1539
<400> 1539
000
<210> 1540
<400> 1540
000
<210> 1541
<400> 1541
000
<210> 1542
<400> 1542
000
<210> 1543
<400> 1543
000
<210> 1544
<400> 1544
000
<210> 1545
<400> 1545
000
<210> 1546
<400> 1546
000
<210> 1547
<400> 1547
000
<210> 1548
<400> 1548
000
<210> 1549
<400> 1549
000
<210> 1550
<400> 1550
000
<210> 1551
<400> 1551
000
<210> 1552
<400> 1552
000
<210> 1553
<400> 1553
000
<210> 1554
<400> 1554
000
<210> 1555
<400> 1555
000
<210> 1556
<400> 1556
000
<210> 1557
<400> 1557
000
<210> 1558
<400> 1558
000
<210> 1559
<400> 1559
000
<210> 1560
<400> 1560
000
<210> 1561
<400> 1561
000
<210> 1562
<400> 1562
000
<210> 1563
<400> 1563
000
<210> 1564
<400> 1564
000
<210> 1565
<400> 1565
000
<210> 1566
<400> 1566
000
<210> 1567
<400> 1567
000
<210> 1568
<400> 1568
000
<210> 1569
<400> 1569
000
<210> 1570
<400> 1570
000
<210> 1571
<400> 1571
000
<210> 1572
<400> 1572
000
<210> 1573
<400> 1573
000
<210> 1574
<400> 1574
000
<210> 1575
<400> 1575
000
<210> 1576
<400> 1576
000
<210> 1577
<400> 1577
000
<210> 1578
<400> 1578
000
<210> 1579
<400> 1579
000
<210> 1580
<400> 1580
000
<210> 1581
<400> 1581
000
<210> 1582
<400> 1582
000
<210> 1583
<400> 1583
000
<210> 1584
<400> 1584
000
<210> 1585
<400> 1585
000
<210> 1586
<400> 1586
000
<210> 1587
<400> 1587
000
<210> 1588
<400> 1588
000
<210> 1589
<400> 1589
000
<210> 1590
<400> 1590
000
<210> 1591
<400> 1591
000
<210> 1592
<400> 1592
000
<210> 1593
<400> 1593
000
<210> 1594
<400> 1594
000
<210> 1595
<400> 1595
000
<210> 1596
<400> 1596
000
<210> 1597
<400> 1597
000
<210> 1598
<400> 1598
000
<210> 1599
<400> 1599
000
<210> 1600
<400> 1600
000
<210> 1601
<400> 1601
000
<210> 1602
<400> 1602
000
<210> 1603
<400> 1603
000
<210> 1604
<400> 1604
000
<210> 1605
<400> 1605
000
<210> 1606
<400> 1606
000
<210> 1607
<400> 1607
000
<210> 1608
<400> 1608
000
<210> 1609
<400> 1609
000
<210> 1610
<400> 1610
000
<210> 1611
<400> 1611
000
<210> 1612
<400> 1612
000
<210> 1613
<400> 1613
000
<210> 1614
<400> 1614
000
<210> 1615
<400> 1615
000
<210> 1616
<400> 1616
000
<210> 1617
<400> 1617
000
<210> 1618
<400> 1618
000
<210> 1619
<400> 1619
000
<210> 1620
<400> 1620
000
<210> 1621
<400> 1621
000
<210> 1622
<400> 1622
000
<210> 1623
<400> 1623
000
<210> 1624
<400> 1624
000
<210> 1625
<400> 1625
000
<210> 1626
<400> 1626
000
<210> 1627
<400> 1627
000
<210> 1628
<400> 1628
000
<210> 1629
<400> 1629
000
<210> 1630
<400> 1630
000
<210> 1631
<400> 1631
000
<210> 1632
<400> 1632
000
<210> 1633
<400> 1633
000
<210> 1634
<400> 1634
000
<210> 1635
<400> 1635
000
<210> 1636
<400> 1636
000
<210> 1637
<400> 1637
000
<210> 1638
<400> 1638
000
<210> 1639
<400> 1639
000
<210> 1640
<400> 1640
000
<210> 1641
<400> 1641
000
<210> 1642
<400> 1642
000
<210> 1643
<400> 1643
000
<210> 1644
<400> 1644
000
<210> 1645
<400> 1645
000
<210> 1646
<400> 1646
000
<210> 1647
<400> 1647
000
<210> 1648
<400> 1648
000
<210> 1649
<400> 1649
000
<210> 1650
<400> 1650
000
<210> 1651
<400> 1651
000
<210> 1652
<400> 1652
000
<210> 1653
<400> 1653
000
<210> 1654
<400> 1654
000
<210> 1655
<400> 1655
000
<210> 1656
<400> 1656
000
<210> 1657
<400> 1657
000
<210> 1658
<400> 1658
000
<210> 1659
<400> 1659
000
<210> 1660
<400> 1660
000
<210> 1661
<400> 1661
000
<210> 1662
<400> 1662
000
<210> 1663
<400> 1663
000
<210> 1664
<400> 1664
000
<210> 1665
<400> 1665
000
<210> 1666
<400> 1666
000
<210> 1667
<400> 1667
000
<210> 1668
<400> 1668
000
<210> 1669
<400> 1669
000
<210> 1670
<400> 1670
000
<210> 1671
<400> 1671
000
<210> 1672
<400> 1672
000
<210> 1673
<400> 1673
000
<210> 1674
<400> 1674
000
<210> 1675
<400> 1675
000
<210> 1676
<400> 1676
000
<210> 1677
<400> 1677
000
<210> 1678
<400> 1678
000
<210> 1679
<400> 1679
000
<210> 1680
<400> 1680
000
<210> 1681
<400> 1681
000
<210> 1682
<400> 1682
000
<210> 1683
<400> 1683
000
<210> 1684
<400> 1684
000
<210> 1685
<400> 1685
000
<210> 1686
<400> 1686
000
<210> 1687
<400> 1687
000
<210> 1688
<400> 1688
000
<210> 1689
<400> 1689
000
<210> 1690
<400> 1690
000
<210> 1691
<400> 1691
000
<210> 1692
<400> 1692
000
<210> 1693
<400> 1693
000
<210> 1694
<400> 1694
000
<210> 1695
<400> 1695
000
<210> 1696
<400> 1696
000
<210> 1697
<400> 1697
000
<210> 1698
<400> 1698
000
<210> 1699
<400> 1699
000
<210> 1700
<400> 1700
000
<210> 1701
<400> 1701
000
<210> 1702
<400> 1702
000
<210> 1703
<400> 1703
000
<210> 1704
<400> 1704
000
<210> 1705
<400> 1705
000
<210> 1706
<400> 1706
000
<210> 1707
<400> 1707
000
<210> 1708
<400> 1708
000
<210> 1709
<400> 1709
000
<210> 1710
<400> 1710
000
<210> 1711
<400> 1711
000
<210> 1712
<400> 1712
000
<210> 1713
<400> 1713
000
<210> 1714
<400> 1714
000
<210> 1715
<400> 1715
000
<210> 1716
<400> 1716
000
<210> 1717
<400> 1717
000
<210> 1718
<400> 1718
000
<210> 1719
<400> 1719
000
<210> 1720
<400> 1720
000
<210> 1721
<400> 1721
000
<210> 1722
<400> 1722
000
<210> 1723
<400> 1723
000
<210> 1724
<400> 1724
000
<210> 1725
<400> 1725
000
<210> 1726
<400> 1726
000
<210> 1727
<400> 1727
000
<210> 1728
<400> 1728
000
<210> 1729
<400> 1729
000
<210> 1730
<400> 1730
000
<210> 1731
<400> 1731
000
<210> 1732
<400> 1732
000
<210> 1733
<400> 1733
000
<210> 1734
<400> 1734
000
<210> 1735
<400> 1735
000
<210> 1736
<400> 1736
000
<210> 1737
<400> 1737
000
<210> 1738
<400> 1738
000
<210> 1739
<400> 1739
000
<210> 1740
<400> 1740
000
<210> 1741
<400> 1741
000
<210> 1742
<400> 1742
000
<210> 1743
<400> 1743
000
<210> 1744
<400> 1744
000
<210> 1745
<400> 1745
000
<210> 1746
<400> 1746
000
<210> 1747
<400> 1747
000
<210> 1748
<400> 1748
000
<210> 1749
<400> 1749
000
<210> 1750
<400> 1750
000
<210> 1751
<400> 1751
000
<210> 1752
<400> 1752
000
<210> 1753
<400> 1753
000
<210> 1754
<400> 1754
000
<210> 1755
<400> 1755
000
<210> 1756
<400> 1756
000
<210> 1757
<400> 1757
000
<210> 1758
<400> 1758
000
<210> 1759
<400> 1759
000
<210> 1760
<400> 1760
000
<210> 1761
<400> 1761
000
<210> 1762
<400> 1762
000
<210> 1763
<400> 1763
000
<210> 1764
<400> 1764
000
<210> 1765
<400> 1765
000
<210> 1766
<400> 1766
000
<210> 1767
<400> 1767
000
<210> 1768
<400> 1768
000
<210> 1769
<400> 1769
000
<210> 1770
<400> 1770
000
<210> 1771
<400> 1771
000
<210> 1772
<400> 1772
000
<210> 1773
<400> 1773
000
<210> 1774
<400> 1774
000
<210> 1775
<400> 1775
000
<210> 1776
<400> 1776
000
<210> 1777
<400> 1777
000
<210> 1778
<400> 1778
000
<210> 1779
<400> 1779
000
<210> 1780
<400> 1780
000
<210> 1781
<400> 1781
000
<210> 1782
<400> 1782
000
<210> 1783
<400> 1783
000
<210> 1784
<400> 1784
000
<210> 1785
<400> 1785
000
<210> 1786
<400> 1786
000
<210> 1787
<400> 1787
000
<210> 1788
<400> 1788
000
<210> 1789
<400> 1789
000
<210> 1790
<400> 1790
000
<210> 1791
<400> 1791
000
<210> 1792
<400> 1792
000
<210> 1793
<400> 1793
000
<210> 1794
<400> 1794
000
<210> 1795
<400> 1795
000
<210> 1796
<400> 1796
000
<210> 1797
<400> 1797
000
<210> 1798
<400> 1798
000
<210> 1799
<400> 1799
000
<210> 1800
<400> 1800
000
<210> 1801
<400> 1801
000
<210> 1802
<400> 1802
000
<210> 1803
<400> 1803
000
<210> 1804
<400> 1804
000
<210> 1805
<400> 1805
000
<210> 1806
<400> 1806
000
<210> 1807
<400> 1807
000
<210> 1808
<400> 1808
000
<210> 1809
<400> 1809
000
<210> 1810
<400> 1810
000
<210> 1811
<400> 1811
000
<210> 1812
<400> 1812
000
<210> 1813
<400> 1813
000
<210> 1814
<400> 1814
000
<210> 1815
<400> 1815
000
<210> 1816
<400> 1816
000
<210> 1817
<400> 1817
000
<210> 1818
<400> 1818
000
<210> 1819
<400> 1819
000
<210> 1820
<400> 1820
000
<210> 1821
<400> 1821
000
<210> 1822
<400> 1822
000
<210> 1823
<400> 1823
000
<210> 1824
<400> 1824
000
<210> 1825
<400> 1825
000
<210> 1826
<400> 1826
000
<210> 1827
<400> 1827
000
<210> 1828
<400> 1828
000
<210> 1829
<400> 1829
000
<210> 1830
<400> 1830
000
<210> 1831
<400> 1831
000
<210> 1832
<400> 1832
000
<210> 1833
<400> 1833
000
<210> 1834
<400> 1834
000
<210> 1835
<400> 1835
000
<210> 1836
<400> 1836
000
<210> 1837
<400> 1837
000
<210> 1838
<400> 1838
000
<210> 1839
<400> 1839
000
<210> 1840
<400> 1840
000
<210> 1841
<400> 1841
000
<210> 1842
<400> 1842
000
<210> 1843
<400> 1843
000
<210> 1844
<400> 1844
000
<210> 1845
<400> 1845
000
<210> 1846
<400> 1846
000
<210> 1847
<400> 1847
000
<210> 1848
<400> 1848
000
<210> 1849
<400> 1849
000
<210> 1850
<400> 1850
000
<210> 1851
<400> 1851
000
<210> 1852
<400> 1852
000
<210> 1853
<400> 1853
000
<210> 1854
<400> 1854
000
<210> 1855
<400> 1855
000
<210> 1856
<400> 1856
000
<210> 1857
<400> 1857
000
<210> 1858
<400> 1858
000
<210> 1859
<400> 1859
000
<210> 1860
<400> 1860
000
<210> 1861
<400> 1861
000
<210> 1862
<400> 1862
000
<210> 1863
<400> 1863
000
<210> 1864
<400> 1864
000
<210> 1865
<400> 1865
000
<210> 1866
<400> 1866
000
<210> 1867
<400> 1867
000
<210> 1868
<400> 1868
000
<210> 1869
<400> 1869
000
<210> 1870
<400> 1870
000
<210> 1871
<400> 1871
000
<210> 1872
<400> 1872
000
<210> 1873
<400> 1873
000
<210> 1874
<400> 1874
000
<210> 1875
<400> 1875
000
<210> 1876
<400> 1876
000
<210> 1877
<400> 1877
000
<210> 1878
<400> 1878
000
<210> 1879
<400> 1879
000
<210> 1880
<400> 1880
000
<210> 1881
<400> 1881
000
<210> 1882
<400> 1882
000
<210> 1883
<400> 1883
000
<210> 1884
<400> 1884
000
<210> 1885
<400> 1885
000
<210> 1886
<400> 1886
000
<210> 1887
<400> 1887
000
<210> 1888
<400> 1888
000
<210> 1889
<400> 1889
000
<210> 1890
<400> 1890
000
<210> 1891
<400> 1891
000
<210> 1892
<400> 1892
000
<210> 1893
<400> 1893
000
<210> 1894
<400> 1894
000
<210> 1895
<400> 1895
000
<210> 1896
<400> 1896
000
<210> 1897
<400> 1897
000
<210> 1898
<400> 1898
000
<210> 1899
<400> 1899
000
<210> 1900
<400> 1900
000
<210> 1901
<400> 1901
000
<210> 1902
<400> 1902
000
<210> 1903
<400> 1903
000
<210> 1904
<400> 1904
000
<210> 1905
<400> 1905
000
<210> 1906
<400> 1906
000
<210> 1907
<400> 1907
000
<210> 1908
<400> 1908
000
<210> 1909
<400> 1909
000
<210> 1910
<400> 1910
000
<210> 1911
<400> 1911
000
<210> 1912
<400> 1912
000
<210> 1913
<400> 1913
000
<210> 1914
<400> 1914
000
<210> 1915
<400> 1915
000
<210> 1916
<400> 1916
000
<210> 1917
<400> 1917
000
<210> 1918
<400> 1918
000
<210> 1919
<400> 1919
000
<210> 1920
<400> 1920
000
<210> 1921
<400> 1921
000
<210> 1922
<400> 1922
000
<210> 1923
<400> 1923
000
<210> 1924
<400> 1924
000
<210> 1925
<400> 1925
000
<210> 1926
<400> 1926
000
<210> 1927
<400> 1927
000
<210> 1928
<400> 1928
000
<210> 1929
<400> 1929
000
<210> 1930
<400> 1930
000
<210> 1931
<400> 1931
000
<210> 1932
<400> 1932
000
<210> 1933
<400> 1933
000
<210> 1934
<400> 1934
000
<210> 1935
<400> 1935
000
<210> 1936
<400> 1936
000
<210> 1937
<400> 1937
000
<210> 1938
<400> 1938
000
<210> 1939
<400> 1939
000
<210> 1940
<400> 1940
000
<210> 1941
<400> 1941
000
<210> 1942
<400> 1942
000
<210> 1943
<400> 1943
000
<210> 1944
<400> 1944
000
<210> 1945
<400> 1945
000
<210> 1946
<400> 1946
000
<210> 1947
<400> 1947
000
<210> 1948
<400> 1948
000
<210> 1949
<400> 1949
000
<210> 1950
<400> 1950
000
<210> 1951
<400> 1951
000
<210> 1952
<400> 1952
000
<210> 1953
<400> 1953
000
<210> 1954
<400> 1954
000
<210> 1955
<400> 1955
000
<210> 1956
<400> 1956
000
<210> 1957
<400> 1957
000
<210> 1958
<400> 1958
000
<210> 1959
<400> 1959
000
<210> 1960
<400> 1960
000
<210> 1961
<400> 1961
000
<210> 1962
<400> 1962
000
<210> 1963
<400> 1963
000
<210> 1964
<400> 1964
000
<210> 1965
<400> 1965
000
<210> 1966
<400> 1966
000
<210> 1967
<400> 1967
000
<210> 1968
<400> 1968
000
<210> 1969
<400> 1969
000
<210> 1970
<400> 1970
000
<210> 1971
<400> 1971
000
<210> 1972
<400> 1972
000
<210> 1973
<400> 1973
000
<210> 1974
<400> 1974
000
<210> 1975
<400> 1975
000
<210> 1976
<400> 1976
000
<210> 1977
<400> 1977
000
<210> 1978
<400> 1978
000
<210> 1979
<400> 1979
000
<210> 1980
<400> 1980
000
<210> 1981
<400> 1981
000
<210> 1982
<400> 1982
000
<210> 1983
<400> 1983
000
<210> 1984
<400> 1984
000
<210> 1985
<400> 1985
000
<210> 1986
<400> 1986
000
<210> 1987
<400> 1987
000
<210> 1988
<400> 1988
000
<210> 1989
<400> 1989
000
<210> 1990
<400> 1990
000
<210> 1991
<400> 1991
000
<210> 1992
<400> 1992
000
<210> 1993
<400> 1993
000
<210> 1994
<400> 1994
000
<210> 1995
<400> 1995
000
<210> 1996
<400> 1996
000
<210> 1997
<400> 1997
000
<210> 1998
<400> 1998
000
<210> 1999
<400> 1999
000
<210> 2000
<400> 2000
000
<210> 2001
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2001
acauagaccu accuuaauca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2002
<400> 2002
000
<210> 2003
<400> 2003
000
<210> 2004
<400> 2004
000
<210> 2005
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2005
ccuaucauac agugcuuaug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2006
<400> 2006
000
<210> 2007
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2007
uagaccuacc uuaaucaugg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2008
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2008
uacagagagu ccaauagccc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2009
<400> 2009
000
<210> 2010
<400> 2010
000
<210> 2011
<400> 2011
000
<210> 2012
<400> 2012
000
<210> 2013
<400> 2013
000
<210> 2014
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2014
uacacuuugg gggauccaaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2015
<400> 2015
000
<210> 2016
<400> 2016
000
<210> 2017
<400> 2017
000
<210> 2018
<400> 2018
000
<210> 2019
<400> 2019
000
<210> 2020
<400> 2020
000
<210> 2021
<400> 2021
000
<210> 2022
<400> 2022
000
<210> 2023
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2023
uauuucuuuu agugccugua guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2024
<400> 2024
000
<210> 2025
<400> 2025
000
<210> 2026
<400> 2026
000
<210> 2027
<211> 102
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2027
cuuuuuauca gucccuaaau cuguuuuaga gcuagaaaua gcaaguuaaa auaaggcuag 60
uccguuauca acuugaaaaa guggcaccga gucggugcuu uu 102
<210> 2028
<400> 2028
000
<210> 2029
<400> 2029
000
<210> 2030
<400> 2030
000
<210> 2031
<400> 2031
000
<210> 2032
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2032
uuuagggacu gauaaagaua guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2033
<400> 2033
000
<210> 2034
<400> 2034
000
<210> 2035
<400> 2035
000
<210> 2036
<400> 2036
000
<210> 2037
<400> 2037
000
<210> 2038
<400> 2038
000
<210> 2039
<400> 2039
000
<210> 2040
<400> 2040
000
<210> 2041
<400> 2041
000
<210> 2042
<400> 2042
000
<210> 2043
<400> 2043
000
<210> 2044
<400> 2044
000
<210> 2045
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2045
ccuuaaucau gguggaaacu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2046
<400> 2046
000
<210> 2047
<400> 2047
000
<210> 2048
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2048
gaaggugacu cugacuucug uuuuagagcu agaaauagca aguuaaaaua aggcuagucc 60
guuaucaacu ugaaaaagug gcaccgaguc ggugcuuuu 99
<210> 2049
<400> 2049
000
<210> 2050
<400> 2050
000
<210> 2051
<400> 2051
000
<210> 2052
<400> 2052
000
<210> 2053
<400> 2053
000
<210> 2054
<400> 2054
000
<210> 2055
<400> 2055
000
<210> 2056
<400> 2056
000
<210> 2057
<400> 2057
000
<210> 2058
<400> 2058
000
<210> 2059
<400> 2059
000
<210> 2060
<400> 2060
000
<210> 2061
<400> 2061
000
<210> 2062
<400> 2062
000
<210> 2063
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2063
cgguuuauua accccaagug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2064
<400> 2064
000
<210> 2065
<400> 2065
000
<210> 2066
<400> 2066
000
<210> 2067
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2067
accgcgaugg gugagcccuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2068
<400> 2068
000
<210> 2069
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2069
accgcacgcu ucagugccuu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2070
<400> 2070
000
<210> 2071
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2071
guguaaguau agccuccuga guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2072
<400> 2072
000
<210> 2073
<400> 2073
000
<210> 2074
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2074
ggaaaggcca gccccacuug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2075
<400> 2075
000
<210> 2076
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2076
ugccacaaag cucgagccca guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2077
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2077
gguguaagua uagccuccug guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2078
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2078
uccugagggc ucacccaucg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2079
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2079
aggaaaggcc agccccacuu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2080
<400> 2080
000
<210> 2081
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<400> 2081
gaggaaaggc cagccccacu guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
<210> 2082
<211> 100
<212> RNA
<213> Artificial Sequence
<220>
<223> Synthetic
<220>
<221> misc_feature
<222> (1)..(20)
<223> n, if present, may repeat up to 20 times; if present, n is a, c,
g, or u
<400> 2082
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu 100
Claims (216)
- LDHA 유전자 내에 이중-가닥 파괴 (DSB) 또는 단일-가닥 파괴 (SSB)를 유도하는 방법으로서, 조성물을 세포에 전달하는 단계를 포함하되, 상기 조성물은 다음을 포함하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - LDHA 유전자의 발현을 감소시키는 방법으로서, 조성물을 세포에 전달하는 단계를 포함하되, 상기 조성물은 다음을 포함하는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 고수산뇨증을 치료 또는 예방하는 방법으로서, 이를 필요로 하는 대상체에게 조성물을 투여하여 고수산뇨증을 치료 또는 예방하는 단계를 포함하되, 상기 조성물은 다음을 포함하는, 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 고수산뇨증으로 야기된 말기 신장 질환 (ESRD)을 치료 또는 예방하는 방법으로서, 조성물을 이를 필요로 하는 대상체에게 투여하여 고수산뇨증으로 야기된 (ESRD)를 치료 또는 예방하는 단계를 포함하되, 상기 조성물은 다음을 포함하는, 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 옥살산칼슘 생성 및 침착, 원발성 고수산뇨증, 옥살산증, 혈뇨 중 임의의 하나를 치료 또는 예방하고, 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는 방법으로서, 조성물을 이를 필요로 하는 대상체에게 투여하여 옥살산칼슘 생성 및 침착, 원발성 고수산뇨증, 옥살산증, 혈뇨 중 임의의 하나를 치료 또는 예방하고, 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는 단계를 포함하되, 상기 조성물은 다음을 포함하는, 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 혈청 글리콜레이트 농도를 증가시키는 방법으로서, 조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하되, 상기 조성물은 다음을 포함하는, 혈청 글리콜레이트 농도를 증가시키는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 대상체의 소변에서 옥실레이트를 감소시키는 방법으로서, 조성물을 이를 필요로 하는 대상체에게 투여하는 단계를 포함하되, 상기 조성물은 다음을 포함하는, 대상체의 소변에서 옥살레이트를 감소시키는 방법:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 청구항 1 내지 7 중 어느 한 항에 있어서, RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산이 투여되는, 방법.
- 다음을 포함하는 조성물:
a. 다음을 포함하는 가이드 RNA:
i. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열; 또는
ii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
iii. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열; 또는
iv. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 어느 하나를 포함하는 가이드 서열; 또는
v. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나를 포함하는 가이드 서열; 또는
vi. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는 가이드 서열; 또는
vii. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는 가이드 서열; 및 임의로
b. RNA-가이드된 DNA 결합제 또는 RNA-가이드된 DNA 결합제를 암호화하는 핵산. - 다음을 포함하는 짧은-단일 가이드 RNA (짧은-sgRNA)를 포함하는 조성물:
i. 다음을 포함하는 가이드 서열:
1. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나; 또는
2. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
3. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일; 또는
4. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나; 또는
5. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나; 또는
6. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나; 또는
7. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나; 및
ii. 헤어핀 영역을 포함하는 sgRNA의 보존된 부분으로서, 여기서, 상기 헤어핀 영역은 적어도 5 내지 10개의 뉴클레오티드가 결여되어 있고 임의로 상기 짧은-sgRNA는 5' 단부 변형 및 3' 단부 변형 중 하나 이상을 포함하는, 보존된 부분. - 청구항 10에 있어서, 서열번호 202의 서열을 포함하는, 조성물.
- 청구항 10 또는 11에 있어서, 5' 단부 변형을 포함하는, 조성물.
- 청구항 10 내지 12 중 어느 한 항에 있어서, 상기 짧은-sgRNA는 3' 단부 변형을 포함하는, 조성물.
- 청구항 10 내지 13 중 어느 한 항에 있어서, 상기 짧은-sgRNA는 5' 단부 변형 및 3' 단부 변형을 포함하는, 조성물.
- 청구항 10 내지 14중 어느 한 항에 있어서, 상기 짧은-sgRNA는 3' 꼬리 (tail)를 포함하는, 조성물.
- 청구항 15에 있어서, 상기 3' 꼬리는 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 뉴클레오티드를 포함하는, 조성물.
- 청구항 15에 있어서, 상기 3' 꼬리는 약 1 내지 2개, 1 내지 3개, 1 내지 4개, 1 내지 5개, 1 내지 7개, 1 내지 10개, 적어도 1 내지 2개, 적어도 1 내지 3개, 적어도 1 내지 4개, 적어도 1 내지 5개, 적어도 1 내지 7개, 또는 적어도 1 내지 10개의 뉴클레오티드를 포함하는, 조성물.
- 청구항 10 내지 17 중 어느 한 항에 있어서, 상기 짧은-sgRNA는 3' 꼬리를 포함하지 않는, 조성물.
- 청구항 10 내지 18 중 어느 한 항에 있어서, 상기 헤어핀 영역에서의 변형을 포함하는, 조성물.
- 청구항 10 내지 19 중 어느 한 항에 있어서, 3' 단부 변형, 및 상기 헤어핀 영역에서의 변형을 포함하는, 조성물.
- 청구항 10 내지 20 중 어느 한 항에 있어서, 3' 단부 변형, 상기 헤어핀 영역에서의 변형, 및 5' 단부 변형을 포함하는, 조성물.
- 청구항 10 내지 21 중 어느 한 항에 있어서, 5' 단부 변형, 및 상기 헤어핀 영역에서의 변형을 포함하는, 조성물.
- 청구항 10 내지 22 중 어느 한 항에 있어서, 상기 헤어핀 영역은 적어도 5개의 연속 뉴클레오티드가 결여된 것인, 조성물.
- 청구항 10 내지 23 중 어느 한 항에 있어서, 상기 적어도 5 내지 10개의 결여된 뉴클레오티드는
a. 헤어핀 1 내에 있거나;
b. 헤어핀 1 내에 있고 헤어핀 1과 헤어핀 2 사이의 "N"이거나;
c. 헤어핀 1 내에 있고 헤어핀 1의 3' 바로 인접한 2개의 뉴클레오티드이거나;
d. 헤어핀 1의 적어도 일부를 포함하거나;
e. 헤어핀 2 내에 있거나;
f. 헤어핀 2의 적어도 일부를 포함하거나;
g. 헤어핀 1 및 헤어핀 2 내에 있거나;
h. 헤어핀 1의 적어도 일부를 포함하고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하거나;
i. 헤어핀 2의 적어도 일부를 포함하고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하거나;
j. 헤어핀 1의 적어도 일부를 포함하고 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하고 헤어핀 2의 적어도 일부를 포함하거나;
k. 헤어핀 1과 헤어핀 2 사이에 "N"을 임의로 포함하는 헤어핀 1 또는 헤어핀 2 내에 있거나;
l. 연속적이거나;
m. 연속적이며 헤어핀 1과 헤어핀 2 사이에 "N"을 포함하거나;
n. 연속적이며 헤어핀 1의 적어도 일부 및 헤어핀 2의 일부에 걸쳐 있거나;
o. 연속적이며 헤어핀 1의 적어도 일부와 헤어핀 1과 헤어핀 2 사이의 "N"에 걸쳐 있거나;
p. 연속적이며 헤어핀 1의 적어도 일부 및 헤어핀 1의 3' 바로 인접한 2개의 뉴클레오티드에 걸쳐 있거나;
q. 5 내지 10개의 뉴클레오티드로 이루어지거나;
r. 6 내지 10개의 뉴클레오티드로 이루어지거나;
s. 5 내지 10개의 연속 뉴클레오티드로 이루어지거나;
t. 6 내지 10개의 연속 뉴클레오티드로 이루어지거나;
u. 서열번호 400의 뉴클레오티드 54 내지 58로 이루어진, 조성물. - 청구항 10 내지 24 중 어느 한 항에 있어서, 넥서스 영역을 포함하는 sgRNA의 보존된 부분을 포함하며, 상기 넥서스 영역은 적어도 하나의 뉴클레오티드가 결여되어 있는, 조성물.
- 청구항 25에 있어서, 상기 넥서스 영역에 결여된 뉴클레오티드는 다음 중 임의의 하나 이상을 포함하는, 조성물:
a. 상기 넥서스 영역에서 적어도 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개의 뉴클레오티드;
b. 상기 넥서스 영역에서 적어도 또는 정확히 1 내지 2개의 뉴클레오티드, 1 내지 3개의 뉴클레오티드, 1 내지 4개의 뉴클레오티드, 1 내지 5개의 뉴클레오티드, 1 내지 6개의 뉴클레오티드, 1 내지 10개의 뉴클레오티드, 또는 1 내지 15개의 뉴클레오티드; 및
c. 상기 넥서스 영역에서 각각의 뉴클레오티드. - 변형된 단일 가이드 RNA (sgRNA)를 포함하는 조성물으로서,
다음 a를 포함하고 다음 b를 추가로 포함하는, 조성물:
a. 다음을 포함하는 가이드 서열:
1. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나; 또는
2. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 가이드 서열 중 임의의 하나의 적어도 17, 18, 19, 또는 20개의 인접 뉴클레오티드; 또는
3. 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일; 또는
4. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80 중 임의의 하나; 또는
5. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48 중 임의의 하나; 또는
6. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나; 또는
7. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나; 그리고
b. 다음으로부터 선택된 하나 이상의 변형:
1. 하나 이상의 가이드 영역 YA 부위에서의 YA 변형;
2. 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
3. 하나 이상의 가이드 영역 YA 부위 및 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
4. i) 2개 이상의 가이드 영역 YA 부위에서의 YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
5. i) 하나 이상의 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 가이드 영역 YA 부위는 5' 말단의 5' 단부로부터 뉴클레오티드 8에 또는 그 뒤에 있는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및 임의로;
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
6. i) 하나 이상의 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 가이드 영역 YA 부위는 상기 가이드 영역의 3' 말단 뉴클레오티드의 13개의 뉴클레오티드 내에 있는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
7. i) 5' 단부 변형 및 3' 단부 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
8. i) 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 가이드 영역 YA 부위의 변형은 상기 가이드 영역 YA 부위의 5'에 위치한 적어도 하나의 뉴클레오티드가 포함하지 않는 변형을 포함하는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) 보존된 영역 YA 부위 1 및 8 중 하나 이상에서의 YA 변형; 또는
9. i) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
ii) 보존된 영역 YA 부위 1 및 8에서 YA 변형; 또는
10. i) 하나 이상의 가이드 영역 YA 부위에서의 YA 변형으로서, 여기서, 상기 YA 부위는 5' 말단으로부터 뉴클레오티드 8에 또는 그 뒤에 있는, YA 변형;
ii) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형; 및
iii) H1-1 및 H2-1 중 하나 이상에서의 변형; 또는
11. i) 보존된 영역 YA 부위 2, 3, 4, 및 10 중 하나 이상에서의 YA 변형;
ii) 보존된 영역 YA 부위 1, 5, 6, 7, 8, 및 9 중 하나 이상에서의 YA 변형; 및
iii) H1-1 및 H2-1 중 하나 이상에서의 변형; 또는
12. i) 5' 말단으로부터 뉴클레오티드 6에 또는 그 뒤에 위치한 하나 이상의 뉴클레오티드에서 YA 변형과 같은 변형;
ii) 하나 이상의 가이드 서열 YA 부위에서의 YA 변형;
iii) B3, B4, 및 B5 중 하나 이상에서의 변형으로서, 여기서, B6은 2'-OMe 변형을 포함하지 않거나 2'-OMe 이외의 변형을 포함하는, 변형;
iv) LS10에서의 변형으로서, 여기서, LS10은 2'-플루오로 이외의 변형을 포함하는, 변형; 및/또는
v) N2, N3, N4, N5, N6, N7, N10, 또는 N11에서의 변형; 및
여기서, 다음 중 적어도 하나는 참이다:
a. 하나 이상의 가이드 영역 YA 부위에서의 YA 변형;
b. 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
c. 하나 이상의 가이드 영역 YA 부위 및 하나 이상의 보존된 영역 YA 부위에서의 YA 변형;
d. 5' 말단의 5' 단부로부터 뉴클레오티드 8 내지 11, 13, 14, 17, 또는 18 중 적어도 하나는 2'-플루오로 변형을 포함하지 않거나;
e. 5' 말단의 5' 단부로부터 뉴클레오티드 6 내지 10 중 적어도 하나는 포스포로티오에이트 연결을 포함하지 않거나;
f. B2, B3, B4, 또는 B5 중 적어도 하나는 2'-OMe 변형을 포함하지 않거나;
g. LS1, LS8, 또는 LS10 중 적어도 하나는 2'-OMe 변형을 포함하지 않거나;
h. N2, N3, N4, N5, N6, N7, N10, N11, N16, 또는 N17 중 적어도 하나는 2'-OMe 변형을 포함하지 않거나;
i. H1-1은 변형을 포함하거나;
j. H2-1은 변형을 포함하거나;
k. H1-2, H1-3, H1-4, H1-5, H1-6, H1-7, H1-8, H1-9, H1-10, H2-1, H2-2, H2-3, H2-4, H2-5, H2-6, H2-7, H2-8, H2-9, H2-10, H2-11, H2-12, H2-13, H2-14, 또는 H2-15 중 적어도 하나는 포스포로티오에이트 연결을 포함하지 않는다. - 청구항 27에 있어서, 서열번호 450을 포함하는, 조성물.
- 청구항 9 내지 28 중 어느 한 항에 있어서, 세포 또는 대상체에서 LDHA 유전자 내에 이중-가닥 파괴 (DSB) 또는 단일-가닥 파괴 (SSB)를 유도하는데 사용하기 위한, 조성물.
- 청구항 9 내지 28 중 어느 한 항에 있어서, 세포 또는 대상체에서 LDHA 유전자의 발현을 감소시키는데 사용하기 위한, 조성물.
- 청구항 9 내지 28 중 어느 한 항에 있어서, 대상체에서 고수산뇨증을 치료 또는 예방하는 데 사용하기 위한, 조성물.
- 청구항 9 내지 28 중 어느 한 항에 있어서, 대상체에서 혈청 및/또는 혈장 글리콜레이트 농도를 증가시키는 데 사용하기 위한, 조성물.
- 청구항 9 내지 28 중 어느 한 항에 있어서, 대상체에서 소변 옥살레이트 농도를 감소시키는 데 사용하기 위한, 조성물.
- 청구항 9 내지 28 중 어느 한 항에 있어서, 옥살레이트 생성, 기관에서의 옥살산칼슘 침착, 원발성 고수산뇨증, 전신성 옥살산증을 포함한 옥살산증, 혈뇨, 말기 신장 질환 (ESRD)을 치료 또는 예방 및/또는 콩팥 또는 간 이식의 필요성을 지연 또는 개선하는 데 사용하기 위한, 조성물.
- 청구항 1 내지 8 중 어느 한 항에 있어서, 다음을 추가로 포함하는, 방법:
a. 세포 또는 대상체에서 상기 LDHA 유전자 내에 이중-가닥 파괴 (DSB) 유도;
b. 세포 또는 대상체에서 상기 LDHA 유전자의 발현 감소;
c. 대상체에서 고수산뇨증 치료 또는 예방;
d. 대상체에서 원발성 고수산뇨증 치료 또는 예방;
e. 대상체에서 PH1, PH2, 및/또는 PH3 치료 또는 예방;
f. 대상체에서 장성 고수산뇨증 치료 또는 예방;
g. 대상체에서 고-옥살레이트 식품 섭취와 관련된 고수산뇨증 치료 또는 예방;
h. 대상체에서 혈청 및/또는 혈장 글리콜레이트 농도 증가;
i. 대상체에서 소변 옥살레이트 농도 감소;
j. 옥살레이트 생성 감소;
k. 기관에서의 옥살산칼슘 침착 감소;
l. 고수산뇨증 감소;
m. 전신성 옥살산증을 포함한 옥살산증 치료 또는 예방;
n. 혈뇨 치료 또는 예방;
o. 말기 신장 질환 (ESRD) 예방; 및/또는
p. 콩팥 또는 간 이식의 필요성 지연 또는 개선. - 청구항 1 내지 8 또는 29 내지 35 중 어느 한 항에 있어서, 상기 조성물은 혈청 및/또는 혈장 글리콜레이트 수준을 증가시키는, 방법 또는 조성물.
- 청구항 1 내지 8 또는 29 내지 35 중 어느 한 항에 있어서, 상기 조성물은 상기 LDHA 유전자의 편집을 초래하는, 방법 또는 조성물.
- 청구항 37에 있어서, 상기 편집이 편집된 집단의 백분율 (퍼센트 편집)로서 계산되는, 방법 또는 조성물.
- 청구항 38에 있어서, 상기 퍼센트 편집은 상기 집단의 30%와 99% 사이인, 방법 또는 조성물.
- 청구항 38에 있어서, 상기 퍼센트 편집은 상기 집단의 30%와 35% 사이, 35%와 40% 사이, 40%와 45% 사이, 45%와 50% 사이, 50%와 55% 사이, 55%와 60% 사이, 60%와 65% 사이, 65%와 70% 사이, 70%와 75% 사이, 75%와 80% 사이, 80%와 85% 사이, 85%와 90% 사이, 90%와 95% 사이, 또는 95%와 99% 사이인, 방법 또는 조성물.
- 청구항 1 내지 8 또는 29 내지 35 중 어느 한 항에 있어서, 상기 조성물은 소변 옥살레이트 농도를 감소시키는, 방법 또는 조성물.
- 청구항 41에 있어서, 소변 옥살레이트의 감소는 콩팥, 간, 방광, 심장, 피부 또는 눈에서 콩팥 결석 및/또는 옥살산칼슘 침착을 감소시키는, 방법 또는 조성물.
- 청구항 1 내지 42 중 어느 한 항에 있어서, 상기 가이드 서열은 다음으로부터 선택되는, 방법 또는 조성물:
a. 서열번호 1 내지 84 및 100 내지 192;
b. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80;
c. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48;
d. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184; 및
e. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123. - 청구항 1 내지 43 중 어느 한 항에 있어서, 상기 조성물은 다음을 포함하는 sgRNA를 포함하는, 방법 또는 조성물:
a. 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나; 또는
b. 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081 중 임의의 하나; 또는
c. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 및 80으로부터 선택된 가이드 서열; 또는
c. 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 및 48로부터 선택된 가이드 서열;
d. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184로부터 선택된 가이드 서열; 및
e. 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123으로부터 선택된 가이드 서열. - 청구항 1 내지 44 중 어느 한 항에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 1 내지 8 중 임의의 하나에 있는, 방법 또는 조성물.
- 청구항 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 1 또는 2에 있는, 방법 또는 조성물.
- 청구항 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 3에 있는, 방법 또는 조성물.
- 청구항 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 4에 있는, 방법 또는 조성물.
- 청구항 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 5 또는 6에 있는, 방법 또는 조성물.
- 청구항 45에 있어서, 상기 표적 서열은 상기 인간 LDHA 유전자의 엑손 7 또는 8에 있는, 방법 또는 조성물.
- 청구항 1 내지 50 중 어느 한 항에 있어서, 상기 가이드 서열은 LDHA의 양성 가닥의 표적 서열에 상보적인, 방법 또는 조성물.
- 청구항 1 내지 50 중 어느 한 항에 있어서, 상기 가이드 서열은 LDHA의 음성 가닥의 표적 서열에 상보적인, 방법 또는 조성물.
- 청구항 1 내지 50 중 어느 한 항에 있어서, 상기 제1 가이드 서열은 상기 LDHA 유전자의 양성 가닥에서 제1 표적 서열에 상보적이고, 상기 조성물은 상기 LDHA 유전자의 음성 가닥에서 제2 표적 서열에 상보적인 제2 가이드 서열을 추가로 포함하는, 방법 또는 조성물.
- 청구항 1 내지 53 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1 내지 84 및 100 내지 192 중 임의의 하나로부터 선택된 가이드 서열을 포함하고, 서열번호 200의 뉴클레오티드 서열을 추가로 포함하고, 서열번호 200의 뉴클레오티드는 이의 3' 단부에서 상기 가이드 서열을 따르는, 방법 또는 조성물.
- 청구항 1 내지 54 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1 내지 84 및 100 내지 192 중 임의의 하나로부터 선택된 가이드 서열을 포함하고, 서열번호 201, 서열번호 202, 서열번호 203, 또는 서열번호 400 내지 450 중 임의의 하나의 뉴클레오티드 서열을 추가로 포함하고, 여기서, 서열번호 201의 뉴클레오티드는 이의 3' 단부에서 상기 가이드 서열을 따르는, 방법 또는 조성물.
- 청구항 1 내지 55 중 어느 한 항에 있어서, 상기 가이드 RNA는 단일 가이드 (sgRNA)인, 방법 또는 조성물.
- 청구항 56에 있어서, 상기 sgRNA는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나를 포함하는 가이드 서열을 포함하는, 방법 또는 조성물.
- 청구항 56에 있어서, 상기 sgRNA는 서열번호 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 및 1081 중 임의의 하나, 또는 이의 변형된 버전을 포함하고, 임의로 상기 변형된 버전은 서열번호 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081을 포함하는, 방법 또는 조성물.
- 청구항 1 내지 58 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 300의 패턴에 따라 변형되고, 상기 N은 집합적으로 표 1의 가이드 서열 (서열번호 1 내지 84 및 100 내지 192) 중 임의의 하나인, 방법 또는 조성물.
- 청구항 59에 있어서, 서열번호 300에서 각각의 N은 임의의 천연 또는 비천연 뉴클레오티드이고, 여기서, 상기 N은 가이드 서열을 형성하고, 상기 가이드 서열은 Cas9를 LDHA 유전자에 표적화하는, 방법 또는 조성물.
- 청구항 1 내지 60 중 어느 한 항에 있어서, 상기 sgRNA는 서열번호 1 내지 84 및 100 내지 192의 가이드 서열 중 임의의 하나 및 서열번호 201, 서열번호 202, 또는 서열번호 203의 뉴클레오티드를 포함하는, 방법 또는 조성물.
- 청구항 56 내지 61 중 어느 한 항에 있어서, 상기 sgRNA는 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열과 적어도 99%, 98%, 97%, 96%, 95%, 94%, 93%, 92%, 91%, 또는 90% 동일한 가이드 서열을 포함하는, 방법 또는 조성물.
- 청구항 62에 있어서, 상기 sgRNA는 서열번호 1, 5, 7, 8, 14, 23, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 1001, 1005, 1007, 1008, 1014, 1023, 1027, 1032, 1045, 1048, 1063, 1067, 1069, 1071, 1074, 1076, 1077, 1078, 1079, 1081, 2001, 2005, 2007, 2008, 2014, 2023, 2027, 2032, 2045, 2048, 2063, 2067, 2069, 2071, 2074, 2076, 2077, 2078, 2079, 및 2081로부터 선택된 서열을 포함하는, 방법 또는 조성물.
- 청구항 1 내지 63 중 어느 한 항에 있어서, 상기 가이드 RNA는 적어도 하나의 변형을 포함하는, 방법 또는 조성물.
- 청구항 64에 있어서, 상기 적어도 하나의 변형은 2'-O-메틸(2'-O-Me) 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
- 청구항 64 또는 65에 있어서, 뉴클레오티드 사이에 포스포로티오에이트 (PS) 결합을 포함하는, 방법 또는 조성물.
- 청구항 64 내지 66 중 어느 한 항에 있어서, 2'-플루오로 (2'-F) 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
- 청구항 64 내지 67 중 어느 한 항에 있어서, 상기 가이드 RNA의 5' 단부에서 처음 5개의 뉴클레오티드 중 하나 이상에서 변형을 포함하는, 방법 또는 조성물.
- 청구항 64 내지 68 중 어느 한 항에 있어서, 상기 가이드 RNA의 3' 단부에서 마지막 5개의 뉴클레오티드 중 하나 이상에서 변형을 포함하는, 방법 또는 조성물.
- 청구항 64 내지 69 중 어느 한 항에 있어서, 상기 가이드 RNA의 처음 4개의 뉴클레오티드 사이에 PS 결합을 포함하는, 방법 또는 조성물.
- 청구항 64 내지 70 중 어느 한 항에 있어서, 상기 가이드 RNA의 마지막 4개의 뉴클레오티드 사이에 PS 결합을 포함하는, 방법 또는 조성물.
- 청구항 64 내지 71 중 어느 한 항에 있어서, 상기 가이드 RNA의 5' 단부에서 처음 3개의 뉴클레오티드에서 2'-O-Me 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
- 청구항 64 내지 72 중 어느 한 항에 있어서, 상기 가이드 RNA의 3' 단부에서 마지막 3개의 뉴클레오티드에서 2'-O-Me 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물.
- 청구항 64 내지 73 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 300의 변형된 뉴클레오티드를 포함하는, 방법 또는 조성물,
- 청구항 1 내지 74 중 어느 한 항에 있어서, 상기 조성물은 약제학적으로 허용되는 부형제를 추가로 포함하는, 방법 또는 조성물.
- 청구항 1 내지 75 중 어느 한 항에 있어서, 상기 가이드 RNA는 지질 나노입자 (LNP)와 회합되는, 방법 또는 조성물.
- 청구항 76에 있어서, 상기 LNP는 양이온성 지질을 포함하는, 방법 또는 조성물.
- 청구항 77에 있어서, 상기 양이온성 지질은 3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 (9Z,12Z)-옥타데카-9,12-디에노에이트로도 불리는 (9Z,12Z)-3-((4,4-비스(옥틸옥시)부타노일)옥시)-2-((((3-(디에틸아미노)프로폭시)카보닐)옥시)메틸)프로필 옥타데카-9,12-디에노에이트인, 방법 또는 조성물.
- 청구항 76 내지 78 중 어느 한 항에 있어서, 상기 LNP는 중성 지질을 포함하는, 방법 또는 조성물.
- 청구항 79에 있어서, 상기 중성 지질은 DSPC인, 방법 또는 조성물.
- 청구항 76 내지 80 중 어느 한 항에 있어서, 상기 LNP는 헬퍼 (helper) 지질을 포함하는, 방법 또는 조성물.
- 청구항 81에 있어서, 상기 헬퍼 지질은 콜레스테롤인, 방법 또는 조성물.
- 청구항 76 내지 82 중 어느 한 항에 있어서, 상기 LNP는 스텔스 (stealth) 지질을 포함하는, 방법 또는 조성물.
- 청구항 83에 있어서, 상기 스텔스 지질은 PEG2k-DMG인, 방법 또는 조성물.
- 청구항 1 내지 84 중 어느 한 항에 있어서, 상기 조성물은 RNA-가이드된 DNA 결합제를 추가로 포함하는, 방법 또는 조성물.
- 청구항 1 내지 85 중 어느 한 항에 있어서, 상기 조성물은 RNA-가이드된 DNA 결합제를 암호화하는 mRNA를 추가로 포함하는, 방법 또는 조성물.
- 청구항 85 또는 86에 있어서, 상기 RNA-가이드된 DNA 결합제는 Cas9인, 방법 또는 조성물.
- 청구항 1 내지 87 중 어느 한 항에 있어서, 상기 조성물은 약제학적 제형이고, 약제학적으로 허용되는 담체를 추가로 포함하는, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 1인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 2인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 3인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 4인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 5인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 6인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 7인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 8인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 9인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 10인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 11인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 12인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 13인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 14인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 15인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 16인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 17인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 18인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 19인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 20인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 21인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 22인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 23인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 24인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 25인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 26인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 27인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 28인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 29인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 30인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 31인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 32인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 33인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 34인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 35인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 36인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 37인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 38인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 39인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 40인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 41인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 42인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 43인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 44인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 45인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 46인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 47인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 48인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 49인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 50인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 51인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 52인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 53인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 54인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 55인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 56인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 57인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 58인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 59인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 60인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 61인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 62인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 63인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 64인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 65인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 66인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 67인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 68인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 69인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 70인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 71인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 72인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 73인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 74인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 75인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 76인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 77인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 78인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 79인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 80인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 81인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 82인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 83인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 84인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 103인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 109인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 123인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 133인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 149인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 156인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 서열번호 1 내지 84 및 100 내지 192로부터 선택된 서열은 서열번호 166인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 서열은 서열번호 2, 9, 13, 16, 22, 24, 25, 27, 30, 31, 32, 33, 35, 36, 40, 44, 45, 53, 55, 57, 60, 61-63, 65, 67, 69, 70, 71, 73, 76, 78, 79, 80, 82-84, 103, 109, 123, 133, 149, 156, 및 166 중 임의의 하나를 포함하는, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 서열은 서열번호 100 내지 102, 104 내지 108, 110 내지 122, 124 내지 132, 134 내지 148, 150 내지 155, 157 내지 165, 및 167 내지 192 중 임의의 하나를 포함하는, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 서열은 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 62, 66, 68, 70, 73, 75, 76, 77, 78, 80, 103, 109, 123, 133, 149, 153, 156, 및 184 중 임의의 하나를 포함하는, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 서열은 서열번호 1, 5, 7, 8, 14, 23, 25, 27, 32, 45, 48, 103, 및 123 중 임의의 하나를 포함하는, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 86 내지 90 중 임의의 하나를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 89를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1001 또는 2001을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1005 또는 2005를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1007 또는 2007을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1008 또는 2008을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1014 또는 2014를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1023 또는 2023을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1027 또는 2027을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1032 또는 2032를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1045 또는 2045를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1048 또는 2048을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1063 또는 2063을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1067 또는 2067을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1069 또는 2069를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1071 또는 2071을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1074 또는 2074를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1076 또는 2076을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1077 또는 2077을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1078 또는 2078을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1079 또는 2079를 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 88 중 어느 한 항에 있어서, 상기 가이드 RNA는 서열번호 1081 또는 2081을 포함하는 sgRNA인, 방법 또는 조성물.
- 청구항 1 내지 205 중 어느 한 항에 있어서, 상기 조성물은 단일 용량으로 투여되는, 방법 또는 조성물.
- 청구항 1 내지 206 중 어느 한 항에 있어서, 상기 조성물은 1회 투여되는, 방법 또는 조성물.
- 청구항 206 또는 207에 있어서, 상기 단일 용량 또는 1회 투여는
a. DSB를 유도하고/하거나;
b. LDHA 유전자의 발현을 감소시키고/시키거나;
c. 고수산뇨증을 치료 또는 예방하고/하거나;
d. 고수산뇨증으로 야기된 ESRD의 치료 또는 예방하고/하거나;
e. 옥살산칼슘 생성 및 침착을 치료 또는 예방하고/하거나;
f. 원발성 고수산뇨증 (PH1, PH2, 및 PH3을 포함)을 치료 또는 예방하고/하거나;
g. 옥살산증을 치료 또는 예방하고/하거나;
h. 혈뇨를 치료 및 예방하고/하거나;
i. 장성 고수산뇨증을 치료 또는 예방하고/하거나;
j. 고-옥살레이트 식품 섭취와 관련된 고수산뇨증을 치료 또는 예방하고/하거나;
k. 콩팥 또는 간 이식의 필요성을 지연 또는 개선하고/하거나;
l. 혈청 글리콜레이트 농도를 증가시키고/시키거나;
m. 소변에서 옥살레이트를 감소시키는, 방법 또는 조성물. - 청구항 208에 있어서, 상기 단일 용량 또는 1회 투여는 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 또는 15주 동안 a) 내지 m) 중 임의의 하나 이상을 달성하는, 방법 또는 조성물.
- 청구항 208에 있어서, 상기 단일 용량 또는 1회 투여는 지속 효과를 달성하는, 방법 또는 조성물.
- 청구항 1 내지 208 중 어느 한 항에 있어서, 지속 효과를 달성하는 단계를 추가로 포함하는, 방법 또는 조성물.
- 청구항 210 또는 211에 있어서, 상기 지속 효과는 적어도 1개월, 적어도 3개월, 적어도 6개월, 적어도 1년, 또는 적어도 5년 지속되는, 방법 또는 조성물.
- 청구항 1 내지 212 중 어느 한 항에 있어서, 상기 조성물의 투여는 치료적으로 관련된 소변 내 옥살레이트의 감소를 초래하는, 방법 또는 조성물.
- 청구항 1 내지 213 중 어느 한 항에 있어서, 상기 조성물의 투여는 치료 범위 내의 소변 옥살레이트 수준을 초래하는, 방법 또는 조성물.
- 청구항 1 내지 214 중 어느 한 항에 있어서, 상기 조성물의 투여는 정상 범위의 100, 120, 또는 150% 내의 옥살레이트 수준을 초래하는, 방법 또는 조성물.
- 고수산뇨증을 가진 인간 대상체를 치료하기 위한 약제의 제조를 위한 청구항 9 내지 215 중 어느 한 항의 조성물 또는 제형의 용도.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862738956P | 2018-09-28 | 2018-09-28 | |
| US62/738,956 | 2018-09-28 | ||
| US201962834334P | 2019-04-15 | 2019-04-15 | |
| US62/834,334 | 2019-04-15 | ||
| US201962841740P | 2019-05-01 | 2019-05-01 | |
| US62/841,740 | 2019-05-01 | ||
| PCT/US2019/053423 WO2020069296A1 (en) | 2018-09-28 | 2019-09-27 | Compositions and methods for lactate dehydrogenase (ldha) gene editing |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210086621A true KR20210086621A (ko) | 2021-07-08 |
Family
ID=68296656
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217012025A KR20210086621A (ko) | 2018-09-28 | 2019-09-27 | 락테이트 데히드로게나제 (ldha) 유전자 편집을 위한 조성물 및 방법 |
Country Status (15)
| Country | Link |
|---|---|
| US (1) | US20210222173A1 (ko) |
| EP (1) | EP3856901A1 (ko) |
| JP (1) | JP2022502055A (ko) |
| KR (1) | KR20210086621A (ko) |
| CN (1) | CN113056559A (ko) |
| AU (1) | AU2019347517A1 (ko) |
| BR (1) | BR112021005718A2 (ko) |
| CA (1) | CA3114425A1 (ko) |
| CO (1) | CO2021005231A2 (ko) |
| IL (1) | IL281529A (ko) |
| MX (1) | MX2021003457A (ko) |
| PH (1) | PH12021550686A1 (ko) |
| SG (1) | SG11202102660RA (ko) |
| TW (1) | TW202028460A (ko) |
| WO (1) | WO2020069296A1 (ko) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022525428A (ja) * | 2019-03-28 | 2022-05-13 | インテリア セラピューティクス,インコーポレイテッド | Ttrガイドrnaと、rnaガイドdna結合剤をコードするポリヌクレオチドとを含む組成物および方法 |
| US20230034581A1 (en) | 2021-06-04 | 2023-02-02 | Arbor Biotechnologies, Inc. | Gene editing systems comprising an rna guide targeting lactate dehydrogenase a (ldha) and uses thereof |
| WO2023077053A2 (en) | 2021-10-28 | 2023-05-04 | Regeneron Pharmaceuticals, Inc. | Crispr/cas-related methods and compositions for knocking out c5 |
| WO2023122433A1 (en) * | 2021-12-22 | 2023-06-29 | Arbor Biotechnologies, Inc. | Gene editing systems targeting hydroxyacid oxidase 1 (hao1) and lactate dehydrogenase a (ldha) |
| WO2023150620A1 (en) | 2022-02-02 | 2023-08-10 | Regeneron Pharmaceuticals, Inc. | Crispr-mediated transgene insertion in neonatal cells |
| CN114657181B (zh) * | 2022-04-01 | 2023-08-25 | 安徽大学 | 一种靶向H1.4的sgRNA以及H1.4基因编辑方法 |
| WO2023212677A2 (en) | 2022-04-29 | 2023-11-02 | Regeneron Pharmaceuticals, Inc. | Identification of tissue-specific extragenic safe harbors for gene therapy approaches |
| WO2023235725A2 (en) | 2022-05-31 | 2023-12-07 | Regeneron Pharmaceuticals, Inc. | Crispr-based therapeutics for c9orf72 repeat expansion disease |
| WO2023235726A2 (en) | 2022-05-31 | 2023-12-07 | Regeneron Pharmaceuticals, Inc. | Crispr interference therapeutics for c9orf72 repeat expansion disease |
| WO2024026474A1 (en) | 2022-07-29 | 2024-02-01 | Regeneron Pharmaceuticals, Inc. | Compositions and methods for transferrin receptor (tfr)-mediated delivery to the brain and muscle |
| WO2024073606A1 (en) | 2022-09-28 | 2024-04-04 | Regeneron Pharmaceuticals, Inc. | Antibody resistant modified receptors to enhance cell-based therapies |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5585481A (en) | 1987-09-21 | 1996-12-17 | Gen-Probe Incorporated | Linking reagents for nucleotide probes |
| US5378825A (en) | 1990-07-27 | 1995-01-03 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogs |
| EP1695979B1 (en) | 1991-12-24 | 2011-07-06 | Isis Pharmaceuticals, Inc. | Gapped modified oligonucleotides |
| US6169169B1 (en) | 1994-05-19 | 2001-01-02 | Dako A/S | PNA probes for detection of Neisseria gonorrhoeae and Chlamydia trachomatis |
| PL2931898T3 (pl) | 2012-12-12 | 2016-09-30 | Le Cong | Projektowanie i optymalizacja systemów, sposoby i kompozycje do manipulacji sekwencją z domenami funkcjonalnymi |
| WO2014093694A1 (en) | 2012-12-12 | 2014-06-19 | The Broad Institute, Inc. | Crispr-cas nickase systems, methods and compositions for sequence manipulation in eukaryotes |
| MX2015007743A (es) | 2012-12-17 | 2015-12-07 | Harvard College | Ingenieria del genoma humano guiada por ácido robonucleico. |
| US20150165054A1 (en) | 2013-12-12 | 2015-06-18 | President And Fellows Of Harvard College | Methods for correcting caspase-9 point mutations |
| US20150376586A1 (en) | 2014-06-25 | 2015-12-31 | Caribou Biosciences, Inc. | RNA Modification to Engineer Cas9 Activity |
| ES2949172T3 (es) | 2014-07-16 | 2023-09-26 | Novartis Ag | Método de encapsulamiento de un ácido nucleico en un hospedante de nanopartículas lipídicas |
| EP3858990A1 (en) | 2015-03-03 | 2021-08-04 | The General Hospital Corporation | Engineered crispr-cas9 nucleases with altered pam specificity |
| US11845933B2 (en) | 2016-02-03 | 2023-12-19 | Massachusetts Institute Of Technology | Structure-guided chemical modification of guide RNA and its applications |
| CN117731805A (zh) | 2016-03-30 | 2024-03-22 | 因特利亚治疗公司 | 用于crispr/cas成分的脂质纳米颗粒制剂 |
| EP3452080A4 (en) * | 2016-05-02 | 2019-10-09 | The Regents of the University of California | MAMMALIAN CELLS WITHOUT LACTATE DEHYDROGENASE ACTIVITY |
| BR112019011509A2 (pt) | 2016-12-08 | 2020-01-28 | Intellia Therapeutics Inc | rnas guias modificados |
-
2019
- 2019-09-27 CN CN201980076179.XA patent/CN113056559A/zh active Pending
- 2019-09-27 BR BR112021005718-8A patent/BR112021005718A2/pt unknown
- 2019-09-27 MX MX2021003457A patent/MX2021003457A/es unknown
- 2019-09-27 TW TW108135340A patent/TW202028460A/zh unknown
- 2019-09-27 WO PCT/US2019/053423 patent/WO2020069296A1/en active Application Filing
- 2019-09-27 CA CA3114425A patent/CA3114425A1/en active Pending
- 2019-09-27 KR KR1020217012025A patent/KR20210086621A/ko not_active Application Discontinuation
- 2019-09-27 AU AU2019347517A patent/AU2019347517A1/en not_active Withdrawn
- 2019-09-27 SG SG11202102660RA patent/SG11202102660RA/en unknown
- 2019-09-27 EP EP19790921.1A patent/EP3856901A1/en active Pending
- 2019-09-27 JP JP2021517350A patent/JP2022502055A/ja active Pending
-
2021
- 2021-03-16 IL IL281529A patent/IL281529A/en unknown
- 2021-03-25 US US17/212,901 patent/US20210222173A1/en active Pending
- 2021-03-26 PH PH12021550686A patent/PH12021550686A1/en unknown
- 2021-04-23 CO CONC2021/0005231A patent/CO2021005231A2/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CA3114425A1 (en) | 2020-04-02 |
| PH12021550686A1 (en) | 2022-02-28 |
| MX2021003457A (es) | 2021-07-16 |
| WO2020069296A1 (en) | 2020-04-02 |
| BR112021005718A2 (pt) | 2021-06-22 |
| AU2019347517A1 (en) | 2021-05-06 |
| JP2022502055A (ja) | 2022-01-11 |
| IL281529A (en) | 2021-05-31 |
| CO2021005231A2 (es) | 2021-06-10 |
| SG11202102660RA (en) | 2021-04-29 |
| US20210222173A1 (en) | 2021-07-22 |
| CN113056559A (zh) | 2021-06-29 |
| TW202028460A (zh) | 2020-08-01 |
| EP3856901A1 (en) | 2021-08-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210222173A1 (en) | Compositions and Methods for Lactate Dehydrogenase (LDHA) Gene Editing | |
| US20210163943A1 (en) | Compositions and Methods for Hydroxyacid Oxidase 1 (HAO1) Gene Editing for Treating Primary Hyperoxaluria Type 1 (PH1) | |
| US20230295587A1 (en) | Compositions and Methods for Kallikrein (KLKB1) Gene Editing | |
| KR20200058509A (ko) | Attr 아밀로이드증의 ttr 유전자 편집 및 치료를 위한 조성물 및 방법 | |
| TW202118873A (zh) | 用於治療與重複性dna有關之病症之組合物及方法 | |
| TW202218686A (zh) | 用於治療杜興氏肌肉失養症(duchenne muscular dystrophy)之組合物及方法 | |
| KR20230016176A (ko) | Pcsk9의 염기 편집 및 질환 치료를 위한 이의 사용 방법 | |
| KR20220004649A (ko) | 폴리펩티드 발현을 위한 폴리뉴클레오티드, 조성물 및 방법 | |
| CA3134544A1 (en) | Compositions and methods for ttr gene editing and treating attr amyloidosis comprising a corticosteroid or use thereof | |
| KR20210141522A (ko) | 타우 시딩 또는 응집의 유전적 변형제를 식별하기 위한 CRISPR/Cas 스크리닝 플랫폼 | |
| CN117042794A (zh) | 用于免疫疗法的t细胞免疫球蛋白和粘蛋白结构域3(tim3)组合物和方法 | |
| WO2022170194A2 (en) | Lymphocyte activation gene 3 (lag3) compositions and methods for immunotherapy | |
| US20230383252A1 (en) | Natural Killer Cell Receptor 2B4 Compositions and Methods for Immunotherapy | |
| WO2023028471A1 (en) | Programmed cell death protein 1 (pd1) compositions and methods for cell-based therapy | |
| TW202334396A (zh) | 用於免疫療法之cd38組成物及方法 | |
| TW202317763A (zh) | 包含靶向羥基酸氧化酶1(hao1)的rna指導物的基因編輯系統及其用途 | |
| TW201924724A (zh) | 調配物 | |
| TW201923077A (zh) | 用於基因組編輯之多核苷酸、組合物及方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| WITB | Written withdrawal of application |