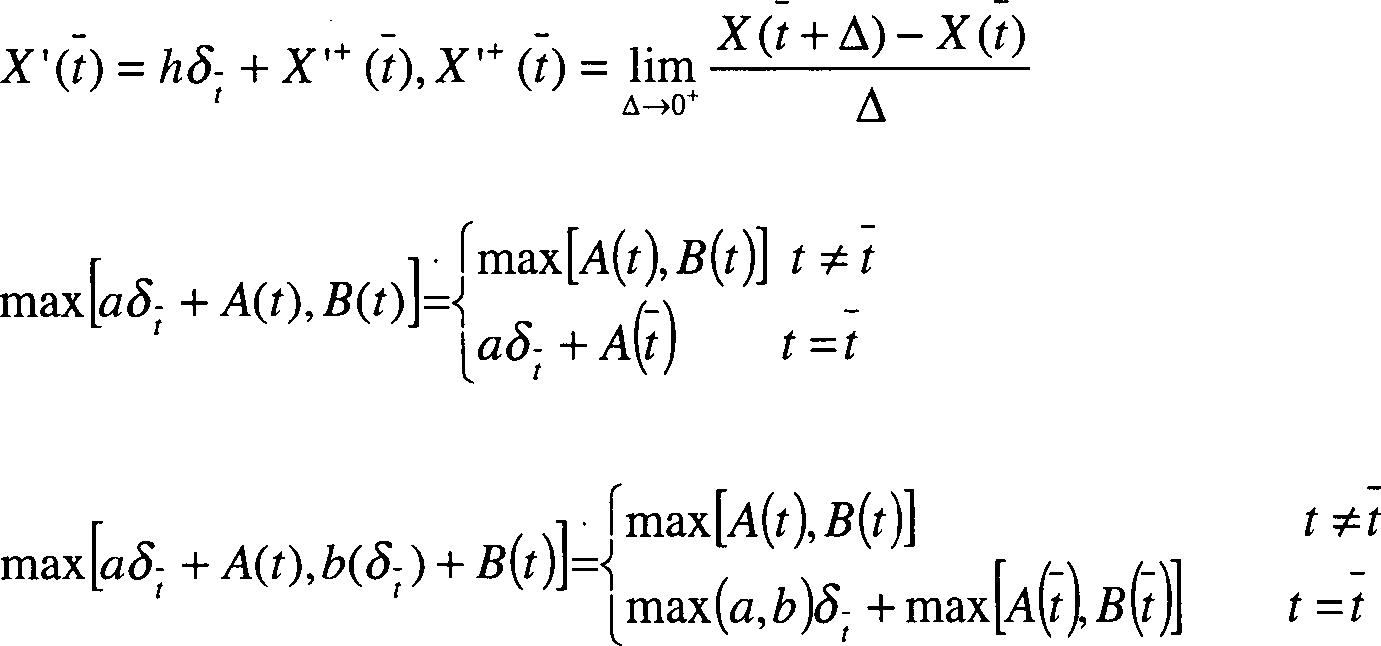-
Die
Erfindung betrifft einen Scheduler für ein Speichersystem, der einer
Datenverarbeitungseinheit meldet, dass in dem Speichersystem gespeicherte
Daten für
einen von dem Benutzer definierten Zeitraum abgespeichert sind.
-
Die
US 5691984 A beschreibt
eine Schaltung, welche die Kommunikation zwischen externen Systemen
mit unterschiedlichen oder gleichen Protokollen unter Verwendung
von Fülldaten
zur Synchronisation erlaubt.
-
1 zeigt
prinzipiell den Aufbau bei einer Datenverarbeitung. Von einer Datenquelle
werden parallel oder seriell Daten an eine Datenverarbeitungseinheit
abgegeben, die die Daten entsprechend einer Berechnungsvorschrift
verarbeitet und die verarbeiteten Daten an eine nachgeschaltete
Datensenke abgibt.
-
Am
Dateneingang der Datenverarbeitungseinheit kommt der Datenstrom
entsprechend einer Datenankunftskurve an. In 2 ist eine
lineare bzw. ideale Datenankunftskurve dargestellt. Bei einer realen
Datenübertragung
ist die Datenankunftskurve nicht linear, sondern weist verschiedene
Steigungen bzw. Sprünge auf,
die beispielsweise von Datenbursts strammen.
-
Die
Datenverarbeitungseinheit verarbeitet die Daten entsprechend einer
Datenbedienkurve, die in 2 dargestellt ist. Kommen, wie
bei dem in 2 dargestellten Beispiel, mehr
Daten am Eingang E der Datenverarbeitungseinheit an, als durch die
Datenverarbeitungseinheit verarbeitet werden können, ist ein Zwischenspeicher
am Eingang E der Datenverarbeitungs-Einheit vorzusehen, um die überschüssigen Daten
zwischenzuspeichern. Die minimale Speichergröße des Zwischenspeichers entspricht
der maximalen Differenz zwischen der Ankunftskurve und der Bedienkurve.
Die in der Datenverarbeitungseinheit verarbeiteten Daten sind der
nachgeschalteten Datensenke innerhalb einer bestimmten Verzögerungszeit ΔT zur Verfügung zu stellen.
Der in der Datenverarbeitungseinheit ankommende Datenstrom ist nach
einer vorbestimmten Verzögerungszeit ΔT an die
nachgeschaltete Datensenke als abzuholende Daten zu melden. In dem
Zeitraum zwischen der Ankunftszeit der Daten und der Abgabezeit,
wenn die Zeitverzögerung
den gewünschten
Zeitverzögerungswert ΔT erreicht,
bleiben die Daten zur Verfügung.
Nach Ablauf dieser Zeitspanne bzw. Zeitdauer werden die nicht an
die Datensenke weitergeleiteten bzw. verarbeiteten Daten zwingend
sofort gesendet, umgespeichert oder gelöscht. Die Datenquelle erzeugt
den Datenstrom mit einer abschnittsweise nahezu linearen Ankunftskurve
am Ausgang der Datenquelle. Der Datenstrom wird durch den Datenübertragungskanal
modifiziert. Die Datenverarbeitungseinheit gibt die empfangenen
Daten nach. der vorgegebenen Zeitverzögerung ΔT ab. Es ist dabei erstrebenswert,
dass die lineare Ankunftskurve der Datenquelle mit einer vorbestimmten Zeitverzögerung am
Ausgang A der Datenverarbeitungseinheit rekonstruiert wird. Die
von der Datenverarbeitungseinheit abgegebenen Daten des Datenstromes
können
an verschiedene Datensenken geroutet werden. Bei einer praktischen
Anwendung innerhalb eines Speicherverwaltungssystems ist es notwendig,
um Dead-Lock-Situationen
zu vermeiden, eine Ablaufzeit für
die ankommenden Daten zu implementieren. Nach dem Ablauf der Ablaufzeit ΔT sind die
zwischengespeicherten Daten entweder zu löschen oder in einen anderen
Speicher abzuspeichern, um den Speicherplatz des Pufferspeichers
freizugeben. Zur Erfüllung
von Quality of Service-Anforderungen ist es dabei von Bedeutung,
eine deterministische vorbestimmte genaue Zeitverzögerung ΔT einzuhalten.
-
Bei
dem sog. Time Stamping nach dem Stand der Technik wird jedes ankommende
Datenpaket DP des am Eingang E der Datenverarbeitungseinheit ankommenden
Datenstroms mit einem Zeitstempel versehen, die die Ankunftszeit
am Eingang E angibt. Das ankommende Datenpaket DP wird eingelesen
und der Zeitpunkt der Ankunft des Datenpakets wird gemessen. Die
gemessene Datenankunftszeit wird als Zeitstempel in einer Tabelle
abgespeichert. Anschließend
wird periodisch kontrolliert, ob das empfangene Datenpaket sich
bereits länger
als die vorgegebene Verzögerungszeit ΔT in der
Datenverarbeitungseinheit befindet. Anschließend werden diejenigen Datenpakete
gelöscht
oder weggespeichert, deren Ablaufzeit erreicht ist.
-
Ein
gravierender Nachteil beim Time Stamping besteht darin, dass ein
Datenstrom, der aus einer Vielzahl von Datenpaketen besteht, mit
einer entsprechenden Anzahl von Zeitstempeln bzw. Time Stamps durch die
Datenverarbeitungseinheit verwaltet werden muss. Es muss einerseits
für jeden
Zeitstempel ein zugehöriger
Speicherplatz zur Verfügung
gestellt werden und darüber
hinaus sind sehr viele Zeitvergleiche notwendig, so dass der schaltungstechnische
Aufwand innerhalb der Datenverarbeitungseinheit erheblich zunimmt,
wenn die Vergleiche der verschiedenen Zeitstempel gleichzeitig erfolgen
sollen. Werden die Zeitvergleiche aufgrund der Vielzahl der Zeitstempel
sequentiell durchgeführt,
nimmt die Ungenauigkeit bzgl. der Verzögerungszeit ΔT zu.
-
Es
wurden daher ein sog. Zeitscheiben (Time-Wheel)-Speicherverwaltungsverfahren nach dem
Stand der Technik vorgeschlagen. 3 zeigt
eine Anordnung zur Erläuterung
des Zeitscheiben-Verfahrens. Eine Datenverarbeitungseinheit empfängt von
einem Scheduler die Informationen zum Abholen der zu verarbeitenden
Daten aus dem Speichersystem. Der Scheduler ist über ein Netzwerk an zwei Datenquellen
A, B angeschlossen. Bei dem in 3 dargestellten
Beispiel gibt jede Datenquelle sequentiell 5 Datenpakete an das Netzwerk
ab. Bei den Datenpaketen bzw. Datenzellen handelt es sich beispielsweise
um ATM-Datenzellen mit einer vorgegebenen Datengröße von 53
Bytes. Die 5 ATM-Datenzellen werden zur Fragmentierung eines größeren Datenpakets
fragmentiert. Dabei wird das große Datenpaket empfangen, in
kleinere Zellen fragmentiert und die fragmentierten Zellen werden
anschließend über das
Netzwerk an eine Datenverarbeitungseinheit übertragen. Die Datenverarbeitungseinheit
fügt die
empfangenen Datenzellen zusammen, um das ursprüngliche Datenpaket wieder zu
erhalten.
-
Die über das
Netzwerk übertragenen
ATM-Zellen kommen in einer beliebigen Reihenfolge bei dem Scheduler
an, der sie in das Speichersystem einschreibt. Weist das Speichersystem
eine relativ große
Größe SP0 auf, werden beispielsweise die Datenzellen
A bis E der ersten Datenquelle A und die Datenzellen α bis ε der zweiten
Datenquelle B, wie in 3 dargestellt, in das Speichersystem
in ein FIFO-Verfahren eingeschrieben.
-
Ein
Problem besteht, wenn die Speichergröße des Speichersystems geringer
ist, beispielsweise SP1. In diesem Falle
kann keine vollständige
Kette (beispielsweise aus fünf
ATM-Zellen) in das
Speichersystem eingeschrieben werden. Nach dem Einschreiben der
ATM-Zelle δ der
zweiten Datenquelle B ist das Speichersystem voll und der Scheduler
muss bei der Ankunft der nächsten
ATM-Zellen ε,
D, E entscheiden, welche bereits abgespeicherten ATM-Zellen innerhalb
des Speichersystems zu löschen
sind, damit eine vollständige ATM-Zellenkette
in dem Speichersystem zwischengespeichert werden kann, die durch
die Datenverarbeitungseinheit anschließend entsprechend verarbeitet
werden kann. Der Scheduler kann daher entsprechend einer Strategie
Datenpakete löschen
bzw. umzuspeichern, wenn das Speichersystem gefüllt ist und weitere Datenpakete
ankommen. Der Scheduler könnte
beispielsweise das erste angekommene Datenpaket A löschen, um
Speicherplatz für
das nächste
ankommende Datenpaket ε zu
schaffen. In diesem Falle wäre
die vollständige
Kette der ATM-Zellen der Datenquelle B in dem Speichersystem zwischengespeichert
und steht für
die Datenverarbeitung durch die Datenverarbeitungseinheit zur Verfügung. Eine
alternative Strategie ist das vollständige Löschen allerempfangenen Datenzellen
von einer Datenquelle, beispielsweise der Datenzellen α, β, γ, δ der Datenquelle
B, um Speicherplatz für
die beiden ankommenden Datenzellen D, E zu schaffen, so dass die
Datenverarbeitungseinheit die Daten der Datenquelle A, d. h. die
ATM-Zellen A bis E, verarbeiten kann.
-
Bei
dem in 3 dargestellten Zeitscheiben-Verfahren werden
die ankommenden ATM-Zellen in der Reihenfolge ihrer Ankunft abgespeichert.
Bei dem Speichersystem handelt es sich um einen FIFO-Speicher. Bei
dem Zeitscheiben-Verfahren bzw. Time-Wheel-Verfahren wird die Speicherbelegung
des Speichersystems als Maß für die Zeit
ausgenutzt. Dazu werden die Daten herkömmlicher Weise in einen kreisförmigen bzw.
zirkulären
FIFO-Datenpuffer abgelegt. Wird eine ankommende Datenzelle an einer
Stelle X zwischengespeichert, werden die nachfolgenden Daten bzw.
Datenpakete an Speicherplätzen
abgespeichert, die auf den Speicherplatz X folgen. Auf diese Weise
wird der FIFO-Speicher sukzessive aufgefüllt, bis der gefüllte Speicherraum
einen bestimmten Pegel erreicht bzw. der Speicher vollständig mit
Daten gefüllt
ist. Wenn die Menge der ankommenden Daten erfasst wird und die Daten
mit einer vorgegebenen Datenmenge R ankommen ist es möglich, die
verstrichene Zeit zu berechnen, seit dem das Datenpaket DP bei der
Position X zwischengespeichert worden ist. Da der Speicher-Voll-Pegel
der Ablaufzeit der zwischengespeicherten Datenzelle bzw. dem zwischengespeicherten
Datenpaket entspricht, kann das zuvor eingespeicherte Datenpaket
der Datenverarbeitungseinheit durch den Scheduler als abgelaufen
gemeldet werden, sobald der Speicher-Voll-Pegel erreicht ist.
-
Ein
Nachteil des Zeitscheiben-Verfahrens bzw. Time-Wheel-Verfahrens besteht
darin, dass der ankommende Datenstrom nur in seltenen Fällen eine
konstante gleichbleibende Datenmenge R aufweist. In vielen Anwendungsfällen bestehen
zeitliche Lücken
zwischen der Ankunft der verschiedenen Datenzellen bzw. Datenpaketen.
Da die Datenrate zur Berechnung als konstant angenommen wird, entstehen
aufgrund der zum Teil stark schwankenden Datenübertragungsraten eine sehr
hohe Ungenauigkeit bei der Berechnung der Ablaufzeit.
-
Es
wurde daher ein verbessertes Zeitscheiben-Verfahren (Enhanced-Time-Wheel)
vorgeschlagen, bei dem zeitliche Lücken zwischen der Ankunft von
Datenpaketen mit sog. Dummy-Zellen bzw. Fülldatenzellen überbrückt werden.
Wenn innerhalb einer einstellbaren Wartezeit kein Datenpaket bzw.
keine Datenzelle an dem Scheduler ankommt, schreibt der Schedule
in den FIFO-Speicher
des Speichersystems eine Fülldatenzelle
ein. 4 zeigt schematisch einen FIFO-Speicher, in dem
eine Folge von ATM-Zellen Z1, Z2, Z3, Z4 entsprechend der Reihenfolge
ihrer Ankunft eingeschrieben werden. Die ATM-Zellen sind untereinander
mit Zeigern bzw. Pointern verkettet und weisen eine feste Datengröße von 53
Byte auf. Durch die Verkettung erkennt die Datenverarbeitungseinheit,
dass die ATM-Zellen von der gleichen Datenquelle stammen. Überschreitet
die Zeitdifferenz zwischen der Ankunft einer ATM-Zelle Zi und einer zweiten ATM-Zelle Zi+1 eine
gewisse Wartezeit, schreibt der Scheduler eine Füllzelle in den FIFO-Speicher
ein. Sobald der FIFO-Speicher voll ist, werden diejenigen ATM-Zellen
gelöscht
bzw. in einem anderen Speicher gespeichert, die zuerst angekommen
sind und somit die ältesten
ATM-Zellen darstellen. Durch das Vorsehen von Dummy- bzw. Füllzellen
wird die Genauigkeit bei der Berechnung der Ablaufzeit erhöht, da die
Füllzellen
die Zeit wiedergeben, bei der keine ATM-Datenzellen durch den Scheduler
empfangen wurden.
-
Ein
Nachteil bei der in 4 dargestellten Vorgehensweise
besteht in der sog. internen Fragmentierung. Die Datenzellen weisen
eine feste Datengröße auf.
Handelt es sich bei den Datenzellen beispielsweise um ATM-Datenpakete
bzw. ATM-Datenzellen
umfassen die Datenzellen 53 Byte. Die Fülldatenzellen weisen die gleiche
Größe wie die
Datenzellen auf, d. h. die Fülldatenzellen
umfassen ebenfalls 53 Byte. Wird bei dem Enhanced-Time-Wheel-Verfahren,
wie es in 4 dargestellt ist, beispielsweise
ein IP-Datenpaket von 54 Byte Größe emp fangen
und dies in einer Protokollumwandlung in eine Folge von ATM-Datenzellen
umgewandelt, erhält
man eine erste Datenzelle mit 53 Byte und eine zweite ATM-Datenzelle,
die nur 1 Byte Nutzdaten enthält.
Die übrigen
52 Byte der zweiten ATM-Datenquelle,
die keine Nutzdaten enthalten, führen
ebenfalls zu einer Belegung von Speicherplatz innerhalb des FIFO-Speichers und somit
zu einer Speicherverschwendung.
-
Je
kleiner die Größe der Datenzellen
bzw. Datenfragmente ist, um so größer wird der Anteil der Overhead-
bzw. Header-Daten der Zellen im Vergleich zu den gespeicherten Nutzdaten.
Darüber
hinaus steigt die Datenbreite der in den Datenzellen enthaltenen
Pointern bzw. Zeigern, die die Verkettung der Zellen untereinander
gewährleisten.
Je größer die
eingesetzten Speicherzellen sind, desto mehr Speicherplatz wird
jedoch aufgrund der Fragmentierung verschwendet und desto größer wird
die Ungenauigkeit bei der berechneten Ablaufzeit. Werden die Zellen
verkleinert, desto weniger Speicherplatz werden für die fragmentierten
Nutzdaten jedoch desto mehr Speicherplatz wird für die Oberhead- bzw. Header-Daten
der Datenzellen verschwendet.
-
Es
ist daher die Aufgabe der vorliegenden Erfindung einen Scheduler
für ein
Speichersystem zu schaffen, der die zur Verfügung stehenden Datenpakete
mit einer sehr hohen Zeitgenauigkeit meldet.
-
Diese
Aufgabe wird erfindungsgemäß durch
einen Scheduler für
ein Speichersystem mit den im Patentanspruch 1 angegebenen Merkmalen
gelöst.
-
Die
Erfindung schafft einen Scheduler für ein Speichersystem zum Zwischenspeichern
von Daten, die durch mindestens eine Datenverarbeitungseinheit verarbeitet
werden,
mit einer Schreib-Einheit zum Einschreiben von Datenobjekten
in das Speichersystem,
wobei die Schreib-Einheit Datenpakte
von mindestens einer Datenquelle mit einer veränderlichen Datenübertragungsrate
empfängt,
Attributdaten für
jedes empfangene Datenpaket berechnet und die in dem Datenpaket enthaltenen
Daten in das Speichersystem als eine aus miteinander verketteten
Datenobjekten bestehende Datenobjektkette einschreibt, die Zeigerdaten
zur Verkettung der Datenobjekte, die berechneten Attributdaten und
die in dem Datenpaket enthaltenen Nutzdaten umfasst,
wobei
die Schreib-Einheit zum Ausgleich der veränderlichen Datenübertragungsrate
beim Einschreiben der Datenobjekt-Kette in das Speichersystem zusätzlich Fülldaten
zwischen die verketteten Datenobjekte in das Speichersystem einschreibt;
einem
Zähler,
der durch die Schreib-Einheit beim Einschreiben der Datenobjekt-Kette
in das Speichersystem entsprechend der Datenmenge der in dem Datenpaket
enthaltenen Daten und der Fülldaten
der Füllobjekte inkrementiert
wird und mit einer Zeitablauf-Meldeeinheit, die der Datenverarbeitungseinheit
meldet, dass ein in dem Speichersystem zwischengespeichertes Datenobjekt
oder Füllobjekt
für die
Datenverarbeitungseinheit zum Auszulesen bereitstellt, wenn der
Zähler
einen Schwellenwert erreicht,
wobei die Zeitablauf-Meldeeinheit
anschließend
den Zähler
entsprechend den in dem bereitgestellten Objekt enthaltenen Daten
dekrementiert.
-
Ein
Vorteil des erfindungsgemäßen Schedulers
besteht darin, dass er beliebige generische Datenpakete DP verarbeiten
kann. Die ankommenden Datenpakete DP müssen kein bestimmtes Datenformat
aufweisen und können
variable Datenpaketgrößen besitzen.
Daher kann der erfindungsgemäße Scheduler
vorzugsweise auch für
Ethernet-Datenpakete oder IP-Datenpakete eingesetzt werden.
-
Der
erfindungsgemäße Scheduler
zählt mit
dem Zähler
die Datenmenge der in den ankommenden Datenpaketen enthaltenen Nutzdaten
und addiert dazu die Datenmenge der Fülldaten. Der Zähler zählt dabei nicht
die Datenmenge der Overhead-Daten bzw. Attributdaten, die für die Datenobjekt-Kette
berechnet werden.
-
Die
ankommenden Datenpakete DP werden als Datenobjekt-Kette in das Speichersystem
eingeschrieben. Jede Datenobjekt-Kette besteht aus mindestens einem
Datenobjekt. Die Datenobjekte der Datenobjekt-Kette sind über Zeigerdaten
miteinander verkettet. Eine Datenobjekt-Kette, die mehrere Datenobjekte umfasst,
besteht aus Datenobjekten unterschiedlichen Datenobjekt-Typs. Eine
typische Datenobjekt-Kette besteht aus einem Ketten-Anfang-Datenobjekt
(KADO), einer Vielzahl von verketteten Ketten-Mitte-Datenobjekten
(KMDO) und einem Ketten-Ende-Datenobjekt
(KEDO). Ist der ankommende Datenstrom so kurz, dass lediglich ein
Datenobjekt benötigt
wird, wird die Datenobjekt-Kette durch ein Datenobjekt gebildet,
das als Ketten-Ende und Anfangs-Datenobjekt (KEADO) bezeichnet wird.
Die verschiedenen Datenobjekt-Typen weisen unterschiedliche Datenformate
und unterschiedliche Datengrößen auf.
-
Zum
Ausgleich von veränderlichen
Datenübertragungsraten
beim Einschreiben der Datenobjekt-Kette werden in das Speichersystem
durch den Scheduler zusätzlich
Fülldatenobjekte
zwischen die verketteten Datenobjekte eingeschrieben. Dazu sind
im wesentlichen zwei verschiedene Fülldatenobjekte, nämlich ein Ein-Byte-Füll-Datenobjekt
EBDFDO und ein Multibyte Fülldatenobjekt
MBFDO vorgesehen.
-
Durch
die Verkettung der Datenobjekte mit variabler Datengröße wird
der Speicherplatz innerhalb des Speichersystems optimal ausgenutzt.
Durch das Vorsehen der Fülldatenobjekte
mit variabler Größe wird
zudem die Genauigkeit bei der Berechnung der Ablaufzeit optimiert,
da die Fülldatenobjekte
genau diejenigen Zeitspannen wiedergeben, an denen der Scheduler
keine Daten von den Datenquellen empfangen hat. Die Fülldatenobjekte
dienen daher zum Ausgleich der veränderlichen Datenübertragungsrate
beim Einschreiben der Datenobjektkette in das Speichersystem.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
ist ein erster Datenobjekt-Typ ein Ketten-Anfangs-Datenobjekt (KADO),
das ein Typ-Datenfeld zur Kennzeichnung als Ketten-Anfangs-Datenobjekt,
ein Sende-Flag, ein Zeigerdatenfeld zur Verkettung, ein Attributdatenfeld
und ein Nutzdatenfeld aufweist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist dieser als zweiten Datenobjekt-Typ ein Ketten-Ende-Datenobjekt
(KEDO) auf, das ein Typ-Datenfeld zur Kennzeichnung als Ketten-Ende-Datenobjekt,
ein Datenfeld zur Angabe der Nutzdatenmenge und ein Nutzdatenfeld
aufweist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist dieser als dritten Datenobjekt-Typ ein Ketten-Ende- und Anfangs-Datenobjekt
(KEADO) auf, das ein Typ-Datenfeld
zur Kennzeichnung als Ketten-Ende- und Anfangs-Datenobjekt, ein Sende-Flag, sein Datenfeld
zur Angabe der Nutzdatenmenge, ein Attributdatenfeld und ein Nutzdatenfeld
aufweist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist dieser als vierten Datenobjekt-Typ ein Ketten-Mitte-Datenobjekt
(KMDO) auf, das ein Typ-Datenfeld zur Kennzeichnung als Ketten-Mitte-Datenobjekt,
ein Zeigerdatenfeld und ein Nutzdatenfeld aufweist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist dieser als fünften Datenobjekt-Typ
ein Ein-Byte-Füll-Datenobjekt
(EBFDO) auf, das ein 1 Byte umfassendes Typ-Datenfeld zur Kennzeichnung
als Ein-Byte-Füll-Datenobjekt
aufweist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist dieser als sechsten Datenobjekt-Typ ein Mehr-Byte-Füll-Datenobjekt
(MBFDO) auf, das ein Typ-Datenfeld zur Kennzeichnung als Mehr-Byte-Füll-Datenobjekt
und ein Datenfeld aufweist, welches die Fülldatenmenge angibt.
-
Bei
dem erfindungsgemäßen Scheduler
weist die Schreibeinheit vorzugsweise einen Steuerpfad und einen
Datenpfad auf.
-
Der
Datenpfad der Schreibeinheit weist vorzugsweise eine FIFO-Steuereinheit
zum Einschreiben und Auslesen von Daten in einen daran angeschlossenen
FIFO-Speicher auf.
-
Die
FIFO-Steuereinheit empfängt
vorzugsweise Daten von mindestens einer Datenquelle paketweise als
Datenpakete.
-
Dabei
weist jedes empfangene Datenpaket vorzugsweise ein Steuerdatum (SoP),
welches den Anfang des Datenpakets kennzeichnet, ein Steuerdatum
(EoP), welches das Ende des Datenpakets kennzeichnet und dazwischenliegende
Datenpaket-Nutzdaten
auf.
-
Die
Datenpaket-Nutzdaten der empfangenen Datenpakete umfassen vorzugsweise
jeweils Verwaltungsdaten (Header) und Informationsdaten (payload).
-
Der
Steuerpfad berechnet vorzugsweise für jedes empfangene Datenpaket
Attributdaten.
-
Dabei
berechnet der Steuerpfad die Attributdaten vorzugsweise in Abhängigkeit
von Systemeinstellungen und/oder den Verwaltungsdaten (Header) der
empfangenen Datenpakete.
-
Der
Steuerpfad speichert vorzugsweise die berechneten Attributdaten
in einen Attributdatenpuffer des FIFO-Speichers.
-
Die
FIFO-Steuereinheit speichert vorzugsweise die Nutzdaten eines Datenpakets
in einen Nutzdatenpuffer des FIFO-Speichers.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist der FIFO-Speicher für
jede Datenquelle einen zugehörigen
Attributdatenpuffer und einen zugehörigen Nutzdatenpuffer auf.
-
Die
FIFO-Steuereinheit erzeugt vorzugsweise ein Fehlersignal (ERROR),
wenn ein zu einer Datenquelle gehöriger Nutzdatenpuffer voll
ist und keine weiteren Daten aufnimmt.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
schreibt die FIFO-Steuereinheit des Datenpfades in Abhängigkeit
von Steuersignalen, die die FIFO-Steuereinheit von dem Steuerpfad
der Schreibeinheit empfängt,
die in dem Attributdatenpuffer zwischengespeicherten Attributdaten
und die in dem Nutzdatenpuffer zwischengespeicherten Nutzdaten eines
Datenpakets in das Speichersystem als eine aus miteinander verketteten
Datenobjekten bestehende Datenobjekt-Kette ein.
-
Die
FIFO-Steuereinheit berechnet vorzugsweise die kumulative Attributdatenmengen
(VA,L) der in das Speichersystem eingeschriebenen
Attributdaten eines Datenpakets.
-
Die
FIFO-Steuereinheit berechnet vorzugsweise eine kumulative Nutzdatenmengen
(PL) der in das Speichersystem eingeschriebenen
Nutzdaten eines Datenpakets.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
enthält
der Datenpfad der Schreibeinheit eine Zähleinrichtung (Timed Adress
Generator), die entsprechend einer linearen Soll-Daten-Ankunfts-Kurve
(α(t)) linear
hochzählt
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist der Datenpfad der Schreibeinheit einen effektiven Datenadressgenerator
auf, der eine Zeitscheibenverteilung (W·
α(t))
in Abhängigkeit
von der berechneten kumula tiven Nutzdatenmenge (P
L)
und dem von der Zähleinrichtung
angelegten Zellwert berechnet.
W·
α(0)
= 0
-
Wobei
zu allen Zeitpunkten t gilt, sodass
wobei die Definition des
Operators „max” folgendermaßen ausgedehnt
wird:
-
Die
Funktion W·α(t)
ist die kumulative Verteilung des abgegebenen Datenstroms für einen
idealen Fall, bei dem ein ankommender Datenstrom mit einer kumulativen
Datenübertragungsmenge
R(t) bei vorgegebener Ankunftskurve bei α(t) empfangen wird,
wobei
R(t) die Datenmenge des empfangenen Datenpakets und α die lineare
Soll-Daten-Ankunfts-Kurve ist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
enthält
der Datenpfad der Schreibeinheit einen Modulo-M-Addierer, der die
kumulative Attributdatenmenge (VA,L) mit
der berechneten Zeitschalt-Verteilung (W·α(t))
zur Erzeu gung einer Datenobjekt-Adresse im Modulo-M addiert, wobei
M die Speicherkapazität
des Speichersystems ist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist der Datenpfad der Schreib-Steuereinheit eine aus mehreren
Basis-Adress-Registern bestehendes Basis-Adress-Register-Bank auf, wobei für jede Datenquelle
ein Basis-Adress-Register
vorgesehen ist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
wird bei einer Änderung der
berechneten kumulativen Nutzdatenmenge (PL)
in das Basis-Adress-Register die Anfangs-Adresse des Datenobjekts
eingeschrieben.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist der Datenpfad der Schreib-Einheit eine aus mehreren Link-Adress-Registern
bestehende Link-Adress-Register-Bank
auf, wobei für
jede Datenquelle ein Link-Adress-Register
vorgesehen ist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
wird in das Link-Adress-Register die Adresse des zuletzt in das
Speichersystem eingeschriebenen Datenobjekts für die Verkettung mit dem nächsten Datenobjekt
der Datenobjekt-Kette zwischengespeichert.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
weist der Datenpfad der Schreibeinheit einen Datenmultiplexer zum
Einschreiben von Daten in das Speichersystem und einen Adressmultiplexer
zum Anlegen einer Adresse an das Speichersystem auf.
-
Dabei
weist der Datenmultiplexer vorzugsweise einen ersten Eingang auf,
der mit dem FIFO-Speicher zum Empfang der aus dem FIFO-Speicher
ausgelesenen Attribut- und Nutzdaten und einen zweiten Eingang, der
mit der Basis-Adress-Register-Bank zum Empfangen der Verkettungsdaten
verbunden ist.
-
Der
Adressmultiplexer weist vorzugsweise einen ersten Eingang auf, der
mit dem Ausgang des Modulo-M-Addierers zum Empfang einer Datenadresse
verbunden ist, und einen zweiten Eingang, der mit der Link-Adress-Register-Bank
zum Empfang einer Verkettungs-Adresse verbunden ist.
-
Bei
einer bevorzugten Ausführungsform
des erfindungsgemäßen Schedulers
ist der Datenpfad der Schreib-Einheit in Abhängigkeit von einem von dem
Steuerpfad generierten Steuersignals zwischen zwei Betriebsmodi
umschaltbar,
wobei in dem ersten Betriebsmodus zum Einschreiben
von Datenobjekten in das Speichersystem jeweils der erste Eingang
des Datenmultiplexers und des Adressmultiplexers an das Speichersystem
geschaltet ist,
wobei in dem zweiten Betriebsmodus zum Verketten
des zuletzt eingeschriebenen Datenobjekts jeweils der zweite Eingang
des Daten- und des Adressmultiplexers an das Speichersystem geschaltet
ist.
-
Im
weiteren werden bevorzugte Ausführungsformen
des erfindungsgemäßen Schedulers
unter Bezugnahme auf die beigefügten
Figuren zur Erläuterung
erfindungswesentlicher Merkmale beschrieben.
-
Es
zeigen:
-
1 ein
Blockschaltbild einer herkömmlichen
Datenverarbeitungsanordnung;
-
2 ein
Diagramm zur Erläuterung
der Funktionsweise eines Schedulers;
-
3 eine
beispielhafte Anordnung zur Erläuterung
eines Zeitscheiben-Scheduling-Verfahrens;
-
4 einen
FIFO-Speicher zur Erläuterung
eines herkömmlichen
Enhanced-Zeitscheiben-Verfahrens nach dem Stand der Technik;
-
5 ein
Blockschaltbild einer Datenverarbeitungsanordnung mit einem erfindungsgemäßen Scheduler;
-
6 ein
Blockschaltbild der in einem erfindungsgemäßen Scheduler enthaltenen Baugruppen;
-
7 den
Aufbau der in dem erfindungsgemäßen Scheduler
enthaltenen Schreibeinheit;
-
8 ein
Ablaufdiagramm zur Erläuterung
des Steuervorgangs innerhalb des Steuerpfads der Schreibeinheit;
-
9 ein
durch den erfindungsgemäßen Scheduler
zu verarbeitenden Datenpaket;
-
10 Datenformate
der durch den erfindungsgemäßen Scheduler
generierten Datenobjekte, die als Datenobjekt-Kette in dem Speichersystem
abgespeichert werden;
-
11 ein
erstes Beispiel einer in dem Speichersystem abgespeicherten Datenobjekt-Kette
gemäß der Erfindung;
-
12 ein
zweites Beispiel einer in dem Speichersystem abgespeicherten Datenobjekt-Kette
gemäß der Erfindung;
-
13 ein Blockschaltbild des in dem erfindungsgemäßen Schedulers
erhaltenen Datenpfades;
-
14 ein
Ablaufdiagramm der FIFO-Steuereinheit zum Einschreiben von Nutzdaten
in Nutzdatenpuffer;
-
15 ein
Ablaufdiagramm der FIFO-Steuereinheit zur Ermittlung der kumulativen
Nutzdatenmenge (PL) und der kumulativen
Attributdatenmenge;
-
16 ein
Ablaufdiagramm des in der Zeitablauf-Meldeeinheit ablaufenden Programms zur
Dekrementierung des Zählers.
-
5 zeigt
eine Datenverarbeitungs-Schaltungsanordnung, die einen erfindungsgemäßen Scheduler 2 enthält. Von
mindestens einer Datenquelle 1 erhält der Scheduler 2 paketweise
Daten über
einen seriellen oder parallelen Datenbus 3. Der Scheduler 2 ist über Leitungen 4 mit
einem Speichersystem 5 verbunden. Eine Datenverarbeitungseinheit 6 liest
die zu verarbeitende Daten aus dem Speichersystem 5 über einen
Datenbus 7 aus. Über
Leitungen 8 meldet der Scheduler 2 der Datenverarbeitungseinheit 6,
dass Daten zur Verarbeitung innerhalb des Speichersystems 5 zur
Verfügung
stehen. 5 zeigt eine Prinzipanordnung.
Der Scheduler 2 kann bei alternativen Anordnungen an eine
Vielzahl von Datenquellen bzw. Datenkanälen eingangsseitig angeschlossen
sein. Falls mehrere Datenkanäle
angeschlossen sind, werden die Daten in einem Zeit-Domain-Multiplexverfahren
TDM mit jeder beliebigen Granularität geliefert. Darüber hinaus
kann an das Speichersystem 5 eine Vielzahl von Datenverarbeitungseinheiten 6 angeschlossen
werden, die das Speichersystem 5 als Shared Memory benutzen.
Bei dem Speichersystem 5 kann es sich um ein beliebiges
Speichersystem bzw. eine Speicherhierarchie mit Arbitrierung der
Zugriffe handeln. Der erfindungsgemäße Scheduler 2 zeigt über Leitung 8 der
Datenverarbeitungseinheit 6 an, dass Datenobjekte für die Datenverarbeitungseinheit zur
weiteren Verarbeitung nach einer Ablaufzeit ΔT bereitstehen. Der Scheduler 2 empfängt ein
beliebiges Datenpaket DP von der Datenquelle. Bei dem Datenpaket
kann es sich um ein generisches Datenpaket DP handeln, d. h. der
erfindungsgemäße Scheduler 2 ist
in der Lage, Datenpakete DP mit einem beliebigen Datenformat zu
verarbeiten. Das Datenpaket DP, welches von der Datenquelle 1 stammt,
weist ein Steuerdatum SoP auf, welches den Anfang des Datenpakets
DP kennzeichnet, und ein Steuerdatum (EoP), welches das Ende des
Datenpakets DP kennzeichnet. Das Datenpaket DP enthält zwischen
den beiden Steuerdaten Nutzdaten. Diese Nutzdaten umfassen sowohl
die Datenpaket-Verwaltungsdaten bzw. Header-Daten als auch die in
dem Datenpaket enthaltenen Informationsdaten bzw. die Payload. Der
erfindungsgemäße Scheduler 2 ist
in der Lage Datenpakete DP beliebiger Größe zu verarbeiten und der Datenverarbeitungseinheit 6 in
Form von verketteten Datenobjekt-Ketten zur Verarbeitung zur Verfügung zu
stellen bzw. zu melden. Bei den empfangenen Datenpaketen DP kann
es sich beispielsweise um Ethernet-Datenpakete oder IP-Datenpakete handeln.
Der Scheduler 2 speichert das von einer Datenquelle 1 stammende
Datenpaket DP als eine Datenobjekt-Kette in das Speichersystem 5 ab.
Dabei nutzt der Scheduler 2 den durch das Speichersystem 5 zur
Verfügung
gestellten Speicherplatz durch die Verkettung der Datenobjekte in
einer Datenobjekt-Kette optimal aus. Die Zeitspanne ΔT zwischen
dem Empfang des Datenpakets und dem Zeitpunkt, an dem das letzte
Datenobjekt der zugehörigen
Datenobjekt-Kette der Datenverarbeitungseinheit 6 durch
den Scheduler 6 gemeldet wird, wird durch eine in dem Scheduler 2 enthaltene
Zeitablaufmeldeeinheit der Datenverarbeitungseinheit 6 als
Ablaufzeit gemeldet. Die Ablaufzeit ΔT ist dabei weitestgehend unempfindlich
gegenüber
Veränderungen
bzw. Schwankungen der Datenübertragungsrate
R'(t), mit welcher
die Datenpakete DP von der Datenquelle 1 an den Scheduler 2 übertragen
werden. Zum Ausgleich der veränderlichen
Datenübertragungsrate
R'(t) schreibt der
Scheduler 2 beim Einschreiben der Datenobjekt-Kette in
das Speichersystem 5 zusätzlich Füllobjekte (FO) zwischen die verketteten
Datenobjekte (DO) in das Speichersystem 5 ein. Die Zeitverzögerung ΔT, mit welcher
der Scheduler 2 ankommende Daten der Datenverarbeitung 6 zur
Verfügung
stellt, ist aufgrund der variablen Größe der zwischen den verketteten
Datenobjekte (DO) gespeicherten Füllobjekte (FO) sehr genau.
-
6 zeigt
den schaltungstechnischen Aufbau des erfindungsgemäßen Schedulers 2.
Der Scheduler 2 weist bei einer bevorzugten Ausführungsform
drei Baugruppen auf. Der Scheduler 2 enthält eine
Schreibeinheit 9, einen Zähler 10 und eine Zeitablaufmeldeeinheit 11.
-
Die
Schreibeinheit
9 des Schedulers
2 ist über mindestens
eine Datenleitung
3-0 an eine Datenquelle
1 angeschlossen.
Bei einer alternativen Ausführungsform
ist die Schreibeinheit
9 über eine Vielzahl von Datenleitungen
an mehrere Datenquellen
1 angeschlossen. Neben der Datenleitung
bzw. dem Datenbus
3-0 sind Steuerleitungen
3-3 bis
3-4 und
optional die Steuerleitungen
3-1 bis
3-2 vorgesehen,
mit der die Schreibeinheit
9 Steuersignale von der Datenquelle
1 empfängt. Über die
Datenleitung
3-0 empfängt
die Schreibeinheit
9 paketweise Daten. Die Steuerdaten,
wie das Steuerdatum SoP, welches den Anfang des Datenpakets DP kennzeichnet,
oder das Steuerdatum EoP, welches das Ende des Datenpakets DP kennzeichnet
können
entweder über
die Datenleitung
3-0 mit dem Datenpaket DP übertragen
werden, je nach Übertragungsprotokoll
oder über
separate Steuerleitungen
3-1,
3-2 wie in
6 dargestellt. Über eine
Steuerleitung
3-3 empfängt
die Schreibeinheit das Steuerdatum, welche die Datenquelle angibt. Über eine
weitere Steuerleitung
3-4 wird der Schreibeinheit
9 mitgeteilt,
dass die anliegenden Daten gültig
(VALID) sind. Die Datenpakete DP werden von der Datenquelle
1 mit
einer Datenübertragungsrate
übertragen
und durch die Schreibeinheiten
9 empfangen. Dabei kann
die Datenübertragungsrate
stark
schwanken. Die Datenquelle
1 sendet beispielsweise eine
Vielzahl von Datenpaketen während
eines Sendevorgangs und sendet dann längere Zeit keine Datenpakete
DP an die Schreibeinheit
9. Die Schreibeinheit
9 empfängt die
Datenpakete DP und schreibt verkettete Datenobjekte in das Speichersystem
5 ein.
Die Schreibeinheit
9 empfängt die Datenpakete von mindestens einer
Datenquelle
1 mit einer veränderlichen Datenübertragungsrate
die
zusätzlich
durch den Datenübertragungskanal
verändert
sein kann. Die Schreibeinheit
9 berechnet für jedes
empfangene Datenpaket DP Attributdaten und schreibt die in dem Datenpaket
enthaltenen Nutzdaten in das Speichersystem als eine, aus miteinander
verketteten Datenobjekten bestehende Datenobjekt-Kette ein. Die
Datenobjekt-Kette umfasst Zeigerdaten zur Verkettung der Datenobjekte,
die durch die Schreibeinheiten
9 berechneten Attributdaten
und die in dem Datenpaket DP enthaltenen Nutzdaten. Zum Ausgleich
der schwankenden bzw. veränderlichen
Datenübertragungsrate
schreibt
die Schreibeinheit
9 beim Einschreiben der Datenobjektkette
in das Speichersystem
5 zusätzlich Füllobjekte (FO) zwischen die
verketteten Datenobjekte (DO) in das Speichersystem
5 ein. Die
Schreibeinheit
9 ist mit dem Speichersystem
6 über eine
Schreibdatenleitung
4-1, eine Schreibadressleitung
4-2,
eine Write-Enable-Anforderungsleitung
4-3 und
eine Write-Enable-Acknowledge-Leitung
4-4 verbunden. Über die
Schreib-Enable-Request-Leitung
4-3 und
die Write-Enable-Acknowledge-Leitung
4-4 übergibt die
Schreibeinheit Daten an das Speichersystem
5 in einem Hand-Shake-Verfahren.
Die Schreibeinheit
9 gibt über eine Anzeigeleitung
13 im
Bedarfsfalle ein Fehlersignal (ERROR) an die Datenverarbeitungseinheit
6 ab.
-
Der
in dem Scheduler 2 enthaltene Zähler 10 wird durch
die Schreibeinheit 9 beim Einschreiben der Datenobjekt-Kette
in das Speichersystem 6 entsprechend der Datenmenge der
in dem Datenpaket DP enthaltenen Daten und der Fülldaten der Füllobjekte über eine
Leitung 14 inkrementiert.
-
Der
erfindungsgemäße Scheduler 2 enthält neben
der Schreibeinheit 9 eine Zeitablauf-Meldeeinheit 11.
Die Zeitablauf-Einheit 11 meldet über Anzeigeleitungen 8-1, 8-2, 8-3 der
Datenverarbeitungseinheit 6, dass ein in dem Speichersystem 5 zwischengespeichertes
Datenobjekt oder Füllobjekt
für die
Datenverarbeitungseinheit 6 zum Auslesen bereitsteht, wenn
der Zähler 10 einen
Schwellenwert SW erreicht. Hierzu liest die Zeitablauf-Meldeeinheit 11 über eine
Leitung 15 den Zählerstand
des Zählers 10 aus
und vergleicht ihn mit dem Schwellenwert. Der Schwellenwert SW ist
dabei vorzugsweise über
eine Programmierleitung 16 programmierbar. Wenn der Zählerstand
den Schwellenwert SW erreicht, meldet die Zeitablauf-Meldeeinheit 11 der
Datenverarbeitungseinheit 6 über eine Leitung 8-1 die
Adresse des bereitstehenden Datenobjekts (DO) und über eine
weitere Leitung 8-2 den Typ des bereitstehenden Datenobjekts.
Optional wird die Datenverarbeitung 6 durch die Zeitablauf-Meldeeinheit 11 über weitere
Leitungen 8-3 mit Informationsdaten über das gespeicherte Datenobjekt
(DO) versorgt. Nachdem der Datenverarbeitungseinheit 6 durch
die Zeitablauf-Meldeeinheit 11 das Bereitstehen des Datenobjekts
im Speichersystem 6 gemeldet worden ist, dekrementiert
die Zeitablauf-Einheit 11 anschließend dem Zähler 10 über eine
Steuerleitung 16 entsprechend der Menge der in dem bereitgestellten
Datenobjekt (DO) oder Füllobjekt
(FO) enthaltenen Daten.
-
7 zeigt
die in dem erfindungsgemäßen Scheduler 2 enthaltenen
Schreibeinheit 9. Die Schreibeinheit 9 enthält einen
Steuerpfad 9a und einen Datenpfad 9b. Der Datenpfad 9b wird
durch den Steuerpfad 9a über interne Steuerleitungen 17 gesteuert.
-
8 zeigt
das Steuerprogramm, welches innerhalb des Steuerpfades 9a abläuft. Zunächst befindet sich
der Steuerpfad 9a im Ruhezustand. Er überprüft im Steuereingang 3-1,
ob ein Steuerdatum SoP den Anfang eines Datenpakets DP anzeigt.
Erkennt der Steuerpfad im Schritt S1, dass ein Datenpaket DP empfangen wird,
geht der Steuerpfad in einen Speicherzustand über. In einem Schritt S2 überprüft der Steuerpfad 9a,
ob das Steuerdatum SoP, welches den Anfang eines Datenpakets DP
anzeigt, noch anliegt. Falls das Steuerdatum SoP den Anfang eines
Datenpakets anzeigt wird in einem Schritt S3 geprüft, ob über die
Steuerleitung 3-2 auch ein Steuerdatum EoP anliegt, welches
gleichzeitig das Ende des Datenpakets DP anzeigt. In diesem Fall gibt
der Steuerpfad 9a über
die Steuerleitungen 17 an den Datenpfad 9b Steuersignale
zum Abspeichern eines bestimmten Datenobjekts, welches als Ketten-Ende-
und Anfangs-Daten-Objekt (KEADO) bezeichnet wird, ab. Die Steuersignale
zum Abspeichern der Header-Daten des Ketten-Ende- und Anfangs-Daten-Objekts
KEADO werden in einem Schritt S4 an den Datenpfad 9b angelegt.
-
In
einem Schritt S5 gibt der Steuerpfad 9a Steuerdaten zum
Speichern der Daten als Ketten-Ende- und Anfangs-Daten-Objekt KEADO
ab. Anschließend
wird in einem Schritt S6 der Zähler 10 über die
Leitung 14 inkrementiert.
-
Erkennt
der Steuerpfad 9a im Schritt S3, dass kein Steuerdatum
EoP an der Steuerleitung 3-2 anliegt, überprüft er, ob die anliegenden Daten
eine bestimmte Länge
L, beispielsweise 32 Byte, überschreiten.
Ergibt die Längenüberprüfung im
Schritt S7, dass die Datenpaketlänge
mehr als 32 Byte beträgt,
gibt der Steuerpfad 9a in einem Schritt S8 Steuersignale
an den Datenpfad 9b über
die Steuerleitungen 17 zum Speichern der Header-Daten eines
zweiten Datenobjekt-Typs, nämlich
eines sog. Ketten-Anfangs-Daten-Objekts (KADO) ab. In einem weiteren
Schritt S9 erfolgt ein Abspeichern des Ketten-Anfangs-Daten-Objekts (KADO). Anschließend wird
der Zähler 10 entsprechend
der in dem Datenobjekt abgespeicherten Datenmenge im Schritt S10 inkrementiert.
-
Erkennt
der Steuerpfad im Schritt 52, dass kein Steuerdatum (SoP),
welches den Anfang eines Datenpakets DP anzeigt, anliegt, wird im
Schritt S11 überprüft, ob an
der Steuerleitung 3-2 ein Steuerdatum (EoP) anliegt, welches
das Ende des Datenpakets DP bezeichnet. Ist das Ende des Datenpakets
DP erreicht, generiert der Steuerpfad 9a in einem Schritt
S12 das Steuersignal für
den Datenpfad 9b, welche diesen anweisen, die Header-Daten
eines zweiten Datenobjekt-Typs, der als Ketten-Ende-Daten-Objekt
KEDO bezeichnet wird, in dem Speicher system 5 abzuspeichern.
Anschließend
generiert der Steuerpfad 9a Steuersignale für den Datenpfad 9b zum
Abspeichern der Nutzdaten in das Nutzdatenfeld des Ketten-Ende-Daten-Objekts
in einem Schritt S13. In einem Schritt S14 wird anschließend der
Zähler 10 über die
Steuerleitung 14 entsprechend der Datenmenge inkrementiert,
die in dem entsprechenden dem Ketten-Ende-Daten-Objekt in dem das Speichersystem 5 abgespeichert
wurde.
-
In
einem Schritt S15 wird das Ketten-Ende-Daten-Objekt (KEDO) mit dem
vorangegangenen Datenobjekt verkettet. Bei dem vorangegangenen Datenobjekt
(DO) handelt es sich entweder um ein Ketten-Anfangs-Daten-Objekt
(KADO) oder um ein sog. Ketten-Mitte-Daten-Objekt
(KMDO), die beide über
Zeiger bzw. Pointer-Datenfelder verfügen, in welche die Anfangsadresse
des Ketten-Ende-Daten-Objekts (KEDO) eingeschrieben wird.
-
Erkennt
der Steuerpfad 9a im Schritt S11, dass das Steuerdatum
EoP nicht anliegt, wird in einem Schritt S16 überprüft, ob die Datenlänge von
beispielsweise 32 Byte überschritten
worden ist. Ist dies der Fall, generiert der Steuerpfad 9a in
einem Schritt S17 Steuersignale, die über die Steuerleitungen 17 an
den Datenpfad 9b angelegt werden und diesen zum Speichern
eines vierten Datenobjekt-Typs ansteuern. Bei dem vierten Datenobjekt-Typ
handelt es sich um Ketten-Mitte-Daten-Objekt KMDO. Anschließend gibt
der Steuerpfad 9a an den Datenpfad 9b in einem
Schritt S18 Steuersignale zum Speichern von Daten in das Nutzdatenfeld
des Ketten-Mitte-Daten-Objekts KMDO ab. In einem Schritt S19 wird
der Zähler 10 entsprechen
der Datenmenge der in dem Ketten-Mitte-Daten-Objekt KMDO gespeicherten
Daten inkrementiert.
-
Ergibt
die Abfrage in den Schritten S7, S16, dass die Datenlänge 32 Byte
nicht erreicht worden ist, werden die Daten durch die Schreibeinheit 9 in
einem Schritt S20 in einem Kanal-spezifischen Nutzdatenpuffer zwischengespeichert.
-
In
den Schritten S1 bis S19 werden Steuerdaten zur Generierung von
verschiedenen Datenobjekten DO unterschiedlichen Datenobjekt-Typs
generiert. Die verschiedenen Datenobjekte, nämlich das Ketten-Ende- und
Anfangs-Daten-Objekt KEADO, das Ketten-Anfangs-Daten-Objekts KADO,
das Ketten-Mitte-Daten-Objekt
KMDO und das Ketten-Ende-Daten-Objekt KEDO werden durch die Schreibeinheit 9 in
das Speichersystem 5 eingeschrieben und in einem Schritt
S15 wird ein eingeschriebenes Datenobjekt DO mit einem Vorgänger mittels
Pointer bzw. Zeigerdaten verkettet. Nachdem zwei Datenobjekte im
Schritt S15 miteinander verkettet worden sind, bzw. ein Anfangs-Daten-Objekt KEADO bzw.
KADO generiert worden ist, werden in den nachfolgenden Schritten
die Datenlücken
zwischen den beiden verketteten Datenobjekten mit Fülldaten
gefüllt.
Hierzu wird in einem Schritt S25 zunächst die Größe der entstandenen Datenlücke in dem
Speichersystem 5 festgestellt. Besteht keine Lücke bzw.
ist die Lückengröße null,
geht der Vorgang über
zu Schritt S22. Ist die Lückengröße genau
1 Byte groß,
wird ein bestimmtes Fülldatenobjekt,
nämlich
ein Ein-Byte-Füll-Daten-Objekt EBFDO durch
den Datenpfad 9b entsprechend den durch den Steuerpfad 9a generierten
Steuerdaten in einem Schritt S22 zwischen die verketteten Datenobjekte
gespeichert. Anschließend
wird der Zähler 10 entsprechend
der eingefügten
Fülldatenmenge
in einem Schritt S23 inkrementiert. Ergibt die Überprüfung in Schritt S21, dass die
bestehende Datenlücke
in dem Speichersystem 5 zwischen den beiden verketteten
Datenobjekten DO mehr als 1 Byte beträgt, generiert der Steuerpfad 9a in
einem Schritt S24 Steuerdaten zum Abspeichern eines sog. Mehr-Byte-Füll-Daten-Objekts
MBFDO und gibt die Steuersignale über die Steuerleitung 17 an
den Datenpfad 9b ab. Der Datenpfad 9b speichert
das Mehr-Byte-Füll-Daten-Objekt
MBFDO in dem Speichersystem 5 ab. Anschließend wird
in einem Schritt S25 der Zähler 10 entsprechend
der gespeicherten Fülldatenmenge
inkrementiert.
-
In
einem Schritt S25 wird anschließend
durch den Steuerpfad 9a überprüft, ob ein Steuerdatum EoP, welches
das Ende des Datenpakets anzeigt, an die Steuerleitung 3-2 anliegt.
Ist dies der Fall, kehrt der Steuerpfad 9a zunächst in
den Ruhezustand zurück.
Ist das Ende des Datenpakets DP noch nicht erreicht, wird der Vorgang
in dem Schritt S2 fortgesetzt.
-
10 zeigt
die Datenstruktur der verschiedenen in dem Speichersystem 5 entsprechend
den Steuersignalen des Steuerpfades 9a abgespeicherten
Datenobjekte DO. Bei dem ersten Datenobjekt-Typ handelt es sich
um ein sog. Ketten-Anfangs-Daten-Objekt
KADO, das ein Typ-Datenfeld zur Kennzeichnung als Ketten-Anfangs-Daten-Objekt
(Bit-Kodierung 1 0X), ein Sende-Flag S, ein Zeigerdatenfeld zur
Verkettung, ein Attributdatenfeld und ein Nutzdatenfeld für K-Byte
Nutzdaten aufweist. Das Typ-Datenfeld, das Sende-Flag, das Zeigerdatenfeld
sowie das Attributdatenfeld bilden die Header-Daten HD dieses Datenobjekts.
-
Das
zweite Datenobjekt ist ein Ketten-Ende-Daten-Objekt KEDO, das ein
Typ-Datenfeld zur Kennzeichnung als Ketten-Ende-Daten-Objekt (Bit-Kodierung 0 1 0),
ein Datenfeld zur Angabe der darin abgespeicherten Nutzdaten und
ein Nutzdatenfeld aufweist. Die Länge L der in dem Ketten-Ende-Daten-Objekt
KEDO abgespeicherten Nutzdaten ist variabel, wobei L ≤ K ist.
-
Der
dritte Datenobjekt-Typ ist ein Ketten-Ende- und Anfangs-Daten-Objekt KEADO,
das ein Typ-Datenfeld zur Kennzeichnung als Ketten-Ende- und Anfangs-Daten-Objekt
(Kodierung 1 1 X), ein Datenfeld zur Angabe der darin enthaltenen
Nutzdatenmenge, ein Sende-Flag S, ein Attributdatenfeld und ein
Nutzdatenfeld aufweist. Die Datengröße des Ketten-Ende- und Anfangs-Daten-Objekts
ist entsprechend der in dem Nutzdatenfeld gespeicherten L-Bytes
variabel, wobei L ≤ K
ist.
-
Das
vierte Datenobjekt ist ein sog. Ketten-Mitte-Daten-Objekt KMDO,
das ein Typ-Datenfeld, nämlich die
Kodierung 0, 0 zur Kennzeichnung als Ketten-Mitte-Daten-Objekt,
ein Zeigerdatenfeld und ein Nutzdatenfeld aufweist. Das Nutzdatenfeld
des vierten Ketten-Mitte-Daten-Objekt KMDO weist wie das Nutzdatenfeld des
Ketten-Anfangs-Daten-Objekts KADO eine konstante Größe von K-Bytes
Nutzdaten auf.
-
Die
ersten vier Datenobjekte KADO, KEDO, KEADO und KMDO dienen zum Speichern
der Datenpaketnutzdaten in dem Speichersystem 5. Die beiden übrigen Datenobjekte
EPFO und MBFO dienen zum Auffüllen
der Datenlücken
zwischen den verketteten Datenobjekten DO. Das fünfte Datenobjekt ist ein Ein-Byte-Füll-Objekt EPFO, das
aus einem 1 Byte umfassenden Typ-Datenfeld zur Kennzeichnung als Ein-Byte-Füll-Daten-Objekt
(Bit Kodierung 0 0 1) besteht. Das sechste Datenobjekt, welches
als Mehr-Byte-Füll-Objekt
(Bit Kodierung 0 1 1) bezeichnet wird (MBFO) dient zum Auffüllen von
größeren Datenlücken, d.
h. von Datenlücken
die größer sind
als 1 Byte. Das Mehr-Byte-Füll-Objekt MBFDO umfasst
ein Typ-Datenfeld zur Kennzeichnung als Mehr-Byte-Füll- Objekt
und ein Datenfeld, welches die Fülldatenmenge angibt.
Als eigentliche Fülldaten
können
die bereits in dem Speichersystem 5 gespeicherten zufällig vorhandenen
Daten eingesetzt werden, damit es nicht nötig ist, Daten durch Schreibzyklen
tatsächlich
zu schreiben. Die Fülldatenmenge
gibt die größte der
zu füllenden
Datenlücke
an.
-
11 zeigt
ein erstes Beispiel einer in dem Speichersystem 5 durch
den erfindungsgemäßen Scheduler 2 abgelegten
Datenobjektkette. Bei dem in 11 dargestellten
Beispiel besteht die Datenobjekt-Kette aus fünf Datenobjekten, nämlich einem
Ketten-Anfangs-Daten-Objekt KADO, drei Ketten-Mitten-Daten-Objekt KMDO
sowie einem Ketten-Ende-Daten-Objekt KEDO. Die Datenobjekte sind über Pointer
bzw. Zeigerdaten miteinander verkettet. Die Zeigerdaten geben jeweils
die Anfangsadresse des nächsten
Datenobjekts der Datenobjektkette an. Die Datenlücken zwischen den verketteten
Datenobjekten werden durch den erfindungsgemäßen Scheduler 2 durch
Fülldatenobjekte
d. h. durch Ein-Byte- oder Mehr-Byte-Füll- Objekte gefüllt.
-
12 zeigt
ein weiteres Beispiel für
das Abspeichern von Datenobjekt-Ketten in dem Speichersystem 5.
Bei dem in 12 dargestellten Beispiel sind
zwei verschiedene Datenobjekt-Ketten
miteinander verschachtelt in dem Speichersystem 5 abgespeichert.
Eine erste Datenobjekt-Kette A besteht ebenfalls aus fünf miteinander
verketteten Datenobjekten, nämlich
einem Ketten-Anfangs-Daten-Objekt KADOA,
drei Ketten-Mitte-Daten-Objekten
KMDOA und einem Ketten-Ende-Daten-Objekt
KEDOA. Die zweite Datenobjekt-Kette B besteht
bei dem dargestellten Beispiel aus vier Datenobjekten, nämlich einem
Ketten-Anfangs-Daten-Objekt
KADOB, zwei Ketten-Mitte-Daten-Objekten
KMDOB und einem Ketten-Ende-Daten-Objekt
KEDOB. Die beiden verschiedenen Datenobjekt-Ketten
A, B stammen von zwei unterschiedlichen Datenpaketen DP bzw. Datenquellen.
Wie man aus 12 erkennen kann, wird durch
die Verschachtelung der Datenobjekt-Ketten der Speicherplatz innerhalb
des Speichersystems 5 optimal ausgenutzt. Sollte aufgrund
der schwankenden Datenübertragungsmenge
R ein Leerlauf beim Empfang der Daten DP entstehen, werden die Lücken durch
die Schreibeinheit 9 mit Füllobjekten FO befüllt.
-
13 zeigt den schaltungstechnischen Aufbau
des in 7 dargestellten Datenpfades 9b. Der Datenpfad 9b enthält eine
FIFO-Steuereinheit 18, die über Leitungen 19, 20 mit
einem FIFO-Speicher 21 verbunden ist. Die FIFO-Steuereinheit 8 empfängt von
mindestens einer Datenquelle 1 paketweise Daten über eine Datenleitung 3-0.
Für jedes
empfangene Datenpaket wird ein Steuerdatum SoP, welches den Anfang
des Datenpakets DP kennzeichnet, und ein Steuerdatum EoP, welches
das Ende des Datenpakets kennzeichnet, durch die FIFO-Steuereinheit 18 überwacht.
Der Steuerpfad berechnet in Abhängigkeit
von Systemeinstellungen und/oder Verwaltungsdaten des empfangenen
Datenpakets DP, sog. Attributdaten. Die Attributdaten umfassen die
Header- bzw. Verwaltungsdaten des empfangenen Datenpakets DP sowie
weitere Information, beispielsweise über die Datenquelle, Paket-Deskriptoren
und dergleichen. Der Steuerpfad speichert die berechneten Attributdaten
in einen Attri butdatenpuffer 22-i ab. Die in dem empfangenen
Datenpaket DP empfangenen Nutzdaten werden durch die FIFO-Steuereinheit 18 in
einen Nutzdatenpuffer 23-i des FIFO-Speichers 21 abgespeichert.
Bei einer bevorzugten Ausführungsform
weist der FIFO-Speicher 21 für jede Datenquelle einen Attributdatenpuffer 22-i und
einen Nutzdatenpuffer 23-i auf. Erkennt die Steuereinheit 18,
dass ein Datenpaket DP von einer bestimmten Datenquelle 1-i stammt,
werden die berechneten Attributdaten in den zugehörigen Attributdatenpuffer 22-i und
die Nutzdaten in den zugehörigen
Nutzdatenpuffer 23-i eingeschrieben. Die FIFO-Steuereinheit 18 erzeugt
ein Fehlersignal (ERROR), wenn ein zu einer Datenquelle 1 gehöriger Nutzdatenpuffer 23-i voll
ist und weitere Datenpakete bzw. Daten von dieser Datenquelle empfangen
werden. Das Fehlersignal (ERROR) wird über eine Steuerleitung 13 abgegeben.
Die FIFO-Steuereinheit 18 empfängt von dem Steuerpfad 9a über Steuersignalleitungen 17-1, 17-2, 17-3 Steuersignale. Über eine
Steuerleitung 17-1 empfängt
die FIFO-Steuereinheit 18 die in den Schritten S4, S8,
S12, S17 generierten Steuersignale zum Einschreiben der Header-Daten
HD der vier verschiedenen Datenobjekte KEADO, KADO, KEDO, KMDO. Über eine
Steuerleitung 17-2 erhält
die FIFO-Steuereinheit 18 die Header-Source. Durch eine
Steuerleitung 17-3 empfängt
die FIFO-Steuereinheit 18 schließlich ein Store-Data-Steuersignal
zur Selektion von Attribut- oder Nutzdaten. Der FIFO-Speicher 21 ist über Datenleitungen 24 mit
einem ersten Eingang 25 eines Datenmultiplexers 26 verbunden. Über die
Datenleitungen 24 werden zur Generierung von Datenobjekten
DO die Attributdatenpuffer 22 und Nutzdatenpuffer 23 des
FIFO-Speichers 1 entsprechend den Steuerbefehlen in das Speichersystem 5 ausgelesen.
Die FIFO-Steuereinheit 18 berechnet
die kumulativen Attributdatenmengen VA,L der
in das Speichersystem 5 eingeschriebenen Attributdaten
eines Datenpakets DP. Die kumulative Attributdatenmenge VA,L wird dabei wie folgt ermittelt.
-
Bei
der Paketierung wird die kumulative Datenpaketlänge L
n wie
folgt definiert:
-
Der
Wert Ln – Ln-1 wird
als Länge
des n-ten Datenpakets interpretiert.
-
Die
kumulative Datenpaketlänge
P
L ergibt sich als Funktion der kumulativen
Datenlänge
L
n wie folgt:
-
Die
Funktion PL wird als die lokale Transferfunktion
angesehen.
-
Bei
der Paketierung wird ein Datenstrom mit einer kumulativen Datenübertragungsmenge
R(t) empfangen und ein Datenstrom mit einer kumulativen Verteilung
PL(R(t)) erzeugt.
-
Um
die berechneten Attributdaten, wie beispielsweise Datenobjekt-Zeiger,
zu berücksichtigen
wird eine weiter kumulative Attributlänge An,
die analog zur Paketlänge
ist, bestimmt, welche die Attributdaten berücksichtigt. Die Datenmenge
An – An-1 bildet die Datengröße für Attributdaten des n-ten Datenpakets.
-
Die
kumulative Attributdatenmenge V
A,L ergibt
sich aus den kumulativen Datenlängen
A
n und L
n gemäß folgender
Gleichung:
-
Die
Funktion VA,L bildet in diesem Falle die
ideale Transferfunktion.
-
Die
Berechnungseinheit zur Berechnung der Attributdaten ergibt zwei
kumulative Datenpaketlängen A
n und L
n und einen
charakteristischen Wert V
A,L. Der entsprechend
obiger Gleichung berechnete kumulative Attributdatenmengenwert V
A,L wird von der Steuereinheit
18 über eine
Leitung
27 und eine Verzögerungsschaltung
28,
die zur Zeitsynchronisierung dient, einem ersten Eingang
29 eines
Modulo-M-Addierers
30 zugeführt. Die berechnete kumulative
Nutzdatenmenge P
L wird von der Steuereinheit
18 über eine
Leitung
31 einem ersten Eingang
32 eines effektiven
Datenadressgenerators (EDAC)
33 zugeführt. Der effektive Datenadressgenerator
33 berechnet
eine Zeitscheiben- bzw. Timing-Wheel-Verteilung bzw. Distribution.
Die Zeitscheiben-Distribution stellt die kumulative Verteilung des
abgehenden Datenflusses da. Die Zeitscheiben-Verteilung (W·
α(t)) wird
in Abhängigkeit
von der durch die Steuereinheit
18 berechneten kumulativen
Nutzdatenmenge (P
L) und der von einer Zähleinrichtung
34 abgegebenen
Datenankunftskurve α berechnet.
Hierzu weist der Datenpfad
9a einen Hochzähl- bzw.
eine Zähleinrichtung
34 auf,
die entsprechend einer idealen Soll-Datenankunftskurve einen ansteigenden
Zählwert über eine
Leitung
35 an einen zweiten Eingang
36 des effektiven
Datenadressgenerators
33 liefert. Die Zeitscheiben-Verteilung
wird entsprechend folgender Gleichung berechnet.
W·
α(0)
= 0
-
Wobei
zu allen Zeitpunkten t gilt, sodass
wobei die Definition des
Operators „max” folgendermaßen ausgedehnt
wird:
-
Die
Funktion W·α(t)
ist die kumulative Verteilung des abgegebenen Datenstroms für einen
idealen Fall, bei dem ein ankommender Datenstrom mit einer kumulativen
Datenübertragungsmenge
R(t) bei vorgegebener Ankunftskurve bei α (t) empfangen wird, wobei R(t)
die Datenmenge des empfangenen Datenpakets und α die lineare Soll-Daten-Ankunfts-Kurve
ist.
-
Die
Zeitscheiben-Verteilung (W·α(t))
bildet die kumulative Verteilung des ausgehenden Datenstroms für eine ideale
Vorrichtung, die einen ankommenden Datenstrom mit einer kumulativen
Datenübertragungsmenge
R(t) zum Erkennen der Datenankunftskurve α empfängt. Die Zeitscheibe stellt
dabei einen Idealfall dar, der bei einer vorgegebenen Datenankunftskurve α und einer
kumulativen Datenverteilung des empfangenen Datenübertragungsmenge
R(t) einen abgehenden Datenstrom (W·α(t))
erzeugt. Die durch den effektiven Adressgenerator 33 erzeugte
Zeitscheiben-Verteilung (W·α(t))
wird über
eine Leitung 37 an einen zweiten Eingang 38 des
Modulo-M-Addierers 30 angelegt. Der Modulo-M-Addierer 38 addiert
die kumulative Attributdatenmenge VA,L mit
der berechneten Zeitscheiben-Verteilung
(W·α(t)),
die zur Erzeugung einer Datenobjektadresse, die über Leitungen 39 an
einen ersten Eingang 40 eines Adressmultiplexers 41 angelegt
wird. Bei der Modulo-M- Addition
stellt M die Speicherkapazität
des Speichersystems 5 dar. Ist die Summe der beiden an den
Eingängen 29, 38 anliegenden
Werte größer als
M, erzeugt der Modulo-M-Addierer ein Überlauf-Anzeigesignal WRAP
und gibt dies über
eine Steuerleitung 42 ab.
-
Das Überlauf-Anzeigesignal
führt dazu,
dass die FIFO-Steuereinheit 18,
die Zähleinrichtung 34 und der
effektive Adressengenerator 33 ihren jeweiligen Datenausgangswert
(VA,L, PL, α, W·2) um M vermindern.
-
Der
Datenpfad 9a der Schreibsteuereinheit 9 weist
einen aus mehreren Basis-Adress-Registern BAR bestehende Basis-Adress-Register-Bank 43 auf.
Dabei ist für
jede Datenquelle 1 vorzugsweise ein Basis-Adress-Register
BAR vorgesehen. Die Basis-Adress-Register-Bank 43 erhält über eine
Datenleitung 44 das Ausgangssignal des Modul-M-Addierers 30.
-
Über eine
Leitung 45 wird der Basis-Adress-Register-Bank 43 ferner
ein Steuersignal von der FIFO-Steuereinheit 18 zugeführt, wenn
sich der Wert der berechneten kumulativen Nutzdatenmenge PL ändert.
Dieses Signal dient als Write-Enable WE für die Basis-Adress-Register-Bank
und zeigt an, dass durch die FIFO-Steuereinheit 18 ein
neues Datenobjekt in das Speichersystem 5 abgespeichert
wird. Über
eine Leitung 46 und eine Verzögerungsschaltung 47 zur
Zeitsynchronisierung empfängt
die Basis-Adress-Register-Bank 43 die Quell- bzw. Schreibadresse
von der FIFO-Steuereinheit 18. Jedes Mal, wenn ein Datenobjekt
DO generiert wird, wird das Basis-Adress-Register der zugehörigen Datenquelle 1 auf
die Anfangsadresse des Datenobjekts DO gesetzt. Die in dem Basis-Adress-Register
BAR zwischengespeicherte Basis-Adresse wird über Leitungen 48 an
einen zweiten Eingang 49 des Datenmultiplexers 26 angelegt.
-
Neben
der Basis-Adress-Register-Bank 43 enthält der Datenpfad 9 eine
Link-Adress-Register-Bank 50, die zur Verkettung der eingeschriebenen
Datenobjekte DO vorgesehen ist. Vorzugsweise ist für jede Datenquelle 1 ein
Link-Adress-Register LAR innerhalb der Link-Adress-Register-Bank 50 vorgesehen.
In dem Link-Adress-Register wird die Adresse des zuletzt in das
Speichersystem 5 eingeschriebenen Datenobjekts DO für die Verkettung
mit dem nächsten
Datenobjekt DO der Datenobjektkette DOK zwischengespeichert. Die zwischengespeicherte
Adresse wird über
Datenleitungen 51 an einen zweiten Eingang 52 des
Adressmultiplexers 41 angelegt. Die Link-Adress-Register-Bank 50 empfängt über eine
Steuerleitung 17-6 ein Enable-Signal von dem Steuerpfad 9a. über eine
Steuerleitung 17-5 wird eine Link-Adress-Quelle der Basis-Adress-Register-Bank 3 und
der Link-Adress-Register-Bank 50 zugeführt. Der Datenmultiplexer 26 weist
einen Steuereingang 52 zum Empfang eines Link-Adress-Selektor-Signals über eine
Steuerleitung 17-4 auf. Der Adressmultiplexer 41 weist
ebenfalls einen Steuereingang 54 auf zum Empfang des Link-Adress-Selektor-Steuersignals.
-
Der
Datenpfad 9a der Schreibeinheit 9 ist in Abhängigkeit
von dem Steuersignal zwischen zwei Betriebsmodi umschaltbar, wobei
in dem ersten Betriebsmodus die Datenobjekte (DO) in das Speichersystem 5 eingeschrieben
werden und in dem zweiten Betriebsmodus die eingeschriebenen Datenobjekte
(DO) miteinander verkettet werden. In dem ersten Betriebsmodus werden
die an dem ersten Eingang 25 des Datenmultiplexers 26 anliegenden
Nutz- und Attributdaten und die über
den ersten Dateneingang 40 des Adressmultiplexers 41 durch
den Modulo-M-Addierer 30 berechnete Adresse durchgeschaltet
und eingeschrieben. Nachdem ein Datenobjekt DOn eingeschrieben
worden ist, wird es mit dem vorherigen Datenobjekt Dn-1 verkettet, indem
beide Multiplexer 26, 41 auf den zweiten Eingang 49 bzw. 52 mittels
des Steuersignals Link-Adress-Selektor umgeschaltet werden. Nach
dem Umschalten wird das in dem Basis-Adress-Register BAR gespeicherte Datum
an die in dem Link-Adress-Register LAR gespeicherte Adresse zur
Verkettung der beiden Datenobjekte DOn,
Don-1 geschrieben.
-
14 zeigt
ein Ablaufdiagramm zum Einschreiben der Nutzdaten in die Nutzdatenpuffer 23-i des FIFO-Speichers 21.
Die FIFO-Steuereinheit 8 befindet sich zunächst in
einem Ruhezustand. Sobald die FIFO-Steuereinheit 18 über die
Steuerleitung 3-4 ein Gültig-
bzw. VALID-Signal in dem Schritt S1 erhält, prüft die Steuereinheit 18 im
Schritt S2, ob der zu der Datenquelle 1 zugehörige Nutzdatenpuffer 23-i bereits
gefüllt ist.
Ist dies der Fall, gibt die FIFO-Steuereinheit 18 in einem
Schritt S3 ein Fehlersignal über
die Anzeigeleitung 13 ab. Ist der Nutzdatenpuffer 23-i noch
nicht gefüllt,
werden die Nutzdaten des empfangenen Datenpakets DP in den für die Datenquelle 1-x vorgesehenen
Nutzdatenpuffer 23-i in einem Schritt S4 eingeschrieben.
Anschließend
kehrt die FIFO-Steuereinheit 18 in
den Ruhezustand zurück.
-
15 zeigt
das Auslesen von Daten aus dem FIFO-Speicher 21 durch die
FIFO-Steuereinheit 18 zum Abspeichern in dem Speichersystem 5 über den
Datenmultiplexer 26. Die FIFO-Steuereinheit 18 befindet sich
zunächst
in einem Ruhezustand. Erhält
die FIFO-Steuereinheit 18 über eine Steuerleitung 17-3 ein POP-Steuersignal
von dem Steuerpfad 9a, prüft die Steuereinheit 18 in
einem Schritt S2, ob Attribut- oder Nutzdaten auszulesen sind. Handelt
es sich bei den auszulesenden Daten um Attributdaten werden in einem Schreiben
S3 Attributdaten aus dem Attributdatenpuffer 22-i entsprechend
der über
die Steuerleitung 17-3 angegebenen Datenlänge L ausgelesen.
Anschließend
wird durch die Steuereinheit 18 die kumulative Attributdatenmenge
VA,L in einem Schritt S4 inkrementiert.
Der inkrementierte Wert wird beispielsweise in einem Register innerhalb
der Steuereinheit 18 zwischengespeichert. Ergibt die Abfrage
in Schritt S2, dass die auszulesenden Daten Nutzdaten sind, werden
in einem Schritt S5 die Nutzdaten entsprechend der angegebenen Datenlänge L aus
dem zu der Datenquelle gehörigen
Nutzdatenpuffer 23-i ausgelesen. Anschließend wird
in einem Schritt S6 die kumulative Nutzdatenmenge PL durch
die FIFO-Steuereinheit 18 inkrementiert und vorzugsweise
in einem Register zwischengespeichert.
-
16 zeigt
den in der Zeitablauf-Meldeeinheit 11 des Schedulers 2 ablaufenden
Vorgang. Zunächst befindet
sich die Zeitablauf-Meldeeinheit 11 in einem Ruhezustand.
Die Zeitablauf-Meldeeinheit 11 fragt über eine Leitung 15 den
Zählerstand
des Zählers 10 in
einem Schritt S1 ab und vergleicht ihn mit einem vorzugsweise programmierbaren
Schwellenwert. SW im Schritt S1. Überschreitet der Zählerwert
den Schwellenwert SW, wird in einem Schritt S2 der Datenobjekt-Header
(HD) aus dem Speichersystem 5 über eine Leitung 4-8 bei
der Anfangsadresse des letzten Datenobjekts der Datenobjektkette
ausgelesen. In dem Schritt S3 wird die Datenobjektgröße des Datenobjekts
bestimmt. In einem nächsten
Schritt S4 wird die Datenmenge der in dem Datenobjekt enthaltenen
Nutzdaten ermittelt. In einem weiteren Schritt S5 wird die „Last Address” um die
Datenmenge „Objekt-Data-Size” inkrementiert.
Anschließend
wird in einem Schritt S6 der Zähler 10 entsprechend der
Datenmenge der in dem letzten Datenobjekt DO enthaltenen Nutzdaten
dekrementiert.