CN112423885B - 多核苷酸合成方法、试剂盒和系统 - Google Patents
多核苷酸合成方法、试剂盒和系统 Download PDFInfo
- Publication number
- CN112423885B CN112423885B CN201980048339.XA CN201980048339A CN112423885B CN 112423885 B CN112423885 B CN 112423885B CN 201980048339 A CN201980048339 A CN 201980048339A CN 112423885 B CN112423885 B CN 112423885B
- Authority
- CN
- China
- Prior art keywords
- nucleotide
- strand
- polynucleotide
- nucleotides
- cycle
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 102000040430 polynucleotide Human genes 0.000 title claims abstract description 894
- 108091033319 polynucleotide Proteins 0.000 title claims abstract description 894
- 239000002157 polynucleotide Substances 0.000 title claims abstract description 894
- 238000001308 synthesis method Methods 0.000 title description 19
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 1321
- 239000002773 nucleotide Substances 0.000 claims abstract description 1314
- 238000000034 method Methods 0.000 claims abstract description 434
- 238000003786 synthesis reaction Methods 0.000 claims abstract description 192
- 230000015572 biosynthetic process Effects 0.000 claims abstract description 190
- 230000002194 synthesizing effect Effects 0.000 claims abstract description 33
- 238000003776 cleavage reaction Methods 0.000 claims description 202
- 230000007017 scission Effects 0.000 claims description 187
- 230000000295 complement effect Effects 0.000 claims description 139
- 230000002441 reversible effect Effects 0.000 claims description 125
- 238000006243 chemical reaction Methods 0.000 claims description 107
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 claims description 98
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 claims description 98
- 102000004190 Enzymes Human genes 0.000 claims description 92
- 108090000790 Enzymes Proteins 0.000 claims description 92
- 108020004414 DNA Proteins 0.000 claims description 71
- 102000004357 Transferases Human genes 0.000 claims description 47
- 108090000992 Transferases Proteins 0.000 claims description 47
- 230000009471 action Effects 0.000 claims description 43
- 239000003153 chemical reaction reagent Substances 0.000 claims description 39
- 102000003960 Ligases Human genes 0.000 claims description 33
- 108090000364 Ligases Proteins 0.000 claims description 33
- 230000000694 effects Effects 0.000 claims description 30
- SGPUHRSBWMQRAN-UHFFFAOYSA-N 2-[bis(1-carboxyethyl)phosphanyl]propanoic acid Chemical compound OC(=O)C(C)P(C(C)C(O)=O)C(C)C(O)=O SGPUHRSBWMQRAN-UHFFFAOYSA-N 0.000 claims description 28
- 229920002401 polyacrylamide Polymers 0.000 claims description 25
- -1 bromoacetyl groups Chemical group 0.000 claims description 23
- 230000005783 single-strand break Effects 0.000 claims description 21
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 claims description 20
- 125000000524 functional group Chemical group 0.000 claims description 20
- 238000009396 hybridization Methods 0.000 claims description 20
- 239000000126 substance Substances 0.000 claims description 20
- 102000012410 DNA Ligases Human genes 0.000 claims description 16
- 108010061982 DNA Ligases Proteins 0.000 claims description 16
- 239000000243 solution Substances 0.000 claims description 15
- 108010008286 DNA nucleotidylexotransferase Proteins 0.000 claims description 14
- 108010082610 Deoxyribonuclease (Pyrimidine Dimer) Proteins 0.000 claims description 14
- 238000000338 in vitro Methods 0.000 claims description 13
- 102000053602 DNA Human genes 0.000 claims description 12
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 claims description 12
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 claims description 12
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical group [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 claims description 12
- 238000002493 microarray Methods 0.000 claims description 12
- 208000035657 Abasia Diseases 0.000 claims description 11
- 102100029764 DNA-directed DNA/RNA polymerase mu Human genes 0.000 claims description 11
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 claims description 9
- 239000007787 solid Substances 0.000 claims description 8
- 239000011521 glass Substances 0.000 claims description 7
- 239000011859 microparticle Substances 0.000 claims description 7
- 230000008569 process Effects 0.000 claims description 7
- 102000004099 Deoxyribonuclease (Pyrimidine Dimer) Human genes 0.000 claims description 6
- 108010072685 Uracil-DNA Glycosidase Proteins 0.000 claims description 6
- 102000006943 Uracil-DNA Glycosidase Human genes 0.000 claims description 6
- 125000003277 amino group Chemical group 0.000 claims description 6
- 125000003396 thiol group Chemical group [H]S* 0.000 claims description 6
- 108010034927 3-methyladenine-DNA glycosylase Proteins 0.000 claims description 5
- 101710081048 Endonuclease III Proteins 0.000 claims description 5
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical group OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 claims description 5
- 239000004202 carbamide Substances 0.000 claims description 5
- 239000003795 chemical substances by application Substances 0.000 claims description 5
- 230000001351 cycling effect Effects 0.000 claims description 5
- 108091008146 restriction endonucleases Proteins 0.000 claims description 5
- 125000001391 thioamide group Chemical group 0.000 claims description 5
- 108020001738 DNA Glycosylase Proteins 0.000 claims description 4
- 102000028381 DNA glycosylase Human genes 0.000 claims description 4
- 102100029765 DNA polymerase lambda Human genes 0.000 claims description 4
- 101710177421 DNA polymerase lambda Proteins 0.000 claims description 4
- 101710137500 T7 RNA polymerase Proteins 0.000 claims description 4
- 108010028263 bacteriophage T3 RNA polymerase Proteins 0.000 claims description 4
- 238000010438 heat treatment Methods 0.000 claims description 4
- KVKFRMCSXWQSNT-UHFFFAOYSA-N n,n'-dimethylethane-1,2-diamine Chemical compound CNCCNC KVKFRMCSXWQSNT-UHFFFAOYSA-N 0.000 claims description 4
- KVLNTIPUCYZQHA-UHFFFAOYSA-N n-[5-[(2-bromoacetyl)amino]pentyl]prop-2-enamide Chemical compound BrCC(=O)NCCCCCNC(=O)C=C KVLNTIPUCYZQHA-UHFFFAOYSA-N 0.000 claims description 4
- 238000005406 washing Methods 0.000 claims description 4
- 108010063362 DNA-(Apurinic or Apyrimidinic Site) Lyase Proteins 0.000 claims description 3
- 102100039128 DNA-3-methyladenine glycosylase Human genes 0.000 claims description 3
- 241000205188 Thermococcus Species 0.000 claims description 3
- 230000002401 inhibitory effect Effects 0.000 claims description 3
- 102100035619 DNA-(apurinic or apyrimidinic site) lyase Human genes 0.000 claims description 2
- 238000004873 anchoring Methods 0.000 claims description 2
- 239000000376 reactant Substances 0.000 claims description 2
- 230000009089 cytolysis Effects 0.000 claims 3
- 102000018054 AP endonuclease 1 Human genes 0.000 claims 1
- 108050007143 AP endonuclease 1 Proteins 0.000 claims 1
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 claims 1
- 150000003857 carboxamides Chemical class 0.000 claims 1
- 125000005647 linker group Chemical group 0.000 description 150
- 108091034117 Oligonucleotide Proteins 0.000 description 76
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 58
- 239000000047 product Substances 0.000 description 57
- 239000000499 gel Substances 0.000 description 43
- 238000010189 synthetic method Methods 0.000 description 43
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 40
- 238000010511 deprotection reaction Methods 0.000 description 40
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 35
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 34
- 239000012634 fragment Substances 0.000 description 24
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 23
- 238000010348 incorporation Methods 0.000 description 21
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 20
- 229940104302 cytosine Drugs 0.000 description 20
- 150000007523 nucleic acids Chemical group 0.000 description 20
- 102000039446 nucleic acids Human genes 0.000 description 18
- 108020004707 nucleic acids Proteins 0.000 description 18
- 230000000903 blocking effect Effects 0.000 description 17
- 229940113082 thymine Drugs 0.000 description 17
- 239000007858 starting material Substances 0.000 description 16
- 239000000758 substrate Substances 0.000 description 15
- 230000000670 limiting effect Effects 0.000 description 14
- 239000002777 nucleoside Substances 0.000 description 14
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 14
- 125000006850 spacer group Chemical group 0.000 description 14
- 239000001226 triphosphate Substances 0.000 description 13
- 230000003321 amplification Effects 0.000 description 11
- 239000011324 bead Substances 0.000 description 11
- 239000000463 material Substances 0.000 description 11
- 238000003199 nucleic acid amplification method Methods 0.000 description 11
- 239000002342 ribonucleoside Substances 0.000 description 11
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 10
- 108020004635 Complementary DNA Proteins 0.000 description 10
- 108010017826 DNA Polymerase I Proteins 0.000 description 10
- 102000004594 DNA Polymerase I Human genes 0.000 description 10
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 10
- 229960005305 adenosine Drugs 0.000 description 10
- 150000002500 ions Chemical class 0.000 description 10
- 102100031780 Endonuclease Human genes 0.000 description 9
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical group O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 9
- 229930010555 Inosine Natural products 0.000 description 9
- 239000005549 deoxyribonucleoside Substances 0.000 description 9
- 229960003786 inosine Drugs 0.000 description 9
- 102100037696 Endonuclease V Human genes 0.000 description 8
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 239000001257 hydrogen Substances 0.000 description 8
- 229910052739 hydrogen Inorganic materials 0.000 description 8
- 230000002255 enzymatic effect Effects 0.000 description 7
- 238000011156 evaluation Methods 0.000 description 7
- 150000003833 nucleoside derivatives Chemical class 0.000 description 7
- 238000011160 research Methods 0.000 description 7
- 239000007790 solid phase Substances 0.000 description 7
- 235000011178 triphosphate Nutrition 0.000 description 7
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 6
- 238000006073 displacement reaction Methods 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 238000005259 measurement Methods 0.000 description 6
- 238000003752 polymerase chain reaction Methods 0.000 description 6
- 239000013641 positive control Substances 0.000 description 6
- 230000037452 priming Effects 0.000 description 6
- 238000012163 sequencing technique Methods 0.000 description 6
- ABZLKHKQJHEPAX-UHFFFAOYSA-N tetramethylrhodamine Chemical compound C=12C=CC(N(C)C)=CC2=[O+]C2=CC(N(C)C)=CC=C2C=1C1=CC=CC=C1C([O-])=O ABZLKHKQJHEPAX-UHFFFAOYSA-N 0.000 description 6
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 5
- 108090000856 Lyases Proteins 0.000 description 5
- 102000004317 Lyases Human genes 0.000 description 5
- 230000006819 RNA synthesis Effects 0.000 description 5
- 241000205101 Sulfolobus Species 0.000 description 5
- 239000007853 buffer solution Substances 0.000 description 5
- 150000002430 hydrocarbons Chemical group 0.000 description 5
- 230000000977 initiatory effect Effects 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 235000000346 sugar Nutrition 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 4
- 102100033215 DNA nucleotidylexotransferase Human genes 0.000 description 4
- 230000006820 DNA synthesis Effects 0.000 description 4
- 241000588724 Escherichia coli Species 0.000 description 4
- 101150003085 Pdcl gene Proteins 0.000 description 4
- 239000002202 Polyethylene glycol Substances 0.000 description 4
- 108010006785 Taq Polymerase Proteins 0.000 description 4
- VGONTNSXDCQUGY-UHFFFAOYSA-N desoxyinosine Natural products C1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 VGONTNSXDCQUGY-UHFFFAOYSA-N 0.000 description 4
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 229920001223 polyethylene glycol Polymers 0.000 description 4
- 230000000717 retained effect Effects 0.000 description 4
- 238000010532 solid phase synthesis reaction Methods 0.000 description 4
- YZEUHQHUFTYLPH-UHFFFAOYSA-N 2-nitroimidazole Chemical compound [O-][N+](=O)C1=NC=CN1 YZEUHQHUFTYLPH-UHFFFAOYSA-N 0.000 description 3
- LAVZKLJDKGRZJG-UHFFFAOYSA-N 4-nitro-1h-indole Chemical compound [O-][N+](=O)C1=CC=CC2=C1C=CN2 LAVZKLJDKGRZJG-UHFFFAOYSA-N 0.000 description 3
- XORHNJQEWQGXCN-UHFFFAOYSA-N 4-nitro-1h-pyrazole Chemical compound [O-][N+](=O)C=1C=NNC=1 XORHNJQEWQGXCN-UHFFFAOYSA-N 0.000 description 3
- WSGURAYTCUVDQL-UHFFFAOYSA-N 5-nitro-1h-indazole Chemical compound [O-][N+](=O)C1=CC=C2NN=CC2=C1 WSGURAYTCUVDQL-UHFFFAOYSA-N 0.000 description 3
- OZFPSOBLQZPIAV-UHFFFAOYSA-N 5-nitro-1h-indole Chemical compound [O-][N+](=O)C1=CC=C2NC=CC2=C1 OZFPSOBLQZPIAV-UHFFFAOYSA-N 0.000 description 3
- PSWCIARYGITEOY-UHFFFAOYSA-N 6-nitro-1h-indole Chemical compound [O-][N+](=O)C1=CC=C2C=CNC2=C1 PSWCIARYGITEOY-UHFFFAOYSA-N 0.000 description 3
- 108010001132 DNA Polymerase beta Proteins 0.000 description 3
- 102000001996 DNA Polymerase beta Human genes 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 108091093037 Peptide nucleic acid Proteins 0.000 description 3
- 108010010677 Phosphodiesterase I Proteins 0.000 description 3
- 239000007983 Tris buffer Substances 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 3
- 239000000839 emulsion Substances 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 230000011987 methylation Effects 0.000 description 3
- 238000007069 methylation reaction Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 125000003835 nucleoside group Chemical group 0.000 description 3
- 230000005298 paramagnetic effect Effects 0.000 description 3
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 3
- 238000011176 pooling Methods 0.000 description 3
- 238000007639 printing Methods 0.000 description 3
- 125000006239 protecting group Chemical group 0.000 description 3
- 239000000523 sample Substances 0.000 description 3
- 125000002264 triphosphate group Chemical class [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 3
- 229940035893 uracil Drugs 0.000 description 3
- NZJKEQFPRPAEPO-UHFFFAOYSA-N 1h-benzimidazol-4-amine Chemical compound NC1=CC=CC2=C1N=CN2 NZJKEQFPRPAEPO-UHFFFAOYSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- 125000000143 2-carboxyethyl group Chemical group [H]OC(=O)C([H])([H])C([H])([H])* 0.000 description 2
- 125000001731 2-cyanoethyl group Chemical group [H]C([H])(*)C([H])([H])C#N 0.000 description 2
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 2
- 125000001494 2-propynyl group Chemical group [H]C#CC([H])([H])* 0.000 description 2
- LOJNBPNACKZWAI-UHFFFAOYSA-N 3-nitro-1h-pyrrole Chemical compound [O-][N+](=O)C=1C=CNC=1 LOJNBPNACKZWAI-UHFFFAOYSA-N 0.000 description 2
- VYDWQPKRHOGLPA-UHFFFAOYSA-N 5-nitroimidazole Chemical compound [O-][N+](=O)C1=CN=CN1 VYDWQPKRHOGLPA-UHFFFAOYSA-N 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- 102100026406 G/T mismatch-specific thymine DNA glycosylase Human genes 0.000 description 2
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 2
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 2
- 238000007397 LAMP assay Methods 0.000 description 2
- VSBXYWSYQIAGRK-UHFFFAOYSA-N N-(7-bromo-6-oxoheptyl)prop-2-enamide Chemical compound C(C=C)(=O)NCCCCCC(CBr)=O VSBXYWSYQIAGRK-UHFFFAOYSA-N 0.000 description 2
- IOVCWXUNBOPUCH-UHFFFAOYSA-M Nitrite anion Chemical compound [O-]N=O IOVCWXUNBOPUCH-UHFFFAOYSA-M 0.000 description 2
- 102000003832 Nucleotidyltransferases Human genes 0.000 description 2
- 108090000119 Nucleotidyltransferases Proteins 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 2
- 108010065868 RNA polymerase SP6 Proteins 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 108010090804 Streptavidin Proteins 0.000 description 2
- 108010035344 Thymine DNA Glycosylase Proteins 0.000 description 2
- 108010001244 Tli polymerase Proteins 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 150000001345 alkine derivatives Chemical class 0.000 description 2
- 125000000217 alkyl group Chemical group 0.000 description 2
- 125000002947 alkylene group Chemical group 0.000 description 2
- 125000002431 aminoalkoxy group Chemical group 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 238000002508 contact lithography Methods 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 230000005684 electric field Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- DNJIEGIFACGWOD-UHFFFAOYSA-N ethyl mercaptane Natural products CCS DNJIEGIFACGWOD-UHFFFAOYSA-N 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N ethylene glycol Natural products OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 239000012530 fluid Substances 0.000 description 2
- 238000007429 general method Methods 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 238000007834 ligase chain reaction Methods 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 125000006502 nitrobenzyl group Chemical group 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 150000008300 phosphoramidites Chemical class 0.000 description 2
- 235000011007 phosphoric acid Nutrition 0.000 description 2
- SCVFZCLFOSHCOH-UHFFFAOYSA-M potassium acetate Chemical compound [K+].CC([O-])=O SCVFZCLFOSHCOH-UHFFFAOYSA-M 0.000 description 2
- 108090000765 processed proteins & peptides Proteins 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 108090000623 proteins and genes Proteins 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 108010068698 spleen exonuclease Proteins 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- NHGXDBSUJJNIRV-UHFFFAOYSA-M tetrabutylammonium chloride Chemical compound [Cl-].CCCC[N+](CCCC)(CCCC)CCCC NHGXDBSUJJNIRV-UHFFFAOYSA-M 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- WETFHJRYOTYZFD-YIZRAAEISA-N (2r,3s,5s)-2-(hydroxymethyl)-5-(3-nitropyrrol-1-yl)oxolan-3-ol Chemical compound C1[C@H](O)[C@@H](CO)O[C@@H]1N1C=C([N+]([O-])=O)C=C1 WETFHJRYOTYZFD-YIZRAAEISA-N 0.000 description 1
- STGXGJRRAJKJRG-JDJSBBGDSA-N (3r,4r,5r)-5-(hydroxymethyl)-3-methoxyoxolane-2,4-diol Chemical compound CO[C@H]1C(O)O[C@H](CO)[C@H]1O STGXGJRRAJKJRG-JDJSBBGDSA-N 0.000 description 1
- HWPZZUQOWRWFDB-UHFFFAOYSA-N 1-methylcytosine Chemical compound CN1C=CC(N)=NC1=O HWPZZUQOWRWFDB-UHFFFAOYSA-N 0.000 description 1
- GUXJXWKCUUWCLX-UHFFFAOYSA-N 2-methyl-2-oxazoline Chemical compound CC1=NCCO1 GUXJXWKCUUWCLX-UHFFFAOYSA-N 0.000 description 1
- HCGYMSSYSAKGPK-UHFFFAOYSA-N 2-nitro-1h-indole Chemical compound C1=CC=C2NC([N+](=O)[O-])=CC2=C1 HCGYMSSYSAKGPK-UHFFFAOYSA-N 0.000 description 1
- BCAIDFOKQCVACE-UHFFFAOYSA-N 3-[dimethyl-[2-(2-methylprop-2-enoyloxy)ethyl]azaniumyl]propane-1-sulfonate Chemical compound CC(=C)C(=O)OCC[N+](C)(C)CCCS([O-])(=O)=O BCAIDFOKQCVACE-UHFFFAOYSA-N 0.000 description 1
- NEJMFSBXFBFELK-UHFFFAOYSA-N 4-nitro-1h-benzimidazole Chemical compound [O-][N+](=O)C1=CC=CC2=C1N=CN2 NEJMFSBXFBFELK-UHFFFAOYSA-N 0.000 description 1
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 1
- 108010057896 5-methylcytosine-DNA glycosylase Proteins 0.000 description 1
- DPRSKJHWKNHBOW-UHFFFAOYSA-N 7-Deazainosine Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2C=C1 DPRSKJHWKNHBOW-UHFFFAOYSA-N 0.000 description 1
- LSMBOEFDMAIXTM-UUOKFMHZSA-N 7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-imidazo[4,5-d]triazin-4-one Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NN=NC(O)=C2N=C1 LSMBOEFDMAIXTM-UUOKFMHZSA-N 0.000 description 1
- DPRSKJHWKNHBOW-KCGFPETGSA-N 7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrrolo[2,3-d]pyrimidin-4-one Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(NC=NC2=O)=C2C=C1 DPRSKJHWKNHBOW-KCGFPETGSA-N 0.000 description 1
- QFFLRMDXYQOYKO-KVQBGUIXSA-N 7-[(2r,4s,5r)-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-imidazo[4,5-d]triazin-4-one Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NN=NC(O)=C2N=C1 QFFLRMDXYQOYKO-KVQBGUIXSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- 108091029845 Aminoallyl nucleotide Proteins 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010061914 DNA polymerase mu Proteins 0.000 description 1
- 230000007018 DNA scission Effects 0.000 description 1
- 102000010719 DNA-(Apurinic or Apyrimidinic Site) Lyase Human genes 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 108010042407 Endonucleases Proteins 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 108010025076 Holoenzymes Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- CERQOIWHTDAKMF-UHFFFAOYSA-M Methacrylate Chemical compound CC(=C)C([O-])=O CERQOIWHTDAKMF-UHFFFAOYSA-M 0.000 description 1
- 108060004795 Methyltransferase Proteins 0.000 description 1
- 101100091501 Mus musculus Ros1 gene Proteins 0.000 description 1
- 239000008118 PEG 6000 Substances 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 101710124239 Poly(A) polymerase Proteins 0.000 description 1
- 229920002584 Polyethylene Glycol 6000 Polymers 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- QCUXLGDVYYRCPI-UHFFFAOYSA-N [O-]P(O)(O)=[S+]N1CCOCC1 Chemical compound [O-]P(O)(O)=[S+]N1CCOCC1 QCUXLGDVYYRCPI-UHFFFAOYSA-N 0.000 description 1
- YDHWWBZFRZWVHO-UHFFFAOYSA-N [hydroxy(phosphonooxy)phosphoryl] phosphono hydrogen phosphate Chemical group OP(O)(=O)OP(O)(=O)OP(O)(=O)OP(O)(O)=O YDHWWBZFRZWVHO-UHFFFAOYSA-N 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 125000002015 acyclic group Chemical group 0.000 description 1
- 125000002252 acyl group Chemical group 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 125000002355 alkine group Chemical group 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- IVRMZWNICZWHMI-UHFFFAOYSA-N azide group Chemical group [N-]=[N+]=[N-] IVRMZWNICZWHMI-UHFFFAOYSA-N 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- QTPILKSJIOLICA-UHFFFAOYSA-N bis[hydroxy(phosphonooxy)phosphoryl] hydrogen phosphate Chemical group OP(O)(=O)OP(O)(=O)OP(O)(=O)OP(O)(=O)OP(O)(O)=O QTPILKSJIOLICA-UHFFFAOYSA-N 0.000 description 1
- 230000003139 buffering effect Effects 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 239000002041 carbon nanotube Substances 0.000 description 1
- 229910021393 carbon nanotube Inorganic materials 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 238000001311 chemical methods and process Methods 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- URYYVOIYTNXXBN-UPHRSURJSA-N cyclooctene Chemical compound C1CCC\C=C/CC1 URYYVOIYTNXXBN-UPHRSURJSA-N 0.000 description 1
- 239000004913 cyclooctene Substances 0.000 description 1
- NHVNXKFIZYSCEB-XLPZGREQSA-N dTTP Chemical class O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 NHVNXKFIZYSCEB-XLPZGREQSA-N 0.000 description 1
- 238000000151 deposition Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 239000010432 diamond Substances 0.000 description 1
- 229920001971 elastomer Polymers 0.000 description 1
- 239000000806 elastomer Substances 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000001973 epigenetic effect Effects 0.000 description 1
- 230000004049 epigenetic modification Effects 0.000 description 1
- 125000004185 ester group Chemical group 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 238000007672 fourth generation sequencing Methods 0.000 description 1
- 238000007306 functionalization reaction Methods 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 238000007641 inkjet printing Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- UEGPKNKPLBYCNK-UHFFFAOYSA-L magnesium acetate Chemical compound [Mg+2].CC([O-])=O.CC([O-])=O UEGPKNKPLBYCNK-UHFFFAOYSA-L 0.000 description 1
- 239000011654 magnesium acetate Substances 0.000 description 1
- 235000011285 magnesium acetate Nutrition 0.000 description 1
- 229940069446 magnesium acetate Drugs 0.000 description 1
- 230000005291 magnetic effect Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 150000003016 phosphoric acids Chemical group 0.000 description 1
- 238000000206 photolithography Methods 0.000 description 1
- 239000004417 polycarbonate Substances 0.000 description 1
- 229920000515 polycarbonate Polymers 0.000 description 1
- 229920002704 polyhistidine Polymers 0.000 description 1
- 229920002338 polyhydroxyethylmethacrylate Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 235000011056 potassium acetate Nutrition 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 102000004169 proteins and genes Human genes 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 238000005096 rolling process Methods 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- FPGGTKZVZWFYPV-UHFFFAOYSA-M tetrabutylammonium fluoride Chemical compound [F-].CCCC[N+](CCCC)(CCCC)CCCC FPGGTKZVZWFYPV-UHFFFAOYSA-M 0.000 description 1
- 238000007651 thermal printing Methods 0.000 description 1
- 230000036962 time dependent Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- PIEPQKCYPFFYMG-UHFFFAOYSA-N tris acetate Chemical compound CC(O)=O.OCC(N)(CO)CO PIEPQKCYPFFYMG-UHFFFAOYSA-N 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images



















































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B01—PHYSICAL OR CHEMICAL PROCESSES OR APPARATUS IN GENERAL
- B01J—CHEMICAL OR PHYSICAL PROCESSES, e.g. CATALYSIS OR COLLOID CHEMISTRY; THEIR RELEVANT APPARATUS
- B01J19/00—Chemical, physical or physico-chemical processes in general; Their relevant apparatus
- B01J19/0046—Sequential or parallel reactions, e.g. for the synthesis of polypeptides or polynucleotides; Apparatus and devices for combinatorial chemistry or for making molecular arrays
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P19/00—Preparation of compounds containing saccharide radicals
- C12P19/26—Preparation of nitrogen-containing carbohydrates
- C12P19/28—N-glycosides
- C12P19/30—Nucleotides
- C12P19/34—Polynucleotides, e.g. nucleic acids, oligoribonucleotides
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Immunology (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
本发明涉及用于根据预定核苷酸序列合成多核苷酸分子的新方法。本发明还涉及用于在合成之后组装合成多核苷酸的方法,以及用于执行合成和/或组装方法的系统和试剂盒。
Description
技术领域
本发明涉及用于根据预定核苷酸序列合成多核苷酸分子的新方法。本发明还涉及用于在合成之后组装合成多核苷酸的方法,以及用于执行合成和/或组装方法的系统和试剂盒。
背景技术
存在用于合成和组装多核苷酸分子(特别是DNA)的两种主要方法。
亚磷酰胺化学法是经由逐步过程将化学活化的T、C、A或G的单体组装成长度为大约100/150个碱基的寡核苷酸的合成方法。化学反应步骤是高度敏感的,并且条件在完全无水(完全不存在水)条件、水性氧化条件和酸性条件之间交替(Roy和Caruthers,Molecules,2013,18,14268-14284)。如果来自先前反应步骤的试剂尚未被完全移除,则这将不利于未来的合成步骤。因此,该合成方法限于产生长度为大约100个核苷酸的多核苷酸。
聚合酶合成方法利用T、C、A和G三磷酸且使用聚合酶来合成DNA模板的互补链。反应条件是水性的且温和的,并且该方法可以用于合成长度为数千个碱基的DNA多核苷酸。该方法的主要缺点是不能通过该方法从头合成单链和双链DNA,该方法需要DNA模板(拷贝根据该模板来制备)。(Kosuri和Church,Nature Methods,2014,11,499-507)。
因此,先前的方法不能用于在没有拷贝的预先存在的模板分子的帮助下从头合成双链DNA。
本发明人开发了新方法,通过所述新方法可以以逐步的方式从头合成单链和双链多核苷酸分子,而无需拷贝预先存在的模板分子。这样的方法还避免了与亚磷酰胺化学法相关联的极端条件,相反,在中性pH附近的温和水性条件下实施。这样的方法还使得能够从头合成单链或双链多核苷酸分子,其与核苷酸长度>100个聚体至完整基因组的当前合成方法相比具有潜在的108改进,可以广泛应用于合成生物学领域中。
发明内容
本发明提供了一种合成具有预定序列的双链多核苷酸的体外方法,所述方法包括执行重复的合成循环,其中,在每个循环中:
(A)通过在连接酶的作用下添加所述预定序列的第一核苷酸来延伸双链多核苷酸的第一链;
(B)通过经由核苷酸转移酶或聚合酶添加所述预定序列的第二核苷酸来延伸所述双链多核苷酸的与所述第一链杂交的第二链;以及
(C)然后在裂解位点处裂解所述双链多核苷酸;
其中,每个循环的所述预定序列的所述第一核苷酸和所述第二核苷酸在裂解之后被保持在所述双链多核苷酸中,并且其中,所述第一核苷酸和所述第二核苷酸成为所述合成的双链多核苷酸中不同的核苷酸对中的配偶体核苷酸。
在任何上述方法中,所述裂解位点可以由包括通用核苷酸的多核苷酸序列定义。
在任何上述方法中,在每个循环中,可以在延伸所述第二链之前,在所述双链多核苷酸中产生裂解位点。
在任何上述方法中,在步骤(A)期间,通过所述连接酶的作用,可以将所述通用核苷酸合并到所述双链多核苷酸的所述第一链中以定义所述裂解位点。
在任何上述方法中,在给定的合成循环中,被添加至所述双链多核苷酸的所述第二链中的所述循环的所述第二核苷酸可以包括可逆终止子基团,所述可逆终止子基团阻止通过所述酶进一步延伸,并且其中,在下一循环的所述第二核苷酸的合成的下一循环中添加之前从所述循环的所述合并的第二核苷酸中移除所述可逆终止子基团。
在任何上述方法中,所述连接反应可以包括粘性末端连接反应。
在任何上述方法中,所述第一核苷酸和所述通用核苷酸可以是多核苷酸连接分子的组分,并且其中,在步骤(A)中,通过所述连接酶的作用,所述多核苷酸连接分子连接至所述双链多核苷酸,并且其中,当所述多核苷酸连接分子连接至所述双链多核苷酸时,所述双链多核苷酸的所述第一链被延伸并产生所述裂解位点。
在任何上述方法中,所述方法可以包括执行第一合成循环,所述第一合成循环包括:
(1)提供支架多核苷酸,所述支架多核苷酸包括合成链和与所述合成链杂交的支持链,其中,所述合成链包括引物链部分,并且其中,所述支持链是所述双链多核苷酸的所述第一链,并且所述合成链是所述双链多核苷酸的所述第二链;
(2)在粘性末端连接反应中,通过所述连接酶的作用,将双链多核苷酸连接分子连接至所述支架多核苷酸,所述多核苷酸连接分子包括支持链和与所述支持链杂交的辅助链,并且所述多核苷酸连接分子还包括互补连接端,所述连接端包括:
(i)在所述支持链中,通用核苷酸和所述预定序列的第一核苷酸;和
(ii)在所述辅助链中,不可连接的末端核苷酸;
其中,在连接时,利用所述第一核苷酸延伸所述双链多核苷酸的所述第一链,并且通过将所述通用核苷酸合并到所述第一链中来产生所述裂解位点;
(3)通过在所述核苷酸转移酶或聚合酶的作用下合并所述预定序列的第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,所述第二核苷酸包括防止通过所述酶进一步延伸的可逆终止子基团;
(4)在所述裂解位点处裂解所述连接的支架多核苷酸,其中,裂解包括:裂解所述支持链并从所述支架多核苷酸中移除所述通用核苷酸,以提供包括所述合并的第一核苷酸和第二核苷酸的经裂解的双链支架多核苷酸;以及
(5)从所述第二核苷酸中移除所述可逆终止子基团;
所述方法还包括执行进一步的合成循环,所述进一步的合成循环包括:
(6)在粘性末端连接反应中,在所述连接酶的作用下,将另外的双链多核苷酸连接分子连接至所述经裂解的支架多核苷酸,所述多核苷酸连接分子包括支持链和与所述支持链杂交的辅助链,并且所述多核苷酸连接分子还包括互补连接端,所述连接端包括:
(i)在所述支持链中,通用核苷酸和所述进一步的合成循环的所述第一核苷酸;和
(ii)在所述辅助链中,不可连接的末端核苷酸;
其中,在连接时,利用所述进一步的合成循环的所述第一核苷酸延伸所述双链多核苷酸的所述第一链,并且通过将所述通用核苷酸合并到所述第一链中来产生所述裂解位点;
(7)通过在所述核苷酸转移酶或聚合酶的作用下合并所述进一步的合成循环的所述第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,所述第二核苷酸包括防止通过所述酶进一步延伸的可逆终止子基团;
(8)在所述裂解位点处裂解所述连接的支架多核苷酸,其中,裂解包括:裂解所述支持链并从所述支架多核苷酸中移除所述通用核苷酸,以提供包括所述第一合成循环和所述进一步的合成循环的所述合并的第一核苷酸和第二核苷酸的经裂解的双链支架多核苷酸;
(9)从所述第二核苷酸中移除所述可逆终止子基团;以及
(10)多次重复步骤6至9以提供具有预定核苷酸序列的所述双链多核苷酸。在任何这样的方法中,在任何一个、多个或所有合成循环中,在所述裂解位点处裂解所述连接的支架多核苷酸的步骤之前,可以替代性地将所述可逆终止子基团从所述第二核苷酸中移除。
在任何上述这样的方法中,在步骤(1)中,所述支架多核苷酸的所述支持链的与所述引物链部分邻近的末端可以包括核苷酸突出端,其中,所述支持链的末端核苷酸突出所述引物链部分的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是所述循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(2)中,在所述多核苷酸连接分子的所述互补连接端处,所述辅助链的末端包括核苷酸突出端,其中,所述辅助链的末端核苷酸突出所述支持链的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是所述循环的所述第一核苷酸并且是在所述下一合成循环中形成的不同的核苷酸对中的配偶体核苷酸;
其中,在步骤(6)中,在所述经裂解的支架多核苷酸中,所述支持链的与所述引物链部分邻近的末端包括核苷酸突出端,其中,所述支持链的末端核苷酸突出所述引物链部分的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是步骤(7)中合并的所述进一步的合成循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(6)中,在所述多核苷酸连接分子的所述互补连接端,所述辅助链的末端包括核苷酸突出端,其中,所述辅助链的末端核苷酸突出所述支持链的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是所述进一步的合成循环的所述第一核苷酸并且是在所述下一合成循环中形成的不同的核苷酸对中的配偶体核苷酸;并且
其中,在第一合成循环和进一步的合成循环中,所述支架多核苷酸中的核苷酸突出端和所述多核苷酸连接分子的所述互补连接端中的核苷酸突出端包括相同数目的核苷酸,其中,所述数目等于或大于一。
在上述这样的方法中:
(a)在所述第一循环的连接步骤(步骤2)和所有进一步的循环的连接步骤中,所述多核苷酸连接分子的所述互补连接端的可以被构造为使得:
i.所述循环的所述预定序列的所述第一核苷酸是所述支持链的末端核苷酸,在所述支持链中占据核苷酸位置n+1,并且与所述辅助链的次末端核苷酸配对;
ii.所述通用核苷酸是所述支持链的次末端核苷酸,在所述支持链中占据核苷酸位置n+2,并且与所述辅助链中的配偶体核苷酸配对;
iii.所述突出端包括一个核苷酸突出端,所述核苷酸突出端包括突出所述循环的所述预定序列的所述第一核苷酸之外的所述辅助链的末端核苷酸;以及
iv.所述辅助链的末端核苷酸是不可连接的核苷酸;
其中,位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置,并且位置n+1和n+2分别是所述支持链中沿远离所述互补连接端的方向相对于位置n的所述第一/下一核苷酸位置和第二核苷酸位置;并且其中,在连接时,所述多核苷酸连接分子的所述支持链的末端核苷酸连接至与所述合成链的所述引物链部分邻近的所述支架多核苷酸的末端核苷酸,并且在所述辅助链的末端核苷酸与所述合成链的所述引物链部分之间产生单链断裂;
(b)在所述第一循环的延伸步骤(步骤3)和所有进一步的循环中,将所述循环的所述第二核苷酸合并到所述第二链中并与所述第一链中的配偶体核苷酸配对;
(c)在所述第一循环的裂解步骤(步骤4)中和所有进一步的循环中,在位置n+2和n+1之间裂解所述连接的支架多核苷酸的所述支持链,从而从所述支架多核苷酸中释放所述多核苷酸连接分子并保持所述循环的所述第一核苷酸不成对并附接至所述经裂解的支架多核苷酸的所述第一链,并且所述循环的所述第二核苷酸与其配偶体核苷酸配对,并且因此,将所述循环的所述第一核苷酸在所述经裂解的支架多核苷酸的所述支持链中占据的位置定义为在所述下一合成循环中的核苷酸位置n。
替代性地,在上述这样的方法中:
(a)在所述第一循环的连接步骤(步骤2)和所有进一步的循环的连接步骤中,所述多核苷酸连接分子的所述互补连接端的可以被构造为使得:
i.所述循环的所述预定序列的所述第一核苷酸是所述支持链的末端核苷酸,在所述支持链中占据核苷酸位置n+1,并且与所述辅助链的次末端核苷酸配对;
ii.所述通用核苷酸在所述支持链中占据核苷酸位置n+3,并且与所述辅助链中的配偶体核苷酸配对;
iii.所述突出端包括一个核苷酸突出端,所述核苷酸突出端包括突出所述循环的所述预定序列的所述第一核苷酸之外的所述辅助链的末端核苷酸;以及
iv.所述辅助链的末端核苷酸是不可连接的核苷酸;
其中,位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置,并且位置n+1、n+2和n+3分别是所述支持链中沿远离所述互补连接端的方向相对于位置n的下一核苷酸位置、第二核苷酸位置和第三核苷酸位置;并且其中,在连接时,所述多核苷酸连接分子的所述支持链的末端核苷酸连接至与所述合成链的所述引物链部分邻近的所述支架多核苷酸的末端核苷酸,并且在所述辅助链的末端核苷酸与所述合成链的所述引物链部分之间产生单链断裂;
(b)在所述第一循环的延伸步骤(步骤3)和所有进一步的循环中,将所述循环的所述第二核苷酸合并到所述第二链中并与所述第一链中的配偶体核苷酸配对;
(c)在所述第一循环的裂解步骤(步骤4)中和所有进一步的循环中,在位置n+2和n+1之间裂解所述连接的支架多核苷酸的所述支持链,从而从所述支架多核苷酸中释放所述多核苷酸连接分子并保持所述循环的所述第一核苷酸不成对并附接至所述经裂解的支架多核苷酸的所述第一链,并且所述循环的所述第二核苷酸与其配偶体核苷酸配对,并且因此,将所述循环的所述第一核苷酸在所述经裂解的支架多核苷酸的所述支持链中占据的位置定义为在所述下一合成循环中的核苷酸位置n。
替代性地,在上述这样的方法中:
(a)在所述第一循环的连接步骤(步骤2)和所有进一步的循环的连接步骤中,所述多核苷酸连接分子的所述互补连接端的可以被构造为使得:
i.所述循环的所述预定序列的所述第一核苷酸是所述支持链的末端核苷酸,在所述支持链中占据核苷酸位置n+1,并且与所述辅助链的次末端核苷酸配对;
ii.所述通用核苷酸在所述支持链中占据核苷酸位置n+3+x,并且与所述辅助链中的配偶体核苷酸配对;
iii.所述突出端包括一个核苷酸突出端,所述核苷酸突出端包括突出所述循环的所述预定序列的所述第一核苷酸之外的所述辅助链的末端核苷酸;以及
iv.所述辅助链的末端核苷酸是不可连接的核苷酸;
其中,位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置,其中,位置n+3是所述支持链中沿远离所述互补连接端的方向相对于位置n的第三核苷酸位置,并且其中,x是沿远离所述互补连接端的方向相对于位置n+3的核苷酸位置的数目,其中,所述数目是1至10或更大的整数;并且其中,在连接时,所述多核苷酸连接分子的所述支持链的末端核苷酸连接至与所述合成链的所述引物链部分邻近的所述支架多核苷酸的末端核苷酸,并且在所述辅助链的末端核苷酸与所述合成链的所述引物链部分之间产生单链断裂;
(b)在所述第一循环的延伸步骤(步骤3)和所有进一步的循环中,将所述循环的所述第二核苷酸合并到所述第二链中并与所述第一链中的配偶体核苷酸配对;
(c)在所述第一循环的裂解步骤(步骤4)中和所有进一步的循环中,在位置n+2和n+1之间裂解所述连接的支架多核苷酸的所述支持链,从而从所述支架多核苷酸中释放所述多核苷酸连接分子并保持所述循环的所述第一核苷酸不成对并附接至所述经裂解的支架多核苷酸的所述第一链,并且所述循环的所述第二核苷酸与其配偶体核苷酸配对,并且因此,将所述循环的所述第一核苷酸在所述经裂解的支架多核苷酸的所述支持链中占据的位置定义为在所述下一合成循环中的核苷酸位置n。
在某些方法中,在步骤(1)中,所述支架多核苷酸的所述支持链的与所述引物链部分邻近的末端可以包括含有1+y个核苷酸的核苷酸突出端,其中,所述支持链的所述1+y个核苷酸突出所述引物链部分的末端核苷酸之外,并且其中,所述突出端的所述第一核苷酸占据所述突出端中的远离所述突出端的末端的位置,占据核苷酸位置n,并且是在步骤(3)中合并的所述第一循环的所述第二核苷酸的配偶体核苷酸,并且其中,所述突出端的占据位置n+1的核苷酸是在步骤(7)中合并的所述下一/第二合成循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(2)中,在所述多核苷酸连接分子的所述互补连接端,所述辅助链的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述辅助链的所述1+y个核苷酸突出所述支持链的末端核苷酸之外,并且是所述支架多核苷酸的所述支持链的突出的所述1+y个核苷酸的配偶体核苷酸,并且其中,所述互补连接端的所述支持链的末端核苷酸是所述循环的所述第一核苷酸,占据核苷酸位置n+2+x并且是在所述第三合成循环中形成的不同的核苷酸对中的配偶体核苷酸;
其中,在步骤(6)中,在所述经裂解的支架多核苷酸中,所述支持链的与所述引物链部分邻近的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述支持链的所述1+y个核苷酸突出所述引物链部分的末端核苷酸,并且其中,所述突出端的所述第一核苷酸占据所述突出端中的远离所述突出端的末端的位置,占据核苷酸位置n,并且是在步骤(7)中合并的所述进一步的合成循环的所述第二核苷酸的配偶体核苷酸,并且其中,所述突出端的占据位置n+1的核苷酸是所述下一合成循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(6)中,在所述多核苷酸连接分子的所述互补连接端,所述辅助链的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述辅助链的所述1+y个核苷酸突出所述支持链的末端核苷酸链并且是所述支架多核苷酸的所述支持链的突出的所述1+y个核苷酸的配偶体核苷酸,并且其中,所述互补连接端的所述支持链的末端核苷酸是所述进一步的合成循环的所述第一核苷酸,占据核苷酸位置n+2+x,并且是在所述下一合成循环中形成的不同的核苷酸对中的配偶体核苷酸;并且其中:
i.位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置;
ii.随后的连接位置n+1和n+2是所述支持链中的沿与所述辅助链邻近/远离所述引物链部分的方向相对于位置n的所述第一核苷酸位置和所述第二核苷酸位置;
iii.y是等于或大于一的整数;
iv.x是等于或大于零的整数;
v.所述支架多核苷酸中的y的数目优选地与所述多核苷酸连接分子的所述互补连接端中的y的数目相同,并且其中,如果y是不同的数目,则所述多核苷酸连接分子的所述互补连接端中的y的数目优选地小于所述支架多核苷酸中的y的数目;以及vi.在任何给定的一系列的第一循环和进一步的循环中,为x选择的数目是为所述支架多核苷酸中的y选择的数目减去一。
在上述方法中,其中,在步骤(1)中,所述支架多核苷酸的所述支持链的与所述引物链部分邻近的末端包括核苷酸突出端,在第一循环和进一步的循环两者中,在所述多核苷酸连接分子和所述连接的支架多核苷酸两者中,所述通用核苷酸占据位置n+3+x,并且在位置n+3+x和n+2+x之间裂解所述支架多核苷酸。替代性地,在第一循环和进一步的循环两者中,在所述多核苷酸连接分子和所述连接的支架多核苷酸两者中,所述通用核苷酸占据位置n+4+x,并且在位置n+3+x和n+2+x之间裂解所述支架多核苷酸。
可以修改上述方法,使得:
(i)在步骤(2)中,所述多核苷酸连接分子设有互补连接端,所述互补连接端包括所述第一循环的所述预定序列的第一核苷酸,并且所述互补连接端还包括所述第一循环的所述预定序列的一个或多个另外的核苷酸;
(ii)在步骤(3)中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述第一循环的所述预定序列的第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,并且其中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述第一循环的所述预定序列的一个或多个另外的核苷酸来进一步延伸所述引物链部分的末端,其中,所述第一循环的所述第二核苷酸和所述另外的核苷酸中的每一个包括可逆终止子基团,所述可逆终止子基团阻止通过所述酶进一步延伸,并且其中,在每次进一步延伸之后,在合并下一核苷酸之前,从核苷酸中移除所述可逆终止子基团;
(iii)在步骤(4)中,在裂解之后,所述第一循环的所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中;
(iv)在步骤(6)中,所述多核苷酸连接分子设有互补连接端,所述互补连接端包括所述进一步的循环的所述预定序列的第一核苷酸,并且所述互补连接端还包括所述进一步的循环的所述预定序列的一个或多个另外的核苷酸;
(v)在步骤(6)中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述进一步的循环的所述预定序列的第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,并且其中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述进一步的循环的所述预定序列的一个或多个另外的核苷酸来进一步延伸所述引物链部分的末端,其中,所述进一步的循环的所述第二核苷酸和所述另外的核苷酸中的每一个包括可逆终止子基团,所述可逆终止子基团阻止通过所述酶进一步延伸,并且其中,在每次进一步延伸之后,在合并下一核苷酸之前,从核苷酸中移除所述可逆终止子基团;
(vi)在步骤(8)中,在裂解之后,所述进一步的循环的所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中。在这些方法中,所述多核苷酸连接分子的所述互补连接端
可以被构造为使得在裂解之前的步骤(4)和(8)中,所述通用核苷酸在所述支持链中占据这样的位置:所述位置是所述支持链中沿远离所述互补连接端的方向在所述第一核苷酸和所述另外的核苷酸的核苷酸位置之后的下一核苷酸位置,并且在最后的所述另外的核苷酸所占据的位置与所述通用核苷酸所占据的位置之间裂解所述支持链。在这些方法中,所述多核苷酸连接分子的所述互补连接端可以被替代性地构造为使得所述多核苷酸连接分子的所述互补连接端被构造为使得在裂解之前的步骤(4)和(8)中,所述通用核苷酸在所述支持链中占据这样的位置:所述位置是所述支持链中沿远离所述互补连接端的方向在所述第一核苷酸和所述另外的核苷酸的核苷酸位置之后的再下一核苷酸位置,并且在所述支持链中的最后的所述另外的核苷酸所占据的位置与所述下一核苷酸所占据的位置之间裂解所述支持链。
在任何上文和本文中描述的方法中,在任何一个、多个或所有合成循环中,与所述预定序列的所述第一核苷酸配对的配偶体核苷酸可以是与所述第一核苷酸互补的核苷酸,优选为与所述第一核苷酸天然互补的核苷酸。
在任何上文和本文中描述的方法中,在任何一个、多个或所有合成循环中,可以在步骤(2)和/或(6)之前提供所述支架多核苷酸,所述支架多核苷酸包括合成链和与所述合成链杂交的支持链,并且其中,所提供的所述合成链没有辅助链。在任何一个、多个或所有合成循环中,在步骤(2)和/或(6)之前,可以从所述支架多核苷酸中移除所述合成链。
在任何上文和本文中描述的方法中,在任何一个、多个或所有合成循环中,在将所述双链多核苷酸连接分子连接至所述经裂解的支架多核苷酸的步骤之后,并且在将所述预定核苷酸序列的所述下一核苷酸合并到所述支架多核苷酸的所述合成链中的步骤之前,可以从所述支架多核苷酸中移除所述合成链的所述辅助链部分。在任何这样的方法中,可以通过以下步骤从所述支架多核苷酸中移除所述合成链的所述辅助链部分:(i)将所述支架多核苷酸加热至约80℃至约95℃的温度,并从所述支架多核苷酸中分离出所述辅助链部分,(ii)用尿素溶液诸如8M尿素处理所述支架多核苷酸,并且从所述支架多核苷酸中分离出所述辅助链部分,(iii)用甲酰胺或甲酰胺溶液诸如100%甲酰胺处理所述支架多核苷酸,并且从所述支架多核苷酸中分离出所述辅助链部分,或(iv)使所述支架多核苷酸与单链多核苷酸分子接触,所述单链多核苷酸分子包括与所述辅助链部分的序列互补的核苷酸序列区域,从而竞争性地抑制所述辅助链部分与所述支架多核苷酸杂交。
在上文和本文中所述的任何这样的方法中,其中,沿与所述合成链的所述引物链部分邻近的方向相对于所述通用核苷酸在所述支持链中的由所述通用核苷酸占据的位置与由所述下一核苷酸占据的位置之间裂解所述支架多核苷酸的所述支持链,每个裂解步骤可以包括两步裂解过程,其中,每个裂解步骤可以包括:第一步,所述第一步包括移除所述通用核苷酸从而形成无碱基位点;和第二步,所述第二步包括在所述无碱基位点处裂解所述支持链。在任何这样的方法中,所述第一步可以利用核苷酸裂解酶来执行。所述核苷酸裂解酶可以是3-甲基腺嘌呤DNA糖基化酶。所述核苷酸切除酶可以是:人类烷基腺嘌呤DNA糖基化酶(hAAG);或尿嘧啶DNA糖基化酶(UDG)。在任何这样的方法中,所述第二步可以用作为碱的化学物质来执行。所述碱可以是NaOH。在任何这样的方法中,所述第二步可以利用具有无碱基位点裂解活性的有机化学物质来执行。所述有机化学物质可以是N,N'-二甲基乙二胺。在任何这样的方法中,所述第二步可以利用具有无碱基位点裂解酶活性的酶来执行,诸如AP核酸内切酶、核酸内切酶III(Nth);或核酸内切酶VIII。
在上文和本文中所述的任何这样的方法中,其中,沿与所述合成链的所述引物链部分邻近的方向相对于所述通用核苷酸在所述支持链中的由所述通用核苷酸占据的位置与由所述下一核苷酸占据的位置之间裂解所述支架多核苷酸的所述支持链,每个裂解步骤可以包括一个步骤的裂解过程,所述裂解过程包括利用裂解酶移除所述通用核苷酸,其中,所述酶是:核酸内切酶III、核酸内切酶VIII、甲酰胺基嘧啶DNA糖基化酶(Fpg)或8-氧桥鸟嘌呤DNA糖基化酶(hOGG1)。
在上文和本文中所述的任何这样的方法中,其中,在沿与所述引物链部分邻近的方向相对于所述通用核苷酸的所述支持链中的由所述下一核苷酸占据的位置和沿与所述引物链部分邻近的方向相对于所述通用核苷酸的所述支持链中的由所述第二核苷酸占据的位置之间裂解所述支架多核苷酸的所述支持链,所述裂解步骤可以包括利用酶裂解所述支持链。这样的酶可以是核酸内切酶V。
在上文和本文中所述的任何方法中,所述合成的双链多核苷酸的两条链都可以是DNA链。所述合成链和所述支持链可以是DNA链。在这样的情况下,合并的核苷酸优选为dNTP,优选为包括可逆终止子基团的dNTP。在任何这样的方法中,包括可逆终止子基团的任何一个或多个或所有所述合并的核苷酸可以包括3’-O-烯丙基-dNTP或3’-O-叠氮甲基-dNTP。
在上文和本文中所述的任何方法中,所述合成的双链多核苷酸的一条链可以是DNA链,并且所述合成的双链多核苷酸的另一条链可以是RNA链。所述合成链可以是RNA链,并且所述支持链可以是RNA或DNA链。在这样的情况下,由所述转移酶或所述聚合酶合并的核苷酸优选为NTP,优选为包括可逆终止子基团的NTP。在任何这样的方法中,包括可逆终止子基团的任何一个或多个或所有所述合并的核苷酸可以是3’-O-烯丙基-NTP或3’-O-叠氮甲基-NTP。
在上文和本文中所述的涉及将核苷酸合并到包括DNA的合成链中(例如合并一个或多个dNTP)的任何方法中,所述酶可以是聚合酶,优选为DNA聚合酶,更优选为修饰的DNA聚合酶,其具有与未修饰的聚合酶相比增强的合并包括可逆终止子基团的dNTP的能力。所述聚合酶可以是来自热球菌物种9°N、优选为物种9°N-7的天然DNA聚合酶的变体。
在上文和本文中所述的涉及将核苷酸合并到包括RNA的合成链中(例如合并一个或多个NTP)的任何方法中,所述酶可以是聚合酶,优选为RNA聚合酶,诸如T3或T7 RNA聚合酶,更优选为修饰的RNA聚合酶,其具有与未修饰的聚合酶相比增强的合并包括可逆终止子基团的NTP的能力。
在上文和本文所述的任何方法中,所述合成的双链多核苷酸的第一链可以是DNA链,并且所述合成的双链多核苷酸的所述第二链可以是RNA链。替代性地,所述合成的双链多核苷酸的第一链可以是RNA链,并且所述合成的双链多核苷酸的所述第二链可以是DNA链。
在上文和本文中所述的任何方法中,所述转移酶具有末端转移酶活性,可选地,其中,所述酶是末端核苷酸转移酶、末端脱氧核苷酸转移酶、末端脱氧核苷酸转移酶(TdT)、pol lambda、pol micro或Φ29 DNA聚合酶。
在上文和本文中所述的任何方法中,可以利用三(羧乙基)膦(TCEP)执行从所述第一/下一核苷酸中移除所述可逆终止子基团的步骤。
在上文和本文中所述的任何方法中,将双链多核苷酸连接分子连接至所述经裂解的支架多核苷酸的步骤优选地利用连接酶来执行。所述连接酶可以是T3 DNA连接酶或T4DNA连接酶。
在上文和本文中所述的任何方法中,在步骤(1)/(6)中的任何一个、多个或所有合成循环中,在所述支架多核苷酸中,包括所述引物链部分的所述合成链和所述支持链的与其杂交的部分可以通过发夹环连接。
在上文和本文中所述的任何方法中,在步骤(2)/(6)中的任何一个、多个或所有合成循环中,在所述多核苷酸连接分子中,所述辅助链和所述支持链的与所述辅助链杂交的部分可以在与所述互补连接端相对的一端通过发夹环连接。
在上文和本文中所述的任何方法中,在任何一个、多个或所有合成循环中:
(a)在步骤(1)/(6)中,在所述支架多核苷酸中,包括所述引物链部分的所述合成链和所述支持链的与其杂交的部分通过发夹环连接;以及
(b)在步骤(2)/(6)中,在所述多核苷酸连接分子中,所述辅助链和所述支持链的与所述辅助链杂交的部分在与所述互补连接端相对的一端通过发夹环连接。
在上文和本文中所述的任何方法中,至少一个或多个或所有所述多核苷酸连接分子可以作为单个分子被提供,所述单个分子包括在与所述互补连接端相对的一端连接所述支持链和所述辅助链的发夹环。在上文和本文中所述的任何方法中,每个合成循环的所述多核苷酸连接分子可以作为单个分子被提供,每个单个分子包括在与所述互补连接端相对的一端连接所述支持链和所述辅助链的发夹环。
在上文和本文中所述的任何方法中,在步骤(1)和(6)中,可以将包括所述引物链部分的所述支架多核苷酸的所述合成链和/或所述支持链的与其杂交的部分束缚至共同的表面。包括所述引物链部分和所述支持链的与所述引物链部分杂交的部分的所述支架多核苷酸的所述合成链可以包括可裂解的接头,其中,在合成之后,所述接头可以被裂解以从所述表面拆离出所述双链多核苷酸。
在上文和本文中所述的任何方法中,在步骤(1)和(6)中,所述合成链的所述引物链部分和所述支持链的与之杂交的部分可以通过发夹环连接,并且其中,所述发夹环被束缚至表面。
在上文和本文中所述的任何方法中,发夹环可以经由可裂解的接头被束缚至表面,其中,在合成之后,所述接头可以被裂解以从所述表面拆离出所述双链多核苷酸。所述可裂解的接头可以是UV可裂解的接头。
在上文和本文中所述的任何方法中,多核苷酸所附接的所述表面可以是微颗粒的表面或平坦表面。
在上文和本文中所述的任何方法中,多核苷酸所附接的表面可以包括凝胶。所述表面可以包括聚丙烯酰胺表面,诸如约2%聚丙烯酰胺,优选地,其中,所述聚丙烯酰胺表面偶联至固体支撑件,诸如玻璃。
在上文和本文中所述的任何方法中,包括所述引物链部分的所述合成链和所述支持链的与其杂交的部分可以经由一个或多个共价键被束缚至所述共同的表面。所述一个或多个共价键可以在所述共同的表面上的官能团与所述支架分子上的官能团之间形成,其中,所述支架分子上的官能团可以是胺基团、硫醇基团、硫代磷酸盐基团或硫代酰胺基团。所述共同的表面上的官能团可以是溴乙酰基团,可选地,其中,所述溴乙酰基团设置在使用N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA)衍生的聚丙烯酰胺表面上。
在上文和本文中所述的任何方法中,与上文和本文中所述的任何所述合成循环有关的反应可以在微流体系统内的液滴中执行。所述微流体系统可以是电润湿系统。所述微流体系统可以是电介质上电润湿系统(EWOD)。
在上文和本文中所述的任何方法中,在合成之后,可以将所述双链多核苷酸的链分离以提供具有预定序列的单链多核苷酸。
在上文和本文中所述的任何方法中,在合成之后,扩增所述双链多核苷酸或所述双链多核苷酸的区域,优选地通过PCR扩增。
本发明还提供了一种组装具有预定序列的多核苷酸的方法,所述方法包括:执行上文和本文中所述的任何合成方法,以合成具有预定序列的第一多核苷酸和具有预定序列的一个或多个附加的多核苷酸;以及将所述第一多核苷酸和所述一个或多个附加的多核苷酸连接在一起。所述第一多核苷酸和所述一个或多个附加的多核苷酸可以优选地包括不同的预定序列。所述第一多核苷酸和所述一个或多个附加的多核苷酸可以是双链的或者可以是单链的。所述第一多核苷酸和所述一个或多个附加的多核苷酸可以首先被裂解以产生相容的末端并且然后被连接在一起,例如通过连接反应被连接在一起。所述第一多核苷酸和所述一个或多个附加的多核苷酸可以在裂解位点处被限制酶裂解以产生相容的末端。
如上文和本文中所述的用于合成具有预定序列的双链多核苷酸的任何体外方法,和/或如上文和本文中所描述的组装具有预定序列的多核苷酸的任何体外方法可以在微流体系统内的液滴中执行。在任何这样的方法中,所述组装方法可以包括组装步骤,所述组装步骤包括:提供第一液滴和第二液滴,所述第一液滴包括具有预定序列的第一合成多核苷酸,所述第二液滴包括具有预定序列的一个或多个附加的合成多核苷酸,其中,使所述液滴彼此接触,并且其中,将所述合成多核苷酸连接在一起,从而组装包括所述第一核苷酸和所述一个或多个附加的多核苷酸的多核苷酸。在任何这样的方法中,所述合成步骤可以通过提供多个液滴来执行,每个液滴包括与所述合成循环的步骤对应的反应试剂,并且根据所述合成循环的步骤将所述液滴依次递送到所述支架多核苷酸。在任何这样的方法中,在递送液滴之后并且在递送下一液滴之前,可以实施洗涤步骤以移除过量的反应试剂。在任何这样的方法中,所述微流体系统可以是电润湿系统。在任何这样的方法中,所述微流体系统可以是电介质上电润湿系统(EWOD)。在任何这样的方法中,所述合成和组装步骤可以在同一系统中执行。
在如上文和本文中所述的用于合成具有预定序列的双链多核苷酸的任何体外方法中,所述通用核苷酸是肌苷或其类似物、变体或衍生物,并且所述辅助链中的所述通用核苷酸的配偶体核苷酸是胞嘧啶。
在相关方面,本发明还提供了延伸双链多核苷酸以合成具有预定序列的双链多核苷酸的体外方法,所述方法包括一个或多个合成循环,其中,在每个合成循环中,在连接反应中将通用核苷酸和所述预定序列的第一核苷酸添加至双链支架多核苷酸的第一链,将所述预定序列的第二核苷酸添加至所述支架多核苷酸的相对链,并且在由包括所述通用核苷酸的序列限定的裂解位点处裂解所述支架多核苷酸,其中,在裂解后,所述通用核苷酸从所述支架多核苷酸释放,并且所述第一核苷酸和所述第二核苷酸被保持在所述支架多核苷酸中;并且其中,所述预定序列的所述第一核苷酸和所述预定序列的所述第二核苷酸成为所述合成的双链多核苷酸中的不同的核苷酸对中的配偶体核苷酸。
在相关方面,本发明还提供了通用核苷酸在一种延伸双链多核苷酸以合成具有预定序列的双链多核苷酸的体外方法中的使用,其中,在合成循环中,在连接反应中将所述通用核苷酸添加至双链支架多核苷酸以在所述支架多核苷酸中产生多核苷酸裂解位点,并且其中,裂解所述支架多核苷酸以提供所述支架多核苷酸的第一链中的位点用于在下一循环中合并所述预定序列的第一核苷酸以及可选的所述预定序列的一个或多个另外的核苷酸,并且提供所述支架多核苷酸的相对链中的位点用于在所述下一循环中合并所述预定序列的第二核苷酸以及可选的所述预定序列的一个或多个另外的核苷酸;并且其中,所述预定序列的第一核苷酸和所述预定序列的第二核苷酸成为所述合成的双链多核苷酸中的不同的核苷酸对中的配偶体核苷酸。
在相关方面,本发明还提供了通用核苷酸在一种合成具有预定序列的双链多核苷酸的体外方法中的使用,其中,在合成循环中使用所述通用核苷酸以在双链支架多核苷酸中产生多核苷酸裂解位点,并且其中,对所述支架多核苷酸的裂解提供了所述支架多核苷酸的每个链中的位点用于合并所述预定序列的一个或多个核苷酸,其中,在每个合成循环中,所述使用包括:提供双链支架多核苷酸,所述双链支架多核苷酸包括合成链和与所述合成链杂交的支持链,其中,所述合成链包括引物链部分;提供双链多核苷酸连接分子,所述双链多核苷酸连接分子包括支持链和与所述支持链杂交的辅助链,并且所述双链多核苷酸连接分子还包括互补连接端,其中,在所述互补连接端的所述辅助链的末端核苷酸包括不可连接的核苷酸,其中,在所述互补连接端的所述支持链的末端核苷酸包括所述预定序列的可连接的第一核苷酸,并且其中,所述支持链包括用于产生多核苷酸裂解位点的通用核苷酸;在连接反应中将所述多核苷酸连接分子的支持链连接至所述支架多核苷酸的支持链,因此,利用所述预定序列的所述第一核苷酸延伸所述支架多核苷酸的支持链,并且在所述辅助链与所述合成链的所述引物链部分之间产生单链断裂,并且然后可选地移除所述辅助链;通过聚合酶或转移酶将包括可逆终止子基团的所述预定序列的第二核苷酸添加至所述支架多核苷酸的所述合成链的所述引物链部分的末端;以及在由包括所述通用核苷酸的序列限定的裂解位点处裂解所述支架多核苷酸的支持链,因此,包括所述通用核苷酸的所述多核苷酸连接分子从所述支架多核苷酸中被移除,并且所述预定序列的所述第一核苷酸和所述第二核苷酸被保持在所述经裂解的支架多核苷酸中;其中,在所述裂解步骤之前或之后,所述可逆终止子基团从所述第二核苷酸中被移除,并且其中,所述预定序列的所述第一核苷酸和所述预定序列的所述第二核苷酸成为所述合成的双链多核苷酸中的不同的核苷酸对中的配偶体核苷酸。
在任何这样的合成具有预定序列的双链多核苷酸的方法中,所述多核苷酸连接分子的支持链还可以包括与所述预定序列的所述第一核苷酸紧邻的所述预定序列的一个或多个另外的核苷酸,其中,所述预定序列的所述第一核苷酸是所述多核苷酸连接分子的支持链的末端核苷酸并且连接至所述支架多核苷酸的支持链的末端核苷酸;并且其中,在添加所述预定序列的所述第二核苷酸之后,所述方法还包括:通过执行添加包括可逆终止子基团的另外的核苷酸的一个或多个循环,在聚合酶或转移酶的作用下将所述预定序列的一个或多个另外的核苷酸添加至所述合成链的所述引物链部分的末端,并且然后移除所述可逆终止子基团,并且其中,在裂解后,所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中。
通用核苷酸在一种合成具有预定序列的双链多核苷酸的方法中的这样的使用可以使用上文和本文中定义和描述的任何特定方法来实现。
在相关方面,本发明还提供了在相同末端利用预定核苷酸延伸双链多核苷酸分子的每个链的体外方法,所述方法包括:提供双链支架多核苷酸,所述双链支架多核苷酸包括合成链和与所述合成链杂交的支持链,其中,所述合成链包括引物链部分;在连接反应中,在连接酶的作用下将所述预定序列的第一核苷酸添加至所述支架多核苷酸的支持链的末端,其中,所述第一核苷酸是双链多核苷酸连接分子的支持链中的末端核苷酸,所述支持链还包括通用核苷酸,其中,所述第一核苷酸连接至所述支架多核苷酸的支持链的末端核苷酸,并且在所述多核苷酸连接分子的所述相对/辅助链与所述合成链的所述引物链部分之间产生单链断裂,以及可选地,移除所述多核苷酸连接分子的所述辅助链;在聚合酶或转移酶的作用下将包括可逆终止子基团的所述预定序列的第二核苷酸添加至所述合成链的所述引物链部分的末端;在由包括所述通用核苷酸的序列限定的裂解位点处裂解所述支架多核苷酸的支持链,因此,包括所述通用核苷酸的所述多核苷酸连接分子从所述支架多核苷酸中被移除,其中,在裂解之后,所述第一核苷酸被保持在所述支持链中,并且所述第二核苷酸被保持在所述引物链部分中;以及从所述第二核苷酸中移除所述可逆终止子基团,其中,所述移除是在裂解之前或之后来执行的,并且其中,所述预定序列的所述第一核苷酸和所述预定序列的所述第二核苷酸成为所述合成的双链多核苷酸中的不同的核苷酸对中的配偶体核苷酸。
在延伸双链多核苷酸分子的每个链的任何这样的方法中,所述多核苷酸连接分子的支持链还可以包括与所述预定序列的所述第一核苷酸紧邻的所述预定序列的一个或多个另外的核苷酸,其中,所述预定序列的所述第一核苷酸是所述多核苷酸连接分子的支持链的末端核苷酸并且连接至所述支架多核苷酸的支持链的末端核苷酸;并且其中,在添加所述预定序列的所述第二核苷酸之后,所述方法还包括:通过执行添加包括可逆终止子基团的另外的核苷酸的一个或多个循环,在聚合酶或转移酶的作用下将所述预定序列的一个或多个另外的核苷酸添加至所述合成链的所述引物链部分的末端,并且然后移除所述可逆终止子基团,并且其中,在裂解后,所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中。
本发明提供了一种合成具有预定序列的双链多核苷酸的体外方法,所述方法包括根据前述延伸方法预形成一个或多个延伸循环。
在利用预定核苷酸延伸双链多核苷酸分子的每个链的任何这样的方法中,或者在合成具有预定序列的双链多核苷酸的任何这样的方法中,所述方法可以使用上文和本文中定义和描述的任何特定方法来实现。
在相关方面,本发明还提供了一种在相同末端利用预定核苷酸延伸双链支架多核苷酸的每个链的循环期间将包括通用核苷酸的多核苷酸连接分子连接至所述双链支架多核苷酸的体外方法,所述方法包括:提供双链支架多核苷酸,所述双链支架多核苷酸包括支持链和与所述支持链杂交的合成链,其中,所述合成链包括引物链部分;以及将双链多核苷酸连接分子连接至所述双链支架多核苷酸,其中,所述多核苷酸连接分子包括支持链和与所述支持链杂交的辅助链,并且所述多核苷酸连接分子还包括互补连接端,其中,在所述互补连接端的所述辅助链的末端核苷酸包括不可连接的核苷酸,其中,在所述互补连接端的所述支持链的末端核苷酸包括所述预定序列的可连接的第一核苷酸,并且其中,所述支持链包括用于产生多核苷酸裂解位点的通用核苷酸,其中,所述连接反应包括:在连接反应中将所述多核苷酸连接分子的支持链连接至所述双链支架多核苷酸的支持链,因此,利用所述预定序列的所述第一核苷酸延伸所述支架多核苷酸的支持链,并且在所述辅助链与所述合成链的所述引物链部分之间产生单链断裂,并且然后,可选地移除所述辅助链;所述方法还包括:通过聚合酶或转移酶将包括可逆终止子基团的所述预定序列的第二核苷酸添加至所述支架多核苷酸的所述合成链的所述引物链部分的末端;以及在由包括所述通用核苷酸的序列限定的裂解位点处裂解所述支架多核苷酸的支持链,因此,包括所述通用核苷酸的所述多核苷酸连接分子从所述支架多核苷酸中被移除,并且所述预定序列的所述第一核苷酸和所述第二核苷酸被保持在所述经裂解的支架多核苷酸中;其中,在所述裂解步骤之前或之后从所述第二核苷酸中移除所述可逆终止子基团,并且其中,所述预定序列的所述第一核苷酸和所述预定序列的所述第二核苷酸成为所述合成的双链多核苷酸中的不同的核苷酸对中的配偶体核苷酸。
在将包括通用核苷酸的多核苷酸连接分子连接至双链支架多核苷酸的任何这样的方法中,所述多核苷酸连接分子的支持链还可以包括与所述预定序列的所述第一核苷酸紧邻的所述预定序列的一个或多个另外的核苷酸,其中,所述预定序列的所述第一核苷酸是所述多核苷酸连接分子的支持链的末端核苷酸并且连接至所述支架多核苷酸的支持链的末端核苷酸;并且其中,在添加所述预定序列的所述第二核苷酸之后,所述方法还包括:通过执行添加包括可逆终止子基团的另外的核苷酸的一个或多个循环,在聚合酶或转移酶的作用下将所述预定序列的一个或多个另外的核苷酸添加至所述合成链的所述引物链部分的末端,并且然后移除所述可逆终止子基团,并且其中,在裂解后,所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中。
本发明提供了一种合成具有预定序列的双链多核苷酸的体外方法,所述方法包括根据前述连接方法预形成一个或多个延伸循环。
在合成具有预定序列的双链多核苷酸的循环期间将包括通用核苷酸的连接多核苷酸连接至双链多核苷酸的任何这样的方法中,所述方法可以使用上文和本文中限定和描述的任何特定方法来实施。
本发明另外提供了一种用于实施上文和本文中所述的任何合成和/或组装方法的多核苷酸合成系统,所述系统包括:(a)反应区域的阵列,其中,每个反应区域包括至少一个支架多核苷酸;和(b)用于将反应试剂递送至所述反应区域的装置;以及可选地(c)用于从所述支架多核苷酸中裂解合成的双链多核苷酸的装置。这样的系统还可以包括:用于以液滴形式提供所述反应试剂的装置;和用于根据合成循环将所述液滴递送至所述支架多核苷酸的装置。
本发明还提供了一种与上文和本文中所述的任何系统一起使用并用于实施上文和本文中所述的任何合成方法的试剂盒,所述试剂盒包括与所述合成循环的步骤对应的反应试剂的容积。
本发明还提供了一种制备多核苷酸微阵列的方法,其中,所述微阵列包括多个反应区域,每个区域包括具有预定序列的一个或多个多核苷酸,所述方法包括:
(a)提供包括多个反应区域的表面,每个区域包括一个或多个双链锚固或支架多核苷酸;以及
(b)在每个反应区域处根据权利要求1至71中任一项所述的方法执行合成循环,从而在每个区域处合成具有预定序列的一个或多个双链多核苷酸。
在这样的方法中,在合成之后,可以将所述双链多核苷酸的链分离以提供微阵列,其中,每个区域包括具有预定序列的一个或多个单链多核苷酸。
附图说明
本文提出和下文描述的相关图示出了使用包括本发明方法在内的方法的合成循环的一些或所有步骤,以及用于执行方法的方面的方式,诸如寡核苷酸、表面、表面附接化学反应、接头等。这些附图以及其所有描述和所有关联的方法、试剂和方案仅用于例示而被提出而不应解释为是限制性的。
相关附图,诸如,例如图7、8、9、10、11、14a、15a、16a等示出了合成循环的一些或所有步骤,包括:合并核苷酸(例如,包括可逆终止子基团的核苷酸)、裂解(例如,将支架多核苷酸裂解成第一部分和第二部分,其中,第一部分包括通用核苷酸,并且第二部分包括合并的核苷酸)、连接(例如,将包括单链部分的多核苷酸构造连接至包括合并的核苷酸的经裂解的支架多核苷酸的第二部分,其中,单链部分包括与合并的核苷酸互补的配偶体核苷酸)和脱保护(例如,从合并的核苷酸中移除可逆终止子基团)。这些方法被提供仅用于例示性支持而不在要求保护的发明的范围内。图1至6以及图53和54所示的方法方案是本发明的方法。
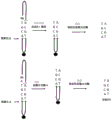
图1.本发明的示例性方法版本1的方案。
示出根据本发明的示例性方法版本1的第一合成循环的方案。
该方法包括这样的循环:提供支架多核苷酸;将多核苷酸连接分子连接至支架多核苷酸;合并包括可逆终止子基团或封闭基团的核苷酸;脱保护;以及裂解。
该方案示出了提供包括支持链(标记为“a”)和与支持链杂交的合成链(标记为“b”)的支架多核苷酸(101、106)。合成链包括引物链部分(虚线)。与引物链部分邻近的支持链的末端核苷酸包括可连接基团,优选为如图所描绘的末端磷酸基团。与引物链部分邻近的支持链的被表示为“A”(腺苷)的末端核苷酸在单核苷酸突出端中突出引物链部分的末端核苷酸之外。引物链部分的末端核苷酸在核苷酸对中与支持链的次末端核苷酸配对。该对的两个核苷酸都被表示为“X”。这两个核苷酸可以是任何两个核苷酸或其类似物或衍生物,而不限于天然互补的核苷酸对。支持链的突出末端核苷酸可以是任何核苷酸或其类似物或衍生物。
该方案示出了提供多核苷酸连接分子(102、107;图右上方的结构)。多核苷酸连接分子包括:辅助链(虚线);与辅助链杂交的支持链;以及互补连接端。互补连接端的支持链的末端核苷酸是预定序列的第一核苷酸且被表示为“G”(鸟嘌呤),并且与辅助链的被表示为“C”(胞嘧啶)的次末端核苷酸配对。互补连接端的辅助链的末端核苷酸被表示为“T”(胸腺嘧啶),并且在单核苷酸突出端处突出互补连接端的支持链的末端核苷酸。互补连接端的辅助链的末端核苷酸包括不可连接的核苷酸。互补连接端在支持链中包括通用核苷酸(被表示为“Un”),并且与辅助链中的配偶体核苷酸(被表示为“X”)配对。G、C和T仅用于例示而被示出,并且可以是任何核苷酸或其类似物或衍生物。X可以是任何核苷酸或其类似物或衍生物。配对的核苷酸不必包括天然互补的核苷酸。
该方案示出了:将多核苷酸连接分子的支持链连接至支架多核苷酸的支持链(102、107),并且在辅助链和引物链部分之间在合成链中产生单链断裂(“缺口”)。
该方案示出了合并预定序列的第二核苷酸(103、108)。该核苷酸包括可逆终止子基团(三角形),并且仅用于例示而被表示为“T”(胸腺嘧啶),其可以是任何核苷酸或其类似物或衍生物。
该方案示出了脱保护步骤(104、109),其包括从预定序列的第二核苷酸中移除可逆终止子基团。
该方案示出了裂解步骤(105、110),其包括在由包括通用核苷酸的序列限定的裂解位点处裂解支持链(锯齿状箭头)。裂解释放了包括通用核苷酸的多核苷酸连接分子,并且引致了第一核苷酸和第二核苷酸被保持在支架多核苷酸中。在本发明版本1的合成方法中,在由通用核苷酸占据的位置与占据支持链中的沿靠近引物链部分/远离辅助链部分的方向的下一核苷酸位置的核苷酸之间裂解支持链。
在本发明版本1的合成方法中,在裂解之后的每个循环中,预定序列的第一核苷酸是未配对的,是与引物链部分邻近的支持链的末端核苷酸,并且以突出预定序列的第二核苷酸之外的单核苷酸突出端的形式被提供,所述预定序列的第二核苷酸是引物链部分的末端核苷酸。因此,预定序列的第一核苷酸和预定序列的第二核苷酸彼此不与彼此形成核苷酸对。
图2.本发明的示例性方法版本2的方案。
该方案示出了本发明的示例性方法版本2的第一合成循环。
该方法包括这样的循环:提供支架多核苷酸;将多核苷酸连接分子连接至支架多核苷酸;合并包括可逆终止子基团或封闭基团的核苷酸;脱保护;以及裂解。
该方案示出了提供包括支持链(标记为“a”)和与支持链杂交的合成链(标记为“b”)的支架多核苷酸(201、206)。合成链包括引物链部分(虚线)。与引物链部分邻近的支持链的末端核苷酸包括可连接基团,优选为如图所描绘的末端磷酸基团。与引物链部分邻近的支持链的被表示为“A”(腺苷)的末端核苷酸在单核苷酸突出端中突出引物链部分的末端核苷酸之外。引物链部分的末端核苷酸在核苷酸对中与支持链的次末端核苷酸配对。该对的两个核苷酸都被表示为“X”。这两个核苷酸可以是任何两个核苷酸或其类似物或衍生物,而不限于天然互补的核苷酸对。支持链的突出末端核苷酸可以是任何核苷酸或其类似物或衍生物。
该方案示出了提供多核苷酸连接分子(202、207;图右上方的结构)。多核苷酸连接分子包括:辅助链(虚线);与辅助链杂交的支持链;以及互补连接端。互补连接端的支持链的末端核苷酸是预定序列的第一核苷酸且被表示为“G”(鸟嘌呤),并且与辅助链的被表示为“C”(胞嘧啶)的次末端核苷酸配对。互补连接端的辅助链的末端核苷酸被表示为“T”(胸腺嘧啶),并且在单核苷酸突出端处突出互补连接端的支持链的末端核苷酸。互补连接端的辅助链的末端核苷酸包括不可连接的核苷酸。互补连接端在支持链中包括通用核苷酸(被表示为“Un”),并且与辅助链中的配偶体核苷酸(被表示为“X”)配对。支持链的次末端核苷酸被表示为“X”,并且与辅助链中的配偶体核苷酸配对。配偶体核苷酸也被表示为“X”。G、C和T仅用于例示而被示出,并且可以是任何核苷酸或其类似物或衍生物。被表示为“X”的核苷酸可以是任何核苷酸或其类似物或衍生物。配对的核苷酸不必包括天然互补的核苷酸。
该方案示出了:将多核苷酸连接分子的支持链连接至支架多核苷酸的支持链(202、207),并且在辅助链与引物链部分之间在合成链中产生单链断裂(“缺口”)。
该方案示出了合并预定序列的第二核苷酸(203、208)。该核苷酸包括可逆终止子基团(三角形),并且仅用于例示而被表示为“T”(胸腺嘧啶),其可以是任何核苷酸或其类似物或衍生物。
该方案示出了脱保护步骤(204、209),其包括从预定序列的第二核苷酸中移除可逆终止子基团。
该方案示出了裂解步骤(205、210),其包括在由包括通用核苷酸的序列限定的裂解位点处裂解支持链(锯齿状箭头)。裂解释放了包括通用核苷酸的多核苷酸连接分子,并且引致了第一核苷酸和第二核苷酸被保持在支架多核苷酸中。在本发明版本2的合成方法中,在占据相对于通用核苷酸的沿靠近引物链部分/远离辅助链部分的方向的下一核苷酸位置的核苷酸与占据相对于通用核苷酸的沿靠近引物链部分/远离辅助链部分的方向的第二核苷酸位置的核苷酸之间裂解支持链。
在本发明版本2的合成方法中,在裂解之后的每个循环中,预定序列的第一核苷酸是未配对的,是与引物链部分邻近的支持链的末端核苷酸,并且以突出预定序列的第二核苷酸之外的单核苷酸突出端的形式被提供,所述预定序列的第二核苷酸是引物链部分的末端核苷酸。因此,预定序列的第一核苷酸和预定序列的第二核苷酸彼此不与彼此形成核苷酸对。
图3.示出本发明的示例性方法版本2的变体的方案。
该方案示出了根据本发明的示例性方法版本2的变体的第一合成循环。
该方法包括这样的循环:提供支架多核苷酸;将多核苷酸连接分子连接至支架多核苷酸;合并包括可逆终止子基团或封闭基团的核苷酸;脱保护;以及裂解。
该方案示出了提供包括支持链(标记为“a”)和与支持链杂交的合成链(标记为“b”)的支架多核苷酸(301、306)。合成链包括引物链部分(虚线)。与引物链部分邻近的支持链的末端核苷酸包括可连接基团,优选为如图所描绘的末端磷酸基团。与引物链部分邻近的支持链的被表示为“A”(腺苷)的末端核苷酸在单核苷酸突出端中突出引物链部分的末端核苷酸之外。引物链部分的末端核苷酸在核苷酸对中与支持链的次末端核苷酸配对。该对的两个核苷酸都被表示为“X”。这两个核苷酸可以是任何两个核苷酸或其类似物或衍生物,而不限于天然互补的核苷酸对。支持链的突出末端核苷酸可以是任何核苷酸或其类似物或衍生物。
该方案示出了提供多核苷酸连接分子(302、307;图右上方的结构)。多核苷酸连接分子包括:辅助链(虚线);与辅助链杂交的支持链;以及互补连接端。互补连接端的支持链的末端核苷酸是预定序列的第一核苷酸且被表示为“G”(鸟嘌呤),并且与辅助链的被表示为“C”(胞嘧啶)的次末端核苷酸配对。互补连接端的辅助链的末端核苷酸被表示为“T”(胸腺嘧啶),并且在单核苷酸突出端处突出互补连接端的支持链的末端核苷酸。互补连接端的辅助链的末端核苷酸包括不可连接的核苷酸。互补连接端在支持链中包括通用核苷酸(被表示为“Un”),并且与辅助链中的配偶体核苷酸(被表示为“X”)配对。在互补连接端,被表示为“X”的两个核苷酸位于支持链中的通用核苷酸和末端核苷酸之间,并且与辅助链中的也被表示为“X”的配偶体核苷酸配对。G、C和T仅用于例示而被示出,并且可以是任何核苷酸或其类似物或衍生物。被表示为“X”的核苷酸可以是任何核苷酸或其类似物或衍生物。配对的核苷酸不必包括天然互补的核苷酸。
该方案示出了将多核苷酸连接分子的支持链连接至支架多核苷酸的支持链(302、307),并且在辅助链和引物链部分之间在合成链中产生单链断裂(“缺口”)。
该方案示出了合并预定序列的第二核苷酸(303、308)。该核苷酸包括可逆终止子基团(三角形),并且仅用于例示而被表示为“T”(胸腺嘧啶),其可以是任何核苷酸或其类似物或衍生物。
该方案示出了脱保护步骤(304、309),其包括从预定序列的第二核苷酸中移除可逆终止子基团。
该方案示出了裂解步骤(305、310),其包括在由包括通用核苷酸的序列限定的裂解位点处裂解支持链(锯齿状箭头)。裂解释放了包括通用核苷酸的多核苷酸连接分子,并且引致了第一核苷酸和第二核苷酸被保持在支架多核苷酸中。在本发明版本2的合成方法的这些变体中,总是在由预定序列的第一核苷酸占据的位置与由支持链中的沿靠近引物链部分/远离辅助链部分的方向的下一核苷酸占据的位置之间裂解支持链。
在本发明版本2的合成方法的这些变体中,在裂解之后的每个循环中,预定序列的第一核苷酸是未配对的,是与引物链部分邻近的支持链的末端核苷酸,并且以突出预定序列的第二核苷酸之外的单核苷酸突出端的形式被提供,所述预定序列的第二核苷酸是引物链部分的末端核苷酸。因此,预定序列的第一核苷酸和预定序列的第二核苷酸彼此不与彼此形成核苷酸对。
图4.示出本发明示例性方法版本1的另外的变体的方案。
该方案示出了根据本发明的示例性方法版本1的另外的变体的第一合成循环。
该方法包括这样的循环:提供支架多核苷酸;将多核苷酸连接分子连接至支架多核苷酸;合并包括可逆终止子基团或封闭基团的核苷酸;脱保护;以及裂解。
该方案示出了提供包括支持链(标记为“a”)和与支持链杂交的合成链(标记为“b”)的支架多核苷酸(401、406)。合成链包括引物链部分(虚线)。与引物链部分邻近的支持链的末端核苷酸包括可连接基团,优选为如图所描绘的末端磷酸基团。支持链的与引物链部分邻近的末端核苷酸被表示为“C”(胞嘧啶)。支持链的次末端核苷酸被表示为“A”(腺苷)。支持链的末端和次末端核苷酸在多核苷酸突出端中突出引物链部分的末端核苷酸之外。支持链可以可选地包括一个或多个另外的核苷酸,由平行竖向线表示。引物链部分的末端核苷酸与支持链中的配偶体核苷酸以核苷酸对的形式配对。该对的两个核苷酸都被表示为“X”。这两个核苷酸可以是任何两个核苷酸或其类似物或衍生物,而不限于天然互补的核苷酸对。支持链的突出核苷酸可以是任何核苷酸或其类似物或衍生物。
该方案示出了提供多核苷酸连接分子(402、407;图右上方的结构)。多核苷酸连接分子包括:辅助链(虚线);与辅助链杂交的支持链;以及互补连接端。互补连接端的支持链的末端核苷酸是预定序列的第一核苷酸且被表示为“G”(鸟嘌呤),并且与辅助链中被表示为“C”(胞嘧啶)的配偶体核苷酸配对。互补连接端的辅助链的末端核苷酸被表示为“T”(胸腺嘧啶)。辅助链的次末端核苷酸被表示为“G”(鸟嘌呤)。辅助链的末端和次末端核苷酸在多核苷酸突出端中突出互补连接端的支持链的末端核苷酸之外。辅助链可以可选地包括在末端和次末端核苷酸之前的一个或多个另外的核苷酸,由平行竖向线表示。互补连接端的辅助链的末端核苷酸包括不可连接的核苷酸。互补连接端在支持链中包括通用核苷酸(被表示为“Un”),并且与辅助链中的配偶体核苷酸(被表示为“X”)配对。G、C和T仅用于例示而被示出,并且可以是任何核苷酸或其类似物或衍生物。X可以是任何核苷酸或其类似物或衍生物。配对的核苷酸不必包括天然互补的核苷酸。
该方案示出了将多核苷酸连接分子的支持链连接至支架多核苷酸的支持链(402、407),并且在辅助链和引物链部分之间在合成链中产生单链断裂(“缺口”)。
该方案示出了合并预定序列的第二核苷酸(403、408)。该核苷酸包括可逆终止子基团(三角形),并且仅用于例示而被表示为“T”(胸腺嘧啶),其可以是任何核苷酸或其类似物或衍生物。
该方案示出了脱保护步骤(404、409),其包括从预定序列的第二核苷酸中移除可逆终止子基团。
该方案示出了裂解步骤(405、410),其包括在由包括通用核苷酸的序列限定的裂解位点处裂解支持链(锯齿状箭头)。裂解释放了包括通用核苷酸的多核苷酸连接分子,并且引致了第一核苷酸和第二核苷酸被保持在支架多核苷酸中。在本发明版本1的合成方法的这些特定变体中,总是在由通用核苷酸占据的位置与支持链中占据沿靠近引物链部分/远离辅助链部分的方向的下一核苷酸位置的核苷酸之间裂解支持链。
在本发明版本1的合成方法的这些特定变体中,在裂解之后的每个循环中,预定序列的第一核苷酸是未配对的,是与引物链部分邻近的支持链的末端核苷酸,并且以突出预定序列的第二核苷酸之外的单核苷酸突出端的形式被提供,所述预定序列的第二核苷酸是引物链部分的末端核苷酸。因此,预定序列的第一核苷酸和预定序列的第二核苷酸彼此不与彼此形成核苷酸对。
图5.示出本发明的示例性方法版本2的另外的变体的方案。
该方案示出了根据本发明的示例性方法版本2的另外的变体的第一合成循环。
该方法包括这样的循环:提供支架多核苷酸;将多核苷酸连接分子连接至支架多核苷酸;合并包括可逆终止子基团或封闭基团的核苷酸;脱保护;以及裂解。
该方案示出了提供包括支持链(标记为“a”)和与支持链杂交的合成链(标记为“b”)的支架多核苷酸(501、506)。合成链包括引物链部分(虚线)。与引物链部分邻近的支持链的末端核苷酸包括可连接基团,优选为如图所描绘的末端磷酸基团。支持链的与引物链部分邻近的末端核苷酸被表示为“C”(胞嘧啶)。支持链的次末端核苷酸被表示为“A”(腺苷)。支持链的末端和次末端核苷酸在多核苷酸突出端中突出引物链部分的末端核苷酸之外。支持链可以可选地包括一个或多个另外的核苷酸,由平行竖向线表示。引物链部分的末端核苷酸与支持链中的配偶体核苷酸以核苷酸对的形式配对。该对的两个核苷酸都被表示为“X”。这两个核苷酸可以是任何两个核苷酸或其类似物或衍生物,而不限于天然互补的核苷酸对。支持链的突出核苷酸可以是任何核苷酸或其类似物或衍生物。
该方案示出了提供多核苷酸连接分子(502、507;图右上方的结构)。多核苷酸连接分子包括:辅助链(虚线);与辅助链杂交的支持链;以及互补连接端。互补连接端的支持链的末端核苷酸是预定序列的第一核苷酸且被表示为“G”(鸟嘌呤),并且与辅助链中被表示为“C”(胞嘧啶)的配偶体核苷酸配对。互补连接端的辅助链的末端核苷酸被表示为“T”(胸腺嘧啶)。辅助链的次末端核苷酸被表示为“G”(鸟嘌呤)。辅助链的末端和次末端核苷酸在多核苷酸突出端中突出互补连接端的支持链的末端核苷酸之外。辅助链可以可选地包括在末端和次末端核苷酸之前的一个或多个另外的核苷酸,由平行竖向线表示。互补连接端的辅助链的末端核苷酸包括不可连接的核苷酸。互补连接端在支持链中包括通用核苷酸(被表示为“Un”),并且与辅助链中的配偶体核苷酸(被表示为“X”)配对。另外的核苷酸(被表示为“X”)位于预定序列的第一核苷酸与互补连接端的支持链中的通用核苷酸之间,并且与辅助链中的配偶体核苷酸配对(也被表示为“X”)。G、C和T仅用于例示而被示出,并且可以是任何核苷酸或其类似物或衍生物。X可以是任何核苷酸或其类似物或衍生物。配对的核苷酸不必包括天然互补的核苷酸。
该方案示出了将多核苷酸连接分子的支持链连接至支架多核苷酸的支持链(502、507),并且在辅助链与引物链部分之间在合成链中产生单链断裂(“缺口”)。
该方案示出了合并预定序列的第二核苷酸(503、508)。该核苷酸包括可逆终止子基团(三角形),并且仅用于例示而被表示为“T”(胸腺嘧啶),其可以是任何核苷酸或其类似物或衍生物。
该方案示出了脱保护步骤(504、509),其包括从预定序列的第二核苷酸中移除可逆终止子基团。
该方案示出了裂解步骤(505、510),其包括在由包括通用核苷酸的序列限定的裂解位点处裂解支持链(锯齿状箭头)。裂解释放了包括通用核苷酸的多核苷酸连接分子,并且引致了第一核苷酸和第二核苷酸被保持在支架多核苷酸中。在本发明版本2的合成方法的这些特定变体中,总是在占据相对于通用核苷酸的沿靠近引物链部分/远离辅助链部分的方向的下一核苷酸位置的核苷酸与占据相对于通用核苷酸的沿靠近引物链部分/远离辅助链部分的方向的第二核苷酸位置的核苷酸之间裂解支持链。
在本发明版本2的合成方法的这些变体中,在裂解之后的每个循环中,预定序列的第一核苷酸是未配对的,是与引物链部分邻近的支持链的末端核苷酸,并且以突出预定序列的第二核苷酸之外的多核苷酸突出端的形式被提供,所述预定序列的第二核苷酸是引物链部分的末端核苷酸。因此,预定序列的第一核苷酸和预定序列的第二核苷酸彼此不与彼此形成核苷酸对。
图6.该方案示出了涉及每个循环合并多于两个的核苷酸的本发明示例性方法版
本1的变体。
该方案示出了根据本发明的示例性方法版本1的变体的第一合成循环,其涉及在连接和合并这两个步骤中合并多个核苷酸。
该方法包括这样的循环:提供支架多核苷酸;将多核苷酸连接分子连接至支架多核苷酸;多个步骤:(a)合并包括可逆终止子基团或封闭基团的核苷酸,随后(b)脱保护;并且然后最终裂解。
该方案示出了提供包括支持链(标记为“a”)和与支持链杂交的合成链(标记为“b”)的支架多核苷酸(601、606)。合成链包括引物链部分(虚线)。与引物链部分邻近的支持链的末端核苷酸包括可连接基团,优选为如图所描绘的末端磷酸基团。与引物链部分邻近的支持链的被表示为“A”(腺苷)的末端核苷酸在单核苷酸突出端中突出引物链部分的末端核苷酸之外。引物链部分的末端核苷酸在核苷酸对中与支持链的次末端核苷酸配对。该对的两个核苷酸都被表示为“X”。这两个核苷酸可以是任何两个核苷酸或其类似物或衍生物,而不限于天然互补的核苷酸对。支持链的突出末端核苷酸可以是任何核苷酸或其类似物或衍生物。
该方案示出了提供多核苷酸连接分子(602、607;图右上方的结构)。多核苷酸连接分子包括:辅助链(虚线);与辅助链杂交的支持链;以及互补连接端。互补连接端的支持链的末端核苷酸是预定序列的第一核苷酸且被表示为“G”(鸟嘌呤),并且与辅助链的被表示为“C”(胞嘧啶)的次末端核苷酸配对。互补连接端的辅助链的末端核苷酸被表示为“T”(胸腺嘧啶),并且在单核苷酸突出端处突出互补连接端的支持链的末端核苷酸。互补连接端的辅助链的末端核苷酸包括不可连接的核苷酸。支持链的次末端核苷酸是预定序列的另外的核苷酸且被表示为“T”(胸腺嘧啶),并且与辅助链中被表示为“A”(腺嘌呤)的配偶体核苷酸配对。互补连接端在支持链中包括通用核苷酸(被表示为“Un”),并且与辅助链中的配偶体核苷酸(被表示为“X”)配对。A、T、G和C仅用于例示而被示出,并且可以是任何核苷酸或其类似物或衍生物。X可以是任何核苷酸或其类似物或衍生物。配对的核苷酸不必包括天然互补的核苷酸。
该方案示出了将多核苷酸连接分子(602、607)的支持链连接至支架多核苷酸的支持链,并且在辅助链和引物链部分之间在合成链中产生单链断裂(“缺口”)。
该方案示出了合并预定序列的第二核苷酸(603、608)。该核苷酸包括可逆终止子基团(三角形),并且仅用于例示而被表示为“T”(胸腺嘧啶),其可以是任何核苷酸或其类似物或衍生物。合并后,第二核苷酸与第一核苷酸形成核苷酸对。
该方案示出了在合并第二核苷酸(604、609)之后的脱保护步骤,其包括从预定序列的第二核苷酸中移除可逆终止子基团。
该方案示出了合并预定序列的另外的核苷酸(603’、608’)。该核苷酸包括可逆终止子基团(三角形),并且被表示为“C”(胞嘧啶)。合并后,所述另外的核苷酸与由步骤(2)中的多核苷酸连接分子提供的被表示为“G”(鸟嘌呤)的预定序列的第一核苷酸形成核苷酸对。胞嘧啶和鸟嘌呤仅用于例示而被示出,这些核苷酸可以是任何核苷酸或其类似物或衍生物,并且不限于天然互补的核苷酸对。
该方案示出了在合并另外的核苷酸(604’、609’)之后的第二脱保护步骤,其包括从预定序列的另外的核苷酸中移除可逆终止子基团。
该方案示出了裂解步骤(605、610),其包括在由包括通用核苷酸的序列限定的裂解位点处裂解支持链(锯齿状箭头)。裂解释放了包括通用核苷酸的多核苷酸连接分子,并且引致了第一核苷酸、第二核苷酸和另外的核苷酸被保持在支架多核苷酸中。在本发明版本1的合成方法的该特定变体中,在由通用核苷酸占据的位置与支持链中占据沿靠近引物链部分/远离辅助链部分的方向的下一核苷酸位置的核苷酸之间裂解支持链。
在本发明版本1的合成方法的所有这些特定变体中,在裂解之后,在步骤(2)中由多核苷酸连接分子提供的所述预定序列的另外的核苷酸是未配对的,是与引物链部分邻近的支持链的末端核苷酸,并且以突出在合并步骤(3’)中提供的所述预定序列的另外的核苷酸之外的单核苷酸突出端的形式被提供,所述预定序列的另外的核苷酸是引物链部分的末端核苷酸。因此,预定序列的第一核苷酸和预定序列的第二核苷酸不与彼此形成核苷酸对,在步骤(2)中由多核苷酸连接分子提供的第一另外的核苷酸和在步骤(3’)中合并的第一另外的核苷酸不与彼此形成核苷酸对,依此类推。
图7.示例性方法版本1的方案。
该方案示出了根据实例部分的示例性方法版本1的第一合成循环。该方法仅用于例示性支持而被提供,并且不在要求保护的本发明的范围内。该方法包括这样的循环:提供支架多核苷酸、合并、裂解、连接和脱保护。该方案示出了在第一合成循环中合并胸腺嘧啶核苷酸(101、102)及其与配偶体腺嘌呤核苷酸相对的配对(104),以及提供用于下一合成循环的支架多核苷酸(106)。该配对仅用于例示目的而被示出而不具有限制性,取决于所需的预定序列,该配对可以是任何配对。核苷酸Z可以是任何核苷酸。核苷酸X可以任何适当的核苷酸。该图还示出了与第二合成循环对应的参考标记。
图8.示例性方法版本2的方案。
该方案示出了根据实例部分的示例性方法版本2的第一合成循环。该方法仅用于例示性支持而被提供,并且不在要求保护的本发明的范围内。该方法包括这样的循环:提供支架多核苷酸、合并、裂解、连接和脱保护。该方案示出了在第一循环(201、202)中合并胸腺嘧啶核苷酸及其与配偶体腺嘌呤核苷酸相对的配对(204),以及提供包括用于在下一合成循环中与胞嘧啶配对的鸟嘌呤的支架多核苷酸(206)。这些配对仅用于例示目的而被示出而不具有限制性,取决于所需的预定序列,这些配对可以是任何配对。核苷酸Z可以是任何核苷酸。核苷酸X可以任何适当的核苷酸。该图还示出了与第二合成循环对应的参考标记。
图9.示例性方法版本3的方案。
该方案示出了根据实例部分的示例性方法版本3的第一合成循环。该方法仅用于例示性支持而被提供,并且不在要求保护的本发明的范围内。该方法包括这样的循环:提供支架多核苷酸、合并、裂解、连接和脱保护。该方案示出了在第一循环(301、302)中合并胸腺嘧啶核苷酸及其与配偶体腺嘌呤核苷酸相对的配对(304),以及提供用于在下一合成循环中使用的支架多核苷酸(306)。该配对仅用于例示目的而被示出而不具有限制性,取决于所需的预定序列,该配对可以是任何配对。该方案还示出了胞嘧啶-鸟嘌呤配对作为支架多核苷酸的组分并且其不是预定序列的一部分。该配对也仅用于例示目的而被示出并且不具有限制性,该配对可以是任何配对。核苷酸Z可以是任何核苷酸。核苷酸X可以任何适当的核苷酸。
图10.示例性方法版本4的方案。
该方案示出了根据实例部分的示例性方法版本4的第一合成循环。该方法仅用于例示性支持而被提供,并且不在要求保护的本发明的范围内。该方法包括这样的循环:提供支架多核苷酸、合并、裂解、连接和脱保护。该方案示出了在第一循环(401、402)中合并胸腺嘧啶核苷酸及其与配偶体通用核苷酸相对的配对(404),以及提供包括用于在下一合成循环中与胞嘧啶配对的鸟嘌呤的支架多核苷酸(406)。这些配对仅用于例示目的而被示出而不具有限制性,取决于所需的预定序列,这些配对可以是任何配对。核苷酸X、Y和Z可以是任何核苷酸。
图11.示例性方法版本5的方案。
该方案示出了根据实例部分的示例性方法版本5的第一合成循环。该方法仅用于例示性支持而被提供,并且不在要求保护的本发明的范围内。该方法包括这样的循环:提供支架多核苷酸、合并、裂解、连接和脱保护。该方案示出了在第一循环(501、502)中合并胸腺嘧啶核苷酸及其与配偶体腺嘌呤核苷酸相对的配对(504),以及提供包括用于在下一合成循环中与胞嘧啶配对的鸟嘌呤的支架多核苷酸(506)。该方案还示出了胞嘧啶-鸟嘌呤配对(位置n-2)作为支架多核苷酸的组分并且其不是预定序列的一部分。这些配对仅用于例示目的而被示出而不具有限制性,取决于所需的预定序列,这些配对可以是任何配对。核苷酸X、Y和Z可以是任何核苷酸。
图12.示出支架多核苷酸的表面固定化的方案。
方案(a至h)示出了支架多核苷酸的可能的示例性发夹环构型及其到表面的固定。
方案(i和j)示出了用于将多核苷酸附接至表面的表面化学法的实例。实例示出了双链实施方案,其中,两条链经由发夹连接,但是相同的化学方法可以用于附接未连接的双链多核苷酸的一个或两个链。
图13.不存在辅助链——合并。
a)该方案以虚线框突出示出了合并步骤。
b)对用于合并与肌苷相对的3’-O-修饰的dTTP的DNA聚合酶进行评估。该图描绘了凝胶,其示出了在50℃下在存在Mn2+离子的情况下通过各种DNA聚合酶(Bst、Deep Vent(Exo-)、终止子I和终止子IX)合并3’-O-修饰的-dTTP的结果。泳道1:使用Bst DNA聚合酶合并3’-O-烯丙基-dTTP。泳道2:使用Bst DNA聚合酶合并3’-O-叠氮甲基-dTTP。泳道3:使用Deep vent(exo-)DNA聚合酶合并3’-O-烯丙基-dTTP。泳道4:使用Deep vent(exo-)DNA聚合酶合并3’-O-叠氮甲基-dTTP。泳道5:使用终止子I DNA聚合酶合并3’-O-烯丙基-dTTP。泳道6:使用终止子I DNA聚合酶合并3’-O-叠氮甲基-dTTP。泳道7:使用终止子IX DNA聚合酶合并3’-O-烯丙基-dTTP。泳道8:使用终止子IX DNA聚合酶合并3’-O-叠氮甲基-dTTP。
c)对用于合并与肌苷相对的3’-O-修饰的-dTTP的DNA聚合酶进行评估。使用各种DNA聚合酶进行合并的结果。
d)使用终止子IX DNA聚合酶评估合并温度。该图描绘了凝胶,其示出了在各种温度下使用终止子IX DNA聚合酶在存在Mn2+离子的情况下合并与肌苷相对的3'-修饰的-dTTP的结果。泳道1:在37℃下合并3’-O-烯丙基-dTTP。泳道2:在37℃下合并3'-O-叠氮甲基-dTTP。泳道3:在50℃下合并3’-O-烯丙基-dTTP。泳道4:在50℃下合并3'-O-叠氮甲基-dTTP。泳道5:在65℃下合并3’-O-烯丙基-dTTP。泳道6:在65℃下合并3'-O-叠氮甲基-dTTP。
e)使用终止子IX DNA聚合酶评估合并温度。在不同温度下执行的合并的结果。
f)使用终止子IX DNA聚合酶评估合并时Mn2+的存在。该图描绘了凝胶,其示出了在65℃下合并与肌苷相对的3'-O-修饰的-dTTP的结果。泳道S:标准。泳道1:在不存在Mn2+离子的情况下合并3’-O-烯丙基-dTTP。泳道2:在不存在Mn2+离子的情况下合并3’-O-叠氮甲基-dTTP。泳道3:在存在Mn2+离子的情况下合并3’-O-烯丙基-dTTP。泳道4:在存在Mn2+离子的情况下合并3’-O-叠氮甲基-dTTP。
g)使用终止子IX DNA聚合酶评估合并时Mn2+的存在。在存在和不存在Mn2+离子的情况下进行合并的结果。
h)用于研究合并步骤的寡核苷酸。
图14.不存在辅助链——裂解。
a)该方案示出了在不存在辅助链的情况下裂解杂交的多核苷酸链。裂解步骤以虚线框突出显示。
b)凝胶分别示出了在37℃和室温24℃下用hAAG和0.2M NaOH(强碱)裂解寡核苷酸。泳道1.起始寡核苷酸。作为含有两条全长链的正对照的泳道2示出了经裂解的与未经裂解的DNA的比率为90%:10%的较高产率。包括没有辅助链的裂解反应的泳道3示出了经裂解的与未经裂解的DNA的比率为10%:90%的低百分比产率。
c)凝胶示出了寡核苷酸在37℃下用hAAG和Endo VIII裂解。作为含有两条全长链的正对照的泳道2示出了经裂解的与未经裂解的DNA的比率为约90%:10%的较高产率。包括没有辅助链的裂解反应的泳道3示出了经裂解的与未经裂解的DNA的比率为约7%:93%的低百分比产率。
d)对用hAAG/Endo VIII和hAAG/化学碱裂解寡核苷酸的总结。
e)用于研究裂解步骤的寡核苷酸。
图15.不存在辅助链——连接。
a)该方案示出了在不存在辅助链的情况下连接杂交的多核苷酸链。以虚线框突出显示连接步骤。
b)凝胶示出了在不存在辅助链的情况下在室温(24℃)下用Quick T4 DNA连接酶连接寡核苷酸。泳道1含有36聚体TAMRA单链寡核苷酸和18聚体TAMRA单链寡核苷酸的混合物。这些寡核苷酸用作参考带。
c)用于研究连接步骤的寡核苷酸。
图16.利用辅助链的版本1化学法——合并。
a)该方案以虚线框突出示出了合并步骤。
b)适用于研究合并步骤的寡核苷酸。
图17.利用辅助链的版本1化学法——裂解。
a)该方案示出了在不存在辅助链的情况下裂解杂交的多核苷酸链。裂解步骤以虚线框突出显示。
b)凝胶分别示出了在37℃和室温24℃下用hAAG和0.2M NaOH(强碱)裂解寡核苷酸。泳道1.起始寡核苷酸。作为含有两条全长链的正对照的泳道2示出了经裂解的与未经裂解的DNA的比率为90%:10%的较高产率。包括没有辅助链的裂解反应的泳道3示出了经裂解的与未经裂解的DNA的比率为10%:90%的低百分比产率。包括利用辅助链的裂解反应的泳道4示出了经裂解的与未经裂解的DNA的比率为50%:50%的相等百分比产率。
c)对用于裂解无碱基位点的核酸内切酶VIII的评估。凝胶示出了在37℃下用hAAG和Endo VIII裂解寡核苷酸。作为含有两条全长链的正对照的泳道2示出了经裂解的与未经裂解的DNA的比率为约90%:10%的较高产率。包括没有辅助链的裂解反应的泳道3示出了经裂解的与未经裂解的DNA的比率为约7%:93%的低百分比产率。包括利用辅助链的裂解反应的泳道4示出了经裂解的与未经裂解的DNA的比率为10%:90%的低百分比产率。
d)对用于裂解无碱基位点的N,N'-二甲基乙二胺的评估。凝胶示出了在37℃下用hAAG和100mM N,N'-二甲基乙二胺裂解寡核苷酸。泳道1.起始寡核苷酸。作为含有两条全长链的正对照的泳道2示出了100%经裂解的DNA。包括利用辅助链的裂解反应的泳道3示出了经裂解的与未经裂解的DNA的比率为90%:10%的较高百分比产率。
e)对用hAAG/Endo VIII、hAAG/化学碱和hAAG/替代性化学碱裂解寡核苷酸的总结。
f)用于研究裂解步骤的寡核苷酸。
图18.利用辅助链的版本1化学法——连接。
a)该方案示出了在存在辅助链的情况下连接杂交的多核苷酸链。以虚线框突出显示连接步骤。
b)凝胶示出了在存在辅助链的情况下在室温(24℃)下用Quick T4 DNA连接酶连接寡核苷酸。泳道1含有36聚体TAMRA单链寡核苷酸和18聚体TAMRA单链寡核苷酸的混合物。这些寡核苷酸用作参考带。在泳道2中,在20分钟后存在预期的带大小为36聚体的可观察到的连接产物。
c)凝胶示出了在存在辅助链的情况下培育过夜后,在室温(24℃)下用Quick T4DNA连接酶连接寡核苷酸。泳道1含有36聚体TAMRA单链寡核苷酸和18聚体TAMRA单链寡核苷酸的混合物。这些寡核苷酸用作参考带。在泳道2中,存在预期的带大小为36聚体的可观察到的完全连接的产物。
d)用于研究连接步骤的寡核苷酸。
图19.利用辅助链的版本2化学法——合并。
a)该方案以橙色虚线框突出示出了合并步骤
b)凝胶示出了在27℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:1分钟后合并,转化率为5%。泳道3:2分钟后合并,转化率为10%。泳道4:5分钟后合并,转化率为20%。泳道5:10分钟后合并,转化率为30%。泳道6:20分钟后合并,转化率为35%。
c)该图描绘了凝胶,其示出了在37℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:1分钟后合并,转化率为30%。泳道3:2分钟后合并,转化率为60%。泳道4:5分钟后合并,转化率为90%。泳道5:10分钟后合并,转化率为90%。泳道6:20分钟后合并,转化率为90%。
d)凝胶示出了在47℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:1分钟后合并,转化率为30%。泳道3:2分钟后合并,转化率为65%。泳道4:5分钟后合并,转化率为90%。泳道5:10分钟后合并,转化率为90%。泳道6:20分钟后合并,转化率为90%。
e)凝胶示出了在27℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:1分钟后合并,转化率为70%。泳道3:2分钟后合并,转化率为85%。泳道4:5分钟后合并,转化率为92%。泳道5:10分钟后合并,转化率为96%。泳道6:20分钟后合并,转化率为96%。
f)凝胶示出了在37℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:1分钟后合并,转化率为85%。泳道3:2分钟后合并,转化率为95%。泳道4:5分钟后合并,转化率为96%。泳道5:10分钟后合并,转化率为96%。泳道6:20分钟后合并,转化率为96%。
g)凝胶示出了在47℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:1分钟后合并,转化率为85%。泳道3:2分钟后合并,转化率为90%。泳道4:5分钟后合并,转化率为96%。泳道5:10分钟后合并,转化率为96%。泳道6:20分钟后合并,转化率为96%。
h)对在各种温度和存在Mn2+离子的情况下合并3’-O-叠氮甲基-dTTP的总结。
i)凝胶示出了在37℃下存在Mn2+的情况下通过终止子IX DNA聚合酶合并与互补碱基相对的3’-O-修饰的-dNTP的结果。泳道1:起始材料。泳道2:3’-O-叠氮甲基-dTTP合并5分钟。泳道3:3’-O-叠氮甲基-dATP合并5分钟。泳道4:3’-O-叠氮甲基-dCTP合并5分钟。泳道5:3’-O-叠氮甲基-dGTP合并5分钟。
j)用于研究合并步骤的寡核苷酸。
图20.利用辅助链的版本2化学法——裂解。
a)该方案示出了在存在辅助链的情况下裂解杂交的多核苷酸链。以橙色虚线框突出显示裂解步骤。
b)凝胶示出了在37℃下用Endo V裂解寡核苷酸。泳道1.起始寡核苷酸。作为含有两条全长链的正对照的泳道2示出了经裂解的与未经裂解的DNA的比率为80%:20%的产率。包括没有辅助链的裂解反应的泳道3示出了经裂解的DNA的>99%的高得多的产率。包括利用辅助链的裂解反应的泳道4也示出了>99%的DNA裂解产率。
c)对核酸内切酶V的裂解研究的总结。
d)用于研究裂解步骤的寡核苷酸。
图21.利用辅助链的版本2化学法——连接。
a)该方案示出了在不存在辅助链的情况下连接杂交的多核苷酸链。以橙色虚线框突出显示连接步骤。
b)用于研究连接步骤的寡核苷酸。
图22.利用辅助链的版本2化学法——脱保护。
a)该方案示出了以橙色虚线框突出显示的脱保护步骤。
b)该图描绘了凝胶,其示出了在合并3’-O-叠氮甲基-dTTP后通过50mM TCEP脱保护3’-O-叠氮甲基基团的结果。泳道1:起始引物
泳道2:在存在Mn2+的情况下合并3’-O-叠氮甲基-dTTP。泳道3:通过添加所有天然dNTP延伸泳道2中的产物。泳道4:通过50mM TCEP脱保护泳道2中的产物(0.5μM)。泳道5:通过添加所有天然dNTP延伸泳道4中的产物。
c)该图描绘了凝胶,其示出了在合并3’-O-叠氮甲基-dTTP后通过300mM TCEP脱保护3’-O-叠氮甲基基团的结果。泳道1:起始引物。泳道2:在存在Mn2+的情况下合并3-O-叠氮甲基-dTTP。泳道3:通过添加所有天然dNTP延伸泳道2中的产物。泳道4:通过300mM TCEP脱保护泳道2中的产物(0.5μM)。泳道5:通过添加所有天然dNTP延伸泳道4中的产物。
d)该图描绘了凝胶,其示出了在合并3’-O-叠氮甲基-dCTP后通过50mM TCEP脱保护3’-O-叠氮甲基基团的结果。泳道1:起始引物。泳道2:在存在Mn2+的情况下合并3-O-叠氮甲基-dCTP。泳道3:通过添加所有天然dNTP延伸泳道2中的产物。泳道4:通过300mM TCEP脱保护泳道2中的产物(0.5μM)。泳道5:通过添加所有天然dNTP延伸泳道4中的产物。
e)该图描绘了凝胶,其示出了在合并3’-O-叠氮甲基-dCTP后通过300mM TCEP脱保护3’-O-叠氮甲基基团的结果。泳道1:起始引物
泳道2:在存在Mn2+的情况下合并3-O-叠氮甲基-dCTP。泳道3:通过添加所有天然dNTP延伸泳道1中的产物。泳道4:通过300mM TCEP脱保护泳道1中的产物(0.5μM)。泳道5:通过添加所有天然dNTP延伸泳道3中的产物。
f)该图描绘了凝胶,其示出了在合并3’-O-叠氮甲基-dATP后通过300mM TCEP脱保护3’-O-叠氮甲基基团的结果。
泳道1:起始引物
泳道2:在存在Mn2+的情况下合并3-O-叠氮甲基-dATP。泳道3:通过添加所有天然dNTP延伸泳道2中的产物。泳道4:通过300mM TCEP脱保护泳道2中的产物(0.5μM)。泳道5:通过添加所有天然dNTP延伸泳道4中的产物。
g)该图描绘了凝胶,其示出了在合并3’-O-叠氮甲基-dGTP后通过300mM TCEP脱保护3’-O-叠氮甲基基团的结果。泳道1:起始引物。
泳道2:在存在Mn2+的情况下合并3-O-叠氮甲基-dGTP。泳道3:通过添加所有天然dNTP延伸泳道2中的产物。泳道4:通过300mM TCEP脱保护泳道2中的产物(0.5μM)。泳道5:通过添加所有天然dNTP延伸泳道4中的产物。
h)通过TCEP对0.2μM DNA脱保护的效率。
i)用于研究裂解步骤的寡核苷酸。
图23.利用双发夹模型的版本2化学法——合并。
a)该方案以虚线框突出示出了合并步骤。
b)对用于合并与其天然对应物相对的3’-O-修饰的-dTTP的DNA聚合酶的评估。该图描绘了凝胶,其示出了在37℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:合并天然dNTP混合物。泳道3:通过终止子IX DNA聚合酶合并3’-O-叠氮甲基-dTTP。泳道4:通过添加所有天然dNTP延伸泳道3中的产物。
c)对用于合并与其天然对应物相对的3’-O-修饰的-dTTP的DNA聚合酶的评估。适用于研究合并步骤的寡核苷酸。
图24.利用双发夹模型的版本2化学法——裂解。
a)该方案示出了发夹寡核苷酸的裂解。裂解步骤以虚线框突出显示。
b)凝胶示出了在37℃下用Endo V裂解发夹寡核苷酸。泳道1.起始发夹寡核苷酸。作为在5分钟后的经裂解的发夹寡核苷酸的泳道2示出了消化的DNA具有约98%的比率的高产率。作为在10分钟后的经裂解的发夹寡核苷酸的泳道3示出了消化的DNA具有约99%的比率的高产率。作为在30分钟后的经裂解的发夹寡核苷酸的泳道4示出了消化的DNA具有约99%的比率的高产率,并且在作为在1hr后的经裂解的发夹寡核苷酸的泳道5中示出了消化的DNA具有约99%的比率的高产率。
c)用于研究裂解步骤的寡核苷酸。
图25.利用双发夹模型的版本2化学法——连接。
a)该方案示出了杂交发夹的连接。以虚线框突出显示连接步骤。
b)凝胶示出了在存在辅助链的情况下在室温(24℃)下用Blunt/TA DNA连接酶连接发夹寡核苷酸。泳道1含有起始发夹寡核苷酸。1分钟后连接的发夹寡核苷酸的泳道2显示出连接DNA产物的比率为约85%的高产率。2分钟后连接的发夹寡核苷酸的泳道3显示出消化DNA的比率为约85%的高产率。3分钟后连接的发夹寡核苷酸的泳道4显示出连接DNA产物的比率为约85%的高产率。4分钟后连接的发夹寡核苷酸的泳道5显示出连接DNA产物的比率为约>85%的高产率。
c)用于研究连接步骤的发夹寡核苷酸。
图26.版本2化学法——双发夹模型的完整循环。
a)该方案示出了涉及酶合并、裂解、连接和脱保护步骤的完整循环。
b)对用于合并与其天然对应物相对的3’-O-修饰的-dTTP的DNA聚合酶的评估。该图描绘了凝胶,其示出了在37℃下通过终止子IX DNA聚合酶合并3'-O-修饰的-dTTP的结果。泳道1:起始材料。泳道2:通过终止子IX DNA聚合酶合并3’-O-叠氮甲基-dTTP。泳道3:通过添加所有天然dNTP延伸泳道2中的产物。泳道4:通过核酸内切酶V裂解泳道2中的产物。泳道5:通过钝性TA连接酶试剂盒连接泳道4中的产物。
c)适用于研究合并步骤的寡核苷酸。
图27.版本2化学法——使用辅助链的单发夹模型的完整循环。
a)该方案示出了涉及酶合并、裂解、连接和脱保护步骤的完整循环。
b)适用于研究合并步骤的寡核苷酸。
图28.版本3化学法——双发夹模型的完整循环。
a)该方案示出了涉及酶合并、裂解、连接和脱保护步骤的完整循环。
b)适用于研究合并步骤的寡核苷酸。
图29.版本2化学法——双发夹模型的完整双循环。
a)该方案示出了涉及酶合并、脱保护、裂解和连接步骤的第一完整循环。
b)该方案示出了在第一完整循环后的第二完整循环,涉及酶合并、脱保护、裂解和连接步骤。
c)该图描绘了凝胶,其示出了完整双循环实验,包括:合并、脱保护、裂解和连接步骤。
泳道1.起始材料。
泳道2.用天然dNTP延伸起始材料。
泳道3.通过终止子IX DNA聚合酶合并3’-O-叠氮甲基-dTTP。
泳道4.通过添加所有天然dNTP延伸泳道3中的产物。
泳道5.通过TCEP脱保护泳道3中的产物。
泳道6.通过添加所有天然dNTP延伸泳道5中的产物。
泳道7.通过核酸内切酶V裂解泳道5中的产物。
泳道8.通过钝性TA连接酶试剂盒连接泳道7中的产物。
泳道9.通过λ核酸外切酶裂解泳道8中的产物。
泳道10.用于第二循环的起始材料——与泳道9中的材料相同。
泳道11.通过终止子IX DNA聚合酶合并3’-O-叠氮甲基-dTTP。
泳道12.通过添加所有天然dNTP延伸泳道11中的产物。
泳道13.通过TCEP脱保护泳道11中的产物。
泳道14.通过添加所有天然dNTP延伸泳道13中的产物。
泳道15.通过核酸内切酶V裂解泳道13中的产物。
泳道16.通过钝性TA连接酶试剂盒连接泳道15中的产物。
d)用于研究的寡核苷酸。
图30.
该实例示出了从根据本文所述方法合成的预定序列的多核苷酸的支架多核苷酸释放的机制。
图31.
用于根据本发明合成RNA的示例性方法的示意图。该示例性方法示出了在不存在辅助链的情况下的合成。
图32.
用于根据本发明合成RNA的示例性方法的示意图。该示例性方法示出了在存在辅助链的情况下的合成。
图33.
用于根据本发明合成RNA的示例性方法的示意图。该示例性方法示出了在存在辅助链的情况下的合成。
图34.
根据利用单发夹模型的合成方法版本2合成DNA的示例性方法的第1完整循环的示意图,其涉及在合并步骤之前使辅助链变性的步骤。
图35.
根据利用单发夹模型的合成方法版本2合成DNA的示例性方法的第2完整循环的示意图,其涉及在合并步骤之前使辅助链变性的步骤。
图36.
根据利用单发夹模型的合成方法版本2合成DNA的示例性方法的第3完整循环的示意图,其涉及在合并步骤之前使辅助链变性的步骤。
图37.
实例9中详述的实验中使用的寡核苷酸。
图38.
凝胶示出了与实例9中详述的完整三循环实验相对应的反应产物。
该图描绘了凝胶,其示出了完整的三循环实验的结果,包括:合并、解封闭、裂解和连接步骤。
泳道1:起始材料。
泳道2.用天然dNTP延伸起始材料
泳道3:通过终止子X DNA聚合酶合并3’-O-叠氮甲基-dTTP。
泳道4:通过添加所有天然dNTP延伸泳道3中的产物。
泳道5:通过TCEP解封闭泳道3中的产物
泳道6:通过添加所有天然dNTP延伸泳道5中的产物。
泳道7:通过核酸内切酶V裂解泳道5中的产物。
泳道8:通过T3 DNA连接酶连接泳道7中的产物
泳道9:用于第2循环的起始材料——与泳道9中的材料相同
泳道10:通过添加所有天然dNTP延伸泳道9中的产物。
泳道11:通过终止子X DNA聚合酶合并3’-O-叠氮甲基-dTTP。
泳道12:通过添加所有天然dNTP延伸泳道11中的产物。
泳道13:通过TCEP解封闭泳道11中的产物
泳道14:通过添加所有天然dNTP延伸泳道13中的产物。
泳道15:通过核酸内切酶V裂解泳道13中的产物
泳道16:通过T3 DNA连接酶连接泳道15中的产物
泳道17:用于第3循环的起始材料——与泳道16中的材料相同
泳道18:通过添加所有天然dNTP延伸泳道17中的产物。
泳道19:通过终止子X DNA聚合酶合并3’-O-叠氮甲基-dTTP。
泳道20:通过添加所有天然dNTP延伸泳道19中的产物。
泳道21:通过TCEP解封闭泳道19中的产物
泳道22:通过添加所有天然dNTP延伸泳道21中的产物。
泳道23:通过核酸内切酶V裂解泳道21中的产物
泳道24:通过T3 DNA连接酶连接泳道23中的产物
图39.
来自以暴露于FITC-PEG-SH和FITC-PEG-COOH的不同量的BRAPA突起的聚丙烯酰胺凝胶表面的荧光信号。
图40.
来自以暴露于FITC-PEG-SH和FITC-PEG-COOH的不同量的BRAPA突起的聚丙烯酰胺凝胶表面上的荧光素通道的测量的荧光信号。
图41.
(a)示出了没有接头固定在不同样品上的发夹DNA的序列。
(b)示出了接头固定在不同样品上的发夹DNA的序列。
图42.
在存在和不存在固定在溴乙酰基官能化的聚丙烯酰胺表面上的接头的情况下来自发夹DNA寡聚体的荧光信号。
图43.
在存在和不存在固定在溴乙酰基官能化的聚丙烯酰胺表面上的接头的情况下来自发夹DNA寡聚体的测量的荧光。
图44.
在合并三磷酸盐后,在存在和不存在固定在溴乙酰基官能化的聚丙烯酰胺表面上的接头的情况下来自发夹DNA寡聚体的荧光信号。
图45.
在合并三磷酸盐之后,在存在和不存在固定在溴乙酰基官能化的聚丙烯酰胺表面上的接头的情况下来自发夹DNA寡聚体的测量的荧光。
图46.
(a)如实例12中详述的每个反应步骤的实验概述和结果。
(b)实例12中详述的实验中使用的寡核苷酸。
图47.
示出了在裂解反应之前和之后来自发夹DNA寡聚体的荧光信号(实例12)。
图48.
示出了在裂解反应之前和之后来自发夹DNA寡聚体的测量的荧光信号(实例12)。
图49.
示出了含肌苷的链和用于连接反应的互补“辅助”链的序列(实例12)。
图50.
与来自对应于连接反应监测的发夹DNA寡聚物的荧光信号有关的结果(实例12)。
图51.
与来自对应于连接反应监测的发夹DNA寡聚物的测量的荧光相关的结果(实例12)。
图52.
与使用根据本发明方法的合并步骤通过终止子X DNA聚合酶合并3'-O-修饰的-dNTP有关的结果,例如本发明1和2的合成方法版本及其变体(图1至图6和实例13)。
图52a提供了引物链的核酸序列(合成链的引物链部分;SEQ ID NO:68)和模板链(支持链;SEQ ID NO:69)。
图52b描绘了示出在37℃下在存在Mn2+离子的情况下通过终止子X DNA聚合酶合并3’-O-修饰的-dNTP的结果的凝胶。
泳道1:起始寡核苷酸。
泳道2:合并3'-O-叠氮甲基-dTTP(效率>99%)
泳道3:合并3'-O-叠氮甲基-dATP(效率>99%)。
泳道4:合并3'-O-叠氮甲基-dCTP(效率>90%)。
泳道5:合并3'-O-叠氮甲基-dGTP(效率>99%)。
添加后,新添加的3'-O-修饰的-dNTP在引物链部分中占据位置n。引物链部分中的下一核苷酸位置被表示为n-1。
图53.
该图示出了描述实例14中所述的DNA合成反应循环的方案。
图54.
该图示出了描述实例14中所述的DNA合成反应循环的方案。
图55.
该图示出了在实例14中描述的实验中使用的寡核苷酸。
图56.
该图示出了凝胶的照片,其证明了包括2-脱氧肌苷(用作通用核苷酸)的多核苷酸连接分子与实例14中所述的发夹支架多核苷酸的连接结果。凝胶的泳道如下:
泳道1:起始发夹支架多核苷酸。
泳道2:连接至多核苷酸连接分子的发夹支架多核苷酸(1碱基T突出端)。
泳道3:连接至多核苷酸连接分子的发夹支架多核苷酸(1碱基C突出端)。
泳道4:起始发夹支架多核苷酸。
泳道5:连接至多核苷酸连接分子的发夹支架多核苷酸(2碱基突出端)。
泳道6:连接至多核苷酸连接分子的发夹支架多核苷酸(3碱基突出端)。
泳道7:连接至多核苷酸连接分子的发夹支架多核苷酸(4碱基突出端)。
附图的解释。
图12、13a、14a、15a、16a、17a、18a、19a、20a、21a、22a、23a、24a、25a、26a、27a、28a、29a、29b、30、31、32、33、34、35和36中所描绘的结构将与图7、8、9、10和11中所描绘的那些一致地解释。因此,在这些图中,双链支架多核苷酸分子的每条左手链均与支持链相关(对应于图7至11中的链“a”);双链支架多核苷酸分子的每条右手链均与合成链相关(对应于图7至11中的链“b”);所有支架多核苷酸分子包含较低的合成链,其对应于包含引物链部分的链(对应于图7至图11的链“b”的实线和虚线);在合并新核苷酸之前,显示出了某些支架多核苷酸分子(例如图16a和24a),其具有上部合成链,该上部合成链对应于包含辅助链部分的链(对应于图7至11中的链中“b”的虚线);某些支架多核苷酸分子(例如在图13a、14a和15a中)显示为没有辅助链部分(对应于在图7至11中不存在虚线“b”的虚线);在连接步骤之后,示出了某些支架多核苷酸分子(例如,图34、35和36),其上部合成链对应于包含辅助链部分的链(对应于图7至11中的链“b”的虚线),并且其中在下一合成循环中合并新核苷酸之前移除辅助链部分。
此外,在这些图中,在适当的位置,每个新核苷酸均显示为与可逆终止子基团结合在一起,标记为rtNTP,并描绘为小圆形结构(对应于图7至11中的小三角形结构),并且末端磷酸酯基团标记为“p”且描绘为小的椭圆形结构。
图12c、12d、12g、12h、23a、24a、25a、26a、28a、29a、29b和30显示了支架多核苷酸分子,其中包含辅助链部分和支持链的链通过发夹环连接。图12b、23a、24a、25a、26a、27a、28a、29a、29b、30、34、35和36显示了支架多核苷酸分子,其中包含引物链部分和支持链的链通过发夹环连接。
例如图28a和29a的图显示了支架多核苷酸分子,其中包含辅助链部分(右上链)和支持链(左上链)的链通过发夹环连接,并且在同一分子中,包含引物链部分(右下链)和支持链(左下链)的链通过发夹环连接。
具体实施方式
本发明提供了根据预定的核苷酸序列从头合成多核苷酸分子的方法。合成的多核苷酸优选为DNA,并且优选为双链多核苷酸分子。与现有的合成方法相比,本发明提供了优点。例如,所有反应步骤可以在温和pH的含水条件下进行,不需要广泛的保护和脱保护程序。此外,合成不依赖于复制包括预定的核苷酸序列的预先存在的模板链。
本发明人已经确定,如本文所定义的通用核苷酸的使用允许在合成区域内创建多核苷酸裂解位点,其促进合成的裂解和重复循环。本发明提供了用于合成多核苷酸和用于组装包括此类合成多核苷酸的大片段的通用方法。
通过参考包括本发明的两个示例性方法版本及其某些变体(图1至图6)的示例性方法,本文将更一般性地描述本发明的合成方法的某些实施方案。应当理解,包括本发明的示例性方法版本及其变型在内的所有示例性方法均不旨在限制本发明。本发明提供了合成具有预定序列的双链多核苷酸分子的体外方法,该方法包括执行合成循环,其中在每个循环中,通过合并预定序列的第一核苷酸来延伸第一多核苷酸链,并且然后通过合并预定序列的第二核苷酸来延伸与第一链杂交的第二多核苷酸链。优选地,所述方法用于合成DNA。提供本文描述的具体方法作为本发明的实施方案。
反应条件
在一个方面,本发明提供了合成具有预定序列的双链多核苷酸的方法。
在一些实施方案中,合成在适合于双链多核苷酸内的核苷酸杂交的条件下进行。通常在允许核苷酸与互补核苷酸杂交的条件下使多核苷酸与试剂接触。允许杂交的条件是本领域公知的(例如,Sambrook等人,2001,Molecular Cloning:a laboratory manual,3rdedition,Cold Spring Harbour Laboratory Press;和Current Protocols in MolecularBiology,Greene Publishing and Wiley-lnterscience,New York(1995))。
可以在合适的条件下将核苷酸合并到多核苷酸中,例如使用聚合酶(例如,终止子IX聚合酶)或末端脱氧核苷酸转移酶(TdT)或其功能变体,以在存在适当的缓冲溶液的情况下在适当的温度下(例如,约65℃)合并修饰的核苷酸(例如,3’-O-修饰-dNTP)。在一个实施方案中,缓冲溶液可以包括2mM Tris-HCL、1mM(NH4)2SO4、1mM KCl、0.2mM MgSO4和0.01% X-100。
X-100。
多核苷酸的裂解可以在合适的条件下进行,例如在存在合适的缓冲溶液的情况下,在与酶相容的温度(例如37℃)下使用多核苷酸裂解酶(例如核酸内切酶)。在一个实施方案中,缓冲溶液可以包括5mM乙酸钾、2mM Tris-乙酸盐、1mM乙酸镁和0.1mM DTT。
多核苷酸的连接可以在合适的条件下进行,例如在存在合适的缓冲溶液的情况下,在与酶相容的温度(例如室温)下使用连接酶(例如T4 DNA连接酶)。在一个实施方案中,缓冲溶液可以包括4.4mM Tris-HCl、7mM MgCl2、0.7mM二硫苏糖醇、0.7mM ATP、5%聚乙二醇(PEG6000)。
脱保护可以在合适的条件下进行,例如使用还原剂(例如TCEP)。例如,可以使用Tris缓冲液中的TCEP(例如终浓度为300mM)进行脱保护。
锚多核苷酸和支架多核苷酸
具有预定序列的双链多核苷酸通过本发明的方法通过将预定的核苷酸合并到预先存在的多核苷酸中来合成,所述多核苷酸在本文中称为支架多核苷酸,其可附接于或能够附接于表面,如本文所述。如本文更详细描述的,支架多核苷酸形成支持结构以容纳新合成的多核苷酸,并且如从本文的描述中显而易见的,其不包括如常规合成方法中那样复制的预先存在的模板链。如果支架多核苷酸附接于表面,则支架多核苷酸可称为锚多核苷酸。本文更详细地描述了用于将支架多核苷酸附接到表面以形成锚多核苷酸的表面附接化学。
在一个实施方案中,支架多核苷酸包括与互补支持链杂交的合成链。合成链包括引物链部分(例如参见图1至图6)。可以提供与互补支持链杂交的合成链。或者,可以分开提供支持链和合成链,然后使其杂交。
可以提供支架多核苷酸,其中每个支持和合成链在相邻末端不连接。支架多核苷酸可以在支架多核苷酸的两端提供有支持和合成链,它们在相邻末端连接,例如通过发夹环。支架多核苷酸可以在支架多核苷酸或任何其它合适的接头的一端提供有支持和合成链,它们在相邻末端连接,例如通过发夹环。
如本文更详细描述的,可以将具有或不具有发夹的支架多核苷酸固定在固体支持物或表面上(参见图12)。
术语“发夹”或“发夹环”通常用于当前技术领域。术语“发夹环”通常也称为“茎环”。这些术语是指多核苷酸中的二级结构区域,其包括未配对核碱基的环,当多核苷酸分子的一条链由于分子内碱基配对而与相同链的另一部分杂交时形成。因此发夹可以类似于U形结构。这种结构的实例如图12所示。
在本文所述的某些方法中,通过连接酶的作用将预定序列的第一核苷酸合并到支架多核苷酸中,从而开始新的合成。因此,如本文进一步所述,预定序列的第一核苷酸与支架多核苷酸的支持链的末端核苷酸连接。预定义序列的第一核苷酸由多核苷酸连接分子提供,该多核苷酸连接分子包括支持链、辅助链和互补连接端。提供预定序列的第一核苷酸作为互补连接端的支持链的末端核苷酸。
辅助链在互补连接端的末端核苷酸是不可连接的核苷酸,并且通常提供为缺少磷酸基团。这防止了辅助链的末端核苷酸与支架多核苷酸的引物链部分的末端核苷酸连接,并且在连接后在辅助链和引物链部分之间产生了单链断裂位点。单链断裂的产生和维持可以通过其他方式实现。例如,辅助链部分的末端核苷酸可以具有合适的封闭基团,其阻止与引物链部分的连接。
在本文所述的某些方法中,通过聚合酶或转移酶的作用将预定序列的第二核苷酸合并到支架多核苷酸中。因此,聚合酶或转移酶将起作用以延伸引物链部分的末端核苷酸。
本文进一步提供了示例性方法的一般方法方案的更多细节。
核苷酸和通用核苷酸
可以通过本文描述的任何方法合并合成多核苷酸中的核苷酸可以是核苷酸、核苷酸类似物和修饰的核苷酸。
核苷酸可以包括天然核碱基或非天然核碱基。核苷酸可以含有天然核碱基、糖和磷酸基团。天然核碱基包括腺苷(A)、胸腺嘧啶(T)、尿嘧啶(U)、鸟嘌呤(G)和胞嘧啶(C)。可进一步修饰核苷酸的一种组分。
核苷酸类似物是在碱基、糖或磷酸盐或其组合中在结构上被修饰并且仍然是聚合酶可接受作为合并寡核苷酸链的底物的核苷酸。
非天然核碱基可以在一定程度上将键合,例如氢键合到目标多核苷酸中的所有核碱基的核碱基。非天然核碱基优选地是在一定程度上将键合,例如氢键合到包括核苷腺苷(A)、胸腺嘧啶(T)、尿嘧啶(U)、鸟嘌呤(G)和胞嘧啶(C)的核苷酸的核碱基。
非天然核苷酸可以是肽核酸(PNA)、锁核酸(LNA)和解锁核酸(UNA)、桥接核酸(BNA)或吗啉代、硫代磷酸酯或甲基膦酸酯。
非天然核苷酸可以包括经修饰的糖和/或经修饰的核碱基。经过修饰的糖包括但不限于2'-O-甲基核糖。经过修饰的核碱基包括但不限于甲基化的核碱基。核碱基的甲基化是表观遗传修饰的公认形式,其具有改变基因和其它元件(如微RNA)的表达的能力。核碱基的甲基化发生在离散的基因座处,所述基因座主要是由CpG基序组成的二核苷酸,但也可以在CHH基序(其中H是A、C或T)处发生。通常,在甲基化过程中,将甲基加到胞嘧啶碱基的第五个碳上以产生甲基胞嘧啶。因此,修饰的核碱基包括但不限于5-甲基胞嘧啶。
预定序列的核苷酸可以与配偶体核苷酸相对合并以形成核苷酸对。配偶体核苷酸可以是互补核苷酸。互补核苷酸是能够在一定程度上键合,例如氢键合到预定序列的核苷酸的核苷酸。
通常,将预定序列的核苷酸合并到与天然互补的配偶体核碱基相对的多核苷酸中。因此,可以合并腺苷与胸腺嘧啶相对,反之亦然。可以合并鸟嘌呤与胞嘧啶相对,反之亦然。可替代地,可以合并预定序列的核苷酸,与其在一定程度上将键合例如氢键合的配偶体核碱基相对。
可替代地,配偶体核苷酸可以是非互补核苷酸。非互补核苷酸是这样的核苷酸,其不能够键合,例如氢键合到预定序列的核苷酸。因此,预定序列的核苷酸可以与配偶体核苷酸相对合并以形成错配,条件是合成的多核苷酸总体上是双链的,并且其中第一链通过杂交与第二链附接。
术语“相对”应理解为涉及所述术语在核酸生物化学领域中的正常使用,并且具体地涉及常规的Watson-Crick碱基配对。因此,序列5'-ACGA-3'的第一核酸分子可与序列5'-TCGT-3'的第二核酸分子形成双链体,其中第一分子的G将位于与第二分子的C相对并与之形成氢键。序列5'-ATGA-3'的第一核酸分子可以与序列5'-TCGT-3'的第二核酸分子形成双链体,其中第一分子的T与第二分子的G错配,但仍然位于与其相对,并将作为配偶体核苷酸。该原理适用于本文公开的任何核苷酸配偶体对关系,包括含有通用核苷酸的配偶体对。
在本文所述的所有方法中,支持链中的位置和合成链中的相对位置被指定为位置编号“n”。该位置是指支架多核苷酸的支持链中核苷酸的位置,该核苷酸在任何给定的合成循环中与合成链中被预定序列的第二或其他核苷酸占据或将被其占据的核苷酸位置相对(在该循环中或在随后循环的合并步骤中将其添加到引物链部分的末端时)。位置“n”还指在连接步骤之前多核苷酸连接分子在支持链中的位置,该位置是与多核苷酸连接分子支架多核苷酸连接以及通过聚合酶或转移酶的作用合并预定序列的第二或其他核苷酸后将与预定序列的第二或其他核苷酸相对的核苷酸位置。
支持链中的位置和合成链中的相对位置都可以称为位置n。
参考图1至图6及其相对于本发明的示例性合成方法版本及其在此更详细描述的变型的描述,提供了关于位置“n”的定义的更多细节。
核苷酸和核苷酸类似物可以优选作为核苷三磷酸提供。因此,在本发明的任何方法中,为了合成DNA多核苷酸,可以从2′-脱氧核糖核苷-5′-O-三磷酸酯(dNTP)中合并核苷酸,例如通过DNA聚合酶的作用或通过具有脱氧核苷酸末端转移酶活性的酶的作用。在本发明的任何方法中,为了合成RNA多核苷酸,可以将核苷酸合并核糖核苷5′-O-三磷酸酯(NTP),例如通过RNA聚合酶的作用或例如通过具有核苷酸末端转移酶活性的酶的作用。三磷酸可以被四磷酸或五磷酸(一般低聚磷酸)取代。这些低聚磷酸可以被其它烷基或酰基取代:

本发明的方法可以使用通用核苷酸。通用核苷酸可以用作支架分子的支持链的组分,以促进新合并的核苷酸在合成的每一个循环期间正确地与其期望的配偶体核苷酸配对。如果需要,通用核苷酸也可以作为预定核苷酸序列的组分合并到合成链中。
通用核苷酸是这样的核苷酸,其中,核碱基将在某种程度上与预定序列的任何核苷酸的核苷碱基键结,例如氢键结。通用核苷酸优选地是这样的核苷酸,其将在某种程度上与包含核苷腺苷(A)、胸腺嘧啶(T)、尿嘧啶(U)、鸟嘌呤(G)和胞嘧啶(C)的核苷酸键结,例如氢键结。与其它核苷酸相比,通用核苷酸可以更强地与一些核苷酸键结。例如,包括核苷2'-脱氧肌苷的通用核苷酸(I)将示出I-C>I-A>I-G约=I-T的优先配对顺序。
可能的通用核苷酸的实例是肌苷或硝基吲哚。通用核苷酸优选地包括以下核碱基中的一个:次黄嘌呤、4-硝基吲哚、5-硝基吲哚、6-硝基吲哚、3-硝基吡咯、硝基咪唑、4-硝基吡唑、4-硝基苯并咪唑、5-硝基吲唑、4-氨基苯并咪唑或苯基(C6-芳环)。通用核苷酸更优选地包括以下核苷之一:2'-脱氧肌苷、肌苷、7-脱氮-2'-脱氧肌苷、7-脱氮-肌苷、2-氮杂-脱氧肌苷、2-氮杂-肌苷、4-硝基吲哚2'-脱氧核糖核苷、4-硝基吲哚核糖核苷、5-硝基吲哚2'脱氧核糖核苷、5-硝基吲哚核糖核苷、6-硝基吲哚2'脱氧核糖核苷、6-硝基吲哚核糖核苷、3-硝基吡咯2'脱氧核糖核苷、3-硝基吡咯核糖核苷、次黄嘌呤的非环糖类似物、硝基咪唑2'脱氧核糖核苷、硝基咪唑核糖核苷、4-硝基吡唑2'脱氧核糖核苷、4-硝基吡唑核糖核苷、4-硝基苯并咪唑2'脱氧核糖核苷、4-硝基苯并咪唑核糖核苷、5-硝基吲唑2'脱氧核糖核苷、5-硝基吲唑核糖核苷、4-氨基苯并咪唑2'脱氧核糖核苷、4-氨基苯并咪唑核糖核苷、苯基C-核糖核苷或苯基C-2'-脱氧核糖基核苷。
通用碱基的一些实例如下所示:


还可以使用合并可裂解碱基的通用核苷酸,包括光可裂解碱基和酶可裂解碱基,所述碱基的一些实例如下所示。
光可裂解碱基:

可通过核酸内切酶III裂解的碱基类似物:

可通过甲酰胺基嘧啶DNA糖基化酶(Fpg)裂解的碱基类似物:

可通过8-氧代鸟嘌呤DNA糖基化酶(hOGG1)裂解的碱基类似物:

可通过hNeil1裂解的碱基类似物:

可通过胸腺嘧啶DNA糖基化酶(TDG)裂解的碱基类似物:

可通过人类烷基腺嘌呤DNA糖基化酶(hAAG)裂解的碱基类似物:

可通过尿嘧啶DNA糖基化酶裂解的碱基:

可通过人类单链选择性单功能的尿嘧啶-DNA糖基化酶(SMUG1)裂解的碱基:

可通过5-甲基胞嘧啶DNA糖基化酶(ROS1)裂解的碱基:

(参见S.S.David,S.D.Williams Chemical reviews 1998,98,1221-1262和M.I.Ponferrada-Marín,T.Roldán-Arjona,R.R.Ariza’Nucleic Acids Res 2009,37,4264-4274)。
在涉及支架多核苷酸的任何方法中,通用核苷酸最优选包括2'-脱氧肌苷。
可以使用本文描述的任何合成方法合并的表观遗传碱基的实例包括以下:

可以使用本文描述的任何合成方法合并的修饰碱基的实例包括以下:

可使用本文所述的任何合成方法合并的卤代碱基的实例包括以下:

其中R1=F、Cl、Br、I、烷基、芳基、荧光标记、氨基炔丙基、氨基烯丙基。
其可以使用本文描述的任何合成方法合并的可以用于例如附接/接头化学的氨基修饰的碱基的实例包括以下:

其中碱基=A、T、G或C,具有炔烃或烯烃接头。
其可以使用本文描述的任何合成方法合并的可以用于例如点击化学的修饰的碱基的实例包括以下:

可以使用本文描述的任何合成方法合并的生物素修饰的碱基的实例包括以下:

其中碱基=A、T、G或C,具有炔烃或烯烃接头。
可以使用本文所述的任何合成方法合并的带有荧光团和猝灭剂的碱基的实例包括以下:

核苷酸合并酶
可获得的酶能够通过添加核苷酸来延伸双链多核苷酸分子的单链多核苷酸部分和/或能够延伸平末端双链多核苷酸分子的一条链的酶。这包括具有不依赖模板的酶活性的酶,例如不依赖模板的聚合酶或不依赖模板的转移酶活性。
因此,在本文所述的任何方法中,所述酶用于将预定序列的第二核苷酸和/或预定序列的另一核苷酸添加至支架多核苷酸的合成链的引物链部分的末端,其具有独立于模板的酶活性,例如独立于模板的聚合酶或独立于模板的转移酶活性。
使用本文所述的方法,可以采用任何合适的酶来添加预定的核苷酸。因此,在本文中所定义和描述的所有方法中,参考聚合酶或转移酶的使用,聚合酶或转移酶可以用能够在本发明的方法的情形下与聚合酶或转移酶执行相同功能的另一种酶取代。
聚合酶可用于本文所描述的方法中。可以基于它们合并修饰的核苷酸的能力来选择聚合酶,特别是具有连接的可逆终止子基团的核苷酸,如本文所述。在本文所述的示例性方法中,作用于DNA的所有聚合酶不得具有3'至5'核酸外切酶活性。聚合酶可具有链置换活性。
因此,优选地,聚合酶是修饰的聚合酶,其与未修饰的聚合酶相比具有增强的合并包括可逆终止子基团的核苷酸的能力。聚合酶更优选地是来自嗜热球菌(Thermococcus)物种9°N,优选地物种9°N-7的天然DNA聚合酶的基因工程变体。修饰的聚合酶的实例是可从New England BioLabs获得的终止子IX DNA聚合酶和终止子X DNA聚合酶。该酶具有增强的合并3'-O-修饰的dNTP的能力。
可用于在本发明的任何方法中合并可逆终止子dNTP的其他聚合酶的实例是DeepVent(exo-)、Vent(Exo-)、9°N DNA聚合酶、终止子DNA聚合酶、终止子IX DNA聚合酶、终止子X DNA聚合酶、Klenow片段(Exo-)、Bst DNA聚合酶、Bsu DNA聚合酶、Sulfolobus DNA聚合酶I和Taq聚合酶。
可用于本发明任何方法中的可逆终止子NTP合并的其他聚合酶的实例是T3 RNA聚合酶、T7 RNA聚合酶、SP6 RNA聚合酶、pol lambda、pol micro或Φ29DNA聚合酶。
对于包括DNA的这种多核苷酸合成分子的延伸,可以使用DNA聚合酶。可以使用任何合适的DNA聚合酶。
DNA聚合酶可以是例如Bst DNA聚合酶全长、Bst DNA聚合酶大片段、Bsu DNA聚合酶大片段、大肠杆菌DNA聚合酶DNA Pol I大(Klenow)片段、M-MuLV逆转录酶、phi29 DNA聚合酶、硫化叶菌DNA聚合酶IV、Taq DNA聚合酶、T4 DNA聚合酶、T7 DNA聚合酶和具有逆转录酶活性的酶,例如M-MuLV逆转录酶。
DNA聚合酶可能缺乏3'到5'核酸外切酶活性。可以使用任何这种合适的聚合酶。这种DNA聚合酶可以是例如Bst DNA聚合酶全长、Bst DNA聚合酶大片段、Bsu DNA聚合酶大片段、DNA Pol I大(Klenow)片段(3’→5’exo-)、M-MuLV逆转录酶、硫化叶菌DNA聚合酶IV、TaqDNA聚合酶。
DNA聚合酶可具有链置换活性。可以使用任何这种合适的聚合酶。这种DNA聚合酶可以是例如Bst DNA聚合酶大片段、Bsu DNA聚合酶大片段、DNA Pol I大(Klenow)片段(3’→5’exo-)、M-MuLV逆转录酶、phi29 DNA聚合酶。
DNA聚合酶可能缺乏3'到5'核酸外切酶活性,并且可以具有链置换活性。可以使用任何这种合适的聚合酶。这种DNA聚合酶可以是例如Bst DNA聚合酶大片段、Bsu DNA聚合酶大片段、大肠杆菌DNA聚合酶DNA Pol I大(Klenow)片段、M-MuLV逆转录酶。
DNA聚合酶可能缺乏5'到3'核酸外切酶活性。可以使用任何这种合适的聚合酶。这种DNA聚合酶可以是例如,Bst DNA聚合酶大片段、Bsu DNA聚合酶大片段、DNA Pol I大(Klenow)片段、DNA Pol I大(Klenow)片段(3’→5’exo-)、M-MuLV逆转录酶、phi29 DNA聚合酶、硫化叶菌DNA聚合酶IV、T4 DNA聚合酶、T7 DNA聚合酶。
DNA聚合酶可能缺乏3'到5'和5'到3'核酸外切酶活性两者,并且可以具有链置换活性。可以使用任何这种合适的聚合酶。这种DNA聚合酶可以是例如Bst DNA聚合酶大片段、BsuDNA聚合酶大片段、DNA Pol I大(Klenow)片段(3’→5’exo-)、M-MuLV逆转录酶。
DNA聚合酶也可以是经过基因工程化的变体。例如,DNA聚合酶可以是来自嗜热球菌物种9°N,例如物种9°N-7的天然DNA聚合酶的基因工程变体。经过修饰的聚合酶的一个这种实例是可从新英格兰生物实验室(New England BioLabs)获得的终止子IX DNA聚合酶。其它经过工程化或变体DNA聚合酶包括Deep Vent(exo-)、Vent(Exo-)、9°N DNA聚合酶、终止子DNA聚合酶、Klenow片段(Exo-)、Bst DNA聚合酶、Bsu DNA聚合酶、硫化叶菌DNA聚合酶I和Taq聚合酶。
为了延伸这种包含RNA的多核苷酸合成分子,可以使用任何合适的酶。例如,可以使用RNA聚合酶。可以使用任何合适的RNA聚合酶。
RNA聚合酶可为T3 RNA聚合酶、T7 RNA聚合酶、SP6 RNA聚合酶、大肠杆菌RNA聚合酶全酶。
酶可以具有末端转移酶活性,例如酶可以是末端核苷酸转移酶或末端脱氧核苷酸转移酶,并且其中多核苷酸合成分子经延伸以形成包括DNA或RNA,优选DNA的多核苷酸分子。这些酶中的任何一种均可用于需要延伸多核苷酸合成分子的本发明方法中。
一种这样的酶是末端核苷酸转移酶,例如末端脱氧核苷酸转移酶(TdT)(参见例如Motea等人,2010;Minhaz Ud-Dean,Syst.Synth.Biol.,2008,2(3-4),67–73)。TdT能够催化来自核苷三磷酸底物(NTP或dNTP)的核苷酸分子(核苷单磷酸)向多核苷酸合成分子的加成。TdT能够催化天然和非天然核苷酸的加成。其还能够催化核苷酸类似物的加成(Motea等人,2010)。还可以使用Polλ和polμ酶(Ramadan K,等人,J.Mol.Biol.,2004,339(2),395-404),如可以使用Φ29 DNA聚合酶。
本领域已经广泛讨论了通过末端转移酶(例如,末端脱氧核苷酸转移酶;TdT)的作用在不存在模板的情况下延伸单链多核苷酸分子DNA和RNA两者以产生人工合成的单链多核苷酸分子的技术。这些技术在例如专利申请公开WO2016/034807、WO 2016/128731、WO2016/139477和WO2017/009663,以及US2014/0363852、US2016/0046973、US2016/0108382和US2016/0168611中公开。这些文献描述了通过TdT的作用产生人工合成的单链多核苷酸分子的单链多核苷酸合成分子的受控延伸。描述了使用这种酶通过天然和非天然/人工核苷酸的延伸,如通过经过修饰的核苷酸的延伸,例如合并封闭基团的核苷酸的延伸。这些文献中公开的任何末端转移酶和其任何酶片段、衍生物、类似物或功能等同物均可以应用于本发明的方法中,条件是末端转移酶功能被保存在所述酶中。
定向进化技术、常规筛选、合理或半合理工程化/诱变方法或任何其它合适的方法可以用于改变任何此类酶以提供和/或优化所需功能。可以使用能够不使用模板而延伸单链多核苷酸分子部分的任何其他酶,例如包含DNA或RNA的分子,或具有核苷酸的平末端分子的一条链。
因此,在本文定义的任何方法中,包括DNA的单链多核苷酸合成分子或包括DNA的平端双链多核苷酸可以通过酶延伸,所述酶具有模板独立性酶活性,如模板独立性聚合酶或转移酶活性。酶可以具有核苷酸转移酶活性,例如脱氧核苷酸转移酶,例如末端脱氧核苷酸转移酶(TdT)或其酶片段、衍生物、类似物或功能等效物。通过这种酶的作用延伸的多核苷酸合成分子包括DNA。
在本文定义的任何方法中,包含RNA的多核苷酸合成分子的单链部分或包含RNA的平末端双链多核苷酸可被具有核苷酸转移酶(例如包括TdT)或酶片段、其衍生物、类似物或功能等同物延伸。通过这种酶的作用延伸的多核苷酸合成分子可以包括RNA。对于包括RNA的单链多核苷酸合成分子或包括RNA的多核苷酸合成分子的单链部分的合成,可以使用任何合适的核苷酸转移酶。核苷酸转移酶,例如聚(U)聚合酶和聚(A)聚合酶(例如来自大肠杆菌)能够将核苷酸单磷酸单元不依赖模板地添加道多核苷酸合成分子。这些酶中的任何一种酶以及其任何酶片段、衍生物、类似物或功能等同物可以应用于本发明的方法中,条件是核苷酸转移酶功能被保存在所述酶中。定向进化技术、常规筛选、合理或半合理工程化/诱变方法或任何其它合适的方法可以用于改变任何此类酶以提供和/或优化所需功能。
可逆终止子基团
在本文定义和描述的本发明的任何合成方法中,优选将通过聚合酶或转移酶的作用合并到合成链中的核苷酸作为包括一个或多个可逆性封闭基团的核苷酸合并,所述核苷酸也被称为本文所述的可逆终止子基团。
这些基团的作用是阻止酶在给定的合成循环中进一步延伸作用,使得只有预定序列的核苷酸可以可控制地用于延伸合成链,因此防止了非特异性核苷酸合并。实现所述效果的任何功能可以用于本文限定和描述的任何方法中。与核苷酸连接的可逆封闭基团/可逆终止子基团和解封闭步骤是实现所述效果的优选方法。然而,这种效果可以通过适当的替代方式来实现。
任何合适的可逆性保护基团都可以连接到核苷酸上,以防止在给定的循环中将核苷酸合并到合成链中后酶进一步延伸,并限制每一步合并到合成链中的一个核苷酸。在本发明的任何方法中,可逆封闭基团优选是可逆终止子基团,其起到防止聚合酶进一步延伸的作用。以下提供可逆终止子的实例。
炔丙基可逆终止子:

烯丙基可逆终止子:

环辛烯可逆终止子:

氰乙基可逆终止子:

硝基苄基可逆终止子:

二硫化物可逆终止子:

叠氮甲基可逆终止子:

氨基烷氧基可逆终止子:

具有与碱基连接的庞大基团的核苷三磷酸可以作为3'-羟基上的可逆终止子基团的替代物并且可以阻止进一步合并。该基团可以通过TCEP或DTT脱保护,产生天然核苷酸。

为了根据本发明的任何方法合成DNA多核苷酸,优选的修饰核苷是3'-O-修饰的-2'-脱氧核糖核苷-5'-O-三磷酸。为了根据本发明的任何方法合成RNA多核苷酸,优选的修饰核苷是3'-O-修饰的-核糖核苷-5'-O-三磷酸。
优选的经修饰的dNTP是经修饰的dNTP,其是3'-O-烯丙基-dNTP和3'-O-叠氮甲基-dNTP。
3'-O-烯丙基-dNTP如下所示。

3'-O-叠氮甲基-dNTP如下所示。


本文描述和限定的本发明方法可以涉及脱保护或解封闭步骤。这样的步骤涉及通过任何合适的方法去除可逆封闭基团(例如可逆终止子基团),或以其它方式逆转阻断/终止子基团的功能以抑制酶/聚合酶的进一步延伸作用。
可以使用任何合适的试剂在脱保护步骤中移除可逆终止子基团。
优选的脱保护试剂是三(羧乙基)膦(TCEP)。TCEP可用于在合并后从3'-O-烯丙基-核苷酸(与Pd0结合)和3'-O-叠氮甲基-核苷酸移除可逆终止子基团。
以下提供了脱保护试剂的实例。
炔丙基可逆终止子:
用Pd催化剂—Na2PdCl4、PdCl2处理。
可以使用配体,例如:三苯基膦-3,3',3”-三磺酸三钠盐。
烯丙基可逆终止子:
用Pd催化剂—Na2PdCl4、PdCl2处理。
可以使用配体,例如:三苯基膦-3,3',3”-三磺酸三钠盐。
叠氮甲基可逆终止子:
通过硫醇(巯基乙醇或二硫苏糖醇)或三(2-羧乙基)膦—TCEP处理。
氰乙基可逆终止子:
通过氟化物—氟化铵、四丁基氯化铵(TBAF)处理。
硝基苄基可逆终止子:
暴露在UV光下
二硫化物可逆终止子:
通过硫醇(巯基乙醇或二硫苏糖醇)或三(2-羧乙基)膦—TCEP处理。
氨基烷氧基可逆终止子:
用亚硝酸盐(NO2 -、HNO2)pH=5.5处理
可以通过在合并步骤之后立即进行的步骤移除可逆的保护基团(例如,可逆的终止剂基团),条件是从合并步骤中移除不需要的试剂以防止在移除可逆的终止剂基团之后进一步合并。
多核苷酸连接分子
在需要存在支架多核苷酸和连接步骤的方法中,多核苷酸连接分子的构型和结构的选择也将取决于所采用的特定方法。多核苷酸连接分子通常包含如本文所述的支持链和如本文所述的辅助链。多核苷酸连接分子在分子的一端包括互补连接端。多核苷酸连接分子的互补连接端将被连接至支架多核苷酸的末端。
多核苷酸连接分子的互补连接端在辅助链中具有不可连接的末端核苷酸,通常是非磷酸化的末端核苷酸。这防止了合成链的辅助链部分与合成链的引物链部分的连接,因此在连接后在合成链中产生了单链断裂。可以使用用于防止合成链中连接的替代方法。例如,封闭部分可以与辅助链中的末端核苷酸连接。此外,可以在裂解之前从支架分子中移除辅助链,例如通过变性,如在本文中进一步描述的。多核苷酸连接分子的互补连接端在支持链中与辅助链中不可连接的末端核苷酸相邻地具有可连接的末端核苷酸。支持链的可连接的末端核苷酸是通过连接酶的作用而被合并到支架分子中的预定序列的第一核苷酸。多核苷酸连接分子的互补连接端在支持链中也具有通用核苷酸。相对于支持链的可连接的末端核苷酸,支持链中通用核苷酸的确切定位将取决于所采用的具体反应化学,这将从具体方法版本及其变体的描述中显而易见。
通过参考本文描述的示例性方法及其在附图中的描绘,可以容易地确定多核苷酸连接分子的适当结构。
连接
在涉及连接步骤的本发明方法中,可以使用任何合适的方法实现连接。优选地,连接步骤将通过连接酶进行。连接酶可以是对单碱基突出端底物具有增强的活性的经过修饰的连接酶。连接酶可以是T3 DNA连接酶或T4 DNA连接酶。连接酶可以是平末端TA连接酶。例如,可从新英格兰生物实验室(NEB)获得平末端TA连接酶。这是T4 DNA连接酶、连接增强子和优化的反应缓冲液的即用型预混合物溶液,其被专门调配以改善平末端和单碱基突出端底物两者的连接和转化。用于连接(连结)单链和双链多核苷酸的分子、酶、化学品和方法是本领域技术人员公知的。
支架多核苷酸的裂解
在需要存在支架多核苷酸和裂解步骤的方法中,进行裂解步骤的试剂的选择将取决于所采用的特定方法。裂解位点由支持链中通用核苷酸的特定位置定义。因此,所需裂解位点的构型和适当裂解试剂的选择将取决于所述方法中采用的特定化学方法,通过参考本文所述的示例性方法将很容易明白。
识别经修饰的碱基的DNA裂解酶的一些实例展示于下表中。

合成链
在本文描述的合成多核苷酸或寡核苷酸的方法中,包括但不限于图1至图6以及在本文中进一步描述的本发明的合成方法版本1和2及其变体,支架多核苷酸具有合成链。合成链包括引物链部分。在合成循环期间,通过延伸引物链部分,将预定序列的每个新的第二核苷酸合并合成链,将预定序列的第一核苷酸合并支持链。诸如聚合酶或具有末端转移酶活性的酶的酶可用于催化每个新的第二核苷酸的合并/添加。预定序列的每个新结合的第二核苷酸将充当引物链部分的末端核苷酸,用于在下一个结合步骤中引发结合。因此,在任何给定的合成循环中,合成链的引物链部分将包括足够的多核苷酸序列以允许通过适当的酶引发。在本文进一步描述的某些实施方案中,在给定的合成循环中,将预定序列的第二核苷酸合并到合成链中,然后将一个或多个其他核苷酸合并到合成链中。在这样的实施方案中,预定序列的第二核苷酸和其他核苷酸包括可逆终止子基团,并且该方法另外包括在合并下一个核苷酸之后和在合并下一个核苷酸之前从核苷酸中移除可逆终止子基团的步骤。
核苷酸的术语“合并”、“延伸”和“添加”在本文中具有相同的含义。
辅助链
可以在多核苷酸连接分子中提供辅助链,以在连接步骤中促进多核苷酸连接分子与支架多核苷酸的连接。辅助链还可在裂解步骤中促进裂解酶的结合。可以省略辅助链,条件是提供替代方式以确保在裂解步骤中裂解酶的结合并且如果需要的话确保在连接步骤中的连接。在本发明的优选方法中,多核苷酸连接分子具有辅助链。
对辅助链的长度、序列和结构的参数没有特殊要求,只要该辅助链适合于根据需要促进连接酶和裂解酶的结合即可。
辅助链可包括核苷酸、核苷酸类似物/衍生物和/或非核苷酸。
优选地,应所述避免辅助链的序列区域内与支持链的错配,应避免富含GC和AT的区域,此外应避免二级结构的区域,例如发夹或凸起。
辅助链的长度可以是10个碱基或更多。可选地,辅助链的长度可以是15个碱基或更多,优选30个碱基或更多。然而,辅助链的长度可以变化,条件是辅助链能够促进裂解和/或连接。
辅助链必须与支持链的相应区域杂交。不必将全部辅助链与支持链的相应区域杂交,只要该辅助链可以在连接步骤中促进连接酶的结合和/或在裂解步骤中促进裂解酶的结合即可。因此,可以容许辅助链和支持链的相应区域之间的错配。辅助链可以比支持链的相应区域长。支持链可以在远离引物链的方向上延伸超出与辅助链相对应的区域。辅助链可以例如通过发夹连接到支持链的相应区域。
辅助链可以与支持链杂交,使得缺口位点处的辅助链的末端核苷酸占据合成链中相对于缺口位点处的引物链部分的末端核苷酸的下一顺序核苷酸位置。因此,在所述构型中,辅助链和引物链之间没有核苷酸位置切口。然而,由于存在单链断裂或切口,辅助链和引物链将是物理上分离的。
与通用核苷酸配对的辅助链中的核苷酸可以是任何合适的核苷酸。优选地,应该避免可能扭曲分子螺旋结构的配对。优选地,胞嘧啶充当通用核苷酸的配偶体。在特别优选的实施方案中,通用核苷酸是肌苷或其类似物、变体或衍生物,并且辅助链中通用核苷酸的配偶体核苷酸是胞嘧啶。
移除辅助链
在本文描述的本发明的任何合成方法中,在合并预定序列的第二核苷酸的步骤之前,可以将多核苷酸连接分子提供的辅助链从支架多核苷酸中移除。
合成链的辅助链部分可通过任何合适的方式从支架多核苷酸中移除,包括但不限于:(i)将支架多核苷酸加热至约80℃至约95℃的温度并从支架多核苷酸中分离辅助链部分,(ii)用尿素溶液(例如8M尿素)处理支架多核苷酸,并从支架多核苷酸中分离辅助链部分,(iii)用甲酰胺或甲酰胺溶液(例如100%甲酰胺)处理支架多核苷酸,并从支架多核苷酸中分离出辅助链部分,或(iv)使支架多核苷酸与单链多核苷酸分子接触,该单链多核苷酸分子包含与辅助链部分的序列互补的核苷酸序列区域,从而竞争性地抑制辅助链部分与支架多核苷酸的杂交。
在将双链多核苷酸连接分子连接至裂解的支架多核苷酸的步骤之后且在裂解支架的多核苷酸的步骤之前,将辅助链部分从支架多核苷酸中去除的方法中,裂解步骤将包括在不存在辅助链提供的双链区的情况下裂解支持链。可以选择任何合适的酶来进行这样的裂解步骤,例如选自本文公开的任何合适的酶。
引物链
引物链部分应适合于允许酶(例如聚合酶或具有末端转移酶活性的酶)引发合成,即催化在引物链部分末端添加新核苷酸。
引物链可包含可用于引发新的多核苷酸合成的序列区域(例如,如在图1至图6中每个所描绘的结构中的虚线所示)。引物链可以由可作用于引发新多核苷酸合成的序列区域组成,因此引物链的全部可以是可作用于引发如本文所述的新多核苷酸合成的序列。
对引物链的长度、序列和结构的参数没有特殊要求,条件是引物链适合引发新的多核苷酸合成。
引物链可以包括核苷酸、核苷酸类似物/衍生物和/或非核苷酸。
技术人员能够容易地构建能够引发新的多核苷酸合成的引物链。因此,在可以起到引发新的多核苷酸的作用的引物链的序列区域内,应所述避免与支持链的错配,应避免富含GC和AT的区域,以及此外应避免二级结构的区域,如发夹或凸起。
本领域技术人员可根据需要和所用的聚合酶选择可用于引发新的多核苷酸合成的引导链的序列区域的长度。所述区域的长度可以是7个碱基或更多、8个碱基或更多、9个碱基或更多个或10个碱基或更多。可选地,该区域的长度为15个碱基或更多,优选30个碱基或更多。
引物链必须与支持链的相应区域杂交。如果引物链能够引发新的多核苷酸合成,则整个引物链与支持链的相应区域杂交不是必需的。因此,引物链和支持链的相应区域之间的错配可以在一定程度上被容许。优选地,可用于引发新多核苷酸合成的引物链序列区域应包括与支持链中相应核碱基互补的核碱基。
引物链可以例如通过发夹连接到支持链的相应区域。
支持链
在包括但不限于如上所述的本发明1和2的合成方法版本及其变体的本发明的方法中,支架多核苷酸提供有支持链。支持链与合成链杂交。对支持链的长度、序列和结构的参数没有特殊要求,只要该支持链与本文所述的引物链部分以及所述合成链的辅助链部分(如果存在)相容即可,如上所述。
合成多核苷酸
具有根据本文所述方法合成的预定序列的多核苷酸是双链的。合成的多核苷酸总体上是双链的,并且其中第一链通过杂交与第二链连接。只要整个第一链通过杂交与第二链连接,可以容许错配和非杂交区域。
杂交可以通过中等严格或严格杂交条件来定义。中等严格的杂交条件是使用含有5x氯化钠/柠檬酸钠(SSC)、0.5%SDS、1.0mM EDTA(pH 8.0)、约50%甲酰胺的杂交缓冲液、6xSSC且杂交温度为55℃的预洗涤溶液(或其他类似的杂交溶液,例如含有约50%甲酰胺的溶液,杂交温度为42℃),并且洗涤条件为60℃,在0.5xSSC、0.1%SDS中进行。严格的杂交条件在45℃下于6xSSC中杂交,然后在68℃下于0.1xSSC、0.2%SDS中进行一次或多次洗涤。
具有根据本文所述方法合成的预定义序列的双链多核苷酸可以保持为双链多核苷酸。或者,可以分离双链多核苷酸的两条链以提供具有预定义序列的单链多核苷酸。允许双链多核苷酸的两条链分离的条件(熔融)是本领域公知的(例如,Sambrook等人,2001,Molecular Cloning:a laboratory manual,3rd edition,Cold Spring HarbourLaboratory Press;和Current Protocols in Molecular Biology,Greene Publishingand Wiley-lnterscience,New York(1995))。
具有根据本文所述方法合成的预定义序列的双链多核苷酸可以在合成后扩增。可以扩增双链多核苷酸的任何区域。双链多核苷酸的全部或任何区域可以与支架多核苷酸的全部或任何区域一起扩增。允许双链多核苷酸扩增的条件是本领域公知的(例如,Sambrook等人,2001,Molecular Cloning:a laboratory manual,3rd edition,Cold SpringHarbour Laboratory Press;和Current Protocols in Molecular Biology,GreenePublishing and Wiley-lnterscience,New York(1995))。因此,本文所述的任何合成方法可以进一步包括扩增步骤,其中如上所述扩增具有预定义序列的双链多核苷酸或其任何区域。可以通过任何合适的方法执行扩增,如聚合酶链反应(PCR)、聚合酶螺旋反应(PSR)、环介导的等温扩增(LAMP)、基于核酸序列的扩增(NASBA)、自主序列复制(3SR)、滚环扩增(RCA)、链置换扩增(SDA)、多重置换扩增(MDA)、连接酶链反应(LCR)、解旋酶依赖性扩增(HDA)、网状分支扩增方法(RAM)等。优选地,通过聚合酶链反应(PCR)执行扩增。
具有根据本文所述方法合成的预定序列的双链或单链多核苷酸可以是任何长度。例如,多核苷酸的长度可以是至少10、至少50、至少100、至少150、至少200、至少250、至少300、至少350、至少400、至少450或至少500个核苷酸或核苷酸对。例如,长度上,多核苷酸可以是约10至约100个核苷酸或核苷酸对,约10至约200个核苷酸或核苷酸对,约10至约300个核苷酸或核苷酸对,约10至约400个核苷酸或核苷酸对和约10至约500个核苷酸或核苷酸对。多核苷酸可以是多达约1000个或更多个核苷酸或核苷酸对,长度多达约5000个或更多个核苷酸或核苷酸对或长度多达约100000个或更多个核苷酸或核苷酸对。
RNA合成
描述用于DNA合成的方法可以适用于RNA的合成。在一种修改方案中,可以修改针对本发明1和2的合成方法版本及其变体描述的合成步骤。因此,如上所述,在合成方法版本1和2及其变体的每一个中,支架多核苷酸的支持链是DNA链。支架多核苷酸的合成链的引物链部分是RNA链。如果存在的话,辅助链可以是RNA链。如果存在,辅助链可以是DNA链。
核苷酸可以从核糖核苷-5'-O-三磷酸(NTP)合并,其可以被修饰以包括可逆终止子基团,如上所述。优选使用3'-O-修饰的核糖核苷-5'-O-三磷酸。通过RNA聚合酶的作用合并修饰的核苷酸。
因此,关于本发明1-5的合成方法版本的描述可以作必要的变通而应用于RNA合成,但是如所描述的那样适用。
图32和33描述了RNA合成的反应方案,其分别是图7和8所示的实例的DNA合成方法版本1和2的修改。分别如图1至图6所示,本发明1和2的方法版本及其变型可以以相同的方式进行修改。
在任何合适的RNA合成方法中,支持链、引物链、辅助链、多核苷酸连接分子和通用核苷酸的上述描述均可以作必要的变通,但可按上述方法进行修改。如前所述的裂解步骤和裂解位置可以作必要的变通,因为包含通用核苷酸的支持链是DNA链。在优选的实施方案中,将SplintR DNA连接酶用于连接步骤。
固相合成
根据本发明的合成方法产生的合成多核苷酸可优选使用固相或可逆固相技术合成。各种这样的技术在本领域中是已知的并且可以使用。在开始合成预定义序列的新双链多核苷酸之前,可以将支架多核苷酸固定到表面上,例如平面,例如玻璃、基于凝胶的材料、或微粒例如珠子或官能化量子点的表面上。包括表面的材料本身可以与基底结合。例如,支架多核苷酸可以固定在基于凝胶的材料上,例如聚丙烯酰胺,并且其中基于凝胶的材料与支持基底如玻璃结合。
多核苷酸可以直接或间接地固定或束缚至表面。例如,它们可以通过化学键合直接附接在表面上。它们可以通过中间表面间接地束缚在表面上,例如微粒或珠子的表面,例如在SPRI中或在电润湿系统中,如下所述。然后可以启动并完成合成循环,同时固定合并新合成的多核苷酸的支架多核苷酸。
在此类方法中,可以在合并预定序列的第一核苷酸之前将双链支架多核苷酸固定到表面。因此,这种固定的双链支架多核苷酸可以充当锚,以在合成期间和之后将预定序列的双链多核苷酸连接到表面。
这种双链锚/支架多核苷酸的仅一条链可以在分子同一端固定在表面上。或者,双链锚/支架多核苷酸的两条链可各自在分子同一末端固定在表面上。可以提供双链锚定/支架多核苷酸,其中每条链在相邻末端连接,例如通过与新合成起始位点相反的末端的发夹环连接,并且连接的末端可以固定在表面上(例如,如图12所示)。
在涉及支架多核苷酸的方法中,如本文所述,支架多核苷酸可以在以预定序列合并第一核苷酸之前附接于表面。因此,如图12(a)和(c)所示,包含引物链部分和与之杂交的支持链部分的合成链都可以分别附接在表面上。包括引物链部分和与其杂交的支持链部分的合成链可以在相邻末端连接,例如通过发夹环,例如在新合成起始位点的相对末端,并且连接末端可以束缚至表面,如图12(b)和(d)所示。如图12(e)至(h)所示,包含引物链部分和与之杂交的支持链部分的合成链中的一条或另一条可以单独连接至表面。优选地,包括引物链部分和与其杂交的支持链部分的合成链附接于表面。
平表面上的固相合成
在开始合成预定义序列的新双链多核苷酸之前,合成锚/支架多核苷酸可通过本领域已知的方法合成,包含本文所述的那些,并束缚至表面。
可以通过常用于产生附接于平表面的核酸微阵列的方法将预形成的多核苷酸束缚至表面。例如,可以产生锚/支架多核苷酸,然后将其点样或印刷到平表面上。可以使用接触印刷技术将锚/支架多核苷酸沉积在表面上。例如,可将固体或空心尖端或针浸入包括预形成的支架多核苷酸的溶液中并与平表面接触。或者,可以将寡核苷酸吸附到微型印模上,然后通过物理接触转移到平表面。非接触印刷技术包括热印刷或压电印刷,其中包括预形成的支架多核苷酸的亚纳升尺寸微滴可以使用与喷墨和喷泡印刷中使用的方法类似的方法从印刷尖端喷出。
单链寡核苷酸可以直接在平表面上合成,例如使用用于产生微阵列的所谓“芯片上”方法。然后,此类单链寡核苷酸可以充当附接位点以固定预先形成的锚/支架多核苷酸。
用于产生单链寡核苷酸的芯片上技术包括光刻法,其涉及使用通过光刻掩模引导的UV光来选择性地激活受保护的核苷酸,从而允许随后合并新的受保护的核苷酸。UV介导的去除保护基和预定核苷酸偶联的循环允许原位产生具有所需序列的寡核苷酸。作为使用光刻掩模的替代方案,可以通过使用喷墨印刷技术顺序沉积核碱基并使用偶联、氧化和脱保护的循环来产生具有所需序列的寡核苷酸,从而在平表面上产生寡核苷酸(对于综述,参见Kosuri和Church,Nature Methods,2014,11,499-507)。
在本文所述的任何合成方法中,包含如下所述的涉及可逆固定的方法,表面可由任何合适的材料制成。通常,表面可包括硅、玻璃或聚合物材料。表面可包括凝胶表面,例如聚丙烯酰胺表面,例如约2%聚丙烯酰胺,可选地使用N-(5-溴乙酰基戊基)丙烯酰胺(BRAPA)衍生的聚丙烯酰胺表面,优选地聚丙烯酰胺表面与固体载体比如玻璃偶联。
可逆固定
具有预定序列的合成多核苷酸可以根据本发明使用促进可逆固定的结合表面和结构(例如微粒和珠子)来合成。固相可逆固定(SPRI)方法或改良方法是本领域已知的并且可以使用(例如参见DeAngelis M.M.等人(1995)Solid-Phase ReversibleImmobilization for the Isolation of PCR Products,Nucleic Acids Research,23(22):4742-4743)。
表面可以以微粒的形式提供,例如顺磁珠。顺磁珠可以在磁场的影响下聚集。例如,顺磁表面可以具有化学基团,例如羧基,其在适当的附接条件下将充当核酸的结合部分,如下面更详细描述的。可以在适当的洗脱条件下从这些表面洗脱核酸。微粒和珠子的表面可以提供UV敏感的聚碳酸酯。在合适的固定缓冲液存在下,核酸可以与活化表面结合。
可使微粒和珠粒在反应溶液中自由移动,然后可逆地固定,例如通过将珠粒保持在微孔或蚀刻到表面中的凹坑中。珠子可以定位为阵列的一部分,例如通过使用附接于珠子的独特核酸“条形码”或通过使用颜色编码。
因此,在开始合成预定序列的新双链多核苷酸之前,可以合成根据本发明的锚/支架多核苷酸,然后可逆地固定到这样的结合表面上。通过本发明方法合成的多核苷酸可以合成,同时可逆地固定在这样的结合表面上。
微流体技术和系统
表面可以是电介质上电润湿系统(EWOD)的一部分。EWOD系统提供电介质涂覆的表面,其有助于以微滴形式的非常小的液体体积的微流体操纵(例如参见Chou,W-L.等人(2015)Recent Advances in Applications of Droplet Microfluidics,Micromachines,6:1249-1271.)。通过电润湿技术可以可编程地在芯片上创建、移动、分区和组合液滴体积。因此,电润湿系统提供了在合成期间和之后可逆地固定多核苷酸的替代方式。
具有预定义序列的多核苷酸可以通过本文所述的方法在固相中合成,其中多核苷酸固定在EWOD表面上,并且通过电润湿技术促进每个循环中所需的步骤。例如,在涉及支架多核苷酸并需要合并、裂解、连接和脱保护步骤的方法中,每个步骤所需的试剂以及用于移除用过的和不需要的试剂的任何所需洗涤步骤,可以以通过电润湿技术在电场的影响下传输的微滴的形式提供。
可以用于本发明的合成方法中的其它微流体平台是可用的。例如,可以使用通常用于核酸操作的基于乳液的微滴技术。在这样的系统中,微滴在通过混合两种不混溶的流体(通常是水和油)产生的乳液中形成。可以在微流体网络中可编程地创建、移动、分割和组合乳液微滴。也可提供水凝胶系统。在本文所述的任何合成方法中,微滴可以在任何合适的相容系统中操作,例如上述EWOD系统和其他微流体系统,例如包括基于包括弹性体材料的组件的结构的微流体系统。
微滴可具有任何合适的尺寸,条件是它们与本文的合成方法相容。微滴尺寸将根据所采用的特定系统和系统的相关架构而变化。因此适当地可以调整尺寸。在本文所述的任何合成方法中,液滴直径可以在约150nm到约5mm的范围内。低于1μm的液滴直径可通过本领域已知的方法验证,例如通过涉及毛细管喷射方法的技术,例如 等人(NaturePhysics,2007,3,pp737–742)中所描述的中间或最终合成产物的测序。
等人(NaturePhysics,2007,3,pp737–742)中所描述的中间或最终合成产物的测序。
可以对合成或组装的中间产物或最终的多核苷酸合成产物进行测序,以进行质量控制检查,从而确定所需的一种或多种多核苷酸是否已正确合成或组装。可以从固相合成平台上移除感兴趣的一种或多种多核苷酸,并通过多种已知的商业上可获得的测序技术中的任一种进行测序,例如使用Oxford Nanopore Technologies Ltd.出售的MinION TM装置进行的纳米孔测序。在特定的实例中,测序可以在固相平台本身上进行,从而无需将多核苷酸转移至单独的合成装置。测序可以方便地在相同的电润湿设备上进行,例如用于合成的EWOD设备,由此合成设备包括一个或多个测量电极对。可以将包括目的多核苷酸的液滴与电极对的电极之一接触,该液滴形成液滴界面双层,其中第二液滴与电极对的第二电极接触,其中液滴双层界面在两亲性膜中包括纳米孔。例如,可以在酶的控制下使多核苷酸移位到纳米孔中,并且可以在多核苷酸通过纳米孔的过程中在电极对之间的电势差下测量通过纳米孔的离子电流。可以记录随时间变化的离子电流测量值,并用于确定多核苷酸序列。测序之前,可对多核苷酸进行一个或多个样品制备步骤,以使其最优化以进行测序,例如专利申请No.PCT/GB2015/050140。可以适当使用的酶,两亲性膜和纳米孔的实例公开于专利申请No.PCT/GB2013/052767和PCT/GB2014/052736。可以通过样品入口将用于制备多核苷酸、纳米孔、两亲性膜等的样品所需的试剂提供给EWOD设备。样品入口可以连接到试剂室。
表面附接化学法
尽管寡核苷酸通常是化学连接的,但它们也可以通过间接方式例如通过亲和相互作用附接于表面。例如,寡核苷酸可以用生物素官能化并结合到用抗生物素蛋白或链酶抗生物素蛋白包被的表面上。
为了将多核苷酸固定到表面(例如平表面)、微粒和珠子等,可以使用各种表面附接方法和化学品。表面可以被官能化或衍生化以促进附接。这种功能化是本领域中已知的。例如,表面可以用以下各者进行功能化:多组氨酸标签(六组氨酸标签、6xHis-标签、His6标签或 )、Ni-NTA、链酶亲和素、生物素、寡核苷酸、多核苷酸(如DNA、RNA、PNA、GNA、TNA或LNA)、羧基、季胺基、硫醇基、叠氮基、炔基、DIBO、脂质、FLAG-标签(FLAG八肽)、多核苷酸结合蛋白、肽、蛋白质、抗体或抗体片段。表面可以用与锚/支架多核苷酸特异性地结合的分子或基团进行功能化。
)、Ni-NTA、链酶亲和素、生物素、寡核苷酸、多核苷酸(如DNA、RNA、PNA、GNA、TNA或LNA)、羧基、季胺基、硫醇基、叠氮基、炔基、DIBO、脂质、FLAG-标签(FLAG八肽)、多核苷酸结合蛋白、肽、蛋白质、抗体或抗体片段。表面可以用与锚/支架多核苷酸特异性地结合的分子或基团进行功能化。
图12i和图12j示出了适合于将多核苷酸附接于表面的化学的一些实例。
在本文所述的任何方法中,包括含有引物链部分和与其杂交的支持链部分的合成链的支架多核苷酸可以通过一个或多个共价键连接到共同表面。一个或多个共价键可以在共同表面上的官能团和支架分子上的官能团之间形成。支架分子上的官能团可以是例如胺基、硫醇基、硫代磷酸酯基或硫代酰胺基。所述共同的表面上的官能团可以是溴乙酰基团,可选地,其中,所述溴乙酰基团设置在使用N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA)衍生的聚丙烯酰胺表面上。
在本发明的任何方法中,支架多核苷酸可以通过接头直接或间接附接于表面。可以使用任何合适的属性是生物相容且亲水的接头。
接头可以是直链接头或支链接头。
接头可包括烃链。烃链可包括2至约2000或更多个碳原子。烃链可包括亚烷基,例如C2至约2000或更多个亚烷基。烃链可具有通式-(CH2)n-,其中n为2至约2000或更高。烃链可以任选地被一个或多个酯基(即,–C(O)-O-)或一个或多个酰胺基(即,-C(O)-N(H)-)打断。
可以使用选自包括以下的组的任何接头:PEG、聚丙烯酰胺、聚(甲基丙烯酸2-羟乙酯)、聚-2-甲基-2-噁唑啉(PMOXA)、两性离子聚合物,例如聚(羧基甜菜碱甲基丙烯酸酯)(PCBMA)、聚[N-(3-磺丙基)-N-甲基丙烯酰氧基乙基-N,N二甲基铵甜菜碱](PSBMA)、糖聚合物和多肽。
接头可包括具有以下通式的聚乙二醇(PEG):
-(CH2-CH2-O)n-,其中n为1至约600或更大。
接头可包括具有通式为-[(CH2-CH2-O)n-PO2 --O]m-的低聚乙二醇磷酸酯单元,其中n是1到约600或更大,并且m可以是1-200或更大。
任何上述接头可以在接头的一端连接至如本文所述的支架分子,并且在接头的另一端连接至第一官能团,其中第一官能团可以提供与表面的共价连接。第一官能团可以是例如胺基、硫醇基、硫代磷酸酯基或硫代酰胺基,如本文进一步描述的。表面可以用另外的官能团官能化以提供与第一官能团的共价键。另外的官能团可以是例如本文进一步描述的2-溴乙酰氨基。可选地,在使用N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA)衍生的聚丙烯酰胺表面上提供溴乙酰基。表面上的进一步官能团可以是溴乙酰基,可选地其中溴乙酰基在使用N-(5-溴乙酰基戊基)丙烯酰胺(BRAPA)衍生的聚丙烯酰胺表面上提供,并且适当时第一官能团可以是例如胺基、巯基、硫代磷酸酯基或硫代酰胺基。多核苷酸附接的表面可包括凝胶。该表面包括聚丙烯酰胺表面,例如约2%的聚丙烯酰胺,优选聚丙烯酰胺表面与固体载体如玻璃偶联。
在本发明的任何方法中,支架多核苷酸可以可选地通过合并支架多核苷酸中的支化核苷酸连接至接头。任何合适的支化核苷酸可以与任何合适的相容性接头一起使用。
在开始本发明的合成循环之前,可以合成支架多核苷酸,其中一个或多个支化核苷酸被合并支架多核苷酸中。将一个或多个支化核苷酸合并支架多核苷酸中并因此可以连接接头的确切位置可以变化,并且可以根据需要选择。该位置可以例如在支持链和/或合成链的末端或例如在包括发夹环的实施方案中将支持链连接至合成链的环区域中。
在支架多核苷酸的合成期间,可以将一个或多个支化核苷酸合并支架多核苷酸中,其中封闭基团阻断支化部分的反应基团。然后可以在偶联至接头的分支部分之前移除(解封闭)封闭基团,或者如果接头包括多个单元,则将接头的第一单元(分子)移除。
在支架多核苷酸的合成期间,可以将一个或多个支化核苷酸合并支架多核苷酸中,该支架多核苷酸具有适合用于随后的“点击化学”反应的基团,以与连接体的分支部分偶联,或者如果接头包括多个单元,与第一个单元偶联。这种基团的一个实例是乙炔基。
一些非限制性示例性支化核苷酸如下所示。

接头可以可选地包括一个或多个间隔分子(单元),诸如例如SP9间隔基,其中第一间隔基单元被附接到分支核苷酸。
接头可包括连接至第一间隔基团的一个或多个其他间隔基团。例如,接头可包括多个例如Sp9间隔基团。将第一间隔基团连接到支化部分,然后依次加入一个或多个另外的间隔基团以延伸包括多个间隔单元的间隔基链,所述间隔单元与其间的磷酸酯基团连接。
下面显示的是间隔基单元(Sp3、Sp9和Sp13)的一些非限制性实例,其可以包括与分支核苷酸连接的第一间隔基单元,或者与已经与分支核苷酸连接的现有间隔基单元连接的另外的间隔基单元。

接头可包括一个或多个乙二醇单元。
接头可包括寡核苷酸,其中多个单元是核苷酸。
在上文描述的结构中,术语5”用于区分与支化部分连接的核苷酸的5'末端,其中5'具有本领域的普通含义。5”意指核苷酸上可以延伸接头的位置。5”的位置可能会有所不同。5”位置通常是核苷酸的核碱基中的位置。核碱基中的5”位置可以根据所需支化部分的性质而变化,如上述结构所示。
微阵列
本文描述的任何多核苷酸合成方法可用于制造多核苷酸微阵列(Trevino,V.等人,Mol.Med.2007 13,pp527-541)。因此,锚或支架多核苷酸可以连接到表面上的多个可单独寻址的反应位点,并且具有预定义序列的多核苷酸可以在微阵列上原位合成。
合成后,在每个反应区域,可以为预定义序列的多核苷酸提供独特的序列。可以向锚或支架多核苷酸提供条形码序列以便于鉴定。
除了合成预定序列的多核苷酸的方法之外,可以使用本技术领域中常用的技术,包括本文所述的技术,进行微阵列制造。例如,可以使用已知的表面附接方法和化学方法将锚或支架多核苷酸拴在表面上,包括本文所述的那些。
在合成预定序列的多核苷酸后,可以提供最终裂解步骤以从无束缚末端移除任何不需要的多核苷酸序列。
可以双链形式在反应位点提供预定序列的多核苷酸。或者,在合成之后,可以分离双链多核苷酸并去除一条链,在反应位点留下单链多核苷酸。可以提供链的选择性束缚以促进该过程。例如,在涉及支架多核苷酸的方法中,合成链可以束缚在表面上,支持链可以不被束缚,反之亦然。合成链可以具有不可裂解的接头,并且支持链可以具有可裂解的接头,反之亦然。链的分离可以通过常规方法进行,例如热处理。
合成多核苷酸的组装
具有通过本文所述方法合成的预定序列并且可选地通过本文所述方法扩增的多核苷酸可以与一种或多种其他此类多核苷酸连接以产生更大的合成多核苷酸。
可以通过本领域公知的技术实现多个多核苷酸的连接。可以裂解通过本文所描述的方法合成的第一多核苷酸和一种或多种另外的多核苷酸以产生相容的末端,并且然后通过连接将多核苷酸接合在一起。可以通过任何合适的方法实现裂解。通常,可以在多核苷酸中产生限制性酶裂解位点,并且然后使用限制性酶执行裂解步骤,从而从任何锚/支架多核苷酸释放合成的多核苷酸。裂解位点可以被设计为锚/支架多核苷酸的一部分。或者,可以在新合成的多核苷酸内产生裂解位点,作为预定的核苷酸序列的一部分。
多核苷酸的组装优选地使用固相方法进行。例如,在合成后,第一多核苷酸可以在远离表面固定位点的合适位置进行单一裂解。因此,第一多核苷酸将保持固定在表面上,并且单个裂解将产生与另一个多核苷酸连接相容的末端。另外的多核苷酸可以在两个合适的位置进行裂解,以在每个末端产生用于连接其他多核苷酸的相容末端,同时从表面固定中释放另外的多核苷酸。另外的多核苷酸可以与第一多核苷酸相容地连接,从而产生更大的固定化多核苷酸,其具有预定序列并且具有与另一个额外多核苷酸连接相容的末端。因此,预选的裂解的合成多核苷酸的连接的迭代循环可以产生更长的合成多核苷酸分子。另外的多核苷酸的连接顺序将由所需的预定义序列测定。
因此,本发明的组装方法可以允许产生长度为一个或多个Mb左右的合成多核苷酸分子。
可以使用本领域已知的装置进行本发明的组装和/或合成方法。可获得的技术和装置允许非常小体积的试剂被选择性地移动、分配并与阵列的不同位置中的其他体积组合,通常以液滴的形式,可以使用电润湿技术,例如电介质上的电润湿(EWOD),如上所述。例如在US8653832、US8828336、US20140197028和US20140202863中公开了可以在本发明中使用的能够操纵液滴的合适的电润湿技术和系统。
可以通过在引物链部分和与其杂交的支持链部分中的一个或两个中提供可裂解接头来实现从固相裂解。可裂解接头可以是例如UV可裂解接头。
在图30中示出了涉及酶促裂解的裂解方法的实例。该示意图示出了附接于表面(通过黑色金刚石结构显示)并包括预定序列的多核苷酸的支架多核苷酸。支架多核苷酸包括顶部和底部发夹。在每种情况下,可以使用通用核苷酸的裂解步骤裂解顶部发夹,以限定裂解位点。底部发夹可以通过限制性核酸内切酶经由设计到支架多核苷酸中的位点移除或者工程化到新合成的预定序列的多核苷酸中。
因此,如上所述,可以合成具有预定义序列的多核苷酸,同时固定在电润湿表面上。合成的多核苷酸可以从电润湿表面裂解下来并以液滴形式在电场的影响下移动。液滴可以在表面上的特定反应位点处组合,在所述特定反应位点其可以递送裂解的合成多核苷酸用于与其它裂解的合成多核苷酸连接。然后可以(例如通过连接)连接多核苷酸。使用这些技术,可以根据所期望的预定义序列合成并且依次连接不同多核苷酸的群体。使用这种系统,可以设计完全自动化的多核苷酸合成和组装系统。系统可以被编程为接收期望的序列、供应试剂、执行合成循环并随后根据期望的预定义序列组装期望的多核苷酸。
系统和试剂盒
本发明还提供了用于实施本文描述和限定的任何合成方法以及本文描述和限定的任何后续扩增和组装步骤的多核苷酸合成系统。
通常,合成循环反应将通过将预定序列的核苷酸合并支架多核苷酸分子来进行,所述支架多核苷酸分子通过本文描述和限定的方式与表面束缚。表面可以是如本文所述和限定的任何合适的表面。
在一个实施方案中,将预定序列的核苷酸合并支架多核苷酸分子的反应涉及在反应区域内在支架多核苷酸上进行任何合成方法。
反应区域是支架多核苷酸分子附接的合适基底的任何区域,并且其中可以递送用于进行合成方法的试剂。
在一个实施方案中,反应区域可以是包括单个支架多核苷酸分子的表面的单个区域,其中单个支架多核苷酸分子可以用试剂寻址。
在另一个实施方案中,反应区域可以是包括多个支架多核苷酸分子的表面的单个区域,其中支架多核苷酸分子不能用彼此隔离的试剂单独寻址。因此,在这样的实施方案中,反应区域中的多个支架多核苷酸分子暴露于相同的试剂和条件,因此可以产生具有相同或基本相同的核苷酸序列的合成多核苷酸分子。
在一个实施方案中,用于实施本文所述和限定的任何合成方法的合成系统可以包括多个反应区域,其中每个反应区域包括一个或多个附接的支架多核苷酸分子,并且其中每个反应区域可以与每个其他反应区域隔离地用试剂单独寻址。这种系统可以例如以阵列的形式配置,例如其中反应区域形成在基底上,通常是平面基底。
具有包括单个反应区域或包括多个反应区域的基底的系统可包括在例如EWOD系统或微流体系统内,并且系统配置成将试剂递送至反应位点。本文更详细地描述了EWOD和微流体系统。例如,EWOD系统可以配置成在电控制下将试剂递送到反应位点。微流体系统,例如包括微制造结构,例如由弹性体或类似材料形成的微流体系统,可以配置成在流体压力和/或抽吸控制下或通过机械方式将试剂输送到反应位点。试剂可以通过任何合适的方式递送,例如通过用作试剂递送导管的碳纳米管。可以设想任何合适的系统。
EWOD、微流体和其他系统可以配置成将任何其他所需的试剂递送至反应位点,例如用于在合成后从支架多核苷酸裂解合成的双链多核苷酸的酶,和/或用于裂解接头以从基底释放整个支架多核苷酸的试剂和/或用于在合成后扩增多核苷酸分子的试剂或其任何区域或部分,和/或用于从较小多核苷酸分子组装较大多核苷酸分子的试剂,所述较小多核苷酸分子是根据本发明的合成方法合成的。
本发明还提供了用于实施本文所述和限定的任何合成方法的试剂盒。试剂盒可含有任何所需的试剂组合,其用于进行本文所述和限定的本发明的任何合成和/或组装方法。例如,试剂盒可包括任何一个或多个体积的反应试剂,其包括支架多核苷酸、对应于本文所述和限定的合成循环的任何一个或多个步骤的反应试剂的体积、包括含有可逆封闭基团或可逆终止子基团的核苷酸的反应试剂的体积、用于在合成之后扩增一种或多种多核苷酸分子或其任何区域或部分的反应试剂的体积、用于从根据本发明的合成方法合成的较小多核苷酸分子组装较大多核苷酸分子的反应试剂的体积、用于在合成后从支架多核苷酸裂解合成的双链多核苷酸的反应试剂的体积、以及用于裂解一个或多个接头从基底释放完整的支架多核苷酸的反应试剂的体积。
示例性方法
本文描述了根据本发明的示例性的非限制性合成多核苷酸或寡核苷酸分子的方法,包括所附权利要求。
在以下根据本发明的合成多核苷酸或寡核苷酸分子及其变体的两种非限制性示例性方法中,将根据分别在图1至图6中列出的反应示意图而不是根据图7至11中任何一个中列出的反应示意图或在“实例”部分中对其进行的描述来解释对合成方法版本1和2的引用。在下面的实例部分中,在图7至图11中列出的反应示意图及其描述提供了基于与本发明的方法相比进行修改的反应方案的对本发明的方法的例示性支持。
在下文所描述的每一示例性方法中,在每一步骤中所描述的结构可在适当时借助于附图标记来参考特定图。下文中的附图标记与图1至6中的附图标记相对应。这样的附图标记不旨在限于附图中所示的特定结构,并且相关结构的描述对应于其整体上本文所提供的描述,包括但不限于具体示出的那些。
下面描述本发明的两种非限制性示例性方法,在本文中称为本发明1和2的方法版本(分别参见例如图1和2)。在这些示例性方法的每种方法的步骤(1)中,提供了一个支架多核苷酸(参见图1和2的步骤1中所示的结构)(101、201),其包括与互补支持链(参见图1和2中的每个图的步骤1中描绘的结构中被标记为“a”的链)杂交的合成链(参见图1和2中的每个图的步骤1中描绘的结构中被标记为“b”的链)。
支架多核苷酸是双链的并且提供支持结构以修改合成多核苷酸的区域,因为它是从头合成的。支架多核苷酸包括合成链,所述合成链包括引物链部分(参见图1和图2中的每个图的步骤1中描绘的结构中被标记为“b”的链的点线部分)和辅助链部分(参见图1和图2中的每个图的步骤1中描绘的结构中被标记为“b”的链的虚线部分)。合成链的引物链部分和辅助链部分都与互补的支持链杂交。
包括引物链部分的支架多核苷酸的末端包括突出端,其中支持链的末端突出引物链部分的末端之外。
在方法的步骤(2)中,进行连接步骤(102、202),其中将多核苷酸连接分子连接至双链支架多核苷酸。多核苷酸连接分子包括预定核苷酸序列的第一核苷酸。多核苷酸连接分子包括支持链和与支持链杂交的辅助链。多核苷酸连接分子包括具有突出端的互补连接端,其中辅助链的末端突出支持链的末端之外。突出的互补连接端与双链支架多核苷酸的突出端互补。多核苷酸连接分子的支持链在互补连接端包括预定核苷酸序列的第一核苷酸。预定义核苷酸序列的第一核苷酸是多核苷酸连接分子在互补连接端的支持链的末端核苷酸。预定核苷酸序列的第一核苷酸是可连接的核苷酸,并与支架多核苷酸的支持链的末端核苷酸连接。在粘性末端连接反应中连接后,通过在双链支架多核苷酸的突出端上附接到双链支架多核苷酸的支持链上,将预定核苷酸序列的第一核苷酸合并双链支架多核苷酸中。
在这两种方法版本及其变体的每一个中,多核苷酸连接分子的支持链在互补连接端还包括通用核苷酸(在图1和图2所示的结构中被标记为“Un”),这将有助于在裂解步骤中进行裂解。通用核苷酸的作用将从以下每种方法的详细描述中显而易见。
提供多核苷酸连接分子的辅助链在互补连接端的末端核苷酸,使得辅助链不能被连接至合成链的引物链部分,即,其被提供为不可连接的核苷酸。这通常是通过提供没有磷酸基的辅助链的末端核苷酸来实现的,即,它以核苷的形式提供。或者,可以使用5'-保护的核苷,在5'位置具有不可连接基团的核苷,例如5'-脱氧核苷或5'-氨基核苷,或任何其他合适的不可连接的核苷酸或核苷。
因此,在将多核苷酸连接分子的支持链与双链支架多核苷酸的支持链连接时,在合成链的引物链部分和辅助链之间在合成链中提供了单链断裂或“缺口”。
将多核苷酸连接分子连接至双链支架多核苷酸后,形成双链支架多核苷酸,其包括新合并的第一核苷酸,用于促进裂解步骤中的裂解的通用核苷酸和“缺口”。
由于该循环的预定序列的第一核苷酸与双链支架多核苷酸的支持链的末端核苷酸连接,因此必须在连接步骤之前为双链支架多核苷酸的支持链的末端核苷酸提供附接的磷酸基团或其他可连接基团,以使双链支架多核苷酸的支持链的末端核苷酸充当连接酶的底物。
如本文中更详细描述的,在与本文所述的版本1和2及其变体有关的某些示例性方法中,可以在将预定序列的第二核苷酸合并到该合成循环中的步骤之前移除辅助链,例如通过变性和从先前与其杂交的支持链中释放。
在合成的第一循环的上下文中,术语“预定序列的第一核苷酸”不必理解为意指预定序列的第一核苷酸。本文所述的方法涉及具有预定序列的双链多核苷酸的合成,并且可以在开始第一合成循环之前在支架多核苷酸中预合成提供预定序列的一部分。在本文中,预定义序列的术语“一”第一核苷酸可以意指预定义序列的“任何”核苷酸。
合成链的引物链部分的末端提供了引物位点,该引物位点是用于附接预定序列的第二核苷酸的位点,该第二核苷酸通过具有延伸寡核苷酸或具有单个核苷酸的多核苷酸分子的能力的酶被附接/合并到合成链中。这样的酶通常是核苷酸转移酶或聚合酶。可以使用本文进一步定义和/或技术人员已知的任何合适的酶。因此,该酶将起作用以延伸引物链部分的末端核苷酸。因此,该末端核苷酸通常将定义引物链部分的3′末端,例如以允许通过聚合酶、转移酶或其他任何催化5'到3'方向延伸的酶进行延伸。因此,包含引物链部分的合成链的相反末端通常将定义合成链的5'末端,并且与合成链5'末端相邻的支持链的末端核苷酸将因此通常限定支持链的3'末端。
位于单链断裂的位点处的合成链的辅助链部分的末端核苷酸通常将限定辅助链部分的5'末端,并因此合成链的辅助链部分的相对末端通常将限定合成链的3'末端。
在合并第二核苷酸的步骤(步骤3;103、203)中,第二核苷酸设置有可逆终止子基团团(在图1和2中的每个图的步骤3中被描绘为合并的核苷酸的小三角形),其防止通过酶进一步延伸。因此,在步骤(3)中仅合并单个核苷酸。
可以使用包括任何合适的可逆终止子基团的核苷酸。具有可逆终止子基团的优选核苷酸是3′-O-烯丙基-dNTP和/或3′-O-叠氮甲基-dNTP或本文进一步描述的其他基团。
从本文中所定义的各种方法的描述中将显而易见的是,术语“预定序列的第二核苷酸”不应理解为是指从包括预定序列的一条链中的线性序列中的第一核苷酸开始的下一核苷酸,而仅是在整个合成的双链多核苷酸的上下文中的预定序列的“一”另外的核苷酸。在本文定义的本发明的特定和非限制性方法版本1和2及其某些变体的情况下,一个循环中的每个“第一核苷酸”将在相同的核酸链中顺序连接至前一循环的“第一核苷酸”,从而每个循环将第一链顺序延伸一个核苷酸。在每个循环中,一个循环中的每个“第二核苷酸”将紧接前一个循环的“第二核苷酸”并入同一核酸链,从而使第二链每个循环依次延伸一个核苷酸。因此,当合成循环完成时,合成的双链多核苷酸分子将包括由每个循环的连接的第一核苷酸限定的一条链的预定序列,以及由每个循环的结合的第二核苷酸限定的相反链的预定序列。两条链的序列都必须预先限定,并由使用者在每个合成循环中选择的第一和第二核苷酸的身份决定。在本文所述的方法版本1和2中,假定每个循环的第一和第二核苷酸与相应的配偶体核苷酸形成核苷酸对,如果使用者选择每个循环的第一和第二核苷酸与它们各自的配偶体核苷酸天然互补在每个循环中,最后的合成链将是完全互补的。如果使用者选择某些循环的第一和第二核苷酸与这些循环的它们各自的配偶体核苷酸不互补,那么最终的合成链将不是完美互补的。然而,在任何一种情况下,最终的合成链均包括序列,该序列在合成的双链多核苷酸整体上是预定的。
在合并第二核苷酸的步骤(步骤3)之后,然后裂解支架多核苷酸(步骤4、104、204)。裂解引起多核苷酸连接分子从支架多核苷酸中释放,并且该循环的第一核苷酸不成对并保持在裂解的支架多核苷酸的支持链上,并且该循环的第二核苷酸保持在合成链上裂解的支架多核苷酸的片段,并与配偶体核苷酸配对。裂解会引起辅助链(如果存在)释放,并在裂解前立即与支持链杂交,并释放包括通用核苷酸的支持链。裂解因此将裂解的双链支架多核苷酸留在原位,该双链支架多核苷酸在裂解位点包括裂解的支持链的裂解末端和包括裂解前切口位点的合成链的引物链部分的末端,其中裂解的双链支架多核苷酸包括该循环的第一核苷酸作为支持链的裂解末端的末端核苷酸,突出该循环的第二核苷酸之外作为合成链的引物链部分的末端核苷酸。突出端可以是单核苷酸突出端或多核苷酸突出端。
在该方法的步骤(5)中,进行脱保护步骤以从预定核苷酸序列(105、205)的合并的第二核苷酸中移除可逆终止子基团。脱保护步骤可以可选地在裂解步骤(步骤4)之前进行,在这种情况下,脱保护步骤定义为步骤(4)(图1和2的步骤4;104、204),并且裂解步骤定义为步骤(5)(图1和2的步骤5;105、205)。
执行包括上述相同步骤的合成的迭代循环,以产生合成的多核苷酸。
在下文更详细地描述具体方法。
合成方法版本1
参考图1,在本发明的合成方法的第一特定的非限制性示例性形式中,提供了双链支架多核苷酸(图1的步骤1;101)。该双链支架多核苷酸包括支持链和与其杂交的合成链。合成链包括引物链部分。所述双链支架多核苷酸具有至少一个突出端,其中所述至少一个突出端包括突出引物链部分的末端之外的支持链的末端。支持链的末端核苷酸能够充当连接酶的底物,并且优选包括磷酸基团或其他可连接基团。
在该方法的步骤(2)中,将多核苷酸连接分子(参见图1上部的右上方所示的结构)连接至支架多核苷酸。连接将预定序列的第一核苷酸合并到支架多核苷酸的支持链中(图1的步骤2;102)。
在该方法的步骤(3)中,在具有利用单核苷酸延伸寡核苷酸或多核苷酸分子的能力的酶的作用下,将预定核苷酸序列的第二核苷酸添加到合成链的引物链部分的末端。这样的酶通常是核苷酸转移酶或聚合酶(图1的步骤3;103)。第二核苷酸设置有可逆终止子基团,其可防止通过酶进一步延伸。因此,在步骤(3)中仅合并单个核苷酸。
然后在每个合成循环中,在由支持链中包含通用核苷酸的序列限定的裂解位点裂解支架多核苷酸(步骤4;104)。在方法版本1中,裂解包括在通用核苷酸之后立即在靠近引物链部分/远离辅助链的方向上裂解支持链,即,在由通用核苷酸占据的位置和支持链中沿靠近引物链部分/远离辅助链的方向的下一核苷酸位置之间裂解支持链。支架多核苷酸的裂解(步骤4)引起多核苷酸连接分子从支架多核苷酸的释放和该循环的第一核苷酸的不成对并附接至裂解的支架多核苷酸的第一链上,并且其第二核苷酸的保持连接到合成链的引物链部分并与配偶体核苷酸配对的循环。支架多核苷酸的裂解(步骤4)引起支架多核苷酸的辅助链丢失(如果存在并在裂解前立即与支持链杂交),以及通用核苷酸从支架多核苷酸丢失。裂解将裂解的双链支架多核苷酸留在原位,所述裂解的双链支架多核苷酸在裂解位点包括裂解的支持链的裂解的末端和包括在裂解之前的切口位点的合成链的引物链部分的末端,并且其中,裂解的双链支架多核苷酸包括该循环的第一核苷酸作为支持链的裂解末端的末端核苷酸,突出该循环的第二核苷酸之外作为合成引物链部分的裂解末端的末端核苷酸链。
在该方法的步骤(5)中,进行脱保护步骤以从新合并的核苷酸中移除终止子基团。脱保护步骤可以可替代地在裂解步骤之前进行,在这种情况下,脱保护步骤定义为步骤(4),而裂解步骤定义为步骤(5),如图1所示(分别为104和105)。
步骤1-提供支架多核苷酸
在本发明的合成方法的示例性版本1中,在步骤(1)(101)中提供了双链支架多核苷酸。提供了双链支架多核苷酸,其包括合成链和与其杂交的支持链,其中所述合成链包括引物链部分。支持链的末端核苷酸包括单核苷酸突出端,其中支持链的末端核苷酸不成对并且突出合成链的引物链部分的末端核苷酸之外。支持链的末端核苷酸能够充当连接酶的底物,并且包括可连接基团,优选磷酸基团。
步骤2-将多核苷酸连接分子连接至支架多核苷酸并合并预定序列的第一核苷酸
在该方法的步骤(2)中,在粘性末端连接反应中,通过连接酶的作用将双链多核苷酸连接分子连接(102)至支架多核苷酸。
多核苷酸连接分子包括支持链和与之杂交的辅助链。多核苷酸连接分子进一步包括互补连接端,其在支持链中包括通用核苷酸和预定序列的第一核苷酸。
多核苷酸连接分子的互补连接端被构造成使得支持链的末端核苷酸是在任何给定的合成循环中被合并到支架多核苷酸中的预定序列的第一核苷酸。支持链的末端核苷酸与辅助链的次末端核苷酸配对。互补连接端包括单核苷酸突出端,其中辅助链的末端核苷酸突出支持链的末端核苷酸之外。支持链的末端核苷酸,即该循环的预定序列的第一核苷酸,在支持链中占据核苷酸位置n+1。位置n是指在合并第二核苷酸时与该循环的预定序列的第二核苷酸相对的核苷酸位置。位置n+1是在互补连接端远端的方向上相对于位置n的下一个核苷酸位置。在图1中,预定序列的第一核苷酸被描述为腺苷,步骤(3)中预定序列的第二核苷酸被描述为胸腺嘧啶,辅助链的末端核苷酸被描述为胸腺嘧啶。腺苷和胸腺嘧啶仅用于例示。辅助链的第一和第二核苷酸以及末端核苷酸可以是使用者选择的任何合适的核苷酸。被描述为X的核苷酸也可以是使用者选择的任何合适的核苷酸。
通常,在互补连接端的支持链的末端核苷酸将定义多核苷酸连接分子的互补连接端的支持链的3'末端。
配置多核苷酸连接分子的辅助链的末端核苷酸,使其不能与多核苷酸链中的另一个多核苷酸连接(标记为“T”的位置仅用于说明图1上部右上方的结构)。该核苷酸称为不可连接的末端核苷酸。通常,该末端核苷酸将缺少磷酸基团,即它将是核苷。通常,如上所述,辅助链的这种非磷酸化末端核苷酸将限定辅助链的5'末端。
在多核苷酸连接分子的互补连接端中,支持链中的通用核苷酸被定位成它是支持链的次末端核苷酸,与辅助链中的配偶体核苷酸配对,并且占据支持链中的核苷酸位置n+2。位置n+2是指在支持链中相对于互补连接端远端的方向上的位置n的第二核苷酸位置。
突出的互补连接端被配置为使得当经受合适的连接条件时,它将与支架多核苷酸的突出的末端相容地连接。在多核苷酸连接分子的支持链与支架多核苷酸连接后,第一核苷酸被合并到支架多核苷酸中。由于多核苷酸连接分子的辅助链的末端核苷酸是不可连接的核苷酸,因此将阻止连接酶连接合成链的辅助链和引物链部分,从而产生单链断裂或“辅助链和合成链引物链部分之间的“缺口”。
多核苷酸连接分子与支架多核苷酸的连接延长了步骤(1)的双链支架多核苷酸的支持链的长度,并且其中,预定核苷酸序列的第一核苷酸被合并到支架多核苷酸的支持链中。
支持链的连接可以通过任何合适的方式进行。连接通常可以并且优选地通过具有连接酶活性的酶来进行。例如,可以用T3 DNA连接酶或T4 DNA连接酶或其功能变体或等同物或本文进一步描述的其他酶进行连接。这样的酶的使用将引起在合成链中维持单链断裂,因为提供了辅助链的末端核苷酸,使得其不能充当连接酶的底物,例如由于不存在末端磷酸基团或存在不可连接的封闭基团。
在将多核苷酸连接分子连接至支架多核苷酸之后,将预定核苷酸序列的第一核苷酸称为占据核苷酸位置n+1,将通用核苷酸称为占据核苷酸位置n+2,并且将连接之前的核苷酸邻近引物链部分的支架多核苷酸的支持链的末端核苷酸被称为占据核苷酸位置n。
步骤3-合并预定序列的第二核苷酸
在该方法的步骤(3)中,在将多核苷酸连接分子连接到支架多核苷酸之后,然后通过延伸引物链部分将预定序列的第二核苷酸合并到合成链中。
引物链部分的延伸可通过任何合适的酶的作用来实现,该酶具有延伸具有单核苷酸的寡核苷酸或多核苷酸分子的能力。这样的酶通常是核苷酸转移酶或聚合酶。可以使用本文进一步定义的或技术人员已知的任何合适的酶。
如果在紧接引物链部分延伸之前,在支架多核苷酸中存在辅助链,特别是如果使用聚合酶,则该酶可起到“侵入”辅助链并置换辅助链末端核苷酸的作用。然后,并入的第二核苷酸将占据先前被辅助链的置换末端核苷酸占据的位置(参见图1下部中间所示的结构)。在某些实施方案中,可以在延伸/合并步骤(3)之前移除辅助链,在这种情况下,酶可以接近并延伸合成链的引物链部分的末端核苷酸,而无需置换辅助链或其一部分。
在步骤(3)中并入的预定序列的第二核苷酸包括阻止通过酶进一步延伸的可逆终止子基团,或包括阻止通过酶进一步延伸的任何其他类似功能。可以使用本文进一步定义的或本领域技术人员已知的任何合适的可逆终止子基团或功能。
将其并入支架多核苷酸的引物链部分中后,该循环的预定序列的第二核苷酸与配偶体核苷酸配对以形成该循环的核苷酸对。核苷酸对可以是本文进一步定义的任何合适的核苷酸对。
步骤4:裂解
在该方法的步骤(4)中,在裂解位点裂解(104)连接的支架多核苷酸。裂解位点由包括支持链中的通用核苷酸的序列限定。裂解引起支架多核苷酸中的双链断裂。支架多核苷酸的裂解(步骤4)引起辅助链的丢失(如果存在并且在裂解前立即与支持链杂交)以及包括通用核苷酸的支持链的丢失。
支架多核苷酸的裂解从而从支架多核苷酸释放多核苷酸连接分子,但是引起该环的第一核苷酸的保持不成对并附接在裂解的支架多核苷酸的支持链上,并且该环的第二核苷酸的保持是连接至裂解的支架多核苷酸的合成链并与配偶体核苷酸配对。支架多核苷酸的裂解将裂解的双链支架多核苷酸留在原位,该双链支架多核苷酸在支持链的末端包括预定序列的第一核苷酸,并在合成链的引物链部分的末端包括预定序列的第二核苷酸。该循环的第一核苷酸,即支持链的裂解末端的末端核苷酸,突出该循环的第二核苷酸之外,即合成链的引物链部分的裂解末端的末端核苷酸。
在该示例性方法中,合成链已经具有单链断裂或“缺口”,因此仅需要裂解支持链即可在支架多核苷酸中提供双链断裂。为了在通用核苷酸在支持链中位于n+2位置时获得这种突出的裂解的双链支架多核苷酸,将支持链在相对于通用核苷酸的特定位置裂解。当在核苷酸位置n+2和n+1之间裂解支架多核苷酸的支持链时,多核苷酸连接分子从支架多核苷酸中释放(参见图1上部左上方所示的结构),除了第一个该循环的核苷酸保持在与裂解的支架多核苷酸的支持链相连的支架多核苷酸中。
磷酸基团应继续在裂解位点连接至裂解的支架多核苷酸的支持链的末端核苷酸。这确保了在下一合成循环的连接步骤中,可以将裂解的支架多核苷酸的支持链连接至多核苷酸连接分子的支持链。进行裂解使得裂解的支架多核苷酸的支持链的末端核苷酸保持可连接基团,优选末端磷酸基团,并且因此不需要进行磷酸化步骤。
因此,在方法版本1中,通用核苷酸在步骤(2),(3)和(4)处位于支持链中的位置n+2,并且在步骤(4)中将支持链在核苷酸位置n+2和n+1之间裂解)。
优选地,通过裂解核苷酸位置n+2和n+1之间的磷酸二酯键(支持链的相对于通用核苷酸的位置的第一磷酸二酯键,在远离辅助链/靠近引物链的方向上)。
可以通过裂解核苷酸位置n+2和n+1之间的磷酸二酯键的一个酯键来裂解支持链。
优选地,通过相对于核苷酸位置n+2的第一酯键的裂解来裂解支持链。这将具有在裂解位置处在裂解的支架多核苷酸的支持链上保持末端磷酸酯基团的作用。
当通用核苷酸占据位置n+2时,可以采用任何合适的机制来实现在核苷酸位置n+2和n+1之间的支持链的裂解。
如上所述,可通过酶的作用在核苷酸位置n+2和n+1之间裂解支持链。
如上所述的在核苷酸位置n+2和n+1之间的支持链的裂解可以作为两步裂解过程进行。
两步裂解过程的第一裂解步骤可以包括从支持链上移除通用核苷酸,从而在位置n+2处形成无碱基位点,而第二裂解步骤可以包括在位置n+2和n+1之间在无碱基位点处裂解支持链。
实例2描述了一种在上述包含通用核苷酸的序列所定义的裂解位点裂解支持链的机制。实例2中描述的裂解机制是示例性的,并且可以采用其他机制,只要实现了包括如上所述的突出端的裂解的双链支架多核苷酸即可。
在两步裂解过程的第一裂解步骤中,将通用核苷酸从支持链上移除,同时保持糖-磷酸主链的完整性。这可以通过酶的作用来实现,所述酶可以从双链多核苷酸中特异性地切除单个通用核苷酸。在示例性裂解方法中,通用核苷酸是肌苷,并且通过酶的作用从支持链切除肌苷,从而形成无碱基位点。在示例性裂解方法中,酶是3-甲基腺嘌呤DNA糖基化酶,特别是人类烷基腺嘌呤DNA糖基化酶(hAAG)。可以使用其它酶、分子或化学品,条件是形成无碱基位点。核苷酸裂解酶可以是催化尿嘧啶从多核苷酸释放的酶,例如尿嘧啶-DNA糖基化酶(UDG)。
在两步裂解过程的第二裂解步骤中,通过单链断裂,在无碱基位点处裂解支持链。在示例性方法中,支持链通过作为碱如NaOH的化学物质的作用裂解。或者,可以使用有机化学品,如N,N'-二甲基乙二胺。或者,可以使用具有无碱基位点裂解酶活性的酶,例如AP核酸内切酶1、核酸内切酶III(Nth)或核酸内切酶VIII。可以使用其他酶、分子或化学品,条件是支持链在如上所述的无碱基位点处被裂解。
因此,在通用核苷酸在步骤(1)和(2)处在支持链的位置n+2且支持链在位置n+2和n+1之间裂解的实施方案中,第一裂解步骤可以用核苷酸切除酶来执行。这种酶的实例是3-甲基腺嘌呤DNA糖基化酶,例如人类烷基腺嘌呤DNA糖基化酶(hAAG)。第二裂解步骤可以用作为碱的化学物质如NaOH进行。第二步可以用具有无碱基位点裂解活性的有机化学品如N,N'-二甲基乙二胺进行。第二步骤可以用具有碱性位点裂解酶活性的酶如核酸内切酶VIII或核酸内切酶III进行。
如上所述的在核苷酸位置n+2和n+1之间的支持链的裂解也可以作为一步裂解过程进行。可用于任何此类方法的酶的实例包括核酸内切酶III、核酸内切酶VIII。可以在任何这样的方法中使用的其他酶包括裂解8-氧代鸟苷的酶,例如甲酰胺基嘧啶DNA糖基化酶(Fpg)和8-氧代鸟嘌呤DNA糖基化酶(hOGG1)。
步骤5——脱保护
在本发明的该示例性方法形式以及所有形式中,为了允许将下一个核苷酸并入下一合成循环,必须将可逆终止子基团从第一个核苷酸中移除(脱保护步骤;105)。这可在第一循环的各个阶段执行。在裂解步骤(4)之后,它可以作为方法的步骤(5)进行。然而,脱保护步骤可以在步骤(3)中引入第二核苷酸之后并且在裂解步骤(4)之前进行,在这种情况下,脱保护步骤被定义为步骤(4),裂解步骤被定义为步骤(5),如图1所示(分别为104和105)。无论执行哪个保护基步骤,都应在步骤(3)之后首先移除酶和残留的未结合的第二核苷酸,以防止在同一合成循环中多次合并第二核苷酸。
可以通过本领域技术人员已知的任何合适的方式从第一核苷酸中移除可逆终止子基团。例如,可以通过使用化学物质如三(羧乙基)膦(TCEP)进行移除。
另外的循环
在完成第一合成循环之后,可以使用相同的方法步骤进行第二合成循环和其他合成循环。
(在步骤6中)提供前一循环的步骤(4)和(5)的裂解产物作为用于下一合成循环的双链支架多核苷酸。
在下一合成循环和每个其他合成循环的步骤(6)中,将另一个双链多核苷酸连接分子连接至上一个循环的步骤(4)和(5)的裂解产物。所述多核苷酸连接分子可以以与上述对于先前循环的步骤(2)相同的方式构造,不同之处在于,所述多核苷酸连接分子包括另外的合成循环的第一核苷酸。多核苷酸连接分子可以以与上述步骤(2)相同的方式连接至前一循环的步骤(4)和(5)的裂解产物。
在下一个和每个另外的合成循环的步骤(7)中,在核苷酸转移酶、聚合酶或其他酶的作用下,通过合并另外的合成循环的第二核苷酸来进一步延长双链支架多核苷酸合成链的引物链部分的末端。可以按照与上述步骤(3)相同的方式合并进一步合成循环的第二核苷酸。
在合成的下一循环和每个进一步循环的步骤(8)中,在裂解位点裂解连接的支架多核苷酸。裂解引起支架多核苷酸中的双链断裂。支架多核苷酸的裂解(步骤8)引起辅助链的丢失(如果存在并且在裂解前立即与支持链杂交)以及包括通用核苷酸的支持链的丢失。支架多核苷酸的裂解从而从支架多核苷酸释放另外的多核苷酸连接分子,但是引起该另外的循环的第一核苷酸的保持不成对并附接于所裂解的支架多核苷酸的支持链,并且保持了该另外的第二核苷酸,该第二核苷酸连接至裂解的支架多核苷酸的合成链并与配偶体核苷酸配对。支架多核苷酸的裂解将裂解的双链支架多核苷酸留在原位,该双链支架多核苷酸在支架多核苷酸的支持链的末端包括另外的循环的第一核苷酸,其在支架多核苷酸的合成链的引物链部分的末端突出另外的循环的第二核苷酸之外。步骤(8)的裂解可以以与上述步骤(4)相同的方式进行。
在步骤(9)中,将可逆终止子基团从另外的循环的第二核苷酸中移除(脱保护步骤;109)。如上面对于第一循环所述,这可以在各个阶段执行。在裂解步骤(8)之后,它可以作为方法的步骤(9)进行。或者,可以在合并步骤(7)之后且在裂解步骤(8)之前的任何步骤进行脱保护步骤,在这种情况下,将脱保护步骤定义为步骤(8),并将裂解步骤定义为步骤(9),如图1所示(分别为109和110)。通过在下一循环和随后的循环中移除可逆终止基团来进行脱保护可以如上文关于第一合成循环所述进行。
如上文所描述根据需要重复合成循环多次,以合成具有预定核苷酸序列的双链多核苷酸。
合成方法版本2
参考图2,在本发明的合成方法的第二特定的非限制性示例性形式中,提供了双链支架多核苷酸(图2的步骤1;201)。该双链支架多核苷酸包括支持链和与其杂交的合成链。合成链包括引物链部分。所述双链支架多核苷酸具有至少一个突出端,其中所述至少一个突出端包括突出引物链部分的末端之外的支持链的末端。支持链的末端核苷酸能够充当连接酶的底物,并且优选包括磷酸基团或其他可连接基团。
在该方法的步骤(2)中,将多核苷酸连接分子(参见图2上部的右上方所示的结构)连接至支架多核苷酸。连接将预定序列的第一核苷酸合并到支架多核苷酸的支持链中(图2的步骤2;202)。
在该方法的步骤(3)中,在具有利用单核苷酸延伸寡核苷酸或多核苷酸分子的能力的酶的作用下,将预定核苷酸序列的第二核苷酸添加到合成链的引物链部分的末端。这种酶通常是核苷酸转移酶或聚合酶(图2的步骤3;203)。第二核苷酸设置有可逆终止子基团,其可防止通过酶进一步延伸。因此,在步骤(3)中仅合并单个核苷酸。
然后在每个合成循环中,在由支持链中包含通用核苷酸的序列限定的裂解位点处裂解支架多核苷酸(步骤4;204)。在方法版本2中,裂解包括在靠近引物链部分/远离辅助链的方向上在紧接通用核苷酸的核苷酸位置的核苷酸之后立即裂解支持链。支架多核苷酸的裂解(步骤4)引起多核苷酸连接分子从支架多核苷酸的释放和该循环的第一核苷酸的不成对并附接至裂解的支架多核苷酸的第一链上,并且其第二核苷酸的保持连接到合成链的引物链部分并与配偶体核苷酸配对的循环。支架多核苷酸的裂解(步骤4)引起支架多核苷酸的辅助链丢失(如果存在并在裂解前立即与支持链杂交),以及通用核苷酸从支架多核苷酸丢失。裂解将裂解的双链支架多核苷酸留在原位,所述裂解的双链支架多核苷酸在裂解位点包括裂解的支持链的裂解的末端和包括在裂解之前的切口位点的合成链的引物链部分的末端,并且其中,裂解的双链支架多核苷酸包括该循环的第一核苷酸作为支持链的裂解末端的末端核苷酸,突出该循环的第二核苷酸之外作为合成引物链部分的裂解末端的末端核苷酸链。
在该方法的步骤(5)中,进行脱保护步骤以从新合并的核苷酸中移除终止子基团。脱保护步骤也可以在裂解步骤之前进行,在这种情况下,脱保护步骤定义为步骤(4),裂解步骤定义为步骤(5),如图2所示(分别为204和205)。
步骤1-提供支架多核苷酸
在本发明的合成方法的示例性版本2中,在步骤(1)中提供了双链支架多核苷酸(201)。提供了双链支架多核苷酸,其包括合成链和与其杂交的支持链,其中所述合成链包括引物链部分。支持链的末端核苷酸包括单核苷酸突出端,其中支持链的末端核苷酸不成对并且突出合成链的引物链部分的末端核苷酸之外。支持链的末端核苷酸能够充当连接酶的底物,并且包括可连接基团,优选磷酸基团。
步骤2-将多核苷酸连接分子连接至支架多核苷酸并合并预定序列的第一核苷酸
在该方法的步骤(2)中,在粘性末端连接反应中,在连接酶的作用下将双链多核苷酸连接分子连接(202)至支架多核苷酸。
多核苷酸连接分子包括支持链和与之杂交的辅助链。多核苷酸连接分子进一步包括互补连接端,其在支持链中包括通用核苷酸和预定序列的第一核苷酸。
多核苷酸连接分子的互补连接端被构造成使得支持链的末端核苷酸是在任何给定的合成循环中被合并到支架多核苷酸中的预定序列的第一核苷酸。支持链的末端核苷酸与辅助链的次末端核苷酸配对。互补连接端包括单核苷酸突出端,其中辅助链的末端核苷酸突出支持链的末端核苷酸之外。支持链的末端核苷酸,即该循环的预定序列的第一核苷酸,在支持链中占据核苷酸位置n+1。位置n是指在合并第二核苷酸时与该循环的预定序列的第二核苷酸相对的核苷酸位置。位置n+1是在互补连接端远端的方向上相对于位置n的下一个核苷酸位置。在图2中,预定序列的第一核苷酸被描述为腺苷,步骤(3)中预定序列的第二核苷酸被描述为胸腺嘧啶,辅助链的末端核苷酸被描述为胸腺嘧啶。腺苷和胸腺嘧啶仅用于例示。辅助链的第一和第二核苷酸以及末端核苷酸可以是任何合适的核苷酸。被描述为X的核苷酸也可以是使用者选择的任何合适的核苷酸。
通常,在互补连接端的支持链的末端核苷酸将定义多核苷酸连接分子的互补连接端的支持链的3'末端。
配置多核苷酸连接分子的辅助链的末端核苷酸,使其不能与多核苷酸链中的另一个多核苷酸连接(纯标记为“T”的位置仅用于说明图2上部右上方的结构)。该核苷酸称为不可连接的末端核苷酸。通常,该末端核苷酸将缺少磷酸基团,即它将是核苷。通常,如上所述,辅助链的这种非磷酸化末端核苷酸将限定辅助链的5'末端。
在多核苷酸连接分子的互补连接端中,支持链中的通用核苷酸被定位成使得它与辅助链中的配偶体核苷酸配对,并在支持链中占据核苷酸位置n+3。位置n+3是指在支持链中相对于互补连接端远端的方向上的位置n的第三核苷酸位置。
突出的互补连接端被配置为使得当经受合适的连接条件时,它将与支架多核苷酸的突出的末端相容地连接。在多核苷酸连接分子的支持链与支架多核苷酸连接后,第一核苷酸被合并到支架多核苷酸中。由于多核苷酸连接分子的辅助链的末端核苷酸是不可连接的核苷酸,因此将阻止连接酶连接合成链的辅助链和引物链部分,从而产生单链断裂或“辅助链和合成链引物链部分之间的“缺口”。
多核苷酸连接分子与支架多核苷酸的连接延长了步骤(1)的双链支架多核苷酸的支持链的长度,并且其中,预定核苷酸序列的第一核苷酸被合并到支架多核苷酸的支持链中。
支持链的连接可以通过任何合适的方式进行。连接通常可以并且优选地通过具有连接酶活性的酶来进行。例如,可以用T3 DNA连接酶或T4 DNA连接酶或其功能变体或等同物或本文进一步描述的其他酶进行连接。这样的酶的使用将引起在合成链中维持单链断裂,因为提供了辅助链的末端核苷酸,使得其不能充当连接酶的底物,例如由于不存在末端磷酸基团或存在不可连接的封闭基团。
在将多核苷酸连接分子连接至支架多核苷酸之后,将预定核苷酸序列的第一核苷酸称为占据核苷酸位置n+1,将通用核苷酸称为占据核苷酸位置n+3,并且将连接之前的核苷酸邻近引物链部分的支架多核苷酸的支持链的末端核苷酸被称为占据核苷酸位置n。
步骤3-合并预定序列的第二核苷酸
在该方法的步骤(3)中,在将多核苷酸连接分子连接到支架多核苷酸之后,然后通过延伸引物链部分将预定序列的第二核苷酸合并到合成链中。
引物链部分的延伸可通过任何合适的酶的作用来实现,该酶具有延伸具有单核苷酸的寡核苷酸或多核苷酸分子的能力。这样的酶通常是核苷酸转移酶或聚合酶。可以使用本文进一步定义的或技术人员已知的任何合适的酶。
如果在紧接引物链部分延伸之前,在支架多核苷酸中存在辅助链,特别是如果使用聚合酶,则该酶可起到“侵入”辅助链并置换辅助链末端核苷酸的作用。然后,合并的第二核苷酸将占据先前被辅助链的置换的末端核苷酸占据的位置(参见图2下部中间所示的结构)。在某些实施方案中,可以在延伸/合并步骤(3)之前移除辅助链,在这种情况下,酶可以接近并延伸合成链的引物链部分的末端核苷酸,而无需置换辅助链或其一部分。
在步骤(3)中并入的预定序列的第二核苷酸包括阻止通过酶进一步延伸的可逆终止子基团,或包括阻止通过酶进一步延伸的任何其他类似功能。可以使用本文进一步定义的或本领域技术人员已知的任何合适的可逆终止子基团或功能。
将其并入支架多核苷酸的引物链部分中后,该循环的预定序列的第二核苷酸与配偶体核苷酸配对以形成该循环的核苷酸对。核苷酸对可以是本文进一步定义的任何合适的核苷酸对。
步骤4:裂解
在该方法的步骤(4)中,在裂解位点处裂解(204)连接的支架多核苷酸。裂解位点由包括支持链中的通用核苷酸的序列限定。裂解引起支架多核苷酸中的双链断裂。支架多核苷酸的裂解(步骤4)引起辅助链的丢失(如果存在并且在裂解前立即与支持链杂交)以及包括通用核苷酸的支持链的丢失。
支架多核苷酸的裂解从而从支架多核苷酸释放多核苷酸连接分子,但是引起该环的第一核苷酸的保持不成对并附接在裂解的支架多核苷酸的支持链上,并且该环的第二核苷酸的保持是连接至裂解的支架多核苷酸的合成链并与配偶体核苷酸配对。支架多核苷酸的裂解将裂解的双链支架多核苷酸留在原位,该双链支架多核苷酸在支持链的末端包括预定序列的第一核苷酸,并在合成链的引物链部分的末端包括预定序列的第二核苷酸。该循环的第一核苷酸,即支持链裂解末端的末端核苷酸,突出该循环的第二核苷酸之外,即合成链引物链部分的裂解末端的末端核苷酸
在该示例性方法中,合成链已经具有单链断裂或“缺口”,因此仅需要裂解支持链即可在支架多核苷酸中提供双链断裂。为了在通用核苷酸在支持链中位于n+3位置时获得这种突出的裂解的双链支架多核苷酸,将支持链在相对于通用核苷酸的特定位置裂解。当在核苷酸位置n+2和n+1之间裂解支架多核苷酸的支持链时,多核苷酸连接分子从支架多核苷酸中释放(参见图1上部左上方所示的结构),除了第一个该循环的核苷酸保持在与裂解的支架多核苷酸的支持链相连的支架多核苷酸中。
磷酸基团应继续在裂解位点连接至裂解的支架多核苷酸的支持链的末端核苷酸。这确保了在下一合成循环的连接步骤中,可以将裂解的支架多核苷酸的支持链连接至多核苷酸连接分子的支持链。进行裂解使得裂解的支架多核苷酸的支持链的末端核苷酸保持可连接基团,优选末端磷酸基团,并且因此不需要进行磷酸化步骤。
因此,在方法版本1中,通用核苷酸在步骤(2),(3)和(4)处位于支持链中的位置n+3,并且在步骤(4)中在核苷酸位置n+2和n+1之间裂解支持链。
优选地,通过裂解核苷酸位置n+2和n+1之间的磷酸二酯键(支持链的相对于通用核苷酸的位置的第一磷酸二酯键,在远离辅助链/靠近引物链的方向上)。
可以通过裂解核苷酸位置n+2和n+1之间的磷酸二酯键的一个酯键来裂解支持链。
优选地,通过相对于核苷酸位置n+2的第一酯键的裂解来裂解支持链。这将具有在裂解位置处在裂解的支架多核苷酸的支持链上保持末端磷酸酯基团的作用。
当通用核苷酸占据位置n+3时,可以采用任何合适的机制来实现在核苷酸位置n+2和n+1之间的支持链的裂解。
如上所述,可通过酶的作用在核苷酸位置n+2和n+1之间裂解支持链。
如上所述,当通用核苷酸占据支持链中的位置n+3时,在核苷酸位置n+2和n+1之间裂解支持链可以通过酶例如核酸内切酶V的作用来进行。
在实例3中以类似方式描述了在由包含在支持链中占据位置n+3的通用核苷酸的序列限定的裂解位点在核苷酸维持n+2和n+1之间裂解支持链的一种机制。所描述的机制是示例性的并且可采用其它机制,其条件是实现上文所描述的裂解布置。
在该示例性机制中,使用核酸内切酶。在示例性方法中,酶是核酸内切酶V。可以使用其他酶、分子或化学物质,只要当通用核苷酸占据支持链中的n+3位时,将支持链在核苷酸n+2和n+1之间裂解即可。
步骤5——脱保护
在本发明的该示例性方法形式以及所有形式中,为了允许将下一个核苷酸并入下一合成循环,必须将可逆终止子基团从第一个核苷酸中移除(脱保护步骤;205)。这可在第一循环的各个阶段执行。在裂解步骤(4)之后,它可以作为方法的步骤(5)进行。然而,脱保护步骤可以在步骤(3)中引入第二核苷酸之后并且在裂解步骤(4)之前进行,在这种情况下,脱保护步骤被定义为步骤(4),并且裂解步骤被定义为步骤(5),如图2所示(分别为204和205)。无论执行哪个保护基步骤,都应在步骤(3)之后首先移除酶和残留的未结合的第二核苷酸,以防止在同一合成循环中多次合并第二核苷酸。
可以通过本领域技术人员已知的任何合适的方式从第一核苷酸中移除可逆终止子基团。例如,可以通过使用化学物质如三(羧乙基)膦(TCEP)进行移除。
另外的循环
在完成第一合成循环之后,可以使用相同的方法步骤进行第二合成循环和其他合成循环。
(在步骤6中)提供前一循环的步骤(4)和(5)的裂解产物作为用于下一合成循环的双链支架多核苷酸。
在下一合成循环和每个其他合成循环的步骤(6)中,将另一个双链多核苷酸连接分子连接至上一个循环的步骤(4)和(5)的裂解产物。所述多核苷酸连接分子可以以与上述对于先前循环的步骤(2)相同的方式构造,不同之处在于,所述多核苷酸连接分子包括另外的合成循环的第一核苷酸。多核苷酸连接分子可以以与上述步骤(2)相同的方式连接至前一循环的步骤(4)和(5)的裂解产物。
在下一个和每个另外的合成循环的步骤(7)中,在核苷酸转移酶、聚合酶或其他酶的作用下,通过合并另外的合成循环的第二核苷酸来进一步延长双链支架多核苷酸合成链的引物链部分的末端。可以按照与上述步骤(3)相同的方式合并进一步合成循环的第二核苷酸。
在合成的下一循环和每个进一步循环的步骤(8)中,在裂解位点裂解连接的支架多核苷酸。裂解引起支架多核苷酸中的双链断裂。支架多核苷酸的裂解(步骤8)引起辅助链的丢失(如果存在并且在裂解前立即与支持链杂交)以及包括通用核苷酸的支持链的丢失。支架多核苷酸的裂解从而从支架多核苷酸释放另外的多核苷酸连接分子,但是引起该另外的循环的第一核苷酸的保持不成对并附接于所裂解的支架多核苷酸的支持链,并且保持了该另外的第二核苷酸,该第二核苷酸连接至裂解的支架多核苷酸的合成链并与配偶体核苷酸配对。支架多核苷酸的裂解将裂解的双链支架多核苷酸留在原位,该双链支架多核苷酸在支架多核苷酸的支持链的末端包括另外的循环的第一核苷酸,并在支架多核苷酸的合成链的引物链部分的末端突出另外的循环的第二核苷酸之外。步骤(8)的裂解可以以与上述步骤(4)相同的方式进行。
在步骤(9)中,将可逆终止子基团从另外的循环的第二核苷酸中移除(脱保护步骤;209)。如上面对于第一循环所述,这可以在各个阶段执行。在裂解步骤(8)之后,它可以作为方法的步骤(9)进行。或者,可以在合并步骤(7)之后且在裂解步骤(8)之前的任何步骤进行脱保护步骤,在这种情况下,将脱保护步骤定义为步骤(8),并将裂解步骤定义为步骤(9),如图2所示(分别为209和210)。通过在下一循环和随后的循环中移除可逆终止基团来进行脱保护可以如上文关于第一合成循环所述进行。
如上文所描述根据需要重复合成循环多次,以合成具有预定核苷酸序列的双链多核苷酸。
合成方法版本2的变体
除了上述方法之外,还提供了合成方法版本2的变体,其中,除了以下变化之外,该方法以与上述合成方法版本2相同的方式执行。
在第一个循环的连接步骤(步骤2)中,多核苷酸连接分子的互补连接端的结构应使通用核苷酸位于支持链上的核苷酸位置n+3+x处,并与寡核苷酸中的配偶体核苷酸配对在互补连接端从辅助链的末端核苷酸移除3+x位的辅助链;其中核苷酸位置n+3是支持链中相对于互补连接端远端方向上核苷酸位置n的第三个核苷酸位置。
在第一循环的裂解步骤(步骤4)中,通用核苷酸取而代之的是在支架多核苷酸的支持链中的核苷酸位置n+3+x,其中核苷酸位置n+3是在靠近辅助链/远离引物链部分的方向上相对于核苷酸位置n的支持链中的第三核苷酸位置;并且在位置n+2和n+1之间裂解支架多核苷酸的支持链。
在第二循环的连接步骤(步骤6)和所有其他循环的连接步骤中,多核苷酸连接分子的互补连接端的结构应使通用核苷酸在支持链中占据核苷酸位置n+3+x,并且与在互补连接端从辅助链的末端核苷酸移除3+x位的配偶体核苷酸配对;其中核苷酸位置n+3是支持链中相对于互补连接端远端方向上核苷酸位置n的第三个核苷酸位置。
最后,在第二循环的裂解步骤(步骤8)和所有其他循环的裂解步骤中,通用核苷酸取而代之的是在支架多核苷酸的支持链中的核苷酸位置n+3+x,其中核苷酸位置n+3是支持链中相对于核苷酸链n在辅助链近侧/引物链部分远端的方向上的第三核苷酸位置;支架多核苷酸的支持链在位置n+2和n+1之间裂解。
在所有这些变型方法中,x是1到10或更大的整数,并且其中x是给定循环序列的步骤(2)、(4)、(6)和(8)中的相同整数。
与版本2的合成方法一样,在基于版本2的变体方法中,应注意的是,在任何给定的循环中,连接后以及合并和裂解步骤中,该循环的第一核苷酸在支持链中占据的核苷酸位置定义为核苷酸位置n+1,并且在完成给定的合成循环后,被裂解的支架多核苷酸的支持链中该循环的第一核苷酸占据的位置被定义为下一合成循环中的核苷酸位置n。
因此,在合成方法版本2的这些特定变体中,裂解位点相对于核苷酸位置n的位置保持恒定,并且通用核苷酸相对于核苷酸位置n的位置通过在靠近辅助链/远离引物链部分的方向上移动通用核苷酸的位置而增加由为x选择的数目确定的核苷酸位置的数目。
这些变体方法的示意图在图3中提供,其中脱保护步骤示为步骤(4),裂解步骤示为步骤(5)。如上所述,可以切换执行这些步骤的顺序。
合成方法版本1和2的其他变体。
除了上述合成方法版本2的变型方法之外,还提供了作为合成方法版本1和2的变型的其他方法。除了下面描述的变化之外,这些方法以与上述合成方法版本1和2相同的方式执行。合成方法版本1和2的这些其他变体根据下面将立即描述的相同通用格式执行。合成方法版本1的其他变体与合成方法版本2的其他变体之间的区别在于通用核苷酸相对于核苷酸位置n的位置。
综合方法版本1和2的其他变体的通用格式。
在第一循环的步骤(1)中,提供支架多核苷酸,使得支架多核苷酸的支持链的靠近引物链部分的末端包括含有1+y核苷酸的多核苷酸突出端。为y选择的数字是一个或多个整数。因此,突出端包括两个或更多个核苷酸。支持链的1+y核苷酸突出于引物链部分的末端核苷酸。
被称为突出端的第一核苷酸的核苷酸在突出端的末端中位于突出端的位置。换句话说,是未配对的核苷酸在支持链中紧挨着核苷酸的核苷酸位置,该核苷酸是引物链部分的末端核苷酸的配偶体核苷酸。突出端的第二核苷酸是未配对的核苷酸,其在接近突出端末端的方向上占据了突出端的第一核苷酸旁边的核苷酸位置。因此,在两个核苷酸的最小突出长度的情况下,突出的第二核苷酸是突出支持链的末端核苷酸。突出端的第一核苷酸占据核苷酸位置n,并且是合并步骤(3)的第一个循环的第二核苷酸的配偶体核苷酸。突出端的第二核苷酸占据核苷酸位置n+1,并且是步骤(7)中合并的下一/第二合成循环的第二核苷酸的配偶体核苷酸。
在第一循环的步骤(2)中,提供多核苷酸连接分子的互补连接端,使得辅助链的末端还包括包括1+y个核苷酸的多核苷酸突出端,其中y为整数,其为一个或多个。因此,互补连接端中的突出端也包括两个或更多个核苷酸。互补连接的辅助链的1+y核苷酸突出于支持链的末端核苷酸,并且是支架多核苷酸的支持链的1+y突出核苷酸的配偶体核苷酸。
在任何给定的合成循环中,就支架多核苷酸和互补连接端的突出端而言,为y选择的数目优选为相同数目。如果是这样,当将多核苷酸连接分子连接至支架多核苷酸时,所有先前突出的核苷酸将与相应的配偶体核苷酸形成对。如果就支架多核苷酸和互补连接端的突出端而言,针对y选择的数目是不同的数目,则优选在多核苷酸连接分子的互补连接端中针对y选择的数目小于针对y选择的数目在支架多核苷酸中。如果是这样,当多核苷酸连接分子与支架多核苷酸连接时,一部分突出的核苷酸将与相应的配偶体核苷酸形成对。这将使邻近缺刻位点的支架多核苷酸的支持链的一个或多个核苷酸不成对。这可以促进转移酶,聚合酶或其他酶在合并/延伸步骤期间接近引物链部分的末端核苷酸。
互补连接端的支持链的末端核苷酸是该循环的第一核苷酸,占据核苷酸位置n+2+x,并且是在合成的第三循环中形成的不同核苷酸对中的配偶体核苷酸。为x选择的数字是零或更大的整数。
为x选择的数目是相对于支架多核苷酸减去一而为y选择的数目。因此,关于支架多核苷酸中的突出端,当y=1时,支架多核苷酸中的突出端的长度为2。支架多核苷酸的末端核苷酸占据位置n+1。如果y=1,则x=0。因此,互补连接端的支持链的末端核苷酸,即该循环的预定序列的第一核苷酸,占据核苷酸位置n+2。关于支架多核苷酸中的突出端,y=2时,支架多核苷酸中的突出端的长度为3。支架多核苷酸的末端核苷酸占据位置n+2。如果y=2,则x=1。因此,互补连接端的支持链的末端核苷酸,即该循环的预定序列的第一核苷酸,占据核苷酸位置n+3,依此类推。
与步骤(2)一样,在步骤(6)中,提供支架多核苷酸,使得支架多核苷酸的支持链的靠近引物链部分的末端包括含有1+y核苷酸的多核苷酸突出端,其中y是一个或多个整数。因此,突出端包括两个或更多个核苷酸。支持链的1+y核苷酸突出于引物链部分的末端核苷酸。
被称为突出端的第一核苷酸的核苷酸在突出端的末端中位于突出端的位置。突出端的第二核苷酸是未配对的核苷酸,其在接近突出端末端的方向上占据了突出端的第一核苷酸旁边的核苷酸位置。因此,在两个核苷酸的最小突出长度的情况下,突出的第二核苷酸是突出支持链的末端核苷酸。突出端的第一核苷酸占据核苷酸位置n,并且是在步骤(7)中并入的当前/第二循环的第二核苷酸的配偶体核苷酸。突出端的第二核苷酸占据核苷酸位置n+1,并且是合成的下一/第三循环的第二核苷酸的配偶体核苷酸。
在步骤(6)中,提供多核苷酸连接分子的互补连接端,使得辅助链的末端还包括包括1+y个核苷酸的多核苷酸突出端,其中y是一个或多个整数。因此,互补连接端中的突出端也包括两个或更多个核苷酸。互补连接的辅助链的1+y核苷酸突出于支持链的末端核苷酸,并且是支架多核苷酸的支持链的1+y突出核苷酸的配偶体核苷酸。
与步骤(2)一样,在任何给定的进一步合成循环中,就支架多核苷酸和互补连接端的突出端而言,步骤(6)中为y选择的数目优选为相同的数目。如果就支架多核苷酸和互补连接端的突出端而言,针对y选择的数目是不同的数目,则优选在多核苷酸连接分子的互补连接端中针对y选择的数目小于针对y选择的数目在支架多核苷酸中。
互补连接端的支持链的末端核苷酸是该循环的第一核苷酸,占据核苷酸位置n+2+x,并且是在第四合成循环中形成的不同核苷酸对中的配偶体核苷酸。为x选择的数字是零或更大的整数。
如前所述,在任何给定的循环或一系列其他循环中,为x选择的数目是相对于支架多核苷酸减去一的y选择的数目。因此,关于支架多核苷酸中的突出端,当y=1时,支架多核苷酸中的突出端的长度为2。支架多核苷酸的末端核苷酸占据位置n+1。如果y=1,则x=0。因此,互补连接端的支持链的末端核苷酸,即该循环的预定序列的第一核苷酸,占据核苷酸位置n+2。关于支架多核苷酸中的突出端,y=2时,支架多核苷酸中的突出端的长度为3。支架多核苷酸的末端核苷酸占据位置n+2。如果y=2,则x=1。因此,互补连接端的支持链的末端核苷酸,即该循环的预定序列的第一核苷酸,占据核苷酸位置n+3,依此类推。
应当注意,在任何给定的循环中,在连接之后以及在结合和裂解步骤期间,该循环的第一核苷酸在支持链中占据的核苷酸位置被定义为核苷酸位置n+2+x,并且在完成给定的合成循环时,在支架多核苷酸的支持链中双核苷酸突出的情况下,被裂解的支架多核苷酸的支持链中该循环的第一个核苷酸占据的位置被定义为下一合成循环中的核苷酸位置n+1在支架多核苷酸的支持链中三核苷酸突出端的情况下,或被定义为下一合成循环中的核苷酸位置n+2,依此类推。
因此,在合成方法版本1和2的这些特定变体中,通用核苷酸的位置和裂解位点相对于核苷酸位置n的位置通过在靠近辅助链/远离引物链部分的方向上移动通用核苷酸的位置和裂解位点的位置而增加由为x选择的数目确定的核苷酸位置的数目。
合成方法版本1的其他变体的特定格式。
本发明另外提供了合成方法版本1的特定的另外的变体。根据上述合成方法版本1和2的其他变体的一般格式以及以下附加功能,执行此变体方法。
在第一个和进一步的循环中,在多核苷酸连接分子中和在连接的支架多核苷酸中,通用核苷酸都占据n+3+x位,并且支架多核苷酸在n+3+x和n+2+x位之间被裂解。
在图4中提供了这些变体方法的图解表示,其中脱保护步骤示为步骤(4),裂解步骤示为步骤(5)。如上所述,可以切换执行这些步骤的顺序。在该图中,竖向双线结构的存在表示在支架多核苷酸的突出支持链和多核苷酸连接分子的互补连接端的突出支持链中都存在一个或多个进一步核苷酸的可能性。支架多核苷酸的突出支持链的末端核苷酸具有末端可连接基团,例如末端磷酸基团。
合成方法版本2的其他变体的特定格式。
本发明另外提供了合成方法版本2的特定的另外的变体。根据上述合成方法版本1和2的其他变体的一般格式以及以下附加功能,执行此变体方法。
在第一和进一步循环中,在多核苷酸连接分子中和在连接的支架多核苷酸中,通用核苷酸都占据n+4+x位,并且支架多核苷酸在n+3+x和n+2+x位之间被裂解。
在图5中提供了这些变体方法的示意图,其中将脱保护步骤示为步骤(4),并且将裂解步骤示为步骤(5)。如上所述,可以切换执行这些步骤的顺序。在该图中,竖向双线结构的存在表示在支架多核苷酸的突出支持链和多核苷酸连接分子的互补连接端的突出支持链中都存在一个或多个进一步核苷酸的可能性。支架多核苷酸的突出支持链的末端核苷酸具有末端可连接基团,例如末端磷酸基团。
合成方法版本1和2的变体,每个循环包括多于两个的核苷酸
本发明进一步提供了另外的另外的变体方法,其中每个循环合并两个以上的核苷酸,包括基于上述特定版本1和2及其变体的其他变体方法。除了可以进行以下修改之外,可以如上所述执行这些任何其他变型方法。
在步骤(2)中,多核苷酸连接分子具有互补连接端,该互补连接端包括第一循环的预定序列的第一核苷酸,并且还包括第一循环的预定序列的一个或多个其他核苷酸。然后将多核苷酸连接分子连接至支架多核苷酸。第一循环的预定序列的第一核苷酸是互补连接端的支持链的末端核苷酸。互补连接端优选地被构造成使得第一循环的预定序列的第一和其他核苷酸包括线性核苷酸序列,其中该序列中的每个核苷酸在互补链远端的方向上在支持链中占据下一个核苷酸位置。
在步骤(3)中,通过核苷酸转移酶或聚合酶的作用,通过合并第一循环的预定序列的第二核苷酸来延长双链支架多核苷酸的合成链的引物链部分的末端。酶,其中引物链部分的末端通过核苷酸转移酶或聚合酶的作用,通过并入第一循环的预定序列的一个或多个其他核苷酸而进一步延伸,其中第二个和第二个第一循环的其他核苷酸包括阻止通过酶进一步延伸的可逆终止子基团,其中在进一步延伸之后,在合并下一个核苷酸之前,在脱保护步骤(步骤4)中从核苷酸上移除可逆终止子基团。
多核苷酸连接分子的互补连接端的结构使得在裂解之前的步骤(4)中,通用核苷酸在支持链中占据一个位置,该位置在互补核苷酸远端的方向上位于第一和其他核苷酸的核苷酸位置之后结扎结束。
在裂解后的步骤(4)中,将第一循环的预定序列的第一、第二和其他核苷酸保持在裂解的支架多核苷酸中。
在步骤(6)中,多核苷酸连接分子具有互补连接端,该互补连接端包括另一循环的预定序列的第一核苷酸,并且还包括另一循环的预定序列的一个或多个其他核苷酸。如步骤(2)中所述,然后将多核苷酸连接分子连接至支架多核苷酸。如在步骤(2)中一样,另外的循环的预定序列的第一核苷酸是互补连接端的支持链的末端核苷酸。互补连接端优选地被结构化,使得另外的循环的预定序列的第一和另外的核苷酸包括线性核苷酸序列,其中该序列中的每个核苷酸在互补链远端的方向上占据支持链中的下一个核苷酸位置。
在步骤(6)中,通过核苷酸转移酶或聚合酶的作用,通过并入进一步循环的预定序列的第二核苷酸来延长双链支架多核苷酸的合成链的引物链部分的末端。酶,其中引物链部分的末端通过核苷酸转移酶或聚合酶的作用通过并入进一步循环的预定序列的一个或多个另外的核苷酸而进一步延伸,其中第二个和第二个所述另外的循环的其他核苷酸包括阻止通过酶进一步延伸的可逆终止子基团,其中在每次进一步延伸后,在合并下一个核苷酸之前,将可逆终止子基团从核苷酸上移除。
在裂解后的步骤(8)中,将另外的循环的预定序列的第一、第二和另外的核苷酸保持在裂解的支架多核苷酸中。
在这些变体方法中,裂解总是在最后的脱保护步骤(步骤4和8)之后按照步骤(5)和(9)进行,除了在任何给定循环中合并的最后的另外核苷酸的可逆终止子基团可以选择地是在裂解位点裂解连接的支架多核苷酸的步骤后,将其从最后的另一个核苷酸中移除。
在这些变体方法中,在任何给定的合成循环中,在裂解之前,在支持链中,预定序列的第一核苷酸占据的位置可以被称为位置n+1,该预定序列的第一个另外的核苷酸在支持链中占据的位置可以被称为位置n+2,并且通用核苷酸占据的位置可以被称为位置n+3+x,其中x是从零到10或更大的整数,其中如果支持链仅包括另外一个核苷酸,则x为零;如果支持链仅包括另外两个核苷酸,则x为一,依此类推。
在这些变体方法中的任何一种中,多核苷酸连接分子的互补连接端的结构使得在裂解之前的步骤(4)和(8)中,通用核苷酸在支持链中占据一个位置,该位置是支持链中沿远离互补连接端的方向在第一个和其他核苷酸的核苷酸位置之后的下一个核苷酸位置,并且在最后一个核苷酸占据的位置与通用核苷酸占据的位置之间裂解支持链。
在图6中提供了这些变体方法的示意图,其中脱保护步骤示为步骤(4),而裂解步骤示为步骤(5)。如上所述,可以相对于待合并的最后一个核苷酸来改变可以执行这些步骤的顺序。图6所示的方法方案基于如上所述的本发明版本1的合成方法的改编,其中支持链在最后的另外的核苷酸占据的位置和通用核苷酸占据的位置之间裂解。
在这些变体方法中的任何一种中,多核苷酸连接分子的互补连接端被交替地构造,使得在裂解之前的步骤(4)和(8)中,通用核苷酸在支持链中占据一个位置,该位置是支持链中沿远离互补连接端的方向在第一个和其他核苷酸的核苷酸位置之后的再下一个核苷酸位置,并且可替代地,在由最后一个另外的核苷酸占据的位置与由支持链中的下一核苷酸占据的位置之间裂解支持链。
基于对本发明版本1的合成方法的修改的图6中所示的方法方案,其中支持链在最后的另外的核苷酸占据的位置和通用核苷酸占据的位置之间裂解,可以同样地进行适配,使得支持物所述链可在支持链中最后一个核苷酸占据的位置与通用核苷酸远端的支持链中下一个核苷酸占据的位置之间裂解。因此,这样的修改将基于如上所述的发明版本2的合成方法。
应当理解,就通用核苷酸相对于核苷酸位置n的位置而言,为了在合成的第一和其他循环中修改其他核苷酸的合并,除了每个第一和第二核苷酸之外,可能需要对多核苷酸连接分子的互补连接端的构型进行常规修改。在本文描述和定义的本发明的所有方法中,核苷酸位置n始终是支持链中的核苷酸位置,该核苷酸位置在合并之前或之后与任何给定循环的预定序列的第二核苷酸相反或将与之相反。因此,本领域技术人员能够容易地对通用核苷酸的位置和相对于核苷酸位置n的裂解位点的选择进行常规修饰,以修改任何方法版本和其变体,以适应对合成的第一和另外的循环的另外的核苷酸的合并。
实例
以下实例对用于合成根据本发明的多核苷酸或寡核苷酸的方法以及用于所述方法的示例性构建体提供支持。实例不限制本发明。
除实例13以外,以下实例描述了根据反应方案的合成方法,该反应方案与本发明的合成方法有关但不在本发明的合成方法的范围内。
实例证明了执行合成反应的能力,所述合成反应包括以下步骤:向支架多核苷酸的合成链中添加预定序列的核苷酸,在由通用核苷酸限定的裂解位点裂解支架多核苷酸并连接多核苷酸连接分子,其包括用于预定序列的添加核苷酸的配偶体核苷酸,以及用于创建裂解位点以用于下一合成循环的新通用核苷酸。本发明的方法以修改的方式结合了这些步骤。因此,除了实例13以外,以下实例提供了对本文定义的本发明方法的说明性支持。实例13提供了与根据本发明方法使用例如本发明1和2的合成方法版本及其变体的合并步骤通过终止子XDNA聚合酶合并3'-O-修饰的-dNTPs的数据(图1至6)。
在以下实例中,以及在对应的图13至图51中,将根据分别在图7、8和9中列出的反应示意图而不是根据图1至6中任何一个所阐述的反应示意图或本文的描述来解释对合成方法“版本1、2和3”或“版本1、2或3化学”等的解释。将根据本发明的合成方法解释实例13和图52。特别地,根据本发明1和2的合成方法及其变体和相关的反应示意图,其在图1至图6中列出,并且更具体地在这种方法中引入步骤3。
实例1:不存在辅助链的合成。
该实例描述了使用4个步骤合成多核苷酸:合并
在部分双链DNA上进行3'-O-修饰的dNTP的裂解,连接和脱保护,第一步是在通用核苷酸(在此情况下为肌苷)的对面进行。
步骤1:合并
第一步描述了通过DNA聚合酶的酶促掺入,可控制地将3'-O保护的单核苷酸添加到寡核苷酸中(图13a)。
材料与方法
材料
1.3’-O-修饰的dNTP根据博士论文中描述的方案内部合成:Jian Wu:MolecularEngineering of Novel Nucleotide Analogues for DNA Sequencing by Synthesis,Columbia University,2008。用于合成的方案还描述于专利申请公开:J.WilliamEfcavitch,Juliesta E.Sylvester,Modified Template-Independent Enzymes forPolydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是在内部设计的,可从Sigma-Aldrich获得(图13h)。以100μM的浓度制备储备溶液。
3.使用终止子IX DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。然而,可以使用任何可以合并修饰的dNTP的DNA聚合酶。
测试了两种类型的可逆终止剂:

方法
1.将2μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与12.25μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与12.25μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将0.5μl的10μM引物(合成链)(5pmol,1当量)(SEQ ID NO:1,图13h)和0.75μl的10μM模板(支持链)(6pmol,1.5当量)(SEQ ID NO:2,图13h)加入到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的终止子IX DNA聚合酶(15U,New England BioLabs)。然而,可以使用任何可以合并修饰的dNTP的DNA聚合酶。
5.将反应物在65℃培育20分钟。
6.将反应物通过加入TBE-尿素样品缓冲液(Novex)停止。
7.将反应物在聚丙烯酰胺凝胶(15%)上用TBE缓冲液分离,并通过ChemiDoc MP成像系统(BioRad)进行可视化。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
结果
来自New England BioLabs的定制工程化终止子IX DNA聚合酶是一种有效的DNA聚合酶,其能够与通用核苷酸例如肌苷相对地合并3’-O-修饰的dNTP(图13b-c)。
相对肌苷有效地合并发生在65℃的温度(图13d-e)。
相对肌苷合并3’-O-修饰的dTTP需要存在Mn2+离子(图13f-g)。成功转换在图13c、e、g和h中以粗体标记。
结论
3-O-修饰的-dTTP与肌苷相对地合并可用New England Biolabs的定制工程化终止子IX DNA聚合酶在Mn2+离子存在下和在65℃的温度下以特别高的效率实现。
步骤2:裂解
第二步描述了用hAAG/Endo VIII或hAAG/化学碱两步裂解多核苷酸(图14a)。
材料与方法
材料
1.实例1中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图14(e)的序列表)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序对寡核苷酸进行裂解反应:
1.用移液管(Gilson)将41μl无菌蒸馏水(ELGA VEOLIA)转移到1.5ml Eppendorf管中。
2.然后将5μl的10X 反应缓冲液NEB(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1%
反应缓冲液NEB(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1% X-100,pH 8.8)加入同一Eppendorf管中。
X-100,pH 8.8)加入同一Eppendorf管中。
3.将1μl每种寡核苷酸(图14e);模板(SEQ ID NO:3)或任何荧光标记的长寡链,具有T(SEQ ID NO:4)的引物和对照(SEQ ID NO:5),均为5pmol添加到同一试管中。
4.将1μl人类烷基腺嘌呤DNA糖基化酶(hAAG)NEB(10单位/μl)添加到同一试管中。
5.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
6.通常在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
在环境条件下纯化。使用下面概述的方案纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将50μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)加入柱膜中心并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop one(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropone。然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
使用以下程序进行产生的无碱基位点的裂解:
1.将2μl(10-100ng/μl)DNA加入无菌的1.5ml Eppendorf管中。
2.在同一试管中加入40μl(0.2M)NaOH或1.5μl Endo VIII NEB(10单位/μl)和5μl的10X反应缓冲液NEB(10mM Tris-HCl,75mM NaCl,1mM EDTA,pH 8@25℃)并通过再悬浮温和混合和在13000rpm离心5秒。
3.将得到的混合物在室温下培育5分钟以使NaOH处理样品,同时将Endo VIII反应混合物在37℃下培育1小时。
4.培育时间过去之后,将反应混合物用如上面概述的纯化方案的步骤1-7纯化。
凝胶电泳和DNA可视化:
1.将5μl的DNA和TBE-尿素样品缓冲液(Novex)加入无菌1.5ml Eppendorf管中,并使用加热热块(Eppendorf)加热至95℃,持续2分钟。
2.然后DNA混合物加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.采用使用Cy3 LEDS的ChemiDoc MP(BioRad)进行检测和DNA在凝胶中的可视化。可视化和分析在Image lab 2.0平台上进行。
结果和结论
没有辅助链的裂解反应显示裂解与未裂解的DNA的比率为约7%:93%的低百分比产率(图14b-d)。
裂解结果显示,在该具体实例中,并且基于所用的特定试剂,与正对照相比,在不存在辅助链的情况下获得了低产率的裂解DNA。此外,与EndoVIII裂解相比,使用化学碱来裂解无碱基位点的时间消耗较少。
步骤3:连接
第三步描述了在不存在辅助链的情况下用DNA连接酶连接多核苷酸。图15中示出了示意图。
材料与方法
材料
1.实例1中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图15c的序列表)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序进行寡核苷酸的连接反应:
1.用移液管(Gilson)将16μl无菌蒸馏水(ELGA VEOLIA)转移到1.5ml Eppendorf管中。
2.然后将10μL的2X快速连接反应缓冲液NEB(132mM Tris-HCl,20mM MgCl2,2mM二硫苏糖醇,2mM ATP,15%聚乙二醇(PEG6000)和pH 7.6,在25℃)加入到相同的Eppendorf管中。
3.将1μl每种寡核苷酸(图15c);TAMRA或任何荧光标记的磷酸链(SEQ ID NO:7),具有T(SEQ ID NO:8)的引物和肌苷链(SEQ ID NO:9),均为5pmol添加到同一试管中。
4.将1μl的Quick T4 DNA连接酶NEB(400单位/μl)加入同一试管中。
5.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
6.通常在培育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。
7.使用如上所述的纯化步骤1-7中概述的方案纯化反应混合物。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGAVEOLIA)到基座平衡NanoDrop one(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropone,然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照上述步骤5-8中的程序可视化。没有引入条件或试剂的变化。
结果和结论
在该具体实例中,并且基于所用的特定试剂,在没有辅助链的情况下,在室温(24℃)下用DNA连接酶(在该特定情况下为快速T4 DNA连接酶)连接寡核苷酸引起减少量的连接产物(图15b)。
实例2利用辅助链的版本1化学法。
该实例描述了使用4个步骤合成多核苷酸:合并
从缺口位点裂解3’-O-修饰的dNTP,连接和脱保护,其中第一步与通用核苷酸相对地进行,在该特定情况下通用核苷酸为肌苷。该方法使用辅助链,其提高了连接和裂解步骤的效率。
步骤1:合并
第一步描述了通过DNA聚合酶的酶合并将3’-O-保护的单核苷酸受控的添加到寡核苷酸中(图16a)。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma-Aldrich获得。以100μM的浓度制备储备溶液。寡核苷酸显示在图16b中。
3.使用终止子IX DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。
测试了两种类型的可逆终止剂:

方法
1.2μl的10X 缓冲液(20mM的Tris-HCl,10mM的(NH4)2SO4,10mM KCl,在1.5ml Eppendorf管中,将2mM MgSO4、0.1%X-100,pH 8.8(New England BioLabs)与10.25μl无菌去离子水(ELGA VEOLIA)混合。
缓冲液(20mM的Tris-HCl,10mM的(NH4)2SO4,10mM KCl,在1.5ml Eppendorf管中,将2mM MgSO4、0.1%X-100,pH 8.8(New England BioLabs)与10.25μl无菌去离子水(ELGA VEOLIA)混合。
2.将0.5μl的10μM引物(5pmol,1当量)(SEQ ID NO:10,图16(b)中的表),0.75μl的10μM模板(6pmol,1.5当量)(SEQ ID NO:11,图16(b)中的表),2μl的10μM的辅助链(SEQ IDNO:12,图16(b)中的表)加入反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的终止子IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在65℃培育20分钟。
6.将反应物通过加入TBE-尿素样品缓冲液(Novex)停止。
7.将反应物在聚丙烯酰胺凝胶(15%)上用TBE缓冲液分离,并通过ChemiDoc MP成像系统(BioRad)进行可视化。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
可以根据上述方案研究合并步骤。
步骤2:裂解
第二步描述了用hAAG/Endo VIII或hAAG/化学碱(x2)两步裂解多核苷酸(图17a)。
材料与方法
材料
1.实例2中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图17f序列)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序进行寡核苷酸的裂解反应:
1.用移液管(Gilson)将41μl无菌蒸馏水(ELGAVEOLIA)转移到1.5ml Eppendorf管中。
2.然后将5μl的10X 反应缓冲液NEB(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1%
反应缓冲液NEB(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1% X-100,pH 8.8)加入同一Eppendorf管中。
X-100,pH 8.8)加入同一Eppendorf管中。
3.将1μl每种寡核苷酸(图17f);模板(SEQ ID NO:13)或任何荧光标记的长寡链,具有T(SEQ ID NO:14)的引物,对照(SEQ ID NO:15)和辅助链(SEQ ID NO:16),均为5pmol添加到同一试管中。
4.将1μl人类烷基腺嘌呤DNA糖基化酶(hAAG)NEB(10单位/μl)加入同一试管中。
5.在使用替代碱的反应中,加入1μl的人类烷基腺嘌呤DNA糖基化酶(hAAG)NEB(100单位/μl)。
6.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
7.通常在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
在环境条件下纯化。使用下面概述的方案纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将50μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)加入柱膜中心并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop one(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropone。然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
使用以下程序进行产生的无碱基位点的裂解:
1.将2μl(10-100ng/μl)DNA加入无菌的1.5ml Eppendorf管中。
2.在同一试管中加入40μl(0.2M)NaOH或1.5μl Endo VIII NEB(10单位/μl)和5μl的10X反应缓冲液NEB(10mM Tris-HCl,75mM NaCl,1mM EDTA,pH 8@25℃)并通过再悬浮温和混合和在13000rpm离心5秒。
3.将得到的混合物在室温下培育5分钟以使0.2M NaOH处理样品,同时将EndoVIII反应混合物在37℃下培育1小时。
4.培育时间过去之后,将反应混合物用如上面所述的纯化方案的步骤1-7纯化。
使用以下程序进行使用替代碱性化学品的产生的无碱基位点的裂解:
1.将1μl(10-100ng/μl)DNA加入无菌的1.5ml Eppendorf管中。然后将在室温下用乙酸溶液sigma(99.8%)缓冲至pH7.4的2μl的N,N'-二甲基乙二胺Sigma(100mM)加入同一试管中。
2.将20μl无菌蒸馏水(ELGA VEOLIA)加入管中,通过重悬浮轻轻混合和在13000rpm离心5秒。
3.将所得混合物在37℃下培育20分钟。
4.培育时间过去之后,将反应混合物用如上面所述的纯化方案的步骤1-7纯化。
凝胶电泳和DNA可视化:
1.将5μl的DNA和TBE-尿素样品缓冲液(Novex)加入无菌1.5ml Eppendorf管中,并使用加热热块(Eppendorf)加热至95℃,持续2分钟。
2.然后DNA混合物加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.采用使用Cy3 LEDS的ChemiDoc MP(BioRad)进行检测和DNA在凝胶中的可视化。可视化和分析在Image lab 2.0平台上进行。
结果
通过hAAG DNA糖基化酶在包括通用核苷酸(在该特定情况下为肌苷)的裂解位点处的裂解效率从辅助链不存在时的10%显著增加至辅助链存在下的50%(图17b)。hAAG和核酸内切酶VIII以比hAAG和NaOH(50%)更低的效率(10%)裂解肌苷。在使用带切口的DNA的所述系统中,使用0.2M NaOH的化学裂解显示对于AP位点的裂解优于核酸内切酶VIII(图17c)。在中性pH下的温和N,N'-二甲基乙二胺具有如0.2M NaOH高的效率裂解无碱基位点,并因此与核酸内切酶VIII和NaOH相比是优选的(图17d-e)。
结论
对于裂解含有肌苷的DNA,评估了三种方法。在实例2中对于DNA裂解研究了一种完全的酶促方法-hAAG/核酸内切酶VIII,以及两种结合化学和酶促裂解的方法-hAAG/NaOH和hAAG/二甲基乙胺。
hAAG/NaOH结果显示,与不存在辅助链(10%)相比,在辅助链存在下裂解DNA的产率(50%)高得多。在这些具体的实例中,并且基于所用的特定试剂,辅助链增加了DNA裂解的产率。
在辅助链存在下,与NaOH(50%)相比,使用核酸内切酶VIII作为NaOH的替代物的酶促裂解效率较低(10%)。
包括替代的温和化学碱N,N'-二甲基乙二胺引起AP位点的高裂解效率,与NaOH一样有效,并且与添加10x hAAG酶一起对裂解的DNA具有显著增加(参见图17e)。
步骤3:连接
第三步描述了在辅助链存在下用DNA连接酶连接多核苷酸。图18a中示出了图解说明。
材料与方法
材料
1.寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图18d序列)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序进行寡核苷酸的连接反应:
1.用移液管(Gilson)将16μl无菌蒸馏水(ELGA VEOLIA)转移到1.5ml Eppendorf管中。
2.然后将10μL的2X快速连接反应缓冲液NEB(132mM Tris-HCl,20mM MgCl2,2mM二硫苏糖醇,2mM ATP,15%聚乙二醇(PEG6000)和pH 7.6,在25℃)加入到相同的Eppendorf管中。
3.将1μl每种寡核苷酸(图18d);TAMRA或任何荧光标记的磷酸酯链(SEQ ID NO:18),具有T(SEQ ID NO:19)和肌苷链(SEQ ID NO:20)和辅助链(SEQ ID NO:21)的引物,均为5pmol加入到同一试管中。
4.将1μl的Quick T4 DNA连接酶NEB(400单位/μl)加入同一试管中。
5.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
6.通常在培育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。
7.使用如上所述的纯化步骤1-7中概述的方案纯化反应混合物。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop one(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropone。然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照上述步骤5-8中的程序可视化。没有引入条件或试剂的变化。
结果和结论
在所述具体实例中,并且基于所使用的特定试剂,在没有辅助链的情况下观察到降低的连接活性(图18b),而在辅助链存在下连接以高效率进行(图18c)并且产物以高产率形成。
实例3利用辅助链的版本2化学法.
该实例描述了使用4个步骤合成多核苷酸:在部分双链DNA上合并3’-O-修饰的dNTP;在第一步合并与天然互补核苷酸相对地进行的情况下裂解、连接和脱保护,该天然互补核苷酸位于支持链中与通用核苷酸相邻,在该特定情况下通用核苷酸为肌苷。
步骤1:合并
材料与方法
材料
第一步描述了通过DNA聚合酶的酶合并将3’-O-保护的单核苷酸受控的添加到寡核苷酸中(图19a)。
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma-Aldrich获得(图19j)。以100μM的浓度制备储备溶液。
3.使用终止子IX DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。
所有dNTP的3'-O-叠氮甲基可逆终止子独立测试其合并:

方法
1.将2μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与12.25μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与12.25μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将0.5μl的10μM引物(5pmol,1当量)(SEQ ID NO:22,图19j)和0.75μl的10μM模板-A/G/T/C(6pmol,1.5当量)(SEQ ID NOS:23-26,图19j)以及1μl的10μM辅助链-T/C/A/G(10pmol,2当量)(SEQ ID NOS:27-30,图19j)加入反应混合物中。
3.加入3’-O-修饰的-dTTP/dCTP/dATP/dGTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的Therminator IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在65℃培育20分钟。
6.将反应物通过加入TBE-尿素样品缓冲液(Novex)停止。
7.将反应物在聚丙烯酰胺凝胶(15%)上用TBE缓冲液分离,并通过ChemiDoc MP成像系统(BioRad)进行可视化。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
结果和结论
关于使用终止子IX DNA聚合酶评估3-O-叠氮甲基-dTTP合并温度,结果表明在5分钟后,在用于连接的辅助链存在下的3'-O-叠氮甲基-dTTP达到90%。在37℃和47℃下20分钟后,10%的引物保持未延伸。
终止子IX DNA聚合酶在2mM的Mn2+离子和37℃的温度下提供了在辅助链的存在下与DNA中互补碱基相对地高效率(从前一个循环开始的连接步骤)合并3’-O-修饰的dNTP的良好条件。
步骤2:裂解
第二步描述了用核酸内切酶V一步裂解多核苷酸(图20a)。
材料与方法
材料
1.实例3中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图20b的序列表)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序进行寡核苷酸的裂解反应:
1.用移液管(Gilson)将41μl无菌蒸馏水(ELGA VEOLIA)转移到1.5ml Eppendorf管中。
2.然后将5μ1的10X Reaction  NEB(50mM的醋酸钾、20mM的Tris-乙酸盐、10mM的醋酸镁、1mM的DTT,pH值7.9在25℃下)加入到相同的Eppendorf管中。
NEB(50mM的醋酸钾、20mM的Tris-乙酸盐、10mM的醋酸镁、1mM的DTT,pH值7.9在25℃下)加入到相同的Eppendorf管中。
3.将1μl每种寡核苷酸(图20d);模板(SEQ ID NO:31)或任何荧光标记的长寡链,具有T的引物(SEQ ID NO:32)和对照(SEQ ID NO:33)以及辅助链(SEQ ID NO:34),均为5pmol加入到同一试管中。
4.将1μl人类核酸内切酶V(Endo V)NEB(10单位/μl)加入到同一试管中。
5.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
6.通常在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
使用下面概述的方案纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将50μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)加入柱膜中心并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop one(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropone。然后在掩蔽后重复步骤2。
4.通过将2μl样品加到基座上并在触摸屏上选择测量图标来测量DNA浓度。凝胶电泳和DNA可视化:
1.将5μl的DNA和TBE-尿素样品缓冲液(Novex)加入无菌1.5ml Eppendorf管中,并使用加热热块(Eppendorf)加热至95℃,持续2分钟。
2.然后DNA混合物加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.采用使用Cy3 LEDS的ChemiDoc MP(BioRad)进行检测和DNA在凝胶中的可视化。可视化和分析在Image lab 2.0平台上进行。
结果和结论
来自实例3的裂解结果显示,在存在或不存在辅助链的情况下,核酸内切酶V可以获得显著高的裂解DNA产量(图20c)。
步骤3:连接
第三步描述了在辅助链存在下用DNA连接酶连接多核苷酸。图21a中示出了图解说明。
材料与方法
材料
1.实例3中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图21b的序列表)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序进行寡核苷酸的连接反应:
1.用移液管(Gilson)将16μl无菌蒸馏水(ELGA VEOLIA)转移到1.5ml Eppendorf管中。
2.然后将10μL的2X快速连接反应缓冲液NEB(132mM Tris-HCl,20mM MgCl2,2mM二硫苏糖醇,2mM ATP,15%聚乙二醇(PEG6000)和pH 7.6,在25℃)加入到相同的Eppendorf管中。
3.将1μl每种寡核苷酸(图21b);TAMRA或任何荧光标记的磷酸酯链(SEQ ID NO:35),具有T(SEQ ID NO:36)的引物和肌苷链(SEQ ID NO:37)和辅助链(SEQ ID NO:38),均为5pmol加入到同一试管中。
4.将1μl的Quick T4 DNA连接酶NEB(400单位/μl)加入同一试管中。
5.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
6.通常在培育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。
7.使用如上所述的纯化步骤1-7中概述的方案纯化反应混合物。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop one(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropone。然后在掩蔽后重复步骤2。
4.通过将2μl样品加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照上述步骤5-8中的程序可视化。没有引入条件或试剂的变化。
凝胶电泳和DNA可视化:
1.将5μl的DNA和TBE-尿素样品缓冲液(Novex)加入无菌1.5ml Eppendorf管中,并使用加热热块(Eppendorf)加热到95℃,持续2分钟。
2.然后DNA混合物加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.采用使用Cy3 LEDS的ChemiDoc MP(BioRad)进行检测和DNA在凝胶中的可视化。可视化和分析在Image lab 2.0平台上进行。
步骤4:脱保护
在DNA模型上研究了脱保护步骤(图22a),该模型带有由通过终止子IX DNA聚合酶合并3'-O-叠氮甲基-dNTP引入到DNA的3′-O-叠氮甲基基团。通过三(羧乙基)膦(TCEP)进行去除保护基,并且当将所有天然dNTP的混合物加入到纯化的去除保护基DNA的溶液中时通过延伸反应进行监测。
材料与方法
材料
1.实例3中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图22i序列)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
3.酶购自New England BioLabs。
方法
1.将2μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与12.25μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与12.25μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将1μl的10μM引物(10pmol,1当量)(SEQ ID NO:39,图22i)和1.5μl的10μM模板-A/G/T/C(15pmol,1.5当量)(SEQ ID NO:40-43,图22i)加入反应混合物中。
3.加入3’-O-修饰的-dTTP/dCTP/dATP/dGTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的Therminator IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在37℃培育5分钟。
6.取出4μL样品并与0.5μL的l5mM dNTP混合物混合并使其反应10分钟以进行对照反应。
7.将在1M TRIS缓冲液pH 7.4中的40μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
8.通过用20μL的1x 缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
9.将1μL的5mM dNTP混合物和1μL的DeepVent(exo-)DNA聚合酶加入到纯化的反应混合物中并使其反应10分钟。
10.将反应物通过加入TBE-尿素样品缓冲液(Novex)停止。
11.将反应物在聚丙烯酰胺凝胶(15%)上用TBE缓冲液分离,并通过ChemiDoc MP成像系统(BioRad)进行可视化。
结果和结论
50mM TCEP不足以在0.2μM DNA模型上高效裂解3'-O-叠氮甲基(图22h)。相反,300mM TCEP成功地在0.2μM DNA模型上以95%的效率裂解3'-O-叠氮甲基(图22h)。
实例4利用双发夹模型的版本2化学法。
该实例描述了使用4个步骤在双发夹模型上合成多核苷酸:从切口位点合并3’-O-修饰的dNTP;在第一步在与天然互补核苷酸相对地发生的情况下裂解、连接和脱保护,该天然互补核苷酸位于支持链中与通用核苷酸相邻,在该特定情况下通用核苷酸为肌苷。
步骤1:合并
第一步描述了通过DNA聚合酶的酶合并将3’-O-保护的单核苷酸受控的添加到寡核苷酸中(图23a)。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma-Aldrich获得(图23c)。以100μM的浓度制备储备溶液。
3.使用终止子IX DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。
测试3'-O-叠氮甲基-dTTP的合并:
3'-O-叠氮甲基-dTTP:

方法
1.2μl的10X 缓冲液(20mM的Tris-HCl,10mM的(NH4)2SO4,10mM KCl,在1.5ml Eppendorf管中,将2mM MgSO4、0.1%X-100,pH 8.8(New England BioLabs)与10.25μl无菌去离子水(ELGA VEOLIA)混合。
缓冲液(20mM的Tris-HCl,10mM的(NH4)2SO4,10mM KCl,在1.5ml Eppendorf管中,将2mM MgSO4、0.1%X-100,pH 8.8(New England BioLabs)与10.25μl无菌去离子水(ELGA VEOLIA)混合。
2.将0.5μl的10μM发夹寡核苷酸(5pmol,1当量)(SEQ ID NO:44,图23c)加入到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的终止子IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在65℃培育20分钟。
6.将反应物通过加入TBE-尿素样品缓冲液(Novex)停止。
7.将反应物在聚丙烯酰胺凝胶(15%)上用TBE缓冲液分离,并通过ChemiDoc MP成像系统(BioRad)进行可视化。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
结果
DNA聚合酶在发夹构建体中合并与其天然互补碱基相对的3’-O-修饰的dTTP。
步骤2:裂解
第二步描述了用核酸内切酶V在此特定情况下一步裂解发夹模型(图24a)。
材料与方法
材料
1.实例4中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图24c序列)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
发夹寡核苷酸的裂解反应使用以下步骤进行:
1.用移液管(Gilson)将43μl无菌蒸馏水(ELGA VEOLIA)转移到1.5ml Eppendorf管中。
2.然后将5μl的10X Reaction  NEB(50mM的醋酸钾,20mM的Tris-乙酸盐,10mM的醋酸镁,1mM的DTT,pH值7.9在25℃下)加入到相同的Eppendorf管中。
NEB(50mM的醋酸钾,20mM的Tris-乙酸盐,10mM的醋酸镁,1mM的DTT,pH值7.9在25℃下)加入到相同的Eppendorf管中。
3.将具有5pmol量的1μl发夹寡核苷酸(SEQ ID NO:45,图24c)加入同一试管中。
4.将1μl人类核酸内切酶V(Endo V)NEB(30单位/μl)加入到同一试管中。
5.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
6.通常在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
使用下面概述的方案纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将50μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)加入柱膜中心并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop One(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropOne。然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
凝胶电泳和DNA可视化:
1.将5μl的DNA和TBE-尿素样品缓冲液(Novex)加入无菌1.5ml Eppendorf管中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续2分钟。
2.然后DNA混合物加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.采用使用Cy3 LEDS的ChemiDoc MP(BioRad)进行检测和DNA在凝胶中的可视化。可视化和分析在Image lab 2.0平台上进行。
结果和结论
来自实例4的裂解结果显示,使用核酸内切酶V在37℃下获得了显著高的消化的发夹DNA产率(图24b)。
步骤3:连接
第三步描述了用DNA连接酶连接发夹模型。示意图如图25a所示。
材料与方法
材料
1.实例4中使用的寡核苷酸是内部设计的并由Sigma Aldrich合成(参见图25c序列)。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法
使用以下程序进行寡核苷酸的连接反应:
1.使用移液管(Gilson)将1μl(5pmol)TAMRA或任何荧光标记磷酸发夹寡核苷酸(SEQ ID NO:46)转移入1.5ml Eppendorf管中。
2.然后将15μl(100pmol)含肌苷的发夹构建体(SEQ ID NO:47)加入到相同的管中,并通过用移液管重悬浮轻轻混合3秒。
3.将40μl的Blunt/TA DNA连接酶NEB(180单位/μl)加入同一试管中。
4.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
5.通常在温育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。
6.使用上面的纯化步骤1-7中概述的方案纯化反应混合物。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop One(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropOne。然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照上述步骤5-8中的方法可视化。没有引入条件或试剂的变化。
凝胶电泳和DNA可视化。
1.将5μl的DNA和TBE-尿素样品缓冲液(Novex)加入无菌1.5ml Eppendorf管中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续2分钟。
2.然后DNA混合物加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.采用使用Cy3 LEDS的ChemiDoc MP(BioRad)进行检测和DNA在凝胶中的可视化。可视化和分析在Image lab 2.0平台上进行。
结果
在辅助链的存在下,在室温(24℃)下用发夹/TA DNA连接酶连接发夹寡核苷酸,得到高产率的连接产物。1分钟后连接的发夹寡核苷酸显示出高产率的连接DNA产物,比率为约85%。2分钟后连接的发夹寡核苷酸显示出高产率的连接DNA,比率为约85%。3分钟后连接的发夹寡核苷酸显示出高产率的连接DNA产物,比率为约85%。4分钟后连接的发夹寡核苷酸显示高产率的连接DNA产物,比率为约>85%(图25b)。
实例5.版本2化学法——双发夹模型的完整循环。
该实例描述了使用4个步骤在双发夹模型上合成多核苷酸:从切口位点合并3’-O-修饰的dNTP;在第一步在与天然互补核苷酸相对地发生的情况下裂解、连接和脱保护,该天然互补核苷酸位于支持链中与通用核苷酸相邻,在该特定情况下通用核苷酸为肌苷。发夹的一端用作附接锚。
该方法首先是通过DNA聚合酶的酶合并,然后肌苷裂解、连接和脱保护,将3'-O-保护的单核苷酸受控的添加到寡核苷酸中(图26a)。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma-Aldrich获得(图26c)。以100μM的浓度制备储备溶液。
3.使用终止子IX DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。
测试3'-O-叠氮甲基-dTTP的合并:
3'-O-叠氮甲基-dTTP:

方法
1.将2μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与12.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与12.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将2μl的10μM双发夹模型寡核苷酸(20pmol,1当量)(SEQ ID NO:48,图26c)加入到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的终止子IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在37℃培育10分钟。
6.从反应混合物取出等分试样(5μL),以及加入0.5μl的天然dNTP混合物并使其反应10分钟。通过凝胶电泳分析反应。
7.使用纯化步骤1-7中概述的方案纯化反应混合物。
8.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
9.将1μl人类核酸内切酶V(Endo V)NEB(30单位/μl)加入到同一试管中。
10.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
11.在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
12.将等分试样(5μL)从反应混合物取出,并在使用TBE缓冲液的聚丙烯酰胺凝胶(15%)上分析,并用ChemiDoc MP成像系统(BioRad)进行可视化。
13.使用上面纯化步骤1-7中概述的方案纯化反应混合物。
14.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
15.将10μl用于连接的100μM链(1nmol)(SEQ ID NO:49,图26c)加入到反应混合物中。
16.将40μl的Blunt/TA DNA连接酶NEB(180单位/μl)加入到纯化的DNA样品中。
17.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
18.将在1M TRIS缓冲液pH 7.4中的40μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
19.通过用20μL的1x 缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90Amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop One(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropOne。然后在掩蔽后重复步骤2。
4.通过将2μl样品添加到基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照章节2步骤5-8中的程序可视化。没有引入条件或试剂的变化。
使用下面概述的方案在每个步骤后纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将20μl适当的反应缓冲液加入到柱膜中心,并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。
结果
DNA聚合酶在双发夹构建体中合并与其天然互补碱基相对的3'-O-修饰的dTTP(图26b)。
实例6.版本2化学法——使用辅助链的单发夹模型的完整循环。
该实例描述了使用4个步骤在单发夹模型上合成多核苷酸:从切口位点合并3’-O-修饰的dNTP;在第一步在与天然互补碱基相对地发生的情况下裂解、连接和脱保护。DNA合成在该过程中使用辅助链。
该方法首先是通过DNA聚合酶的酶合并,然后肌苷裂解、连接和脱保护,将3'-O-保护的单核苷酸受控的添加到寡核苷酸中(图27a)。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma Aldrich获得(图27b)。以100μM的浓度制备储备溶液。
3.使用终止子IX DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。
测试3'-O-叠氮甲基-dTTP的合并:
3'-O-叠氮甲基-dTTP:

方法
1. 2μl的10X 缓冲液(20mM的Tris-HCl,10mM的(NH4)2SO4,10mM KCl,在1.5ml Eppendorf管中,将2mM MgSO4,0.1%X-100,pH 8.8(New England BioLabs)与12.5μl无菌去离子水(ELGA VEOLIA)混合。
缓冲液(20mM的Tris-HCl,10mM的(NH4)2SO4,10mM KCl,在1.5ml Eppendorf管中,将2mM MgSO4,0.1%X-100,pH 8.8(New England BioLabs)与12.5μl无菌去离子水(ELGA VEOLIA)混合。
2.将2μl的10μM单发夹模型寡核苷酸(20pmol,1当量)(SEQ ID NO:50,图27b)和辅助链(30pmol,1.5当量)(SEQ ID NO:51,图27b)加入到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的终止子IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在37℃培育10分钟。
6.从反应混合物取出等分试样(5μL),以及加入0.5μl的天然dNTP混合物并使其反应10分钟。通过凝胶电泳分析反应。
7.使用上面纯化步骤1-7中概述的方案纯化反应混合物。
8.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
9.将1μl人类核酸内切酶V(Endo V)NEB(30单位/μl)加入到同一试管中。
10.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
11.在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
12.将等分试样(5μL)从反应混合物取出,并在使用TBE缓冲液的聚丙烯酰胺凝胶(15%)上分析,并用ChemiDoc MP成像系统(BioRad)进行可视化。
13.使用上面纯化步骤1-7中概述的方案纯化反应混合物。
14.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
15.将用于连接的10μl的100μM链(1nmol)(SEQ ID NO:52,图27b)和用于连接的10μl的100μM辅助链(1nmol)(SEQ ID NO:53,图27b)加入到反应混合物中。
16.将40μl的Blunt/TA DNA连接酶NEB(180单位/μl)加入同一试管中。
17.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
18.将在1M TRIS缓冲液pH 7.4中的40μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
19.通过用20μL的1x NEB 缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
20.通常在培育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop One(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropOne。然后在掩蔽后重复步骤2。
4.通过将2μl样品加在基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照上述步骤5-8中的程序可视化。没有引入条件或试剂的变化。
使用下面概述的方案在每个步骤后纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将20μl适当的反应缓冲液加入到柱膜中心,并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。
实例7.版本3化学法——双发夹模型的完整循环。
该实例描述了使用4个步骤在双发夹构建体模型上合成多核苷酸:从切口位点合并3’-O-修饰的dNTP;在第一步在与通用核苷酸相邻(在该特定情况下是苷酸)相对地发生的情况下裂解、连接和脱保护。
该方法首先是通过DNA聚合酶的酶合并,然后肌苷裂解、连接和脱保护,将3'-O-保护的单核苷酸受控的添加到寡核苷酸中(图28a)。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma-Aldrich获得(图28b)。以100μM的浓度制备储备溶液。
3.其由New England BioLabs工程化的终止子IX DNA聚合酶具有增强的合并3-O-修饰的dNTP的能力。
测试3'-O-叠氮甲基-dTTP的合并:
3'-O-叠氮甲基-dTTP:

方法
1.将2μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与12.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与12.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将2μl的10μM双发夹模型寡核苷酸(20pmol,1当量)(SEQ ID NO:54,图28b)加入到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的终止子IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在37℃培育10分钟。
6.从反应混合物取出等分试样(5μL),以及加入0.5μl的天然dNTP混合物并使其反应10分钟。通过凝胶电泳分析反应。
7.使用纯化步骤1-7中概述的方案纯化反应混合物。
8.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
9.将1μl人类核酸内切酶V(Endo V)NEB(30单位/μl)加入到同一试管中。
10.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
11.在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
12.将等分试样(5μL)从反应混合物取出,并在使用TBE缓冲液的聚丙烯酰胺凝胶(15%)上分析,并用ChemiDoc MP成像系统(BioRad)进行可视化。
13.使用上面纯化步骤1-7中概述的方案纯化反应混合物。
14.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
15.将10μl用于连接的100μM链(1nmol)(SEQ ID NO:55,图28b)加入到反应混合物中。
16.将40μl的Blunt/TA DNA连接酶NEB(180单位/μl)加入同一试管中。
17.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
18.将在1M TRIS缓冲液pH 7.4中的40μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
19.通过用20μL的1x NEB 缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
缓冲液洗脱,使用QIAGEN核苷酸移除试剂盒纯化反应混合物。
20.通常在培育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。
凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并在以下条件下进行电泳;260V,90amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop One(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropOne。然后在掩蔽后重复步骤2。
4.通过将2μl样品加在基座上并在触摸屏上选择测量图标来测量DNA浓度。
5.将纯化的DNA在聚丙烯酰胺凝胶上运行,并按照章节2步骤5-8中的程序可视化。没有引入条件或试剂的变化。
使用下面概述的方案在每个步骤后纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将20μl适当的反应缓冲液加入到柱膜中心,并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。测量洗脱的DNA浓度并储存在-20℃下以备后用。
实例8.版本2化学法——双发夹模型的完整双循环实验。
该实例描述了在双发夹模型上使用4个步骤合成多核苷酸的完整双循环实验:从切口位点合并3'-O-修饰的dNTP;在第一步在与互补碱基相对地发生的情况下脱保护、裂解和连接。
该方法首先是通过DNA聚合酶的酶合并,然后脱保护、肌苷裂解和连接,将3'-O-保护的单核苷酸受控地加入寡核苷酸,如图29a所示的第一个循环的反应示意图所示。图29b示出了第二循环的反应示意图。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis.Columbia University,2008.用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Sigma-Aldrich获得(图29d)。以100μM的浓度制备储备溶液。
3.其由New England BioLabs工程化的终止子IX DNA聚合酶具有增强的合并3’-O-修饰的dNTP的能力。
3’-O-叠氮甲基-dTTP和3'-O-叠氮甲基-dCTP被用于合并:

方法
第1循环:
1.将2μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与12.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与12.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将2μl的10μM双发夹模型寡核苷酸(20pmol,1当量)(SEQ ID NO:56,图29d)加入到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(1μl的40mM)。
4.然后加入1.5μl的Therminator IX DNA聚合酶(15U,New England BioLabs)。
5.将反应物在37℃培育10分钟。
6.从反应混合物取出等分试样(5μL),以及加入0.5μl的天然dNTP混合物并使其反应10分钟。通过凝胶电泳分析反应。
7.将在1M TRIS缓冲液pH 7.4中的40μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
8.使用纯化步骤1-7中概述的方案纯化反应混合物。
9.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mMDTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
10.将1μl人类核酸内切酶V(Endo V)NEB(30单位/μl)加入到同一试管中。
11.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
12.在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
13.将等分试样(5μL)从反应混合物取出,并在使用TBE缓冲液的聚丙烯酰胺凝胶(15%)上分析,并用ChemiDoc MP成像系统(BioRad)进行可视化。
14.使用QIAGEN核苷酸移除试剂盒,使用纯化步骤1-7中概述的方案纯化反应混合物。
15.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
16.将10μl用于连接的100μM链(1nmol)(SEQ ID NO:57,图29d)加入到反应混合物中。
17.将40μl的Blunt/TA DNA连接酶NEB(180单位/μl)加入同一试管中。
18.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育20分钟。
19.使用纯化步骤1-5中概述的方案,通过链酶抗生物素蛋白磁珠试剂盒纯化反应混合物。
20.未连接的寡核苷酸用λ核酸外切酶消化。
21.使用QIAGEN核苷酸移除试剂盒,使用纯化步骤1-7中概述的方案纯化反应混合物。
22.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。第2循环:
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。第2循环:
23.加入3’-O-修饰的-dCTP(2μl的100μM)和MnCl2(1μl的40mM)。
24.然后加入1.5μl的Therminator IX DNA聚合酶(15U,New England BioLabs)。
25.将反应物在37℃培育10分钟。
26.从反应混合物取出等分试样(5μL),以及加入0.5μl的天然dNTP混合物并使其反应10分钟。通过凝胶电泳分析反应。
27.将在1M TRIS缓冲液pH 7.4中的40μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
28.使用纯化步骤1-7中概述的方案纯化反应混合物。
29.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
30.将1μl人类核酸内切酶V(Endo V)NEB(30单位/μl)加入到同一试管中。
31.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在37℃培育1小时。
32.在培育时间过去之后,将反应物通过酶促热失活(即65℃下20分钟)终止。
33.将等分试样(5μL)从反应混合物取出,并在使用TBE缓冲液的聚丙烯酰胺凝胶(15%)上分析,并用ChemiDoc MP成像系统(BioRad)进行可视化。
34.使用纯化步骤1-7中概述的方案纯化反应混合物。
35.通过20μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
36.将10μl用于连接的100μM链(1nmol)(SEQ ID NO:58,图29d)加入到反应混合物中。
37.将40μl的Blunt/TA DNA连接酶NEB(180单位/μl)加入同一试管中。
38.然后将反应混合物通过用移液管重悬温和混合,13,000rpm下离心5秒钟并在室温培育10分钟。
39.在培育时间过去后,加入TBE-尿素样品缓冲液(Novex)终止反应。凝胶电泳和DNA可视化:
1.在无菌1.5ml Eppendorf管中将5μl反应混合物加入5μl的TBE-尿素样品缓冲液(Novex)中,并使用加热ThermoMixer(Eppendorf)加热至95℃,持续5分钟。
2.然后将5μl样品加载到15%TBE-尿素凝胶1.0mm x 10孔(Invitrogen)的孔中,该凝胶含有预热的1X TBE缓冲液Thermo Scientific(89mM Tris,89mM硼酸和2mM EDTA)。
3.将X-cell sure lock模块(Novex)固定到位并通过应用以下条件下进行电泳;260V,90amp,室温下40分钟。
4.将凝胶通过使用Cy3 LEDS的ChemiDoc MP(BioRad)可视化。可视化和分析在Image lab 2.0平台上进行。
使用以下方案测定纯化的DNA浓度:
1.加入2μl灭菌蒸馏水(ELGA VEOLIA)到基座平衡NanoDrop One(ThermoScientific)。
2.平衡后,用不起毛的镜片清洁纸(Whatman)轻轻擦去水。
3.通过加入2μl缓冲液EB QIAGEN(10mM Tris.CL,pH 8.5)掩蔽(blank)NanoDropOne。然后在掩蔽后重复步骤2。
4.通过将2μl样品加在基座上并在触摸屏上选择测量图标来测量DNA浓度。使用下面概述的方案,通过QIAGEN核苷酸移除试剂盒纯化样品混合物:
1.将500μl缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
2.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
3.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
4.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
5.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
6.对于DNA洗脱,将20μl适当的反应缓冲液加入到柱膜中心,并在室温下静置1分钟。
7.然后将管以13000rpm离心1分钟。
在连接步骤后,使用链酶抗生物素蛋白磁珠通过下面概述的方案纯化样品混合物:
1.用200μl结合缓冲液(20mM TRIS,500mM NaCl,pH=7.4)洗涤100μl链酶抗生物素蛋白磁珠(新英格兰实验室)3次。
2.连接步骤之后反应混合物与10倍体积的结合缓冲液(20mM的TRIS,500mM的NaCl,pH值=7.4)混合,并用链酶抗生物素蛋白磁珠在20℃培育15分钟。
3.用200μl结合缓冲液(20mM TRIS,500mM NaCl,pH=7.4)洗涤链酶抗生物素蛋白磁珠3次。
4.用去离子水洗涤链酶抗生物素蛋白磁珠3次。
5.通过加热至95℃持续3分钟将寡核苷酸用40μl去离子水洗脱。
图29c中所示的结果证明了使用本发明的示例性方法的两个完整合成循环的性能。
实例9.版本2化学法——单发夹模型上的完整三循环实验。
该实例描述了在双发夹模型上使用5个步骤合成多核苷酸的完整三循环实验:从切口位点合并3'-O-修饰的dNTP;在第一步在与互补碱基相对地发生的情况下脱保护、裂解、连接和变性步骤。
所述方法的示例性示意图概述显示在图34、35和36中。
该方法首先是通过DNA聚合酶的酶合并,然后肌苷脱保护、裂解、连接和辅助链的变性,将3'-O-保护的单核苷酸受控的添加到寡核苷酸中。图34示出了涉及酶合并、脱保护、裂解、连接和变性步骤的第1完整循环。在所述实例中,寡核苷酸由T核苷酸延伸。图35示出了第1循环后的第2完整循环,包括酶合并、脱保护、裂解、连接步骤和变性步骤。在所述实例中,寡核苷酸由T核苷酸延伸。图36示出了第2循环后的第3完整循环,包括酶合并、脱保护、裂解、连接和变性步骤。在所述实例中,寡核苷酸由T核苷酸延伸。
材料与方法
材料
1.根据描述于以下的方案内部合成3'-O-经修饰的dNTP:博士毕业论文Jian Wu:Molecular Engineering of Novel Nucleotide Analogues for DNA Sequencing bySynthesis,Columbia University,2008。用于合成的方案还描述于专利申请公开:J.William Efcavitch,Juliesta E.Sylvester,Modified Template-IndependentEnzymes for Polydeoxynucleotide Synthesis,Molecular Assemblies US2016/0108382A1。
2.寡核苷酸是内部设计的并从Integrated DNA Technologies,Sigma-Aldrich获得(图37)。以100μM的浓度制备储备溶液。
3.使用终止子X DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。可以替代地使用任何可以合并修饰的dNTP的DNA聚合酶或其他酶。
使用3'-O-叠氮甲基-dTTP合并:

方法
第1循环:
1.将20μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)和MnCl2溶液(10μl的40mM)与139μl无菌去离子水(ELGA VEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)和MnCl2溶液(10μl的40mM)与139μl无菌去离子水(ELGA VEOLIA)在1.5ml Eppendorf管中混合。
2.将20μl的100μM单发夹模型寡核苷酸(2nmol,1当量)(SEQ ID NO:59,图37)加入到反应混合物中。
3.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
4.加入3'-O-修饰的-dTTP(10μl,2mM)。
5.然后加入5μl的Therminator IX DNA聚合酶(50U,New England BioLabs)。然而,可以使用任何可以合并修饰的dNTP的DNA聚合酶或其他酶。
6.将反应物在37℃培育30分钟。
7.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒纯化反应混合物。
8.通过200μl的TE缓冲液将DNA样品洗脱到干净的Eppendorf管中。
9.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
10.将400μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
11.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒纯化反应混合物。
12.通过150μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH 7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
13.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
14.将5μl的人类核酸内切酶V(Endo V)NEB(30单位/μl)加入洗脱液并在37℃培育30分钟。可以使用任何合适的替代性核酸内切酶。
15.在培育时间过去之后,将反应物通过在65℃下酶促热失活20分钟终止。
16.将等分试样(5μl)从反应混合物取出,并在聚丙烯酰胺凝胶上分析。
17.通过QIAGEN核苷酸移除试剂盒,使用纯化步骤66-72中概述的方案纯化反应混合物。
18.通过100μl的T3 DNA连接酶缓冲液(2x浓度)将DNA样品洗脱到干净的Eppendorf管中。
19.将20μl的100μM用于连接的肌苷链(2nmol)和20μl的100μM用于连接的辅助链(2nmol)(SEQ ID NO:60,51,图37)以及40μl水加入到反应混合物中。
20.将20μl的T3 DNA连接酶NEB(3000单位/μl)加入同一试管中(这可包括任何DNA连接酶)并在室温下培育30分钟。
使用对于链酶抗生物素蛋白磁珠试剂盒的方案纯化反应混合物,包括纯化步骤73-78中概述的变性步骤。
21.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒的方案纯化反应混合物。
22.通过100μl的TE缓冲液将DNA样品洗脱到干净的Eppendorf管中。
第2循环:
23.加入15μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1% X-100,pH 8.8,New England BioLabs)、MnCl2溶液(7.5μl,40mM)和19μl去离子水。
X-100,pH 8.8,New England BioLabs)、MnCl2溶液(7.5μl,40mM)和19μl去离子水。
24.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
25.加入3'-O-修饰的-dTTP(7.5μl,2mM)。
26.然后加入5μl的Therminator IX DNA聚合酶(50U,New England BioLabs)。可以使用任何可以合并修饰的dNTP的DNA聚合酶。
27.将反应物在37℃培育30分钟。
28.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒纯化反应混合物。
29.通过100μl的TE缓冲液将DNA样品洗脱到干净的Eppendorf管中。
30.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
31.将200μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
32.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒纯化反应混合物。
33.通过100μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
34.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
35.将5μl的人类核酸内切酶V(Endo V)NEB(30单位/μl)加入洗脱液并在37℃培育30分钟。可以使用任何合适的替代性核酸内切酶。
36.在培育时间过去之后,将反应物通过在65℃下酶促热失活20分钟终止。
37.将等分试样(5μl)取出反应混合物,并在聚丙烯酰胺凝胶上分析。
38.通过QIAGEN核苷酸移除试剂盒,使用纯化步骤66-72中概述的方案纯化反应混合物。
39.通过60μl的T3 DNA连接酶缓冲液(2x浓度)将DNA样品洗脱到干净的Eppendorf管中。
40.将20μl的100μM用于连接的肌苷链(2nmol)和20μl的100μM用于连接的辅助链(2nmol)(SEQ ID NO:60,51,图37)以及10μl去离子水加入到反应混合物中。
41.将10μl的T3 DNA连接酶NEB(3000单位/μl)加入同一试管中并在室温下培育30分钟。可以使用任何合适的DNA连接酶。
42.使用对于链酶抗生物素蛋白磁珠试剂盒的方案纯化反应混合物,包括纯化步骤73-78中概述的变性步骤。
43.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒的方案纯化反应混合物。
44.通过46μl的TE缓冲液将DNA样品洗脱到干净的Eppendorf管中。
第3循环:
45.加入6μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mM MgSO4,0.1% X-100,pH 8.8,New England BioLabs)、MnCl2溶液(3μl,40mM)。
X-100,pH 8.8,New England BioLabs)、MnCl2溶液(3μl,40mM)。
46.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
47.加入3'-O-修饰的dTTP(6μl的200μM)。
48.然后加入3μl的Therminator IX DNA聚合酶(30U,New England BioLabs)。可以使用任何可以合并修饰的dNTP的DNA聚合酶或其他合适的酶。
49.将反应物在37℃培育30分钟。
50.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒纯化反应混合物。
51.通过50μl的TE缓冲液将DNA样品洗脱到干净的Eppendorf管中。
52.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
53.将100μL的500mM TCEP加入到反应混合物中,并使其在37℃反应10分钟。
54.使用在纯化步骤66-72中概述的QIAGEN核苷酸移除试剂盒纯化反应混合物。
55.通过49μl的NEB (50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
(50mM乙酸钾,20mM Tris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9,25℃下)将DNA样品洗脱到干净的Eppendorf管中。
56.从反应混合物取出等分试样(4μl),以及加入0.5μl的天然dNTP混合物(4mM)和0.5μl的Bst DNA聚合酶以及0.5μl的Sulfolobus DNA聚合酶IV并使其反应10分钟。通过凝胶电泳分析反应。
57.将5μl的人类核酸内切酶V(Endo V)NEB(30单位/μl)加入洗脱液并在37℃培育30分钟。或者可以使用任何合适的核酸内切酶。
58.在培育时间过去之后,将反应物通过在65℃下酶促热失活20分钟终止。
59.将等分试样(5μl)取出反应混合物,并在聚丙烯酰胺凝胶上分析。
60.通过QIAGEN核苷酸移除试剂盒,使用纯化步骤66-72中概述的方案纯化反应混合物。
61.通过30μl的T3 DNA连接酶缓冲液(2x浓度)将DNA样品洗脱到干净的Eppendorf管中。
62.将10μl的100μM用于连接的肌苷链(2nmol)、10μl的100μM用于连接的辅助链(2nmol)(SEQ ID NO:60,51,图37)以及5μl水加入到反应混合物中。
63.将5μl的T3 DNA连接酶NEB(3000单位/μl)加入同一试管中。(这可包含任何DNA连接酶)并在室温下培育30分钟。
64.通过凝胶电泳分析反应混合物。
使用下述方案在合并、解封闭和裂解步骤后通过QIAGEN核苷酸移除试剂盒纯化反应混合物:
65.将10体积的缓冲液PNI QIAGEN(5M氯化胍)加入到样品中并通过用移液管重悬浮温和混合。
66.将混合物转移到QIAquick旋转柱(QIAGEN)并以6000rpm离心1分钟。
67.离心后,弃去流过液,向旋转柱中加入750μl缓冲液PE QIAGEN(10mM Tris-HClpH7.5和80%乙醇),并以6000rpm离心1分钟。
68.将流过液丢弃并将旋转柱以13000rpm离心另外的1分钟以移除残余的PE缓冲液。
69.然后将旋转柱置于无菌的1.5ml Eppendorf管中。
70.对于DNA洗脱,将20-200μl适当的反应缓冲液加入到柱膜中心,并在室温下静置1分钟。
71.然后将管以13000rpm离心1分钟。
通过下面概述的方案,在使用涉及变性步骤的链酶抗生物素蛋白磁珠的连接步骤后进行反应的纯化:
72.用100μl结合缓冲液(20mM TRIS,500mM NaCl,pH=7.4)洗涤200μl链酶抗生物素蛋白磁珠(New England BioLabs)3次。
73.连接步骤之后反应混合物与10倍体积的结合缓冲液(20mM的TRIS,500mM的NaCl,pH值=7.4)混合,并用链酶抗生物素蛋白磁珠在20℃使其培育15分钟。
74.用200μl结合缓冲液(20mM TRIS,500mM NaCl,pH=7.4)洗涤链酶抗生物素蛋白磁珠3次。
75.为了移除辅助链,在放置于磁体上的200μl结合缓冲液(20mM TRIS,500mMNaCl,pH=7.4)中将链酶抗生物素蛋白磁珠加热至80℃,并将上清液迅速丢弃。
76.用去离子水洗涤链酶抗生物素蛋白磁珠3次。
77.通过加热至95℃持续3分钟将寡核苷酸用50-100μl去离子水洗脱。
结果和结论
图38描绘了显示对应于完整三循环实验的反应产物的凝胶,所述实验包括:合并、解封闭、裂解和连接步骤。所示结果证明了使用本发明的示例性方法的三个完整合成循环的性能。
实例10.衍生化聚丙烯酰胺表面并随后固定分子。
所述实例描述了使用N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA)在聚丙烯酰胺表面上呈现溴乙酰基,并且随后通过它们与溴乙酰基的共价偶联来表面固定硫醇化分子。
材料与方法
通过在丙酮、乙醇和水中依次超声处理,每次10分钟,并用氩气干燥,清洁玻璃显微镜载玻片和盖玻片。将清洁的盖玻片在聚苯乙烯培养皿中用三氯(1H,1H,2H,2H-全氟辛基)硅烷在气相中硅烷化,在乙醇中超声处理两次并用Ar干燥(下文‘氟化盖玻片')。在玻璃显微镜载玻片上,将4%丙烯酰胺/N,N'-亚甲基双丙烯酰胺(19:1)溶液与100μl的10%(w/v)过硫酸铵(APS)、10μl的四甲基乙二胺(TEMED)混合,用0、0.1、0.2和0.3%(w/v)的N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA)掺杂,并快速分配到4mm直径的橡胶垫圈中,随后用氟化盖玻片夹在中间,氟化面朝向丙烯酰胺溶液,并聚合10分钟。10分钟后,将表面浸入去离子水中并浸没总共4小时,在此期间小心地移除氟化盖玻片。聚合的聚丙烯酰胺表面用氩气干燥。
随后将聚丙烯酰胺表面暴露于磷酸钠缓冲液(10mM,pH 8)中的硫醇化聚乙二醇(1kDa)荧光素(FITC-PEG-SH)和作为负对照的羧化聚乙二醇(1kDa)荧光素(FITC-PEG-COOH)1小时,然后依次用磷酸钠缓冲液(10mM,pH7)和含有0.05%Tween20/0.5M NaCl的相同缓冲液洗涤,以移除非特异性吸附的硫醇化和羧化荧光团。随后通过ChemiDoc(Bio-Rad)在荧光素通道中对表面成像。
结果和结论
图39显示荧光信号,图40显示从聚丙烯酰胺凝胶表面测量的荧光,其中合并不同量的BRAPA,其暴露于FITC-PEG-SH和FITC-PEG-COOH。荧光素的固定仅在掺有BRAPA并且仅有硫醇化荧光素的聚丙烯酰胺表面成功,对羧化荧光素的非特异性吸附接近于零。
与不含BRAPA(BRAPA 0%)的那些聚丙烯酰胺表面和含有BRAPA和羧化分子(FITC-PEG-COOH)的那些聚丙烯酰胺表面相比,含有(BRAPA 0.1、0.2和0.3%)和仅来自巯基化分子(FITC-PEG-SH)的聚丙烯酰胺表面获得了显著高的正荧光信号。结果表明,来自表面的溴乙酰基部分和来自荧光素标记分子的硫醇部分之间发生了特异性共价偶联。
结果表明,分子,例如包括用于本发明方法的支持链和合成链的分子,可以容易地固定在与本文所述的多核苷酸合成反应相容的表面基底上。
实例11.发夹DNA寡聚体的表面固定和随后合并荧光标记的脱氧核苷三磷酸。
本实例描述:
(1)在薄的聚丙烯酰胺表面上呈现溴乙酰基的方法;
(2)随后通过硫代磷酸酯官能化的发夹DNA在有或没有接头下的共价偶联来固定发夹DNA;和
(3)将2'-脱氧核苷酸三磷酸(dNTP)合并发夹DNA中。
所述方法几乎与任何类型的材料表面(例如金属、聚合物等)相容。
(1):溴乙酰基官能化的薄聚丙烯酰胺表面的制备
材料与方法
首先在纯净的Decon 90(30分钟)、水(30分钟)、1M NaOH(15分钟)、水(30分钟)、0.1M HCl(15分钟)、水(30分钟)中通过超声处理清洁玻璃显微镜载玻片,最后用氩干燥。
首先通过将1g丙烯酰胺单体溶解在50ml水中制备2%(w/v)丙烯酰胺单体溶液。将丙烯酰胺单体溶液涡旋并在氩气中脱气15分钟。将N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA,82.5mg)溶解在825μl的DMF中,并加入到丙烯酰胺单体溶液中并进一步涡旋。最后,将1ml5%(w/v)过硫酸钾(KPS)和115μl纯四甲基乙二胺(TEMED)加入到丙烯酰胺溶液中,涡旋并将干净的玻璃显微镜载玻片暴露于该丙烯酰胺聚合混合物中90分钟。90分钟后,用去离子水洗涤表面并用氩气干燥。在这个实例的下文中,这些表面将被称为“BRAPA改性表面”。作为负对照,通过排除向丙烯酰胺单体溶液中添加BRAPA溶液,也以与上述类似的方式制备不含BRAPA的聚丙烯酰胺表面。在这个实例的下文中,这些表面将被称为“BRAPA对照表面”。
(2):硫代磷酸酯官能化的发夹DNA在聚丙烯酰胺表面上的共价偶联材料与方法
将具有4mm直径圆形开口的橡胶垫圈放置并固定在BRAPA改性表面和BRAPA对照表面上。首先用磷酸钠缓冲液(10mM,pH 7)引发表面10分钟。随后移除缓冲液,并将表面暴露于5'-荧光标记的(Alexa 647)发夹DNA寡聚体,分别具有和不具有以1μM浓度用六种和单一硫代磷酸酯修饰的接头,并在黑暗中温育1小时。BRAPA改性表面也与具有和不具有接头但没有硫代磷酸酯作为对照的DNA寡聚体一起培育(在下文中称为“寡聚体对照表面”)。培育后,将表面用磷酸钠(100mM,pH7)冲洗,然后用Tris-EDTA缓冲液(10mM Tris,10mM EDTA,pH8)冲洗,最后用水冲洗。为了移除任何非特异性吸附的DNA寡聚体,随后用含有1M氯化钠和0.05%(v/v)Tween20的水洗涤表面,用水洗涤并用氩气干燥。在ChemiDoc成像仪上在Alexa 647通道中扫描表面。
图41a示出了固定在不同样品上的没有接头的发夹DNA序列。图41b示出了固定在不同样品上的具有接头的发夹DNA序列。
结果
结果显示在图42和43中。图42显示源自发夹DNA寡聚体的荧光信号,其中有和没有接头固定在溴乙酰基官能化的聚丙烯酰胺表面上,但不是来自BRAPA或寡聚体对照。
图43示出了在聚丙烯酰胺表面上DNA固定后测量的荧光强度。该图示出了从各种聚丙烯酰胺表面获得的表面荧光信号,并显示由于DNA在溴乙酰基官能化的聚丙烯酰胺表面上成功的共价固定,与BRAPA和寡聚体对照表面(如(2)中所述)相比,从固定在BRAPA改性表面上的发夹DNA寡聚体获得显著更高的信号。
结论
来自DNA的荧光信号仅悬垂地存在于掺有BRAPA的BRAPA改性表面,表明通过硫代磷酸酯官能团将DNA成功共价偶联到表面上。与没有接头的DNA相比,从有接头的DNA获得同源和更高的信号。
(3):将三磷酸酯合并具有接头的发夹DNA寡聚体中
材料与方法
将具有9mm直径的圆形开口的橡胶密封垫放在固定有具有接头的DNA寡聚体的BRAPA改性表面上,并用合并缓冲液(50mM TRIS pH 8,1mM EDTA,6mM MgSO4,0.05%tween20 and 2mM MnCl2)引发10分钟。随后将表面暴露于含有DNA聚合酶(0.5U/μl终止子XDNA聚合酶)和三磷酸盐(20μM Alexa488标记的dUTP)的合并缓冲液中并温育1小时(此后在该实例中称为“聚合酶表面”)。另外一组表面也暴露于没有终止子X DNA聚合酶的合并缓冲液1小时作为负对照(在下文中称为“负表面”)。1小时后,将两种类型的样品在水中洗涤,随后暴露于含有1M氯化钠和0.05%(v/v)Tween20的水中,并再次用水洗涤。在Alexa 647和Alexa 488通道中使用ChemiDoc测量来自表面的荧光信号,以监测发夹DNA(Alexa 647)的存在和dUTP(Alexa 488)的合并。
结果
图44显示在合并Alexa 488标记的dUTP之前和之后从Alexa 647和Alexa 488通道检测到的荧光信号。在合并之前和之后来自Alexa 647的未改变的正信号表明表面固定的发夹DNA在合并反应期间是稳定的,而来自Alexa 488的正信号仅在合并反应后从聚合酶表面观察到,显示仅在聚合酶存在时成功合并dUTP。
图45示出了如(3)中所述在合并Alexa 488标记的dUTP之前和之后从‘聚合酶表面'和‘负表面'获得的Alexa 647(发夹DNA)和Alexa 488(dUTP)通道中的测量荧光信号。由于成功合并,在聚合酶表面的合并反应后获得Alexa 488荧光信号的显著增加,而由于不存在聚合酶,来自负表面的信号在合并反应后保持相同。在合并反应后,Alexa 647通道中的荧光信号基本保持不变,表明表面上存在发夹DNA。荧光信号的轻微降低可能归因于第二轮曝光引起的光漂白效应。
结论
结果表明,包括用于本发明方法的支持链和合成链的分子,可以容易地固定在与本文所述的多核苷酸合成反应相容的表面基底上。结果进一步证明,这种分子可以接受新dNTP的合并以延伸合成链,同时分子保持稳定并附接于基底。
实例12.通过接头和硫代磷酸酯共价键连接固定于衍生化表面的发夹DNA寡聚体
的裂解和连接。
该实例描述了用接头与硫代磷酸酯官能化的发夹DNA的衍生化表面的共价偶联,然后是裂解和连接反应。如实例11所述进行基底制备和发夹DNA的偶联。
(1):裂解具有接头的固定的发夹DNA寡聚体
材料与方法
如实例11中所述,将发夹DNA固定在表面BRAPA改性表面上。制备四组一式三份表面,包括用于裂解和连接反应的所有实验对照。实验条件如图46a所示。图46b显示固定在不同样品上的发夹DNA的序列。
在DNA固定步骤后,将具有9mm直径圆形开口的橡胶垫圈放置在所有表面上,所述表面用在5'末端用Alexa 647标记的DNA固定,并用1X NEBuffer 4(50mM醋酸钾,20mMTris-乙酸盐,10mM乙酸镁,1mM DTT,pH7.9)引发10分钟。注意,对于样品D,固定的发夹DNA不含肌苷,肌苷被鸟嘌呤取代。随后将所有样品暴露于含有1.5U/μl核酸内切酶V的NEBuffer 4(样品A、B和D)或不含核酸内切酶V的NEBuffer 4(样品C)1小时。随后用1X T3DNA连接酶缓冲液(66mM Tris-HCl,10mM MgCl2,1mM ATP,7.5%PEG6000,1mM DTT,pH7.6)、含有1M氯化钠和0.05%(v/v)Tween20的1X T3 DNA连接酶缓冲液洗涤所有样品,再用1X T3 DNA连接酶缓冲液洗涤,并在Alexa 647通道中在ChemiDoc成像仪上扫描。
结果
图47示出了在裂解反应之前和之后来自发夹DNA寡聚体的荧光信号。
图48示出了如上所述从DNA固定表面获得的在裂解反应之前和之后测量的荧光信号。仅从样品A和B观察到成功的裂解反应,而由于序列中没有核酸内切酶V(样品C)或肌苷(样品D),样品C和D的荧光信号强度保持几乎相同。
从样品A和B中观察到荧光信号的显著降低是由于在核酸内切酶V存在下在DNA链内的肌苷位点的成功裂解反应。对于样品C和D,在DNA内没有核酸内切酶V和缺乏肌苷分别引起荧光信号保持与DNA固定后获得的初始信号几乎相同的水平。
(2):连接反应
材料与方法
在如(1)中所述的裂解反应后,将样品A和B(如图46a中所述)暴露于含有MnCl2(2mM)、在5'末端用Alexa 647标记的肌苷链(16μM)和互补‘辅助'链(16μM)(序列显示在下面的图49中)的1X T3 DNA连接酶缓冲液,用于样品A用T3 DNA连接酶(250U/μl),对于样品B,没有T3 DNA连接酶,作为负对照。将样品在各自的溶液中温育1小时。1小时后,将表面在水中洗涤,随后暴露于含有1M氯化钠和0.05%(v/v)Tween20的水中,并再次用水洗涤。在Alexa 647通道中使用ChemiDoc测量来自表面的荧光信号。图49示出了用于连接反应的含肌苷链和互补“辅助”链的序列。
结果
图50示出了与连接反应监测有关的结果。在连接反应之前和之后从Alexa 647通道检测到荧光信号。连接后Alexa 647通道中荧光信号的增加仅从具有T3 DNA连接酶的样品A获得,而由于不存在T3 DNA连接酶,在样品B的连接反应后荧光信号保持在相同水平。
图51显示,由于成功连接,样品A的连接反应后Alexa 647荧光信号显著增加,其中信号水平恢复到如图48所示的DNA固定后和裂解反应前的初始信号水平。由于不存在T3DNA连接酶,来自样品B的荧光信号在连接反应后保持相同。
结论
该实例中的结果表明,包括用于本发明方法的支持链和合成链的分子,可以容易地固定在与本文所述的多核苷酸合成反应相容的表面基底上,并且可以在保持稳定以及附接于基底的同时进行裂解和连接反应。
实例13将3'-O-叠氮甲基-dNTPs合并平末端DNA的3'末端。
该实例描述了将3'-O-叠氮甲基-dNTPs合并平末端双链DNA的3'末端。
下面的步骤证明了通过DNA聚合酶的酶合并,将3'-O-保护的单核苷酸受控地添加到平末端双链寡核苷酸中。这些步骤与图1至图6所示的合并步骤3一致。
材料和方法
材料
1.内部合成的3'-O-叠氮甲基-dNTP。
2.使用终止子X DNA聚合酶,其由New England BioLabs工程化,具有增强的合并3-O-修饰的dNTP的能力。
3.平末端双链DNA寡核苷酸。
测试四种类型的可逆终止子:

方法
1.将5μl的10x 缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1%
缓冲液(20mM Tris-HCl,10mM(NH4)2SO4,10mM KCl,2mMMgSO4,0.1% X-100,pH 8.8,New England BioLabs)与33.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
X-100,pH 8.8,New England BioLabs)与33.5μl无菌去离子水(ELGAVEOLIA)在1.5ml Eppendorf管中混合。
2.将2μl的20μM引物(40pmol,1当量)(SEQ ID:NO:68,图52a)和3μl的20μM模板(60pmol,1.5当量)(SEQ ID:NO:69,图52a)添加到反应混合物中。
3.加入3’-O-修饰的-dTTP(2μl的100μM)和MnCl2(2.5μl的40mM)。
4.然后加入2μl的Therminator IX DNA聚合酶(20U,New England BioLabs)。
5.将反应物在37℃培育30分钟。
6.将反应物通过加入TBE-尿素样品缓冲液(Novex)停止。
7.将反应物在聚丙烯酰胺凝胶(15%)上用TBE缓冲液分离,并通过ChemiDoc MP成像系统(BioRad)进行可视化。
结果
图52b描绘了凝胶,其示出了在37℃下在存在Mn2+离子的情况下通过终止子DNA X聚合酶合并3'-o-修饰的-dNTP的结果。数据显示,终止子X DNA聚合酶能够成功地将3'-O-修饰的dNTPs合并平末端DNA寡核苷酸的3'末端,从而产生一个碱基突出的碱基。
实例14.使用突出端连接,示例性地将多核苷酸连接分子连接至支架多核苷酸。
该实例描述了使用DNA连接酶将多核苷酸连接分子与支架多核苷酸的连接。该实例涉及具有突出端的分子的连接,这与图2中描述的发明版本2的合成方法一致。
图53提供了描述DNA合成反应循环的方案。该方案旨在与图2所示的发明版本2的合成方法一致。因此,图53中的方案显示提供具有突出端的支架多核苷酸(该方案的最上面面板中的右手发夹结构),左链对应于支持链,右链对应于合成链。支持链的末端核苷酸仅出于说明目的而描绘为“T”,并且突出于合成链的末端核苷酸。支持链的末端核苷酸在5'末端包括磷酸基团。在该循环的下一步骤中,提供了多核苷酸连接分子(方案最上面部分的最右边的结构)。多核苷酸连接分子具有支持链(左链)和辅助链(右链)。多核苷酸连接分子具有互补连接端,该末端具有突出的末端并且包括2-脱氧肌苷(In)的通用核苷酸。辅助链在互补连接端的末端包括不可连接的核苷酸,并突出于支持链的末端核苷酸。支持链在互补连接端的末端仅包括预定义序列的核苷酸,其被描述为“G”,仅用于例示。将多核苷酸连接分子连接至支架多核苷酸后,将多核苷酸连接分子互补连接端的支持链末端核苷酸连接至支架多核苷酸支持链末端核苷酸,并且在多核苷酸连接分子的辅助链和支架多核苷酸的合成链之间产生单链断裂(“缺口”)。多核苷酸连接分子的支持链的末端核苷酸包括预定序列的核苷酸,并且位于位置n+1。通用核苷酸因此占据位置n+3。在下一步骤中,在此情况下,仅出于说明目的,通过聚合酶或核苷酸转移酶的作用将另外的核苷酸(仅描述为“A”)合并到支架多核苷酸的合成链中。所述另外的核苷酸包括可逆终止子基团或封闭基团。纯粹为了举例说明,另外的核苷酸与支持链中的配偶体核苷酸配对,在这种情况下被描绘为“T”,从而形成核苷酸对。然后,该方案描述了脱保护或解封闭步骤,其中移除了可逆终止子基团或保护基。在图53所示的反应方案中,辅助步骤显示为在合并步骤之前作为可选步骤被移除。合并后,通过在位置n+1和n+2之间裂解支持链来裂解多核苷酸连接分子。裂解后,待整合的预定序列的第一核苷酸“G”保持在支架多核苷酸中,作为突出端中支持链的末端核苷酸。要合并的预定序列的第二核苷酸“A”作为合成链的末端核苷酸保持在支架多核苷酸中,并与配偶体核苷酸“T”配对。
图54示出了与图53所示相同的合成反应方案,除了增加了待延伸的支架多核苷酸末端的突出端的长度。为了在连接步骤中保持相容性,多核苷酸连接分子中将发生相应的增加。
如下所述,该实例14描述了将多核苷酸连接分子连接至支架多核苷酸的步骤,如图53和54中的虚线框所示。
材料和方法
材料:
1.在本实例中使用的寡核苷酸是在室内设计的,并由Integrated DNA技术合成。这些在图55中进行了描述。
2.使用无菌蒸馏水(ELGA VEOLIA)将寡核苷酸稀释到100μM的储备浓度。
方法:
使用以下步骤进行寡核苷酸的连接反应:
1.将12μl无菌蒸馏水(ELGA VEOLIA)加入1.5ml Eppendorf管中。
2.然后将30μl 2X T3 DNA连接酶反应缓冲液NEB(132mM Tris-HCl,20mM MgCl2、2mM二硫苏糖醇,2mM ATP,15%聚乙二醇(PEG6000)并且pH为7.6,25℃)和2μl 40mM MnCl2添加到同一Eppendorf管中。
3.将5μl 2-脱氧肌苷(In)链(200μmol/l)(SEQ ID:No 6)和5μl辅助链(200μmol/l)(SEQ ID:No 7、8)和1μl TAMRA或任何其他将具有5'突出端(20μmol/l)(SEQ ID:No 70、71、72、73或74)的荧光标记多核苷酸添加到同一试管中。
4.将5μl T3 DNA连接酶NEB(3000单位/μl)加入同一试管中。
5.然后将反应混合物在室温下培育30分钟。
6.在培育时间过去之后,通过添加TBE-尿素样品缓冲液(Novex)终止反应。
结果
结果示出在图56中。
在上述实例中,SEQ ID NO 1-80中所示的所有寡核苷酸在3'末端具有羟基。除了SEQ ID NO 7、SEQ ID NO 18、SEQ ID NO 35和SEQ ID NO 70至74之外,SEQ ID NO 1-80中所示的所有寡核苷酸在5'末端缺少磷酸基团。
应当理解,所公开方法和产品的不同应用可以根据本领域的特定需要而定制。还应理解,本文所使用的术语仅出于对本发明的特定实例进行描述的目的而并不旨在是限制性的。
如在本说明书和所附权利要求中所使用的,单数形式“一(a)”、“一(an)”和“所述(the)”包括复数指示物,除非上下文另外明确指明。因此,例如,提及“多核苷酸连接分子”包括两个或更多个这样的多核苷酸,提及“支架多核苷酸”包括两个或更多个这样的支架多核苷酸,等等。
本文所引用的所有公开、专利和专利申请特此通过引用整体掺入。
序列表
<110> 牛津纳米孔科技公司
<120> 多核苷酸合成方法、试剂盒和系统
<130> N414125WO
<140> To be assigned
<141> 2019-07-19
<150> GB1811811.7
<151> 2018-07-19
<160> 80
<170> PatentIn version 3.5
<210> 1
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 1
gcgacaggtg actgcagc 18
<210> 2
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 2
cacatcacgt cgtagtcngc tgcagtcacc tgtcgc 36
<210> 3
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 3
cacatcacgt cgtagtcngc tgcagtcacc tgtcgc 36
<210> 4
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 4
gcgacaggtg actgcagct 19
<210> 5
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 5
gcgacaggtg actgcagctg actacgacgt gatgtg 36
<210> 6
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (17)..(17)
<223> 2’-脱氧肌苷
<400> 6
cacatcacgt cgtagtnagc tgcagtcacc tgtcgc 36
<210> 7
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 7
gctgcagtca cctgtcgc 18
<210> 8
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 8
gcgacaggtg actgcagct 19
<210> 9
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (17)..(17)
<223> 2’-脱氧肌苷
<400> 9
cacatcacgt cgtagtna 18
<210> 10
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 10
gcgacaggtg actgcagc 18
<210> 11
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 11
cacatcacgt cgtagtcngc tgcagtcacc tgtcgc 36
<210> 12
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 12
cgactacgac gtgatgtg 18
<210> 13
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 脱氧肌苷
<400> 13
cacatcacgt cgtagtcngc tgcagtcacc tgtcgc 36
<210> 14
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 14
gcgacaggtg actgcagct 19
<210> 15
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 15
gcgacaggtg actgcagctg actacgacgt gatgtg 36
<210> 16
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 16
tgactacgac gtgatgtg 18
<210> 17
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (17)..(17)
<223> 2’-脱氧肌苷
<400> 17
cacatcacgt cgtagtnagc tgcagtcacc tgtcgc 36
<210> 18
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 18
gctgcagtca cctgtcgc 18
<210> 19
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 19
gcgacaggtg actgcagct 19
<210> 20
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (17)..(17)
<223> 2’-脱氧肌苷
<400> 20
cacatcacgt cgtagtna 18
<210> 21
<211> 17
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 21
cactacgacg tgatgtg 17
<210> 22
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 22
gcgacaggtg actgcagc 18
<210> 23
<211> 37
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 23
cacatcacgt cgtagtcnag ctgcagtcac ctgtcgc 37
<210> 24
<211> 37
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 24
cacatcacgt cgtagtcngg ctgcagtcac ctgtcgc 37
<210> 25
<211> 37
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 25
cacatcacgt cgtagtcnag ctgcagtcac ctgtcgc 37
<210> 26
<211> 37
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 2’-脱氧肌苷
<400> 26
cacatcacgt cgtagtcnag ctgcagtcac ctgtcgc 37
<210> 27
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 27
tcgactacga cgtgatgtg 19
<210> 28
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 28
ccgactacga cgtgatgtg 19
<210> 29
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 29
acgactacga cgtgatgtg 19
<210> 30
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 30
gcgactacga cgtgatgtg 19
<210> 31
<211> 37
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (18)..(18)
<223> 脱氧肌苷
<400> 31
cacatcacgt cgtagtcnag ctgcagtcac ctgtcgc 37
<210> 32
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 32
gcgacaggtg actgcagct 19
<210> 33
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 33
gcgacaggtg actgcagctg actacgacgt gatgtg 36
<210> 34
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 34
tcgactacga cgtgatgtg 19
<210> 35
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 35
gctgcagtca cctgtcgc 18
<210> 36
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 36
gcgacaggtg actgcagct 19
<210> 37
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (17)..(17)
<223> 2’-脱氧肌苷
<400> 37
cacatcacgt cgtagtnga 19
<210> 38
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 38
ccactacgac gtgatgtg 18
<210> 39
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
引物”
<400> 39
gcgacaggtg actgcagc 18
<210> 40
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 40
cacatcacgt cgtagtcagc tgcagtcacc tgtcgc 36
<210> 41
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 41
cacatcacgt cgtagtcggc tgcagtcacc tgtcgc 36
<210> 42
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 42
cacatcacgt cgtagtctgc tgcagtcacc tgtcgc 36
<210> 43
<211> 36
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 43
cacatcacgt cgtagtccgc tgcagtcacc tgtcgc 36
<210> 44
<211> 78
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (36)..(36)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (58)..(58)
<223> Tamra-dT
<400> 44
tcgactacga cgtgactttt agtcacgtcg tagtcnagct gcagtcacct gctgcttntt 60
gcagcaggtg actgcagc 78
<210> 45
<211> 79
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (36)..(36)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (58)..(58)
<223> Tamra-dT
<400> 45
tcgactacga cgtgactttt agtcacgtcg tagtcnagct gcagtcacct gctgcttntt 60
gcagcaggtg actgcagct 79
<210> 46
<211> 42
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (21)..(21)
<223> Tamra-dT磷酸盐
<400> 46
gctgcagtca cctgctgctt nttgcagcag gtgactgcag ct 42
<210> 47
<211> 38
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (36)..(36)
<223> 2’-脱氧肌苷
<400> 47
ccgactacga cgtgactttt agtcacgtcg tagtcnga 38
<210> 48
<211> 78
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (36)..(36)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (58)..(58)
<223> Tamra-dT
<400> 48
tcgactacga cgtgactttt agtcacgtcg tagtcnagct gcagtcacct gctgcttntt 60
gcagcaggtg actgcagc 78
<210> 49
<211> 38
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (36)..(36)
<223> 2’-脱氧肌苷
<400> 49
ccgactacga cgtgactttt agtcacgtcg tagtcnga 38
<210> 50
<211> 58
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (38)..(38)
<223> Tamra-dT
<400> 50
agtcacgtcg tagtcnagct gcagtcacct gctgcttntt gcagcaggtg actgcagc 58
<210> 51
<211> 17
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 51
tcgactacga cgtgact 17
<210> 52
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<400> 52
agtcacgtcg tagtcnga 18
<210> 53
<211> 17
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<400> 53
ccgactacga cgtgact 17
<210> 54
<211> 78
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (35)..(35)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (57)..(57)
<223> Tamra-dT
<400> 54
cgactacgac gtgactttta gtcacgtcgt agtcnagctg cagtcacctg ctgcttnttg 60
cagcaggtga ctgcagct 78
<210> 55
<211> 37
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (35)..(35)
<223> 2’-脱氧肌苷
<400> 55
cgactacgac gtgactttta gtcacgtcgt agtcnaa 37
<210> 56
<211> 78
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (35)..(35)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (52)..(52)
<223> Tamra-dT
<220>
<221> 经修饰的_碱基
<222> (57)..(57)
<223> 生物素-dT
<400> 56
cgactacgac gtgactttta gtcacgtcgt agtcnagctg cagtcacctg cngcttnttg 60
cagcaggtga ctgcagct 78
<210> 57
<211> 38
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (36)..(36)
<223> 2’-脱氧肌苷
<400> 57
ccgactacga cgtgactttt agtcacgtcg tagtcnga 38
<210> 58
<211> 62
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (60)..(60)
<223> 2’-脱氧肌苷
<400> 58
acgagtgacc tggttttttt tttttttttt tttttttttt tttttttacc aggtcactcn 60
tg 62
<210> 59
<211> 58
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (33)..(33)
<223> Tamra-dT
<220>
<221> 经修饰的_碱基
<222> (38)..(38)
<223> 生物素-dT
<400> 59
agtcacgtcg tagtcnagct gcagtcacct gcngcttntt gcagcaggtg actgcagc 58
<210> 60
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<400> 60
agtcacgtcg tagtcnaa 18
<210> 61
<211> 67
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<400> 61
agtcacgtcg tagtcnagct gcagtcacct gctgcttttt tttttttttg cagcaggtga 60
ctgcagc 67
<210> 62
<211> 67
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<400> 62
agtcacgtcg tagtcnagct gcagtcacct gctgcttttt tttttttttg cagcaggtga 60
ctgcagc 67
<210> 63
<211> 58
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (38)..(38)
<223> 5''-硫代磷酸盐-Sp9-Sp9-Sp9-5-甲基C
<400> 63
agtcacgtcg tagtcnagct gcagtcacct gctgcttctt gcagcaggtg actgcagc 58
<210> 64
<211> 58
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (38)..(38)
<223> 5''-磷酸-Sp9-Sp9-Sp9-5-甲基C
<400> 64
agtcacgtcg tagtcnagct gcagtcacct gctgcttctt gcagcaggtg actgcagc 58
<210> 65
<211> 59
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<220>
<221> 经修饰的_碱基
<222> (38)..(38)
<223> 5''-硫代磷酸盐-Sp9-Sp9-Sp9-5-甲基C
<400> 65
agtcacgtcg tagtcnagct gcagtcacct gctgcttctt gcagcaggtg actgcagct 59
<210> 66
<211> 59
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (38)..(38)
<223> 5''-硫代磷酸盐-Sp9-Sp9-Sp9-5-甲基C
<400> 66
agtcacgtcg tagtcgagct gcagtcacct gctgcttctt gcagcaggtg actgcagct 59
<210> 67
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:合成
寡核苷酸”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<400> 67
agtcacgtcg tagtcnaa 18
<210> 68
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 引物序列-图51
<400> 68
gcgacaggtg actgcagc 18
<210> 69
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 模板序列-图51
<400> 69
gctgcagtca cctgtcgc 18
<210> 70
<211> 44
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:发夹1碱基突出端T-图55”
<220>
<221> 经修饰的_碱基
<222> (20)..(20)
<223> TAMRA-dT
<400> 70
tgctgtagtc accatctgcn tttttagcag atggtgacta cagc 44
<210> 71
<211> 44
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:发夹1碱基突出端C-图55”
<220>
<221> 经修饰的_碱基
<222> (20)..(20)
<223> TAMRA-dT
<400> 71
cgctgtagtc accatctgcn tttttagcag atggtgacta cagc 44
<210> 72
<211> 45
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:发夹2碱基突出端-图55”
<220>
<221> 经修饰的_碱基
<222> (21)..(21)
<223> TAMRA-dT
<400> 72
acgctgtagt caccatctgc ntttttagca gatggtgact acagc 45
<210> 73
<211> 46
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:发夹3碱基突出端-图55”
<220>
<221> 经修饰的_碱基
<222> (22)..(22)
<223> TAMRA-dT
<400> 73
cacgctgtag tcaccatctg cntttttagc agatggtgac tacagc 46
<210> 74
<211> 47
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:发夹4碱基突出端-图55”
<220>
<221> 经修饰的_碱基
<222> (23)..(23)
<223> TAMRA-dT
<400> 74
tcacgctgta gtcaccatct gcntttttag cagatggtga ctacagc 47
<210> 75
<211> 18
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<221> 来源
<223> / note =“人工序列的描述:In链-图55”
<220>
<221> 经修饰的_碱基
<222> (16)..(16)
<223> 2’-脱氧肌苷
<400> 75
agtcacgtcg tagtcncg 18
<210> 76
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 辅助链-突出端T-图55
<400> 76
acgcgactac gacgtgact 19
<210> 77
<211> 19
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 辅助链-突出端C-图55
<400> 77
gcgcgactac gacgtgact 19
<210> 78
<211> 20
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 辅助链-2碱基突出端-图55
<400> 78
gtcgcgacta cgacgtgact 20
<210> 79
<211> 21
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 辅助链-3碱基突出端-图55
<400> 79
gtgcgcgact acgacgtgac t 21
<210> 80
<211> 22
<212> DNA
<213> 人工序列(Artificial sequence)
<220>
<223> 辅助链-4碱基突出端-图55
<400> 80
gtgacgcgac tacgacgtga ct 22
Claims (99)
1.一种合成具有预定序列的双链多核苷酸的体外方法,所述方法包括执行重复的合成循环,其中,在每个循环中:
(A)通过在连接酶的作用下添加所述预定序列的第一核苷酸来延伸双链多核苷酸的第一链;
(B)通过经由核苷酸转移酶或聚合酶添加所述预定序列的第二核苷酸来延伸所述双链多核苷酸的与所述第一链杂交的第二链;以及
(C)然后在裂解位点处裂解所述双链多核苷酸;
其中,每个循环的所述预定序列的所述第一核苷酸和所述第二核苷酸在裂解之后被保持在所述双链多核苷酸中,并且其中,所述第一核苷酸和所述第二核苷酸成为所述合成的双链多核苷酸中不同的核苷酸对中的配偶体核苷酸。
2.根据权利要求1所述的方法,其中,所述裂解位点由包括通用核苷酸的多核苷酸序列定义。
3.根据权利要求1所述的方法,其中,在每个循环中,在延伸所述第二链之前,在所述双链多核苷酸中产生裂解位点。
4.根据权利要求2所述的方法,其中,在每个循环中,在延伸所述第二链之前,在所述双链多核苷酸中产生裂解位点。
5.根据权利要求4所述的方法,其中,在步骤(A)期间,通过所述连接酶的作用,将所述通用核苷酸合并到所述双链多核苷酸的所述第一链中以定义所述裂解位点。
6.根据权利要求5所述的方法,其中,在给定的合成循环中,被添加至所述双链多核苷酸的所述第二链中的所述循环的所述第二核苷酸包括可逆终止子基团,所述可逆终止子基团阻止通过所述酶进一步延伸;并且其中,在下一循环的所述第二核苷酸的合成的下一循环中添加之前从所述循环的所述合并的第二核苷酸中移除所述可逆终止子基团。
7.根据权利要求5所述的方法,其中,所述第一核苷酸和所述通用核苷酸是多核苷酸连接分子的组分,并且其中,在步骤(A)中,通过所述连接酶的作用,所述多核苷酸连接分子连接至所述双链多核苷酸,并且其中,当所述多核苷酸连接分子连接至所述双链多核苷酸时,所述双链多核苷酸的所述第一链被延伸并产生所述裂解位点。
8.根据权利要求2所述的方法,所述方法包括执行第一合成循环,所述第一合成循环包括:
(1)提供支架多核苷酸,所述支架多核苷酸包括合成链和与所述合成链杂交的支持链,其中,所述合成链包括引物链部分,并且其中,所述支持链是所述双链多核苷酸的所述第一链,并且所述合成链是所述双链多核苷酸的所述第二链;
(2)在粘性末端连接反应中,通过所述连接酶的作用,将双链多核苷酸连接分子连接至所述支架多核苷酸,所述多核苷酸连接分子包括支持链和与所述支持链杂交的辅助链,并且所述多核苷酸连接分子还包括互补连接端,所述连接端包括:
(i)在所述支持链中,通用核苷酸和所述预定序列的第一核苷酸;和
(ii)在所述辅助链中,不可连接的末端核苷酸;
其中,在连接时,利用所述第一核苷酸延伸所述双链多核苷酸的所述第一链,并且通过将所述通用核苷酸合并到所述第一链中来产生所述裂解位点;
(3)通过在所述核苷酸转移酶或聚合酶的作用下合并所述预定序列的第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,所述第二核苷酸包括防止通过所述酶进一步延伸的可逆终止子基团;
(4)在所述裂解位点处裂解所述连接的支架多核苷酸,其中,裂解包括:裂解所述支持链并从所述支架多核苷酸中移除所述通用核苷酸,以提供包括所述合并的第一核苷酸和第二核苷酸的经裂解的双链支架多核苷酸;以及
(5)从所述第二核苷酸中移除所述可逆终止子基团;
所述方法还包括执行进一步的合成循环,所述进一步的合成循环包括:
(6)在粘性末端连接反应中,在所述连接酶的作用下,将另外的双链多核苷酸连接分子连接至所述经裂解的支架多核苷酸,所述多核苷酸连接分子包括支持链和与所述支持链杂交的辅助链,并且所述多核苷酸连接分子还包括互补连接端,所述连接端包括:
(i)在所述支持链中,通用核苷酸和所述进一步的合成循环的所述第一核苷酸;和
(ii)在所述辅助链中,不可连接的末端核苷酸;
其中,在连接时,利用所述进一步的合成循环的所述第一核苷酸延伸所述双链多核苷酸的所述第一链,并且通过将所述通用核苷酸合并到所述第一链中来产生所述裂解位点;
(7)通过在所述核苷酸转移酶或聚合酶的作用下合并所述进一步的合成循环的所述第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,所述第二核苷酸包括防止通过所述酶进一步延伸的可逆终止子基团;
(8)在所述裂解位点处裂解所述连接的支架多核苷酸,其中,裂解包括:裂解所述支持链并从所述支架多核苷酸中移除所述通用核苷酸,以提供包括所述第一合成循环和所述进一步的合成循环的所述合并的第一核苷酸和第二核苷酸的经裂解的双链支架多核苷酸;
(9)从所述第二核苷酸中移除所述可逆终止子基团;以及
(10)多次重复步骤6至9以提供具有预定核苷酸序列的所述双链多核苷酸。
9.根据权利要求8所述的方法,其中,在任何一个、多个或所有合成循环中,在所述裂解位点处裂解所述连接的支架多核苷酸的步骤之前,替代性地将所述可逆终止子基团从所述第二核苷酸中移除。
10.根据权利要求8所述的方法,其中,在步骤(1)中,所述支架多核苷酸的所述支持链的与所述引物链部分邻近的末端包括核苷酸突出端,其中,所述支持链的末端核苷酸突出所述引物链部分的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是所述循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(2)中,在所述多核苷酸连接分子的所述互补连接端处,所述辅助链的末端包括核苷酸突出端,其中,所述辅助链的末端核苷酸突出所述支持链的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是所述循环的所述第一核苷酸并且是在所述下一合成循环中形成的不同的核苷酸对中的配偶体核苷酸;
其中,在步骤(6)中,在所述经裂解的支架多核苷酸中,所述支持链的与所述引物链部分邻近的末端包括核苷酸突出端,其中,所述支持链的末端核苷酸突出所述引物链部分的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是步骤(7)中合并的所述进一步的合成循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(6)中,在所述多核苷酸连接分子的所述互补连接端,所述辅助链的末端包括核苷酸突出端,其中,所述辅助链的末端核苷酸突出所述支持链的末端核苷酸之外,并且其中,所述支持链的末端核苷酸是所述进一步的合成循环的所述第一核苷酸并且是在所述下一合成循环中形成的不同的核苷酸对中的配偶体核苷酸;并且
其中,在第一合成循环和进一步的合成循环中,所述支架多核苷酸中的核苷酸突出端和所述多核苷酸连接分子的所述互补连接端中的核苷酸突出端包括相同数目的核苷酸,其中,所述数目等于或大于一。
11.根据权利要求10所述的方法,其中:
(a)在所述第一循环的连接步骤和所有进一步的循环的连接步骤中,所述多核苷酸连接分子的所述互补连接端的被构造为使得:
i.所述循环的所述预定序列的所述第一核苷酸是所述支持链的末端核苷酸,在所述支持链中占据核苷酸位置n+1,并且与所述辅助链的次末端核苷酸配对;
ii.所述通用核苷酸是所述支持链的次末端核苷酸,在所述支持链中占据核苷酸位置n+2,并且与所述辅助链中的配偶体核苷酸配对;
iii.所述突出端包括一个核苷酸突出端,所述核苷酸突出端包括突出所述循环的所述预定序列的所述第一核苷酸之外的所述辅助链的末端核苷酸;以及
iv.所述辅助链的末端核苷酸是不可连接的核苷酸;
其中,位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置,并且位置n+1和n+2分别是所述支持链中沿远离所述互补连接端的方向相对于位置n的所述第一/下一核苷酸位置和第二核苷酸位置;并且其中,在连接时,所述多核苷酸连接分子的所述支持链的末端核苷酸连接至与所述合成链的所述引物链部分邻近的所述支架多核苷酸的末端核苷酸,并且在所述辅助链的末端核苷酸与所述合成链的所述引物链部分之间产生单链断裂;
(b)在所述第一循环的延伸步骤和所有进一步的循环中,将所述循环的所述第二核苷酸合并到所述第二链中并与所述第一链中的配偶体核苷酸配对;
(c)在所述第一循环的裂解步骤中和所有进一步的循环中,在位置n+2和n+1之间裂解所述连接的支架多核苷酸的所述支持链,从而从所述支架多核苷酸中释放所述多核苷酸连接分子并保持所述循环的所述第一核苷酸不成对并附接至所述经裂解的支架多核苷酸的所述第一链,并且所述循环的所述第二核苷酸与其配偶体核苷酸配对,并且因此,将所述循环的所述第一核苷酸在所述经裂解的支架多核苷酸的所述支持链中占据的位置定义为在所述下一合成循环中的核苷酸位置n。
12.根据权利要求10所述的方法,其中:
(a)在所述第一循环的连接步骤和所有进一步的循环的连接步骤中,所述多核苷酸连接分子的所述互补连接端的被构造为使得:
i.所述循环的所述预定序列的所述第一核苷酸是所述支持链的末端核苷酸,在所述支持链中占据核苷酸位置n+1,并且与所述辅助链的次末端核苷酸配对;
ii.所述通用核苷酸在所述支持链中占据核苷酸位置n+3,并且与所述辅助链中的配偶体核苷酸配对;
iii.所述突出端包括一个核苷酸突出端,所述核苷酸突出端包括突出所述循环的所述预定序列的所述第一核苷酸之外的所述辅助链的末端核苷酸;以及
iv.所述辅助链的末端核苷酸是不可连接的核苷酸;
其中,位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置,并且位置n+1、n+2和n+3分别是所述支持链中沿远离所述互补连接端的方向相对于位置n的下一核苷酸位置、第二核苷酸位置和第三核苷酸位置;并且其中,在连接时,所述多核苷酸连接分子的所述支持链的末端核苷酸连接至与所述合成链的所述引物链部分邻近的所述支架多核苷酸的末端核苷酸,并且在所述辅助链的末端核苷酸与所述合成链的所述引物链部分之间产生单链断裂;
(b)在所述第一循环的延伸步骤和所有进一步的循环中,将所述循环的所述第二核苷酸合并到所述第二链中并与所述第一链中的配偶体核苷酸配对;
(c)在所述第一循环的裂解步骤中和所有进一步的循环中,在位置n+2和n+1之间裂解所述连接的支架多核苷酸的所述支持链,从而从所述支架多核苷酸中释放所述多核苷酸连接分子并保持所述循环的所述第一核苷酸不成对并附接至所述经裂解的支架多核苷酸的所述第一链,并且所述循环的所述第二核苷酸与其配偶体核苷酸配对,并且因此,将所述循环的所述第一核苷酸在所述经裂解的支架多核苷酸的所述支持链中占据的位置定义为在所述下一合成循环中的核苷酸位置n。
13.根据权利要求10所述的方法,其中:
(a)在所述第一循环的连接步骤和所有进一步的循环的连接步骤中,所述多核苷酸连接分子的所述互补连接端的被构造为使得:
i.所述循环的所述预定序列的所述第一核苷酸是所述支持链的末端核苷酸,在所述支持链中占据核苷酸位置n+1,并且与所述辅助链的次末端核苷酸配对;
ii.所述通用核苷酸在所述支持链中占据核苷酸位置n+3+x,并且与所述辅助链中的配偶体核苷酸配对;
iii.所述突出端包括一个核苷酸突出端,所述核苷酸突出端包括突出所述循环的所述预定序列的所述第一核苷酸之外的所述辅助链的末端核苷酸;以及
iv.所述辅助链的末端核苷酸是不可连接的核苷酸;
其中,位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置,其中,位置n+3是所述支持链中沿远离所述互补连接端的方向相对于位置n的第三核苷酸位置,并且其中,x是沿远离所述互补连接端的方向相对于位置n+3的核苷酸位置的数目,其中,所述数目是1至10或更大的整数;并且其中,在连接时,所述多核苷酸连接分子的所述支持链的末端核苷酸连接至与所述合成链的所述引物链部分邻近的所述支架多核苷酸的末端核苷酸,并且在所述辅助链的末端核苷酸与所述合成链的所述引物链部分之间产生单链断裂;
(b)在所述第一循环的延伸步骤和所有进一步的循环中,将所述循环的所述第二核苷酸合并到所述第二链中并与所述第一链中的配偶体核苷酸配对;
(c)在所述第一循环的裂解步骤中和所有进一步的循环中,在位置n+2和n+1之间裂解所述连接的支架多核苷酸的所述支持链,从而从所述支架多核苷酸中释放所述多核苷酸连接分子并保持所述循环的所述第一核苷酸不成对并附接至所述经裂解的支架多核苷酸的所述第一链,并且所述循环的所述第二核苷酸与其配偶体核苷酸配对,并且因此,将所述循环的所述第一核苷酸在所述经裂解的支架多核苷酸的所述支持链中占据的位置定义为在所述下一合成循环中的核苷酸位置n。
14.根据权利要求8所述的方法,其中,在步骤(1)中,所述支架多核苷酸的所述支持链的与所述引物链部分邻近的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述支持链的所述1+y个核苷酸突出所述引物链部分的末端核苷酸之外,并且其中,所述突出端的所述第一核苷酸占据所述突出端中的远离所述突出端的末端的位置,占据核苷酸位置n,并且是在步骤(3)中合并的所述第一循环的所述第二核苷酸的配偶体核苷酸,并且其中,所述突出端的占据位置n+1的核苷酸是在步骤(7)中合并的所述下一/第二合成循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(2)中,在所述多核苷酸连接分子的所述互补连接端,所述辅助链的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述辅助链的所述1+y个核苷酸突出所述支持链的末端核苷酸之外,并且是所述支架多核苷酸的所述支持链的突出的所述1+y个核苷酸的配偶体核苷酸,并且其中,所述互补连接端的所述支持链的末端核苷酸是所述循环的所述第一核苷酸,占据核苷酸位置n+2+x并且是在所述第三合成循环中形成的不同的核苷酸对中的配偶体核苷酸;
其中,在步骤(6)中,在所述经裂解的支架多核苷酸中,所述支持链的与所述引物链部分邻近的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述支持链的所述1+y个核苷酸突出所述引物链部分的末端核苷酸,并且其中,所述突出端的所述第一核苷酸占据所述突出端中的远离所述突出端的末端的位置,占据核苷酸位置n,并且是在步骤(7)中合并的所述进一步的合成循环的所述第二核苷酸的配偶体核苷酸,并且其中,所述突出端的占据位置n+1的核苷酸是所述下一合成循环的所述第二核苷酸的配偶体核苷酸;
其中,在步骤(6)中,在所述多核苷酸连接分子的所述互补连接端,所述辅助链的末端包括含有1+y个核苷酸的核苷酸突出端,其中,所述辅助链的所述1+y个核苷酸突出所述支持链的末端核苷酸链并且是所述支架多核苷酸的所述支持链的突出的所述1+y个核苷酸的配偶体核苷酸,并且其中,所述互补连接端的所述支持链的末端核苷酸是所述进一步的合成循环的所述第一核苷酸,占据核苷酸位置n+2+x,并且是在所述下一合成循环中形成的不同的核苷酸对中的配偶体核苷酸;并且其中:
i.位置n是在所述循环的所述预定序列的所述第二核苷酸被合并后与所述第二核苷酸相对的核苷酸位置;
ii.随后的连接位置n+1和n+2是所述支持链中的沿与所述辅助链邻近/远离所述引物链部分的方向相对于位置n的所述第一核苷酸位置和所述第二核苷酸位置;
iii.y是等于或大于一的整数;
iv.x是等于或大于零的整数;
v.所述支架多核苷酸中的y的数目与所述多核苷酸连接分子的所述互补连接端中的y的数目相同,并且其中,如果y是不同的数目,则所述多核苷酸连接分子的所述互补连接端中的y的数目小于所述支架多核苷酸中的y的数目;以及
vi.在任何给定的一系列的第一循环和进一步的循环中,为x选择的数目是为所述支架多核苷酸中的y选择的数目减去一。
15.根据权利要求10所述的方法,其中,在第一循环和进一步的循环两者中,在所述多核苷酸连接分子和所述连接的支架多核苷酸两者中,所述通用核苷酸占据位置n+3+x,并且在位置n+3+x和n+2+x之间裂解所述支架多核苷酸。
16.根据权利要求10所述的方法,其中,在第一循环和进一步的循环两者中,在所述多核苷酸连接分子和所述连接的支架多核苷酸两者中,所述通用核苷酸占据位置n+4+x,并且在位置n+3+x和n+2+x之间裂解所述支架多核苷酸。
17.根据权利要求8所述的方法,其中,修改所述方法使得
(i)在步骤(2)中,所述多核苷酸连接分子设有互补连接端,所述互补连接端包括所述第一循环的所述预定序列的第一核苷酸,并且所述互补连接端还包括所述第一循环的所述预定序列的一个或多个另外的核苷酸;
(ii)在步骤(3)中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述第一循环的所述预定序列的第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,并且其中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述第一循环的所述预定序列的一个或多个另外的核苷酸来进一步延伸所述引物链部分的末端,其中,所述第一循环的所述第二核苷酸和所述另外的核苷酸中的每一个包括可逆终止子基团,所述可逆终止子基团阻止通过所述酶进一步延伸,并且其中,在每次进一步延伸之后,在合并下一核苷酸之前,从核苷酸中移除所述可逆终止子基团;
(iii)在步骤(4)中,在裂解之后,所述第一循环的所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中;
(iv)在步骤(6)中,所述多核苷酸连接分子设有互补连接端,所述互补连接端包括所述进一步的循环的所述预定序列的第一核苷酸,并且所述互补连接端还包括所述进一步的循环的所述预定序列的一个或多个另外的核苷酸;
(v)在步骤(6)中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述进一步的循环的所述预定序列的第二核苷酸来延伸所述双链支架多核苷酸的所述合成链的所述引物链部分的末端,并且其中,通过在所述核苷酸转移酶或聚合酶的作用下合并所述进一步的循环的所述预定序列的一个或多个另外的核苷酸来进一步延伸所述引物链部分的末端,其中,所述进一步的循环的所述第二核苷酸和所述另外的核苷酸中的每一个包括可逆终止子基团,所述可逆终止子基团阻止通过所述酶进一步延伸,并且其中,在每次进一步延伸之后,在合并下一核苷酸之前,从核苷酸中移除所述可逆终止子基团;
(vi)在步骤(8)中,在裂解之后,所述进一步的循环的所述预定序列的所述第一核苷酸、所述第二核苷酸和所述另外的核苷酸被保持在所述经裂解的支架多核苷酸中。
18.根据权利要求17所述的方法,其中,所述多核苷酸连接分子的所述互补连接端被构造为使得在裂解之前的步骤(4)和(8)中,所述通用核苷酸在所述支持链中占据这样的位置:所述位置是所述支持链中沿远离所述互补连接端的方向在所述第一核苷酸和所述另外的核苷酸的核苷酸位置之后的下一核苷酸位置,并且在最后的所述另外的核苷酸所占据的位置与所述通用核苷酸所占据的位置之间裂解所述支持链。
19.根据权利要求17所述的方法,其中,所述多核苷酸连接分子的所述互补连接端被构造为使得在裂解之前的步骤(4)和(8)中,所述通用核苷酸在所述支持链中占据这样的位置:所述位置是所述支持链中沿远离所述互补连接端的方向在所述第一核苷酸和所述另外的核苷酸的核苷酸位置之后的再下一核苷酸位置,并且在所述支持链中的最后的所述另外的核苷酸所占据的位置与所述下一核苷酸所占据的位置之间裂解所述支持链。
20.根据权利要求1所述的方法,其中,在任何一个、多个或所有合成循环中,与所述预定序列的所述第一核苷酸配对的配偶体核苷酸是与所述第一核苷酸互补的核苷酸。
21.根据权利要求8所述的方法,其中,在任何一个、多个或所有合成循环中,在步骤(4)和/或(8)之前提供所述支架多核苷酸,所述支架多核苷酸包括合成链和与所述合成链杂交的支持链,并且其中,所提供的所述合成链没有辅助链。
22.根据权利要求8所述的方法,其中,在任何一个、多个或所有合成循环中,在步骤(4)和/或(8)之前,从所述支架多核苷酸中移除所述合成链的所述辅助链部分。
23.根据权利要求22所述的方法,其中,通过以下步骤从所述支架多核苷酸中移除所述合成链的所述辅助链部分:(i)将所述支架多核苷酸加热至80℃至95℃的温度,并从所述支架多核苷酸中分离出所述辅助链部分,(ii)用尿素溶液处理所述支架多核苷酸,并且从所述支架多核苷酸中分离出所述辅助链部分,(iii)用甲酰胺或甲酰胺溶液处理所述支架多核苷酸,并且从所述支架多核苷酸中分离出所述辅助链部分,或(iv)使所述支架多核苷酸与单链多核苷酸分子接触,所述单链多核苷酸分子包括与所述辅助链部分的序列互补的核苷酸序列区域,从而竞争性地抑制所述辅助链部分与所述支架多核苷酸杂交。
24.根据权利要求8所述的方法,其中,每个裂解步骤包括两步裂解过程,其中,每个裂解步骤包括:第一步,所述第一步包括移除所述通用核苷酸从而形成无碱基位点;和第二步,所述第二步包括在所述无碱基位点处裂解所述支持链。
25.根据权利要求24所述的方法,其中,所述第一步是利用核苷酸裂解酶来执行的。
26.根据权利要求25所述的方法,其中,所述核苷酸裂解酶是3-甲基腺嘌呤DNA糖基化酶。
27.根据权利要求26所述的方法,其中,所述核苷酸切除酶是:
i.人类烷基腺嘌呤DNA糖基化酶(hAAG);或
ii.尿嘧啶DNA糖基化酶(UDG)。
28.根据权利要求24所述的方法,其中,所述第二步是利用作为碱的化学物质来执行的。
29.根据权利要求28所述的方法,其中,所述碱是NaOH。
30.根据权利要求24所述的方法,其中,所述第二步是利用具有无碱基位点裂解活性的有机化学物质来执行的。
31.根据权利要求30所述的方法,其中,所述有机化学物质是N,N'-二甲基乙二胺。
32.根据权利要求24所述的方法,其中,所述第二步是利用具有无碱基位点裂解酶活性的酶来执行的。
33.根据权利要求32所述的方法,其中,所述具有无碱基位点裂解酶活性的酶是:
(i)AP核酸内切酶1;
(ii)核酸内切酶III(Nth);或
(iii)核酸内切酶VIII。
34.根据权利要求2所述的方法,其中,每个裂解步骤包括一个步骤的裂解过程,所述裂解过程包括利用裂解酶移除所述通用核苷酸,其中,所述酶是:
(i)核酸内切酶III;
(ii)核酸内切酶VIII;
(iii)甲酰胺基嘧啶DNA糖基化酶(Fpg);或
(iv)8-氧桥鸟嘌呤DNA糖基化酶(hOGG1)。
35.根据权利要求8所述的方法,其中,所述裂解步骤包括利用酶裂解所述支持链。
36.根据权利要求35所述的方法,其中,所述酶在核苷酸位置n+1和n之间裂解所述支持链。
37.根据权利要求34所述的方法,其中,所述酶是核酸内切酶V。
38.根据权利要求1-37中任一项所述的方法,其中,所述合成的双链多核苷酸的两条链都是DNA链。
39.根据权利要求38所述的方法,其中,合并的核苷酸是dNTP。
40.根据权利要求39所述的方法,其中,合并的核苷酸是包括可逆终止子基团的dNTP。
41.根据权利要求40所述的方法,其中,包括可逆终止子基团的一个或多个所述合并的核苷酸是3’-O-烯丙基-dNTP。
42.根据权利要求40所述的方法,其中,包括可逆终止子基团的一个或多个所述合并的核苷酸是3’-O-叠氮甲基-dNTP。
43.根据权利要求8所述的方法,其中,所述合成的双链多核苷酸的一条链是DNA链,并且所述合成的双链多核苷酸的另一条链是RNA链。
44.根据权利要求43所述的方法,其中,所述合成链是RNA链,并且所述支持链是DNA链。
45.根据权利要求44所述的方法,其中,合并的核苷酸是NTP。
46.根据权利要求45所述的方法,其中,合并的核苷酸是包括可逆终止子基团的NTP。
47.根据权利要求46所述的方法,其中,包括可逆终止子基团的合并的核苷酸是3’-O-烯丙基-NTP。
48.根据权利要求46所述的方法,其中,包括可逆终止子基团的合并的核苷酸是3’-O-叠氮甲基-NTP。
49.根据权利要求1所述的方法,其中,所述聚合酶是DNA聚合酶。
50.根据权利要求49所述的方法,其中,所述DNA聚合酶为修饰的DNA聚合酶,其具有与未修饰的聚合酶相比增强的合并包括可逆终止子基团的dNTP的能力。
51.根据权利要求49所述的方法,其中,所述聚合酶是来自热球菌物种9°N的天然DNA聚合酶的变体。
52.根据权利要求51所述的方法,其中,所述聚合酶是来自热球菌物种9°N-7的天然DNA聚合酶的变体。
53.根据权利要求1所述的方法,其中,所述聚合酶是RNA聚合酶。
54.根据权利要求53所述的方法,其中,所述RNA聚合酶为T3或T7 RNA聚合酶。
55.根据权利要求53所述的方法,其中,所述RNA聚合酶为修饰的RNA聚合酶,其具有与未修饰的聚合酶相比增强的合并包括可逆终止子基团的NTP的能力。
56.根据权利要求1所述的方法,其中,所述转移酶具有末端转移酶活性。
57.根据权利要求1所述的方法,其中,所述转移酶是末端核苷酸转移酶、末端脱氧核苷酸转移酶、末端脱氧核苷酸转移酶(TdT)、pol lambda、pol micro或Φ29DNA聚合酶。
58.根据权利要求6所述的方法,其中,利用三(羧乙基)膦(TCEP)执行从所述第二核苷酸中移除所述可逆终止子基团的步骤。
59.根据权利要求1所述的方法,其中,所述连接酶是T3 DNA连接酶或T4 DNA连接酶。
60.根据权利要求8所述的方法,其中,在步骤(1)/(6)中的任何一个、多个或所有合成循环中,在所述支架多核苷酸中,包括所述引物链部分的所述合成链和所述支持链的与其杂交的部分通过发夹环连接。
61.根据权利要求8所述的方法,其中,在步骤(2)/(6)中的任何一个、多个或所有合成循环中,在所述多核苷酸连接分子中,所述辅助链和所述支持链的与所述辅助链杂交的部分在与所述互补连接端相对的一端通过发夹环连接。
62.根据权利要求8所述的方法,其中,在任何一个、多个或所有合成循环中:
(a)在步骤(1)/(6)中,在所述支架多核苷酸中,包括所述引物链部分的所述合成链和所述支持链的与其杂交的部分通过发夹环连接;以及
(b)在步骤(2)/(6)中,在所述多核苷酸连接分子中,所述辅助链和所述支持链的与所述辅助链杂交的部分在与所述互补连接端相对的一端通过发夹环连接。
63.根据权利要求8所述的方法,其中,在步骤(1)和(6)中,将包括所述引物链部分的所述合成链和/或所述支持链的与其杂交的部分束缚至共同的表面。
64.根据权利要求63所述的方法,其中,所述引物链部分和所述支持链的与所述引物链部分杂交的部分包括可裂解的接头,其中,在合成之后,所述接头能被裂解以从所述表面拆离出所述双链多核苷酸。
65.根据权利要求61所述的方法,其中,在步骤(1)和(6)中,所述支架多核苷酸中的所述发夹环被束缚至表面。
66.根据权利要求65所述的方法,其中,所述发夹环经由可裂解的接头被束缚至表面,其中,在合成之后,所述接头能被裂解以从所述表面拆离出所述双链多核苷酸。
67.根据权利要求64所述的方法,其中,所述可裂解的接头是UV可裂解的接头。
68.根据权利要求63所述的方法,其中,所述表面是微颗粒。
69.根据权利要求63所述的方法,其中,所述表面是平坦表面。
70.根据权利要求65所述的方法,其中,所述表面包括凝胶。
71.根据权利要求70所述的方法,其中,所述表面包括聚丙烯酰胺表面。
72.根据权利要求71所述的方法,其中,所述聚丙烯酰胺表面偶联至固体支撑件。
73.根据权利要求72所述的方法,其中,所述固体支撑件为玻璃。
74.根据权利要求63所述的方法,其中,包括所述引物链部分的所述合成链和所述支持链的与其杂交的部分经由一个或多个共价键被束缚至所述共同的表面。
75.根据权利要求74所述的方法,其中,所述一个或多个共价键在所述共同的表面上的官能团与所述支架多核苷酸上的官能团之间形成,其中,所述支架多核苷酸上的官能团是胺基团、硫醇基团、硫代磷酸盐基团或硫代酰胺基团。
76.根据权利要求75所述的方法,其中,所述共同的表面上的官能团是溴乙酰基团。
77.根据权利要求76所述的方法,其中,所述溴乙酰基团设置在使用N-(5-溴乙酰胺基戊基)丙烯酰胺(BRAPA)衍生的聚丙烯酰胺表面上。
78.根据权利要求1所述的方法,其中,合成循环是在微流体系统内的液滴中执行的。
79.根据权利要求78所述的方法,其中,所述微流体系统是电润湿系统。
80.根据权利要求79所述的方法,其中,所述微流体系统是电介质上电润湿系统(EWOD)。
81.根据权利要求1所述的方法,其中,在合成之后,将所述双链多核苷酸的链分离以提供具有预定序列的单链多核苷酸。
82.根据权利要求1所述的方法,其中,在合成之后,扩增所述双链多核苷酸或所述双链多核苷酸的区域。
83.根据权利要求1所述的方法,其中,在合成之后,通过PCR扩增所述双链多核苷酸或所述双链多核苷酸的区域。
84.一种组装具有预定序列的多核苷酸的方法,所述方法包括:执行根据权利要求1-82中任一项所述的方法,以合成具有预定序列的第一多核苷酸和具有预定序列的一个或多个附加的多核苷酸;以及将所述第一多核苷酸和所述一个或多个附加的多核苷酸连接在一起。
85.根据权利要求84所述的方法,其中,所述第一多核苷酸和所述一个或多个附加的多核苷酸是双链的。
86.根据权利要求84所述的方法,其中,所述第一多核苷酸和所述一个或多个附加的多核苷酸是单链的。
87.根据权利要求84所述的方法,其中,所述第一多核苷酸和所述一个或多个附加的多核苷酸被裂解以产生相容的末端并且被连接在一起。
88.根据权利要求87所述的方法,其中,所述第一多核苷酸和所述一个或多个附加的多核苷酸在裂解位点处被限制酶裂解。
89.根据权利要求84所述的方法,其中,所述合成和/或组装步骤是在微流体系统内的液滴中执行的。
90.根据权利要求89所述的方法,其中,所述组装步骤包括:提供第一液滴和第二液滴,所述第一液滴包括具有预定序列的第一合成多核苷酸,所述第二液滴包括具有预定序列的一个或多个附加的合成多核苷酸,其中,使所述液滴彼此接触,并且其中,将所述合成多核苷酸连接在一起,从而组装包括所述第一核苷酸和所述一个或多个附加的多核苷酸的多核苷酸。
91.根据权利要求90所述的方法,其中,所述合成步骤是通过提供多个液滴来执行的,每个液滴包括与所述合成循环的步骤对应的反应试剂,并且根据所述合成循环的步骤将所述液滴依次递送到支架多核苷酸。
92.根据权利要求91所述的方法,其中,在递送液滴之后并且在递送下一液滴之前,实施洗涤步骤以移除过量的反应试剂。
93.根据权利要求91所述的方法,其中,所述微流体系统是电润湿系统。
94.根据权利要求93所述的方法,其中,所述微流体系统是电介质上电润湿系统(EWOD)。
95.根据权利要求91所述的方法,其中,合成和组装步骤是在同一系统中执行的。
96.一种用于实施根据权利要求1至95中任一项所述的方法的多核苷酸合成系统,所述系统包括:(a)反应区域的阵列,其中,每个反应区域包括至少一个支架多核苷酸;和(b)用于将反应试剂递送至所述反应区域的装置;以及(c)用于从所述支架多核苷酸中裂解合成的双链多核苷酸的装置。
97.根据权利要求96所述的系统,还包括:用于以液滴形式提供所述反应试剂的装置;和用于根据合成循环将所述液滴递送至所述支架多核苷酸的装置。
98.一种制备多核苷酸微阵列的方法,其中,所述微阵列包括多个反应区域,每个区域包括具有预定序列的一个或多个多核苷酸,所述方法包括:
(a)提供包括多个反应区域的表面,每个区域包括一个或多个双链锚固或支架多核苷酸;以及
(b)在每个反应区域处根据权利要求1至80中任一项所述的方法执行合成循环,从而在每个区域处合成具有预定序列的一个或多个双链多核苷酸。
99.根据权利要求98所述的方法,其中,在合成之后,将所述双链多核苷酸的链分离以提供微阵列,其中,每个区域包括具有预定序列的一个或多个单链多核苷酸。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB1811811.7 | 2018-07-19 | ||
| GBGB1811811.7A GB201811811D0 (en) | 2018-07-19 | 2018-07-19 | Method |
| PCT/GB2019/052036 WO2020016605A1 (en) | 2018-07-19 | 2019-07-19 | Polynucleotide synthesis method, kit and system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112423885A CN112423885A (zh) | 2021-02-26 |
| CN112423885B true CN112423885B (zh) | 2023-07-04 |
Family
ID=63364456
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980048339.XA Active CN112423885B (zh) | 2018-07-19 | 2019-07-19 | 多核苷酸合成方法、试剂盒和系统 |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US12037636B2 (zh) |
| EP (1) | EP3823755A1 (zh) |
| JP (1) | JP7509745B2 (zh) |
| CN (1) | CN112423885B (zh) |
| AU (1) | AU2019307836B2 (zh) |
| CA (1) | CA3104698A1 (zh) |
| GB (1) | GB201811811D0 (zh) |
| WO (1) | WO2020016605A1 (zh) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2559117B (en) | 2017-01-19 | 2019-11-27 | Oxford Nanopore Tech Ltd | Double stranded polynucleotide synthesis method, kit and system |
| GB2574197B (en) * | 2018-05-23 | 2022-01-05 | Oxford Nanopore Tech Ltd | Double stranded polynucleotide synthesis method and system. |
| GB201811813D0 (en) * | 2018-07-19 | 2018-09-05 | Oxford Nanopore Tech Ltd | Method |
| GB201811810D0 (en) * | 2018-07-19 | 2018-09-05 | Oxford Nanopore Tech Ltd | Method |
| GB201811811D0 (en) | 2018-07-19 | 2018-09-05 | Oxford Nanopore Tech Ltd | Method |
| WO2021148809A1 (en) * | 2020-01-22 | 2021-07-29 | Nuclera Nucleics Ltd | Methods of nucleic acid synthesis |
| GB202013102D0 (en) * | 2020-08-21 | 2020-10-07 | Nuclera Nucleics Ltd | Methods of nucleic acid synthesis |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001088173A2 (en) * | 2000-05-16 | 2001-11-22 | Hercules Incorporated | Methods for the enzymatic assembly of polynucleotides and identification of polynucleotides having desired characteristics |
| WO2012078312A2 (en) * | 2010-11-12 | 2012-06-14 | Gen9, Inc. | Methods and devices for nucleic acids synthesis |
Family Cites Families (43)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5438131A (en) | 1992-09-16 | 1995-08-01 | Bergstrom; Donald E. | 3-nitropyrrole nucleoside |
| US6190865B1 (en) * | 1995-09-27 | 2001-02-20 | Epicentre Technologies Corporation | Method for characterizing nucleic acid molecules |
| US8137906B2 (en) | 1999-06-07 | 2012-03-20 | Sloning Biotechnology Gmbh | Method for the synthesis of DNA fragments |
| DE19925862A1 (de) | 1999-06-07 | 2000-12-14 | Diavir Gmbh | Verfahren zur Synthese von DNA-Fragmenten |
| EP1314783B1 (de) | 2001-11-22 | 2008-11-19 | Sloning BioTechnology GmbH | Nukleinsäure-Linker und deren Verwendung in der Gensynthese |
| US7435572B2 (en) | 2002-04-12 | 2008-10-14 | New England Biolabs, Inc. | Methods and compositions for DNA manipulation |
| DE10223057A1 (de) | 2002-05-24 | 2003-12-11 | Basf Ag | Verfahren zur Erzeugung von Polynukleotidmolekülen |
| WO2005035757A1 (en) | 2003-10-02 | 2005-04-21 | Basf Aktiengesellschaft | A process for sequence saturation mutagenesis (sesam) |
| ES2292270B1 (es) * | 2004-04-14 | 2009-02-16 | Oryzon Genomics, S.A. | Procedimiento para detectar selectivamente acidos nucleicos con estructuras atipicas convertibles en muescas. |
| WO2008128111A1 (en) | 2007-04-13 | 2008-10-23 | Sequenom, Inc. | Comparative sequence analysis processes and systems |
| US8716190B2 (en) | 2007-09-14 | 2014-05-06 | Affymetrix, Inc. | Amplification and analysis of selected targets on solid supports |
| US8808986B2 (en) | 2008-08-27 | 2014-08-19 | Gen9, Inc. | Methods and devices for high fidelity polynucleotide synthesis |
| US9187777B2 (en) | 2010-05-28 | 2015-11-17 | Gen9, Inc. | Methods and devices for in situ nucleic acid synthesis |
| US8653832B2 (en) | 2010-07-06 | 2014-02-18 | Sharp Kabushiki Kaisha | Array element circuit and active matrix device |
| US8828336B2 (en) | 2011-02-02 | 2014-09-09 | Sharp Kabushiki Kaisha | Active matrix device |
| US10378051B2 (en) * | 2011-09-29 | 2019-08-13 | Illumina Cambridge Limited | Continuous extension and deblocking in reactions for nucleic acids synthesis and sequencing |
| EP2807292B1 (en) | 2012-01-26 | 2019-05-22 | Tecan Genomics, Inc. | Compositions and methods for targeted nucleic acid sequence enrichment and high efficiency library generation |
| WO2014064444A1 (en) | 2012-10-26 | 2014-05-01 | Oxford Nanopore Technologies Limited | Droplet interfaces |
| US9492824B2 (en) | 2013-01-16 | 2016-11-15 | Sharp Kabushiki Kaisha | Efficient dilution method, including washing method for immunoassay |
| US9169573B2 (en) | 2013-01-23 | 2015-10-27 | Sharp Kabushiki Kaisha | AM-EWOD device and method of driving with variable voltage AC driving |
| US9279149B2 (en) | 2013-04-02 | 2016-03-08 | Molecular Assemblies, Inc. | Methods and apparatus for synthesizing nucleic acids |
| US9771613B2 (en) | 2013-04-02 | 2017-09-26 | Molecular Assemblies, Inc. | Methods and apparatus for synthesizing nucleic acid |
| US8808989B1 (en) | 2013-04-02 | 2014-08-19 | Molecular Assemblies, Inc. | Methods and apparatus for synthesizing nucleic acids |
| US10683536B2 (en) | 2013-04-02 | 2020-06-16 | Molecular Assemblies, Inc. | Reusable initiators for synthesizing nucleic acids |
| JP6448097B2 (ja) * | 2013-10-15 | 2019-01-09 | モレキュラー アセンブリーズ, インコーポレイテッド | 核酸を合成するための方法および装置 |
| CN118086476A (zh) | 2013-10-18 | 2024-05-28 | 牛津纳米孔科技公开有限公司 | 经修饰的酶 |
| CA2937411C (en) | 2014-01-22 | 2023-09-26 | Oxford Nanopore Technologies Limited | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| FR3020071B1 (fr) | 2014-04-17 | 2017-12-22 | Dna Script | Procede de synthese d'acides nucleiques, notamment d'acides nucleiques de grande longueur, utilisation du procede et kit pour la mise en œuvre du procede |
| US20170218416A1 (en) | 2014-05-16 | 2017-08-03 | The Regents Of The University Of California | Compositions and methods for single-molecule construction of dna |
| FR3025201B1 (fr) | 2014-09-02 | 2018-10-12 | Dna Script | Nucleotides modifies pour la synthese d'acides nucleiques, un kit renfermant de tels nucleotides et leur utilisation pour la production de genes ou sequences d'acides nucleiques synthetiques |
| US10059929B2 (en) | 2014-10-20 | 2018-08-28 | Molecular Assemblies, Inc. | Modified template-independent enzymes for polydeoxynucleotide synthesis |
| GB201502152D0 (en) | 2015-02-10 | 2015-03-25 | Nuclera Nucleics Ltd | Novel use |
| GB201503534D0 (en) | 2015-03-03 | 2015-04-15 | Nuclera Nucleics Ltd | Novel method |
| GB201512372D0 (en) | 2015-07-15 | 2015-08-19 | Nuclera Nucleics Ltd | Novel method |
| CN114874337A (zh) * | 2016-06-24 | 2022-08-09 | 加利福尼亚大学董事会 | 使用栓系的核苷三磷酸的核酸合成和测序 |
| GB2559117B (en) | 2017-01-19 | 2019-11-27 | Oxford Nanopore Tech Ltd | Double stranded polynucleotide synthesis method, kit and system |
| EP3737755B1 (en) | 2018-01-12 | 2024-08-28 | Camena Bioscience Limited | Method for template-free geometric enzymatic nucleic acid synthesis |
| GB201801768D0 (en) | 2018-02-02 | 2018-03-21 | Oxford Nanopore Tech Ltd | Synthesis method |
| GB2574197B (en) | 2018-05-23 | 2022-01-05 | Oxford Nanopore Tech Ltd | Double stranded polynucleotide synthesis method and system. |
| GB201811810D0 (en) * | 2018-07-19 | 2018-09-05 | Oxford Nanopore Tech Ltd | Method |
| GB201811813D0 (en) | 2018-07-19 | 2018-09-05 | Oxford Nanopore Tech Ltd | Method |
| GB201811811D0 (en) | 2018-07-19 | 2018-09-05 | Oxford Nanopore Tech Ltd | Method |
| GB201913039D0 (en) | 2019-09-10 | 2019-10-23 | Oxford Nanopore Tech Ltd | Polynicleotide synthesis method kit and system |
-
2018
- 2018-07-19 GB GBGB1811811.7A patent/GB201811811D0/en not_active Ceased
-
2019
- 2019-07-19 JP JP2021500840A patent/JP7509745B2/ja active Active
- 2019-07-19 CA CA3104698A patent/CA3104698A1/en active Pending
- 2019-07-19 WO PCT/GB2019/052036 patent/WO2020016605A1/en unknown
- 2019-07-19 EP EP19748893.5A patent/EP3823755A1/en active Pending
- 2019-07-19 US US17/260,615 patent/US12037636B2/en active Active
- 2019-07-19 AU AU2019307836A patent/AU2019307836B2/en active Active
- 2019-07-19 CN CN201980048339.XA patent/CN112423885B/zh active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001088173A2 (en) * | 2000-05-16 | 2001-11-22 | Hercules Incorporated | Methods for the enzymatic assembly of polynucleotides and identification of polynucleotides having desired characteristics |
| WO2012078312A2 (en) * | 2010-11-12 | 2012-06-14 | Gen9, Inc. | Methods and devices for nucleic acids synthesis |
Also Published As
| Publication number | Publication date |
|---|---|
| CA3104698A1 (en) | 2020-01-23 |
| AU2019307836A1 (en) | 2021-01-07 |
| US12037636B2 (en) | 2024-07-16 |
| JP2021529548A (ja) | 2021-11-04 |
| AU2019307836B2 (en) | 2024-04-04 |
| JP7509745B2 (ja) | 2024-07-02 |
| CN112423885A (zh) | 2021-02-26 |
| WO2020016605A1 (en) | 2020-01-23 |
| US20220213537A1 (en) | 2022-07-07 |
| GB201811811D0 (en) | 2018-09-05 |
| EP3823755A1 (en) | 2021-05-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7393351B2 (ja) | ポリヌクレオチドの合成法、システム、およびキット | |
| CN112423885B (zh) | 多核苷酸合成方法、试剂盒和系统 | |
| KR102618717B1 (ko) | 폴리뉴클레오티드 분자의 합성을 위한 방법 및 시약 | |
| JP7518812B2 (ja) | ポリヌクレオチドの合成法、キット、およびシステム | |
| JP7393412B2 (ja) | ポリヌクレオチドの合成法、キット、およびシステム | |
| US20220396818A1 (en) | Polynucleotide synthesis method, kit and system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information |
Address after: Cambridge County, England Applicant after: Oxford nanopore Technology Public Co.,Ltd. Address before: Cambridge County, England Applicant before: Oxford nanopore technology Co. |
|
| CB02 | Change of applicant information | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |