JP6212947B2 - 情報処理装置、制御装置及び制御プログラム - Google Patents
情報処理装置、制御装置及び制御プログラム Download PDFInfo
- Publication number
- JP6212947B2 JP6212947B2 JP2013104098A JP2013104098A JP6212947B2 JP 6212947 B2 JP6212947 B2 JP 6212947B2 JP 2013104098 A JP2013104098 A JP 2013104098A JP 2013104098 A JP2013104098 A JP 2013104098A JP 6212947 B2 JP6212947 B2 JP 6212947B2
- Authority
- JP
- Japan
- Prior art keywords
- abnormality
- component
- access processing
- processing value
- occurrences
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0706—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment
- G06F11/0727—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment in a storage system, e.g. in a DASD or network based storage system
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0751—Error or fault detection not based on redundancy
- G06F11/0754—Error or fault detection not based on redundancy by exceeding limits
- G06F11/076—Error or fault detection not based on redundancy by exceeding limits by exceeding a count or rate limit, e.g. word- or bit count limit
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/079—Root cause analysis, i.e. error or fault diagnosis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Debugging And Monitoring (AREA)
Description
1つの側面では、本発明は、故障箇所の特定における信頼性を向上させることを目的とする。
以下、図面を参照して情報処理装置、制御装置及び制御プログラムに係る一実施の形態を説明する。ただし、以下に示す実施形態はあくまでも例示に過ぎず、実施形態で明示しない種々の変形例や技術の適用を排除する意図はない。すなわち、本実施形態を、その趣旨を逸脱しない範囲で種々変形して実施することができる。
〔A−1〕システム構成
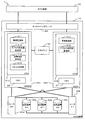
図1は実施形態の一例としてのストレージシステムの機能構成を模式的に示す図である。
本実施形態の一例としてのストレージシステム1は、図1に示すようにRAID装置(情報処理装置)10及びホスト装置70を備える。
図1に示すように、これらのRAID装置10とホスト装置70とは、例えば、Local Area Network(LAN)で互いに通信可能に接続されている。
RAID装置10は、複数(図1に示す例では2つ)のCM(制御装置)20a,20b、共有メモリ30、複数(図1に示す例では2つ)のルータ40a,40b、複数(図1に示す例では3つ)の記憶装置50a〜50c及びチャネルインタフェース60を備える。本RAID装置10は、複数の記憶装置50a〜50cを仮想的に1つの記憶装置として管理し、ホスト装置70に対して記憶領域を提供するものである。
図1に示すように、CM20とチャネルインタフェース60との間、CM20と共有メモリ30との間、CM20とルータ40との間及びルータ40と記憶装置50との間は、例えば、バス線で互いに通信可能に接続されている。
以下、CM20,ルータ40及び記憶装置50をまとめてRAID装置10の構成部品もしくは単に構成部品という場合がある。そして、本RAID装置10は、これらの構成部品における異常を検知し、異常が検知された構成部品の中から故障箇所を特定する機能を備える。
ルータ40は、CM20と記憶装置50とを中継する既知の装置である。これらのルータ40は、互いに同様の機能構成を備える。
本実施形態の一例においては、CM#0はルータ#0又はルータ#1を介して各記憶装置50にアクセスできるように冗長化されて構成されており、CM#1もルータ#0又はルータ#1を介して各記憶装置50にアクセスできるように冗長化されて構成されている。
共有メモリ30は、CM#0及びCM#1に共有される記憶装置である。本実施形態の一例においては、共有メモリ30は、図2に示すように、RAID装置10の構成部品であるCM#0,#1、ルータ#0,#1及び記憶装置#0〜#2における異常発生回数とアクセス処理値(ともに詳細は図3を用いて後述)とを対応づけた情報を共有情報300として保持している。本RAID装置10の起動時には、各構成部品の異常発生回数及びアクセス処理値は、図2に示すように、それぞれ初期値としての0が設定されている。また、異常発生回数及びアクセス処理値の閾値についても、図3を用いて後述する。
CM20は、種々の制御を行なう制御装置であり、ホスト装置70からのストレージアクセス要求に従って、各種制御を行なう。
メモリ22は、Read Only Memory(ROM)及びRandom Access Memory(RAM)を含む記憶装置である。メモリ22のROMには、Operating System(OS)、故障箇所特定の制御に係るソフトウェアプログラム(制御プログラム)やこのプログラム用のデータ類が書き込まれている。メモリ22上のソフトウェアプログラムは、CPU21aに適宜読み込まれて実行される。また、メモリ22のRAMは、一次記録メモリあるいはワーキングメモリとして利用される。
なお、異常監視部211,アクセス処理値監視部212,故障箇所特定部213及びリセット処理部214としての機能を実現するためのプログラム(制御プログラム)は、例えばフレキシブルディスク,CD(CD−ROM,CD−R,CD−RW等),DVD(DVD−ROM,DVD−RAM,DVD−R,DVD+R,DVD−RW,DVD+RW,HD DVD等),ブルーレイディスク,磁気ディスク,光ディスク,光磁気ディスク等の、コンピュータ読取可能な記録媒体に記録された形態で提供される。そして、コンピュータはその記録媒体から図示しない読取装置を介してプログラムを読み取って内部記録装置または外部記録装置に転送し格納して用いる。又、そのプログラムを、例えば磁気ディスク,光ディスク,光磁気ディスク等の記憶装置(記録媒体)に記録しておき、その記憶装置から通信経路を介してコンピュータに提供してもよい。
異常監視部211は、各構成部品における異常を検知し、又、構成部品毎の異常発生回数を計測する。
具体的には、異常監視部211は、図1に示したRAID装置10の構成部品であるCM#0,#1、ルータ#0,#1及び記憶装置#0〜#2のいずれかで発生した異常を検知する。
図3に示す例においては、CM#0,ルータ#0及び記憶装置#0で異常が発生している。このように複数の構成部品で異常が検知されるのは、例えば、CM#0がルータ#0を介して記憶装置#0に対するアクセス処理を行なっている場合である。なお、構成部品における異常の原因は、例えば、回路故障やソフトウェアエラー、記憶装置50内のチップにおける断線である。例えば、CM#0がルータ#0を介して記憶装置#0に対するアクセス処理を行なっている場合に、これらのいずれかの構成部品において回路故障等が発生すると、図3に示すようにCM#0,ルータ#0及び記憶装置#0において異常が検知される。そして、異常監視部211は、図3に示すように、これらの異常を検知する毎に対応する構成部品の異常発生回数を1ずつ加算(累計)し、共有情報300として共有メモリ30に上書きしていく。なお、異常監視部211は、後述するリセット処理部214によるリセット処理が行なわれるまで、異常発生回数の計数を継続する。
具体的には、アクセス処理値監視部212は、異常監視部211がいずれかの構成部品について異常発生回数の計測を開始すると、その構成部品についてのアクセス処理値の計測を開始する。
図3に示す例においては、異常監視部211がCM#0,ルータ#0及び記憶装置#0について異常発生回数の計測を開始したため、アクセス処理値監視部212は、これらCM#0,ルータ#0及び記憶装置#0についてアクセス処理値の計測を開始する。なお、アクセス処理値とは、例えば、各構成部品が処理するデータ量やコマンド(Read/Writeコマンド)発行数である。以下、特筆しない限りアクセス処理値は各構成部品が処理するデータ量であるものとする。本実施形態の一例においては、アクセス処理値として各構成部品が処理するデータ量を用いた方が高い精度での故障箇所の特定を期待できる。そして、アクセス処理値監視部212は、各構成部品が処理するデータ量が増加する毎に対応する構成部品のアクセス処理値を加算(累計)し、共有情報300として共有メモリ30に上書きしていく。なお、アクセス処理値監視部212は、異常が検知されているアクセス処理に限らず、正常なアクセス処理についても計測する。また、アクセス処理値監視部212は、後述するリセット処理部214によるリセット処理が行なわれるまで、アクセス処理値の計測を継続する。
上述したように、異常監視部211及びアクセス処理値監視部212は2つのCM20がともに備える機能であるため、2つのCM20はともに上述した異常監視及びアクセス処理値監視を行ない、共有メモリ20の共有情報300を更新していく。
具体的には、故障箇所特定部213は、異常監視部211が計測するいずれかの構成部品についての異常発生回数が閾値に達すると、その構成部品における異常発生回数とアクセス処理値との比率を算出する。例えば、故障箇所特定部213は、異常発生回数をアクセス処理値で除算して比率を算出する。そして、故障箇所特定部213は、この比率が最も大きい構成部品を故障箇所として特定する。
具体的には、リセット処理部214は、アクセス処理値監視部213が計測するいずれかの構成部品についてのアクセス処理値が閾値に達すると、共有情報300におけるその構成部品についての異常発生回数とアクセス処理値とをリセットする。
図3に示す例においては、アクセス処理値の閾値(単位アクセス処理値)が100GBに設定されている。つまり、アクセス処理値監視部211が計測したアクセス処理値が閾値である100GBに達した構成部品がある場合には、リセット処理部214は、共有情報300におけるその構成部品についての異常発生回数とアクセス処理値とをリセットする。なお、上述したようにアクセス処理値としてコマンド発行数を用いる場合には、アクセス処理値の閾値にはコマンド発行数が設定される。
〔A−2〕動作
上述の如く構成された実施形態の一例としてのストレージシステム1における故障箇所の特定処理の一例を図4に示すフローチャート(ステップS10〜S100)に従って説明する。
故障箇所特定部213は、異常監視部211が計測した異常発生回数が閾値に達した構成部品(被疑箇所)が1箇所のみであるかを判定する(ステップS20)。
被疑箇所が1箇所のみである場合には(ステップS20のYESルート参照)、故障箇所特定部213は、閾値に達した構成部品を故障箇所として特定する(ステップS30)。
以下のステップS40〜S100においては、被疑箇所がCM#0,ルータ#0及び記憶装置#0である場合について説明する。
被疑箇所のうちCM#0の比率が最大である場合には(ステップS40のYESルート参照)、故障箇所特定部213は、CM#0を故障箇所として特定する(ステップS50)。例えば、正常なCM#1と異常なCM#0とが正常な1つの記憶装置#0に対してアクセスした場合には、このステップS50に到達する。
被疑箇所のうちルータ#0の比率が最大である場合には(ステップS60のYESルート参照)、故障箇所特定部213は、ルータ#0を故障箇所として特定する(ステップS70)。
被疑箇所のうち記憶装置#0の比率が最大である場合には(ステップS80のYESルート参照)、故障箇所特定部213は、記憶装置#0を故障箇所として特定する(ステップS90)。例えば、正常な1つのCM#0が正常な複数の記憶装置#1,#2と異常な1つの記憶装置#0とに対してアクセスした場合には、このステップS90に到達する。
なお、故障箇所特定部213による比率が最大であるかについての判定(ステップS40,S60,S80)の回数は被疑箇所の数によって決まるため、図4に示した例に限定されるものではない。また、障箇所特定部213による比率が最大であるかについての判定(ステップS40,S60,S80)の順序も図4に示した例に限定されるものではなく、故障箇所特定部213は、例えば、ステップS80,S60,S40の順に判定しても良い。更に、故障箇所特定部213は、故障箇所を特定した際には(ステップS30,S50,S70,S90)、その故障箇所を図示しないディスプレイ等に表示させ、オペレータに提示しても良い。一方、故障箇所特定部213は、故障箇所は不定であると判断した際には(ステップS100)、故障箇所が不定であるというメッセージを図示しないディスプレイ等に表示させ、オペレータに提示しても良い。
リセット処理部214は、アクセス処理値監視部212が計測したCM#0におけるアクセス処理値が閾値に達したかを判定する(ステップS120)。
アクセス処理値監視部212が計測したCM#0におけるアクセス処理値が閾値に達した場合には(ステップS120のYESルート参照)、リセット処理部214は、CM#0における異常発生回数及びアクセス処理値の計測をリセットさせ(ステップS130)、ステップS140に移行する。
リセット処理部214は、アクセス処理値監視部212が計測したCM#1におけるアクセス処理値が閾値に達したかを判定する(ステップS140)。
アクセス処理値監視部212が計測したCM#1におけるアクセス処理値が閾値に達していない場合には(ステップS140のNOルート参照)、次の構成部品についての判定処理に移行する。
更に、リセット処理部214は、アクセス処理値監視部212が計測した記憶装置#2におけるアクセス処理値が閾値に達したかを判定する(ステップS160)。
アクセス処理値監視部212が計測した記憶装置#2におけるアクセス処理値が閾値に達した場合には(ステップS160のYESルート参照)、リセット処理部214は、記憶装置#2における異常発生回数及びアクセス処理値の計測をリセットさせ(ステップS170)、ステップS180に移行する。
以上で、リセットが完了し(ステップS180)、本リセット処理の一例が終了する。
なお、リセット処理部214によるアクセス処理値が閾値に達したかの判定(ステップS120,S140,…,S160)の順序は図5に示した例に限定されるものではない。リセット処理部214は、例えば、ステップS160,…,S140,S120の順に判定しても良い。
このように、実施形態の一例としてのストレージシステム1によれば、以下のような効果を奏することができる。
すなわち、1つの構成部品の故障により複数の構成部品において異常が検知された場合でも、故障箇所を特定することができる。
開示の技術は上述した実施形態に限定されるものではなく、本実施形態の趣旨を逸脱しない範囲で種々変形して実施することができる。本実施形態の各構成及び各処理は、必要に応じて取捨選択することができ、あるいは適宜組み合わせてもよい。
上述した実施形態の一例においては、CM#1がCPU21bを備えることとしたが、これに限定されるものではなく、例えば、CM#1がCM#0と同様のCPU21aを備えることとしても良い。これにより、例えば、CM#0が故障した際にも、CM#1によって故障箇所の特定を行なうことができる。
〔C〕付記
(付記1)
複数の構成部品を備える情報処理装置であって、
前記構成部品における異常を検知すると、前記構成部品毎の異常発生回数を計測する異常監視部と、
前記構成部品毎のアクセス処理値を計測するアクセス処理値監視部と、
前記構成部品における前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する故障箇所特定部と、
を備えることを特徴とする情報処理装置。
前記アクセス処理値監視部は、
前記異常監視部がいずれかの構成部品について前記異常発生回数の計測を開始すると、当該構成部品についての前記アクセス処理値の計測を開始することを特徴とする付記1記載の情報処理装置。
前記故障箇所特定部は、
前記異常監視部が計測するいずれかの構成部品についての前記異常発生回数が閾値に達すると、当該構成部品における前記比率を算出することを特徴とする付記1又は2に記載の情報処理装置。
前記故障箇所特定部は、
前記複数の構成部品のうち、前記異常発生回数を前記アクセス処理値で除算して求める前記比率が最も大きい構成部品を前記故障箇所として特定することを特徴とする付記1〜3のいずれか1項に記載の情報処理装置。
前記アクセス処理値監視部が計測するいずれかの構成部品についての前記アクセス処理値が閾値に達すると、当該構成部品についての前記異常発生回数と前記アクセス処理値との計測をリセットさせるリセット処理部
を備えることを特徴とする付記1〜4のいずれか1項に記載の情報処理装置。
前記アクセス処理値は、前記複数の構成部品が処理するデータ量であることを特徴とする付記1〜5のいずれか1項に記載の情報処理装置。
(付記7)
前記アクセス処理値は、前記複数の構成部品が処理するコマンド数であることを特徴とする付記1〜5のいずれか1項に記載の情報処理装置。
複数の構成部品を備える情報処理装置に備えられ、
前記構成部品における異常を検知すると、前記構成部品毎の異常発生回数を計測する異常監視部と、
前記構成部品毎のアクセス処理値を計測するアクセス処理値監視部と、
前記構成部品における前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する故障箇所特定部と、
を備えることを特徴とする制御装置。
前記アクセス処理値監視部は、
前記異常監視部がいずれかの構成部品について前記異常発生回数の計測を開始すると、当該構成部品についての前記アクセス処理値の計測を開始することを特徴とする付記8記載の制御装置。
前記故障箇所特定部は、
前記異常監視部が計測するいずれかの構成部品についての前記異常発生回数が閾値に達すると、当該構成部品における前記比率を算出することを特徴とする付記8又は9に記載の制御装置。
前記故障箇所特定部は、
前記複数の構成部品のうち、前記異常発生回数を前記アクセス処理値で除算して求める前記比率が最も大きい構成部品を前記故障箇所として特定することを特徴とする付記8〜10のいずれか1項に記載の制御装置。
前記アクセス処理値監視部が計測するいずれかの構成部品についての前記アクセス処理値が閾値に達すると、当該構成部品についての前記異常発生回数と前記アクセス処理値との計測をリセットさせるリセット処理部
を備えることを特徴とする付記8〜11のいずれか1項に記載の制御装置。
前記アクセス処理値は、前記複数の構成部品が処理するデータ量であることを特徴とする付記8〜12のいずれか1項に記載の制御装置。
(付記14)
前記アクセス処理値は、前記複数の構成部品が処理するコマンド数であることを特徴とする付記8〜12のいずれか1項に記載の制御装置。
複数の構成部品を備える情報処理装置に備えられるコンピュータに、
前記構成部品における異常を検知すると、前記構成部品毎の異常発生回数を計測し、
前記構成部品毎のアクセス処理値を計測し、
前記構成部品における前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する
処理を実行させることを特徴とする制御プログラム。
いずれかの構成部品について前記異常発生回数の計測を開始すると、当該構成部品についての前記アクセス処理値の計測を開始する処理を前記コンピュータに実行させることを特徴とする付記15記載の制御プログラム。
(付記17)
いずれかの構成部品についての前記異常発生回数が閾値に達すると、当該構成部品における前記比率を算出する処理を前記コンピュータに実行させることを特徴とする付記15又は16に記載の制御プログラム。
前記複数の構成部品のうち、前記異常発生回数を前記アクセス処理値で除算して求める前記比率が最も大きい構成部品を前記故障箇所として特定する処理を前記コンピュータに実行させることを特徴とする付記15〜17のいずれか1項に記載の制御プログラム。
(付記19)
いずれかの構成部品についての前記アクセス処理値が閾値に達すると、当該構成部品についての前記異常発生回数と前記アクセス処理値との計測をリセットさせる
処理を前記コンピュータに実行させることを特徴とする付記15〜18のいずれか1項に記載の制御プログラム。
前記アクセス処理値は、前記複数の構成部品が処理するデータ量であることを特徴とする付記15〜19のいずれか1項に記載の制御プログラム。
(付記21)
前記アクセス処理値は、前記複数の構成部品が処理するコマンド数であることを特徴とする付記15〜19のいずれか1項に記載の制御プログラム。
10 RAID装置(情報処理装置)
20 CM(制御装置,構成部品)
21 CPU(コンピュータ)
211 異常監視部
212 アクセス処理値監視部
213 故障箇所特定部
214 リセット処理部
22 メモリ
30 共有メモリ
300 共有情報
40 ルータ(構成部品)
50 記憶装置(構成部品)
60 チャネルインタフェース
70 ホスト装置
Claims (9)
- 複数の構成部品を備える情報処理装置であって、
前記複数の構成部品のうちのいずれかの構成部品における異常を検知すると、前記構成部品毎の異常発生回数を計測する異常監視部と、
前記異常監視部が前記いずれかの構成部品について前記異常発生回数の計測を開始すると、当該構成部品についてのアクセス処理値の計測を開始するアクセス処理値監視部と、
前記構成部品における前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する故障箇所特定部と、
を備えることを特徴とする情報処理装置。 - 前記故障箇所特定部は、
前記アクセス処理値監視部が前記アクセス処理値を計測する前記いずれかの構成部品について、前記異常監視部によって計測された前記異常発生回数が閾値に達すると、当該構成部品における前記比率を算出することを特徴とする請求項1に記載の情報処理装置。 - 前記故障箇所特定部は、
前記複数の構成部品のうち、前記異常発生回数を前記アクセス処理値で除算して求める前記比率が最も大きい構成部品を前記故障箇所として特定することを特徴とする請求項1又は2に記載の情報処理装置。 - 前記アクセス処理値監視部が計測する前記いずれかの構成部品についての前記アクセス処理値が閾値に達すると、当該構成部品についての前記異常発生回数と前記アクセス処理値との計測をリセットさせるリセット処理部
を備えることを特徴とする請求項1〜3のいずれか1項に記載の情報処理装置。 - 前記アクセス処理値は、前記複数の構成部品が処理するデータ量であることを特徴とする請求項1〜4のいずれか1項に記載の情報処理装置。
- 前記アクセス処理値は、前記複数の構成部品が処理するコマンド数であることを特徴とする請求項1〜4のいずれか1項に記載の情報処理装置。
- 複数の構成部品を備える情報処理装置であって、
第1の制御装置に備えられ、前記複数の構成部品のうち前記第1の制御装置に接続された構成部品における異常を検知すると、当該構成部品毎の異常発生回数を計測するとともに、当該構成部品毎のアクセス処理値を計測する第1の監視部と、
第2の制御装置に備えられ、前記複数の構成部品のうち前記第2の制御装置に接続された構成部品における異常を検知すると、当該構成部品毎の異常発生回数を計測するとともに、当該構成部品毎のアクセス処理値を計測する第2の監視部と、
前記第1の監視部によって計測された異常発生回数及びアクセス処理値と、前記第2の監視部によって計測された異常発生回数及びアクセス処理値と、を記憶する記憶部と、
前記記憶部に記憶された前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する故障箇所特定部と、
を備えることを特徴とする情報処理装置。 - 複数の構成部品を備える情報処理装置に備えられ、
前記複数の構成部品のうちのいずれかの構成部品における異常を検知すると、前記構成部品毎の異常発生回数を計測する異常監視部と、
前記異常監視部が前記いずれかの構成部品について前記異常発生回数の計測を開始すると、当該構成部品についてのアクセス処理値の計測を開始するアクセス処理値監視部と、
前記構成部品における前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する故障箇所特定部と、
を備えることを特徴とする制御装置。 - 複数の構成部品を備える情報処理装置に備えられるコンピュータに、
前記複数の構成部品のうちのいずれかの構成部品における異常を検知すると、前記構成部品毎の異常発生回数を計測し、
前記いずれかの構成部品について前記異常発生回数の計測を開始すると、当該構成部品についてのアクセス処理値の計測を開始し、
前記構成部品における前記異常発生回数と前記アクセス処理値との比率に基づいて、故障箇所としての構成部品を特定する
処理を実行させることを特徴とする制御プログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013104098A JP6212947B2 (ja) | 2013-05-16 | 2013-05-16 | 情報処理装置、制御装置及び制御プログラム |
| US14/256,077 US9459943B2 (en) | 2013-05-16 | 2014-04-18 | Fault isolation by counting abnormalities |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013104098A JP6212947B2 (ja) | 2013-05-16 | 2013-05-16 | 情報処理装置、制御装置及び制御プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014225133A JP2014225133A (ja) | 2014-12-04 |
| JP6212947B2 true JP6212947B2 (ja) | 2017-10-18 |
Family
ID=51896806
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013104098A Expired - Fee Related JP6212947B2 (ja) | 2013-05-16 | 2013-05-16 | 情報処理装置、制御装置及び制御プログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US9459943B2 (ja) |
| JP (1) | JP6212947B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9495235B2 (en) * | 2013-11-18 | 2016-11-15 | Hitachi, Ltd. | Identifying a physical device in which a fault has occurred in a storage system |
| CN107992415B (zh) * | 2017-11-28 | 2021-04-16 | 中国银联股份有限公司 | 一种交易系统的故障定位和分析方法及相关服务器 |
| JP2020086538A (ja) * | 2018-11-15 | 2020-06-04 | 株式会社日立製作所 | 計算機システム、及びデバイス管理方法 |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4380067A (en) * | 1981-04-15 | 1983-04-12 | International Business Machines Corporation | Error control in a hierarchical system |
| JPS62198944A (ja) * | 1986-02-27 | 1987-09-02 | Toshiba Corp | 装置異常検出方式 |
| JPH01271828A (ja) | 1988-04-22 | 1989-10-30 | Nec Corp | 磁気ディスク装置の予防保守方式 |
| JPH04219676A (ja) * | 1990-12-19 | 1992-08-10 | Nec Corp | 記憶媒体品質管理システム |
| JPH04321140A (ja) * | 1991-04-22 | 1992-11-11 | Fujitsu Ltd | エラー発生部指摘方法および装置 |
| JPH05274629A (ja) * | 1992-03-27 | 1993-10-22 | Nec Corp | 情報処理装置 |
| JP3212677B2 (ja) * | 1992-04-07 | 2001-09-25 | 日本電気株式会社 | 周辺制御装置 |
| EP0799541A1 (en) * | 1994-12-23 | 1997-10-08 | BRITISH TELECOMMUNICATIONS public limited company | Fault monitoring |
| JPH11296311A (ja) * | 1998-04-08 | 1999-10-29 | Hitachi Ltd | 記憶装置の耐故障制御方式 |
| JPH11353819A (ja) | 1998-06-08 | 1999-12-24 | Nec Software Hokkaido Ltd | ディスク装置およびディスク装置の予防保守方法 |
| US6816461B1 (en) * | 2000-06-16 | 2004-11-09 | Ciena Corporation | Method of controlling a network element to aggregate alarms and faults of a communications network |
| US7058844B2 (en) * | 2001-06-15 | 2006-06-06 | Sun Microsystems, Inc. | System and method for rapid fault isolation in a storage area network |
| GB2376612B (en) * | 2001-06-15 | 2004-06-09 | Ibm | Method and apparatus for fault location in a loop network |
| JP2003114811A (ja) * | 2001-10-05 | 2003-04-18 | Nec Corp | 自動障害復旧方法及びシステム並びに装置とプログラム |
| US7437611B2 (en) * | 2004-10-21 | 2008-10-14 | International Business Machines Corporation | System and method for problem determination using dependency graphs and run-time behavior models |
| JP2007299213A (ja) * | 2006-04-28 | 2007-11-15 | Fujitsu Ltd | Raid制御装置および障害監視方法 |
| US7779306B1 (en) * | 2007-03-23 | 2010-08-17 | Emc Corporation | Method for automatically diagnosing hardware faults in a data storage system |
| JP4968078B2 (ja) | 2008-01-16 | 2012-07-04 | ソニー株式会社 | 故障診断装置及び故障診断方法 |
| JP5186982B2 (ja) * | 2008-04-02 | 2013-04-24 | 富士通株式会社 | データ管理方法及びスイッチ装置 |
| JP4627327B2 (ja) | 2008-05-23 | 2011-02-09 | 富士通株式会社 | 異常判定装置 |
| US8069370B1 (en) * | 2010-07-02 | 2011-11-29 | Oracle International Corporation | Fault identification of multi-host complex systems with timesliding window analysis in a time series |
| US8230262B2 (en) * | 2010-07-02 | 2012-07-24 | Oracle International Corporation | Method and apparatus for dealing with accumulative behavior of some system observations in a time series for Bayesian inference with a static Bayesian network model |
| JP5618204B2 (ja) * | 2010-11-17 | 2014-11-05 | Necプラットフォームズ株式会社 | 障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法 |
-
2013
- 2013-05-16 JP JP2013104098A patent/JP6212947B2/ja not_active Expired - Fee Related
-
2014
- 2014-04-18 US US14/256,077 patent/US9459943B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014225133A (ja) | 2014-12-04 |
| US9459943B2 (en) | 2016-10-04 |
| US20140344630A1 (en) | 2014-11-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11119874B2 (en) | Memory fault detection | |
| CN105468484B (zh) | 用于在存储系统中确定故障位置的方法和装置 | |
| TWI632462B (zh) | 開關裝置及偵測積體電路匯流排之方法 | |
| US7412631B2 (en) | Methods and structure for verifying domain functionality | |
| US8832501B2 (en) | System and method of processing failure | |
| JP2013161235A (ja) | ストレージ装置、ストレージ装置の制御方法及びストレージ装置の制御プログラム | |
| CN103455395A (zh) | 一种硬盘故障的检测方法及装置 | |
| US10606490B2 (en) | Storage control device and storage control method for detecting storage device in potential fault state | |
| US20210133081A1 (en) | Server status monitoring system and method using baseboard management controller | |
| US9152519B2 (en) | Storage control apparatus, method of setting reference time, and computer-readable storage medium storing reference time setting program | |
| TW201414257A (zh) | 儲存設備監控系統及方法 | |
| JP6212947B2 (ja) | 情報処理装置、制御装置及び制御プログラム | |
| JP5419819B2 (ja) | 計算機システムの管理方法、及び管理システム | |
| JP2007299213A (ja) | Raid制御装置および障害監視方法 | |
| JP2006092070A (ja) | ディスクアレイ装置及びその制御方法並びに制御プログラム | |
| JP5689783B2 (ja) | コンピュータ、コンピュータシステム、および障害情報管理方法 | |
| JP2017090959A (ja) | ストレージ装置,性能推定プログラム及び性能推定方法 | |
| CN112804115B (zh) | 一种虚拟网络功能的异常检测方法、装置及设备 | |
| JP2001014113A (ja) | ディスク装置故障検出システム | |
| JP2009282848A (ja) | 異常判定装置 | |
| JP5273185B2 (ja) | 記録媒体制御システム、記録媒体制御方法、記録媒体制御プログラム | |
| JP2013196410A (ja) | サーバ装置及び障害管理方法及び障害管理プログラム | |
| CN111190781A (zh) | 服务器系统的测试自检方法 | |
| JP5729238B2 (ja) | 管理サーバ、異常予測システム、異常予測方法、及び、異常予測プログラム | |
| TWI607455B (zh) | 記憶體資料檢測方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160226 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161227 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170117 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170321 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170822 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170904 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6212947 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |