JP5283810B2 - プロセッサおよびコプロセッサを含むコンピュータ・システム - Google Patents
プロセッサおよびコプロセッサを含むコンピュータ・システム Download PDFInfo
- Publication number
- JP5283810B2 JP5283810B2 JP2001503043A JP2001503043A JP5283810B2 JP 5283810 B2 JP5283810 B2 JP 5283810B2 JP 2001503043 A JP2001503043 A JP 2001503043A JP 2001503043 A JP2001503043 A JP 2001503043A JP 5283810 B2 JP5283810 B2 JP 5283810B2
- Authority
- JP
- Japan
- Prior art keywords
- burst
- coprocessor
- instruction
- processor
- execution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 239000000872 buffer Substances 0.000 claims description 167
- 230000015654 memory Effects 0.000 claims description 146
- 238000012546 transfer Methods 0.000 claims description 34
- 230000007246 mechanism Effects 0.000 claims description 31
- 238000000034 method Methods 0.000 claims description 20
- 238000004891 communication Methods 0.000 claims description 9
- 238000012545 processing Methods 0.000 claims description 4
- 230000000903 blocking effect Effects 0.000 claims description 2
- 238000004364 calculation method Methods 0.000 description 35
- 238000004422 calculation algorithm Methods 0.000 description 18
- 230000006870 function Effects 0.000 description 9
- 230000000694 effects Effects 0.000 description 8
- 239000013598 vector Substances 0.000 description 8
- 238000003491 array Methods 0.000 description 7
- 230000003139 buffering effect Effects 0.000 description 7
- 230000008569 process Effects 0.000 description 7
- 241000238876 Acari Species 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- 238000013459 approach Methods 0.000 description 5
- 230000006399 behavior Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 239000007853 buffer solution Substances 0.000 description 5
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 4
- 238000005094 computer simulation Methods 0.000 description 4
- 238000012986 modification Methods 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 230000001360 synchronised effect Effects 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 230000004913 activation Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 102000012199 E3 ubiquitin-protein ligase Mdm2 Human genes 0.000 description 1
- 108050002772 E3 ubiquitin-protein ligase Mdm2 Proteins 0.000 description 1
- 230000009172 bursting Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3877—Concurrent instruction execution, e.g. pipeline or look ahead using a slave processor, e.g. coprocessor
- G06F9/3879—Concurrent instruction execution, e.g. pipeline or look ahead using a slave processor, e.g. coprocessor for non-native instruction execution, e.g. executing a command; for Java instruction set
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/20—Handling requests for interconnection or transfer for access to input/output bus
- G06F13/28—Handling requests for interconnection or transfer for access to input/output bus using burst mode transfer, e.g. direct memory access DMA, cycle steal
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Advance Control (AREA)
- Executing Machine-Instructions (AREA)
Description
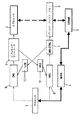
このシステムの個々のエレメントが、以下でより詳細に論じられる。プロセッサ1は一般に計算を制御するが、計算自体におけるステップのいくつか(または、記載された実施形態では、すべて)がコプロセッサ2において実行されるような方法で制御する。プロセッサ1が、バースト命令待ち行列6を通じて特定のタスクのための命令、すなわち、バースト・バッファ・コントローラ7の構成、およびバースト・バッファ・メモリ5とメイン・メモリ3の間のデータの転送のための命令を提供する。さらに、コプロセッサ命令待ち行列8を通じて、プロセッサ1はさらなるタスクのための命令、すなわち、コプロセッサ・コントローラ9の構成、およびコプロセッサ2上の計算の開始のための命令を提供する。コプロセッサ2上で実行されるこの計算は、バースト・バッファ・メモリ5を通じてデータにアクセスする。
2)「ダブル・バッファリング」とよばれる技術を使用した、コプロセッサ2上の計算の同時実行、およびメイン・メモリ3とバースト・バッファ・メモリ5の間のデータ転送、および
3)プロセッサ1の実行をコプロセッサ2およびバースト・バッファ・メモリ5の実行から、命令待ち行列の使用を通じて切り離すことである。
バースト={B+S×i|B,S,i∈N∧0≦i<L}
ソフトウェアでは、バーストをエレメントサイズによって定義することもできる。これは、バーストをバイト、ハーフワード、またはワードのサイズにすることができることを意味する。ストライドの単位は、このことを考慮しなければならない。「サイズド・バースト」は、次の形式の4個のエレメントからなる集合によって定義される。
「チャネル・バースト」は、サイズがメモリへのチャネルの幅である、サイズド・バーストである。コンパイラが、ソフトウェア・サイズド・バーストからチャネル・バーストへのマッピングを担う。チャネル・バーストは、次の4個のエレメントからなる集合によって定義することができる。
チャネル幅が32ビット(または4バイト)である場合、チャネル・バーストが常に以下の形式である。
あるいは、3個のエレメントからなる集合(base_address,1ength,stride)に短縮される。

block_incrementビットが設定される場合、MATにおいて索引付けされたエントリのmemaddrフィールドが、転送が完了するときに自動的に更新される(以下で論じられるように)。
1.メモリ・アドレス(memaddr)。メイン・メモリにおける関連領域の開始アドレス。この位置が物理メモリ空間にあることが理想的であり、これは、仮想アドレス変換が2つの物理ページにまたがるバースト要求の結果となる可能性があり、これがメモリ・コントローラに難点を引き起こすからである。
2.エクステント(extent)。転送のエクステント。これは転送の長さであり、ストライドで乗算され、転送された最後のアドレス+1を与える。転送の長さは、エクステントをストライドにより除算することによって計算され、これは、転送が完了した後で、関連するBAT66(以下参照)のbufsizeフィールドへ自動的にコピーされる。
3.ストライド(stride)。転送における連続したエレメントの間の間隔。
これは、32語(32個の4バイト語)バーストの結果となり、各語が4語(4個の4バイト語)によって分離される。
1.バッファ・アドレス(bufaddr)。バッファ領域におけるバッファの開始。
2.バッファ・サイズ(bufsize)。最後の転送で使用されたバッファ領域のサイズ。
・CC_CURRENT_PORTは、ポートの1つを、すべての後続のCC_PORT_xxx命令の受信者として、次のCC_CURRENT_PORTまで、選択する。
・CC_PORT_PERIOD()は、現在のポートの活動化の周期を、整数パラメータの値に設定する。
・CC_PORT_PHASE_START/CC_PORT_PHASE_END(start end)は、現在のポートの活動化の段階の開始/終了を、整数のパラメータ(start end)の値に設定する。
・CC_PORT_TIME_START/CC_PORT_TIME_END(tstart tend)は、現在のポートの活動の最初/最後のサイクルを設定する。
・CC_PORT_ADDRESS(addrstart)は、現在のポートの現在のアドレスを、整数のパラメータaddrstartの値に設定する。
・CC_PORT_INCREMENT(addrincr)は、現在のポートのアドレス増分を、整数のパラメータaddrincrの値に設定する。
・CC_PORT_IS_WRITE(rw)は、現在のポートのためのデータ転送方向を、ブール・パラメータrwの値に設定する。
・CC_START_EXEC ncyclesは、コプロセッサ・コントローラ2の実行を、関連付けられた整数パラメータncyclesによって指定されたクロック・サイクルの数だけ開始する。
・CC_LXS_DECREMENTは、LXセマフォの値を(以前に記載されたように、中断の方法において)減分する。
・CC_XSS_INCREMENTは、XSセマフォの値を増分する。
1.メイン・コプロセッサ・コントローラ9が、前に記載されたように、Chessアレイにおいて存在する各論理ストリーム毎の合計数、周期、段階およびアドレス増分に従って構成される。所望の機能を実行するためのコプロセッサ・コントローラ9のプログラミングの一例が、下に示される。
2.コプロセッサ・コントローラ9の構成における次のステップは、アドレス構成である。各論理ストリームの特性(周期、段階)がアルゴリズム中で同じであり続ける可能性が高いが、バースト・バッファ・メモリ5におけるコプロセッサ・コントローラ9によってアクセスされた実アドレスは変わる。それはこの可変性であり、これは、バースト・バッファ・コントローラ7がダブル・バッファリングを、バースト・バッファ・アーキテクチャ内で直接の方法で実行できるようにする。このダブル・バッファリングの効果は、先に述べられたように、コプロセッサ2に、それが連続ストリームと対話中である印象を与えることであるが、実際にはバッファが連続的に交換されている。
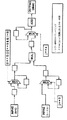
計算モデル全体の例を図5を参照して説明する。この例は、アルゴリズムがこのアーキテクチャにおいて使用するためにどのように記録することができるかを指示し、一例として簡素なベクトル加算を使用し、これは従来のマイクロプロセッサ向けに以下のようにCでコーディングすることができる。
int a[1024],b[1024],c[1024];
for(i=0;i<1024;i++)
a[i]=b[i]+c[i];
CC_CURRENT_PORT(0);
CC_PORT_INCREMENT(4);
CC_TRANSFER_SIZE(4);
CC_PORT_PERIOD(3);
CC_PORT_PHASE_START(0);
CC_PORT_PHASE_END(1);
CC_PORT_START_TIME(0);
CC_PORT_END_TIME(3*BLEN*MAXK+3);
CC_PORT_IS_WRITE(0);
CIQ_LXD(N):N個のCC_LXS_DECREMENT命令をコプロセッサ命令待ち行列8に挿入する。
CIQ_SA(ポート、アドレス):CC_CURRENT_PORT(ポート)およびCC_PORT_ADDRESS(アドレス)命令をコプロセッサ命令待ち行列8に挿入する。
CIQ_ST(cycleno):コプロセッサ2にカウンタ42のcyclenoチックだけ実行させるために、CC_EXECUTE_START(cycleno)命令を挿入する。
CIQ_XSI(N):N個のCC_XSS_INCREMENT命令をコプロセッサ命令待ち行列8に挿入する。
BIQ_FLB(mate,bate):BB_ロードバースト(mate,bate,TRUE)命令をバースト命令待ち行列6に挿入する。
BIQ_LXI(N):N個のBB_LX_INCREMENT命令をバースト命令待ち行列6に挿入する。
BIQ_FSB(mate,bate):BB_ストアバースト(mate,bate,TRUE)命令をバースト命令待ち行列6に挿入する。
BIQ_XSD(N):N個のBB_XS_DECREMENT命令をバースト命令待ち行列6に挿入する。
計算モデルの原理を、ハンド・コーディングによって直接の様式で活用することができる。つまり、手動でCコードを書いて、従来の方法でシステム構成エレメントの適切な動作をスケジュールするように適合されたCPU上で実行して(命令を適切な待ち行列に配置し、記載されたようにシステム構成エレメントを動作に設定し)、コプロセッサのための適切な構成を、そのコプロセッサを構成するための標準の合成ツールに従って提供することである。CHESSのような、構成可能またはFPGAに基づいたプロセッサでは、このツールが一般にハードウェア記述言語となる。CHESSに使用するための適切なハードウェア記述言語はJHDLであり、たとえば、Peter BellowsおよびBrad Hutchingsによる1998年4月の「JHDL−An HDL for Reconfigurable Systems」Proceedings of the IEEE Symposium on Field−Programmable Custom Computing Machinesに記載されている。
int i,j,src[],kernel[],dst[];
for(i=0 ; i<1000; i++)
for(j=0;j<4; j++)
dst[i]=dst[i]+src[4+i-j]*kernel[j];
画像たたみこみアルゴリズムが、次の表のループ・ネストによって記述される。
for(i=0;i<IMAGE_HEIGHT;i++)
for(j=0;j<IMAGE_WIDTH;j++)
for(k=0;k<KERNEL_HEIGHT;k++)
for(l=0;1<KERNEL_WIDTH;l++)
Dest[i,j]+=Source[(i+1)-k,(j+1)-l]*C[k,l];
プロセッサ1をコプロセッサ2およびバースト・バッファ・メモリ5から切り離す機能を、命令待ち行列6、8以外によって達成することができる。有効な代替物は、2つの待ち行列を、図12に記載されたような、命令をバースト・バッファ・メモリ5およびコプロセッサ2へ発行することに完全に専用にされた2つの小型プロセッサ(それぞれが各待ち行列用)と置換することである。バースト命令待ち行列が(図1の実施形態を参照して)バースト・コマンド・プロセッサ106によって置換され、コプロセッサ命令待ち行列が、コプロセッサ・コマンド・プロセッサ108によって置換される。これは、これらの2つの構成エレメントによって実行された唯一のタスクとなるので、これらがコプロセッサ2およびバースト・バッファ7からそれぞれ切り離される必要はなくなる。コマンド・プロセッサ106、108のそれぞれが、コマンドをコプロセッサまたはバースト・バッファ(適切なように)へ発行することによって動作でき、次いで、そのコマンドがその実行を完了するまで何も行わず、別のコマンドを発行することなどができる。これは、設計を複雑にするが、メイン・プロセッサ1をその残りの、命令を待ち行列へ発行する単純なタスクから解放する。プロセッサ1によって実行される唯一の作業は、次いで、これらの2つのプロセッサの初期設定となり、これは計算の開始直前に行われる。したがって、計算中に、プロセッサ1が完全にコプロセッサ2およびバースト・バッファ・メモリ5の実行から切り離される。
CC_LX_DECREMENT、
CC_LX_DECREMENT、
CC_START_EXEC、
CC_XS_INCREMENT
2:M*周期i+段階i=ECであるようなMが存在する場合、状態機械iを実行のために選択する
3:このような状態機械iが発見された場合、状態機械iによって記述された命令を実行する(これは、中断動作を含むことができる)
4:1へ戻る
Claims (17)
- 第1のプロセッサと、
前記第1のプロセッサへのコプロセッサとして使用するための第2のプロセッサと、
メモリと、
バースト命令に従ってデータ・バーストにおいて前記メモリに書き込みまたは読み取るデータを入れるための、少なくとも1つのデータ・バッファと、
前記バースト命令を実行するためのバースト・コントローラと、
前記バースト・コントローラによる実行のためにバースト命令を順番に提供するためのバースト命令エレメントと、
コプロセッサ命令およびバースト命令の実行を、前記コプロセッサ命令およびバースト命令が実行するデータの可用性により、同期化するための同期化機構と
を含み、
バースト命令が前記第1のプロセッサによって前記バースト命令エレメントへ提供され、前記バースト・コントローラによって実行されたバースト命令に従って前記少なくとも1つのデータ・バッファを通じて、データが、前記第2のプロセッサへの入力データとして前記メモリから読み取られ、前記第2のプロセッサからの出力データとして前記メモリへ書き込まれ、
前記同期化機構は、
特定のバースト命令の実行により増分され、特定のコプロセッサ命令の実行により減分される第1のカウンタを少なくとも含み、
前記第1のカウンタを、第1の低しきい値を越えてさらに減分することができないとき、前記第2のプロセッサの関連付けられた実行のためのコプロセッサ命令がストールあるいは防止され、
前記第1のカウンタを、第1の高しきい値を越えてさらに増分することができないとき、前記少なくとも1つのバッファから前記メモリへのデータの関連付けられた格納のためのバースト命令がストールあるいは防止される
コンピュータ・システム。
- 前記第2のプロセッサの実行を順番に制御するためのコプロセッサ命令を提供するためのコプロセッサ命令エレメントをさらに含み、前記コプロセッサ命令が前記第1のプロセッサによって提供される、
請求項1に記載のコンピュータ・システム。
- コプロセッサ・コントローラをさらに含み、
前記コプロセッサ・コントローラがコプロセッサ命令を前記コプロセッサ命令エレメントから受信し、前記第2のプロセッサの実行を、受信されたコプロセッサ命令に従って制御し、前記コプロセッサと前記少なくとも1つのデータ・バッファの間の通信を制御する、
請求項2に記載のコンピュータ・システム。
- 前記同期化機構が、前記少なくとも1つのデータ・バッファにまだロードされていないデータにおける前記第2のプロセッサの実行を必要とするコプロセッサ命令の実行をブロックするように適合され、前記少なくとも1つのデータ・バッファから前記メモリへのデータの格納のためのバースト命令の実行を、このようなデータが前記第2のプロセッサによって前記少なくとも1つのデータ・バッファへ提供されていない場合にブロックするように適合される、
請求項1に記載のコンピュータ・システム。
- 前記同期化機構は、
特定のコプロセッサ命令の実行により増分され、特定のバースト命令の実行により減分される第2のカウンタをさらに含み、
前記第2のカウンタを、第2の低しきい値を越えてさらに減分することができないとき、前記少なくとも1つのバッファから前記メモリへのデータの関連付けられた格納のためのバースト命令がストールあるいは防止される、
請求項1に記載のコンピュータ・システム。
- 前記第2のカウンタを、第2の高しきい値を越えてさらに増分すること
ができないとき、前記第2のプロセッサの関連付けられた実行のためのコプロセッサ命令がストールあるいは防止される、
請求項5に記載のコンピュータ・システム。
- 前記バースト命令エレメントは、命令キューである、
請求項1に記載のコンピュータ・システム。
- 前記バースト命令エレメントは、さらに加えられたプロセッサである、
請求項1に記載のコンピュータ・システム。
- 前記バースト命令エレメントは、プログラム可能な状態機械である、
請求項1に記載のコンピュータ・システム。
- 前記第1のプロセッサは、コンピュータ装置の中央処理装置である、
請求項1に記載のコンピュータ・システム。
- コンピュータ・システムを動作する方法であって、
第1のプロセッサ、および前記第1のプロセッサへのコプロセッサとして動作する第2のプロセッサによる実行のためのコードを提供することと、
前記第2のプロセッサによって実行されるタスクを提供することとしての、前記コードの一部の識別することと、
前記タスクを提供するコードを、コプロセッサ・コントローラによる実行のためのコプロセッサ命令で置換すること
を含み、
前記コプロセッサ命令は、
前記第2のプロセッサによる前記タスクの実行を制御するように決定され、
前記コードおよび前記タスクから、少なくとも1つのデータ・バッファにより、前記第2のプロセッサによるアクセスのためにデータ・バーストにおいてメイン・メモリからデータを読み取り、そこへ書き込むことができるようにするためのバースト命令を決定することと、
前記少なくとも1つのデータ・バッファと前記メイン・メモリの間でデータの転送を制御するバースト・コントローラによるバースト命令の実行と共に、前記コプロセッサ上で前記タスクを実行することと
を含み、
前記タスクの実行において、コプロセッサ命令の実行とバースト命令の実行の間の同期化が、同期化機構によって達成され、
前記同期化機構は、
特定のバースト命令の実行により増分され、特定のコプロセッサ命令の実行により減分される第1のカウンタを少なくとも含み、
前記第1のカウンタを、第1の低しきい値を越えてさらに減分することができないとき、前記第2のプロセッサの関連付けられた実行のためのコプロセッサ命令がストールあるいは防止され、
前記第1のカウンタを、第1の高しきい値を越えてさらに増分することができないとき、前記少なくとも1つのバッファから前記メモリへのデータの関連付けられた格納のためのバースト命令がストールあるいは防止される
方法。
- バースト命令を決定する前記ステップが、前記バースト命令を、前記第1のプロセッサによって実行される前記コードの一部内に含めることをさらに含む、
請求項11に記載の方法。
- バースト命令を決定する前記ステップが、前記コードから前記第2のプロセッサによってアクセスされるメモリ・アドレスを決定すること、および少なくとも1つのデータ・バッファにより、前記第2のプロセッサによるアクセスのためにデータ・バーストにおいてメイン・メモリからデータを読み取り、そこへ書き込むことができるように、前記第2のプロセッサによって行われるメモリ・アクセスを編成することをさらに含む、
請求項11に記載の方法。
- 前記同期化機構が、前記第1の命令の正しい実行のために完了が必要である第2の命令が完了するまで、前記第1の命令をブロックすることを含む、
請求項11に記載の方法。
- 前記コプロセッサ命令エレメントは、命令キューである、
請求項2に記載のコンピュータ・システム。
- 前記コプロセッサ命令エレメントは、さらに加えられたプロセッサである、
請求項2に記載のコンピュータ・システム。
- 前記コプロセッサ命令エレメントは、プログラム可能な状態機械である、
請求項2に記載のコンピュータ・システム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP99304659.8 | 1999-06-15 | ||
| EP99304659A EP1061439A1 (en) | 1999-06-15 | 1999-06-15 | Memory and instructions in computer architecture containing processor and coprocessor |
| PCT/GB2000/002331 WO2000077627A1 (en) | 1999-06-15 | 2000-06-15 | Memory and instructions in computer architecture containing processor and coprocessor |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2003502728A JP2003502728A (ja) | 2003-01-21 |
| JP2003502728A5 JP2003502728A5 (ja) | 2007-07-26 |
| JP5283810B2 true JP5283810B2 (ja) | 2013-09-04 |
Family
ID=8241459
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2001503043A Expired - Fee Related JP5283810B2 (ja) | 1999-06-15 | 2000-06-15 | プロセッサおよびコプロセッサを含むコンピュータ・システム |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US6782445B1 (ja) |
| EP (2) | EP1061439A1 (ja) |
| JP (1) | JP5283810B2 (ja) |
| DE (1) | DE60045093D1 (ja) |
| WO (1) | WO2000077627A1 (ja) |
Families Citing this family (62)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7266725B2 (en) | 2001-09-03 | 2007-09-04 | Pact Xpp Technologies Ag | Method for debugging reconfigurable architectures |
| DE19651075A1 (de) | 1996-12-09 | 1998-06-10 | Pact Inf Tech Gmbh | Einheit zur Verarbeitung von numerischen und logischen Operationen, zum Einsatz in Prozessoren (CPU's), Mehrrechnersystemen, Datenflußprozessoren (DFP's), digitalen Signal Prozessoren (DSP's) oder dergleichen |
| DE19654595A1 (de) | 1996-12-20 | 1998-07-02 | Pact Inf Tech Gmbh | I0- und Speicherbussystem für DFPs sowie Bausteinen mit zwei- oder mehrdimensionaler programmierbaren Zellstrukturen |
| DE59710317D1 (de) | 1996-12-27 | 2003-07-24 | Pact Inf Tech Gmbh | VERFAHREN ZUM SELBSTÄNDIGEN DYNAMISCHEN UMLADEN VON DATENFLUSSPROZESSOREN (DFPs) SOWIE BAUSTEINEN MIT ZWEI- ODER MEHRDIMENSIONALEN PROGRAMMIERBAREN ZELLSTRUKTUREN (FPGAs, DPGAs, o.dgl.) |
| US6542998B1 (en) | 1997-02-08 | 2003-04-01 | Pact Gmbh | Method of self-synchronization of configurable elements of a programmable module |
| US8686549B2 (en) | 2001-09-03 | 2014-04-01 | Martin Vorbach | Reconfigurable elements |
| DE19861088A1 (de) | 1997-12-22 | 2000-02-10 | Pact Inf Tech Gmbh | Verfahren zur Reparatur von integrierten Schaltkreisen |
| DE10081643D2 (de) | 1999-06-10 | 2002-05-29 | Pact Inf Tech Gmbh | Sequenz-Partitionierung auf Zellstrukturen |
| JP2004506261A (ja) | 2000-06-13 | 2004-02-26 | ペーアーツェーテー イクスペーペー テクノロジーズ アクチエンゲゼルシャフト | パイプラインctプロトコルおよびct通信 |
| US8058899B2 (en) | 2000-10-06 | 2011-11-15 | Martin Vorbach | Logic cell array and bus system |
| US9037807B2 (en) | 2001-03-05 | 2015-05-19 | Pact Xpp Technologies Ag | Processor arrangement on a chip including data processing, memory, and interface elements |
| US7844796B2 (en) | 2001-03-05 | 2010-11-30 | Martin Vorbach | Data processing device and method |
| US7210129B2 (en) * | 2001-08-16 | 2007-04-24 | Pact Xpp Technologies Ag | Method for translating programs for reconfigurable architectures |
| US7444531B2 (en) | 2001-03-05 | 2008-10-28 | Pact Xpp Technologies Ag | Methods and devices for treating and processing data |
| US7155602B2 (en) | 2001-04-30 | 2006-12-26 | Src Computers, Inc. | Interface for integrating reconfigurable processors into a general purpose computing system |
| US7210022B2 (en) * | 2001-05-15 | 2007-04-24 | Cloudshield Technologies, Inc. | Apparatus and method for interconnecting a processor to co-processors using a shared memory as the communication interface |
| US7657877B2 (en) | 2001-06-20 | 2010-02-02 | Pact Xpp Technologies Ag | Method for processing data |
| US7996827B2 (en) | 2001-08-16 | 2011-08-09 | Martin Vorbach | Method for the translation of programs for reconfigurable architectures |
| US7434191B2 (en) | 2001-09-03 | 2008-10-07 | Pact Xpp Technologies Ag | Router |
| US8686475B2 (en) | 2001-09-19 | 2014-04-01 | Pact Xpp Technologies Ag | Reconfigurable elements |
| AU2002254549A1 (en) * | 2001-12-05 | 2003-06-23 | Src Computers, Inc. | An interface for integrating reconfigurable processors into a general purpose computing system |
| US7653736B2 (en) * | 2001-12-14 | 2010-01-26 | Nxp B.V. | Data processing system having multiple processors and a communications means in a data processing system |
| WO2003060747A2 (de) | 2002-01-19 | 2003-07-24 | Pact Xpp Technologies Ag | Reconfigurierbarer prozessor |
| EP2043000B1 (de) | 2002-02-18 | 2011-12-21 | Richter, Thomas | Bussysteme und Rekonfigurationsverfahren |
| US8914590B2 (en) | 2002-08-07 | 2014-12-16 | Pact Xpp Technologies Ag | Data processing method and device |
| DE10221206B4 (de) * | 2002-05-13 | 2008-04-03 | Systemonic Ag | Burst Zugriffsverfahren auf Co-Prozessoren |
| US20040006667A1 (en) * | 2002-06-21 | 2004-01-08 | Bik Aart J.C. | Apparatus and method for implementing adjacent, non-unit stride memory access patterns utilizing SIMD instructions |
| US7657861B2 (en) | 2002-08-07 | 2010-02-02 | Pact Xpp Technologies Ag | Method and device for processing data |
| AU2003286131A1 (en) | 2002-08-07 | 2004-03-19 | Pact Xpp Technologies Ag | Method and device for processing data |
| US7394284B2 (en) | 2002-09-06 | 2008-07-01 | Pact Xpp Technologies Ag | Reconfigurable sequencer structure |
| WO2004042562A2 (en) * | 2002-10-31 | 2004-05-21 | Lockheed Martin Corporation | Pipeline accelerator and related system and method |
| US20040136241A1 (en) | 2002-10-31 | 2004-07-15 | Lockheed Martin Corporation | Pipeline accelerator for improved computing architecture and related system and method |
| US7430652B2 (en) * | 2003-03-28 | 2008-09-30 | Tarari, Inc. | Devices for performing multiple independent hardware acceleration operations and methods for performing same |
| EP1676208A2 (en) | 2003-08-28 | 2006-07-05 | PACT XPP Technologies AG | Data processing device and method |
| US20050055594A1 (en) * | 2003-09-05 | 2005-03-10 | Doering Andreas C. | Method and device for synchronizing a processor and a coprocessor |
| JP2005202767A (ja) | 2004-01-16 | 2005-07-28 | Toshiba Corp | プロセッサシステム、dma制御回路、dma制御方法、dmaコントローラの制御方法、画像処理方法および画像処理回路 |
| US7743376B2 (en) * | 2004-09-13 | 2010-06-22 | Broadcom Corporation | Method and apparatus for managing tasks in a multiprocessor system |
| US20060085781A1 (en) | 2004-10-01 | 2006-04-20 | Lockheed Martin Corporation | Library for computer-based tool and related system and method |
| US7472261B2 (en) * | 2005-11-08 | 2008-12-30 | International Business Machines Corporation | Method for performing externally assisted calls in a heterogeneous processing complex |
| US8250503B2 (en) | 2006-01-18 | 2012-08-21 | Martin Vorbach | Hardware definition method including determining whether to implement a function as hardware or software |
| US8032734B2 (en) * | 2006-09-06 | 2011-10-04 | Mips Technologies, Inc. | Coprocessor load data queue for interfacing an out-of-order execution unit with an in-order coprocessor |
| US9946547B2 (en) * | 2006-09-29 | 2018-04-17 | Arm Finance Overseas Limited | Load/store unit for a processor, and applications thereof |
| US7594079B2 (en) | 2006-09-29 | 2009-09-22 | Mips Technologies, Inc. | Data cache virtual hint way prediction, and applications thereof |
| US20080082793A1 (en) * | 2006-09-29 | 2008-04-03 | Mips Technologies, Inc. | Detection and prevention of write-after-write hazards, and applications thereof |
| US7934063B2 (en) | 2007-03-29 | 2011-04-26 | International Business Machines Corporation | Invoking externally assisted calls from an isolated environment |
| US7817657B1 (en) | 2007-06-14 | 2010-10-19 | Xilinx, Inc. | Circuit for processing network packets |
| US8144702B1 (en) * | 2007-06-14 | 2012-03-27 | Xilinx, Inc. | Generation of a pipeline for processing a type of network packets |
| US7788470B1 (en) * | 2008-03-27 | 2010-08-31 | Xilinx, Inc. | Shadow pipeline in an auxiliary processor unit controller |
| EP2996035A1 (en) | 2008-10-15 | 2016-03-16 | Hyperion Core, Inc. | Data processing device |
| US9104403B2 (en) * | 2010-08-18 | 2015-08-11 | Freescale Semiconductor, Inc. | Data processing system having selective redundancy and method therefor |
| JP2012252374A (ja) * | 2011-05-31 | 2012-12-20 | Renesas Electronics Corp | 情報処理装置 |
| US9880852B2 (en) * | 2012-12-27 | 2018-01-30 | Intel Corporation | Programmable hardware accelerators in CPU |
| US10936198B2 (en) | 2016-07-26 | 2021-03-02 | MemRay Corporation | Resistance switching memory-based coprocessor and computing device including the same |
| US10929059B2 (en) | 2016-07-26 | 2021-02-23 | MemRay Corporation | Resistance switching memory-based accelerator |
| JP2018120448A (ja) * | 2017-01-26 | 2018-08-02 | ソニーセミコンダクタソリューションズ株式会社 | 演算処理装置および情報処理システム |
| US11294678B2 (en) | 2018-05-29 | 2022-04-05 | Advanced Micro Devices, Inc. | Scheduler queue assignment |
| US11138009B2 (en) * | 2018-08-10 | 2021-10-05 | Nvidia Corporation | Robust, efficient multiprocessor-coprocessor interface |
| US11334384B2 (en) * | 2019-12-10 | 2022-05-17 | Advanced Micro Devices, Inc. | Scheduler queue assignment burst mode |
| US11249766B1 (en) | 2020-09-14 | 2022-02-15 | Apple Inc. | Coprocessor synchronizing instruction suppression |
| US11948000B2 (en) | 2020-10-27 | 2024-04-02 | Advanced Micro Devices, Inc. | Gang scheduling for low-latency task synchronization |
| US12066955B2 (en) * | 2021-05-19 | 2024-08-20 | Hughes Network Systems, Llc | System and method for enhancing throughput during data transfer |
| CN116804915B (zh) * | 2023-08-28 | 2023-12-15 | 腾讯科技(深圳)有限公司 | 基于存储器的数据交互方法、处理器、设备以及介质 |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4099236A (en) * | 1977-05-20 | 1978-07-04 | Intel Corporation | Slave microprocessor for operation with a master microprocessor and a direct memory access controller |
| JPS5840214B2 (ja) * | 1979-06-26 | 1983-09-03 | 株式会社東芝 | 計算機システム |
| US4589067A (en) * | 1983-05-27 | 1986-05-13 | Analogic Corporation | Full floating point vector processor with dynamically configurable multifunction pipelined ALU |
| US6438683B1 (en) * | 1992-07-28 | 2002-08-20 | Eastman Kodak Company | Technique using FIFO memory for booting a programmable microprocessor from a host computer |
| US5708830A (en) * | 1992-09-15 | 1998-01-13 | Morphometrix Inc. | Asynchronous data coprocessor utilizing systolic array processors and an auxiliary microprocessor interacting therewith |
| US5884050A (en) * | 1996-06-21 | 1999-03-16 | Digital Equipment Corporation | Mechanism for high bandwidth DMA transfers in a PCI environment |
| US5784582A (en) * | 1996-10-28 | 1998-07-21 | 3Com Corporation | Data processing system having memory controller for supplying current request and next request for access to the shared memory pipeline |
| EP0853283A1 (en) * | 1997-01-09 | 1998-07-15 | Hewlett-Packard Company | Computer system with memory controller for burst transfer |
| DE69727465T2 (de) * | 1997-01-09 | 2004-12-23 | Hewlett-Packard Co. (N.D.Ges.D.Staates Delaware), Palo Alto | Rechnersystem mit Speichersteuerung für Stossbetrieb-Übertragung |
| EP0862118B1 (en) | 1997-01-09 | 2004-02-04 | Hewlett-Packard Company, A Delaware Corporation | Computer system comprising a memory controller for burst transfer |
| EP0858168A1 (en) | 1997-01-29 | 1998-08-12 | Hewlett-Packard Company | Field programmable processor array |
| EP0858167A1 (en) | 1997-01-29 | 1998-08-12 | Hewlett-Packard Company | Field programmable processor device |
| DE69827589T2 (de) | 1997-12-17 | 2005-11-03 | Elixent Ltd. | Konfigurierbare Verarbeitungsanordnung und Verfahren zur Benutzung dieser Anordnung, um eine Zentraleinheit aufzubauen |
| EP0924625B1 (en) | 1997-12-17 | 2004-11-17 | Elixent Limited | Configurable processing device and method of using said device to construct a central processing unit |
| US6442671B1 (en) * | 1999-03-03 | 2002-08-27 | Philips Semiconductors | System for priming a latch between two memories and transferring data via the latch in successive clock cycle thereafter |
-
1999
- 1999-06-15 EP EP99304659A patent/EP1061439A1/en not_active Withdrawn
-
2000
- 2000-06-15 DE DE60045093T patent/DE60045093D1/de not_active Expired - Lifetime
- 2000-06-15 US US09/763,021 patent/US6782445B1/en not_active Expired - Fee Related
- 2000-06-15 WO PCT/GB2000/002331 patent/WO2000077627A1/en active Application Filing
- 2000-06-15 JP JP2001503043A patent/JP5283810B2/ja not_active Expired - Fee Related
- 2000-06-15 EP EP00942188A patent/EP1104562B1/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| DE60045093D1 (de) | 2010-11-25 |
| EP1061439A1 (en) | 2000-12-20 |
| WO2000077627A1 (en) | 2000-12-21 |
| EP1104562A1 (en) | 2001-06-06 |
| US6782445B1 (en) | 2004-08-24 |
| JP2003502728A (ja) | 2003-01-21 |
| EP1104562B1 (en) | 2010-10-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5283810B2 (ja) | プロセッサおよびコプロセッサを含むコンピュータ・システム | |
| JP6243935B2 (ja) | コンテキスト切替方法及び装置 | |
| US10203958B2 (en) | Streaming engine with stream metadata saving for context switching | |
| US7904702B2 (en) | Compound instructions in a multi-threaded processor | |
| US20220179652A1 (en) | Inserting null vectors into a stream of vectors | |
| JP3752224B2 (ja) | コンピュータ・システムにおいて命令を処理する方法および装置 | |
| JP2003505753A (ja) | セル構造におけるシーケンス分割方法 | |
| US20230385063A1 (en) | Streaming engine with early exit from loop levels supporting early exit loops and irregular loops | |
| KR20030074047A (ko) | 멀티 프로세서 시스템 | |
| EP1061438A1 (en) | Computer architecture containing processor and coprocessor | |
| US7383424B1 (en) | Computer architecture containing processor and decoupled coprocessor | |
| JPH0228721A (ja) | プロセシング・システム | |
| EP0521486B1 (en) | Hierarchical structure processor | |
| US11900117B2 (en) | Mechanism to queue multiple streams to run on streaming engine | |
| US6327648B1 (en) | Multiprocessor system for digital signal processing | |
| WO2004092949A2 (en) | Processing system with instruction-and thread-level parallelism | |
| JP3789937B2 (ja) | ベクトルプロセッサのためのチャンク連鎖 | |
| US20230004391A1 (en) | Streaming engine with stream metadata saving for context switching | |
| WO2020237231A1 (en) | Inserting predefined pad values into a stream of vectors | |
| JP2004515856A (ja) | ディジタル信号処理装置 | |
| JP2668987B2 (ja) | データ処理装置 | |
| US20230251970A1 (en) | Padding and suppressing rows and columns of data | |
| US12019561B2 (en) | Pseudo-first in, first out (FIFO) tag line replacement | |
| JP3668643B2 (ja) | 情報処理装置 | |
| JP3743155B2 (ja) | パイプライン制御型計算機 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070604 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070604 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100629 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100901 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110628 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20110708 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20111024 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20111027 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20120302 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20120820 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20120821 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20121023 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130529 |
|
| LAPS | Cancellation because of no payment of annual fees |