CN1175730A - 使用浮点运算硬件进行微处理器整数除法操作的方法和装置 - Google Patents
使用浮点运算硬件进行微处理器整数除法操作的方法和装置 Download PDFInfo
- Publication number
- CN1175730A CN1175730A CN97115450A CN97115450A CN1175730A CN 1175730 A CN1175730 A CN 1175730A CN 97115450 A CN97115450 A CN 97115450A CN 97115450 A CN97115450 A CN 97115450A CN 1175730 A CN1175730 A CN 1175730A
- Authority
- CN
- China
- Prior art keywords
- integer
- cpu
- denominator
- approximate value
- reciprocal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/52—Multiplying; Dividing
- G06F7/535—Dividing only
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2207/00—Indexing scheme relating to methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F2207/38—Indexing scheme relating to groups G06F7/38 - G06F7/575
- G06F2207/3804—Details
- G06F2207/3808—Details concerning the type of numbers or the way they are handled
- G06F2207/3812—Devices capable of handling different types of numbers
- G06F2207/3824—Accepting both fixed-point and floating-point numbers
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/499—Denomination or exception handling, e.g. rounding or overflow
- G06F7/49942—Significance control
- G06F7/49947—Rounding
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Complex Calculations (AREA)
Abstract
一种在多个整数分子被一个公共整数分母除时用于产生多个整数商的方法和装置,通过如下方式实现:用整数分母倒数的浮点数近似值乘以浮点数分子,进行舍入前,对产生的浮点商进行偏差处理。通过计算分母倒数的限定精度平方根的平方计算分母倒数的一个初始近似值。使用有限次幂级数计算最终倒数。计算修正分子同倒数的多次乘积并据要求对乘积进行向上或向下舍入取整处理。
Description
本发明主要涉及微处理器除法,特别涉及使用能进行浮点加乘运算的浮点运算硬件得到整数除法结果的方法和装置。
在现代计算机界,使用计算机系统中的中央处理单元(CPU)执行整数除法的必要性在逐步增长。整数除法操作包括一个整数分子和一个整数分母,在许多应用中都将用到这一操作。典型地,整数除法可用于Internet上MPEG序列或JPEG图象的计算。整数除法可用于计算机图形处理、各种绘图算法、三维屏幕显示、图形用户界面(GUIs)以及其他使用整数除法进行比例换算和/或压缩的应用。同线性代数和矩阵计算紧密相连的多媒体应用需要使用整数除法。视频处理、整数线性规划、多倍精度(multiple-precision)算术以及欧几里德(Euclid)的最大公分母(GCD)算法的使用也需要大量的整数除法。因此,随着这些应用的逐步扩展,以一种效果和效率不断提高的方式执行整数除法对于现代计算机和微处理器设计已变得越来越重要。
现在,整数除法是通过中央处理单元(CPU)的除法操作来完成的。整数除法由CPU的整数执行单元(integer execution unit)执行,其精度一般不超过32位(bits)。大多数除法操作需要至少20至40个时钟周期,并且对于大多数现代计算机的中央处理单元(CPU),除法操作通常是最耗时的算术操作。正如业界已认识到的,计算机运行得越快,其价值越高,因此除法操作的使用并不是优化的。在上面谈到的应用中,整数除法典型发生在比例换算中,总是涉及相同的整数分母。当执行除法操作时,分母连续保持相同值,每次除法必须彼此独立地串行执行,无法通过并行操作获取加速优势或者在遇到后面的除法操作是相同分母时,无法通过在除法操作之间传递信息来加速随后的除法处理。总之,当上面谈到的应用要求在合理的时间范围内以合理的效率执行整数除法操作时,在整数执行单元中执行整数除法操作并不是一种有效的方法。现在的整数除法操作速度慢,对于相同整数分母的聚集比例换算缺乏效率和精度,总之对上面的应用来说是一种无效的方法。同时,由通常的经验可知,浮点处理器可以为浮点数的加、减和乘操作提供有效的流水线处理。这些浮点处理器的精度典型可达53位。
因此,需要一种新的装置和方法来进行以浮点格式表示的整数除法操作,这样,这些整数除法操作的执行速度会得到提高,操作精度也将得到提高,并且当使用相同分母进行多个除法操作时,可以以更佳的时间效率方式进行流水线处理。
图1是数字直线图,用于举例说明本发明所阐述的问题之一;
图2是数字直线图,用于举例说明本发明;
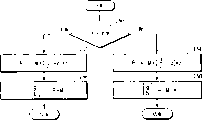
图3是高层流程图,用来举例说明本发明的操作;
图4到图6都是流程图,用来举例说明图3中的操作步骤;
图7是一张调度说明表,用来举例说明本发明在流水线处理器系统中的操作;
图8是方框图,用来举例说明本发明的集成电路实现设计;
图9和图10都是方框图,用来举例说明本发明的数据处理系统实现。
总的说来,本发明涉及在中央处理单元(CPU)内部执行整数除法操作,但避免使用除法硬件和算法。相反,本文所述的硬件和方法通过使用CPU内的浮点运算硬件的更有效的加法和乘法资源,以一种既精确又快捷有效的方式来处理整数除法操作。现有技术使用算术除法操作来实现整数除法功能。除法操作涉及整数分子a和整数分母b,
 的结果约等于某个整数值x。
向下取整,记作
的结果约等于某个整数值x。
向下取整,记作
 ,是不大于
,是不大于
 的最大整数,
的最大整数,
 向上取整,记作
,是不小于
向上取整,记作
,是不小于
 的最小整数。在本文的方法和装置中,整数除法
是通过两个数的乘法实现的,一个是b的倒数即
的最小整数。在本文的方法和装置中,整数除法
是通过两个数的乘法实现的,一个是b的倒数即
 的近似值;另一个数是经偏差处理的分子a′=±(a+p),两数相乘的结果将近似为最接近的最大整数或最小整数。
的近似值;另一个数是经偏差处理的分子a′=±(a+p),两数相乘的结果将近似为最接近的最大整数或最小整数。
需要重点说明的是,在使用本方法时,由于值
 在CPU中不能表示为无穷位或完整精度值,因此,需要这里所讨论的a的附加修正偏差。例如,值1/3在大多数CPU中不能表示为无穷位或完整精度值。所以,当中央处理单元(CPU)接收到整数分子a和整数分母b时,这两个数或者以浮点格式或者转化为浮点格式提供以进行浮点处理。这里的a进行了偏差校正以补偿
取近似值带来的精度损失。
在CPU中不能表示为无穷位或完整精度值,因此,需要这里所讨论的a的附加修正偏差。例如,值1/3在大多数CPU中不能表示为无穷位或完整精度值。所以,当中央处理单元(CPU)接收到整数分子a和整数分母b时,这两个数或者以浮点格式或者转化为浮点格式提供以进行浮点处理。这里的a进行了偏差校正以补偿
取近似值带来的精度损失。
实验表明,使用整数单元进行的典型整数除法操作可能占用20至40个时钟周期,数据精度为32位。采用浮点运算单元中的加乘方法来实现数据精度为50位的整数除法操作,则占用30个时钟周期。如果除法操作使用相同的分母b,则第二个除法可能仅需要1个时钟周期,第三个除法同样也仅再附加1个时钟周期,附加的除法操作相当节省时间。换而言之,一个典型整数除法单元如果计算24/11,101/11和65/11大约需要60至120个时钟周期,而计算a′b-1的近似值的方法在32个时钟周期内就可以得到这三个除法的整数商。另外,这些结果是用浮点格式表示的,这使得在具有更佳流水线性能的浮点运算单元中直接利用这些结果变得更容易了。所需时间比在浮点运算单元中进行单个浮点数除法更快,因为进行提供整数商结果的浮点操作时,多个附加计算可能被覆盖。
所以,这里所述的整数除法过程及装置可提供浮点数计算,这一计算在浮点运算硬件上进行,这一方式较之整数硬件单元具有更有效的流水线性能。采用浮点运算单元,即使只进行一个整数除法操作,速度也可明显得以改善,对于具有相同分母b(例如JPEG中的比例换算等)的多个除法操作,在性能上则可以得到很大提高。浮点运算硬件单元提供更多位精度,因此本文所述的方法和装置可以为整数执行单元中通常使用的超过32位的整数提供准确的整数除法精度。另外,整数值以浮点格式进行维护,因此减少了整数和浮点数之间的转换时间。总之,本文所述用于计算整数除法的方法可以进行快速计算,从而适用于MPEG应用、JPEG处理,图形界面、三维图形、最大公分母(GCD)计算、线性代数计算、矩阵计算、视频处理、数字音响处理、整数线性规划等等,使这些应用以先前不可能达到的速度进行计算。
参照理论讨论部分及图1至图10可以进一步理解本发明。
在举例说明用于不同计算机应用中整数除法的具体的方法和装置之前,下面的理论讨论将有助于理解本文所述的整数除法处理。
值小于某个最大值A的所有整数都可表示为浮点格式。设|a|<A和A>b>0是提供给CPU的两个整数值。整数下限
 和整数上限
也是范围处于(-A,A)之间的整数。通过使用z≈b-1的近似值及计算
和整数上限
也是范围处于(-A,A)之间的整数。通过使用z≈b-1的近似值及计算 和/或 达到不进行精确除法计算而进行下限取整计算和上限取整计算的目标。这种CPU计算方式可以以较快的式进行,并且具有前面讨论的所有优点。如果z有足够的精确度近似等于
 ,使δ=1-bz满足
,使δ=1-bz满足
 则上面的计算可以得到正确的结果。
则上面的计算可以得到正确的结果。
在CPU中计算z的一种方便方法是得到
 的一个初始估计值,记为近似值y,计算e=1-by,最后通过CPU中一或多次循环处理由y得到z。经截尾的以幂级数表示的近似值记为z=y(1+e+e2+e3+e4+...+em)。如果精确计算这一被截尾的以幂级数表示的近似值,结果会得到一个误差值δ=em+1。可以只使用一次(也就是说,一次循环)或按序列(也就是说,多次循环)使用这个表达式来进行计算。对于具有中等或较高时延的流水线处理器,使用m具有较高阶的单元多项式比较合适;对于具有较低时延的处理器,则重复使用低阶多项式更合适一些。另外,对于m具有确定值的多项式,更容易进行因式分解,从而可以比其他方式更快地进行单元高阶多项式的估算。上面所述的这种情况,如下例所示,特别合适。
的一个初始估计值,记为近似值y,计算e=1-by,最后通过CPU中一或多次循环处理由y得到z。经截尾的以幂级数表示的近似值记为z=y(1+e+e2+e3+e4+...+em)。如果精确计算这一被截尾的以幂级数表示的近似值,结果会得到一个误差值δ=em+1。可以只使用一次(也就是说,一次循环)或按序列(也就是说,多次循环)使用这个表达式来进行计算。对于具有中等或较高时延的流水线处理器,使用m具有较高阶的单元多项式比较合适;对于具有较低时延的处理器,则重复使用低阶多项式更合适一些。另外,对于m具有确定值的多项式,更容易进行因式分解,从而可以比其他方式更快地进行单元高阶多项式的估算。上面所述的这种情况,如下例所示,特别合适。
对于现代具有流水线的微处理器(见图8至9),通常存在一条指令用于计算浮点数倒数的近似值。如果这一指令以8位精度来计算y的近似值,则m=6是满足z的精度大于50位(如果直接计算)的最小m值。如果这一指令执行得快,则这是一个好的开端。
如果这一指令执行得慢或者没有提供,则使用一条指令,用来计算浮点数平方根倒数的近似值。如果这一指令执行
 的近似值为r,r可精确到5位,则
的近似值y可通过y=r2来计算,精度可以小于4位。这种方法较之上一段中描述的初始近似值的计算方法,计算速度明显加快,m可以取到16。
的近似值为r,r可精确到5位,则
的近似值y可通过y=r2来计算,精度可以小于4位。这种方法较之上一段中描述的初始近似值的计算方法,计算速度明显加快,m可以取到16。
使用y这一精度小于4的值,而同时为保证正确,A取值为250,这看上去是一个令人生畏的问题,比较适宜的方法是取阶m=16的单元多项式。经过因式分解,近似值最终可表示为:
z=y+ye(1+e)(1+e2)(1+e4)(1+e9)这一因式分解可以通过选择算术操作被执行的阶以多种方式进行计算。当组合乘法/加法指令可用时,有一种特别快捷和方便的方法,即
z=y+(e+e2)(y+y·e)((e+e2)+(e+e2)·e4)(1+e9)为了减小计算z的时间,还有其他一些选择阶的方法,一种特别好的方法示例如下。
如果进行精确计算,则z将满足δ所表示的误差范围。但是,在计算z时,必然会发生多次数学舍入。可被引入的最大总误差(the maximum totalerror)具体依赖于操作发生时的阶。对于图7所描述操作的具体选择,若同时考虑精度差异和算术舍入的不精确性,可以用枯燥但却直接了当的方式来表示最终的δ,δ限定在小于为给定值A而设定的所需值范围内。对于四种IEEE算术舍入模式的任何一种,这一精确性都可以得到保证。注意,在许多CPU或数字信号处理器(DSP)中以硬件线路实现的乘-加指令对于有效地及精确地实现这一多项式的估计是相当有用的。尽管该方法可能在“舍入正无穷(round-to-plus-infinity)模式”下执行,但为了最终的舍入处理,在“舍入0(round-to-0)”或“舍入负无穷(round-to-negative-infinity)”两种模式下执行更为方便。
借助把a′z加到一个大数M的技巧,使用标准浮点指令可以有效得到最终整数结果,此时,在舍入负无穷或舍入0模式下可以提供小于M+a′z(值M+a′z永不可能精确为一个整数)的最大整数值,在舍入正无穷(round-to-plus-infinity)模式可提供大于M+a′z(值M+a′z永不可能精确为一个整数)的最小整数值。用结果减去M或者用M减去结果,可以得到正确的整数下限或整数上限。在舍入0或舍入负无穷模式下, 而在舍入正无穷模式下,
使用这些方法,可在现代具有流水线处理方式的CPU(见图9)上计算出范围小于或等于250的整数a和b比率的正确整数下限和整数上限,还可在现有技术基础上得到如前描述的所有优点。注意,相同的z值可以用于所有具有相同分母b的分数中。还要注意,对于这些整数,a的偏差结果用双精度来表示。总之,如果希望精确处理N位整数,则需要在浮点运算时加入一小部分附加位以完成计算z过程中产生的算术舍入。
参照图1-10可以进一步理解本发明。
图1是数字直线图,用于举例说明本发明所阐述问题之一。该数字直线图上的刻度(tick)示出了一整数被整数b除后的可能结果值。这些结果用整数n加上
 的倍数表示。在两个相邻整数n和n+1之间,可能的结果值有n,
的倍数表示。在两个相邻整数n和n+1之间,可能的结果值有n,

 如此直到
最终到n+1。数字直线上部示出了精确的可能合理结果值。如果这些结果仅进行近似计算,如乘以一个倒数的近似值而不是除以分母的精确值,则在这些精确点上会延伸出一些分支。在精确点上部的短线段指示了这一延伸的最大范围。如果近似结果处于整段之上的某个下半段中,则随后的截尾操作会产生一个错误的整数下限结果。例如,线n左面的某个值会被截尾为n-1,尽管其实际整数下限值是n。如果近似结果处于整段之上的某个上半段中,则随后的舍入操作会产生一个错误的整数上限结果。例如,对线n右半段的值,其整数上限会是n+1,而不是正确结果n。
如此直到
最终到n+1。数字直线上部示出了精确的可能合理结果值。如果这些结果仅进行近似计算,如乘以一个倒数的近似值而不是除以分母的精确值,则在这些精确点上会延伸出一些分支。在精确点上部的短线段指示了这一延伸的最大范围。如果近似结果处于整段之上的某个下半段中,则随后的截尾操作会产生一个错误的整数下限结果。例如,线n左面的某个值会被截尾为n-1,尽管其实际整数下限值是n。如果近似结果处于整段之上的某个上半段中,则随后的舍入操作会产生一个错误的整数上限结果。例如,对线n右半段的值,其整数上限会是n+1,而不是正确结果n。
图2是本发明的示例数字直线图。如前所示,该数字直线图上的刻度示出了一整数被整数b除后的可能合理结果值。数字直线上部示出了一整数加上
再除以b后的精确的可能合理结果。这些结果相对于图1有
 的偏差。精确偏差点上部的短线段示出了与精确值倒数的近似值相关的不确定延伸。如果如图示偏移靠右并且延伸小于
的偏差。精确偏差点上部的短线段示出了与精确值倒数的近似值相关的不确定延伸。如果如图示偏移靠右并且延伸小于
 ,则偏差结果的近似值总可以向下舍入到下一个最小整数以得到精确值
,则偏差结果的近似值总可以向下舍入到下一个最小整数以得到精确值
 ,但如果偏移靠左(图未示出)并且延伸小于
,则偏差结果的近似值总可以向上舍入到下一个整数以得到精确值
,但如果偏移靠左(图未示出)并且延伸小于
,则偏差结果的近似值总可以向上舍入到下一个整数以得到精确值
 。因此无论a取何值都不会导致计算失败。将偏移和用于得到
。因此无论a取何值都不会导致计算失败。将偏移和用于得到
 足够精确近似值的有效方法相结合是本发明的关键。
足够精确近似值的有效方法相结合是本发明的关键。
注意图2所示的向上偏移,该偏移同向下舍入相结合用来产生下限取整函数。向下偏移同向上舍入相结合用来产生上限取整函数。各种等价性,如
 ,可以用来提供示例方法的轻变式(slight variants)。图3是本发明的高层示例流程图。首先在步骤102,生成
的初始近似值y。接着,在步骤104计算
,可以用来提供示例方法的轻变式(slight variants)。图3是本发明的高层示例流程图。首先在步骤102,生成
的初始近似值y。接着,在步骤104计算
 的最终近似值z。在步骤106形成修正后的分子。最后在步骤108,对z与修正后的分子的乘积进行舍入处理。图4是步骤102的示例流程图。首先在步骤112计算
的近似值r,接着在步骤114通过计算r2来得到y。
的最终近似值z。在步骤106形成修正后的分子。最后在步骤108,对z与修正后的分子的乘积进行舍入处理。图4是步骤102的示例流程图。首先在步骤112计算
的近似值r,接着在步骤114通过计算r2来得到y。
图5是一个示例流程图,用来说明步骤104中
 的最终近似值z的计算过程。图5中的两个输入值是方框120中的y和方框122中的b。方框120中的值y在步骤114和图4中计算。方框122中的输入值b是分母。值e在步骤124中按e=1-b*y=(1-by)进行计算。在本等式及随后的等式中,中间项表示待执行的操作,右边项表示经精确计算得到的精确代数值。值e用来参与步骤126中的s=e*e=e2及步骤128中的n=e+e*e=e(1+e)的计算。
的最终近似值z的计算过程。图5中的两个输入值是方框120中的y和方框122中的b。方框120中的值y在步骤114和图4中计算。方框122中的输入值b是分母。值e在步骤124中按e=1-b*y=(1-by)进行计算。在本等式及随后的等式中,中间项表示待执行的操作,右边项表示经精确计算得到的精确代数值。值e用来参与步骤126中的s=e*e=e2及步骤128中的n=e+e*e=e(1+e)的计算。
步骤126中的值s用来参与步骤130中k=y+y*s=y(1+e2)的计算。步骤126中的值s也用来参与步骤132中q=s*s=e4的计算。步骤132中的值q用来参与步骤134中d=1+q*q=1+e8的计算。步骤132中的值q及步骤128中的值n用来参与步骤136中c=n+n*q=e(1+e)(1+e4)的计算。步骤130中的值k和步骤134中的值d用来参与步骤138中m=k*d=y(1+e2)(1+e8)的计算。最后,方框120中的值y,步骤138的m以及步骤136中的c用来参与步骤140中z=y+m*c=y+ye(1+e)(1+e2)(1+e4)(1+e8)的计算。精确结果为y(1+e+e2+...+e16),这对于示例实现而言已足够精确了。
图6是图3步骤106和108的示例流程图。在步骤150进行舍入类型(下限取整函数或上限取整函数)判断。如果舍入类型表明是下限取整函数,则值R按
在步骤152来计算,结果
 在步骤156通过从R中减去M来计算。如果步骤150指示是上限舍入,则R在步骤154按
在步骤156通过从R中减去M来计算。如果步骤150指示是上限舍入,则R在步骤154按 来计算,结果
在步骤158通过从M中减去R来计算。这里所示例的舍入计算方法假设浮点计算是在前面所讨论的两种模式,即舍入0或舍入负无穷模式下进行的。
图7是一张指令调度表,用来说明实现本发明的流水线CPU的执行过程。该表有四列,列1包含周期号,列2包含所进行的操作,本表示例了

 和
和
 的计算过程。注意,周期20,25和28仅是用于计算
的计算过程。注意,周期20,25和28仅是用于计算 的附加周期,周期22,26和29仅是用于计算
的附加周期,周期22,26和29仅是用于计算
 的附加周期。第三列表明第二列所示操作的结果在哪个周期可为随后的操作使用。调度假设每个时钟周期发布一次,所有指令的时延为3个时钟周期。在周期0,计算
,计算结果在周期3可用。然后在周期3,计算y=r*r,其结果在周期6准备好,以用来计算e=1-b*y。流水线特性在周期9和周期10表现明显,值e用来计算周期9中的值s和周期10中的值n。最后第四列包含描述某些操作结果的注解。本调度执行图5所描述的计算。注意,结果
的附加周期。第三列表明第二列所示操作的结果在哪个周期可为随后的操作使用。调度假设每个时钟周期发布一次,所有指令的时延为3个时钟周期。在周期0,计算
,计算结果在周期3可用。然后在周期3,计算y=r*r,其结果在周期6准备好,以用来计算e=1-b*y。流水线特性在周期9和周期10表现明显,值e用来计算周期9中的值s和周期10中的值n。最后第四列包含描述某些操作结果的注解。本调度执行图5所描述的计算。注意,结果
 在周期30可用,结果
在周期30可用,结果
 在周期31可用,而结果
在周期32可用。在32个周期内除了得到三个运算结果外,另外还初始化和完成了10个浮点操作,这些操作没有占用额外的时间。如果仅计算
,在前30个周期内将执行16个附加的浮点操作,但是如果同时计算
在周期31可用,而结果
在周期32可用。在32个周期内除了得到三个运算结果外,另外还初始化和完成了10个浮点操作,这些操作没有占用额外的时间。如果仅计算
,在前30个周期内将执行16个附加的浮点操作,但是如果同时计算
 和
和
 ,则在前31个周期内要执行14个附加的浮点操作。在同一处理器条件下,这些运算的执行速度一般均比单个双精度浮点除法快。另外,通常除法操作不能发布其他浮点操作指令。
,则在前31个周期内要执行14个附加的浮点操作。在同一处理器条件下,这些运算的执行速度一般均比单个双精度浮点除法快。另外,通常除法操作不能发布其他浮点操作指令。
图8示出了一个用来执行图1至图7操作的定制设计的集成电路。图8示出了执行图8所清晰标注的步骤102到步骤108的硬件。换句话说,图8中的硬件单元102用来执行图3中步骤102,图8中的硬件单元104周来执行图3中步骤104,硬件单元106用来执行图3中步骤106,图8中的硬件单元108用来执行图3中步骤108。
在图8中,输入整数分子a和整数分母b通过导线162和164提供,而控制是上限取整操作还是下限取整操作的信号通过导线166提供。
硬件单元102说明该硬件用来提供输入值b的倒数的初始近似值y。值b如浮点格式170所示,格式170有一个指数部分和一个小数部分,小数部分包含标记为fhigh的高阶位和标记为flow的低阶位。指数部分用来构造y0的指数部分,这里的y0是b倒数的初始近似值。格式170小数部分的fhigh部分用来存取存储在存储器中的一张表。存储在存储器中的表174典型地可以存于ROM存储器或RAM存储器中,该表可提供y0,的小数部分f′high的高阶位,而小数部分的低端部分则如图8中格式176所示填为0。数值y0,是通过导体162输入的值b的倒数的初始近似值,格式176示出了值y0,的指数部分和小数部分。值y0通过导体178提供给硬件的下一部分。通过硬件单元104以循环方式或流水线方式对值y0进行处理,得到精确到限定公差范围内的
 的最终近似值。
的最终近似值。
硬件单元104通过导体178将值y0和通过导体162将值b作为其输入。一旦导体178和162提供了这些输入值,则或者单一硬件单元以循环方式逐步计算更精确的倒数近似值,或者一组以流水线方式排列的硬件单元以按序流水线操作来计算更精确的值b的倒数近似值。所示例的实现方法利用了易于流水线化的简单公式。如果这些计算阶段共享硬件,则较前阶段较之后面阶段可以进行较低精度运算。如果在这些计算阶段循环使用同一硬件,则通过执行计算的一部分可以在较前阶段减小乘方。
在硬件图104示例了一个更为精确的用以计算b倒数近似值的方法。在流水线的第一个阶段或者在循环计算的第一个步骤中,硬件180通过硬件182来计算误差项。通过硬件184可以使用误差项和值y0来计算更精确的b的倒数近似值。通过循环处理的后续步骤或流水线处理的阶段180’,使用示例所示的循环处理方式或流水线处理方式来执行180中示例的类似操作以进一步对b的倒数近似值进行精确化。一旦在硬件104中执行了足以达到指定精度公差的循环次数或流水线阶段,则输出z通过导体186提供。为了硬件单元102和104能并行处理,输入整数分子a通过硬件106来处理。硬件单元106和108通过导体166接收下限取整及上限取整控制信息。线166上的信号用于控制执行操作是下限取整操作还是上限取整操作。在步骤106,这一控制信号用于确定a的偏差方式(+表示下限取整,-表示上限取整)。偏差值R通过导体188提供给硬件108。硬件108接着执行通过导体186提供的值z和通过导体188提供的值R的乘积。然后这一乘积被舍入为最接近的最小整数值。导体166的控制信号确定是否改变整数的取整记号(no表示下限取整,yes表示上限取整)。硬件108的输出是通过导体168提供的整数商。如果b的值不变,则根据图3结构对图8所进行的划分使得易于保持z的值;如果最近使用过b,则图8的划分使得易于从高速缓存(cache)中得到z。正如前面所讨论的,在实现时进行少许变换就可以利用数学等价性来提供功能等价性。
图9和图10一起示例了一个数据处理系统,该系统可用来执行这里所述的整数除法操作。图9和图10示例了中央处理单元(CPU)部分200,该部分通过一条32位地址总线272和一条64位数据总线272同外部存储器280相连。中央处理单元(CPU)200有一个提取单元(fetch unit)212,通过128位总线258,利用指令存储器管理单元(IMMU)250,该提取单元212负责从16KBI(I表示指令)高速缓存254提取计算机指令。如图10所示,提取单元212所提供的指令将填入一个容量为8条指令的队列214。提取单元212以每次4条指令的速度不断提取指令以确保队列214充满用于CPU200处理的指令。包含分支判断信息的分支处理单元(branchprocessing unit)216用于控制提取器212以便维护指令队列214中正确的指令执行流。如图9和图10的中央部分所示,一个分派单元(dispatchunit)218被用来解码和发布指令到适当的执行单元。分派单元218可为图9和图10中央部分所示的四种执行单元类型之一提供解码后的指令。这四种类型是浮点运算单元240,装入/存储单元(load/store unit)234,单循环整数运算单元228及多循环整数运算单元224。单元218,216,214和212是一个较大指令单元210的所有部分,该指令单元负责为图9和图10中的多个执行单元之一提供连续的指令流。
如图9和图10所示,所提供的指令通过128位总线220送到保留站(reservation station)222,226,232和238。保留站222,226,232和238中的每个保留站为执行单元224,228,234和240中的一或多个执行单元输送指令。224,228,234和240这些执行单元将执行由指令单元210提供的经解码的指令。在指令执行期间,存储在通用寄存器(GPR)文件230区的多个通用寄存器和存储在浮点寄存器(FPR)文件236区的多个浮点寄存器可被执行单元存取。另外,装入/存储单元234可以存取存储队列(store queues)和装入完成(finish load queues)队列244,数据高速缓存264同D(数据)高速缓存标志(data cache tags)262和数据高速缓存管理单元260相联。装入/存储单元234可存取这一标志信息以维护处理单元内部数据的完整性。
总线接口单元(bus interface unit)270提供到外部总线272和274的接口。总线接口单元270将指令放入与指令标志252相联的I(指令)高速缓存254中。数据也通过总线接口单元270从外部存储器进行读取,读入后放入D(数据)高速缓存264中。如上所讨论的,指令也通过指令存储器管理单元(MMU)250被送往指令提取单元212。一旦指令被提供并通过执行单元224,228,234和240得以执行后,指令会进入到一个结束单元(completion unit),该结束单元通常在处理器200所执行的流水线序列的最后,对异常的执行和错误的分支判断进行补救处理。32位地址总线272和64位数据总线274与外部存储器280和计算机可读介质286相连。外部存储器280中包含四组指令,用于执行硬件单元200中特定的操作。特别地,存储器280包含四个软件程序单元102,104,106和108,它们分别对应图3中的步骤102,104,106和108。因此,CPU200通过存取外部存储器280可以执行这里所述的图1至图7的操作。存储在存储器280中的软件单元102,104,106和108总是从计算机可读介质286装入存储器280,可读介质有EPROM,EEPROM,ROM,DRAM,SRAM,磁存储器,带存储器,光存储器,激光磁盘(CD),闪速存储器,网络存储器,通过通信连接的另一台计算机,或者象用于计算机可执行代码或计算机数据的存储设备。
熟练的技术人员能够识别本发明的修改和变动而不偏离本发明的宗旨,因此,本发明计划完成所有象附加的权利说明书中的修改和变动。
Claims (10)
1.一个产生整数分子(a)和整数分母(b)的整数商的方法,其特征在于:
整数分子(a)、整数分母(b)和整数除法指令一起提供给中央处理单元(CPU);
使用中央处理单元(CPU)确定整数分母(b)倒数的初始近似值(y);
对初始近似值(y)进行精细处理,产生更为精确的整数分母(b)倒数的近似值(z);
通过偏差值(p)对整数分子(a)进行偏差处理,产生偏差分子(a′);并通过将更精确的近似值(z)和偏差分子(a′)相乘来确定a/b的整数商,以此响应CPU中发布的控制信号并在CPU中执行舍入操作以确保a/b的整数商是一个整数。
2.根据权利要求1中的方法,提供整数分子(a)和整数分母(b)的这一步骤的特征在于:
以一种整数格式提供整数分子(a)和整数分母(b),该整数格式在处理之前由CPU中的一个浮点运算单元转换为浮点格式。
3.根据权利要求1中的方法,确定初始近似值(y)这一步骤的特征在于:
从存储在存储器中的一张表中找到初始近似值(y)的小数部分,并
由整数分母(b)的指数部分来计算初始近似值(y)的指数部分。
4.根据权利要求1的方法,确定整数分母(b)倒数的初始近似值(y)并精细处理(y)从而生成一个更为精确的近似值(z),上面这一步骤的特征在于:
使用整数分母(b)作为一个高速缓存标志值,通过存取该高速缓存找到更精确的近似值(z)。
5.根据权利要求1的方法,精细处理初始近似值(y)以生成一个更精确的近似值(z)这一步骤的特征在于:
按e=1-b*y确定一个误差值(e);并
据z=f(e,y)找到一个更精确的近似值(z)。
6.一种用于产生整数分子(a)和整数分母(b)的整数商的方法,其特征在于:
整数分子(a)、整数分母(b)和整数除法指令一起提供给中央处理单元(CPU);
使用中央处理单元(CPU)确定整数分母(b)倒数的初始近似值(y);确定整数分母(b)的平方根倒数的近似值(r),即
 ;并且
;并且
计算初始近似值(y)同平方根倒数近似值(r)和平方根倒数近似值(r)的乘积,即y=r*r;
精细化初始近似值(y)得到一个更精确的整数分母(b)的倒数近似值(z),这一步骤的特征在于:
按e=1-b*y确定一个误差值(e),并据z=f(e,y)找到一个更精确的近似值(z);通过偏差值(p)对整数分子(a)进行偏差处理,产生偏差分子(a′);这一步骤的特征在于:
按a′=a+p找到偏差分子(a′),这里的p等于±1/2;并且
通过将更精确的近似值(z)和偏差分子(a′)相乘来确定a/b的整数商,以此响应CPU中发布的控制信号并在CPU中执行舍入操作以确保a/b的整数商是一个整数。
7.一种在流水线浮点处理器中执行整数除法的方法,其特征在于:
提供一个整数分子(a)和一个整数分母(b)给流水线浮点处理器;
通过流水线浮点处理器确定整数分母(b)倒数的初始近似值(y),即y≈1/b;
通过流水线浮点处理器找到初始近似值(y)的误差值(e),e=1-b*y;
通过在浮点处理器中至少一次的循环处理,循环确定更精确的分母(b)倒数的近似值(z),不断进行循环处理直到更精确近似值(z)在指定的误差公差(δ)内,更精确近似值(z)是初始近似值(y)和误差值(e)的函数。
对整数分子(a)进行偏差处理,得到偏差值(a′),在a′=±(a+p)中的|p|是一个用于下限取整操作的小于1.0的小数值;在a′=±(a-p)中的|p|则是一个用于上限取整操作的小于1.0的小数值;
通过将整数分子(a′)与更精确近似值(z)相乘,确定一个初步结果;然后对该初步结果进行舍入处理,得到一个整数值。
8.一个整数除法器,其特征在于:
浮点运算装置,该装置用于确定整数分母(b)倒数的初始近似值(y);
浮点运算装置,该装置用于将初始近似值(y)精细处理为整数分母(b)倒数的一个更为精确的近似值(z);
浮点运算装置,该装置通过一个偏差值(p)对整数分子(a)进行偏差处理,从而得到一个经偏差化的分子(a′);并且
该装置在CPU内通过对更精确近似值(z)和偏差分子(a′)的乘积执行舍入操作来确定a/b的整数商,从而确保a/b的整数商是一个整数。
9.存储在计算机可读取介质中的一个整数除法器,计算机可读取介质的特征在于:
至少有一条计算机指令,该指令用于确定整数分母(b)倒数的初始近似值(y);
至少有一条计算机指令,该指令用于对初始近似值(y)进行精细处理,从而得到整数分母(b)倒数的一个更精确的近似值(z);
至少有一条计算机指令,该指令通过偏差值(p)对整数分子(a)进行偏差处理,从而生成一个经偏差的分子(a′);并且
至少有一条计算机指令,该指令在CPU内通过对更精确近似值(z)和偏差分子(a′)的乘积执行舍入操作来确定a/b的整数商,从而确保a/b的整数商是一个整数。
10.一种用于得到整数分子(a)和整数分母(b)的整数商的装置,该装置的特征在于:
包含流水线浮点运算电路的中央处理单元(CPU);
同中央处理单元(CPU)相连的存储器,该存储器包含一或多条计算机指令,这些指令由CPU进行存取并经解码执行下面的操作:
使用流水线浮点运算电路确定整数分母(b)倒数的初始近似值(y);
使用流水线浮点运算电路对初始近似值(y)进行精细处理,得到整数分母(b)倒数的一个更精确的近似值(z);
使用流水线浮点运算电路通过一个偏差值(p)对整数分子(a)进行偏差处理,从而得到一个经偏差化的分子(a′);并且
使用流水线浮点运算电路在CPU内通过对更精确近似值(z)和偏差分子(a′)的乘积执行舍入操作来响应CPU内发布的控制信号,确定a/b的整数商,从而确保a/b的整数商是一个整数值。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US08/685,995 US5768170A (en) | 1996-07-25 | 1996-07-25 | Method and apparatus for performing microprocessor integer division operations using floating point hardware |
| US685995 | 1996-07-25 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN1175730A true CN1175730A (zh) | 1998-03-11 |
Family
ID=24754483
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN97115450A Pending CN1175730A (zh) | 1996-07-25 | 1997-07-24 | 使用浮点运算硬件进行微处理器整数除法操作的方法和装置 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US5768170A (zh) |
| EP (1) | EP0821303A3 (zh) |
| JP (1) | JPH1078863A (zh) |
| KR (1) | KR100528269B1 (zh) |
| CN (1) | CN1175730A (zh) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1296816C (zh) * | 2002-05-27 | 2007-01-24 | 华邦电子股份有限公司 | 以少位处理器作多位求方根的方法 |
| CN101036113B (zh) * | 2004-10-15 | 2010-11-03 | 日本电信电话株式会社 | 信息编码方法、解码方法、利用这些方法的装置 |
| CN104375800A (zh) * | 2014-12-09 | 2015-02-25 | 国网重庆市电力公司电力科学研究院 | 一种嵌入式系统的浮点除法运算方法、系统和嵌入式系统 |
| CN105302520A (zh) * | 2015-10-16 | 2016-02-03 | 北京中科汉天下电子技术有限公司 | 一种倒数运算的求解方法及系统 |
Families Citing this family (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5973705A (en) * | 1997-04-24 | 1999-10-26 | International Business Machines Corporation | Geometry pipeline implemented on a SIMD machine |
| JPH11242585A (ja) * | 1998-02-24 | 1999-09-07 | Sony Corp | 除算回路およびグラフィック演算装置 |
| US6266769B1 (en) | 1998-04-30 | 2001-07-24 | Intel Corporation | Conversion between packed floating point data and packed 32-bit integer data in different architectural registers |
| US6282554B1 (en) | 1998-04-30 | 2001-08-28 | Intel Corporation | Method and apparatus for floating point operations and format conversion operations |
| US6292815B1 (en) * | 1998-04-30 | 2001-09-18 | Intel Corporation | Data conversion between floating point packed format and integer scalar format |
| US6247116B1 (en) | 1998-04-30 | 2001-06-12 | Intel Corporation | Conversion from packed floating point data to packed 16-bit integer data in different architectural registers |
| US6263426B1 (en) | 1998-04-30 | 2001-07-17 | Intel Corporation | Conversion from packed floating point data to packed 8-bit integer data in different architectural registers |
| US6175907B1 (en) * | 1998-07-17 | 2001-01-16 | Ip First, L.L.C | Apparatus and method for fast square root calculation within a microprocessor |
| US6341300B1 (en) | 1999-01-29 | 2002-01-22 | Sun Microsystems, Inc. | Parallel fixed point square root and reciprocal square root computation unit in a processor |
| US6384748B1 (en) | 1998-12-21 | 2002-05-07 | Base One International Corporation | Method of encoding numeric data and manipulating the same |
| US6351760B1 (en) | 1999-01-29 | 2002-02-26 | Sun Microsystems, Inc. | Division unit in a processor using a piece-wise quadratic approximation technique |
| US6732259B1 (en) | 1999-07-30 | 2004-05-04 | Mips Technologies, Inc. | Processor having a conditional branch extension of an instruction set architecture |
| US7242414B1 (en) | 1999-07-30 | 2007-07-10 | Mips Technologies, Inc. | Processor having a compare extension of an instruction set architecture |
| JP3447614B2 (ja) | 1999-05-31 | 2003-09-16 | 株式会社東芝 | 分数演算器、グラフィック用セットアップエンジン、分数演算方法、及び機械読み出し可能な記憶媒体 |
| US7346643B1 (en) | 1999-07-30 | 2008-03-18 | Mips Technologies, Inc. | Processor with improved accuracy for multiply-add operations |
| US6912559B1 (en) | 1999-07-30 | 2005-06-28 | Mips Technologies, Inc. | System and method for improving the accuracy of reciprocal square root operations performed by a floating-point unit |
| US6631392B1 (en) | 1999-07-30 | 2003-10-07 | Mips Technologies, Inc. | Method and apparatus for predicting floating-point exceptions |
| US6697832B1 (en) | 1999-07-30 | 2004-02-24 | Mips Technologies, Inc. | Floating-point processor with improved intermediate result handling |
| KR100429195B1 (ko) * | 2000-03-16 | 2004-04-28 | 엘지전자 주식회사 | 근사값을 이용한 나누기 방법 |
| US6963895B1 (en) * | 2000-05-01 | 2005-11-08 | Raza Microelectronics, Inc. | Floating point pipeline method and circuit for fast inverse square root calculations |
| US6996596B1 (en) | 2000-05-23 | 2006-02-07 | Mips Technologies, Inc. | Floating-point processor with operating mode having improved accuracy and high performance |
| GB2386984B (en) * | 2002-03-28 | 2005-07-20 | David Robinson | A data processing system and method for performing a mathematical operation on multi bit binary integer numbers using floating point arithmetic |
| KR100480724B1 (ko) * | 2002-10-31 | 2005-04-07 | 엘지전자 주식회사 | 가변 스텝사이즈 적응형 역수기 |
| US7523152B2 (en) * | 2002-12-26 | 2009-04-21 | Intel Corporation | Methods for supporting extended precision integer divide macroinstructions in a processor |
| JP3755602B2 (ja) * | 2003-03-04 | 2006-03-15 | ソニー株式会社 | 信号処理装置、信用処理装置用プログラム、信号処理装置用プログラムを記録した記録媒体、及び信号処理方法 |
| US7421139B2 (en) * | 2004-10-07 | 2008-09-02 | Infoprint Solutions Company, Llc | Reducing errors in performance sensitive transformations |
| US7747667B2 (en) * | 2005-02-16 | 2010-06-29 | Arm Limited | Data processing apparatus and method for determining an initial estimate of a result value of a reciprocal operation |
| US8015228B2 (en) | 2005-02-16 | 2011-09-06 | Arm Limited | Data processing apparatus and method for performing a reciprocal operation on an input value to produce a result value |
| US7676535B2 (en) * | 2005-09-28 | 2010-03-09 | Intel Corporation | Enhanced floating-point unit for extended functions |
| KR101718817B1 (ko) * | 2010-11-17 | 2017-03-29 | 삼성전자주식회사 | 부동 소수점 데이터와 정수형 데이터 간의 변환장치 및 그 방법 |
| GB201117318D0 (en) | 2011-10-06 | 2011-11-16 | Imagination Tech Ltd | Method and apparatus for use in the design and manufacture of integrated circuits |
| US10313118B2 (en) | 2016-10-27 | 2019-06-04 | Cisco Technology, Inc. | Authenticated access to cacheable sensor information in information centric data network |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS60142738A (ja) * | 1983-12-30 | 1985-07-27 | Hitachi Ltd | 内挿近似を使用する除算装置 |
| JPS60164837A (ja) * | 1984-02-07 | 1985-08-27 | Nec Corp | 除算装置 |
| JPS61243532A (ja) * | 1985-04-22 | 1986-10-29 | Toshiba Corp | 演算装置 |
| US4878190A (en) * | 1988-01-29 | 1989-10-31 | Texas Instruments Incorporated | Floating point/integer processor with divide and square root functions |
| JP2578482B2 (ja) * | 1988-08-15 | 1997-02-05 | 富士通株式会社 | 浮動小数点演算器 |
| US5249149A (en) * | 1989-01-13 | 1993-09-28 | International Business Machines Corporation | Method and apparatus for performining floating point division |
| US5206823A (en) * | 1990-12-13 | 1993-04-27 | Micron Technology, Inc. | Apparatus to perform Newton iterations for reciprocal and reciprocal square root |
| US5309353A (en) * | 1992-10-02 | 1994-05-03 | Westinghouse Electric Corp. | Multiple reference frame controller for active filters and power line conditioners |
| US5341321A (en) * | 1993-05-05 | 1994-08-23 | Hewlett-Packard Company | Floating point arithmetic unit using modified Newton-Raphson technique for division and square root |
| US5563818A (en) * | 1994-12-12 | 1996-10-08 | International Business Machines Corporation | Method and system for performing floating-point division using selected approximation values |
-
1996
- 1996-07-25 US US08/685,995 patent/US5768170A/en not_active Expired - Fee Related
-
1997
- 1997-07-16 JP JP9208462A patent/JPH1078863A/ja active Pending
- 1997-07-24 CN CN97115450A patent/CN1175730A/zh active Pending
- 1997-07-24 EP EP97112694A patent/EP0821303A3/en not_active Withdrawn
- 1997-07-25 KR KR1019970036389A patent/KR100528269B1/ko not_active IP Right Cessation
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1296816C (zh) * | 2002-05-27 | 2007-01-24 | 华邦电子股份有限公司 | 以少位处理器作多位求方根的方法 |
| CN101036113B (zh) * | 2004-10-15 | 2010-11-03 | 日本电信电话株式会社 | 信息编码方法、解码方法、利用这些方法的装置 |
| CN104375800A (zh) * | 2014-12-09 | 2015-02-25 | 国网重庆市电力公司电力科学研究院 | 一种嵌入式系统的浮点除法运算方法、系统和嵌入式系统 |
| CN105302520A (zh) * | 2015-10-16 | 2016-02-03 | 北京中科汉天下电子技术有限公司 | 一种倒数运算的求解方法及系统 |
| CN105302520B (zh) * | 2015-10-16 | 2018-03-23 | 北京中科汉天下电子技术有限公司 | 一种倒数运算的求解方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR100528269B1 (ko) | 2006-02-01 |
| KR980010751A (ko) | 1998-04-30 |
| EP0821303A2 (en) | 1998-01-28 |
| EP0821303A3 (en) | 1998-03-11 |
| JPH1078863A (ja) | 1998-03-24 |
| US5768170A (en) | 1998-06-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1175730A (zh) | 使用浮点运算硬件进行微处理器整数除法操作的方法和装置 | |
| US9753695B2 (en) | Datapath circuit for digital signal processors | |
| CN101201644B (zh) | 指数处理方法与系统 | |
| Pineiro et al. | Algorithm and architecture for logarithm, exponential, and powering computation | |
| US9146901B2 (en) | Vector floating point argument reduction | |
| CN108351761A (zh) | 使用冗余表示的第一和第二操作数的乘法 | |
| CN1172539A (zh) | 利用截尾泰勒级数的对数/反对数转换器及其使用方法 | |
| JPH04227535A (ja) | 除算を行なう装置 | |
| JPH08185309A (ja) | 4倍精度演算の実行方法 | |
| US20130185345A1 (en) | Algebraic processor | |
| CN105930128B (zh) | 一种利用浮点数计算指令实现大整数乘法计算加速方法 | |
| EP2208132A1 (en) | Apparatus and method for performing magnitude detection for arithmetic operations | |
| CN108351776A (zh) | 用于向量的处理的通道位置信息 | |
| CN113138749B (zh) | 基于cordic算法的三角函数计算装置及方法 | |
| CN108351762A (zh) | 使用重叠位的数值的冗余表示 | |
| JPH0477932B2 (zh) | ||
| GB2423386A (en) | Performing a reciprocal operation on an input value to produce a result value | |
| CN108351763A (zh) | 重叠传播操作 | |
| US7016930B2 (en) | Apparatus and method for performing operations implemented by iterative execution of a recurrence equation | |
| EP0166999A2 (en) | Time saving method for computing square roots on a computer having a "one bit at a time" division instruction | |
| US6487576B1 (en) | Zero anticipation method and apparatus | |
| Schulte et al. | A software interface and hardware design for variable-precision interval arithmetic | |
| US6256656B1 (en) | Apparatus and method for extending computational precision of a computer system having a modular arithmetic processing unit | |
| US20040117415A1 (en) | Arithmetic and relational operations | |
| JPH0445860B2 (zh) |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C01 | Deemed withdrawal of patent application (patent law 1993) | ||
| WD01 | Invention patent application deemed withdrawn after publication |