WO2022004200A1 - 投与計画提案システム、方法およびプログラム - Google Patents
投与計画提案システム、方法およびプログラム Download PDFInfo
- Publication number
- WO2022004200A1 WO2022004200A1 PCT/JP2021/019872 JP2021019872W WO2022004200A1 WO 2022004200 A1 WO2022004200 A1 WO 2022004200A1 JP 2021019872 W JP2021019872 W JP 2021019872W WO 2022004200 A1 WO2022004200 A1 WO 2022004200A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- drug
- genotype
- relevance
- patient
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M1/00—Apparatus for enzymology or microbiology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M1/00—Apparatus for enzymology or microbiology
- C12M1/34—Measuring or testing with condition measuring or sensing means, e.g. colony counters
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/10—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to drugs or medications, e.g. for ensuring correct administration to patients
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y10/00—Economic sectors
- G16Y10/60—Healthcare; Welfare
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y20/00—Information sensed or collected by the things
- G16Y20/40—Information sensed or collected by the things relating to personal data, e.g. biometric data, records or preferences
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y40/00—IoT characterised by the purpose of the information processing
- G16Y40/20—Analytics; Diagnosis
Definitions
- the present invention relates to a system for proposing a drug administration plan to a user, and more particularly to a system for proposing a drug administration plan suitable for a patient based on a genotype peculiar to the patient.
- the current out-of-hospital and in-hospital prescriptions (specifying the type, dose and usage of the drug) prepared by the doctor have uniform factors (mainly the type of disease the patient is suffering from and the severity of the disease). Degree and patient age, weight and gender, etc.) are still applied.
- Such a prescription may mean that it is not possible to specify the type, dose and dosage of the drug suitable for the individual patient.
- multiple patients who use the drug as prescribed show very different reactions. It has been pointed out that the reaction may include the drug having only adverse effects on the patient (showing only side effects and no efficacy).
- drugs used for the treatment of mental illness show relatively low efficacy.
- Administration of less effective drugs delays recovery and increases treatment costs, thus imposing a physical, mental or financial burden on the patient.
- the side effects of the drug can cause distress that is inherently unrelated to the disease.
- one aspect of the present invention is to propose to the user a drug administration plan suitable for the patient based on the genotype peculiar to the patient.
- the system is a system that proposes a suitable administration plan for a patient.
- the drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
- Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
- Genotype information acquisition department that acquires the genotype information of the above patients;
- Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
- a medical information changing unit that changes the medical information when the goodness of fit is low; and an information presentation unit that presents the changed medical information that the medical information changing department has changed to the user.
- the system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information.
- Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- the method according to another aspect of the present invention is a method for proposing a suitable administration plan for a patient.
- a drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
- Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
- the genotype information acquisition step in which the computer acquires the genotype information of the patient;
- a goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
- a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user.
- the computer described above when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above.
- Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- the administration plan proposal program is a dose plan proposal program for operating a computer as a system for proposing a suitable administration plan for a patient.
- the above system is equipped with a control unit.
- the control unit Obtain drug information indicating the drug to be administered to the above patients and its dose; Obtained relevance information indicating the relevance of the above drugs and genotypes; Obtain genotype information for the above patients; Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined; When the goodness of fit is low, the above medical information is changed; The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death, The genotype information includes information representing variants having a frequency of less than 1% in the human population.
- the computer functions as the control unit.
- the system is a system that proposes a suitable administration plan for a patient.
- the drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
- Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
- Genotype information acquisition department that acquires the genotype information of the above patients;
- Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
- the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user.
- the system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information.
- Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- One aspect of the present invention is a system that proposes a suitable administration plan for a patient based on a genotype peculiar to the patient, and obtains pharmaceutical information indicating a drug to be administered to the patient and a dose thereof.
- Acquisition unit Relevance information acquisition unit that acquires relevance information indicating the relationship between the drug and the genotype; Genotype information acquisition unit that acquires the genotype information of the patient; Based on the relevance information and genotype information
- the conformity determination unit that determines the conformity of the drug information; the drug information change unit that changes the drug information when the conformity is low; and the modified drug information that the drug information change department has changed. It has an information presentation unit to present to the user.
- the "administration plan” includes at least information indicating a specific patient and information indicating the type and dose of the drug to be administered to the specific patient.
- the administration plan is a guideline (for example, a prescription) indicating that a certain drug is administered to the specific patient at a certain dose.
- the above system is a system that assists the judgment of healthcare professionals (particularly doctors) by creating an administration plan (custom-made administration plan) suitable for the patient.
- pharmaceutical is used herein for the purpose of a drug that directly causes improvement of symptoms in a disease by exerting a medicinal effect in a patient receiving administration, or for the purpose of assisting medical practice (examination and anesthesia, etc.). Represents the substance used (contrast, anesthetic, etc.).
- a “genotype” (also referred to as a genotype) is the genetic composition of an individual or a particular locus of an individual, herein a type of combination of alleles (alleles) in one or more loci in the genome. When targeting two or more loci for genotypes, it refers to the sum of each type).
- "Allele” as used herein refers to an individual gene and DNA sequence present at one locus of a chromosome.
- the term “genotype” or “allelic type” is used herein as a concept that includes “zygotes.”
- “Pharmaceutical information” includes at least information that identifies the patient (eg, the patient's ID number), information that identifies the drug (eg, the brand name or substance name of the drug), and information that specifies the dose of the drug to the patient. Represents the information you have.
- the pharmaceutical information can be, for example, a medical record or prescription created by a doctor on a computer.
- “Relevance information” refers to information indicating the type of drug and the relevance of genes (groups) that affect the action of the drug in vivo.
- Goodness of fit (of pharmaceutical information) refers to the patient and the type and / or dose of the drug specified in the drug information, based on the patient's specific genetic type specified in the drug information. The relationship is appropriate and represents a certain degree.
- a “DNA variant” as used herein is a specific site on the genome in which two or more changes in a nucleotide sequence (including alleles and chromosomal structures) are present in a human population (regardless of its frequency) and the like thereof. Described as a general concept of change. Nucleotide sequence changes in the above "DNA variant” mean the sum of all changes, including substitutions, deletions, insertions and / or additions, duplications of one or more nucleotides (see bottom of FIG. 1).
- CNV Cosmetic Number Variant
- DNA variant is described as a concept including “polymorphism” and “variant” regardless of the frequency in the human population as described above (see the lower part of FIG. 1).
- the total type of allele combination (“allele type”), including the mating type in one locus, is determined by the nucleotide sequence of each allele and / or the number of alleles contained in the combination.
- Administration of the drug to a patient ie, a patient with an unusual type in which at least one of the nucleotide sequences is not the most abundant wild-type nucleotide sequence in the human population and / or the number of alleles is not the usual two is It can have undesired effects on the patient.
- the undesired effects are, for example, (a) a decrease, loss or excessive increase in the efficacy of the drug, (b) the onset or increase of side effects of the drug, and / / when the type is compared to a normal patient. Or (c) a high incidence of a specific disease that did not occur prior to administration of the above-mentioned drug.
- the undesired effect does not appear in just one "allele type", but in many "allele types” for many sitting positions. It often appears when it is accumulated.
- the system has a doctor-designated dosing regimen for drug B (including dose C designation) for patient A according to the uniform factors described above, with the adverse effects described above being patient.
- a doctor-designated dosing regimen for drug B (including dose C designation) for patient A according to the uniform factors described above, with the adverse effects described above being patient.
- a tailor-made administration plan eg, drug B'and dose C'
- Criteria for changing the dosing regimen include (1) pharmacokinetic factors of drug B, (2) pharmacodynamic factors of drug B, and (3) risk of developing secondary diseases due to drug B. ..
- [Embodiment 1] described later an example in which (1) and (2) are used as the above-mentioned determination criteria will be described.
- the degree to which the chemical structure of drug B administered to the patient interacts with the protein expressed in the patient's body is used to properly control.
- (3) is used to prevent the risk of developing a certain disease based on the genetic background peculiar to the patient from being manifested (that is, developing the disease) by administration of a drug (artificial act).
- the graph in (the system of invention) of FIG. 1 visually shows the risk of developing a specific disease.
- the human population for one disease The risk of developing the disease has been shown to be approximately normally distributed.
- the population to the right of the threshold (horizontal axis, dashed line of threshold and part surrounded by curve / horizontal axis and part surrounded by curve) is inherited to develop a certain disease.
- the genotype information of patient A can be determined, for example, by two different methods shown below (see the bottom of FIG. 1). For example, at least one locus of a string representing the entire nucleotide sequence of the genome obtained from the patient (approximately 3 billion characters represented by the four alphabets ATGC, hereinafter referred to as "full-length string”).
- a character string (hereinafter referred to as "allergen character string”) representing a partial nucleotide sequence containing a known DNA variant present in is extracted. The string is then compared to a string representing the entire nucleotide sequence of a standard human genome (approximately 3 billion characters represented by the four alphabets ATGC, hereinafter referred to as "reference string").
- the reference character string can be obtained from a public database such as an ensemble (Ensembl, URL: http://ensembl.org).
- the genotype information of patient A is obtained by, for example, using a part of the genomic DNA sample obtained from the patient using the current microarray technology (genome-exhaustive polymorphism analysis technology). By hybridizing each fragment consisting of a nucleotide sequence containing all known SNPs corresponding to the "reference string” under stringent conditions (conditions that allow only perfectly matched sequences (temperature, salt concentration)). It can be determined by experimental methods.
- the goodness of fit will be determined based on the efficacy of the drug expected to occur in the patient, as an example.
- the system of this embodiment is a combination of allele types ("" Allelic type ”) is at least referred to as the above genotype. That is, the system of the present embodiment refers to the information indicating the degree to which the genotype related to the gene (“allele type”) affects the drug efficacy of the drug (pharmaceutical efficacy-related gene information), and refers to the above-mentioned goodness of fit. To determine.
- Proteins involved in pharmacokinetics include, for example, proteins involved in drug absorption, circulation, delivery, metabolism and excretion. That is, pharmacokinetics refers to the in vivo behavior of a drug or its metabolites that alters the probability of contact between the drug and the target molecule. Proteins involved in pharmacodynamics can be drug target molecules. Target molecules include, for example, receptors, signal molecules, and proteins that constitute biological pathways associated with pharmacological and genetic actions of drugs.
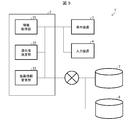
- the administration plan proposal system (system that presents an administration plan suitable for a patient) 1 includes a control unit 2 built in a computer and a display device (information display unit) 3.
- the control unit 2 (FIG. 2) includes an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genotype information acquisition unit) 21, a goodness-of-fit determination unit 22, and a drug information change unit 23 of FIG. ..
- the information acquisition unit 21, the goodness-of-fit determination unit 22, and the medical information change unit 23 of FIG. 2 are included in the CPU (Central Processing Unit) of the control unit 2 (FIG. 2).
- the control unit 2 (FIG. 2) is connected to the input device 4 (for example, keyboard and / or mouse) of FIG.
- the administration plan proposal system 1 of FIG. 2 is controlled by the control unit 2 (FIG. 2) based on the information acquired from the input device 4 and the above two DBs (database: that is, the drug efficacy-related gene information DB 5 and the genomic information DB 6). This is a system that outputs the generated information to the user via the display device 3 (FIG. 2).
- the input device 4 (FIG. 2) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.).
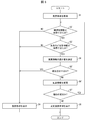
- the input medical information 301 (FIG. 4) is sent to the information acquisition unit 21 (FIG. 2) (S1 step in FIG. 3).
- the information acquisition unit 21 of FIG. 2 has the name of the drug represented by the drug name contained in the drug information 301 (FIG. 4), the name of the gene related to the efficacy of the drug, and the known DNA related to the gene.
- the relevance information 311 (FIG. 4) describing the entire “genotype” in the variant (for example, SNP) and the drug efficacy of the drug according to the genotype is provided in the pharmaceutical efficacy-related gene information DB 5 of FIG. (For example, it can be constructed based on the information of DGIdb: Drug Gene Interaction database, URL: http://dgidb.org/) (“YES” in the S2 step of FIG. 3).
- the information acquisition unit 21 of FIG. 2 has a patient ID and a gene based on the "patient ID" information described in the drug information 301 (FIG. 4) and the gene name contained in the relevance information 311 (FIG. 4).
- the genetic type information of the patient corresponding to the above is acquired from the genomic information DB 6 (FIG. 2) as a symbol according to the notation of "genetic type” described in the relevance information 311 of FIG. 4 (in the step S3 of FIG. 3). "YES").
- the information acquisition unit 21 (FIG. 2) determines the goodness of fit of the patient's genotype information acquired from the acquired drug information 301 (FIG. 4), the relevance information 311 (FIG. 4), and the genomic information DB 6 (FIG. 2). Send to 22 (Fig. 2).
- the information acquisition unit 21 of FIG. 4 is sent to the display device 3 (FIG. 2) (step S9 in FIG. 3).
- the display device 3 of FIG. 2 displays the above-mentioned drug information, and the administration plan proposal system 1 (FIG. 2) ends the process.
- the information acquisition unit 21 (FIG. 2) receives the drug information 301 (for example, FIG. 4) is sent to the display device 3 (FIG. 2) (step S9 in FIG. 3).
- the display device 3 (FIG. 2) displays the above-mentioned drug information, and the administration plan proposal system 1 of FIG. 2 ends the process.
- the goodness-of-fit determination unit 22 in FIG. 2 has medical information based on the genotype information of the patient acquired from the relevance information 311 (FIG. 4) and the genomic information DB 6 (FIG. 2) via the information acquisition unit 21 (FIG. 2).
- the goodness of fit of 301 (FIG. 4) is determined (step S4 of FIG. 3). The details of the S4 process of FIG. 3 will be described with reference to FIG.
- the relevance information 311 shown in FIG. 4 refers to an active ingredient corresponding to a drug name (pharmaceutical name: phenytoin (antiepileptic drug)) and a gene encoding a protein involved in the pharmacokinetics of the active ingredient (related gene).
- a drug name pharmaceutical name: phenytoin (antiepileptic drug)
- a gene encoding a protein involved in the pharmacokinetics of the active ingredient related gene
- Phenytoin is a drug that has the effect of relieving symptoms such as seizures of epilepsy such as tonic seizures (generalized seizures, major seizures), focal epilepsy (including Jackson-type seizures), autonomic seizures, and psychomotor seizures. be.
- SNP rs1057910
- its genotype type "* 1" represents a wild-type allele, and the actual nucleotide type of the nucleotide. Is "Adenine (A)”.
- the genotype type "* 3” represents a low-metabolic allele that is known to reduce the metabolic rate of phenytoin, and the actual base type of nucleotide is "cytosine (C)”.
- Relevance information 311 shows the most frequent CYP2C9 genetic type (normal type) "* 1 / * 1" (actual nucleotide combination type: "A / A”) in the population.
- the relevance information 311 shows that the administration of phenytoin according to the conventional uniform factor is the combination type of nucleotide change of SNP at the 1075 position of the gene CYP2C9 (“A / A”, “A / C”).
- the goodness-of-fit determination unit 22 uses the pharmaceutical information 301 (FIG. 4), the relevance information 311 (FIG. 4), and the patient's genotype information as “* 1”.
- the value of the metabolic rate (medicinal efficacy) of phenytoin in the drug information 301 (FIG. 4) is determined to be "-1".
- the above "* 1 / * 3" is genotype information indicating that the "allele type" of CYP2C9 in the patient is a heterozygous type.
- the genotype information is obtained based on the "patient ID: 123456789” described in the drug information 301 (FIG. 4) and the "related gene: CYP2C9" described in the relevance information 311 (FIG. 4). Obtained from genomic information DB 6 (FIG. 2) by unit 21 (FIG. 2).
- the information acquisition unit 21 (FIG. 2) has two relational information R (relationship) 1 and R2 corresponding to the gene names G1 and G2, and the genotype information Gt (genotype) 1 and Gt2 of the patient. Is sent to the fitness determination unit 22 (FIG. 2).
- the goodness-of-fit determination unit 22 (FIG.
- the metabolic rate (medicinal effect) of phenytoin is exemplified as an element of the above goodness of fit.
- the goodness-of-fit factor varies.
- the antiplatelet drug clopidogrel sulfate prodrug, hereinafter simply referred to as "clopidogrel”
- clopidogrel drug metabolizing enzyme gene
- Clopidogrel is a drug that inhibits the action of ADP (adenosine diphosphate), suppresses platelet aggregation based on platelet activation, suppresses the formation of thrombi and prevents blood vessels from becoming clogged, and is usually an ischemic cerebrovascular disease. It is used to suppress the recurrence of disorders and to suppress thrombus / embolism formation in peripheral arterial diseases.
- ACE angiotensin converting enzyme
- perindopril erbumin active ingredient
- Perindopril erbumin is a prodrug that is hydrolyzed to a diacid form (perindoprilate) after oral absorption, and this diacid form specifically inhibits ACE in blood and tissues, and angiotensin II, which is a pressor substance, It suppresses production and reduces peripheral vascular resistance.
- angiotensin II which is a pressor substance, It suppresses production and reduces peripheral vascular resistance.
- the conformity determination unit 22 in FIG. 2 acquires the heterozygous type “* 1 / * 3” as the genotype information regarding the SNP (rs1057910) in CYP2C9 in the relevance information 311 (FIG. 4).
- the metabolic rate (medicinal effect) value " ⁇ 0" corresponding to the normal genotype (normal type) "* 1 / * 1” and the metabolic rate of phenitoin corresponding to the heterozygous type "* 1 / * 3"
- the value "-1" which is the sum of the values "-1" of the rate (drug efficacy), is determined as the degree of suitability (only 1 lower) with respect to the metabolic rate (drug efficacy) of the drug information 301 (FIG. 4).
- the goodness-of-fit determination unit 22 sends the pharmaceutical information 301 (FIG. 4) and the goodness of fit “-1” to the pharmaceutical information change unit 23 (FIG. 2).
- the pharmaceutical information changing unit 23 in FIG. 2 determines that the goodness of fit “-1”, which is a negative value, is low (step S5 in FIG. 3).
- the drug information change unit 23 (FIG. 2) continuously adjusts the maintenance dose (after the lapse of the initial administration period) among the daily doses in the drug information 301 (FIG. 4) according to the metabolic rate (drug efficacy) “-1”.
- the medicinal effect is set to " ⁇ 0" (step S6 in FIG. 3). Since the change in the step S6 of FIG.
- the drug information change unit 23 (FIG. 2)
- the modified drug information 302 (FIG. 4) changed to 225 mg is sent to the display device 3 (FIG. 2) as the dose obtained by reducing the “daily dose (maintenance dose)” from 300 mg by 25%.
- the initial dose is unchanged, and remains the same as the "daily dose (initial dose) 300 mg" described in Pharmaceutical Information 301 in FIG.
- the display device 3 (FIG. 2) displays the changed drug information 302 (FIG. 4), and the administration plan proposal system 1 (FIG. 2) ends the process.
- the drug information changing unit 23 executes the drug change in the modified drug information 302 (FIG. 4) (shown). figure).
- the suitability determination unit 22 acquires the normal type “* 1 / * 1” as the genotype information of the patient from the genomic information DB 6 (FIG. 2).
- the value of the metabolic rate (medicinal effect) of phenytoin is determined to be " ⁇ 0" and sent to the drug information change unit 23 (FIG. 2).
- the drug information changing unit 23 determines that the value “ ⁇ 0” of the metabolic rate (medicinal effect) is not low, and sends the drug information 301 (FIG. 4) to the display device 3 (FIG. 2).
- the display device 3 (FIG. 2) displays the above-mentioned drug information, and the administration plan proposal system 1 (FIG. 2) ends the process.
- the drug information changing unit 23 in FIG. 2 changes the type of drug.
- the drug name described in the drug information is "clopidogrel”
- the information acquisition unit 21 (FIG. 2) is the relevance information 312 (FIG. 4)
- the information is acquired from the genomic information DB 6 (FIG. 2). Since the patient's genotype information is either "* 2 / * 2", “* 3 / * 3" or "* 2 / * 3", the metabolic rate (drug efficacy) is very low "-2".
- clopidogrel is a prodrug and has no medicinal properties unless it is converted to its active compound. That is, when the above conditions are met, the active compound of clopidogrel, which is an active ingredient, is hardly produced in the patient's body regardless of the dose. Therefore, since an increase in the dose cannot be expected to have a drug effect, the drug information changing unit 23 (FIG. 2) in FIG. 2 changes the type of drug.
- the drug information changing unit 23 (FIG. 2) sends the drug information whose drug name has been changed (corresponding to the determination “YES” in the step S7 in FIG. 3) to the information acquisition unit 21 (FIG. 2), and processes S2 in FIG. Return to the process.
- the details of the relevance information 311 to 313 in FIG. 4 and other related matters are described later in the items (relevance information 311 to 313) in the present embodiment.
- the administration plan proposal system 1 (FIG. 2) of the present embodiment sets the type or dose of the drug described in the drug information 301 (FIG. 4) specified by the doctor as the "genotype" of the patient (the relevant). Change when determined to be incompatible with the patient's "genotype") as a combination of alleles associated with genes that affect the efficacy of the drug. Therefore, the administration plan proposal system 1 (FIG. 2) can propose a tailor-made administration plan having excellent drug efficacy according to the genotype of the patient, without being bound by the conventional uniform factors.
- the genotype information represents a combination type (“allele type”) of an allele (in this embodiment, an allele associated with one gene) that is unique to the patient and is present in one lotus coition.
- allele type a combination type of an allele (in this embodiment, an allele associated with one gene) that is unique to the patient and is present in one lotus coition.
- Method 1 uses information representing the structure of the full length of the genome obtained from the patient ("full length character string"), and a genomic DNA sample derived from the patient, which is frequently and automatically performed in the population.
- Method 2 which uses an experimental method based on genome-wide polymorphism analysis targeting only DNA variants suitable for analysis (for example, SNP).
- the former "method 1" can be carried out by using a large-scale massively parallel DNA sequence determination method (next-generation nucleotide sequence determination method).
- Large-scale parallel DNA sequencing methods can simultaneously and evenly sequence complex DNA samples containing a large number (sometimes millions) of nucleotide sequences. For this reason, the large-scale parallel DNA sequencing method uses genomic DNA samples extracted by a conventional method from patient-derived blood cells and various tissues, as compared with the conventional dideoxy sequencing method (Sanger method). It is possible to convert the information into a character string (“full-length character string”) corresponding to the entire genome (about 3 billion nucleotides) of the patient in a short time and at low cost.
- the patient's The genetic type for a particular locus on the genome can be determined.
- allele string a string representing the nucleotide sequence of an allele that may be in a locus
- information representing a position within the population that causes a nucleotide sequence change between the alleles known DNA variant
- DB eg, dbSNP (https://www.ncbi.nlm.nih.gov/snp/)
- the outline of the process of determining the genotype information of a patient will be described below.
- DB eg, the above-mentioned dbSNP.
- two character strings for example, about 10 to 100 characters
- the above DNA variant is a DNA variant that is frequently used in the population and suitable for automatic analysis.
- the types of polymorphisms in hundreds of thousands) genomic fragments can be determined in a short time. For more information on microarray technology, see the kit manual or the contractor's HP.
- the genotype information of the patient is obtained by the above-mentioned "method 1" using the former "full-length character string” information and / or the latter "method 2" using an experimental method by genome-wide polymorphism analysis. It can be determined (or during the implementation of these methods). Therefore, the patient's genetic type information stored in the genomic information DB 6 of FIG. 2 includes (1) "full-length character string” (patient's genomic information) and (2) the patient's "hereditary type” associated with each other. At least one of the information representing and the information representing the patient, and (3) the information in which the two relevant information are symbolized (see, for example, the "genome type" described in the relevance information 311 of FIG. 4 above). Can be one.
- the genotype information is preferably (2) or (3).
- (2) or (3) as the genotype information reduces the performance required for the administration plan proposal system 1 (FIG. 2) and the genomic information DB 6 (FIG. 2), and reduces the performance required for the administration plan proposal system 1 (FIG. 2).
- (3) can be concealed from an unspecified number of third parties who cannot decipher the meaning of the symbol.
- the "genotype" determined for the SNP (rs4244285) present in the drug metabolizing enzyme gene CYP2C19 is symbolized ("* 1 / * 1", "*". 1 / * 2 ",” * 1 / * 3 ",” * 2 / * 2 ",” * 2 / * 3 "or” * 3 / * 3 ").
- the "allele type" of the individual DNA variants to generate (2) and (3) as patient genotype information depends on the type (determination range) of the DNA variant based on the frequency within the population. Can be determined in two stages (see bottom of FIG. 1). As a first step, only all known SNPs are genomically determined as DNA variants with a frequency of 1% or higher in the population and suitable for automated analysis, and the information is stored in DB, recording media, or It is stored in a storage device (not shown). In addition, the patient's "genotype” information based on the analysis of all SNPs described above is stored in the genomic information DB 6 (FIG. 2).
- the determination of the "allele type” (genotype of the patient) for all SNPs can be determined by "method 2" by an experimental method using the genomic DNA sample of the patient. That is, first, the genomic DNA sample is extracted from the patient's peripheral blood, oral cells, buccal mucosa, or the like by a conventional method. Subsequently, using the above sample, the "allelic type” (patient's "genotype”) for all known SNPs can be determined by an experimental method by genome-wide polymorphism analysis by the current microarray technology.
- the patient's "genotype" ("allele type") for all SNPs described above is determined by “method 1" by information analysis using the above-mentioned “full-length character string” (genome information of the patient). May be (see bottom of Figure 1).
- the "allelic type” (patient's “genotype) for the remaining DNA variants not stored in the DB, recording medium or storage device is the "full length string”. It is determined by "Method 1" using information (patient's genomic information).
- the "remaining DNA variants” include DNA variants that are infrequent in the population (eg, SNV, CNV), or DNA variants that are not suitable for automated analysis (eg, CNP, STRP, or other special DNA variants). Is assumed (see the bottom of FIG. 1).
- the "allelic type” (patient “genotype") of the remaining DNA variants is determined after input of pharmaceutical information 301 (FIG. 4) to input device 4 (FIG. 2).
- the administration plan proposal system 1 of FIG. 2 is related to the drug efficacy from the drug efficacy-related gene information DB 5 (FIG. 2) based on the drug name included in the drug information 301 (FIG. 4). Get the name of the gene.
- the dosing regimen proposal system 1 (FIG. 2) searches for the latest genomic information DB 6 (FIG. 2) based on the name and "allelic type” (ie, patient genotype information) for the required DNA variant. If is not stored, as described above, the "reference string" information is searched to specify the loci on the genome where the remaining DNA variants are located.
- the administration plan proposal system 1 (FIG.
- the dosing regimen proposal system 1 displays the "allelic type” (patient genotype information) of the remaining DNA variants determined in the genomic information DB 6 (FIG. 2), as well as the DB, recording medium or storage device. Store in (not shown).
- the method (“method 1”) for determining the “allele type” (patient genotype information) of the DNA variant using the above character string (“full-length character string”) information will be described later, including specific examples. It is also described in detail in [Embodiment 4].
- the genome information DB 6 is shown in FIG. 2 as a configuration existing on a network, a storage unit or a storage unit built in the control unit 2 (FIG. 2), a reading unit that can read a recording medium, or a control unit.
- the external storage device or recording medium connected to 2 (FIG. 2) can be replaced as a readable reader.
- the above genotype information according to (2) or (3) can be updated based on the latest report.
- the report is a comprehensive report of new DNA variants associated with a gene, as well as "allelic types" ("genotypes") for the DNA variants.
- the "method 1" using the above-mentioned "full-length character string" information (patient's genomic information) can generate a new (2) or (3) based on the existing report and the latest report.
- the genotype of the patient is divided into two stages from the genomic information DB 6 (FIG. 2).
- An example of acquiring (2) and (3) as information is shown. That is, as the first step, it was determined by "Method 2" using an experimental method using known DNA microarray technology (or “Method 1" using "full-length character string” information (patient's genomic information)). All SNP analysis information of the patient is stored in the genome information DB 6 (FIG. 2). Subsequently, as a second step, the remaining DNA variant information is analyzed by "Method 1" using the "full-length character string” information (patient's genomic information), if necessary.
- the control unit 2 in FIG. 2 does not store all the SNP analysis information of the patient in the genomic information DB 6 (FIG. 2) as the first step described above, and from the beginning, as the second step, if necessary.
- "method 1" using "full length string” information may be performed. That is, the control unit 2 (FIG. 2) acquires (1) the "full-length character string” (patient's genome information) from the genome information DB 6 (FIG. 2), and extracts the allele character string contained in (1).
- the above procedure may be performed to determine the genotype for a particular locus or loci on a patient's genome.
- full-length character string information patient's genomic information
- method 1 the patient's “genotype” (allele type) related to a specific SNP or new SNV. It may be determined by the method 1 ”. That is, regardless of conditions such as frequency in the population and suitability for automatic analysis, "method 1" using "full-length character string” information may be applied to all DNA variants from the beginning (FIG. 1). See bottom).
- the patient's "genotype” for a particular SNP or new SNV is not yet stored in the genomic information DB 6 (FIG. 2), the patient's "genotype” for a particular SNP or new SNV.
- the current amplification-resistant mutation system (a technique for detecting specific point mutations) by PCR using allele-specific primers for the "genotype” of patients with the above-mentioned specific SNPs or novel SNVs.
- a method capable of distinguishing a mutant allele that is one base different from a normal allele) may be used to individually identify the genotype.
- the information in the genome information DB 6 in FIG. 2 may be encrypted, or the information in the genome information DB 6 (FIG. 2) may be provided with access restrictions.
- the above encryption and access restriction can be realized by a method known in the field of information technology.
- the system may acquire genotype information recorded on a recording medium instead of the genomic information DB6 (FIG. 2).
- the genotype is a genotype relating to a gene encoding a protein involved in pharmacokinetics, as shown in relevance information 311 in FIG.
- Relevance information 311 in FIG. 4 represents drug-gene association (particularly the effect of the metabolic rate of the active ingredient on the genotype of the allele associated with the gene function of the gene).
- Relevance information 311 shows the CYP2C9 gene as a gene encoding a protein involved in pharmacokinetics for phenytoin.
- the presence of SNPs associated with enzyme activity has been demonstrated in the CYP2C9 gene.
- Proteins expressed by the CYP2C9 gene, including mutant alleles, have low activity to oxidize (metabolize) phenytoin, the active ingredient of antiepileptic drugs. As shown in the relevance information 311 (Fig. 4)
- the relevance information 312 in FIG. 4 shows the CYP2C19 gene as a gene encoding a protein involved in the pharmacokinetics of clopidogrel. It is known that there may be several mutant allele types in the known SNPs (rs4244285) present within the CYP2C19 gene (see relevance information 312 in FIG. 4). The protein expressed by the CYP2C19 gene containing the mutant allele does not metabolize in the body of a drug that is oxidized and exerts a medicinal effect like clopidogrel, or weakens the metabolism.
- the CYP2C19 gene containing the mutant allele lowers the metabolic rate of clopidogrel to the active compound depending on the genetic type of the patient, as shown in the association information 312 (Fig. 4) (metabolic rate (medicinal effect): "-”. 1 "), or make the metabolic rate substantially 0 (metabolic rate (medicinal effect):” -2 ").
- “Recommended treatment policy (dose adjustment)” see CLIMINICAL PHARMACOLOGY & THERAPEUTICS 89 (5): 662-673, 2011 and Organ Biology 21 (2): 247-253, 2014, etc.
- the drug information changing unit 23 in FIG. 2 has a negative metabolic rate (metabolic rate (medicinal effect): "-1" and "-2”).
- the type of medicine may be changed uniformly.
- the ACE gene as a gene encoding a protein (direct target protein) involved in the pharmacokinetics of perindopril erbumin.
- a protein direct target protein
- a gene into which an Alu sequence has been inserted causes splicing abnormalities or exon deletions, so the expression of abnormal proteins or abnormal protein expression patterns is higher than that of the gene lacking the Alu sequence. show. That is, perindopril erbumin has low or little efficacy in individuals carrying the ACE gene with the Alu sequence inserted.
- the drug efficacy is determined to be “-1”.
- the drug efficacy is determined to be “-2” (see relevance information 313 in FIG. 4).
- the relevance information 311 to 313 in FIG. 4 shows the gene encoding the pharmacokinetics of the drug or the protein involved in pharmacodynamics, the genotype of the gene, and the fitness element that changes depending on the genotype. Information representing each is included.
- the relevance information (pharmaceuticals, related genes, genotypes, and pharmacological efficacy information) described in the above information (relevance information 311 to 313 in FIG. 4) and other relevance information relating to the drug are known documents (eg, for example).
- CLINICAL PHARMACOLOGY & THERAPEUTICS 89 (5): 662-673, 2011 Tabel 1 and Organ Biology 21 (2): 247-253, 2014 Table 1 and Table 2) are summarized and easily available. It is possible.
- Table 1 of Organ Biology 21 (2): 247-253, 2014 is an excerpt from the old version of the prescription drug collection.
- the relevance information 311 to 313 (FIG. 4) and the relevance information regarding other medicines are prepared based on the latest information at the time of the embodiment of the present embodiment.
- relevance information 311-313 (FIG. 4), as well as relevance information about other medicines can be generated by artificial intelligence (hereinafter referred to as "AI") (see FIG. 1).
- AI artificial intelligence
- the AI may output new drug and gene relevance used to update the old information.
- the information representing the goodness-of-fit element (for example, metabolic rate and drug efficacy) that changes depending on the genotype is related to the above-mentioned known documents and materials. It can be described arbitrarily according to the sexual information.
- the metabolic rate (drug efficacy) values corresponding to each genotype in the SNP (rs4244285) in the drug metabolizing enzyme gene CYP2C19 are " ⁇ 0", "-1" and "-”. 2 "is described.
- Organ Biology 21 (2): 247-253, 2014 "CYP2C19 * 2 and * 3 types are important for CYP2C19 gene polymorphisms.
- the value "-2" of the metabolic rate (medicinal effect) in the relevance information 312 (FIG. 4) may be rewritten as "disappearance".
- the metabolic rate (drug effect) "disappearance" in the relevance information 312 (FIG. 4) can indicate, for example, that the prodrug clopidogrel is not metabolized (converted to a medicinal component) by CYP2C19 into its active compound. Therefore, the metabolic rate (medicinal effect) "disappearance” is determined by the goodness-of-fit determination unit 22 in FIG. Change the drug name in 4) to an alternative drug.
- the changed drug information in which the dose is changed to "0" may be output to the user.
- a warning indicating that the drug name (or drug information including the dose) in the drug information 301 in FIG. 4 has a low goodness of fit may be issued to the user. ..
- the configuration of the system 1a at this time (which further includes the warning unit 24) is illustrated in FIG. 12 as an example.
- genotypes related to pharmacokinetic factors include the following are examples of transporter gene polymorphisms.
- HMG-CoA reductase inhibitors (bravastatin, atorvastatin, etc.), which are therapeutic agents for dyslipidemia, are selectively taken up by the liver and show efficacy, but the transporter protein OATP1B1 (Organic Anion Transporting Polypeptide 1B1) is used for the uptake. It plays an important role.
- OATP1B1 Organic Anion Transporting Polypeptide 1B1
- the mutant type with amino acid substitution base change: "521T> C”
- Drugs such as statins and atorvastatin escape metabolism and excretion in bile and flow through the central vein, resulting in increased blood levels.
- the heterozygous type is "-1" (genotype: "T / C") and homozygous type (hereditary) compared to the medicinal effect value " ⁇ 0" of the normal type (genotype: "T / T”).
- Genotype: "C / C" can be determined to be "-2" lower.
- examples of gene polymorphisms of drug receptors as examples of genotypes related to pharmacodynamic factors are as follows.
- the relevance information 311-313 (including the above-mentioned additional example contents) of FIG. 4 regarding pharmacokinetics and pharmacodynamics has a low goodness of fit for the specific patient in the administration plan specified by the doctor.
- pharmacokinetics and pharmacodynamics has a low goodness of fit for the specific patient in the administration plan specified by the doctor.
- the administration plan proposal system 1 (FIG. 2), which uses the relevance information 311 to 313 (FIG. 4) as a criterion for determining the goodness of fit of the pharmaceutical information 301 (FIG. 4), makes a proposal to the doctor for improvement of the low goodness of fit. It can be presented.
- the information acquisition unit 21 of FIG. 2 can acquire a plurality of relevance information at the same time (see “(administration plan)” of FIG. 1), and systemizes the drug information 304 (FIG. 11) for patients with non-small cell lung cancer.
- the case of inputting in 1 (FIG. 2) will be described as an example.
- the information acquisition unit 21 of FIG. 2 Upon receiving the drug information 304 (FIG. 11) describing the drug name (ALK tyrosine kinase inhibitor) including the target molecule or the mechanism of action in the name, the information acquisition unit 21 of FIG. 2 receives the drug information 304 (FIG. 11) in the S1 step of FIG.
- a plurality of relevance information 315 and 316 are acquired at the same time.
- drug names can generally refer to a plurality of specific drugs.
- the relevance information 315 (including lyxothinib as a specific drug name) and 316 (including ceritinib as a specific drug name) in FIG. 11 are both based on the ALK tyrosine kinase inhibitor and its genotype. Information that describes the medicinal effect.
- the information acquisition unit 21 and the goodness-of-fit determination unit 22 of FIG. 2 that acquired the relevance information 315 and 316 of FIG. 11 are the treatment when the drug name in the drug information 304 of FIG. 11 is lyxotinib and the drug name in the drug information 304.
- the treatment when is ceritinib (S3 to S5 in FIG. 3) is carried out in parallel.
- the suitability determination unit 22 of FIG. 2 is of lyxotinib and ceritinib. Both are determined to be invalid "- ⁇ " for the patient in S4 of FIG. 3 and sent to the drug information changing unit 23 of FIG.
- the drug information changing unit 23 in FIG. 2 changes the drug name in the drug information 304 (including the ALK tyrosine kinase inhibitor) in FIG. 11 according to the negative symbol “ ⁇ ” and the infinity “ ⁇ ”.
- the drug name includes the mechanism of action as described above. Therefore, it is a therapeutic agent for non-small cell lung cancer different from the ALK tyrosine kinase inhibitor (therapeutic agent for non-small cell lung cancer) in the pharmaceutical information 304 of FIG. EGFR tyrosine kinase inhibitor) is selected.
- the information acquisition unit 21 (FIG. 2) provides relevant information 317 and 318 of FIG. 11 in S2 of FIG. get.
- the information acquisition unit 21 and the goodness-of-fit determination unit 22 in FIG. 2 are processed when the drug name in the drug information 304 of FIG. 11 is gefitinib and when the drug name in the drug information 304 is ossimertinib mesylate. (S3 to S5 in FIG. 3) are carried out in parallel.
- the non-small cell lung cancer patient described in Pharmaceutical Information 304 of FIG. 11 has, for example, a homozygous mutation at position 2573 of the EGFR gene (genotype: G / G), and the EGFR gene. It has a heterozygous mutation (genotype: T / C) at position 2369 of.
- the goodness-of-fit determination unit 22 in FIG. 2 determines the goodness of fit of gefitinib as "1" from the total numerical value of each element (medicinal effect) (that is, the total value of 2 and -1) (that is, the total value of 2 and -1). (Refer to the relevance information 317 in FIG.
- the goodness of fit of osimertinib mesylate was determined to be "3" from the total numerical value of each element (medicinal effect) (that is, the total value of 2 and 1). (See relevance information 318 in FIG. 11).
- the goodness-of-fit determination unit 22 of FIG. 2 sends the two determined goodness of fits to the pharmaceutical information changing unit 23 of FIG.
- the drug information changing unit 23 in FIG. 2 is an absolute value among the two goodness of fit (the reference value for changing the drug is a value lower than 0 and both are positive values, so “YES” in S5 in FIG. 3). Select the "osyltinib mesylate” corresponding to the large “3" and send the modified drug information 306 of FIG. 11 to the display device 3 of FIG. The display device 3 presents the modified drug information 306 of FIG. 11 to the user.
- the above-mentioned treatment proposes one of the optimal administration plans for the treatment of non-small cell lung cancer of a patient identified by the patient ID in the drug information 304 of FIG. 11 for the following reasons.
- Administration of ALK tyrosine kinase inhibitors is not effective for non-small cell lung cancer in the patient (who does not have the EML-ALK fusion gene (ie, does not develop a chromosomal translocation)).
- Relevance information of FIG. 11 Medicinal efficacy “ ⁇ ” in 315 and 316).
- EGFR tyrosine kinase inhibitors are only effective against non-small cell lung cancer in patients who have at least a homozygous or heterozygous mutation (G / G or G / T) at position 2573 of the EGFR gene (" The efficacy “2” and “1” of the relevant information 317 and 318 in FIG. 11).
- the patient may show resistance to the administration of gefitinib (drug efficacy "-1" in the relevant information 317 of FIG. 11).
- ossimertinib mesylate is a drug expected to have a therapeutic effect in patients who are resistant to gefitinib.
- the ossimeltinib mesylate irreversibly inhibits the kinase activity of the EGFR protein having the T790M mutation (replacement of threonine with methionine at position 790) associated with the above resistance to gefitinib.
- a name including a mechanism of action (which may include a plurality of drugs) is exemplified. Further exemplifying that a plurality of relevance information can be acquired at the same time even when the drug information 305 representing a single drug as a drug name is input to the system 1 (FIG. 2).
- the drug information change unit 23 of FIG. 2 determines “NO” in S5 of FIG. Since the same patient ID and (a type of) ALK tyrosine kinase inhibitor as in the drug information 304 of FIG. 11 are described in the drug information 305 of FIG. 11, the same process as the above-mentioned process (YES in S7 of FIG. 3). ”) Is carried out.
- the drug name in the drug information 305 of FIG. 11 is changed to a drug name that is not an ALK tyrosine kinase inhibitor that always has insufficient goodness of fit. Since the condition for selecting the drug name is "not an ALK tyrosine kinase inhibitor", the drug name can be "EGFR tyrosine kinase inhibitor".
- System 1 of FIG. 2 acquires the relevance information 317 and 318 of FIG. 11 as described above based on the pharmaceutical information 305 of FIG. 11 whose drug name has been changed to "EGFR tyrosine kinase inhibitor".
- the information acquisition unit 21 and the goodness-of-fit determination unit 22 in FIG. 2 are processed when the drug name in the drug information 304 of FIG. 11 is gefitinib and when the drug name in the drug information 304 is ossimertinib mesylate. (S3 to S5 in FIG. 3) are carried out in parallel.
- the modified pharmaceutical information 306 (including osimertinib mesylate) of FIG. 11 is displayed on the display device 3 of FIG.
- the administration plan proposal system 1 includes the above-mentioned four drug names (lyxotinib, seritinib, gefitinib and osimertinib mesylate) as the drug name and "123456789" as the patient ID (that is, the above-mentioned drug information). Even when the input of the non-small cell lung cancer patient having the same hereditary type is received, the modified drug information 306 of FIG. The determination is "YES", and there is no change in the drug information 305 (FIG. 11). Finally, the ossimertinib mesylate is displayed by the above-mentioned step. That is, the administration plan proposal system 1 can select and propose one drug having the highest goodness of fit from a plurality of input drug names.
- the above-exemplified ALK tyrosine kinase inhibitor and EGFR tyrosine kinase inhibitor are called molecular-targeted drugs used for the treatment of non-small cell lung cancer.
- Molecular-targeted drug is a term that refers to a drug that targets a gene product with a specific mutation.
- the ALK tyrosine kinase inhibitor is only effective in patients who carry the EML-ALK fusion gene (ie, have a chromosomal translocation) (relevance information 315 and FIG. 11). See 316).
- the EGFR tyrosine kinase inhibitor is only effective in patients who have at least a homozygous or heterozygous mutation at position 2573 of the EGFR gene (see relevance information 317 and 318 in FIG. 11).
- most of the above molecular-targeted drugs are anticancer agents.
- it is expected that molecular-targeted drugs will be developed as therapeutic agents for other diseases.
- the entire program that executes the system can be executed via an intranet or the Internet accessible from the outside (computer used by the user).
- the system may be connected to a printing device (for example, a printer or a multifunction device) for printing the information output to the user on paper.
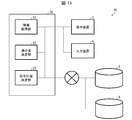
- FIG. 13 Another aspect of the present invention exemplifying the configuration in FIG. 13 is a system (administration plan proposal system 10) that proposes an administration plan suitable for a patient, and is a medicine that represents the medicine to be administered to the patient and the dose thereof.
- Administration plan determination unit 25 that determines suitable drug information for the patient based on the suitability of the drug information; an information presentation unit (display) that presents the drug information determined by the administration plan determination unit to the user. It is equipped with a device 3).
- the administration plan proposal system 10 of FIG. 13 is different from the administration plan proposal system 1 of FIG. 2 in that the administration plan determination unit 25 is provided instead of the drug information change unit 23 (FIG. 2). Therefore, the administration plan proposal system 10 of FIG. 13 executes the process shown in FIG. 3, except for the process of the administration plan determination unit 25 (FIG. 13) described below.
- the administration plan determination unit 25 in FIG. 13 determines suitable pharmaceutical information for the patient based on the goodness of fit of the pharmaceutical information determined by the goodness-of-fit determination unit 22 (FIG. 13).
- the administration plan determination unit 25 may have the same function as the drug information change unit 23 (FIG. 2). That is, the drug information whose goodness of fit determined by the goodness-of-fit determination unit 22 (FIG. 13) is less than the reference value (for example, “0”) is determined as the drug information unsuitable for the patient (“NO” in S5 of FIG. 3). ), The drug information obtained by modifying the drug information may be determined as the drug information suitable for the patient (see S6 in FIG. 3).
- the administration planning unit 25 suitable for the patient the medical information whose goodness of fit determined by the goodness of fit determination unit 22 (FIG. 13) is equal to or higher than the reference value (for example, “0”).
- the drug information may be determined as the appropriate drug information (“YES” in S5 of FIG. 3), or the drug information having the highest goodness of fit may be determined as the drug information suitable for the patient (for example, [Embodiment 1] above]. (Refer to the series of examples of anti-cancer drug administration plans for patients with non-small cell lung cancer described in the item (Examples of drug names and relevance information in drug information and treatments using them)). ..
- the goodness of fit will be described as an example in which the goodness of fit is determined based on the predisposition (risk of onset) to develop a disease that is not the target of treatment by administration of a drug.
- the system according to this embodiment refers to a set of allele combinations for multiple loci on the human genome as the genotype, but the present embodiment is not limited to this, and alleles for one or a few loci are loci.
- a set of combinations of types can be referred to as the above genotypes (eg, examples of "monogenic disease” described below).
- the presence or absence of the above predisposition is determined by the genotype.
- the system of the present embodiment determines the goodness of fit with reference to information indicating a predisposition to develop a disease in connection with administration of a drug (pharmaceutical-related disease information). That is, in this embodiment, a contraindicated drug for a disease that the patient is genetically prone to develop but has not yet developed (a serious side effect that aggravates the condition when the drug is administered appears. Suppress the onset of continuous and high-dose administration of (drugs known to increase the possibility of diminishing the effect of the drug).
- the administration plan proposal system 1' provides a drug-related disease information DB 7 (FIG. 5) in place of the drug efficacy-related gene information DB 5 (FIG. 2) in the administration plan proposal system 1 of FIG. It is the same as the administration plan proposal system 1 (FIG. 2) except that.
- the administration plan proposal system 1'(FIG. 5) is a system that proposes a highly safe administration plan that avoids the onset of a disease that is not a treatment target by administration of a drug.
- the above-mentioned diseases may include symptoms of serious side effects due to idiosyncratic drug and related diseases (details of "serious side effects due to idiosyncratic drug" will be described later).
- the input device 4 (FIG. 5) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.).
- the input medical information 303 (FIG. 7) is sent to the information acquisition unit 21 (FIG. 5) (step S1'in FIG. 6).
- the information acquisition unit 21 (FIG. 5) determines the name of the drug represented by the drug name included in the drug information 303 of FIG.
- Relevance information 314 (FIG. 7) describing the range of the represented hereditary type is acquired from the drug-related disease information DB 7 (FIG. 5) (step S2'in FIG. 6).
- the information acquisition unit 21 (FIG. 5) provides the patient ID (see Pharmaceutical Information 303 in FIG. 7) and DNA variant group information regarding the genotype indicating the presence or absence of a predisposition to the disease (see relevance information 314 in FIG. 7). Based on this, genotype information corresponding to the patient ID and the name of the disease is acquired from the genomic information DB 6 (FIG. 5) (step S3'in FIG. 6).
- the information acquisition unit 21 determines the goodness of fit of the patient's genotype information acquired from the acquired pharmaceutical information 303 (FIG. 7), relevance information 314 (FIG. 7), and genomic information DB 6 (FIG. 5). Send to section 22 (FIG. 5).
- the information acquisition unit 21 sends the medical information 303 of FIG. 7 to the display device 3 (FIG. 5).
- the display device 3 (FIG. 5) displays the above-mentioned drug information, and the administration plan proposal system 1'(FIG. 5) ends the process.
- the information acquisition unit 21 is shown in FIG.
- the medical information 303 is sent to the display device 3 (FIG. 5).
- the display device 3 (FIG. 5) displays the above-mentioned drug information, and the administration plan proposal system 1'in FIG. 5 ends the process.
- the goodness-of-fit determination unit 22 of FIG. 5 determines the goodness of fit of pharmaceutical information 303 (FIG. 7) based on the genotype information acquired from the relevance information 314 (FIG. 7) and the genomic information DB 6 (FIG. 5). (Step S4'in FIG. 6). The details of the S4'process of FIG. 6 will be described with reference to FIG. 7.
- the relevance information 314 of FIG. 7 shows an active ingredient corresponding to a drug name (medicine name: olanzapine, a multi-receptor action antipsychotic drug MARTA), and a disease name known to be caused by administration of the active ingredient (medicine name: olanzapine, antipsychotic drug MARTA).
- the numerical range of the PRS percentile associated with the hereditary type that determines the predisposition to the disease (hereditary type (PRS percentile): 0-69, 70-84 and 85-100)
- of type 2 diabetes Includes effects on onset (risk of onset: ⁇ 0, +1 and +2), and "alternative dosing regimen" (none, glycemic control, and drug change to X).
- the genomic information DB 6 of FIG. 5 stores a numerical value (PRS percentile) from 0 to 100, which represents a predisposition for a patient to develop a certain disease, as hereditary information for each disease name. The closer the value is to 100, the greater the predisposition to develop a certain disease. Therefore, when the goodness-of-fit determination unit 22 in FIG. 5 acquires the relevance information 314 (FIG.
- the risk of developing type 2 diabetes due to administration of olanzapine in FIG. 7) is determined to be "+2".
- the goodness-of-fit determination unit 22 determines the goodness of fit as “-2”, which is obtained by multiplying the onset risk “+2”, which is a negative factor, by the value “-1”, which represents a negative factor.
- the goodness-of-fit determination unit 22 (FIG. 5) of the pharmaceutical information 303 (FIG. 7), the goodness of fit “-2”, and the relevance information 314 (FIG. 7) corresponding to the goodness of fit (“-2”).
- "Drug change to X" as an alternative administration plan is sent to the drug information change department 23 (FIG. 5).
- the pharmaceutical information changing unit 23 in FIG. 5 determines that the goodness of fit "-2", which is a negative value, is very low (S5'step in FIG. 6).
- the drug information changing unit 23 (FIG. 5) changes the drug name in the drug information 303 (FIG. 7) to “X” according to the alternative administration plan “drug change to X” (S6'step in FIG. 6). Since the change in the step S6'(FIG. 6) is a change in the drug (the judgment in the step S7' in FIG. 6 is "YES"), the drug information change unit 23 (FIG. 5) changed the drug name to X.
- the drug information is sent to the information acquisition unit 21 (FIG. 5), and the process returns to the S2'step of FIG.
- the administration plan proposal system 1' repeats the steps S2'to S7' in FIG. 6 until the judgment in the S7'step (FIG. 6) becomes "NO” (changes when it becomes “NO”.
- the drug information is sent to the display device 3 (FIG. 5) (step S8'in FIG. 6).
- the display device 3 (FIG. 5) displays the changed drug information, and the administration plan proposal system 1'in FIG. 5 ends the process.
- the goodness-of-fit determination unit 22 sets the value of the risk of developing type 2 diabetes by administration of olanzapine to "60" when the genotype information is "60". ⁇ 0 "is determined.
- the goodness-of-fit determination unit 22 determines the goodness of fit as “ ⁇ 0”, which is obtained by multiplying the negative factor “onset risk” “ ⁇ 0” by the value “-1” representing the negative factor, and changes the goodness of fit.
- the pharmaceutical information changing unit 23 determines that the goodness of fit “ ⁇ 0” is not low, and sends the pharmaceutical information 303 (FIG. 7) to the display device 3 (FIG. 5).
- the display device 3 (FIG. 5) displays the drug information 303 (FIG. 7), and the administration plan proposal system 1'of FIG. 5 ends the process.
- the administration plan proposal system 1'in FIG. 5 uses the drug information (type of drug or its dose) specified in the prescription as the genotype of the patient specified in the prescription (secondary to the drug). Change when determined to be incompatible with a genotype that represents a combination of alleles associated with a predisposition to the risk of developing the disease. Secondary diseases caused by the drug include serious side effects due to idiosyncratic constitution (details will be described later). Therefore, the dosing regimen proposal system 1'(FIG. 5) enables the presentation of low-risk, high-safety prescriptions according to the genotype of the patient.
- the genotype information for the patient is expressed as a value corresponding to each disease (PRS (Polygenes Risk Score) percentile).
- PRS Polygenes Risk Score
- the PRS percentile for type 2 diabetes indicates what percentage of the patient's PRS corresponds to the lowest percentage of the normal distribution of PRS for the risk of developing type 2 diabetes (see Figure 1) in the human population. Represents. That is, the PRS percentile is 0 to 100, and the larger the PRS percentile, the higher the risk of onset.
- the PRS for type 2 diabetes is the sum of the combinations of "aller types" of all DNA variants that affect the onset of type 2 diabetes.
- GWAS genome-wide association study
- the genotype information represents, by the PRS percentile, how many DNA variants a patient has as part of a combination of DNA variants that contributes to the predisposition to develop a particular disease.
- the genotype information contains the same number of PRS percentiles corresponding to each disease as the number of all known diseases.
- the "combination of these DNA variants" described above varies from disease to disease. Therefore, including the above-mentioned genotype information necessary for creating the PRS percentile corresponding to all diseases as the genotype information for a certain patient maximizes the convenience of the administration plan proposal system 1'. It is preferable that the number of PRS percentiles contained in the genotype information is close to the number of all known diseases, because the convenience of the administration plan proposal system 1'is improved.
- DNA variants eg, SNV, CNV
- SNV SNV
- CNV DNA variants that are infrequent in the population to generate genotypic information containing the PRS percentile corresponding to the disease, as well as or close to the number of all diseases, or Information on DNA variants that are not suitable for automatic analysis (eg, CNP, STRP, or other special DNA variants) is likely to be needed, so the former "method 1" using "full-length string” information is preferred. .. The details of the "method 1" using the "full-length character string” information are also described later in [Embodiment 4].
- the genome information DB 6 of FIG. 5 further stores "full-length character string” information in addition to the patient's "genotype” information. That is, when a DNA variant involved in a disease is newly identified and it is necessary to determine the patient's "allergenotype” for the DNA variant and score it as part of the PRS, also in [Embodiment 1].
- "Method 1" by information analysis using the above-mentioned "full-length character string” is time-consuming and labor-intensive due to experimental techniques such as "Method 2" using DNA microarray technology and individual methods by PCR. There is no burden and some genotypic information about the disease can be easily updated.
- the genotype is a genotype relating to a combination of DNA variants that contributes to a predisposition to develop a particular disease.
- Relevance information 314 (FIG. 7) represents the relevance of a drug to a disease not treated (particularly the effect of administration of the drug on the onset of the disease).
- Relevance information 314 of FIG. 7 shows type 2 diabetes as a disease whose incidence can be increased by administration of olanzapine. As mentioned above, it is known that the presence of a large number of DNA variants (genetic predisposition) is involved in the increase in the incidence of type 2 diabetes.
- Relevance information 314 (FIG. 7) shows a numerical range representing the genotype as a criterion for determining the degree of genetic predisposition. Each numerical range is associated with the degree of risk of onset (“ ⁇ 0” to “+2”).
- Each numerical range can be set arbitrarily, but the lower limit of the numerical range corresponding to "+1" (dose reduction or necessary response) is 70 or more (eg 70, 75, 80, 85, 90 and). 95), and the lower limit of the numerical range corresponding to "+2" (drug change) can be 85 or greater (eg, 85, 90, 95 and 99).
- the goodness-of-fit determination unit 22 of FIG. 5 determines that the goodness of fit of the pharmaceutical information 303 (FIG. 7) is low (in the genomic information, a part of the combination of DNA variants contributing to the predisposition to type 2 diabetes is present above the threshold value). As a reference, at least one of the above lower limit values is used.
- the PRS percentile with a median of 50 represents the average risk of onset in the population, and the numerical range corresponding to " ⁇ 0" includes 50.
- the relevance information 314 of FIG. 7 shows three numerical ranges, but may show only two numerical ranges (eg 0-84 and 85-100). At this time, for example, 0 to 84 correspond to " ⁇ 0", and 85 to 100 correspond to "+2" or "+1". That is, the relevance information 314 (FIG. 7) may allow the dosing regimen proposal system 1'of FIG. 5 to select only drug changes or dose changes. Further, for example, the relevance information 314 (FIG. 7) may correspond the numerical range 70 to 84 with the alternative drug X rather than without the alternative drug. In other words, the relevance information 314 (Fig.
- the dosing regimen proposal system 1'of FIG. 5 using relevance information 314 is of olanzapine (multireceptor-acting antipsychotic: MARTA) regardless of whether the patient has type 2 diabetes. It may be suggested to reduce the dose, take the necessary response, or change the type of the drug.
- olanzapine, timiperone a treatment for schizophrenia, can promote the onset or aggravation of Parkinson's disease, and carvedilol, a treatment for chronic heart failure and arrhythmic, can promote the onset or aggravation of bronchial asthma.
- MARTA multireceptor-acting antipsychotic
- the dosing regimen proposal system 1' (FIG. 5) using relevance information 314 (FIG. 7) is a contraindicated drug (here, olanzapine) for the above patients with a genotype showing a high risk of developing type 2 diabetes. ) It is preferable to make a proposal to change the administration.
- the definition of "contraindicated drug” is as follows. That is, the "contraindication” in the "package insert” information of the ethical drug describes the patient who should not use the drug. Considering the following points, it is decided not to use a certain drug because it is highly likely that the condition will worsen, side effects will be more likely to occur, and the effect of the drug will be weakened. : ⁇ Current illness (current illness) ⁇ Another illness (complication) caused by one illness ⁇ Illnesses (history) ⁇ Illness of family members (family history) ⁇ Other medicines currently used (concomitant medicines) ⁇ The constitution of those who use medicines (from the website of "Pharmaceuticals and Medical Devices Agency").
- "contraindication” is one of the items described in the "package insert" of a drug, and indicates a patient who should not take a certain drug, its condition, and a drug that should not be used in combination. If the drug is not followed, there is a high possibility that the condition will be aggravated, serious side effects will occur, and the effect of the drug will be weakened.
- the condition in which it is determined that medication should not be taken may indicate the patient's current disease name, complications, medical history, family history, constitution, and the like.
- substitution includes a genetic constitution and corresponds to a secondary disease having an extremely high risk of onset due to administration of a drug in this embodiment and other embodiments.
- the genetic constitution may also include symptoms and related diseases as "serious side effects due to the idiosyncratic constitution” described later. Therefore, in the present embodiment, various disease names specified as “contraindicated” in the “package insert” of the current various drugs, as well as symptoms and related diseases of "serious side effects due to idiosyncratic drug” are used. It can be registered as disease information for the drug in the related disease information DB 7 (FIG. 5).
- Type A side effects are relatively common and dose-dependent. This is pharmacologically predictable and usually mild.
- Type B side effects are idiosyncratic reactions and are not merely drug-related. This side effect is rare but often severe. Genetic diversity is important for both type A and type B side effects.
- statin drugs such as atrubastatin (drug for treating lipid disorders), suxamethonium chloride Respiratory palsy due to hydrate (quick-acting muscle relaxant), myelotoxicity due to mercaptopurine hydrate (anti-malignant tumor drug) and azathiopurine (immunosuppressive drug), induction of liver damage due to isoniazide (anti-tuberculosis drug), and Polymorphic ventricular tachycardia caused by various drugs such as clarislomycin (antibacterial drug) may be mentioned and may be life-threatening.
- statin drugs such as atrubastatin (drug for treating lipid disorders), suxamethonium chloride Respiratory palsy due to hydrate (quick-acting muscle relaxant), myelotoxicity due to mercaptopurine hydrate (anti-malignant tumor drug) and azathiopurine (immunosuppressive drug), induction of liver damage due to isoniazide (anti
- the symptoms and related diseases of "serious side effects due to idiosyncratic drug" corresponding to the above-mentioned type B due to various drugs are also affected by the genetic type of the patient due to genetic diversity, and therefore develop.
- Risk-related information can be registered in the drug-related disease information DB 7 (FIG. 5) and dealt with.
- onset risk includes monogenic diseases to multigene diseases (multifactorial diseases, complex diseases).
- Human genetic traits including various diseases, often depend on the expression of many genes and environmental factors. However, for certain diseases and some traits, a particular genotype in a single locus acts as the primary determinant, and this genotype expresses the trait, or develops the disease, in normal environmental conditions. Necessary and sufficient for.
- a sexual disorder complex disorder, multifactorial disorder.
- the scope of application of this embodiment mainly assumes “multigene disease”, but can also deal with “monogenic disease”.
- the onset risk-related information in the present embodiment can be registered in the drug-related disease information DB 7 (FIG. 5) and dealt with.
- the allele associated with the causative gene carries a homozygous mutant type (two mutant alleles).
- the onset risk is extremely high, and the onset risk value can be determined as "+2" and set as "drug change”.
- the risk of developing the disease is extremely high, and the risk of developing the disease is increased. It can be determined as "+2" and set as "drug change”. Taking the above Huntington's disease as an example, a method for determining a genotype associated with a causative gene will be described later in [Embodiment 4].
- FIG. 1 a system for executing the processes described in [Embodiment 1] and [Embodiment 2] in a complex manner will be described (see FIG. 1). That is, in the present embodiment, as shown in FIG. 1, the pharmacodynamic factors of (1) Pharmacodynamic B ([Embodiment 1]) and (2) Pharmacodynamic B are used as criteria for changing the administration plan.
- the administration plan proposal system 1'' includes a control unit 2 and a display device (information display unit) 3.
- the control unit 2 includes an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genotype information acquisition unit) 21, a goodness-of-fit determination unit 22, and a drug information change unit 23 (FIG. 8). reference). Further, the control unit 2 (FIG. 8) is connected to the input device 4, the drug efficacy-related gene information DB 5, the genome information DB 6, and the drug-related disease information DB 7 (see FIG. 8). That is, the system 1 ′′ of the present embodiment of FIG.
- the dosing regimen proposal system 1'' (FIG. 8) performs the S1 to S7 (including S9) steps (see FIG. 3) and does not perform the S8 step (see FIG. 3), but the modified drug information or The steps S2'to S8'(including S9') (see FIG. 6) for the unchanged drug information are performed. Therefore, the process of shifting from S7 of FIG. 3 to the S2'process of FIG. 6 and the details of executing the S2'process (FIG. 6) will be described.
- phenytoin pharmaceutical information 301 in FIG. 4 shown in [Embodiment 1]
- heterozygotes as genotype information regarding SNP (rs1057910) in CYP2C9 in the relevance information 311 (FIG. 4) as described above.
- the drug information changing unit 23 of the administration plan proposal system 1'' makes a judgment "NO”.
- the changed drug information 302 (FIG. 4) in which the "daily dose (maintenance dose)" is changed to 225 mg is sent to the information acquisition unit 21 (FIG. 8) (shift to the S2'step of FIG. 6).
- the information acquisition unit 21 receives the drug-related disease from the drug-related disease information DB 7 (FIG. 8). Get information.
- “medicine information” was replaced with "changed drug information”
- the drug information changing unit 23 changed the drug name (S7' in FIG. 6).
- the present embodiment is described in the above-described embodiment, except for two points in which the drug information (corresponding to the determination “YES” in the process) is sent to the information acquisition unit 21 (FIG. 8) and the process returns to the process S2 step of FIG. It conforms to the system that executes the processes described in 1] and [Embodiment 2].
- the administration plan proposal system 1'' in FIG. 8 uses the drug information (type of drug or its dose) specified in the prescription as the genotype of the patient specified in the prescription (effectiveness of the drug). If it is determined that the genotype of a specific gene that affects sex and the genotype of a specific gene that indicates the existence of a risk of developing a secondary disease due to the drug are not compatible, the change is made. Therefore, the dosing regimen proposal system 1 ′′ (FIG. 8) enables the presentation of a comprehensive prescription (excellent in efficacy, low risk and safe) according to the patient's genotype.
- a method for determining a type (genotype of a patient) (“method 1” described in each item (genotype information of a patient) of [Embodiment 1] and [Embodiment 2]) will be described.
- the DNA variants are variations of any nucleodo, including SNPs, SNVs, indels, CNPs, CNVs, microsatellite polymorphisms (“STRP”).
- two character strings representing the two nucleotide sequences sandwiching the target nucleotide are extracted from a known character string (“reference character string”) representing the reference human genome and used.
- the character string (1) is a character string 902 representing a target nucleotide (SNP, SNV or indel), a two character string 901 representing two nucleotide sequences sandwiching the character string 902, and a character string 901.
- the strings 901 and 903 are determined as part of a string representing the reference human genome (“reference string”) (eg, available from an ensemble (URL: http://ensembl.org)) (ensemble, URL: http://ensembl.org). Step S11 in FIG. 10).
- the character string 902 (character (string) representing the target nucleotide) is stored in a known DB as a DNA variant known at the time of carrying out the method according to the present embodiment (hereinafter, simply referred to as "known”). ing. That is, the above-mentioned "DNA variant” may also include a DNA variant found after the filing of the present application.
- information about all known SNPs can be obtained from the dbSNP database (https://www.ncbi.nlm.nih.gov/snp/).
- Information on the position where the character string 902 (character (string) representing the target nucleotide) exists in the character string representing the reference human genome (“reference character string”) is also stored in the DB (for example, the above dbSNP database). ing.
- the character string of (1) it is preferable that the lengths of the character string 901 and the character string 903 are set to be the same, and the analysis part (character string 902) is arranged in the center.
- the character string (1) is included in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual with the known “allele type” of SNP, SNV or indel. It is determined depending on whether or not it is present (step S12 in FIG. 10).
- the position where the character string of (1) can be included in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual is the reference human genome (“reference character string”) stored in the above DB. It can be estimated from the information of the position of. Therefore, for example, when one character string that completely matches the character string of (1) is found (step S13 in FIG.
- full-length character string representing the nucleotide sequence of the entire genome of an individual
- SNV or Indel "type of allele” can be determined (step S14 in FIG. 10).
- the length of the character strings 901 and 903 in FIG. 9 is at least 10 characters (for example, 10, 20, 30, 40, 50, 100, 150, 200 characters or more), preferably 10 to 1000 characters. be.
- the lengths of the two character strings (character string 901 and character string 903 in FIG. 9).
- step S16 in FIG. 10 Is evenly extended by one or more characters (for example, 1, 3, 5, 10, 20, 25, 50 or 100 characters) (step S16 in FIG. 10) to reduce the above probability.
- the total of the two character strings is, for example, 10,000 characters or less.
- SNP alleles there are up to four types of known SNP alleles at specific positions on the genome, similar to nucleotide types. For example, when the nucleotides of a normal allele are represented by A, the allele containing the nucleotides represented by T, G and C is a mutant allele. Therefore, by designating the character string 902 of FIG. 9 as A, T, G, and C and trying the above process four times, it is possible to determine the type of allele of a known SNP at the specific position (). Step S14 in FIG. 10).
- known SNPs can be easily determined in almost two trials, as two (rarely three) nucleotides are common in the population.
- the character strings 901 to 903 (normal character strings) including the normal character strings and the character strings 901 to 903 (variable character strings) including the mutant character strings are homozygous or homozygous with respect to the SNP of the individual's genome. It can be used to determine if it is heterojunction. For example, both strings (“full-length strings”) that represent the nucleotide sequences of an individual's entire genome (usually the genome exists as a conjugation that holds two sets from the mother and father) have normal strings. When they match and the mutant strings do not match, the individual's genome is a normal allele (normal: N / N).
- a normal character string matches one of the character strings representing the nucleotide sequence of the entire genome of an individual and a mutant character string matches the other
- the individual's genome has a mutant allele in one genome.
- Heterojunction type: N / M when the normal string does not match both the strings representing the nucleotide sequences of the entire genome of the individual and the mutant strings match, the individual's genome has the mutant allele in both genomes.
- Homozygous type M / M).
- the process of determining the genetic type in the individual is CYP2C9 based on the information of the pharmaceutical information 301 (FIG. 4) regarding the phenytoin (antiepileptic drug) described in [Embodiment 1] and the relevance information 311 (FIG. 4).
- a known SNP (rs1057910) existing in the coding region of (drug metabolizing enzyme gene) will be specifically described as an example.
- the base type of the nucleotide of the wild type (normal type) allele in SNP is "adenine (A)", and it is known that the metabolism rate of phenitoin is lowered.
- the base type of nucleotides in metabolic alleles is "cytosine (C)".
- C cytosine
- wild-type character string matches the character string representing the nucleotide sequence of the entire genome of an individual ("full-length character string”) and the "low-metaphoric character string” does not match, the relevant character string is concerned.
- the individual's genome has wild-type alleles in both genomes (wild-type: "A / A”).
- wild-type character string wild-type: "A / A”
- the genome of the individual has the low-metabolizing allele in one of the genomes ( Heterozygous type: "A / C”).
- the individual's genome has the low-metabolizing allele in both genomes. Has (homogeneous low metabolism: "C / C").
- Relevance information 311 (“A / A”, “A / C” or “C / C”) depending on the type of combination of nucleotide changes in SNP (rs1057910) of CYP2C9 in the individual determined by the above process. As shown in Figure 4), different symbolized genotypes (“* 1 / * 1”, “* 1 / * 3” or “* 3 / * 3”), and different metabolic rates (drug effects) (“ ⁇ ”). 0 ”,“ -1 ”or“ -2 ”) can be determined.
- Step S15 Information representing DNA variants present in an individual's genome, along with the determined genotype, is stored in a DB, recording medium or storage device (not shown), as well as genomic information DB 6 (FIGS. 2, 5 and 8). ) (Step S15).
- allele type including the mating type of any DNA variant (including the SNP, SNV or indel described above).
- allele type the type of allele
- it is an effective method when the length of the target nucleotide is changed, and there are many options, or the details of the target nucleotide are unknown. Changes in the length of the target nucleotide, as well as a large number of options, occur when simple repeat sequences with different repeat counts are used as the target nucleotide, for example, microsatellite polymorphisms (“STRP”).
- STRP microsatellite polymorphisms
- the character string (2) is particularly effective when it is necessary to determine the number of target nucleotides and also the full-length nucleotide sequence of the target nucleotides.
- the total length of the target nucleotide can reach tens of thousands of nucleotides, and the length of the target nucleotide can vary greatly from individual to individual. Therefore, the full-length nucleotide sequence of a particular target nucleotide needs to be determined individually based on the genome of the individual.
- the loci on the genome where the target nucleotides (CNP, CNV, STRP) are present have already been identified in the human reference genome, as are SNPs, SNVs or indels.
- the location of the target nucleotide in the locus is also relatively determined. That is, the character string (2) is known in the character string representing the human reference genome (“reference character string”) (step S11 in FIG. 10).
- the character string of (2) can completely match the character string representing the nucleotide sequences adjacent to both sides of the target nucleotide representing the known DNA valinant existing in the genome of an individual. Therefore, whether or not the character string (two pairs: character strings 901 and 903 in FIG. 9) of (2) exists in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual. By determining (step S13 in FIG. 10), it is possible to determine whether or not the target nucleotide is present on the genome of an individual (step S14 in FIG. 10).
- the length of the character string (two sets: character strings 901 and 903 in FIG. 9) of (2) can be set in the same manner as the lengths of the character strings 901 and 903 in the character string of (1).
- the extracted string represents a simple repetitive sequence (length of 1 to 4 base pairs) of a very short sequence (length of 1 to 4 base pairs) such as a microsatellite polymorph (“STRP”)
- the repetition contained in the string is further determined.
- the simple repetitive sequence may have different number of repetitions in the genome of an individual, for example, with a unit of several nucleotides to several tens of nucleotides.
- Detect the "allele type" corresponding to the number of times. For example, when two types of sequences having different lengths are detected, it is determined to be “heterozygous type", and when only one type of sequence is detected, it is determined to be “homozygous type”.
- CAG causative gene
- HTP causative gene
- Embodiment 2 a late-onset monogenic disease described in [Embodiment 2]
- Huntington's disease results from the production of long polyglutamine chains by the unstable elongation of CAG repeats present on the coding sequence of its causative gene HTT.
- Normal glutamine repeats are 6-35, whereas diseased patients (or young adult asymptomatic individuals at extremely high risk of developing the disease) are 36-121.
- the corresponding character strings 901 and 903 can be easily obtained by the above method.
- the presence of the character string (2 pairs: the character strings 901 and 903 in FIG. 9) in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of the asymptomatic person of the young adult After confirmation, the sequence of the character string (902 in FIG. 9: representing the full-length nucleotide sequence of the target nucleotide) existing between the two character strings and the length thereof are extracted and determined.
- the number of CAG repeats is two types, "80 (number of nucleotides: 240)" and “113 (number of nucleotides: 339)" as a result of extracting the sequence and its length, it is a heterozygous type.
- both alleles have the number of repeats corresponding to disease-type alleles, the risk of developing the disease is extremely high "+2".
- the number of CAG repeats is one type of "5 (number of nucleotides: 15)". If it is, it is a homozygous type.
- both allele types have the same number of repeats as normal alleles, the risk of developing the disease is low " ⁇ 0".
- the above method using the character string (2) described above can also be applied to the presence or absence of known chromosomal translocations (generation of DNA variants).
- the target nucleotide at this time is the character string (2) (character strings 901 and 903 in FIG. 9).
- the genomic location of the translocation point in a known chromosomal translocation is all known as the linking site between fragment A1 present on chromosome A and fragment B2 present on chromosome B, and the linking site between fragment A2 and fragment B1. Has been done.
- fragments A1 and A2 are arranged in the order of 1 ⁇ 2 on the chromosome A, and the fragments B1 and B2 are arranged in the order of 1 ⁇ 2 on the chromosome B. Therefore, the sequences of the fragments A1, A2, B1 and B2 are also known.
- the character strings 901 and 903 are continuous or discontinuous on the genome of the individual.
- the presence may indicate the presence or absence of translocation.
- Discontinuity represents the absence of translocation, and continuity represents the possibility of translocation.
- the fragment A1 is represented by the character string 901 and the fragment A2 is represented by the character string 903, centering on the connecting portion of the fragment A1 and the fragment A2. Just do it.
- the fragments A1 and A2 are present consecutively, the above possibility (existence of translocation) is completely denied, and when they are present discontinuously, the existence of translocation is confirmed.
- the administration plan proposal system 1-1'' (FIG. 2, FIG. 5 and FIG. 8) has a control block (particularly, an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genetic information acquisition unit) 21), and a degree of conformity.
- the determination unit 22 and the medical information change unit 23 may be realized by a logic circuit (hardware) formed in an integrated circuit (IC chip) or the like, or may be realized by software.
- the administration plan proposal systems 1 to 1 ′′ include a computer that executes the instructions of the program which is the software that realizes each function.
- the computer includes, for example, one or more processors and a computer-readable recording medium that stores the program. Then, in the computer, the processor reads the program from the recording medium and executes the program, thereby achieving the object of the present invention.
- the processor for example, a CPU can be used.
- the recording medium a “non-temporary tangible medium”, for example, a ROM (Read Only Memory) or the like, a tape, a disk, a card, a semiconductor memory, a programmable logic circuit, or the like can be used.
- a RAM RandomAccessMemory
- the program may be supplied to the computer via an arbitrary transmission medium (communication network, broadcast wave, etc.) capable of transmitting the program.
- a transmission medium communication network, broadcast wave, etc.
- one aspect of the present invention can also be realized in the form of a data signal embedded in a carrier wave, in which the above program is embodied by electronic transmission.
- a system that proposes a suitable administration plan for patients.
- the drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
- Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
- Genotype information acquisition department that acquires the genotype information of the above patients;
- Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
- a system including a drug information changing unit that changes the drug information when the goodness of fit is low; and an information presentation unit that presents the changed drug information that the drug information changing unit has changed to the user.
- the goodness-of-fit determination unit determines the goodness of fit by referring to the pharmacokinetics of the drug or the drug efficacy-related gene information regarding the gene encoding the protein involved in pharmacodynamics.
- the genotype is a genotype related to the gene, and the relevance information includes the drug efficacy-related gene information.
- the goodness-of-fit determination unit determines the goodness of fit with reference to drug-related disease information indicating a disease that develops or becomes serious due to administration of the drug.
- the genotype is a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information includes the drug-related disease information.
- the fitness determination unit determines that the fitness for the genotype including the combination of alleles associated with the predisposition to the disease is very low.
- the fitness information change unit is a contraindicated drug for the disease.
- the goodness-of-fit determination unit includes information on pharmaceutical efficacy-related genes representing genes encoding the pharmacokinetics of the drug or proteins involved in pharmacodynamics, and diseases that develop or become serious due to administration of the drug.
- the above-mentioned goodness of fit is determined by referring to the drug-related disease information indicating
- the genotype is a genotype relating to a gene encoding a pharmacokinetics or a protein involved in the pharmacokinetics of the drug and a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information is provided. It contains the above-mentioned drug-related genetic information and drug-related disease information.
- the system according to any one of [1] to [5], wherein the change is an increase or decrease in the dose or a change in the drug.
- the genetic type information is determined based on the information representing the DNA variant contained in the information representing all the nucleotide sequences constituting the genome of the patient acquired from the genome information DB using the patient ID.
- the system according to any one of [1] to [6].
- the genetic type information does not record the genetic type existing in the locus associated with the drug represented by the pharmaceutical information in the relevance represented by the relevant information
- the genetic type information is recorded.
- the system according to [7] which is updated based on the information representing the DNA variant present in the locus contained in the information representing all the nucleotide sequences constituting the genome of the patient.
- Information representing a single nucleotide polymorphism among the above DNA variants is determined using the genomic fragment of the patient or based on the information representing the entire nucleotide sequence, and the information representing the single nucleotide polymorphism determined. Record, The system according to [7] or [8], wherein the information representing the unrecorded DNA variant is determined based on the textual information representing the entire nucleotide sequence.
- the information presenting unit selects the medicine having the highest goodness of fit among the plurality of candidate medicines.
- the system according to any one of [1] to [11] shown to the user.
- the information presenting unit is the drug having the highest goodness of fit among the plurality of suitable candidate drug information.
- the system according to any one of [1] to [12], which presents information to the user.
- the fitness determination unit corresponds to the mutation in the genome of the patient.
- the system according to any one of [1] to [13], wherein the fitness is determined based on the presence or absence of a DNA variant.
- a method for proposing a suitable administration plan for a patient A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof; Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype; The genotype information acquisition step in which the computer acquires the genotype information of the patient; A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information; When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user.
- the computer described above when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above.
- Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information comprises information representing variants having a frequency of less than 1% in the human population.
- a dosing plan proposal program for operating a computer as a system for proposing a dosing plan suitable for a patient is equipped with a control unit.
- the control unit Obtain drug information indicating the drug to be administered to the above patients and its dose; Obtained relevance information indicating the relevance of the above drugs and genotypes; Obtain genotype information for the above patients; Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined; When the goodness of fit is low, the above medical information is changed; The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- a system that proposes a suitable administration plan for patients The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses; Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes; Genotype information acquisition department that acquires the genotype information of the above patients; Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information; Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user.
- the system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information.
- Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information is a system comprising information representing variants having a frequency of less than 1% in the human population.
- Administration plan proposal system (system that proposes a suitable administration plan for patients) 1a Administration plan proposal system (system that proposes a suitable administration plan for patients) 1'Administration plan proposal system (system that proposes a suitable administration plan for patients) 1'' Dosing plan proposal system (system that proposes a suitable dosing plan for patients) 2 Control unit 2a Control unit 2b Control unit 3 Display device (information presentation unit) 4 Input device 5 Pharmaceutical efficacy-related gene information DB 6 Genome information DB 7 Pharmaceutical-related disease information DB 10 Administration plan proposal system (system that proposes a suitable administration plan for patients) 21 Information acquisition department (medicine information acquisition department, relevance information acquisition department and genotype information acquisition department) 22 Goodness of fit determination unit 23 Pharmaceutical information change department 24 Warning unit 25 Administration plan determination unit 301 Pharmaceutical information (phenytoin) 302 Changed Pharmaceutical Information 303 Pharmaceutical Information (Olanzapine) 304 Pharmaceutical information (candidate drug group) 305 Pharmaceutical Information (Lixotinib) 306 Modified Pharmaceutical Information 311 Relevance Information (Pheny
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Computing Systems (AREA)
- Medicinal Chemistry (AREA)
- Epidemiology (AREA)
- Medical Informatics (AREA)
- Primary Health Care (AREA)
- Sustainable Development (AREA)
- Plant Pathology (AREA)
- Analytical Chemistry (AREA)
- Immunology (AREA)
- Bioethics (AREA)
- Business, Economics & Management (AREA)
- Accounting & Taxation (AREA)
- Development Economics (AREA)
- Economics (AREA)
- General Business, Economics & Management (AREA)
- Public Health (AREA)
- Crystallography & Structural Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Medical Treatment And Welfare Office Work (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022533742A JP7671073B2 (ja) | 2020-06-29 | 2021-05-25 | 投与計画提案システム、方法およびプログラム |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-112023 | 2020-06-29 | ||
| JP2020112023A JP6893052B1 (ja) | 2020-06-29 | 2020-06-29 | 投与計画提案システム、方法およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022004200A1 true WO2022004200A1 (ja) | 2022-01-06 |
Family
ID=76464621
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/019872 Ceased WO2022004200A1 (ja) | 2020-06-29 | 2021-05-25 | 投与計画提案システム、方法およびプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (2) | JP6893052B1 (https=) |
| WO (1) | WO2022004200A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20250132061A1 (en) * | 2021-09-30 | 2025-04-24 | Nippon Telegraph And Telephone Corporation | Online dispensing system, information linkage server, online dispensing method, and program |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510817A (ja) * | 1998-04-03 | 2002-04-09 | トライアングル・ファーマシューティカルズ,インコーポレイテッド | 治療処方計画の選択をガイドするためのシステム、方法及びコンピュータ・プログラム製品 |
| WO2005038049A2 (en) * | 2003-10-06 | 2005-04-28 | Heinrich Guenther | System and method for optimizing drug therapy |
| US20060223058A1 (en) * | 2005-04-01 | 2006-10-05 | Perlegen Sciences, Inc. | In vitro association studies |
| US20140025783A1 (en) * | 2009-09-04 | 2014-01-23 | Viasat, Inc. | Distributed Cache - Adaptive Multicast Architecture for Bandwidth Reduction |
| US20170061080A1 (en) * | 2001-08-29 | 2017-03-02 | Druglogic, Inc. | Method and system for the analysis and association of patient-specific and population-based genomic data with drug safety adverse event data |
| JP2020034993A (ja) * | 2018-08-27 | 2020-03-05 | 秀一 大津 | 遠隔診療アプリケーションおよびシステム |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2005321925A1 (en) * | 2004-12-30 | 2006-07-06 | Proventys, Inc. | Methods, systems, and computer program products for developing and using predictive models for predicting a plurality of medical outcomes, for evaluating intervention strategies, and for simultaneously validating biomarker causality |
| JP2009070096A (ja) * | 2007-09-12 | 2009-04-02 | Michio Kimura | ゲノム情報と臨床情報との統合データベースシステム、および、これが備えるデータベースの製造方法 |
| CN101842496A (zh) * | 2007-09-26 | 2010-09-22 | 纳维哲尼克斯公司 | 使用祖先数据进行基因组分析的方法和系统 |
| CA2807949C (en) * | 2010-08-13 | 2022-10-25 | Intellimedicine, Inc. | System and methods for the production of personalized drug products |
| US20140257851A1 (en) * | 2013-03-05 | 2014-09-11 | Clinton Colin Graham Walker | Automated interactive health care application for patient care |
| US20140274764A1 (en) * | 2013-03-15 | 2014-09-18 | Pathway Genomics Corporation | Method and system to predict response to treatments for mental disorders |
| US20140274763A1 (en) * | 2013-03-15 | 2014-09-18 | Pathway Genomics Corporation | Method and system to predict response to pain treatments |
-
2020
- 2020-06-29 JP JP2020112023A patent/JP6893052B1/ja active Active
-
2021
- 2021-05-25 WO PCT/JP2021/019872 patent/WO2022004200A1/ja not_active Ceased
- 2021-05-25 JP JP2022533742A patent/JP7671073B2/ja active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510817A (ja) * | 1998-04-03 | 2002-04-09 | トライアングル・ファーマシューティカルズ,インコーポレイテッド | 治療処方計画の選択をガイドするためのシステム、方法及びコンピュータ・プログラム製品 |
| US20170061080A1 (en) * | 2001-08-29 | 2017-03-02 | Druglogic, Inc. | Method and system for the analysis and association of patient-specific and population-based genomic data with drug safety adverse event data |
| WO2005038049A2 (en) * | 2003-10-06 | 2005-04-28 | Heinrich Guenther | System and method for optimizing drug therapy |
| US20060223058A1 (en) * | 2005-04-01 | 2006-10-05 | Perlegen Sciences, Inc. | In vitro association studies |
| US20140025783A1 (en) * | 2009-09-04 | 2014-01-23 | Viasat, Inc. | Distributed Cache - Adaptive Multicast Architecture for Bandwidth Reduction |
| JP2020034993A (ja) * | 2018-08-27 | 2020-03-05 | 秀一 大津 | 遠隔診療アプリケーションおよびシステム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022024213A (ja) | 2022-02-09 |
| JPWO2022004200A1 (https=) | 2022-01-06 |
| JP6893052B1 (ja) | 2021-06-23 |
| JP7671073B2 (ja) | 2025-05-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Siedlinski et al. | Genome-wide association study of smoking behaviours in patients with COPD | |
| US20200048712A1 (en) | Methods for selecting medications | |
| Celedón et al. | The transforming growth factor-β1 (TGFB1) gene is associated with chronic obstructive pulmonary disease (COPD) | |
| US8688385B2 (en) | Methods for selecting initial doses of psychotropic medications based on a CYP2D6 genotype | |
| Breen et al. | A genome-wide significant linkage for severe depression on chromosome 3: the depression network study | |
| Rasmussen‐Torvik et al. | High density GWAS for LDL cholesterol in African Americans using electronic medical records reveals a strong protective variant in APOE | |
| Tanner et al. | Combinatorial pharmacogenomics and improved patient outcomes in depression: treatment by primary care physicians or psychiatrists | |
| Escamilla et al. | Genetics of bipolar disorder | |
| Schuit et al. | Pharmacotherapy for smoking cessation: effects by subgroup defined by genetically informed biomarkers | |
| Rasmussen et al. | Genome-wide association study of angioedema induced by angiotensin-converting enzyme inhibitor and angiotensin receptor blocker treatment | |
| Mur et al. | DNA methylation in APOE: The relationship with Alzheimer's and with cardiovascular health | |
| Liu et al. | Biological pathway‐based genome‐wide association analysis identified the vasoactive intestinal peptide (VIP) pathway important for obesity | |
| Lai et al. | Genome‐wide association studies of the self‐rating of effects of ethanol (SRE) | |
| Ghouse et al. | Polygenic risk score for ACE-inhibitor-associated cough based on the discovery of new genetic loci | |
| Blue et al. | Association of uncommon, noncoding variants in the APOE region with risk of Alzheimer disease in adults of European ancestry | |
| Hotaling et al. | Pilot genome-wide association search identifies potential loci for risk of erectile dysfunction in type 1 diabetes using the DCCT/EDIC study cohort | |
| Kappel et al. | Rare variants in pharmacogenes influence clozapine metabolism in individuals with schizophrenia | |
| Zobeck et al. | Novel risk factors for glucarpidase use in pediatric acute lymphoblastic leukemia: Hispanic ethnicity, age, and the ABCC4 gene | |
| Toikumo et al. | Multi-ancestry meta-analysis of tobacco use disorder prioritizes novel candidate risk genes and reveals associations with numerous health outcomes | |
| JP7671073B2 (ja) | 投与計画提案システム、方法およびプログラム | |
| Wang et al. | Identification of novel mutations in preaxial polydactyly patients through whole‐exome sequencing | |
| Main et al. | Genetic analysis of cognitive preservation in the midwestern Amish reveals a novel locus on chromosome 2 | |
| El Rouby et al. | Genome Wide Association Study (GWAS) Identifies Novel Genetic Loci for Second‐Generation Antipsychotics (SGA)‐Induced Metabolic Syndrome (MetS) | |
| JP7756414B2 (ja) | 投与計画決定支援システム、投与計画決定支援方法、および投与計画決定支援プログラム | |
| Alekseienko et al. | Leveraging primary health care data from Estonian Biobank to find novel genetic associations |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21831785 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022533742 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21831785 Country of ref document: EP Kind code of ref document: A1 |