WO2025028506A1 - 情報処理装置、情報処理方法、および、情報処理装置用のプログラム - Google Patents
情報処理装置、情報処理方法、および、情報処理装置用のプログラム Download PDFInfo
- Publication number
- WO2025028506A1 WO2025028506A1 PCT/JP2024/027078 JP2024027078W WO2025028506A1 WO 2025028506 A1 WO2025028506 A1 WO 2025028506A1 JP 2024027078 W JP2024027078 W JP 2024027078W WO 2025028506 A1 WO2025028506 A1 WO 2025028506A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- document
- image
- information processing
- masking
- type
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
























Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/412—Layout analysis of documents structured with printed lines or input boxes, e.g. business forms or tables
Definitions
- the present invention relates to an information processing device, an information processing method, and a program for an information processing device that performs information processing on image data of a document.
- Patent Document 1 discloses a program that causes a computer to execute a process of generating a first component image by extracting horizontally extending lines from an image of a form and a second component image by extracting vertically extending lines, dividing the first component image into a plurality of blocks, generating a first feature value that indicates the characteristics of the distribution of the lines in the first component image based on the presence or absence of lines in each block, and dividing the second component image into a plurality of blocks, generating a second feature value that indicates the characteristics of the distribution of the lines in the second component image based on the presence or absence of lines in each block, and identifying and classifying the type of form in the image based on the difference between the first feature value in the form definition registered in advance in a definition body and the generated first feature value, and the difference between the second feature value in the form definition and the generated second feature value.
- the present invention has been made in consideration of the above problems, and one example of the objective of the invention is to provide information processing etc. that improves the accuracy of document sorting.
- the invention described in claim 1 is characterized by comprising a document image acquisition means for acquiring a document image of a standardized document in which the positions of items are determined according to the document type, a template information acquisition means for acquiring template information of a template image prepared for each of the document types, a standardized document discrimination means for comparing the template information with information on the document image to discriminate the document type, a masking item position identification means for identifying the positions of masking items to be masked in the document image, and a masking image generation means for generating a masking image in which the masking items of the document image are masked based on the information on the positions of the masking items.
- the invention described in claim 2 is characterized in that in the information processing device described in claim 1, the masking item position identification means identifies the position of the masking item using a machine learning model for masking item identification that has been machine-trained to identify the position of the masking item in the document image.
- the machine learning model for identifying masking items is a machine learning model for identifying masking items for each document type that is machine-learned for each document type so that the position of the masking items can be identified
- the masking item position identification means identifies the position of the masking items using a machine learning model for identifying masking items for each document type selected for each of the determined document types.
- the invention described in claim 4 is characterized in that, in the information processing device described in claim 1, the template information acquisition means acquires information on feature points of the template image, and the standard document discrimination means extracts feature points from the document image and compares the extracted feature points with the feature points of the template image to discriminate the type of the document.
- the invention described in claim 5 is characterized in that in the information processing device described in claim 4, the feature points of the template image are feature points extracted from an image obtained by removing variable information, including character information, from the template image.
- the invention described in claim 6 is characterized in that, in the information processing device described in claim 4 or claim 5, the standard document discrimination means extracts feature points corresponding to feature points of the template image from the feature points extracted from the document image, selects feature points from the corresponding feature points according to the Hamming distance between the feature points, and discriminates the type of the document based on the number of selected feature points.
- the invention described in claim 7 is characterized in that in the information processing device described in claim 6, the standard document discrimination means discriminates the type of the document based on the number of the selected feature points and the number of feature points of the template image.
- the invention described in claim 8 is characterized in that in the information processing device described in claim 4, the type of the document is determined based on the number of feature points of the document image that correspond to the feature points of the template image.
- the invention described in claim 9 is characterized in that the information processing device described in claim 4 further includes an image correction means for correcting the document image based on feature points extracted from the document image.
- the invention described in claim 10 is characterized in that the information processing device described in claim 1 further includes a code reading means for reading a code written on the document from the document image, and the standard document discrimination means compares the read code with a code associated with the template image to discriminate the type of the document.
- the invention described in claim 11 is characterized in that in the information processing device described in claim 1 or claim 10, the standard document discrimination means compares the document image with the template image to discriminate the type of the document.
- the invention described in claim 12 is characterized by comprising: a document image acquisition means for acquiring a document image of a document including an identification document; a character feature extraction means for extracting character features from text data generated by optically reading the document image; a document discrimination means for discriminating the type of the document based on the extracted character features using a trained machine learning model for document type that outputs a document type when character features are input; a masking item position identification means for identifying the position of a masking item to be masked in the document image; and a masking image generation means for generating a masking image in which the masking item of the document image is masked based on information on the position of the masking item.
- the invention described in claim 13 is characterized in that in the information processing device described in claim 12, the masking item position identification means identifies the position of the masking item using a machine learning model for masking item identification that has been machine-trained to identify the position of the masking item in the document image.
- the invention described in claim 14 is characterized in that, in the information processing device described in claim 13, the machine learning model for identifying masking items is a machine learning model for identifying masking items for each document type that is machine-learned for each document type so that the position of the masking items can be identified, and the masking item position identification means identifies the position of the masking items using a machine learning model for identifying masking items for each document type selected for each of the determined document types.
- the invention described in claim 15 is characterized in that in the information processing device described in any one of claims 12 to 14, the character feature extraction means extracts the character feature consisting of character strings obtained by dividing the text data into predetermined character units and the frequency of occurrence of each of the divided character strings in the text data, and there are a plurality of the predetermined character units.
- the invention described in claim 16 is characterized in that in the information processing device described in claim 15, at least one of the predetermined character units is a one-character unit.
- the invention described in claim 17 is characterized in that in the information processing device described in claim 15, the character feature extraction means extracts the character feature weighted based on the frequency of occurrence of each of the divided character strings.
- the invention described in claim 18 is characterized by including a document image acquisition step in which a document image acquisition means acquires a document image of a standardized document in which the positions of items are determined for each document type, a template information acquisition step in which a template information acquisition means acquires template information of a template image prepared for each document type, a standardized document discrimination step in which a standardized document discrimination means compares the template information with information on the document image to discriminate the document type, a masking item position identification step in which a masking item position identification means identifies the positions of masking items to be masked in the document image, and a masking image generation step in which a masking image generation means generates a masking image in which the masking items of the document image are masked based on the positions of the masking items.
- the document image acquisition means includes a document image acquisition means for acquiring a document image of a document including an identification document, a character feature extraction step for extracting character features from text data generated by optically reading the document image, a document discrimination step for discriminating the type of the document based on the extracted character features using a trained machine learning model for document type that outputs a document type when a character feature is input, a masking item position identification step for identifying the position of a masking item to be masked in the document image, and a masking image generation step for generating a masking image in which the masking item of the document image is masked based on information on the position of the masking item.
- the invention described in claim 20 is characterized in that the computer functions as a document image acquisition means for acquiring a document image of a standardized document in which the positions of items are determined according to the document type, a template information acquisition means for acquiring template information of a template image prepared for each of the document types, a standardized document discrimination means for comparing the template information with information on the document image to discriminate the document type, a masking item position identification means for identifying the positions of masking items to be masked in the document image, and a masking image generation means for generating a masking image in which the masking items of the document image are masked based on the information on the positions of the masking items.
- the invention described in claim 21 is characterized in that a computer is made to function as a document image acquisition means for acquiring document images of documents including personal identification documents, a character feature extraction means for extracting character features from text data generated by optically reading the document image, a document discrimination means for discriminating the type of the document based on the extracted character features using a trained machine learning model for document type that outputs a document type when a character feature is input, a masking item position identification means for identifying the position of a masking item to be masked in the document image, and a masking image generation means for generating a masking image in which the masking item of the document image is masked based on information on the position of the masking item.
- the present invention can improve the accuracy of document sorting and masking.
- FIG. 1 is a schematic diagram illustrating an example of a schematic configuration of an information processing system according to an embodiment of the present invention.
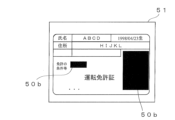
- FIG. 2 is a schematic diagram showing an example of a document.
- FIG. 2 is a schematic diagram showing an example of a document.
- FIG. 2 is a schematic diagram showing an example of a document.
- FIG. 2 is a schematic diagram showing an example of a document.
- 2 is a block diagram showing an example of a schematic configuration of the information processing server shown in FIG. 1 .
- FIG. 2 is a schematic diagram illustrating an example of an image template.
- FIG. 4 is a schematic diagram showing an example of feature points of an image template. 4 is a flowchart showing an example of the operation of the information processing server of FIG.
- FIG. 13 is a schematic diagram showing an example of specifying a masking target.
- FIG. 13 is a schematic diagram showing an example of masking.
- 8B is a flowchart showing a subroutine of the pattern matching sorting of FIG. 8A.
- 10 is a flowchart showing a subroutine for pattern matching sorting of documents in FIG. 9;
- 11 is a flowchart showing a chord determination subroutine of FIG. 10 .
- 11 is a flowchart showing a subroutine of the pattern matching determination in FIG. 10 .
- 8B is a flowchart showing a feature point sorting subroutine of FIG. 8A;
- 14 is a flowchart showing a subroutine for sorting feature points of the document shown in FIG. 13;
- FIG. 13 is a schematic diagram showing an example of specifying a masking target.
- FIG. 13 is a schematic diagram showing an example of masking.
- 8B is a flowchart showing a subroutine of the pattern
- FIG. 2 is a schematic diagram showing an example of a target document.
- FIG. 2 is a schematic diagram showing an example of feature points of a target document.
- FIG. 13 is a schematic diagram showing an example of matched feature points.
- FIG. 13 is a schematic diagram showing an example of unique and matching feature points.
- 8B is a flowchart showing a subroutine of the AI sorting of FIG. 8A.
- 20 is a flowchart showing a subroutine for AI sorting of documents in FIG. 18.
- FIG. 2 is a schematic diagram illustrating an example of text data.
- FIG. 13 is a schematic diagram showing an example of the frequency of appearance of a divided character string;
- FIG. 13 is a schematic diagram showing an example of the frequency of appearance of divided character strings.
- FIG. 1 Overview of management system configuration and functions
- FIG. 1 is a schematic diagram showing an example of the general configuration of an information processing system according to an embodiment of the present invention.
- FIGS. 2A to 4B are schematic diagrams showing examples of documents.
- the information processing system 1 includes an information processing server device 10 that processes information about services such as applications, investigations, and account opening, a terminal device 20 where workers can work on documents, and a user terminal device 30 for users who apply for services.
- the information processing system 1 may also include an image input device (not shown) that captures an image of the document and imports image data of the document image.
- the information processing server device 10 which is an example of an information processing device, is the server of a BPO (Business Process Outsourcing) company that is a service provider or service agent for applications, surveys, account opening, applications for various services, questionnaire surveys, etc.
- the information processing server device 10 performs information processing such as sorting the document types, etc. from the image data of each document included in a set of documents received on paper or via the web.
- the terminal device 20 is, for example, a mobile terminal such as a personal computer, a portable wireless telephone including a smartphone, or a tablet terminal.
- the terminal device 20 is installed according to each worker.
- the terminal device 20 displays document images, etc. on the display unit.
- the user terminal device 30 is, for example, a mobile terminal such as a personal computer, a portable wireless telephone including a smartphone, or a tablet terminal. Using the user terminal device 30, a user can apply for services such as opening a bank account online, or download application forms for services from the web and print them out.
- the image input device has a scanner or digital camera with an imaging element such as a CCD (Charge Coupled Device) image sensor or a CMOS (Complementary Metal Oxide Semiconductor) image sensor.
- the image input device scans or captures documents received from the agent's client or documents sent by the applicant, and generates image data.
- the image input device is connected to the information processing server device 10.
- the information processing server device 10, the terminal device 20, and the user terminal device 30 are capable of transmitting and receiving data to and from each other via the network 3 using, for example, a communication protocol such as TCP/IP.
- the network 3 is constructed, for example, from a local area network, the Internet, a dedicated communication line (for example, a CATV (Community Antenna Television) line), a mobile communication network, a gateway, etc.
- a service provided by a BPO business operator there is an agency service that investigates and confirms the purpose of a transaction by sending a questionnaire or confirmation letter to a customer who has already opened an account with a financial institution and has a transaction, depending on the content and situation of the transaction. This investigation is required for financial institutions to continuously confirm customer information in order to strengthen measures against money laundering and terrorist financing. Customers must respond by accessing a website via documents sent by mail or e-mail. Confirmation is required to be carried out periodically. For example, a BPO business operator prints out the documents to be sent and mails them to the customer or sends them using a communication method such as e-mail.
- the customer writes the necessary information on documents such as a questionnaire by hand, seals them in an envelope, and sends them to the financial institution along with a copy of the identification document or an image taken with a mobile terminal device.
- the necessary information can be entered on a website and sent.
- the BPO business operator then receives the information sent by mail or entered on the website, extracts personal information from the information, and performs screening such as identity verification.
- Submitting documents Online
- Survey subjects who have bank accounts will receive an email or envelope.
- the email or envelope will contain a URL for accessing a questionnaire to confirm the purpose of the transaction, etc., and users can access the URL and answer the questionnaire. They will take a photo of their identity document using a smartphone camera or similar, and send the image of the identity document along with the survey.
- the survey will be submitted as text data, and the identity document will be submitted as image data.
- Sorting (determining the type of document)
- the identification document images are sorted by an information processing system 1 that realizes a sorting system. Different systems are used depending on the type of document.
- the documents are questionnaires for confirming the purpose of the transaction, etc., questionnaires for opening a bank account, identity verification documents, contracts, delivery notes, etc.
- An example of a set of documents that is related to multiple documents is, for example, in the case of confirming the purpose of the transaction, etc., multiple documents such as questionnaires for confirming the purpose of the transaction, etc., identity verification documents, etc.
- the set of documents may include a photograph of the person and multiple identity verification documents.
- the questionnaire (customer information confirmation document) has columns for each item, such as name, sex, date of birth, address, telephone number, place of employment, occupation, purpose of transaction, assets, etc., and often consists of multiple pages, such as questionnaire document 40 on the first page and questionnaire document 41 on the second page.
- Identification documents include driver's licenses, resident registration cards, family register cards, health insurance cards, passports, My Number cards, receipts (for example, receipts for utility bills such as electricity and gas that show the name and address), etc.
- questionnaires examples include questionnaires, applications for opening a bank account (application forms, application forms), identity documents, blank sheets, and other documents.
- questionnaires include the first page of the questionnaire, the second page of the questionnaire, the third page of the questionnaire, etc.
- identity documents include driver's licenses, passports, My Number cards, insurance cards, resident registration cards, receipts, etc.
- documents are classified into standard documents in which the positions of items written on the document are determined for the document type, and non-standard documents in which the positions of items written on the document are not determined for the document type.
- standard documents include driver's licenses, passports, and My Number cards.
- non-standard documents include resident's certificates, the format of which varies from city to city, and insurance cards and receipts, the format of which varies depending on the issuing body.
- the format of license 42 is standardized nationwide, and license 42 is classified as a standard document.
- the format of resident's certificates is not standardized like resident's certificates 43 and 44, and therefore resident's certificates are classified as non-standard documents.
- the questionnaire document may be considered to be a standard document.
- the information processing server device 10 has multiple sorting engines, such as a sorting engine that can sort standard documents by document type, a sorting engine that can sort non-standard documents by document type, and a sorting engine that can sort specific documents with high efficiency.
- a sorting engine is an algorithm or information processing method for determining the document type from image data of a document.
- the review of the above-mentioned task (4) involves comparing the application information in the application documents with the identity verification documents.
- the subject of review in the review is the review items such as the name and address written on the document, and the document as a whole.
- the review items are, for example, review items that can be converted to text, such as the name in kanji, the name in kana, the address, and dates (date of birth, date of entry), as well as review items that are images such as photographs and official seals.
- the application information is, for example, the content of each review item in the application documents.
- Exact match review is a review in which two review items are compared to determine whether there is an exact match, etc.
- Exact content match review is a review in which a review item is compared with a pre-set string to determine whether there is an exact match, etc.
- Date comparison review is a review in which the dates of two review items are compared, or the date of a review item is compared with a pre-set date to determine whether there is a match, etc.
- Kana name review is a review in which a kana name and a kanji name are compared to determine whether there is a match, etc.
- screening questions are set, and workers conduct the screening by answering the screening questions.
- screening questions There are various screening questions, depending on the combination of screening method, document to be screened, and screening item. For example, there are questions to check whether the name in kanji on the questionnaire matches the name in kanji on the driver's license (identification document), whether the address on the driver's license matches the address on the health insurance card, whether the name in kanji on the questionnaire matches the name in kana, and whether the address on the questionnaire matches the address on the resident's card.
- the screening questions may include information on the answer options for the screening questions (such as "match”, "mismatch”, and "unreadable”).
- the screening process may be carried out by a human worker, but may also involve automated screening using a computer.
- automated screening a computer performs screening by comparing the text information of the application documents and the identity document in accordance with predetermined screening rules.
- OCR is performed on the identity document to convert it to text, and a judgment is made as to whether the two match by comparing the text of the application information in the application documents with the text of the application documents.
- an exact match screening can be performed by converting the name written on the identity document to text using OCR, and then comparing this text with the text of the name in the questionnaire by a computer. In this way, the screening process can be automated by having a computer perform exact match screening using text strings, thereby reducing the burden on the screening workers.
- FIG. 5 is a block diagram showing an example of the general configuration of the information processing server device 10.
- FIG. 6 is a schematic diagram showing an example of an image template.
- FIG. 7 is a schematic diagram showing an example of feature points of an image template.
- the information processing server device 10 which is a computer, includes a control unit 11 that controls the information processing server device 10, a storage unit 12 that has various databases, a communication unit 13 that communicates with terminal devices 20 and the like, and an output unit 14 that displays system management information, etc.
- the control unit 11 has, for example, a CPU (Central Processing Unit), a ROM (Read Only Memory), and a RAM (Random Access Memory).
- the control unit 11 may have a calculation chip dedicated to AI calculations, such as a GPU (Graphics Processing Unit).
- the control unit 11 reads and executes various control programs stored in the ROM and RAM by the CPU reading and executing various programs stored in the ROM and memory unit 12.
- the control unit 11 controls each part of the information processing server device 10 (the memory unit 12, the communication unit 13, the output unit 14, etc.).
- the control unit 11 may also read and execute these programs from a recording medium or the like on which they are stored.
- the memory unit 12 (an example of a storage means) is composed of, for example, a hard disk drive, a silicon disk drive, etc.
- the memory unit 12 stores a template database 12a that stores template images of each document, an image feature database 12b that stores features of the template images of each document, an image database 12c that stores image data of each document, and a business information database 12d that stores associations between business information and the sorting engine to be applied.
- the memory unit 12 also stores various trained models for performing processes such as sorting by AI.
- the template database 12a stores pixel data of blank template images associated with document type codes, etc.
- a template image is a sample image used to identify an image similar to a document.
- the top two digits of the document type code may indicate a broad classification code such as "questionnaire document”, “identification document”, “blank”, “other document”, etc.
- the lower digits of the document type code may indicate a more detailed classification such as “first page of questionnaire document”, “second page of questionnaire document”, “third page of questionnaire document” or the type of questionnaire document in the case of a questionnaire document, or a more detailed classification such as “driver's license”, “passport”, “My Number card”, “insurance card” or the like in the case of an identity document.
- the template database 12a may not have template images. Templates may be categorized by business.
- the template database 12a when a one-dimensional code or two-dimensional code is already displayed on a questionnaire document or the like, information on the one-dimensional code or two-dimensional code to be affixed to the questionnaire document or the like is stored in association with a code for the document type. Multiple one-dimensional codes or two-dimensional codes may be printed or otherwise set on the questionnaire document or the like. The total number of one-dimensional codes or two-dimensional codes is the number of set codes. In addition to the code indicating the document type, the code may also include other codes such as information about the customer.
- the template database 12a stores image data of each one-dimensional code and two-dimensional code as a code template image, associated with the document type code. If the number of codes set is two or more, there is a template for each code image. This code image is an example of a template image.
- multiple template images may be used for one document type.
- multiple pattern matching may be performed with the target document image using each template image. If there are two template images for one document type and pattern matching is performed twice, the number of pattern matching settings is "2".
- a code obtained by adding a sub-number to the document type code may be assigned to multiple template images belonging to the same document type. The number of pattern matching settings is stored in the template database 12a.
- the document type code and the code obtained by adding a sub-number or customer code to the document type code are examples of template information for template images for each document type.
- the template image may not be of the entire document, but may be of a part of the document that is likely to have characteristics.
- the template database 12a stores coordinate information for each item such as name, address, and gender in association with a document type code, etc.
- item coordinate information include the range of the item field, and in the case of a name field, the coordinate information of the area in which the name is written, etc.
- the image feature database 12b stores feature data of feature points p extracted by applying a feature extraction algorithm (e.g., Accelerated-KAZE, ORB (Oriented FAST and Rotated BRIEF), SIFT (Scale Invariant Feature Transform), etc.) to a template image in which each item is left blank, in association with a document type code, etc.
- a feature extraction algorithm e.g., Accelerated-KAZE, ORB (Oriented FAST and Rotated BRIEF), SIFT (Scale Invariant Feature Transform), etc.
- feature point data include coordinate information of feature points p and phase information of each feature point p.
- variable information is information that differs for each identity verification document, such as name, address, and face photo.
- feature point extraction is performed using a feature extraction algorithm, there is a possibility that names and face photos will also be extracted as feature points, which increases the number of feature points to be matched, increasing the amount of calculations and slowing down the processing.
- variable information differs for each identity verification document, it is difficult to use it as a feature for sorting or distortion correction, which will be described later.
- the feature point p in the template image is an example of a feature point extracted from an image in which variable information, including text information, has been removed from the template image.
- image database 12c the acquired image data is stored in association with the document set ID of the document set, the document ID issued sequentially for each document, etc.
- image data of items cut out from the document image in the process of dividing the image into document items is stored in association with the document ID, item ID, etc.
- the business information database 12d stores business information associated with the customer information requesting the service, such as the opening of a bank account, the content of the service (e.g., questionnaire surveys), whether manual sorting is required, information on the type of identification document (e.g., whether only a driver's license or whether a resident's certificate is also included), whether the document is a standard or non-standard document, and information on the method of submission (submission via the web, paper submission by mail, or a mixture of both).
- business information associated with the customer information requesting the service such as the opening of a bank account, the content of the service (e.g., questionnaire surveys), whether manual sorting is required, information on the type of identification document (e.g., whether only a driver's license or whether a resident's certificate is also included), whether the document is a standard or non-standard document, and information on the method of submission (submission via the web, paper submission by mail, or a mixture of both).
- various trained machine learning models are constructed in the memory unit 12 for performing processes such as sorting documents by type and detecting document items using AI.
- a trained machine learning model that has been pre-trained is constructed by inputting a feature vector in which the character information of the learning document is one element into multiple machine learning models such as a linear SVM (Support Vector Machine) and a machine learning model for classification such as a gradient boosting tree.
- a linear SVM Small Vector Machine
- a machine learning model for classification such as a gradient boosting tree.
- the memory unit 12 also stores a confidence threshold for the machine learning model used for classification for each type of document.
- This threshold is a judgment threshold for each type of document that has been determined in advance through testing, etc. For example, if the type of document is a driver's license, the confidence threshold is xx%, if the type of document is an insurance card, the confidence threshold is x%, etc.
- AI that performs item detection processing
- teacher data with information tags added to each item of the document is created, and machine learning is performed by AI to build a machine learning model for item detection (an example of a machine learning model for identifying masked items).
- machine learning may be performed by taking the difference before and after the masking work from the actual data of the document and mechanically detecting it.
- machine learning may be performed for each type of document so that each item is identified for each type of document, and a machine learning model for detecting items for each type of document may be built in the storage unit 12.
- the masking items are items that are subject to personal information protection and correspond to information that is not used in the review.
- each database may be managed by the same database on the same information processing server device 10, or each database may be stored in a database on a different information processing server device.
- the storage unit 12 may also store various programs such as an operating system and a server program. Note that the various programs may be obtained, for example, from another server via the network 3, or may be recorded on a recording medium and read via a drive device.
- the communication unit 13 connects to the network 3 and controls communication with the terminal device 20 and the user terminal device 30.
- the output unit 14 is composed of, for example, a liquid crystal display element or an organic EL (Electro Luminescence) element.
- FIG. 8A is a flowchart showing an operation example of the information processing server of Fig. 1.
- Fig. 8B is a schematic diagram showing an example of masking target specification.
- Fig. 8C is a schematic diagram showing an example of masking.
- the information processing server device 10 acquires a series of image data of a set of documents such as identity verification documents from the user terminal device 30, and stores them in the memory unit 12 together with the document set ID of the document set and the document ID issued for each document.
- the identity verification documents are image data photographed with a mobile terminal device equipped with a camera.
- the set of documents may also include image data of the applicant's face.
- the information processing server device 10 acquires data from the user terminal device 30 that associates a document type ID, an item ID indicating each item, and text data entered in the field for each item displayed on the user terminal device 30.
- questionnaire documents such as questionnaire documents 40 and 41 may be assigned a document ID such as a code to identify each document.
- a document ID such as a code to identify each document.
- One example of the assigned code is a one-dimensional code or a two-dimensional code.
- the two-dimensional code or one-dimensional code may be displayed in advance in a specified position such as the bottom right of the document, or it may be included in the image data later.
- documents such as application forms 40 and 41 and questionnaires may be assigned a document ID such as a code to identify each document.
- a document ID such as a code to identify each document.
- One example of the assigned code is a one-dimensional code or a two-dimensional code.
- the two-dimensional code or one-dimensional code may be displayed in advance in a specified position, such as the bottom right of the document, or it may be included in the image data later.
- the envelopes etc. sent by mail are opened.
- the delivered cardboard box is opened and an envelope containing a set of documents such as a questionnaire containing necessary information and a copy of an identification document is removed.
- the envelope is then opened and the set of documents is removed.
- a document ID such as a code for identifying each document is assigned to each of the removed paper documents.
- An image input device scans each document in the set of documents, converts it into image data, and transmits it to the information processing server device 10.
- the information processing server device 10 obtains the series of image data of the set of documents from the image input device and stores it in the memory unit 12 together with the ID of the set of documents and the document IDs issued for each document.
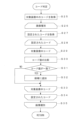
- the information processing server device 10 acquires business information (step S1). Specifically, the control unit 11 refers to the business information database 12d to acquire business information corresponding to the service of the outsourced customer.
- the information processing server device 10 checks the advance designation and determines whether manual sorting is specified (step S2). Specifically, the control unit 11 refers to the business information database 12d to check the advance designation of whether the document type for the set of documents will be sorted using a sorting engine or manually, and determines whether manual sorting is required. Note that there may be a higher-level server device (not shown) that manages the entire system for the information processing server device 10, and the higher-level server device may check the advance designation of whether the document type for the set of documents will be sorted using a sorting engine or manually.
- step S2 If manual sorting is specified (step S2; YES), the information processing server device 10 registers manual sorting for the set of documents (step S3).
- step S4 the information processing server device 10 judges whether or not the documents in the document set are all standard documents. Specifically, the control unit 11 judges whether or not the documents in the document set are all standard documents, based on the business information.
- step S5 the information processing server device 10 determines whether the image is distorted. Specifically, the control unit 11 calculates the degree of distortion of the shape from a rectangle through image processing. When copying an identification document or photographing an identification document with a camera, the image may be distorted.
- the information processing server device 10 determines that the image is distorted.
- the information processing server device 10 may determine whether the document has a code, such as a two-dimensional code or a one-dimensional code. In this case, the presence of a code on the document corresponds to a case where the image is distorted, and the absence of a code on the document corresponds to a case where the image is not distorted.
- step S6 the information processing server device 10 performs pattern matching sorting. Specifically, the control unit 11 sorts the document type for each document by code judgment, which reads the code on the document to determine the document type, or pattern matching (PM) judgment, which determines the document type by pattern matching with a template image. Note that the details of the process will be described later in the pattern matching sorting subroutine. Also, in the case of applications via the web and only text data, pattern matching sorting may be omitted.
- step S7 the information processing server device 10 performs feature point sorting (step S7). Specifically, the control unit 11 sorts each document in the document set into document types by pattern matching with the feature points of the template image. The details of the process will be described later in the feature point sorting subroutine.
- step S8 the information processing server device 10 performs AI sorting (step S8). Specifically, the control unit 11 extracts character features from the text data generated by optically reading the documents, and sorts each document in the set into document types based on the extracted character features using a trained model that outputs the document type when the character features are input. The details of the process will be described later in the AI sorting subroutine.
- the information processing server device 10 performs a masking process (step S9).
- the control unit 11 uses the machine learning model for masking in the memory unit 12 to identify the coordinate positions of the written areas 50a of the items to be masked, such as the license conditions and the face photo, for the document 50 whose document type has been determined, as shown in FIG. 8B.
- the questionnaire document is text data
- image data of the image 50 to be displayed on the terminal device 20 may be generated from the text data, the document type ID and each item ID added to the text data.
- the control unit 11 may refer to the memory unit 12 to select a machine learning model for detecting corresponding items based on the confirmed document type, and use the machine learning of the selected document type to identify the description area 50a of items such as license conditions and facial photographs for the document 50 whose document type has been confirmed.
- the information processing server device 10 functions as an example of a masking item position identification means that identifies the position of the masking item to be masked in the document image.
- the information processing server device 10 functions as an example of a masking item position identification means that identifies the position of the masking item using a machine learning model for masking item identification that has been machine-learned to be able to identify the position of the masking item in the document image.
- the information processing server device 10 functions as an example of a masking item position identification means that identifies the position of the masking item using a machine learning model for masking item identification for each document type selected for each of the determined document types.
- control unit 11 generates an image 51 in which the identified written area 50a is filled in black using masking 50b.
- the information processing server device 10 stores the image data of the image 51 in the image database 12c.
- the information processing server device 10 functions as an example of a masking image generating means that generates a masking image in which the masking items of the document image are masked based on the information on the positions of the masking items.
- the information processing server device 10 transmits the image data of image 51 to the terminal device 20 of the worker in charge of the next task.
- steps S1 to S5 may be performed by a human.
- a human may decide which sorting engine to select from among pattern matching sorting, feature point sorting, and AI sorting.
- Fig. 9 shows the pattern matching sorting subroutine.
- the information processing server device 10 starts loop processing for the target image (an example of a document image) of each document in the document set (step S10).
- the control unit 11 refers to the image database 12c to obtain the number of documents included in the document set, i.e., information on the target images, and performs processing in the loop in order starting from the document set, according to the document ID.
- the questionnaire document is text data, it does not need to be included in the target image.
- the document type is determined by the document type ID added to the text data.
- the information processing server device 10 performs pattern matching sorting of the documents (step S11). Specifically, the control unit 11 performs code judgment, which reads the code of the document to determine the document type, or pattern matching (PM) judgment, which determines the document type by pattern matching with a template image. If there is only one candidate for judgment, the control unit 11 confirms the document type, and if there is not only one candidate for judgment, the control unit 11 marks the document type as undetermined, thereby outputting the result of whether the document type is confirmed or undetermined.
- code judgment which reads the code of the document to determine the document type
- PM pattern matching
- the information processing server device 10 functions as an example of a standard document discrimination means that compares the template information with the document image information to determine the type of the document.
- the information processing server device 10 determines whether the document type has been determined (step S12). Specifically, the control unit 11 determines whether the document type has been determined based on the result of the document pattern matching sorting subroutine indicating whether the document type has been determined or not. The control unit 11 refers to a flag indicating whether the document type has been determined or not.
- the information processing server device 10 registers the document type as a target for manual sorting (step S13). Specifically, the control unit 11 stores the document in the target image, together with the document ID, in the database of the storage unit 12 as a target for manual sorting.
- the information processing server device 10 divides the image (step S14). Specifically, the control unit 11 refers to the template database 12a, acquires coordinate information for each item based on the document type ID of the document type, and cuts out the area corresponding to each item from the image data of the target image to generate an item image. The control unit 11 stores the item image data in the image database 12c in association with the document type ID and item ID of the document type. Note that if the document type is "blank", the information processing server device 10 does not divide the image.
- the information processing server device 10 functions as an example of an extraction means that extracts item images for items according to the determined type of document.
- the information processing server device 10 determines whether the number of loops has reached the number of target images. If the number of target images has not been reached, the information processing server device 10 returns to the processing in step S10 and proceeds to processing the next target image according to the next document ID. If the number of target images has been reached, the information processing server device 10 ends the target image loop processing and ends the pattern matching sorting subroutine (step S15). Note that the determination of the document type sorting determination in step S12 and the manual sorting registration process in step S13 may be outside the target image loop. Also, if the document type is determined in manual sorting, the image division process is performed. After the type is determined in manual sorting, the loop process returns to the processing in step S10, skipping the processing in step S11, and since the type has already been determined in step S12, the image division process in step S14 is performed.
- Fig. 10 shows the subroutine for sorting documents by pattern matching.
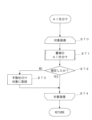
- the information processing server device 10 acquires the target image (step S16).
- the control unit 11 refers to the image database 12c and acquires image data of the target image according to the document ID of the document.
- the information processing server device 10 functions as an example of a document image acquisition means that acquires document images of standardized documents in which the positions of items are determined according to the type of document.
- the information processing server device 10 performs processing for determining whether the target image is blank (step S17). Specifically, the control unit 11 calculates the area of black in the image data of the target image, that is, the area of the part whose brightness is darker than the set threshold value.
- the information processing server device 10 determines whether the image is blank or not (step S18). Specifically, if the ratio of the area of black in the image data of the target image, i.e., the area of the area that is darker than the set threshold, to the area of the entire target image is less than the set threshold, the control unit 11 determines that the target image is blank.
- documents such as questionnaires are printed on only one side of a specified sheet of paper, and the reverse side may be blank. Furthermore, copies of identification documents are usually made on one side of the paper as well.
- image input device When reading a document using an image input device, both sides of the document are actually scanned, taking into consideration the possibility that it may have been printed or copied on both sides. If there is a side that has not been printed, written on, or copied on, that image is sorted as a blank image and is excluded from processing, which can reduce the effort required to process and work with unnecessary images in post-processing and can also reduce the data volume.
- step S19 the information processing server device 10 performs code determination (step S19). Specifically, the control unit 11 uses image processing to read the code value from the image of a one-dimensional code or two-dimensional code within the specified range, compares it with the codes in the template database 12a, and selects the document type corresponding to the matching code as a candidate. The details of the process will be described later in the code determination subroutine.
- the information processing server device 10 functions as an example of a standard document discrimination means that compares the template information with the document image information to determine the type of the document.
- the information processing server device 10 performs a pattern matching determination (step S20). Specifically, the control unit 11 performs pattern matching between the target image and the template image on a pixel-by-pixel basis, calculates a score for the degree of match, and if the score is equal to or greater than a threshold, stores the result as a candidate for the document type. Note that the details of the process will be described later in the pattern matching determination subroutine. Note that the pattern matching determination may be performed before the code determination.
- the information processing server device 10 functions as an example of a standard document discrimination means that compares the template information with the document image information to determine the type of the document.
- the information processing server device 10 determines whether the number of judgment candidates is 1 or not (step S21). Specifically, the control unit 11 determines whether the number of judgment candidates is 1 or not by code judgment or pattern matching judgment.
- the information processing server device 10 determines that the document type has been confirmed (step S22). Specifically, the control unit 11 determines that the document type has been confirmed when the total number of judgment candidates based on the code judgment and pattern matching judgment is one. For example, the control unit 11 sets a flag indicating that the document type has been confirmed, and stores the confirmed document type. Note that if the page is blank, the document type is set to "blank.”
- step S21 determines that the document type is undetermined (step S23). Specifically, the control unit 11 determines that the document type is undetermined if the total number of judgment candidates based on code judgment and pattern matching judgment is not 1. For example, the control unit 11 sets a flag indicating that the document type is undetermined. If the results of the code judgment and PM judgment differ, two results will be registered for one document. In this case, the two judgments do not match, so the document type is undetermined. Even if there is only either code judgment or pattern matching judgment, it is determined as long as it is uniquely determined.
- Fig. 11 shows the chord determination subroutine of Fig. 10.
- the information processing server device 10 acquires the code in the target image (step S25). Specifically, the control unit 11 converts the image of a one-dimensional code or two-dimensional code within a specified range into a code value based on the coordinate information of the code in the document. If there are multiple codes in a single document, each code is read and the codes in the target image are acquired. When acquiring the codes in the target image, the information processing server device 10 counts the number of times a code has been acquired in the target image and determines the number of target codes. At this time, the control unit 11 may cut out the code image of the part where the code is located from the target image. If there are multiple codes, each corresponding code image is cut out.
- the information processing server device 10 functions as an example of a code reading means that reads the code written on the document from the image data.
- the information processing server device 10 starts processing the image type loop (step S26).
- the control unit 11 refers to the image database 12c and performs processing within the image type loop and the number of image types. Note that the code of the template image to be matched may be narrowed down based on the business information.
- the information processing server device 10 acquires the set code (step S27). Specifically, the control unit 11 refers to the template database 12a and acquires the set one-dimensional code or two-dimensional code corresponding to the template image. When acquiring the set code, the information processing server device 10 counts the code to be read and determines the number of set codes. The information processing server device 10 may also acquire the number of set codes by referring to the template database 12a.
- the information processing server device 10 functions as an example of a template information acquisition means that acquires template information of template images prepared for each type of document.
- the information processing server device 10 starts processing the loop of the set code (step S28). Specifically, the control unit 11 performs processing within the loop of the set code the number of times equal to the number of code settings, starting from the document set.
- the information processing server device 10 starts processing the loop of the code in the target image (step S29). Specifically, the control unit 11 processes the loop of the code in the target image a number of times equal to the number of target codes.
- the information processing server device 10 compares the code values (step S30). Specifically, the control unit 11 compares the code value of the target image with the code value of the template image. Note that if the set code includes a code related to a customer, the information processing server device 10 extracts only the document type code and compares it with the code of the template image.
- the information processing server device 10 functions as an example of a standard document type discrimination means that compares the read code with a code associated with the template image to determine the type of the document.
- the information processing server device 10 determines whether the code values match (step S31).
- step S31 If the code values match (step S31; YES), the information processing server device 10 adds them to the candidates (step S32). Specifically, the control unit 11 stores the matching code values and counts the number of judgment candidates.
- step S32 determines whether the number of loops has reached the number of codes in the target image, and if the number of codes has not been reached, returns to the processing of step S29 and compares the code value with the code in the next target image. If the number of codes in the target image has been reached, the loop processing of the codes in the target image ends (step S33).
- the information processing server device 10 determines whether the number of loops has reached the set number of codes, and if the set number of codes has not been reached, returns to the processing of step S28 and starts a new loop of the codes in the target image. If the set number of codes has been reached, the loop processing of the set codes ends (step S34).
- the information processing server device 10 determines whether the number of loops has reached the number of image types, and if the number of image types has not been reached, returns to the processing of step S26 and starts a new loop for the set code. If the number of image types has been reached, the image type loop processing ends, and the code determination subroutine ends (step S35).
- FIG. 12 shows the subroutine for pattern matching determination in FIG. 10.
- the information processing server device 10 starts processing the image type loop as in step S26 (step S36).
- the information processing server device 10 acquires the set template image (step S37). Specifically, the control unit 11 acquires a template image corresponding to the document type code by referring to the template database 12a based on the document type code. If the number of pattern matching settings is not 1, template images equal to the number of pattern matching settings are acquired according to the document type code with a branch number. The information processing server device 10 acquires the number of pattern matching settings by referring to the template database 12a.
- the template image is a template image of a code, a template image of the entire document, or a template image of a portion of a document.
- the information processing server device 10 starts the set pattern matching loop (step S38). Specifically, the control unit 11 performs the processing in the set pattern matching loop the number of times equal to the pattern matching setting number.
- the information processing server device 10 performs pattern matching (step S39). Specifically, the control unit 11 performs pattern matching between the target image and the read-out template image on a pixel-by-pixel basis, and obtains a score (likelihood) of the likelihood of the pattern. For example, a convolution operation is performed between the target image and the template image to calculate the maximum value, and a score is calculated from this maximum value as the degree of match. In the case of a code image, matching is performed between the code image 41a cut out from the target image and the template image of the code image.
- the information processing server device 10 functions as an example of a standard document discrimination means that compares the document image with the template image and determines the type of the document.
- the information processing server device 10 determines whether the score is equal to or greater than a threshold value (step S40). For example, if the score value is equal to or greater than a predetermined value, it is determined that the template is matched.
- step S40 If the score is equal to or greater than the threshold (step S40; YES), the information processing server device 10 adds it to the candidates (step S41). Specifically, the control unit 11 stores the document type code of the matching template image and the score.
- step S40 If the score is not greater than or equal to the threshold (step S40; NO), the information processing server device 10 skips step 41 of adding the candidate.
- the information processing server device 10 determines whether the number of loops has reached the pattern matching set number, and if the pattern matching set number has not been reached, returns to the processing of step S38 and performs pattern matching, etc., using the template image of the next sub-number. If the pattern matching set number has been reached, ends the set pattern matching loop processing (step S42).
- the information processing server device 10 determines whether the number of loops has reached the number of image types, and if the number of image types has not been reached, returns to the processing of step S36 and starts a new pattern matching loop that has been set. If the number of image types has been reached, the information processing server device 10 ends the loop processing of the image type loop and ends the pattern matching determination subroutine (step S43).
- Fig. 13 shows the feature point classification subroutine of Fig. 8.
- the information processing server device 10 starts loop processing for the target image of each document in the document set, as in the processing in step S10 (step S50).
- the questionnaire document is text data, it does not need to be included in the target images.
- the document type is determined by the document type ID added to the text data.
- the information processing server device 10 sorts the document by its feature points (step S51). Specifically, the control unit 11 compares the feature points of the template image, counts the number of unique and matching feature points, and determines the document type if the count is equal to or greater than a predetermined number, and determines the document type as undetermined if the count is less than the predetermined number, thereby outputting the result of whether the document type is determined or undetermined. The details of the process will be described later in the document feature point sorting subroutine.
- the information processing server device 10 functions as an example of a standard document discrimination means that compares the template information with the document image information to determine the type of the document.
- the information processing server device 10 determines whether the document type has been determined (step S52). Specifically, the control unit 11 determines whether the document type has been determined based on the result of the document feature point sorting subroutine indicating whether the document type has been determined or not.
- the information processing server device 10 registers the document type as a target for manual sorting (step S53). Specifically, the control unit 11 stores the document in the target image, together with the document ID, in the database of the storage unit 12 as a target for manual sorting.
- step S52 If the document type has been determined (step S52; YES), the information processing server device 10 divides the image (step S54), as in step S14.
- the information processing server device 10 functions as an example of an extraction means that extracts item images for items according to the determined type of document.
- the information processing server device 10 determines whether the number of loops has reached the number of target images, and if the number of target images has not been reached, returns to the processing of step S50 and proceeds to processing the next target image according to the next document ID, and if the number of target images has been reached, ends the target image loop processing and ends the feature point sorting subroutine (step S55). Note that the determination of the document type sorting confirmation in step S52 and the processing of registering manual sorting in step S53 may be outside the target image loop.
- FIG. 14 shows a subroutine for sorting feature points of the document shown in FIG.
- the information processing server device 10 acquires feature points of the template image (step S56).
- the control unit 11 refers to the image feature database 12b to acquire information on the feature points of each template image.
- the information processing server device 10 functions as an example of a template information acquisition means that acquires template information of the template image prepared for each type of document.
- the information processing server device 10 functions as an example of a template information acquisition means that acquires information on the feature points of the template image.
- the information processing server device 10 acquires the target image (step S57), as in step S16.
- the control unit 11 acquires the target image 45 as shown in FIG. 15.
- the information processing server device 10 functions as an example of a document image acquisition means that acquires a document image of a standardized document in which the positions of items are determined according to the type of document.
- the information processing server device 10 detects feature points of the target image (step S58). Specifically, the control unit 11 applies a feature extraction algorithm to the image data of the target image to extract feature points p of the target image, as shown in FIG. 16. For example, intersections and corners of ruled lines are feature points.
- the information processing server device 10 counts the number of unique matching feature points (step S59).
- the control unit 11 refers to the image feature database 12b, compares the feature points p of the target image as shown in FIG. 16 with the feature points of the template image as shown in FIG. 7, calculates the Hamming distance, and extracts the closest feature point Mp as the matching feature point.
- the closest feature point Mp is extracted as the matching feature point.
- FIG. 17A in the case of the template image #99-12345 in FIG. 7, the feature point Mp corresponding to the feature point of the square shape is extracted from the target image, and in the case of the template image #99-12346 in FIG. 7, the feature point Mp corresponding to the feature point of the lattice square shape is extracted from the target image.
- the first and second closest feature points are also extracted and used to select the unique feature points described below.
- the information processing server device 10 functions as an example of a standard document discrimination means that extracts the feature points from the document image, compares the extracted feature points with the feature points of the template image, and discriminates the type of the document.
- the control unit 11 detects unique feature points Up (an example of a selected feature point) from among the matched feature points Mp (corresponding feature points).
- the most similar feature point and the second most similar feature point are extracted from the target image among the matched feature points, and if the similarity rate is equal to or greater than a threshold, the most similar feature point is selected as a unique feature point, i.e., a matched unique feature point. That is, as shown in FIG. 17B, if the most similar feature point and the second most similar feature point are similar to each other by a certain percentage or more, they are considered to be matched but not unique, and are deleted from the valid feature point list.
- Accelerated-KAZE features are represented as bit strings (binary values) of 0s and 1s, so the similarity can be compared using the number of digits (Hamming distance) that 0s and 1s differ when two bit strings are lined up.
- the information processing server device 10 functions as an example of a standard document discrimination means that discriminates the type of the document based on the number of selected feature points and the number of feature points of the template image.
- the information processing server device 10 determines a template image of the sorting result (step S61). Specifically, the control unit 11 determines the template image with the highest similarity among the similarities calculated in step S60 as the sorting result.
- the information processing server device 10 functions as an example of a standard document discrimination means that discriminates the type of the document based on the number of selected feature points and the number of feature points of the template image.
- the information processing server device 10 judges whether the number of matched unique feature points is equal to or greater than a threshold value (step S62). Specifically, the control unit 11 judges whether the number of matched unique feature points in the most similar template image is equal to or greater than a predetermined value. This process is performed because, even if the most similar template image results, if the number of matched unique feature points in the target image is not equal to or greater than a predetermined value, there is a possibility of erroneous judgment or distortion correction cannot be performed correctly.
- the information processing server device 10 functions as an example of a standard document discrimination means that discriminates the type of the document based on the number of feature points of the target image that correspond to the feature points of the template image.
- step S63 the information processing server device 10 calculates a homography transformation matrix (step S63). Specifically, the control unit 11 calculates a homography transformation matrix using each of the extracted, matched unique feature points, and applies the homography transformation matrix to calculate a distortion-corrected image for the target image.
- the information processing server device 10 functions as an example of an image correction means that corrects the document image based on feature points extracted from the document image.
- the information processing server device 10 judges whether the post-conversion area is within the normal range (step S64). Specifically, the control unit 11 detects "points corresponding to the four corners of the target image" in the coordinate system of the distortion-corrected image by multiplying the area calculated from the four corners of the target image (image before distortion correction) and each point of the four corners of the target image by a homography transformation matrix, and compares this with the post-conversion area calculated from these points to judge whether the post-conversion area is within the normal range.
- step S64 If the converted area is within the normal range (step S64; YES), the information processing server device 10 outputs the sorting result (step S65). Specifically, the control unit 11 stores the confirmed document type and sets a flag indicating that the document type has been confirmed.
- the information processing server device 10 outputs the image after the distortion correction (step S66). Specifically, the control unit 11 transmits the image after the distortion correction, in which the document type has been determined, to the terminal device 20 for the next task.
- step S67 the control unit 11 sets a flag indicating that the document type is undetermined.
- FIG. 18 shows the subroutine for AI sorting in FIG.
- the information processing server device 10 starts loop processing for the target image of each document in the document set, as in the processing in step S10 (step S70).
- the questionnaire document is text data, it does not need to be included in the target images.
- the document type is determined by the document type ID added to the text data.
- the information processing server device 10 performs AI sorting of the documents (step S71). Specifically, the control unit 11 determines the document type using AI from the character features of the target image, and outputs the result of whether the document type is confirmed or not confirmed. The details of the process will be described later in the AI document sorting subroutine.
- the information processing server device 10 registers the document type as a target for manual sorting (step S73). Specifically, the control unit 11 stores the document in the target image, together with the document ID, in the database of the storage unit 12 as a target for manual sorting.
- step S72 the information processing server device 10 determines whether the number of loops has reached the number of target images, and if the number of target images has not been reached, returns to the processing of step S70 and moves on to processing the next target image according to the next document ID, and if the number of target images has been reached, ends the target image loop processing and ends the AI sorting subroutine (step S74). Note that the determination of the finalization of document type sorting in step S72 and the processing of registering manual sorting in step S73 may be outside the target image loop.
- the position of a specific item in the document image may be identified according to the determined document type, and an item image for the identified item may be extracted.
- control unit 11 refers to the storage unit 12 and selects a machine learning model for detecting corresponding items based on the confirmed document type, and uses the machine learning of the selected document type to identify the writing area of each item for the document whose document type has been confirmed.
- the control unit 11 cuts out the area corresponding to each item from the coordinate information of each item whose writing area has been identified and the image data of the target image, and generates an item image.
- the control unit 11 stores the item image data in the image database 12c in association with the document type ID and item ID of the document type.
- the information processing server device 10 functions as an example of an extraction means that identifies the position of a specific item in the document image according to the determined type of the document, and extracts an item image for the identified item.
- FIG. 19 shows a subroutine for AI sorting of the documents shown in FIG.
- the information processing server device 10 acquires the target image (step S75) as in step S16.
- the control unit 11 acquires image data of a document such as a questionnaire document 40 as shown in FIG. 2A.
- the information processing server device 10 functions as an example of a document image acquisition means that acquires document images of documents including identity verification documents.
- the information processing server device 10 performs a sharpening process (step S76). Specifically, the control unit 11 applies a filter to the image data that enhances the contrast of edges to enhance the contours of the target image.
- the information processing server device 10 performs binarization processing (step S77). Specifically, the control unit 11 converts the pixel luminance value to "1" if the pixel luminance value is equal to or greater than a predetermined luminance value, and converts the pixel luminance value to "0" if the pixel luminance value is less than the predetermined luminance value. By performing binarization and sharpening processing, processing is performed to remove noise and emphasize the outlines of characters in preparation for the next OCR processing.
- the information processing server device 10 performs OCR processing (step S78). Specifically, the control unit 11 performs OCR processing on the image data that has been sharpened and binarized, and concatenates multiple pieces of text data obtained to generate text data as shown in FIG. 20. In the case of horizontal writing, the control unit 11 scans horizontally from the top left of the image and concatenates the text data in order.
- the information processing server device 10 uses AI to determine the type of document (step S79). Specifically, the control unit 11 divides the string into one-character units and two-character units, which are examples of predetermined character units. Character n-grams can be used to divide text data. Character n-grams are a method of dividing a document into n consecutive characters. In the case of dividing a string into two-character units, the text data in FIG. 20 is divided into two consecutive characters. As shown in FIG. 21A, the string is divided into two characters, such as " ⁇ ", " ⁇ ”, etc. In the case of dividing a string into one-character units, the string is divided into " ⁇ ", " ⁇ ", " ⁇ ”, etc., as shown in FIG. 21B.
- Strings split into multiple character increments include strings split into 1-character and 2-character increments, strings split into 1-character and 3-character increments, strings split into 2-character and 3-character increments, and strings split into 1-character, 2-character and 3-character increments.
- strings split into 1-character, 2-character and 3-character increments since the text is converted using OCR, there is a possibility of characters being misread or omitted, so it is preferable that single-character increments are included.
- the control unit 11 divides one piece of text data into multiple character strings of a predetermined length, and then calculates the frequency of occurrence of each character string in the text data.
- the frequency of occurrence is calculated for each character string divided into two characters.
- the frequency of occurrence is calculated for each character string divided into one character.
- Two feature vectors are extracted, each of which has each divided character string as an element and the frequency of occurrence of that character string as the element value. That is, as shown in FIG. 21A, the feature vector is composed of two-character strings and the frequency of occurrence of the string, and as shown in FIG. 21B, the feature vector is composed of one-character strings and the frequency of occurrence of the string.
- These feature vectors are also called character features.
- the number of character strings divided into two-character units and the number of character strings divided into one-character units are the number of dimensions of the feature vector.
- the character strings split by the control unit 11 may be weighted according to their importance.
- a weighting method may be the TF-IDF method. Two other feature vectors (feature vectors with weighted elements of frequency of occurrence) are extracted, with each of the split character strings as an element and the element value weighted by the frequency of occurrence of the character string.
- TF Term Frequency
- IDF Inverse Document Frequency
- the TF-IDF value will be low and the character string will have low importance when sorting documents by type. Additionally, the TF-IDF value will be high for a character string that appears frequently in a document and infrequently in other identity verification documents.
- the control unit 11 performs the sorting process. For example, in a driver's license, which is an identification document, the character string "drive” is unlikely to appear in other identification documents such as My Number and insurance cards, and is therefore thought to have a high TF-IDF value. Therefore, in determining the document type using this AI, if an image of an identification document is read and the character string "drive" appears in the image, the control unit 11 can determine that the document type of the identification document image is a "driver's license.”
- the information processing server device 10 functions as an example of a character feature extraction means that extracts character features from text data generated by optically reading the document image.
- the information processing server device 10 extracts the character features composed of character strings obtained by dividing the text data into predetermined character units and the frequency of occurrence of each of the divided character strings in the text data, and functions as an example of a character feature extraction means having a plurality of the predetermined character units.
- the information processing server device 10 functions as an example of a character feature extraction means that extracts the character features by weighting the frequency of occurrence of each of the divided character strings.
- the control unit 11 then inputs each two-character and single-character feature vector for the target image into multiple machine learning models for classification, which output the confidence level for each document type, and outputs the maximum value as the AI sorting result.
- the information processing server device 10 determines whether or not the confidence level for each document type is equal to or greater than the threshold value for that document type (step S80). Specifically, the control unit 11 refers to the database in the storage unit 12 and determines whether or not the confidence level for the maximum document type is equal to or greater than the threshold value for that document type.
- the information processing server device 10 functions as an example of a document discrimination means that discriminates the type of document based on the extracted character features using a trained machine learning model for document type that outputs the document type when character features are input.
- step S80 If it is equal to or greater than the threshold (step S80; YES), the information processing server device 10 outputs the document type sorting result (step S81). Specifically, the control unit 11 stores the confirmed document type and sets a flag indicating that the document type has been confirmed.
- step S80 determines that the document type is undetermined (step S82). Specifically, the control unit 11 sets a flag indicating that the document type is undetermined.
- the sorted identity verification documents and questionnaire documents are then screened in a screening process (4).
- the information processing system 1 compares the cut-out image (cut-out name) with the image of the identity verification document on the work screen, allowing the worker to check whether they are the same.
- the sorting process (2) separates the questionnaire documents and identity verification documents; for example, the sorting process (2) identifies documents on which the name is written on the questionnaire.
- the sorting process (2) also separates the identity verification documents, and the type of identity verification document is determined.
- identification documents In order to strengthen measures against money laundering and terrorist financing, guidelines and other requirements require that investigations of account transactions at financial institutions and other institutions require identity verification using identification documents.
- the review in the review task (4) can be carried out more quickly and reliably. If appropriate identification documents have not been submitted, identification documents are insufficient, or the name on the questionnaire does not match the name on the identification documents (results of the review do not match), the documents will be sent back to the customer and they will be prompted to resubmit the missing documents, etc.
- the necessary identification documents and types are determined by the case, such as if the identification document has a photograph (driver's license, My Number card, etc.), one document is required, and if the identification document does not have a photograph (health insurance card, resident card, etc.), two documents are required.
- the appropriate identification document is not submitted or there is a shortage of identification documents, it means that an identification document that does not meet the regulations has been submitted, or only one identification document has been submitted when two types should be submitted.
- the examination results in the information processing system 1 (matching results with the identification document) and the text data of the questionnaire are prepared for delivery to the customer in the operation (5).
- the contents of the text questionnaire are checked by the customer's bank, etc., and ultimately a check is carried out to see if there has been any fraudulent use of the account.
- a document image of a standardized document in which the positions of items are fixed for each document type is obtained, template information for a template image prepared for each document type is obtained, the template information is compared with the document image information to determine the document type, the positions of the masking items to be masked in the document image are identified, and a masking image in which the masking items in the document image are masked based on the information on the positions of the items to be masked is generated.
- the template information can be effectively used to improve the accuracy of document sorting.
- masking By masking documents after sorting them by type, masking can be performed after the document type has been confirmed, improving the accuracy of automatic masking.
- masking can be performed after the document type has been confirmed, improving the accuracy of automatic masking.
- identifying the position of the masking items to be masked in the document image it is possible to automate the masking process not only for standard form images (driver's licenses, residence cards, etc.), but also for non-standard form images (insurance cards, resident registration cards, etc.) that are difficult to process using image processing.
- the machine learning model for item identification has been trained to identify the location of masked items in document images, making it possible to identify the location of masked items with greater accuracy.
- the machine learning model for identifying items is a machine learning model for identifying masking items for each document type that has been machine-learned for each document type so that the location of masking items can be identified.
- the machine learning time can be shortened and the accuracy of identifying items can be further improved.
- digital data can be handled from the start without the need for paper output, it can be easily integrated into the automation of subsequent processes.
- the data arrives as text data for the application form and image data for the identity verification document, so all that is required is to send the image data to the sorting system, eliminating the need to open envelopes sent in envelopes and the process of scanning paper documents, improving work efficiency.
- feature points p are extracted from a document image, and the extracted feature points p are compared with feature points p of the template image to determine the type of document, the feature points can be used to quickly and accurately sort documents.
- the greater the number of selected feature points Up relative to the number of feature points p in the template image the more similar the target image can be determined to be to the template image, thereby further improving the accuracy of document sorting.
- the distortion of the distorted document image is corrected based on the feature points Up, and OCR is performed on the corrected document image, improving the accuracy of the OCR.
- OCR is performed on the document image of the identification document to convert the items written on the identification document into text. Therefore, correcting the distortion of the document image improves the accuracy of OCR, which ultimately improves the accuracy of the automatic review.
- pattern matching can improve the accuracy of document sorting.
- the code can be used to quickly determine the type.
- the code value read from the code can be combined with pattern matching of the code image to further improve the accuracy of document sorting.
- the cut-out portion is determined by the document type, allowing for efficient image cut-out. Since personal information such as names can be cut out and separated, it is possible to separate workers who handle each item, which leads to the protection of information.
- the document images of documents including identification documents are acquired, character features are extracted from the text data generated by optically reading the document images, and a trained machine learning model for document types that outputs the document type when the character features are input is used to determine the document type based on the extracted character features, and the position of a specific item in the document image is identified and masked according to the document type, thereby generating an image in which the specific items in the document image are masked.
- the entire image is converted to text by OCR, and character features are generated, making it possible to handle not only standard documents such as driver's licenses and residence cards, but also non-standard documents that are difficult to classify in image processing, such as insurance cards and resident cards, and improving the accuracy of document sorting.
- masking can be performed after the document type is confirmed, improving the accuracy of automatic masking.
- the text data is divided into character strings at predetermined character units, and character features composed of the frequency of occurrence of each divided character string in the text data are extracted.
- the accuracy of document sorting can be further improved by using multiple character features. For example, by obtaining two types of features, one for one character unit and one for two characters unit, it is possible to obtain significant features even if the document is in poor condition and the text information as a result of OCR is noisy.
- At least one of the specified character units is a string of two or more characters, missing characters due to blurring of characters, etc., tend to result in a different string of characters, resulting in other components in the feature vector. However, if at least one of the specified character units is a single character unit, only some components of the feature vector are missing, so the feature vector does not change significantly and there is less impact on the accuracy of document sorting.
- weighting the frequency of occurrence using TF-IDF or similar can be used to make it possible to detect a feature that appears frequently in data obtained by OCR conversion of one form but appears infrequently in data obtained by OCR conversion of another form; this is likely to be an important feature, and the use of character features with this weighting can further improve the accuracy of document sorting.
- multiple machine learning models may be used. For example, by combining multiple classifiers such as linear SVM and gradient boosting trees, the accuracy of document classification can be improved.
Landscapes
- Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- Multimedia (AREA)
- Character Input (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2025537433A JPWO2025028506A1 (https=) | 2023-07-31 | 2024-07-30 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023-125141 | 2023-07-31 | ||
| JP2023125141 | 2023-07-31 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2025028506A1 true WO2025028506A1 (ja) | 2025-02-06 |
Family
ID=94394773
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2024/027078 Pending WO2025028506A1 (ja) | 2023-07-31 | 2024-07-30 | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2025028506A1 (https=) |
| WO (1) | WO2025028506A1 (https=) |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000057266A (ja) * | 1998-08-07 | 2000-02-25 | Ricoh Co Ltd | 帳票識別装置、帳票識別方法及び帳票識別プログラムを記録した媒体 |
| JP2007026110A (ja) * | 2005-07-15 | 2007-02-01 | Ricoh Co Ltd | 取引書類管理システム |
| JP2011065646A (ja) * | 2009-09-18 | 2011-03-31 | Fujitsu Ltd | 文字列認識装置及び文字列認識方法 |
| JP2012098984A (ja) * | 2010-11-04 | 2012-05-24 | Nomura Research Institute Ltd | 帳票データ補正方法および帳票データ補正プログラム |
| JP2016130942A (ja) * | 2015-01-14 | 2016-07-21 | 富士ゼロックス株式会社 | 情報処理装置、システム及びプログラム |
| JP2016139335A (ja) * | 2015-01-28 | 2016-08-04 | キヤノン株式会社 | 個人番号管理システム、画像処理装置、画像処理方法、及びプログラム |
| JP2020027524A (ja) * | 2018-08-15 | 2020-02-20 | 株式会社シグマクシス | 文字認識装置、文字認識方法及び文字認識プログラム |
| JP2020113240A (ja) * | 2019-01-09 | 2020-07-27 | 大日本印刷株式会社 | ファイル生成装置、ファイル生成方法、ファイル生成装置用プログラム、および、ファイル生成システム |
| JP2021034772A (ja) * | 2019-08-19 | 2021-03-01 | 大日本印刷株式会社 | 画像処理装置、画像処理方法、画像処理装置用プログラム、および、書類管理システム |
| JP2022108130A (ja) * | 2021-01-12 | 2022-07-25 | 大日本印刷株式会社 | 情報処理装置及びコンピュータプログラム |
| JP2022150290A (ja) * | 2021-03-26 | 2022-10-07 | 沖電気工業株式会社 | 情報処理装置、情報処理方法、プログラムおよび情報処理システム |
-
2024
- 2024-07-30 WO PCT/JP2024/027078 patent/WO2025028506A1/ja active Pending
- 2024-07-30 JP JP2025537433A patent/JPWO2025028506A1/ja active Pending
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000057266A (ja) * | 1998-08-07 | 2000-02-25 | Ricoh Co Ltd | 帳票識別装置、帳票識別方法及び帳票識別プログラムを記録した媒体 |
| JP2007026110A (ja) * | 2005-07-15 | 2007-02-01 | Ricoh Co Ltd | 取引書類管理システム |
| JP2011065646A (ja) * | 2009-09-18 | 2011-03-31 | Fujitsu Ltd | 文字列認識装置及び文字列認識方法 |
| JP2012098984A (ja) * | 2010-11-04 | 2012-05-24 | Nomura Research Institute Ltd | 帳票データ補正方法および帳票データ補正プログラム |
| JP2016130942A (ja) * | 2015-01-14 | 2016-07-21 | 富士ゼロックス株式会社 | 情報処理装置、システム及びプログラム |
| JP2016139335A (ja) * | 2015-01-28 | 2016-08-04 | キヤノン株式会社 | 個人番号管理システム、画像処理装置、画像処理方法、及びプログラム |
| JP2020027524A (ja) * | 2018-08-15 | 2020-02-20 | 株式会社シグマクシス | 文字認識装置、文字認識方法及び文字認識プログラム |
| JP2020113240A (ja) * | 2019-01-09 | 2020-07-27 | 大日本印刷株式会社 | ファイル生成装置、ファイル生成方法、ファイル生成装置用プログラム、および、ファイル生成システム |
| JP2021034772A (ja) * | 2019-08-19 | 2021-03-01 | 大日本印刷株式会社 | 画像処理装置、画像処理方法、画像処理装置用プログラム、および、書類管理システム |
| JP2022108130A (ja) * | 2021-01-12 | 2022-07-25 | 大日本印刷株式会社 | 情報処理装置及びコンピュータプログラム |
| JP2022150290A (ja) * | 2021-03-26 | 2022-10-07 | 沖電気工業株式会社 | 情報処理装置、情報処理方法、プログラムおよび情報処理システム |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2025028506A1 (https=) | 2025-02-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| USRE47309E1 (en) | System and method for capture, storage and processing of receipts and related data | |
| US20210124919A1 (en) | System and Methods for Authentication of Documents | |
| US12111953B2 (en) | Sensitive data detection and replacement | |
| US9626555B2 (en) | Content-based document image classification | |
| US10140511B2 (en) | Building classification and extraction models based on electronic forms | |
| US8879846B2 (en) | Systems, methods and computer program products for processing financial documents | |
| US11393272B2 (en) | Systems and methods for updating an image registry for use in fraud detection related to financial documents | |
| KR101462289B1 (ko) | 모바일 장치 시스템을 이용한 디지털 이미지 아카이빙 및 검색 | |
| US9552516B2 (en) | Document information extraction using geometric models | |
| JP6528147B2 (ja) | 会計データ入力支援システム、方法およびプログラム | |
| US20250273003A1 (en) | Efficient location and identification of documents in images | |
| US20150286860A1 (en) | Method and Device for Generating Data from a Printed Document | |
| US9390089B2 (en) | Distributed capture system for use with a legacy enterprise content management system | |
| US20140268250A1 (en) | Systems and methods for receipt-based mobile image capture | |
| US20220092878A1 (en) | Method and apparatus for document management | |
| US12033367B2 (en) | Automated categorization and assembly of low-quality images into electronic documents | |
| JP7380039B2 (ja) | 設問生成装置、設問生成方法、設問生成装置用プログラム、および、書類管理システム | |
| CN112487982A (zh) | 商户信息的审核方法、系统和存储介质 | |
| WO2025028506A1 (ja) | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム | |
| US20160321499A1 (en) | Learn-Sets from Document Images and Stored Values for Extraction Engine Training | |
| WO2025028505A1 (ja) | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム | |
| JP4356908B2 (ja) | 財務諸表自動入力装置 | |
| WO2025028507A1 (ja) | 情報処理装置、情報処理方法、および、情報処理装置用のプログラム | |
| Bogahawatte et al. | Online digital cheque clearance and verification system using block chain | |
| JP2026047278A (ja) | 書類審査システム、書類審査サーバ装置、審査パッケージ設定装置、書類審査方法、審査パッケージ設定方法、書類審査サーバ装置用プログラム、および、審査パッケージ設定装置用プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24849157 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2025537433 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2025537433 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |