KR20130096164A - 말라리아에 대항하는 렌티바이러스 벡터 기반의 면역학적 화합물 - Google Patents
말라리아에 대항하는 렌티바이러스 벡터 기반의 면역학적 화합물 Download PDFInfo
- Publication number
- KR20130096164A KR20130096164A KR1020127031691A KR20127031691A KR20130096164A KR 20130096164 A KR20130096164 A KR 20130096164A KR 1020127031691 A KR1020127031691 A KR 1020127031691A KR 20127031691 A KR20127031691 A KR 20127031691A KR 20130096164 A KR20130096164 A KR 20130096164A
- Authority
- KR
- South Korea
- Prior art keywords
- asn
- ala
- pro
- gly
- lys
- Prior art date
Links
- 239000013598 vector Substances 0.000 title claims abstract description 282
- 201000004792 malaria Diseases 0.000 title claims abstract description 73
- 150000001875 compounds Chemical class 0.000 title claims description 46
- 230000001900 immune effect Effects 0.000 title description 3
- 239000002245 particle Substances 0.000 claims abstract description 198
- 108091007433 antigens Proteins 0.000 claims abstract description 120
- 102000036639 antigens Human genes 0.000 claims abstract description 120
- 239000000427 antigen Substances 0.000 claims abstract description 118
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 96
- 244000045947 parasite Species 0.000 claims abstract description 92
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 78
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 73
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 73
- 239000002157 polynucleotide Substances 0.000 claims abstract description 73
- 229920001184 polypeptide Polymers 0.000 claims abstract description 73
- 230000028993 immune response Effects 0.000 claims abstract description 44
- 241000223960 Plasmodium falciparum Species 0.000 claims abstract description 34
- 108010003533 Viral Envelope Proteins Proteins 0.000 claims abstract description 24
- 241001493065 dsRNA viruses Species 0.000 claims abstract description 7
- 108090000623 proteins and genes Proteins 0.000 claims description 166
- 235000018102 proteins Nutrition 0.000 claims description 137
- 102000004169 proteins and genes Human genes 0.000 claims description 137
- 108020004414 DNA Proteins 0.000 claims description 82
- 239000013612 plasmid Substances 0.000 claims description 79
- 210000004027 cell Anatomy 0.000 claims description 75
- 101710091045 Envelope protein Proteins 0.000 claims description 66
- 101710188315 Protein X Proteins 0.000 claims description 66
- 230000014509 gene expression Effects 0.000 claims description 58
- 238000002649 immunization Methods 0.000 claims description 40
- 230000003053 immunization Effects 0.000 claims description 40
- 210000003743 erythrocyte Anatomy 0.000 claims description 34
- 241000713772 Human immunodeficiency virus 1 Species 0.000 claims description 33
- 208000015181 infectious disease Diseases 0.000 claims description 30
- 238000000034 method Methods 0.000 claims description 30
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 27
- 102000018697 Membrane Proteins Human genes 0.000 claims description 25
- 108010052285 Membrane Proteins Proteins 0.000 claims description 25
- 208000030852 Parasitic disease Diseases 0.000 claims description 24
- 108020004705 Codon Proteins 0.000 claims description 23
- 230000005867 T cell response Effects 0.000 claims description 23
- 230000024932 T cell mediated immunity Effects 0.000 claims description 22
- 210000004185 liver Anatomy 0.000 claims description 22
- 239000000203 mixture Substances 0.000 claims description 22
- 230000003612 virological effect Effects 0.000 claims description 22
- 238000012856 packing Methods 0.000 claims description 21
- 230000001105 regulatory effect Effects 0.000 claims description 21
- 241000713666 Lentivirus Species 0.000 claims description 20
- 206010070834 Sensitisation Diseases 0.000 claims description 20
- 238000004519 manufacturing process Methods 0.000 claims description 19
- 230000007170 pathology Effects 0.000 claims description 19
- 108010027225 gag-pol Fusion Proteins Proteins 0.000 claims description 18
- 230000001681 protective effect Effects 0.000 claims description 18
- 230000002950 deficient Effects 0.000 claims description 15
- 239000002773 nucleotide Substances 0.000 claims description 15
- 125000003729 nucleotide group Chemical group 0.000 claims description 15
- 238000013518 transcription Methods 0.000 claims description 15
- 230000035897 transcription Effects 0.000 claims description 15
- 241000725303 Human immunodeficiency virus Species 0.000 claims description 14
- 101710125418 Major capsid protein Proteins 0.000 claims description 14
- 230000004044 response Effects 0.000 claims description 14
- 230000008313 sensitization Effects 0.000 claims description 14
- 108091026890 Coding region Proteins 0.000 claims description 13
- 230000010354 integration Effects 0.000 claims description 13
- 230000000069 prophylactic effect Effects 0.000 claims description 13
- 238000010839 reverse transcription Methods 0.000 claims description 13
- 101710132601 Capsid protein Proteins 0.000 claims description 12
- 101710094648 Coat protein Proteins 0.000 claims description 12
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 claims description 12
- 101710141454 Nucleoprotein Proteins 0.000 claims description 12
- 101710083689 Probable capsid protein Proteins 0.000 claims description 12
- 150000007523 nucleic acids Chemical group 0.000 claims description 12
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 claims description 10
- 238000003776 cleavage reaction Methods 0.000 claims description 10
- 230000007017 scission Effects 0.000 claims description 10
- 238000010361 transduction Methods 0.000 claims description 10
- 230000026683 transduction Effects 0.000 claims description 10
- 208000009182 Parasitemia Diseases 0.000 claims description 9
- 238000004873 anchoring Methods 0.000 claims description 8
- 230000003416 augmentation Effects 0.000 claims description 8
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 8
- 230000000694 effects Effects 0.000 claims description 8
- 239000013613 expression plasmid Substances 0.000 claims description 8
- 108020001507 fusion proteins Proteins 0.000 claims description 8
- 102000037865 fusion proteins Human genes 0.000 claims description 8
- 230000001939 inductive effect Effects 0.000 claims description 8
- 238000005457 optimization Methods 0.000 claims description 8
- 230000036281 parasite infection Effects 0.000 claims description 8
- 241000124008 Mammalia Species 0.000 claims description 7
- 241000223810 Plasmodium vivax Species 0.000 claims description 7
- 230000003321 amplification Effects 0.000 claims description 7
- 238000001727 in vivo Methods 0.000 claims description 7
- 210000004962 mammalian cell Anatomy 0.000 claims description 7
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 7
- 229910052703 rhodium Inorganic materials 0.000 claims description 7
- 239000010948 rhodium Substances 0.000 claims description 7
- MHOVAHRLVXNVSD-UHFFFAOYSA-N rhodium atom Chemical compound [Rh] MHOVAHRLVXNVSD-UHFFFAOYSA-N 0.000 claims description 7
- 101150052200 CS gene Proteins 0.000 claims description 6
- 108010057081 Merozoite Surface Protein 1 Proteins 0.000 claims description 6
- 241000223821 Plasmodium malariae Species 0.000 claims description 6
- 230000027455 binding Effects 0.000 claims description 6
- 230000001086 cytosolic effect Effects 0.000 claims description 6
- 230000002440 hepatic effect Effects 0.000 claims description 6
- 230000005764 inhibitory process Effects 0.000 claims description 6
- 230000007774 longterm Effects 0.000 claims description 6
- 230000003071 parasitic effect Effects 0.000 claims description 6
- 229940118768 plasmodium malariae Drugs 0.000 claims description 6
- 208000037369 susceptibility to malaria Diseases 0.000 claims description 6
- 101710189301 101 kDa malaria antigen Proteins 0.000 claims description 5
- 108090000565 Capsid Proteins Proteins 0.000 claims description 5
- 241000223801 Plasmodium knowlesi Species 0.000 claims description 5
- 210000000234 capsid Anatomy 0.000 claims description 5
- 239000003623 enhancer Substances 0.000 claims description 5
- 230000015654 memory Effects 0.000 claims description 5
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 claims description 4
- 101710091366 Clustered-asparagine-rich protein Proteins 0.000 claims description 4
- 101710193609 Knob-associated histidine-rich protein Proteins 0.000 claims description 4
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 claims description 4
- 102000014842 Multidrug resistance proteins Human genes 0.000 claims description 4
- 108050005144 Multidrug resistance proteins Proteins 0.000 claims description 4
- 241001505293 Plasmodium ovale Species 0.000 claims description 4
- 229960001230 asparagine Drugs 0.000 claims description 4
- 235000009582 asparagine Nutrition 0.000 claims description 4
- 210000005220 cytoplasmic tail Anatomy 0.000 claims description 4
- 210000003617 erythrocyte membrane Anatomy 0.000 claims description 4
- 230000002163 immunogen Effects 0.000 claims description 4
- 230000001568 sexual effect Effects 0.000 claims description 4
- 101710145634 Antigen 1 Proteins 0.000 claims description 3
- 101000636214 Arabidopsis thaliana Transcription factor MYC2 Proteins 0.000 claims description 3
- 101710172314 Aspartate-rich protein Proteins 0.000 claims description 3
- 101100532584 Clostridium perfringens (strain 13 / Type A) sspC1 gene Proteins 0.000 claims description 3
- 102100029095 Exportin-1 Human genes 0.000 claims description 3
- 101100095550 Homo sapiens SENP7 gene Proteins 0.000 claims description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 3
- 101150098865 SSP2 gene Proteins 0.000 claims description 3
- 102100031406 Sentrin-specific protease 7 Human genes 0.000 claims description 3
- 208000035896 Twin-reversed arterial perfusion sequence Diseases 0.000 claims description 3
- 239000002671 adjuvant Substances 0.000 claims description 3
- 101150078331 ama-1 gene Proteins 0.000 claims description 3
- 238000012761 co-transfection Methods 0.000 claims description 3
- 230000029142 excretion Effects 0.000 claims description 3
- 108700002148 exportin 1 Proteins 0.000 claims description 3
- 210000004602 germ cell Anatomy 0.000 claims description 3
- 230000002458 infectious effect Effects 0.000 claims description 3
- 210000004698 lymphocyte Anatomy 0.000 claims description 3
- 210000003071 memory t lymphocyte Anatomy 0.000 claims description 3
- 230000002265 prevention Effects 0.000 claims description 3
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 claims description 3
- 230000004936 stimulating effect Effects 0.000 claims description 3
- 239000013603 viral vector Substances 0.000 claims description 3
- YURDCJXYOLERLO-LCYFTJDESA-N (2E)-5-methyl-2-phenylhex-2-enal Chemical compound CC(C)C\C=C(\C=O)C1=CC=CC=C1 YURDCJXYOLERLO-LCYFTJDESA-N 0.000 claims description 2
- 101710197318 Asparagine-rich protein Proteins 0.000 claims description 2
- 101100457021 Caenorhabditis elegans mag-1 gene Proteins 0.000 claims description 2
- 102000012286 Chitinases Human genes 0.000 claims description 2
- 108010022172 Chitinases Proteins 0.000 claims description 2
- 102000005927 Cysteine Proteases Human genes 0.000 claims description 2
- 108010005843 Cysteine Proteases Proteins 0.000 claims description 2
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 claims description 2
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 claims description 2
- 108091006027 G proteins Proteins 0.000 claims description 2
- 102000030782 GTP binding Human genes 0.000 claims description 2
- 108091000058 GTP-Binding Proteins 0.000 claims description 2
- 101100024440 Globodera rostochiensis MSP-3 gene Proteins 0.000 claims description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 claims description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 claims description 2
- 108010006519 Molecular Chaperones Proteins 0.000 claims description 2
- 101100067996 Mus musculus Gbp1 gene Proteins 0.000 claims description 2
- 101100385694 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) msp-6 gene Proteins 0.000 claims description 2
- HCUVEUVIUAJXRB-UHFFFAOYSA-N OC1=C(C=C(CNC(CCCC=2SC=CC=2)=O)C=C1)OC Chemical compound OC1=C(C=C(CNC(CCCC=2SC=CC=2)=O)C=C1)OC HCUVEUVIUAJXRB-UHFFFAOYSA-N 0.000 claims description 2
- 101710160107 Outer membrane protein A Proteins 0.000 claims description 2
- 102000003697 P-type ATPases Human genes 0.000 claims description 2
- 108090000069 P-type ATPases Proteins 0.000 claims description 2
- 101710194807 Protective antigen Proteins 0.000 claims description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 2
- 239000004473 Threonine Substances 0.000 claims description 2
- 230000007969 cellular immunity Effects 0.000 claims description 2
- 229930195712 glutamate Natural products 0.000 claims description 2
- 230000003308 immunostimulating effect Effects 0.000 claims description 2
- 239000002243 precursor Substances 0.000 claims description 2
- 108010034467 ribosomal protein P0 Proteins 0.000 claims description 2
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 claims 6
- 102100031675 DnaJ homolog subfamily C member 5 Human genes 0.000 claims 5
- 229960003387 progesterone Drugs 0.000 claims 3
- 239000000186 progesterone Substances 0.000 claims 3
- 241000711975 Vesicular stomatitis virus Species 0.000 claims 2
- 101000705294 Arabidopsis thaliana Oxygen-evolving enhancer protein 1-2, chloroplastic Proteins 0.000 claims 1
- 102100031262 Deleted in malignant brain tumors 1 protein Human genes 0.000 claims 1
- 101000844721 Homo sapiens Deleted in malignant brain tumors 1 protein Proteins 0.000 claims 1
- 208000012868 Overgrowth Diseases 0.000 claims 1
- 101710179519 Ring-infected erythrocyte surface antigen Proteins 0.000 claims 1
- 230000006735 deficit Effects 0.000 claims 1
- ZINJLDJMHCUBIP-UHFFFAOYSA-N ethametsulfuron-methyl Chemical compound CCOC1=NC(NC)=NC(NC(=O)NS(=O)(=O)C=2C(=CC=CC=2)C(=O)OC)=N1 ZINJLDJMHCUBIP-UHFFFAOYSA-N 0.000 claims 1
- 230000001737 promoting effect Effects 0.000 claims 1
- SWLOHUMCUDRTCL-ZLUOBGJFSA-N Asn-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N SWLOHUMCUDRTCL-ZLUOBGJFSA-N 0.000 description 99
- 241000699670 Mus sp. Species 0.000 description 96
- 108010077245 asparaginyl-proline Proteins 0.000 description 95
- XCVRVWZTXPCYJT-BIIVOSGPSA-N Ala-Asn-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N XCVRVWZTXPCYJT-BIIVOSGPSA-N 0.000 description 84
- UVKNEILZSJMKSR-FXQIFTODSA-N Pro-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 UVKNEILZSJMKSR-FXQIFTODSA-N 0.000 description 77
- 102100034349 Integrase Human genes 0.000 description 58
- JTXVXGXTRXMOFJ-FXQIFTODSA-N Asn-Pro-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O JTXVXGXTRXMOFJ-FXQIFTODSA-N 0.000 description 50
- 108010047495 alanylglycine Proteins 0.000 description 50
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 48
- 108010087924 alanylproline Proteins 0.000 description 39
- 241000223830 Plasmodium yoelii Species 0.000 description 35
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 35
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 34
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 32
- 108010054155 lysyllysine Proteins 0.000 description 31
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 30
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 29
- NHLAEBFGWPXFGI-WHFBIAKZSA-N Ala-Gly-Asn Chemical compound C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N NHLAEBFGWPXFGI-WHFBIAKZSA-N 0.000 description 29
- NSORZJXKUQFEKL-JGVFFNPUSA-N Gln-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)N)N)C(=O)O NSORZJXKUQFEKL-JGVFFNPUSA-N 0.000 description 28
- 108010029020 prolylglycine Proteins 0.000 description 28
- 238000011081 inoculation Methods 0.000 description 27
- BWJZSLQJNBSUPM-FXQIFTODSA-N Asp-Pro-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O BWJZSLQJNBSUPM-FXQIFTODSA-N 0.000 description 26
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 26
- 108010078144 glutaminyl-glycine Proteins 0.000 description 26
- YNDLOUMBVDVALC-ZLUOBGJFSA-N Asn-Ala-Ala Chemical compound C[C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CC(=O)N)N YNDLOUMBVDVALC-ZLUOBGJFSA-N 0.000 description 25
- 108700019146 Transgenes Proteins 0.000 description 23
- FEGOCLZUJUFCHP-CIUDSAMLSA-N Ala-Pro-Gln Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FEGOCLZUJUFCHP-CIUDSAMLSA-N 0.000 description 22
- ACRYGQFHAQHDSF-ZLUOBGJFSA-N Asn-Asn-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ACRYGQFHAQHDSF-ZLUOBGJFSA-N 0.000 description 22
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 22
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 22
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 22
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 21
- 241000700605 Viruses Species 0.000 description 21
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 21
- AHXPYZRZRMQOAU-QXEWZRGKSA-N Pro-Asn-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1)C(O)=O AHXPYZRZRMQOAU-QXEWZRGKSA-N 0.000 description 20
- 102100034347 Integrase Human genes 0.000 description 19
- 108010050848 glycylleucine Proteins 0.000 description 19
- 108010077112 prolyl-proline Proteins 0.000 description 19
- KIUYPHAMDKDICO-WHFBIAKZSA-N Ala-Asp-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KIUYPHAMDKDICO-WHFBIAKZSA-N 0.000 description 18
- KMSHNDWHPWXPEC-BQBZGAKWSA-N Arg-Asp-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O KMSHNDWHPWXPEC-BQBZGAKWSA-N 0.000 description 18
- 239000012634 fragment Substances 0.000 description 18
- 229960005486 vaccine Drugs 0.000 description 18
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 17
- 108010061833 Integrases Proteins 0.000 description 17
- 241000224016 Plasmodium Species 0.000 description 17
- 108010015792 glycyllysine Proteins 0.000 description 17
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 16
- 108010047857 aspartylglycine Proteins 0.000 description 16
- 108010069495 cysteinyltyrosine Proteins 0.000 description 16
- 238000002360 preparation method Methods 0.000 description 16
- JZLFYAAGGYMRIK-BYULHYEWSA-N Asn-Val-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O JZLFYAAGGYMRIK-BYULHYEWSA-N 0.000 description 15
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 15
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 15
- 241000880493 Leptailurus serval Species 0.000 description 15
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 15
- 238000002347 injection Methods 0.000 description 15
- 239000007924 injection Substances 0.000 description 15
- 244000005700 microbiome Species 0.000 description 15
- IVCOYUURLWQDJQ-LPEHRKFASA-N Gln-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O IVCOYUURLWQDJQ-LPEHRKFASA-N 0.000 description 14
- PBYFVIQRFLNQCO-GUBZILKMSA-N Gln-Pro-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O PBYFVIQRFLNQCO-GUBZILKMSA-N 0.000 description 14
- 210000004369 blood Anatomy 0.000 description 14
- 239000008280 blood Substances 0.000 description 14
- GGEJHJIXRBTJPD-BYPYZUCNSA-N Gly-Asn-Gly Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GGEJHJIXRBTJPD-BYPYZUCNSA-N 0.000 description 13
- 108010062796 arginyllysine Proteins 0.000 description 13
- 108010092854 aspartyllysine Proteins 0.000 description 13
- 108010018866 cysteinyl-seryl-valyl-threonyl-cysteinyl-glycine Proteins 0.000 description 13
- 238000011161 development Methods 0.000 description 13
- 108010009298 lysylglutamic acid Proteins 0.000 description 13
- 102100021277 Beta-secretase 2 Human genes 0.000 description 12
- 101710150190 Beta-secretase 2 Proteins 0.000 description 12
- ZPPVJIJMIKTERM-YUMQZZPRSA-N Pro-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)N)NC(=O)[C@@H]1CCCN1 ZPPVJIJMIKTERM-YUMQZZPRSA-N 0.000 description 12
- GFHOSBYCLACKEK-GUBZILKMSA-N Pro-Pro-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O GFHOSBYCLACKEK-GUBZILKMSA-N 0.000 description 12
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 12
- 230000000844 anti-bacterial effect Effects 0.000 description 12
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 12
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 12
- 230000035772 mutation Effects 0.000 description 12
- HZPSDHRYYIORKR-WHFBIAKZSA-N Asn-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O HZPSDHRYYIORKR-WHFBIAKZSA-N 0.000 description 11
- LJUOLNXOWSWGKF-ACZMJKKPSA-N Asn-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N LJUOLNXOWSWGKF-ACZMJKKPSA-N 0.000 description 11
- ZYPWIUFLYMQZBS-SRVKXCTJSA-N Asn-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ZYPWIUFLYMQZBS-SRVKXCTJSA-N 0.000 description 11
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 11
- AZGZDDNKFFUDEH-QWRGUYRKSA-N Tyr-Gly-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AZGZDDNKFFUDEH-QWRGUYRKSA-N 0.000 description 11
- 108010093581 aspartyl-proline Proteins 0.000 description 11
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 11
- 230000010076 replication Effects 0.000 description 11
- YKLNMGJYMNPBCP-ACZMJKKPSA-N Glu-Asn-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YKLNMGJYMNPBCP-ACZMJKKPSA-N 0.000 description 10
- ALGGDNMLQNFVIZ-SRVKXCTJSA-N Lys-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ALGGDNMLQNFVIZ-SRVKXCTJSA-N 0.000 description 10
- HAQLBBVZAGMESV-IHRRRGAJSA-N Met-Lys-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O HAQLBBVZAGMESV-IHRRRGAJSA-N 0.000 description 10
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 10
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 10
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 10
- 108091093126 WHP Posttrascriptional Response Element Proteins 0.000 description 10
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 10
- 238000002474 experimental method Methods 0.000 description 10
- 102000039446 nucleic acids Human genes 0.000 description 10
- 108020004707 nucleic acids Proteins 0.000 description 10
- ZDOQDYFZNGASEY-BIIVOSGPSA-N Asn-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)C(=O)O ZDOQDYFZNGASEY-BIIVOSGPSA-N 0.000 description 9
- ZMUQQMGITUJQTI-CIUDSAMLSA-N Asn-Leu-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O ZMUQQMGITUJQTI-CIUDSAMLSA-N 0.000 description 9
- ORJQQZIXTOYGGH-SRVKXCTJSA-N Asn-Lys-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ORJQQZIXTOYGGH-SRVKXCTJSA-N 0.000 description 9
- NNQHEEQNPQYPGL-FXQIFTODSA-N Gln-Ala-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NNQHEEQNPQYPGL-FXQIFTODSA-N 0.000 description 9
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 9
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 9
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 9
- AYBKPDHHVADEDA-YUMQZZPRSA-N Gly-His-Asn Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O AYBKPDHHVADEDA-YUMQZZPRSA-N 0.000 description 9
- GVKKVHNRTUFCCE-BJDJZHNGSA-N Ile-Leu-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)O)N GVKKVHNRTUFCCE-BJDJZHNGSA-N 0.000 description 9
- ZGUMORRUBUCXEH-AVGNSLFASA-N Leu-Lys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZGUMORRUBUCXEH-AVGNSLFASA-N 0.000 description 9
- JIYJYFIXQTYDNF-YDHLFZDLSA-N Phe-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N JIYJYFIXQTYDNF-YDHLFZDLSA-N 0.000 description 9
- FYKUEXMZYFIZKA-DCAQKATOSA-N Pro-Pro-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FYKUEXMZYFIZKA-DCAQKATOSA-N 0.000 description 9
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 9
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 9
- IDKGBVZGNTYYCC-QXEWZRGKSA-N Val-Asn-Pro Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(O)=O IDKGBVZGNTYYCC-QXEWZRGKSA-N 0.000 description 9
- 210000004443 dendritic cell Anatomy 0.000 description 9
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 9
- 210000003494 hepatocyte Anatomy 0.000 description 9
- 108700004029 pol Genes Proteins 0.000 description 9
- 210000004988 splenocyte Anatomy 0.000 description 9
- 108020004463 18S ribosomal RNA Proteins 0.000 description 8
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 8
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 8
- MFFOYNGMOYFPBD-DCAQKATOSA-N Asn-Arg-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MFFOYNGMOYFPBD-DCAQKATOSA-N 0.000 description 8
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 8
- OLVIPTLKNSAYRJ-YUMQZZPRSA-N Asn-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N OLVIPTLKNSAYRJ-YUMQZZPRSA-N 0.000 description 8
- LGYZYFFDELZWRS-DCAQKATOSA-N Glu-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O LGYZYFFDELZWRS-DCAQKATOSA-N 0.000 description 8
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 8
- AIJAPFVDBFYNKN-WHFBIAKZSA-N Gly-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN)C(=O)N AIJAPFVDBFYNKN-WHFBIAKZSA-N 0.000 description 8
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 8
- NGRPGJGKJMUGDM-XVKPBYJWSA-N Gly-Val-Gln Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O NGRPGJGKJMUGDM-XVKPBYJWSA-N 0.000 description 8
- 241000282412 Homo Species 0.000 description 8
- GLYJPWIRLBAIJH-FQUUOJAGSA-N Ile-Lys-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N GLYJPWIRLBAIJH-FQUUOJAGSA-N 0.000 description 8
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 8
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 8
- BYEBKXRNDLTGFW-CIUDSAMLSA-N Lys-Cys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O BYEBKXRNDLTGFW-CIUDSAMLSA-N 0.000 description 8
- RDFQNDHEHVSONI-ZLUOBGJFSA-N Ser-Asn-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RDFQNDHEHVSONI-ZLUOBGJFSA-N 0.000 description 8
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 8
- 125000003275 alpha amino acid group Chemical group 0.000 description 8
- 125000000539 amino acid group Chemical group 0.000 description 8
- 238000013459 approach Methods 0.000 description 8
- 101150026451 csp gene Proteins 0.000 description 8
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 8
- 230000008348 humoral response Effects 0.000 description 8
- 108010051673 leucyl-glycyl-phenylalanine Proteins 0.000 description 8
- 101150088264 pol gene Proteins 0.000 description 8
- 238000003752 polymerase chain reaction Methods 0.000 description 8
- 108010026333 seryl-proline Proteins 0.000 description 8
- OLGCWMNDJTWQAG-GUBZILKMSA-N Asn-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(N)=O OLGCWMNDJTWQAG-GUBZILKMSA-N 0.000 description 7
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 7
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 7
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 7
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 7
- QYPKJXSMLMREKF-BPUTZDHNSA-N Glu-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)N QYPKJXSMLMREKF-BPUTZDHNSA-N 0.000 description 7
- LZMQSTPFYJLVJB-GUBZILKMSA-N Glu-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N LZMQSTPFYJLVJB-GUBZILKMSA-N 0.000 description 7
- ILWHFUZZCFYSKT-AVGNSLFASA-N Glu-Lys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ILWHFUZZCFYSKT-AVGNSLFASA-N 0.000 description 7
- NPMSEUWUMOSEFM-CIUDSAMLSA-N Glu-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N NPMSEUWUMOSEFM-CIUDSAMLSA-N 0.000 description 7
- DXMOIVCNJIJQSC-QEJZJMRPSA-N Glu-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N DXMOIVCNJIJQSC-QEJZJMRPSA-N 0.000 description 7
- BRFJMRSRMOMIMU-WHFBIAKZSA-N Gly-Ala-Asn Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O BRFJMRSRMOMIMU-WHFBIAKZSA-N 0.000 description 7
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 7
- KPYAOIVPJKPIOU-KKUMJFAQSA-N Leu-Lys-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O KPYAOIVPJKPIOU-KKUMJFAQSA-N 0.000 description 7
- HWMZUBUEOYAQSC-DCAQKATOSA-N Lys-Gln-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O HWMZUBUEOYAQSC-DCAQKATOSA-N 0.000 description 7
- WOEDRPCHKPSFDT-MXAVVETBSA-N Lys-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCCN)N WOEDRPCHKPSFDT-MXAVVETBSA-N 0.000 description 7
- RBEATVHTWHTHTJ-KKUMJFAQSA-N Lys-Leu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O RBEATVHTWHTHTJ-KKUMJFAQSA-N 0.000 description 7
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 7
- QEWBZBLXDKIQPS-STQMWFEESA-N Pro-Gly-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O QEWBZBLXDKIQPS-STQMWFEESA-N 0.000 description 7
- LWMQRHDTXHQQOV-MXAVVETBSA-N Ser-Ile-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LWMQRHDTXHQQOV-MXAVVETBSA-N 0.000 description 7
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 7
- CWQZAUYFWRLITN-AVGNSLFASA-N Tyr-Gln-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N)O CWQZAUYFWRLITN-AVGNSLFASA-N 0.000 description 7
- WYOBRXPIZVKNMF-IRXDYDNUSA-N Tyr-Tyr-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)NCC(O)=O)C1=CC=C(O)C=C1 WYOBRXPIZVKNMF-IRXDYDNUSA-N 0.000 description 7
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 7
- 238000006243 chemical reaction Methods 0.000 description 7
- 238000012217 deletion Methods 0.000 description 7
- 230000037430 deletion Effects 0.000 description 7
- 238000013461 design Methods 0.000 description 7
- 230000004927 fusion Effects 0.000 description 7
- 108010010147 glycylglutamine Proteins 0.000 description 7
- 210000005260 human cell Anatomy 0.000 description 7
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 7
- 239000000047 product Substances 0.000 description 7
- 108010070643 prolylglutamic acid Proteins 0.000 description 7
- 210000002966 serum Anatomy 0.000 description 7
- 210000000952 spleen Anatomy 0.000 description 7
- 108010005652 splenotritin Proteins 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 7
- 108010073969 valyllysine Proteins 0.000 description 7
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 6
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 6
- QPOARHANPULOTM-GMOBBJLQSA-N Arg-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N QPOARHANPULOTM-GMOBBJLQSA-N 0.000 description 6
- PBSQFBAJKPLRJY-BYULHYEWSA-N Asn-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N PBSQFBAJKPLRJY-BYULHYEWSA-N 0.000 description 6
- SPCONPVIDFMDJI-QSFUFRPTSA-N Asn-Ile-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O SPCONPVIDFMDJI-QSFUFRPTSA-N 0.000 description 6
- TZFQICWZWFNIKU-KKUMJFAQSA-N Asn-Leu-Tyr Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 TZFQICWZWFNIKU-KKUMJFAQSA-N 0.000 description 6
- OERMIMJQPQUIPK-FXQIFTODSA-N Asp-Arg-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O OERMIMJQPQUIPK-FXQIFTODSA-N 0.000 description 6
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 6
- NSNUZSPSADIMJQ-WDSKDSINSA-N Gln-Gly-Asp Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NSNUZSPSADIMJQ-WDSKDSINSA-N 0.000 description 6
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 6
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 6
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 6
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 6
- SFKMXFWWDUGXRT-NWLDYVSISA-N Glu-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N)O SFKMXFWWDUGXRT-NWLDYVSISA-N 0.000 description 6
- GZUKEVBTYNNUQF-WDSKDSINSA-N Gly-Ala-Gln Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GZUKEVBTYNNUQF-WDSKDSINSA-N 0.000 description 6
- BULIVUZUDBHKKZ-WDSKDSINSA-N Gly-Gln-Asn Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BULIVUZUDBHKKZ-WDSKDSINSA-N 0.000 description 6
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 6
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 6
- FXJLRZFMKGHYJP-CFMVVWHZSA-N Ile-Tyr-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FXJLRZFMKGHYJP-CFMVVWHZSA-N 0.000 description 6
- KEVYYIMVELOXCT-KBPBESRZSA-N Leu-Gly-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KEVYYIMVELOXCT-KBPBESRZSA-N 0.000 description 6
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 6
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 6
- XZNJZXJZBMBGGS-NHCYSSNCSA-N Leu-Val-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O XZNJZXJZBMBGGS-NHCYSSNCSA-N 0.000 description 6
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 6
- WBSCNDJQPKSPII-KKUMJFAQSA-N Lys-Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O WBSCNDJQPKSPII-KKUMJFAQSA-N 0.000 description 6
- OXIWIYOJVNOKOV-SRVKXCTJSA-N Met-Met-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCNC(N)=N OXIWIYOJVNOKOV-SRVKXCTJSA-N 0.000 description 6
- 241001465754 Metazoa Species 0.000 description 6
- 241000699666 Mus <mouse, genus> Species 0.000 description 6
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 6
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 6
- PEVVXUGSAKEPEN-AVGNSLFASA-N Tyr-Asn-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PEVVXUGSAKEPEN-AVGNSLFASA-N 0.000 description 6
- DANHCMVVXDXOHN-SRVKXCTJSA-N Tyr-Asp-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 DANHCMVVXDXOHN-SRVKXCTJSA-N 0.000 description 6
- JLFKWDAZBRYCGX-ZKWXMUAHSA-N Val-Asn-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N JLFKWDAZBRYCGX-ZKWXMUAHSA-N 0.000 description 6
- DDNIHOWRDOXXPF-NGZCFLSTSA-N Val-Asp-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DDNIHOWRDOXXPF-NGZCFLSTSA-N 0.000 description 6
- FEXILLGKGGTLRI-NHCYSSNCSA-N Val-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N FEXILLGKGGTLRI-NHCYSSNCSA-N 0.000 description 6
- 108010044940 alanylglutamine Proteins 0.000 description 6
- 108010038633 aspartylglutamate Proteins 0.000 description 6
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 6
- 108010019832 glycyl-asparaginyl-glycine Proteins 0.000 description 6
- 108010037850 glycylvaline Proteins 0.000 description 6
- 108010003700 lysyl aspartic acid Proteins 0.000 description 6
- 108010017391 lysylvaline Proteins 0.000 description 6
- 210000004779 membrane envelope Anatomy 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 238000006386 neutralization reaction Methods 0.000 description 6
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 6
- 108010004914 prolylarginine Proteins 0.000 description 6
- 238000003753 real-time PCR Methods 0.000 description 6
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 5
- MPLOSMWGDNJSEV-WHFBIAKZSA-N Ala-Gly-Asp Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MPLOSMWGDNJSEV-WHFBIAKZSA-N 0.000 description 5
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 5
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 5
- CVXXSWQORBZAAA-SRVKXCTJSA-N Arg-Lys-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N CVXXSWQORBZAAA-SRVKXCTJSA-N 0.000 description 5
- BNYNOWJESJJIOI-XUXIUFHCSA-N Arg-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N BNYNOWJESJJIOI-XUXIUFHCSA-N 0.000 description 5
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 5
- XVAPVJNJGLWGCS-ACZMJKKPSA-N Asn-Glu-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N XVAPVJNJGLWGCS-ACZMJKKPSA-N 0.000 description 5
- DXVMJJNAOVECBA-WHFBIAKZSA-N Asn-Gly-Asn Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O DXVMJJNAOVECBA-WHFBIAKZSA-N 0.000 description 5
- DJIMLSXHXKWADV-CIUDSAMLSA-N Asn-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(N)=O DJIMLSXHXKWADV-CIUDSAMLSA-N 0.000 description 5
- KHCNTVRVAYCPQE-CIUDSAMLSA-N Asn-Lys-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O KHCNTVRVAYCPQE-CIUDSAMLSA-N 0.000 description 5
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 5
- CBWCQCANJSGUOH-ZKWXMUAHSA-N Asn-Val-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O CBWCQCANJSGUOH-ZKWXMUAHSA-N 0.000 description 5
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 5
- XOQYDFCQPWAMSA-KKHAAJSZSA-N Asn-Val-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XOQYDFCQPWAMSA-KKHAAJSZSA-N 0.000 description 5
- JUWZKMBALYLZCK-WHFBIAKZSA-N Asp-Gly-Asn Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O JUWZKMBALYLZCK-WHFBIAKZSA-N 0.000 description 5
- TZOZNVLBTAFJRW-UGYAYLCHSA-N Asp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N TZOZNVLBTAFJRW-UGYAYLCHSA-N 0.000 description 5
- KQBVNNAPIURMPD-PEFMBERDSA-N Asp-Ile-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(O)=O KQBVNNAPIURMPD-PEFMBERDSA-N 0.000 description 5
- DWOGMPWRQQWPPF-GUBZILKMSA-N Asp-Leu-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O DWOGMPWRQQWPPF-GUBZILKMSA-N 0.000 description 5
- YVHGKXAOSVBGJV-CIUDSAMLSA-N Asp-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N YVHGKXAOSVBGJV-CIUDSAMLSA-N 0.000 description 5
- UAXIKORUDGGIGA-DCAQKATOSA-N Asp-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O UAXIKORUDGGIGA-DCAQKATOSA-N 0.000 description 5
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 5
- 101710205625 Capsid protein p24 Proteins 0.000 description 5
- JAHCWGSVNZXHRR-SVSWQMSJSA-N Cys-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CS)N JAHCWGSVNZXHRR-SVSWQMSJSA-N 0.000 description 5
- 241000255925 Diptera Species 0.000 description 5
- 238000002965 ELISA Methods 0.000 description 5
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 5
- 108010070675 Glutathione transferase Proteins 0.000 description 5
- UGVQELHRNUDMAA-BYPYZUCNSA-N Gly-Ala-Gly Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)NCC([O-])=O UGVQELHRNUDMAA-BYPYZUCNSA-N 0.000 description 5
- 108090000288 Glycoproteins Proteins 0.000 description 5
- 102000003886 Glycoproteins Human genes 0.000 description 5
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 description 5
- FFYYUUWROYYKFY-IHRRRGAJSA-N His-Val-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O FFYYUUWROYYKFY-IHRRRGAJSA-N 0.000 description 5
- AWTDTFXPVCTHAK-BJDJZHNGSA-N Ile-Cys-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N AWTDTFXPVCTHAK-BJDJZHNGSA-N 0.000 description 5
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 5
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 5
- SVBJIZVVYJYGLA-DCAQKATOSA-N Leu-Ser-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O SVBJIZVVYJYGLA-DCAQKATOSA-N 0.000 description 5
- XOEDPXDZJHBQIX-ULQDDVLXSA-N Leu-Val-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOEDPXDZJHBQIX-ULQDDVLXSA-N 0.000 description 5
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 5
- GZGWILAQHOVXTD-DCAQKATOSA-N Lys-Met-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O GZGWILAQHOVXTD-DCAQKATOSA-N 0.000 description 5
- OBZHNHBAAVEWKI-DCAQKATOSA-N Lys-Pro-Asn Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O OBZHNHBAAVEWKI-DCAQKATOSA-N 0.000 description 5
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 5
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 5
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 5
- HTTYNOXBBOWZTB-SRVKXCTJSA-N Phe-Asn-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N HTTYNOXBBOWZTB-SRVKXCTJSA-N 0.000 description 5
- 101710177166 Phosphoprotein Proteins 0.000 description 5
- 241000223808 Plasmodium reichenowi Species 0.000 description 5
- VPVHXWGPALPDGP-GUBZILKMSA-N Pro-Asn-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O VPVHXWGPALPDGP-GUBZILKMSA-N 0.000 description 5
- FISHYTLIMUYTQY-GUBZILKMSA-N Pro-Gln-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 FISHYTLIMUYTQY-GUBZILKMSA-N 0.000 description 5
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 5
- IFPBAGJBHSNYPR-ZKWXMUAHSA-N Ser-Ile-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O IFPBAGJBHSNYPR-ZKWXMUAHSA-N 0.000 description 5
- 101710149279 Small delta antigen Proteins 0.000 description 5
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 5
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 5
- 102100022563 Tubulin polymerization-promoting protein Human genes 0.000 description 5
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 5
- WBAJDGWKRIHOAC-GVXVVHGQSA-N Val-Lys-Gln Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O WBAJDGWKRIHOAC-GVXVVHGQSA-N 0.000 description 5
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 5
- 230000005875 antibody response Effects 0.000 description 5
- 210000000612 antigen-presenting cell Anatomy 0.000 description 5
- 108010016616 cysteinylglycine Proteins 0.000 description 5
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 5
- 238000003114 enzyme-linked immunosorbent spot assay Methods 0.000 description 5
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 5
- 239000005090 green fluorescent protein Substances 0.000 description 5
- 230000036039 immunity Effects 0.000 description 5
- 230000001976 improved effect Effects 0.000 description 5
- 108010027338 isoleucylcysteine Proteins 0.000 description 5
- 230000005923 long-lasting effect Effects 0.000 description 5
- 238000012544 monitoring process Methods 0.000 description 5
- 108010089520 pol Gene Products Proteins 0.000 description 5
- 238000011002 quantification Methods 0.000 description 5
- 230000028327 secretion Effects 0.000 description 5
- 208000003265 stomatitis Diseases 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 4
- CVGNCMIULZNYES-WHFBIAKZSA-N Ala-Asn-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CVGNCMIULZNYES-WHFBIAKZSA-N 0.000 description 4
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 4
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 4
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 4
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 4
- OVVUNXXROOFSIM-SDDRHHMPSA-N Arg-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O OVVUNXXROOFSIM-SDDRHHMPSA-N 0.000 description 4
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 4
- GRRXPUAICOGISM-RWMBFGLXSA-N Arg-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GRRXPUAICOGISM-RWMBFGLXSA-N 0.000 description 4
- DNBMCNQKNOKOSD-DCAQKATOSA-N Arg-Pro-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O DNBMCNQKNOKOSD-DCAQKATOSA-N 0.000 description 4
- ISVACHFCVRKIDG-SRVKXCTJSA-N Arg-Val-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O ISVACHFCVRKIDG-SRVKXCTJSA-N 0.000 description 4
- NUHQMYUWLUSRJX-BIIVOSGPSA-N Asn-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N NUHQMYUWLUSRJX-BIIVOSGPSA-N 0.000 description 4
- PIWWUBYJNONVTJ-ZLUOBGJFSA-N Asn-Asp-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N PIWWUBYJNONVTJ-ZLUOBGJFSA-N 0.000 description 4
- VJTWLBMESLDOMK-WDSKDSINSA-N Asn-Gln-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VJTWLBMESLDOMK-WDSKDSINSA-N 0.000 description 4
- BZMWJLLUAKSIMH-FXQIFTODSA-N Asn-Glu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BZMWJLLUAKSIMH-FXQIFTODSA-N 0.000 description 4
- WONGRTVAMHFGBE-WDSKDSINSA-N Asn-Gly-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N WONGRTVAMHFGBE-WDSKDSINSA-N 0.000 description 4
- HPNDBHLITCHRSO-WHFBIAKZSA-N Asp-Ala-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)NCC(O)=O HPNDBHLITCHRSO-WHFBIAKZSA-N 0.000 description 4
- BLQBMRNMBAYREH-UWJYBYFXSA-N Asp-Ala-Tyr Chemical compound N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O BLQBMRNMBAYREH-UWJYBYFXSA-N 0.000 description 4
- GWTLRDMPMJCNMH-WHFBIAKZSA-N Asp-Asn-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O GWTLRDMPMJCNMH-WHFBIAKZSA-N 0.000 description 4
- SBHUBSDEZQFJHJ-CIUDSAMLSA-N Asp-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O SBHUBSDEZQFJHJ-CIUDSAMLSA-N 0.000 description 4
- LKIYSIYBKYLKPU-BIIVOSGPSA-N Asp-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O LKIYSIYBKYLKPU-BIIVOSGPSA-N 0.000 description 4
- DJCAHYVLMSRBFR-QXEWZRGKSA-N Asp-Met-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC(O)=O DJCAHYVLMSRBFR-QXEWZRGKSA-N 0.000 description 4
- 241000713756 Caprine arthritis encephalitis virus Species 0.000 description 4
- 241000711969 Chandipura virus Species 0.000 description 4
- 101710177291 Gag polyprotein Proteins 0.000 description 4
- RMOCFPBLHAOTDU-ACZMJKKPSA-N Gln-Asn-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RMOCFPBLHAOTDU-ACZMJKKPSA-N 0.000 description 4
- LMPBBFWHCRURJD-LAEOZQHASA-N Gln-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N LMPBBFWHCRURJD-LAEOZQHASA-N 0.000 description 4
- OACPJRQRAHMQEQ-NHCYSSNCSA-N Gln-Val-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O OACPJRQRAHMQEQ-NHCYSSNCSA-N 0.000 description 4
- AKJRHDMTEJXTPV-ACZMJKKPSA-N Glu-Asn-Ala Chemical compound C[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AKJRHDMTEJXTPV-ACZMJKKPSA-N 0.000 description 4
- UMIRPYLZFKOEOH-YVNDNENWSA-N Glu-Gln-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UMIRPYLZFKOEOH-YVNDNENWSA-N 0.000 description 4
- YVYVMJNUENBOOL-KBIXCLLPSA-N Glu-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N YVYVMJNUENBOOL-KBIXCLLPSA-N 0.000 description 4
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 4
- CUPSDFQZTVVTSK-GUBZILKMSA-N Glu-Lys-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O CUPSDFQZTVVTSK-GUBZILKMSA-N 0.000 description 4
- OCJRHJZKGGSPRW-IUCAKERBSA-N Glu-Lys-Gly Chemical compound NCCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O OCJRHJZKGGSPRW-IUCAKERBSA-N 0.000 description 4
- GUOWMVFLAJNPDY-CIUDSAMLSA-N Glu-Ser-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O GUOWMVFLAJNPDY-CIUDSAMLSA-N 0.000 description 4
- HMJULNMJWOZNFI-XHNCKOQMSA-N Glu-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)O)N)C(=O)O HMJULNMJWOZNFI-XHNCKOQMSA-N 0.000 description 4
- OCDLPQDYTJPWNG-YUMQZZPRSA-N Gly-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN OCDLPQDYTJPWNG-YUMQZZPRSA-N 0.000 description 4
- XRTDOIOIBMAXCT-NKWVEPMBSA-N Gly-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)CN)C(=O)O XRTDOIOIBMAXCT-NKWVEPMBSA-N 0.000 description 4
- KQDMENMTYNBWMR-WHFBIAKZSA-N Gly-Asp-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KQDMENMTYNBWMR-WHFBIAKZSA-N 0.000 description 4
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 4
- GDOZQTNZPCUARW-YFKPBYRVSA-N Gly-Gly-Glu Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O GDOZQTNZPCUARW-YFKPBYRVSA-N 0.000 description 4
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 4
- BXICSAQLIHFDDL-YUMQZZPRSA-N Gly-Lys-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BXICSAQLIHFDDL-YUMQZZPRSA-N 0.000 description 4
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 4
- AFPFGFUGETYOSY-HGNGGELXSA-N His-Ala-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AFPFGFUGETYOSY-HGNGGELXSA-N 0.000 description 4
- HAPWZEVRQYGLSG-IUCAKERBSA-N His-Gly-Glu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O HAPWZEVRQYGLSG-IUCAKERBSA-N 0.000 description 4
- 241000713340 Human immunodeficiency virus 2 Species 0.000 description 4
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 4
- GVNNAHIRSDRIII-AJNGGQMLSA-N Ile-Lys-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N GVNNAHIRSDRIII-AJNGGQMLSA-N 0.000 description 4
- QPRQGENIBFLVEB-BJDJZHNGSA-N Leu-Ala-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O QPRQGENIBFLVEB-BJDJZHNGSA-N 0.000 description 4
- XBBKIIGCUMBKCO-JXUBOQSCSA-N Leu-Ala-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XBBKIIGCUMBKCO-JXUBOQSCSA-N 0.000 description 4
- QLQHWWCSCLZUMA-KKUMJFAQSA-N Leu-Asp-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QLQHWWCSCLZUMA-KKUMJFAQSA-N 0.000 description 4
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 4
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 4
- RZXLZBIUTDQHJQ-SRVKXCTJSA-N Leu-Lys-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O RZXLZBIUTDQHJQ-SRVKXCTJSA-N 0.000 description 4
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 4
- QQXJROOJCMIHIV-AVGNSLFASA-N Leu-Val-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O QQXJROOJCMIHIV-AVGNSLFASA-N 0.000 description 4
- ZQCVMVCVPFYXHZ-SRVKXCTJSA-N Lys-Asn-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCCN ZQCVMVCVPFYXHZ-SRVKXCTJSA-N 0.000 description 4
- QUYCUALODHJQLK-CIUDSAMLSA-N Lys-Asp-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QUYCUALODHJQLK-CIUDSAMLSA-N 0.000 description 4
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 4
- ISHNZELVUVPCHY-ZETCQYMHSA-N Lys-Gly-Gly Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O ISHNZELVUVPCHY-ZETCQYMHSA-N 0.000 description 4
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 4
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 4
- YXPJCVNIDDKGOE-MELADBBJSA-N Lys-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)N)C(=O)O YXPJCVNIDDKGOE-MELADBBJSA-N 0.000 description 4
- XFOAWKDQMRMCDN-ULQDDVLXSA-N Lys-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CCCCN)CC1=CC=CC=C1 XFOAWKDQMRMCDN-ULQDDVLXSA-N 0.000 description 4
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 4
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 4
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 4
- RQILLQOQXLZTCK-KBPBESRZSA-N Lys-Tyr-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O RQILLQOQXLZTCK-KBPBESRZSA-N 0.000 description 4
- IYXDSYWCVVXSKB-CIUDSAMLSA-N Met-Asn-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IYXDSYWCVVXSKB-CIUDSAMLSA-N 0.000 description 4
- MPCKIRSXNKACRF-GUBZILKMSA-N Met-Pro-Asn Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O MPCKIRSXNKACRF-GUBZILKMSA-N 0.000 description 4
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 4
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 4
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 4
- DVOCGBNHAUHKHJ-DKIMLUQUSA-N Phe-Ile-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O DVOCGBNHAUHKHJ-DKIMLUQUSA-N 0.000 description 4
- TXPUNZXZDVJUJQ-LPEHRKFASA-N Pro-Asn-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O TXPUNZXZDVJUJQ-LPEHRKFASA-N 0.000 description 4
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 4
- XQPHBAKJJJZOBX-SRVKXCTJSA-N Pro-Lys-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O XQPHBAKJJJZOBX-SRVKXCTJSA-N 0.000 description 4
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 4
- SBVPYBFMIGDIDX-SRVKXCTJSA-N Pro-Pro-Pro Chemical compound OC(=O)[C@@H]1CCCN1C(=O)[C@H]1N(C(=O)[C@H]2NCCC2)CCC1 SBVPYBFMIGDIDX-SRVKXCTJSA-N 0.000 description 4
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 4
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 4
- IYCBDVBJWDXQRR-FXQIFTODSA-N Ser-Ala-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O IYCBDVBJWDXQRR-FXQIFTODSA-N 0.000 description 4
- GXXTUIUYTWGPMV-FXQIFTODSA-N Ser-Arg-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O GXXTUIUYTWGPMV-FXQIFTODSA-N 0.000 description 4
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 4
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 4
- RWDVVSKYZBNDCO-MELADBBJSA-N Ser-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CO)N)C(=O)O RWDVVSKYZBNDCO-MELADBBJSA-N 0.000 description 4
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 4
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 4
- JMGJDTNUMAZNLX-RWRJDSDZSA-N Thr-Glu-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JMGJDTNUMAZNLX-RWRJDSDZSA-N 0.000 description 4
- UDNVOQMPQBEITB-MEYUZBJRSA-N Thr-His-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O UDNVOQMPQBEITB-MEYUZBJRSA-N 0.000 description 4
- NYQIZWROIMIQSL-VEVYYDQMSA-N Thr-Pro-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O NYQIZWROIMIQSL-VEVYYDQMSA-N 0.000 description 4
- PZXUIGWOEWWFQM-SRVKXCTJSA-N Tyr-Asn-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O PZXUIGWOEWWFQM-SRVKXCTJSA-N 0.000 description 4
- ZNFPUOSTMUMUDR-JRQIVUDYSA-N Tyr-Asn-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZNFPUOSTMUMUDR-JRQIVUDYSA-N 0.000 description 4
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 4
- LNYOXPDEIZJDEI-NHCYSSNCSA-N Val-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LNYOXPDEIZJDEI-NHCYSSNCSA-N 0.000 description 4
- TZVUSFMQWPWHON-NHCYSSNCSA-N Val-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N TZVUSFMQWPWHON-NHCYSSNCSA-N 0.000 description 4
- OUUBKKIJQIAPRI-LAEOZQHASA-N Val-Gln-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OUUBKKIJQIAPRI-LAEOZQHASA-N 0.000 description 4
- YCMXFKWYJFZFKS-LAEOZQHASA-N Val-Gln-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCMXFKWYJFZFKS-LAEOZQHASA-N 0.000 description 4
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 4
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 4
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 108010013835 arginine glutamate Proteins 0.000 description 4
- 230000032823 cell division Effects 0.000 description 4
- 230000036755 cellular response Effects 0.000 description 4
- 238000002784 cytotoxicity assay Methods 0.000 description 4
- 231100000263 cytotoxicity test Toxicity 0.000 description 4
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 4
- 230000013595 glycosylation Effects 0.000 description 4
- 238000006206 glycosylation reaction Methods 0.000 description 4
- 108010045383 histidyl-glycyl-glutamic acid Proteins 0.000 description 4
- 230000005847 immunogenicity Effects 0.000 description 4
- 230000006698 induction Effects 0.000 description 4
- 108010034529 leucyl-lysine Proteins 0.000 description 4
- 108010057821 leucylproline Proteins 0.000 description 4
- 108010044348 lysyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 230000001404 mediated effect Effects 0.000 description 4
- 238000010172 mouse model Methods 0.000 description 4
- 230000003472 neutralizing effect Effects 0.000 description 4
- 238000012809 post-inoculation Methods 0.000 description 4
- 108010066381 preproinsulin Proteins 0.000 description 4
- 102220036548 rs140382474 Human genes 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 230000000638 stimulation Effects 0.000 description 4
- 238000004448 titration Methods 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 108010051110 tyrosyl-lysine Proteins 0.000 description 4
- YIQAOPNCIJVKDN-XKNYDFJKSA-N Ala-Asn-Asp-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(O)=O YIQAOPNCIJVKDN-XKNYDFJKSA-N 0.000 description 3
- BGNLUHXLSAQYRQ-FXQIFTODSA-N Ala-Glu-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BGNLUHXLSAQYRQ-FXQIFTODSA-N 0.000 description 3
- VQAVBBCZFQAAED-FXQIFTODSA-N Ala-Pro-Asn Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)N)C(=O)O)N VQAVBBCZFQAAED-FXQIFTODSA-N 0.000 description 3
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 3
- USNSOPDIZILSJP-FXQIFTODSA-N Arg-Asn-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O USNSOPDIZILSJP-FXQIFTODSA-N 0.000 description 3
- MAISCYVJLBBRNU-DCAQKATOSA-N Arg-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N MAISCYVJLBBRNU-DCAQKATOSA-N 0.000 description 3
- ITVINTQUZMQWJR-QXEWZRGKSA-N Arg-Asn-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ITVINTQUZMQWJR-QXEWZRGKSA-N 0.000 description 3
- YVTHEZNOKSAWRW-DCAQKATOSA-N Arg-Lys-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O YVTHEZNOKSAWRW-DCAQKATOSA-N 0.000 description 3
- GMRGSBAMMMVDGG-GUBZILKMSA-N Asn-Arg-Arg Chemical compound C(C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N GMRGSBAMMMVDGG-GUBZILKMSA-N 0.000 description 3
- KSBHCUSPLWRVEK-ZLUOBGJFSA-N Asn-Asn-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KSBHCUSPLWRVEK-ZLUOBGJFSA-N 0.000 description 3
- KXEGPPNPXOKKHK-ZLUOBGJFSA-N Asn-Asp-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O KXEGPPNPXOKKHK-ZLUOBGJFSA-N 0.000 description 3
- UGXVKHRDGLYFKR-CIUDSAMLSA-N Asn-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(N)=O UGXVKHRDGLYFKR-CIUDSAMLSA-N 0.000 description 3
- PAXHINASXXXILC-SRVKXCTJSA-N Asn-Asp-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N)O PAXHINASXXXILC-SRVKXCTJSA-N 0.000 description 3
- KLKHFFMNGWULBN-VKHMYHEASA-N Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)NCC(O)=O KLKHFFMNGWULBN-VKHMYHEASA-N 0.000 description 3
- COWITDLVHMZSIW-CIUDSAMLSA-N Asn-Lys-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O COWITDLVHMZSIW-CIUDSAMLSA-N 0.000 description 3
- WSWYMRLTJVKRCE-ZLUOBGJFSA-N Asp-Ala-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O WSWYMRLTJVKRCE-ZLUOBGJFSA-N 0.000 description 3
- JDHOJQJMWBKHDB-CIUDSAMLSA-N Asp-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N JDHOJQJMWBKHDB-CIUDSAMLSA-N 0.000 description 3
- RDRMWJBLOSRRAW-BYULHYEWSA-N Asp-Asn-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O RDRMWJBLOSRRAW-BYULHYEWSA-N 0.000 description 3
- WLKVEEODTPQPLI-ACZMJKKPSA-N Asp-Gln-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O WLKVEEODTPQPLI-ACZMJKKPSA-N 0.000 description 3
- VFUXXFVCYZPOQG-WDSKDSINSA-N Asp-Glu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VFUXXFVCYZPOQG-WDSKDSINSA-N 0.000 description 3
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 3
- POTCZYQVVNXUIG-BQBZGAKWSA-N Asp-Gly-Pro Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O POTCZYQVVNXUIG-BQBZGAKWSA-N 0.000 description 3
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 3
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 3
- 108090000746 Chymosin Proteins 0.000 description 3
- LBSKYJOZIIOZIO-DCAQKATOSA-N Cys-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CS)N LBSKYJOZIIOZIO-DCAQKATOSA-N 0.000 description 3
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 3
- 241000713800 Feline immunodeficiency virus Species 0.000 description 3
- MFLMFRZBAJSGHK-ACZMJKKPSA-N Gln-Cys-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N MFLMFRZBAJSGHK-ACZMJKKPSA-N 0.000 description 3
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 3
- MLSKFHLRFVGNLL-WDCWCFNPSA-N Gln-Leu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MLSKFHLRFVGNLL-WDCWCFNPSA-N 0.000 description 3
- OGMQXTXGLDNBSS-FXQIFTODSA-N Glu-Ala-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O OGMQXTXGLDNBSS-FXQIFTODSA-N 0.000 description 3
- ZOXBSICWUDAOHX-GUBZILKMSA-N Glu-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CCC(O)=O ZOXBSICWUDAOHX-GUBZILKMSA-N 0.000 description 3
- YLJHCWNDBKKOEB-IHRRRGAJSA-N Glu-Glu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YLJHCWNDBKKOEB-IHRRRGAJSA-N 0.000 description 3
- AIGROOHQXCACHL-WDSKDSINSA-N Glu-Gly-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O AIGROOHQXCACHL-WDSKDSINSA-N 0.000 description 3
- KRGZZKWSBGPLKL-IUCAKERBSA-N Glu-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N KRGZZKWSBGPLKL-IUCAKERBSA-N 0.000 description 3
- IOUQWHIEQYQVFD-JYJNAYRXSA-N Glu-Leu-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IOUQWHIEQYQVFD-JYJNAYRXSA-N 0.000 description 3
- OHWJUIXZHVIXJJ-GUBZILKMSA-N Glu-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N OHWJUIXZHVIXJJ-GUBZILKMSA-N 0.000 description 3
- BCYGDJXHAGZNPQ-DCAQKATOSA-N Glu-Lys-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O BCYGDJXHAGZNPQ-DCAQKATOSA-N 0.000 description 3
- BIYNPVYAZOUVFQ-CIUDSAMLSA-N Glu-Pro-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O BIYNPVYAZOUVFQ-CIUDSAMLSA-N 0.000 description 3
- PYTZFYUXZZHOAD-WHFBIAKZSA-N Gly-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)CN PYTZFYUXZZHOAD-WHFBIAKZSA-N 0.000 description 3
- HFXJIZNEXNIZIJ-BQBZGAKWSA-N Gly-Glu-Gln Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFXJIZNEXNIZIJ-BQBZGAKWSA-N 0.000 description 3
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 3
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 3
- VDCRBJACQKOSMS-JSGCOSHPSA-N Gly-Phe-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O VDCRBJACQKOSMS-JSGCOSHPSA-N 0.000 description 3
- GJHWILMUOANXTG-WPRPVWTQSA-N Gly-Val-Arg Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GJHWILMUOANXTG-WPRPVWTQSA-N 0.000 description 3
- 208000031886 HIV Infections Diseases 0.000 description 3
- 101150106931 IFNG gene Proteins 0.000 description 3
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 3
- TZCGZYWNIDZZMR-UHFFFAOYSA-N Ile-Arg-Ala Natural products CCC(C)C(N)C(=O)NC(C(=O)NC(C)C(O)=O)CCCN=C(N)N TZCGZYWNIDZZMR-UHFFFAOYSA-N 0.000 description 3
- QIHJTGSVGIPHIW-QSFUFRPTSA-N Ile-Asn-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N QIHJTGSVGIPHIW-QSFUFRPTSA-N 0.000 description 3
- IDAHFEPYTJJZFD-PEFMBERDSA-N Ile-Asp-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N IDAHFEPYTJJZFD-PEFMBERDSA-N 0.000 description 3
- ZDNORQNHCJUVOV-KBIXCLLPSA-N Ile-Gln-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O ZDNORQNHCJUVOV-KBIXCLLPSA-N 0.000 description 3
- KMBPQYKVZBMRMH-PEFMBERDSA-N Ile-Gln-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O KMBPQYKVZBMRMH-PEFMBERDSA-N 0.000 description 3
- DVRDRICMWUSCBN-UKJIMTQDSA-N Ile-Gln-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DVRDRICMWUSCBN-UKJIMTQDSA-N 0.000 description 3
- SNHYFFQZRFIRHO-CYDGBPFRSA-N Ile-Met-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)O)N SNHYFFQZRFIRHO-CYDGBPFRSA-N 0.000 description 3
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 3
- 102100037850 Interferon gamma Human genes 0.000 description 3
- 108010074328 Interferon-gamma Proteins 0.000 description 3
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 3
- YOZCKMXHBYKOMQ-IHRRRGAJSA-N Leu-Arg-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N YOZCKMXHBYKOMQ-IHRRRGAJSA-N 0.000 description 3
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 3
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 3
- ZALAVHVPPOHAOL-XUXIUFHCSA-N Leu-Ile-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CC(C)C)N ZALAVHVPPOHAOL-XUXIUFHCSA-N 0.000 description 3
- ZDBMWELMUCLUPL-QEJZJMRPSA-N Leu-Phe-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 ZDBMWELMUCLUPL-QEJZJMRPSA-N 0.000 description 3
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 3
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 3
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 3
- ALSRJRIWBNENFY-DCAQKATOSA-N Lys-Arg-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O ALSRJRIWBNENFY-DCAQKATOSA-N 0.000 description 3
- HQVDJTYKCMIWJP-YUMQZZPRSA-N Lys-Asn-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HQVDJTYKCMIWJP-YUMQZZPRSA-N 0.000 description 3
- HIIZIQUUHIXUJY-GUBZILKMSA-N Lys-Asp-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HIIZIQUUHIXUJY-GUBZILKMSA-N 0.000 description 3
- MQMIRLVJXQNTRJ-SDDRHHMPSA-N Lys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O MQMIRLVJXQNTRJ-SDDRHHMPSA-N 0.000 description 3
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 3
- SQJSXOQXJYAVRV-SRVKXCTJSA-N Lys-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N SQJSXOQXJYAVRV-SRVKXCTJSA-N 0.000 description 3
- XOQMURBBIXRRCR-SRVKXCTJSA-N Lys-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN XOQMURBBIXRRCR-SRVKXCTJSA-N 0.000 description 3
- CNGOEHJCLVCJHN-SRVKXCTJSA-N Lys-Pro-Glu Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O CNGOEHJCLVCJHN-SRVKXCTJSA-N 0.000 description 3
- IKXQOBUBZSOWDY-AVGNSLFASA-N Lys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N IKXQOBUBZSOWDY-AVGNSLFASA-N 0.000 description 3
- VZBXCMCHIHEPBL-SRVKXCTJSA-N Met-Glu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN VZBXCMCHIHEPBL-SRVKXCTJSA-N 0.000 description 3
- SODXFJOPSCXOHE-IHRRRGAJSA-N Met-Leu-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O SODXFJOPSCXOHE-IHRRRGAJSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- 241000711965 Piry virus Species 0.000 description 3
- 241000224017 Plasmodium berghei Species 0.000 description 3
- 241000223992 Plasmodium gallinaceum Species 0.000 description 3
- SMCHPSMKAFIERP-FXQIFTODSA-N Pro-Asn-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 SMCHPSMKAFIERP-FXQIFTODSA-N 0.000 description 3
- OBVCYFIHIIYIQF-CIUDSAMLSA-N Pro-Asn-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OBVCYFIHIIYIQF-CIUDSAMLSA-N 0.000 description 3
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 3
- JFNPBBOGGNMSRX-CIUDSAMLSA-N Pro-Gln-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O JFNPBBOGGNMSRX-CIUDSAMLSA-N 0.000 description 3
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 3
- UUHXBJHVTVGSKM-BQBZGAKWSA-N Pro-Gly-Asn Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UUHXBJHVTVGSKM-BQBZGAKWSA-N 0.000 description 3
- 108091027981 Response element Proteins 0.000 description 3
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 3
- UBRMZSHOOIVJPW-SRVKXCTJSA-N Ser-Leu-Lys Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O UBRMZSHOOIVJPW-SRVKXCTJSA-N 0.000 description 3
- UPLYXVPQLJVWMM-KKUMJFAQSA-N Ser-Phe-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UPLYXVPQLJVWMM-KKUMJFAQSA-N 0.000 description 3
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 3
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 3
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 3
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 3
- 241000713311 Simian immunodeficiency virus Species 0.000 description 3
- KOVXHANYYYMBRF-IRIUXVKKSA-N Tyr-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O KOVXHANYYYMBRF-IRIUXVKKSA-N 0.000 description 3
- UDLYXGYWTVOIKU-QXEWZRGKSA-N Val-Asn-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UDLYXGYWTVOIKU-QXEWZRGKSA-N 0.000 description 3
- ISERLACIZUGCDX-ZKWXMUAHSA-N Val-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N ISERLACIZUGCDX-ZKWXMUAHSA-N 0.000 description 3
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 3
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 3
- DEGUERSKQBRZMZ-FXQIFTODSA-N Val-Ser-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O DEGUERSKQBRZMZ-FXQIFTODSA-N 0.000 description 3
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 3
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 3
- 208000010094 Visna Diseases 0.000 description 3
- 108010070944 alanylhistidine Proteins 0.000 description 3
- 235000001014 amino acid Nutrition 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 3
- 108010066988 asparaginyl-alanyl-glycyl-alanine Proteins 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 230000003197 catalytic effect Effects 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 229940080701 chymosin Drugs 0.000 description 3
- 239000011248 coating agent Substances 0.000 description 3
- 238000000576 coating method Methods 0.000 description 3
- 108010054813 diprotin B Proteins 0.000 description 3
- 201000010099 disease Diseases 0.000 description 3
- 108010078428 env Gene Products Proteins 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 108010049041 glutamylalanine Proteins 0.000 description 3
- 108010079547 glutamylmethionine Proteins 0.000 description 3
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 3
- 230000028996 humoral immune response Effects 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 230000003834 intracellular effect Effects 0.000 description 3
- 230000009545 invasion Effects 0.000 description 3
- 108010047926 leucyl-lysyl-tyrosine Proteins 0.000 description 3
- 238000011068 loading method Methods 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 230000000394 mitotic effect Effects 0.000 description 3
- GNOLWGAJQVLBSM-UHFFFAOYSA-N n,n,5,7-tetramethyl-1,2,3,4-tetrahydronaphthalen-1-amine Chemical compound C1=C(C)C=C2C(N(C)C)CCCC2=C1C GNOLWGAJQVLBSM-UHFFFAOYSA-N 0.000 description 3
- 210000004940 nucleus Anatomy 0.000 description 3
- 108010012581 phenylalanylglutamate Proteins 0.000 description 3
- 230000002516 postimmunization Effects 0.000 description 3
- 230000001124 posttranscriptional effect Effects 0.000 description 3
- 230000002441 reversible effect Effects 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 241001430294 unidentified retrovirus Species 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- JNTMAZFVYNDPLB-PEDHHIEDSA-N (2S,3S)-2-[[[(2S)-1-[(2S,3S)-2-amino-3-methyl-1-oxopentyl]-2-pyrrolidinyl]-oxomethyl]amino]-3-methylpentanoic acid Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNTMAZFVYNDPLB-PEDHHIEDSA-N 0.000 description 2
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 2
- WOJJIRYPFAZEPF-YFKPBYRVSA-N 2-[[(2s)-2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]propanoyl]amino]acetate Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)CNC(=O)CN WOJJIRYPFAZEPF-YFKPBYRVSA-N 0.000 description 2
- 102100040623 60S ribosomal protein L41 Human genes 0.000 description 2
- AAQGRPOPTAUUBM-ZLUOBGJFSA-N Ala-Ala-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O AAQGRPOPTAUUBM-ZLUOBGJFSA-N 0.000 description 2
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 2
- GFBLJMHGHAXGNY-ZLUOBGJFSA-N Ala-Asn-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GFBLJMHGHAXGNY-ZLUOBGJFSA-N 0.000 description 2
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 2
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 2
- HMRWQTHUDVXMGH-GUBZILKMSA-N Ala-Glu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HMRWQTHUDVXMGH-GUBZILKMSA-N 0.000 description 2
- FBHOPGDGELNWRH-DRZSPHRISA-N Ala-Glu-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O FBHOPGDGELNWRH-DRZSPHRISA-N 0.000 description 2
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 2
- TZDNWXDLYFIFPT-BJDJZHNGSA-N Ala-Ile-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O TZDNWXDLYFIFPT-BJDJZHNGSA-N 0.000 description 2
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 2
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 2
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 2
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 2
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 2
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 2
- VNFSAYFQLXPHPY-CIQUZCHMSA-N Ala-Thr-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VNFSAYFQLXPHPY-CIQUZCHMSA-N 0.000 description 2
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 2
- XCIGOVDXZULBBV-DCAQKATOSA-N Ala-Val-Lys Chemical compound CC(C)[C@H](NC(=O)[C@H](C)N)C(=O)N[C@@H](CCCCN)C(O)=O XCIGOVDXZULBBV-DCAQKATOSA-N 0.000 description 2
- 241000256186 Anopheles <genus> Species 0.000 description 2
- DFCIPNHFKOQAME-FXQIFTODSA-N Arg-Ala-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O DFCIPNHFKOQAME-FXQIFTODSA-N 0.000 description 2
- GHNDBBVSWOWYII-LPEHRKFASA-N Arg-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O GHNDBBVSWOWYII-LPEHRKFASA-N 0.000 description 2
- ZTKHZAXGTFXUDD-VEVYYDQMSA-N Arg-Asn-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZTKHZAXGTFXUDD-VEVYYDQMSA-N 0.000 description 2
- NTAZNGWBXRVEDJ-FXQIFTODSA-N Arg-Asp-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NTAZNGWBXRVEDJ-FXQIFTODSA-N 0.000 description 2
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 2
- SKTGPBFTMNLIHQ-KKUMJFAQSA-N Arg-Glu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SKTGPBFTMNLIHQ-KKUMJFAQSA-N 0.000 description 2
- PNIGSVZJNVUVJA-BQBZGAKWSA-N Arg-Gly-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O PNIGSVZJNVUVJA-BQBZGAKWSA-N 0.000 description 2
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 2
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 2
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 2
- QHUOOCKNNURZSL-IHRRRGAJSA-N Arg-Tyr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O QHUOOCKNNURZSL-IHRRRGAJSA-N 0.000 description 2
- LEFKSBYHUGUWLP-ACZMJKKPSA-N Asn-Ala-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LEFKSBYHUGUWLP-ACZMJKKPSA-N 0.000 description 2
- VDCIPFYVCICPEC-FXQIFTODSA-N Asn-Arg-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O VDCIPFYVCICPEC-FXQIFTODSA-N 0.000 description 2
- XHFXZQHTLJVZBN-FXQIFTODSA-N Asn-Arg-Asn Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)CN=C(N)N XHFXZQHTLJVZBN-FXQIFTODSA-N 0.000 description 2
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 2
- NLCDVZJDEXIDDL-BIIVOSGPSA-N Asn-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O NLCDVZJDEXIDDL-BIIVOSGPSA-N 0.000 description 2
- ZWASIOHRQWRWAS-UGYAYLCHSA-N Asn-Asp-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZWASIOHRQWRWAS-UGYAYLCHSA-N 0.000 description 2
- HLTLEIXYIJDFOY-ZLUOBGJFSA-N Asn-Cys-Asn Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O HLTLEIXYIJDFOY-ZLUOBGJFSA-N 0.000 description 2
- NNMUHYLAYUSTTN-FXQIFTODSA-N Asn-Gln-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O NNMUHYLAYUSTTN-FXQIFTODSA-N 0.000 description 2
- FUHFYEKSGWOWGZ-XHNCKOQMSA-N Asn-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O FUHFYEKSGWOWGZ-XHNCKOQMSA-N 0.000 description 2
- PPMTUXJSQDNUDE-CIUDSAMLSA-N Asn-Glu-Arg Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PPMTUXJSQDNUDE-CIUDSAMLSA-N 0.000 description 2
- HCAUEJAQCXVQQM-ACZMJKKPSA-N Asn-Glu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HCAUEJAQCXVQQM-ACZMJKKPSA-N 0.000 description 2
- UBKOVSLDWIHYSY-ACZMJKKPSA-N Asn-Glu-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UBKOVSLDWIHYSY-ACZMJKKPSA-N 0.000 description 2
- RAQMSGVCGSJKCL-FOHZUACHSA-N Asn-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(N)=O RAQMSGVCGSJKCL-FOHZUACHSA-N 0.000 description 2
- NKLRWRRVYGQNIH-GHCJXIJMSA-N Asn-Ile-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O NKLRWRRVYGQNIH-GHCJXIJMSA-N 0.000 description 2
- JWKDQOORUCYUIW-ZPFDUUQYSA-N Asn-Lys-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JWKDQOORUCYUIW-ZPFDUUQYSA-N 0.000 description 2
- AYOAHKWVQLNPDM-HJGDQZAQSA-N Asn-Lys-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AYOAHKWVQLNPDM-HJGDQZAQSA-N 0.000 description 2
- MDDXKBHIMYYJLW-FXQIFTODSA-N Asn-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N MDDXKBHIMYYJLW-FXQIFTODSA-N 0.000 description 2
- UYCPJVYQYARFGB-YDHLFZDLSA-N Asn-Phe-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O UYCPJVYQYARFGB-YDHLFZDLSA-N 0.000 description 2
- QYRMBFWDSFGSFC-OLHMAJIHSA-N Asn-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QYRMBFWDSFGSFC-OLHMAJIHSA-N 0.000 description 2
- GOPFMQJUQDLUFW-LKXGYXEUSA-N Asn-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O GOPFMQJUQDLUFW-LKXGYXEUSA-N 0.000 description 2
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 2
- GHWWTICYPDKPTE-NGZCFLSTSA-N Asn-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N GHWWTICYPDKPTE-NGZCFLSTSA-N 0.000 description 2
- WQAOZCVOOYUWKG-LSJOCFKGSA-N Asn-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CC(=O)N)N WQAOZCVOOYUWKG-LSJOCFKGSA-N 0.000 description 2
- KRXIWXCXOARFNT-ZLUOBGJFSA-N Asp-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O KRXIWXCXOARFNT-ZLUOBGJFSA-N 0.000 description 2
- RYEWQKQXRJCHIO-SRVKXCTJSA-N Asp-Asn-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RYEWQKQXRJCHIO-SRVKXCTJSA-N 0.000 description 2
- VPSHHQXIWLGVDD-ZLUOBGJFSA-N Asp-Asp-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VPSHHQXIWLGVDD-ZLUOBGJFSA-N 0.000 description 2
- KHBLRHKVXICFMY-GUBZILKMSA-N Asp-Glu-Lys Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O KHBLRHKVXICFMY-GUBZILKMSA-N 0.000 description 2
- OMMIEVATLAGRCK-BYPYZUCNSA-N Asp-Gly-Gly Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)NCC(O)=O OMMIEVATLAGRCK-BYPYZUCNSA-N 0.000 description 2
- RWHHSFSWKFBTCF-KKUMJFAQSA-N Asp-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)O)N RWHHSFSWKFBTCF-KKUMJFAQSA-N 0.000 description 2
- SPKCGKRUYKMDHP-GUDRVLHUSA-N Asp-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N SPKCGKRUYKMDHP-GUDRVLHUSA-N 0.000 description 2
- PAYPSKIBMDHZPI-CIUDSAMLSA-N Asp-Leu-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O PAYPSKIBMDHZPI-CIUDSAMLSA-N 0.000 description 2
- HKEZZWQWXWGASX-KKUMJFAQSA-N Asp-Leu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 HKEZZWQWXWGASX-KKUMJFAQSA-N 0.000 description 2
- QNIACYURSSCLRP-GUBZILKMSA-N Asp-Lys-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O QNIACYURSSCLRP-GUBZILKMSA-N 0.000 description 2
- VSMYBNPOHYAXSD-GUBZILKMSA-N Asp-Lys-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O VSMYBNPOHYAXSD-GUBZILKMSA-N 0.000 description 2
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 2
- RXBGWGRSWXOBGK-KKUMJFAQSA-N Asp-Lys-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RXBGWGRSWXOBGK-KKUMJFAQSA-N 0.000 description 2
- LTCKTLYKRMCFOC-KKUMJFAQSA-N Asp-Phe-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O LTCKTLYKRMCFOC-KKUMJFAQSA-N 0.000 description 2
- RVMXMLSYBTXCAV-VEVYYDQMSA-N Asp-Pro-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMXMLSYBTXCAV-VEVYYDQMSA-N 0.000 description 2
- 241000501789 Cocal virus Species 0.000 description 2
- 241000252233 Cyprinus carpio Species 0.000 description 2
- BGIRVSMUAJMGOK-FXQIFTODSA-N Cys-Ala-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CS)N BGIRVSMUAJMGOK-FXQIFTODSA-N 0.000 description 2
- KABHAOSDMIYXTR-GUBZILKMSA-N Cys-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N KABHAOSDMIYXTR-GUBZILKMSA-N 0.000 description 2
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 2
- 102000015833 Cystatin Human genes 0.000 description 2
- 230000007018 DNA scission Effects 0.000 description 2
- 230000006820 DNA synthesis Effects 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- 102100021062 Ferritin light chain Human genes 0.000 description 2
- 101710099785 Ferritin, heavy subunit Proteins 0.000 description 2
- 101000834253 Gallus gallus Actin, cytoplasmic 1 Proteins 0.000 description 2
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 2
- JHPFPROFOAJRFN-IHRRRGAJSA-N Gln-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O JHPFPROFOAJRFN-IHRRRGAJSA-N 0.000 description 2
- DQPOBSRQNWOBNA-GUBZILKMSA-N Gln-His-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O DQPOBSRQNWOBNA-GUBZILKMSA-N 0.000 description 2
- YRWWJCDWLVXTHN-LAEOZQHASA-N Gln-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N YRWWJCDWLVXTHN-LAEOZQHASA-N 0.000 description 2
- HSHCEAUPUPJPTE-JYJNAYRXSA-N Gln-Leu-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HSHCEAUPUPJPTE-JYJNAYRXSA-N 0.000 description 2
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 2
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 2
- SZXSSXUNOALWCH-ACZMJKKPSA-N Glu-Ala-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O SZXSSXUNOALWCH-ACZMJKKPSA-N 0.000 description 2
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 2
- IYAUFWMUCGBFMQ-CIUDSAMLSA-N Glu-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)CN=C(N)N IYAUFWMUCGBFMQ-CIUDSAMLSA-N 0.000 description 2
- RJONUNZIMUXUOI-GUBZILKMSA-N Glu-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N RJONUNZIMUXUOI-GUBZILKMSA-N 0.000 description 2
- PCBBLFVHTYNQGG-LAEOZQHASA-N Glu-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N PCBBLFVHTYNQGG-LAEOZQHASA-N 0.000 description 2
- NTBDVNJIWCKURJ-ACZMJKKPSA-N Glu-Asp-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NTBDVNJIWCKURJ-ACZMJKKPSA-N 0.000 description 2
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 2
- WLIPTFCZLHCNFD-LPEHRKFASA-N Glu-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N)C(=O)O WLIPTFCZLHCNFD-LPEHRKFASA-N 0.000 description 2
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 2
- APHGWLWMOXGZRL-DCAQKATOSA-N Glu-Glu-His Chemical compound N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O APHGWLWMOXGZRL-DCAQKATOSA-N 0.000 description 2
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 2
- OGNJZUXUTPQVBR-BQBZGAKWSA-N Glu-Gly-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OGNJZUXUTPQVBR-BQBZGAKWSA-N 0.000 description 2
- DRLVXRQFROIYTD-GUBZILKMSA-N Glu-His-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N DRLVXRQFROIYTD-GUBZILKMSA-N 0.000 description 2
- QXDXIXFSFHUYAX-MNXVOIDGSA-N Glu-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O QXDXIXFSFHUYAX-MNXVOIDGSA-N 0.000 description 2
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 2
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 2
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 2
- JHSRJMUJOGLIHK-GUBZILKMSA-N Glu-Met-Glu Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N JHSRJMUJOGLIHK-GUBZILKMSA-N 0.000 description 2
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 2
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 2
- SWDNPSMMEWRNOH-HJGDQZAQSA-N Glu-Pro-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWDNPSMMEWRNOH-HJGDQZAQSA-N 0.000 description 2
- JDAYMLXPUJRSDJ-XIRDDKMYSA-N Glu-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 JDAYMLXPUJRSDJ-XIRDDKMYSA-N 0.000 description 2
- KCCNSVHJSMMGFS-NRPADANISA-N Glu-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N KCCNSVHJSMMGFS-NRPADANISA-N 0.000 description 2
- VIPDPMHGICREIS-GVXVVHGQSA-N Glu-Val-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O VIPDPMHGICREIS-GVXVVHGQSA-N 0.000 description 2
- LURCIJSJAKFCRO-QWRGUYRKSA-N Gly-Asn-Tyr Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LURCIJSJAKFCRO-QWRGUYRKSA-N 0.000 description 2
- FUTAPPOITCCWTH-WHFBIAKZSA-N Gly-Asp-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FUTAPPOITCCWTH-WHFBIAKZSA-N 0.000 description 2
- SABZDFAAOJATBR-QWRGUYRKSA-N Gly-Cys-Phe Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SABZDFAAOJATBR-QWRGUYRKSA-N 0.000 description 2
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 2
- XTQFHTHIAKKCTM-YFKPBYRVSA-N Gly-Glu-Gly Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O XTQFHTHIAKKCTM-YFKPBYRVSA-N 0.000 description 2
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 2
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 2
- ITZOBNKQDZEOCE-NHCYSSNCSA-N Gly-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)CN ITZOBNKQDZEOCE-NHCYSSNCSA-N 0.000 description 2
- FCKPEGOCSVZPNC-WHOFXGATSA-N Gly-Ile-Phe Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FCKPEGOCSVZPNC-WHOFXGATSA-N 0.000 description 2
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 2
- SCJJPCQUJYPHRZ-BQBZGAKWSA-N Gly-Pro-Asn Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O SCJJPCQUJYPHRZ-BQBZGAKWSA-N 0.000 description 2
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 2
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- PNUFMLXHOLFRLD-KBPBESRZSA-N Gly-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 PNUFMLXHOLFRLD-KBPBESRZSA-N 0.000 description 2
- YDIDLLVFCYSXNY-RCOVLWMOSA-N Gly-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN YDIDLLVFCYSXNY-RCOVLWMOSA-N 0.000 description 2
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 2
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 2
- 108010067802 HLA-DR alpha-Chains Proteins 0.000 description 2
- FIMNVXRZGUAGBI-AVGNSLFASA-N His-Glu-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O FIMNVXRZGUAGBI-AVGNSLFASA-N 0.000 description 2
- CTJHHEQNUNIYNN-SRVKXCTJSA-N His-His-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O CTJHHEQNUNIYNN-SRVKXCTJSA-N 0.000 description 2
- RNAYRCNHRYEBTH-IHRRRGAJSA-N His-Met-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O RNAYRCNHRYEBTH-IHRRRGAJSA-N 0.000 description 2
- WSAILOWUJZEAGC-DCAQKATOSA-N His-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N WSAILOWUJZEAGC-DCAQKATOSA-N 0.000 description 2
- 101000674326 Homo sapiens 60S ribosomal protein L41 Proteins 0.000 description 2
- 101000818390 Homo sapiens Ferritin light chain Proteins 0.000 description 2
- 206010020565 Hyperaemia Diseases 0.000 description 2
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 2
- TZCGZYWNIDZZMR-NAKRPEOUSA-N Ile-Arg-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C)C(=O)O)N TZCGZYWNIDZZMR-NAKRPEOUSA-N 0.000 description 2
- BOTVMTSMOUSDRW-GMOBBJLQSA-N Ile-Arg-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O BOTVMTSMOUSDRW-GMOBBJLQSA-N 0.000 description 2
- SACHLUOUHCVIKI-GMOBBJLQSA-N Ile-Arg-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N SACHLUOUHCVIKI-GMOBBJLQSA-N 0.000 description 2
- NULSANWBUWLTKN-NAKRPEOUSA-N Ile-Arg-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N NULSANWBUWLTKN-NAKRPEOUSA-N 0.000 description 2
- AZEYWPUCOYXFOE-CYDGBPFRSA-N Ile-Arg-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N AZEYWPUCOYXFOE-CYDGBPFRSA-N 0.000 description 2
- QYZYJFXHXYUZMZ-UGYAYLCHSA-N Ile-Asn-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N QYZYJFXHXYUZMZ-UGYAYLCHSA-N 0.000 description 2
- SCHZQZPYHBWYEQ-PEFMBERDSA-N Ile-Asn-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SCHZQZPYHBWYEQ-PEFMBERDSA-N 0.000 description 2
- JDAWAWXGAUZPNJ-ZPFDUUQYSA-N Ile-Glu-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N JDAWAWXGAUZPNJ-ZPFDUUQYSA-N 0.000 description 2
- AFERFBZLVUFWRA-HTFCKZLJSA-N Ile-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CS)C(=O)O)N AFERFBZLVUFWRA-HTFCKZLJSA-N 0.000 description 2
- KLBVGHCGHUNHEA-BJDJZHNGSA-N Ile-Leu-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)O)N KLBVGHCGHUNHEA-BJDJZHNGSA-N 0.000 description 2
- HUORUFRRJHELPD-MNXVOIDGSA-N Ile-Leu-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N HUORUFRRJHELPD-MNXVOIDGSA-N 0.000 description 2
- FZWVCYCYWCLQDH-NHCYSSNCSA-N Ile-Leu-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)O)N FZWVCYCYWCLQDH-NHCYSSNCSA-N 0.000 description 2
- PHRWFSFCNJPWRO-PPCPHDFISA-N Ile-Leu-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N PHRWFSFCNJPWRO-PPCPHDFISA-N 0.000 description 2
- OVDKXUDMKXAZIV-ZPFDUUQYSA-N Ile-Lys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OVDKXUDMKXAZIV-ZPFDUUQYSA-N 0.000 description 2
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 2
- CAHCWMVNBZJVAW-NAKRPEOUSA-N Ile-Pro-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)O)N CAHCWMVNBZJVAW-NAKRPEOUSA-N 0.000 description 2
- JODPUDMBQBIWCK-GHCJXIJMSA-N Ile-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O JODPUDMBQBIWCK-GHCJXIJMSA-N 0.000 description 2
- ANTFEOSJMAUGIB-KNZXXDILSA-N Ile-Thr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N ANTFEOSJMAUGIB-KNZXXDILSA-N 0.000 description 2
- ZYVTXBXHIKGZMD-QSFUFRPTSA-N Ile-Val-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ZYVTXBXHIKGZMD-QSFUFRPTSA-N 0.000 description 2
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 2
- 108010065920 Insulin Lispro Proteins 0.000 description 2
- 102100034353 Integrase Human genes 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- ZRLUISBDKUWAIZ-CIUDSAMLSA-N Leu-Ala-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O ZRLUISBDKUWAIZ-CIUDSAMLSA-N 0.000 description 2
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 2
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 2
- KKXDHFKZWKLYGB-GUBZILKMSA-N Leu-Asn-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKXDHFKZWKLYGB-GUBZILKMSA-N 0.000 description 2
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 2
- ILJREDZFPHTUIE-GUBZILKMSA-N Leu-Asp-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ILJREDZFPHTUIE-GUBZILKMSA-N 0.000 description 2
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 2
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 2
- CCQLQKZTXZBXTN-NHCYSSNCSA-N Leu-Gly-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CCQLQKZTXZBXTN-NHCYSSNCSA-N 0.000 description 2
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 2
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 2
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 2
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 2
- BIZNDKMFQHDOIE-KKUMJFAQSA-N Leu-Phe-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(O)=O)CC1=CC=CC=C1 BIZNDKMFQHDOIE-KKUMJFAQSA-N 0.000 description 2
- KTOIECMYZZGVSI-BZSNNMDCSA-N Leu-Phe-His Chemical compound C([C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CC=CC=C1 KTOIECMYZZGVSI-BZSNNMDCSA-N 0.000 description 2
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 2
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 2
- FMFNIDICDKEMOE-XUXIUFHCSA-N Leu-Val-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMFNIDICDKEMOE-XUXIUFHCSA-N 0.000 description 2
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 2
- DGAAQRAUOFHBFJ-CIUDSAMLSA-N Lys-Asn-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O DGAAQRAUOFHBFJ-CIUDSAMLSA-N 0.000 description 2
- ABHIXYDMILIUKV-CIUDSAMLSA-N Lys-Asn-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ABHIXYDMILIUKV-CIUDSAMLSA-N 0.000 description 2
- QYOXSYXPHUHOJR-GUBZILKMSA-N Lys-Asn-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QYOXSYXPHUHOJR-GUBZILKMSA-N 0.000 description 2
- YVSHZSUKQHNDHD-KKUMJFAQSA-N Lys-Asn-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N YVSHZSUKQHNDHD-KKUMJFAQSA-N 0.000 description 2
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 2
- LLSUNJYOSCOOEB-GUBZILKMSA-N Lys-Glu-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O LLSUNJYOSCOOEB-GUBZILKMSA-N 0.000 description 2
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 2
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 2
- JYXBNQOKPRQNQS-YTFOTSKYSA-N Lys-Ile-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JYXBNQOKPRQNQS-YTFOTSKYSA-N 0.000 description 2
- XREQQOATSMMAJP-MGHWNKPDSA-N Lys-Ile-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XREQQOATSMMAJP-MGHWNKPDSA-N 0.000 description 2
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 2
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 2
- YDDDRTIPNTWGIG-SRVKXCTJSA-N Lys-Lys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O YDDDRTIPNTWGIG-SRVKXCTJSA-N 0.000 description 2
- PLDJDCJLRCYPJB-VOAKCMCISA-N Lys-Lys-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PLDJDCJLRCYPJB-VOAKCMCISA-N 0.000 description 2
- BXPHMHQHYHILBB-BZSNNMDCSA-N Lys-Lys-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BXPHMHQHYHILBB-BZSNNMDCSA-N 0.000 description 2
- VSTNAUBHKQPVJX-IHRRRGAJSA-N Lys-Met-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O VSTNAUBHKQPVJX-IHRRRGAJSA-N 0.000 description 2
- KFSALEZVQJYHCE-AVGNSLFASA-N Lys-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCCN)N KFSALEZVQJYHCE-AVGNSLFASA-N 0.000 description 2
- AEIIJFBQVGYVEV-YESZJQIVSA-N Lys-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCCN)N)C(=O)O AEIIJFBQVGYVEV-YESZJQIVSA-N 0.000 description 2
- WGILOYIKJVQUPT-DCAQKATOSA-N Lys-Pro-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WGILOYIKJVQUPT-DCAQKATOSA-N 0.000 description 2
- DNWBUCHHMRQWCZ-GUBZILKMSA-N Lys-Ser-Gln Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O DNWBUCHHMRQWCZ-GUBZILKMSA-N 0.000 description 2
- JMNRXRPBHFGXQX-GUBZILKMSA-N Lys-Ser-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JMNRXRPBHFGXQX-GUBZILKMSA-N 0.000 description 2
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 2
- VVURYEVJJTXWNE-ULQDDVLXSA-N Lys-Tyr-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O VVURYEVJJTXWNE-ULQDDVLXSA-N 0.000 description 2
- BLIPQDLSCFGUFA-GUBZILKMSA-N Met-Arg-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O BLIPQDLSCFGUFA-GUBZILKMSA-N 0.000 description 2
- QXEVZBXTDTVPCP-GMOBBJLQSA-N Met-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCSC)N QXEVZBXTDTVPCP-GMOBBJLQSA-N 0.000 description 2
- OSOLWRWQADPDIQ-DCAQKATOSA-N Met-Asp-Leu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OSOLWRWQADPDIQ-DCAQKATOSA-N 0.000 description 2
- UYAKZHGIPRCGPF-CIUDSAMLSA-N Met-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCSC)N UYAKZHGIPRCGPF-CIUDSAMLSA-N 0.000 description 2
- AETNZPKUUYYYEK-CIUDSAMLSA-N Met-Glu-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O AETNZPKUUYYYEK-CIUDSAMLSA-N 0.000 description 2
- RBGLBUDVQVPTEG-DCAQKATOSA-N Met-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N RBGLBUDVQVPTEG-DCAQKATOSA-N 0.000 description 2
- JCMMNFZUKMMECJ-DCAQKATOSA-N Met-Lys-Asn Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O JCMMNFZUKMMECJ-DCAQKATOSA-N 0.000 description 2
- HOZNVKDCKZPRER-XUXIUFHCSA-N Met-Lys-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HOZNVKDCKZPRER-XUXIUFHCSA-N 0.000 description 2
- RIIFMEBFDDXGCV-VEVYYDQMSA-N Met-Thr-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O RIIFMEBFDDXGCV-VEVYYDQMSA-N 0.000 description 2
- 101100508420 Mus musculus Ifng gene Proteins 0.000 description 2
- 241001481499 Perinet vesiculovirus Species 0.000 description 2
- RJYBHZVWJPUSLB-QEWYBTABSA-N Phe-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N RJYBHZVWJPUSLB-QEWYBTABSA-N 0.000 description 2
- GXDPQJUBLBZKDY-IAVJCBSLSA-N Phe-Ile-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GXDPQJUBLBZKDY-IAVJCBSLSA-N 0.000 description 2
- UXQFHEKRGHYJRA-STQMWFEESA-N Phe-Met-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O UXQFHEKRGHYJRA-STQMWFEESA-N 0.000 description 2
- OWSLLRKCHLTUND-BZSNNMDCSA-N Phe-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OWSLLRKCHLTUND-BZSNNMDCSA-N 0.000 description 2
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 2
- GTMSCDVFQLNEOY-BZSNNMDCSA-N Phe-Tyr-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N GTMSCDVFQLNEOY-BZSNNMDCSA-N 0.000 description 2
- YUPRIZTWANWWHK-DZKIICNBSA-N Phe-Val-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N YUPRIZTWANWWHK-DZKIICNBSA-N 0.000 description 2
- RGMLUHANLDVMPB-ULQDDVLXSA-N Phe-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N RGMLUHANLDVMPB-ULQDDVLXSA-N 0.000 description 2
- 241001246321 Plasmodium coatneyi Species 0.000 description 2
- 229920001213 Polysorbate 20 Polymers 0.000 description 2
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 2
- IWNOFCGBMSFTBC-CIUDSAMLSA-N Pro-Ala-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IWNOFCGBMSFTBC-CIUDSAMLSA-N 0.000 description 2
- MTHRMUXESFIAMS-DCAQKATOSA-N Pro-Asn-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O MTHRMUXESFIAMS-DCAQKATOSA-N 0.000 description 2
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 2
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 2
- FKVNLUZHSFCNGY-RVMXOQNASA-N Pro-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 FKVNLUZHSFCNGY-RVMXOQNASA-N 0.000 description 2
- DWGFLKQSGRUQTI-IHRRRGAJSA-N Pro-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 DWGFLKQSGRUQTI-IHRRRGAJSA-N 0.000 description 2
- POQFNPILEQEODH-FXQIFTODSA-N Pro-Ser-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O POQFNPILEQEODH-FXQIFTODSA-N 0.000 description 2
- KIDXAAQVMNLJFQ-KZVJFYERSA-N Pro-Thr-Ala Chemical compound C[C@@H](O)[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](C)C(O)=O KIDXAAQVMNLJFQ-KZVJFYERSA-N 0.000 description 2
- AJJDPGVVNPUZCR-RHYQMDGZSA-N Pro-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1)O AJJDPGVVNPUZCR-RHYQMDGZSA-N 0.000 description 2
- DYJTXTCEXMCPBF-UFYCRDLUSA-N Pro-Tyr-Phe Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CC3=CC=CC=C3)C(=O)O DYJTXTCEXMCPBF-UFYCRDLUSA-N 0.000 description 2
- XDKKMRPRRCOELJ-GUBZILKMSA-N Pro-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 XDKKMRPRRCOELJ-GUBZILKMSA-N 0.000 description 2
- OQSGBXGNAFQGGS-CYDGBPFRSA-N Pro-Val-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OQSGBXGNAFQGGS-CYDGBPFRSA-N 0.000 description 2
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 2
- 230000006819 RNA synthesis Effects 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 108020005091 Replication Origin Proteins 0.000 description 2
- TUYBIWUZWJUZDD-ACZMJKKPSA-N Ser-Cys-Gln Chemical compound OC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(N)=O TUYBIWUZWJUZDD-ACZMJKKPSA-N 0.000 description 2
- MAWSJXHRLWVJEZ-ACZMJKKPSA-N Ser-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N MAWSJXHRLWVJEZ-ACZMJKKPSA-N 0.000 description 2
- HBTCFCHYALPXME-HTFCKZLJSA-N Ser-Ile-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HBTCFCHYALPXME-HTFCKZLJSA-N 0.000 description 2
- CRJZZXMAADSBBQ-SRVKXCTJSA-N Ser-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO CRJZZXMAADSBBQ-SRVKXCTJSA-N 0.000 description 2
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 2
- FBLNYDYPCLFTSP-IXOXFDKPSA-N Ser-Phe-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FBLNYDYPCLFTSP-IXOXFDKPSA-N 0.000 description 2
- XQAPEISNMXNKGE-FXQIFTODSA-N Ser-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CO)N)C(=O)N[C@@H](CS)C(=O)O XQAPEISNMXNKGE-FXQIFTODSA-N 0.000 description 2
- ILZAUMFXKSIUEF-SRVKXCTJSA-N Ser-Ser-Phe Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ILZAUMFXKSIUEF-SRVKXCTJSA-N 0.000 description 2
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 2
- SQHKXWODKJDZRC-LKXGYXEUSA-N Ser-Thr-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQHKXWODKJDZRC-LKXGYXEUSA-N 0.000 description 2
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 2
- FLMYSKVSDVHLEW-SVSWQMSJSA-N Ser-Thr-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FLMYSKVSDVHLEW-SVSWQMSJSA-N 0.000 description 2
- HAYADTTXNZFUDM-IHRRRGAJSA-N Ser-Tyr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HAYADTTXNZFUDM-IHRRRGAJSA-N 0.000 description 2
- YLXAMFZYJTZXFH-OLHMAJIHSA-N Thr-Asn-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O YLXAMFZYJTZXFH-OLHMAJIHSA-N 0.000 description 2
- JHBHMCMKSPXRHV-NUMRIWBASA-N Thr-Asn-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O JHBHMCMKSPXRHV-NUMRIWBASA-N 0.000 description 2
- JTEICXDKGWKRRV-HJGDQZAQSA-N Thr-Asn-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O JTEICXDKGWKRRV-HJGDQZAQSA-N 0.000 description 2
- KZUJCMPVNXOBAF-LKXGYXEUSA-N Thr-Cys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KZUJCMPVNXOBAF-LKXGYXEUSA-N 0.000 description 2
- LYGKYFKSZTUXGZ-ZDLURKLDSA-N Thr-Cys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)NCC(O)=O LYGKYFKSZTUXGZ-ZDLURKLDSA-N 0.000 description 2
- YAAPRMFURSENOZ-KATARQTJSA-N Thr-Cys-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O YAAPRMFURSENOZ-KATARQTJSA-N 0.000 description 2
- RKDFEMGVMMYYNG-WDCWCFNPSA-N Thr-Gln-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O RKDFEMGVMMYYNG-WDCWCFNPSA-N 0.000 description 2
- TZJSEJOXAIWOST-RHYQMDGZSA-N Thr-Lys-Arg Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N TZJSEJOXAIWOST-RHYQMDGZSA-N 0.000 description 2
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 2
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 2
- YJVJPJPHHFOVMG-VEVYYDQMSA-N Thr-Met-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O YJVJPJPHHFOVMG-VEVYYDQMSA-N 0.000 description 2
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 2
- YRJOLUDFVAUXLI-GSSVUCPTSA-N Thr-Thr-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O YRJOLUDFVAUXLI-GSSVUCPTSA-N 0.000 description 2
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 2
- CJEHCEOXPLASCK-MEYUZBJRSA-N Thr-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@H](O)C)CC1=CC=C(O)C=C1 CJEHCEOXPLASCK-MEYUZBJRSA-N 0.000 description 2
- JONPRIHUYSPIMA-UWJYBYFXSA-N Tyr-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JONPRIHUYSPIMA-UWJYBYFXSA-N 0.000 description 2
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 2
- TWAVEIJGFCBWCG-JYJNAYRXSA-N Tyr-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N TWAVEIJGFCBWCG-JYJNAYRXSA-N 0.000 description 2
- AXWBYOVVDRBOGU-SIUGBPQLSA-N Tyr-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AXWBYOVVDRBOGU-SIUGBPQLSA-N 0.000 description 2
- OGPKMBOPMDTEDM-IHRRRGAJSA-N Tyr-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N OGPKMBOPMDTEDM-IHRRRGAJSA-N 0.000 description 2
- QFXVAFIHVWXXBJ-AVGNSLFASA-N Tyr-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O QFXVAFIHVWXXBJ-AVGNSLFASA-N 0.000 description 2
- YKBUNNNRNZZUID-UFYCRDLUSA-N Tyr-Val-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YKBUNNNRNZZUID-UFYCRDLUSA-N 0.000 description 2
- AGKDVLSDNSTLFA-UMNHJUIQSA-N Val-Gln-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N AGKDVLSDNSTLFA-UMNHJUIQSA-N 0.000 description 2
- CVIXTAITYJQMPE-LAEOZQHASA-N Val-Glu-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CVIXTAITYJQMPE-LAEOZQHASA-N 0.000 description 2
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 2
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 2
- BZMIYHIJVVJPCK-QSFUFRPTSA-N Val-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N BZMIYHIJVVJPCK-QSFUFRPTSA-N 0.000 description 2
- UKEVLVBHRKWECS-LSJOCFKGSA-N Val-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](C(C)C)N UKEVLVBHRKWECS-LSJOCFKGSA-N 0.000 description 2
- DAVNYIUELQBTAP-XUXIUFHCSA-N Val-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N DAVNYIUELQBTAP-XUXIUFHCSA-N 0.000 description 2
- QRVPEKJBBRYISE-XUXIUFHCSA-N Val-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N QRVPEKJBBRYISE-XUXIUFHCSA-N 0.000 description 2
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 2
- YQMILNREHKTFBS-IHRRRGAJSA-N Val-Phe-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)O)N YQMILNREHKTFBS-IHRRRGAJSA-N 0.000 description 2
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 2
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 2
- 108010067390 Viral Proteins Proteins 0.000 description 2
- 241001492404 Woodchuck hepatitis virus Species 0.000 description 2
- 239000004480 active ingredient Substances 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 2
- 229940024606 amino acid Drugs 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 2
- 108010068380 arginylarginine Proteins 0.000 description 2
- 108010068265 aspartyltyrosine Proteins 0.000 description 2
- 230000003190 augmentative effect Effects 0.000 description 2
- 210000001185 bone marrow Anatomy 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 125000004122 cyclic group Chemical group 0.000 description 2
- 108050004038 cystatin Proteins 0.000 description 2
- 210000000805 cytoplasm Anatomy 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 108010054812 diprotin A Proteins 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 108700004026 gag Genes Proteins 0.000 description 2
- 102000034356 gene-regulatory proteins Human genes 0.000 description 2
- 108091006104 gene-regulatory proteins Proteins 0.000 description 2
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 2
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 2
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 2
- 108010081551 glycylphenylalanine Proteins 0.000 description 2
- 108010077515 glycylproline Proteins 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 230000002147 killing effect Effects 0.000 description 2
- 231100000225 lethality Toxicity 0.000 description 2
- 108010083708 leucyl-aspartyl-valine Proteins 0.000 description 2
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 2
- 108010087810 leucyl-seryl-glutamyl-leucine Proteins 0.000 description 2
- 108010089256 lysyl-aspartyl-glutamyl-leucine Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 108010038320 lysylphenylalanine Proteins 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 108010063431 methionyl-aspartyl-glycine Proteins 0.000 description 2
- 108010056582 methionylglutamic acid Proteins 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 108010051242 phenylalanylserine Proteins 0.000 description 2
- 230000019612 pigmentation Effects 0.000 description 2
- 239000013600 plasmid vector Substances 0.000 description 2
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 2
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010025826 prolyl-leucyl-arginine Proteins 0.000 description 2
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 108010053725 prolylvaline Proteins 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 238000013207 serial dilution Methods 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 210000004989 spleen cell Anatomy 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 108010061238 threonyl-glycine Proteins 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 238000002255 vaccination Methods 0.000 description 2
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 2
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- RRBGTUQJDFBWNN-MUGJNUQGSA-N (2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-6-amino-2-[[(2s)-2,6-diaminohexanoyl]amino]hexanoyl]amino]hexanoyl]amino]hexanoic acid Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O RRBGTUQJDFBWNN-MUGJNUQGSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- YRNWIFYIFSBPAU-UHFFFAOYSA-N 4-[4-(dimethylamino)phenyl]-n,n-dimethylaniline Chemical compound C1=CC(N(C)C)=CC=C1C1=CC=C(N(C)C)C=C1 YRNWIFYIFSBPAU-UHFFFAOYSA-N 0.000 description 1
- HQWQVBJUIIJTRE-LKRNKTNVSA-N 4-amino-n-(5,6-dimethoxypyrimidin-4-yl)benzenesulfonamide;(s)-[2,8-bis(trifluoromethyl)quinolin-4-yl]-[(2r)-piperidin-2-yl]methanol;5-(4-chlorophenyl)-6-ethylpyrimidine-2,4-diamine;hydron;chloride Chemical compound Cl.CCC1=NC(N)=NC(N)=C1C1=CC=C(Cl)C=C1.COC1=NC=NC(NS(=O)(=O)C=2C=CC(N)=CC=2)=C1OC.C([C@@H]1[C@@H](O)C=2C3=CC=CC(=C3N=C(C=2)C(F)(F)F)C(F)(F)F)CCCN1 HQWQVBJUIIJTRE-LKRNKTNVSA-N 0.000 description 1
- QRXMUCSWCMTJGU-UHFFFAOYSA-N 5-bromo-4-chloro-3-indolyl phosphate Chemical compound C1=C(Br)C(Cl)=C2C(OP(O)(=O)O)=CNC2=C1 QRXMUCSWCMTJGU-UHFFFAOYSA-N 0.000 description 1
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 1
- WQVFQXXBNHHPLX-ZKWXMUAHSA-N Ala-Ala-His Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O WQVFQXXBNHHPLX-ZKWXMUAHSA-N 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 1
- FXKNPWNXPQZLES-ZLUOBGJFSA-N Ala-Asn-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FXKNPWNXPQZLES-ZLUOBGJFSA-N 0.000 description 1
- ZIBWKCRKNFYTPT-ZKWXMUAHSA-N Ala-Asn-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZIBWKCRKNFYTPT-ZKWXMUAHSA-N 0.000 description 1
- XAGIMRPOEJSYER-CIUDSAMLSA-N Ala-Cys-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N XAGIMRPOEJSYER-CIUDSAMLSA-N 0.000 description 1
- HJCMDXDYPOUFDY-WHFBIAKZSA-N Ala-Gln Chemical compound C[C@H](N)C(=O)N[C@H](C(O)=O)CCC(N)=O HJCMDXDYPOUFDY-WHFBIAKZSA-N 0.000 description 1
- YIGLXQRFQVWFEY-NRPADANISA-N Ala-Gln-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O YIGLXQRFQVWFEY-NRPADANISA-N 0.000 description 1
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 1
- LMFXXZPPZDCPTA-ZKWXMUAHSA-N Ala-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N LMFXXZPPZDCPTA-ZKWXMUAHSA-N 0.000 description 1
- BLIMFWGRQKRCGT-YUMQZZPRSA-N Ala-Gly-Lys Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN BLIMFWGRQKRCGT-YUMQZZPRSA-N 0.000 description 1
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 1
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 1
- OSRZOHXQCUFIQG-FPMFFAJLSA-N Ala-Phe-Pro Chemical compound C([C@H](NC(=O)[C@@H]([NH3+])C)C(=O)N1[C@H](CCC1)C([O-])=O)C1=CC=CC=C1 OSRZOHXQCUFIQG-FPMFFAJLSA-N 0.000 description 1
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 1
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 1
- MMLHRUJLOUSRJX-CIUDSAMLSA-N Ala-Ser-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN MMLHRUJLOUSRJX-CIUDSAMLSA-N 0.000 description 1
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 241001414900 Anopheles stephensi Species 0.000 description 1
- KWKQGHSSNHPGOW-BQBZGAKWSA-N Arg-Ala-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)NCC(O)=O KWKQGHSSNHPGOW-BQBZGAKWSA-N 0.000 description 1
- OTOXOKCIIQLMFH-KZVJFYERSA-N Arg-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N OTOXOKCIIQLMFH-KZVJFYERSA-N 0.000 description 1
- WOPFJPHVBWKZJH-SRVKXCTJSA-N Arg-Arg-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O WOPFJPHVBWKZJH-SRVKXCTJSA-N 0.000 description 1
- NONSEUUPKITYQT-BQBZGAKWSA-N Arg-Asn-Gly Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N)CN=C(N)N NONSEUUPKITYQT-BQBZGAKWSA-N 0.000 description 1
- SNBHMYQRNCJSOJ-CIUDSAMLSA-N Arg-Gln-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SNBHMYQRNCJSOJ-CIUDSAMLSA-N 0.000 description 1
- JUWQNWXEGDYCIE-YUMQZZPRSA-N Arg-Gln-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O JUWQNWXEGDYCIE-YUMQZZPRSA-N 0.000 description 1
- MZRBYBIQTIKERR-GUBZILKMSA-N Arg-Glu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MZRBYBIQTIKERR-GUBZILKMSA-N 0.000 description 1
- PBSOQGZLPFVXPU-YUMQZZPRSA-N Arg-Glu-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O PBSOQGZLPFVXPU-YUMQZZPRSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- QKSAZKCRVQYYGS-UWVGGRQHSA-N Arg-Gly-His Chemical compound N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O QKSAZKCRVQYYGS-UWVGGRQHSA-N 0.000 description 1
- NVUIWHJLPSZZQC-CYDGBPFRSA-N Arg-Ile-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NVUIWHJLPSZZQC-CYDGBPFRSA-N 0.000 description 1
- OOIMKQRCPJBGPD-XUXIUFHCSA-N Arg-Ile-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O OOIMKQRCPJBGPD-XUXIUFHCSA-N 0.000 description 1
- SSZGOKWBHLOCHK-DCAQKATOSA-N Arg-Lys-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N SSZGOKWBHLOCHK-DCAQKATOSA-N 0.000 description 1
- HRCIIMCTUIAKQB-XGEHTFHBSA-N Arg-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O HRCIIMCTUIAKQB-XGEHTFHBSA-N 0.000 description 1
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 1
- VJIQPOJMISSUPO-BVSLBCMMSA-N Arg-Trp-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VJIQPOJMISSUPO-BVSLBCMMSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- VYZBPPBKFCHCIS-WPRPVWTQSA-N Arg-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N VYZBPPBKFCHCIS-WPRPVWTQSA-N 0.000 description 1
- QEYJFBMTSMLPKZ-ZKWXMUAHSA-N Asn-Ala-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QEYJFBMTSMLPKZ-ZKWXMUAHSA-N 0.000 description 1
- ZZXMOQIUIJJOKZ-ZLUOBGJFSA-N Asn-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O ZZXMOQIUIJJOKZ-ZLUOBGJFSA-N 0.000 description 1
- RCENDENBBJFJHZ-ACZMJKKPSA-N Asn-Asn-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCENDENBBJFJHZ-ACZMJKKPSA-N 0.000 description 1
- GNKVBRYFXYWXAB-WDSKDSINSA-N Asn-Glu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O GNKVBRYFXYWXAB-WDSKDSINSA-N 0.000 description 1
- CTQIOCMSIJATNX-WHFBIAKZSA-N Asn-Gly-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O CTQIOCMSIJATNX-WHFBIAKZSA-N 0.000 description 1
- OPEPUCYIGFEGSW-WDSKDSINSA-N Asn-Gly-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O OPEPUCYIGFEGSW-WDSKDSINSA-N 0.000 description 1
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 1
- BZWRLDPIWKOVKB-ZPFDUUQYSA-N Asn-Leu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BZWRLDPIWKOVKB-ZPFDUUQYSA-N 0.000 description 1
- LZLCLRQMUQWUHJ-GUBZILKMSA-N Asn-Lys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N LZLCLRQMUQWUHJ-GUBZILKMSA-N 0.000 description 1
- GIQCDTKOIPUDSG-GARJFASQSA-N Asn-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N)C(=O)O GIQCDTKOIPUDSG-GARJFASQSA-N 0.000 description 1
- PLTGTJAZQRGMPP-FXQIFTODSA-N Asn-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O PLTGTJAZQRGMPP-FXQIFTODSA-N 0.000 description 1
- YRTOMUMWSTUQAX-FXQIFTODSA-N Asn-Pro-Asp Chemical compound NC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O YRTOMUMWSTUQAX-FXQIFTODSA-N 0.000 description 1
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 1
- NJSNXIOKBHPFMB-GMOBBJLQSA-N Asn-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CC(=O)N)N NJSNXIOKBHPFMB-GMOBBJLQSA-N 0.000 description 1
- ATHZHGQSAIJHQU-XIRDDKMYSA-N Asn-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ATHZHGQSAIJHQU-XIRDDKMYSA-N 0.000 description 1
- RTFXPCYMDYBZNQ-SRVKXCTJSA-N Asn-Tyr-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O RTFXPCYMDYBZNQ-SRVKXCTJSA-N 0.000 description 1
- SKQTXVZTCGSRJS-SRVKXCTJSA-N Asn-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O SKQTXVZTCGSRJS-SRVKXCTJSA-N 0.000 description 1
- KTDWFWNZLLFEFU-KKUMJFAQSA-N Asn-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O KTDWFWNZLLFEFU-KKUMJFAQSA-N 0.000 description 1
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 1
- VZNOVQKGJQJOCS-SRVKXCTJSA-N Asp-Asp-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O VZNOVQKGJQJOCS-SRVKXCTJSA-N 0.000 description 1
- HRGGPWBIMIQANI-GUBZILKMSA-N Asp-Gln-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O HRGGPWBIMIQANI-GUBZILKMSA-N 0.000 description 1
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- DGKCOYGQLNWNCJ-ACZMJKKPSA-N Asp-Glu-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O DGKCOYGQLNWNCJ-ACZMJKKPSA-N 0.000 description 1
- WBDWQKRLTVCDSY-WHFBIAKZSA-N Asp-Gly-Asp Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O WBDWQKRLTVCDSY-WHFBIAKZSA-N 0.000 description 1
- PZXPWHFYZXTFBI-YUMQZZPRSA-N Asp-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PZXPWHFYZXTFBI-YUMQZZPRSA-N 0.000 description 1
- NRIFEOUAFLTMFJ-AAEUAGOBSA-N Asp-Gly-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O NRIFEOUAFLTMFJ-AAEUAGOBSA-N 0.000 description 1
- CLUMZOKVGUWUFD-CIUDSAMLSA-N Asp-Leu-Asn Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O CLUMZOKVGUWUFD-CIUDSAMLSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- ORRJQLIATJDMQM-HJGDQZAQSA-N Asp-Leu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O ORRJQLIATJDMQM-HJGDQZAQSA-N 0.000 description 1
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 1
- CTWCFPWFIGRAEP-CIUDSAMLSA-N Asp-Lys-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O CTWCFPWFIGRAEP-CIUDSAMLSA-N 0.000 description 1
- NZWDWXSWUQCNMG-GARJFASQSA-N Asp-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)C(=O)O NZWDWXSWUQCNMG-GARJFASQSA-N 0.000 description 1
- LIJXJYGRSRWLCJ-IHRRRGAJSA-N Asp-Phe-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LIJXJYGRSRWLCJ-IHRRRGAJSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- GWWSUMLEWKQHLR-NUMRIWBASA-N Asp-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GWWSUMLEWKQHLR-NUMRIWBASA-N 0.000 description 1
- KBJVTFWQWXCYCQ-IUKAMOBKSA-N Asp-Thr-Ile Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KBJVTFWQWXCYCQ-IUKAMOBKSA-N 0.000 description 1
- XOASPVGNFAMYBD-WFBYXXMGSA-N Asp-Trp-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O XOASPVGNFAMYBD-WFBYXXMGSA-N 0.000 description 1
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 1
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 1
- NWAHPBGBDIFUFD-KKUMJFAQSA-N Asp-Tyr-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O NWAHPBGBDIFUFD-KKUMJFAQSA-N 0.000 description 1
- BJDHEININLSZOT-KKUMJFAQSA-N Asp-Tyr-Lys Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(O)=O BJDHEININLSZOT-KKUMJFAQSA-N 0.000 description 1
- 102220638993 Beta-enolase_H16C_mutation Human genes 0.000 description 1
- 241001446316 Bohle iridovirus Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 108010041397 CD4 Antigens Proteins 0.000 description 1
- 108010032795 CD8 receptor Proteins 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- 101100131403 Caenorhabditis elegans msp-142 gene Proteins 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 239000004215 Carbon black (E152) Substances 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 102100023321 Ceruloplasmin Human genes 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- AEJSNWMRPXAKCW-WHFBIAKZSA-N Cys-Ala-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O AEJSNWMRPXAKCW-WHFBIAKZSA-N 0.000 description 1
- IIGHQOPGMGKDMT-SRVKXCTJSA-N Cys-Asp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N IIGHQOPGMGKDMT-SRVKXCTJSA-N 0.000 description 1
- YZFCGHIBLBDZDA-ZLUOBGJFSA-N Cys-Asp-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YZFCGHIBLBDZDA-ZLUOBGJFSA-N 0.000 description 1
- ASHTVGGFIMESRD-LKXGYXEUSA-N Cys-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N)O ASHTVGGFIMESRD-LKXGYXEUSA-N 0.000 description 1
- QADHATDBZXHRCA-ACZMJKKPSA-N Cys-Gln-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CS)N QADHATDBZXHRCA-ACZMJKKPSA-N 0.000 description 1
- HQZGVYJBRSISDT-BQBZGAKWSA-N Cys-Gly-Arg Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQZGVYJBRSISDT-BQBZGAKWSA-N 0.000 description 1
- BSFFNUBDVYTDMV-WHFBIAKZSA-N Cys-Gly-Asn Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BSFFNUBDVYTDMV-WHFBIAKZSA-N 0.000 description 1
- VCIIDXDOPGHMDQ-WDSKDSINSA-N Cys-Gly-Gln Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O VCIIDXDOPGHMDQ-WDSKDSINSA-N 0.000 description 1
- XTHUKRLJRUVVBF-WHFBIAKZSA-N Cys-Gly-Ser Chemical compound SC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O XTHUKRLJRUVVBF-WHFBIAKZSA-N 0.000 description 1
- YKKHFPGOZXQAGK-QWRGUYRKSA-N Cys-Gly-Tyr Chemical compound SC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 YKKHFPGOZXQAGK-QWRGUYRKSA-N 0.000 description 1
- KCSDYJSCUWLILX-BJDJZHNGSA-N Cys-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N KCSDYJSCUWLILX-BJDJZHNGSA-N 0.000 description 1
- UCSXXFRXHGUXCQ-SRVKXCTJSA-N Cys-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CS)N UCSXXFRXHGUXCQ-SRVKXCTJSA-N 0.000 description 1
- MBRWOKXNHTUJMB-CIUDSAMLSA-N Cys-Pro-Glu Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O MBRWOKXNHTUJMB-CIUDSAMLSA-N 0.000 description 1
- ZALVANCAZFPKIR-GUBZILKMSA-N Cys-Pro-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N ZALVANCAZFPKIR-GUBZILKMSA-N 0.000 description 1
- GGRDJANMZPGMNS-CIUDSAMLSA-N Cys-Ser-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O GGRDJANMZPGMNS-CIUDSAMLSA-N 0.000 description 1
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 1
- GFAPBMCRSMSGDZ-XGEHTFHBSA-N Cys-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](CS)N)O GFAPBMCRSMSGDZ-XGEHTFHBSA-N 0.000 description 1
- IWVNIQXKTIQXCT-SRVKXCTJSA-N Cys-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CS)N)O IWVNIQXKTIQXCT-SRVKXCTJSA-N 0.000 description 1
- GQNZIAGMRXOFJX-GUBZILKMSA-N Cys-Val-Met Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O GQNZIAGMRXOFJX-GUBZILKMSA-N 0.000 description 1
- UPEZCKBFRMILAV-JNEQICEOSA-N Ecdysone Natural products O=C1[C@H]2[C@@](C)([C@@H]3C([C@@]4(O)[C@@](C)([C@H]([C@H]([C@@H](O)CCC(O)(C)C)C)CC4)CC3)=C1)C[C@H](O)[C@H](O)C2 UPEZCKBFRMILAV-JNEQICEOSA-N 0.000 description 1
- 101710121417 Envelope glycoprotein Proteins 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 101150066516 GST gene Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- DLOHWQXXGMEZDW-CIUDSAMLSA-N Gln-Arg-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O DLOHWQXXGMEZDW-CIUDSAMLSA-N 0.000 description 1
- SOBBAYVQSNXYPQ-ACZMJKKPSA-N Gln-Asn-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SOBBAYVQSNXYPQ-ACZMJKKPSA-N 0.000 description 1
- ODBLJLZVLAWVMS-GUBZILKMSA-N Gln-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N ODBLJLZVLAWVMS-GUBZILKMSA-N 0.000 description 1
- IXFVOPOHSRKJNG-LAEOZQHASA-N Gln-Asp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IXFVOPOHSRKJNG-LAEOZQHASA-N 0.000 description 1
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 1
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 1
- VSXBYIJUAXPAAL-WDSKDSINSA-N Gln-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O VSXBYIJUAXPAAL-WDSKDSINSA-N 0.000 description 1
- FTIJVMLAGRAYMJ-MNXVOIDGSA-N Gln-Ile-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(N)=O FTIJVMLAGRAYMJ-MNXVOIDGSA-N 0.000 description 1
- ITZWDGBYBPUZRG-KBIXCLLPSA-N Gln-Ile-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O ITZWDGBYBPUZRG-KBIXCLLPSA-N 0.000 description 1
- SXGMGNZEHFORAV-IUCAKERBSA-N Gln-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N SXGMGNZEHFORAV-IUCAKERBSA-N 0.000 description 1
- LURQDGKYBFWWJA-MNXVOIDGSA-N Gln-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N LURQDGKYBFWWJA-MNXVOIDGSA-N 0.000 description 1
- DOQUICBEISTQHE-CIUDSAMLSA-N Gln-Pro-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O DOQUICBEISTQHE-CIUDSAMLSA-N 0.000 description 1
- OUBUHIODTNUUTC-WDCWCFNPSA-N Gln-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O OUBUHIODTNUUTC-WDCWCFNPSA-N 0.000 description 1
- WPJDPEOQUIXXOY-AVGNSLFASA-N Gln-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WPJDPEOQUIXXOY-AVGNSLFASA-N 0.000 description 1
- MKRDNSWGJWTBKZ-GVXVVHGQSA-N Gln-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MKRDNSWGJWTBKZ-GVXVVHGQSA-N 0.000 description 1
- UTKICHUQEQBDGC-ACZMJKKPSA-N Glu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N UTKICHUQEQBDGC-ACZMJKKPSA-N 0.000 description 1
- CGYDXNKRIMJMLV-GUBZILKMSA-N Glu-Arg-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O CGYDXNKRIMJMLV-GUBZILKMSA-N 0.000 description 1
- VTTSANCGJWLPNC-ZPFDUUQYSA-N Glu-Arg-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VTTSANCGJWLPNC-ZPFDUUQYSA-N 0.000 description 1
- VAZZOGXDUQSVQF-NUMRIWBASA-N Glu-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N)O VAZZOGXDUQSVQF-NUMRIWBASA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 1
- OBIHEDRRSMRKLU-ACZMJKKPSA-N Glu-Cys-Asp Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OBIHEDRRSMRKLU-ACZMJKKPSA-N 0.000 description 1
- XMVLTPMCUJTJQP-FXQIFTODSA-N Glu-Gln-Cys Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N XMVLTPMCUJTJQP-FXQIFTODSA-N 0.000 description 1
- VFZIDQZAEBORGY-GLLZPBPUSA-N Glu-Gln-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VFZIDQZAEBORGY-GLLZPBPUSA-N 0.000 description 1
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- GGJOGFJIPPGNRK-JSGCOSHPSA-N Glu-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)N)C(O)=O)=CNC2=C1 GGJOGFJIPPGNRK-JSGCOSHPSA-N 0.000 description 1
- WVYJNPCWJYBHJG-YVNDNENWSA-N Glu-Ile-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O WVYJNPCWJYBHJG-YVNDNENWSA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- DCBSZJJHOTXMHY-DCAQKATOSA-N Glu-Pro-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DCBSZJJHOTXMHY-DCAQKATOSA-N 0.000 description 1
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 1
- TWYSSILQABLLME-HJGDQZAQSA-N Glu-Thr-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O TWYSSILQABLLME-HJGDQZAQSA-N 0.000 description 1
- MIWJDJAMMKHUAR-ZVZYQTTQSA-N Glu-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N MIWJDJAMMKHUAR-ZVZYQTTQSA-N 0.000 description 1
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 1
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- XQHSBNVACKQWAV-WHFBIAKZSA-N Gly-Asp-Asn Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O XQHSBNVACKQWAV-WHFBIAKZSA-N 0.000 description 1
- PMNHJLASAAWELO-FOHZUACHSA-N Gly-Asp-Thr Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PMNHJLASAAWELO-FOHZUACHSA-N 0.000 description 1
- JMQFHZWESBGPFC-WDSKDSINSA-N Gly-Gln-Asp Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JMQFHZWESBGPFC-WDSKDSINSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- YYPFZVIXAVDHIK-IUCAKERBSA-N Gly-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN YYPFZVIXAVDHIK-IUCAKERBSA-N 0.000 description 1
- JNGJGFMFXREJNF-KBPBESRZSA-N Gly-Glu-Trp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JNGJGFMFXREJNF-KBPBESRZSA-N 0.000 description 1
- XMPXVJIDADUOQB-RCOVLWMOSA-N Gly-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C([O-])=O)NC(=O)CNC(=O)C[NH3+] XMPXVJIDADUOQB-RCOVLWMOSA-N 0.000 description 1
- QITBQGJOXQYMOA-ZETCQYMHSA-N Gly-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QITBQGJOXQYMOA-ZETCQYMHSA-N 0.000 description 1
- ADZGCWWDPFDHCY-ZETCQYMHSA-N Gly-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 ADZGCWWDPFDHCY-ZETCQYMHSA-N 0.000 description 1
- KGVHCTWYMPWEGN-FSPLSTOPSA-N Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CN KGVHCTWYMPWEGN-FSPLSTOPSA-N 0.000 description 1
- TVUWMSBGMVAHSJ-KBPBESRZSA-N Gly-Leu-Phe Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 TVUWMSBGMVAHSJ-KBPBESRZSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- VLIJYPMATZSOLL-YUMQZZPRSA-N Gly-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VLIJYPMATZSOLL-YUMQZZPRSA-N 0.000 description 1
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 1
- JPVGHHQGKPQYIL-KBPBESRZSA-N Gly-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 JPVGHHQGKPQYIL-KBPBESRZSA-N 0.000 description 1
- IEGFSKKANYKBDU-QWHCGFSZSA-N Gly-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)CN)C(=O)O IEGFSKKANYKBDU-QWHCGFSZSA-N 0.000 description 1
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 1
- GAAHQHNCMIAYEX-UWVGGRQHSA-N Gly-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GAAHQHNCMIAYEX-UWVGGRQHSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 1
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 1
- COZMNNJEGNPDED-HOCLYGCPSA-N Gly-Val-Trp Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O COZMNNJEGNPDED-HOCLYGCPSA-N 0.000 description 1
- 229920002683 Glycosaminoglycan Polymers 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 102000001554 Hemoglobins Human genes 0.000 description 1
- 108010054147 Hemoglobins Proteins 0.000 description 1
- 206010019842 Hepatomegaly Diseases 0.000 description 1
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 1
- DCRODRAURLJOFY-XPUUQOCRSA-N His-Ala-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)NCC(O)=O DCRODRAURLJOFY-XPUUQOCRSA-N 0.000 description 1
- OMNVOTCFQQLEQU-CIUDSAMLSA-N His-Asn-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMNVOTCFQQLEQU-CIUDSAMLSA-N 0.000 description 1
- HRGGKHFHRSFSDE-CIUDSAMLSA-N His-Asn-Ser Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N HRGGKHFHRSFSDE-CIUDSAMLSA-N 0.000 description 1
- ORZGPQXISSXQGW-IHRRRGAJSA-N His-His-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O ORZGPQXISSXQGW-IHRRRGAJSA-N 0.000 description 1
- LVXFNTIIGOQBMD-SRVKXCTJSA-N His-Leu-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O LVXFNTIIGOQBMD-SRVKXCTJSA-N 0.000 description 1
- PGRPSOUCWRBWKZ-DLOVCJGASA-N His-Lys-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CN=CN1 PGRPSOUCWRBWKZ-DLOVCJGASA-N 0.000 description 1
- XIGFLVCAVQQGNS-IHRRRGAJSA-N His-Pro-His Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1NC=NC=1)C(O)=O)C1=CN=CN1 XIGFLVCAVQQGNS-IHRRRGAJSA-N 0.000 description 1
- CGAMSLMBYJHMDY-ONGXEEELSA-N His-Val-Gly Chemical compound CC(C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CN=CN1)N CGAMSLMBYJHMDY-ONGXEEELSA-N 0.000 description 1
- 108700020129 Human immunodeficiency virus 1 p31 integrase Proteins 0.000 description 1
- 108700039609 IRW peptide Proteins 0.000 description 1
- NKVZTQVGUNLLQW-JBDRJPRFSA-N Ile-Ala-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)O)N NKVZTQVGUNLLQW-JBDRJPRFSA-N 0.000 description 1
- HLYBGMZJVDHJEO-CYDGBPFRSA-N Ile-Arg-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HLYBGMZJVDHJEO-CYDGBPFRSA-N 0.000 description 1
- ZXJFURYTPZMUNY-VKOGCVSHSA-N Ile-Arg-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 ZXJFURYTPZMUNY-VKOGCVSHSA-N 0.000 description 1
- WEWCEPOYKANMGZ-MMWGEVLESA-N Ile-Cys-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N WEWCEPOYKANMGZ-MMWGEVLESA-N 0.000 description 1
- GECLQMBTZCPAFY-PEFMBERDSA-N Ile-Gln-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GECLQMBTZCPAFY-PEFMBERDSA-N 0.000 description 1
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 1
- NYEYYMLUABXDMC-NHCYSSNCSA-N Ile-Gly-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)O)N NYEYYMLUABXDMC-NHCYSSNCSA-N 0.000 description 1
- ZXIGYKICRDFISM-DJFWLOJKSA-N Ile-His-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ZXIGYKICRDFISM-DJFWLOJKSA-N 0.000 description 1
- CMNMPCTVCWWYHY-MXAVVETBSA-N Ile-His-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(C)C)C(=O)O)N CMNMPCTVCWWYHY-MXAVVETBSA-N 0.000 description 1
- YNMQUIVKEFRCPH-QSFUFRPTSA-N Ile-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O)N YNMQUIVKEFRCPH-QSFUFRPTSA-N 0.000 description 1
- OTSVBELRDMSPKY-PCBIJLKTSA-N Ile-Phe-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OTSVBELRDMSPKY-PCBIJLKTSA-N 0.000 description 1
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 1
- HXIDVIFHRYRXLZ-NAKRPEOUSA-N Ile-Ser-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)O)N HXIDVIFHRYRXLZ-NAKRPEOUSA-N 0.000 description 1
- WXLYNEHOGRYNFU-URLPEUOOSA-N Ile-Thr-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N WXLYNEHOGRYNFU-URLPEUOOSA-N 0.000 description 1
- NSPNUMNLZNOPAQ-SJWGOKEGSA-N Ile-Tyr-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N NSPNUMNLZNOPAQ-SJWGOKEGSA-N 0.000 description 1
- NGKPIPCGMLWHBX-WZLNRYEVSA-N Ile-Tyr-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N NGKPIPCGMLWHBX-WZLNRYEVSA-N 0.000 description 1
- WIYDLTIBHZSPKY-HJWJTTGWSA-N Ile-Val-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 WIYDLTIBHZSPKY-HJWJTTGWSA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 101000668058 Infectious salmon anemia virus (isolate Atlantic salmon/Norway/810/9/99) RNA-directed RNA polymerase catalytic subunit Proteins 0.000 description 1
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 1
- 241000890148 Jerseyvirus Species 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- SENJXOPIZNYLHU-UHFFFAOYSA-N L-leucyl-L-arginine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CCCN=C(N)N SENJXOPIZNYLHU-UHFFFAOYSA-N 0.000 description 1
- XIRYQRLFHWWWTC-QEJZJMRPSA-N Leu-Ala-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XIRYQRLFHWWWTC-QEJZJMRPSA-N 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 1
- RFUBXQQFJFGJFV-GUBZILKMSA-N Leu-Asn-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O RFUBXQQFJFGJFV-GUBZILKMSA-N 0.000 description 1
- POJPZSMTTMLSTG-SRVKXCTJSA-N Leu-Asn-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N POJPZSMTTMLSTG-SRVKXCTJSA-N 0.000 description 1
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 1
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 1
- GBDMISNMNXVTNV-XIRDDKMYSA-N Leu-Asp-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GBDMISNMNXVTNV-XIRDDKMYSA-N 0.000 description 1
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 1
- PRZVBIAOPFGAQF-SRVKXCTJSA-N Leu-Glu-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O PRZVBIAOPFGAQF-SRVKXCTJSA-N 0.000 description 1
- HVJVUYQWFYMGJS-GVXVVHGQSA-N Leu-Glu-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O HVJVUYQWFYMGJS-GVXVVHGQSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- KVOFSTUWVSQMDK-KKUMJFAQSA-N Leu-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KVOFSTUWVSQMDK-KKUMJFAQSA-N 0.000 description 1
- QJXHMYMRGDOHRU-NHCYSSNCSA-N Leu-Ile-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O QJXHMYMRGDOHRU-NHCYSSNCSA-N 0.000 description 1
- SEMUSFOBZGKBGW-YTFOTSKYSA-N Leu-Ile-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SEMUSFOBZGKBGW-YTFOTSKYSA-N 0.000 description 1
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 1
- REPBGZHJKYWFMJ-KKUMJFAQSA-N Leu-Lys-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N REPBGZHJKYWFMJ-KKUMJFAQSA-N 0.000 description 1
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 1
- SYRTUBLKWNDSDK-DKIMLUQUSA-N Leu-Phe-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYRTUBLKWNDSDK-DKIMLUQUSA-N 0.000 description 1
- RRVCZCNFXIFGRA-DCAQKATOSA-N Leu-Pro-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O RRVCZCNFXIFGRA-DCAQKATOSA-N 0.000 description 1
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 1
- YUTNOGOMBNYPFH-XUXIUFHCSA-N Leu-Pro-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YUTNOGOMBNYPFH-XUXIUFHCSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- SQUFDMCWMFOEBA-KKUMJFAQSA-N Leu-Ser-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SQUFDMCWMFOEBA-KKUMJFAQSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- URHJPNHRQMQGOZ-RHYQMDGZSA-N Leu-Thr-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O URHJPNHRQMQGOZ-RHYQMDGZSA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- LSLUTXRANSUGFY-XIRDDKMYSA-N Leu-Trp-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(O)=O)C(O)=O LSLUTXRANSUGFY-XIRDDKMYSA-N 0.000 description 1
- OZTZJMUZVAVJGY-BZSNNMDCSA-N Leu-Tyr-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N OZTZJMUZVAVJGY-BZSNNMDCSA-N 0.000 description 1
- RDFIVFHPOSOXMW-ACRUOGEOSA-N Leu-Tyr-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RDFIVFHPOSOXMW-ACRUOGEOSA-N 0.000 description 1
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 1
- JCFYLFOCALSNLQ-GUBZILKMSA-N Lys-Ala-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JCFYLFOCALSNLQ-GUBZILKMSA-N 0.000 description 1
- NFLFJGGKOHYZJF-BJDJZHNGSA-N Lys-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN NFLFJGGKOHYZJF-BJDJZHNGSA-N 0.000 description 1
- NTEVEUCLFMWSND-SRVKXCTJSA-N Lys-Arg-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O NTEVEUCLFMWSND-SRVKXCTJSA-N 0.000 description 1
- DEFGUIIUYAUEDU-ZPFDUUQYSA-N Lys-Asn-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DEFGUIIUYAUEDU-ZPFDUUQYSA-N 0.000 description 1
- NCTDKZKNBDZDOL-GARJFASQSA-N Lys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O NCTDKZKNBDZDOL-GARJFASQSA-N 0.000 description 1
- OVIVOCSURJYCTM-GUBZILKMSA-N Lys-Asp-Glu Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(O)=O OVIVOCSURJYCTM-GUBZILKMSA-N 0.000 description 1
- ZAWOJFFMBANLGE-CIUDSAMLSA-N Lys-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N ZAWOJFFMBANLGE-CIUDSAMLSA-N 0.000 description 1
- VSRXPEHZMHSFKU-IUCAKERBSA-N Lys-Gln-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VSRXPEHZMHSFKU-IUCAKERBSA-N 0.000 description 1
- GJJQCBVRWDGLMQ-GUBZILKMSA-N Lys-Glu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O GJJQCBVRWDGLMQ-GUBZILKMSA-N 0.000 description 1
- VEGLGAOVLFODGC-GUBZILKMSA-N Lys-Glu-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VEGLGAOVLFODGC-GUBZILKMSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- CTBMEDOQJFGNMI-IHPCNDPISA-N Lys-His-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC3=CN=CN3)NC(=O)[C@H](CCCCN)N CTBMEDOQJFGNMI-IHPCNDPISA-N 0.000 description 1
- MXMDJEJWERYPMO-XUXIUFHCSA-N Lys-Ile-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MXMDJEJWERYPMO-XUXIUFHCSA-N 0.000 description 1
- QBEPTBMRQALPEV-MNXVOIDGSA-N Lys-Ile-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN QBEPTBMRQALPEV-MNXVOIDGSA-N 0.000 description 1
- UDXSLGLHFUBRRM-OEAJRASXSA-N Lys-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCCCN)N)O UDXSLGLHFUBRRM-OEAJRASXSA-N 0.000 description 1
- YSPZCHGIWAQVKQ-AVGNSLFASA-N Lys-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN YSPZCHGIWAQVKQ-AVGNSLFASA-N 0.000 description 1
- MGKFCQFVPKOWOL-CIUDSAMLSA-N Lys-Ser-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N MGKFCQFVPKOWOL-CIUDSAMLSA-N 0.000 description 1
- ZFNYWKHYUMEZDZ-WDSOQIARSA-N Lys-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCCN)N ZFNYWKHYUMEZDZ-WDSOQIARSA-N 0.000 description 1
- PSVAVKGDUAKZKU-BZSNNMDCSA-N Lys-Tyr-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCCCN)N)O PSVAVKGDUAKZKU-BZSNNMDCSA-N 0.000 description 1
- IMDJSVBFQKDDEQ-MGHWNKPDSA-N Lys-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCCCN)N IMDJSVBFQKDDEQ-MGHWNKPDSA-N 0.000 description 1
- LMMBAXJRYSXCOQ-ACRUOGEOSA-N Lys-Tyr-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O LMMBAXJRYSXCOQ-ACRUOGEOSA-N 0.000 description 1
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 1
- 241000283923 Marmota monax Species 0.000 description 1
- SBSIKVMCCJUCBZ-GUBZILKMSA-N Met-Asn-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N SBSIKVMCCJUCBZ-GUBZILKMSA-N 0.000 description 1
- TUSOIZOVPJCMFC-FXQIFTODSA-N Met-Asp-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O TUSOIZOVPJCMFC-FXQIFTODSA-N 0.000 description 1
- WGBMNLCRYKSWAR-DCAQKATOSA-N Met-Asp-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN WGBMNLCRYKSWAR-DCAQKATOSA-N 0.000 description 1
- OFNCSQNBSWGGNV-DCAQKATOSA-N Met-Cys-His Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC1=CNC=N1 OFNCSQNBSWGGNV-DCAQKATOSA-N 0.000 description 1
- WVTYEEPGEUSFGQ-LPEHRKFASA-N Met-Cys-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N WVTYEEPGEUSFGQ-LPEHRKFASA-N 0.000 description 1
- FWTBMGAKKPSTBT-GUBZILKMSA-N Met-Gln-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FWTBMGAKKPSTBT-GUBZILKMSA-N 0.000 description 1
- QMIXOTQHYHOUJP-KKUMJFAQSA-N Met-Gln-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N QMIXOTQHYHOUJP-KKUMJFAQSA-N 0.000 description 1
- FWAHLGXNBLWIKB-NAKRPEOUSA-N Met-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCSC FWAHLGXNBLWIKB-NAKRPEOUSA-N 0.000 description 1
- HWROAFGWPQUPTE-OSUNSFLBSA-N Met-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CCSC)N HWROAFGWPQUPTE-OSUNSFLBSA-N 0.000 description 1
- UROWNMBTQGGTHB-DCAQKATOSA-N Met-Leu-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UROWNMBTQGGTHB-DCAQKATOSA-N 0.000 description 1
- KMSMNUFBNCHMII-IHRRRGAJSA-N Met-Leu-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN KMSMNUFBNCHMII-IHRRRGAJSA-N 0.000 description 1
- RATXDYWHIYNZLE-DCAQKATOSA-N Met-Lys-Cys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)O)N RATXDYWHIYNZLE-DCAQKATOSA-N 0.000 description 1
- VSJAPSMRFYUOKS-IUCAKERBSA-N Met-Pro-Gly Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O VSJAPSMRFYUOKS-IUCAKERBSA-N 0.000 description 1
- WXXNVZMWHOLNRJ-AVGNSLFASA-N Met-Pro-Lys Chemical compound CSCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O WXXNVZMWHOLNRJ-AVGNSLFASA-N 0.000 description 1
- GWADARYJIJDYRC-XGEHTFHBSA-N Met-Thr-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O GWADARYJIJDYRC-XGEHTFHBSA-N 0.000 description 1
- CQRGINSEMFBACV-WPRPVWTQSA-N Met-Val-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O CQRGINSEMFBACV-WPRPVWTQSA-N 0.000 description 1
- 102220485636 Mitogen-activated protein kinase 15_K42A_mutation Human genes 0.000 description 1
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 1
- 108010079364 N-glycylalanine Proteins 0.000 description 1
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 1
- 108010065395 Neuropep-1 Proteins 0.000 description 1
- 101100151229 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) msp-4 gene Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 108091092724 Noncoding DNA Proteins 0.000 description 1
- 108090001074 Nucleocapsid Proteins Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 102220497402 Oxysterol-binding protein-related protein 3_K71A_mutation Human genes 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- JEGFCFLCRSJCMA-IHRRRGAJSA-N Phe-Arg-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N JEGFCFLCRSJCMA-IHRRRGAJSA-N 0.000 description 1
- BXNGIHFNNNSEOS-UWVGGRQHSA-N Phe-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 BXNGIHFNNNSEOS-UWVGGRQHSA-N 0.000 description 1
- KIEPQOIQHFKQLK-PCBIJLKTSA-N Phe-Asn-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KIEPQOIQHFKQLK-PCBIJLKTSA-N 0.000 description 1
- XXAOSEUPEMQJOF-KKUMJFAQSA-N Phe-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 XXAOSEUPEMQJOF-KKUMJFAQSA-N 0.000 description 1
- WKTSCAXSYITIJJ-PCBIJLKTSA-N Phe-Ile-Asn Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O WKTSCAXSYITIJJ-PCBIJLKTSA-N 0.000 description 1
- KDYPMIZMXDECSU-JYJNAYRXSA-N Phe-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KDYPMIZMXDECSU-JYJNAYRXSA-N 0.000 description 1
- SCKXGHWQPPURGT-KKUMJFAQSA-N Phe-Lys-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O SCKXGHWQPPURGT-KKUMJFAQSA-N 0.000 description 1
- CBENHWCORLVGEQ-HJOGWXRNSA-N Phe-Phe-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 CBENHWCORLVGEQ-HJOGWXRNSA-N 0.000 description 1
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 1
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 1
- BONHGTUEEPIMPM-AVGNSLFASA-N Phe-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O BONHGTUEEPIMPM-AVGNSLFASA-N 0.000 description 1
- MCIXMYKSPQUMJG-SRVKXCTJSA-N Phe-Ser-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MCIXMYKSPQUMJG-SRVKXCTJSA-N 0.000 description 1
- CQZNGNCAIXMAIQ-UBHSHLNASA-N Pro-Ala-Phe Chemical compound C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O CQZNGNCAIXMAIQ-UBHSHLNASA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 1
- WPQKSRHDTMRSJM-CIUDSAMLSA-N Pro-Asp-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 WPQKSRHDTMRSJM-CIUDSAMLSA-N 0.000 description 1
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 1
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 1
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- FDINZVJXLPILKV-DCAQKATOSA-N Pro-His-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O FDINZVJXLPILKV-DCAQKATOSA-N 0.000 description 1
- JUJGNDZIKKQMDJ-IHRRRGAJSA-N Pro-His-His Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(O)=O JUJGNDZIKKQMDJ-IHRRRGAJSA-N 0.000 description 1
- MRYUJHGPZQNOAD-IHRRRGAJSA-N Pro-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 MRYUJHGPZQNOAD-IHRRRGAJSA-N 0.000 description 1
- DRKAXLDECUGLFE-ULQDDVLXSA-N Pro-Leu-Phe Chemical compound CC(C)C[C@H](NC(=O)[C@@H]1CCCN1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O DRKAXLDECUGLFE-ULQDDVLXSA-N 0.000 description 1
- VTFXTWDFPTWNJY-RHYQMDGZSA-N Pro-Leu-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VTFXTWDFPTWNJY-RHYQMDGZSA-N 0.000 description 1
- SXMSEHDMNIUTSP-DCAQKATOSA-N Pro-Lys-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O SXMSEHDMNIUTSP-DCAQKATOSA-N 0.000 description 1
- FNGOXVQBBCMFKV-CIUDSAMLSA-N Pro-Ser-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O FNGOXVQBBCMFKV-CIUDSAMLSA-N 0.000 description 1
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 1
- FZXSYIPVAFVYBH-KKUMJFAQSA-N Pro-Tyr-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O FZXSYIPVAFVYBH-KKUMJFAQSA-N 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 101710150344 Protein Rev Proteins 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 238000011530 RNeasy Mini Kit Methods 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 108020003564 Retroelements Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- SRTCFKGBYBZRHA-ACZMJKKPSA-N Ser-Ala-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SRTCFKGBYBZRHA-ACZMJKKPSA-N 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 1
- RNFKSBPHLTZHLU-WHFBIAKZSA-N Ser-Cys-Gly Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N)O RNFKSBPHLTZHLU-WHFBIAKZSA-N 0.000 description 1
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 1
- KJMOINFQVCCSDX-XKBZYTNZSA-N Ser-Gln-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KJMOINFQVCCSDX-XKBZYTNZSA-N 0.000 description 1
- OQPNSDWGAMFJNU-QWRGUYRKSA-N Ser-Gly-Tyr Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 OQPNSDWGAMFJNU-QWRGUYRKSA-N 0.000 description 1
- HZNFKPJCGZXKIC-DCAQKATOSA-N Ser-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N HZNFKPJCGZXKIC-DCAQKATOSA-N 0.000 description 1
- YIUWWXVTYLANCJ-NAKRPEOUSA-N Ser-Ile-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YIUWWXVTYLANCJ-NAKRPEOUSA-N 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- IAORETPTUDBBGV-CIUDSAMLSA-N Ser-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N IAORETPTUDBBGV-CIUDSAMLSA-N 0.000 description 1
- LRWBCWGEUCKDTN-BJDJZHNGSA-N Ser-Lys-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LRWBCWGEUCKDTN-BJDJZHNGSA-N 0.000 description 1
- KJKQUQXDEKMPDK-FXQIFTODSA-N Ser-Met-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(O)=O KJKQUQXDEKMPDK-FXQIFTODSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 1
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 1
- PZHJLTWGMYERRJ-SRVKXCTJSA-N Ser-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)O PZHJLTWGMYERRJ-SRVKXCTJSA-N 0.000 description 1
- PLQWGQUNUPMNOD-KKUMJFAQSA-N Ser-Tyr-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O PLQWGQUNUPMNOD-KKUMJFAQSA-N 0.000 description 1
- UKKROEYWYIHWBD-ZKWXMUAHSA-N Ser-Val-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O UKKROEYWYIHWBD-ZKWXMUAHSA-N 0.000 description 1
- LSHUNRICNSEEAN-BPUTZDHNSA-N Ser-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CO)N LSHUNRICNSEEAN-BPUTZDHNSA-N 0.000 description 1
- 102220509593 Small integral membrane protein 10_H51A_mutation Human genes 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 206010041660 Splenomegaly Diseases 0.000 description 1
- 101710172711 Structural protein Proteins 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- PXQUBKWZENPDGE-CIQUZCHMSA-N Thr-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H]([C@@H](C)O)N PXQUBKWZENPDGE-CIQUZCHMSA-N 0.000 description 1
- CEXFELBFVHLYDZ-XGEHTFHBSA-N Thr-Arg-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CEXFELBFVHLYDZ-XGEHTFHBSA-N 0.000 description 1
- UNURFMVMXLENAZ-KJEVXHAQSA-N Thr-Arg-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O UNURFMVMXLENAZ-KJEVXHAQSA-N 0.000 description 1
- JNQZPAWOPBZGIX-RCWTZXSCSA-N Thr-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)O)CCCN=C(N)N JNQZPAWOPBZGIX-RCWTZXSCSA-N 0.000 description 1
- SKHPKKYKDYULDH-HJGDQZAQSA-N Thr-Asn-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O SKHPKKYKDYULDH-HJGDQZAQSA-N 0.000 description 1
- OHAJHDJOCKKJLV-LKXGYXEUSA-N Thr-Asp-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O OHAJHDJOCKKJLV-LKXGYXEUSA-N 0.000 description 1
- ZUUDNCOCILSYAM-KKHAAJSZSA-N Thr-Asp-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ZUUDNCOCILSYAM-KKHAAJSZSA-N 0.000 description 1
- UDQBCBUXAQIZAK-GLLZPBPUSA-N Thr-Glu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDQBCBUXAQIZAK-GLLZPBPUSA-N 0.000 description 1
- IMULJHHGAUZZFE-MBLNEYKQSA-N Thr-Gly-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IMULJHHGAUZZFE-MBLNEYKQSA-N 0.000 description 1
- KRGDDWVBBDLPSJ-CUJWVEQBSA-N Thr-His-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O KRGDDWVBBDLPSJ-CUJWVEQBSA-N 0.000 description 1
- GMXIJHCBTZDAPD-QPHKQPEJSA-N Thr-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N GMXIJHCBTZDAPD-QPHKQPEJSA-N 0.000 description 1
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 1
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 1
- SCSVNSNWUTYSFO-WDCWCFNPSA-N Thr-Lys-Glu Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O SCSVNSNWUTYSFO-WDCWCFNPSA-N 0.000 description 1
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 1
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 1
- TZQWJCGVCIJDMU-HEIBUPTGSA-N Thr-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N)O TZQWJCGVCIJDMU-HEIBUPTGSA-N 0.000 description 1
- KHTIUAKJRUIEMA-HOUAVDHOSA-N Thr-Trp-Asp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 KHTIUAKJRUIEMA-HOUAVDHOSA-N 0.000 description 1
- NLWDSYKZUPRMBJ-IEGACIPQSA-N Thr-Trp-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O NLWDSYKZUPRMBJ-IEGACIPQSA-N 0.000 description 1
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- UPOGHWJJZAZNSW-XIRDDKMYSA-N Trp-His-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O UPOGHWJJZAZNSW-XIRDDKMYSA-N 0.000 description 1
- ULHASJWZGUEUNN-XIRDDKMYSA-N Trp-Lys-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O ULHASJWZGUEUNN-XIRDDKMYSA-N 0.000 description 1
- KXFYAQUYJKOQMI-QEJZJMRPSA-N Trp-Ser-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 KXFYAQUYJKOQMI-QEJZJMRPSA-N 0.000 description 1
- GEGYPBOPIGNZIF-CWRNSKLLSA-N Trp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O GEGYPBOPIGNZIF-CWRNSKLLSA-N 0.000 description 1
- ZZDFLJFVSNQINX-HWHUXHBOSA-N Trp-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)O ZZDFLJFVSNQINX-HWHUXHBOSA-N 0.000 description 1
- ZKVANNIVSDOQMG-HKUYNNGSSA-N Trp-Tyr-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)NCC(=O)O)N ZKVANNIVSDOQMG-HKUYNNGSSA-N 0.000 description 1
- RKISDJMICOREEL-QRTARXTBSA-N Trp-Val-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RKISDJMICOREEL-QRTARXTBSA-N 0.000 description 1
- NOXKHHXSHQFSGJ-FQPOAREZSA-N Tyr-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NOXKHHXSHQFSGJ-FQPOAREZSA-N 0.000 description 1
- CKKFTIQYURNSEI-IHRRRGAJSA-N Tyr-Asn-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 CKKFTIQYURNSEI-IHRRRGAJSA-N 0.000 description 1
- JFDGVHXRCKEBAU-KKUMJFAQSA-N Tyr-Asp-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N)O JFDGVHXRCKEBAU-KKUMJFAQSA-N 0.000 description 1
- GHUNBABNQPIETG-MELADBBJSA-N Tyr-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O GHUNBABNQPIETG-MELADBBJSA-N 0.000 description 1
- HVHJYXDXRIWELT-RYUDHWBXSA-N Tyr-Glu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O HVHJYXDXRIWELT-RYUDHWBXSA-N 0.000 description 1
- JWGXUKHIKXZWNG-RYUDHWBXSA-N Tyr-Gly-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O JWGXUKHIKXZWNG-RYUDHWBXSA-N 0.000 description 1
- PJWCWGXAVIVXQC-STECZYCISA-N Tyr-Ile-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PJWCWGXAVIVXQC-STECZYCISA-N 0.000 description 1
- BXPOOVDVGWEXDU-WZLNRYEVSA-N Tyr-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BXPOOVDVGWEXDU-WZLNRYEVSA-N 0.000 description 1
- PRONOHBTMLNXCZ-BZSNNMDCSA-N Tyr-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PRONOHBTMLNXCZ-BZSNNMDCSA-N 0.000 description 1
- PGEFRHBWGOJPJT-KKUMJFAQSA-N Tyr-Lys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O PGEFRHBWGOJPJT-KKUMJFAQSA-N 0.000 description 1
- CYTJBBNFJIWKGH-STECZYCISA-N Tyr-Met-Ile Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CYTJBBNFJIWKGH-STECZYCISA-N 0.000 description 1
- WTTRJMAZPDHPGS-KKXDTOCCSA-N Tyr-Phe-Ala Chemical compound C[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(O)=O WTTRJMAZPDHPGS-KKXDTOCCSA-N 0.000 description 1
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 1
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 1
- ZZDYJFVIKVSUFA-WLTAIBSBSA-N Tyr-Thr-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O ZZDYJFVIKVSUFA-WLTAIBSBSA-N 0.000 description 1
- JQOMHZMWQHXALX-FHWLQOOXSA-N Tyr-Tyr-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O JQOMHZMWQHXALX-FHWLQOOXSA-N 0.000 description 1
- OBKOPLHSRDATFO-XHSDSOJGSA-N Tyr-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)N OBKOPLHSRDATFO-XHSDSOJGSA-N 0.000 description 1
- 102220635504 Vacuolar protein sorting-associated protein 33A_D41A_mutation Human genes 0.000 description 1
- LABUITCFCAABSV-UHFFFAOYSA-N Val-Ala-Tyr Natural products CC(C)C(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-UHFFFAOYSA-N 0.000 description 1
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 1
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 1
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 1
- CFSSLXZJEMERJY-NRPADANISA-N Val-Gln-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CFSSLXZJEMERJY-NRPADANISA-N 0.000 description 1
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 1
- BEGDZYNDCNEGJZ-XVKPBYJWSA-N Val-Gly-Gln Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O BEGDZYNDCNEGJZ-XVKPBYJWSA-N 0.000 description 1
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 1
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 1
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 1
- DJQIUOKSNRBTSV-CYDGBPFRSA-N Val-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](C(C)C)N DJQIUOKSNRBTSV-CYDGBPFRSA-N 0.000 description 1
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 1
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 1
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 1
- DVLWZWNAQUBZBC-ZNSHCXBVSA-N Val-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N)O DVLWZWNAQUBZBC-ZNSHCXBVSA-N 0.000 description 1
- DFQZDQPLWBSFEJ-LSJOCFKGSA-N Val-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(=O)N)C(=O)O)N DFQZDQPLWBSFEJ-LSJOCFKGSA-N 0.000 description 1
- 241000711973 Vesicular stomatitis Indiana virus Species 0.000 description 1
- 108020005202 Viral DNA Proteins 0.000 description 1
- 108700010756 Viral Polyproteins Proteins 0.000 description 1
- 108020000999 Viral RNA Proteins 0.000 description 1
- 241000713325 Visna/maedi virus Species 0.000 description 1
- 208000003152 Yellow Fever Diseases 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 230000033289 adaptive immune response Effects 0.000 description 1
- 108010045023 alanyl-prolyl-tyrosine Proteins 0.000 description 1
- 108010070783 alanyltyrosine Proteins 0.000 description 1
- UPEZCKBFRMILAV-UHFFFAOYSA-N alpha-Ecdysone Natural products C1C(O)C(O)CC2(C)C(CCC3(C(C(C(O)CCC(C)(C)O)C)CCC33O)C)C3=CC(=O)C21 UPEZCKBFRMILAV-UHFFFAOYSA-N 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 244000309464 bull Species 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- TWFZGCMQGLPBSX-UHFFFAOYSA-N carbendazim Chemical compound C1=CC=C2NC(NC(=O)OC)=NC2=C1 TWFZGCMQGLPBSX-UHFFFAOYSA-N 0.000 description 1
- JGPOSNWWINVNFV-UHFFFAOYSA-N carboxyfluorescein diacetate succinimidyl ester Chemical compound C=1C(OC(=O)C)=CC=C2C=1OC1=CC(OC(C)=O)=CC=C1C2(C1=C2)OC(=O)C1=CC=C2C(=O)ON1C(=O)CCC1=O JGPOSNWWINVNFV-UHFFFAOYSA-N 0.000 description 1
- 230000021164 cell adhesion Effects 0.000 description 1
- 230000004709 cell invasion Effects 0.000 description 1
- 210000004238 cell nucleolus Anatomy 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000007248 cellular mechanism Effects 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 210000000172 cytosol Anatomy 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- UPEZCKBFRMILAV-JMZLNJERSA-N ecdysone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@@H]([C@H](O)CCC(C)(C)O)C)CC[C@]33O)C)C3=CC(=O)[C@@H]21 UPEZCKBFRMILAV-JMZLNJERSA-N 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 210000003162 effector t lymphocyte Anatomy 0.000 description 1
- 108700004025 env Genes Proteins 0.000 description 1
- 239000003797 essential amino acid Substances 0.000 description 1
- 235000020776 essential amino acid Nutrition 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 239000012894 fetal calf serum Substances 0.000 description 1
- 230000004992 fission Effects 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 231100000221 frame shift mutation induction Toxicity 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 101150098622 gag gene Proteins 0.000 description 1
- 108700010758 gag-pro Proteins 0.000 description 1
- 101150081889 gag-pro gene Proteins 0.000 description 1
- 108700010759 gag-pro-pol Proteins 0.000 description 1
- 101150061559 gag-pro-pol gene Proteins 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 238000001476 gene delivery Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 108010085059 glutamyl-arginyl-proline Proteins 0.000 description 1
- 108010033719 glycyl-histidyl-glycine Proteins 0.000 description 1
- 108010066198 glycyl-leucyl-phenylalanine Proteins 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 1
- 210000002288 golgi apparatus Anatomy 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 108010080417 hemozoin Proteins 0.000 description 1
- 108010040030 histidinoalanine Proteins 0.000 description 1
- 108010018006 histidylserine Proteins 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 238000007654 immersion Methods 0.000 description 1
- 230000002519 immonomodulatory effect Effects 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 230000003832 immune regulation Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 238000010166 immunofluorescence Methods 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 230000006054 immunological memory Effects 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 239000012678 infectious agent Substances 0.000 description 1
- 230000004941 influx Effects 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 108010076756 leucyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 1
- 108010000761 leucylarginine Proteins 0.000 description 1
- 108010091871 leucylmethionine Proteins 0.000 description 1
- 210000005229 liver cell Anatomy 0.000 description 1
- 230000005960 long-lasting response Effects 0.000 description 1
- 230000012976 mRNA stabilization Effects 0.000 description 1
- 238000012768 mass vaccination Methods 0.000 description 1
- 102000006240 membrane receptors Human genes 0.000 description 1
- 108020004084 membrane receptors Proteins 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- 238000007431 microscopic evaluation Methods 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 210000004898 n-terminal fragment Anatomy 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 108010065135 phenylalanyl-phenylalanyl-phenylalanine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 230000010287 polarization Effects 0.000 description 1
- 230000023603 positive regulation of transcription initiation, DNA-dependent Effects 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 108010015796 prolylisoleucine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 229940023143 protein vaccine Drugs 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000004445 quantitative analysis Methods 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000008593 response to virus Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 102200052245 rs199469625 Human genes 0.000 description 1
- 102220128858 rs200860772 Human genes 0.000 description 1
- 102220139188 rs35702995 Human genes 0.000 description 1
- 102220237139 rs376184349 Human genes 0.000 description 1
- 102220045124 rs587781846 Human genes 0.000 description 1
- 102200155054 rs80358230 Human genes 0.000 description 1
- 102220146256 rs886059153 Human genes 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 239000010409 thin film Substances 0.000 description 1
- 108010031491 threonyl-lysyl-glutamic acid Proteins 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 210000003412 trans-golgi network Anatomy 0.000 description 1
- 230000002463 transducing effect Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 239000013638 trimer Substances 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 108010035534 tyrosyl-leucyl-alanine Proteins 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 229940125575 vaccine candidate Drugs 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Images

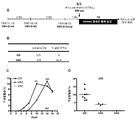
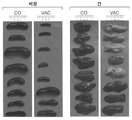









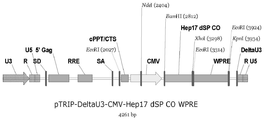



Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/44—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from protozoa
- C07K14/445—Plasmodium
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/002—Protozoa antigens
- A61K39/015—Hemosporidia antigens, e.g. Plasmodium antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P33/00—Antiparasitic agents
- A61P33/02—Antiprotozoals, e.g. for leishmaniasis, trichomoniasis, toxoplasmosis
- A61P33/06—Antimalarials
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
- C12N15/867—Retroviral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/525—Virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/525—Virus
- A61K2039/5256—Virus expressing foreign proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/525—Virus
- A61K2039/5258—Virus-like particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/15011—Lentivirus, not HIV, e.g. FIV, SIV
- C12N2740/15023—Virus like particles [VLP]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/15011—Lentivirus, not HIV, e.g. FIV, SIV
- C12N2740/15041—Use of virus, viral particle or viral elements as a vector
- C12N2740/15043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16023—Virus like particles [VLP]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16041—Use of virus, viral particle or viral elements as a vector
- C12N2740/16043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2810/00—Vectors comprising a targeting moiety
- C12N2810/50—Vectors comprising as targeting moiety peptide derived from defined protein
- C12N2810/60—Vectors comprising as targeting moiety peptide derived from defined protein from viruses
- C12N2810/6072—Vectors comprising as targeting moiety peptide derived from defined protein from viruses negative strand RNA viruses
- C12N2810/6081—Vectors comprising as targeting moiety peptide derived from defined protein from viruses negative strand RNA viruses rhabdoviridae, e.g. VSV
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Biochemistry (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Molecular Biology (AREA)
- Virology (AREA)
- Biophysics (AREA)
- Veterinary Medicine (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Mycology (AREA)
- Epidemiology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
Abstract
본 발명은 RNA 바이러스로부터 기원하는 결정된 이종 바이러스 외피 단백질 또는 바이러스 외피 단백질들로 위형화되고 그의 게놈 내에 포유류 숙주를 감염시킬 수 있는 플라스모듐 기생충의 항원의 에피토프(들)을 갖는 하나 이상의 폴리펩티드(들)을 코딩하는 하나 이상의 재조합 폴리뉴클레오티드를 포함하는 렌티바이러스 벡터 입자에 관한 것이다. 렌티바이러스 벡터 입자는 말라리아 기생충에 대항하여 면역학적 반응을 도출하기 위해 사용된다.
Description
본 발명은 말라리아에 대항하는 렌티바이러스 벡터 기반의 면역학적 화합물에 관한 것이다.
백신 전략 디자인에서 관찰되는 장애 관점에서, 말라리아와 같은 높은 사망률 및 유병률을 초래하는 많은 질환은 여전히 강한 T-세포 매개 면역성 및 유리하게는 강력한 체액성 면역 반응을 도출할 수 있는 신규한 백신 플랫폼의 발달을 필요로 한다. 인간에 영향을 주는 기생충 감염 중에서, 말라리아는 이러한 백신에 대한 수많은 시도가 제안된 질환이다.
그러나, 말라리아와 관련해서는, 오로지 방사능 약독화 포자소체를 함유하는 백신만이 설치류(Nussenzweig R.S. et al, Nature 216, 160-162 (1967)), 원숭이(Gwadz; R.W. et al, Bull World Health Organ 57 Suppl 1, 165-173 (1979)) 및 인간(Clyde, D. F. et al, Am J. Med Sci 266, 169-177 (1973)에서 살균 면역을 지속적으로 유도한다. 매우 흥미로울지라도, 방사능에 조사된 포자소체 백신 접근법은 여전히 대량 백신화에 유망하다고 고려될 수 있기 전에 특히 안정성, 제조, 저장 및 분배와 관련된 다양한 도전을 극복할 필요가 있다.
리뷰 논문 Limbach K.J. & Richie T. L. (Parasit immunology, 2009, 31, 501-519)에서는 면역 반응을 도출하는 항원에 대한 전달 수단으로서 바이러스 벡터의 사용에 근거한, 말라리아에 대항하는 상이한 이용가능한 백신 플랫폼을 고려한다. 이러한 플랫폼에는 폭스바이러스-벡터의 말라리아 항원, 또는 아데노바이러스-벡터의 말라리아 항원에 근거하여 디자인된 백신이 포함되며, 두 유형의 벡터는 특히 투여를 위해 이종 초기감작-증강 섭생을 포함하는 접근법에서 제안된다. 상기 폭스바이러스 또는 아데노바이러스 기반 기술 외에, 리뷰의 저자는 신규 벡터 시스템이 동물 모델에서 유망하고 따라서 황열병 벡터화 전략 또는 알파 바이러스 레플리콘 벡터화 전략을 고려할 수 있다고 기재한다. 이들은 또한 포유류 숙주에서 장기간 지속되는 면역성을 제공하는데 효과적이고 인간 숙주에 대한 투여 안정성의 요구사항을 이행할 수 있는 백신 벡터 디자인에 있어 지속적인 어려움을 극복하기 위한 다양한 잠재적으로 흥미로운 방식을 계획한다. 이러한 방식은 항원에 대한 이종 전달 수단, 아쥬반트 또는 면역조절성 성분의 사용의 조합을 포함할 것이다.
종래 기술의 제안된 백신 조성물을 검정할 때 관찰된 단점 중 적어도 일부를 극복하고자 하는 시도로, 본 출원인은 말라리아에 대항하는 예방 백신을 개발하기 위한 접근법의 신규한 백신화 플랫폼에 대한 근거로서 렌티바이러스 벡터의 접근법을 고려하였다.
말라리아는 아노펠레(Anophele) 모기에 의해 숙주로 전염되는 병리학이고 매년 수백만 명의 인구의 사망을 야기하는 많은 국가에서 풍토병이다. 사망률 외에도, 말라리아는 이것이 풍토병인 국가에서 큰 비율의 집단에서 유병률을 야기하여, 상기 국가의 의료 및 경제적 주요관심사가 된다.
5 가지 종의 플라스모듐 기생충이 인간을 감염시킨다고 알려져 있으며: 플라스모듐 비박스(Plasmodium vivax), 플라스모듐 오발레(Plasmodium ovale), 플라스모듐 말라리아에(Plasmodium malariae), 플라스모듐 놀레시(Plasmodium knowlesi) (17) 및 플라스모듐 팔시파룸(Plasmodium falciparum), 플라스모듐 팔시파룸(Plasmodium falciparum)이 대부분의 모든 사망률 경우를 야기하는 말라리아의 작용제이다. 인간에서의 감염은 암컷 모기로부터 기원하는 기생충의 포자소체 형태의 접종으로 시작된다. 상기 형태의 기생충은 혈류에서 인간 숙주의 간으로 빠르게 전달되고, 이곳에서 간세포의 침입이 진행된다. 플라스모듐(Plasmodium)의 균주에 따라, 기생충의 간-내 사이클의 지속기간은 5 내지 15일이고, P. 팔시파룸(P. falciparum)의 경우 더 짧다(약 5.5일). 기생충은 감염된 세포 내의 무성 복제의 결과로서 간에서 증폭하여, 기생충의 분열소체 형태를 만든다. 분열소체가 간세포로부터 방출된 후, 이들은 인간 숙주에서 감염의 징후 상에 상응하는 혈액-단계 감염을 향해 진행된다. 따라서, 분열소체는 특이적 막 수용체를 통해 적혈구 세포(적혈구) 내로 빠르게 침투한다. 적혈구의 분열소체 침입은 플라스모듐(Plasmodium)의 균주에 따라 48 내지 72시간 동안 지속되는 사이클의 적혈구 단계에 상응한다. 상기 단계 동안, 분열소체는 다중 핵 분열을 겪어, 추가의 분열소체의 방출을 일으키고, 이것은 부가적인 적혈구 세포의 침입을 수행하여 사이클을 반복할 수 있다. 인간에서, 징후 질환은 적혈구의 침입 효과, 이들의 파괴 및 숙주의 반응의 결과이다. 감염 동안, 기생충 형태 중 일부는 포자 사이클을 겪는, 이후 모기에 의해 섭취되는 생식모세포로 분화하여, 이후 인간을 감염시키는 포자소체를 산출한다.
인체 중의 구별되는 단계를 포함하는 감염 사이클, 및 상이한 형태의 기생충으로 인해, 다양한 전략이 백신 원리를 전달하기 위해 제안되고, 플라스모듐(Plasmodium)의 다양한 항원이 특히 체액 항체 반응을 지정할 때 면역 반응에 대한 표적으로 제안된다.
면역 반응을 야기하거나 개선하기에 적합한 표적 후보자는 백신을 디자인하는 관점에서 다양한 항원을 계획하고 따라서 "간-단계 항원"(또한 "전-적혈구 단계 항원"으로서 지칭됨) 및/또는 "혈액-단계 항원"을 계획할 수 있다.
본 발명의 체계 내에서, 본 출원인은 말라리아 기생충의 전-적혈구 단계 항원이 유리하게는, 인간에서 기생충의 사이클 중 후기 단계에서 나타나는 항원보다 덜 가변성을 나타내기 때문에, 집단의 수준에서 균일하게 효과적일 보호성 면역 반응을 도출하는데 사용될 수 있다는 것을 먼저 고려하였다. 본 출원인은 또한 말라리아에 대항하는 장기간 보호에 대해, 세포 반응을 도출하는데 적합한 수단이 필요할 것이고, 유리하게는 체액 반응에 의해 보충될 것으로 고려하였다.
본 출원인은 따라서 보호성 면역 반응이 효과적인 효과기 세포 및 기억 세포의 개시 및 발달을 필요로 할 것이고, 상기 반응이 자연적 감염에 대해 관찰된 면역 반응의 효능을 능가할 정도로 충분히 강해야만 한다는 것을 측정하였다.
그러므로 본 발명은 말라리아에 대해 통상 사용되는 쥣과 모델에서 입증된 바와 같이, 면역 조성물에 대한 활성 성분의 전달 수단 외에, 인간에 적용되는 경우 강하고 장기간의 면역 반응을 도출하는데 적합한 적합한 면역화 패턴의 측정을 가능하게 하는 말라리아 백신의 제조 또는 개발에 대한 신규한 플랫폼으로서 신규한 렌티바이러스-기반 벡터를 제공한다.
본 발명은 따라서 (i) RNA 바이러스로부터 기원하는 결정된 이종 바이러스 외피 단백질 또는 바이러스 외피 단백질들로 위형화되고 (ii) 포유류 숙주를 감염시킬 수 있는 플라스모듐 기생충의 전-적혈구 단계 항원의 에피토프(들)을 갖는 하나 이상의 폴리펩티드(들)을 코딩하는 하나 이상의 재조합 폴리뉴클레오티드를 그의 게놈 내에 포함하며, 상기 에피토프(들)이 T-에피토프(들)을 포함하는 것을 특징으로 하는, 렌티바이러스 벡터 입자, 특히 복제-무능 렌티바이러스 벡터 입자, 특히 복제-무능 HIV-기반 벡터 입자인 렌티바이러스 벡터 입자에 관한 것이다.
본 발명의 특정 구현예에서, 플라스모듐 기생충의 전-적혈구 단계 항원의 코딩된 폴리펩티드는 추가로 B-에피토프(들)을 포함한다.
본 발명에 따르면, 렌티바이러스 벡터 입자는 능숙(즉, 통합-유능) 또는 결핍(즉, 통합-무능) 입자를 발현하도록 디자인된다.
표현 "말라리아 기생충" 및 "플라스모듐 기생충"은 본 출원에서 상호교환적으로 사용된다. 이들은 특히 포자소체, 특히 접종 후 혈류에 존재하는 포자소체, 또는 간세포에서 발달된 포자소체, 간세포에서 생성된 특히 분열소체(전-적혈구 단계의 형태 및 사이클의 적혈구 세포에 함유된 분열소체와 같은 사이클의 적혈구 단계의 형태를 포함함)를 비롯한 분열소체를 포함하여, 포유류, 특히 인간 숙주에서 다양한 단계의 사이클과 연관된 기생충의 각각의 및 모든 형태를 지정한다. 상기 형태의 기생충은 당업계에 잘 알려지고 확인된 다양한 특이적인 항원을 특징으로 하고, 또한 감염 단계를 참조로 하여 지정될 수 있다.
표현 "T-에피토프" 및 "B-에피토프"는 각각 T 세포에 의해 유도된 적응성 면역 반응 및 B 세포에 의해 유도된 면역 반응에 포함되는 항원 결정소를 말한다. 특히 상기 T-에피토프 및 B-에피토프는 각각 적합한 조건에서 숙주로 전달될 때 T 세포, 각각 B 세포 면역 반응을 도출한다.
본 발명에 정의된 렌티바이러스 벡터 입자(또는 렌티바이러스 벡터 또는 렌티바이러스-기반 벡터 입자)는 렌티바이러스 벡터 입자의 벡터 게놈을 제공하는, 특정 렌티바이러스, 특히 HIV, 특히 HIV-1과 상이한 바이러스로부터 기원하는 외피 단백질 또는 외피 단백질들을 갖는 벡터 입자로 이루어진 위형화된 렌티바이러스 벡터이다. 따라서, 상기 외피 단백질 또는 외피 단백질들은, 입자의 벡터 게놈과 관련하여 "이종" 바이러스 외피 단백질 또는 바이러스 외피 단백질들이다. 다음 페이지에서, 본 발명을 수행하는데 적합한 임의의 유형의 외피 단백질 또는 외피 단백질들을 포함하도록 "외피 단백질(들)"에 대한 참조가 이루어질 것이다.
본 출원에서 "렌티바이러스" 벡터(렌티바이러스-기반 벡터)를 참조할 때, 특정 구현예에서, HIV-기반 벡터, 특히 HIV-1-기반 벡터를 계획한다.
본 발명에 따른 렌티바이러스 벡터는 대체 벡터이고, 단백질을 코딩하는 본래 렌티바이러스의 서열이 벡터의 게놈에서 본질적으로 결실되거나, 존재하는 경우, 생물학적으로 활성인 렌티바이러스 단백질의 발현을 방지하기 위해, 특히, HIV의 경우, 기능적 ENV, GAG, 및 POL 단백질의, 임의로 렌티바이러스, 특히 HIV의 추가의 구조 및/또는 보조 및/또는 조절 단백질의, 상기 전달 벡터에 의한 발현을 방지하기 위해 개질된 특히 돌연변이된, 특히 절단된 것을 의미한다.
벡터 입자의 "벡터 게놈"은 또한 말라리아 기생충의 폴리펩티드(들)을 코딩하는 관심의 폴리뉴클레오티드 또는 이식유전자를 포함하는 재조합 벡터이다. 벡터 게놈의 렌티바이러스-기반 서열 및 폴리뉴클레오티드/이식유전자는 플라스미드 벡터에 의해 기원하므로, 또한 "서열 벡터"로서 불리는 "전달 벡터"를 산출한다. 따라서, 상기 표현은 본 출원에서 상호교환적으로 사용된다.
본원에 정의된 벡터 게놈은 따라서 이의 발현을 위한 적합한 조절 서열의 조절 하에 놓인 소위 재조합 폴리뉴클레오티드외에, 상기 게놈의 비-코딩 영역이고, DNA 또는 RNA 합성 및 프로세싱에 대한 인지 신호를 제공하는데 필요한 본래 렌티바이러스 게놈(미니-바이러스 게놈)의 서열을 함유한다. 상기 서열은 팩킹, 역전사 및 전사에, 게다가 본 발명의 특정 목적에 수적인 시스-작용 서열이고, 이들은 세포 내 핵 유입을 선호하는 따라서 상기 세포 내 이식유전자 이동 효율을 선호하는 기능적인 서열을 함유하고, 상기 요소는 DNA 플랩(flap) 요소로 기재되고, 렌티바이러스 게놈 서열 또는 이스트의 것과 같은 일부 레트로요소(retroelement)에 존재하는 소위 중앙 cPPT-CTS 뉴클레오티드 도메인을 함유하거나 이것으로 이루어진다.
본 발명의 렌티바이러스 벡터를 제조하는데 사용되는 벡터 게놈의 구조 및 조성은 당업계에 기재된 원리 및 (Zennou et al, 2000; Firat H. et al, 2002; VandenDriessche T. et al)에 이전에 기재된 그러한 렌티바이러스 벡터의 예에 기반한다. 상기 유형의 구축물은 본원에 언급될 것인 CNCM(Institut Pasteur, France)에 기탁된다. 이와 관련하여 또한 기탁된 생물학적 물질을 포함하여 문헌에, 특허 출원 WO 99/55892, WO 01/27300 및 WO 01/27304를 참조로 한다.
본 발명의 특정 구현예에 따르면, 벡터 게놈은 2개의 긴 말단 반복(LTR) 사이의 바이러스 단백질 코딩 서열 모두는 말라리아 기생충의 폴리펩티드를 코딩하는 재조합 폴리뉴클레오티드에 의해 대체되고, DNA-플랩 요소는 본원에 기재된 필요한 시스-작용 서열과 조합으로 재-삽입된 대체 벡터일 수 있다. 벡터 게놈의 조성물과 관련된 추가의 특징은 입자의 제조와 관련되어 기재된다.
본 발명의 렌티바이러스 벡터 입자는 그의 게놈 내에 본원에 기재된 전-적혈구 단계 항원의 에피토프(들)을 갖는 하나 이상의 폴리펩티드를 코딩하는 하나 초과의 재조합 폴리뉴클레오티드를 포함할 수 있다. 특히, 상기 벡터 게놈은 게놈 상에서 연속 또는 분리되어 있고, 플라스모듐 기생충의 전-적혈구 단계의 동일한 또는 구별되는 항원의 상이한 폴리펩티드 또는 말라리아 기생충의 상이한 형태의 구별되는 항원, 특히 전-적혈구 단계의 항원 및 기생충의 적혈구 단계의 항원의 상이한 폴리펩티드를 코딩하는 2개의 폴리뉴클레오티드를 포함한다.
특정 구현예에서, 벡터 게놈은 2개의 재조합 폴리뉴클레오티드를 함유하고, 이들 각각은 구별되는 폴리펩티드를 코딩하고 각각의 폴리펩티드는 동일한 단계의 상이한 항원으로부터 기원한다.
"항원의 에피토프(들)를 갖는 폴리펩티드"라는 표현에 의해, 본 발명에 따르면 플라스모듐 기생충의 고유의 항원, 이의 돌연변이된 버전 및 특히 이러한 고유의 항원의 절편 및 특히 이러한 고유의 항원의 절단된 버전일 수 있는 폴리펩티드를 의도한다. 폴리펩티드는 하나 또는 여러 개의 에피토프(들)을 제공하는데 충분한 아미노산 서열을 갖고, 따라서 형태적 B 에피토프에 대해 적어도 약 4개의 아미노산 잔기, 특히 약 4 내지 약 8개의 아미노산 잔기 또는 순차적 T 에피토프에 대해 적어도 약 9개의 아미노산 잔기, 특히 약 9 내지 약 19개의 아미노산 잔기의 길이를 가질 수 있다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터 입자의 재조합 폴리뉴클레오티드는 말라리아 기생충의 항원의 절단된 버전, 특히 상기 도메인은 유용하지 않고 숙주 내 면역 반응의 도출에 유해한 경우 전장(즉, 고유의) 항원의 기능적 도메인의 결실로부터 산출되는 절편을 코딩한다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터 입자는 그의 게놈 내에 플라스모듐 기생충, 특히 플라스모듐 팔시파룸(Plasmodium falciparum) 또는 플라스모듐 말라리아에(Plasmodium malariae), 플라스모듐 비박스(Plasmodium vivax), 플라스모듐 오발레(Plasmodium ovale) 또는 플라스모듐 놀레시(Plasmodium knowlesi)의 환상포자소체 단백질로부터의 항원의 폴리펩티드(들)을 코딩하는 하나 이상의 재조합 폴리뉴클레오티드를 포함한다. 이것은 특히 CSP의 절단된 버전, 특히 CSP의 GPI 정박 모티브가 없는 폴리펩티드이다.
본 발명의 구현예에서, 렌티바이러스 벡터 입자는 그의 게놈 내에 포자소체 표면 단백질 2(TRAP/SSP2), 간-단계 항원(LSA 특히 LSA3), Pf 배출 단백질 1(Pf Exp1)/Py 간세포 적혈구 단백질(PyHEP17), 및 Pf 항원 2(Pf는 플라스모듐 팔시파룸(Plasmodium falciparum)을 나타내고, Py는 플라스모듐 욜레이이(Plamsodium yoelii)를 나타냄), 포자소체 및 간 단계 항원(SALSA), 포자소체 트레오닌 및 아스파라긴-풍부(STARP) 또는 가능하게는 CSP의 항원의 폴리펩티드 외에 다른 전-적혈구 항원의 군으로부터 선택되는 항원의 폴리펩티드(들)를 코딩하는 재조합 폴리뉴클레오티드를 포함한다.
본 발명의 특정 구현예에서, 말라리아 기생충의 항원의 폴리펩티드는 CSP 단백질의 절편이고 전-적혈구 단계로부터의 항원 또는 적혈구 단계의 항원인 말라리아 기생충의 또다른 항원의 폴리펩티드와 벡터 게놈에 의해 공동발현된다. 본 발명에 따른 폴리펩티드를 코딩하는 폴리뉴클레오티드를 디자인하기 위해 사용될 수 있는 적혈구 단계의 항원은 분열소체 표면 단백질 1(MSP2), 특히 분열소체 표면 단백질 1(Msp-1), 분열소체 표면 단백질 2(Msp-2) 분열소체 표면 단백질 3(MSP-3), 분열소체 표면 단백질 4(MSP-4), 분열소체 표면 단백질 6(MSP-6), 고리-감염된 적혈구 표면 항원(RESA), 곤봉체 연관 단백질 1(RAP-1), 첨단막 항원 1(AMA-1), 적혈구 결합 항원(EBA-175), 적혈구 막-연관 거대 단백질 또는 항원 332(Ag332), dnaK-유형 분자 샤페론, 글루타메이트-풍부 단백질(GLURP), 특히 MSP3-GLURP 융합 단백질(WO 2004/043488; ref 28), 적혈구 막 단백질 1(EMP-1), 세린 반복 항원(SERA), 군집된-아스파라긴-풍부 단백질(CARP), 환형포자소체 단백질-관련 항원 전구체(CRA), 세포부착-연결 무성 단백질(CLAG), 산성 염기성 반복 항원(ABRA) 또는 101 kDa 말라리아 항원, 곤봉체 항원 단백질(RAP-2), Knob-연관 히스티딘-풍부 단백질(KHRP), 곤봉체 항원 단백질(RAP), 시스테인 프로테아제, 가상 단백질 PFE1325w, 보호성 항원(MAg-1), 프룩토오스-비스포스페이트 알돌라아제, 리보솜 인단백질 P0, P-유형 ATPase, 글루코오스-조절 단백질(GRP78), 아스파라긴 및 아스파테이트-풍부 단백질(AARP1), 산재 반복 항원 또는 PFE0070w이다.
본 발명에 따른 폴리펩티드를 코딩하는 폴리뉴클레오티드를 디자인하는데 사용될 수 있는 성적(sexual) 단계의 항원은 성적 단계 및 포자소체 표면 항원, 항원 Pfg27/25, 항원 QF122, 11-1 폴리펩티드, 생식모세포-특이적 표면 단백질(Pfs230) 오오키니트 표면 단백질(P25), 키티나아제, 멀티약물 내성 단백질(MRP)이다.
상기 항원은 P. 팔시파룸(P. falciparum)을 참조로 하여 기재되고 다른 팔시파룸 종에서 대응부를 가질 수 있다. 이들은 Vaughan K. et al에 보고된다(18).
Vaughan K et al에는 특히 본 발명의 벡터에 사용되는 재조합 폴리뉴클레오티드(들)을 제조하기 위한 근거로서 당업자에 의해 사용될 수 있는 상기 항원의 에피토프가 기재된다.
플라스모듐 기생충의 상기 언급된 항원은 데이터 베이스에서 이용가능한 이들의 서열을 통한 것을 비롯하여 당업계에 기재되어 있다.
환상포자소체 단백질(CSP)은 본 발명의 렌티바이러스 벡터 입자의 제조를 위한 바람직한 항원 중 하나이다. 이것은 보호 항체의 표적으로 과거에 인지된 포자소체 코팅 단백질로 구성된다. 항-CS 항체를 도출하는 능력 외에, 상기 항원은 추가로 특히 CD8+ T-세포 에피토프 및 CD4+ T-세포 에피토프를 비롯한 T-에피토프를 함유한다. 특정 CSP 항원은 상기 서열의 합의를 위해 SEQ ID No 20, 23, 26, 27, 28, 29, 30, 31, 또는 SEQ ID No 32로서 이들의 아미노산 서열을 통해 기재된다. P. 비박스(P. vivax)는 GenBank에서 AY674050.1로서 제시된다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터 입자는 그의 게놈 내에 적어도 예에 예증된 플라스모듐 요엘리이(Plasmodium yoelii)의 또는 유리하게는 플라스모듐 팔시파룸(Plasmodium falciparum)의 CSP-항원의 폴리펩티드를 코딩하는 재조합 폴리뉴클레오티드를 가지며, 예를 들어, 플라스모듐 요엘리이(Plasmodium yoelii) 중의 GPI-정박 모티브가 없는 상기 CSP-항원의 절편에 상응하는 폴리펩티드는 서열 SEQ ID No 21을 갖는 CSP DGPI이다. 상기 GPI 모티프는 플라스모듐 요엘리이(Plasmodium yoelii)의 CSP 항원의 고유의 아미노산 서열 중의 C-말단 부분 내 최종 12개의 아미노산 잔기에 상응한다. P. 팔시파룸(P. falciparum) 중의 CSP 단백질의 상기 절편의 대응부는 도면 및 서열목록(고유의 단백질의 경우 SEQ ID No 23, GPI 모티프가 없는 서열의 경우 SEQ ID No 24, N-말단에서 절단된 서열의 경우 SEQ ID No 25)에 기재되어 있고 보호성 면역 반응 및 심지어 말라리아에 대항하는 살균 보호를 도출하는 폴리펩티드의 능력의 적합한 쥣과 모델에서의 증거를 제시하는데 사용된다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터 입자의 폴리뉴클레오티드(들)은 포유류 코돈 최적화된(CO) 뉴클레오티드 서열을 갖고, 임의로 상기 입자의 게놈의 렌티바이러스 서열은 포유류 코돈 최적화된 뉴클레오티드 서열을 갖는다.
코돈 최적화된 뉴클레오티드 서열은, 특히 포유류, 특히 인간 세포에서 발현을 위해 최적화된 경우에는, 이러한 포유류 또는 인간 세포에서 입자의 높은 수율의 제조를 가능하게 한다는 것이 관찰되었다. 제조 세포는 실시예에 예시된다. 따라서, 본 발명의 렌티바이러스 벡터 입자가 포유류, 특히 인간 숙주에 투여되는 경우, 많은 양의 입자가 강한 면역 반응의 도출을 선호하는 상기 숙주에서 제조된다.
본 발명의 특정 구현예에서, 본원에 기재된 렌티바이러스 벡터 입자는 추가로 그의 게놈 내에, 상기 기재된 기생충의 사이클의 혈액 단계의 항원 및/또는 성적 단계의 항원의 폴리펩티드를 코딩하는 재조합 폴리뉴클레오티드를 함유한다.
폴리펩티드는 고유의 항원 또는 이의 개질된 버전, 특히 T-세포 에피토프(들) 또는 B-세포 에피토프(들) 또는 모두에서 포함하는 또는 이루어지는 절편이다.
본 발명의 렌티바이러스 벡터 입자의 투여 결과로서 표현되는 폴리펩티드의 예는 본원에 이후 기재된 벡터 플라스미드(또는 서열 벡터)에 의해 코딩되는 폴리펩티드이다.
본 발명은 또한 특히 2010년 4월 20일에 CNCM(Paris, France)에 기탁되고 하기 특징 및 접근 번호를 갖는 상기 벡터 플라스미드에 관한 것이다:

상기 플라스미드는 본 출원의 도면 및 서열에 기재된다. 이들이 함유하는 이식유전자의 서열은 P. 요엘리이(P. yoelii)로부터 유래된다. 상기 이식유전자는 유리하게는 P. 팔시파룸(P. falciparum)로부터의 적합한 서열에 의해 대체될 수 있다.
본 발명은 또한 상기 플라스미드의 변이체에 관한 것이고, 플라스모듐 항원의 폴리뉴클레오티드를 코딩하는 폴리뉴클레오티드는 이의 기능적 면역원성 변이체를 코딩하도록 개질되거나 또다른 플라스모듐 균주 특히 플라스모듐 팔시파룸(Plasmodium falciparum)로부터 최적화된 상응하는 폴리뉴클레오티드 코돈으로 대체되거나 본원에 언급된 프로모터 중 하나에 의해 CMV 프로모터를 대체하도록 개질된다.
기탁된 플라스미드에서 플라스모듐 요엘리이(Plasmodium yoelii) 항원의 폴리펩티드를 코딩하는 폴리뉴클레오티드는 코돈 최적화된다.
본 발명에 따르면, 렌티바이러스 벡터 입자는 렌티바이러스 입자의 게놈의 렌티바이러스 서열을 제공하는 렌티바이러스가 아닌 RNA 바이러스로부터 기원하는 이종 바이러스 외피 단백질 또는 외피의 바이러스 다단백질로 위형화된다.
렌티바이러스 벡터 입자의 제조를 위한 외피 단백질의 형태화 예로서, 본 발명은 수포성 구내염 바이러스(VSV)의 바이러스 막통과 글리코실화(소위 G 단백질) 외피 단백질(들)에 관한 것이고, 이들은 예를 들어 인디아나 균주의 VSV-G 단백질(들), 뉴저지 균주의 VSV-G 단백질(들), 코칼 균주의 VSV-G 단백질(들), 이스파한 균주의 VSV-G 단백질, 찬디푸라 균주의 VSV-G 단백질(들), 피리 균주의 VSV-G 단백질(들) 또는 SVCV 균주의 VSV-G 단백질(들)의 군에서 선택된다.
수포성 구내염 바이러스 (VSV-G)의 외피 당단백질은 야생형 바이러스 입자의 표면 코팅으로서 기능하는 막통과 단백질이다. 이것은 또한 조작된 렌티바이러스 벡터에 대한 적합한 코팅 단백질이다. 지금까지, 9개의 바이러스 종이 VSV 성별로 명확하게 분류되고, 19개의 라브도바이러스가 상기 성별로 잠정적으로 분류되고, 모두 다양한 정도의 교차-중화를 나타낸다. 서열분석하면, 단백질 G 유전자는 서열 유사성을 나타낸다. VSV-G 단백질은 N-말단 엑토도메인, 막통과 영역 및 C-말단 세포질 꼬리를 나타낸다. 이것은 트랜스골지 네트워크(소포체 및 골지체)를 통해 세포 표면에 노출된다.
수포성 구내염 인디아나 바이러스(VSIV) 및 수포성 구내염 뉴저지 바이러스(VSNJV)는 본 발명의 렌티바이러스 벡터를 위형화하는데, 또는 렌티바이러스 벡터를 위형화하기 위해 재조합 외피 단백질(들)을 디자인하는데 바람직하다. 이들의 VSV-G 단백질은 여러 균주가 제시되어 있는 GenBank에 기재되어 있다. VSV-G 뉴저지 균주에 대해 특히 접근 번호 V01214를 갖는 서열을 참조한다. 인디아나 균주의 VSV-G의 경우, 균주 JO2428에 상응하는 Genbank에서 접근 번호 AAA48370.1을 갖는 서열을 참조한다.
대안적으로는, VSV 중에서, 찬디푸라 바이러스(Chandipura virus: CHPV), 코칼 바이러스(Cocal virus: COCV), 페리네트 바이러스(Perinet virus: PERV), 피리 바이러스(Piry virus: PIRYV), SVCV 또는 이스파한(Isfahan) 바이러스가 위형화 외피 단백질을 디자인하는데, 특히 면역화의 증강 단계에 사용되는 입자를 제조하는데 양호한 후보일 수 있고, 따라서 본 발명의 벡터 입자가 초기감작-증강 투여 섭생에 사용되는 경우 제 2 외피 단백질(들) 또는 제 3 외피 단백질(들), 또는 추가의 외피 단백질(들)을 제공한다. 따라서 사용되는 경우, 코칼 바이러스 외피 단백질(들)은 초기감작-증강 섭생에서 후기 또는 최종 투여에 대해 바람직할 것이다. 그러나, 찬디푸라 바이러스(CHPV) 및 피리 바이러스(PIRYV)는 상이한 외피로 제조된 입자로 수득된 벡터 적정농도와 비교할 때, 상기 수용체에 대한 낮은 친화성의 결과로서 낮은 융합원성(fusogenicity)을 갖는 외피 단백질을 제공할 수 있다. 그러므로 첫번째 접근법에서, 상기 외피는 효율적인 형질도입 능력을 가진 입자를 제조하기 위해 외피의 선택으로부터 배재될 수 있다.
본원에 언급된 VSV-G 단백질의 아미노산 서열 및 코딩 서열은 특허 출원 WO 2009/019612에 기재된다. 상기 아미노산 서열의 특정 예는 또한 SEQ ID No 77, 79, 82, 84, 86, 88, 90으로서 본 출원에 제공된다. VSV-G 코딩 서열을 함유하는 플라스미드는 참조로서 인용된 상기 출원 WO 2009/019612에 기재된다. 플라스미드는 CNCM(Paris, France)에 기탁되었다. 상기 외피 단백질을 코딩하는 뉴클레오티드 서열은 본 출원에 SEQ ID No 76, 78, 81, 83, 85, 87, 89로서 기재된다.
본 발명의 특정 구현예에서, 상기 제 1 및 제 2 및 임의의 상기 제 3 및 추가의 바이러스 외피 단백질(들)은 항원 제시 세포에 의해, 특히 융합 및/또는 세포내섭취에 의해 간 수지상 세포에 의한 것을 포함하여 수지상 세포에 의해 섭취될 수 있다. 특정 구현예에서, 섭취 효능은 위형화를 위해 VSV의 외피를 선택하는 특징으로서 사용될 수 있다. 이와 관련하여 형질도입의 상대적 적정농도(다른 형질도입된 세포 예를 들어, 293T 세포의 적정농도 DS/적정농도)는 시험으로서 고려될 수 있고, DC와 융합되는 비교적 양호한 능력을 갖는 외피가 바람직할 것이다. 형질도입의 상대적 적정농도는 실시예에 예증된다.
항원 제시 세포(APC) 및 특히 수지상 세포(DC)는 면역 조성물로서 따라서 사용되는 위형화된 렌티바이러스 벡터에 대한 적합한 표적 세포이다.
VSV 외피 단백질(들)(VSV-G)을 코딩하는 폴리뉴클레오티드는 또한 비장세포, 특히 항원 제시 세포(APC) 또는 수지상 세포(DC), 또는 간 수지상 세포를 포함하는 간 세포, 간세포 또는 비 실질 세포에 표적한다.
종종 표면 단백질로서 디자인되는 외피 단백질(들) 특히 바이러스는 상이한 유기체로부터, 특히 상이한 RNA 바이러스 균주로부터 "기원"하는 것으로 언급되고, 상기 단백질(들)에서, 결정된 RNA 바이러스에서 발현된 상응하는 단백질(들)의 본질적인 특징이 유지된다는 것을 의미한다. 상기 필수적인 특징은, 단백질의 구조 또는 기능에 관한 것이고, 특히 수득된 단백질(들)이 상기 벡터를 위형화하기 위한 벡터 입자의 표면에서 발현되도록 할 수 있는 것이다. 외피 단백질은 이후 벡터 입자 상에 제시되었을 때 숙주의 표적 세포를 인지하고 내재화할 수 있다.
특정 구현예에서, 화합물의 키트의 위형화된 렌티바이러스 벡터의 디자인에서 사용하는데 적합한 단백질(들) 또는 당단백질(들)은 다량체성 단백질, 예컨대 삼량체인 VSV-G 단백질로서 사용된다.
외피 단백질(들)은 상기 단백질(들)에 대한 코딩 서열을 함유하는 폴리뉴클레오티드로부터 발현되고, 상기 폴리뉴클레오티드는 본 발명의 렌티바이러스 벡터 입자의 제조에 사용되는 플라스미드(디자인된 외피 발현 플라스미드 또는 위형화 env 플라스미드)에 삽입된다. 외피 단백질(들)을 코딩하는 폴리뉴클레오티드는 코딩 서열(임의로 전사-후 조절 요소 (PRE) 특히 Woodchuck 간염 바이러스의 요소와 같은 폴리뉴클레오티드, 즉, Invitrogen에서 입수가능한 WPRE 서열을 포함)의 전사 및/또는 발현을 위한 조절 서열의 조절 하에 있다.
따라서, 핵산 구축물은 인 비보 포유류 세포, 특히 인간 세포에서 사용하는데 적합한 내부 프로모터 및 상기 프로모터의 조절 하에서 외피 단백질을 코딩하는 핵산을 포함하여 제공된다. 상기 구축물을 함유하는 플라스미드는 트랜스펙션 또는 입자의 제조에 적합한 세포의 형질도입에 사용된다. 프로모터는 특히 구성적 프로모터, 조직-특이적 프로모터, 또는 유도성 프로모터로서 이들의 특성에 대해 선택될 수 있다. 적합한 프로모터의 예는 하기 유전자: EF1α, 인간 PGK, PPI(프리프로인슐린), 티오덱스트린, HLA DR 불변 사슬(P33), HLA DR 알파 사슬, 페리틴 L 사슬 또는 페리틴 H 사슬, 키모신 베타 4, 키모신 베타 10, 시스타틴 리보솜 단백질 L41, CMVie 또는 키메라성 프로모터, 예컨대 Jones S. et al(19)에 기재된 GAG(CMV 초기 인핸서/닭 β 액틴)의 프로모터를 포함한다.
상기 프로모터는 또한 캡시드화 플라스미드로부터의 gag - pol 유래 단백질의 발현에 관여하는 조절 발현 서열에 사용될 수 있다.
대안적으로는, 외피 발현 플라스미드가 안정한 팩킹 세포주에서의 발현, 특히 지속적으로 발현되는 바이러스 입자로서 안정한 발현에 의도되는 경우, 외피 단백질(들)을 발현하기 위한 내부 프로모터는 유리하게는 Cockrell A.S. et al. (20)에 기재된 것과 같은 유도성 프로모터이다. 이러한 프로모터의 예로서, 테트라사이클린 및 에크디손 유도성 프로모터를 참조한다. 팩킹 세포주는 STAR 팩킹 세포주 (ref 20, 21) 또는 SODk 팩킹 세포주, 예컨대 SODk1 및 SODk3을 포함하는 SODkO 유도 세포주(ref 20, 22, 23, 24)일 수 있다.
렌티바이러스 벡터 입자의 위형화에 필요한 외피 단백질(들)의 발현에 사용되는 뉴클레오티드 서열은 대안적으로 개질되어, 참조로서 사용되는 고유의 외피 단백질(들)을 코딩하는 핵산과 관련한 변이체를 제공할 수 있다. 개질은 벡터 입자의 제조를 위한 세포에서 및/또는 숙주의 형질도입된 세포에서 코돈 사용(코돈 최적화)를 개선하기 위해 실시될 수 있다. 이것은 고유의 단백질(들)과 상이한 단백질을 발현하도록 개질될 수 있고, 특히 이 중 하나는 화합물의 키트에 사용되는 다른 외피 단백질(들)과의 개선된 위형화 능력, 제조 수준에서 개선된 능력, 또는 혈청-중화의 방지와 관련하여 개선된 능력(또한 교차-반응성 단백질로서 지정됨)을 갖는다.
외피 단백질(들)을 코딩하는 폴리뉴클레오티드의 이러한 개질 또는 외피 단백질(들)의 개질(고유의 외피의 변이체를 생성하기 위한)이 세포 숙주에서 제조 의수준 또는 가능하게는 슈도비리온과 연관된 외피 단백질(들)의 밀도를 개선하기 위한 벡터 입자를 위형화하는 능력에 영향을 줄 수 있고, 특히 개선시킨다. 상기 개질은 상기 단백질(들)의 아미노산 서열에서, 예를 들어 1개 또는 여러 개의 뉴클레오티드 또는 뉴클레오티드 절편의 부가, 결실 또는 치환에 의해 돌연변이로부터 유래될 수 있거나, 번역후 개질 및 특히 상기 외피 단백질(들)의 글리코실화 상태와 관련될 수 있다.
본 발명의 렌티바이러스 벡터의 위형화에 사용되는 외피 단백질(들)은 게다가 특히 당단백질이다.
수포성 구내염 바이러스 당단백질(VSV-G)로의 바이러스 벡터의 위형화가 상이한 종으로부터의 넓은 범위의 세포 유형의 형질도입을 가능하게 한다는 것이 이미 제시되었다. 상기 VSV-G 당단백질은, 이의 넓은 향성 외에, 벡터 위형화에 사용되는 경우 흥미로운 안정성을 갖는다. 그러므로, VSV-G는 다른 위형의 효율을 평가하기 위한 표준으로서 사용된다(Cronin J. et al, 2005).
본 발명에 따르면, 렌티바이러스 벡터 입자는 포유류 세포의 하기와의 공동-트랜스펙션으로부터 회수된 생성물이다:
- (i) 렌티바이러스, 특히 HIV-1, 팩킹, 역전사, 및 전사에 필요한 시스-작용 서열을 포함하고, 특히 HIV-1로부터 유래된 기능적 렌티바이러스, DNA 플랩 요소를 추가로 포함하는 벡터 플라스미드, 및 (ii) 조절 발현 서열의 조절 하에 본원에 기재된 말라리아 기생충의 항원의 폴리펩티드를 코딩하고, 임의로 통합을 위한 서열을 포함하는 폴리뉴클레오티드;
- RNA 바이러스로부터 유래된 위형화 외피를 코딩하는 발현 플라스미드, 상기 발현 플라스미드는 외피 단백질 또는 위형화를 위한 단백질을 코딩하는 폴리뉴클레오티드를 포함하며, 상기 외피 위형화 단백질은 유리하게는 VSV로부터 유래되고, 특히 VSV-G 또는 이의 변이체임, 및
- 캡시드화 플라스미드, 이것은 렌티바이러스, 특히 HIV-1, 통합-유능 벡터 입자의 생성에 적합한 gag - pol 팩킹 서열 또는 통합-결핍 벡터 입자의 생성에 적합한 개질된 gag - pol 팩킹 서열을 포함함.
그러므로 본 발명은 또한 하기를 갖는 안정한 세포주로부터 회수된 생성물인, 상기 기재된 렌티바이러스 벡터 입자에 관한 것이다:
- (i) 렌티바이러스, 특히 HIV-1, 팩킹, 역전사, 및 전사에 필요한 시스-작용 서열을 포함하고 기능적 렌티바이러스, 특히 HIV-1, DNA 플랩 요소를 추가로 포함하고 임의로 통합에 필요한 시스-작용 서열을 포함하는 벡터 플라스미드, 상기 벡터 플라스미드는 (ii) 절단된 포유류, 특히 인간의 폴리뉴클레오티드, 플라스모듐 기생충의 cs 유전자의 코돈-최적화 서열을 조절 발현 서열, 특히 프로모터의 조절 하에 추가로 포함함;
- VSV-G 외피 단백질 또는 외피 단백질들을 코딩하는 폴리뉴클레오티드를 포함하는 VSV-G 외피 발현 플라스미드, 상기 폴리뉴클레오티드는 조절 발현 서열, 특히 유도성 프로모터를 포함하는 조절 발현 서열의 조절 하에 있음; 및
- 캡시드화 플라스미드, 캡시드화 플라스미드는 렌티바이러스, 특히 HIV-1, 통합-유능 벡터 입자의 생성에 적합한 gag - pol 코딩 서열 또는 통합-결핍 벡터 입자의 생성에 적합한 개질된 gag - pol 코딩 서열을 포함하며, 상기 gag - pol 서열은 DNA 플랩 요소와 동일한 렌티바이러스 서브-계열 유래이고, 상기 렌티바이러스 gag - pol 또는 개질된 gag - pol 서열은 조절 발현 서열의 조절 하에 있음.
본 발명의 벡터 입자를 발현하는 안정한 세포주는 특히 플라스미드의 형질도입에 의해 수득된다.
폴리뉴클레오티드는 본 출원에 기재된 임의의 구현예에 따른 말라리아 항원의 하나 이상의 폴리펩티드를 코딩한다. 특히, 이것은 플라스모듐 기생충, 특히 플라스모듐 팔시파룸(Plasmodium falciparum)의 cs 유전자의 절단된 포유류, 특히 인간, 코돈-최적화 서열인 폴리펩티드를 코딩한다.
특정 구현예에서, 폴리뉴클레오티드는 말라리아 기생충의 구별되는 항원의 또다른 폴리펩티드를 코딩하거나, 또는 이것은 다양한 구현예에 기재된 바와 같은 상기 기생충의 구별되는 항원으로부터 기원하는 및/또는 유래되는 2개 이상의 폴리펩티드를 코딩한다. 따라서, 벡터 플라스미드는 다양한 폴리펩티드의 발현을 위한 여러 발현 카세트를 포함할 수 있거나, 다양한 폴리펩티드를 코딩하는 폴리뉴클레오티드가 바이러스 기원의 IRES 서열(Internal Ribosome Entry Site)에 의해 분리되는 이중시스트론성 또는 다중시스티론성 발현 카세트를 포함할 수 있거나, 또는 이것은 융합 단백질(들)을 코딩할 수 있다.
벡터 게놈에 함유되고 말라리아 기생충의 항원의 폴리펩티드를 코딩하는폴리뉴클레오티드의 발현을 조절하는 내부 프로모터(이식유전자로서 또는 발현 카세트 내)는 하기 유전자: EF1α, 인간 PGK, PPI(프리프로인슐린), 티오덱스트린, HLA DR 불변 사슬(P33), HLA DR 알파 사슬, 페리틴 L 사슬 또는 페리틴 H 사슬, 키모신 베타 4, 키모신 베타 10, 또는 시스타틴 리보솜 단백질 L41 CMVie 또는 키메라성 프로모터, 예컨대 Jones S. et al (19)에 기재된 GAG(CMV 초기 인핸서/닭 β 액틴)의 프로모터로부터 선택될 수 있다.
상기 언급된 내부 프로모터 중의 프로모터는 또한 외피 단백질(들) 및 팩킹 (gag-pol 유래된) 단백질의 발현을 위해 선택될 수 있다.
대안적으로는, 벡터 입자는 본원에 기재된 플라스미드의 공동-트랜스펙션으로부터 제조될 수 있고, 그러므로 안정한 팩킹 세포주에서 벡터 입자를 지속적으로 분비할 수 있게 된다. 외피 단백질(들)의 발현에 관여하는 조절 발현 서열에서 사용되는 프로모터는 유리하게는 유도성 프로모터이다.
하기 특정 구현예는 인간 렌티바이러스 기반의, 특히 HIV 바이러스 기반의 렌티바이러스 벡터 입자를 제조할 때 수행될 수 있다.
본 발명에 따르면, 렌티바이러스 벡터 입자의 게놈은 인간 렌티바이러스, 특히 HIV 렌티바이러스로부터 유래된다. 특히, 위형화된 렌티바이러스 벡터는 HIV-기반 벡터, 예컨대 HIV-1, 또는 HIV-2 기반 벡터이고, 특히 HIV-1 M, 예를 들어 BRU 또는 LAI 단리물로부터 유래된다. 대안적으로는, 벡터 게놈에 대해 필요한 서열을 제공하는 렌티바이러스 벡터는 인간 세포를 트랜스펙션할 수 있는 EIAV, CAEV, VISNA, FIV, BIV, SIV, HIV-2, HIV-O와 같은 렌티바이러스로부터 기원할 수 있다.
상기 언급된 바와 같이, 최종적으로 함유하는 재조합 폴리뉴클레오티드와 별개로 고려하는 경우, 벡터 게놈은 숙주에서 세포의 핵에 이식유전자의 효과적인 전달을 위해 포함하는 본래 렌티바이러스 게놈에서 2개의 긴 말단 반복(LTR) 사이의 핵산이 DNA 또는 RNA 합성 및 프로세싱을 위한 시스-작용 서열에 제한되어 있는, 또는 생물학적 기능 GAG 다단백질 및 가능하게는 POL 및 ENV 단백질을 포함하는 렌티바이러스 구조 단백질의 발현을 가능하게 할 필수적 핵산 분절에 대해 적어도 결실되거나 돌연변이된 대체 벡터이다.
특정 구현예에서, 벡터 게놈은 생물학적 기능 GAG의 발현, 유리하게는 생물학적으로 기능하는 POL 및 ENV 단백질에 결함이 있다. 따라서, 벡터 게놈에는 상기 단백질을 코딩하는 서열이 없다.
특정 구현예에서, 렌티바이러스의 5'LTR 및 3'LTR 서열은 벡터 게놈에서 사용되나, 3'-LTR은 적어도 예를 들어 인핸서에 대해 결실되거나 또는 부분적으로 결실될 수 있는 적어도 U3 영역 내의 본래 렌티바이러스의 3'LTR에 대해 개질된다. 5'LTR은 또한, 특히 예를 들어 Tat-독립적 프로모터가 U3 내인성 프로모터에 대해 치환될 수 있는 그의 프로모터 영역에서 개질될 수 있다.
특정 구현예에서, 벡터 게놈은 Vif-, Vpr, Vpu- 및 Nef-부속 유전자 (HIV-1 렌티바이러스 벡터의 경우)에 대한 1개 또는 여러 개의 코딩 서열을 포함한다. 대안적으로는, 상기 서열은 서로 독립적으로 결실될 수 있거나 비-작용성일 수 있다.
렌티바이러스 벡터 입자의 벡터 게놈은 삽입된 시스-작용 절편으로서, DNA 플랩 요소로 이루어지는 또는 이러한 DNA 플랩 요소를 함유하는 하나 이상의 폴리뉴클레오티드를 포함한다. 특정 구현예에서, DNA 플랩은 말라리아 항원의 폴리펩티드를 코딩하는 폴리뉴클레오티드의 업스트림에 삽입되고, 유리하게는(비록 필수적이지는 않으나) 벡터 게놈 내 대략 중간 위치에 위치한다. 본 발명에 적합한 DNA 플랩은 레트로바이러스, 특히 렌티바이러스, 특히 인간 렌티바이러스 특히 HIV-1 레트로바이러스, 또는 레트로트랜스포존과 같은 레트로바이러스-유사 유기체로부터 수득될 수 있다. 이것은 대안적으로는 CAEV(Caprine Arthritis Encephalitis Virus) 바이러스, EIAV(Equine Infectious Anaemia Virus) 바이러스, VISNA 바이러스, SIV(Simian Immunodeficiency Virus) 바이러스 또는 FIV(Feline Immunodeficiency Virus) 바이러스로부터 수득될 수 있다. DNA 플랩은 합성적으로(화학적 합성) 또는 폴리머라아제 연쇄 반응(PCR)에 의한 것과 같이 상기 정의된 적합한 공급원으로부터 DNA 플랩을 제공하는 DNA의 증폭에 의해 제조될 수 있다. 더욱 바람직한 구현예에서, DNA 플랩은 상기 2개 유형의 임의의 단리물을 포함하는 HIV 레트로바이러스, 예를 들어 HIV-1 또는 HIV-2 바이러스로부터 수득된다.
DNA 플랩(Zennou V. et al. ref 27, 2000, Cell vol 101, 173-185 또는 WO 99/55892 및 WO 01/27304에 정의됨)은 일부 렌티바이러스의 게놈 내, 특히 HIV 내 중심에 있는 구조이고, 특히 HIV 역전사 동안 통상 합성되는 3가닥 DNA 구조를 산출하고, 이것은 HIV 게놈 핵 유입의 시스-결정소로서 작용한다. DNA 플랩은 역전사 동안 중심 폴리퓨린 트랙(cPPT) 및 중심 종결 서열(CTS)에 의해 시스로 조절된 중심 가닥 대치 사건을 가능하게 한다. 렌티바이러스-유도 벡터에 삽입되는 경우, 역-전사 동안 DNA 플랩이 생성되게 하는 폴리뉴클레오티드는 유전자 전달 효율을 자극하고, 핵 유입의 수준을 야생형 수준까지 보완한다(Zennou et al., Cell, 2000).
DNA 플랩의 서열은 종래 기술, 특히 상기 언급된 특허 출원에 기재되어 있다. 상기 서열은 또한 SEQ ID NO 69 내지 SEQ ID NO 75에 기재되어 있다. 이들은 바람직하게는, 임의로 벡터 게놈 내에, 바람직하게는 상기 벡터 게놈의 중심 근처의 위치에 부가적인 측면 서열을 갖는 절편으로서 삽입된다. 대안적으로 이들은 본 발명의 폴리뉴클레오티드(들)의 발현을 조절하는 프로모터로부터 바로 업스트림에 삽입될 수 있다. 벡터 게놈에 삽입된 DNA 플랩을 포함하는 상기 절편은 이의 기원 및 제조에 따라 약 80 내지 약 200 bp의 서열을 가질 수 있다.
특정 구현예에 따르면, DNA 플랩은 약 90 내지 약 140개의 뉴클레오티드의 뉴클레오티드 서열을 갖는다.
HIV-1에서, DNA 플랩은 안정한 99-뉴클레오티드-길이 및 가닥 중복이다. 본 발명의 렌티바이러스 벡터의 게놈 벡터에 사용되는 경우, 특히 이것이 PCR 절편으로서 제조되는 경우 이것은 긴 서열로서 삽입될 수 있다. DNA 플랩을 제공하는 구조를 포함하는 특히 적합한 폴리뉴클레오티드는 HIV-1 DNA의 cPPT 및 CTS 영역을 포함하는 178-염기 쌍 폴리머라아제 연쇄 반응(PCR) 절편이다(Zennou et al 2000).
상기 PCR 절편은 특히 뉴클레오티드 4793 내지 4971로부터의 서열에 상응하는 절편으로서, HIV-1 LAI의 감염성 DNA 클론 특히 HIV1의 pLAI3으로부터 유래될 수 있다. 적합한 경우, 제한 부위는 클로닝을 위해 수득된 절편의 하나 또는 양 말단에 부가된다. 예를 들어, Nar I 제한 부위는 PCR 반응을 수행하는데 사용되는 프라이머의 5' 말단에 부가될 수 있다.
그러므로, 본 발명에 사용되는 DNA 플랩은, 본래 렌티바이러스 게놈의 pol 유전자의 불필요한 5' 및 3' 부분으로부터 결실되고, 상이한 기원의 서열과 재조합된다.
게놈 벡터에 사용되는 DNA 플랩 및 GAG 및 POL 다단백질을 코딩하는 캡시드화 플라스미드의 폴리뉴클레오티드는 동일한 렌티바이러스 서브-계열로부터 또는 동일한 레트로바이러스-유사 유기체로부터 기원해야만 한다는 것이 명시된다.
바람직하게는, 게놈 벡터의 다른 시스-작용 서열은 또한 DNA 플랩을 제공하면, 동일한 렌티바이러스 또는 레트로바이러스-유사 유기체로부터 기원한다.
벡터 게놈은 재조합 폴리뉴클레오티드의 클로닝을 위한 하나 또는 여러 개의 독특한 제한 부위(들)을 추가로 포함할 수 있다.
바람직한 구현예에서, 상기 벡터 게놈에서, 렌티바이러스 벡터 게놈의 3' LTR 서열에는 적어도 촉진자(인핸서) 및 가능하게는 U3 영역의 프로모터가 없다. 또다른 특정 구현예에서, 3' LTR 영역에는 U3 영역 (델타 U3)이 없다. 이와 관련하여, WO 01/27300 및 WO 01/27304의 설명을 참조한다.
특정 구현예에서, 벡터 게놈에서, LTR 5'의 U3 영역은 비 렌티바이러스 U3에 의해 또는 tat-독립적 일차 전사의 유도에 적합한 프로모터에 의해 대체된다. 이러한 경우, 벡터는 tat 전사촉진자와 독립적이다.
벡터 게놈은 또한 psi(ψ) 팩킹 신호를 포함한다. 팩킹 신호는 gag ORF의 N-말단 절편으로부터 유래된다. 특정 구현예에서, 이의 서열은 gag 펩티드의 가능한 전사/번역의 임의의 간섭을 방해하기 위해 이식유전자의 것으로의 프레임시프트(frameshift) 돌연변이(들)에 의해 개질될 것이다.
벡터 게놈은 임의로 또한 스플라이싱 기여 부위(SD), 스플라이싱 수용 부위(SA) 및/또는 Rev-반응 요소(RRE) 중에서 선택되는 요소를 포함할 수 있다.
특정 구현예에 따르면, 벡터 플라스미드(또는 부가된 게놈 벡터)는 형질전환 발현 카세트에 대해 하기 시스-작용 서열을 포함한다:
1. 역전사에 필요한 LTR 서열(긴-말단 반복), 전사에 필요한 서열 및 임의로 바이러스 DNA 통합을 위한 서열을 포함함. 3' LTR은 U3 영역에서 적어도 SIN 벡터를 제공하기 위한 프로모터에 대해(자가-비활성화), 유전자 전달에 필요한 기능의 동요 없이, 첫째로, 일단 DNA가 게놈 내에 통합되면 숙주 유전자의 트랜스-활성화를 피하고, 둘째로 역전사 후 바이러스 시스-서열의 자가-비활성화를 가능하게 하는, 2가지 주요 이유로 결실된다. 임의로, 게놈의 전사를 유도하는 5'-LTR로부터의 tat-의존적 U3 서열은 비 내인성 프로모터 서열로 대체된다. 그러므로, 표적 세포에서 내부 프로모터로부터의 서열만이 전사될 것이다(이식유전자).
2. 바이러스 RNA 캡시드화에 필요한 ψ 영역.
3. Rev 단백질의 결합 후 핵에서 시토졸로 바이러스 메신저 RNA의 유출을 가능하게 하는 RRE 서열(REV 반응 요소).
4. 핵 유입을 용이하게 하는 DNA 플랩 요소(cPPT/CTS, 보통 Pol에 함유됨).
5. 또한 mRNA의 안정성을 최적화하기 위해 부가되는 WPRE 시스-작용 서열(Woodchuck B형 간염 바이러스 반응후 요소)과 같은 임의로 전사-후 요소 (Zufferey et al., 1999), 면역글로불린-카파 유전자의 영역과 같은 매트릭스 또는 스캐폴드 부착 영역(SAR 및 MAR 서열)(Park F. et al Mol Ther 2001; 4: 164-173).
본 발명의 렌티바이러스 벡터는 비 복제성(복제-무능)인, 즉, 벡터 및 렌티바이러스 벡터 게놈은 복제 유능 렌티바이러스와 관련된 우려를 경감시키는데 적합한 것으로 고려되고, 특히 투여 후 감염된 숙주 세포로부터 뻗어나는 신규한 입자를 형성할 수 없다. 이것은 gag, pol 또는 env 유전자의 렌티바이러스 게놈 내 부재, 또는 이들의 "기능적 유전자"로서의 부재의 결과로서 잘 알려진 방식으로 달성될 수 있다. gag 및 pol 유전자는 그러므로, 오직 트랜스로만 제공된다. 이것은 또한 입자 형성에 필요한 다른 바이러스 코딩 서열(들) 및/또는 시스-작용 유전적 요소를 결실시킴으로써 달성될 수 있다.
"기능적"이라는 것은 올바르게 전사된, 및/또는 올바르게 발현된 유전자를 의미하는 것이다. 그러므로, 본 발명의 렌티바이러스 벡터 게놈에 존재하는 경우 상기 구현예에서 전사되지 않은 또는 불완전하게 전사된 gag, pol 또는 env의 서열을 함유한다; 표현 "불완전하게 전사된"은 그 중 하나 또는 그 중 여러 개가 전사되지 않은 전사물 gag, gag-pro 또는 gag-pro-pol 중의 변형을 말한다. 렌티바이러스 복제에 관여된 다른 서열은 또한, 상기 상태를 달성하기 위해 벡터 게놈에서 돌연변이될 수 있다. 렌티바이러스 벡터의 복제의 부재는 렌티바이러스 게놈의 복제와 구별되어야만 한다. 게다가, 이전에 기재된 바와 같이, 렌티바이러스 게놈은 벡터 입자의 복제를 필수적으로 확보하지 않으면서 렌티바이러스 벡터 게놈의 복제를 확보하는 복제 기원을 함유할 수 있다.
본 발명에 따른 렌티바이러스 벡터를 수득하기 위해, 벡터 게놈(벡터 플라스미드와 같은)은 입자 또는 위형-입자 내에 캡시드화되어야만 한다. 따라서, 렌티바이러스 단백질은 외피 단백질 외에, gag 유전자 및 pol 렌티바이러스 유전자 또는 통합-무능 pol 유전자를 갖는, 바람직하게는 Vif -, Vpr , Vpu - 및 Nef-부속 유전자에 대한(HIV-1 렌티바이러스 벡터에 대한) 코딩 서열 일부 또는 모두가 결여된 하나 이상의 캡시드화 플라스미드에 대한 의지를 갖는, 벡터 게놈과 함께 제조 시스템, 특히 in 제조 세포 내에서 벡터 게놈에 대해 트랜스로 제공되어야만 한다.
렌티바이러스 벡터 입자의 위형화를 위해 선택된 외피 위형화 단백질(들)을 코딩하는 폴리뉴클레오티드를 갖는 추가의 플라스미드가 사용된다.
바람직한 구현예에서, 팩킹 플라스미드는 바이러스 입자 합성에 필수적인 렌티바이러스 단백질만을 코딩한다. 플라스미드 내의 존재가 안전성을 상승시킬 것인 부속 유전자가 따라서 제거된다. 따라서, 팩킹에 대해 트랜스가 되는 바이러스 단백질은 각각 HIV-1로부터 기원하는 것에 대해 설명되는 바와 같다:
1. 매트릭스(MA, 명백한 분자량 p17을 가짐), 캡시드(CA, p24) 및 뉴클레오캡시드(NC, p6)의 설립을 위한 GAG 단백질.
2. POL 코딩된 효소: 인테그라아제, 프로테아제 및 역전사효소.
3. TAT 및 REV 조절 단백질(TAT가 LTR-매개 전사의 개시에 필요한 경우); TAT 발현은 5'LTR의 U3 영역이 프로모터 유도 tat-독립적 전사를 위해 대체되는 경우, 생략될 수 있다. REV는 개질될 수 있고 따라서 예를 들어 벡터 게놈 중의 RRE 서열을 대체하는 도메인의 인지를 가능하게 할 재조합 단백질에 사용되거나, 또는 그의 RBD(RNA Binding Domain)을 통해 RRE 서열에 결합할 수 있게 하는 절편으로서 사용될 수 있다.
바이러스 입자 내의 팩킹 플라스미드에 함유되는 유전자로부터 발생되는 mRNA의 임의의 팩킹을 피하기 위해, ψ 영역은 팩킹 플라스미드로부터 제거된다. 이종 프로모터는 재조합 논의를 피하기 위해 플라스미드 내에 삽입되고, 폴리-A 꼬리가 단백질을 코딩하는 서열로부터 3'에 부가된다. 적합한 프로모터는 상기 기재되었다.
외피 플라스미드는 본원에 기재된 바와 같이 내부 프로모터의 조절 하에, 본원에 기재된 위형화를 위한 외피 단백질(들)을 코딩한다.
본 발명의 렌티바이러스 벡터 입자의 제조를 위한 임의의 또는 모든 기재된 플라스미드는 단백질 코딩 분절에서 코돈 최적화(CO)될 수 있다. 본 발명에 따른 코돈 최적화는 바람직하게는 포유류 세포, 특히 인간 세포에서 플라스미드 내에 함유된 코딩 서열의 번역을 개선하기 위해 수행된다. 본 발명에 따르면, 코돈 최적화는 특히 벡터 입자의 제조를 직접 또는 간접적으로 개선하는데 또는 투여되는 숙주의 세포에 의한 섭취를 개선하는데, 또는 숙주의 형질도입된 세포의 게놈에서 말라리아 기생충 (이식유전자)의 항원의 폴리펩티드를 코딩하는 폴리뉴클레오티드의 수송 효율을 개선하는데 적합하다. 코돈 최적화 방법은 당업계에 잘 알려져 있고, 코돈 최적화는 특히 그 효과에 대해 이용가능한 프로그램을 사용하여 수행된다. 코돈 최적화는 기재된 pTRIP 또는 실시예에 예시된 본 발명의 pThV 플라스미드에 함유된 코딩 서열에 대해 예증된다.
본 발명의 특정 구현예에서, 위형화된 렌티바이러스 벡터는 또한, 또는 대안적으로는, 통합-무능이다. 이러한 경우, 벡터 게놈 및 그러므로 이것이 함유하는 재조합 폴리뉴클레오티드 형질도입된 세포의 게놈 내에 또는 투여된 숙주의 세포에서 통합되지 않는다.
본 발명은 발현된 인테그라아제 단백질이 결함이 있고 특히 면역원성 조성물에서 플라스모듐 기생충의 전-적혈구 단계 항원의 에피토프(들)을 갖는 하나 이상의 폴리펩티드를 코딩하는 폴리뉴클레오티드를 포함하는 렌티바이러스 벡터의 용도에 관한 것이다.
"통합-무능"이라는 것은, 바람직하게는 렌티바이러스 기원의 인테그라아제가 렌티바이러스 게놈의 숙주 세포의 게놈 내로의 통합 능력이 없는, 즉, 특이적으로 그의 인테그라아제 활성을 변경하기 위해 돌연변이된 인테그라아제 단백질을 의미한다.
통합-무능 렌티바이러스 벡터는 인테그라아제를 코딩하는 pol 유전자를 개질하여, 통합 결핍 인테그라아제를 코딩하는 돌연변이된 pol 유전자를 수득하고, 상기 개질된 pol 유전자가 캡시드화 플라스미드에 함유되는 것에 의해 수득된다. 이러한 통합-무능 렌티바이러스 벡터는 특허 출원 WO 2006/010834에 기재되어 있다. 따라서, 단백질의 인테그라아제 능력은 변형되는 반면, GAG, PRO 및 POL 단백질의 캡시드화 플라스미드 및/또는 캡시드 및 그러므로 벡터 입자의 형성으로부터 올바른 발현, 뿐 아니라 통합 단계에 선행 또는 후속하는 바이러스 사이클의 다른 단계, 예컨대 역전사, 핵 유입은 미손상되어 남아 있다. 상응하는 야생형 인테그라아제를 함유하는 렌티바이러스 벡터와 비교할 때, 통합 단계가 1000분의 1 미만, 바람직하게는 10000분의 1 미만으로 일어나는 식으로 가능해야만 하는 통합이 변형되는 경우 인테그라아제는 결함이 있다고 언급된다.
본 발명의 특정 구현예에서, 결함이 있는 인테그라아제는 계열 1의 돌연변이, 바람직하게는 아미노산 치환(1개의-아미노산 치환) 또는 결함이 있는 인테그라아제의 발현의 필요성을 이행하는 짧은 결실로부터 산출된다. 돌연변이는 pol 유전자 내에서 실시된다. 상기 벡터는 효소의 촉매성 도메인 내에 돌연변이 D64V를 갖는 결함이 있는 인테그라아제를 가질 수 있고, 이것은 통합 단계의 DNA 분할 및 연결 반응을 특이적으로 차단한다. D64V 돌연변이는 위형화된 HIV-1의 통합을 야생형의 1/10,000까지 감소시키나, 비 분열 세포를 형질도입하는 능력을 유지하여, 효과적인 이식유전자 발현을 가능하게 한다.
HIV-1의 인테그라아제의 인테그라아제 능력에 영향을 주는데 적합한 pol 유전자 중의 다른 돌연변이는 다음과 같다: H12N, H12C, H16C, H16V, S81R, D41A, K42A, H51A, Q53C, D55V, D64E, D64V, E69A, K71A, E85A, E87A, D116N, D116I, D116A, N120G, N120I, N120E, E152G, E152A, D-35-E, K156E, K156A, E157A, K159E, K159A, K160A, R166A, D167A, E170A, H171A, K173A, K186Q, K186T, K188T, E198A, R199C, R199T, R199A, D202A, K211A, Q214L, Q216L, Q221L, W235F, W235E, K236S, K236A, K246A, G247W, D253A, R262A, R263A 및 K264H.
특정 구현예에서, pol 유전자 중의 돌연변이는 하기 위치 D64, D116 또는 E152에서, 또는 단백질의 촉매성 부위 내에 있는 상기 위치 중 여러 곳에서 수행된다. 상기 위치에서의 임의의 치환은 상기 기재된 것을 포함하여, 적합하다.
또다른 제안된 치환은 아미노산 잔기 RRK(위치 262 내지 264)의 아미노산 잔기 AAH에 의한 대체이다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터는 통합-무능인 경우, 렌티바이러스 게놈은 복제 기원(ori)을 추가로 포함하고, 그 서열은 렌티바이러스 게놈이 발현되어야 하는 세포의 특성에 따라 다르다. 상기 복제 기원은 진핵생물 기원, 바람직하게는 포유류 기원, 가장 바람직하게는 인간 기원의 것일 수 있다. 이것은 대안적으로는 바이러스 기원, 특히 DNA 환형 에피좀성 바이러스 예컨대 SV40 또는 RPS로부터 유래하는 것일 수 있다. 본 발명의 렌티바이러스 벡터의 렌티바이러스 게놈 내에 삽입된 복제 기원을 갖는 것이 본 발명의 유리한 구현예이다. 게다가, 렌티바이러스 게놈이 세포 숙주 게놈 내에 통합되지 않는 경우(결함이 있는 인테그라아제 때문에), 렌티바이러스 게놈은 빈번한 세포 분열을 겪는 세포에서 상실되며, 이것은 특히 면역 세포, 예컨대 B 또는 T 세포의 경우에서 그러하다. 복제 기원의 존재는 하나 이상의 렌티바이러스 게놈이 심지어 세포 분열 후에도, 각각의 세포 내에 존재하며, 따라서 면역 반응의 효율을 최대화한다는 것을 확보한다.
본 발명의 상기 렌티바이러스 벡터의 렌티바이러스 벡터 게놈은 특히 번호 I-2330으로 1999년 10월 11일에 CNCM(Paris, France)에 기탁된(또한 WO01/27300에 기재됨) HIV-1 플라스미드 pTRIPΔU3.CMV-GFP로부터 유래될 수 있다. pTRIPΔU3.CMV-eGFP의 서열은 SEQ ID No 35로서 제시되고 도 11에 기재된다.
벡터 게놈이 상기 특정 플라스미드로부터 유래된 경우, 본 출원에 기재된 재조합 폴리뉴클레오티드의 서열은 GFP 코딩 절편 외에 또는 대체하여 내부에 삽입된다. GFP 코딩 서열은 또한 상이한 마커로 대체될 수 있다. CMV 프로모터는 또한 또다른 프로모터, 특히 이식유전자의 발현과 관련해 특히 상기 기재된 프로모터 중 하나로 치환될 수 있다.
특정 기탁된 pTRIP 벡터에 또한 함유된 WPRE 서열은 임의로 결실될 수 있다.
벡터 입자는 상기 플라스미드에 의한, 또는 다른 과정에 의한 적합한 세포(예컨대 포유류 세포 또는 인간 세포, 예컨대 293T 세포에 의해 예시된 인간 배아 신장 세포)의 트랜스펙션 후 제조될 수 있다. 렌티바이러스 입자의 발현에 사용되는 세포에서, 모든 또는 일부 플라스미드가 이들의 코딩 폴리뉴클레오티드를 안정적으로 발현하는데, 또는 이들의 코딩 폴리뉴클레오티드를 일시적으로 또는 반-안정적으로 발현하는데 사용될 수 있다.
제조된 입자의 농도는 세포 상청액의 P24(HIV-1의 경우 캡시드 단백질) 함량을 측정함으로써 측정될 수 있다.
본 발명의 렌티바이러스 벡터는, 일단 숙주 내에 투여되면, 위형화되었던 외피 단백질에 따라, 숙주의 세포, 가능하게는 특이적 세포를 감염시킨다. 감염은 렌티바이러스 벡터 게놈의 역전사가 일어나는 숙주 세포의 세포질 내로의 방출을 야기한다. 일단 삼중 형태 하에서(DNA 플랩을 통해), 렌티바이러스 벡터 게놈은 핵 내로 유입되고, 말라리아 기생충의 항원(들)의 폴리펩티드(들)을 코딩하는 폴리뉴클레오티드(들)가 세포 기작을 통해 발현된다. 비-분열 세포가 형질도입되는 경우(예컨대 DC), 발현은 안정적일 수 있다. B 세포와 같은 분열 세포가 형질도입되는 경우, 발현은 핵산 희석 및 세포 분열 때문에, 렌티바이러스 게놈 내의 복제 기원의 부재에서 일시적이다. 발현은 세포 분열 후 딸 세포 내로 렌티바이러스 벡터 게놈의 적합한 확산을 확보하는 복제 기원을 제공함으로써 더욱 길어질 수 있다. 안정성 및/또는 발현은 또한 벡터 게놈 내에 MAR(Matrix Associated Region) 또는 SAR(Scaffold Associated Region)의 삽입에 의해 증가될 수 있다 .
게다가, 상기 SAR 또는 MAR 영역은 AT-풍부 서열이고, 렌티바이러스 게놈을 세포 염색체의 매트릭스에 정착시키므로, 하나 이상의 항원 폴리펩티드를 코딩하는 폴리뉴클레오티드의 전사를 조절하고, 특히 이식유전자의 유전자 발현을 자극하고 염색질 접근능을 개선할 수 있다.
렌티바이러스 게놈이 비 통합성인 경우, 숙주 세포 게놈 내에 통합되지 않는다. 그럼에도 불구하고, 이식유전자에 의해 코딩되는 하나 이상의 폴리펩티드는 충분히 발현되고 프로세싱되기에 충분히 길게, MHC 분자와 연합되고 최종적으로 세포 표면을 향해 이동한다. 말라리아 기생충의 항원(들)의 폴리펩티드(들)을 코딩하는 폴리뉴클레오티드(들)의 특성에 따라, MHC 분자와 연합된 하나 이상의 폴리펩티드 에피토프는 체액성 또는 세포성 면역 반응을 촉발한다.
다르게 언급되지 않으면, 또는 기술적으로 관련이 없지 않으면, 특히 이들의 외피 단백질(들)과 관련된 렌티바이러스 입자, 또는 재조합 폴리뉴클레오티드의 구조 또는 용도의 다양한 특징, 구현예 또는 예 중 임의의 것과 관련하여 본 출원에 기재된 특징은 임의의 가능한 조합에 따라 조합될 수 있다.
본 발명은 추가로 적어도 하기를 포함하는, 포유류 숙주에 대한 개별 투여를 위한 화합물의 조합에 관한 것이다 :
(i) 제 1의 결정된 이종 바이러스 외피 위형화 단백질 또는 바이러스 외피 위형화 단백질로 위형화된 본 발명의 렌티바이러스 벡터 입자;
(ii) (i)에서의 렌티바이러스 벡터 입자로부터 개별적으로 제공된, 상기 제 1 이종 바이러스 외피 위형화 단백질(들)과 구별되는 제 2 결정된 이종 바이러스 외피 위형화 단백질 또는 바이러스 외피 위형화 단백질로 위형화된 본 발명의 렌티바이러스 벡터 입자;
상기 제 1 및 제 2 바이러스 외피 위형화 단백질(들)은 서로 혈청-중화하지 않고, 포유류 세포, 특히 인간 세포의 인 비보 형질도입에 적합함.
표현 "화합물의 조합" 또는 대안적으로 "화합물의 키트"는 키트 또는 조합의 유효 성분을 구성하는 렌티바이러스 벡터 입자가, 상기 키트 또는 조합에서 개별 화합물로서 제공되고, 숙주에 대한 개별 투여, 특히 적시의 개별 투여에 대해 의도되는 것을 의미한다. 따라서, 본 발명은 제 1 투여 단계는 면역, 특히 세포성, 면역 반응을 도출하고, 이후 투여 단계(들)은 세포 면역 반응을 포함하는 면역 반응을 증강시키는, 이를 필요로 하는 숙주에 초회감작-증강 투여를 수행할 수 있게 한다. 투여의 각 단계를 위해, 벡터 입자의 위형화 외피 단백질(들)이 다른 단계(들)에 사용되는 것과 상이한 것이 바람직하다. 따라서, 본 발명의 키트 또는 조합의 개별 화합물은 적어도 위형화 외피 단백질과의 상이함으로 인해 구별되는 입자를 갖는다.
키트의 화합물은 그러므로 이를 필요로 하는 숙주에, 특히 포유류 숙주, 특히 인간 숙주에 적시에 개별적으로 제공된다.
따라서, 상기 렌티바이러스 벡터는 별도의 패키지에 제공될 수 있거나 이의 분리된 사용을 위한 통상의 패키지로 제공될 수 있다.
그러므로, 패키지에 포함되고 용도 지침을 포함하는 주의사항은 구별되는 위형화 외피 단백질 또는 위형화 외피 단백질로 위형화된 상기 렌티바이러스 벡터 입자는 적시의 개별 투여를 위한, 특히 숙주에서 변역 반응을 초회감작하고 이후 증강시키기 위한 것임을 표시할 수 있다.
본 발명에 따르면, 화합물의 조합에서 제 1 결정된 이종 바이러스 위형화 외피 단백질, 또는 바이러스 위형화 외피 단백질로 위형화된 렌티바이러스 벡터 입자, 및 제 2 결정된 이종 바이러스 위형화 외피 단백질 또는 바이러스 위형화 외피 단백질로 위형화된 렌티바이러스 바이러스 벡터 입자가 제공된다. 따라서, 상기 제 1 및 제 2 이종 바이러스 외피 단백질(들)은 상이하며, 특히 상이한 바이러스 균주로부터 기원한다. 그러므로, 본 발명의 화합물의 키트의 개별 화합물에 함유된 렌티바이러스 벡터 입자는 적어도 벡터 입자의 위형화에 사용되는 특정 위형화 외피 단백질(들)로 인해 서로 상이하다.
본 발명의 특정 구현예에서, 화합물의 조합은 제 3 렌티바이러스 벡터의 위형화 외피 단백질(들)이 상기 제 1 및 제 2 위형화 외피 단백질(들)과 상이하고, 특히 상이한 바이러스 균주로부터 기원하는 제 3 또는 추가 유형의 렌티바이러스 벡터 입자를 포함한다.
상이한 위형화 외피를 갖는 입자가 연속으로 투여되는 경우, 상기 외피에 대한 하기 투여 순서가 바람직할 수 있다: 인디아나; 뉴저지; 이스파한; SVCV/코칼. 코칼 위형화된 렌티바이러스 벡터가 여러 개의 다른 외피를 혈청-중화하기 때문에, 백신화 연대순에서, 코칼 외피가 입자의 제조에 사용되어지는 경우, 투여 섭생 중 최종 것으로서 이들로 위형화된 입자를 투여하는 것이 바람직하다.
이들의 위형화 외피 단백질(들) 외에도, 본 발명의 렌티바이러스 벡터는 동일할 수 있고, 특히 동일한 벡터 게놈을 가질 수 있다.
대안적으로는, 이들의 벡터 게놈은 이들이 상기 재조합 측정된 폴리뉴클레오티드(또한 이식유전자로서 지정됨), 특히 동일한 재조합 폴리뉴클레오티드를 가질 수 있는 한, 상이할 수 있다.
본 발명의 또다른 구현예에서, 렌티바이러스 벡터의 벡터 게놈은 상기 상이한 폴리뉴클레오티드 중 하나 이상이 공통의 항원 결정소(뜰), 또는 공통의 에피토프(들)을 갖는 폴리펩티드(들)를 코딩한다면, 하나 이상의 상이한 재조합 폴리뉴클레오티드를 가짐으로써 상이하다. 그러므로 상이한 폴리뉴클레오티드는 상이한 또는 변이체 폴리펩티드를 코딩하는 서로 변이체일 수 있거나 상이한 폴리펩티드를 코딩하는 서열을 포함할 수 있다.
특정 화합물의 키트는 개별 화합물 중 적어도 하나에서, 벡터가 상이한 바이러스, 특히 상이한 종의 VSV의 상이한 속의 상이한 외피 단백질(들)로부터 기원하는 조합된 도메인 또는 절편을 포함하는 재조합 위형화 외피 단백질(들)로 위형화된 렌티바이러스 벡터를 포함한다.
본 발명의 특정 구현예에서, 적어도 하나의 제 1, 제 2 및 임의의 제 3 또는 추가의 위형화 외피 단백질(들)은 인디아나 균주의 VSV-G의 배출 결정기를 포함하는 재조합 외피 단백질(들)이다.
인디아나 균주의 VSV-G의 배출 결정기는 외피의 오픈 리딩 프레임의 세포질 절편에 의해 코딩된 폴리펩티드이다.
인디아나 균주의 VSV-G의 배출 결정기는 세포질 꼬리에 아미노산 서열 YTDIE를 포함하거나 갖는 폴리펩티드이다(Nishimua N. et al. 2002).
상기 재조합 외피 단백질(들)은 소수성 막통과 도메인에 의해 구획화된 VSV-G의 세포내 부분인 인디아나 균주의 VSV-G의 세포질 꼬리를 포함할 수 있다.
특정 화합물의 키트는 이들 중 하나 또는 둘 이상이 인디아나 VSV의 세포질 도메인 및 상이한 VSV 혈청형의 균주의 엑토도메인을 포함하는 재조합 외피 단백질(들)로 위형화된 렌티바이러스 벡터를 포함한다. 막통과 도메인은 또한 인디아나 VSV-G 중 하나일 수 있다.
특정 화합물의 키트는 이들 중 하나 또는 모두가 인디아나 VSV의 막통과 도메인 및 세포질 도메인 및 뉴저지 VSV의 엑토도메인을 포함하는 재조합 외피 단백질(들)로 위형화된 렌티바이러스 벡터를 포함한다.
적합한 다른 개질은 위형화를 개선하는 돌연변이, 특히 지점 돌연변이를 포함한다. VSV-G 단백질에 대한 이러한 돌연변이는 하나 또는 여러 개의 아미노산 잔기를 치환 또는 결실시킴으로써 막통과 도메인에서 수행될 수 있다. 적합한 돌연변이의 다른 예는 Fredericksen B.L. et al(1995) 또는 Nishimura N. et al(2003)에 기재되어 있다.
또한 특히 숙주에 투여되는 경우, 상기 VSV-G 단백질로 위형화된 렌티바이러스 벡터의 형질도입 효율을 개선시키기 위해 VSV-G의 글리코실화 상태를 개질하는 것이 가능하다.
VSV의 다양한 균주로부터의 VSV-G 단백질은 도면에 기재되어 있고, 이들의 서열은 데이터베이스, 특히 GenBank로부터 유래될 수 있다. 특히 인디아나 및 뉴저지 균주의 VSV-G 단백질은 뉴저지 VSV-G에 대해 GenBank # AF170624 또는 인디아나 균주에 대해 GenBank # M11048에 기재된 서열을 참조하여 수득될 수 있다.
VSV의 뉴저지 및 인디아나 균주의 당단백질을 고려하면, 2개의 아스파라긴 잔기(N180 및 N336)에서의 당화가 렌티바이러스 벡터의 효과적인 위형화를 선호한다는 것이 제안되었다. 상기 특정의 특징이 본 발명의 렌티바이러스 벡터의 제조에 적용될 수 있다.
VSV-G 유래 외피 단백질을 코딩하는 하기 구축물이 본 발명의 렌티바이러스 벡터 입자의 조합의 제조에 사용하기 위한 구축물의 특정 예이고, WO 2009/019612에 기재되어 있다.
코돈 최적화된 VSV-G 인디아나 유전자는 SEQ ID No 76에 제시된다. 특정 캡시드화 플라스미드는 2007년 10월 10일, 번호 I-3842로 CNCM(Paris, France)에 기탁된 pThV-VSV.G (IND-CO)이고, 또는 플라스미드 구축물의 대안적인 버전에서 2008년 7월 31일, 번호 CNCM I-4056이 VSV-G 인디아나 뉴저지 유래의 외피를 갖는 위형화된 입자의 제조에 사용하기에 적합하다. 다른 구축물은 특히 프로모터를 본 출원에 열거된 것 중의 프로모터로 치환함으로써 상기 특정 플라스미드로부터 유래될 수 있다.
코돈 최적화된 VSV-G 뉴저지 유전자는 SEQ ID No 78에 제시된다. 특정 캡시드화 플라스미드는 2007년 10월 10일, 번호 I-3843로 CNCM(Paris, France)에 기탁된 pThV-VSV.G (NJ-CO)이고, 또는 플라스미드 구축물의 대안적인 버전에서 2008년 7월 31일, 번호 CNCM I-4058이 VSV-G 인디아나 뉴저지 유래의 외피를 갖는 위형화된 입자의 제조에 사용하기에 적합하다. 다른 구축물은 특히 프로모터를 본 출원에 열거된 것 중의 프로모터로 치환함으로써 상기 특정 플라스미드로부터 유래될 수 있다.
코돈 최적화된 서열을 갖는 본 발명을 실시하는데 적합한 다른 외피 유전자는 WO2009/019612에 예시되고, 특히 VSV-G 찬디푸라 유전자 및 이의 발현 생성물, VSV-G 코칼 유전자 및 이의 발현 생성물, VSV-G 피리 유전자 및 이의 발현 생성물, VSV-G 이스파한 유전자 및 이의 발현 생성물, VSV-G 잉어 봄 바이러스 유전자 및 이의 발현 생성물을 포함한다. VSV-G 코칼에 대한 외피 유전자를 함유하는 특정 캡시드화 플라스미드는 2008년 7월 31일에, 번호 CNCM I-4055로 CNCM(Paris, France)에 기탁된 pThV-VSV.G (COCAL-CO)이다. VSV-G 이스파한에 대한 외피 유전자를 함유하는 또다른 특정 캡시드화 플라스미드는 2008년 7월 31일에, 번호 CNCM I-4057로 CNCM(Paris, France)에 기탁된 pThV-VSV.G (ISFA-CO)이다. VSV-G 잉어 봄 바이러스에 대한 외피 유전자를 함유하는 또다른 특정 캡시드화 플라스미드는 2008년 7월 31일에, 번호 CNCM I-4059로 CNCM(Paris, France)에 기탁된 pThV-VSV.G (SVCV-CO)이다. 상기 구축물은 특허 출원 WO2009/019612에 기재된다.
융합 외피 단백질, 특히 상이한 바이러스의 VSV-G 단백질의 여러 상이한 절편을 수반하는 융합 단백질 및 이러한 단백질을 코딩하는 핵산 구축물은 대안적인 구현예로서 사용되고, 또한 WO 2009/019612에 기재되어 있다. 특정 융합 외피는 본원에 제시된 서열에 예시되는 뉴저지 외피 단백질의 엑토도메인 및 인디아나 외피 단백질의 막통과 도메인 및 세포질 도메인 사이의 융합이다.
본 발명을 실시하는데 적합한 또다른 융합 외피 단백질은 VSV-G 찬디푸라, VSV-G 코칼, VSV-G 피리, VSV-G 이스파한, 또는 VSV-G SVCV 중에서 선택된 하나의 VSV-G 단백질의 엑토도메인 및 VSV-G 인디아나의 막통과 및 세포질 도메인을 포함한다. 상기 융합 단백질을 코딩하는 핵산 분자는 유리하게는 코돈 최적화된 핵산이다. 융합 단백질을 코딩하는 핵산은 또한 SEQ ID No 77, 79, 81, 83 85, 87, 89로서 기재된다.
본 발명의 특정 구현예에서, 개별 화합물의 렌티바이러스 입자가 (i) CSP 항원의 폴리펩티드 또는 (ii) GPI-정박 모티브가 없는 CSP 항원의 폴리펩티드(CSP 델타GPI) 또는 N-말단에서 절단된 CSP 단백질 (CSP NTer 또는 또한 CSP 델타SP)를 코딩하는 화합물의 조합이 제공된다.
특정 구현예에서, 상기 화합물 또는 이 중 일부는 본원에 기재된 군에서 선택되는 말라리아 기생충의 항원의 하나 이상의 부가적인 폴리펩티드를 추가로 코딩하고, 상기 항원의 구별되는 폴리펩티드는 동일한 렌티바이러스 입자로부터 또는 구별되는 렌티바이러스 입자로부터 발현된다.
본 발명의 또다른 특정 구현예에서, 상기 화합물 또는 이 중 일부는 본원에 기재된 군에서 선택되는 말라리아 기생충의 항원의 하나 이상의 부가적인 폴리펩티드를 추가로 코딩한다.
본 발명은 특히, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하는 또는 기생충-유도 병리학에 대항하는 예방 면역화에 대해 본원에 정의된 바와 같은 렌티바이러스 벡터 입자 또는 화합물의 조합에 관한 것이다.
따라서, 렌티바이러스 벡터 입자, 렌티바이러스 벡터 입자를 포함하는 조성물 또는 본 발명의 화합물의 조합은 이를 필요로 하는 숙주, 특히 포유류 특히 인간 숙주에 투여되는 경우, 말라리아 기생충의 항원(들)에 대항하여 미접촉(naive) 림프구의 활성화 및 효과기 T-세포 반응의 발생 및 면역 기억 항원-특이적 T-세포 반응의 발생을 포함하는 면역 반응을 도출한다. 면역 반응은 기생충이 숙주에 포자소체로서 접종되는 경우 말라리아 기생충에 의한 감염을 예방할 수 있거나, 또는 포자소체의 형태로 말라리아 기생충의 접종으로부터 유발되는 병리학적 상태의 발병 또는 발달을 예방할 수 있거나, 또는 분열소체가 형성하는 상기 기생충의 추가 형태의 발생의 결과의 발병 또는 발달을 예방한다.
따라서, 본 발명의 렌티바이러스 벡터 입자 또는 화합물의 조합은 기생충의 접종에 의한 또는 말라리아 기생충의 사이클의 엑소-적혈구, 즉 간, 단계의 유도에 의해 야기되는 병리학의 발병의 예방, 조절 또는 억제에 적합하고 유리한 구현예에서 상기 기생충의 적혈구 사이클의 발병 또는 발달을 예방, 경감 또는 억제하는데 적합하다. 유리하게는, 투여의 초기감작-증강 섭생에 사용되는 본 발명의 렌티바이러스 벡터 입자가 보호 면역성의 발달을 가능하게 하고, 특히 말라리아 기생충-유도 병리학에 대항하는 살균 보호가 가능하게 한다는 것이 관찰되었다. 이러한 살균 보호는 간 감염 단계에서, 그 전이 아니라면, 기생충의 사이클에서 감염 결과를 조절하는 것으로부터 야기될 수 있다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터 입자의 조성물은 상기 렌티바이러스 벡터 입자가 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하는 또는 기생충-유도 병리학에 대항하는 예방 면역화에 사용하는데 적합한 투여 비히클로 제형화되어 제조된다.
생리학적으로 허용가능한 비히클은 면역화 조성물의 투여 경로에 대해 선택될 수 있다. 바람직한 구현예에서, 투여는 근육내로 또는 어린이에게는 비강내로 실시될 수 있다.
따라서, 화합물의 조합은 조합 또는 화합물의 키트의 각각의 개별적인 조성물이 결정된 이종 바이러스 위형화 외피 단백질 또는 단백질들로 위형화된 렌티바이러스 벡터 입자를 포함하고, 상기 위형화 외피 단백질이 조합 또는 화합물의 키트의 또다른 조성물의 렌티바이러스 벡터 입자의 위형화 외피 단백질을 혈청중화하기 위해 교차반응 하지 않는, 렌티바이러스 벡터 입자의 개별적으로 제공되는 조성물을 포함할 수 있다.
따라서, 상기 조성물 또는 상기 조성물의 화합물의 조합은 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하는 또는 기생충-유도 병리학에 대항하는 예방 면역화에 사용되며, 상기 사용은 숙주의 세포 면역 반응을 초회감작하기 위해 유효량의 렌티바이러스 입자를 투여하는 단계 및 이후 적시에 숙주의 세포 면역 반응을 증강하기 위해 유효량의 렌티바이러스 입자를 투여하는 단계, 및 임의로 증강을 위해 상기 투여 단계를 (1회 또는 수회) 반복하는 단계를 포함하는 면역화 패턴을 수반하며, 초회감작 또는 증강 단계 각각에 투여된 렌티바이러스 입자가 서로 교차-중화하지 않는 구별되는 위형화 외피 단백질(들)로 위형화되고, 상기 초회감작 및 증강 단계가 적시에 적어도 6주, 특히 적어도 8주 분리된다.
마우스 모델이 본 발명의 렌티바이러스 벡터 입자가 있는 초기감작-증강 섭생에 따라 처리된 하기 예에서, 이러한 섭생에 따라 면역화되고 최종 면역화 단계 6개월 후 접종된 마우스가 여전히 본 발명의 렌티바이러스 벡터 입자가 숙주에서 장기-지속 살균 보호를 도출하는 것을 예증하는 상당한 비율의 백신화된 마우스(40% 초과)에 대해 살균 보호를 나타내고, 그러므로 특히 인간 숙주에서 면역화에 적합한 화합물을 구성할 것임이 본 발명에 의해 제시된다 .
본 발명은 특정 구현예에서, 렌티바이러스 입자의 개별적으로 제공된 투여량을 포함하는 투여 섭생으로, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하는 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위해 사용되고, 세포 면역 반응의 초회감작 및 증강에 의도되는 투여량이 중간 투여량이고 세포 면역 반응의 증강에 의도되는 투여량이 초회감작에 대한 투여량보다 높은 본원에 정의된 바와 같은 렌티바이러스 벡터 입자 또는 화합물의 조합에 관한 것이다.
따라서, 투여 패턴에 사용되는 세포 면역 반응의 초회감작 및 증강에 의도되는 투여량은 통합 벡터가 사용되는 경우 107 TU 내지 109 TU의 바이러스 입자를 포함하고, 어린이에 대해 의도되는 투여량은 107TU의 범위이고 어른의 경우 109TU의 범위이다. 초회감작 및 증강에 의도되는 투여량은 통합-무능 벡터가 사용되는 경우 108 내지 1010의 렌티바이러스 입자를 포함한다.
본 발명의 렌티바이러스 벡터 입자 또는 화합물의 조합은 특히 숙주에서 하기 효과 중 하나 이상을 수득하기에 적합한 투여량 및 투여 섭생으로, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하는 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위한 특정 구현예에 사용된다:
- 인간 숙주에서, 특히 플라스모듐 팔시파룸(Plasmodium falciparum), 플라스모듐 말라리아에(Plasmodium malariae), 플라스모듐 비박스(Plasmodium vivax), 플라스모듐 놀레시(Plasmodium knowlesi) 또는 플라스모듐 오발레(Plasmodium ovale)에 의한, 말라리아 기생충 감염에 대항하여 살균 보호를 도출함;
- 말라리아 기생충의 세포외 형태를 억제함;
- 말라리아 기생충에 의한 간세포 감염 또는 감염의 간 단계 증폭의 억제를 예방함;
- 말라리아 기생충 항원(들)에 대항하는 특이적 T-세포 면역 반응, 특히 CD8+ T-세포 반응 및/또는 특이적 CD4+ T-세포 반응을 도출함;
- 기생충 항원(들)에 대항하는 B-세포 반응을 도출함;
- 말라리아 기생충에 의한 감염의 효과를 감소 또는 경감하도록 기생충혈증을 조절함;
- 기생충에 의한 감염에 대항하여 또는 기생충-유도 병리학에 대항하여 보호성 세포 면역성을 도출함;
- 기억 T-세포 면역 반응을 도출함
- 말라리아 기생충에 의한 감염 동안 CD4+ 및 CD8+ T-세포 반응의 초기 및 높은 리바운드를 도출함;
- 플라스모듐 감염시 간 내 기억 림프구를 자극함으로써 초기 및 강한 CT (CD8+T) 반응을 도출함;
- 면역 반응으로부터 말라리아 기생충 탈출을 예방하여 말라리아 기생충에 의한 감염의 장기간 조절을 가능하게 함.
상기 표적된 효과 중에서, 세포 면역 반응(T-세포 면역 반응), 특히 CD8-매개 세포 면역 반응 또는 CD4-매개 세포 면역 반응, 즉, CD8 또는 CD4 수용체를 가지고 있는 활성화된 세포에 의해 매개되는 면역 반응, 바람직하게는 세포독성 T 림프구(CTL) 및 기억 T 세포 반응이, 본 발명의 렌티바이러스 입자의 면역화 섭생을 정의하는 경우 유리하게는 표적화된다.
면역 반응은 또한 체액 반응 즉, 상기 렌티바이러스 벡터 입자에 의해 도출되는, 렌티바이러스 벡터의 상기 하나 이상의 폴리펩티드에 대항하여 생성되는 항체가 수반될 수 있다. 특정 구현예에서, 상기 체액 반응은 보호성 체액 반응이다. 보호성 체액 반응은 주로 이들의 항원, 예컨대 IgG에 대한 높은 친화성을 갖는 성숙된 항체를 야기한다. 특정 양상에서, 보호성 체액 반응은 T-세포 의존성이다. 특정 구현예에서, 보호성 체액 반응은 중화 항체의 제조를 유도한다.
본 발명의 특정 구현예에서, 본 발명의 렌티바이러스 벡터는, 심지어 결함이 있는 인테그라아제를 갖는 형태로 사용되는 경우, 초기 면역 반응을 도출할 수 있다. 표현 "초기 면역 반응"은 조성물의 투여 후 약 1주 내에 부여된 보호성 면역 반응(기생충에 대항하는 또는 기생충-유도 병리학에 대항하는 보호)을 말한다.
또다른 특히 유리한 구현예에서, 본 발명의 렌티바이러스 입자에 의해 부여된 면역 반응은 장기-지속 면역 반응이다, 즉, 상기 면역 반응은 기억 세포 반응 및 특히 중심 기억 세포 반응을 포함하고; 특정 구현예에서 이것은 여전히 적어도 수 개월 동안 검출될 수 있고(실시예에서 마우스에 대해 예시된 바와 같이 입자의 투여 후 적어도 6개월 후에 보호가 여전히 수득됨), 이것은 투여 후 수년에 걸쳐 인간 숙주에서 보호가 지속될 수 있다고 고려할 수 있게 한다.
면역 반응에 체액 반응이 포함되는 경우, 장기-지속 반응은 특이적 항체의 검출에 의해, ELISA, 면역형광(IFA), 초점 환원 중화 시험(FRNT), 면역침전, 또는 웨스턴 블롯팅과 같은 임의의 적합한 방법에 의해 제시될 수 있다.
특정 구현예에서, 상기 면역 반응 체액성 또는 세포성, 초기 면역 반응 및/또는 장기-지속 면역 반응이든, 본 발명의 조성물의 단일 투여 후 비-통합성 유전자 전달 벡터로 도출된다.
본 발명은 또한 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하는 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위한 면역원성 조성물의 제조를 위한, 본원에 제시된 정의에 따른 렌티바이러스 벡터 입자의 용도 또는 화합물의 조합의 용도에 관한 것이다.
본 발명은 또한 본 발명에 따라 면역 반응을 도출하기 위해 본 발명의 렌티바이러스 벡터를 투여하는 단계, 및 임의로 상기 반응을 증강시키기 위해 투여 단계를 1회 또는 수회 반복하는 단계를 포함하는 포유류 숙주에서의, 특히 인간 숙주에서의 면역화 제공 방법에 관한 것이다.
본 발명의 특정 구현예에서, 렌티바이러스 벡터 입자 또는 화합물의 조합은 포유류, 특히 인간 숙주에 대한 투여에 적합한 아쥬반트 화합물, 및/또는 면역자극 화합물을, 적합한 전달 비히클과 함께 조합하여 사용될 수 있다.
상기 언급된 조성물은 상이한 경로를 통해 숙주에 주사될 수 있다: 경피(s.c), 피내(i.d.), 근육내(i.m.) 또는 정맥내(i.v.) 주사, 경구 투여 및 점막 투여, 특히 비강내 투여 또는 흡입. 투여되어야 하는 양(투여량)은 환자의 상태, 개인의 면역계 상태, 투여 경로 및 숙주의 크기를 고려하여 치료되는 대상에 따라 다르다. 적합한 투여량 범위는 벡터 입자(HIV-1 렌티바이러스 벡터의 경우)의 등가의 p24 항원 중의 함량에 대해 표현되고 측정될 수 있다.
본 발명의 다른 예 및 특징은 본 발명에 제시된 정의와 개별적으로 조합될 수 있는 특징을 갖는 렌티바이러스 벡터 입자의 제조 및 적용을 나타내는 실시예 및 도면을 판독할 때 명백해질 것이다.
도 1. 비통합성 렌티바이러스 벡터-기반 백신화는 간 단계 발달의 총 억제를 부여한다. A. 연구 디자인. 미접촉 마우스를 VSV-G 인디아나(VSV-G Ind) 외피로 위형화된 100ng의 TRIP.NI CS 입자로 0주에 초회감작한 후, VSV-G 뉴저지(VSV-G NJ) 외피로 위형화된 1500ng의 TRIP.NI CS 입자로 8주에 증강시켰다. 한 그룹의 백신화된 마우스를 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL-gfp+ 균주)의 80.000개의 포자소체(spz)로 접종하고, 이후 간 기생충 적재 40시간을 정량함으로써 보호 효율을 측정하였다. 두번째 그룹의 백신화된 마우스를 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL-gfp+ 균주)의 500개의 spz로 접종하고, Giemsa-염색 혈액 도말에 의해 14일까지 주사 후 3일부터 격일로 혈액 단계 기생충혈증을 모니터링함으로써 보호 효율을 평가하였다. 두 경우에서, 접종을 최종 면역화 후 1개월에 수행하였다. B. 접종된 마우스의 간에서 P. 요엘리이(P. yoelii) 18S rRNA에 대해 실시간 RT-PCR을 사용하여 정량된 기생충 적재의 결과. 데이터를 개별 대조군 마우스(n=5) 및 백신화된 마우스(n=4)에서 검출된 플라스모듐 18S rRNA의 카피 수로서 나타낸다. 이중실험의 평균 +/- SD를 제시한다. C. 혈액 단계 기생충혈증의 모니터링 결과. 0는 기생충의 부재를 나타내고, +는 기생충의 존재를 나타낸다.
도 2. A. 연구 디자인. VSV-G 인디아나(VSV-G Ind) 외피로 위형화된 100ng의 TRIP.NI CS 입자로 초회감작하고, 8주 후 VSV-G 뉴저지(VSV-G NJ) 외피로 위형화된 1500ng의 TRIP.NI CS 입자로 증강된 마우스에게 VSV-G 코칼로 위형화된 1500ng의 TRIP.NI CS 입자로 이후 5개월 제 3 면역화 투여량을 주었다. 백신화된 마우스를 1개월 후 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL 균주)의 500개의 spz로 접종하고, Giemsa-염색 혈액 도말에 의해 16일까지 주사 후 3일부터 격일로 혈액 단계 기생충혈증을 모니터링함으로써 보호 효율을 평가하였다. B. 비통합적 렌티바이러스 벡터-기반 섭생 후 포자소체 접종에 대항하여 완전히 보호된 마우스의 백분율. C. 미접촉 마우스(CO-검은색 곡선), 완전히 보호된 백신화된 마우스(VAC-밝은 회색 곡선) 및 부분적으로 보호된 백신화된 마우스(VAC-회색 곡선)의 기생충혈증의 평균을 도시한다. D. 접종 10일 후 미접촉 마우스(CO-검은색), 부분적으로 보호된 백신화된 마우스(VAC-회색) 및 완전히 보호된 백신화된 마우스(VAC-회색)로부터의 기생충혈증의 평균.
도 3. 플라스모듐 요엘리이(Plasmodium yoelii)의 500개의 포자소체로의 최종 치사(접종후 3주)에서의 백신화된(VAC) 또는 그렇지 않은(CO) 마우스로부터의 비장 및 간의 총체적 형태학.
도 4. 접종 3주 후 백신화된 마우스의 비장세포로부터의 CS 단백질-특이적 T 세포 반응. 플라스모듐 요엘리이(Plasmodium yoelii)로의 접종 3주 후에 수확된 백신화된 마우스로부터의 비장세포를 사용하여 엑스 비보 IFN□ ELISPOT를 실시하였다. 비장세포를 CD8+ 또는 CD4+정의된 에피토프를 나타내는 합성 펩티드로 자극시켰다. 데이터는 이중 웰의 스팟 형성 세포(sfc)의 평균 +/- SD로서 표현된다. 보호된 그룹 내 n=5 및 비보호된 그룹 내 n=3. * : 비보호된 그룹과 상이함 p<0.05.
도 5. 최적화된 비 통합적 렌티바이러스 벡터는 말라리아에 대항하여 장기간 살균 보호를 부여한다 (a) 백신 스케쥴. 마우스를 VSV-G 인디아나 외피로 위형화된 100ng의 TRIP.NI CSP 입자로 초회감작하고, VSV-G 뉴저지 외피로 위형화된 1500ng의 TRIP.NI CSP 입자로 8주에 증강시켰다. 5개월 후, 이들에게 VSV-G 코칼 외피로 위형화된 TRIP.NI CS 입자(1500ng)의 제 3 주사를 주었다. 동물을 6개월 후 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL 균주)의 500개의 포자소체로 접종하고, 16일까지 주사 후 3일부터 격일로 혈액 단계 기생충혈증을 모니터링함으로써 보호 효율을 평가하였다. (b) 접종 10일 후, 미접촉 마우스(CO-검은색), 부분적으로 보호된 백신화된 마우스(VAC-밝은 회색(중간)) 및 완전히 보호된 백신화된 마우스(VAC-회색(우측))의 기생충혈증의 평균, (c) 최종 치사(접종후 3주)에 마우스의 비장, 골수 및 간으로부터의 CSP-특이적 CD8+ T 세포의%의 5량체 분석. 검은색 막대는 부분적으로 보호된 백신화된 마우스를 나타내고, 백색 막대는 완전히 보호된 백신화된 마우스를 나타낸다, (d) 마우스의 비장, 골수 및 간 내의 CSP-특이적 CD8+ T 세포의 INF-g ELISPOT 정량. * P< 0.05 (Student's t-test)
도 6. 비통합적 렌티바이러스 벡터에 의해 유도된 Hep17-특이적 T 세포 반응. 미접촉 마우스(n=5/그룹)를 Hep17에 대해 코딩하는 다양한 투여량(100 또는 600ng)의 비통합적 렌티바이러스 벡터의 단일 주사로 i.p. 면역화하거나 하지 않았다(-). 후-면역화 11일 후, CD8+ T 세포 에피토프(A) 및 CD4+ T 세포 에피토프(B)에 대항하는 Hep17-특이적 세포 면역 반응을 IFN-γ ELISPOT에 의해 평가하였다. SFC, 스팟-형성 세포.
도 7. 통합적 렌티바이러스 벡터에 의해 유도된 Hep17-특이적 T 세포 반응. 미접촉 마우스(n=5/그룹)를 Hep17에 대해 코딩하는 통합적 렌티바이러스 벡터 (1x107 TU)의 단일 주사로 i.m. 면역화였다(또는 하지 않음: -). 후-면역화 11일 후, CD8+ T 세포 에피토프(A) 및 CD4+ T 세포 에피토프(B)에 대항하는 Hep17-특이적 세포 면역 반응을 IFN-γ ELISPOT에 의해 평가하였다. SFC, 스팟-형성 세포.
도 8. 렌티바이러스 입자로의 공동면역화 후 도출된 CS- 및 Hep17 특이적 T 세포 반응. 미접촉 마우스(n=5/그룹)를 CS (도 A 및 B에 CSP라고 명명됨) 또는 Hep17(도 C 및 D에 Hep17로 명명됨)에 대해 코딩하는 통합적 렌티바이러스 벡터 (1x107 TU)의 단일 주사로 i.m. 면역화였다. 공동면역화 실험을 위해, 미접촉 마우스에 TRIP.I CS로 하나의 사두근 내에, TRIP.I Hep17 입자(도 A, B,C,D에서 CSP+Hep로 명명됨)로 반대 사두근 내에 주사하였다. 후-면역화 11일 후, CS-특이적 세포 면역 반응(A) 및 Hep17-특이적 세포 면역 반응(C)을 IFN-γ ELISPOT에 의해 평가하였다. SFC, 스팟-형성 세포. 인 비보 세포독성 검정을 위해, 면역화된 마우스를 11일에 CS 펩티드(C) 또는 Hep17 텝티드(D)로 펄스된 표적 세포로 주사하였다. 특이적 살해 %를 물질 및 방법 섹션에 기재된 바와 같이 18시간 후에 측정하였다.
도 9. MSP1 42 에 대해 코딩하는 비통합적 렌티바이러스 벡터의 단일 투여량은 강하고 특이적인 항체 반응을 도출한다. A. 성체 마우스 그룹(n=5)에 등급화된 투여량의 TRIP.I MSP142로 복막내 면역화하였다. 21일 후, 모집된 혈청(그룹 당 5마리 마우스)을 MSP-119-특이적 항체의 존재에 대해 평가하였다. B. 마우스를 VSV-G 인디아나 외피로 위형화된 100ng의 TRIP.I MSP142 입자로 초회감작하였다. 3개월 후, 마우스를 VSV-G 코칼 외피로 위형화된 1000ng의 TRIP.NI MSP142 입자로 증강시켰다. 결과는 최종 면역화 3주 후 마우스의 혈청에서 검출된 MSP-119-특이적 항체의 평균 적정농도이다.
도 10. 플라스모듐 ( Plasmodium ) CSP 단백질 및 공통 서열의 정렬.
도 11. 플라스미드 pTRIP - DeltaU3 - CMV - eGFP 의 제한 맵. SEQ ID No 33
도 12. 플라스미드 pTRIP -Δ U3 - CMV - MSP1 42 CO - WPRE 의 제한 맵(CNCM I-4303 또는 SEQ ID No 34).
도 13. 플라스미드 pTRIP -Δ U3 - CMV - Hep17 CO - WPRE 의 제한 맵(CNCM I-4304 또는 SEQ ID No 37).
도 14. 플라스미드 pTRIP -Δ U3 - CMV - Hep17 Δ SP CO - WPRE 의 제한 맵(CNCM I-4305 또는 SEQ ID No 40).
도 15. 플라스미드 pTRIP -Δ U3 - CMV - CSP CO - WPRE 의 제한 맵(CNCM I-4306 또는 SEQ ID No 43).
도 16. 플라스미드 pTRIP -Δ U3 - CMV - CSP Δ SP CO - WPRE 의 제한 맵(CNCM I-4307 또는 SEQ ID No 45).
도 17. 플라스미드 pTRIP -Δ U3 - CMV - CSP Δ GPI CO - WPRE 의 제한 맵(CNCM I-4308 또는 SEQ ID No 47).
도 2. A. 연구 디자인. VSV-G 인디아나(VSV-G Ind) 외피로 위형화된 100ng의 TRIP.NI CS 입자로 초회감작하고, 8주 후 VSV-G 뉴저지(VSV-G NJ) 외피로 위형화된 1500ng의 TRIP.NI CS 입자로 증강된 마우스에게 VSV-G 코칼로 위형화된 1500ng의 TRIP.NI CS 입자로 이후 5개월 제 3 면역화 투여량을 주었다. 백신화된 마우스를 1개월 후 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL 균주)의 500개의 spz로 접종하고, Giemsa-염색 혈액 도말에 의해 16일까지 주사 후 3일부터 격일로 혈액 단계 기생충혈증을 모니터링함으로써 보호 효율을 평가하였다. B. 비통합적 렌티바이러스 벡터-기반 섭생 후 포자소체 접종에 대항하여 완전히 보호된 마우스의 백분율. C. 미접촉 마우스(CO-검은색 곡선), 완전히 보호된 백신화된 마우스(VAC-밝은 회색 곡선) 및 부분적으로 보호된 백신화된 마우스(VAC-회색 곡선)의 기생충혈증의 평균을 도시한다. D. 접종 10일 후 미접촉 마우스(CO-검은색), 부분적으로 보호된 백신화된 마우스(VAC-회색) 및 완전히 보호된 백신화된 마우스(VAC-회색)로부터의 기생충혈증의 평균.
도 3. 플라스모듐 요엘리이(Plasmodium yoelii)의 500개의 포자소체로의 최종 치사(접종후 3주)에서의 백신화된(VAC) 또는 그렇지 않은(CO) 마우스로부터의 비장 및 간의 총체적 형태학.
도 4. 접종 3주 후 백신화된 마우스의 비장세포로부터의 CS 단백질-특이적 T 세포 반응. 플라스모듐 요엘리이(Plasmodium yoelii)로의 접종 3주 후에 수확된 백신화된 마우스로부터의 비장세포를 사용하여 엑스 비보 IFN□ ELISPOT를 실시하였다. 비장세포를 CD8+ 또는 CD4+정의된 에피토프를 나타내는 합성 펩티드로 자극시켰다. 데이터는 이중 웰의 스팟 형성 세포(sfc)의 평균 +/- SD로서 표현된다. 보호된 그룹 내 n=5 및 비보호된 그룹 내 n=3. * : 비보호된 그룹과 상이함 p<0.05.
도 5. 최적화된 비 통합적 렌티바이러스 벡터는 말라리아에 대항하여 장기간 살균 보호를 부여한다 (a) 백신 스케쥴. 마우스를 VSV-G 인디아나 외피로 위형화된 100ng의 TRIP.NI CSP 입자로 초회감작하고, VSV-G 뉴저지 외피로 위형화된 1500ng의 TRIP.NI CSP 입자로 8주에 증강시켰다. 5개월 후, 이들에게 VSV-G 코칼 외피로 위형화된 TRIP.NI CS 입자(1500ng)의 제 3 주사를 주었다. 동물을 6개월 후 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL 균주)의 500개의 포자소체로 접종하고, 16일까지 주사 후 3일부터 격일로 혈액 단계 기생충혈증을 모니터링함으로써 보호 효율을 평가하였다. (b) 접종 10일 후, 미접촉 마우스(CO-검은색), 부분적으로 보호된 백신화된 마우스(VAC-밝은 회색(중간)) 및 완전히 보호된 백신화된 마우스(VAC-회색(우측))의 기생충혈증의 평균, (c) 최종 치사(접종후 3주)에 마우스의 비장, 골수 및 간으로부터의 CSP-특이적 CD8+ T 세포의%의 5량체 분석. 검은색 막대는 부분적으로 보호된 백신화된 마우스를 나타내고, 백색 막대는 완전히 보호된 백신화된 마우스를 나타낸다, (d) 마우스의 비장, 골수 및 간 내의 CSP-특이적 CD8+ T 세포의 INF-g ELISPOT 정량. * P< 0.05 (Student's t-test)
도 6. 비통합적 렌티바이러스 벡터에 의해 유도된 Hep17-특이적 T 세포 반응. 미접촉 마우스(n=5/그룹)를 Hep17에 대해 코딩하는 다양한 투여량(100 또는 600ng)의 비통합적 렌티바이러스 벡터의 단일 주사로 i.p. 면역화하거나 하지 않았다(-). 후-면역화 11일 후, CD8+ T 세포 에피토프(A) 및 CD4+ T 세포 에피토프(B)에 대항하는 Hep17-특이적 세포 면역 반응을 IFN-γ ELISPOT에 의해 평가하였다. SFC, 스팟-형성 세포.
도 7. 통합적 렌티바이러스 벡터에 의해 유도된 Hep17-특이적 T 세포 반응. 미접촉 마우스(n=5/그룹)를 Hep17에 대해 코딩하는 통합적 렌티바이러스 벡터 (1x107 TU)의 단일 주사로 i.m. 면역화였다(또는 하지 않음: -). 후-면역화 11일 후, CD8+ T 세포 에피토프(A) 및 CD4+ T 세포 에피토프(B)에 대항하는 Hep17-특이적 세포 면역 반응을 IFN-γ ELISPOT에 의해 평가하였다. SFC, 스팟-형성 세포.
도 8. 렌티바이러스 입자로의 공동면역화 후 도출된 CS- 및 Hep17 특이적 T 세포 반응. 미접촉 마우스(n=5/그룹)를 CS (도 A 및 B에 CSP라고 명명됨) 또는 Hep17(도 C 및 D에 Hep17로 명명됨)에 대해 코딩하는 통합적 렌티바이러스 벡터 (1x107 TU)의 단일 주사로 i.m. 면역화였다. 공동면역화 실험을 위해, 미접촉 마우스에 TRIP.I CS로 하나의 사두근 내에, TRIP.I Hep17 입자(도 A, B,C,D에서 CSP+Hep로 명명됨)로 반대 사두근 내에 주사하였다. 후-면역화 11일 후, CS-특이적 세포 면역 반응(A) 및 Hep17-특이적 세포 면역 반응(C)을 IFN-γ ELISPOT에 의해 평가하였다. SFC, 스팟-형성 세포. 인 비보 세포독성 검정을 위해, 면역화된 마우스를 11일에 CS 펩티드(C) 또는 Hep17 텝티드(D)로 펄스된 표적 세포로 주사하였다. 특이적 살해 %를 물질 및 방법 섹션에 기재된 바와 같이 18시간 후에 측정하였다.
도 9. MSP1 42 에 대해 코딩하는 비통합적 렌티바이러스 벡터의 단일 투여량은 강하고 특이적인 항체 반응을 도출한다. A. 성체 마우스 그룹(n=5)에 등급화된 투여량의 TRIP.I MSP142로 복막내 면역화하였다. 21일 후, 모집된 혈청(그룹 당 5마리 마우스)을 MSP-119-특이적 항체의 존재에 대해 평가하였다. B. 마우스를 VSV-G 인디아나 외피로 위형화된 100ng의 TRIP.I MSP142 입자로 초회감작하였다. 3개월 후, 마우스를 VSV-G 코칼 외피로 위형화된 1000ng의 TRIP.NI MSP142 입자로 증강시켰다. 결과는 최종 면역화 3주 후 마우스의 혈청에서 검출된 MSP-119-특이적 항체의 평균 적정농도이다.
도 10. 플라스모듐 ( Plasmodium ) CSP 단백질 및 공통 서열의 정렬.
도 11. 플라스미드 pTRIP - DeltaU3 - CMV - eGFP 의 제한 맵. SEQ ID No 33
도 12. 플라스미드 pTRIP -Δ U3 - CMV - MSP1 42 CO - WPRE 의 제한 맵(CNCM I-4303 또는 SEQ ID No 34).
도 13. 플라스미드 pTRIP -Δ U3 - CMV - Hep17 CO - WPRE 의 제한 맵(CNCM I-4304 또는 SEQ ID No 37).
도 14. 플라스미드 pTRIP -Δ U3 - CMV - Hep17 Δ SP CO - WPRE 의 제한 맵(CNCM I-4305 또는 SEQ ID No 40).
도 15. 플라스미드 pTRIP -Δ U3 - CMV - CSP CO - WPRE 의 제한 맵(CNCM I-4306 또는 SEQ ID No 43).
도 16. 플라스미드 pTRIP -Δ U3 - CMV - CSP Δ SP CO - WPRE 의 제한 맵(CNCM I-4307 또는 SEQ ID No 45).
도 17. 플라스미드 pTRIP -Δ U3 - CMV - CSP Δ GPI CO - WPRE 의 제한 맵(CNCM I-4308 또는 SEQ ID No 47).
렌티바이러스 벡터가 대안적인 전략을 나타낼 수 있는지를 평가하고자 하는 관점에서, 플라스모듐 요엘리이(Plasmodium yoelii)의 환상포자소체(CS) 단백질의 절단된 형태에 대해 코딩하는 비통합적 렌티바이러스 벡터(TRIP.NI CS)를 디자인하고 말라리아와 관련있는 동물 마우스 모델에서 검정하였다. CS 단백질은 포자소체의 표면 위에 균일하게 분포하고, 또한 감염된 간 세포에서 검출된다4 ,5. 그러므로, CS 단백질에 대항하는 체액성 면역 반응의 유도가 간세포 감염력을 감소시키는 반면, 상기 항원에 대항하는 세포 면역 반응은 기생충-감염된 간세포를 치사시킨다. 상기 개념은 최근 CS 단백질이 조사된(irradiated) 포자소체 면역화 모델에서 보호 면역성의 주요 표적이었음을 증명한 연구에 의해 뒷받침되었다6. 게다가, 임상 시험에서 지금까지 시험된 모든 백신 후보 중에서, CS 단백질-기반 백신 RTS,S 만이 풍토 국가에서 말라리아 발병 및 중증 말라리아의 경우를 유의하게 감소시킴을 보였다7,8.
CS 단백질에 대항하여 최적 면역 반응을 도출하기 위해, 3가지 전략을 조합하였다: 1) 형질도입된 세포에서 항원 발현 수준을 증가시키기 위해, 벡터 백본 내에 CS 단백질의 포유류 코돈-최적화 서열을 강한 사이토메갈로바이러스 프로모터의 조절 하에 삽입하였고, 이식유전자 다운스트림에 mRNA 안정화 및 세포질로의 배출을 증가시키기 위한 woodchuck 전사-후 조절 요소 서열을 첨가하였다; 2) GPI-정박 모티브의 결실이 CS 단백질의 면역원성을 개선하는 것으로 보여졌으므로9, cs 유전자의 3' 말단에 위치한 GPI 정착 서열을 결실시키고, 3) 특이적 면역 반응을 증가시키기 위해, 특히, 포자소체 접종에 의해 감염으로부터 마우스를 보호하기 위해, 마우스에게 LV-기반 부스터를 주었다. 첫번째 면역화 후 유도된 중화 항-외피 항체의 존재를 회피하기 위해, 증강 면역화에 사용된 렌티바이러스 입자를 비-교차 반응성 혈청형으로부터 VSV-G 외피로 위형화하였다(각각, 초회감작을 위해 VSV-G 인디아나, 제 1 및 제 2 증강을 위해 VSV-G 뉴저지 및 코칼).
첫번째 시리즈 실험에서, 마우스를 중간 투여량의 TRIP.NI CS로 초회감작시키고, 8주 후 고 투여량의 TRIP.NI CS로 증강시켰다(도 1a). 상기 초기감작-증강 섭생에 의해 유도된 보호를 평가하기 위해, BALB/c 마우스를 모기에 존재하는 기생충의 침입 형태인, 플라스모듐 요엘리이(Plasmodium yoelii)(17XNL gfp+ 균주)의 80.103개의 포자소체로 접종하였다. 면역화 섭생의 완료 4주 후에 접종을 수행하였다. 접종 40시간 후, 간 단계 발달의 억제 수준을 마우스의 간에서 원형질성 18S rRNA를 정량함으로써 측정하였다. 본 목적을 위해, 간-추출 RNA를 EXPRESS One-Step SYBR® GreenER™ 키트(invitrogen) 및 플라스모듐 요엘리이(Plasmodium yoelii)의 18S rRNA의 증폭을 위한 특이적 프라이머를 사용하는, 원형질성 18S rRNA 서열의 실시간 PCR 증폭에 사용하였다. 도 1b에 제시되는 바와 같이, 기생충의 간 단계 발달의 억제는 모든 면역화된 마우스에 대해 완료되었다, 즉, 기생충 18S rRNA가 정량적 RT-PCR에 의해 검출될 수 없었다. 동시 실험에서, 보호는 또한 적혈구 단계의 발생에 대해, 500개의 플라스모듐 요엘리이(Plasmodium yoelii) 포자소체로 접종되었던 면역화된 마우스의 혈액 도말을 평가함으로써 측정되었다. 말초 혈액 도말을 접종후 3 내지 14일까지 매일 수득하고, Giemsa로 염색하고, 현미경으로 관찰하여, 면역화된 마우스에 기생충증이 있는지, 즉 보호 발달에 실패하였는지를 측정하였다. 도 1c에 제시되는 바와 같이, 60%의 면역화된 마우스에서 완전한 보호가 발생했다.
두번째 시리즈 실험에서, 인디아나 및 뉴저지 혈청형에 대항하는 항체와 교차-반응성이 아닌 VSV-G 코칼 외피로 위형화된 TRIP.NI CS의 제 3 주사를 첨가하였다. 최종 증강 1개월 후, 면역화된 마우스에 500개의 포자소체로 정맥 내 접종하였다(도 2a). Giemsa-염색 혈액 도말에 의해 21일까지 주사 후 3일부터 격일로 혈액 단계 기생충혈증을 모니터링함으로써 보호 효율을 평가하였다. 5일 후, 모든 미접촉 마우스는 명백한 혈액 단계 기생충혈증을 나타냈다. 반대로, 면역화된 마우스의 62,5%는 살균 면역을 나타냈다(이후 21일에 걸친 기생충혈증의 부재에 의해 정의됨) (도 2b). 게다가, 미접촉 마우스와 비교하여, 기생충혈증이 발달된 면역화된 마우스는 적혈구 침입의 과정에 유의한 지연을 나타냈다(도 2c). 접종후 제 10일에, 부분적으로 보호된 면역화된 마우스는 미접촉 마우스에 비해 기생충혈증 수준이 2배 감소를 보여, 이 경우, 백신이 비록 부분적이지만 기생충의 면역 조절을 제공하였음을 나타낸다(도 2d).
간비증대는 말라리아의 중요한 특징이다. 이후 접종후 3주에 희생된 마우스로부터의 장기의 정량 분석을 수행하였다. 기생충에 감염된 미접촉 마우스는 현저한 비장비대증을 나타냈다(도 3). 게다가, 비장 및 간은 적혈구 세포 헤모글로빈의 소화 동안 기생충에 의해 생성된 헤모조인의 축적으로부터 기인한 어두운 색소침착을 보였다. 반대로, 살균 면역 반응을 고정하기 위한 8마리 백신화된 마우스 중의 5마리의 능력은 정상 크기 및 색소침착을 나타낸 간 및 비장의 보존과 일치하였다.
면역화된 마우스의 1/3이 살균 보호를 보이지 않았는지를 이해하고자 하는 시도로, 접종후 3주에 희생된 백신화된 동물에서의 CS 단백질-특이적 면역 반응을 평가하였다.
접종된 미접촉 마우스는 검출가능한 CS 단백질-특이적 IFN-μ 생성 T 세포를 나타내지 않았다(데이터 제시되지 않음). 반대로, 백신화된 그룹에서, 완전히 보호된 마우스는 백신화되었으나 부분적으로 보호된 마우스에 비해 5 내지 8배 큰 CSP-특이적 T 세포 반응을 나타내어, 면역 조절에 대한 T 세포 반응의 강도의 결정적인 중요성을 강조하였다(도 4).
중요하게는, 또한 최종 면역화 6개월에 접종 실험을 수행하였다. 이 경우, 백신화된 마우스 중 40% 초과는 여전히 접종 후 검출가능한 기생충혈증의 발달에 실패하여, 본 백신 전략에 의해 부여되는 장기-지속 살균 보호를 예증한다(도 5).
함께 취합하여, 상기 데이터는 비 통합적 렌티바이러스 벡터에 근거한 초기감작-증강 섭생이 플라스모듐과 같은 접종 감염제에 대항하여 높은 정도의 보호를 부여할 수 있음을 입증하였다.
상기 결과에 근거하여, 현재 다단계 백신 접근법을 개발하고 있다. 상기 전략의 근거는 간 단계에서 발현되고 T-세포 반응에 의해 표적화되는 항원 뿐 아니라, 혈액-단계에서 발현되고 항체 반응에 의해 표적화되는 항원에 대항하는 다중-면역 반응을 유도함으로써 백신 접근법에 의해 부여된 보호 효능을 증가시키려는 것이다. 이를 위해, 2개의 전-적혈구 단계 항원(CS 단백질 및 간세포 적혈구 단백질 17kDa - HEP17) 및 1개의 적혈구 단계 항원 (분열소체 표면 단백질 1의 42-kDa 절편 - MSP-142)을 선택하였다. 상기 항원은 Hep17에 특이적인 세포독성 T 세포 반응이 포자소체 접종에 대항하여 부분적으로 보호적이고, MSP-142에 특이적인 항체 반응이 또한 혈액-단계 기생충으로의 치명적 접종에 대항하여 마우스를 보호할 수 있다는 것이 입증되었기 때문에 선택되었다10 ,11. Hep17 또는 MSP-142에 대해 코딩하는 렌티바이러스 벡터를 물질 및 방법 부분에 상세히 기재된 바와 같이 구축하였다. Hep17을 발현하는 렌티바이러스 입자의 단일 주사의 면역원성을 평가하기 위해, 마우스 그룹(n=5/그룹)을 100ng(3,2x107 TU) 또는 600ng(1,9x108 TU)의 TRIP.NI Hep17로 면역화하고 특이적 면역 반응을 Elispot에 의해 검정하였다. 도 6에 제시되는 바와 같이, 비교적 약한 CD8 및 CD4 반응은 이전에 기재된 9량체 및 15량체로의 자극 후 면역화된 마우스의 비장에서 검출될 수 있었다12.
또한 TRIP.I Hep17 렌티바이러스 입자의 면역원성을 시험하였다. 마우스 그룹(n=5)을 1x107 TRIP.I Hep17 입자로 면역화하였다. Hep-17-특이적 IFNg Elispot 반응을 면역화된 마우스로부터의 비장세포에 대해 11일 후 평가하였다. 도 7에 제시되는 바와 같이, 대부분의 강력한 반응이 CD4+ T 세포 에피토프(KL14 및 EK15) 및 하나의 CD8+ T 세포 에피토프(LA9)에 대항하여 검출되었다. 또한 TRIP.I Hep17 입자와 TRIP.I CS 입자로의 공동 면역화 후 수득된 T-세포 반응을 평가하였다. 마우스에 2가지 주사를 주었다: 좌측 사두근에 1x107 TRIP.I Hep17 입자의 1회 주사 및 우측 사두근에 1x107 TRIP.I CS 입자의 1회 주사. 동시에, 마우스 그룹을 TRIP.I CS 입자 단독(1x107 TU im) 또는 TRIP.I Hep17 입자 단독(1x107 TU im)으로 면역화하였다. 11일에, 면역화된 마우스의 일부분을 Elispot 실험을 위해 희생시켰다. TRIP.CS 입자 단독 또는 TRIP.I CS 및 TRIP.I Hep17 입자로 면역화된 마우스에서 CS-특이적 IFNg T 세포의 빈도 사이에는 큰 차이가 없었다(도 8A). 면역화된 마우스에서 세포독성 T 세포 반응을 평가하기 위해, 인 비보 세포독성 검정(물질 및 방법에 기재된 바와 같음)을 수행하였다. 11일에, TRIP.I CS 입자 단독으로 면역화된 또는 TRIP.I CS 및 Hep17 입자로 공동면역화된 마우스 그룹을 CS 펩티드로 펄스된 표적 세포로의 iv 주사에 의해 접종하였다. 예상대로, TRIP.I CS 입자로 면역화된 마우스는 표적 세포를 효과적으로 용해하였고, TRIP.I CS 입자 단독으로 면역된 마우스 그룹과 TRIP.I CS 및 TRIP.I Hep17 입자를 모두 받은 마우스 그룹 사이에 유의한 차이점을 검출하지 못했다(도 8B). 함께 취합하여, 상기 결과는 TRIP.I CS 입자와 공동 투여된 TRIP.I Hep17 입자가 TRIP.I CS 입자에 의해 도출된 CS-특이적 T 세포 반응을 유의하게 간섭하지 않았다는 것을 증명하였다. 또한 TRIP.I Hep17 단독으로 면역화된 또는 TRIP.I CS 입자와 공동 투여된 마우스에서 Hep17-특이적 IFNg T 세포의 빈도를 평가하였다. 5개의 9량체 펩티드(CD8+ T 세포 에피토프)에 대한 자극에 반응하는 특이적 T 세포의 빈도는 2개 그룹 뿐 아니라, KL14 에피토프(CD4+ T 세포 에피토프)로의 자극 후 측정된 것에서 동일하였다. 현저하게, CD4+ T 세포 에피토프 EK15에 대항하여 검출되는 반응은 TRIP.I Hep17 단독으로 면역화된 마우스에서보다 공동 면역화된 마우스에서 2배 높았다(도 8C). 도 8D에서 제시되는 바와 같이, Hep17 펩티드-펄스된 표적에 대항하는 T 세포의 세포독성 능력은 또한 TRIP.I Hep17 및 TRIP.I CS 입자로 공동 면역화된 마우스에서 크게 증가하였다. 집합적으로, 상기 데이터는 CS-특이적 면역 반응이 Hep17에 특이적인 세포독성 T 세포 반응을 향상시킨다는 것을 입증한다.
그 다음 혈액 단계 말라리아 항원 분열소체 표면 단백질-1(MSP1)에 대항하는 B 세포 반응을 개시하는 렌티바이러스 벡터의 능력을 평가하였다. 마우스(n=5)를 칼레티쿨린의 분비 신호에 대해 N 말단에 융합된 플라스모듐 요엘리이(Plasmodium yoelii)(TRIP.I MSP142)로부터의 MSP1의 42-kDa 영역에 대해 코딩하는 다양한 투여량의 통합적 렌티바이러스 벡터로 면역화하였다. 면역화 3주 후, 각 그룹의 면역화된 마우스로부터 수집된 모집된 혈청을 항원의 보호성 C-말단 19-kDa 영역(MSP-119)13,14 에 대항하는 총 항-MSP1 항체의 존재에 대해 시험하였다. 도 9A에 제시되는 바와 같이, 1x106 TU 정도로 낮은 투여량으로 면역화된 마우스는 항-MSP-119 항체의 검출가능한 수준을 나타내고, 상기 벡터의 1x107 TU로의 면역화는 2 x 103에 달하는 평균 적정농도를 가진 항-MSP-119 Ig의 강한 분비를 유도하였다. 렌티바이러스 벡터 면역화에 의해 부여된 항-MSP1 반응이 제 2 면역화에 의해 향상될 수 있는지를 알아보기 위해, VSV-G 인디아나 외피로 위형화된 100ng의 TRIP.I MSP142 입자로 면역화된 마우스를 3개월 후 VSV-G 코칼 외피로 위형화된 1000ng의 TRIP.NI MSP142 입자로 증강시켰다(도 9B). 최종 면역화 3주 후, 초회감작-증강된 마우스에서의 항-MSP-119 항체의 수준은 4 x 105의 평균 값에 도달한 반면, 단독으로 초회감작된 마우스의 혈장 내 적정농도는 2 x 104 였다. 요약하면, 통합적 렌티바이러스 벡터로의 면역화는 기생충에 의한 적혈구 세포의 감염에 대항하여 보호적으로 제시된 강력한 항-MSP-119 Ig를 유도할 수 있다.
재료 및 방법
동물 및 기생충. Balb/c Ola Hsd(6주령 암컷)를 Harlan Laboratories (Gannat, France)에서 구입하였다. 모든 동물 실험은 파스퇴르 연구소(Pasteur Institute)의 동물 관리 지침에 따라 실행하였다. 감염 실험은 야생형 또는 녹색 형광 단백질을 발현하도록 유전적으로 개질하여, 살아 있는 모기에서 난모세포 및 포자소체의 검출을 가능하게 하는 플라스모듐 요엘리이(Plasmodium yoelii) (17XNL 균주)로 수행하였다. 플라스모듐 요엘리이(Plasmodium yoelii)를 아노펠레스 스테펜시(Anopheles stephensi) 및 Balb/c 마우스에서 교대 사이클 계대에 의해 유지하였다. 모기는 표준 절차를 사용하여 파스퇴르 연구소의 아노펠레(Anophele) 모기의 생성 및 감염 센터(CEPIA)에서 사육되었다.
플라스미드 벡터 구축. Py CS 단백질의 전장에 대해 코딩하는 유전자의 포유류 코돈 최적화된 형태(아미노산 1-367; GenBank Accession No. M58295)를 Geneart에 의해 합성하였다. GPI-정박 모티브의 결실이 CS 단백질의 면역원성을 증가시키는 것으로 제시되었으므로, 마지막 11개의 아미노산을 코딩하는 서열의 결실된 cs 유전자의 코돈 최적화된 형태를 제작하였다. 상기 서열은 하기 올리고뉴클레오티드(Sigma-Proligo)를 사용하는 코돈 최적화된 cs 유전자 절편의 PCR 증폭에 의해 수득되었다: (정방향) 5' GGTACCGGATCCGCCACCATGAAGAAATGCACC-3'(밑줄친 것은 BamHI 부위임); (역방향) 5'-AGCTCGAGTCATCACAGGCTGTTGGACACGATGTTGAAGATGC-3'(밑줄친 것은 Xhol 부위임). 산출된 엠플리콘을 pCR 2.1-TOPO 플라스미드(Invitrogen)에서 클로닝하고 서열분석하였다(pCR 2.1 -TOPO CS로서 언급된 플라스미드). pTRIP CS 벡터 플라스미드를, pCR 2.1-TOPO CS의 BamHI/xhoI 소화 후 수득된 절단된 코돈-최적화된 CS 서열에 의해 BamHI/XhoI 소화된 pTRIP CMV-GFP-WPRE으로부터의 GFP 서열을 대체함으로써 생성시켰다. pTRIP Hep17의 경우, kozak 서열을 포함하고 5'에 있는 BamHI 부위 및 3'에 있는 XhoI 부위를 측면으로 하는 Py Hep17 유전자(GenBank Accession No. U43539)의 포유류 코돈-최적화 서열(Geneart)을 BamHI/XhoI 소화된 pTRIP CMV-WPRE 내에 클로닝하였다. MSP1 구축물의 경우, 복합 포유류 코돈 최적화된 서열(Geneart)을 하기를 포함하도록 디자인하였다:Py MSP142의 코돈 최적화된 서열(GenBank Accession No. JO4668)에 융합된 칼레티쿨린의 분비 신호에 대한 코딩 서열(MLLSVPLLLGLLGLAVA). BamHI/XhoI 소화된 전체 서열을 BamHI/XhoI 소화된 pTRIP CMV-WPRE 내에 클로닝하였다.
pTRIP 벡터의 서열은 각각: SEQ ID NO 34, 37, 40, 43, 45 및 47로 지정되었다.
렌티바이러스 벡터 제조. 벡터 입자를 이전에 기재된 바와 같이15 통합-결핍 벡터의 생성을 위한 293T 세포와 벡터 플라스미드 pTRIP CS, VSV-G 외피 발현 플라스미드(pHCMV-G) 및 pD64V 캡시드화 GAG POL 플라스미드와의 일시적인 칼슘 포스페이트 공동-트랜스펙션에 의해 산출하였다(인테그라아제의 촉매성 도메인 내 D64V 치환은 통합 단계의 DNA 분할 및 연결 반응을 차단함). 농축된 벡터 입자의 p24 항원 함량의 정량화는 상업적인 HIV-1 p24 효소-연결 면역흡착 검정(ELISA) 키트(Perkin Elmer Life Sciences)로 수행하였다. TRIP.I 및 TRIP.NI 입자의 벡터 적정농도는 아피디콜린(SIGMA)으로 처리된 HeLa 세포를 형질도입하고 이전에 기재된 바와 같이15 정량 PCR을 수행하여 측정하였다. 통합적 및 비통합적 렌티바이러스 벡터의 적정농도는 성장-정지 세포에서 측정된 p24 함량 및 정량 PCR에 따라 유사하였다.
마우스 면역화 및 접종. 6주령 BALB/c 마우스를 0.1 ml 둘베코(Dulbecco) 인산염-완축 식염수에 희석된, VSV-G 인디아나 외피로 위형화된 100ng의 TRIP.NI CS 벡터 입자로 복막내(i.p.) 면역화하였다. 8주 후, 마우스를 VSV-G 뉴저지 외피로 위형화된 1500ng의 TRIP.NI CS 벡터 입자로 i.p. 증강시켰다. 면역화된 및 대조군 마우스의 접종은 최종 면역화 4주 이상 후에 80,000개의 포자소체의 정맥내 주사로 이루어졌다. 접종 결과는 이후 상세화되는 바와 같이 정량적 실시간 RT-PCR 방법을 사용하여 마우스의 간 내의 기생충 부담(burden)을 측정함으로써 측정되었다. 또한 대조군 및 면역화된 마우스 그룹에서 500개의 포자소체의 i.v. 접종 후 마우스에서 기생충혈증이 발달되었는지를 14일까지 접종 후 3일부터 매일 Giemsa-염색된 박막 혈액 도말의 현미경 평가에 의해 측정하였다. 간략하게는, 접종된 마우스로부터의 혈액 몇 방울을 현미경 슬라이드 상에 놓았다. 두번째 슬라이드를 사용하여 방울을 도말하고, 공기 건조시키고, 100% 메탄올에서 30초 동안 고정하였다. 고정된 슬라이드를 물(Volvic)에 희석된 10% Giemsa (Reactfs RAL)의 신선한 용액에 30 분 동안 염색하고, 물로 헹구고 공기중에서 건조시켰다. 슬라이드를 x100 유침용 대물렌즈로 관찰하였다.
실시간
RT
-
PCR
에 의한 P.
요엘리이(
P. yoelii
)의
정량.
접종된 마우스의 간 내 기생충 적재의 정량을 이전에 기재된 바와 같이16 약간 변경하여 수행하였다. 접종 40시간 후, 간을 수확하고, RNA를 RNeasy 미니 키트(Qiagen)로 추출하였다. 2㎍의 RNA를 기생충 특이적 18S rRNA의 정량에 사용하였다. 실시간 RT-PCR의 반응을 EXPRESS One-Step SYBR® GreenER™ 키트(invitrogen) 및 P. 요엘리이(P. yoelii)의 18S rRNA의 증폭에 특이적인 프라이머로 수행하였다. 프라이머(Sigma-Proligo)의 서열은 다음과 같다: 5'-GGGGATTGGTTTTGACGTTTTTGCG-3' (정방향 프라이머) 및 5'-AAGCATTAAATAAAGCGAATACATCCTTAT-3' (역방향 프라이머). 실험을 LightCycler™ 장치(Roche diagnostics)로 수행하였다. 기생충 RNA 카피의 양을 기생충의 18S cDNA PCR-증폭된 절편을 함유하는 플라스미드 구축물(pCR 2.1-TOPO 플라스미드-Invitrogen)의 연속 희석액으로부터 제작된 내부 표준 곡선에 대해 역치 형광 값을 외삽함으로써 평가하였다.
Elispot 검정. 니트로셀룰로오스 마이크로플레이트(MAHA S4510, Millipore)를 포획 항체(Mouse IFNg Elispot pair, BD Pharmingen)로 코팅하고, 10% FCS, 항생제, Hepes, 비-필수 아미노산, b-메르캅토에탄올 및 나트륨 피루베이트가 보충된 RPMI 1640 Glutamax로 구성된 완전 배지로 차단하였다. 벡터-면역화된 마우스로부터의 비장세포를 플레이트에 0,125x106 세포/웰에 삼중으로 첨가하였다. CS-특이적 CD8+ T 세포 반응의 정량을 위해, 비장세포를 2g/ml의 펩티드(PolyPeptide Laboratories France) SYVPSAEQI(Py CS280 -288) 또는 IYNRNIVNRL(Py CS58 -67)와 인큐베이션하였다. CS-특이적 CD4+ T 세포 반응을 평가하기 위해, 비장세포를 2 Mg/ml의 펩티드 SYVPSAEQILEFVKQI(Py CS280 -295)와 인큐베이션하였다. 20시간 후, 스팟을 비오틴-공액 항체(Mouse IFNg Elispot pair, BD Pharmingen) 후 스트렙타비딘-AP(Roche) 및 BCIP/NB 기질 용액(Promega)으로 노출시켰다. Bioreader 2000(Biosys, Karben, Germany)를 사용하여 스팟을 계수하고, 결과를 백만 비장세포 당 IFNγ 스팟-형성 세포(sfc)로서 표현하였다. 동일한 프로토콜을 Hep17-특이적 T 세포 반응의 정량에 적용하였다. Elispot에서의 자극 및 인 비보 세포독성 검정에 사용되는 펩티드를 표 1에 요약한다.
인 비보 세포독성 검정. 표적 세포 제조를 위해, 미접촉 마우스로부터의 비장세포를 다양한 농도(고, 5 μΜ ; 저, 1 μΜ)의 CFSE(카르복시플루오레세인-디아세테이트 숙신이미딜 에스테르, Vybrant CFDA-SE 세포-추적 키트, Molecular Probes)로 표지하였다. 고농도의 CFSE로 표지된 비장세포를 5㎍/ml에서 펩티드의 조합으로 펄스하였다. 저 투여량의 CFSE로 염색된 대조군 집단을 펩티드가 없는 배지에 인큐베이션하였다. 각각의 마우스에게 안와후 정맥을 통해 각 분획으로부터 동일 수의 세포를 함유하는 믹스의 107 CFSE-표지된 세포를 주었다. 15-18h 후, 비장으로부터의 단일-세포 현탁액을 유세포 측정(Becton Dickinson, CellQuest 소프트웨어)에 의해 분석하였다. 펩티드-펄스된 세포의 소실을 면역화된 대 미접촉 마우스 중의 펄스된(높은 CFSE 플루오레세인 강도) 대 비펄스된(낮은 CFSE 플루오레세인 강도) 집단의 비를 비교함으로써 측정하였다. 특이적 살해 %를 하기 계산에 따라 성립하였다: (1 -((CFSE저 미접촉/CFSE고 미접촉)/(CFSE저 면역화된/CFSE고 면역화된)))*100.

재조합 MSP1 19 단백질. P. 요엘리이(P. yoelii) YM MSP119(aa 1649-1757)를 pTRIP MSP142로부터의 정방향 프라이머 5'-CGTGGATCCATGGACGGCATGGATCTGCTG-3' 및 역방향 프라이머 5'-GATGAATTCGGAGCTGCTGCTGCAGAACACG-3'를 사용하는 PCR에 의해 증폭하고, 글루타티온 S-트랜스페라아제(GST)-융합 단백질 발현 벡터 pGEX-2T(Amersham Biosciences, Bucks, UK) 내로 클로닝하였다. 에스케리챠 콜라이(Escherichia coli) BL21 스타(Invitrogen)를 pGEX-2T MSP119로 변형시키고, 제조자의 지침(pGEX 벡터, GST 유전자 융합 시스템, Amersham)에 따라 성장 및 유도를 수행하였다. BL21에서 단백질의 발현 유도 후, 세포를 수확하고, BugBuster 시약(Novagen)을 사용하여 용리하였다. 재조합 단백질을 제조자의 지침에 따른 GST 결합 정제 키트(Novagen)를 사용하는 GST 결합 수지 크로마토그래피에 의해 정제하였다.
혈청 항체 반응의 측정. 혈청을 효소-연결 면역흡착 검정(ELISA)에 의한 MSP119-특이적 항체의 측정을 위한 최종 면역화 3주 후에 수집하였다. 재조합 GST-MSP119 융합 단백질 또는 GST 대조군을 PBS 중의 2㎍/ml로 96 웰 Nunc-lmmuno Maxisorp 플레이트(Fischer Scientific, Wohlen, Germany)에 4℃에서 밤새 흡착시켰다. PBS 중의 0.05%Tween 20으로 3회 세정한 후, 웰을 실온에서 1시간 동안 10%의 우태 혈청(FBS)을 함유하는 100㎕의 PBS의 첨가에 의해 차단하였다. 플레이트를 PBS 중의 0.05%Tween 20으로 3회 세정하고, 혈청의 100㎕의 10배 연속 희석액을 웰에 첨가하였다. 실온에서 2시간 동안 인큐베이션 후, 웰을 세정하고, PBS 10% FBS 중에 1/4000로 희석된 100㎕ 의 퍼옥시다아제 염소 항-마우스 면역글로불린 (H+L) (Jackson Immuno Research)을 각각의 웰에 첨가하였다. 실온에서 1시간 동안의 인큐베이션 후, 웰을 세정하고, 100㎕의 테트라메틸벤지딘 기질 시약(BD Pharmingen)을 각각의 웰에 첨가하였다. 플레이트를 실온에서 30분 동안 인큐베이션하고, 100㎕ 의 1N H2S04를 첨가하여 반응을 중지시켰다. 플레이트를 450nm에서 광학 밀도에 대해 판독하였다. 종결점 적정농도를 비 면역화된 마우스로부터의 혈청의 광학 밀도의 2배를 도출하는 최정 희석의 상호로서 계산하였다.
참조문헌



SEQUENCE LISTING
<110> INSTITUT PASTEUR
<110> THERAVECTYS
<120> LENTIVIRAL VECTOR BASED IMMUNOLOGICAL COMPOUNDS AGAINST MALARIA
<130> IP20122094FR
<150> EP 10290238.4
<151> 2010-05-03
<160> 90
<170> KopatentIn 2.0
<210> 1
<211> 33
<212> DNA
<213> artificial
<220>
<223> oligonucleotide
<400> 1
ggtaccggat ccgccaccat gaagaaatgc acc 33
<210> 2
<211> 43
<212> DNA
<213> Artificial
<220>
<223> oligonucleotide
<400> 2
agctcgagtc atcacaggct gttggacacg atgttgaaga tgc 43
<210> 3
<211> 17
<212> PRT
<213> artificial
<220>
<223> sequence coding for the secretion signal of the calreticuline
<400> 3
Met Leu Leu Ser Val Pro Leu Leu Leu Gly Leu Leu Gly Leu Ala Val
1 5 10 15
Ala
<210> 4
<211> 25
<212> DNA
<213> artificial
<220>
<223> primer
<400> 4
ggggattggt tttgacgttt ttgcg 25
<210> 5
<211> 30
<212> DNA
<213> Artificial
<220>
<223> primer
<400> 5
aagcattaaa taaagcgaat acatccttat 30
<210> 6
<211> 9
<212> PRT
<213> Artificial
<220>
<223> peptide from Plasmodium yoelii cs protein
<400> 6
Ser Tyr Val Pro Ser Ala Glu Gln Ile
1 5
<210> 7
<211> 10
<212> PRT
<213> Artificial
<220>
<223> peptide from Plasmodium yoelii cs protein
<400> 7
Ile Tyr Asn Arg Asn Ile Val Asn Arg Leu
1 5 10
<210> 8
<211> 16
<212> PRT
<213> Artificial
<220>
<223> peptide from Plasmodium yoelii cs protein
<400> 8
Ser Tyr Val Pro Ser Ala Glu Gln Ile Leu Glu Phe Val Lys Gln Ile
1 5 10 15
<210> 9
<211> 14
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii CSP
<400> 9
Lys Ile Tyr Asn Arg Asn Ile Val Asn Arg Leu Leu Gly Asp
1 5 10
<210> 10
<211> 21
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii CSP
<400> 10
Tyr Asn Arg Asn Ile Val Asn Arg Leu Leu Gly Asp Ala Leu Asn Gly
1 5 10 15
Lys Pro Glu Glu Lys
20
<210> 11
<211> 9
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 11
Leu Arg Lys Ile Asn Val Ala Leu Ala
1 5
<210> 12
<211> 9
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 12
Glu Glu Ile Val Lys Leu Thr Lys Asn
1 5
<210> 13
<211> 9
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 13
Lys Lys Ser Leu Arg Lys Ile Asn Val
1 5
<210> 14
<211> 9
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 14
Ile Asn Val Ala Leu Ala Thr Ala Leu
1 5
<210> 15
<211> 9
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 15
Leu Ser Val Val Ser Ala Ile Leu Leu
1 5
<210> 16
<211> 15
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 16
Glu Glu Ile Val Lys Leu Thr Lys Asn Lys Lys Ser Leu Arg Lys
1 5 10 15
<210> 17
<211> 14
<212> PRT
<213> Artificial
<220>
<223> synthetic peptide from Plasmodium yoelii Hep17 protein
<400> 17
Lys Ser Leu Arg Lys Ile Asn Val Ala Leu Ala Thr Ala Leu
1 5 10
<210> 18
<211> 30
<212> DNA
<213> Artificial
<220>
<223> primer
<400> 18
cgtggatcca tggacggcat ggatctgctg 30
<210> 19
<211> 31
<212> DNA
<213> Artificial
<220>
<223> primer
<400> 19
gatgaattcg gagctgctgc tgcagaacac g 31
<210> 20
<211> 367
<212> PRT
<213> Plasmodium yoelii
<220>
<221> MISC_FEATURE
<222> (1)..(367)
<223> CSP protein
<400> 20
Met Lys Lys Cys Thr Ile Leu Val Val Ala Ser Leu Leu Leu Val Asp
1 5 10 15
Ser Leu Leu Pro Gly Tyr Gly Gln Asn Lys Ser Val Gln Ala Gln Arg
20 25 30
Asn Leu Asn Glu Leu Cys Tyr Asn Glu Glu Asn Asp Asn Lys Leu Tyr
35 40 45
His Val Leu Asn Ser Lys Asn Gly Lys Ile Tyr Asn Arg Asn Ile Val
50 55 60
Asn Arg Leu Leu Gly Asp Ala Leu Asn Gly Lys Pro Glu Glu Lys Lys
65 70 75 80
Asp Asp Pro Pro Lys Asp Gly Asn Lys Asp Asp Leu Pro Lys Glu Glu
85 90 95
Lys Lys Asp Asp Leu Pro Lys Glu Glu Lys Lys Asp Asp Pro Pro Lys
100 105 110
Asp Pro Lys Lys Asp Asp Pro Pro Lys Glu Ala Gln Asn Lys Leu Asn
115 120 125
Gln Pro Val Val Ala Asp Glu Asn Val Asp Gln Gly Pro Gly Ala Pro
130 135 140
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
145 150 155 160
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
165 170 175
Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro
180 185 190
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
195 200 205
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
210 215 220
Pro Gly Ala Pro Gln Glu Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro
225 230 235 240
Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro
245 250 255
Gln Gln Pro Arg Pro Gln Pro Asp Gly Asn Asn Asn Asn Asn Asn Asn
260 265 270
Asn Gly Asn Asn Asn Glu Asp Ser Tyr Val Pro Ser Ala Glu Gln Ile
275 280 285
Leu Glu Phe Val Lys Gln Ile Ser Ser Gln Leu Thr Glu Glu Trp Ser
290 295 300
Gln Cys Ser Val Thr Cys Gly Ser Gly Val Arg Val Arg Lys Arg Lys
305 310 315 320
Asn Val Asn Lys Gln Pro Glu Asn Leu Thr Leu Glu Asp Ile Asp Thr
325 330 335
Glu Ile Cys Lys Met Asp Lys Cys Ser Ser Ile Phe Asn Ile Val Ser
340 345 350
Asn Ser Leu Gly Phe Val Ile Leu Leu Val Leu Val Phe Phe Asn
355 360 365
<210> 21
<211> 355
<212> PRT
<213> Plasmodium yoelii
<220>
<221> MISC_FEATURE
<222> (1)..(355)
<223> CSP DGPI protein (deletion from residues GFVILLVLVFFN from CSP)
<400> 21
Met Lys Lys Cys Thr Ile Leu Val Val Ala Ser Leu Leu Leu Val Asp
1 5 10 15
Ser Leu Leu Pro Gly Tyr Gly Gln Asn Lys Ser Val Gln Ala Gln Arg
20 25 30
Asn Leu Asn Glu Leu Cys Tyr Asn Glu Glu Asn Asp Asn Lys Leu Tyr
35 40 45
His Val Leu Asn Ser Lys Asn Gly Lys Ile Tyr Asn Arg Asn Ile Val
50 55 60
Asn Arg Leu Leu Gly Asp Ala Leu Asn Gly Lys Pro Glu Glu Lys Lys
65 70 75 80
Asp Asp Pro Pro Lys Asp Gly Asn Lys Asp Asp Leu Pro Lys Glu Glu
85 90 95
Lys Lys Asp Asp Leu Pro Lys Glu Glu Lys Lys Asp Asp Pro Pro Lys
100 105 110
Asp Pro Lys Lys Asp Asp Pro Pro Lys Glu Ala Gln Asn Lys Leu Asn
115 120 125
Gln Pro Val Val Ala Asp Glu Asn Val Asp Gln Gly Pro Gly Ala Pro
130 135 140
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
145 150 155 160
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
165 170 175
Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro
180 185 190
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
195 200 205
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
210 215 220
Pro Gly Ala Pro Gln Glu Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro
225 230 235 240
Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro
245 250 255
Gln Gln Pro Arg Pro Gln Pro Asp Gly Asn Asn Asn Asn Asn Asn Asn
260 265 270
Asn Gly Asn Asn Asn Glu Asp Ser Tyr Val Pro Ser Ala Glu Gln Ile
275 280 285
Leu Glu Phe Val Lys Gln Ile Ser Ser Gln Leu Thr Glu Glu Trp Ser
290 295 300
Gln Cys Ser Val Thr Cys Gly Ser Gly Val Arg Val Arg Lys Arg Lys
305 310 315 320
Asn Val Asn Lys Gln Pro Glu Asn Leu Thr Leu Glu Asp Ile Asp Thr
325 330 335
Glu Ile Cys Lys Met Asp Lys Cys Ser Ser Ile Phe Asn Ile Val Ser
340 345 350
Asn Ser Leu
355
<210> 22
<211> 349
<212> PRT
<213> Plasmodium yoelii
<220>
<221> MISC_FEATURE
<222> (1)..(349)
<223> CSP NTer protein (Deletion of residues 1-19 from CSP)
<400> 22
Met Pro Gly Tyr Gly Gln Asn Lys Ser Val Gln Ala Gln Arg Asn Leu
1 5 10 15
Asn Glu Leu Cys Tyr Asn Glu Glu Asn Asp Asn Lys Leu Tyr His Val
20 25 30
Leu Asn Ser Lys Asn Gly Lys Ile Tyr Asn Arg Asn Ile Val Asn Arg
35 40 45
Leu Leu Gly Asp Ala Leu Asn Gly Lys Pro Glu Glu Lys Lys Asp Asp
50 55 60
Pro Pro Lys Asp Gly Asn Lys Asp Asp Leu Pro Lys Glu Glu Lys Lys
65 70 75 80
Asp Asp Leu Pro Lys Glu Glu Lys Lys Asp Asp Pro Pro Lys Asp Pro
85 90 95
Lys Lys Asp Asp Pro Pro Lys Glu Ala Gln Asn Lys Leu Asn Gln Pro
100 105 110
Val Val Ala Asp Glu Asn Val Asp Gln Gly Pro Gly Ala Pro Gln Gly
115 120 125
Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro
130 135 140
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
145 150 155 160
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
165 170 175
Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro
180 185 190
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
195 200 205
Ala Pro Gln Glu Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln
210 215 220
Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln
225 230 235 240
Pro Arg Pro Gln Pro Asp Gly Asn Asn Asn Asn Asn Asn Asn Asn Gly
245 250 255
Asn Asn Asn Glu Asp Ser Tyr Val Pro Ser Ala Glu Gln Ile Leu Glu
260 265 270
Phe Val Lys Gln Ile Ser Ser Gln Leu Thr Glu Glu Trp Ser Gln Cys
275 280 285
Ser Val Thr Cys Gly Ser Gly Val Arg Val Arg Lys Arg Lys Asn Val
290 295 300
Asn Lys Gln Pro Glu Asn Leu Thr Leu Glu Asp Ile Asp Thr Glu Ile
305 310 315 320
Cys Lys Met Asp Lys Cys Ser Ser Ile Phe Asn Ile Val Ser Asn Ser
325 330 335
Leu Gly Phe Val Ile Leu Leu Val Leu Val Phe Phe Asn
340 345
<210> 23
<211> 397
<212> PRT
<213> Plasmodium falciparum
<220>
<221> MISC_FEATURE
<222> (1)..(397)
<223> CSP protein
<400> 23
Met Met Arg Lys Leu Ala Ile Leu Ser Val Ser Ser Phe Leu Phe Val
1 5 10 15
Glu Ala Leu Phe Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr
20 25 30
Arg Val Leu Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr
35 40 45
Asn Glu Leu Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser
50 55 60
Leu Lys Lys Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Gly Asn Asn
65 70 75 80
Glu Asp Asn Glu Lys Leu Arg Lys Pro Lys His Lys Lys Leu Lys Gln
85 90 95
Pro Ala Asp Gly Asn Pro Asp Pro Asn Ala Asn Pro Asn Val Asp Pro
100 105 110
Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro
115 120 125
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
130 135 140
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
145 150 155 160
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
165 170 175
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
180 185 190
Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Ala Asn Pro
195 200 205
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
210 215 220
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
225 230 235 240
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
245 250 255
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
260 265 270
Asn Lys Asn Asn Gln Gly Asn Gly Gln Gly His Asn Met Pro Asn Asp
275 280 285
Pro Asn Arg Asn Val Asp Glu Asn Ala Asn Ala Asn Ser Ala Val Lys
290 295 300
Asn Asn Asn Asn Glu Glu Pro Ser Asp Lys His Ile Lys Glu Tyr Leu
305 310 315 320
Asn Lys Ile Gln Asn Ser Leu Ser Thr Glu Trp Ser Pro Cys Ser Val
325 330 335
Thr Cys Gly Asn Gly Ile Gln Val Arg Ile Lys Pro Gly Ser Ala Asn
340 345 350
Lys Pro Lys Asp Glu Leu Asp Tyr Ala Asn Asp Ile Glu Lys Lys Ile
355 360 365
Cys Lys Met Glu Lys Cys Ser Ser Val Phe Asn Val Val Asn Ser Ser
370 375 380
Ile Gly Leu Ile Met Val Leu Ser Phe Leu Phe Leu Asn
385 390 395
<210> 24
<211> 368
<212> PRT
<213> Plasmodium falciparum
<220>
<221> MISC_FEATURE
<222> (1)..(368)
<223> CSP DGPI protein
<400> 24
Met Met Arg Lys Leu Ala Ile Leu Ser Val Ser Ser Phe Leu Phe Val
1 5 10 15
Glu Ala Leu Phe Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr
20 25 30
Arg Val Leu Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr
35 40 45
Asn Glu Leu Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser
50 55 60
Leu Lys Lys Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Gly Asn Asn
65 70 75 80
Glu Asp Asn Glu Lys Leu Arg Lys Pro Lys His Lys Lys Leu Lys Gln
85 90 95
Pro Ala Asp Gly Asn Pro Asp Pro Asn Ala Asn Pro Asn Val Asp Pro
100 105 110
Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro
115 120 125
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
130 135 140
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
145 150 155 160
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
165 170 175
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
180 185 190
Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Ala Asn Pro
195 200 205
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
210 215 220
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
225 230 235 240
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
245 250 255
Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro
260 265 270
Asn Lys Asn Asn Gln Gly Asn Gly Gln Gly His Asn Met Pro Asn Asp
275 280 285
Pro Asn Arg Asn Val Asp Glu Asn Ala Asn Ala Asn Ser Ala Val Lys
290 295 300
Asn Asn Asn Asn Glu Glu Pro Ser Asp Lys His Ile Lys Glu Tyr Leu
305 310 315 320
Asn Lys Ile Gln Asn Ser Leu Ser Thr Glu Trp Ser Pro Cys Ser Val
325 330 335
Thr Cys Gly Asn Gly Ile Gln Val Arg Ile Lys Pro Gly Ser Ala Asn
340 345 350
Lys Pro Lys Asp Glu Leu Asp Tyr Ala Asn Asp Ile Glu Lys Lys Ile
355 360 365
<210> 25
<211> 378
<212> PRT
<213> Plasmodium falciparum
<220>
<221> MISC_FEATURE
<222> (1)..(378)
<223> CSP NTer protein
<400> 25
Met Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr Arg Val Leu
1 5 10 15
Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr Asn Glu Leu
20 25 30
Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser Leu Lys Lys
35 40 45
Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Gly Asn Asn Glu Asp Asn
50 55 60
Glu Lys Leu Arg Lys Pro Lys His Lys Lys Leu Lys Gln Pro Ala Asp
65 70 75 80
Gly Asn Pro Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn
85 90 95
Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn
100 105 110
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
115 120 125
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
130 135 140
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
145 150 155 160
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
165 170 175
Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
180 185 190
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
195 200 205
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
210 215 220
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
225 230 235 240
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Lys Asn
245 250 255
Asn Gln Gly Asn Gly Gln Gly His Asn Met Pro Asn Asp Pro Asn Arg
260 265 270
Asn Val Asp Glu Asn Ala Asn Ala Asn Ser Ala Val Lys Asn Asn Asn
275 280 285
Asn Glu Glu Pro Ser Asp Lys His Ile Lys Glu Tyr Leu Asn Lys Ile
290 295 300
Gln Asn Ser Leu Ser Thr Glu Trp Ser Pro Cys Ser Val Thr Cys Gly
305 310 315 320
Asn Gly Ile Gln Val Arg Ile Lys Pro Gly Ser Ala Asn Lys Pro Lys
325 330 335
Asp Glu Leu Asp Tyr Ala Asn Asp Ile Glu Lys Lys Ile Cys Lys Met
340 345 350
Glu Lys Cys Ser Ser Val Phe Asn Val Val Asn Ser Ser Ile Gly Leu
355 360 365
Ile Met Val Leu Ser Phe Leu Phe Leu Asn
370 375
<210> 26
<211> 329
<212> PRT
<213> Plasmodium berghei
<220>
<221> MISC_FEATURE
<222> (1)..(329)
<223> CSP protein
<400> 26
Met Lys Lys Cys Thr Ile Leu Val Val Ala Ser Leu Leu Leu Val Asn
1 5 10 15
Ser Leu Leu Pro Gly Tyr Gly Gln Asn Lys Ile Ile Gln Ala Gln Arg
20 25 30
Asn Leu Asn Glu Leu Cys Tyr Asn Glu Gly Asn Asp Asn Lys Leu Tyr
35 40 45
His Val Leu Asn Ser Lys Asn Gly Lys Ile Tyr Asn Arg Asn Thr Val
50 55 60
Asn Arg Leu Leu Ala Asp Ala Pro Glu Gly Lys Lys Asn Glu Lys Lys
65 70 75 80
Asn Glu Lys Ile Glu Arg Asn Asn Lys Leu Lys Pro Pro Pro Asn Pro
85 90 95
Asn Asp Pro Pro Pro Pro Asn Pro Asn Asp Pro Pro Pro Pro Asn Pro
100 105 110
Asn Asp Pro Pro Pro Pro Asn Pro Asn Asp Pro Ala Pro Pro Asn Ala
115 120 125
Asn Asp Pro Ala Pro Pro Asn Ala Asn Asp Pro Ala Pro Pro Asn Ala
130 135 140
Asn Asp Pro Ala Pro Pro Asn Ala Asn Asp Pro Ala Pro Pro Asn Ala
145 150 155 160
Asn Asp Pro Ala Pro Pro Asn Ala Asn Asp Pro Ala Pro Pro Asn Ala
165 170 175
Asn Asp Pro Pro Pro Pro Asn Pro Asn Asp Pro Ala Pro Pro Gln Gly
180 185 190
Asn Asn Asn Pro Gln Pro Gln Pro Arg Pro Gln Pro Gln Pro Gln Pro
195 200 205
Gln Pro Gln Pro Gln Pro Gln Pro Gln Pro Gln Pro Arg Pro Gln Pro
210 215 220
Gln Pro Gln Pro Gly Gly Asn Asn Asn Asn Lys Asn Asn Asn Asn Asp
225 230 235 240
Asp Ser Tyr Ile Pro Ser Ala Glu Lys Ile Leu Glu Phe Val Lys Gln
245 250 255
Ile Arg Asp Ser Ile Thr Glu Glu Trp Ser Gln Cys Asn Val Thr Cys
260 265 270
Gly Ser Gly Ile Arg Val Arg Lys Arg Lys Gly Ser Asn Lys Lys Ala
275 280 285
Glu Asp Leu Thr Leu Glu Asp Ile Asp Thr Glu Ile Cys Lys Met Asp
290 295 300
Lys Cys Ser Ser Ile Phe Asn Ile Val Ser Asn Ser Leu Gly Phe Val
305 310 315 320
Ile Leu Leu Val Leu Val Phe Phe Asn
325
<210> 27
<211> 429
<212> PRT
<213> Plasmodium malariae
<220>
<221> MISC_FEATURE
<222> (1)..(429)
<223> CSP protein
<400> 27
Met Lys Lys Leu Ser Val Leu Ala Ile Ser Ser Phe Leu Ile Val Asp
1 5 10 15
Phe Leu Phe Pro Gly Tyr His His Asn Ser Asn Ser Thr Lys Ser Arg
20 25 30
Asn Leu Ser Glu Leu Cys Tyr Asn Asn Val Asp Thr Lys Leu Phe Asn
35 40 45
Glu Leu Glu Val Arg Tyr Ser Thr Asn Gln Asp His Phe Tyr Asn Tyr
50 55 60
Asn Lys Thr Ile Arg Leu Leu Asn Glu Asn Asn Asn Glu Lys Asp Gly
65 70 75 80
Asn Val Thr Asn Glu Arg Lys Lys Lys Pro Thr Lys Ala Val Glu Asn
85 90 95
Lys Leu Lys Gln Pro Pro Gly Asp Asp Asp Gly Ala Gly Asn Asp Ala
100 105 110
Gly Asn Asp Ala Gly Asn Asp Ala Gly Asn Ala Ala Gly Asn Ala Ala
115 120 125
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
130 135 140
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
145 150 155 160
Gly Asn Asp Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
165 170 175
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Asp Ala Gly Asn Ala Ala
180 185 190
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
195 200 205
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
210 215 220
Gly Asn Ala Ala Gly Asn Asp Ala Gly Asn Ala Ala Gly Asn Ala Ala
225 230 235 240
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
245 250 255
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
260 265 270
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
275 280 285
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
290 295 300
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Glu Lys Ala Lys Asn Lys
305 310 315 320
Asp Asn Lys Val Asp Ala Asn Thr Asn Lys Lys Asp Asn Gln Glu Glu
325 330 335
Asn Asn Asp Ser Ser Asn Gly Pro Ser Glu Glu His Ile Lys Asn Tyr
340 345 350
Leu Glu Ser Ile Arg Asn Ser Ile Thr Glu Glu Trp Ser Pro Cys Ser
355 360 365
Val Thr Cys Gly Ser Gly Ile Arg Ala Arg Arg Lys Val Gly Ala Lys
370 375 380
Asn Lys Lys Pro Ala Glu Leu Val Leu Ser Asp Leu Glu Thr Glu Ile
385 390 395 400
Cys Ser Leu Asp Lys Cys Ser Ser Ile Phe Asn Val Val Ser Asn Ser
405 410 415
Leu Gly Ile Val Leu Val Leu Val Leu Ile Leu Phe His
420 425
<210> 28
<211> 344
<212> PRT
<213> Plasmodium coatneyi
<220>
<221> MISC_FEATURE
<222> (1)..(344)
<223> CSP protein
<400> 28
Met Lys Asn Phe Ile Leu Leu Ala Val Ser Ser Ile Leu Leu Val Asp
1 5 10 15
Leu Phe Pro Thr His Phe Gly His Asn Val Asp Leu Ser Arg Ala Ile
20 25 30
Asn Leu Asn Gly Val Ser Phe Asn Asn Val Asp Thr Ser Leu Leu Gly
35 40 45
Ala Ala Gln Val Arg Gln Ser Ala Ser Arg Gly Arg Gly Leu Gly Glu
50 55 60
Lys Pro Lys Lys Lys Ala Glu Lys Lys Glu Glu Glu Pro Lys Lys Pro
65 70 75 80
Asn Glu Asn Lys Cys Ser Pro Leu Lys Gln Pro Val Asp Gly Ala Arg
85 90 95
Asp Gly Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro
100 105 110
Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Ala Ala Asp Gly Ala
115 120 125
Arg Asp Gly Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala
130 135 140
Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Ala Ala Asp Gly
145 150 155 160
Ala Arg Asp Gly Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro
165 170 175
Ala Pro Pro Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Pro Ala Ala
180 185 190
Asp Gly Ala Arg Asp Gly Pro Ala Pro Pro Ala Ala Asp Gly Ala Arg
195 200 205
Asp Gly Pro Ala Pro Pro Ala Gly Gln Gly Gly Gly Asn Ala Ala Gly
210 215 220
Gln Ala Gln Gly Gly Gly Asn Ala Gly Asn Lys Lys Ala Gly Asp Ala
225 230 235 240
Ala Gly Asn Ala Gly Ala Ala Lys Gly Gln Gly Gln Asn Asn Glu Gly
245 250 255
Ala Asn Val Pro Asn Glu Lys Val Val Asn Asp Tyr Leu Gln Lys Ile
260 265 270
Arg Ser Thr Val Thr Thr Glu Trp Thr Pro Cys Ser Val Thr Cys Gly
275 280 285
Asn Gly Val Arg Leu Arg Arg Lys Ala His Ala Glu Lys Lys Lys Pro
290 295 300
Glu Asp Leu Thr Met Asp Asp Leu Asp Val Glu Val Cys Ala Met Asp
305 310 315 320
Lys Cys Ala Gly Ile Phe Asn Phe Val Ser Asn Ser Leu Gly Leu Val
325 330 335
Ile Leu Leu Val Leu Ala Phe Asn
340
<210> 29
<211> 347
<212> PRT
<213> Plasmodium knowlesi
<220>
<221> MISC_FEATURE
<222> (1)..(347)
<223> CSP protein
<400> 29
Met Arg Asn Phe Ile Leu Leu Ala Val Ser Ser Ile Leu Leu Val Asp
1 5 10 15
Leu Phe Pro Thr His Phe Glu His Asn Val Asp Leu Ser Arg Ala Ile
20 25 30
Asn Val Asn Gly Val Ser Phe Asn Asn Val Asp Thr Ser Ser Leu Gly
35 40 45
Ala Ala Gln Val Arg Gln Ser Ala Ser Arg Gly Arg Gly Leu Gly Glu
50 55 60
Lys Arg Lys Glu Gly Ala Asp Lys Glu Lys Lys Lys Glu Lys Glu Glu
65 70 75 80
Glu Pro Lys Lys Pro Asn Glu Asn Lys Leu Lys Gln Pro Asp Gln Ala
85 90 95
Ala Pro Gly Ala Gly Gly Glu Gln Pro Ala Pro Gly Ala Gly Gly Glu
100 105 110
Gln Pro Ala Pro Gly Ala Gly Gly Glu Arg Pro Ala Pro Gly Ala Gly
115 120 125
Gly Glu Gln Pro Ala Pro Gly Ala Gly Gly Glu Gln Pro Ala Pro Gly
130 135 140
Ala Gly Gly Glu Arg Pro Ala Pro Gly Ala Gly Gly Glu Gln Pro Ala
145 150 155 160
Pro Gly Ala Gly Gly Glu Gln Pro Ala Pro Gly Ala Gly Gly Glu Gln
165 170 175
Pro Ala Pro Gly Ala Gly Gly Glu Gln Pro Ala Pro Gly Ala Gly Gly
180 185 190
Glu Arg Pro Ala Pro Gly Ala Gly Gly Glu Arg Pro Ala Pro Gly Ala
195 200 205
Gly Gly Glu Gln Pro Ala Pro Gly Ala Gly Gly Glu Gln Pro Ala Pro
210 215 220
Ala Pro Arg Arg Glu Gln Pro Ala Pro Gly Pro Gly Ala Gly Asp Gly
225 230 235 240
Ala Arg Gly Gly Asn Ala Gly Ala Gly Lys Gly Gln Gly Gln Asn Asn
245 250 255
Gln Gly Ala Asn Val Pro Asn Glu Lys Val Val Asn Asp Tyr Leu His
260 265 270
Lys Ile Arg Ser Ser Val Thr Thr Glu Trp Thr Pro Cys Ser Val Thr
275 280 285
Cys Gly Asn Gly Val Arg Ile Arg Arg Arg Gln Asn Ala Gly Asn Lys
290 295 300
Lys Ala Glu Asp Leu Thr Met Asp Asp Leu Glu Val Glu Ala Cys Val
305 310 315 320
Met Asp Lys Cys Ala Gly Ile Phe Asn Val Val Ser Asn Ser Leu Gly
325 330 335
Leu Val Ile Leu Leu Val Leu Ala Leu Phe Asn
340 345
<210> 30
<211> 388
<212> PRT
<213> Plasmodium reichenowi
<400> 30
Met Met Arg Lys Leu Ala Ile Leu Ser Val Ser Ser Phe Leu Phe Val
1 5 10 15
Glu Ala Leu Phe Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr
20 25 30
Arg Val Leu Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr
35 40 45
Asn Glu Leu Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser
50 55 60
Leu Lys Lys Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Ala Asp Asn
65 70 75 80
Gly Asp Ala Asp Asn Gly Asp Glu Gly Ile Asp Glu Asn Arg Arg His
85 90 95
Arg Asn Lys Glu Gly Lys Glu Lys Leu Lys Lys Pro Lys His Asn Lys
100 105 110
Leu Lys Gln Pro Gly Asn Asp Asn Val Asp Pro Asn Ala Asn Pro Asn
115 120 125
Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
130 135 140
Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
145 150 155 160
Val Asn Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
165 170 175
Val Asn Pro Asn Ala Asn Pro Asn Val Asn Pro Asn Ala Asn Pro Asn
180 185 190
Val Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
195 200 205
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
210 215 220
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
225 230 235 240
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
245 250 255
Ala Asn Pro Asn Ala Asn Pro Asn Arg Asn Asn Glu Ala Asn Gly Gln
260 265 270
Gly His Asn Lys Pro Asn Asp Gln Asn Arg Asn Val Asn Glu Asn Ala
275 280 285
Asn Ala Asn Asn Ala Gly Arg Asn Asn Asn Asn Glu Glu Pro Ser Asp
290 295 300
Lys His Ile Glu Glu Phe Leu Lys Gln Ile Gln Asn Asn Leu Ser Thr
305 310 315 320
Glu Trp Ser Pro Cys Ser Val Thr Cys Gly Asn Gly Ile Gln Val Arg
325 330 335
Ile Lys Pro Gly Ser Ala Gly Lys Pro Lys Asp Gln Leu Asp Tyr Glu
340 345 350
Asn Asp Leu Glu Lys Lys Ile Cys Lys Met Glu Lys Cys Ser Ser Val
355 360 365
Phe Asn Val Val Asn Ser Ser Ile Gly Leu Ile Met Val Leu Ser Phe
370 375 380
Leu Phe Leu Asn
385
<210> 31
<211> 388
<212> PRT
<213> Plasmodium gallinaceum
<400> 31
Met Lys Lys Leu Ala Ile Leu Ser Ala Ser Ser Phe Leu Phe Ala Asp
1 5 10 15
Phe Leu Phe Gln Glu Tyr Gln His Asn Gly Asn Tyr Lys Asn Phe Arg
20 25 30
Leu Leu Asn Glu Val Cys Tyr Asn Asn Met Asn Ile Gln Leu Tyr Asn
35 40 45
Glu Leu Glu Met Glu Asn Tyr Met Ser Asn Thr Tyr Phe Tyr Asn Asn
50 55 60
Lys Lys Thr Ile Arg Leu Leu Gly Glu Asn Asp Asn Glu Ala Asn Val
65 70 75 80
Asn Arg Ala Asn Asn Asn Val Ala Asn Asp Asn Arg Ala Asn Gly Asn
85 90 95
Arg Gly Asn Val Asn Arg Ala Asn Asp Arg Asn Ile Pro Tyr Phe Arg
100 105 110
Glu Asn Val Val Asn Leu Asn Gln Pro Val Gly Gly Asn Gly Gly Val
115 120 125
Gln Pro Ala Gly Gly Asn Gly Gly Val Gln Pro Ala Gly Gly Asn Gly
130 135 140
Gly Val Gln Pro Ala Gly Gly Asn Gly Gly Val Gln Pro Ala Gly Gly
145 150 155 160
Asn Gly Gly Val Gln Pro Ala Gly Gly Asn Gly Gly Val Gln Pro Ala
165 170 175
Gly Gly Asn Gly Gly Val Gln Pro Ala Gly Gly Asn Gly Gly Ala Gln
180 185 190
Pro Val Ala Ala Gly Gly Gly Ala Gln Pro Val Val Ala Asp Gly Gly
195 200 205
Val Gln Pro Leu Arg Gln Glu Gly Asp Ala Glu Glu Asp Gly Gly Asn
210 215 220
Gly Gly Ala Gln Pro Ala Gly Gly Asn Gly Gly Ala Gln Pro Ala Gly
225 230 235 240
Gly Asn Gly Gly Ala Gln Pro Ala Gly Gly Asn Gly Gly Ala Gln Pro
245 250 255
Ala Gly Gly Asn Gly Gly Ala Gln Pro Ala Gly Gly Asn Asp Ala Ala
260 265 270
Lys Pro Asp Gly Gly Asn Asp Asp Asp Lys Pro Glu Gly Gly Asp Glu
275 280 285
Lys Ser Glu Glu Glu Lys Glu Asp Glu Pro Ile Pro Asp Pro Thr Gln
290 295 300
Glu Glu Ile Asp Lys Tyr Leu Lys Ser Ile Leu Gly Asn Val Thr Ser
305 310 315 320
Glu Trp Thr Asn Cys Asn Val Thr Cys Gly Lys Gly Ile Gln Ala Lys
325 330 335
Ile Lys Ser Thr Ser Ala Asn Lys Lys Arg Glu Glu Ile Thr Pro Asn
340 345 350
Asp Val Glu Val Lys Ile Cys Glu Leu Glu Arg Cys Ser Phe Ser Ile
355 360 365
Phe Asn Val Ile Ser Asn Ser Leu Gly Leu Ala Ile Ile Leu Thr Phe
370 375 380
Leu Phe Phe Tyr
385
<210> 32
<211> 258
<212> PRT
<213> Consensus
<400> 32
Met Lys Lys Ile Leu Ser Val Ser Ser Ile Leu Leu Val Asp Ala Leu
1 5 10 15
Gln Tyr Asn Leu Ser Arg Asn Leu Asn Glu Leu Tyr Asn Tyr Asn Glu
20 25 30
Leu Glu Met His Val Gly Ala Asn Ser Arg Asn Gly Asn Asp Ala Asp
35 40 45
Glu Lys Glu Lys Lys Pro Asn Asn Lys Leu Pro Asn Ala Pro Asn Asp
50 55 60
Pro Ala Pro Asn Pro Ala Ala Gly Ala Ala Ala Ala Asn Asn Ala Pro
65 70 75 80
Ala Ala Asn Ala Pro Ala Pro Asn Ala Gly Asn Ala Pro Asn Ala Gly
85 90 95
Gly Ala Pro Asn Ala Asn Gly Ala Asn Pro Asn Ala Gly Ala Ala Pro
100 105 110
Pro Ala Gly Ala Asn Ala Pro Asn Ala Gly Pro Asn Ala Ala Gly Pro
115 120 125
Ala Gly Ala Ala Pro Asn Ala Pro Ala Ala Asn Gly Asn Ala Asn Pro
130 135 140
Asn Ala Pro Asn Ala Pro Asn Ala Pro Asn Ala Asn Pro Asn Ala Pro
145 150 155 160
Asn Asn Ala Gly Gln Asp Asn Ala Asn Asn Lys Asn Asn Gly Asn Asn
165 170 175
Glu Ser Val Pro Ser Glu Lys Ile Glu Tyr Leu Lys Ile Arg Ser Leu
180 185 190
Thr Thr Glu Trp Ser Pro Cys Ser Val Thr Cys Gly Asn Gly Ile Arg
195 200 205
Val Arg Arg Lys Gly Ser Ala Asn Lys Lys Glu Asp Leu Thr Leu Asp
210 215 220
Asp Leu Glu Glu Ile Cys Lys Met Asp Lys Cys Ser Ser Ile Phe Asn
225 230 235 240
Val Val Ser Asn Ser Leu Gly Leu Val Ile Leu Leu Val Leu Leu Phe
245 250 255
Phe Asn
<210> 33
<211> 4024
<212> DNA
<213> Artificial
<220>
<223> PLASMID pTRIP-DeltaU3-CMVeGFP
<400> 33
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggg gcgataagct 2220
tgggagttcc gcgttacata acttacggta aatggcccgc ctggctgacc gcccaacgac 2280
ccccgcccat tgacgtcaat aatgacgtat gttcccatag taacgccaat agggactttc 2340
cattgacgtc aatgggtgga gtatttacgg taaactgccc acttggcagt acatcaagtg 2400
tatcatatgc caagtacgcc ccctattgac gtcaatgacg gtaaatggcc cgcctggcat 2460
tatgcccagt acatgacctt atgggacttt cctacttggc agtacatcta cgtattagtc 2520
atcgctatta ccatggtgat gcggttttgg cagtacatca atgggcgtgg atagcggttt 2580
gactcacggg gatttccaag tctccacccc attgacgtca atgggagttt gttttggcac 2640
caaaatcaac gggactttcc aaaatgtcgt aacaactccg ccccattgac gcaaatgggc 2700
ggtaggcgtg tacggtggga ggtctatata agcagagctc gtttagtgaa ccgtcagatc 2760
gcctggagac gccatccacg ctgttttgac ctccatagaa gacaccgact ctagaggatc 2820
cccaccggtc gccaccatgg tgagcaaggg cgaggagctg ttcaccgggg tggtgcccat 2880
cctggtcgag ctggacggcg acgtaaacgg ccacaagttc agcgtgtccg gcgagggcga 2940
gggcgatgcc acctacggca agctgaccct gaagttcatc tgcaccaccg gcaagctgcc 3000
cgtgccctgg cccaccctcg tgaccaccct gacctacggc gtgcagtgct tcagccgcta 3060
ccccgaccac atgaagcagc acgacttctt caagtccgcc atgcccgaag gctacgtcca 3120
ggagcgcacc atcttcttca aggacgacgg caactacaag acccgcgccg aggtgaagtt 3180
cgagggcgac accctggtga accgcatcga gctgaagggc atcgacttca aggaggacgg 3240
caacatcctg gggcacaagc tggagtacaa ctacaacagc cacaacgtct atatcatggc 3300
cgacaagcag aagaacggca tcaaggtgaa cttcaagatc cgccacaaca tcgaggacgg 3360
cagcgtgcag ctcgccgacc actaccagca gaacaccccc atcggcgacg gccccgtgct 3420
gctgcccgac aaccactacc tgagcaccca gtccgccctg agcaaagacc ccaacgagaa 3480
gcgcgatcac atggtcctgc tggagttcgt gaccgccgcc gggatcactc tcggcatgga 3540
cgagctgtac aagtaaagcg gccggactct agctcgagac ctagaaaaac atggagcaat 3600
cacaagtagc aatacagcag ctaccaatgc tgattgtgcc tggctagaag cacaagagga 3660
ggaggaggtg ggttttccag tcacacctca ggtaccttta agaccaatga cttacaaggc 3720
agctgtagat cttagccact ttttaaaaga aaagggggga ctggaagggc taattcactc 3780
ccaacgaaga caagatcgtc gagagatgct gcatataagc agctgctttt tgcttgtact 3840
gggtctctct ggttagacca gatctgagcc tgggagctct ctggctaact agggaaccca 3900
ctgcttaagc ctcaataaag cttgccttga gtgcttcaag tagtgtgtgc ccgtctgttg 3960
tgtgactctg gtaactagag atccctcaga cccttttagt cagtgtggaa aatctctagc 4020
agtg 4024
<210> 34
<211> 4927
<212> DNA
<213> Artificial
<220>
<223> plasmid pTRIP-deltaU3-CMV-MSP142 CO-WPRE
<220>
<221> misc_feature
<222> (1)..(4927)
<223> Complete nucleotide sequence of the provirus
<400> 34
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggc tgatacgcgt 2220
ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc ccaacgaccc 2280
ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag ggactttcca 2340
ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac atcaagtgta 2400
tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg cctggcatta 2460
tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg tattagtcat 2520
cgctattacc atggtgatgc ggttttggca gtacatcaat gggcgtggat agcggtttga 2580
ctcacgggga tttccaagtc tccaccccat tgacgtcaat gggagtttgt tttggcacca 2640
aaatcaacgg gactttccaa aatgtcgtaa caactccgcc ccattgacgc aaatgggcgg 2700
taggcgtgta cggtgggagg tctatataag cagagctcgt ttagtgaacc gtcagatcgc 2760
ctggagacgc catccacgct gttttgacct ccatagaaga caccgcgatc ggatccgcca 2820
ccatgctgct gtccgtgccc ctgctgctgg gcctgctggg actggccgtg gccgctcccg 2880
agaaggacat cctgagcgag ttcaccaacg agagcctgta cgtgtacaca aagagactgg 2940
gcagcaccta caagagcctg aagaaacaca tgctgcggga gttcagcacc atcaaagaag 3000
atatgaccaa cggcctgaac aacaagagcc agaagcggaa cgacttcctg gaggtgctgt 3060
cccacgagct ggacctgttc aaggacctga gcaccaataa gtacgtgatc cggaacccct 3120
accagctgct ggacaacgac aagaaggaca agcagatcgt caacctgaag tacgccacca 3180
agggcatcaa cgaggatatc gagacaacca ccgacggcat caagttcttc aacaagatgg 3240
tggagctgta caacacccag ctggccgccg tgaaggagca gatcgccacc atcgaggccg 3300
agacaaacga cacaaacaag gaggagaaga agaagtacat ccccatcctg gaggacctga 3360
agggcctgta cgagacagtg attggccagg ccgaggagta cagcgaggag ctgcagaaca 3420
gactggataa ctacaagaac gagaaggccg agttcgagat cctgaccaag aacctggaga 3480
agtacatcca gatcgacgag aagctggacg agttcgtgga gcacgccgag aacaacaagc 3540
atatcgcctc tatcgccctg aacaacctga ataagagcgg cctggtggga gagggcgaga 3600
gcaaaaagat cctggctaag atgctgaaca tggacggcat ggatctgctg ggcgtggacc 3660
ccaagcacgt gtgcgtggac accagagaca tccccaagaa cgccggctgc ttcagggacg 3720
acaacggcac cgaggagtgg agatgtctgc tgggctacaa gaagggcgag ggcaacacct 3780
gcgtggagaa caataacccc acctgcgaca tcaacaacgg cggctgcgac cccaccgcca 3840
gctgccagaa cgccgagagc accgagaact ccaagaagat catctgcacc tgcaaggagc 3900
ccacccccaa cgcctactac gagggcgtgt tctgcagcag cagctccttc atgggctgat 3960
gactcgagct caagcttcga attcccgata atcaacctct ggattacaaa atttgtgaaa 4020
gattgactgg tattcttaac tatgttgctc cttttacgct atgtggatac gctgctttaa 4080
tgcctttgta tcatgctatt gcttcccgta tggctttcat tttctcctcc ttgtataaat 4140
cctggttgct gtctctttat gaggagttgt ggcccgttgt caggcaacgt ggcgtggtgt 4200
gcactgtgtt tgctgacgca acccccactg gttggggcat tgccaccacc tgtcagctcc 4260
tttccgggac tttcgctttc cccctcccta ttgccacggc ggaactcatc gccgcctgcc 4320
ttgcccgctg ctggacaggg gctcggctgt tgggcactga caattccgtg gtgttgtcgg 4380
ggaagctgac gtcctttcca tggctgctcg cctgtgttgc cacctggatt ctgcgcggga 4440
cgtccttctg ctacgtccct tcggccctca atccagcgga ccttccttcc cgcggcctgc 4500
tgccggctct gcggcctctt ccgcgtcttc gccttcgccc tcagacgagt cggatctccc 4560
tttgggccgc ctccccgcgt cgacgcgtga attcggtacc tttaagacca atgacttaca 4620
aggcagctgt agatcttagc cactttttaa aagaaaaggg gggactggaa gggctaattc 4680
actcccaacg aagacaagat cgtcgagaga tgctgcatat aagcagctgc tttttgcttg 4740
tactgggtct ctctggttag accagatctg agcctgggag ctctctggct aactagggaa 4800
cccactgctt aagcctcaat aaagcttgcc ttgagtgctt caagtagtgt gtgcccgtct 4860
gttgtgtgac tctggtaact agagatccct cagacccttt tagtcagtgt ggaaaatctc 4920
tagcagt 4927
<210> 35
<211> 1140
<212> DNA
<213> Artificial
<220>
<223> Plasmid pTRIP-deltaU3-CMV-MSP142 CO-WPRE
<220>
<221> misc_feature
<222> (1)..(1140)
<223> Sequence of transgene for MSP142-CO
<220>
<221> CDS
<222> (1)..(1140)
<400> 35
atg ctg ctg tcc gtg ccc ctg ctg ctg ggc ctg ctg gga ctg gcc gtg 48
Met Leu Leu Ser Val Pro Leu Leu Leu Gly Leu Leu Gly Leu Ala Val
1 5 10 15
gcc gct ccc gag aag gac atc ctg agc gag ttc acc aac gag agc ctg 96
Ala Ala Pro Glu Lys Asp Ile Leu Ser Glu Phe Thr Asn Glu Ser Leu
20 25 30
tac gtg tac aca aag aga ctg ggc agc acc tac aag agc ctg aag aaa 144
Tyr Val Tyr Thr Lys Arg Leu Gly Ser Thr Tyr Lys Ser Leu Lys Lys
35 40 45
cac atg ctg cgg gag ttc agc acc atc aaa gaa gat atg acc aac ggc 192
His Met Leu Arg Glu Phe Ser Thr Ile Lys Glu Asp Met Thr Asn Gly
50 55 60
ctg aac aac aag agc cag aag cgg aac gac ttc ctg gag gtg ctg tcc 240
Leu Asn Asn Lys Ser Gln Lys Arg Asn Asp Phe Leu Glu Val Leu Ser
65 70 75 80
cac gag ctg gac ctg ttc aag gac ctg agc acc aat aag tac gtg atc 288
His Glu Leu Asp Leu Phe Lys Asp Leu Ser Thr Asn Lys Tyr Val Ile
85 90 95
cgg aac ccc tac cag ctg ctg gac aac gac aag aag gac aag cag atc 336
Arg Asn Pro Tyr Gln Leu Leu Asp Asn Asp Lys Lys Asp Lys Gln Ile
100 105 110
gtc aac ctg aag tac gcc acc aag ggc atc aac gag gat atc gag aca 384
Val Asn Leu Lys Tyr Ala Thr Lys Gly Ile Asn Glu Asp Ile Glu Thr
115 120 125
acc acc gac ggc atc aag ttc ttc aac aag atg gtg gag ctg tac aac 432
Thr Thr Asp Gly Ile Lys Phe Phe Asn Lys Met Val Glu Leu Tyr Asn
130 135 140
acc cag ctg gcc gcc gtg aag gag cag atc gcc acc atc gag gcc gag 480
Thr Gln Leu Ala Ala Val Lys Glu Gln Ile Ala Thr Ile Glu Ala Glu
145 150 155 160
aca aac gac aca aac aag gag gag aag aag aag tac atc ccc atc ctg 528
Thr Asn Asp Thr Asn Lys Glu Glu Lys Lys Lys Tyr Ile Pro Ile Leu
165 170 175
gag gac ctg aag ggc ctg tac gag aca gtg att ggc cag gcc gag gag 576
Glu Asp Leu Lys Gly Leu Tyr Glu Thr Val Ile Gly Gln Ala Glu Glu
180 185 190
tac agc gag gag ctg cag aac aga ctg gat aac tac aag aac gag aag 624
Tyr Ser Glu Glu Leu Gln Asn Arg Leu Asp Asn Tyr Lys Asn Glu Lys
195 200 205
gcc gag ttc gag atc ctg acc aag aac ctg gag aag tac atc cag atc 672
Ala Glu Phe Glu Ile Leu Thr Lys Asn Leu Glu Lys Tyr Ile Gln Ile
210 215 220
gac gag aag ctg gac gag ttc gtg gag cac gcc gag aac aac aag cat 720
Asp Glu Lys Leu Asp Glu Phe Val Glu His Ala Glu Asn Asn Lys His
225 230 235 240
atc gcc tct atc gcc ctg aac aac ctg aat aag agc ggc ctg gtg gga 768
Ile Ala Ser Ile Ala Leu Asn Asn Leu Asn Lys Ser Gly Leu Val Gly
245 250 255
gag ggc gag agc aaa aag atc ctg gct aag atg ctg aac atg gac ggc 816
Glu Gly Glu Ser Lys Lys Ile Leu Ala Lys Met Leu Asn Met Asp Gly
260 265 270
atg gat ctg ctg ggc gtg gac ccc aag cac gtg tgc gtg gac acc aga 864
Met Asp Leu Leu Gly Val Asp Pro Lys His Val Cys Val Asp Thr Arg
275 280 285
gac atc ccc aag aac gcc ggc tgc ttc agg gac gac aac ggc acc gag 912
Asp Ile Pro Lys Asn Ala Gly Cys Phe Arg Asp Asp Asn Gly Thr Glu
290 295 300
gag tgg aga tgt ctg ctg ggc tac aag aag ggc gag ggc aac acc tgc 960
Glu Trp Arg Cys Leu Leu Gly Tyr Lys Lys Gly Glu Gly Asn Thr Cys
305 310 315 320
gtg gag aac aat aac ccc acc tgc gac atc aac aac ggc ggc tgc gac 1008
Val Glu Asn Asn Asn Pro Thr Cys Asp Ile Asn Asn Gly Gly Cys Asp
325 330 335
ccc acc gcc agc tgc cag aac gcc gag agc acc gag aac tcc aag aag 1056
Pro Thr Ala Ser Cys Gln Asn Ala Glu Ser Thr Glu Asn Ser Lys Lys
340 345 350
atc atc tgc acc tgc aag gag ccc acc ccc aac gcc tac tac gag ggc 1104
Ile Ile Cys Thr Cys Lys Glu Pro Thr Pro Asn Ala Tyr Tyr Glu Gly
355 360 365
gtg ttc tgc agc agc agc tcc ttc atg ggc tga tga 1140
Val Phe Cys Ser Ser Ser Ser Phe Met Gly
370 375
<210> 36
<211> 378
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 36
Met Leu Leu Ser Val Pro Leu Leu Leu Gly Leu Leu Gly Leu Ala Val
1 5 10 15
Ala Ala Pro Glu Lys Asp Ile Leu Ser Glu Phe Thr Asn Glu Ser Leu
20 25 30
Tyr Val Tyr Thr Lys Arg Leu Gly Ser Thr Tyr Lys Ser Leu Lys Lys
35 40 45
His Met Leu Arg Glu Phe Ser Thr Ile Lys Glu Asp Met Thr Asn Gly
50 55 60
Leu Asn Asn Lys Ser Gln Lys Arg Asn Asp Phe Leu Glu Val Leu Ser
65 70 75 80
His Glu Leu Asp Leu Phe Lys Asp Leu Ser Thr Asn Lys Tyr Val Ile
85 90 95
Arg Asn Pro Tyr Gln Leu Leu Asp Asn Asp Lys Lys Asp Lys Gln Ile
100 105 110
Val Asn Leu Lys Tyr Ala Thr Lys Gly Ile Asn Glu Asp Ile Glu Thr
115 120 125
Thr Thr Asp Gly Ile Lys Phe Phe Asn Lys Met Val Glu Leu Tyr Asn
130 135 140
Thr Gln Leu Ala Ala Val Lys Glu Gln Ile Ala Thr Ile Glu Ala Glu
145 150 155 160
Thr Asn Asp Thr Asn Lys Glu Glu Lys Lys Lys Tyr Ile Pro Ile Leu
165 170 175
Glu Asp Leu Lys Gly Leu Tyr Glu Thr Val Ile Gly Gln Ala Glu Glu
180 185 190
Tyr Ser Glu Glu Leu Gln Asn Arg Leu Asp Asn Tyr Lys Asn Glu Lys
195 200 205
Ala Glu Phe Glu Ile Leu Thr Lys Asn Leu Glu Lys Tyr Ile Gln Ile
210 215 220
Asp Glu Lys Leu Asp Glu Phe Val Glu His Ala Glu Asn Asn Lys His
225 230 235 240
Ile Ala Ser Ile Ala Leu Asn Asn Leu Asn Lys Ser Gly Leu Val Gly
245 250 255
Glu Gly Glu Ser Lys Lys Ile Leu Ala Lys Met Leu Asn Met Asp Gly
260 265 270
Met Asp Leu Leu Gly Val Asp Pro Lys His Val Cys Val Asp Thr Arg
275 280 285
Asp Ile Pro Lys Asn Ala Gly Cys Phe Arg Asp Asp Asn Gly Thr Glu
290 295 300
Glu Trp Arg Cys Leu Leu Gly Tyr Lys Lys Gly Glu Gly Asn Thr Cys
305 310 315 320
Val Glu Asn Asn Asn Pro Thr Cys Asp Ile Asn Asn Gly Gly Cys Asp
325 330 335
Pro Thr Ala Ser Cys Gln Asn Ala Glu Ser Thr Glu Asn Ser Lys Lys
340 345 350
Ile Ile Cys Thr Cys Lys Glu Pro Thr Pro Asn Ala Tyr Tyr Glu Gly
355 360 365
Val Phe Cys Ser Ser Ser Ser Phe Met Gly
370 375
<210> 37
<211> 4300
<212> DNA
<213> Artificial
<220>
<223> plasmid pTRIP-deltaU3-CMV-Hep17 CO-WPRE
<220>
<221> misc_feature
<222> (1)..(4300)
<223> Complete nucleotide sequence of the provirus
<400> 37
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggc tgatacgcgt 2220
ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc ccaacgaccc 2280
ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag ggactttcca 2340
ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac atcaagtgta 2400
tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg cctggcatta 2460
tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg tattagtcat 2520
cgctattacc atggtgatgc ggttttggca gtacatcaat gggcgtggat agcggtttga 2580
ctcacgggga tttccaagtc tccaccccat tgacgtcaat gggagtttgt tttggcacca 2640
aaatcaacgg gactttccaa aatgtcgtaa caactccgcc ccattgacgc aaatgggcgg 2700
taggcgtgta cggtgggagg tctatataag cagagctcgt ttagtgaacc gtcagatcgc 2760
ctggagacgc catccacgct gttttgacct ccatagaaga caccgcgatc ggatccgcca 2820
ccatgaagat caatatcgcc agcatcatct ttatcatctt cagcctgtgc ctggtcaacg 2880
acgcctacgg caagaacaag tacgggaaga acggcaagta cggcagccag aacgtgatca 2940
agaaacacgg cgagcccgtg atcaacgtgc aggacctgat cagcgacatg gtccggaaag 3000
aggaagagat cgtcaagctg accaagaaca agaagagcct gaggaagatc aacgtggccc 3060
tggccaccgc cctgagcgtg gtgtccgcca tcctgctggg cggagccggc ctggtcatgt 3120
acaacaccga gaagggcaga aggcccttcc agatcggcaa gagcaagaaa ggcggcagcg 3180
ccatggccag ggacagcagc ttccccatga acgaggaaag ccccctgggc ttcagccccg 3240
aggaaatgga agccgtggcc agcaagttcc gggagagcat gctgaaggac ggcgtgcctg 3300
cccccagcaa cacccccaac gtgcagaact gatgactcga gctcaagctt cgaattcccg 3360
ataatcaacc tctggattac aaaatttgtg aaagattgac tggtattctt aactatgttg 3420
ctccttttac gctatgtgga tacgctgctt taatgccttt gtatcatgct attgcttccc 3480
gtatggcttt cattttctcc tccttgtata aatcctggtt gctgtctctt tatgaggagt 3540
tgtggcccgt tgtcaggcaa cgtggcgtgg tgtgcactgt gtttgctgac gcaaccccca 3600
ctggttgggg cattgccacc acctgtcagc tcctttccgg gactttcgct ttccccctcc 3660
ctattgccac ggcggaactc atcgccgcct gccttgcccg ctgctggaca ggggctcggc 3720
tgttgggcac tgacaattcc gtggtgttgt cggggaagct gacgtccttt ccatggctgc 3780
tcgcctgtgt tgccacctgg attctgcgcg ggacgtcctt ctgctacgtc ccttcggccc 3840
tcaatccagc ggaccttcct tcccgcggcc tgctgccggc tctgcggcct cttccgcgtc 3900
ttcgccttcg ccctcagacg agtcggatct ccctttgggc cgcctccccg cgtcgacgcg 3960
tgaattcggt acctttaaga ccaatgactt acaaggcagc tgtagatctt agccactttt 4020
taaaagaaaa ggggggactg gaagggctaa ttcactccca acgaagacaa gatcgtcgag 4080
agatgctgca tataagcagc tgctttttgc ttgtactggg tctctctggt tagaccagat 4140
ctgagcctgg gagctctctg gctaactagg gaacccactg cttaagcctc aataaagctt 4200
gccttgagtg cttcaagtag tgtgtgcccg tctgttgtgt gactctggta actagagatc 4260
cctcagaccc ttttagtcag tgtggaaaat ctctagcagt 4300
<210> 38
<211> 513
<212> DNA
<213> Artificial
<220>
<223> Sequence for transgene for Hep17-CO
<220>
<221> CDS
<222> (1)..(513)
<400> 38
atg aag atc aat atc gcc agc atc atc ttt atc atc ttc agc ctg tgc 48
Met Lys Ile Asn Ile Ala Ser Ile Ile Phe Ile Ile Phe Ser Leu Cys
1 5 10 15
ctg gtc aac gac gcc tac ggc aag aac aag tac ggg aag aac ggc aag 96
Leu Val Asn Asp Ala Tyr Gly Lys Asn Lys Tyr Gly Lys Asn Gly Lys
20 25 30
tac ggc agc cag aac gtg atc aag aaa cac ggc gag ccc gtg atc aac 144
Tyr Gly Ser Gln Asn Val Ile Lys Lys His Gly Glu Pro Val Ile Asn
35 40 45
gtg cag gac ctg atc agc gac atg gtc cgg aaa gag gaa gag atc gtc 192
Val Gln Asp Leu Ile Ser Asp Met Val Arg Lys Glu Glu Glu Ile Val
50 55 60
aag ctg acc aag aac aag aag agc ctg agg aag atc aac gtg gcc ctg 240
Lys Leu Thr Lys Asn Lys Lys Ser Leu Arg Lys Ile Asn Val Ala Leu
65 70 75 80
gcc acc gcc ctg agc gtg gtg tcc gcc atc ctg ctg ggc gga gcc ggc 288
Ala Thr Ala Leu Ser Val Val Ser Ala Ile Leu Leu Gly Gly Ala Gly
85 90 95
ctg gtc atg tac aac acc gag aag ggc aga agg ccc ttc cag atc ggc 336
Leu Val Met Tyr Asn Thr Glu Lys Gly Arg Arg Pro Phe Gln Ile Gly
100 105 110
aag agc aag aaa ggc ggc agc gcc atg gcc agg gac agc agc ttc ccc 384
Lys Ser Lys Lys Gly Gly Ser Ala Met Ala Arg Asp Ser Ser Phe Pro
115 120 125
atg aac gag gaa agc ccc ctg ggc ttc agc ccc gag gaa atg gaa gcc 432
Met Asn Glu Glu Ser Pro Leu Gly Phe Ser Pro Glu Glu Met Glu Ala
130 135 140
gtg gcc agc aag ttc cgg gag agc atg ctg aag gac ggc gtg cct gcc 480
Val Ala Ser Lys Phe Arg Glu Ser Met Leu Lys Asp Gly Val Pro Ala
145 150 155 160
ccc agc aac acc ccc aac gtg cag aac tga tga 513
Pro Ser Asn Thr Pro Asn Val Gln Asn
165
<210> 39
<211> 169
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 39
Met Lys Ile Asn Ile Ala Ser Ile Ile Phe Ile Ile Phe Ser Leu Cys
1 5 10 15
Leu Val Asn Asp Ala Tyr Gly Lys Asn Lys Tyr Gly Lys Asn Gly Lys
20 25 30
Tyr Gly Ser Gln Asn Val Ile Lys Lys His Gly Glu Pro Val Ile Asn
35 40 45
Val Gln Asp Leu Ile Ser Asp Met Val Arg Lys Glu Glu Glu Ile Val
50 55 60
Lys Leu Thr Lys Asn Lys Lys Ser Leu Arg Lys Ile Asn Val Ala Leu
65 70 75 80
Ala Thr Ala Leu Ser Val Val Ser Ala Ile Leu Leu Gly Gly Ala Gly
85 90 95
Leu Val Met Tyr Asn Thr Glu Lys Gly Arg Arg Pro Phe Gln Ile Gly
100 105 110
Lys Ser Lys Lys Gly Gly Ser Ala Met Ala Arg Asp Ser Ser Phe Pro
115 120 125
Met Asn Glu Glu Ser Pro Leu Gly Phe Ser Pro Glu Glu Met Glu Ala
130 135 140
Val Ala Ser Lys Phe Arg Glu Ser Met Leu Lys Asp Gly Val Pro Ala
145 150 155 160
Pro Ser Asn Thr Pro Asn Val Gln Asn
165
<210> 40
<211> 4261
<212> DNA
<213> Artificial
<220>
<223> plasmid pTRIP-deltaU3-CMV-Hep17 deltaSP CO-WPRE
<220>
<221> misc_feature
<222> (1)..(4261)
<223> Complete sequence of the plasmid
<220>
<221> misc_feature
<222> (1)..(4261)
<223> Complete nucleotide sequence of the plasmid
<400> 40
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggc tgatacgcgt 2220
ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc ccaacgaccc 2280
ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag ggactttcca 2340
ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac atcaagtgta 2400
tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg cctggcatta 2460
tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg tattagtcat 2520
cgctattacc atggtgatgc ggttttggca gtacatcaat gggcgtggat agcggtttga 2580
ctcacgggga tttccaagtc tccaccccat tgacgtcaat gggagtttgt tttggcacca 2640
aaatcaacgg gactttccaa aatgtcgtaa caactccgcc ccattgacgc aaatgggcgg 2700
taggcgtgta cggtgggagg tctatataag cagagctcgt ttagtgaacc gtcagatcgc 2760
ctggagacgc catccacgct gttttgacct ccatagaaga caccgcgatc ggatccgcca 2820
ccatgctgtg cctggtcaac gacgcctacg gcaagaacaa gtacgggaag aacggcaagt 2880
acggcagcca gaacgtgatc aagaaacacg gcgagcccgt gatcaacgtg caggacctga 2940
tcagcgacat ggtccggaaa gaggaagaga tcgtcaagct gaccaagaac aagaagagcc 3000
tgaggaagat caacgtggcc ctggccaccg ccctgagcgt ggtgtccgcc atcctgctgg 3060
gcggagccgg cctggtcatg tacaacaccg agaagggcag aaggcccttc cagatcggca 3120
agagcaagaa aggcggcagc gccatggcca gggacagcag cttccccatg aacgaggaaa 3180
gccccctggg cttcagcccc gaggaaatgg aagccgtggc cagcaagttc cgggagagca 3240
tgctgaagga cggcgtgcct gcccccagca acacccccaa cgtgcagaac tgatgactcg 3300
agctcaagct tcgaattccc gataatcaac ctctggatta caaaatttgt gaaagattga 3360
ctggtattct taactatgtt gctcctttta cgctatgtgg atacgctgct ttaatgcctt 3420
tgtatcatgc tattgcttcc cgtatggctt tcattttctc ctccttgtat aaatcctggt 3480
tgctgtctct ttatgaggag ttgtggcccg ttgtcaggca acgtggcgtg gtgtgcactg 3540
tgtttgctga cgcaaccccc actggttggg gcattgccac cacctgtcag ctcctttccg 3600
ggactttcgc tttccccctc cctattgcca cggcggaact catcgccgcc tgccttgccc 3660
gctgctggac aggggctcgg ctgttgggca ctgacaattc cgtggtgttg tcggggaagc 3720
tgacgtcctt tccatggctg ctcgcctgtg ttgccacctg gattctgcgc gggacgtcct 3780
tctgctacgt cccttcggcc ctcaatccag cggaccttcc ttcccgcggc ctgctgccgg 3840
ctctgcggcc tcttccgcgt cttcgccttc gccctcagac gagtcggatc tccctttggg 3900
ccgcctcccc gcgtcgacgc gtgaattcgg tacctttaag accaatgact tacaaggcag 3960
ctgtagatct tagccacttt ttaaaagaaa aggggggact ggaagggcta attcactccc 4020
aacgaagaca agatcgtcga gagatgctgc atataagcag ctgctttttg cttgtactgg 4080
gtctctctgg ttagaccaga tctgagcctg ggagctctct ggctaactag ggaacccact 4140
gcttaagcct caataaagct tgccttgagt gcttcaagta gtgtgtgccc gtctgttgtg 4200
tgactctggt aactagagat ccctcagacc cttttagtca gtgtggaaaa tctctagcag 4260
t 4261
<210> 41
<211> 474
<212> DNA
<213> Artificial
<220>
<223> Sequence of transgene from Hep17deltaSP CO
<220>
<221> CDS
<222> (1)..(474)
<400> 41
atg ctg tgc ctg gtc aac gac gcc tac ggc aag aac aag tac ggg aag 48
Met Leu Cys Leu Val Asn Asp Ala Tyr Gly Lys Asn Lys Tyr Gly Lys
1 5 10 15
aac ggc aag tac ggc agc cag aac gtg atc aag aaa cac ggc gag ccc 96
Asn Gly Lys Tyr Gly Ser Gln Asn Val Ile Lys Lys His Gly Glu Pro
20 25 30
gtg atc aac gtg cag gac ctg atc agc gac atg gtc cgg aaa gag gaa 144
Val Ile Asn Val Gln Asp Leu Ile Ser Asp Met Val Arg Lys Glu Glu
35 40 45
gag atc gtc aag ctg acc aag aac aag aag agc ctg agg aag atc aac 192
Glu Ile Val Lys Leu Thr Lys Asn Lys Lys Ser Leu Arg Lys Ile Asn
50 55 60
gtg gcc ctg gcc acc gcc ctg agc gtg gtg tcc gcc atc ctg ctg ggc 240
Val Ala Leu Ala Thr Ala Leu Ser Val Val Ser Ala Ile Leu Leu Gly
65 70 75 80
gga gcc ggc ctg gtc atg tac aac acc gag aag ggc aga agg ccc ttc 288
Gly Ala Gly Leu Val Met Tyr Asn Thr Glu Lys Gly Arg Arg Pro Phe
85 90 95
cag atc ggc aag agc aag aaa ggc ggc agc gcc atg gcc agg gac agc 336
Gln Ile Gly Lys Ser Lys Lys Gly Gly Ser Ala Met Ala Arg Asp Ser
100 105 110
agc ttc ccc atg aac gag gaa agc ccc ctg ggc ttc agc ccc gag gaa 384
Ser Phe Pro Met Asn Glu Glu Ser Pro Leu Gly Phe Ser Pro Glu Glu
115 120 125
atg gaa gcc gtg gcc agc aag ttc cgg gag agc atg ctg aag gac ggc 432
Met Glu Ala Val Ala Ser Lys Phe Arg Glu Ser Met Leu Lys Asp Gly
130 135 140
gtg cct gcc ccc agc aac acc ccc aac gtg cag aac tga tga 474
Val Pro Ala Pro Ser Asn Thr Pro Asn Val Gln Asn
145 150 155
<210> 42
<211> 156
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 42
Met Leu Cys Leu Val Asn Asp Ala Tyr Gly Lys Asn Lys Tyr Gly Lys
1 5 10 15
Asn Gly Lys Tyr Gly Ser Gln Asn Val Ile Lys Lys His Gly Glu Pro
20 25 30
Val Ile Asn Val Gln Asp Leu Ile Ser Asp Met Val Arg Lys Glu Glu
35 40 45
Glu Ile Val Lys Leu Thr Lys Asn Lys Lys Ser Leu Arg Lys Ile Asn
50 55 60
Val Ala Leu Ala Thr Ala Leu Ser Val Val Ser Ala Ile Leu Leu Gly
65 70 75 80
Gly Ala Gly Leu Val Met Tyr Asn Thr Glu Lys Gly Arg Arg Pro Phe
85 90 95
Gln Ile Gly Lys Ser Lys Lys Gly Gly Ser Ala Met Ala Arg Asp Ser
100 105 110
Ser Phe Pro Met Asn Glu Glu Ser Pro Leu Gly Phe Ser Pro Glu Glu
115 120 125
Met Glu Ala Val Ala Ser Lys Phe Arg Glu Ser Met Leu Lys Asp Gly
130 135 140
Val Pro Ala Pro Ser Asn Thr Pro Asn Val Gln Asn
145 150 155
<210> 43
<211> 4897
<212> DNA
<213> Artificial
<220>
<223> Plasmid pTRIP-DeltaU3-CMV-CSP CO WPRE
<400> 43
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggc tgatacgcgt 2220
ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc ccaacgaccc 2280
ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag ggactttcca 2340
ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac atcaagtgta 2400
tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg cctggcatta 2460
tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg tattagtcat 2520
cgctattacc atggtgatgc ggttttggca gtacatcaat gggcgtggat agcggtttga 2580
ctcacgggga tttccaagtc tccaccccat tgacgtcaat gggagtttgt tttggcacca 2640
aaatcaacgg gactttccaa aatgtcgtaa caactccgcc ccattgacgc aaatgggcgg 2700
taggcgtgta cggtgggagg tctatataag cagagctcgt ttagtgaacc gtcagatcgc 2760
ctggagacgc catccacgct gttttgacct ccatagaaga caccgcgatc ggatccgcca 2820
ccatgaagaa atgcaccatc ctggtggtgg ccagcctgct gctggtcgat agcctgctgc 2880
ccggctacgg ccagaataag agcgtgcagg cccagcggaa cctgaacgag ctgtgctaca 2940
acgaggaaaa cgacaacaag ctgtaccacg tgctgaacag caagaacggc aagatctaca 3000
accggaacat cgtgaacagg ctgctgggcg acgctctgaa cggcaagccc gaggaaaaga 3060
aggacgaccc ccccaaggac ggcaacaagg acgacctgcc caaagaagag aagaaagacg 3120
atctgcctaa agaggaaaaa aaagacgatc ctcctaagga ccccaagaag gatgaccctc 3180
ctaaagaggc ccagaacaag ctgaaccagc ccgtggtggc cgacgagaac gtggatcagg 3240
gacctggcgc ccctcagggc ccaggcgctc cacagggacc cggggcaccc caggggcctg 3300
gggccccaca gggaccaggg gctcctcagg gccctggcgc acctcagggg ccaggggccc 3360
ctcaggggcc tggcgctccc cagggacctg gcgcaccaca gggccctggg gctccccagg 3420
gcccaggcgc ccctcaggga ccaggcgcac cccagggacc cggcgctcct cagggacctg 3480
gggctccaca ggggccaggc gcaccacagg aacctcccca gcagcctcct cagcagccac 3540
cccagcagcc ccctcagcag cctcctcagc agcccccaca gcagcctcca cagcagccta 3600
gaccccagcc cgacggcaat aacaacaaca ataataacaa cggcaacaac aacgaggaca 3660
gctacgtgcc cagcgccgag cagatcctgg aattcgtgaa gcagatcagc agccagctga 3720
ccgaagagtg gagccagtgc agcgtgacat gcggctctgg cgtgagagtg cggaagcgga 3780
agaacgtgaa caagcagccc gagaacctga ccctggaaga tatcgacacc gagatctgca 3840
agatggacaa gtgcagcagc atcttcaaca tcgtgtccaa cagcctgggc ttcgtgatcc 3900
tgctggtgct ggtgttcttc aactgatgac tcgagctcaa gcttcgaatt cccgataatc 3960
aacctctgga ttacaaaatt tgtgaaagat tgactggtat tcttaactat gttgctcctt 4020
ttacgctatg tggatacgct gctttaatgc ctttgtatca tgctattgct tcccgtatgg 4080
ctttcatttt ctcctccttg tataaatcct ggttgctgtc tctttatgag gagttgtggc 4140
ccgttgtcag gcaacgtggc gtggtgtgca ctgtgtttgc tgacgcaacc cccactggtt 4200
ggggcattgc caccacctgt cagctccttt ccgggacttt cgctttcccc ctccctattg 4260
ccacggcgga actcatcgcc gcctgccttg cccgctgctg gacaggggct cggctgttgg 4320
gcactgacaa ttccgtggtg ttgtcgggga agctgacgtc ctttccatgg ctgctcgcct 4380
gtgttgccac ctggattctg cgcgggacgt ccttctgcta cgtcccttcg gccctcaatc 4440
cagcggacct tccttcccgc ggcctgctgc cggctctgcg gcctcttccg cgtcttcgcc 4500
ttcgccctca gacgagtcgg atctcccttt gggccgcctc cccgcgtcga cgcgtgaatt 4560
cggtaccttt aagaccaatg acttacaagg cagctgagat cttagccact ttttaaaaga 4620
aaagggggga ctggaagggc taattcactc ccaacgaaga caagatcgtc gagagatgct 4680
gcatataagc agctgctttt tgcttgtact gggtctctct ggttagacca gatctgagcc 4740
tgggagctct ctggctaact agggaaccca ctgcttaagc ctcaataaag cttgccttga 4800
gtgcttcaag tagtgtgtgc ccgtctgttg tgtgactctg gtaactagag atccctcaga 4860
cccttttagt cagtgtggaa aatctctagc agtattt 4897
<210> 44
<211> 1107
<212> DNA
<213> Artificial
<220>
<223> Sequence of transgene for CSP-CO
<400> 44
atgaagaaat gcaccatcct ggtggtggcc agcctgctgc tggtcgatag cctgctgccc 60
ggctacggcc agaataagag cgtgcaggcc cagcggaacc tgaacgagct gtgctacaac 120
gaggaaaacg acaacaagct gtaccacgtg ctgaacagca agaacggcaa gatctacaac 180
cggaacatcg tgaacaggct gctgggcgac gctctgaacg gcaagcccga ggaaaagaag 240
gacgaccccc ccaaggacgg caacaaggac gacctgccca aagaagagaa gaaagacgat 300
ctgcctaaag aggaaaaaaa agacgatcct cctaaggacc ccaagaagga tgaccctcct 360
aaagaggccc agaacaagct gaaccagccc gtggtggccg acgagaacgt ggatcaggga 420
cctggcgccc ctcagggccc aggcgctcca cagggacccg gggcacccca ggggcctggg 480
gccccacagg gaccaggggc tcctcagggc cctggcgcac ctcaggggcc aggggcccct 540
caggggcctg gcgctcccca gggacctggc gcaccacagg gccctggggc tccccagggc 600
ccaggcgccc ctcagggacc aggcgcaccc cagggacccg gcgctcctca gggacctggg 660
gctccacagg ggccaggcgc accacaggaa cctccccagc agcctcctca gcagccaccc 720
cagcagcccc ctcagcagcc tcctcagcag cccccacagc agcctccaca gcagcctaga 780
ccccagcccg acggcaataa caacaacaat aataacaacg gcaacaacaa cgaggacagc 840
tacgtgccca gcgccgagca gatcctggaa ttcgtgaagc agatcagcag ccagctgacc 900
gaagagtgga gccagtgcag cgtgacatgc ggctctggcg tgagagtgcg gaagcggaag 960
aacgtgaaca agcagcccga gaacctgacc ctggaagata tcgacaccga gatctgcaag 1020
atggacaagt gcagcagcat cttcaacatc gtgtccaaca gcctgggctt cgtgatcctg 1080
ctggtgctgg tgttcttcaa ctgatga 1107
<210> 45
<211> 4840
<212> DNA
<213> Artificial
<220>
<223> plasmid pTRIP-deltaU3-CMV-CSP deltaSP CO-WPRE
<400> 45
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggc tgatacgcgt 2220
ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc ccaacgaccc 2280
ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag ggactttcca 2340
ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac atcaagtgta 2400
tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg cctggcatta 2460
tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg tattagtcat 2520
cgctattacc atggtgatgc ggttttggca gtacatcaat gggcgtggat agcggtttga 2580
ctcacgggga tttccaagtc tccaccccat tgacgtcaat gggagtttgt tttggcacca 2640
aaatcaacgg gactttccaa aatgtcgtaa caactccgcc ccattgacgc aaatgggcgg 2700
taggcgtgta cggtgggagg tctatataag cagagctcgt ttagtgaacc gtcagatcgc 2760
ctggagacgc catccacgct gttttgacct ccatagaaga caccgcgatc ggatccgcca 2820
ccatgcccgg ctacggccag aataagagcg tgcaggccca gcggaacctg aacgagctgt 2880
gctacaacga ggaaaacgac aacaagctgt accacgtgct gaacagcaag aacggcaaga 2940
tctacaaccg gaacatcgtg aacaggctgc tgggcgacgc tctgaacggc aagcccgagg 3000
aaaagaagga cgaccccccc aaggacggca acaaggacga cctgcccaaa gaagagaaga 3060
aagacgatct gcctaaagag gaaaaaaaag acgatcctcc taaggacccc aagaaggatg 3120
accctcctaa agaggcccag aacaagctga accagcccgt ggtggccgac gagaacgtgg 3180
atcagggacc tggcgcccct cagggcccag gcgctccaca gggacccggg gcaccccagg 3240
ggcctggggc cccacaggga ccaggggctc ctcagggccc tggcgcacct caggggccag 3300
gggcccctca ggggcctggc gctccccagg gacctggcgc accacagggc cctggggctc 3360
cccagggccc aggcgcccct cagggaccag gcgcacccca gggacccggc gctcctcagg 3420
gacctggggc tccacagggg ccaggcgcac cacaggaacc tccccagcag cctcctcagc 3480
agccacccca gcagccccct cagcagcctc ctcagcagcc cccacagcag cctccacagc 3540
agcctagacc ccagcccgac ggcaataaca acaacaataa taacaacggc aacaacaacg 3600
aggacagcta cgtgcccagc gccgagcaga tcctggaatt cgtgaagcag atcagcagcc 3660
agctgaccga agagtggagc cagtgcagcg tgacatgcgg ctctggcgtg agagtgcgga 3720
agcggaagaa cgtgaacaag cagcccgaga acctgaccct ggaagatatc gacaccgaga 3780
tctgcaagat ggacaagtgc agcagcatct tcaacatcgt gtccaacagc ctgggcttcg 3840
tgatcctgct ggtgctggtg ttcttcaact gatgactcga gctcaagctt cgaattcccg 3900
ataatcaacc tctggattac aaaatttgtg aaagattgac tggtattctt aactatgttg 3960
ctccttttac gctatgtgga tacgctgctt taatgccttt gtatcatgct attgcttccc 4020
gtatggcttt cattttctcc tccttgtata aatcctggtt gctgtctctt tatgaggagt 4080
tgtggcccgt tgtcaggcaa cgtggcgtgg tgtgcactgt gtttgctgac gcaaccccca 4140
ctggttgggg cattgccacc acctgtcagc tcctttccgg gactttcgct ttccccctcc 4200
ctattgccac ggcggaactc atcgccgcct gccttgcccg ctgctggaca ggggctcggc 4260
tgttgggcac tgacaattcc gtggtgttgt cggggaagct gacgtccttt ccatggctgc 4320
tcgcctgtgt tgccacctgg attctgcgcg ggacgtcctt ctgctacgtc ccttcggccc 4380
tcaatccagc ggaccttcct tcccgcggcc tgctgccggc tctgcggcct cttccgcgtc 4440
ttcgccttcg ccctcagacg agtcggatct ccctttgggc cgcctccccg cgtcgacgcg 4500
tgaattcggt acctttaaga ccaatgactt acaaggcagc tgtagatctt agccactttt 4560
taaaagaaaa ggggggactg gaagggctaa ttcactccca acgaagacaa gatcgtcgag 4620
agatgctgca tataagcagc tgctttttgc ttgtactggg tctctctggt tagaccagat 4680
ctgagcctgg gagctctctg gctaactagg gaacccactg cttaagcctc aataaagctt 4740
gccttgagtg cttcaagtag tgtgtgcccg tctgttgtgt gactctggta actagagatc 4800
cctcagaccc ttttagtcag tgtggaaaat ctctagcagt 4840
<210> 46
<211> 1053
<212> DNA
<213> Artificial
<220>
<223> Sequence of transgene for CSP-deltaSP
<220>
<221> misc_feature
<222> (1)..(1053)
<223> Sequence of transgene for CSP-deltaSP
<400> 46
atgcccggct acggccagaa taagagcgtg caggcccagc ggaacctgaa cgagctgtgc 60
tacaacgagg aaaacgacaa caagctgtac cacgtgctga acagcaagaa cggcaagatc 120
tacaaccgga acatcgtgaa caggctgctg ggcgacgctc tgaacggcaa gcccgaggaa 180
aagaaggacg acccccccaa ggacggcaac aaggacgacc tgcccaaaga agagaagaaa 240
gacgatctgc ctaaagagga aaaaaaagac gatcctccta aggaccccaa gaaggatgac 300
cctcctaaag aggcccagaa caagctgaac cagcccgtgg tggccgacga gaacgtggat 360
cagggacctg gcgcccctca gggcccaggc gctccacagg gacccggggc accccagggg 420
cctggggccc cacagggacc aggggctcct cagggccctg gcgcacctca ggggccaggg 480
gcccctcagg ggcctggcgc tccccaggga cctggcgcac cacagggccc tggggctccc 540
cagggcccag gcgcccctca gggaccaggc gcaccccagg gacccggcgc tcctcaggga 600
cctggggctc cacaggggcc aggcgcacca caggaacctc cccagcagcc tcctcagcag 660
ccaccccagc agccccctca gcagcctcct cagcagcccc cacagcagcc tccacagcag 720
cctagacccc agcccgacgg caataacaac aacaataata acaacggcaa caacaacgag 780
gacagctacg tgcccagcgc cgagcagatc ctggaattcg tgaagcagat cagcagccag 840
ctgaccgaag agtggagcca gtgcagcgtg acatgcggct ctggcgtgag agtgcggaag 900
cggaagaacg tgaacaagca gcccgagaac ctgaccctgg aagatatcga caccgagatc 960
tgcaagatgg acaagtgcag cagcatcttc aacatcgtgt ccaacagcct gggcttcgtg 1020
atcctgctgg tgctggtgtt cttcaactga tga 1053
<210> 47
<211> 4858
<212> DNA
<213> Artificial
<220>
<223> Plasmid pTRIP-deltaU3-CMV-CSP deltaGPI CO-WPRE
<220>
<221> misc_feature
<222> (1)..(4858)
<223> Complete nucleotide sequence of the provirus
<400> 47
tggaagggct aattcactcc caacgaagac aagatatcct tgatctgtgg atctaccaca 60
cacaaggcta cttccctgat tagcagaact acacaccagg gccagggatc agatatccac 120
tgacctttgg atggtgctac aagctagtac cagttgagcc agagaagtta gaagaagcca 180
acaaaggaga gaacaccagc ttgttacaac ctgtgagcct gcatgggatg gatgacccgg 240
agagagaagt gttagagtgg aggtttgaca gccgcctagc atttcatcac ggtggcccga 300
gagctgcatc cggagtactt caagaactgc tgatatcgag cttgctacaa gggactttcc 360
gctgggggac tttccaggga ggcgtggcct gggcgggact ggggagtggc gagccctcag 420
atcctgcata taagcagctg ctttttgcct gtactgggtc tctctggtta gaccagatct 480
gagcctggga gctctctggc taactaggga acccactgct taagcctcaa taaagcttgc 540
cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga ctctggtaac tagagatccc 600
tcagaccctt ttagtcagtg tggaaaatct ctagcagtgg cgcccgaaca gggacttgaa 660
agcgaaaggg aaaccagagg agctctctcg acgcaggact cggcttgctg aagcgcgcac 720
ggcaagaggc gaggggcggc gactggtgag tacgccaaaa attttgacta gcggaggcta 780
gaaggagaga gatgggtgcg agagcgtcag tattaagcgg gggagaatta gatcgcgatg 840
ggaaaaaatt cggttaaggc cagggggaaa gaaaaaatat aaattaaaac atatagtatg 900
ggcaagcagg gagctagaac gattcgcagt taatcctggc ctgttagaaa catcagaagg 960
ctgtagacaa atactgggac agctacaacc atcccttcag acaggatcag aagaacttag 1020
atcattatat aatacagtag caaccctcta ttgtgtgcat caaaggatag agataaaaga 1080
caccaaggaa gctttagaca agatagagga agagcaaaac aaaagtaaga ccaccgcaca 1140
gcaagcggcc gctgatcttc agacctggag gaggagatat gagggacaat tggagaagtg 1200
aattatataa atataaagta gtaaaaattg aaccattagg agtagcaccc accaaggcaa 1260
agagaagagt ggtgcagaga gaaaaaagag cagtgggaat aggagctttg ttccttgggt 1320
tcttgggagc agcaggaagc actatgggcg cagcgtcaat gacgctgacg gtacaggcca 1380
gacaattatt gtctggtata gtgcagcagc agaacaattt gctgagggct attgaggcgc 1440
aacagcatct gttgcaactc acagtctggg gcatcaagca gctccaggca agaatcctgg 1500
ctgtggaaag atacctaaag gatcaacagc tcctggggat ttggggttgc tctggaaaac 1560
tcatttgcac cactgctgtg ccttggaatg ctagttggag taataaatct ctggaacaga 1620
tttggaatca cacgacctgg atggagtggg acagagaaat taacaattac acaagcttaa 1680
tacactcctt aattgaagaa tcgcaaaacc agcaagaaaa gaatgaacaa gaattattgg 1740
aattagataa atgggcaagt ttgtggaatt ggtttaacat aacaaattgg ctgtggtata 1800
taaaattatt cataatgata gtaggaggct tggtaggttt aagaatagtt tttgctgtac 1860
tttctatagt gaatagagtt aggcagggat attcaccatt atcgtttcag acccacctcc 1920
caaccccgag gggacccgac aggcccgaag gaatagaaga agaaggtgga gagagagaca 1980
gagacagatc cattcgatta gtgaacggat ctcgacggta tcgccgaatt cacaaatggc 2040
agtattcatc cacaatttta aaagaaaagg ggggattggg gggtacagtg caggggaaag 2100
aatagtagac ataatagcaa cagacataca aactaaagaa ttacaaaaac aaattacaaa 2160
aattcaaaat tttcgggttt attacaggga cagcagagat ccactttggc tgatacgcgt 2220
ggagttccgc gttacataac ttacggtaaa tggcccgcct ggctgaccgc ccaacgaccc 2280
ccgcccattg acgtcaataa tgacgtatgt tcccatagta acgccaatag ggactttcca 2340
ttgacgtcaa tgggtggagt atttacggta aactgcccac ttggcagtac atcaagtgta 2400
tcatatgcca agtacgcccc ctattgacgt caatgacggt aaatggcccg cctggcatta 2460
tgcccagtac atgaccttat gggactttcc tacttggcag tacatctacg tattagtcat 2520
cgctattacc atggtgatgc ggttttggca gtacatcaat gggcgtggat agcggtttga 2580
ctcacgggga tttccaagtc tccaccccat tgacgtcaat gggagtttgt tttggcacca 2640
aaatcaacgg gactttccaa aatgtcgtaa caactccgcc ccattgacgc aaatgggcgg 2700
taggcgtgta cggtgggagg tctatataag cagagctcgt ttagtgaacc gtcagatcgc 2760
ctggagacgc catccacgct gttttgacct ccatagaaga caccgcgatc ggatccgcca 2820
ccatgaagaa atgcaccatc ctggtggtgg ccagcctgct gctggtcgat agcctgctgc 2880
ccggctacgg ccagaataag agcgtgcagg cccagcggaa cctgaacgag ctgtgctaca 2940
acgaggaaaa cgacaacaag ctgtaccacg tgctgaacag caagaacggc aagatctaca 3000
accggaacat cgtgaacagg ctgctgggcg acgctctgaa cggcaagccc gaggaaaaga 3060
aggacgaccc ccccaaggac ggcaacaagg acgacctgcc caaagaagag aagaaagacg 3120
atctgcctaa agaggaaaaa aaagacgatc ctcctaagga ccccaagaag gatgaccctc 3180
ctaaagaggc ccagaacaag ctgaaccagc ccgtggtggc cgacgagaac gtggatcagg 3240
gacctggcgc ccctcagggc ccaggcgctc cacagggacc cggggcaccc caggggcctg 3300
gggccccaca gggaccaggg gctcctcagg gccctggcgc acctcagggg ccaggggccc 3360
ctcaggggcc tggcgctccc cagggacctg gcgcaccaca gggccctggg gctccccagg 3420
gcccaggcgc ccctcaggga ccaggcgcac cccagggacc cggcgctcct cagggacctg 3480
gggctccaca ggggccaggc gcaccacagg aacctcccca gcagcctcct cagcagccac 3540
cccagcagcc ccctcagcag cctcctcagc agcccccaca gcagcctcca cagcagccta 3600
gaccccagcc cgacggcaat aacaacaaca ataataacaa cggcaacaac aacgaggaca 3660
gctacgtgcc cagcgccgag cagatcctgg aattcgtgaa gcagatcagc agccagctga 3720
ccgaagagtg gagccagtgc agcgtgacat gcggctctgg cgtgagagtg cggaagcgga 3780
agaacgtgaa caagcagccc gagaacctga ccctggaaga tatcgacacc gagatctgca 3840
agatggacaa gtgcagcagc atcttcaaca tcgtgtccaa cagcctgtga tgactcgagc 3900
tcaagcttcg aattcccgat aatcaacctc tggattacaa aatttgtgaa agattgactg 3960
gtattcttaa ctatgttgct ccttttacgc tatgtggata cgctgcttta atgcctttgt 4020
atcatgctat tgcttcccgt atggctttca ttttctcctc cttgtataaa tcctggttgc 4080
tgtctcttta tgaggagttg tggcccgttg tcaggcaacg tggcgtggtg tgcactgtgt 4140
ttgctgacgc aacccccact ggttggggca ttgccaccac ctgtcagctc ctttccggga 4200
ctttcgcttt ccccctccct attgccacgg cggaactcat cgccgcctgc cttgcccgct 4260
gctggacagg ggctcggctg ttgggcactg acaattccgt ggtgttgtcg gggaagctga 4320
cgtcctttcc atggctgctc gcctgtgttg ccacctggat tctgcgcggg acgtccttct 4380
gctacgtccc ttcggccctc aatccagcgg accttccttc ccgcggcctg ctgccggctc 4440
tgcggcctct tccgcgtctt cgccttcgcc ctcagacgag tcggatctcc ctttgggccg 4500
cctccccgcg tcgacgcgtg aattcggtac ctttaagacc aatgacttac aaggcagctg 4560
tagatcttag ccacttttta aaagaaaagg ggggactgga agggctaatt cactcccaac 4620
gaagacaaga tcgtcgagag atgctgcata taagcagctg ctttttgctt gtactgggtc 4680
tctctggtta gaccagatct gagcctggga gctctctggc taactaggga acccactgct 4740
taagcctcaa taaagcttgc cttgagtgct tcaagtagtg tgtgcccgtc tgttgtgtga 4800
ctctggtaac tagagatccc tcagaccctt ttagtcagtg tggaaaatct ctagcagt 4858
<210> 48
<211> 1071
<212> DNA
<213> Artificial
<220>
<223> Sequence of transgene for CSP-delta GPI CO
<400> 48
atgaagaaat gcaccatcct ggtggtggcc agcctgctgc tggtcgatag cctgctgccc 60
ggctacggcc agaataagag cgtgcaggcc cagcggaacc tgaacgagct gtgctacaac 120
gaggaaaacg acaacaagct gtaccacgtg ctgaacagca agaacggcaa gatctacaac 180
cggaacatcg tgaacaggct gctgggcgac gctctgaacg gcaagcccga ggaaaagaag 240
gacgaccccc ccaaggacgg caacaaggac gacctgccca aagaagagaa gaaagacgat 300
ctgcctaaag aggaaaaaaa agacgatcct cctaaggacc ccaagaagga tgaccctcct 360
aaagaggccc agaacaagct gaaccagccc gtggtggccg acgagaacgt ggatcaggga 420
cctggcgccc ctcagggccc aggcgctcca cagggacccg gggcacccca ggggcctggg 480
gccccacagg gaccaggggc tcctcagggc cctggcgcac ctcaggggcc aggggcccct 540
caggggcctg gcgctcccca gggacctggc gcaccacagg gccctggggc tccccagggc 600
ccaggcgccc ctcagggacc aggcgcaccc cagggacccg gcgctcctca gggacctggg 660
gctccacagg ggccaggcgc accacaggaa cctccccagc agcctcctca gcagccaccc 720
cagcagcccc ctcagcagcc tcctcagcag cccccacagc agcctccaca gcagcctaga 780
ccccagcccg acggcaataa caacaacaat aataacaacg gcaacaacaa cgaggacagc 840
tacgtgccca gcgccgagca gatcctggaa ttcgtgaagc agatcagcag ccagctgacc 900
gaagagtgga gccagtgcag cgtgacatgc ggctctggcg tgagagtgcg gaagcggaag 960
aacgtgaaca agcagcccga gaacctgacc ctggaagata tcgacaccga gatctgcaag 1020
atggacaagt gcagcagcat cttcaacatc gtgtccaaca gcctgtgatg a 1071
<210> 49
<211> 442
<212> PRT
<213> Plasmodium falciparum
<220>
<221> MISC_FEATURE
<222> (1)..(442)
<223> CSP protein GenBank: M15505.1
<400> 49
Met Met Arg Lys Leu Ala Ile Leu Ser Val Ser Ser Phe Leu Phe Val
1 5 10 15
Glu Ala Leu Phe Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr
20 25 30
Arg Val Leu Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr
35 40 45
Asn Glu Leu Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser
50 55 60
Leu Lys Lys Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Gly Asp Asn
65 70 75 80
Asp Asn Gly Asn Asn Asn Asn Gly Asn Asn Asn Asn Gly Asp Asn Gly
85 90 95
Arg Glu Gly Lys Asp Glu Asp Lys Arg Asp Gly Asn Asn Glu Asp Asn
100 105 110
Glu Lys Leu Arg Lys Pro Lys His Lys Lys Leu Lys Gln Pro Gly Asp
115 120 125
Gly Asn Pro Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn
130 135 140
Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
145 150 155 160
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
165 170 175
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
180 185 190
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
195 200 205
Pro Asn Val Asp Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
210 215 220
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
225 230 235 240
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
245 250 255
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
260 265 270
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
275 280 285
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn
290 295 300
Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Lys Asn
305 310 315 320
Asn Gln Gly Asn Gly Gln Gly His Asn Met Pro Asn Asp Pro Asn Arg
325 330 335
Asn Val Asp Glu Asn Ala Asn Ala Asn Asn Ala Val Lys Asn Asn Asn
340 345 350
Asn Glu Glu Pro Ser Asp Lys His Ile Glu Gln Tyr Leu Lys Lys Ile
355 360 365
Gln Asn Ser Leu Ser Thr Glu Trp Ser Pro Cys Ser Val Thr Cys Gly
370 375 380
Asn Gly Ile Gln Val Arg Ile Lys Pro Gly Ser Ala Asp Lys Pro Lys
385 390 395 400
Asp Gln Leu Asp Tyr Glu Asn Asp Ile Glu Lys Lys Ile Cys Lys Met
405 410 415
Glu Lys Cys Ser Ser Val Phe Asn Val Val Asn Ser Ser Ile Gly Leu
420 425 430
Ile Met Val Leu Ser Phe Leu Phe Leu Asn
435 440
<210> 50
<211> 1669
<212> DNA
<213> Plasmodium falciparum
<220>
<221> misc_feature
<222> (1)..(1669)
<223> CSP gene GenBank: M15505.1
<400> 50
gtagaaacca cgtaatatta taaattacaa ttcatgatga gaaaattagc tattttatct 60
gtttcttcct ttttatttgt tgaggcctta ttccaggaat accagtgcta tggaagttcg 120
tcaaacacaa gggttctaaa tgaattaaat tatgataatg caggcactaa tttatataat 180
gaattagaaa tgaattatta tgggaaacag gaaaattggt atagtcttaa aaaaaatagt 240
agatcacttg gagaaaatga tgatggagat aatgataatg gaaataataa taatggaaat 300
aataataatg gagataatgg tcgtgaaggt aaagatgaag ataaaagaga tggaaataac 360
gaagacaacg agaaattaag gaaaccaaaa cataaaaaat taaagcaacc aggggatggt 420
aatcctgatc caaatgccaa cccaaatgta gatccaaatg ccaacccaaa tgtagatcca 480
aatgcaaacc caaatgcaaa cccaaatgca aacccaaatg caaacccaaa tgcaaaccca 540
aatgcaaacc caaatgcaaa cccaaatgca aacccaaatg caaacccaaa tgcaaaccca 600
aatgcaaacc caaatgcaaa cccaaatgca aacccaaatg caaacccaaa tgcaaaccca 660
aacgtagatc ctaatgcaaa tccaaatgca aacccaaatg caaacccaaa cgcaaaccca 720
aatgcaaatc ctaatgcaaa tcctaatgca aatcctaatg ccaatccaaa tgcaaatcca 780
aatgcaaacc caaacgcaaa ccccaatgca aatcctaatg ccaatccaaa tgcaaatcca 840
aatgcaaacc caaacgcaaa ccccaatgca aatcctaatg ccaatccaaa tgcaaatcca 900
aatgcaaacc ccaatgcaaa tcctaatgcc aatccaaatg caaatccaaa tgcaaaccca 960
aatgcaaacc caaatgcaaa tcctaataaa aacaatcaag gtaatggaca aggtcacaat 1020
atgccaaatg acccaaaccg aaatgtagat gaaaatgcta atgccaacaa tgctgtaaaa 1080
aataataata acgaagaacc aagtgataag cacatagaac aatatttaaa gaaaatacaa 1140
aattctcttt caactgaatg gtccccatgt agtgtaactt gtggaaatgg tattcaagtt 1200
agaataaagc ctggctctgc tgataaacct aaagaccaat tagattatga aaatgatatt 1260
gaaaaaaaaa tttgtaaaat ggaaaaatgt tccagtgtgt ttaatgtcgt aaatagttca 1320
ataggattaa taatggtatt atccttcttg ttccttaatt agataaagaa cacatcttag 1380
tttgagttgt acaatattta taaaaatata tactactttt tttcttaatt ttcatttttc 1440
tttatatttt cctatttaat ttattttttt gtgaatattt aattatgttt gcgattaatt 1500
gtagaaatat atatgtatat actatattta tagaatgtgt tattctcaaa aacaacaaca 1560
aaaaaaaaaa aaaaaaaaaa aaaaaagaaa aaaggattaa aagtaaaata gttataaata 1620
ttttcaaaaa tatttataac acaaaaaata cttcgaagtt catttaaca 1669
<210> 51
<211> 388
<212> PRT
<213> Plasmodium reichenowi
<220>
<221> MISC_FEATURE
<222> (1)..(388)
<223> CSP protein GenBank M60972.1
<400> 51
Met Met Arg Lys Leu Ala Ile Leu Ser Val Ser Ser Phe Leu Phe Val
1 5 10 15
Glu Ala Leu Phe Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr
20 25 30
Arg Val Leu Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr
35 40 45
Asn Glu Leu Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser
50 55 60
Leu Lys Lys Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Ala Asp Asn
65 70 75 80
Gly Asp Ala Asp Asn Gly Asp Glu Gly Ile Asp Glu Asn Arg Arg His
85 90 95
Arg Asn Lys Glu Gly Lys Glu Lys Leu Lys Lys Pro Lys His Asn Lys
100 105 110
Leu Lys Gln Pro Gly Asn Asp Asn Val Asp Pro Asn Ala Asn Pro Asn
115 120 125
Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
130 135 140
Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
145 150 155 160
Val Asn Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
165 170 175
Val Asn Pro Asn Ala Asn Pro Asn Val Asn Pro Asn Ala Asn Pro Asn
180 185 190
Val Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
195 200 205
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
210 215 220
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
225 230 235 240
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
245 250 255
Ala Asn Pro Asn Ala Asn Pro Asn Arg Asn Asn Glu Ala Asn Gly Gln
260 265 270
Gly His Asn Lys Pro Asn Asp Gln Asn Arg Asn Val Asn Glu Asn Ala
275 280 285
Asn Ala Asn Asn Ala Gly Arg Asn Asn Asn Asn Glu Glu Pro Ser Asp
290 295 300
Lys His Ile Glu Glu Phe Leu Lys Gln Ile Gln Asn Asn Leu Ser Thr
305 310 315 320
Glu Trp Ser Pro Cys Ser Val Thr Cys Gly Asn Gly Ile Gln Val Arg
325 330 335
Ile Lys Pro Gly Ser Ala Gly Lys Pro Lys Asp Gln Leu Asp Tyr Glu
340 345 350
Asn Asp Leu Glu Lys Lys Ile Cys Lys Met Glu Lys Cys Ser Ser Val
355 360 365
Phe Asn Val Val Asn Ser Ser Ile Gly Leu Ile Met Val Leu Ser Phe
370 375 380
Leu Phe Leu Asn
385
<210> 52
<211> 1167
<212> DNA
<213> Plasmodium reichenowi
<220>
<221> misc_feature
<222> (1)..(1167)
<223> CSP gene GenBank M60972.1
<400> 52
atgatgagaa aattagctat tttatctgtt tcttcctttt tatttgttga ggccttattc 60
caggaatatc agtgctatgg aagttcgtca aacacaaggg ttctaaatga attaaattat 120
gataatgcag gcactaattt atataatgaa ttagaaatga attattatgg gaaacaggaa 180
aattggtata gccttaaaaa aaatagtaga tcacttggag aaaatgatga tgcagataat 240
ggtgatgcag ataatggtga tgaaggtata gatgaaaata gaagacatag aaataaagaa 300
ggcaaagaga aattaaagaa accaaaacat aataaattaa agcaaccagg gaatgataat 360
gttgatccaa atgccaaccc aaatgtagat ccaaatgcca acccaaatgt agatcccaat 420
gcaaacccaa atgtagatcc caatgcaaac ccaaatgtag atcctaatgc aaacccaaat 480
gtaaatccca atgcaaaccc aaatgtagat cctaatgcaa acccaaatgt aaatcccaat 540
gcaaacccaa atgtaaatcc caatgcaaac ccaaatgtaa atcccaatgc aaacccaaat 600
gcaaatccta atgcaaatcc caatgcaaat cccaatgcaa acccaaatgc aaatcctaat 660
gcaaatccca atgcaaatcc caatgcaaac ccaaatgcaa atcctaatgc aaatcctaat 720
gcaaatccta atgcaaatcc taatgcaaat cctaatgcca atccaaacgc aaacccaaat 780
gcaaatccta atagaaacaa tgaagctaat ggacaaggtc acaataagcc aaatgaccaa 840
aaccgaaatg taaatgaaaa tgctaatgcc aacaatgctg gaagaaataa taataacgaa 900
gaaccaagtg ataagcacat agaagaattt ttaaagcaaa tacaaaataa tctttcaact 960
gaatggtccc catgtagtgt aacttgtgga aatggtattc aagttagaat aaagcctggc 1020
tctgctggta aacctaaaga ccaattagat tatgaaaatg accttgaaaa aaaaatttgt 1080
aaaatggaaa aatgttccag tgtgttcaat gtcgtaaata gttcaatagg attaataatg 1140
gtattatcct tcttgttcct taattag 1167
<210> 53
<211> 367
<212> PRT
<213> Plasmodium yoelii
<220>
<221> MISC_FEATURE
<222> (1)..(367)
<223> CSP protein GenBank: J02695.1
<400> 53
Met Lys Lys Cys Thr Ile Leu Val Val Ala Ser Leu Leu Leu Val Asp
1 5 10 15
Ser Leu Leu Pro Gly Tyr Gly Gln Asn Lys Ser Val Gln Ala Gln Arg
20 25 30
Asn Leu Asn Glu Leu Cys Tyr Asn Glu Glu Asn Asp Asn Lys Leu Tyr
35 40 45
His Val Leu Asn Ser Lys Asn Gly Lys Ile Tyr Asn Arg Asn Ile Val
50 55 60
Asn Arg Leu Leu Gly Asp Ala Leu Asn Gly Lys Pro Glu Glu Lys Lys
65 70 75 80
Asp Asp Pro Pro Lys Asp Gly Asn Lys Asp Asp Leu Pro Lys Glu Glu
85 90 95
Lys Lys Asp Asp Leu Pro Lys Glu Glu Lys Lys Asp Asp Pro Pro Lys
100 105 110
Asp Pro Lys Lys Asp Asp Pro Pro Lys Glu Ala Gln Asn Lys Leu Asn
115 120 125
Gln Pro Val Val Ala Asp Glu Asn Val Asp Gln Gly Pro Gly Ala Pro
130 135 140
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
145 150 155 160
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
165 170 175
Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro
180 185 190
Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly
195 200 205
Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly Pro Gly Ala Pro Gln Gly
210 215 220
Pro Gly Ala Pro Gln Glu Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro
225 230 235 240
Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro Gln Gln Pro Pro
245 250 255
Gln Gln Pro Arg Pro Gln Pro Asp Gly Asn Asn Asn Asn Asn Asn Asn
260 265 270
Asn Gly Asn Asn Asn Glu Asp Ser Tyr Val Pro Ser Ala Glu Gln Ile
275 280 285
Leu Glu Phe Val Lys Gln Ile Ser Ser Gln Leu Thr Glu Glu Trp Ser
290 295 300
Gln Cys Ser Val Thr Cys Gly Ser Gly Val Arg Val Arg Lys Arg Lys
305 310 315 320
Asn Val Asn Lys Gln Pro Glu Asn Leu Thr Leu Glu Asp Ile Asp Thr
325 330 335
Glu Ile Cys Lys Met Asp Lys Cys Ser Ser Ile Phe Asn Ile Val Ser
340 345 350
Asn Ser Leu Gly Phe Val Ile Leu Leu Val Leu Val Phe Phe Asn
355 360 365
<210> 54
<211> 1580
<212> DNA
<213> Plasmodium yoelii
<220>
<221> misc_feature
<222> (1)..(1580)
<223> CSP gene GenBank J02695.1
<400> 54
aaaatgaaga agtgtaccat tttagttgta gcgtcacttt tattagttga ttctctactt 60
ccaggatatg gacaaaataa aagtgtccaa gcccaaagaa acttaaacga gctatgttac 120
aatgaagaaa atgataataa attgtatcac gtccttaact cgaagaatgg aaaaatatac 180
aatcgaaata tagtcaacag attacttggc gatgctctca acggaaaacc agaagaaaaa 240
aaagatgatc ccccaaaaga tggcaacaaa gatgatcttc caaaagaaga aaaaaaagat 300
gatcttccaa aagaagaaaa aaaagatgat cccccaaaag atcctaaaaa agatgatcca 360
ccaaaagagg ctcaaaataa attgaatcaa ccagtagtgg cagatgaaaa tgtagatcaa 420
gggccaggag caccacaagg gccaggagca ccacaaggac caggagcacc acagggtcca 480
ggagcaccac aaggaccagg agcaccacaa ggaccaggag caccacaagg tccaggagca 540
ccacagggtc caggagcacc acagggtcca ggagcaccac aaggaccagg agcaccacag 600
gggccaggag caccacaagg accaggagca ccacaaggac caggagcacc acaggggcca 660
ggagcaccac aagggccagg agcaccacaa gaaccacccc aacaaccacc ccaacaacca 720
ccacaacagc caccacaaca gccaccacaa cagccaccac aacagccacc acaacaacca 780
cgcccacagc cagatggtaa taacaacaat aacaataata atggtaataa taatgaagat 840
tcttatgtcc caagcgcgga acaaatacta gaatttgtta aacagataag tagtcaactc 900
acagaggaat ggtctcaatg tagtgtaacc tgtggttctg gtgtaagagt tagaaaacga 960
aaaaatgtaa acaagcaacc agaaaatttg accttagagg atattgatac tgaaatttgt 1020
aaaatggata aatgttcaag tatatttaat attgtaagca attcattagg atttgtaata 1080
ttattagtat tagtattctt taattaaata aacattacac attattataa atatttatat 1140
attatataaa tatttaatat acatataatg tgtgtagact ttattttttg tattgtgaac 1200
tttcctcatt tattacgatt atttttatat atatacatat ttaatatgta aattaaaaga 1260
aaaaagaaat aatagaaatc ttattatatt tatgatataa attaaaaaaa taaaatatat 1320
atacattaca aaatttactt tttttagttt atttttttcg tgtttattat atatgtaatt 1380
aacttgttat gacgatatcg aaactttatt tttgagaata tatttttatg aattagaata 1440
ttaataatta ttatggttat ttgtttggga atttatataa tttacaatat tatttaaggg 1500
caatctaaaa atattttatt gttatgatat ttgaaacatt ttatgtagct atccaaatta 1560
tttatttgtg taaaatattt 1580
<210> 55
<211> 341
<212> PRT
<213> Plasmodium coateneyi
<220>
<221> MISC_FEATURE
<222> (1)..(341)
<223> CSP Protein GenBank AY135360.1
<400> 55
Met Lys Asn Phe Ile Leu Leu Ala Val Ser Ser Ile Leu Leu Val Asp
1 5 10 15
Leu Phe Pro Thr His Phe Gly His Asn Val Asp Leu Ser Arg Ala Ile
20 25 30
Asn Leu Asn Gly Val Ser Phe Asn Asn Val Asp Thr Ser Leu Leu Gly
35 40 45
Ala Ala Gln Val Arg Gln Ser Ala Ser Arg Gly Arg Gly Leu Gly Glu
50 55 60
Lys Pro Lys Lys Lys Ala Glu Lys Lys Glu Glu Glu Pro Lys Lys Pro
65 70 75 80
Asn Glu Asn Lys Leu Lys Gln Pro Val Asp Gly Ala Arg Asp Gly Pro
85 90 95
Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Ala Ala Asp
100 105 110
Gly Ala Arg Asp Gly Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly
115 120 125
Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Ala Ala
130 135 140
Asp Gly Ala Arg Asp Gly Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp
145 150 155 160
Gly Pro Ala Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Pro
165 170 175
Ala Asp Gly Ala Arg Asp Gly Pro Ala Pro Pro Ala Ala Asp Gly Ala
180 185 190
Arg Asp Gly Pro Ala Pro Pro Ala Ala Asp Gly Ala Arg Asp Gly Pro
195 200 205
Ala Pro Pro Ala Gly Gln Gly Gly Gly Asn Ala Ala Gly Gln Ala Gln
210 215 220
Gly Gly Gly Asn Ala Gly Asn Lys Lys Ala Gly Asp Ala Ala Gly Asn
225 230 235 240
Ala Gly Ala Ala Lys Gly Gln Gly Gln Asn Asn Glu Gly Ala Asn Val
245 250 255
Pro Asn Glu Lys Val Val Asn Asp Tyr Leu Gln Lys Ile Arg Ser Thr
260 265 270
Val Thr Thr Glu Trp Thr Pro Cys Ser Val Thr Cys Gly Asn Gly Val
275 280 285
Arg Leu Arg Arg Lys Ala His Ala Glu Lys Lys Lys Pro Glu Asp Leu
290 295 300
Thr Met Asp Asp Leu Asp Val Glu Val Cys Ala Met Asp Lys Cys Ala
305 310 315 320
Gly Ile Phe Asn Phe Val Ser Asn Ser Leu Gly Leu Val Ile Leu Leu
325 330 335
Val Leu Ala Phe Asn
340
<210> 56
<211> 1049
<212> DNA
<213> Plasmodium coatneyi
<220>
<221> misc_feature
<222> (1)..(1049)
<223> CSP gene AY135360.1
<400> 56
atgaagaact tcattctctt ggctgtttct tccatcctgt tggtggactt gttccccacg 60
cacttcggac ataatgtaga tctctccagg gccataaatt taaatggagt aagcttcaat 120
aatgtagaca ccagtttact tggcgcagca caggtaagac aaagtgctag ccgaggcaga 180
ggacttggtg agaaaccaaa aaaaaaggcg gaaaaaaaag aagaagaacc aaaaaagcca 240
aatgaaaata agctgaagca accagtagat ggagcacgag atgggccagc accagcagca 300
gatggagcaa gagatggacc agcaccagca gcagatggag cacgagatgg accagcacca 360
gcagcagatg gagcaagaga tggaccagca ccagcagcag atggagcaag agatggacca 420
gcaccagcag cagatggagc aagagatgga ccagcaccag cagcagatgg agcacgagat 480
ggaccagcac cagcagcaga tggagcaaga gatgggccag caccaccagc cgatggagca 540
agagatgggc cagcaccacc agcagcagat ggagcacgag atggaccagc accaccagca 600
gcagatggag cacgagatgg gccagcacca ccagcaggac aaggaggagg aaatgcagca 660
ggccaagcac aaggaggagg aaatgccgga aacaaaaaag caggagacgc agctggaaac 720
gcaggagcag caaaaggaca gggacaaaat aatgaaggtg cgaatgtccc aaatgagaaa 780
gttgtgaatg attacctaca gaaaattaga tctaccgtta ccaccgaatg gactccatgc 840
agtgtaacct gtggaaatgg tgtaagactt agaagaaaag ctcatgcaga aaagaaaaaa 900
ccagaggacc ttaccatgga tgaccttgac gtggaagttt gtgcaatgga taagtgcgct 960
ggcatattta actttgtgag taattcatta gggctagtca tattgttagt cctagcattc 1020
aattaagtag ctgacatcca ttattttcg 1049
<210> 57
<211> 371
<212> PRT
<213> Plasmodium knowlesi
<220>
<221> MISC_FEATURE
<222> (1)..(371)
<223> CSP protein GenBank: DQ350294.2
<400> 57
Met Arg Asn Phe Ile Leu Leu Ala Val Ser Ser Ile Leu Leu Val Asp
1 5 10 15
Leu Leu Pro Thr His Phe Glu His Asn Val Asp Leu Ser Arg Ala Ile
20 25 30
Asn Val Asn Gly Val Ser Phe Asn Asn Val Asp Thr Ser Ser Leu Gly
35 40 45
Ala Ala Gln Val Arg Gln Ser Ala Ser Arg Gly Arg Gly Leu Gly Glu
50 55 60
Lys Arg Lys Glu Gly Ala Asp Lys Glu Lys Lys Lys Glu Lys Glu Glu
65 70 75 80
Glu Pro Lys Lys Pro Asn Glu Asn Lys Leu Lys Gln Pro Asn Pro Gly
85 90 95
Gln Pro Gln Ala Gln Gly Asp Gly Ala Asn Ala Gly Gln Pro Gln Ala
100 105 110
Gln Gly Asp Gly Ala Asn Ala Gly Gln Pro Gln Ala Gln Gly Asp Gly
115 120 125
Ala Asn Ala Gly Gln Pro Gln Ala Gln Gly Asp Gly Ala Asn Ala Gly
130 135 140
Gln Pro Gln Ala Gln Gly Asp Gly Ala Asn Ala Gly Gln Pro Gln Ala
145 150 155 160
Gln Gly Asp Gly Ala Asn Ala Gly Gln Pro Gln Ala Gln Gly Asp Gly
165 170 175
Ala Asn Ala Gly Gln Pro Gln Ala Gln Gly Asp Gly Ala Asn Ala Gly
180 185 190
Gln Pro Gln Ala Gln Gly Asp Gly Ala Asn Ala Gly Gln Pro Gln Ala
195 200 205
Gln Gly Asp Gly Ala Asn Ala Gly Gln Pro Gln Ala Gln Gly Asp Gly
210 215 220
Ala Asn Ala Gly Gln Pro Gln Ala Gln Gly Asp Arg Ala Asn Ala Gly
225 230 235 240
Gln Pro Gln Ala Gln Gly Asp Gly Ala Asn Val Pro Arg Gln Gly Arg
245 250 255
Asn Gly Gly Gly Ala Pro Ala Gly Gly Asn Glu Gly Asn Lys Gln Ala
260 265 270
Gly Lys Gly Gln Gly Gln Asn Asn Gln Gly Ala Asn Ala Pro Asn Glu
275 280 285
Lys Val Val Asn Asp Tyr Leu His Lys Ile Arg Ser Ser Val Thr Thr
290 295 300
Glu Trp Thr Pro Cys Ser Val Thr Cys Gly Asn Gly Val Arg Ile Arg
305 310 315 320
Arg Lys Ala His Ala Gly Asn Lys Lys Ala Glu Asp Leu Thr Met Asp
325 330 335
Asp Leu Glu Val Glu Ala Cys Val Met Asp Lys Cys Ala Gly Ile Phe
340 345 350
Asn Val Val Ser Asn Ser Leu Gly Leu Val Ile Leu Leu Val Leu Ala
355 360 365
Leu Phe Asn
370
<210> 58
<211> 1113
<212> DNA
<213> Plasmodium knowlesi
<220>
<221> misc_feature
<222> (1)..(1113)
<223> CSP gene GenBank: DQ350294.2
<400> 58
atgaggaact tcattctctt ggccgtctcc tccatcctgc tggtggactt gctccccaca 60
cacttcgaac ataatgtaga tctctccagg gccataaatg taaatggagt aagcttcaat 120
aatgtagaca ccagttcact tggcgcagca caggtaagac aaagtgctag ccgaggcaga 180
ggacttggtg agaagcgaaa agaaggagct gataaagaaa agaaaaaaga aaaagaagaa 240
gaaccaaaga agccaaatga aaataagctg aaacaaccga atccaggaca accacaagca 300
caaggagatg gagcaaatgc aggacaacca caagcacaag gagatggagc aaatgcagga 360
caaccacaag cacagggtga tggagcaaat gcaggacaac cacaagcaca aggagatgga 420
gcaaatgcag gacaaccaca agcacagggt gatggagcaa atgcaggaca accacaagca 480
caaggagatg gagcaaatgc aggacaacca caagcacagg gtgatggagc aaatgcagga 540
caaccacaag cacaaggaga tggagcaaat gcaggacaac cacaagcaca gggtgatgga 600
gcaaatgcag gacaaccaca agcacagggt gatggagcaa atgcaggaca accacaagca 660
cagggtgatg gagcaaatgc aggacaacca caagcacagg gtgatagggc gaatgcagga 720
caaccacaag cacaaggaga tggggcaaat gtaccacgac aaggaagaaa cgggggaggt 780
gcaccagcag gaggaaatga ggggaataaa caagcaggaa aaggacaggg acaaaacaat 840
cagggtgcga atgccccaaa tgaaaaagtt gtgaatgatt acctacacaa aattagatct 900
agcgttacca ccgagtggac tccatgcagt gtaacctgtg gaaatggtgt aagaattaga 960
agaaaagctc atgcaggtaa taaaaaggca gaggacctta ctatggatga ccttgaggtg 1020
gaagcttgtg taatggataa gtgcgctggc atatttaacg ttgtgagtaa ttcattaggg 1080
ttagtcatat tgttagtcct agcattattc aat 1113
<210> 59
<211> 332
<212> PRT
<213> Plasmodium berghei
<220>
<221> MISC_FEATURE
<222> (1)..(332)
<223> CSP protein GenBank M28887.1
<400> 59
Met Lys Lys Cys Thr Ile Leu Val Val Ala Ser Leu Leu Leu Val Asn
1 5 10 15
Ser Leu Leu Pro Gly Tyr Gly Gln Asn Lys Ile Ile Gln Ala Gln Arg
20 25 30
Asn Leu Asn Glu Leu Cys Tyr Asn Glu Gly Asn Asp Asn Lys Leu Tyr
35 40 45
His Val Leu Asn Ser Lys Asn Gly Lys Ile Tyr Asn Arg Asn Thr Val
50 55 60
Asn Arg Leu Leu Ala Asp Ala Pro Glu Gly Lys Lys Asn Glu Lys Lys
65 70 75 80
Asn Glu Lys Ile Glu Arg Asn Asn Lys Leu Lys Gln Pro Pro Pro Pro
85 90 95
Pro Asn Pro Asn Asp Pro Pro Pro Pro Asn Pro Asn Asp Pro Pro Pro
100 105 110
Pro Asn Pro Asn Asp Pro Pro Pro Pro Asn Pro Asn Asp Pro Ala Pro
115 120 125
Pro Asn Ala Asn Asp Pro Ala Pro Pro Asn Ala Asn Asp Pro Ala Pro
130 135 140
Pro Asn Ala Asn Asp Pro Ala Pro Pro Asn Ala Asn Asp Pro Ala Pro
145 150 155 160
Pro Asn Ala Asn Asp Pro Ala Pro Pro Asn Ala Asn Asp Pro Ala Pro
165 170 175
Pro Asn Ala Asn Asp Pro Pro Pro Pro Asn Pro Asn Asp Pro Ala Pro
180 185 190
Pro Gln Gly Asn Asn Asn Pro Gln Pro Gln Pro Arg Pro Gln Pro Gln
195 200 205
Pro Gln Pro Gln Pro Gln Pro Gln Pro Gln Pro Gln Pro Gln Pro Arg
210 215 220
Pro Gln Pro Gln Pro Gln Pro Gly Gly Asn Asn Asn Asn Lys Asn Asn
225 230 235 240
Asn Asn Asp Asp Ser Tyr Ile Pro Ser Ala Glu Lys Ile Leu Glu Phe
245 250 255
Val Lys Gln Ile Arg Asp Ser Ile Thr Glu Glu Trp Ser Gln Cys Asn
260 265 270
Val Thr Cys Gly Ser Gly Ile Arg Val Arg Lys Arg Lys Gly Ser Asn
275 280 285
Lys Lys Ala Glu Asp Leu Thr Leu Glu Asp Ile Asp Thr Glu Ile Cys
290 295 300
Lys Met Asp Lys Cys Ser Ser Ile Phe Asn Ile Val Ser Asn Ser Leu
305 310 315 320
Gly Phe Val Ile Leu Leu Val Leu Val Phe Phe Asn
325 330
<210> 60
<211> 999
<212> DNA
<213> Plasmodium berghei
<220>
<221> misc_feature
<222> (1)..(999)
<223> CSP gene GenBank: M28887.1
<400> 60
atgaagaagt gtaccatttt agttgtagcg tcacttttat tagttaattc tctacttcca 60
ggatatggac aaaataaaat catccaagcc caaaggaact taaacgagct atgttacaat 120
gaaggaaatg ataataaatt gtatcacgtg cttaactcta agaatggaaa aatatacaat 180
cgaaatacag tcaacagatt acttgccgat gctcccgaag gaaaaaaaaa tgagaaaaaa 240
aacgaaaaaa tagagcgtaa taataaattg aaacaaccac caccaccacc aaacccaaat 300
gacccaccac caccaaaccc aaatgaccca ccaccaccaa acccaaatga cccaccacca 360
ccaaacccaa atgacccagc accaccaaac gcaaatgacc cagcaccacc aaacgcaaat 420
gacccagcac caccaaacgc aaatgaccca gcaccaccaa acgcaaatga cccagcacca 480
ccaaacgcaa atgacccagc accaccaaac gcaaatgacc cagcaccacc aaacgcaaat 540
gacccaccac caccaaaccc aaatgaccca gcaccaccac aaggaaataa caatccacaa 600
ccacagccac ggccgcagcc acaaccacag ccacagccac aaccacagcc acagccacaa 660
ccacagccac gaccacagcc acaaccacag ccaggtggta ataacaataa caaaaataat 720
aataatgacg attcttatat cccaagcgcg gaaaaaatac tagaatttgt taaacagatc 780
agggatagta tcacagagga atggtctcaa tgtaacgtaa catgtggttc tggtataaga 840
gttagaaaac gaaaaggttc aaataagaaa gcagaagatt tgaccttaga agatattgat 900
actgaaattt gtaaaatgga taaatgttca agtatattta atattgtaag caattcatta 960
ggatttgtaa tattattagt attagtattc tttaattaa 999
<210> 61
<211> 322
<212> PRT
<213> Plasmodium vivax
<220>
<221> MISC_FEATURE
<222> (1)..(322)
<223> CSP protein GenBank: AY674050.1
<400> 61
Lys Ala Ile Asn Leu Asn Gly Val Asn Phe Asn Asn Val Asp Ala Ser
1 5 10 15
Ser Leu Gly Ala Ala His Val Gly Gln Ser Ala Ser Arg Gly Arg Gly
20 25 30
Leu Gly Glu Asn Pro Asp Asp Glu Glu Gly Asp Ala Lys Lys Lys Lys
35 40 45
Asp Gly Lys Lys Ala Glu Pro Lys Asn Pro Arg Glu Asn Lys Leu Lys
50 55 60
Gln Pro Gly Asp Arg Ala Asp Gly Gln Pro Ala Gly Asp Arg Ala Asp
65 70 75 80
Gly Gln Pro Ala Gly Asp Arg Ala Asp Gly Gln Pro Ala Gly Asp Arg
85 90 95
Ala Ala Gly Gln Pro Ala Gly Asp Arg Ala Asp Gly Gln Pro Ala Gly
100 105 110
Asp Arg Ala Ala Gly Gln Pro Ala Gly Asp Arg Ala Asp Gly Gln Pro
115 120 125
Ala Gly Asp Arg Ala Ala Gly Gln Pro Ala Gly Asp Arg Ala Asp Gly
130 135 140
Gln Pro Ala Gly Asp Arg Ala Ala Gly Gln Pro Ala Gly Asp Arg Ala
145 150 155 160
Asp Gly Gln Pro Ala Gly Asp Arg Ala Ala Gly Gln Pro Ala Gly Asp
165 170 175
Arg Ala Ala Gly Gln Pro Ala Gly Asp Arg Ala Asp Gly Gln Pro Ala
180 185 190
Gly Asp Arg Ala Ala Gly Gln Pro Ala Gly Asp Arg Ala Ala Gly Gln
195 200 205
Pro Ala Gly Asp Arg Ala Ala Gly Gln Pro Ala Gly Asn Gly Ala Gly
210 215 220
Gly Gln Ala Ala Gly Gly Asn Ala Ala Asn Lys Lys Ala Glu Asp Ala
225 230 235 240
Gly Gly Asn Ala Gly Gly Gln Gly Gln Asn Asn Glu Gly Ala Asn Ala
245 250 255
Pro Asn Glu Lys Ser Val Lys Glu Tyr Leu Asp Lys Val Arg Ala Thr
260 265 270
Val Gly Thr Glu Trp Thr Pro Cys Ser Val Thr Cys Gly Val Gly Val
275 280 285
Arg Val Arg Arg Arg Val Asn Ala Ala Asn Lys Lys Pro Glu Asp Leu
290 295 300
Thr Leu Asn Asp Leu Glu Thr Asp Val Cys Thr Met Asp Lys Cys Ala
305 310 315 320
Gly Ile
<210> 62
<211> 968
<212> DNA
<213> Plasmodium vivax
<220>
<221> misc_feature
<222> (1)..(968)
<223> CSP gene GenBank: AY674050.1
<400> 62
ccaaggccat aaatttaaat ggagtaaact tcaataatgt agacgccagt tcacttggcg 60
cggcacacgt aggacaaagt gctagccgag gcagaggact tggtgagaac ccagatgacg 120
aggaaggaga tgctaaaaaa aaaaaggatg gaaagaaagc agaaccaaaa aatccacgtg 180
aaaataagct gaaacaacca ggagacagag cagatggaca gccagcagga gacagagcag 240
atggacagcc agcaggagac agagcagatg gacagccagc aggtgataga gcagctggac 300
aaccagcagg tgatagagca gatggacagc cagcaggcga tagagcagct ggacagccag 360
caggcgatag agcagatgga cagccagcag gagatagagc agctggacag ccagcaggcg 420
atagagcaga tggacagcca gcaggagata gagcagctgg acagccagca ggcgatagag 480
cagatggaca gccagcagga gatagagcag ctggacaacc agcaggtgat agagcagctg 540
gacaaccagc aggagataga gcagatggac aaccagcagg agatagagca gctggacagc 600
cagcaggaga tagagcagct ggacagccag caggagatag agcagctgga cagccagcag 660
gaaatggtgc aggtggacag gcagcaggag gaaatgcggc aaacaagaag gcagaagacg 720
caggaggaaa cgcaggagga cagggacaaa ataatgaagg tgcgaatgcc ccaaatgaaa 780
agtctgtgaa agaataccta gataaagtta gagctaccgt tggcaccgaa tggactccat 840
gcagtgtaac ctgtggagtg ggtgtaagag tcagaagaag agttaatgca gctaacaaaa 900
aaccagagga tcttactttg aatgaccttg agactgatgt ttgtacaatg gataagtgtg 960
ctggcata 968
<210> 63
<211> 429
<212> PRT
<213> Plasmodium malariae
<220>
<221> MISC_FEATURE
<222> (1)..(429)
<223> CSP protein GenBank: J03992.1
<400> 63
Met Lys Lys Leu Ser Val Leu Ala Ile Ser Ser Phe Leu Ile Val Asp
1 5 10 15
Phe Leu Phe Pro Gly Tyr His His Asn Ser Asn Ser Thr Lys Ser Arg
20 25 30
Asn Leu Ser Glu Leu Cys Tyr Asn Asn Val Asp Thr Lys Leu Phe Asn
35 40 45
Glu Leu Glu Val Arg Tyr Ser Thr Asn Gln Asp His Phe Tyr Asn Tyr
50 55 60
Asn Lys Thr Ile Arg Leu Leu Asn Glu Asn Asn Asn Glu Lys Asp Gly
65 70 75 80
Asn Val Thr Asn Glu Arg Lys Lys Lys Pro Thr Lys Ala Val Glu Asn
85 90 95
Lys Leu Lys Gln Pro Pro Gly Asp Asp Asp Gly Ala Gly Asn Asp Ala
100 105 110
Gly Asn Asp Ala Gly Asn Asp Ala Gly Asn Ala Ala Gly Asn Ala Ala
115 120 125
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
130 135 140
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
145 150 155 160
Gly Asn Asp Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
165 170 175
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Asp Ala Gly Asn Ala Ala
180 185 190
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
195 200 205
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
210 215 220
Gly Asn Ala Ala Gly Asn Asp Ala Gly Asn Ala Ala Gly Asn Ala Ala
225 230 235 240
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
245 250 255
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
260 265 270
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
275 280 285
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Ala Ala
290 295 300
Gly Asn Ala Ala Gly Asn Ala Ala Gly Asn Glu Lys Ala Lys Asn Lys
305 310 315 320
Asp Asn Lys Val Asp Ala Asn Thr Asn Lys Lys Asp Asn Gln Glu Glu
325 330 335
Asn Asn Asp Ser Ser Asn Gly Pro Ser Glu Glu His Ile Lys Asn Tyr
340 345 350
Leu Glu Ser Ile Arg Asn Ser Ile Thr Glu Glu Trp Ser Pro Cys Ser
355 360 365
Val Thr Cys Gly Ser Gly Ile Arg Ala Arg Arg Lys Val Gly Ala Lys
370 375 380
Asn Lys Lys Pro Ala Glu Leu Val Leu Ser Asp Leu Glu Thr Glu Ile
385 390 395 400
Cys Ser Leu Asp Lys Cys Ser Ser Ile Phe Asn Val Val Ser Asn Ser
405 410 415
Leu Gly Ile Val Leu Val Leu Val Leu Ile Leu Phe His
420 425
<210> 64
<211> 1545
<212> DNA
<213> Plasmodium malariae
<400> 64
tttcacatac ataatttgct gaatattaaa aaaaaataaa taataagtaa ataataaaaa 60
cacaaaaaag tatatataaa tatagacttg ctccaacatg aagaagttat ctgtcttagc 120
aatatcctct tttttaattg ttgatttcct cttccctgga tatcatcaca actcaaattc 180
caccaagtca agaaatttaa gtgagttgtg ttacaataat gtggacacta aattatttaa 240
tgagttagaa gtcagatata gcacgaatca agatcatttc tataactata ataagacaat 300
cagattactt aatgaaaata acaatgaaaa agatggaaat gtgaccaatg aaagaaaaaa 360
aaaacccaca aaagctgttg aaaataaatt gaaacaaccc cccggagatg atgatggcgc 420
aggaaatgat gcaggaaatg atgcaggaaa tgatgcagga aatgcagcag gaaatgcagc 480
aggaaatgca gcaggaaatg cagcaggtaa cgcagcaggt aacgcagcag gaaatgcagc 540
aggaaatgca gcaggtaacg cagcaggaaa tgcagcagga aatgatgcag gaaatgcagc 600
aggtaacgca gcaggaaatg cagcaggaaa tgcagcagga aatgcagcag gaaatgatgc 660
aggaaatgca gcaggaaatg cagcaggaaa tgcagcaggt aacgcagcag gaaatgcagc 720
aggaaatgca gcaggtaacg cagcaggtaa cgcagcagga aatgcagcag gaaatgcagc 780
aggaaatgat gcaggaaatg cagcaggtaa cgcagcagga aatgcagcag gaaatgcagc 840
aggtaacgca gcaggtaacg cagcaggaaa tgcagcagga aatgcagcag gtaacgcagc 900
aggaaatgca gcaggaaatg cagcaggtaa cgcagcaggt aacgcagcag gaaatgcagc 960
aggaaatgca gcaggtaacg cagcaggaaa tgcagcagga aatgcagcag gtaacgcagc 1020
aggaaatgca gcaggaaatg aaaaagcgaa aaataaggat aataaagtgg atgcaaatac 1080
gaataaaaag gacaaccagg aagaaaataa tgattcgtct aatggtccat ctgaagaaca 1140
tataaagaat tatttagaaa gtattcgtaa tagtattacg gaggaatggt caccatgtag 1200
tgtaacttgt ggaagtggta taagggctag aagaaaggtt ggtgcaaaaa ataagaaacc 1260
tgcagaatta gttttaagtg accttgaaac tgaaatttgt tcactagata aatgctccag 1320
tatatttaat gtcgtaagta attcgttagg aatagtatta gttttagtct taatactctt 1380
tcactaaata aatagcatgt atctttcgaa atattatata catatatatt tatatatatt 1440
ttttctttct tttttctttt ttttgtgaat gattactaat gtttgcactt aattgtatat 1500
atattatata tattcaatat ataattctaa aaattaccag tattt 1545
<210> 65
<211> 388
<212> PRT
<213> Plasmodium gallinaceum
<400> 65
Met Lys Lys Leu Ala Ile Leu Ser Ala Ser Ser Phe Leu Phe Ala Asp
1 5 10 15
Phe Leu Phe Gln Glu Tyr Gln His Asn Gly Asn Tyr Lys Asn Phe Arg
20 25 30
Leu Leu Asn Glu Val Cys Tyr Asn Asn Met Asn Ile Gln Leu Tyr Asn
35 40 45
Glu Leu Glu Met Glu Asn Tyr Met Ser Asn Thr Tyr Phe Tyr Asn Asn
50 55 60
Lys Lys Thr Ile Arg Leu Leu Gly Glu Asn Asp Asn Glu Ala Asn Val
65 70 75 80
Asn Arg Ala Asn Asn Asn Val Ala Asn Asp Asn Arg Ala Asn Gly Asn
85 90 95
Arg Gly Asn Val Asn Arg Ala Asn Asp Arg Asn Ile Pro Tyr Phe Arg
100 105 110
Glu Asn Val Val Asn Leu Asn Gln Pro Val Gly Gly Asn Gly Gly Val
115 120 125
Gln Pro Ala Gly Gly Asn Gly Gly Val Gln Pro Ala Gly Gly Asn Gly
130 135 140
Gly Val Gln Pro Ala Gly Gly Asn Gly Gly Val Gln Pro Ala Gly Gly
145 150 155 160
Asn Gly Gly Val Gln Pro Ala Gly Gly Asn Gly Gly Val Gln Pro Ala
165 170 175
Gly Gly Asn Gly Gly Val Gln Pro Ala Gly Gly Asn Gly Gly Ala Gln
180 185 190
Pro Val Ala Ala Gly Gly Gly Ala Gln Pro Val Val Ala Asp Gly Gly
195 200 205
Val Gln Pro Leu Arg Gln Glu Gly Asp Ala Glu Glu Asp Gly Gly Asn
210 215 220
Gly Gly Ala Gln Pro Ala Gly Gly Asn Gly Gly Ala Gln Pro Ala Gly
225 230 235 240
Gly Asn Gly Gly Ala Gln Pro Ala Gly Gly Asn Gly Gly Ala Gln Pro
245 250 255
Ala Gly Gly Asn Gly Gly Ala Gln Pro Ala Gly Gly Asn Asp Ala Ala
260 265 270
Lys Pro Asp Gly Gly Asn Asp Asp Asp Lys Pro Glu Gly Gly Asp Glu
275 280 285
Lys Ser Glu Glu Glu Lys Glu Asp Glu Pro Ile Pro Asp Pro Thr Gln
290 295 300
Glu Glu Ile Asp Lys Tyr Leu Lys Ser Ile Leu Gly Asn Val Thr Ser
305 310 315 320
Glu Trp Thr Asn Cys Asn Val Thr Cys Gly Lys Gly Ile Gln Ala Lys
325 330 335
Ile Lys Ser Thr Ser Ala Asn Lys Lys Arg Glu Glu Ile Thr Pro Asn
340 345 350
Asp Val Glu Val Lys Ile Cys Glu Leu Glu Arg Cys Ser Phe Ser Ile
355 360 365
Phe Asn Val Ile Ser Asn Ser Leu Gly Leu Ala Ile Ile Leu Thr Phe
370 375 380
Leu Phe Phe Tyr
385
<210> 66
<211> 1260
<212> DNA
<213> Plasmodium gallinaceum
<220>
<221> misc_feature
<222> (1)..(1260)
<223> CSP gene GenBank: U65959.1
<400> 66
tgatttcact aaaaatttta atatatataa tataatagtt taaaatagtg aagaatatat 60
ataggtgtac ttcaaaatga agaaattagc cattttatcg gcatcttcgt ttttatttgc 120
tgactttcta tttcaagagt atcaacacaa tggaaactac aaaaatttta gacttttaaa 180
tgaggtgtgt tataataata tgaatattca attatataat gaattggaaa tggaaaatta 240
catgagtaac acatatttct ataataataa aaaaaccatt agattacttg gagaaaatga 300
taatgaagca aatgttaata gagcaaataa taatgtagca aatgataata gagcaaatgg 360
taatagagga aatgttaata gagcaaatga tagaaatata ccatatttta gagaaaatgt 420
tgtgaatctt aatcaaccag ttggaggaaa tggtggtgtt caacctgctg gaggaaatgg 480
tggtgttcaa cctgctggag gaaatggtgg tgttcaacct gctggaggta atggtggtgt 540
tcaacctgct ggaggaaatg gtggtgttca acctgctgga ggaaatggtg gtgttcaacc 600
tgctggaggt aatggtggtg ttcaacctgc tggaggcaat ggtggtgctc aaccagttgc 660
agcaggtggt ggtgctcaac cagttgtagc agatggtggt gttcagcctc ttagacaaga 720
aggtgatgct gaagaggatg gaggaaatgg tggtgcccaa ccagctggag gaaatggtgg 780
tgctcaacca gctggaggaa atggtggtgc tcaaccagct ggaggaaatg gtggtgccca 840
acctgctgga ggaaatggtg gtgctcaacc tgctggagga aatgatgctg ctaaacctga 900
tggaggaaat gatgatgaca aacctgaagg aggagatgaa aaatctgaag aagaaaagga 960
ggatgaacca ataccagatc caactcaaga agaaatagat aaatatttaa aaagcatact 1020
tggtaatgtt acatctgaat ggactaattg caatgtaaca tgtgggaaag gtatacaagc 1080
taaaataaaa tctacatctg ctaataagaa aagagaagaa attactccaa atgatgttga 1140
agtaaaaatt tgcgaactag aaagatgttc ttttagcata tttaatgtta taagcaattc 1200
gttaggttta gctataattt taaccttttt atttttttat taaataaata ttataaaatt 1260
<210> 67
<211> 388
<212> PRT
<213> Plasmodium reichenowi
<220>
<221> MISC_FEATURE
<222> (1)..(388)
<223> CSP protein GenBank: U65959.1
<400> 67
Met Met Arg Lys Leu Ala Ile Leu Ser Val Ser Ser Phe Leu Phe Val
1 5 10 15
Glu Ala Leu Phe Gln Glu Tyr Gln Cys Tyr Gly Ser Ser Ser Asn Thr
20 25 30
Arg Val Leu Asn Glu Leu Asn Tyr Asp Asn Ala Gly Thr Asn Leu Tyr
35 40 45
Asn Glu Leu Glu Met Asn Tyr Tyr Gly Lys Gln Glu Asn Trp Tyr Ser
50 55 60
Leu Lys Lys Asn Ser Arg Ser Leu Gly Glu Asn Asp Asp Ala Asp Asn
65 70 75 80
Gly Asp Ala Asp Asn Gly Asp Glu Gly Ile Asp Glu Asn Arg Arg His
85 90 95
Arg Asn Lys Glu Gly Lys Glu Lys Leu Lys Lys Pro Lys His Asn Lys
100 105 110
Leu Lys Gln Pro Gly Asn Asp Asn Val Asp Pro Asn Ala Asn Pro Asn
115 120 125
Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
130 135 140
Val Asp Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
145 150 155 160
Val Asn Pro Asn Ala Asn Pro Asn Val Asp Pro Asn Ala Asn Pro Asn
165 170 175
Val Asn Pro Asn Ala Asn Pro Asn Val Asn Pro Asn Ala Asn Pro Asn
180 185 190
Val Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
195 200 205
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
210 215 220
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
225 230 235 240
Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn Ala Asn Pro Asn
245 250 255
Ala Asn Pro Asn Ala Asn Pro Asn Arg Asn Asn Glu Ala Asn Gly Gln
260 265 270
Gly His Asn Lys Pro Asn Asp Gln Asn Arg Asn Val Asn Glu Asn Ala
275 280 285
Asn Ala Asn Asn Ala Gly Arg Asn Asn Asn Asn Glu Glu Pro Ser Asp
290 295 300
Lys His Ile Glu Glu Phe Leu Lys Gln Ile Gln Asn Asn Leu Ser Thr
305 310 315 320
Glu Trp Ser Pro Cys Ser Val Thr Cys Gly Asn Gly Ile Gln Val Arg
325 330 335
Ile Lys Pro Gly Ser Ala Gly Lys Pro Lys Asp Gln Leu Asp Tyr Glu
340 345 350
Asn Asp Leu Glu Lys Lys Ile Cys Lys Met Glu Lys Cys Ser Ser Val
355 360 365
Phe Asn Val Val Asn Ser Ser Ile Gly Leu Ile Met Val Leu Ser Phe
370 375 380
Leu Phe Leu Asn
385
<210> 68
<211> 1167
<212> DNA
<213> Plasmodium reichenowi
<400> 68
atgatgagaa aattagctat tttatctgtt tcttcctttt tatttgttga ggccttattc 60
caggaatatc agtgctatgg aagttcgtca aacacaaggg ttctaaatga attaaattat 120
gataatgcag gcactaattt atataatgaa ttagaaatga attattatgg gaaacaggaa 180
aattggtata gccttaaaaa aaatagtaga tcacttggag aaaatgatga tgcagataat 240
ggtgatgcag ataatggtga tgaaggtata gatgaaaata gaagacatag aaataaagaa 300
ggcaaagaga aattaaagaa accaaaacat aataaattaa agcaaccagg gaatgataat 360
gttgatccaa atgccaaccc aaatgtagat ccaaatgcca acccaaatgt agatcccaat 420
gcaaacccaa atgtagatcc caatgcaaac ccaaatgtag atcctaatgc aaacccaaat 480
gtaaatccca atgcaaaccc aaatgtagat cctaatgcaa acccaaatgt aaatcccaat 540
gcaaacccaa atgtaaatcc caatgcaaac ccaaatgtaa atcccaatgc aaacccaaat 600
gcaaatccta atgcaaatcc caatgcaaat cccaatgcaa acccaaatgc aaatcctaat 660
gcaaatccca atgcaaatcc caatgcaaac ccaaatgcaa atcctaatgc aaatcctaat 720
gcaaatccta atgcaaatcc taatgcaaat cctaatgcca atccaaacgc aaacccaaat 780
gcaaatccta atagaaacaa tgaagctaat ggacaaggtc acaataagcc aaatgaccaa 840
aaccgaaatg taaatgaaaa tgctaatgcc aacaatgctg gaagaaataa taataacgaa 900
gaaccaagtg ataagcacat agaagaattt ttaaagcaaa tacaaaataa tctttcaact 960
gaatggtccc catgtagtgt aacttgtgga aatggtattc aagttagaat aaagcctggc 1020
tctgctggta aacctaaaga ccaattagat tatgaaaatg accttgaaaa aaaaatttgt 1080
aaaatggaaa aatgttccag tgtgttcaat gtcgtaaata gttcaatagg attaataatg 1140
gtattatcct tcttgttcct taattag 1167
<210> 69
<211> 200
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of CAEV
<400> 69
gttccagcca caatttgtcg ctgtagaatc agccatagca gcagccctag tcgccataaa 60
tataaaaaga aagggtgggc tggggacaag ccctatggat atttttatat ataataaaga 120
acagaaaaga ataaataata aatataataa aaattctcaa aaaattcaat tctgttatta 180
cagaataagg aaaagaggac 200
<210> 70
<211> 200
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of EIAV
<400> 70
cttgtaacaa agggagggaa agtatgggag gacagacacc atgggaagta tttatcacta 60
atcaagcaca agtaatacat gagaaacttt tactacagca agcacaatcc tccaaaaaat 120
tttgttttta caaaatccct ggtgaacatg attggaaggg acctactagg gtgctgtgga 180
agggtgatgg tgcagtagta 200
<210> 71
<211> 200
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of VISNA
<400> 71
ggaccctcat tactctaaat ataaaaagaa agggtgggct agggacaagc cctatggata 60
tatttatatt taataaggaa caacaaagaa tacagcaaca aagtaaatca aaacaagaaa 120
aaattcgatt ttgttattac agaacaagaa aaagagggca tccaggagag tggcaaggac 180
caacacaggt actttggggc 200
<210> 72
<211> 200
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of VISNA
<400> 72
tactgatggc ttgcatactt cacaatttta aaagaaaggg aggaataggg ggacagactt 60
cagcagagag actaattaat ataataacaa cacaattaga aatacaacat ttacaaacca 120
aaattcaaaa aattttaaat tttagagtct actacagaga agggagagac cctgtgtgga 180
aaggaccggc acaattaatc 200
<210> 73
<211> 200
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of HIV-2 ROD
<400> 73
tgcatgaatt ttaaaagaag ggggggaata ggggatatga ctccatcaga aagattaatc 60
aatatgatca ccacagaaca agagatacaa ttcctccaag ccaaaaattc aaaattaaaa 120
gattttcggg tctatttcag agaaggcaga gatcagttgt ggaaaggacc tggggaacta 180
ctgtggaaag gagaaggagc 200
<210> 74
<211> 200
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of HIV-1 LAI
<400> 74
cagtattcat ccacaatttt aaaagaaaag gggggattgg ggggtacagt gcaggggaaa 60
gaatagtaga cataatagca acagacatac aaactaaaga attacaaaaa caaattacaa 120
aaattcaaaa ttttcgggtt tattacaggg acagcagaga tccactttgg aaaggaccag 180
caaagctcct ctggaaaggt 200
<210> 75
<211> 119
<212> DNA
<213> Artificial
<220>
<223> DNA FLAP of HIV-1
<400> 75
ttttaaaaga aaagggggga ttggggggta cagtgcaggg gaaagaatag tagacataat 60
agcaacagac atacaaacta aagaattaca aaaacaaatt acaaaaattc aaaattttc 119
<210> 76
<211> 1578
<212> DNA
<213> Artificial
<220>
<223> VSV-G Indiana optimized
<400> 76
ctcggatcct gatcagccac catgaaatgc ctgctctatc tggccttcct ctttatcggc 60
gtgaactgta agttcacgat cgtgtttccc cacaatcaga agggaaactg gaagaacgtc 120
ccgagcaact accactactg ccctagctca agcgacctga actggcacaa cgacctgatc 180
ggcaccgcta tccaggtgaa gatgccaaag agccacaagg ccatccaagc cgacggctgg 240
atgtgtcacg ccagcaaatg ggtgacgacg tgcgattttc gctggtatgg ccccaagtac 300
atcacccaat caatccgctc atttacaccc agcgtggagc aatgtaagga gagcatcgag 360
cagaccaagc aggggacctg gctcaacccc ggcttcccac cgcaaagctg cggatacgcc 420
accgtgaccg acgctgaggc cgtcatcgtg caggtgaccc cgcaccacgt gctggtggac 480
gagtacaccg gcgagtgggt ggattcacag tttatcaacg gaaagtgtag caattacatc 540
tgccccaccg tgcacaacag caccacctgg cactcagact ataaggtgaa gggcctctgc 600
gacagcaatc tgatctcaat ggacatcacc ttctttagcg aagacggcga actctcaagc 660
ctcgggaagg aaggcaccgg gttccgcagc aattactttg cttacgaaac cggcggcaag 720
gcctgcaaga tgcaatactg caagcactgg ggcgtgcgcc tgccaagcgg cgtgtggttt 780
gagatggctg ataaggacct gttcgccgct gcccgcttcc cggaatgccc cgaggggagc 840
agcatcagcg cccccagcca gacatcagtg gacgtgagcc tgatccagga tgtggaacgc 900
atcctggact acagcctgtg tcaggaaacg tggagcaaga tccgcgccgg actgcctatc 960
agccccgtgg atctcagcta cctggcccca aagaacccag gcaccggacc cgcctttaca 1020
atcatcaacg gcaccctgaa gtactttgaa acacgctaca tccgcgtcga catcgccgct 1080
cccatcctct cacgcatggt gggcatgatc tcagggacga ccacggagcg cgagctgtgg 1140
gatgactggg ccccgtatga agatgtggag atcggaccta acggcgtgct gcgcacatca 1200
agcgggtaca agttcccgct gtacatgatc ggccacggca tgctggacag cgacctgcac 1260
ctcagctcaa aggcccaggt ctttgagcac ccacacatcc aggacgctgc cagccagctc 1320
cccgacgacg aaagcctgtt ctttggagat acagggctca gcaagaaccc catcgagctg 1380
gtcgagggct ggttctcaag ctggaagagc agcatcgctt catttttttt catcatcggc 1440
ctcatcatcg ggctgtttct ggtgctgcgc gtcggcatcc acctgtgcat caagctgaag 1500
cacaccaaga agcgccagat ctataccgac atcgagatga atcgcctggg gaagtaagaa 1560
ttctgcagat atccagca 1578
<210> 77
<211> 511
<212> PRT
<213> Artificial
<220>
<223> VSV-G Indiana
<400> 77
Met Lys Cys Leu Leu Tyr Leu Ala Phe Leu Phe Ile Gly Val Asn Cys
1 5 10 15
Lys Phe Thr Ile Val Phe Pro His Asn Gln Lys Gly Asn Trp Lys Asn
20 25 30
Val Pro Ser Asn Tyr His Tyr Cys Pro Ser Ser Ser Asp Leu Asn Trp
35 40 45
His Asn Asp Leu Ile Gly Thr Ala Ile Gln Val Lys Met Pro Lys Ser
50 55 60
His Lys Ala Ile Gln Ala Asp Gly Trp Met Cys His Ala Ser Lys Trp
65 70 75 80
Val Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys Tyr Ile Thr Gln
85 90 95
Ser Ile Arg Ser Phe Thr Pro Ser Val Glu Gln Cys Lys Glu Ser Ile
100 105 110
Glu Gln Thr Lys Gln Gly Thr Trp Leu Asn Pro Gly Phe Pro Pro Gln
115 120 125
Ser Cys Gly Tyr Ala Thr Val Thr Asp Ala Glu Ala Val Ile Val Gln
130 135 140
Val Thr Pro His His Val Leu Val Asp Glu Tyr Thr Gly Glu Trp Val
145 150 155 160
Asp Ser Gln Phe Ile Asn Gly Lys Cys Ser Asn Tyr Ile Cys Pro Thr
165 170 175
Val His Asn Ser Thr Thr Trp His Ser Asp Tyr Lys Val Lys Gly Leu
180 185 190
Cys Asp Ser Asn Leu Ile Ser Met Asp Ile Thr Phe Phe Ser Glu Asp
195 200 205
Gly Glu Leu Ser Ser Leu Gly Lys Glu Gly Thr Gly Phe Arg Ser Asn
210 215 220
Tyr Phe Ala Tyr Glu Thr Gly Gly Lys Ala Cys Lys Met Gln Tyr Cys
225 230 235 240
Lys His Trp Gly Val Arg Leu Pro Ser Gly Val Trp Phe Glu Met Ala
245 250 255
Asp Lys Asp Leu Phe Ala Ala Ala Arg Phe Pro Glu Cys Pro Glu Gly
260 265 270
Ser Ser Ile Ser Ala Pro Ser Gln Thr Ser Val Asp Val Ser Leu Ile
275 280 285
Gln Asp Val Glu Arg Ile Leu Asp Tyr Ser Leu Cys Gln Glu Thr Trp
290 295 300
Ser Lys Ile Arg Ala Gly Leu Pro Ile Ser Pro Val Asp Leu Ser Tyr
305 310 315 320
Leu Ala Pro Lys Asn Pro Gly Thr Gly Pro Ala Phe Thr Ile Ile Asn
325 330 335
Gly Thr Leu Lys Tyr Phe Glu Thr Arg Tyr Ile Arg Val Asp Ile Ala
340 345 350
Ala Pro Ile Leu Ser Arg Met Val Gly Met Ile Ser Gly Thr Thr Thr
355 360 365
Glu Arg Glu Leu Trp Asp Asp Trp Ala Pro Tyr Glu Asp Val Glu Ile
370 375 380
Gly Pro Asn Gly Val Leu Arg Thr Ser Ser Gly Tyr Lys Phe Pro Leu
385 390 395 400
Tyr Met Ile Gly His Gly Met Leu Asp Ser Asp Leu His Leu Ser Ser
405 410 415
Lys Ala Gln Val Phe Glu His Pro His Ile Gln Asp Ala Ala Ser Gln
420 425 430
Leu Pro Asp Asp Glu Ser Leu Phe Phe Gly Asp Thr Gly Leu Ser Lys
435 440 445
Asn Pro Ile Glu Leu Val Glu Gly Trp Phe Ser Ser Trp Lys Ser Ser
450 455 460
Ile Ala Ser Phe Phe Phe Ile Ile Gly Leu Ile Ile Gly Leu Phe Leu
465 470 475 480
Val Leu Arg Val Gly Ile His Leu Cys Ile Lys Leu Lys His Thr Lys
485 490 495
Lys Arg Gln Ile Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505 510
<210> 78
<211> 1597
<212> DNA
<213> Artificial
<220>
<223> VSV-G New Jersey optimized
<400> 78
taccgagctc ggatcctgat cagccaccat gctgtcatat ctgatctttg ccctggctgt 60
gagcccaatc ctcggaaaga tcgaaatcgt gttcccacaa cacaccacag gggactggaa 120
gcgcgtgccc cacgagtaca actactgccc gacctcagcc gacaagaata gccacggcac 180
gcagaccggc atccctgtgg agctgaccat gcccaagggg ctcacaacgc accaagtcga 240
aggcttcatg tgccacagcg ctctctggat gacaacctgc gattttcgct ggtatggccc 300
caagtacatc acgcacagca tccacaatga ggaaccaacc gactaccagt gcctcgaagc 360
catcaagtca tacaaggatg gggtgagctt caaccccggc ttcccgcccc aatcatgtgg 420
ctacggcacc gtgaccgacg ccgaggccca catcgtgacc gtgacacccc actcagtcaa 480
ggtggacgag tacacaggcg aatggatcga cccccacttc atcgggggcc gctgtaaggg 540
ccaaatctgc gagaccgtgc acaacagcac caagtggttt acgtcatcag acggcgaaag 600
cgtgtgcagc caactgttta cgctcgtggg cggcatcttc tttagcgaca gcgaggagat 660
caccagcatg ggcctcccgg agacaggaat ccgcagcaac tactttccgt acatcagcac 720
cgagggaatc tgtaagatgc ctttttgccg caagcaggga tataagctga agaatgacct 780
gtggttccag atcatggacc cggacctgga caagaccgtc cgcgatctgc cccacatcaa 840
ggactgtgat ctgtcatcaa gcatcatcac ccccggagaa cacgccacgg acatcagcct 900
catcagcgat gtggagcgca tcctcgacta cgctctctgc cagaacacat ggagcaagat 960
cgaaagcggc gaacccatca ccccagtgga cctgagctat ctcggcccaa agaaccccgg 1020
cgtggggccc gtgttcacca tcatcaacgg gagcctgcac tactttacaa gcaagtatct 1080
gcgcgtggag ctcgaaagcc cagtcatccc ccgcatggag gggaaggtgg ccgggacccg 1140
catcgtgcgc cagctgtggg accagtggtt cccttttggc gaggtggaaa tcggccccaa 1200
cggcgtgctg aagaccaagc aaggatataa gttcccgctg cacatcatcg ggacgggcga 1260
agtggacagc gatatcaaga tggagcgcgt ggtcaagcac tgggagcacc cacacatcga 1320
ggctgctcag acctttctca agaaggacga taccggcgaa gtcctgtatt acggggatac 1380
gggagtgagc aagaaccctg tggagctggt ggaaggctgg ttcagcggat ggcgctcaag 1440
cctgatgggc gtgctggccg tcatcatcgg atttgtgatc ctgatgttcc tcatcaagct 1500
gatcggcgtg ctgtcaagcc tgttccgccc taagcgccgc ccaatctaca agagcgacgt 1560
cgagatggcc cactttcgct aagaattctg cagatat 1597
<210> 79
<211> 1563
<212> DNA
<213> Artificial
<220>
<223> fusion VSV-G Ghandipura / Indiana
<220>
<221> CDS
<222> (1)..(1563)
<400> 79
atg acc agc agc gtg acc atc agc gtg gtg ctg ctg atc agc ttc atc 48
Met Thr Ser Ser Val Thr Ile Ser Val Val Leu Leu Ile Ser Phe Ile
1 5 10 15
acc ccc ctg tac agc tac ctg agc att gcc ttc ccc gag aac acc aag 96
Thr Pro Leu Tyr Ser Tyr Leu Ser Ile Ala Phe Pro Glu Asn Thr Lys
20 25 30
ctg gac tgg aag ccc gtg acc aag aac acc cgg tac tgc ccc atg ggc 144
Leu Asp Trp Lys Pro Val Thr Lys Asn Thr Arg Tyr Cys Pro Met Gly
35 40 45
ggc gag tgg ttt ctg gaa ccc ggc ctg cag gaa gag agc ttc ctg agc 192
Gly Glu Trp Phe Leu Glu Pro Gly Leu Gln Glu Glu Ser Phe Leu Ser
50 55 60
agc acc ccc atc ggc gcc acc ccc agc aag agc gac ggc ttc ctg tgc 240
Ser Thr Pro Ile Gly Ala Thr Pro Ser Lys Ser Asp Gly Phe Leu Cys
65 70 75 80
cac gcc gcc aag tgg gtg acc acc tgc gac ttc cgg tgg tac ggc ccc 288
His Ala Ala Lys Trp Val Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro
85 90 95
aag tac atc acc cac agc atc cac aac atc aag ccc acc aga agc gac 336
Lys Tyr Ile Thr His Ser Ile His Asn Ile Lys Pro Thr Arg Ser Asp
100 105 110
tgc gac aca gcc ctg gcc tct tac aag agc ggc acc ctg gtg tcc ctg 384
Cys Asp Thr Ala Leu Ala Ser Tyr Lys Ser Gly Thr Leu Val Ser Leu
115 120 125
ggc ttc cct ccc gag agc tgc ggc tac gcc agc gtg acc gac agc gag 432
Gly Phe Pro Pro Glu Ser Cys Gly Tyr Ala Ser Val Thr Asp Ser Glu
130 135 140
ttc ctg gtg att atg att acc ccc cac cac gtg ggc gtg gac gac tac 480
Phe Leu Val Ile Met Ile Thr Pro His His Val Gly Val Asp Asp Tyr
145 150 155 160
cgg ggc cac tgg gtg gac cct ctg ttc gtg gga ggg gaa tgc gac cag 528
Arg Gly His Trp Val Asp Pro Leu Phe Val Gly Gly Glu Cys Asp Gln
165 170 175
agc tac tgc gat acc atc cac aac tcc agc gtg tgg att ccc gcc gac 576
Ser Tyr Cys Asp Thr Ile His Asn Ser Ser Val Trp Ile Pro Ala Asp
180 185 190
cag acc aag aag aac atc tgc ggc cag agc ttc acc cct ctg acc gtg 624
Gln Thr Lys Lys Asn Ile Cys Gly Gln Ser Phe Thr Pro Leu Thr Val
195 200 205
acc gtg gcc tac gac aag acc aaa gag att gcc gcc gga ggg atc gtg 672
Thr Val Ala Tyr Asp Lys Thr Lys Glu Ile Ala Ala Gly Gly Ile Val
210 215 220
ttc aag agc aag tac cac agc cac atg gaa ggc gcc agg acc tgc aga 720
Phe Lys Ser Lys Tyr His Ser His Met Glu Gly Ala Arg Thr Cys Arg
225 230 235 240
ctg tcc tac tgc ggc cgg aac ggc atc aag ttc ccc aac ggc gag tgg 768
Leu Ser Tyr Cys Gly Arg Asn Gly Ile Lys Phe Pro Asn Gly Glu Trp
245 250 255
gtg tcc ctg atg ctg aag ctg cgg agc aag cgg aac ctg tac ttc ccc 816
Val Ser Leu Met Leu Lys Leu Arg Ser Lys Arg Asn Leu Tyr Phe Pro
260 265 270
tgc ctg aag atg tgc ccc acc ggc atc cgg ggc gag atc tac ccc agc 864
Cys Leu Lys Met Cys Pro Thr Gly Ile Arg Gly Glu Ile Tyr Pro Ser
275 280 285
atc aga tgg gcc cag gtg ctg acc agc gag atc cag aga atc ctg gac 912
Ile Arg Trp Ala Gln Val Leu Thr Ser Glu Ile Gln Arg Ile Leu Asp
290 295 300
tac agc ctg tgc cag aac acc tgg gac aag gtg gag cgg aaa gag ccc 960
Tyr Ser Leu Cys Gln Asn Thr Trp Asp Lys Val Glu Arg Lys Glu Pro
305 310 315 320
ctg agc ccc ctg gac ctg agc tac ctg gcc agc aag tcc ccc ggc aag 1008
Leu Ser Pro Leu Asp Leu Ser Tyr Leu Ala Ser Lys Ser Pro Gly Lys
325 330 335
ggc ctg gcc tac acc gtg atc aac ggc acc ctg agc ttc gcc cac acc 1056
Gly Leu Ala Tyr Thr Val Ile Asn Gly Thr Leu Ser Phe Ala His Thr
340 345 350
aga tac gtg cgg atg tgg atc gac ggc ccc gtg ctg aaa gag ccc aag 1104
Arg Tyr Val Arg Met Trp Ile Asp Gly Pro Val Leu Lys Glu Pro Lys
355 360 365
ggc aag aga gag agc ccc agc ggc atc agc agc gac atc tgg acc cag 1152
Gly Lys Arg Glu Ser Pro Ser Gly Ile Ser Ser Asp Ile Trp Thr Gln
370 375 380
tgg ttc aag tac ggc gac atg gaa atc ggc ccc aac ggc ctg ctg aaa 1200
Trp Phe Lys Tyr Gly Asp Met Glu Ile Gly Pro Asn Gly Leu Leu Lys
385 390 395 400
aca gcc ggc gga tac aag ttt cct tgg cac ctg atc ggc atg ggc atc 1248
Thr Ala Gly Gly Tyr Lys Phe Pro Trp His Leu Ile Gly Met Gly Ile
405 410 415
gtg gac aac gag ctg cac gag ctg tcc gag gcc aac ccc ctg gat cac 1296
Val Asp Asn Glu Leu His Glu Leu Ser Glu Ala Asn Pro Leu Asp His
420 425 430
ccc cag ctg ccc cac gcc cag agc att gcc gac gac agc gag gaa atc 1344
Pro Gln Leu Pro His Ala Gln Ser Ile Ala Asp Asp Ser Glu Glu Ile
435 440 445
ttc ttc ggc gac acc ggc gtg agc aag aac ccc gtg gaa ctg gtg aca 1392
Phe Phe Gly Asp Thr Gly Val Ser Lys Asn Pro Val Glu Leu Val Thr
450 455 460
ggc tgg ttc acc agc tgg aaa agc agc atc gct tca ttt ttt ttc atc 1440
Gly Trp Phe Thr Ser Trp Lys Ser Ser Ile Ala Ser Phe Phe Phe Ile
465 470 475 480
atc ggc ctc atc atc ggg ctg ttt ctg gtg ctg cgc gtc ggc atc cac 1488
Ile Gly Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His
485 490 495
ctg tgc atc aag ctg aag cac acc aag aag cgc cag atc tat acc gac 1536
Leu Cys Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp
500 505 510
atc gag atg aat cgc ctg ggg aag taa 1563
Ile Glu Met Asn Arg Leu Gly Lys
515 520
<210> 80
<211> 520
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 80
Met Thr Ser Ser Val Thr Ile Ser Val Val Leu Leu Ile Ser Phe Ile
1 5 10 15
Thr Pro Leu Tyr Ser Tyr Leu Ser Ile Ala Phe Pro Glu Asn Thr Lys
20 25 30
Leu Asp Trp Lys Pro Val Thr Lys Asn Thr Arg Tyr Cys Pro Met Gly
35 40 45
Gly Glu Trp Phe Leu Glu Pro Gly Leu Gln Glu Glu Ser Phe Leu Ser
50 55 60
Ser Thr Pro Ile Gly Ala Thr Pro Ser Lys Ser Asp Gly Phe Leu Cys
65 70 75 80
His Ala Ala Lys Trp Val Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro
85 90 95
Lys Tyr Ile Thr His Ser Ile His Asn Ile Lys Pro Thr Arg Ser Asp
100 105 110
Cys Asp Thr Ala Leu Ala Ser Tyr Lys Ser Gly Thr Leu Val Ser Leu
115 120 125
Gly Phe Pro Pro Glu Ser Cys Gly Tyr Ala Ser Val Thr Asp Ser Glu
130 135 140
Phe Leu Val Ile Met Ile Thr Pro His His Val Gly Val Asp Asp Tyr
145 150 155 160
Arg Gly His Trp Val Asp Pro Leu Phe Val Gly Gly Glu Cys Asp Gln
165 170 175
Ser Tyr Cys Asp Thr Ile His Asn Ser Ser Val Trp Ile Pro Ala Asp
180 185 190
Gln Thr Lys Lys Asn Ile Cys Gly Gln Ser Phe Thr Pro Leu Thr Val
195 200 205
Thr Val Ala Tyr Asp Lys Thr Lys Glu Ile Ala Ala Gly Gly Ile Val
210 215 220
Phe Lys Ser Lys Tyr His Ser His Met Glu Gly Ala Arg Thr Cys Arg
225 230 235 240
Leu Ser Tyr Cys Gly Arg Asn Gly Ile Lys Phe Pro Asn Gly Glu Trp
245 250 255
Val Ser Leu Met Leu Lys Leu Arg Ser Lys Arg Asn Leu Tyr Phe Pro
260 265 270
Cys Leu Lys Met Cys Pro Thr Gly Ile Arg Gly Glu Ile Tyr Pro Ser
275 280 285
Ile Arg Trp Ala Gln Val Leu Thr Ser Glu Ile Gln Arg Ile Leu Asp
290 295 300
Tyr Ser Leu Cys Gln Asn Thr Trp Asp Lys Val Glu Arg Lys Glu Pro
305 310 315 320
Leu Ser Pro Leu Asp Leu Ser Tyr Leu Ala Ser Lys Ser Pro Gly Lys
325 330 335
Gly Leu Ala Tyr Thr Val Ile Asn Gly Thr Leu Ser Phe Ala His Thr
340 345 350
Arg Tyr Val Arg Met Trp Ile Asp Gly Pro Val Leu Lys Glu Pro Lys
355 360 365
Gly Lys Arg Glu Ser Pro Ser Gly Ile Ser Ser Asp Ile Trp Thr Gln
370 375 380
Trp Phe Lys Tyr Gly Asp Met Glu Ile Gly Pro Asn Gly Leu Leu Lys
385 390 395 400
Thr Ala Gly Gly Tyr Lys Phe Pro Trp His Leu Ile Gly Met Gly Ile
405 410 415
Val Asp Asn Glu Leu His Glu Leu Ser Glu Ala Asn Pro Leu Asp His
420 425 430
Pro Gln Leu Pro His Ala Gln Ser Ile Ala Asp Asp Ser Glu Glu Ile
435 440 445
Phe Phe Gly Asp Thr Gly Val Ser Lys Asn Pro Val Glu Leu Val Thr
450 455 460
Gly Trp Phe Thr Ser Trp Lys Ser Ser Ile Ala Ser Phe Phe Phe Ile
465 470 475 480
Ile Gly Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His
485 490 495
Leu Cys Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp
500 505 510
Ile Glu Met Asn Arg Leu Gly Lys
515 520
<210> 81
<211> 1539
<212> DNA
<213> Artificial
<220>
<223> fusion VSV-G Cocal / Indiana
<220>
<221> CDS
<222> (1)..(1539)
<400> 81
atg aac ttt ctg ctg ctg aca ttc atc gtg ctg cct ctg tgc agc cac 48
Met Asn Phe Leu Leu Leu Thr Phe Ile Val Leu Pro Leu Cys Ser His
1 5 10 15
gcc aag ttc agc atc gtg ttc ccc cag agc cag aag ggc aac tgg aag 96
Ala Lys Phe Ser Ile Val Phe Pro Gln Ser Gln Lys Gly Asn Trp Lys
20 25 30
aac gtg ccc agc agc tac cac tac tgc ccc agc agc agc gac cag aac 144
Asn Val Pro Ser Ser Tyr His Tyr Cys Pro Ser Ser Ser Asp Gln Asn
35 40 45
tgg cac aac gac ctg ctg ggc atc acc atg aag gtg aaa atg ccc aag 192
Trp His Asn Asp Leu Leu Gly Ile Thr Met Lys Val Lys Met Pro Lys
50 55 60
acc cac aag gcc att cag gct gac ggc tgg atg tgc cac gcc gcc aag 240
Thr His Lys Ala Ile Gln Ala Asp Gly Trp Met Cys His Ala Ala Lys
65 70 75 80
tgg atc acc acc tgc gac ttc cgg tgg tac ggc ccc aag tac atc acc 288
Trp Ile Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys Tyr Ile Thr
85 90 95
cac agc atc cac tcc atc cag ccc acc tcc gag cag tgc aaa gag agc 336
His Ser Ile His Ser Ile Gln Pro Thr Ser Glu Gln Cys Lys Glu Ser
100 105 110
atc aag cag acc aag cag ggc acc tgg atg agc ccc ggc ttc cca ccc 384
Ile Lys Gln Thr Lys Gln Gly Thr Trp Met Ser Pro Gly Phe Pro Pro
115 120 125
cag aac tgc ggc tac gcc acc gtg acc gac agc gtg gcc gtg gtg gtg 432
Gln Asn Cys Gly Tyr Ala Thr Val Thr Asp Ser Val Ala Val Val Val
130 135 140
cag gcc acc ccc cac cac gtg ctg gtc gac gag tac acc ggc gag tgg 480
Gln Ala Thr Pro His His Val Leu Val Asp Glu Tyr Thr Gly Glu Trp
145 150 155 160
atc gac agc cag ttc ccc aac ggc aag tgc gag aca gag gaa tgc gag 528
Ile Asp Ser Gln Phe Pro Asn Gly Lys Cys Glu Thr Glu Glu Cys Glu
165 170 175
aca gtg cac aac agc acc gtg tgg tac agc gac tac aag gtg acc ggc 576
Thr Val His Asn Ser Thr Val Trp Tyr Ser Asp Tyr Lys Val Thr Gly
180 185 190
ctg tgc gac gcc acc ctg gtg gac acc gag atc acc ttt ttc agc gag 624
Leu Cys Asp Ala Thr Leu Val Asp Thr Glu Ile Thr Phe Phe Ser Glu
195 200 205
gac ggc aag aaa gag tcc atc ggc aag ccc aac acc ggc tac aga agc 672
Asp Gly Lys Lys Glu Ser Ile Gly Lys Pro Asn Thr Gly Tyr Arg Ser
210 215 220
aac tac ttc gcc tac gag aag ggc gac aaa gtg tgc aag atg aac tac 720
Asn Tyr Phe Ala Tyr Glu Lys Gly Asp Lys Val Cys Lys Met Asn Tyr
225 230 235 240
tgc aag cat gcc gga gtg agg ctg cct agc ggc gtg tgg ttc gag ttc 768
Cys Lys His Ala Gly Val Arg Leu Pro Ser Gly Val Trp Phe Glu Phe
245 250 255
gtg gac cag gac gtg tac gcc gcc gcc aag ctg ccc gag tgc ccc gtg 816
Val Asp Gln Asp Val Tyr Ala Ala Ala Lys Leu Pro Glu Cys Pro Val
260 265 270
ggc gcc acc atc agc gcc ccc acc cag acc agc gtg gac gtg agc ctg 864
Gly Ala Thr Ile Ser Ala Pro Thr Gln Thr Ser Val Asp Val Ser Leu
275 280 285
atc ctg gac gtg gag aga atc ctg gac tac tct ctg tgt cag gaa acc 912
Ile Leu Asp Val Glu Arg Ile Leu Asp Tyr Ser Leu Cys Gln Glu Thr
290 295 300
tgg tcc aag atc aga tcc aag cag ccc gtg agc cct gtg gac ctg agc 960
Trp Ser Lys Ile Arg Ser Lys Gln Pro Val Ser Pro Val Asp Leu Ser
305 310 315 320
tac ctg gcc cct aag aac ccc ggc acc ggc cct gcc ttc acc atc atc 1008
Tyr Leu Ala Pro Lys Asn Pro Gly Thr Gly Pro Ala Phe Thr Ile Ile
325 330 335
aac ggc acc ctg aag tac ttc gag aca cgg tac atc cgg atc gac atc 1056
Asn Gly Thr Leu Lys Tyr Phe Glu Thr Arg Tyr Ile Arg Ile Asp Ile
340 345 350
gac aac ccc atc atc agc aag atg gtg ggc aag atc agc ggc agc cag 1104
Asp Asn Pro Ile Ile Ser Lys Met Val Gly Lys Ile Ser Gly Ser Gln
355 360 365
acc gag cgg gag ctg tgg acc gag tgg ttc ccc tac gag ggc gtg gag 1152
Thr Glu Arg Glu Leu Trp Thr Glu Trp Phe Pro Tyr Glu Gly Val Glu
370 375 380
atc ggc ccc aat ggc atc ctg aaa acc cct acc ggc tac aag ttc ccc 1200
Ile Gly Pro Asn Gly Ile Leu Lys Thr Pro Thr Gly Tyr Lys Phe Pro
385 390 395 400
ctg ttc atg atc ggc cac ggc atg ctg gac agc gac ctg cac aag acc 1248
Leu Phe Met Ile Gly His Gly Met Leu Asp Ser Asp Leu His Lys Thr
405 410 415
tcc cag gcc gag gtg ttc gag cac ccc cac ctg gcc gag gcc ccc aag 1296
Ser Gln Ala Glu Val Phe Glu His Pro His Leu Ala Glu Ala Pro Lys
420 425 430
cag ctg ccc gaa gag gaa acc ctg ttc ttc ggc gac acc ggc atc tcc 1344
Gln Leu Pro Glu Glu Glu Thr Leu Phe Phe Gly Asp Thr Gly Ile Ser
435 440 445
aag aac cct gtg gag ctg atc gag ggc tgg ttc agc agc tgg aag agc 1392
Lys Asn Pro Val Glu Leu Ile Glu Gly Trp Phe Ser Ser Trp Lys Ser
450 455 460
agc atc gct tca ttt ttt ttc atc atc ggc ctc atc atc ggg ctg ttt 1440
Ser Ile Ala Ser Phe Phe Phe Ile Ile Gly Leu Ile Ile Gly Leu Phe
465 470 475 480
ctg gtg ctg cgc gtc ggc atc cac ctg tgc atc aag ctg aag cac acc 1488
Leu Val Leu Arg Val Gly Ile His Leu Cys Ile Lys Leu Lys His Thr
485 490 495
aag aag cgc cag atc tat acc gac atc gag atg aat cgc ctg ggg aag 1536
Lys Lys Arg Gln Ile Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505 510
taa 1539
<210> 82
<211> 512
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 82
Met Asn Phe Leu Leu Leu Thr Phe Ile Val Leu Pro Leu Cys Ser His
1 5 10 15
Ala Lys Phe Ser Ile Val Phe Pro Gln Ser Gln Lys Gly Asn Trp Lys
20 25 30
Asn Val Pro Ser Ser Tyr His Tyr Cys Pro Ser Ser Ser Asp Gln Asn
35 40 45
Trp His Asn Asp Leu Leu Gly Ile Thr Met Lys Val Lys Met Pro Lys
50 55 60
Thr His Lys Ala Ile Gln Ala Asp Gly Trp Met Cys His Ala Ala Lys
65 70 75 80
Trp Ile Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys Tyr Ile Thr
85 90 95
His Ser Ile His Ser Ile Gln Pro Thr Ser Glu Gln Cys Lys Glu Ser
100 105 110
Ile Lys Gln Thr Lys Gln Gly Thr Trp Met Ser Pro Gly Phe Pro Pro
115 120 125
Gln Asn Cys Gly Tyr Ala Thr Val Thr Asp Ser Val Ala Val Val Val
130 135 140
Gln Ala Thr Pro His His Val Leu Val Asp Glu Tyr Thr Gly Glu Trp
145 150 155 160
Ile Asp Ser Gln Phe Pro Asn Gly Lys Cys Glu Thr Glu Glu Cys Glu
165 170 175
Thr Val His Asn Ser Thr Val Trp Tyr Ser Asp Tyr Lys Val Thr Gly
180 185 190
Leu Cys Asp Ala Thr Leu Val Asp Thr Glu Ile Thr Phe Phe Ser Glu
195 200 205
Asp Gly Lys Lys Glu Ser Ile Gly Lys Pro Asn Thr Gly Tyr Arg Ser
210 215 220
Asn Tyr Phe Ala Tyr Glu Lys Gly Asp Lys Val Cys Lys Met Asn Tyr
225 230 235 240
Cys Lys His Ala Gly Val Arg Leu Pro Ser Gly Val Trp Phe Glu Phe
245 250 255
Val Asp Gln Asp Val Tyr Ala Ala Ala Lys Leu Pro Glu Cys Pro Val
260 265 270
Gly Ala Thr Ile Ser Ala Pro Thr Gln Thr Ser Val Asp Val Ser Leu
275 280 285
Ile Leu Asp Val Glu Arg Ile Leu Asp Tyr Ser Leu Cys Gln Glu Thr
290 295 300
Trp Ser Lys Ile Arg Ser Lys Gln Pro Val Ser Pro Val Asp Leu Ser
305 310 315 320
Tyr Leu Ala Pro Lys Asn Pro Gly Thr Gly Pro Ala Phe Thr Ile Ile
325 330 335
Asn Gly Thr Leu Lys Tyr Phe Glu Thr Arg Tyr Ile Arg Ile Asp Ile
340 345 350
Asp Asn Pro Ile Ile Ser Lys Met Val Gly Lys Ile Ser Gly Ser Gln
355 360 365
Thr Glu Arg Glu Leu Trp Thr Glu Trp Phe Pro Tyr Glu Gly Val Glu
370 375 380
Ile Gly Pro Asn Gly Ile Leu Lys Thr Pro Thr Gly Tyr Lys Phe Pro
385 390 395 400
Leu Phe Met Ile Gly His Gly Met Leu Asp Ser Asp Leu His Lys Thr
405 410 415
Ser Gln Ala Glu Val Phe Glu His Pro His Leu Ala Glu Ala Pro Lys
420 425 430
Gln Leu Pro Glu Glu Glu Thr Leu Phe Phe Gly Asp Thr Gly Ile Ser
435 440 445
Lys Asn Pro Val Glu Leu Ile Glu Gly Trp Phe Ser Ser Trp Lys Ser
450 455 460
Ser Ile Ala Ser Phe Phe Phe Ile Ile Gly Leu Ile Ile Gly Leu Phe
465 470 475 480
Leu Val Leu Arg Val Gly Ile His Leu Cys Ile Lys Leu Lys His Thr
485 490 495
Lys Lys Arg Gln Ile Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505 510
<210> 83
<211> 1518
<212> DNA
<213> Artificial
<220>
<223> Fusion VSV-G Piry / Indiana
<220>
<221> CDS
<222> (1)..(1518)
<400> 83
atg acc gat aca gtg ctg ggc aag ttc cag atc gtg ttc ccc gac cag 48
Met Thr Asp Thr Val Leu Gly Lys Phe Gln Ile Val Phe Pro Asp Gln
1 5 10 15
aac gag ctg gaa tgg acc ccc gtc gtg ggc gac agc cgg cat tgc cct 96
Asn Glu Leu Glu Trp Thr Pro Val Val Gly Asp Ser Arg His Cys Pro
20 25 30
cag tcc agc gag atg cag ttc gac ggc agc aga agc cag acc atc ctg 144
Gln Ser Ser Glu Met Gln Phe Asp Gly Ser Arg Ser Gln Thr Ile Leu
35 40 45
acc ggc aag gcc ccc gtg ggc atc aca ccc agc aag agc gac ggc ttc 192
Thr Gly Lys Ala Pro Val Gly Ile Thr Pro Ser Lys Ser Asp Gly Phe
50 55 60
atc tgc cac gcc gcc aag tgg gtg acc acc tgc gac ttc cgg tgg tac 240
Ile Cys His Ala Ala Lys Trp Val Thr Thr Cys Asp Phe Arg Trp Tyr
65 70 75 80
ggc ccc aag tac atc acc cac agc atc cac cac ctg cgg ccc acc acc 288
Gly Pro Lys Tyr Ile Thr His Ser Ile His His Leu Arg Pro Thr Thr
85 90 95
tcc gac tgc gag aca gcc ctg cag cgg tac aag gac ggc agc ctg atc 336
Ser Asp Cys Glu Thr Ala Leu Gln Arg Tyr Lys Asp Gly Ser Leu Ile
100 105 110
aac ctg ggc ttc cct ccc gag agc tgc ggc tac gcc acc gtg aca gac 384
Asn Leu Gly Phe Pro Pro Glu Ser Cys Gly Tyr Ala Thr Val Thr Asp
115 120 125
agc gag gcc atg ctg gtg cag gtg acc ccc cac cac gtg ggc gtg gac 432
Ser Glu Ala Met Leu Val Gln Val Thr Pro His His Val Gly Val Asp
130 135 140
gac tac cgg ggc cac tgg atc gac ccc ctg ttc cct ggc ggc gag tgc 480
Asp Tyr Arg Gly His Trp Ile Asp Pro Leu Phe Pro Gly Gly Glu Cys
145 150 155 160
agc acc aat ttc tgc gat acc gtg cac aac agc agc gtg tgg att ccc 528
Ser Thr Asn Phe Cys Asp Thr Val His Asn Ser Ser Val Trp Ile Pro
165 170 175
aag agc cag aaa acc gac atc tgc gcc cag agc ttc aag aac atc aag 576
Lys Ser Gln Lys Thr Asp Ile Cys Ala Gln Ser Phe Lys Asn Ile Lys
180 185 190
atg acc gcc agc tac ccc agc gag gga gcc ctg gtg tcc gac cgg ttc 624
Met Thr Ala Ser Tyr Pro Ser Glu Gly Ala Leu Val Ser Asp Arg Phe
195 200 205
gcc ttc cac agc gcc tac cac ccc aac atg ccc ggc agc acc gtg tgc 672
Ala Phe His Ser Ala Tyr His Pro Asn Met Pro Gly Ser Thr Val Cys
210 215 220
atc atg gat ttc tgc gag cag aag ggc ctg cgg ttc acc aac ggc gag 720
Ile Met Asp Phe Cys Glu Gln Lys Gly Leu Arg Phe Thr Asn Gly Glu
225 230 235 240
tgg atg ggc ctg aac gtg gag cag agc atc cgg gag aag aag atc agc 768
Trp Met Gly Leu Asn Val Glu Gln Ser Ile Arg Glu Lys Lys Ile Ser
245 250 255
gcc atc ttc ccc aac tgc gtg gcc ggc acc gag atc cgg gcc acc ctg 816
Ala Ile Phe Pro Asn Cys Val Ala Gly Thr Glu Ile Arg Ala Thr Leu
260 265 270
gaa tcc gag ggc gcc agg acc ctg acc tgg gag aca cag cgg atg ctg 864
Glu Ser Glu Gly Ala Arg Thr Leu Thr Trp Glu Thr Gln Arg Met Leu
275 280 285
gac tac agc ctg tgc cag aac acc tgg gac aag gtg tcc cgg aaa gag 912
Asp Tyr Ser Leu Cys Gln Asn Thr Trp Asp Lys Val Ser Arg Lys Glu
290 295 300
cct ctg tcc ccc ctg gac ctg agc tac ctg agc cct aga gcc cct ggc 960
Pro Leu Ser Pro Leu Asp Leu Ser Tyr Leu Ser Pro Arg Ala Pro Gly
305 310 315 320
aag ggc atg gcc tac acc gtg atc aac ggc acc ctg cac agc gcc cac 1008
Lys Gly Met Ala Tyr Thr Val Ile Asn Gly Thr Leu His Ser Ala His
325 330 335
gcc aag tat atc cgg acc tgg atc gac tac ggc gag atg aaa gag atc 1056
Ala Lys Tyr Ile Arg Thr Trp Ile Asp Tyr Gly Glu Met Lys Glu Ile
340 345 350
aag ggc ggc agg ggc gag tac agc aag gcc cct gag ctg ctg tgg agc 1104
Lys Gly Gly Arg Gly Glu Tyr Ser Lys Ala Pro Glu Leu Leu Trp Ser
355 360 365
cag tgg ttc gac ttc ggc ccc ttc aag atc ggc ccc aac ggc ctg ctg 1152
Gln Trp Phe Asp Phe Gly Pro Phe Lys Ile Gly Pro Asn Gly Leu Leu
370 375 380
cac acc ggc aag acc ttc aag ttc cct ctg tat ctg atc gga gcc ggc 1200
His Thr Gly Lys Thr Phe Lys Phe Pro Leu Tyr Leu Ile Gly Ala Gly
385 390 395 400
atc atc gac gag gac ctg cac gag ctg gac gaa gcc gcc cct atc gac 1248
Ile Ile Asp Glu Asp Leu His Glu Leu Asp Glu Ala Ala Pro Ile Asp
405 410 415
cac ccc cag atg ccc gac gcc aag agc gtg ctg ccc gag gac gag gaa 1296
His Pro Gln Met Pro Asp Ala Lys Ser Val Leu Pro Glu Asp Glu Glu
420 425 430
atc ttc ttc ggc gac acc ggc gtg agc aag aac ccc atc gag ctg atc 1344
Ile Phe Phe Gly Asp Thr Gly Val Ser Lys Asn Pro Ile Glu Leu Ile
435 440 445
cag ggc tgg ttc agc aac tgg cgg agc agc atc gct tca ttt ttt ttc 1392
Gln Gly Trp Phe Ser Asn Trp Arg Ser Ser Ile Ala Ser Phe Phe Phe
450 455 460
atc atc ggc ctc atc atc ggg ctg ttt ctg gtg ctg cgc gtc ggc atc 1440
Ile Ile Gly Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile
465 470 475 480
cac ctg tgc atc aag ctg aag cac acc aag aag cgc cag atc tat acc 1488
His Leu Cys Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr
485 490 495
gac atc gag atg aat cgc ctg ggg aag taa 1518
Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505
<210> 84
<211> 505
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 84
Met Thr Asp Thr Val Leu Gly Lys Phe Gln Ile Val Phe Pro Asp Gln
1 5 10 15
Asn Glu Leu Glu Trp Thr Pro Val Val Gly Asp Ser Arg His Cys Pro
20 25 30
Gln Ser Ser Glu Met Gln Phe Asp Gly Ser Arg Ser Gln Thr Ile Leu
35 40 45
Thr Gly Lys Ala Pro Val Gly Ile Thr Pro Ser Lys Ser Asp Gly Phe
50 55 60
Ile Cys His Ala Ala Lys Trp Val Thr Thr Cys Asp Phe Arg Trp Tyr
65 70 75 80
Gly Pro Lys Tyr Ile Thr His Ser Ile His His Leu Arg Pro Thr Thr
85 90 95
Ser Asp Cys Glu Thr Ala Leu Gln Arg Tyr Lys Asp Gly Ser Leu Ile
100 105 110
Asn Leu Gly Phe Pro Pro Glu Ser Cys Gly Tyr Ala Thr Val Thr Asp
115 120 125
Ser Glu Ala Met Leu Val Gln Val Thr Pro His His Val Gly Val Asp
130 135 140
Asp Tyr Arg Gly His Trp Ile Asp Pro Leu Phe Pro Gly Gly Glu Cys
145 150 155 160
Ser Thr Asn Phe Cys Asp Thr Val His Asn Ser Ser Val Trp Ile Pro
165 170 175
Lys Ser Gln Lys Thr Asp Ile Cys Ala Gln Ser Phe Lys Asn Ile Lys
180 185 190
Met Thr Ala Ser Tyr Pro Ser Glu Gly Ala Leu Val Ser Asp Arg Phe
195 200 205
Ala Phe His Ser Ala Tyr His Pro Asn Met Pro Gly Ser Thr Val Cys
210 215 220
Ile Met Asp Phe Cys Glu Gln Lys Gly Leu Arg Phe Thr Asn Gly Glu
225 230 235 240
Trp Met Gly Leu Asn Val Glu Gln Ser Ile Arg Glu Lys Lys Ile Ser
245 250 255
Ala Ile Phe Pro Asn Cys Val Ala Gly Thr Glu Ile Arg Ala Thr Leu
260 265 270
Glu Ser Glu Gly Ala Arg Thr Leu Thr Trp Glu Thr Gln Arg Met Leu
275 280 285
Asp Tyr Ser Leu Cys Gln Asn Thr Trp Asp Lys Val Ser Arg Lys Glu
290 295 300
Pro Leu Ser Pro Leu Asp Leu Ser Tyr Leu Ser Pro Arg Ala Pro Gly
305 310 315 320
Lys Gly Met Ala Tyr Thr Val Ile Asn Gly Thr Leu His Ser Ala His
325 330 335
Ala Lys Tyr Ile Arg Thr Trp Ile Asp Tyr Gly Glu Met Lys Glu Ile
340 345 350
Lys Gly Gly Arg Gly Glu Tyr Ser Lys Ala Pro Glu Leu Leu Trp Ser
355 360 365
Gln Trp Phe Asp Phe Gly Pro Phe Lys Ile Gly Pro Asn Gly Leu Leu
370 375 380
His Thr Gly Lys Thr Phe Lys Phe Pro Leu Tyr Leu Ile Gly Ala Gly
385 390 395 400
Ile Ile Asp Glu Asp Leu His Glu Leu Asp Glu Ala Ala Pro Ile Asp
405 410 415
His Pro Gln Met Pro Asp Ala Lys Ser Val Leu Pro Glu Asp Glu Glu
420 425 430
Ile Phe Phe Gly Asp Thr Gly Val Ser Lys Asn Pro Ile Glu Leu Ile
435 440 445
Gln Gly Trp Phe Ser Asn Trp Arg Ser Ser Ile Ala Ser Phe Phe Phe
450 455 460
Ile Ile Gly Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile
465 470 475 480
His Leu Cys Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr
485 490 495
Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505
<210> 85
<211> 1560
<212> DNA
<213> Artificial
<220>
<223> Fusion VSV-G Isfahan / Indiana
<220>
<221> CDS
<222> (1)..(1560)
<400> 85
atg aca tcc gtg ctg ttt atg gtg ggc gtg ctg ctc gga gct ttc gga 48
Met Thr Ser Val Leu Phe Met Val Gly Val Leu Leu Gly Ala Phe Gly
1 5 10 15
tct acc cac tgc agc atc cag atc gtg ttc ccc agc gag aca aag ctg 96
Ser Thr His Cys Ser Ile Gln Ile Val Phe Pro Ser Glu Thr Lys Leu
20 25 30
gtg tgg aag ccc gtg ctg aag ggc acc cgg tac tgc ccc cag agc gcc 144
Val Trp Lys Pro Val Leu Lys Gly Thr Arg Tyr Cys Pro Gln Ser Ala
35 40 45
gag ctg aac ctg gaa ccc gac ctg aaa acc atg gcc ttc gac agc aag 192
Glu Leu Asn Leu Glu Pro Asp Leu Lys Thr Met Ala Phe Asp Ser Lys
50 55 60
gtg ccc atc ggc atc acc ccc agc aac agc gac ggc tac ctg tgc cac 240
Val Pro Ile Gly Ile Thr Pro Ser Asn Ser Asp Gly Tyr Leu Cys His
65 70 75 80
gcc gcc aag tgg gtg acc acc tgc gac ttc cgg tgg tac ggc ccc aag 288
Ala Ala Lys Trp Val Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys
85 90 95
tac atc acc cac agc gtg cac agc ctg cgg ccc acc gtg agc gac tgc 336
Tyr Ile Thr His Ser Val His Ser Leu Arg Pro Thr Val Ser Asp Cys
100 105 110
aag gcc gcc gtg gaa gct tac aac gct ggc acc ctg atg tac ccc ggc 384
Lys Ala Ala Val Glu Ala Tyr Asn Ala Gly Thr Leu Met Tyr Pro Gly
115 120 125
ttc ccc ccc gag agc tgc ggc tac gcc agc atc acc gac agc gag ttc 432
Phe Pro Pro Glu Ser Cys Gly Tyr Ala Ser Ile Thr Asp Ser Glu Phe
130 135 140
tac gtg atg ctg gtg acc ccc cac ccc gtg gga gtg gac gac tac cgg 480
Tyr Val Met Leu Val Thr Pro His Pro Val Gly Val Asp Asp Tyr Arg
145 150 155 160
ggc cac tgg gtg gac cct ctg ttc ccc acc tcc gag tgc aac agc aac 528
Gly His Trp Val Asp Pro Leu Phe Pro Thr Ser Glu Cys Asn Ser Asn
165 170 175
ttc tgc gag aca gtg cac aac gcc acc atg tgg att ccc aag gat ctg 576
Phe Cys Glu Thr Val His Asn Ala Thr Met Trp Ile Pro Lys Asp Leu
180 185 190
aaa acc cac gac gtg tgc agc cag gac ttc cag acc atc aga gtg agc 624
Lys Thr His Asp Val Cys Ser Gln Asp Phe Gln Thr Ile Arg Val Ser
195 200 205
gtg atg tac cct cag acc aag ccc acc aag gga gct gac ctg aca ctg 672
Val Met Tyr Pro Gln Thr Lys Pro Thr Lys Gly Ala Asp Leu Thr Leu
210 215 220
aag agc aag ttc cac gcc cac atg aag ggc gac aga gtg tgc aag atg 720
Lys Ser Lys Phe His Ala His Met Lys Gly Asp Arg Val Cys Lys Met
225 230 235 240
aag ttc tgc aac aag aac ggc ctg cgg ctg ggc aac ggc gag tgg atc 768
Lys Phe Cys Asn Lys Asn Gly Leu Arg Leu Gly Asn Gly Glu Trp Ile
245 250 255
gaa gtg ggc gac gag gtg atg ctg gac aac agc aag ctg ctg tcc ctg 816
Glu Val Gly Asp Glu Val Met Leu Asp Asn Ser Lys Leu Leu Ser Leu
260 265 270
ttc ccc gac tgc ctg gtg ggc agc gtg gtg aag agc acc ctg ctg tcc 864
Phe Pro Asp Cys Leu Val Gly Ser Val Val Lys Ser Thr Leu Leu Ser
275 280 285
gag ggc gtg cag acc gcc ctg tgg gag aca gac cgg ctg ctg gac tac 912
Glu Gly Val Gln Thr Ala Leu Trp Glu Thr Asp Arg Leu Leu Asp Tyr
290 295 300
agc ctg tgc cag aac acc tgg gag aag atc gac cgg aaa gag ccc ctg 960
Ser Leu Cys Gln Asn Thr Trp Glu Lys Ile Asp Arg Lys Glu Pro Leu
305 310 315 320
agc gcc gtc gac ctg agc tac ctg gcc cct aga agc ccc ggc aag ggc 1008
Ser Ala Val Asp Leu Ser Tyr Leu Ala Pro Arg Ser Pro Gly Lys Gly
325 330 335
atg gcc tac atc gtg gcc aac ggc agc ctg atg agc gcc cct gcc cgg 1056
Met Ala Tyr Ile Val Ala Asn Gly Ser Leu Met Ser Ala Pro Ala Arg
340 345 350
tac atc aga gtg tgg atc gac agc ccc atc ctg aaa gag atc aag ggc 1104
Tyr Ile Arg Val Trp Ile Asp Ser Pro Ile Leu Lys Glu Ile Lys Gly
355 360 365
aag aaa gag agc gcc agc ggc atc gac acc gtg ctg tgg gag cag tgg 1152
Lys Lys Glu Ser Ala Ser Gly Ile Asp Thr Val Leu Trp Glu Gln Trp
370 375 380
ctg ccc ttc aac ggc atg gaa ctg ggc ccc aac ggc ctg atc aag acc 1200
Leu Pro Phe Asn Gly Met Glu Leu Gly Pro Asn Gly Leu Ile Lys Thr
385 390 395 400
aag agc ggc tac aag ttc ccc ctg tac ctg ctg ggc atg ggc atc gtg 1248
Lys Ser Gly Tyr Lys Phe Pro Leu Tyr Leu Leu Gly Met Gly Ile Val
405 410 415
gac cag gac ctg cag gaa ctg agc agc gtc aac ccc gtg gac cac ccc 1296
Asp Gln Asp Leu Gln Glu Leu Ser Ser Val Asn Pro Val Asp His Pro
420 425 430
cac gtg cct atc gcc cag gcc ttc gtg agc gag ggc gag gaa gtg ttc 1344
His Val Pro Ile Ala Gln Ala Phe Val Ser Glu Gly Glu Glu Val Phe
435 440 445
ttc ggc gac acc ggc gtg agc aag aac ccc atc gag ctg atc agc ggc 1392
Phe Gly Asp Thr Gly Val Ser Lys Asn Pro Ile Glu Leu Ile Ser Gly
450 455 460
tgg ttc agc gac tgg aaa agc agc atc gct tca ttt ttt ttc atc atc 1440
Trp Phe Ser Asp Trp Lys Ser Ser Ile Ala Ser Phe Phe Phe Ile Ile
465 470 475 480
ggc ctc atc atc ggg ctg ttt ctg gtg ctg cgc gtc ggc atc cac ctg 1488
Gly Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His Leu
485 490 495
tgc atc aag ctg aag cac acc aag aag cgc cag atc tat acc gac atc 1536
Cys Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp Ile
500 505 510
gag atg aat cgc ctg ggg aag taa 1560
Glu Met Asn Arg Leu Gly Lys
515
<210> 86
<211> 519
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 86
Met Thr Ser Val Leu Phe Met Val Gly Val Leu Leu Gly Ala Phe Gly
1 5 10 15
Ser Thr His Cys Ser Ile Gln Ile Val Phe Pro Ser Glu Thr Lys Leu
20 25 30
Val Trp Lys Pro Val Leu Lys Gly Thr Arg Tyr Cys Pro Gln Ser Ala
35 40 45
Glu Leu Asn Leu Glu Pro Asp Leu Lys Thr Met Ala Phe Asp Ser Lys
50 55 60
Val Pro Ile Gly Ile Thr Pro Ser Asn Ser Asp Gly Tyr Leu Cys His
65 70 75 80
Ala Ala Lys Trp Val Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys
85 90 95
Tyr Ile Thr His Ser Val His Ser Leu Arg Pro Thr Val Ser Asp Cys
100 105 110
Lys Ala Ala Val Glu Ala Tyr Asn Ala Gly Thr Leu Met Tyr Pro Gly
115 120 125
Phe Pro Pro Glu Ser Cys Gly Tyr Ala Ser Ile Thr Asp Ser Glu Phe
130 135 140
Tyr Val Met Leu Val Thr Pro His Pro Val Gly Val Asp Asp Tyr Arg
145 150 155 160
Gly His Trp Val Asp Pro Leu Phe Pro Thr Ser Glu Cys Asn Ser Asn
165 170 175
Phe Cys Glu Thr Val His Asn Ala Thr Met Trp Ile Pro Lys Asp Leu
180 185 190
Lys Thr His Asp Val Cys Ser Gln Asp Phe Gln Thr Ile Arg Val Ser
195 200 205
Val Met Tyr Pro Gln Thr Lys Pro Thr Lys Gly Ala Asp Leu Thr Leu
210 215 220
Lys Ser Lys Phe His Ala His Met Lys Gly Asp Arg Val Cys Lys Met
225 230 235 240
Lys Phe Cys Asn Lys Asn Gly Leu Arg Leu Gly Asn Gly Glu Trp Ile
245 250 255
Glu Val Gly Asp Glu Val Met Leu Asp Asn Ser Lys Leu Leu Ser Leu
260 265 270
Phe Pro Asp Cys Leu Val Gly Ser Val Val Lys Ser Thr Leu Leu Ser
275 280 285
Glu Gly Val Gln Thr Ala Leu Trp Glu Thr Asp Arg Leu Leu Asp Tyr
290 295 300
Ser Leu Cys Gln Asn Thr Trp Glu Lys Ile Asp Arg Lys Glu Pro Leu
305 310 315 320
Ser Ala Val Asp Leu Ser Tyr Leu Ala Pro Arg Ser Pro Gly Lys Gly
325 330 335
Met Ala Tyr Ile Val Ala Asn Gly Ser Leu Met Ser Ala Pro Ala Arg
340 345 350
Tyr Ile Arg Val Trp Ile Asp Ser Pro Ile Leu Lys Glu Ile Lys Gly
355 360 365
Lys Lys Glu Ser Ala Ser Gly Ile Asp Thr Val Leu Trp Glu Gln Trp
370 375 380
Leu Pro Phe Asn Gly Met Glu Leu Gly Pro Asn Gly Leu Ile Lys Thr
385 390 395 400
Lys Ser Gly Tyr Lys Phe Pro Leu Tyr Leu Leu Gly Met Gly Ile Val
405 410 415
Asp Gln Asp Leu Gln Glu Leu Ser Ser Val Asn Pro Val Asp His Pro
420 425 430
His Val Pro Ile Ala Gln Ala Phe Val Ser Glu Gly Glu Glu Val Phe
435 440 445
Phe Gly Asp Thr Gly Val Ser Lys Asn Pro Ile Glu Leu Ile Ser Gly
450 455 460
Trp Phe Ser Asp Trp Lys Ser Ser Ile Ala Ser Phe Phe Phe Ile Ile
465 470 475 480
Gly Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His Leu
485 490 495
Cys Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp Ile
500 505 510
Glu Met Asn Arg Leu Gly Lys
515
<210> 87
<211> 1536
<212> DNA
<213> Artificial
<220>
<223> Fusion VSV-G New Jersey / Indiana
<220>
<221> CDS
<222> (1)..(1536)
<400> 87
atg agc atc atc agc tat atc gcc ttt ctg ctg ctg atc gac agc acc 48
Met Ser Ile Ile Ser Tyr Ile Ala Phe Leu Leu Leu Ile Asp Ser Thr
1 5 10 15
ctg ggc atc ccc atc ttc gtg ccc agc ggc cag aac atc agc tgg cag 96
Leu Gly Ile Pro Ile Phe Val Pro Ser Gly Gln Asn Ile Ser Trp Gln
20 25 30
ccc gtg atc cag ccc ttc gac tac cag tgc ccc atc cac ggc aac ctg 144
Pro Val Ile Gln Pro Phe Asp Tyr Gln Cys Pro Ile His Gly Asn Leu
35 40 45
ccc aac acc atg ggc ctg agc gcc acc aag ctg acc atc aag agc ccc 192
Pro Asn Thr Met Gly Leu Ser Ala Thr Lys Leu Thr Ile Lys Ser Pro
50 55 60
agc gtg ttc agc acc gac aag gtg tcc ggc tgg atc tgc cac gcc gcc 240
Ser Val Phe Ser Thr Asp Lys Val Ser Gly Trp Ile Cys His Ala Ala
65 70 75 80
gag tgg aaa acc acc tgc gac tac cgg tgg tac ggc ccc cag tac atc 288
Glu Trp Lys Thr Thr Cys Asp Tyr Arg Trp Tyr Gly Pro Gln Tyr Ile
85 90 95
acc cac agc atc cac ccc atc agc ccc acc atc gac gag tgc aag cgg 336
Thr His Ser Ile His Pro Ile Ser Pro Thr Ile Asp Glu Cys Lys Arg
100 105 110
atc atc agc cgg atc gcc agc ggc acc gac gag gac ctg ggc ttc cca 384
Ile Ile Ser Arg Ile Ala Ser Gly Thr Asp Glu Asp Leu Gly Phe Pro
115 120 125
ccc cag agc tgc ggc tgg gcc agc gtg acc acc gtg agc aac acc aac 432
Pro Gln Ser Cys Gly Trp Ala Ser Val Thr Thr Val Ser Asn Thr Asn
130 135 140
tac aag gtg gtg ccc cac agc gtg cac ctg gaa ccc tac ggc ggc cac 480
Tyr Lys Val Val Pro His Ser Val His Leu Glu Pro Tyr Gly Gly His
145 150 155 160
tgg atc gac cac gac ttc aac ggc ggc gag tgc cgg gag aaa gtg tgc 528
Trp Ile Asp His Asp Phe Asn Gly Gly Glu Cys Arg Glu Lys Val Cys
165 170 175
gag atg aag ggc aac cac agc atc tgg atc acc gac gag aca gtg cag 576
Glu Met Lys Gly Asn His Ser Ile Trp Ile Thr Asp Glu Thr Val Gln
180 185 190
cac gag tgc gag aag cac atc gag gaa gtg gag ggc atc atg tac ggc 624
His Glu Cys Glu Lys His Ile Glu Glu Val Glu Gly Ile Met Tyr Gly
195 200 205
aac gcc ccc agg ggc gac gcc atc tac atc aac aac ttc atc atc gac 672
Asn Ala Pro Arg Gly Asp Ala Ile Tyr Ile Asn Asn Phe Ile Ile Asp
210 215 220
aag cac cac cgg gtg tac cgg ttc ggc ggc tcc tgc cgg atg aag ttc 720
Lys His His Arg Val Tyr Arg Phe Gly Gly Ser Cys Arg Met Lys Phe
225 230 235 240
tgc aac aag gac ggc atc aag ttc acc aga ggc gac tgg gtg gag aaa 768
Cys Asn Lys Asp Gly Ile Lys Phe Thr Arg Gly Asp Trp Val Glu Lys
245 250 255
acc gcc ggc acc ctg acc aac atc tac gag aac atc ccc gag tgc gcc 816
Thr Ala Gly Thr Leu Thr Asn Ile Tyr Glu Asn Ile Pro Glu Cys Ala
260 265 270
gac ggc aca ctg gtg tcc ggc cac aga ccc ggc ctg gac ctg atc gac 864
Asp Gly Thr Leu Val Ser Gly His Arg Pro Gly Leu Asp Leu Ile Asp
275 280 285
acc gtg ttc aac ctg gaa aac gtg gtg gag tac acc ctg tgc gag ggc 912
Thr Val Phe Asn Leu Glu Asn Val Val Glu Tyr Thr Leu Cys Glu Gly
290 295 300
acc aag cgg aag atc aac aag cag gaa aag ctg acc agc gtc gac ctg 960
Thr Lys Arg Lys Ile Asn Lys Gln Glu Lys Leu Thr Ser Val Asp Leu
305 310 315 320
agc tac ctg gcc ccc agg atc ggc ggc ttc ggc agc gtg ttc cgc gtg 1008
Ser Tyr Leu Ala Pro Arg Ile Gly Gly Phe Gly Ser Val Phe Arg Val
325 330 335
cgg aat ggg acc ctg gaa aga gga agc aca aca tac att cgg atc gaa 1056
Arg Asn Gly Thr Leu Glu Arg Gly Ser Thr Thr Tyr Ile Arg Ile Glu
340 345 350
gtg gaa ggc ccc gtg gtg gac agc ctg aac ggc atc gac ccc cgg acc 1104
Val Glu Gly Pro Val Val Asp Ser Leu Asn Gly Ile Asp Pro Arg Thr
355 360 365
aac gcc agc cgg gtg ttc tgg gac gac tgg gag ctg gac ggc aac atc 1152
Asn Ala Ser Arg Val Phe Trp Asp Asp Trp Glu Leu Asp Gly Asn Ile
370 375 380
tac cag ggc ttc aat ggc gtg tac aag ggc aag gat ggc aag atc cac 1200
Tyr Gln Gly Phe Asn Gly Val Tyr Lys Gly Lys Asp Gly Lys Ile His
385 390 395 400
atc ccc ctg aac atg atc gag agc ggc atc atc gac gac gag ctg cag 1248
Ile Pro Leu Asn Met Ile Glu Ser Gly Ile Ile Asp Asp Glu Leu Gln
405 410 415
cac gcc ttc cag gcc gac atc atc ccc cac ccc cac tac gac gac gac 1296
His Ala Phe Gln Ala Asp Ile Ile Pro His Pro His Tyr Asp Asp Asp
420 425 430
gag atc cgg gag gac gac atc ttc ttc gac aac acc ggc gag aac ggc 1344
Glu Ile Arg Glu Asp Asp Ile Phe Phe Asp Asn Thr Gly Glu Asn Gly
435 440 445
aac ccc gtg gac gcc gtg gtg gaa tgg gtg tcc gga tgg ggc agc agc 1392
Asn Pro Val Asp Ala Val Val Glu Trp Val Ser Gly Trp Gly Ser Ser
450 455 460
atc gct tca ttt ttt ttc atc atc ggc ctc atc atc ggg ctg ttt ctg 1440
Ile Ala Ser Phe Phe Phe Ile Ile Gly Leu Ile Ile Gly Leu Phe Leu
465 470 475 480
gtg ctg cgc gtc ggc atc cac ctg tgc atc aag ctg aag cac acc aag 1488
Val Leu Arg Val Gly Ile His Leu Cys Ile Lys Leu Lys His Thr Lys
485 490 495
aag cgc cag atc tat acc gac atc gag atg aat cgc ctg ggg aag taa 1536
Lys Arg Gln Ile Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505 510
<210> 88
<211> 511
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 88
Met Ser Ile Ile Ser Tyr Ile Ala Phe Leu Leu Leu Ile Asp Ser Thr
1 5 10 15
Leu Gly Ile Pro Ile Phe Val Pro Ser Gly Gln Asn Ile Ser Trp Gln
20 25 30
Pro Val Ile Gln Pro Phe Asp Tyr Gln Cys Pro Ile His Gly Asn Leu
35 40 45
Pro Asn Thr Met Gly Leu Ser Ala Thr Lys Leu Thr Ile Lys Ser Pro
50 55 60
Ser Val Phe Ser Thr Asp Lys Val Ser Gly Trp Ile Cys His Ala Ala
65 70 75 80
Glu Trp Lys Thr Thr Cys Asp Tyr Arg Trp Tyr Gly Pro Gln Tyr Ile
85 90 95
Thr His Ser Ile His Pro Ile Ser Pro Thr Ile Asp Glu Cys Lys Arg
100 105 110
Ile Ile Ser Arg Ile Ala Ser Gly Thr Asp Glu Asp Leu Gly Phe Pro
115 120 125
Pro Gln Ser Cys Gly Trp Ala Ser Val Thr Thr Val Ser Asn Thr Asn
130 135 140
Tyr Lys Val Val Pro His Ser Val His Leu Glu Pro Tyr Gly Gly His
145 150 155 160
Trp Ile Asp His Asp Phe Asn Gly Gly Glu Cys Arg Glu Lys Val Cys
165 170 175
Glu Met Lys Gly Asn His Ser Ile Trp Ile Thr Asp Glu Thr Val Gln
180 185 190
His Glu Cys Glu Lys His Ile Glu Glu Val Glu Gly Ile Met Tyr Gly
195 200 205
Asn Ala Pro Arg Gly Asp Ala Ile Tyr Ile Asn Asn Phe Ile Ile Asp
210 215 220
Lys His His Arg Val Tyr Arg Phe Gly Gly Ser Cys Arg Met Lys Phe
225 230 235 240
Cys Asn Lys Asp Gly Ile Lys Phe Thr Arg Gly Asp Trp Val Glu Lys
245 250 255
Thr Ala Gly Thr Leu Thr Asn Ile Tyr Glu Asn Ile Pro Glu Cys Ala
260 265 270
Asp Gly Thr Leu Val Ser Gly His Arg Pro Gly Leu Asp Leu Ile Asp
275 280 285
Thr Val Phe Asn Leu Glu Asn Val Val Glu Tyr Thr Leu Cys Glu Gly
290 295 300
Thr Lys Arg Lys Ile Asn Lys Gln Glu Lys Leu Thr Ser Val Asp Leu
305 310 315 320
Ser Tyr Leu Ala Pro Arg Ile Gly Gly Phe Gly Ser Val Phe Arg Val
325 330 335
Arg Asn Gly Thr Leu Glu Arg Gly Ser Thr Thr Tyr Ile Arg Ile Glu
340 345 350
Val Glu Gly Pro Val Val Asp Ser Leu Asn Gly Ile Asp Pro Arg Thr
355 360 365
Asn Ala Ser Arg Val Phe Trp Asp Asp Trp Glu Leu Asp Gly Asn Ile
370 375 380
Tyr Gln Gly Phe Asn Gly Val Tyr Lys Gly Lys Asp Gly Lys Ile His
385 390 395 400
Ile Pro Leu Asn Met Ile Glu Ser Gly Ile Ile Asp Asp Glu Leu Gln
405 410 415
His Ala Phe Gln Ala Asp Ile Ile Pro His Pro His Tyr Asp Asp Asp
420 425 430
Glu Ile Arg Glu Asp Asp Ile Phe Phe Asp Asn Thr Gly Glu Asn Gly
435 440 445
Asn Pro Val Asp Ala Val Val Glu Trp Val Ser Gly Trp Gly Ser Ser
450 455 460
Ile Ala Ser Phe Phe Phe Ile Ile Gly Leu Ile Ile Gly Leu Phe Leu
465 470 475 480
Val Leu Arg Val Gly Ile His Leu Cys Ile Lys Leu Lys His Thr Lys
485 490 495
Lys Arg Gln Ile Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
500 505 510
<210> 89
<211> 1557
<212> DNA
<213> Artificial
<220>
<223> Fusion VSV-G New Jersey / Indiana
<220>
<221> CDS
<222> (1)..(1557)
<400> 89
atg ctg tca tat ctg atc ttt gcc ctg gct gtg agc cca atc ctc gga 48
Met Leu Ser Tyr Leu Ile Phe Ala Leu Ala Val Ser Pro Ile Leu Gly
1 5 10 15
aag atc gaa atc gtg ttc cca caa cac acc aca ggg gac tgg aag cgc 96
Lys Ile Glu Ile Val Phe Pro Gln His Thr Thr Gly Asp Trp Lys Arg
20 25 30
gtg ccc cac gag tac aac tac tgc ccg acc tca gcc gac aag aat agc 144
Val Pro His Glu Tyr Asn Tyr Cys Pro Thr Ser Ala Asp Lys Asn Ser
35 40 45
cac ggc acg cag acc ggc atc cct gtg gag ctg acc atg ccc aag ggg 192
His Gly Thr Gln Thr Gly Ile Pro Val Glu Leu Thr Met Pro Lys Gly
50 55 60
ctc aca acg cac caa gtc gaa ggc ttc atg tgc cac agc gct ctc tgg 240
Leu Thr Thr His Gln Val Glu Gly Phe Met Cys His Ser Ala Leu Trp
65 70 75 80
atg aca acc tgc gat ttt cgc tgg tat ggc ccc aag tac atc acg cac 288
Met Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys Tyr Ile Thr His
85 90 95
agc atc cac aat gag gaa cca acc gac tac cag tgc ctc gaa gcc atc 336
Ser Ile His Asn Glu Glu Pro Thr Asp Tyr Gln Cys Leu Glu Ala Ile
100 105 110
aag tca tac aag gat ggg gtg agc ttc aac ccc ggc ttc ccg ccc caa 384
Lys Ser Tyr Lys Asp Gly Val Ser Phe Asn Pro Gly Phe Pro Pro Gln
115 120 125
tca tgt ggc tac ggc acc gtg acc gac gcc gag gcc cac atc gtg acc 432
Ser Cys Gly Tyr Gly Thr Val Thr Asp Ala Glu Ala His Ile Val Thr
130 135 140
gtg aca ccc cac tca gtc aag gtg gac gag tac aca ggc gaa tgg atc 480
Val Thr Pro His Ser Val Lys Val Asp Glu Tyr Thr Gly Glu Trp Ile
145 150 155 160
gac ccc cac ttc atc ggg ggc cgc tgt aag ggc caa atc tgc gag acc 528
Asp Pro His Phe Ile Gly Gly Arg Cys Lys Gly Gln Ile Cys Glu Thr
165 170 175
gtg cac aac agc acc aag tgg ttt acg tca tca gac ggc gaa agc gtg 576
Val His Asn Ser Thr Lys Trp Phe Thr Ser Ser Asp Gly Glu Ser Val
180 185 190
tgc agc caa ctg ttt acg ctc gtg ggc ggc atc ttc ttt agc gac agc 624
Cys Ser Gln Leu Phe Thr Leu Val Gly Gly Ile Phe Phe Ser Asp Ser
195 200 205
gag gag atc acc agc atg ggc ctc ccg gag aca gga atc cgc agc aac 672
Glu Glu Ile Thr Ser Met Gly Leu Pro Glu Thr Gly Ile Arg Ser Asn
210 215 220
tac ttt ccg tac atc agc acc gag gga atc tgt aag atg cct ttt tgc 720
Tyr Phe Pro Tyr Ile Ser Thr Glu Gly Ile Cys Lys Met Pro Phe Cys
225 230 235 240
cgc aag cag gga tat aag ctg aag aat gac ctg tgg ttc cag atc atg 768
Arg Lys Gln Gly Tyr Lys Leu Lys Asn Asp Leu Trp Phe Gln Ile Met
245 250 255
gac ccg gac ctg gac aag acc gtc cgc gat ctg ccc cac atc aag gac 816
Asp Pro Asp Leu Asp Lys Thr Val Arg Asp Leu Pro His Ile Lys Asp
260 265 270
tgt gat ctg tca tca agc atc atc acc ccc gga gaa cac gcc acg gac 864
Cys Asp Leu Ser Ser Ser Ile Ile Thr Pro Gly Glu His Ala Thr Asp
275 280 285
atc agc ctc atc agc gat gtg gag cgc atc ctc gac tac gct ctc tgc 912
Ile Ser Leu Ile Ser Asp Val Glu Arg Ile Leu Asp Tyr Ala Leu Cys
290 295 300
cag aac aca tgg agc aag atc gaa agc ggc gaa ccc atc acc cca gtg 960
Gln Asn Thr Trp Ser Lys Ile Glu Ser Gly Glu Pro Ile Thr Pro Val
305 310 315 320
gac ctg agc tat ctc ggc cca aag aac ccc ggc gtg ggg ccc gtg ttc 1008
Asp Leu Ser Tyr Leu Gly Pro Lys Asn Pro Gly Val Gly Pro Val Phe
325 330 335
acc atc atc aac ggg agc ctg cac tac ttt aca agc aag tat ctg cgc 1056
Thr Ile Ile Asn Gly Ser Leu His Tyr Phe Thr Ser Lys Tyr Leu Arg
340 345 350
gtg gag ctc gaa agc cca gtc atc ccc cgc atg gag ggg aag gtg gcc 1104
Val Glu Leu Glu Ser Pro Val Ile Pro Arg Met Glu Gly Lys Val Ala
355 360 365
ggg acc cgc atc gtg cgc cag ctg tgg gac cag tgg ttc cct ttt ggc 1152
Gly Thr Arg Ile Val Arg Gln Leu Trp Asp Gln Trp Phe Pro Phe Gly
370 375 380
gag gtg gaa atc ggc ccc aac ggc gtg ctg aag acc aag caa gga tat 1200
Glu Val Glu Ile Gly Pro Asn Gly Val Leu Lys Thr Lys Gln Gly Tyr
385 390 395 400
aag ttc ccg ctg cac atc atc ggg acg ggc gaa gtg gac agc gat atc 1248
Lys Phe Pro Leu His Ile Ile Gly Thr Gly Glu Val Asp Ser Asp Ile
405 410 415
aag atg gag cgc gtg gtc aag cac tgg gag cac cca cac atc gag gct 1296
Lys Met Glu Arg Val Val Lys His Trp Glu His Pro His Ile Glu Ala
420 425 430
gct cag acc ttt ctc aag aag gac gat acc ggc gaa gtc ctg tat tac 1344
Ala Gln Thr Phe Leu Lys Lys Asp Asp Thr Gly Glu Val Leu Tyr Tyr
435 440 445
ggg gat acg gga gtg agc aag aac cct gtg gag ctg gtg gaa ggc tgg 1392
Gly Asp Thr Gly Val Ser Lys Asn Pro Val Glu Leu Val Glu Gly Trp
450 455 460
ttc agc gga tgg cgc agc agc atc gct tca ttt ttt ttc atc atc ggc 1440
Phe Ser Gly Trp Arg Ser Ser Ile Ala Ser Phe Phe Phe Ile Ile Gly
465 470 475 480
ctc atc atc ggg ctg ttt ctg gtg ctg cgc gtc ggc atc cac ctg tgc 1488
Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His Leu Cys
485 490 495
atc aag ctg aag cac acc aag aag cgc cag atc tat acc gac atc gag 1536
Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp Ile Glu
500 505 510
atg aat cgc ctg ggg aag taa 1557
Met Asn Arg Leu Gly Lys
515
<210> 90
<211> 518
<212> PRT
<213> Artificial
<220>
<223> Synthetic Construct
<400> 90
Met Leu Ser Tyr Leu Ile Phe Ala Leu Ala Val Ser Pro Ile Leu Gly
1 5 10 15
Lys Ile Glu Ile Val Phe Pro Gln His Thr Thr Gly Asp Trp Lys Arg
20 25 30
Val Pro His Glu Tyr Asn Tyr Cys Pro Thr Ser Ala Asp Lys Asn Ser
35 40 45
His Gly Thr Gln Thr Gly Ile Pro Val Glu Leu Thr Met Pro Lys Gly
50 55 60
Leu Thr Thr His Gln Val Glu Gly Phe Met Cys His Ser Ala Leu Trp
65 70 75 80
Met Thr Thr Cys Asp Phe Arg Trp Tyr Gly Pro Lys Tyr Ile Thr His
85 90 95
Ser Ile His Asn Glu Glu Pro Thr Asp Tyr Gln Cys Leu Glu Ala Ile
100 105 110
Lys Ser Tyr Lys Asp Gly Val Ser Phe Asn Pro Gly Phe Pro Pro Gln
115 120 125
Ser Cys Gly Tyr Gly Thr Val Thr Asp Ala Glu Ala His Ile Val Thr
130 135 140
Val Thr Pro His Ser Val Lys Val Asp Glu Tyr Thr Gly Glu Trp Ile
145 150 155 160
Asp Pro His Phe Ile Gly Gly Arg Cys Lys Gly Gln Ile Cys Glu Thr
165 170 175
Val His Asn Ser Thr Lys Trp Phe Thr Ser Ser Asp Gly Glu Ser Val
180 185 190
Cys Ser Gln Leu Phe Thr Leu Val Gly Gly Ile Phe Phe Ser Asp Ser
195 200 205
Glu Glu Ile Thr Ser Met Gly Leu Pro Glu Thr Gly Ile Arg Ser Asn
210 215 220
Tyr Phe Pro Tyr Ile Ser Thr Glu Gly Ile Cys Lys Met Pro Phe Cys
225 230 235 240
Arg Lys Gln Gly Tyr Lys Leu Lys Asn Asp Leu Trp Phe Gln Ile Met
245 250 255
Asp Pro Asp Leu Asp Lys Thr Val Arg Asp Leu Pro His Ile Lys Asp
260 265 270
Cys Asp Leu Ser Ser Ser Ile Ile Thr Pro Gly Glu His Ala Thr Asp
275 280 285
Ile Ser Leu Ile Ser Asp Val Glu Arg Ile Leu Asp Tyr Ala Leu Cys
290 295 300
Gln Asn Thr Trp Ser Lys Ile Glu Ser Gly Glu Pro Ile Thr Pro Val
305 310 315 320
Asp Leu Ser Tyr Leu Gly Pro Lys Asn Pro Gly Val Gly Pro Val Phe
325 330 335
Thr Ile Ile Asn Gly Ser Leu His Tyr Phe Thr Ser Lys Tyr Leu Arg
340 345 350
Val Glu Leu Glu Ser Pro Val Ile Pro Arg Met Glu Gly Lys Val Ala
355 360 365
Gly Thr Arg Ile Val Arg Gln Leu Trp Asp Gln Trp Phe Pro Phe Gly
370 375 380
Glu Val Glu Ile Gly Pro Asn Gly Val Leu Lys Thr Lys Gln Gly Tyr
385 390 395 400
Lys Phe Pro Leu His Ile Ile Gly Thr Gly Glu Val Asp Ser Asp Ile
405 410 415
Lys Met Glu Arg Val Val Lys His Trp Glu His Pro His Ile Glu Ala
420 425 430
Ala Gln Thr Phe Leu Lys Lys Asp Asp Thr Gly Glu Val Leu Tyr Tyr
435 440 445
Gly Asp Thr Gly Val Ser Lys Asn Pro Val Glu Leu Val Glu Gly Trp
450 455 460
Phe Ser Gly Trp Arg Ser Ser Ile Ala Ser Phe Phe Phe Ile Ile Gly
465 470 475 480
Leu Ile Ile Gly Leu Phe Leu Val Leu Arg Val Gly Ile His Leu Cys
485 490 495
Ile Lys Leu Lys His Thr Lys Lys Arg Gln Ile Tyr Thr Asp Ile Glu
500 505 510
Met Asn Arg Leu Gly Lys
515
Claims (22)
- (i) RNA 바이러스 유래의 결정된 이종 바이러스 외피 단백질 또는 바이러스 외피 단백질들로 위형화(pseudotype)되고 (ii) 포유류 숙주를 감염시킬 수 있는 플라스모듐(Plasmodium) 기생충의 전-적혈구 단계 항원의 에피토프를 갖는 하나 이상의 폴리펩티드를 코딩하는 하나 이상의 재조합 폴리뉴클레오티드를 그의 게놈 내에 포함하는 렌티바이러스 벡터 입자로서,
상기 에피토프는 T-에피토프 및 임의로 B-에피토프를 포함하는 것인 렌티바이러스 벡터 입자. - 제1항에 있어서,
복제-무능(replication-incompetent) HIV-기반 벡터 입자인 렌티바이러스 벡터 입자. - 제1항에 있어서,
상기 하나 이상의 재조합 폴리뉴클레오티드는 인간을 감염시키는 플라스모듐 기생충의 환상포자소체 단백질(CSP)로부터의 항원의 폴리펩티드를 코딩하는 핵산 서열, 또는 포자소체 표면 단백질 2(TRAP/SSP2), 간-단계 항원(LSA), LSA3, Pf 배출 단백질 1(Pf Exp1), Pf 항원 2 포자소체 및 간 단계 항원(SALSA), 포자소체 트레오닌 및 아스파라긴-풍부(STARP)의 군으로부터 선택된 항원의 폴리펩티드를 코딩하는 핵산 서열을 포함하는 것을 특징으로 하는 렌티바이러스 벡터 입자. - 제1항 내지 제3항 중 어느 한 항에 있어서,
분열소체 표면 단백질 1(MSP2), 특히 분열소체 표면 단백질 1(MSP-1), 분열소체 표면 단백질 2(MSP-2) 분열소체 표면 단백질 3(MSP-3), 분열소체 표면 단백질 4(MSP-4), 분열소체 표면 단백질 6(MSP-6), MSP3-GLURP 융합 단백질, 고리-감염된 적혈구 표면 항원(RESA), 곤봉체 연관 단백질 1(RAP-1), 첨단막 항원 1(AMA-1), 적혈구 결합 항원(EBA-175), 적혈구 막-연관 거대 단백질 또는 항원 332(Ag332), dnaK-유형 분자 샤페론, 글루타메이트-풍부 단백질(GLURP); MSP3-GLURP 융합 단백질, 적혈구 막 단백질 1(EMP-1), 세린 반복 항원(SERA), 군집된-아스파라긴-풍부 단백질(CARP), 환형포자소체 단백질-관련 항원 전구체(CRA), 세포부착-연결 무성 단백질(CLAG), 산성 염기성 반복 항원(ABRA) 또는 101 kDa 말라리아 항원, 곤봉체 항원 단백질(RAP-2), Knob-연관 히스티딘-풍부 단백질(KHRP), 곤봉체 항원 단백질(RAP), 시스테인 프로테아제, 가상 단백질 PFE1325w, 보호성 항원(MAg-1), 프룩토오스-비스포스페이트 알돌라아제, 리보솜 인단백질 P0, P-유형 ATPase, 글루코오스-조절 단백질(GRP78), 아스파라긴 및 아스파테이트-풍부 단백질(AARP1), 산재 반복 항원 또는 PFE0070w의 군으로부터 선택된 폴리펩티드를 코딩하는 폴리뉴클레오티드, 및/또는 성적 단계 및 포자소체 표면 항원, 항원 Pfg27/25, 항원 QF122, 11-1 폴리펩티드, 생식모세포-특이적 표면 단백질(Pfs230) 오오키니트 표면 단백질(P25), 키티나아제, 멀티약물 내성 단백질(MRP)의 군에서 선택된 폴리펩티드를 코딩하는 폴리뉴클레오티드를 그의 게놈 내에 포함하는 것을 특징으로 하는 렌티바이러스 벡터 입자. - 제1항 내지 제4항 중 어느 한 항에 있어서,
상기 재조합 폴리뉴클레오티드가 포유류 코돈 최적화된 뉴클레오티드 서열을 갖고, 임의로 게놈의 HIV-기반 서열이 포유류 코돈 최적화된 뉴클레오티드 서열을 갖는 것을 특징으로 하는 렌티바이러스 벡터 입자. - 제1항 내지 제5항 중 어느 한 항에 있어서,
재조합 폴리뉴클레오티드가 CSP 항원의 하나 이상의 폴리펩티드를 코딩하고, 상기 폴리펩티드는 상기 CSP의 GPI-정박 모티브가 없는 것을 특징으로 하는 렌티바이러스 벡터 입자. - 제1항 내지 제6항 중 어느 한 항에 있어서,
통합-결핍(integration-deficient) 벡터 입자 또는 통합-유능(integration-competent) 벡터 입자 중에서 선택되는 것을 특징으로 하는 렌티바이러스 벡터 입자. - 제1항 내지 제7항 중 어느 한 항에 있어서,
인디아나(Indiana) 균주의 VSV-G 단백질, 뉴저지(New Jersey) 균주의 VSV-G 단백질, 코칼(Cocal) 균주의 VSV-G 단백질, 이스파한(Isfahan) 균주의 VSV-G 단백질, 찬디푸라(Chandipura) 균주의 VSV-G 단백질, 피리(Pyri) 균주의 VSV-G 단백질 또는 SVCV 균주의 VSV-G 단백질의 군에서 선택된 수포성 구내염 바이러스(VSV)의 바이러스 막통과 글리코실화(G) 외피 단백질로 위형화된 것을 특징으로 하는 렌티바이러스 벡터 입자. - 제1항 내지 제8항 중 어느 한 항에 있어서,
포유류 세포와 하기의 공동-트랜스펙션으로부터 회수된 생성물인 렌티바이러스 벡터 입자:
- (i) 렌티바이러스, 특히 HIV-1, 팩킹, 역전사 및 전사에 필요한 시스-작용 서열을 포함하고, 기능적 렌티바이러스, 특히 HIV-1, DNA 플랩 요소를 추가로 포함하고, 임의로 통합(integration)에 필요한 시스-작용 서열을 포함하는 벡터 플라스미드, 여기서 상기 벡터 플라스미드는 조절 발현 서열, 특히 프로모터의 제어 하에 (ii) 절단된 포유류, 특히 인간의 폴리뉴클레오티드, 플라스모듐 기생충의 cs 유전자의 코돈-최적화 서열을 추가로 포함함;
- VSV-G 외피 단백질 또는 외피 단백질들을 코딩하는 폴리뉴클레오티드를 포함하는 VSV-G 외피 발현 플라스미드, 여기서 상기 폴리뉴클레오티드는 조절 발현 서열의 제어 하에 있음; 및
- 캡시드화(encapsidation) 플라스미드, 여기서 상기 캡시드화 플라스미드는 렌티바이러스, 특히 HIV-1, 통합-유능 벡터 입자의 생성에 적합한 gag - pol 코딩 서열 또는 통합-결핍 벡터 입자의 생성에 적합한 개질된 gag - pol 코딩 서열을 포함하며, 상기 gag - pol 서열은 DNA 플랩 요소와 동일한 렌티바이러스 서브-계열로부터 유래된 것이고, 상기 gag - pol 또는 개질된 gag-pol 서열은 조절 발현 서열의 제어 하에 있음. - 제1항 내지 제9항 중 어느 한 항에 있어서,
하기와 함께 안정한 세포주로부터 회수된 생성물인 렌티바이러스 벡터 입자:
- (i) 렌티바이러스, 특히 HIV-1, 팩킹, 역전사 및 전사에 필요한 시스-작용 서열을 포함하고, 기능적 렌티바이러스, 특히 HIV-1, DNA 플랩 요소를 추가로 포함하고, 임의로 통합에 필요한 시스-작용 서열을 포함하는 벡터 플라스미드, 여기서 상기 벡터 플라스미드는 조절 발현 서열, 특히 프로모터의 제어 하에 (ii) 절단된 포유류, 특히 인간의 폴리뉴클레오티드, 플라스모듐 기생충의 cs 유전자의 코돈-최적화 서열을 추가로 포함함;
- VSV-G 외피 단백질 또는 외피 단백질들을 코딩하는 폴리뉴클레오티드를 포함하는 VSV-G 외피 발현 플라스미드, 여기서 상기 폴리뉴클레오티드는 조절 발현 서열, 특히 유도성 프로모터를 포함하는 조절 발현 서열의 제어 하에 있음; 및
- 캡시드화 플라스미드, 여기서 상기 캡시드화 플라스미드는 렌티바이러스, 특히 HIV-1, 통합-유능 벡터 입자의 생성에 적합한 gag - pol 코딩 서열 또는 통합-결핍 벡터 입자의 생성에 적합한 개질된 gag - pol 코딩 서열을 포함하며, 상기 gag - pol 서열은 DNA 플랩 요소와 동일한 렌티바이러스 서브-계열로부터 유래된 것이고, 상기 렌티바이러스 gag - pol 또는 개질된 gag - pol 서열은 조절 발현 서열의 제어 하에 있음. - 제1항 내지 제10항 중 어느 한 항에 있어서,
기능적 렌티바이러스 유전자가 없고, 팩킹, 역전사 및 전사에 필요한 시스-작용 서열을 포함하고, 기능적 렌티바이러스, 특히 HIV-1, DNA 플랩 요소를 추가로 포함하는 렌티바이러스-기반 서열, 특히 HIV-1-기반 서열이 벡터 게놈에 포함되며, 여기서 상기 벡터 게놈은 상기 시스-작용 서열에서 하나 이상이 하기의 개질된 폴리뉴클레오티드인 것을 추가로 특징으로 하는, 렌티바이러스 벡터 입자:
a) 렌티바이러스 게놈으로부터의 3'LTR 서열이 절단되고, U3 영역의 인핸서가 없음;
b) 렌티바이러스 게놈으로부터의 3'LTR 서열이 절단되고, U3 영역이 없거나 U3 영역에서 부분적으로 결실됨;
c) LTR5'의 U3 영역이 비 렌티바이러스 U3 영역에 의해 대체되거나, 또는 tat-독립적 일차 전사를 추진하는데 적합한 프로모터에 의해 대체됨. - 적어도 하기를 포함하는, 포유류 숙주에 대한 개별투여용 화합물의 조합:
(i) 제 1 결정된 이종 바이러스 외피 단백질 또는 바이러스 외피 단백질들로 위형화된, 제1항 내지 제11항 중 어느 한 항에 따른 렌티바이러스 벡터 입자;
(ii) 상기 (i)의 렌티바이러스 벡터 입자와 별개로 제공되는, 상기 제 1 이종 바이러스 외피 단백질과 구별되는 제 2 결정된 이종 바이러스 외피 단백질 또는 바이러스 외피 단백질들로 위형화된, 제1항 내지 제11항 중 어느 한 항에 따른 렌티바이러스 벡터 입자;
상기 제 1 바이러스 외피 단백질과 제 2 바이러스 외피 단백질은 서로 혈청-중화적이지 않고, 포유류 세포의 인 비보 형질도입에 적합함. - 제12항에 있어서,
상기 제 1 바이러스 외피 단백질 및 제 2 바이러스 외피 단백질이 하기인 것을 특징으로 하는, 화합물의 조합:
- 각각 인디아나 균주의 VSV-G 및 뉴저지 균주의 VSV-G, 또는 그 반대, 또는
- 상기 제 1 외피 단백질 및 제 2 외피 단백질 중 하나 또는 모두는 인디아나 균주의 고유의 VSV-G 또는/및 뉴저지 균주의 VSV-G의 개질된 버전이거나, 또는
- 상기 제 1 외피 단백질 및 제 2 외피 단백질 중 하나 이상은 키메라성 VSV-G 단백질이고, 배출 결정기(export determinant) YTDIE, 세포질 꼬리, 막통과 도메인 또는 세포질 도메인 중 하나 이상의 도메인이 인디아나 균주로부터 유래된 것이거나, 또는
- 제 1 바이러스 외피 단백질은 인디아나 균주의 VSV-G 또는 뉴저지 균주의 VSV-G이고, 제 2 바이러스 외피 단백질은 코칼 균주의 VSV-G 단백질, 이스파한 균주의 VSV-G 단백질, 찬디푸라 균주의 VSV-G 단백질, 피리 균주의 VSV-G 단백질 및 SVCV 균주의 VSV-G 단백질의 군에서 선택됨. - 제9항 또는 제10항에 있어서,
렌티바이러스 입자가 (i) CSP 항원의 폴리펩티드 또는 GPI-정박 모티브가 없는 CSP 항원의 폴리펩티드 및 (ii) 포자소체 표면 단백질 2(TRAP/SSP2), 간-단계 항원(LSA), Pf 배출 단백질 1(Pf Exp1), Pf 항원 2의 군에서 선택된 말라리아 기생충의 항원의 하나 이상의 부가적인 폴리펩티드를 포함하는 구별되는 폴리펩티드를 코딩하고,
여기서 상기 항원의 상기 구별되는 폴리펩티드는 동일한 렌티바이러스 입자로부터 발현된 것이거나 또는 구별되는 렌티바이러스 입자로부터 발현된 것을 특징으로 하는, 개별적으로 제공된 화합물의 조합. - 제12항 내지 제14항 중 어느 한 항에 있어서,
렌티바이러스 입자가 분열소체 표면 단백질 1(Msp-1), 분열소체 표면 단백질 2(Msp-2), 첨단막 항원 1(AMA-1), 세린 반복 항원(SERA), GLURP 항원, Pf 155/RESA(고리 감염 적혈구 표면 항원) 또는 곤봉체-연관 단백질 1(RAP-1) 또는 곤봉체-연관 단백질 2(RAP-2)의 군에서 선택된 폴리펩티드를 코딩하는 것을 특징으로 하는, 개별적으로 제공된 화합물의 조합. - 제1항 내지 제15항 중 어느 한 항에 있어서,
포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위한, 렌티바이러스 벡터 입자 또는 화합물의 조합. - 제1항 내지 제16항 중 어느 한 항에 있어서,
포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화에 사용하기 위한 적합한 투여 비히클로 제형화된 것을 특징으로 하는, 렌티바이러스 벡터 입자의 조성물 또는 화합물의 조합으로서,
상기 사용은 유효량의 렌티바이러스 입자를 투여하여 숙주의 세포 면역 반응을 초회감작(prime)하는 단계, 및 이후 적시에 유효량의 렌티바이러스 입자를 투여하여 숙주의 세포 면역 반응을 증강시키는 단계, 및 임의로 증강을 위해 상기 투여 단계를 반복하는 단계를 포함하는 면역화 패턴을 포함하고,
상기 초회감작 단계 또는 증강 단계 각각에서 투여된 렌티바이러스 입자는 서로 혈청-중화시키지 않는 구별되는 외피 단백질로 위형화되고, 상기 초회감작 단계 및 증강 단계가 적시에 적어도 6주, 특히 적어도 8주 분리되는 것을 특징으로 하는, 렌티바이러스 벡터 입자의 조성물 또는 화합물의 조합. - 제1항 내지 제17항 중 어느 한 항에 있어서,
상기 렌티바이러스 입자의 개별적으로 제공된 투여량을 포함하는 투여 섭생으로, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위해 사용되고,
상기 세포 면역 반응의 초회감작을 위한 투여량이 중간 투여량이고, 세포 면역 반응의 증강을 위한 투여량이 초회감작을 위한 투여량보다 높은 것을 특징으로 하는, 렌티바이러스 벡터 입자 또는 화합물의 조합. - 제1항 내지 제18항 중 어느 한 항에 있어서,
상기 렌티바이러스 입자의 개별적으로 제공된 투여량을 포함하는 투여 섭생으로, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위해 사용되고,
통합-유능 벡터 입자가 사용되는 경우 세포 면역 반응의 초회감작 및 증강을 위한 투여량은 107 내지 109개의 렌티바이러스 입자를 포함하고, 통합-무능 벡터 입자가 사용되는 경우 세포 면역 반응의 초회감작 및 증강을 위한 투여량은 108 내지 1010개의 렌티바이러스 입자를 포함하는 것을 특징으로 하는, 렌티바이러스 벡터 입자 또는 화합물의 조합. - 제1항 내지 제19항 중 어느 한 항에 있어서,
숙주에서 하기 효과 중 하나 이상을 수득하기에 적합한 투여량 및 투여 섭생으로, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위해 사용되는, 렌티바이러스 벡터 입자 또는 화합물의 조합:
(I) 인간 숙주에서, 특히 플라스모듐 팔시파룸(Plasmodium falciparum), 플라스모듐 말라리아에(Plasmodium malariae), 플라스모듐 비박스(Plasmodium vivax), 플라스모듐 놀레시(Plasmodium knowlesi) 또는 플라스모듐 오발레(Plasmodium ovale)에 의한, 말라리아 기생충 감염에 대항하여 살균 보호를 도출함;
(II) 말라리아 기생충의 세포외 형태를 억제함;
(III) 말라리아 기생충에 의한 간세포 감염의 예방 또는 감염의 간 단계 증폭의 억제;
(IV) 말라리아 기생충 항원에 대항하는 특이적 T-세포 면역 반응, 특히 CD8+ T-세포 반응 및/또는 특이적 CD4+ T-세포 반응을 도출함;
(V) 기생충 항원에 대항하는 B-세포 반응을 도출함;
(VI) 말라리아 기생충에 의한 감염의 효과를 감소 또는 경감하도록, 기생충혈증을 조절함;
(VII) 기생충에 의한 감염에 대항하거나 또는 기생충-유도 병리학에 대항하여 보호성 세포 면역성을 도출함;
(VIII) 기억 T-세포 면역 반응을 도출함;
(IX) 말라리아 기생충에 의한 감염 동안 CD4+ 및 CD8+ T-세포 반응의 초기 및 높은 리바운드를 도출함;
(X) 플라스모듐 감염시 간 내 기억 림프구를 자극함으로써 초기 및 강한 CT (CD8+T) 반응을 도출함;
(XI) 면역 반응으로부터 말라리아 기생충 탈출을 예방하여, 말라리아 기생충에 의한 감염의 장기간 조절을 가능하게 함. - 제1항 내지 제20항 중 어느 한 항에 따른 렌티바이러스 벡터 입자 또는 화합물의 조합을 사용하여, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위한 면역원성 조성물을 제조하는 방법.
- 제1항 내지 제20항 중 어느 한 항에 있어서,
아쥬반트 화합물 및/또는 면역자극 화합물 및 적합한 전달 비히클과 조합되어, 포유류 숙주, 특히 인간 숙주에서 말라리아 기생충 감염에 대항하거나 또는 기생충-유도 병리학에 대항하는 예방 면역화를 위해 사용되는 것을 특징으로 하는, 렌티바이러스 벡터 입자 또는 화합물의 조합.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP10290238.4 | 2010-05-03 | ||
| EP10290238.4A EP2385107B1 (en) | 2010-05-03 | 2010-05-03 | Lentiviral vector based immunological compounds against malaria |
| PCT/EP2011/056887 WO2011138251A1 (en) | 2010-05-03 | 2011-04-29 | Lentiviral vector based immunological compounds against malaria |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20130096164A true KR20130096164A (ko) | 2013-08-29 |
Family
ID=42731903
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020127031691A KR20130096164A (ko) | 2010-05-03 | 2011-04-29 | 말라리아에 대항하는 렌티바이러스 벡터 기반의 면역학적 화합물 |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US9109234B2 (ko) |
| EP (2) | EP2385107B1 (ko) |
| JP (2) | JP5937574B2 (ko) |
| KR (1) | KR20130096164A (ko) |
| CN (1) | CN103314104B (ko) |
| BR (1) | BR112012027999A2 (ko) |
| DK (1) | DK2385107T3 (ko) |
| WO (1) | WO2011138251A1 (ko) |
Families Citing this family (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9169304B2 (en) | 2012-05-01 | 2015-10-27 | Pfenex Inc. | Process for purifying recombinant Plasmodium falciparum circumsporozoite protein |
| CN103965320A (zh) * | 2013-01-29 | 2014-08-06 | 苏州偲聚生物材料有限公司 | 多肽、包含该多肽的检测器件和检测试剂盒 |
| BR112015030211A2 (pt) * | 2013-06-03 | 2017-08-22 | Theravectys | Vetores lentivirais contendo uma sequência promotora a montante da mhc de classe i, mhc de classe ii ou microglobulina beta-2 |
| EP2878674A1 (en) * | 2013-11-28 | 2015-06-03 | Fundación Centro Nacional de Investigaciones Cardiovasculares Carlos III (CNIC) | Stable episomes based on non-integrative lentiviral vectors |
| US10538785B2 (en) | 2013-12-23 | 2020-01-21 | Renaud Vaillant | Lyophilized lentiviral vector particles, compositions and methods |
| US10010607B2 (en) | 2014-09-16 | 2018-07-03 | Institut Curie | Method for preparing viral particles with cyclic dinucleotide and use of said particles for inducing immune response |
| CN106290840A (zh) * | 2015-05-13 | 2017-01-04 | 上海凯创生物技术有限公司 | 间日疟原虫乳胶法检测试剂盒 |
| CN105754962A (zh) * | 2016-01-07 | 2016-07-13 | 中南大学 | 一种单循环复制艾滋病毒样颗粒及其制备方法和应用 |
| WO2017157437A1 (en) | 2016-03-16 | 2017-09-21 | Institut Curie | Method for preparing viral particles with cyclic dinucleotide and use of said particles for treating cancer |
| MX2018014253A (es) | 2016-05-19 | 2019-11-11 | Univ Pennsylvania | Inmunógenos de malaria sintéticos, combinaciones de estos y su uso para prevenir y tratar infecciones de malaria. |
| WO2018029256A1 (en) | 2016-08-09 | 2018-02-15 | Aarhus Universitet | Modulation of ifi16 and sting activity |
| EP3357504A1 (en) * | 2017-02-02 | 2018-08-08 | Institut Pasteur | Functional screening of antigenic polypeptides - use for the identification of antigens eliciting a protective immune response and for the selection of antigens with optimal protective activity |
| EP3357506A1 (en) * | 2017-02-02 | 2018-08-08 | Institut Pasteur | Multiple malaria pre-erythrocytic antigens and their use in the elicitation of a protective immune response in a host |
| CN109251929A (zh) * | 2018-04-27 | 2019-01-22 | 杭州贝英福生物科技有限公司 | 一种干扰二化螟几丁质酶基因CsCht10的siRNA |
| EP3796931A1 (en) * | 2018-05-23 | 2021-03-31 | Institut Pasteur | Malaria pre-erythrocytic antigens as a fusion polypeptide and their use in the elicitation of a protective immune response in a host |
| EP3820997A4 (en) * | 2018-07-09 | 2022-09-21 | Board of Supervisors of Louisiana State University and Agricultural and Mechanical College | MALARIA VIRAL VACCINE |
| CN109022456B (zh) * | 2018-07-24 | 2021-03-02 | 江南大学 | 一种表达卵形疟原虫ama1蛋白的病毒疫苗的制备方法 |
| GB201906283D0 (en) * | 2019-05-03 | 2019-06-19 | Moredun Res Institute | Vector |
| JP2023539761A (ja) * | 2020-09-01 | 2023-09-19 | ザ トラスティーズ オブ ザ ユニバーシティ オブ ペンシルバニア | コカルエンベロープを使用したt細胞形質導入のためのレンチウイルスベクターの生成の改善 |
| US20220324917A1 (en) * | 2021-04-12 | 2022-10-13 | Sk Bioscience Co., Ltd. | Recombinant rsv live vaccine strain and the preparing method thereof |
| JP2024517131A (ja) | 2021-04-20 | 2024-04-19 | アンスティテュ・クリー | 免疫療法における使用のための組成物及び方法 |
| JP2024514707A (ja) | 2021-04-20 | 2024-04-02 | アンスティテュ・クリー | 免疫療法における使用のための組成物及び方法 |
| CN116987157B (zh) * | 2023-09-27 | 2023-11-28 | 深圳华大生命科学研究院 | 一种弹状病毒包膜蛋白、含其的靶向慢病毒载体及其应用 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5766597A (en) * | 1991-03-07 | 1998-06-16 | Virogenetics Corporation | Malaria recombinant poxviruses |
| FR2777909B1 (fr) | 1998-04-24 | 2002-08-02 | Pasteur Institut | Utilisation de sequences d'adn de structure triplex pour le tranfert de sequences de nucleotides dans des cellules, vecteurs recombinants contenant ces sequences triplex |
| US8163893B2 (en) * | 2006-02-15 | 2012-04-24 | The Regents Of The University Of Caifornia | Pseudotyped retroviral vectors and methods of use thereof |
| PT2169073E (pt) | 1999-10-11 | 2014-02-20 | Pasteur Institut | Vectores para a preparação de composições imunoterapêuticas |
| CA2382832C (en) | 1999-10-12 | 2012-06-26 | Institut Pasteur | Lentiviral triplex dna, and vectors and recombinant cells containing lentiviral triplex dna |
| DK200201741A (da) | 2002-11-12 | 2003-09-16 | Statens Seruminstitut | Vaccine comprising chimeric malaria proteins derived from Plasmodium falciparum |
| NZ539813A (en) | 2002-12-17 | 2008-04-30 | Crucell Holland Bv | A replication defective recombinant adenovirus comprising a antigenic determinant of Plasmodium falciparum wherein the antigenic determinant is SEQ ID 6 |
| FR2872170B1 (fr) | 2004-06-25 | 2006-11-10 | Centre Nat Rech Scient Cnrse | Lentivirus non interactif et non replicatif, preparation et utilisations |
| US8158413B2 (en) | 2005-10-17 | 2012-04-17 | Institut Pasteur | Lentiviral vector-based vaccine |
| CA2620495A1 (en) * | 2005-08-31 | 2007-03-08 | Genvec, Inc. | Adenoviral vector-based malaria vaccines |
| AU2008285224B2 (en) | 2007-08-03 | 2015-01-22 | Centre National De La Recherche Scientifique (Cnrs) | Lentiviral gene transfer vectors and their medicinal applications |
| EP2190470B1 (en) * | 2007-08-13 | 2017-12-13 | GlaxoSmithKline Biologicals SA | Vaccines |
-
2010
- 2010-05-03 DK DK10290238.4T patent/DK2385107T3/en active
- 2010-05-03 EP EP10290238.4A patent/EP2385107B1/en active Active
-
2011
- 2011-04-29 BR BR112012027999A patent/BR112012027999A2/pt not_active Application Discontinuation
- 2011-04-29 KR KR1020127031691A patent/KR20130096164A/ko not_active Application Discontinuation
- 2011-04-29 US US13/695,683 patent/US9109234B2/en active Active
- 2011-04-29 JP JP2013508445A patent/JP5937574B2/ja active Active
- 2011-04-29 WO PCT/EP2011/056887 patent/WO2011138251A1/en active Application Filing
- 2011-04-29 CN CN201180027852.4A patent/CN103314104B/zh active Active
- 2011-04-29 EP EP11716434A patent/EP2566956A1/en not_active Withdrawn
-
2015
- 2015-07-15 US US14/799,633 patent/US9822153B2/en active Active
- 2015-11-30 JP JP2015233691A patent/JP2016041076A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20150368307A1 (en) | 2015-12-24 |
| US20130171195A1 (en) | 2013-07-04 |
| CN103314104A (zh) | 2013-09-18 |
| EP2566956A1 (en) | 2013-03-13 |
| WO2011138251A1 (en) | 2011-11-10 |
| JP2013527760A (ja) | 2013-07-04 |
| US9109234B2 (en) | 2015-08-18 |
| EP2385107A1 (en) | 2011-11-09 |
| BR112012027999A2 (pt) | 2017-03-21 |
| US9822153B2 (en) | 2017-11-21 |
| JP5937574B2 (ja) | 2016-06-22 |
| JP2016041076A (ja) | 2016-03-31 |
| EP2385107A8 (en) | 2014-03-12 |
| DK2385107T3 (en) | 2016-12-12 |
| EP2385107B1 (en) | 2016-08-24 |
| CN103314104B (zh) | 2016-11-09 |
| WO2011138251A8 (en) | 2013-04-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DK2385107T3 (en) | Lentiviral vector-based immunological compounds against malaria | |
| JP6480028B2 (ja) | レンチウイルス遺伝子導入ベクター及びそれらの医薬品への適用 | |
| EP2676676B1 (en) | Recombinant viral vectors | |
| KR102585864B1 (ko) | 렌티바이러스 벡터-기반의 일본 뇌염 면역원성 조성물 | |
| WO1991019803A1 (en) | Self assembled, defective, nonself-propagating viral particles | |
| KR20210013589A (ko) | 면역 체크포인트 억제제 공동-발현 벡터 | |
| Kuate et al. | Immunogenicity and efficacy of immunodeficiency virus-like particles pseudotyped with the G protein of vesicular stomatitis virus | |
| JP4125128B2 (ja) | ヒト免疫不全ウイルスのキメラタンパク質用組換えポックスウイルス | |
| Hasenkrug et al. | Immunoprotective determinants in friend murine leukemia virus envelope protein | |
| EP2020444B1 (en) | Defective non-integrative lentiviral transfer vectors for vaccines | |
| CN110582295B (zh) | 多种疟疾红前期抗原及其在宿主中引发保护性免疫应答的用途 | |
| Jounai et al. | Contribution of the rev gene to the immunogenicity of DNA vaccines targeting the envelope glycoprotein of HIV | |
| JP2003535577A (ja) | 免疫不全ウイルス用生ウイルスワクチンとしての組換えラブドウイルス | |
| US20210187089A1 (en) | Malaria pre-erythrocytic antigens as a fusion polypeptide and their use in the elicitation of a protective immune response in a host | |
| Wang et al. | Polyvalent DNA prime and envelope protein boost HIV‐1 vaccine elicits humoral and cellular responses and controls... |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |