JP2006195094A - 発音学習支援装置 - Google Patents
発音学習支援装置 Download PDFInfo
- Publication number
- JP2006195094A JP2006195094A JP2005005695A JP2005005695A JP2006195094A JP 2006195094 A JP2006195094 A JP 2006195094A JP 2005005695 A JP2005005695 A JP 2005005695A JP 2005005695 A JP2005005695 A JP 2005005695A JP 2006195094 A JP2006195094 A JP 2006195094A
- Authority
- JP
- Japan
- Prior art keywords
- speaker
- student
- information
- pronunciation
- level
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images















Abstract
【課題】 外国語の発音を学習する学習者が、高い学習意欲を維持したまま学習を続けられるようにすること。
【解決手段】 発音評価サービスにおいては、各生徒が生徒端末10から自らの音声情報をDSPサーバ装置40へ送信すると、その音声情報を基に特定した習熟レベルがDSPサーバ装置40へ蓄積される。練習相手紹介サービスにおいては、DSPサーバ装置40が、同じ習熟レベルの生徒端末10同士をマッチングし、それら両端末間での音声情報の遣り取りを制御する。
【選択図】 図1
【解決手段】 発音評価サービスにおいては、各生徒が生徒端末10から自らの音声情報をDSPサーバ装置40へ送信すると、その音声情報を基に特定した習熟レベルがDSPサーバ装置40へ蓄積される。練習相手紹介サービスにおいては、DSPサーバ装置40が、同じ習熟レベルの生徒端末10同士をマッチングし、それら両端末間での音声情報の遣り取りを制御する。
【選択図】 図1
Description
本発明は、発音の矯正を支援する技術に関する。
従来より、外国語の学習を支援する種々の技術が提案されてきた。例えば、特許文献1には、一人の指導者による複数の学習者に対する発音指導を好適に支援する技術の開示がある。同文献に開示された集合語学研修支援装置は、各学習者及び指導者が利用する端末である研修支援ユニットに、話者の口の動きや顔の表情などを撮像する撮像装置を搭載させてなる。この装置によれば、指導者は、各学習者の研修支援ユニットから自らに送信されてくる画像情報を基に各学習者の発音の様子を了解し、各々に合わせた指導を効率的に行うことができる。
特開平11−212437
ところで、特許文献1に開示された類の装置を用いた発音指導の多くは、お手本となる単語やセンテンスを真似て学習者が発音し、その発音内容について矯正すべき点を指導者が指摘する、といった遣り取りを繰返しながら進められる。しかしながら、学習者にしてみると、このような遣り取りの単純な繰り返しは面白みに欠けるため、高い学習意欲を維持したまま学習を続けることが難しかった。
本発明は、このような背景の下に案出されたものであり、外国語の発音を学習する学習者が、高い学習意欲を維持したまま学習を続けられるようなシステムを提供することを目的とする。
本発明は、このような背景の下に案出されたものであり、外国語の発音を学習する学習者が、高い学習意欲を維持したまま学習を続けられるようなシステムを提供することを目的とする。
本発明の好適な態様である発音学習支援装置は、発音のお手本となるセンテンス又は単語の発音手順を示す発音記号列を記憶した発音記号記憶手段と、発音の各習得レベルを夫々示すレベル情報をそれらの各習得レベルに達した話者の話者識別子と対応付けて記憶する話者レベル記憶手段と、発音の評価を求める話者の端末から、その話者が発音した前記センテンス若しくは単語を示す音声情報、又はその音声情報が示す波形の解析結果である特徴パラメータ列を当該話者の話者識別子と共に受信する発音内容受信手段と、前記発音記号記憶手段から発音記号列を読み出す記号列読出手段と、前記受信した音声情報又は特徴パラメータ列に所定の変換処理を施すことにより、前記話者の発音内容を表す発音記号列を取得する記号列取得手段と、前記記号列取得手段が取得した発音記号列と前記記号列読出手段が読み出した発音記号列とを比較し、その比較結果を基に前記評価を求める話者が達した習得レベルを特定する評価手段と、前記音声情報又は特徴パラメータ列と共に受信した話者識別子を前記評価手段が特定した習得レベルを示すレベル情報と対応付けて前記話者レベル記憶手段に記憶するレベル登録手段と、他者との会話を求める話者の端末から、その話者の話者識別子を受信する会話要求受信手段と、前記会話要求受信手段が話者識別子を受信すると、その話者識別子と共通のレベル情報と対応付けて前記話者レベル記憶手段に記憶された他の話者識別子を特定する会話相手マッチング手段と、前記特定した話者識別子が示す話者の端末と前記会話を求める話者の端末との間で音声情報を遣り取りさせる会話制御手段とを備える。
この態様において、前記会話相手マッチング手段は、前記受信した話者識別子と共通のレベル情報と対応付けて前記話者レベル記憶手段に記憶された他の一又は複数の話者識別子を読み出し、読み出した話者識別子を前記会話を求める話者の端末に宛てて通知する通知手段と、前記読み出した一又は複数の話者識別子のうち、前記通知の宛先であった端末から指定された話者識別子を特定する特定手段とを備えてもよい。
また、他者への紹介の要否を示す要否情報を前記各話者識別子と各々対応付けて記憶した要否情報記憶手段を備え、前記通知手段は、前記話者レベル記憶手段から読み出した一又は複数の話者識別情報のうち、前記要否情報記憶手段にて他者への紹介を要する要否情報と対応付けられている話者識別情報を前記会話を求める話者の端末に宛てて通知するようにしてもよい。
本発明によると、語学を学習する学習者が、高い学習意欲を維持したまま学習を続けることができる。
(発明の実施の形態)
本願発明の実施形態について説明する。
まず、以降の説明において用いる主要な用語を定義しておく。「センテンス」の語は、発音のお手本となる一纏まりのフレーズを意味する。「発音記号」の語は、英語に存在する母音及び子音を夫々固有に表す記号を意味する。「音声素片」の語は、音声の構成要素を意味し、母音のみからなる音素、母音から子音に遷移する音素連鎖、子音から母音に遷移する音素連鎖、及び母音から別の母音に遷移する音素連鎖のいずれをも含む。

本願発明の実施形態について説明する。
まず、以降の説明において用いる主要な用語を定義しておく。「センテンス」の語は、発音のお手本となる一纏まりのフレーズを意味する。「発音記号」の語は、英語に存在する母音及び子音を夫々固有に表す記号を意味する。「音声素片」の語は、音声の構成要素を意味し、母音のみからなる音素、母音から子音に遷移する音素連鎖、子音から母音に遷移する音素連鎖、及び母音から別の母音に遷移する音素連鎖のいずれをも含む。
本実施形態にかかる英語発音向上LLシステムの特徴は、英語の正しい発音の習得を希望する者(以下、「生徒」と呼ぶ)に対し、ネットワーク上に設けた専用のサーバ装置を介して以下の2つのサービスを提供するようにした点である。
(1)発音評価サービス
これは、教材として予め準備しておいた複数のセンテンスを生徒に発音させてそれらの音声情報を解析することにより、その生徒の発音の習得レベルを評価するサービスである。
(2)練習相手紹介サービス
これは、他の生徒との会話を通じた習得レベルの向上を求める生徒に対し、会話の相手となる生徒を紹介するサービスである。
(1)発音評価サービス
これは、教材として予め準備しておいた複数のセンテンスを生徒に発音させてそれらの音声情報を解析することにより、その生徒の発音の習得レベルを評価するサービスである。
(2)練習相手紹介サービス
これは、他の生徒との会話を通じた習得レベルの向上を求める生徒に対し、会話の相手となる生徒を紹介するサービスである。
図1は、本発明の実施形態にかかる英語発音向上LL(language laboratory)システムの全体構成を示すブロック図である。図に示すように、このシステムは、複数の生徒端末10と、講師端末30と、DSP(digital signal processor)サーバ装置40とを備える。
生徒端末10の各々は、マイクロホンアレイ30と接続される。このマイクロホンアレイ30は、話者である生徒の発した音声を最適に集音する機能に加えて、その発音が行われた際の息遣いの状況を計測する機能を搭載している。
生徒端末10の各々は、マイクロホンアレイ30と接続される。このマイクロホンアレイ30は、話者である生徒の発した音声を最適に集音する機能に加えて、その発音が行われた際の息遣いの状況を計測する機能を搭載している。
図2は、マイクロホンアレイ30のハードウェア構成を示すブロック図である。図に示すように、このマイクロホンアレイ30は、集音手段である複数のマイクロホンユニット31、アナログ/デジタル(以下、「A/D」と称す)変換器32、音圧測定部33、加算器34、パラメータ記憶制御部35、パラメータ記憶メモリ36、集音特性制御部37、及び入出力インターフェース38を備える。
複数のマイクロホンユニット31は、生徒の口元の方向に指向性を持たせるべく、縦方向及び横方向に夫々16列ずつ配列されている。それらマイクロホンユニット31の各々は、自身に到達した音波をアナログ音声信号に変換し、A/D変換器32へ供給する。すると、A/D変換器32にて変換されたデジタル音声信号が、音圧測定部33を経由して加算器34に供給される。
音圧測定部33は、自身を経由するデジタル音声信号を基に、各マイクロホンユニット31に到達した音波の音圧を夫々測定する。そして、各マイクロホンユニット31の位置とそれらに到達した音波の音圧との関係を示す音圧分布情報を入出力インターフェース38を介して生徒端末10へ出力する。出力された音圧分布情報は、生徒端末10からDSPサーバ装置40に送信され、同サーバ装置40にて発音時の息遣いの良否を評価する材料として利用される。
パラメータ記憶制御部35は、入出力インターフェース38を介して生徒端末10から入力される集音特性制御パラメータをパラメータ記憶メモリ36に記憶させる。この集音特性制御パラメータは、フィルタのカットオフ周波数を表すパラメータであり、DSPサーバ装置40から生徒端末10を経由して取得されることになっている。
集音特性制御部37は、ハイパスフィルタやローパスフィルタなどを内蔵しており、自身が内蔵する各フィルタのカットオフ周波数をパラメータ記憶メモリ36の集音特性制御パラメータに応じて設定する。加算器34にてミキシングされたデジタル音声信号は、集音特性制御部37にて所定の周波数成分が減衰された後、入出力インターフェース38を介して生徒端末10に出力されることになる。
図3は、生徒端末10のハードウェア構成を示すブロック図である。図に示すように、この端末10は、各種制御を行うCPU11、CPU11にワークエリアを提供するRAM12、IPL(initial program loader)を記憶したROM13、マイクロホンアレイ30との間で各種情報の入出力を行うマイクインターフェース14、スピーカ60に音声信号を出力するスピーカインターフェース15のほか、ネットワークインターフェース16、コンピュータディスプレイ17、キーボード18、マウス19、ハードディスク20などを備える。そして、ハードディスク20は、OS(operating system)や、ブラウザなどの各種アプリケーションソフトウェアを記憶する。
図4は、DSPサーバ装置40のハードウェア構成を示すブロック図である。図に示すように、この装置40は、CPU41、RAM42、ROM43、ネットワークインターフェース44、ハードディスク45などを備える。そして、ハードディスク45は、センテンスデータベース45a、生徒管理データベース45b、生徒別素片データベース45c、及び発音記号辞書データベース45dを記憶する。これら各データベースのうち、生徒別素片データベース45cは、各生徒毎に個別に設けられ、それら各生徒の生徒IDと各々対応付けられる。
図5は、センテンスデータベース45aのデータ構造図である。このデータベースは、各々が1つのセンテンスと対応する複数のレコードの集合体であり、それら各レコードは、発音の難易度が低いセンテンスと対応するものから順にソートされている。このデータベースを構成する1つのレコードは、「センテンス」、「欧文字スペル」、「発音記号列」、「息遣い」、及び「音声素片列」の5つのフィールドを有している。「センテンス」のフィールドには、各センテンスを識別するセンテンス識別子が記憶される。「欧文字スペル」のフィールドには、各センテンスのスペルを欧文字列として表すスペル情報が記憶される。「発音記号列」のフィールドには、各センテンスの発音手順を発音記号列として表すお手本記号列情報が記憶される。「息遣い」のフィールドには、お手本息遣い情報を記憶する。お手本息遣い情報は、各センテンスを良好に発音するための息遣いを音圧分布の遷移として示す情報である。「音声素片列」のフィールドには、各センテンスの音声を音声素片列として表す音声素片列情報が記憶される。
図6は、生徒管理データベース45bのデータ構造図である。このデータベースは、各々が一人の生徒と対応する複数のレコードの集合体である。このデータベースを構成する1つのレコードは、「生徒」、「認証情報」、「評価ポイント」、「紹介要否」、及び「レベル」の5つのフィールドを有している。「生徒」のフィールドには、各生徒を識別する生徒IDを記憶する。「認証情報」のフィールドには、集音特性制御パラメータを記憶する。DSPサーバ装置40は、各生徒の声質の解析結果を基に生成した集音特性制御パラメータをそれら各生徒のマイクロホンアレイ30に設定させる一方で、生成した集音特性制御パラメータを各生徒に固有の認証キーとして「認証情報」のフィールドに記憶することになっている。
「評価ポイント」のフィールドには、評価ポイントを記憶する。評価ポイントとは、各生徒の発音の巧拙の程度を客観的に表すポイントを意味する。後の動作説明の項にて詳述するように、本実施形態では、生徒の発音内容を示す音声情報を変換して得た発音記号列とセンテンスデータベース45aの「発音記号列」のフィールドに記憶された発音記号列との差異を発音減点ポイントとして定量化すると共に、生徒のマイクロホンアレイ30から取得した音圧分布情報とセンテンスデータベース45aの「息遣い」のフィールドに記憶されたお手本息遣い情報との差異を息遣い減点ポイントとして定量化することになっている。そして、満点である「100」から発音減点ポイントと息遣い減点ポイントとを減じて得た残りのポイントが、評価ポイントとして生徒に提示されると共に、「評価ポイント」のフィールドに記憶されることになる。
「紹介要否」のフィールドには、練習相手紹介サービスを通じた他者への紹介を許可することを示す「1」、又は紹介を拒否することを示す「0」の何れかの要否情報が記憶される。
「紹介要否」のフィールドには、練習相手紹介サービスを通じた他者への紹介を許可することを示す「1」、又は紹介を拒否することを示す「0」の何れかの要否情報が記憶される。
「レベル」のフィールドには、レベル情報を記憶する。レベル情報は、各生徒の発音の習得レベルを示す情報である。
図7に示すように、本実施形態では、評価ポイントが50ポイント未満であれば「レベル1」、50ポイント以上70ポイント未満であれば「レベル2」、70ポイント以上85ポイント未満であれば「レベル3」、85ポイント以上95ポイント未満であれば「レベル4」、95ポイント以上であれば「レベル5」の各習得レベルに夫々該当する。
図7に示すように、本実施形態では、評価ポイントが50ポイント未満であれば「レベル1」、50ポイント以上70ポイント未満であれば「レベル2」、70ポイント以上85ポイント未満であれば「レベル3」、85ポイント以上95ポイント未満であれば「レベル4」、95ポイント以上であれば「レベル5」の各習得レベルに夫々該当する。
図8は、ある生徒と対応する生徒別素片データベース45cのデータ構造図である。このデータベースは、各々が1つの音声素片と対応する複数のレコードの集合体である。このデータベースを構成する1つのレコードは、「音声素片」と「特徴パラメータ」の2つのフィールドを有している。「音声素片」のフィールドには、各音声素片の名称を示す素片名情報が記憶される。「特徴パラメータ」のフィールドには、特徴パラメータを記憶する。特徴パラメータは、各音声素片毎の周波数スペクトルの特徴を示すパラメータである。
図9は、発音記号辞書データベース45dのデータ構造図である。このデータベースは、各々が英語に存在する1つの母音又は子音と対応する複数のレコードの集合体である。このデータベース45dを構成する1つのレコードは、「発音記号」、「フォルマント」、及び「スペクトル情報」の3つのフィールドを有している。
「発音記号」のフィールドには、母音又は子音の発音記号を表す発音記号情報が記憶される。「フォルマント」のフィールドには、フォルマント情報が記憶される。フォルマント情報は、第1、第2、及び第3フォルマントのフォルマントレベルとフォルマント周波数とを示す情報である。フォルマントとは、音声波形の周波数スペクトル上の優勢な周波数成分であり、周波数の低い順に第1フォルマント、第2フォルマント、第3フォルマント、第4フォルマント・・・と呼ばれる。これらのうち、第3フォルマントまでが音韻性に寄与しており、第1乃至第3フォルマントの特徴を参照すれば、発音された音声に含まれる母音の種類を一意に特定できる。「スペクトル情報」のフィールドには、スペクトル情報が記憶される。スペクトル情報は、各母音及び子音のスペクトルの遷移を示す情報である。子音は第1乃至第3フォルマントを参照しただけではその種類を特定できないことも多いが、そのような場合は、フォルマントに加えてスペクトルの遷移を参照することによって、子音の種類を一意に特定できる。
「発音記号」のフィールドには、母音又は子音の発音記号を表す発音記号情報が記憶される。「フォルマント」のフィールドには、フォルマント情報が記憶される。フォルマント情報は、第1、第2、及び第3フォルマントのフォルマントレベルとフォルマント周波数とを示す情報である。フォルマントとは、音声波形の周波数スペクトル上の優勢な周波数成分であり、周波数の低い順に第1フォルマント、第2フォルマント、第3フォルマント、第4フォルマント・・・と呼ばれる。これらのうち、第3フォルマントまでが音韻性に寄与しており、第1乃至第3フォルマントの特徴を参照すれば、発音された音声に含まれる母音の種類を一意に特定できる。「スペクトル情報」のフィールドには、スペクトル情報が記憶される。スペクトル情報は、各母音及び子音のスペクトルの遷移を示す情報である。子音は第1乃至第3フォルマントを参照しただけではその種類を特定できないことも多いが、そのような場合は、フォルマントに加えてスペクトルの遷移を参照することによって、子音の種類を一意に特定できる。
講師端末50は、生徒端末10と同様に、CPU、RAM、ROM、マイクインターフェース、スピーカインターフェース、ネットワークインターフェース、コンピュータディスプレイ、キーボード、マウス、ハードディスクなどを備えており、各生徒端末10とDSPサーバ装置40の間の情報の遣り取りの履歴や、同サーバ装置40のデータベースの記憶内容などを適宜取得できるようになっている。
次に本実施形態の動作を説明する。
本実施形態の動作は、初期登録処理と、音声評価処理と、高評価音声提示処理とに分けることができる。
ある生徒端末10がDSPサーバ装置40へアクセスすると、DSPサーバ装置40のCPU41はその生徒端末10へサービス選択画面の表示データを送信する。そして、表示データを受信した生徒端末10のCPU11は、サービス選択画面を自らのコンピュータディスプレイ17に表示させる。
本実施形態の動作は、初期登録処理と、音声評価処理と、高評価音声提示処理とに分けることができる。
ある生徒端末10がDSPサーバ装置40へアクセスすると、DSPサーバ装置40のCPU41はその生徒端末10へサービス選択画面の表示データを送信する。そして、表示データを受信した生徒端末10のCPU11は、サービス選択画面を自らのコンピュータディスプレイ17に表示させる。
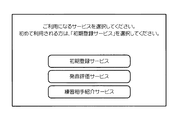
図10に示すように、このサービス選択画面の上段には、「ご利用になるサービスを選択してください。始めて利用される方は、「初期登録サービス」を選択してください。」という内容を示す文字列が表示され、その下には、「初期登録サービス」、「発音評価サービス」、及び「練習相手紹介サービス」と夫々記したボタンが表示される。そして、「初期登録サービス」と記したボタンが選択されると初期登録処理が、「発音評価サービス」と記したボタンが選択されると発音評価サービス処理が、「練習相手紹介サービス」と記したボタンが選択されると練習相手紹介サービス処理が夫々実行される。
図11及び12は、初期登録処理を示すフローチャートである。
「初期登録サービス」と記したボタンが選択されると、生徒端末10のCPU11は、初期登録サービスの提供を求めるメッセージをDSPサーバ装置40へ送信する(S100)。
メッセージを受信したDSPサーバ装置40のCPU41は、生徒管理データベース45bにレコードを一つ追加する(S110)。
続いて、CPU41は、新規な生徒IDを生成し、その生徒IDをステップ110で追加したレコードの「生徒」のフィールドに記憶する(S120)。
更に、CPU41は、ステップ110で追加したレコードの「レベル」のフィールドに、最初の習得レベルである「レベル1」を示すレベル情報を記憶する(S130)。
「初期登録サービス」と記したボタンが選択されると、生徒端末10のCPU11は、初期登録サービスの提供を求めるメッセージをDSPサーバ装置40へ送信する(S100)。
メッセージを受信したDSPサーバ装置40のCPU41は、生徒管理データベース45bにレコードを一つ追加する(S110)。
続いて、CPU41は、新規な生徒IDを生成し、その生徒IDをステップ110で追加したレコードの「生徒」のフィールドに記憶する(S120)。
更に、CPU41は、ステップ110で追加したレコードの「レベル」のフィールドに、最初の習得レベルである「レベル1」を示すレベル情報を記憶する(S130)。
CPU41は、マイク調整用フレーズ発音要求画面の表示データを生成し、その表示データを生徒端末10へ送信する(S140)。
表示データを受信した生徒端末10のCPU11は、マイク調整用フレーズ発音要求画面をコンピュータディスプレイ17に表示させる(S150)。
マイク調整用フレーズ発音要求画面の上段には、「マイクロホンアレイの集音特性を最適化しますので、以下のフレーズをはっきりと発音してください。」という内容の文字列が表示され、その下には、マイク調整用フレーズを示す文字列が表示される。
表示データを受信した生徒端末10のCPU11は、マイク調整用フレーズ発音要求画面をコンピュータディスプレイ17に表示させる(S150)。
マイク調整用フレーズ発音要求画面の上段には、「マイクロホンアレイの集音特性を最適化しますので、以下のフレーズをはっきりと発音してください。」という内容の文字列が表示され、その下には、マイク調整用フレーズを示す文字列が表示される。
この画面を参照した生徒は、自らの生徒端末10にマイクロホンアレイ30が接続されていることを確認した後、同画面に表示されているマイク調整用フレーズをマイクロホンアレイ30に向かって発音する。すると、その発音内容を示すデジタル音声信号が、入出力インターフェース38から生徒端末10に順次入力される。
生徒端末10は、マイクロホンアレイ30から自端末10に入力されてくるデジタル音声信号に所定の符号化処理を施して得た音声情報をDSPサーバ装置40へ送信する(S160)。
生徒端末10は、マイクロホンアレイ30から自端末10に入力されてくるデジタル音声信号に所定の符号化処理を施して得た音声情報をDSPサーバ装置40へ送信する(S160)。
DSPサーバ装置40のCPU41は、生徒端末10から受信した音声情報を復号化して音声信号を取得すると、その音声信号が示す所定時間長分の時間波形の周波数成分の分布に応じて集音特性制御パラメータを生成する(S170)。例えば、マイク調整用フレーズを発音した生徒が比較的高い声質の持ち主であった場合、高い周波数域に周波数成分が偏ることになるため、生成される集音特性制御パラメータが示すカットオフ周波数もそれだけ高いものにする。反対に、生徒が比較的低い声質の持ち主であった場合、低い周波数域に周波数成分が偏ることになるため、集音特性制御パラメータが示すカットオフ周波数もそれだけ低いものにする。
CPU41は、ステップ170で生成した集音特性制御パラメータをステップ110で追加したレコードの「認証情報」のフィールドに記憶する(S180)。
更に、CPU41は、ステップ180で記憶したものと同じ集音特性制御パラメータを生徒端末10へ送信する(S190)。
集音特性制御パラメータを受信した生徒端末10のCPU11は、その集音特性制御パラメータをマイクロホンアレイ30に出力する(S200)。上述したように、マイクロホンアレイ30は、集音特性制御パラメータを記憶するためのパラメータ記憶メモリ36を備えている。生徒端末10から入力された集音特性制御パラメータがパラメータ記憶制御部35によってこのメモリ36に記憶されると、集音特性制御部37は、記憶されたパラメータに応じて自身が内蔵するフィルタのカットオフ周波数を直ちに設定する。この設定により、マイクロホンアレイ30の集音特性がその利用者である生徒の声質に応じて最適化されることになる。
更に、CPU41は、ステップ180で記憶したものと同じ集音特性制御パラメータを生徒端末10へ送信する(S190)。
集音特性制御パラメータを受信した生徒端末10のCPU11は、その集音特性制御パラメータをマイクロホンアレイ30に出力する(S200)。上述したように、マイクロホンアレイ30は、集音特性制御パラメータを記憶するためのパラメータ記憶メモリ36を備えている。生徒端末10から入力された集音特性制御パラメータがパラメータ記憶制御部35によってこのメモリ36に記憶されると、集音特性制御部37は、記憶されたパラメータに応じて自身が内蔵するフィルタのカットオフ周波数を直ちに設定する。この設定により、マイクロホンアレイ30の集音特性がその利用者である生徒の声質に応じて最適化されることになる。
集音特性制御パラメータをマイクロホンアレイ30に出力した生徒端末10のCPU11は、マイクの調整が完了したことを示すメッセージをDSPサーバ装置40に送信する(S210)。
メッセージを受信したDSPサーバ装置40のCPU41は、新たな生徒別素片データベース45cをハードディスク45に設ける(S220)。設けられた生徒別素片データベース45cを構成する各レコードの「音声素片」のフィールドには、各音声素片の素片名情報が既に記憶されている。その一方で、「特徴パラメータ」のフィールドには未だ特徴パラメータが記憶されておらず、以下に実行される一連の処理を通じて、特徴パラメータが順次蓄積されることになる。
CPU41は、予め準備されている素片抽出用フレーズ群のうちの1つを所定の雛形に埋め込んで素片抽出用フレーズ発音要求画面の表示データを生成し、生成した表示データを生徒端末10へ送信する(S230)。
メッセージを受信したDSPサーバ装置40のCPU41は、新たな生徒別素片データベース45cをハードディスク45に設ける(S220)。設けられた生徒別素片データベース45cを構成する各レコードの「音声素片」のフィールドには、各音声素片の素片名情報が既に記憶されている。その一方で、「特徴パラメータ」のフィールドには未だ特徴パラメータが記憶されておらず、以下に実行される一連の処理を通じて、特徴パラメータが順次蓄積されることになる。
CPU41は、予め準備されている素片抽出用フレーズ群のうちの1つを所定の雛形に埋め込んで素片抽出用フレーズ発音要求画面の表示データを生成し、生成した表示データを生徒端末10へ送信する(S230)。
ここで、素片抽出用フレーズ群とは、全ての音声素片が網羅されるように体系化された複数のフレーズの纏まりを意味する。
表示データをDSPサーバ装置40から受信した生徒端末10のCPU11は、素片抽出用フレーズ発音要求画面をコンピュータディスプレイ17に表示させる(S240)。
素片抽出用フレーズ発音要求画面の上段には、「あなたの肉声を基に音声合成用のデータベースを作成します。以下のフレーズを発音してください。」という内容の文字列が表示され、その下には、素片抽出用フレーズを示す文字列が表示される。
素片抽出用フレーズ発音要求画面の上段には、「あなたの肉声を基に音声合成用のデータベースを作成します。以下のフレーズを発音してください。」という内容の文字列が表示され、その下には、素片抽出用フレーズを示す文字列が表示される。
この画面を参照した生徒は、同画面に表示されている素片抽出用フレーズをマイクロホンアレイ30に向かって発音する。すると、その発音内容を示すデジタル音声信号が、入出力インターフェース38から生徒端末10に順次入力される。
生徒端末10のCPU11は、マイクロホンアレイ30から自端末10に入力されてくるデジタル音声信号に所定の符号化処理を施して得た音声情報をDSPサーバ装置40へ送信する(S250)。
生徒端末10のCPU11は、マイクロホンアレイ30から自端末10に入力されてくるデジタル音声信号に所定の符号化処理を施して得た音声情報をDSPサーバ装置40へ送信する(S250)。
DSPサーバ装置40のCPU41は、生徒端末10から送信されてきた音声情報をRAM42に記憶する(S260)。
CPU41は、ステップ250でRAM42に記憶した音声情報に復号化処理を施して元の音声信号を取得すると、その音声信号が示す時間波形を解析して音声素片の特徴パラメータを取得する(S270)。
このステップについて更に具体的に説明する。本ステップでは、まず、音声情報を復号化して得た音声信号が示す時間波形に高速フーリエ変換をかけ、所定のフレーム毎の周波数スペクトルの特徴を示す特徴パラメータ列を取得する。そして、取得された一連の特徴パラメータを、時間波形に含まれる各音声素片の長さと夫々対応する区間毎に切り出す。
CPU41は、ステップ250でRAM42に記憶した音声情報に復号化処理を施して元の音声信号を取得すると、その音声信号が示す時間波形を解析して音声素片の特徴パラメータを取得する(S270)。
このステップについて更に具体的に説明する。本ステップでは、まず、音声情報を復号化して得た音声信号が示す時間波形に高速フーリエ変換をかけ、所定のフレーム毎の周波数スペクトルの特徴を示す特徴パラメータ列を取得する。そして、取得された一連の特徴パラメータを、時間波形に含まれる各音声素片の長さと夫々対応する区間毎に切り出す。
CPU41は、ステップ270で取得した特徴パラメータを、それらの音声素片名を示す素片名情報と対応付け、ステップ220で設けた生徒別素片データベース45cに記憶する(S280)。
全ての素片抽出用フレーズの音声信号から取得した特徴パラメータが生徒別素片データベース45cに蓄積されるまで、ステップ230乃至ステップ280の処理は繰返される。
全ての特徴パラメータを蓄積し終えると、CPU41は、紹介要否選択要求画面の表示データを生成し、その表示データを生徒端末10へ送信する(S290)。
全ての素片抽出用フレーズの音声信号から取得した特徴パラメータが生徒別素片データベース45cに蓄積されるまで、ステップ230乃至ステップ280の処理は繰返される。
全ての特徴パラメータを蓄積し終えると、CPU41は、紹介要否選択要求画面の表示データを生成し、その表示データを生徒端末10へ送信する(S290)。
表示データを受信した生徒端末10のCPU11は、紹介要否選択要求画面をコンピュータディスプレイ17に表示させる(S300)。
紹介要否選択要求画面の上段には、「練習相手紹介サービスを通じた紹介を希望しますか。」という内容を示す文字列が表示され、その下には、「希望します」、及び「希望しません」と夫々記したボタンが表示される。
この画面を参照した生徒は、何れかのボタンを選択する。
何れかのボタンが選択されると、生徒端末10のCPU11は、その選択内容を示す要否情報をDSPサーバ装置40へ送信する(S310)。
紹介要否選択要求画面の上段には、「練習相手紹介サービスを通じた紹介を希望しますか。」という内容を示す文字列が表示され、その下には、「希望します」、及び「希望しません」と夫々記したボタンが表示される。
この画面を参照した生徒は、何れかのボタンを選択する。
何れかのボタンが選択されると、生徒端末10のCPU11は、その選択内容を示す要否情報をDSPサーバ装置40へ送信する(S310)。
DSPサーバ装置40のCPU41は、生徒端末10から送信されてきた要否情報を、ステップ110で追加したレコードの「紹介要否」のフィールドへ記憶する(S320)。
続いて、CPU41は、ステップ120で「生徒」のフィールドに記憶したものと同じ生徒IDを生徒端末10へ送信する(S330)。
生徒IDを受信した生徒端末10のCPU11は、その生徒IDをハードディスク20の所定領域に記憶する(S340)。
以上で、初期登録処理が終了する。
続いて、CPU41は、ステップ120で「生徒」のフィールドに記憶したものと同じ生徒IDを生徒端末10へ送信する(S330)。
生徒IDを受信した生徒端末10のCPU11は、その生徒IDをハードディスク20の所定領域に記憶する(S340)。
以上で、初期登録処理が終了する。
図13及び14は、発音評価サービス処理を示すフローチャートである。
「発音評価サービス」と記したボタンが選択されると、生徒端末10のCPU11は、発音評価サービスの提供を求めるメッセージをDSPサーバ装置40へ送信する(S400)。
メッセージを受信したDSPサーバ装置40のCPU41は、生徒IDの送信を求めるメッセージを生徒端末10へ送信する(S410)。
メッセージを受信した生徒端末10のCPU11は、初期登録処理を通じてDSPサーバ装置40から取得していた生徒IDをハードディスク20の所定領域から読み出し、その生徒IDをDSPサーバ装置40へ送信する(S420)。
「発音評価サービス」と記したボタンが選択されると、生徒端末10のCPU11は、発音評価サービスの提供を求めるメッセージをDSPサーバ装置40へ送信する(S400)。
メッセージを受信したDSPサーバ装置40のCPU41は、生徒IDの送信を求めるメッセージを生徒端末10へ送信する(S410)。
メッセージを受信した生徒端末10のCPU11は、初期登録処理を通じてDSPサーバ装置40から取得していた生徒IDをハードディスク20の所定領域から読み出し、その生徒IDをDSPサーバ装置40へ送信する(S420)。
DSPサーバ装置40のCPU41は、生徒端末10から送信されたものと同じ生徒IDを「生徒」のフィールドに記憶したレコードを生徒管理データベース45bから特定する(S430)。
続いて、CPU41は、集音特性制御パラメータの送信を求めるメッセージを生徒端末10へ送信する(S440)。
メッセージを受信した生徒端末10のCPU11は、自端末10に接続されたマイクロホンアレイ30のパラメータ記憶メモリ36に記憶されている集音特性制御パラメータを取得し、取得した集音特性制御パラメータをDSPサーバ装置40へ送信する(S450)。
続いて、CPU41は、集音特性制御パラメータの送信を求めるメッセージを生徒端末10へ送信する(S440)。
メッセージを受信した生徒端末10のCPU11は、自端末10に接続されたマイクロホンアレイ30のパラメータ記憶メモリ36に記憶されている集音特性制御パラメータを取得し、取得した集音特性制御パラメータをDSPサーバ装置40へ送信する(S450)。
DSPサーバ装置40のCPU41は、生徒端末10から送信されてきた集音特性制御パラメータと、ステップ430で特定したレコードの「認証情報」のフィールドに記憶された集音特性制御パラメータとが一致するか否か判断する(S460)。
ステップ460にて、集音特性制御パラメータが一致しないと判断したCPU41は、サービスの提供を拒否するメッセージを生徒端末10へ送信する(S470)。
一方、ステップ460にて、集音特性制御パラメータが一致すると判断したCPU41は、評価ポイントの算出に用いる領域(以下、「ポイント算出領域」と呼ぶ)をRAM42の一部に確保し、そのポイント算出領域に評価ポイントの満点である「100」を記憶する(S480)。
ステップ460にて、集音特性制御パラメータが一致しないと判断したCPU41は、サービスの提供を拒否するメッセージを生徒端末10へ送信する(S470)。
一方、ステップ460にて、集音特性制御パラメータが一致すると判断したCPU41は、評価ポイントの算出に用いる領域(以下、「ポイント算出領域」と呼ぶ)をRAM42の一部に確保し、そのポイント算出領域に評価ポイントの満点である「100」を記憶する(S480)。
CPU41は、センテンスデータベース45aのレコードの1つを参照対象として特定する(S490)。なお、上述したように、このセンテンスデータベース45aは、発音の難易度が低いセンテンスと対応するレコードから順にソートされており、本ステップからステップ680までの一連の処理は、参照対象となるレコードをシフトさせながら繰返されることになっている。
CPU41は、ステップ490で特定したレコードの「発音記号列」のフィールドに記憶されているお手本記号列情報、「息遣い」のフィールドに記憶されたお手本息遣い情報、及び「音声素片列」のフィールドに記憶された音声素片列情報をRAM42に読み出す(S500)。
CPU41は、ステップ490で特定したレコードの「発音記号列」のフィールドに記憶されているお手本記号列情報、「息遣い」のフィールドに記憶されたお手本息遣い情報、及び「音声素片列」のフィールドに記憶された音声素片列情報をRAM42に読み出す(S500)。
続いて、CPU41は、ステップ490で特定したレコードの「欧文字スペル」のフィールドに記憶されているスペル情報を所定の雛形に埋め込んで発音課題提示画面の表示データを生成し、その表示データを生徒端末10へ送信する(S510)。
表示データを受信した生徒端末10のCPU11は、発音課題提示画面をコンピュータディスプレイ17に表示させる(S520)。
発音課題提示画面の上段には、「以下のセンテンスをはっきり発音して下さい。」という内容を示す文字列が表示され、その下には、センテンスのスペルの示す欧文字列が表示される。
表示データを受信した生徒端末10のCPU11は、発音課題提示画面をコンピュータディスプレイ17に表示させる(S520)。
発音課題提示画面の上段には、「以下のセンテンスをはっきり発音して下さい。」という内容を示す文字列が表示され、その下には、センテンスのスペルの示す欧文字列が表示される。
この画面を参照した生徒は、自らの生徒端末10にマイクロホンアレイ30が接続されていることを確認した後、同画面に表示されているセンテンスをマイクロホンアレイ30に向かって発音する。すると、各マイクロホンユニット31に到達した音波を示すデジタル音声信号が、音圧測定部33を経由して加算器34に夫々供給される。加算器34にてミキシングされたデジタル音声信号は、集音特性制御部37において所定の周波数成分が減衰された後、音圧測定部33によって生成された音圧分布情報と共に入出力インターフェース38から生徒端末10へと順次出力される。
生徒端末10のCPU11は、マイクロホンアレイ30から自端末10へデジタル音声信号と音圧分布情報とが入力されてくると、デジタル音声信号を音声情報化し、その音声情報を音圧分布情報と併せてDSPサーバ装置40へ順次送信する(S530)。
生徒端末10のCPU11は、マイクロホンアレイ30から自端末10へデジタル音声信号と音圧分布情報とが入力されてくると、デジタル音声信号を音声情報化し、その音声情報を音圧分布情報と併せてDSPサーバ装置40へ順次送信する(S530)。
DSPサーバ装置40のCPU41は、生徒端末10から送信されてくる音声情報と音圧分布情報とをRAM42に順次記憶する(S540)。
CPU41は、ステップ540でRAM42に記憶した音声情報に所定の変換処理を施すことにより、生徒の発音内容を示す発音記号列を取得する(S550)。
このステップについて更に具体的に説明する。本ステップでは、まず、音声情報を復号化して得た音声信号に高速フーリエ変換をかけ、所定のフレーム毎の周波数スペクトルを取得する。そして、取得された周波数スペクトルから、第1、第2、及び第3フォルマントのフォルマント周波数とフォルマントレベルとを抽出する。続いて、抽出したフォルマント周波数とフォルマントレベルの各対を、時間波形に含まれる子音及び母音の長さと各々対応する区間毎に夫々切り出す。更に、発音記号辞書データベース45dの各レコードを参照し、切り出したフォルマント周波数及びフォルマントレベルと「フォルマント」のフィールドの記憶内容が最も近い母音又は子音の発音記号を取得する。なお、子音については、各レコードの「フォルマント」のフィールドを参照しただけでは発音記号の候補を1つに絞り込めないケースが生じうる。その場合は、その子音と対応する区間の周波数スペクトルの遷移と各レコードの「スペクトル情報」の記憶内容とを夫々比較して更なる絞込みを行い、周波数スペクトルの遷移の特徴が最も近似する唯一の子音の発音記号を取得する。
CPU41は、ステップ540でRAM42に記憶した音声情報に所定の変換処理を施すことにより、生徒の発音内容を示す発音記号列を取得する(S550)。
このステップについて更に具体的に説明する。本ステップでは、まず、音声情報を復号化して得た音声信号に高速フーリエ変換をかけ、所定のフレーム毎の周波数スペクトルを取得する。そして、取得された周波数スペクトルから、第1、第2、及び第3フォルマントのフォルマント周波数とフォルマントレベルとを抽出する。続いて、抽出したフォルマント周波数とフォルマントレベルの各対を、時間波形に含まれる子音及び母音の長さと各々対応する区間毎に夫々切り出す。更に、発音記号辞書データベース45dの各レコードを参照し、切り出したフォルマント周波数及びフォルマントレベルと「フォルマント」のフィールドの記憶内容が最も近い母音又は子音の発音記号を取得する。なお、子音については、各レコードの「フォルマント」のフィールドを参照しただけでは発音記号の候補を1つに絞り込めないケースが生じうる。その場合は、その子音と対応する区間の周波数スペクトルの遷移と各レコードの「スペクトル情報」の記憶内容とを夫々比較して更なる絞込みを行い、周波数スペクトルの遷移の特徴が最も近似する唯一の子音の発音記号を取得する。
CPU41は、ステップ550で取得した発音記号列を構成する一連の発音記号のうち、ステップ500で読み出したお手本記号列情報が示す発音記号列と一致しない箇所を特定する(S560)。
CPU41は、お手本記号列情報が示す発音記号列と一致しなかった箇所の発音記号の数に所定のポイント換算率を作用させて発音減点ポイントを取得する(S570)。
続いて、CPU41は、ステップ540でRAM42に記憶した一連の音圧分布情報が示す音圧分布の遷移と、ステップ500で読み出したお手本息遣い情報が示す音圧分布の遷移との差分を求め、求めた差分値に所定のポイント換算率を作用させて息遣い減点ポイントを取得する(S580)。
CPU41は、お手本記号列情報が示す発音記号列と一致しなかった箇所の発音記号の数に所定のポイント換算率を作用させて発音減点ポイントを取得する(S570)。
続いて、CPU41は、ステップ540でRAM42に記憶した一連の音圧分布情報が示す音圧分布の遷移と、ステップ500で読み出したお手本息遣い情報が示す音圧分布の遷移との差分を求め、求めた差分値に所定のポイント換算率を作用させて息遣い減点ポイントを取得する(S580)。
CPU41は、ステップ570で取得した発音減点ポイントとステップ580で取得した息遣い減点ポイントの合計を、RAM42のポイント算出領域に記憶させてある評価ポイントから減算する(S590)。
更に、CPU41は、ステップ500で読み出したお手本記号列情報とステップ560で特定した箇所との関係を表す要矯正箇所提示画面の表示データを生成し、生成した表示データを生徒端末10に送信する(S600)。
更に、CPU41は、ステップ500で読み出したお手本記号列情報とステップ560で特定した箇所との関係を表す要矯正箇所提示画面の表示データを生成し、生成した表示データを生徒端末10に送信する(S600)。
表示データを受信した生徒端末10のCPU11は、要矯正箇所提示画面をコンピュータディスプレイ17に表示させる(S610)。
図15は、要矯正箇所提示画面である。
「センテンスの正しい発音手順を示す発音記号は以下のようになっています。赤色で表示された箇所の発音をお手本のように矯正する必要があります。」という内容の文字列が表示され、その下には、発音記号列表示領域Aと、スペル表示領域Bとが表示される。
図15は、要矯正箇所提示画面である。
「センテンスの正しい発音手順を示す発音記号は以下のようになっています。赤色で表示された箇所の発音をお手本のように矯正する必要があります。」という内容の文字列が表示され、その下には、発音記号列表示領域Aと、スペル表示領域Bとが表示される。
発音記号列表示領域Aには、お手本記号列情報が示す一連の発音記号列が表示される。これら一連の発音記号列のうち、ステップ560で特定した箇所と対応する発音記号は、残りの発音記号とは別の色である赤色で表示される(図面上では赤色の文字を鎖線の矩形として標記)。
なお、本実施形態では、ステップ560で特定した箇所と対応する発音記号を残りの発音記号と異なる色によって表わしているが、文字の大きさ、書体等によって両者の表示態様に違いを与えてもよい。
また、スペル表示領域Bには、センテンスのスペルを示す欧文字列が表示される。
更に、画面の下段には、「自分の声の正しい発音を聴いてみる」と記したボタンと、「次のセンテンスに進む」と記したボタンとが表示される。
また、スペル表示領域Bには、センテンスのスペルを示す欧文字列が表示される。
更に、画面の下段には、「自分の声の正しい発音を聴いてみる」と記したボタンと、「次のセンテンスに進む」と記したボタンとが表示される。
生徒は、画面上の発音記号列表示領域Aとスペル表示領域Bとを参照し、矯正を要する発音の箇所を確認した後、何れかのボタンを選択する。
「自分の声の正しい発音を聴いてみる」と記したボタンが選択されると、生徒端末10のCPU11は、矯正音声情報の送信を求めるメッセージをDSPサーバ装置40へ送信する(S620)。
メッセージを受信したDSPサーバ装置40のCPU41は、ステップ500で読み出した音声素片列情報が示す一連の音声素片のうち、ステップ560で特定した箇所と対応する一部の音声素片又は音声素片列を抽出し、抽出した音声素片又は音声素片列と特徴パラメータを生徒別音声データベース45cから読み出す(S630)。
「自分の声の正しい発音を聴いてみる」と記したボタンが選択されると、生徒端末10のCPU11は、矯正音声情報の送信を求めるメッセージをDSPサーバ装置40へ送信する(S620)。
メッセージを受信したDSPサーバ装置40のCPU41は、ステップ500で読み出した音声素片列情報が示す一連の音声素片のうち、ステップ560で特定した箇所と対応する一部の音声素片又は音声素片列を抽出し、抽出した音声素片又は音声素片列と特徴パラメータを生徒別音声データベース45cから読み出す(S630)。
CPU41は、ステップ630で読み出した特徴パラメータを基にセンテンスの矯正音声情報を合成する(S640)。
このステップについて更に具体的に説明する。本ステップでは、まず、音声情報を復号化して得た音声信号が示す時間波形に高速フーリエ変換をかけ、所定のフレーム毎の周波数スペクトルの特徴を示す特徴パラメータ列を取得する。そして、取得された一連の特徴パラメータのうち、ステップ560で特定した箇所の音声素片又は音声素片列と対応する区間を特定し、特定した区間の特徴パラメータをステップ630で読み出した特徴パラメータに置換する。次に、置換が施された後の特徴パラメータ列に逆フーリエ変換をかけ、時間波形を示すデジタル音声信号を取得した後、その音声信号に所定の符号化処理を施すことにより、矯正音声情報を取得する。
このステップについて更に具体的に説明する。本ステップでは、まず、音声情報を復号化して得た音声信号が示す時間波形に高速フーリエ変換をかけ、所定のフレーム毎の周波数スペクトルの特徴を示す特徴パラメータ列を取得する。そして、取得された一連の特徴パラメータのうち、ステップ560で特定した箇所の音声素片又は音声素片列と対応する区間を特定し、特定した区間の特徴パラメータをステップ630で読み出した特徴パラメータに置換する。次に、置換が施された後の特徴パラメータ列に逆フーリエ変換をかけ、時間波形を示すデジタル音声信号を取得した後、その音声信号に所定の符号化処理を施すことにより、矯正音声情報を取得する。
DSPサーバ装置40のCPU41は、ステップ640で取得した矯正音声情報を生徒端末10へ送信する(S650)。
矯正音声情報を受信した生徒端末10のCPU11は、その矯正音声情報を復号化して得たデジタル音声信号をスピーカインターフェース15を介してスピーカ60へ供給する(S660)。すると、スピーカ60からは、センテンスの正しい発音が、生徒自身の声質の音声として放音される。
矯正音声情報を受信した生徒端末10のCPU11は、その矯正音声情報を復号化して得たデジタル音声信号をスピーカインターフェース15を介してスピーカ60へ供給する(S660)。すると、スピーカ60からは、センテンスの正しい発音が、生徒自身の声質の音声として放音される。
一方、要矯正箇所提示画面において、「次のセンテンスに進む」と記したボタンが選択されると、生徒端末10のCPU11は、次のセンテンスの提示を求めるメッセージをDSPサーバ装置40へ送信する(S670)。
メッセージを受信したDSPサーバ装置40のCPU41は、未だ参照対象となっていないレコードがセンテンスデータベース45aに残っているか否かを判断する(S680)。
ステップ680にて、参照対象となっていないレコードが残っていると判断されると、再びステップ490に戻って、参照対象となるレコードを1つシフトさせた後、以降の一連の処理が繰返される。
メッセージを受信したDSPサーバ装置40のCPU41は、未だ参照対象となっていないレコードがセンテンスデータベース45aに残っているか否かを判断する(S680)。
ステップ680にて、参照対象となっていないレコードが残っていると判断されると、再びステップ490に戻って、参照対象となるレコードを1つシフトさせた後、以降の一連の処理が繰返される。
ステップ680にて、参照対象となっていないレコードが残っていないと判断されると、DSPサーバ装置40のCPU41は、RAM42のポイント算出領域に記憶されている評価ポイントを、ステップ430で特定したレコードの「評価ポイント」のフィールドに記憶する(S690)。
続いて、CPU41は、ステップ690で記憶した評価ポイントを図7に示した基準と照らし合わせることにより、今回の発音評価サービスによって生徒が到達した習得レベルを特定し、特定した習得レベルを示すレベル情報をステップ430で特定したレコードの「レベル」のフィールドへ記憶する(S700)。
続いて、CPU41は、ステップ690で記憶した評価ポイントを図7に示した基準と照らし合わせることにより、今回の発音評価サービスによって生徒が到達した習得レベルを特定し、特定した習得レベルを示すレベル情報をステップ430で特定したレコードの「レベル」のフィールドへ記憶する(S700)。
CPU41は、評価ポイントとレベル情報とを所定の雛形に埋め込んで評価結果通知画面の表示データを生成し、その表示データを生徒端末10に送信する(S710)。
表示データを受信した生徒端末10のCPU11は、評価結果通知画面をコンピュータディスプレイ17に表示させる(S720)。
評価結果通知画面の上段には、「あなたの今回の評価ポイントと習得レベルは以下の通りです。」という内容を示す文字列が表示され、その下には、評価ポイントと習得レベルとが表示される。
以上で、発音評価サービス処理が終了する。
表示データを受信した生徒端末10のCPU11は、評価結果通知画面をコンピュータディスプレイ17に表示させる(S720)。
評価結果通知画面の上段には、「あなたの今回の評価ポイントと習得レベルは以下の通りです。」という内容を示す文字列が表示され、その下には、評価ポイントと習得レベルとが表示される。
以上で、発音評価サービス処理が終了する。
図16は、練習相手紹介サービス処理を示すフローチャートである。
「練習相手紹介サービス」と記したボタンが選択されると、生徒端末10のCPU11は、練習相手紹介サービスの提供を求めるメッセージをDSPサーバ装置40へ送信し、その後、DSPサーバ装置40は、集音特性制御パラメータを用いた認証を行う。これら一連の処理の内容は、図13に示したステップ400乃至460と同様であるので、再度の説明を割愛する。
ステップ460にて、集音特性制御パラメータが一致すると判断したDSPサーバ装置40のCPU41は、ステップ430で生徒管理データベース45bから特定したレコードの「レベル」のフィールドに記憶されているレベル情報をRAM42に読み出す(S800)。
「練習相手紹介サービス」と記したボタンが選択されると、生徒端末10のCPU11は、練習相手紹介サービスの提供を求めるメッセージをDSPサーバ装置40へ送信し、その後、DSPサーバ装置40は、集音特性制御パラメータを用いた認証を行う。これら一連の処理の内容は、図13に示したステップ400乃至460と同様であるので、再度の説明を割愛する。
ステップ460にて、集音特性制御パラメータが一致すると判断したDSPサーバ装置40のCPU41は、ステップ430で生徒管理データベース45bから特定したレコードの「レベル」のフィールドに記憶されているレベル情報をRAM42に読み出す(S800)。
CPU41は、生徒管理データベース45bの各レコードのうちから、「紹介要否」のフィールドの記憶内容が「1」となっており且つ「レベル」のフィールドの記憶内容がステップ800で読み出したレベル情報と共通している一又は複数のレコードを特定する(S810)。
CPU41は、ステップ810で特定した一又は複数のレコードの「生徒」のフィールドから生徒IDを読み出し、読み出した生徒IDを所定の雛形に埋め込んで得た会話相手リスト画面の表示データを生徒端末10へ送信する(S820)。
CPU41は、ステップ810で特定した一又は複数のレコードの「生徒」のフィールドから生徒IDを読み出し、読み出した生徒IDを所定の雛形に埋め込んで得た会話相手リスト画面の表示データを生徒端末10へ送信する(S820)。
表示データを受信した生徒端末10のCPU11は、会話相手リスト画面をコンピュータディスプレイ17に表示させる(S830)。
会話相手リスト画面の上段には、「あなたと同じ習得レベルにある方は以下の通りです。会話を申し込む方を選択してください。」という内容を示す文字列が表示される。そして、その下には、会話の相手として選択可能な生徒の生徒IDがリストとして表示される。
この画面を参照した生徒は、自らの会話の相手とする他の生徒を選択する。
生徒端末10のCPU11は、選択された生徒の生徒IDを内包する会話相手指定情報をDSPサーバ装置40へ送信する(S840)。
会話相手リスト画面の上段には、「あなたと同じ習得レベルにある方は以下の通りです。会話を申し込む方を選択してください。」という内容を示す文字列が表示される。そして、その下には、会話の相手として選択可能な生徒の生徒IDがリストとして表示される。
この画面を参照した生徒は、自らの会話の相手とする他の生徒を選択する。
生徒端末10のCPU11は、選択された生徒の生徒IDを内包する会話相手指定情報をDSPサーバ装置40へ送信する(S840)。
DSPサーバ装置40のCPU41は、生徒端末10から送信されてきた会話相手指定情報に内包されている生徒IDを取得し、その生徒IDと対応する生徒端末10に宛てて会話申込通知画面の表示データを送信する(S850)。
表示データを受信した生徒端末10のCPU11は、会話申込通知画面をコンピュータディスプレイ17に表示させる(S860)。
会話申込通知画面には、「会話の申込がありました。申込を受けますか」という内容を示す文字列が表示され、その下には、「はい」及び「いいえ」と夫々記したボタンが表示される。
この画面を参照した他の生徒は、何れかのボタンを選択する。
表示データを受信した生徒端末10のCPU11は、会話申込通知画面をコンピュータディスプレイ17に表示させる(S860)。
会話申込通知画面には、「会話の申込がありました。申込を受けますか」という内容を示す文字列が表示され、その下には、「はい」及び「いいえ」と夫々記したボタンが表示される。
この画面を参照した他の生徒は、何れかのボタンを選択する。
生徒端末10のCPU11は、選択されたボタンを示す応答通知情報をDSPサーバ装置40へ送信する(S870)。
DSPサーバ装置40が受信した応答通知情報が「いいえ」の選択を示すものであるとき、CPU41は、申込が拒絶されたことを示すメッセージを生徒端末10へ送信する(S880)。
このメッセージを受信した生徒端末10のCPU11は、再びステップ830に戻り、申込が拒絶されたことを示す文字列と併せて会話相手リスト画面をコンピュータディスプレイ17に表示させる。
DSPサーバ装置40が受信した応答通知情報が「いいえ」の選択を示すものであるとき、CPU41は、申込が拒絶されたことを示すメッセージを生徒端末10へ送信する(S880)。
このメッセージを受信した生徒端末10のCPU11は、再びステップ830に戻り、申込が拒絶されたことを示す文字列と併せて会話相手リスト画面をコンピュータディスプレイ17に表示させる。
一方、DSPサーバ装置40が受信した応答通知情報が「はい」の選択を示すものであるとき、CPU41は、申込が受け容れられたことを示すメッセージを生徒端末へ送信する(S890)。
このメッセージが送信されたことをトリガーとして、両生徒端末10は、DSPサーバ装置40を介した音声情報の遣り取りが可能な状態となる。つまり、DSPサーバ装置40のCPU41は、一方の生徒端末10から送信される音声情報を他方の生徒端末10へリアルタイムで転送する処理を行う。
このメッセージが送信されたことをトリガーとして、両生徒端末10は、DSPサーバ装置40を介した音声情報の遣り取りが可能な状態となる。つまり、DSPサーバ装置40のCPU41は、一方の生徒端末10から送信される音声情報を他方の生徒端末10へリアルタイムで転送する処理を行う。
以上説明した本実施形態は、以下に示す有用な効果を奏する。
第1に、自身の発音内容のどの箇所が良好でないかを生徒に具体的に把握させることができる。本実施形態における発音評価サービスでは、DSPサーバ装置40が、生徒の発音内容を示す音声情報を変換して得た発音記号列とお手本となる発音記号列の不一致の度合いを評価する。そして、その結果が要矯正箇所提示画面として生徒に提示される。この要矯正箇所提示画面では、お手本記号列情報が示す一連の発音記号列のうち、生徒が正しく発音できなかった箇所の発音記号が残りの発音記号とは異なる色で表示されるようになっている。従って、各生徒は、要矯正箇所提示画面を参照することにより、自らが正しく発音できていた箇所と正しく発音できなかった箇所とを発音記号レベルではっきりと把握することができる。
第1に、自身の発音内容のどの箇所が良好でないかを生徒に具体的に把握させることができる。本実施形態における発音評価サービスでは、DSPサーバ装置40が、生徒の発音内容を示す音声情報を変換して得た発音記号列とお手本となる発音記号列の不一致の度合いを評価する。そして、その結果が要矯正箇所提示画面として生徒に提示される。この要矯正箇所提示画面では、お手本記号列情報が示す一連の発音記号列のうち、生徒が正しく発音できなかった箇所の発音記号が残りの発音記号とは異なる色で表示されるようになっている。従って、各生徒は、要矯正箇所提示画面を参照することにより、自らが正しく発音できていた箇所と正しく発音できなかった箇所とを発音記号レベルではっきりと把握することができる。
第2に、生徒の学習意欲を持続させることができる。本実施形態における発音評価サービスでは、生徒の発音内容から評価ポイントを算出するだけでなく、各生徒の習熟レベルを5段階に分けて分類するようになっている。そして、練習相手紹介サービスでは、他者との会話を求める生徒に対し、同じ習熟レベルの他の生徒を会話の相手として紹介するようになっている。従って、生徒は、学習意欲を損なうことなく、他の生徒との会話を楽しみながら自らの英会話能力を向上させていくことができる。
第3に、英語の話し方の良否を複数の切り口から総合的に評価することができる。本実施形態では、各生徒端末10にマイクロホンアレイ30が接続され、このマイクロホンアレイ30は、生徒の発音した音声の波形を示すデジタル音声信号だけでなく、その発音を行った際の息遣いの状態を示す音圧分布情報をも生徒端末10へ供給するようになっている。そして、DSPサーバ装置40は、生徒端末10から送信されてくる音声情報を基に生徒の発音内容である音声そのものの評価を行うだけでなく、同端末10から送信されてくる音圧分布情報を基に息遣いの評価をも行い、2つの評価の結果を評価ポイントに反映させるようになっている。従って、音声の波形を解析するだけでは得られないような精緻な評価結果を生徒に提示することができる。
第4に、サービスを不正に利用する悪意者を簡易且つ確実に排除することができる。本実施形態では、所定の周波数成分を減衰させて集音特性を最適化する集音特性制御部37を各生徒のマイクロホンアレイ30に内蔵させており、この集音特性制御部37の制御内容を示す集音特性制御パラメータは、生徒の認証キーとしてDSPサーバ装置40側に登録されることになっている。そして、発音評価サービス又は練習相手紹介サービスを利用する生徒端末10は、DSPサーバ装置40にアクセスするとマイクロホンアレイ30の集音特性制御パラメータを引き渡し、引渡した集音特性制御パラメータがDSPサーバ装置40に登録されているものと一致することを条件として、両サービスの提供が許可されるようになっている。このように、各生徒の声質に依存して生成される固有の集音特性制御パラメータを認証キーとしても利用することにより、不正なサービスの利用を確実に排除することができる。また、パスワードやIDの入力といった煩わしい認証手続きを生徒に強いる必要も無くなる。
(他の実施形態)
本願発明は、種々の変形実施が可能である。
上記実施形態における初期登録処理では、DSPサーバ装置40が、生徒端末10から送信されてきた音声情報を復号化して音声信号を取得し、その音声信号が示す波形に高速フーリエ変換をかけて得た周波数スペクトルの特徴パラメータを生徒別素片データベース45cに蓄積するようになっていた。また、発音評価サービス処理においても同様に、DSPサーバ装置40が、生徒端末10から送信されてきた音声情報を復号化して音声信号を取得した後、その音声信号が示す波形に高速フーリエ変換をかけて得た周波数スペクトルの特徴パラメータ列の一部を生徒別素片データベース45cから抽出した特徴パラメータで置換することによって矯正音声情報を取得していた。
これに対し、音声信号の波形に高速フーリエ変換をかける機能を生徒端末10にも搭載させ、同端末10はマイクロホンアレイ30から入力されたデジタル音声信号に高速フーリエ変換を施して得た特徴パラメータ列をDSPサーバ装置40に送信するようにしてもよい。かかる変形例によると、DSPサーバ装置40は、音声信号に改めて高速フーリエ変換を施す必要がなくなり、同サーバ装置40の処理負担が軽減される。つまり、初期登録処理においては、生徒端末10から送信されてきた特徴パラメータ列を各音声素片と対応する区間毎に切り出して生徒別素片データベース45cに蓄積すればよく、また、発音評価サービス処理においては、送信されてきた特徴パラメータ列のうち、お手本と一致しなかった箇所を生徒別素片データベース45cから読み出した特徴パラメータで置換するだけでよい。
本願発明は、種々の変形実施が可能である。
上記実施形態における初期登録処理では、DSPサーバ装置40が、生徒端末10から送信されてきた音声情報を復号化して音声信号を取得し、その音声信号が示す波形に高速フーリエ変換をかけて得た周波数スペクトルの特徴パラメータを生徒別素片データベース45cに蓄積するようになっていた。また、発音評価サービス処理においても同様に、DSPサーバ装置40が、生徒端末10から送信されてきた音声情報を復号化して音声信号を取得した後、その音声信号が示す波形に高速フーリエ変換をかけて得た周波数スペクトルの特徴パラメータ列の一部を生徒別素片データベース45cから抽出した特徴パラメータで置換することによって矯正音声情報を取得していた。
これに対し、音声信号の波形に高速フーリエ変換をかける機能を生徒端末10にも搭載させ、同端末10はマイクロホンアレイ30から入力されたデジタル音声信号に高速フーリエ変換を施して得た特徴パラメータ列をDSPサーバ装置40に送信するようにしてもよい。かかる変形例によると、DSPサーバ装置40は、音声信号に改めて高速フーリエ変換を施す必要がなくなり、同サーバ装置40の処理負担が軽減される。つまり、初期登録処理においては、生徒端末10から送信されてきた特徴パラメータ列を各音声素片と対応する区間毎に切り出して生徒別素片データベース45cに蓄積すればよく、また、発音評価サービス処理においては、送信されてきた特徴パラメータ列のうち、お手本と一致しなかった箇所を生徒別素片データベース45cから読み出した特徴パラメータで置換するだけでよい。
上記実施形態において、DSPサーバ装置40のセンテンスデータベース45aには、お手本記号列情報やお手本息遣い情報がセンテンス毎に記憶さており、発音評価サービス処理における減点ポイントの算出もセンテンス毎に行われていた。これに対し、センテンスよりも細かな会話の構成要素である単語ごとにお手本記号列情報やお手本息遣い情報をデータベース化しておき、発音評価サービス処理では、それら各単語毎に減点ポイントの算出を行うようにしてもよい。
上記実施形態において、DSPサーバ装置40は、音声信号が示す時間波形に高速フーリエ変換をかけて得た一連の特徴パラメータのうち、お手本どおりに発音できていない区間を正しい音声素片の特徴パラメータで置換することによって矯正音声情報を合成していた。これに対し、以下に示すような他の手順に従って矯正音声情報を合成してもよい。この手順では、まず、生徒の音声情報の時間軸を、その音声情報に含まれる各音声素片の位置がお手本として準備されている音声情報に含まれる各音声素片の位置と夫々一致するように正規化する。その上で、お手本となる音声情報のピッチとベロシティを、生徒の音声情報のそれと差し替える。最後に、生徒の音声情報に含まれる子音の部分だけをお手本となる音声情報のそれと入れ替える。このような手順によっても、矯正音声情報、つまり、発音の仕方を矯正するための正しい発音内容を示す音声情報の生成は可能である。
上記実施形態におけるマイクロホンアレイ30の集音部は、複数のマイクロホンユニット31を縦方向及び横方向に夫々16列ずつ配列した構造を取っていた。しかしながら、マイクロホンユニット31をこのような方向及び数で並べる必要はなく、生徒の発音時における音圧分布をデータ化できるようになってさえいれば、別の構造にしてもよい。
上記実施形態において、DSPサーバ装置40の発音記号辞書データベース45dは、フォルマント情報に加えてスペクトル情報を各母音及び子音の各々と対応付けて蓄積していた。そして、同サーバ装置40は、生徒の発音情報を発音記号列に変換する際、その音声情報の時間波形に含まれるある子音の種類をフォルマントの比較によって一意に特定できなかったときは、その子音と対応する区間の周波数スペクトルの遷移と発音記号辞書データベース45dに記憶された各スペクトル情報とを比較することによって種類を特定していた。これに対し、Hidden Markov Model(隠れマルコフモデル)を利用して変換を行なってもよい。この変形例によると、音節、単語、文節といったセグメンテーション単位で発音記号列の候補を絞り込んでいくことになるため、母音及び子音毎の独立した認識を行う上記実施形態よりも確度の高い変換結果を得ることができる。
10…生徒端末、11,41…CPU、12,42…RAM、13,43…ROM、14…マイクインターフェース、15…スピーカインターフェース、16,44…ネットワークインターフェース、17…コンピュータディスプレイ、18…キーボード、19…マウス、20,45…ハードディスク、50…講師端末、30…マイクロホンアレイ、31…マイクロホンユニット、32…A/D変換器、33…音圧測定部、34…加算器、35…パラメータ記憶制御部、36…パラメータ記憶メモリ、37…集音特性制御部、38…入出力インターフェース、40…DSPサーバ装置、60…スピーカ
Claims (3)
- 発音のお手本となるセンテンス又は単語の発音手順を示す発音記号列を記憶した発音記号記憶手段と、
発音の各習得レベルを夫々示すレベル情報をそれらの各習得レベルに達した話者の話者識別子と対応付けて記憶する話者レベル記憶手段と、
発音の評価を求める話者の端末から、その話者が発音した前記センテンス若しくは単語を示す音声情報、又はその音声情報が示す波形の解析結果である特徴パラメータ列を当該話者の話者識別子と共に受信する発音内容受信手段と、
前記発音記号記憶手段から発音記号列を読み出す記号列読出手段と、
前記受信した音声情報又は特徴パラメータ列に所定の変換処理を施すことにより、前記話者の発音内容を表す発音記号列を取得する記号列取得手段と、
前記記号列取得手段が取得した発音記号列と前記記号列読出手段が読み出した発音記号列とを比較し、その比較結果を基に前記評価を求める話者が達した習得レベルを特定する評価手段と、
前記音声情報又は特徴パラメータ列と共に受信した話者識別子を前記評価手段が特定した習得レベルを示すレベル情報と対応付けて前記話者レベル記憶手段に記憶するレベル登録手段と、
他者との会話を求める話者の端末から、その話者の話者識別子を受信する会話要求受信手段と、
前記会話要求受信手段が話者識別子を受信すると、その話者識別子と共通のレベル情報と対応付けて前記話者レベル記憶手段に記憶された他の話者識別子を特定する会話相手マッチング手段と、
前記特定した話者識別子が示す話者の端末と前記会話を求める話者の端末との間で音声情報を遣り取りさせる会話制御手段と
を備えた発音学習支援装置。 - 請求項1に記載の発音学習支援装置において、
前記会話相手マッチング手段は、
前記受信した話者識別子と共通のレベル情報と対応付けて前記話者レベル記憶手段に記憶された他の一又は複数の話者識別子を読み出し、読み出した話者識別子を前記会話を求める話者の端末に宛てて通知する通知手段と、
前記読み出した一又は複数の話者識別子のうち、前記通知の宛先であった端末から指定された話者識別子を特定する特定手段と
を備えた発音学習支援装置。 - 請求項2に記載の発音学習支援装置において、
他者への紹介の要否を示す要否情報を前記各話者識別子と各々対応付けて記憶した要否情報記憶手段を備え、
前記通知手段は、
前記話者レベル記憶手段から読み出した一又は複数の話者識別情報のうち、前記要否情報記憶手段にて他者への紹介を要する要否情報と対応付けられている話者識別情報を前記会話を求める話者の端末に宛てて通知する
発音学習支援装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005005695A JP2006195094A (ja) | 2005-01-12 | 2005-01-12 | 発音学習支援装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005005695A JP2006195094A (ja) | 2005-01-12 | 2005-01-12 | 発音学習支援装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2006195094A true JP2006195094A (ja) | 2006-07-27 |
Family
ID=36801232
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005005695A Withdrawn JP2006195094A (ja) | 2005-01-12 | 2005-01-12 | 発音学習支援装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2006195094A (ja) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012168266A (ja) * | 2011-02-10 | 2012-09-06 | Ntt Docomo Inc | 言語能力判定装置、言語能力判定方法、コンテンツ配信システム及びプログラム |
| JP2013536468A (ja) * | 2010-08-20 | 2013-09-19 | ヒ ユン,ヒョク | 語学学習システムおよびその制御方法 |
| JP6172417B1 (ja) * | 2016-08-17 | 2017-08-02 | 健一 海沼 | 語学学習システム及び語学学習プログラム |
| JP2019219991A (ja) * | 2018-06-21 | 2019-12-26 | トヨタ自動車株式会社 | 情報処理装置及び情報処理方法、プログラム |
| JP7422113B2 (ja) | 2021-08-20 | 2024-01-25 | Lineヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
-
2005
- 2005-01-12 JP JP2005005695A patent/JP2006195094A/ja not_active Withdrawn
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013536468A (ja) * | 2010-08-20 | 2013-09-19 | ヒ ユン,ヒョク | 語学学習システムおよびその制御方法 |
| JP2012168266A (ja) * | 2011-02-10 | 2012-09-06 | Ntt Docomo Inc | 言語能力判定装置、言語能力判定方法、コンテンツ配信システム及びプログラム |
| JP6172417B1 (ja) * | 2016-08-17 | 2017-08-02 | 健一 海沼 | 語学学習システム及び語学学習プログラム |
| WO2018033979A1 (ja) * | 2016-08-17 | 2018-02-22 | 健一 海沼 | 語学学習システム及び語学学習プログラム |
| CN108431883A (zh) * | 2016-08-17 | 2018-08-21 | 海沼健 | 语言学习系统以及语言学习程序 |
| CN108431883B (zh) * | 2016-08-17 | 2020-04-28 | 海沼健一 | 语言学习系统以及语言学习程序 |
| US11145222B2 (en) | 2016-08-17 | 2021-10-12 | Ken-ichi KAINUMA | Language learning system, language learning support server, and computer program product |
| JP2019219991A (ja) * | 2018-06-21 | 2019-12-26 | トヨタ自動車株式会社 | 情報処理装置及び情報処理方法、プログラム |
| JP7059823B2 (ja) | 2018-06-21 | 2022-04-26 | トヨタ自動車株式会社 | 情報処理装置及び情報処理方法、プログラム |
| JP7422113B2 (ja) | 2021-08-20 | 2024-01-25 | Lineヤフー株式会社 | 情報処理装置、情報処理方法および情報処理プログラム |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3520022B2 (ja) | 外国語学習装置、外国語学習方法および媒体 | |
| US7155391B2 (en) | Systems and methods for speech recognition and separate dialect identification | |
| US7149690B2 (en) | Method and apparatus for interactive language instruction | |
| JP6172417B1 (ja) | 語学学習システム及び語学学習プログラム | |
| US20030229497A1 (en) | Speech recognition method | |
| JP2005321817A (ja) | 教育及び試験における適応対話の音声信号から複合情報を得る方法及び装置 | |
| JP2002040926A (ja) | インターネット上での自動発音比較方法を用いた外国語発音学習及び口頭テスト方法 | |
| JP5105943B2 (ja) | 発話評価装置及び発話評価プログラム | |
| JP2008158055A (ja) | 言語発音練習支援システム | |
| JP2006195094A (ja) | 発音学習支援装置 | |
| JP4779365B2 (ja) | 発音矯正支援装置 | |
| JP4626310B2 (ja) | 発音評価装置 | |
| JP7376071B2 (ja) | コンピュータプログラム、発音学習支援方法及び発音学習支援装置 | |
| JP2003228279A (ja) | 音声認識を用いた語学学習装置、語学学習方法及びその格納媒体 | |
| JP4899383B2 (ja) | 語学学習支援方法 | |
| KR20000049500A (ko) | 음성 인식 및 음성 합성을 이용한 외국어 교육 서비스방법 및 그 시스템 | |
| JP2006195095A (ja) | 音声処理サービス提供装置、マイクロホン | |
| JP2007071904A (ja) | 地域別発音学習支援装置 | |
| KR101004940B1 (ko) | 음성인식을 활용한 컴퓨터 주도형 말하기 능력 평가방법 | |
| JP2001282096A (ja) | 外国語発音評価装置 | |
| KR20140073768A (ko) | 의미단위 및 원어민의 발음 데이터를 이용한 언어교육 학습장치 및 방법 | |
| KR20090081046A (ko) | 인터넷을 이용한 언어 학습 시스템 및 방법 | |
| Kasrani | Development of a Performance Assessment System for Language Learning | |
| KR20140075145A (ko) | 단어 및 문장과 이미지 데이터 그리고 원어민의 발음 데이터를 이용한 파닉스 학습장치 및 방법 | |
| KR20140074449A (ko) | 단어와 이미지 데이터 및 원어민 발음 데이터를 이용한 단어 학습장치 및 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071120 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20090128 |