JP4142141B2 - コンピュータ・システム - Google Patents
コンピュータ・システム Download PDFInfo
- Publication number
- JP4142141B2 JP4142141B2 JP35991697A JP35991697A JP4142141B2 JP 4142141 B2 JP4142141 B2 JP 4142141B2 JP 35991697 A JP35991697 A JP 35991697A JP 35991697 A JP35991697 A JP 35991697A JP 4142141 B2 JP4142141 B2 JP 4142141B2
- Authority
- JP
- Japan
- Prior art keywords
- burst
- memory
- buffer
- data
- instruction
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/20—Handling requests for interconnection or transfer for access to input/output bus
- G06F13/28—Handling requests for interconnection or transfer for access to input/output bus using burst mode transfer, e.g. direct memory access DMA, cycle steal
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2213/00—Indexing scheme relating to interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F2213/28—DMA
- G06F2213/2806—Space or buffer allocation for DMA transfers
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Memory System (AREA)
Description
【発明の属する技術分野】
本発明は、コンピュータ・システムに関するもので、特に媒体データを処理するシステムに関するものである。
【0002】
【従来の技術】
最適なコンピュータ・アーキテクチャは、性能上の要件を充足しながらかつ最小限度のコストを達成するものである。現状では、媒体の処理に重点を置いた装置システムにおける主要なハードウェア・コスト要因はメモリである。メモリは媒体データを保持するに足る十分な容量を持たなければならないし、またコンピュータのスループット要件を充足することができる十分なアクセス・バンド幅を提供しなければならない。命令スループットを常に最大にしなければならない通常のプロセッサとは対照的に、そのような装置システムはデータ・スループットを最大にする必要がある。本発明は、媒体集約的アルゴリズムを処理する上での制約を所与として、低コスト・メモリから高性能を引き出すことを(その点に限定するものではないが)特に対象とする。
【0003】
本発明は、特に、データを処理するための処理システム、処理システムによって処理されるまたは処理されるべきデータを記憶するためのメモリ(例えばダイナミックRAMすなわちDRAM)、メモリへのアクセスを制御するためのメモリ・アクセス・コントローラ、およびメモリとの間で読み書きが行われるべきデータをバッファするためのデータ・バッファ(例えばスタティックRAMすなわちSRAM)を備えるタイプのコンピュータ・システムに関するものである。
【0004】
現在、最も廉価な形式の対称性読み書きメモリはDRAMである(対称性は、フラッシュ・メモリの場合の読み書きと違って、読み取りおよび書き込みアクセス時間が全く同じであることを意味する)。現在、DRAMはパーソナル・コンピュータにおいてメイン・メモリとして広く使用されているが、プロセッサにより近いデータ・バッファやキャッシュではSRAMのような比較的高速な(しかしより高価な)メモリ技術が使用されている。低コスト・システムにおいては、処理性能(および能力)の目標が満たされるような最も低コストのメモリを使用する必要がある。
【0005】
本発明の開発過程で、達成可能な最大データ・バンド幅を理解するため、最も廉価なDRAM技術について分析を行ったが、明らかに、既存システムは利用可能なバンド幅を活用していない。本発明は、利用可能なバンド幅の使用度を増加させること、従って、上記のようなコンピュータ・システムにおけるメモリの全般効率を増加させることを目的とする。
【0006】
典型的プロセッサは、SRAMキャッシュに10nsでアクセスすることができる。しかし、メモリ・コストを最小限にとどめなければならないシステムにおけるメインDRAMメモリへのアクセスは200nsを要し、キャッシュのアクセス時間の20倍である。従って、高いスループットを確実にするためには、必要とされる前に可能な限り多くのデータを局所的キャッシュ・メモリ・ブロックに置かなければならない。そうすることによって、プロセッサは、メイン・メモリに関する場合のような比較的長い遅延ではなく、迅速な局所的キャッシュ・メモリに対するアクセス待ち時間を経験するだけである。
【0007】
ここで「待ち時間」とは、メモリからデータを取り出すために要する時間のことである。システムの処理性能がプロセッサに依存するような「計算処理中心」のシステムにおいて待ち時間は重大な関心事である。局所的メモリとメイン・メモリの速度の間の大きい係数によって、処理がメモリ・システムの性能に左右される場合がある。そのようなケースは、「バンド幅依存的」であって、メモリ・システムのバンド幅によって究極的に制限される。プロセッサの処理速度がメモリに比較して十分早ければ、プロセッサは、メモリが応ずることができるよりも速い速度で要求を生成するであろう。今日の多くのシステム性能は、計算処理依存型からバンド幅依存型へ移行している。
【0008】
【発明が解決しようとする課題】
より速いメモリを使用することは、性能問題を軽減するための1つの技法である。しかし、それにはコストの増加がともなう。高速メモリの使用に代わって、既存のメモリ・チップの使用度が効率ではないという認識に基づいて、現在使用のメモリに対して一層効率的にアクセスする新しい方法を展開することが必要とされている。
【0009】
【課題を解決するための手段】
伝統的DRAM構成の特徴は、それが「バースト」モードでのアクセスを可能にするという点である。DRAMは、矩形マトリックスの形態のメモリ位置から構成されるアレイを含む。アレイにおける1つのエレメントにアクセスするためには、先ず行を選択(すなわちオープン)して、次に該当する列を選択しなければならない。しかし、一旦ある行が選択されると、その行の中の複数列への連続したアクセスは、単に列アドレスを与えることによって実行される。ある行をオープンしてその行にとって局所的な一連のアクセスを実行する概念は、「バースト(burst)」と呼ばれる。
【0010】
本明細書で使用される用語「バースト効率」は、DRAMへの平均アクセス時間(b)を分母としDRAMへの最小アクセス時間(b)を分子とする比率の測定値である。DRAMアクセスにおいて、n個のデータ項目をバーストするためには、1回の長いアクセスと(n−1)回のそれより短いアクセスが必要とされる。このように、バーストが長いほど、平均アクセス時間は減少し、従ってバンド幅は増大する。典型的には、キャッシュ型システムは、(キャッシュ・アーキテクチャおよびバス幅がその理由であるが)、4回のアクセス・バーストを使用する。これは、約25ないし40%のバースト効率に相当する。16ないし32回のアクセスというバースト長の場合に効率は約80%と倍になる。
【0011】
本明細書において使用される用語「飽和効率」とは、DRAMバスにおけるトラヒック頻度の測定値を指す。性能がプロセッサに依存するシステムにおいては、キャッシュ・ミスが発生し、そこで新しいキャッシュ行を取り出すため4アクセス・バーストが実行されるまで、バスはアイドルである。この場合、待ち時間は非常に重要である。このように、バスがほとんど使用されていないので、飽和効率は低い。本発明人のテストでは、ある1つのシステムにおける飽和効率は20%であった。従って、バスから5倍の性能向上を引き出す機会が存在する。
【0012】
バースト効率と飽和効率の向上の可能性を組み合わせることによって、現在使用されているものと同等のメモリについて約10倍のスループト向上を獲得できる可能性がある。
【0013】
本発明は、第1の局面において、バースト命令をメモリ・アクセス・コントローラに伝達する手段、およびそのようなバースト命令を待ち行列に記憶する手段を備える。該メモリ・アクセス・コントローラは、バースト命令に応答して、単一のメモリ・トランザクションで複数のデータをメモリとデータ・バッファの間で転送させる。また、バースト命令の待ち行列への記憶によって、先行したバースト命令が実行された直後に次のバースト命令がメモリ・アクセス・コントローラによって実行される状態に置かれる。
【0014】
第2の局面において、本発明は、バースト命令をメモリ・アクセス・コントローラに伝達する手段を備え、この場合、そのようなバースト命令は、そのバースト命令に応答してアクセスされるメモリの位置の間の間隔を定義するパラメータを含むかあるいはそのようなパラメータに関連づけられ、該メモリ・アクセス・コントローラは、バースト命令に応答して、単一のメモリ・トランザクションの間に、上記間隔パラメータに従って間隔を置いたメモリ位置とデータ・バッファの間で複数のデータを転送させる。
【0015】
第3の局面において、本発明は、コンピュータ・システムにおいて、少なくとも1つのデータ・バッファへコンパイルしなければならない計算処理エレメントおよびそのデータ・バッファを介する実行にとって適切な計算処理エレメントを原始コードの中で特定するステップ、該原始コードにおいて特定した上記計算処理エレメントを、各々が上記少なくとも1つのデータ・バッファのサイズより小さいメモリ・トランザクションを含み、バースト命令のような演算を表す一連の演算に変換するステップ、および上記特定した計算処理エレメントが上記少くとも1つのデータ・バッファへのアクセスを通して処理されるように、上記原始コードを処理システムによって実行するステップを含む。
【0016】
【発明の実施の形態】
本発明は、それに限定はされないが、特に、「媒体集約的」アルゴリズムと呼ばれる特定のクラスのアルゴリズムに適用できる。このアルゴリズムは、データに依存するアドレス指定を用いることなく長いアレイにアクセスすることができる通常のプログラム・ループを使用するアルゴリズムを意味する。そのようなアルゴリズムは、高度の空間上の局所性および規則性を示すが、一時的局所性は低い。高度の空間上の局所性および規則性が発生する理由は、アレイ項目nが使用されるとすると、sをアレイにおけるデータ・エレメント間の一定のストライド(間隔)を示すとすればアレイ項目n+sが使用される可能性が非常に高いからである。低い一時的局所性は、典型的にはアレイ項目nが一度だけアクセスされるという事実による。
【0017】
普通のキャッシュは、頻繁に使用されているデータをプロセッサの近くに保持することによって高い一時的局所性を開拓するように設計される。空間局所性は開拓されるが、それは行取り出しメカニズムによる非常に限られた形態である。これは、通常は、単位ストライドであり、相対的に短い。これら2つの点は、キャッシュが媒体データストリームを取り扱うのが不得意であることを意味する。動作の際、キャッシュにおいて冗長データによって役立つデータが置き換えられることが頻繁に発生し、DRAMバンド幅は極大化されない。伝統的キャッシュは特定のデータ・タイプには理想的に適しているが、媒体データには適していない。
【0018】
本発明と伝統的キャッシュのバースト・バッファリングの主な相違は、充填方針、すなわちバッファの内容を空にし充填する状況および方法にある。
【0019】
本発明に従って、伝統的データ・キャッシュを補強し、特に媒体データにアクセスするために使用される新しいメモリ・インタフェース構造すなわちバースト・バッファが提供される。媒体データ特性を活用することによって、DRAMまたはそれと同等の機構が最適化され、また、制御のために使用されるその他のデータ・タイプに関してデータ・キャッシュは一層効果的に動作することができる。媒体データがキャッシュのデータと衝突する可能性が少ないので、性能を犠牲にすることなくデータ・キャッシュ・サイズを減少することができる場合が出てくる。バースト・バッファのために必要とされる全追加メモリが、データ・キャッシュのために必要とされるメモリの節約と同じ大きさであるような場合に、上記のようなケースとなる可能性がある。
【0020】
システムは、いくつかのバースト・バッファを含むことができる。典型的には、各バースト・バッファは、それぞれのデータストリームに割り当てられる。アルゴリズムは可変的数のデータストリームを持つので、バースト・バッファにとって利用できるSRAMの量を固定させることが提案される。この量は、必要とされるバッファの数に従って等量に分割される。例えば、固定的SRAMの量が2KBでアルゴリズムが4つのデータストリームを持つとすれば、メモリ領域は、4つの512バイトのバースト・バッファに細分化される。6個のデータストリームを持つアルゴリズムの場合は、各々が256バイトの8個のバースト・バッファに細分化される。換言すれば、データストリームが2の累乗でない場合、バースト・バッファの数は、好ましくは、次に大きい2の累乗である。
【0021】
本発明に従うアーキテクチャにおいて、バーストは次式によって定義されるアドレス・セットを含む。
burst {B + s × i | B,S,i ∈ N ∧ 0 ≦ i < L}
上式において、Bは転送の基底アドレスであり、Sはエレメントの間のストライドであり、Lは長さであり、Nは自然数のセットである。この式において明示的に定義されていないが、バーストの順序は、0からL-1へ増分するiによって定義される。従って、1つのバーストは、
(base_address, length, stride)
という3タプルによって定義することができる(ここで、base_addressは基底アドレス、lengthは長さ、strideはストライドを意味する)。
また、ソフトウェアにおいて、バーストはエレメント・サイズによって定義するこができる。これは、バーストが、バイト、ハーフワードまたはワードという単位でサイズを与えられることを意味する。ストライドの単位はサイズを考察しなければならない。「サイズを与えられたバースト」は、
(base_address, length, stride, size)
という4タプルによって定義することができる(sizeはサイズを意味する)。
【0022】
「経路バースト」は、メモリへの経路の幅であるようなサイズを与えられたバーストを指す。コンパイラは、ソフトウェアがサイズを与えたバーストを経路バーストに対応づける責任がある。経路バーストは、
(base_address, length, stride, width)
という4タプルによって定義される(widthは経路幅を意味する)。
【0023】
経路幅が32ビット(すなわち4バイト)であれば、経路バースの形式は、常に(base_address, length, stride, 4)であり、簡略化して、(base_address, length, stride)という3タプルで表される。
【0024】
このメモリの制御およびバースト・バッファの割り当て(および解放)は、より高レベルのソフトウェアまたはハードウェア・プロセスによって取り扱われることもできる。このプロセスは、バースト・バッファの名前を自動的に変更するような別のアーキテクチャ上の機能を含むこともできる。
【0025】
図1に示されるように、本発明に従うコンピュータ・システムは、i960のようなプロセッサ10、メイン・メモリ・インターフェースまたはアクセス・コントローラ16を持つEDO DRAMのようなメインDRAMメモリ14、メモリ・インターフェース16からの経路20aおよびプロセッサ10への経路20bをもつ小規模SRAM命令キャッシュ18、データ・キャッシュ19とメモリ・インターフェース16の間の経路21aおよびデータ・キャッシュ19とプロセッサ10の間の経路21bを持つSRAMデータ・キャッシュ19、および、キャッシュ・バイパス・プロセッサ・ロード/ストア命令を実行するためのプロセッサ10とメモリ・インターフェース16の間の経路22を備える。既知のコンピュータ・システムとは違って、本コンピュータ・システムには、図1において点線で囲われて示されているバースト・バッファ・システム24が含まれる。
【0026】
バースト・バッファ・システム24は、(1)例えばプロセッサ10のためのコプロセッサであるプロセッサ・インターフェース12、(2)例えば2KBという固定量のSRAMを持つバースト・バッファ・メモリ26、(3)プロセッサ10からメモリ要求を受け取り、必要とされるデータがバースト・バッファ・メモリ26に駐在しているかあるいはデータを取り出すためメイン・メモリ14へのアクセスを始動すべきかをプロセッサに対して透過的に決定する範囲比較機構28、(4)少くとも1つのFIFO形態をなし、プロセッサ10からバースト命令を受け取ることができるバースト命令待ち行列30、(5)現在時のシステム状態を評価し、バースト命令待ち行列30から次の適切なバースト命令を取り出し、その命令または要求をメイン・メモリ14に伝達するように動作することができるバースト・コントローラ32、(6)バースト転送に関連するパラメータを保持し特定のバースト命令によって更新されるパラメータ記憶機構34、(7)ミスしたデータに関してバースト・バッファ・メモリ26をバイパスする経路を含め、バースト・バッファ・メモリ26とプロセッサおよびメモリ・インターフェース12、16の間のデータ移動のための経路36a乃至36d、および(8)状態情報およびバースト命令をバースト・バッファ・システム24内およびプロセッサならびにメモリ・インターフェース12、16へ移動させるための制御経路38a乃至38f、を含む。
【0027】
図2および図3に示されるように、バースト・バッファ・メモリ26は選択可能な数のバッファ40として構成することができる。例えば、図2の(A)のように単一2KBバッファ40(0)として、図2の(B)のようにそれぞれが1KBの2つのバッファ40(0)、(1)として、図3の(C)のようにそれぞれが512バイトの4つのバッファ40(0)、(1)、(2)、(3)として、また、図3の(D)のようにそれぞれが256バイトの8つのバッファ40(0)、(1)、(2)、(3)、(4)、(5)、(6)、(7))として、構成できる。また、各バッファは、例えば図3の(C)のバッファ40(2)、(3)をメイン・メモリ14からプロセッサ10への入力バッファとして、例えば図3の(C)のバッファ40(0)、(1)をプロセッサ10からメイン・メモリ14への出力バッファとして、あるいは例えば図2の(A)のバッファ40(0)を双方向バッファとして、配置することが可能である。バースト命令待ち行列は、バースト・バッファ40の数と同数のFIFO42を持つように構成される。図2の(A)はデータストリームが1つの場合に、図2の(B)はデータストリームが2つの場合に、図3の(C)はデータストリームが3または4つの場合に、図3の(D)はデータストリームが5乃至8つの場合に、それぞれ使用される。代替的構成として、単一のバースト命令待ち行列FIFO42をバースト・バッファ40の数と無関係に使用することも可能である。
【0028】
プロセッサ10はロード命令"ld"のような普通のi960命令に従って動作することができる。パラメータを持つロード命令の形式は次の通りである。
ld (g5),r4
これは、プロセッサに対して、そのレジスタg5にあるアドレスによってポイントされるデータ・ワードを取り出して取り出したデータ・ワードをレジスタr4に格納することを命令している。しかしながら、本発明の1つの実施形態において、命令セットは、同等のロードバースト命令"loadburst"を含むように拡張される。ロードバースト命令は次の形式を持つ。
loadburst src, stride, size, buf
これは、srcが示すメモリ・アドレスを開始点としてstrideが示す量増分したアドレスまでのメモリ14から、sizeで示された大きさのバースト・データ・ワードを、bufで識別された入力または双方向性バースト・バッファ40の1つ(buf)に転送させるものである。これに対応する次の形式のストア・バースト命令"sotreburst"がある。
storeburst buf, src, stride, size
これは、bufで識別された入力または双方向性バースト・バッファ40の1つ(buf)から、srcが示すメモリ・アドレスを開始点としてstrideが示す量増分したアドレスまでのメモリ14へsizeで示された大きさのバースト・データ・ワードを転送させるものである。
【0029】
命令loadburstおよびstoreburstは、たとえ転送が発生しなかったとしてもそれらが単一サイクルで終了するという点において、通常のloadおよびstore命令とは相違する。要するに、loadburstおよびstoreburst命令はメモリ・インターフェース16にバーストを実行するように伝えるが、バーストの完了を待たない。
【0030】
上記のシステムにおいて、メモリ・インターフェース16は、良識の範囲内ではあるが、いかなるサイズおよびストライドを持つバースト要求にも応じることができなければならない。マイクロプロセッサ10に対する高度な追加機構が必要ではあるが、同一のチップへの組み込みが最善の実施策である。プロセッサ1Oからのメモリ要求の実行にはいくつかの方法があるが、そのうちの2つは、(a)バースト命令待ち行列30に関してメモリ・マップ化対応レジスタを使用する方法と、(b)コプロセッサを使用してload/storeメカニズムをバイパスする方法である。後者の方法が好ましいけれども、必ずしもアーキテクチャ機能がプロセッサに常に存在しなければならないことはない。後者のモデルの使用には、また、新しいプロセッサ命令の定義および使用が必要とされる。
【0031】
キャッシュの主な利点のうちの1つは、正しさの透過性である。正しいデータがプロセッサに常に与えられ、必要な場合プロセッサに視認できないハードウェア方法を使用してデータはいつでもメイン・メモリにおいて更新される。バースト・バッファ・システム24も同様の機能性を提供する。
【0032】
上記のシステムにおいて、バースト・バッファ40のデータは、メイン・メモリ14の領域からコピーされる。位置情報(すなわちアドレス、ストライド等々)は、それぞれのバッファ40にヒットがある(すなわちそのメモリ位置のデータが現在キャッシュに存在する)か否かを判断するためプロセッサ10からのすべてのメモリ要求に対して比較される。比較は次の2つの方法で実行される。すなわち、(1)バッファ40におけるすべてのアドレスを範囲比較器28を使用して(通常キャッシュ・タグに関して)プロセッサ・アドレスと連想比較すること、および(2)プロセッサ・アドレスを使用して、範囲比較器によってバッファのアドレスを指定する式を検査して、解があるか調べること、である。前者は高価であり(そして速度を早くするほど高価となり)、後者は安くて速いが、満足のゆく性能を得るためストライドを2の累乗に制限する。
【0033】
アドレス範囲比較が真であれば、読取りはバッファ40においてヒットする。この場合、データはバッファからプロセッサへ迅速に返される。一方、読み取りがミスすれば(すなわちバッファ40においてヒットしなければ)、バースト・バッファ・メモリ26を迂回して、要求されたデータはメイン・メモリ14から直接取り出される。しかし、データがその時点でロードされつつある範囲にあると、その範囲がロードされ次にバッファ40から取り出されプロセッサ10に渡されるまで読取りは「停止」または「阻止」される。(待ち時間を節約するため、データは受け取られ次第渡されるようにシステムは修正されている)。当該データが送出されるべきバーストに含まれていれば、当該データが近接した連続動作で2度読み取られることを防ぐため、バーストの実行が完了するまで、データ読み取りは阻止される。
【0034】
書込みのヒットがあると、対応するバッファ40のデータは更新される。その時点でメイン・メモリ14は更新されないが、メイン・メモリ14に関する整合性は、後刻ソフトウェア制御の下storeburst命令によって達成される。一方、書込みミスが発生すると、同じデータを含むstoreburst命令が保留状態または活動状態にない限り、メイン・メモリのデータが直接更新される。この場合、書込みは、storeburst命令が完了するまで阻止される。
【0035】
命令をメモリ・インターフェース16へ送達するバースト・コントローラ32は、「遅延」と呼ばれるメカニズムを使用することがある。これは、命令が発せられる時間が後刻またはなにがしかの事象まで延期されることを意味する。例えば、次の命令が、例えばstoreburst-deferred-16access命令であれば、バースト・バッファへの16回のアクセスが完了するまでそれは待機し、そのその後自動的にstoreburst命令を発する。その他の遅延メカニズムとして、時間(すなわちサイクルのカウント)、外部割り込みのような事象、およびバッファ空き有無インジケータを使用することもできる。アクセス・カウントに基づく遅延の使用は、プログラムの流れとメモリ・インターフェース16への命令伝達を切り離すので、バースト・バッファ・システム24の強力な機能である。
【0036】
バースト・バッファ・コントローラ32は、経路38fを経由してプロセッサ10へ状態情報を提供する。バースト・バッファ・コントローラ32は、また、バッファ割当ておよび論理バッファの名前変更がソフトウェア制御の下実施されるように、ユニークなバッファ識別子を提供する。
【0037】
バーストの長さが対応するバッファ40のサイズより長ければ、1つの手順として、バッファ40の長さと同じになるようにバースト長が切り捨てされる。しかし、修正された手順では、非常に長いストリームがバッファに持ち込まれる。loadstream-deferred-32accessのような単一命令を使用して、それぞれがバースト・バッファのサイズを持ついくつかの断片に長いストリームを格納し、断片の各々は指定された数のアクセスが完了すると次の断片と置き換えられる。
【0038】
プロセッサ10にとって透過的でないアクセス・モードをサポートすることも可能である。最も簡単な方法は、先入れ先出し方式(FIFO)バッファである。この場合、プロセッサ10は単一のアドレスを使用してバッファ40にアクセスする。読取りの場合は、バースト・バッファ40から最初のエレメントを取り出す。後続の読取りはバッファ全体を通して次々とエレメントを取り出す。空きの有無の概念がここで導入される。より一般的に拡張すれば、バッファ40上に「窓」が与えられる。この窓は、バッファに対する相対的アクセスを可能にする。この窓における固定数のアクセスの後(あるいは別のトリガーに従って)、窓は、その位置がもう1つのデータに対して中央となるように、進められる。前進の量はプログラムできる。これを「循環窓」方法と呼ぶ場合があり、多くの実施形態が可能である。
【0039】
以下に、バースト・バッファ・システム24の動作の詳細を記述する。バッファ40の中のデータは、要求されたアドレスを開始アドレス、長さおよびストライド情報を使用した計算結果と比較することによって有効性を検査される。(レジスタ・サイズは別として)長さおよびストライド値に対する制約はない。しかし、通常のloadburstおよびstoreburst命令に関しては、長さがバッファ・サイズより大きければ、データは切り捨てられる。レジスタから読み戻される値は切り捨てられた値である。
【0040】
アドレス・タグが使用されない限り、範囲比較は非常に遅い。範囲検査はワード・アドレスのみを考慮するので、ビット0および1は無視される。バッファ40における読み取りヒットによってデータ項目は復元される。ミスはメイン・メモリ14からの取り出しを引き起こす。書込みヒットによって、該当するバッファ40が更新される。書込みミスはメイン・メモリ14を直接更新する。メイン・メモリ14に完全なバッファ40を最後に書き戻すことによって、整合性が維持される。
【0041】
データがデータ・キャッシュに存在する場合に発生する整合性問題を防止するため、バッファ40を使用するデータに「キャッシュ使用不可」というマークを付けることもできる。これは、バッファ40に関するデータを含む同じ領域のメモリにおける行取り出しからデータ・キャッシュは制約されなければならないことを意味する。
【0042】
読み取り用の状態レジスタが各バッファ40に関連づけられる。このレジスタは、バッファが使用中であるか否かを示す有効ビットを含む。ソフトウェアは、このようなフラグを検査してどのバッファが利用できるか判断する。現在動作状態を含むその他の状態情報も利用できる。無効なバッファへのアクセスが発生すると、通常のメモリ・ロード/ストア命令が生成される。有効性メカニズムはソフトウェアにとって透過的である。
【0043】
バースト命令待ち行列30に書き込まれるloadburst命令によって、指定された特性を持つバーストが目標バッファに記憶される。loadburst命令が発信され次第、書き込み動作が完了するまでバッファは完全に無効状態にされる。バッファに保持されていたいかなるデータも、消去され回復はできない。
【0044】
storeburst命令によって、目標バッファは空にされる。storeburst命令が発信され次第、バッファはロックされ(すなわちすべてのアクセスが禁止され)、バッファはメモリへコピーされる。次にそのバッファは無効状態にされる。
【0045】
loadburstおよびstoreburst命令は両者とも遅延化できる。これは、動作開始を誘導するため、実行されねばならない読み取り/書き込み数を記述するカウントが各命令に関連づけされることを意味する。(その他のオプションとして、計時や命令カウントが含まれる)。これは、例えば16回のアクセスだけ遅延されるburststore命令をバッファに伝達することができることを意味する。そこで、バッファ・コントローラはバッファへ16回アクセスが行われるのを待ち、その時点でバッファを空にする。
【0046】
バッファは"allocbuffer"命令によって有効状態に変更される。この命令は、範囲計算機構へアドレス情報を提供する点でloadburst命令と同じであるが、いかなるデータのロードも行わない。この命令は、先行loadburst命令を必要とするのではなく、プロセッサ書き込みを使用してバッファに書き込みが行われるのを可能にする。allocbuff命令によってバッファは有効状態にされる。バッファに含まれているデータは不変のままであり、これは、バッファをいっぱいにしているデータが異なるメモリ領域に再配置されることを意味する。
【0047】
同様の"freebuffer"命令がある。これは、バッファを単に無効状態にしてその内容を不変のままとする命令である。その後に続くallocbuff命令によって、バッファをその前の状態に復帰させることができる。
【0048】
プロセッサはいくつかの条件によって処理を停止させられる。それらの条件には、(1)バッファ命令待ち行列がいっぱいであるにもかかわらずバースト命令が出される場合、(2)バースト命令が進捗中に目標バッファへのアクセスが要求される場合、および(3)バッファ命令がバッファをミスし、通常のメモリ・アクセスが実行されなければならない場合、が含まれる。
【0049】
転送のため指定された長さがバッファの長さ未満の場合は、部分的アクセスが実行され、バッファ中の未使用位置は未定義とされる。バースト転送は、バースト命令によって示唆される順序でバッファが常に空にされるという制約を持つ。部分的アクセスは常にバッファの最初の位置から始まる。
ストライドは符号付き量であるので、バースト・データの順序は、常に、昇順または降順のいずれかである。特定のアプリケーションまたはシステムによって要求されるバッファの数は、性能要件、サポートすべきストリームの数等々によって変わる。命令は、前の命令が完了した時のみ実行される。
【0050】
"storeburst value O"コマンドを出して、目標メモリ区域をゼロで埋めることができる。バースト・バッファ自体はゼロにされないが、別々のデータ経路がメイン・メモリに値0を書き込む。この拡張コマンドにおいて、どのような値でも指定することは可能であり、必要とされる値に設定されるレジスタが提供される。
"loadburst value O"命令によってバッファをゼロで埋めることができる。メモリ・トラヒックは生成されないが、この演算は同じ方法で実行され1サイクル以上を要する。このように、この命令は他のloadburst命令と同様に取り扱われる。
【0051】
データストリームが以下の条件に合致することをアプリケーションが保証するという前提で、メモリ・コントローラによってバーストに分解された上で、データストリームがメモリに送られる。その条件は、(1)各データ・エレメントは順次持ち込まれること、(2)各データ・エレメントは、正確に1度またはあらかじめ定められた使用パターンに従って、使用されること、(3)バッファ・サイズの断片の形態でのストリーム処理が適用されること、である。これらの条件が満たされれば、書込みストリームまたは読取りストリームは、該当する数のアクセスだけ遅延されるバースト命令に分解される。
【0052】
バースト転送に関連づけられる長さは通常バッファ・サイズに切り捨てられるが、loadburstストリームおよびstoreburstストリーム命令を使用することで、長さはストリーム長と解釈される。これらの命令も初期的に遅延されるかもしれないが、これは最初のバースト転送の開始に影響を及ぼすだけである。後続のバーストは、バッファのサイズだけ自動的に遅延される。
【0053】
"burstabort"コマンドはバースト転送を中止するため使用される。その機能性は、進捗中のバーストを終了させることができない点で制約される。しかし、バーストが保留中であれば(すなわち遅延されていれば)、それはキャンセルされる。いずれにせよ、バッファは常に無効状態にされる。その本当の用途は、現在のバーストの終了時にあるいはバーストが保留中であれば即刻ストリームを終了させるためのものである。
【0054】
次に、システムのファームウェア・インターフェースを記述する。各バースト・バッファ40には4つのレジスタが関連づけられている。これらのレジスタは、メモリに対応付けされていて、プロセッサによって単一サイクルのロード/ストアでアクセスされる。それらレジスタの名前は、1.基底アドレス、2.長さ、3.ストライド、および4.制御/状態、である。最初の3つのレジスタは、バースト命令のために使用されるパラメータを含む。バースト命令は制御レジスタに書き書き込まれ、状態情報が制御レジスタを読むことによって取得される。すべてのレジスタは、1ワード幅である(本実施形態では32ビットである)。各レジスタについて以下に記述する。レジスタの意味を理解するためには、1バーストでデータを取り出すために使用される関数を定義することが必要である。1バースト転送における各エレメントiは、以下の式によって与えられるメイン・メモリのアドレス(address)から取り出される。
Address[i] = base_address + (i- 1)*stride (式1)
但し、base_addressは基底アドレス、strideはストライドを意味し、iは1からlengthまでの範囲の値である。
【0055】
base_addressレジスタは、バースト命令が出される前に、初期化されていなければならない。バースト命令が出されると、基底アドレスを使用してデータ・アドレスが計算される。基底アドレスは、ストリーム・アクセスに関しても自動的に変更されることはない。バッファが有効である時のbase_addressレジスタへの書き込みは、バッファを無効状態にさせる。レジスタ自体はハードウェアによって隠されていて、たとえバッファがその後無効状態にされるとしてもすべての活動的バーストが正しく完了することが保証される。基底アドレスは、バイト単位で指定されワード単位で整列されなければならない。そうでなければ、値は自動的に切り捨てらされ、丸めは実行されない。レジスタから読まれる値は変更されない。
【0056】
長さレジスタは、バースト命令が出される前に、初期化されなければならない。バースト命令が出されると、長さ(length)を使用して、データ・アドレスが計算される。非ストリーム・バーストに関しては、長さレジスタは、バースト・バッファ長以下の長さに制限される。バースト命令が出され、長さレジスタの値がこの基準を上回ると、それはバッファ長に自動的に切り捨てられる。この切り捨ては、バースト命令が出される際発生するが、長さレジスタへの書込みが行われる時は発生しない。切り捨てられる値は、このレジスタから順次読み取られている値である。ストリーム・アクセスの場合、長さレジスタは、全ストリーム転送の長さを指定する。バッファが有効である時の長さレジスタへの書き込みはバッファを無効状態にする。レジスタ自体はハードウェアによって隠されていて、たとえバッファがその後無効状態にされるとしてもすべての活動的バーストが正しく完了することが保証される。転送の長さはバイト単位で測定されるが、ワード(すなわち4バイト)の倍数に制限される。ワード境界に整列されない値は切り捨てられ、丸めは実行されない。レジスタから読み取られる値は変更されない。
【0057】
ストライド・レジスタには、バースト命令が出される前に、初期化されなければならない。バースト命令が出されると、ストライドを使用して、データ・アドレスが計算される。ストライドは、ストリーム・アクセスに関しても、自動的に変更されることはない。バッファが有効である時のストライドへの書き込みはバッファを無効状態にさせる。レジスタ自体はハードウェアによって隠されていて、たとえバッファがその後無効状態にされるとしてもすべての活動的バーストが正しく完了することが保証される。ストライドはバイト単位で測定されるが、ワード(すなわち4バイト)の倍数に制限される。ワード境界に整列されない値は切り捨てられ、丸めは実行されない。レジスタから読まれる値は変更されない。
【0058】
制御/状態レジスタに関しては、すべてのバースト命令は制御レジスタへの書き込みの別名である。これらのアクセスにおいて使用されるデータは、各命令に関して定義される形式に従って構成される。ワードの最初の3ビットは、命令を識別するために使用される。
【0059】
以下、種々のバースト命令を記述する。
最初に、"allocbuffer"命令は、メモリの領域を対応させるバッファを構成するために使用される。バーストは実行されないが、バッファは有効にされ、範囲検査が実行される。転送の長さはバッファのサイズ以下でなければならない。これより大きい値はバッファ・サイズに自動的に切り捨てられる。範囲検査は、上記(式1)に従って生成されたアドレス・セットに対して比較を行う。この命令を出すために使用されるデータ・ワードの形式は、
allocbuffer: [000] [29 reserved bits]
である。
バッファの中のデータは無効化を通してバッファに残るので、バッファ・パラメータを変更し第2のallocbuff命令を出すことによってバッファは再配置される。
【0060】
"burstabort"命令はバースト命令を中止するため使用される。メモリからバッファへのバーストは、一旦始まれば、中止することはできない。しかし、遅延バーストは、保留の間中止することはできるし、loadstreamコマンドはバースト境界上で中止することは可能である。すべての場合、バッファは無効状態にされる。バッファのどのデータも変更されない。この命令の形式は、
burstabort: [001] [29 reserved bits]
である。
【0061】
"freebuffer"命令を使用して、関係バッファが無効状態にされる。パラメータはなにも使用されない。形式は、
freebuffer:[O10][29 unused bits]
である。
【0062】
"loadburst"および"storeburst"命令を使用して、それぞれ、バースト・データをメイン・メモリからバースト・バッファへ取り出し、バスト・バッファからメイン・メモリへバースト・データを書き込む。転送の長さはバッファのサイズ以下でなければならない。これより大きい値は、バッファの大きさに自動的に切り捨てられる。バースト・アドレスは、上記(式1)に従って生成される。これらの命令を出すために使用されるデータ・ワードの形式は、
loadburst:[011] [V] [12 reserved bits] [16 bit deferral_count]
storeburst:[100] [V] [12 reserved bits] [16 bit deferral_count]
である。但し、Vは、バッファにロードされたデータがすべてゼロであるか(V=0)、メモリからの実際のデータであるか(V=1)を示すビット値である。最後の16ビットは、遅延カウントである。この値が0を超えていれば、遅延カウントのアクセス数がバッファに対して実行されるまでバースト命令は延期され。そのようなアクセスは読取りまたは書き込みのいずれかである。転送は、開始アドレス、長さおよびストライドの点でワード境界に整列されている。
【0063】
"loadstream"および"storestream"コマンドを使用して、完全なデータストリームがバッファへロードされ、完全なデータストリームがバッファからコピーされる。ストリームの長さは長さレジスタにおいて定義され、232バイトに制限される。バッファ管理機構が、メモリからバッファへおよびバッファからメモリへ転送されるバースト・セットにストリームを自動的に分解する。バッファへの書き込みは、ハードウェアによって自動的に調整される。遅延カウントを使用してバースト境界が検出される。これは、あるバッファは、あらかじめ定義された数のアクセスの後シーケンスの中の次のバッファと置き換えられることを意味する。ストリームを進める他のどのようなメカニズムも利用できないが、他の命令を使用してストリームを進めるメカニズムを考慮することは可能である。長さLバイトのストリームに関して、4バイト幅を持つメモリ・バス上に長さSのL/4S個のバーストに加えて、残りを記憶しコピーするための1つのバーストがある。長さは4バイトの倍数でなければならず、そうでなければ最も近い倍数まで切り捨てられる。loadstream値0は、バッファへ継続的にゼロをロードし、実際のメモリ・アクセスは起きない。storestream値0は、メモリへ継続的にゼロをロードする。これらの命令の形式は、
loadstream: [101] [V] [12 reserved bits] [16 bit deferral_count]
storestream : [110] [V] [12 reserved bits] [16 bit deferral_count]
但し、Vは上記定義されたとおりのものである。最後の16ビットは遅延カウントである。
【0064】
関係バースト・バッファの条件を評価するため、"querystatus"コマンドが使用される。これは、バッファに対してサポートされる読み取りコマンドである。返される値は、バッファが割り当てらていなければ0、割り当てられていれば1である。現在の対応付けに関する情報は、他のレジスタを読むことによって取得できる。その他のいかなる情報も利用できない。
【0065】
本発明に従ったコンピュータ・システムの第2の実施形態が、図4および図5に示されている。この実施形態において、第1の実施形態のキャッシュ的インターフェースが、ペアを構成する2つのテーブルに基づくインターフェースと置き換えられる。2つのテーブルは、バースト・バッファ・メモリとの間でバースト転送を行うメイン・メモリの領域を記述するMAT(Memory Access Tableすなわちメモリ・アクセス・テーブル)およびバースト・バッファ・メモリの領域を記述するBAT(Buffer Access Tableすなわちバッファ・アクセス・テーブル)である。この実施形態においては、2ポート型SRAMの同等区域がバースト・バッファに使用される。
【0066】
第2の実施形態のアーキテクチャの主な機構が図4に示されている。
本質的に第1の実施形態と類似している機構に関しては、同じ参照番号が使用されている。バースト命令は、バースト命令待ち行列30によってプロセッサ・インターフェース12から提供される。バースト命令待ち行列30からの命令は、バッファ・コントローラ54によって処理され、MAT65およびBAT66の基準スロットへ送られる。バッファ・コントローラは、また、8つのバースト制御レジスタ52から制御入力を受け取る。これらの2つのテーブルに含まれる情報は実行時に結合され、完全なmain-memory-to-burst-buffer transaction(メモリからバースト・バッファへのトランザクション)を記述する。出力は、バッファ・コントローラ54からDMAコントローラ50従ってメモリ・データ経路アービタ58に提供され、メイン・メモリ14とバースト・バッファ・メモリ26の間のトランザクションが有効となる。
【0067】
本実施形態において、バースト・バッファ・メモリ26は、2KBの2ポート型SRAMとして提供される。SRAMの1つのポートはプロセッサ・メモリ空間にあり、迅速なプロセッサ・アクセスに対して使用されることができる。このアーキテクチャの利点は、バースト・バッファ・メモリ26からのアクセスがメイン・メモリ14からのアクセスに比較して非常に速いことが必要なだけであるが、バースト・バッファ・メモリ26への単一サイクル・プロセッサ・アクセスは特に利点がある。もう1つのポートの機能は、後述されるように、メイン・メモリとSRAMの間のDMA転送を可能にすることである。バースト・バッファ・メモリ26内の個々のバッファは、バッファ・アドレスおよびその長さによって定義されるバッファ領域に保持される。プロセッサ・ポートに関して、バイト、ハーフワードおよびワードのアクセス(すなわち動的バス幅指定)がサポートされることが望ましい。これはDMAポートにも望ましいが、必要性は少ない。この2ポート機能は、メイン・メモリとの間のバースト転送をプロセッサからのアクセスと並列して実行させることを可能にする。適切なインターロックまたは優先度メカニズムがない場合は、ソフトウェアが同一SRAM位置への書き込み衝突を防止する必要がある。
【0068】
SRAMのサイズは、計算処理の際いくつかのストリームを取り扱うことができ、かつ長いバーストに関連する要求を取り扱うことができるような大きさでなければならない。多数のアプリケーションに関して、8つのストリームを取り扱うことができる資源を備えれば十分であり、各ストリームは、1つが到来および出力のためもう1つが進行中の計算処理のためという2つのバッファを備えることが望ましいことが判明している。従って、16個のバッファが必要となることが示唆される。また、メモリへの経路幅が32ビットであるSDRAMを使用するバンド幅の約80%の利用度は、32個のバーストで達成できることが判明している。この場合、各バースト・バッファのサイズは128バイトで、合計2KBのSRAMとなる。
【0069】
次に、バースト制御レジスタ52に関して記述する。
主バッファ制御レジスタはbufcntlである。このレジスタは、バースト・バッファ・アーキテクチャの集中制御を提供する。次の表1はバッファ制御レジスタの定義であり、このレジスタの各ビットに関連する機能性を示す。
【0070】
【表1】

バージョン・レジスタ(version)は読み取り専用で、その目的は自明である。同期レジスタ(sync)は読み取り専用レジスタであって、バースト命令待ち行列が空になるまでプロセッサを停止させるために使用される。このレジスタは、プロセッサ命令とバースト命令の並列実行を同期化に役立つ。このレジスタを読むと、下記表2に示されるような4つの値のうちの1つが戻される。この値は、同期命令の前に実行される最後のバースト命令に関連する。
【0072】
【表2】
デフォルト値は0x0である。これはビット2:0だけが使用されその他は常にゼロであることを意味する。(ビット0は停止が必要とされていたか否かを示し、ビット2:1はビット31:30の命令形式に合致するか否かを示す。注:同期命令(sync)はこのレジスタの読み取りを停止できないので、ここでは使用のための定義はされてない)。例外的な状況においてこのレジスタへの書き込みを可能にするような容量が提供される。具体的には、例外処理機構が戻る前に同期レジスタの状態を元に戻すことを可能にする。
【0074】
以下の4つのレジスタは、バースト命令待ち行列からメモリ・コントローラへバースト命令進捗度を逐次通知するために使用される。図6は、それらのレジスタの構造および位置を示す。
【0075】
currcmdレジスタは、読み取り専用レジスタであって、メモリ・コントローラによって現在実行されている命令を保持する。これはbufcntl.transferが1である時のみ有効である。しかしながら、そのアイドル状態において、このレジスタは、ロードまたはストア・バースト命令の読み取りが進行中のバーストが存在することを自動的に意味するnull(ヌル)命令を戻す。
【0076】
lastcmdは読み/書きレジスタである。通常の動作では、メモリ・コントローラによって実行された最後の命令を持っているので、このレジスタは読み取り専用である。しかしながら、文脈切り替えの時点の状態を全面的に元へ戻すことができるようにするため文脈切り替えから戻った後このレジスタは書き直されなければならないので、このレジスタは書き込み機能を持つ。このレジスタは、初期的にはヌル・コマンドに設定される。
【0077】
queuetopレジスタは、文脈切り替えにおいてバースト命令待ち行列を空にするため使用される。bufcntl.enableへゼロの書き込みによってバースト命令を実行不可状態にした後、待ち行列が空になるまで命令毎に待ち行列の内容が読み取られる。queuetopレジスタの読み取りは、待ち行列から最上部の命令(すなわち実行中の命令ではない命令)を削除する効果を持つ。このレジスタはいつでも読み取ることができ、常に待ち行列の最上部から削除した命令を返す。この命令は実行されない。
【0078】
待ち行列の深さは、bufcntl.pendingに保持される。ヌル命令を読むことは待ち行列が空であることを意味する。
【0079】
バースト命令は、バースト命令待ち行列レジスタbiqに書き込まれる。命令は、待ち行列の始めに置かれる。biqレジスタの読み取りは、queuetopレジスタ読み取りと同様に、バースト命令待ち行列の最上部の命令(すなわちメモリ・コントローラによって実行されるべき次の命令)を返す。しかしながら、この場合、それがレジスタ読み取りが行うすべてである。queuetopから読み取られた命令と対照的に、biqから読み取られる命令は実行される。ヌル命令の読み取りは、待ち行列が空であるかまたはその初期化がまさに完了したことを意味する。注:biqレジスタが論理的に待ち行列であるので、待ち行列が空でない限り、読取りが後に続く書き込みは、同じ値に戻らない可能性がある。
【0080】
最後はdebugレジスタである。このレジスタの詳細説明は行わないが、レジスタ定義を下記表3に示す。
【0081】
バースト命令待ち行列は、上述の通りFIFOメモリを含む。バースト命令はプロセッサによって提供される。この構造への原始コードのコンパイルの詳細は次の通りである。本実施形態では、次の4つのフィールドがバースト命令において提供される。
1. 命令
2. MATに関する自動ストライド・インジケータ(ブロック増分ビット)
3. 転送を制御するために使用されるMATエントリに対するインデックス
4. 転送を制御するために使用されるBATエントリに対するインデックス
基本的な動作は、メモリ・アクセスおよびバッファ・アクセスという2つのテーブルの各々におけるエントリをインデックスする命令を発信することである。メモリ・アクセス・テーブルへのインデックスは、転送メモリの最後に使用されるアドレス、範囲およびストライドを取り出す。バッファ・アクセス・テーブルへのインデックスは、バースト・バッファ・メモリ領域の基底アドレスを取り出す。本実施形態では、バースト命令において提供されるインデックスは、アドレス値そのものではない点注意する必要がある(アドレス値そのものとする実施形態も可能ではある)。本実施形態においては、詳細は後述するが、文脈テーブルを介してマスクおよびオフセットがインデックス値に与えられる。DMAコントローラは、2つのテーブルからパラメータを渡され、それらを使用して必要とされる転送を指定する。
【0083】
以下の表4に示されるように2つの代替的形式が与えられる。
【0084】
【表4】
形式は、バッファ制御レジスタにおけるbufcntl.swapビットによって選択される。0というデフォルト値は形式Aを選択し、一方、値1は形式Bを選択する。このスワップ機能の使用によって、コンパイラは容易に命令を増分させることが可能とされ、それによってバッファとメイン・メモリの両方に対して異なる領域へのDMA動作が実行される。スワップ機能がない場合、一方だけに対してこれを達成する(従って1つの命令へのループ・パイプライン化のオーバーヘッドを減少させる)ことができるにすぎない。
【0086】
バースト命令は第1の実施形態の場合と本質的に同じであるが、異なるアーキテクチャの観点から構文および動作の点で変更が行われる。
【0087】
storeburstはビット31:30を00に設定することによって実行される。この命令は、所望の転送の特性を定義するMATおよびBATのパラメータをインデックスする。block_incrementビットが設定されていれば、インデックスを付けられたMATエントリのmemaddrフィールドは転送が完了すると自動的に更新される。
【0088】
loadburstはビット31:30を01に設定することによって実行される。この命令も、所望の転送の特性を定義するMATおよびBATのパラメータをインデックスする。この場合も、block_incrementビットが設定されていれば、インデックスを付けられたMATエントリのmemaddrフィールドは転送が完了すると自動的に更新される。
【0089】
Sync(同期)およびNull(ヌル)は、ビット31:30を11にビット29:0を0xFFFF_FFFFに設定することによって実行される。この命令の主な目的は、ソフトウェアおよびバースト命令の実行の間の同期化メカニズムを提供することである。バースト命令待ち行列30に同期命令syncを書き込むことによって、他のいかなるバースト命令も該待ち行列に置くことが防止される。これは、いかなる1時点においてもその待ち行列には1つのsync命令が存在するだけであること、および同期命令の読み取りがその待ち行列が空であることを示すことを意味する。同期コマンドはDMAアクセスを始動させないが、同期レジスタに連係する同期メカニズムを活動状態にする。同期命令の使用は以下に更に説明される。
【0090】
図5に、メモリ・アクセス・テーブル(MAT)65が示されている。
これは、バースト処理に必要とされるメイン・メモリ位置に関連する情報を保有するメモリ記述子テーブルである。MATの各エントリは、メイン・メモリに対するトランザクションを記述するインデックス付けされたスロットである。本実施形態中では、MAT65は16個のエントリを持つが、当然のことながら異なる形態も可能である。各エントリは、次の3つのフィールドを含む。
1. メモリ・アドレス(memaddr)−メイン・メモリの該当する領域の開始アドレス。仮想アドレス変換によって2つの物理ページにわたるバースト要求が発生し、そのためメモリ・コントローラにとって困難が生じることになる可能性があるので、このメモリ位置は理想的には物理的メモリ・アドレスであることが望ましい。
2. 範囲(extent)−転送範囲。これは、ストライドを乗算された転送長であり、転送される最後のアドレスに1を加えたものである。転送の長さは、範囲をストライドによって除することによって計算され、転送の完了後関連するBAT66のbufsizeフィールド(下記参照)に自動的にコピーされる。
3. ストライド(stride)−転送における連続エレメント間の間隔
フィールドの各々は、通常メモリ・マップ・レジスタとして読み取られる。各レジスタは32ビット幅であるが、次の表5に示されるように、選択されたたフィールドだけが書き込み可能である。
【0091】
【表5】
memaddr:これは、符号なし32ビットであって、経路バーストの最初のエレメントのワード境界整列のアドレスである。境界整列されてない値は、切り捨てによって自動的に整列される。このレジスタの読取りは、バーストのために使用される値を返す。
extent:範囲レジスタのパラメータは、バースト転送の範囲を示すオフセットされたアドレスである。転送がSというストライドだけ間隔を置いたL個のレメントを必要とするとすれば、範囲はS*Lである。バーストがメモリ・コントローラによって実行される時、この値にmemaddr値を加えた値がバッファ域のサイズより大きければ、bufcntl.buffer_overrun_warnフラグが設定される。結果として生じるバーストは、バッファ区域の最初にラップされる。デフォルト値はゼロで、転送がないことを示す。
stride:パラメータstrideは、アクセスの間スキップされるバイトの数である。転送ストライド間隔値は、1から1024の範囲に限定される。1024を越える値は自動的に1024にされ、bufcntl.stride_overrun_warnフラグが設定される。このレジスタの読取りは、バーストに使用される値を返す。ストライドは、また、この場合4バイトであるメモリ・バス幅の倍数である。4バイトの倍数に整列させるため自動的切り捨てが行われる。デフォルト値はゼロで、これは1というストライド長さに等しい。
【0093】
MATスロットによって含められる値の例を示せば、
{0x1feelbad, 128, 16}
である。これは、それぞれが4個の4バイト長ワードの間隔をおいた32個の4バイト長ワードとなる。
【0094】
バースト命令の自動ストライド標識ビットもMAT65にとって意味を持つ。このビットがバースト命令において設定されていれば、開始アドレス・エントリは、バーストが連続している限り次のメモリ位置に次々と増加される。これは、長いシーケンスのメモリ・アクセスにおける次のバーストに関する開始アドレスを計算するプロセッサ・オーバーヘッドを節約する。
【0095】
次に図5に示されるバッファ・アクセス・テーブル(BAT)66を説明する。これもまたメモリ記述子テーブルであるが、この場合はバースト・バッファ・メモリ区域26に関連する情報を保有する。BAT66の各エントリは、バースト・バッファ・メモリ区域26に対するトランザクションを記述する。MAT65の場合と同様に、BAT66は16個のエントリを含むが、別の形態も当然のことながら可能である。本実施形態では、各エントリは次の2つのフィールドを含む。
1. バッファ・アドレス(bufaddr)−バッファ区域のバッファの開始アドレス。
2. バッファ・サイズ(bufsize)−最後の転送に使用されるバッファ区域のサイズ。
フィールドの各々は、この場合も、通常メモリ・マップ・レジスタとして読み書きされる。
MAT65の場合と同様に、各レジスタは32ビット幅であるが、下記表6に記述されるように、レジスタ内の選択されたフィールドだけが書き込み可能である。すべての書き込み禁止ビットは常にゼロとして読み取られる。
【0096】
【表6】
バッファ・アドレス・パラメータbufaddrは、バッファ区域の経路バーストの最初のエレメントに対するオフセットされたアドレスである。バースト・バッファ区域は、ハードウェアによってプロセッサのメモリ空間の1つの領域に物理的にマップされる。これは、バースト・バッファ区域にアクセスする時プロセッサは絶対アドレスを使用しなければならないことを意味する。しかし、DMA転送は単にオフセットを使用するので、ハードウェアが所望のアドレス決定を管理する必要がある。無効な境界整列は切り捨てによって調整される。このレジスタの読取りはバーストに使用される値を返す。デフォルト値はゼロである。
【0098】
パラメータbufsizeは、最新のバーストによって占有されるバッファ区域内の領域のサイズである。このレジスタは、そのエントリに向けられたバースト転送が完了次第設定される。ゼロという値が未使用バッファ・エントリを示すので、記憶される値はバースト長である点注意する必要がある。このレジスタは書き込みされるが、バッファが保存され復元される場合文脈切り替えの後に役立つだけである。デフォルト値はゼロである。
【0099】
バッファ・コントローラ54の残りの機能は、文脈テーブル62である。これは、入力としてバースト命令のインデックスを取り出し、MAT65およびBAT66において使用されるべき対応するスロットを出力として与える。文脈テーブル62のエントリは、バースト命令によってアクセスされるエントリの領域を制御するために使用される。文脈テーブル62の機能をソフトウェアの形態で実施することも可能である。文脈テーブルの使用は、バッファ・アーキテクチャの効率的管理にとって利点がある。
【0100】
文脈テーブルは、「文脈切り替え」の場合に特に役立つ。システムの文脈を変更する必要性を示す3つの事象は、内部トラップまたは例外、スレッド切り替え信号および外部割り込みである(スレッドとはプロセッサ実行の基本単位であり、単一シーケンスの計算処理のために必要とされたプロセッサ状態からなる)。上記事象のいずれも、バースト・バッファ・インターフェース資源を新しいスレッドが使用する必要性を確立する。文脈テーブルは、システム制御およびMAT65ならびにBAT66の間に付加的間接部分を加えることによってそのような事象の影響を最小限にとどめる。コンパイルの際複数のスレッドがMAT65とBAT66における同等のスロット領域を使用するように構成され、相互干渉なしに実行することができるように、オペレーティング・システムによってそれらスレッドに異なる文脈識別子が与えられる。
【0101】
スレッドが活動状態におかれる時文脈識別子が制御レジスタに書き込まれ、このメカニズムを使用して、各スレッドがテーブルの異なるスロット領域を使用するようにコンパイル時にオフセットがインデックス値に追加される。十分なテーブル資源が利用可能であると仮定すれば、上記メカニズムは、文脈切り替えの間のテーブル状態の保存復元を防止する。
【0102】
本実施形態において、文脈テーブル62は、8個のエントリを持っているが、実施形態によってどのような整数値の数のエントリを持つことも可能である。各エントリは次の4つのフィールドを含む。
1. メモリ・オフセット(memoffset)−これはマスク(下記参照)の後バースト命令のMATに加えられるオフセットである。これは、MAT65をインデックスするために使用される値である。
2. メモリ・マスク(memmask)−これは、オフセットの追加の前にバースト命令のMATインデックス・フィールドに適用されるマスクである。
3. バッファ・オフセット(bufoffset)−これはマスク(下記参照)の後バースト命令のBATに加えられるオフセットである。これは、BAT66をインデックスするために使用される値である。
4. バッファ・マスク(bufmask)−これは、オフセットの追加の前にバースト命令のBATインデックス・フィールドに適用されるマスクである。
【0103】
オフセットおよびマスク・レジスタは、MATおよびBATの連続スロット・セットが定義されることを可能にする。これは、複数のバースト・バッファ計算がMAT65およびBAT66において行われるので望ましい。文脈テーブル62のマスク機能の重要性は以下の例によって理解されるであろう。ある特定の文脈が、バッファ・アクセス・テーブルのエントリ2、3、4および5の使用を必要とする場合を仮定する。バースト命令の増分によって、例えば値が10から20へ増加する。3というバッファ・マスクの使用によって、形式パターンは2, 3, O, 1, 2, 3, O, 1, 2, 3, Oとなる。次に、2というオフセットの使用によって、必要とされるエントリの範囲をインデックスするためのパターンは、4, 5, 2, 3, 4, 5, 2, 3, 4, 5, 2となる。別の文脈は、別の文脈テーブル・エントリを使用してアクセスされる別の範囲のエントリを使用することとなる。この方法は、外部および内部ループを含む文脈間の高速切り替えを可能にする。上述のように、このような文脈切り替えは制御レジスタ52で提供されるが、バッファ・コントローラで提供することも可能である。しかしながら、このようなバッファ資源管理機能をソフトウェアで実施することもできる点は注意されるべきである。
【0104】
文脈テーブル・パラメータは次のように定義される。
memoffset:このパラメータは、MAT65のエントリにアクセスするために使用されるオフセットを定義する。テーブル・サイズが16であるので、この最大値は16である。それより高い値は16へ自動的に切り捨てられ、負の値は許容される。
memmask:このパラメータは、MAT65のエントリにアクセスするために使用されるマスクを定義する。テーブル・サイズが16であるので、許容される最大値は15である。これは値の最下位4ビットを使用することに対応し、他のどのビット・セットも無視される。
bufoffset:このパラメータは、BAT66のエントリにアクセスするために使用されるオフセットを定義する。テーブル・サイズが16であるので、この最大値は16である。それより高い値は16へ自動的に切り捨てられ、負の値は許容される。
bufmask:このパラメータは、BAT66のエントリにアクセスするために使用されるマスクを定義する。テーブル・サイズが16であるので、許容される最大値は15である。これは値の最下位4ビットを使用することに対応し、他のどのビット・セットも無視される。
【0105】
従って、DMAコントローラ56は、バッファ・コントローラ54からロードまたはストアからなる命令と共に、MAT65から添付されるメイン・メモリ・アドレス、ストライドおよび転送長を、またBAT66からバッファ・アドレスを受け取る。メモリ・コントローラ構成の要件は、MAT65に関して定義される最大のサイズおよびストライドのバースト要求がサポートされること、ページ境界横断が透過的方法で取り扱われること、および転送が完了した時点を標示するハンドシェーキング信号が提供されることである。
【0106】
本実施形態のシステムは仮想メモリをサポートしていない。しかしながら、仮想DMAをサポートするように構成されるDMAコントローラを用いれば、上述のようなバースト・アーキテクチャが動作するように構成できる点は、当業者に認められるであろう。本実施形態に記述されているシステムは、また、メモリ・キャッシュを含むアーキテクチャにおいて動作することができるが、バースト・バッファ動作の事象においてメイン・メモリとそのようなキャッシュの間の整合性を確認するためには適切な処理ステップの実行が必要とされるであろう。例えば、より高い優先度のDMAプロセスを可能にするためバースト・バッファ動作を中止する必要がある場合、割り込みシステムを提供すなければならないであろう。デバッグ機能の支援のため警告フラッグをセットする必要があるかもしれない。
【0107】
プロセッサが計算処理を実行している間に並列的にデータをバースト処理するようにアーキテクチャはプログラムされるので、連続するバーストのそれぞれの後にバースト・バッファの名前を変更することができるという利点がある。これによって、プロセッサは、1つのバッファから代替バッファへ自動的に切り替えを行うことが可能とされる。そのような場合、代替バッファが次の計算処理ブロックのため(バースト命令を介して)書き込まれている間、一方のバッファは計算処理のため使用される。バーストおよび計算処理が完了すると、それらバッファの名前が変更(スワップ)され、プロセスは再び続行する。
【0108】
このため、BATテーブルは、更に次の3つのレジスタ・フィールドを含むように拡張される。
オリジナル・フィールド:buffer_start_ad_ dress, buffer_size
新フィールド:buffer_offset_A, buffer_offset_B, Select_bit
上記のbuffer_offset_Aおよび buffer_offset_Bは、等しいサイズの2つのバッファの2つの開始アドレスを含むようにコンパイラによってプログラムされる。これらのバッファは、2ポート・バースト・バッファ・メモリ26に存在しなければならない。select_bitレジスタは1または0を含み、1はbuffer_offset_Bが選択されることを示し、0はbuffer_offset_Aが選択されることを示す。このBATスロットを参照する命令が発信される場合、その命令がバースト命令待ち行列30に書き込まれた直後に、Select_bitは、バースト・バッファ・コントローラによって自動的に反転される。次に、バースト・バッファ・コントローラは、新しく選択されたbuffer_offset_Xアドレスを(オリジナルのBATフィールドにおける)buffer_start_addressフィールドへコピーする。計算処理のため使用されるバッファを標示するためプロセッサ上で実行中のプログラムによって読み取られるのは、このエントリである。発信された命令は、後刻、バースト・バッファ・アーキテクチャによってバースト命令待ち行列30から取り出され、処理される。その時点で、DMAコントローラ56に渡されるバッファ・アドレスは、select_bitによって選択されてない代替buffer_offset_Xアドレス・レジスタからコピーされる。次の表7のコードはこのプロセスを処理するプログラムの例である。
【0109】
【表7】
本発明のアーキテクチャの第2の実施形態におけるバースト命令の処理を以下図7を参照して説明する。バースト動作はバースト命令の発信によって始動される。上述のように、この命令は、MAT65のエントリへのインデックスおよびBAT66のエントリへのインデックスを含む。前述のように、MATエントリは、メイン・メモリの開始アドレス、転送の範囲およびストライドを含み、一方、BATエントリは、バッファ領域26における目標アドレスと共に、このエントリを使用して完了される最後の転送の長さ(すなわちバッファ・サイズ)を含む。
【0111】
この命令は、FIFOメモリに類似するバースト命令待ち行列30に置かれる。この構造は、DRAMからのデータのバースト処理とプロセッサによるデータのアクセスの間の切り離しを可能にする。この切り離しは、「事前取り出し」の性能利得を達成するために必要である。「事前取り出し」は、データがプロセッサによって必要とされる前にメイン・メモリからデータを取得し、プロセッサその事前取得したデータに対して同時に動作するプロセスである。プロセッサは、単一のサイクルにおいて命令を待ち行列に渡し、次に動作を続行する。このように、バースト命令は「非割り込み型」と述べることができる。すなわち、バースト命令は完了するまでプロセッサの停止を強制しない(しかしながら、場合によってはプロセッサを停止させる実施形態もある。例えば、 新しいバースト命令が出される時新しいバースト命令のための空間がが利用できるようになるまでバースト命令待ち行列30がいっぱいであるような場合である)。バースト命令待ち行列30はDMAコントローラ56によって読み取られる。DMAコントローラ56は、バースト命令に代わってメイン・メモリDRAM14にアクセスする準備ができている時(すなわちバースト・バッファ・インターフェースが優先権を持っている時)、待ち行列の次の命令を読み取りその命令の実行を開始する。
【0112】
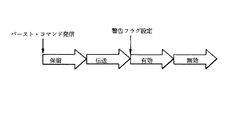
図7に示されるように、この構成はバースト命令実行における独立した4つのフェーズをとる。第1は、命令が出された直後の「保留」フェーズであり、命令はバースト命令待ち行列30に格納されている。命令が待ち行列にあってDMAコントローラ56によって認識されると、Dまプロセスが実行される。これは「転送」フェーズである。転送フェーズが完了すると、バッファ領域26のバースト・バッファとメイン・メモリ14の対応する領域の内容が同一となる(またそのトランザクションに適切な警告フラグがセットされる)。そこで、バースト・バッファは「有効」と呼ばれ、その結果「有効」フェーズが始動される。これは、バッファ領域26のバースト・バッファとメイン・メモリ14の対応する領域の対応関係を変化させるなにがしかの事象が発生するまで、継続する。そのような変化の事象が発生すると、バースト・バッファは「無効」と呼ばれ、その結果「無効」フェーズが始動される。
【0113】
命令の発信は、物理的バッファとメイン・メモリの領域の間の関連性を定義するが、このような結合動作は命令が実行される実行時にのみ発生する。この実行時結合は、本アーキテクチャを使用する際の柔軟性および低いプロセッサ命令オーバーヘッドの主要要因をなすものである。両者の間で維持される相互関係はないが、バッファ名変更および再使用が許容される。移転フェーズの間に、本アーキテクチャは、bufcntl.transferビットに従って命令にラベルをつける。その他のフェーズは、ソフトウェアを通して追跡されるかまたは追跡可能である。
【0114】
有効なフェーズへの入口は、上述のように、関連バースト命令で指示されたバースト転送が完了したという標示である。これは、バースト命令直後の同期命令syncのソフトウェアによる発信によって検出されることができる。上述の通り、バースト命令待ち行列30は1時点で1つの同期命令しか含むことができないので、待ち行列が同期命令を含む間は更なるバースト命令をバースト命令待ち行列に書き込むことはできない。同期命令syncを使用して同期化を実行するために使用できる次の3つの方法がある。
1. 同期命令を発信し同期レジスタを読み取る。待ち行列の中のすべてのバースト命令が完了し同期命令が出現するまで読取りが禁止される。
2. 同期命令を発信し、次に待ち行列にもう1つのバースト命令を書き込む。この場合は、待ち行列の中のすべてのバースト命令が完了し同期命令が出現するまで書き込みが禁止される。
3. 同期命令を発信し同期命令に関してlastcmdレジスタをポーリングする。
方法1および2はプロセッサをブロックするが、方法3はブロックしない。
バッファ領域がその有効フェーズにあれば、プロセッサは、それが含むデータに動作することができる。本実施形態では、プロセッサはバイト、ハーフワードおよびワード単位のアクセスを使用してバッファのデータにアクセスする。
【0115】
本発明に従うコンピュータ・システムの第2の実施形態へ原始コードをコンパイルするプロセスを以下に記述する。本実施形態のバースト・バッファ・アーキテクチャは、大規模なデータ・アレイに関して反復される単純な動作を含む通常の単純なループ構造を取り扱う場合、特に効果的である。そのようなループ構造には、例えば、媒体計算処理においてしばしば出会うことがある。バースト・バッファ・アーキテクチャへのコードのコンパイルは、原始コードにおける該当ループを識別して、それらループがバースト・バッファを利用してオリジナルの動作を正しく実行することができるように、それらループを再構築することを必要とする。
【0116】
該当するループの識別は手走査で行うことができる。代替的方法として、既知の技術によって適切なループを識別することもできる(例えば、1つの方法が"Compiler Transformations for High- Performance Computing " David F Bacon Susan L Graham and Oliver J.Sharp, Technical Report No.UCB/CSD-93-781, University of California, Berkeleyに記載されている)。 識別されたなら、それらループは、バースト・バッファによって利用されることができる形式に、正しく変換される必要がある。
【0117】
識別されるコードはループ形式をしている。バースト・バッファを通して処理されるためには、ループは、各々が1バーストのサイズである一連の断片に広げられる必要がある。その後、一連のバースト・ロードおよびストアという観点から本アーキテクチャによるループの取り扱いを定義することが可能となる。しかしながら、バースト・バッファはソフトウェアによって制御される資源であるので、ロードまたはストア・バースト命令が出される前、およびバッファが計算処理の目標として使用される前に、バッファを割り当てることが必要である。ロードおよび割当てに続いて、計算処理が実行される。このような方法は、識別したループを上記のように複数の断片に広げた場合、またはループそれ自体が1つのバーストより小さい場合に適用される。計算処理の直後に、storeburst命令を使用してバッファに記憶され、入力バッファが解放される。storeburst命令が完了すれば、出力バッファも解放される。
以下の表8は、上記動作を行うコードの1例を示す。
【0118】
【表8】
上記変換されたコードに関する依存性グラフが図8に示されている。例えば、目標をバッファ04に向けた計算処理は、バッファ01、02および03のloadburstにのみ依存するが、出力バッファ04自体の割り当てにも依存する。図8上の括弧の中の番号はノード識別子である。ここで変換されているコードは、単純ではあるが相対的に役立たないスケジュールを作成する。これは,利用できる並列機能が開拓されなかった(すなわちコードがバースト命令を出している時計算処理が実行されていないまたはその逆)ためである。依存性グラフの分析を使用すれば、一層すぐれたスケジュールを生成するスケジューリング・プログラムを駆動させることができる。この場合、追加のバースト・バッファの使用を通して改善が図られる。
【0120】
必要とされるバースト・バッファの最小数は、各入力ストリームのための1つに計算処理を実行するためのものを加えた数である(計算処理用のバッファは計算処理が完了した後、空にし、解放し,次の計算処理のため割り当てられる)。リスト・スケジューリングおよびバッファ割当ての考察を通して、改善されるスケジュールを見出すことができる。可能な限り効率的にDRAMメモリ・バンド幅を使用するためバースト効率を最適化する解決策は測定可能である。これは、計算効率を最大にすることを目標とする通常の計算戦略とは異なる。相違は、本発明が考慮するシステムの主要制約がバンド幅にあることによる。
【0121】
バッファ割当てを管理することに加えて、メモリおよびバッファ・アクセス・テーブルはバッファ名変更をサポートする。コンパイラの目的の1つは、断片掘り出しと呼ばれるプロセスを使用して潜在的バーストを露顕させるようにループを変換することである。ループが断片掘り出しされると、モジュール・スケジューリング(またはソフトウェア・パイプライン化)と呼ばれる次のプロセスが適用される。この後者のプロセスは、部分的に広げられたループ内の特定の点でバッファ名が変更されることを必要とする。例えば、ループ計算処理は、'A'と名付けられた論理的バッファが物理的バッファ'2'からバッファ'5'へマップされることを必要とするかもしれない。この例では、別のバッファがプロセッサによって計算処理のためアクセスされている間に、1つの物理的バッファがメモリへのバースト転送のために使用されることができる。バースト動作および計算処理が並列に動作し、従って、処理性能が向上する。
【0122】
コンパイラによって実行されなければならない更なる機能は、メモリ・バス幅(本実施形態のケースでは32ビット)の幅を持つバーストだけがバースト・バッファ・アーキテクチャによって処理されることができるので、ソフトウェアにおけるsizedburstをチャネル−バーストへ変換することである。コンパイルの間、ソフトウェアによって検出されるsizedburstはchanelburstへマップされる。
【0123】
以下に、バースト・バッファ・システム24使用の典型例を記述する。
第1に、バースト・バッファは局所的データ・バッファとして使用され、バッファ・サイズのメモリ領域がバースト・バッファ40へ直接マップされる。これは次の2つの方法で実施されることができる。(1)データが初期化されていなければ、allocbufferコマンドを使用して、バッファ40が取得されアドレス・マッピングが実行される。(2)データがメイン・メモリ14で初期化されていれば、loadburstを使用してデータがバースト・バッファ40へコピーされる。マッピングが行われたなら、プロセッサ10は同じアドレスへのアクセスを継続し、それらアドレスがバッファ40によって捕捉される。完了時点、またはシステムが整合している必要がある時、storebufferコマンドが使用される。第2に、バースト・バッファ・システム24は参照テーブルとして使用される可能性がある。局所的データ・バッファとまったく同じ方法で、バースト・バッファ40は、loadburstコマンドを使用して参照テーブル・データで初期化されることもできる。バッファをヒットするアドレスへの参照は適切なデータを返す。テーブル・サイズは制限されるが、より大きいテーブルの一部をバッファ40へ配置し残りをメイン・メモリ14に置くことができない理由はない。バッファ40に保持される区域が最も頻繁に使用されれば、性能向上に役立つ。整合性はこの場合問題でない。従って、テーブルの使用が完了したならば、freebufferコマンドが出されなければならない。
【0124】
上述されたシステムに対する制約の可能性は、バースト・バッファ40が単純なFIFOとして使用されることができないかもしれないということである。アドレスはバッファの中のデータをアクセスするために常に使用されなければならない。このバッファをあたかもFIFOであるかのようにみせるラップ機構をソフトウェアで開発することは可能である。しかしながら、バッファが論理的にいっぱいになった時ストア・バーストが出されることを意味するバッファ・サイズ分のロードおよびストア・バーストの遅延という点でのFIFO機能性を模倣するため遅延カウントが使用される。
【0125】
上述された実施形態の典型的動作において、バースト・データがメイン・メモリ14からバースト・バッファ・メモリ26へ読み込まれ、プロセッサ10/プロセッサ・インターフェース12によって処理され、バースト・バッファ・メモリ26へ戻され、次にメイン・メモリ14に書き込まれる。別の実施形態においては、プロセッサ10/プロセッサ・インターフェース12によって実行される処理の代わりに、バースト・バッファ・メモリ26に接続される専用計算エンジンによってそれが実行される。
【0126】
本発明の範囲を逸脱することなく上述の実施形態に対し種々の変更を行うことができる点は認められるであろう。
【0127】
本発明には、例として次のような実施様態が含まれる。
(1)データを処理する処理システムと、上記処理システムによって処理されるデータまたは該システムによって処理されるべきデータを記憶するメモリと、上記メモリへのアクセスを制御するメモリ・アクセス・コントローラと、上記メモリとの間で読み書きされるべきデータをバッファするための少くとも1つのデータ・バッファと、上記メモリ・アクセス・コントローラへバースト命令を発信する手段と、上記メモリ・アクセス・コントローラへ発信されるバースト命令を待ち行列に記憶する手段と、を備えるコンピュータ・システムであって、上記メモリ・アクセス・コントローラが上記バースト命令に応答して単一のメモリ・トランザクションで上記メモリと上記データ・バッファの間で複数のデータ・ワードを転送し、上記待ち行列記憶手段によって、先行バースト命令が実行された直後に次のバースト命令が上記メモリ・アクセス・コントローラによる実行のため使用可能な状態にされることを特徴とする、コンピュータ・システム。
(2)上記バースト命令のうちの少くとも1つが遅延パラメータを含み、上記バースト命令発信手段が、上記遅延パラメータに従って上記メモリ・アクセス・コントローラへのそのような命令発信を遅延するように動作する、上記(1)に記載のコンピュータ・システム。
(3)上記バースト命令の各々が、そのバースト命令に応答してアクセスされるべきメモリ位置の間の間隔を定義するパラメータを含むかあるいはそのようなパラメータに関連づけられる、上記(1)または(2)に記載のコンピュータ・システム。
【0128】
(4)データを処理する処理システムと、上記処理システムによって処理されるまたは該システムによって処理されるべきデータを記憶するメモリと、上記メモリへのアクセスを制御するメモリ・アクセス・コントローラと、上記メモリとの間で読み書きされるべきデータをバッファするための少くとも1つのデータ・バッファと、上記メモリ・アクセス・コントローラへバースト命令を発信する手段と、を備えるコンピュータ・システムであって、そのようなバースト命令の各々が、そのバースト命令に応答してアクセスされるべきメモリ位置の間の間隔を定義するパラメータを含むかあるいはそのようなパラメータに関連づけられ、上記メモリ・アクセス・コントローラが、上記バースト命令に応答して、上記間隔パラメータに従った間隔をあけたメモリ位置と上記データ・バッファの間で複数のデータ・エレメントを単一トランザクションで転送することを特徴とする、コンピュータ・システム。
(5)上記処理システムからのメモリ要求に応答して、対応するメモリ位置がデータ・バッファにマップされているか否かを判断し、マップされていればデータ・バッファのマップされている位置にアクセスするように動作する比較手段を更に備える、上記(1)乃至(4)のいずれかに記載のコンピュータ・システム。
(6)バースト命令をメモリ・アクセス・コントローラに発信する上記手段が、メモリに対するトランザクションの記述のためのメモリ・アクセス・テーブルおよび少くとも1つのデータ・バッファに対するトランザクションの記述のためのバッファ・アクセス・テーブルを含み、発信されるバースト命令の各々が、上記メモリ・アクセス・テーブルおよび上記バッファ・アクセス・テーブルをインデックスする、上記(1)乃至(4)のいずれかに記載のコンピュータ・システム。
(7)バースト命令に関して、メモリおよび少くとも1つのデータ・バッファの間のトランザクションを定義するため、メモリ・アクセス・テーブルおよびバッファ・アクセス・テーブルにおける情報が実行時に結合される、上記(6)に記載のコンピュータ・システム。
【0129】
(8)バースト命令をメモリ・アクセス・コントローラに発信する上記手段が、バースト命令による上記メモリ・アクセス・テーブルおよび上記バッファ・アクセス・テーブルのインデックス付けを文脈に応じて修正するための文脈テーブルを含む、上記(6)または(7)に記載のコンピュータ・システム。
(9)バースト命令のうちの少くとも1つが、データ・バッファに1時点で記憶することができるものより多い数のデータ・エレメントに関連し、そのような命令に応答して当該システムが一連のバースト命令を実行するように動作する、上記(1)乃至(8)のいずれかに記載のコンピュータ・システム。
(10)そのようなデータ・バッファの数をハードウェアまたはソフトウェアの制御の下当該システムによって構成することが可能な、上記(1)乃至(9)のいずれかに記載のコンピュータ・システム。
(11)少くとも1つのデータ・バッファが2ポート・メモリ内で提供され、2ポートのうちの1つのポートが上記処理システムによってアクセスされ、他のポートがメモリによってアクセスされる、上記(1)乃至(10)のいずれかに記載のコンピュータ・システム。
(12)上記2ポート・メモリが上記処理システムおよび上記メモリによって同時にアクセスされることができる、上記(11)に記載のコンピュータ・システム。
(13)上記処理システムが、主マイクロプロセッサ、および、データ・バッファのデータを処理するように構成されたコプロセッサを含む、上記(1)乃至(12)のいずれかに記載のコンピュータ・システム。
(14)上記処理システムが、主マイクロプロセッサ、および、データ・バッファのデータを処理するように構成された独立計算処理エンジンを含む、上記(1)乃至(12)のいずれかに記載のコンピュータ・システム。
【0130】
(15)上記(1)乃至(14)のいずれかに記載のコンピュータ・システムにおいて実行される方法であって、少なくとも1つのデータ・バッファへコンパイルすることが適切な,あるいは少なくとも1つのデータ・バッファの支援の下での実行に適切な計算処理エレメントを原始コードの中で識別するステップと、原始コードの中の上記識別した計算処理エレメントを、各々が少くとも1つのデータ・バッファのサイズより大きくないメモリ・トランザクションを含む一連の命令に変換し、そのような命令をバースト命令として表すステップと、上記処理システムによって原始コードを実行し、上記少なくとも1つのデータ・バッファに対するアクセスを通して上記識別した計算処理エレメントを処理するステップと、を含む方法。
(16)上記識別した計算処理エレメントによって必要とされるデータが、上記処理システムによって要求される前にメモリから少くとも1つのデータ・バッファへ取り出される、上記(15)に記載の方法。
(17)メモリと少くとも1つのデータ・バッファの間のトランザクションが完了するまで処理システムを停止させる手段が提供される、上記(15)または(16)に記載の方法。
【0131】
【発明の効果】
本発明によって、マルチメディアなどの媒体データを処理するために適したキャッシュ・システムが実現し、メモリ・アクセスのバンド幅の極大化が図られる。
【図面の簡単な説明】
【図1】本発明に従うコンピュータ・システムの第1の実施形態のブロック図である。
【図2】図1のシステムにおけるバースト・バッファ・メモリおよびバースト命令待ち行列がハードウェアまたはソフトウェア制御の下で構成される種々の形態を図3と共に示すブロック図である。
【図3】図1のシステムにおけるバースト・バッファ・メモリおよびバースト命令待ち行列がハードウェアまたはソフトウェア制御の下で構成される種々の形態を図2と共に示すブロック図である。
【図4】本発明に従うコンピュータ・システムの第2の実施形態におけるバースト・バッファ・アーキテクチャを示すブロック図である。
【図5】図4のバッファ・コントローラを示すブロック図である。
【図6】図4のバースト・バッファ・アーキテクチャにおける制御レジスタの機能を示すブロック図である。
【図7】図4のバースト・バッファ・アーキテクチャによるバースト命令の実行の流れを示すブロック図である。
【図8】本発明に従ってコンパイルされる原始コードの相互関係を示すグラフ図である。
【符号の説明】
10 プロセッサ、
12 プロセッサ・インターフェース
14 メインDRAMメモリ
16 メイン・メモリ・インターフェースまたはアクセス・コントローラ
18 SRAM命令キャッシュ
19 SRAMデータ・キャッシュ
20a、20b、21a、21b、36a、36b、36c、36d、38a、38b、38c、38d 経路
22 データ・キャッシュ・バイパス・ロード/ストア経路
24 バースト・バッファ・システム
26 バースト・バッファ・メモリ
28 範囲比較機構28
30 バースト命令待ち行列
32 バースト・コントローラ
34 パラメータ記憶機構
52 バースト制御レジスタ
54 バッファ・コントローラ
56 DMAコントローラ
58 メモリ・データ経路アービタ
61 バースト命令フィールド
62 文脈テーブル
63 スワップ機構
64 ループ/文脈レジスタ
65 メモリ・アクセス・テーブル(MAT)
66 バッファ・アクセス・テーブル(BAT)
Claims (16)
- データを処理する処理システム(10,12)と、
前記処理システムによって処理されたデータ、または該処理システムによって処理されるべきデータを記憶するメモリ(14)と、
前記メモリへのアクセスを制御するメモリ・アクセス・コントローラ(16)と、
前記メモリとの間で読み書きされるべきデータをバッファするための少なくとも1つのデータ・バッファ(40)を含むバースト・バッファ・メモリと、を備え、
前記メモリはDRAMであり、前記バースト・バッファ・メモリは、より高速にアクセス可能なメモリであり、さらに、
前記メモリ・アクセス・コントローラへバースト命令を発信するバースト命令コントローラであって、該メモリ・アクセス・コントローラは、バースト命令に応答して、前記メモリおよび前記データ・バッファの間で、前記メモリのメモリ位置の列が選択され、該列に局所的な一連のアクセスが実行されるデータ・バーストによって、複数のデータ・ワードを転送する、バースト命令コントローラ(32)と、
先行バースト命令が実行された直後に前記バースト命令が前記メモリ・アクセス・コントローラによる実行のため使用可能な状態にされるように、バースト命令を並べるバースト命令待ち行列(30)と、
を備える、コンピュータ・システム。 - 前記バースト命令のうちの少なくとも1つが遅延パラメータを含み、前記バースト命令コントローラが、前記遅延パラメータに従って前記メモリ・アクセス・コントローラへの前記命令の発信を遅延するように動作可能である、請求項1に記載のコンピュータ・システム。
- 前記バースト命令の各々が、該バースト命令に応答してアクセスされるべきメモリ位置の間の間隔を定義するパラメータを含み、または該パラメータに関連づけられる、請求項1または請求項2に記載のコンピュータ・システム。
- 前記処理システムからのメモリ要求に応答して、対応するメモリ位置が前記データ・バッファにマップされているか否かを判断し、マップされていれば前記データ・バッファ内のマップされている位置にアクセスするように動作する比較手段(28)を更に備える、請求項1乃至請求項3のいずれかに記載のコンピュータ・システム。
- 前記バースト命令コントローラが、前記メモリへのトランザクションの記述のためのメモリ・アクセス・テーブル(65)および少なくとも1つのデータ・バッファへのトランザクションの記述のためのバッファ・アクセス・テーブル(66)を含み、
各々のバースト命令が、前記メモリ・アクセス・テーブルおよび前記バッファ・アクセス・テーブルに対するインデックスを発行する、請求項1乃至請求項4のいずれかに記載のコンピュータ・システム。 - バースト命令に関して、メモリおよび少なくとも1つのデータ・バッファの間のトランザクションを定義するため、前記メモリ・アクセス・テーブルおよび前記バッファ・アクセス・テーブルにおける情報が実行時に結合される、請求項5に記載のコンピュータ・システム。
- 前記バースト命令コントローラが、バースト命令による前記メモリ・アクセス・テーブルおよび前記バッファ・アクセス・テーブルのインデックス付けを文脈に応じて修正するための文脈テーブルをさらに有する、請求項5または請求項6に記載のコンピュータ・システム。
- 前記バースト命令のうちの少なくとも1つが、データ・バッファに一度に記憶することができるものより多い数のデータ・エレメントに関連し、該命令に応答して当該システムが一連のバースト命令を実行するように動作する、請求項1乃至請求項7のいずれかに記載のコンピュータ・システム。
- 前記データ・バッファは、ハードウェアまたはソフトウェアの制御の下当該システムによって構成することが可能である、請求項1乃至請求項8のいずれかに記載のコンピュータ・システム。
- 前記少なくとも1つのデータ・バッファが、2ポート・メモリ内で提供され、2ポートのうちの1つのポートが前記処理システムによってアクセスされ、他のポートが前記メモリによってアクセスされる、請求項1乃至請求項9のいずれかに記載のコンピュータ・システム。
- 前記2ポート・メモリが前記処理システムおよび前記メモリによって同時にアクセス可能である、請求項10に記載のコンピュータ・システム。
- 前記処理システムが、主マイクロプロセッサ、および、データ・バッファのデータを処理するように構成されたコプロセッサを含む、請求項1乃至請求項11のいずれかに記載のコンピュータ・システム。
- 前記処理システムが、主マイクロプロセッサ、および、データ・バッファのデータを処理するように構成された独立計算処理エンジンを含む、請求項1乃至請求項11のいずれかに記載のコンピュータ・システム。
- 請求項1乃至請求項13のいずれかに記載のコンピュータ・システムにおいて実行される方法であって、
少なくとも1つのデータ・バッファの支援の下での実行に適切な計算処理エレメントを原始コード内で識別するステップと、
前記原始コード内の前記識別された計算処理エレメントを、各々が少なくとも1つのデータ・バッファのサイズより大きくないメモリ・トランザクションを含む一連の命令に変換し、該命令をバースト命令として表すステップと、
前記処理システムによって前記原始コードを実行し、前記少なくとも1つのデータ・バッファに対するアクセスを通して前記識別された計算処理エレメントを処理するステップと、を含む方法。 - 前記識別された計算処理エレメントによって要求されるデータが、前記処理システムによって要求される前にメモリから少なくとも1つのデータ・バッファへ取り出される、請求項14に記載の方法。
- 前記メモリと少なくとも1つの前記データ・バッファの間のトランザクションが完了するまで、前記処理システムを停止させる手段が提供される、請求項14または請求項15に記載の方法。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP97300113A EP0853283A1 (en) | 1997-01-09 | 1997-01-09 | Computer system with memory controller for burst transfer |
| GB9723704.4 | 1997-11-11 | ||
| GB97300113.4 | 1997-11-11 | ||
| GBGB9723704.4A GB9723704D0 (en) | 1997-11-11 | 1997-11-11 | Computer systems |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH10232826A JPH10232826A (ja) | 1998-09-02 |
| JP4142141B2 true JP4142141B2 (ja) | 2008-08-27 |
Family
ID=26147251
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP35991697A Expired - Fee Related JP4142141B2 (ja) | 1997-01-09 | 1997-12-26 | コンピュータ・システム |
Country Status (3)
| Country | Link |
|---|---|
| US (2) | US6321310B1 (ja) |
| JP (1) | JP4142141B2 (ja) |
| DE (1) | DE69727465T2 (ja) |
Families Citing this family (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1061438A1 (en) * | 1999-06-15 | 2000-12-20 | Hewlett-Packard Company | Computer architecture containing processor and coprocessor |
| EP1061439A1 (en) * | 1999-06-15 | 2000-12-20 | Hewlett-Packard Company | Memory and instructions in computer architecture containing processor and coprocessor |
| JP4354583B2 (ja) * | 1999-09-09 | 2009-10-28 | 独立行政法人科学技術振興機構 | アクセス方法及びアクセス処理プログラムを記録した記録媒体 |
| GB2366426B (en) * | 2000-04-12 | 2004-11-17 | Ibm | Coprocessor data processing system |
| US6807587B1 (en) * | 2000-09-18 | 2004-10-19 | Xilinx Inc. | Methods and apparatuses for guaranteed coherency of buffered direct-memory-access data |
| US6862653B1 (en) * | 2000-09-18 | 2005-03-01 | Intel Corporation | System and method for controlling data flow direction in a memory system |
| US6711646B1 (en) * | 2000-10-20 | 2004-03-23 | Sun Microsystems, Inc. | Dual mode (registered/unbuffered) memory interface |
| US6557090B2 (en) * | 2001-03-09 | 2003-04-29 | Micron Technology, Inc. | Column address path circuit and method for memory devices having a burst access mode |
| JP2002366509A (ja) * | 2001-06-06 | 2002-12-20 | Mitsubishi Electric Corp | ダイレクトメモリアクセスコントローラおよびそのアクセス制御方法 |
| US7139873B1 (en) * | 2001-06-08 | 2006-11-21 | Maxtor Corporation | System and method for caching data streams on a storage media |
| CN1280734C (zh) * | 2001-09-07 | 2006-10-18 | 皇家菲利浦电子有限公司 | 用于分段存取控制的控制装置和方法和具有该控制装置的视频存储器装置 |
| JP2003140886A (ja) * | 2001-10-31 | 2003-05-16 | Seiko Epson Corp | インストラクションセット及びコンパイラ |
| US20030126591A1 (en) * | 2001-12-21 | 2003-07-03 | Youfeng Wu | Stride-profile guided prefetching for irregular code |
| US7389315B1 (en) * | 2002-02-28 | 2008-06-17 | Network Appliance, Inc. | System and method for byte swapping file access data structures |
| US7222170B2 (en) * | 2002-03-14 | 2007-05-22 | Hewlett-Packard Development Company, L.P. | Tracking hits for network files using transmitted counter instructions |
| JP2003281084A (ja) * | 2002-03-19 | 2003-10-03 | Fujitsu Ltd | 外部バスへのアクセスを効率的に行うマイクロプロセッサ |
| GB0221464D0 (en) | 2002-09-16 | 2002-10-23 | Cambridge Internetworking Ltd | Network interface and protocol |
| CN1602499A (zh) * | 2002-10-04 | 2005-03-30 | 索尼株式会社 | 数据管理系统、数据管理方法、虚拟存储设备、虚拟存储器控制方法、阅读器/写入器装置、 ic模块访问设备、以及ic模块访问控制方法 |
| US7191318B2 (en) * | 2002-12-12 | 2007-03-13 | Alacritech, Inc. | Native copy instruction for file-access processor with copy-rule-based validation |
| CN100416494C (zh) * | 2003-04-15 | 2008-09-03 | 威盛电子股份有限公司 | 显示控制器读取系统存储器中的存储数据的方法 |
| US7478016B2 (en) * | 2003-04-16 | 2009-01-13 | The Mathworks, Inc. | Block modeling input/output buffer |
| US7055000B1 (en) | 2003-08-29 | 2006-05-30 | Western Digital Technologies, Inc. | Disk drive employing enhanced instruction cache management to facilitate non-sequential immediate operands |
| US20050063008A1 (en) * | 2003-09-24 | 2005-03-24 | Perry Lea | System and method of processing image data |
| JP4455593B2 (ja) * | 2004-06-30 | 2010-04-21 | 株式会社ルネサステクノロジ | データプロセッサ |
| US7962731B2 (en) * | 2005-10-20 | 2011-06-14 | Qualcomm Incorporated | Backing store buffer for the register save engine of a stacked register file |
| US7844804B2 (en) * | 2005-11-10 | 2010-11-30 | Qualcomm Incorporated | Expansion of a stacked register file using shadow registers |
| US9201819B2 (en) * | 2005-12-26 | 2015-12-01 | Socionext Inc. | Command processing apparatus, method and integrated circuit apparatus |
| US8572302B1 (en) * | 2006-10-13 | 2013-10-29 | Marvell International Ltd. | Controller for storage device with improved burst efficiency |
| US7617354B2 (en) * | 2007-03-08 | 2009-11-10 | Qimonda North America Corp. | Abbreviated burst data transfers for semiconductor memory |
| KR100891508B1 (ko) * | 2007-03-16 | 2009-04-06 | 삼성전자주식회사 | 가상 디엠에이를 포함하는 시스템 |
| US8806461B2 (en) * | 2007-06-21 | 2014-08-12 | Microsoft Corporation | Using memory usage to pinpoint sub-optimal code for gaming systems |
| US7730244B1 (en) * | 2008-03-27 | 2010-06-01 | Xilinx, Inc. | Translation of commands in an interconnection of an embedded processor block core in an integrated circuit |
| US8386664B2 (en) * | 2008-05-22 | 2013-02-26 | International Business Machines Corporation | Reducing runtime coherency checking with global data flow analysis |
| US8281295B2 (en) * | 2008-05-23 | 2012-10-02 | International Business Machines Corporation | Computer analysis and runtime coherency checking |
| US8285670B2 (en) | 2008-07-22 | 2012-10-09 | International Business Machines Corporation | Dynamically maintaining coherency within live ranges of direct buffers |
| JP2010146084A (ja) * | 2008-12-16 | 2010-07-01 | Toshiba Corp | キャッシュメモリ制御部を備えるデータ処理装置 |
| US9417685B2 (en) * | 2013-01-07 | 2016-08-16 | Micron Technology, Inc. | Power management |
| KR102449333B1 (ko) * | 2015-10-30 | 2022-10-04 | 삼성전자주식회사 | 메모리 시스템 및 그것의 읽기 요청 관리 방법 |
| US9965326B1 (en) * | 2016-06-27 | 2018-05-08 | Rockwell Collins, Inc. | Prediction and management of multi-core computation deration |
| US10108374B2 (en) * | 2016-07-12 | 2018-10-23 | Nxp Usa, Inc. | Memory controller for performing write transaction with stall when write buffer is full and abort when transaction spans page boundary |
| US10175912B1 (en) * | 2017-07-05 | 2019-01-08 | Google Llc | Hardware double buffering using a special purpose computational unit |
Family Cites Families (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4099236A (en) | 1977-05-20 | 1978-07-04 | Intel Corporation | Slave microprocessor for operation with a master microprocessor and a direct memory access controller |
| JPS5840214B2 (ja) | 1979-06-26 | 1983-09-03 | 株式会社東芝 | 計算機システム |
| US4589067A (en) | 1983-05-27 | 1986-05-13 | Analogic Corporation | Full floating point vector processor with dynamically configurable multifunction pipelined ALU |
| US5121498A (en) | 1988-05-11 | 1992-06-09 | Massachusetts Institute Of Technology | Translator for translating source code for selective unrolling of loops in the source code |
| JPH02250138A (ja) | 1989-01-18 | 1990-10-05 | Fujitsu Ltd | メモリ制御装置 |
| JPH02250137A (ja) | 1989-01-18 | 1990-10-05 | Fujitsu Ltd | メモリ制御装置 |
| US5175825A (en) | 1990-02-02 | 1992-12-29 | Auspex Systems, Inc. | High speed, flexible source/destination data burst direct memory access controller |
| EP0447145B1 (en) | 1990-03-12 | 2000-07-12 | Hewlett-Packard Company | User scheduled direct memory access using virtual addresses |
| GB2250615B (en) | 1990-11-21 | 1995-06-14 | Apple Computer | Apparatus for performing direct memory access with stride |
| EP0549924A1 (en) | 1992-01-03 | 1993-07-07 | International Business Machines Corporation | Asynchronous co-processor data mover method and means |
| US6438683B1 (en) | 1992-07-28 | 2002-08-20 | Eastman Kodak Company | Technique using FIFO memory for booting a programmable microprocessor from a host computer |
| US5708830A (en) | 1992-09-15 | 1998-01-13 | Morphometrix Inc. | Asynchronous data coprocessor utilizing systolic array processors and an auxiliary microprocessor interacting therewith |
| JP3220881B2 (ja) | 1992-12-29 | 2001-10-22 | 株式会社日立製作所 | 情報処理装置 |
| US5590307A (en) * | 1993-01-05 | 1996-12-31 | Sgs-Thomson Microelectronics, Inc. | Dual-port data cache memory |
| JP3417984B2 (ja) | 1993-09-10 | 2003-06-16 | 株式会社日立製作所 | キャッシュ競合削減コンパイル方法 |
| US5603007A (en) * | 1994-03-14 | 1997-02-11 | Apple Computer, Inc. | Methods and apparatus for controlling back-to-back burst reads in a cache system |
| US5627994A (en) * | 1994-07-29 | 1997-05-06 | International Business Machines Corporation | Method for the assignment of request streams to cache memories |
| US5537620A (en) | 1994-09-16 | 1996-07-16 | International Business Machines Corporation | Redundant load elimination on optimizing compilers |
| US5664230A (en) * | 1995-05-26 | 1997-09-02 | Texas Instruments Incorporated | Data processing with adaptable external burst memory access |
| US6209071B1 (en) * | 1996-05-07 | 2001-03-27 | Rambus Inc. | Asynchronous request/synchronous data dynamic random access memory |
| US5884050A (en) | 1996-06-21 | 1999-03-16 | Digital Equipment Corporation | Mechanism for high bandwidth DMA transfers in a PCI environment |
| US6085261A (en) * | 1996-07-29 | 2000-07-04 | Motorola, Inc. | Method and apparatus for burst protocol in a data processing system |
| JPH10124447A (ja) * | 1996-10-18 | 1998-05-15 | Fujitsu Ltd | データ転送制御方法及び装置 |
| US5784582A (en) * | 1996-10-28 | 1998-07-21 | 3Com Corporation | Data processing system having memory controller for supplying current request and next request for access to the shared memory pipeline |
| US6006289A (en) * | 1996-11-12 | 1999-12-21 | Apple Computer, Inc. | System for transferring data specified in a transaction request as a plurality of move transactions responsive to receipt of a target availability signal |
| EP0853283A1 (en) | 1997-01-09 | 1998-07-15 | Hewlett-Packard Company | Computer system with memory controller for burst transfer |
-
1997
- 1997-11-26 DE DE69727465T patent/DE69727465T2/de not_active Expired - Lifetime
- 1997-12-26 JP JP35991697A patent/JP4142141B2/ja not_active Expired - Fee Related
-
1998
- 1998-01-06 US US09/003,526 patent/US6321310B1/en not_active Expired - Fee Related
-
2000
- 2000-06-20 US US09/599,030 patent/US6336154B1/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JPH10232826A (ja) | 1998-09-02 |
| US6336154B1 (en) | 2002-01-01 |
| US6321310B1 (en) | 2001-11-20 |
| DE69727465D1 (de) | 2004-03-11 |
| DE69727465T2 (de) | 2004-12-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4142141B2 (ja) | コンピュータ・システム | |
| US6076151A (en) | Dynamic memory allocation suitable for stride-based prefetching | |
| US5375216A (en) | Apparatus and method for optimizing performance of a cache memory in a data processing system | |
| JP3816586B2 (ja) | 先取り命令を生成する方法とシステム | |
| US7437517B2 (en) | Methods and arrangements to manage on-chip memory to reduce memory latency | |
| US5944815A (en) | Microprocessor configured to execute a prefetch instruction including an access count field defining an expected number of access | |
| US6665749B1 (en) | Bus protocol for efficiently transferring vector data | |
| US20030145136A1 (en) | Method and apparatus for implementing a relaxed ordering model in a computer system | |
| EP0439025B1 (en) | A data processor having a deferred cache load | |
| US6782454B1 (en) | System and method for pre-fetching for pointer linked data structures | |
| JP3425158B2 (ja) | マルチバッファデータキャッシュを具えているコンピュータシステム | |
| US6513107B1 (en) | Vector transfer system generating address error exception when vector to be transferred does not start and end on same memory page | |
| JP4599172B2 (ja) | フリーバッファプールを使用することによるメモリの管理 | |
| JPH08272779A (ja) | コンピュータ・システム | |
| US5893159A (en) | Methods and apparatus for managing scratchpad memory in a multiprocessor data processing system | |
| EP1039377B1 (en) | System and method supporting multiple outstanding requests to multiple targets of a memory hierarchy | |
| US6892280B2 (en) | Multiprocessor system having distributed shared memory and instruction scheduling method used in the same system | |
| CN114579188A (zh) | 一种risc-v向量访存处理系统及处理方法 | |
| US7321964B2 (en) | Store-to-load forwarding buffer using indexed lookup | |
| EP0862118B1 (en) | Computer system comprising a memory controller for burst transfer | |
| Berenbaum et al. | Architectural Innovations in the CRISP Microprocessor. | |
| EP0156307A2 (en) | Pipelined processor having dual cache memories | |
| JPH0756808A (ja) | データキャッシュバッファ及び記憶方法 | |
| JP2668987B2 (ja) | データ処理装置 | |
| JP4680340B2 (ja) | プロセッサ |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20040927 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20040927 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20071205 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20071225 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080317 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080415 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080416 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20080520 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20080612 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110620 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120620 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130620 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130620 Year of fee payment: 5 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130620 Year of fee payment: 5 |
|
| R360 | Written notification for declining of transfer of rights |
Free format text: JAPANESE INTERMEDIATE CODE: R360 |
|
| R360 | Written notification for declining of transfer of rights |
Free format text: JAPANESE INTERMEDIATE CODE: R360 |
|
| R371 | Transfer withdrawn |
Free format text: JAPANESE INTERMEDIATE CODE: R371 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130620 Year of fee payment: 5 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130620 Year of fee payment: 5 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |