JP4451908B2 - ユニコード・コンバータ - Google Patents
ユニコード・コンバータ Download PDFInfo
- Publication number
- JP4451908B2 JP4451908B2 JP2008050694A JP2008050694A JP4451908B2 JP 4451908 B2 JP4451908 B2 JP 4451908B2 JP 2008050694 A JP2008050694 A JP 2008050694A JP 2008050694 A JP2008050694 A JP 2008050694A JP 4451908 B2 JP4451908 B2 JP 4451908B2
- Authority
- JP
- Japan
- Prior art keywords
- character
- string
- text element
- source
- code
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 claims description 212
- 238000006243 chemical reaction Methods 0.000 claims description 194
- 238000013507 mapping Methods 0.000 claims description 176
- 239000000872 buffer Substances 0.000 claims description 53
- 230000011218 segmentation Effects 0.000 claims description 3
- 230000008569 process Effects 0.000 description 164
- 230000009471 action Effects 0.000 description 96
- 238000012545 processing Methods 0.000 description 95
- 238000010586 diagram Methods 0.000 description 20
- 230000006870 function Effects 0.000 description 10
- 239000003607 modifier Substances 0.000 description 10
- 230000008859 change Effects 0.000 description 9
- 230000008707 rearrangement Effects 0.000 description 9
- 238000013515 script Methods 0.000 description 9
- 238000013461 design Methods 0.000 description 8
- 230000014509 gene expression Effects 0.000 description 7
- 230000002457 bidirectional effect Effects 0.000 description 6
- 238000004422 calculation algorithm Methods 0.000 description 6
- 230000006399 behavior Effects 0.000 description 5
- 239000000945 filler Substances 0.000 description 4
- 230000007704 transition Effects 0.000 description 4
- 230000004913 activation Effects 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 239000012634 fragment Substances 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 230000002730 additional effect Effects 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 230000006835 compression Effects 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- 230000001960 triggered effect Effects 0.000 description 2
- PCTMTFRHKVHKIS-BMFZQQSSSA-N (1s,3r,4e,6e,8e,10e,12e,14e,16e,18s,19r,20r,21s,25r,27r,30r,31r,33s,35r,37s,38r)-3-[(2r,3s,4s,5s,6r)-4-amino-3,5-dihydroxy-6-methyloxan-2-yl]oxy-19,25,27,30,31,33,35,37-octahydroxy-18,20,21-trimethyl-23-oxo-22,39-dioxabicyclo[33.3.1]nonatriaconta-4,6,8,10 Chemical compound C1C=C2C[C@@H](OS(O)(=O)=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2.O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C=C/C=C/C=C/[C@H](C)[C@@H](O)[C@@H](C)[C@H](C)OC(=O)C[C@H](O)C[C@H](O)CC[C@@H](O)[C@H](O)C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 PCTMTFRHKVHKIS-BMFZQQSSSA-N 0.000 description 1
- 235000016496 Panda oleosa Nutrition 0.000 description 1
- 240000000220 Panda oleosa Species 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000011022 operating instruction Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000007493 shaping process Methods 0.000 description 1
- QZRSVBDWRWTHMT-UHFFFAOYSA-M silver;3-carboxy-3,5-dihydroxy-5-oxopentanoate Chemical compound [Ag+].OC(=O)CC(O)(C([O-])=O)CC(O)=O QZRSVBDWRWTHMT-UHFFFAOYSA-M 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images






















Landscapes
- Document Processing Apparatus (AREA)
Description

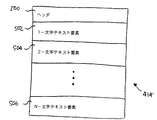
1.コード・ポイント:コード・ポイントとは、特定のコード化におけるビット・パターンである。通常、ビット・パターンは1または2バイト以上の長さになっている。ユニコードのコード・ポイントは常に16ビットまたは2バイトである。
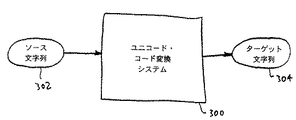
本発明による一般的変換手法はソース文字を異なるコード化のターゲット文字に変換する。好ましくは、ソース文字またはターゲット文字のどちらかはユニコード文字になっている。
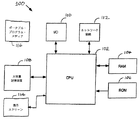
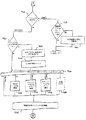
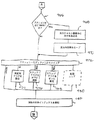
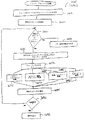
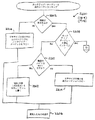
スキャナ408はスキャナ・テーブル410と一緒に使用されて、ユニコード文字列404をスキャンし、ルックアップ・ハンドラ412が必要とする次のテキスト要素と追加情報を戻す。追加情報には、方向情報、コンテキスト情報、および種々の状態インジケータの1つまたは2つ以上が含まれている。以下では、スキャナ408の一般的オペレーションについて説明する。スキャナ408は入力ユニコード文字列404の文字をスキャンして行く。ターゲット・コード化のために方向情報が必要であれば、テキスト要素内の各文字ごとに文字方向が取得される。また、ターゲット・コード化のために文字コンテキスト情報が必要であれば、テキスト要素内の各文字ごとに文字コンテキスト情報が取得される。そのあと、スキャナ408が文字の各々をスキャンしていくとき、スキャナ408はスキャナ・テーブル410に入っている情報に従って文字に対するアクションをとる。スキャナ408がどのようなアクションをとるかは、状態と文字クラスに基づいて判断される。スキャナ408がとることができるアクションとしては、現在の文字にマークを付けること、シメトリック・スワッピング・ビットをセットまたはクリアすること、テキスト要素のコンテキスト形式を記録すること、テキスト要素が再配列を必要とすることを示すフラグをセットすること、テキスト要素の終わりを示すこと、などがある。シメトリック・スワッピング・ビット、コンテキストおよび方向はスキャナの状態に関する情報として状態管理機構418によってセーブされる。戻す前に、スキャナ408はテキスト要素のコンテキスト情報をセーブしておく。スキャナ408はテキスト要素(入力文字列内の各テキスト要素)とその属性を返却する。属性には次のものがある。方向、クラス、優先順位、シメトリック・スワッピング状態、サブセットおよびコンテキストである。スキャナ408がテキスト要素を判断したあと、文字を標準形順序に再配列する必要が起こる場合がある。1つの例として、テキスト要素内の文字の再配列はユニコードで定義されている標準形順序になっていない非スペース・マークがテキスト要素に含まれているときに行われる。
マッピング・テーブル414は1つまたは複数のユニコード文字の入力シーケンスをターゲット・コード化における1つまたは複数の出力シーケンスと突き合わせるためにルックアップ・ハンドラ412によって使用される。ユニコード・シーケンス(つまり、テキスト要素)自体のほかに、入力シーケンスに関するある種の追加情報が得られ(例えば、方向、コンテキスト、シメトリック・スワッピング状態、垂直形式要求、フォールバック要求、許容範囲、変種)、ある種のテーブルはこの情報を利用している。好ましくは、マッピング・テーブル414はフォールバック・ハンドラ416が必要とするデータもストアしているが、別のテーブルを用意してフォールバック・ハンドラ416に使用させることも可能である。
・ ユニコードu000DがASCIIx0D「キャリッジリターン」に厳格にマッピングされていれば、ユニコードu2029「パラグラフ・セパレータ」はASCIIx0Dにゆるやかにマッピングすることができる。
・ ユニコードu002D「ハイフン−マイナス」がASCIIx2D「ハイフン−マイナス」に厳格にマッピングされていれば、ユニコードu2010「ハイフン」とu2212「マイナス記号」はASCIIx2Dにゆるやかにマッピングすることができる。
・ ユニコードu00EO「グラーブ付きのラテン小文字A」がISO 8859−1xEO「アクサングラーブ付きの小文字a」に厳格にマッピングされていれば、2文字のユニコード・シーケンスu0061+u0300「ラテン小文字A」+「結合アクサングラーブ」はISO 8859−1xEOにゆるやかにマッピングすることができる。
・ Shift−JISは半幅文字と全幅文字を区別しているので、Shift−JISの緩和マッピングもこれらを区別しておかなければならない。つまり、ユニコードuFF40「全幅アクサングラーブ」はShift−JISx814D「アクサングラーブ(全幅)に厳格にマッピングされており、これはShift−JISx60「アクサングラーブ(半幅)と区別されている。ユニコード・シーケンスu3000+u0300「表意文字スペース」+「結合アクサングラーブ」はShift−JISx814Dにゆるやかにマッピングすることができる。しかし、ユニコード・シーケンスu0020+u0300「スペース」+「結合アクサングラーブ」はShift−JISx814Dにゆるやかにマッピングしてはならない。これはShift−JISx60にマッピングされるべきである。
・ ユニコード文字u0300「結合アクサングラーブ」はフォールバック・マッピングとしてASCIIx60「アクサングラーブ[スペース])にマッピングすることができる。違いは、ユニコード文字が結合マーク(非スペース)であるのに対し、ASCII文字はスペース・マークであることである。
・ ユニコード文字u01C0「ラテン文字デンタル・クリック」はフォールバック・マッピングとしてASCIIx7C「垂直線」にマッピングすることが可能である。
・ ユニコード文字u2001「EM QUAD」はフォールバック・マッピングとしてASCIIx20「スペース」にマッピングすることが可能である。
・ 一般的識別情報−フォーマット、長さ、チェックサムおよびバージョン。
・ 最小ターゲット文字サイズ(バイト数)(文字サイズともいう)。
・ 一般的フラグ(例えば、そのルップアップ・テーブルが方向またはコンテキスト・データを必要としているかどうか)。
・ そのテーブルによって処理される最大入力シーケンス長、および1からこの最大長までの入力シーケンス長を処理するテーブルを指定しているオフセット/長さのペアのリスト。
・ そのユニコードからのマッピングのデフォルト・フォールバック文字または文字シーケンス。
・ そのテーブルによってサポートされる変種のカウントとリスト。各変種ごとに、1つまたは2つ以上の関連ビット・マスクが指定される。単一の変種に複数のビット・マスクがある場合は、属性情報(方向、コンテキスト、および垂直形式の要求)はどのビット・マスクが使用されるかを判断するために使用される。ビット・マスクで「1」にセットされたビットは異なる変種をサポートするために種々のサブテーブルをオンにするために使用される。
・ 可能とされる4つの許容範囲設定値(厳格/緩和、フォールバック・オン/オフ)の各々に関連する追加のビット・マスクのセット。該当する許容範囲レベル・マスクは変種マスクとORがとられて、サブテーブルを使用可能または使用禁止にするために使用されるビット・マスクを形成する。
以下では、ユニコード・コード変換システム400の好適実施例によって実行される処理について詳しく説明する。
例:“...ABCD`EFG...”
バッファに置かれている部分が“D”の直後で終わっていれば、切り捨て
処理はバッファに置かれている部分を切り捨てて、切り捨てられた長さが
“C”のあとで終わるようにする。バッファに置かれた部分を切り捨てる
必要があるのは、そのようにしないと、テキスト要素“D”がそのあとに
置かれた結合マーク“`”から切り離されることになるからである。切り
離されると、テキストはターゲット・コード化に正しく変換されないこと
になる。残余部分は“D`”であり、次の部分にキャリーオーバされ、
“D`EFG..”となる。
CC −制御文字
OS −他のスペース
NS −非スペース
LD −ラテン・ディジット
FS −フラクション・スラッシュ
JL(f)−ジャモス先頭子音(フィラー)
JV(f)−ジャモス母音(フィラー)
JT −ジャモス・トレーラ
NU −有効なユニコード文字でない
ISS −シメトリック・スワッピング禁止
ASS −シメトリック・スワッピング活動化
状態0 −終了。テキスト要素を戻すべきかどうかを、2重および半分音符号の状態に基づいて判断する。
状態2 −非スペース(分音符号)の追加
状態3 −数値フラクションの有無チェック
状態7 −朝鮮語ジャモス
Adv −[ADVANCE]次の文字へ進む(現在文字は現在テ
キスト要素(TE)に含まれている場合と含まれていな
い場合がある)
AdvMark −[ADVANCE+MARK]現在文字に最終文字の
マークを付け次の文字へ進む
AdvMarkS −[ADVANCE+MARK+S]現在文字に最終文字
のマークを付け次の文字へ進み、再配列フラグをセット
する
AdvMarkASS −[ADVANCE+MARK+ASS]現在文字に
最終文字のマークを付け次の文字へ進み、シメトリック・
マッピングを活動化する
AdvMarkISS −[ADVANCE+MARK+ISS]現在文字に
最終文字のマークを付け次の文字へ進み、シメトリック・
マッピングを禁止する
End −テキスト要素を最終のマークを付けた文字で終了する
CC −制御文字
OS −他のスペース
NS −非スペース
LD −ラテン・ディジット
FS −フラクション・スラッシュ
DD −二重分音符号
HD −半分音符号
CH −ジャモス先頭子音(フィラー)
JO −ジャモス母音(フィラー)
JV −ジャモス子音トレーラ
NU −有効なユニコード文字でない
ISS −シメトリック・マッピング禁止
ASS −シメトリック・マッピング活動化
HH −高ハーフゾーン
LH −低ハーフゾーン
V −Virama
ZWNJ −ゼロ幅の非ジョインダ
R −右リンク
D −2重リンク
C −リンクを引き起こす
T −透過
状態0 −終了。テキスト要素を戻すべきかどうかを2重分音符号と半分音符号に基づいて判断する
状態1 −開始状態
状態2 −非スペース(分音符号)追加
状態3 −ラテン・ディジット
状態4 −ラテン・ディジット・シーケンス
状態5 −ラテン・ディジット・シーケンスとそのあとに続くフラクション・スラッシュ
状態6 −ラテン・ディジット・シーケンス、フラクション・スラッシュ、ラテン・ディジット・シーケンス
状態7 −Choseongシーケンス
状態8 −Choseongシーケンスとそのあとに続く
Jungseongシーケンス
状態9 −Choseongシーケンス、Jungseongシーケンス、Jongseong
状態10 −高半文字
状態11 −高半文字とそのあとに続く低半文字
状態12 −Viramaとそのあとに続くゼロ幅ジョインダまたはゼロ幅非ジョインダ
状態13 −コンテキストの特殊開始
状態14 −右リンク文字(特殊コンテキスト状態)
状態15 −2重リンク文字(特殊コンテキスト状態)
状態16 −リンクを引き起こす文字(通常または特殊状態)
状態17 −右リンク文字(通常状態)
状態18 −2重リンク文字(通常状態)
開始1 −開始状態
開始13 −コンテキストの特殊開始状態
Adv −[ADVANCE]次の文字へ進む(現在文字は現在テ
キスト要素(TE)に含まれている場合と含まれていな
い場合がある)
AdvMark −[ADVANCE+MARK]現在文字に最終文字の
マークを付け次の文字へ進む
AdvMarkS −[ADVANCE+MARK+S]現在文字に最終文字
のマークを付け次の文字へ進み、再配列フラグをセット
する
AdvMarkASS −[ADVANCE+MARK+ASS]現在文字に
最終文字のマークを付け次の文字へ進み、シメトリック・
マッピングを活動化する
AdvMarkISS −[ADVANCE+MARK+ISS]現在文字に
最終文字のマークを付け次の文字へ進み、シメトリック・
マッピングを禁止する
End −テキスト要素を最終のマークを付けた文字で終了する
EndOutputXn −[END+単独コンテキスト]テキスト要素を終
了し、単独コンテキストであることを示す
EndOutputX1 −[END+初期コンテキスト]テキスト要素を終
了し、初期コンテキストであることを示す
EndOutputXr −[END+終了コンテキスト]テキスト要素を終
了し、終了コンテキストであることを示す
EndOutputXm −[END+中間コンテキスト]テキスト要素を終
了し、中間コンテキストであることを示す
文字クラスは3文字ともOSである。最初の文字“A”が取得される。開始状態(状態1)から始まり、最初のアクションはAdvMark、次の状態は状態2である。これにより、最初の文字“A”が現在テキスト要素内に挿入され、次の文字(2番目の文字“A”)が取得される。次に、状態2では、アクションはEnd、次の状態は状態0である。従って、テキスト要素は最初のテキスト要素だけを含んでいる。同じシーケンスはこの特定入力文字列の2番目と3番目の文字について繰り返される。このようにして、入力文字列の文字の各々は分離しているが、隣接しているテキスト要素に割り当てられる。
文字クラスは入力文字列の最初と最後の文字ではOSである。2番目の文字の文字クラスがNSであるのは、これが結合マークであるためである。最初の文字“A”が取得される。開始状態(状態1)から始まり、最初のアクションはAdvMark、次の状態は状態2である。これにより、最初の文字“A”が現在テキスト要素内に挿入され、次の文字(2番目の文字“`”)が取得される。次に、状態2では、アクションはAdvMarkS、次の状態は状態2である。これにより、2番目の文字“`”が現在テキスト要素に挿入される。次に、3番目の文字が取得される。この時点の状態2のアクションはEnd、次の状態は状態0である。従って、テキスト要素は入力文字列の1番目と2番目の文字を含んでいる。3番目の文字は例1の場合と同じように、自身のテキスト要素に置かれる。
RL 右から左へが主流
AL アラビア文字(右から左へが主流)
LRE 左から右への埋め込みマーク
RLE 右から左への埋め込みマーク
LRO 左から右へのオーバライド・マーク
RLO 右から左へのオーバライド・マーク
PDF ポップ方向フォーマット・マーク
AN アラビア数字
EN ヨーロッパ数字
ET ヨーロッパ数字ターミネータ
ES ヨーロッパ数字セパレータ
CS 共通数字セパレータ
ON その他の中立文字
BS ブロック・セパレータ
シュされる実際の値は現れた実際の埋め込み制御によって決ま
る。このインプリメンテーションでは、これを処理するアクショ
ン動詞は4つある。
トップを現在の埋め込み状態にする。新しい埋め込みがオーバラ
イドであれば、セルに入っているターゲット状態にではなくOR
状態に遷移が行われる。
移る。すなわち、エプシロン遷移を行う。リセットには出力はな
い。
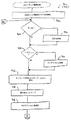
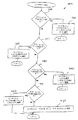
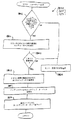
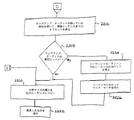
NO_OUTPUT、L−to−RまたはR−to−Lである。これらの制御フラグはユニコード・コード変換システム400を起動するアプリケーションによってセットされる(つまり、制御フラグはコンバータへの入力である)。制御フラグがR−to−Lを示しているときは、グローバル方向はR−to−Lにセットされる(1604)。制御フラグがL−to−Rにセットされているときは、グローバル方向はL−to−Rにセットされる(1606)。制御フラグがNO_OUTPUTにセットされているときは、スモール・ループが開始され、方向が判断できるまで入力文字列のユニコード文字をスキャンしていく。ループは状態を“START STATE”にセット(1608)することから開始される。次に、ユニコード文字が入力文字列から取得される(1610)。ユニコード文字の属性が次に調べられる(1612)。属性は図9Aのブロック914で使用され、図12に詳しく説明されているものと同じ方法を用いて調べられる(1612)。次にユニコード文字の方向が属性(つまり、方向属性)を使用して判断される(1614)。方向が“NO_OUTPUT”に等しいかどうかがの判断1616が行われる。方向が“NO_OUTPUT”であれば、入力文字列の終わりまで達したかどうかの判断1618が行われる。入力文字列の終わりまで達していなければ、処理は戻り、ブロック1610〜1618を繰り返す。文字列の終わりまで達していると、判断1618は方向を見つけることなく特殊方向スキャニング・ループを終わらせる(例えば、NO_OUTPUT)。そうでなければ、スキャニング・ループは判断1616が方向を判断したとき終了する。
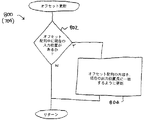
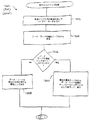
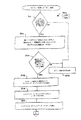
(2402)。次に、現在のカウントがテキスト要素の長さより大であるか等しいかの判断2404が行われる。そうであれば、デフォルト処理2400は完了し、戻る。そうでなければ、フォールバック・フラグがセットされた単一ユニコード文字に対してルックアップ処理が実行される(2406)。ここでは、ルックアップはテキスト要素の個別文字に対するものであるが、以前(ブロック3202)では、ルックアップはテキスト要素全体に対するものであった。そのあと、単一ユニコード文字の変換コードが見つかったかどうかの判断2408が行われる。見つからなければ、ユニコード文字で使用できる個別マッピングがなかったことをエラー・コードで通知してデフォルト処理2400は戻る(2410)。他方、変換コードが見つかっていれば、現在のカウントがインクリメントされ(2412)、処理はテキスト要素内の次のユニコード文字の処理を行うためにブロック2404に戻る。
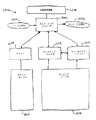
200 フォーマット
400 ユニコード・コード変換システム
414 マッピング・テーブル
1004 属性テーブル
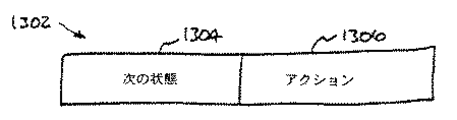
1300 スキャナ・テーブル
1302 要素
1400 テーブル
1511 双方向状態テーブル
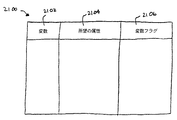
2100 変種リスト
2108 実際属性ビット・マスク
2110,2112,2114,2116 部分
Claims (27)
- ユニコード変換のためにコンピュータ上でソース文字列をターゲット文字列に変換する方法であって、前記コンピュータは、ソース文字列のターゲット文字列への変換を制御するコンバータ手段と、前記ソース文字列をスキャンして前記ソース文字列のテキスト要素を判定するスキャナ手段と、複数のマッピング・テーブルを格納するメモリ手段とを含み、前記方法は、
(a)バッファ手段が、第1の文字コード化を有するソース文字列を受け取ることと、
(b)前記スキャナ手段が、前記バッファ手段が受け取った前記ソース文字列をテキスト要素に順次分割することであって、各テキスト要素は、前記ソース文字列の1または複数の文字を含み、前記テキスト要素の少なくとも1つは、前記ソース文字列の複数の文字を含むことと、
(c)前記スキャナ手段が、前記分割(b)の後または間に前記テキスト要素についての属性情報を得ることと、
(d)前記コンバータ手段が、前記テキスト要素のそれぞれについて第2の文字コード化に関連付けられた変換コードをマッピング・テーブルでルックアップすることであって、前記テキスト要素のそれぞれについての変換コードを有するマッピング・テーブルでルックアップすること(d)は、要求された変種を識別するオペレーションと、前記属性情報、前記要求された変種、および前記テキスト要素の長さに基づいて前記メモリ手段に格納された複数のマッピング・テーブルの1つを選択するオペレーションと、前記マッピング・テーブルの選択された1つから変換コードをルックアップすることを含むことと、
(e)前記コンバータ手段が、前記第2の文字コード化のターゲット文字列を形成するように前記テキスト要素の前記変換コードを結合することと
を備えることを特徴とする方法。 - 請求項1に記載の方法であって、
前記変換コードは、前記第2の文字コード化中の1または複数の文字からなり、
前記得られた属性情報は、方向、クラス、優先順位、サブセット、コンテキスト、シメトリック・スワッピング状態の少なくともいずれか2つを含むことを特徴とする方法。 - 請求項1に記載の方法であって、前記テキスト要素は、互いに隣接し、複数の文字を含む前記テキスト要素のそれぞれについて、前記文字は、前記ソース文字列において隣接することを特徴とする方法。
- 請求項1に記載の方法であって、前記マッピング・テーブルは、レギュラ・マッピングとフォールバック・マッピングを含み、
前記ルックアップすること(d)は、前記レギュラ・マッピングを使用して前記マッピング・テーブルが前記テキスト要素についての変換コードを含んでいないとき、前記フォールバック・マッピングを使用して前記テキスト要素のそれぞれについての変換コードを判定することを特徴とする方法。 - 請求項1に記載の方法であって、前記文字のそれぞれは、関連する文字クラスを有し、
前記分割すること(b)は、前記ソース文字列内の前記文字の文字クラスに少なくとも一部基づくことを特徴とする方法。 - 請求項1に記載の方法であって、前記分割すること(b)は、
(b1)前記ソース文字列から次のソース文字を獲得することと、
(b2)獲得した前記ソース文字を現在のテキスト要素に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかをスキャナ・テーブルに基づいて判定することと、
(b3)前記判定すること(b2)に従い、獲得した前記ソース文字を前記現在のテキスト要素または前記新たな次のテキスト要素に配置することと、
(b4)前記ソース文字列がテキスト要素に完全に配置されるまで、(b1)から(b3)までを繰り返すことと
を備えることを特徴とする方法。 - 請求項6に記載の方法であって、前記判定すること(b2)は、
(i)前記スキャナ・テーブルにおいて前記ソース文字に関連付けられた属性情報をルックアップすることであって、前記属性情報は少なくともクラス・インディケータを含むことと、
(ii)前記クラス・インディケータに基づき、獲得した前記ソース文字を前記現在のテキスト要素に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかを判定することと
を備えることを特徴とする方法。 - 請求項6に記載の方法であって、前記判定すること(b2)は、
(i)前記スキャナ・テーブルにおいて前記ソース文字に関連付けられた属性情報をルックアップすることであって、前記属性情報は少なくともクラス・インディケータを含むことと、
(ii)複数の状態を有するステート・マシンを提供することであって、前記ステート・マシンは、前記クラス・インディケータおよび前記ステート・マシンの現在の状態に基づき、獲得した前記ソース文字を前記現在のテキスト要素に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかを判定するのに使用されることと、
(iii)前記ステート・マシンの前記現在の状態を更新することと
を備えることを特徴とする方法。 - 請求項1に記載の方法であって、前記第1の文字コード化および前記第2の文字コード化の1つは、ユニコード標準に準拠することを特徴とする方法。
- 請求項1に記載の方法であって、前記結合すること(e)は、
(e1)前記第2の文字コード化についてターゲット文字サイズを判定することと、
(e2)ルップアップされた前記テキスト要素の前記変換コードを、前記ターゲット文字サイズの単位で前記ターゲット文字列にコピーすることにより前記ターゲット文字列を形成することと
を備えることを特徴とする方法。 - 請求項10に記載の方法であって、ルックアップ(d)された前記変換コードは、間接シーケンスまでのオフセットを指定することを特徴とする方法。
- 請求項1に記載の方法であって、
(f)前記分割(b)の後であるが前記ルックアップ(c)の前に、前記コンバータ手段またはスキャナ手段が、ある文字が前記テキスト要素に存在する場合、前記テキスト要素のそれぞれの前記ある文字を再配列することをさらに備えることを特徴とする方法。 - 請求項12に記載の方法であって、前記再配列すること(f)は、異なる文字クラスの加重値を用いて実行されることを特徴とする方法。
- ユニコードについてソース文字列をターゲット文字列に変換するコード変換システムであって、
第1の文字コード化を有する前記ソース文字列について第2の文字コード化を有する前記ターゲット文字列への変換を制御するコンバータと、
前記コンバータに動作するよう結合され、前記ソース文字列をテキスト要素に分割するスキャナであって、各テキスト要素は前記ソース文字列の1または複数の文字を含み、前記テキスト要素の少なくとも1つは前記ソース文字列の複数の文字を含むスキャナと、
前記ソース・コード化のテキスト要素についてターゲット・コード化を格納するマッピング・テーブルであって、複数のマッピング部分を含み、前記テキスト要素の属性情報および長さに応じて前記マッピング部分の適切な1つが前記テキスト要素のそれぞれに利用されるマッピング・テーブルと、
前記コンバータおよび前記マッピング・テーブルに動作するよう結合され、前記テキスト要素のそれぞれについて第2の文字コード化に関連付けられた変換コードを前記マッピング・テーブルでルックアップするルックアップ・ハンドラと
を備えたことを特徴とするコード変換システム。 - 請求項14に記載のコード変換システムであって、
前記コンバータに動作するように結合され、特定の場合にフォールバック変換コードを提供するフォールバック・ハンドラであって、前記ルックアップ・ハンドラが1または複数のテキスト要素について変換コードを提供できないとき、前記フォールバック変換コードは、前記テキスト要素の文字と等価ではないが、類似するグラフィカル上の外観を有する、前記ターゲット・コード化における1または複数のコード・ポイントを含む、フォールバック・ハンドラをさらに備えたことを特徴とするコード変換システム。 - 請求項15に記載のコード変換システムであって、
前記入力文字列中の個々の文字を現在のテキスト要素内に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかの判定において前記スキャナを支援するスキャナ・テーブル手段をさらに備えたことを特徴とするコード変換システム。 - 請求項14に記載のコード変換システムであって、
前記スキャナに動作するよう結合され、前記入力文字列中の個々の文字を現在のテキスト要素内に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかの判定において前記スキャナを支援するスキャナ・テーブルをさらに備えたことを特徴とするコード変換システム。 - 請求項17に記載のコード変換システムであって、前記ソース文字列の前記文字は、関連する文字クラスを有し、
前記スキャナ・テーブルは、要素の配列を備え、前記配列は文字クラスによりインデックス付けされていることを特徴とするコード変換システム。 - 請求項14に記載のコード変換システムであって、前記ソース文字列中の前記文字は、ユニコード文字であることを特徴とするコード変換システム。
- 請求項14に記載のコード変換システムであって、前記ターゲット文字列中の前記文字は、ユニコード文字であることを特徴とするコード変換システム。
- ユニコード変換のためにコンピュータ上でソース文字列をターゲット文字列に変換する方法であって、前記コンピュータは、ソース文字列のターゲット文字列への変換を制御するコンバータ手段と、前記ソース文字列をスキャンして前記ソース文字列のテキスト要素を判定するスキャナ手段と、複数のマッピング・テーブルを格納するメモリ手段とを含み、前記方法は、
(a)バッファ手段が、第1の文字コード化を有するソース文字列を受け取ることと、
(b)前記スキャナ手段が、前記バッファが受け取った前記ソース文字列をテキスト要素に順次分割することであって、各テキスト要素は、前記ソース文字列の1または複数の文字を含み、前記テキスト要素の少なくとも1つは、前記ソース文字列の複数の文字を含むことと、
(c)前記スキャナ手段が、前記分割(b)の後または間に前記テキスト要素についての属性情報を得ることと、
(d)前記コンバータ手段が、前記テキスト要素のそれぞれについて第2の文字コード化に関連付けられた変換コードをマッピング・テーブルでルックアップすることであって、前記テキスト要素のそれぞれについての変換コードを有するマッピング・テーブルでルックアップすること(d)は、(d1)前記属性情報、および前記テキスト要素の長さに基づいて前記メモリ手段に格納された複数のマッピング・テーブルの1つを選択するオペレーションと、(d2)前記マッピング・テーブルの選択された1つから変換コードをルックアップするオペレーションを含むことと、
(e)前記コンバータ手段が、前記第2の文字コード化のターゲット文字列を形成するように前記テキスト要素の前記変換コードを結合することと
を備えることを特徴とする方法。 - 請求項21に記載の方法であって、前記分割すること(b)は、
(b1)前記ソース文字列から次のソース文字を獲得することと、
(b2)獲得した前記ソース文字を現在のテキスト要素に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかをスキャナ・テーブルに基づいて判定することと、
(b3)前記判定すること(b2)に従い、獲得した前記ソース文字を前記現在のテキスト要素または前記新たな次のテキスト要素に配置することと、
(b4)前記ソース文字列がテキスト要素に完全に配置されるまで、(b1)から(b3)までを繰り返すことと
を備えることを特徴とする方法。 - 請求項22に記載の方法であって、前記判定すること(b2)は、
(i)前記スキャナ・テーブルにおいて前記ソース文字に関連付けられた属性情報をルックアップすることであって、前記属性情報は少なくともクラス・インディケータを含むことと、
(ii)複数の状態を有するステート・マシンを提供することであって、前記ステート・マシンは、前記クラス・インディケータおよび前記ステート・マシンの現在の状態に基づき、獲得した前記ソース文字を前記現在のテキスト要素に含めるべきか、あるいはまた、新たな次のテキスト要素として始めるかを判定するのに使用されることと、
(iii)前記ステート・マシンの前記現在の状態を更新することと
を備えることを特徴とする方法。 - 請求項23に記載の方法であって、
(f)前記分割(b)の後であるが前記ルックアップ(c)の前に、前記コンバータ手段またはスキャナ手段が、ある文字が前記テキスト要素に存在する場合、前記テキスト要素のそれぞれの前記ある文字を再配列することをさらに備えることを特徴とする方法。 - 請求項14に記載のコード変換システムであって、
前記マッピング・テーブルは、前記ソース・コード化のあるテキスト要素について1つ以上のターゲット・コード化を含み、前記あるテキスト要素についての前記ターゲット・コード化の特定の1つを前記あるテキスト要素について判定された属性情報によって獲得することを特徴とするコード変換システム。 - 請求項14に記載のコード変換システムであって、
前記コード変換システムは、
スキャン情報を格納するスキャナ・テーブルと、
前記ソース文字列中の文字についての属性情報を格納する属性テーブルと
をさらに備え、
前記スキャナは、前記スキャナ・テーブルに格納されたスキャナ情報および前記属性テーブルに格納された属性情報に従って前記ソース文字列をテキスト要素に分割するように動作することを特徴とするコード変換システム。 - 請求項21に記載の方法であって、
前記テキスト要素のそれぞれについて変換コードのマッピング・テーブルでルックアップすること(d)は、(d3)前記選択(d1)の前に要求された変種を特定するオペレーションをさらに含み、
前記複数のマッピング・テーブルの1つを選択すること(d2)は、前記属性情報、前記要求された変種、および前記テキスト要素の長さに基づき行われることを特徴とする方法。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US08/527,831 US5682158A (en) | 1995-09-13 | 1995-09-13 | Code converter with truncation processing |
| US08/527,438 US5793381A (en) | 1995-09-13 | 1995-09-13 | Unicode converter |
| US08/527,837 US5784071A (en) | 1995-09-13 | 1995-09-13 | Context-based code convertor |
| US08/527,827 US5784069A (en) | 1995-09-13 | 1995-09-13 | Bidirectional code converter |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007182633A Division JP2007317214A (ja) | 1995-09-13 | 2007-07-11 | ユニコード・コンバータ |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008192163A JP2008192163A (ja) | 2008-08-21 |
| JP4451908B2 true JP4451908B2 (ja) | 2010-04-14 |
Family
ID=27504609
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP51211397A Expired - Fee Related JP4584359B2 (ja) | 1995-09-13 | 1996-09-13 | ユニコード・コンバータ |
| JP2007182633A Pending JP2007317214A (ja) | 1995-09-13 | 2007-07-11 | ユニコード・コンバータ |
| JP2008050694A Expired - Fee Related JP4451908B2 (ja) | 1995-09-13 | 2008-02-29 | ユニコード・コンバータ |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP51211397A Expired - Fee Related JP4584359B2 (ja) | 1995-09-13 | 1996-09-13 | ユニコード・コンバータ |
| JP2007182633A Pending JP2007317214A (ja) | 1995-09-13 | 2007-07-11 | ユニコード・コンバータ |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP0852037B1 (ja) |
| JP (3) | JP4584359B2 (ja) |
| AU (1) | AU7360596A (ja) |
| DE (1) | DE69605433T2 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7051278B1 (en) | 2000-07-10 | 2006-05-23 | International Business Machines Corporation | Method of, system for, and computer program product for scoping the conversion of unicode data from single byte character sets, double byte character sets, or mixed character sets comprising both single byte and double byte character sets |
| US7278100B1 (en) | 2000-07-10 | 2007-10-02 | International Business Machines Corporation | Translating a non-unicode string stored in a constant into unicode, and storing the unicode into the constant |
| US6400287B1 (en) | 2000-07-10 | 2002-06-04 | International Business Machines Corporation | Data structure for creating, scoping, and converting to unicode data from single byte character sets, double byte character sets, or mixed character sets comprising both single byte and double byte character sets |
| JP4308676B2 (ja) | 2003-01-24 | 2009-08-05 | 株式会社リコー | 文字列処理装置,文字列処理方法および画像形成装置 |
| KR102489574B1 (ko) * | 2022-02-09 | 2023-01-18 | (주)큐브더모먼트 | 가명정보 파일을 판별하기 위한 정보집합물 내에 삽입된 서명을 포함하는 가명정보 파일의 생성 및 판별 방법, 장치 및 컴퓨터프로그램 |
-
1996
- 1996-09-13 JP JP51211397A patent/JP4584359B2/ja not_active Expired - Fee Related
- 1996-09-13 DE DE69605433T patent/DE69605433T2/de not_active Expired - Lifetime
- 1996-09-13 AU AU73605/96A patent/AU7360596A/en not_active Abandoned
- 1996-09-13 EP EP96935813A patent/EP0852037B1/en not_active Expired - Lifetime
-
2007
- 2007-07-11 JP JP2007182633A patent/JP2007317214A/ja active Pending
-
2008
- 2008-02-29 JP JP2008050694A patent/JP4451908B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2007317214A (ja) | 2007-12-06 |
| DE69605433T2 (de) | 2000-07-20 |
| JP2008192163A (ja) | 2008-08-21 |
| AU7360596A (en) | 1997-04-01 |
| JPH11512543A (ja) | 1999-10-26 |
| DE69605433D1 (de) | 2000-01-05 |
| JP4584359B2 (ja) | 2010-11-17 |
| EP0852037B1 (en) | 1999-12-01 |
| EP0852037A1 (en) | 1998-07-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US5784069A (en) | Bidirectional code converter | |
| US5793381A (en) | Unicode converter | |
| US5682158A (en) | Code converter with truncation processing | |
| US5784071A (en) | Context-based code convertor | |
| JP2502021B2 (ja) | 多バイトデ―タ変換方法及びシステム | |
| US6204782B1 (en) | Unicode conversion into multiple encodings | |
| US7697000B2 (en) | Method and apparatus for typographic glyph construction including a glyph server | |
| JP4017659B2 (ja) | テキスト入力フォント・システム | |
| AU2003200547B2 (en) | Method for selecting a font | |
| US9158742B2 (en) | Automatically detecting layout of bidirectional (BIDI) text | |
| JP4451908B2 (ja) | ユニコード・コンバータ | |
| KR100584038B1 (ko) | 큰 문자 세트 브라우저 | |
| US4727511A (en) | Multitype characters processing method and terminal device | |
| US20050251519A1 (en) | Efficient language-dependent sorting of embedded numerics | |
| WO1997010556A1 (en) | Unicode converter | |
| WO1997010556A9 (en) | Unicode converter | |
| KR100859766B1 (ko) | 프레젠테이션 데이터 스트림의 복잡한 텍스트를 식별하기위한 시스템 및 방법 | |
| KR100712001B1 (ko) | 중국어 데이타 및 사용자에 의해 정정된 데이타를작성하고 사용하는 방법 및 시스템 | |
| US20110219014A1 (en) | Systems and Methods For Representing Text | |
| US6032165A (en) | Method and system for converting multi-byte character strings between interchange codes within a computer system | |
| JP2629040B2 (ja) | 日本語処理システム | |
| Peruginelli et al. | Character sets: towards a standard solution? | |
| JPS5928190A (ja) | 文字パタ−ン発生方式 | |
| JP3470377B2 (ja) | 情報出力装置 | |
| Felici | Unicode: The Quiet Revolution. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20080701 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20080704 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080731 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20080926 |
|
| RD13 | Notification of appointment of power of sub attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7433 Effective date: 20090106 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090126 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20090106 |
|
| A911 | Transfer of reconsideration by examiner before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20090327 |
|
| A912 | Removal of reconsideration by examiner before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20090417 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20091216 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100128 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130205 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130205 Year of fee payment: 3 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: R3D04 |
|
| RD15 | Notification of revocation of power of sub attorney |
Free format text: JAPANESE INTERMEDIATE CODE: R3D15 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130205 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140205 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |