KR20150035798A - 현지화된 사용자 인터페이스의 생성 방법 - Google Patents
현지화된 사용자 인터페이스의 생성 방법 Download PDFInfo
- Publication number
- KR20150035798A KR20150035798A KR1020147036897A KR20147036897A KR20150035798A KR 20150035798 A KR20150035798 A KR 20150035798A KR 1020147036897 A KR1020147036897 A KR 1020147036897A KR 20147036897 A KR20147036897 A KR 20147036897A KR 20150035798 A KR20150035798 A KR 20150035798A
- Authority
- KR
- South Korea
- Prior art keywords
- translation
- rule
- string
- adaptation
- computer
- Prior art date
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/36—Preventing errors by testing or debugging software
- G06F11/3668—Software testing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/151—Transformation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/42—Data-driven translation
- G06F40/47—Machine-assisted translation, e.g. using translation memory
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/55—Rule-based translation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/30—Creation or generation of source code
- G06F8/38—Creation or generation of source code for implementing user interfaces
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/451—Execution arrangements for user interfaces
- G06F9/454—Multi-language systems; Localisation; Internationalisation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Artificial Intelligence (AREA)
- Human Computer Interaction (AREA)
- Computer Hardware Design (AREA)
- Quality & Reliability (AREA)
- Machine Translation (AREA)
- Information Transfer Between Computers (AREA)
Abstract
조어 문자열을 조어 변종으로 각색하기 위해, 각색 규칙이 준비되어 조어 문자열에 적용된다. 이전의 각색 번역이 먼저 사용되고 나서, 번역 유닛을 각색하기 위해 적용되는 각색 규칙에 각색되지 않은 번역 유닛이 매칭된다. 사용자 인터페이스를 디자인하거나 테스트하기 위해, 소스 언어 문자열에 대해 일련의 번역 후보들을 얻고 그 크기에 기반하여 번역 후보들 중 어느 하나가 선택된다. 선택된 번역 후보의 영역이 계산되고, 선택된 번역 후보에 대해 계산된 영역에 기반하여 유사-현지화된 문자열이 생성된다. 유사-현지화된 문자열은 이후에 사용자 인터페이스 디스플레이를 생성하거나 테스트할 때 사용된다.
Description
현재 전세계 많은 다른 지리적 지역에서 제공되는 많은 컴퓨터 프로그램과 시스템들이 있다. 이는 보통 컴퓨터 소프트웨어 및 관련 문서가 수많은 다른 언어로 번역되어야 함을 의미한다. 예를 들어, 컴퓨터 프로그램의 지원 문서는 물론, 자원 파일과 그 밖의 사용자 인터페이스 텍스트 문자열(text string)은, 대응 제품이 다양한 다른 언어들을 사용하는 나라에서 판매될 때, 보통 그런 다른 언어들로 번역된다.
일부 언어들이 여러 다른 변종을 갖고 있기 때문에, 컴퓨터 프로그램, 및 관련 문서에서 사용된 텍스트 문자열을 다양한 다른 언어로 번역(또는 현지화)하는 것과 관련된 문제가 악화된다. 예를 들어, 제품이 독일어와 같이 조어(parent language)를 사용하는 나라에서 판매되고 있다고 가정하자. 이런 나라의 특수한 언어 요구를 정확하게 충족시키기 위해서, 이들 나라에서 제공되는 제품은 보통 대응 조어의 언어 변종으로 번역(각색(adaptation)이라고 함)될 필요가 있다. 예를 들어, 독일어는 독일에서와 오스트리아에서 약간 다르다. 양쪽 나라 모두 조어(독일어)를 사용하지만, 각 나라는 독일어-독일 및 독일어-오스트리아와 같이, 그 조어의 자신만의 변종을 가지고 있다.
제품에 대응하는 텍스트 문자열을 조어의 변종으로 번역하는 것은 보통 수동으로 행해져 왔다. 즉, 수동 통역사는 조어 컨텐츠를 사용하여, 이를 각색된 언어(또는 조어 변종)에서 사용된 변경을 수용하도록 수동으로 각색한다.
목표 언어로 사용될 컴퓨터 제품을 번역(현지화)하는 것과 관련된 또 다른 문제는 컴퓨터 프로그램과 함께 사용되는 사용자 인터페이스 디스플레이의 디자인과 관련이 있다. 예를 들어, 개발자가 소스 언어(source language)로 제품을 개발할 때, 그 개발자는 소스 언어로 된 텍스트가 잘려나가거나(truncated) 어색하게 디스플레이되지 않고 적절하게 디스플레이될 수 있도록 사용자 인터페이스 디스플레이를 디자인한다. 한편, 소스 언어 텍스트가 목표 언어 혹은 목표 언어 변종으로 번역될 때, 텍스트의 크기가 소스 언어 텍스트보다 (목표 언어에서 사용되는 폰트에 따라) 길거나 크거나 또는 짧거나 작을 수 있다. 따라서, 제품이 번역되거나 현지화될 때, 목표 언어(또는 목표 언어 변종)의 텍스트 문자열은 잘려나가거나 어색하게 디스플레이될 수 있다.
이런 문제를 다루기 위해, 현 일부 개발자들은 국제적 적합성을 위해 소프트웨어를 구축하고 테스트하는 데에 유사-현지화(pseudo-localization)라고 알려진 방법을 사용한다. 유사-현지화 프로세스는 (영어 문자열에서와 같은) 특정 소스 언어로 된 글자들을 (유니코드와 같은) 목표 셋의 글자들로 대체하고 거기에 추가 글자들을 추가함으로써 문자열의 크기를 변경한다. 예를 들어, 소스 언어가 영어인 제품에서 어느 하나의 그러한 유사-현지화 프로세스가 실행될 때, 그 프로세스는 소스 언어의 자원 문자열에 글자들을 추가하기 위해 고정된 공식을 사용한다. 특정 예로 영어 소스 문자열에 있는 글자 수의 140 퍼센트를 사용하는 유사-현지화된 목표 글자 셋을 생성한다. 즉, 어떤 번역(또는 현지화)의 결과물도 소스 문자열에 있는 글자 수의 140 퍼센트보다는 크지 않을 것임을 유사-현지화를 위한 고정된 공식에서 가정한다. 그러나, 이런 고정된 공식 접근 방법은 세상의 문어(written language)의 동적이고 다양한 크기를 정확하게 표현하지 못한다.
고정된 공식 유사-현지화 접근 방법이 통하지 못하는 일례가 영어를 그리스어와 같은 언어로 번역할 때이다. 고정-공식 현지화 접근 방법이 적용되면, "e-mail"이라는 단어는 140 퍼센트까지 확장하게 된다. 즉, ("타호마" 8 pt. 폰트로 33 픽셀 길이인) 6-글자 길이의 문자열 "e-mail"이 최대 길이 17 글자("타호마" 8 pt. 폰트로 110 픽셀 길이)로 확장될 것이다. 이는 다음과 같이 계산된다:
33 픽셀 X 140 % + 시작 구획 문자(delimiter) 너비인 50 픽셀 + 종료 구획 문자 너비인 15 픽셀.
따라서, 유사-현지화된 문자열은 110 픽셀 길이가 된다. 그러나, 이는 여러 다른 언어로 번역할 때 정확한 유사-현지화된 문자열을 제공하지 못한다. 예를 들어, 그리스어로 번역된 단어 "e-mail"은 ("타호마" 8 pt. 폰트로 192 픽셀 길이인) 35 글자-길이 문자열이다.
상기의 논의는 단지 일반적인 배경 기술 정보를 위해 제공된 것으로, 청구 대상의 범위를 결정하는 데 일조하기 위해 사용되는 것은 아니다.
조어 문자열을 조어 변종으로 각색하기 위해, 각색 규칙이 준비되어 조어 문자열에 적용된다. 이전의 각색 번역이 먼저 사용되고 나서, 번역 유닛을 각색하기 위해 적용되는 각색 규칙에 각색되지 않은 번역 유닛이 매칭된다.
사용자 인터페이스를 디자인하거나 테스트하기 위해, 소스 언어 문자열에 대해 일련의 번역 후보들을 얻고 그 크기에 기반하여 번역 후보들 중 어느 하나가 선택된다. 선택된 번역 후보의 영역이 계산되고, 선택된 번역 후보에 대해 계산된 영역에 기반하여 유사-현지화된 문자열이 생성된다. 유사-현지화된 문자열은 이후에 사용자 인터페이스 디스플레이를 생성하거나 테스트할 때 사용된다.
본 요약은 아래의 상세한 설명에서 추가적으로 설명되는 일련의 개념들을 단순화된 형태로 소개하기 위해 제공된다. 본 요약은 청구 대상의 핵심적인 특징 또는 필수적인 특징을 식별하고자 하는 것이 아니며, 이러한 본 요약이 청구 대상의 범위를 결정하는 데 일조하기 위해 사용되는 것도 아니다. 더욱이, 청구 대상은 배경 기술에서 언급된 임의의 또는 모든 단점들을 해결하는 구현예에 제한되지 않는다.
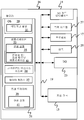
도 1은 비즈니스 각색 시스템의 블록도이다.
도 2는 도 1에 도시된 시스템의 전체 동작을 도시하는 블록도이다.
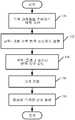
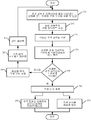
도 3은 각색 규칙이 생성되는 방법을 도시하는 순서도이다.
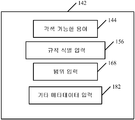
도 3a는 사용자 인터페이스 디스플레이의 일례이다.
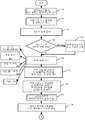
도 4a 및 4b는 규칙-기반 각색 번역 프로세스의 실행을 도시하는 순서도이다.
도 5는 기존의 각색 번역을 재활용(recycling)하는 일 실시예를 도시하는 순서도이다.
도 6은 번역 유닛을 검토하는 일 실시예를 도시하는 순서도이다.
도 6a는 사용자 인터페이스 디스플레이의 일례이다.
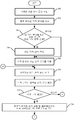
도 7은 규칙 검증(validation)의 예시적인 일 실시예를 도시하는 순서도이다.
도 8은 사용자 인터페이스 생성/테스트 시스템의 일 실시예의 블록도를 도시한다.
도 9a 및 9b는 도 8에 도시된 시스템의 전체 동작의 일 실시예를 도시하는 순서도를 도시한다.
도 10은 사용자 인터페이스 디스플레이의 일례이다.
도 11은 이용 가능한 다양한 아키텍처의 블록도를 도시한다.
도 12-16은 모바일 장치의 다양한 실시예들을 도시한다.
도 17은 컴퓨팅 환경의 일례의 블록도이다.
도 2는 도 1에 도시된 시스템의 전체 동작을 도시하는 블록도이다.
도 3은 각색 규칙이 생성되는 방법을 도시하는 순서도이다.
도 3a는 사용자 인터페이스 디스플레이의 일례이다.
도 4a 및 4b는 규칙-기반 각색 번역 프로세스의 실행을 도시하는 순서도이다.
도 5는 기존의 각색 번역을 재활용(recycling)하는 일 실시예를 도시하는 순서도이다.
도 6은 번역 유닛을 검토하는 일 실시예를 도시하는 순서도이다.
도 6a는 사용자 인터페이스 디스플레이의 일례이다.
도 7은 규칙 검증(validation)의 예시적인 일 실시예를 도시하는 순서도이다.
도 8은 사용자 인터페이스 생성/테스트 시스템의 일 실시예의 블록도를 도시한다.
도 9a 및 9b는 도 8에 도시된 시스템의 전체 동작의 일 실시예를 도시하는 순서도를 도시한다.
도 10은 사용자 인터페이스 디스플레이의 일례이다.
도 11은 이용 가능한 다양한 아키텍처의 블록도를 도시한다.
도 12-16은 모바일 장치의 다양한 실시예들을 도시한다.
도 17은 컴퓨팅 환경의 일례의 블록도이다.
도 1은 비즈니스 각색 시스템(100)의 블록도이다. 시스템(100)은 프로세서(102), 각색 엔진(104), 규칙 검증 컴포넌트(106), 이전 비즈니스 각색 번역 저장소(108), (각색 규칙들(112)을 포함하는) 각색 규칙 저장소(110) 및 사용자 인터페이스 컴포넌트(114)를 포함한다. 도 1에 도시된 실시예에서, 시스템(100)은 번역 컴포넌트(116)와 비즈니스 제품(118)에 결합된 것으로 도시된다.
프로세서(102)는 예를 들어, 관련 메모리와 타이밍 회로(도시되지 않음)를 갖는 컴퓨터 프로세서를 포함한다. 예를 들어, 프로세서(102)는 시스템(100)의 기능부를 형성하고, 시스템(100)의 다른 컴포넌트와 엔진에 의해 활성화되어, 다른 컴포넌트와 엔진의 기능을 하게 한다.
데이터 저장소들(108 및 110)은 시스템(100) 내부에 있는 것으로 도시된다. 물론, 저장소들은 시스템(100)과 원격으로 있거나 다른 아키텍처에 있을 수도 있다. 마찬가지로, 각각의 데이터 저장소(108 및 110)가 다수의 데이터 저장소일 수 있고, 데이터 저장소들이 하나의 데이터 저장소로 결합될 수도 있다. 이런 아키텍처들 모두가 본원에서 고려된다.
시스템(100)의 동작의 다양한 실시예들이 다른 도면과 관련하여 아래에서 설명된다. 간단히 말해서, 그러나, 개요를 돕기 위해서, 시스템(100)은 조어로 된 문서를 언어 변종으로 각색하는 데 사용된다. 예를 들어, 조어가 독일어면, 시스템(100)은 독일어 문서를 오스트리아에서 사용되는 독일어의 특정 변종으로 각색한다. 어떤 경우라도, 소스 언어 문서(120)는 번역 컴포넌트(116)에 의해 조어로 된 문서로 번역된다. 부모 문서(parent document)는 블록(122)으로 표시된다. 부모 문서(122)가 특정 언어 변종으로 각색되도록 각색 엔진(104)은 데이터 저장소(110)의 각색 규칙들(112)을 적용하고, 저장소(108)의 이전 각색 번역을 사용하여 부모 문서(122)의 번역 유닛들을 각색한다. 규칙 검증 컴포넌트(106)는 규칙들이 올바르게 적용되었고 시스템(100)이 비즈니스 제품(118)에 포함될 각색된 문서(124)를 출력하고 있음을 검증한다.
사용자 인터페이스 컴포넌트(114)는 예를 들어, 사용자(126)에게 정보를 디스플레이하는 사용자 인터페이스 디스플레이(125)를 생성한다. 예를 들어, 사용자 인터페이스 디스플레이(125)는 사용자(126)가 시스템(100)의 다양한 부분들과 인터랙션할 수 있도록, 사용자(126)로부터 입력을 수신하는 입력 메커니즘도 포함한다. 사용자(126)는 각색 규칙(112)을 생성하거나, 각색된 문서를 검토하거나, 또는 그 밖의 다른 이유로 인터랙션을 할 수 있다. 일 실시예에서, 사용자 입력 메커니즘은 (마우스와 같은) 포인트 앤 클릭(point and click) 장치, 하드웨어 키보드, 가상 키보드, 음성 입력, 키패드로부터의 사용자 입력, 또는 기타 입력들을 수신할 수 있다. 또한, 터치 감지 스크린에 사용자 인터페이스(125)가 디스플레이되는 경우, 사용자 입력은 손가락, 스타일러스, 또는 기타 입력 메커니즘을 사용하여 사용자(126)가 입력하는 터치 제스처일 수 있다.
도 2는 도 1에 도시된 시스템(100)의 전체 동작의 일 실시예를 보다 상세하게 도시한 순서도이다. 시스템(100)은 먼저 적절한 사용자 인터페이스 디스플레이(125)를 통해 사용자(126)로부터 각색 규칙들을 준비하거나 수정하는 입력을 수신하고, 이들을 각색 규칙 저장소(110)에 저장한다. 이는 도 2의 블록(130)으로 표시된다. 그 후에 각색 엔진(104)은 부모 문서(122)를 수신하고 부모 문서(122)가 변종 언어를 반영하도록 각색하기 위해 규칙-기반 각색 번역 프로세스를 부모 문서(122)에 실행한다. 규칙-기반 각색 번역 프로세스의 실행은 도 2의 블록(132)으로 표시된다.
프로세스를 적용할 때, 각색 엔진(104)은 예를 들어, 추가 검토를 위해 특정 번역 유닛에 표시를 해둔다(또는 플래그를 표시한다). 따라서, 플래그 표시된 번역 유닛을 갖고 있는 문서가 사용자(126)의 검토를 위해 사용자 인터페이스 컴포넌트(114)에 의해 디스플레이된다. 각색-플래그 표시된 번역 유닛의 검토는 도 2의 블록(134)으로 표시된다. 이들 번역 유닛을 검토할 때, 사용자(126)는 번역 유닛들을 정정하거나 승인하고, 그에 따라 관련 플래그를 변경한다.
다음으로 규칙 검증 컴포넌트(106)는 각색 규칙들(112)이 부모 문서에 올바르게 적용되었음을 검증한다. 예를 들어, 규칙 검증 컴포넌트(106)는 규칙 예외 및 규칙 범위를 따랐음을 검증한다. 규칙 검증 단계는 도 2의 블록(136)으로 표시된다. 최종적으로, 각색된 문서(124)가 출력되어 비즈니스 제품(118)에 통합된다. 이는 도 2의 블록(138)으로 표시된다.
도 3 및 도 3a는 각색 규칙들(112)의 준비를 보다 상세하게 도시한다. 일 실시예에서, 사용자 인터페이스 컴포넌트(114)는 각색 규칙(112)을 생성하기 위해 사용자(126)로부터 입력을 수신하는 적절한 사용자 인터페이스 디스플레이(125)를 생성한다. 초기 프로세스로서, 번역가는 소스 문자열들 및 각색 가능한 용어들을 갖고 있을 수 있는 대응 부모 번역을 식별하기 위해 소스 언어 문서(120)와 조어 문서(122)를 분석할 수 있다. 이는 자동 프로세스에 의해 또는 수동으로 실행될 수 있다. 일 실시예에서, 이는 프로젝트 번역 사이클 동안, 간헐적으로 실행되는 연속적인 프로세스일 수 있다. 어떤 경우라도, 번역가는 예를 들어, 조어와, 조어 및 각색된 언어 간의 차이점에 관한 언어학적 지식을 지니고 있다.
각색 가능한 용어가 식별되면, 이는 시스템(100)에서 수신되어 사용자(126)에게 디스플레이된다. 이는 도 3의 블록(140)으로 표시된다. 도 3a는 사용자(126)에게 각색 가능한 용어(144)를 디스플레이하는 사용자 인터페이스 디스플레이(142)의 일례를 도시한다. 일 실시예에서, 사용자(126)에게 디스플레이되는 각색 가능한 용어(144)는 소스 용어(146), 부모 번역(148), 각색된 번역(150), 및 그 밖의 임의의 원하는 정보(152)를 포함한다. 그 후에 사용자(126)가 이런 각색 가능한 특정 용어에 대해 각색 규칙(112)이 생성될 필요가 있음을 결정할 수 있다.
다음으로, 시스템(100)은 다시 예시된 사용자 인터페이스 디스플레이를 통해, 사용자(126)로부터 이러한 각색 규칙에 대한 식별 정보를 수신한다. 식별 정보의 수신은 도 3의 블록(154)으로 표시된다. 도 3a에 도시된 실시예에서, 사용자 인터페이스 디스플레이(142)는 적절한 사용자 입력 메커니즘(156)을 통해 식별 입력을 수신한다. 식별 정보는, 예를 들어, 규칙 식별자(158), 조어 이름(160), 각색된 언어 이름(162) 및 기타 정보(164)를 포함할 수 있다. 예를 들어, 조어 이름은 "독일어"이고, 각색된 언어 이름은 "독일어-오스트리아"일 수 있다. 물론, 이는 단지 예를 들기 위한 것이다.
각색 규칙이 식별되면, 시스템(100)은 (다시 예시된 사용자 인터페이스 디스플레이를 통해) 사용자(126)로부터 이런 각색 정보에 할당되어야 할 규칙 범위를 수신할 수 있다. 규칙 범위 수신은 도 3의 블록(166)으로 표시되며, 도 3a는 사용자 인터페이스 디스플레이(142)에서 범위 입력을 수신하기 위해 적절한 사용자 입력 메커니즘(168)이 사용될 수 있음을 도시한다.
사용자(126)는 각색 가능한 용어 각각의 경우에 대해, 각색 규칙의 범위가 전체적으로(globally) 적용되어야 함을 결정할 수 있다. 전체(global) 범위란 특정 번역 컨테이너 안에 있는(예컨대, 특정 자원 파일, 오류 메시지 등에 있는) 모든 번역 유닛들에 대해 각색 규칙이 적용되는 것을 의미한다. 번역 유닛은 예를 들어, 자원 파일에서, 번역 가능한 문장의 낮은 레벨의 엔티티이다. 번역 유닛은 번역될 소스 용어, 특정 번역 및 (자원 식별자, 번역이 행해져서는 안 되는 번역 잠금, 번역 상태를 탐지하는 다양한 번역 플래그, 번역의 기점과 범위, 및 커스터마이즈된 추가 정보와 같은) 자원에 관한 메타데이터를 포함한다. 전체 범위는 도 3의 블록(170)으로 표시된다.
사용자(126)는 현재의 각색 규칙에 대해 다른 범위를 부여할 수도 있다. 예를 들어, 제한된 범위란 각색 규칙이 어떤 조건에 기반하여 특정 번역 컨테이너의 번역 유닛들의 부분 집합에 적용됨을 의미한다. 파일 레벨 조건은, 예를 들어, 파일 이름 또는 다수의 자원 파일을 선택하기 위한 정규 표현일 수 있고, 각색 규칙이 그 파일 혹은 다수의 자원 파일에 적용될 수 있다. 자원 ID 범위, 표현, 번역 유닛 플래그, 혹은 그 밖의 자원 레벨 조건들에 기반하여 번역 유닛들 그룹 중에서 하나 이상을 선택하기 위해 자원 레벨 조건이 사용될 수 있다. 제한된 범위는 도 3의 블록(172)으로 표시된다.
사용자(126)는 예를 들어, 사전 정의된 각색 범위를 할당할 수도 있다. 이런 경우에, 각색 규칙은 전체 및 제한된 범위 모두를 우선하도록 정의된다. 이는, 파일 이름과 자원 ID의 도움을 받아 목표된 특정 단어들 또는 선택된 번역 유닛들을 고유하게 식별함으로써 실행될 수 있다. 사전 정의된 각색 범위는 도 3의 블록(174)으로 표시된다.
사용자(126)는 각색 규칙이 제외되거나 적용되지 않는 예외(exclusion)를 정의함으로써 범위를 할당할 수 있다. 예외는 각색 프로세스에서 제외된, 표현된 번역 유닛을 정의한다. 물론, 예외는 자원 ID 범위, 번역 유닛 플래그 등에 기반하여 프로세스에서 제외된 번역 유닛 그룹 혹은 기타 영역을 정의하는 데에 사용될 수도 있다. 범위의 일부로서 예외를 할당하는 단계는 도 3의 블록(176)으로 표시된다.
물론, 사용자(126)가 그 밖의 또는 다른 범위를 제공할 수도 있다. 이는 도 3의 블록(178)으로 표시된다.
사용자(126)가 현재 각색 규칙에 범위를 할당하면, 사용자는 예를 들어, 도 3의 블록(180)으로 표시된 바와 같이 기타 메타데이터 또한 제공할 수 있다. 도 3a는 사용자 인터페이스 디스플레이(142)가 사용자(126)로 하여금 적절한 사용자 인터페이스 메커니즘(182)을 통해 기타 메타데이터를 입력할 수 있게 함을 도시한다. 일 실시예에서, 이런 기타 메타데이터는 고려 대상인 각색된 용어의 특성(nature)을 포함한다. 이 특성은 문화, 용어의 법적 중요성, 각색 가능한 특정 용어에 관련된 언어 개량 정보 또는 도메인 특정 정보를 포함할 수 있다. 용어의 특성은 도 3의 블록(184)으로 표시된다. 사용자는 또한, 규칙이 새로운 규칙인지, 오래된 규칙인지, 또는 상대적으로 오래된 규칙인지 등을 사용자들이 나중에 결정할 수 있도록 각색 규칙 연대(age)를 입력할 수 있다. 이는 블록(186)에 의해 표시된다. 사용자는 또한 각색 가능한 용어가 속한 파일 이름이나 자원 ID를 포함할 수 있으며, 이는 블록(188)으로 표시된다. 사용자(126)는 블록(190)으로 표시된 바와 같이 그 밖의 코멘트도 제공할 수 있다. 물론, 이런 유형의 메타데이터는 단지 예를 들기 위한 것으로 그 밖의 다른 메타데이터(192)가 입력될 수도 있다.
어떤 경우라도, 사용자가 각색 규칙을 생성하면, 예를 들어, 아래의 표 1에 도시된 정보를 포함할 수 있다.
표 1
각색 ID - 각색 규칙에 대한 고유한 식별
조어 이름 - 조어 정보(LCID, 문화 이름이 될 수 있음) 등
각색된 언어 이름 - 각색된 언어 정보(LCID, 문화 이름이 될 수 있음) 등
소스 용어 - 각색이 실행되는 소스 용어(영어)
부모 번역 - 소스 용어에 대한 조어 번역
각색된 번역 - 소스 용어에 대한 각색된 언어 번역
각색 범위 - 전술함
각색 특성 - 문화, 법률 관련, 언어 개량, 도메인 특정을 비롯한 각색된 용어의 특성
각색 규칙 연대 - 특정 규칙이 새로운 것인지 오래된 것인지 결정, 이에 기반하여 각색 실행 범위가 결정될 수 있음
파일 이름, 자원 ID - 일부 각색 범위에서 유용함
코멘트 - 일반적인 수준의 코멘트
시스템(100)에서 일련의 각색 규칙(112)이 사용자(126)에 의해 생성되면, 조어 문서(122)에 규칙-기반 각색 규칙을 실행할 때 각색 엔진(104)에 의해 이 규칙들이 적용될 수 있다. 도 4a 및 4b(통칭해서 도 4라고 함)는 이와 같은 규칙-기반 프로세스를 실행할 때 시스템(100)의 동작의 일 실시예를 보여주는 순서도를 도시한다.
시스템(100)은 먼저 조어 문서(122)(또는 부모 문서(122))를 수신한다. 부모 문서(122)는 예를 들어, 조어 번역이 마무리되고 검증된 특정 문서 혹은 자원 파일일 수 있다. 각색을 위한 부모 문서 수신은 도 4의 블록(200)으로 표시된다. 다음으로 엔진(104)이 조어 문서(122)를 각색 문서에 복사하면, 이에 의해 각색 프로세스가 실행될 것이다. 이는 도 4의 블록(202)으로 표시된다.
그 후에 각색 엔진(104)은 이 각색 문서에 대해 데이터 저장소(108)에서 이용 가능한 이전 각색 번역이 있는지 여부를 결정한다. 이는 도 4의 블록(204)으로 표시된다. 예를 들어, 이전에 배포된 문서나 자원 파일에서, 각색 번역이 이미 완료되었을 수 있다. 그 경우에, 부모 문서(122)가 이전 발표에서와 동일할 때, 더 이상의 각색을 실행할 필요가 없고 단순히 이전 각색 번역이 복사될 수 있다. 물론, 부모 문서(122)의 개별 번역 유닛들은 마찬가지로 적용될 수 있는 이전의 번역 각색을 갖고 있을 수도 있다. 어떤 경우라도, 각색 엔진(104)은 현재 부모 문서에 적용될 수 있는 이전 각색 번역을 검색하고 적용하며, 이는 도 4의 블록(206)으로 표시된다. 이전 각색 번역을 식별하고 적용하는 것은 도 5와 관련하여 아래에서 더욱 상세하게 설명된다.
다음으로 각색 엔진(104)은 각색 문서의 모든 번역 유닛들을 식별하기 위해 각색 문서를 분석한다. 이는 도 4의 블록(208)으로 표시된다. 이후에 각색 엔진(104)은 추가 처리를 위해, 블록(208)에서 식별된 각색되지 않은 번역 유닛들 중 어느 하나를 선택한다. 이는 도 4의 블록(210)으로 표시된다.
이어서 각색 엔진(104)은 데이터 저장소(110)의 각색 규칙(112)에 선택된 번역 유닛을 매칭한다. 이는 도 4의 블록(212)으로 표시된다. 예시적인 일 실시예에서, 전체로 범위 지어진(globally scoped) 각색 규칙이 마지막으로 매칭된다. 따라서, (전체 범위 각색 규칙 이외의) 임의의 각색 규칙(112)이 규칙에서 정의된 범위에 기반하여 선택된 각색 유닛에 매칭되면, 대응하는 각색 번역(상기의 표 1 참조)이 각색 문서에 매칭되었던 각색 규칙으로부터 복사되고, (각색 번역 승인 상태를 나타내는) 각색 번역 상태 플래그가 "승인"으로 설정된다. 이와 같이 각색된 번역을 생성하기 위해 적용되었던 각색 규칙(112)에 관한 그 밖의 추가 세부 사항이 추가될 수 있다. 선택된 번역 유닛과 각색 규칙의 매칭, 및 각색된 번역과 승인 상태(및 기타 메타데이터)의 매칭 규칙으로부터의 각색 문서로의 복사는 도 4의 블록들(214 및 216)로 표시된다.
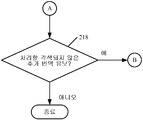
전체로 범위 지어진 각색 규칙이 선택된 번역 유닛에 매칭되는 것으로 발견되면, 번역 유닛에 대한 소스 용어가 단어로 토큰화되어(tokenized), 전체로 범위 지어진 각색 규칙의 각색된 용어에 대해 매칭되도록 전체로 범위 지어진 각색 규칙에 매칭된다. 매칭이 발견되면, 매칭된 규칙의 각색된 번역이 각색 문서에서 대응하는 각색된 번역을 대체하고, 각색 번역 승인 상태 플래그가 "승인됨" 대신에 "추가 검토"로 설정된다. 그 후에 각색 엔진(104)은 각색 문서에서 처리되어야 할 각색되지 않은 번역 유닛이 더 있는지 여부를 결정한다. 더 있다면, 각색되지 않은 다음 번역 유닛이 선택되는 블록(210)으로 처리가 되돌아 간다. 더 이상 없다면, 프로세스는 종료된다. 이는 도 4의 블록(218)으로 표시된다.
도 5는 (도 4의 블록(206)으로 표시되었던 것처럼) 이전 각색 번역이 각색 문서에 적용될 수 있는 방법을 보다 상세하게 도시하는 순서도이다. 일 실시예에서, 각색 엔진(104)은 먼저 이전 비즈니스 각색 번역 데이터 저장소(혹은 메모리)(108)에 액세스한다. 이는 도 5의 블록(220)으로 표시된다. 다음으로 각색 엔진(104)은 데이터 저장소(108)에 저장된 번역 유닛들에 대한 메타데이터에 액세스한다. 이는 블록(222)으로 표시된다. 이어서 엔진(104)은 데이터 저장소(108)의 각색 번역 유닛들 중 임의의 유닛이 각색 문서에 적용되는지 여부를 결정한다. 이는 도 5의 블록(224)으로 표시된다. 적용되지 않으면, 처리는 단순히 도 4의 블록(208)으로 진행된다. 그러나, 적용되면, 처리는 도 4의 "적용" 단계(206)로 진행되어, 이전에 각색된 번역과 관련 메타데이터를 각색 문서로 전파한다. 이는 도 5의 블록(226)으로 표시된다.
도 6은 사용자(126)가 검토할 문서를 생성할 때 (도 1에 도시된) 시스템(100)의 동작의 일 실시예를 도시하는 순서도이다. 먼저, 각색 엔진(104)은 예를 들어, 추가 검토가 실행되어야 할 것임을 나타내는 승인 상태를 갖고 있는 각색 문서의 모든 번역 유닛들을 식별한다. 이는 도 6의 블록(230)으로 표시된다.
다음으로 각색 엔진(104)은 사용자(126)의 검토를 위해 식별된 번역 유닛들을 디스플레이하도록 사용자 인터페이스 컴포넌트(114)를 사용하여 적절한 사용자 인터페이스 디스플레이(125)를 생성한다. 이는 도 6의 블록(232)으로 표시된다. 도 6a는 적절한 사용자 인터페이스 메커니즘(236)에서 추가 검토를 필요로 하는 번역 유닛들을 사용자(126)에게 디스플레이하기 위해 사용되는 예시적인 사용자 인터페이스 디스플레이(234)를 도시한다. 다음으로 사용자(126)는 문맥 혹은 그 밖의 언어학적인 문법 문제로 번역 유닛을 정정하는 편집(editing) 입력을 제공할 수 있다. 편집 입력의 수신은 도 6의 블록(238)으로 표시된다. 일 실시예에서, 편집 입력은 도 6a에 도시된 적절한 사용자 입력 메커니즘(240)을 통해서 제공될 수 있다.
사용자(126)가 번역 유닛을 승인하면, 사용자(126)는 이 각색 문서의 승인 상태를 "승인됨"으로 표시하기 위해 적절한 사용자 입력 메커니즘(240)을 통해 상태 표시기(242)를 수정할 수 있다. 이는 도 6의 블록(244)로 표시된다.
사용자 인터페이스 메커니즘(236)에 번역 유닛을 디스플레이할 때, 각색 엔진(234)은 사용자(126)의 검토를 위해 조어 번역 및 각색된 번역 또한 출력할 수 있다. 이는 번역 유닛 검토에 도움이 된다.
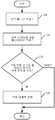
각색 문서가 충분히 검토되어 승인된 후에, 규칙 검증 컴포넌트(106)는 예를 들어, 각색 규칙들(112)이 정확하게 적용되었음을 검증한다. 도 7은 이런 검증의 실행 시의 규칙 검증 컴포넌트(106)의 동작의 일 실시예를 보다 상세하게 도시하는 순서도이다.
검증 컴포넌트(106)는 먼저 추가 검토가 실행되어야 함을 나타내는 상태를 여전히 갖고 있는 문서의 번역 유닛들을 식별하고 보고한다. 이들은, 사용자가 추가 행동을 취하고 이들을 "승인됨"으로 표시할 수 있도록 사용자(126)에게 디스플레이된다. 이는 도 7의 블록들(250 및 252)로 표시된다. 다음으로 규칙 검증 컴포넌트(106)는 각색 문서에 적용된 각색 규칙들(112)을 식별한다. 이는 블록(254)으로 표시된다.
다음으로 규칙 검증 컴포넌트(106)는 식별된 각색 규칙들이 적절하게 적용되었는지 여부를 확인한다. 이는 블록(256)으로 표시된다. 예를 들어, 규칙이 예외를 갖는 경우, 검증 컴포넌트(106)는 예외 상황에서 규칙이 확실히 적용되지 않게 한다. 즉, 검증 컴포넌트(106)는 규칙이 제외되어야 하는 곳에까지 남용되지 않도록 보장한다. 또한, 번역 유닛의 컨텍스트에서, 규칙 검증 컴포넌트(106)는 특정 각색 규칙에 더 이상의 예외가 추가되지 않도록 보장한다. 식별된 각색 규칙들이 적절하게 적용되었는지에 대한 결정은 그 밖의 다른 처리도 포함할 수 있으며, 도 7의 블록(258)으로 표시된다.
규칙에 수정이 필요하면, 필요에 따라 각색 컴포넌트(106)는 사용자(126)가 각색 규칙들(112)을 수정할 수 있게 하는 적절한 사용자 인터페이스(125)를 생성한다. 이는 도 7의 블록(260)으로 표시된다.
각색 규칙들(112) 중 임의의 규칙이 수정되었으면, 각색 규칙들(112)이 적절하게 적용되었는지 확인하기 위해 각색 엔진(104)은 각색 문서에 각색 번역 프로세스를 재실행한다. 이는 도 7의 블록(262)으로 표시된다. 이어서 각색 엔진(104)은 블록(264)으로 표시된 바와 같이 사용자(126)가 다시 각색 문서를 검토할 수 있게 하고, 처리는 규칙 검증 컴포넌트(106)가 다시 각색 규칙들이 적절하게 적용되었는지를 검증하기 시작하는 블록(250)으로 되돌아 간다.
블록(258)에서, 각색 규칙들이 적절하게 적용되었다고 규칙 검증 컴포넌트(106)에서 결정하면, 도 7의 블록(266)으로 표시된 바와 같이 각색 문서(124)(또는 각색된 언어 문서(124))가 출력된다. 문서(124)는 블록(268)으로 표시된 바와 같이 사용자 인터페이스 디스플레이를 디자인하거나 테스트하는 데 사용될 수 있고, 또는 단순히 비즈니스 제품(118)에 복사될 수도 있다. 이는 도 7의 블록(270)으로 표시된다.
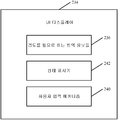
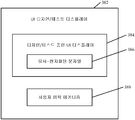
도 8은 사용자 인터페이스 생성 또는 테스트 시스템(300)을 도시하는 블록도이다. 도 8에 도시된 아키텍처에서, 시스템(300)은 번역 크기 서비스(302)와 클라이언트(304)를 포함한다. 클라이언트(304)는 특정 제품에서 사용자 인터페이스를 생성하거나 사용자 인터페이스의 디자인을 테스트하기 위해 사용자(306)에 의해 사용된다. 또한 도 8은 시스템(300)이 기존의 번역 저장소(306)와 번역 컴포넌트(308)에 액세스하고 있음을 보여준다. 물론, 기존의 번역 저장소(306)와 번역 컴포넌트(308)는 서비스(302)의 일부이거나 서비스(302)와 원격일 수 있다. 또한, 클라이언트/서비스 아키텍처는 아키텍처의 일례에 불과하며, 클라이언트 및 서비스 양쪽 모두의 일부분들이 결합되거나 분리될 수 있고 다른 아키텍처로 이용될 수도 있다.
도 8에 도시된 실시예에서, 번역 크기 서비스(302)는 프로세서(310), 번역 식별기(identifier)(312), 및 크기 계산 컴포넌트(314)를 포함한다. 클라이언트(304)는 예를 들어, 프로세서(316), 소스 문자열 식별기(318), 유사-현지화된 문자열 생성기(320), 및 사용자 인터페이스(UI) 디자인/테스트 컴포넌트(322)를 포함하고 있다.
데이터 저장소(306)와 컴포넌트(308)는 서비스(302)의 일부일 수 있거나 또는 서비스(302)와 분리될 수 있음을 알아야 한다. 또한, 일 실시예에서, 프로세서들(310 및 316)은 관련 메모리와 타이밍 회로(도시되지 않음)를 갖는 컴퓨터 프로세서들이다. 프로세서들(310 및 316)은 각각 서비스(302)와 클라이언트(304)의 기능부를 형성하고, 다른 컴포넌트들, 또는 서비스(302)와 클라이언트(304)의 생성기 또는 그 밖의 아이템들의 기능을 하게 한다.
시스템(300)의 상세한 동작은 도 9와 관련하여 아래에서 논의될 것이지만, 개관을 위해 여기서 간략하게 논의될 것이다. 일반적으로, 클라이언트(304)는, 예를 들어, 현지화될 아이템(324)을 수신한다. 이 아이템은, 예를 들어, 자원 파일로부터의 문자열이거나 그 밖의 임의의 아이템일 수 있다. 다음으로 클라이언트(304)는 소스 문자열(326)을 아이템(324)로부터 번역 크기 서비스(302)로 전송한다. 이어서 서비스(302)는 저장소(306)에 소스 문자열(326)의 기존 번역이 있는지 여부를 식별한다. 없다면, 서비스(302)는 소스 문자열(326)을 번역하는 번역 컴포넌트(308)에 소스 문자열(326)을 제공한다. 다음으로 목표 언어에서 사용되는 특정 폰트(330)에 기반하여, 이용 가능한 번역 후보들(328)의 (정방형 픽셀들(square pixels)의 단위와 같은) 정방형 단위로 그 크기를 계산하는 크기 계산 컴포넌트(314)로 이용 가능한 번역 후보들(328)이 제공된다. 그 후에 서비스(302)는 선택된 번역 후보의 영역(332)을 다시 클라이언트(304)에 제공한다. 유사-현지화된 문자열 생성기(320)는 서비스(302)가 전송한 영역(332)과 거의 같은 크기의 유사-현지화된 문자열(334)을 생성한다. 블록(336)으로 표시된 바와 같이 유사-현지화된 문자열을 갖는 사용자 인터페이스 디스플레이를 생성하거나 테스트하기 위해, UI 디자인/테스트 컴포넌트(322)에서 유사-현지화된 문자열(334)을 사용할 수 있다.
도 9a 및 9b(총괄하여 도 9)는 시스템(300)의 전체 동작을 보여주는 순서도를 보다 상세하게 도시한다. 클라이언트(304)는 먼저 소스 문자열과 그 소스 문자열의 컨텍스트를 수신한다. 일 실시예에서, 그 컨텍스트와 함께 소스 문자열(326)은 현지화될 아이템(324)의 소스 문자열 식별기(318)에 의해 식별된다. 일 실시예에서, 소스 문자열 식별기(318)는 현지화될 아이템(324)을 하나 이상의 다른 소스 문자열로 나눈다. 다음으로 소스 문자열(326) 중 선택된 어느 하나가 (그 컨텍스트와 함께) 클라이언트(304)에 의해 번역 크기 서비스(302)로 제공된다. (그 컨텍스트와 함께) 소스 문자열을 수신하고 소스 문자열과 컨텍스트를 서비스(302)로 전송하는 단계는 각각 도 9의 블록들(350 및 352)로 표시된다.
그 후에 번역 식별기(312)는 기존의 번역 저장소(306)에서 소스 문자열(326)의 하나 이상의 목표 언어로 된 기존의 번역을 검색한다. 이는 도 9의 블록(354)으로 표시된다. 번역 식별기(312)는 데이터 저장소(306)에 이미 존재하는 가능한 모든 후보 번역을 식별한다.
저장소(306)에 기존의 번역이 없는 경우(기존의 번역이 있더라도 선택적으로), 번역 식별기(312)는 소스 문자열(326)이 번역되도록 번역 컴포넌트(308)에 소스 문자열(326)을 전송한다. 기존의 번역이 있는지 여부의 결정과 번역 컴포넌트(308)로의 소스 문자열(326)의 전송은 각각 도 9의 블록들(356 및 358)로 표시된다. 번역 컴포넌트(308)는 통계적인 또는 규칙-기반의 번역 컴포넌트와 같이 기계 번역 컴포넌트일 수 있다. 물론, 이는 자연 언어 처리 능력 및 그 밖의 번역 기능도 포함할 수 있다. 어떤 경우라도, 번역 식별기(312)는 하나 이상의 이용 가능한 번역 후보(328)를 얻는다. 이는 도 9의 블록(360)으로 표시된다.
이용 가능한 번역 후보들(328)을 얻을 때, 번역 식별기(312)는 여러 다른 접근 방법을 사용할 수 있음을 알아야 한다. 이는 사용자(307)가 설정 가능하거나 그렇지 않을 수도 있다. 예를 들어, 번역 식별기(312)는 선택된 언어에 대한 모든 번역 후보들을 식별할 수 있다. 이는 도 9의 블록(362)으로 표시된다. 대신에, 아니면 이에 더해서, 번역 식별기(312)는 소스 문자열(326)의 모든 언어에 대한 모든 번역을 얻을 수 있다. 이는 도 9의 블록(364)으로 표시된다. 물론, 번역 식별기(312)는 언어에 상관 없이, 단지 가장 긴 번역과 같이, 그 밖의 다른 번역들도 얻을 수 있다. 이는 블록(366)으로 표시된다. 번역 식별기(312)는 물론, 블록(368)으로 표시된 바와 같이 가장 짧은 번역을 얻을 수도 있고, 또는 블록(370)으로 표시된 바와 같이 그 밖의 다른 번역 후보들, 또는 그들의 부분 집합을 얻을 수도 있다.
다음으로 크기 계산 컴포넌트(314)는 번역 식별기(312)가 제공한 이용 가능한 번역 후보들(328) 각각의 크기를 계산한다. 이는 다양한 다른 단위를 사용하여 실행될 수 있다. 일 실시예에서, 컴포넌트(314)는 정방형 픽셀로 이용 가능한 번역 후보들(328)의 영역을 계산한다. 일 실시예에서, 그 영역은 일부 유형의 사용자 인터페이스 디스플레이 단위로 계산된다. 이는 (평방 인치, 평방 센티미터 등과 같은) 측정 단위이거나, 또는 정방형 픽셀과 같이 다른 유형의 디스플레이 단위일 수 있다. 이는 도 9의 블록(372)으로 표시된다. 영역 계산 시에, 크기 계산 컴포넌트(314)는 이용 가능한 각각의 번역 후보(328)와 함께 사용되는 특정 폰트(330)를 고려한다. 예를 들어, 일부 컴퓨터 시스템은 사용되는 특정 언어에 따라 다른 폰트들을 사용한다. 크기 계산 컴포넌트(314)는 이용 가능한 번역 후보들(328) 각각의 영역을 계산할 때 이들 폰트(330)의 크기를 고려한다.
다음으로 번역 식별기(312)는 크기 및 컨텍스트에 기반하여 원하는 번역을 식별하기 위해 다양한 번역 후보들을 비교한다. 일 실시예에서, 번역 식별기(312)는 그 크기에 기반하여 특정 번역을 선택하기 위해, 디자인 중인 제품의 특성과 소스 문자열(326)의 특성이나 컨텍스트를 인식한다. 예를 들어, 모바일 애플리케이션의 번역은 모바일 장치에서 이용할 수 있는 제한된 디스플레이 공간으로 인해 데스크탑 애플리케이션의 번역보다 더 짧은 경향이 있다. 또한, 소스 문자열의 목적으로 인해 메뉴 이름의 번역이 오류 메시지의 번역보다 더 짧은 경향이 있다. 일 실시예에서, 번역 식별기(312)는 장치 및 소스 문자열 및 제품의 목적과 특성을 고려할 뿐만 아니라, 소스 문자열(326)의 그 밖의 컨텍스트 아이템들도 포함하고 있다. 번역 식별기(312)는 이용 가능한 번역 후보들(328)에 가중치를 주기 위해서 이런 컨텍스트 정보를 사용하고, 그 가중치에 기반하여 그리고 이용 가능한 번역 후보들(328)의 (예컨대, 정방형 픽셀의) 크기에 기반하여 이용 가능한 번역 후보들 중 어느 하나를 선택한다. 이는 도 9의 블록(374)으로 표시된다.
번역 식별기(312)가 원하는 번역 후보를 식별한 경우, 크기 계산 컴포넌트(314)는 선택된 번역의 영역을 클라이언트(304)로 전송한다. 일례로, 번역 식별기(312)가 가장 긴 번역을 식별하고, 따라서 크기 계산 컴포넌트(314)가 가장 긴 번역 후보의 영역(332)을 클라이언트(304)로 전송한다. 물론, 어떤 번역이 선택되더라도, 크기 계산 컴포넌트(314)는 선택된 번역의 영역을 클라이언트(304)로 전송한다. 이는 도 9의 블록(376)으로 표시된다.
다음으로 유사-현지화된 문자열 생성기(320)는 서비스(302)로부터 수신한 영역(332)과 거의 동일한 크기의 유사-현지화된 문자열(334)을 생성한다. 유사-현지화된 문자열을 생성하는 데에는 여러 다른 방식들이 있다. 예를 들어, 유사-현지화된 문자열 생성기(320)는 서비스(302)로부터 수신한 것과 동일한 영역을 갖는 한, 유사-현지화된 문자열로서 랜덤 글자들(random characters)을 조합할 수 있다. 물론, 생성기(320)는 선택된 번역 자체를 포함하는, 비-랜덤 또는 유사-랜덤 글자들, 또는 그 밖의 다른 글자 셋이나 조합을 사용할 수도 있다. 어떤 경우라도, 계산된 영역(332)에 기반한 유사-현지화된 문자열의 생성 단계는 도 9의 블록(378)으로 표시된다.
다음으로 생성기(320)는, 유사-현지화된 문자열(334)이 사용자 인터페이스 디스플레이를 생성하거나, 이미-생성된 사용자 인터페이스 디스플레이를 현지화된 제품으로 현지화하거나, 절단(truncation) 오류, 워드랩(word wrap) 오류, 또는 그 밖의 유형의 오류 등을 식별하기 위해 사용자 인터페이스 디스플레이를 테스트하는 데 사용될 수 있는 UI 디자인/테스트 컴포넌트(322)로 유사-현지화된 문자열(334)을 출력한다. UI 디스플레이의 생성 또는 테스트 시에 사용되도록 유사-현지화된 문자열을 출력하는 단계는 도 9의 블록(380)으로 표시된다.
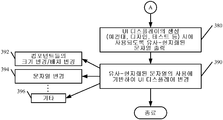
일 실시예에서, UI 디자인/테스트 컴포넌트(322)는 사용자 인터페이스 디스플레이 상에 유사-현지화된 문자열을 갖는 UI(336)를 사용자(307)에게 제공한다. 도 10은 사용 가능한 사용자 인터페이스 디스플레이(382)의 일 실시예를 도시한다. UI 디자인/테스트 디스플레이(382)는 현재 디자인 중이거나 테스트 중인 특정 사용자 인터페이스 디스플레이 또는 사용자 인터페이스 스크린의 디스플레이를 포함한다. 이는 도 10의 블록(384)으로 표시된다. UI 디스플레이(384)는 예를 들어, (텍스트 상자 또는 기타 사용자 인터페이스 디스플레이 요소와 같은) 사용자 인터페이스 디스플레이 요소(386)에 유사-현지화된 문자열을 포함한다. 또한, 디스플레이 요소(386)에서 유사-현지화된 문자열의 크기를 수용하기 위해서, 디스플레이(382)는 예를 들어, 사용자(307)가 현재 디자인 중이거나 테스트 중인 UI 디스플레이(384)에 수정을 가할 수 있게 하는 사용자 입력 메커니즘(388)을 제공한다. 유사-현지화된 문자열의 사용에 기반하여 UI 디스플레이를 변경하는 단계는 도 9의 블록(390)으로 표시된다. 물론, 이런 변경은 매우 다양한 변경일 수 있다. 예를 들어, 사용자(307)는 유사-현지화된 문자열에 기반하여 (디스플레이 아이템(386)과 같은) 사용자 인터페이스 컴포넌트들의 크기 변경 또는 배치 변경을 할 수 있다. 이는 블록(392)으로 표시된다. 사용자(307)는 문자열을 변경하여 이를 더 크게 또는 더 작게 할 수 있다. 이는 블록(394)으로 표시된다. 물론, 사용자(307)는 블록(396)으로 표시된 바와 같이 그 밖의 다른 변경도 할 수 있다.
따라서, 시스템(300)은 실제의 기존 번역이나 기계 번역에 기반하여 유사-현지화된 문자열의 크기를 바꾼다고 볼 수 있다. 이는 (정방형 픽셀 또는 기타 단위와 같은) 평방 단위로 특정 문자열이 차지할 스크린 영역을 계산한다. 또한, 그런 크기의 유사-현지화된 문자열을 생성하는 데 사용될 수 있는 번역들의 범위를 좁히기 위해 컨텍스트에 의존한다. 이는 소스 문자열의 도메인, 제품 디자인 중인 장치, 소스 문자열이 비롯된 장치, 소스 문자열의 특정 특성, 또는 그 밖의 컨텍스트 정보에 기반하여 실행될 수 있다. 게다가, 시스템은 유사-현지화된 문자열에 대한 크기를 얻을 때, 생성될 최종적인 문자열의 특정 폰트 및 스타일을 동적으로 고려한다. 이는, 새로운 운영 체제 또는 애플리케이션이 다수의 장치들에 제공되거나 또는 언어들 중에서 일반 폰트와는 다른 문자형(glyph)을 갖는 새로운 폰트를 소개할 때, UI 디자인을 개선하지만, UI 문자열이나 중대한 디자인 변경을 필요로 하지는 않는다.
도 11은 클라우드 컴퓨팅 아키텍처(500)를 포함하는 다양한 아키텍처로 도시되는 시스템(100 및 300)의 블록도이다. 클라우드 컴퓨터는, 서비스를 전달하는 시스템의 물리적 위치 혹은 구성에 대한 최종 사용자의 지식을 요하지 않는 계산, 소프트웨어, 데이터 액세스, 및 저장 서비스를 제공한다. 다양한 실시예에서, 클라우드 컴퓨팅은 적절한 프로토콜을 이용해 인터넷과 같은 광역 통신망을 통해 서비스를 전달한다. 예를 들어, 클라우드 컴퓨팅 제공자는 광역 통신망을 통해 애플리케이션을 전달하며, 웹 브라우저 또는 임의의 그 밖의 다른 컴퓨팅 컴포넌트를 통해 액세스될 수 있다. 시스템(100 및 300)의 소프트웨어 또는 컴포넌트 및 대응하는 데이터가 원격지의 서버 상에 저장될 수 있다. 클라우드 컴퓨팅 환경 내 컴퓨팅 자원이 원격 데이터 센터 위치에서 통합되거나 분산될 수 있다. 클라우드 컴퓨팅 기반 시설은 이들이 사용자를 위한 단일 액세스 포인트로서 보일지라도, 공유 데이터 센터를 통해 서비스를 전달할 수 있다. 따라서, 본 명세서에 기재된 컴포넌트 및 기능은 클라우드 컴퓨팅 아키텍처를 이용해 원격지에 있는 서비스 제공자로부터 제공될 수 있다. 대안적으로, 이들은 종래의 서버로부터 제공되거나 클라이언트 장치 상에 직접 또는 그 밖의 다른 방식으로 설치될 수 있다.
설명은 공공 클라우드 컴퓨팅과 개인 클라우드 컴퓨팅 모두를 포함하는 것을 의도한다. 클라우드 컴퓨팅(공공 및 개인 모두)은 실질적으로 매끄러운 자원의 풀링(pooling)을 제공하는 것은 물론, 기저의 하드웨어 기반 시설을 관리하고 구성할 필요를 감소시킨다.
공공 클라우드는 판매 회사가 관리하고, 통상적으로 동일한 기반 시설을 사용하여 다수의 소비자들을 지원한다. 또한, 개인 클라우드와는 달리, 공공 클라우드는 최종 사용자들을 하드웨어 관리에서 자유롭게 할 수 있다. 개인 클라우드는 조직 자체에서 관리되며, 기반 시설은 통상적으로 다른 조직과 공유되지 않는다. 조직은 설치 및 보수 등과 같이, 어느 정도까지는 여전히 하드웨어를 유지한다.
도 11에 도시된 실시예는 시스템(100 및 300)의 전체 또는 일부가 (공공, 개인, 또는 일부는 공공이고 일부는 개인인 조합일 수 있는) 클라우드(502)에 위치할 수 있음을 구체적으로 도시한다. 따라서, 사용자(126, 307)는 사용자 장치(504)를 사용하여 클라우드(502)를 통해 이들 시스템에 액세스한다.
또한 도 11은 클라우드 아키텍처의 또 다른 실시예를 도시한다. 도 11은 시스템(100 및 300)의 일부 요소들이 클라우드(502)에 배치되고 다른 요소들은 배치되지 않는 경우도 고려하고 있음을 도시한다. 예를 들어, 데이터 저장소들(108, 110, 306)은 클라우드(502) 밖에 배치되어 클라우드(502)를 통해 액세스될 수 있다. 또 다른 실시예에서, 시스템(100 및 300)의 컴포넌트들의 일부 또는 전부가 역시 클라우드(502)의 바깥에 있다. 어디에 배치가 되었는지와 상관 없이, 이들은 (광역 통신망 또는 근거리 통신망 중 어느 하나인) 네트워크를 통해 장치(504)에 의해 직접 액세스될 수 있고, 서비스에 의해 원격 사이트에서 호스팅될 수 있으며, 또는 클라우드를 통해 서비스로서 제공되거나 클라우드에 속한 접속 서비스에 의해 액세스될 수 있다. 나아가 도 11은 시스템(100 및 300)의 전체 또는 일부가 장치(504)에 위치할 수 있음을 도시한다. 이런 아키텍처의 전부가 본원에서 고려된다.
또한 시스템(100 및 300) 또는 그 일부가 아주 다양한 장치들에 배치될 수도 있음을 알 것이다. 이들 장치의 일부는 서버, 데스크탑 컴퓨터, 랩탑 컴퓨터, 태블릿 컴퓨터와, 또는 팝탑(palm top) 컴퓨터, 휴대 전화, 스마트폰, 멀티미디어 플레이어, PDA 등과 같은 기타 모바일 장치들을 포함한다.
도 12는 본 발명의 시스템(또는 이의 일부분)이 배치될 수 있는 사용자 또는 클라이언트의 핸드헬드 장치(16)로서 사용될 수 있는 핸드헬드 또는 모바일 컴퓨팅 장치의 하나의 예시적인 실시예의 단순화된 블록도이다. 도 13-16은 핸드헬드 또는 모바일 장치의 예시이다.
도 12는 시스템(100) 또는 시스템(300)의 컴포넌트를 운영할 수 있거나 시스템(100 또는 300)과 인터랙션하는, 또는 이들 둘 모두를 하는 클라이언트 장치(16)의 컴포넌트의 일반적인 블록도를 제공한다. 장치(16)에서, 핸드헬드 장치가 다른 컴퓨팅 장치와 통신할 수 있게 하고 일부 실시예에서 자동으로, 가령, 스캐닝에 의해 정보를 수신하기 위한 채널을 제공하는 통신 링크(13)가 제공된다. 통신 링크(13)의 예시로는 적외선 포트, 직렬/USB 포트, 케이블 네트워크 포트, 가령, 이더넷 포트, 및 셀룰러 액세스를 네트워크로 제공하도록 사용되는 무선 서비스인 GPRS(General Packet Radio Service), LTE, HSPA, HSPA+, 및 기타 3G 및 4G 무선 프로토콜, 1Xrtt, 및 단문 메시지 서비스를 포함하는 하나 이상의 통신 프로토콜은 물론, 로컬 무선 연결을 네트워크로 제공하는 802.11 및 802.11b (Wi-Fi) 프로토콜 및 블루투스(Bluetooth) 프로토콜을 통한 통신을 가능하게 하는 무선 네트워크 포트를 포함한다.
그 밖의 다른 실시예에 따라, (시스템(100) 또는 시스템(300)과 같은) 애플리케이션 또는 시스템이 SD(Secure Digital) 카드 인터페이스(15)로 연결되는 이동식 SD 카드 상에서 수신된다. SD 카드 인터페이스(15) 및 통신 링크(13)는 메모리(21) 및 입/출력(I/O) 컴포넌트(23)는 물론, 클록(25) 및 측위 시스템(location system, 27)으로도 연결된 버스(19)를 따라 프로세서(17)(도 1의 프로세서(100) 또는 도 8의 프로세서(310 및 316)를 구현할 수도 있음)와 통신한다.
일 실시예에서, I/O 컴포넌트(23)는 입출력 연산을 촉진하도록 제공된다. 장치(16)의 다양한 실시예에 대한 I/O 컴포넌트(23)는 입력 컴포넌트, 가령, 버튼, 터치 센서, 멀티-터치 센서, 광학 또는 비디오 센서, 음성 센서, 터치 스크린, 근접도 센서, 마이크로폰, 틸트 센서 및 중력 스위치와, 출력 컴포넌트, 가령, 디스플레이 장치, 스피커 및/또는 프린터 포트를 포함할 수 있다. 그 밖의 다른 I/O 컴포넌트(23)도 사용될 수 있다.
예를 들어, 클록(25)은 시각과 날짜를 출력하는 실시간 클록 컴포넌트를 포함한다. 또한 예를 들어, 프로세서(17)를 위한 타이밍 기능을 제공할 수 있다.
예를 들어, 측위 시스템(27)은 장치(16)의 지리적인 현 위치를 출력하는 컴포넌트를 포함한다. 예를 들어, 이는 GPS(global positioning system) 수신기, LORAN 시스템, 추측 항법 시스템(dead reckoning system), 셀룰러 삼각 측량 시스템, 또는 그 밖의 다른 위치 결정 시스템을 포함할 수 있다. 또한 예를 들어, 이는 원하는 맵, 네비게이션 경로, 및 그 밖의 다른 지리적 기능을 생성하는 매핑 소프트웨어 또는 네비게이션 소프트웨어를 포함할 수 있다.
메모리(21)는 운영 체제(29), 네트워크 설정(31), 애플리케이션(33), 애플리케이션 구성 설정(35), 데이터 저장소(37), 통신 드라이버(39) 및 통신 구성 설정(41)을 저장한다. 메모리(21)는 모든 종류의 유형(tangible) 휘발성 및 비휘발성 컴퓨터 판독 가능 메모리 장치를 포함할 수 있다. 또한 메모리는 컴퓨터 저장 매체를 더 포함할 수 있다(이하에서 설명됨). 메모리(21)는 프로세서(17)에 의해 실행될 때 프로세서로 하여금 명령에 따라 컴퓨터-구현 단계 또는 기능을 수행하도록 하는 컴퓨터 판독 가능 명령어를 저장한다. 예를 들어, 시스템(100 또는 300) 또는 데이터 저장소(108, 110, 306)의 아이템들이 메모리(21)에 상주할 수 있다. 마찬가지로, 장치(16)는 다양한 비즈니스 애플리케이션을 실행하거나 시스템(100) 또는 시스템(300)의 일부 혹은 전부를 구현하거나 이들 모두를 할 수 있는 클라이언트 비즈니스 시스템(24)을 가질 수 있다. 프로세서(17)는 그들 기능을 촉진하기 위해 다른 컴포넌트에 의해서도 활성화될 수 있다.
네트워크 설정(31)의 예시는 프록시 정보, 인터넷 연결 정보, 및 맵핑 등을 포함한다. 애플리케이션 구성 설정(35)은 특정 기업 또는 사용자에게 애플리케이션을 맞춤구성하는 설정을 포함한다. 통신 구성 설정(41)은 그 밖의 다른 컴퓨터와 통신하기 위한 파라미터를 제공하고 GPRS 파라미터, SMS 파라미터, 연결 사용자 이름 및 비밀번호와 같은 아이템들을 제공한다.
애플리케이션(33)은 장치(16)에 이전에 저장된 애플리케이션 또는 사용 중에 설치된 애플리케이션일 수 있으며, 이들은 운영 체제(29)의 일부이거나 장치(16) 외부에서 호스팅될 수도 있다.
도 13 및 14는 장치(16)가 태블릿 컴퓨터(600)인 일 실시예를 도시한다. 도 13에서, 컴퓨터(600)는 도 3a의 사용자 인터페이스 디스플레이가 디스플레이된 디스플레이 스크린(602)으로 도시된다. 도 14는 도 10의 사용자 인터페이스 디스플레이가 디스플레이된 컴퓨터(600)를 도시한다. 스크린(602)은 터치 스크린이거나(따라서, 애플리케이션과 인터랙션하도록 사용자의 손가락(605)의 터치 제스처가 사용될 수 있음) 또는 펜 혹은 스타일러스로부터 입력을 수신하는 펜-사용 가능한 인터페이스일 수 있다. 또한 온-스크린 가상 키보드를 사용할 수도 있다. 물론, 이는 예를 들어, 무선 링크 혹은 USB 포트와 같이 적절한 부착 메커니즘을 통해 키보드 혹은 그 밖의 사용자 입력 장치에 부착될 수도 있다. 예를 들어, 컴퓨터(600)는 음성 입력도 수신할 수 있다.
도 15 및 16은 사용될 수 있는 장치(16)의 예시를 제공하지만, 그 밖의 다른 것도 역시 사용될 수 있다. 도 15에서, 스마트 폰 또는 모바일 폰(45)이 장치(16)로서 제공된다. 폰(45)은 전화 번호를 다이얼링하기 위한 키패드(47), 애플리케이션 이미지, 아이콘, 웹 페이지, 사진, 및 비디오를 포함하는 이미지를 디스플레이할 수 있는 디스플레이(49), 및 디스플레이 상에서 나타난 아이템을 선택하기 위한 제어 버튼(51)으로 구성된 세트를 포함한다. 상기 폰은 GPRS(General Packet Radio Service) 및 1Xrtt, 및 단문 메시지 서비스 신호를 비롯한 셀룰러 폰 신호를 수신하기 위한 안테나(53)를 포함한다. 일부 실시예에서, 폰(45)은 SD 카드(57)를 수용하는 SD 카드 슬롯(55)을 더 포함한다.
도 16의 모바일 장치는 PDA(59) 또는 멀티미디어 재생기 또는 태블릿 컴퓨팅 장치 등(이하, PDA(59)로 지칭됨)이다. PDA(59)는 스타일러스(63)가 스크린 위에 놓일 때 상기 스타일러스(63)(또는 다른 포인터, 가령, 사용자의 손가락)의 위치를 감지하는 유도성 스크린(61)을 포함한다. 이는 사용자가 스크린 상의 아이템을 선택, 강조, 및 이동시킬 수 있게 할 뿐 아니라 그리고(draw) 쓸(write) 수 있게 한다. 또한 PDA(59)는 디스플레이(61)를 접촉하지 않고, 사용자가 디스플레이(61) 상에 디스플레이되는 메뉴 옵션 또는 그 밖의 다른 디스플레이 옵션을 통해 스크롤할 수 있게 하고 사용자가 애플리케이션을 변경하거나 사용자 입력 기능을 선택할 수 있게 하는 다수의 사용자 입력 키 또는 버튼(가령, 버튼(65))을 포함한다. 도시되지 않았지만, PDA(59)는 다른 컴퓨터와의 무선 통신을 가능하게 하는 내부 안테나 및 적외선 송신기/수신기와 다른 컴퓨팅 장치로의 하드웨어 연결을 가능하게 하는 연결 포트를 포함할 수 있다. 일반적으로 이러한 하드웨어 연결은 직렬 또는 USB 포트를 통해 다른 컴퓨터로 연결되는 크래들(cradle)을 통해 이뤄진다. 따라서 이들 연결은 비-네트워크 연결이다. 일 실시예에서, 모바일 장치(59)는 SD 카드(69)를 수용하는 SD 카드 슬롯(67)을 더 포함한다.
다른 형태의 장치들(16)도 가능함을 알 것이다.
도 17은 (예를 들어) 시스템(100) 또는 시스템(300)이 배치될 수 있는 컴퓨팅 환경의 일 실시예이다. 도 17을 참조하면, 일부 실시예를 구현하는 예시적 시스템이 컴퓨터(810)의 형태로 된 범용 컴퓨팅 장치를 포함한다. 컴퓨터(810)의 컴포넌트는, (프로세서(102, 310 또는 316)를 포함할 수 있는) 처리 장치(820), 시스템 메모리(830), 및 시스템 메모리를 포함하는 다양한 시스템 컴포넌트들을 처리 장치(820)로 연결하는 시스템 버스(821)를 포함할 수 있지만, 이에 제한되지는 않는다. 시스템 버스(821)는 몇 가지 유형의 버스 구조 중 임의의 것일 수 있으며, 가령, 메모리 버스 또는 메모리 제어기, 주변 장치 버스, 및 다양한 버스 아키텍처 중 임의의 것을 이용하는 로컬 버스일 수 있다. 예를 들어, 그러나 제한 없이, 이러한 아키텍처는 산업 표준 아키텍처(ISA: Industry Standard Architecture) 버스, 마이크로 채널 아키텍처(MCA: Micro Channel Architecture) 버스, 강화된 ISA(EISA: Enhanced ISA) 버스, 비디오 일렉트로닉스 표준 연합(VESA: Video Electronics Standards Association) 로컬 버스, 및 메자닌 버스(Mezzanine bus)라고도 알려진 주변 장치 인터커넥트(PCI: Peripheral Component Interconnect) 버스를 포함한다. 도 1-10과 관련하여 설명한 메모리 및 프로그램이 도 17의 대응 부분에 배치될 수 있다.
컴퓨터(810)는 통상 다양한 컴퓨터 판독 가능 매체를 포함할 수 있다. 컴퓨터 판독 가능 매체는 컴퓨터(810)에 의해 액세스될 수 있고, 휘발성 및 비휘발성 매체, 이동식 및 비이동식 매체 모두를 포함하는 이용 가능한 임의의 매체일 수 있다. 예를 들어, 그러나 제한 없이, 컴퓨터 판독 가능 매체는 컴퓨터 저장 매체 및 통신 매체를 포함할 수 있다. 컴퓨터 저장 매체는 변조된 데이터 신호 또는 반송파와는 다르고, 이를 포함하지는 않는다. 컴퓨터 저장 매체는 컴퓨터 판독 가능한 명령어, 데이터 구조, 프로그램 모듈 또는 다른 데이터와 같은 정보를 저장하는 임의의 방법 또는 기술로 구현되는 휘발성 및 비휘발성, 이동식 및 비이동식 매체를 포함하는 하드웨어 저장 매체를 포함한다. 컴퓨터 저장 매체는 RAM, ROM, EEPROM, 플래시 메모리 또는 다른 메모리 기술, CD-ROM, DVD(digital versatile disk) 또는 다른 광 디스크 저장 장치, 자기 카세트, 자기 테이프, 자기 디스크 저장 또는 다른 자기 저장 장치, 또는 원하는 정보를 저장하는 데 이용될 수 있고, 컴퓨터(810)에 의해 액세스될 수 있는 임의의 다른 매체를 포함하지만, 이에 제한되지 않는다. 일반적으로 통신 매체는 컴퓨터 판독가능 명령어, 데이터 구조, 프로그램 모듈, 또는 전송 메커니즘의 기타 데이터로 구현하고, 임의의 정보 전달 매체를 포함한다. "변조된 데이터 신호"라는 용어는 신호 내에서 정보를 인코딩하도록 그 특징들 중 하나 이상이 설정 또는 변경된 신호를 의미한다. 예를 들어, 그러나 제한 없이, 통신 매체는 유선 네트워크 또는 직접 배선된 연결과 같은 유선 매체, 및 음향, RF, 적외선 및 그 밖의 다른 무선 매체와 같은 무선 매체를 포함한다. 상기의 임의의 조합은 컴퓨터 판독 가능 매체의 범주 내에 또한 포함되어야 한다.
시스템 메모리(830)는 ROM(read only memory)(831) 및 RAM(random access memory)(832)과 같은 휘발성 및/또는 비휘발성 메모리의 형태의 컴퓨터 저장 매체를 포함한다. 예컨대, 시동 중에, 컴퓨터(810) 내의 요소들 사이로 정보를 전달하는 데 도움을 주는 기본적 루틴을 포함하는 기본적 입력/출력 시스템(833)(BIOS)은 일반적으로 ROM(831) 내에 저장된다. RAM(832)은 일반적으로 처리 장치(820)에 즉시 액세스 가능하고 및/또는 처리 장치(820)에 의해 현재 동작되는 데이터 및/또는 프로그램 모듈을 포함한다. 예컨대, 그러나 제한 없이, 도 17은 운영 체제(834), 애플리케이션 프로그램(835), 다른 프로그램 모듈(836) 및 프로그램 데이터(837)를 도시한다.
컴퓨터(810)는 다른 이동식/비이동식, 휘발성/비휘발성 컴퓨터 저장 매체를 포함할 수 있다. 단지 예를 들면, 도 17은 비이동식, 비휘발성 자기 매체로부터/로 읽고/쓰기를 하는 하드 디스크 드라이브(841), 이동식, 비휘발성 자기 디스크(852)로부터/로 읽고/쓰기를 하는 자기 디스크 드라이브(851), 및 CD ROM 또는 다른 광 매체와 같은 이동식, 비휘발성 광 디스크(856)로부터/로 읽기/쓰기를 하는 광 디스크 드라이브(855)를 도시한다. 예시적인 운영 환경에 사용될 수 있는 다른 이동식/비이동식, 휘발성/비휘발성 유형의 컴퓨터 저장 매체로는 자기 테이프 카세트, 플래시 메모리 카드, DVD(digital versatile disks), 디지털 비디오 테이프, 고체 상태 RAM, 고체 상태 ROM 등이 포함되나 그러한 것에 국한되지 않는다. 하드 디스크 드라이브(841)는 통상적으로 인터페이스(840)와 같은 비이동식 메모리 인터페이스를 통해 시스템 버스(821)에 연결되고, 자기 디스크 드라이브(851) 및 광 디스크 드라이브(855)는 통상적으로 인터페이스(850)와 같은 이동식 메모리 인터페이스를 통해 시스템 버스(821)에 연결된다.
상기에서 논의되고 도 17에 도시된 드라이브들 및 그 관련 컴퓨터 저장 매체는 컴퓨터(810)에 컴퓨터 판독 가능 명령어, 데이터 구조, 프로그램 모듈 및 기타 데이터의 저장을 지원한다. 도 17에서, 예를 들어 하드 디스크 드라이브(841)는 운영 체제(844), 애플리케이션 프로그램(845), 기타 프로그램 모듈(846), 및 프로그램 데이터(847)를 저장하는 것으로 도시된다. 이런 컴포넌트들은 운영 체제(834), 애플리케이션 프로그램(835), 기타 프로그램 모듈(836), 및 프로그램 데이터(837)와 같거나 다를 수도 있다는 것을 알아야 한다. 운영 체제(844), 애플리케이션 프로그램(845), 기타 프로그램 모듈(846), 및 프로그램 데이터(847)에는 여기서 최소한 그들이 다른 사본들임을 묘사하기 위해 다른 부호들이 주어진다.
사용자는 키보드(862), 마이크로폰(863) 및 마우스, 트랙볼 또는 터치 패드와 같은 포인팅 장치(861) 등의 입력 장치들을 통해 컴퓨터(810)에 명령어와 정보를 입력할 수 있다. 다른 입력 장치들(도시되지 않음)에는 조이스틱, 게임 패드, 위성 접시, 스캐너 등이 포함될 수 있다. 이들 및 기타 입력 장치들은 흔히 시스템 버스에 연결된 사용자 입력 인터페이스(860)를 통해 처리 장치(820)에 연결되나, 병렬 포트나 게임 포트 또는 USB(universal serial bus)와 같은 다른 인터페이스 및 버스 구조에 의해 연결될 수도 있다. 영상 디스플레이(891) 또는 다른 유형의 디스플레이 장치 역시 비디오 인터페이스(890)와 같은 인터페이스를 통해 시스템 버스(821)에 연결된다. 모니터 외에, 컴퓨터들은 출력 주변 장치 인터페이스(895)를 통해 연결될 수 있는 스피커(897) 및 프린터(896)와 같은 다른 주변 출력 장치들을 포함할 수도 있다.
컴퓨터(810)는 원격 컴퓨터(880)와 같은 한 개 이상의 원격 컴퓨터로의 논리 접속을 이용하여, 네트워킹 환경 안에서 동작한다. 원격 컴퓨터(880)는 개인용 컴퓨터, 핸드헬드 장치, 서버, 라우터, 네트워크 PC, 피어 장치 또는 다른 일반적 네트워크 노드일 수 있으며, 통상적으로 컴퓨터(810)와 관련해 상기에서 기술된 요소들 중 다수나 전부를 포함한다. 도 17에 도시된 논리 접속들은 LAN(local area network)(871) 및 WAN(wide area network)(873)을 포함하지만, 다른 네트워크들 역시 포함할 수 있다. 이와 같은 네트워킹 환경은 사무실, 기업 전체의 컴퓨터 네트워크, 인트라넷 및 인터넷에서 일반적이다.
LAN 네트워킹 환경에서 사용될 때, 컴퓨터(810)는 네트워크 인터페이스나 어댑터(870)를 통해 LAN(871)에 연결된다. WAN 네트워킹 환경에서 사용될 때, 컴퓨터(810)는 통상적으로, 인터넷 같은 WAN(873)을 통한 통신을 설정하기 위한 모뎀(872) 또는 다른 수단을 포함한다. 내장형 또는 외장형일 수 있는 모뎀(872)이 사용자 입력 인터페이스(860)나 다른 적절한 메커니즘을 통해 시스템 버스(821)에 연결될 수 있다. 네트워킹 환경에서, 컴퓨터(810)와 관련해 도시된 프로그램 모듈들이나 그 일부는 원격 메모리 저장 장치에 저장될 수 있다. 예를 들어, 그러나 제한 없이, 도 17은 원격 애플리케이션 프로그램(885)을 원격 컴퓨터(881) 상에 상주하는 것으로서 묘사한다. 도시된 네트워크 접속은 예시적인 것이며 컴퓨터들 사이에 통신 링크를 설정하는 다른 수단 역시 사용될 수 있음을 알 것이다.
본 대상은 구조적인 특징 및/또는 방법적인 동작에 특수한 언어로 설명되었지만, 첨부된 청구항에 정의된 대상이 전술한 특정 특징이나 동작에 국한될 필요는 없다. 오히려 특정의 특징 및 동작은 청구항을 구현하는 예시적인 형태로서 기재된 것이다.
Claims (10)
- 조어(parent language)로 된 부모 문서를 상기 조어의 변종(variant)인 변종 언어로 된 각색된 문서(adapted document)로 각색하는 컴퓨터-구현 방법으로서,
상기 부모 문서를 수신하는 단계,
상기 각색된 문서를 얻기 위해 컴퓨터-구현, 규칙-중심의(rule-driven) 각색 프로세스를 실행하는 단계, 및
상기 부모 언어의 변종으로 된 상기 각색된 문서를 디스플레이하는 단계
를 포함하는 컴퓨터-구현 방법.
- 제 1 항에 있어서,
상기 컴퓨터-구현, 규칙-중심의 각색 프로세스를 실행하는 단계는
상기 부모 문서에서 각색되지 않은 번역 유닛을 식별하는 단계,
매칭되는 각색 규칙을 식별하기 위해 상기 식별된 각색되지 않은 번역 유닛을 복수의 각색 규칙에 매칭하는 단계, 및
상기 식별된 각색되지 않은 번역 유닛에 대해, 상기 매칭되는 각색 규칙으로부터 각색된 유닛을 상기 부모 문서로 복사하는 단계
를 포함하는 컴퓨터-구현 방법.
- 제 2 항에 있어서,
상기 컴퓨터-구현, 규칙-중심의 각색 프로세스를 실행하는 단계는
상기 매칭되는 각색 규칙의 검토 여부를 결정하는 단계,
검토되어야 하는 경우, 검토 상태 표시기를 설정하는 단계, 및
검토되어야 함을 나타내는 시각 표시기와 함께 상기 각색된 문서의 상기 각색된 유닛을 디스플레이하는 단계
를 포함하는 컴퓨터-구현 방법.
- 제 3 항에 있어서,
상기 컴퓨터-구현, 규칙-중심의 각색 프로세스를 실행하는 단계는
상기 각색된 유닛을 편집하기 위해 임의의 편집 입력을 수신하는 단계, 및
추가 검토가 필요하지 않음을 나타내기 위해 상기 검토 상태 표시기를 리셋하는 리셋 입력을 수신하는 단계
를 포함하는 컴퓨터-구현 방법.
- 제 2 항에 있어서,
상기 방법은
규칙 입력 사용자 인터페이스 디스플레이를 디스플레이하는 단계, 및
상기 규칙 입력 사용자 인터페이스 디스플레이를 통해 상기 각색 규칙을 수신하는 단계를 더 포함하고,
상기 각색 규칙을 수신하는 단계는 각각의 특정 각색 규칙에 대응하는 범위 입력을 수신하는 단계
를 포함하며,
상기 범위 입력은 상기 부모 문서의 각색되지 않은 번역 유닛에 대한 각각의 특정 각색 규칙의 적용 범위를 나타내는
컴퓨터-구현 방법.
- 제 5 항에 있어서,
상기 컴퓨터-구현, 규칙-중심의 각색 프로세스를 실행하는 단계는, 상기 매칭되는 각색 규칙으로부터 상기 각색된 유닛을 복사한 후에, 상기 매칭되는 각색 규칙에 대응하는 상기 적용 범위에 의해 표시된 범위로 상기 매칭되는 각색 규칙이 적용되었음을 검증하는 단계를 포함하는
컴퓨터-구현 방법.
- 제 2 항에 있어서,
상기 컴퓨터-구현, 규칙-중심의 각색 프로세스를 실행하는 단계는
상기 식별된 각색되지 않은 번역 유닛을 복수의 각색 규칙에 매칭하는 단계 이전에, 상기 식별된 각색되지 않은 번역 유닛이 이미 상기 변종 언어로 각색되어 각색 번역 저장소에 저장되었는지 여부를 결정하기 위해 상기 각색 번역 저장소에 액세스하는 단계, 및
저장되어 있는 경우, 상기 식별된 각색되지 않은 번역 유닛에 대해, 상기 각색 번역 저장소로부터 상기 각색된 유닛을 상기 부모 문서로 복사하는 단계
를 포함하는 컴퓨터-구현 방법.
- 제 2 항에 있어서,
상기 방법은
상기 각색된 유닛의 크기를 디스플레이 단위로 계산하는 단계, 및
사용자 인터페이스 디스플레이의 디자인을 검증하기 위해 유사-현지화된 문자열(pseudo-localized string)의 생성을 위한 유사-현지화된 문자열 생성기로 상기 크기를 전송하는 단계
를 더 포함하는 컴퓨터-구현 방법.
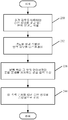
- 사용자 인터페이스 디스플레이 요소를 생성하는 컴퓨터-구현 방법으로서,
소스 언어로 된 소스 문자열을 번역 크기 서비스로 전송하는 단계,
상기 번역 크기 서비스로부터, 번역 후보의 크기를 디스플레이 단위로 나타내는 크기 표시기를 수신하는 단계 - 상기 번역 후보는 상기 소스 문자열의 목표 언어로 된 목표 문자열로의 번역임 -,
유사-현지화된 문자열의 디스플레이 크기가 상기 크기 표시기로 표시된 크기를 따르도록 크기가 정해진 글자들을 갖는 유사-현지화된 문자열을 생성하는 단계, 및
상기 유사-현지화된 문자열에 기반한 요소 크기를 갖는 상기 사용자 인터페이스 디스플레이 요소를 생성하는 단계
를 포함하는 컴퓨터-구현 방법.
- 클라이언트로부터 소스 언어로 된 소스 문자열을 수신하는 단계,
상기 소스 문자열의 목표 언어로 된 목표 문자열로의 번역을 얻는 단계,
상기 목표 문자열의 크기를 디스플레이 단위로 계산하는 단계, 및
상기 목표 문자열의 크기를 상기 클라이언트로 전송하는 단계
를 포함하는 컴퓨터-구현 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261667045P | 2012-07-02 | 2012-07-02 | |
| US61/667,045 | 2012-07-02 | ||
| US13/645,516 US20140006004A1 (en) | 2012-07-02 | 2012-10-05 | Generating localized user interfaces |
| US13/645,516 | 2012-10-05 | ||
| PCT/US2013/048994 WO2014008216A2 (en) | 2012-07-02 | 2013-07-02 | Generating localized user interfaces |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150035798A true KR20150035798A (ko) | 2015-04-07 |
Family
ID=49778995
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020147036897A KR20150035798A (ko) | 2012-07-02 | 2013-07-02 | 현지화된 사용자 인터페이스의 생성 방법 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20140006004A1 (ko) |
| EP (1) | EP2867797A2 (ko) |
| JP (1) | JP2015528162A (ko) |
| KR (1) | KR20150035798A (ko) |
| CN (1) | CN104412256B (ko) |
| WO (1) | WO2014008216A2 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190033749A (ko) * | 2017-09-22 | 2019-04-01 | 주식회사 한글과컴퓨터 | 문서작성 장치 및 이를 이용한 문서작성 방법 |
Families Citing this family (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9330402B2 (en) | 2012-11-02 | 2016-05-03 | Intuit Inc. | Method and system for providing a payroll preparation platform with user contribution-based plug-ins |
| WO2014074629A1 (en) | 2012-11-06 | 2014-05-15 | Intuit Inc. | Stack-based adaptive localization and internationalization of applications |
| JP5449633B1 (ja) * | 2013-03-22 | 2014-03-19 | パナソニック株式会社 | 広告翻訳装置、広告表示装置、および広告翻訳方法 |
| US9922351B2 (en) | 2013-08-29 | 2018-03-20 | Intuit Inc. | Location-based adaptation of financial management system |
| US9524293B2 (en) * | 2014-08-15 | 2016-12-20 | Google Inc. | Techniques for automatically swapping languages and/or content for machine translation |
| US9659009B2 (en) * | 2014-09-24 | 2017-05-23 | International Business Machines Corporation | Selective machine translation with crowdsourcing |
| US10025474B2 (en) * | 2015-06-03 | 2018-07-17 | Ricoh Company, Ltd. | Information processing apparatus, system, and method, and recording medium |
| US9442923B1 (en) | 2015-11-24 | 2016-09-13 | International Business Machines Corporation | Space constrained text translator |
| US9639528B1 (en) * | 2016-01-29 | 2017-05-02 | Sap Se | Translation-based visual design |
| US9792282B1 (en) * | 2016-07-11 | 2017-10-17 | International Business Machines Corporation | Automatic identification of machine translation review candidates |
| US10140260B2 (en) | 2016-07-15 | 2018-11-27 | Sap Se | Intelligent text reduction for graphical interface elements |
| US10503808B2 (en) | 2016-07-15 | 2019-12-10 | Sap Se | Time user interface with intelligent text reduction |
| CN106708591B (zh) * | 2017-01-25 | 2020-06-02 | 东软集团股份有限公司 | 操作系统的文字检测方法及装置 |
| US10366172B2 (en) * | 2017-02-03 | 2019-07-30 | International Business Machines Corporation | Intelligent pseudo translation |
| US10235361B2 (en) * | 2017-02-15 | 2019-03-19 | International Business Machines Corporation | Context-aware translation memory to facilitate more accurate translation |
| JP6984145B2 (ja) * | 2017-03-09 | 2021-12-17 | 富士フイルムビジネスイノベーション株式会社 | 情報処理装置 |
| US10795799B2 (en) * | 2017-04-18 | 2020-10-06 | Salesforce.Com, Inc. | Website debugger for natural language translation and localization |
| CN107741931A (zh) * | 2017-08-30 | 2018-02-27 | 捷开通讯(深圳)有限公司 | 操作系统框架的翻译方法、移动终端和存储装置 |
| CN107918608A (zh) * | 2017-12-12 | 2018-04-17 | 广东欧珀移动通信有限公司 | 词条处理方法、移动终端及计算机可读存储介质 |
| CN108563645B (zh) * | 2018-04-24 | 2022-03-22 | 成都智信电子技术有限公司 | His系统的元数据翻译方法和装置 |
| US11048885B2 (en) * | 2018-09-25 | 2021-06-29 | International Business Machines Corporation | Cognitive translation service integrated with context-sensitive derivations for determining program-integrated information relationships |
| US12079569B2 (en) | 2019-06-07 | 2024-09-03 | Microsoft Technology Licensing, Llc | Document editing models and localized content management |
| CN110852038B (zh) * | 2019-11-11 | 2022-02-11 | 腾讯科技(深圳)有限公司 | 一种文本显示方法及相关设备 |
| CN113778582B (zh) * | 2021-07-28 | 2024-06-28 | 赤子城网络技术(北京)有限公司 | 本地化多语言适配的设置方法、装置、设备及存储介质 |
Family Cites Families (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL128295A (en) * | 1999-01-31 | 2004-03-28 | Jacob Frommer | Computerized translator displaying visual mouth articulation |
| US6507812B1 (en) * | 1999-06-29 | 2003-01-14 | International Business Machines Corporation | Mock translation method, system, and program to test software translatability |
| US6393389B1 (en) * | 1999-09-23 | 2002-05-21 | Xerox Corporation | Using ranked translation choices to obtain sequences indicating meaning of multi-token expressions |
| US6957425B1 (en) * | 1999-11-30 | 2005-10-18 | Dell Usa, L.P. | Automatic translation of text files during assembly of a computer system |
| US20020111787A1 (en) * | 2000-10-13 | 2002-08-15 | Iko Knyphausen | Client-driven workload environment |
| US6778950B2 (en) * | 2000-12-07 | 2004-08-17 | Benyamin Gohari | Translation arrangement |
| US7761288B2 (en) * | 2001-04-30 | 2010-07-20 | Siebel Systems, Inc. | Polylingual simultaneous shipping of software |
| US20030040899A1 (en) * | 2001-08-13 | 2003-02-27 | Ogilvie John W.L. | Tools and techniques for reader-guided incremental immersion in a foreign language text |
| US20030187681A1 (en) * | 2001-11-13 | 2003-10-02 | Spain Wanda Hudgins | Systems and methods for rendering multilingual information on an output device |
| EP1315084A1 (en) * | 2001-11-27 | 2003-05-28 | Sun Microsystems, Inc. | Method and apparatus for localizing software |
| US7509251B2 (en) * | 2002-12-23 | 2009-03-24 | International Business Machines Corporation | Mock translating software applications at runtime |
| US7627817B2 (en) * | 2003-02-21 | 2009-12-01 | Motionpoint Corporation | Analyzing web site for translation |
| US7496230B2 (en) * | 2003-06-05 | 2009-02-24 | International Business Machines Corporation | System and method for automatic natural language translation of embedded text regions in images during information transfer |
| US7389223B2 (en) * | 2003-09-18 | 2008-06-17 | International Business Machines Corporation | Method and apparatus for testing a software program using mock translation input method editor |
| US20050240393A1 (en) * | 2004-04-26 | 2005-10-27 | Glosson John F | Method, system, and software for embedding metadata objects concomitantly wit linguistic content |
| GB2415518A (en) * | 2004-06-24 | 2005-12-28 | Sharp Kk | Method and apparatus for translation based on a repository of existing translations |
| US20060080082A1 (en) * | 2004-08-23 | 2006-04-13 | Geneva Software Technologies Limited | System and method for product migration in multiple languages |
| US20060206797A1 (en) * | 2005-03-08 | 2006-09-14 | Microsoft Corporation | Authorizing implementing application localization rules |
| US7698126B2 (en) * | 2005-03-08 | 2010-04-13 | Microsoft Corporation | Localization matching component |
| JP2006268150A (ja) * | 2005-03-22 | 2006-10-05 | Fuji Xerox Co Ltd | 翻訳を行う装置、方法、プログラムおよび該プログラムを記憶した記憶媒体 |
| CN1896923A (zh) * | 2005-06-13 | 2007-01-17 | 余可立 | 英语巴蜀杆栏式汉字化词型翻译中间文本计算机输入方法 |
| US7987087B2 (en) * | 2005-06-15 | 2011-07-26 | Xerox Corporation | Method and system for improved software localization |
| CN1716241A (zh) * | 2005-07-04 | 2006-01-04 | 张�杰 | 采用声频数据比较的自动翻译处理方法及自动翻译器 |
| US20070244691A1 (en) * | 2006-04-17 | 2007-10-18 | Microsoft Corporation | Translation of user interface text strings |
| CN101118738B (zh) * | 2006-07-31 | 2011-02-02 | 夏普株式会社 | 显示装置及显示方法 |
| US20080040094A1 (en) * | 2006-08-08 | 2008-02-14 | Employease, Inc. | Proxy For Real Time Translation of Source Objects Between A Server And A Client |
| US20080077384A1 (en) * | 2006-09-22 | 2008-03-27 | International Business Machines Corporation | Dynamically translating a software application to a user selected target language that is not natively provided by the software application |
| US7801721B2 (en) * | 2006-10-02 | 2010-09-21 | Google Inc. | Displaying original text in a user interface with translated text |
| US20080177528A1 (en) * | 2007-01-18 | 2008-07-24 | William Drewes | Method of enabling any-directional translation of selected languages |
| US7797151B2 (en) * | 2007-02-02 | 2010-09-14 | Darshana Apte | Translation process component |
| US7877251B2 (en) * | 2007-05-07 | 2011-01-25 | Microsoft Corporation | Document translation system |
| CN101452446A (zh) * | 2007-12-07 | 2009-06-10 | 株式会社东芝 | 目标语言单词变形的方法及装置 |
| CN101207880A (zh) * | 2007-12-11 | 2008-06-25 | 汪健辉 | 一种基于服务器客户机模式的手机指路导航系统 |
| US8249858B2 (en) * | 2008-04-24 | 2012-08-21 | International Business Machines Corporation | Multilingual administration of enterprise data with default target languages |
| US8594995B2 (en) * | 2008-04-24 | 2013-11-26 | Nuance Communications, Inc. | Multilingual asynchronous communications of speech messages recorded in digital media files |
| JP5300442B2 (ja) * | 2008-12-01 | 2013-09-25 | ニスカ株式会社 | 表示装置および印刷装置 |
| US8185373B1 (en) * | 2009-05-05 | 2012-05-22 | The United States Of America As Represented By The Director, National Security Agency, The | Method of assessing language translation and interpretation |
| CN101713663A (zh) * | 2009-11-02 | 2010-05-26 | 深圳市凯立德计算机系统技术有限公司 | 一种导航系统中的文本框显示方法及导航系统 |
| JP5124001B2 (ja) * | 2010-09-08 | 2013-01-23 | シャープ株式会社 | 翻訳装置、翻訳方法、コンピュータプログラムおよび記録媒体 |
| US8862455B2 (en) * | 2011-05-09 | 2014-10-14 | Microsoft Corporation | Creating and implementing language-dependent string pluralizations |
-
2012
- 2012-10-05 US US13/645,516 patent/US20140006004A1/en not_active Abandoned
-
2013
- 2013-07-02 EP EP13739552.1A patent/EP2867797A2/en not_active Withdrawn
- 2013-07-02 CN CN201380035461.6A patent/CN104412256B/zh not_active Expired - Fee Related
- 2013-07-02 KR KR1020147036897A patent/KR20150035798A/ko not_active Application Discontinuation
- 2013-07-02 JP JP2015520634A patent/JP2015528162A/ja active Pending
- 2013-07-02 WO PCT/US2013/048994 patent/WO2014008216A2/en active Application Filing
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190033749A (ko) * | 2017-09-22 | 2019-04-01 | 주식회사 한글과컴퓨터 | 문서작성 장치 및 이를 이용한 문서작성 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN104412256B (zh) | 2017-08-04 |
| WO2014008216A3 (en) | 2014-05-22 |
| JP2015528162A (ja) | 2015-09-24 |
| WO2014008216A2 (en) | 2014-01-09 |
| EP2867797A2 (en) | 2015-05-06 |
| US20140006004A1 (en) | 2014-01-02 |
| CN104412256A (zh) | 2015-03-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20150035798A (ko) | 현지화된 사용자 인터페이스의 생성 방법 | |
| US10963651B2 (en) | Reformatting of context sensitive data | |
| US9436712B2 (en) | Data migration framework | |
| US9990191B2 (en) | Cloud-based localization platform | |
| CN110362372A (zh) | 页面转译方法、装置、介质及电子设备 | |
| US10073618B2 (en) | Supplementing a virtual input keyboard | |
| US11106757B1 (en) | Framework for augmenting document object model trees optimized for web authoring | |
| US9633001B2 (en) | Language independent probabilistic content matching | |
| US20230316792A1 (en) | Automated generation of training data comprising document images and associated label data | |
| US10152308B2 (en) | User interface display testing system | |
| KR20170016362A (ko) | 컴파일 동안 표시 메타데이터를 브라우저 렌더링 가능 포맷으로 변환하는 기법 | |
| US20220198157A1 (en) | Multilingual Model Training Using Parallel Corpora, Crowdsourcing, and Accurate Monolingual Models | |
| EP4237987A1 (en) | Determining lexical difficulty in textual content | |
| US11138289B1 (en) | Optimizing annotation reconciliation transactions on unstructured text content updates | |
| US20180335909A1 (en) | Using sections for customization of applications across platforms | |
| US9736032B2 (en) | Pattern-based validation, constraint and generation of hierarchical metadata | |
| US20150193209A1 (en) | Specifying compiled language code in line with markup language code | |
| US9575751B2 (en) | Data extraction and generation tool | |
| US11989189B2 (en) | Data processing system and method | |
| CN113870394A (zh) | 一种动画生成方法、装置、设备及存储介质 | |
| KR101645674B1 (ko) | 자동완성 후보 단어 제공 방법 및 장치 | |
| CN106569785B (zh) | 一种作业表单生成方法及设备 | |
| US20240061999A1 (en) | Automatic writing style detection and rewriting | |
| US20240177511A1 (en) | Generating synthetic training data including document images with key-value pairs | |
| US20240289549A1 (en) | Autocorrect Candidate Selection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| N231 | Notification of change of applicant | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |