JP4371911B2 - 関数化処理方法及び関数化処理装置 - Google Patents
関数化処理方法及び関数化処理装置 Download PDFInfo
- Publication number
- JP4371911B2 JP4371911B2 JP2004161571A JP2004161571A JP4371911B2 JP 4371911 B2 JP4371911 B2 JP 4371911B2 JP 2004161571 A JP2004161571 A JP 2004161571A JP 2004161571 A JP2004161571 A JP 2004161571A JP 4371911 B2 JP4371911 B2 JP 4371911B2
- Authority
- JP
- Japan
- Prior art keywords
- contour
- contacts
- extracting
- contact
- image data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



























Landscapes
- Image Generation (AREA)
- Image Analysis (AREA)
Description
2値化処理302では、入力された文書画像データより輝度情報を抽出し、その輝度値のヒストグラムを作成する。ヒストグラム上より複数の閾値を設定し、各々の閾値で2値化された2値画像上の黒画素の連結等を解析することで最適な閾値を導出し、その閾値による2値画像を得る。
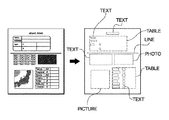
像域分離処理303とは、図4に示す左側の読み取られた1ページのイメージデータをオブジェクト毎の塊(ブロック)として認識し、各々の塊を文字/図画/写真/線/表等の属性に判定し、図4に示す右側のように、異なる属性(TEXT/PICTURE/PHOTE/LINE/TABLE)を持つ領域に分割する処理である。
文字認識部305では、文字単位で切り出された画像に対して、パターンマッチングの一手法を用いて認識を行い、対応する文字コードを得る。この認識処理は、文字画像から得られる特徴を数十次元の数値列に変換した観測特徴ベクトルと、予め字種毎に求められている辞書特徴ベクトルとを比較し、最も距離の近い字種を認識結果とする処理である。この特徴ベクトルの抽出には種々の公知手法があり、例えば文字をメッシュ状に分割し、各メッシュ内の文字線を方向別に線素としてカウントしたメッシュ数次元ベクトルを特徴とする方法がある。
アウトライン作成部306、307では、像域分離処理で得られた文字、表、枠、線について、輪郭形状を直線及び滑らかな曲線により表現されるアウトラインベクトルデータに変換する。この手法は、オブジェクト原型よりアウトラインベクトルデータを作成する際に、画質劣化を抑えつつ、高速に処理する手法であり、詳細に説明する。
まず、ノイズ除去(ステップS1001)では、粗輪郭データよりノイズ除去を行う。図11は、除去するノイズの一例を示す図である。尚、図中の“1”は、ラスター画像における1画素大のサイズを表し、1画素サイズの凹凸を除去することを目的とする。このノイズ除去では、図11の(a)、(b)の網点ノイズ、同(c)に示す角欠けノイズを除去するが、図12に示すように、ノイズに似た粗輪郭データも存在する。特に、ここでは、小さな文字から大きな文字までを扱うことを前提としているので、図12に示す形状のものを全て除去しては画質の劣化を招く。
(a)1つの凸ノイズについて、次の式を満たす。
(c)次式を全て満たす。
以上でノイズ除去が行えるが、元々粗輪郭抽出前に2値のラスター画像データにおいてノイズ除去することも可能であり、ラスター画像データでノイズ除去してあれば、ここで行わなくても良い。しかしながら、ラスター画像上でノイズを除去する場合は、画像一面を処理する必要があり、かつ上述した条件を満たす除去を行う場合は、非常に処理が重くなってしまう。これに対して、粗輪郭データでは扱うデータ量も少なくて済むので、非常に効率的である。
次に、ステップS1002では、ノイズ除去された粗輪郭データより、オブジェクトに対する接線線分を抽出する。接線線分とは、粗輪郭データの線分中、ある線分がそのままオブジェクト形状の接線成分となる線分である。

また、各オブジェクトサイズに応じて条件(1)〜(4)のうち、適用する条件を選択しても良い。
B(t)=(1-t)2・Q1'+2(1-t)・t・Q2'+t2・Q3' …式2
図14において、点Q1,Q4,Q1’,Q3’,Q1”,Q2”をアンカーポイントとし、曲線を制御しているQ2,Q3,Q2’をコントロールポイントと呼ぶ。ここで、コントロールポイントとアンカーポイントを結ぶ直線、例えば直線Q1Q2は、アンカーポイントQ1において曲線と接する。
ステップS1003では、上述のステップS1002で抽出された接線線分上に新たな点を抽出し、それをアンカーポイントとする。アンカーポイントは、接線線分の端2つに対してそれぞれ抽出される。よって、一つの接線線分に対して2つのアンカーポイントが抽出されるが、2つのアンカーポイントが一致した場合には一つのアンカーポイントのみ抽出されるものとする。2つのアンカーポイントが抽出される場合は、アンカーポイントに挟まれた部位は自動的にオブジェクト上の直線となる。
次に、ステップS1004、S1005では、ステップS1003で抽出されたアンカーポイント間をベジェ関数で曲線近似する。尚、ステップS1003で自動的に直線属性となった線分に対しては曲線近似処理を行わない。
尚、平行制限を用いたベジェ曲線を使用することで、近似処理を簡易に行うことが可能となる。
C1x=K×pfx+p1x
C1y=K×pfy+p1y
K=(3p1x−4pfx)(pNy−p1y)+(pNx−p1x)(4pfy−3p1y)
+p1x(pNy−p1y)−p1y(pNx−p1x)
/(3(pNy−p1y)pcx+3(pNx−p1x)pcy)
となり、pfの座標値より一意に決定することができる。また、C2についても、C1と同様に求めることが可能である。
以上、ステップS1001〜S1005により、オブジェクトの外形を直線及び曲線により構成されたアウトラインベクトルデータへ変換できるが、本手法では水平ベクトルと垂直ベクトルのみを使用した粗輪郭データから変換するため、また処理を効率化して行っているために、一連のステップで作成されたアウトラインベクトルデータは一種の癖をもつベクトルデータとなる。即ち、ステップS1006では、アウトラインベクトルデータを解析し、これらの癖を補正する処理を行う。
以上の通り、1頁分のイメージデータを像域分離処理303し、ベクトル化処理304した結果は図21に示すような中間データ形式のファイルとして変換される。このようなデータ形式は、ドキュメント・アナリシス・アウトプット・フォーマット(DAOF)と呼ばれる。
本実施例では、ラスター画像より得られる粗輪郭データをそのまま使用しており、扱うデータは水平ベクトルと垂直ベクトルである。解析はノイズ判別、特徴量抽出、局所的な曲線近似の工程を含み、解析手法としてパターンマッチングを採用し、水平ベクトル及び垂直ベクトルのみに対するパターンマッチングは非常に効率良く行うことが可能となる。即ち、直線近似処理という繰り返し演算、複雑な処理を必要としない、また解析に際し、一旦ショートベクトルに変換する必要がないという点で、パフォーマンスの点においても非常に有効である。
本実施例では、一つの輪郭線について、アウトラインベクトル化する際、画質の劣化が目立つようなオブジェクト上の細かく変化する部位について、第1の近似処理でパターンマッチングによる曲線近似を行う。尚、細かな部位に対するパターンマッチングでは接線線分等の解析結果に応じて変更しているため、少ないデータ量で表現された綺麗な曲線を得ることが可能である。
本実施例では、ノイズ、形状解析および局所的な近似にパターンマッチングを使用しており、オブジェクトの大きさ及び輪郭線の大きさに応じてパターンマッチングを変更しているため、細かなオブジェクトから大きなオブジェクトまで柔軟に対応することが可能となる。ここでパターンマッチングで変更するパラメータは、粗輪郭線分の長さであるため、各パターンマッチングに対し、パラメータを柔軟に変更することが可能であり、小さなオブジェクト及び輪郭線から、大きなオブジェクト及び輪郭線に対し、柔軟に対応することが可能となる。
Claims (13)
- 入力手段が、画像データを入力する入力工程と、
2値化手段が、入力された画像データを2値化する2値化工程と、
輪郭抽出手段が、2値化された画像データから画像の輪郭を抽出する輪郭抽出工程と、
接点推定手段が、抽出された輪郭より接線を抽出し、抽出された接線より接点を推定する接点推定工程と、
関数近似手段が、推定された接点に対して隣接する接点間の輪郭を所定の関数で近似する関数近似工程とを有し、
前記接点推定工程では、水平及び垂直方向の直線パターンをパターンマッチングによって検出し、検出された直線パターンと近傍の輪郭画素との相対位置関係によって接点を推定することを特徴とする関数化処理方法。 - 前記輪郭抽出工程では、前記画像の1画素を4点からなる正方形として扱い、該正方形の周囲を追跡するように輪郭線を抽出することで、垂直及び水平ベクトルからなる前記画像の輪郭を抽出することを特徴とする請求項1記載の関数化処理方法。
- 入力手段が、画像データを入力する入力工程と、
2値化手段が、入力された画像データを2値化する2値化工程と、
輪郭抽出手段が、2値化された画像データから画像の輪郭を抽出する輪郭抽出工程と、
接点推定手段が、抽出された輪郭より接線を抽出し、抽出された接線より接点を推定する接点推定工程と、
関数近似手段が、推定された接点に対して隣接する接点間の輪郭を所定の関数で近似する関数近似工程とを有し、
前記関数近似工程は、
前記接点間の輪郭線分数が予め定めた閾値よりも小さい接点間の輪郭線分群に対して、接点間の相対位置関係により接点間を一つの二次ベジェ曲線、一つの三次ベジェ曲線、或いは直線をあてはめる第1の近似処理と、
前記接点間の輪郭線分数が予め定めた閾値よりも小さくない接点間の輪郭線分群に対して、一つ或いは複数の三次ベジェ曲線により曲線をあてはめる第2の近似処理とを有することを特徴とする関数化処理方法。 - 前記第1の近似処理は、前記接点推定工程における水平及び垂直方向の直線パターンのパターン推定結果に応じて、二次ベジェ曲線、三次ベジェ曲線、或いは直線の何れか1つをあてはめて近似することを特徴とする請求項3記載の関数化処理方法。
- 前記第2の近似処理は、輪郭線分群に対して1つ或いは複数の三次ベジェ曲線をあてはめる処理で、該三次ベジェ曲線はアンカーポイント間を結ぶ直線とコントロールポイント間を結ぶ直線とが平行であることを特徴とする請求項3記載の関数化処理方法。
- 入力手段が、画像データを入力する入力工程と、
2値化手段が、入力された画像データを2値化する2値化工程と、
輪郭抽出手段が、2値化された画像データから画像の輪郭を抽出する輪郭抽出工程と、
接点推定手段が、抽出された輪郭より接線を抽出し、抽出された接線より接点を推定する接点推定工程と、
関数近似手段が、推定された接点に対して隣接する接点間の輪郭を所定の関数で近似する関数近似工程とを有し、
前記関数近似工程は、
前記接点間の輪郭線分数が予め定めた閾値よりも小さい接点間の輪郭線分群に対して、接点間の相対位置関係により近似処理を行うことを特徴とする関数化処理方法。 - 画像データを入力する入力手段と、
入力された画像データを2値化する2値化手段と、
2値化された画像データから画像の輪郭を抽出する輪郭抽出手段と、
抽出された輪郭より接線を抽出し、抽出された接線より接点を推定する接点推定手段と、
推定された接点に対して隣接する接点間の輪郭を所定の関数で近似する関数近似手段とを有し、
前記接点推定手段は、水平及び垂直方向の直線パターンをパターンマッチングによって検出し、検出された直線パターンと近傍の輪郭画素との相対位置関係によって接点を推定することを特徴とする関数化処理装置。 - 前記輪郭抽出手段は、前記画像の1画素を4点からなる正方形として扱い、該正方形の周囲を追跡するように輪郭線を抽出することで、垂直及び水平ベクトルからなる前記画像の輪郭を抽出することを特徴とする請求項7記載の関数化処理装置。
- 画像データを入力する入力手段と、
入力された画像データを2値化する2値化手段と、
2値化された画像データから画像の輪郭を抽出する輪郭抽出手段と、
抽出された輪郭より接線を抽出し、抽出された接線より接点を推定する接点推定手段と、
推定された接点に対して隣接する接点間の輪郭を所定の関数で近似する関数近似手段とを有し、
前記関数近似手段は、
前記接点間の輪郭線分数が予め定めた閾値よりも小さい接点間の輪郭線分群に対して、接点間の相対位置関係により接点間を一つの二次ベジェ曲線、一つの三次ベジェ曲線、或いは直線をあてはめる第1の近似処理と、
前記接点間の輪郭線分数が予め定めた閾値よりも小さくない接点間の輪郭線分群に対して、一つ或いは複数の三次ベジェ曲線により曲線をあてはめる第2の近似処理とを有することを特徴とする関数化処理装置。 - 前記第1の近似処理は、前記接点推定手段における水平及び垂直方向の直線パターンのパターン推定結果に応じて、二次ベジェ曲線、三次ベジェ曲線、或いは直線の何れか1つをあてはめて近似することを特徴とする請求項9記載の関数化処理装置。
- 前記第2の近似処理は、輪郭線分群に対して1つ或いは複数の三次ベジェ曲線をあてはめる処理で、該三次ベジェ曲線はアンカーポイント間を結ぶ直線とコントロールポイント間を結ぶ直線とが平行であることを特徴とする請求項9記載の関数化処理装置。
- 画像データを入力する入力手段と、
入力された画像データを2値化する2値化手段と、
2値化された画像データから画像の輪郭を抽出する輪郭抽出手段と、
抽出された輪郭より接線を抽出し、抽出された接線より接点を推定する接点推定手段と、
推定された接点に対して隣接する接点間の輪郭を所定の関数で近似する関数近似手段とを有し、
前記関数近似手段は、
前記接点間の輪郭線分数が予め定めた閾値よりも小さい接点間の輪郭線分群に対して、接点間の相対位置関係により近似処理を行うことを特徴とする関数化処理装置。 - 請求項1乃至6の何れか1項記載の関数化処理方法の各手順をコンピュータに実行させるためのプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004161571A JP4371911B2 (ja) | 2004-05-31 | 2004-05-31 | 関数化処理方法及び関数化処理装置 |
| US11/109,851 US7873218B2 (en) | 2004-04-26 | 2005-04-20 | Function approximation processing method and image processing method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004161571A JP4371911B2 (ja) | 2004-05-31 | 2004-05-31 | 関数化処理方法及び関数化処理装置 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2005346137A JP2005346137A (ja) | 2005-12-15 |
| JP2005346137A5 JP2005346137A5 (ja) | 2007-07-19 |
| JP4371911B2 true JP4371911B2 (ja) | 2009-11-25 |
Family
ID=35498495
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004161571A Expired - Fee Related JP4371911B2 (ja) | 2004-04-26 | 2004-05-31 | 関数化処理方法及び関数化処理装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4371911B2 (ja) |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7889938B2 (en) | 2006-03-31 | 2011-02-15 | Canon Kabushiki Kaisha | Method and apparatus for processing line drawings in images |
| JP4764231B2 (ja) | 2006-03-31 | 2011-08-31 | キヤノン株式会社 | 画像処理装置、制御方法、コンピュータプログラム |
| JP5058575B2 (ja) | 2006-12-12 | 2012-10-24 | キヤノン株式会社 | 画像処理装置及びその制御方法、プログラム |
| JP5028174B2 (ja) * | 2007-07-19 | 2012-09-19 | キヤノン株式会社 | 画像処理装置、画像処理方法、及び、画像処理プログラム |
| JP5017031B2 (ja) * | 2007-09-13 | 2012-09-05 | キヤノン株式会社 | 画像処理装置、画像処理方法、画像処理プログラム、並びに、記憶媒体 |
| JP4933404B2 (ja) | 2007-11-07 | 2012-05-16 | キヤノン株式会社 | 画像処理装置、画像処理方法、画像処理プログラム、並びに、プログラム記録媒体 |
| JP5137679B2 (ja) * | 2008-05-07 | 2013-02-06 | キヤノン株式会社 | 画像処理装置および画像処理方法 |
| JP4582200B2 (ja) | 2008-06-03 | 2010-11-17 | コニカミノルタビジネステクノロジーズ株式会社 | 画像処理装置、画像変換方法、およびコンピュータプログラム |
| JP5111242B2 (ja) | 2008-06-04 | 2013-01-09 | キヤノン株式会社 | 画像処理装置及び方法 |
| JP4582204B2 (ja) | 2008-06-11 | 2010-11-17 | コニカミノルタビジネステクノロジーズ株式会社 | 画像処理装置、画像変換方法、およびコンピュータプログラム |
| JP5121599B2 (ja) | 2008-06-30 | 2013-01-16 | キヤノン株式会社 | 画像処理装置、画像処理方法およびそのプログラムならびに記憶媒体 |
| JP5049920B2 (ja) | 2008-08-26 | 2012-10-17 | キヤノン株式会社 | 画像処理装置及び画像処理方法 |
| JP4600552B2 (ja) | 2008-09-16 | 2010-12-15 | コニカミノルタビジネステクノロジーズ株式会社 | アウトライン化方法およびそれを用いた画像圧縮方法、アウトライン化装置、ならびにアウトライン化プログラム |
| JP5328510B2 (ja) | 2009-06-24 | 2013-10-30 | キヤノン株式会社 | 画像処理装置、画像処理方法、コンピュータプログラム |
| JP5361574B2 (ja) * | 2009-07-01 | 2013-12-04 | キヤノン株式会社 | 画像処理装置、画像処理方法、及びプログラム |
| JP5465015B2 (ja) | 2010-01-06 | 2014-04-09 | キヤノン株式会社 | 文書を電子化する装置及び方法 |
| JP5653141B2 (ja) * | 2010-09-01 | 2015-01-14 | キヤノン株式会社 | 画像処理方法、画像処理装置、及び、プログラム |
| RU2469400C1 (ru) * | 2011-11-17 | 2012-12-10 | Корпорация "САМСУНГ ЭЛЕКТРОНИКС Ко., Лтд." | Способ преобразования растрового изображения в метафайл |
| JP7235105B2 (ja) * | 2019-05-08 | 2023-03-08 | 日本電信電話株式会社 | 点群解析装置、推定装置、点群解析方法、およびプログラム |
| WO2020225890A1 (ja) * | 2019-05-08 | 2020-11-12 | 日本電信電話株式会社 | 点群解析装置、方法、およびプログラム |
-
2004
- 2004-05-31 JP JP2004161571A patent/JP4371911B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005346137A (ja) | 2005-12-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4371911B2 (ja) | 関数化処理方法及び関数化処理装置 | |
| US7873218B2 (en) | Function approximation processing method and image processing method | |
| US6993185B2 (en) | Method of texture-based color document segmentation | |
| JP4646797B2 (ja) | 画像処理装置及びその制御方法、プログラム | |
| US8200012B2 (en) | Image determination apparatus, image search apparatus and computer readable recording medium storing an image search program | |
| CN105528614B (zh) | 一种漫画图像版面的识别方法和自动识别系统 | |
| CN108146093B (zh) | 一种去除票据印章的方法 | |
| JP5361574B2 (ja) | 画像処理装置、画像処理方法、及びプログラム | |
| JP4267475B2 (ja) | 図面照合装置 | |
| JP2006253892A (ja) | 画像処理方法及び画像処理装置 | |
| JP3950777B2 (ja) | 画像処理方法、画像処理装置および画像処理プログラム | |
| JP5137759B2 (ja) | 画像処理装置 | |
| US8300946B2 (en) | Image processing apparatus, image processing method, and computer program | |
| JP2002190957A (ja) | 文書処理装置及び方法 | |
| JPH11345339A (ja) | 画像セグメンテ―ション方法及び装置及びシステム及びコンピュ―タ可読メモリ | |
| JP5049922B2 (ja) | 画像処理装置及び画像処理方法 | |
| JP4391704B2 (ja) | 多値画像から二値画像を生成する画像処理装置および方法 | |
| JP2011248702A (ja) | 画像処理装置、画像処理方法、画像処理プログラム及びプログラム記憶媒体 | |
| JP5335581B2 (ja) | 画像処理装置、画像処理方法及びプログラム | |
| JP4049560B2 (ja) | 網点除去方法及びシステム | |
| JP2006345314A (ja) | 画像処理装置および画像処理方法 | |
| Strouthopoulos et al. | Identification of text-only areas in mixed-type documents | |
| Roy et al. | Multi-oriented English text line extraction using background and foreground information | |
| JP5159588B2 (ja) | 画像処理装置、画像処理方法、コンピュータプログラム | |
| JP2006106971A (ja) | 表ベクトルデータ生成方法及び文書処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070531 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070531 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20070531 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090518 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090525 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090724 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090831 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090901 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120911 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4371911 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120911 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130911 Year of fee payment: 4 |
|
| LAPS | Cancellation because of no payment of annual fees |