JP2010086497A - 画像処理装置及びデータプロセッサ - Google Patents
画像処理装置及びデータプロセッサ Download PDFInfo
- Publication number
- JP2010086497A JP2010086497A JP2008258039A JP2008258039A JP2010086497A JP 2010086497 A JP2010086497 A JP 2010086497A JP 2008258039 A JP2008258039 A JP 2008258039A JP 2008258039 A JP2008258039 A JP 2008258039A JP 2010086497 A JP2010086497 A JP 2010086497A
- Authority
- JP
- Japan
- Prior art keywords
- data
- circuit
- storage
- control
- arithmetic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30101—Special purpose registers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Image Processing (AREA)
- Memory System (AREA)
Abstract
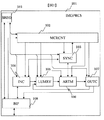
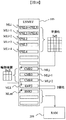
【解決手段】ハードワイヤード方式で実現される画像処理のための演算機能とバッファメモリのメモリアクセス制御に制約を設けて、その制約の範囲をプログラム制御等によって可変可能とする。バッファメモリ(105)は記憶ライン単位という制約を受けて外部からデータを入力し、入力する記憶ライン数と記憶ラインの位置を制御回路(101,102)によりプログラマブルにでき、演算回路(106)はバッファメモリから供給される単数又は複数の記憶ラインのデータ単位で演算を行うという制約を受け、そのデータ単位に対する演算処理単位の演算処理内容を制御回路(101,102)によりプログラマブルに指定することができる。
【選択図】図1
Description
先ず、本願において開示される発明の代表的な実施の形態について概要を説明する。代表的な実施の形態についての概要説明で括弧を付して参照する図面中の参照符号はそれが付された構成要素の概念に含まれるものを例示するに過ぎない。
実施の形態について更に詳述する。以下、本発明を実施するための形態を図面に基づいて詳細に説明する。なお、発明を実施するための形態を説明するための全図において、同一の機能を有する要素には同一の符号を付して、その繰り返しの説明を省略する。
PCは、プログラムカウンタであり、現在実行中の命令の場所を示す特別なレジスタ。
R0〜R7は、汎用レジスタであり、マイクロプログラム中での一時データの保持に使えるレジスタである。
R8は、ラインメモリのリードポインタのためのレジスタであり、ソースのA側のレジスタである。
R9は、ラインメモリのリードポインタのためのレジスタであり、ソースのB側のレジスタである。
R10は、ラインメモリに予め画像処理に必要なデータを記録しておく情報量を指定するレジスタである。
R11は、画像処理に必要な画像データのライン数が複数本ある場合に、マイクロプログラムがそれを把握するために必要なデータを記録するレジスタである。例えば、必要なライン数であったり、現在読み込んでいるラインメモリのライン位置であったりする。
R12は、入力回路104からのデータ取り込み先のA側用であり、R13は入力回路104からのデータ取り込み先のB側用である。
R14は、 出力回路107からのデータ取り込み先である。
R15は、スタックポインタである。
102 マイクロコントローラ
103 同期化回路
104 入力回路
105 ラインメモリ
106 演算回路
107 出力回路
108 バスインタフェース
201 画像処理装置
202 チップ内バス
203 周辺インタフェース
204 リードオンリーメモリ(ROM)
205 表示回路
206 主記憶インタフェース
207 ビデオ入力回路
208 CPU
Claims (14)
- 演算対象とするデータを外部から読み出して入力するための入力回路と、入力回路によって入力したデータを一時的に保持するバッファメモリと、前記バッファメモリから出力されたデータの演算処理を行なう演算回路と、前記演算回路による演算結果を外部又は前記バッファメモリに書き戻すための出力回路と、制御回路と、を有し、
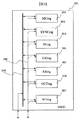
前記バッファメモリは記憶領域として論理上直列な記憶ラインを複数有し、前記制御回路で指定された前記記憶ラインに入力データを書き込み書き込まれたデータの読出しが可能とされ、
前記演算回路はバッファから出力された単数又は複数の前記記憶ラインのデータを前記制御回路により指定された処理内容で演算処理単位毎に繰り返し演算し、
前記制御回路は、指定した記憶ラインのデータを記憶ライン単位で前記バッファメモリから前記演算回路に出力させる、画像処理装置。 - 前記制御回路は、外部から入力されるデータを書き込む単数又は複数の前記記憶ラインを指示し、演算回路による演算結果を書き戻す前記記憶ラインを指示する、請求項1記載の画像処理装置。
- 画像処理装置と、前記画像処理装置の制御及びメモリのアクセス制御を行う中央処理装置とを有するデータプロセッサであって、
前記画像処理装置は、演算対象とするデータを前記メモリから読み出して入力するための入力回路と、入力回路によって入力したデータを一時的に保持するバッファメモリと、前記バッファメモリから出力されたデータの演算処理を行なう演算回路と、前記演算回路による演算結果を前記メモリ又は前記バッファメモリに書き戻すための出力回路と、制御回路と、を有し、
前記バッファメモリは記憶領域として論理上直列な記憶ラインを複数有し、指定された前記記憶ラインに入力データを書き込み書き込まれたデータの読出しが可能とされ、
前記演算回路はバッファから出力された単数又は複数の前記記憶ラインのデータを指定された処理内容で演算処理単位毎に繰り返し演算し、
前記制御回路は、前記入力回路から入力されるデータを書き込む単数又は複数の前記記憶ラインを指示し、前記演算回路による演算処理内容を指示し、演算回路による演算結果を書き戻す前記記憶ラインを指示し、バッファメモリから演算回路にデータを供給する記憶ラインを指示する、データプロセッサ。 - 前記中央処理装置は画像処理装置の演算動作中に、画像処理装置による演算結果を前記メモリから参照する、請求項3記載のデータプロセッサ。
- 画像処理装置とメモリとを有するデータプロセッサであって、
前記画像処理装置は、演算対象とするデータを前記メモリから読み出して入力するための入力回路と、入力回路によって入力したデータを一時的に保持するバッファメモリと、前記バッファメモリから出力されたデータの演算処理を行なう演算回路と、前記演算回路による演算結果を前記メモリ又は前記バッファメモリに書き戻すための出力回路と、制御回路と、を有し、
前記バッファメモリは記憶領域として論理上直列な記憶ラインを複数有し、前記制御回路で指定された前記記憶ラインに入力データを書き込み書き込まれたデータの読出しが可能とされ、
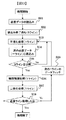
前記演算回路は前記バッファメモリから読み出された複数の前記記憶ラインのデータを前記制御回路で指定された処理内容に従って並列に演算可能であり、
前記制御回路は、前記バッファメモリの複数の記憶ライン分に相当する第1の記憶領域のデータに対して順次データ処理単位毎に前記演算回路に第1の演算を繰り返し実行させ、繰り返し実行された第1の演算による演算家結果が前記バッファメモリの複数の記憶ライン分に相当する第2の記憶領域の記憶ラインに格納されたとき、第1の記憶領域で最も先にデータ記憶が行われた記憶ラインに対してデータ入換えを行ってから、再び前記第1の演算を繰り返し実行させる制御を行う、データプロセッサ。 - 前記制御部は、前記第2の記憶領域の記憶ラインに必要な演算結果が揃ったとき、第2の記憶領域のデータに対して順次データ処理単位毎に前記演算回路に第2の演算を繰り返し実行させ、繰り返し実行された第2の演算による演算家結果を前記バッファメモリの第3の記憶領域の記憶ラインに格納させる制御を行う、請求項5記載のデータプロセッサ。
- 前記制御部は、前記第3の記憶領域の記憶ラインに必要な演算結果が揃ったとき、第3の記憶領域のデータに対して前記演算回路に第3の演算を繰り返し実行させ、繰り返し実行された第3の演算による演算家結果を前記バッファメモリの第4の記憶領域の記憶ラインに格納させる制御を行う、請求項6記載のデータプロセッサ。
- 前記制御回路は、前記第4の記憶領域の記憶ラインに必要な演算結果が揃ったとき、前記出力回路に指示を与えて当該演算結果を前記メモリに書き込む制御を行う、請求項7記載のデータプロセッサ。
- 前記制御部は、前記第3の記憶領域の記憶ラインに必要な演算結果が揃ったとき、第3の記憶領域のデータに対して前記演算回路に第3の演算を繰り返し実行させ、繰り返し実行された第3の演算による演算家結果を前記出力回路に外部へ出力させる制御を行う、請求項6記載のデータプロセッサ。
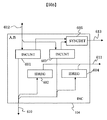
- 前記制御回路は、マイクロコントローラ、制御レジスタ、及び同期化制御回路を有し、
前記マイクロコントローラはプログラムを実行して前記制御レジスタに制御データを書き込む制御を行い、
前記同期化制御回路は前記入力回路及び前記演算回路の動作状態に従って前記前記制御レジスタの書き込み制御を行い、
前記制御レジスタは書き込まれた制御データに従って前記入力回路、前記バッファ回路、前記演算回路及び前記出力回路に制御信号を出力する、請求項5乃至9の何れか1項記載のデータプロセッサ。 - 前記制御レジスタは、入力回路からデータを取り込む記憶ラインを指定するための制御情報、出力回路からデータを取り込む記憶ラインを指定するための制御情報、データを取り込む記憶ラインの本数を指定する制御情報、データを出力する記憶ラインを指定するための制御情報、及びデータを出力する記憶ラインの本数を指定する制御情報が設定される、請求項10記載のデータプロセッサ。
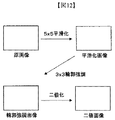
- 前記第1の演算は、複数記憶ラインの画像データに対してm×n画素単位のデータをデータ処理単位とする平滑化のためのコンボリューション演算である、請求項7記載のデータプロセッサ。
- 前記第2の演算は、前記コンボリューション演算された複数記憶ラインの画像データに対してi×j画素単位もデータをデータ処理単位とする輪郭強調のためのフィルタ演算である、請求項12記載のデータプロセッサ。
- 前記第3の演算は、前記前記フィルタ演算された画像データを2値化する演算である、請求項13記載のデータプロセッサ。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008258039A JP2010086497A (ja) | 2008-10-03 | 2008-10-03 | 画像処理装置及びデータプロセッサ |
| US12/566,123 US20100088493A1 (en) | 2008-10-03 | 2009-09-24 | Image processing device and data processor |
| US13/839,278 US20130212362A1 (en) | 2008-10-03 | 2013-03-15 | Image processing device and data processor |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008258039A JP2010086497A (ja) | 2008-10-03 | 2008-10-03 | 画像処理装置及びデータプロセッサ |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010086497A true JP2010086497A (ja) | 2010-04-15 |
| JP2010086497A5 JP2010086497A5 (ja) | 2011-11-17 |
Family
ID=42076721
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008258039A Pending JP2010086497A (ja) | 2008-10-03 | 2008-10-03 | 画像処理装置及びデータプロセッサ |
Country Status (2)
| Country | Link |
|---|---|
| US (2) | US20100088493A1 (ja) |
| JP (1) | JP2010086497A (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8464030B2 (en) * | 2010-04-09 | 2013-06-11 | International Business Machines Corporation | Instruction cracking and issue shortening based on instruction base fields, index fields, operand fields, and various other instruction text bits |
| CN110046699B (zh) * | 2018-01-16 | 2022-11-18 | 华南理工大学 | 降低加速器外部数据存储带宽需求的二值化系统和方法 |
| CN116957908B (zh) * | 2023-09-20 | 2023-12-15 | 上海登临科技有限公司 | 一种硬件处理架构、处理器以及电子设备 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07295858A (ja) * | 1994-04-28 | 1995-11-10 | Sony Corp | 画像処理装置及び並列コンピュータのデバッグ処理方法 |
| JPH10340340A (ja) * | 1997-06-09 | 1998-12-22 | Hitachi Ltd | 画像処理装置 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6393520B2 (en) * | 1997-04-17 | 2002-05-21 | Matsushita Electric Industrial Co., Ltd. | Data processor and data processing system with internal memories |
| US6333744B1 (en) * | 1999-03-22 | 2001-12-25 | Nvidia Corporation | Graphics pipeline including combiner stages |
| US7158141B2 (en) * | 2002-01-17 | 2007-01-02 | University Of Washington | Programmable 3D graphics pipeline for multimedia applications |
| CN101443809A (zh) * | 2006-05-09 | 2009-05-27 | 皇家飞利浦电子股份有限公司 | 可编程数据处理电路 |
-
2008
- 2008-10-03 JP JP2008258039A patent/JP2010086497A/ja active Pending
-
2009
- 2009-09-24 US US12/566,123 patent/US20100088493A1/en not_active Abandoned
-
2013
- 2013-03-15 US US13/839,278 patent/US20130212362A1/en not_active Abandoned
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07295858A (ja) * | 1994-04-28 | 1995-11-10 | Sony Corp | 画像処理装置及び並列コンピュータのデバッグ処理方法 |
| JPH10340340A (ja) * | 1997-06-09 | 1998-12-22 | Hitachi Ltd | 画像処理装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20130212362A1 (en) | 2013-08-15 |
| US20100088493A1 (en) | 2010-04-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2987308B2 (ja) | 情報処理装置 | |
| JP4536618B2 (ja) | リコンフィグ可能な集積回路装置 | |
| JP3778573B2 (ja) | データプロセッサ及びデータ処理システム | |
| TWI514267B (zh) | 用於多股亂序處理器中之指令排程的方法及裝置與系統 | |
| CA2016532C (en) | Serializing system between vector instruction and scalar instruction in data processing system | |
| KR20010031192A (ko) | 기계시각시스템에서의 영상데이터와 같은 논리적으로인접한 데이터샘플들을 위한 데이터처리시스템 | |
| JP2007133456A (ja) | 半導体装置 | |
| TWI546736B (zh) | 多執行緒圖形處理單元管線 | |
| JP3797570B2 (ja) | セマフォ命令用のセマフォ・バッファを用いた装置と方法 | |
| JP2010086497A (ja) | 画像処理装置及びデータプロセッサ | |
| JP2010102732A (ja) | 情報処理装置、例外制御回路及び例外制御方法 | |
| US7539847B2 (en) | Stalling processor pipeline for synchronization with coprocessor reconfigured to accommodate higher frequency operation resulting in additional number of pipeline stages | |
| JP2010020363A (ja) | 演算処理装置 | |
| JP4728581B2 (ja) | アレイ型プロセッサ | |
| JP2022072452A (ja) | 情報処理装置、及びプログラム | |
| JP3821198B2 (ja) | 信号処理装置 | |
| JP3719241B2 (ja) | 演算装置 | |
| JP2011186850A (ja) | データ処理システム及びその制御方法 | |
| JP2006155637A (ja) | 信号処理装置 | |
| JP2006285719A (ja) | 情報処理装置および情報処理方法 | |
| JPH06139071A (ja) | 並列計算機 | |
| JP2011008416A (ja) | 並列計算装置 | |
| JP2004070869A (ja) | 演算システム | |
| JP2002268876A (ja) | パイプライン処理方法、及び情報処理装置 | |
| JPH0279122A (ja) | 浮動小数点演算機構 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20100527 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110929 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110929 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120726 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120802 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120928 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130327 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130404 |