CN107109352B - 甘露聚糖酶、纤维素酶和果胶酶缺陷型的表达β-半乳糖苷酶和/或转半乳糖基化活性的重组宿主细胞 - Google Patents
甘露聚糖酶、纤维素酶和果胶酶缺陷型的表达β-半乳糖苷酶和/或转半乳糖基化活性的重组宿主细胞 Download PDFInfo
- Publication number
- CN107109352B CN107109352B CN201580070585.7A CN201580070585A CN107109352B CN 107109352 B CN107109352 B CN 107109352B CN 201580070585 A CN201580070585 A CN 201580070585A CN 107109352 B CN107109352 B CN 107109352B
- Authority
- CN
- China
- Prior art keywords
- polypeptide
- activity
- host cell
- seq
- galactosidase
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 230000000694 effects Effects 0.000 title claims abstract description 267
- 108010055059 beta-Mannosidase Proteins 0.000 title claims abstract description 107
- 102100032487 Beta-mannosidase Human genes 0.000 title claims abstract description 103
- 108010059892 Cellulase Proteins 0.000 title claims abstract description 88
- 108010005774 beta-Galactosidase Proteins 0.000 title claims abstract description 86
- 108010059820 Polygalacturonase Proteins 0.000 title claims abstract description 82
- 108010093305 exopolygalacturonase Proteins 0.000 title claims abstract description 80
- 229940106157 cellulase Drugs 0.000 title claims abstract description 78
- 102000005936 beta-Galactosidase Human genes 0.000 title claims abstract description 65
- 230000002950 deficient Effects 0.000 title abstract description 21
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 469
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 469
- 229920001184 polypeptide Polymers 0.000 claims abstract description 468
- 238000000034 method Methods 0.000 claims description 151
- 229940088598 enzyme Drugs 0.000 claims description 143
- 102000004190 Enzymes Human genes 0.000 claims description 141
- 108090000790 Enzymes Proteins 0.000 claims description 141
- 239000008267 milk Substances 0.000 claims description 117
- 235000013336 milk Nutrition 0.000 claims description 116
- 210000004080 milk Anatomy 0.000 claims description 116
- 239000000203 mixture Substances 0.000 claims description 108
- 108010065511 Amylases Proteins 0.000 claims description 65
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 claims description 64
- 150000007523 nucleic acids Chemical class 0.000 claims description 64
- 108090000623 proteins and genes Proteins 0.000 claims description 64
- 239000008101 lactose Substances 0.000 claims description 63
- 102000013142 Amylases Human genes 0.000 claims description 62
- 235000019418 amylase Nutrition 0.000 claims description 61
- 239000004382 Amylase Substances 0.000 claims description 58
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 50
- 102000039446 nucleic acids Human genes 0.000 claims description 44
- 108020004707 nucleic acids Proteins 0.000 claims description 44
- 230000014509 gene expression Effects 0.000 claims description 33
- 239000013604 expression vector Substances 0.000 claims description 27
- 230000002829 reductive effect Effects 0.000 claims description 27
- 230000009467 reduction Effects 0.000 claims description 17
- 239000003550 marker Substances 0.000 claims description 16
- 244000063299 Bacillus subtilis Species 0.000 claims description 15
- 235000014469 Bacillus subtilis Nutrition 0.000 claims description 15
- 241000186016 Bifidobacterium bifidum Species 0.000 claims description 13
- 229940002008 bifidobacterium bifidum Drugs 0.000 claims description 13
- 230000003197 catalytic effect Effects 0.000 claims description 11
- 238000012217 deletion Methods 0.000 claims description 11
- 230000037430 deletion Effects 0.000 claims description 11
- 238000010353 genetic engineering Methods 0.000 claims description 11
- 239000001963 growth medium Substances 0.000 claims description 10
- 238000003780 insertion Methods 0.000 claims description 10
- 230000037431 insertion Effects 0.000 claims description 10
- 230000002779 inactivation Effects 0.000 claims description 8
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 claims description 6
- 108090000637 alpha-Amylases Proteins 0.000 claims description 6
- 238000012258 culturing Methods 0.000 claims description 6
- 230000009368 gene silencing by RNA Effects 0.000 claims description 6
- 230000002255 enzymatic effect Effects 0.000 claims description 5
- 108020005544 Antisense RNA Proteins 0.000 claims description 4
- 102000004139 alpha-Amylases Human genes 0.000 claims description 4
- 239000003184 complementary RNA Substances 0.000 claims description 4
- 108010087558 pectate lyase Proteins 0.000 claims description 4
- 101100022267 Bacillus subtilis (strain 168) gmuG gene Proteins 0.000 claims description 3
- 238000002741 site-directed mutagenesis Methods 0.000 claims description 3
- 229940024171 alpha-amylase Drugs 0.000 claims description 2
- 210000004027 cell Anatomy 0.000 description 148
- 239000000047 product Substances 0.000 description 106
- 239000000523 sample Substances 0.000 description 81
- 239000002773 nucleotide Substances 0.000 description 69
- 125000003729 nucleotide group Chemical group 0.000 description 69
- 239000000758 substrate Substances 0.000 description 66
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 60
- 239000000243 solution Substances 0.000 description 55
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 52
- 235000021255 galacto-oligosaccharides Nutrition 0.000 description 50
- 150000003271 galactooligosaccharides Chemical class 0.000 description 50
- 125000000539 amino acid group Chemical group 0.000 description 49
- 235000001014 amino acid Nutrition 0.000 description 47
- 229940024606 amino acid Drugs 0.000 description 46
- 150000001413 amino acids Chemical class 0.000 description 43
- 238000006243 chemical reaction Methods 0.000 description 43
- 238000003556 assay Methods 0.000 description 38
- 239000000416 hydrocolloid Substances 0.000 description 37
- 238000004519 manufacturing process Methods 0.000 description 36
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical compound CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 34
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 33
- 235000013305 food Nutrition 0.000 description 29
- 108020004414 DNA Proteins 0.000 description 28
- 108091028043 Nucleic acid sequence Proteins 0.000 description 27
- 238000002835 absorbance Methods 0.000 description 27
- 238000002360 preparation method Methods 0.000 description 27
- 102000004169 proteins and genes Human genes 0.000 description 27
- 229910001868 water Inorganic materials 0.000 description 27
- 241000894006 Bacteria Species 0.000 description 26
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 26
- 239000001768 carboxy methyl cellulose Substances 0.000 description 26
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 25
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 25
- 235000018102 proteins Nutrition 0.000 description 25
- 235000013351 cheese Nutrition 0.000 description 23
- 235000013618 yogurt Nutrition 0.000 description 23
- 239000013598 vector Substances 0.000 description 22
- 102100026189 Beta-galactosidase Human genes 0.000 description 21
- 239000002609 medium Substances 0.000 description 21
- 238000000855 fermentation Methods 0.000 description 20
- 230000004151 fermentation Effects 0.000 description 20
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 19
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 19
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 19
- 239000012895 dilution Substances 0.000 description 19
- 238000010790 dilution Methods 0.000 description 19
- 239000012634 fragment Substances 0.000 description 19
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 18
- 108010059881 Lactase Proteins 0.000 description 18
- 229930182830 galactose Natural products 0.000 description 18
- 229940116108 lactase Drugs 0.000 description 18
- 108091033319 polynucleotide Proteins 0.000 description 18
- 102000040430 polynucleotide Human genes 0.000 description 18
- 239000002157 polynucleotide Substances 0.000 description 18
- 241000186000 Bifidobacterium Species 0.000 description 17
- 108091026890 Coding region Proteins 0.000 description 17
- 108010076504 Protein Sorting Signals Proteins 0.000 description 17
- 239000003153 chemical reaction reagent Substances 0.000 description 17
- 239000004310 lactic acid Substances 0.000 description 17
- 235000014655 lactic acid Nutrition 0.000 description 17
- 244000005700 microbiome Species 0.000 description 17
- 238000006467 substitution reaction Methods 0.000 description 17
- 229920002678 cellulose Polymers 0.000 description 16
- 239000001913 cellulose Substances 0.000 description 16
- 238000009472 formulation Methods 0.000 description 16
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 15
- 235000014048 cultured milk product Nutrition 0.000 description 15
- 239000008103 glucose Substances 0.000 description 15
- 235000000346 sugar Nutrition 0.000 description 15
- ZZUFCTLCJUWOSV-UHFFFAOYSA-N furosemide Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC(C(O)=O)=C1NCC1=CC=CO1 ZZUFCTLCJUWOSV-UHFFFAOYSA-N 0.000 description 14
- -1 galactose monosaccharides Chemical class 0.000 description 14
- 239000000463 material Substances 0.000 description 14
- 230000001580 bacterial effect Effects 0.000 description 13
- 239000000872 buffer Substances 0.000 description 13
- 235000014633 carbohydrates Nutrition 0.000 description 13
- 239000008367 deionised water Substances 0.000 description 13
- 239000011159 matrix material Substances 0.000 description 13
- 239000003381 stabilizer Substances 0.000 description 13
- 150000001720 carbohydrates Chemical class 0.000 description 12
- 230000000295 complement effect Effects 0.000 description 12
- 229910021641 deionized water Inorganic materials 0.000 description 12
- 235000015243 ice cream Nutrition 0.000 description 12
- 230000002879 macerating effect Effects 0.000 description 12
- 238000002703 mutagenesis Methods 0.000 description 12
- 231100000350 mutagenesis Toxicity 0.000 description 12
- 230000002441 reversible effect Effects 0.000 description 12
- 238000013518 transcription Methods 0.000 description 12
- 230000035897 transcription Effects 0.000 description 12
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 11
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 11
- 239000011521 glass Substances 0.000 description 11
- 238000009396 hybridization Methods 0.000 description 11
- 239000007788 liquid Substances 0.000 description 11
- 229920001542 oligosaccharide Polymers 0.000 description 11
- 239000002245 particle Substances 0.000 description 11
- 230000008569 process Effects 0.000 description 11
- 239000000126 substance Substances 0.000 description 11
- 238000012360 testing method Methods 0.000 description 11
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 10
- 229920000161 Locust bean gum Polymers 0.000 description 10
- 235000010420 locust bean gum Nutrition 0.000 description 10
- 239000000711 locust bean gum Substances 0.000 description 10
- 239000000843 powder Substances 0.000 description 10
- 229960000268 spectinomycin Drugs 0.000 description 10
- 239000007858 starting material Substances 0.000 description 10
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 9
- 229920002472 Starch Polymers 0.000 description 9
- 238000009835 boiling Methods 0.000 description 9
- 230000001976 improved effect Effects 0.000 description 9
- 238000005259 measurement Methods 0.000 description 9
- 239000013612 plasmid Substances 0.000 description 9
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 9
- 239000008107 starch Substances 0.000 description 9
- 235000019698 starch Nutrition 0.000 description 9
- 150000008163 sugars Chemical class 0.000 description 9
- WQZGKKKJIJFFOK-SVZMEOIVSA-N (+)-Galactose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-SVZMEOIVSA-N 0.000 description 8
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 8
- GUBGYTABKSRVRQ-CUHNMECISA-N D-Cellobiose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-CUHNMECISA-N 0.000 description 8
- 241000233866 Fungi Species 0.000 description 8
- 238000004422 calculation algorithm Methods 0.000 description 8
- 230000008859 change Effects 0.000 description 8
- 235000013365 dairy product Nutrition 0.000 description 8
- 108020004999 messenger RNA Proteins 0.000 description 8
- 238000002156 mixing Methods 0.000 description 8
- 150000002482 oligosaccharides Chemical class 0.000 description 8
- 229920005862 polyol Polymers 0.000 description 8
- 150000003077 polyols Chemical class 0.000 description 8
- 238000011002 quantification Methods 0.000 description 8
- 108010084185 Cellulases Proteins 0.000 description 7
- 102000005575 Cellulases Human genes 0.000 description 7
- 239000007987 MES buffer Substances 0.000 description 7
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 7
- 239000002253 acid Substances 0.000 description 7
- 235000013361 beverage Nutrition 0.000 description 7
- 101150091659 bglC gene Proteins 0.000 description 7
- 238000004364 calculation method Methods 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- 235000013325 dietary fiber Nutrition 0.000 description 7
- 239000012153 distilled water Substances 0.000 description 7
- 238000004128 high performance liquid chromatography Methods 0.000 description 7
- 238000011534 incubation Methods 0.000 description 7
- 238000012986 modification Methods 0.000 description 7
- 230000004048 modification Effects 0.000 description 7
- 239000002853 nucleic acid probe Substances 0.000 description 7
- 239000007787 solid Substances 0.000 description 7
- 238000003756 stirring Methods 0.000 description 7
- 230000009466 transformation Effects 0.000 description 7
- 241000193830 Bacillus <bacterium> Species 0.000 description 6
- 241000933527 Bifidobacterium bifidum DSM 20215 Species 0.000 description 6
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 6
- 244000303965 Cyamopsis psoralioides Species 0.000 description 6
- 238000002105 Southern blotting Methods 0.000 description 6
- 239000005862 Whey Substances 0.000 description 6
- 108010046377 Whey Proteins Proteins 0.000 description 6
- 102000007544 Whey Proteins Human genes 0.000 description 6
- 239000008351 acetate buffer Substances 0.000 description 6
- 229940025131 amylases Drugs 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 6
- 235000015872 dietary supplement Nutrition 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 230000002538 fungal effect Effects 0.000 description 6
- 239000000499 gel Substances 0.000 description 6
- 235000011187 glycerol Nutrition 0.000 description 6
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 6
- 238000010369 molecular cloning Methods 0.000 description 6
- 235000002639 sodium chloride Nutrition 0.000 description 6
- 241000894007 species Species 0.000 description 6
- 239000000725 suspension Substances 0.000 description 6
- 238000012546 transfer Methods 0.000 description 6
- 235000010469 Glycine max Nutrition 0.000 description 5
- 241000192132 Leuconostoc Species 0.000 description 5
- 108020004511 Recombinant DNA Proteins 0.000 description 5
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 5
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 5
- CDBYLPFSWZWCQE-UHFFFAOYSA-L Sodium Carbonate Chemical compound [Na+].[Na+].[O-]C([O-])=O CDBYLPFSWZWCQE-UHFFFAOYSA-L 0.000 description 5
- 239000011324 bead Substances 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 230000027455 binding Effects 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 239000012496 blank sample Substances 0.000 description 5
- 239000006071 cream Substances 0.000 description 5
- 238000007824 enzymatic assay Methods 0.000 description 5
- 238000010438 heat treatment Methods 0.000 description 5
- 150000002772 monosaccharides Chemical class 0.000 description 5
- 235000015097 nutrients Nutrition 0.000 description 5
- 239000001814 pectin Substances 0.000 description 5
- 235000010987 pectin Nutrition 0.000 description 5
- 229920001277 pectin Polymers 0.000 description 5
- 239000006041 probiotic Substances 0.000 description 5
- 230000000529 probiotic effect Effects 0.000 description 5
- 235000018291 probiotics Nutrition 0.000 description 5
- 230000000717 retained effect Effects 0.000 description 5
- 150000003839 salts Chemical class 0.000 description 5
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- VHUUQVKOLVNVRT-UHFFFAOYSA-N Ammonium hydroxide Chemical compound [NH4+].[OH-] VHUUQVKOLVNVRT-UHFFFAOYSA-N 0.000 description 4
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 4
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- 241000235395 Mucor Species 0.000 description 4
- 108091005461 Nucleic proteins Proteins 0.000 description 4
- 150000007513 acids Chemical class 0.000 description 4
- 239000000908 ammonium hydroxide Substances 0.000 description 4
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 4
- 230000009286 beneficial effect Effects 0.000 description 4
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 4
- KGBXLFKZBHKPEV-UHFFFAOYSA-N boric acid Chemical compound OB(O)O KGBXLFKZBHKPEV-UHFFFAOYSA-N 0.000 description 4
- 229910052799 carbon Inorganic materials 0.000 description 4
- 150000002016 disaccharides Chemical class 0.000 description 4
- 238000001704 evaporation Methods 0.000 description 4
- 230000008020 evaporation Effects 0.000 description 4
- 239000000835 fiber Substances 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 230000001965 increasing effect Effects 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 239000004615 ingredient Substances 0.000 description 4
- JCQLYHFGKNRPGE-FCVZTGTOSA-N lactulose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 JCQLYHFGKNRPGE-FCVZTGTOSA-N 0.000 description 4
- 229960000511 lactulose Drugs 0.000 description 4
- 235000020191 long-life milk Nutrition 0.000 description 4
- VZOPRCCTKLAGPN-ZFJVMAEJSA-L potassium;sodium;(2r,3r)-2,3-dihydroxybutanedioate;tetrahydrate Chemical compound O.O.O.O.[Na+].[K+].[O-]C(=O)[C@H](O)[C@@H](O)C([O-])=O VZOPRCCTKLAGPN-ZFJVMAEJSA-L 0.000 description 4
- 239000003755 preservative agent Substances 0.000 description 4
- 230000002335 preservative effect Effects 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 239000012898 sample dilution Substances 0.000 description 4
- 235000020183 skimmed milk Nutrition 0.000 description 4
- 238000003860 storage Methods 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 3
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 3
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 3
- KUWPCJHYPSUOFW-YBXAARCKSA-N 2-nitrophenyl beta-D-galactoside Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OC1=CC=CC=C1[N+]([O-])=O KUWPCJHYPSUOFW-YBXAARCKSA-N 0.000 description 3
- CSCPPACGZOOCGX-UHFFFAOYSA-N Acetone Chemical compound CC(C)=O CSCPPACGZOOCGX-UHFFFAOYSA-N 0.000 description 3
- 102100033770 Alpha-amylase 1C Human genes 0.000 description 3
- 101100449954 Bacillus subtilis (strain 168) eglS gene Proteins 0.000 description 3
- 241001608472 Bifidobacterium longum Species 0.000 description 3
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 3
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 3
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 3
- 241000588724 Escherichia coli Species 0.000 description 3
- 101100031701 Escherichia coli (strain K12) bglF gene Proteins 0.000 description 3
- 101100218687 Escherichia coli (strain K12) bglG gene Proteins 0.000 description 3
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 3
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- PNNNRSAQSRJVSB-UHFFFAOYSA-N L-rhamnose Natural products CC(O)C(O)C(O)C(O)C=O PNNNRSAQSRJVSB-UHFFFAOYSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- 241000186660 Lactobacillus Species 0.000 description 3
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 3
- 241001465754 Metazoa Species 0.000 description 3
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 3
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 3
- 241000192031 Ruminococcus Species 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 244000057717 Streptococcus lactis Species 0.000 description 3
- 235000014897 Streptococcus lactis Nutrition 0.000 description 3
- 241000187747 Streptomyces Species 0.000 description 3
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 3
- 229930006000 Sucrose Natural products 0.000 description 3
- 108700005078 Synthetic Genes Proteins 0.000 description 3
- 239000004098 Tetracycline Substances 0.000 description 3
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 3
- 239000004473 Threonine Substances 0.000 description 3
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 3
- 229960000583 acetic acid Drugs 0.000 description 3
- 230000002378 acidificating effect Effects 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 239000000654 additive Substances 0.000 description 3
- 235000004279 alanine Nutrition 0.000 description 3
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 3
- 101150069003 amdS gene Proteins 0.000 description 3
- 230000000692 anti-sense effect Effects 0.000 description 3
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 3
- 229940009291 bifidobacterium longum Drugs 0.000 description 3
- 101150052795 cbh-1 gene Proteins 0.000 description 3
- 239000007795 chemical reaction product Substances 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 235000020186 condensed milk Nutrition 0.000 description 3
- 235000009508 confectionery Nutrition 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- 239000012470 diluted sample Substances 0.000 description 3
- 230000001747 exhibiting effect Effects 0.000 description 3
- 239000012467 final product Substances 0.000 description 3
- 235000012041 food component Nutrition 0.000 description 3
- 239000005417 food ingredient Substances 0.000 description 3
- 235000013350 formula milk Nutrition 0.000 description 3
- 239000008187 granular material Substances 0.000 description 3
- 230000007062 hydrolysis Effects 0.000 description 3
- 238000006460 hydrolysis reaction Methods 0.000 description 3
- 239000005457 ice water Substances 0.000 description 3
- 230000000415 inactivating effect Effects 0.000 description 3
- 238000009776 industrial production Methods 0.000 description 3
- 230000010354 integration Effects 0.000 description 3
- 230000000968 intestinal effect Effects 0.000 description 3
- PFCRQPBOOFTZGQ-UHFFFAOYSA-N lactulose keto form Natural products OCC(=O)C(O)C(C(O)CO)OC1OC(CO)C(O)C(O)C1O PFCRQPBOOFTZGQ-UHFFFAOYSA-N 0.000 description 3
- 235000020121 low-fat milk Nutrition 0.000 description 3
- 230000000813 microbial effect Effects 0.000 description 3
- 230000003287 optical effect Effects 0.000 description 3
- 229960003104 ornithine Drugs 0.000 description 3
- 239000008188 pellet Substances 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 238000003752 polymerase chain reaction Methods 0.000 description 3
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical compound CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 238000002864 sequence alignment Methods 0.000 description 3
- 229910000029 sodium carbonate Inorganic materials 0.000 description 3
- 239000000600 sorbitol Substances 0.000 description 3
- 238000001694 spray drying Methods 0.000 description 3
- 239000005720 sucrose Substances 0.000 description 3
- 239000013589 supplement Substances 0.000 description 3
- 229960002180 tetracycline Drugs 0.000 description 3
- 229930101283 tetracycline Natural products 0.000 description 3
- 235000019364 tetracycline Nutrition 0.000 description 3
- 150000003522 tetracyclines Chemical class 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 241001148471 unidentified anaerobic bacterium Species 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- LWFUFLREGJMOIZ-UHFFFAOYSA-N 3,5-dinitrosalicylic acid Chemical compound OC(=O)C1=CC([N+]([O-])=O)=CC([N+]([O-])=O)=C1O LWFUFLREGJMOIZ-UHFFFAOYSA-N 0.000 description 2
- FHVDTGUDJYJELY-UHFFFAOYSA-N 6-{[2-carboxy-4,5-dihydroxy-6-(phosphanyloxy)oxan-3-yl]oxy}-4,5-dihydroxy-3-phosphanyloxane-2-carboxylic acid Chemical compound O1C(C(O)=O)C(P)C(O)C(O)C1OC1C(C(O)=O)OC(OP)C(O)C1O FHVDTGUDJYJELY-UHFFFAOYSA-N 0.000 description 2
- DLFVBJFMPXGRIB-UHFFFAOYSA-N Acetamide Chemical compound CC(N)=O DLFVBJFMPXGRIB-UHFFFAOYSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 241000228212 Aspergillus Species 0.000 description 2
- 241000193752 Bacillus circulans Species 0.000 description 2
- 241000193749 Bacillus coagulans Species 0.000 description 2
- 241000194108 Bacillus licheniformis Species 0.000 description 2
- 241000193388 Bacillus thuringiensis Species 0.000 description 2
- 241000534000 Berula erecta Species 0.000 description 2
- 241001134770 Bifidobacterium animalis Species 0.000 description 2
- 241000194002 Blautia hansenii Species 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- QSJXEFYPDANLFS-UHFFFAOYSA-N Diacetyl Chemical group CC(=O)C(C)=O QSJXEFYPDANLFS-UHFFFAOYSA-N 0.000 description 2
- 241000224495 Dictyostelium Species 0.000 description 2
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 2
- 241000588722 Escherichia Species 0.000 description 2
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 235000003332 Ilex aquifolium Nutrition 0.000 description 2
- 241000209027 Ilex aquifolium Species 0.000 description 2
- 108091092195 Intron Proteins 0.000 description 2
- 241000235649 Kluyveromyces Species 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- SHZGCJCMOBCMKK-JFNONXLTSA-N L-rhamnopyranose Chemical compound C[C@@H]1OC(O)[C@H](O)[C@H](O)[C@H]1O SHZGCJCMOBCMKK-JFNONXLTSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 244000199866 Lactobacillus casei Species 0.000 description 2
- 235000013958 Lactobacillus casei Nutrition 0.000 description 2
- 241000186673 Lactobacillus delbrueckii Species 0.000 description 2
- 241000194036 Lactococcus Species 0.000 description 2
- 201000010538 Lactose Intolerance Diseases 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 229920000057 Mannan Polymers 0.000 description 2
- VZUNGTLZRAYYDE-UHFFFAOYSA-N N-methyl-N'-nitro-N-nitrosoguanidine Chemical compound O=NN(C)C(=N)N[N+]([O-])=O VZUNGTLZRAYYDE-UHFFFAOYSA-N 0.000 description 2
- 241000221960 Neurospora Species 0.000 description 2
- 241000221961 Neurospora crassa Species 0.000 description 2
- 239000000020 Nitrocellulose Substances 0.000 description 2
- 241000589779 Pelomonas saccharophila Species 0.000 description 2
- WCUXLLCKKVVCTQ-UHFFFAOYSA-M Potassium chloride Chemical compound [Cl-].[K+] WCUXLLCKKVVCTQ-UHFFFAOYSA-M 0.000 description 2
- 241000186429 Propionibacterium Species 0.000 description 2
- 241000192142 Proteobacteria Species 0.000 description 2
- 238000010240 RT-PCR analysis Methods 0.000 description 2
- 240000005384 Rhizopus oryzae Species 0.000 description 2
- 241000221662 Sclerotinia Species 0.000 description 2
- 241000221696 Sclerotinia sclerotiorum Species 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 241000194017 Streptococcus Species 0.000 description 2
- 241000194020 Streptococcus thermophilus Species 0.000 description 2
- 241000499912 Trichoderma reesei Species 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 229940072056 alginate Drugs 0.000 description 2
- 235000010443 alginic acid Nutrition 0.000 description 2
- 229920000615 alginic acid Polymers 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 235000003704 aspartic acid Nutrition 0.000 description 2
- 229940054340 bacillus coagulans Drugs 0.000 description 2
- 229940097012 bacillus thuringiensis Drugs 0.000 description 2
- 238000002869 basic local alignment search tool Methods 0.000 description 2
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 2
- 229940118852 bifidobacterium animalis Drugs 0.000 description 2
- 239000004327 boric acid Substances 0.000 description 2
- 235000014121 butter Nutrition 0.000 description 2
- 235000015155 buttermilk Nutrition 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- 239000012876 carrier material Substances 0.000 description 2
- 239000013592 cell lysate Substances 0.000 description 2
- 235000015165 citric acid Nutrition 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 239000000470 constituent Substances 0.000 description 2
- 238000001816 cooling Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 2
- BNIILDVGGAEEIG-UHFFFAOYSA-L disodium hydrogen phosphate Chemical compound [Na+].[Na+].OP([O-])([O-])=O BNIILDVGGAEEIG-UHFFFAOYSA-L 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 230000003828 downregulation Effects 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 238000006911 enzymatic reaction Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 235000019197 fats Nutrition 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 239000000796 flavoring agent Substances 0.000 description 2
- 235000013373 food additive Nutrition 0.000 description 2
- 239000002778 food additive Substances 0.000 description 2
- 230000004927 fusion Effects 0.000 description 2
- 238000012239 gene modification Methods 0.000 description 2
- 230000005017 genetic modification Effects 0.000 description 2
- 235000013617 genetically modified food Nutrition 0.000 description 2
- 239000012362 glacial acetic acid Substances 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 150000004676 glycans Chemical class 0.000 description 2
- 230000008821 health effect Effects 0.000 description 2
- 239000000017 hydrogel Substances 0.000 description 2
- 230000003301 hydrolyzing effect Effects 0.000 description 2
- 229910052500 inorganic mineral Inorganic materials 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 235000015110 jellies Nutrition 0.000 description 2
- 235000015141 kefir Nutrition 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 238000012417 linear regression Methods 0.000 description 2
- 230000002366 lipolytic effect Effects 0.000 description 2
- 235000004213 low-fat Nutrition 0.000 description 2
- 238000003760 magnetic stirring Methods 0.000 description 2
- 239000002075 main ingredient Substances 0.000 description 2
- 230000014759 maintenance of location Effects 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- LXCFILQKKLGQFO-UHFFFAOYSA-N methylparaben Chemical group COC(=O)C1=CC=C(O)C=C1 LXCFILQKKLGQFO-UHFFFAOYSA-N 0.000 description 2
- 235000021243 milk fat Nutrition 0.000 description 2
- 235000010755 mineral Nutrition 0.000 description 2
- 239000011707 mineral Substances 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 229920001220 nitrocellulos Polymers 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 238000002515 oligonucleotide synthesis Methods 0.000 description 2
- 238000009928 pasteurization Methods 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- 239000005017 polysaccharide Substances 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 210000001938 protoplast Anatomy 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 239000011541 reaction mixture Substances 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 2
- 235000015067 sauces Nutrition 0.000 description 2
- 238000012216 screening Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 239000002002 slurry Substances 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000007974 sodium acetate buffer Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000004575 stone Substances 0.000 description 2
- 239000012089 stop solution Substances 0.000 description 2
- 150000005846 sugar alcohols Chemical class 0.000 description 2
- 238000010361 transduction Methods 0.000 description 2
- 230000026683 transduction Effects 0.000 description 2
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 235000013311 vegetables Nutrition 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 238000001262 western blot Methods 0.000 description 2
- 235000008939 whole milk Nutrition 0.000 description 2
- 235000008924 yoghurt drink Nutrition 0.000 description 2
- IYKLZBIWFXPUCS-VIFPVBQESA-N (2s)-2-(naphthalen-1-ylamino)propanoic acid Chemical compound C1=CC=C2C(N[C@@H](C)C(O)=O)=CC=CC2=C1 IYKLZBIWFXPUCS-VIFPVBQESA-N 0.000 description 1
- CNMAQBJBWQQZFZ-LURJTMIESA-N (2s)-2-(pyridin-2-ylamino)propanoic acid Chemical compound OC(=O)[C@H](C)NC1=CC=CC=N1 CNMAQBJBWQQZFZ-LURJTMIESA-N 0.000 description 1
- WSWCOQWTEOXDQX-MQQKCMAXSA-M (E,E)-sorbate Chemical compound C\C=C\C=C\C([O-])=O WSWCOQWTEOXDQX-MQQKCMAXSA-M 0.000 description 1
- HNSDLXPSAYFUHK-UHFFFAOYSA-N 1,4-bis(2-ethylhexyl) sulfosuccinate Chemical compound CCCCC(CC)COC(=O)CC(S(O)(=O)=O)C(=O)OCC(CC)CCCC HNSDLXPSAYFUHK-UHFFFAOYSA-N 0.000 description 1
- VUDQSRFCCHQIIU-UHFFFAOYSA-N 1-(3,5-dichloro-2,6-dihydroxy-4-methoxyphenyl)hexan-1-one Chemical compound CCCCCC(=O)C1=C(O)C(Cl)=C(OC)C(Cl)=C1O VUDQSRFCCHQIIU-UHFFFAOYSA-N 0.000 description 1
- BLCJBICVQSYOIF-UHFFFAOYSA-N 2,2-diaminobutanoic acid Chemical compound CCC(N)(N)C(O)=O BLCJBICVQSYOIF-UHFFFAOYSA-N 0.000 description 1
- QRBLKGHRWFGINE-UGWAGOLRSA-N 2-[2-[2-[[2-[[4-[[2-[[6-amino-2-[3-amino-1-[(2,3-diamino-3-oxopropyl)amino]-3-oxopropyl]-5-methylpyrimidine-4-carbonyl]amino]-3-[(2r,3s,4s,5s,6s)-3-[(2s,3r,4r,5s)-4-carbamoyl-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-4,5-dihydroxy-6-(hydroxymethyl)- Chemical compound N=1C(C=2SC=C(N=2)C(N)=O)CSC=1CCNC(=O)C(C(C)=O)NC(=O)C(C)C(O)C(C)NC(=O)C(C(O[C@H]1[C@@]([C@@H](O)[C@H](O)[C@H](CO)O1)(C)O[C@H]1[C@@H]([C@](O)([C@@H](O)C(CO)O1)C(N)=O)O)C=1NC=NC=1)NC(=O)C1=NC(C(CC(N)=O)NCC(N)C(N)=O)=NC(N)=C1C QRBLKGHRWFGINE-UGWAGOLRSA-N 0.000 description 1
- AXAVXPMQTGXXJZ-UHFFFAOYSA-N 2-aminoacetic acid;2-amino-2-(hydroxymethyl)propane-1,3-diol Chemical compound NCC(O)=O.OCC(N)(CO)CO AXAVXPMQTGXXJZ-UHFFFAOYSA-N 0.000 description 1
- WTOFYLAWDLQMBZ-UHFFFAOYSA-N 2-azaniumyl-3-thiophen-2-ylpropanoate Chemical compound OC(=O)C(N)CC1=CC=CS1 WTOFYLAWDLQMBZ-UHFFFAOYSA-N 0.000 description 1
- WDMUXYQIMRDWRC-UHFFFAOYSA-N 2-hydroxy-3,4-dinitrobenzoic acid Chemical compound OC(=O)C1=CC=C([N+]([O-])=O)C([N+]([O-])=O)=C1O WDMUXYQIMRDWRC-UHFFFAOYSA-N 0.000 description 1
- GHCZTIFQWKKGSB-UHFFFAOYSA-N 2-hydroxypropane-1,2,3-tricarboxylic acid;phosphoric acid Chemical compound OP(O)(O)=O.OC(=O)CC(O)(C(O)=O)CC(O)=O GHCZTIFQWKKGSB-UHFFFAOYSA-N 0.000 description 1
- MIIIXQJBDGSIKL-UHFFFAOYSA-N 2-morpholin-4-ylethanesulfonic acid;hydrate Chemical compound O.OS(=O)(=O)CCN1CCOCC1 MIIIXQJBDGSIKL-UHFFFAOYSA-N 0.000 description 1
- MIDXCONKKJTLDX-UHFFFAOYSA-N 3,5-dimethylcyclopentane-1,2-dione Chemical compound CC1CC(C)C(=O)C1=O MIDXCONKKJTLDX-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- IFBHRQDFSNCLOZ-YBXAARCKSA-N 4-nitrophenyl-beta-D-galactoside Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1OC1=CC=C([N+]([O-])=O)C=C1 IFBHRQDFSNCLOZ-YBXAARCKSA-N 0.000 description 1
- XQMVBICWFFHDNN-UHFFFAOYSA-N 5-amino-4-chloro-2-phenylpyridazin-3-one;(2-ethoxy-3,3-dimethyl-2h-1-benzofuran-5-yl) methanesulfonate Chemical compound O=C1C(Cl)=C(N)C=NN1C1=CC=CC=C1.C1=C(OS(C)(=O)=O)C=C2C(C)(C)C(OCC)OC2=C1 XQMVBICWFFHDNN-UHFFFAOYSA-N 0.000 description 1
- 244000215068 Acacia senegal Species 0.000 description 1
- 241000222518 Agaricus Species 0.000 description 1
- 244000251953 Agaricus brunnescens Species 0.000 description 1
- 235000001674 Agaricus brunnescens Nutrition 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- TWCMVXMQHSVIOJ-UHFFFAOYSA-N Aglycone of yadanzioside D Natural products COC(=O)C12OCC34C(CC5C(=CC(O)C(O)C5(C)C3C(O)C1O)C)OC(=O)C(OC(=O)C)C24 TWCMVXMQHSVIOJ-UHFFFAOYSA-N 0.000 description 1
- 101710152845 Arabinogalactan endo-beta-1,4-galactanase Proteins 0.000 description 1
- 241000567551 Ascovaginospora Species 0.000 description 1
- 241001513093 Aspergillus awamori Species 0.000 description 1
- 241000892910 Aspergillus foetidus Species 0.000 description 1
- 241001480052 Aspergillus japonicus Species 0.000 description 1
- 241000351920 Aspergillus nidulans Species 0.000 description 1
- 241000228245 Aspergillus niger Species 0.000 description 1
- 240000006439 Aspergillus oryzae Species 0.000 description 1
- 235000002247 Aspergillus oryzae Nutrition 0.000 description 1
- PLMKQQMDOMTZGG-UHFFFAOYSA-N Astrantiagenin E-methylester Natural products CC12CCC(O)C(C)(CO)C1CCC1(C)C2CC=C2C3CC(C)(C)CCC3(C(=O)OC)CCC21C PLMKQQMDOMTZGG-UHFFFAOYSA-N 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 241000193744 Bacillus amyloliquefaciens Species 0.000 description 1
- 241000193422 Bacillus lentus Species 0.000 description 1
- 241000194107 Bacillus megaterium Species 0.000 description 1
- 241000223014 Bacillus novalis Species 0.000 description 1
- 241000194103 Bacillus pumilus Species 0.000 description 1
- 241000770536 Bacillus thermophilus Species 0.000 description 1
- 108700026883 Bacteria AprE Proteins 0.000 description 1
- 241000186012 Bifidobacterium breve Species 0.000 description 1
- 241000186015 Bifidobacterium longum subsp. infantis Species 0.000 description 1
- 241001474374 Blennius Species 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 241000193764 Brevibacillus brevis Species 0.000 description 1
- 241000186146 Brevibacterium Species 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 108010008885 Cellulose 1,4-beta-Cellobiosidase Proteins 0.000 description 1
- 241000221955 Chaetomium Species 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- 108090000746 Chymosin Proteins 0.000 description 1
- 241000588923 Citrobacter Species 0.000 description 1
- 241000588919 Citrobacter freundii Species 0.000 description 1
- 241001112696 Clostridia Species 0.000 description 1
- 241000193468 Clostridium perfringens Species 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- SHZGCJCMOBCMKK-SVZMEOIVSA-N D-fucopyranose Chemical compound C[C@H]1OC(O)[C@H](O)[C@@H](O)[C@H]1O SHZGCJCMOBCMKK-SVZMEOIVSA-N 0.000 description 1
- 150000008151 D-glucosides Chemical class 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- GUBGYTABKSRVRQ-WFVLMXAXSA-N DEAE-cellulose Chemical compound OC1C(O)C(O)C(CO)O[C@H]1O[C@@H]1C(CO)OC(O)C(O)C1O GUBGYTABKSRVRQ-WFVLMXAXSA-N 0.000 description 1
- 239000003298 DNA probe Substances 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 206010012735 Diarrhoea Diseases 0.000 description 1
- 108010082495 Dietary Plant Proteins Proteins 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 241000607473 Edwardsiella <enterobacteria> Species 0.000 description 1
- 241000607471 Edwardsiella tarda Species 0.000 description 1
- 101710147028 Endo-beta-1,4-galactanase Proteins 0.000 description 1
- 241000588914 Enterobacter Species 0.000 description 1
- 241000588697 Enterobacter cloacae Species 0.000 description 1
- 241000194033 Enterococcus Species 0.000 description 1
- 241000194031 Enterococcus faecium Species 0.000 description 1
- 241000588698 Erwinia Species 0.000 description 1
- 108090000371 Esterases Proteins 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 101710112457 Exoglucanase Proteins 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 108050001049 Extracellular proteins Proteins 0.000 description 1
- 241000192125 Firmicutes Species 0.000 description 1
- 235000016623 Fragaria vesca Nutrition 0.000 description 1
- 240000009088 Fragaria x ananassa Species 0.000 description 1
- 235000011363 Fragaria x ananassa Nutrition 0.000 description 1
- 229930091371 Fructose Natural products 0.000 description 1
- 239000005715 Fructose Substances 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- 241000193385 Geobacillus stearothermophilus Species 0.000 description 1
- 244000168141 Geotrichum candidum Species 0.000 description 1
- 235000017388 Geotrichum candidum Nutrition 0.000 description 1
- 229920001503 Glucan Polymers 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 229920000084 Gum arabic Polymers 0.000 description 1
- 101100295959 Halobacterium salinarum (strain ATCC 700922 / JCM 11081 / NRC-1) arcB gene Proteins 0.000 description 1
- 101000779870 Homo sapiens Alpha-amylase 1B Proteins 0.000 description 1
- 101000779869 Homo sapiens Alpha-amylase 1C Proteins 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- 108010093096 Immobilized Enzymes Proteins 0.000 description 1
- 239000005909 Kieselgur Substances 0.000 description 1
- 241000588748 Klebsiella Species 0.000 description 1
- 241000588915 Klebsiella aerogenes Species 0.000 description 1
- 241000588747 Klebsiella pneumoniae Species 0.000 description 1
- 244000285963 Kluyveromyces fragilis Species 0.000 description 1
- 235000014663 Kluyveromyces fragilis Nutrition 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- ZGUNAGUHMKGQNY-ZETCQYMHSA-N L-alpha-phenylglycine zwitterion Chemical compound OC(=O)[C@@H](N)C1=CC=CC=C1 ZGUNAGUHMKGQNY-ZETCQYMHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 1
- 241000218587 Lactobacillus paracasei subsp. paracasei Species 0.000 description 1
- 241000194034 Lactococcus lactis subsp. cremoris Species 0.000 description 1
- 244000172809 Leuconostoc cremoris Species 0.000 description 1
- 235000017632 Leuconostoc cremoris Nutrition 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 239000004367 Lipase Substances 0.000 description 1
- GMPKIPWJBDOURN-UHFFFAOYSA-N Methoxyamine Chemical compound CON GMPKIPWJBDOURN-UHFFFAOYSA-N 0.000 description 1
- 108010011756 Milk Proteins Proteins 0.000 description 1
- 239000012901 Milli-Q water Substances 0.000 description 1
- 108020005196 Mitochondrial DNA Proteins 0.000 description 1
- 206010027940 Mood altered Diseases 0.000 description 1
- 241000498617 Mucor javanicus Species 0.000 description 1
- 101100128278 Mus musculus Lins1 gene Proteins 0.000 description 1
- 241000223251 Myrothecium Species 0.000 description 1
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 1
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 1
- 240000007357 Nauclea orientalis Species 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 101100032401 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) pyr-4 gene Proteins 0.000 description 1
- IOVCWXUNBOPUCH-UHFFFAOYSA-N Nitrous acid Chemical compound ON=O IOVCWXUNBOPUCH-UHFFFAOYSA-N 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 241000194109 Paenibacillus lautus Species 0.000 description 1
- 241000588912 Pantoea agglomerans Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108010029182 Pectin lyase Proteins 0.000 description 1
- 241000192001 Pediococcus Species 0.000 description 1
- 241000191996 Pediococcus pentosaceus Species 0.000 description 1
- 241000228143 Penicillium Species 0.000 description 1
- 240000000064 Penicillium roqueforti Species 0.000 description 1
- 235000002233 Penicillium roqueforti Nutrition 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- LTQCLFMNABRKSH-UHFFFAOYSA-N Phleomycin Natural products N=1C(C=2SC=C(N=2)C(N)=O)CSC=1CCNC(=O)C(C(O)C)NC(=O)C(C)C(O)C(C)NC(=O)C(C(OC1C(C(O)C(O)C(CO)O1)OC1C(C(OC(N)=O)C(O)C(CO)O1)O)C=1NC=NC=1)NC(=O)C1=NC(C(CC(N)=O)NCC(N)C(N)=O)=NC(N)=C1C LTQCLFMNABRKSH-UHFFFAOYSA-N 0.000 description 1
- 108010035235 Phleomycins Proteins 0.000 description 1
- 108010064785 Phospholipases Proteins 0.000 description 1
- 102000015439 Phospholipases Human genes 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 108010026552 Proteome Proteins 0.000 description 1
- 241000588768 Providencia Species 0.000 description 1
- 241000588778 Providencia stuartii Species 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 241000222644 Pycnoporus <fungus> Species 0.000 description 1
- 108020004518 RNA Probes Proteins 0.000 description 1
- 239000003391 RNA probe Substances 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108090000783 Renin Proteins 0.000 description 1
- 102100028255 Renin Human genes 0.000 description 1
- 241000235402 Rhizomucor Species 0.000 description 1
- 241000235525 Rhizomucor pusillus Species 0.000 description 1
- 241000235527 Rhizopus Species 0.000 description 1
- 235000013752 Rhizopus oryzae Nutrition 0.000 description 1
- 241000235546 Rhizopus stolonifer Species 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 1
- 241000607720 Serratia Species 0.000 description 1
- 241000607717 Serratia liquefaciens Species 0.000 description 1
- 241000607715 Serratia marcescens Species 0.000 description 1
- 241000607768 Shigella Species 0.000 description 1
- 241000607762 Shigella flexneri Species 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- DWAQJAXMDSEUJJ-UHFFFAOYSA-M Sodium bisulfite Chemical compound [Na+].OS([O-])=O DWAQJAXMDSEUJJ-UHFFFAOYSA-M 0.000 description 1
- 108010073771 Soybean Proteins Proteins 0.000 description 1
- 235000014962 Streptococcus cremoris Nutrition 0.000 description 1
- 241000186988 Streptomyces antibioticus Species 0.000 description 1
- 241000187398 Streptomyces lividans Species 0.000 description 1
- 241001468239 Streptomyces murinus Species 0.000 description 1
- 241000187175 Streptomyces violaceus Species 0.000 description 1
- 208000037065 Subacute sclerosing leukoencephalitis Diseases 0.000 description 1
- 206010042297 Subacute sclerosing panencephalitis Diseases 0.000 description 1
- 241000192707 Synechococcus Species 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- 241000222354 Trametes Species 0.000 description 1
- 241000222645 Trametes cinnabarina Species 0.000 description 1
- 241000042002 Trametes sanguinea Species 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 241000223261 Trichoderma viride Species 0.000 description 1
- 241000223238 Trichophyton Species 0.000 description 1
- 241000223229 Trichophyton rubrum Species 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 241000607734 Yersinia <bacteria> Species 0.000 description 1
- 241000607447 Yersinia enterocolitica Species 0.000 description 1
- 238000011481 absorbance measurement Methods 0.000 description 1
- 235000010489 acacia gum Nutrition 0.000 description 1
- 239000000205 acacia gum Substances 0.000 description 1
- 108010048241 acetamidase Proteins 0.000 description 1
- 235000011054 acetic acid Nutrition 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical class [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 235000020167 acidified milk Nutrition 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- PNEYBMLMFCGWSK-UHFFFAOYSA-N aluminium oxide Inorganic materials [O-2].[O-2].[O-2].[Al+3].[Al+3] PNEYBMLMFCGWSK-UHFFFAOYSA-N 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000845 anti-microbial effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000004599 antimicrobial Substances 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 101150008194 argB gene Proteins 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 210000004666 bacterial spore Anatomy 0.000 description 1
- 229940050390 benzoate Drugs 0.000 description 1
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 1
- 108010019077 beta-Amylase Proteins 0.000 description 1
- 229940004120 bifidobacterium infantis Drugs 0.000 description 1
- 230000008033 biological extinction Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 239000012490 blank solution Substances 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 230000005587 bubbling Effects 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 235000012970 cakes Nutrition 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000011088 calibration curve Methods 0.000 description 1
- 235000013736 caramel Nutrition 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 235000010418 carrageenan Nutrition 0.000 description 1
- 239000000679 carrageenan Substances 0.000 description 1
- 229920001525 carrageenan Polymers 0.000 description 1
- 229940113118 carrageenan Drugs 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 108020001778 catalytic domains Proteins 0.000 description 1
- 101150114858 cbh2 gene Proteins 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000003196 chaotropic effect Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000001311 chemical methods and process Methods 0.000 description 1
- 239000002962 chemical mutagen Substances 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 229940080701 chymosin Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 230000000112 colonic effect Effects 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 235000008504 concentrate Nutrition 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 235000015146 crème fraîche Nutrition 0.000 description 1
- 235000021403 cultural food Nutrition 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 235000015142 cultured sour cream Nutrition 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 230000018044 dehydration Effects 0.000 description 1
- 238000006297 dehydration reaction Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 235000011850 desserts Nutrition 0.000 description 1
- 230000009025 developmental regulation Effects 0.000 description 1
- 235000005911 diet Nutrition 0.000 description 1
- 230000000378 dietary effect Effects 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000007865 diluting Methods 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 229910000397 disodium phosphate Inorganic materials 0.000 description 1
- 235000019800 disodium phosphate Nutrition 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 235000013399 edible fruits Nutrition 0.000 description 1
- 101150066032 egl-1 gene Proteins 0.000 description 1
- 101150003727 egl2 gene Proteins 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- 108010091371 endoglucanase 1 Proteins 0.000 description 1
- 108010091384 endoglucanase 2 Proteins 0.000 description 1
- 108010092450 endoglucanase Z Proteins 0.000 description 1
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 229940092559 enterobacter aerogenes Drugs 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 210000000416 exudates and transudate Anatomy 0.000 description 1
- 206010016766 flatulence Diseases 0.000 description 1
- 235000019541 flavored milk drink Nutrition 0.000 description 1
- 235000019634 flavors Nutrition 0.000 description 1
- 235000021060 food property Nutrition 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 235000015061 fromage frais Nutrition 0.000 description 1
- 235000011389 fruit/vegetable juice Nutrition 0.000 description 1
- 238000004362 fungal culture Methods 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 230000005021 gait Effects 0.000 description 1
- 210000003736 gastrointestinal content Anatomy 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 239000003349 gelling agent Substances 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 238000002873 global sequence alignment Methods 0.000 description 1
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 1
- 230000002641 glycemic effect Effects 0.000 description 1
- 230000001279 glycosylating effect Effects 0.000 description 1
- 235000013882 gravy Nutrition 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- XLYOFNOQVPJJNP-ZSJDYOACSA-N heavy water Substances [2H]O[2H] XLYOFNOQVPJJNP-ZSJDYOACSA-N 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- PFOARMALXZGCHY-UHFFFAOYSA-N homoegonol Natural products C1=C(OC)C(OC)=CC=C1C1=CC2=CC(CCCO)=CC(OC)=C2O1 PFOARMALXZGCHY-UHFFFAOYSA-N 0.000 description 1
- 238000000265 homogenisation Methods 0.000 description 1
- 150000002433 hydrophilic molecules Chemical class 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000003100 immobilizing effect Effects 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229910017053 inorganic salt Inorganic materials 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000001155 isoelectric focusing Methods 0.000 description 1
- 239000008274 jelly Substances 0.000 description 1
- 229940039696 lactobacillus Drugs 0.000 description 1
- 229940017800 lactobacillus casei Drugs 0.000 description 1
- 238000012886 linear function Methods 0.000 description 1
- 235000019421 lipase Nutrition 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 101150039489 lysZ gene Proteins 0.000 description 1
- 230000013011 mating Effects 0.000 description 1
- 239000008268 mayonnaise Substances 0.000 description 1
- 235000010746 mayonnaise Nutrition 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 239000004292 methyl p-hydroxybenzoate Substances 0.000 description 1
- 235000010270 methyl p-hydroxybenzoate Nutrition 0.000 description 1
- 229960002216 methylparaben Drugs 0.000 description 1
- 238000001471 micro-filtration Methods 0.000 description 1
- 238000009629 microbiological culture Methods 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 229910000403 monosodium phosphate Inorganic materials 0.000 description 1
- 235000019799 monosodium phosphate Nutrition 0.000 description 1
- 238000002887 multiple sequence alignment Methods 0.000 description 1
- 239000003471 mutagenic agent Substances 0.000 description 1
- 231100000707 mutagenic chemical Toxicity 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- GNOLWGAJQVLBSM-UHFFFAOYSA-N n,n,5,7-tetramethyl-1,2,3,4-tetrahydronaphthalen-1-amine Chemical compound C1=C(C)C=C2C(N(C)C)CCCC2=C1C GNOLWGAJQVLBSM-UHFFFAOYSA-N 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 239000012038 nucleophile Substances 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000012466 permeate Substances 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 239000001103 potassium chloride Substances 0.000 description 1
- 235000011164 potassium chloride Nutrition 0.000 description 1
- 235000013406 prebiotics Nutrition 0.000 description 1
- 230000001376 precipitating effect Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- KCXFHTAICRTXLI-UHFFFAOYSA-N propane-1-sulfonic acid Chemical compound CCCS(O)(=O)=O KCXFHTAICRTXLI-UHFFFAOYSA-N 0.000 description 1
- 235000019260 propionic acid Nutrition 0.000 description 1
- 239000004405 propyl p-hydroxybenzoate Substances 0.000 description 1
- 235000010232 propyl p-hydroxybenzoate Nutrition 0.000 description 1
- 235000013772 propylene glycol Nutrition 0.000 description 1
- 229960003415 propylparaben Drugs 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 235000021568 protein beverage Nutrition 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 230000029983 protein stabilization Effects 0.000 description 1
- IUVKMZGDUIUOCP-BTNSXGMBSA-N quinbolone Chemical compound O([C@H]1CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)CC[C@@]21C)C1=CCCC1 IUVKMZGDUIUOCP-BTNSXGMBSA-N 0.000 description 1
- VMXUWOKSQNHOCA-UKTHLTGXSA-N ranitidine Chemical compound [O-][N+](=O)\C=C(/NC)NCCSCC1=CC=C(CN(C)C)O1 VMXUWOKSQNHOCA-UKTHLTGXSA-N 0.000 description 1
- 239000002994 raw material Substances 0.000 description 1
- 235000020185 raw untreated milk Nutrition 0.000 description 1
- 235000020122 reconstituted milk Nutrition 0.000 description 1
- 230000007363 regulatory process Effects 0.000 description 1
- 238000000518 rheometry Methods 0.000 description 1
- 235000014438 salad dressings Nutrition 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 210000003079 salivary gland Anatomy 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 239000012266 salt solution Substances 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 238000004062 sedimentation Methods 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 101150091813 shfl gene Proteins 0.000 description 1
- 239000013605 shuttle vector Substances 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- AJPJDKMHJJGVTQ-UHFFFAOYSA-M sodium dihydrogen phosphate Chemical compound [Na+].OP(O)([O-])=O AJPJDKMHJJGVTQ-UHFFFAOYSA-M 0.000 description 1
- FQENQNTWSFEDLI-UHFFFAOYSA-J sodium diphosphate Chemical compound [Na+].[Na+].[Na+].[Na+].[O-]P([O-])(=O)OP([O-])([O-])=O FQENQNTWSFEDLI-UHFFFAOYSA-J 0.000 description 1
- 235000010267 sodium hydrogen sulphite Nutrition 0.000 description 1
- 239000001488 sodium phosphate Substances 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- 235000011008 sodium phosphates Nutrition 0.000 description 1
- 229940048086 sodium pyrophosphate Drugs 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- 235000008983 soft cheese Nutrition 0.000 description 1
- 238000010563 solid-state fermentation Methods 0.000 description 1
- 229940075554 sorbate Drugs 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 235000014347 soups Nutrition 0.000 description 1
- 229940001941 soy protein Drugs 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000012289 standard assay Methods 0.000 description 1
- 239000012086 standard solution Substances 0.000 description 1
- 238000012414 sterilization procedure Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 238000010998 test method Methods 0.000 description 1
- 235000019818 tetrasodium diphosphate Nutrition 0.000 description 1
- 239000001577 tetrasodium phosphonato phosphate Substances 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 238000004809 thin layer chromatography Methods 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 150000004043 trisaccharides Chemical class 0.000 description 1
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 229940098232 yersinia enterocolitica Drugs 0.000 description 1
- UHVMMEOXYDMDKI-JKYCWFKZSA-L zinc;1-(5-cyanopyridin-2-yl)-3-[(1s,2s)-2-(6-fluoro-2-hydroxy-3-propanoylphenyl)cyclopropyl]urea;diacetate Chemical compound [Zn+2].CC([O-])=O.CC([O-])=O.CCC(=O)C1=CC=C(F)C([C@H]2[C@H](C2)NC(=O)NC=2N=CC(=CC=2)C#N)=C1O UHVMMEOXYDMDKI-JKYCWFKZSA-L 0.000 description 1
Images





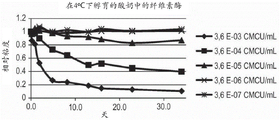
Classifications
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23C—DAIRY PRODUCTS, e.g. MILK, BUTTER OR CHEESE; MILK OR CHEESE SUBSTITUTES; MAKING THEREOF
- A23C9/00—Milk preparations; Milk powder or milk powder preparations
- A23C9/12—Fermented milk preparations; Treatment using microorganisms or enzymes
- A23C9/1203—Addition of, or treatment with, enzymes or microorganisms other than lactobacteriaceae
- A23C9/1206—Lactose hydrolysing enzymes, e.g. lactase, beta-galactosidase
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23C—DAIRY PRODUCTS, e.g. MILK, BUTTER OR CHEESE; MILK OR CHEESE SUBSTITUTES; MAKING THEREOF
- A23C9/00—Milk preparations; Milk powder or milk powder preparations
- A23C9/12—Fermented milk preparations; Treatment using microorganisms or enzymes
- A23C9/1203—Addition of, or treatment with, enzymes or microorganisms other than lactobacteriaceae
- A23C9/1216—Other enzymes
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23C—DAIRY PRODUCTS, e.g. MILK, BUTTER OR CHEESE; MILK OR CHEESE SUBSTITUTES; MAKING THEREOF
- A23C9/00—Milk preparations; Milk powder or milk powder preparations
- A23C9/12—Fermented milk preparations; Treatment using microorganisms or enzymes
- A23C9/13—Fermented milk preparations; Treatment using microorganisms or enzymes using additives
- A23C9/1322—Inorganic compounds; Minerals, including organic salts thereof, oligo-elements; Amino-acids, peptides, protein-hydrolysates or derivatives; Nucleic acids or derivatives; Yeast extract or autolysate; Vitamins; Antibiotics; Bacteriocins
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23C—DAIRY PRODUCTS, e.g. MILK, BUTTER OR CHEESE; MILK OR CHEESE SUBSTITUTES; MAKING THEREOF
- A23C9/00—Milk preparations; Milk powder or milk powder preparations
- A23C9/152—Milk preparations; Milk powder or milk powder preparations containing additives
- A23C9/1526—Amino acids; Peptides; Protein hydrolysates; Nucleic acids; Derivatives thereof
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23G—COCOA; COCOA PRODUCTS, e.g. CHOCOLATE; SUBSTITUTES FOR COCOA OR COCOA PRODUCTS; CONFECTIONERY; CHEWING GUM; ICE-CREAM; PREPARATION THEREOF
- A23G9/00—Frozen sweets, e.g. ice confectionery, ice-cream; Mixtures therefor
- A23G9/32—Frozen sweets, e.g. ice confectionery, ice-cream; Mixtures therefor characterised by the composition containing organic or inorganic compounds
- A23G9/38—Frozen sweets, e.g. ice confectionery, ice-cream; Mixtures therefor characterised by the composition containing organic or inorganic compounds containing peptides or proteins
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS, OR NON-ALCOHOLIC BEVERAGES, NOT COVERED BY SUBCLASSES A21D OR A23B-A23J; THEIR PREPARATION OR TREATMENT, e.g. COOKING, MODIFICATION OF NUTRITIVE QUALITIES, PHYSICAL TREATMENT; PRESERVATION OF FOODS OR FOODSTUFFS, IN GENERAL
- A23L33/00—Modifying nutritive qualities of foods; Dietetic products; Preparation or treatment thereof
- A23L33/10—Modifying nutritive qualities of foods; Dietetic products; Preparation or treatment thereof using additives
- A23L33/135—Bacteria or derivatives thereof, e.g. probiotics
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS, OR NON-ALCOHOLIC BEVERAGES, NOT COVERED BY SUBCLASSES A21D OR A23B-A23J; THEIR PREPARATION OR TREATMENT, e.g. COOKING, MODIFICATION OF NUTRITIVE QUALITIES, PHYSICAL TREATMENT; PRESERVATION OF FOODS OR FOODSTUFFS, IN GENERAL
- A23L33/00—Modifying nutritive qualities of foods; Dietetic products; Preparation or treatment thereof
- A23L33/20—Reducing nutritive value; Dietetic products with reduced nutritive value
- A23L33/21—Addition of substantially indigestible substances, e.g. dietary fibres
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS, OR NON-ALCOHOLIC BEVERAGES, NOT COVERED BY SUBCLASSES A21D OR A23B-A23J; THEIR PREPARATION OR TREATMENT, e.g. COOKING, MODIFICATION OF NUTRITIVE QUALITIES, PHYSICAL TREATMENT; PRESERVATION OF FOODS OR FOODSTUFFS, IN GENERAL
- A23L33/00—Modifying nutritive qualities of foods; Dietetic products; Preparation or treatment thereof
- A23L33/20—Reducing nutritive value; Dietetic products with reduced nutritive value
- A23L33/21—Addition of substantially indigestible substances, e.g. dietary fibres
- A23L33/24—Cellulose or derivatives thereof
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2408—Glucanases acting on alpha -1,4-glucosidic bonds
- C12N9/2411—Amylases
- C12N9/2428—Glucan 1,4-alpha-glucosidase (3.2.1.3), i.e. glucoamylase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2434—Glucanases acting on beta-1,4-glucosidic bonds
- C12N9/2445—Beta-glucosidase (3.2.1.21)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2468—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1) acting on beta-galactose-glycoside bonds, e.g. carrageenases (3.2.1.83; 3.2.1.157); beta-agarase (3.2.1.81)
- C12N9/2471—Beta-galactosidase (3.2.1.23), i.e. exo-(1-->4)-beta-D-galactanase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y302/00—Hydrolases acting on glycosyl compounds, i.e. glycosylases (3.2)
- C12Y302/01—Glycosidases, i.e. enzymes hydrolysing O- and S-glycosyl compounds (3.2.1)
- C12Y302/01023—Beta-galactosidase (3.2.1.23), i.e. exo-(1-->4)-beta-D-galactanase
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23C—DAIRY PRODUCTS, e.g. MILK, BUTTER OR CHEESE; MILK OR CHEESE SUBSTITUTES; MAKING THEREOF
- A23C2220/00—Biochemical treatment
- A23C2220/20—Treatment with microorganisms
- A23C2220/202—Genetic engineering of microorganisms used in dairy technology
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Food Science & Technology (AREA)
- Polymers & Plastics (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Biotechnology (AREA)
- Nutrition Science (AREA)
- Mycology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Inorganic Chemistry (AREA)
- Enzymes And Modification Thereof (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Dairy Products (AREA)
Abstract
披露了一种宿主细胞,该宿主细胞能够表达具有β‑半乳糖苷酶活性和/或转半乳糖基化活性的多肽,并且该宿主细胞是被修饰为纤维素酶、甘露聚糖酶和果胶酶缺陷型。
Description
技术领域
本发明涉及一种其中不希望的酶失活的宿主细胞,并且涉及该宿主细胞在酶组合物的制备中的用途,该酶组合物用于制造具有降低的不想要的特性的食品。
背景技术
普遍使用酶改进食品的化学性质。另外,在牛乳和其他动物衍生底物的加工中,酶的使用显著增加了最终产品的价值。
半乳寡糖(GOS)是在人和动物中不易消化的碳水化合物,其包括通过糖苷键连接的两个或更多个(通常多达九个)半乳糖分子。GOS还可以包括一个或多个葡萄糖分子。GOS的有益作用之一是它们作为益生元化合物通过选择性地刺激有益的结肠微生物(如细菌)以向消费者给出生理益处的能力。已经形成的健康作用导致对作为各种类型食物的食物成分的GOS的兴趣日益增加。
酶β-半乳糖苷酶(EC 3.2.1.23)通常将乳糖水解成单糖D-葡萄糖和D-半乳糖。在β-半乳糖苷酶的正常酶反应中,酶水解乳糖并瞬时结合半乳糖单糖在半乳糖-酶复合物中,该复合物将半乳糖转移到水的羟基基团上,导致D-半乳糖和D-葡萄糖的释放。然而,在高乳糖浓度下,在称为转半乳糖基化的过程中,一些β-半乳糖苷酶能够将半乳糖转移到D-半乳糖或D-葡萄糖的羟基中,由此产生半乳寡糖。同样,在高乳糖浓度下,一些β-半乳糖苷酶能够将半乳糖转移到乳糖或更高级寡糖的羟基基团上。
双歧杆菌是奶业中最常用类型的细菌培养物之一,用于发酵各种奶产品。另外,摄入含双歧杆菌的产品具有促进健康的作用。这种作用不仅通过降低肠内容物的pH值而且通过双歧杆菌在个体中重新填充肠道菌群的能力来实现,这些个体的肠道菌群受到例如抗生素的摄入的干扰。双歧杆菌还具有战胜潜在有害肠道微生物的潜力。
已知半乳寡糖可增强双歧杆菌的生长。这种作用可能通过双歧杆菌利用半乳寡糖作为碳源的独特能力来实现。还考虑了半乳寡糖的膳食补充剂具有许多长期的疾病保护作用。例如,已经显示出半乳寡糖摄入对大鼠结肠直肠癌发展具有高度保护作用。因此,有兴趣开发用于生产在工业中使用以改进膳食补充剂和奶产品的半乳寡糖的廉价且有效的方法。
已经将来自两歧双歧杆菌DSM20215的具有约580个氨基酸的截短的细胞外乳糖酶(BIF3-d3)描述为在包含溶解在水中的乳糖的溶液中的转糖半乳糖酶(乔根森 等人,(2001),应用微生物学和生物技术(Appl.Microbiol.Biotechnol.),57:647-652)。WO 01/90317还描述了作为转半乳糖基化酶的截短变体(OLGA347),并且在WO2012/010597中,显示OLGA347将半乳糖部分转移到D-岩藻糖、N-乙酰基-半乳糖胺和木糖。
等人,(2001),应用微生物学和生物技术(Appl.Microbiol.Biotechnol.),57:647-652)。WO 01/90317还描述了作为转半乳糖基化酶的截短变体(OLGA347),并且在WO2012/010597中,显示OLGA347将半乳糖部分转移到D-岩藻糖、N-乙酰基-半乳糖胺和木糖。
在WO 2009/071539中,与BIF3-d3相比,不同的截短片段被描述为在乳中测试时导致GOS的高效水解和非常低的产量。
WO 2013/182686描述了一种多肽,该多肽具有反式半乳糖基化与水解活性的有用比率,并且因此即使在低乳糖水平如乳基产品中与乳糖一起孵育时也是GOS的有效生产者。
然而,仍然需要提供改进的方法,用于在奶产品中现场从乳糖生产处于GOS形式的膳食纤维。本发明解决了这一需要。
发明内容
酶的副活性通常用于描述不想要的酶,其活性对方法或产物产生负面影响。它们主要存在于作为例如生产宿主的副产物的酶产物中,并且可能阻碍这些酶的商业应用。奶应用对少量的纤维素酶、果胶酶、淀粉酶和甘露聚糖酶特别敏感,因为许多奶产品用水状胶体例如CMC、GUAR、淀粉和果胶进行配制/稳定(参见表1)。
表1
| 酶 | 可降解的水状胶体/稳定剂 |
| 纤维素酶 | CMC |
| 甘露聚糖酶 | GUAR、LBG |
| 果胶酶(果胶酸裂解酶) | 果胶 |
| 淀粉酶 | 淀粉 |
我们现在已经能够开发包含β-半乳糖苷酶活性,任选地具有转半乳糖基化活性的产物或由其产生的GOS,其中纤维素、甘露聚糖酶、果胶酶和淀粉酶的水平得以降低。作为增稠剂、凝胶剂和稳定剂,水状胶体对许多食品和饮料产品作出了重要贡献。本发明允许提供这样的食品和饮料产品,其中不仅保留由水状胶体的使用产生的所期望的特性,而且其中另外地,食品和饮料产品能够保持处于GOS形式的膳食纤维。
水状胶体或树胶是不同类的长链聚合物,其特征在于当分散在水中时其形成粘性分散体和/或凝胶的特性。这些材料首先在树木或灌木丛的渗出物、植物或海藻的提取物、种子或谷物的粉状物质、发酵过程中的粘液和许多其他天然产物中发现。大量羟基基团的出现明显增加了它们结合水分子的亲和力,使它们成为亲水性化合物。此外,它们产生一种分散体,该分散体是在真溶液和悬浮液之间的中间体,并表现出胶体的特性。考虑到这两种特性,它们被适当地称为‘亲水胶体’或‘水状胶体’。
水状胶体在食品中具有广泛的功能特性,这些功能特性包括:增稠、胶凝、乳化、稳定、涂层等。当以如下水平使用时,水状胶体对食品特性具有深远的影响,这些水平范围从在加热处理奶产品中角叉菜胶的百万分之几至胶冻质糖食中的阿拉伯树胶、淀粉或明胶的高水平。水状胶体在食品中充分利用的主要原因是它们能够改变食品系统的流变学。这包括食品系统的两个基本特性,即流动行为(粘度)和机械固体特性(质感)。食品系统的质感和/或粘度的改变有助于改变其感官特性,因此将水状胶体用作重要的食品添加剂来执行特定目的。很显然,若干种水状胶体属于世界上许多国家中允许的食品添加剂类别。各种食物配制品如汤、肉汁、沙拉酱、调味汁和浇头使用水状胶体作为添加剂以达到优选的粘度和口感。它们也被用于许多食品像冰淇淋、果酱、果冻、凝胶甜点、蛋糕和糖果中,以产生所期望的质感。
除了功能属性之外,未来的接受以及可能的积极的认可可能来自于认识到纤维对身体的自然功能和健康有许多生理益处。
由于其水结合特性,水状胶体对食品的质感和口感有重大影响-通常为质感创新创造机会。这些产品中的若干种还与蛋白质相互作用,是用于蛋白质稳定和保护的有用特性。本发明提供了基于使用水状胶体的溶液,其中不仅保留使用水状胶体上述所期望的特性,而且其中另外地,食品和饮料产品能够包含处于GOS形式的膳食纤维。
在所培养的产品中,水状胶体提供细腻的质感和光泽的外观。水状胶体可以在降低的乳固体配制品中优化成本,并且在整个保质期中保持质感。水状胶体还改进所培养的产品的本体,尤其是处于较高消耗温度下。本发明提供了基于使用水状胶体的溶液,其中不仅保留使用水状胶体上述所期望的特性,而且其中另外地,食品和饮料产品能够包含处于GOS形式的膳食纤维。
在奶产品和低pH蛋白饮料中,水状胶体可以稳定乳和大豆蛋白质,防止沉降和乳清脱落,并可以实现各种质感。此外,更多的水状胶体可以用减少的乳固体、糖和/或脂肪替代配制品中的质感,并且从而给食品制造提供更好的低脂肪产品。本发明提供了基于使用水状胶体的溶液,其中不仅保留使用水状胶体上述所期望的特性,而且其中另外地,食品和饮料产品能够包含处于GOS形式的膳食纤维。
本发明通过提供包含具有转半乳糖基化活性的多肽的酶组合物来解决这些问题,但是该酶组合物没有或基本上没有归因于以下酶的活性:纤维素、甘露聚糖酶、果胶酶和任选地淀粉酶。
根据本发明的第1方面,提供一种能够表达具有β-半乳糖苷酶活性的多肽的宿主细胞,并且将该所述宿主细胞修饰为纤维素酶、甘露聚糖酶和果胶酶缺陷型。
在一个优选的实施例中,本发明中使用的具有β-半乳糖苷酶活性的多肽具有转半乳糖基化活性。
根据本发明的第2方面,提供一种能够表达具有转半乳糖基化活性的多肽的宿主细胞,并且将该所述宿主细胞修饰为纤维素酶、甘露聚糖酶和果胶酶缺陷型。
优选地,该宿主细胞还被修饰为淀粉酶缺陷型。
在一个实施例中,通过常规诱变技术修饰该宿主细胞。
在另一个实施例中,通过常规遗传操作技术修饰该宿主细胞。
根据本发明的第3方面,提供一种能够表达具有β-半乳糖苷酶活性的多肽的宿主细胞,并且其中具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽基本上是无活性的。
根据本发明的第4方面,提供一种能够表达具有转半乳糖基化活性的多肽的宿主细胞,并且其中具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽基本上是无活性的。
另外,优选地,在宿主细胞中,具有淀粉酶活性的多肽基本上是无活性的。
在第三和第四方面的一个实施例中,关于酶活性,该基本上无活性的纤维素酶、甘露聚糖酶和果胶酶多肽以及任选地该淀粉酶多肽在功能上是无活性的。
在一个实施例中,通过常规诱变技术使得该具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽以及任选地该具有淀粉酶活性的多肽基本上无活性。
在另一个实施例中,通过常规遗传操作技术使得该具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽以及任选地该具有淀粉酶活性的多肽基本上无活性。
可以使用的常规诱变技术是化学或物理诱变。
可以使用的常规遗传操作技术是一步基因破坏法、标志物插入、定点诱变、缺失、RNA干扰或反义RNA。
优选地,该宿主细胞是一种细菌。
该宿主细胞可以是乳酸菌。
优选地,该宿主细胞是枯草芽孢杆菌。
优选地,本发明中使用的具有转半乳糖基化活性的多肽选自由以下各项组成的组:
a.包含与SEQ ID NO:1具有至少90%序列同一性的氨基酸序列的多肽,其中所述多肽由至多980个氨基酸残基组成,
b.包含与SEQ ID NO:2具有至少97%序列同一性的氨基酸序列的多肽,其中所述多肽由至多975个氨基酸残基组成,
c.包含与SEQ ID NO:3具有至少96.5%序列同一性的氨基酸序列的多肽,其中所述多肽由至多1300个氨基酸残基组成,
d.由多核苷酸编码的多肽,该多核苷酸在至少低严格条件下与以下各项杂交:i)包含在SEQ ID NO:9、10、11、12或13中的编码SEQ ID NO:1、2、3、4或5的多肽的核酸序列;或ii)i)的互补链,
e.由包含如下各项的多核苷酸编码的多肽:与编码SEQ ID NO:1、2、3、4或5的多肽的核苷酸序列具有至少70%同一性的核苷酸序列,或包含在SEQ ID NO:9、10、11、12或13中的编码成熟多肽的核苷酸序列,和
f.包括SEQ ID NO:1、2、3、4或5的一个或多个氨基酸残基的缺失、插入和/或保守取代的多肽。
在一个实施例中,该宿主细胞包含一种表达载体,该表达载体包含编码具有β-半乳糖苷酶活性的多肽的核酸。
在一个实施例中,用编码具有β-半乳糖苷酶活性的多肽的核酸转化该宿主细胞。
在一个实施例中,该宿主细胞包含一种表达载体,该表达载体包含编码具有转半乳糖基化活性的多肽的核酸。
在一个实施例中,用编码具有转半乳糖基化活性的多肽的核酸转化该宿主细胞。
根据本发明的第5方面,提供了一种用于提供多肽组合物的方法,该多肽组合物包含具有β-半乳糖苷酶活性并且具有降低量的所不希望的纤维素、甘露聚糖酶和果胶酶酶副活性的多肽,该方法包括:提供能够表达该具有β-半乳糖苷酶活性的多肽、具有纤维素酶活性的多肽、具有甘露聚糖酶活性的多肽和具有果胶酶活性的多肽的宿主细胞;并且使所述纤维素、甘露聚糖酶和果胶酶失活。
根据本发明的第6方面,提供了一种用于提供多肽组合物的方法,该多肽组合物包含具有转半乳糖基化活性并且具有降低量的所不希望的纤维素、甘露聚糖酶和果胶酶酶副活性的多肽,该方法包括:提供能够表达该具有转半乳糖基化活性的多肽、具有纤维素酶活性的多肽、具有甘露聚糖酶活性的多肽和具有果胶酶活性的多肽的宿主细胞;并且使所述纤维素、甘露聚糖酶和果胶酶失活。
优选地,该方法还包括使具有淀粉酶活性的多肽失活。
在本方法的一个实施例中,通过常规诱变技术使得该具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽以及任选地该具有淀粉酶活性的多肽基本上无活性。
在本方法的另一个实施例中,通过遗传操作使得该具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽以及任选地该具有淀粉酶活性的多肽基本上无活性。
优选地,在该方法中,该宿主细胞是一种细菌。
在该方法的一个实施例中,该宿主细胞是乳酸菌。
优选地,在该方法中,该宿主细胞是枯草芽孢杆菌。
优选地,在该方法中,具有转半乳糖基化活性的多肽选自由以下各项组成的组:
a.包含与SEQ ID NO:1具有至少90%序列同一性的氨基酸序列的多肽,其中所述多肽由至多980个氨基酸残基组成,
b.包含与SEQ ID NO:2具有至少97%序列同一性的氨基酸序列的多肽,其中所述多肽由至多975个氨基酸残基组成,
c.包含与SEQ ID NO:3具有至少96.5%序列同一性的氨基酸序列的多肽,其中所述多肽由至多1300个氨基酸残基组成,
d.由多核苷酸编码的多肽,该多核苷酸在至少低严格条件下与以下各项杂交:i)包含在SEQ ID NO:9、10、11、12或13中的编码SEQ ID NO:1、2、3、4或5的多肽的核酸序列;或ii)i)的互补链,
e.由包含如下各项的多核苷酸编码的多肽:与编码SEQ ID NO:1、2、3、4或5的多肽的核苷酸序列具有至少70%同一性的核苷酸序列,或包含在SEQ ID NO:9、10、11、12或13中的编码成熟多肽的核苷酸序列,和
f.包括SEQ ID NO:1、2、3、4或5的一个或多个氨基酸残基的缺失、插入和/或保守取代的多肽。
在本方法的一个实施例中,该宿主细胞包含一种表达载体,该表达载体包含编码具有β-半乳糖苷酶活性的多肽的核酸。
在本方法的另一个实施例中,用编码具有β-半乳糖苷酶活性的多肽的核酸转化该宿主细胞。
在本方法的一个实施例中,该宿主细胞包含一种表达载体,该表达载体包含编码具有转半乳糖基化活性的多肽的核酸。
在本方法的另一个实施例中,用编码具有转半乳糖基化活性的多肽的核酸转化该宿主细胞。
根据本发明的第7方面,提供了生产具有β-半乳糖苷酶活性的多肽的方法,该方法包括在培养基中,在适合表达具有β-半乳糖苷酶活性的多肽的条件下培养本发明的宿主细胞,并且任选地从该培养基或该宿主细胞回收具有β-半乳糖苷酶活性的多肽。
根据本发明的第8方面,提供了生产具有转半乳糖基化活性的多肽的方法,该方法包括在培养基中,在适合表达具有转半乳糖基化活性的多肽的条件下培养本发明的宿主细胞,并且任选地从该培养基或该宿主细胞回收具有转半乳糖基化活性的多肽。
根据本发明的第9方面,提供了使用本发明宿主细胞或本发明方法产生的具有β-半乳糖苷酶活性的多肽。
优选地,根据本发明的具有β-半乳糖苷酶活性的多肽没有或基本上没有纤维素、甘露聚糖酶和果胶酶活性,以及任选地淀粉酶活性。
在一个实施例中,根据本发明的具有β-半乳糖苷酶活性的多肽没有或基本上没有纤维素、甘露聚糖酶和果胶酶活性,这样使得以粘度相对降低表示的粘度降低是至少0.85或至少0.9、或更少,该粘度降低由与没有添加酶或水的水状胶体溶液相比添加具有β-半乳糖苷酶活性的多肽的含水状胶体溶液的粘度计算得出。
根据本发明的第10方面,提供了包括使用本发明宿主细胞或本发明方法产生的具有β-半乳糖苷酶活性的多肽的多肽组合物。
根据本发明的第11方面,提供了使用本发明宿主细胞或本发明方法产生的具有转半乳糖基化活性的多肽。
优选地,根据本发明的具有转半乳糖基化活性的多肽没有或基本上没有纤维素、甘露聚糖酶和果胶酶活性,以及任选地淀粉酶活性。
在一个实施例中,根据本发明的具有转半乳糖基化活性的多肽没有或基本上没有纤维素、甘露聚糖酶和果胶酶活性,这样使得以粘度相对降低表示的粘度降低是至少0.85或至少0.9、或更少,该粘度降低由与没有添加酶或水的水状胶体溶液相比添加具有转半乳糖基化活性的多肽的含水状胶体溶液的粘度计算得出。
根据本发明的第12方面,提供了包括使用本发明宿主细胞或本发明方法产生的具有转半乳糖基化活性的多肽的多肽组合物。
优选地,本发明的多肽组合物没有或基本上没有纤维素、甘露聚糖酶和果胶酶活性,以及任选地淀粉酶活性。
在一个实施例中,多肽组合物没有或基本上没有纤维素、甘露聚糖酶和果胶酶活性,这样使得以粘度相对降低表示的粘度降低是至少0.85或至少0.9、或更少,该粘度降低由与没有添加酶或水的水状胶体溶液相比添加本发明的多肽组合物的含水状胶体溶液的粘度计算得出。
根据本发明的第13方面,提供了包括本发明具有β-半乳糖苷酶活性的多肽或本发明的多肽组合物的奶产品。
根据本发明的第14方面,提供了生产奶产品的方法,该方法包括向含有乳糖的奶产品中添加本发明具有β-半乳糖苷酶活性的多肽或本发明的多肽组合物。
根据本发明的第15方面,提供了生产包含GOS的奶产品的方法,该方法包括向含有乳糖的奶产品中添加本发明具有β-半乳糖苷酶活性的多肽或本发明的多肽组合物。
根据本发明的第16方面,提供了根据本发明的具有转半乳糖基化活性的多肽或根据本发明的多肽组合物用于制备奶产品的用途。
根据本发明的第17方面,提供了根据本发明的具有转半乳糖基化活性的多肽或根据本发明的多肽组合物用于制备包含GOS的奶产品的用途。
根据本发明的第18方面,提供了包含本发明的具有转半乳糖基化活性的多肽或本发明的多肽组合物的奶产品。
根据本发明的第19方面,提供了生产奶产品的方法,该方法包括向含有乳糖的奶产品中添加本发明的具有转半乳糖基化活性的多肽或本发明的多肽组合物。
根据本发明的第20方面,提供了生产包含GOS的奶产品的方法,该方法包括向含有乳糖的奶产品中添加本发明的具有转半乳糖基化活性的多肽或本发明的多肽组合物。
根据本发明的第21方面,提供了根据本发明的具有转半乳糖基化活性的多肽或根据本发明的多肽组合物用于制备奶产品的用途。
根据本发明的第22方面,提供了根据本发明的具有转半乳糖基化活性的多肽或根据本发明的多肽组合物用于制备包含GOS的奶产品的用途。
在一个实施例中,本发明的用途是防止奶产品的粘度和/或质感降低,该用途是与具有β-半乳糖苷酶和/或转半乳糖基化活性的、由表达纤维素酶、甘露聚糖酶和果胶酶的宿主细胞制备的多肽的用途相比而言的。
本发明具体可用于在包含乳糖的组合物如奶产品中现场生产GOS膳食纤维。
序列表
SEQ ID NO:1(在此又称为(BIF_917))是SEQ ID NO:22的887个氨基酸的截短的片段。
SEQ ID NO:2(在此又称为(BIF_995))是SEQ ID NO:22的965个氨基酸的截短的片段。
SEQ ID NO:3(在此又称为(BIF_1068))是SEQ ID NO:22的1038个氨基酸的截短的片段。
SEQ ID NO:4(在此又称为(BIF_1172))是SEQ ID NO:22的1142个氨基酸的截短的片段。
SEQ ID NO:5(在此又称为(BIF_1241))是SEQ ID NO:22的1211个氨基酸的截短的片段。
SEQ ID NO:6(在此又称为(BIF_1326))是SEQ ID NO:22的1296个氨基酸的截短的片段。
SEQ ID NO:7是两歧双歧杆菌糖苷水解酶催化核心
SEQ ID NO:8是编码来自两歧双歧杆菌DSM20215的胞外乳糖酶的核苷酸序列
SEQ ID NO:9是编码BIF_917的核苷酸序列
SEQ ID NO:10是编码BIF_995的核苷酸序列
SEQ ID NO:11是编码BIF 1068的核苷酸序列
SEQ ID NO:12是编码BIF_1172的核苷酸序列
SEQ ID NO:13是编码BIF_1241的核苷酸序列
SEQ ID NO:14是编码BIF_1326的核苷酸序列
SEQ ID NO:15是用于生成上述BIF变体的正向引物
SEQ ID NO:16是BIF917的反向引物
SEQ ID NO:17是BIF995的反向引物
SEQ ID NO:18是BIF1068的反向引物
SEQ ID NO:19是BIF1241的反向引物
SEQ ID NO:20是BIF1326的反向引物
SEQ ID NO:21是BIF1478的反向引物
SEQ ID NO:22是来自两歧双歧杆菌DSM20215的胞外乳糖酶。
SEQ ID NO:23是来自两歧双歧杆菌DSM20215的胞外乳糖酶的信号序列。
发明详细披露
定义
根据此详细描述,适用下列简称和定义。应当注意,如在此所用,单数形式“一种(a)”、“一种(an)”以及“该”包括复数个指示物,除非上下文中另外明确指明。因而,例如,提及“一个/种多肽”时包括多个/种此类多肽,并且提及“所述/该配制品”时包括提及一个或多个配制品和本领域技术已知的其等效物,等等。
除非另外定义,否则在此使用的所有技术和科学术语具有与本领域普通技术人员通常所理解的相同的含义。下文中提供了下述术语。
除其他事项之外,“转半乳糖基酶”意指能够将半乳糖转移到D-半乳糖或D-葡萄糖的羟基基团的酶,由此产生半乳寡糖。在一方面,通过酶在乳糖上的反应来鉴定转半乳糖基酶,其中产生的半乳糖的量小于在任何给定时间产生的葡萄糖的量。
在上下文中,术语“转半乳糖基化活性”意指将半乳糖部分转移至除水以外的分子。活性可以测定为[葡萄糖]-反应期间的任何给定时间产生的[半乳糖],或通过直接定量在反应期间的任何给定时间产生的GOS来测量。该测量可以以若干种方式进行,如通过实例中所示的HPLC方法进行。当比较转半乳糖基化活性的测量值时,它们已经在给定的初始乳糖浓度下进行,例如像,3%、4%、5%、6%、7%、8%、9%或10%(w/w)。
在上下文中,术语“β-半乳糖苷酶活性”意指酶将β-半乳糖苷例如像乳糖水解成单糖、葡萄糖和半乳糖的能力。
在计算转半乳糖基化活性:β-半乳糖苷酶活性的情况下,β-半乳糖苷酶活性被测量为在反应期间的任何给定时间产生[半乳糖]。该测量可以以若干种方式进行,如通过实例中所示的HPLC方法进行。
在上下文中,使用邻硝基苯酚-β-D-吡喃半乳糖苷(ONPG),如下计算术语“转半乳糖基化活性的比率”:将比率计算为具有存在的受体的Abs420除以没有存在的受体的Abs420之间的比率乘以100。指数100的或以下的变体是纯水解变体,而上述水平描绘了相对的转半乳糖基化活性。
转半乳糖基化活性的比率=(Abs420+纤维二糖/Abs420-纤维二糖)*100%,其中Abs420+纤维二糖是使用以下描述的方法3在420nm处读取的吸光度,在反应中包括纤维二糖,并且Abs420-纤维二糖是使用以下描述的方法3在420nm处读取的吸光度,而在反应中没有纤维二糖。以上方程仅适用于吸光度在0.5和1.0之间的稀释。
在一方面,在15min反应、30min反应、60min反应、90min反应、120min反应或180min反应后测量本发明涉及的任何酶的活性。因此,在一方面,作为实例,在添加酶后15分钟,如添加酶后30分钟,如添加酶后60分钟,如添加酶后90分钟,如添加酶后120分钟或如添加酶后180分钟,测量相对转半乳糖基化活性。
在上下文中,术语“转半乳糖基化活性:β-半乳糖苷酶活性的比率”意指([葡萄糖]-[半乳糖]/[半乳糖])。
在上下文中,术语[葡萄糖]意指如通过HPLC测量的以重量%计的葡萄糖浓度。
在上下文中,术语[半乳糖]意指如通过HPLC测量的以重量%计的半乳糖浓度。
在上下文中,术语“已经将乳糖转半乳糖基化”意指半乳糖分子已经共价连接至乳糖分子,例如像共价连接至乳糖分子中的任何游离羟基基团,或者如通过内部转半乳糖基化产生,例如形成异乳糖。
在上下文中,在“乳基测定”(酸奶应用模拟物)中测试了在半乳寡糖(GOS)生产中在此披露的多肽的性能评估。使用由98,60%(w/v)新鲜巴氏杀菌低脂乳(爱氏晨曦迷你乳(Arla ))和1.4%(w/v)Nutrilac YQ-5075乳清成分(爱氏晨曦)组成的酸奶混合物在96孔MTP板中进行体积为100μl的分批实验。为了完全使Nutrilac YQ-5075与水化合,将混合物搅拌20h,并且然后添加20mM磷酸钠(pH 6.5),以确保pH为6.5。将这种酸奶基简单地使用或与各种补充剂如另外的乳糖、海藻糖、麦芽糖、木糖或盐一起使用。将90μl酸奶与10μl纯化的酶或粗制酵素混合,用胶带密封并在43℃下孵育3小时。通过100μl 10%Na2CO3终止反应。将样品储存于-20℃下。通过HPLC定量半乳寡糖(GOS)、乳糖、葡萄糖和半乳糖。在Dionex ICS 3000上进行样品分析。IC参数如下:流动相:150mM NaOH,流速:等度,0,25ml/min,柱:Carbopac PA1,柱温:RT,注射体积:10μl,检测器:PAD,积分:手动,样品制备:在Milli-Q水中稀释100倍(0,1ml样品+9,9ml水),并通过0.45ìm针筒式滤器过滤,定量:标准品的峰面积的百分比中的峰面积。将GOS糖浆(Vivanal GOS,菲仕兰坎皮纳公司(FrieslandCampina))用作GOS定量的标准品。
))和1.4%(w/v)Nutrilac YQ-5075乳清成分(爱氏晨曦)组成的酸奶混合物在96孔MTP板中进行体积为100μl的分批实验。为了完全使Nutrilac YQ-5075与水化合,将混合物搅拌20h,并且然后添加20mM磷酸钠(pH 6.5),以确保pH为6.5。将这种酸奶基简单地使用或与各种补充剂如另外的乳糖、海藻糖、麦芽糖、木糖或盐一起使用。将90μl酸奶与10μl纯化的酶或粗制酵素混合,用胶带密封并在43℃下孵育3小时。通过100μl 10%Na2CO3终止反应。将样品储存于-20℃下。通过HPLC定量半乳寡糖(GOS)、乳糖、葡萄糖和半乳糖。在Dionex ICS 3000上进行样品分析。IC参数如下:流动相:150mM NaOH,流速:等度,0,25ml/min,柱:Carbopac PA1,柱温:RT,注射体积:10μl,检测器:PAD,积分:手动,样品制备:在Milli-Q水中稀释100倍(0,1ml样品+9,9ml水),并通过0.45ìm针筒式滤器过滤,定量:标准品的峰面积的百分比中的峰面积。将GOS糖浆(Vivanal GOS,菲仕兰坎皮纳公司(FrieslandCampina))用作GOS定量的标准品。
转半乳糖基化活性可以通过如WO 2013/182686中所述的HPLC定量或酶测定来测量。
在上下文中,术语“将该多肽喷雾干燥”意指已经通过将溶液或悬浮液中的多肽在合适的温度下喷雾干燥并且持续适当的时间除去水而获得多肽。
在上下文中,术语“该多肽在溶液中”涉及可溶于溶剂而不会沉淀出溶液的多肽。用于该目的的溶剂包括多肽可以存在的任何环境,如水性缓冲液或盐溶液、发酵液或表达宿主的细胞质。
在上下文中,术语“稳定剂”意指用于稳定多肽的任何稳定剂,例如,多元醇,例如像甘油或丙二醇、糖或糖醇,乳酸,硼酸或硼酸衍生物(例如芳族硼酸酯)。在一方面,稳定剂不是多元醇,或该多元醇以0.1wt%或更低水平存在。
术语“分离的”意指多肽至少基本上不含与该序列在自然界中天然缔合或者在自然界中存在的至少一种其他组分,和/或基本上不含纤维素、甘露聚糖、果胶酶或淀粉酶。在一方面,如在此所用“分离的多肽”是指如通过SDS-PAGE确定的是至少30%纯、至少40%纯、至少60%纯、至少80%纯、至少90%纯、和至少95%纯的多肽。
因此,术语“基本上不含纤维素酶”在此意指按重量计包含至多10%,优选至多8%,更优选至多6%,更优选至多5%,更优选至多4%,至多3%,甚至更优选至多2%,最优选至多1%,并且甚至最优选至多0.5%的纤维素酶的制剂。因此,在此术语“基本上不含”可以被看作与术语“分离的多肽”和“分离形式的多肽”同义。
因此,术语“基本上不含甘露聚糖酶”在此意指按重量计包含至多10%,优选至多8%,更优选至多6%,更优选至多5%,更优选至多4%,至多3%,甚至更优选至多2%,最优选至多1%,并且甚至最优选至多0.5%的甘露聚糖酶的制剂。因此,在此术语“基本上不含”可以被看作与术语“分离的多肽”和“分离形式的多肽”同义。
因此,术语“基本上不含果胶酶”在此意指按重量计包含至多10%,优选至多8%,更优选至多6%,更优选至多5%,更优选至多4%,至多3%,甚至更优选至多2%,最优选至多1%,并且甚至最优选至多0.5%的果胶酶的制剂。因此,在此术语“基本上不含”可以被看作与术语“分离的多肽”和“分离形式的多肽”同义。
因此,术语“基本上不含淀粉酶”在此意指按重量计包含至多10%,优选至多8%,更优选至多6%,更优选至多5%,更优选至多4%,至多3%,甚至更优选至多2%,最优选至多1%,并且甚至最优选至多0.5%的淀粉酶的制剂。因此,在此术语“基本上不含”可以被看作与术语“分离的多肽”和“分离形式的多肽”同义。
术语“基本上纯的多肽”在此意指包含按重量计至多10%,优选至多8%,更优选至多6%,更优选至多5%,更优选至多4%,至多3%,甚至更优选至多2%,最优选至多1%,并且甚至最优选至多0.5%的与其天然缔合的其他多肽材料的多肽制剂。因此,优选的是该基本上纯的多肽是按制剂中存在的所有的多肽材料的重量计至少92%纯,优选至少94%纯,更优选至少95%纯,更优选至少96%纯,更优选至少96%纯,更优选至少97%纯,更优选至少98%纯,甚至更优选至少99%纯,最优选至少99.5%纯,并且甚至最优选100%纯的。在此披露的多肽优选为基本上纯的形式。特别地,优选的是这些多肽是“基本上纯的形式”,即多肽制剂基本上不含与其天然缔合的其他多肽材料。例如,这可以通过熟知的重组方法或通过经典的纯化方法制备多肽来完成。在此,术语“基本上纯的多肽”与术语“分离的多肽”和“分离形式的多肽”同义。
术语“纯化”或“纯”意指给定的组分以高水平状态存在-例如,至少约51%纯如至少51%纯,或至少约75%如至少75%纯,或至少约80%如至少80%纯,或至少约90%如至少90%纯,或至少约95%如至少95%纯,或至少约98%如至少98%纯。希望的是,该组分是组合物中存在的主要活性组分。
关于本发明的术语“微生物”包括任何“微生物”,该任何“微生物”可以包括根据本发明所述的核苷酸序列或编码具有如在此定义的特定特性的多肽的核苷酸序列和/或由其获得的产物。在上下文中,“微生物”可以包括能够发酵乳基质的任何细菌或真菌。
关于本发明的术语“宿主细胞”包括任何细胞,该任何细胞包括编码具有如在此定义的特定特性的多肽的核苷酸序列或如上所述的并用于生产具有如在此定义的特定特性的多肽的表达载体。在一方面,生产是重组生产。
在本发明的上下文中,术语“乳”应理解为从任何哺乳动物如牛、绵羊、山羊、水牛或骆驼获得的乳状分泌物。
在上下文中,术语“乳基底物”意指任何生的和/或加工的乳材料或衍生自乳成分的材料。有用的乳基底物包括但不限于包括乳糖的任何乳或乳样产品的溶液/悬浮液,如全脂或低脂乳、脱脂乳、酪乳、复原乳粉、炼乳、奶粉溶液、UHT乳、乳清、乳清渗透物、酸乳清或奶油。优选地,乳基底物是乳或脱脂乳粉的水溶液。乳基底物可以比生乳更浓。在一个实施例中,乳基底物的蛋白质与乳糖的比率为至少0.2,优选至少0.3,至少0.4,至少0.5,至少0.6,或最优选至少0.7。可以根据本领域已知的方法对乳基底物进行均化和/或巴氏杀菌。
如在此所用“均质化”意指强烈混合以获得可溶性悬浮液或乳液。可以进行该均质化以便将乳脂分解成更小的尺寸,这样使得乳脂不再与该乳分离。这可以通过在高压下使该乳通过小孔来实现。
如在此所用“巴氏杀菌”意指减少或消除活生物体如微生物在乳基底物中的存在。优选地,通过将规定温度保持规定的时间来实现巴氏杀菌。指定的温度通常通过加热来实现。可以选择温度和持续时间以便杀灭或使某些细菌,如有害细菌失活,和/或使该乳中的酶失活。可以遵循快速冷却步骤。本发明上下文中的“食品”或“食物组合物”可以是适合于动物或人类消费的任何可食用食品或饲料产品。
在本发明的上下文中的“奶产品”可以是主要成分之一是乳基的任何食品。优选地,主要成分是乳基的。更优选地,主要成分是已经用具有转半乳糖基化活性的酶处理过的乳基底物。
在上下文中,“主要成分之一”意指具有干物质的成分,该干物质占奶产品总干物质的20%以上,优选30%以上或40%以上,而“主要成分”意指具有干物质的成分,该干物质占奶产品总干物质的50%以上,优选60%以上或70%以上。
在上下文中,“发酵的奶产品”应被理解为任何奶产品,其中任何类型的发酵形成生产过程的一部分。发酵的奶产品的实例是产品像酸奶、酪乳、鲜奶油、奶渣和清爽干酪。发酵的奶产品的另一个实例是奶酪。发酵的奶产品可以通过本领域已知的任何方法来生产。
术语“发酵”意指通过微生物如起子培养物的作用将碳水化合物转化为醇或酸。在一方面,发酵包括将乳糖转化为乳酸。
在上下文中,“微生物”可以包括能够发酵乳基质的任何细菌或真菌。
在上下文中,术语“Pfam结构域”意指基于多重序列比对和隐马尔可夫基序的存在,被鉴定为Pfam-A或Pfam-B的蛋白质序列内的区域(“Pfam蛋白家族数据库(The Pfamprotein families database)”:R.D.芬恩(Finn),J.米斯特里(Mistry),J.塔特(Tate),P.柯吉尔(Coggill),A.赫格尔(Heger),J.E.普林顿(Pollington),O.L.加文(Gavin),P.古恩赛卡伦(Gunesekaran),G.赛利克(Ceric),K.福斯隆德(Forslund),L.霍尔姆(Holm),E.L.松哈默(Sonnhammer),S.R.艾迪(Eddy),A.贝特曼(Bateman),核酸研究(Nucleic AcidsResearch)(2010),数据库专辑38:D211-222)。作为Pfam结构域的实例,可以提及Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)、Glyco_hydro 2C(PF02836)和细菌Ig样结构域(组4)(PF07532)。
如在此所用,术语“表达”是指基于基因的核酸序列产生多肽的过程。此过程包括转录和翻译。
如在此所用,“转化的细胞”包括已经通过使用重组DNA技术转化的细胞,包括细菌和真菌细胞。转化通常通过将一个或多个核苷酸序列插入细胞而发生。所插入的核苷酸序列可以是异源核苷酸序列,即,对于待转化的细胞不是天然的序列,如融合蛋白。
如在此所用,“可操作地连接”意指所描述的组分处于允许它们以其预期方式起作用的关系。例如,将可操作地连接到编码序列的调控序列以如下这样方式连接:在与控制序列相容的条件下实现编码序列的表达。
如在此所用,“载体”是指设计用于将核酸引入一种或多种细胞类型的多核苷酸序列。载体包括克隆载体、表达载体、穿梭载体、质粒、噬菌体颗粒、盒等。
如在此所用,术语“表达”是指基于基因的核酸序列产生多肽的过程。此过程包括转录和翻译。表达可能涉及使用宿主生物来产生多肽。宿主生物体,又简称为宿主,可以包括原核生物和真核生物,并且在一些实施例中可以包括细菌和真菌物种。
如在此所用,“表达载体”是指包含DNA编码序列(例如,基因序列)的DNA构建体,其可操作地连接到能够影响编码序列在宿主中表达的一种或多种合适的控制序列。这样的控制序列包括影响转录的启动子,控制这种转录的任选的操纵子序列,编码合适的mRNA核糖体结合位点的序列,以及控制转录和翻译终止的序列。载体可以是质粒、噬菌体颗粒,或简单地是潜在的基因组插入物。一旦转化入合适的宿主中,载体可以独立于宿主基因组复制和起作用,或者在某些情况下可以整合入基因组本身。质粒是最常用的表达载体形式。然而,该描述旨在包括发挥等效功能并且本领域已知或将成为已知的其他形式的表达载体。
“启动子”是指参与结合RNA聚合酶以启动基因转录的调控序列。启动子可以是诱导型启动子或组成型启动子。可以使用的诱导型启动子的非限制性实例是里氏木霉cbh1,其是诱导型启动子。
术语“可操作地连接”是指并置,其中元件处于使得它们在功能上相关的布置。例如,如果启动子控制编码序列的转录,则启动子可操作地连接到编码序列。
“在转录控制下”是本领域中众所周知的术语,该术语表明多核苷酸序列的转录取决于其与有助于启动或促进转录的元件可操作地连接。
“在翻译控制下”是本领域中众所周知的术语,其表示在mRNA形成后发生的调节过程。
“基因”是指参与产生多肽并且包括编码区之前和之后的区域以及个体编码区段(外显子)之间的间插序列(内含子)的DNA区段。
如在此所用,术语“宿主细胞”是指用于产生多肽的重组表达载体可以转染入其中以表达该多肽的细胞或细胞系。宿主细胞包括单个宿主细胞的后代,并且由于天然的、意外的或故意的突变,后代可能不一定(在形态学或总基因组DNA补体方面)与原始亲本细胞完全同一。宿主细胞包括用表达载体体内转染或转化的细胞。
术语“重组”当用于提及一种细胞、核酸、蛋白或载体时是指该细胞、核酸、蛋白或载体已经通过导入异源核酸或蛋白或者改变天然的核酸或蛋白进行修饰,或者表明该细胞衍生自经这样修饰的细胞。因此,例如,这些重组细胞表达在细胞的天然形式(非重组)中未发现的基因或表达以其他方式异常表达的、低表达的或根本不表达的天然基因。
“信号序列”(又称为“前序列”、“信号肽”、“前导序列”或“前导肽”)是指与蛋白质的N端部分结合的氨基酸序列,该氨基酸序列促进了成熟形式的蛋白质从细胞的分泌(例如,SEQ ID NO:5)。信号序列将多肽靶向分泌途径,并且一旦其在内质网膜中被转位就从新生多肽切割。成熟形式的细胞外蛋白质(例如SEQ ID NO:1)缺乏在分泌过程中被切除的信号序列。
术语“选择性标志物”或“可选择的标志物”是指能够在宿主细胞中表达的基因,其允许容易地选择包含引入的核酸或载体的那些宿主。可选择的标志物的实例包括但不限于在宿主细胞上赋予代谢优势,如营养优势的抗微生物物质(例如,潮霉素、博来霉素或氯霉素)和/或基因。
术语“培养”是指在液体或固体培养基中在生长适合生长条件下使微生物细胞群生长。术语“培养基”是指在该过程中使用的介质
在将核酸序列插入细胞的上下文中,术语“引入的”包括“转染”、“转化”或“转导”,并且是指将核酸序列并入真核或原核细胞中,其中可以将核酸序列并入细胞的基因组(例如,染色体、质粒、质体或线粒体DNA)中,转化成自主复制子或进行瞬时表达。
如在此所用,术语“转化的”,“稳定转化的”和“转基因的”是指具有整合到其基因组中的或作为通过多代维持的附加型质粒的非天然(例如,异源的)核酸序列的细胞。
如在此所用,术语“修改”和“改变”可互换使用并且意指变化或变更。在修饰或改变多肽的上下文中,这些术语可以意指直接或通过改变编码核酸来改变氨基酸序列,或如将酶糖基化来改变多肽的结构。
除非另有说明,本发明的实践将使用在本领域技术范围内的分子生物学(包括重组技术)、微生物学、细胞生物学和生物化学的常规技术。这些技术在文献中得到充分解释,这些文献例如,分子克隆:实验室手册(Molecular Cloning:A Laboratory Manual),第二版(萨姆布鲁克(Sambrook)等人,1989,分子克隆:实验室手册);寡核苷酸合成 (Oligonucleotide Synthesis)(M.J.盖特(Gait)编辑,1984;分子生物学现代方法 (Current Protocols in Molecular Biology)(F.M.奥苏贝尔(Ausubel)等人编辑,1994);PCR:聚合酶链式反应(PCR:The Polymerase Chain Reaction)(穆利斯(Mullis)等人编辑,1994);和基因转移和表达:实验室手册(Gene Transfer and Expression:A Laboratory Manual)(克里格勒(Kriegler),1990)。
除非在此另外定义,否则在此所用的所有技术与科学术语均具有与本发明所属领域的普通技术人员通常理解的相同含义。辛格尔顿(Singleton)等人,“微生物与分子生物 学杂志(Dictionary of Microbiology and Molecular Biology)”,第二版,约翰威利父子出版公司(John Wiley and Sons),纽约(1994)和黑尔(Hale)与马卡姆(Markham),哈珀柯 林斯生物学词典(The Harper Collins Dictionary of Biology),哈珀永久出版社(Harper Perennial),纽约(1991)向技术人员提供本发明中使用的许多术语的通用词典。与在此所述那些类似或等效的任何方法和材料可用于本发明的实践或测试。
除非另有说明,分别地,核酸以5'至3'取向从左向右书写;氨基酸序列以氨基至羧基取向从左向右书写。
在此提供的数字范围包括定义范围的数字。
在酶产物中,少量不需要的酶活性主要来源于生产宿主,并且称为酶副活性。本发明涉及减少不需要的酶副活性。乳制品应用中的酶活性应优选在适用于应用的Ph和温度下进行测量。在乳中,pH值从6.4至6.8不等,酸奶:pH约4,婴儿配方奶pH 5.9-7.3,马苏里拉奶酪pH 5.2-5.5,以及蛋黄酱pH 4。最佳地,可以通过每个预期应用中的应用测试来确定不希望的活性的水平。
纤维素酶
在一方面,本发明涉及不含或基本上不含纤维素酶活性的组合物。在另一方面,本发明提供了一种新颖的细菌,其中使编码纤维素酶的基因失活。这样的组合物包含具有转半乳糖基化活性的多肽。根据本发明的宿主细胞能够表达具有转半乳糖基化活性的多肽。这种转半乳糖基化活性应以如下这样水平存在:GOS能够在产品中由乳糖生产,即优选多肽存在于组合物中,或者宿主细胞能够以如下这种水平表达它:GOS形式的膳食纤维可以由添加有组合物或宿主细胞的奶产品中存在的乳糖产生。
纤维素酶是水解纤维素(β-1,4-葡聚糖或β-D-糖苷键)的酶,其导致葡萄糖、纤维二糖、纤维寡糖等的形成。纤维素酶传统上分为三大类:内切葡聚糖酶(EC 3.2.1.4)(“EG”)、外切葡聚糖酶或纤维二糖水解酶(EC3.2.1.91)(“CBH”)和β-葡糖苷酶([β]-D-葡萄糖苷葡糖水解酶;EC3.2.1.21)(“BG”)。根据一个实施例,失活的纤维素酶基因是bgLC内切葡聚糖酶。
甘露聚糖酶
甘露聚糖酶是一种酶,其分解称为甘露聚糖的化合物。这些多糖由单糖甘露糖构成,并且在自然界中广泛发现。在许多植物(并且,例如,在其种子中),甘露聚糖用作碳水化合物储备。在一方面,酶选自由以下各项组成的组:甘露聚糖酶,特别是内切β-甘露聚糖酶、酯酶、外切甘露聚糖酶、半乳聚糖酶。根据一个实施例,失活的甘露聚糖酶基因是gmuG甘露聚糖酶。
果胶酶
果胶酶是分解果胶(植物细胞壁中发现的多糖)的酶。通常被称为果胶酶,它们包括果胶降解酶、果胶糖酶(pectozyme)和多聚半乳糖醛酸酶。研究最多并最广泛使用的商业果胶酶之一是多聚半乳糖醛酸酶。根据一个实施例,失活的果胶酶基因是pel果胶酸裂解酶。
淀粉酶
淀粉酶是一种催化淀粉水解成糖的酶。淀粉酶存在于人类和一些其他哺乳动物的唾液中,其中它开始消化的化学过程。胰腺和唾液腺产生淀粉酶(α淀粉酶)来将膳食淀粉水解成二糖和三糖,这些二糖和三糖通过其他酶转化成葡萄糖,为身体提供能量。植物和一些细菌也产生淀粉酶。特定的淀粉酶蛋白由不同的希腊字母指定。所有淀粉酶都是糖苷水解酶,并且作用于α-1,4-糖苷键。本发明优选另外涉及(EC 3.2.1.1)(CAS#9014-71-5)(替代名称:1,4-α-D-葡聚糖葡聚糖水解酶;糖原酶)的失活。根据一个实施例,失活的淀粉酶基因是amyEα-淀粉酶。
在一方面,在此所用的术语“淀粉酶”是指淀粉酶,如[α]-淀粉酶(EC 3.2.1.1)、[β]-淀粉酶(EC 3.2.1.2)和[γ]-淀粉酶(EC 3.2.1.3。)。
同一性程度
两个氨基酸序列之间或两个核苷酸序列之间的关联性由参数“同一性”描述。
在一个实施例中,通过以下方式来确定查询序列与参考序列之间的序列同一性程度:1)通过使用默认评分矩阵和默认空位罚分的任何合适的比对程序来比对两种序列,2)鉴别精确匹配的数量,其中精确匹配是比对程序已经在比对的给定位置处鉴别出两个比对序列中的同一的氨基酸或核苷酸,以及3)将精确匹配的数目除以参考序列的长度。
在一个实施例中,通过以下方式来确定查询序列与参考序列之间的序列同一性程度:1)通过使用默认评分矩阵和默认空位罚分的任何合适的比对程序来比对两种序列,2)鉴别精确匹配的数量,其中精确匹配是其中比对程序已经在比对的给定位置处鉴别出两个比对序列中的同一的氨基酸或核苷酸,以及3)将精确匹配的数目除以两个序列中最长的长度。
在另一个实施例中,通过以下方式来确定查询序列与参考序列之间的序列同一性程度:1)通过使用默认评分矩阵和默认空位罚分的任何合适的比对程序来比对两种序列,2)鉴别精确匹配的数量,其中精确匹配是其中比对程序已经在比对的给定位置处鉴别出两个比对序列中的同一的氨基酸或核苷酸,以及3)将精确匹配数目除以“比对长度”,其中该比对长度是包括序列的空位和突出部分的整个比对的长度。
序列同一性比较可以通过眼睛,或更通常地借助于容易获得的序列比较程序进行。这些商业可得的计算机程序使用复杂的比较算法来比对两个或更多个序列,其最好地反映出可能导致两个或更多个序列之间的一个或多个差异的进化事件。因此,这些算法使用评分系统进行操作,评分系统奖励同一或相似氨基酸的比对,并惩罚空位的插入,空位延伸和不相似氨基酸的比对。比较算法的评分系统包括:
i)每当插入空位时指定罚分(空位罚分),
ii)每当现有的空位用额外的位置扩大时指定罚分(延伸罚分),
iii)当比对同一的氨基酸时指定高分,以及
iv)当比对非同一的氨基酸时指定可变分数。
大多数比对程序允许修改空位罚分。然而,当使用这种序列比较软件时优选使用默认值。
对于非同一的氨基酸的比对给出的得分是根据评分矩阵(也称作取代矩阵)指定的。在所述取代矩阵中提供的得分所反映的事实是:进化过程中一个氨基酸被另一个所取代的可能性是变化的并且其取决于将被取代的氨基酸的物理/化学性质。例如,与被疏水性氨基酸取代相比,极性氨基酸被另一极性氨基酸取代的可能性更高。因此,评分矩阵将为同一的氨基酸指定最高分数,为非同一但相似的氨基酸指定较低分数,并且为非同一的不相似氨基酸指定甚至更低分数。最常用的评分矩阵是PAM矩阵(戴霍夫(Dayhoff)等人,(1978),琼斯(Jones)等人,(1992))、BLOSUM矩阵(亨尼科夫(Henikoff)和亨尼科夫(1992))和贡内特(Gonnet)矩阵(贡内特等人,(1992))。
用于进行这种比对的合适的计算机程序包括但不限于Vector NTI(英杰公司(Invitrogen Corp.))和ClustalV,ClustalW和ClustalW2程序(希金斯(Higgins)DG和夏普(Sharp)PM(1988),希金斯等人(1992),汤普森(Thompson)等人(1994),拉金(Larkin)等人(2007))。可从位于www.expasy.org的ExPASy蛋白质组服务器(Proteomics server)获得不同比对工具的选择。可以执行序列比对的软件的另一个实例是BLAST(基本局部比对搜索工具(Basic Local Alignment Search Tool)),该BLAST可从美国国家生物技术信息中心的网页获得,该网页目前可以在http://www.ncbi.nlm.nih.gov/找到,并且该BLAST首先在阿尔丘尔等人(1990)分子生物学杂志(J.Mol.Biol.)215;403-410中进行了描述。
在本发明的一个优选实施例中,该比对程序正在执行全局比对程序,其优化了全长序列的比对。在另一个优选实施例中,全局比对程序是基于尼德尔曼-翁施(Needleman-Wunsch)算法(尼德尔曼,索尔(Saul)B.;和翁施,克里斯蒂安(Christian)D.(1970),“适用于搜索两种蛋白质氨基酸序列相似性的一般方法(A general method applicable to thesearch for similarities in the amino acid sequence of two proteins)”,分子生物学杂志(Journal of Molecular Biology)48(3):443-53)。使用尼德尔曼-翁施算法执行全局比对的当前程序的实例是EMBOSS Needle和EMBOSS Stretcher程序,两者均可以在http://www.ebi.ac.uk/Tools/psa/上获得。
EMBOSS Needle使用德尔曼-翁施比对算法执行最佳全局序列比对,以沿其整个长度找到两个序列的最佳比对(包括空位)。
EMBOSS Stretcher使用德尔曼-翁施算法的修改版,该修改版允许更大序列进行全局比对。
在一个实施例中,通过全局比对程序对序列进行比对,并且通过鉴别由程序鉴别的精确匹配数目除以“比对长度”来计算序列同一性,其中比对长度是包括序列的空位和突出部分的整个比对的长度。
在另一个实施例中,全局比对程序使用德尔曼-翁施算法,并且通过鉴别由程序鉴别的精确匹配数目除以“比对长度”来计算序列同一性,其中比对长度是包括序列的空位和突出部分的整个比对的长度。
在又另一个实施例中,全局比对程序选自由以下各项组成的组:EMBOSS Needle和EMBOSS stretcher,并且通过鉴别由程序鉴别的精确匹配数目除以“比对长度”来计算序列同一性,其中比对长度是包括序列的空位和突出部分的整个比对的长度。
一旦软件生成了比对,就可以计算出相似度%和序列同一性%。该软件通常进行这种计算作为序列比较的一部分,并产生数值结果。
在一个实施例中,优选使用ClustalW软件来执行序列比对。优选地,使用以下成对比对的参数进行采用ClustalW的比对:
| 取代矩阵: | Gonnet 250 |
| 空位开放罚分: | 20 |
| 空位延伸罚分: | 0.2 |
| 空位终止罚分: | 无 |
例如,ClustalW2可以在互联网上由欧洲生物信息学研究所在EMBL-EBI网页www.ebi.ac.uk的工具-序列分析-ClustalW2下获得。目前,ClustalW2工具的确切地址是www.ebi.ac.uk/Tools/clustalw2。
在另一个实施例中,优选使用Vector NTI(英杰公司)中的程序Align X进行序列比对。在一个实施例中,Exp10可以与默认设置一起使用:
空位开放罚分:10
空位延伸罚分:0.05
空位分离罚分范围:8
在另一个实施例中,通过使用分数矩阵:blosum62mt2和VectorNTI成对比对设置来确定一个氨基酸序列与,或相对于,另一个氨基酸序列的比对

在一个实施例中,通过使用字大小为3并且BLOSUM 62作为具有转半乳糖基化活性的取代矩阵的Blast来确定一个氨基酸序列与,或相对于,另一个氨基酸序列的同一性的百分比。
多肽
在一方面,在此披露的本发明使用等于或高于3%w/w初始乳糖浓度浓度的具有如下转半乳糖基化活性:β-半乳糖苷酶活性的比率的多肽:至少0.5、至少1、至少2、至少2.5、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10、至少11、或至少12。
在一方面,在此披露的本发明使用多肽,其中糖苷水解酶催化核心具有SEQ IDNO:7的氨基酸序列。
在一方面,在此披露的本发明使用包含Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)和/或Glyco_hydro 2C(PF02836)结构域的多肽。
在一方面,在此披露了包含细菌Ig样结构域(组4)(PF07532)的多肽。
在一方面,在此披露了具有选自下组的转半乳糖基化活性的多肽,该组由以下各项组成:
g.包含与SEQ ID NO:1具有至少90%序列同一性的氨基酸序列的多肽,其中所述多肽由至多980个氨基酸残基组成,
h.包含与SEQ ID NO:2具有至少97%序列同一性的氨基酸序列的多肽,其中所述多肽由至多975个氨基酸残基组成,
i.包含与SEQ ID NO:3具有至少96.5%序列同一性的氨基酸序列的多肽,其中所述多肽由至多1300个氨基酸残基组成,
j.由多核苷酸编码的多肽,该多核苷酸在至少低严格条件下与以下各项杂交:i)包含在SEQ ID NO:9、10、11、12或13中的编码SEQ ID NO:1、2、3、4或5的多肽的核酸序列;或ii)i)的互补链,
k.由包含如下各项的多核苷酸编码的多肽:与编码SEQ ID NO:1、2、3、4或5的多肽的核苷酸序列具有至少70%同一性的核苷酸序列,或包含在SEQ ID NO:9、10、11、12或13中的编码成熟多肽的核苷酸序列,和
l.包括SEQ ID NO:1、2、3、4或5的一个或多个氨基酸残基的缺失、插入和/或保守取代的多肽。
在另一方面,在此披露的本发明使用具有选自下组的转半乳糖基化活性的多肽,该组由以下各项组成:
a.包含与SEQ ID NO:3具有至少96.5%序列同一性的氨基酸序列的多肽,其中所述多肽由至多1300个氨基酸残基组成,
b.包含与SEQ ID NO:1具有至少90%序列同一性的氨基酸序列的多肽,其中所述多肽由至多980个氨基酸残基组成,
c.由多核苷酸编码的多肽,该多核苷酸在至少低严格条件下与以下各项杂交:i)包含在SEQ ID NO:9、10、11、12或13中的编码SEQ ID NO:1、2、3、4或5的多肽的核酸序列;或ii)i)的互补链,
d.由包含如下各项的多核苷酸编码的多肽:与编码SEQ ID NO:1、2、3、4或5的多肽的核苷酸序列具有至少70%同一性的核苷酸序列,或包含在SEQ ID NO:9、10、11、12或13中的编码成熟多肽的核苷酸序列,和
e.包括SEQ ID NO:1、2、3、4或5的一个或多个氨基酸残基的缺失、插入和/或保守取代的多肽。
在一方面,在此披露的本发明使用多肽,其中氨基酸序列与SEQ ID NO:1、2、3、4或5的成熟氨基酸序列具有至少68%、70%、72%、74%、76%、78%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、或99%序列同一性。
在一方面,在此披露的本发明使用与SEQ ID NO:1的成熟氨基酸序列具有90%序列同一性的多肽。
在一方面,在此披露的本发明使用与SEQ ID NO:2的成熟氨基酸序列具有90%序列同一性的多肽。
在一方面,在此披露的本发明使用与SEQ ID NO:3的成熟氨基酸序列具有96.5%序列同一性的多肽。
在一方面,在此披露的本发明使用与SEQ ID NO:4的成熟氨基酸序列具有96.5%序列同一性的多肽。
在一方面,在此披露的本发明使用与SEQ ID NO:5的成熟氨基酸序列具有96.5%序列同一性的多肽。
在一方面,在此披露的本发明使用包括SEQ ID NO:1、2、3、4或5的氨基酸序列的或由其组成的多肽。
在一方面,在此披露的本发明使用衍生自两歧双歧杆菌的多肽。
在一方面,在此披露的本发明使用pH最佳值为6.5-7.5的多肽。
在一方面,在此披露的本发明使用温度最佳值为30-60如42-60摄氏度的多肽。
可以将对碳水化合物具有活性的多肽使用基于其底物特异性的IUBMB分类系统或CaZy指定分类为当前125个糖苷水解酶家族之一。在CaZy数据库中,指定是基于序列和结构信息,结合底物和产品的立体化学知识而进行的。
在此披露了多肽的用途,当在包括编码所述多肽的核酸序列的合适的宿主菌株(例如,枯草芽孢杆菌)中是表达产物时,该多肽是表现出转半乳糖基化活性的所述核酸序列的唯一多肽表达产物。这可以通过使用本领域技术人员已知的以下技术来评估。使待评估的样品经受SDS-PAGE,并使用适合于蛋白质定量的染料例如像伯乐标准(Bio-RadCriterion)系统进行可视化。然后使用适当的光密度扫描仪(例如像伯乐标准系统)扫描凝胶,并确保所得图像处于动态范围内。对与衍生自SEQ ID NO:8的任何变体/片段相对应的条带进行定量,并且如下计算多肽的百分比:所讨论的多肽的百分比=所讨论的多肽/(表现出转半乳糖基化活性的所有多肽的总和)*100。组合物中衍生自SEQ ID NO:8的多肽变体/片段的总数可以通过本领域技术人员已知的方法使用多克隆抗体通过蛋白质印迹检测衍生自SEQ ID NO:8的片段来确定。
在此披露的多肽包括酶内包含的至少两个分离的功能结构域。首先,如下所述,多肽应包含糖苷水解酶催化核。催化核心应属于相关糖苷水解酶家族的GH-A族。GH-A族的特征在于通过保留机制切割糖苷键,并具有基于TIM桶折叠的催化结构域(维伦加(Wierenga),2001,欧洲生化学会联合会快报(FEBS Letters),492(3),第193-8页)。催化结构域包含作为质子供体和亲核体的两个谷氨酸残基,这两个谷氨酸残基源于桶结构域的链4和7(詹金斯(Jenkins),1995,欧洲生化学会联合会快报,362(3),第281-5页)。TIM桶的总体结构是由8个β链和8个α-螺旋组成的(β/α)8折叠。在一方面,在此披露的糖苷水解酶催化核心属于糖苷水解酶家族GH-2和-35之一,这些糖苷水解酶家族GH-2和-35都是属于GH-A族的TIM-桶酶。在另一方面,糖苷水解酶催化核心属于家族GH-2或GH-35。在另一方面,糖苷水解酶催化核心属于家族GH-2。一个共同特点是这些酶是所谓的保留酶,使得底物的立体化学在产品中是保守的(亨利萨特(Henrissat),1997,结构生物学当前观点(Curr OpinStruct Biol),7(5),637-44)。
在一方面,在此披露的多肽对具有β(1→4)构象的碳水化合物键具有活性。这有效地将该酶归入β-半乳糖苷酶的IUBMB EC 3.2.1.23类。该活性可以但不限于通过利用合成底物如对硝基苯酚-β-D-吡喃半乳糖苷(PNPG)、邻硝基苯酚-β-D-吡喃半乳糖苷(ONPG)或具有显色糖苷配基的β-D-吡喃半乳糖苷(XGal)来确定。作为确定酶是否属于β-半乳糖苷酶的EC 3.2.1.23类的替代方法是与底物如乳糖一起孵育,并通过方法如酶测定、HPLC、TLC或本领域技术人员已知的其他方法测量葡萄糖的释放。
为了预测多肽的功能实体,可以应用若干个可用的公共储存库,例如像Pfam(核酸研究(Nucl.Acids Res.)(2010)38(增刊1):D211-D222.doi:10.1093/nar/gkp985)和Interpro(核酸研究(2009)37(增刊1):D211-D215.doi:10.1093/nar/gkn785)。应当指出,当进行这种分析时,应该在从公共储存库数据库中获得的多肽的全长序列上进行分析。
在另一方面,提供了包含选自以下的一种或多种Pfam结构域的多肽:Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)、Glyco_hydro 2C(PF02836)和细菌Ig样结构域(组4)(PF07532)。在又另一方面,提供包含Pfam结构域Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)、Glyco_hydro 2C(PF02836)和细菌Ig样结构域(组4)(PF07532)的多肽。在又另一方面,使用包含构成多肽催化结构域的Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)和Glyco_hydro 2C(PF02836)结构域的多肽。
在另一方面,使用如在此披露的并具有如下转半乳糖基化活性:β-半乳糖苷酶活性比率的多肽,如在100ppm浓度下,在乳基测定中,在37℃和5w/w%乳糖下,在15、30或180如180分钟反应后所测量的,该比率为至少1、至少2.5、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10、至少11、或至少12。在另一方面,该多肽衍生自两歧双歧杆菌。
在一方面,在此所披露的一种或多种多肽具有转半乳糖基化活性,这样使得如在100ppm的浓度下,在乳基测定中,在37℃和5w/w%乳糖下,在15、30或180如180分钟反应后所测量的,超过20%、超过30%、超过40%、高达50%的初始乳糖发生了转半乳糖基化。
在另一方面,在此披露的一种或多种多肽具有β-半乳糖苷酶活性,这样使得如在100ppm的浓度下,在乳基测定中,在37℃和5w/w%乳糖下,在15、30或180如180分钟反应后所测量的,小于80%、小于70%、小于60%、小于50%、小于40%、小于30%、小于20%的乳糖已被水解。
在一方面,按照方法4中规定的,在对应于2.13LAU的100ppm的浓度下测量β-半乳糖苷酶活性和/或转半乳糖基化活性。通常,酶的活性单位可以根据WO 2003/186286中披露为方法4的测定来测量,并在以下实例部分4中重现。
在另一方面,在此披露的一种或多种多肽具有以下特征中的一个或多个:
a)如在100ppm浓度下,在乳基测定中,在37℃和5w/w%乳糖下,在15、30或180如180分钟反应后所测量的,为至少1、至少2.5、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10、至少11、或至少12的转半乳糖基化活性:β-半乳糖苷酶活性比率,和/或
b)具有转半乳糖基化活性,这样使得如在100ppm的浓度下,在乳基测定中,在37℃和5w/w%乳糖下,在15、30或180如180分钟反应后所测量的,超过20%、超过30%、超过40%、以及高达50%的初始乳糖已经发生了转半乳糖基化。
在一方面,提供了包含与SEQ ID NO:3具有至少96.5%序列同一性的氨基酸序列的多肽,其中所述多肽由至多1300个氨基酸残基组成。在另一方面,提供了包含与SEQ IDNO:1具有至少90%序列同一性的氨基酸序列的多肽,如其中所述序列同一性是至少95%,例如像至少96%、至少97%、至少98%、至少99%或至少100%序列同一性,并且其中所述多肽由至多980个氨基酸残基组成。在另一方面,提供了包含与SEQ ID NO:1具有至少90%序列同一性的氨基酸序列的多肽,其中所述多肽由至多980个氨基酸残基组成。在又另一方面,提供了一种多肽,其中所述多肽与SEQ ID NO:1具有至少90%序列同一性,如其中所述多肽与SEQ ID NO:1具有至少90%,例如像至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、或至少99%序列同一性。在另一方面,提供了与SEQID NO:2具有至少96,5%序列同一性的多肽,如其中所述多肽与SEQ ID NO:2具有至少97%,例如像至少98%或至少99%序列同一性。在一方面,提供了在此披露的多肽,这些多肽由至多975个氨基酸残基,例如像,至多970个氨基酸残基、如至多950个氨基酸残基、如至多940个氨基酸残基、至多930个氨基酸残基、至多920个氨基酸残基、至多910个氨基酸残基、至多900个氨基酸残基、至多895个氨基酸残基或至多890个氨基酸残基组成。在一方面,提供了由887或965个氨基酸残基组成的特定的多肽。在一方面,提供了一种多肽,该多肽包含与SEQ ID NO:2具有至少97%序列同一性的氨基酸序列,如其中所述序列同一性为至少98%,例如像至少99%或至少100%序列同一性,其中所述多肽由至多975个氨基酸残基,例如像,至多970个或至少965个氨基酸残基组成。在一方面,使用包含与SEQ ID NO:2具有至少97%序列同一性的氨基酸序列的多肽,其中所述多肽由至多975个氨基酸残基组成。
在另一优选的方面,提供了包括SEQ ID NO:1、2、3、4或5的多肽。在又一优选方面,使用由SEQ ID NO:1、2、3、4或5的氨基酸序列组成的多肽,特别是由SEQ ID NO:1或2的氨基酸序列组成的多肽。
在另一方面,使用包含与SEQ ID NO:3具有至少96.5%序列同一性的氨基酸序列的多肽,如其中所述序列同一性是至少97%,例如像至少98%、至少99或至少100%序列同一性,其中所述多肽由至多1300个氨基酸残基组成。
在另一方面,提供一种多肽,其中所述多肽与SEQ ID NO:5具有至少98.5%,如至少99%或至少99.5%序列同一性。在一方面,这样的多肽由至多1290个氨基酸残基,例如像,至多1280、至多1270、至多1260、至多1250、至多1240、至多1230、至多1220或至多1215个氨基酸残基组成。在一优选方面,使用由1211个氨基酸残基组成的多肽。
在另一方面,提供一种多肽,其中所述多肽与SEQ ID NO:4具有至少96%,如至少97%,例如像至少98%或至少99%序列同一性。在一方面,使用一种多肽,该多肽由至多1210个氨基酸残基,例如像至多1200、至多1190、至多1180、至多1170、至多1160、至多1150或至多1145个氨基酸残基,如1142个氨基酸残基组成。
在另一方面,提供一种多肽,其中所述多肽与SEQ ID NO:3具有至少96.5%,如至少97%,例如像至少98%或至少99%序列同一性。在一方面,提供了一种多肽,该多肽由至多1130个氨基酸残基,例如像至多1120、至多1110、至多1100、至多1090、至多1080、至多1070、至多1060、至多1050、至多1055或至多1040个氨基酸残基组成。在一优选方面,使用由1038个氨基酸残基组成的多肽。
在另一方面,在此披露的多肽具有高于100%,如高于150%,175%或200%的转半乳糖基化活性比率。
蛋白质通常由一个或多个功能区域(通常称为结构域)组成。不同结构域在不同蛋白质的不同组合中的存在产生了在自然界中发现的蛋白质的多样性谱。描述结构域的一种方式是借助于Pfam数据库,该Pfam数据库是如以下描述的蛋白质结构域家族的大集合:“Pfam蛋白家族数据库”:R.D.芬恩,J.米斯特里,J.塔特,P.柯吉尔,A.赫格尔,J.E.普林顿,O.L.加文,P.古恩赛卡伦,G.赛利克,K.福斯隆德,L.霍尔姆,E.L.松哈默,S.R.艾迪,A.贝特曼,核酸研究(2010),数据库专辑38:D211-222。每个家族由多个序列比对和隐马尔可夫模型(HMM)表示。在此提供的一种或多种多肽优选包含Pfam结构域Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)、Glyco_hydro 2C(PF02836)和细菌Ig样结构域(组4)(PF07532)中的一种或多种。在一方面,在此提供的一种或多种多肽包含Glyco_hydro2N(PF02837)、Glyco_hydro(PF00703)、Glyco_hydro 2C(PF02836)和细菌Ig样结构域(组4)(PF07532)。
在一方面,在此使用的多肽在4-9,如5-8、如5.5-7.5、如6.5-7.5的pH范围内具有有益的转半乳糖基化活性。
本发明涵盖与在此定义的一种或多种氨基酸序列或与具有如在此定义的具体特性的多肽具有一定程度的序列同一性或序列同源性的多肽的用途。具体地而言,本发明涵盖与以下定义的SEQ ID NO:1、2、3、4或5中任一个或其同系物具有一定程度的序列同一性的肽的用途。
同源氨基酸序列和/或核苷酸序列应提供和/或编码一种多肽,与SEQ ID NO:1、2、3、4或5的多肽相比,该多肽保留了功能性转半乳糖基化活性和/或增强了转半乳糖基化活性。
在上下文中,同源序列被认为包括一种氨基酸序列,该氨基酸序列可以与主题序列具有至少66%、70%、75%、78%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%或至少99%同一性。通常,同系物将包括与主题氨基酸序列相同的活性位点等。尽管同源性也可以根据相似性(即具有相似化学特性/功能的氨基酸残基)来考虑,但在本发明的上下文中,优选的是根据序列同一性来表示同源性。
因此,本发明还涵盖如在此定义的蛋白质或多肽的任何氨基酸序列的变体、同系物和衍生物的用途,特别是以下定义的SEQ ID NO:1、2、3、4或5的那些。
这些序列,特别是以下定义的SEQ ID NO:1、2、3、4或5的变体、同系物和衍生物,还可以具有氨基酸残基的缺失、插入或取代,这产生沉默变化并且形成功能上等效的物质。可以基于残基的极性、电荷、溶解度、疏水性、亲水性和/或两亲性性质的相似性进行有意的氨基酸取代,只要保留底物的次要结合活性即可。例如,带负电荷的氨基酸包括天冬氨酸和谷氨酸;带正电荷的氨基酸包括赖氨酸和精氨酸;并且具有不带电极性头部基团(该基团具有类似的亲水性值)的氨基酸包括亮氨酸、异亮氨酸、缬氨酸、甘氨酸、丙氨酸、天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸、苯丙氨酸和酪氨酸。
本发明还涵盖了可能出现的保守取代(取代和置换在此均用于意指现有氨基酸残基与替代残基的交换),即对等取代,如碱性对碱性、酸性对酸性、极性对极性等。也可以发生非保守取代,即从一类残基到另一类残基或者可替代地涉及包括非天然氨基酸如鸟氨酸(在下文中称为Z)、二氨基丁酸鸟氨酸(在下文中称为B)、正亮氨酸鸟氨酸(在下文中称为O)、吡啶基丙氨酸、噻吩丙氨酸、萘基丙氨酸以及苯基甘氨酸。
可以进行的保守取代是例如在如下组内:碱性氨基酸(精氨酸、赖氨酸和组氨酸)、酸性氨基酸(谷氨酸和天冬氨酸)、脂肪族氨基酸(丙氨酸、缬氨酸、亮氨酸、异亮氨酸)、极性氨基酸(谷氨酰胺、天冬酰胺、丝氨酸、苏氨酸)、芳香族氨基酸(苯丙氨酸、色氨酸和酪氨酸)、羟基氨基酸(丝氨酸、苏氨酸)、大氨基酸(苯丙氨酸和色氨酸)和小氨基酸(甘氨酸、丙氨酸)。
在一方面,本发明中使用的多肽序列处于纯化形式。
在一方面,用于本发明的多肽或蛋白质处于分离形式。
在一方面,本发明的多肽是重组生产的。
变体多肽包含与SEQ ID NO:1或2具有一定百分比,例如至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的多肽。
变体多肽包含与SEQ ID NO:3、4或5具有一定百分比,例如至少96%、97%、98%或99%序列同一性的多肽。
在一方面,在此使用的多肽包括与由编码转半乳糖基酶的核苷酸序列编码的、包含在两歧双歧杆菌DSM20215中、在此示为SEQ ID NO:22的成熟多肽的氨基酸序列具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、或99%序列同一性的氨基酸序列。根据SEQ ID NO:1、2、3、4或5讨论的与序列同一性和功能有关的所有考虑和限制比照适用于这些多肽和核苷酸的序列同一性和官能度。
在一方面,主题氨基酸序列是SEQ ID NO:1、2、3、4或5,并且主题核苷酸序列优选地是SEQ ID NO:9、10、11、12或13。
在一方面,多肽是从SEQ ID NO:1、2、3、4或5的多肽的氨基和/或羧基末端缺失的一个或多个(若干个)氨基酸的片段;其中该片段具有转半乳糖基化活性。
在一方面,片段包含至少500、550、600、650、700、750、800、850、900、950或1000个氨基酸残基。
在另一方面,多肽变体的长度为500至1300个氨基酸残基。在另一方面,多肽变体的长度为600至1300个氨基酸。在另一方面,多肽变体的长度为700至1300个氨基酸。在另一方面,多肽变体的长度为800至1300个氨基酸。在另一方面,多肽变体的长度为800至1300个氨基酸。
为了评估变体在宿主细胞中的表达,测定可以测量所表达的蛋白质、相应的mRNA或β-半乳糖苷酶活性。例如,合适的测定包括使用适当标记的杂交探针的RNA印迹法和DNA印迹法、RT-PCR(逆转录酶聚合酶链式反应)和原位杂交。合适的测定还包括测量样品中的活性。该变体的活性的合适的测定包括但不限于基于ONPG的测定或确定例如像在此的方法和实例中所描述的反应混合物中的葡萄糖。
SEQ ID NO:1、2、3、4或5的多肽变体
在一方面,使用相对于SEQ ID NO:1、2、3、4或5在一个或多个位置处具有取代的SEQ ID NO:1、2、3、4或5的变体,该取代影响改变的特性,如改进的转半乳糖基化。在本文件中为了方便起见,这样的变体多肽又称为“变体多肽”、“多肽变体”或“变体”。在一方面,与SEQ ID NO:1、2、3、4或5的多肽相比,在此定义的多肽具有改进的转半乳糖基化活性。在另一方面,与SEQ ID NO:1、2、3、4或5的多肽相比,如在此所定义的多肽具有改进的反应速度。
在此使用的多肽和变体多肽包括转半乳糖基化活性。
在一方面,在如高于3%w/w初始乳糖浓度的浓度下30min反应后,转半乳糖基化活性:β-半乳糖苷酶活性的比率为至少0.5,如至少1,如至少1.5,或如至少2。
在一方面,在如高于3%w/w初始乳糖浓度的浓度下30min反应后,转半乳糖基化活性:β-半乳糖苷酶活性的比率为至少2.5、如至少3、如至少4、如至少5、如至少6、如至少7、如至少8、如至少9、如至少10、如至少11、或如至少12。
在一方面,如在此定义的多肽和变体可衍生自微生物来源,特别是可衍生自丝状真菌或酵母,或可衍生自细菌。该酶可以例如衍生自如下各项的菌株:伞菌属,例如双孢蘑菇;Ascovaginospora;曲霉属,例如黑曲霉、泡盛曲霉、臭曲霉、日本曲霉、米曲霉;念珠菌属;毛壳菌属;Chaetotomastia;网柄菌属,例如盘基网柄菌;克鲁维酵母菌属,例如脆壁克鲁维酵母、乳酸克鲁维酵母;毛霉属,例如爪哇毛霉、高大毛霉、细小毛霉;脉孢菌属,例如粗糙脉孢菌;根毛霉属,例如微小根毛霉;根霉属,例如少根根霉、日本根霉、匍枝根霉;核盘霉属,例如白腐核盘霉;圆酵母属;球拟酵母属;毛癣菌属,例如红色毛癣菌;维氏核盘菌属,例如大豆维氏核盘菌;芽孢杆菌属,例如凝结芽孢杆菌、环状芽孢杆菌、巨大芽孢杆菌、诺瓦利斯芽孢杆菌(B.novalis)、枯草芽孢杆菌、短小芽孢杆菌、嗜热脂肪芽孢杆菌、苏云金芽孢杆菌;双歧杆菌属,例如长双歧杆菌、两歧双歧杆菌、动物双歧杆菌;金黄杆菌属;柠檬酸杆菌属,例如弗氏柠檬酸杆菌;梭菌属,例如产气荚膜梭菌;色二孢属,例如棉色二孢;肠杆菌属,例如产气肠杆菌,阴沟肠杆菌;爱德华菌属,迟钝爱德华菌;欧文氏菌属,例如草生欧文氏菌;埃希氏菌属,例如大肠杆菌;克雷伯氏菌属,例如肺炎克雷伯氏菌;多球菌属(Miriococcum);漆斑菌属;毛霉属;脉孢菌属,例如粗糙脉孢菌;变形杆菌属,例如普通变形杆菌;普罗维登斯菌属,例如斯氏普罗威登斯菌;密孔菌属,例如朱红密孔菌、血红密孔菌;瘤胃球菌属,例如扭链瘤胃球菌;沙门氏菌属,例如鼠伤寒沙门菌;沙雷氏菌属,例如液化沙雷氏菌、粘质沙雷氏菌;志贺菌属,例如弗氏志贺菌;链霉菌属,例如抗生链霉菌、栗色球孢链霉菌、紫红链霉菌;栓菌属;木霉属,例如里氏木霉、绿色木霉;耶尔森氏菌属,例如小肠结肠炎耶尔森氏菌。
提供包括如在此定义的多肽或变体多肽的分离的和/或纯化的多肽。在一个实施例中,变体多肽是多肽(SEQ ID NO:1、2、3、4或5)的成熟形式。在一方面,这些变体包括C端结构域。
在一方面,如在此定义的变体多肽包括变体,其中相对于SEQ ID NO:1、2、3、4或5已经添加或缺失了在一个和约25个之间的氨基酸残基。在一方面,如在此定义的变体多肽包括变体,其中相对于SEQ ID NO:1、2、3、4或5已经取代、添加或缺失了在一个和25个之间的氨基酸残基。在一方面,该变体具有SEQ ID NO:1、2、3、4或5的氨基酸序列,其中已经取代了在一个和约25个之间任何数目的氨基酸。在另一方面,该变体具有SEQ ID NO:1、2、3、4或5的氨基酸序列,其中已经取代了在三个和十二个之间任何数目的氨基酸。在另一方面,该变体具有SEQ ID NO:1、2、3、4或5的氨基酸序列,其中已经取代了在五个和九个之间任何数目的氨基酸。
在一方面,SEQ ID NO:1、2、3、4或5中的至少两个,在另一方面,至少三个,并且在又另一方面,至少五个氨基酸已经被取代。
在一方面,在此披露的一个或多个多肽具有1、2、3、4或5的序列。
在一方面,在此披露的一个或多个多肽具有SEQ ID NO:1、2、3、4或5的序列,其中N末端中的10,如9、如8、如7、如6、如5、如4、如3、如2、如1个氨基酸被取代和/或缺失。
其酶和酶变体可以通过以下表征:其核酸和初级多肽序列、三维结构建模和/或其比活度。如在此所定义的多肽或多肽变体的另外的特征包括例如稳定性、pH范围、氧化稳定性和热稳定性。可以使用本领域技术人员已知的标准测定来评估表达水平和酶活性。在另一方面,变体表现出相对于具有SEQ ID NO:1、2、3、4或5的多肽的改进的性能特征,如在高温,例如,65℃-85℃下改进的稳定性。
提供如在此定义的具有如下氨基酸序列的多肽变体,该氨基酸序列与SEQ ID NO:1、2、3、4或5的多肽具有至少约66%、68%、70%、72%、74%、78%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、100%同一性。
核苷酸
在一方面,本发明使用如上所述的具有转半乳糖基化活性的分离的多肽,该多肽由如下多核苷酸编码,这些多核苷酸在非常低的严格条件,优选地低严格条件,更优选地中严格条件,更优选地中-高严格条件,甚至更优选地高严格条件,以及最优选地非常高严格条件下与i)包含在SEQ ID NO:9、10、11、12或13中的编码SEQ ID NO:1、2、3、4或5的成熟多肽的核酸序列;ii)i)的cDNA序列;或iii)i)或ii)的互补链杂交(J.萨姆布鲁克,E.F.弗里奇(Fritsch),和T.马尼亚蒂斯(Maniatis),1989,分子克隆,实验室手册(MolecularCloning,A Laboratory Manual),第2版,冷泉港,纽约州)。SEQ ID NO:9、10、11、12或13的子序列包含至少100个连续核苷酸或优选至少200个连续核苷酸。此外,子序列可以编码具有乳糖酶活性的多肽片段。
可以使用SEQ ID NO:9、10、11、12或13的核苷酸序列或其子序列、连同SEQ ID NO:1、2、3、4或5的氨基酸序列或其片段来设计核酸探针,以根据本领域众所周知的方法来鉴定并克隆对来自不同属或物种的菌株的具有转半乳糖基酶活性的多肽进行编码的DNA。具体地说,这类探针可以用于按照标准DNA印迹程序与感兴趣的属或物种的基因组或cDNA杂交,以便鉴定并分离其中的相应基因。这些探针可以比完整序列短得多,但是长度应当是至少14个、优选至少25个、更优选至少35个、且最优选至少70个核苷酸。然而,优选的是核酸探针的长度是至少100个核苷酸。例如,核酸探针的长度可以是至少200个核苷酸,优选至少300个核苷酸,更优选至少400个核苷酸,或最优选至少500个核苷酸。可使用甚至更长的探针,例如长度为至少600个核苷酸,至少优选至少700个核苷酸,更优选至少800个核苷酸,或最优选至少900个核苷酸的核酸探针。DNA和RNA探针都可以使用。通常将探针标记以探测相应的基因(例如,用32P、3H、35S、生物素或抗生物素蛋白标记)。这类探针涵盖于本发明中。
因此,可以针对与以上所描述的探针杂交并且编码具有乳糖酶活性的多肽的DNA对由这类其他生物体制备的基因组DNA文库进行筛选。可通过琼脂糖或聚丙烯酰胺凝胶电泳、或其他分离技术分离来自这类其他生物的基因组或其他DNA。可以将来自文库的DNA或分离的DNA转移并且固定在硝酸纤维素(nitrocellulose)或其他适合的载体材料上。为鉴定与SEQ ID NO:9、10、11、12或13或其子序列同源的克隆或DNA,在DNA印迹法中使用载体材料。
出于本发明的目的,杂交表明该核苷酸序列在非常低到非常高严格条件下与一种被标记的核酸探针杂交,该探针对应于SEQ ID NO:9、10、11、12或13中所示的核苷酸序列、其互补链、或其子序列。可以使用X射线胶片检测在这些条件下与核酸探针杂交的分子。
该核酸探针可以是SEQ ID NO:9、10、11、12或13的成熟多肽编码区域。
对于至少100个核苷酸长度的长探针,非常低至非常高严格性条件被定义为最佳地按照标准DNA印迹程序,在42℃下在5X SSPE、0.3%SDS、200g/ml剪切和变性的鲑鱼精子DNA中,以及对于非常低和低严格性在25%甲酰胺中,对于中和中-高严格性在35%甲酰胺中,或对于高和非常高严格性在50%甲酰胺中预杂交和杂交12至24小时。
对于长度为至少100个核苷酸的长探针而言,载体材料最终使用2X SSC、0.2%SDS,优选至少在45℃下(非常低严格性),更优选至少在50℃下(低严格性),更优选至少在55℃下(中严格性),更优选至少在60℃下(中-高严格性),甚至更优选至少在65℃下(高严格性),并且最优选至少在70℃下(非常高严格性)洗涤三次,每次15分钟。
在一个具体实施例中,洗涤使用0.2X SSC、0.2%SDS,优选至少在45℃下(非常低严格性),更优选至少在50℃下(低严格性),更优选至少在55℃下(中严格性),更优选至少在60℃下(中高严格性),甚至更优选至少在65℃下(高严格性),并且最优选至少在70℃下(非常高严格性)进行。在另一个具体实施例中,洗涤使用0.1X SSC、0.2%SDS,优选至少在45℃下(非常低严格性),更优选至少在50℃下(低严格性),更优选至少在55℃下(中严格性),更优选至少在60℃下(中高严格性),甚至更优选至少在65℃下(高严格性),并且最优选至少在70℃下(非常高严格性)进行。
对于长度为约15个核苷酸至约70个核苷酸的短探针而言,严格条件被定义为根据标准DNA印迹程序,在比使用根据博尔顿(Bolton)和麦卡锡(McCarthy)(1962,美国国家科学院院刊(Proceedings of the National Academy of Sciences USA)48:1390)的计算计算的Tm低约5℃至约10℃下,在0.9M NaCl、0.09M Tris-HCl(pH 7.6)、6mM EDTA、0.5%NP-40、1X登哈特氏溶液(Denhardt's solution)、1mM焦磷酸钠、1mM磷酸二氢钠、0.1mM ATP、以及每ml 0.2mg的酵母RNA中预杂交、杂交及杂交后洗涤。
对于长度为约15个核苷酸至约70个核苷酸的短探针而言,将载体材料在比计算的Tm低5℃至10℃下,在6X SCC加0.1%SDS中洗涤一次,持续15分钟,并且使用6X SSC洗涤两次,每次15分钟。
在包含盐的杂交条件下,有效Tm控制了用于成功杂交的探针和滤器结合的DNA之间所需的同一性程度。可以使用以下公式确定有效Tm,以确定两种DNA在各种严格条件下杂交所需的同一性程度。
有效Tm=81.5±16.6(log M[Na+])+0.41(G+C%)-0.72(甲酰胺%)
(参见www.ndsu.nodak.edu/instruct/mcclean/plsc731/dna/dna6.htm)
SEQ ID NO:10的G+C含量为42%,并且SEQ ID NO:11的G+C含量为44%。对于中严格性,甲酰胺为35%,并且5X SSPE的Na+浓度为0.75M。
另一个相关关系是两个DNA的1%错配将Tm降低1.4℃。为了确定两个DNA在42℃的中严格条件下杂交所需的同一性程度,使用下列公式:
同源性%=100-[(有效Tm-杂交温度)/1.4]
(参见www.ndsu.nodak.edu/instruct/mcclean/plsc731/dna/dna6.htm)
变体核酸包括与编码SEQ ID NO:1、2、3、4或5的核酸具有一定百分比,例如60%、65%、70%、75%、80%、85%、90%、95%、或99%序列同一性的多核苷酸。在一方面,提供了能够编码如在此披露的多肽的核酸。在另一方面,在此披露的核酸具有与SEQ ID NO:9、10、11、12或13具有至少60%,如至少65%,如至少70%,如至少75%,如至少80%,如至少85%,如至少90%,如至少95%,如至少99%同一性的核酸序列。
可以使用包括如在此所述的核酸的质粒。
可以使用包括在此所述的核酸或能够表达如在此所述的多肽的表达载体。
提供了与编码本文中所定义的任意多肽变体的核酸互补的核酸。另外,提供了能够与补体杂交的核酸。在另一个实施例中,用于本文所述方法和组合物的序列是合成序列。它包括但不限于:用最佳密码子使用制备的用于在宿主生物体如酵母中表达的序列。
根据本领域众所周知的程序,如在此提供的多肽变体可以经合成或通过在宿主细胞中重组表达来产生。在一方面,在此披露的一种或多种多肽是一种或多种重组多肽。任选地将如在此定义的所表达的多肽变体在使用前分离。
在另一个实施例中,如在此定义的多肽变体在表达后进行纯化。例如,在美国专利号7,371,552、7,166,453、6,890,572、和6,667,065;以及美国公开申请号2007/0141693、2007/0072270、2007/0020731、2007/0020727、2006/0073583、2006/0019347、2006/0018997、2006/0008890、2006/0008888、和2005/0137111中描述了多肽变体的遗传修饰和重组生产方法。这些披露的相关教导通过引用并入本文,这些相关教导包括编码多肽的多核苷酸序列、引物、载体、选择方法、宿主细胞、所表达的多肽变体的纯化和重构以及如在此定义的多肽变体的表征,包括有用的缓冲液、pH范围、Ca2+浓度、底物浓度和用于酶法测定的酶浓度。
提供编码SEQ ID NO:1、2、3、4或5的蛋白质的核酸序列或与编码SEQ ID NO:1、2、3、4或5的蛋白质的核酸具有至少约66%、68%、70%、72%、74%、78%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的核酸序列。在一个实施例中,核酸序列与SEQ ID NO:9、10、11、12或13的核酸具有至少约60%、66%、68%、70%、72%、74%、78%、80%、85%、90%、95%、96%、97%、98%或99%序列同一性。
载体
在一方面,本发明使用包括多核苷酸的载体。在一方面,细菌细胞包括载体。在一些实施例中,将包括编码变体的核酸的DNA构建体在包括与编码序列可操作地连接的调节序列的表达载体中转移到宿主细胞。载体可以是可以整合到真菌宿主细胞基因组中并且当被引入宿主细胞时进行复制的任何载体。密苏里大学FGSC菌株目录列出合适的载体。萨姆布鲁克等人,分子克隆:实验室手册,第3版,冷泉港实验室出版社,冷泉港,纽约州(2001);班尼特(Bennett)等人,真菌中更多的基因操作(More Gene Manipulations in Fungi),学术出版社,圣迭哥(1991),第396-428页;和美国专利号5,874,276中提供了合适的表达和/或整合载体的另外的实例。示例性载体包括pFB6、pBR322、PUC18、pUC100和pENTR/D、pDONTM201、pDONRTM221、pENTRTM、 3Z以及
3Z以及 4Z。用于细菌细胞的示例包括允许在大肠杆菌中复制的pBR322和pUC19,以及例如允许在芽孢杆菌属中复制的pE194。
4Z。用于细菌细胞的示例包括允许在大肠杆菌中复制的pBR322和pUC19,以及例如允许在芽孢杆菌属中复制的pE194。
在一些实施例中,编码变体的核酸可操作地连接到合适的启动子,其允许在宿主细胞中转录。启动子可以衍生自编码与宿主细胞同源或异源的蛋白质的基因。启动子的合适的非限制性实例包括cbh1、cbh2、egl1、和egl2启动子。在一个实施例中,该启动子是对宿主细胞天然的启动子。例如,当宿主为嗜糖假单胞菌时,启动子为天然的嗜糖假单胞菌启动子。“诱导型启动子”是指在环境调节或发育调节下具有活性的启动子。在另一个实施例中,该启动子是对宿主细胞异源的启动子。
在一些实施例中,将编码序列可操作地连接到编码信号序列的DNA序列上。在另一方面,代表性的信号肽是SEQ ID NO:27。代表性的信号肽是SEQ ID NO:9,该SEQ ID NO:9是枯草芽孢杆菌aprE前体的天然信号序列。在其他实施例中,将编码信号序列的DNA用编码来自其他细胞外枯草芽孢杆菌前体的信号序列的核苷酸序列替代。在一个实施例中,编码信号序列的多核苷酸紧邻编码多肽的多核苷酸的上游并在框内。信号序列可以选自与宿主细胞相同的物种。
在另外的实施例中,包扩待引入真菌宿主细胞的DNA构建体或载体的信号序列和启动子序列衍生自相同的来源。在一些实施例中,表达载体还包括终止序列。在一个实施例中,终止序列和启动子序列衍生自相同的来源。在另一个实施例中,终止序列与宿主细胞是同源的。
在一些实施例中,表达载体包括选可选择的标志物。合适的可选择的标志物的实例包括赋予抗微生物剂抗性的那些,例如潮霉素或腐草霉素。营养选择性标志物也是合适的,并且包括amdS、argB和pyr4。在一个实施例中,选择性标志物是编码乙酰胺酶的amdS基因;它允许转化的细胞在作为氮源的乙酰胺上生长。在凯利(Kelley)等人,欧洲分子生物学学会杂志(EMBO J.)4:475-479(1985)和彭蒂拉(Penttila)等人,基因(Gene)61:155-164(1987)中描述了构巢曲霉amdS基因作为选择性标志物的用途。
包含具有编码变体的多核苷酸的DNA构建体的合适的表达载体可以是能够在给定宿主生物体中自主复制的或整合到宿主DNA中的任何载体。在一些实施例中,表达载体是质粒。在一些实施例中,考虑了两种类型的表达载体,用于获得基因表达。第一表达载体包括DNA序列,其中启动子、编码区和终止子全部来源于待表达基因。在一些实施例中,在其自身的转录和翻译调节序列的控制下,通过删除不想要的DNA序列以留下待表达的结构域而获得基因截短。预先组装第二种类型表达载体,并且包含高水平转录所需的序列和可选择的标志物。在一些实施例中,将基因或其部分的编码区插入到该通用表达载体中,这样使得它处于表达构建体启动子和终止子序列的转录控制下。在一些实施例中,将基因或其部分插入强cbh1启动子的下游。
表达宿主/宿主细胞
在另一方面,使用包括如在此所述的质粒或如在此所述的表达载体的,优选经其转化的,宿主细胞。
在另一方面,使用能够表达如在此所述的多肽的细胞。
在一方面,如在此所述的宿主细胞或如在此所述的细胞是细菌、真菌或酵母细胞。
在另一方面,宿主细胞选自由以下各项组成的组:瘤胃球菌属、双歧杆菌属、乳球菌属、乳杆菌属、链球菌属、明串珠菌属、埃希氏杆菌属、芽孢杆菌属、链霉菌属、酵母菌属、克鲁维酵母菌属、念珠菌属、圆酵母属、球拟酵母属和曲霉属。
在另一方面,该宿主细胞选自由以下各项组成的组:汉逊瘤胃球菌(Ruminococcushansenii)、短双岐杆菌、长双歧杆菌、婴儿双岐杆菌、两歧双歧杆菌和乳酸乳球菌。
在另一个实施例中,合适的宿主细胞包括选自下组的革兰氏阳性细菌,该组由以下各项组成:枯草芽孢杆菌、地衣芽孢杆菌、迟缓芽孢杆菌、短芽孢杆菌、嗜热芽孢杆菌、嗜碱芽孢杆菌、解淀粉芽孢杆菌、凝结芽孢杆菌、环状芽孢杆菌、灿烂芽孢杆菌、苏云金芽孢杆菌、变铅青链霉菌、或鼠灰链霉菌;或革兰氏阴性细菌,其中所述革兰氏阴性细菌为大肠杆菌或假单胞菌属物种。在一方面,宿主细胞是枯草芽孢杆菌或地衣芽孢杆菌。在一个实施例中,宿主细胞是枯草芽孢杆菌,并且所表达的蛋白质被工程化以包括枯草芽孢杆菌信号序列,如以下进一步详细阐述的。
在一些实施例中,宿主细胞被遗传工程化以表达如在此定义的具有如下氨基酸序列的多肽变体,该氨基酸序列与SEQ ID NO:1、2、3、4或5的多肽具有至少约66%、68%、70%、72%、74%、78%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、100%同一性。在一些实施例中,编码如在此定义的多肽变体的多核苷酸将具有编码SEQ ID NO:1、2、3、4或5的蛋白质的核酸序列或与编码SEQ ID NO:1、2、3、4或5的蛋白质的核酸具有至少约66%、68%、70%、72%、74%、78%、80%、85%、90%、95%、96%、97%、98%、99%或100%序列同一性的核酸序列。在一个实施例中,核酸序列与SEQ ID NO:9、10、11、12或13的核酸具有至少约60%、66%、68%、70%、72%、74%、78%、80%、85%、90%、95%、96%、97%、98%或99%序列同一性。
诱变
可以通过使用重组遗传操作技术的基因工程、使宿主经受诱变、或两者来获得纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型宿主细胞或其中这些酶基本上是无活性的宿主细胞。编码本发明的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶的基因的修饰或失活可能是由于使亲本细胞经受诱变和选择突变细胞造成的,在突变细胞中与亲本细胞相比,表达这些酶的能力已经降低。诱变可能是特异性的或随机的,可以通过例如使用适合的物理或化学诱变剂进行,通过使用适合的寡核苷酸进行,或通过将所述DNA序列经受PCR产生的诱变来进行。此外,诱变可通过使用这些诱变剂的任意组合来进行。
适用于本发明目的的物理或化学诱变剂的实例包括γ或紫外线(UV)照射、羟胺、N-甲基-N’-硝基-N-亚硝基胍(MNNG)、邻甲基羟胺、亚硝酸、乙基甲磺酸(EMS)、亚硫酸氢钠、甲酸和核苷酸类似物。当使用这些试剂时,通常通过如下方法来进行诱变:在合适的条件下在选择的诱变剂的存在下孵育待诱变的亲本细胞,并选择表现出基因表达降低的突变细胞。可替代地,可以使用遗传技术如杂交或交配、和原生质体融合或任何其他经典遗传技术来诱导遗传多样性来分离这些菌株。随后可以通过监测酶的表达水平来选择所获得的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型菌株。任选地,随后通过测量宿主细胞中待表达的给定的感兴趣基因的表达水平来选择纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型菌株。具有降低的酶活性的菌株的选择可以通过直接测量培养肉汤、培养上清液、透化细胞或细胞裂解物中的酶活性来进行。
重组DNA技术
可替代地,可以使用重组DNA技术构建具有减少量的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的宿主细胞或其中这些酶基本上无活性的宿主细胞。本领域中描述了基因失活或基因破坏的若干种技术,例如一步基因破坏法、标志物插入、定点诱变、缺失、RNA干扰、反义RNA等,并且都可以用于降低、抑制或干扰纤维素酶、甘露聚糖酶和果胶酶的合成以及任选地干扰淀粉酶活性,以便获得具有降低的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的工业生产菌株。此外,通过改变指导纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶基因的表达的一个或多个控制序列使纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶失活是本发明的一部分。其实例是通过基因破坏降低启动子活性。
使用现代遗传修饰技术,人们可以获得重组纤维素酶、甘露聚糖酶和果胶酶,以及任选地淀粉酶缺陷型菌株,优选通过干扰编码纤维素酶、甘露聚糖酶和果胶酶,以及任选地淀粉酶活性的基因,更优选地通过将标记基因插入编码酶活性的基因,最优选地通过从基因组去除部分或全部酶编码区进行。已经针对许多不同的微生物描述了进行这种基因失活的方法,并且是本领域技术人员已知的(即,参见EP 357127)。因此可以减少或消除纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶在突变细胞中表达。取决于使用这些技术修饰的宿主菌株,该过程可重复若干次以除去所有或大部分纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶编码序列。
宿主基因如纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶的修饰或失活可以通过已建立的反义技术、使用与该基因的核苷酸序列互补的核苷酸序列进行。更具体地,可以通过引入与核苷酸序列互补的核苷酸序列来减少或消除基因的表达,该核苷酸序列可以在细胞中转录并且能够与细胞中产生的mRNA杂交。在允许互补的反义核苷酸序列与mRNA杂交的条件下,由此降低或消除了所翻译的蛋白质的量。尼安(Ngiam)等人(应用与环境微生物学(Appl.Environ.Microbiol.)66:775-782,2000)和茨伦纳(Zrenner)等人(普兰塔(Planta)190:247-252,1993)提供了表达反义RNA的实例。
可以通过RNA干扰(RNAi)技术(欧洲微生物学会联合会微生物学快报(FEMSMicrob.Lett.)237:317-324,2004)获得宿主基因的修饰、下调或失活。更具体地说,丝状真菌细胞基因表达可以通过如下来减少或消除:克隆其表达待受影响的核苷酸序列的同一的正义和反义部分(其后各自具有位于其间的核苷酸间隔物),插入表达载体,并且将表达载体引入细胞中,在该细胞中双链RNA(dsRNA)可以被转录,并且然后加工成能够杂交至靶mRNA的较短的siRNA。dsRNA转录后,小(21-23)核苷酸siRNA片段的形成将导致待受影响的mRNA的靶向降解。特异性mRNA的消除可以是各种程度的。WO 2005/05672和WO 2005/026356中描述的RNA干扰技术可用于宿主基因的修饰、下调或失活。
纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型宿主细胞可能具有另一个核苷酸序列,该宿主细胞已经通过上述任何方法修饰或失活,并且在相同条件下培养时产生比亲本细胞更少的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性,如使用与之前定义的相同测定所测量的。
具有降低的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的,通过经典遗传技术或重组DNA技术分离的或构建的这些工业生产菌株可以用于需要最终产品包含膳食纤维的相关工业方法。优选地,这些菌株用于生产具有转半乳糖基化活性的工业上相关的酶。更优选地,这些菌株用于生产食品工业中使用的酶,甚至更优选地,这些酶用于奶产品的加工。最优选地,将具有降低的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的这种工业生产菌株用于从乳糖生产GOS。
优选地,本发明的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型宿主细胞是如在模式反应中所检测的具有少于50%的可检测的细胞内或细胞外纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的菌株(参见实例2、3或4中的实验信息)。更优选地,本发明的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型菌株是具有少于50%的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的菌株。更优选地,本发明的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型菌株是具有如下纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性的菌株,如在模式反应中所检测的,该活性少于其来源的宿主细胞的纤维素酶、甘露聚糖酶和果胶酶及任选地淀粉酶活性的25%,优选地少于10%,更优选地少于5%,更优选地少于1%,并且最优选地该纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶活性在本发明的缺陷型宿主细胞中是不可检测的。
多种用于检测多肽的系统是本领域技术人员已知的。检测系统包括用于检测多肽或酶活性的任何可能的测定。举例来说,这些测定系统包括但不限于基于以下测定:比色、光度、荧光、比浊、粘度、免疫学、生物学、色谱和其他可用测定。
优选地,如果产生的多肽是酶,则通过在模式反应中测量其活性来确定产生的活性酶的量(参见实例2、3或4)。
根据另一个优选的实施例,本发明的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型宿主细胞的特征在于如下事实:当该菌株已经用包括编码具有转半乳糖基化活性的多肽的基因的表达构建体转化时,所述菌株至少产生其来源的野生型菌株在相同培养条件下产生的多肽的量(当野生型菌株也已经用与纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型宿主细胞相同的表达构建体转化时)。
优选地,本发明的纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型菌株是在相同培养条件下产生比其来源的野生型菌株相同或更多量的具有转半乳糖基化活性的多肽的菌株。更优选地,纤维素酶、甘露聚糖酶和果胶酶以及任选地淀粉酶缺陷型菌株比在相同培养条件下其来源的野生型菌株产生更多的给定多肽。
具有转半乳糖基化活性的多肽的生产
根据又另一个实施例,本发明涉及在缺乏纤维素、甘露聚糖酶、果胶酶和/或淀粉酶活性的宿主细胞中转录核苷酸序列的方法,其中该转录序列编码具有转半乳糖基化活性的多肽,该方法包括:
(a)在培养基中培养本发明的宿主细胞,该宿主细胞包括(i)启动子,
(iv)编码多肽的下游核苷酸序列,(iii)翻译停止信号和(iv)转录终止信号,
(b)在宿主细胞中表达多肽,并且
(c)任选地,从培养基或从宿主细胞中回收多肽。
优选地,根据本发明的方法产生缺陷型菌株。可以使用本领域已知的方法将缺陷型菌株在适于产生所需多肽的营养介质中生长或维持。例如,可以将细胞接种在固体基质上,在烧瓶中摇动,在小规模或大规模发酵(包括连续、分批、补料分批或固态发酵)中在实验室或工业发酵罐中在适合的介质中并且在允许表达和/或分离多肽的条件下培养。使用本领域已知的程序,在包括碳源和氮源和无机盐的合适营养介质中进行培养(参见,例如,班尼特和拉热(LaSure)编辑,真菌中更多的基因操作,学术出版社,加利福尼亚州,1991)。适合的介质可从商业供应商获得或可以使用公开的组合物(例如,在美国典型培养物保藏中心的目录中)来制备。如果多肽分泌到该营养介质中,那么可直接从介质中回收多肽。如果多肽不被分泌,那么其可从细胞裂解液中回收。
可以通过本领域已知的方法来分离该所得的多肽。例如,可以通过常规程序从营养介质中分离多肽,这些常规程序包括但不限于离心、过滤、提取、喷雾干燥、蒸发或沉淀。然后可以通过本领域已知的多种程序进一步纯化分离的多肽,这些程序包括但不限于色谱法(例如,离子交换、亲和力、疏水性、色谱聚焦或尺寸排阻),电泳(例如,制备型等电聚焦),差异溶解度(例如,丙酮或硫酸铵沉淀)或萃取(例如离液剂、盐或pH)。参见,例如詹森(Janson)和赖登(Ryden)编辑,蛋白质纯化(Protein Purification),VCH出版商,纽约,1989。
可以使用特异性针对具有转半乳糖基化活性的多肽的本领域已知的方法来检测该多肽。这些检测方法可以包括使用特异性抗体、酶产物的形成、酶底物的消失或SDS-PAGE。例如,可以使用酶测定来确定多肽的活性。对于许多酶,用于确定酶活性的程序在本领域中是已知的。
用于生产多肽的方法
在另一方面,如在此所述的表达多肽的方法包括获得如在此所述的宿主细胞或细胞,并从该细胞或宿主细胞表达具有转半乳糖基化活性的多肽,以及任选地纯化该多肽。可以在本发明中使用这样的多肽。
宿主细胞的转化、表达和培养
将DNA构建体或载体引入宿主细胞中包括如下技术如:转化;电穿孔;核显微注射;转导;转染,例如脂质介导的转染和DEAE-糊精介导的转染;用磷酸钙DNA沉淀孵育;用DNA包被的微粒高速轰击;和原生质体融合。通用转化技术是本领域已知的。参见,例如,奥苏贝尔等人(1987),同上,第9章;萨姆布鲁克等人(2001),同上;和坎贝尔(Campbell)等人,当代遗传学(Curr.Genet.)16:53-56(1989)。
本领域已知的方法可用于选择转化体。
用于固定和配制多肽和多肽组合物的方法
多肽组合物可以根据本领域已知的方法制备,并可以是液体或干组合物的形式。例如,该多肽组合物可以呈颗粒或微粒的形式。包括在该组合物中的多肽可以根据本领域中已知的方法稳定化。
应用
以下给出了本发明的多肽或多肽组合物的优选用途的实例。
在一方面,在此披露了通过用在如此所述的多肽或多肽组合物处理包括乳糖的底物来生产食品的方法。
在一方面,在此披露了通过用如在此所述的多肽或多肽组合物处理包括乳糖的乳基底物来生产奶产品的方法。
在一方面,将包括乳糖的底物进一步用水解的β-半乳糖苷酶处理。
酶制剂(如处于根据本发明制备的食物成分的形式)可以是溶液形式或作为固体-这取决于用途和/或应用模式和/或给予模式。固体形式可以是呈干燥酶粉末或呈造粒酶。
干酶配制品的实例包括喷雾干燥的产物,混合器造粒产物,层状产物如流化床颗粒,挤出或颗粒状颗粒造粒产物,冻干产物。
酶制剂(如处于根据本发明制备的食物成分的形式)可以是溶液形式或作为固体-这取决于用途和/或应用模式和/或给予模式。固体形式可以是呈干燥酶粉末或呈造粒酶。
在一方面,提供组合物,优选食物组合物,更优选包括如在此所述的细胞或多肽或多肽组合物的奶产品。
此外,基于在组合物中与SEQ ID NO:22具有至少70%,例如像72%、74%、74%、78%、80%、82%、84%、86%、88%、90%序列同一性的多肽的总量,在此披露了包括至少5%,例如像,10%、15%、20%、25%、30%、35%、40%、45%、50%w/w的一种或多种多肽的组合物。这可以通过使用本领域技术人员已知的以下技术来评估。使待评估的样品进行SDS-PAGE,并使用适合于蛋白质定量的染料例如像伯乐标准(Bio-Rad Criterion)系统进行可视化。然后使用适当的光密度扫描仪(例如像伯乐标准系统)扫描凝胶,并确保所得图像处于动态范围内。对与衍生自SEQ ID NO:8的任何变体/片段相对应的条带进行定量,并且如下计算多肽的百分比:所讨论的多肽的百分比=所讨论的多肽/(表现出转半乳糖基化活性的所有多肽的总和)*100。组合物中衍生自SEQ ID NO:8的多肽变体/片段的总数可以通过本领域技术人员已知的方法使用多克隆抗体通过蛋白质印迹检测衍生自SEQ ID NO:8的片段来确定。
在一方面,根据本发明的组合物包括选自下组的一种或多种多肽,该组由SEQ IDNO:1、2、3、4和5组成的多肽组成。在另一方面,组合物包括一种或多种选自下组的多肽,该组由SEQ ID NO:1、2和3组成的多肽组成。在又另一方面,组合物包括一种或多种选自下组的多肽,该组由SEQ ID NO:1和2组成的多肽组成。
在一方面,本发明提供了包括根据本发明所述的酶复合物、酶载体和任选地稳定剂和/或防腐剂的酶复合物制剂。
在本发明的又另一方面,酶载体选自下组,该组由甘油或水组成。在一个实施例中,酶载体不包括多元醇(例如,甘油、丙二醇或山梨糖醇)。
在另一方面,制剂/组合物包括稳定剂。在一方面,该稳定剂选自由以下各项组成的组:无机盐、多元醇、糖及其组合。在一方面,该稳定剂是无机盐如氯化钾。在另一方面,该多元醇是甘油、丙二醇或山梨糖醇。在另一方面,该稳定剂不是多元醇,如甘油、丙二醇或山梨糖醇。在又另一方面,糖是小分子碳水化合物,特别是若干种甜味碳水化合物如葡萄糖、半乳糖、果糖和蔗糖中的任何一种。
在又另一方面,制剂包括防腐剂。在一方面,该防腐剂是对羟基苯甲酸甲酯、对羟基苯甲酸丙酯、苯甲酸酯、山梨酸酯或其他食品认可的防腐剂或其混合物。
本发明的方法可以用固定化酶实施,例如,固定化的乳糖酶或其他产生半乳寡糖的酶。可以将酶固定在任何有机或无机支持物上。示例性无机支持物包括氧化铝、硅藻土、Dowex-1氯化物、玻璃珠和硅胶。示例性有机支持物包括DEAE-纤维素、藻酸盐水凝胶或藻酸盐珠或等效物。在本发明的各个方面,可以通过物理吸附到无机支持物上来优化乳糖酶的固定化。可以将用于实施本发明的酶固定在不同的介质中,包括水、Tris-HCl缓冲液和磷酸盐缓冲溶液。可以将酶固定在任何类型的底物上,例如滤器、纤维、柱、珠、胶体、凝胶、水凝胶、网眼等。
在一方面,提供了通过用如在此所述的多肽或多肽组合物处理包括乳糖的乳基底物来生产奶产品的方法。在另一方面,提供了通过将包括乳糖的乳基底物用一种多肽处理用于生产奶产品的方法,该多肽在15min反应后具有高于60%、如高于70%、如高于75%的相对转半乳糖基化活性。在一方面,在30min反应后相对转半乳糖基化活性高于3。在另一方面,在30min反应后相对转半乳糖基化活性高于6。在又另一方面,在30min反应后相对转半乳糖基化活性高于12。在一方面,提供了一种方法,其中在酶的活性的最佳温度下进行如在此所述的多肽或多肽组合物的处理。在另一方面,将多肽或多肽组合物以0.01-1000ppm的浓度添加到乳基底物中。在又另一方面,将多肽或多肽组合物以0.1-100ppm的浓度添加到乳基底物中。在另一方面,将多肽或多肽组合物以1-10ppm的浓度添加到乳基底物中。在一方面,提供了一种进一步包括用微生物发酵底物如奶产品的方法。在另一方面,该奶产品是酸奶。在另一方面,基本上同时进行多肽或多肽组合物和微生物的处理。在一方面,基本上同时将多肽或多肽组合物和微生物添加到乳基底物中。
在一方面,提供包括如在此所述的细胞或多肽或多肽组合物的奶产品。在一方面,以0.01-1000ppm的浓度添加如在此定义的多肽或多肽组合物。
在一方面,提供包括由如在此定义的多肽或多肽组合物原位形成的GOS的奶产品。在一方面,提供了包括如在此定义的细胞的奶产品。
如在此所述的奶产品可以是例如脱脂乳、低脂乳、全脂乳、奶油、UHT乳、具有延长的保质期的乳、发酵的奶产品、奶酪、酸奶、黄油、乳质涂抹料(dairy spread)、黄油乳、酸化乳饮料、酸奶油、乳清基饮料、冰淇淋、炼乳、牛奶焦糖酱(dulce de leche)或风味乳饮料。奶产品可以通过本领域已知的任何方法制造。
奶产品还可以包括非乳组分,例如,植物组分如植物油,植物蛋白和/或植物碳水化合物。奶产品还可以包括另外的添加剂,如酶、调味剂、微生物培养物如益生菌培养物、盐、甜味剂、糖、酸、水果、果汁或本领域已知的可作为奶产品的组分或添加到奶产品中的任何其他组分。
在本发明的一个实施例中,一种或多种乳组分和/或乳馏分占奶产品的至少50%(重量/重量),如至少70%,例如至少80%,优选地至少90%。
在本发明的一个实施例中,已经用如在此定义的具有转半乳糖基化活性的酶处理的一种或多种乳基底物占奶产品的至少50%(重量/重量),如至少70%,例如至少80%,优选地至少90%。
在本发明的一个实施例中,该奶产品是未通过添加预先生产的半乳寡糖而被浓缩的奶产品。
在本发明的一个实施例中,多肽处理的乳基底物在用作奶产品中的成分之前未进行干燥。
在本发明的一个实施例中,该奶产品是冰淇淋。在上下文中,冰淇淋可以是任何种类的冰淇淋,如全脂冰淇淋、低脂冰淇淋或基于酸奶或其他发酵的乳产品的冰淇淋。冰淇淋可以通过本领域已知的任何方法制造。
在本发明的一个实施例中,该奶产品是乳或炼乳。
在本发明的一个实施例中,该奶产品是UHT乳。在本发明的上下文中的UHT乳是已经进行灭菌程序的乳,其旨在杀死包括细菌孢子在内的所有微生物。UHT(超高温)处理可以是例如在130℃下热处理30秒,或者在145℃下热处理1秒。
在本发明的一个优选实施例中,该奶产品是ESL乳。在上下文中,ESL乳是由于微量过滤和/或热处理而具有延长的保质期,并且能够在2℃-5℃的商店架上保持新鲜至少15天,优选至少20天的乳。
在本发明的另一个优选实施例中,该奶产品是发酵的奶产品,例如酸奶。
用于大多数发酵的乳产品的微生物选自下组,该组由通常称为乳酸菌的细菌组成。如在此所用,术语“乳酸菌”是指革兰氏阳性、微量需氧或厌氧细菌,该细菌发酵糖,并且产生酸,这些酸包括作为主要产生的酸的乳酸、乙酸和丙酸。工业上最有用的乳酸菌可在“乳杆菌(Lactobacillales)”目中找到,其中包括乳球菌属物种、链球菌属物种、乳杆菌属物种、明串珠菌属物种、假明串珠菌属物种、片球菌属物种、短杆菌属物种、肠球菌属物种和丙酸菌属物种。此外,乳酸菌组中通常包括属于厌氧细菌的组的产乳酸细菌,双歧杆菌,即双歧杆菌属物种,这些产乳酸细菌常单独或与乳酸菌组合用作食品培养物。
乳酸菌通常作为冷冻或冻干培养物供应给奶业,用于进行起子增殖(bulkstarter propagation)或者所谓的“直投式”(DVS)培养物,旨在直接接种入发酵容器或桶中用于产生发酵奶产品。这种培养物通常称作“起子培养物”或“起子”。
常用的乳酸菌的起子培养物菌株通常分成嗜常温生物体(其最适生长温度约30℃),和嗜热生物体(其最适生长温度在约40℃至约45℃的范围内)。属于嗜常温组的典型生物体包括乳酸乳球菌、乳酸乳球菌乳脂亚种(Lactococus lactis subsp.cremoris)、肠膜状明串珠菌乳脂亚种(Leuconostoc mesenteroides subsp.cremoris)、肠膜状假明串珠菌乳脂亚种(Pseudoleuconostoc mesenteroides subsp.cremoris)、戊糖片球菌(Pediococcus pentosaceus)、乳酸乳球菌乳酸亚种双乙酰生物突变株(Lactococuslactis subsp.lactis biovar.diacetylactis)、干酪乳杆菌干酪亚种(Lactococus caseisubsp.casei)和副干酪乳杆菌副干酪亚种(Lactococus paracasei subsp.paracasei)。嗜热乳酸细菌物种包括例如嗜热链球菌、屎肠球菌、德氏乳杆菌乳酸亚种、瑞士乳杆菌、德氏乳杆菌保加利亚亚种和嗜酸乳杆菌。
此外,属于双歧杆菌属的厌氧细菌,包括两歧双歧杆菌、动物双歧杆菌和长双歧杆菌常用作乳品起子培养物,并且通常包括在乳酸菌组中。此外,丙酸杆菌属物种用作乳品起子培养物,特别是在奶酪的制造中。此外,属于双歧杆菌属的生物体通常用作食物起子培养物。
另一组微生物起子培养物是真菌培养物,包括丝状真菌的酵母培养物和培养物,其具体用于制造某些类型的奶酪和饮料。真菌的实例包括娄地青霉、白青霉(Penicilliumcandidum)、白地霉、开菲尔圆酵母、开菲尔酵母和酿酒酵母。
在本发明的一个实施例中,用于乳基底物发酵的微生物是干酪乳杆菌、或嗜热链球菌和德氏乳酸杆菌保加利亚亚种的混合物。
本发明的方法中使用的发酵方法是众所周知的,并且本领域的技术人员知道如何选择合适的工艺条件,如温度、氧、微生物的量和特征、添加剂如碳水化合物、调味剂、矿物质、酶、和处理时间。显然,选择发酵条件以便支持本发明的实现。
作为发酵的结果,将降低乳基底物的pH。本发明的发酵奶产品的pH可以是,例如,在3.5-6的范围内,如在3.5-5的范围内,优选在3.8-4.8的范围内。
在一方面,提供了使用多肽或多肽组合物或使用上述细胞类型中的任何一种或多种用于产生寡糖的方法。寡糖包括但不限于果寡糖、半乳寡糖、异麦芽寡糖、麦芽寡糖、乳果糖和木寡糖。
在本发明的一个实施例中,寡糖通过在包括二糖底物的介质中孵育表达多肽的细胞而产生,该二糖底物例如像乳果糖、海藻糖、鼠李糖、麦芽糖、蔗糖、乳糖或纤维二糖。孵育在生产寡糖的条件下进行。细胞可以是选自下组的产物的一部分,该组由以下各项组成:酸奶、奶酪、发酵的乳产品、膳食补充剂和益生菌食物产品。可替代地,可以回收寡糖并随后在其制备之前或之后将其添加到感兴趣的产品中。
在一方面,提供了在此披露的细胞用于生产选自下组的产品的用途,该组由以下各项组成:酸奶、奶酪、发酵的乳产品、膳食补充剂和益生菌食物产品。
在一方面,可以将在此所述的多肽或多肽组合物用于制备奶酪产品并且可以在制备奶酪产品的方法中使用。例如,奶酪产品可以选自由以下各项组成的组:奶油奶酪、松软奶酪、和精制奶酪。通过添加多肽或多肽组合物,奶酪可以包含显著增加的半乳寡糖水平和降低的乳糖水平。在一方面,最终奶酪产品中的乳糖水平可以降低至少约25%,优选至少约50%,并且更优选至少约75%。多肽或多肽组合物可以用于将乳酪产品中的乳糖降低至少于约1克/份,这是大多数乳糖不耐个体可以耐受的一个量。
在此提供的奶酪产品是具有增加的可溶性纤维含量、降低的热量含量、优异的感官特性、改进的质地和风味的营养增强的奶酪产品。此外,在此所述的多肽可以降低奶酪产品的血糖指数,因为GOS比乳糖或其水解产物更慢地吸收。最后,多肽或多肽组合物可以降低奶酪产品,特别是奶油奶酪产品的生产成本,因为GOS令人惊奇地为奶油奶酪产品提供了改进的质地,从而允许减少稳定剂的使用,或通过允许增加水分含量而无需脱水。
在另一方面,提供了包括如在此所述的多肽或多肽组合物和碳水化合物底物的组合物。在另一方面,该碳水化合物底物是二糖。另一方面,该二糖是例如乳果糖、海藻糖、鼠李糖、麦芽糖、蔗糖、乳糖或纤维二糖。在又另一方面,该碳水化合物底物是乳糖。制备组合物,这样使得产生寡糖。如在此所述的多肽可以是选自下组的产物的一部分,该组由以下各项组成:酸奶、奶酪、发酵的乳产品、膳食补充剂和益生菌食物产品。在一方面,提供了包括如在此所述的多肽和稳定剂的组合物。稳定剂的实例是例如多元醇,例如像甘油或丙二醇、糖或糖醇、乳酸、硼酸或硼酸衍生物(例如芳族硼酸酯)。
在一方面,提供了如在此披露的转半乳糖基化多肽或多肽组合物或如在此披露的细胞用于产生半乳寡糖的用途。在一方面,提供了如在此披露的转半乳糖基化多肽或多肽组合物或如在此披露的细胞用于生产半乳寡糖的用途,该半乳寡糖将成为选自下组的产品的一部分,该组由以下各项组成:酸奶、奶酪、发酵的奶产品、膳食补充剂和益生菌食物产品。在一方面,该产品是酸奶、奶酪或发酵的奶产品。在一方面,提供了如在此披露的转半乳糖基化多肽或多肽组合物或如在此披露的细胞用于产生半乳寡糖以增强双歧杆菌生长的用途。在一方面,提供了如在此披露的转半乳糖基化多肽或多肽组合物或如在此披露的细胞用于产生半乳寡糖以增强双歧杆菌在混合培养物发酵中的生长的用途。
在一方面,提供了用于生产如在此披露的转半乳糖基化多肽或多肽组合物的方法,该方法包括在允许表达所述多肽的条件下在适合的培养基中培养如在此披露的细胞,并且从培养物回收得到的多肽。提供了一种用于生产半乳寡糖的方法,该方法包括使如在此披露的多肽或多肽组合物或如在此披露的细胞与包括乳糖的乳基溶液接触。
添加寡糖可以增强单独的双歧杆菌或在混合培养物中的双歧杆菌的生长。
用将乳糖转化为单糖或GOS的酶处理乳产品具有若干个优点。首先,产品可以被患有乳糖不耐症的人消耗,否则会出现症状如胃肠气胀和腹泻。其次,与乳糖相比,用乳糖酶处理的奶产品将比类似的未处理产品具有更高的甜度,这是因为葡萄糖和半乳糖的更高的感知甜度。这种效果对于应用如酸奶和冰淇淋尤为有益,其中最终产品的高甜度是所希望的,并且这允许所消耗的产品中的碳水化合物的净减少。第三,在冰淇淋生产中,经常看到称为沙质的现象,其中乳糖分子由于乳糖的相对低的溶解度而结晶。当乳糖转化为单糖或GOS时,冰淇淋的口感比未处理产品大大改进。可以消除由于乳糖结晶引起的沙感的存在,并且可以通过用乳清粉替代脱脂乳粉来降低原料成本。酶处理的主要作用是增加甜味。
在一方面,如在此披露的转半乳糖基化多肽或多肽组合物可以与其他酶如蛋白酶如凝乳酶或肾素,脂酶如磷脂酶,淀粉酶,转移酶和乳糖酶一起使用。在一方面,如在此披露的一种或多种转半乳糖基化多肽可与乳糖酶一起使用。当用如在此披露的一种或多种转半乳糖基化多肽处理后,特别是在低乳糖水平下希望减少残留的乳糖时,这可以是特别有用的。
在一个实施例中,酶是来自细菌的乳糖酶,例如,来自双歧杆菌科,如来自双歧杆菌属如特别是在WO 2009/071539和WO 2013/182686中描述的乳糖酶。
实例1-根据本发明的宿主细胞的构建
本实例的宿主细胞衍生自枯草芽孢杆菌。
去除amyEα-淀粉酶基因:通过重组DNA技术将野生型基因(amyE)的体外产生的缺失引入枯草芽孢杆菌菌株中。通过活性以及DNA印迹法监测amyE缺失。宿主菌株中不存在异源DNA。
通过壮观霉素标志物替代bglC内切葡聚糖酶基因:为了使bglC基因缺失,使用了采用cre-lox方法的策略。克隆上游和下游bglC序列,并且将中间(待删除)部分替代为允许在转化中进行选择的loxP-壮观霉素盒。用构建体转化枯草芽孢杆菌菌株,选择大观霉素,将基因组bglC基因用克隆的变体替代。将来自包含壮观霉素标志物的菌株的基因组DNA整合到内切葡聚糖酶bglC基因座的缺失中,用于通过自然感受态转化菌株。阳性克隆由壮观霉素抗性确定。壮观霉素抗性基因的侧翼是能够除去基因的loxP序列。
用四环素标志物替代gmuG甘露聚糖酶基因:使用与针对bglC基因相同的技术使甘露聚糖酶gmuG缺失,尽管这次使用四环素标志物而不是壮观霉素标志物。在包含四环素的介质上选择转化体,并且用PCR验证阳性克隆。
用壮观霉素标志物替代pel果胶酸裂解酶基因:使用与用于bglC基因相同的技术,通过用壮观霉素标志物替代pel ORF,使果胶酸裂解酶基因pel缺失。在壮观霉素平板上选择转化体,并通过cPCR筛选。
BIF917基因的引入:使用本出版物中阐述的方法将在WO 2013/182626中披露为“BIF917”的β-半乳糖苷酶的编码序列转化到枯草芽孢杆菌中。一般来说,这描述了使用合成基因生产多肽,该合成基因被设计编码两歧双歧杆菌全长(1752个残基)基因,针对在枯草芽孢杆菌中的表达所优化的密码子购自GeneART(雷根斯堡,德国)SEQ ID NO.8。
采用反向引物,使用聚合酶链式反应构建两歧双歧杆菌截短突变体,其允许合成基因的所选择的区域的特异性扩增。
正向引物:GGGGTAACTAGTGGAAGATGCAACAAGAAG(加下划线的SpeI)(SEQ ID NO:15)。
截短突变体和相应的反向引物的SEQ ID如下表2所示。

表2
使用独特的限制性位点SpeI和PacI将合成基因克隆到pBNspe枯草芽孢杆菌表达载体中,并且将分离的质粒转化到枯草芽孢杆菌菌株中。将转化体作为选择重新划线到包含10μg/mL新霉素的LB平板上。
测量β-半乳糖苷酶活性
使用市售的底物2-硝基苯基-β-D-吡喃半乳糖苷(ONPG)(西格玛(Sigma)N1127)测量酶活性。
ONPG w/o受体
100mM KPO4pH 6.0
12,3mM ONPG
补充有受体的ONPG
100mM KPO4pH 6.0
20mM纤维二糖
12,3mM ONPG
终止溶液
10%Na2CO3
将10μl稀释系列的纯化的酶添加到包含90μl ONPG缓冲液的具有或没有受体的微量滴定板的孔中。将样品混合并在37℃下孵育10min,然后向每个孔中添加100μl终止溶液以终止反应。在由Softmax软件包控制的分子装置SpectraMax平板读数器上在420nm下记录吸光度测量值。
如下计算转半乳糖基化活性的比率:
对于其中吸光度在0.5和1.0之间的稀释液,转半乳糖基化活性比率=(Abs420+纤维二糖/Abs420-纤维二糖)*100。
LAU活性的确定
原理:
该测定方法的原理是乳糖酶在37℃下将2-邻硝基苯基-β-D-吡喃半乳糖苷(ONPG)水解成2-邻硝基苯酚(ONP)和半乳糖。用碳酸钠停止反应,并在分光光度计或色度计在420nm下测量释放的ONP。
试剂:
MES缓冲液pH 6.4(100mM MES pH 6.4,10mM CaCl2):将19,52g MES水合物(Mw:195.2g/mol,西格玛-奥德里奇(Sigma-aldrich)#M8250-250G)和1.470g CaCl2二水合物(Mw:147.01g/mol,西格玛-奥德里奇)溶解在1000ml ddH2O中,通过10M NaOH将pH调节至6.4。通过0.2μm滤器过滤溶液,并在4℃下储存1个月。
ONPG底物pH 6.4(12.28mM ONPG,100mM MES pH 6.4,10mM CaCl2):将0.370g 2-邻硝基苯基-β-D-吡喃半乳糖苷(ONPG,Mw:301.55g/mol,西格玛-奥德里奇#N1127)溶解在100ml MES缓冲液pH 6.4中,并在4℃下黑暗保存长达7天。
终止试剂(10%Na2CO3):将20.0g Na2CO3溶解在200ml ddH2O中,通过0.2μm滤器过滤溶液,并在室温下保存1个月。
程序:
在MES缓冲液(pH 6.4)中制备稀释系列的酶样品,并且将10μL每个样品稀释液转移到包含90μl ONPG底物(pH 6.4)的微量滴定板(96孔格式)的孔中。将样品混合并使用恒温混匀仪(舒适型恒温混匀仪(Comfort Thermomixer),艾本德(Eppendorf))在37℃下孵育5min,并且随后向每个孔中添加100μl终止试剂以终止反应。使用MES缓冲液(pH 6.4)代替酶样品构建空白。在ELISA读数器(SpectraMax平板读数器,分子装置公司(MolecularDevice))上针对空白测量在420nm处的吸光度的增加。
酶活性计算:
确定MES缓冲液(pH 6.4)中2-邻硝基苯酚(西格玛-奥德里奇#33444-25G)的摩尔消光系数(0.5998x 10-6M-1x cm-1)。一个单位(U)的乳糖酶活性(LAU)被定义为对应于每分钟1nmol的ONPG水解的量。使用总反应体积为200μL(光路径为0.52cm)的微量滴定板,可以使用以下公式计算每mL酶样品的乳糖酶活性:

计算在此示为SEQ ID NO:1的BIF917的比活度:
BIF917浓度的确定:
使用Criterion Stain free SDS-page系统(伯乐公司(BioRad))确定靶酶(BIF917)和截短产物的定量。将任何kD Stain free预制凝胶4%-20%Tris-HCl,18孔(康贝公司(Comb)#345-0418)与塞尔瓦(Serva)Tris-甘氨酸/SDS缓冲液(伯乐公司目录号42529)一起使用。使用以下参数运行凝胶:200V、120mA、25W、50min。使用BSA(1,43mg/ml)(西格玛-奥德里奇,目录号500-0007)作为蛋白质标准品,并且将Criterion Stain Free成像仪(伯乐公司)与Image Lab软件(伯乐公司)一起使用,用于使用与色氨酸含量相关的带强度进行定量。
从两种独立发酵(如方法1中所述)的粗制酵素(超滤浓缩物)并且使用5种不同稀释度(参见表1)确定BIF917的特异性LAU活性。
发现BIF917比活度为21.3LAU/mg或0.0213LAU/ppm。
表1:BIF917比活度的确定

实例2
测试:1
测定:P-甘露聚糖酶活性,还原糖(MU)
该测试方法用于以MU(甘露聚糖酶单位)单位确定甘露聚糖酶活性。
目的
该测定适用于甘露聚糖酶活性的QA/QC监测。
原理
该测定通过内切-1,4-P-D-甘露聚糖酶对槐豆胶(LBG)底物的作用测量还原糖的释放。将二硝基水杨酸反应用于确定还原糖含量的增加,这与所添加的酶活性成正比。
程序
1.材料和设备
1.1能够达到3500rpm的离心机
1.2设置为40℃的水浴
1.3设置为60℃的水浴
1.4沸水浴
1.5外置活塞式移液器(Positive displacement pipet)和吸头(瑞宁公司(RaninInc))
1.6涡旋
1.7 16x 100mm玻璃试管(带帽)
1.8计时器
1.9容量瓶、刻度量筒、烧杯
1.10磁力搅拌棒和搅拌板/加热板
1.11垂熔玻璃滤器漏斗
1.12pH计
1.13分析天平
1.14制备平衡
1.15温度计
1.16冰水浴
1.17分光光度计,能够读取540nm
1.18具有一次性吸头的可变移液装置(1ml)
1.20玻璃器皿的烤箱或高压釜
2.试剂:使用以下试剂或等效物
2.1氢氧化铵,浓缩的(28%-30%)
2.2Tris-羟甲基氨基甲烷(Tris)盐酸化物
2.3氢氧化钠颗粒
2.4 3,5-二硝基水杨酸,98%,(DNS),西格玛-奥德里奇目录号128848
2.5槐豆胶,西格玛化学#G0753
2.6酒石酸钾钠,四水合物,西格玛-奥德里奇目录号217255
2.7去离子水
2.8 1-丙醇
3.试剂制备
3.1氢氧化铵1.5%
3.1.1使用去离子水,在容量瓶中将5ml 30%氢氧化铵稀释至100ml。
3.2Tris-盐酸盐缓冲液
3.2.1在约1900ml去离子水中溶解15.67gm Tris-盐酸盐。用氢氧化铵(1.5%)调节至pH 7.5±0.05,并用去离子水稀释至2000ml。该溶液可以在室温下保持至少两周。
3.3氢氧化钠10.67%
3.3.1添加32.0gm氢氧化钠颗粒至200ml去离子水中。搅拌至溶解并冷却。用去离子水使达到300ml
3.4DNS试剂
(a)在2L烧杯中将20gm的DNS悬浮于1000g去离子水中。添加300ml的10.67%氢氧化钠溶液。
(b)将悬浮液在加热搅拌板上加热,直至溶液澄清。温度不应超过50℃。
(c)逐渐添加600gm酒石酸钾钠四水合物至溶液中,并持续混合。使溶液达到室温。
(d)用去离子水将溶液稀释至2000ml,并且如果需要,通过烧结玻璃滤器过程过滤。在室温下存放在深琥珀色瓶中。该溶液持续至少两个月保持良好。
3.5槐豆胶(LBG)底物溶液
3.5.1确保与底物接触的所有玻璃器皿都非常干净,并且没有可能的甘露聚糖酶污染。推荐在120℃下进行1-丙醇洗涤或烘烤。
5.1.1将500ml Tris-盐酸盐缓冲液放入1000ml烧杯中。将烧杯放在沸水浴或加热搅拌板中,并且使烧杯中的温度达到80℃。快速搅拌溶液,同时非常缓慢地添加1.4gm的槐豆胶。减少混合并在水浴中将溶液保持在60℃持续60分钟。冷却至室温。用去离子水调节至500ml。以3500rpm离心10分钟。使用澄清的上清液作为底物。
3.6酶标准品制备
3.6.1选择大量的甘露聚糖酶最终产品作为标准品。将其设置为等于批次分析证书上所报告的MU值。使用这种材料,使用以MU/升计的已知浓度的样品制作3点标准曲线。相应地使用Tris-盐酸盐缓冲液稀释该标准品,这样使得其净吸光度在减去试剂空白后落入测定的线性范围内。该测定的线性范围为0.17和0.52AA。0.050-0.140MU/升之间的标准曲线和样品浓度通常落入该测定的线性范围内。
3.7液体样品制备
3.7.1在Tris-盐酸盐缓冲液中稀释每个样品(w/v),这样使得部分4中概述的测定反应在540nm下落入17和0.52AA之间。
3.7.2将稀释的酶溶液储存在冰上。为最佳结果,应在1小时内测定稀释的酶溶液。
4.测定程序
4.1酶样品-应将酶样品一式两份进行检测
4.1.1将2ml LBG底物在40℃下在16×100玻璃试管中平衡20分钟。
4.1.2添加0.5ml酶样品稀释液,混合并且精确孵育10分钟。
4.1.3通过添加3.0ml的DNS溶液并混合来终止反应。
4.1.4在沸水浴中将样品煮沸15分钟,用帽覆盖每个试管的顶部以防止蒸发。在冰水浴中冷却50分钟。使样品平衡至室温持续10分钟。
5.1.1针对去离子水空白,读取540nm处的吸光度。在减去空白试剂后,吸光度应在0.17和0.52AA之间。
4.2空白试剂
4.2.1可以单独运行空白。该反应对照用于LBG底物中存在的或酶样品中存在的还原糖。
5.1.1将2ml LBG底物在40℃下在16×100玻璃试管中平衡20分钟。
5.1.2孵育另外10分钟。
5.1.3添加3.0ml DNS溶液并混合。添加0.5ml酶稀释液并再次混合。
5.1.4在沸水浴中煮沸15分钟,用帽覆盖试管的顶部以防止蒸发。在冰水浴中冷却5分钟。使样品平衡至室温持续10分钟。
5.1.5针对去离子水空白,读取540nm处的吸光度。
5.计算
5.1为了确定净吸光度,从所有标准品和样品的吸光度读数中减去平均试剂/酶空白。
5.2使用线性回归制备标准曲线,其中净吸光度在y轴上,并且浓度(MU/升)在x轴上。
5.3相关系数必须是>0.998。
5.4从线性回归确定每个样品的浓度。
5.5对于液体:MU甘露聚糖酶/kg样品=来自曲线的值(MU/升)*样品稀释因子(总体积(升)/样品重量(kg))
实例3
测试2:内切葡聚糖酶活性,羧甲基纤维素(CMC)活性
目的该测定方法用于以CMC单位计确定纤维素酶的内切葡聚糖酶活性。
注意:以IU/g或IU/ml(国际单位)所报告的纤维素酶分别相当于CMC/g或CMC/ml。
原理该测定通过纤维素酶对CMC底物的作用来测量还原糖的释放。如通过与3,5-二硝基水杨酸(DNS)的反应所测量的,还原糖释放速率与酶活性成正比。一个CMC单位定义为在测定条件下每分钟产生1^摩尔葡萄糖还原糖当量所需的酶量。相对于酶标准品,以指定的CMC单位测量此程序中的活性。
程序
1.0材料和设备
1.18 18x 150mm试管
1.19石珠
1.20比色皿
1.21外置活塞式移液器和吸头,瑞宁公司
1.22pH计
1.23设置为50℃的水浴
1.24冰浴
1.25沸水浴
1.26分光光度计
1.27磁力搅拌器
1.28秒表
1.29Coarse glass VWR KT93700-47
VWR KT93700-47
1.30深琥珀色瓶
1.31外置活塞式移液器
1.32涡旋振荡器
1.33试管架
2.0试剂:使用以下试剂或等效物。
2.9羧甲基纤维素钠盐Fluka 21900取代度必须为0.70-0.85
2.10 3,5-二硝基水杨酸,钠盐(DNS),默克(Merck)10846
2.11酒石酸钾钠,四水合物,默克8087
2.12氢氧化钠,试剂级别
2.13冰乙酸,试剂级别
3.0试剂制备
3.1 0.05M乙酸钠缓冲液,pH 4.8
3.1.1向900mL蒸馏水中添加2.85mL冰乙酸。在用磁力搅拌棒搅拌的同时,用50%氢氧化钠调节pH至4.8。用蒸馏水使总体积为一升。
3.4 10.67%(w/v)氢氧化钠溶液
3.2.1将32.0g氢氧化钠颗粒添加到200mL蒸馏水中。搅拌至溶解并冷却。用蒸馏水使达到300mL。
3.5 1%CMC底物溶液
3.3.1向99mL乙酸钠缓冲液中添加1.00g CMC。搅拌来彻底混合,并且保持在4℃下持续至少1小时,然后再使用。将该溶液在4℃下稳定3天
3.6 1%3,-5二硝基水杨酸(DNS)
(e)将20.0g DNS悬浮于1000mL蒸馏水中,并在混合的同时逐渐添加300mL的10.67%氢氧化钠溶液。
(f)在设置为50℃(122°F)的水浴中加热该悬浮液直到该溶液澄清。水浴温度应当不超过50℃。
3.4.3逐渐向溶液中添加600g酒石酸钾钠四水合物,并连续混合。
3.4.4用蒸馏水将溶液稀释至2000mL,并通过粗玻璃滤器过滤。在室温下存放在深琥珀色瓶中。该溶液稳定2个月。溶液必须澄清才能使用。
4.1颗粒样品制备
3.7.2将颗粒样品溶解在乙酸盐缓冲液中,这样使得从部分4.5中概述的测定反应产生的净吸光度落入0.4和0.5之间。约0.2CMC/mL的制剂通常会产生所需的吸光度。
3.7.3在制备样品时,称重至少100mg颗粒。相应地按4.1.1用乙酸盐缓冲液通过磁力搅拌溶解。针对5.1中的计算以mg/mL记录颗粒浓度。以中等速度混合持续至少20分钟。将稀释的样品储存在冰上。稳定至少2小时。
3.7.4注意一些样品在混合时间后会形成细浆。应取代表性的浆液样品进行4.5中的测定。
4.1.4一式三份执行每个颗粒样品制备。
4.2液体样品制备
4.1.3将每个样品稀释在乙酸盐缓冲液中,这样使得从部分4.5中概述的测定反应产生的净吸光度落入0.4和0.5之间。约0.2CMC/mL的制剂通常会产生所需的吸光度。
4.1.4当制备样品时,使用外置活塞式移液器等分出至少0.10mL的液体样品。将稀释的样品储存在冰上。稳定至少2小时。
4.1.5一式三份执行每个液体样品制备。
4.3工作标准品准备
4.4
4.3.1选择大量的纤维素酶最终产品(液体或颗粒)作为标准品。将其设置为等于批次分析证书上所报告的CMC值。使用此材料,按4.1或4.2制备已知CMC/mL的工作标准品。使用乙酸盐缓冲液稀释标准品,这样使得来自部分4.5中概述的测定反应的净吸光度产率落入0.4和0.5之间。制备约0.2CMC/mL的标准品溶液通常会产生所需的吸光度。
4.3.2以CMC/mL记录工作标准品的活性。将其在计算部分5.1和5.2中使用。
4.3.3一式三份准备标准品。
4.4空白溶液
4.4.1在部分4.5中使用乙酸盐缓冲液作为空白酶溶液。一式两份运行每个空白酶溶液。
4.5酶测定反应
4.5.1在50℃下,在18x 150mm玻璃试管中孵育1.00mL的CMC底物10-15分钟,这些玻璃试管竖立在试管架中。
4.5.2以20秒的间隔,使用外置活塞式移液器将1.00mL的酶稀释液和空白添加到CMC底物中。在50℃(122°F)下,将每个反应混合并孵育10分钟。
4.5.3以与4.5.2中相同的时间间隔,添加3.0mL DNS溶液并且进行混合。
4.5.4通过将试管和支架置于沸水浴中,将所有反应混合物+DNS精确煮沸5分钟。用石珠盖住试管的顶部,以防止沸腾期间蒸发。所有样品,标准品和空白应一起煮沸。煮沸后,在冰浴中将管冷却。
4.5.5针对作为零吸光度的蒸馏水,测量酶样品和空白样品在540nm处的吸光度。
4.5.6从平均样品和标准品吸光度中减去平均空白吸光度。此净吸光度应在0.4-0.5之间。如果不是,则应重复该测定。
4.5.7在测定中一式三份运行每个酶样品。
5.0计算
5.1如下计算颗粒样品中的活性:
CMC/g(或IU/g)=(样品的净吸光度)(CMC/mL的工作标准品)(1000mg/g)(工作标准品的净吸光度)(mg颗粒/mL乙酸盐缓冲液)
5.2如下计算液体样品中的活性:
CMC/mL(或IU/ml)=(样品的净吸光度)(CMC/mL的工作标准品)(样品稀释液)
(工作标准品的净吸光度)
注意:以IU/g或IU/ml(国际单位)所报告的纤维素酶分别相当于CMC/g或CMC/ml。
实例4
测试3
使用基于Viscoman的粘度法。该方法目前可用于检测非常低水平的甘露聚糖酶、淀粉酶、CMC酶和果胶酶活性。(有用的粘度方法也在US2013/0045498中公开,其通过引用结合在此)。水状胶体被酶切割,从而导致水状胶体溶液的粘度降低。粘度的降低表示为从添加酶的水状胶体样品的粘度相对于添加H2O的水状胶体样品的粘度所计算出的相对粘度值。因此,该值始终将在1和0之间,其中1意指样品的粘度没有降低。
底物为GUAR、淀粉、CMC或果胶。
根据底物使用两种缓冲液;
Mcllvaine的柠檬酸磷酸盐:
A)0.1M柠檬酸;21.0g C6H8O7,H2O/1L去离子水
B)0.2M磷酸氢二钠;35.6g Na2HPO4,2H2O/1L去离子水。保质期:3个月
缓冲液(pH 4.0)=71.50ml A+28.50ml B(在带刻度的量筒中)
缓冲液(pH 6.7)=25.00ml A+75.00ml B
底物浓度

底物溶液的制备:
将用于特定底物的缓冲液用水稀释五次,并在带有磁铁的电热板上在Blue Cap瓶中加热。称重水状胶体,并且当缓冲液冒泡时,粉末在剧烈搅拌下撒入直至稀释(约30分钟)。对于淀粉,建议在添加底物时关掉加热,并且取下瓶盖,并且避免底物沸溢-以防止形成块状物等。将水状胶体溶液冷却至40℃,淀粉溶液除外。必须将淀粉储存在50℃下直到使用,以便防止老化。
样品处理
将包括空白的每个样品的5ml底物转移到Wheaton玻璃杯。将100μl酶样品或样品的稀释液(用水制成的)添加到5mL底物溶液中并混合。最多可添加500μL的样品,只要将相同的体积应用于空白样品。将样品在40℃下孵育20h,并且然后通过将样品放在冰上终止反应。然后使用Brookfield将样品回火至10℃进行粘度测量。
实例5
酶副活性筛选
对样品1和商业GODO YNL2乳糖酶进行筛选,用于进行比较。样品1是包括由枯草芽 孢杆菌宿主细胞产生的具有转半乳糖基化活性的酶的多肽组合物,其中纤维素、甘露聚糖酶和果胶酶未失活。测定和结果列于表2中。观察到,与GODO YNL2乳糖酶相比,样品1具有显著更高水平的甘露聚糖酶和CMC酶活性。
表2

甘露聚糖酶和纤维素酶水平的半定量
通过稀释样品直到几乎不能再观察到粘度变化来评估样品1中存在的纤维素酶和甘露聚糖酶的水平。测试浸解酶以确定当在发酵期间在大豆介质中使用时,它是否对存在于最终产品中的甘露聚糖酶和纤维素酶的水平有影响。浸解酶是一种已知的纤维素酶,并且因此它只测试甘露聚糖酶活性,因为纤维素酶活性将被预期。稀释度(参见表3)表明在浸解酶中高水平的甘露聚糖酶活性和样品中高水平的甘露聚糖酶和纤维素酶活性。存在于浸解酶中的甘露聚糖酶活性水平不能仅仅解释存在的甘露聚糖酶水平,因为在浸解酶的F10.000稀释液中相对粘度接近1,而样品1必须稀释超过F100.000以便相对粘度接近1。
添加100μL所指示浸解酶原料或样品1的稀释液的GUAR或CMC溶液的相对粘度。浸解酶原料是浸渍样品的54倍稀释液,该浸渍样品对应于在发酵期间向大豆介质中添加酶时所制备的稀释液。
表3

在敲除果胶酶、甘露聚糖酶和纤维素酶的新宿主菌株中的副活性筛选
决定从枯草芽孢杆菌宿主菌株(样品2)中敲除果胶酶、纤维素酶和甘露聚糖酶,并且然后重新测试副活性的存在。收到使用新菌株的第一次3K发酵样品,用于分析。将来自3K样品的结果与使用样品1的结果进行比较,显然使用样品2,果胶酶、纤维素酶和甘露聚糖酶的副活性水平降低(参见表4)。
表4

使用Gilson Viscoman的粘度测定规范
为了确定酸奶应用中的甘露聚糖酶和纤维素酶活性的阈值水平,使用了基于粘度降低来定量甘露聚糖酶和纤维素酶活性的测定。对于该测定,使用来自Biolab A/S的Viscoman自动移液器来确定每个样品中的粘度。
为了确定使用Viscoman的样品中的变化,在根据测试3制备的0.5%GUAR底物上测量粘度。在6种不同的底物制剂上进行三次样品测量。6次运行中最大变化为约4%。为了安全起见,将样品中的变化限设定为5%。为了使空白样品的变化不与添加酶的样品的变化重叠,我们需要观察粘度的变化处于大于10%。这意味着为了说样品包含甘露聚糖酶活性,相对粘度应该小于0.9。因此,将标准曲线的相对粘度的上限设定为0.85。
表5

使用标准品(699MU/Kg)测试适用于甘露聚糖酶粘度测定的酶稀释范围。还测试了包含甘露聚糖酶活性的样品,样品1。通过最小二乘法发现当相对粘度相对于LN(MU/Kg)进行绘制时,数据呈现直线(参见图2)。从在GUAR底物中具有标准酶稀释液的6次运行得出结论,R2≥0.98的直线呈现在0.25-0.85的范围内(数据未显示)。为了限制测试量,对于使用的所有底物,相对粘度值的规定设定为≥0.25且≤0.85。
图2中的曲线图显示样品1(标准品)的稀释液相对于LN(MU/Kg)绘制的相对粘度,其中基于Viscoman使用速度2确定粘度。它还显示了相对于LN(MU/Kg)所绘制的,以速度1所确定的样品1的1-4MU/Kg样品的相对粘度,和以速度2所确定的样品1的5-80MU/Kg样品的相对粘度。
另外,还显而易见的是,仅当基于Viscoman使用相同速度获得数据时才能获得线性函数(参见图1)。基于Viscoman使用相同速度获得数据。针对该测定,低粘度样品使最相关的,并且因此所有样品应使用速度2测量,这意味着粘度低于400mPa.s。因此,定义了当以速度2用Viscoman测量时,底物空白样品应具有在60-130mPa.s内的粘度。
甘露聚糖酶定量测定:
为了建立基于相对粘度的甘露聚糖酶定量测定,我们使用来自甘露聚糖酶比色测定的建立的对照和标准品450MU/Kg。确定样品1、样品2和浸解酶的甘露聚糖酶活性。外推该线,发现粉末的检测限为约0.003MU/Kg(在10mL中最大1g),并且液体的检测限为0.0003MU/Kg。
每个样品如测试3中所述进行处理,但使用Viscoman确定粘度。使用四点标准曲线计算每个样品的甘露聚糖酶活性。下表涉及图3。

计算表明,样品2中的甘露聚糖酶活性主要来源于浸解酶(3MU/Kg除以54,相当于在大豆介质中添加浸解酶时的稀释度)。因此可以确认甘露聚糖酶基因已被有效地从宿主菌株中敲除。
纤维素酶定量测定
基于相对粘度,使用对照2222CMCU/g和标准品2306CMCU/g来建立的纤维素酶定量测定。将标准品的相对粘度值相对于LN(CMCU/g)进行绘制,并在相对粘度为0,242-0,885(参见图4)内,被证实是线性的。外推该线,发现该测定的液体检测限为约0.002CMCU/g,并且粉末检测限为0.02CMCU/g。
将来自发酵的具有或没有浸解酶的两个额外样品与现有样品一起进行纤维素酶活性测试。结果显示,从宿主菌株敲除纤维素酶是有效的(34CMCU/g对比约4CMCU/g),尽管由于在发酵期间在大豆介质中浸解酶的添加,仍存在一定活性(参见表6和图4)。
表6
| 样品ID | CMCU/g |
| 对照 | 2414 |
| 样品1 | 34,38 |
| 样品2 | 4,1 |
| 标准品:用浸解酶发酵,806LAU/g | 3,4 |
| 标准品:用浸解酶发酵,971LAU/g | <0,002 |
在酸奶应用中的纤维素酶阈值水平
为了建立酸奶应用的纤维素酶阈值水平,采用用于粘度测定的纤维素酶对照处理饮用酸奶。将一份饮用酸奶(MILRAM,开菲尔饮品(Kefir Drink),草莓(Erdbeere);BB 14-02-14)等分5mL在Wheaton玻璃杯中,每份样品一式两份。将原料稀释液(0,081mL,在1000mL中)进一步以10倍因子稀释为四个新样品。将每个样品的100μL以及空白样品的100μLddH2O添加到每个5mL酸奶中。然后将样品储存在4℃下或40℃下。在各个时间点,使用Viscoman以速度2测量粘度。
将相对粘度相对于在a)40℃或b)4℃下稀释样品的孵育时间(a)小时b)天)进行绘制。对于每次稀释,注意CMCU/mL酸奶。
这些结果呈现为相对于在40℃(图5a)或4℃(图5b)下孵育的时间所绘制的相对粘度。曲线显示随时间的推移类似的发展,表明40℃孵育可用作加速测定,代替耗时的4℃孵育测定。
为了计算阈值水平,定义了纤维素酶活性的可接受水平在储存期间内会降低粘度小于10%。基于图5b中所示的数据,计算每个数据点的比活度(相对粘度降低/CMCU/每mL酸奶/h),假设观察到的最高比活度将代表初始速率。
发现最高的比活度为9.6相对粘度降低/CMCU/每mL乳酸/h,意味着在一mL酸奶中每小时粘度将降低960%每CMCU。然后可以计算各储存时期允许10%粘度降低的CMCU/mL阈值水平(参见表7)。
阈值水平=0,1/(比活度*储存时间)
对于1个月的储存,如下计算阈值水平:0.1/(9.6*720)=1,45x 10-5
表7
纤维素酶对照960%粘度降低/h/CMCU/mL

将计算与图5b中的数据进行比较,发现它们与在4℃下孵育1个月的所有稀释液所获得数据相关。3.6x 10-6CMCU/mL或更低的水平在一个月内没有降低粘度超过10%,而超过3.6x 10-6CMCU/mL则使粘度降低了10%以上。
结论
果胶酶、纤维素酶和甘露聚糖酶基因已被有效地从宿主菌株中敲除。
上述说明书中提及的所有出版物通过引用结合在此。本发明的所描述的方法和系统的各种修改和变化对于本领域的技术人员将是显而易知的,而不背离本发明的范围和精神。虽然已结合特定优选实施例描述了本发明,但应当理解,要求保护的本发明不应不适当地限于这类特定实施例。事实上,对于化学、生物化学、生物学、或相关领域的技术人员而言显而易见的、用于执行本发明的所述模式的各种修改预期在以下权利要求的范围内。
序列表
>SEQ ID NO:1(BIF_917)
vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstekt
>SEQ ID NO:2(BIF_995)
vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstektvrsfyysrnyyvktgnkpilpsdvevrysdgtsdrqnvtwdavsddqiakagsfsvagtvagqkisvrvtmideigal
>SEQ ID NO:3(BIF_1068)
Vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstektvrsfyysrnyyvktgnkpilpsdvevrysdgtsdrqnvtwdavsddqiakagsfsvagtvagqkisvrvtmideigallnysastpvgtpavlpgsrpavlpdgtvtsanfavhwtkpadtvyntagtvkvpgtatvfgkefkvtatirvq
>SEQ ID NO:4(BIF_1172)
vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstektvrsfyysrnyyvktgnkpilpsdvevrysdgtsdrqnvtwdavsddqiakagsfsvagtvagqkisvrvtmideigallnysastpvgtpavlpgsrpavlpdgtvtsanfavhwtkpadtvyntagtvkvpgtatvfgkefkvtatirvqrsqvtigssvsgnalrltqnipadkqsdtldaikdgsttvdantggganpsawtnwayskaghntaeitfeyateqqlgqivmyffrdsnavrfpdagktkiqi
>SEQ ID NO:5(BIF_1241)
vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstektvrsfyysrnyyvktgnkpilpsdvevrysdgtsdrqnvtwdavsddqiakagsfsvagtvagqkisvrvtmideigallnysastpvgtpavlpgsrpavlpdgtvtsanfavhwtkpadtvyntagtvkvpgtatvfgkefkvtatirvqrsqvtigssvsgnalrltqnipadkqsdtldaikdgsttvdantggganpsawtnwayskaghntaeitfeyateqqlgqivmyffrdsnavrfpdagktkiqisadgknwtdlaatetiaaqessdrvkpytydfapvgatfvkvtvtnadtttpsgvvcaglteielktat
>SEQ ID NO:6(BIF_1326)
vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstektvrsfyysrnyyvktgnkpilpsdvevrysdgtsdrqnvtwdavsddqiakagsfsvagtvagqkisvrvtmideigallnysastpvgtpavlpgsrpavlpdgtvtsanfavhwtkpadtvyntagtvkvpgtatvfgkefkvtatirvqrsqvtigssvsgnalrltqnipadkqsdtldaikdgsttvdantggganpsawtnwayskaghntaeitfeyateqqlgqivmyffrdsnavrfpdagktkiqisadgknwtdlaatetiaaqessdrvkpytydfapvgatfvkvtvtnadtttpsgvvcaglteielktatskfvtntsaalssltvngtkvsdsvlaagsyntpaiiadvkaegegnasvtvlpahdnvirvitesedhvtrktftinlgteqef
>SEQ ID NO:7两歧双歧杆菌糖苷水解酶催化核心
qnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmty
>SEQ ID NO:8编码全长的核苷酸序列
gcagttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaacagtccgcagcttttattacagccgcaactattatgtcaaaacaggcaacaaaccgattctgccgtcagatgttgaagttcgctattcagatggaacaagcgatagacaaaacgttacatgggatgcagtttcagatgatcaaattgcaaaagcaggctcattttcagttgcaggcacagttgcaggccaaaaaattagcgttcgcgtcacaatgattgatgaaattggcgcactgctgaattattcagcaagcacaccggttggcacaccggcagttcttccgggatcaagaccggcagtcctgccggatggcacagtcacatcagcaaattttgcagtccattggacaaaaccggcagatacagtctataatacagcaggcacagtcaaagtaccgggaacagcaacagtttttggcaaagaatttaaagtcacagcgacaattagagttcaaagaagccaagttacaattggctcatcagtttcaggaaatgcactgagactgacacaaaatattccggcagataaacaatcagatacactggatgcgattaaagatggctcaacaacagttgatgcaaatacaggcggaggcgcaaatccgtcagcatggacaaattgggcatattcaaaagcaggccataacacagcggaaattacatttgaatatgcgacagaacaacaactgggccagatcgtcatgtatttttttcgcgatagcaatgcagttagatttccggatgctggcaaaacaaaaattcagatcagcgcagatggcaaaaattggacagatctggcagcaacagaaacaattgcagcgcaagaatcaagcgatagagtcaaaccgtatacatatgattttgcaccggttggcgcaacatttgttaaagtgacagtcacaaacgcagatacaacaacaccgtcaggcgttgtttgcgcaggcctgacagaaattgaactgaaaacagcgacaagcaaatttgtcacaaatacatcagcagcactgtcatcacttacagtcaatggcacaaaagtttcagattcagttctggcagcaggctcatataacacaccggcaattatcgcagatgttaaagcggaaggcgaaggcaatgcaagcgttacagtccttccggcacatgataatgttattcgcgtcattacagaaagcgaagatcatgtcacacgcaaaacatttacaatcaacctgggcacagaacaagaatttccggctgattcagatgaaagagattatccggcagcagatatgacagtcacagttggctcagaacaaacatcaggcacagcaacagaaggaccgaaaaaatttgcagtcgatggcaacacatcaacatattggcatagcaattggacaccgacaacagttaatgatctgtggatcgcgtttgaactgcaaaaaccgacaaaactggatgcactgagatatcttccgcgtccggcaggctcaaaaaatggcagcgtcacagaatataaagttcaggtgtcagatgatggaacaaactggacagatgcaggctcaggcacatggacaacggattatggctggaaactggcggaatttaatcaaccggtcacaacaaaacatgttagactgaaagcggttcatacatatgcagatagcggcaacgataaatttatgagcgcaagcgaaattagactgagaaaagcggtcgatacaacggatatttcaggcgcaacagttacagttccggcaaaactgacagttgatagagttgatgcagatcatccggcaacatttgcaacaaaagatgtcacagttacactgggagatgcaacactgagatatggcgttgattatctgctggattatgcaggcaatacagcagttggcaaagcaacagtgacagttagaggcattgataaatattcaggcacagtcgcgaaaacatttacaattgaactgaaaaatgcaccggcaccggaaccgacactgacatcagttagcgtcaaaacaaaaccgagcaaactgacatatgttgtcggagatgcatttgatccggcaggcctggttctgcaacatgatagacaagcagatagacctccgcaaccgctggttggcgaacaagcggatgaacgcggactgacatgcggcacaagatgcgatagagttgaacaactgcgcaaacatgaaaatagagaagcgcatagaacaggcctggatcatctggaatttgttggcgcagcagatggcgcagttggagaacaagcaacatttaaagtccatgtccatgcagatcagggagatggcagacatgatgatgcagatgaacgcgatattgatccgcatgttccggtcgatcatgcagttggcgaactggcaagagcagcatgccatcatgttattggcctgagagtcgatacacatagacttaaagcaagcggctttcaaattccggctgatgatatggcagaaatcgatcgcattacaggctttcatcgttttgaacgccatgtc
>SEQ ID NO:9编码BIF_917的核苷酸序列
gttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaaca
>SEQ ID NO:10编码BIF_995的核苷酸序列
gttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaacagtccgcagcttttattacagccgcaactattatgtcaaaacaggcaacaaaccgattctgccgtcagatgttgaagttcgctattcagatggaacaagcgatagacaaaacgttacatgggatgcagtttcagatgatcaaattgcaaaagcaggctcattttcagttgcaggcacagttgcaggccaaaaaattagcgttcgcgtcacaatgattgatgaaattggcgcactg
>SEQ ID NO:11编码BIF_1068的核苷酸序列
gttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaacagtccgcagcttttattacagccgcaactattatgtcaaaacaggcaacaaaccgattctgccgtcagatgttgaagttcgctattcagatggaacaagcgatagacaaaacgttacatgggatgcagtttcagatgatcaaattgcaaaagcaggctcattttcagttgcaggcacagttgcaggccaaaaaattagcgttcgcgtcacaatgattgatgaaattggcgcactgctgaattattcagcaagcacaccggttggcacaccggcagttcttccgggatcaagaccggcagtcctgccggatggcacagtcacatcagcaaattttgcagtccattggacaaaaccggcagatacagtctataatacagcaggcacagtcaaagtaccgggaacagcaacagtttttggcaaagaatttaaagtcacagcgacaattagagttcaa
>SEQ ID NO:12编码BIF_1172的核苷酸序列
gttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaacagtccgcagcttttattacagccgcaactattatgtcaaaacaggcaacaaaccgattctgccgtcagatgttgaagttcgctattcagatggaacaagcgatagacaaaacgttacatgggatgcagtttcagatgatcaaattgcaaaagcaggctcattttcagttgcaggcacagttgcaggccaaaaaattagcgttcgcgtcacaatgattgatgaaattggcgcactgctgaattattcagcaagcacaccggttggcacaccggcagttcttccgggatcaagaccggcagtcctgccggatggcacagtcacatcagcaaattttgcagtccattggacaaaaccggcagatacagtctataatacagcaggcacagtcaaagtaccgggaacagcaacagtttttggcaaagaatttaaagtcacagcgacaattagagttcaaagaagccaagttacaattggctcatcagtttcaggaaatgcactgagactgacacaaaatattccggcagataaacaatcagatacactggatgcgattaaagatggctcaacaacagttgatgcaaatacaggcggaggcgcaaatccgtcagcatggacaaattgggcatattcaaaagcaggccataacacagcggaaattacatttgaatatgcgacagaacaacaactgggccagatcgtcatgtatttttttcgcgatagcaatgcagttagatttccggatgctggcaaaacaaaaattcagatc
>SEQ ID NO:13编码BIF_1241的核苷酸序列
gttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaacagtccgcagcttttattacagccgcaactattatgtcaaaacaggcaacaaaccgattctgccgtcagatgttgaagttcgctattcagatggaacaagcgatagacaaaacgttacatgggatgcagtttcagatgatcaaattgcaaaagcaggctcattttcagttgcaggcacagttgcaggccaaaaaattagcgttcgcgtcacaatgattgatgaaattggcgcactgctgaattattcagcaagcacaccggttggcacaccggcagttcttccgggatcaagaccggcagtcctgccggatggcacagtcacatcagcaaattttgcagtccattggacaaaaccggcagatacagtctataatacagcaggcacagtcaaagtaccgggaacagcaacagtttttggcaaagaatttaaagtcacagcgacaattagagttcaaagaagccaagttacaattggctcatcagtttcaggaaatgcactgagactgacacaaaatattccggcagataaacaatcagatacactggatgcgattaaagatggctcaacaacagttgatgcaaatacaggcggaggcgcaaatccgtcagcatggacaaattgggcatattcaaaagcaggccataacacagcggaaattacatttgaatatgcgacagaacaacaactgggccagatcgtcatgtatttttttcgcgatagcaatgcagttagatttccggatgctggcaaaacaaaaattcagatcagcgcagatggcaaaaattggacagatctggcagcaacagaaacaattgcagcgcaagaatcaagcgatagagtcaaaccgtatacatatgattttgcaccggttggcgcaacatttgttaaagtgacagtcacaaacgcagatacaacaacaccgtcaggcgttgtttgcgcaggcctgacagaaattgaactgaaaacagcgaca
>SEQ ID NO:14编码BIF_1326的核苷酸序列
gttgaagatgcaacaagaagcgatagcacaacacaaatgtcatcaacaccggaagttgtttattcatcagcggtcgatagcaaacaaaatcgcacaagcgattttgatgcgaactggaaatttatgctgtcagatagcgttcaagcacaagatccggcatttgatgattcagcatggcaacaagttgatctgccgcatgattatagcatcacacagaaatatagccaaagcaatgaagcagaatcagcatatcttccgggaggcacaggctggtatagaaaaagctttacaattgatagagatctggcaggcaaacgcattgcgattaattttgatggcgtctatatgaatgcaacagtctggtttaatggcgttaaactgggcacacatccgtatggctattcaccgttttcatttgatctgacaggcaatgcaaaatttggcggagaaaacacaattgtcgtcaaagttgaaaatagactgccgtcatcaagatggtattcaggcagcggcatttatagagatgttacactgacagttacagatggcgttcatgttggcaataatggcgtcgcaattaaaacaccgtcactggcaacacaaaatggcggagatgtcacaatgaacctgacaacaaaagtcgcgaatgatacagaagcagcagcgaacattacactgaaacagacagtttttccgaaaggcggaaaaacggatgcagcaattggcacagttacaacagcatcaaaatcaattgcagcaggcgcatcagcagatgttacaagcacaattacagcagcaagcccgaaactgtggtcaattaaaaacccgaacctgtatacagttagaacagaagttctgaacggaggcaaagttctggatacatatgatacagaatatggctttcgctggacaggctttgatgcaacatcaggcttttcactgaatggcgaaaaagtcaaactgaaaggcgttagcatgcatcatgatcaaggctcacttggcgcagttgcaaatagacgcgcaattgaaagacaagtcgaaatcctgcaaaaaatgggcgtcaatagcattcgcacaacacataatccggcagcaaaagcactgattgatgtctgcaatgaaaaaggcgttctggttgtcgaagaagtctttgatatgtggaaccgcagcaaaaatggcaacacggaagattatggcaaatggtttggccaagcaattgcaggcgataatgcagttctgggaggcgataaagatgaaacatgggcgaaatttgatcttacatcaacaattaaccgcgatagaaatgcaccgtcagttattatgtggtcactgggcaatgaaatgatggaaggcatttcaggctcagtttcaggctttccggcaacatcagcaaaactggttgcatggacaaaagcagcagattcaacaagaccgatgacatatggcgataacaaaattaaagcgaactggaacgaatcaaatacaatgggcgataatctgacagcaaatggcggagttgttggcacaaattattcagatggcgcaaactatgataaaattcgtacaacacatccgtcatgggcaatttatggctcagaaacagcatcagcgattaatagccgtggcatttataatagaacaacaggcggagcacaatcatcagataaacagctgacaagctatgataattcagcagttggctggggagcagttgcatcatcagcatggtatgatgttgttcagagagattttgtcgcaggcacatatgtttggacaggatttgattatctgggcgaaccgacaccgtggaatggcacaggctcaggcgcagttggctcatggccgtcaccgaaaaatagctattttggcatcgttgatacagcaggctttccgaaagatacatattatttttatcagagccagtggaatgatgatgttcatacactgcatattcttccggcatggaatgaaaatgttgttgcaaaaggctcaggcaataatgttccggttgtcgtttatacagatgcagcgaaagtgaaactgtattttacaccgaaaggctcaacagaaaaaagactgatcggcgaaaaatcatttacaaaaaaaacaacagcggcaggctatacatatcaagtctatgaaggcagcgataaagattcaacagcgcataaaaacatgtatctgacatggaatgttccgtgggcagaaggcacaatttcagcggaagcgtatgatgaaaataatcgcctgattccggaaggcagcacagaaggcaacgcatcagttacaacaacaggcaaagcagcaaaactgaaagcagatgcggatcgcaaaacaattacagcggatggcaaagatctgtcatatattgaagtcgatgtcacagatgcaaatggccatattgttccggatgcagcaaatagagtcacatttgatgttaaaggcgcaggcaaactggttggcgttgataatggctcatcaccggatcatgattcatatcaagcggataaccgcaaagcattttcaggcaaagtcctggcaattgttcagtcaacaaaagaagcaggcgaaattacagttacagcaaaagcagatggcctgcaatcaagcacagttaaaattgcaacaacagcagttccgggaacaagcacagaaaaaacagtccgcagcttttattacagccgcaactattatgtcaaaacaggcaacaaaccgattctgccgtcagatgttgaagttcgctattcagatggaacaagcgatagacaaaacgttacatgggatgcagtttcagatgatcaaattgcaaaagcaggctcattttcagttgcaggcacagttgcaggccaaaaaattagcgttcgcgtcacaatgattgatgaaattggcgcactgctgaattattcagcaagcacaccggttggcacaccggcagttcttccgggatcaagaccggcagtcctgccggatggcacagtcacatcagcaaattttgcagtccattggacaaaaccggcagatacagtctataatacagcaggcacagtcaaagtaccgggaacagcaacagtttttggcaaagaatttaaagtcacagcgacaattagagttcaaagaagccaagttacaattggctcatcagtttcaggaaatgcactgagactgacacaaaatattccggcagataaacaatcagatacactggatgcgattaaagatggctcaacaacagttgatgcaaatacaggcggaggcgcaaatccgtcagcatggacaaattgggcatattcaaaagcaggccataacacagcggaaattacatttgaatatgcgacagaacaacaactgggccagatcgtcatgtatttttttcgcgatagcaatgcagttagatttccggatgctggcaaaacaaaaattcagatcagcgcagatggcaaaaattggacagatctggcagcaacagaaacaattgcagcgcaagaatcaagcgatagagtcaaaccgtatacatatgattttgcaccggttggcgcaacatttgttaaagtgacagtcacaaacgcagatacaacaacaccgtcaggcgttgtttgcgcaggcctgacagaaattgaactgaaaacagcgacaagcaaatttgtcacaaatacatcagcagcactgtcatcacttacagtcaatggcacaaaagtttcagattcagttctggcagcaggctcatataacacaccggcaattatcgcagatgttaaagcggaaggcgaaggcaatgcaagcgttacagtccttccggcacatgataatgttattcgcgtcattacagaaagcgaagatcatgtcacacgcaaaacatttacaatcaacctgggcacagaacaagaattt
>SEQ ID NO:15用于生成BIF变体的正向引物
GGGGTAACTAGTGGAAGATGCAACAAGAAG
>SEQ ID NO:16BIF917的反向引物
GCGCTTAATTAATTATGTTTTTTCTGTGCTTGTTC
>SEQ ID NO:17BIF995的反向引物
GCGCTTAATTAATTACAGTGCGCCAATTTCATCAATCA
>SEQ ID NO:18BIF1068的反向引物
GCGCTTAATTAATTATTGAACTCTAATTGTCGCTG
>SEQ ID NO:19BIF1241的反向引物
GCGCTTAATTAATTATGTCGCTGTTTTCAGTTCAAT
>SEQ ID NO:20BIF1326的反向引物
GCGCTTAATTAATTAAAATTCTTGTTCTGTGCCCA
>SEQ ID NO:21BIF1478的反向引物
GCGCTTAATTAATTATCTCAGTCTAATTTCGCTTGCGC
>SEQ ID NO:22两歧双歧杆菌BIF1750
vedatrsdsttqmsstpevvyssavdskqnrtsdfdanwkfmlsdsvqaqdpafddsawqqvdlphdysitqkysqsneaesaylpggtgwyrksftidrdlagkriainfdgvymnatvwfngvklgthpygyspfsfdltgnakfggentivvkvenrlpssrwysgsgiyrdvtltvtdgvhvgnngvaiktpslatqnggdvtmnlttkvandteaaanitlkqtvfpkggktdaaigtvttasksiaagasadvtstitaaspklwsiknpnlytvrtevlnggkvldtydteygfrwtgfdatsgfslngekvklkgvsmhhdqgslgavanrraierqveilqkmgvnsirtthnpaakalidvcnekgvlvveevfdmwnrskngntedygkwfgqaiagdnavlggdkdetwakfdltstinrdrnapsvimwslgnemmegisgsvsgfpatsaklvawtkaadstrpmtygdnkikanwnesntmgdnltanggvvgtnysdganydkirtthpswaiygsetasainsrgiynrttggaqssdkqltsydnsavgwgavassawydvvqrdfvagtyvwtgfdylgeptpwngtgsgavgswpspknsyfgivdtagfpkdtyyfyqsqwnddvhtlhilpawnenvvakgsgnnvpvvvytdaakvklyftpkgstekrligeksftkkttaagytyqvyegsdkdstahknmyltwnvpwaegtisaeaydennrlipegstegnasvtttgkaaklkadadrktitadgkdlsyievdvtdanghivpdaanrvtfdvkgagklvgvdngsspdhdsyqadnrkafsgkvlaivqstkeageitvtakadglqsstvkiattavpgtstektvrsfyysrnyyvktgnkpilpsdvevrysdgtsdrqnvtwdavsddqiakagsfsvagtvagqkisvrvtmideigallnysastpvgtpavlpgsrpavlpdgtvtsanfavhwtkpadtvyntagtvkvpgtatvfgkefkvtatirvqrsqvtigssvsgnalrltqnipadkqsdtldaikdgsttvdantggganpsawtnwayskaghntaeitfeyateqqlgqivmyffrdsnavrfpdagktkiqisadgknwtdlaatetiaaqessdrvkpytydfapvgatfvkvtvtnadtttpsgvvcaglteielktatskfvtntsaalssltvngtkvsdsvlaagsyntpaiiadvkaegegnasvtvlpahdnvirvitesedhvtrktftinlgteqefpadsderdypaadmtvtvgseqtsgtategpkkfavdgntstywhsnwtpttvndlwiafelqkptkldalrylprpagskngsvteykvqvsddgtnwtdagsgtwttdygwklaefnqpvttkhvrlkavhtyadsgndkfmsaseirlrkavdttdisgatvtvpakltvdrvdadhpatfatkdvtvtlgdatlrygvdylldyagntavgkatvtvrgidkysgtvaktftielknapapeptltsvsvktkpskltyvvgdafdpaglvlqhdrqadrppqplvgeqadergltcgtrcdrveqlrkhenreahrtgldhlefvgaadgavgeqatfkvhvhadqgdgrhddaderdidphvpvdhavgelaraachhviglrvdthrlkasgfqipaddmaeidritgfhrferhvg
>SEQ ID NO:23来自两歧双歧杆菌DSM20215的胞外乳糖酶的信号序列
Vrskklwisllfalaliftmafgstssaqa












































Claims (17)
1.一种能够表达编码具有β-半乳糖苷酶活性和/或转半乳糖基化活性的多肽的异源核酸的重组宿主细胞,其中所述宿主细胞相对于亲本宿主细胞被修饰为具有敲除失活的纤维素酶、甘露聚糖酶、果胶酶和淀粉酶,且其中所述宿主细胞是枯草芽孢杆菌细胞;
其中所述宿主细胞包含含有编码该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽的核酸的表达载体,或者所述宿主细胞用编码该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽的核酸转化,
其中该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽选自由以下各项组成的组:
a.来自两歧双歧杆菌且与SEQ ID NO:1具有至少99%序列同一性的氨基酸序列的多肽,
b.来自两歧双歧杆菌且与SEQ ID NO:2具有至少99%序列同一性的氨基酸序列的多肽,
c.来自两歧双歧杆菌且与SEQ ID NO:3具有至少99%序列同一性的氨基酸序列的多肽,
d.SEQ ID NO:1、2、3、4或5的多肽;
且其中所述多肽包含SEQ ID NO:7的催化核心序列。
2.根据权利要求1所述的宿主细胞,其中通过遗传操作修饰该宿主细胞。
3.根据权利要求1所述的宿主细胞,其中该纤维素酶、甘露聚糖酶和果胶酶多肽以及该淀粉酶多肽就酶活性而言在功能上是无活性的。
4.根据权利要求1所述的宿主细胞,其中通过遗传操作使得该具有纤维素酶、甘露聚糖酶和果胶酶活性的多肽以及该具有淀粉酶活性的多肽无活性。
5.根据权利要求2或4所述的宿主细胞,其中该遗传操作是一步基因破坏法、标志物插入、定点诱变、缺失、RNA干扰或反义RNA。
6.根据权利要求1所述的宿主细胞,其中该宿主细胞包含一种表达载体,该表达载体包含编码该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽的核酸。
7.根据权利要求1所述的宿主细胞,其中用一种核酸转化该宿主细胞,该核酸编码该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽。
8.根据权利要求1所述的宿主细胞,其中所述失活的甘露聚糖酶基因是gmuG甘露聚糖酶。
9.根据权利要求1所述的宿主细胞,其中所述失活的纤维素酶基因是bgLC内切葡聚糖酶。
10.根据权利要求1所述的宿主细胞,其中所述失活的果胶酶基因是pel果胶酸裂解酶。
11.根据权利要求1所述的宿主细胞,其中所述宿主细胞具有失活的淀粉酶基因,其中所述基因是amyEα-淀粉酶。
12.一种生产具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽、或包含所述多肽的组合物的方法,该方法包括在培养基中,在适合表达该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽的条件下,培养如权利要求1至11中任一项所述的宿主细胞,并且任选地从该培养基或该宿主细胞中回收该具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽。
13.根据权利要求12的方法,其中从所述培养基或所述宿主细胞获得所述具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽或获得包含所述多肽的组合物,其中所述组合物包含具有所述β-半乳糖苷酶和/或转半乳糖基化活性的多肽并且具有降低量的所述纤维素酶、甘露聚糖酶和果胶酶的酶副活性。
14.根据权利要求12或权利要求13所述的方法,其中所述具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽、或包含所述多肽的组合物没有纤维素酶、甘露聚糖酶和果胶酶活性。
15.一种生产奶产品的方法,该方法包括:通过权利要求12或13的方法提供所述具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽或包含所述多肽的组合物;向含有乳糖的奶产品中添加所述的具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽或所述的组合物。
16.一种生产包含GOS的奶产品的方法,该方法包括:通过权利要求12或13的方法提供所述具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽或包含所述多肽的组合物;向含有乳糖的奶产品中添加所述的具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽或所述的组合物。
17.根据权利要求15或权利要求16所述的方法,其中与使用由表达纤维素酶、甘露聚糖酶和果胶酶的宿主细胞制备的、具有β-半乳糖苷酶和/或转半乳糖基化活性的多肽或包含所述多肽的组合物相比,所述方法用于防止奶产品的粘度和/或质感降低。
Applications Claiming Priority (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB1419897.2A GB201419897D0 (en) | 2014-11-07 | 2014-11-07 | Host cell |
| GBGB1419900.4A GB201419900D0 (en) | 2014-11-07 | 2014-11-07 | Method |
| GBGB1419894.9A GB201419894D0 (en) | 2014-11-07 | 2014-11-07 | Method |
| GB1419897.2 | 2014-11-07 | ||
| GB1419894.9 | 2014-11-07 | ||
| GB1419900.4 | 2014-11-07 | ||
| GBGB1515645.8A GB201515645D0 (en) | 2015-09-03 | 2015-09-03 | Method |
| GB1515645.8 | 2015-09-03 | ||
| PCT/EP2015/075950 WO2016071504A1 (en) | 2014-11-07 | 2015-11-06 | Recombinant host cell expressing beta-galactosidase and/or transgalactosylating activity deficient in mannanase, cellulase and pectinase |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107109352A CN107109352A (zh) | 2017-08-29 |
| CN107109352B true CN107109352B (zh) | 2022-03-04 |
Family
ID=54540056
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201580070585.7A Expired - Fee Related CN107109352B (zh) | 2014-11-07 | 2015-11-06 | 甘露聚糖酶、纤维素酶和果胶酶缺陷型的表达β-半乳糖苷酶和/或转半乳糖基化活性的重组宿主细胞 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US10842163B2 (zh) |
| EP (2) | EP3915384A1 (zh) |
| JP (1) | JP6974166B2 (zh) |
| CN (1) | CN107109352B (zh) |
| AU (1) | AU2015341684B2 (zh) |
| BR (1) | BR112017009189A2 (zh) |
| CA (1) | CA2966718A1 (zh) |
| CL (1) | CL2017001101A1 (zh) |
| CO (1) | CO2017004542A2 (zh) |
| DK (1) | DK3214942T3 (zh) |
| MX (2) | MX2017005981A (zh) |
| WO (1) | WO2016071504A1 (zh) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4165999A1 (en) | 2013-12-11 | 2023-04-19 | DuPont Nutrition Biosciences ApS | A method for preparing a dairy product having a stable content of galacto-oligosaccharide(s) |
| US11479763B2 (en) * | 2017-04-07 | 2022-10-25 | Dupont Nutrition Biosciences Aps | Bacillus host cells producing β-galactosidases and lactases in the absence of p-nitrobenzylesterase side activity |
| CN114343049B (zh) * | 2021-12-31 | 2023-09-29 | 淮阴工学院 | 一种菱角冰淇淋的制备方法 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009071539A1 (en) * | 2007-12-03 | 2009-06-11 | Novozymes A/S | Method for producing a dairy product |
| WO2013182686A1 (en) * | 2012-06-08 | 2013-12-12 | Dupont Nutrition Biosciences Aps | Polypeptides having transgalactosylating activity |
Family Cites Families (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE3650202T3 (de) | 1985-08-29 | 2004-06-03 | Genencor International, Inc., South San Francisco | Expression von heterologen Polypeptiden in filamentösen Pilzen, Verfahren zu deren Herstellung und Vektoren zu deren Herstellung. |
| GB8610600D0 (en) | 1986-04-30 | 1986-06-04 | Novo Industri As | Transformation of trichoderma |
| JP2518663B2 (ja) | 1987-12-24 | 1996-07-24 | 株式会社ヤクルト本社 | ガラクトオリゴ糖含有加工乳の製造法 |
| CA1341226C (en) | 1988-08-16 | 2001-05-01 | Wim Van Hartingsveldt | Gene replacement as a tool for the construction of aspergillus strains |
| JP2930370B2 (ja) | 1990-05-25 | 1999-08-03 | 雪印乳業株式会社 | ガラクトオリゴ糖類含有脱脂粉乳の製造方法 |
| WO1992010581A1 (en) | 1990-12-10 | 1992-06-25 | Genencor International, Inc. | IMPROVED SACCHARIFICATION OF CELLULOSE BY CLONING AND AMPLIFICATION OF THE β-GLUCOSIDASE GENE OF TRICHODERMA REESEI |
| US5861271A (en) | 1993-12-17 | 1999-01-19 | Fowler; Timothy | Cellulase enzymes and systems for their expressions |
| BR9909280A (pt) | 1998-04-01 | 2000-11-21 | Danisco | Exoamilases não maltogênicas e sua utilização no retardo de retrogradação de amido |
| US6268328B1 (en) | 1998-12-18 | 2001-07-31 | Genencor International, Inc. | Variant EGIII-like cellulase compositions |
| JP5042431B2 (ja) | 2000-05-26 | 2012-10-03 | アルラ・フーズ・エイ・エム・ビィ・エイ | Bifidobacteriumから単離された新たな酵素 |
| AU2003230830A1 (en) | 2002-04-09 | 2003-10-27 | The Curators Of The University Of Missouri | Treatment of type 1 diabetes before and after expression of predisposition markers |
| PL1654355T3 (pl) | 2003-06-13 | 2010-09-30 | Dupont Nutrition Biosci Aps | Warianty polipeptydów Pseudomonas o aktywności niemaltogennej egzoamylazy i ich zastosowanie do wytwarzania produktów żywnościowych |
| WO2005007818A2 (en) | 2003-07-07 | 2005-01-27 | Genencor International, Inc. | Exo-specific amylase polypeptides, nucleic acids encoding those polypeptides and uses thereof |
| US8143048B2 (en) | 2003-07-07 | 2012-03-27 | Danisco A/S | Exo-specific amylase polypeptides, nucleic acids encoding those polypeptides and uses thereof |
| EP1644542B1 (en) | 2003-07-15 | 2011-11-02 | Mintek | Oxidative leach process |
| WO2005026356A1 (en) | 2003-09-12 | 2005-03-24 | Commonwealth Scientific And Industrial Research Organisation | Modified gene-silencing nucleic acid molecules and uses thereof |
| US20060018997A1 (en) | 2004-07-07 | 2006-01-26 | Kragh Karsten M | Polypeptide |
| US20060008890A1 (en) | 2004-07-07 | 2006-01-12 | Kragh Karsten M | Polypeptide |
| US20060073583A1 (en) | 2004-09-22 | 2006-04-06 | Kragh Karsten M | Polypeptide |
| US20060008888A1 (en) | 2004-07-07 | 2006-01-12 | Kragh Karsten M | Polypeptide |
| CA2569381A1 (en) | 2004-07-21 | 2006-08-31 | Ambrx, Inc. | Biosynthetic polypeptides utilizing non-naturally encoded amino acids |
| JP4784224B2 (ja) | 2004-09-24 | 2011-10-05 | 味の素株式会社 | 糖鎖転移方法および糖鎖転移酵素 |
| CA2614274A1 (en) | 2005-07-07 | 2007-01-18 | Danisco A/S | Modified amylase from pseudomonas saccharophilia |
| JP2007259733A (ja) * | 2006-03-28 | 2007-10-11 | Sanei Gen Ffi Inc | 発酵乳食品用安定剤および該安定剤を含有する発酵乳食品 |
| FI20065593L (fi) | 2006-09-26 | 2008-03-27 | Valio Oy | Menetelmä galakto-oligosakkarideja sisältävien tuotteiden valmistamiseksi ja niiden käyttö |
| DK2126026T4 (da) | 2007-01-12 | 2023-01-09 | Danisco Us Inc | Forbedret sprøjtetørringsproces |
| CN101396048A (zh) | 2008-11-25 | 2009-04-01 | 内蒙古蒙牛乳业(集团)股份有限公司 | 一种富含低聚半乳糖奶的生产方法 |
| CN102449148B (zh) | 2009-06-05 | 2014-04-30 | 天野酶株式会社 | 来自环状芽孢杆菌的β-半乳糖苷酶 |
| CN101845424B (zh) | 2010-02-20 | 2013-01-16 | 中诺生物科技发展江苏有限公司 | 一种制备β-D-半乳糖苷半乳糖水解酶酶制剂的方法 |
| CN102781587A (zh) | 2010-03-01 | 2012-11-14 | 诺维信公司 | 粘压测定 |
| US9107440B2 (en) | 2010-03-29 | 2015-08-18 | Dupont Nutrition Biosciences Aps | Polypeptides having transgalactosylating activity |
| NZ607149A (en) | 2010-07-19 | 2014-12-24 | Arla Foods Amba | Galacto-oligosaccharide-containing composition and a method of producing it |
| TWI527522B (zh) | 2010-08-13 | 2016-04-01 | 愛之味股份有限公司 | 製備富含半乳寡醣及低乳糖之易吸收乳製品之方法及以該方法製備之機能性乳製品 |
| EP2672019B1 (en) | 2012-06-07 | 2017-01-18 | Caterpillar Work Tools B. V. | A jaw assembly for a demolition tool |
| WO2015061135A1 (en) | 2013-10-24 | 2015-04-30 | Danisco Us Inc. | Functional oligosaccharides composition and a method for reducing fermentable sugars |
| EP4165999A1 (en) | 2013-12-11 | 2023-04-19 | DuPont Nutrition Biosciences ApS | A method for preparing a dairy product having a stable content of galacto-oligosaccharide(s) |
| GB201419900D0 (en) | 2014-11-07 | 2014-12-24 | Dupont Nutrition Biosci Aps | Method |
-
2015
- 2015-11-06 MX MX2017005981A patent/MX2017005981A/es unknown
- 2015-11-06 WO PCT/EP2015/075950 patent/WO2016071504A1/en active Application Filing
- 2015-11-06 CA CA2966718A patent/CA2966718A1/en not_active Abandoned
- 2015-11-06 DK DK15793768.1T patent/DK3214942T3/da active
- 2015-11-06 EP EP21152385.7A patent/EP3915384A1/en not_active Withdrawn
- 2015-11-06 JP JP2017525112A patent/JP6974166B2/ja active Active
- 2015-11-06 CN CN201580070585.7A patent/CN107109352B/zh not_active Expired - Fee Related
- 2015-11-06 AU AU2015341684A patent/AU2015341684B2/en not_active Ceased
- 2015-11-06 EP EP15793768.1A patent/EP3214942B1/en not_active Not-in-force
- 2015-11-06 BR BR112017009189A patent/BR112017009189A2/pt not_active Application Discontinuation
- 2015-11-06 US US15/524,807 patent/US10842163B2/en active Active
-
2017
- 2017-05-04 CL CL2017001101A patent/CL2017001101A1/es unknown
- 2017-05-05 CO CONC2017/0004542A patent/CO2017004542A2/es unknown
- 2017-05-08 MX MX2020014151A patent/MX2020014151A/es unknown
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009071539A1 (en) * | 2007-12-03 | 2009-06-11 | Novozymes A/S | Method for producing a dairy product |
| WO2013182686A1 (en) * | 2012-06-08 | 2013-12-12 | Dupont Nutrition Biosciences Aps | Polypeptides having transgalactosylating activity |
Non-Patent Citations (4)
| Title |
|---|
| Carbohydrate metabolism in Bifidobacteria;KARINA PAKUSAEVA等;《GENES&NUTRITION》;20110216;第6卷(第3期);第294-295页、表6 * |
| KARINA PAKUSAEVA等.Carbohydrate metabolism in Bifidobacteria.《GENES&NUTRITION》.2011,第6卷(第3期), * |
| Purification and characterization of a recombinant β-galactosidase with transgalactosylation activity from BBifidobacterium infantis HL96;M.N. HUNG等;《APPLIED MICROBIOLOGY AND BIOTECHNOLOGY》;20020331;第58卷(第4期);439-445 * |
| THE COMPLETE GENOME SEQUENCE OF THE LACTIC ACID BACTERIUM LACTOCOCCUS LACTIS SSP. LACTIS IL1403;BOLOTIN A.等;《GENOME RESEARCH》;20010531;第11卷(第5期);731-735 * |
Also Published As
| Publication number | Publication date |
|---|---|
| US10842163B2 (en) | 2020-11-24 |
| JP6974166B2 (ja) | 2021-12-01 |
| AU2015341684B2 (en) | 2021-01-07 |
| EP3214942A1 (en) | 2017-09-13 |
| CN107109352A (zh) | 2017-08-29 |
| WO2016071504A1 (en) | 2016-05-12 |
| US20190021352A1 (en) | 2019-01-24 |
| EP3915384A1 (en) | 2021-12-01 |
| MX2017005981A (es) | 2017-06-29 |
| JP2017533712A (ja) | 2017-11-16 |
| DK3214942T3 (da) | 2021-05-25 |
| MX2020014151A (es) | 2021-03-09 |
| CL2017001101A1 (es) | 2017-11-10 |
| BR112017009189A2 (pt) | 2018-03-06 |
| CO2017004542A2 (es) | 2017-09-29 |
| CA2966718A1 (en) | 2016-05-12 |
| EP3214942B1 (en) | 2021-02-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12089609B2 (en) | Polypeptides having transgalactosylating activity | |
| EP4165999A1 (en) | A method for preparing a dairy product having a stable content of galacto-oligosaccharide(s) | |
| US20230301335A1 (en) | Spray-dried composition comprising beta-galactosidase having transgalactosylating activity in combination with maltodextrin and/or nacl and application of the composition | |
| CN107109352B (zh) | 甘露聚糖酶、纤维素酶和果胶酶缺陷型的表达β-半乳糖苷酶和/或转半乳糖基化活性的重组宿主细胞 | |
| EP3392268B1 (en) | Polypeptides having transgalactosylating activity |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20220304 |