KR20180098654A - 적응적 텍스트-투-스피치 출력 - Google Patents
적응적 텍스트-투-스피치 출력 Download PDFInfo
- Publication number
- KR20180098654A KR20180098654A KR1020187021923A KR20187021923A KR20180098654A KR 20180098654 A KR20180098654 A KR 20180098654A KR 1020187021923 A KR1020187021923 A KR 1020187021923A KR 20187021923 A KR20187021923 A KR 20187021923A KR 20180098654 A KR20180098654 A KR 20180098654A
- Authority
- KR
- South Korea
- Prior art keywords
- user
- text
- complexity
- score
- determining
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
-
- G10L13/043—
-
- G06F17/274—
-
- G06F17/2775—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- User Interface Of Digital Computer (AREA)
- Electrically Operated Instructional Devices (AREA)
- Telephone Function (AREA)
- Telephonic Communication Services (AREA)
- Document Processing Apparatus (AREA)
Abstract
Description
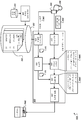
도 2은 사용자 컨텍스트에 기초하여 적응적 텍스트-투-스피치 출력을 생성하기 위한 시스템의 예시를 도시하는 도면이다.
도 3은 텍스트-투-스피치 출력 내에서 문장 구조를 수정하기 위한 시스템의 예시를 도시하는 도면이다.
도 4는 클러스터링 기법들을 사용하는 것에 기초하여 적응적 텍스트-투-스피치 출력을 생성하기 위한 시스템의 예시를 도시하는 블록도이다.
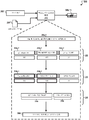
도 5는 적응적 텍스트-투-스피치 출력을 생성하기 위한 프로세스의 예시를 도시하는 흐름도이다.
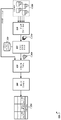
도 6은 본 명세서에 기술된 프로세스들 또는 그 부분들이 구현될 수 있는 컴퓨팅 디바이스들의 블록도이다.
도면에서, 동일한 번호는 전체에 걸처 대응하는 부분들을 표현한다.
Claims (35)
- 하나 이상의 컴퓨터들에 의해 수행되는 방법으로서,
상기 하나 이상의 컴퓨터들에 의해, 클라이언트 디바이스의 사용자의 언어 능숙도를 결정하는 단계;
상기 하나 이상의 컴퓨터들에 의해, 상기 사용자의 상기 결정된 언어 능숙도에 기초하여 텍스트-투-스피치 모듈에 의한 출력을 위한 텍스트 세그먼트를 결정하는 단계;
상기 하나 이상의 컴퓨터들에 의해, 상기 텍스트 세그먼트의 합성된 발언을 포함하는 오디오 데이터를 생성하는 단계;
상기 하나 이상의 컴퓨터들에 의해, 상기 텍스트 세그먼트의 상기 합성된 발언을 포함하는 상기 오디오 데이터를 상기 클라이언트 디바이스에 제공하는 단계를 포함하는 것을 특징으로 하는 방법. - 청구항 1에 있어서,
상기 클라이언트 디바이스는 텍스트-투-스피치 인터페이스를 사용하는 모바일 어플리케이션을 디스플레이하는 것을 특징으로 하는 방법. - 청구항 1 또는 2에 있어서,
상기 사용자의 상기 언어 능숙도를 결정하는 단계는 상기 사용자에 의해 제출된 이전의 쿼리들에 적어도 기초하여 상기 사용자의 언어 능숙도를 추론하는 것을 포함하는 것을 특징으로 하는 방법. - 임의의 선행하는 청구항에 있어서,
상기 텍스트-투-스피치 모듈에 의한 출력을 위한 상기 텍스트 세그먼트를 결정하는 단계는:
다수의 텍스트 세그먼트들을 상기 사용자에 대한 텍스트-투-스피치 출력을 위한 후보들로서 식별하는 것, 상기 다수의 텍스트 세그먼트들은 상이한 레벨의 언어 복잡도를 가지며; 및
상기 클라이언트 디바이스의 사용자의 상기 결정된 언어 능숙도에 적어도 기초하여 상기 다수의 텍스트 세그먼트들 중에서 선택하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 4에 있어서,
상기 다수의 텍스트 세그먼트들 중에서 선택하는 것은:
상기 다수의 텍스트 세그먼트들 각각에 대해 언어 복잡도 스코어를 결정하는 것; 및
상기 클라이언트 디바이스의 사용자의 상기 언어 능숙도를 기술하는 기준 스코어와 가장 잘 매칭되는 상기 언어 복잡도 스코어를 가지는 상기 텍스트 세그먼트를 선택하는 것을 포함하는 것을 특징으로 하는 방법. - 임의의 선행하는 청구항에 있어서,
상기 텍스트-투-스피치 모듈에 의한 출력을 위한 상기 텍스트 세그먼트를 결정하는 단계는:
상기 사용자에 대한 텍스트-투-스피치 출력을 위한 텍스트 세그먼트를 식별하는 것;
상기 텍스트-투-스피치 출력에 대한 상기 텍스트 세그먼트의 복잡도 스코어를 계산하는 것; 및
상기 사용자의 상기 결정된 언어 능숙도 및 상기 텍스트-투-스피치 출력을 위한 텍스트 세그먼트의 상기 복잡도 스코어에 적어도 기초하여 상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 6에 있어서,
상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것은:
상기 사용자의 상기 결정된 언어 능숙도에 적어도 기초하여 상기 사용자에 대한 종합적(overall) 복잡도 스코어를 결정하는 것;
상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트 내에서 개별 부분들에 대한 복잡도 스코어를 결정하는 것;
상기 사용자에 대한 상기 종합적 복잡도 스코어보다 큰 복잡도 스코어들을 가지는 상기 텍스트 세그먼트 내의 하나 이상의 개별 부분들을 식별하는 것; 및
복잡도 스코어들을 상기 종합적 복잡도 스코어 미만으로 감소시키기 위해 상기 텍스트 세그먼트 내에서 상기 하나 이상의 개별 부분들을 수정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 6에 있어서,
상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것은:
상기 사용자와 연관된 컨텍스트를 표시하는 데이터를 수신하는 것;
상기 사용자와 연관된 상기 컨텍스트에 대한 종합적 복잡도 스코어를 결정하는 것;
상기 텍스트 세그먼트의 상기 복잡도 스코어가 상기 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어를 초과함을 결정하는 것; 및
상기 복잡도 스코어를 상기 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어 미만으로 감소시키기 위해 상기 텍스트 세그먼트를 수정하는 것을 포함하는 것을 특징으로 하는 방법. - 시스템으로서,
하나 이상의 컴퓨터들; 및
명령어들이 저장된 상기 하나 이상의 컴퓨터들에 연결된 비일시적 컴퓨터 판독가능 매체를 포함하며, 상기 명령어들은 상기 하나 이상의 컴퓨터들에 의해 실행될 때, 상기 하나 이상의 컴퓨터들로 하여금 동작들을 수행하게 하며, 상기 동작들은:
상기 하나 이상의 컴퓨터들에 의해, 클라이언트 디바이스의 사용자의 언어 능숙도를 결정하는 동작;
상기 하나 이상의 컴퓨터들에 의해, 상기 사용자의 상기 결정된 언어 능숙도에 기초하여 텍스트-투-스피치 모듈에 의한 출력을 위한 텍스트 세그먼트를 결정하는 동작;
상기 하나 이상의 컴퓨터들에 의해, 상기 텍스트 세그먼트의 합성된 발언을 포함하는 오디오 데이터를 생성하는 동작;
상기 하나 이상의 컴퓨터들에 의해, 상기 텍스트 세그먼트의 상기 합성된 발언을 포함하는 상기 오디오 데이터를 상기 클라이언트 디바이스에 제공하는 동작을 포함하는 것을 특징으로 하는 시스템. - 청구항 9에 있어서,
상기 클라이언트 디바이스는 텍스트-투-스피치 인터페이스를 사용하는 모바일 어플리케이션을 디스플레이하는 것을 특징으로 하는 시스템. - 청구항 9 또는 10에 있어서,
상기 사용자의 상기 언어 능숙도를 결정하는 동작은 상기 사용자에 의해 제출된 이전의 쿼리들에 적어도 기초하여 상기 사용자의 언어 능숙도를 추론하는 것을 포함하는 것을 특징으로 하는 시스템. - 청구항 9 내지 10 중 어느 한 항에 있어서,
상기 텍스트-투-스피치 모듈에 의한 출력을 위한 상기 텍스트 세그먼트를 결정하는 동작은:
다수의 텍스트 세그먼트들을 상기 사용자에게 텍스트-투-스피치 출력을 위한 후보들로서 식별하는 것, 상기 다수의 텍스트 세그먼트들은 상이한 레벨의 언어 복잡도를 가지며; 및
상기 클라이언트 디바이스의 사용자의 상기 결정된 언어 능숙도에 적어도 기초하여 상기 다수의 텍스트 세그먼트들 중에서 선택하는 것을 포함하는 것을 특징으로 하는 시스템. - 청구항 12에 있어서,
상기 다수의 텍스트 세그먼트들 중에서 선택하는 것은:
상기 다수의 텍스트 세그먼트들 각각에 대해 언어 복잡도 스코어를 결정하는 것; 및
상기 클라이언트 디바이스의 사용자의 상기 언어 능숙도를 기술하는 기준 스코어와 가장 잘 매칭되는 상기 언어 복잡도 스코어를 가지는 상기 텍스트 세그먼트를 선택하는 것을 포함하는 것을 특징으로 하는 시스템. - 청구항 9 내지 13 중 어느 한 항에 있어서,
상기 텍스트-투-스피치 모듈에 의한 출력을 위한 상기 텍스트 세그먼트를 결정하는 동작은:
상기 사용자에 대한 텍스트-투-스피치 출력을 위한 텍스트 세그먼트를 식별하는 것;
상기 텍스트-투-스피치 출력에 대한 상기 텍스트 세그먼트의 복잡도 스코어를 계산하는 것; 및
상기 사용자의 상기 결정된 언어 능숙도 및 상기 텍스트-투-스피치 출력을 위한 텍스트 세그먼트의 상기 복잡도 스코어에 적어도 기초하여 상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것을 포함하는 것을 특징으로 하는 시스템. - 청구항 14에 있어서,
상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것은:
상기 사용자의 상기 결정된 언어 능숙도에 적어도 기초하여 상기 사용자에 대한 전체적 복잡도 스코어를 결정하는 것;
상기 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트 내에서 개별 부분들에 대한 복잡도 스코어를 결정하는 것;
상기 사용자에 대한 상기 종합적 복잡도 스코어보다 큰 복잡도 스코어들을 가지는 상기 텍스트 세그먼트 내의 하나 이상의 개별 부분들을 식별하는 것; 및
복잡도 스코어들을 상기 종합적 복잡도 스코어 미만으로 감소시키기 위해 상기 텍스트 세그먼트 내에서 상기 하나 이상의 개별 부분들을 수정하는 것을 포함하는 것을 특징으로 하는 시스템. - 하나 이상의 컴퓨터들에 의해 수행되는 방법으로서,
상기 사용자와 연관된 컨텍스트를 표시하는 데이터를 수신하는 단계;
상기 사용자와 연관된 상기 컨텍스트에 대한 종합적 복잡도 스코어를 결정하는 단계;
상기 사용자에 대한 텍스트-투-스피치 출력을 위한 텍스트 세그먼트를 식별하는 단계;
상기 텍스트 세그먼트의 복잡도 스코어가 상기 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어를 초과함을 결정하는 단계; 및
상기 복잡도 스코어를 상기 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어 미만으로 감소시키기 위해 상기 텍스트 세그먼트를 수정하는 단계를 포함하는 것을 특징으로 하는 방법. - 청구항 16에 있어서,
상기 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어를 결정하는 단계는:
상기 사용자가 상기 컨텍스트에 있었던 것으로 결정된 경우 상기 사용자에 의해 이전에 제출된 쿼리들 내에 포함된 용어들을 식별하는 것; 및
상기 식별된 용어들에 적어도 기초하여 상기 사용자와 연관된 상기 컨텍스트에 대한 종합적 복잡도 스코어를 결정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 16 또는 17에 있어서,
상기 사용자와 연관된 상기 컨텍스트를 표시하는 상기 데이터는 상기 사용자에 의해 이전에 제출되었던 쿼리들을 포함하는 것을 특징으로 하는 방법. - 청구항 16 내지 18 중 어느 한 항에 있어서,
상기 사용자와 연관된 상기 컨텍스트를 표시하는 상기 데이터는 상기 사용자와 연관된 현재 위치를 표시하는 GPS 신호를 포함하는 것을 특징으로 하는 방법. - 청구항 16 내지 19 중 어느 한 항에 있어서,
상기 사용자와 연관된 상기 컨텍스트를 표시하는 상기 데이터는 상기 사용자의 모바일 디바이스로부터의 센서 데이터를 포함하는 것을 특징으로 하는 방법. - 하나 이상의 프로세싱 디바이스들에 의해 수행되는 방법으로서,
상기 하나 이상의 프로세싱 디바이스들에 의해, 디바이스에 대한 음성 입력의 복잡도 레벨을 결정하는 단계;
상기 하나 이상의 프로세싱 디바이스들에 의해, 상기 음성 입력에 응답하여, 출력을 위한 메시지를 결정하는 단계, 상기 메시지는 상기 음성 입력과 연관된 상기 결정된 복잡도에 기초하여 결정되며;
상기 하나 이상의 프로세싱 디바이스들에 의해, 상기 메시지의 합성된 발언을 포함하는 오디오 데이터를 생성하는 단계; 및;
상기 하나 이상의 프로세싱 디바이스들에 의해, 상기 음성 입력에 응답하여, 상기 합성된 발언을 포함하는 상기 오디오 데이터를 출력을 위해 제공하는 단계를 포함하는 것을 특징으로 하는 방법. - 청구항 21에 있어서,
상기 음성 입력의 상기 복잡도 레벨은 상기 음성 입력의 언어 복잡도를 포함하는 것을 특징으로 하는 방법. - 청구항 21 또는 22에 있어서,
상기 디바이스에 상기 음성 입력을 제출한 사용자의 언어 능숙도를 결정하는 단계를 더 포함하며;
상기 메시지를 결정하는 단계는 상기 디바이스에 상기 음성 입력을 제출한 상기 사용자의 언어 능숙도에 기초하는 것을 특징으로 하는 방법. - 청구항 21 내지 23 중 어느 한 항에 있어서,
출력을 위한 상기 메시지를 결정하는 단계는:
상기 음성 입력에 응답하여 출력을 위한 기본 메시지(baseline message)를 획득하는 것; 및
상기 디바이스에 대한 상기 음성 입력에 대한 상기 결정된 복잡도 레벨에 기초하여 상기 기본 메시지의 복잡도 레벨을 증가시킴으로써 조절된 메시지를 생성하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 21에 있어서,
출력을 위한 상기 메시지를 결정하는 단계는:
상기 음성 입력에 응답하여 출력을 위한 기본 메시지(baseline message)를 획득하는 것; 및
상기 디바이스에 대한 상기 음성 입력에 대한 상기 결정된 복잡도 레벨에 기초하여 상기 기본 메시지의 복잡도 레벨을 감소시킴으로써 조절된 메시지를 생성하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 21에 있어서,
상기 디바이스는 텍스트-투-스피치 인터페이스를 사용하는 모바일 어플리케이션를 실행하는 것을 특징으로 하는 방법. - 하나 이상의 컴퓨터들에 의해 수행되는 방법으로서,
상기 하나 이상의 컴퓨터들에 의해, (i) 특정한 음성 입력이 제1 사용자에 의해 제공되었고 및 (ii) 상기 특정한 음성 입력이 상기 제1 사용자와는 상이한 제2 사용자에 의해 제공되었다는 것을 표시하는 데이터를 획득하는 단계;
상기 하나 이상의 컴퓨터들에 의해, (i) 상기 제1 사용자에 대한 제1 언어 능숙도 스코어 및 상기 제2 사용자에 대한 제2 언어 능숙도 스코어를 결정하는 단계, 상기 제1 언어 능숙도 스코어가 상기 제2 언어 능숙도 스코어보다 높은 레벨의 언어 능숙도를 표시하며;
상기 하나 이상의 컴퓨터들에 의해, (i) 상기 제1 언어 능숙도 스코어에 기초하여 제1 메시지의 합성된 발언을 포함하는 제1 오디오 데이터 및 (ii) 상기 제2 언어 능숙도 스코어에 기초하여 제2 메시지의 합성된 발언을 포함하는 제2 오디오 데이터를 생성하는 단계, 상기 제1 메시지는 상기 제2 메시지보다 높은 언어 복잡도를 가지며; 및
상기 하나 이상의 컴퓨터들에 의해, (i) 상기 특정한 음성 입력에 응답하여 상기 제1 사용자의 클라이언트 디바이스에 상기 제1 오디오 데이터를 그리고 (ii) 상기 특정한 음성 입력에 응답하여 상기 제2 사용자의 클라이언트 디바이스에 상기 제2 오디오 데이터를 제공하는 단계를 포함하는 것을 특징으로 하는 방법. - 청구항 27에 있어서,
상기 제1 오디오 데이터를 생성하는 단계는 상기 제1 언어 능숙도 스코어에 기초하여 상기 제1 메시지의 텍스트를 결정하는 것을 포함하며, 상기 제2 오디오 데이터를 생성하는 단계는 상기 제2 언어 능숙도 스코어에 기초하여 상기 제2 메시지의 텍스트를 결정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 27 또는 28에 있어서,
상기 제1 사용자의 상기 제1 언어 능숙도 및 상기 제2 사용자의 상기 제2 언어 능숙도 스코어를 결정하는 단계는 상기 제1 사용자 및 상기 제2 사용자에 의해 제출된 각각의 이전의 쿼리들에 적어도 기초하여 상기 제1 사용자 및 제2 사용자의 각각의 언어 능숙도를 추론하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 27 내지 29 중 어느 한 항에 있어서,
상기 제1 오디오 데이터를 생성하는 단계는:
상기 제1 사용자에 대한 텍스트-투-스피치 출력을 위한 텍스트 세그먼트를 식별하는 것;
상기 텍스트 세그먼트의 복잡도 스코어를 계산하는 것; 및
상기 제1 사용자의 상기 제1 언어 능숙도 스코어 및 상기 텍스트-투-스피치 출력을 위한 텍스트 세그먼트의 상기 복잡도 스코어에 적어도 기초하여 상기 제1 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 30에 있어서,
상기 제1 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것은:
상기 제1 사용자의 상기 제1 언어 능숙도에 적어도 기초하여 상기 제1 사용자에 대한 종합적(overall) 복잡도 스코어를 결정하는 것;
상기 제1 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트 내에서 개별 부분들에 대한 복잡도 스코어를 결정하는 것;
상기 제1 사용자에 대한 상기 종합적 복잡도 스코어보다 큰 복잡도 스코어들을 가지는 상기 텍스트 세그먼트 내의 하나 이상의 개별 부분들을 식별하는 것; 및
복잡도 스코어들을 상기 종합적 복잡도 스코어 미만으로 감소시키기 위해 상기 텍스트 세그먼트 내에서 상기 하나 이상의 개별 부분들을 수정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 30 또는 31에 있어서,
상기 제1 사용자에 대한 상기 텍스트-투-스피치 출력을 위한 상기 텍스트 세그먼트를 수정하는 것은:
상기 제1 사용자와 연관된 컨텍스트를 표시하는 데이터를 수신하는 것;
상기 제1 사용자와 연관된 상기 컨텍스트에 대한 종합적 복잡도 스코어를 결정하는 것;
상기 텍스트 세그먼트의 상기 복잡도 스코어가 상기 제1 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어를 초과함을 결정하는 것; 및
상기 복잡도 스코어를 상기 제1 사용자와 연관된 상기 컨텍스트에 대한 상기 종합적 복잡도 스코어 미만으로 감소시키기 위해 상기 텍스트 세그먼트를 수정하는 것을 포함하는 것을 특징으로 하는 방법. - 청구항 27 내지 32 중 어느 한 항에 있어서,
상기 제1 오디오 데이터 및 상기 제2 오디오 데이터를 제공하는 단계는:
상기 하나 이상의 컴퓨터들에 의해, (i) 컴퓨터 네트워크를 통해 상기 제1 오디오 데이터를 상기 제1 사용자의 상기 클라이언트 디바이스에 그리고 (ii) 컴퓨터 네트워크를 통해 상기 제2 오디오 데이터를 상기 제2 사용자의 상기 클라이언트 디바이스에 제공하는 것을 포함하는 것을 특징으로 하는 방법. - 하나 이상의 프로세싱 디바이스들 및 명령어들을 저장하는 하나 이상의 기계 판독가능 저장 디바이스들을 포함하는 시스템으로서, 상기 명령어들은 상기 하나 이상의 프로세싱 디바이스들에 의해 수행될 때, 상기 시스템으로 하여금 청구항 1 내지 9 또는 16 내지 33 중 어느 한 항의 방법을 수행하게 하는 것을 특징으로 하는 시스템.
- 명령어들을 저장하는 하나 이상의 기계 판독가능 저장 디바이스들로서, 상기 명령어들은 하나 이상의 프로세싱 디바이스들에 의해 수행될 때, 상기 하나 이상의 프로세싱 디바이스들로 하여금 청구항 1 내지 9 또는 16 내지 33 중 어느 한 항의 방법을 수행하게 하는 것을 특징으로 하는 기계 판독가능 저장 디바이스.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/009,432 | 2016-01-28 | ||
| US15/009,432 US9799324B2 (en) | 2016-01-28 | 2016-01-28 | Adaptive text-to-speech outputs |
| PCT/US2016/069182 WO2017131924A1 (en) | 2016-01-28 | 2016-12-29 | Adaptive text-to-speech outputs |
Related Child Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217004584A Division KR20210021407A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020207001576A Division KR20200009134A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020207001575A Division KR20200009133A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20180098654A true KR20180098654A (ko) | 2018-09-04 |
| KR102219274B1 KR102219274B1 (ko) | 2021-02-24 |
Family
ID=57799938
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217004584A Ceased KR20210021407A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020207001575A Ceased KR20200009133A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020207001576A Ceased KR20200009134A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020187021923A Active KR102219274B1 (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
Family Applications Before (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217004584A Ceased KR20210021407A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020207001575A Ceased KR20200009133A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
| KR1020207001576A Ceased KR20200009134A (ko) | 2016-01-28 | 2016-12-29 | 적응적 텍스트-투-스피치 출력 |
Country Status (6)
| Country | Link |
|---|---|
| US (8) | US9799324B2 (ko) |
| EP (3) | EP4478349A3 (ko) |
| JP (3) | JP6727315B2 (ko) |
| KR (4) | KR20210021407A (ko) |
| CN (2) | CN116504221A (ko) |
| WO (1) | WO2017131924A1 (ko) |
Families Citing this family (34)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9799324B2 (en) * | 2016-01-28 | 2017-10-24 | Google Inc. | Adaptive text-to-speech outputs |
| US10339481B2 (en) * | 2016-01-29 | 2019-07-02 | Liquid Analytics, Inc. | Systems and methods for generating user interface-based service workflows utilizing voice data |
| CN105653738B (zh) * | 2016-03-01 | 2020-05-22 | 北京百度网讯科技有限公司 | 基于人工智能的搜索结果播报方法和装置 |
| US10210147B2 (en) * | 2016-09-07 | 2019-02-19 | International Business Machines Corporation | System and method to minimally reduce characters in character limiting scenarios |
| US10586527B2 (en) | 2016-10-25 | 2020-03-10 | Third Pillar, Llc | Text-to-speech process capable of interspersing recorded words and phrases |
| KR102367778B1 (ko) * | 2017-03-15 | 2022-02-25 | 삼성전자주식회사 | 언어 정보를 처리하기 위한 방법 및 그 전자 장치 |
| US10909978B2 (en) * | 2017-06-28 | 2021-02-02 | Amazon Technologies, Inc. | Secure utterance storage |
| RU2692051C1 (ru) | 2017-12-29 | 2019-06-19 | Общество С Ограниченной Ответственностью "Яндекс" | Способ и система для синтеза речи из текста |
| US10573298B2 (en) | 2018-04-16 | 2020-02-25 | Google Llc | Automated assistants that accommodate multiple age groups and/or vocabulary levels |
| US11042597B2 (en) | 2018-06-28 | 2021-06-22 | International Business Machines Corporation | Risk-based comprehension intervention for important documents |
| CN112334974B (zh) * | 2018-10-11 | 2024-07-05 | 谷歌有限责任公司 | 使用跨语言音素映射的语音生成 |
| US11403463B2 (en) * | 2018-10-31 | 2022-08-02 | Microsoft Technology Licensing, Llc | Language proficiency inference system |
| US10971134B2 (en) * | 2018-10-31 | 2021-04-06 | International Business Machines Corporation | Cognitive modification of speech for text-to-speech |
| US11023470B2 (en) * | 2018-11-14 | 2021-06-01 | International Business Machines Corporation | Voice response system for text presentation |
| JP7296029B2 (ja) * | 2019-03-13 | 2023-06-22 | 株式会社エヌ・ティ・ティ・データ | 語学教材生成システム |
| KR20210014909A (ko) * | 2019-07-31 | 2021-02-10 | 삼성전자주식회사 | 대상의 언어 수준을 식별하는 전자 장치 및 방법 |
| US11861312B2 (en) * | 2019-09-10 | 2024-01-02 | International Business Machines Corporation | Content evaluation based on machine learning and engagement metrics |
| CN110767209B (zh) * | 2019-10-31 | 2022-03-15 | 标贝(北京)科技有限公司 | 语音合成方法、装置、系统和存储介质 |
| US12019980B2 (en) * | 2019-11-19 | 2024-06-25 | Click Therapeutics, Inc. | Apparatus, system, and method for adaptive parsing and processing of text to facilitate user engagement |
| KR102905958B1 (ko) * | 2020-02-07 | 2025-12-29 | 삼성전자주식회사 | 오디오 신호 제공 방법 및 장치 |
| US11886812B2 (en) * | 2020-03-02 | 2024-01-30 | Grammarly, Inc. | Proficiency and native language-adapted grammatical error correction |
| CN111429880A (zh) * | 2020-03-04 | 2020-07-17 | 苏州驰声信息科技有限公司 | 一种切割段落音频的方法、系统、装置、介质 |
| US11475226B2 (en) | 2020-09-21 | 2022-10-18 | International Business Machines Corporation | Real-time optimized translation |
| CN113053357B (zh) * | 2021-01-29 | 2024-03-12 | 网易(杭州)网络有限公司 | 语音合成方法、装置、设备和计算机可读存储介质 |
| US11984112B2 (en) | 2021-04-29 | 2024-05-14 | Rovi Guides, Inc. | Systems and methods to alter voice interactions |
| US12272366B2 (en) * | 2021-04-29 | 2025-04-08 | Adeia Guides Inc. | Systems and methods to alter voice interactions |
| US11568139B2 (en) * | 2021-06-18 | 2023-01-31 | Google Llc | Determining and utilizing secondary language proficiency measure |
| US11899922B2 (en) * | 2021-07-27 | 2024-02-13 | Carnegie Mellon University | System, method, and device for interactive neurological training |
| US12387725B2 (en) | 2021-12-16 | 2025-08-12 | Samsung Electronics Co., Ltd. | Electronic device and method for recommending voice command thereof |
| US12406655B2 (en) * | 2022-05-20 | 2025-09-02 | International Business Machines Corporation | Increased accessibility of synthesized speech by replacement of difficulty to understand words |
| JP2024166641A (ja) * | 2023-05-19 | 2024-11-29 | Lineヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
| CN116679827B (zh) * | 2023-05-26 | 2025-07-25 | 岚图汽车科技有限公司 | 人机交互任务复杂度确定方法及装置 |
| WO2024249986A1 (en) | 2023-06-02 | 2024-12-05 | Intuitive Surgical Operations, Inc. | Surgical clip applier instruments with articulating jaws |
| EP4687138A1 (en) * | 2024-07-30 | 2026-02-04 | Tata Consultancy Services Limited | Information-entropy-based metric for usable machine response of voice user interface to match with communication ability of speaker |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2810750B2 (ja) * | 1990-01-31 | 1998-10-15 | 株式会社沖テクノシステムズラボラトリ | 語学訓練用装置 |
| JP2010145873A (ja) * | 2008-12-19 | 2010-07-01 | Casio Computer Co Ltd | テキスト置換装置、テキスト音声合成装置、テキスト置換方法、及び、テキスト置換プログラム |
| US20150332665A1 (en) * | 2014-05-13 | 2015-11-19 | At&T Intellectual Property I, L.P. | System and method for data-driven socially customized models for language generation |
Family Cites Families (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0335296A (ja) * | 1989-06-30 | 1991-02-15 | Sharp Corp | テキスト音声合成装置 |
| JP3225389B2 (ja) | 1993-12-22 | 2001-11-05 | コニカ株式会社 | 電子写真感光体用塗布液の製造方法及び電子写真感光体 |
| EP0956552B1 (en) | 1995-12-04 | 2002-07-17 | Jared C. Bernstein | Method and apparatus for combined information from speech signals for adaptive interaction in teaching and testing |
| US6029156A (en) * | 1998-12-22 | 2000-02-22 | Ac Properties B.V. | Goal based tutoring system with behavior to tailor to characteristics of a particular user |
| US6993513B2 (en) * | 1999-05-05 | 2006-01-31 | Indeliq, Inc. | Interactive simulations utilizing a remote knowledge base |
| US20010049602A1 (en) * | 2000-05-17 | 2001-12-06 | Walker David L. | Method and system for converting text into speech as a function of the context of the text |
| JP3601411B2 (ja) * | 2000-05-22 | 2004-12-15 | 日本電気株式会社 | 音声応答装置 |
| JP2002171348A (ja) * | 2000-12-01 | 2002-06-14 | Docomo Mobile Inc | 音声情報提供システムおよび方法 |
| GB2372864B (en) * | 2001-02-28 | 2005-09-07 | Vox Generation Ltd | Spoken language interface |
| JP2002312386A (ja) * | 2001-04-12 | 2002-10-25 | Kobelco Systems Corp | 音声検索サービスシステム |
| US7519529B1 (en) * | 2001-06-29 | 2009-04-14 | Microsoft Corporation | System and methods for inferring informational goals and preferred level of detail of results in response to questions posed to an automated information-retrieval or question-answering service |
| JP2003225389A (ja) | 2002-02-01 | 2003-08-12 | Ace Denken:Kk | 遊技機 |
| US7096183B2 (en) | 2002-02-27 | 2006-08-22 | Matsushita Electric Industrial Co., Ltd. | Customizing the speaking style of a speech synthesizer based on semantic analysis |
| JP2004193421A (ja) | 2002-12-12 | 2004-07-08 | Olympus Corp | フレキシブル基板の接続構造 |
| US7389228B2 (en) | 2002-12-16 | 2008-06-17 | International Business Machines Corporation | Speaker adaptation of vocabulary for speech recognition |
| US7280968B2 (en) * | 2003-03-25 | 2007-10-09 | International Business Machines Corporation | Synthetically generated speech responses including prosodic characteristics of speech inputs |
| US20050015307A1 (en) * | 2003-04-28 | 2005-01-20 | Simpson Todd Garrett | Method and system of providing location sensitive business information to customers |
| US20050175970A1 (en) * | 2004-02-05 | 2005-08-11 | David Dunlap | Method and system for interactive teaching and practicing of language listening and speaking skills |
| US7512579B2 (en) * | 2004-12-17 | 2009-03-31 | Clairvista Llc | System and method for interactively delivering expert information to remote outlets |
| US8150872B2 (en) * | 2005-01-24 | 2012-04-03 | The Intellection Group, Inc. | Multimodal natural language query system for processing and analyzing voice and proximity-based queries |
| US7873654B2 (en) * | 2005-01-24 | 2011-01-18 | The Intellection Group, Inc. | Multimodal natural language query system for processing and analyzing voice and proximity-based queries |
| US7490042B2 (en) | 2005-03-29 | 2009-02-10 | International Business Machines Corporation | Methods and apparatus for adapting output speech in accordance with context of communication |
| JP2006330629A (ja) * | 2005-05-30 | 2006-12-07 | Kenwood Corp | 対話装置、プログラム及び方法 |
| US8239762B2 (en) | 2006-03-20 | 2012-08-07 | Educational Testing Service | Method and system for automatic generation of adapted content to facilitate reading skill development for language learners |
| US9318108B2 (en) | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| US20080109224A1 (en) * | 2006-11-02 | 2008-05-08 | Motorola, Inc. | Automatically providing an indication to a speaker when that speaker's rate of speech is likely to be greater than a rate that a listener is able to comprehend |
| JP2010033139A (ja) * | 2008-07-25 | 2010-02-12 | Nec Corp | 情報処理装置、電子辞書提供方法及びプログラム |
| WO2010084881A1 (ja) * | 2009-01-20 | 2010-07-29 | 旭化成株式会社 | 音声対話装置、対話制御方法及び対話制御プログラム |
| US9547642B2 (en) * | 2009-06-17 | 2017-01-17 | Empire Technology Development Llc | Voice to text to voice processing |
| JP5545467B2 (ja) * | 2009-10-21 | 2014-07-09 | 独立行政法人情報通信研究機構 | 音声翻訳システム、制御装置、および情報処理方法 |
| JP2011100191A (ja) * | 2009-11-04 | 2011-05-19 | Nippon Telegr & Teleph Corp <Ntt> | 文書検索装置、文書検索方法、及び文書検索プログラム |
| KR20110067517A (ko) * | 2009-12-14 | 2011-06-22 | 주식회사 케이티 | 사용자 응답 문장의 프레임을 기반으로 한 외국어 회화 학습 방법 |
| US10679605B2 (en) * | 2010-01-18 | 2020-06-09 | Apple Inc. | Hands-free list-reading by intelligent automated assistant |
| US20120016674A1 (en) * | 2010-07-16 | 2012-01-19 | International Business Machines Corporation | Modification of Speech Quality in Conversations Over Voice Channels |
| US8744855B1 (en) * | 2010-08-09 | 2014-06-03 | Amazon Technologies, Inc. | Determining reading levels of electronic books |
| JP5727810B2 (ja) * | 2011-02-10 | 2015-06-03 | 株式会社Nttドコモ | 言語能力判定装置、言語能力判定方法、コンテンツ配信システム及びプログラム |
| US20130031476A1 (en) * | 2011-07-25 | 2013-01-31 | Coin Emmett | Voice activated virtual assistant |
| US8954423B2 (en) * | 2011-09-06 | 2015-02-10 | Microsoft Technology Licensing, Llc | Using reading levels in responding to requests |
| US9082414B2 (en) * | 2011-09-27 | 2015-07-14 | General Motors Llc | Correcting unintelligible synthesized speech |
| US8996519B2 (en) * | 2012-03-12 | 2015-03-31 | Oracle International Corporation | Automatic adaptive content delivery |
| US20130325482A1 (en) * | 2012-05-29 | 2013-12-05 | GM Global Technology Operations LLC | Estimating congnitive-load in human-machine interaction |
| US9824695B2 (en) * | 2012-06-18 | 2017-11-21 | International Business Machines Corporation | Enhancing comprehension in voice communications |
| JP6040715B2 (ja) * | 2012-11-06 | 2016-12-07 | ソニー株式会社 | 画像表示装置及び画像表示方法、並びにコンピューター・プログラム |
| US9009028B2 (en) * | 2012-12-14 | 2015-04-14 | Google Inc. | Custom dictionaries for E-books |
| JP6026881B2 (ja) | 2012-12-26 | 2016-11-16 | 関西ペイント株式会社 | 塗料組成物及び複層塗膜形成方法 |
| US20140188479A1 (en) * | 2013-01-02 | 2014-07-03 | International Business Machines Corporation | Audio expression of text characteristics |
| US9245257B2 (en) * | 2013-03-12 | 2016-01-26 | Salesforce.Com, Inc. | System and method for generating a user profile based on skill information |
| JP6111802B2 (ja) * | 2013-03-29 | 2017-04-12 | 富士通株式会社 | 音声対話装置及び対話制御方法 |
| CN105247609B (zh) * | 2013-05-31 | 2019-04-12 | 雅马哈株式会社 | 利用言语合成对话语进行响应的方法及装置 |
| US9799324B2 (en) * | 2016-01-28 | 2017-10-24 | Google Inc. | Adaptive text-to-speech outputs |
-
2016
- 2016-01-28 US US15/009,432 patent/US9799324B2/en active Active
- 2016-12-29 JP JP2018539396A patent/JP6727315B2/ja active Active
- 2016-12-29 KR KR1020217004584A patent/KR20210021407A/ko not_active Ceased
- 2016-12-29 KR KR1020207001575A patent/KR20200009133A/ko not_active Ceased
- 2016-12-29 CN CN202310511278.4A patent/CN116504221A/zh active Pending
- 2016-12-29 EP EP24210665.6A patent/EP4478349A3/en active Pending
- 2016-12-29 CN CN201680080197.1A patent/CN108604446B/zh active Active
- 2016-12-29 WO PCT/US2016/069182 patent/WO2017131924A1/en not_active Ceased
- 2016-12-29 KR KR1020207001576A patent/KR20200009134A/ko not_active Ceased
- 2016-12-29 KR KR1020187021923A patent/KR102219274B1/ko active Active
- 2016-12-29 EP EP21212730.2A patent/EP4002353B1/en active Active
- 2016-12-29 EP EP16826663.3A patent/EP3378059B1/en active Active
-
2017
- 2017-04-03 US US15/477,360 patent/US9886942B2/en active Active
- 2017-07-19 US US15/653,872 patent/US10109270B2/en active Active
-
2018
- 2018-09-19 US US16/135,885 patent/US10453441B2/en active Active
-
2019
- 2019-09-17 US US16/573,492 patent/US10923100B2/en active Active
-
2020
- 2020-04-22 JP JP2020076068A patent/JP6903787B2/ja active Active
-
2021
- 2021-01-20 US US17/153,463 patent/US11670281B2/en active Active
- 2021-06-22 JP JP2021103122A patent/JP7202418B2/ja active Active
-
2023
- 2023-04-28 US US18/309,754 patent/US12198671B2/en active Active
-
2025
- 2025-01-02 US US19/007,920 patent/US20250131909A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2810750B2 (ja) * | 1990-01-31 | 1998-10-15 | 株式会社沖テクノシステムズラボラトリ | 語学訓練用装置 |
| JP2010145873A (ja) * | 2008-12-19 | 2010-07-01 | Casio Computer Co Ltd | テキスト置換装置、テキスト音声合成装置、テキスト置換方法、及び、テキスト置換プログラム |
| US20150332665A1 (en) * | 2014-05-13 | 2015-11-19 | At&T Intellectual Property I, L.P. | System and method for data-driven socially customized models for language generation |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7202418B2 (ja) | 適応的テキスト-音声出力 | |
| US10553214B2 (en) | Determining dialog states for language models | |
| US11282513B2 (en) | Negative n-gram biasing | |
| US10002608B2 (en) | System and method for using prosody for voice-enabled search | |
| US20240013782A1 (en) | History-Based ASR Mistake Corrections | |
| US12431139B1 (en) | System and method for enhanced customer service through automated real-time FAQ generation from call center interactions |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| PA0105 | International application |
St.27 status event code: A-0-1-A10-A15-nap-PA0105 |
|
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-2-2-P10-P22-nap-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-2-2-P10-P22-nap-X000 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| PA0104 | Divisional application for international application |
St.27 status event code: A-0-1-A10-A18-div-PA0104 St.27 status event code: A-0-1-A10-A16-div-PA0104 |
|
| E90F | Notification of reason for final refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-2-2-P10-P22-nap-X000 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| A107 | Divisional application of patent | ||
| PA0104 | Divisional application for international application |
St.27 status event code: A-0-1-A10-A18-div-PA0104 St.27 status event code: A-0-1-A10-A16-div-PA0104 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
St.27 status event code: A-2-2-U10-U12-oth-PR1002 Fee payment year number: 1 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 4 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 5 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 6 |
|
| U11 | Full renewal or maintenance fee paid |
Free format text: ST27 STATUS EVENT CODE: A-4-4-U10-U11-OTH-PR1001 (AS PROVIDED BY THE NATIONAL OFFICE) Year of fee payment: 6 |