WO2022004200A1 - Dosage regime proposing system, method, and program - Google Patents
Dosage regime proposing system, method, and program Download PDFInfo
- Publication number
- WO2022004200A1 WO2022004200A1 PCT/JP2021/019872 JP2021019872W WO2022004200A1 WO 2022004200 A1 WO2022004200 A1 WO 2022004200A1 JP 2021019872 W JP2021019872 W JP 2021019872W WO 2022004200 A1 WO2022004200 A1 WO 2022004200A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- drug
- genotype
- relevance
- patient
- Prior art date
Links
Images










Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M1/00—Apparatus for enzymology or microbiology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12M—APPARATUS FOR ENZYMOLOGY OR MICROBIOLOGY; APPARATUS FOR CULTURING MICROORGANISMS FOR PRODUCING BIOMASS, FOR GROWING CELLS OR FOR OBTAINING FERMENTATION OR METABOLIC PRODUCTS, i.e. BIOREACTORS OR FERMENTERS
- C12M1/00—Apparatus for enzymology or microbiology
- C12M1/34—Measuring or testing with condition measuring or sensing means, e.g. colony counters
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H20/00—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance
- G16H20/10—ICT specially adapted for therapies or health-improving plans, e.g. for handling prescriptions, for steering therapy or for monitoring patient compliance relating to drugs or medications, e.g. for ensuring correct administration to patients
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y10/00—Economic sectors
- G16Y10/60—Healthcare; Welfare
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y20/00—Information sensed or collected by the things
- G16Y20/40—Information sensed or collected by the things relating to personal data, e.g. biometric data, records or preferences
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Y—INFORMATION AND COMMUNICATION TECHNOLOGY SPECIALLY ADAPTED FOR THE INTERNET OF THINGS [IoT]
- G16Y40/00—IoT characterised by the purpose of the information processing
- G16Y40/20—Analytics; Diagnosis
Definitions
- the present invention relates to a system for proposing a drug administration plan to a user, and more particularly to a system for proposing a drug administration plan suitable for a patient based on a genotype peculiar to the patient.
- the current out-of-hospital and in-hospital prescriptions (specifying the type, dose and usage of the drug) prepared by the doctor have uniform factors (mainly the type of disease the patient is suffering from and the severity of the disease). Degree and patient age, weight and gender, etc.) are still applied.
- Such a prescription may mean that it is not possible to specify the type, dose and dosage of the drug suitable for the individual patient.
- multiple patients who use the drug as prescribed show very different reactions. It has been pointed out that the reaction may include the drug having only adverse effects on the patient (showing only side effects and no efficacy).
- drugs used for the treatment of mental illness show relatively low efficacy.
- Administration of less effective drugs delays recovery and increases treatment costs, thus imposing a physical, mental or financial burden on the patient.
- the side effects of the drug can cause distress that is inherently unrelated to the disease.
- one aspect of the present invention is to propose to the user a drug administration plan suitable for the patient based on the genotype peculiar to the patient.
- the system is a system that proposes a suitable administration plan for a patient.
- the drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
- Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
- Genotype information acquisition department that acquires the genotype information of the above patients;
- Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
- a medical information changing unit that changes the medical information when the goodness of fit is low; and an information presentation unit that presents the changed medical information that the medical information changing department has changed to the user.
- the system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information.
- Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- the method according to another aspect of the present invention is a method for proposing a suitable administration plan for a patient.
- a drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
- Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
- the genotype information acquisition step in which the computer acquires the genotype information of the patient;
- a goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
- a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user.
- the computer described above when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above.
- Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- the administration plan proposal program is a dose plan proposal program for operating a computer as a system for proposing a suitable administration plan for a patient.
- the above system is equipped with a control unit.
- the control unit Obtain drug information indicating the drug to be administered to the above patients and its dose; Obtained relevance information indicating the relevance of the above drugs and genotypes; Obtain genotype information for the above patients; Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined; When the goodness of fit is low, the above medical information is changed; The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death, The genotype information includes information representing variants having a frequency of less than 1% in the human population.
- the computer functions as the control unit.
- the system is a system that proposes a suitable administration plan for a patient.
- the drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
- Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
- Genotype information acquisition department that acquires the genotype information of the above patients;
- Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
- the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user.
- the system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information.
- Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- One aspect of the present invention is a system that proposes a suitable administration plan for a patient based on a genotype peculiar to the patient, and obtains pharmaceutical information indicating a drug to be administered to the patient and a dose thereof.
- Acquisition unit Relevance information acquisition unit that acquires relevance information indicating the relationship between the drug and the genotype; Genotype information acquisition unit that acquires the genotype information of the patient; Based on the relevance information and genotype information
- the conformity determination unit that determines the conformity of the drug information; the drug information change unit that changes the drug information when the conformity is low; and the modified drug information that the drug information change department has changed. It has an information presentation unit to present to the user.
- the "administration plan” includes at least information indicating a specific patient and information indicating the type and dose of the drug to be administered to the specific patient.
- the administration plan is a guideline (for example, a prescription) indicating that a certain drug is administered to the specific patient at a certain dose.
- the above system is a system that assists the judgment of healthcare professionals (particularly doctors) by creating an administration plan (custom-made administration plan) suitable for the patient.
- pharmaceutical is used herein for the purpose of a drug that directly causes improvement of symptoms in a disease by exerting a medicinal effect in a patient receiving administration, or for the purpose of assisting medical practice (examination and anesthesia, etc.). Represents the substance used (contrast, anesthetic, etc.).
- a “genotype” (also referred to as a genotype) is the genetic composition of an individual or a particular locus of an individual, herein a type of combination of alleles (alleles) in one or more loci in the genome. When targeting two or more loci for genotypes, it refers to the sum of each type).
- "Allele” as used herein refers to an individual gene and DNA sequence present at one locus of a chromosome.
- the term “genotype” or “allelic type” is used herein as a concept that includes “zygotes.”
- “Pharmaceutical information” includes at least information that identifies the patient (eg, the patient's ID number), information that identifies the drug (eg, the brand name or substance name of the drug), and information that specifies the dose of the drug to the patient. Represents the information you have.
- the pharmaceutical information can be, for example, a medical record or prescription created by a doctor on a computer.
- “Relevance information” refers to information indicating the type of drug and the relevance of genes (groups) that affect the action of the drug in vivo.
- Goodness of fit (of pharmaceutical information) refers to the patient and the type and / or dose of the drug specified in the drug information, based on the patient's specific genetic type specified in the drug information. The relationship is appropriate and represents a certain degree.
- a “DNA variant” as used herein is a specific site on the genome in which two or more changes in a nucleotide sequence (including alleles and chromosomal structures) are present in a human population (regardless of its frequency) and the like thereof. Described as a general concept of change. Nucleotide sequence changes in the above "DNA variant” mean the sum of all changes, including substitutions, deletions, insertions and / or additions, duplications of one or more nucleotides (see bottom of FIG. 1).
- CNV Cosmetic Number Variant
- DNA variant is described as a concept including “polymorphism” and “variant” regardless of the frequency in the human population as described above (see the lower part of FIG. 1).
- the total type of allele combination (“allele type”), including the mating type in one locus, is determined by the nucleotide sequence of each allele and / or the number of alleles contained in the combination.
- Administration of the drug to a patient ie, a patient with an unusual type in which at least one of the nucleotide sequences is not the most abundant wild-type nucleotide sequence in the human population and / or the number of alleles is not the usual two is It can have undesired effects on the patient.
- the undesired effects are, for example, (a) a decrease, loss or excessive increase in the efficacy of the drug, (b) the onset or increase of side effects of the drug, and / / when the type is compared to a normal patient. Or (c) a high incidence of a specific disease that did not occur prior to administration of the above-mentioned drug.
- the undesired effect does not appear in just one "allele type", but in many "allele types” for many sitting positions. It often appears when it is accumulated.
- the system has a doctor-designated dosing regimen for drug B (including dose C designation) for patient A according to the uniform factors described above, with the adverse effects described above being patient.
- a doctor-designated dosing regimen for drug B (including dose C designation) for patient A according to the uniform factors described above, with the adverse effects described above being patient.
- a tailor-made administration plan eg, drug B'and dose C'
- Criteria for changing the dosing regimen include (1) pharmacokinetic factors of drug B, (2) pharmacodynamic factors of drug B, and (3) risk of developing secondary diseases due to drug B. ..
- [Embodiment 1] described later an example in which (1) and (2) are used as the above-mentioned determination criteria will be described.
- the degree to which the chemical structure of drug B administered to the patient interacts with the protein expressed in the patient's body is used to properly control.
- (3) is used to prevent the risk of developing a certain disease based on the genetic background peculiar to the patient from being manifested (that is, developing the disease) by administration of a drug (artificial act).
- the graph in (the system of invention) of FIG. 1 visually shows the risk of developing a specific disease.
- the human population for one disease The risk of developing the disease has been shown to be approximately normally distributed.
- the population to the right of the threshold (horizontal axis, dashed line of threshold and part surrounded by curve / horizontal axis and part surrounded by curve) is inherited to develop a certain disease.
- the genotype information of patient A can be determined, for example, by two different methods shown below (see the bottom of FIG. 1). For example, at least one locus of a string representing the entire nucleotide sequence of the genome obtained from the patient (approximately 3 billion characters represented by the four alphabets ATGC, hereinafter referred to as "full-length string”).
- a character string (hereinafter referred to as "allergen character string”) representing a partial nucleotide sequence containing a known DNA variant present in is extracted. The string is then compared to a string representing the entire nucleotide sequence of a standard human genome (approximately 3 billion characters represented by the four alphabets ATGC, hereinafter referred to as "reference string").
- the reference character string can be obtained from a public database such as an ensemble (Ensembl, URL: http://ensembl.org).
- the genotype information of patient A is obtained by, for example, using a part of the genomic DNA sample obtained from the patient using the current microarray technology (genome-exhaustive polymorphism analysis technology). By hybridizing each fragment consisting of a nucleotide sequence containing all known SNPs corresponding to the "reference string” under stringent conditions (conditions that allow only perfectly matched sequences (temperature, salt concentration)). It can be determined by experimental methods.
- the goodness of fit will be determined based on the efficacy of the drug expected to occur in the patient, as an example.
- the system of this embodiment is a combination of allele types ("" Allelic type ”) is at least referred to as the above genotype. That is, the system of the present embodiment refers to the information indicating the degree to which the genotype related to the gene (“allele type”) affects the drug efficacy of the drug (pharmaceutical efficacy-related gene information), and refers to the above-mentioned goodness of fit. To determine.
- Proteins involved in pharmacokinetics include, for example, proteins involved in drug absorption, circulation, delivery, metabolism and excretion. That is, pharmacokinetics refers to the in vivo behavior of a drug or its metabolites that alters the probability of contact between the drug and the target molecule. Proteins involved in pharmacodynamics can be drug target molecules. Target molecules include, for example, receptors, signal molecules, and proteins that constitute biological pathways associated with pharmacological and genetic actions of drugs.
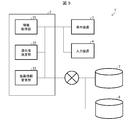
- the administration plan proposal system (system that presents an administration plan suitable for a patient) 1 includes a control unit 2 built in a computer and a display device (information display unit) 3.
- the control unit 2 (FIG. 2) includes an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genotype information acquisition unit) 21, a goodness-of-fit determination unit 22, and a drug information change unit 23 of FIG. ..
- the information acquisition unit 21, the goodness-of-fit determination unit 22, and the medical information change unit 23 of FIG. 2 are included in the CPU (Central Processing Unit) of the control unit 2 (FIG. 2).
- the control unit 2 (FIG. 2) is connected to the input device 4 (for example, keyboard and / or mouse) of FIG.
- the administration plan proposal system 1 of FIG. 2 is controlled by the control unit 2 (FIG. 2) based on the information acquired from the input device 4 and the above two DBs (database: that is, the drug efficacy-related gene information DB 5 and the genomic information DB 6). This is a system that outputs the generated information to the user via the display device 3 (FIG. 2).
- the input device 4 (FIG. 2) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.).
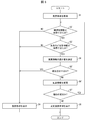
- the input medical information 301 (FIG. 4) is sent to the information acquisition unit 21 (FIG. 2) (S1 step in FIG. 3).
- the information acquisition unit 21 of FIG. 2 has the name of the drug represented by the drug name contained in the drug information 301 (FIG. 4), the name of the gene related to the efficacy of the drug, and the known DNA related to the gene.
- the relevance information 311 (FIG. 4) describing the entire “genotype” in the variant (for example, SNP) and the drug efficacy of the drug according to the genotype is provided in the pharmaceutical efficacy-related gene information DB 5 of FIG. (For example, it can be constructed based on the information of DGIdb: Drug Gene Interaction database, URL: http://dgidb.org/) (“YES” in the S2 step of FIG. 3).
- the information acquisition unit 21 of FIG. 2 has a patient ID and a gene based on the "patient ID" information described in the drug information 301 (FIG. 4) and the gene name contained in the relevance information 311 (FIG. 4).
- the genetic type information of the patient corresponding to the above is acquired from the genomic information DB 6 (FIG. 2) as a symbol according to the notation of "genetic type” described in the relevance information 311 of FIG. 4 (in the step S3 of FIG. 3). "YES").
- the information acquisition unit 21 (FIG. 2) determines the goodness of fit of the patient's genotype information acquired from the acquired drug information 301 (FIG. 4), the relevance information 311 (FIG. 4), and the genomic information DB 6 (FIG. 2). Send to 22 (Fig. 2).
- the information acquisition unit 21 of FIG. 4 is sent to the display device 3 (FIG. 2) (step S9 in FIG. 3).
- the display device 3 of FIG. 2 displays the above-mentioned drug information, and the administration plan proposal system 1 (FIG. 2) ends the process.
- the information acquisition unit 21 (FIG. 2) receives the drug information 301 (for example, FIG. 4) is sent to the display device 3 (FIG. 2) (step S9 in FIG. 3).
- the display device 3 (FIG. 2) displays the above-mentioned drug information, and the administration plan proposal system 1 of FIG. 2 ends the process.
- the goodness-of-fit determination unit 22 in FIG. 2 has medical information based on the genotype information of the patient acquired from the relevance information 311 (FIG. 4) and the genomic information DB 6 (FIG. 2) via the information acquisition unit 21 (FIG. 2).
- the goodness of fit of 301 (FIG. 4) is determined (step S4 of FIG. 3). The details of the S4 process of FIG. 3 will be described with reference to FIG.
- the relevance information 311 shown in FIG. 4 refers to an active ingredient corresponding to a drug name (pharmaceutical name: phenytoin (antiepileptic drug)) and a gene encoding a protein involved in the pharmacokinetics of the active ingredient (related gene).
- a drug name pharmaceutical name: phenytoin (antiepileptic drug)
- a gene encoding a protein involved in the pharmacokinetics of the active ingredient related gene
- Phenytoin is a drug that has the effect of relieving symptoms such as seizures of epilepsy such as tonic seizures (generalized seizures, major seizures), focal epilepsy (including Jackson-type seizures), autonomic seizures, and psychomotor seizures. be.
- SNP rs1057910
- its genotype type "* 1" represents a wild-type allele, and the actual nucleotide type of the nucleotide. Is "Adenine (A)”.
- the genotype type "* 3” represents a low-metabolic allele that is known to reduce the metabolic rate of phenytoin, and the actual base type of nucleotide is "cytosine (C)”.
- Relevance information 311 shows the most frequent CYP2C9 genetic type (normal type) "* 1 / * 1" (actual nucleotide combination type: "A / A”) in the population.
- the relevance information 311 shows that the administration of phenytoin according to the conventional uniform factor is the combination type of nucleotide change of SNP at the 1075 position of the gene CYP2C9 (“A / A”, “A / C”).
- the goodness-of-fit determination unit 22 uses the pharmaceutical information 301 (FIG. 4), the relevance information 311 (FIG. 4), and the patient's genotype information as “* 1”.
- the value of the metabolic rate (medicinal efficacy) of phenytoin in the drug information 301 (FIG. 4) is determined to be "-1".
- the above "* 1 / * 3" is genotype information indicating that the "allele type" of CYP2C9 in the patient is a heterozygous type.
- the genotype information is obtained based on the "patient ID: 123456789” described in the drug information 301 (FIG. 4) and the "related gene: CYP2C9" described in the relevance information 311 (FIG. 4). Obtained from genomic information DB 6 (FIG. 2) by unit 21 (FIG. 2).
- the information acquisition unit 21 (FIG. 2) has two relational information R (relationship) 1 and R2 corresponding to the gene names G1 and G2, and the genotype information Gt (genotype) 1 and Gt2 of the patient. Is sent to the fitness determination unit 22 (FIG. 2).
- the goodness-of-fit determination unit 22 (FIG.
- the metabolic rate (medicinal effect) of phenytoin is exemplified as an element of the above goodness of fit.
- the goodness-of-fit factor varies.
- the antiplatelet drug clopidogrel sulfate prodrug, hereinafter simply referred to as "clopidogrel”
- clopidogrel drug metabolizing enzyme gene
- Clopidogrel is a drug that inhibits the action of ADP (adenosine diphosphate), suppresses platelet aggregation based on platelet activation, suppresses the formation of thrombi and prevents blood vessels from becoming clogged, and is usually an ischemic cerebrovascular disease. It is used to suppress the recurrence of disorders and to suppress thrombus / embolism formation in peripheral arterial diseases.
- ACE angiotensin converting enzyme
- perindopril erbumin active ingredient
- Perindopril erbumin is a prodrug that is hydrolyzed to a diacid form (perindoprilate) after oral absorption, and this diacid form specifically inhibits ACE in blood and tissues, and angiotensin II, which is a pressor substance, It suppresses production and reduces peripheral vascular resistance.
- angiotensin II which is a pressor substance, It suppresses production and reduces peripheral vascular resistance.
- the conformity determination unit 22 in FIG. 2 acquires the heterozygous type “* 1 / * 3” as the genotype information regarding the SNP (rs1057910) in CYP2C9 in the relevance information 311 (FIG. 4).
- the metabolic rate (medicinal effect) value " ⁇ 0" corresponding to the normal genotype (normal type) "* 1 / * 1” and the metabolic rate of phenitoin corresponding to the heterozygous type "* 1 / * 3"
- the value "-1" which is the sum of the values "-1" of the rate (drug efficacy), is determined as the degree of suitability (only 1 lower) with respect to the metabolic rate (drug efficacy) of the drug information 301 (FIG. 4).
- the goodness-of-fit determination unit 22 sends the pharmaceutical information 301 (FIG. 4) and the goodness of fit “-1” to the pharmaceutical information change unit 23 (FIG. 2).
- the pharmaceutical information changing unit 23 in FIG. 2 determines that the goodness of fit “-1”, which is a negative value, is low (step S5 in FIG. 3).
- the drug information change unit 23 (FIG. 2) continuously adjusts the maintenance dose (after the lapse of the initial administration period) among the daily doses in the drug information 301 (FIG. 4) according to the metabolic rate (drug efficacy) “-1”.
- the medicinal effect is set to " ⁇ 0" (step S6 in FIG. 3). Since the change in the step S6 of FIG.
- the drug information change unit 23 (FIG. 2)
- the modified drug information 302 (FIG. 4) changed to 225 mg is sent to the display device 3 (FIG. 2) as the dose obtained by reducing the “daily dose (maintenance dose)” from 300 mg by 25%.
- the initial dose is unchanged, and remains the same as the "daily dose (initial dose) 300 mg" described in Pharmaceutical Information 301 in FIG.
- the display device 3 (FIG. 2) displays the changed drug information 302 (FIG. 4), and the administration plan proposal system 1 (FIG. 2) ends the process.
- the drug information changing unit 23 executes the drug change in the modified drug information 302 (FIG. 4) (shown). figure).
- the suitability determination unit 22 acquires the normal type “* 1 / * 1” as the genotype information of the patient from the genomic information DB 6 (FIG. 2).
- the value of the metabolic rate (medicinal effect) of phenytoin is determined to be " ⁇ 0" and sent to the drug information change unit 23 (FIG. 2).
- the drug information changing unit 23 determines that the value “ ⁇ 0” of the metabolic rate (medicinal effect) is not low, and sends the drug information 301 (FIG. 4) to the display device 3 (FIG. 2).
- the display device 3 (FIG. 2) displays the above-mentioned drug information, and the administration plan proposal system 1 (FIG. 2) ends the process.
- the drug information changing unit 23 in FIG. 2 changes the type of drug.
- the drug name described in the drug information is "clopidogrel”
- the information acquisition unit 21 (FIG. 2) is the relevance information 312 (FIG. 4)
- the information is acquired from the genomic information DB 6 (FIG. 2). Since the patient's genotype information is either "* 2 / * 2", “* 3 / * 3" or "* 2 / * 3", the metabolic rate (drug efficacy) is very low "-2".
- clopidogrel is a prodrug and has no medicinal properties unless it is converted to its active compound. That is, when the above conditions are met, the active compound of clopidogrel, which is an active ingredient, is hardly produced in the patient's body regardless of the dose. Therefore, since an increase in the dose cannot be expected to have a drug effect, the drug information changing unit 23 (FIG. 2) in FIG. 2 changes the type of drug.
- the drug information changing unit 23 (FIG. 2) sends the drug information whose drug name has been changed (corresponding to the determination “YES” in the step S7 in FIG. 3) to the information acquisition unit 21 (FIG. 2), and processes S2 in FIG. Return to the process.
- the details of the relevance information 311 to 313 in FIG. 4 and other related matters are described later in the items (relevance information 311 to 313) in the present embodiment.
- the administration plan proposal system 1 (FIG. 2) of the present embodiment sets the type or dose of the drug described in the drug information 301 (FIG. 4) specified by the doctor as the "genotype" of the patient (the relevant). Change when determined to be incompatible with the patient's "genotype") as a combination of alleles associated with genes that affect the efficacy of the drug. Therefore, the administration plan proposal system 1 (FIG. 2) can propose a tailor-made administration plan having excellent drug efficacy according to the genotype of the patient, without being bound by the conventional uniform factors.
- the genotype information represents a combination type (“allele type”) of an allele (in this embodiment, an allele associated with one gene) that is unique to the patient and is present in one lotus coition.
- allele type a combination type of an allele (in this embodiment, an allele associated with one gene) that is unique to the patient and is present in one lotus coition.
- Method 1 uses information representing the structure of the full length of the genome obtained from the patient ("full length character string"), and a genomic DNA sample derived from the patient, which is frequently and automatically performed in the population.
- Method 2 which uses an experimental method based on genome-wide polymorphism analysis targeting only DNA variants suitable for analysis (for example, SNP).
- the former "method 1" can be carried out by using a large-scale massively parallel DNA sequence determination method (next-generation nucleotide sequence determination method).
- Large-scale parallel DNA sequencing methods can simultaneously and evenly sequence complex DNA samples containing a large number (sometimes millions) of nucleotide sequences. For this reason, the large-scale parallel DNA sequencing method uses genomic DNA samples extracted by a conventional method from patient-derived blood cells and various tissues, as compared with the conventional dideoxy sequencing method (Sanger method). It is possible to convert the information into a character string (“full-length character string”) corresponding to the entire genome (about 3 billion nucleotides) of the patient in a short time and at low cost.
- the patient's The genetic type for a particular locus on the genome can be determined.
- allele string a string representing the nucleotide sequence of an allele that may be in a locus
- information representing a position within the population that causes a nucleotide sequence change between the alleles known DNA variant
- DB eg, dbSNP (https://www.ncbi.nlm.nih.gov/snp/)
- the outline of the process of determining the genotype information of a patient will be described below.
- DB eg, the above-mentioned dbSNP.
- two character strings for example, about 10 to 100 characters
- the above DNA variant is a DNA variant that is frequently used in the population and suitable for automatic analysis.
- the types of polymorphisms in hundreds of thousands) genomic fragments can be determined in a short time. For more information on microarray technology, see the kit manual or the contractor's HP.
- the genotype information of the patient is obtained by the above-mentioned "method 1" using the former "full-length character string” information and / or the latter "method 2" using an experimental method by genome-wide polymorphism analysis. It can be determined (or during the implementation of these methods). Therefore, the patient's genetic type information stored in the genomic information DB 6 of FIG. 2 includes (1) "full-length character string” (patient's genomic information) and (2) the patient's "hereditary type” associated with each other. At least one of the information representing and the information representing the patient, and (3) the information in which the two relevant information are symbolized (see, for example, the "genome type" described in the relevance information 311 of FIG. 4 above). Can be one.
- the genotype information is preferably (2) or (3).
- (2) or (3) as the genotype information reduces the performance required for the administration plan proposal system 1 (FIG. 2) and the genomic information DB 6 (FIG. 2), and reduces the performance required for the administration plan proposal system 1 (FIG. 2).
- (3) can be concealed from an unspecified number of third parties who cannot decipher the meaning of the symbol.
- the "genotype" determined for the SNP (rs4244285) present in the drug metabolizing enzyme gene CYP2C19 is symbolized ("* 1 / * 1", "*". 1 / * 2 ",” * 1 / * 3 ",” * 2 / * 2 ",” * 2 / * 3 "or” * 3 / * 3 ").
- the "allele type" of the individual DNA variants to generate (2) and (3) as patient genotype information depends on the type (determination range) of the DNA variant based on the frequency within the population. Can be determined in two stages (see bottom of FIG. 1). As a first step, only all known SNPs are genomically determined as DNA variants with a frequency of 1% or higher in the population and suitable for automated analysis, and the information is stored in DB, recording media, or It is stored in a storage device (not shown). In addition, the patient's "genotype” information based on the analysis of all SNPs described above is stored in the genomic information DB 6 (FIG. 2).
- the determination of the "allele type” (genotype of the patient) for all SNPs can be determined by "method 2" by an experimental method using the genomic DNA sample of the patient. That is, first, the genomic DNA sample is extracted from the patient's peripheral blood, oral cells, buccal mucosa, or the like by a conventional method. Subsequently, using the above sample, the "allelic type” (patient's "genotype”) for all known SNPs can be determined by an experimental method by genome-wide polymorphism analysis by the current microarray technology.
- the patient's "genotype" ("allele type") for all SNPs described above is determined by “method 1" by information analysis using the above-mentioned “full-length character string” (genome information of the patient). May be (see bottom of Figure 1).
- the "allelic type” (patient's “genotype) for the remaining DNA variants not stored in the DB, recording medium or storage device is the "full length string”. It is determined by "Method 1" using information (patient's genomic information).
- the "remaining DNA variants” include DNA variants that are infrequent in the population (eg, SNV, CNV), or DNA variants that are not suitable for automated analysis (eg, CNP, STRP, or other special DNA variants). Is assumed (see the bottom of FIG. 1).
- the "allelic type” (patient “genotype") of the remaining DNA variants is determined after input of pharmaceutical information 301 (FIG. 4) to input device 4 (FIG. 2).
- the administration plan proposal system 1 of FIG. 2 is related to the drug efficacy from the drug efficacy-related gene information DB 5 (FIG. 2) based on the drug name included in the drug information 301 (FIG. 4). Get the name of the gene.
- the dosing regimen proposal system 1 (FIG. 2) searches for the latest genomic information DB 6 (FIG. 2) based on the name and "allelic type” (ie, patient genotype information) for the required DNA variant. If is not stored, as described above, the "reference string" information is searched to specify the loci on the genome where the remaining DNA variants are located.
- the administration plan proposal system 1 (FIG.
- the dosing regimen proposal system 1 displays the "allelic type” (patient genotype information) of the remaining DNA variants determined in the genomic information DB 6 (FIG. 2), as well as the DB, recording medium or storage device. Store in (not shown).
- the method (“method 1”) for determining the “allele type” (patient genotype information) of the DNA variant using the above character string (“full-length character string”) information will be described later, including specific examples. It is also described in detail in [Embodiment 4].
- the genome information DB 6 is shown in FIG. 2 as a configuration existing on a network, a storage unit or a storage unit built in the control unit 2 (FIG. 2), a reading unit that can read a recording medium, or a control unit.
- the external storage device or recording medium connected to 2 (FIG. 2) can be replaced as a readable reader.
- the above genotype information according to (2) or (3) can be updated based on the latest report.
- the report is a comprehensive report of new DNA variants associated with a gene, as well as "allelic types" ("genotypes") for the DNA variants.
- the "method 1" using the above-mentioned "full-length character string" information (patient's genomic information) can generate a new (2) or (3) based on the existing report and the latest report.
- the genotype of the patient is divided into two stages from the genomic information DB 6 (FIG. 2).
- An example of acquiring (2) and (3) as information is shown. That is, as the first step, it was determined by "Method 2" using an experimental method using known DNA microarray technology (or “Method 1" using "full-length character string” information (patient's genomic information)). All SNP analysis information of the patient is stored in the genome information DB 6 (FIG. 2). Subsequently, as a second step, the remaining DNA variant information is analyzed by "Method 1" using the "full-length character string” information (patient's genomic information), if necessary.
- the control unit 2 in FIG. 2 does not store all the SNP analysis information of the patient in the genomic information DB 6 (FIG. 2) as the first step described above, and from the beginning, as the second step, if necessary.
- "method 1" using "full length string” information may be performed. That is, the control unit 2 (FIG. 2) acquires (1) the "full-length character string” (patient's genome information) from the genome information DB 6 (FIG. 2), and extracts the allele character string contained in (1).
- the above procedure may be performed to determine the genotype for a particular locus or loci on a patient's genome.
- full-length character string information patient's genomic information
- method 1 the patient's “genotype” (allele type) related to a specific SNP or new SNV. It may be determined by the method 1 ”. That is, regardless of conditions such as frequency in the population and suitability for automatic analysis, "method 1" using "full-length character string” information may be applied to all DNA variants from the beginning (FIG. 1). See bottom).
- the patient's "genotype” for a particular SNP or new SNV is not yet stored in the genomic information DB 6 (FIG. 2), the patient's "genotype” for a particular SNP or new SNV.
- the current amplification-resistant mutation system (a technique for detecting specific point mutations) by PCR using allele-specific primers for the "genotype” of patients with the above-mentioned specific SNPs or novel SNVs.
- a method capable of distinguishing a mutant allele that is one base different from a normal allele) may be used to individually identify the genotype.
- the information in the genome information DB 6 in FIG. 2 may be encrypted, or the information in the genome information DB 6 (FIG. 2) may be provided with access restrictions.
- the above encryption and access restriction can be realized by a method known in the field of information technology.
- the system may acquire genotype information recorded on a recording medium instead of the genomic information DB6 (FIG. 2).
- the genotype is a genotype relating to a gene encoding a protein involved in pharmacokinetics, as shown in relevance information 311 in FIG.
- Relevance information 311 in FIG. 4 represents drug-gene association (particularly the effect of the metabolic rate of the active ingredient on the genotype of the allele associated with the gene function of the gene).
- Relevance information 311 shows the CYP2C9 gene as a gene encoding a protein involved in pharmacokinetics for phenytoin.
- the presence of SNPs associated with enzyme activity has been demonstrated in the CYP2C9 gene.
- Proteins expressed by the CYP2C9 gene, including mutant alleles, have low activity to oxidize (metabolize) phenytoin, the active ingredient of antiepileptic drugs. As shown in the relevance information 311 (Fig. 4)
- the relevance information 312 in FIG. 4 shows the CYP2C19 gene as a gene encoding a protein involved in the pharmacokinetics of clopidogrel. It is known that there may be several mutant allele types in the known SNPs (rs4244285) present within the CYP2C19 gene (see relevance information 312 in FIG. 4). The protein expressed by the CYP2C19 gene containing the mutant allele does not metabolize in the body of a drug that is oxidized and exerts a medicinal effect like clopidogrel, or weakens the metabolism.
- the CYP2C19 gene containing the mutant allele lowers the metabolic rate of clopidogrel to the active compound depending on the genetic type of the patient, as shown in the association information 312 (Fig. 4) (metabolic rate (medicinal effect): "-”. 1 "), or make the metabolic rate substantially 0 (metabolic rate (medicinal effect):” -2 ").
- “Recommended treatment policy (dose adjustment)” see CLIMINICAL PHARMACOLOGY & THERAPEUTICS 89 (5): 662-673, 2011 and Organ Biology 21 (2): 247-253, 2014, etc.
- the drug information changing unit 23 in FIG. 2 has a negative metabolic rate (metabolic rate (medicinal effect): "-1" and "-2”).
- the type of medicine may be changed uniformly.
- the ACE gene as a gene encoding a protein (direct target protein) involved in the pharmacokinetics of perindopril erbumin.
- a protein direct target protein
- a gene into which an Alu sequence has been inserted causes splicing abnormalities or exon deletions, so the expression of abnormal proteins or abnormal protein expression patterns is higher than that of the gene lacking the Alu sequence. show. That is, perindopril erbumin has low or little efficacy in individuals carrying the ACE gene with the Alu sequence inserted.
- the drug efficacy is determined to be “-1”.
- the drug efficacy is determined to be “-2” (see relevance information 313 in FIG. 4).
- the relevance information 311 to 313 in FIG. 4 shows the gene encoding the pharmacokinetics of the drug or the protein involved in pharmacodynamics, the genotype of the gene, and the fitness element that changes depending on the genotype. Information representing each is included.
- the relevance information (pharmaceuticals, related genes, genotypes, and pharmacological efficacy information) described in the above information (relevance information 311 to 313 in FIG. 4) and other relevance information relating to the drug are known documents (eg, for example).
- CLINICAL PHARMACOLOGY & THERAPEUTICS 89 (5): 662-673, 2011 Tabel 1 and Organ Biology 21 (2): 247-253, 2014 Table 1 and Table 2) are summarized and easily available. It is possible.
- Table 1 of Organ Biology 21 (2): 247-253, 2014 is an excerpt from the old version of the prescription drug collection.
- the relevance information 311 to 313 (FIG. 4) and the relevance information regarding other medicines are prepared based on the latest information at the time of the embodiment of the present embodiment.
- relevance information 311-313 (FIG. 4), as well as relevance information about other medicines can be generated by artificial intelligence (hereinafter referred to as "AI") (see FIG. 1).
- AI artificial intelligence
- the AI may output new drug and gene relevance used to update the old information.
- the information representing the goodness-of-fit element (for example, metabolic rate and drug efficacy) that changes depending on the genotype is related to the above-mentioned known documents and materials. It can be described arbitrarily according to the sexual information.
- the metabolic rate (drug efficacy) values corresponding to each genotype in the SNP (rs4244285) in the drug metabolizing enzyme gene CYP2C19 are " ⁇ 0", "-1" and "-”. 2 "is described.
- Organ Biology 21 (2): 247-253, 2014 "CYP2C19 * 2 and * 3 types are important for CYP2C19 gene polymorphisms.
- the value "-2" of the metabolic rate (medicinal effect) in the relevance information 312 (FIG. 4) may be rewritten as "disappearance".
- the metabolic rate (drug effect) "disappearance" in the relevance information 312 (FIG. 4) can indicate, for example, that the prodrug clopidogrel is not metabolized (converted to a medicinal component) by CYP2C19 into its active compound. Therefore, the metabolic rate (medicinal effect) "disappearance” is determined by the goodness-of-fit determination unit 22 in FIG. Change the drug name in 4) to an alternative drug.
- the changed drug information in which the dose is changed to "0" may be output to the user.
- a warning indicating that the drug name (or drug information including the dose) in the drug information 301 in FIG. 4 has a low goodness of fit may be issued to the user. ..
- the configuration of the system 1a at this time (which further includes the warning unit 24) is illustrated in FIG. 12 as an example.
- genotypes related to pharmacokinetic factors include the following are examples of transporter gene polymorphisms.
- HMG-CoA reductase inhibitors (bravastatin, atorvastatin, etc.), which are therapeutic agents for dyslipidemia, are selectively taken up by the liver and show efficacy, but the transporter protein OATP1B1 (Organic Anion Transporting Polypeptide 1B1) is used for the uptake. It plays an important role.
- OATP1B1 Organic Anion Transporting Polypeptide 1B1
- the mutant type with amino acid substitution base change: "521T> C”
- Drugs such as statins and atorvastatin escape metabolism and excretion in bile and flow through the central vein, resulting in increased blood levels.
- the heterozygous type is "-1" (genotype: "T / C") and homozygous type (hereditary) compared to the medicinal effect value " ⁇ 0" of the normal type (genotype: "T / T”).
- Genotype: "C / C" can be determined to be "-2" lower.
- examples of gene polymorphisms of drug receptors as examples of genotypes related to pharmacodynamic factors are as follows.
- the relevance information 311-313 (including the above-mentioned additional example contents) of FIG. 4 regarding pharmacokinetics and pharmacodynamics has a low goodness of fit for the specific patient in the administration plan specified by the doctor.
- pharmacokinetics and pharmacodynamics has a low goodness of fit for the specific patient in the administration plan specified by the doctor.
- the administration plan proposal system 1 (FIG. 2), which uses the relevance information 311 to 313 (FIG. 4) as a criterion for determining the goodness of fit of the pharmaceutical information 301 (FIG. 4), makes a proposal to the doctor for improvement of the low goodness of fit. It can be presented.
- the information acquisition unit 21 of FIG. 2 can acquire a plurality of relevance information at the same time (see “(administration plan)” of FIG. 1), and systemizes the drug information 304 (FIG. 11) for patients with non-small cell lung cancer.
- the case of inputting in 1 (FIG. 2) will be described as an example.
- the information acquisition unit 21 of FIG. 2 Upon receiving the drug information 304 (FIG. 11) describing the drug name (ALK tyrosine kinase inhibitor) including the target molecule or the mechanism of action in the name, the information acquisition unit 21 of FIG. 2 receives the drug information 304 (FIG. 11) in the S1 step of FIG.
- a plurality of relevance information 315 and 316 are acquired at the same time.
- drug names can generally refer to a plurality of specific drugs.
- the relevance information 315 (including lyxothinib as a specific drug name) and 316 (including ceritinib as a specific drug name) in FIG. 11 are both based on the ALK tyrosine kinase inhibitor and its genotype. Information that describes the medicinal effect.
- the information acquisition unit 21 and the goodness-of-fit determination unit 22 of FIG. 2 that acquired the relevance information 315 and 316 of FIG. 11 are the treatment when the drug name in the drug information 304 of FIG. 11 is lyxotinib and the drug name in the drug information 304.
- the treatment when is ceritinib (S3 to S5 in FIG. 3) is carried out in parallel.
- the suitability determination unit 22 of FIG. 2 is of lyxotinib and ceritinib. Both are determined to be invalid "- ⁇ " for the patient in S4 of FIG. 3 and sent to the drug information changing unit 23 of FIG.
- the drug information changing unit 23 in FIG. 2 changes the drug name in the drug information 304 (including the ALK tyrosine kinase inhibitor) in FIG. 11 according to the negative symbol “ ⁇ ” and the infinity “ ⁇ ”.
- the drug name includes the mechanism of action as described above. Therefore, it is a therapeutic agent for non-small cell lung cancer different from the ALK tyrosine kinase inhibitor (therapeutic agent for non-small cell lung cancer) in the pharmaceutical information 304 of FIG. EGFR tyrosine kinase inhibitor) is selected.
- the information acquisition unit 21 (FIG. 2) provides relevant information 317 and 318 of FIG. 11 in S2 of FIG. get.
- the information acquisition unit 21 and the goodness-of-fit determination unit 22 in FIG. 2 are processed when the drug name in the drug information 304 of FIG. 11 is gefitinib and when the drug name in the drug information 304 is ossimertinib mesylate. (S3 to S5 in FIG. 3) are carried out in parallel.
- the non-small cell lung cancer patient described in Pharmaceutical Information 304 of FIG. 11 has, for example, a homozygous mutation at position 2573 of the EGFR gene (genotype: G / G), and the EGFR gene. It has a heterozygous mutation (genotype: T / C) at position 2369 of.
- the goodness-of-fit determination unit 22 in FIG. 2 determines the goodness of fit of gefitinib as "1" from the total numerical value of each element (medicinal effect) (that is, the total value of 2 and -1) (that is, the total value of 2 and -1). (Refer to the relevance information 317 in FIG.
- the goodness of fit of osimertinib mesylate was determined to be "3" from the total numerical value of each element (medicinal effect) (that is, the total value of 2 and 1). (See relevance information 318 in FIG. 11).
- the goodness-of-fit determination unit 22 of FIG. 2 sends the two determined goodness of fits to the pharmaceutical information changing unit 23 of FIG.
- the drug information changing unit 23 in FIG. 2 is an absolute value among the two goodness of fit (the reference value for changing the drug is a value lower than 0 and both are positive values, so “YES” in S5 in FIG. 3). Select the "osyltinib mesylate” corresponding to the large “3" and send the modified drug information 306 of FIG. 11 to the display device 3 of FIG. The display device 3 presents the modified drug information 306 of FIG. 11 to the user.
- the above-mentioned treatment proposes one of the optimal administration plans for the treatment of non-small cell lung cancer of a patient identified by the patient ID in the drug information 304 of FIG. 11 for the following reasons.
- Administration of ALK tyrosine kinase inhibitors is not effective for non-small cell lung cancer in the patient (who does not have the EML-ALK fusion gene (ie, does not develop a chromosomal translocation)).
- Relevance information of FIG. 11 Medicinal efficacy “ ⁇ ” in 315 and 316).
- EGFR tyrosine kinase inhibitors are only effective against non-small cell lung cancer in patients who have at least a homozygous or heterozygous mutation (G / G or G / T) at position 2573 of the EGFR gene (" The efficacy “2” and “1” of the relevant information 317 and 318 in FIG. 11).
- the patient may show resistance to the administration of gefitinib (drug efficacy "-1" in the relevant information 317 of FIG. 11).
- ossimertinib mesylate is a drug expected to have a therapeutic effect in patients who are resistant to gefitinib.
- the ossimeltinib mesylate irreversibly inhibits the kinase activity of the EGFR protein having the T790M mutation (replacement of threonine with methionine at position 790) associated with the above resistance to gefitinib.
- a name including a mechanism of action (which may include a plurality of drugs) is exemplified. Further exemplifying that a plurality of relevance information can be acquired at the same time even when the drug information 305 representing a single drug as a drug name is input to the system 1 (FIG. 2).
- the drug information change unit 23 of FIG. 2 determines “NO” in S5 of FIG. Since the same patient ID and (a type of) ALK tyrosine kinase inhibitor as in the drug information 304 of FIG. 11 are described in the drug information 305 of FIG. 11, the same process as the above-mentioned process (YES in S7 of FIG. 3). ”) Is carried out.
- the drug name in the drug information 305 of FIG. 11 is changed to a drug name that is not an ALK tyrosine kinase inhibitor that always has insufficient goodness of fit. Since the condition for selecting the drug name is "not an ALK tyrosine kinase inhibitor", the drug name can be "EGFR tyrosine kinase inhibitor".
- System 1 of FIG. 2 acquires the relevance information 317 and 318 of FIG. 11 as described above based on the pharmaceutical information 305 of FIG. 11 whose drug name has been changed to "EGFR tyrosine kinase inhibitor".
- the information acquisition unit 21 and the goodness-of-fit determination unit 22 in FIG. 2 are processed when the drug name in the drug information 304 of FIG. 11 is gefitinib and when the drug name in the drug information 304 is ossimertinib mesylate. (S3 to S5 in FIG. 3) are carried out in parallel.
- the modified pharmaceutical information 306 (including osimertinib mesylate) of FIG. 11 is displayed on the display device 3 of FIG.
- the administration plan proposal system 1 includes the above-mentioned four drug names (lyxotinib, seritinib, gefitinib and osimertinib mesylate) as the drug name and "123456789" as the patient ID (that is, the above-mentioned drug information). Even when the input of the non-small cell lung cancer patient having the same hereditary type is received, the modified drug information 306 of FIG. The determination is "YES", and there is no change in the drug information 305 (FIG. 11). Finally, the ossimertinib mesylate is displayed by the above-mentioned step. That is, the administration plan proposal system 1 can select and propose one drug having the highest goodness of fit from a plurality of input drug names.
- the above-exemplified ALK tyrosine kinase inhibitor and EGFR tyrosine kinase inhibitor are called molecular-targeted drugs used for the treatment of non-small cell lung cancer.
- Molecular-targeted drug is a term that refers to a drug that targets a gene product with a specific mutation.
- the ALK tyrosine kinase inhibitor is only effective in patients who carry the EML-ALK fusion gene (ie, have a chromosomal translocation) (relevance information 315 and FIG. 11). See 316).
- the EGFR tyrosine kinase inhibitor is only effective in patients who have at least a homozygous or heterozygous mutation at position 2573 of the EGFR gene (see relevance information 317 and 318 in FIG. 11).
- most of the above molecular-targeted drugs are anticancer agents.
- it is expected that molecular-targeted drugs will be developed as therapeutic agents for other diseases.
- the entire program that executes the system can be executed via an intranet or the Internet accessible from the outside (computer used by the user).
- the system may be connected to a printing device (for example, a printer or a multifunction device) for printing the information output to the user on paper.
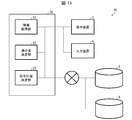
- FIG. 13 Another aspect of the present invention exemplifying the configuration in FIG. 13 is a system (administration plan proposal system 10) that proposes an administration plan suitable for a patient, and is a medicine that represents the medicine to be administered to the patient and the dose thereof.
- Administration plan determination unit 25 that determines suitable drug information for the patient based on the suitability of the drug information; an information presentation unit (display) that presents the drug information determined by the administration plan determination unit to the user. It is equipped with a device 3).
- the administration plan proposal system 10 of FIG. 13 is different from the administration plan proposal system 1 of FIG. 2 in that the administration plan determination unit 25 is provided instead of the drug information change unit 23 (FIG. 2). Therefore, the administration plan proposal system 10 of FIG. 13 executes the process shown in FIG. 3, except for the process of the administration plan determination unit 25 (FIG. 13) described below.
- the administration plan determination unit 25 in FIG. 13 determines suitable pharmaceutical information for the patient based on the goodness of fit of the pharmaceutical information determined by the goodness-of-fit determination unit 22 (FIG. 13).
- the administration plan determination unit 25 may have the same function as the drug information change unit 23 (FIG. 2). That is, the drug information whose goodness of fit determined by the goodness-of-fit determination unit 22 (FIG. 13) is less than the reference value (for example, “0”) is determined as the drug information unsuitable for the patient (“NO” in S5 of FIG. 3). ), The drug information obtained by modifying the drug information may be determined as the drug information suitable for the patient (see S6 in FIG. 3).
- the administration planning unit 25 suitable for the patient the medical information whose goodness of fit determined by the goodness of fit determination unit 22 (FIG. 13) is equal to or higher than the reference value (for example, “0”).
- the drug information may be determined as the appropriate drug information (“YES” in S5 of FIG. 3), or the drug information having the highest goodness of fit may be determined as the drug information suitable for the patient (for example, [Embodiment 1] above]. (Refer to the series of examples of anti-cancer drug administration plans for patients with non-small cell lung cancer described in the item (Examples of drug names and relevance information in drug information and treatments using them)). ..
- the goodness of fit will be described as an example in which the goodness of fit is determined based on the predisposition (risk of onset) to develop a disease that is not the target of treatment by administration of a drug.
- the system according to this embodiment refers to a set of allele combinations for multiple loci on the human genome as the genotype, but the present embodiment is not limited to this, and alleles for one or a few loci are loci.
- a set of combinations of types can be referred to as the above genotypes (eg, examples of "monogenic disease” described below).
- the presence or absence of the above predisposition is determined by the genotype.
- the system of the present embodiment determines the goodness of fit with reference to information indicating a predisposition to develop a disease in connection with administration of a drug (pharmaceutical-related disease information). That is, in this embodiment, a contraindicated drug for a disease that the patient is genetically prone to develop but has not yet developed (a serious side effect that aggravates the condition when the drug is administered appears. Suppress the onset of continuous and high-dose administration of (drugs known to increase the possibility of diminishing the effect of the drug).
- the administration plan proposal system 1' provides a drug-related disease information DB 7 (FIG. 5) in place of the drug efficacy-related gene information DB 5 (FIG. 2) in the administration plan proposal system 1 of FIG. It is the same as the administration plan proposal system 1 (FIG. 2) except that.
- the administration plan proposal system 1'(FIG. 5) is a system that proposes a highly safe administration plan that avoids the onset of a disease that is not a treatment target by administration of a drug.
- the above-mentioned diseases may include symptoms of serious side effects due to idiosyncratic drug and related diseases (details of "serious side effects due to idiosyncratic drug" will be described later).
- the input device 4 (FIG. 5) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.).
- the input medical information 303 (FIG. 7) is sent to the information acquisition unit 21 (FIG. 5) (step S1'in FIG. 6).
- the information acquisition unit 21 (FIG. 5) determines the name of the drug represented by the drug name included in the drug information 303 of FIG.
- Relevance information 314 (FIG. 7) describing the range of the represented hereditary type is acquired from the drug-related disease information DB 7 (FIG. 5) (step S2'in FIG. 6).
- the information acquisition unit 21 (FIG. 5) provides the patient ID (see Pharmaceutical Information 303 in FIG. 7) and DNA variant group information regarding the genotype indicating the presence or absence of a predisposition to the disease (see relevance information 314 in FIG. 7). Based on this, genotype information corresponding to the patient ID and the name of the disease is acquired from the genomic information DB 6 (FIG. 5) (step S3'in FIG. 6).
- the information acquisition unit 21 determines the goodness of fit of the patient's genotype information acquired from the acquired pharmaceutical information 303 (FIG. 7), relevance information 314 (FIG. 7), and genomic information DB 6 (FIG. 5). Send to section 22 (FIG. 5).
- the information acquisition unit 21 sends the medical information 303 of FIG. 7 to the display device 3 (FIG. 5).
- the display device 3 (FIG. 5) displays the above-mentioned drug information, and the administration plan proposal system 1'(FIG. 5) ends the process.
- the information acquisition unit 21 is shown in FIG.
- the medical information 303 is sent to the display device 3 (FIG. 5).
- the display device 3 (FIG. 5) displays the above-mentioned drug information, and the administration plan proposal system 1'in FIG. 5 ends the process.
- the goodness-of-fit determination unit 22 of FIG. 5 determines the goodness of fit of pharmaceutical information 303 (FIG. 7) based on the genotype information acquired from the relevance information 314 (FIG. 7) and the genomic information DB 6 (FIG. 5). (Step S4'in FIG. 6). The details of the S4'process of FIG. 6 will be described with reference to FIG. 7.
- the relevance information 314 of FIG. 7 shows an active ingredient corresponding to a drug name (medicine name: olanzapine, a multi-receptor action antipsychotic drug MARTA), and a disease name known to be caused by administration of the active ingredient (medicine name: olanzapine, antipsychotic drug MARTA).
- the numerical range of the PRS percentile associated with the hereditary type that determines the predisposition to the disease (hereditary type (PRS percentile): 0-69, 70-84 and 85-100)
- of type 2 diabetes Includes effects on onset (risk of onset: ⁇ 0, +1 and +2), and "alternative dosing regimen" (none, glycemic control, and drug change to X).
- the genomic information DB 6 of FIG. 5 stores a numerical value (PRS percentile) from 0 to 100, which represents a predisposition for a patient to develop a certain disease, as hereditary information for each disease name. The closer the value is to 100, the greater the predisposition to develop a certain disease. Therefore, when the goodness-of-fit determination unit 22 in FIG. 5 acquires the relevance information 314 (FIG.
- the risk of developing type 2 diabetes due to administration of olanzapine in FIG. 7) is determined to be "+2".
- the goodness-of-fit determination unit 22 determines the goodness of fit as “-2”, which is obtained by multiplying the onset risk “+2”, which is a negative factor, by the value “-1”, which represents a negative factor.
- the goodness-of-fit determination unit 22 (FIG. 5) of the pharmaceutical information 303 (FIG. 7), the goodness of fit “-2”, and the relevance information 314 (FIG. 7) corresponding to the goodness of fit (“-2”).
- "Drug change to X" as an alternative administration plan is sent to the drug information change department 23 (FIG. 5).
- the pharmaceutical information changing unit 23 in FIG. 5 determines that the goodness of fit "-2", which is a negative value, is very low (S5'step in FIG. 6).
- the drug information changing unit 23 (FIG. 5) changes the drug name in the drug information 303 (FIG. 7) to “X” according to the alternative administration plan “drug change to X” (S6'step in FIG. 6). Since the change in the step S6'(FIG. 6) is a change in the drug (the judgment in the step S7' in FIG. 6 is "YES"), the drug information change unit 23 (FIG. 5) changed the drug name to X.
- the drug information is sent to the information acquisition unit 21 (FIG. 5), and the process returns to the S2'step of FIG.
- the administration plan proposal system 1' repeats the steps S2'to S7' in FIG. 6 until the judgment in the S7'step (FIG. 6) becomes "NO” (changes when it becomes “NO”.
- the drug information is sent to the display device 3 (FIG. 5) (step S8'in FIG. 6).
- the display device 3 (FIG. 5) displays the changed drug information, and the administration plan proposal system 1'in FIG. 5 ends the process.
- the goodness-of-fit determination unit 22 sets the value of the risk of developing type 2 diabetes by administration of olanzapine to "60" when the genotype information is "60". ⁇ 0 "is determined.
- the goodness-of-fit determination unit 22 determines the goodness of fit as “ ⁇ 0”, which is obtained by multiplying the negative factor “onset risk” “ ⁇ 0” by the value “-1” representing the negative factor, and changes the goodness of fit.
- the pharmaceutical information changing unit 23 determines that the goodness of fit “ ⁇ 0” is not low, and sends the pharmaceutical information 303 (FIG. 7) to the display device 3 (FIG. 5).
- the display device 3 (FIG. 5) displays the drug information 303 (FIG. 7), and the administration plan proposal system 1'of FIG. 5 ends the process.
- the administration plan proposal system 1'in FIG. 5 uses the drug information (type of drug or its dose) specified in the prescription as the genotype of the patient specified in the prescription (secondary to the drug). Change when determined to be incompatible with a genotype that represents a combination of alleles associated with a predisposition to the risk of developing the disease. Secondary diseases caused by the drug include serious side effects due to idiosyncratic constitution (details will be described later). Therefore, the dosing regimen proposal system 1'(FIG. 5) enables the presentation of low-risk, high-safety prescriptions according to the genotype of the patient.
- the genotype information for the patient is expressed as a value corresponding to each disease (PRS (Polygenes Risk Score) percentile).
- PRS Polygenes Risk Score
- the PRS percentile for type 2 diabetes indicates what percentage of the patient's PRS corresponds to the lowest percentage of the normal distribution of PRS for the risk of developing type 2 diabetes (see Figure 1) in the human population. Represents. That is, the PRS percentile is 0 to 100, and the larger the PRS percentile, the higher the risk of onset.
- the PRS for type 2 diabetes is the sum of the combinations of "aller types" of all DNA variants that affect the onset of type 2 diabetes.
- GWAS genome-wide association study
- the genotype information represents, by the PRS percentile, how many DNA variants a patient has as part of a combination of DNA variants that contributes to the predisposition to develop a particular disease.
- the genotype information contains the same number of PRS percentiles corresponding to each disease as the number of all known diseases.
- the "combination of these DNA variants" described above varies from disease to disease. Therefore, including the above-mentioned genotype information necessary for creating the PRS percentile corresponding to all diseases as the genotype information for a certain patient maximizes the convenience of the administration plan proposal system 1'. It is preferable that the number of PRS percentiles contained in the genotype information is close to the number of all known diseases, because the convenience of the administration plan proposal system 1'is improved.
- DNA variants eg, SNV, CNV
- SNV SNV
- CNV DNA variants that are infrequent in the population to generate genotypic information containing the PRS percentile corresponding to the disease, as well as or close to the number of all diseases, or Information on DNA variants that are not suitable for automatic analysis (eg, CNP, STRP, or other special DNA variants) is likely to be needed, so the former "method 1" using "full-length string” information is preferred. .. The details of the "method 1" using the "full-length character string” information are also described later in [Embodiment 4].
- the genome information DB 6 of FIG. 5 further stores "full-length character string” information in addition to the patient's "genotype” information. That is, when a DNA variant involved in a disease is newly identified and it is necessary to determine the patient's "allergenotype” for the DNA variant and score it as part of the PRS, also in [Embodiment 1].
- "Method 1" by information analysis using the above-mentioned "full-length character string” is time-consuming and labor-intensive due to experimental techniques such as "Method 2" using DNA microarray technology and individual methods by PCR. There is no burden and some genotypic information about the disease can be easily updated.
- the genotype is a genotype relating to a combination of DNA variants that contributes to a predisposition to develop a particular disease.
- Relevance information 314 (FIG. 7) represents the relevance of a drug to a disease not treated (particularly the effect of administration of the drug on the onset of the disease).
- Relevance information 314 of FIG. 7 shows type 2 diabetes as a disease whose incidence can be increased by administration of olanzapine. As mentioned above, it is known that the presence of a large number of DNA variants (genetic predisposition) is involved in the increase in the incidence of type 2 diabetes.
- Relevance information 314 (FIG. 7) shows a numerical range representing the genotype as a criterion for determining the degree of genetic predisposition. Each numerical range is associated with the degree of risk of onset (“ ⁇ 0” to “+2”).
- Each numerical range can be set arbitrarily, but the lower limit of the numerical range corresponding to "+1" (dose reduction or necessary response) is 70 or more (eg 70, 75, 80, 85, 90 and). 95), and the lower limit of the numerical range corresponding to "+2" (drug change) can be 85 or greater (eg, 85, 90, 95 and 99).
- the goodness-of-fit determination unit 22 of FIG. 5 determines that the goodness of fit of the pharmaceutical information 303 (FIG. 7) is low (in the genomic information, a part of the combination of DNA variants contributing to the predisposition to type 2 diabetes is present above the threshold value). As a reference, at least one of the above lower limit values is used.
- the PRS percentile with a median of 50 represents the average risk of onset in the population, and the numerical range corresponding to " ⁇ 0" includes 50.
- the relevance information 314 of FIG. 7 shows three numerical ranges, but may show only two numerical ranges (eg 0-84 and 85-100). At this time, for example, 0 to 84 correspond to " ⁇ 0", and 85 to 100 correspond to "+2" or "+1". That is, the relevance information 314 (FIG. 7) may allow the dosing regimen proposal system 1'of FIG. 5 to select only drug changes or dose changes. Further, for example, the relevance information 314 (FIG. 7) may correspond the numerical range 70 to 84 with the alternative drug X rather than without the alternative drug. In other words, the relevance information 314 (Fig.
- the dosing regimen proposal system 1'of FIG. 5 using relevance information 314 is of olanzapine (multireceptor-acting antipsychotic: MARTA) regardless of whether the patient has type 2 diabetes. It may be suggested to reduce the dose, take the necessary response, or change the type of the drug.
- olanzapine, timiperone a treatment for schizophrenia, can promote the onset or aggravation of Parkinson's disease, and carvedilol, a treatment for chronic heart failure and arrhythmic, can promote the onset or aggravation of bronchial asthma.
- MARTA multireceptor-acting antipsychotic
- the dosing regimen proposal system 1' (FIG. 5) using relevance information 314 (FIG. 7) is a contraindicated drug (here, olanzapine) for the above patients with a genotype showing a high risk of developing type 2 diabetes. ) It is preferable to make a proposal to change the administration.
- the definition of "contraindicated drug” is as follows. That is, the "contraindication” in the "package insert” information of the ethical drug describes the patient who should not use the drug. Considering the following points, it is decided not to use a certain drug because it is highly likely that the condition will worsen, side effects will be more likely to occur, and the effect of the drug will be weakened. : ⁇ Current illness (current illness) ⁇ Another illness (complication) caused by one illness ⁇ Illnesses (history) ⁇ Illness of family members (family history) ⁇ Other medicines currently used (concomitant medicines) ⁇ The constitution of those who use medicines (from the website of "Pharmaceuticals and Medical Devices Agency").
- "contraindication” is one of the items described in the "package insert" of a drug, and indicates a patient who should not take a certain drug, its condition, and a drug that should not be used in combination. If the drug is not followed, there is a high possibility that the condition will be aggravated, serious side effects will occur, and the effect of the drug will be weakened.
- the condition in which it is determined that medication should not be taken may indicate the patient's current disease name, complications, medical history, family history, constitution, and the like.
- substitution includes a genetic constitution and corresponds to a secondary disease having an extremely high risk of onset due to administration of a drug in this embodiment and other embodiments.
- the genetic constitution may also include symptoms and related diseases as "serious side effects due to the idiosyncratic constitution” described later. Therefore, in the present embodiment, various disease names specified as “contraindicated” in the “package insert” of the current various drugs, as well as symptoms and related diseases of "serious side effects due to idiosyncratic drug” are used. It can be registered as disease information for the drug in the related disease information DB 7 (FIG. 5).
- Type A side effects are relatively common and dose-dependent. This is pharmacologically predictable and usually mild.
- Type B side effects are idiosyncratic reactions and are not merely drug-related. This side effect is rare but often severe. Genetic diversity is important for both type A and type B side effects.
- statin drugs such as atrubastatin (drug for treating lipid disorders), suxamethonium chloride Respiratory palsy due to hydrate (quick-acting muscle relaxant), myelotoxicity due to mercaptopurine hydrate (anti-malignant tumor drug) and azathiopurine (immunosuppressive drug), induction of liver damage due to isoniazide (anti-tuberculosis drug), and Polymorphic ventricular tachycardia caused by various drugs such as clarislomycin (antibacterial drug) may be mentioned and may be life-threatening.
- statin drugs such as atrubastatin (drug for treating lipid disorders), suxamethonium chloride Respiratory palsy due to hydrate (quick-acting muscle relaxant), myelotoxicity due to mercaptopurine hydrate (anti-malignant tumor drug) and azathiopurine (immunosuppressive drug), induction of liver damage due to isoniazide (anti
- the symptoms and related diseases of "serious side effects due to idiosyncratic drug" corresponding to the above-mentioned type B due to various drugs are also affected by the genetic type of the patient due to genetic diversity, and therefore develop.
- Risk-related information can be registered in the drug-related disease information DB 7 (FIG. 5) and dealt with.
- onset risk includes monogenic diseases to multigene diseases (multifactorial diseases, complex diseases).
- Human genetic traits including various diseases, often depend on the expression of many genes and environmental factors. However, for certain diseases and some traits, a particular genotype in a single locus acts as the primary determinant, and this genotype expresses the trait, or develops the disease, in normal environmental conditions. Necessary and sufficient for.
- a sexual disorder complex disorder, multifactorial disorder.
- the scope of application of this embodiment mainly assumes “multigene disease”, but can also deal with “monogenic disease”.
- the onset risk-related information in the present embodiment can be registered in the drug-related disease information DB 7 (FIG. 5) and dealt with.
- the allele associated with the causative gene carries a homozygous mutant type (two mutant alleles).
- the onset risk is extremely high, and the onset risk value can be determined as "+2" and set as "drug change”.
- the risk of developing the disease is extremely high, and the risk of developing the disease is increased. It can be determined as "+2" and set as "drug change”. Taking the above Huntington's disease as an example, a method for determining a genotype associated with a causative gene will be described later in [Embodiment 4].
- FIG. 1 a system for executing the processes described in [Embodiment 1] and [Embodiment 2] in a complex manner will be described (see FIG. 1). That is, in the present embodiment, as shown in FIG. 1, the pharmacodynamic factors of (1) Pharmacodynamic B ([Embodiment 1]) and (2) Pharmacodynamic B are used as criteria for changing the administration plan.
- the administration plan proposal system 1'' includes a control unit 2 and a display device (information display unit) 3.
- the control unit 2 includes an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genotype information acquisition unit) 21, a goodness-of-fit determination unit 22, and a drug information change unit 23 (FIG. 8). reference). Further, the control unit 2 (FIG. 8) is connected to the input device 4, the drug efficacy-related gene information DB 5, the genome information DB 6, and the drug-related disease information DB 7 (see FIG. 8). That is, the system 1 ′′ of the present embodiment of FIG.
- the dosing regimen proposal system 1'' (FIG. 8) performs the S1 to S7 (including S9) steps (see FIG. 3) and does not perform the S8 step (see FIG. 3), but the modified drug information or The steps S2'to S8'(including S9') (see FIG. 6) for the unchanged drug information are performed. Therefore, the process of shifting from S7 of FIG. 3 to the S2'process of FIG. 6 and the details of executing the S2'process (FIG. 6) will be described.
- phenytoin pharmaceutical information 301 in FIG. 4 shown in [Embodiment 1]
- heterozygotes as genotype information regarding SNP (rs1057910) in CYP2C9 in the relevance information 311 (FIG. 4) as described above.
- the drug information changing unit 23 of the administration plan proposal system 1'' makes a judgment "NO”.
- the changed drug information 302 (FIG. 4) in which the "daily dose (maintenance dose)" is changed to 225 mg is sent to the information acquisition unit 21 (FIG. 8) (shift to the S2'step of FIG. 6).
- the information acquisition unit 21 receives the drug-related disease from the drug-related disease information DB 7 (FIG. 8). Get information.
- “medicine information” was replaced with "changed drug information”
- the drug information changing unit 23 changed the drug name (S7' in FIG. 6).
- the present embodiment is described in the above-described embodiment, except for two points in which the drug information (corresponding to the determination “YES” in the process) is sent to the information acquisition unit 21 (FIG. 8) and the process returns to the process S2 step of FIG. It conforms to the system that executes the processes described in 1] and [Embodiment 2].
- the administration plan proposal system 1'' in FIG. 8 uses the drug information (type of drug or its dose) specified in the prescription as the genotype of the patient specified in the prescription (effectiveness of the drug). If it is determined that the genotype of a specific gene that affects sex and the genotype of a specific gene that indicates the existence of a risk of developing a secondary disease due to the drug are not compatible, the change is made. Therefore, the dosing regimen proposal system 1 ′′ (FIG. 8) enables the presentation of a comprehensive prescription (excellent in efficacy, low risk and safe) according to the patient's genotype.
- a method for determining a type (genotype of a patient) (“method 1” described in each item (genotype information of a patient) of [Embodiment 1] and [Embodiment 2]) will be described.
- the DNA variants are variations of any nucleodo, including SNPs, SNVs, indels, CNPs, CNVs, microsatellite polymorphisms (“STRP”).
- two character strings representing the two nucleotide sequences sandwiching the target nucleotide are extracted from a known character string (“reference character string”) representing the reference human genome and used.
- the character string (1) is a character string 902 representing a target nucleotide (SNP, SNV or indel), a two character string 901 representing two nucleotide sequences sandwiching the character string 902, and a character string 901.
- the strings 901 and 903 are determined as part of a string representing the reference human genome (“reference string”) (eg, available from an ensemble (URL: http://ensembl.org)) (ensemble, URL: http://ensembl.org). Step S11 in FIG. 10).
- the character string 902 (character (string) representing the target nucleotide) is stored in a known DB as a DNA variant known at the time of carrying out the method according to the present embodiment (hereinafter, simply referred to as "known”). ing. That is, the above-mentioned "DNA variant” may also include a DNA variant found after the filing of the present application.
- information about all known SNPs can be obtained from the dbSNP database (https://www.ncbi.nlm.nih.gov/snp/).
- Information on the position where the character string 902 (character (string) representing the target nucleotide) exists in the character string representing the reference human genome (“reference character string”) is also stored in the DB (for example, the above dbSNP database). ing.
- the character string of (1) it is preferable that the lengths of the character string 901 and the character string 903 are set to be the same, and the analysis part (character string 902) is arranged in the center.
- the character string (1) is included in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual with the known “allele type” of SNP, SNV or indel. It is determined depending on whether or not it is present (step S12 in FIG. 10).
- the position where the character string of (1) can be included in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual is the reference human genome (“reference character string”) stored in the above DB. It can be estimated from the information of the position of. Therefore, for example, when one character string that completely matches the character string of (1) is found (step S13 in FIG.
- full-length character string representing the nucleotide sequence of the entire genome of an individual
- SNV or Indel "type of allele” can be determined (step S14 in FIG. 10).
- the length of the character strings 901 and 903 in FIG. 9 is at least 10 characters (for example, 10, 20, 30, 40, 50, 100, 150, 200 characters or more), preferably 10 to 1000 characters. be.
- the lengths of the two character strings (character string 901 and character string 903 in FIG. 9).
- step S16 in FIG. 10 Is evenly extended by one or more characters (for example, 1, 3, 5, 10, 20, 25, 50 or 100 characters) (step S16 in FIG. 10) to reduce the above probability.
- the total of the two character strings is, for example, 10,000 characters or less.
- SNP alleles there are up to four types of known SNP alleles at specific positions on the genome, similar to nucleotide types. For example, when the nucleotides of a normal allele are represented by A, the allele containing the nucleotides represented by T, G and C is a mutant allele. Therefore, by designating the character string 902 of FIG. 9 as A, T, G, and C and trying the above process four times, it is possible to determine the type of allele of a known SNP at the specific position (). Step S14 in FIG. 10).
- known SNPs can be easily determined in almost two trials, as two (rarely three) nucleotides are common in the population.
- the character strings 901 to 903 (normal character strings) including the normal character strings and the character strings 901 to 903 (variable character strings) including the mutant character strings are homozygous or homozygous with respect to the SNP of the individual's genome. It can be used to determine if it is heterojunction. For example, both strings (“full-length strings”) that represent the nucleotide sequences of an individual's entire genome (usually the genome exists as a conjugation that holds two sets from the mother and father) have normal strings. When they match and the mutant strings do not match, the individual's genome is a normal allele (normal: N / N).
- a normal character string matches one of the character strings representing the nucleotide sequence of the entire genome of an individual and a mutant character string matches the other
- the individual's genome has a mutant allele in one genome.
- Heterojunction type: N / M when the normal string does not match both the strings representing the nucleotide sequences of the entire genome of the individual and the mutant strings match, the individual's genome has the mutant allele in both genomes.
- Homozygous type M / M).
- the process of determining the genetic type in the individual is CYP2C9 based on the information of the pharmaceutical information 301 (FIG. 4) regarding the phenytoin (antiepileptic drug) described in [Embodiment 1] and the relevance information 311 (FIG. 4).
- a known SNP (rs1057910) existing in the coding region of (drug metabolizing enzyme gene) will be specifically described as an example.
- the base type of the nucleotide of the wild type (normal type) allele in SNP is "adenine (A)", and it is known that the metabolism rate of phenitoin is lowered.
- the base type of nucleotides in metabolic alleles is "cytosine (C)".
- C cytosine
- wild-type character string matches the character string representing the nucleotide sequence of the entire genome of an individual ("full-length character string”) and the "low-metaphoric character string” does not match, the relevant character string is concerned.
- the individual's genome has wild-type alleles in both genomes (wild-type: "A / A”).
- wild-type character string wild-type: "A / A”
- the genome of the individual has the low-metabolizing allele in one of the genomes ( Heterozygous type: "A / C”).
- the individual's genome has the low-metabolizing allele in both genomes. Has (homogeneous low metabolism: "C / C").
- Relevance information 311 (“A / A”, “A / C” or “C / C”) depending on the type of combination of nucleotide changes in SNP (rs1057910) of CYP2C9 in the individual determined by the above process. As shown in Figure 4), different symbolized genotypes (“* 1 / * 1”, “* 1 / * 3” or “* 3 / * 3”), and different metabolic rates (drug effects) (“ ⁇ ”). 0 ”,“ -1 ”or“ -2 ”) can be determined.
- Step S15 Information representing DNA variants present in an individual's genome, along with the determined genotype, is stored in a DB, recording medium or storage device (not shown), as well as genomic information DB 6 (FIGS. 2, 5 and 8). ) (Step S15).
- allele type including the mating type of any DNA variant (including the SNP, SNV or indel described above).
- allele type the type of allele
- it is an effective method when the length of the target nucleotide is changed, and there are many options, or the details of the target nucleotide are unknown. Changes in the length of the target nucleotide, as well as a large number of options, occur when simple repeat sequences with different repeat counts are used as the target nucleotide, for example, microsatellite polymorphisms (“STRP”).
- STRP microsatellite polymorphisms
- the character string (2) is particularly effective when it is necessary to determine the number of target nucleotides and also the full-length nucleotide sequence of the target nucleotides.
- the total length of the target nucleotide can reach tens of thousands of nucleotides, and the length of the target nucleotide can vary greatly from individual to individual. Therefore, the full-length nucleotide sequence of a particular target nucleotide needs to be determined individually based on the genome of the individual.
- the loci on the genome where the target nucleotides (CNP, CNV, STRP) are present have already been identified in the human reference genome, as are SNPs, SNVs or indels.
- the location of the target nucleotide in the locus is also relatively determined. That is, the character string (2) is known in the character string representing the human reference genome (“reference character string”) (step S11 in FIG. 10).
- the character string of (2) can completely match the character string representing the nucleotide sequences adjacent to both sides of the target nucleotide representing the known DNA valinant existing in the genome of an individual. Therefore, whether or not the character string (two pairs: character strings 901 and 903 in FIG. 9) of (2) exists in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual. By determining (step S13 in FIG. 10), it is possible to determine whether or not the target nucleotide is present on the genome of an individual (step S14 in FIG. 10).
- the length of the character string (two sets: character strings 901 and 903 in FIG. 9) of (2) can be set in the same manner as the lengths of the character strings 901 and 903 in the character string of (1).
- the extracted string represents a simple repetitive sequence (length of 1 to 4 base pairs) of a very short sequence (length of 1 to 4 base pairs) such as a microsatellite polymorph (“STRP”)
- the repetition contained in the string is further determined.
- the simple repetitive sequence may have different number of repetitions in the genome of an individual, for example, with a unit of several nucleotides to several tens of nucleotides.
- Detect the "allele type" corresponding to the number of times. For example, when two types of sequences having different lengths are detected, it is determined to be “heterozygous type", and when only one type of sequence is detected, it is determined to be “homozygous type”.
- CAG causative gene
- HTP causative gene
- Embodiment 2 a late-onset monogenic disease described in [Embodiment 2]
- Huntington's disease results from the production of long polyglutamine chains by the unstable elongation of CAG repeats present on the coding sequence of its causative gene HTT.
- Normal glutamine repeats are 6-35, whereas diseased patients (or young adult asymptomatic individuals at extremely high risk of developing the disease) are 36-121.
- the corresponding character strings 901 and 903 can be easily obtained by the above method.
- the presence of the character string (2 pairs: the character strings 901 and 903 in FIG. 9) in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of the asymptomatic person of the young adult After confirmation, the sequence of the character string (902 in FIG. 9: representing the full-length nucleotide sequence of the target nucleotide) existing between the two character strings and the length thereof are extracted and determined.
- the number of CAG repeats is two types, "80 (number of nucleotides: 240)" and “113 (number of nucleotides: 339)" as a result of extracting the sequence and its length, it is a heterozygous type.
- both alleles have the number of repeats corresponding to disease-type alleles, the risk of developing the disease is extremely high "+2".
- the number of CAG repeats is one type of "5 (number of nucleotides: 15)". If it is, it is a homozygous type.
- both allele types have the same number of repeats as normal alleles, the risk of developing the disease is low " ⁇ 0".
- the above method using the character string (2) described above can also be applied to the presence or absence of known chromosomal translocations (generation of DNA variants).
- the target nucleotide at this time is the character string (2) (character strings 901 and 903 in FIG. 9).
- the genomic location of the translocation point in a known chromosomal translocation is all known as the linking site between fragment A1 present on chromosome A and fragment B2 present on chromosome B, and the linking site between fragment A2 and fragment B1. Has been done.
- fragments A1 and A2 are arranged in the order of 1 ⁇ 2 on the chromosome A, and the fragments B1 and B2 are arranged in the order of 1 ⁇ 2 on the chromosome B. Therefore, the sequences of the fragments A1, A2, B1 and B2 are also known.
- the character strings 901 and 903 are continuous or discontinuous on the genome of the individual.
- the presence may indicate the presence or absence of translocation.
- Discontinuity represents the absence of translocation, and continuity represents the possibility of translocation.
- the fragment A1 is represented by the character string 901 and the fragment A2 is represented by the character string 903, centering on the connecting portion of the fragment A1 and the fragment A2. Just do it.
- the fragments A1 and A2 are present consecutively, the above possibility (existence of translocation) is completely denied, and when they are present discontinuously, the existence of translocation is confirmed.
- the administration plan proposal system 1-1'' (FIG. 2, FIG. 5 and FIG. 8) has a control block (particularly, an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genetic information acquisition unit) 21), and a degree of conformity.
- the determination unit 22 and the medical information change unit 23 may be realized by a logic circuit (hardware) formed in an integrated circuit (IC chip) or the like, or may be realized by software.
- the administration plan proposal systems 1 to 1 ′′ include a computer that executes the instructions of the program which is the software that realizes each function.
- the computer includes, for example, one or more processors and a computer-readable recording medium that stores the program. Then, in the computer, the processor reads the program from the recording medium and executes the program, thereby achieving the object of the present invention.
- the processor for example, a CPU can be used.
- the recording medium a “non-temporary tangible medium”, for example, a ROM (Read Only Memory) or the like, a tape, a disk, a card, a semiconductor memory, a programmable logic circuit, or the like can be used.
- a RAM RandomAccessMemory
- the program may be supplied to the computer via an arbitrary transmission medium (communication network, broadcast wave, etc.) capable of transmitting the program.
- a transmission medium communication network, broadcast wave, etc.
- one aspect of the present invention can also be realized in the form of a data signal embedded in a carrier wave, in which the above program is embodied by electronic transmission.
- a system that proposes a suitable administration plan for patients.
- the drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
- Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
- Genotype information acquisition department that acquires the genotype information of the above patients;
- Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
- a system including a drug information changing unit that changes the drug information when the goodness of fit is low; and an information presentation unit that presents the changed drug information that the drug information changing unit has changed to the user.
- the goodness-of-fit determination unit determines the goodness of fit by referring to the pharmacokinetics of the drug or the drug efficacy-related gene information regarding the gene encoding the protein involved in pharmacodynamics.
- the genotype is a genotype related to the gene, and the relevance information includes the drug efficacy-related gene information.
- the goodness-of-fit determination unit determines the goodness of fit with reference to drug-related disease information indicating a disease that develops or becomes serious due to administration of the drug.
- the genotype is a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information includes the drug-related disease information.
- the fitness determination unit determines that the fitness for the genotype including the combination of alleles associated with the predisposition to the disease is very low.
- the fitness information change unit is a contraindicated drug for the disease.
- the goodness-of-fit determination unit includes information on pharmaceutical efficacy-related genes representing genes encoding the pharmacokinetics of the drug or proteins involved in pharmacodynamics, and diseases that develop or become serious due to administration of the drug.
- the above-mentioned goodness of fit is determined by referring to the drug-related disease information indicating
- the genotype is a genotype relating to a gene encoding a pharmacokinetics or a protein involved in the pharmacokinetics of the drug and a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information is provided. It contains the above-mentioned drug-related genetic information and drug-related disease information.
- the system according to any one of [1] to [5], wherein the change is an increase or decrease in the dose or a change in the drug.
- the genetic type information is determined based on the information representing the DNA variant contained in the information representing all the nucleotide sequences constituting the genome of the patient acquired from the genome information DB using the patient ID.
- the system according to any one of [1] to [6].
- the genetic type information does not record the genetic type existing in the locus associated with the drug represented by the pharmaceutical information in the relevance represented by the relevant information
- the genetic type information is recorded.
- the system according to [7] which is updated based on the information representing the DNA variant present in the locus contained in the information representing all the nucleotide sequences constituting the genome of the patient.
- Information representing a single nucleotide polymorphism among the above DNA variants is determined using the genomic fragment of the patient or based on the information representing the entire nucleotide sequence, and the information representing the single nucleotide polymorphism determined. Record, The system according to [7] or [8], wherein the information representing the unrecorded DNA variant is determined based on the textual information representing the entire nucleotide sequence.
- the information presenting unit selects the medicine having the highest goodness of fit among the plurality of candidate medicines.
- the system according to any one of [1] to [11] shown to the user.
- the information presenting unit is the drug having the highest goodness of fit among the plurality of suitable candidate drug information.
- the system according to any one of [1] to [12], which presents information to the user.
- the fitness determination unit corresponds to the mutation in the genome of the patient.
- the system according to any one of [1] to [13], wherein the fitness is determined based on the presence or absence of a DNA variant.
- a method for proposing a suitable administration plan for a patient A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof; Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype; The genotype information acquisition step in which the computer acquires the genotype information of the patient; A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information; When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user.
- the computer described above when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above.
- Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information comprises information representing variants having a frequency of less than 1% in the human population.
- a dosing plan proposal program for operating a computer as a system for proposing a dosing plan suitable for a patient is equipped with a control unit.
- the control unit Obtain drug information indicating the drug to be administered to the above patients and its dose; Obtained relevance information indicating the relevance of the above drugs and genotypes; Obtain genotype information for the above patients; Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined; When the goodness of fit is low, the above medical information is changed; The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information.
- the genotype information includes information representing variants having a frequency of less than 1% in the human population.
- a system that proposes a suitable administration plan for patients The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses; Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes; Genotype information acquisition department that acquires the genotype information of the above patients; Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information; Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user.
- the system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information.
- Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
- the genotype information is a system comprising information representing variants having a frequency of less than 1% in the human population.
- Administration plan proposal system (system that proposes a suitable administration plan for patients) 1a Administration plan proposal system (system that proposes a suitable administration plan for patients) 1'Administration plan proposal system (system that proposes a suitable administration plan for patients) 1'' Dosing plan proposal system (system that proposes a suitable dosing plan for patients) 2 Control unit 2a Control unit 2b Control unit 3 Display device (information presentation unit) 4 Input device 5 Pharmaceutical efficacy-related gene information DB 6 Genome information DB 7 Pharmaceutical-related disease information DB 10 Administration plan proposal system (system that proposes a suitable administration plan for patients) 21 Information acquisition department (medicine information acquisition department, relevance information acquisition department and genotype information acquisition department) 22 Goodness of fit determination unit 23 Pharmaceutical information change department 24 Warning unit 25 Administration plan determination unit 301 Pharmaceutical information (phenytoin) 302 Changed Pharmaceutical Information 303 Pharmaceutical Information (Olanzapine) 304 Pharmaceutical information (candidate drug group) 305 Pharmaceutical Information (Lixotinib) 306 Modified Pharmaceutical Information 311 Relevance Information (Pheny
Abstract
A dosage regime proposing system 1 of the present disclosure is provided with: a medicine information acquiring unit (21) for acquiring medicine information representing a medicine and a dosage for administration to a patient; a relevance information acquiring unit (21) for acquiring relevance information representing relevance between the medicine and a genotype; a genotype information acquiring unit (21) for acquiring genotype information representing a genotype of the patient; a matching degree determination unit (22) for determining a matching degree of the medicine information on the basis of the relevance information and the genotype information; a medicine information modifying unit (23) for modifying the medicine information when the matching degree is low; and an information presenting unit (3) for presenting to the user modified medicine information obtained by the modifying performed by the medicine information modifying unit.
Description
本発明は、医薬の投与計画をユーザに提案するシステムに関し、より詳細には、患者に固有の遺伝型に基づいて当該患者に適した医薬の投与計画を、ユーザに提案するシステムに関する。
The present invention relates to a system for proposing a drug administration plan to a user, and more particularly to a system for proposing a drug administration plan suitable for a patient based on a genotype peculiar to the patient.
遺伝子の機能と、医薬の有効性との関連性は、以前から指摘されている。また、特定患者の情報を活かして、当該特定患者に即した医薬を処方することの提案は、これまでにある(例えば特許文献1)。
The relationship between gene function and drug efficacy has been pointed out for some time. In addition, there have been proposals to prescribe a drug suitable for the specific patient by utilizing the information of the specific patient (for example, Patent Document 1).
しかし、ある疾患に有効と考えられている薬剤が実際に特定の患者にとって安全かつ有効かを、患者の遺伝情報を利用して判断するシステムさえ、実際には提案されるに至っていない。それは、1つの疾患に薬効を有していることが知られている薬剤は複数あるし、1つの薬剤の薬効または副作用に影響する遺伝子は複数あるし、1遺伝子の機能の発現には、複数の他の遺伝子が関与することが、よく知られているからである。
However, even a system that uses the genetic information of a patient to determine whether a drug that is considered to be effective for a certain disease is actually safe and effective for a specific patient has not been proposed. It is because there are multiple drugs known to have medicinal properties for one disease, there are multiple genes that affect the medicinal effects or side effects of one drug, and there are multiple genes for the expression of the function of one gene. It is well known that other genes are involved.
したがって、医師が作成する現状の院外処方箋および院内処方箋(薬剤の種類、用量および用法が指定されている)には、一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)が依然として適用されている。このような処方箋は、個々の患者に適した薬剤の種類、その用量および用法を指定できていないことを意味し得る。実際に、処方箋通りに薬剤を用いた複数の患者は、大きく異なる反応を示す。当該反応には、薬剤が患者に悪影響のみを与える(副作用のみを示し、かつ薬効を示さない)ことも含まれ得ると指摘されている。
Therefore, the current out-of-hospital and in-hospital prescriptions (specifying the type, dose and usage of the drug) prepared by the doctor have uniform factors (mainly the type of disease the patient is suffering from and the severity of the disease). Degree and patient age, weight and gender, etc.) are still applied. Such a prescription may mean that it is not possible to specify the type, dose and dosage of the drug suitable for the individual patient. In fact, multiple patients who use the drug as prescribed show very different reactions. It has been pointed out that the reaction may include the drug having only adverse effects on the patient (showing only side effects and no efficacy).
処方箋にしたがって患者が用いる薬剤のほかに、患者への投与または使用に、医療従事者の管理を要する薬剤およびそれ以外の物質(麻酔薬など)がある。当該薬剤または物質の投与または使用は、過剰な反応を一部の人に引き起こし得、副作用をしばしばともなうことがよく知られている。例えば、英国のある研究では、医療施設の入院患者のうち約7%がなんらかの副作用を生じていると、報告されている。上述の過剰な反応または副作用は、重大な結果(身体障害、回復不能な損傷、先天的な異常の顕在化または死亡)を患者にもたらす。過剰な反応または副作用による死亡者は、米国では年間約10万人に上る。
In addition to the drugs used by patients according to the prescription, there are drugs that require the control of healthcare professionals and other substances (anesthetics, etc.) for administration or use to patients. It is well known that administration or use of such agents or substances can cause excessive reactions in some people and is often accompanied by side effects. For example, a study in the United Kingdom reported that about 7% of inpatients in medical facilities had some side effects. The overreactions or side effects described above have serious consequences for the patient (disability, irreparable damage, manifestation of congenital abnormalities or death). The death toll from overreaction or side effects is about 100,000 per year in the United States.
以上の通り、医療全般に用いられている薬剤および物質の有効性は、大きな個体差を示す。国から承認を受けている(有効性および安全性について一定以上の条件を満たす)薬剤または物質でさえ、投与または使用を受けた患者のすべてに有効であることは少ない。つまり、現状では、薬効を示し得ない薬剤の投与を受けている患者、および薬効を示すには不適切な量の薬剤の投与を受けている患者がいるということである。
As described above, the effectiveness of drugs and substances used in general medical treatment shows large individual differences. Even drugs or substances that have been approved by the state (that meet certain efficacy and safety requirements) are rarely effective for all patients who receive or use them. In other words, at present, there are patients who are receiving drugs that cannot show efficacy, and patients who are receiving drugs in an inappropriate amount to show efficacy.
なかでも精神疾患の治療に使われる薬剤は、相対的に低い薬効を示す。薬効の低い薬剤の投与は、回復を遅らせ、治療費を増大させるので、患者に身体的、精神的または経済的な負担を強いる。これらの負担の他に、上述の通り、薬剤の副作用は、疾患と本来的に無関係な苦痛を生じ得る。
Among them, drugs used for the treatment of mental illness show relatively low efficacy. Administration of less effective drugs delays recovery and increases treatment costs, thus imposing a physical, mental or financial burden on the patient. In addition to these burdens, as mentioned above, the side effects of the drug can cause distress that is inherently unrelated to the disease.
薬剤の有効性や副作用に関する個体差は、疾患の種類、環境要因(生活様式など)および/または服用している薬剤の組み合わせなどの影響よりも、ヒト集団における遺伝学的な多様性に、多く起因する。
Individual differences in drug efficacy and side effects are more due to genetic diversity in the human population than to the effects of disease type, environmental factors (such as lifestyle) and / or the combination of drugs being taken. to cause.
したがって、本発明の一態様は、患者に固有の遺伝型に基づいて当該患者に適した薬剤の投与計画をユーザに提案することを目的とする。
Therefore, one aspect of the present invention is to propose to the user a drug administration plan suitable for the patient based on the genotype peculiar to the patient.
上記の課題を解決するために、本発明の一態様に係るシステムは、患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。 In order to solve the above problems, the system according to one aspect of the present invention is a system that proposes a suitable administration plan for a patient.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
A medical information changing unit that changes the medical information when the goodness of fit is low; and an information presentation unit that presents the changed medical information that the medical information changing department has changed to the user.
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。 In order to solve the above problems, the system according to one aspect of the present invention is a system that proposes a suitable administration plan for a patient.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
A medical information changing unit that changes the medical information when the goodness of fit is low; and an information presentation unit that presents the changed medical information that the medical information changing department has changed to the user.
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
上記の課題を解決するために、本発明の他の態様に係る方法は、患者にとって好適な投与計画を提案する方法であって、
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。 In order to solve the above-mentioned problems, the method according to another aspect of the present invention is a method for proposing a suitable administration plan for a patient.
A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
The genotype information acquisition step in which the computer acquires the genotype information of the patient;
A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user. Including,
In the above method, when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above. Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。 In order to solve the above-mentioned problems, the method according to another aspect of the present invention is a method for proposing a suitable administration plan for a patient.
A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
The genotype information acquisition step in which the computer acquires the genotype information of the patient;
A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user. Including,
In the above method, when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above. Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
上記の課題を解決するために、本発明の他の態様に係る投与計画提案プログラムは、患者にとって好適な投与計画を提案するシステムとしてコンピュータを機能させるための投与計画提案プログラムであって、
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させる。 In order to solve the above-mentioned problems, the administration plan proposal program according to another aspect of the present invention is a dose plan proposal program for operating a computer as a system for proposing a suitable administration plan for a patient.
The above system is equipped with a control unit.
The control unit
Obtain drug information indicating the drug to be administered to the above patients and its dose;
Obtained relevance information indicating the relevance of the above drugs and genotypes;
Obtain genotype information for the above patients;
Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined;
When the goodness of fit is low, the above medical information is changed;
The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death,
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
The computer functions as the control unit.
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させる。 In order to solve the above-mentioned problems, the administration plan proposal program according to another aspect of the present invention is a dose plan proposal program for operating a computer as a system for proposing a suitable administration plan for a patient.
The above system is equipped with a control unit.
The control unit
Obtain drug information indicating the drug to be administered to the above patients and its dose;
Obtained relevance information indicating the relevance of the above drugs and genotypes;
Obtain genotype information for the above patients;
Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined;
When the goodness of fit is low, the above medical information is changed;
The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death,
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
The computer functions as the control unit.
上記の課題を解決するために、本発明の一態様に係るシステムは、患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部;ならびに
上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。 In order to solve the above problems, the system according to one aspect of the present invention is a system that proposes a suitable administration plan for a patient.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user. Equipped with an information presentation unit to present to
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部;ならびに
上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む。 In order to solve the above problems, the system according to one aspect of the present invention is a system that proposes a suitable administration plan for a patient.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user. Equipped with an information presentation unit to present to
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
本発明の一態様によれば、患者に固有の遺伝型に基づいて当該患者に適した医薬の投与計画を提案できる。
According to one aspect of the present invention, it is possible to propose a drug administration plan suitable for a patient based on the genotype peculiar to the patient.
本発明の一態様は、患者に固有の遺伝型に基づいて当該患者にとって好適な投与計画を提案するシステムであって、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;上記患者の遺伝型情報を取得する遺伝型情報取得部;上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部を備えている。
One aspect of the present invention is a system that proposes a suitable administration plan for a patient based on a genotype peculiar to the patient, and obtains pharmaceutical information indicating a drug to be administered to the patient and a dose thereof. Acquisition unit; Relevance information acquisition unit that acquires relevance information indicating the relationship between the drug and the genotype; Genotype information acquisition unit that acquires the genotype information of the patient; Based on the relevance information and genotype information The conformity determination unit that determines the conformity of the drug information; the drug information change unit that changes the drug information when the conformity is low; and the modified drug information that the drug information change department has changed. It has an information presentation unit to present to the user.
「投与計画」は、特定患者を表す情報、ならびに当該特定患者に投与する医薬の種類および投与量を表す情報を少なくとも含んでいる。上記投与計画は、上記特定患者に対してある投与量においてある医薬を投与することを示す指針(例えば処方箋)である。上記システムは、患者にとって好適な投与計画(オーダーメイド投与計画)を作成することによって、医療従事者(特に医師)の判断を補助するシステムである。
The "administration plan" includes at least information indicating a specific patient and information indicating the type and dose of the drug to be administered to the specific patient. The administration plan is a guideline (for example, a prescription) indicating that a certain drug is administered to the specific patient at a certain dose. The above system is a system that assists the judgment of healthcare professionals (particularly doctors) by creating an administration plan (custom-made administration plan) suitable for the patient.
「医薬」は、本明細書では、投与を受けた患者において薬効を発揮することによって、疾患における症状の改善を直接的に生じさせる医薬、または医療行為を補助する目的(検査および麻酔など)に使用される物質(造影剤および麻酔剤など)を表す。
The term "pharmaceutical" is used herein for the purpose of a drug that directly causes improvement of symptoms in a disease by exerting a medicinal effect in a patient receiving administration, or for the purpose of assisting medical practice (examination and anesthesia, etc.). Represents the substance used (contrast, anesthetic, etc.).
「遺伝型」(genotypeとも呼ばれる)は、個体全体または個体の特定の座位の遺伝的構成であり、本明細書では、ゲノムにおける1つ以上の座位にあるアレル(対立遺伝子)の組み合わせの型(2つ以上の座位を遺伝型の対象にするとき、各型の総和)を指す。「アレル」は、本明細書では、1本の染色体のうち、1つの座位に存在する個々の遺伝子およびDNA配列を指す。「遺伝型」または「アレルの型」と記載した場合は、本明細書では、「接合型」を含む概念として用いる。
A "genotype" (also referred to as a genotype) is the genetic composition of an individual or a particular locus of an individual, herein a type of combination of alleles (alleles) in one or more loci in the genome. When targeting two or more loci for genotypes, it refers to the sum of each type). "Allele" as used herein refers to an individual gene and DNA sequence present at one locus of a chromosome. The term "genotype" or "allelic type" is used herein as a concept that includes "zygotes."
「医薬情報」は、患者を特定する情報(例えば患者のID番号)、医薬を特定する情報(例えば医薬の商品名または物質名)、および患者に対する医薬の投与量を指定する情報を少なくとも含んでいる情報を表す。医薬情報は、例えば医師がコンピュータ上で作成するカルテまたは処方箋であり得る。
"Pharmaceutical information" includes at least information that identifies the patient (eg, the patient's ID number), information that identifies the drug (eg, the brand name or substance name of the drug), and information that specifies the dose of the drug to the patient. Represents the information you have. The pharmaceutical information can be, for example, a medical record or prescription created by a doctor on a computer.
「関連性情報」は、医薬の種類、および生体内における当該医薬の作用に影響する遺伝子(群)の関連性を表している情報を指す。
"Relevance information" refers to information indicating the type of drug and the relevance of genes (groups) that affect the action of the drug in vivo.
「(医薬情報の)適合度」は、医薬情報に特定されている患者に固有の遺伝型を基準とした、当該患者と、医薬情報に特定されている医薬の種類および/またはその投与量との関係が適切である程度を表す。
"Goodness of fit (of pharmaceutical information)" refers to the patient and the type and / or dose of the drug specified in the drug information, based on the patient's specific genetic type specified in the drug information. The relationship is appropriate and represents a certain degree.
「DNAバリアント(DNAvariant)」は、本明細書では、ヒト集団において(その頻度に関わらず)、ヌクレオチド配列(アレルならびに染色体構造を含む)の変化が2つ以上存在するゲノム上の特定部位ならびにその変化の総体の概念として記載する。上記「DNAバリアント」におけるヌクレオチド配列の変化とは、1ヌクレオチド以上の置換、欠失、挿入および/または付加、重複を含め、あらゆる変化の総体を意味する(図1の下部を参照)。
A "DNA variant" as used herein is a specific site on the genome in which two or more changes in a nucleotide sequence (including alleles and chromosomal structures) are present in a human population (regardless of its frequency) and the like thereof. Described as a general concept of change. Nucleotide sequence changes in the above "DNA variant" mean the sum of all changes, including substitutions, deletions, insertions and / or additions, duplications of one or more nucleotides (see bottom of FIG. 1).
上記「DNAバリアント」のうち、集団内で頻度の高い(1%以上)変化であるとき「多型(P:Polymorphism)」と呼び、例えば、1塩基多型(Single Nucleotide Polymorphism、以降では「SNP」と記載する)、コピー数多型(Copy Number Polymorphism、以降では「CNP」と記載する)、マイクロサテライト多型(短鎖縦列反復配列: Short Tandem Repeat Polymorphism 、以降では「STRP」と記載する)がある。また、集団内で頻度の低い(1%未満)変化であるとき「バリアント(V:Variant)」と呼び、例えば、1塩基バリアント(Single Nucleotide Variant、以降では「SNV」と記載する)、コピー数バリアント(Copy Number Variant、以降では「CNV」と記載する)がある。なお、本明細書では、上記「DNAバリアント」は、上述の通り、ヒト集団における頻度によらず、「多型」および「バリアント」を含む概念として記載する(図1の下部を参照)。
Among the above "DNA variants", when the change is frequent (1% or more) in the population, it is called "polymorphism (P: Polymorphism)". ”), Copy number polymorphism (hereinafter referred to as“ CNP ”), Microsatellite polymorphism (short chain column repeat sequence: Short Tandem Repeat Polymorphism, hereinafter referred to as“ STRP ”) There is. In addition, when the change is infrequent (less than 1%) in the population, it is called a "variant (V: Variant)", for example, a single nucleotide variant (Single Nucleotide Variant, hereinafter referred to as "SNV"), copy number. There is a variant (Copy Number Variant, hereinafter referred to as "CNV"). In the present specification, the above-mentioned "DNA variant" is described as a concept including "polymorphism" and "variant" regardless of the frequency in the human population as described above (see the lower part of FIG. 1).
1つの座位にある接合型を含むアレルの組み合わせの型(「アレルの型」)の総体は、各アレルのヌクレオチド配列および/または当該組み合わせに含まれているアレルの数によって決まる。上記ヌクレオチド配列の少なくとも1つがヒト集団に最も多い野生型ヌクレオチド配列ではない、および/または上記アレルの数が通常の2つでない、患者(つまり上記型が通常でない患者)に対する上記医薬の投与は、当該患者に所望されない影響を生じ得る。当該所望されない影響は、例えば、上記型が通常の患者と比べたときの、(a)上記医薬の薬効の低下、喪失もしくは過剰な上昇、(b)上記医薬による副作用の発現もしくは増大、および/または(c)上記医薬の投与前に生じていない特定疾患の高い発症率である。しかし、実際には、後述の〔実施形態2〕に例示する通り、上記所望されない影響は、1つの上記「アレルの型」のみでは現れず、多数の座位についての多数の「アレルの型」によって累積されたときに現れることが多い。
The total type of allele combination (“allele type”), including the mating type in one locus, is determined by the nucleotide sequence of each allele and / or the number of alleles contained in the combination. Administration of the drug to a patient (ie, a patient with an unusual type) in which at least one of the nucleotide sequences is not the most abundant wild-type nucleotide sequence in the human population and / or the number of alleles is not the usual two is It can have undesired effects on the patient. The undesired effects are, for example, (a) a decrease, loss or excessive increase in the efficacy of the drug, (b) the onset or increase of side effects of the drug, and / / when the type is compared to a normal patient. Or (c) a high incidence of a specific disease that did not occur prior to administration of the above-mentioned drug. However, in practice, as illustrated in [Embodiment 2] below, the undesired effect does not appear in just one "allele type", but in many "allele types" for many sitting positions. It often appears when it is accumulated.
したがって、図1に示すように、上記システムは、上述した一律の要因にしたがって医師が指定した患者Aに対する医薬Bの投与計画(投与量Cの指定が含まれている)を、上記悪影響が患者Aの遺伝型情報に合わせて抑えられているオーダーメイド投与計画(例えば医薬B’および投与量C’)に変更する提案を行う。投与計画を変更するための判断基準としては、(1)医薬Bの薬物動態学的要因、(2)医薬Bの薬力学的要因および(3)医薬Bによる副次疾患の発症リスクが挙げられる。後述する〔実施形態1〕では、(1)および(2)を上記判断基準にする例を説明する。後述する〔実施形態2〕では、(3)を上記判断基準にする例を説明する。後述する〔実施形態3〕では、(1)~(3)の組み合わせを上記判断基準にする例を説明する。なお、「薬物動態学(pharmacokinetics)」は、ある薬物と標的分子とが接触する確率を変化させる、薬物またはその代謝物の生体内における挙動を表し、「薬力学(pharmacodynamics)」は、ある物質(薬物)が生体内の標的物質に作用する強度を表す。上記「薬物動態学」および「薬力学」については、関連タンパク質の特徴とともに、〔実施形態1〕にも後述されている。
Therefore, as shown in FIG. 1, the system has a doctor-designated dosing regimen for drug B (including dose C designation) for patient A according to the uniform factors described above, with the adverse effects described above being patient. We propose to change to a tailor-made administration plan (eg, drug B'and dose C') that is suppressed according to the genotype information of A. Criteria for changing the dosing regimen include (1) pharmacokinetic factors of drug B, (2) pharmacodynamic factors of drug B, and (3) risk of developing secondary diseases due to drug B. .. In [Embodiment 1] described later, an example in which (1) and (2) are used as the above-mentioned determination criteria will be described. In [Embodiment 2] described later, an example in which (3) is used as the above-mentioned determination criterion will be described. In [Embodiment 3] described later, an example in which the combination of (1) to (3) is used as the above-mentioned determination criterion will be described. In addition, "pharmacokinetics" represents the behavior of a drug or its metabolite in vivo, which changes the probability of contact between a drug and a target molecule, and "pharmacodynamics" is a substance. Represents the intensity with which (drug) acts on a target substance in the living body. The above-mentioned "pharmacokinetics" and "pharmacodynamics" are described later in [Embodiment 1] together with the characteristics of related proteins.
(1)および(2)は、患者に投与される医薬Bの化学構造が、患者の体内で発現されているタンパク質と相互作用する程度(医薬Bの薬物動態学的要因または薬力学的要因)を適切に制御するために、利用される。(3)は、患者に固有の遺伝学的背景に基づくある疾患の発症リスクを、医薬の投与(人為行為)によって顕在化(つまり当該疾患を発症)させないために、利用される。
In (1) and (2), the degree to which the chemical structure of drug B administered to the patient interacts with the protein expressed in the patient's body (pharmacokinetic factor or pharmacodynamic factor of drug B). Is used to properly control. (3) is used to prevent the risk of developing a certain disease based on the genetic background peculiar to the patient from being manifested (that is, developing the disease) by administration of a drug (artificial act).
図1の(発明のシステム)にあるグラフは、ある特定の疾患の発症リスクを視覚的に示している。当該グラフでは、ヒト母集団における遺伝的背景の頻度を縦軸に、各遺伝的背景と相関するある疾患への感受性(罹りやすさ)を横軸にしたとき、1つの疾患に対するヒト母集団の発症リスクはおよそ正規分布をとることが示されている。グラフに示す通り、ヒト母集団のうち、閾値の右側に存在する集団(横軸、閾値の破線および曲線に囲まれる部分/横軸および曲線に囲まれる部分)が、ある疾患を発症しやすい遺伝的背景を有している(例えば、Falconer DS (1965) The inheritance of liability to certain diseases estimated from the incidence among relatives. Ann Hum Genet 29:51-76; doi 10.1111/j.1469-1809.も参照)。ただし、閾値の右側に存在するヒト個体A1およびA2は、高い発症リスクを有しているだけで、実際に発症しているとは限らない。A1およびA2は非常に近い発症リスクを有している。しかし、例えば、A1は未発症であるが、A2は発症していることがあり得る。疾患の発症には種々の要因が関与するが、医薬の投与(ある疾患の遺伝的素因を疾患の発症につなげる人為的な環境要因)が未発症のA1にある疾患を発症させることを防ぐ目的で、上記(3)は利用される。
The graph in (the system of invention) of FIG. 1 visually shows the risk of developing a specific disease. In the graph, when the frequency of the genetic background in the human population is on the vertical axis and the susceptibility (susceptibility) to a certain disease that correlates with each genetic background is on the horizontal axis, the human population for one disease The risk of developing the disease has been shown to be approximately normally distributed. As shown in the graph, in the human population, the population to the right of the threshold (horizontal axis, dashed line of threshold and part surrounded by curve / horizontal axis and part surrounded by curve) is inherited to develop a certain disease. (See also Falconer DS (1965) The inheritance of liability to protect diseases estimated from the inclusion relatives. Ann Hum Genet 29: 51-76; doi 10.111 / j.1469-1809.) .. However, the human individuals A1 and A2 existing on the right side of the threshold have only a high risk of developing the disease, and do not necessarily actually develop the disease. A1 and A2 have a very close risk of developing. However, for example, A1 may have not developed, but A2 may have. Various factors are involved in the onset of the disease, but the purpose is to prevent the administration of drugs (artificial environmental factors that link the genetic predisposition of a certain disease to the onset of the disease) to cause the onset of the unaffected A1 disease. So, the above (3) is used.
患者Aの遺伝型情報は、一例として、以下に示す2つの異なる方法により決定し得る(図1の下部参照)。例えば、当該患者から得られたゲノムの全ヌクレオチド配列を表す文字列(4種類のアルファベットATGCによって表記される約30億文字、以降では「全長文字列」と記載する)のうち、少なくとも1つの座位に存在する既知のDNAバリアントを含む部分ヌクレオチド配列を表す文字列(以降では「アレル文字列」と記載する)を抽出する。次いで、当該文字列を、標準的なヒトゲノムの全ヌクレオチド配列を表す全文字列(4種類のアルファベットATGCによって表記される約30億文字、以降では「参照文字列」と記載する)と比較し、当該DNAバリアントのアレルの組み合わせの型(患者の「遺伝型」)を特定することによって決定され得る。なお、参照文字列は、アンサンブル(Ensembl、URL:http://ensembl.org)をはじめとした公共のデータベースから取得可能である。あるいは、別の方法として、患者Aの遺伝型情報は、例えば、当該患者から得られたゲノムDNA試料の一部を、現行のマイクロアレイ技術(ゲノム網羅的な多型解析技術)などを用いて、「参照文字列」に対応する既知の全SNPを含むヌクレオチド配列からなる各断片と、ストリンジェントな条件(完全マッチの配列のみを許容する条件(温度、塩濃度))でハイブリダイズさせることによって、実験的手法により決定され得る。なお、患者の「遺伝型」情報の決定方法の詳細については、各実施形態内にも後述されている(特に、〔実施形態4〕においては、上記「全長文字列」を用いた情報解析による決定法について、具体例も含め、詳述されている)。
The genotype information of patient A can be determined, for example, by two different methods shown below (see the bottom of FIG. 1). For example, at least one locus of a string representing the entire nucleotide sequence of the genome obtained from the patient (approximately 3 billion characters represented by the four alphabets ATGC, hereinafter referred to as "full-length string"). A character string (hereinafter referred to as "allergen character string") representing a partial nucleotide sequence containing a known DNA variant present in is extracted. The string is then compared to a string representing the entire nucleotide sequence of a standard human genome (approximately 3 billion characters represented by the four alphabets ATGC, hereinafter referred to as "reference string"). It can be determined by identifying the type of allele combination of the DNA variant (the patient's "hereditary type"). The reference character string can be obtained from a public database such as an ensemble (Ensembl, URL: http://ensembl.org). Alternatively, as another method, the genotype information of patient A is obtained by, for example, using a part of the genomic DNA sample obtained from the patient using the current microarray technology (genome-exhaustive polymorphism analysis technology). By hybridizing each fragment consisting of a nucleotide sequence containing all known SNPs corresponding to the "reference string" under stringent conditions (conditions that allow only perfectly matched sequences (temperature, salt concentration)). It can be determined by experimental methods. The details of the method for determining the "genotype" information of the patient are also described later in each embodiment (in particular, in [Embodiment 4], the information analysis using the above-mentioned "full-length character string" is performed. The determination method is described in detail, including specific examples).
本発明の係るいくつかの実施形態を、以下に詳細に説明する。
Some embodiments of the present invention will be described in detail below.
〔実施形態1〕
本実施形態では、上記適合度が、上記患者に生じると予想される上記医薬の薬効に基づいて判断されることを例に説明する。本実施形態のシステムは、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子が存在する座位および当該遺伝子に関連する座位にある接合型を含むアレルの組み合わせの型(「アレルの型」)を、上記遺伝型として少なくとも参照する。つまり、本実施形態のシステムは、当該遺伝子に関連する遺伝型(「アレルの型」)が上記医薬の薬効に影響する程度を表す情報(医薬薬効関連遺伝子情報)を参照して、上記適合度を決定する。 [Embodiment 1]
In the present embodiment, the goodness of fit will be determined based on the efficacy of the drug expected to occur in the patient, as an example. The system of this embodiment is a combination of allele types ("" Allelic type ") is at least referred to as the above genotype. That is, the system of the present embodiment refers to the information indicating the degree to which the genotype related to the gene (“allele type”) affects the drug efficacy of the drug (pharmaceutical efficacy-related gene information), and refers to the above-mentioned goodness of fit. To determine.
本実施形態では、上記適合度が、上記患者に生じると予想される上記医薬の薬効に基づいて判断されることを例に説明する。本実施形態のシステムは、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子が存在する座位および当該遺伝子に関連する座位にある接合型を含むアレルの組み合わせの型(「アレルの型」)を、上記遺伝型として少なくとも参照する。つまり、本実施形態のシステムは、当該遺伝子に関連する遺伝型(「アレルの型」)が上記医薬の薬効に影響する程度を表す情報(医薬薬効関連遺伝子情報)を参照して、上記適合度を決定する。 [Embodiment 1]
In the present embodiment, the goodness of fit will be determined based on the efficacy of the drug expected to occur in the patient, as an example. The system of this embodiment is a combination of allele types ("" Allelic type ") is at least referred to as the above genotype. That is, the system of the present embodiment refers to the information indicating the degree to which the genotype related to the gene (“allele type”) affects the drug efficacy of the drug (pharmaceutical efficacy-related gene information), and refers to the above-mentioned goodness of fit. To determine.
(薬物動態学および薬力学に関与するタンパク質)
薬物の薬効は、薬物動態学に関与するタンパク質および/または薬力学に関与するタンパク質の遺伝学的多様性によって部分的に決定される。薬物動態学に関与するタンパク質としては、例えば、薬物の吸収、循環、送達、代謝および排泄に関与するタンパク質が挙げられる。つまり、薬物動態学は、薬物と標的分子とが接触する確率を変化させる、薬物またはその代謝物の生体内における挙動を指す。薬力学に関与するタンパク質は、薬物の標的分子であり得る。当該標的分子としては、例えば、受容体、シグナル分子、および薬物の薬理遺伝学的作用に関連する生物学的経路を構成するタンパク質が挙げられる。 (Pharmacokinetics and proteins involved in pharmacodynamics)
The efficacy of a drug is partially determined by the genetic diversity of proteins involved in pharmacokinetics and / or proteins involved in pharmacodynamics. Proteins involved in pharmacokinetics include, for example, proteins involved in drug absorption, circulation, delivery, metabolism and excretion. That is, pharmacokinetics refers to the in vivo behavior of a drug or its metabolites that alters the probability of contact between the drug and the target molecule. Proteins involved in pharmacodynamics can be drug target molecules. Target molecules include, for example, receptors, signal molecules, and proteins that constitute biological pathways associated with pharmacological and genetic actions of drugs.
薬物の薬効は、薬物動態学に関与するタンパク質および/または薬力学に関与するタンパク質の遺伝学的多様性によって部分的に決定される。薬物動態学に関与するタンパク質としては、例えば、薬物の吸収、循環、送達、代謝および排泄に関与するタンパク質が挙げられる。つまり、薬物動態学は、薬物と標的分子とが接触する確率を変化させる、薬物またはその代謝物の生体内における挙動を指す。薬力学に関与するタンパク質は、薬物の標的分子であり得る。当該標的分子としては、例えば、受容体、シグナル分子、および薬物の薬理遺伝学的作用に関連する生物学的経路を構成するタンパク質が挙げられる。 (Pharmacokinetics and proteins involved in pharmacodynamics)
The efficacy of a drug is partially determined by the genetic diversity of proteins involved in pharmacokinetics and / or proteins involved in pharmacodynamics. Proteins involved in pharmacokinetics include, for example, proteins involved in drug absorption, circulation, delivery, metabolism and excretion. That is, pharmacokinetics refers to the in vivo behavior of a drug or its metabolites that alters the probability of contact between the drug and the target molecule. Proteins involved in pharmacodynamics can be drug target molecules. Target molecules include, for example, receptors, signal molecules, and proteins that constitute biological pathways associated with pharmacological and genetic actions of drugs.
図2に示すように、投与計画提案システム(患者にとって好適な投与計画を提示するシステム)1は、コンピュータに内蔵されている制御部2、および表示装置(情報表示部)3を備えている。制御部2(図2)は、図2の情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23を備えている。図2の情報取得部21、適合度決定部22および医薬情報変更部23は、制御部2(図2)におけるCPU(Central Processing Unit)に含まれている。制御部2(図2)は、図2の入力装置4(例えばキーボードおよび/またはマウス)、医薬薬効関連遺伝子情報DB5およびゲノム情報DB6と接続されている。図2の投与計画提案システム1は、入力装置4および上記の2つのDB(データベース:すなわち、医薬薬効関連遺伝子情報DB5およびゲノム情報DB6)から取得した情報に基づいて制御部2(図2)によって生成された情報を、表示装置3(図2)を介してユーザに出力するシステムである。
As shown in FIG. 2, the administration plan proposal system (system that presents an administration plan suitable for a patient) 1 includes a control unit 2 built in a computer and a display device (information display unit) 3. The control unit 2 (FIG. 2) includes an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genotype information acquisition unit) 21, a goodness-of-fit determination unit 22, and a drug information change unit 23 of FIG. .. The information acquisition unit 21, the goodness-of-fit determination unit 22, and the medical information change unit 23 of FIG. 2 are included in the CPU (Central Processing Unit) of the control unit 2 (FIG. 2). The control unit 2 (FIG. 2) is connected to the input device 4 (for example, keyboard and / or mouse) of FIG. 2, the pharmaceutical efficacy-related gene information DB 5 and the genomic information DB 6. The administration plan proposal system 1 of FIG. 2 is controlled by the control unit 2 (FIG. 2) based on the information acquired from the input device 4 and the above two DBs (database: that is, the drug efficacy-related gene information DB 5 and the genomic information DB 6). This is a system that outputs the generated information to the user via the display device 3 (FIG. 2).
(投与計画提案システム1の処理)
医薬の有効性を向上させるために、図2の投与計画提案システム1が実行する処理の一例を、図3を参照して以下に説明する。入力装置4(図2)は、従来の一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)にしたがって、ユーザである医師によって入力された医薬情報301(図4)を情報取得部21(図2)に送る(図3のS1工程)。図2の情報取得部21は、医薬情報301(図4)に含まれている医薬名が表す薬剤の名称と、当該薬剤の薬効と関連する遺伝子の名称と、当該遺伝子に関連する既知のDNAバリアント(例えばSNP)における全通りの「遺伝型」と、当該遺伝型に応じた当該薬剤の薬効とを記述している関連性情報311(図4)を、図2の医薬薬効関連遺伝子情報DB5(例えば、DGIdb:Drug Gene Interaction database、URL:http://dgidb.org/の情報を元に構築可能)から取得する(図3のS2工程で「YES」)。図2の情報取得部21は、医薬情報301(図4)に記載された「患者ID」情報、および関連性情報311(図4)に含まれている遺伝子名に基づいて、患者IDおよび遺伝子に対応する患者の遺伝型情報を、図4の関連性情報311に記載の「遺伝型」の表記法にしたがった記号として、ゲノム情報DB6(図2)から取得する(図3のS3工程で「YES」)。情報取得部21(図2)は、取得した医薬情報301(図4)、関連性情報311(図4)、およびゲノム情報DB6(図2)から取得した患者の遺伝型情報を適合度決定部22(図2)に送る。 (Processing of administration plan proposal system 1)
An example of the processing performed by the administrationplan proposal system 1 of FIG. 2 in order to improve the effectiveness of the medicine will be described below with reference to FIG. The input device 4 (FIG. 2) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.). The input medical information 301 (FIG. 4) is sent to the information acquisition unit 21 (FIG. 2) (S1 step in FIG. 3). The information acquisition unit 21 of FIG. 2 has the name of the drug represented by the drug name contained in the drug information 301 (FIG. 4), the name of the gene related to the efficacy of the drug, and the known DNA related to the gene. The relevance information 311 (FIG. 4) describing the entire “genotype” in the variant (for example, SNP) and the drug efficacy of the drug according to the genotype is provided in the pharmaceutical efficacy-related gene information DB 5 of FIG. (For example, it can be constructed based on the information of DGIdb: Drug Gene Interaction database, URL: http://dgidb.org/) (“YES” in the S2 step of FIG. 3). The information acquisition unit 21 of FIG. 2 has a patient ID and a gene based on the "patient ID" information described in the drug information 301 (FIG. 4) and the gene name contained in the relevance information 311 (FIG. 4). The genetic type information of the patient corresponding to the above is acquired from the genomic information DB 6 (FIG. 2) as a symbol according to the notation of "genetic type" described in the relevance information 311 of FIG. 4 (in the step S3 of FIG. 3). "YES"). The information acquisition unit 21 (FIG. 2) determines the goodness of fit of the patient's genotype information acquired from the acquired drug information 301 (FIG. 4), the relevance information 311 (FIG. 4), and the genomic information DB 6 (FIG. 2). Send to 22 (Fig. 2).
医薬の有効性を向上させるために、図2の投与計画提案システム1が実行する処理の一例を、図3を参照して以下に説明する。入力装置4(図2)は、従来の一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)にしたがって、ユーザである医師によって入力された医薬情報301(図4)を情報取得部21(図2)に送る(図3のS1工程)。図2の情報取得部21は、医薬情報301(図4)に含まれている医薬名が表す薬剤の名称と、当該薬剤の薬効と関連する遺伝子の名称と、当該遺伝子に関連する既知のDNAバリアント(例えばSNP)における全通りの「遺伝型」と、当該遺伝型に応じた当該薬剤の薬効とを記述している関連性情報311(図4)を、図2の医薬薬効関連遺伝子情報DB5(例えば、DGIdb:Drug Gene Interaction database、URL:http://dgidb.org/の情報を元に構築可能)から取得する(図3のS2工程で「YES」)。図2の情報取得部21は、医薬情報301(図4)に記載された「患者ID」情報、および関連性情報311(図4)に含まれている遺伝子名に基づいて、患者IDおよび遺伝子に対応する患者の遺伝型情報を、図4の関連性情報311に記載の「遺伝型」の表記法にしたがった記号として、ゲノム情報DB6(図2)から取得する(図3のS3工程で「YES」)。情報取得部21(図2)は、取得した医薬情報301(図4)、関連性情報311(図4)、およびゲノム情報DB6(図2)から取得した患者の遺伝型情報を適合度決定部22(図2)に送る。 (Processing of administration plan proposal system 1)
An example of the processing performed by the administration
なお、図3のS2工程で「NO」(例えば、開発されてから間もない薬剤であるため、関連性情報が存在しない)のとき、図2の情報取得部21は、医薬情報301(図4)を表示装置3(図2)に送る(図3のS9工程)。図2の表示装置3が上記医薬情報を表示し、投与計画提案システム1(図2)は処理を終了する。また、図3のS3工程で「NO」(例えば、患者における特定の遺伝子に対応する遺伝型情報が、まだ決定されていない)のとき、情報取得部21(図2)は、医薬情報301(図4)を表示装置3(図2)に送る(図3のS9工程)。表示装置3(図2)が上記医薬情報を表示し、図2の投与計画提案システム1は処理を終了する。
When the result is "NO" in the step S2 of FIG. 3 (for example, since the drug has just been developed, there is no relevance information), the information acquisition unit 21 of FIG. 4) is sent to the display device 3 (FIG. 2) (step S9 in FIG. 3). The display device 3 of FIG. 2 displays the above-mentioned drug information, and the administration plan proposal system 1 (FIG. 2) ends the process. Further, when "NO" (for example, the genotype information corresponding to a specific gene in the patient has not been determined yet) in the S3 step of FIG. 3, the information acquisition unit 21 (FIG. 2) receives the drug information 301 (for example, FIG. 4) is sent to the display device 3 (FIG. 2) (step S9 in FIG. 3). The display device 3 (FIG. 2) displays the above-mentioned drug information, and the administration plan proposal system 1 of FIG. 2 ends the process.
図2の適合度決定部22は、関連性情報311(図4)およびゲノム情報DB6(図2)から情報取得部21(図2)を介して取得した患者の遺伝型情報に基づいて医薬情報301(図4)の適合度を決定する(図3のS4工程)。図3のS4工程の詳細を、図4を参照して説明する。
The goodness-of-fit determination unit 22 in FIG. 2 has medical information based on the genotype information of the patient acquired from the relevance information 311 (FIG. 4) and the genomic information DB 6 (FIG. 2) via the information acquisition unit 21 (FIG. 2). The goodness of fit of 301 (FIG. 4) is determined (step S4 of FIG. 3). The details of the S4 process of FIG. 3 will be described with reference to FIG.
図4に示されている関連性情報311は、医薬名に対応する有効成分(医薬名:フェニトイン(抗てんかん薬))、当該有効成分の薬物動態学に関与するタンパク質をコードする遺伝子(関連遺伝子:CYP2C9(薬剤代謝酵素遺伝子))、当該遺伝子上に存在する既知のSNP(SNP部位:rs1057910)、SNP(rs1057910)における記号化された「遺伝型」の総体(遺伝型:「*1/*1」、「*1/*3」および「*3/*3」)、および各遺伝型に対応する有効成分の代謝率(薬効に対応)(代謝率(薬効):「±0」、「-1」および「-2」)を含んでいる関連性情報を示している。フェニトインは、強直間代発作(全般痙攣発作、大発作)、焦点発作(ジャクソン型発作を含む)などのてんかんの痙攣発作、自律神経発作、精神運動発作などの症状を緩和する効果を示す薬剤である。
The relevance information 311 shown in FIG. 4 refers to an active ingredient corresponding to a drug name (pharmaceutical name: phenytoin (antiepileptic drug)) and a gene encoding a protein involved in the pharmacokinetics of the active ingredient (related gene). : CYP2C9 (drug metabolizing enzyme gene)), known SNP (SNP site: rs1057910) existing on the gene, total of symbolized "hereditary type" in SNP (rs1057910) (hereditary type: "* 1 / *" 1 ”,“ * 1 / * 3 ”and“ * 3 / * 3 ”), and the metabolic rate of the active ingredient corresponding to each genetic type (corresponding to the medicinal effect) (metalytic rate (medicinal effect):“ ± 0 ”,“ Relevance information including -1 "and" -2 ") is shown. Phenytoin is a drug that has the effect of relieving symptoms such as seizures of epilepsy such as tonic seizures (generalized seizures, major seizures), focal epilepsy (including Jackson-type seizures), autonomic seizures, and psychomotor seizures. be.
関連性情報311(図4)では、CYP2C9のコード領域内の1075位にSNP(rs1057910)が存在し、その遺伝型のタイプ「*1」は野生型アレルを表し、実際のヌクレオチドの塩基の種類は「アデニン(A)」である。また、遺伝型のタイプ「*3」は、フェニトインの代謝率が低下することが知られている低代謝型アレルを表し、実際のヌクレオチドの塩基の種類は「シトシン(C)」である。関連性情報311(図4)には、集団内での頻度が最も多いCYP2C9の遺伝型(正常型)「*1/*1」(実際のヌクレオチドの組み合わせの型:「A/A」)に対応するフェニトインの代謝率(薬効)「±0」を基準にして、特定の患者の遺伝型が低代謝型アレル「*3」(実際のヌクレオチドの塩基:「C」)を含んでいる数(無名数)だけ差し引かれた代謝率(薬効)が示されている。つまり、関連性情報311(図4)は、従来の一律の要因にしたがうフェニトインの投与が、遺伝子CYP2C9の1075位にあるSNPのヌクレオチド変化の組み合わせの型(「A/A」、「A/C」または「C/C」)に応じて異なる記号化された遺伝型(「*1/*1」、「*1/*3」または「*1/*1」)を有している患者に対して、異なる代謝率(薬効)(「±0」、「-1」または「-2」)を示すことを表している。
In the relevance information 311 (Fig. 4), SNP (rs1057910) is present at position 1075 in the coding region of CYP2C9, and its genotype type "* 1" represents a wild-type allele, and the actual nucleotide type of the nucleotide. Is "Adenine (A)". In addition, the genotype type "* 3" represents a low-metabolic allele that is known to reduce the metabolic rate of phenytoin, and the actual base type of nucleotide is "cytosine (C)". Relevance information 311 (Fig. 4) shows the most frequent CYP2C9 genetic type (normal type) "* 1 / * 1" (actual nucleotide combination type: "A / A") in the population. Based on the corresponding phenitoin metabolic rate (medicinal effect) "± 0", the number of genetic types of a specific patient containing a low metabolic rate allele "* 3" (actual nucleotide base: "C") ( The metabolic rate (medicinal effect) subtracted by the number of anonymous numbers) is shown. In other words, the relevance information 311 (Fig. 4) shows that the administration of phenytoin according to the conventional uniform factor is the combination type of nucleotide change of SNP at the 1075 position of the gene CYP2C9 (“A / A”, “A / C”). Or "C / C") in patients with different symbolized genotypes ("* 1 / * 1", "* 1 / * 3" or "* 1 / * 1") On the other hand, it indicates that they show different metabolic rates (drug effects) (“± 0”, “-1” or “-2”).
以上に説明した図3のS4工程にしたがって、適合度決定部22(図2)は、医薬情報301(図4)、関連性情報311(図4)、および患者の遺伝型情報として「*1/*3」を情報取得部21(図2)から取得しているとき、医薬情報301(図4)におけるフェニトインの代謝率(薬効)の値を「-1」と決定する。なお、上記「*1/*3」は、患者におけるCYP2C9の「アレルの型」がヘテロ接合型であることを表す遺伝型情報である。当該遺伝型情報は、医薬情報301(図4)に記述されている「患者ID:123456789」および関連性情報311(図4)に記述されている「関連遺伝子:CYP2C9」に基づいて、情報取得部21(図2)によってゲノム情報DB6(図2)から取得されている。
According to the step S4 of FIG. 3 described above, the goodness-of-fit determination unit 22 (FIG. 2) uses the pharmaceutical information 301 (FIG. 4), the relevance information 311 (FIG. 4), and the patient's genotype information as “* 1”. When "/ * 3" is acquired from the information acquisition unit 21 (FIG. 2), the value of the metabolic rate (medicinal efficacy) of phenytoin in the drug information 301 (FIG. 4) is determined to be "-1". The above "* 1 / * 3" is genotype information indicating that the "allele type" of CYP2C9 in the patient is a heterozygous type. The genotype information is obtained based on the "patient ID: 123456789" described in the drug information 301 (FIG. 4) and the "related gene: CYP2C9" described in the relevance information 311 (FIG. 4). Obtained from genomic information DB 6 (FIG. 2) by unit 21 (FIG. 2).
なお、図4の医薬情報301に含まれている医薬名M(medicine)に関連する遺伝子が2つ存在する(図4の関連性情報311に2つ遺伝子名G(gene)1およびG2が記述されている)とき、情報取得部21(図2)は、遺伝子名G1およびG2に対応する2つの関連性情報R(relationship)1およびR2、ならびに患者の遺伝型情報Gt(genotype)1およびGt2を適合度決定部22(図2)に送る。2つの関連性情報R1およびR2、ならびに2つの患者の遺伝型情報Gt1およびGt2を受け取った適合度決定部22(図2)は、当該医薬名に対応する適合度の要素F(factor)の値を、各遺伝子名G1およびG2ごとに決定し、2つの値(例えば、G1:±0、G2:-2)を合計した値「-2」を医薬Mの適合度として決定する。
In addition, there are two genes related to the drug name M (medicine) included in the drug information 301 of FIG. 4 (two gene names G (gene) 1 and G2 are described in the relationship information 311 of FIG. 4). When the information acquisition unit 21 (FIG. 2) is displayed, the information acquisition unit 21 (FIG. 2) has two relational information R (relationship) 1 and R2 corresponding to the gene names G1 and G2, and the genotype information Gt (genotype) 1 and Gt2 of the patient. Is sent to the fitness determination unit 22 (FIG. 2). The goodness-of-fit determination unit 22 (FIG. 2), which received the two relevance information R1 and R2 and the genotype information Gt1 and Gt2 of the two patients, determines the value of the goodness-of-fit element F (factor) corresponding to the drug name. Is determined for each gene name G1 and G2, and the value "-2", which is the sum of the two values (for example, G1: ± 0, G2: -2), is determined as the goodness of fit of the drug M.
以上の説明では上記適合度の要素として、フェニトインの代謝率(薬効)を例示している。薬剤および薬剤に関与する遺伝子の種類に応じて、適合度の要素は変化する。例えば、図4の関連性情報312には、薬物動態学的要因により、抗血小板薬であるクロピドグレル硫酸塩(プロドラッグ、以降では、単に「クロピドグレル」と記載する)が、CYP2C19(薬剤代謝酵素遺伝子)によってクロピドグレルの活性化合物に変換される代謝率(薬効に対応)が用いられている。クロピドグレルは、ADP(アデノシン2リン酸)の働きを阻害し、血小板の活性化に基づく血小板凝集を抑え、血栓の形成を抑え血管をつまらせないようにする薬剤であり、通常、虚血性脳血管障害の再発の抑制、末梢動脈疾患における血栓・塞栓形成の抑制などに用いられる。また例えば、図4の関連性情報313には、薬力学的要因により、高血圧症治療薬であるペリンドプリルエルブミン(有効成分)の標的分子であるアンジオテンシン転換酵素(以降では、「ACE」と記載する)に対する直接的な作用(つまり薬効)が用いられている。ペリンドプリルエルブミンはプロドラッグであり、経口吸収後ジアシド体(ペリンドプリラート)に加水分解され、このジアシド体が血中および組織中のACEを特異的に阻害し、昇圧物質であるアンジオテンシンIIの生成を抑制し、末梢血管抵抗を減少させる。1つの薬剤の代謝率および薬効(適合度)にそれぞれ関与する複数のアレルに、多型やバリアントが知られているとき、適合度の要素F(factor)の数と同じ関連性情報(図2の医薬薬効関連遺伝子情報DB5に格納)ならびに患者の遺伝型情報(図2のゲノム情報DB6に格納)を、情報取得部21(図2)は取得し、適合度の要素ごとにF1、F2・・・Fnの値を決定し、合計することにより最終的な適合度を算出する。
In the above explanation, the metabolic rate (medicinal effect) of phenytoin is exemplified as an element of the above goodness of fit. Depending on the drug and the type of gene involved in the drug, the goodness-of-fit factor varies. For example, in the relevant information 312 of FIG. 4, due to pharmacokinetic factors, the antiplatelet drug clopidogrel sulfate (prodrug, hereinafter simply referred to as "clopidogrel") is CYP2C19 (drug metabolizing enzyme gene). ) Is used to convert the active compound of clopidogrel into a metabolic rate (corresponding to the medicinal effect). Clopidogrel is a drug that inhibits the action of ADP (adenosine diphosphate), suppresses platelet aggregation based on platelet activation, suppresses the formation of thrombi and prevents blood vessels from becoming clogged, and is usually an ischemic cerebrovascular disease. It is used to suppress the recurrence of disorders and to suppress thrombus / embolism formation in peripheral arterial diseases. Further, for example, in the relevant information 313 of FIG. 4, angiotensin converting enzyme (hereinafter, "ACE"), which is a target molecule of perindopril erbumin (active ingredient), which is a therapeutic agent for hypertension, is described as "ACE" due to pharmacodynamic factors. ) Direct action (that is, medicinal effect) is used. Perindopril erbumin is a prodrug that is hydrolyzed to a diacid form (perindoprilate) after oral absorption, and this diacid form specifically inhibits ACE in blood and tissues, and angiotensin II, which is a pressor substance, It suppresses production and reduces peripheral vascular resistance. When polymorphisms and variants are known for multiple alleles involved in the metabolism rate and fitness (goodness of fit) of one drug, the same association information as the number of goodness-of-fit factors F (factor) (Fig. 2). The information acquisition unit 21 (FIG. 2) acquires the medicinal drug efficacy-related gene information DB5) and the patient's genotype information (stored in the genome information DB6 of FIG. 2), and F1, F2, for each goodness-of-fit element. The final goodness of fit is calculated by determining the value of Fn and summing it up.
図2の適合度決定部22は、関連性情報311(図4)において、上述の通り、CYP2C9内のSNP(rs1057910)に関する遺伝型情報としてヘテロ接合型「*1/*3」を取得しているとき、通常の遺伝型(正常型)「*1/*1」に対応する代謝率(薬効)の値「±0」、およびヘテロ接合型「*1/*3」に対応するフェニトインの代謝率(薬効)の値「-1」を合計した値「-1」を、医薬情報301(図4)の代謝率(薬効)に関する適合度(1だけ低い)として決定する。適合度決定部22(図2)は、医薬情報301(図4)および適合度「-1」を医薬情報変更部23(図2)に送る。
As described above, the conformity determination unit 22 in FIG. 2 acquires the heterozygous type “* 1 / * 3” as the genotype information regarding the SNP (rs1057910) in CYP2C9 in the relevance information 311 (FIG. 4). When present, the metabolic rate (medicinal effect) value "± 0" corresponding to the normal genotype (normal type) "* 1 / * 1" and the metabolic rate of phenitoin corresponding to the heterozygous type "* 1 / * 3" The value "-1", which is the sum of the values "-1" of the rate (drug efficacy), is determined as the degree of suitability (only 1 lower) with respect to the metabolic rate (drug efficacy) of the drug information 301 (FIG. 4). The goodness-of-fit determination unit 22 (FIG. 2) sends the pharmaceutical information 301 (FIG. 4) and the goodness of fit “-1” to the pharmaceutical information change unit 23 (FIG. 2).
図2の医薬情報変更部23は、負の値である適合度「-1」を低いと判断する(図3のS5工程)。医薬情報変更部23(図2)は、代謝率(薬効)「-1」にしたがって、医薬情報301(図4)における一日服用量のうち、維持投与量(初期投与期間の経過後に継続的に投与される薬剤の投与量で、医薬情報301(図4)に記載された「1日服用量(維持量)」)を1単位(1単位=医薬情報301に記載の25%)だけ減少させ、薬効「±0」にする(図3のS6工程)。図3のS6工程における変更が「一日服用量(維持量)」である(図3のS7工程での判断は「NO」)ので、上述の通り、医薬情報変更部23(図2)は「一日服用量(維持量)」を300mgから25%減じた投与量として、225mgに変更した変更医薬情報302(図4)を表示装置3(図2)に送る。なお、初期投与量に変更は無く、図4の医薬情報301に記載された「一日服用量(初期量)300mg」」のままである。表示装置3(図2)が変更医薬情報302(図4)を表示し、投与計画提案システム1(図2)は処理を終了する。なお、図4の変更医薬情報302における一日服用量が投与限界を超えるとき、医薬情報変更部23(図2)は、変更医薬情報302(図4)における医薬の変更を実行する(図示せず)。
The pharmaceutical information changing unit 23 in FIG. 2 determines that the goodness of fit “-1”, which is a negative value, is low (step S5 in FIG. 3). The drug information change unit 23 (FIG. 2) continuously adjusts the maintenance dose (after the lapse of the initial administration period) among the daily doses in the drug information 301 (FIG. 4) according to the metabolic rate (drug efficacy) “-1”. The dose of the drug administered to the drug is reduced by 1 unit (1 unit = 25% described in the drug information 301) in the “daily dose (maintenance amount)” described in the drug information 301 (FIG. 4). The medicinal effect is set to "± 0" (step S6 in FIG. 3). Since the change in the step S6 of FIG. 3 is the “daily dose (maintenance amount)” (the judgment in the step S7 of FIG. 3 is “NO”), as described above, the drug information change unit 23 (FIG. 2) The modified drug information 302 (FIG. 4) changed to 225 mg is sent to the display device 3 (FIG. 2) as the dose obtained by reducing the “daily dose (maintenance dose)” from 300 mg by 25%. The initial dose is unchanged, and remains the same as the "daily dose (initial dose) 300 mg" described in Pharmaceutical Information 301 in FIG. The display device 3 (FIG. 2) displays the changed drug information 302 (FIG. 4), and the administration plan proposal system 1 (FIG. 2) ends the process. When the daily dose in the modified drug information 302 of FIG. 4 exceeds the administration limit, the drug information changing unit 23 (FIG. 2) executes the drug change in the modified drug information 302 (FIG. 4) (shown). figure).
以上の例示した図3のS4工程と異なり、適合度決定部22(図2)は、ゲノム情報DB6(図2)から患者の遺伝型情報として正常型「*1/*1」を取得しているとき、フェニトインの代謝率(薬効)の値を「±0」と決定し、医薬情報変更部23(図2)に送る。医薬情報変更部23(図2)は、代謝率(薬効)の値「±0」を低くないと判断し、医薬情報301(図4)を表示装置3(図2)に送る。表示装置3(図2)が上記医薬情報を表示し、投与計画提案システム1(図2)は処理を終了する。
Unlike the S4 step of FIG. 3 illustrated above, the suitability determination unit 22 (FIG. 2) acquires the normal type “* 1 / * 1” as the genotype information of the patient from the genomic information DB 6 (FIG. 2). At that time, the value of the metabolic rate (medicinal effect) of phenytoin is determined to be "± 0" and sent to the drug information change unit 23 (FIG. 2). The drug information changing unit 23 (FIG. 2) determines that the value “± 0” of the metabolic rate (medicinal effect) is not low, and sends the drug information 301 (FIG. 4) to the display device 3 (FIG. 2). The display device 3 (FIG. 2) displays the above-mentioned drug information, and the administration plan proposal system 1 (FIG. 2) ends the process.
また、上述の例では医薬情報に対する変更は医薬の種類の変更ではなかったので、図2の医薬情報変更部23は図3のS7工程で判断「NO」を行った。しかし、例えば、下記条件にあてはまるとき、医薬情報変更部23(図2)は医薬の種類を変更する。条件:医薬情報に記述されている医薬名が「クロピドグレル」であり、かつ情報取得部21(図2)が関連性情報312(図4)であり、かつゲノム情報DB6(図2)から取得した患者の遺伝型情報が「*2/*2」、「*3/*3」または「*2/*3」のいずれかであるため、代謝率(薬効)が非常に低い「-2」。上述の通り、クロピドグレルは、プロドラッグであり、その活性化合物に変換されない限り、薬効を生じない。つまり、上記条件にあてまるとき、有効成分であるクロピドグレルの活性化合物は、投与量に関わらず、患者の体内にほとんど産生されない。したがって、投与量の増加は薬効を見込めないので、図2の医薬情報変更部23(図2)は医薬の種類を変更する。医薬情報変更部23(図2)は、医薬名を変更した(図3のS7工程で判断「YES」に該当する)医薬情報を情報取得部21(図2)に送り、図3の処理S2工程に戻る。なお、図4の関連性情報311~313、およびその他の関連事項の詳細については、本実施形態における項目(関連性情報311~313)にて後述されている。
Further, in the above example, the change to the drug information was not a change in the type of drug, so the drug information change unit 23 in FIG. 2 made a judgment "NO" in the step S7 in FIG. However, for example, when the following conditions are met, the drug information changing unit 23 (FIG. 2) changes the type of drug. Condition: The drug name described in the drug information is "clopidogrel", the information acquisition unit 21 (FIG. 2) is the relevance information 312 (FIG. 4), and the information is acquired from the genomic information DB 6 (FIG. 2). Since the patient's genotype information is either "* 2 / * 2", "* 3 / * 3" or "* 2 / * 3", the metabolic rate (drug efficacy) is very low "-2". As mentioned above, clopidogrel is a prodrug and has no medicinal properties unless it is converted to its active compound. That is, when the above conditions are met, the active compound of clopidogrel, which is an active ingredient, is hardly produced in the patient's body regardless of the dose. Therefore, since an increase in the dose cannot be expected to have a drug effect, the drug information changing unit 23 (FIG. 2) in FIG. 2 changes the type of drug. The drug information changing unit 23 (FIG. 2) sends the drug information whose drug name has been changed (corresponding to the determination “YES” in the step S7 in FIG. 3) to the information acquisition unit 21 (FIG. 2), and processes S2 in FIG. Return to the process. The details of the relevance information 311 to 313 in FIG. 4 and other related matters are described later in the items (relevance information 311 to 313) in the present embodiment.
以上の通り、本実施形態の投与計画提案システム1(図2)は、医師の指定した医薬情報301(図4)に記載された医薬の種類またはその用量を、患者の「遺伝型」(当該医薬の薬効に影響を与える遺伝子と関連するアレルの組み合わせとしての患者の「遺伝型」)に適合していないと判断したとき、変更する。したがって、投与計画提案システム1(図2)は、従来の一律の要因にとらわれずに、患者の遺伝型に応じて薬効に優れたオーダーメード投与計画を提案できる。
As described above, the administration plan proposal system 1 (FIG. 2) of the present embodiment sets the type or dose of the drug described in the drug information 301 (FIG. 4) specified by the doctor as the "genotype" of the patient (the relevant). Change when determined to be incompatible with the patient's "genotype") as a combination of alleles associated with genes that affect the efficacy of the drug. Therefore, the administration plan proposal system 1 (FIG. 2) can propose a tailor-made administration plan having excellent drug efficacy according to the genotype of the patient, without being bound by the conventional uniform factors.
投与計画提案システム1(図2)が患者にとって適切な投与計画を提示するための遺伝型情報および関連性情報の詳細を、以下に説明する。
The details of the genotype information and the relevance information for the administration plan proposal system 1 (Fig. 2) to present an appropriate administration plan for the patient will be described below.
(患者の遺伝型情報)
遺伝型情報は、患者に固有な、1つの座位に存在するアレル(本実施形態では1つの遺伝子に関連するアレル)の組み合わせの型(「アレルの型」)を表している。当該「アレルの型」の決定には、大きく分けて2通りの方法がある。当該方法は、患者から得られたゲノム全長の構造を表す情報(「全長文字列」)を用いる「方法1」、および患者由来のゲノムDNA試料を用いて、集団内で頻度の高く、かつ自動解析に適したDNAバリアントのみ(例えば、SNP)を対象に、ゲノム網羅的な多型解析による実験的手法を用いる「方法2」である。 (Patient genotype information)
The genotype information represents a combination type (“allele type”) of an allele (in this embodiment, an allele associated with one gene) that is unique to the patient and is present in one lotus coition. There are roughly two methods for determining the "allele type". The method uses "Method 1", which uses information representing the structure of the full length of the genome obtained from the patient ("full length character string"), and a genomic DNA sample derived from the patient, which is frequently and automatically performed in the population. This is "Method 2", which uses an experimental method based on genome-wide polymorphism analysis targeting only DNA variants suitable for analysis (for example, SNP).
遺伝型情報は、患者に固有な、1つの座位に存在するアレル(本実施形態では1つの遺伝子に関連するアレル)の組み合わせの型(「アレルの型」)を表している。当該「アレルの型」の決定には、大きく分けて2通りの方法がある。当該方法は、患者から得られたゲノム全長の構造を表す情報(「全長文字列」)を用いる「方法1」、および患者由来のゲノムDNA試料を用いて、集団内で頻度の高く、かつ自動解析に適したDNAバリアントのみ(例えば、SNP)を対象に、ゲノム網羅的な多型解析による実験的手法を用いる「方法2」である。 (Patient genotype information)
The genotype information represents a combination type (“allele type”) of an allele (in this embodiment, an allele associated with one gene) that is unique to the patient and is present in one lotus coition. There are roughly two methods for determining the "allele type". The method uses "
前者の「方法1」は、大規模並列DNA塩基配列決定法(次世代塩基配列決定法)を利用して実施され得る。大規模並列DNA塩基配列決定法では、非常に多くの(時には数百万もの)ヌクレオチド配列を含む複雑なDNAサンプルを、同時かつ均等に配列決定できる。このため、大規模並列DNA塩基配列決定法は、従来のジデオキシ塩基配列決定法(サンガー法)と比較して、患者由来の血液細胞や各種組織などから定法により抽出されたゲノムDNA試料を用いて、短時間かつ低コストで、当該患者の全ゲノム(約30億のヌクレオチド数)に対応する文字列(「全長文字列」)情報に変換することが可能である。上記「全長文字列」に含まれている文字もしくは文字列(およびそれらの位置)をすべて決定し、ヒトゲノムの参照ヌクレオチド配列を表す文字列(「参照文字列」)と比較することによって、患者のゲノム上の特定の座位に関する遺伝型を決定できる。
The former "method 1" can be carried out by using a large-scale massively parallel DNA sequence determination method (next-generation nucleotide sequence determination method). Large-scale parallel DNA sequencing methods can simultaneously and evenly sequence complex DNA samples containing a large number (sometimes millions) of nucleotide sequences. For this reason, the large-scale parallel DNA sequencing method uses genomic DNA samples extracted by a conventional method from patient-derived blood cells and various tissues, as compared with the conventional dideoxy sequencing method (Sanger method). It is possible to convert the information into a character string (“full-length character string”) corresponding to the entire genome (about 3 billion nucleotides) of the patient in a short time and at low cost. By determining all the characters or strings (and their positions) contained in the above "full length string" and comparing them with the string representing the reference nucleotide sequence of the human genome ("reference string"), the patient's The genetic type for a particular locus on the genome can be determined.
例えば、ある座位に存在し得るアレルのヌクレオチド配列を表す文字列(「アレル文字列」)および集団内で当該アレル間にヌクレオチド配列の変化を生じている位置(既知のDNAバリアント)を表す情報は、集団での頻度の高い場合(例えば、SNP)、一般に利用可能なDB(例えば、dbSNP(https://www.ncbi.nlm.nih.gov/snp/))に格納されている。したがって、1つの座位に関するアレル文字列の組み合わせの型(「アレルの型」)のうち、「全長文字列」がどの型を含んでいるかを決定することによって、患者の有している1つの座位に関する遺伝型を決定できる。一例として、患者の遺伝型情報の決定過程の概略を、以下に説明する。
・一般に利用可能なDB(例えば、上述したdbSNP)に格納されている既知のDNAバリアントの位置を表す上記情報に基づいて、「全長文字列」に含まれている、上記「アレル文字列」における、当該DNAバリアントの両側の位置に隣接する2つの文字列(例えば約10~100文字)を決定する
・「全長文字列」における上記2つの文字列(すなわち、当該DNAバリアントの両側の位置に隣接する2つの文字列)が「参照文字列」と完全一致する位置を、周知の文字比較アプリケーションを用いて決定する
・「全長文字列」と「参照文字列」の間で、上記2つの文字列が完全一致する位置に挟まれている当該DNAバリアントに対応する文字(列)の一致、不一致にしたがって、「全長文字列」にある当該DNAバリアントの「アレルの型」(すなわち、患者の「遺伝型」)を決定する。 For example, a string representing the nucleotide sequence of an allele that may be in a locus (“allele string”) and information representing a position within the population that causes a nucleotide sequence change between the alleles (known DNA variant) , If the frequency is high in a group (eg, SNP), it is stored in a generally available DB (eg, dbSNP (https://www.ncbi.nlm.nih.gov/snp/)). Therefore, one lotus coition possessed by the patient is determined by determining which type the "full-length character string" includes among the types of allele character strings combined for one lotus coition ("allele type"). Can determine the hereditary type of. As an example, the outline of the process of determining the genotype information of a patient will be described below.
-In the above-mentioned "all-character string" included in the "full-length character string" based on the above information indicating the position of a known DNA variant stored in a generally available DB (eg, the above-mentioned dbSNP). , Determine two character strings (for example, about 10 to 100 characters) adjacent to the positions on both sides of the DNA variant.-The above two character strings in the "full-length character string" (that is, adjacent to the positions on both sides of the DNA variant). Use a well-known character comparison application to determine the position where the two character strings) exactly match the "reference character string".-Between the "full-length character string" and the "reference character string", the above two character strings According to the match or mismatch of the character (string) corresponding to the DNA variant sandwiched at the position where is exactly matched, the "allergen type" (that is, the patient's "inheritance" of the DNA variant in the "full-length character string" Type ") is determined.
・一般に利用可能なDB(例えば、上述したdbSNP)に格納されている既知のDNAバリアントの位置を表す上記情報に基づいて、「全長文字列」に含まれている、上記「アレル文字列」における、当該DNAバリアントの両側の位置に隣接する2つの文字列(例えば約10~100文字)を決定する
・「全長文字列」における上記2つの文字列(すなわち、当該DNAバリアントの両側の位置に隣接する2つの文字列)が「参照文字列」と完全一致する位置を、周知の文字比較アプリケーションを用いて決定する
・「全長文字列」と「参照文字列」の間で、上記2つの文字列が完全一致する位置に挟まれている当該DNAバリアントに対応する文字(列)の一致、不一致にしたがって、「全長文字列」にある当該DNAバリアントの「アレルの型」(すなわち、患者の「遺伝型」)を決定する。 For example, a string representing the nucleotide sequence of an allele that may be in a locus (“allele string”) and information representing a position within the population that causes a nucleotide sequence change between the alleles (known DNA variant) , If the frequency is high in a group (eg, SNP), it is stored in a generally available DB (eg, dbSNP (https://www.ncbi.nlm.nih.gov/snp/)). Therefore, one lotus coition possessed by the patient is determined by determining which type the "full-length character string" includes among the types of allele character strings combined for one lotus coition ("allele type"). Can determine the hereditary type of. As an example, the outline of the process of determining the genotype information of a patient will be described below.
-In the above-mentioned "all-character string" included in the "full-length character string" based on the above information indicating the position of a known DNA variant stored in a generally available DB (eg, the above-mentioned dbSNP). , Determine two character strings (for example, about 10 to 100 characters) adjacent to the positions on both sides of the DNA variant.-The above two character strings in the "full-length character string" (that is, adjacent to the positions on both sides of the DNA variant). Use a well-known character comparison application to determine the position where the two character strings) exactly match the "reference character string".-Between the "full-length character string" and the "reference character string", the above two character strings According to the match or mismatch of the character (string) corresponding to the DNA variant sandwiched at the position where is exactly matched, the "allergen type" (that is, the patient's "inheritance" of the DNA variant in the "full-length character string" Type ") is determined.
なお、上述した「全長文字列」を用いた情報解析による「患者の遺伝型情報」の決定方法(「方法1」)の詳細については、具体例も含め、〔実施形態4〕に後述されている。
The details of the method for determining "patient genotype information" ("method 1") by information analysis using the above-mentioned "full-length character string" will be described later in [Embodiment 4], including specific examples. There is.
一方、上述した後者の「方法2」(ゲノム網羅的な多型解析による実験的手法を用いた方法)としては、上記DNAバリアントが、集団内で頻度の高く、かつ自動解析に適したDNAバリアント(例えば、SNP、またはゲノムにおける1から数ヌクレオチドの欠失もしくは挿入(インデル))であるとき、すでに商業化(市販キットおよび委託実施サービスの存在)されているマイクロアレイ技術は、多数(数万~数十万)のゲノム断片における多型の種類を短時間に決定可能である。マイクロアレイ技術の詳細については、キットのマニュアルまたは委託業者のHPを参照すればよい。
On the other hand, as the latter "method 2" (method using an experimental method by genome-wide polymorphism analysis) described above, the above DNA variant is a DNA variant that is frequently used in the population and suitable for automatic analysis. A large number (tens of thousands to tens of thousands) of microarray technologies already commercialized (existence of commercial kits and commissioned services) when (eg, SNPs, or deletions or insertions of one to several nucleotides in the genome (Indel)). The types of polymorphisms in hundreds of thousands) genomic fragments can be determined in a short time. For more information on microarray technology, see the kit manual or the contractor's HP.
以上の通り、患者の遺伝型情報は、上述した前者の「全長文字列」情報を用いる「方法1」および/または後者のゲノム網羅的な多型解析による実験的手法を用いる「方法2」によって(またはこれらの方法の実施の間に)決定され得る。したがって、図2のゲノム情報DB6に格納されている患者の遺伝型情報は、(1)「全長文字列」(患者のゲノム情報)、(2)互いに関連付けられている患者の「遺伝型」を表す情報および当該患者を表す情報、ならびに(3)2つの当該情報が記号化されている情報(例えば、上述した図4の関連性情報311に記載された「遺伝型」を参照)の少なくとも1つであり得る。上記遺伝型情報は、(2)または(3)であることが好ましい。上記遺伝型情報として(2)または(3)を用いることは、投与計画提案システム1(図2)およびゲノム情報DB6(図2)に求められる性能を小さくし、投与計画提案システム1(図2)の処理速度を向上させ得る。また、上記遺伝型情報として(3)を用いることは、記号の意味を解読できない不特定多数の第三者に(1)および(2)を秘匿できる。例えば、図4の関連性情報312に示すように、薬剤代謝酵素遺伝子CYP2C19内に存在するSNP(rs4244285)について決定された「遺伝型」は、記号化(「*1/*1」、「*1/*2」、「*1/*3」、「*2/*2」、「*2/*3」または「*3/*3」)され得る。
As described above, the genotype information of the patient is obtained by the above-mentioned "method 1" using the former "full-length character string" information and / or the latter "method 2" using an experimental method by genome-wide polymorphism analysis. It can be determined (or during the implementation of these methods). Therefore, the patient's genetic type information stored in the genomic information DB 6 of FIG. 2 includes (1) "full-length character string" (patient's genomic information) and (2) the patient's "hereditary type" associated with each other. At least one of the information representing and the information representing the patient, and (3) the information in which the two relevant information are symbolized (see, for example, the "genome type" described in the relevance information 311 of FIG. 4 above). Can be one. The genotype information is preferably (2) or (3). Using (2) or (3) as the genotype information reduces the performance required for the administration plan proposal system 1 (FIG. 2) and the genomic information DB 6 (FIG. 2), and reduces the performance required for the administration plan proposal system 1 (FIG. 2). ) Can be improved. Further, by using (3) as the genotype information, (1) and (2) can be concealed from an unspecified number of third parties who cannot decipher the meaning of the symbol. For example, as shown in the relevance information 312 of FIG. 4, the "genotype" determined for the SNP (rs4244285) present in the drug metabolizing enzyme gene CYP2C19 is symbolized ("* 1 / * 1", "*". 1 / * 2 "," * 1 / * 3 "," * 2 / * 2 "," * 2 / * 3 "or" * 3 / * 3 ").
患者の遺伝型情報としての(2)および(3)を生成するための個々のDNAバリアントの「アレルの型」は、集団内での頻度を基準にしたDNAバリアントの種類(決定範囲)に応じて、2段階に分けて決定され得る(図1の下部を参照)。第1段階として、まず集団内で1%以上の頻度であり、かつ自動解析にも適したDNAバリアントとして、既知の全SNPのみがゲノム網羅的に決定され、その情報は、DB、記録媒体または記憶装置(図示せず)に格納される。また、上記の全SNPの解析に基づく患者の「遺伝型」情報が、ゲノム情報DB6(図2)に格納される。なお、全SNPに関する「アレルの型」(患者の「遺伝型」)の決定には、上述した通り、当該患者のゲノムDNA試料を用いた実験的手法による「方法2」により、決定され得る。すなわち、まず上記ゲノムDNA試料は、患者の末梢血、口腔内細胞または頬粘膜などから定法により抽出される。続いて、上記試料を用いて、現行のマイクロアレイ技術によるゲノム網羅的な多型解析による実験的手法により、既知の全SNPに関する「アレルの型」(患者の「遺伝型」)は決定され得る。あるいは、上記の全SNPに関する患者の「遺伝型」(「アレルの型」)を、上述した「全長文字列」(患者のゲノム情報)を用いた情報解析による「方法1」により、決定してもよい(図1の下部を参照)。
The "allele type" of the individual DNA variants to generate (2) and (3) as patient genotype information depends on the type (determination range) of the DNA variant based on the frequency within the population. Can be determined in two stages (see bottom of FIG. 1). As a first step, only all known SNPs are genomically determined as DNA variants with a frequency of 1% or higher in the population and suitable for automated analysis, and the information is stored in DB, recording media, or It is stored in a storage device (not shown). In addition, the patient's "genotype" information based on the analysis of all SNPs described above is stored in the genomic information DB 6 (FIG. 2). In addition, as described above, the determination of the "allele type" (genotype of the patient) for all SNPs can be determined by "method 2" by an experimental method using the genomic DNA sample of the patient. That is, first, the genomic DNA sample is extracted from the patient's peripheral blood, oral cells, buccal mucosa, or the like by a conventional method. Subsequently, using the above sample, the "allelic type" (patient's "genotype") for all known SNPs can be determined by an experimental method by genome-wide polymorphism analysis by the current microarray technology. Alternatively, the patient's "genotype" ("allele type") for all SNPs described above is determined by "method 1" by information analysis using the above-mentioned "full-length character string" (genome information of the patient). May be (see bottom of Figure 1).
次いで、第2段階として、必要に応じて、上記DB、記録媒体または記憶装置に格納されていない残りのDNAバリアントに関する「アレルの型」(患者の「遺伝型」)が、「全長文字列」情報(患者のゲノム情報)を用いた「方法1」により決定される。上記「残りのDNAバリアント」としては、集団内で頻度の低いDNAバリアント(例えば、SNV、CNV)、または自動解析に適しないDNAバリアント(例えば、CNP、STRP、あるいはその他の特殊なDNAバリアント)などが想定される(図1の下部を参照)。残りのDNAバリアントの「アレルの型」(患者の「遺伝型」)は、入力装置4(図2)に対する医薬情報301(図4)の入力後に決定される。図2の投与計画提案システム1は、上述の通り、医薬情報301(図4)に含まれている医薬名に基づいて、医薬薬効関連遺伝子情報DB5(図2)から、薬剤の薬効と関連する遺伝子の名称を取得する。投与計画提案システム1(図2)は、当該名称に基づいて、最新のゲノム情報DB6(図2)を検索して、必要なDNAバリアントに関する「アレルの型」(すなわち、患者の遺伝型情報)が格納されていない場合、上述した通り、「参照文字列」情報を検索して、残りのDNAバリアントが存在するゲノム上の座位を、指定する。投与計画提案システム1(図2)は、当該座位のみに存在する残りのDNAバリアントの「アレルの型」(患者の「遺伝型」)を、上記文字列(「全長文字列」)を用いた「方法1」により決定する。投与計画提案システム1(図2)は、決定された残りのDNAバリアントの「アレルの型」(患者の遺伝型情報)を上記ゲノム情報DB6(図2)、ならびに上記DB、記録媒体または記憶装置に格納する(図示せず)。なお、上記文字列(「全長文字列」)情報を用いたDNAバリアントの「アレルの型」(患者の遺伝型情報)の決定方法(「方法1」)は、具体例を含め、後の項目〔実施形態4〕にも詳述されている。
Then, as a second step, if necessary, the "allelic type" (patient's "genotype") for the remaining DNA variants not stored in the DB, recording medium or storage device is the "full length string". It is determined by "Method 1" using information (patient's genomic information). The "remaining DNA variants" include DNA variants that are infrequent in the population (eg, SNV, CNV), or DNA variants that are not suitable for automated analysis (eg, CNP, STRP, or other special DNA variants). Is assumed (see the bottom of FIG. 1). The "allelic type" (patient "genotype") of the remaining DNA variants is determined after input of pharmaceutical information 301 (FIG. 4) to input device 4 (FIG. 2). As described above, the administration plan proposal system 1 of FIG. 2 is related to the drug efficacy from the drug efficacy-related gene information DB 5 (FIG. 2) based on the drug name included in the drug information 301 (FIG. 4). Get the name of the gene. The dosing regimen proposal system 1 (FIG. 2) searches for the latest genomic information DB 6 (FIG. 2) based on the name and "allelic type" (ie, patient genotype information) for the required DNA variant. If is not stored, as described above, the "reference string" information is searched to specify the loci on the genome where the remaining DNA variants are located. The administration plan proposal system 1 (FIG. 2) used the above-mentioned character string (“full-length character string”) for the “allelic type” (patient's “genotype”) of the remaining DNA variants existing only in the locus. Determined by "method 1". The dosing regimen proposal system 1 (FIG. 2) displays the "allelic type" (patient genotype information) of the remaining DNA variants determined in the genomic information DB 6 (FIG. 2), as well as the DB, recording medium or storage device. Store in (not shown). The method (“method 1”) for determining the “allele type” (patient genotype information) of the DNA variant using the above character string (“full-length character string”) information will be described later, including specific examples. It is also described in detail in [Embodiment 4].
図2には、ゲノム情報DB6は、ネットワーク上に存在する構成として示されているが、制御部2(図2)に内蔵されている記憶部もしくは記録媒体を読み取り可能な読み取り部、または制御部2(図2)に接続されている外部記憶装置または記録媒体を読み取り可能な読み取り装置として、代替可能である。
Although the genome information DB 6 is shown in FIG. 2 as a configuration existing on a network, a storage unit or a storage unit built in the control unit 2 (FIG. 2), a reading unit that can read a recording medium, or a control unit. The external storage device or recording medium connected to 2 (FIG. 2) can be replaced as a readable reader.
上記(2)または(3)である上記遺伝型情報は、最新の報告に基づいて更新され得る。当該報告は、ある遺伝子に関連した新たなDNAバリアント、ならびに当該DNAバリアントに関する「アレルの型」(「遺伝型」)の総体の報告である。上述した通り、上記「全長文字列」情報(患者のゲノム情報)を用いた「方法1」により、既存の報告および最新の報告に基づいて新たな(2)または(3)を生成できる。
The above genotype information according to (2) or (3) can be updated based on the latest report. The report is a comprehensive report of new DNA variants associated with a gene, as well as "allelic types" ("genotypes") for the DNA variants. As described above, the "method 1" using the above-mentioned "full-length character string" information (patient's genomic information) can generate a new (2) or (3) based on the existing report and the latest report.
図3および図4を参照して説明した、投与計画提案システム1(図2)が実行する処理として、上述した通り、2段階に分けて、ゲノム情報DB6(図2)から、患者の遺伝型情報として(2)および(3)を取得する例を示した。すなわち、第1段階として、既知のDNAマイクロアレイ技術を利用した実験的手法を用いる「方法2」(または、「全長文字列」情報(患者のゲノム情報)を用いた「方法1」)により決定した当該患者の全SNP解析情報を、ゲノム情報DB6(図2)に格納する。続いて、第2段階として、必要に応じて、「全長文字列」情報(患者のゲノム情報)を用いた「方法1」により、残りのDNAバリアント情報の解析を実施する。
As described above, as the process executed by the administration plan proposal system 1 (FIG. 2) described with reference to FIGS. 3 and 4, the genotype of the patient is divided into two stages from the genomic information DB 6 (FIG. 2). An example of acquiring (2) and (3) as information is shown. That is, as the first step, it was determined by "Method 2" using an experimental method using known DNA microarray technology (or "Method 1" using "full-length character string" information (patient's genomic information)). All SNP analysis information of the patient is stored in the genome information DB 6 (FIG. 2). Subsequently, as a second step, the remaining DNA variant information is analyzed by "Method 1" using the "full-length character string" information (patient's genomic information), if necessary.
しかし、図2の制御部2が、上述した第1段階として当該患者の全SNP解析情報をゲノム情報DB6(図2)に格納せずに、最初から、第2段階として、必要に応じて、特定のDNAバリアントの「アレルの型」(患者の「遺伝型」)を決定するため、「全長文字列」情報(患者のゲノム情報)を用いた「方法1」を実行してもよい。すなわち、制御部2(図2)が、ゲノム情報DB6(図2)から(1)「全長文字列」(患者のゲノム情報)を取得し、(1)に含まれているアレル文字列を抽出し、患者のゲノム上にある特定の1つの座位、あるいは複数の座位に関する遺伝型を決定する上述の手順を実行してもよい。例えば、最初から、特定のSNPや新規のSNVに関する患者の「遺伝型」(「アレルの型」)を、個別的に、上述した「全長文字列」情報(患者のゲノム情報)を用いた「方法1」により、決定してもよい。つまり、集団内の頻度や自動解析の適性などの条件に関わらず、あらゆるDNAバリアントに対して、最初から、「全長文字列」情報を用いる「方法1」を適用してもよい(図1の下部を参照)。
However, the control unit 2 in FIG. 2 does not store all the SNP analysis information of the patient in the genomic information DB 6 (FIG. 2) as the first step described above, and from the beginning, as the second step, if necessary. In order to determine the "allelic type" (patient's "genotype") of a particular DNA variant, "method 1" using "full length string" information (patient's genomic information) may be performed. That is, the control unit 2 (FIG. 2) acquires (1) the "full-length character string" (patient's genome information) from the genome information DB 6 (FIG. 2), and extracts the allele character string contained in (1). However, the above procedure may be performed to determine the genotype for a particular locus or loci on a patient's genome. For example, from the beginning, the patient's "genotype" ("allele type") related to a specific SNP or new SNV is individually referred to as "full-length character string" information (patient's genomic information) described above. It may be determined by the method 1 ”. That is, regardless of conditions such as frequency in the population and suitability for automatic analysis, "method 1" using "full-length character string" information may be applied to all DNA variants from the beginning (FIG. 1). See bottom).
あるいは、状況次第で、例えば、「全長文字列」情報(患者のゲノム情報)が、まだゲノム情報DB6(図2)に格納されていない場合、特定のSNPや新規のSNVに関する患者の「遺伝型」に対して、あえて、時間や労力を必要とする個別的な実験手技による方法を用いてもよい。例えば、上述した特定のSNPや新規のSNVに関する患者の「遺伝型」に対して、アレル特異的プライマーを使用したPCRによる現行の増幅抵抗性変異システム(特異的な点変異を検出する技術であり、正常アレルと1塩基違う変異アレルを区別できる方法)などの解析技術を利用して、個別的に、遺伝型を特定してもよい。
Alternatively, depending on the situation, for example, if the "full length string" information (patient's genomic information) is not yet stored in the genomic information DB 6 (FIG. 2), the patient's "genotype" for a particular SNP or new SNV. However, you may dare to use a method by an individual experimental technique that requires time and effort. For example, the current amplification-resistant mutation system (a technique for detecting specific point mutations) by PCR using allele-specific primers for the "genotype" of patients with the above-mentioned specific SNPs or novel SNVs. , A method capable of distinguishing a mutant allele that is one base different from a normal allele) may be used to individually identify the genotype.
個人情報を保護する観点から、図2のゲノム情報DB6の情報は暗号化されているか、またはゲノム情報DB6(図2)の情報には、アクセス制限が設けられていてもよい。上記暗号化およびアクセス制限は、情報技術分野で公知の手法によって、実現され得る。個人情報を保護する類似の観点から、上記システムは、ゲノム情報DB6(図2)ではなく、記録媒体に記録されている遺伝型情報を取得してもよい。
From the viewpoint of protecting personal information, the information in the genome information DB 6 in FIG. 2 may be encrypted, or the information in the genome information DB 6 (FIG. 2) may be provided with access restrictions. The above encryption and access restriction can be realized by a method known in the field of information technology. From a similar point of view of protecting personal information, the system may acquire genotype information recorded on a recording medium instead of the genomic information DB6 (FIG. 2).
(関連性情報311~313)
本実施形態では、上記遺伝型は、図4の関連性情報311に示されている通り、薬物動態学に関与するタンパク質をコードしている遺伝子に関する遺伝型である。図4の関連性情報311は、医薬および遺伝子の関連性(特に有効成分の代謝速度が、遺伝子の遺伝子機能と関連したアレルの遺伝型によって受ける影響)を表している。 (Relevance information 311 to 313)
In this embodiment, the genotype is a genotype relating to a gene encoding a protein involved in pharmacokinetics, as shown in relevance information 311 in FIG. Relevance information 311 in FIG. 4 represents drug-gene association (particularly the effect of the metabolic rate of the active ingredient on the genotype of the allele associated with the gene function of the gene).
本実施形態では、上記遺伝型は、図4の関連性情報311に示されている通り、薬物動態学に関与するタンパク質をコードしている遺伝子に関する遺伝型である。図4の関連性情報311は、医薬および遺伝子の関連性(特に有効成分の代謝速度が、遺伝子の遺伝子機能と関連したアレルの遺伝型によって受ける影響)を表している。 (Relevance information 311 to 313)
In this embodiment, the genotype is a genotype relating to a gene encoding a protein involved in pharmacokinetics, as shown in relevance information 311 in FIG. Relevance information 311 in FIG. 4 represents drug-gene association (particularly the effect of the metabolic rate of the active ingredient on the genotype of the allele associated with the gene function of the gene).
関連性情報311(図4)には、フェニトインに対する薬物動態学に関与するタンパク質をコードしている遺伝子としてCYP2C9遺伝子が示されている。CYP2C9遺伝子には、酵素活性に関連するSNP(rs1057910:図4の関連性情報311を参照)の存在が証明されている。変異アレルを含むCYP2C9遺伝子によって発現されるタンパク質は、抗てんかん薬の有効成分であるフェニトインを酸化する(代謝する)活性が低い。関連性情報311(図4)に示されている通り、活性が低いCYP2C9は、フェニトインの代謝速度を下げる(代謝率(薬効):「-1」または「-2」)ので、フェニトインの循環時間を必要以上に延長し得る。循環時間の延長は、特に長期にわたる薬剤の投与に対して、副作用の増大および薬効の過剰(いずれも有害事象である)をもたらす。
Relevance information 311 (Fig. 4) shows the CYP2C9 gene as a gene encoding a protein involved in pharmacokinetics for phenytoin. The presence of SNPs associated with enzyme activity (rs1057910: see relevance information 311 in FIG. 4) has been demonstrated in the CYP2C9 gene. Proteins expressed by the CYP2C9 gene, including mutant alleles, have low activity to oxidize (metabolize) phenytoin, the active ingredient of antiepileptic drugs. As shown in the relevance information 311 (Fig. 4), the less active CYP2C9 slows down the metabolic rate of phenytoin (metabolic rate (metabolic rate): "-1" or "-2"), so that the circulation time of phenytoin Can be extended more than necessary. Prolonged circulation time results in increased side effects and excessive efficacy (both are adverse events), especially for long-term drug administration.
図4の関連性情報312には、クロピドグレルの薬物動態学に関与するタンパク質をコードしている遺伝子としてCYP2C19遺伝子が示されている。CYP2C19遺伝子内に存在する既知のSNP(rs4244285)には、いくつかの変異アレルの型が存在し得ることが知られている(図4の関連性情報312を参照)。当該変異アレルを含むCYP2C19遺伝子によって発現されるタンパク質は、クロピドグレルのように酸化を受けて薬効を発揮する医薬の体内における代謝を行わない、または当該代謝を弱める。つまり、変異アレルを含むCYP2C19遺伝子は、関連性情報312(図4)に示されている通り、患者の遺伝型によってはクロピドグレルの活性化合物への代謝率を下げる(代謝率(薬効):「-1」)、または当該代謝率を実質的に0にする(代謝率(薬効):「-2」)。なお、「推奨される治療方針(用量調整)」(CLINICAL PHARMACOLOGY & THERAPEUTICS 89(5): 662-673, 2011およびOrgan Biology 21(2): 247-253, 2014などを参照)にしたがって、医薬情報に記述されている一日投与量が投与限界量に近いとき、図2の医薬情報変更部23は、負の値の代謝率(代謝率(薬効):「-1」および「-2」)に対して、一律に医薬の種類の変更を実行してもよい。
The relevance information 312 in FIG. 4 shows the CYP2C19 gene as a gene encoding a protein involved in the pharmacokinetics of clopidogrel. It is known that there may be several mutant allele types in the known SNPs (rs4244285) present within the CYP2C19 gene (see relevance information 312 in FIG. 4). The protein expressed by the CYP2C19 gene containing the mutant allele does not metabolize in the body of a drug that is oxidized and exerts a medicinal effect like clopidogrel, or weakens the metabolism. That is, the CYP2C19 gene containing the mutant allele lowers the metabolic rate of clopidogrel to the active compound depending on the genetic type of the patient, as shown in the association information 312 (Fig. 4) (metabolic rate (medicinal effect): "-". 1 "), or make the metabolic rate substantially 0 (metabolic rate (medicinal effect):" -2 "). In addition, according to "Recommended treatment policy (dose adjustment)" (see CLIMINICAL PHARMACOLOGY & THERAPEUTICS 89 (5): 662-673, 2011 and Organ Biology 21 (2): 247-253, 2014, etc.) When the daily dose described in is close to the dose limit, the drug information changing unit 23 in FIG. 2 has a negative metabolic rate (metabolic rate (medicinal effect): "-1" and "-2"). However, the type of medicine may be changed uniformly.
他の例である図4の関連性情報313には、特殊なDNAバリアントの一つとして、ペリンドプリルエルブミンの薬力学に関与するタンパク質(直接的な標的タンパク質)をコードしている遺伝子としてACE遺伝子には、そのイントロン15内に短鎖散在反復配列であるAlu配列の欠失/挿入の多型が含まれ得ることが知られている。Alu配列が挿入された遺伝子は、スプライシング異常またはエクソン欠失などを生じるため、Alu配列を欠失している当該遺伝子と比べて、異常なタンパク質の発現またはタンパク質の異常な発現パターンを高頻度に示す。つまり、Alu配列が挿入されたACE遺伝子を有している個体には、ペリンドプリルエルブミンの薬効が低いか、またはほとんどない。例えば、ACE遺伝子内にAlu配列が挿入されたアレルを1つ保持するヘテロ接合体(「Alu+/Alu-」)の場合、薬効「-1」と決定する。あるいはAlu配列が挿入されたアレルを2つとも保持するホモ接合体(「Alu+/Alu+」)の場合は、薬効「-2」と決定する(図4の関連性情報313を参照)。
In the relevance information 313 of FIG. 4, which is another example, as one of the special DNA variants, the ACE gene as a gene encoding a protein (direct target protein) involved in the pharmacokinetics of perindopril erbumin. Is known to contain a polymorph of deletion / insertion of the Alu sequence, which is a short interspersed repeat sequence, within the intron 15. A gene into which an Alu sequence has been inserted causes splicing abnormalities or exon deletions, so the expression of abnormal proteins or abnormal protein expression patterns is higher than that of the gene lacking the Alu sequence. show. That is, perindopril erbumin has low or little efficacy in individuals carrying the ACE gene with the Alu sequence inserted. For example, in the case of a heterozygote (“Alu + / Alu-”) that retains one allele with an Alu sequence inserted in the ACE gene, the drug efficacy is determined to be “-1”. Alternatively, in the case of a homozygote (“Alu + / Alu +”) that retains both alleles into which the Alu sequence has been inserted, the drug efficacy is determined to be “-2” (see relevance information 313 in FIG. 4).
図4の関連性情報311~313には、医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子、当該遺伝子の遺伝型および当該遺伝型に応じて変化する適合度の要素のそれぞれを表す情報が含まれている。上記情報(図4の関連性情報311~313)に記載された関連性情報(医薬、関連遺伝子、遺伝型、ならびに薬効情報)、およびその他の医薬に関する関連性情報は、公知の文献(例えば、CLINICAL PHARMACOLOGY & THERAPEUTICS 89(5): 662-673, 2011のTabel 1、ならびにOrgan Biology 21(2): 247-253, 2014の表1および表2などを参照)にまとめられており、容易に入手可能である。Organ Biology 21(2): 247-253, 2014の表1は、旧版の医療用医薬品集から抜粋されている。最新の医療用医薬品集の内容は、書籍名「JAPIC医療用医薬品集2020(発行日:2019年8月30日、発売元:丸善出版株式会社)を参照すればよい。CLINICAL PHARMACOLOGY & THERAPEUTICS 89(5): 662-673, 2011のタイトルの一部「An Update of Guideline」および医療用医薬品集における内容の更新などから明らかな通り、上記情報(図4の関連性情報311~313)の関連性情報、ならびにその他の医薬に関する関連性情報は、新情報の追加および旧情報の更新によって、今後もより拡充され、かつより精度を増す。したがって、関連性情報311~313(図4)、ならびにその他の医薬に関する関連性情報は、本実施形態の実施時における最新の情報に基づいて作成されることが好ましい。例えば、関連性情報311~313(図4)、ならびにその他の医薬に関する関連性情報は、人工知能(Artificial Intelligence、以降では「AI」と記載する)によって生成され得る(図1を参照)。上記新情報の追加の入力を受けたAIは、旧情報の更新に使用される新たな、医薬および遺伝子の関連性を出力し得る。
The relevance information 311 to 313 in FIG. 4 shows the gene encoding the pharmacokinetics of the drug or the protein involved in pharmacodynamics, the genotype of the gene, and the fitness element that changes depending on the genotype. Information representing each is included. The relevance information (pharmaceuticals, related genes, genotypes, and pharmacological efficacy information) described in the above information (relevance information 311 to 313 in FIG. 4) and other relevance information relating to the drug are known documents (eg, for example). CLINICAL PHARMACOLOGY & THERAPEUTICS 89 (5): 662-673, 2011 Tabel 1 and Organ Biology 21 (2): 247-253, 2014 Table 1 and Table 2) are summarized and easily available. It is possible. Table 1 of Organ Biology 21 (2): 247-253, 2014 is an excerpt from the old version of the prescription drug collection. For the contents of the latest ethical drug collection, refer to the book title "JAPIC ethical drug collection 2020 (issue date: August 30, 2019, publisher: Maruzen Publishing Co., Ltd.). CLINICAL PHARMACOLOGY & THERAPEUTICS 89 ( 5): As is clear from the partial "An Update of Guideline" title of 662-673, 2011 and the update of the contents in the ethical drug collection, the relevance of the above information (relevance information 311 to 313 in Fig. 4). Information, as well as other drug-related relevant information, will continue to be expanded and more accurate with the addition of new information and updates to old information. Therefore, it is preferable that the relevance information 311 to 313 (FIG. 4) and the relevance information regarding other medicines are prepared based on the latest information at the time of the embodiment of the present embodiment. For example, relevance information 311-313 (FIG. 4), as well as relevance information about other medicines, can be generated by artificial intelligence (hereinafter referred to as "AI") (see FIG. 1). Upon receiving the additional input of the new information, the AI may output new drug and gene relevance used to update the old information.
上記情報(図4の関連性情報311~313)のうち、遺伝型に応じて変化する適合度の要素(例えば、代謝率および薬効)を表す情報は、上記公知の文献や資料に記載の関連性情報にしたがって、任意に記述され得る。関連性情報312(図4)には、薬剤代謝酵素遺伝子CYP2C19内のSNP(rs4244285)における各遺伝型に対応する代謝率(薬効)の値は、「±0」、「-1」および「-2」と記述されている。例えば、Organ Biology 21(2): 247-253, 2014には、「CYP2C19の遺伝子多型では、CYP2C19*2と*3タイプが重要である.いずれも活性の消失を伴うタイプであるため、この2種類の対応の組み合わせで酵素欠損者と診断される.」と記載されている。この記載にしたがって、関連性情報312(図4)における代謝率(薬効)の値「-2」を「消失」に書き換えてもよい。関連性情報312(図4)における代謝率(薬効)「消失」は、例えば、プロドラッグであるクロピドグレルがCYP2C19によってその活性化合物に代謝されない(薬効成分に変換されない)ことを表し得る。したがって、代謝率(薬効)「消失」を、図2の適合度決定部22は「-∞(医薬が適合しない)」と判断し、医薬情報変更部23(図2)は医薬情報301(図4)における医薬名を代替薬に変更する。このとき、代替薬がなければ、投与量を「0」に変更した変更医薬情報をユーザに出力してもよい。また、代替薬の有無にかかわらず、図4の医薬情報301における医薬名(あるいは、服用量を含む医薬情報)が低い適合度を有していることを表す警告を、ユーザに発してもよい。このときのシステム1aの構成(警告部24をさらに備えている)を図12に、例示的に図示する。
Among the above information (relevance information 311 to 313 in FIG. 4), the information representing the goodness-of-fit element (for example, metabolic rate and drug efficacy) that changes depending on the genotype is related to the above-mentioned known documents and materials. It can be described arbitrarily according to the sexual information. In the relevance information 312 (Fig. 4), the metabolic rate (drug efficacy) values corresponding to each genotype in the SNP (rs4244285) in the drug metabolizing enzyme gene CYP2C19 are "± 0", "-1" and "-". 2 "is described. For example, in Organ Biology 21 (2): 247-253, 2014, "CYP2C19 * 2 and * 3 types are important for CYP2C19 gene polymorphisms. Since both are types with loss of activity, this is the type. A combination of the two types of correspondence is diagnosed as an enzyme deficient person. " According to this description, the value "-2" of the metabolic rate (medicinal effect) in the relevance information 312 (FIG. 4) may be rewritten as "disappearance". The metabolic rate (drug effect) "disappearance" in the relevance information 312 (FIG. 4) can indicate, for example, that the prodrug clopidogrel is not metabolized (converted to a medicinal component) by CYP2C19 into its active compound. Therefore, the metabolic rate (medicinal effect) "disappearance" is determined by the goodness-of-fit determination unit 22 in FIG. Change the drug name in 4) to an alternative drug. At this time, if there is no alternative drug, the changed drug information in which the dose is changed to "0" may be output to the user. Further, regardless of the presence or absence of an alternative drug, a warning indicating that the drug name (or drug information including the dose) in the drug information 301 in FIG. 4 has a low goodness of fit may be issued to the user. .. The configuration of the system 1a at this time (which further includes the warning unit 24) is illustrated in FIG. 12 as an example.
なお、本発明の対象となる薬剤および遺伝型は、当然、上記に示したものに限定されず、様々な薬剤および遺伝型を対象とすることができる。例えば、薬物動態学的要因に関する遺伝型の例としてトランスポーターの遺伝子多型の例を挙げれば、以下の通りである。
Of course, the drug and genotype to be the subject of the present invention are not limited to those shown above, and various drugs and genotypes can be targeted. For example, examples of genotypes related to pharmacokinetic factors include the following are examples of transporter gene polymorphisms.
脂質異常治療薬であるHMG-CoA還元酵素阻害薬(ブラバスタチン、アトルバスタチンなど)は、肝臓に選択的に取り込まれて薬効を示すが、その取り込みにトランスポータータンパク質OATP1B1(Organic Anion Transporting Polypeptide 1B1)が重要な働きをしている。そのOATP1B1をコードする遺伝子内のSNPのうち、アミノ酸置換を伴う変異型(塩基変化:「521T>C」)では、正常型と比較して、肝臓への取り込みの減少により、経口投与されたブラバスタチンやアトルバスタチンなどの薬物は、代謝、胆汁中排泄を免れて中心静脈を流れるため、血中濃度が上昇する。その結果、血中の薬物濃度が治療濃度域より高い状態になり、薬物中毒などの副作用を起こすリスクが高い。そこで、正常型(遺伝型:「T/T」)の薬効の値「±0」に比べて、ヘテロ接合型は「-1」(遺伝型:「T/C」)、ホモ接合型(遺伝型:「C/C」)は「-2」低いと決定し得る。
HMG-CoA reductase inhibitors (bravastatin, atorvastatin, etc.), which are therapeutic agents for dyslipidemia, are selectively taken up by the liver and show efficacy, but the transporter protein OATP1B1 (Organic Anion Transporting Polypeptide 1B1) is used for the uptake. It plays an important role. Among the SNPs in the gene encoding OATP1B1, the mutant type with amino acid substitution (base change: "521T> C") was orally administered due to decreased uptake into the liver compared to the normal type. Drugs such as statins and atorvastatin escape metabolism and excretion in bile and flow through the central vein, resulting in increased blood levels. As a result, the drug concentration in the blood becomes higher than the therapeutic concentration range, and there is a high risk of causing side effects such as drug addiction. Therefore, the heterozygous type is "-1" (genotype: "T / C") and homozygous type (hereditary) compared to the medicinal effect value "± 0" of the normal type (genotype: "T / T"). Genotype: "C / C") can be determined to be "-2" lower.
また、薬力学的要因に関する遺伝型の例として薬物受容体の遺伝子多型の例を挙げれば、以下の通りである。
In addition, examples of gene polymorphisms of drug receptors as examples of genotypes related to pharmacodynamic factors are as follows.
薬物受容体タンパク質β2-アドレナリン受容体(ADRB2)をコードする遺伝子内のSNPのうち、アミノ酸置換を伴う変異型(塩基変化:「46A>G」)では、気管支拡張薬クレンブテロール塩酸塩などのβ2作動薬の投与により、ADRB2をコードする遺伝子の発現量が減少するダウンレギュレーションが起こる。その結果、気管支喘息の重症化やβ2作動薬への反応性が低下する。そこで、正常型受容体(遺伝型:「A/A」)の薬効の値「±0」に比べて、ヘテロ接合型(遺伝型:「A/G」)は「-1」、ホモ接合型(遺伝型:「G/G」)は「-2」低いと決定し得る。
Among the SNPs in the gene encoding the drug receptor protein β 2 -adrenaline receptor (ADRB2), in the mutant type with amino acid substitution (base change: "46A>G"), β such as the bronchodilator clenbuterol hydrochloride 2 Administration of the agonist causes down-regulation that reduces the expression level of the gene encoding ADRB2. As a result, bronchial asthma becomes more severe and responsiveness to β 2 agonists decreases. Therefore, the heterozygous type (genotype: "A / G") is "-1" and homozygous type compared to the medicinal effect value "± 0" of the normal receptor (genotype: "A / A"). (Genotype: "G / G") can be determined to be "-2" lower.
また、ADRB2遺伝子の別の変異(塩基変化:「491C>T」)では、β2受容体作動薬などのアゴニストとの結合能が、正常型(遺伝型:「C/C」)の4分の1に低下して、β2作動薬への反応性が低下する。そこで、正常型の薬効の値「±0」に比べて、ヘテロ接合型(遺伝型:「C/T」)は「-1」、ホモ接合型(遺伝型:「T/T」)は「-2」低いと決定し得る。
In addition, in another mutation of the ADRB2 gene (base change: "491C>T"), the ability to bind to agonists such as β 2 receptor agonists is 4 minutes of the normal type (hereditary type: "C / C"). It decreases to 1 and the reactivity to β 2 agonist decreases. Therefore, the heterozygous type (genotype: "C / T") is "-1" and the homozygous type (genotype: "T / T") is "-1" compared to the normal drug efficacy value "± 0". -2 "Can be determined to be low.
以上の通り、薬物動態学および薬力学に関する図4の関連性情報311~313(上記追加の実例内容を含む)は、医師の指定した投与計画が特定の患者に対して低い適合度を有しているとき、当該低い適合度を改善させる提案として、投与量(増加または減少)の変更または医薬の変更を、少なくとも記述している。医薬情報301(図4)の適合度を判断する基準として関連性情報311~313(図4)を使用する投与計画提案システム1(図2)は、低い適合度の改善を求める提案を医師に提示可能である。
As described above, the relevance information 311-313 (including the above-mentioned additional example contents) of FIG. 4 regarding pharmacokinetics and pharmacodynamics has a low goodness of fit for the specific patient in the administration plan specified by the doctor. When, at least a dose change (increase or decrease) change or drug change is described as a suggestion to improve the low goodness of fit. The administration plan proposal system 1 (FIG. 2), which uses the relevance information 311 to 313 (FIG. 4) as a criterion for determining the goodness of fit of the pharmaceutical information 301 (FIG. 4), makes a proposal to the doctor for improvement of the low goodness of fit. It can be presented.
(医薬情報における医薬名、および関連性情報と、それらを用いた処理との例示)
図2の情報取得部21は、複数の関連性情報を同時に取得し得る(図1の「(投与計画)」を参照)ことを、非小細胞肺がん患者に対する医薬情報304(図11)をシステム1(図2)に入力した場合を例に挙げて説明する。図2の情報取得部21は、図3のS1工程において、標的分子または作用機序を名称に含む医薬名(ALKチロシンキナーゼ阻害剤)を記述している医薬情報304(図11)を受け取ると、後述する通り複数の関連性情報315および316を同時に取得する。このような医薬名は、一般に、複数の具体的な薬剤を指し得る。例えば、図11の関連性情報315(リクゾチニブを具体的な医薬名として含む)および316(セリチニブを具体的な医薬名として含む)は、いずれも、ALKチロシンキナーゼ阻害剤、およびその遺伝型に基づく薬効を記述している情報である。 (Examples of drug names and relevance information in drug information and processing using them)
Theinformation acquisition unit 21 of FIG. 2 can acquire a plurality of relevance information at the same time (see “(administration plan)” of FIG. 1), and systemizes the drug information 304 (FIG. 11) for patients with non-small cell lung cancer. The case of inputting in 1 (FIG. 2) will be described as an example. Upon receiving the drug information 304 (FIG. 11) describing the drug name (ALK tyrosine kinase inhibitor) including the target molecule or the mechanism of action in the name, the information acquisition unit 21 of FIG. 2 receives the drug information 304 (FIG. 11) in the S1 step of FIG. , As will be described later, a plurality of relevance information 315 and 316 are acquired at the same time. Such drug names can generally refer to a plurality of specific drugs. For example, the relevance information 315 (including lyxothinib as a specific drug name) and 316 (including ceritinib as a specific drug name) in FIG. 11 are both based on the ALK tyrosine kinase inhibitor and its genotype. Information that describes the medicinal effect.
図2の情報取得部21は、複数の関連性情報を同時に取得し得る(図1の「(投与計画)」を参照)ことを、非小細胞肺がん患者に対する医薬情報304(図11)をシステム1(図2)に入力した場合を例に挙げて説明する。図2の情報取得部21は、図3のS1工程において、標的分子または作用機序を名称に含む医薬名(ALKチロシンキナーゼ阻害剤)を記述している医薬情報304(図11)を受け取ると、後述する通り複数の関連性情報315および316を同時に取得する。このような医薬名は、一般に、複数の具体的な薬剤を指し得る。例えば、図11の関連性情報315(リクゾチニブを具体的な医薬名として含む)および316(セリチニブを具体的な医薬名として含む)は、いずれも、ALKチロシンキナーゼ阻害剤、およびその遺伝型に基づく薬効を記述している情報である。 (Examples of drug names and relevance information in drug information and processing using them)
The
図11の関連性情報315および316を取得した図2の情報取得部21および適合度決定部22は、図11の医薬情報304における医薬名がリクゾチニブであるときの処理および医薬情報304における医薬名がセリチニブであるときの処理(図3のS3~S5)を並行して、実施する。図11の医薬情報304に記述されている非小細胞肺がん患者が、EML-ALK融合遺伝子を有していない(遺伝型:-)とき、図2の適合度決定部22は、リクゾチニブおよびセリチニブの両方を、当該患者には無効「-∞」であると、図3のS4において決定し、図2の医薬情報変更部23に送る。
The information acquisition unit 21 and the goodness-of-fit determination unit 22 of FIG. 2 that acquired the relevance information 315 and 316 of FIG. 11 are the treatment when the drug name in the drug information 304 of FIG. 11 is lyxotinib and the drug name in the drug information 304. The treatment when is ceritinib (S3 to S5 in FIG. 3) is carried out in parallel. When the non-small cell lung cancer patient described in Pharmaceutical Information 304 of FIG. 11 does not have the EML-ALK fusion gene (genotype :-), the suitability determination unit 22 of FIG. 2 is of lyxotinib and ceritinib. Both are determined to be invalid "-∞" for the patient in S4 of FIG. 3 and sent to the drug information changing unit 23 of FIG.
図2の医薬情報変更部23は、負の記号「-」および無限大「∞」にしたがって、図11の医薬情報304(ALKチロシンキナーゼ阻害剤を含む)における医薬名を変更する。当該医薬名は上述の通り作用機序を含んでいる。したがって、図11の医薬情報304におけるALKチロシンキナーゼ阻害剤(非小細胞肺がんの治療薬)と異なる非小細胞肺がんの治療薬であり、かつ他の作用機序を含んでいる医薬名(例えば、EGFRチロシンキナーゼ阻害剤)が選択される。
The drug information changing unit 23 in FIG. 2 changes the drug name in the drug information 304 (including the ALK tyrosine kinase inhibitor) in FIG. 11 according to the negative symbol “−” and the infinity “∞”. The drug name includes the mechanism of action as described above. Therefore, it is a therapeutic agent for non-small cell lung cancer different from the ALK tyrosine kinase inhibitor (therapeutic agent for non-small cell lung cancer) in the pharmaceutical information 304 of FIG. EGFR tyrosine kinase inhibitor) is selected.
医薬名がEGFRチロシンキナーゼ阻害剤に変更される(図3のS7において「YES」)と、情報取得部21(図2)は、図3のS2において、図11の関連性情報317および318を取得する。図2の情報取得部21および適合度決定部22は、図11の医薬情報304における医薬名がゲフィチニブであるときの処理および医薬情報304における医薬名がオシメルチニブメシル酸塩であるときの処理(図3のS3~S5)を並行して、実施する。
When the drug name is changed to EGFR tyrosine kinase inhibitor (“YES” in S7 of FIG. 3), the information acquisition unit 21 (FIG. 2) provides relevant information 317 and 318 of FIG. 11 in S2 of FIG. get. The information acquisition unit 21 and the goodness-of-fit determination unit 22 in FIG. 2 are processed when the drug name in the drug information 304 of FIG. 11 is gefitinib and when the drug name in the drug information 304 is ossimertinib mesylate. (S3 to S5 in FIG. 3) are carried out in parallel.
ここで、図11の医薬情報304に記述されている非小細胞肺がん患者は、例えば、EGFR遺伝子の2573位にホモ接合型の変異を有しており(遺伝型:G/G)、EGFR遺伝子の2369位にヘテロ接合型の変異(遺伝型:T/C)を有している。このとき、図2の適合度決定部22は、ゲフィチニブの適合度を、各要素(薬効)の数値の合計(すなはち、2と-1の合計値)から、「1」と決定し(図11の関連性情報317を参照)、オシメルチニブメシル酸塩の適合度を、各要素(薬効)の数値の合計(すなはち、2と1の合計値)から、「3」と決定する(図11の関連性情報318を参照)。図2の適合度決定部22は、決定した2つの適合度を、図2の医薬情報変更部23に送る。
Here, the non-small cell lung cancer patient described in Pharmaceutical Information 304 of FIG. 11 has, for example, a homozygous mutation at position 2573 of the EGFR gene (genotype: G / G), and the EGFR gene. It has a heterozygous mutation (genotype: T / C) at position 2369 of. At this time, the goodness-of-fit determination unit 22 in FIG. 2 determines the goodness of fit of gefitinib as "1" from the total numerical value of each element (medicinal effect) (that is, the total value of 2 and -1) (that is, the total value of 2 and -1). (Refer to the relevance information 317 in FIG. 11), the goodness of fit of osimertinib mesylate was determined to be "3" from the total numerical value of each element (medicinal effect) (that is, the total value of 2 and 1). (See relevance information 318 in FIG. 11). The goodness-of-fit determination unit 22 of FIG. 2 sends the two determined goodness of fits to the pharmaceutical information changing unit 23 of FIG.
図2の医薬情報変更部23は、2つの適合度(上記医薬変更の基準値は0より低い値であり、いずれも正の値なので、図3のS5では「YES」)のうち、絶対値の大きい「3」に対応する「オシメルチニブメシル酸塩」を選択し、図11の変更医薬情報306を図2の表示装置3に送る。表示装置3は、図11の変更医薬情報306をユーザに提示する。
The drug information changing unit 23 in FIG. 2 is an absolute value among the two goodness of fit (the reference value for changing the drug is a value lower than 0 and both are positive values, so “YES” in S5 in FIG. 3). Select the "osyltinib mesylate" corresponding to the large "3" and send the modified drug information 306 of FIG. 11 to the display device 3 of FIG. The display device 3 presents the modified drug information 306 of FIG. 11 to the user.
以上の述べた処理は、以下の理由から、図11の医薬情報304における患者IDによって特定される患者の非小細胞肺がんの処置にとって最適な投与計画の1つを提案している。当該患者(EML-ALK融合遺伝子を有していない(つまり染色体転座を生じていない))の非小細胞肺がんには、ALKチロシンキナーゼ阻害剤(リクゾチニブおよびセリチニブ)の投与は、有効ではない(図11の関連性情報315および316の薬効「-∞」)。EGFRチロシンキナーゼ阻害剤は、ホモ接合型またはヘテロ接合型の変異(G/GまたはG/T)を、EGFR遺伝子の2573位に少なくとも有している患者の非小細胞肺がんにのみ有効である(図11の関連性情報317および318の薬効「2」および「1」)。一方、上記EGFRチロシンキナーゼ阻害剤のうち、ゲフィチニブの投与に対して、上記患者は耐性を示し得る(図11の関連性情報317の薬効「-1」)。上記EGFRチロシンキナーゼ阻害剤のうち、オシメルチニブメシル酸塩は、ゲフィチニブに耐性を示す患者における治療効果を期待されている薬剤である。当該オシメルチニブメシル酸塩は、ゲフィチニブへの上記耐性と関連するT790M変異(790位におけるトレオニンのメチオニンへの置換)を有しているEGFRタンパク質のキナーゼ活性を、不可逆的に阻害する。
The above-mentioned treatment proposes one of the optimal administration plans for the treatment of non-small cell lung cancer of a patient identified by the patient ID in the drug information 304 of FIG. 11 for the following reasons. Administration of ALK tyrosine kinase inhibitors (lyxotinib and ceritinib) is not effective for non-small cell lung cancer in the patient (who does not have the EML-ALK fusion gene (ie, does not develop a chromosomal translocation)). Relevance information of FIG. 11 Medicinal efficacy “−∞” in 315 and 316). EGFR tyrosine kinase inhibitors are only effective against non-small cell lung cancer in patients who have at least a homozygous or heterozygous mutation (G / G or G / T) at position 2573 of the EGFR gene (" The efficacy “2” and “1” of the relevant information 317 and 318 in FIG. 11). On the other hand, among the EGFR tyrosine kinase inhibitors, the patient may show resistance to the administration of gefitinib (drug efficacy "-1" in the relevant information 317 of FIG. 11). Among the above-mentioned EGFR tyrosine kinase inhibitors, ossimertinib mesylate is a drug expected to have a therapeutic effect in patients who are resistant to gefitinib. The ossimeltinib mesylate irreversibly inhibits the kinase activity of the EGFR protein having the T790M mutation (replacement of threonine with methionine at position 790) associated with the above resistance to gefitinib.
以上では、図11の医薬情報304に含まれている医薬名として、作用機序を含む名称(複数の薬剤を包含し得る)を例示した。医薬名として単一の薬剤を表している医薬情報305を、システム1(図2)に入力したときにも、複数の関連性情報を同時に取得し得ることをさらに例示する。医薬情報として図11の医薬情報305を図2の情報取得部21が取得すると、図2の医薬情報変更部23は、図3のS5において「NO」と判定する。図11の医薬情報305には、図11の医薬情報304と同じ患者IDおよびALKチロシンキナーゼ阻害剤(の一種)が記述されているから、上述した処理と同じ処理(図3のS7において「YES」)が実施される。
In the above, as the drug name included in the drug information 304 of FIG. 11, a name including a mechanism of action (which may include a plurality of drugs) is exemplified. Further exemplifying that a plurality of relevance information can be acquired at the same time even when the drug information 305 representing a single drug as a drug name is input to the system 1 (FIG. 2). When the information acquisition unit 21 of FIG. 2 acquires the drug information 305 of FIG. 11 as the drug information, the drug information change unit 23 of FIG. 2 determines “NO” in S5 of FIG. Since the same patient ID and (a type of) ALK tyrosine kinase inhibitor as in the drug information 304 of FIG. 11 are described in the drug information 305 of FIG. 11, the same process as the above-mentioned process (YES in S7 of FIG. 3). ") Is carried out.
図11の医薬情報305における医薬名は、十分でない適合度を必ず有しているALKチロシンキナーゼ阻害剤ではない、医薬名に変更される。当該医薬名を選択する条件は、「ALKチロシンキナーゼ阻害剤ではない」なので、当該医薬名は「EGFRチロシンキナーゼ阻害剤」であり得る。
The drug name in the drug information 305 of FIG. 11 is changed to a drug name that is not an ALK tyrosine kinase inhibitor that always has insufficient goodness of fit. Since the condition for selecting the drug name is "not an ALK tyrosine kinase inhibitor", the drug name can be "EGFR tyrosine kinase inhibitor".
図2のシステム1は、医薬名が「EGFRチロシンキナーゼ阻害剤」に変更された図11の医薬情報305に基づいて、上述したように、図11の関連性情報317および318を取得する。図2の情報取得部21および適合度決定部22は、図11の医薬情報304における医薬名がゲフィチニブであるときの処理および医薬情報304における医薬名がオシメルチニブメシル酸塩であるときの処理(図3のS3~S5)を並行して、実施する。最終的に、上述した工程により、図11の変更医薬情報306(オシメルチニブメシル酸塩を含む)を、図2の表示装置3に表示する。
System 1 of FIG. 2 acquires the relevance information 317 and 318 of FIG. 11 as described above based on the pharmaceutical information 305 of FIG. 11 whose drug name has been changed to "EGFR tyrosine kinase inhibitor". The information acquisition unit 21 and the goodness-of-fit determination unit 22 in FIG. 2 are processed when the drug name in the drug information 304 of FIG. 11 is gefitinib and when the drug name in the drug information 304 is ossimertinib mesylate. (S3 to S5 in FIG. 3) are carried out in parallel. Finally, by the steps described above, the modified pharmaceutical information 306 (including osimertinib mesylate) of FIG. 11 is displayed on the display device 3 of FIG.
なお、投与計画提案システム1は、上述した4つの薬剤名(リクゾチニブ、セリチニブ、ゲフィチニブおよびオシメルチニブメシル酸塩)を医薬名として、「123456789」を患者IDとして含んでいる医薬情報(すなわち、上述した遺伝型を保持する非小細胞肺がん患者の医薬情報)の入力を受けた場合にも、図11の変更医薬情報306(または、適合度が基準値以上で好適であるため、図3のS5の判定で「YES」となり、変更がない医薬情報305(図11)として)、最終的に、上述した工程により、オシメルチニブメシル酸塩を表示する。つまり、投与計画提案システム1は、入力された複数の薬剤名から、最も高い適合度を有している1つの薬剤を選択し、提案できる。
In addition, the administration plan proposal system 1 includes the above-mentioned four drug names (lyxotinib, seritinib, gefitinib and osimertinib mesylate) as the drug name and "123456789" as the patient ID (that is, the above-mentioned drug information). Even when the input of the non-small cell lung cancer patient having the same hereditary type is received, the modified drug information 306 of FIG. The determination is "YES", and there is no change in the drug information 305 (FIG. 11). Finally, the ossimertinib mesylate is displayed by the above-mentioned step. That is, the administration plan proposal system 1 can select and propose one drug having the highest goodness of fit from a plurality of input drug names.
以上に例示した上記ALKチロシンキナーゼ阻害剤およびEGFRチロシンキナーゼ阻害剤は、非小細胞肺がんの治療に用いられる分子標的医薬と呼ばれる。分子標的医薬は、特定の変異を有する遺伝子産物を標的とする医薬を指す、用語である。例えば、上述したように、上記ALKチロシンキナーゼ阻害剤は、EML-ALK融合遺伝子を有している(つまり染色体転座が生じている)患者にのみ有効である(図11の関連性情報315および316を参照)。上記EGFRチロシンキナーゼ阻害剤は、ホモ接合型またはヘテロ接合型の変異を、EGFR遺伝子の2573位に少なくとも有している患者にのみ有効である(図11の関連性情報317および318を参照)。現在、上記分子標的医薬のほとんどは、抗がん剤である。しかし、将来的には、他の疾患に対する治療薬としての分子標的医薬が開発されると予想される。
The above-exemplified ALK tyrosine kinase inhibitor and EGFR tyrosine kinase inhibitor are called molecular-targeted drugs used for the treatment of non-small cell lung cancer. Molecular-targeted drug is a term that refers to a drug that targets a gene product with a specific mutation. For example, as mentioned above, the ALK tyrosine kinase inhibitor is only effective in patients who carry the EML-ALK fusion gene (ie, have a chromosomal translocation) (relevance information 315 and FIG. 11). See 316). The EGFR tyrosine kinase inhibitor is only effective in patients who have at least a homozygous or heterozygous mutation at position 2573 of the EGFR gene (see relevance information 317 and 318 in FIG. 11). Currently, most of the above molecular-targeted drugs are anticancer agents. However, in the future, it is expected that molecular-targeted drugs will be developed as therapeutic agents for other diseases.
(その他)
上記システムを実行するプログラム全体は、外部(ユーザの使用するコンピュータ)からアクセス可能なイントラネットまたはインターネットを介して実行可能である。上記システムは、ユーザに出力した情報を、紙面に印刷するための印刷装置(例えばプリンタまたは複合機)と接続されていてもよい。 (others)
The entire program that executes the system can be executed via an intranet or the Internet accessible from the outside (computer used by the user). The system may be connected to a printing device (for example, a printer or a multifunction device) for printing the information output to the user on paper.
上記システムを実行するプログラム全体は、外部(ユーザの使用するコンピュータ)からアクセス可能なイントラネットまたはインターネットを介して実行可能である。上記システムは、ユーザに出力した情報を、紙面に印刷するための印刷装置(例えばプリンタまたは複合機)と接続されていてもよい。 (others)
The entire program that executes the system can be executed via an intranet or the Internet accessible from the outside (computer used by the user). The system may be connected to a printing device (for example, a printer or a multifunction device) for printing the information output to the user on paper.
〔実施形態1-1〕
図13にその構成を例示する本発明の他の態様は、患者にとって好適な投与計画を提案するシステム(投与計画提案システム10)であって、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部(情報取得部21);上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部(情報取得部21);上記患者の遺伝型情報を取得する遺伝型情報取得部(情報取得部21);上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部22;ならびに上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部25;上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部(表示装置3)を備えている。 [Embodiment 1-1]
Another aspect of the present invention exemplifying the configuration in FIG. 13 is a system (administration plan proposal system 10) that proposes an administration plan suitable for a patient, and is a medicine that represents the medicine to be administered to the patient and the dose thereof. Pharmaceutical information acquisition unit (information acquisition unit 21) for acquiring information; relevance information acquisition unit (information acquisition unit 21) for acquiring relevance information indicating the relationship between the drug and the genotype; genotype information of the patient The genotype information acquisition unit (information acquisition unit 21) to be acquired; theconformity determination unit 22 that determines the degree of conformity of the pharmaceutical information based on the relevance information and the genotype information; and the conformity determination unit. Administration plan determination unit 25 that determines suitable drug information for the patient based on the suitability of the drug information; an information presentation unit (display) that presents the drug information determined by the administration plan determination unit to the user. It is equipped with a device 3).
図13にその構成を例示する本発明の他の態様は、患者にとって好適な投与計画を提案するシステム(投与計画提案システム10)であって、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部(情報取得部21);上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部(情報取得部21);上記患者の遺伝型情報を取得する遺伝型情報取得部(情報取得部21);上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部22;ならびに上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部25;上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部(表示装置3)を備えている。 [Embodiment 1-1]
Another aspect of the present invention exemplifying the configuration in FIG. 13 is a system (administration plan proposal system 10) that proposes an administration plan suitable for a patient, and is a medicine that represents the medicine to be administered to the patient and the dose thereof. Pharmaceutical information acquisition unit (information acquisition unit 21) for acquiring information; relevance information acquisition unit (information acquisition unit 21) for acquiring relevance information indicating the relationship between the drug and the genotype; genotype information of the patient The genotype information acquisition unit (information acquisition unit 21) to be acquired; the
つまり、図13の投与計画提案システム10は、医薬情報変更部23(図2)の代わりに投与計画決定部25を備えている点で、図2の投与計画提案システム1と異なる。したがって、図13の投与計画提案システム10は、以下に述べる投与計画決定部25(図13)の処理を除いて、図3に示されている処理を実行する。
That is, the administration plan proposal system 10 of FIG. 13 is different from the administration plan proposal system 1 of FIG. 2 in that the administration plan determination unit 25 is provided instead of the drug information change unit 23 (FIG. 2). Therefore, the administration plan proposal system 10 of FIG. 13 executes the process shown in FIG. 3, except for the process of the administration plan determination unit 25 (FIG. 13) described below.
図13の投与計画決定部25は、適合度決定部22(図13)により決定された医薬情報の適合度に基づき、患者に対する好適な医薬情報を決定する。
The administration plan determination unit 25 in FIG. 13 determines suitable pharmaceutical information for the patient based on the goodness of fit of the pharmaceutical information determined by the goodness-of-fit determination unit 22 (FIG. 13).
一態様において、投与計画決定部25(図13)は、医薬情報変更部23(図2)と同様の機能を有していてもよい。すなわち、適合度決定部22(図13)によって決定された適合度が基準値(例えば「0」)未満の医薬情報を、患者にとって好適でない医薬情報として決定し(図3のS5において「NO」)、当該医薬情報に変更を加えたものを患者にとって好適な医薬情報として決定してもよい(図3のS6を参照)。
In one embodiment, the administration plan determination unit 25 (FIG. 13) may have the same function as the drug information change unit 23 (FIG. 2). That is, the drug information whose goodness of fit determined by the goodness-of-fit determination unit 22 (FIG. 13) is less than the reference value (for example, “0”) is determined as the drug information unsuitable for the patient (“NO” in S5 of FIG. 3). ), The drug information obtained by modifying the drug information may be determined as the drug information suitable for the patient (see S6 in FIG. 3).
また、一態様において、投与計画決定部25(図13)は、適合度決定部22(図13)によって決定された適合度が基準値(例えば「0」)以上の医薬情報を、患者にとって好適な医薬情報として決定してもよいし(図3のS5において「YES」)、適合度が最も高い医薬情報を患者にとって好適な医薬情報として決定してもよい(例えば、上記〔実施形態1〕内の項目(医薬情報における医薬名、および関連性情報と、それらを用いた処理との例示)に記載された非小細胞肺がん患者に対する抗がん剤の投与計画に関する一連の実例内容を参照)。
Further, in one embodiment, the administration planning unit 25 (FIG. 13) suitable for the patient the medical information whose goodness of fit determined by the goodness of fit determination unit 22 (FIG. 13) is equal to or higher than the reference value (for example, “0”). The drug information may be determined as the appropriate drug information (“YES” in S5 of FIG. 3), or the drug information having the highest goodness of fit may be determined as the drug information suitable for the patient (for example, [Embodiment 1] above]. (Refer to the series of examples of anti-cancer drug administration plans for patients with non-small cell lung cancer described in the item (Examples of drug names and relevance information in drug information and treatments using them)). ..
以上の通り、図13の投与計画提案システム10によれば、患者にとって好適な投与計画を提案することができる。
As described above, according to the administration plan proposal system 10 of FIG. 13, it is possible to propose an administration plan suitable for the patient.
〔実施形態2〕
本実施形態では、上記適合度が、医薬の投与によって治療対象でない疾患を発症する素因(発症リスク)に基づいて判断されることを例に説明する。本実施形態に係るシステムは、ヒトゲノム上の多数の座位に関するアレルの組み合わせの型の集合を、上記遺伝型として参照するが、本実施形態はこれに限定されず、1つまたは少数の座位に関するアレルの組み合わせの型の集合を、上記遺伝型として参照し得る(例えば、「単一遺伝子疾患」の実例について、後述されている)。当該遺伝型により上記素因の有無を決定する。つまり、本実施形態のシステムは、医薬の投与と関連して疾患を発症する素因を表す情報(医薬関連疾患情報)を参照して、上記適合度を決定する。つまり、本実施形態は、患者が遺伝学的に発症しやすいが、未だ発症していない疾患の、当該疾患に対する禁忌薬(投薬を行ったときに病状を悪化させる、深刻な副作用が出現する、薬の効果が弱まるなどの可能性が高まることが知られている医薬品)の継続的かつ多量な投与による発症を抑える。 [Embodiment 2]
In the present embodiment, the goodness of fit will be described as an example in which the goodness of fit is determined based on the predisposition (risk of onset) to develop a disease that is not the target of treatment by administration of a drug. The system according to this embodiment refers to a set of allele combinations for multiple loci on the human genome as the genotype, but the present embodiment is not limited to this, and alleles for one or a few loci are loci. A set of combinations of types can be referred to as the above genotypes (eg, examples of "monogenic disease" described below). The presence or absence of the above predisposition is determined by the genotype. That is, the system of the present embodiment determines the goodness of fit with reference to information indicating a predisposition to develop a disease in connection with administration of a drug (pharmaceutical-related disease information). That is, in this embodiment, a contraindicated drug for a disease that the patient is genetically prone to develop but has not yet developed (a serious side effect that aggravates the condition when the drug is administered appears. Suppress the onset of continuous and high-dose administration of (drugs known to increase the possibility of diminishing the effect of the drug).
本実施形態では、上記適合度が、医薬の投与によって治療対象でない疾患を発症する素因(発症リスク)に基づいて判断されることを例に説明する。本実施形態に係るシステムは、ヒトゲノム上の多数の座位に関するアレルの組み合わせの型の集合を、上記遺伝型として参照するが、本実施形態はこれに限定されず、1つまたは少数の座位に関するアレルの組み合わせの型の集合を、上記遺伝型として参照し得る(例えば、「単一遺伝子疾患」の実例について、後述されている)。当該遺伝型により上記素因の有無を決定する。つまり、本実施形態のシステムは、医薬の投与と関連して疾患を発症する素因を表す情報(医薬関連疾患情報)を参照して、上記適合度を決定する。つまり、本実施形態は、患者が遺伝学的に発症しやすいが、未だ発症していない疾患の、当該疾患に対する禁忌薬(投薬を行ったときに病状を悪化させる、深刻な副作用が出現する、薬の効果が弱まるなどの可能性が高まることが知られている医薬品)の継続的かつ多量な投与による発症を抑える。 [Embodiment 2]
In the present embodiment, the goodness of fit will be described as an example in which the goodness of fit is determined based on the predisposition (risk of onset) to develop a disease that is not the target of treatment by administration of a drug. The system according to this embodiment refers to a set of allele combinations for multiple loci on the human genome as the genotype, but the present embodiment is not limited to this, and alleles for one or a few loci are loci. A set of combinations of types can be referred to as the above genotypes (eg, examples of "monogenic disease" described below). The presence or absence of the above predisposition is determined by the genotype. That is, the system of the present embodiment determines the goodness of fit with reference to information indicating a predisposition to develop a disease in connection with administration of a drug (pharmaceutical-related disease information). That is, in this embodiment, a contraindicated drug for a disease that the patient is genetically prone to develop but has not yet developed (a serious side effect that aggravates the condition when the drug is administered appears. Suppress the onset of continuous and high-dose administration of (drugs known to increase the possibility of diminishing the effect of the drug).
図5に示すように、投与計画提案システム1’は、図2の投与計画提案システム1における医薬薬効関連遺伝子情報DB5(図2)の代わりに、医薬関連疾患情報DB7(図5)を備えている点を除いて、投与計画提案システム1(図2)と同じである。投与計画提案システム1’(図5)は、医薬の投与によって治療対象でない疾患の発症を回避する安全性の高い投与計画を提案するシステムである。上記疾患には、特異体質による重篤な副作用の症状や関連疾患も含まれ得る(「特異体質による重篤な副作用」の詳細については、後述されている)。
As shown in FIG. 5, the administration plan proposal system 1'provides a drug-related disease information DB 7 (FIG. 5) in place of the drug efficacy-related gene information DB 5 (FIG. 2) in the administration plan proposal system 1 of FIG. It is the same as the administration plan proposal system 1 (FIG. 2) except that. The administration plan proposal system 1'(FIG. 5) is a system that proposes a highly safe administration plan that avoids the onset of a disease that is not a treatment target by administration of a drug. The above-mentioned diseases may include symptoms of serious side effects due to idiosyncratic drug and related diseases (details of "serious side effects due to idiosyncratic drug" will be described later).
(投与計画提案システム1’の処理)
投与計画の安全性を高めるために、図5の投与計画提案システム1’が実行する処理の一例を、図6を参照して以下に説明する。入力装置4(図5)は、従来の一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)にしたがって、ユーザである医師によって入力された医薬情報303(図7)を情報取得部21(図5)に送る(図6のS1’工程)。情報取得部21(図5)は、図7の医薬情報303に含まれている医薬名が表す薬剤の名称と、当該薬剤の投与によって発症し得る疾患の名称と、当該疾患に対する素因の有無を表す遺伝型の範囲とを記述している関連性情報314(図7)を医薬関連疾患情報DB7(図5)から取得する(図6のS2’工程)。情報取得部21(図5)は、患者ID(図7の医薬情報303を参照)および当該疾患に対する素因の有無を表す遺伝型に関するDNAバリアント群情報(図7の関連性情報314を参照)に基づいて、患者IDおよび疾患の名称に対応する遺伝型情報をゲノム情報DB6(図5)から取得する(図6のS3’工程)。情報取得部21(図5)は、取得した医薬情報303(図7)、関連性情報314(図7)およびゲノム情報DB6(図5)から取得された患者の遺伝型情報を、適合度決定部22(図5)に送る。 (Processing of administration plan proposal system 1')
An example of the process performed by the dosing regimen proposal system 1'in FIG. 5 in order to enhance the safety of the dosing regimen will be described below with reference to FIG. The input device 4 (FIG. 5) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.). The input medical information 303 (FIG. 7) is sent to the information acquisition unit 21 (FIG. 5) (step S1'in FIG. 6). The information acquisition unit 21 (FIG. 5) determines the name of the drug represented by the drug name included in the drug information 303 of FIG. 7, the name of the disease that may develop due to the administration of the drug, and the presence or absence of a predisposition to the disease. Relevance information 314 (FIG. 7) describing the range of the represented hereditary type is acquired from the drug-related disease information DB 7 (FIG. 5) (step S2'in FIG. 6). The information acquisition unit 21 (FIG. 5) provides the patient ID (see Pharmaceutical Information 303 in FIG. 7) and DNA variant group information regarding the genotype indicating the presence or absence of a predisposition to the disease (see relevance information 314 in FIG. 7). Based on this, genotype information corresponding to the patient ID and the name of the disease is acquired from the genomic information DB 6 (FIG. 5) (step S3'in FIG. 6). The information acquisition unit 21 (FIG. 5) determines the goodness of fit of the patient's genotype information acquired from the acquired pharmaceutical information 303 (FIG. 7), relevance information 314 (FIG. 7), and genomic information DB 6 (FIG. 5). Send to section 22 (FIG. 5).
投与計画の安全性を高めるために、図5の投与計画提案システム1’が実行する処理の一例を、図6を参照して以下に説明する。入力装置4(図5)は、従来の一律の要因(主に、患者が患っている疾患の種類、当該疾患の重症度ならびに患者の年齢、体重および性別など)にしたがって、ユーザである医師によって入力された医薬情報303(図7)を情報取得部21(図5)に送る(図6のS1’工程)。情報取得部21(図5)は、図7の医薬情報303に含まれている医薬名が表す薬剤の名称と、当該薬剤の投与によって発症し得る疾患の名称と、当該疾患に対する素因の有無を表す遺伝型の範囲とを記述している関連性情報314(図7)を医薬関連疾患情報DB7(図5)から取得する(図6のS2’工程)。情報取得部21(図5)は、患者ID(図7の医薬情報303を参照)および当該疾患に対する素因の有無を表す遺伝型に関するDNAバリアント群情報(図7の関連性情報314を参照)に基づいて、患者IDおよび疾患の名称に対応する遺伝型情報をゲノム情報DB6(図5)から取得する(図6のS3’工程)。情報取得部21(図5)は、取得した医薬情報303(図7)、関連性情報314(図7)およびゲノム情報DB6(図5)から取得された患者の遺伝型情報を、適合度決定部22(図5)に送る。 (Processing of administration plan proposal system 1')
An example of the process performed by the dosing regimen proposal system 1'in FIG. 5 in order to enhance the safety of the dosing regimen will be described below with reference to FIG. The input device 4 (FIG. 5) is provided by the user's physician according to conventional uniform factors (mainly the type of disease the patient is suffering from, the severity of the disease and the patient's age, weight and gender, etc.). The input medical information 303 (FIG. 7) is sent to the information acquisition unit 21 (FIG. 5) (step S1'in FIG. 6). The information acquisition unit 21 (FIG. 5) determines the name of the drug represented by the drug name included in the drug information 303 of FIG. 7, the name of the disease that may develop due to the administration of the drug, and the presence or absence of a predisposition to the disease. Relevance information 314 (FIG. 7) describing the range of the represented hereditary type is acquired from the drug-related disease information DB 7 (FIG. 5) (step S2'in FIG. 6). The information acquisition unit 21 (FIG. 5) provides the patient ID (see Pharmaceutical Information 303 in FIG. 7) and DNA variant group information regarding the genotype indicating the presence or absence of a predisposition to the disease (see relevance information 314 in FIG. 7). Based on this, genotype information corresponding to the patient ID and the name of the disease is acquired from the genomic information DB 6 (FIG. 5) (step S3'in FIG. 6). The information acquisition unit 21 (FIG. 5) determines the goodness of fit of the patient's genotype information acquired from the acquired pharmaceutical information 303 (FIG. 7), relevance information 314 (FIG. 7), and genomic information DB 6 (FIG. 5). Send to section 22 (FIG. 5).
なお、図6のS2’工程で「NO」(例えば、開発されてから間もない薬剤であるか、あるいは対応する疾患がないため、関連性情報が存在しない)のとき、情報取得部21(図5)は、図7の医薬情報303を表示装置3(図5)に送る。表示装置3(図5)が上記医薬情報を表示し、投与計画提案システム1’(図5)は処理を終了する。また、図6のS3’工程で「NO」(例えば、患者における特定の遺伝子に対応する遺伝型情報が、まだ決定されていない)のとき、情報取得部21(図5)は、図7の医薬情報303を表示装置3(図5)に送る。表示装置3(図5)が上記医薬情報を表示し、図5の投与計画提案システム1’は処理を終了する。
When "NO" (for example, there is no relevant information because the drug has just been developed or there is no corresponding disease) in the S2'step of FIG. 6, the information acquisition unit 21 (for example, FIG. 5) sends the medical information 303 of FIG. 7 to the display device 3 (FIG. 5). The display device 3 (FIG. 5) displays the above-mentioned drug information, and the administration plan proposal system 1'(FIG. 5) ends the process. Further, when “NO” (for example, the genotype information corresponding to a specific gene in the patient has not been determined yet) in the step S3 ′ of FIG. 6, the information acquisition unit 21 (FIG. 5) is shown in FIG. The medical information 303 is sent to the display device 3 (FIG. 5). The display device 3 (FIG. 5) displays the above-mentioned drug information, and the administration plan proposal system 1'in FIG. 5 ends the process.
図5の適合度決定部22は、関連性情報314(図7)、およびゲノム情報DB6(図5)から取得された遺伝型情報に基づいて医薬情報303(図7)の適合度を決定する(図6のS4’工程)。図6のS4’工程の詳細を、図7を参照して説明する。
The goodness-of-fit determination unit 22 of FIG. 5 determines the goodness of fit of pharmaceutical information 303 (FIG. 7) based on the genotype information acquired from the relevance information 314 (FIG. 7) and the genomic information DB 6 (FIG. 5). (Step S4'in FIG. 6). The details of the S4'process of FIG. 6 will be described with reference to FIG. 7.
図7の関連性情報314は、医薬名に対応する有効成分(医薬名:オランザピン、多元受容体作用抗精神病薬MARTA)、当該有効成分の投与によって発症し得ることが知られている疾患名(疾患名:2型糖尿病)、当該疾患にとっての素因を決める遺伝型と関連したPRSパーセンタイルの数値範囲(遺伝型(PRSパーセンタイル):0-69、70-84および85-100)、2型糖尿病の発症への影響(発症リスク:±0、+1および+2)、および「代替投与計画」(なし、要血糖コントロール、およびXへの薬剤変更)を含んでいる。上記「PRSパーセンタイル」の詳細は、下記項目(患者の遺伝型情報)に後述されている。オランザピンは、統合失調症等の治療、双極性障害における躁症状およびうつ症状の改善ならびに抗悪性腫瘍剤の投与に伴う消化器症状(悪心、嘔吐)の改善などに効果を示す非定型抗精神薬である。図5のゲノム情報DB6は、患者がある疾患を発症する素因を表す0~100までの数値(PRSパーセンタイル)を、疾患名ごとに遺伝型情報として格納している。当該数値が100に近いほど、ある疾患を発症する素因が大きいことを表す。したがって、図5の適合度決定部22は、関連性情報314(図7)および2型糖尿病を発症する素因を表す患者の遺伝型情報として「90」を取得しているとき、医薬情報303(図7)におけるオランザピン投与による2型糖尿病の発症リスクを「+2」と決定する。適合度決定部22(図5)は、負の要素である発症リスク「+2」に負の要素を表す値「-1」を乗じた「-2」を適合度として決定する。次いで、適合度決定部22(図5)は、医薬情報303(図7)、適合度「-2」、およびその適合度(「-2」)に対応する関連性情報314(図7)の代替投与計画としての「Xへの薬剤変更」を、医薬情報変更部23(図5)に送る。
The relevance information 314 of FIG. 7 shows an active ingredient corresponding to a drug name (medicine name: olanzapine, a multi-receptor action antipsychotic drug MARTA), and a disease name known to be caused by administration of the active ingredient (medicine name: olanzapine, antipsychotic drug MARTA). Disease name: type 2 diabetes), the numerical range of the PRS percentile associated with the hereditary type that determines the predisposition to the disease (hereditary type (PRS percentile): 0-69, 70-84 and 85-100), of type 2 diabetes Includes effects on onset (risk of onset: ± 0, +1 and +2), and "alternative dosing regimen" (none, glycemic control, and drug change to X). Details of the above "PRS percentile" are described later in the following items (patient genotype information). Olanzapine is an atypical antipsychotic drug that is effective in treating schizophrenia, improving manic and depressive symptoms in bipolar disorder, and improving gastrointestinal symptoms (nausea and vomiting) associated with administration of antineoplastic agents. Is. The genomic information DB 6 of FIG. 5 stores a numerical value (PRS percentile) from 0 to 100, which represents a predisposition for a patient to develop a certain disease, as hereditary information for each disease name. The closer the value is to 100, the greater the predisposition to develop a certain disease. Therefore, when the goodness-of-fit determination unit 22 in FIG. 5 acquires the relevance information 314 (FIG. 7) and the genetic type information of the patient representing the predisposition to develop type 2 diabetes, the pharmaceutical information 303 (FIG. 7). The risk of developing type 2 diabetes due to administration of olanzapine in FIG. 7) is determined to be "+2". The goodness-of-fit determination unit 22 (FIG. 5) determines the goodness of fit as “-2”, which is obtained by multiplying the onset risk “+2”, which is a negative factor, by the value “-1”, which represents a negative factor. Next, the goodness-of-fit determination unit 22 (FIG. 5) of the pharmaceutical information 303 (FIG. 7), the goodness of fit “-2”, and the relevance information 314 (FIG. 7) corresponding to the goodness of fit (“-2”). "Drug change to X" as an alternative administration plan is sent to the drug information change department 23 (FIG. 5).
図5の医薬情報変更部23は負の値である適合度「-2」を非常に低いと判断する(図6のS5’工程)。医薬情報変更部23(図5)は、代替投与計画「Xへの薬剤変更」にしたがって、医薬情報303(図7)における医薬名を「X」に変更する(図6のS6’工程)。S6’工程(図6)における変更が医薬の変更である(図6のS7’工程での判断は「YES」)ので、医薬情報変更部23(図5)は医薬名をXに変更した変更医薬情報を情報取得部21(図5)に送り、図6のS2’工程に戻る。S7’工程(図6)における判断が「NO」になるまで、投与計画提案システム1’(図5)は、図6のS2’~S7’工程を繰り返す(「NO」になった場合、変更医薬情報を表示装置3(図5)に送る(図6のS8’工程)。また、S6’工程(図6)において1日服用量を変更した場合は、変更医薬情報を表示装置3(図5)に送る。最終的に、表示装置3(図5)が変更医薬情報を表示し、図5の投与計画提案システム1’は処理を終了する。
The pharmaceutical information changing unit 23 in FIG. 5 determines that the goodness of fit "-2", which is a negative value, is very low (S5'step in FIG. 6). The drug information changing unit 23 (FIG. 5) changes the drug name in the drug information 303 (FIG. 7) to “X” according to the alternative administration plan “drug change to X” (S6'step in FIG. 6). Since the change in the step S6'(FIG. 6) is a change in the drug (the judgment in the step S7' in FIG. 6 is "YES"), the drug information change unit 23 (FIG. 5) changed the drug name to X. The drug information is sent to the information acquisition unit 21 (FIG. 5), and the process returns to the S2'step of FIG. The administration plan proposal system 1'(FIG. 5) repeats the steps S2'to S7' in FIG. 6 until the judgment in the S7'step (FIG. 6) becomes "NO" (changes when it becomes "NO". The drug information is sent to the display device 3 (FIG. 5) (step S8'in FIG. 6). When the daily dose is changed in the step S6'(FIG. 6), the changed drug information is displayed in the display device 3 (FIG. 6). Finally, the display device 3 (FIG. 5) displays the changed drug information, and the administration plan proposal system 1'in FIG. 5 ends the process.
以上の例示した図6のS4’と異なり、適合度決定部22(図5)は、遺伝型情報として「60」を取得しているとき、オランザピン投与による2型糖尿病の発症リスクの値を「±0」と決定する。適合度決定部22(図5)は、負の要素である発症リスク「±0」に負の要素を表す値「-1」を乗じた「±0」を適合度として決定し、医薬情報変更部23(図5)に送る。医薬情報変更部23(図5)は、適合度「±0」を低くないと判断し、医薬情報303(図7)を表示装置3(図5)に送る。表示装置3(図5)が医薬情報303(図7)を表示し、図5の投与計画提案システム1’は処理を終了する。
Unlike S4'in FIG. 6 illustrated above, the goodness-of-fit determination unit 22 (FIG. 5) sets the value of the risk of developing type 2 diabetes by administration of olanzapine to "60" when the genotype information is "60". ± 0 "is determined. The goodness-of-fit determination unit 22 (FIG. 5) determines the goodness of fit as “± 0”, which is obtained by multiplying the negative factor “onset risk” “± 0” by the value “-1” representing the negative factor, and changes the goodness of fit. Send to section 23 (FIG. 5). The pharmaceutical information changing unit 23 (FIG. 5) determines that the goodness of fit “± 0” is not low, and sends the pharmaceutical information 303 (FIG. 7) to the display device 3 (FIG. 5). The display device 3 (FIG. 5) displays the drug information 303 (FIG. 7), and the administration plan proposal system 1'of FIG. 5 ends the process.
以上の通り、図5の投与計画提案システム1’は、処方箋に指定されている医薬情報(医薬の種類またはその用量)を、当該処方箋に指定されている患者の遺伝型(当該医薬による副次疾患の発症リスクの素因に関連するアレルの組み合わせを表す遺伝型)に適合していないと判断したとき、変更する。当該医薬による副次疾患には、特異体質による重篤な副作用を含むものとする(詳細は後述)。したがって、投与計画提案システム1’(図5)は、患者の遺伝型に応じてリスクの小さく、安全性の高い処方の提示を可能にする。
As described above, the administration plan proposal system 1'in FIG. 5 uses the drug information (type of drug or its dose) specified in the prescription as the genotype of the patient specified in the prescription (secondary to the drug). Change when determined to be incompatible with a genotype that represents a combination of alleles associated with a predisposition to the risk of developing the disease. Secondary diseases caused by the drug include serious side effects due to idiosyncratic constitution (details will be described later). Therefore, the dosing regimen proposal system 1'(FIG. 5) enables the presentation of low-risk, high-safety prescriptions according to the genotype of the patient.
図5の投与計画提案システム1’が、患者にとって適切な投与計画を提示するための本実施形態に係る遺伝型情報および関連性情報の詳細を、以下に説明する。
The details of the genotype information and the relevance information according to the present embodiment for the administration plan proposal system 1'in FIG. 5 to present an appropriate administration plan for the patient will be described below.
(患者の遺伝型情報)
本実施形態では、患者にとっての遺伝型情報は、疾患ごとに対応する値(PRS(Polygenes Risk Score;多遺伝子リスクスコア)パーセンタイル)として表されている。2型糖尿病に対応するPRSパーセンタイルは、ヒト母集団が示す2型糖尿病の発症リスクに関するPRSの正規分布(図1を参照)において、患者のPRSが最下位から数えて何%に該当するかを表している。つまりPRSパーセンタイルは0~100であり、PRSパーセンタイルが大きいほど高い発症リスクを表す。2型糖尿病に関するPRSは、2型糖尿病の発症に影響を与える全てのDNAバリアントの「アレルの型」の組み合わせを点数化し、合計した値である。ある疾患の発症に影響する全てのDNAバリアントの「アレルの型」は、例えば、複雑疾患の感受性を支配する因子を同定する標準的手法であるゲノムワイド関連解析(GWAS: Genomewide Association Study)によって同定されている。任意の疾患に関するPRSパーセンタイルおよびPRSの概要は、ReFlections Vol 45, September 2018(https://rgare.com/docs/default-source/newsletters-articles/reflections-vol-45-sept-2018.pdf?sfvrsn=66979288_0)などに示されている。 (Patient genotype information)
In the present embodiment, the genotype information for the patient is expressed as a value corresponding to each disease (PRS (Polygenes Risk Score) percentile). The PRS percentile fortype 2 diabetes indicates what percentage of the patient's PRS corresponds to the lowest percentage of the normal distribution of PRS for the risk of developing type 2 diabetes (see Figure 1) in the human population. Represents. That is, the PRS percentile is 0 to 100, and the larger the PRS percentile, the higher the risk of onset. The PRS for type 2 diabetes is the sum of the combinations of "aller types" of all DNA variants that affect the onset of type 2 diabetes. The "allergen types" of all DNA variants that affect the development of a disease are identified, for example, by a genome-wide association study (GWAS), which is a standard method for identifying factors that govern susceptibility to complex diseases. Has been done. For an overview of the PRS percentile and PRS for any disease, see ReFlections Vol 45, September 2018 (https://rgare.com/docs/default-source/newsletters-articles/reflections-vol-45-sept-2018.pdf?sfvrsn) = 66979288_0), etc.
本実施形態では、患者にとっての遺伝型情報は、疾患ごとに対応する値(PRS(Polygenes Risk Score;多遺伝子リスクスコア)パーセンタイル)として表されている。2型糖尿病に対応するPRSパーセンタイルは、ヒト母集団が示す2型糖尿病の発症リスクに関するPRSの正規分布(図1を参照)において、患者のPRSが最下位から数えて何%に該当するかを表している。つまりPRSパーセンタイルは0~100であり、PRSパーセンタイルが大きいほど高い発症リスクを表す。2型糖尿病に関するPRSは、2型糖尿病の発症に影響を与える全てのDNAバリアントの「アレルの型」の組み合わせを点数化し、合計した値である。ある疾患の発症に影響する全てのDNAバリアントの「アレルの型」は、例えば、複雑疾患の感受性を支配する因子を同定する標準的手法であるゲノムワイド関連解析(GWAS: Genomewide Association Study)によって同定されている。任意の疾患に関するPRSパーセンタイルおよびPRSの概要は、ReFlections Vol 45, September 2018(https://rgare.com/docs/default-source/newsletters-articles/reflections-vol-45-sept-2018.pdf?sfvrsn=66979288_0)などに示されている。 (Patient genotype information)
In the present embodiment, the genotype information for the patient is expressed as a value corresponding to each disease (PRS (Polygenes Risk Score) percentile). The PRS percentile for
ほとんどの疾患において、各疾患の発症には、ゲノム上にある多数(数十~数百万)のDNAバリアント(例えばSNP)の存在が関与していることが知られている。個々のDNAバリアントは、疾患の発症率にわずかな影響しか与えないが、これらのDNAバリアントの組み合わせは疾患の発症率を顕著に上昇させる。したがって、上記組み合わせに含まれているDNAバリアントのうち、患者のゲノムに存在する一部のDNAバリアントは、例えば、オランザピンの投与を受けた患者が2型糖尿病を発症する素因の有無(およびその程度)を判断する材料であり得る。本実施形態では、遺伝型情報は、ある特定の疾患を発症する素因に寄与するDNAバリアントの組み合わせの一部として患者がどれだけのDNAバリアントを有しているかを、PRSパーセンタイルによって表している。
It is known that in most diseases, the presence of a large number (tens to millions) of DNA variants (for example, SNPs) on the genome is involved in the onset of each disease. Although individual DNA variants have little effect on the incidence of disease, the combination of these DNA variants significantly increases the incidence of disease. Therefore, among the DNA variants included in the above combinations, some DNA variants present in the patient's genome are, for example, predisposed (and to some extent) to develop type 2 diabetes in patients receiving olanzapine. ) Can be a material for judging. In this embodiment, the genotype information represents, by the PRS percentile, how many DNA variants a patient has as part of a combination of DNA variants that contributes to the predisposition to develop a particular disease.
上記遺伝型情報は、公知の全疾患の数と同じ数の、各疾患に対応するPRSパーセンタイルを含んでいることが最も好ましい。上述した「これらのDNAバリアントの組み合わせ」は、疾患ごとに異なる。よって、ある患者にとっての遺伝型情報として、全疾患に対応するPRSパーセンタイルを作成するのに必要な上記遺伝型情報を含んでいることは、投与計画提案システム1’の利便性を最大化する。上記遺伝型情報に含まれているPRSパーセンタイルの数が、公知の全疾患の数に近いほど、投与計画提案システム1’の利便性を向上させるので、好ましい。
Most preferably, the genotype information contains the same number of PRS percentiles corresponding to each disease as the number of all known diseases. The "combination of these DNA variants" described above varies from disease to disease. Therefore, including the above-mentioned genotype information necessary for creating the PRS percentile corresponding to all diseases as the genotype information for a certain patient maximizes the convenience of the administration plan proposal system 1'. It is preferable that the number of PRS percentiles contained in the genotype information is close to the number of all known diseases, because the convenience of the administration plan proposal system 1'is improved.
公知のDNAバリアントの接合型を含むアレルの型(「アレルの型」)を、患者のゲノムを対象に、〔実施形態1〕の項目(患者の遺伝型情報)に記載した2通りの方法(「方法1」ならびに「方法2」)にしたがって、決定可能である。当該方法は、大規模並列DNA塩基配列決定法を利用して決定した「全長文字列」情報を用いる「方法1」、およびDNAマイクロアレイ技術を利用してゲノム網羅的な多型解析をおこなう実験的手法を用いる「方法2」である。全疾患の数と同じ、または当該数に近い数の、疾患に対応するPRSパーセンタイルを含んでいる遺伝型情報の生成には、集団内で頻度の低いDNAバリアント(例えば、SNV、CNV) 、または自動解析に適しないDNAバリアント(例えば、CNP、STRP、あるいはその他の特殊なDNAバリアント)に関する情報も必要になる可能性が高いため、前者の「全長文字列」情報を用いる「方法1」が好ましい。「全長文字列」情報を用いる「方法1」の詳細については、〔実施形態4〕にも後述されている。
The two methods described in the item (Patient genotype information) of [Embodiment 1] for the allele type (“allele type”) including the junction type of a known DNA variant for the patient's genome (the patient's genotype information). It can be determined according to "Method 1" and "Method 2"). This method is an experimental method for performing genome-wide polymorphic analysis using "Method 1" using "full-length character string" information determined using the large-scale parallel DNA sequence determination method and DNA microarray technology. It is "method 2" using the method. DNA variants (eg, SNV, CNV) that are infrequent in the population to generate genotypic information containing the PRS percentile corresponding to the disease, as well as or close to the number of all diseases, or Information on DNA variants that are not suitable for automatic analysis (eg, CNP, STRP, or other special DNA variants) is likely to be needed, so the former "method 1" using "full-length string" information is preferred. .. The details of the "method 1" using the "full-length character string" information are also described later in [Embodiment 4].
上記理由により、図5のゲノム情報DB6は、患者の「遺伝型」情報に加えて、「全長文字列」情報をさらに格納していることが好ましい。すなわち、ある疾患に関与するDNAバリアントが新たに同定され、当該DNAバリアントに関する患者の「アレルの型」を決定して、PRSの一部として点数化する必要がある場合、〔実施形態1〕でも説明したように、上述した「全長文字列」を用いた情報解析による「方法1」は、DNAマイクロアレイ技術を用いた「方法2」やPCRによる個別的な方法などの実験手技による時間や労力の負担がなく、当該疾患に関する一部の遺伝型情報を容易に更新可能である。
For the above reason, it is preferable that the genome information DB 6 of FIG. 5 further stores "full-length character string" information in addition to the patient's "genotype" information. That is, when a DNA variant involved in a disease is newly identified and it is necessary to determine the patient's "allergenotype" for the DNA variant and score it as part of the PRS, also in [Embodiment 1]. As explained, "Method 1" by information analysis using the above-mentioned "full-length character string" is time-consuming and labor-intensive due to experimental techniques such as "Method 2" using DNA microarray technology and individual methods by PCR. There is no burden and some genotypic information about the disease can be easily updated.
(関連性情報314)
本実施形態では、上記遺伝型は、ある特定の疾患に発症する素因に寄与するDNAバリアントの組み合わせに関する遺伝型である。関連性情報314(図7)は、医薬および治療対象外の疾患の関連性(特に医薬の投与が、当該疾患の発症に与える影響)を表している。 (Relevance information 314)
In this embodiment, the genotype is a genotype relating to a combination of DNA variants that contributes to a predisposition to develop a particular disease. Relevance information 314 (FIG. 7) represents the relevance of a drug to a disease not treated (particularly the effect of administration of the drug on the onset of the disease).
本実施形態では、上記遺伝型は、ある特定の疾患に発症する素因に寄与するDNAバリアントの組み合わせに関する遺伝型である。関連性情報314(図7)は、医薬および治療対象外の疾患の関連性(特に医薬の投与が、当該疾患の発症に与える影響)を表している。 (Relevance information 314)
In this embodiment, the genotype is a genotype relating to a combination of DNA variants that contributes to a predisposition to develop a particular disease. Relevance information 314 (FIG. 7) represents the relevance of a drug to a disease not treated (particularly the effect of administration of the drug on the onset of the disease).
図7の関連性情報314には、オランザピンの投与によって発症率が上昇し得る疾患として2型糖尿病が示されている。2型糖尿病の発症率の上昇には、上述の通り、多数のDNAバリアントの存在(遺伝学的素因)が関与することが知られている。関連性情報314(図7)には、遺伝学的素因の程度を判断する基準として、上記遺伝型を表す数値範囲が示されている。各数値範囲には、発症リスクに与える度合い(「±0」~「+2」)が対応付けられている。
Relevance information 314 of FIG. 7 shows type 2 diabetes as a disease whose incidence can be increased by administration of olanzapine. As mentioned above, it is known that the presence of a large number of DNA variants (genetic predisposition) is involved in the increase in the incidence of type 2 diabetes. Relevance information 314 (FIG. 7) shows a numerical range representing the genotype as a criterion for determining the degree of genetic predisposition. Each numerical range is associated with the degree of risk of onset (“± 0” to “+2”).
各数値範囲は任意に設定され得るが、「+1」(投与量の減少、または必要な対応処置)に対応する数値範囲の下限値は70以上(例えば、70、75、80、85、90および95)であり得、「+2」(医薬の変更)に対応する数値範囲の下限値は85以上(例えば、85、90、95および99)であり得る。図5の適合度決定部22は、医薬情報303(図7)の適合度が低いと決定する(ゲノム情報に、2型糖尿病の素因に寄与するDNAバリアントの組み合わせの一部が閾値以上に存在する)基準として、上記下限値の一方を少なくとも使用する。なお、中央値50のPRSパーセンタイルは、母集団の平均的な発症リスクを表しており、「±0」に対応する数値範囲は50を含んでいる。
Each numerical range can be set arbitrarily, but the lower limit of the numerical range corresponding to "+1" (dose reduction or necessary response) is 70 or more (eg 70, 75, 80, 85, 90 and). 95), and the lower limit of the numerical range corresponding to "+2" (drug change) can be 85 or greater (eg, 85, 90, 95 and 99). The goodness-of-fit determination unit 22 of FIG. 5 determines that the goodness of fit of the pharmaceutical information 303 (FIG. 7) is low (in the genomic information, a part of the combination of DNA variants contributing to the predisposition to type 2 diabetes is present above the threshold value). As a reference, at least one of the above lower limit values is used. The PRS percentile with a median of 50 represents the average risk of onset in the population, and the numerical range corresponding to "± 0" includes 50.
図7の関連性情報314は、3つの数値範囲を示しているが、2つの数値範囲(例えば0~84および85~100)のみを示してもよい。このとき、例えば、0~84は「±0」に対応し、85~100は「+2」または「+1」に対応する。つまり、関連性情報314(図7)は、医薬の変更または投与量の変更のみを、図5の投与計画提案システム1’に選択させ得る。また例えば、関連性情報314(図7)は、数値範囲70~84に、代替薬なしではなく、代替薬Xを対応させ得る。つまり、関連性情報314(図7)は、遺伝型に応じて発症リスクを少しでも上昇させる医薬(医薬がある疾患にとっての禁忌薬)に、「非常に低い適合度」を割り当て、「医薬の変更」のみを図5の投与計画提案システム1’に選択させ得る。
The relevance information 314 of FIG. 7 shows three numerical ranges, but may show only two numerical ranges (eg 0-84 and 85-100). At this time, for example, 0 to 84 correspond to "± 0", and 85 to 100 correspond to "+2" or "+1". That is, the relevance information 314 (FIG. 7) may allow the dosing regimen proposal system 1'of FIG. 5 to select only drug changes or dose changes. Further, for example, the relevance information 314 (FIG. 7) may correspond the numerical range 70 to 84 with the alternative drug X rather than without the alternative drug. In other words, the relevance information 314 (Fig. 7) assigns "very low goodness of fit" to drugs (contraindicated drugs for certain diseases) that increase the risk of developing the disease as much as possible according to the genotype, and "the drug of the drug". Only "change" may be selected by the dosing regimen proposal system 1'in FIG.
関連性情報314(図7)を用いる図5の投与計画提案システム1’は、患者が2型糖尿病を発症しているか否かに関わらず、オランザピン(多元受容体作用抗精神病薬:MARTA)の投与量を減らす、必要な対応処置をする、またはその薬剤の種類を変更することを提案可能である。オランザピンの他に、統合失調症治療薬であるチミペロンがパーキンソン病の発症または重篤化を、あるいは慢性心不全・不整脈治療薬であるカルベジロールが気管支喘息の発症または重篤化を、それぞれ促し得ることが知られている。1つの治療薬(特に低分子薬)が、2以上の分子標的に作用すること、または分子標的ではない複数の分子の生理活性に影響することは、よく知られている。特に、関連性情報314(図7)を用いる投与計画提案システム1’(図5)は、2型糖尿病に対する高い発症リスクを示す遺伝型を有している上記患者への禁忌薬(ここではオランザピン)の投与を変更させる提案を行うことが好ましい。
The dosing regimen proposal system 1'of FIG. 5 using relevance information 314 (FIG. 7) is of olanzapine (multireceptor-acting antipsychotic: MARTA) regardless of whether the patient has type 2 diabetes. It may be suggested to reduce the dose, take the necessary response, or change the type of the drug. In addition to olanzapine, timiperone, a treatment for schizophrenia, can promote the onset or aggravation of Parkinson's disease, and carvedilol, a treatment for chronic heart failure and arrhythmic, can promote the onset or aggravation of bronchial asthma. Are known. It is well known that one therapeutic agent (particularly a small molecule drug) acts on more than one molecular target or affects the bioactivity of multiple molecules that are not molecular targets. In particular, the dosing regimen proposal system 1'(FIG. 5) using relevance information 314 (FIG. 7) is a contraindicated drug (here, olanzapine) for the above patients with a genotype showing a high risk of developing type 2 diabetes. ) It is preferable to make a proposal to change the administration.
なお、「独立行政法人医薬品医療機器総合機構」によれば「禁忌薬」に関する定義は以下の通りである。すなわち、医療用医薬品の「添付文書」情報における「禁忌」とは、当該医薬品を使用してはいけない患者を記載している。以下のような点から考えて、ある医薬品を使用することにより、病状が悪化したり、副作用が起こり易くなったり、薬の効果が弱まるなどの可能性が高いため、使用しないこととされている:
・現在の病気(現疾患)
・ある病気が原因となって起こる別の病気(合併症)
・これまでにかかった病気(既往歴)
・ご家族の方の病気(家族歴)
・現在使われている他のお薬(併用薬剤)
・医薬品を使用する方の体質
(以上、「独立行政法人医薬品医療機器総合機構」ホームページより)。 According to the Pharmaceuticals and Medical Devices Agency, the definition of "contraindicated drug" is as follows. That is, the "contraindication" in the "package insert" information of the ethical drug describes the patient who should not use the drug. Considering the following points, it is decided not to use a certain drug because it is highly likely that the condition will worsen, side effects will be more likely to occur, and the effect of the drug will be weakened. :
・ Current illness (current illness)
・ Another illness (complication) caused by one illness
・ Illnesses (history)
・ Illness of family members (family history)
・ Other medicines currently used (concomitant medicines)
・ The constitution of those who use medicines (from the website of "Pharmaceuticals and Medical Devices Agency").
・現在の病気(現疾患)
・ある病気が原因となって起こる別の病気(合併症)
・これまでにかかった病気(既往歴)
・ご家族の方の病気(家族歴)
・現在使われている他のお薬(併用薬剤)
・医薬品を使用する方の体質
(以上、「独立行政法人医薬品医療機器総合機構」ホームページより)。 According to the Pharmaceuticals and Medical Devices Agency, the definition of "contraindicated drug" is as follows. That is, the "contraindication" in the "package insert" information of the ethical drug describes the patient who should not use the drug. Considering the following points, it is decided not to use a certain drug because it is highly likely that the condition will worsen, side effects will be more likely to occur, and the effect of the drug will be weakened. :
・ Current illness (current illness)
・ Another illness (complication) caused by one illness
・ Illnesses (history)
・ Illness of family members (family history)
・ Other medicines currently used (concomitant medicines)
・ The constitution of those who use medicines (from the website of "Pharmaceuticals and Medical Devices Agency").
すなわち、「禁忌」とは、医薬品の「添付文書」に記載される項目の一つであり、ある医薬品を投薬すべきない患者やその状態、併用してはいけない薬剤を示すものである。これを守らず投薬した場合、病状を悪化させる、深刻な副作用が出現する、薬の効果が弱まるなどの可能性が高まる。投薬してはいけないと判断される状態としては、患者の現疾患名や合併症、既往歴、家族歴や体質などが示され得る。
That is, "contraindication" is one of the items described in the "package insert" of a drug, and indicates a patient who should not take a certain drug, its condition, and a drug that should not be used in combination. If the drug is not followed, there is a high possibility that the condition will be aggravated, serious side effects will occur, and the effect of the drug will be weakened. The condition in which it is determined that medication should not be taken may indicate the patient's current disease name, complications, medical history, family history, constitution, and the like.
また、上記「体質」とは、遺伝的体質を含み、本実施形態およびその他の実施形態における、医薬の投与による発症リスクの極めて高い副次的疾患に該当する。遺伝的体質は、後述する「特異体質による重篤な副作用」としての症状や関連疾患も含み得る。このため、現行の各種医薬品の「添付文書」内に「禁忌」として明記された各種の疾患名、ならびに、「特異体質による重篤な副作用」の症状や関連疾患は、本実施形態において、医薬関連疾患情報DB7(図5)における当該薬剤に対する疾患情報として登録することができる。
Further, the above-mentioned "constitution" includes a genetic constitution and corresponds to a secondary disease having an extremely high risk of onset due to administration of a drug in this embodiment and other embodiments. The genetic constitution may also include symptoms and related diseases as "serious side effects due to the idiosyncratic constitution" described later. Therefore, in the present embodiment, various disease names specified as "contraindicated" in the "package insert" of the current various drugs, as well as symptoms and related diseases of "serious side effects due to idiosyncratic drug" are used. It can be registered as disease information for the drug in the related disease information DB 7 (FIG. 5).
また、診療に使われる治療薬およびその他の薬物(麻酔薬など)は、一部の人々において過剰な反応を示すことがある。薬物の副作用にはさまざまな原因がある。タイプAの副作用は比較的一般的で、用量依存的である。これは薬理学で予測可能であり、通常軽度である。一方、タイプBの副作用は、特異体質反応で、単に薬物の用量に関連したものではない。この副作用はまれだが、重篤になることがしばしばある。遺伝的多様性はタイプA、Bの両方の副作用において重要である。
In addition, therapeutic drugs and other drugs (anesthetics, etc.) used in medical treatment may show an excessive reaction in some people. There are various causes for side effects of drugs. Type A side effects are relatively common and dose-dependent. This is pharmacologically predictable and usually mild. Type B side effects, on the other hand, are idiosyncratic reactions and are not merely drug-related. This side effect is rare but often severe. Genetic diversity is important for both type A and type B side effects.
タイプBの副作用のようないわゆる「特異体質による重篤な副作用」の症状や関連疾患には、上述した通り、本実施形態における副次疾患による発症リスクの判断基準によって対処が可能である。
As described above, the symptoms of so-called "serious side effects due to idiosyncratic constitution" such as type B side effects and related diseases can be dealt with by the criteria for determining the risk of developing a secondary disease in the present embodiment.
例えば、抗てんかん薬のカルバマゼピンや高尿酸症・痛風治療薬のアロプリノールを用いた治療においては、稀に、中毒性表皮壊死融解症(ライエル症候群)などの重篤な皮膚障害の副作用を誘発する。当該副作用にとって重要な遺伝的要因のひとつとして、ヒト白血球抗原(Human Leukocyte Antigen、以降「HLA」と記載する)をコードする遺伝子群のうち、特定の遺伝型(例えば、「HLA-B*1502」、「HLA-A*3101」、「HLA-B*5801」)を保持する個人は、上記疾患の発症リスクが高い。このため、カルバマゼピンやアロプリノールなどの薬剤に対する中毒性表皮壊死融解症(ライエル症候群)の発症リスク関連情報を、医薬関連疾患情報DB7(図5)に登録して対処し得る。
For example, treatment with carbamazepine, an antiepileptic drug, or allopurinol, a therapeutic drug for hyperuric acid disease / gout, rarely induces side effects of serious skin disorders such as toxic epidermal necrolysis (Riel syndrome). As one of the important genetic factors for the side effect, a specific genetic type (for example, "HLA-B * 1502") among the genes encoding human leukocyte antigen (hereinafter referred to as "HLA") , "HLA-A * 3101", "HLA-B * 5801")) are at high risk of developing the above diseases. Therefore, information related to the risk of developing toxic epidermal necrolysis (Riel syndrome) to drugs such as carbamazepine and allopurinol can be registered in the drug-related disease information DB7 (FIG. 5) and dealt with.
その他に、薬物による「特異体質による重篤な副作用」の症状や関連疾患として、アトルバスタチンなどのスタチン系薬物(脂質異常症治療薬)による横紋筋融解症(筋組織の破壊)、スキサメトニウム塩化物水和物(即効性筋弛緩薬)による呼吸麻痺、メルカプトプリン水和物(抗悪性腫瘍薬)やアザチオプリン(免疫抑制薬)による骨髄毒性、イソニアジド(抗結核薬)などによる肝障害の誘発、およびクラリスロマイシン(抗菌薬)をはじめとする種々の薬物による多形性心室頻脈などが挙げられ、生命に関わる場合もある。上述した実例をはじめ、様々な薬物による上記タイプBに該当する「特異体質による重篤な副作用」の症状や関連疾患についても、遺伝学的多様性による患者の遺伝型に左右されるため、発症リスク関連情報を、医薬関連疾患情報DB7(図5)に登録して対処し得る。
In addition, as symptoms of "serious side effects due to idiosyncratic constitution" caused by drugs and related diseases, rhizome myolysis (destruction of muscle tissue) due to statin drugs such as atrubastatin (drug for treating lipid disorders), suxamethonium chloride Respiratory palsy due to hydrate (quick-acting muscle relaxant), myelotoxicity due to mercaptopurine hydrate (anti-malignant tumor drug) and azathiopurine (immunosuppressive drug), induction of liver damage due to isoniazide (anti-tuberculosis drug), and Polymorphic ventricular tachycardia caused by various drugs such as clarislomycin (antibacterial drug) may be mentioned and may be life-threatening. In addition to the above-mentioned examples, the symptoms and related diseases of "serious side effects due to idiosyncratic drug" corresponding to the above-mentioned type B due to various drugs are also affected by the genetic type of the patient due to genetic diversity, and therefore develop. Risk-related information can be registered in the drug-related disease information DB 7 (FIG. 5) and dealt with.
また、「発症リスク」の適応範囲としては、単一遺伝子疾患~多遺伝子性疾患(多因子疾患、複雑疾患)が含まれる。種々の疾患を含むヒトの遺伝的形質は、多数の遺伝子の発現や環境要因に依存することが多い。しかし、特定の疾患や一部の形質に関しては、単一の座位における特定の遺伝型が主たる決定要因として働き、この遺伝型は、通常の環境化において、形質を発現する、つまり疾患を発症するために必要かつ十分である。
In addition, the scope of indication of "onset risk" includes monogenic diseases to multigene diseases (multifactorial diseases, complex diseases). Human genetic traits, including various diseases, often depend on the expression of many genes and environmental factors. However, for certain diseases and some traits, a particular genotype in a single locus acts as the primary determinant, and this genotype expresses the trait, or develops the disease, in normal environmental conditions. Necessary and sufficient for.
疾患への遺伝子の関与が基本的に1つの座位によって決定される疾患である「単一遺伝子疾患」はまれであり、一般的な遺伝性疾患は、複数の座位に依存しており、多遺伝子性疾患(複雑疾患、多因子疾患)と呼ばれている。本実施形態の適用範囲は、主として「多遺伝子性疾患」を想定しているが、「単一遺伝子疾患」についても対処し得る。
"Monogenic diseases", in which the involvement of genes in the disease is basically determined by one locus, are rare, and common hereditary diseases are dependent on multiple loci and are multigene. It is called a sexual disorder (complex disorder, multifactorial disorder). The scope of application of this embodiment mainly assumes "multigene disease", but can also deal with "monogenic disease".
例えば、晩発性の単一遺伝子疾患であるハンチントン病の原因遺伝子の変異型を保持する発症リスクの高い若年成人や、乳癌の原因遺伝子BRCA1、BRCA2の変異型を保持しており、将来的に症状が進展する高いリスクがある無症候な個人に対しても、本実施形態における発症リスク関連情報を、医薬関連疾患情報DB7(図5)に登録し対処し得る。
For example, young adults with a high risk of developing a variant of the causative gene of Huntington's disease, which is a late-onset monogenic disease, and mutants of the causative genes BRCA1 and BRCA2 of breast cancer are retained in the future. Even for asymptomatic individuals who have a high risk of developing symptoms, the onset risk-related information in the present embodiment can be registered in the drug-related disease information DB 7 (FIG. 5) and dealt with.
具体的には、単一遺伝子疾患における医薬関連疾患情報DB7(図5)への登録方法として、劣性遺伝疾患においては、その原因遺伝子に関連したアレルが、ホモ変異型(2つの変異アレルを保持)の場合、発症リスクが極めて高く、発症リスク値を「+2」と決定し、「薬剤変更」と設定し得る。また、優性遺伝疾患においては、原因遺伝子に関連したアレルが、ヘテロ接合型(正常なアレルと変異アレルとを保持)か、または、ホモ接合型の場合、発症リスクが極めて高く、発症リスク値を「+2」と決定して、「薬剤変更」と設定し得る。上記ハンチントン病を例に、原因遺伝子に関連した遺伝型の決定方法について、〔実施形態4〕にて後述する。
Specifically, as a method of registering in the drug-related disease information DB7 (FIG. 5) in a single gene disease, in a recessive genetic disease, the allele associated with the causative gene carries a homozygous mutant type (two mutant alleles). In the case of), the onset risk is extremely high, and the onset risk value can be determined as "+2" and set as "drug change". In addition, in dominant genetic diseases, if the allele associated with the causative gene is heterozygous (retaining normal alleles and mutant alleles) or homozygous, the risk of developing the disease is extremely high, and the risk of developing the disease is increased. It can be determined as "+2" and set as "drug change". Taking the above Huntington's disease as an example, a method for determining a genotype associated with a causative gene will be described later in [Embodiment 4].
〔実施形態3〕
本実施形態では、〔実施形態1〕および〔実施形態2〕に説明した処理を複合的に実行するシステムを説明する(図1参照)。すなわち、本実施形態では、図1に示すように、投与計画を変更するための判断基準として、(1)医薬Bの薬物動態学的要因(〔実施形態1〕)、(2)医薬Bの薬力学的要因(〔実施形態1〕)、および(3)医薬Bによる副次疾患の発症リスク(〔実施形態2〕)、以上(1)~(3)の組み合わせを上記判断基準にするシステムを説明する。図8に示すように、投与計画提案システム1’’は、制御部2および表示装置(情報表示部)3を備えている。制御部2(図8)は、情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23を備えている(図8参照)。また、制御部2(図8)は、入力装置4、医薬薬効関連遺伝子情報DB5、ゲノム情報DB6および医薬関連疾患情報DB7と接続されている(図8参照)。つまり、図8の本実施形態のシステム1’’は、(i)上記遺伝子の遺伝型が上記医薬の薬効に影響する程度を表す情報(〔実施形態1〕)および(ii)上記素因の遺伝型が上記医薬の投与によって上記疾患(副次的疾患)の発症リスクに影響する程度を表す発症リスク情報(〔実施形態2〕)の両方を参照して、上記適合度を決定する。 [Embodiment 3]
In this embodiment, a system for executing the processes described in [Embodiment 1] and [Embodiment 2] in a complex manner will be described (see FIG. 1). That is, in the present embodiment, as shown in FIG. 1, the pharmacodynamic factors of (1) Pharmacodynamic B ([Embodiment 1]) and (2) Pharmacodynamic B are used as criteria for changing the administration plan. A system based on the combination of pharmacodynamic factors ([Embodiment 1]), (3) risk of developing a secondary disease due to drug B ([Embodiment 2]), and the above (1) to (3) as the above-mentioned criteria. To explain. As shown in FIG. 8, the administration plan proposal system 1'' includes acontrol unit 2 and a display device (information display unit) 3. The control unit 2 (FIG. 8) includes an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genotype information acquisition unit) 21, a goodness-of-fit determination unit 22, and a drug information change unit 23 (FIG. 8). reference). Further, the control unit 2 (FIG. 8) is connected to the input device 4, the drug efficacy-related gene information DB 5, the genome information DB 6, and the drug-related disease information DB 7 (see FIG. 8). That is, the system 1 ″ of the present embodiment of FIG. 8 is: (i) information indicating the degree to which the genotype of the gene affects the efficacy of the drug ([Embodiment 1]) and (ii) inheritance of the predisposition. The degree of suitability is determined with reference to both onset risk information ([Embodiment 2]) indicating the extent to which the type affects the onset risk of the disease (secondary disease) by administration of the drug.
本実施形態では、〔実施形態1〕および〔実施形態2〕に説明した処理を複合的に実行するシステムを説明する(図1参照)。すなわち、本実施形態では、図1に示すように、投与計画を変更するための判断基準として、(1)医薬Bの薬物動態学的要因(〔実施形態1〕)、(2)医薬Bの薬力学的要因(〔実施形態1〕)、および(3)医薬Bによる副次疾患の発症リスク(〔実施形態2〕)、以上(1)~(3)の組み合わせを上記判断基準にするシステムを説明する。図8に示すように、投与計画提案システム1’’は、制御部2および表示装置(情報表示部)3を備えている。制御部2(図8)は、情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23を備えている(図8参照)。また、制御部2(図8)は、入力装置4、医薬薬効関連遺伝子情報DB5、ゲノム情報DB6および医薬関連疾患情報DB7と接続されている(図8参照)。つまり、図8の本実施形態のシステム1’’は、(i)上記遺伝子の遺伝型が上記医薬の薬効に影響する程度を表す情報(〔実施形態1〕)および(ii)上記素因の遺伝型が上記医薬の投与によって上記疾患(副次的疾患)の発症リスクに影響する程度を表す発症リスク情報(〔実施形態2〕)の両方を参照して、上記適合度を決定する。 [Embodiment 3]
In this embodiment, a system for executing the processes described in [Embodiment 1] and [Embodiment 2] in a complex manner will be described (see FIG. 1). That is, in the present embodiment, as shown in FIG. 1, the pharmacodynamic factors of (1) Pharmacodynamic B ([Embodiment 1]) and (2) Pharmacodynamic B are used as criteria for changing the administration plan. A system based on the combination of pharmacodynamic factors ([Embodiment 1]), (3) risk of developing a secondary disease due to drug B ([Embodiment 2]), and the above (1) to (3) as the above-mentioned criteria. To explain. As shown in FIG. 8, the administration plan proposal system 1'' includes a
投与計画提案システム1’’(図8)は、S1~S7(S9を含む)工程(図3を参照)を実行し、S8工程(図3を参照)を実行せずに、変更医薬情報または変更なしの医薬情報に対するS2’~S8’(S9’を含む)工程(図6を参照)を実行する。したがって、図3のS7から図6のS2’工程に移行する処理、およびS2’工程(図6)を実行する詳細を説明する。
The dosing regimen proposal system 1'' (FIG. 8) performs the S1 to S7 (including S9) steps (see FIG. 3) and does not perform the S8 step (see FIG. 3), but the modified drug information or The steps S2'to S8'(including S9') (see FIG. 6) for the unchanged drug information are performed. Therefore, the process of shifting from S7 of FIG. 3 to the S2'process of FIG. 6 and the details of executing the S2'process (FIG. 6) will be described.
例えば、〔実施形態1〕で示したフェニトイン(図4の医薬情報301)の場合、関連性情報311(図4)において、上述の通り、CYP2C9内のSNP(rs1057910)に関する遺伝型情報としてヘテロ接合型「*1/*3」を取得しているとき、S7工程(図3)において、投与計画提案システム1’’(図8)の医薬情報変更部23は、判断「NO」を行った後に、「一日服用量(維持量)」を225mgに変更した変更医薬情報302(図4)を情報取得部21(図8)に送る(図6のS2’工程に移行)。S2’工程(図6)において、変更医薬情報に含まれている変更が一日服用量であるとき、情報取得部21(図8)は、医薬関連疾患情報DB7(図8)から医薬関連疾患情報を取得する。以降のS3’~S9’工程(図6)では、「医薬情報」が「変更医薬情報」に置き換わり、かつ医薬情報変更部23(図8)は、医薬名を変更した(図6のS7’工程で判断「YES」に該当する)医薬情報を情報取得部21(図8)に送り、図3の処理S2工程に戻る2点を除いて、本実施形態は、上述の通り、〔実施形態1〕および〔実施形態2〕において説明した処理を実行するシステムに準ずるものである。
For example, in the case of phenytoin (pharmaceutical information 301 in FIG. 4) shown in [Embodiment 1], heterozygotes as genotype information regarding SNP (rs1057910) in CYP2C9 in the relevance information 311 (FIG. 4) as described above. When the type "* 1 / * 3" is acquired, in the S7 step (FIG. 3), the drug information changing unit 23 of the administration plan proposal system 1'' (FIG. 8) makes a judgment "NO". , The changed drug information 302 (FIG. 4) in which the "daily dose (maintenance dose)" is changed to 225 mg is sent to the information acquisition unit 21 (FIG. 8) (shift to the S2'step of FIG. 6). In the step S2'(FIG. 6), when the change included in the changed drug information is the daily dose, the information acquisition unit 21 (FIG. 8) receives the drug-related disease from the drug-related disease information DB 7 (FIG. 8). Get information. In the subsequent steps S3'to S9'(FIG. 6), "medicine information" was replaced with "changed drug information", and the drug information changing unit 23 (FIG. 8) changed the drug name (S7' in FIG. 6). As described above, the present embodiment is described in the above-described embodiment, except for two points in which the drug information (corresponding to the determination “YES” in the process) is sent to the information acquisition unit 21 (FIG. 8) and the process returns to the process S2 step of FIG. It conforms to the system that executes the processes described in 1] and [Embodiment 2].
以上の通り、図8の投与計画提案システム1’’は、処方箋に指定されている医薬情報(医薬の種類またはその用量)を、当該処方箋に指定されている患者の遺伝型(当該医薬の有効性に影響する特定遺伝子の遺伝型、および当該医薬による副次疾患の発症リスクの存在を表す特定遺伝子の遺伝型)に適合していないと判断したとき、変更する。したがって、投与計画提案システム1’’(図8)は、患者の遺伝型に応じた総合的な(薬効に優れ、かつリスクが小さく安全である)処方の提示を可能にする。
As described above, the administration plan proposal system 1'' in FIG. 8 uses the drug information (type of drug or its dose) specified in the prescription as the genotype of the patient specified in the prescription (effectiveness of the drug). If it is determined that the genotype of a specific gene that affects sex and the genotype of a specific gene that indicates the existence of a risk of developing a secondary disease due to the drug are not compatible, the change is made. Therefore, the dosing regimen proposal system 1 ″ (FIG. 8) enables the presentation of a comprehensive prescription (excellent in efficacy, low risk and safe) according to the patient's genotype.
〔実施形態4〕
本実施形態では、公知のDBに格納されているヒトゲノム(「参照文字列」)ではなく、個人から得られたゲノムの全ヌクレオチド配列(「全長文字列」)における任意のDNAバリアントの「アレルの型」(患者の「遺伝型」)を決定する方法(〔実施形態1〕および〔実施形態2〕の各項目(患者の遺伝型情報)に記載した「方法1」)を説明する。上記DNAバリアントは、SNP、SNV、インデル、CNP、CNV、マイクロサテライト多型(「STRP」)を含むあらゆるヌクレオドの変化である。当該方法では、上記標的ヌクレオチドを挟む2つのヌクレオチド配列を表す2つの文字列を、基準のヒトゲノムを表す公知の文字列(「参照文字列」)から抽出し、使用する。 [Embodiment 4]
In this embodiment, the "allergen" of any DNA variant in the entire nucleotide sequence of the genome obtained from an individual ("full length string") rather than the human genome ("reference string") stored in a known DB. A method for determining a type (genotype of a patient) (“method 1” described in each item (genotype information of a patient) of [Embodiment 1] and [Embodiment 2]) will be described. The DNA variants are variations of any nucleodo, including SNPs, SNVs, indels, CNPs, CNVs, microsatellite polymorphisms (“STRP”). In this method, two character strings representing the two nucleotide sequences sandwiching the target nucleotide are extracted from a known character string (“reference character string”) representing the reference human genome and used.
本実施形態では、公知のDBに格納されているヒトゲノム(「参照文字列」)ではなく、個人から得られたゲノムの全ヌクレオチド配列(「全長文字列」)における任意のDNAバリアントの「アレルの型」(患者の「遺伝型」)を決定する方法(〔実施形態1〕および〔実施形態2〕の各項目(患者の遺伝型情報)に記載した「方法1」)を説明する。上記DNAバリアントは、SNP、SNV、インデル、CNP、CNV、マイクロサテライト多型(「STRP」)を含むあらゆるヌクレオドの変化である。当該方法では、上記標的ヌクレオチドを挟む2つのヌクレオチド配列を表す2つの文字列を、基準のヒトゲノムを表す公知の文字列(「参照文字列」)から抽出し、使用する。 [Embodiment 4]
In this embodiment, the "allergen" of any DNA variant in the entire nucleotide sequence of the genome obtained from an individual ("full length string") rather than the human genome ("reference string") stored in a known DB. A method for determining a type (genotype of a patient) (“
上記方法では、標的ヌクレオチドの種類に応じて、(1)標的ヌクレオチドおよびこれを挟む「参照文字列」由来の2つのヌクレオチド配列が結合した配列を表す1つの連続した文字列、または(2)標的ヌクレオチドを挟む「参照文字列」由来の2つのヌクレオチド配列のそれぞれを示す2つの文字列が使用される。(1)は、標的ヌクレオチドが、ヒトゲノムにおいて公知であり、かつSNP、SNVまたはインデルであるときに、「アレルの型」(患者の「遺伝型」)の簡便な決定法として使用される。(2)は、あらゆるDNAバリアント(上述したSNP、SNVまたはインデルを含む)の「アレルの型」の決定に適用可能であるが、特に、標的ヌクレオチドの長さの変化、ならびに多数の選択肢が存在する、または標的ヌクレオチドの詳細が不明な場合に有効な方法である。図9および10を参照して、(1)および(2)の文字列を用いる上記方法を以下に説明する。
In the above method, depending on the type of target nucleotide, (1) one continuous character string representing a sequence in which two nucleotide sequences derived from the target nucleotide and the "reference character string" sandwiching the target nucleotide are combined, or (2) the target. Two strings are used that indicate each of the two nucleotide sequences derived from the "reference string" that sandwiches the nucleotides. (1) is used as a convenient method for determining the "allelic type" (patient's "genotype") when the target nucleotide is known in the human genome and is SNP, SNV or indel. (2) is applicable for determining the "allele type" of any DNA variant (including the SNPs, SNVs or indels described above), but in particular there are variations in the length of the target nucleotide and numerous options. This is an effective method when the details of the target nucleotide are unknown. The above method using the character strings of (1) and (2) will be described below with reference to FIGS. 9 and 10.
(SNP、SNVまたはインデルの「アレルの型」を決定する簡便な方法)
上述した(1)の文字列による当該方法は、特に、SNP、SNVまたはインデルのアレルの型を決定する簡便な方法である。図9に示されているように、(1)の文字列は、標的ヌクレオチド(SNP、SNVまたはインデル)を表す文字列902、文字列902を挟む2つのヌクレオチド配列を表す2つ文字列901および903を含んでいる、1つの連続した文字列である。文字列901および903は、基準のヒトゲノムを表す文字列(「参照文字列」)(例えば、アンサンブル(Ensemble、URL:http://ensembl.org)から取得可能)の一部として決定される(図10のS11工程)。文字列902(標的ヌクレオチドを表す文字(列))は、本実施形態に係る方法を実施する時点で既知の(以降では単に「既知の」と記載する)DNAバリアントとして、既知のDBに格納されている。つまり上記「DNAバリアント」は、本願の出願以降に見いだされたDNAバリアントも含まれ得る。たとえば、既知の全SNPに関する情報は、dbSNPデータベース(https://www.ncbi.nlm.nih.gov/snp/)より取得可能である。文字列902(標的ヌクレオチドを表す文字(列))が、基準のヒトゲノムを表す文字列(「参照文字列」)に存在する位置の情報も、当該DB(例えば、上記のdbSNPデータベース)に格納されている。(1)の文字列において、文字列901と文字列903の長さは同一に設定し、解析部位(文字列902)を中央に配置することが好ましい。 (A simple way to determine the "allele type" of an SNP, SNV or indel)
The above-mentioned method using the character string (1) is, in particular, a simple method for determining the type of SNP, SNV, or indel allele. As shown in FIG. 9, the character string (1) is acharacter string 902 representing a target nucleotide (SNP, SNV or indel), a two character string 901 representing two nucleotide sequences sandwiching the character string 902, and a character string 901. One contiguous string containing 903. The strings 901 and 903 are determined as part of a string representing the reference human genome (“reference string”) (eg, available from an ensemble (URL: http://ensembl.org)) (ensemble, URL: http://ensembl.org). Step S11 in FIG. 10). The character string 902 (character (string) representing the target nucleotide) is stored in a known DB as a DNA variant known at the time of carrying out the method according to the present embodiment (hereinafter, simply referred to as "known"). ing. That is, the above-mentioned "DNA variant" may also include a DNA variant found after the filing of the present application. For example, information about all known SNPs can be obtained from the dbSNP database (https://www.ncbi.nlm.nih.gov/snp/). Information on the position where the character string 902 (character (string) representing the target nucleotide) exists in the character string representing the reference human genome (“reference character string”) is also stored in the DB (for example, the above dbSNP database). ing. In the character string of (1), it is preferable that the lengths of the character string 901 and the character string 903 are set to be the same, and the analysis part (character string 902) is arranged in the center.
上述した(1)の文字列による当該方法は、特に、SNP、SNVまたはインデルのアレルの型を決定する簡便な方法である。図9に示されているように、(1)の文字列は、標的ヌクレオチド(SNP、SNVまたはインデル)を表す文字列902、文字列902を挟む2つのヌクレオチド配列を表す2つ文字列901および903を含んでいる、1つの連続した文字列である。文字列901および903は、基準のヒトゲノムを表す文字列(「参照文字列」)(例えば、アンサンブル(Ensemble、URL:http://ensembl.org)から取得可能)の一部として決定される(図10のS11工程)。文字列902(標的ヌクレオチドを表す文字(列))は、本実施形態に係る方法を実施する時点で既知の(以降では単に「既知の」と記載する)DNAバリアントとして、既知のDBに格納されている。つまり上記「DNAバリアント」は、本願の出願以降に見いだされたDNAバリアントも含まれ得る。たとえば、既知の全SNPに関する情報は、dbSNPデータベース(https://www.ncbi.nlm.nih.gov/snp/)より取得可能である。文字列902(標的ヌクレオチドを表す文字(列))が、基準のヒトゲノムを表す文字列(「参照文字列」)に存在する位置の情報も、当該DB(例えば、上記のdbSNPデータベース)に格納されている。(1)の文字列において、文字列901と文字列903の長さは同一に設定し、解析部位(文字列902)を中央に配置することが好ましい。 (A simple way to determine the "allele type" of an SNP, SNV or indel)
The above-mentioned method using the character string (1) is, in particular, a simple method for determining the type of SNP, SNV, or indel allele. As shown in FIG. 9, the character string (1) is a
したがって、上記方法によって、既知のSNP、SNVまたはインデルの「アレルの型」を、個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)に、(1)の文字列が含まれているか否かによって決定する(図10のS12工程)。個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)に、(1)の文字列が含まれ得る位置は、上記DBに格納されている基準のヒトゲノム(「参照文字列」)の位置の情報から推定可能である。したがって、例えば、(1)の文字列と完全一致する1つの文字列を見出したとき(図10のS13工程)、個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)から、(1)の文字列を含み得る文字列を抽出し、当該文字列と(1)の文字列とを比較することによって、個人の全ゲノムのヌクレオチド配列(「全長文字列」)における既知のSNP、SNVまたはインデルの「アレルの型」を決定できる(図10のS14工程)。
Therefore, by the above method, the character string (1) is included in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual with the known “allele type” of SNP, SNV or indel. It is determined depending on whether or not it is present (step S12 in FIG. 10). The position where the character string of (1) can be included in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual is the reference human genome (“reference character string”) stored in the above DB. It can be estimated from the information of the position of. Therefore, for example, when one character string that completely matches the character string of (1) is found (step S13 in FIG. 10), from the character string representing the nucleotide sequence of the entire genome of an individual (“full-length character string”), By extracting a character string that can contain the character string of (1) and comparing the character string with the character string of (1), a known SNP in the nucleotide sequence (“full-length character string”) of the entire genome of an individual. , SNV or Indel "type of allele" can be determined (step S14 in FIG. 10).
ここで、図9の文字列901および903の長さは、少なくとも10文字(例えば、10、20、30、40、50、100、150、200文字またはそれ以上)、好ましくは10~1000文字である。(1)の文字列の文字数が少ないほど、個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)に、(1)の文字列と完全一致する2以上の文字列を見出す確率が高くなる。(1)の文字列と完全一致する2以上の文字列を見出したとき(図10のS13工程で「NO」)、2つの文字列(図9の文字列901と文字列903)の長さを均等にそれぞれ1文字以上(例えば、1、3、5、10、20、25、50または100文字)ずつ延長する(図10のS16工程)ことによって、上記確率が低下する。ただし、2つの文字列の合計は、例えば、10000文字以下である。極端に長い2つの文字列(図9の文字列901と文字列903)の一方が、標的ヌクレオチド(図9の文字列902)以外のDNAバリアントを表す文字列を含んでいるとき、結果「(1)の文字列は、個人の全ゲノムのヌクレオチド配列を表す文字列に含まれていない」が必ず現れるためである。
Here, the length of the character strings 901 and 903 in FIG. 9 is at least 10 characters (for example, 10, 20, 30, 40, 50, 100, 150, 200 characters or more), preferably 10 to 1000 characters. be. The smaller the number of characters in the character string of (1), the higher the probability of finding two or more character strings that exactly match the character string of (1) in the character string representing the nucleotide sequence of the entire genome of an individual (“full-length character string”). Will be higher. When two or more character strings that exactly match the character string of (1) are found (“NO” in step S13 in FIG. 10), the lengths of the two character strings (character string 901 and character string 903 in FIG. 9). Is evenly extended by one or more characters (for example, 1, 3, 5, 10, 20, 25, 50 or 100 characters) (step S16 in FIG. 10) to reduce the above probability. However, the total of the two character strings is, for example, 10,000 characters or less. When one of the two extremely long strings (string 901 and string 903 in FIG. 9) contains a string representing a DNA variant other than the target nucleotide (string 902 in FIG. 9), the result "( This is because "the character string of 1) is not included in the character string representing the nucleotide sequence of the entire genome of an individual" always appears.
例えば、ゲノム上の特定の位置における既知のSNPのアレルの型は、ヌクレオチドの種類と同じく、最大で4種類である。例えば、正常型アレルのヌクレオチドがAで表されるとき、T、GおよびCによって表されるヌクレオチドを含むアレルは、変異型アレルである。したがって、図9の文字列902をA、T、GおよびCに指定して、上述の処理を4回試行することによって、上記特定の位置における既知のSNPのアレルの型を決定可能である(図10のS14工程)。しかしながら、実際には、既知のSNPは、集団内で2種類(まれに3種類)のヌクレオチドが一般的であることから、ほとんど2回の試行で容易に決定可能である。
For example, there are up to four types of known SNP alleles at specific positions on the genome, similar to nucleotide types. For example, when the nucleotides of a normal allele are represented by A, the allele containing the nucleotides represented by T, G and C is a mutant allele. Therefore, by designating the character string 902 of FIG. 9 as A, T, G, and C and trying the above process four times, it is possible to determine the type of allele of a known SNP at the specific position (). Step S14 in FIG. 10). However, in practice, known SNPs can be easily determined in almost two trials, as two (rarely three) nucleotides are common in the population.
図9において、正常型文字列を含む文字列901~903(正常文字列)および変異型文字列を含む文字列901~903(変異文字列)は、個人のゲノムがSNPに関して、ホモ接合型またはヘテロ接合型であるかの決定に使用され得る。例えば、個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)の両方(通常、ゲノムは、母親ならびに父親由来の2セットを保持する接合型として存在する)に、正常文字列が一致し、変異文字列が一致しないとき、当該個人のゲノムは正常型アレルである(正常型:N/N)。また例えば、個人の全ゲノムのヌクレオチド配列を表す文字列の一方に、正常文字列が一致し、他方に変異文字列が一致するとき、当該個人のゲノムは、変異型アレルを一方のゲノムに有している(ヘテロ接合型:N/M)。また例えば、個人の全ゲノムのヌクレオチド配列を表す文字列の両方に、正常文字列が一致せず、変異文字列が一致するとき、当該個人のゲノムは、変異型アレルを両方のゲノムに有している(ホモ接合型:M/M)。
In FIG. 9, the character strings 901 to 903 (normal character strings) including the normal character strings and the character strings 901 to 903 (variable character strings) including the mutant character strings are homozygous or homozygous with respect to the SNP of the individual's genome. It can be used to determine if it is heterojunction. For example, both strings (“full-length strings”) that represent the nucleotide sequences of an individual's entire genome (usually the genome exists as a conjugation that holds two sets from the mother and father) have normal strings. When they match and the mutant strings do not match, the individual's genome is a normal allele (normal: N / N). Also, for example, when a normal character string matches one of the character strings representing the nucleotide sequence of the entire genome of an individual and a mutant character string matches the other, the individual's genome has a mutant allele in one genome. (Heterojunction type: N / M). Also, for example, when the normal string does not match both the strings representing the nucleotide sequences of the entire genome of the individual and the mutant strings match, the individual's genome has the mutant allele in both genomes. (Homozygous type: M / M).
当該個人における上記遺伝型の決定過程を、〔実施形態1〕に記載したフェニトイン(抗てんかん薬)に関する医薬情報301(図4)、ならびに関連性情報311(図4)の情報に基づいて、CYP2C9(薬剤代謝酵素遺伝子)のコード領域内に存在する既知のSNP(rs1057910)を例に、具体的に説明する。上記文字列902に対して、SNP(rs1057910)における野生型(正常型)アレルのヌクレオチドの塩基の種類は「アデニン(A)」であり、フェニトインの代謝率が低下することが知られている低代謝型アレルのヌクレオチドの塩基の種類は「シトシン(C)」である。また、既知のSNPの場合、対応する901ならびに903の文字列は、上記方法により容易に取得可能である。そこで、野生型文字「A」を含む文字列901~903(「野生型文字列」)、および低代謝型文字「C」を含む文字列901~903(「低代謝型文字列」)を抽出して、上記工程を2回試行することにより当該個人の遺伝型を容易に決定できる。
The process of determining the genetic type in the individual is CYP2C9 based on the information of the pharmaceutical information 301 (FIG. 4) regarding the phenytoin (antiepileptic drug) described in [Embodiment 1] and the relevance information 311 (FIG. 4). A known SNP (rs1057910) existing in the coding region of (drug metabolizing enzyme gene) will be specifically described as an example. With respect to the above character string 902, the base type of the nucleotide of the wild type (normal type) allele in SNP (rs1057910) is "adenine (A)", and it is known that the metabolism rate of phenitoin is lowered. The base type of nucleotides in metabolic alleles is "cytosine (C)". Further, in the case of a known SNP, the corresponding character strings 901 and 903 can be easily obtained by the above method. Therefore, the character strings 901 to 903 containing the wild type character "A" ("wild type character string") and the character strings 901 to 903 containing the low metabolism type character "C" ("low metabolism type character string") are extracted. Then, by trying the above steps twice, the genetic type of the individual can be easily determined.
具体的には、個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)に対して、「野生型文字列」が一致し、「低代謝型文字列」が一致しないとき、当該個人のゲノムは野生型アレルを両方のゲノムに有している(野生型:「A/A」)。また例えば、「全長文字列」に対して、「野生型文字列」と「低代謝型文字列」の両方に一致するとき、当該個人のゲノムは、低代謝型アレルを一方のゲノムに有する(ヘテロ接合型:「A/C」)。また例えば、「全長文字列」に対して、「野生型文字列」が一致せず、「低代謝型文字列」が一致するとき、当該個人のゲノムは、低代謝型アレルを両方のゲノムに有している(ホモ接合の低代謝型:「C/C」)。
Specifically, when the "wild-type character string" matches the character string representing the nucleotide sequence of the entire genome of an individual ("full-length character string") and the "low-metaphoric character string" does not match, the relevant character string is concerned. The individual's genome has wild-type alleles in both genomes (wild-type: "A / A"). Also, for example, when both the "wild-type character string" and the "low-metabolizing character string" are matched with respect to the "full-length character string", the genome of the individual has the low-metabolizing allele in one of the genomes ( Heterozygous type: "A / C"). Also, for example, when the "wild-type string" does not match the "full-length string" and the "low-metabolizing string" matches, the individual's genome has the low-metabolizing allele in both genomes. Has (homogeneous low metabolism: "C / C").
以上の過程により決定した当該個人におけるCYP2C9のSNP(rs1057910)のヌクレオチド変化の組み合わせの型(「A/A」、「A/C」または「C/C」)に応じて、関連性情報311(図4)に示す通り、異なる記号化された遺伝型(「*1/*1」、「*1/*3」または「*3/*3」)、ならびに異なる代謝率(薬効)(「±0」、「-1」または「-2」)を決定可能である。
Relevance information 311 (“A / A”, “A / C” or “C / C”) depending on the type of combination of nucleotide changes in SNP (rs1057910) of CYP2C9 in the individual determined by the above process. As shown in Figure 4), different symbolized genotypes (“* 1 / * 1”, “* 1 / * 3” or “* 3 / * 3”), and different metabolic rates (drug effects) (“±”). 0 ”,“ -1 ”or“ -2 ”) can be determined.
決定された遺伝型とともに、個人のゲノムに存在するDNAバリアントを表す情報は、DB、記録媒体または記憶装置に保存されるとともに(図示せず)、ゲノム情報DB6(図2、図5および図8)に格納される(S15工程)。
Information representing DNA variants present in an individual's genome, along with the determined genotype, is stored in a DB, recording medium or storage device (not shown), as well as genomic information DB 6 (FIGS. 2, 5 and 8). ) (Step S15).
(あらゆるDNAバリアントの「アレルの型」の決定に適用できる一般的な方法)
上述した(2)の文字列による当該方法は、あらゆるDNAバリアント(上述したSNP、SNVまたはインデルを含む)の接合型を含むアレルの型(「アレルの型」)の決定に適用可能であるが、特に、標的ヌクレオチドの長さの変化、ならびに多数の選択肢が存在する、または標的ヌクレオチドの詳細が不明な場合に有効な方法である。標的ヌクレオチドの長さの変化、ならびに多数の選択肢は、例えば、マイクロサテライト多型(「STRP」)などのように、反復回数の異なる単純反復配列を標的ヌクレオチドにするときに生じる。また、詳細が不明なときは、例えば、〔実施形態1〕で示したACE遺伝子内に存在するAlu配列の欠失/挿入の多型解析などのほかに、既知の染色体転座が想定され得る。つまり、(2)の文字列は、標的ヌクレオチドの数、さらには標的ヌクレオチドの全長ヌクレオチド配列も決定する必要のあるときに特に有効である。 (General method applicable to determine "allergen type" of any DNA variant)
Although the method according to the string of (2) above is applicable for determining the type of allele (“allele type”) including the mating type of any DNA variant (including the SNP, SNV or indel described above). In particular, it is an effective method when the length of the target nucleotide is changed, and there are many options, or the details of the target nucleotide are unknown. Changes in the length of the target nucleotide, as well as a large number of options, occur when simple repeat sequences with different repeat counts are used as the target nucleotide, for example, microsatellite polymorphisms (“STRP”). When the details are unknown, for example, in addition to the polymorphism analysis of the deletion / insertion of the Alu sequence present in the ACE gene shown in [Embodiment 1], a known chromosomal translocation can be assumed. .. That is, the character string (2) is particularly effective when it is necessary to determine the number of target nucleotides and also the full-length nucleotide sequence of the target nucleotides.
上述した(2)の文字列による当該方法は、あらゆるDNAバリアント(上述したSNP、SNVまたはインデルを含む)の接合型を含むアレルの型(「アレルの型」)の決定に適用可能であるが、特に、標的ヌクレオチドの長さの変化、ならびに多数の選択肢が存在する、または標的ヌクレオチドの詳細が不明な場合に有効な方法である。標的ヌクレオチドの長さの変化、ならびに多数の選択肢は、例えば、マイクロサテライト多型(「STRP」)などのように、反復回数の異なる単純反復配列を標的ヌクレオチドにするときに生じる。また、詳細が不明なときは、例えば、〔実施形態1〕で示したACE遺伝子内に存在するAlu配列の欠失/挿入の多型解析などのほかに、既知の染色体転座が想定され得る。つまり、(2)の文字列は、標的ヌクレオチドの数、さらには標的ヌクレオチドの全長ヌクレオチド配列も決定する必要のあるときに特に有効である。 (General method applicable to determine "allergen type" of any DNA variant)
Although the method according to the string of (2) above is applicable for determining the type of allele (“allele type”) including the mating type of any DNA variant (including the SNP, SNV or indel described above). In particular, it is an effective method when the length of the target nucleotide is changed, and there are many options, or the details of the target nucleotide are unknown. Changes in the length of the target nucleotide, as well as a large number of options, occur when simple repeat sequences with different repeat counts are used as the target nucleotide, for example, microsatellite polymorphisms (“STRP”). When the details are unknown, for example, in addition to the polymorphism analysis of the deletion / insertion of the Alu sequence present in the ACE gene shown in [Embodiment 1], a known chromosomal translocation can be assumed. .. That is, the character string (2) is particularly effective when it is necessary to determine the number of target nucleotides and also the full-length nucleotide sequence of the target nucleotides.
標的ヌクレオチドの全長が数万ヌクレオチドに達し得、標的ヌクレオチドの長さには大きな個体差が生じ得る。したがって、特定の標的ヌクレオチドの全長ヌクレオチド配列は、当該個体のゲノムに基づいて、個々に決定される必要がある。しかし、標的ヌクレオチド(CNP、CNV、STRP)が存在するゲノム上の座位は、SNP、SNVまたはインデルと同様に、ヒトの基準ゲノムではすでに同定されている。当該座位における標的ヌクレオチドの存在位置も相対的に決定されている。つまり、(2)の文字列は、ヒトの基準ゲノムを表す文字列(「参照文字列」)において既知である(図10のS11工程)。
The total length of the target nucleotide can reach tens of thousands of nucleotides, and the length of the target nucleotide can vary greatly from individual to individual. Therefore, the full-length nucleotide sequence of a particular target nucleotide needs to be determined individually based on the genome of the individual. However, the loci on the genome where the target nucleotides (CNP, CNV, STRP) are present have already been identified in the human reference genome, as are SNPs, SNVs or indels. The location of the target nucleotide in the locus is also relatively determined. That is, the character string (2) is known in the character string representing the human reference genome (“reference character string”) (step S11 in FIG. 10).
(2)の文字列は、個人のゲノムに存在する既知のDNAバリンアントを表す標的ヌクレオチドの両側に隣接するヌクレオチド配列を表す文字列と完全一致し得る。したがって、個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)に、(2)の文字列(2つ1組:図9の文字列901ならびに903)が存在するか否かを決定する(図10のS13工程)ことによって、標的ヌクレオチドが個人のゲノム上に存在するか否かを決定できる(図10のS14工程)。(2)の文字列(2つ1組:図9の文字列901ならびに903)の長さは、(1)の文字列における文字列901および903の長さと同様に設定され得る。
The character string of (2) can completely match the character string representing the nucleotide sequences adjacent to both sides of the target nucleotide representing the known DNA valinant existing in the genome of an individual. Therefore, whether or not the character string (two pairs: character strings 901 and 903 in FIG. 9) of (2) exists in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual. By determining (step S13 in FIG. 10), it is possible to determine whether or not the target nucleotide is present on the genome of an individual (step S14 in FIG. 10). The length of the character string (two sets: character strings 901 and 903 in FIG. 9) of (2) can be set in the same manner as the lengths of the character strings 901 and 903 in the character string of (1).
個人の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)における(2)の文字列(2つ1組:図9の文字列901ならびに903)の存在が確認された後に、2つ1組の文字列の間に存在する文字列(図9の文字列902であり、標的ヌクレオチドの全長ヌクレオチド配列を表す)が、抽出される。
After confirming the existence of the character string (2 pairs: character strings 901 and 903 in FIG. 9) in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of an individual, two A string existing between a set of strings (string 902 in FIG. 9, representing the full-length nucleotide sequence of the target nucleotide) is extracted.
例えば、抽出された文字列がマイクロサテライト多型(「STRP」)のように非常に短い配列(1~4塩基対の長さ)の単純反復配列を表すとき、文字列に含まれている反復回数(および、ヌクレオチド総数)がさらに決定される。単純反復配列は、個体のゲノムにおいて、例えば数ヌクレオチド~数十ヌクレオチドを1単位として、反復回数が異なり得る。回数に対応する「アレルの型」を検出する。例えば、2種類の異なる長さの配列を検出した場合、「ヘテロ接合型」、また1種類のみ長さの配列を検出した場合、「ホモ接合型」と決定する。
For example, when the extracted string represents a simple repetitive sequence (length of 1 to 4 base pairs) of a very short sequence (length of 1 to 4 base pairs) such as a microsatellite polymorph (“STRP”), the repetition contained in the string. The number of times (and the total number of nucleotides) is further determined. The simple repetitive sequence may have different number of repetitions in the genome of an individual, for example, with a unit of several nucleotides to several tens of nucleotides. Detect the "allele type" corresponding to the number of times. For example, when two types of sequences having different lengths are detected, it is determined to be "heterozygous type", and when only one type of sequence is detected, it is determined to be "homozygous type".
〔実施形態2〕にて記載した晩発性の単一遺伝子疾患であるハンチントン病の原因遺伝子(HTT)をコード配列内に存在する3ヌクレオチド(CAG)のマイクロサテライト多型(「STRP」)を例に、当該若年成人の無症候者における上記遺伝型の決定過程を具体的に説明する。ハンチントン病の患者では、変異アレルが細胞(特に神経細胞)にとって有害な異常タンパク質を産生する。ニューロンの消失は緩徐であるが、最終的には破壊的な神経変性状態へと至る。症状の発症は通常中年期から更年期に生じる。ハンチントン病は、その原因遺伝子HTTのコード配列上に存在するCAGリピートの不安定な伸長によって長いポリグルタミン鎖が産生されるために起こる。正常型のグルタミンの反復回数は6~35であるのに対して、疾患患者(あるいは、疾患の発症リスクの極めて高い若年成人の無症候者)は、36~121である。
A 3-nucleotide (CAG) microsatellite polymorphism (“STRP”) in which the causative gene (HTT) of Huntington's disease, which is a late-onset monogenic disease described in [Embodiment 2], is present in the coding sequence. As an example, the process of determining the genotype in the asymptomatic young adult will be specifically described. In patients with Huntington's disease, mutant alleles produce abnormal proteins that are detrimental to cells, especially nerve cells. The disappearance of neurons is slow, but eventually leads to a destructive neurodegenerative state. The onset of symptoms usually occurs from middle age to menopause. Huntington's disease results from the production of long polyglutamine chains by the unstable elongation of CAG repeats present on the coding sequence of its causative gene HTT. Normal glutamine repeats are 6-35, whereas diseased patients (or young adult asymptomatic individuals at extremely high risk of developing the disease) are 36-121.
上記のような既知のマイクロサテライト多型(「STRP」)の場合、対応する901ならびに903の文字列は、上記方法により容易に取得可能である。当該若年成人の無症候者の全ゲノムのヌクレオチド配列を表す文字列(「全長文字列」)における(2)の文字列(2つ1組:図9の901ならびに903の文字列)の存在が確認された後に、2つ1組の文字列の間に存在する文字列(図9の902:標的ヌクレオチドの全長ヌクレオチド配列を表す)の配列およびその長さが、抽出・決定される。例えば、配列およびその長さを抽出した結果、CAGのリピート回数が「80(ヌクレオチド数:240)」ならびに「113(ヌクレオチド数:339)」の2種類であった場合、ヘテロ接合型である。(両アレルとも、疾患型アレルに相当するリピート数を有していることから、発症リスクが極めて高い「+2」。)また、CAGのリピート回数が「5(ヌクレオチド数:15)」の1種類であった場合、ホモ接合型である。(両アレルの型は正常型アレルに相当するリピート数を有していることから、発症リスクは低い「±0」。)
In the case of the known microsatellite polymorphism (“STRP”) as described above, the corresponding character strings 901 and 903 can be easily obtained by the above method. The presence of the character string (2 pairs: the character strings 901 and 903 in FIG. 9) in the character string (“full-length character string”) representing the nucleotide sequence of the entire genome of the asymptomatic person of the young adult After confirmation, the sequence of the character string (902 in FIG. 9: representing the full-length nucleotide sequence of the target nucleotide) existing between the two character strings and the length thereof are extracted and determined. For example, when the number of CAG repeats is two types, "80 (number of nucleotides: 240)" and "113 (number of nucleotides: 339)" as a result of extracting the sequence and its length, it is a heterozygous type. (Since both alleles have the number of repeats corresponding to disease-type alleles, the risk of developing the disease is extremely high "+2".) In addition, the number of CAG repeats is one type of "5 (number of nucleotides: 15)". If it is, it is a homozygous type. (Since both allele types have the same number of repeats as normal alleles, the risk of developing the disease is low "± 0".)
上述した(2)の文字列による上記方法は、既知の染色体転座(DNAバリアントの生成)の有無にも応用可能である。ただし、このときの標的ヌクレオチドは、(2)の文字列(図9の文字列901および903)である。既知の染色体転座における転座点のゲノム上の位置は、染色体Aに存在した断片A1と、染色体Bに存在した断片B2との連結箇所、および断片A2と断片B1との連結箇所としてすべて知られている。転座を生じていないとき、断片A1およびA2は、染色体Aにおいて1→2の順に並んでおり、断片B1およびB2は、染色体Bにおいて1→2の順に並んでいる。よって、上記断片A1、A2、B1およびB2の配列も既知である。
The above method using the character string (2) described above can also be applied to the presence or absence of known chromosomal translocations (generation of DNA variants). However, the target nucleotide at this time is the character string (2) ( character strings 901 and 903 in FIG. 9). The genomic location of the translocation point in a known chromosomal translocation is all known as the linking site between fragment A1 present on chromosome A and fragment B2 present on chromosome B, and the linking site between fragment A2 and fragment B1. Has been done. When no translocation has occurred, the fragments A1 and A2 are arranged in the order of 1 → 2 on the chromosome A, and the fragments B1 and B2 are arranged in the order of 1 → 2 on the chromosome B. Therefore, the sequences of the fragments A1, A2, B1 and B2 are also known.
以上のことから、転座点を中心において、例えば断片A1を文字列901で表し、かつ断片B2を文字列903で表すと、文字列901および903が、個体のゲノム上に連続または非連続に存在することは、転座の有無を表し得る。非連続は転座の非存在を表し、連続は転座の存在の可能性を表す。当該存在の可能性を、存在または非存在として確実に見分けるには、例えば、断片A1および断片A2の連結部分を中心において、断片A1を文字列901で表し、かつ断片A2を文字列903で表せばよい。断片A1およびA2が連続して存在するとき、上記可能性(転座の存在)は完全に否定され、非連続に存在するとき、転座の存在が確定される。
From the above, if, for example, the fragment A1 is represented by the character string 901 and the fragment B2 is represented by the character string 903 around the translocation point, the character strings 901 and 903 are continuous or discontinuous on the genome of the individual. The presence may indicate the presence or absence of translocation. Discontinuity represents the absence of translocation, and continuity represents the possibility of translocation. To reliably distinguish the possibility of existence as existence or non-existence, for example, the fragment A1 is represented by the character string 901 and the fragment A2 is represented by the character string 903, centering on the connecting portion of the fragment A1 and the fragment A2. Just do it. When the fragments A1 and A2 are present consecutively, the above possibility (existence of translocation) is completely denied, and when they are present discontinuously, the existence of translocation is confirmed.
決定された「アレルの型」(患者の遺伝型)とともに、個人のゲノムに存在するDNAバリアントを表す情報は、DB、記録媒体または記憶装置に保存されるとともに(図示せず)、ゲノム情報DB6(図2、図5および図8)に格納される(S15工程)。
Information representing a DNA variant present in an individual's genome, along with the determined "allelic type" (genotype of the patient), is stored in a DB, recording medium or storage device (not shown), as well as genomic information DB6. It is stored in (FIG. 2, FIG. 5 and FIG. 8) (step S15).
〔ソフトウェアによる実現例〕
投与計画提案システム1~1’’(図2、図5および図8)は、制御ブロック(特に情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23)を、集積回路(ICチップ)等に形成された論理回路(ハードウェア)によって実現してもよいし、ソフトウェアによって実現してもよい。 [Example of implementation by software]
The administration plan proposal system 1-1'' (FIG. 2, FIG. 5 and FIG. 8) has a control block (particularly, an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genetic information acquisition unit) 21), and a degree of conformity. Thedetermination unit 22 and the medical information change unit 23) may be realized by a logic circuit (hardware) formed in an integrated circuit (IC chip) or the like, or may be realized by software.
投与計画提案システム1~1’’(図2、図5および図8)は、制御ブロック(特に情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)21、適合度決定部22および医薬情報変更部23)を、集積回路(ICチップ)等に形成された論理回路(ハードウェア)によって実現してもよいし、ソフトウェアによって実現してもよい。 [Example of implementation by software]
The administration plan proposal system 1-1'' (FIG. 2, FIG. 5 and FIG. 8) has a control block (particularly, an information acquisition unit (medicine information acquisition unit, relevance information acquisition unit, and genetic information acquisition unit) 21), and a degree of conformity. The
後者の場合、投与計画提案システム1~1’’(図2、図5および図8)は、各機能を実現するソフトウェアであるプログラムの命令を実行するコンピュータを備えている。このコンピュータは、例えば1つ以上のプロセッサを備えていると共に、上記プログラムを記憶したコンピュータ読み取り可能な記録媒体を備えている。そして、上記コンピュータにおいて、上記プロセッサが上記プログラムを上記記録媒体から読み取って実行することにより、本発明の目的が達成される。上記プロセッサとしては、例えばCPUを用いることができる。上記記録媒体としては、「一時的でない有形の媒体」、例えば、ROM(Read Only Memory)等の他、テープ、ディスク、カード、半導体メモリ、プログラマブルな論理回路などを用いることができる。また、上記プログラムを展開するRAM(Random Access Memory)などをさらに備えていてもよい。また、上記プログラムは、当該プログラムを伝送可能な任意の伝送媒体(通信ネットワークや放送波等)を介して上記コンピュータに供給されてもよい。なお、本発明の一態様は、上記プログラムが電子的な伝送によって具現化された、搬送波に埋め込まれたデータ信号の形態でも実現され得る。
In the latter case, the administration plan proposal systems 1 to 1 ″ (FIGS. 2, 5 and 8) include a computer that executes the instructions of the program which is the software that realizes each function. The computer includes, for example, one or more processors and a computer-readable recording medium that stores the program. Then, in the computer, the processor reads the program from the recording medium and executes the program, thereby achieving the object of the present invention. As the processor, for example, a CPU can be used. As the recording medium, a “non-temporary tangible medium”, for example, a ROM (Read Only Memory) or the like, a tape, a disk, a card, a semiconductor memory, a programmable logic circuit, or the like can be used. Further, a RAM (RandomAccessMemory) for expanding the above program may be further provided. Further, the program may be supplied to the computer via an arbitrary transmission medium (communication network, broadcast wave, etc.) capable of transmitting the program. It should be noted that one aspect of the present invention can also be realized in the form of a data signal embedded in a carrier wave, in which the above program is embodied by electronic transmission.
〔まとめ〕
これまでに説明した発明を、以下のようにまとめることができる。 〔summary〕
The inventions described so far can be summarized as follows.
これまでに説明した発明を、以下のようにまとめることができる。 〔summary〕
The inventions described so far can be summarized as follows.
〔1〕患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備えている、システム。 [1] A system that proposes a suitable administration plan for patients.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
A system including a drug information changing unit that changes the drug information when the goodness of fit is low; and an information presentation unit that presents the changed drug information that the drug information changing unit has changed to the user.
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備えている、システム。 [1] A system that proposes a suitable administration plan for patients.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
A system including a drug information changing unit that changes the drug information when the goodness of fit is low; and an information presentation unit that presents the changed drug information that the drug information changing unit has changed to the user.
〔2〕上記適合度決定部は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する医薬薬効関連遺伝子情報を参照して、上記適合度を決定し、
上記遺伝型は上記遺伝子に関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、〔1〕に記載のシステム。 [2] The goodness-of-fit determination unit determines the goodness of fit by referring to the pharmacokinetics of the drug or the drug efficacy-related gene information regarding the gene encoding the protein involved in pharmacodynamics.
The genotype is a genotype related to the gene, and the relevance information includes the drug efficacy-related gene information.
The system according to [1], wherein the change is an increase or decrease in the dose or a change in the drug.
上記遺伝型は上記遺伝子に関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、〔1〕に記載のシステム。 [2] The goodness-of-fit determination unit determines the goodness of fit by referring to the pharmacokinetics of the drug or the drug efficacy-related gene information regarding the gene encoding the protein involved in pharmacodynamics.
The genotype is a genotype related to the gene, and the relevance information includes the drug efficacy-related gene information.
The system according to [1], wherein the change is an increase or decrease in the dose or a change in the drug.
〔3〕上記適合度決定部は、上記医薬の投与によって発症または重篤化する疾患を表す医薬関連疾患情報を参照して、上記適合度を決定し、
上記遺伝型は、上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬関連疾患情報を含んでおり、
上記変更は、上記医薬の変更または上記投与量の減少である、〔1〕または〔2〕に記載のシステム。 [3] The goodness-of-fit determination unit determines the goodness of fit with reference to drug-related disease information indicating a disease that develops or becomes serious due to administration of the drug.
The genotype is a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information includes the drug-related disease information.
The system according to [1] or [2], wherein the modification is a modification of the pharmaceutical or a reduction of the dosage.
上記遺伝型は、上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬関連疾患情報を含んでおり、
上記変更は、上記医薬の変更または上記投与量の減少である、〔1〕または〔2〕に記載のシステム。 [3] The goodness-of-fit determination unit determines the goodness of fit with reference to drug-related disease information indicating a disease that develops or becomes serious due to administration of the drug.
The genotype is a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information includes the drug-related disease information.
The system according to [1] or [2], wherein the modification is a modification of the pharmaceutical or a reduction of the dosage.
〔4〕上記医薬が上記疾患にとっての禁忌薬であるとき、上記適合度決定部は、上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断し、
上記適合度決定部が上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断したとき、上記医薬情報変更部は、上記疾患にとっての禁忌薬である上記医薬の変更を上記医薬情報に加える、〔3〕に記載のシステム。 [4] When the drug is a contraindicated drug for the disease, the fitness determination unit determines that the fitness for the genotype including the combination of alleles associated with the predisposition to the disease is very low.
When the fitness determination unit determines that the fitness for the genotype, including combinations of alleles associated with the predisposition to the disease, is very low, the fitness information change unit is a contraindicated drug for the disease. The system according to [3], which adds a drug change to the above drug information.
上記適合度決定部が上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断したとき、上記医薬情報変更部は、上記疾患にとっての禁忌薬である上記医薬の変更を上記医薬情報に加える、〔3〕に記載のシステム。 [4] When the drug is a contraindicated drug for the disease, the fitness determination unit determines that the fitness for the genotype including the combination of alleles associated with the predisposition to the disease is very low.
When the fitness determination unit determines that the fitness for the genotype, including combinations of alleles associated with the predisposition to the disease, is very low, the fitness information change unit is a contraindicated drug for the disease. The system according to [3], which adds a drug change to the above drug information.
〔5〕上記疾患は、特異体質による重篤な副作用と関連した疾患、または特異体質による重篤な副作用の症状を含む、〔3〕に記載のシステム。
[5] The system according to [3], wherein the above-mentioned disease includes a disease related to a serious side effect due to an idiosyncratic drug, or a symptom of a serious side effect due to an idiosyncratic drug.
〔6〕上記適合度決定部は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子を表す医薬薬効関連遺伝子情報と、上記医薬の投与によって発症または重篤化する疾患を表す医薬関連疾患情報とを参照して、上記適合度を決定し、
上記遺伝型は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する遺伝型ならびに上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報および医薬関連疾患情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、〔1〕~〔5〕のいずれかに記載のシステム。 [6] The goodness-of-fit determination unit includes information on pharmaceutical efficacy-related genes representing genes encoding the pharmacokinetics of the drug or proteins involved in pharmacodynamics, and diseases that develop or become serious due to administration of the drug. The above-mentioned goodness of fit is determined by referring to the drug-related disease information indicating
The genotype is a genotype relating to a gene encoding a pharmacokinetics or a protein involved in the pharmacokinetics of the drug and a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information is provided. It contains the above-mentioned drug-related genetic information and drug-related disease information.
The system according to any one of [1] to [5], wherein the change is an increase or decrease in the dose or a change in the drug.
上記遺伝型は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する遺伝型ならびに上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報および医薬関連疾患情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、〔1〕~〔5〕のいずれかに記載のシステム。 [6] The goodness-of-fit determination unit includes information on pharmaceutical efficacy-related genes representing genes encoding the pharmacokinetics of the drug or proteins involved in pharmacodynamics, and diseases that develop or become serious due to administration of the drug. The above-mentioned goodness of fit is determined by referring to the drug-related disease information indicating
The genotype is a genotype relating to a gene encoding a pharmacokinetics or a protein involved in the pharmacokinetics of the drug and a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information is provided. It contains the above-mentioned drug-related genetic information and drug-related disease information.
The system according to any one of [1] to [5], wherein the change is an increase or decrease in the dose or a change in the drug.
〔7〕上記遺伝型情報は、患者IDを用いてゲノム情報DBから取得された患者のゲノムを構成する全ヌクレオチド配列を表す情報に含まれているDNAバリアントを表す情報に基づいて決定される、〔1〕~〔6〕のいずれかに記載のシステム。
[7] The genetic type information is determined based on the information representing the DNA variant contained in the information representing all the nucleotide sequences constituting the genome of the patient acquired from the genome information DB using the patient ID. The system according to any one of [1] to [6].
〔8〕上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記遺伝型情報は、患者のゲノムを構成する全ヌクレオチド配列を表す情報に含まれている前記座位に存在するDNAバリアントを表す情報に基づいて更新される、〔7〕に記載のシステム。
[8] When the genetic type information does not record the genetic type existing in the locus associated with the drug represented by the pharmaceutical information in the relevance represented by the relevant information, the genetic type information is recorded. The system according to [7], which is updated based on the information representing the DNA variant present in the locus contained in the information representing all the nucleotide sequences constituting the genome of the patient.
〔9〕上記DNAバリアントのうち一塩基多型を表す情報を、上記患者のゲノム断片を用いて、または上記全ヌクレオチド配列を表す情報に基づいて決定し、決定された一塩基多型を表す情報を記録し、
記録されていない上記DNAバリアントを表す情報を、上記全ヌクレオチド配列を表す文字情報に基づいて決定する、〔7〕または〔8〕に記載のシステム。 [9] Information representing a single nucleotide polymorphism among the above DNA variants is determined using the genomic fragment of the patient or based on the information representing the entire nucleotide sequence, and the information representing the single nucleotide polymorphism determined. Record,
The system according to [7] or [8], wherein the information representing the unrecorded DNA variant is determined based on the textual information representing the entire nucleotide sequence.
記録されていない上記DNAバリアントを表す情報を、上記全ヌクレオチド配列を表す文字情報に基づいて決定する、〔7〕または〔8〕に記載のシステム。 [9] Information representing a single nucleotide polymorphism among the above DNA variants is determined using the genomic fragment of the patient or based on the information representing the entire nucleotide sequence, and the information representing the single nucleotide polymorphism determined. Record,
The system according to [7] or [8], wherein the information representing the unrecorded DNA variant is determined based on the textual information representing the entire nucleotide sequence.
〔10〕上記医薬情報取得部は、上記医薬情報を処方箋またはお薬手帳から取得する、〔1〕~〔9〕のいずれかに記載のシステム。
[10] The system according to any one of [1] to [9], wherein the drug information acquisition unit acquires the drug information from a prescription or a medicine notebook.
〔11〕上記関連性情報が人工知能によって生成される、〔1〕~〔10〕のいずれかに記載のシステム。
[11] The system according to any one of [1] to [10], wherein the above-mentioned relevance information is generated by artificial intelligence.
〔12〕上記変更が上記医薬の変更を含んでおり、かつ当該変更の候補として複数の候補医薬がある場合に、上記情報提示部は、当該複数の候補医薬のうち最も適合度が高い医薬をユーザに示す、〔1〕~〔11〕のいずれかに記載のシステム。
[12] When the above-mentioned change includes the change of the above-mentioned medicine and there are a plurality of candidate medicines as candidates for the change, the information presenting unit selects the medicine having the highest goodness of fit among the plurality of candidate medicines. The system according to any one of [1] to [11] shown to the user.
〔13〕上記情報提示部がユーザに提示することが好適な複数の候補医薬情報が存在する場合に、上記情報提示部は、当該複数の好適な候補医薬情報のうち、最も適合度が高い医薬情報をユーザに提示する、〔1〕~〔12〕のいずれかに記載のシステム。
[13] When there are a plurality of candidate drug information that the information presenting unit is suitable for presenting to the user, the information presenting unit is the drug having the highest goodness of fit among the plurality of suitable candidate drug information. The system according to any one of [1] to [12], which presents information to the user.
〔14〕上記適合度決定部は、上記医薬情報に表される医薬が、特定の変異を有する遺伝子産物を標的とする分子標的医薬である場合に、上記患者のゲノムに、当該変異に対応するDNAバリアントが存在するか否かに基づいて上記適合度を判定する、〔1〕~〔13〕のいずれかに記載のシステム。
[14] When the drug represented in the drug information is a molecular target drug that targets a gene product having a specific mutation, the fitness determination unit corresponds to the mutation in the genome of the patient. The system according to any one of [1] to [13], wherein the fitness is determined based on the presence or absence of a DNA variant.
〔15〕上記適合度決定部が判定した上記適合度が基準を下回る場合に、上記医薬情報が不適であることを警告する警告部をさらに備えている、〔1〕~〔14〕のいずれか1項に記載のシステム。
[15] Any of [1] to [14] further comprising a warning unit for warning that the medical information is inappropriate when the goodness of fit determined by the goodness-of-fit determination unit is below the standard. The system according to item 1.
〔16〕患者にとって好適な投与計画を提案する方法であって、
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、方法。 [16] A method for proposing a suitable administration plan for a patient.
A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
The genotype information acquisition step in which the computer acquires the genotype information of the patient;
A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user. Including,
In the above method, when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above. Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information comprises information representing variants having a frequency of less than 1% in the human population.
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、方法。 [16] A method for proposing a suitable administration plan for a patient.
A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
The genotype information acquisition step in which the computer acquires the genotype information of the patient;
A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user. Including,
In the above method, when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above. Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information comprises information representing variants having a frequency of less than 1% in the human population.
〔17〕患者にとって好適な投与計画を提案するシステムとしてコンピュータを機能させるための投与計画提案プログラムであって、
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させるための投与計画提案プログラム。 [17] A dosing plan proposal program for operating a computer as a system for proposing a dosing plan suitable for a patient.
The above system is equipped with a control unit.
The control unit
Obtain drug information indicating the drug to be administered to the above patients and its dose;
Obtained relevance information indicating the relevance of the above drugs and genotypes;
Obtain genotype information for the above patients;
Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined;
When the goodness of fit is low, the above medical information is changed;
The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death,
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
A dosing plan proposal program for operating a computer as the control unit.
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させるための投与計画提案プログラム。 [17] A dosing plan proposal program for operating a computer as a system for proposing a dosing plan suitable for a patient.
The above system is equipped with a control unit.
The control unit
Obtain drug information indicating the drug to be administered to the above patients and its dose;
Obtained relevance information indicating the relevance of the above drugs and genotypes;
Obtain genotype information for the above patients;
Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined;
When the goodness of fit is low, the above medical information is changed;
The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death,
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
A dosing plan proposal program for operating a computer as the control unit.
〔18〕患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部;ならびに
上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、システム。 [18] A system that proposes a suitable administration plan for patients.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user. Equipped with an information presentation unit to present to
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information is a system comprising information representing variants having a frequency of less than 1% in the human population.
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部;ならびに
上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、システム。 [18] A system that proposes a suitable administration plan for patients.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user. Equipped with an information presentation unit to present to
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information is a system comprising information representing variants having a frequency of less than 1% in the human population.
1 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
1a 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
1’ 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
1’’ 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
2 制御部
2a 制御部
2b 制御部
3 表示装置(情報提示部)
4 入力装置
5 医薬薬効関連遺伝子情報DB
6 ゲノム情報DB
7 医薬関連疾患情報DB
10 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
21 情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)
22 適合度決定部
23 医薬情報変更部
24 警告部
25 投与計画決定部
301 医薬情報(フェニトイン)
302 変更医薬情報
303 医薬情報(オランザピン)
304 医薬情報(候補医薬群)
305 医薬情報(リクゾチニブ)
306 変更医薬情報
311 関連性情報(フェニトイン)
312 関連性情報(クロピドグレル)
313 関連性情報(ペリンドプリルエルブミン)
314 関連性情報(オランザピン)
315 関連性情報(リクゾチニブ)
316 関連性情報(セリチニブ)
317 関連性情報(ゲフィチニブ)
318 関連性情報(オシメルチニブメシル酸塩)
901 文字列
902 文字列(標的ヌクレオチド)
903 文字列 1 Administration plan proposal system (system that proposes a suitable administration plan for patients)
1a Administration plan proposal system (system that proposes a suitable administration plan for patients)
1'Administration plan proposal system (system that proposes a suitable administration plan for patients)
1'' Dosing plan proposal system (system that proposes a suitable dosing plan for patients)
2Control unit 2a Control unit 2b Control unit 3 Display device (information presentation unit)
4Input device 5 Pharmaceutical efficacy-related gene information DB
6 Genome information DB
7 Pharmaceutical-related disease information DB
10 Administration plan proposal system (system that proposes a suitable administration plan for patients)
21 Information acquisition department (medicine information acquisition department, relevance information acquisition department and genotype information acquisition department)
22 Goodness offit determination unit 23 Pharmaceutical information change department 24 Warning unit 25 Administration plan determination unit 301 Pharmaceutical information (phenytoin)
302 Changed Pharmaceutical Information 303 Pharmaceutical Information (Olanzapine)
304 Pharmaceutical information (candidate drug group)
305 Pharmaceutical Information (Lixotinib)
306 Modified Pharmaceutical Information 311 Relevance Information (Phenytoin)
312 Relevance information (clopidogrel)
313 Relevance Information (Perindopril Elbumin)
314 Relevance Information (Olanzapine)
315 Relevance Information (Lixotinib)
316 Relevance Information (Ceritinib)
317 Relevance Information (Gefitinib)
318 Relevance Information (Osimertinib Mesylate)
901string 902 string (target nucleotide)
903 string
1a 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
1’ 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
1’’ 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
2 制御部
2a 制御部
2b 制御部
3 表示装置(情報提示部)
4 入力装置
5 医薬薬効関連遺伝子情報DB
6 ゲノム情報DB
7 医薬関連疾患情報DB
10 投与計画提案システム(患者にとって好適な投与計画を提案するシステム)
21 情報取得部(医薬情報取得部、関連性情報取得部および遺伝型情報取得部)
22 適合度決定部
23 医薬情報変更部
24 警告部
25 投与計画決定部
301 医薬情報(フェニトイン)
302 変更医薬情報
303 医薬情報(オランザピン)
304 医薬情報(候補医薬群)
305 医薬情報(リクゾチニブ)
306 変更医薬情報
311 関連性情報(フェニトイン)
312 関連性情報(クロピドグレル)
313 関連性情報(ペリンドプリルエルブミン)
314 関連性情報(オランザピン)
315 関連性情報(リクゾチニブ)
316 関連性情報(セリチニブ)
317 関連性情報(ゲフィチニブ)
318 関連性情報(オシメルチニブメシル酸塩)
901 文字列
902 文字列(標的ヌクレオチド)
903 文字列 1 Administration plan proposal system (system that proposes a suitable administration plan for patients)
1a Administration plan proposal system (system that proposes a suitable administration plan for patients)
1'Administration plan proposal system (system that proposes a suitable administration plan for patients)
1'' Dosing plan proposal system (system that proposes a suitable dosing plan for patients)
2
4
6 Genome information DB
7 Pharmaceutical-related disease information DB
10 Administration plan proposal system (system that proposes a suitable administration plan for patients)
21 Information acquisition department (medicine information acquisition department, relevance information acquisition department and genotype information acquisition department)
22 Goodness of
302 Changed Pharmaceutical Information 303 Pharmaceutical Information (Olanzapine)
304 Pharmaceutical information (candidate drug group)
305 Pharmaceutical Information (Lixotinib)
306 Modified Pharmaceutical Information 311 Relevance Information (Phenytoin)
312 Relevance information (clopidogrel)
313 Relevance Information (Perindopril Elbumin)
314 Relevance Information (Olanzapine)
315 Relevance Information (Lixotinib)
316 Relevance Information (Ceritinib)
317 Relevance Information (Gefitinib)
318 Relevance Information (Osimertinib Mesylate)
901
903 string
Claims (18)
- 患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更部;ならびに
上記医薬情報変更部が変更を加えた変更医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、システム。 It is a system that proposes a suitable administration plan for patients.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
A medical information changing unit that changes the medical information when the goodness of fit is low; and an information presentation unit that presents the changed medical information that the medical information changing department has changed to the user.
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information is a system comprising information representing variants having a frequency of less than 1% in the human population. - 上記システムは、上記DNAバリアントを検出するために、
当該DNAバリアントに対応する標的ヌクレオチド配列と、基準のヒトゲノムにおいて当該DNAバリアントに対応する位置の両側の部分ヌクレオチド配列とが結合した結合配列を生成し、当該結合配列と、上記患者のゲノムを構成する全ヌクレオチド配列とを比較することを、
上記部分ヌクレオチド配列の長さを増加させながら繰り返す、請求項1に記載のシステム。 The system is used to detect the DNA variant.
A binding sequence is generated in which the target nucleotide sequence corresponding to the DNA variant and the partial nucleotide sequences on both sides of the position corresponding to the DNA variant in the reference human genome are bound to form the binding sequence and the genome of the patient. Comparing with the entire nucleotide sequence,
The system according to claim 1, wherein the system is repeated while increasing the length of the partial nucleotide sequence. - 上記システムは、上記DNAバリアントを検出するために、
基準のヒトゲノムにおいて当該DNAバリアントに対応する位置の両側の部分ヌクレオチド配列に対応する2つのヌクレオチド配列を生成し、当該2つのヌクレオチド配列と、上記患者のゲノムを構成する全ヌクレオチド配列とを比較することを、
上記部分ヌクレオチド配列の長さを増加させながら繰り返す、請求項1に記載のシステム。 The system is used to detect the DNA variant.
Generate two nucleotide sequences corresponding to the partial nucleotide sequences on both sides of the position corresponding to the DNA variant in the reference human genome, and compare the two nucleotide sequences with all the nucleotide sequences constituting the patient's genome. of,
The system according to claim 1, wherein the system is repeated while increasing the length of the partial nucleotide sequence. - 上記適合度決定部は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する医薬薬効関連遺伝子情報を参照して、上記適合度を決定し、
上記遺伝型は上記遺伝子に関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、請求項1~3のいずれか1項に記載のシステム。 The goodness-of-fit determination unit determines the goodness of fit by referring to the pharmacokinetics of the drug or the drug efficacy-related gene information regarding the gene encoding the protein involved in the pharmacodynamics.
The genotype is a genotype related to the gene, and the relevance information includes the drug efficacy-related gene information.
The system according to any one of claims 1 to 3, wherein the change is an increase or decrease in the dose or a change in the drug. - 上記適合度決定部は、上記医薬の投与によって発症または重篤化する疾患を表す医薬関連疾患情報を参照して、上記適合度を決定し、
上記遺伝型は、上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬関連疾患情報を含んでおり、
上記変更は、上記医薬の変更または上記投与量の減少である、請求項1~4のいずれか1項に記載のシステム。 The goodness-of-fit determination unit determines the goodness of fit with reference to drug-related disease information indicating a disease that develops or becomes serious due to administration of the drug.
The genotype is a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information includes the drug-related disease information.
The system according to any one of claims 1 to 4, wherein the modification is a modification of the drug or a reduction of the dosage. - 上記医薬が上記疾患にとっての禁忌薬であるとき、上記適合度決定部は、上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断し、
上記適合度決定部が上記疾患の素因に関連するアレルの組み合わせを含む上記遺伝型に関する上記適合度を非常に低いと判断したとき、上記医薬情報変更部は、上記疾患にとっての禁忌薬である上記医薬の変更を上記医薬情報に加える、請求項5に記載のシステム。 When the drug is a contraindicated drug for the disease, the fitness determination unit determines that the fitness for the genotype, including combinations of alleles associated with the predisposition to the disease, is very low.
When the fitness determination unit determines that the fitness for the genotype, including combinations of alleles associated with the predisposition to the disease, is very low, the fitness information change unit is a contraindicated drug for the disease. The system of claim 5, wherein changes in the drug are added to the above drug information. - 上記疾患は、特異体質による重篤な副作用と関連した疾患、または特異体質による重篤な副作用の症状を含む、請求項5に記載のシステム。 The system according to claim 5, wherein the disease includes a disease associated with a serious side effect due to an idiosyncratic drug, or a symptom of a serious side effect due to an idiosyncratic drug.
- 上記適合度決定部は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子を表す医薬薬効関連遺伝子情報と、上記医薬の投与によって発症または重篤化する疾患を表す医薬関連疾患情報とを参照して、上記適合度を決定し、
上記遺伝型は、上記医薬の薬物動態学または薬力学に関与するタンパク質をコードしている遺伝子に関する遺伝型ならびに上記疾患の素因に関連するアレルの組み合わせに関する遺伝型であり、上記関連性情報は、上記医薬薬効関連遺伝子情報および医薬関連疾患情報を含んでおり、
上記変更は、上記投与量の増加もしくは減少または上記医薬の変更である、請求項1~7のいずれか1項に記載のシステム。 The goodness-of-fit determination unit includes information on pharmacokinetics-related gene information representing a gene encoding a protein involved in pharmacokinetics or pharmacodynamics of the drug, and a drug representing a disease that develops or becomes serious due to administration of the drug. With reference to related disease information, determine the above goodness of fit,
The genotype is a genotype relating to a gene encoding a pharmacokinetics or a protein involved in the pharmacokinetics of the drug and a genotype relating to a combination of alleles associated with the predisposition to the disease, and the relevance information is provided. It contains the above-mentioned drug-related genetic information and drug-related disease information.
The system according to any one of claims 1 to 7, wherein the change is an increase or decrease in the dose or a change in the drug. - 上記DNAバリアントのうち一塩基多型を表す情報を、上記患者のゲノム断片を用いて、または上記全ヌクレオチド配列を表す情報に基づいて決定し、決定された一塩基多型を表す情報を記録し、
記録されていない上記DNAバリアントを表す情報を、上記全ヌクレオチド配列を表す文字情報に基づいて決定する、請求項1~8のいずれか1項に記載のシステム。 Information representing a single nucleotide polymorphism among the above DNA variants was determined using the genomic fragment of the patient or based on the information representing the entire nucleotide sequence, and the information representing the determined single nucleotide polymorphism was recorded. ,
The system according to any one of claims 1 to 8, wherein the information representing the unrecorded DNA variant is determined based on the textual information representing the entire nucleotide sequence. - 上記医薬情報取得部は、上記医薬情報を処方箋またはお薬手帳から取得する、請求項1~9のいずれか1項に記載のシステム。 The system according to any one of claims 1 to 9, wherein the drug information acquisition department acquires the drug information from a prescription or a medicine notebook.
- 上記関連性情報が人工知能によって生成される、請求項1~10のいずれか1項に記載のシステム。 The system according to any one of claims 1 to 10, wherein the relevant information is generated by artificial intelligence.
- 上記変更が上記医薬の変更を含んでおり、かつ当該変更の候補として複数の候補医薬がある場合に、上記情報提示部は、当該複数の候補医薬のうち最も適合度が高い医薬をユーザに示す、請求項1~11のいずれか1項に記載のシステム。 When the change includes the change of the medicine and there are a plurality of candidate medicines as candidates for the change, the information presenting unit indicates to the user the medicine having the highest goodness of fit among the plurality of candidate medicines. , The system according to any one of claims 1 to 11.
- 上記情報提示部がユーザに提示することが好適な複数の候補医薬情報が存在する場合に、上記情報提示部は、当該好適な複数の候補医薬情報のうち、最も適合度が高い医薬情報をユーザに提示する、請求項1~12のいずれか1項に記載のシステム。 When there are a plurality of candidate drug information that the information presenting unit is suitable for presenting to the user, the information presenting unit selects the drug information having the highest goodness of fit among the plurality of suitable candidate drug information. The system according to any one of claims 1 to 12, which is presented in 1.
- 上記適合度決定部は、上記医薬情報に表される医薬が、特定の変異を有する遺伝子産物を標的とする分子標的医薬である場合に、上記患者のゲノムに、当該変異に対応するDNAバリアントが存在するか否かに基づいて上記適合度を判定する、請求項1~13のいずれか1項に記載のシステム。 When the fitness represented by the drug information is a molecular target drug that targets a gene product having a specific mutation, the fitness determination unit has a DNA variant corresponding to the mutation in the genome of the patient. The system according to any one of claims 1 to 13, wherein the fitness is determined based on the presence or absence.
- 上記適合度決定部が判定した上記適合度が基準を下回る場合に、上記医薬情報が不適であることを警告する警告部をさらに備えている、請求項1~14のいずれか1項に記載のシステム。 The invention according to any one of claims 1 to 14, further comprising a warning unit for warning that the pharmaceutical information is inappropriate when the goodness of fit determined by the goodness-of-fit determination unit is less than the standard. system.
- 患者にとって好適な投与計画を提案する方法であって、
コンピュータが、上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得工程;
上記コンピュータが、上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得工程;
上記コンピュータが、上記患者の遺伝型情報を取得する遺伝型情報取得工程;
上記コンピュータが、上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定工程;
上記コンピュータが、上記適合度が低いとき、上記医薬情報に変更を加える医薬情報変更工程;ならびに
上記コンピュータが、上記医薬情報変更工程において変更を加えた変更医薬情報をユーザに提示する情報提示工程
を含み、
上記方法において、上記コンピュータは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、方法。 A method of proposing a suitable dosing regimen for a patient,
A drug information acquisition step in which a computer acquires drug information representing the drug to be administered to the patient and the dose thereof;
Relevance information acquisition step in which the computer acquires relevance information representing the relevance between the drug and the genotype;
The genotype information acquisition step in which the computer acquires the genotype information of the patient;
A goodness-of-fit determination step in which the computer determines the goodness of fit of the pharmaceutical information based on the relevance information and the genotype information;
When the computer has a low goodness of fit, a drug information change step of changing the drug information; and an information presentation process in which the computer presents the changed drug information changed in the drug information change step to the user. Including,
In the above method, when the genotype information does not record the genotype present in the locus associated with the drug represented by the drug information in the relevance represented by the relevance information, the computer described above. Information representing all the nucleotide sequences constituting the genome of the patient is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information comprises information representing variants having a frequency of less than 1% in the human population. - 患者にとって好適な投与計画を提案するシステムとしてコンピュータを機能させるための投与計画提案プログラムであって、
上記システムは、制御部を備え、
上記制御部は、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得し;
上記医薬および遺伝型の関連性を表す関連性情報を取得し;
上記患者の遺伝型情報を取得し;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定し;
上記適合度が低いとき、上記医薬情報に変更を加え;
当該変更を加えた変更医薬情報をユーザに提示し;かつ
上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、
上記制御部としてコンピュータを機能させるための投与計画提案プログラム。 A dosing plan proposal program for operating a computer as a system for proposing a dosing plan suitable for a patient.
The above system is equipped with a control unit.
The control unit
Obtain drug information indicating the drug to be administered to the above patients and its dose;
Obtained relevance information indicating the relevance of the above drugs and genotypes;
Obtain genotype information for the above patients;
Based on the relevance information and genotype information, the goodness of fit of the above drug information is determined;
When the goodness of fit is low, the above medical information is changed;
The modified drug information with the modification is presented to the user; and the genotype information contains a genotype existing in a locus associated with the drug represented by the drug information in the relevance represented by the relevance information. When not recorded, information representing all the nucleotide sequences constituting the genome of the patient is acquired, and the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence to update the genotype information. death,
The genotype information includes information representing variants having a frequency of less than 1% in the human population.
A dosing plan proposal program for operating a computer as the control unit. - 患者にとって好適な投与計画を提案するシステムであって、
上記患者に投与する医薬およびその投与量を表す医薬情報を取得する医薬情報取得部;
上記医薬および遺伝型の関連性を表す関連性情報を取得する関連性情報取得部;
上記患者の遺伝型情報を取得する遺伝型情報取得部;
上記関連性情報および遺伝型情報に基づいて、上記医薬情報の適合度を決定する適合度決定部;
上記適合度決定部により決定された上記医薬情報の上記適合度に基づき、上記患者に対する好適な上記医薬情報を決定する投与計画決定部;ならびに
上記投与計画決定部によって決定された上記医薬情報をユーザに提示する情報提示部
を備え、
上記システムは、上記遺伝型情報に、上記関連性情報によって表される関連性において上記医薬情報に表される医薬と関連する座位に存在する遺伝型が記録されていないとき、上記患者のゲノムを構成する全ヌクレオチド配列を表す情報を取得し、上記全ヌクレオチド配列を表す情報から、前記座位に存在するDNAバリアントを検出して、上記遺伝型情報を更新し、
上記遺伝型情報は、ヒト集団における頻度が1%未満であるバリアントを表す情報を含む、システム。 It is a system that proposes a suitable administration plan for patients.
The drug information acquisition department that acquires drug information indicating the drugs to be administered to the above patients and their doses;
Relevance information acquisition department that acquires relevance information indicating the relevance of the above drugs and genotypes;
Genotype information acquisition department that acquires the genotype information of the above patients;
Goodness-of-fit determination unit that determines the goodness of fit of the above-mentioned pharmaceutical information based on the above-mentioned relevance information and genotype information;
Based on the goodness of fit of the drug information determined by the goodness-of-fit determination unit, the administration plan determination unit that determines suitable drug information for the patient; and the drug information determined by the administration plan determination unit are used by the user. Equipped with an information presentation unit to present to
The system captures the genome of the patient when the genotype information does not record the genotype present in the locus associated with the drug represented in the drug information in the association represented by the relevance information. Information representing all the constituent nucleotide sequences is acquired, the DNA variant existing in the locus is detected from the information representing the whole nucleotide sequence, and the genotype information is updated.
The genotype information is a system comprising information representing variants having a frequency of less than 1% in the human population.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022533742A JPWO2022004200A1 (en) | 2020-06-29 | 2021-05-25 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020112023A JP6893052B1 (en) | 2020-06-29 | 2020-06-29 | Dosing plan proposal system, method and program |
| JP2020-112023 | 2020-06-29 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022004200A1 true WO2022004200A1 (en) | 2022-01-06 |
Family
ID=76464621
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/019872 WO2022004200A1 (en) | 2020-06-29 | 2021-05-25 | Dosage regime proposing system, method, and program |
Country Status (2)
| Country | Link |
|---|---|
| JP (2) | JP6893052B1 (en) |
| WO (1) | WO2022004200A1 (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510817A (en) * | 1998-04-03 | 2002-04-09 | トライアングル・ファーマシューティカルズ,インコーポレイテッド | System, method and computer program product for guiding treatment prescription plan selection |
| WO2005038049A2 (en) * | 2003-10-06 | 2005-04-28 | Heinrich Guenther | System and method for optimizing drug therapy |
| US20060223058A1 (en) * | 2005-04-01 | 2006-10-05 | Perlegen Sciences, Inc. | In vitro association studies |
| US20140025783A1 (en) * | 2009-09-04 | 2014-01-23 | Viasat, Inc. | Distributed Cache - Adaptive Multicast Architecture for Bandwidth Reduction |
| US20170061080A1 (en) * | 2001-08-29 | 2017-03-02 | Druglogic, Inc. | Method and system for the analysis and association of patient-specific and population-based genomic data with drug safety adverse event data |
| JP2020034993A (en) * | 2018-08-27 | 2020-03-05 | 秀一 大津 | Application and system for remote medical care |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2006072011A2 (en) * | 2004-12-30 | 2006-07-06 | Proventys, Inc. | Methods, systems, and computer program products for developing and using predictive models for predicting a plurality of medical outcomes, for evaluating intervention strategies, and for simultaneously validating biomarker causality |
| JP2009070096A (en) * | 2007-09-12 | 2009-04-02 | Michio Kimura | Integrated database system of genome information and clinical information, and method for making database provided therewith |
| JP5491400B2 (en) * | 2007-09-26 | 2014-05-14 | ナビジェニクス インコーポレイティド | Method and system for genome analysis using ancestor data |
| BR112013003331A2 (en) * | 2010-08-13 | 2017-07-11 | l kraft Daniel | systems and methods for the production of custom drug products |
| US20140257851A1 (en) * | 2013-03-05 | 2014-09-11 | Clinton Colin Graham Walker | Automated interactive health care application for patient care |
| US20140274764A1 (en) * | 2013-03-15 | 2014-09-18 | Pathway Genomics Corporation | Method and system to predict response to treatments for mental disorders |
| US20140274763A1 (en) * | 2013-03-15 | 2014-09-18 | Pathway Genomics Corporation | Method and system to predict response to pain treatments |
-
2020
- 2020-06-29 JP JP2020112023A patent/JP6893052B1/en active Active
-
2021
- 2021-05-25 WO PCT/JP2021/019872 patent/WO2022004200A1/en active Application Filing
- 2021-05-25 JP JP2022533742A patent/JPWO2022004200A1/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002510817A (en) * | 1998-04-03 | 2002-04-09 | トライアングル・ファーマシューティカルズ,インコーポレイテッド | System, method and computer program product for guiding treatment prescription plan selection |
| US20170061080A1 (en) * | 2001-08-29 | 2017-03-02 | Druglogic, Inc. | Method and system for the analysis and association of patient-specific and population-based genomic data with drug safety adverse event data |
| WO2005038049A2 (en) * | 2003-10-06 | 2005-04-28 | Heinrich Guenther | System and method for optimizing drug therapy |
| US20060223058A1 (en) * | 2005-04-01 | 2006-10-05 | Perlegen Sciences, Inc. | In vitro association studies |
| US20140025783A1 (en) * | 2009-09-04 | 2014-01-23 | Viasat, Inc. | Distributed Cache - Adaptive Multicast Architecture for Bandwidth Reduction |
| JP2020034993A (en) * | 2018-08-27 | 2020-03-05 | 秀一 大津 | Application and system for remote medical care |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022024213A (en) | 2022-02-09 |
| JP6893052B1 (en) | 2021-06-23 |
| JPWO2022004200A1 (en) | 2022-01-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Zouk et al. | Harmonizing clinical sequencing and interpretation for the eMERGE III network | |
| US20200048712A1 (en) | Methods for selecting medications | |
| Siedlinski et al. | Genome-wide association study of smoking behaviours in patients with COPD | |
| Ruhno et al. | Complete sequencing of the SMN2 gene in SMA patients detects SMN gene deletion junctions and variants in SMN2 that modify the SMA phenotype | |
| US8688385B2 (en) | Methods for selecting initial doses of psychotropic medications based on a CYP2D6 genotype | |
| Simonson et al. | Recent methods for polygenic analysis of genome-wide data implicate an important effect of common variants on cardiovascular disease risk | |
| Schuit et al. | Pharmacotherapy for smoking cessation: effects by subgroup defined by genetically informed biomarkers | |
| Liu et al. | Biological pathway‐based genome‐wide association analysis identified the vasoactive intestinal peptide (VIP) pathway important for obesity | |
| Rasmussen‐Torvik et al. | High density GWAS for LDL cholesterol in African Americans using electronic medical records reveals a strong protective variant in APOE | |
| Wechsler et al. | How pharmacogenomics will play a role in the management of asthma | |
| Mok et al. | Genomewide association study in cervical dystonia demonstrates possible association with sodium leak channel | |
| Tanner et al. | Combinatorial pharmacogenomics and improved patient outcomes in depression: treatment by primary care physicians or psychiatrists | |
| Hebbar et al. | Genome-wide association study identifies novel recessive genetic variants for high TGs in an Arab population | |
| Escamilla et al. | Genetics of bipolar disorder | |
| Kulminski et al. | Genetic and regulatory architecture of Alzheimer's disease in the APOE region | |
| Perlis et al. | Genetic association study of treatment response with olanzapine/fluoxetine combination or lamotrigine in bipolar I depression | |
| Lai et al. | Genome‐wide association studies of the self‐rating of effects of ethanol (SRE) | |
| Mur et al. | DNA methylation in APOE: The relationship with Alzheimer's and with cardiovascular health | |
| Awan et al. | Saudi familial hypercholesterolemia patients with rare LDLR stop gain variant showed variable clinical phenotype and resistance to multiple drug regimen | |
| Hotaling et al. | Pilot genome-wide association search identifies potential loci for risk of erectile dysfunction in type 1 diabetes using the DCCT/EDIC study cohort | |
| Blue et al. | Association of uncommon, noncoding variants in the APOE region with risk of Alzheimer disease in adults of European ancestry | |
| Kappel et al. | Genomic stratification of clozapine prescription patterns using schizophrenia polygenic scores | |
| Lecluze et al. | Association analyses of predicted loss-of-function variants prioritized 15 genes as blood pressure regulators | |
| Ghouse et al. | Polygenic risk score for ACE-inhibitor-associated cough based on the discovery of new genetic loci | |
| WO2022004200A1 (en) | Dosage regime proposing system, method, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21831785 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022533742 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21831785 Country of ref document: EP Kind code of ref document: A1 |