JP6893052B1 - 投与計画提案システム、方法およびプログラム - Google Patents
投与計画提案システム、方法およびプログラム Download PDFInfo
- Publication number
- JP6893052B1 JP6893052B1 JP2020112023A JP2020112023A JP6893052B1 JP 6893052 B1 JP6893052 B1 JP 6893052B1 JP 2020112023 A JP2020112023 A JP 2020112023A JP 2020112023 A JP2020112023 A JP 2020112023A JP 6893052 B1 JP6893052 B1 JP 6893052B1
- Authority
- JP
- Japan
- Prior art keywords
- information
- drug
- genotype
- patient
- disease
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 108
- 239000003814 drug Substances 0.000 claims abstract description 418
- 229940079593 drug Drugs 0.000 claims abstract description 392
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 138
- 201000010099 disease Diseases 0.000 claims description 135
- 108090000623 proteins and genes Proteins 0.000 claims description 111
- 108700028369 Alleles Proteins 0.000 claims description 103
- 239000002773 nucleotide Substances 0.000 claims description 103
- 125000003729 nucleotide group Chemical group 0.000 claims description 102
- 108020004414 DNA Proteins 0.000 claims description 93
- 230000008859 change Effects 0.000 claims description 67
- 230000000694 effects Effects 0.000 claims description 51
- 230000008569 process Effects 0.000 claims description 30
- 102000004169 proteins and genes Human genes 0.000 claims description 27
- 230000003285 pharmacodynamic effect Effects 0.000 claims description 24
- 230000002068 genetic effect Effects 0.000 claims description 23
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 20
- 230000007423 decrease Effects 0.000 claims description 9
- 238000012986 modification Methods 0.000 claims description 6
- 230000004048 modification Effects 0.000 claims description 6
- 230000036961 partial effect Effects 0.000 claims description 6
- 239000012634 fragment Substances 0.000 claims description 4
- 238000013473 artificial intelligence Methods 0.000 claims description 3
- 230000009467 reduction Effects 0.000 claims description 3
- 239000000470 constituent Substances 0.000 claims description 2
- 238000010586 diagram Methods 0.000 abstract description 2
- 230000037323 metabolic rate Effects 0.000 description 29
- 230000007721 medicinal effect Effects 0.000 description 23
- 238000004458 analytical method Methods 0.000 description 21
- CXOFVDLJLONNDW-UHFFFAOYSA-N Phenytoin Chemical compound N1C(=O)NC(=O)C1(C=1C=CC=CC=1)C1=CC=CC=C1 CXOFVDLJLONNDW-UHFFFAOYSA-N 0.000 description 18
- 229960002036 phenytoin Drugs 0.000 description 17
- 208000001072 type 2 diabetes mellitus Diseases 0.000 description 15
- 229960003009 clopidogrel Drugs 0.000 description 12
- 229960005017 olanzapine Drugs 0.000 description 12
- KVWDHTXUZHCGIO-UHFFFAOYSA-N olanzapine Chemical compound C1CN(C)CCN1C1=NC2=CC=CC=C2NC2=C1C=C(C)S2 KVWDHTXUZHCGIO-UHFFFAOYSA-N 0.000 description 12
- 239000005552 B01AC04 - Clopidogrel Substances 0.000 description 11
- 108010000543 Cytochrome P-450 CYP2C9 Proteins 0.000 description 11
- GKTWGGQPFAXNFI-HNNXBMFYSA-N clopidogrel Chemical compound C1([C@H](N2CC=3C=CSC=3CC2)C(=O)OC)=CC=CC=C1Cl GKTWGGQPFAXNFI-HNNXBMFYSA-N 0.000 description 11
- 208000024891 symptom Diseases 0.000 description 11
- 102000002269 Cytochrome P-450 CYP2C9 Human genes 0.000 description 10
- 239000004480 active ingredient Substances 0.000 description 9
- 238000002474 experimental method Methods 0.000 description 9
- 102200155813 rs1057910 Human genes 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 108091023043 Alu Element Proteins 0.000 description 7
- 108090000790 Enzymes Proteins 0.000 description 7
- 208000024556 Mendelian disease Diseases 0.000 description 7
- 108091092878 Microsatellite Proteins 0.000 description 7
- 230000004060 metabolic process Effects 0.000 description 7
- 102000054765 polymorphisms of proteins Human genes 0.000 description 7
- 208000037921 secondary disease Diseases 0.000 description 7
- 238000003860 storage Methods 0.000 description 7
- 102100040458 2',3'-cyclic-nucleotide 3'-phosphodiesterase Human genes 0.000 description 5
- 101150003340 CYP2C19 gene Proteins 0.000 description 5
- 206010010904 Convulsion Diseases 0.000 description 5
- 102000019057 Cytochrome P-450 CYP2C19 Human genes 0.000 description 5
- 108010026925 Cytochrome P-450 CYP2C19 Proteins 0.000 description 5
- 208000023105 Huntington disease Diseases 0.000 description 5
- 150000001875 compounds Chemical class 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 238000012423 maintenance Methods 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 101150100998 Ace gene Proteins 0.000 description 4
- 108091026890 Coding region Proteins 0.000 description 4
- 238000001712 DNA sequencing Methods 0.000 description 4
- 230000009471 action Effects 0.000 description 4
- 239000001961 anticonvulsive agent Substances 0.000 description 4
- 238000006243 chemical reaction Methods 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- 238000001647 drug administration Methods 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 238000012775 microarray technology Methods 0.000 description 4
- 210000000056 organ Anatomy 0.000 description 4
- IPVQLZZIHOAWMC-QXKUPLGCSA-N perindopril Chemical compound C1CCC[C@H]2C[C@@H](C(O)=O)N(C(=O)[C@H](C)N[C@@H](CCC)C(=O)OCC)[C@H]21 IPVQLZZIHOAWMC-QXKUPLGCSA-N 0.000 description 4
- 229960002582 perindopril Drugs 0.000 description 4
- 229940002612 prodrug Drugs 0.000 description 4
- 239000000651 prodrug Substances 0.000 description 4
- 102100030988 Angiotensin-converting enzyme Human genes 0.000 description 3
- XUKUURHRXDUEBC-KAYWLYCHSA-N Atorvastatin Chemical compound C=1C=CC=CC=1C1=C(C=2C=CC(F)=CC=2)N(CC[C@@H](O)C[C@@H](O)CC(O)=O)C(C(C)C)=C1C(=O)NC1=CC=CC=C1 XUKUURHRXDUEBC-KAYWLYCHSA-N 0.000 description 3
- XUKUURHRXDUEBC-UHFFFAOYSA-N Atorvastatin Natural products C=1C=CC=CC=1C1=C(C=2C=CC(F)=CC=2)N(CCC(O)CC(O)CC(O)=O)C(C(C)C)=C1C(=O)NC1=CC=CC=C1 XUKUURHRXDUEBC-UHFFFAOYSA-N 0.000 description 3
- 101150053096 CYP2C9 gene Proteins 0.000 description 3
- 238000000018 DNA microarray Methods 0.000 description 3
- 208000034826 Genetic Predisposition to Disease Diseases 0.000 description 3
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 3
- 208000026350 Inborn Genetic disease Diseases 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 230000002411 adverse Effects 0.000 description 3
- 239000000556 agonist Substances 0.000 description 3
- 230000000561 anti-psychotic effect Effects 0.000 description 3
- 229960003965 antiepileptics Drugs 0.000 description 3
- 229960005370 atorvastatin Drugs 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 230000008034 disappearance Effects 0.000 description 3
- 230000000857 drug effect Effects 0.000 description 3
- 230000007613 environmental effect Effects 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 230000013011 mating Effects 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 230000003252 repetitive effect Effects 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- XTWYTFMLZFPYCI-KQYNXXCUSA-N 5'-adenylphosphoric acid Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP(O)(=O)OP(O)(O)=O)[C@@H](O)[C@H]1O XTWYTFMLZFPYCI-KQYNXXCUSA-N 0.000 description 2
- 102000017919 ADRB2 Human genes 0.000 description 2
- 229930024421 Adenine Natural products 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 2
- XTWYTFMLZFPYCI-UHFFFAOYSA-N Adenosine diphosphate Natural products C1=NC=2C(N)=NC=NC=2N1C1OC(COP(O)(=O)OP(O)(O)=O)C(O)C1O XTWYTFMLZFPYCI-UHFFFAOYSA-N 0.000 description 2
- 108010078791 Carrier Proteins Proteins 0.000 description 2
- 102000013138 Drug Receptors Human genes 0.000 description 2
- 108010065556 Drug Receptors Proteins 0.000 description 2
- 208000032928 Dyslipidaemia Diseases 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 description 2
- 108010058607 HLA-B Antigens Proteins 0.000 description 2
- 101000959437 Homo sapiens Beta-2 adrenergic receptor Proteins 0.000 description 2
- 208000017170 Lipid metabolism disease Diseases 0.000 description 2
- 206010042033 Stevens-Johnson syndrome Diseases 0.000 description 2
- 206010044223 Toxic epidermal necrolysis Diseases 0.000 description 2
- 231100000087 Toxic epidermal necrolysis Toxicity 0.000 description 2
- 238000010521 absorption reaction Methods 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 229960000643 adenine Drugs 0.000 description 2
- OFCNXPDARWKPPY-UHFFFAOYSA-N allopurinol Chemical compound OC1=NC=NC2=C1C=NN2 OFCNXPDARWKPPY-UHFFFAOYSA-N 0.000 description 2
- 229960003459 allopurinol Drugs 0.000 description 2
- 150000001413 amino acids Chemical group 0.000 description 2
- 229940035674 anesthetics Drugs 0.000 description 2
- 208000006673 asthma Diseases 0.000 description 2
- 230000005540 biological transmission Effects 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 229960000623 carbamazepine Drugs 0.000 description 2
- FFGPTBGBLSHEPO-UHFFFAOYSA-N carbamazepine Chemical compound C1=CC2=CC=CC=C2N(C(=O)N)C2=CC=CC=C21 FFGPTBGBLSHEPO-UHFFFAOYSA-N 0.000 description 2
- 210000004027 cell Anatomy 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000029142 excretion Effects 0.000 description 2
- 239000003193 general anesthetic agent Substances 0.000 description 2
- 208000016361 genetic disease Diseases 0.000 description 2
- 239000002471 hydroxymethylglutaryl coenzyme A reductase inhibitor Substances 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 208000030603 inherited susceptibility to asthma Diseases 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- 239000002207 metabolite Substances 0.000 description 2
- 239000003158 myorelaxant agent Substances 0.000 description 2
- 238000007639 printing Methods 0.000 description 2
- 201000000980 schizophrenia Diseases 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 208000011580 syndromic disease Diseases 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 229940126585 therapeutic drug Drugs 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- UUUHXMGGBIUAPW-UHFFFAOYSA-N 1-[1-[2-[[5-amino-2-[[1-[5-(diaminomethylideneamino)-2-[[1-[3-(1h-indol-3-yl)-2-[(5-oxopyrrolidine-2-carbonyl)amino]propanoyl]pyrrolidine-2-carbonyl]amino]pentanoyl]pyrrolidine-2-carbonyl]amino]-5-oxopentanoyl]amino]-3-methylpentanoyl]pyrrolidine-2-carbon Chemical compound C1CCC(C(=O)N2C(CCC2)C(O)=O)N1C(=O)C(C(C)CC)NC(=O)C(CCC(N)=O)NC(=O)C1CCCN1C(=O)C(CCCN=C(N)N)NC(=O)C1CCCN1C(=O)C(CC=1C2=CC=CC=C2NC=1)NC(=O)C1CCC(=O)N1 UUUHXMGGBIUAPW-UHFFFAOYSA-N 0.000 description 1
- 101150033809 ADRB2 gene Proteins 0.000 description 1
- 206010002091 Anaesthesia Diseases 0.000 description 1
- 102000005862 Angiotensin II Human genes 0.000 description 1
- 101800000733 Angiotensin-2 Proteins 0.000 description 1
- 206010049612 Autonomic seizure Diseases 0.000 description 1
- 108700020463 BRCA1 Proteins 0.000 description 1
- 101150072950 BRCA1 gene Proteins 0.000 description 1
- 102000052609 BRCA2 Human genes 0.000 description 1
- 108700020462 BRCA2 Proteins 0.000 description 1
- 208000020925 Bipolar disease Diseases 0.000 description 1
- 101150008921 Brca2 gene Proteins 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 206010007558 Cardiac failure chronic Diseases 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- 206010010356 Congenital anomaly Diseases 0.000 description 1
- 206010054089 Depressive symptom Diseases 0.000 description 1
- 208000030453 Drug-Related Side Effects and Adverse reaction Diseases 0.000 description 1
- 201000005569 Gout Diseases 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 206010020772 Hypertension Diseases 0.000 description 1
- CZGUSIXMZVURDU-JZXHSEFVSA-N Ile(5)-angiotensin II Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C([O-])=O)NC(=O)[C@@H](NC(=O)[C@H](CCCNC(N)=[NH2+])NC(=O)[C@@H]([NH3+])CC([O-])=O)C(C)C)C1=CC=C(O)C=C1 CZGUSIXMZVURDU-JZXHSEFVSA-N 0.000 description 1
- 206010067125 Liver injury Diseases 0.000 description 1
- 206010026749 Mania Diseases 0.000 description 1
- 240000002853 Nelumbo nucifera Species 0.000 description 1
- 235000006508 Nelumbo nucifera Nutrition 0.000 description 1
- 235000006510 Nelumbo pentapetala Nutrition 0.000 description 1
- 206010033799 Paralysis Diseases 0.000 description 1
- 208000018737 Parkinson disease Diseases 0.000 description 1
- 206010061334 Partial seizures Diseases 0.000 description 1
- 108090000882 Peptidyl-Dipeptidase A Proteins 0.000 description 1
- 208000005764 Peripheral Arterial Disease Diseases 0.000 description 1
- 101710150593 Protein beta Proteins 0.000 description 1
- 208000037012 Psychomotor seizures Diseases 0.000 description 1
- 108091006172 SLC21 Proteins 0.000 description 1
- 208000007536 Thrombosis Diseases 0.000 description 1
- 206010043994 Tonic convulsion Diseases 0.000 description 1
- 206010047700 Vomiting Diseases 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 239000013566 allergen Substances 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000037005 anaesthesia Effects 0.000 description 1
- 230000003444 anaesthetic effect Effects 0.000 description 1
- 229950006323 angiotensin ii Drugs 0.000 description 1
- 229940124350 antibacterial drug Drugs 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 230000009876 antimalignant effect Effects 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 239000002246 antineoplastic agent Substances 0.000 description 1
- 229940127218 antiplatelet drug Drugs 0.000 description 1
- 230000002763 arrhythmic effect Effects 0.000 description 1
- 239000003693 atypical antipsychotic agent Substances 0.000 description 1
- 229940127236 atypical antipsychotics Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- 229940124748 beta 2 agonist Drugs 0.000 description 1
- 210000000941 bile Anatomy 0.000 description 1
- 230000008236 biological pathway Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 230000036765 blood level Effects 0.000 description 1
- 210000004204 blood vessel Anatomy 0.000 description 1
- 229940124630 bronchodilator Drugs 0.000 description 1
- 210000005178 buccal mucosa Anatomy 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- NPAKNKYSJIDKMW-UHFFFAOYSA-N carvedilol Chemical compound COC1=CC=CC=C1OCCNCC(O)COC1=CC=CC2=NC3=CC=C[CH]C3=C12 NPAKNKYSJIDKMW-UHFFFAOYSA-N 0.000 description 1
- 229960004195 carvedilol Drugs 0.000 description 1
- 208000026106 cerebrovascular disease Diseases 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 229960001399 clenbuterol hydrochloride Drugs 0.000 description 1
- OPXKTCUYRHXSBK-UHFFFAOYSA-N clenbuterol hydrochloride Chemical compound Cl.CC(C)(C)NCC(O)C1=CC(Cl)=C(N)C(Cl)=C1 OPXKTCUYRHXSBK-UHFFFAOYSA-N 0.000 description 1
- FDEODCTUSIWGLK-RSAXXLAASA-N clopidogrel sulfate Chemical compound [H+].OS([O-])(=O)=O.C1([C@H](N2CC=3C=CSC=3CC2)C(=O)OC)=CC=CC=C1Cl FDEODCTUSIWGLK-RSAXXLAASA-N 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000001066 destructive effect Effects 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 230000009429 distress Effects 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 206010013663 drug dependence Diseases 0.000 description 1
- 239000003596 drug target Substances 0.000 description 1
- 230000010102 embolization Effects 0.000 description 1
- 206010015037 epilepsy Diseases 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 201000007186 focal epilepsy Diseases 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 230000002641 glycemic effect Effects 0.000 description 1
- 231100000234 hepatic damage Toxicity 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 229940124589 immunosuppressive drug Drugs 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000000302 ischemic effect Effects 0.000 description 1
- 229960003350 isoniazid Drugs 0.000 description 1
- QRXWMOHMRWLFEY-UHFFFAOYSA-N isoniazide Chemical compound NNC(=O)C1=CC=NC=C1 QRXWMOHMRWLFEY-UHFFFAOYSA-N 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 230000008818 liver damage Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000002483 medication Methods 0.000 description 1
- 230000009245 menopause Effects 0.000 description 1
- 230000003340 mental effect Effects 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- WFFQYWAAEWLHJC-UHFFFAOYSA-N mercaptopurine hydrate Chemical compound O.S=C1NC=NC2=C1NC=N2 WFFQYWAAEWLHJC-UHFFFAOYSA-N 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 230000000626 neurodegenerative effect Effects 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 239000002547 new drug Substances 0.000 description 1
- 238000007481 next generation sequencing Methods 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 208000021090 palsy Diseases 0.000 description 1
- ODAIHABQVKJNIY-PEDHHIEDSA-N perindoprilat Chemical compound C1CCC[C@H]2C[C@@H](C(O)=O)N(C(=O)[C@H](C)N[C@@H](CCC)C(O)=O)[C@H]21 ODAIHABQVKJNIY-PEDHHIEDSA-N 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 230000036513 peripheral conductance Effects 0.000 description 1
- 230000004526 pharmaceutical effect Effects 0.000 description 1
- 230000002974 pharmacogenomic effect Effects 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 229940096701 plain lipid modifying drug hmg coa reductase inhibitors Drugs 0.000 description 1
- 230000010118 platelet activation Effects 0.000 description 1
- 229920000155 polyglutamine Polymers 0.000 description 1
- 108010040003 polyglutamine Proteins 0.000 description 1
- 208000014321 polymorphic ventricular tachycardia Diseases 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 208000020016 psychiatric disease Diseases 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 229940044601 receptor agonist Drugs 0.000 description 1
- 239000000018 receptor agonist Substances 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000004043 responsiveness Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 238000001963 scanning near-field photolithography Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 208000012201 sexual and gender identity disease Diseases 0.000 description 1
- 208000015891 sexual disease Diseases 0.000 description 1
- 230000001568 sexual effect Effects 0.000 description 1
- -1 signal molecules Proteins 0.000 description 1
- 208000017520 skin disease Diseases 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 208000010110 spontaneous platelet aggregation Diseases 0.000 description 1
- 208000011117 substance-related disease Diseases 0.000 description 1
- 239000013076 target substance Substances 0.000 description 1
- YDLQKLWVKKFPII-UHFFFAOYSA-N timiperone Chemical compound C1=CC(F)=CC=C1C(=O)CCCN1CCC(N2C(NC3=CC=CC=C32)=S)CC1 YDLQKLWVKKFPII-UHFFFAOYSA-N 0.000 description 1
- 229950000809 timiperone Drugs 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 239000000814 tuberculostatic agent Substances 0.000 description 1
- 210000003462 vein Anatomy 0.000 description 1
- 206010047302 ventricular tachycardia Diseases 0.000 description 1
- 230000008673 vomiting Effects 0.000 description 1
- 230000003313 weakening effect Effects 0.000 description 1
Images









Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M1/00—Apparatus for enzymology or microbiology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M1/00—Apparatus for enzymology or microbiology
- C12M1/34—Measuring or testing with condition measuring or sensing means, e.g. colony counters
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/10—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to drugs or medications, e.g. for ensuring correct administration to patients
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y10/00—Economic sectors
- G16Y10/60—Healthcare; Welfare
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y20/00—Information sensed or collected by the things
- G16Y20/40—Information sensed or collected by the things relating to personal data, e.g. biometric data, records or preferences
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y40/00—IoT characterised by the purpose of the information processing
- G16Y40/20—Analytics; Diagnosis
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Computing Systems (AREA)
- Medicinal Chemistry (AREA)
- Epidemiology (AREA)
- Medical Informatics (AREA)
- Primary Health Care (AREA)
- Sustainable Development (AREA)
- Plant Pathology (AREA)
- Analytical Chemistry (AREA)
- Immunology (AREA)
- Bioethics (AREA)
- Business, Economics & Management (AREA)
- Accounting & Taxation (AREA)
- Development Economics (AREA)
- Economics (AREA)
- General Business, Economics & Management (AREA)
- Public Health (AREA)
- Crystallography & Structural Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Medical Treatment And Welfare Office Work (AREA)
Abstract
Description
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させる。
本実施形態では、上記適合度が、上記患者に生じると予想される上記医薬の薬効に基づいて判断されることを例に説明する。本実施形態のシステムは、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子が存在する座位および当該遺伝子に関連する座位にある接合型を含むアレルの組み合わせの型(「アレルの型」)を、上記遺伝型として少なくとも参照する。つまり、本実施形態のシステムは、当該遺伝子に関連する遺伝型(「アレルの型」)が上記医薬の薬効に影響する程度を表す情報(医薬薬効関連遺伝子情報)を参照して、上記適合度を決定する。
薬物の薬効は、薬物動態学に関与するタンパク質および/または薬力学に関与するタンパク質の遺伝学的多様性によって部分的に決定される。薬物動態学に関与するタンパク質としては、例えば、薬物の吸収、循環、送達、代謝および排泄に関与するタンパク質が挙げられる。つまり、薬物動態学は、薬物と標的分子とが接触する確率を変化させる、薬物またはその代謝物の生体内における挙動を指す。薬力学に関与するタンパク質は、薬物の標的分子であり得る。当該標的分子としては、例えば、受容体、シグナル分子、および薬物の薬理遺伝学的作用に関連する生物学的経路を構成するタンパク質が挙げられる。
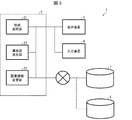
医薬の有効性を向上させるために、図2の投与計画提案システム1が実行する処理の一例を、図3を参照して以下に説明する。入力装置4(図2)は、従来の一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)にしたがって、ユーザである医師によって入力された医薬情報301(図4)を情報取得部21(図2)に送る(図3のS1工程)。図2の情報取得部21は、医薬情報301(図4)に含まれている医薬名が表す薬剤の名称と、当該薬剤の薬効と関連する遺伝子の名称と、当該遺伝子に関連する既知のDNAバリアント(例えばSNP)における全通りの「遺伝型」と、当該遺伝型に応じた当該薬剤の薬効とを記述している関連性情報311(図4)を、図2の医薬薬効関連遺伝子情報DB5(例えば、DGIdb:Drug Gene Interaction database、URL:http://dgidb.org/の情報を元に構築可能)から取得する(図3のS2工程で「YES」)。図2の情報取得部21は、医薬情報301(図4)に記載された「患者ID」情報、および関連性情報311(図4)に含まれている遺伝子名に基づいて、患者IDおよび遺伝子に対応する患者の遺伝型情報を、図4の関連性情報311に記載の「遺伝型」の表記法にしたがった記号として、ゲノム情報DB6(図2)から取得する(図3のS3工程で「YES」)。情報取得部21(図2)は、取得した医薬情報301(図4)、関連性情報311(図4)、およびゲノム情報DB6(図2)から取得した患者の遺伝型情報を適合度決定部22(図2)に送る。
遺伝型情報は、患者に固有な、1つの座位に存在するアレル(本実施形態では1つの遺伝子に関連するアレル)の組み合わせの型(「アレルの型」)を表している。当該「アレルの型」の決定には、大きく分けて2通りの方法がある。当該方法は、患者から得られたゲノム全長の構造を表す情報(「全長文字列」)を用いる「方法1」、および患者由来のゲノムDNA試料を用いて、集団内で頻度の高く、かつ自動解析に適したDNAバリアントのみ(例えば、SNP)を対象に、ゲノム網羅的な多型解析による実験的手法を用いる「方法2」である。
・一般に利用可能なDB(例えば、上述したdbSNP)に格納されている既知のDNAバリアントの位置を表す上記情報に基づいて、「全長文字列」に含まれている、上記「アレル文字列」における、当該DNAバリアントの両側の位置に隣接する2つの文字列(例えば約10〜100文字)を決定する
・「全長文字列」における上記2つの文字列(すなわち、当該DNAバリアントの両側の位置に隣接する2つの文字列)が「参照文字列」と完全一致する位置を、周知の文字比較アプリケーションを用いて決定する
・「全長文字列」と「参照文字列」の間で、上記2つの文字列が完全一致する位置に挟まれている当該DNAバリアントに対応する文字(列)の一致、不一致にしたがって、「全長文字列」にある当該DNAバリアントの「アレルの型」(すなわち、患者の「遺伝型」)を決定する。
本実施形態では、上記遺伝型は、図4の関連性情報311に示されている通り、薬物動態学に関与するタンパク質をコードしている遺伝子に関する遺伝型である。図4の関連性情報311は、医薬および遺伝子の関連性(特に有効成分の代謝速度が、遺伝子の遺伝子機能と関連したアレルの遺伝型によって受ける影響)を表している。
上記システムを実行するプログラム全体は、外部(ユーザの使用するコンピュータ)からアクセス可能なイントラネットまたはインターネットを介して実行可能である。上記システムは、ユーザに出力した情報を、紙面に印刷するための印刷装置(例えばプリンタまたは複合機)と接続されていてもよい。
本実施形態では、上記適合度が、医薬の投与によって治療対象でない疾患を発症する素因(発症リスク)に基づいて判断されることを例に説明する。本実施形態に係るシステムは、ヒトゲノム上の多数の座位に関するアレルの組み合わせの型の集合を、上記遺伝型として参照するが、本実施形態はこれに限定されず、1つまたは少数の座位に関するアレルの組み合わせの型の集合を、上記遺伝型として参照し得る(例えば、「単一遺伝子疾患」の実例について、後述されている)。当該遺伝型により上記素因の有無を決定する。つまり、本実施形態のシステムは、医薬の投与と関連して疾患を発症する素因を表す情報(医薬関連疾患情報)を参照して、上記適合度を決定する。つまり、本実施形態は、患者が遺伝学的に発症しやすいが、未だ発症していない疾患の、当該疾患に対する禁忌薬(投薬を行ったときに病状を悪化させる、深刻な副作用が出現する、薬の効果が弱まるなどの可能性が高まることが知られている医薬品)の継続的かつ多量な投与による発症を抑える。
投与計画の安全性を高めるために、図5の投与計画提案システム1’が実行する処理の一例を、図6を参照して以下に説明する。入力装置4(図5)は、従来の一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)にしたがって、ユーザである医師によって入力された医薬情報303(図7)を情報取得部21(図5)に送る(図6のS1’工程)。情報取得部21(図5)は、図7の医薬情報303に含まれている医薬名が表す薬剤の名称と、当該薬剤の投与によって発症し得る疾患の名称と、当該疾患に対する素因の有無を表す遺伝型の範囲とを記述している関連性情報314(図7)を医薬関連疾患情報DB7(図5)から取得する(図6のS2’工程)。情報取得部21(図5)は、患者ID(図7の医薬情報303を参照)および当該疾患に対する素因の有無を表す遺伝型に関するDNAバリアント群情報(図7の関連性情報314を参照)に基づいて、患者IDおよび疾患の名称に対応する遺伝型情報をゲノム情報DB6(図5)から取得する(図6のS3’工程)。情報取得部21(図5)は、取得した医薬情報303(図7)、関連性情報314(図7)およびゲノム情報DB6(図5)から取得された患者の遺伝型情報を、適合度決定部22(図5)に送る。
本実施形態では、患者にとっての遺伝型情報は、疾患ごとに対応する値(PRS(Polygenes Risk Score;多遺伝子リスクスコア)パーセンタイル)として表されている。2型糖尿病に対応するPRSパーセンタイルは、ヒト母集団が示す2型糖尿病の発症リスクに関するPRSの正規分布(図1を参照)において、患者のPRSが最下位から数えて何%に該当するかを表している。つまりPRSパーセンタイルは0〜100であり、PRSパーセンタイルが大きいほど高い発症リスクを表す。2型糖尿病に関するPRSは、2型糖尿病の発症に影響を与える全てのDNAバリアントの「アレルの型」の組み合わせを点数化し、合計した値である。ある疾患の発症に影響する全てのDNAバリアントの「アレルの型」は、例えば、複雑疾患の感受性を支配する因子を同定する標準的手法であるゲノムワイド関連解析(GWAS: Genomewide Association Study)によって同定されている。任意の疾患に関するPRSパーセンタイルおよびPRSの概要は、ReFlections Vol 45, September 2018(https://rgare.com/docs/default-source/newsletters-articles/reflections-vol-45-sept-2018.pdf?sfvrsn=66979288_0)などに示されている。
本実施形態では、上記遺伝型は、ある特定の疾患に発症する素因に寄与するDNAバリアントの組み合わせに関する遺伝型である。関連性情報314(図7)は、医薬および治療対象外の疾患の関連性(特に医薬の投与が、当該疾患の発症に与える影響)を表している。
・現在の病気(現疾患)
・ある病気が原因となって起こる別の病気(合併症)
・これまでにかかった病気(既往歴)
・ご家族の方の病気(家族歴)
・現在使われている他のお薬(併用薬剤)
・医薬品を使用する方の体質
(以上、「独立行政法人医薬品医療機器総合機構」ホームページより)。
本実施形態では、〔実施形態1〕および〔実施形態2〕に説明した処理を複合的に実行するシステムを説明する(図1参照)。すなわち、本実施形態では、図1に示すように、投与計画を変更するための判断基準として、(1)医薬Bの薬物動態学的要因(〔実施形態1〕)、(2)医薬Bの薬力学的要因(〔実施形態1〕)、および(3)医薬Bによる副次疾患の発症リスク(〔実施形態2〕)、以上(1)〜(3)の組み合わせを上記判断基準にするシステムを説明する。図8に示すように、投与計画提案システム1’’は、制御部2および表示装置(情報表示部)3を備えている。制御部2(図8)は、情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23を備えている(図8参照)。また、制御部2(図8)は、入力装置4、医薬薬効関連遺伝子情報DB5、ゲノム情報DB6および医薬関連疾患情報DB7と接続されている(図8参照)。つまり、図8の本実施形態のシステム1’’は、(i)上記遺伝子の遺伝型が上記医薬の薬効に影響する程度を表す情報(〔実施形態1〕)および(ii)上記素因の遺伝型が上記医薬の投与によって上記疾患(副次的疾患)の発症リスクに影響する程度を表す発症リスク情報(〔実施形態2〕)の両方を参照して、上記適合度を決定する。
本実施形態では、公知のDBに格納されているヒトゲノム(「参照文字列」)ではなく、個人から得られたゲノムの全ヌクレオチド配列(「全長文字列」)における任意のDNAバリアントの「アレルの型」(患者の「遺伝型」)を決定する方法(〔実施形態1〕および〔実施形態2〕の各項目(患者の遺伝型情報)に記載した「方法1」)を説明する。上記DNAバリアントは、SNP、SNV、インデル、CNP、CNV、マイクロサテライト多型(「STRP」)を含むあらゆるヌクレオドの変化である。当該方法では、上記標的ヌクレオチドを挟む2つのヌクレオチド配列を表す2つの文字列を、基準のヒトゲノムを表す公知の文字列(「参照文字列」)から抽出し、使用する。
上述した(1)の文字列による当該方法は、特に、SNP、SNVまたはインデルのアレルの型を決定する簡便な方法である。図9に示されているように、(1)の文字列は、標的ヌクレオチド(SNP、SNVまたはインデル)を表す文字列902、文字列902を挟む2つのヌクレオチド配列を表す2つ文字列901および903を含んでいる、1つの連続した文字列である。文字列901および903は、基準のヒトゲノムを表す文字列(「参照文字列」)(例えば、アンサンブル(Ensemble、URL:http://ensembl.org)から取得可能)の一部として決定される(図10のS11工程)。文字列902(標的ヌクレオチドを表す文字(列))は、本実施形態に係る方法を実施する時点で既知の(以降では単に「既知の」と記載する)DNAバリアントとして、既知のDBに格納されている。つまり上記「DNAバリアント」は、本願の出願以降に見いだされたDNAバリアントも含まれ得る。たとえば、既知の全SNPに関する情報は、dbSNPデータベース(https://www.ncbi.nlm.nih.gov/snp/)より取得可能である。文字列902(標的ヌクレオチドを表す文字(列))が、基準のヒトゲノムを表す文字列(「参照文字列」)に存在する位置の情報も、当該DB(例えば、上記のdbSNPデータベース)に格納されている。(1)の文字列において、文字列901と文字列903の長さは同一に設定し、解析部位(文字列902)を中央に配置することが好ましい。
上述した(2)の文字列による当該方法は、あらゆるDNAバリアント(上述したSNP、SNVまたはインデルを含む)の接合型を含むアレルの型(「アレルの型」)の決定に適用可能であるが、特に、標的ヌクレオチドの長さの変化、ならびに多数の選択肢が存在する、または標的ヌクレオチドの詳細が不明な場合に有効な方法である。標的ヌクレオチドの長さの変化、ならびに多数の選択肢は、例えば、マイクロサテライト多型(「STRP」)などのように、反復回数の異なる単純反復配列を標的ヌクレオチドにするときに生じる。また、詳細が不明なときは、例えば、〔実施形態1〕で示したACE遺伝子内に存在するAlu配列の欠失/挿入の多型解析などが想定され得る。つまり、(2)の文字列は、標的ヌクレオチドの数、さらには標的ヌクレオチドの全長ヌクレオチド配列も決定する必要のあるときに特に有効である。
決定された「アレルの型」(患者の遺伝型)とともに、個人のゲノムに存在するDNAバリアントを表す情報は、DB、記録媒体または記憶装置に保存されるとともに(図示せず)、ゲノム情報DB6(図2、図5および図8)に格納される(S15工程)。
投与計画提案システム1〜1’’(図2、図5および図8)は、制御ブロック(特に情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23)を、集積回路(ICチップ)等に形成された論理回路(ハードウェア)によって実現してもよいし、ソフトウェアによって実現してもよい。
これまでに説明した発明を、以下のようにまとめることができる。
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備えている、システム。
上記遺伝型は上記遺伝子に関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、〔1〕に記載のシステム。
上記遺伝型は、上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬関連疾患情報を含んでおり、
上記変更は、上記医薬の変更または上記投与量の減少である、〔1〕または〔2〕に記載のシステム。
上記適合度決定部が上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断したとき、上記医薬情報変更部は、上記疾患にとっての禁忌薬である上記医薬の変更を上記医薬情報に加える、〔3〕に記載のシステム。
上記遺伝型は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する遺伝型ならびに上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報および医薬関連疾患情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、〔1〕〜〔5〕のいずれかに記載のシステム。
記録されていない上記DNAバリアントを表す情報を、上記全ヌクレオチド配列を表す文字情報に基づいて決定する、〔7〕または〔8〕に記載のシステム。
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記医薬情報変更工程が変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含んでいる、方法。
上記システムは、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部を備えており、
上記医薬情報取得部、上記関連性情報取得部、上記遺伝型情報取得部、上記適合度決定部、上記医薬情報変更部および上記情報提示部としてコンピュータを機能させるための投与計画提案プログラム。
1’ 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
1’’ 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
2 制御部
3 表示装置(情報提示部)
4 入力装置
5 医薬薬効関連遺伝子情報DB
6 ゲノム情報DB
7 医薬関連疾患情報DB
21 情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)
22 適合度決定部
23 医薬情報変更部
301 医薬情報(フェニトイン)
302 変更医薬情報
303 医薬情報(オランザピン)
311 関連性情報(フェニトイン)
312 関連性情報(クロピドグレル)
313 関連性情報(ペリンドプリルエルブミン)
314 関連性情報(オランザピン)
901 文字列
902 文字列(標的ヌクレオチド)
903 文字列
Claims (13)
- 患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、システム。 - 上記システムは、上記DNAバリアントを検出するために、
当該DNAバリアントに対応する標的ヌクレオチド配列と、基準のヒトゲノムにおいて当該DNAバリアントに対応する位置の両側の部分ヌクレオチド配列とが結合した結合配列を生成し、当該結合配列と、上記患者のゲノムを構成する全ヌクレオチド配列とを比較することを、
上記部分ヌクレオチド配列の長さを増加させながら繰り返す、請求項1に記載のシステム。 - 上記システムは、上記DNAバリアントを検出するために、
基準のヒトゲノムにおいて当該DNAバリアントに対応する位置の両側の部分ヌクレオチド配列に対応する2つのヌクレオチド配列を生成し、当該2つのヌクレオチド配列と、上記患者のゲノムを構成する全ヌクレオチド配列とを比較することを、
上記部分ヌクレオチド配列の長さを増加させながら繰り返す、請求項1に記載のシステム。 - 上記適合度決定部は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する医薬薬効関連遺伝子情報を参照して、上記適合度を決定し、
上記遺伝型は上記遺伝子に関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、請求項1〜3のいずれか1項に記載のシステム。 - 上記適合度決定部は、上記医薬の投与によって発症または重篤化する疾患を表す医薬関連疾患情報を参照して、上記適合度を決定し、
上記遺伝型は、上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬関連疾患情報を含んでおり、
上記変更は、上記医薬の変更または上記投与量の減少である、請求項1〜4のいずれか1項に記載のシステム。 - 上記医薬が上記疾患にとっての禁忌薬であるとき、上記適合度決定部は、上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断し、
上記適合度決定部が上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断したとき、上記医薬情報変更部は、上記疾患にとっての禁忌薬である上記医薬の変更を上記医薬情報に加える、請求項5に記載のシステム。 - 上記疾患は、特異体質による重篤な副作用と関連した疾患、または特異体質による重篤な副作用の症状を含む、請求項5に記載のシステム。
- 上記適合度決定部は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子を表す医薬薬効関連遺伝子情報と、上記医薬の投与によって発症または重篤化する疾患を表す医薬関連疾患情報とを参照して、上記適合度を決定し、
上記遺伝型は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する遺伝型ならびに上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報および医薬関連疾患情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、請求項1〜7のいずれか1項に記載のシステム。 - 上記DNAバリアントのうち一塩基多型を表す情報を、上記患者のゲノム断片を用いて、または上記全ヌクレオチド配列を表す情報に基づいて決定し、決定された一塩基多型を表す情報を記録し、
記録されていない上記DNAバリアントを表す情報を、上記全ヌクレオチド配列を表す文字情報に基づいて決定する、請求項1〜8のいずれか1項に記載のシステム。 - 上記医薬情報取得部は、上記医薬情報を処方箋またはお薬手帳から取得する、請求項1〜9のいずれか1項に記載のシステム。
- 上記関連性情報が人工知能によって生成される、請求項1〜10のいずれか1項に記載のシステム。
- 患者にとって好適な投与計画を提案する方法であって、
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、方法。 - 患者にとって好適な投与計画を提案するシステムとしてコンピュータを機能させるための投与計画提案プログラムであって、
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させるための投与計画提案プログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020112023A JP6893052B1 (ja) | 2020-06-29 | 2020-06-29 | 投与計画提案システム、方法およびプログラム |
| PCT/JP2021/019872 WO2022004200A1 (ja) | 2020-06-29 | 2021-05-25 | 投与計画提案システム、方法およびプログラム |
| JP2022533742A JPWO2022004200A1 (ja) | 2020-06-29 | 2021-05-25 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020112023A JP6893052B1 (ja) | 2020-06-29 | 2020-06-29 | 投与計画提案システム、方法およびプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP6893052B1 true JP6893052B1 (ja) | 2021-06-23 |
| JP2022024213A JP2022024213A (ja) | 2022-02-09 |
Family
ID=76464621
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020112023A Active JP6893052B1 (ja) | 2020-06-29 | 2020-06-29 | 投与計画提案システム、方法およびプログラム |
| JP2022533742A Pending JPWO2022004200A1 (ja) | 2020-06-29 | 2021-05-25 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022533742A Pending JPWO2022004200A1 (ja) | 2020-06-29 | 2021-05-25 |
Country Status (2)
| Country | Link |
|---|---|
| JP (2) | JP6893052B1 (ja) |
| WO (1) | WO2022004200A1 (ja) |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510817A (ja) * | 1998-04-03 | 2002-04-09 | トライアングル・ファーマシューティカルズ,インコーポレイテッド | 治療処方計画の選択をガイドするためのシステム、方法及びコンピュータ・プログラム製品 |
| WO2005038049A2 (en) * | 2003-10-06 | 2005-04-28 | Heinrich Guenther | System and method for optimizing drug therapy |
| US20060223058A1 (en) * | 2005-04-01 | 2006-10-05 | Perlegen Sciences, Inc. | In vitro association studies |
| JP2008532104A (ja) * | 2004-12-30 | 2008-08-14 | プロベンティス インコーポレーテッド | 複数の医療関連アウトカムの予測を行い、インターベンション計画の評価を行い、更に同時にバイオマーカー因果性検証を行うことのできる、予測モデルを生成して適用する方法、そのシステム、及びそのコンピュータ・プログラム製品 |
| JP2009070096A (ja) * | 2007-09-12 | 2009-04-02 | Michio Kimura | ゲノム情報と臨床情報との統合データベースシステム、および、これが備えるデータベースの製造方法 |
| JP2010539947A (ja) * | 2007-09-26 | 2010-12-24 | ナビジェニクス インコーポレイティド | 祖先データを用いるゲノム解析の方法及びシステム |
| JP2013535756A (ja) * | 2010-08-13 | 2013-09-12 | インテリメディシン インコーポレイテッド | 個別化された医薬品の生産のためのシステムおよび方法 |
| US20140257837A1 (en) * | 2013-03-05 | 2014-09-11 | Clinton Colin Graham Walker | Automated interactive health care application for patient care |
| US20140274763A1 (en) * | 2013-03-15 | 2014-09-18 | Pathway Genomics Corporation | Method and system to predict response to pain treatments |
| US20170051350A1 (en) * | 2013-03-15 | 2017-02-23 | Pathway Genomics Corporation | Method and system to predict response to treatments for mental disorders |
| US20170061080A1 (en) * | 2001-08-29 | 2017-03-02 | Druglogic, Inc. | Method and system for the analysis and association of patient-specific and population-based genomic data with drug safety adverse event data |
| JP2020034993A (ja) * | 2018-08-27 | 2020-03-05 | 秀一 大津 | 遠隔診療アプリケーションおよびシステム |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8000259B2 (en) * | 2009-09-04 | 2011-08-16 | Viasat, Inc. | Distributed cache—adaptive multicast architecture for bandwidth reduction |
-
2020
- 2020-06-29 JP JP2020112023A patent/JP6893052B1/ja active Active
-
2021
- 2021-05-25 WO PCT/JP2021/019872 patent/WO2022004200A1/ja active Application Filing
- 2021-05-25 JP JP2022533742A patent/JPWO2022004200A1/ja active Pending
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510817A (ja) * | 1998-04-03 | 2002-04-09 | トライアングル・ファーマシューティカルズ,インコーポレイテッド | 治療処方計画の選択をガイドするためのシステム、方法及びコンピュータ・プログラム製品 |
| US20170061080A1 (en) * | 2001-08-29 | 2017-03-02 | Druglogic, Inc. | Method and system for the analysis and association of patient-specific and population-based genomic data with drug safety adverse event data |
| WO2005038049A2 (en) * | 2003-10-06 | 2005-04-28 | Heinrich Guenther | System and method for optimizing drug therapy |
| JP2008532104A (ja) * | 2004-12-30 | 2008-08-14 | プロベンティス インコーポレーテッド | 複数の医療関連アウトカムの予測を行い、インターベンション計画の評価を行い、更に同時にバイオマーカー因果性検証を行うことのできる、予測モデルを生成して適用する方法、そのシステム、及びそのコンピュータ・プログラム製品 |
| US20060223058A1 (en) * | 2005-04-01 | 2006-10-05 | Perlegen Sciences, Inc. | In vitro association studies |
| JP2009070096A (ja) * | 2007-09-12 | 2009-04-02 | Michio Kimura | ゲノム情報と臨床情報との統合データベースシステム、および、これが備えるデータベースの製造方法 |
| JP2010539947A (ja) * | 2007-09-26 | 2010-12-24 | ナビジェニクス インコーポレイティド | 祖先データを用いるゲノム解析の方法及びシステム |
| JP2013535756A (ja) * | 2010-08-13 | 2013-09-12 | インテリメディシン インコーポレイテッド | 個別化された医薬品の生産のためのシステムおよび方法 |
| US20140257837A1 (en) * | 2013-03-05 | 2014-09-11 | Clinton Colin Graham Walker | Automated interactive health care application for patient care |
| US20140274763A1 (en) * | 2013-03-15 | 2014-09-18 | Pathway Genomics Corporation | Method and system to predict response to pain treatments |
| US20170051350A1 (en) * | 2013-03-15 | 2017-02-23 | Pathway Genomics Corporation | Method and system to predict response to treatments for mental disorders |
| JP2020034993A (ja) * | 2018-08-27 | 2020-03-05 | 秀一 大津 | 遠隔診療アプリケーションおよびシステム |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022004200A1 (ja) | 2022-01-06 |
| JP2022024213A (ja) | 2022-02-09 |
| JPWO2022004200A1 (ja) | 2022-01-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Ruhno et al. | Complete sequencing of the SMN2 gene in SMA patients detects SMN gene deletion junctions and variants in SMN2 that modify the SMA phenotype | |
| US20200048712A1 (en) | Methods for selecting medications | |
| Gowans et al. | Association studies and direct DNA sequencing implicate genetic susceptibility loci in the etiology of nonsyndromic orofacial clefts in sub-Saharan African populations | |
| Attia et al. | How to use an article about genetic association: A: Background concepts | |
| Shen et al. | Familial defective apolipoprotein B-100 and increased low-density lipoprotein cholesterol and coronary artery calcification in the old order amish | |
| US8688385B2 (en) | Methods for selecting initial doses of psychotropic medications based on a CYP2D6 genotype | |
| Simonson et al. | Recent methods for polygenic analysis of genome-wide data implicate an important effect of common variants on cardiovascular disease risk | |
| Rasmussen‐Torvik et al. | High density GWAS for LDL cholesterol in African Americans using electronic medical records reveals a strong protective variant in APOE | |
| Schuit et al. | Pharmacotherapy for smoking cessation: effects by subgroup defined by genetically informed biomarkers | |
| Kim et al. | A polymorphism in AGT and AGTR1 gene is associated with lead-related high blood pressure | |
| Tanner et al. | Combinatorial pharmacogenomics and improved patient outcomes in depression: treatment by primary care physicians or psychiatrists | |
| Himes et al. | Integration of mouse and human genome-wide association data identifies KCNIP4 as an asthma gene | |
| Moreno et al. | Association of GWAS top genes with late-onset Alzheimer’s disease in Colombian population | |
| Shirts et al. | Evaluation of the gene–age interactions in HDL cholesterol, LDL cholesterol, and triglyceride levels: the impact of the SORT1 polymorphism on LDL cholesterol levels is age dependent | |
| Rasmussen et al. | Genome-wide association study of angioedema induced by angiotensin-converting enzyme inhibitor and angiotensin receptor blocker treatment | |
| Cruz et al. | Exclusion of Class III malocclusion candidate loci in Brazilian families | |
| Hebbar et al. | Genome-wide association study identifies novel recessive genetic variants for high TGs in an Arab population | |
| Perlis et al. | Genetic association study of treatment response with olanzapine/fluoxetine combination or lamotrigine in bipolar I depression | |
| Xu et al. | Genome-wide analysis indicates association between heterozygote advantage and healthy aging in humans | |
| Reay et al. | Genetic association and causal inference converge on hyperglycaemia as a modifiable factor to improve lung function | |
| Hotaling et al. | Pilot genome-wide association search identifies potential loci for risk of erectile dysfunction in type 1 diabetes using the DCCT/EDIC study cohort | |
| Blue et al. | Association of uncommon, noncoding variants in the APOE region with risk of Alzheimer disease in adults of European ancestry | |
| Johnston et al. | The ACMG SF v3. 0 gene list increases returnable variant detection by 22% when compared with v2. 0 in the ClinSeq cohort | |
| Ghouse et al. | Polygenic risk score for ACE-inhibitor-associated cough based on the discovery of new genetic loci | |
| Kazani et al. | The role of pharmacogenomics in improving the management of asthma |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200629 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20200629 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20200828 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20201020 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20201201 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210126 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210323 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20210402 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210524 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6893052 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |