JP7405486B2 - 超長時間作用型インスリン-fc融合タンパク質および使用法 - Google Patents
超長時間作用型インスリン-fc融合タンパク質および使用法 Download PDFInfo
- Publication number
- JP7405486B2 JP7405486B2 JP2022536936A JP2022536936A JP7405486B2 JP 7405486 B2 JP7405486 B2 JP 7405486B2 JP 2022536936 A JP2022536936 A JP 2022536936A JP 2022536936 A JP2022536936 A JP 2022536936A JP 7405486 B2 JP7405486 B2 JP 7405486B2
- Authority
- JP
- Japan
- Prior art keywords
- insulin
- fusion protein
- seq
- fragment
- human
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0684—Cells of the urinary tract or kidneys
- C12N5/0686—Kidney cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/22—Hormones
- A61K38/28—Insulins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/0012—Galenical forms characterised by the site of application
- A61K9/0019—Injectable compositions; Intramuscular, intravenous, arterial, subcutaneous administration; Compositions to be administered through the skin in an invasive manner
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/62—Insulins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0681—Cells of the genital tract; Non-germinal cells from gonads
- C12N5/0682—Cells of the female genital tract, e.g. endometrium; Non-germinal cells from ovaries, e.g. ovarian follicle cells
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Diabetes (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Endocrinology (AREA)
- Biochemistry (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gastroenterology & Hepatology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Emergency Medicine (AREA)
- Hematology (AREA)
- Obesity (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Toxicology (AREA)
- Epidemiology (AREA)
- Dermatology (AREA)
- Immunology (AREA)
- Urology & Nephrology (AREA)
- Cell Biology (AREA)
Description
本出願は、2019年12月19日に出願された米国仮特許出願第62/950,803号、および、2020年3月12日に出願された米国仮特許出願第62/988,441号に関連し、これらの優先権の利益を主張するものである。上記の各特許出願の内容は、その全体が参照によって本明細書に援用される。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGAGGGGAGGGGAGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号87)、
を含む、融合タンパク質を提供する。
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYX1STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号77)、
を含み、X1はS、D、A、またはRであり、上記インスリンポリペプチドはC鎖を介してインスリンA鎖アナログに連結されたインスリンB鎖アナログからなり、上記インスリンポリペプチドのインスリンB鎖アナログのN末端から16番目のアミノ酸(すなわち、B16)はアラニンである(すなわち、B16A)、融合タンパク質を提供する。
FVNQHLCGSX1LVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCX2STCSLDQLENYC(配列番号9)、
を含み、X1はDではなく、X2はHではない。いくつかの実施形態において、上記インスリンポリペプチドは、以下の配列:
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYC(配列番号10)、
を含む。
GGGGGQGGGGQGGGGQGGGGG(配列番号13)、
を含む。構成において、上記リンカーは、配列:
GGGGGAGGGGAGGGGAGGGGG(配列番号67)、
を含む。構成において、上記リンカーは、配列:
GGGGAGGGG(配列番号11)、
を含む。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGAGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号89)、
を含む。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号78)、
を含む。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYDSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号80)、
を含む。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号82)、
を含む。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYRSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号84)、
を含む。
(N末端)-インスリンポリペプチド-リンカー-Fcフラグメント-(C末端)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtgcaggaggcggtggagccggtggaggtggggctggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagcagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号88)、
を含む。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtgccggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagcagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号90)、
を含む。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagcagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号79)、
を含む。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacgacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号81)、
を含む。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacgccagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号83)、
を含む。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagaagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号85)、
を含む。
本明細書で使用される場合、冠詞「a」および「an」は、その冠詞の文法上の目的語が1つであること、または2つ以上であることを指し、例えば、少なくとも1つであることを指す。本明細書において「含む(comprising)」という用語と共に使用された場合での、「a」または「an」という語の使用は、「1つ」を意味する場合もあるが、「1つまたは複数」、「少なくとも1つ」、および「1つまたは2つ以上」という意味とも合致する。
本開示は、ペプチドリンカーを介して種特異的なFcフラグメントに連結されたインスリンポリペプチドを含む融合タンパク質(すなわち、インスリン-Fc融合タンパク質)の組成、並びに、糖尿病(例えば、ヒトおよび/またはイヌにおける糖尿病)を治療するためのその使用に関する。本明細書で使用される場合、「融合タンパク質」および「インスリン-Fc融合タンパク質」という用語は、ペプチド結合を介して共有結合した、例えば異なる供給源(異なるタンパク質、ポリペプチド、細胞など)からの、2以上の部分からなるタンパク質を指す。インスリン-Fc融合タンパク質は、(i)各部分をコードする遺伝子を連結して1つの核酸分子にし、(ii)核酸分子が以下のようにコードしているタンパク質を宿主細胞(例えば、HEKまたはCHO)中で発現することで、共有結合される:(N末端)--インスリンポリペプチド--リンカー--Fcフラグメント--(C末端)。完全に組換え合成するアプローチの方が、インスリンポリペプチドとFcフラグメントを別々に合成してから化学的に結合させる方法よりも好ましい。化学的結合工程とその後の精製プロセスは、製造の複雑さを増加させ、製品の収量を減少させ、コストを増加させる。
インスリンポリペプチドは、例えば、膵臓内のランゲルハンス島のβ細胞によって産生されるインスリンまたはインスリン類似体であってもよい。インスリンは、血液からのグルコースの吸収を調節することで機能する。タンパク質レベルの上昇およびグルコースレベルの上昇などの刺激により、インスリンはβ細胞から放出され、IRに結合し、哺乳類(例えば、ヒト)の代謝の多くの側面に影響を与えるシグナルカスケードを開始する。このプロセスの崩壊は、いくつかの疾患、特に糖尿病、インスリノーマ、インスリン抵抗性、メタボリックシンドローム、および多嚢胞性卵巣症候群に直接関係する。本開示のインスリン類似体は、インスリンの構造に関連しているが、1またはそれ以上の改変を含んでいるものであってもよい。いくつかの実施形態において、インスリン類似体は、インスリンに対する少なくとも1つのアミノ酸の置換、欠失、付加、または化学修飾を含み、これらは、インスリン-Fc融合タンパク質の構成の特定の特徴または特性に影響を与える可能性がある。例えば、本明細書に記載の修飾または変更は、参照標準と比較して、インスリン-Fc融合タンパク質の構成の構造、安定性、pH感受性、生物活性、または細胞表面受容体(例えば、インスリンホルモン受容体)に対する結合親和性に影響を与える可能性がある。
FVNQHLCGSHLVEALYLVCGERGFFYTPKT(配列番号1)
GIVEQCCTSICSLYQLENYCN(配列番号2)。
FVNQHLCGSHLVEALYLVCGERGFFYTPKTRREAEDLQVGQVELGGGPGAGSLQPLALEGSLQKRGIVEQCCTSICSLYQLENYCN(配列番号3)。
単鎖インスリンポリペプチドの、生理活性を有する2鎖ポリペプチドへの変換は、通常、グルコース刺激によるインスリン分泌より前に、ランゲルハンス島のβ細胞内で、I型エンドプロテアーゼ(Cペプチド-B鎖接続を破壊するPC1およびPC3、並びにPC2)、およびCペプチド-A鎖結合を正しい部位で正確に切断するII型エンドプロテアーゼの2つのエンドプロテアーゼによって達成されている。しかし、インスリンなどの治療用分子の生合成に用いられる細胞系(例えば、細菌、酵母、および哺乳類(HEKおよびCHO)細胞系)はこの経路を有していないため、化学的または酵素的な方法を用いて単鎖ポリペプチドを発現および回収した後に変換を行わなければならない。発現および回収後にC鎖を切断するための公知の技術は全て、C鎖がA鎖のN末端直前のリジンで終端するように、まずC鎖を改変することに依存している。次に、リジン残基のC末端で特異的にペプチド結合を切断する、トリプシンまたはLys-Cファミリーから選択される酵素を用いて、単鎖インスリンポリペプチドをC鎖のC末端リジンおよびB鎖のN末端から29番目の位置のC末端リジンで切断する。場合によっては、得られた生物活性を示す2鎖インスリンは、B鎖のN末端から30番目の位置の切断されたアミノ酸を再付加せずに使用され、場合によっては、B鎖のN末端から30番目の位置の切断されたアミノ酸が追加の酵素的方法を用いて当該分子に再付加される。このような処理がインスリンではうまくいくのは、インスリンが2鎖ポリペプチド形態の全体の中にリジンを1つしか含まないためである。しかし、既知のFcフラグメントは全て複数のリジン残基を含むため、この処理は本明細書に含まれるインスリン-Fc融合タンパク質に対しては使用することができない。従って、酵素切断プロセスは、Fcフラグメントを非機能的な部分にまで消化することによって、インビボでインスリンポリペプチドの作用を延長するFcフラグメントの能力を取り除くことになる。従って、本発明のインスリン-Fc融合タンパク質は、C鎖切断を必要としないことから単鎖形態で生物活性を示す、インスリンポリペプチドを含まなければならない。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCZ(配列番号7_NULL)。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYC(配列番号7)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYC(配列番号10)。
いくつかの例では、インスリンポリペプチドのC末端は、FcフラグメントのN末端に直接接続される(例えば、無リンカーまたはリンカーなし)。他の例では、組換え製造されたインスリン-Fc融合タンパク質の構築を成功させるために、インスリンポリペプチドをFcフラグメントに接続するリンカーが必要となる。実施形態において、本明細書に記載のインスリン-Fc融合タンパク質の構成は、アミノ酸(例えば、天然アミノ酸または非天然アミノ酸)から構成される、インスリンポリペプチドとFcフラグメントとの間のペプチドリンカーを含む。実施形態において、例えば、単一の核酸分子が、インスリンポリペプチド内の様々なペプチドと、ペプチドリンカーおよびFcフラグメントとをコードできるように、ペプチドリンカーは核酸分子にコードさせることができる。ペプチドリンカーの選択肢(例えば、長さ、組成、疎水性、および二次構造)は、インスリン-Fc融合タンパク質の構成の製造性(すなわち、ホモ二量体力価)、化学的および酵素的な安定性、生物活性(すなわち、NAOC値)、生物活性と相関するパラメータ(すなわち、FcRnアッセイにおけるEC50値)、並びにインスリン-Fc融合タンパク質の免疫原性に影響し得る(Chen,X.、Zaro,J.、Shen,W.C.、Adv Drug Deliv Rev.、2013年10月15日;65巻(10号):pp1357~1369)。表1は、ホモ二量体力価と生物活性を向上させる目的で、インスリン-Fc融合タンパク質の構成の設計に使用されるいくつかのリンカーを挙げている。

GGGGGQGGGGQGGGGQGGGGG(配列番号13)
を有する。他の実施形態において、ペプチドリンカーは、配列:
GGGGSGGGG(配列番号12)
を有する。好ましい実施形態において、ペプチドリンカーは、配列:
GGGGGAGGGGAGGGGAGGGGG(配列番号67)
または、配列:
GGGGAGGGG(配列番号11)
を含む。
GGGGAGGGG(配列番号11)
を含む。
「Fcフラグメント」、「Fc領域」、「Fcドメイン」、または「Fcポリペプチド」という用語は、本明細書では、免疫グロブリン重鎖のC末端領域を規定するために使用される。Fcフラグメント、Fc領域、Fcドメイン、またはFcポリペプチドは、天然型配列のFc領域であってもよいし、バリアント/変異型Fc領域であってもよい。免疫グロブリン重鎖のFc領域の境界は様々であり得るが、一般に、重鎖のヒンジ領域、重鎖のCH2領域、および重鎖のCH3領域の一部または全部から構成される。イヌFcフラグメントまたはヒトFcフラグメントのヒンジ領域は、重鎖のCH1ドメインと重鎖のCH2領域とを接続し、また、2つの同一だが別々のFc融合タンパク質単量体からFc融合タンパク質のホモ二量体を形成するための1または複数の重鎖間ジスルフィド架橋を形成する1または複数のシステインを含む、アミノ酸配列を含む。ヒンジ領域は、天然に存在するアミノ酸配列または天然に存在しないアミノ酸配列の全部または一部を含んでもよい。
RCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVMHETLQNHYTDLSLSHSPG(配列番号14)
DCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号15)
CNNCPCPGCGLLGGPSVFIFPPKPKDILVTARTPTVTCVVVDLDPENPEVQISWFVDSKQVQTANTQPREEQSNGTYRVVSVLPIGHQDWLSGKQFKCKVNNKALPSPIEEIISKTPGQAHQPNVYVLPPSRDEMSKNTVTLTCLVKDFFPPEIDVEWQSNGQQEPESKYRMTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQISLSHSPG(配列番号16)
CISPCPVPESLGGPSVFIFPPKPKDILRITRTPEITCVVLDLGREDPEVQISWFVDGKEVHTAKTQPREQQFNSTYRVVSVLPIEHQDWLTGKEFKCRVNHIGLPSPIERTISKARGQAHQPSVYVLPPSPKELSSSDTVTLTCLIKDFFPPEIDVEWQSNGQPEPESKYHTTAPQLDEDGSYFLYSKLSVDKSRWQQGDTFTCAVMHEALQNHYTDLSLSHSPG(配列番号17)。
ヒトインスリン-Fc融合タンパク質の構成において、C末端リジンを欠いたヒトFcフラグメント配列としては、以下のものがある:
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号73)
ECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号74)。
DCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号18)。
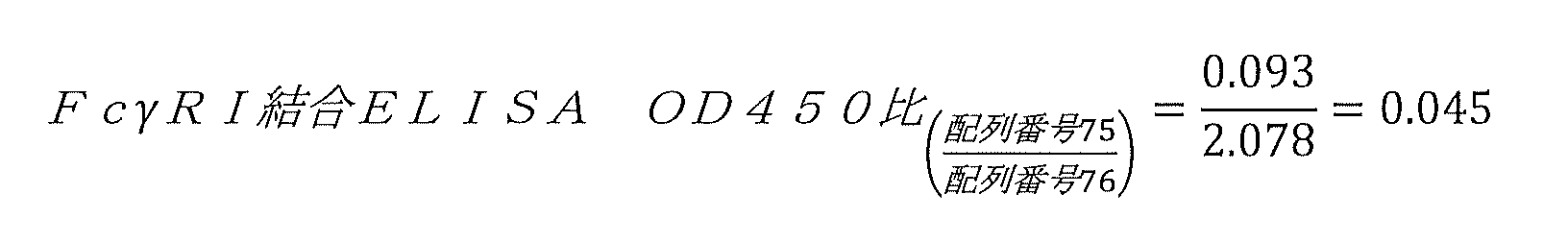

DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYX 1 STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号77)、
例において、X1はS、D、A、R、またはQである。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号91)
本明細書において、インスリンポリペプチドと、Fcフラグメントと、当該インスリンポリペプチドと当該Fcフラグメントとの間のリンカーと、を含む、インスリン-Fc融合タンパク質の構成が提供される。実施形態において、インスリンポリペプチドは、N末端からC末端へ以下の配向で各ドメインを含む:
(N末端)--B鎖--C鎖--A鎖--(C末端)。
実施形態において、インスリンポリペプチドは、FcフラグメントのN末端側に位置する。実施形態において、上記融合タンパク質は、N末端からC末端へ以下の配向で各ドメインを含む:
(N末端)--インスリンポリペプチド--リンカー--Fcフラグメント--(C末端)(例えば、(N末端)--B鎖--C鎖--A鎖--リンカー--Fcフラグメント--(C末端))(図1に図示)。
実施形態において、配列番号5の好ましい非免疫原性生物活性インスリンポリペプチドを、配列番号13の好ましいリンカーを用いて、配列番号15の好ましいイヌIgGB Fcフラグメントと組み合わせたところ、イヌにおける一連の反復注射の3回目の注射の後、50mg/Lを超えるホモ二量体力価、イヌにおいて150%FBGL・日・kg/mgを超えるNAOC値、および、0.5を超えるNAOCR値を示す、配列番号20の、高いホモ二量体力価をもたらす、非凝集性の、生物活性を有する、非免疫原性の、イヌインスリン-Fc融合構成ファミリーが得られた。以下は配列番号20を示しており、非天然型のアミノ酸には下線が引かれており:
FVNQHLCGSX 1 LVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCX 2 STCSLDQLENYCX 3 GGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号20)、
X1はDではなく、X2はHではなく、X3は存在しないかNである。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCX 3 GGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号21)、
X3は存在しないかNである。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号26)。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCNGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号28)。
FVNQHLCGSX 1 LVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCX 2 STCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号22)、
X1はDではなく、X2はHではない。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号30)。
他の非グリコシル化インスリン-Fc融合タンパク質の構成が同じ挙動を示すかどうかを判定するための、さらなる実験を行った。cNg部位に下線が引かれた、ヒトIgG1 Fcフラグメントの一般構成は以下の通りであり:
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYX 1 STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号77)、
X1はS、D、A、R、またはQである。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号91)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYDSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号92)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号93)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYRSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号94)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号95)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号78)。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYDSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号80)。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号82)。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYRSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号84)。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号86)。
MEWSWVFLFFLSVTTGVHS(配列番号24)
が挙げられる。いくつかの実施形態において、本明細書に記載のインスリン-Fc融合タンパク質の構成は、細胞(例えば、真核細胞、例えば、哺乳類細胞)での発現(例えば、組み換え発現)などのためのリーダー配列を含む核酸分子にコードされている。ある実施形態では、リーダー配列は、細胞培養などにおいて、発現中に切断される。リーダー配列をコードする例示的な核酸配列としては、核酸配列:
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactcc(配列番号23)
が挙げられる。実施形態において、配列番号23の例示的な核酸は、配列番号24の例示的なリーダー配列をコードする。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagcagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号79)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacgacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号81)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacgccagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号83)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagaagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号85)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtcaaggaggcggtggacagggtggaggtgggcagggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtaccaaagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号100)。
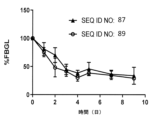
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGAGGGGAGGGGAGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号87)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtggtgcaggaggcggtggagccggtggaggtggggctggaggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagcagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号88)。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGAGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号89)。
atggaatggagctgggtctttctcttcttcctgtcagtaacgactggtgtccactccttcgtgaaccagcacctgtgcggctcccacctggtggaagctctggcactcgtgtgcggcgagcggggcttccactacgggggtggcggaggaggttctggtggcggcggaggcatcgtggaacagtgctgcacctccacctgctccctggaccagctggaaaactactgcggtggcggaggtgccggaggcgggggagacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacagcagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggttag(配列番号90)。
実施形態において、融合タンパク質は、実施例のセクションでより詳細に記載されるように、細胞に発現させることができる。
実施形態において、インスリン-Fc融合タンパク質は、哺乳類細胞や非哺乳類細胞などの真核細胞などにおいて、組換え発現することができる。発現に用いられる例示的な哺乳類細胞としては、HEK細胞(例えば、HEK293細胞)またはCHO細胞が挙げられる。CHO細胞は種々の株やサブクラスに細分することができ(例えば、CHO DG44、CHO-M、およびCHO-K1)、これらの細胞株のいくつかは、実施例セクションに記載されるような、特定の種類の核酸分子(例えば、DNAを含むベクター)や特定の細胞増殖培地組成との使用を最適化するために、遺伝子改変されていてもよい。実施形態において、細胞は、インスリン-Fc融合タンパク質をコードする核酸分子(例えば、ベクター)(例えば、インスリン-Fc融合タンパク質全体が単一の核酸分子にコードされている)でトランスフェクトされる。実施形態において、HEK293細胞は、インスリン-Fc融合タンパク質をコードするベクターでトランスフェクトしても、当該宿主細胞がはっきり認められるレベルのインスリン-Fc融合タンパク質を発現しなくなるまでの期間(例えば、3日間、4日間、5日間、7日間、10日間、12日間、14日間、またはそれ以上)、インスリン-Fc融合タンパク質を一次的に発現するのみである(すなわち、一過性トランスフェクション)。インスリン-Fc融合タンパク質をコードする核酸配列で一過性にトランスフェクトされたHEK293細胞は、複数のインスリン-Fc融合タンパク質候補の作製と選別を容易にする、より迅速な組換えタンパク質生産を可能にする場合が多い。実施形態において、CHO細胞は、宿主細胞DNAに恒久的に組み込まれ、細胞が適切に培養されている限りインスリン-Fc融合タンパク質の一貫性のある永続的な発現(すなわち、安定なトランスフェクション)をもたらす、ベクターでトランスフェクトされる。インスリン-Fc融合タンパク質をコードする核酸で安定にトランスフェクトされたCHO細胞およびCHO細胞株は、成長するのにより時間がかかる場合があるが、より高い総タンパク質収量が得られる場合が多く、低コスト製品(例えば、比較的コモディティ化が進んだヒトインスリン市場用の製品)の製造により適している。細胞および細胞株は、当該技術分野における標準方法を用いて培養することができる。
インスリン受容体との相互作用により標的対象(例えば、イヌまたはヒト)の血糖を低下させる方法であって、インスリン-Fc融合タンパク質、例えば本明細書に記載の融合タンパク質を対象に投与することを含む、方法が本明細書に記載される。いくつかの実施形態において、対象は糖尿病と診断されたものである(例えば、イヌの場合はイヌ糖尿病、あるいは、ヒトの場合は1型糖尿病または2型糖尿病)。
糖尿病(例えば、ヒトにおける1型糖尿病または2型糖尿病)を治療するための方法であって、インスリン-Fc融合タンパク質(例えば、本明細書に記載のインスリン-Fc融合タンパク質の構成)を標的対象に投与することを含む、方法が、本明細書に記載される。
標的対象の血糖を低下させるために用いることができる、本明細書に記載のインスリン-Fc融合タンパク質の構成を含有する医薬組成物が、本明細書で提供される。医薬組成物中のインスリン-Fc融合タンパク質の含量および濃度、並びに医薬組成物の標的対象への投与量は、医学的に関連性がある対象の特徴(例えば、年齢、体重、性別、他の医学的条件など)、医薬組成物中の化合物の溶解性、化合物の効力および活性、並びに医薬組成物の投与様式などの臨床的に関連性がある要因に基づいて、選択することができる。投与経路および投与レジメンに関するさらなる情報について、読者は、Comprehensive Medicinal Chemistry(Corwin Hansch;編集委員長)、ペルガモン・プレス社、1990年の第5巻の25.3章を参照されたい。
本明細書に記載される構成のインスリン-Fc融合タンパク質の実際の投与量レベルは、特定の標的対象(例えば、イヌまたはヒト)において、所望の治療反応を達成するのに有効な、有効成分の量を得るために、変えることができる。選択された投与量レベルは、種々の要因に依存することとなり、例えば、使用された特定の融合タンパク質、またはそのエステル、塩、もしくはアミドの活性、投与経路、投与時期、使用されている化合物の排泄速度、治療期間、使用された特定の融合タンパク質と組み合わせて使用された他の薬剤、化合物および/または物質、治療を受けている対象の年齢、性別、体重、状態、全体的な健康、および既往歴、並びに医学分野で周知の同様の要因が挙げられる。
実施例1:HEK293細胞におけるインスリン-Fc融合タンパク質の合成および作製法
インスリン-Fc融合タンパク質を以下の通りに合成した。目的の遺伝子配列を、プロプライエタリソフトウェア(レイクファーマ社(LakePharma)、ベルモント、カリフォルニア州)を用いて構築し、高発現哺乳類ベクターにクローニングした。HEK293細胞をトランスフェクションの24時間前に振盪フラスコ内に播種し、無血清合成培地を用いて増殖させた。目的のインスリン-Fc融合タンパク質をコードするDNA発現コンストラクトを、一過性トランスフェクションのための標準操作手順(レイクファーマ社、ベルモント、カリフォルニア州)を用いて、HEK293細胞浮遊液に一過性にトランスフェクトした。20時間後、細胞を計数して生存率と生細胞数を求め、ForteBio(登録商標)Octet(登録商標)(ポール・フォルテバイオ社(Pall ForteBio LLC)、フリーモント、カリフォルニア州)で力価を測定した。一過性トランスフェクションのプロダクションラン中、追加の測定値を得た。5日目以降に培養物の回収を行った。
CHO細胞株は、元はCHO-K1(レイクファーマ社、ベルモント、カリフォルニア州)由来のものであり、当該技術分野において公知の方法を用いた組換え技術によって内在性グルタミンシンテターゼ(GS)遺伝子をノックアウトしたものである。CHO発現およびGSセレクション用の安定発現DNAベクターを設計・最適化し、高発現哺乳類ベクター(レイクファーマ社、ベルモント、カリフォルニア州)に組み込んだ。完成したコンストラクトの配列をそれぞれ確認してから、スケールアップ実験を開始した。浮遊液順応CHO細胞を、37℃、5%CO2の加湿恒温器内の、合成培地(CD OptiCHO;インビトロジェン社(Invitrogen)、カールズバッド、カリフォルニア州)中で、培養した。CHO細胞の培養では、血清などの動物由来産物は用いなかった。
CHO細胞株は、元はCHO-K1(レイクファーマ社、ベルモント、カリフォルニア州)由来のものであり、当該技術分野において公知の方法を用いた組換え技術によって内在性グルタミンシンテターゼ(GS)遺伝子をノックアウトしたものである。CHO発現およびGSセレクション用の安定発現DNAベクターを設計・最適化し、高発現哺乳類ベクター(レイクファーマ社、ベルモント、カリフォルニア州)に組み込む。完成したコンストラクトの配列をそれぞれ確認してから、スケールアップ実験を開始する。浮遊液順応CHO細胞を、37℃、5%CO2の加湿恒温器内の、合成培地(CD OptiCHO;インビトロジェン社、カールズバッド、カリフォルニア州)中で、培養する。CHO細胞の培養では、血清などの動物由来産物は用いない。
インスリン-Fc融合タンパク質の精製は以下の通りに行った。分泌インスリン-Fc融合タンパク質を含有する条件培地上清を、一過性トランスフェクトHEK、安定トランスフェクトHEK、または安定トランスフェクトCHOのプロダクションランから回収し、遠心分離で清澄化した。所望のインスリン-Fc融合タンパク質を含有する上清をプロテインAカラムに流し、0.15~0.50M塩化ナトリウムを含む各種洗浄バッファーで洗浄し、その後、低pH液を用いて溶出させた。その後、所望のタンパク質を含有する溶出画分をプールし、緩衝液を200mM HEPES、100mM NaCl、50mM NaOAc、pH7.0の緩衝液に交換した。最後の濾過工程は0.2μmメンブランフィルターを用いて行った。最終的なタンパク質濃度は280nmでの溶液吸光度から算出した。イオン交換クロマトグラフィー(例えば、陰イオン交換ビーズ樹脂または陽イオン交換ビーズ樹脂を用いるイオン交換クロマトグラフィー)、ゲル濾過クロマトグラフィー、などの方法による任意のさらなる精製を、必要に応じて行った。
インスリン-Fc融合タンパク質の精製は以下の通りに行う。分泌インスリン-Fc融合タンパク質を含有する条件培地上清を、一過性トランスフェクトHEK、安定トランスフェクトHEK、または安定トランスフェクトCHOのプロダクションランから回収し、遠心分離で清澄化する。所望のインスリン-Fc融合タンパク質を含有する上清をプロテインAカラムに流し、0.15~0.50M塩化ナトリウムを含む各種洗浄バッファーで洗浄し、その後、低pH液を用いて溶出させる。その後、所望のタンパク質を含有する溶出画分をプールし、緩衝液を200mM HEPES、100mM NaCl、50mM NaOAc、pH7.0の緩衝液に交換する。最後の濾過工程は0.2μmメンブランフィルターを用いて行う。最終的なタンパク質濃度は280nmでの溶液吸光度から算出する。イオン交換クロマトグラフィー(例えば、陰イオン交換ビーズ樹脂または陽イオン交換ビーズ樹脂を用いるイオン交換クロマトグラフィー)、ゲル濾過クロマトグラフィー、などの方法による任意のさらなる精製を、必要に応じて行う。
キャピラリー電気泳動ドデシル硫酸ナトリウム(CE-SDS)分析を、LabChip(登録商標)GXII(パーキンエルマー社(Perkin Elmer)、ウォルサム、マサチューセッツ州)において、200mM HEPES、100mM NaCl、50mM NaOAc、pH7.0の緩衝液中に溶解された精製インスリン-Fc融合タンパク質の溶液に対して行い、電気泳動図をプロットした。非還元条件下で、試料を分子量(MW)既知のタンパク質標準と共に泳動した。溶出ピークはインスリン-Fc融合タンパク質ホモ二量体の「見かけの」分子量を表すものであった。
キャピラリー電気泳動ドデシル硫酸ナトリウム(CE-SDS)分析を、LabChip(登録商標)GXII(パーキンエルマー社(Perkin Elmer)、ウォルサム、マサチューセッツ州)において、200mM HEPES、100mM NaCl、50mM NaOAc、pH7.0の緩衝液中に溶解された精製インスリン-Fc融合タンパク質の溶液に対して行い、電気泳動図をプロットする。非還元条件下で、試料を分子量(MW)既知のタンパク質標準と共に泳動する。溶出ピークはインスリン-Fc融合タンパク質ホモ二量体の「見かけの」分子量を表す。
質量分析(MS)によるインスリン-Fc融合タンパク質質量の正確な評価のために、インスリン-Fc融合タンパク質が天然でグリコシル化されている場合は、試料にまず、MS分析に干渉し得る天然起源グリカンを除去する処理を行った。200mM HEPES、100mM NaCl、50mM NaOAc、pH7.0の緩衝溶液中に溶解させた2.5mg/mLインスリン-Fc融合タンパク質100μLを、まず、Zeba脱塩カラム(ピアス、サーモフィッシャー・サイエンティフィック社、ウォルサム、マサチューセッツ州)を用いて、5mM EDTAを含有する0.1M Tris、pH8.0の緩衝液に緩衝液交換した。融合タンパク質に存在するN結合型グリカン(例えば、cNg-N部位に位置するアスパラギンの側鎖に連結したグリカン)を除去するために、この溶液に、1.67μLのPNGase F酵素(Prozyme N-グリカナーゼ)を添加し、この混合物を37℃の恒温器内で一晩インキュベートした。次に、試料をLC-MS(ノババイオアッセイズ社、ウォバーン、マサチューセッツ州)による分析にかけ、グリカンを含まない所望のホモ二量体に対応する分子の分子量を得た。cNg-アスパラギンからグリカンを切断するために用いられた酵素過程は、アスパラギン側鎖を脱アミノ化してアスパラギン酸の形成も引き起こすため、この質量のさらなる補正を次に行った。補正を行う場合、酵素処理後のホモ二量体は全体として2Da増加し、これは、ホモ二量体に存在する各鎖において、1Daの質量に相当する。従って、実際の分子量は、分析試料中のインスリン-Fc融合タンパク質構造の酵素修飾を補正するために、測定質量から2Daを引いたものである。
質量分析(MS)によるインスリン-Fc融合タンパク質質量の正確な評価のために、インスリン-Fc融合タンパク質が天然でグリコシル化されている場合は、試料にまず、MS分析に干渉し得る天然起源グリカンを除去する処理を行う。200mM HEPES、100mM NaCl、50mM NaOAc、pH7.0の緩衝溶液中に溶解させた2.5mg/mLインスリン-Fc融合タンパク質100μLを、まず、Zeba脱塩カラム(ピアス、サーモフィッシャー・サイエンティフィック社、ウォルサム、マサチューセッツ州)を用いて、5mM EDTAを含有する0.1M Tris、pH8.0の緩衝液に緩衝液交換する。融合タンパク質に存在するN結合型グリカン(例えば、cNg-N部位に位置するアスパラギンの側鎖に連結したグリカン)を除去するために、この溶液に、1.67μLのPNGase F酵素(Prozyme N-グリカナーゼ)を添加し、この混合物を37℃の恒温器内で一晩インキュベートする。次に、試料をLC-MS(ノババイオアッセイズ社、ウォバーン、マサチューセッツ州)による分析にかけ、グリカンを含まない所望のホモ二量体に対応する分子の分子量を得る。cNg-アスパラギンからグリカンを切断するために用いられた酵素過程は、アスパラギン側鎖を脱アミノ化してアスパラギン酸の形成も引き起こすため、この質量のさらなる補正を次に行う。補正を行う場合、酵素処理後のホモ二量体は全体として2Da増加し、これは、ホモ二量体に存在する各鎖において、1Daの質量に相当する。従って、実際の分子量は、分析試料中のインスリン-Fc融合タンパク質構造の酵素修飾を補正するために、測定質量から2Daを引いたものである。
インスリン-Fc融合タンパク質の分子ふるいクロマトグラフィー(SEC-HPLC)は、2998フォトダイオードアレイに接続したWaters 2795HT HPLC(ウォーターズ社(Waters Corporation)、ミルフォード、マサチューセッツ州)を用いて、280nmの波長で行った。100μL以下の、目的のインスリン-Fc融合タンパク質を含有する試料を、流速0.2mL/分で、50mMリン酸ナトリウム、300mM NaCl、および0.05%w/vアジ化ナトリウムを含むpH6.2の移動相を用いて機能する、MAbPac SEC-1、5μm、4×300mmカラム(サーモフィッシャー・サイエンティフィック社、ウォルサム、マサチューセッツ州)に注入した。このMAbPac SEC-1カラムは、分子サイズ分離の原則に基づいて機能する。すなわち、大型の可溶性インスリン-Fc凝集体(例えば、インスリン-Fc融合タンパク質ホモ二量体の多量体)ほど、より早い滞留時間で溶出し、非凝集性のホモ二量体はより遅い滞留時間に溶出した。分析用SEC-HPLCにより、ホモ二量体の凝集型多量体からホモ二量体の混合物を分離する場合、非凝集型ホモ二量体の割合に対して、インスリン-Fc融合タンパク質溶液の純度を確認した。
インスリン-Fc融合タンパク質の分子ふるいクロマトグラフィー(SEC-HPLC)は、2998フォトダイオードアレイに接続したWaters 2795HT HPLC(ウォーターズ社、ミルフォード、マサチューセッツ州)を用いて、280nmの波長で行う。100μL以下の、目的のインスリン-Fc融合タンパク質を含有する試料を、流速0.2mL/分で、50mMリン酸ナトリウム、300mM NaCl、および0.05%w/vアジ化ナトリウムを含むpH6.2の移動相を用いて機能する、MAbPac SEC-1、5μm、4×300mmカラム(サーモフィッシャー・サイエンティフィック社、ウォルサム、マサチューセッツ州)に注入する。このMAbPac SEC-1カラムは、分子サイズ分離の原則に基づいて機能する。すなわち、大型の可溶性インスリン-Fc凝集体(例えば、インスリン-Fc融合タンパク質ホモ二量体の多量体)ほど、より早い滞留時間で溶出し、非凝集性のホモ二量体はより遅い滞留時間に溶出することとなる。分析用SEC-HPLCにより、ホモ二量体の凝集型多量体からホモ二量体の混合物を分離する場合、非凝集型ホモ二量体の割合に対して、インスリン-Fc融合タンパク質溶液の純度を確認する。
ヒトIRを発現するヒトIM-9細胞(ATTC番号CCL-159)を、5%FBS含有RPMI完全培地中で、70~80%コンフルエントに培養・維持した。IM-9細胞の培養物を250×g(約1000rpm)で10分間遠心し、細胞をペレット化した。細胞をHBSS緩衝液またはPBS緩衝液で1回洗浄し、8×106細胞/mLの濃度となるように冷FACS染色用培地(HBSS/2mM EDTA/0.1%ナトリウムアジド+4%ウマ血清)中に再懸濁し、試験液が作製されるまで氷上または4℃で維持した。インスリン-Fcタンパク質を、1.2mLチューブ内で、FACS緩衝液で1:3連続希釈して(各希釈液の体積はおよそ60μL)、2×濃度とし、この溶液はピペッティングの準備ができるまで氷上で保冷した。
ヒトIRを発現するヒトIM-9細胞(ATTC番号CCL-159)を、5%FBS含有RPMI完全培地中で、70~80%コンフルエントに培養・維持する。IM-9細胞の培養物を250×g(約1000rpm)で10分間遠心し、細胞をペレット化する。細胞をHBSS緩衝液またはPBS緩衝液で1回洗浄し、8×106細胞/mLの濃度となるように冷FACS染色用培地(HBSS/2mM EDTA/0.1%ナトリウムアジド+4%ウマ血清)中に再懸濁し、試験液が作製されるまで氷上または4℃で維持する。インスリン-Fcタンパク質を、1.2mLチューブ内で、FACS緩衝液で1:3連続希釈して(各希釈液の体積はおよそ60μL)、2×濃度とし、この溶液はピペッティングの準備ができるまで氷上で保冷する。
ヒトFcγRI(すなわち、rhFcγRI)を用いた以下のようなELISAアッセイを用いて、pH7.4におけるインスリン-Fc融合タンパク質のFcγRIに対する結合を実施した。インスリン-Fc融合タンパク質を、pH9.6の炭酸水素ナトリウム緩衝液で10μg/mLに希釈し、Maxisorp(ヌンク社(Nunc))マイクロタイタープレート上に4℃で一晩コートし、その後、そのマイクロプレートの各ストリップをPBST(PBS/0.05%Tween-20)緩衝液で5回洗浄し、Superblockブロッキング試薬(サーモフィッシャー社)でブロッキングした。ビオチン化rhFcγRI(組換えヒトFcγRI;R&Dシステムズ社(R&D Systems))の連続希釈物を、3000ng/mLから4.1ng/mLまで、PBST/10%Superblock緩衝液中で作製し、インスリン-Fc融合タンパク質でコートされたマイクロプレートストリップ上に100μL/ウェルで添加した。このマイクロタイタープレートを室温で1時間インキュベートした後、マイクロプレートストリップをPBSTで5回洗浄してから、PBST/10%Superblock緩衝液で1:10000希釈したストレプトアビジン-HRPを100μL/ウェルで添加した。45分間のインキュベーション後、マイクロプレートストリップを再度PBSTで5回洗浄した。TMBを添加して結合したFcγRIタンパク質を除去し、ELISA反応停止試薬(ボストン・バイオプロダクツ社(Boston Bioproducts))で停止させた。プレートをELISAプレートリーダーにおいて450nmで読み取り、各ウェルに添加されたrhFcγRIの対数濃度に対してOD450値(rhFcγRIのインスリン-Fcタンパク質に対する結合に比例)をプロットして、GraphPad Prismソフトウェアを用いて結合曲線を作成した。曲線がやや似ている化合物の分類については、例えば3000ng/mLのrhFcγRI濃度のような、高濃度のうちの1つにおけるOD450を用いることで、コートされたインスリン-Fc融合タンパク質化合物間の違いを識別することができる。様々な時間にランが行われた複数のインスリン-Fc融合タンパク質間の違いを比較するために、ヒトFcγRIアッセイにおけるOD450比は、を、3000ng/mLのビオチン化FcγRI濃度で得られた試験インスリン-Fc融合タンパク質化合物のOD450値を、3000ng/mLのビオチン化FcγRI濃度で得られた配列番号76の参照インスリン-Fc融合タンパク質のOD450値で割ったものとして算出した。
ヒトFcγRI(すなわち、rhFcγRI)を用いた以下のようなELISAアッセイを用いて、pH7.4におけるインスリン-Fc融合タンパク質のFcγRIに対する結合を実施する。インスリン-Fc融合タンパク質を、pH9.6の炭酸水素ナトリウム緩衝液で10μg/mLに希釈し、Maxisorp(ヌンク社)マイクロタイタープレート上に4℃で一晩コートし、その後、そのマイクロプレートの各ストリップをPBST(PBS/0.05%Tween-20)緩衝液で5回洗浄し、Superblockブロッキング試薬(サーモフィッシャー社)でブロッキングする。ビオチン化rhFcγRI(組換えヒトFcγRI;R&Dシステムズ社)の連続希釈物を、3000ng/mLから4.1ng/mLまで、PBST/10%Superblock緩衝液中で作製し、インスリン-Fc融合タンパク質でコートされたマイクロプレートストリップ上に100μL/ウェルで添加する。このマイクロタイタープレートを室温で1時間インキュベートした後、マイクロプレートストリップをPBSTで5回洗浄してから、PBST/10%Superblock緩衝液で1:10000希釈したストレプトアビジン-HRPを100μL/ウェルで添加する。45分間のインキュベーション後、マイクロプレートストリップを再度PBSTで5回洗浄する。TMBを添加して結合したFcγRIタンパク質を除去し、ELISA反応停止試薬(ボストン・バイオプロダクツ社)で停止させる。プレートをELISAプレートリーダーにおいて450nmで読み取り、各ウェルに添加されたrhFcγRIの対数濃度に対してOD450値(rhFcγRIのインスリン-Fcタンパク質に対する結合に比例)をプロットして、GraphPad Prismソフトウェアを用いて結合曲線を作成する。曲線がやや似ている化合物の分類については、例えば3000ng/mLのrhFcγRI濃度のような、高濃度のうちの1つにおけるOD450を用いることで、コートされたインスリン-Fc融合タンパク質化合物間の違いを識別することができる。様々な時間にランが行われた複数のインスリン-Fc融合タンパク質間の違いを比較するために、ヒトFcγRIアッセイにおけるOD450比は、を、3000ng/mLのビオチン化FcγRI濃度で得られた試験インスリン-Fc融合タンパク質化合物のOD450値を、3000ng/mLのビオチン化FcγRI濃度で得られた配列番号76の参照インスリン-Fc融合タンパク質のOD450値で割ったものとして算出する。
ヒト補体成分C1qを用いた以下のようなELISAアッセイを用いて、pH7.4におけるインスリン-Fc融合タンパク質の補体成分C1qに対する結合を実施した。インスリン-Fc融合タンパク質を、pH9.6の炭酸水素ナトリウム緩衝液で10μg/mLに希釈し、Maxisorp(ヌンク社(Nunc))マイクロタイタープレート上に4℃で一晩コートし、その後、そのマイクロプレートの各ストリップをPBST(PBS/0.05%Tween-20)緩衝液で5回洗浄し、Superblockブロッキング試薬(サーモフィッシャー社)でブロッキングした。ビオチン化補体成分C1q(ヒト補体成分C1q;シグマ・アルドリッチ社(Sigma-Aldrich))の連続希釈物を、1000ng/mLから1.4ng/mLまで、PBST/10%Superblock緩衝液中で作製し、インスリン-Fc融合タンパク質でコートされたマイクロプレートストリップ上に100μL/ウェルで添加した。このマイクロタイタープレートを室温で1時間インキュベートした後、マイクロプレートストリップをPBSTで5回洗浄してから、PBST/10%Superblock緩衝液で1:12000希釈したストレプトアビジン-HRPを100μL/ウェルで添加した。45分間のインキュベーション後、マイクロプレートストリップを再度PBSTで5回洗浄した。TMBを添加して結合した補体C1qタンパク質を除去し、ELISA反応停止試薬(ボストン・バイオプロダクツ社)で停止させた。プレート吸光度をELISAプレートリーダーにおいて450nmで読み取り(OD450)、各ウェルに添加された補体成分C1qの対数濃度に対してこのOD450値(補体成分C1qのインスリン-Fcタンパク質に対する結合に比例)をプロットして、GraphPad Prismソフトウェアを用いて結合曲線を作成した。曲線がやや似ている化合物の分類については、例えば1000ng/mLの補体成分C1q濃度のような、高濃度のうちの1つにおけるOD450を用いることで、コートされたインスリン-Fc融合タンパク質化合物間の違いを識別した。さらに、様々な時間にランが行われた複数のインスリン-Fc融合タンパク質間の違いを比較するために、ヒトC1qアッセイにおけるOD450比は、を、1000ng/mLのビオチン化C1q濃度で得られた試験インスリン-Fc融合タンパク質化合物のOD450を、1000ng/mLのビオチン化C1q濃度で得られた配列番号76の参照インスリン-Fc融合タンパク質のOD450で割ったものとして算出した。
ヒト補体成分C1qを用いた以下のようなELISAアッセイを用いて、pH7.4におけるインスリン-Fc融合タンパク質の補体成分C1qに対する結合を実施する。インスリン-Fc化合物を、pH9.6の炭酸水素ナトリウム緩衝液で10μg/mLに希釈し、Maxisorp(ヌンク社)マイクロタイタープレート上に4℃で一晩コートし、その後、そのマイクロプレートの各ストリップをPBST(PBS/0.05%Tween-20)緩衝液で5回洗浄し、Superblockブロッキング試薬(サーモフィッシャー社)でブロッキングする。ビオチン化補体成分C1q(ヒト補体成分C1q;シグマ・アルドリッチ社)の連続希釈物を、1000ng/mLから1.4ng/mLまで、PBST/10%Superblock緩衝液中で作製し、インスリン-Fc融合タンパク質でコートされたマイクロプレートストリップ上に100μL/ウェルで添加する。このマイクロタイタープレートを室温で1時間インキュベートした後、マイクロプレートストリップをPBSTで5回洗浄してから、PBST/10%Superblock緩衝液で1:12000希釈したストレプトアビジン-HRPを100μL/ウェルで添加する。45分間のインキュベーション後、マイクロプレートストリップを再度PBSTで5回洗浄する。TMBを添加して結合した補体C1qタンパク質を除去し、ELISA反応停止試薬(ボストン・バイオプロダクツ社)で停止させる。プレート吸光度をELISAプレートリーダーにおいて450nmで読み取り(OD450)、各ウェルに添加された補体成分C1qの対数濃度に対してこのOD450値(補体成分C1qのインスリン-Fcタンパク質に対する結合に比例)をプロットして、GraphPad Prismソフトウェアを用いて結合曲線を作成する。曲線がやや似ている化合物の分類については、例えば1000ng/mLの補体成分C1q濃度のような、高濃度のうちの1つにおけるOD450を用いることで、コートされたインスリン-Fc融合タンパク質化合物間の違いを識別することができる。さらに、様々な時間にランが行われた複数のインスリン-Fc融合タンパク質間の違いを比較するために、ヒトC1qアッセイにおけるOD450比は、を、1000ng/mLのビオチン化C1q濃度で得られた試験インスリン-Fc融合タンパク質化合物のOD450を、1000ng/mLのビオチン化C1q濃度で得られた配列番号76の参照インスリン-Fc融合タンパク質のOD450で割ったものとして算出する。
イヌIgG由来のFcフラグメントを含むインスリン-Fc融合タンパク質のイヌFcRn受容体に対するインビトロ結合親和性を、溶液pH5.5で実施されたELISA法により測定した。この弱酸性のpHは、Fcフラグメント含有分子がFcRn受容体に結合するのに好ましい結合環境である。インビボでは、細胞はFcRnを細胞表面上に発現し、また、エンドソーム内に内部発現する。Fcフラグメントを含む分子が天然プロセス(ピノサイトーシスやエンドサイトーシスなど)を通じて細胞に運ばれると、エンドソーム内ではpHがより低いpHへと変化するため、そこでFcRn受容体がエンドソーム-リソソーム区画で分解されるはずであったFcフラグメント含有分子に結合し、それによって、これらの分子がpHが中性付近(例えば、pH7.0~7.4)である細胞表面に戻されて再利用される。中性pHはFcRn受容体に対する結合に好適でないため、Fcフラグメント含有分子は放出されて、血行中に戻される。これが、Fcフラグメント含有分子がインビボにおいて示す薬物動態学的な血中半減期が長い、主な仕組みである。
ヒトIgG由来のFcフラグメントを含むインスリン-Fc融合タンパク質のヒトFcRn受容体に対するインビトロ結合親和性を、溶液pH5.5で実施されたELISA法により測定した。この弱酸性のpHは、Fcフラグメント含有分子がFcRn受容体に結合するのに好ましい結合環境である。インビボでは、細胞はFcRnを細胞表面上に発現し、また、エンドソーム内に内部発現する。Fcフラグメントを含む分子が天然プロセス(ピノサイトーシスやエンドサイトーシスなど)を通じて細胞に運ばれると、エンドソーム内ではpHがより低いpHへと変化するため、そこでFcRn受容体がエンドソーム-リソソーム区画で分解されるはずであったFcフラグメント含有分子に結合し、それによって、これらの分子がpHが中性付近(例えば、pH7.0~7.4)である細胞表面に戻されて再利用される。中性pHはFcRn受容体に対する結合に好適でないため、Fcフラグメント含有分子は放出されて、血行中に戻される。これが、Fcフラグメント含有分子がインビボにおいて示す薬物動態学的な血中半減期が長い、主な仕組みである。
ヒトIgG由来のFcフラグメントを含むインスリン-Fc融合タンパク質のヒトFcRn受容体に対するインビトロ結合親和性を、溶液pH5.5で実施されたELISA法により測定する。この弱酸性のpHは、Fcフラグメント含有分子がFcRn受容体に結合するのに好ましい結合環境である。インビボでは、細胞はFcRnを細胞表面上に発現し、また、エンドソーム内に内部発現する。Fcフラグメントを含む分子が天然プロセス(ピノサイトーシスやエンドサイトーシスなど)を通じて細胞に運ばれると、エンドソーム内ではpHがより低いpHへと変化するため、そこでFcRn受容体がエンドソーム-リソソーム区画で分解されるはずであったFcフラグメント含有分子に結合し、それによって、これらの分子がpHが中性付近(例えば、pH7.0~7.4)である細胞表面に戻されて再利用される。中性pHはFcRn受容体に対する結合に好適でないため、Fcフラグメント含有分子は放出されて、血行中に戻される。これが、Fcフラグメント含有分子がインビボにおいて示す薬物動態学的な血中半減期が長い、主な仕組みである。
イヌにおける空腹時血糖値に対する作用について、以下のように、インスリン-Fc融合タンパク質を評価した。およそ10~15kgの重量の、N=1、2、3、またはそれ以上の、健常な抗体未処置のイヌを、各インスリン-Fc融合タンパク質に対して1匹ずつ用いた。アナフィラキシー、嗜眠、窮迫、疼痛などの徴候がないか、動物の観察も1日2回行い、所望によりいくつかの化合物については、追加で3週間以上の皮下注射により治療を継続し、中和抗薬物抗体の誘導性を示すものとして重要な、当該化合物のグルコース低減能が経時的に低下するかどうかの確認を行った。0日目、動物に、インスリンFc融合タンパク質ホモ二量体を含有する医薬組成物の、静脈内投与または皮下投与による単回投与を、10~50mMのリン酸水素ナトリウム、50~150mMの塩化ナトリウム、0.005~0.05%v/vのTween-80、および所望により濃度0.02~1.00mg/mLの静菌剤(例えば、フェノール、m‐クレゾール、またはメチルパラベン)の溶液中1~10mg/mLの濃度、7.0~8.0の溶液pH、0.08~0.80mgのインスリン-Fc融合タンパク質/kg(または、モルベースで、およそ1.2~12.3nmol/kgまたはおよそ0.4~4.0U/kgのインスリン当量に相当)の投与量で、実施した。0日目に、注射の直前と、注射の15分後、30分後、45分後、60分後、120分後、240分後、360分後、および480分後、並びに1日後、2日後、3日後、4日後、5日後、6日後、および7日後に、適当な静脈から、血液を採取した。
反復注射の際の血糖値に対する作用について、以下のように、インスリン-Fc融合タンパク質を評価した。およそ10kg~20kgの重量の健常な抗体未処置のイヌを用いて、各動物にインスリン-Fc融合タンパク質を反復投与した。アナフィラキシー、嗜眠、窮迫、疼痛などの負の副作用の徴候がないか、動物を1日2回観察し、所望によりいくつかの化合物については、追加で2~5回の皮下注射の分だけ治療を継続し、インビボで中和抗薬物抗体が存在する可能性を示す、当該化合物のグルコース低減能が経時的に低下するかどうかの確認を行った。0日目、動物に、インスリンFc融合タンパク質を含有する医薬組成物の単回皮下注射を、10~50mMのリン酸水素ナトリウム、50~150mMの塩化ナトリウム、0.005~0.05%v/vのTween-80、および所望により濃度0.02~1.00mg/mLの静菌剤(例えば、フェノール、m‐クレゾール、またはメチルパラベン)の溶液中、7.0~8.0の溶液pH、0.08~0.80mgのインスリン-Fc融合タンパク質/kg(または、モルベースで、およそ1.2~12.3nmol/kgまたはおよそ0.4~4.0U/kgのインスリン当量に相当)の投与量で、実施した。0日目に、注射の直前と、注射の15分後、30分後、45分後、60分後、120分後、240分後、360分後、および480分後、並びに1日後、2日後、3日後、4日後、5日後、6日後、および7日後に、適当な静脈から、血液を採取した。
NAOCR=(NAOC(N回目注射)/NAOC(1回目注射))。
一連の注射のN回目注射についての所与のインスリン-Fc融合タンパク質製剤のNAOCRを評価することによって、インビボにおける所与のインスリン-Fc融合タンパク質のグルコース低減能が、一連のN回の投与の間に、その生物活性を実質的に保持した(例えば、N回目投与のNAOCRが0.5より大きい)かどうか、あるいは、所与のインスリン-Fc融合タンパク質のインビボでのグルコース低減活性が、N回の投与の間に、その効力のかなりの部分を失った(例えば、N回目投与のNAOCRが0.5未満)かどうか、を判定することができ、これにより、インビボにおいて中和抗薬物抗体が形成される可能性が示される。好ましい実施形態において、3回目皮下注射後のNAOCの、1回目皮下注射後のNAOCに対する比は、0.5よりも大きかった(すなわち、3回目の皮下注射のNAOCRは0.5よりも大きかった)。
イヌ血清中のイヌアイソタイプのFcフラグメントを含むインスリン-Fc融合タンパク質の濃度を測定するためのアッセイを、以下のように構築した。このアッセイにはサンドイッチ形式のELISAが含まれ、当該ELISAでは、血清試料中の治療化合物を、ELISAプレート上にコートされた抗インスリン/プロインスリンモノクローナル抗体(mAb)に捕捉させ、次いでHRP結合型抗イヌIgG Fc特異的抗体で検出し、その後、TMB基質系を用いて発色を行った。Maxisorp ELISAプレート(ヌンク社)を、コーティング緩衝液(pH=9.6の炭酸ナトリウム-重炭酸ナトリウム緩衝液)中5μg/mlの抗インスリンmAbクローンD6C4(バイオラド社(Biorad))で、4℃で一晩コートした。次いで、プレートを、PBST(PBS+0.05%Tween20)で5回洗浄し、SuperBlockブロッキング液(サーモフィッシャー社)で室温で最低1時間(または4Cで一晩)ブロッキングした。試験血清試料をPBST/SB/20%HS試料希釈緩衝液(PBS+0.1%Tween20+10%SuperBlock+20%ウマ血清)で1:20希釈した。検量線を作成する場合、目的のインスリン-Fc融合タンパク質を、試料希釈緩衝液(PBST/SB/20%HS)+5%ビーグル血清プール(バイオIVT社(BioIVT))で、200ng/mlから0.82ng/mlまでの濃度範囲で、1:2.5連続希釈で、希釈した。標準および希釈後血清試料を、デュプリケートで100μl/ウェルでブロッキング後のプレートに添加し、室温で1時間インキュベートした。インキュベーション後、試料および標準をPBSTで5回洗い流した。HRP結合型ヤギ抗イヌIgG Fc(シグマ社)検出用抗体をPBST/SB/20%HS緩衝液で約1:15,000希釈し、100μlを全てのウェルに添加し、室温、暗所で45分間インキュベートした。プレートをPBSTで5回、脱イオン水で1回洗浄し、100μl/ウェルのTMB(インビトロジェン社)を室温で8~10分間添加することで発色させた。その後、100μl/ウェルのELISA停止液(ボストン・バイオプロダクツ社)を添加することで発色を停止させ、30分以内にSpectraMaxプレートリーダー(モレキュラーデバイス社)を用いて450nmの吸光度を読み取った。試料中のインスリン-Fc融合タンパク質化合物の濃度は、SoftMaxProソフトウェアを用いて4-PL曲線上の補間を行うことにより算出した。
Maxisorp ELISAプレート(ヌンク社)を、コーティング緩衝液(pH=9.6、炭酸塩-重炭酸塩(Biocarbonate)緩衝液)で希釈された、10μg/mLの目的のインスリン-Fc融合タンパク質で4℃で一晩コートし、試験化合物に対するADAの測定を行った。イヌIgG由来のFcフラグメントを含むインスリン-Fc融合タンパク質のインスリン部分に対するADAの測定のために、プレートをコーティング緩衝液中30μg/mLの精製インスリンでコートした。次いで、プレートを、PBST(PBS+0.05%Tween20)で5回洗浄し、SuperBlockブロッキング液(サーモフィッシャー社、ウォルサム、マサチューセッツ州)で少なくとも1時間(または一晩)ブロッキングした。イヌIgGユニットにおけるADAを算出するため、ストリップを直接、pH=9.6の炭酸-重炭酸(Biocarb)コーティング緩衝液で1:2連続希釈した、濃度300~4.69ng/mlのイヌIgG(ジャクソン・イムノリサーチ・ラボラトリーズ社(Jackson Immunoresearch Laboratories)、ウェスト・グローブ、ペンシルベニア州)で、4℃で一晩コートし、7点疑似検量線の作成に用いた。標準用のストリッププレートも、洗浄して、SuperBlockブロッキング液で少なくとも1時間(または一晩)ブロッキングした。
空腹時血糖値に対する作用について、以下のように、インスリン-Fc融合タンパク質を評価した。1群当たりN=3のbalb/cマウスまたは糖尿病の野生型非肥満性糖尿病(wt NOD)マウス(ジャクソン・ラボラトリーズ社)からデータを収集した。実験の1時間前に動物を絶食させ、その後、0時間の時点で、マウスに、インスリンFc融合タンパク質ホモ二量体を含有する医薬組成物の単回皮下投与を、10~50mMのリン酸水素ナトリウム、50~150mMの塩化ナトリウム、0.005~0.05%v/vのTween-80、および所望により濃度0.02~1.00mg/mLの静菌剤(例えばフェノール、m‐クレゾール、またはメチルパラベン)の溶液中、300μg/kgのインスリン-Fc融合タンパク質濃度で、最終的な溶液pHは水酸化ナトリウムおよび/または塩酸を用いて7.0~8.0に調整して、実施した。
空腹時血糖値に対する作用について、以下のように、インスリン-Fc融合タンパク質を評価する。1群当たりN=3のbalb/cマウスまたは糖尿病wt NODマウス(ジャクソン・ラボラトリーズ社)からデータを収集する。実験の1時間前に動物を絶食させ、その後、0時間の時点で、マウスに、インスリンFc融合タンパク質ホモ二量体を含有する医薬組成物の単回皮下投与を、10~50mMのリン酸水素ナトリウム、50~150mMの塩化ナトリウム、0.005~0.05%v/vのTween-80、および所望により濃度0.02~1.00mg/mLの静菌剤(例えばフェノール、m‐クレゾール、またはメチルパラベン)の溶液中、300μg/kgのインスリン-Fc融合タンパク質濃度で、最終的な溶液pHは水酸化ナトリウムおよび/または塩酸を用いて7.0~8.0に調整して、実施する。
ライブラリー中の各化合物をELISAマイクロプレートウェルの個別のストリップ上にコートする以外は、実施例25の抗薬物抗体ELISAアッセイにおける記載と同様に、Maxisorp ELISAマイクロプレート(ヌンク社)を、アミノ酸配列既知のインスリン-Fc融合タンパク質ホモ二量体化合物ライブラリーでコートし、このコートされたプレートをブロッキングした。ライブラリー中の化合物は、様々なB鎖、C鎖、およびA鎖のアミノ酸変異を含んで、インスリンポリペプチドのアミノ酸組成が異なり、リンカー組成が異なり、ヒト由来のいくつかのものを含んで、Fcフラグメント組成が異なる、一連のインスリン-Fc融合タンパク質からなる。別に、実施例24に記載したように、それぞれ、イヌIgGユニットにおける抗薬物抗体(ADA)を算出するため、いくつかのプレートストリップウェルを直接、1:2連続希釈したイヌIgG(ジャクソン・イムノリサーチ・ラボラトリーズ社、ウェスト・グローブ、ペンシルベニア州)でコートした。
発明を実施するための形態に記載された設計目標を達成するためのプロセスは、以下の工程を含むものであった。まず、得られるインスリン-Fc融合タンパク質が、免疫原性が最小限であり、長時間作用性の生物活性を有する産物をもたらす可能性が最も高いように(例えば、Fcγ受容体I結合性が最小限の種特異的なIgGアイソタイプを選択した)、配列番号4または配列番号5のインスリンポリペプチドを、特定のIgGアイソタイプの種特異的なFcフラグメントおよびリンカーと組み合わせた。所望の融合タンパク質をコードするDNA配列を作製し、ベクター(レイクファーマ社、サン・カルロス、カリフォルニア州)にクローニングした後、そのベクターを用いて、実施例1に記載の手順に従って、HEK細胞に一過性にトランスフェクトした。次いで、インスリン-Fc融合タンパク質を実施例4に従って精製し、総タンパク質収量およびホモ二量体率を実施例10に従って測定した。ホモ二量体力価が50mg/Lよりも大きい候補のみを許容可能なものと見なしたが、これは、このレベルに満たない力価では、動物用製品の厳しい低製造コスト要件を満たす商業生産力価は得られにくいからである。選別されたインスリン-Fc融合タンパク質を、次に、実施例12に記載したような、インビトロのインスリン受容体結合研究を通じて、生物活性の各指標でスクリーニングした。経験に基づいて、IR活性のIC50値が5000nM未満の化合物のみを、標的種で生物活性を示す可能性があるものと見なした。インビトロにおけるIRのIC50値は、定性的なスクリーニングツールとして有用であるが、ヒトインスリン受容体を発現するヒトIM-9細胞を利用するため、イヌIRとヒトIRとの間の親和性の小さな違いの一部を捉えられない場合がある。さらに、インスリン受容体結合以外の要素が、インビボにおける化合物の生物活性に影響を与える場合がある(例えば、インビボにおける薬物動態学的な排出半減期の延長を可能にするイヌFcRnに対する親和性)。そこで、製造およびIR活性IC50値の観点から許容できる選別されたインスリン-Fc融合タンパク質を、イヌでの生物活性についてさらに選別し、所望の効力および/または生物活性の持続時間に満たない(例えば、NAOCが150%FBGL・日・kg/mg未満)物質を振るい落とした。ここでも経験に基づくが、NAOC値が150%FBGL・日・kg/mgより大きいと、標的種における投与量要件は、許容できる治療コストを達成するのに十分に低いものとなる。最後に、当該技術分野ではほとんど言及されない評価基準をさらに追加した。下記の実施例でより詳細に論じるが、初回投与後の標的種で許容できるNAOCレベルを示す多くのインスリン-Fc融合タンパク質実施形態が、予想外にも、反復投与後にその生物活性レベルを維持できない。さらに、ほとんどの場合で、標的種における反復投与時の生物活性の低減は中和抗薬物抗体の発生と相関していた。抗薬物抗体がつくられて活性を維持できないというこの傾向は、このようなインスリン-Fc融合タンパク質のイヌ糖尿病などの慢性疾患の治療での使用を非実用的なものにしている。そこで、許容できる反復投与後生物活性レベル(例えば、1回目投与に対する3回目投与のNAOCR値が0.5よりも大きい)を示し、抗薬物抗体が最低レベルの、インスリン-Fc融合体タンパク質のみを、本発明で使用するのに許容できるものと見なした。
発明を実施するための形態に記載された設計目標を達成するためのプロセスは、以下の工程を含むものであった。まず、得られるインスリン-Fc融合タンパク質が、長時間作用性の生物活性を有する産物をもたらす可能性が最も高いように、配列番号7または配列番号10のインスリンポリペプチドを、特定のIgGアイソタイプ(IgG2またはIgG1)のヒトFcフラグメントおよびリンカーと組み合わせた。所望の融合タンパク質をコードするDNA配列を作製し、ベクター(レイクファーマ社、サン・カルロス、カリフォルニア州)にクローニングした後、そのベクターを用いて、実施例1に記載の手順に従って、HEK細胞に一過性にトランスフェクトした。次いで、インスリン-Fc融合タンパク質を実施例4に従って精製し、総タンパク質収量およびホモ二量体率を実施例10に従って測定し、ホモ二量体力価を算出した。ホモ二量体力価が150mg/Lよりも大きい候補のみを許容可能なものと見なしたが、これは、このレベルに満たないホモ二量体力価は、ホモ二量体力価が高いCHO安定感染細胞株とは換言しにくく、比較的コモディティ化したヒトインスリン市場の低製造コスト要件を満たす商業生産力価が得られにくいからである。選別されたインスリン-Fc融合タンパク質の構成を、次に、実施例12に記載したような、インビトロのIR結合研究を通じて、生物活性の各指標でスクリーニングした。経験に基づいて、IR活性のIC50値が2400nM未満、より好ましくは2000nM未満の化合物のみを、インビボで生物活性を示す可能性があるものと見なした。インビトロにおけるIR IC50値は、このアッセイはヒトIRを発現するヒトIM-9細胞を利用しており、結合性が小さい(IR IC50値が大きい)化合物と比較して、結合性が大きいほど(IR IC50値が小さいほど)、所与の投与量でインビボ効力が大きくなると予想されることから、有用な定性的スクリーニング手段である。さらに、IR結合以外の要因が、インビボにおける化合物の生物活性に影響を与えている可能性がある。例えば、Fc融合タンパク質のヒトFcRn受容体に対する親和性は、化合物のインビボ薬物動態学的排出半減期に関係している。インスリン-Fc融合タンパク質のインビボ半減期の数日間以上の延長は、インビトロにおけるヒトFcRn結合アッセイ(実施例19)で測定されるEC50値が1500ng/mL未満、より好ましくは1000ng/mL未満であることと、よく相関している。
実施例30:イヌFc IgGAアイソタイプを含むイヌインスリン-Fc融合タンパク質
配列番号4のインスリンポリペプチド配列とイヌIgGAアイソタイプのFcフラグメント(配列番号14)とを含み、配列番号11のペプチドリンカーを用いる、インスリン-Fc融合タンパク質の作製を試みた。得られたインスリン-Fc融合タンパク質の完全アミノ酸配列は以下の通りである:
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGRCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVMHETLQNHYTDLSLSHSPG(配列番号31)。
配列番号31のインスリン-Fc融合タンパク質のホモ二量体含有率を増加させ、生物活性を向上させ、半減期を延長する試みでは、当該FcフラグメントのCH3領域に変異を挿入して、分子間の会合(例えば、Fcフラグメント-Fcフラグメント分子間相互作用)を妨げて、FcRn受容体により強く結合する(例えば、FcRnに対するより高い親和性)ことを促すことで、再循環および体循環時間を増加させる試みを行った。以下のインスリン-Fc融合タンパク質を、実施例1に従ってHEK細胞で合成し、実施例4に従って精製し、実施例6、実施例8、および実施例10に従って試験した。試験の結果は以下の表2に示す。配列番号31に対しての、配列番号32、配列番号33、配列番号34、および配列番号35の配列アラインメント、並びに、アミノ酸配列の相違を、図3に示す。
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGRCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVLHEALHSHYTQKSLSLSPG(配列番号32)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGRCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVLHETLQSHYTDLSLSHSPG(配列番号33)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGRCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVMHETLQSHYTDLSLSHSPG(配列番号34)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGRCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVLHETLQNHYTDLSLSHSPG(配列番号35)

上記のように、イヌIgGAは、イヌにおいてFcγIエフェクター機能を示さないため(ヒトにおけるヒトIgG2アイソタイプとよく似ている)、イヌ用の非免疫原性インスリン-Fc融合タンパク質を作製するためのFcフラグメントのアイソタイプとして好ましいと考えられている。しかし、イヌIgGA Fcフラグメントを用いて製造されたインスリン-Fc融合タンパク質は、凝集性が高く、ホモ二量体力価が許容できないほど低く、生物活性と作用持続時間が許容できないほど低いレベルであった。そのため、配列番号31のインスリン-Fc融合物のイヌIgGA Fcフラグメントの代わりとして、他のイヌIgGアイソタイプ(配列番号15のイヌIgGB)、配列番号16のイヌIgGC、および配列番号17のイヌIgGDのFcフラグメントを評価した。イヌIgGBアイソタイプ、イヌIgGCアイソタイプ、およびイヌIgGDアイソタイプをベースとしたFcフラグメントを含むこれら3種のインスリン-Fc融合タンパク質は、配列番号31のインスリン-Fc融合タンパク質の作製に用いたものと同じ、配列番号4のインスリンポリペプチドと配列番号11のペプチドリンカーを用いて、合成した。タンパク質製造は実施例1に従ってHEK293細胞で行った。次いで、インスリン-Fc融合タンパク質を、実施例4に従ってプロテインAカラムを用いて精製した。インスリン-Fc融合タンパク質の構造は実施例6に従って非還元CE-SDSおよび還元CE-SDSで確認し、さらに、実施例8に記載のグリカン除去を伴うLC-MSによって配列の確認を行った。ホモ二量体率は実施例10に従って分子ふるいクロマトグラフィーで測定した。これらの配列を以下に示し、配列番号31に対するこれらの配列アラインメント比較を図4に示す:
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号36)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGCNNCPCPGCGLLGGPSVFIFPPKPKDILVTARTPTVTCVVVDLDPENPEVQISWFVDSKQVQTANTQPREEQSNGTYRVVSVLPIGHQDWLSGKQFKCKVNNKALPSPIEEIISKTPGQAHQPNVYVLPPSRDEMSKNTVTLTCLVKDFFPPEIDVEWQSNGQQEPESKYRMTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQISLSHSPG(配列番号37)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGCISPCPVPESLGGPSVFIFPPKPKDILRITRTPEITCVVLDLGREDPEVQISWFVDGKEVHTAKTQPREQQFNSTYRVVSVLPIEHQDWLTGKEFKCRVNHIGLPSPIERTISKARGQAHQPSVYVLPPSPKELSSSDTVTLTCLIKDFFPPEIDVEWQSNGQPEPESKYHTTAPQLDEDGSYFLYSKLSVDKSRWQQGDTFTCAVMHEALQNHYTDLSLSHSPG(配列番号38)

実施例32の有望なホモ二量体力価およびインスリン受容体活性の結果を考慮して、配列番号36のインスリン-Fc融合タンパク質を、およそ10kgの重さのN=3の健常な抗体未処置ビーグル犬のそれぞれに静脈内注射後、実施例21に従ってインビボ生物活性について試験した。別の実験で、上記化合物をN=3の未処置ビーグル犬に皮下投与した。図5は、配列番号36のインスリン-Fc融合タンパク質を単回静脈内投与した場合の、時間に対する%FBGLを示しており、図6は、配列番号36のインスリン-Fc融合タンパク質を単回皮下投与した場合の、時間に対する%FBGLを示しており、共に、配列番号36のインスリン-Fc融合タンパク質が、イヌにおいて顕著な生物活性を示すことを示している。
イヌにおいて、配列番号36のインスリン-Fc融合タンパク質を反復皮下投与した場合の生物活性を、実施例22に記載の方法に従って試験した。N=3の動物に0日目、35日目、および42日目に皮下投与を行い、実施例22に従って、各投与後の7日間の枠について、%FBGLを測定した。反復皮下注射のそれぞれについて、実施例22の手順に従って、NAOCおよびNAOCRを算出した。表4に示されているように、イヌにおける反復皮下投与では、予想外にも、NAOCRにおける顕著な減少(すなわち、3回目注射のNAOCが、1回目注射のNAOCの0.40、すなわち40%しかない)によって判断されるように、3回目の投与までに生物活性が顕著に減衰することが明らかになった。

実施例32および実施例33で示したように、配列番号36のインスリン-Fc融合タンパク質は、イヌにおいて、許容可能なホモ二量体含有率、ホモ二量体力価、および生物活性を示した。しかし、糖尿病などの慢性疾患へのその使用には、反復皮下投与に伴って生物活性が低減し(実施例34)、抗薬物抗体が産生される(実施例34)という欠陥がある。特定の理論に束縛されるものではないが、抗薬物抗体の産生と生物活性の低減の可能性のある1つの原因として、イヌIgGB Fcフラグメントが、イヌ免疫系の各種受容体(例えば、FcγRIなどのFcγ受容体)と、相互作用することが増えることが挙げられる。しかしながら、イヌIgGBアイソタイプは、4種のイヌIgGアイソタイプの中で、Fcフラグメントに用いられた場合に、製造性および単回投与生物活性の各設計目標を達成するインスリン-Fc融合タンパク質をもたらす(実施例28)、唯一のアイソタイプであった。発明を実施するための形態に記載したように、Fcγ相互作用を低減するための1つの方法には、FcフラグメントのcNg部位を変異させることで、宿主細胞内で合成される際のグリコシル化を妨げることが行われる。すなわち、cNg部位の変異を配列番号36のFcフラグメント領域に対して行ったことで、実施例14に記載のインビトロヒトFcγRIアッセイにおける結合性によって評価される、インビボにおけるFcγ受容体に対するFcフラグメントの結合親和性が低減された。グリカンを持たないことの確認は、実施例8のLC-MS法を用いて行い、ただし、PNGアーゼF処理工程は省略した。配列番号36のインスリン-Fc融合タンパク質におけるcNg部位の位置はcNg-NB139である。配列番号36への変異としては、cNg-NB139-Qという変異を含む配列番号39、cNg-NB139-Sという変異を含む配列番号40、cNg-NB139-Dという変異を含む配列番号41、およびcNg-NB139-Kという変異を含む配列番号42があった。cNg変異型インスリン-Fc融合タンパク質の完全アミノ酸配列を以下に挙げ(NB139位には下線)、得られた配列アラインメントを図8に示した(クラスタルオメガ):
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFQGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号39)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号40)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFDGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号41)
FVNQHLCGSDLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCHSICSLYQLENYCNGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFKGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号42)。


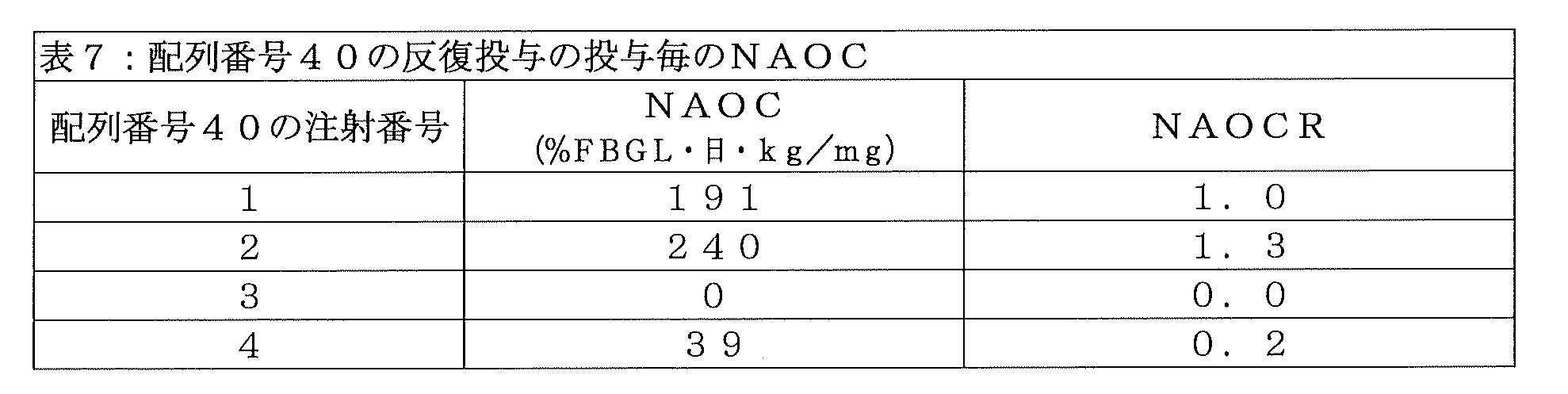
cNg-S変異を含む配列番号40のインスリン-Fc融合タンパク質が、イヌにおける反復投与時の生物活性の成績を向上させたかどうかを確かめるため、当該化合物をN=1のイヌに、0日目、7日目、14日目、および28日目に、実施例22の手順に従って皮下投与した。イヌの%FBGLが低下し過ぎた場合、そのイヌに餌を与えて、血糖を安全なレベルまで上昇させた。1回目注射のNAOCは191%FBGL・日・kg/mgであり、配列番号40のインスリン-Fc融合タンパク質がインビボにおいて十分な生物活性を示すことが示された。それ以降の各投与についても、実施例22の一般手順に従って、NAOCおよびNAOCRの測定を行い、投与を施行した時間から次の投与を施行する直前までを算出した。表7に示されるNAOCおよびNAOCRは、配列番号40のインスリン-Fc融合タンパク質が、4回投与レジメンの3回目投与および4回目投与時にNAOCRの顕著な減少を示したことを表している。すなわち、cNg-S変異を含む配列番号40のインスリン-Fc融合タンパク質は、配列番号36のインスリン-Fc融合タンパク質のFcγRI結合の1/4という低いFcγRI結合を有しているにもかかわらず、イヌにおいて反復投与時の生物活性を示すことができない。

イヌIgGB FcフラグメントのcNg部位のLysへの変異(すなわち、cNg-K)は、配列番号4のインスリンポリペプチドと配列番号11のペプチドリンカーとを含むインスリン-融合タンパク質の反復投与時の生物活性を向上させたが(実施例36)、得られた配列番号42のインスリン-Fc融合タンパク質は抗薬物抗体を発生させてしまった(実施例36)。このことから、配列番号4のインスリンポリペプチドが、予想外にも、イヌの免疫系の対象にされる特定のエピトープ(すなわち、免疫原性の「ホットスポット」)を含む可能性があるという仮定が得られた。そのため、実施例24に記載の血清試料中に存在する抗体の結合特異性を、実施例27の一般手順に従って評価した。コートされたインスリン-Fc融合タンパク質ライブラリーに対する、配列番号36のインスリン-Fc融合タンパク質(実施例32)の反復投与から得られた抗体含有血清試料の解析によって、予想外にも、配列番号5のインスリンポリペプチド配列内に、B鎖のN末端から10番目の位置(すなわち、B10)のアスパラギン酸変異、および、別に、A鎖のN末端から8番目の位置(すなわち、A8)のヒスチジン変異という、2つの主要な「ホットスポット」が存在することが示された。これらの結果は、これら2つの特定のアミノ酸変異を含むインスリンポリペプチドアミノ酸組成を含むインスリン-Fc融合タンパク質が、イヌにおいて免疫原性である可能性があり、そのため、反復注射後に生物活性を中和する抗薬物抗体を発生する可能性があることを示唆している。以上から、B10アスパラギン酸とA8ヒスチジンを含んでいないインスリンポリペプチドが、長期間に亘ってイヌに反復投与(例えば、イヌ糖尿病を治療するため)する必要があるインスリン-Fc融合タンパク質には好適であることが確認された。
「ホットスポット」変異の置換が、配列番号4のインスリンポリペプチドとイヌIgGBアイソタイプフラグメントとを含むインスリン-Fc融合タンパク質の免疫原性および反復投与時の生物活性を向上させるかどうかを評価するために、例示的なインスリン-Fc融合タンパク質(配列番号43)において、インスリンポリペプチドのB10アミノ酸とA8アミノ酸を、以下に挙げる当該インスリンポリペプチドの天然組成であるヒスチジンおよびスレオニンにそれぞれ戻したもの(配列番号63)(非天然アミノ酸には下線)を合成した。
FVNQHLCGSHLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCN(配列番号63)。
FVNQHLCGSHLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCNGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFQGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号43)。
配列番号36のインスリン-Fc融合タンパク質(実施例33)と比べて、配列番号43のインスリン-Fc融合タンパク質が抗薬物抗体を発生させなかったこと(実施例38)は、配列番号4のインスリンポリペプチドにおけるB10D変異およびA8H変異が、抗薬物抗体産生の原因となる、免疫原性のエピトープである可能性があるという説の強力な証拠である。しかし、配列番号36のものと比較して、配列番号43のインスリン-Fc融合タンパク質はインビボにおける効力が欠如しており、このことは、これら2つのアミノ酸変異が、許容できる生物活性レベルの達成にも関与していることを示している。配列番号43のインスリン-Fc融合タンパク質のインビボにおける効力の欠如は、実施例12の方法に従ってインスリン受容体結合アッセイで測定された、その高いIC50(以下の表9に示す)と関連がある。よって、インスリンポリペプチドにおける天然のB10アミノ酸およびA8アミノ酸を保持することで免疫原性の程度を低く維持しながら、インスリン-Fc融合タンパク質の生物活性を増加させる(すなわち、インスリン受容体結合アッセイにおけるIC50値を5000nM未満、より好ましくは4000nM未満、さらにより好ましくは3000nM未満に減少させる)ための、さらなる試みが必要であった。
FVNQHLCGSHLVQALYLVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号44)
FVNQHLCGSELVEALALVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号45)
FVNQHLCGSHLVEALALVCGEAGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号46)
FVNQHLCGSHLVEALALVCGERGFYYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号47)
FVNQHLCGSHLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号48)
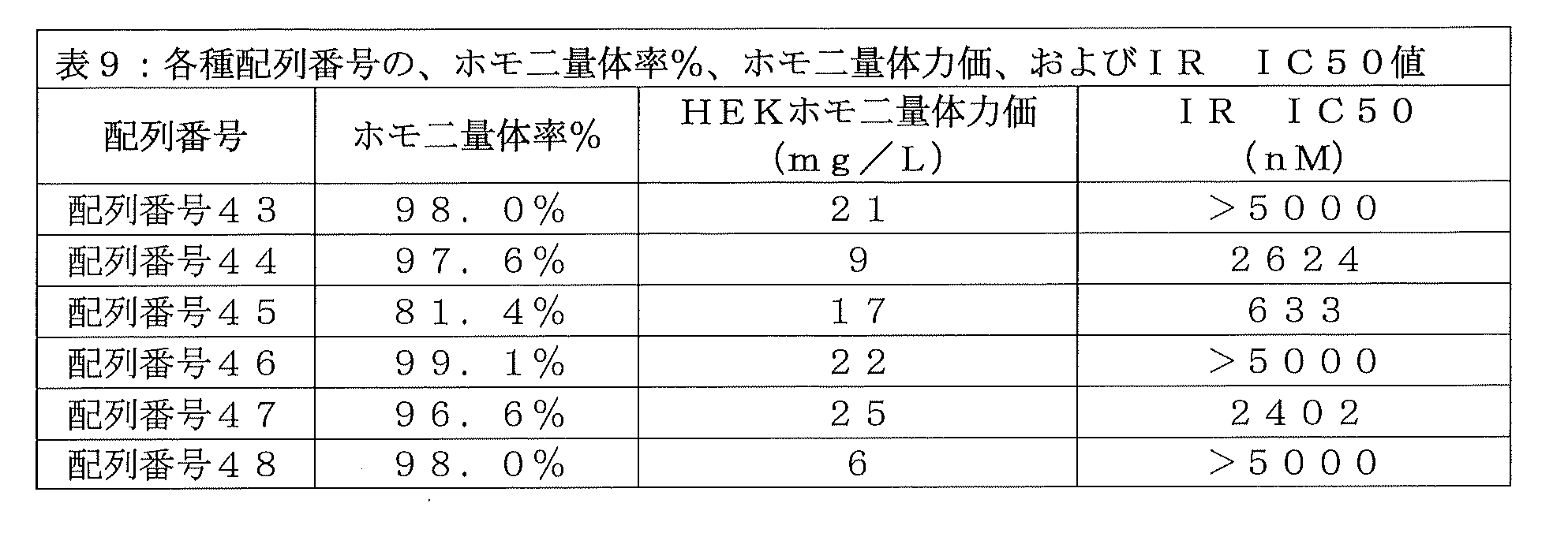
実施例39で得られた結果は、配列番号63のインスリンポリペプチドのA鎖およびB鎖を変異させる試みが全て、関連インスリン-Fc融合物のHEKホモ二量体力価が許容できないほどに低い(すなわち、25mg/L以下のホモ二量体力価)結果となったことを示している。そのため、さらなる実験が必要となった。本実施例では、配列番号63のインスリンポリペプチドのC鎖組成を、より長くすることで、あるいは可動性を増加させることで、変異させた。天然インスリン(例えばヒトインスリン)は、インスリン受容体に結合する際に、B鎖およびA鎖両方の折り畳みの移動を含む、顕著な立体構造変化を起こすことが示されている(例えば、Mentingら、Nature、2013年;493巻(7431号):pp241~245によって説明されている)。本発明のインスリンポリペプチドと異なり、天然インスリンは、天然型では2鎖ポリペプチドであり、2本のジスルフィド結合だけで接続され、A鎖とB鎖の可動性を制限するC鎖は存在しないため、インスリン受容体においてこの立体構造変化を自由に起こすことができる。特定の理論に束縛されるものではないが、配列番号63のインスリンポリペプチド内に含まれるC鎖が、柔軟でなさ過ぎる(例えば、B鎖とA鎖の間での動きを容易なものにしないアミノ酸組成およびアミノ酸配列)、且つ/または、短過ぎる(例えば、B鎖のC末端とA鎖のN末端との間のアミノ酸が十分ではない)ために、インスリンポリペプチドが、インスリン受容体への強力な結合に必要な分子形状変化を起こすことが妨げられると仮定した。よって、以下に示すように、配列番号43のインスリン-Fc融合タンパク質をベースとして、インスリンポリペプチドC鎖を変化させて、いくつかのインスリン-Fc融合タンパク質を合成した。配列番号43に対して得られた配列アラインメントを図13に示す(クラスタルオメガ)。
FVNQHLCGSHLVQALYLVCGERGFFYTDPTQRGGGGGQRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号49)
FVNQHLCGSHLVEALALVCGERGFFYTDPTGGGGGGSGGGGGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号50)
FVNQHLCGSHLVEALALVCGERGFFYTDPGGGGGGGGGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号51)
FVNQHLCGSHLVEALALVCGERGFFYTPGGGGGGGGGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号52)
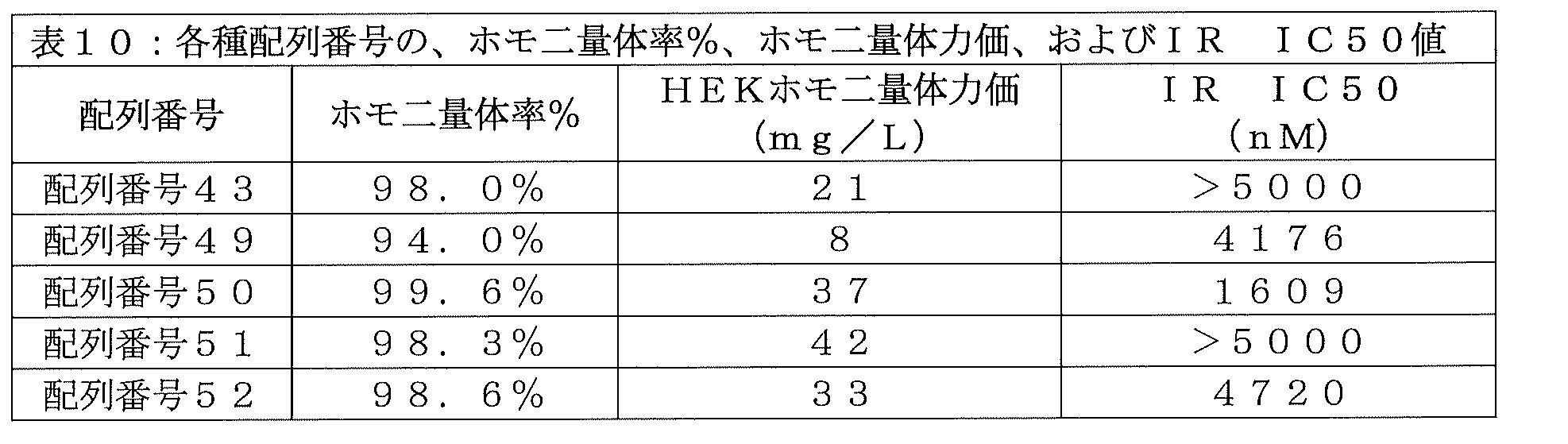
特定の理論に束縛されるものではないが、配列番号43のインスリン-Fc融合タンパク質のインスリン受容体結合が不十分であることの、別の考えられる理由として、はるかに大きいFcフラグメント分子がペプチドリンカーを介してインスリンポリペプチドに極めて近接して結合していることから生じる、インスリンポリペプチドとインスリン受容体との間の立体障害が関係していると考えられていた。ペプチドリンカーがより短かったり、ペプチドリンカーの折り畳みがより密であると、この問題が悪化する可能性があると考えられ、一方、ペプチドリンカーがより長かったり、ペプチドリンカーが自ら折り返しを起こしにくい(例えば、リンカーの分子剛性がより高い)場合、インスリンポリペプチドとFcフラグメントとの間により多くの空間がつくられることで、この問題が緩和されることがある。インスリンポリペプチドとFcフラグメントとの間の空間の増加は、インスリン受容体とFcフラグメントとの間の距離も増加させ、インスリン受容体結合中の干渉が少なくなる。配列番号43のインスリン-Fc融合タンパク質の構築に用いられた配列番号11(すなわち、GGGGAGGGG)のペプチドリンカーは、当該リンカーを構成するアミノ酸が側鎖を含まないものである(すなわち、グリシンとアラニンというアミノ酸しか含んでいない)ため、短過ぎ、且つ/または可動性があり過ぎる可能性がある、という仮説が立てられた。よって、この仮説を検証するため、配列番号43のインスリン-Fc融合タンパク質とは別の2つのインスリン-Fc融合タンパク質バリアントを合成した。配列番号48のインスリン-Fc融合タンパク質は、配列番号43のインスリン-Fc融合タンパク質の構築に用いられたものと同じペプチドリンカーを含むが、A鎖のN末端から21番目の位置(すなわち、A21)のアスパラギンが存在しない(すなわち、des-A21)インスリンポリペプチドを含む。この特定の変異を組み込むことにより、A鎖とペプチドリンカーとの間の接合部が、タンパク質収量および/または上記分子の生物活性に影響しているかどうかを確かめた。もう一方の配列番号53のインスリン-Fc融合タンパク質は、このdes-A21N A鎖変異と、配列番号43のインスリン-Fc融合タンパク質の構築に用いられたものの長さの2倍より長いペプチドリンカーと、を含む。このより長いペプチドリンカーにおいては、アラニンは好ましくなく、代わりに、極性アミド側鎖を含むグルタミンと置き換わっている。このグルタミン置換は、このペプチドリンカーの親水性を増強し、場合によってはリンカーが折れ返ることを妨げることが期待された。これらの配列を以下に示し、配列番号43に対する配列アラインメントを図14に示す(クラスタルオメガ):
FVNQHLCGSHLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号53)
FVNQHLCGSHLVEALALVCGERGFFYTDPTGGGPRRGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号48)

実施例41の結果は、ペプチドリンカーを改変することで、天然のB10アミノ酸とA8アミノ酸を含む配列番号43のインスリン-Fc融合タンパク質のインスリン受容体に対する結合親和性を増加させることができることを示している。しかし、このペプチドリンカーの変異では、ホモ二量体力価を、製造設計目標を達成するのに十分なほどに増加させることはできなかった。ホモ二量体力価は、細胞内合成および細胞内プロセシングを含むいくつかの特性の関数であるため、インスリン-Fc分子は、合成中および合成後、2つのホモ二量体モノマー間で分子内で、または、2以上の別々のホモ二量体間で分子間で、自己会合(すなわち、凝集)していたかもしれないという仮説を立てた。この凝集によって、実施例1、実施例4、および実施例10に記載された製造工程中に細胞培養上清から得られたホモ二量体力価は許容できないほどに低いものであった。このインスリン-Fc融合タンパク質分子間の相互作用の可能性は、部分的には、自己会合し凝集体を形成するインスリンの周知の傾向によるものであり得る。インスリンの自己会合する傾向を低減するための当該技術分野において公知の1つの方法は、B鎖のC末端付近のアミノ酸を変異させることを含む。例えば、インスリンリスプロ(B28K変異;B29P変異)およびインスリンアスパルト(B28D変異)は、会合と凝集を防ぐことで、主に単量体型のインスリンを溶液中に生じさせる非天然型のB鎖変異を含む、周知の市販2鎖インスリンである。凝集を防ぐための別のアプローチは、アミノ酸の構造的な欠失を含む。例えば、デスペンタペプチドインスリンとして知られている2鎖インスリン(despentapeptide insulin)(DPPI;Brange J.、Dodson G.G.、Edwards J.、Holden P.H.、Whittingham J.L.、1997年b.、“A model of insulin fibrils derived from the x-ray crystal structure of a monomeric insulin (despentapeptide insulin)”、Proteins、27巻、pp507~516を参照)は、B鎖の5個のC末端アミノ酸(YTPKT)が除去されている以外は、天然型の2鎖ヒトインスリンと同一である。DPPIは、天然型2鎖ヒトインスリンと比べて、インスリン受容体に対する結合親和性が低いが、溶液中で完全に単量体の状態であり、これは、DPPI分子間では会合も凝集もほとんど起こらないことを意味している。よって、分子内および分子間の自己会合の可能性を低減し、インスリン-Fc融合タンパク質のホモ二量体力価を向上させる試みでは、DPPI、インスリンリスプロ、およびインスリンアスパルトについて上記したような、部分的なB鎖アミノ酸切断およびB鎖アミノ酸変異を用いて、配列番号43のインスリン-Fc融合タンパク質のいくつかのバリアントを構築した。これらの配列を以下に示し、配列番号43に対する配列アラインメントを図15に示す(クラスタルオメガ):
FVNQHLCGSHLVEALALVCGERGFFYTDPGGGGGGGGGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号51)
FVNQHLCGSHLVEALALVCGERGFFYTPGGGGGGGGGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号52)
FVNQHLCGSHLVEALALVCGERGFFYTQGGGGGGGGGIVEQCCTSICSLYQLENYCGGGGAGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号54)
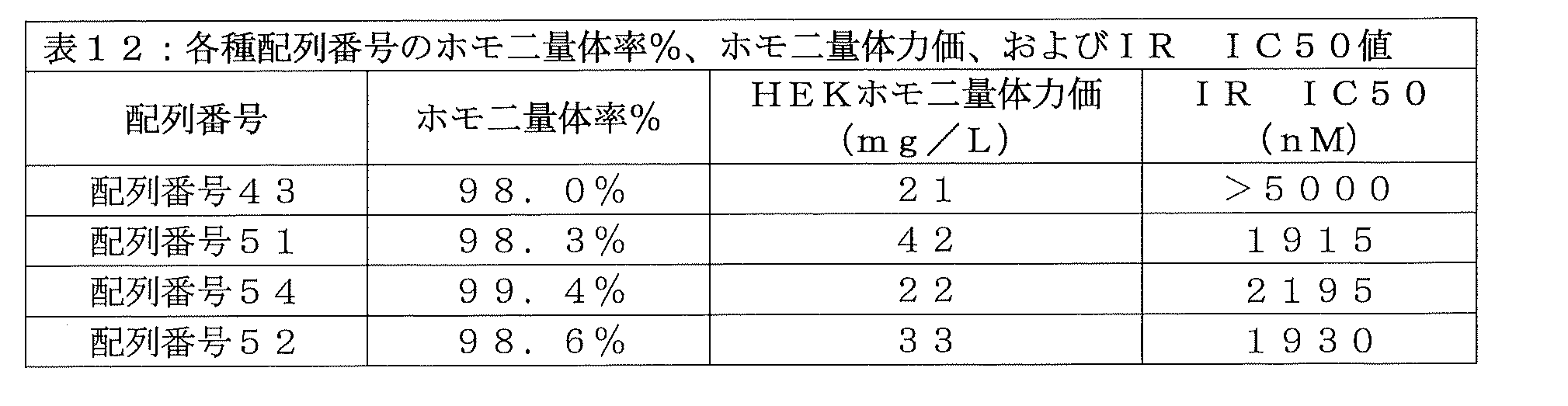
実施例39、実施例40、実施例41、および実施例42で示されたように、単一の戦略で、非免疫原性の天然型のB10アミノ酸およびA8アミノ酸を含むインスリンポリペプチドと、イヌIgGB Fcフラグメントを組み込んで、許容できるインスリン受容体活性およびホモ二量体力価を有するインスリン-Fc融合タンパク質を形成することに成功したものはない。そこで、C鎖をより長くし、ペプチドリンカーをより長くし、B鎖のC末端アミノ酸を切断するというコンセプトを組み合わせた。さらに、自己会合や凝集の傾向をさらに低減する可能性があるため、生理的pHで負または正に帯電する側基を有するアミノ酸といった、疎水性の低いアミノ酸を用いて、天然型インスリンの疎水性アミノ酸残基部位にさらなる点変異を導入した。変異の例としては、チロシンからアラニン、チロシンからグルタミン酸、イソロイシンからスレオニン、およびフェニルアラニンからヒスチジンの変異が挙げられる。さらに、解析を単純にするため、全ての場合で、イヌIgGB FcフラグメントのcNg部位を天然型であるアスパラギンに戻した。これらのインスリン-Fc融合タンパク質バリアントの配列を以下に示し、配列番号43に対して得られた配列アラインメントを図16に示す(クラスタルオメガ):
FVNQHLCGSHLVEALELVCGERGFFYTPKTGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号55)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCNHGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号56)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCNGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号28)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号26)
FVNQHLCGSHLVEALELVCGERGFFYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号57)
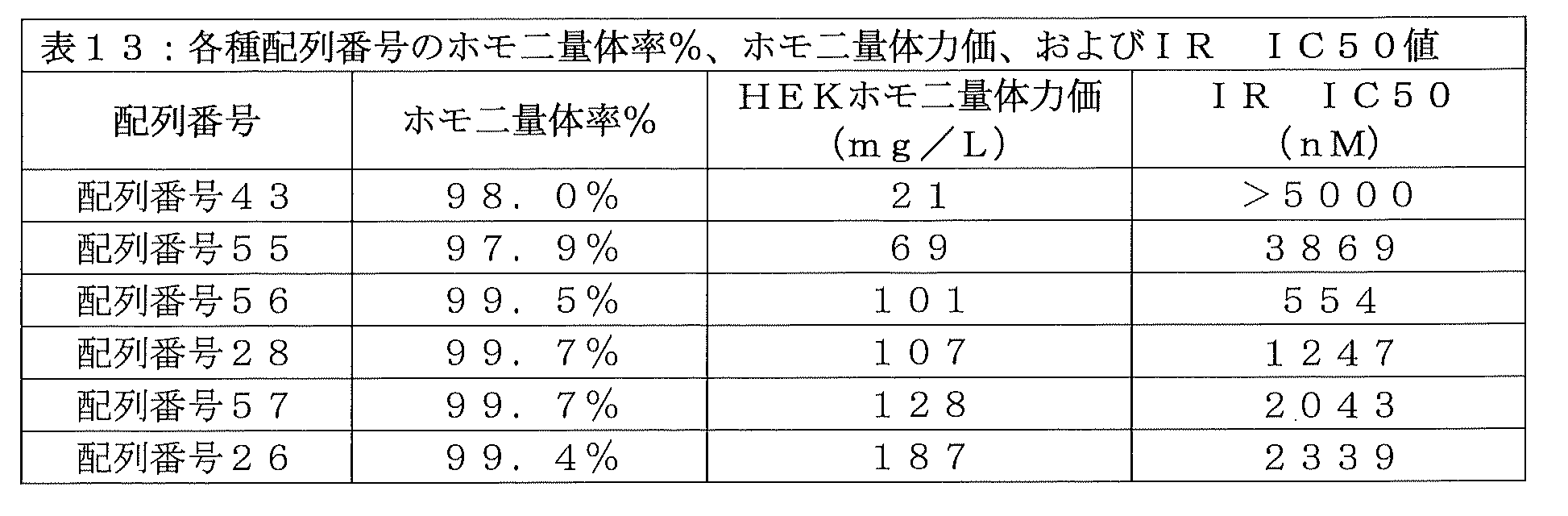
実施例43より得られた肯定的なホモ二量体力価およびインスリン受容体結合活性の結果から、2種の最も有望なインスリン-Fc融合タンパク質(配列番号26および配列番号28)を、イヌにおいて、反復投与生物活性および免疫原性を評価する試験にかけた。それぞれの化合物は、より長く、より親水性が高い配列番号13のペプチドリンカーと、より製造性が高く、より凝集性が低い配列番号15のイヌIgGB Fcフラグメントと、を含む。最も重要なこととして、どちらのインスリン-Fc融合タンパク質も、免疫原性が低いと推定される天然型のB10アミノ酸およびA8アミノ酸(すなわち、一般配列番号6)を有するインスリンポリペプチドを含んでいる。配列番号28のインスリン-Fc融合タンパク質の場合、A21位にアスパラギンが存在する(すなわちインスリンポリペプチドは配列番号8を含む)。配列番号26のインスリン-Fc融合タンパク質の場合、A21位にアスパラギンが存在しない(すなわちインスリンポリペプチドは配列番号7を含む)。


実施例43および実施例44に記載されたように、免疫原性がなく、収量が多く、純度が高く、生物活性が高いインスリン-Fc融合タンパク質が得られる、インスリンポリペプチドとペプチドリンカーの新規組み合わせが発見されたことから、イヌIgGB Fcフラグメントが、実施例32および実施例33でのインスリン-Fc融合タンパク質の場合では事実であったように、ホモ二量体力価および生物活性の観点で好ましいアイソタイプであるどうかに関する疑問が、残った。そこで、配列番号26のインスリン-Fc融合タンパク質のインスリンポリペプチド(配列番号7)とペプチドリンカー(配列番号13)は維持し、配列番号15のイヌIgGB Fcフラグメントを配列番号14のイヌIgGA Fcフラグメント、配列番号16のイヌIgGC Fcフラグメント、または配列番号17のイヌIgGD Fcフラグメントに置き換えた、さらなるインスリン-Fc融合タンパク質を設計した。これらの得られたインスリン-Fc融合タンパク質バリアントの配列を以下に示す:
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFNGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号26)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGRCTDTPPCPVPEPLGGPSVLIFPPKPKDILRITRTPEVTCVVLDLGREDPEVQISWFVDGKEVHTAKTQSREQQFNGTYRVVSVLPIEHQDWLTGKEFKCRVNHIDLPSPIERTISKARGRAHKPSVYVLPPSPKELSSSDTVSITCLIKDFYPPDIDVEWQSNGQQEPERKHRMTPPQLDEDGSYFLYSKLSVDKSRWQQGDPFTCAVMHETLQNHYTDLSLSHSPG(配列番号58)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGCNNCPCPGCGLLGGPSVFIFPPKPKDILVTARTPTVTCVVVDLDPENPEVQISWFVDSKQVQTANTQPREEQSNGTYRVVSVLPIGHQDWLSGKQFKCKVNNKALPSPIEEIISKTPGQAHQPNVYVLPPSRDEMSKNTVTLTCLVKDFFPPEIDVEWQSNGQQEPESKYRMTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQISLSHSPG(配列番号59)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGCISPCPVPESLGGPSVFIFPPKPKDILRITRTPEITCVVLDLGREDPEVQISWFVDGKEVHTAKTQPREQQFNSTYRVVSVLPIEHQDWLTGKEFKCRVNHIGLPSPIERTISKARGQAHQPSVYVLPPSPKELSSSDTVTLTCLIKDFFPPEIDVEWQSNGQPEPESKYHTTAPQLDEDGSYFLYSKLSVDKSRWQQGDTFTCAVMHEALQNHYTDLSLSHSPG(配列番号60)。

配列番号26のインスリン-Fc融合タンパク質は設計目標の全てを達成しているが(実施例28)、治療が長期に亘った場合(例えば、6か月、1年、2年、またはそれ以上)に免疫原性リスクが生じる恐れがあり、これが起こった場合、糖尿病治療における本インスリン-Fc融合タンパク質の使用が損なわれる可能性がある。発明を実施するための形態、実施例34および実施例35に記載したように、反復投与後の生物活性を低減させる、考えられる原因の1つは、イヌIgGB Fcフラグメントがイヌの免疫系と望ましくない相互作用を起こすことによる、中和抗薬物抗体の産生である。しかし、実施例45で示された結果は、予想外にも、イヌIgGBアイソタイプが、4種のイヌIgGアイソタイプの中で、所望の製造性および生物活性をもたらす唯一の選択肢であったことを示している。そこで、FcγRI受容体結合性が低く、長期の慢性的な免疫原性リスクが低減されるはずの、非グリコシル化インスリン-Fc融合タンパク質を得るための、さらなるFc変異を探索した。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVALDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号61)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号62)。
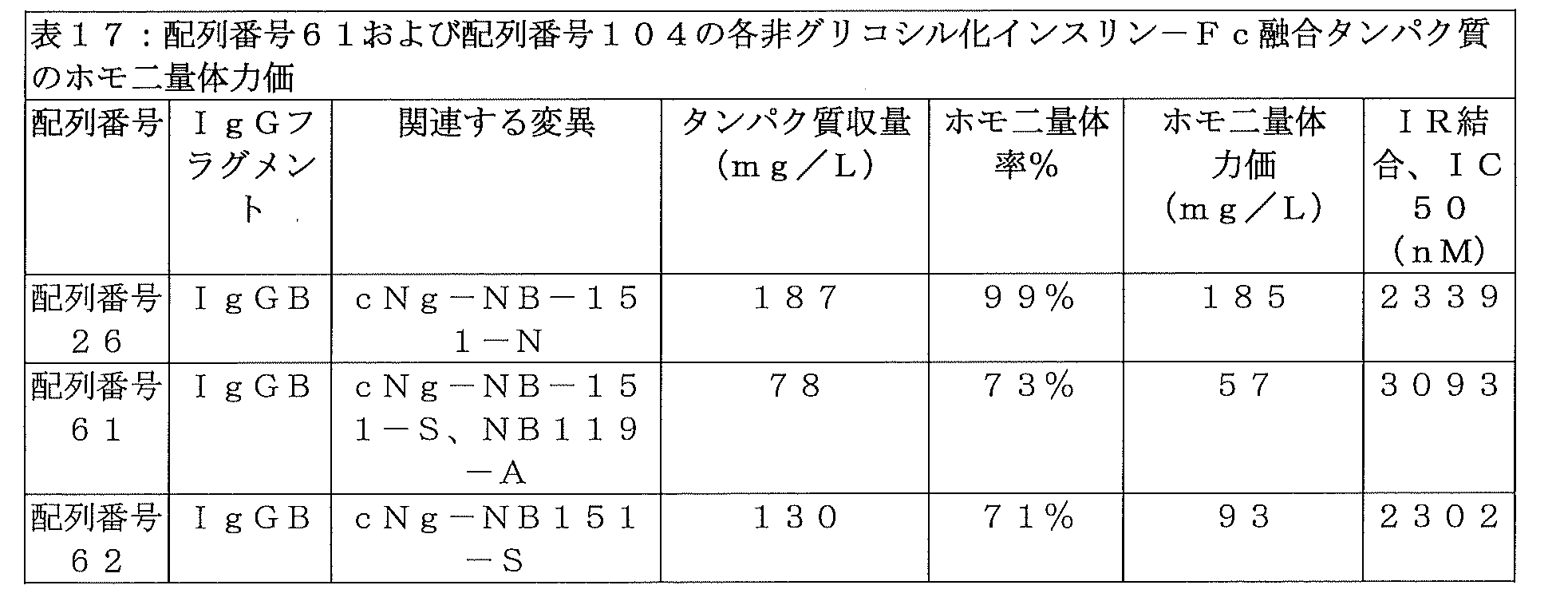
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDCPKCPAPEMLGGPSVFIFPPKPKDTLLIARTPEVTCVVVDLDPEDPEVQISWFVDGKQMQTAKTQPREEQFSGTYRVVSVLPIGHQDWLKGKQFTCKVNNKALPSPIERTISKARGQAHQPSVYVLPPSREELSKNTVSLTCLIKDFFPPDIDVEWQSNGQQEPESKYRTTPPQLDEDGSYFLYSKLSVDKSRWQRGDTFICAVMHEALHNHYTQESLSHSPG(配列番号30)。
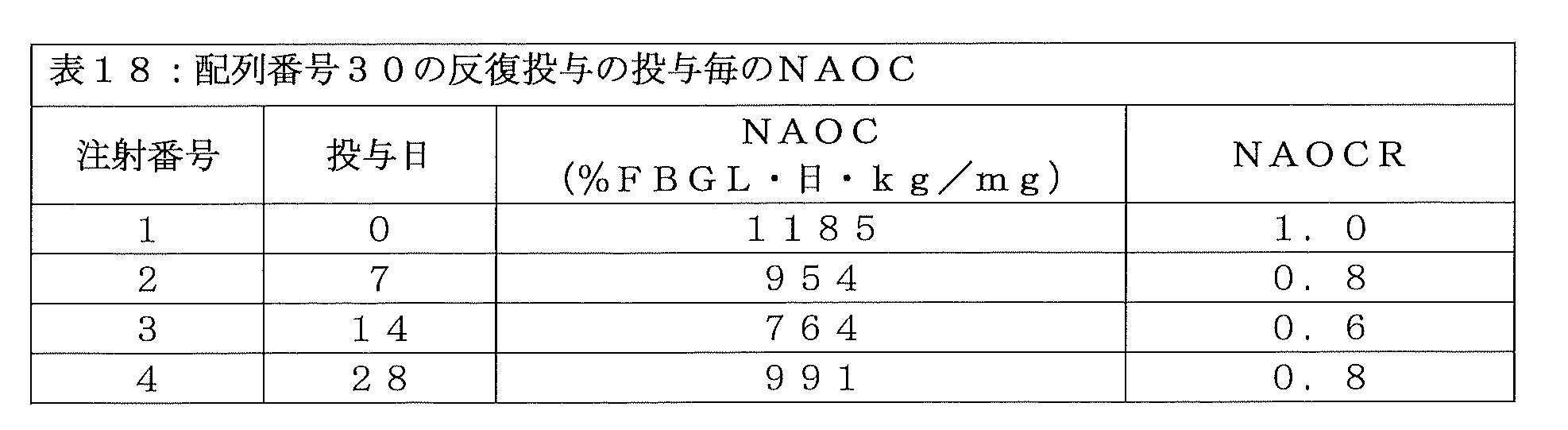

配列番号26または配列番号30をコードするベクターで安定にトランスフェクトされた別々のCHO細胞株を、実施例2に記載されたように構築した。フェッドバッチ式振盪フラスコ14日間プロダクションラン(0.5~2.0Lの培地規模)の播種を、37℃、5%二酸化炭素に設定された振盪恒温器内で、0.5×106細胞/mLとなるように行った。増殖培地としてCD OptiCHOをDynamis(サーモフィッシャー社)に置き換え、フィードとしてEfficient Feed C(サーモフィッシャー社)を用いた以外は、上記実施例2に記載したように、ランを実行した。3%v/vのフィードの添加をプロダクションラン3日目から開始して、さらに4日目にも添加を行い、振盪フラスコ温度を32℃に調整し、振盪恒温器内の二酸化炭素濃度を5%から2%に下げた。このランの間に、細胞は8~14×106細胞/mLまで増加し、14日目に、プロダクションランを回収して細胞を取り除き、実施例4、実施例6、実施例8、および実施例10に記載されたように培養上清の精製と試験を行って、インスリン-Fc融合タンパク質を得た。表20には、安定にトランスフェクトされたCHO細胞株を含むプロダクションランから得られた製造データが記載されている。

配列番号28をコードするベクターで安定にトランスフェクトされたCHO細胞株を、実施例2に記載されたように構築する。フェッドバッチ式振盪フラスコ14日間プロダクションラン(0.5~2.0Lの培地規模)の播種を、37℃、5%二酸化炭素に設定された振盪恒温器内で、0.5×106細胞/mLとなるように行う。増殖培地としてCD OptiCHOをDynamis(サーモフィッシャー社)に置き換え、フィードとしてEfficient Feed C(サーモフィッシャー社)を用いる以外は、実施例2に記載したように、ランを実行する。3%v/vのフィードの添加をプロダクションラン3日目から開始して、さらに4日目にも添加を行い、振盪フラスコ温度を32℃に調整し、振盪恒温器内の二酸化炭素濃度を5%から2%に下げる。14日目に、プロダクションランを回収して細胞を取り除き、実施例4、実施例6、実施例8、および実施例10に記載されたように培養上清の精製と試験を行って、インスリン-Fc融合タンパク質を得る。得られるプロダクションランからは、配列番号28の、200mg/Lを超えるタンパク質収量、95%を超えるホモ二量体、および190mg/Lを超えるホモ二量体力価が得られると期待される。
結果:ヒトFcフラグメントを含むインスリン-FC融合タンパク質
配列番号7のインスリンポリペプチド配列とヒトIgG2アイソタイプのFcフラグメント(配列番号74)とを含み、配列番号13のペプチドリンカーを用いる、インスリン-Fc融合タンパク質の作製を試みた。得られたインスリン-Fc融合タンパク質の完全アミノ酸配列は以下の通りである:
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGECPPCPAPPVAGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTFRVVSVLTVVHQDWLNGKEYKCKVSNKGLPAPIEKTISKTKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPMLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号75)。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号76)。
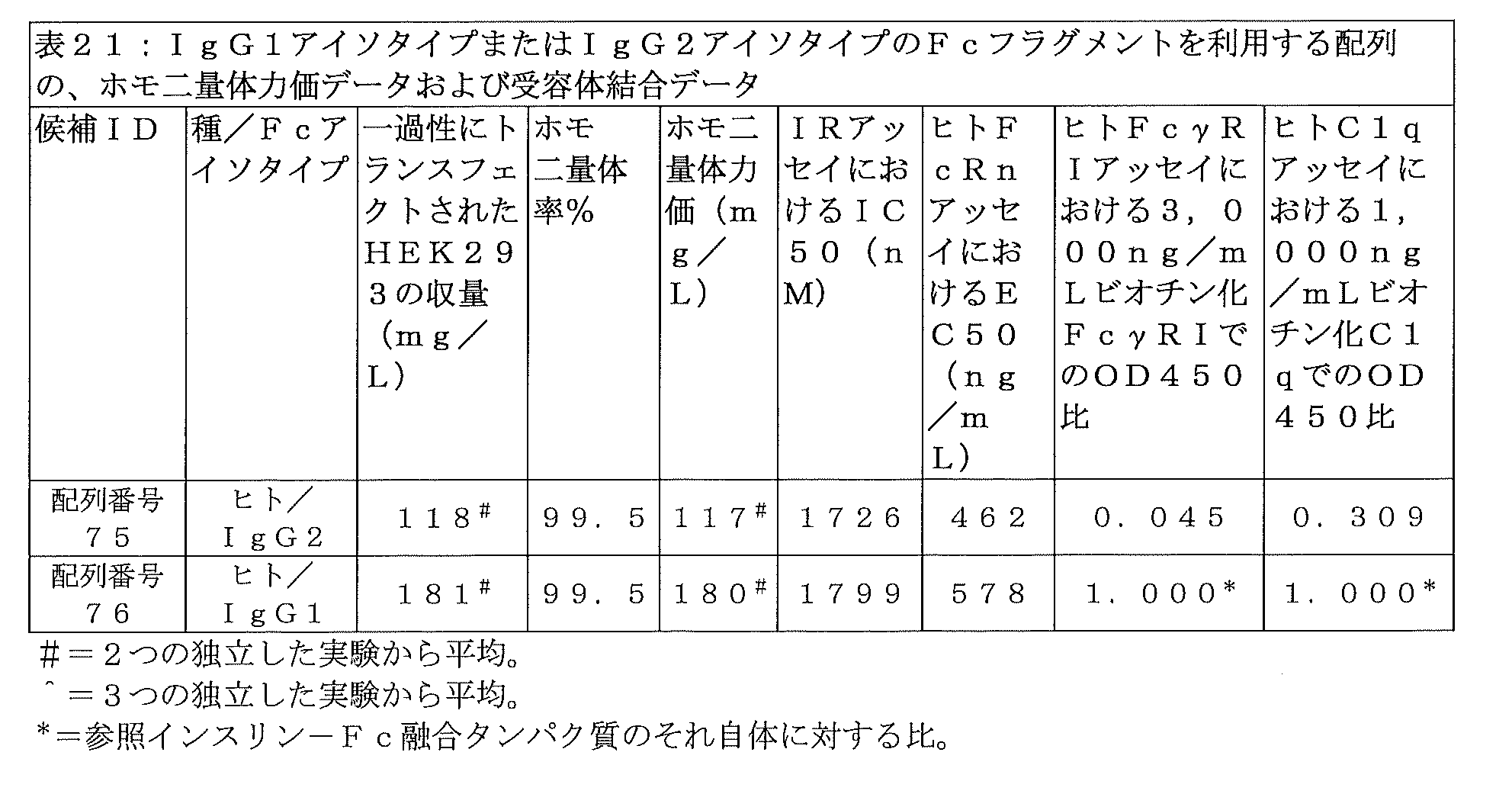
配列番号76のインスリン-Fc融合タンパク質の、ホモ二量体含有率、IR結合親和性、および許容できるFcRn受容体に対する結合親和性を維持する試みの中で、FcγRIに対する結合およびC1qに対する結合を低減しようと、cNg-S変異をFcフラグメントのCH3領域に挿入したところ、以下のような配列番号91のインスリン-Fc融合タンパク質の構成が得られた:
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号91)。
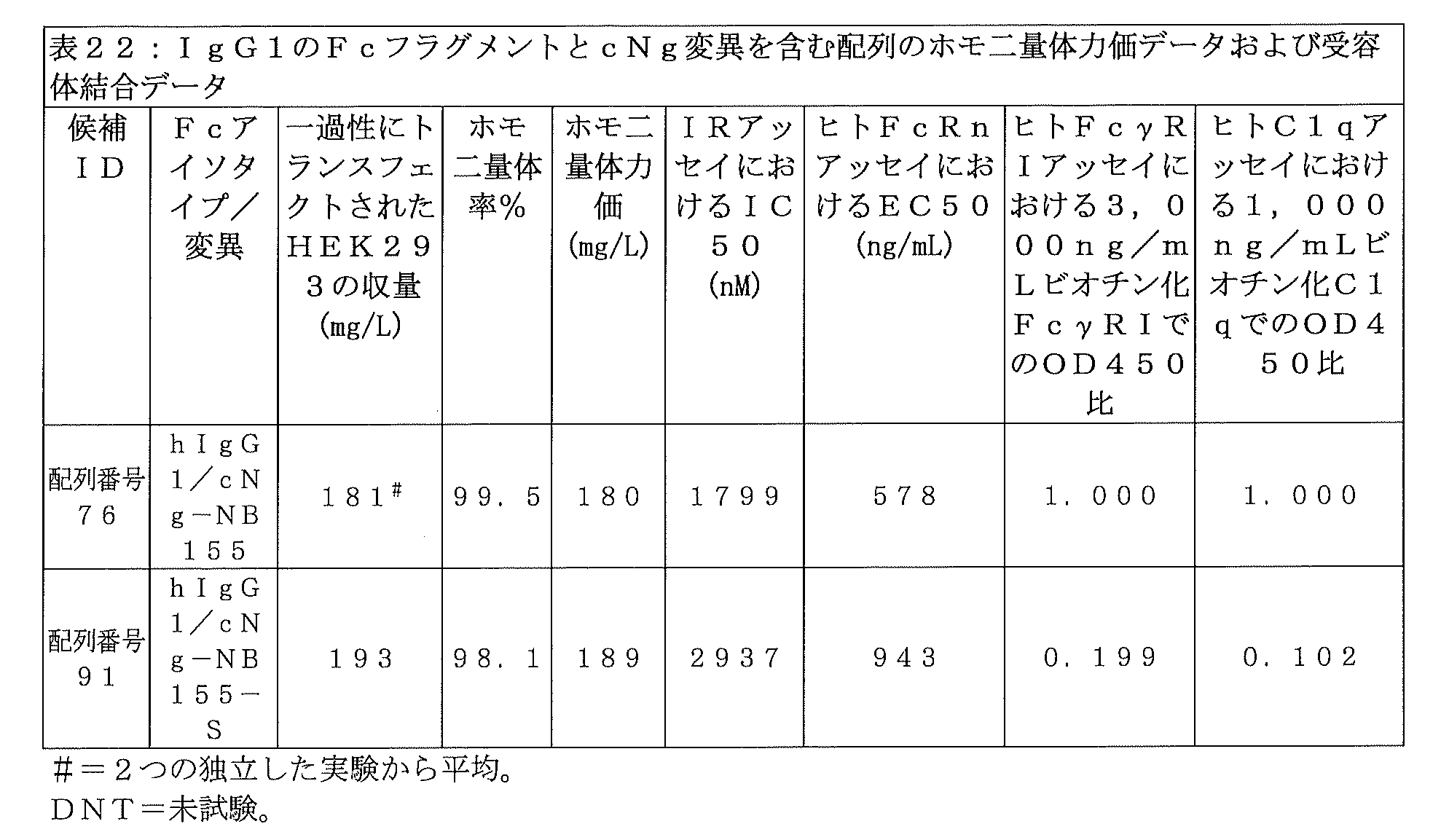
上記のように、IgG1アイソタイプFcフラグメントにおけるcNg-S変異では、FcγRIおよびC1qに対する親和性が顕著に低減した、インスリン-Fc融合タンパク質の構成が得られたが、このインスリン-Fc融合タンパク質の構成は、許容できないほどに低いIR受容体親和性を有している(すなわち、IC50値が2400nMより大きい)。そこで、インスリンポリペプチドに変異を加え、その変異がIR親和性を改善させるかどうかを確かめる目的で、得られた物質をIRアッセイにおけるIC50に対するスクリーニングにかけた。B鎖のN末端から16番目のアミノ酸をチロシンからアラニンにかえた(すなわち、B16A)ところ、配列番号10のインスリンポリペプチドが得られた。配列番号10の変異型インスリンポリペプチドおよび配列番号13のペプチドリンカーを、X1がSである配列番号77のcNg変異型Fcフラグメントと共に用いたところ、配列番号78のインスリン-Fc融合タンパク質の構成が得られた。インスリン-Fc融合タンパク質の構成におけるcNg-S変異を、Fcフラグメント領域に対して行うことで、実施例15に記載のインビトロヒトFcγRIアッセイにおける結合性によって評価される、インビボにおける当該FcフラグメントのFcγ受容体に対する結合親和性が低減された。配列番号78のインスリン-Fc融合タンパク質におけるcNg-S部位の位置は、cNg部位における「N」から「S」への変異を含むcNg-NB155である。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号78)。

インビボ生物活性が延長され、免疫原性を示す可能性が低く、配列番号76のインスリン-Fc融合タンパク質と同様のホモ二量体含有率とIR結合親和性を維持し、FcRn受容体に対する結合親和性が許容できるものである、インスリン-Fc融合タンパク質の構成を作製するさらなる試みにおいて、FcγRI結合およびC1q結合を低減しようと、他のcNg変異をFcフラグメントのCH3領域に挿入し、配列番号92、配列番号93、配列番号94、および配列番号95を得た。インスリン-Fc融合タンパク質の実施形態を、実施例1に従ってHEK細胞で合成し、実施例4に従って精製し、実施例6、実施例8、実施例10、実施例12、実施例14、および実施例16に従って試験した。結果は表24に示す。配列番号75、配列番号76、および配列番号91に対しての、配列番号92、配列番号93、配列番号94、および配列番号95の配列アラインメントを、アミノ酸配列の相違を強調表示して、図28に示す(クラスタルオメガ)。「*」は、所与の配列位置において全ての配列間で完全に相同であることを示しており、一方、「:」、「.」、空白は、それぞれ、所与の配列位置における配列間のアミノ酸変異が保存的であること、中程度であること、または全く異なるものであること、を示している。
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYDSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号92)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号93)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYRSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号94)
FVNQHLCGSHLVEALELVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号95)。

上記のように、IgG1アイソタイプFcフラグメントのcNg部位における変異では、FcγRIおよびC1qに対する親和性が顕著に低減した、インスリン-Fc融合タンパク質が得られたが、これらの化合物は、許容できないほどに低いIR受容体親和性を有している(すなわち、IC50値が2400nMより大きい)。そこで、配列番号78中のインスリンポリペプチドに同じ変異をなして(B鎖のN末端から16番目のアミノ酸をチロシンからアラニンにかえ(すなわち、B16A)ところ、配列番号10のインスリンポリペプチドが得られた)、IR親和性を向上させた変異型インスリンポリペプチドがあるかどうかを確かめるために、得られたインスリン-Fc融合タンパク質の構成を、IRアッセイにおけるIC50に対するスクリーニングにかけた。配列番号10の変異型インスリンポリペプチドおよび配列番号13のペプチドリンカーを用いて、以下に示すような、配列番号80、配列番号82、配列番号84、および配列番号86のインスリン-Fc融合タンパク質の構成を作製した。これらのインスリン-Fc融合タンパク質の構成はそれぞれ、実施例15に記載のインビトロヒトFcγRIアッセイにおける結合性によって評価される、インビボにおけるFcフラグメントのFcγ受容体に対する結合親和性を低減されせるためにFcフラグメント領域に対して行われた、cNg部位変異を含む。配列番号80、配列番号82、配列番号84、および配列番号86のインスリン-Fc融合タンパク質の構成におけるcNg部位の位置はcNg-NB155である。配列番号80のインスリン-Fc融合タンパク質は、cNg部位に「N」から「D」への変異を含む。配列番号82のインスリン-Fc融合タンパク質は、cNg部位に「N」から「A」への変異を含む。配列番号84のインスリン-Fc融合タンパク質は、cNg部位に「N」から「R」への変異を含む。配列番号86のインスリン-Fc融合タンパク質は、cNg部位に「N」から「Q」への変異を含む。
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYDSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号80)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYASTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号82)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYRSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号84)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号86)。
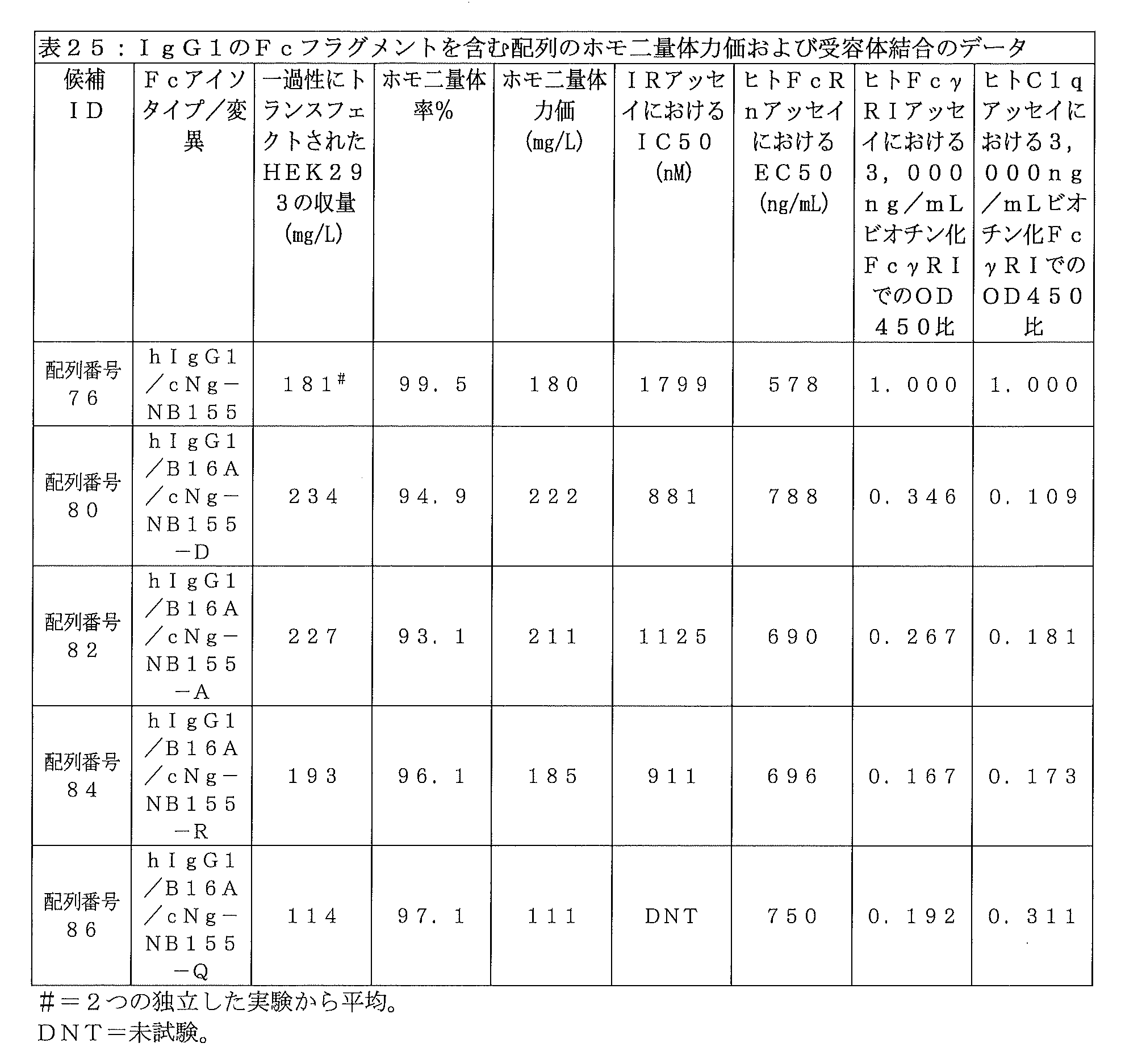
上記のように、IgG1アイソタイプFcフラグメントのcNg部位における変異と、インスリンポリペプチド上の変異は、IR、FcRn、FcγRI(受容体)結合、およびC1q結合といった物性に予想外の変化をもたらした。リンカー組成物がこれらの特性にどのような影響を与えたかをさらに深く理解するため、配列番号10のB16A変異型インスリンポリペプチドと、cNg-S変異を有する非グリコシル化hIgG1 Fcフラグメント(配列番号77;X1はS)と、配列番号13のリンカー配列と、を含む特定のインスリン-Fc融合タンパク質の構成(配列番号78)を出発点として選び、そこから、リンカーの長さと組成を以下の表26に示すように変更した。

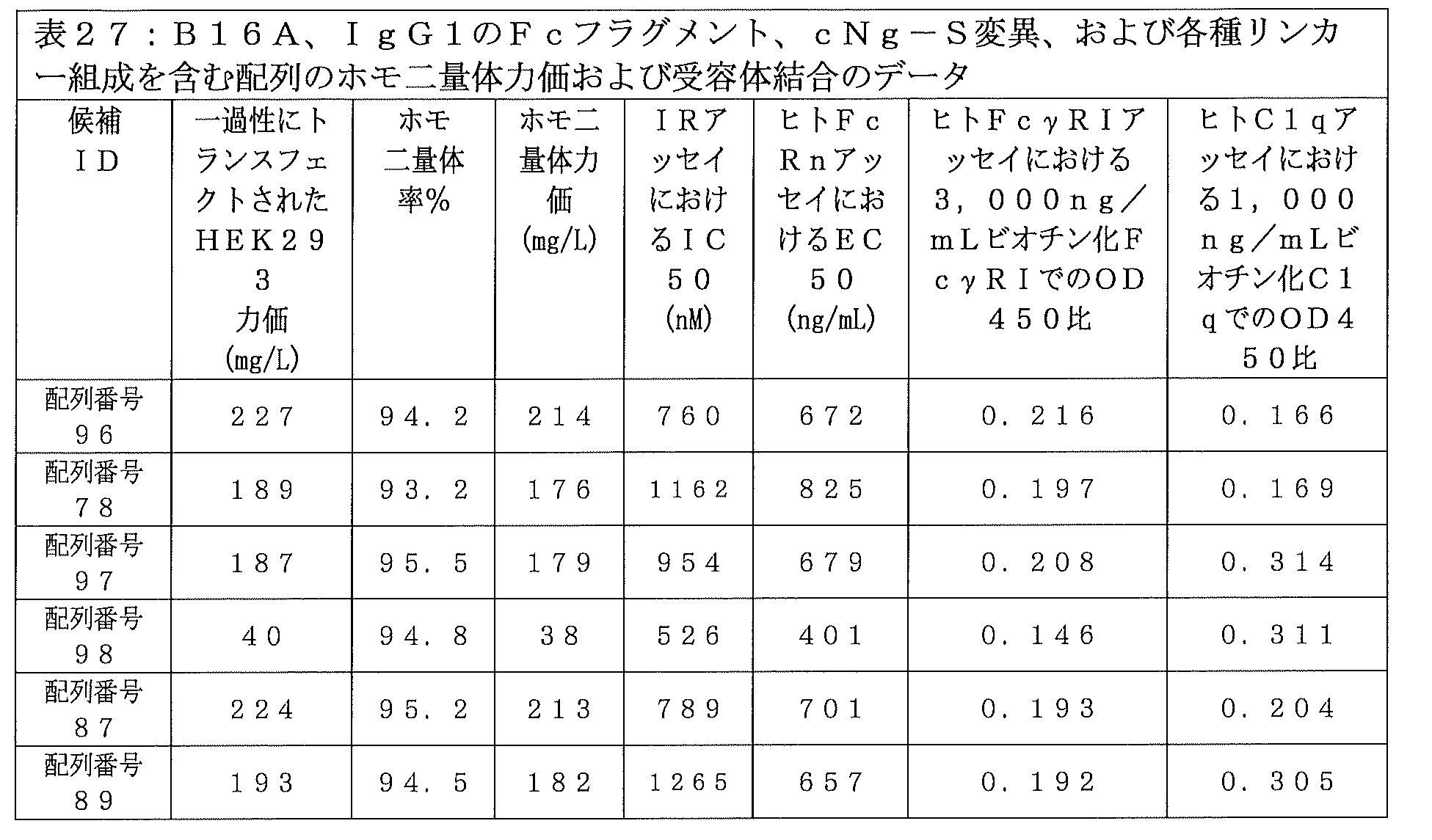
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGAGGGGAGGGGAGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号87)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGGQGGGGQGGGGQGGGGGQGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号96)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGQGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号97)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCGGGGAGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号89)
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYSSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG(配列番号98)。
実施例53の有望なホモ二量体力価、IR活性、およびFcRn活性の結果を考慮して、配列番号78、配列番号80、配列番号82、および配列番号84のインスリン-Fc融合タンパク質を、およそ10kgの重さのN=3の健常な抗体未処置ビーグル犬のそれぞれに皮下注射後、実施例22に従ってインビボ生物活性について試験する。配列番号78、配列番号80、配列番号82、および配列番号84の各インスリン-Fc融合タンパク質を単回皮下投与した場合の、時間に対する%FBGLのプロットを作成する。この時間に対する%FBGLのデータは、配列番号78、配列番号80、配列番号82、および配列番号84のインスリン-Fc融合タンパク質が、イヌにおいて顕著な生物活性を有することを示すと期待される。
実施例54の有望なホモ二量体力価、IR活性、およびFcRn活性の結果を考慮して、配列番号89のインスリン-Fc融合タンパク質を、およそ10kgの重さのN=3の健常な抗体未処置ビーグル犬のそれぞれに皮下注射後、実施例22に従ってインビボ生物活性について試験する。配列番号89のインスリン-Fc融合タンパク質を単回皮下投与した場合の、時間に対する%FBGLのプロットを作成する。この時間に対する%FBGLのデータは、配列番号89のインスリン-Fc融合タンパク質が、イヌにおいて顕著な生物活性を有することを示すと期待される。
実施例54の有望なホモ二量体力価、IR活性、およびFcRn活性の結果を考慮して、配列番号87のインスリン-Fc融合タンパク質を、およそ10kgの重さのN=3の健常な抗体未処置ビーグル犬のそれぞれに皮下注射後、実施例22に従ってインビボ生物活性について試験する。配列番号87のインスリン-Fc融合タンパク質を単回皮下投与した場合の、時間に対する%FBGLのプロットを作成する。この時間に対する%FBGLのデータは、配列番号87のインスリン-Fc融合タンパク質が、イヌにおいて顕著な生物活性を有することを示すと期待される。
配列番号78、配列番号80、配列番号82、配列番号84、配列番号87、および配列番号89のインスリン-Fc融合タンパク質の構成をコードするベクターで安定にトランスフェクトされた別々のCHO細胞株を、実施例2に記載されたように作製する。フェッドバッチ式振盪フラスコ14日間プロダクションラン(0.5~2.0Lの培地規模)の播種を、37℃、5%二酸化炭素に設定された振盪恒温器内で、0.5×106細胞/mLとなるように行う。増殖培地としてCD OptiCHOをDynamis(サーモフィッシャー社)に置き換え、フィードとしてEfficient Feed C(サーモフィッシャー社)を用いる以外は、実施例2に記載したように、ランを実行する。3%v/vのフィードの添加をプロダクションラン3日目から開始して、さらに4日目にも添加を行い、振盪フラスコ温度を32℃に調整し、振盪恒温器内の二酸化炭素濃度を5%から2%に下げる。このランの間に、細胞密度は8~14×106細胞/mLまで増加し、14日目に、プロダクションランを回収して細胞を取り除き、実施例4、実施例6、実施例8、および実施例10に記載されたように培養上清の精製と試験を行って、インスリン-Fc融合タンパク質を得る。安定にトランスフェクトされたCHO細胞株を用いた配列番号78、配列番号80、配列番号82、配列番号84、配列番号87、および配列番号89のインスリン-Fc融合タンパク質の構成の別々のプロダクションランからの、製造およびインビトロ試験データは、ホモ二量体力価が一過性にトランスフェクトされたHEK293細胞で得られたものよりも大きく、IR、FcRn受容体、FcγRI受容体結合特性、およびC1q結合特性が設計目標(実施例29)を達成することを示すと期待される。
空腹時血糖値に対する作用について、以下のように、インスリン-Fc融合タンパク質を評価した。1群当たりN=3のbalb/cマウスまたは糖尿病のwt NODマウス(ジャクソン・ラボラトリーズ社)からデータを収集した。実験の1時間前に動物を絶食させ、その後、0時間の時点で、マウスに、インスリンFc融合タンパク質ホモ二量体を含有する医薬組成物の単回皮下投与を、10~50mMのリン酸水素ナトリウム、50~150mMの塩化ナトリウム、0.005~0.05%v/vのTween-80、および所望により濃度0.02~1.00mg/mLの静菌剤(例えばフェノール、m‐クレゾール、またはメチルパラベン)の溶液中、300μg/kgのインスリン-Fc融合タンパク質濃度で、最終的な溶液pHは水酸化ナトリウムおよび/または塩酸を用いて7.0~8.0に調整して、実施した。
空腹時血糖値に対する作用について、以下のように、インスリン-Fc融合タンパク質を評価する。1群当たりN=3のbalb/cマウスまたは糖尿病wt NODマウス(ジャクソン・ラボラトリーズ社)からデータを収集する。実験の1時間前に動物を絶食させ、その後、0時間の時点で、マウスに、インスリンFc融合タンパク質ホモ二量体を含有する医薬組成物の単回皮下投与を、10~50mMのリン酸水素ナトリウム、50~150mMの塩化ナトリウム、0.005~0.05%v/vのTween-80、および所望により濃度0.02~1.00mg/mLの静菌剤(例えばフェノール、m‐クレゾール、またはメチルパラベン)の溶液中、300μg/kgのインスリン-Fc融合タンパク質濃度で、最終的な溶液pHは水酸化ナトリウムおよび/または塩酸を用いて7.0~8.0に調整して、実施する。
上記の実施例で使用された例示的なインスリン-Fc融合タンパク質のアミノ酸配列および対応するDNA配列を、図31、図32、図33、図34、図35、図36、および図37に示す。
均等論
Claims (29)
- インスリンポリペプチドと、Fcフラグメントと、を含む融合タンパク質であって、
前記インスリンポリペプチドおよび前記Fcフラグメントはリンカーによって接続されており、N末端からC末端へ以下の配向:
(N末端)-インスリンポリペプチド-リンカー-Fcフラグメント-(C末端)
で各ドメインを含み、
前記Fcフラグメントはヒト由来であり、且つ以下の配列(配列番号77):

前記インスリンポリペプチドは
以下の配列:
FVNQHLCGSHLVEALALVCGERGFHYGGGGGGSGGGGGIVEQCCTSTCSLDQLENYC(配列番号10)、
を含み、かつ
前記リンカーが以下の配列:
GGGGGAGGGGAGGGGAGGGGG(配列番号67);
GGGGGQGGGGQGGGGQGGGGGQGGGG(配列番号99);または
GGGGGQGGGGQGGGGQGGGGG(配列番号13)
を含む、
融合タンパク質。 - インスリンポリペプチドと、Fcフラグメントと、を含む融合タンパク質であって、
前記インスリンポリペプチドおよび前記Fcフラグメントはリンカーによって接続されており、
前記融合タンパク質は以下の配列(配列番号87):
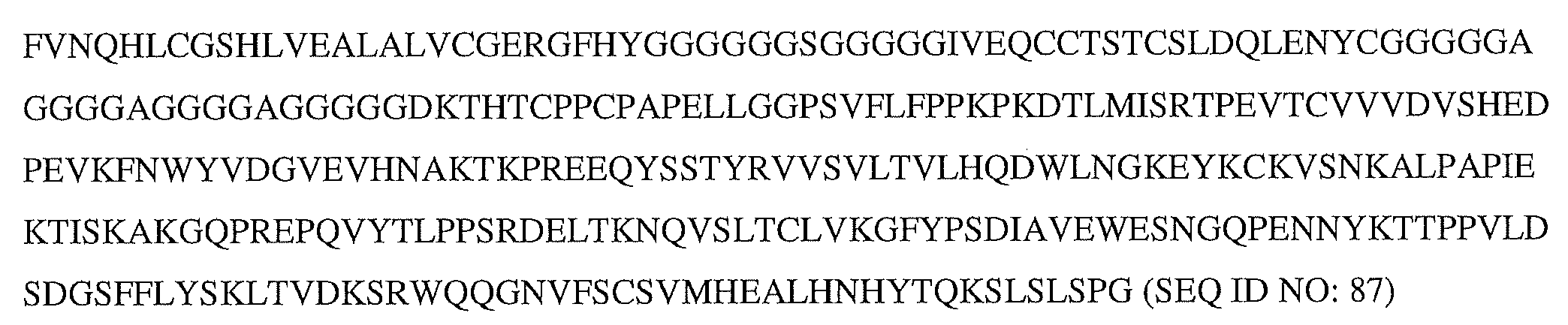
- 以下の配列(配列番号78):
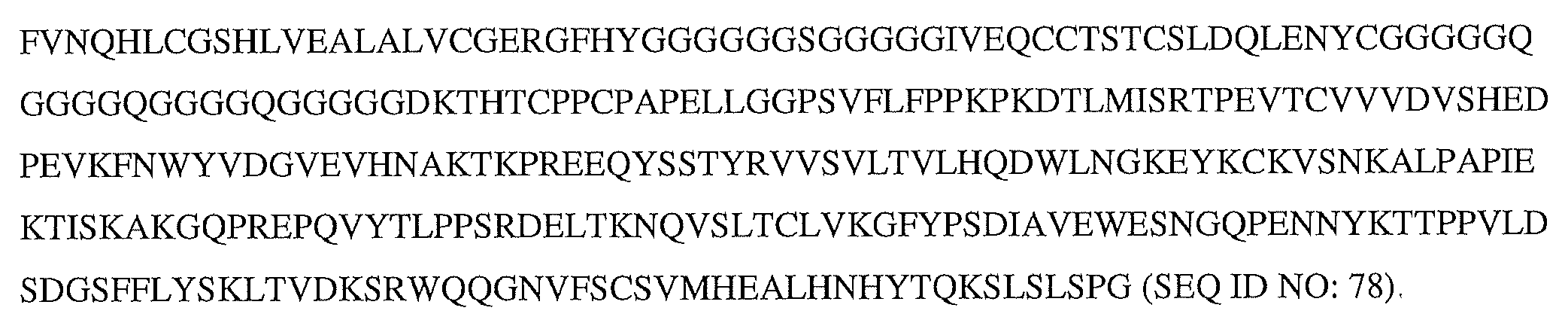
- 以下の配列(配列番号84):
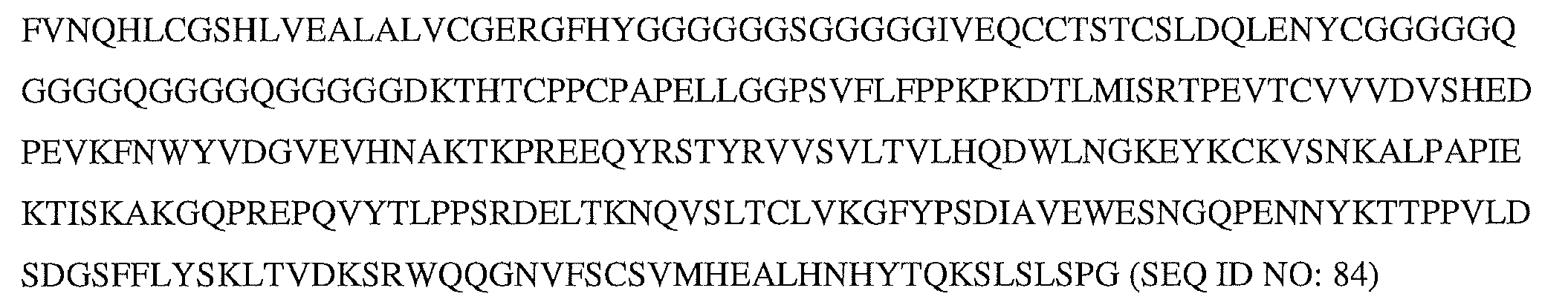
- 以下の配列(配列番号96):

- ホモ二量体である、請求項1に記載の融合タンパク質。
- ホモ二量体である、請求項2~5のいずれか一項に記載の融合タンパク質。
- 融合タンパク質のホモ二量体率が90%超である、請求項6または請求項7に記載の融合タンパク質。
- ホモ二量体の力価が150mg/Lを超える、請求項6または請求項7に記載の融合タンパク質。
- 融合タンパク質のインスリン受容体IC50が5000nM以下である、請求項6または請求項7に記載の融合タンパク質。
- 融合タンパク質のインスリン受容体IC50が2400nM以下である、請求項6または請求項7に記載の融合タンパク質。
- 融合タンパク質のヒトFcRn受容体EC50が1000ng/mL以下である、請求項6または請求項7に記載の融合タンパク質。
- 融合タンパク質の、ビオチン化FcγRI濃度が3000ng/mLである場合のヒトFcγRI受容体アッセイにおけるOD450比が0.50以下である、請求項6または請求項7に記載の融合タンパク質。
- ビオチン化C1q濃度が1000ng/mLである場合のヒトC1qアッセイにおけるOD450比が0.35以下である、請求項6または請求項7に記載の融合タンパク質。
- 請求項6または請求項7に記載の融合タンパク質を含む、医薬組成物。
- 前記融合タンパク質が約3mg/mL以上の濃度で医薬組成物中に存在する、請求項15に記載の医薬組成物。
- 皮下投与に好適である、請求項15に記載の医薬組成物。
- 患者の血糖値を低下させるために用いられる、請求項15~17のいずれか一項に記載の医薬組成物。
- 前記患者が糖尿病と診断された患者である、請求項18に記載の医薬組成物。
- 前記融合タンパク質が皮下投与される、請求項18に記載の医薬組成物。
- 前記融合タンパク質が毎日、週2回、または週1回患者に投与される、請求項18に記載の医薬組成物。
- 前記融合タンパク質が0.025~0.5mg/kg/週の投与量で患者に週1回投与される、請求項18に記載の医薬組成物。
- 請求項2~5のいずれか一項に記載の融合タンパク質を発現するように改変された細胞。
- 前記融合タンパク質をコードする核酸でトランスフェクトされた、請求項23に記載の細胞。
- HEK293細胞またはCHO細胞である、請求項23に記載の細胞。
- 請求項1に記載の融合タンパク質をコードするcDNA。
- 以下の核酸配列(配列番号88):

- 以下の核酸配列(配列番号79):

- 以下の核酸配列(配列番号85):

Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962950803P | 2019-12-19 | 2019-12-19 | |
| US62/950,803 | 2019-12-19 | ||
| US202062988441P | 2020-03-12 | 2020-03-12 | |
| US62/988,441 | 2020-03-12 | ||
| PCT/US2020/063673 WO2021126584A1 (en) | 2019-12-19 | 2020-12-07 | Ultra-long acting insulin-fc fusion proteins and methods of use |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023507376A JP2023507376A (ja) | 2023-02-22 |
| JP7405486B2 true JP7405486B2 (ja) | 2023-12-26 |
Family
ID=74104207
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022536936A Active JP7405486B2 (ja) | 2019-12-19 | 2020-12-07 | 超長時間作用型インスリン-fc融合タンパク質および使用法 |
Country Status (17)
| Country | Link |
|---|---|
| US (3) | US11352407B2 (ja) |
| EP (2) | EP4282473A3 (ja) |
| JP (1) | JP7405486B2 (ja) |
| KR (2) | KR20250142943A (ja) |
| CN (1) | CN114846025B (ja) |
| AU (1) | AU2020407365B2 (ja) |
| BR (1) | BR112022012071A2 (ja) |
| CA (1) | CA3159486A1 (ja) |
| DK (1) | DK4073098T5 (ja) |
| FI (1) | FI4073098T3 (ja) |
| HR (1) | HRP20231433T1 (ja) |
| HU (1) | HUE064376T2 (ja) |
| IL (1) | IL294051A (ja) |
| LT (1) | LT4073098T (ja) |
| SI (1) | SI4073098T1 (ja) |
| WO (1) | WO2021126584A1 (ja) |
| ZA (1) | ZA202206047B (ja) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210029210A (ko) | 2018-06-29 | 2021-03-15 | 악스톤 바이오사이언시스 코퍼레이션 | 초장기 작용 인슐린-fc 융합 단백질 및 사용 방법 |
| KR20250142943A (ko) | 2019-12-19 | 2025-09-30 | 악스톤 바이오사이언시스 코퍼레이션 | 초-장기 작용 인슐린-fc 융합 단백질 및 사용 방법 |
| US11186623B2 (en) | 2019-12-24 | 2021-11-30 | Akston Bioscience Corporation | Ultra-long acting insulin-Fc fusion proteins and methods of use |
| US11192930B2 (en) | 2020-04-10 | 2021-12-07 | Askton Bioscences Corporation | Ultra-long acting insulin-Fc fusion protein and methods of use |
| LT3972987T (lt) | 2020-04-10 | 2023-09-25 | Akston Biosciences Corporation | Antigenui specifinė imunoterapija, skirta sulietiems covid-19 baltymams ir naudojimo būdai |
| US11198719B2 (en) | 2020-04-29 | 2021-12-14 | Akston Biosciences Corporation | Ultra-long acting insulin-Fc fusion protein and methods of use |
| EP4373861A4 (en) | 2021-07-23 | 2025-08-20 | Akston Biosciences Corp | INSULIN-FC FUSION PROTEINS AND METHODS OF USE FOR TREATING CANCER |
| TWI871539B (zh) | 2021-11-15 | 2025-02-01 | 美商美國禮來大藥廠 | 可保存之調配物 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015504679A (ja) | 2012-01-12 | 2015-02-16 | バイオジェン・アイデック・エムエイ・インコーポレイテ | キメラ第viii因子ポリペプチドおよびその使用 |
| JP2016510003A (ja) | 2013-02-26 | 2016-04-04 | ハンミ ファーム.カンパニー リミテッドHanmi Pharm.Co.,Ltd. | 新規なインスリンアナログ及びその用途 |
| JP2018515088A (ja) | 2015-05-07 | 2018-06-14 | イーライ リリー アンド カンパニー | 融合タンパク質 |
| WO2018107117A1 (en) | 2016-12-09 | 2018-06-14 | Akston Biosciences Corporation | Insulin-fc fusions and methods of use |
| US20180340031A1 (en) | 2017-05-25 | 2018-11-29 | Bristol-Myers Squibb Company | Antagonistic cd40 monoclonal antibodies and uses thereof |
Family Cites Families (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030040601A1 (en) | 2001-06-08 | 2003-02-27 | Ivan Diers | Method for making insulin precursors and insulin analog precursors |
| US8188231B2 (en) | 2002-09-27 | 2012-05-29 | Xencor, Inc. | Optimized FC variants |
| WO2010107520A1 (en) | 2009-03-20 | 2010-09-23 | Smartcells, Inc. | Soluble non-depot insulin conjugates and uses thereof |
| CA2754408A1 (en) | 2009-03-30 | 2010-10-14 | Boehringer Ingelheim International Gmbh | Fusion proteins comprising canine fc portions |
| CN101891823B (zh) | 2010-06-11 | 2012-10-03 | 北京东方百泰生物科技有限公司 | 一种Exendin-4及其类似物融合蛋白 |
| AU2011282977A1 (en) | 2010-07-28 | 2013-02-21 | Smartcells, Inc. | Drug-ligand conjugates, synthesis thereof, and intermediates thereto |
| JP2013535467A (ja) | 2010-07-28 | 2013-09-12 | スマートセルズ・インコーポレイテツド | 組換えにより発現されたインスリンポリペプチドおよびその使用 |
| AR087433A1 (es) | 2011-08-08 | 2014-03-26 | Merck Sharp & Dohme | Analogos de insulina n-glicosilados |
| US20140302028A1 (en) | 2011-11-18 | 2014-10-09 | Merck Sharp & Dohme Corp. | Fc containing polypeptides having increased anti-inflammatory properties and increased fcrn binding |
| KR102041412B1 (ko) | 2011-12-30 | 2019-11-11 | 한미사이언스 주식회사 | 면역글로불린 Fc 단편 유도체 |
| CN103509118B (zh) | 2012-06-15 | 2016-03-23 | 郭怀祖 | 胰岛素-Fc融合蛋白 |
| JP6649250B2 (ja) * | 2013-05-21 | 2020-02-19 | プレジデント・アンド・フェロウズ・オブ・ハーバード・カレッジ | 操作されたヘム結合性構成物およびその使用 |
| EP3194429A4 (en) | 2014-09-18 | 2018-06-13 | Askgene Pharma, Inc. | Novel feline erythropoietin receptor agonists |
| WO2016105545A2 (en) | 2014-12-24 | 2016-06-30 | Case Western Reserve University | Insulin analogues with enhanced stabilized and reduced mitogenicity |
| WO2016119023A1 (en) | 2015-01-29 | 2016-08-04 | Nexvet Australia Pty Ltd | Therapeutic and diagnostic agents |
| EP3260139A4 (en) | 2015-02-17 | 2018-09-05 | Hanmi Pharm. Co., Ltd. | Long-acting insulin or insulin analogue complex |
| ES2754432T3 (es) | 2015-05-04 | 2020-04-17 | Apogenix Ag | Proteínas agonistas de receptor CD40 de cadena sencilla |
| ES2784603T3 (es) | 2015-06-02 | 2020-09-29 | Novo Nordisk As | Insulinas con extensiones recombinantes polares |
| WO2017055314A1 (en) * | 2015-10-02 | 2017-04-06 | F. Hoffmann-La Roche Ag | Bispecific anti-cd19xcd3 t cell activating antigen binding molecules |
| CN114835793A (zh) | 2015-11-16 | 2022-08-02 | Ubi蛋白公司 | 用于延长蛋白质半衰期的方法 |
| EP3481413A4 (en) | 2016-07-08 | 2020-01-08 | Askgene Pharma, Inc. | FUSION PROTEIN WITH LEPTIN AND METHOD FOR THE PRODUCTION AND USE THEREOF |
| JP7158378B2 (ja) | 2016-09-23 | 2022-10-21 | ハンミ ファーマシューティカル カンパニー リミテッド | インスリン受容体との結合力が減少された、インスリンアナログ及びその用途 |
| US20200181258A1 (en) | 2016-10-17 | 2020-06-11 | Vetoquinol Sa | Modified antibody constant region |
| UY37629A (es) | 2017-03-07 | 2018-10-31 | Univ Case Western Reserve | Análogos de insulina de cadena simple estabilizados por un cuarto puente disulfuro |
| US12297272B2 (en) | 2017-08-15 | 2025-05-13 | Eianco US inc. | IgG Fc variants for veterinary use |
| EP3781147A4 (en) | 2018-04-16 | 2022-04-20 | University of Utah Research Foundation | Glucose-responsive insulin |
| KR20210029210A (ko) | 2018-06-29 | 2021-03-15 | 악스톤 바이오사이언시스 코퍼레이션 | 초장기 작용 인슐린-fc 융합 단백질 및 사용 방법 |
| US11267862B2 (en) | 2018-06-29 | 2022-03-08 | Akston Biosciences Corporation | Ultra-long acting insulin-Fc fusion proteins and methods of use |
| WO2020069011A1 (en) | 2018-09-25 | 2020-04-02 | Absci, Llc | Protein purification methods |
| WO2020070276A1 (en) | 2018-10-05 | 2020-04-09 | Novo Nordisk A/S | Bifunctional compounds comprising insulin peptides and egf(a) peptides |
| CN113330025A (zh) | 2018-11-19 | 2021-08-31 | 卡斯西部储备大学 | 具有聚丙氨酸c结构域子区段的单链胰岛素类似物 |
| CA3139946A1 (en) | 2019-05-17 | 2020-11-26 | Case Western Reserve University | Variant single-chain insulin analogues |
| WO2021011827A1 (en) | 2019-07-16 | 2021-01-21 | Akston Biosciences Corporation | Ultra-long acting insulin-fc fusion proteins and methods of use |
| TWI844709B (zh) | 2019-07-31 | 2024-06-11 | 美商美國禮來大藥廠 | 鬆弛素(relaxin)類似物及其使用方法 |
| KR20250142943A (ko) | 2019-12-19 | 2025-09-30 | 악스톤 바이오사이언시스 코퍼레이션 | 초-장기 작용 인슐린-fc 융합 단백질 및 사용 방법 |
| US11186623B2 (en) | 2019-12-24 | 2021-11-30 | Akston Bioscience Corporation | Ultra-long acting insulin-Fc fusion proteins and methods of use |
| US11192930B2 (en) | 2020-04-10 | 2021-12-07 | Askton Bioscences Corporation | Ultra-long acting insulin-Fc fusion protein and methods of use |
| US11198719B2 (en) | 2020-04-29 | 2021-12-14 | Akston Biosciences Corporation | Ultra-long acting insulin-Fc fusion protein and methods of use |
| KR20240158331A (ko) | 2022-03-16 | 2024-11-04 | 베이징 투오 지에 바이오파마수티컬 컴퍼니 리미티드 | 인간 인슐린 유사체, 이의 융합 단백질 및 의약적 용도 |
-
2020
- 2020-12-07 KR KR1020257031841A patent/KR20250142943A/ko active Pending
- 2020-12-07 WO PCT/US2020/063673 patent/WO2021126584A1/en not_active Ceased
- 2020-12-07 EP EP23198760.3A patent/EP4282473A3/en active Pending
- 2020-12-07 HR HRP20231433TT patent/HRP20231433T1/hr unknown
- 2020-12-07 KR KR1020227022527A patent/KR102865175B1/ko active Active
- 2020-12-07 DK DK20830444.4T patent/DK4073098T5/da active
- 2020-12-07 JP JP2022536936A patent/JP7405486B2/ja active Active
- 2020-12-07 HU HUE20830444A patent/HUE064376T2/hu unknown
- 2020-12-07 AU AU2020407365A patent/AU2020407365B2/en active Active
- 2020-12-07 IL IL294051A patent/IL294051A/en unknown
- 2020-12-07 CA CA3159486A patent/CA3159486A1/en active Pending
- 2020-12-07 LT LTEPPCT/US2020/063673T patent/LT4073098T/lt unknown
- 2020-12-07 CN CN202080088372.8A patent/CN114846025B/zh active Active
- 2020-12-07 SI SI202030309T patent/SI4073098T1/sl unknown
- 2020-12-07 FI FIEP20830444.4T patent/FI4073098T3/fi active
- 2020-12-07 BR BR112022012071A patent/BR112022012071A2/pt unknown
- 2020-12-07 EP EP20830444.4A patent/EP4073098B1/en active Active
- 2020-12-07 US US17/114,395 patent/US11352407B2/en active Active
-
2021
- 2021-11-19 US US17/531,033 patent/US11555058B2/en active Active
-
2022
- 2022-05-31 ZA ZA2022/06047A patent/ZA202206047B/en unknown
-
2023
- 2023-01-10 US US18/152,595 patent/US12606605B2/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015504679A (ja) | 2012-01-12 | 2015-02-16 | バイオジェン・アイデック・エムエイ・インコーポレイテ | キメラ第viii因子ポリペプチドおよびその使用 |
| JP2016510003A (ja) | 2013-02-26 | 2016-04-04 | ハンミ ファーム.カンパニー リミテッドHanmi Pharm.Co.,Ltd. | 新規なインスリンアナログ及びその用途 |
| JP2018515088A (ja) | 2015-05-07 | 2018-06-14 | イーライ リリー アンド カンパニー | 融合タンパク質 |
| WO2018107117A1 (en) | 2016-12-09 | 2018-06-14 | Akston Biosciences Corporation | Insulin-fc fusions and methods of use |
| US20180340031A1 (en) | 2017-05-25 | 2018-11-29 | Bristol-Myers Squibb Company | Antagonistic cd40 monoclonal antibodies and uses thereof |
Non-Patent Citations (1)
| Title |
|---|
| PROTEIN & CELL, 2017, Vol.9, No.1, pp.63-73 |
Also Published As
| Publication number | Publication date |
|---|---|
| HUE064376T2 (hu) | 2024-03-28 |
| CN114846025B (zh) | 2025-11-11 |
| FI4073098T3 (fi) | 2023-11-15 |
| AU2020407365A1 (en) | 2022-06-09 |
| KR20220115975A (ko) | 2022-08-19 |
| EP4282473A2 (en) | 2023-11-29 |
| DK4073098T3 (da) | 2023-11-20 |
| NZ788617A (en) | 2024-10-25 |
| US11555058B2 (en) | 2023-01-17 |
| EP4282473A3 (en) | 2024-02-21 |
| CA3159486A1 (en) | 2021-06-24 |
| ZA202206047B (en) | 2023-08-30 |
| SI4073098T1 (sl) | 2023-12-29 |
| WO2021126584A1 (en) | 2021-06-24 |
| KR102865175B1 (ko) | 2025-09-30 |
| JP2023507376A (ja) | 2023-02-22 |
| HRP20231433T1 (hr) | 2024-03-29 |
| EP4073098B1 (en) | 2023-09-27 |
| US20220064251A1 (en) | 2022-03-03 |
| US20210309709A1 (en) | 2021-10-07 |
| IL294051A (en) | 2022-08-01 |
| DK4073098T5 (da) | 2024-07-22 |
| US20230250148A1 (en) | 2023-08-10 |
| CN114846025A (zh) | 2022-08-02 |
| AU2020407365B2 (en) | 2023-09-21 |
| LT4073098T (lt) | 2023-12-11 |
| BR112022012071A2 (pt) | 2022-08-30 |
| EP4073098A1 (en) | 2022-10-19 |
| KR20250142943A (ko) | 2025-09-30 |
| US12606605B2 (en) | 2026-04-21 |
| US11352407B2 (en) | 2022-06-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7510728B2 (ja) | 超長期作用性インスリン-fc融合タンパク質および使用方法 | |
| JP7405486B2 (ja) | 超長時間作用型インスリン-fc融合タンパク質および使用法 | |
| US11267862B2 (en) | Ultra-long acting insulin-Fc fusion proteins and methods of use | |
| WO2021011827A1 (en) | Ultra-long acting insulin-fc fusion proteins and methods of use | |
| WO2023064711A2 (en) | Ultra-long acting insulin-fc fusion proteins and methods of use |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220825 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220825 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230711 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230714 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20231011 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231018 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20231114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20231208 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7405486 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |