JP2012194875A - 情報処理装置、電子機器、プログラム及び情報処理方法 - Google Patents
情報処理装置、電子機器、プログラム及び情報処理方法 Download PDFInfo
- Publication number
- JP2012194875A JP2012194875A JP2011059308A JP2011059308A JP2012194875A JP 2012194875 A JP2012194875 A JP 2012194875A JP 2011059308 A JP2011059308 A JP 2011059308A JP 2011059308 A JP2011059308 A JP 2011059308A JP 2012194875 A JP2012194875 A JP 2012194875A
- Authority
- JP
- Japan
- Prior art keywords
- name
- file
- byte
- character
- byte character
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images









Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【課題】複数バイト文字を含む名称が付けられていても、複数バイト文字のコードの一部を、ディレクトリの境界を表すコードであると誤認識することがない情報処理装置、電子機器、プログラム及び情報処理方法を提供する。
【解決手段】ファイルシステムは複数種のFATとファイル名変換部を備える。ファイル名変換部は、フルパスファイル名の階層毎のファイル特定名称(ディレクトリ名、ファイル名)を1文字ずつ解析する。このとき、1バイト文字であるか複数バイト文字であるかを判定し(S330)、複数バイト文字であり(S330で否定判定)、かつユニコードの英数字でもなければ(S340で否定判定)、ディレクトリエントリー配列のインデックスを取得する(S390)。そして、インデックスを7桁のIDとした後にASCIIコードに変換し、その先頭に識別コード「FF」(16進数)を付与して、ショートファイル名形式のファイル特定名称を生成する(S400)。
【選択図】図9
【解決手段】ファイルシステムは複数種のFATとファイル名変換部を備える。ファイル名変換部は、フルパスファイル名の階層毎のファイル特定名称(ディレクトリ名、ファイル名)を1文字ずつ解析する。このとき、1バイト文字であるか複数バイト文字であるかを判定し(S330)、複数バイト文字であり(S330で否定判定)、かつユニコードの英数字でもなければ(S340で否定判定)、ディレクトリエントリー配列のインデックスを取得する(S390)。そして、インデックスを7桁のIDとした後にASCIIコードに変換し、その先頭に識別コード「FF」(16進数)を付与して、ショートファイル名形式のファイル特定名称を生成する(S400)。
【選択図】図9
Description
本発明は、アプリケーション部からの要求に応じて記憶媒体にアクセスするファイルシステムなどの情報処理装置、電子機器、プログラム及び情報処理方法に関する。
例えば特許文献1には、メモリーカード等の記憶媒体にアクセスする機能を有するプリンター等の電子機器が開示されている。従来、この種の電子機器では、アプリケーション部はファイルシステムを介して記憶媒体にアクセスし、記憶媒体から読み込んだファイル情報やファイル等を使って、画像枚数のカウント、画像の表示、画像の印刷等の必要な各種処理を行う。ファイルシステムは複数種のFAT(File Allocation Table)を備え、記憶媒体のフォーマットに合った1つのFATを用いて記憶媒体にアクセスし、必要なファイル情報やファイルを取得する。
従来、FAT12、FAT16、FAT32に対応する形式でフォーマットされた記憶媒体に記憶されたファイル情報中のファイル名やディレクトリ名(フォルダー名)には、ASCIIコード等の1バイト文字コードで表現されたショートファイル名形式(例えば8.3形式)が採用されていた。このため、アプリケーション部はショートファイル名形式(例えば8.3形式)にしか対応しておらず、ファイルシステムに対してショートファイル名形式で表現されたアクセス先(例えばフルパスファイル名等のデータ特定情報)を指定してアクセス要求を出すことで、記憶媒体に対してリード(読込み)及びライト(書込み)を行っていた。
ここで、1バイト文字コードであるASCIIコードは、英数字等の限られた文字を符号化する1バイト系符号化文字コードであり、使用できるファイル名等はショートファイル名に限られる。これに対して、1バイト文字と2バイト文字の組合わせなど異なるバイト数の文字が混在するマルチバイト文字や、2バイト文字だけからなるなど同じバイト数の文字だけからなるワイド文字コードなどがある。マルチバイト文字の符号化方式の場合、ほとんどの場合、1バイト文字については、ASCIIあるいはISO 646をベースにしたものになる。例えば日本語ロケールであれば、一般的にシフトJIS(Shift JIS)やEUC-JPが採用され、UTF-8が用いられる場合もある。この場合、1バイト文字である英数字以外の日本語の文字、例えば漢字、全角平仮名、全角カタカナなどは2バイト文字となる。なお、ワイド文字集合の1つとして、例えばUnicode(ユニコード)が挙げられる。
例えば特許文献2には、ローカルコード列とユニコード列との間の変換を行うファイル管理モジュールが開示されている。このファイル管理モジュールは、記憶媒体内のファイル名のローカルコード列を、1バイトコードそれぞれに対していずれかのユニコードを重複なく割り当てた変換テーブルを用いて、ユニコード列に変換して提供する。
従来の電子機器のアプリケーション部は、ASCIIコードのショートファイル名を前提にリードとライトを行っている。そのため、アプリケーション部は、ASCIIコードで表現されたファイル名の文字列を1バイト(1文字分)ずつ解析し、ファイル名を解読している。
例えばシフトJIS等のマルチバイト文字の符号化方式や、ワイド文字の符号化方式の中には、2バイト文字の中に、1バイト文字の「\」を表す「5C」(16進数)を含むものがある。「5C」(16進数)が意味する『\』は、フルパスファイル名ではディレクトリの境界を意味する。
このため、従来の電子機器のアプリケーション部は、「5C」のコードが含まれる日本語の文字を使用したファイル名に対して、正しくファイル名を認識できず、ファイルアクセスができないという問題があった。つまり、ファイル名やディレクトリ名に、ディレクトリの境界を表す『\』の1バイト文字コードである「5C」をコード中に含む2バイト文字が存在すると、アプリケーション部はその箇所でディレクトリが区切られていると判断してしまい、正しいファイル名、ディレクトリ名を認識することができない。例えば電子機器がプリンターの場合、記憶媒体に保存されたファイルに基づく画像の表示も印刷もできなくなる。
特許文献2のファイル管理モジュールは、記憶媒体側のローカルコードをユニコードに変換する構成であるので、ユニコードに対応していないアプリケーション部はやはりファイル名を認識することができない。このため、電子機器に特許文献2のファイル管理モジュールを設けても、記憶媒体に正しくアクセスできない。また、ASCIIコード等の1バイト文字コードからなるローカルコードであれば、変換テーブルのデータサイズも比較的小さく済むが、複数バイト文字からなるローカルコードに対応する変換テーブルはデータサイズがかなり大きくなり、メモリー容量の比較的小さなプリンター等の電子機器で使用するうえで現実的ではない。
本発明は、上記課題に鑑みてなされたものであり、その目的の一つは、複数バイト文字を含む名称が付けられていても、複数バイト文字のコードの一部を、ディレクトリの境界を表すコードであると誤認識することがない情報処理装置、電子機器、プログラム及び情報処理方法を提供することにある。
上記目的の一つを達成するために、本発明の態様の一つは、記憶媒体を接続可能な電子機器内に設けられ、当該電子機器内のアプリケーション部からの要求に応じて接続中の記憶媒体にアクセスして取得したデータ特定情報を前記アプリケーション部に渡す情報処理装置であって、前記データ特定情報に含まれる第1名称が複数バイト文字を含むか否かを判定する判定手段と、前記第1名称が複数バイト文字を含むと判定された場合に、前記第1名称を1バイト文字列の第2名称に変換する名称変換手段と、を備え、前記名称変換手段は、前記記憶媒体における前記データ特定情報の所在位置を示す一意な所在位置情報のうち前記第1名称に対応する部分を前記1バイト文字列に変換し、当該1バイト文字列を含む前記第2名称を生成することを要旨とする。なお、所在位置情報のうち第1名称と対応する部分が所在位置情報の全部である場合は、所在位置情報を変換した1バイト文字列を含む第2名称を生成することになる。
本発明の一実施態様によれば、記憶媒体にアクセスして取得したデータ特定情報に含まれる第1名称の文字列が複数バイト文字を含むと判定された場合、名称変換手段によって、第1名称の文字列は1バイト文字列の第2名称に変換される。このとき、データ特定情報の所在位置を示す一意な所在位置情報のうち第1名称に対応する部分を1バイト文字列に変換し、この1バイト文字列を含む第2名称が生成される。よって、複数バイト文字を含む符号化方式を扱う形式でフォーマットされた記憶媒体にアクセスしても、複数バイト文字の一部をディレクトリの境界を表すコードであると誤認識することがない。
本発明の態様の一つである情報処理装置では、前記1バイト文字列に変換された前記第2名称であることを特定可能な特定文字を含む前記第2名称を生成することが好ましい。
本発明の一実施態様によれば、名称変換手段が生成した第2名称には、一意な所在位置情報のうち第1名称に対応する部分を変換した1バイト文字列と、1バイト文字列に変換された第2名称であることを特定可能な特定文字とが含まれる。このため、例えばアプリケーション部から第2名称でアクセス位置を指定したアクセス要求を受け付けた場合、第2名称に対して特定文字の有無を調べ、特定文字があれば第2名称のうち特定文字以外の1バイト文字列からデータ特定情報のうち第1名称と対応する部分を取得することが可能になる。例えば、データ特定情報が階層構造で表されている場合、階層毎の第2名称からデータ特定情報のうち第1名称と対応する部分を階層毎に取得することにより、所在位置情報が得られる。そして、所在位置情報から取得されるデータ特定情報に基づき、要求されたデータを取得してアプリケーション部に渡すことが可能になる。
本発明の一実施態様によれば、名称変換手段が生成した第2名称には、一意な所在位置情報のうち第1名称に対応する部分を変換した1バイト文字列と、1バイト文字列に変換された第2名称であることを特定可能な特定文字とが含まれる。このため、例えばアプリケーション部から第2名称でアクセス位置を指定したアクセス要求を受け付けた場合、第2名称に対して特定文字の有無を調べ、特定文字があれば第2名称のうち特定文字以外の1バイト文字列からデータ特定情報のうち第1名称と対応する部分を取得することが可能になる。例えば、データ特定情報が階層構造で表されている場合、階層毎の第2名称からデータ特定情報のうち第1名称と対応する部分を階層毎に取得することにより、所在位置情報が得られる。そして、所在位置情報から取得されるデータ特定情報に基づき、要求されたデータを取得してアプリケーション部に渡すことが可能になる。
本発明の態様の一つである情報処理装置では、前記判定手段は、前記第1名称の文字列コードを1バイトずつ解析し、解析対象の1バイトが1バイト文字に属さないコードであるか否かを判定し、1バイト文字に属さないコードである場合に複数バイト文字を含むと判定することが好ましい。
本発明の一実施態様によれば、判定手段は、第1名称の文字列を1バイトずつ解析し、解析対象の1バイトが1バイト文字に属さないコードであれば、複数バイト文字を含むと判定する。このため、文字コード列を1バイトずつ解析しても、複数バイト文字を含むか否かを判定できる。
本発明の態様の一つである情報処理装置では、前記判定手段は、前記第1名称の文字数がショートファイル名形式の最大文字数以下であるか否かを判定する文字数判定手段を更に備え、前記名称変換手段は、前記第1名称の文字数が前記最大文字数以下でないと判定された場合は、前記第1名称が複数バイト文字を含むと判定されていなくても、当該第1名称を、前記1バイト文字列を含む前記第2名称に変換することが好ましい。
本発明の一実施態様によれば、名称変換手段は、第1名称の文字数が最大文字数以下でないと判定された場合は、第1名称が複数バイト文字を含むと判定されていなくても、第1名称を、一意な所在位置情報のうち第1名称と対応する部分を変換した1バイト文字列を含む第2名称に変換する。よって、ショートファイル名形式の最大文字数を超えるロングファイル名形式の第1名称を、その文字列の最後まで解析する無駄を極力回避しつつ、1バイト文字列の第2名称に変換できる。
本発明の態様の一つである情報処理装置では、前記判定手段は、前記第1名称が複数バイト文字を含むと判定した場合であっても、当該第1名称が1バイト文字列で表現可能であるか否かを判定する文字判定手段を有し、前記名称変換手段は、前記第1名称が1バイト文字列で表現可能と判定された場合、当該第1名称に含まれる複数バイトの文字を1バイト文字に変換して、当該第1名称と同一文字列の1バイト文字列で表された前記第2名称を生成することが好ましい。
本発明の一実施態様によれば、第1名称が複数バイト文字を含む場合であっても、当該第1名称が1バイト文字列で表現可能な場合は、名称変換手段により、当該第1名称に含まれる複数バイトの文字が1バイト文字に変換されることにより、第1名称の文字列をそのまま使った1バイト文字列の第2名称に変換される。よって、このような第1名称については、記憶媒体から一意な所在位置情報を取得する処理などを省略できる。
本発明の態様の一つである情報処理装置では、前記判定手段は、前記第1名称の文字数がショートファイル名形式の最大文字数以下であるか否かを判定する文字数判定手段を備え、前記名称変換手段は、前記第1名称の文字列が1バイト文字列で表現可能と判定され、かつ前記第1名称の文字数が前記最大文字数以下であると判定された場合に、当該第1名称を同一文字列の1バイト文字列に変換することが好ましい。
本発明の一実施態様によれば、第1名称が1バイト文字列で表現可能と判定され、かつ第1名称の文字数が前記最大文字数以下であると判定された場合は、第1名称の文字列をそのまま使った1バイト文字列のショートファイル名に変換されて第2名称とされる。よって、このような第1名称の同一文字列のショートファイル名形式への変換の際は、記憶媒体から所在位置情報を取得する処理などを省略できる。
本発明の態様の一つである情報処理装置では、前記名称変換手段は、前記アプリケーション部から前記一意な所在位置情報を表す1バイト文字列を含む前記第2名称でアクセス位置を指定したアクセス要求を受け付けると、前記第2名称の1バイト文字列を前記所在位置情報に逆変換する逆変換部を備え、前記記憶媒体に対して前記逆変換部による逆変換で取得した前記所在位置情報で示される所在位置にアクセスして前記データ特定情報を取得し、当該データ特定情報に基づきデータを取得することが好ましい。
本発明の一実施態様によれば、アプリケーション部から一意な所在位置情報を表す1バイト文字列を含む第2名称でアクセス位置を指定したアクセス要求を受け付けた場合、第2名称の1バイト文字列を逆変換して所在位置情報を取得し、記憶媒体に対しその所在位置情報で示された所在位置にアクセスすればデータ特定情報を取得できる。そして、データ特定情報に基づくアクセス位置から、要求されたデータを取得できる。従って、第1名称を第2名称に変換したデータ特定情報をアプリケーション部に渡した後、アプリケーション部から第2名称でアクセス位置を指定したアクセス要求を受け付けても、その要求されたデータを記憶媒体から取得してアプリケーション部に渡すことができる。
本発明の態様の一つは、記憶媒体を接続可能な電子機器であって、上記発明の一態様に係る情報処理装置と、前記情報処理装置に記憶媒体からのデータ特定情報の取得を要求するアプリケーション部と、を備えたことを要旨とする。本発明の一実施態様によれば、電子機器によって、上記情報処理装置の発明と同様の効果を得ることができる。
本発明の態様の一つは、アプリケーション部からの要求に応じて電子機器に接続された記憶媒体にアクセスして取得したデータ特定情報を前記アプリケーション部に渡す処理をコンピューターに実行させるためのプログラムであって、コンピューターに、前記記憶媒体にアクセスして取得したデータ特定情報に含まれる第1名称が複数バイト文字を含むか否かを判定する判定ステップと、前記第1名称が複数バイト文字を含むと判定された場合に、前記第1名称を1バイト文字列の第2名称に変換する名称変換ステップと、を実行させ、前記名称変換ステップでは、前記記憶媒体における前記データ特定情報の所在位置を示す一意な所在位置情報のうち前記第1名称に対応する部分を前記1バイト文字列に変換し、当該1バイト文字列を含む前記第2名称を生成することを要旨とする。本発明の一実施態様によれば、コンピューターにプログラムを実行させることにより、上記情報処理装置の発明と同様の作用効果を得ることができる。
本発明の態様の一つは、アプリケーション部からの要求に応じて電子機器に接続された記憶媒体にアクセスして取得したデータ特定情報を前記アプリケーション部に渡す情報処理方法であって、前記記憶媒体にアクセスして取得したデータ特定情報に含まれる第1名称が複数バイト文字を含むか否かを判定する判定ステップと、前記第1名称が複数バイト文字を含むと判定された場合に、前記第1名称を1バイト文字列の第2名称に変換する名称変換ステップと、を備え、前記名称変換ステップでは、前記記憶媒体における前記データ特定情報の所在位置を示す一意な所在位置情報のうち第1名称に対応する部分を前記1バイト文字列に変換し、当該1バイト文字列を含む前記第2名称を生成する。この発明によれば、上記情報処理装置の発明と同様の作用効果を得ることができる。
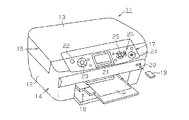
以下、本発明を具体化した一実施形態を図1〜図10に基づいて説明する。図1に示す電子機器の一例としての複合機11は、本体12とカバー13とを備える。本体12の下側部分がプリンター部14になっており、上側部分がスキャナー部15になっている。プリンター部14は、例えばインクジェット式の記録方式を採用する。本体12の前側上段部には、操作パネル17が設けられている。また、本体12の前側下部には、印刷済みの用紙Pが排出される排紙部18が設けられている。本体12において排紙部18の図1における右上位置には、記憶媒体の一例であるメモリーカード19を挿抜可能なカードスロット20が設けられている。
図1に示すように、操作パネル17には、その幅方向中央部に配置された表示部21と、電源ボタン22、モード選択ボタン23、印刷/スキャンを開始するスタートボタン24、選択ボタン25等を含む操作部26とが設けられている。
本実施形態の複合機11では、モード選択ボタン23の操作によって、「メモリーカード」「コピー」「スキャン」等を含む複数のモードのうち一つを選択できる。表示部21には選択されたモードに対応するメニュー画面が表示され、選択ボタン25等の操作により所望の印刷条件等の設定が可能になっている。ここで、「メモリーカード」モードは、カードスロット20に挿着されたメモリーカード19から読み取った画像データに基づき写真等の画像を印刷するときに用いられる。
次に、複合機11の電気的構成を図2を用いて説明する。複合機11は、コンピューター31(例えばマイクロコンピューター)を備える。コンピューター31は、メモリーカードI/F32を介して接続されたメモリーカード19にアクセスする。また、コンピューター31には、操作パネル17の操作部26と表示部21が接続されている。さらにコンピューター31は、スキャナー部15にスキャニング動作を行わせるスキャンエンジン33と、プリンター部14に印刷動作を行わせるプリントエンジン34とに接続されている。
コンピューター31は、CPU35、ASIC36(Application SpecificIC)、ROM37、RAM38等を内蔵している。ROM37には、アプリケーション用プログラム(例えば図7)や、ファイルシステム用プログラム(例えば図8〜図10)、各種処理に必要な設定データなどが記憶されている。CPU35はROM37から読み出したプログラム(例えばアプリケーション用プログラム)を実行して各種の処理を行う。コンピューター31は、検出したメモリーカード19にアクセスしてファイル情報FI(図3参照)を読み込んで登録する処理や、ファイル情報に基づいてメモリーカード19内のファイルF(画像データ)を読み込む処理や、画像データに基づく画像の表示部21への表示処理及び印刷処理などを実行する。
図3は、コンピューターにおいて、メモリーカードからファイル情報やファイルを読み込む処理を行う部分の機能構成を示す。なお、図3ではメモリーカードI/F32は省略されている。コンピューター31は、CPU35がアプリケーション用プログラムを実行することで構築されるアプリケーション部41と、CPU35がファイルシステム用プログラムを実行することで構築されるファイルシステム42とを備える。
アプリケーション部41は、カードスロット20に挿着されたメモリーカード19を検出したとき、表示部21にメモリーカード19中の画像を表示するとき、あるいは印刷対象のファイルF(画像データ)をメモリーカード19から取得するときには、ファイルシステム42を介してメモリーカード19にアクセスする。すなわち、アプリケーション部41がファイルシステム42にアクセス要求を出すと、ファイルシステム42はメモリーカード19にアクセスしてその要求されたファイル情報FIやファイルF(画像データ)を読み込み、その読み込んだファイル情報FI等をアプリケーション部41へ送る。
アプリケーション部41は、カウントアップ処理部43、ファイル情報登録部44及びファイル要求部45を備える。また、ファイルシステム42は、複数種のFAT51〜54等(ファイル・アロケーション・テーブル(File Allocation Table))と、ファイル名変換部60とを備えている。本例では、複数種のFAT51〜54等として、「FAT12」、「FAT16」、「FAT32」及び「exFAT」などを備えている。
ファイル名変換部60は、ファイル名やディレクトリ名などのファイル特定名称を、マルチバイト文字コードのロングファイル名から1バイト(シングルバイト)文字コードのショートファイル名に変換する文字コード変換処理を行う。この文字コード変換処理を行うために、ファイル名変換部60は、図3に示すように、フォーマット形式判定部61、カウンター62、文字判定手段の一例である名称構成判定部63、文字数判定手段の一例である文字数判定部64、第1変換部65、逆変換部の一例である第2変換部66及びパス解析部67を備えている。
本実施形態では、1バイト文字集合とマルチバイト文字集合とワイド文字集合とを次のように定義する。1バイト文字集合(シングルバイト文字集合)とは、1文字を1バイトで表現する文字集合であり、ASCIIとISO646を挙げることができる。1バイトの符号化方式としては、ASCIIとISO646が使用される。
マルチバイト文字集合とは、1バイト文字集合(ASCII、ISO646)と、この1バイト文字集合の中に存在しない文字(例えば漢字)を複数バイト(例えば2バイト)で表現した複数バイト文字集合(例えば2バイト文字集合)とからなる文字集合である。マルチバイト文字の符号化方式としては、シフトJISとUTF−8などが使用される。例えばシフトJISでは、複数バイト文字集合の中の複数バイト文字を複数バイトで表したときの1バイト分が、ASCIIやISO 646など符号化方式における文字『\』を表す「5C」が使われている。日本では『\』が使われるが、他国ではバックスラッシュを表す。『\』又はバックスラッシュは、ディレクトリの境界を示す文字として使用される。
ワイド文字集合とは、1文字を複数バイトで表現する文字集合である。ASCIIやISO646などの1バイト文字集合で表現可能な文字も複数バイトで表現される。一例としてユニコード(Unicode)を挙げることができる。ワイド文字の符号化方式としては、UTF−16やUTF−32が使われる。
本実施形態では、マルチバイト文字集合やワイド文字集合のように複数バイト文字を含む文字集合の文字コードで表現された変換前のファイル特定名称が、第1名称に相当する。また、1バイト文字集合の文字コードで表現された変換後のファイル特定名称が、第2名称に相当する。また、フォーマット形式判定部61、名称構成判定部63及び文字数判定部64により、判定手段の一例が構成される。さらに第1変換部65及び第2変換部66により、名称変換手段の一例が構成される。
カウントアップ処理部43は、複合機11に接続(つまりカードスロット20に挿入)されているメモリーカード19を検出すると、メモリーカード19中の画像枚数(ファイル数)をカウントアップする。このとき、カウントアップ処理部43はファイルシステム42に対してファイル検索を要求する(図中(1))。ファイルシステム42はファイル検索要求を受け付けると、メモリーカード19にアクセスしてディレクトリエントリーを取得する(図中(2))。そして、ファイルシステム42はディレクトリエントリー中のファイル情報FIをアプリケーション部41へ送る(図中(3))。このファイル情報FIには、「ファイル名」、「拡張子」、「フルパスファイル名」、「作成日付」、「作成時刻」などファイルFに関する各種情報が含まれている。なお、本実施形態では、ファイル名及びフルパスファイル名が、データ特定情報の一例に相当する。
ファイル情報登録部44は、ファイルシステム42から受け取ったファイル情報FIを、RAM38に作成したファイルリストFLに登録する(図中(4))。このとき、ファイル情報登録部44は、ファイル情報FI中のファイル名から複合機11が印刷の対象とすることができる印刷対応のファイルであるか否かを判断し、印刷非対応のファイルのファイル情報は除去するので、ファイルリストFLには印刷可能なファイルのファイル情報FIだけが登録される。カウントアップ処理部43は、ファイル情報登録部44がファイル情報を1つ登録する度に「1」ずつカウントアップし、ファイル情報の登録数、すなわちメモリーカード19中で印刷可能な画像枚数をカウントする。こうしてRAM38の所定記憶領域には、メモリーカード19中のファイル情報FIが登録されたファイルリストFLが作成される。
また、ファイル要求部45は、メモリーカード19内からファイルを取得する必要が生じた場合、その必要なファイルに係るファイル情報をファイルリストFLから読み出す(図中(5))。そして、ファイル要求部45は、読み出したファイルリストFL中のフルパスファイル名を指定してファイルシステム42に対してファイル読込要求を行う(図中(6))。
ファイルシステム42は、ファイル読込要求を受け付けると、フルパスファイル名を手掛かりにメモリーカード19内における指定のファイルにアクセスする(図中(7))。そして、ファイルシステム42は、メモリーカード19からファイルFを読み込み、読み込んだファイルFを要求元のアプリケーション部41へ送る(図中(8))。
本実施形態の複合機11におけるアプリケーション部41は、1バイト文字の一例としてのASCIIコードの文字符号化方式であるショートファイル名形式(「8.3形式」)に対応している。しかし、アプリケーション部41は、シフトJISなどの文字符号化方式や、ユニコード(Unicode)の文字符号化方式の一例である「UTF−16(UCS/Unicode Transformation Format 16)」で扱われるロングファイル名形式には対応していない。しかし、ユニコードで表現されるロングファイル名形式でフォーマットされたメモリーカード19が、カードスロット20に挿入される場合もある。このため、図3に示すように、ファイルシステム42が備える複数種のFAT51〜54等の中には、ASCIIコードで表現されるショートファイル名形式に対応する「FAT12」、「FAT16」、「FAT32」の他、ユニコード(UTF−16)で表現されるロングファイル名形式でフォーマットされたメモリーカード19に対応可能な「exFAT」が追加されている。
「FAT16」、「FAT32」では、日本語文字コードの文字符号化方式として例えばシフトJISが採用される。また、「exFAT」では、ユニコード(UTF−16)が日本語にも対応しているため、日本語の文字についてもユニコードの文字符号化方式が使用される。
ここで、ロングファイル名では、1文字が2バイトだけで表現されるユニコード(UTF−16)が使用され、最大255文字までのファイル名を設定できる。一方、ショートファイル名形式(8.3形式)では、1文字が1バイトで表現される1バイト系文字コードであるASCIIコードが使用され、ファイル名が8文字以下かつ拡張子が3文字以下の文字数に限られる。シフトJISにおける日本語の文字は2バイト文字なので、ショートファイル名形式(8.3形式)では、2バイト文字の1文字は、2文字として扱われる。また、「ユニコード」では、英数字は上位1バイトに「00」(16進数)が付き、下位1バイトはその文字の「ASCIIコード」と同じ値をとる。なお、「ASCIIコード」では「00」(16進数)は終端文字を表す。
本実施形態のアプリケーション部41は、ショートファイル名形式(8.3形式)にしか対応していない。アプリケーション部41は、FAT54(「exFAT」)を介してユニコード(UTF−16)のファイル情報FIを取得しても、そのままでは解読することができない。また、ファイルシステム42のFAT52,53(「FAT16」「FAT32」)は、日本語の文字(漢字、片仮名、平仮名)を含むファイル情報FIに対応できるように、ファイル情報FIをシフトJISの文字コードで表現する。この日本語の文字(漢字、片仮名、平仮名)は、シフトJISでは2バイト文字である。
アプリケーション部41は、ショートファイル名形式かロングファイル名形式かの違いによらず、また1バイト文字か複数バイト文字であるかによらず、ファイル名やディレクトリ名等のファイル特定名称の文字コード列を、1バイトずつ解析する。例えばシフトJISの2バイト文字を表す文字コードの中には、例えばASCIIコードで「\」を意味する「5C」(16進数)を含む文字コードがある。アプリケーション部41は、ファイル特定名称の文字コード列を、1バイトずつ解析し、「\」を意味する「5C」(16進数)があると、ディレクトリの境界であると間違って解読する。本実施形態では、このように複数バイト文字のうちその文字コード(2バイトコード)中に「\」を意味する「5C」を含む文字の解析中に、2バイト文字コード中の1バイトを「\」を意味する「5C」と間違って解読することを回避するため、ファイルシステム42にはファイル名変換部60が設けられている。
なお、シフトJISにおいて「5C」(16進数)を含む2バイト文字の一例を挙げると、[―](815C)、[ソ](835C)、[Ы](845C)、[IX](875C)、[噂](895C)、[欺](8B5C)、[圭](8C5C)、[構](8D5C)、[蚕](8E5C)、[十](8F5C)、[申](905C)、 [貼](935C)、[能](945C)、[表](955C)、[暴](965C)、[予](975C)、[禄](985C)、[臀](E45C)、[饅](E95C)などがある。これらの文字コードから分かるように、どの文字も、1バイト目はASCIIコードで未使用の「0x80」〜「0xFF」の範囲内にあり、2バイト目が「0x5C」になっている。
本実施形態では、図3に示すファイル名変換部60が、ファイル情報FIに含まれるファイル特定名称を、1バイト文字(ASCII形式)の名称に変換する。本例では、ファイル情報FIのうち「フルパスファイル名」と「ファイル名」が、ファイル名変換部60の変換処理対象とされる。そして、「フルパスファイル名」の場合は、階層別の構成要素である「ディレクトリ名(サブディレクトリ名も含む)」と「ファイル名」などがファイル特定名称となる。
次にファイル名変換部60を構成する各部61〜67の詳細を説明する。
フォーマット形式判定部61は、所定の形式でフォーマットされたメモリーカード19のフォーマット形式を判定する。
フォーマット形式判定部61は、所定の形式でフォーマットされたメモリーカード19のフォーマット形式を判定する。
ファイルシステム42は、複数のFAT51〜54等のうちから、フォーマット形式判定部61により判定されたフォーマット形式に対応する1つのFATを介してメモリーカード19にアクセスする。また、フォーマット形式判定部61は、判定したフォーマット形式によって、変換前のファイル特定名称(第1名称)に適用される文字符号化方式が、日本語文字に対応するマルチバイト文字のローカルコードであるシフトJISか、ユニコードに対応するUTF−16の文字符号化方式であるかを判定する。
ファイル特定名称が複数バイト文字を含む文字列で表現されている場合、各部62〜65が複数バイト文字を含む文字列を1バイト文字(ASCIIコード)の文字列へ変換する変換処理を行う。この変換処理では、複数バイト文字を含む文字列からなる「ファイル特定名称」の文字列構造から1バイト文字コード(ASCIIコード)に変換できるかどうかを解析し、その解析結果に応じた変換処理を行う。具体的には、ショートファイル名形式で使用可能な最大文字数以下(本例では8文字以下)であるかどうか、「ASCIIコード」に変換可能な文字(本例では英数字)のみからなる文字列であるかどうかなどを解析する。この解析処理は、「ファイル特定名称」の文字列を構成する文字を先頭から1文字(1バイト)ずつ順番に解析する。ファイル名変換部60はこの解析を、カウンター62、名称構成判定部63、文字数判定部64を用いて行う。そして、第1変換部65は、予め用意された2種類の変換方式のうち解析結果に応じて選択した1つの変換方法で、「ファイル特定名称」を、1バイト文字コード(ASCIIコード)で表現されたショートファイル名形式に変換する。
より具体的には、カウンター62は、解析対象の文字が先頭から何番目(何文字目)であるかを計数する。名称構成判定部63は、メモリーカード19のフォーマット形式から「FAT12」を使用する場合は「ASCII」が適用され、「FAT16」「FAT32」を使用する場合は「シフトJIS」が適用され、「exFAT」を使用する場合は「ユニコード(UTF−16)」が適用されると判断する。名称構成判定部63は、ユニコード(UTF−16)が適用される場合、ファイル特定名称の文字列が全て複数バイト文字であると判定する。
また、名称構成判定部63は、シフトJISが適用される場合、ファイル特定名称が1バイト文字だけからなるのか、複数バイト文字(例えば2バイト)を含むのかを判定する。ここで、シフトJISの場合、英数字は1バイト文字であり、しかもその1バイト文字のコードはASCIIコードと同じ値である。また、シフトJISでは、2バイト文字のうち上位1バイトにASCIIコードと同じ値が使用されていない。このため、名称構成判定部63は、ファイル特定名称の文字列を構成する文字が英数字などのASCIIコードと同じコードで表現される1バイト文字であるか否かを、1文字(1バイト)ずつ順番に判定する。
また、名称構成判定部63は、複数バイト文字(例えば2バイト文字)であっても、ユニコードである場合は、ASCIIコードで表現可能な特定の文字であるか否かを判定する。ユニコード(UTF−16)では、英数字は、1文字で使用される2バイトのうち、上位1バイト(第1バイト目)が「00」(16進数)、下位バイト(第2バイト目)がその英数字のASCIIコードと同じ値をとる。このため、名称構成判定部63は、先頭から1文字ずつ順番に判定する際に、1文字を表す2バイトのうち上位バイトが「00」(16進数)であるか否かを判定する。これにより、複数バイト文字がユニコードである場合に、その文字が、下位1バイトがASCIIコードと値が同じになる英数字であるか否かを判定する。
また、文字数判定部64は、ファイル特定名称の文字数がショートファイル名形式の最大文字数の「8文字」を超えるか否かを判定する。ショートファイル名に変換できるためには、文字数が8文字(8バイト)以下である必要がある。このため、文字数判定部64は、「ファイル特定名称」の文字列の先頭から1文字ずつ計数するカウンター62の計数値で示される文字数が、8文字以下であるか否かを判定する。文字列を先頭から1文字ずつ順番に解析(判定)していって次の文字がなかった場合にその直前の文字までの計数値が8以下であれば、「ファイル特定名称」が8文字以下であると判定できる。このとき、文字数判定部64は、ファイル特定名称が「ファイル名」である場合、名称と拡張子の間のドット「.」を終端文字とし、次の文字が終端文字「.」があった場合はその文字がないと判定する。
第1変換部65は、名称構成判定部63及び文字数判定部64による解析結果(判定結果)に応じた変換方法に従って、「ファイル特定名称」を、複数バイト文字を含む文字列のショートファイル名形式又はロングファイル名形式から、1バイト文字コードのショートファイル名形式に変換する。すなわち、第1変換部65は、名称構成判定部63が、ファイル特定名称の文字コード列中に複数バイト文字が含まれていると判定した場合、ファイル特定名称(第1名称)の文字列を、そのファイル特定名称の所在位置情報(本例では数字)を1バイト文字コード列(ASCIIコード列)で表現したファイル特定名称(第2名称)に変換する。この1バイト文字コード列で表現されたファイル特定名称(第2名称)への変換により、値に「5C」を含む複数バイト文字を含むファイル特定名称をアプリケーション部41に渡すことを回避する。
但し、複数バイト文字がユニコードである場合、名称構成判定部63は、その複数バイト文字の対象文字の上位1バイトが「00」(16進数)であるか否かを判定し、上位1バイトが「00」(16進数)であると判定した場合、その複数バイト文字がユニコードの英数字であることになる。この場合、第1変換部65は、複数バイト文字コード中の1バイト目の「00」(16進数)を削除し、その文字をASCIIコードで表現したときの文字コードと同じ値の2バイト目を残して1バイト文字(ASCIIコードの英数字)とする。
また、文字数判定部64が、ファイル特定名称の文字数がショートファイル名形式の最大文字数の「8文字」を超えると判定した場合、第1変換部65は、ファイル特定名称の文字列を、その所在位置情報を1バイト文字コード列(ASCIIコード列)で表現したファイル特定名称(第2名称)に変換する。
ここで、本実施形態では、所在位置情報として、フルパスファイル名から特定されるディレクトリエントリー配列のインデックスI(図4に示す)を使用する。フルパスファイル名は、ディレクトリ名(フォルダー名)、ファイル名などの階層構造で表されている。第1変換部65は、これらディレクトリ名、ファイル名などのファイル特定名称(第1名称)を、それぞれの所在位置を示すディレクトリエントリー配列のインデックスIをASCIIコードで表現したファイル特定名称(第2名称)へ変換する変換処理を行う。なお、以下の説明では、このファイル特定名称(第2名称)を「特別ファイル名」と呼ぶ。
また、アプリケーション部41がメモリーカード19からファイルFを読み込むときは、ファイル要求部45がファイルシステム42にファイル読込要求を行う。このとき、ファイル要求部45は、読み出すべきファイルFに対応するファイル情報FIをファイルリストFLから読み出し、ファイル情報FIに含まれるフルパスファイル名を指定してファイル読込要求を行う。このフルパスファイル名が、特別ファイル名を含むものである場合、このままのフルパスファイル名を指定しても、「FAT16」、「FAT32」、「exFAT」形式にフォーマットされたメモリーカード19中のファイルにアクセスできない。
そのため、ファイル名変換部60は、特別ファイル名を含むフルパスファイル名を、元のディレクトリエントリー配列のインデックスI(所在位置情報)に逆変換する第2変換部66を備えている。第2変換部66は、フルパスファイル名中の特別ファイル名(第2名称)を、ディレクトリエントリー配列のインデックスIを表すシフトJIS又はユニコード(UTF−16)の文字コードへ逆変換する。さらにファイル名変換部60は、第2変換部66が逆変換した値(ディレクトリエントリー配列のインデックスI)から、クラスター位置情報を取得するパス解析部67を備えている。なお、これら第2変換部66及びパス解析部67による処理については後述する。
図4は、メモリーカードにおけるディレクトリ構造を示す。root(ルート)直下の第1階層のディレクトリエントリー配列は、ファイル及びディレクトリのうち少なくとも一方に関する情報を含むディレクトリエントリーDEが1つ以上配列された配列構造をとる。各ディレクトリエントリーDEには配列位置を示すインデックス[0]〜[n]が付されている。例えばインデックス[0]のディレクトリエントリーDEには、ファイル「A.JPG」に関するディレクトリエントリー構造体DCが格納されている。このディレクトリエントリー構造体DC中には、ファイル名(サブディレクトリ名)、ファイル情報FI、ファイル(サブディレクトリ)本体のクラスター位置を示すクラスター位置情報CPが格納されている。このファイル本体のクラスター位置とは、メモリーカード19においてファイル本体がクラスターデータとして格納されている格納位置(クラスター番号)に相当する。
また、図4において、ディレクトリエントリー配列におけるインデックス[2]のディレクトリ「い」は、第2階層のサブディレクトリのディレクトリエントリー配列を有する。第2階層のディレクトリエントリー配列も、ファイル及びディレクトリのうち少なくとも一方に関する情報を含むディレクトリエントリーDEが1つ以上配列された配列構造をとる。第2階層も同様に各ディレクトリエントリーDEには配列位置を示すインデックス[0]〜[m]が付されている。以下、第3階層以上がある場合も、同様に階層毎にディレクトリエントリー配列を有している。
第2変換部66は、フルパスファイル名を構成するファイル特定名称を、1バイト文字コードのショートファイル名形式(8.3形式)から、複数バイト文字を含む文字コードに逆変換する。本実施形態の第2変換部66は、第1変換部65による2種類の変換方式に対応する2種類の逆変換方式に対応している。この逆変換方式の詳細は後述する。
次に、ファイル特定名称をショートファイル名形式の特別ファイル名へ変換する方法について説明する。カウンター62、名称構成判定部63及び文字数判定部64を用いて文字列構造解析を行った結果、ファイル特定名称が、1バイト文字列で表現されたショートファイル名でなく、また同じ文字列の1バイト文字列で表現されたショートファイル名への変換も不可能な場合、次の変換方法で1バイト文字列のショートファイル名に変換する。
図5は、1バイト文字列のショートファイル名形式に変換したファイル名の例を示す。文字をASCIIコードに変換できない場合は、後述する特別な変換方法で変換するため、図5に示すように、先頭に、特別な変換方法によるショートファイル名であることを示す識別コードとして「FF」(16進数)を置く。この識別コード「FF」は、ASCIIコードと共存しても識別できるように、ASCIIコードに現れない値(コード)を採用する。もちろん、識別コードは「FF」に限らず、ASCIIコードに現れなければ他の値でもよい。例えば「FE」(16進数)でもよい。
そして、図5に示すように、先頭の識別コード「FF」に、「7桁のID」をASCIIコードに変換したものを付加してファイル名とし、これにASCIIコードに変換した3文字の拡張子を付けて一意のショートファイル名を生成する。なお、ファイル特定名称が「ディレクトリ名」である場合は、先頭の識別コード「FF」に「7桁のID」をASCIIコードに変換したものを付加した8文字のディレクトリ名を生成する。
図6は、フルパスファイル名をショートファイル名形式に変換する変換例を示す説明図である。本実施形態では、7桁のIDとして、ディレクトリエントリー配列のインデックスIを採用する。図4に示すディレクトリエントリー配列を参照しつつ、図6における変換例を説明する。まず、図6(a)に示すようにフルパスファイル名が「ファイル」の階層だけからなる「root¥あ.JPG」の場合を説明する。図4においてroot直下のディレクトリエントリー配列では、ファイル名「あ.JPG」は、ディレクトリエントリー配列のインデックスIは[1]である。そのため、図6(a)では、このインデックス[1]を7桁のIDとして表した「0000001」(10進数)とし、先頭の識別コード「FF」に、この7桁のIDである「0000001」をASCIIコードで表現した「30303030303031」(16進数)を付加する。こうしてASCIIコードで表現されたショートファイル名形式のファイル名(特別ファイル名)として「FF30303030303031」(16進数)を生成する。なお、図6(a)では、特別ファイル名のみを16進数のコードで示している。
次に、図6(b)に示すようにフルパスファイル名が「ディレクトリ+ファイル」の階層構造をもつ「root¥い¥あ.JPG」の場合を説明する。図4においてroot直下のディレクトリエントリー配列において、ディレクトリ名「い」は、ディレクトリエントリー配列のインデックスIが[2]である。さらにその下位階層のファイル名「あ.JPG」は、サブディレクトリエントリー配列のインデックスIが[0]である。そのため、図6(b)では、まず、ディレクトリエントリー配列のインデックス[2]を7桁のIDとして表した「0000002」(10進数)とし、先頭の識別コード「FF」(16進数)に、この7桁のIDである「0000002」をASCIIコードで表現した「30303030303032」(16進数)を付加する。こうしてASCIIコードで表現されたショートファイル名形式のディレクトリ名(特別ファイル名)として「FF30303030303032」(16進数)を生成する。次に、サブディレクトリのディレクトリエントリー配列のインデックス[0]を7桁のIDとして表した「0000000」(10進数)とし、先頭の識別コード「FF」(16進数)に、この7桁のIDである「0000000」をASCIIコードで表現した「30303030303030」(16進数)を付加する。こうしてショートファイル名形式のファイル名(特別ファイル名)として「FF30303030303030」(16進数)を生成する。なお、図6(b)では、ファイル特定名称に相当するディレクトリ名とファイル名のみを16進数のコードで示している。
次に、上記のように構成された複合機11の作用を説明する。以下、アプリケーション部41の処理及びファイルシステム42の処理を図7〜図10のフローチャートに従って説明する。図7は、アプリケーション部41が行うアプリケーション処理を示すフローチャートである。また、図8は、ファイルシステム42が行うファイルシステム処理を示すフローチャートである。以下、このアプリケーション処理を図7に従って説明する。なお、この処理は、複合機11が電源オン状態にあるきにコンピューター31が所定時間毎に実行する。
まずステップS10では、メモリーカード19を検出したか否かを判断する。新しいメモリーカードを検出した場合にステップS20に進み、新しいメモリーカードを検出しなかった場合は当該処理を終了する。
ステップS20では、ファイルシステム42にファイル検索を要求する。
ステップS30では、ファイル検索要求の応答としてファイルシステム42からファイル情報FIを順次取得する。
ステップS30では、ファイル検索要求の応答としてファイルシステム42からファイル情報FIを順次取得する。
ステップS40では、ファイルが適切であるか否かを判断する。詳しくは、アプリケーション部41は、ファイル情報FIからファイル名中の拡張子を取得し、取得した拡張子と、予め設定された設定拡張子とを比較し、取得した拡張子が設定拡張子と一致すればファイルが適切と判断し、一方、不一致であればファイルが不適切と判断する。本実施形態では、3文字の特定の拡張子が設定拡張子として設定されているので、設定拡張子以外の3文字の拡張子及び4文字以上の拡張子を含むファイルは不適切と判断される。ファイルが適切な場合はステップS50に進み、ファイルが不適切な場合はステップS70に進む。
ステップS50では、ファイルリストFLにファイル情報を登録する。
次のステップS60では、ファイル数をカウントアップする。
次のステップS70では、全ファイル情報を取得したか否かを判断する。全ファイル情報を取得していなければ(否定判定の場合)、ステップS30〜S70の処理を繰り返してファイル情報FIを順次取得し、各ファイル情報FIに対して、適切性の判断(S40)、登録(S50)、カウントアップ(S60)等の処理を行う。そして、全ファイル情報を取得して、ステップS70で全ファイル情報を取得したと判断すると、ステップS80に進む。
次のステップS60では、ファイル数をカウントアップする。
次のステップS70では、全ファイル情報を取得したか否かを判断する。全ファイル情報を取得していなければ(否定判定の場合)、ステップS30〜S70の処理を繰り返してファイル情報FIを順次取得し、各ファイル情報FIに対して、適切性の判断(S40)、登録(S50)、カウントアップ(S60)等の処理を行う。そして、全ファイル情報を取得して、ステップS70で全ファイル情報を取得したと判断すると、ステップS80に進む。
ステップS80では、ユーザーによるファイル選択操作があったか否かを判断する。ユーザーは印刷を目的としてメモリーカード19内の画像データを選択する際は、操作部26を操作してメモリーカード19内の画像を表示部21に表示させる。ユーザーがファイルを選択操作すると、その選択されたファイルの画像が表示部21に表示される。そして、操作部26を操作して表示部21の画像を順番に切り替え、所望の画像が見つかると、その画像を印刷対象に決定する。このため、コンピューター31は、操作部26の操作でファイルが選択されると、その選択されたファイル(画像データ)をメモリーカード19から読み込む必要がある。コンピューター31は、ユーザーによるファイル選択操作があると(S80で肯定判定)、ステップS90に進む。なお、ファイル選択操作には、ユーザーが特定のファイルを選択する操作と、メモリーカード19内の画像を先頭から順番に表示させる操作とがある。
ステップS90では、ファイルシステム42にファイルの読込要求を行う。
ステップS100では、ファイルを取得したか否かを判断する。すなわち、アプリケーション部41は、ファイルシステム42からファイルFを取得するまで待ち、ファイルFを取得すると、ステップS110に進む。
ステップS100では、ファイルを取得したか否かを判断する。すなわち、アプリケーション部41は、ファイルシステム42からファイルFを取得するまで待ち、ファイルFを取得すると、ステップS110に進む。
ステップS110では、ファイルF(画像データ)に基づく画像の表示部21への表示又は当該画像の印刷を行う。すなわち、ユーザーが操作部26で選択したファイルに対応する画像を表示部21に表示する。ユーザーは必要に応じて操作部26を操作して表示部21の画像を切り替えて、所望の画像があると印刷対象に決定する。また、表示部21にサムネイル画像が表示される構成の場合は、画像データ(本画像)が複合機11側に読み込まれていないので、スタートボタン24による印刷実行操作(S80におけるファイル選択操作)が行われたときにファイル読込要求(S90)を行って、ファイルを取得すると(S100で肯定判定)、そのファイル(画像データ)に基づく画像の印刷を行う。
ファイルシステム42は、このアプリケーション処理においてアプリケーション部41から要求された処理を実行する。次に、ファイルシステム42が実行するファイルシステム処理を図8に従って説明する。このファイルシステム処理は、コンピューター31が例えばファイルシステム用プログラムを実行することにより行われる。
まずステップS210では、ファイル検索要求を受信したか否かを判断する。ファイルシステム42はアプリケーション部41からファイル検索要求があると、ステップS220に進み、ファイル検索要求がなければ当該処理を終了する。
ステップS220では、メモリーカード19にアクセスしてフォーマット形式を判定する。すなわち、フォーマット形式判定部61がメモリーカード19からフォーマット情報を取得し、そのフォーマット情報に基づいてメモリーカード19のフォーマット形式を判定する。
次のステップS230では、複数のFAT51〜54等のうち、判定したフォーマット形式に応じたFATを起動し、その起動したFATがディレクトリエントリーを取得する。
次のステップS240では、ファイル特定名称の変換処理を行う。前のS230で取得したディレクトリエントリー中のファイル情報FIを取り出し、ファイル情報FIに含まれるファイル名、又はフルパスファイル名の階層毎のディレクトリ名やファイル名からなる「ファイル特定名称」の変換処理を行う。この変換処理はファイル名変換部60が行い、メモリーカード19のフォーマット形式が例えばユニコード(UTF−16)を用いるものであれば、ファイル特定名称を、ユニコード(UTF−16)で表現されたロングファイル名から、1バイト文字コード(ASCIIコード)で表現されたショートファイル名に変換する。また、メモリーカード19のフォーマット形式が例えばシフトJISを用いるもの(「FAT16」「FAT32」)であれば、シフトJISで表現されたファイル特定名称を、1バイト文字コード(ASCIIコード)に変換する。フルパスファイル名を変換する場合、階層毎の各ファイル特定名称に対してこの変換処理をそれぞれ行う。この変換処理は、コンピューター31のファイル名変換部60が図9に示すファイル特定名称変換処理ルーチンを実行することにより行われる。このファイル特定名称変換処理の詳細は後述する。
次のステップS250では、アプリケーション部41にファイル情報FIを送信する。例えば複数バイト文字を含む文字列から1バイト文字コード(ASCIIコード)に変換されたファイル名及びフルパスファイル名を含むファイル情報FIがアプリケーション部41に送信される。このとき、ロングファイル名は、1バイト文字コード(ASCIIコード)のショートファイル名に変換される。
こうしてアプリケーション部41へはショートファイル名形式(8.3形式)のファイル情報FIが送信される。その後、ユーザーが操作部26でメモリーカード19内のファイルの選択操作を行うと、ファイルシステム42は、アプリケーション部41からファイルアクセス要求(ファイル読込要求)を受け付ける。
ステップS260では、ファイルアクセス要求を受け付けたか否かを判断する。ファイルアクセス要求を受け付けていなければ待機し、ファイルアクセス要求を受け付ければ、ステップS270に進む。
ステップS270では、ファイルアクセス処理を行う。このとき、ファイルアクセス要求で指定されるフルパスファイル名は、ファイル名変換部60による変換処理で生成された特別ファイル名を含むものである場合がある。この場合、ファイル名変換部60は、特別ファイル名を、ディレクトリエントリー配列のインデックスIへ逆変換して、シフトJIS又はユニコード(UTF−16)のインデックスIを取得する。そして、インデックスIで特定されるディレクトリエントリーDEにアクセスしてクラスター位置情報CPを取得する。さらに、その取得したクラスター位置情報CPに基づくクラスター位置にアクセスして、ファイル(クラスタデータ)を取得する。このファイルアクセス処理は、コンピューター31が図10にフローチャートで示すファイルアクセス処理ルーチンを実行することにより行われる。このファイルアクセス処理の詳細は後述する。
そして、次のステップS280では、ファイル(クラスタデータ)をアプリケーション部41に送信する。こうしてアプリケーション部41は要求したファイルFを取得し、そのファイル(画像データ)に基づく画像を表示部21に表示する。又は、ユーザーが印刷すべき画像を確定してスタートボタン24を操作すると、プリンター部14はファイル(画像データ)に基づく画像を用紙Pに印刷する。
次に、図8におけるファイルシステム処理におけるファイル特定名称変換処理(S240)と、ファイルアクセス処理(S270)の詳細を、図9及び図10を用いて説明する。まずファイル特定名称変換処理を図9に従って説明する。なお、図9において登場する「J」とは、ファイル特定名称を構成する文字列において先頭から何番目の文字であるかを示す数字である。
また、本例では、メモリーカード19は、ASCIIコードに対応する「FAT12」でフォーマットされている場合、シフトJISに対応する「FAT16」「FAT32」でフォーマットされている場合、ユニコード(UTF−16)のロングファイル名形式に対応する「exFAT」でフォーマットされている場合がある。ファイル名変換部60は、FAT51〜54のうちどのFATが使用(起動)されているかを認識し、使用中のFATに対応する文字符号化方式が、ASCII、シフトJIS、ユニコード(UTF−16)のうちのどれであるかも認識している。
また、ファイル特定名称変換処理の前の処理では、メモリーカード19からディレクトリエントリーを取得し、取得したディレクトリエントリー中のファイル情報FIからフルパスファイル名を取得している。そして、フルパスファイル名の各階層のファイル特定名称(ディレクトリ名、サブディレクトリ名、ファイル名等)を、上位階層から順番に名称変換処理の対象とする。最初は、例えば第1階層のディレクトリ名が処理対象とされる。
まずステップS310では、初期値J=1を設定する。なお、Jは、1バイト文字換算で何文字目かを示す値である。但し、英数字は2バイト文字(例えばユニコードのとき)であっても1文字と計数する。
次のステップS320では、J番目の文字があるか否かを判断する。この判断は、文字数判定部64が行う。ファイル特定名称が、例えばディレクトリ名(フォルダー名)の場合、ディレクトリの境界を意味する記号「\」の値「5C」(16進数)を終端文字とする。そして、対象の文字(これから名称構成解析しようとする次の文字)が、終端文字(「5C」)でなければ文字があると判断し、終端文字であると文字がないと判断する。また、ファイル特定名称が、例えばファイル名である場合、名称と拡張子との間の「.」(ドット)の値「2E」(16進数)を終端文字とする。そして、対象の文字が、終端文字(「2E」)でなければ文字があると判断し、終端文字であると文字がないと判断する。J番目の文字があればステップS330に進み、J番目の文字がなければステップS370に進む。今回はJ=1で1文字目なので、文字があると判断され、ステップS330に進むことになる。
ステップS330では、J番目の文字が1バイト文字であるか複数バイト文字であるかを判定する。この判定は、名称構成判定部63が行う。名称構成判定部63は、まず使用中のFATを確認し、使用中のFATが「exFAT」であればユニコード(UTF−16)が使用されるので、対象文字が複数バイト文字であると判定する。一方、使用中のFATが「FAT16」又は「FAT32」であれば、1バイト文字と複数バイト文字の両方を含むシフトJISが使用される。このため、シフトJISが使用される場合、名称構成判定部63は、対象文字が1バイト文字か複数バイト文字かを判定するために、対象文字の文字構成を解析する。本例では、使用中のFATが「FAT12」である場合は1バイト文字のASCIIが使用されるが、この場合も、名称構成判定部63は、対象文字が1バイト文字か複数バイト文字かを判定する。
名称構成判定部63は、対象の文字コードを1バイトずつ判定する。シフトJISの場合、日本語の文字は2バイト文字になり、その上位1バイト(1バイト目)はASCII(又はISO646)で未使用の値になる。例えばASCIIでは、「00」〜「7F」、「A1」〜「DF」(16進数)が使用される。シフトJISでは、漢字、平仮名、片仮名(全角文字)は、上位1ビットに、ASCIIで未使用の「81」〜「9F」、「E0」〜「EA」、「ED」,「EE」が使用される。そして、前述のように、下位1バイト(2バイト目)にディレクトリの境界を意味する「5C」を含む文字もある。
名称構成判定部63は、対象の文字コードを1バイトずつASCIIに属する値であるか否かを判定する。名称構成判定部63は、対象の文字コードの1バイト目がASCIIに属する値であれば、対象文字を1バイト文字であると判定し、一方、対象の文字コードの1バイト目がASCIIに属さない値であれば、対象文字を複数バイト文字であると判定する。例えば対象文字がシフトJISにおける日本語の文字の「表」(955C)であった場合、1バイト目の「95」がASCIIに属さない値なので、複数バイト文字と判定される。この場合、既に判定結果が出たので、2バイト目の「5C」(16進数)の判定は行わない。また、「FAT12」が使用中で文字符号化方式がASCIIの場合、対象文字の1バイトがASCIIに属する値と判定されるので、対象文字が1バイト文字であると判定される。もちろん、使用中のFATを判定し、ASCIIが使用される「FAT12」であれば、対象文字が1バイト文字であると判定してもよい。対象文字が1バイト文字でなければ(つまり複数バイト文字であれば)ステップS340に進み、1バイト文字であればステップS350に進む。なお、本実施形態では、ステップS330の判定処理が、1バイト文字であるか複数バイト文字であるかを判定する判定ステップに相当する。
ステップS340では、英数字であるか否かを判断する。この判断は、名称構成判定部63が行う。ここでは、ユニコードの英数字であるか否かを判断する。ユニコードは、2バイト文字であるが、英数字は上位1ビットが「00」(16進数)であり、下位1ビットがその英数字をASCIIコードで表したときの値になっている。このため、名称構成判定部63は、対象文字の上位1バイトが「00」(16進数)であるか否かを判断する。上位1バイトが「00」(16進数)であって対象文字が英数字である場合はステップS350に進み、英数字でない場合はステップS390に進む。なお、本実施形態では、このステップS350の処理を実行するCPU35により、文字判定手段が構成される。
ステップS350では、J>8であるか否かを判断する。つまり、ファイル特定名称の文字数が、ショートファイル名形式(8.3形式)の最大文字数である8文字を超えるか否かを判断する。J>8が成立した場合はステップS390に進み、J>8が不成立の場合はステップS360に進む。例えば1文字目(J=1)である場合、J>8が不成立なので、ステップS360に進む。
ステップS360では、Jをインクリメントする(J=J+1)。つまり、対象文字を次の文字に移行させる。例えば1文字目の解析(S330,S340)を終えると、J=2とし、解析の対象を2文字目に移す。その後、ステップS320に戻る。
次の対象文字についてステップS320〜S340の処理を行い、対象文字が8文字目を超えていなければ(S350で否定判定)、対象文字を次のJ番目(=J+1)とする。こうして1文字ずつ順番にステップS320〜S340の処理を行う。例えばファイル特定名称が、8文字以下の英数字からなる場合、最終文字の次のJ番目の文字がないと判断されるので(S320で否定判定)、ステップS370に進む。
ステップS370では、exFATであるか否かを判断する。つまり、ファイル特定名称がユニコード(UTF−16)であるか否かを判断する。exFATであればステップS380に進み、exFATでなければステップS410に進む。
ステップS380では、文字毎に上位1バイト「00」を削除し、下位1バイトを文字数分配列する。これにより、8文字以下の英数字からなるユニコード列(複数バイト文字列)を、ショートファイル名形式の英数字からなるASCIIコード列(1バイト文字列)で表現されたファイル特定名称に変換する。このようにユニコードでも8文字以下の英数字からなる場合は、同じ英数字がそのまま使われた同一文字のASCIIコード列からなるショートファイル名に変換される。
一方、英数字以外の文字、例えば日本語文字を1文字でも含んでいたり(S330とS340で否定判定)、文字数が8文字を超えたりして(S350で肯定判定)、そのままの文字を使ったショートファイル名に変換できない場合は、ステップS390に進む。ファイル特定名称が、シフトJISの日本語文字を含む場合、1バイト文字ではないと判定され(S330で否定判定)、かつ英数字でもないと判定される(S340で否定判定)ので、ステップS390に進む。そして、ステップS390及びS400の各処理が行われることで、ファイル特定名称は、ショートファイル名形式の特別ファイル名に変換される。
まずステップS390では、ディレクトリエントリー配列のインデックスIを取得する。ファイルシステム42は、起動中のFATを介してメモリーカード19にアクセスし、ディレクトリエントリー配列のインデックスIを取得する。例えば図6(a)の例のように、root直下のファイル「あ.JPG」のファイル情報FIを取得しようとする場合、ディレクトリエントリー配列のインデックス[1]を取得する。また、例えば図6(b)の例のように、root直下のディレクトリ「い」の下位階層のファイル「あ.JPG」のファイル情報FIを取得しようとしたとする。この場合、図4に示すように、ディレクトリ「い」に対応するディレクトリエントリー配列のインデックス[2]と、そのサブディレクトリ中のファイル「あ.JPG」に対応するディレクトリエントリー配列のインデックス[0]とを取得する。但し、階層毎に処理を行うので、まずディレクトリ「い」に対応するディレクトリエントリー配列のインデックス[2]を取得する。
次のステップS400では、インデックスIを7桁のIDとしてASCIIコードで表現し、先頭に識別コード「FF」を付与して、ショートファイル名形式のファイル特定名称を生成する。図6(a)の例では、ディレクトリエントリー配列のインデックス[1]を7桁のID「0000001」(10進数)とし、これをASCIIコードに変換して「30303030303031」(16進数)を取得する。そして、先頭に特別ファイル名であることを示す識別コードを置き、この下位に「30303030303031」(16進数)を付加して、ASCIIコードで表現されたショートファイル名「FF30303030303031」(16進数)を生成する。よって、図6(a)に示すようなショートファイル名形式のフルパスファイル名「rootFF30303030303031」を取得できる。
また、図6(b)の例では、ディレクトリ「い」に対応するディレクトリエントリー配列のインデックス[2]を7桁のID「0000002」(10進数)とし、これをASCIIコードに変換して「30303030303032」(16進数)を取得する。そして、先頭に特別ファイル名であることを示す識別コード「FF」(16進数)を置き、この下位に、「30303030303032」を付加して、ASCIIコードで表現されたショートファイル名形式のディレクトリ名「FF30303030303032」(16進数)を生成する。
そして、ステップS410では、全てのファイル特定名称の変換を終了したか否かを判断する。全てのファイル特定名称の変換を終了していなければ(S410で否定判定)、処理対象を次のファイル特定名称に切り替え(ステップS420)、次のファイル特定名称を対象にステップS310〜S400の処理を同様に行う。例えば複数階層からなるフルパスファイル名である場合、階層毎のファイル特定名称にそれぞれステップS310〜S400の処理を行う。
次の階層のファイル特定名称が日本語文字を含む場合、また日本語文字を含まなくても8文字を超える場合は、ステップS390に進む。そして、ステップS390及びS400の処理を行うことによって、識別コード「FF」(16進数)と、ディレクトリエントリー配列のインデックスIを示す7桁のIDをASCIIコードで表現した値とを含むショートファイル名形式のファイル特定名称を生成する。
図6(b)の例では、下位階層のサブディレクトリ中のファイル「あ.JPG」に対応するディレクトリエントリー配列のインデックス[0]を7桁のID「0000000」とし、これをASCIIコードに変換して「30303030303030」(16進数)を取得する。そして、先頭に特別ファイル名であることを示す識別コード「FF」(16進数)を置き、この下位に、「30303030303030」を付加して、ASCIIコードで表現されたショートファイル名形式のファイル名「FF30303030303030」(16進数)を生成する。よって、図6(b)に示す例ではショートファイル名形式のフルパスファイル名「rootFF30303030303032FF30303030303030.JPG」を生成する。なお、図6の例では、ファイル特定名称に相当するディレクトリ名及びファイル名のみを16進数のコードで示している。実際は、「root」、ディレクトリの境界記号「\」、ドット「.」拡張子「JPG」もASCIIコードに変換される。また、本実施形態では、ステップS390及びS400が、名称変換ステップに相当する。
そして、フルパスファイル名に含まれる全階層のファイル特定名称の変換処理を終了すると(S410で肯定判定)、図8のステップS250に進む。なお、ファイル情報FI中のファイル名については、フルパスファイル名の最終階層のファイル特定名称で処理したものを使用するが、ファイル名についても個別にファイル特定名称変換処理(図9)を行ってもよい。
図8に示すステップS250では、ファイル情報FIをアプリケーション部41に送信する。よって、ファイルシステム42からアプリケーション部41へは、フルパスファイル名及びファイル名が1バイト文字コード(ASCIIコード)のショートファイル名形式に変換されたファイル情報FIが送られる。この結果、アプリケーション部41は、ショートファイル名形式にしか対応していなくても、受け取ったファイル情報FI中のファイル名及びフルパスファイル名を解読でき、適切なファイル情報FIをファイルリストFLに登録できる。
本実施形態の複合機11は複数のカードスロット20(図1では1つのみ図示)を備えており、複数枚のメモリーカード19が挿着されているときは、先に挿着された一方のみを認識し、その認識中の先のメモリーカード19が抜き取られた時点で、後から挿着されたメモリーカード19を認識する。このため、同時に複数のメモリーカード19を認識することはない。よって、ファイル名変換部60によって生成されたフルパスファイル名は及びファイル名は、一意の名称(コード)になっている。
次にファイルアクセス処理を図10に従って説明する。ファイルシステム42は、アプリケーション部41からファイル読込要求を受け付けると、ファイルアクセス処理を実行する。このファイル読込要求で指定されたフルパスファイル名中の最上位階層(root直下の階層)のファイル特定名称(図6(a)の例ではファイル名、図6(b)の例ではディレクトリ名)を1回目の処理対象として取得する。なお、このファイルアクセス処理は、コンピューター31がファイルシステム用プログラム中のファイルアクセス用プログラムを実行することにより行われる。
ステップS510では、特別ファイル名であるか否かを判断する。すなわち、ファイル特定名称の先頭に識別コード「FF」(16進数)が存在するか否かを判断する。例えば図6(a)に示すショートファイル名「FF30303030303031」(16進数)の場合は、先頭に「FF」が存在するので、特別ファイル名と判断される。また、図6(b)に示すショートファイル名「FF30303030303032」(16進数)の場合も、先頭に「FF」が存在するので、特別ファイル名と判断される。特別ファイル名において先頭の識別コード以外の文字列は、インデックスIを示している。このような特別ファイル名であった場合はステップS520に進む。なお、ここでいう「特別ファイル名」とは、先頭が識別コードでそれ以外の文字列がインデックスIを示すファイル名とディレクトリ名の総称である。
一方、ファイル特定名称が特別ファイル名でない場合はステップS540に進む。ここで、特別ファイル名でないファイル特定名称には、例えば図4においてディレクトリエントリー配列のインデックス[0]にあるファイル「A.JPG」のように、8文字以下の英数字からなるファイル名が該当する。この場合、英数字「A」はASCIIコードで「41」(16進数)であり、先頭に識別コード「FF」が存在しないので、特別ファイル名ではないと判断される。特別ファイル名でないファイル特定名称には、元々ASCIIコードで表現され変換が行われていないものと、第1変換部65によりユニコードからASCIIコードに変換されたものとがある。
ステップS520では、文字列になっているインデックスIを数値に変換(逆変換)する。例えば特別ファイル名「FF30303030303031」(16進数)は、インデックス[1]に逆変換される。この逆変換は第2変換部66が行う。詳しくは、第2変換部66は、特別ファイル名「FF30303030303031」(16進数)のうち先頭の識別コード「FF」以外の7桁のIDに相当する部分「30303030303031」(16進数)を抜取り、「30303030303031」(16進数)から7桁にするために付加した数字「0」(「30」(16進数))を削除して「31」(16進数)を得る。そして、この「31」(16進数)を、そのとき使用中のFATに対応する文字符号化方式(ASCII、シフトJIS、ユニコード(UTF−16))に基づく文字コードに変換する。このとき、ASCIIとシフトJISのときは1バイト文字「31」(16進数)のまま、ユニコードのときは2バイト文字「0031」(16進数)に変換される。
ステップS530では、ディレクトリエントリーから、先に変換したインデックスIに保存されているクラスター位置情報CPを取得する。例えばインデックス[1]のときは、図4におけるインデックス[1]のファイル「あ.JPG」のディレクトリエントリー構造体DC中のクラスター位置情報CPを取得する。この処理は、パス解析部67が行う。
一方、ステップS540では、メモリーカード19のフォーマットに対応するFATが「exFAT」であるか否かを判定する。「exFAT」であればステップS550に進み、exFATでなければステップS560に進む。なお、「exFAT」以外のFATである場合、すなわち「FAT12」「FAT16」「FAT32」の場合は、符号化方式としてASCII又はシフトJISが使用され、英数字は1バイト文字であってASCIIコードと同じ値なので、ASCIIコードからの変換の必要がない。
ステップS550では、ASCIIからUTF−16に変換する。例えば文字「A」の1バイト系文字コードであるASCIIコードで示された「41」(16進数)を、2バイト系文字コードであるユニコード(UTF−16)で示された「0041」(16進数)に変換する。この変換後のユニコードの文字列はフルパスファイル名のうち第1階層のファイル特定名称(ディレクトリ名又はファイル名)を示している。
そして、次のステップS560では、文字列比較しながらディレクトリエントリーを検索し、指定のファイル特定名称(ディレクトリ名又はファイル名)に該当するクラスター位置情報CPを取得する。例えば文字列「A.JPG」であれば、この文字列と一致する文字列のディレクトリエントリーを検索し、検索したディレクトリエントリーが指し示すディレクトリエントリー構造体DC(図4参照)内のクラスター位置情報CPを取得する。
ステップS570では、クラスターデータにアクセスする。すなわち、メモリーカード19におけるクラスター位置情報CPで示されたクラスター位置(クラスター番号)にアクセスしてクラスターデータを読み出す。
ステップS580では、ディレクトリの階層回数繰り返したか否かを判断する。ディレクトリの階層回数繰り返していなければ、ステップS590で次の階層(下位階層)へ移行した後、ステップS510に戻る。そして、複数階層の場合は、次の階層でもステップS510〜S570の処理を同様に繰り返す。そして、ディレクトリの全階層で取得した全てのクラスター位置からクラスターデータを取得することで、最終的にファイル(画像データ)を取得する。
こうしてファイルアクセス処理を終わると、取得したファイルFはファイルシステム42からアプリケーション部41へ送られる(図8におけるS280、図3における(8))。そして、アプリケーション部41は、ファイルに基づく画像を表示部21に表示させたり、ファイルに基づく画像をプリンター部14により用紙Pに印刷したりする。
以上詳述したように、本実施形態では、以下に示す効果を得ることができる。
(1)ファイル名変換部60(名称変換手段)により、複数バイト文字を含むファイル名及びディレクトリ名などのファイル特定名称(第1名称)を、1バイト文字コードで表現された特別ファイル名(第2名称)に変換する。このとき、ファイル名変換部60は、メモリーカード19においてフルパスファイル名(データ特定情報)の所在位置を示すディレクトリエントリー配列の一意なインデックスIを1バイト文字コードに変換してショートファイル名形式の特別ファイル名(第2名称)を生成する。よって、アプリケーション部41がファイル特定名称を解析するとき、複数バイト文字の値の一部の「5C」をディレクトリの境界を意味する『\』と解釈する不都合を回避できる。このため、アプリケーション部41は、ディレクトリの境界を間違うことなくフルパスファイル名を正しく解釈することができる。この結果、例えばユーザーが選択した画像のファイルを、フルパスファイル名を指定してファイルシステム42に対してファイル読込要求をした際に、メモリーカード19からファイルシステム42を介して正しいファイルFを読み込むことができる。この結果、ユーザーが表示部21を見ながら操作部26で選択した画像を印刷することができる。また、既存のアプリケーション部41を修正することなくそのまま使用し、「5C」を含む複数バイト文字を含む文字列で示されたフルパスファイル名を指定して、ファイルFにアクセスすることが可能となる。
(1)ファイル名変換部60(名称変換手段)により、複数バイト文字を含むファイル名及びディレクトリ名などのファイル特定名称(第1名称)を、1バイト文字コードで表現された特別ファイル名(第2名称)に変換する。このとき、ファイル名変換部60は、メモリーカード19においてフルパスファイル名(データ特定情報)の所在位置を示すディレクトリエントリー配列の一意なインデックスIを1バイト文字コードに変換してショートファイル名形式の特別ファイル名(第2名称)を生成する。よって、アプリケーション部41がファイル特定名称を解析するとき、複数バイト文字の値の一部の「5C」をディレクトリの境界を意味する『\』と解釈する不都合を回避できる。このため、アプリケーション部41は、ディレクトリの境界を間違うことなくフルパスファイル名を正しく解釈することができる。この結果、例えばユーザーが選択した画像のファイルを、フルパスファイル名を指定してファイルシステム42に対してファイル読込要求をした際に、メモリーカード19からファイルシステム42を介して正しいファイルFを読み込むことができる。この結果、ユーザーが表示部21を見ながら操作部26で選択した画像を印刷することができる。また、既存のアプリケーション部41を修正することなくそのまま使用し、「5C」を含む複数バイト文字を含む文字列で示されたフルパスファイル名を指定して、ファイルFにアクセスすることが可能となる。
(2)ロングファイル名形式で8文字を超えるファイル特定名称(第1名称)を、1バイト文字コードで表現されたショートファイル名形式のファイル特定名称(第2名称)に変換する。よって、ショートファイル名形式にのみ対応可能なアプリケーション部41は、メモリーカード19からファイルシステム42を介して読み込んだフルパスファイル名を正しく解釈できる。
(3)アプリケーション部41が解読可能なショートファイル名形式(8.3形式)のファイル特定名称であるか否かを、1バイト文字であるか否かの判断、及び8文字以下であるか否かの判断により判定し、ショートファイル名形式(8.3形式)のファイル特定名称である場合には、特別ファイル名への変換は行わない。よって、ファイル名変換部60がインデックスIを取得して特別ファイル名へ変換する処理、及び特別ファイル名からインデックスIへ逆変換する処理の実施回数を相対的に減らし、この種の変換処理の負担を軽減できる。この結果、要求したファイル情報FIがファイルシステム42からアプリケーション部41へ送られてくる応答速度、及び要求したファイルFがファイルシステム42からアプリケーション部41へ送られてくる応答速度を相対的に高めることができる。このため、アプリケーション部41によるファイル情報FIの登録処理や、アプリケーション部41がファイルを読み込んでその画像を表示したりその画像の印刷を開始したりする際の処理の遅延を比較的小さく抑えることができる。
(4)ファイル特定名称の文字列がユニコード(ワイド文字)で表現されるものであっても、英数字からなる8文字以下のファイル特定名称については、1バイト文字コード(ASCIIコード)に変換する。この場合、ユニコードの上位1バイトの「00」(16進数)を削除するだけの簡単な処理で済む。よって、ファイル名変換部60の処理負担を一層軽減でき、アプリケーション部41によるファイル情報FIの登録処理の遅延を比較的小さく抑えることができる。また、逆変換処理の負担も軽減されるので、アプリケーション部41がファイルを読み込んでその画像を表示したりその画像の印刷を開始したりする際の処理の遅延を一層小さく抑えることができる。
(5)ファイル特定名称の文字コード列を1バイトずつ解析し、1バイト文字コード(ASCIIコード)であるか否かを判定する。そして、判定対象の1バイトが1バイト文字コードでない場合に複数バイト文字であると判定する。よって、複数バイト文字であることを比較的簡単かつ適切に判定できる。
(6)ファイル特定名称が複数バイト文字を含む場合は、ディレクトリエントリー配列のインデックスIを7桁のIDとしてASCIIコードに変換するとともに、先頭に識別コード「FF」を付してショートファイル名形式(8.3形式)のファイル特定名称を生成する。よって、一意なショートファイル名を生成できるうえ、識別コード「FF」の有無によって、特別ファイル名であるか否かを適切に判断できる。このため、特別ファイル名を逆変換して適切なインデックスIを取得でき、その取得したインデックスIを基にクラスター位置情報を取得することができる。
(7)複合機11は、ファイル名変換部60を内蔵するファイルシステム42を備えるので、アプリケーション部41は、ファイルシステム42がシフトJIS及びユニコードに対応する形式でフォーマットされたメモリーカード19にアクセスした取得したデータ特定情報(フルパスファイル名やファイル名)を解読することができる。
なお、上記実施形態は以下のような形態に変更することもできる。
・判定手段は、1バイトずつ解析する方法に限定されない。記憶媒体にアクセスして当該記憶媒体に設定されているフォーマット形式を判定し、当該判定したフォーマット形式で使用される符号化方式から複数バイト文字を含むか否かを判定してもよい。複数バイト文字を含むと判定された場合、ファイル名変換部60は、ファイル特定名称が英数字などの1バイト文字だけからなる文字列で構成されているか否かに関わらず、ファイル特定名称を特別ファイル名に変換する。
・判定手段は、1バイトずつ解析する方法に限定されない。記憶媒体にアクセスして当該記憶媒体に設定されているフォーマット形式を判定し、当該判定したフォーマット形式で使用される符号化方式から複数バイト文字を含むか否かを判定してもよい。複数バイト文字を含むと判定された場合、ファイル名変換部60は、ファイル特定名称が英数字などの1バイト文字だけからなる文字列で構成されているか否かに関わらず、ファイル特定名称を特別ファイル名に変換する。
・ディレクトリの境界を意味する「5C」を値に含むマルチバイト系文字コードは、日本語文字コードを含むシフトJISに限定されない。その他の日本語の文字符号化方式でもよい。さらに他国の言語の文字コードを含むマルチバイト系文字コードでもよい。要するに、2バイト以上の複数バイト文字が、ディレクトリの境界を意味する『\』(円記号)又は「バックスラッシュ」を表す値「5C」(16進数)を含むような文字符号化方式あればよい。そして、その文字符号化方式で表現されたファイル特定名称を、1バイト文字だけで表現される8・3形式の特別ファイル名に変換する構成であれば、本発明を適用することができる。
・インデックスは、ディレクトリエントリー配列のインデックスIに限定されない。情報処理装置(例えばファイルシステム)が独自に一意の番号を付してもよい。この場合、ディレクトリエントリー配列のインデックスIと番号との対応関係を示す参照テーブルを作成しておけば、その参照テーブルを参照して番号から所在位置情報を取得し、データ特定情報で示された位置にアクセスしてデータ本体(ファイルF)を取得できる。
・インデックスは数字に限定されない。一意な文字又は文字列であれば任意に設定してよい。例えば1バイト文字コードで使用できる英字や制御記号などの文字や文字列を採用できる。
・ディレクトリの境界を表す「5C」(16進数)を値の一部にもつ複数バイト文字を含むファイル特定名称についてのみ特別ファイル名に変換する構成も採用できる。例えばそれ以外の日本語文字(複数バイト文字)については、他の変換方法を採用してもよい。
・8文字以下の英数字からなるファイル特定名称についても、特別ファイル名に変換してもよい。つまり、ファイル特定名称は常に特別ファイル名に変換する構成とすることもできる。
・マルチバイト文字コードのうちの複数バイト文字は、2バイト系に限定されず、3バイト系、4バイト系、5バイト系以上であってもよい。また、2バイトと3バイトが混在するなどのマルチバイト文字でもよい。
・2バイト系文字コードから1バイト系文字コードへの変換に限定されない。例えば3バイト系文字コード又は4バイト系文字コードから1バイト系文字コードへ変換する構成でもよい。
・ユニコード(Unicode)の文字符号化方式は、UTF−8やUTF−32、UTF−7、UTF−EBCDIC、SCSU、BOCU−1などでもよい。
・ファイル名変換部60のうちフォーマット形式判定部61以外の各部62〜67を有する変換モジュール(情報処理装置)を、アプリケーション部41とファイルシステム42との間に介在させた構成も採用できる。この場合、変換モジュールは、ファイルシステムから受け取ったディレクトリエントリー配列のインデックスを1バイト文字コードに変換することで第2名称を生成する。この構成であっても、アプリケーション部41は、データ特定情報中の複数バイト文字を含む第1名称を、1バイト文字コードの第2名称として取得できる。
・ファイル名変換部60のうちフォーマット形式判定部61以外の各部62〜67を有する変換モジュール(情報処理装置)を、アプリケーション部41とファイルシステム42との間に介在させた構成も採用できる。この場合、変換モジュールは、ファイルシステムから受け取ったディレクトリエントリー配列のインデックスを1バイト文字コードに変換することで第2名称を生成する。この構成であっても、アプリケーション部41は、データ特定情報中の複数バイト文字を含む第1名称を、1バイト文字コードの第2名称として取得できる。
・記憶媒体はメモリーカードに限定されず、他の可搬性(リムーバブル)の記憶媒体であってもよい。例えば、CD(コンパクトディスク)やDVD(Digital Versatile Disk)などの光ディスク、MO(光磁気ディスク)、USBフラッシュメモリー、リムーバブルハードディスク等でもよい。
・電子機器が記録装置である場合、複合機11のようなインクジェット式記録装置に限定されず、ワイヤインパクト式記録装置、熱転写式記録装置、電子写真式記録装置等の記録装置を採用してもよい。また、スキャナー機能を備えない記録装置を採用してもよい。
・電子機器は、記録装置にも限定されない。例えばプロジェクター、テレビ、デジタルフォトフレーム、デジタルカメラ、オーディオ機器などでもよい。
11…電子機器の一例としての複合機、19…記憶媒体の一例であるメモリーカード、20…カードスロット、31…コンピューター、32…メモリーカードI/F、35…CPU、36…ASIC、37…ROM、38…RAM、41…アプリケーション部、42…情報処理装置としてのファイルシステム、43…カウントアップ処理部、44…ファイル情報登録部、45…ファイル要求部、51〜54…FAT、60…ファイル名変換部、61…判定手段を構成するフォーマット形式判定部、62…カウンター、63…判定手段を構成するとともに文字判定手段の一例としての名称構成判定部、64…判定手段を構成するとともに文字数判定手段の一例としての文字数判定部、65…第1変換部、66…逆変換部の一例としての第2変換部、67…パス解析部、FL…ファイルリスト、FI…データ特定情報の一例であるファイル情報、F…データの一例であるファイル、CP…データ特定情報の所在位置にあるアクセス位置情報の一例としてのクラスター位置情報、DE…データ特定情報の所在位置の一例としてのディレクトリエントリー、I…一意な所在位置情報のうち第1名称と対応する部分の一例としてのディレクトリエントリー配列のインデックス、P…媒体としての用紙。
Claims (10)
- 記憶媒体を接続可能な電子機器内に設けられ、当該電子機器内のアプリケーション部からの要求に応じて接続中の記憶媒体にアクセスして取得したデータ特定情報を前記アプリケーション部に渡す情報処理装置であって、
前記データ特定情報に含まれる第1名称が複数バイト文字を含むか否かを判定する判定手段と、
前記第1名称が複数バイト文字を含むと判定された場合に、前記第1名称を1バイト文字列の第2名称に変換する名称変換手段と、を備え、
前記名称変換手段は、前記記憶媒体における前記データ特定情報の所在位置を示す一意な所在位置情報のうち前記第1名称と対応する部分を前記1バイト文字列に変換し、当該1バイト文字列を含む前記第2名称を生成することを特徴とする情報処理装置。 - 前記名称変換手段は、前記1バイト文字列に変換された前記第2名称であることを特定可能な特定文字を含む前記第2名称を生成することを特徴とする請求項1に記載の情報処理装置。
- 前記判定手段は、前記第1名称の文字列コードを1バイトずつ解析し、解析対象の1バイトが1バイト文字に属さないコードであるか否かを判定し、1バイト文字に属さないコードである場合に複数バイト文字を含むと判定することを特徴とする請求項1又は2に記載の情報処理装置。
- 前記判定手段は、前記第1名称の文字数がショートファイル名形式の最大文字数以下であるか否かを判定する文字数判定手段を更に備え、
前記名称変換手段は、前記第1名称の文字数が前記最大文字数以下でないと判定された場合は、前記第1名称が複数バイト文字を含むと判定されていなくても、当該第1名称を、前記1バイト文字列を含む前記第2名称に変換することを特徴とする請求項1乃至3のうちいずれか一項に記載の情報処理装置。 - 前記判定手段は、前記第1名称が複数バイト文字を含むと判定した場合であっても、当該第1名称が1バイト文字列で表現可能であるか否かを判定する文字判定手段を有し、前記名称変換手段は、前記第1名称が1バイト文字列で表現可能と判定された場合、当該第1名称に含まれる複数バイトの文字を1バイト文字に変換して、当該第1名称と同一文字列の1バイト文字列で表された前記第2名称を生成することを特徴とする請求項1乃至4のうちいずれか一項に記載の情報処理装置。
- 前記判定手段は、前記第1名称の文字数がショートファイル名形式の最大文字数以下であるか否かを判定する文字数判定手段を備え、
前記名称変換手段は、前記第1名称が1バイト文字列で表現可能と判定され、かつ前記第1名称の文字数が前記最大文字数以下であると判定された場合に、当該第1名称を同一文字列の1バイト文字列に変換することを特徴とする請求項5に記載の情報処理装置。 - 前記名称変換手段は、前記アプリケーション部から前記一意な所在位置情報を表す1バイト文字列を含む前記第2名称でアクセス位置を指定したアクセス要求を受け付けると、前記第2名称の1バイト文字列を前記所在位置情報に逆変換する逆変換部を備え、
前記記憶媒体に対して前記逆変換部による逆変換で取得した前記所在位置情報で示される所在位置にアクセスして前記データ特定情報を取得し、当該データ特定情報に基づきデータを取得することを特徴とする請求項1乃至6のうちいずれか一項に記載の情報処理装置。 - 記憶媒体を接続可能な電子機器であって、
請求項1乃至7のうちいずれか一項に記載の情報処理装置と、
前記情報処理装置に記憶媒体からの前記データ特定情報の取得を要求するアプリケーション部と、
を備えたことを特徴とする電子機器。 - アプリケーション部からの要求に応じて電子機器に接続された記憶媒体にアクセスして取得したデータ特定情報を前記アプリケーション部に渡す処理をコンピューターに実行させるためのプログラムであって、
コンピューターに、
前記記憶媒体にアクセスして取得したデータ特定情報に含まれる第1名称が複数バイト文字を含むか否かを判定する判定ステップと、
前記第1名称が複数バイト文字を含むと判定された場合に、前記第1名称を1バイト文字列の第2名称に変換する名称変換ステップと、を実行させ、
前記名称変換ステップでは、前記記憶媒体における前記データ特定情報の所在位置を示す一意な所在位置情報のうち前記第1名称に対応する部分を前記1バイト文字列に変換し、当該1バイト文字列を含む前記第2名称を生成することを特徴とするプログラム。 - アプリケーション部からの要求に応じて電子機器に接続された記憶媒体にアクセスして取得したデータ特定情報を前記アプリケーション部に渡す情報処理方法であって、
前記記憶媒体にアクセスして取得したデータ特定情報に含まれる第1名称が複数バイト文字を含むか否かを判定する判定ステップと、
前記第1名称が複数バイト文字を含むと判定された場合に、前記第1名称を1バイト文字列の第2名称に変換する名称変換ステップと、を備え、
前記名称変換ステップでは、前記記憶媒体における前記データ特定情報の所在位置を示す一意な所在位置情報のうち前記第1名称に対応する部分を前記1バイト文字列に変換し、当該1バイト文字列を含む前記第2名称を生成することを特徴とする情報処理方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011059308A JP2012194875A (ja) | 2011-03-17 | 2011-03-17 | 情報処理装置、電子機器、プログラム及び情報処理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011059308A JP2012194875A (ja) | 2011-03-17 | 2011-03-17 | 情報処理装置、電子機器、プログラム及び情報処理方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2012194875A true JP2012194875A (ja) | 2012-10-11 |
Family
ID=47086682
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011059308A Withdrawn JP2012194875A (ja) | 2011-03-17 | 2011-03-17 | 情報処理装置、電子機器、プログラム及び情報処理方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2012194875A (ja) |
-
2011
- 2011-03-17 JP JP2011059308A patent/JP2012194875A/ja not_active Withdrawn
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1455284B1 (en) | Image processing method and image processing system | |
| CN102077178B (zh) | 信息处理装置、其控制方法以及存储介质 | |
| CN101233511B (zh) | 检索设备和检索方法 | |
| US20080263036A1 (en) | Document search apparatus, document search method, program, and storage medium | |
| US8493595B2 (en) | Image processing apparatus, image processing method, program, and storage medium | |
| AU2008205134B2 (en) | A document management system | |
| US8045228B2 (en) | Image processing apparatus | |
| KR20240020719A (ko) | 정보 처리 장치, 저장 매체, 및 저장 방법 | |
| US20170004147A1 (en) | Retrieval device, retrieval method, and computer-readable storage medium for computer program | |
| JP2010165019A (ja) | ファイル名生成システム | |
| US8867091B2 (en) | Image processing system, image processing apparatus, image scanning apparatus, and control method and program for image processing system | |
| US9152354B2 (en) | Pull copying using document-file identifiers | |
| JP2017069943A (ja) | 画像処理装置及び複合装置 | |
| JP5526710B2 (ja) | ファイル選択プログラム、及び印刷システム | |
| US8482763B2 (en) | Method and apparatus for generating a file using address and information tags | |
| JP2011216048A (ja) | 情報処理装置、電子機器、プログラム及び情報処理方法 | |
| JP2012194875A (ja) | 情報処理装置、電子機器、プログラム及び情報処理方法 | |
| US20070245226A1 (en) | Data processing apparatus and method | |
| JP6749583B2 (ja) | 情報処理装置、画像処理装置およびプログラム | |
| JP2012252418A (ja) | 情報処理装置、プログラム及び情報処理方法 | |
| JP2005149210A (ja) | 画像処理装置及びその制御方法、プログラム | |
| KR101516595B1 (ko) | 인쇄매체에 인쇄된 문서를 스캔하는 펜형 디지털 스캐너를 이용한 인쇄매체 스크랩 서비스 시스템 및 인쇄매체 스크랩 서비스 제공방법. | |
| JP4827519B2 (ja) | 画像処理装置、画像処理方法、およびプログラム | |
| JP2004102678A (ja) | データ管理装置及びデータ管理プログラム | |
| KR101604241B1 (ko) | 인쇄매체에 인쇄된 문서를 스캔하는 펜형 디지털 스캐너를 이용한 인쇄매체 스크랩 서비스 시스템 및 인쇄매체 스크랩 서비스 제공방법. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A300 | Application deemed to be withdrawn because no request for examination was validly filed |
Free format text: JAPANESE INTERMEDIATE CODE: A300 Effective date: 20140603 |