JP2010086547A - 乗算器/アキュムレータ・ユニット - Google Patents
乗算器/アキュムレータ・ユニット Download PDFInfo
- Publication number
- JP2010086547A JP2010086547A JP2009255129A JP2009255129A JP2010086547A JP 2010086547 A JP2010086547 A JP 2010086547A JP 2009255129 A JP2009255129 A JP 2009255129A JP 2009255129 A JP2009255129 A JP 2009255129A JP 2010086547 A JP2010086547 A JP 2010086547A
- Authority
- JP
- Japan
- Prior art keywords
- input
- bit
- mac unit
- gate
- stage
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/52—Multiplying; Dividing
- G06F7/523—Multiplying only
- G06F7/533—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even
- G06F7/5334—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even by using multiple bit scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate precalculated multiple of the multiplicand as a partial product
- G06F7/5336—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even by using multiple bit scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate precalculated multiple of the multiplicand as a partial product overlapped, i.e. with successive bitgroups sharing one or more bits being recoded into signed digit representation, e.g. using the Modified Booth Algorithm
- G06F7/5338—Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even by using multiple bit scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate precalculated multiple of the multiplicand as a partial product overlapped, i.e. with successive bitgroups sharing one or more bits being recoded into signed digit representation, e.g. using the Modified Booth Algorithm each bitgroup having two new bits, e.g. 2nd order MBA
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/499—Denomination or exception handling, e.g. rounding or overflow
- G06F7/49905—Exception handling
- G06F7/4991—Overflow or underflow
- G06F7/49921—Saturation, i.e. clipping the result to a minimum or maximum value
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/544—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices for evaluating functions by calculation
- G06F7/5443—Sum of products
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3885—Concurrent instruction execution, e.g. pipeline or look ahead using a plurality of independent parallel functional units
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2207/00—Indexing scheme relating to methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F2207/38—Indexing scheme relating to groups G06F7/38 - G06F7/575
- G06F2207/3804—Details
- G06F2207/3808—Details concerning the type of numbers or the way they are handled
- G06F2207/3812—Devices capable of handling different types of numbers
- G06F2207/382—Reconfigurable for different fixed word lengths
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/499—Denomination or exception handling, e.g. rounding or overflow
- G06F7/49942—Significance control
- G06F7/49947—Rounding
- G06F7/49963—Rounding to nearest
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/499—Denomination or exception handling, e.g. rounding or overflow
- G06F7/49942—Significance control
- G06F7/49947—Rounding
- G06F7/49968—Rounding towards positive infinity
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Complex Calculations (AREA)
Abstract
【解決手段】MACユニット(100)において、第1のバイナリ・オぺランドX(102)と第2のバイナリ・オぺランドY(104)との複数の部分積を発生するブース記録ロジック(120)と、低減した前記部分積を第3のオぺランドと算術的に組み合わせて最後の部分積を得るワラス・ツリー加算器(130)と、最後の和を発生する最後の加算器(140)と、前記最後の加算器を選択的に丸める即ち飽和させる飽和回路(150)とを備える。
【選択図】図1
Description
分数モード制御信号122の制御により、2つの17ビット・オぺランド入力104(Yin)及び102(Xin)をそれぞれ受け取って、複数の部分積(PP)を発生し、これを次段の部分積加算ツリー130に供給する分数モード・ブロック(図示なし)を有する部分積発生段120、
丸めが丸め制御信号132の制御により適用可能とされ(215 二進重み付けが付加され)、飽和が2入力102、104の値、及び予め選択された制御信号132に従って、「強制設定」可能にされ(図1において「800×800SAT」により表されている)、かつ加算又は減算される第3の数142(Ain)の一部が入力として供給される(図1には示されていない)ときに、入力として複数の部分積を受け取り、かつ34ビット出力134を供給する部分積加算ツリー130、
部分積加算ツリー130の34ビット出力134及び第3の数142(Ain)の一部を受け取って最後の算術値即ち数を決定し、かつこれら条件の発生の適当な表示を有する適当なゼロ及びオーバーフロー検出144を含む、40ビット最後の加算器段140、及び
加算器140からの最後の算術値即ち数を、32ビットのときは「0X007fffffff」(オーバーフロー)若しくは「0Xff80000000」(アンダーフロー)へ、又は40ビットのときは「0X7ffffffffff」(オーバーフロー)若しくは「0X8000000000」(アンダーフロー)へ選択的に飽和させる最後の飽和段150からなる。この最後の飽和段150は、丸め制御信号152がアクティブのとき、例えば丸めが指定されたときに、16LSBをゼロにクリアするために設けられている。最後の飽和段150は40ビット出力154を供給し、この出力154は、好ましくは、アキュムレータ(図1には示されていない)に記憶される。種々の制御信号122、132、146、152は、命令デコード・ユニット(図1には示されていない)から供給され、ここで説明され、かつ本発明のMACユニット100の動作を制御するために使用されている。

’0’、Y0、Y1−−→第1のエンコーダ、
Y1、Y2、Y3−−→第2のエンコーダ、
Y3、Y4、Y5−−→第3のエンコーダ、
..........
Y13、Y14、Y15−−→第8のエンコーダ、
Y15、Y16−−→第9のエンコーダ、
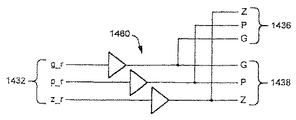
ORゲート324の出力は、p2信号302に対する第2の入力として供給される。NANDゲート328からの出力は、2入力ANDゲート330に対する2入力として供給される。2入力ANDゲート330からの出力は、第2のXORゲート332に対する1入力として供給される。第2のXORゲート332に対する第2の入力は、加算/減算信号122bである。第2のXORゲート332の出力は、sg信号306である。この特定の組み合わせゲートは表1のロジックを実施する。明らかに、これと同一の論理機能を得るために、他の組み合わせのゲートを採用してもよい。
(n,k+1)のステートはゼロ検出(即ち、(12)におけるステートのうちの1つと同一)である (B)
又は
(k,m)のステートはゼロ検出であり、かつスライスは「g」を含む
(C)
(n,k+1)のステップは全てpである (D)
これは次式のようになる。
信号を発生させる。このロー信号の作用は、ORゲート1366の出力がゼロとなるように、ANDゲート1360、1362、1364を禁止することであり、このゼロはビット位置16をゼロに強制設定させる作用を有する。従って、LSBフィールド[15:0]が0.5に等しい値を有し、かつMSBフィールド[31:16]が丸めの前に奇数値を有するときは、ビット516はゼロに強制設定される。同様に、LSBフィールドが0.5に等しい値を有し、かつMSBフィールドが丸めの前に偶数値を有するときは、ビット516はゼロに強制設定されることはない。
信号は、ハイとなるので、UR信号がANDゲート1360、1362、1364を禁止しない。その結果、ビット位置16のセット処理は、ビット位置39〜17に対すると同じように、飽和モードに従って制御される。UR信号、及びこの信号を発生させる回路がなければ、ビット位置16に対するセルは、ビット位置39〜17のものに対応することを理解すべきである。
丸め(rnd)が「オン」ときは、
RDM=0:+無限に対して丸めを発生する。
40ビット・データ値の場合、これは、215の加算を意味し、かつ16最下位ビット(LSB)はゼロにクリアされる。
RMD=1:最近に対して丸めを発生する。
40ビット・データ値の場合、これが16LSBの真の解析であり、これらが(i)丸めが発生しない215−1〜0(0.5より低い値)、(ii)40ビット値に215を加算することにより、丸めが発生する215+1〜216−1(0.5より大きい値)、又は(iii)データ値に215を加算することにより、40ビット値の16ビットの上位部分が奇数のときに丸めが発生する215(0.5に等しい値)の範囲内にあるか否かを検出する。
メモリから: 2 RAMからの16ビット・データ、
1 「係数」RAMからの16ビット・データ、
内部データ・レジスタから:
2 レジスタの上位部分(ビット32〜16)からの17
ビット・データ、
1 積算用の40ビット・データ、
命令デコードから 1 16ビット「即時」値、
他の16ビット・レジスタから:
1 16ビット・データ。
‐第2のMACのハードウェアのプラグ・インが、メインのものと同様にオぺランド・ソース及び行先に対する接続性により可能とする。
‐アルゴリズムの実行中に唯一のMAC/サイクルが必要とされるときは、プラグ・イン・オペレータを停止する。
‐第2のMACの制御は、命令クラス「二重MAC」を介して行なわれ、これが2つのオペレータ上の演算MPY/MAC/MASの組み合わせを可能にし、これらをデコードすることで第2のMACの実行クロックのゲート処理に必要な制御信号が生成される。
‐スループットの観点から、二重MAC実効の最も効果的な使用には、DSPアルゴリズム用に3オぺランド/サイクルと共に2アキュムレータ内容の持続的な送出を必要とする。バス・アーキテクチャー全体を損なうことなく、計算能力の増大を得るために、Bバス・システムは、このスループット要求を満足させる最良の柔軟性を与える。従って、「係数」バス及びその関連メモリ・バンクは、図24に説明した2つのオペレータにより共有される。効果的に、係数バス及びその関連メモリ・バンクを共有することにより、複製された係数構造を有するシステムでの電力消費を減少させる。同様に、電力節減は、MAC1とMAC2との間で共有されるDRxCPUレジスタにMAC係数を記憶することによっている。
102 第1のオぺランド(Xin )
120 部分積発生段
130 ワラス・ツリー加算器/圧縮器段
140 最後の加算器段
142 第3の数(Ain)
150 最後の飽和段
Claims (4)
- 第一のMACユニットと、
クロック制御を備えた第二のMACユニットと、
前記第一のMACユニットの一の入力と前記第二のMACユニットの一の入力に接続された第一のバスと、
前記第一のMACユニットの他の入力に接続された第二のバスと、
前記第二のMACユニットの他の入力に接続された第三のバスと、を有し、
FIR演算を行う場合、前記第二のMACユニットに対しクロックが供給され、前記第一のバスに係数データのj(jは0以上の整数)番目の成分が供給され、前記第二のバスに入力データのi−j(iは0以上の整数)番目の成分が供給され、前記第三のバスに前記入力データのi−j+1番目の成分が供給され、前記第一のMACユニットは出力データのi番目の成分を演算し、前記第二のMACユニットは前記出力データのi+1番目の成分を演算すること、を特徴とするプロセッサ。 - 第一のMACユニットと、
クロック制御を備えた第二のMACユニットと、
前記第一のMACユニットの一の入力と前記第二のMACユニットの一の入力に接続された第一のバスと、
前記第一のMACユニットの他の入力に接続された第二のバスと、
前記第二のMACユニットの他の入力に接続された第三のバスと、を有し、
マトリックス演算を行う場合、前記第二のMACユニットに対しクロックが供給され、前記第一のバスに第一の入力データの(k、j)(kおよびjは0以上の整数)番目の成分が供給され、前記第二のバスに第二の入力データの(i、k)(iは0以上の整数)番目の成分が供給され、前記第三のバスに前記第二の入力データの(i+1、k)番目の成分が供給され、前記第一のMACユニットは出力データの(i、j)番目の成分を演算し、前記第二のMACユニットは前記出力データの(i+1、j)番目の成分を演算すること、を特徴とするプロセッサ。 - 第一のMACユニットと、
クロック制御を備えた第二のMACユニットと、
前記第一のMACユニットの一の入力と前記第二のMACユニットの一の入力に接続された第一のバスと、
前記第一のMACユニットの他の入力に接続された第二のバスと、
前記第二のMACユニットの他の入力に接続された第三のバスと、を有し、
IIR演算を行う場合、前記第二のMACユニットに対しクロックが供給され、前記第一のバスに出力データのi−j−1(iおよびjは0以上の整数)番目の成分が供給され、前記第二のバスに係数データのj番目の成分が供給され、前記第三のバスに前記係数データのj+1番目の成分が供給され、前記第一のMACユニットは前記出力データのi番目の成分を演算し、前記第二のMACユニットは前記出力データのi+1番目の成分を演算すること、を特徴とするプロセッサ。 - 第一のMACユニットと、
クロック制御を備えた第二のMACユニットと、
前記第一のMACユニットの一の入力と前記第二のMACユニットの一の入力に接続された第一のバスと、
前記第一のMACユニットの他の入力に接続された第二のバスと、
前記第二のMACユニットの他の入力に接続された第三のバスと、を有し、
FFT演算を行う場合、前記第二のMACユニットに対しクロックが供給され、前記第一のバスに係数データのj(jは0以上の整数)番目の成分が供給され、前記第二のバスに実数部入力データのj番目の成分が供給され、前記第三のバスに虚数部入力データのj番目の成分が供給され、前記第一のMACユニットは実数部出力データを演算し、前記第二のMACユニットは虚数部出力データを演算すること、を特徴とするプロセッサ。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP98402452.1 | 1998-10-06 | ||
| EP98402452A EP0992885B1 (en) | 1998-10-06 | 1998-10-06 | Multiplier accumulator circuits |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP11321529A Division JP2000215028A (ja) | 1998-10-06 | 1999-10-06 | 乗算器/アキュムレ―タ・ユニット |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010086547A true JP2010086547A (ja) | 2010-04-15 |
| JP5273866B2 JP5273866B2 (ja) | 2013-08-28 |
Family
ID=8235509
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP11321529A Pending JP2000215028A (ja) | 1998-10-06 | 1999-10-06 | 乗算器/アキュムレ―タ・ユニット |
| JP2009255129A Expired - Lifetime JP5273866B2 (ja) | 1998-10-06 | 2009-11-06 | 乗算器/アキュムレータ・ユニット |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP11321529A Pending JP2000215028A (ja) | 1998-10-06 | 1999-10-06 | 乗算器/アキュムレ―タ・ユニット |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP0992885B1 (ja) |
| JP (2) | JP2000215028A (ja) |
| DE (1) | DE69832985T2 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020507154A (ja) * | 2017-01-23 | 2020-03-05 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 回路、システム、および組合せ結果を演算するように再設定可能な複数の再設定可能ユニットを備えたプロセッサにより実装される方法 |
| US11327718B2 (en) | 2020-03-19 | 2022-05-10 | Kabushiki Kaisha Toshiba | Arithmetic circuitry for power-efficient multiply-add operations |
Families Citing this family (68)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8620980B1 (en) | 2005-09-27 | 2013-12-31 | Altera Corporation | Programmable device with specialized multiplier blocks |
| US7513702B2 (en) * | 2005-11-16 | 2009-04-07 | Va, Inc. | Non-contact shutter activation system and method |
| US8082287B2 (en) * | 2006-01-20 | 2011-12-20 | Qualcomm Incorporated | Pre-saturating fixed-point multiplier |
| US8301681B1 (en) | 2006-02-09 | 2012-10-30 | Altera Corporation | Specialized processing block for programmable logic device |
| US8266199B2 (en) | 2006-02-09 | 2012-09-11 | Altera Corporation | Specialized processing block for programmable logic device |
| US8266198B2 (en) * | 2006-02-09 | 2012-09-11 | Altera Corporation | Specialized processing block for programmable logic device |
| US7809783B2 (en) | 2006-02-15 | 2010-10-05 | Qualcomm Incorporated | Booth multiplier with enhanced reduction tree circuitry |
| JP5074425B2 (ja) * | 2006-02-15 | 2012-11-14 | クゥアルコム・インコーポレイテッド | 拡張された削減ツリー回路構成を有するブース乗算器 |
| US7797366B2 (en) | 2006-02-15 | 2010-09-14 | Qualcomm Incorporated | Power-efficient sign extension for booth multiplication methods and systems |
| US7836117B1 (en) | 2006-04-07 | 2010-11-16 | Altera Corporation | Specialized processing block for programmable logic device |
| US7822799B1 (en) | 2006-06-26 | 2010-10-26 | Altera Corporation | Adder-rounder circuitry for specialized processing block in programmable logic device |
| US8386550B1 (en) | 2006-09-20 | 2013-02-26 | Altera Corporation | Method for configuring a finite impulse response filter in a programmable logic device |
| US7930336B2 (en) | 2006-12-05 | 2011-04-19 | Altera Corporation | Large multiplier for programmable logic device |
| US8386553B1 (en) | 2006-12-05 | 2013-02-26 | Altera Corporation | Large multiplier for programmable logic device |
| US7814137B1 (en) | 2007-01-09 | 2010-10-12 | Altera Corporation | Combined interpolation and decimation filter for programmable logic device |
| US8650231B1 (en) | 2007-01-22 | 2014-02-11 | Altera Corporation | Configuring floating point operations in a programmable device |
| US7865541B1 (en) | 2007-01-22 | 2011-01-04 | Altera Corporation | Configuring floating point operations in a programmable logic device |
| US8645450B1 (en) | 2007-03-02 | 2014-02-04 | Altera Corporation | Multiplier-accumulator circuitry and methods |
| US7949699B1 (en) | 2007-08-30 | 2011-05-24 | Altera Corporation | Implementation of decimation filter in integrated circuit device using ram-based data storage |
| US8959137B1 (en) | 2008-02-20 | 2015-02-17 | Altera Corporation | Implementing large multipliers in a programmable integrated circuit device |
| US8244789B1 (en) | 2008-03-14 | 2012-08-14 | Altera Corporation | Normalization of floating point operations in a programmable integrated circuit device |
| US8626815B1 (en) | 2008-07-14 | 2014-01-07 | Altera Corporation | Configuring a programmable integrated circuit device to perform matrix multiplication |
| US8255448B1 (en) | 2008-10-02 | 2012-08-28 | Altera Corporation | Implementing division in a programmable integrated circuit device |
| GB2464292A (en) * | 2008-10-08 | 2010-04-14 | Advanced Risc Mach Ltd | SIMD processor circuit for performing iterative SIMD multiply-accumulate operations |
| US8307023B1 (en) | 2008-10-10 | 2012-11-06 | Altera Corporation | DSP block for implementing large multiplier on a programmable integrated circuit device |
| US8645449B1 (en) | 2009-03-03 | 2014-02-04 | Altera Corporation | Combined floating point adder and subtractor |
| US8549055B2 (en) | 2009-03-03 | 2013-10-01 | Altera Corporation | Modular digital signal processing circuitry with optionally usable, dedicated connections between modules of the circuitry |
| US8886696B1 (en) | 2009-03-03 | 2014-11-11 | Altera Corporation | Digital signal processing circuitry with redundancy and ability to support larger multipliers |
| US8468192B1 (en) | 2009-03-03 | 2013-06-18 | Altera Corporation | Implementing multipliers in a programmable integrated circuit device |
| US8706790B1 (en) | 2009-03-03 | 2014-04-22 | Altera Corporation | Implementing mixed-precision floating-point operations in a programmable integrated circuit device |
| US8805916B2 (en) | 2009-03-03 | 2014-08-12 | Altera Corporation | Digital signal processing circuitry with redundancy and bidirectional data paths |
| US8650236B1 (en) | 2009-08-04 | 2014-02-11 | Altera Corporation | High-rate interpolation or decimation filter in integrated circuit device |
| US8396914B1 (en) | 2009-09-11 | 2013-03-12 | Altera Corporation | Matrix decomposition in an integrated circuit device |
| US8412756B1 (en) | 2009-09-11 | 2013-04-02 | Altera Corporation | Multi-operand floating point operations in a programmable integrated circuit device |
| US8539016B1 (en) | 2010-02-09 | 2013-09-17 | Altera Corporation | QR decomposition in an integrated circuit device |
| US7948267B1 (en) | 2010-02-09 | 2011-05-24 | Altera Corporation | Efficient rounding circuits and methods in configurable integrated circuit devices |
| US8601044B2 (en) | 2010-03-02 | 2013-12-03 | Altera Corporation | Discrete Fourier Transform in an integrated circuit device |
| US8458243B1 (en) | 2010-03-03 | 2013-06-04 | Altera Corporation | Digital signal processing circuit blocks with support for systolic finite-impulse-response digital filtering |
| US8484265B1 (en) | 2010-03-04 | 2013-07-09 | Altera Corporation | Angular range reduction in an integrated circuit device |
| US8510354B1 (en) | 2010-03-12 | 2013-08-13 | Altera Corporation | Calculation of trigonometric functions in an integrated circuit device |
| US8539014B2 (en) | 2010-03-25 | 2013-09-17 | Altera Corporation | Solving linear matrices in an integrated circuit device |
| US8862650B2 (en) | 2010-06-25 | 2014-10-14 | Altera Corporation | Calculation of trigonometric functions in an integrated circuit device |
| US8589463B2 (en) | 2010-06-25 | 2013-11-19 | Altera Corporation | Calculation of trigonometric functions in an integrated circuit device |
| US8577951B1 (en) | 2010-08-19 | 2013-11-05 | Altera Corporation | Matrix operations in an integrated circuit device |
| US8645451B2 (en) | 2011-03-10 | 2014-02-04 | Altera Corporation | Double-clocked specialized processing block in an integrated circuit device |
| US9600278B1 (en) | 2011-05-09 | 2017-03-21 | Altera Corporation | Programmable device using fixed and configurable logic to implement recursive trees |
| US8812576B1 (en) | 2011-09-12 | 2014-08-19 | Altera Corporation | QR decomposition in an integrated circuit device |
| US9053045B1 (en) | 2011-09-16 | 2015-06-09 | Altera Corporation | Computing floating-point polynomials in an integrated circuit device |
| US8949298B1 (en) | 2011-09-16 | 2015-02-03 | Altera Corporation | Computing floating-point polynomials in an integrated circuit device |
| US8762443B1 (en) | 2011-11-15 | 2014-06-24 | Altera Corporation | Matrix operations in an integrated circuit device |
| US8543634B1 (en) | 2012-03-30 | 2013-09-24 | Altera Corporation | Specialized processing block for programmable integrated circuit device |
| US9098332B1 (en) | 2012-06-01 | 2015-08-04 | Altera Corporation | Specialized processing block with fixed- and floating-point structures |
| US8996600B1 (en) | 2012-08-03 | 2015-03-31 | Altera Corporation | Specialized processing block for implementing floating-point multiplier with subnormal operation support |
| US9207909B1 (en) | 2012-11-26 | 2015-12-08 | Altera Corporation | Polynomial calculations optimized for programmable integrated circuit device structures |
| US9189200B1 (en) | 2013-03-14 | 2015-11-17 | Altera Corporation | Multiple-precision processing block in a programmable integrated circuit device |
| US9348795B1 (en) | 2013-07-03 | 2016-05-24 | Altera Corporation | Programmable device using fixed and configurable logic to implement floating-point rounding |
| JP5951570B2 (ja) | 2013-09-13 | 2016-07-13 | 株式会社東芝 | 行列演算装置 |
| US9379687B1 (en) | 2014-01-14 | 2016-06-28 | Altera Corporation | Pipelined systolic finite impulse response filter |
| JP6350111B2 (ja) * | 2014-08-22 | 2018-07-04 | 富士通株式会社 | 乗算回路及びその乗算方法 |
| US9684488B2 (en) | 2015-03-26 | 2017-06-20 | Altera Corporation | Combined adder and pre-adder for high-radix multiplier circuit |
| US10140090B2 (en) | 2016-09-28 | 2018-11-27 | International Business Machines Corporation | Computing and summing up multiple products in a single multiplier |
| US10942706B2 (en) | 2017-05-05 | 2021-03-09 | Intel Corporation | Implementation of floating-point trigonometric functions in an integrated circuit device |
| CN114424161A (zh) * | 2019-09-20 | 2022-04-29 | 华为技术有限公司 | 一种乘法器 |
| EP3798893B1 (en) * | 2019-09-26 | 2022-12-14 | Rambus Inc. | Side-channel attack protected gates having low-latency and reduced complexity |
| RU2744815C1 (ru) * | 2020-06-22 | 2021-03-16 | федеральное государственное автономное образовательное учреждение высшего образования "Северо-Кавказский федеральный университет" | Устройство для перевода чисел из системы остаточных классов и расширения оснований |
| US12118060B2 (en) * | 2021-12-08 | 2024-10-15 | Tenstorrent Inc. | Computational circuit with hierarchical accumulator |
| US12165041B2 (en) | 2022-06-09 | 2024-12-10 | Recogni Inc. | Low power hardware architecture for handling accumulation overflows in a convolution operation |
| CN119512501A (zh) * | 2024-11-01 | 2025-02-25 | 杭州电子科技大学 | 一种基于基-4Booth编码和改进Wallace压缩树的乘法器 |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60164868A (ja) * | 1984-02-06 | 1985-08-27 | Sony Corp | 高速フ−リエ変換装置 |
| JPS62233894A (ja) * | 1986-04-04 | 1987-10-14 | Fuji Electric Co Ltd | ずらし類似度演算装置 |
| JPS62260280A (ja) * | 1986-05-07 | 1987-11-12 | Sony Corp | 演算処理装置 |
| JPS62284510A (ja) * | 1986-03-10 | 1987-12-10 | ゾ−ラン コ−ポレ−シヨン | 移動係数を用いた縦続接続可能なデジタルフイルタプロセツサ |
| JPS6326716A (ja) * | 1986-07-18 | 1988-02-04 | Nec Ic Microcomput Syst Ltd | 中央処理装置 |
| JPH01126819A (ja) * | 1987-11-12 | 1989-05-18 | Matsushita Electric Ind Co Ltd | ディジタル信号処理装置 |
| JPH0298777A (ja) * | 1988-10-05 | 1990-04-11 | Nec Corp | 並列積和演算回路及びベクトル行列積演算方法 |
| JPH02173871A (ja) * | 1988-12-27 | 1990-07-05 | Casio Comput Co Ltd | バタフライ演算装置 |
| JPH03211604A (ja) * | 1990-01-17 | 1991-09-17 | Nec Corp | ディジタル信号処理装置 |
| JPH0498903A (ja) * | 1990-08-16 | 1992-03-31 | Nec Corp | 信号処理装置 |
| JPH04307662A (ja) * | 1991-04-05 | 1992-10-29 | Nec Corp | 離散コサイン変換装置および逆離散コサイン変換装置 |
| JPH10171778A (ja) * | 1996-12-13 | 1998-06-26 | Nec Corp | ブロックiirプロセッサ |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0738217B2 (ja) * | 1985-04-18 | 1995-04-26 | ファナック株式会社 | 空間積和演算装置 |
| JPS61241879A (ja) * | 1985-04-18 | 1986-10-28 | Fanuc Ltd | 空間積和演算装置 |
| US4876660A (en) * | 1987-03-20 | 1989-10-24 | Bipolar Integrated Technology, Inc. | Fixed-point multiplier-accumulator architecture |
| JPH01267728A (ja) * | 1988-04-19 | 1989-10-25 | Ricoh Co Ltd | 乗算器 |
| JPH10207859A (ja) * | 1989-12-15 | 1998-08-07 | Hitachi Ltd | 消費電力制御方法,半導体集積回路装置およびマイクロプロセッサ |
| JPH04127210A (ja) * | 1990-09-19 | 1992-04-28 | Hitachi Ltd | 低消費電力プロセッサ |
| JP3139137B2 (ja) * | 1992-06-25 | 2001-02-26 | 日本電気株式会社 | ディジタルフィルタ処理のフィルタ演算を行うディジタル信号処理回路 |
| JP3305406B2 (ja) * | 1993-04-26 | 2002-07-22 | 松下電器産業株式会社 | プログラム制御のプロセッサ |
| JP3618109B2 (ja) * | 1993-07-02 | 2005-02-09 | 株式会社ソニー・コンピュータエンタテインメント | 中央演算処理装置 |
| JPH0876973A (ja) * | 1994-09-07 | 1996-03-22 | Sanyo Electric Co Ltd | 演算処理装置及び拡張演算装置 |
| JPH08180040A (ja) * | 1994-12-26 | 1996-07-12 | Sony Corp | ディジタル信号処理装置 |
| JP3649478B2 (ja) * | 1995-07-20 | 2005-05-18 | 株式会社ソニー・コンピュータエンタテインメント | 画像情報処理装置及び画像情報処理方法 |
| EP0806722A1 (en) * | 1996-05-06 | 1997-11-12 | Motorola, Inc. | Method and apparatus for a multiply and accumulate circuit having a dynamic saturation range |
| US5933797A (en) * | 1997-02-28 | 1999-08-03 | Telefonaktiebolaget Lm Ericsson (Publ) | Adaptive dual filter echo cancellation |
-
1998
- 1998-10-06 EP EP98402452A patent/EP0992885B1/en not_active Expired - Lifetime
- 1998-10-06 DE DE1998632985 patent/DE69832985T2/de not_active Expired - Lifetime
-
1999
- 1999-10-06 JP JP11321529A patent/JP2000215028A/ja active Pending
-
2009
- 2009-11-06 JP JP2009255129A patent/JP5273866B2/ja not_active Expired - Lifetime
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60164868A (ja) * | 1984-02-06 | 1985-08-27 | Sony Corp | 高速フ−リエ変換装置 |
| JPS62284510A (ja) * | 1986-03-10 | 1987-12-10 | ゾ−ラン コ−ポレ−シヨン | 移動係数を用いた縦続接続可能なデジタルフイルタプロセツサ |
| JPS62233894A (ja) * | 1986-04-04 | 1987-10-14 | Fuji Electric Co Ltd | ずらし類似度演算装置 |
| JPS62260280A (ja) * | 1986-05-07 | 1987-11-12 | Sony Corp | 演算処理装置 |
| JPS6326716A (ja) * | 1986-07-18 | 1988-02-04 | Nec Ic Microcomput Syst Ltd | 中央処理装置 |
| JPH01126819A (ja) * | 1987-11-12 | 1989-05-18 | Matsushita Electric Ind Co Ltd | ディジタル信号処理装置 |
| JPH0298777A (ja) * | 1988-10-05 | 1990-04-11 | Nec Corp | 並列積和演算回路及びベクトル行列積演算方法 |
| JPH02173871A (ja) * | 1988-12-27 | 1990-07-05 | Casio Comput Co Ltd | バタフライ演算装置 |
| JPH03211604A (ja) * | 1990-01-17 | 1991-09-17 | Nec Corp | ディジタル信号処理装置 |
| JPH0498903A (ja) * | 1990-08-16 | 1992-03-31 | Nec Corp | 信号処理装置 |
| JPH04307662A (ja) * | 1991-04-05 | 1992-10-29 | Nec Corp | 離散コサイン変換装置および逆離散コサイン変換装置 |
| JPH10171778A (ja) * | 1996-12-13 | 1998-06-26 | Nec Corp | ブロックiirプロセッサ |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020507154A (ja) * | 2017-01-23 | 2020-03-05 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 回路、システム、および組合せ結果を演算するように再設定可能な複数の再設定可能ユニットを備えたプロセッサにより実装される方法 |
| US11327718B2 (en) | 2020-03-19 | 2022-05-10 | Kabushiki Kaisha Toshiba | Arithmetic circuitry for power-efficient multiply-add operations |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0992885A1 (en) | 2000-04-12 |
| JP5273866B2 (ja) | 2013-08-28 |
| JP2000215028A (ja) | 2000-08-04 |
| EP0992885B1 (en) | 2005-12-28 |
| DE69832985T2 (de) | 2006-08-17 |
| DE69832985D1 (de) | 2006-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5273866B2 (ja) | 乗算器/アキュムレータ・ユニット | |
| US6571268B1 (en) | Multiplier accumulator circuits | |
| US7047272B2 (en) | Rounding mechanisms in processors | |
| US5790446A (en) | Floating point multiplier with reduced critical paths using delay matching techniques | |
| US7774400B2 (en) | Method and system for performing calculation operations and a device | |
| US6009451A (en) | Method for generating barrel shifter result flags directly from input data | |
| US7395304B2 (en) | Method and apparatus for performing single-cycle addition or subtraction and comparison in redundant form arithmetic | |
| US6381625B2 (en) | Method and apparatus for calculating a power of an operand | |
| EP0847551B1 (en) | A set of instructions for operating on packed data | |
| US8341204B2 (en) | Vector SIMD processor | |
| CN101221490B (zh) | 一种具有数据前送结构的浮点乘加单元 | |
| US5892698A (en) | 2's complement floating-point multiply accumulate unit | |
| Bruguera et al. | Floating-point fused multiply-add: reduced latency for floating-point addition | |
| US5633819A (en) | Inexact leading-one/leading-zero prediction integrated with a floating-point adder | |
| Danysh et al. | Architecture and implementation of a vector/SIMD multiply-accumulate unit | |
| WO2011137209A1 (en) | Operand-optimized asynchronous floating-point units and methods of use thereof | |
| JPH08212058A (ja) | 加算オーバフロ検出回路 | |
| Pineiro et al. | High-radix logarithm with selection by rounding | |
| US6826588B2 (en) | Method and apparatus for a fast comparison in redundant form arithmetic | |
| Isseven et al. | A dual-mode quadruple precision floating-point divider | |
| US6615228B1 (en) | Selection based rounding system and method for floating point operations | |
| EP1031073A2 (en) | A method and apparatus for multi-function arithmetic | |
| JPH04172526A (ja) | 浮動小数点除算器 | |
| Grossschadl et al. | A single-cycle (32/spl times/32+ 32+ 64)-bit multiply/accumulate unit for digital signal processing and public-key cryptography | |
| EP0992883B1 (en) | Rounding mechanism |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110125 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110418 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110927 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120113 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20120120 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20120406 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130513 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 5273866 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |