WO2024225425A1 - 標的ヌクレオチド配列の改変のための非天然型ポリヌクレオチド - Google Patents
標的ヌクレオチド配列の改変のための非天然型ポリヌクレオチド Download PDFInfo
- Publication number
- WO2024225425A1 WO2024225425A1 PCT/JP2024/016395 JP2024016395W WO2024225425A1 WO 2024225425 A1 WO2024225425 A1 WO 2024225425A1 JP 2024016395 W JP2024016395 W JP 2024016395W WO 2024225425 A1 WO2024225425 A1 WO 2024225425A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- nucleotide
- nucleotides
- geo
- mismatched
- natural
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





















Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/712—Nucleic acids or oligonucleotides having modified sugars, i.e. other than ribose or 2'-deoxyribose
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/102—Mutagenizing nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7125—Nucleic acids or oligonucleotides having modified internucleoside linkage, i.e. other than 3'-5' phosphodiesters
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/323—Chemical structure of the sugar modified ring structure
- C12N2310/3231—Chemical structure of the sugar modified ring structure having an additional ring, e.g. LNA, ENA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/352—Nature of the modification linked to the nucleic acid via a carbon atom
- C12N2310/3525—MOE, methoxyethoxy
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
Definitions
- the present invention relates to a non-natural polynucleotide capable of specifically binding to a target nucleotide sequence in double-stranded DNA in a cell, for modifying one or more nucleotides contained in the target nucleotide sequence.
- CRISPR-Cas is a genome editing technology that applies the adaptive immune mechanism of eubacteria and archaea, and is used as a genetic engineering tool.
- CRISPR-Cas9 Patent Document 1
- CRISPR Clustered Regularly Interspaced Short Palindromic Repeats
- Cas9 a DNA cleavage enzyme from Streptococcus pyogenes
- CRISPR-Cas9 has problems with off-target effects, such as the misrecognition of genome sequences by the guide RNA sequence and the introduction of unexpected mutations in locations other than the target DNA sequence due to cleavage of double-stranded DNA.
- CRISPR-Cas3 which takes advantage of the fact that the recognition sequence of Cas9 is 20 bases long, while that of E. coli-derived Cas3 is 27 bases long, has enabled more specific mutation introduction (Patent Document 2).
- Patent Document 2 A method that uses a complex linking a guide RNA with DNA sequence recognition ability to a deaminase that converts nucleic acid bases, and a mutant Cas nuclease that has inactivated the cleavage activity of one of the strands of double-stranded DNA, has realized safer and more specific genome editing than CRISPR-Cas9 without inducing double-stranded DNA cleavage (Patent Document 3).
- CRISPR-Cas is a technology that introduces bacterial Cas nuclease or a gene that codes for Cas nuclease into cells, so the problem of unexpected risks from introducing foreign genes remains.
- a genome editing technology that does not use Cas nuclease protein is known to use single-stranded synthetic DNA containing modified nucleic acids.
- a method for modifying a target nucleotide sequence in double-stranded DNA using a single-stranded synthetic DNA in which part of the nucleotide sequence has been replaced with a locked nucleic acid (LNA)
- LNA locked nucleic acid
- a method is known in which an oligonucleotide containing at least one mismatched nucleotide and at least two LNAs, each LNA being positioned at a distance of at least one nucleotide from the at least one mismatched nucleotide, is used in a cell-free experiment (Patent Document 4).
- Non-Patent Document 1 As another example of genome editing technology that does not use Cas nuclease protein, it has been reported that a single-stranded synthetic DNA in which part of the nucleotide sequence is LNA can be introduced into mouse ES cells to introduce 1-3 base mutations into the target nucleotide sequence (Non-Patent Document 1). It is suggested that the technology of Non-Patent Document 1 can improve the problem of off-target effects compared to genome editing technology that uses Cas nuclease protein.
- Non-Patent Document 1 decoded the base sequence of a 335 bp region surrounding the target nucleotide sequence for 33 cells in which the modification of the target nucleotide sequence was confirmed as intended by deciphering the base sequence, and confirmed that no unintended modification had occurred in any part other than the target nucleotide sequence. From this result, the authors explain that the single-stranded synthetic DNA used by the authors of Non-Patent Document 1 was able to achieve very accurate genome editing in mouse-derived ES cells in which the mismatch repair mechanism is functioning.
- Non-Patent Document 1 concluded that it is important that the mismatch nucleotide is LNA in order to avoid the intracellular mismatch repair mechanism and modify the target nucleotide sequence, and have conducted intensive experiments based on this conclusion. In fact, Non-Patent Document 1 conducted experiments using a total of more than 60 types of single-stranded synthetic DNAs, and 41 types of single-stranded synthetic DNAs had at least an LNA mismatch nucleotide.
- Non-Patent Document 2 is a follow-up report by the same authors as Non-Patent Document 1, based on the discovery in Non-Patent Document 1 that when the mismatch nucleotide contained in single-stranded synthetic DNA is LNA, it is possible to avoid the mismatch repair mechanism in cells.
- the main focus of Non-Patent Document 2 is to clarify the mechanism by which single-stranded synthetic DNA with an LNA mismatch nucleotide modifies the genome of mammalian cells.
- the objective of the present invention is to provide a novel non-natural polynucleotide having structural features that enable improved editing efficiency in genome editing technology using non-natural polynucleotides related to single-stranded synthetic DNA in which part of the nucleotide sequence is a cross-linked nucleic acid.
- nucleotides other than the mismatch nucleotides contain nucleotides complementary to the target nucleotide sequence, at least one nucleotide adjacent to the mismatch nucleotide or the 5'-terminal nucleotide is a cross-linked nucleic acid, and which is within a specific chain length range, improves the editing efficiency (yield) of the target nucleotide sequence, thereby completing the present invention.
- a non-natural polynucleotide capable of specifically binding to a target nucleotide sequence for modifying one or more nucleotides contained in the target nucleotide sequence in a double-stranded DNA in a cell comprising: containing one or more mismatched nucleotides relative to the target nucleotide sequence, A non-natural polynucleotide having at least one of the following crosslinked nucleic acids (A) and (B) and further having the characteristics (C) and (D).
- phosphate moiety modification bond includes at least one bond selected from the group consisting of a phosphorothioate bond, a methyl phosphate bond, a boranophosphate bond, and a mesyl phosphoramidate bond.
- the non-naturally occurring polynucleotide according to any one of [1] to [6] above, further comprising the following characteristic (M): (M) One or more nucleotides arranged between the nucleotide adjacent to the 5' upstream side of the mismatch nucleotide and the 5' terminal nucleotide, and arranged at a distance of at least one nucleotide from both the nucleotide adjacent to the 5' upstream side of the mismatch nucleotide and the 5' terminal nucleotide, are bridged nucleic acids.
- M One or more nucleotides arranged between the nucleotide adjacent to the 5' upstream side of the mismatch nucleotide and the 5' terminal nucleotide, and arranged at a distance of at least one nucleotide from both the nucleotide adjacent to the 5' upstream side of the mismatch nucleotide and the 5' terminal nucleotide, are bridged nucleic acids.
- the 3'-terminal nucleotide and/or one or more nucleotides adjacent to the 3'-terminal nucleotide are nucleic acids modified at the 2' site [13].
- the non-natural polynucleotide according to [12] above, wherein the nucleic acid modified at the 2' site comprises at least one selected from the group consisting of 2'-F, 2'-OMe, 2'-MOE, and 2'-O-(2-carbamoylethyl).
- a non-natural polynucleotide capable of specifically binding to a target nucleotide sequence for modifying one or more nucleotides contained in the target nucleotide sequence in a double-stranded DNA in a cell comprising: containing one or more mismatched nucleotides relative to the target nucleotide sequence, A non-naturally occurring polynucleotide having at least one of the following crosslinked nucleic acids (A) and (B), having characteristic (D), and further having one or more characteristics selected from the group consisting of (H2), (Y1), and (Y3).
- a non-natural polynucleotide capable of specifically binding to a target nucleotide sequence for modifying one or more nucleotides contained in the target nucleotide sequence in a double-stranded DNA in a cell comprising: containing one or more mismatched nucleotides relative to the target nucleotide sequence, A non-natural polynucleotide having at least one of the following crosslinked nucleic acids (A) and (B) and further having the characteristics (D) and (X7): (A) one or more nucleotides adjacent to the 5' upstream side of the mismatched nucleotide are bridged nucleic acids; (B) one or more nucleotides adjacent to the 3' downstream side of the mismatched nucleotide are bridged nucleic acids; (D) the chain length is 22 to 95 nucleotides; (X7) one or more nucleotides located between the mismatched nucleotide and the 5' terminal nucleotide are bridged nu
- a non-natural polynucleotide capable of specifically binding to a target nucleotide sequence for modifying one or more nucleotides contained in the target nucleotide sequence in a double-stranded DNA in a cell, comprising: containing one or more mismatch nucleotides relative to the target nucleotide sequence, A non-naturally occurring polynucleotide having all of the following characteristics (C), (D), (I) and (X6).
- the 5'-terminal nucleotide is a bridged nucleic acid
- the chain length is 22 to 95 nucleotides
- the phosphodiester bond between the 3'-terminal nucleotide and one or more nucleotides adjacent to the 3'-terminal nucleotide is replaced with a phosphorothioate bond
- the mismatched nucleotide is a bridged nucleic acid
- a kit for modifying a target nucleotide sequence comprising the non-natural polynucleotide according to any one of [1] to [33] above.
- a pharmaceutical composition comprising the non-naturally occurring polynucleotide according to any one of [1] to [33] above.
- a method for modifying one or more nucleotides contained in a target nucleotide sequence in a double-stranded DNA in a cell comprising: introducing into a cell a non-naturally occurring polynucleotide that contains one or more mismatch nucleotides relative to the target nucleotide sequence;
- the modification of the target nucleotide sequence includes at least one selected from the group consisting of deletion, insertion, and substitution of one or more nucleotides of the target nucleotide sequence;
- the method, wherein the non-natural polynucleotide is the non-natural polynucleotide according to any one of [1] to [33] above.
- the cell is a prokaryotic cell or a eukaryotic cell.
- the eukaryotic cell is at least one selected from the group consisting of a plant cell, an insect cell, and an animal cell.
- the present invention provides a non-natural polynucleotide that has excellent editing efficiency for a target nucleotide sequence.
- FIG. 1 is a schematic diagram showing an overview of the method for modifying a base to be edited in a target nucleotide sequence using a non-natural polynucleotide of the present invention.
- FIG. 2 is a schematic diagram showing an experimental system in which a mutation in an inactive luciferase gene in the genome of a 293-nLD1 cell is edited using a non-natural polynucleotide of the present invention, and the editing efficiency is detected as the luminescence of luciferase.
- 3A is a diagram showing the structures of the unnatural polynucleotides shown in Example 1-1 of the present invention, i.e., 12 types of unnatural polynucleotides, GEO-1 to GEO-9, GEO-242, GEO-11 and GEO-94.
- GEO-94 is a negative control having a base sequence without a mismatched nucleotide.
- G indicates a mismatched nucleotide
- G with an asterisk (i.e., "G*") and L indicate that the pentose in the nucleotide is replaced with LNA.
- 3B is a bar graph showing the editing efficiency (%) of the 12 types of non-natural polynucleotides shown in Example 1-1 of the present invention, namely, GEO-1 to GEO-9, GEO-242, GEO-11, and GEO-94.
- 4 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-2 of the present invention, in which G represents a mismatch nucleotide, and L represents that the pentose in the nucleotide has been replaced with LNA.
- Example 5 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-3 of the present invention, in which G represents a mismatch nucleotide, and L represents that the pentose in the nucleotide has been replaced with LNA.
- 6 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-4 of the present invention, in which G represents a mismatch nucleotide, and L represents that the pentose in the nucleotide has been replaced with LNA.
- FIG. 7 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-5 of the present invention, in which G represents a mismatch nucleotide, and L represents that the pentose in the nucleotide has been replaced with LNA.
- 8A to 8C are diagrams showing the structure of a non-natural polynucleotide shown in Examples 1-6 of the present invention.
- Fig. 8A is a diagram showing the structure of a non-natural polynucleotide in which the phosphodiester bond between the 5'-terminal LNA and the 1st to 5th nucleotides adjacent thereto is replaced with a phosphorothioate bond.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide has been replaced with LNA
- S indicates that the phosphodiester bond has been replaced with a phosphorothioate bond.
- 8B is a diagram showing the structure of a non-natural polynucleotide in which the phosphodiester bond between the 3'-terminal nucleotide and the 1st to 7th nucleotides adjacent thereto is replaced with a phosphorothioate bond.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide is replaced with LNA
- S indicates that the phosphodiester bond is replaced with a phosphorothioate bond.
- 8C is a diagram showing a non-natural polynucleotide structure in which the phosphodiester bond between the 5'-terminal LNA and the four adjacent nucleotides is replaced with a phosphorothioate bond and the phosphodiester bond between the 3'-terminal nucleotide and the four adjacent nucleotides is replaced with a phosphorothioate bond; a non-natural polynucleotide structure in which the phosphodiester bond between the LNA adjacent to the 5'-upstream side of the mismatch nucleotide G and the two or four further adjacent nucleotides is replaced with a phosphorothioate bond; and a non-natural polynucleotide structure in which the nucleotide adjacent
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide is replaced with LNA
- S indicates that the phosphodiester bond is replaced with a phosphorothioate bond.
- 9 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-7 of the present invention, in which G indicates a mismatch nucleotide, L indicates that the pentose in the nucleotide has been replaced with LNA, and S indicates that the phosphodiester bond has been replaced with a phosphorothioate bond.
- 10A is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-8 of the present invention, in which G represents a mismatch nucleotide, and L represents that the pentose in the nucleotide has been replaced with LNA.
- 10B is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-8 of the present invention, in which G represents a mismatch nucleotide, and L represents that the pentose in the nucleotide has been replaced with LNA.
- Example 11 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-9 of the present invention, in which G represents a mismatch nucleotide, L represents that the pentose in the nucleotide has been replaced with LNA, and R represents that the pentose in the nucleotide has been replaced with ribose.
- 12 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-10 of the present invention.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide is replaced with LNA
- P indicates that the 5'-terminal nucleotide and/or the 3'-terminal nucleotide is phosphorylated
- S indicates that the phosphodiester bond moiety is replaced with a phosphorothioate bond.
- 13 is a diagram showing the structure of the non-natural polynucleotide shown in Example 1-11 of the present invention.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide has been replaced with LNA
- H indicates that the pentose in the nucleotide has been replaced with BNA-N-H
- M indicates that the pentose in the nucleotide has been replaced with BNA-N-Me
- E indicates that the pentose in the nucleotide has been replaced with ENA.
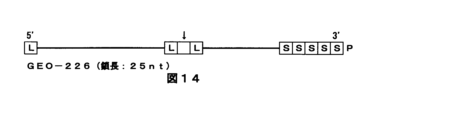
- 1 is a diagram showing an outline of the structure of the non-natural polynucleotide (GEO-226) shown in Example 1-12 of the present invention.
- the arrow indicates the position of the mismatched nucleotide
- L indicates that the pentose in the nucleotide is replaced with LNA
- S indicates that the phosphodiester bond is replaced with a phosphorothioate bond
- P indicates that the 3' end is phosphorylated.
- 1 is a diagram showing an outline of the structure of the non-natural polynucleotide (GEO-172) shown in Example 1-13 of the present invention.
- FIG. 1 shows an outline of the structure of the non-natural polynucleotides (GEO-602 to GEO-605) shown in Example 3-3 of the present invention.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide has been replaced with LNA.
- FIG. 1 shows an outline of the structure of the non-natural polynucleotides (GEO-606 and GEO-693 to GEO-695) shown in Example 3-3 of the present invention.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide has been replaced with LNA.
- the nucleotides L, G, and the black bars are DNA, and the nucleotides in the white bars are RNA.
- FIG. 3 is a diagram showing an outline of the structure of the non-natural polynucleotides (GEO-696, GEO-697, GEO-701, and GEO-702) shown in Example 3-3 of the present invention.
- G indicates a mismatch nucleotide
- L indicates that the pentose in the nucleotide has been replaced with LNA
- S indicates that the phosphodiester bond has been replaced with a phosphorothioate bond.
- the nucleotides at the positions of L, G, and the black bands are DNA
- the nucleotides at the positions of the white bands are RNA.
- Example 1 shows an outline of the structure of the non-natural polynucleotides (GEO-703, GEO-822, and GEO-823) shown in Example 3-3 of the present invention.
- G indicates a mismatched nucleotide
- L indicates that the pentose in the nucleotide has been replaced with LNA
- P indicates that the 3' end has been phosphorylated.
- the nucleotides at the positions of L, G, and black bars are DNA
- the nucleotides at the positions of white bars are RNA.
- the polynucleotide introduced into a cell specifically recognizes and binds to a target nucleotide sequence in the lagging strand of a replication fork during replication of double-stranded DNA, and acts as a primer for synthesis of Okazaki fragments by DNA polymerase.
- the polynucleotide is incorporated into the nascent DNA strand, thereby editing the genome sequence.
- the cells of living organisms are equipped with a mismatch repair mechanism that repairs mismatches that occur during DNA replication, mismatches caused by polynucleotides introduced from outside are also immediately repaired.
- the non-natural polynucleotide of the present invention promotes editing due to the presence of a cross-linked nucleic acid at a specific position in the non-natural polynucleotide, while at the same time reducing the effects of the mismatch repair mechanism, and thus significantly increasing the editing efficiency of the target nucleotide sequence compared to previous reports.
- the efficiency of target nucleotide sequence modification can be further increased by appropriately combining, for example, the number and positions of mismatched nucleotides, the number and positions of cross-linked nucleic acids, the chain length of the polynucleotide, the type of cross-linked nucleic acid, the replacement of a phosphodiester bond between one or more nucleotides with a phosphate-modified bond (e.g., phosphorothioate bond), the replacement of a pentose sugar in one or more nucleotides with a ribose (sometimes abbreviated as "RNA replacement" in this specification), phosphorylation of the 3' or 5' end, addition of an adapter, etc.
- a phosphodiester bond between one or more nucleotides with a phosphate-modified bond e.g., phosphorothioate bond
- RNA replacement sometimes abbreviated as "RNA replacement" in this specification
- phosphorylation of the 3' or 5' end
- nucleotide is a general term for a substance in which a phosphate group is bound to a nucleoside.
- a nucleoside is a pentose in which a purine base or a pyrimidine base is bound to the first position via a glycosidic bond.
- a chain-shaped biopolymer in which nucleotides are the units is a polynucleotide (also called “nucleic acid”).
- DNA deoxyribonucleotides
- RNA ribonucleotides
- DNA is composed of four types of nucleotides: adenosine monophosphate (AMP, hereinafter referred to as “A”), guanosine monophosphate (GMP, hereinafter referred to as “G”), cytidine monophosphate (CMP, hereinafter referred to as “C”), and thymidine monophosphate (dTMP, hereinafter referred to as “T”).
- AMP adenosine monophosphate
- G guanosine monophosphate
- CMP cytidine monophosphate
- T thymidine monophosphate
- RNA contains A, G, and T in common with DNA, but contains uridine monophosphate (UMP, hereinafter referred to as "U”) instead of T.
- U uridine monophosphate
- double-stranded DNA refers to a DNA in which single-stranded DNAs having complementary base sequences form hydrogen bonds between bases in opposite directions to form a double helix.
- the double-stranded DNA in the present invention is not particularly limited, but examples thereof include genomic DNA, mitochondrial DNA, and chloroplast DNA.
- the double-stranded DNA containing a "target nucleotide sequence” is preferably a gene involved in a genetic disease, more preferably a gene involved in a human genetic disease.
- genes related to adrenoleukodystrophy include a gene associated with mucopolysaccharidosis type I (IDUA), a gene associated with primary immunodeficiency syndrome (IKBKB), a gene associated with familial hypertension (ABCD1), genes related to medium-chain acyl-CoA dehydrogenase deficiency (ACADM), genes related to Wilson's disease (ATP7B), genes related to hereditary pulmonary hypertension (BMPR2), genes related to X-linked agammaglobulinemia (BTK), genes related to cystinuria (CTNS), genes related to Duchenne muscular dystrophy (DMD), genes related to hemophilia A (F8), genes related to hemophilia B (F9), genes related to tyrosinemia (FAH), genes related to hepatic glycogen storage disease type Ia (G6PC), genes related to familial frontotemporal lobar degeneration (GRN), genes related to mucopolysaccharidosis type II (IDS),
- a "mismatched nucleotide” refers to a nucleotide that cannot form a Watson-Crick type hydrogen bond between two bases, or a nucleotide that cannot form a Watson-Crick type hydrogen bond between two bases because there is no corresponding nucleotide.
- a "nucleotide that cannot form a Watson-Crick type hydrogen bond between two bases” refers to a nucleotide other than C for G, other than T for A, other than A for T, and other than G for C.
- a Watson-Crick type hydrogen bond between two bases cannot be formed because there is no corresponding nucleotide refers to a nucleotide that does not have any of the corresponding nucleotides A, T, G, and C for G, a nucleotide that does not have any of the corresponding nucleotides A, T, G, and C for A, a nucleotide that does not have any of the corresponding nucleotides A, T, G, and C for T, and a nucleotide that does not have any of the corresponding nucleotides A, T, G, and C for G.
- the non-natural polynucleotide of the present invention may have one or more "mismatch nucleotides” for modifying the base to be edited, and may also have one or more "mismatch nucleotides” that are not involved in the modification.
- the latter "mismatch nucleotide” is a mismatch nucleotide for the purpose of improving editing efficiency, and includes, for example, a mismatch nucleotide inserted between the mismatch nucleotide to be modified and the 3'-terminal nucleotide, and a mismatch nucleotide in the nucleotide when the adaptor is a nucleotide.
- the "target nucleotide sequence” refers to a nucleotide sequence to which a non-natural polynucleotide, which will be described later, specifically binds.
- “specifically binds” includes the following aspects 1 and 2.
- Mode 1 When the non-natural polynucleotide has only a mismatch with the base to be edited, it means that the non-natural polynucleotide binds to a sequence complementary to the non-natural polynucleotide except for the mismatch with the base to be edited.
- Mode 2 When the non-natural polynucleotide has mismatches other than the mismatch with the base to be edited, it means that the non-natural polynucleotide binds to a sequence complementary to the non-natural polynucleotide excluding the mismatched portion.
- Modification of a target nucleotide sequence refers to the substitution of a specific nucleotide (e.g., G) with any of the other three nucleotides (A, T, or C) for one or more nucleotides in the target nucleotide sequence (hereinafter referred to as “substitution”), the deletion of one or more nucleotides in the target nucleotide sequence (hereinafter referred to as “deletion”), or the insertion of another nucleotide or nucleotide sequence between two specific nucleotides in the target nucleotide sequence (hereinafter referred to as "insertion”).
- substitution of a target nucleotide sequence includes substitution, deletion, and insertion each occurring alone, as well as combinations of these.
- non-natural polynucleotide refers to a polynucleotide that contains nucleotides (hereinafter referred to as “non-natural nucleotides”) other than naturally occurring nucleotides (A, T, G, C, or U) among the nucleotides that constitute the polynucleotide.
- the origin of the non-natural nucleotide is not particularly limited, and includes artificially synthesized nucleotides and nucleotides extracted and purified from substances containing non-natural nucleotides.
- Non-natural nucleotides include, but are not limited to, nucleic acids with modified phosphate moieties, nucleic acids with modified sugar moieties, nucleic acids with modified base moieties, nucleic acids with adapters added to the 3' and/or 5' ends, and nucleic acids with one or more nucleotides inserted between the mismatch nucleotide and the 3' end nucleotide.
- Nucleic acids with modified phosphate moieties include, but are not limited to, nucleic acids in which the phosphodiester bond between one or more nucleotides is replaced with a phosphorothioate bond.
- nucleotide having a phosphorothioate bond is called a "phosphorothioated" or "S-modified” nucleotide.
- nucleic acids in which the phosphate moiety is modified include nucleic acids having a methyl phosphate bond, nucleic acids having a boranophosphate bond in which one of the non-bridging oxygen atoms of the phosphate diester bond is replaced with a borano group ( BH3 ) , and nucleic acids having a mesyl phosphoramidate bond in which one of the non-bridging oxygen atoms of the phosphate diester bond is replaced with -NSO2CH3 .
- Nucleic acids with modified sugar moieties include, but are not limited to, nucleic acids with modified 2' sites, and cross-linked nucleic acids in which the 2' and 4' sites are cross-linked.
- Nucleic acids with modified 2' sites include, but are not limited to, 2'-F (F-modified), 2'-O-Methyl (2'-OMe), 2'-O-Methoxyethyl (2'-MOE), 2'-O-(2-carbamoylethyl), etc.
- bridged nucleic acids examples include, but are not limited to, 2'-O,4'-C-methylene-bridged nucleic acid (2',4'-BNA), BNA NC , bicyclic or tricyclic bridged nucleic acid, other bridged nucleic acids, etc.
- 2',4'-BNA is also called Locked Nucleic Acid (LNA) and has the structure shown below.
- BNA/LNA analogues include, but are not limited to, ethylene-bridged BNA (ENA), amide-bridged BNA (AmNA), 2'-(alkylamino)-LNA, 2'-(acylamino)-LNA, 2'-N-substituted-2'-amino-LNA, ⁇ -LNA, ⁇ -L-LNA, ⁇ -D-LNA, 2'-amino-LNA, 2'-thio-LNA, xylo-LNA, 2'-O,4'-C-constrained ethyl (cEt)LNA, 2'-O,4'-C-constrained methoxyethyl (cMOEt)LNA, carba (cLNA), BNACOC, spirocyclopropylene-bridged nucleic acid (scpBNA), heterocyclic-bridged BNA, urea-bridged BNA, sulfonamide-bridged BNA,
- BNA NC includes, but is not limited to, BNA NH, BNA N-Me, and BNA N-Bn.
- Bicyclic or tricyclic bridged nucleic acids include, but are not limited to, TriNA, ⁇ -L-TriNA, F-bcDNA, tricyclic DNA (tcDNA), F-tcDNA, bicyclic carbocyclic nucleotides, bicyclic DNA (bcDNA), 2'-C-bridged bicyclic nucleotides (CBBN), etc.
- cross-linked nucleic acids include, but are not limited to, oxetane nucleotides, locked PMOs derived from 2'-amino-LNA, cyclohexenyl nucleic acid (CeNA), alitriol nucleic acid (ANA), hexitol nucleic acid (HNA), fluorinated HNA (F-HNA), pyranosyl-RNA (p-RNA), 3'-deoxypyranosyl-DNA (p-DNA), etc.
- oxetane nucleotides locked PMOs derived from 2'-amino-LNA, cyclohexenyl nucleic acid (CeNA), alitriol nucleic acid (ANA), hexitol nucleic acid (HNA), fluorinated HNA (F-HNA), pyranosyl-RNA (p-RNA), 3'-deoxypyranosyl-DNA (p-DNA), etc.
- the proportion of cross-linked nucleic acid in the non-natural polynucleotide of the present invention is preferably 2 to 30%, more preferably 2 to 20%, and even more preferably 2 to 15%, assuming that the total number of nucleotides constituting the non-natural polynucleotide is 100%.
- an adapter to the 3'-end and/or 5'-end, since this shows higher editing efficiency.
- examples of adapters include those that have the function of inhibiting mismatch repair in host cells, those that have the function of protecting the non-natural polynucleotide of the present invention from nuclease digestion, and those that have the function of imparting higher editing efficiency than the non-natural polynucleotide (GEO-8) defined by SEQ ID NO: 9 when added to the 3'-end and/or 5'-end.
- the adapter in the present invention has one or more of these functions, and more specific examples of such adapters include (1) nucleotides as adapters and (2) compounds other than nucleotides that modify the ends (referred to as "modifying compounds" in this specification).
- mismatch repair begins when a mismatch repair enzyme in the cell recognizes the strand with the 3'-end as the target for repair, and then the mismatched nucleotide on the strand with the 3'-end is removed and repaired.
- the mismatched nucleotide of the non-natural polynucleotide is repaired because the non-natural polynucleotide has a 3'-end structure.
- a nucleotide is added as an adapter to the 3'-end of the non-natural polynucleotide, the 3'-end of the non-natural polynucleotide does not specifically bind to the target sequence and dissociates, so that it may be avoided from being recognized by the mismatch repair enzyme.
- a modifying compound is added to the 3'-end of the non-natural polynucleotide, it may also be possible that the 3'-end of the non-natural polynucleotide is avoided from being recognized by the mismatch repair enzyme. For these reasons, it is presumed that the editing efficiency of non-natural polynucleotides with adapter nucleotides or modifying compounds added to the 3' end is increased by inhibiting mismatch repair in host cells.
- the estimated mechanism by which the non-natural polynucleotide of the present invention is protected from nuclease digestion in host cells by adding an adapter to the 3'-end and/or 5'-end of the non-natural polynucleotide of the present invention is as follows.
- a single-stranded non-natural polynucleotide introduced into a host cell is subject to digestion by nuclease in the host cell.
- nucleotide as an adapter acts as a buffer to inhibit digestion by exonuclease from progressing to the mismatched nucleotide located in the center of the non-natural polynucleotide.
- IdT is used to increase the nuclease resistance of antisense nucleic acids by adding it to the 3'-end of the antisense nucleic acid.
- the function of inhibiting mismatch repair in a host cell and the function of protecting the non-natural polynucleotide of the present invention from nuclease digestion are achieved by different mechanisms, so the non-natural polynucleotide of the present invention may have both of these functions.
- the structure of the nucleotide as the adaptor includes, for example, a linear nucleotide and a nucleotide forming a stem structure which may have a loop.
- the chain length of the nucleotide as the adaptor is preferably 1 nt (nucleotide) or more, more preferably 3 nt or more, and even more preferably 6 or more, and is preferably 50 nt or less, more preferably 40 nt or less, and even more preferably 30 nt or less.
- the non-natural polynucleotide of the present invention does not include a nucleotide as an adaptor, and therefore the chain length of the nucleotide as the adaptor does not affect the chain length of the non-natural polynucleotide of the present invention.
- the nucleotides serving as adapters are preferably nucleotides containing mismatched nucleotides, and it is more preferable that the nucleotide sequences of the nucleotides serving as adapters are all mismatched with respect to the 5' upstream sequence adjacent to the target nucleotide sequence or the 3' downstream sequence adjacent to the target nucleotide sequence, although one or more may be complementary to the target nucleotide sequence.
- the modifying compound serving as the adaptor is preferably a compound capable of binding to the 3'-terminus and/or 5'-terminus of the non-natural polynucleotide of the present invention.
- the modifying compound is preferably a compound having a certain degree of size.
- the molecular weight of the modifying compound is preferably 50 or more, more preferably 100 or more, and is preferably 2,000 or less, more preferably 1,500 or less, further preferably 1,000 or less, further preferably 800 or less, and further preferably 500 or less.
- Preferred specific examples of the modifying compound include at least one selected from the group consisting of fluorescein (FAM), biotin, puromycin, cholesterol, digoxigenin (DIG) and inverted dT.
- FAM fluorescein
- DIG digoxigenin
- the non-natural polynucleotide of the present invention is a single-stranded polynucleotide, which contains one or more mismatched nucleotides with respect to a target nucleotide sequence, and the nucleotides other than the mismatched nucleotides are nucleotides complementary to the target nucleotide sequence. Therefore, by introducing the non-natural polynucleotide of the present invention into a cell, it can specifically bind to the target nucleotide sequence. As a result, one or more nucleotides in the target nucleotide sequence can be modified to a desired nucleotide.
- the two or more mismatched nucleotides may be adjacent to each other or may be located at different positions.
- the term "multiple" with respect to the number of mismatched nucleotides includes integers of 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 or more, and also includes ranges with these as upper and lower limits. For example, 2 to 3, 2 to 4, 2 to 5, ... 2 to 20, 3 to 4, 3 to 5, 3 to 6, ... 3 to 20, 4 to 5, 4 to 6, 4 to 7, ... 4 to 20, 5 to 6, 5 to 7, 5 to 8, ... 5 to 20, ... 18 to 19, 18 to 20, 19 to 20.
- One embodiment (embodiment (i)) of the non-naturally occurring polynucleotide of the present invention is (A) one or more nucleotides adjacent to the 5' upstream side of the mismatched nucleotide are bridged nucleic acids; (B) one or more nucleotides adjacent to the 3' downstream side of the mismatched nucleotide are bridged nucleic acids; (C) the 5'-terminal nucleotide is a bridged nucleic acid, and (D) the chain length is 22 to 95 nucleotides.
- A one or more nucleotides adjacent to the 5' upstream side of the mismatched nucleotide are bridged nucleic acids
- B one or more nucleotides adjacent to the 3' downstream side of the mismatched nucleotide are bridged nucleic acids
- C the 5'-terminal nucleotide is a bridged nucleic acid
- (D) the chain length is 22 to 95 nucleotides.
- the cross-linked nucleic acid contained in the non-natural polynucleotide of aspect (i) is not particularly limited, but may be at least one selected from the group consisting of LNA, AmNA, BNA N-H, BNA N-Me, and ENA.
- the cross-linked nucleic acid of (A) and/or (B) is preferably LNA or BNA N-H, and more preferably LNA.
- the cross-linked nucleic acid of (C) is preferably LNA, AmNA, BNA N-H, BNA N-Me, or ENA.
- the mismatched nucleotide may or may not be a bridged nucleic acid, but in aspect (i), it is more preferable that the mismatched nucleotide is not a bridged nucleic acid.
- the number of bridged nucleic acids is preferably two.
- the term "multiple” in “multiple nucleotides are bridged nucleic acids" as defined in (A) and (B) above is not particularly limited, but it is preferable that there are two consecutive bridged nucleic acids rather than three or more consecutive bridged nucleic acids, and one is more preferable.
- Another embodiment (embodiment (ii)) of the non-naturally occurring polynucleotide of the present invention is (A) one or more nucleotides adjacent to the 5' upstream side of the mismatched nucleotide are bridged nucleic acids; (C) the 5'-terminal nucleotide is a bridged nucleic acid, and (D) the chain length is 22 to 95 nucleotides (however, the structure does not have the characteristic of (B) above). Even with such a structure, the effects of the present invention can be exhibited.
- the cross-linked nucleic acid contained in the non-natural polynucleotide of embodiment (ii) is not particularly limited, but may be at least one selected from the group consisting of LNA, AmNA, BNA N-H, BNA N-Me, and ENA.
- the cross-linked nucleic acid contained in the non-natural polynucleotide is preferably LNA.
- the mismatched nucleotide may or may not be a bridged nucleic acid, but in aspect (ii), it is more preferable that the mismatched nucleotide is not a bridged nucleic acid.
- the number of bridged nucleic acids is preferably two.
- the term "multiple" in “multiple nucleotides are bridged nucleic acids" as defined in (A) above is not particularly limited, but it is preferable that there are two consecutive bridged nucleic acids rather than three or more consecutive bridged nucleic acids, and one is more preferable.
- a further aspect (aspect (iii)) of the non-naturally occurring polynucleotide of the present invention is (B) one or more nucleotides adjacent to the 3' downstream side of the mismatched nucleotide are bridged nucleic acids; (C) the 5'-terminal nucleotide is a bridged nucleic acid, and (D) the chain length is 22 to 95 nucleotides (however, the structure does not have the characteristic of (A) above). Even with such a structure, the effects of the present invention can be exhibited.
- the cross-linked nucleic acid contained in the non-natural polynucleotide of embodiment (iii) is not particularly limited, but may be at least one selected from the group consisting of LNA, AmNA, BNA N-H, BNA N-Me, and ENA.
- the cross-linked nucleic acid contained in the non-natural polynucleotide is preferably LNA.
- the mismatched nucleotide may or may not be a bridged nucleic acid, but in aspect (iii), it is more preferable that the mismatched nucleotide is not a bridged nucleic acid.
- the number of bridged nucleic acids is preferably two.
- the term "multiple" in “multiple nucleotides are bridged nucleic acids" as defined in (B) above is not particularly limited, but it is preferable that there are two consecutive bridged nucleic acids rather than three or more consecutive bridged nucleic acids, and one is more preferable.
- the length of the non-natural polynucleotide of the present invention is 22 to 95 nt (nucleotide), preferably 23 to 95 nt, more preferably 24 to 95 nt, even more preferably 25 to 95 nt, even more preferably 27 to 62 nt, and even more preferably 35 to 53 nt.
- the target polynucleotide sequence can be modified with high editing efficiency, which is preferable.
- the non-natural polynucleotide of the present invention can exhibit sufficient editing efficiency for a target nucleotide sequence, even if the mismatched nucleotide is a bridged nucleic acid.
- the bridged nucleic acid is an LNA.
- the number of consecutive bridged nucleic acids is not particularly limited, but when there are multiple consecutive bridged nucleic acids, including the case where the mismatched nucleotide is a bridged nucleic acid, the number of consecutive bridged nucleic acids is preferably two.
- the non-natural polynucleotide of the present invention can further improve the editing efficiency of the target nucleotide sequence when, for example, (F) one or more nucleotides adjacent to the 5'-terminal nucleotide are bridged nucleic acids.
- one nucleotide adjacent to the 5'-terminal nucleotide is a bridged nucleic acid.
- the bridged nucleic acid is an LNA.
- the number of consecutive bridged nucleic acids at the 5'-terminal nucleotide is not particularly limited, but for example, when the number of 5'-terminal nucleotides from the mismatch nucleotide is 12 nt, it is preferably 2, and when the number of 5'-terminal nucleotides is 25 nt, it is preferably 3.
- nucleic acid with bridged nucleotide adjacent to the 3' end In the non-natural polynucleotide of the present invention, in any of the above aspects (i) to (iii), or in addition to the above aspects (E) and/or (F), for example, when one or more nucleotides adjacent to the 3'-terminal nucleotide (G) are bridged nucleic acids, the editing efficiency of the target nucleotide sequence can be further improved. In this case, it is more preferable that the bridged nucleic acid is an LNA.
- the number of bridged nucleic acids adjacent to the 3'-terminal nucleotide is not particularly limited, but for example, when the number of 3'-terminal nucleotides from the mismatched nucleotide is 27 nt, the number is preferably 3 or less, more preferably 2 or less, and even more preferably 1. Furthermore, for example, when the number of 3'-terminal nucleotides from the mismatched nucleotide is 12 nt, the number of bridged nucleic acids adjacent to the 3'-terminal nucleotide is preferably 3 or less, more preferably 2 or less, and even more preferably 1.
- the phosphate moiety modified bond is a bond in which some atoms of a phosphodiester bond are replaced with other atoms or substituents, such as sulfur atoms, boron atoms, nitrogen atoms, methyl groups, and ester groups.
- Specific examples of the phosphate moiety modified bond include phosphorothioate bonds, methyl phosphate bonds, boranophosphate bonds, and mesyl phosphoramidate bonds.
- the number and positions of the phosphate moiety modified bonds are not particularly limited.
- the non-natural polynucleotide of the present invention may have one type of phosphate moiety modified bond or two or more types of phosphate moiety modified bonds.
- the number of phosphate moiety modified bonds may be 1, or the ratio of phosphate moiety modified bonds in the phosphodiester bonds may be 60% or less.
- the phosphate moiety modification bond is preferably a phosphorothioate bond.
- the phosphate moiety modification bond being a phosphorothioate bond include any one or combination of the following (H1), (I), (K) and (L).
- H1 The phosphodiester bond between the 5'-terminal nucleotide and one or more nucleotides adjacent to the 5'-terminal nucleotide is replaced with a phosphorothioate bond.
- I The phosphodiester bond between the 3'-terminal nucleotide and one or more nucleotides adjacent to the 3'-terminal nucleotide is replaced with a phosphorothioate bond.
- the phosphodiester bond between the crosslinked nucleic acid and one nucleotide directly adjacent to the crosslinked nucleic acid may or may not be replaced by a phosphorothioate bond.
- the non-natural polynucleotide of the present invention may have both the above characteristics (H1) and (I).
- the non-natural polynucleotide of the present invention preferably has the characteristic that "the phosphodiester bond between the 5'-terminal nucleotide and one or more consecutive nucleotides adjacent to the 5'-terminal nucleotide, and the phosphodiester bond between the 3'-terminal nucleotide and one or more consecutive nucleotides adjacent to the 3'-terminal nucleotide are replaced with phosphorothioate bonds.”
- the non-natural polynucleotide of the present invention can further enhance the editing efficiency of a target nucleotide sequence when, for example, (M) one or more nucleotides located between the nucleotide adjacent to the 5' upstream side of the mismatch nucleotide and the 5'-terminal nucleotide and spaced at a distance of at least one nucleotide from both the nucleotide adjacent to the 5' upstream side of the mismatch nucleotide and the 5'-terminal nucleotide are bridged nucleic acids.
- the bridged nucleic acid is between the bridged nucleic acid adjacent to the 3' downstream side of the mismatched nucleotide and the bridged nucleic acid at the 3' end]
- the editing efficiency of the target nucleotide sequence can be further improved.
- the non-natural polynucleotide of the present invention is a single-stranded polynucleotide, and deoxyribose in one or more nucleotides may be replaced with ribose.
- deoxyribose in one or more nucleotides may be replaced with ribose.
- the editing efficiency of the target nucleotide sequence can be further improved.
- mismatch nucleotide refers to a mismatch nucleotide for the purpose of modification.
- the inserted nucleotide in (X5) is a mismatch nucleotide, but the mismatch nucleotide here is a mismatch nucleotide for the purpose of improving the editing efficiency, and does not correspond to a mismatch nucleotide for the purpose of modification.
- the inserted nucleotide may be the above-mentioned nucleic acid with a modified phosphate moiety, the above-mentioned nucleic acid with a modified sugar moiety, or the above-mentioned nucleic acid with a modified base moiety.
- the number of inserted nucleotides may be one, and when multiple nucleotides are inserted, it is preferably two or more, while it is preferably six or less, more preferably three or less.
- a further embodiment (embodiment (iv)) of the non-naturally occurring polynucleotide of the present invention is (A) one or more nucleotides adjacent to the 5' upstream side of the mismatched nucleotide are bridged nucleic acids, and/or (B) one or more nucleotides adjacent to the 3' downstream side of the mismatched nucleotide are bridged nucleic acids, (D) the chain length is 22 to 95 nucleotides, and further, the structure is one or more selected from the group consisting of: (H2) the phosphodiester bond between the 5'-terminal nucleotide and one or more nucleotides adjacent to the 5'-terminal nucleotide is replaced with a phosphate moiety modified bond, (Y1) the 5'-terminal nucleotide is a mismatch nucleotide and one or more nucleotides adjacent to the 5'-terminal nucleotide are mismatch nucle
- mismatched nucleotide may or may not be a bridged nucleic acid, but in embodiment (iv), it is more preferable that the mismatched nucleotide is not a bridged nucleic acid.
- the phosphate moiety modified bond is a bond in which some atoms of a phosphodiester bond are replaced with other atoms or substituents, such as sulfur atoms, boron atoms, nitrogen atoms, methyl groups, and ester groups.
- Specific examples of the phosphate moiety modified bond include phosphorothioate bonds, methyl phosphate bonds, boranophosphate bonds, and mesyl phosphoramidate bonds.
- the number and positions of the phosphate moiety modified bonds are not particularly limited.
- the non-natural polynucleotide of the present invention may have one type of phosphate moiety modified bond or two or more types of phosphate moiety modified bonds.
- the number of phosphate moiety modified bonds may be 1, or the ratio of phosphate moiety modified bonds in the phosphodiester bonds may be 60% or less.
- the 5'-terminal nucleotide of (Y1) is a mismatched nucleotide, and one or more nucleotides adjacent to the 5'-terminal nucleotide are mismatched nucleotides.
- the mismatched nucleotide in (Y1) is a "mismatched nucleotide for the purpose of improving editing efficiency" and does not fall under the category of "mismatched nucleotide for modifying the target nucleotide sequence.”
- the mismatched nucleotides may or may not be adjacent to each other.
- the number is preferably 2 or more, and more preferably 10 or less, and more preferably 7 or less.
- an adaptor is preferably added to the 5' end of (Y3) from the viewpoint of editing efficiency. Details of the adaptor are as described above.
- the non-natural polynucleotide of the present invention is a single-stranded polynucleotide, and deoxyribose in one or more nucleotides may be replaced with ribose.
- deoxyribose in one or more nucleotides may be replaced with ribose.
- the editing efficiency of the target nucleotide sequence can be further improved.
- a further embodiment (embodiment (v)) of the non-naturally occurring polynucleotide of the present invention is (A) one or more nucleotides adjacent to the 5' upstream side of the mismatched nucleotide are bridged nucleic acids, and/or (B) one or more nucleotides adjacent to the 3' downstream side of the mismatched nucleotide are bridged nucleic acids, (D) the length is 22 to 95 nucleotides; (X7) One or more nucleotides located between the mismatched nucleotide and the 5'-terminal nucleotide are bridged nucleic acids. Such a configuration can exert the effects of the present invention.
- (A), (B) and (D) are the same as those in the embodiment (i).
- mismatched nucleotide may or may not be a bridged nucleic acid, but in embodiment (v), it is more preferable that the mismatched nucleotide is not a bridged nucleic acid.
- (X7) one or more nucleotides located between the mismatch nucleotide and the 5'-terminal nucleotide are bridged nucleic acids.
- the bridged nucleic acid defined in (X7) is not particularly limited, but may be at least one selected from the group consisting of LNA, AmNA, BNA N-H, BNA N-Me and ENA, with LNA being preferred.
- a further aspect (aspect (vi)) of the non-naturally occurring polynucleotide of the present invention is (C) the 5'-terminal nucleotide is a bridged nucleic acid; (D) the length is 22 to 95 nucleotides; (I) the phosphodiester bond between the 3'-terminal nucleotide and one or more nucleotides adjacent to the 3'-terminal nucleotide is replaced with a phosphorothioate bond; (X6) The mismatch nucleotide is a crosslinked nucleic acid. Such a configuration can exert the effects of the present invention.
- (C), (D) and (I) in embodiment (vi) are the same as embodiment (i).
- the mismatched nucleotide in view of editing efficiency, in aspect (vi), (X6) the mismatched nucleotide is a bridged nucleic acid.
- the bridged nucleic acid defined in (X6) is not particularly limited, but may be at least one selected from the group consisting of LNA, AmNA, BNA N-H, BNA N-Me and ENA, with LNA being preferred.
- the editing efficiency of the target nucleotide sequence can be further improved.
- the bridged nucleic acid defined in (E) is not particularly limited, but includes at least one selected from the group consisting of LNA, AmNA, BNA NH, BNA N-Me, and ENA, and LNA is preferred.
- editing efficiency The efficiency of modifying a target nucleotide sequence using the non-natural polynucleotide of the present invention (referred to as "editing efficiency" in this specification) can be, for example, in the range of 0.4 or more, preferably 0.5 or more, and more preferably 0.6 or more, when expressed relatively to the editing efficiency of 1.0 when using GEO-8 in the Examples described below, which is the non-natural polynucleotide shown in SEQ ID NO: 9.
- kits refers to a genetic engineering tool used to modify a target nucleotide sequence containing a non-natural polynucleotide.
- the kit of the present invention may contain a buffer, a stabilizer, a preservative, other reagents, an instruction manual describing a protocol for modifying a target nucleotide sequence with a non-natural polynucleotide, and the like, within the scope of not impairing the effects of the present invention.
- compositions By utilizing a pharmaceutical composition containing a non-naturally occurring polynucleotide of the present invention (hereinafter referred to as the "pharmaceutical composition" of the present invention), it is possible to provide a pharmaceutical composition that can treat a target disease by modifying a gene having a mutation that does not function normally into a gene that functions normally through the action of the non-naturally occurring polynucleotide.
- the pharmaceutical composition of the present invention When used, it can be administered, for example, orally, intravenously, through the muscle, oral mucosa, rectum, vagina, transdermally, via the nasal cavity, or via inhalation.
- an ex vivo therapy can be used in which the pharmaceutical composition of the present invention is applied to cells extracted from a patient, and the treated cells are cultured as necessary and returned to the patient.
- the non-natural polynucleotide of the pharmaceutical composition of the present invention may be formulated alone or in combination with other components, but it can also be provided in the form of a formulation by incorporating a pharma- ceutical acceptable carrier or formulation additive.
- pharma-ceutical acceptable carriers or additives include, but are not limited to, lipid nanoparticles, excipients, disintegrants, disintegration aids, binders, lubricants, coating agents, dyes, diluents, solubilizers, solubilization aids, isotonicity agents, pH adjusters, stabilizers, etc.
- Administration of the pharmaceutical compositions of the present invention will last for several days to several months, depending on the severity and responsiveness of the condition being treated, or until a cure is effected or a diminution of the condition is achieved.
- One skilled in the art can determine optimal dosages, administration methods, and repetition frequency.
- diseases that the pharmaceutical composition of the present invention can treat include diseases caused by the substitution of a single base in the human genome, such as adrenoleukodystrophy, medium-chain acyl-CoA dehydrogenase deficiency, Wilson's disease, hereditary pulmonary hypertension, X-linked agammaglobulinemia, cystinuria, Duchenne muscular dystrophy, hemophilia A, hemophilia B, tyrosinemia, hepatic glycogen storage disease type Ia, familial frontotemporal lobar degeneration, mucopolysaccharidosis type II, mucopolysaccharidosis type I, primary immunodeficiency syndrome, familial hypertrophic cardiomyopathy, peroxisome biogenesis disorder, hepatic glycogen storage disease type IX, protein C deficiency, hepatic glycogen storage disease type V, familial dilated cardiomyopathy, ⁇ 1-antitrypsin
- the non-naturally occurring polynucleotide of the present invention can be easily prepared by methods known in the field of the present invention.
- introducing a non-natural polynucleotide into a cell can be carried out according to a known method depending on the cell to be introduced.
- Known methods for introducing a polynucleotide into a cell are broadly divided into two types: a viral vector system and a non-viral vector system.
- the viral vector system is a method for introducing a gene into a cell by utilizing the cell entry mechanism that a virus originally has, and is a method using, but not limited to, adenovirus, retrovirus, lentivirus, etc. as a vector.
- non-viral vector systems include, but are not limited to, lipofection, electroporation, microinjection, particle gun, etc.
- the lipofection method is a method that utilizes the phenomenon in which a positively charged cationic liposome binds around a negatively charged polynucleotide to form a complex, and the polynucleotide is taken up into the cell from the cell surface by the endocytosis phenomenon.
- the electroporation method is a method in which a high voltage pulse is directly applied to the cell using a dedicated machine, and the polynucleotide is taken up through small holes on the cell surface.
- the microinjection method is a method in which a substance to be introduced is placed in a glass needle with a tip diameter of about 1 ⁇ m and directly introduced into a cell.
- the particle gun method is a method in which the surface of gold particles is coated with DNA by co-precipitating gold particles and DNA, and the gold particles are ejected toward a target cell by helium gas pressure or the like.
- the present invention is a method for modifying a target nucleotide sequence by introducing only a non-natural polynucleotide without introducing Cas nuclease into a cell, and a non-viral vector-based method is more preferable from the viewpoint of safety. Examples of the method of the present invention include a method performed inside the human body and a method including a step performed inside the human body.
- the non-natural polynucleotide (also referred to as "edited nucleic acid” in this specification) introduced into the cell in this manner selectively binds to the target nucleotide sequence in genomic DNA, as shown diagrammatically in FIG. 1.
- the non-natural polynucleotide of the present invention is preferably designed so that it is mismatched with the base to be edited in the target nucleotide sequence in double-stranded DNA in the cell, such as genomic DNA, and all base sequences other than the base to be edited are complementary to the target nucleotide sequence.
- there may be mismatched nucleotides other than the base to be edited as long as this does not contradict the purpose of the present invention.
- the mismatch nucleotide in the non-natural polynucleotide of the present invention is set to G.
- a person skilled in the art can set the mismatch nucleotide in the non-natural polynucleotide to change the base to be edited to the desired base based on common technical knowledge.
- the "method for modifying one or more nucleotides contained in a target nucleotide sequence in a double-stranded DNA in a cell” of the present invention comprises the step of introducing the above-mentioned non-natural polynucleotide of the present invention into a cell.
- the modification of the target nucleotide sequence includes at least one selected from the group consisting of deletion, insertion, and substitution of one or more nucleotides in the target nucleotide sequence.
- the non-natural polynucleotide used in the modification method of the present invention those described in the above aspects (i) to (vi) can be preferably used.
- Methods for confirming modification of a target nucleotide sequence in the present invention include a method for measuring the activity of a gene containing the target nucleotide sequence, and a method for directly measuring the target nucleotide sequence using a next-generation sequencer (NGS) and digital PCR.
- NGS next-generation sequencer
- the method of modifying a target nucleotide sequence using a non-natural polynucleotide of the present invention can be applied to all cells having double-stranded DNA. Furthermore, as long as the intracellular DNA replication mechanism can be utilized, the target nucleotide sequence can be modified not only from double-stranded DNA present in the cell, but also from single-stranded DNA derived from a virus in a virus-infected cell.
- the "cell" of the present invention includes prokaryotic cells and eukaryotic cells.
- prokaryotic cells is not particularly limited, but examples thereof include bacterial cells and archaeal cells.
- eukaryotic cells is not particularly limited, but includes animal cells, insect cells, plant cells, algae cells, and fungal cells.
- animal cells includes, but is not limited to, vertebrate cells, invertebrate cells, cells derived from animal tissues, germ cells, somatic cells, and stem cells.
- Germ cells include oocytes and sperm cells.
- Somatic cells include, but are not limited to, fibroblasts, hematopoietic cells, neurons, muscle cells, bone cells, liver cells, pancreatic cells, brain cells, kidney cells, and the like.
- Stem cells include, but are not limited to, induced pluripotent stem cells (iPS cells) and embryonic stem cells (ES cells).
- iPS cells induced pluripotent stem cells
- ES cells embryonic stem cells
- mammal refers to a group of vertebrates belonging to the mammalian species, and humans are also included in the mammalian species.
- mammalian cells refers to cells that constitute a mammal or cells derived from a mammal.
- mammals other than humans include, but are not limited to, deer, sea lions, hamsters, dogs, mice, wolves, whales, zebras, donkeys, weasels, bats, dolphins, anteaters, seals, cows, wild boars, horses, squirrels, bears, cats, moles, monkeys, raccoons, kangaroos, pigs, foxes, sheep, etc.
- human cells include cells derived from tissues, germ cells, somatic cells, and stem cells.
- the modification of the target nucleotide sequence was confirmed using HEK293 cells, but it can also be confirmed using other cells, such as HeLa cells.
- Insects is a general term for arthropods classified in the class Insecta. Insects that can be used include, but are not limited to, silkworm larvae, fruit flies, crickets, etc.
- insect cells include, but are not limited to, cells that constitute the body tissue of insects and cells derived from insect tissue.
- Plant cells includes, but is not limited to, seed plants, ferns, mosses, algae, etc.
- plant cell refers to a cell that constitutes a plant or a cell derived from a plant.
- Seed plants include angiosperms and gymnosperms.
- Angiosperms include dicotyledons and monocotyledons.
- Dicotyledons include, but are not limited to, morning glory, dandelion, azalea, azalea, eggplant, rapeseed, pea, etc.
- Monocotyledons include, but are not limited to, rice, lily, tulip, Japanese silver grass, corn, etc.
- Gymnosperms include, but are not limited to, pine, cedar, ginkgo, cypress, etc. Ferns include, but are not limited to, bracken, fern, Japanese oak, horsetail, etc. Bryophytes include, but are not limited to, Marchantia polymorpha, Hornwort, Polytrichum japonicum, Sphagnum, etc.
- Algae include multicellular algae and unicellular algae. Examples of multicellular algae include, but are not limited to, kelp, wakame, Ulva, Spirogyra, etc. Examples of unicellular algae include, but are not limited to, Chlorella, Euglena, Spirulina, Chlamydomonas, Coccomyxa, Botryococcus, Mikania, Diatom, etc.
- NanoLuc registered trademark
- plasmid Based on the wild-type base sequence of the luciferase gene NanoLuc (GenBank JQ513379), DNA from base number 847 to 1,380 was synthesized (Gene Universal Inc.), and XhoI and ApaI linkers were ligated to it, and it was inserted into the corresponding restriction enzyme site of pcDNA TM 5/FRT/TO plasmid (Thermo Fisher Scientific Inc.) (pcDNA5-nLW1).
- the wild-type base sequence of the NanoLuc gene is SEQ ID NO: 1.
- a mutant base sequence was synthesized in which the cytosine (C) at base number 922 of the NanoLuc gene was changed to thymine (T), and the mutant was created by incorporating the mutant into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD1).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the point mutation described above.
- pcDNA5-nLD1 or pcDNA5-nLW1 plasmid (1 ⁇ g) and pOG44 plasmid (3 ⁇ g, Thermo Fisher Scientific Inc.) were transfected using Lipofectamine 3000 (Thermo Fisher Scientific Inc.) according to the standard protocol.
- TrypLE TM Express Enzyme (Thermo Fisher Scientific Inc.) was added and incubated at 37°C for 3 minutes. The detached cells were collected and suspended in DMEM + 10% FBS medium containing 50 ⁇ g/ml of hygromycin (Thermo Fisher Scientific Inc.), and cultured in two 10cm dishes. Culture was then continued with the same medium replaced every 3 days. After culturing for about 20 days, the formation of sufficient number and size of colonies was confirmed, and all cells were detached from the dish using TrypLE TM Express Enzyme and collected.
- the cells with mutant NanoLuc integrated into the genome were named 293-nLD1 cells.
- the mutant NanoLuc gene in 293-nLD1 cells is an inactive luciferase gene, as described above. These 293-nLD1 cells were used in the subsequent genome editing experiments.
- cells in which wild-type NanoLuc was integrated into the genome were named 293-nLW1 and used as a positive control for subsequent genome editing experiments.
- NanoLuc Luciferase Assay After 72 hours of culture from the transfection, NanoLuc Luciferase activity was measured. NanoLuc Luciferase activity was measured using the Nano-Glo® Luciferase Assay System (Promega Corporation) according to the standard protocol. Luciferase luminescence was measured using an EnSpire multimode plate reader (PerkinElmer Co., Ltd.).
- the number of viable cells was measured using CellTiter-Blue (registered trademark) Cell Viability Assay (Promega Corporation) according to the standard protocol.
- the fluorescence value of CellTiter-Blue was measured using an EnSpire multimode plate reader (PerkinElmer Co., Ltd.).
- the number of viable edited cells was calculated by creating a standard curve of CellTiter-Blue measurements and cell numbers using a two-fold dilution series of 293-nLD1 cells between 5 x 103 and 2 x 105 , and calculating the number of viable cells based on this standard curve.
- Genomic DNA was prepared from 293-nLD1 cells transfected with non-natural polynucleotides using NucleoSpin Tissue (Takara Inc.) according to the standard protocol. A region of approximately 200 bases upstream and downstream of the edited base was amplified by PCR from the prepared genomic DNA to create a library, and amplicon sequencing of this library was performed using MiSeq/MiSeq Reagent Kit v3 (Illumin) (Bioengineering Lab. Co., Ltd.). 30,000 to 50,000 amplicon sequences were analyzed per sample, and the editing efficiency was calculated from the ratio of the edited sequence count to the wild-type sequence count.
- NGS Next Generation Sequencing
- Non-natural Polynucleotides All non-natural polynucleotides, including those with modified nucleic acids, were synthesized by Gene Design Co., Ltd. (Japan) and purified using a simple column or HPLC.
- Example 1-1 Modification of a target nucleotide sequence by a non-natural polynucleotide An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- the codon (CAA) encoding glutamine 22 (Gln-22) in the luciferase gene introduced into 293-nLD1 cells is mutated to a stop codon (TAA), and the gene does not show luciferase activity.
- T in the stop codon (TAA) in the inactive luciferase gene can be replaced with a C, the luciferase activity of the 293-nLD1 cells is restored, and the modification of the target nucleotide sequence can be detected by the luminescence produced by luciferase ( Figure 2).
- Example 1-1 11 types of non-natural polynucleotides, GEO-1 to GEO-9, GEO-242, and GEO-11, as well as the non-natural polynucleotide GEO-94, which does not contain mismatched nucleotides and therefore cannot repair inactivating mutations as a negative control, were introduced into 293-nLD1 cells by transfection ( Figure 3A).
- GEO-1 to GEO-9, GEO-242 and GEO-11 all have a G nucleotide at the position corresponding to the T in the stop codon TAA in the target polynucleotide sequence, i.e. a mismatch, and nucleotides other than the mismatch nucleotide are nucleotides complementary to the target polynucleotide sequence.
- GEO-1 to GEO-4 are 21 nt
- GEO-5 to GEO-9, GEO-242, GEO-11 and GEO-94 are 25 nt.
- the mismatch nucleotide G is LNA.
- one nucleotide 5' upstream and one nucleotide 3' downstream adjacent to the mismatch nucleotide G are LNA.
- the mismatch nucleotide G and the nucleotide at the 5' end are LNA.
- one nucleotide 5' upstream and one nucleotide 3' downstream adjacent to the mismatch nucleotide G are LNA, and the nucleotide at the 5' end is LNA.
- GEO-11 has an LNA nucleotide at the 5' end.
- GEO-242 has an LNA nucleotide at the 3' end.
- GEO-9 has no LNA.
- the nucleotide at the position corresponding to the base to be edited is A, i.e., complementary. Furthermore, in GEO-94, one nucleotide adjacent to this nucleotide A on the 5' upstream side and one nucleotide adjacent to the 3' downstream side are LNA, and the nucleotide at the 5' end is LNA.
- the base sequences, chain lengths, and editing efficiencies (%) of the above edited nucleic acids GEO-1 to GEO-9, GEO-242, GEO-11, and the negative control (GEO-94) are shown in Table 1.
- the editing efficiency (%) of each edited nucleic acid is also shown in a bar graph ( Figure 3B).
- GEO-8 had the highest absolute editing efficiency at 0.25%, and GEO-7 had the second highest absolute editing efficiency at 0.05%. Furthermore, the editing efficiency of the negative control GEO-94 was nearly 0%. If the editing efficiency of GEO-8 is taken as 1.0, the relative editing efficiencies of GEO-1 to GEO-6, GEO-9, GEO-242 and GEO-11 were all less than 0.2. Note that GEO-1, GEO-2, GEO-3, GEO-5, GEO-6 and GEO-7 have the same configuration as disclosed in Non-Patent Document 1. Thus, GEO-8, the non-natural polynucleotide of the present invention, showed an editing efficiency more than five times higher than that of the previously reported GEO-7.
- Example 1-2 Chain Length of Non-natural Polynucleotide Although GEO-4 and GEO-8 in Example 1-1 had the same LNA arrangement, a difference of 4 nt caused a large difference in editing efficiency. In this Example 1-2, in order to investigate the preferred chain length of the non-natural polynucleotide, an experiment similar to that in Example 1-1 was carried out using nine non-natural polynucleotides having the same LNA arrangement as GEO-8 but different chain lengths ( Figure 4).
- the nine non-natural polynucleotides used in this Example 1-2 were GEO-23 (29 nt), GEO-79 (31 nt), GEO-24 (35 nt), GEO-25 (41 nt), GEO-174 (45 nt), GEO-175 (49 nt), GEO-176 (53 nt), GEO-281 (75 nt) and GEO-282 (95 nt).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 2.
- Example 1-3 LNA Modification of the 3'-Terminus of a Non-Natural Polynucleotide
- the editing efficiency of a configuration in which the pentose in the 3'-terminal nucleotide was replaced with LNA was examined. Specifically, the editing efficiency was measured using GEO-16, which is GEO-6 with an LNA 3'-terminal nucleotide, and GEO-17, which is GEO-8 with an LNA 3'-terminal nucleotide ( Figure 5).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 3.
- the relative editing efficiency of GEO-16 was 0.16, and that of GEO-17 was 2.00. From these results, it was found that the configuration in which one nucleotide on the 5' upstream side and one nucleotide on the 3' downstream side adjacent to the mismatched nucleotide are LNA and the 3' end is LNA (GEO-16) had a low relative editing efficiency. It was shown that in the configuration in which one nucleotide on the 5' upstream side and one nucleotide on the 3' downstream side adjacent to the mismatched nucleotide are LNA and the 5' end is LNA (hereinafter referred to as the "GEO-8 configuration"), the relative editing efficiency is improved when the 3' end is also LNA.
- Example 1-4 LNA modification of one or more nucleotides adjacent to the LNA at the 5' end of a non-natural polynucleotide
- the editing efficiency of a configuration in which one or more nucleotides adjacent to the 5' end were further replaced with LNA in the GEO-8 configuration of Example 1-1 and the GEO-17 configuration of Example 1-3 was examined.
- the editing efficiency was measured in the same manner as in Example 1-1 using GEO-18, in which one nucleotide adjacent to the 5' end of GEO-8 is additionally LNA; GEO-19, in which two consecutive nucleotides adjacent to the 5' end of GEO-8 are additionally LNA; and GEO-68, in which one nucleotide adjacent to the 5' end of GEO-17 is additionally LNA (Figure 6).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 4.
- the relative editing efficiency of GEO-18 was 2.05, and that of GEO-19 was 0.66. These results indicate that sufficient editing efficiency is exhibited even in the GEO-8 configuration in which one or more nucleotides adjacent to the 5' end are replaced with LNA. Furthermore, the relative editing efficiency of GEO-17 was 2.00, and that of GEO-68 was 1.64. These results indicate that sufficient editing efficiency is exhibited even in the configuration in which one nucleotide adjacent to the 5' end is replaced with LNA in which one nucleotide adjacent to the 5' end is replaced with LNA in which one nucleotide adjacent to the 5' end is replaced with LNA (hereinafter referred to as the "GEO-17 configuration").
- the relative editing efficiency of GEO-19 in which two nucleotides adjacent to the 5' end of the GEO-8 configuration were further replaced with LNA, was 0.66, which was slightly lower than the relative editing efficiency of the GEO-8 configuration.
- Example 1-8 described below when the 5' upstream side of the mismatched nucleotide was extended, the relative editing efficiency of GEO-313, in which one nucleotide adjacent to the 5' end of the GEO-8 configuration was further replaced with LNA, was 5.23, and the relative editing efficiency of GEO-315, in which two nucleotides adjacent to the 5' end of the GEO-8 configuration were further replaced with LNA, was 6.59. It was suggested that even when multiple nucleotides adjacent to the 5' end of the GEO-8 configuration were further replaced with LNA, the editing efficiency may increase if other configurations, such as the chain length of the non-natural polynucleotide, are changed.
- Example 1-5 LNA modification of one or more nucleotides adjacent to the LNA at the 3' end of a non-natural polynucleotide
- the editing efficiency of a configuration in which one or more nucleotides adjacent to the 3' end nucleotide were further replaced with LNA in addition to the GEO-17 configuration in Example 1-3 was examined. Specifically, editing efficiency was measured using GEO-69, in which one nucleotide adjacent to the 3'-terminal nucleotide of GEO-17 is LNA; and GEO-71, in which two consecutive nucleotides adjacent to the 3'-terminal nucleotide of GEO-17 are LNA, in a manner similar to that of Example 1-1 ( Figure 7).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 5.
- the relative editing efficiency of GEO-69 was 1.01, and that of GEO-71 was 0.51. From these results, when one nucleotide adjacent to the 3'-terminal nucleotide in the GEO-17 configuration was further replaced with LNA, it showed an editing efficiency similar to that of GEO-8, and when two nucleotides adjacent to the 3'-terminal nucleotide were replaced with LNA, it showed an editing efficiency about half that of GEO-8.
- Example 1-8 when the 3' downstream side of the mismatched nucleotide was extended, the relative editing efficiency of GEO-319, in which one nucleotide adjacent to the 3' end was further replaced with LNA in the GEO-17 configuration, was 2.18, and the relative editing efficiency of GEO-321, in which two nucleotides adjacent to the 3' end were further replaced with LNA in the GEO-17 configuration, was 1.40.
- the editing efficiency may increase if other configurations, such as the chain length of the non-natural polynucleotide, are changed.
- Example 1-6 Replacement of one or more internucleotide phosphodiester bonds contained in a non-natural polynucleotide with phosphorothioate bonds (1)
- this Example 1-6 the editing efficiency of a configuration in which one or more internucleotide phosphodiester bonds are further replaced with phosphorothioate bonds in addition to the configuration of GEO-8 in Example 1-1 was examined.
- GEO-158, GEO-159, GEO-160, GEO-29 and GEO-161 are GEO-8 in which the phosphodiester bond between the 5'-terminal nucleotide and 1 to 5 consecutive nucleotides adjacent to the 5'-terminal nucleotide is replaced with a phosphorothioate bond; GEO-162, GEO-163, GEO-164, GEO-30, GEO-165, GEO-272 and GEO-196 (FIG.
- the relative editing efficiency of GEO-31 was 5.68. This result indicates that in the configuration of GEO-8, the editing efficiency is improved when the phosphodiester bond between the 5'-terminal nucleotide and the four consecutive nucleotides adjacent to the 5'-terminal nucleotide and between the 3'-terminal nucleotide and the four consecutive nucleotides adjacent to the 3'-terminal nucleotide are replaced with phosphorothioate bonds.
- Example 1-7 Replacement of one or more internucleotide phosphodiester bonds contained in a non-natural polynucleotide with phosphorothioate bonds (2) In this Example 1-7, the editing efficiency of a configuration in which one or more internucleotide phosphodiester bonds are further replaced with phosphorothioate bonds in the configuration of GEO-17 in Example 1-3 was examined.
- the editing efficiency was measured in the same manner as in Example 1-1 using GEO-155, GEO-167, GEO-168, and GEO-169, which are GEO-17 in which the 3'-terminal nucleotide and the phosphodiester bond between 1 to 4 consecutive nucleotides adjacent to the 3'-terminal nucleotide were further replaced with phosphorothioate bonds (Figure 9).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 7.
- Example 1-8 Extension of chain length on the 5' upstream side and 3' downstream side of the mismatched nucleotide and position of LNA
- the effect on the editing efficiency when the chain length of the 5' upstream region and the chain length of the 3' downstream region of the mismatched nucleotide are changed was examined. Furthermore, the editing efficiency was examined when the number and position of LNA near the 5' end and the number and position of LNA near the 3' end were appropriately changed.
- GEO-25 has a chain length of 41 nt, a 5' upstream region of the mismatched nucleotide G of 20 nt and a 3' downstream region of 20 nt, one nucleotide adjacent to the mismatched nucleotide G on the 5' upstream side and one nucleotide adjacent to the mismatched nucleotide G on the 3' downstream side are LNA, and the 5' terminal nucleotide is LNA;
- GEO-311 has a chain length of 38 nt, a 5' upstream region of the mismatched nucleotide G of 25 nt and a 3' downstream region of 12 nt, one nucleotide adjacent to the mismatched nucleotide G on the 5' upstream side and one nucleotide adjacent to the mismatched nucleotide G on the 3' downstream side are LNA, and the 5' terminal nucleotide is LNA;
- GEO-312 has a chain length of 38 nt, a 5'
- GEO-317 has a chain length of 40 nt, a 5' upstream region of the mismatched nucleotide G of 12 nt and a 3' downstream region of 27 nt, one nucleotide on the 5' upstream side and one nucleotide on the 3' downstream side adjacent to the mismatched nucleotide G are LNA, and the nucleotides at the 5' and 3' ends are LNA; GEO-318 in which the 12th nucleotide counting from the nucleotide on the 3' downstream side adjacent to the mismatched nucleotide G toward the 3' downstream side is LNA in GEO-317; GEO-319 in which the nucleotide adjacent to the LNA at the 3' end in GEO-317 is LNA; and The editing efficiency was measured in the same manner as in Example 1-1 using GEO-320, in which the 12th nucleotide in the 3' downstream direction from the 3' downstream nucleotide adjacent to the mismatched nucleotide
- the relative editing efficiency of GEO-25 was 3.47, that of GEO-311 was 3.31, that of GEO-312 was 4.16, that of GEO-313 was 5.23, that of GEO-314 was 6.57, that of GEO-315 was 6.59, that of GEO-316 was 7.02, that of GEO-317 was 2.55, that of GEO-318 was 2.66, that of GEO-319 was 2.18, that of GEO-320 was 2.51, that of GEO-321 was 1.40, and that of GEO-322 was 0.77.
- GEO-311, GEO-312, GEO-313, GEO-314, GEO-315, and GEO-316, in which the length of the 5' upstream region of the mismatched nucleotide was extended GEO-317, GEO-318, GEO-319, GEO-320, GEO-321, and GEO-322, in which the length of the 3' downstream region of the mismatched nucleotide was extended, had relatively low editing efficiency, suggesting that extending the length of the 5' upstream region of the mismatched nucleotide is effective.
- Example 1-9 RNA Substitution of Nucleotides Near the 3'-Terminal
- the editing efficiency of a construct in which one or more nucleotides adjacent to the 3'-terminal nucleotide were further substituted with RNA in the GEO-17 construct of Example 1-3 was examined.
- the editing efficiency was measured in the same manner as in Example 1-1 using GEO-150, in which one nucleotide adjacent to the 3'-terminal nucleotide in GEO-17 was replaced with RNA; GEO-73, in which two consecutive nucleotides adjacent to the 3'-terminal nucleotide were replaced with RNA; GEO-151, in which three consecutive nucleotides adjacent to the 3'-terminal nucleotide were replaced with RNA; and GEO-74, in which four consecutive nucleotides adjacent to the 3'-terminal nucleotide were replaced with RNA ( Figure 11).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 9.
- Example 1-10 Phosphorylation of 3'- and/or 5'-terminal nucleotides
- the editing efficiency of a configuration in which the 3'- and/or 5'-terminal nucleotides were phosphorylated in addition to the configuration of GEO-8 in Example 1-1 or GEO-17 in Example 1-3 was examined.
- the editing efficiency was measured in the same manner as in Example 1-1 using GEO-8, GEO-26 in which the 5'-terminal nucleotide is phosphorylated; GEO-27 in which the 3'-terminal nucleotide is phosphorylated, and GEO-28 in which both the 5'-terminal and 3'-terminal nucleotides are phosphorylated; GEO-17, GEO-223 in which the 3'-terminal nucleotide is phosphorylated; and GEO-17, GEO-224 in which the phosphodiester bond between the 3'-terminal nucleotide and the adjacent nucleotide is replaced with a phosphorothioate bond and the 3'-terminal nucleotide is phosphorylated (Figure 12).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 10.
- Example 1-11 Types of bridged nucleic acids
- the editing efficiency of a configuration in which the LNA at the 5' end in the configuration of GEO-8 in Example 1-1 was replaced with another bridged nucleic acid was examined. Specifically, the editing efficiency was measured in the same manner as in Example 1-1 using GEO-41, in which the LNA at the 5' end of GEO-8 was replaced with BNA-NH; GEO-43, in which the LNA at the 5' end was replaced with BNA-N-Me; and GEO-57, in which the LNA at the 5' end of GEO-8 was replaced with ENA (Figure 13).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 11.
- Example 1-12 Combination of nucleic acid modifications (1)
- the editing efficiency of a configuration in which the phosphodiester bond moiety in the GEO-8 configuration of Example 1-1 was further combined with substitution of a phosphorothioate bond and phosphorylation of the 3' end was examined.
- the editing efficiency was measured using GEO-226, in which the phosphodiester bond between the five consecutive nucleotides adjacent to the 3'-terminal nucleotide in GEO-8 was replaced with a phosphorothioate bond and the 3'-terminus was phosphorylated, in the same manner as in Example 1-1 ( Figure 14).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 12.
- the relative editing efficiency of GEO-226 was 8.19. This result indicates that the editing efficiency is significantly increased by further combining the substitution of the phosphodiester bond with a phosphorothioate bond and phosphorylation of the 3' end in the GEO-8 configuration.
- Example 1-13 Combination of nucleic acid modifications (2)
- the editing efficiency of a configuration in which the phosphodiester bond moiety is replaced with a phosphorothioate bond, RNA replacement, and phosphorylation of the 3' end are further combined in the GEO-23 configuration of Example 1-3 was examined.
- the editing efficiency was measured in the same manner as in Example 1-1 using GEO-172, in which the phosphodiester bond between the four consecutive nucleotides adjacent to the 5'-terminal nucleotide in GEO-23 was replaced with a phosphorothioate bond, two consecutive nucleotides adjacent to the 3'-terminal nucleotide were replaced with RNA, and the 3'-terminal was phosphorylated (Figure 15).
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 13.
- the relative editing efficiency of GEO-172 was 8.48. This result indicates that the editing efficiency is significantly increased by further combining the replacement of the phosphodiester bond with a phosphorothioate bond, RNA replacement, and phosphorylation of the 3' end in the GEO-17 configuration.
- Example 1-1 shows that GEO-8, a non-natural polynucleotide of the present invention, exhibited an editing efficiency 5 times or more higher than that of GEO-7 (i.e., the chain length, the position of the mismatched nucleotide, and the position of LNA are the same as those of GEO-8), which corresponds to the polynucleotide with the highest editing efficiency among the configurations disclosed in Non-Patent Document 1.
- GEO-8 a non-natural polynucleotide of the present invention
- GEO-8 is different from GEO-7 in that the mismatched nucleotide itself is not LNA, and both the 5'-side nucleotide and the 3'-side nucleotide adjacent to the mismatched nucleotide are substituted with LNA.
- Patent Document 4 describes that oligonucleotides containing an LNA adjacent to the mismatched nucleotide showed no improvement, but oligonucleotides with an LNA spaced one nucleotide further from the mismatch showed an average increase of 5-fold, and it can be said that Patent Document 4 actively excludes configurations that include an LNA adjacent to the mismatched nucleotide.
- Non-Patent Document 1 focuses on avoiding mismatch repair, and Non-Patent Documents 1 and 2 focus on elucidating the mechanism of how single-stranded synthetic DNA with a mismatched nucleotide of LNA modifies the genome of mammalian cells.
- Non-Patent Document 1 emphasizes that it is important to make the mismatched nucleotide itself LNA in avoiding mismatch repair, and does not mention that both the 5'-side nucleotide and the 3'-side nucleotide adjacent to the mismatched nucleotide were substituted with LNA.
- Patent Document 4 and Non-Patent Documents 1 and 2 are an obstacle to adopting the feature in which both the 5'-side nucleotide and the 3'-side nucleotide adjacent to the mismatched nucleotide are replaced with LNA to improve editing efficiency, i.e., the motivation to adopt feature (A) and feature (B) of the present invention.
- the experimental results shown in Example 1-1 of this specification are the exact opposite of what is suggested by Patent Document 4, and in terms of the effects of the invention, it can be said that the effects of the present invention are heterogeneous effects that cannot be predicted from Patent Document 4 and Non-Patent Documents 1 and 2.
- Non-Patent Documents 1 and 2 Of the more than 110 types of single-stranded synthetic DNA tested in Non-Patent Documents 1 and 2, only one type of single-stranded synthetic DNA in which the 5'-terminal nucleotide was LNA and the 3'-terminal was not LNA was found in each document. Although single-stranded synthetic DNA in which the 5'-terminal nucleotide and both the mismatch nucleotides were LNA showed approximately twice the editing efficiency compared to single-stranded synthetic DNA in which only the mismatch nucleotide was LNA, no further investigation was conducted on single-stranded synthetic DNA in which the 5'-terminal was LNA.
- Non-Patent Document 2 concludes that the region 5' from the mismatched nucleotide is degraded by endonucleases, not exonucleases, suggesting that the effect of LNA modification of the 5' end to protect it from exonucleases is limited.
- LNA modification of the 5' end only doubled the editing efficiency, which leads to the conclusion that LNA modification of the 5' end is not that important. Therefore, no attempt has been made to combine LNA modification of the 5' end with a nucleotide sequence in which both the 5' and 3' nucleotides adjacent to the mismatched nucleotide have been replaced with LNA.
- Non-Patent Documents 1 and 2 can be said to be an obstacle to attempts to replace the 5' end of a non-natural polynucleotide with LNA in order to improve editing efficiency.
- Non-Patent Document 1 examines the optimal length of an edited nucleic acid using a polynucleotide in which only the mismatch nucleotide is LNA, and as a result, it is shown that 25 bases is optimal, and editing efficiency decreases when the length is longer than 25 bases.
- Patent Document 4 uses a polynucleotide with a length of 24 bases.
- the editing efficiency is further increased when the polynucleotide is longer than 25 bases.
- Examples 1-3 showed that in order for a compound in which both the 5'- and 3'-terminal nucleotides adjacent to a mismatched nucleotide are replaced with LNA to exert an effect, the feature (C) that the 5'-terminal nucleotide is a bridged nucleic acid is important. Furthermore, a comparison with GEO-8, GEO-16, and GEO-17 showed that when both the 5'- and 3'-terminal nucleotides are bridged nucleic acids, the editing efficiency increased by two times. It was also found that the effect of the 3'-terminal nucleotide being LNA was strongly exhibited when the 5'-terminal nucleotide was LNA.
- Examples 1-8 show that extending the length of the 5' upstream and 3' downstream regions of the mismatched nucleotide increases the editing efficiency, and that substituting some of the nucleotides in the extended regions with LNAs increases the editing efficiency. Such an effect was not described or suggested in any of the patent or non-patent literature mentioned above.
- Examples 1-9, 1-10, 1-12, and 1-13 show that the editing efficiency can be significantly increased by combining the substitution of a crosslinked nucleic acid with a phosphorothioate bond at the phosphodiester bond, RNA substitution, and phosphorylation of the 3' end or 5' end. None of the above patent documents or non-patent documents describes or suggests such an effect.
- Examples 1-11 show that the effect of improving editing efficiency can be achieved by substituting a cross-linked nucleic acid at the 5' end not only with LNA but also with other cross-linked nucleic acids such as BNA-N-H, BNA-N-Me, and ENA. Such an effect was not described or suggested in any of the above patent or non-patent documents.
- nDL2 A mutant base sequence was synthesized in which the guanine (G) at base number 894 of the NanoLuc gene was changed to adenine (A) and the cytosine (C) at base number 895 to thymine (T), and the mutant was created by incorporating the mutant into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD2).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the above mutation.
- nDL3 A mutant base sequence was synthesized in which the thymine (T) at base number 956 of the NanoLuc gene was changed to adenine (A), the thymine (T) at base number 957 to guanine (G), and the cytosine (C) at base number 958 to thymine (T), and a mutant was created by incorporating this into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD3).
- the luciferase gene contained in this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the above mutations.
- nDL4-1 A mutant base sequence was synthesized in which the cytosine (C) at base number 922 of the NanoLuc gene was changed to thymine (T) and the guanine (G) at base number 931 was changed to thymine (T), and the mutant was created by incorporating the mutant into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD4-1).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the above mutation.
- nDL4-2 A mutant base sequence was synthesized in which the cytosine (C) at base number 922 of the NanoLuc gene was changed to thymine (T) and the guanine (G) at base number 937 to thymine (T), and a mutant was created by incorporating this into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD4-2).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the point mutations mentioned above.
- nDL4-3 A mutant base sequence was synthesized in which the guanine (G) at base number 937 of the NanoLuc gene was changed to thymine (T) and the cytosine (C) at base number 958 to thymine (T), and a mutant was created by incorporating this into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD4-3).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the point mutations mentioned above.
- nDL5 A mutant base sequence in which the guanine (G) at base number 976 of the NanoLuc gene was deleted was synthesized, and a mutant was created by incorporating it into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD5).
- the luciferase gene of this mutant is an inactive luciferase gene that does not show luciferase activity due to the point mutation described above.
- nDL6 A mutant base sequence was synthesized in which the adenine (A) at base number 911 and the cytosine (C) at base number 912 of the NanoLuc gene were deleted, and the mutant was created by incorporating the mutant into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD6).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the point mutation described above.
- nDL7 A mutant base sequence in which thymine (T) was inserted between thymine (T) at base number 930 and guanine (G) at base number 931 of the NanoLuc gene was synthesized, and a mutant was created by incorporating it into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD7).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the point mutation described above.
- nDL8 A mutant base sequence was synthesized in which thymine (T) and adenine (A) were inserted in this order between the adenine (A) at base number 978 and the adenine (A) at base number 979 of the NanoLuc gene, and the mutant was created by incorporating the mutant into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD8).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the point mutation described above.
- nDL9 A mutant base sequence was synthesized in which thymine (T) at base number 981, cytosine (C) at base number 982, cytosine (C) at base number 983, and guanine (G) at base number 984 of the NanoLuc gene were deleted, and the mutant was created by incorporating the mutant into the pcDNA TM 5/FRT/TO plasmid in the same manner as above (pcDNA5-nLD9).
- the luciferase gene of this mutant is an inactive luciferase gene that does not exhibit luciferase activity due to the above point mutation.
- pcDNA5-nLD2, pcDNA5-nLD3, pcDNA5-nLD4-1, pcDNA5-nLD4-2, pcDNA5-nLD4-3, pcDNA5-nLD5, pcDNA5-nLD6, pcDNA5-nLD7, pcDNA5-nLD8 or pcDNA5-nLD9 plasmid (1 ⁇ g) and pOG44 plasmid (3 ⁇ g, Thermo Fisher Scientific Inc.) were transfected using Lipofectamine 3000 (Thermo Fisher Scientific Inc.) according to the standard protocol.
- TrypLE TM Express Enzyme (Thermo Fisher Scientific Inc.) was added and incubated at 37°C for 3 minutes, and the detached cells were collected and suspended in DMEM + 10% FBS medium containing hygromycin (Thermo Fisher Scientific Inc.) at a concentration of 50 ⁇ g/ml, and cultured in two 10cm dishes. After that, the culture was continued while changing the medium every 3 days. After about 20 days of culture, the formation of a sufficient number and size of colonies was confirmed, and all the cells were detached from the petri dish using TrypLE TM Express Enzyme and collected.
- the cell lines obtained using the above-mentioned various plasmids were named as follows: The cells in which pcDNA5-nLD2 was integrated into the genome were named 293-nLD2 cells. The cells in which pcDNA5-nLD3 was integrated into the genome were named 293-nLD3 cells. The cells in which pcDNA5-nLD4-1 was integrated into the genome were named 293-nLD4-1 cells. The cells in which pcDNA5-nLD4-2 was integrated into the genome were named 293-nLD4-2 cells. The cells in which pcDNA5-nLD4-3 was integrated into the genome were named 293-nLD4-3 cells.
- the cells in which pcDNA5-nLD5 was integrated into the genome were named 293-nLD5 cells.
- the cells in which pcDNA5-nLD6 was integrated into the genome were named 293-nLD6 cells.
- the cells in which pcDNA5-nLD7 was integrated into the genome were named 293-nLD7 cells.
- the cells in which pcDNA5-nLD8 was integrated into the genome were named 293-nLD8 cells, and the cells in which pcDNA5-nLD9 was integrated into the genome were named 293-nLD9 cells.
- the mutant NanoLuc gene in each of the cells was an inactive luciferase gene as described above. Each of the cells was used in the subsequent genome editing experiment.
- 293-nLD3 cells, 293-nLD4-1 cells, 293-nLD4-2 cells, 293-nLD4-3 cells, 293-nLD5 cells, 293-nLD6 cells, 293-nLD7 cells, 293-nLD8 cells and 293-nLD9 cells were also transfected in the same manner as 293-nLD2 cells.
- NanoLuc Luciferase Assay After 72 hours of culture from the transfection, NanoLuc Luciferase activity was measured. NanoLuc Luciferase activity was measured using the Nano-Glo® Luciferase Assay System (Promega Corporation) according to the standard protocol. Luciferase luminescence was measured using an EnSpire multimode plate reader (PerkinElmer Co., Ltd.).
- the number of viable cells was measured using CellTiter-Blue (registered trademark) Cell Viability Assay (Promega Corporation) according to the standard protocol.
- the fluorescence value of CellTiter-Blue was measured using an EnSpire multimode plate reader (PerkinElmer Co., Ltd.).
- the number of viable edited cells was calculated by creating a standard curve of CellTiter-Blue measurements and cell numbers using a two-fold dilution series of 293-nLD2 cells between 5 x 103 and 2 x 105 , and calculating the number of viable cells based on this standard curve.
- the viable cell numbers of 293-nLD3 cells, 293-nLD4-1 cells, 293-nLD4-2 cells, 293-nLD4-3 cells, 293-nLD5 cells, 293-nLD6 cells, 293-nLD7 cells, 293-nLD8 cells, and 293-nLD9 cells were calculated in the same manner as for 293-nLD2 cells.
- AUC log the area under the curve
- Non-natural Polynucleotides All non-natural polynucleotides, including those with modified nucleic acids, were synthesized by Gene Design Co., Ltd. (Japan) and purified using a simple column or HPLC.
- Example 2-1 Examination of two base substitutions (1) Experiments were performed to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD2 cells.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 14.
- Tris-EDTA Tris-HCl 10 mM, EDTA 1 mM, pH 7.4, hereinafter referred to as "TE"
- TE Tris-HCl 10 mM, EDTA 1 mM, pH 7.4, hereinafter referred to as "TE”
- the AUC was 123
- the AUC of D2-2 was 64,642.
- the relative editing efficiency of D2-1 was 0.13
- that of D2-3 was 4.94
- that of D2-4 was 3.13
- that of D2-5 was 1.71
- D2-6 was 1.64.
- Example 2-2 Examination of Three-Base Substitution An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD3 cells.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 15.
- Example 2-3 Examination of two-base substitution (2) Experiments were performed to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD4-1, 293-nLD4-2, or 293-nLD4-3 cells.
- each of the three types of non-natural polynucleotides, D4-1-1 to D4-1-4 was introduced into 293-nLD4-1 cells by transfection.
- each of the three types of non-natural polynucleotides, D4-2-1 to D4-2-4 was introduced into 293-nLD4-2 cells by transfection.
- each of the three types of non-natural polynucleotides, D4-3-1 to D4-3-4 was introduced into 293-nLD4-3 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 16.
- the structures shown in Table 16 all have two base substitutions at distant positions, and no such examples have been reported before.
- D4-1-1 to D4-1-4 the two mismatched nucleotides in the target nucleotide sequence are spaced apart by 8 bases.
- the relative editing efficiency was calculated based on the AUC value of D4-1-2 as the standard (1.00) and is shown in Table 16.
- the AUC was 47.16
- the AUC of D4-1-2 was 14904.
- the relative editing efficiency of D4-1-1 was 0.67
- that of D4-1-3 was 3.19
- D4-1-4 was 9.45.
- D4-2-1 to D4-2-4 the two mismatched nucleotides in the target nucleotide sequence are spaced 14 bases apart.
- the relative editing efficiency was calculated based on the AUC value of D4-2-2 as the standard (1.00) and is shown in Table 16.
- the AUC was 47.16
- the AUC of D4-2-2 was 63770.
- the relative editing efficiency of D4-2-1 was 0.04, that of D4-2-3 was 2.83, and that of D4-2-4 was 3.87.
- D4-3-1 to D4-3-4 the two mismatched nucleotides in the target nucleotide sequence are spaced 20 bases apart.
- the relative editing efficiency was calculated based on the AUC value of D4-3-2 as the standard (1.00) and is shown in Table 16.
- the AUC was 47.16
- the AUC of D4-3-2 was 104690.
- the relative editing efficiency of D4-3-1 was 0.00
- that of D4-3-3 was 1.76
- that of D4-3-4 was 4.70.
- Example 2-4 Study of Single Base Insertion An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD5 cells.
- nucleotides in [ ] indicate the nucleotides for inserting the nucleotide complementary to the nucleotide in [ ] into the target nucleotide sequence.
- D5-2 The structure of D5-2 is similar to that reported in Non-Patent Document 1.
- the relative editing efficiency was calculated with the AUC value of D5-2 as the standard (1.00) and is shown in Table 17.
- Tris-EDTA Tris-HCl 10 mM, EDTA 1 mM, pH 7.4, hereafter referred to as "TE"
- TE Tris-HCl 10 mM, EDTA 1 mM, pH 7.4, hereafter referred to as "TE”
- TE Tris-EDTA
- Example 2-5 Study of 2-base insertion An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD6 cells.
- each of the nine types of non-natural polynucleotides D6-1 to D6-10 was introduced into 293-nLD6 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 18.
- nucleotides in [ ] indicate the nucleotides for inserting the nucleotide complementary to the nucleotide in [ ] into the target nucleotide sequence.
- Example 2-6 Examination of Single-Base Deletion An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD7 cells.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 19.
- mismatched nucleotides are underlined, and nucleotides replaced by bridged nucleic acids are shown in capital letters.
- Mismatched nucleotide x in Table 19 means that one nucleotide complementary to a nucleotide present in the target nucleotide sequence is missing in the edited nucleic acid.
- All bridged nucleic acids in Table 19 were LNA. Where a phosphodiester bond between two or more nucleotides was replaced by a phosphorothioate bond, an asterisk (*) was inserted between the corresponding two or more nucleotides.
- Example 2-7 Study of 2-base deletion An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD8 cells.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 20.
- mismatched nucleotides are underlined, and nucleotides replaced by bridged nucleic acids are shown in capital letters.
- Mismatched nucleotides xx in Table 20 mean that two nucleotides complementary to nucleotides present in the target nucleotide sequence are missing in the edited nucleic acid. All bridged nucleic acids in Table 20 were LNA. Where a phosphodiester bond between two or more nucleotides was replaced by a phosphorothioate bond, an asterisk (*) was inserted between the corresponding two or more nucleotides.
- Example 2-8 Study of 4-base insertion An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD9 cells.
- each of the four types of non-natural polynucleotides was introduced into 293-nLD9 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 21.
- nucleotides in [ ] indicate the nucleotides for inserting the nucleotide complementary to the nucleotide in [ ] into the target nucleotide sequence.
- D9-2 The structure of D9-2 is similar to that reported in Non-Patent Document 1.
- the relative editing efficiency was calculated with the AUC value of D9-2 as the standard (1.00), and is shown in Table 21.
- Tris-EDTA Tris-HCl 10 mM, EDTA 1 mM, pH 7.4, hereinafter referred to as "TE"
- TE Tris-HCl 10 mM, EDTA 1 mM, pH 7.4, hereinafter referred to as "TE”
- the AUC was 383.8
- the AUC of D9-2 was 18543.
- the relative editing efficiency of D9-1 was 0.37
- that of D9-3 was 5.12
- that of D9-5 was 7.02
- D9-6 was 3.14.
- Genome editing experiment using 293-nLD1 cells (2) The following genome editing experiment was carried out using the 293-nLD1 cells prepared in the above section “A. Genome editing experiment using 293-nLD1 cells (1)”.
- Non-natural Polynucleotides All non-natural polynucleotides, including those with modified nucleic acids, were synthesized by Gene Design Co., Ltd. (Japan) and purified using a simple column or HPLC.
- Example 3-1 Modification of target nucleotide sequence by non-natural polynucleotides having various characteristics An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Table 31 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 31.
- G(F) and T(F) in GEO-204 indicate that they are 2'-Fluoro modified
- A(MT) in GEO-213 indicates that they are 2'-O-Methyl modified
- t*(MP)a in GEO-651 indicates that the bond between t and a is a methyl phosphate bond.
- the non-natural polynucleotide of the present invention was found to have an editing efficiency four times higher than that of the standard GEO-8.
- Example 3-2 Modification of a target nucleotide sequence by a non-natural polynucleotide having a mismatch nucleotide at the 3' end
- An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Table 32 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length, and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 32. Note that in Table 32, the chain length of the edited nucleic acid body and the chain length of the adapter are listed separately, but each sequence defined as a sequence number is the combined length of the edited nucleic acid body and the adapter.
- [t], [tt], and [ttt] indicate that one, two, and three thymidine monophosphates have been inserted, respectively, and [a], [aa], and [aaa] indicate that one, two, and three adenosine monophosphates have been inserted, respectively.
- the non-natural polynucleotides of the present invention were found to have higher editing efficiency than the standard GEO-8.
- Example 3-3 Modification of a target nucleotide sequence by a non-natural polynucleotide having an adaptor at the 3' end
- An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Table 33 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length, and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 33. Note that in Table 33, the chain length of the edited nucleic acid body and the chain length of the adapter are listed separately, but each sequence defined as a sequence number is the combined length of the edited nucleic acid body and the adapter.
- each of the non-natural polynucleotides shown in Table 33 the nucleotides in the second line are adaptors, and each adaptor forms a stem structure that may have a loop.
- Figures 16A, 16B, 17A, and 17B show schematic diagrams of the stem structure of each of the non-natural polynucleotides.
- the non-natural polynucleotides of the present invention were found to have editing efficiency equal to or higher than that of the standard GEO-8.
- Example 3-4 Modification of target nucleotide sequence by non-natural polynucleotide of embodiment (vi) An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Table 34 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 34.
- the non-natural polynucleotides of the present invention were found to have higher editing efficiency than the standard GEO-8.
- Example 3-5 Modification of target nucleotide sequence by non-natural polynucleotide having a 5'-terminal nucleotide other than LNA An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Table 41 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Table 41.
- the mismatched nucleotides are underlined, and the nucleotides replaced by the bridged nucleic acid are shown in capital letters. All bridged nucleic acids here were LNA. The RNA-substituted nucleotides are indicated by an arrow at the base symbol of the corresponding nucleotide. Where the phosphodiester bond between nucleotides has been replaced by a phosphorothioate bond, an asterisk (*) is inserted between the corresponding nucleotides.
- the bridged nucleic acid in GEO-827 and GEO-831 was LNA.
- mismatched nucleotide at or near the 5' end in GEO-649, GEO-650, GEO-653, GEO-654, GEO-656, and GEO-657 is a mismatched nucleotide for the purpose of improving editing efficiency, and is not a mismatched nucleotide for the purpose of modification.
- the non-natural polynucleotides of the present invention were found to have higher editing efficiency than the standard GEO-8.
- Example 3-6 Modification of target nucleotide sequence by non-natural polynucleotide having a modifying compound at the 5'-end or 3'-end Experiments were carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Tables 42 and 43 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Tables 42 and 43.
- Biotin is biotin as a modifying compound
- FAM fluorescein (FAM) as a modifying compound
- Pur is puromycin as a modifying compound
- Chol is cholesterol as a modifying compound
- DIG digoxigenin as a modifying compound
- IdT is inverted dT as a modifying compound.
- the molecular weight of biotin is 244.31
- the molecular weight of FAM is 376.32
- the molecular weight of puromycin (Pur) is 471.51
- the molecular weight of cholesterol (Chol) is 386.65
- the molecular weight of digoxigenin (DIG) is 414.31
- the molecular weight of inverted dT (IdT) is 304.2.
- mismatched nucleotides at or near the 5' end in GEO-649, GEO-650, GEO-653, GEO-654, GEO-656 and GEO-657 are mismatched nucleotides for the purpose of improving editing efficiency and are not mismatched nucleotides for the purpose of modification.
- the non-natural polynucleotides of the present invention were found to have higher editing efficiency than the standard GEO-8.
- Example 3-7 Study on introduction of phosphate modified bond to the 5' or 3' side An experiment was carried out to measure the editing efficiency of a target polynucleotide sequence by introducing a non-natural polynucleotide with a phosphate modified bond to the 5' or 3' side of the mismatched nucleotide to be modified into 293-nLD1 cells.
- each of the non-natural polynucleotides shown in Tables 44 to 45 was introduced into 293-nLD1 cells by transfection.
- the base sequence, chain length and relative editing efficiency of each of the above edited nucleic acids are as shown in Tables 44 to 45.
- the non-natural polynucleotides of the present invention were found to have higher editing efficiency than the standard GEO-8.
- the method of the present invention using a non-natural polynucleotide makes it possible to modify a target nucleotide sequence by only introducing a polynucleotide, without introducing an exogenous nuclease or a gene encoding an exogenous nuclease into cells, and can be applied to extremely safe genome editing technology, and therefore has industrial applicability.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biochemistry (AREA)
- Epidemiology (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Public Health (AREA)
- Medicinal Chemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Crystallography & Structural Chemistry (AREA)
- Saccharide Compounds (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024551649A JP7660960B2 (ja) | 2023-04-26 | 2024-04-26 | 標的ヌクレオチド配列の改変のための非天然型ポリヌクレオチド |
| AU2024260090A AU2024260090A1 (en) | 2023-04-26 | 2024-04-26 | Non-natural polynucleotides for modification of target nucleotide sequence |
| KR1020257036092A KR20250168544A (ko) | 2023-04-26 | 2024-04-26 | 표적 뉴클레오티드 서열의 개변을 위한 비천연형 폴리뉴클레오티드 |
| CN202480028181.0A CN121443735A (zh) | 2023-04-26 | 2024-04-26 | 用于改变靶核苷酸序列的非天然型多核苷酸 |
| EP24797170.8A EP4703472A1 (en) | 2023-04-26 | 2024-04-26 | Non-natural polynucleotides for modification of target nucleotide sequence |
| JP2025051903A JP2025092562A (ja) | 2023-04-26 | 2025-03-26 | 標的ヌクレオチド配列の改変のための非天然型ポリヌクレオチド |
| IL324176A IL324176A (en) | 2023-04-26 | 2025-10-23 | Non-natural polynucleotides for modification of target nucleotide sequence |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023-071927 | 2023-04-26 | ||
| JP2023071927 | 2023-04-26 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024225425A1 true WO2024225425A1 (ja) | 2024-10-31 |
Family
ID=93256810
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2024/016395 Ceased WO2024225425A1 (ja) | 2023-04-26 | 2024-04-26 | 標的ヌクレオチド配列の改変のための非天然型ポリヌクレオチド |
Country Status (7)
| Country | Link |
|---|---|
| EP (1) | EP4703472A1 (https=) |
| JP (2) | JP7660960B2 (https=) |
| KR (1) | KR20250168544A (https=) |
| CN (1) | CN121443735A (https=) |
| AU (1) | AU2024260090A1 (https=) |
| IL (1) | IL324176A (https=) |
| WO (1) | WO2024225425A1 (https=) |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009520499A (ja) * | 2005-12-22 | 2009-05-28 | キージーン ナムローゼ フェンノートシャップ | Lna修飾オリゴヌクレオチドにより改善された標的化ヌクレオチド交換 |
| US20100068712A1 (en) * | 2006-11-02 | 2010-03-18 | Prchal Josef T | Oligonucleotides for use in allele-specific pcr |
| JP2010530750A (ja) * | 2007-06-22 | 2010-09-16 | キージーン・エン・フェー | 改善された修飾オリゴヌクレオチドを用いた標的ヌクレオチドの交換 |
| JP2011062207A (ja) * | 2004-07-07 | 2011-03-31 | National Institute Of Agrobiological Sciences | 核酸を配列特異的に標識する方法、およびそれを利用した新規核酸検出法 |
| JP2016517273A (ja) * | 2013-03-14 | 2016-06-16 | ソマロジック, インコーポレイテッドSomaLogic, Inc. | Il−6に結合するアプタマー及びil−6介在性状態の治療または診断におけるそれらの使用 |
| JP6206893B2 (ja) | 2014-03-05 | 2017-10-04 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換するゲノム配列の改変方法及びそれに用いる分子複合体 |
| JP6343605B2 (ja) | 2012-05-25 | 2018-06-13 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | Rna依存性標的dna修飾およびrna依存性転写調節のための方法および組成物 |
| JP6480647B1 (ja) | 2017-06-08 | 2019-03-13 | 国立大学法人大阪大学 | Dnaが編集された真核細胞を製造する方法、および当該方法に用いられるキット |
| JP2020500035A (ja) * | 2016-11-11 | 2020-01-09 | バイオ−ラド ラボラトリーズ,インコーポレイティド | 核酸試料をプロセシングする方法 |
| WO2022256440A2 (en) * | 2021-06-01 | 2022-12-08 | Arbor Biotechnologies, Inc. | Gene editing systems comprising a crispr nuclease and uses thereof |
-
2024
- 2024-04-26 EP EP24797170.8A patent/EP4703472A1/en active Pending
- 2024-04-26 AU AU2024260090A patent/AU2024260090A1/en active Pending
- 2024-04-26 JP JP2024551649A patent/JP7660960B2/ja active Active
- 2024-04-26 KR KR1020257036092A patent/KR20250168544A/ko active Pending
- 2024-04-26 WO PCT/JP2024/016395 patent/WO2024225425A1/ja not_active Ceased
- 2024-04-26 CN CN202480028181.0A patent/CN121443735A/zh active Pending
-
2025
- 2025-03-26 JP JP2025051903A patent/JP2025092562A/ja active Pending
- 2025-10-23 IL IL324176A patent/IL324176A/en unknown
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011062207A (ja) * | 2004-07-07 | 2011-03-31 | National Institute Of Agrobiological Sciences | 核酸を配列特異的に標識する方法、およびそれを利用した新規核酸検出法 |
| JP2009520499A (ja) * | 2005-12-22 | 2009-05-28 | キージーン ナムローゼ フェンノートシャップ | Lna修飾オリゴヌクレオチドにより改善された標的化ヌクレオチド交換 |
| JP2009520495A (ja) * | 2005-12-22 | 2009-05-28 | キージーン ナムローゼ フェンノートシャップ | 改善された標的化ヌクレオチド交換のための代替ヌクレオチド |
| JP5405121B2 (ja) | 2005-12-22 | 2014-02-05 | キージーン ナムローゼ フェンノートシャップ | 二重鎖アクセプターdna塩基配列の標的化改変のための方法 |
| US20100068712A1 (en) * | 2006-11-02 | 2010-03-18 | Prchal Josef T | Oligonucleotides for use in allele-specific pcr |
| JP2010530750A (ja) * | 2007-06-22 | 2010-09-16 | キージーン・エン・フェー | 改善された修飾オリゴヌクレオチドを用いた標的ヌクレオチドの交換 |
| JP6343605B2 (ja) | 2012-05-25 | 2018-06-13 | ザ リージェンツ オブ ザ ユニバーシティ オブ カリフォルニア | Rna依存性標的dna修飾およびrna依存性転写調節のための方法および組成物 |
| JP2016517273A (ja) * | 2013-03-14 | 2016-06-16 | ソマロジック, インコーポレイテッドSomaLogic, Inc. | Il−6に結合するアプタマー及びil−6介在性状態の治療または診断におけるそれらの使用 |
| JP6206893B2 (ja) | 2014-03-05 | 2017-10-04 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換するゲノム配列の改変方法及びそれに用いる分子複合体 |
| JP2020500035A (ja) * | 2016-11-11 | 2020-01-09 | バイオ−ラド ラボラトリーズ,インコーポレイティド | 核酸試料をプロセシングする方法 |
| JP6480647B1 (ja) | 2017-06-08 | 2019-03-13 | 国立大学法人大阪大学 | Dnaが編集された真核細胞を製造する方法、および当該方法に用いられるキット |
| WO2022256440A2 (en) * | 2021-06-01 | 2022-12-08 | Arbor Biotechnologies, Inc. | Gene editing systems comprising a crispr nuclease and uses thereof |
Non-Patent Citations (3)
| Title |
|---|
| THOMAS W. VAN RAVESTEYNMARCOS ARRANZ DOLSWIETSKE PIETERSMARLEEN DEKKERHEIN TE RIELE: "Extensive trimming of short single-stranded DNA oligonucleotides during replication-coupled gene editing in mammalian cells", PLOS GENET, vol. 16, no. 10, 2020, pages 1009041, Retrieved from the Internet <URL:https://doi.org/10.1371/journal.pgen.1009041> |
| THOMAS W. VAN RAVESTEYNMARLEEN DEKKERALEXANDER FISHTITIA K. SIXMAASTRID WOLTERSROB J. DEKKERHEIN P. J. TE RIELE: "LNA modification of single-stranded DNA oligonucleotides allows subtle gene modification in mismatch-repair-proficient cells", PNAS, vol. 113, no. 15, 2016, pages 4122 - 4127 |
| VAN RAVESTEYN, T. W . ET AL.: "LNA modification of single-stranded DNA oligonucleotides allows subtle gene modification in mismatch-repair-proficient cells", PNAS, vol. 113, no. 15, 2016, pages 4122 - 4127, XP055440289, DOI: 10.1073/pnas.1513315113 * |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2024260090A1 (en) | 2025-12-04 |
| IL324176A (en) | 2025-12-01 |
| EP4703472A1 (en) | 2026-03-04 |
| KR20250168544A (ko) | 2025-12-02 |
| JPWO2024225425A1 (https=) | 2024-10-31 |
| JP7660960B2 (ja) | 2025-04-14 |
| JP2025092562A (ja) | 2025-06-19 |
| CN121443735A (zh) | 2026-01-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11560555B2 (en) | Engineered proteins | |
| US11851656B2 (en) | Chemically modified single-stranded RNA-editing oligonucleotides | |
| KR102691636B1 (ko) | 상동 재조합에 의한 crispr/cas-기반 게놈 편집을 위한 화합물 및 방법 | |
| CA2968336C (en) | Construct for site directed editing of an adenosine nucleotide in target rna | |
| CA3136735A1 (en) | Methods and compositions for editing rnas | |
| GB2617658A (en) | Class II, type V CRISPR systems | |
| EP3571300A1 (en) | Oligonucleotide complexes for use in rna editing | |
| WO2018117746A1 (ko) | 동물 배아의 염기 교정용 조성물 및 염기 교정 방법 | |
| US20240218339A1 (en) | Class ii, type v crispr systems | |
| WO2023086834A1 (en) | Direct replacement genome editing | |
| WO2018030536A1 (ja) | ゲノム編集方法 | |
| KR102679001B1 (ko) | 신규의 개량된 염기 편집 또는 교정용 융합단백질 및 이의 용도 | |
| JP7660960B2 (ja) | 標的ヌクレオチド配列の改変のための非天然型ポリヌクレオチド | |
| CA3245468A1 (en) | Compositions, systems and methods for eukaryotic gene editing | |
| CN117693585A (zh) | Ii类v型crispr系统 | |
| WO2026094932A1 (ja) | 標的ヌクレオチド配列の改変のための二本鎖ヌクレオチド複合体 | |
| US20240425850A1 (en) | Noncanonical crRNA for Highly Efficient Genome Editing | |
| US20250290056A1 (en) | Modrna-based cas endonuclease and base editor and uses thereof | |
| WO2026050560A1 (en) | Cas9 fusion proteins with internal nls: compositions and methods | |
| WO2024081383A2 (en) | Compositions and methods for targeting, editing, or modifying genes | |
| WO2024220715A2 (en) | Effector proteins and uses thereof | |
| WO2024124237A2 (en) | Gene-modifying endonucleases |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024551649 Country of ref document: JP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 24797170 Country of ref document: EP Kind code of ref document: A1 |
|
| DPE1 | Request for preliminary examination filed after expiration of 19th month from priority date (pct application filed from 20040101) | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 324176 Country of ref document: IL |
|
| ENP | Entry into the national phase |
Ref document number: 1020257036092 Country of ref document: KR Free format text: ST27 STATUS EVENT CODE: A-0-1-A10-A15-NAP-PA0105 (AS PROVIDED BY THE NATIONAL OFFICE) |
|
| WWE | Wipo information: entry into national phase |
Ref document number: KR1020257036092 Country of ref document: KR Ref document number: 1020257036092 Country of ref document: KR |
|
| WWP | Wipo information: published in national office |
Ref document number: 324176 Country of ref document: IL |
|
| WWE | Wipo information: entry into national phase |
Ref document number: AU2024260090 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024797170 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| WWP | Wipo information: published in national office |
Ref document number: 1020257036092 Country of ref document: KR |
|
| ENP | Entry into the national phase |
Ref document number: 2024260090 Country of ref document: AU Date of ref document: 20240426 Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| ENP | Entry into the national phase |
Ref document number: 2024797170 Country of ref document: EP Effective date: 20251126 |
|
| WWP | Wipo information: published in national office |
Ref document number: 2024797170 Country of ref document: EP |