WO2021200503A1 - 学習システム及びデータ収集装置 - Google Patents
学習システム及びデータ収集装置 Download PDFInfo
- Publication number
- WO2021200503A1 WO2021200503A1 PCT/JP2021/012368 JP2021012368W WO2021200503A1 WO 2021200503 A1 WO2021200503 A1 WO 2021200503A1 JP 2021012368 W JP2021012368 W JP 2021012368W WO 2021200503 A1 WO2021200503 A1 WO 2021200503A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- learning
- unit
- model
- segment
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/174—Facial expression recognition
- G06V40/176—Dynamic expression
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/012—Head tracking input arrangements
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/015—Input arrangements based on nervous system activity detection, e.g. brain waves [EEG] detection, electromyograms [EMG] detection, electrodermal response detection
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G06N3/0442—Recurrent networks, e.g. Hopfield networks characterised by memory or gating, e.g. long short-term memory [LSTM] or gated recurrent units [GRU]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/091—Active learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/092—Reinforcement learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/098—Distributed learning, e.g. federated learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/25—Management operations performed by the server for facilitating the content distribution or administrating data related to end-users or client devices, e.g. end-user or client device authentication, learning user preferences for recommending movies
- H04N21/258—Client or end-user data management, e.g. managing client capabilities, user preferences or demographics, processing of multiple end-users preferences to derive collaborative data
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/16—Devices for psychotechnics; Testing reaction times ; Devices for evaluating the psychological state
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2203/00—Indexing scheme relating to G06F3/00 - G06F3/048
- G06F2203/01—Indexing scheme relating to G06F3/01
- G06F2203/011—Emotion or mood input determined on the basis of sensed human body parameters such as pulse, heart rate or beat, temperature of skin, facial expressions, iris, voice pitch, brain activity patterns
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
Definitions
- the technology disclosed in the present specification includes a learning system for learning a machine learning model, a data collecting device for collecting learning data for learning a machine learning model, and data.
- the information processing device that performs the analysis processing of.
- digital cameras are widespread. For example, in each home, digital video cameras and digital still cameras are used to record various events such as daily life, entrance ceremonies, graduation ceremonies, and weddings of children. It is desirable to shoot a more moving scene, but it is difficult to determine whether the scene that a general user is observing through the viewfinder is a moving scene. Of course, even for professional photographers, it is difficult to determine whether the scene they are shooting is moving.
- a method of handling emotional content can be considered using artificial intelligence technology equipped with a trained neural network model.
- a deep learning neural network model (hereinafter, also referred to as "DNN") having multiple layers of convolutional neural networks extracts features that developers cannot imagine through training, that is, deep learning, from a large amount of data. It is possible to develop artificial intelligence functions that can solve complex problems that developers cannot imagine algorithms.
- learning data for learning artificial intelligence is required.
- a learning data collection unit that collects learning data for machine learning of a specified ability and a learning processing unit that performs machine learning of a learning device so as to acquire a specified ability using the collected learning data.
- a proposal has been made for a learning device provided see Patent Document 1).
- To handle inspiring content using artificial intelligence technology first a large amount of learning used to learn machine learning models that estimate camera operations to generate inspiring content or shoot inspiring content. I need data.
- a data collection method that reflects subjectivity can be considered by utilizing favorite information that appears on SNS (Social Network Service), but it is not easy to execute because it may threaten privacy.
- SNS Social Network Service
- the context of the scenes before and after is also considered to be an element that creates excitement, but the method of collecting data depending only on the image collects data that reflects the context. It's difficult to do.
- An object of the present disclosure is a learning system that learns a machine learning model that estimates camera operation for generating moving content or shooting moving content, and for generating moving content or shooting moving content. It is an object of the present invention to provide a data collecting device that collects learning data of a machine learning model that estimates camera operation, and an information processing device that analyzes the impression given by the collected data.
- a data collecting device for collecting data and a learning device for learning a machine learning model using the data collected by the data collecting device are provided.
- the learning device collects learning data that affects the learning of the machine learning model based on the results of analysis, learning data that affects the learning of the machine learning model by a predetermined value or more, missing learning data, and the like.
- the machine learning model is retrained using data similar to these. It is a learning system.
- system here means a logical assembly of a plurality of devices (or functional modules that realize a specific function), and each device or functional module is in a single housing. It does not matter whether or not it is.
- the learning device learns a machine learning model that estimates a camera operation for generating moving content or shooting moving content.
- the analysis can also be performed by XAI, confidence score calculation, influence function, or Bayesian DNN.
- the learning device analyzes learning data that affects the learning of the machine learning model, and based on the analysis result, learning data that affects the learning of the machine learning model by a predetermined amount or more, and missing learning data. , Or a request signal requesting the transmission of data similar to these is transmitted to the data acquisition device. Then, the data collecting device transmits the data collected based on the received request signal to the learning device, so that the learning device can use the data transmitted from the data collecting device in response to the request signal. Based on this, the machine learning model can be retrained.
- the machine learning model among the collected data is based on the result of analyzing the influence of the collected data on the learning of the machine learning model.
- the learning data having a predetermined or greater effect on the learning of the above, the missing learning data, or data similar thereto is transmitted to the learning device.
- the learning device can relearn the machine learning model based on the data transmitted from the data collecting device in response to the request signal.
- the learning device may transmit the information necessary for the analysis to the data acquisition device at the time of transmitting the request signal.
- the second aspect of the present disclosure is A receiving unit that receives a request signal requesting transmission of learning data of the machine learning model from a learning device that learns the machine learning model.
- a data collection unit that collects learning data that has a predetermined or greater effect on the learning of the machine learning model, missing learning data, or data similar thereto in response to receiving the request signal.
- a transmission unit that transmits the data collected by the data collection unit to the learning device, and a transmission unit. It is a data collection device provided with.
- the receiving unit receives from the learning device the learning data that affects the learning of the machine learning model by a predetermined value or more, the missing learning data, or the request signal that requests data similar thereto. Then, the data collecting unit collects data based on the received request signal, and the transmitting unit transmits the data collected by the data collecting unit to the learning device.
- the data collection device further includes an analysis unit that analyzes the influence of the data collected by the data collection unit on the learning of the machine learning model. Then, based on the analysis result by the analysis unit, the transmission unit receives learning data having a predetermined or greater effect on the learning of the machine learning model among the data collected by the data collection unit, and missing learning data. Alternatively, data similar to these is transmitted to the learning device.
- the third aspect of the present disclosure is A segment extraction unit that extracts segments from the content based on the content evaluation information of the content and the biometric information of the person who views the content.
- a facial expression identification unit that detects the face of a person in a segment and identifies the facial expression
- a relationship estimation unit that estimates the relationships between people in the segment
- An emotional identification unit that identifies the emotional label of a segment based on the facial expression of the person in the segment and the relationship between the persons. It is an information processing device provided with.
- the segment extraction unit extracts the segment of the content in which the biometric information having a high audience rating and positive emotions matches. In addition, the segment extraction unit further extracts segments in which the biometric information having a high audience rating and positive emotions does not match.
- the relationship estimation unit estimates the relationship between the persons in the current segment by using the face detection of the person in the past segment and the facial expression identification result of the detected face as the context.
- the information processing apparatus detects the first emotion analysis unit that analyzes emotions based on the text information obtained by recognizing the voice included in the segment, and the music included in the segment.
- a second sentiment analysis unit that analyzes the emotions given by the music is further provided.
- the emotion identification unit identifies the emotion label of the segment by further considering the emotion identified by the first emotion analysis unit from the text information and the emotion identified by the second emotion analysis unit from the music. ..
- the data acquisition device performs the analysis by calculating the reliability score.
- the learning device transmits the information of the neural network model that has been learned by the current time to the data collecting device as the information necessary for the analysis.
- a learning system that learns a machine learning model that estimates camera operation for generating moving content or shooting moving content, and for generating moving content or shooting moving content. It is possible to provide a data collecting device that collects learning data of a machine learning model that estimates the camera operation of the content, and an information processing device that identifies the impression given by the content.
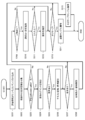
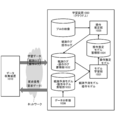
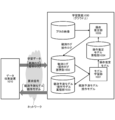
- FIG. 1 is a diagram showing a functional configuration of the data collection system 100.
- FIG. 2 is a flowchart showing the operation of the data collection system 100.
- FIG. 3 is a diagram showing a mechanism for estimating the relationship between people based on the context of the segment and the results of face detection and facial expression identification.
- FIG. 4 is a diagram showing the overall flow of the learning process of the impression discriminator using the collected learning data.
- FIG. 5 is a diagram showing a configuration example of the digital camera 500.
- FIG. 6 is a diagram showing a functional configuration for performing emotional identification labeling of content captured by the digital camera 500.
- FIG. 7 is a diagram showing a functional configuration of a digital camera 500 for automatically controlling camera work based on a moving identification result of captured content.
- FIG. 8 is a diagram showing a functional configuration of the digital camera 500 for automatically generating captions based on the impression identification result of the captured content.
- FIG. 9 is a diagram showing a functional configuration of the digital camera 500 for automatically adding background music based on the impression identification result of the captured content.
- FIG. 10 is a diagram showing a configuration of a learning system 1000 for efficiently learning a neural network model for automatic operation of a camera.
- FIG. 11 is a diagram showing the configuration of the observation prediction model 1100.
- FIG. 12 is a diagram showing the configuration of the operation model 1200.
- FIG. 13 is a diagram showing the configuration of the operation estimation model 1300.
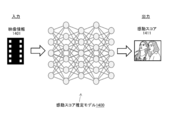
- FIG. 14 is a diagram showing an impression score estimation model 1400.
- FIG. 15 is a diagram showing the relationship between the controlled object and the average impression score.
- FIG. 16 is a diagram showing a neural network model trained to estimate output error.
- FIG. 17 is a diagram showing an example of the internal configuration of the data acquisition device 1010.
- FIG. 18 is a diagram showing another internal configuration example of the data acquisition device 1010.
- FIG. 19 is a diagram showing an example of the internal configuration of the learning device 1030.
- FIG. 20 is a diagram showing another internal configuration example of the learning device 1030.
- FIG. 21 is a diagram showing still another internal configuration example of the learning device 1030.
- FIG. 22 is a diagram showing an example of the internal configuration of the model utilization device 1020.
- FIG. 23 is a diagram showing an example of the internal configuration of the model utilization device 1020 as the edge AI.
- FIG. 1 schematically shows a functional configuration of a data collection system 100 that performs data collection processing according to the present disclosure.
- the illustrated data collection system 100 collects data used for learning a machine learning model that estimates camera operation for generating moving content or shooting moving content from a huge amount of video content 101. Perform processing.
- the data collected by the data collection system 100 is basically a machine learning model (for example, for inferring whether or not it is a scene or content that impresses humans) for handling content that impresses humans (for example, for inferring whether the data is a scene or content that impresses humans).
- it is used for training data for training a neural network), but of course it may be used for other purposes.
- the data collection system 100 handles the content that is broadcast on a television, an Internet broadcasting station, or the like as the video content 101 and is provided with the content evaluation information such as the audience rating information, and the content is mainly a video. It consists of data and audio data. Further, as the video content 101, content evaluation information that evaluates the content that is similar to the audience rate information (or can be replaced with the audience rate information) such as "Like! (Like, fun, supportable)" is provided. If it is given, it may include various contents such as a video sharing site. Further, the data collection system 100 shall process the content extracted from the video content 101 in units of fixed-length or variable-length segments.
- the data collection system 100 includes a content evaluation information acquisition unit 102, a biometric information acquisition unit 103, a comparison unit 104, a segment extraction unit 105, a context extraction unit 106, a voice recognition unit 107, and a music detection unit 108. It includes a face detection unit 109, a first emotion analysis unit 110, a second emotion analysis unit 111, a facial expression identification unit 112, a relationship estimation unit 113, and an emotion identification unit 114.
- the data collection system 100 is assumed to be configured as a service in which computer resources are provided on a wide-area computer network such as the cloud, that is, the Internet. Each component of the data collection system 100 may be integrated in one computer or distributed in a plurality of computers. Each part will be described below.
- the content evaluation information acquisition unit 102 acquires content evaluation information such as an audience rating given to the content extracted from the video content 101.
- the content evaluation information acquisition unit 102 may acquire the audience rating information of the target content from the audience rating research company.
- the data collection system 100 uses the audience rating information in order to determine whether or not each scene of the content impresses a human being.
- the merits of using the audience rating information are that it does not conflict with privacy issues and that the information already reflects the reaction of a large number of people.
- the audience rating information also reflects the context such as the origination and transfer of the content in the story, the context information before and after the scene with a high audience rating can be effectively used.
- the content evaluation information acquisition unit 102 provides content evaluation information such as "Like! (Like, fun, supportable)" attached by SNS or the like. May be obtained.
- the biometric information acquisition unit 103 acquires biometric information of a human being who views the content extracted from the video content 101.
- a biometric information sensor that detects biometric information such as brain waves, sweating, gaze, and myoelectric potential is installed in the home, and the biometric information detected when viewing content such as television or Internet broadcasting is used as biometric information.
- the acquisition unit 103 may collect the information. When a huge amount of biometric information is collected from a large number of households, the biometric information acquisition unit 103 may be used after performing statistical processing such as averaging.
- Biological information such as brain wave information acquired by the biological information acquisition unit 103 is used. Studies to identify emotions from brain wave information have already been conducted (see, for example, Non-Patent Document 1).
- An electroencephalogram is an electric potential measured from the scalp of electrical activity generated from the brain.
- An electroencephalograph is generally configured to measure an electroencephalograph from an electrode placed on the scalp. The international 10-20 method is known as the position of the electrode, but the present disclosure is not particularly limited to this.
- the comparison unit 104 compares the content evaluation information such as the audience rating acquired by the content evaluation information acquisition unit 102 with the human biometric information acquired by the biometric information acquisition unit 103. Then, the segment extraction unit 105 uses the segment in which the biometric information having a high audience rating and positive emotions (such as “impressed”) matches among the contents extracted from the video content 101 for learning the emotional identification. Extract as data. In addition, the segment extraction unit 105 extracts a segment in which the biometric information having a high audience rating and positive emotions does not match as a negative sample (such as "not impressed”).
- the context extraction unit 106 extracts the context of the content extracted from the video content 101. More specifically, the context extraction unit 106 extracts the context before and after the scene with a high audience rating and the context before and after the segment extracted by the segment extraction unit 105.
- the context extraction unit 106 may extract the context using a trained neural network model trained to estimate the context from the content consisting of video and audio data.
- the voice recognition unit 107 applies voice recognition processing (ASR: Automatic Speech Recognition) to the voice component of the audio data included in the segment extracted by the segment extraction unit 105, and recognizes the voice such as dialogue. Convert to text (speech translation).
- ASR Automatic Speech Recognition
- the first sentiment analysis unit 110 applies natural language processing that performs sentiment analysis to text information such as dialogue output from the voice recognition unit 107, and the segment (scene) is composed of what kind of emotion. Analyze if it is.
- the first sentiment analysis unit 110 may perform the sentiment analysis in a wider context by referring to the lines of the preceding and following segments (scenes). Based on the emotion analysis result of the dialogue, the emotion of the segment (scene) can be grasped more accurately.
- the voice recognition unit 107 and the first sentiment analysis unit 110 can each be configured by using a trained machine learning model such as a convolutional neural network (CNN). Further, the voice recognition unit 107 and the first sentiment analysis unit 110 can be combined as a "speech discriminator" and can be configured by a machine learning model such as one CNN.
- CNN convolutional neural network
- the music detection unit 108 applies music detection processing to the audio data included in the segment extracted by the segment extraction unit 105, and detects the background music added to the video.
- the second emotion analysis unit 111 identifies whether or not the background music detected by the music detection unit 108 is mood or moving.
- Several techniques for identifying emotions given by music have been proposed (see, for example, Non-Patent Document 2). Based on the emotion analysis result of the background music, the emotion of the segment (scene) can be grasped more accurately.
- the music detection unit 108 and the second emotion analysis unit 111 can be configured by using a trained machine learning model such as CNN, respectively. Further, the music detection unit 108 and the second emotion analysis unit 111 can be combined as a "music discriminator" and configured by a machine learning model such as one CNN.
- the face detection unit 109 executes face detection processing (face detection) of a person appearing in the video data included in the segment extracted by the segment extraction unit 105.
- the facial expression identification unit 112 identifies the facial expression of the face detected by the face detection unit 109. For example, the facial expression identification unit 112 analyzes the pattern of the face image from the detected face and estimates which emotion the pattern of the face image corresponds to. Human emotions can be estimated using artificial intelligence that has pre-learned the correlation between facial image patterns and human emotions.
- the pattern of the face image can be composed of a combination of face parts such as eyebrows, eyes, nose, mouth, and cheeks, but can also be composed of an image of the entire face image without being divided into face parts.
- the face detection unit 109 and the facial expression identification unit 112 can each be configured by using a learned machine learning model such as CNN. Further, the face detection unit 109 and the facial expression identification unit 112 can be combined as a "facial expression identification machine" and can be configured by a machine learning model such as one CNN.
- the relationship estimation unit 113 is based on the context between the facial expressions of the individual persons identified by the facial expression identification unit 112 and the segments before and after the person extracted by the context extraction unit 106 when there are two or more persons in the segment. To estimate the relationships and intimacy between people. Because, even if one person has the same facial expression, it depends on the relationship and intimacy with the other person in the picture (for example, whether it is in the picture with family or close friends). This is because there is a difference in the ease of connecting to the impression of the human being who sees it, which affects the impression identification process in the subsequent stage.
- the emotion identification unit 114 includes the emotion identification result of the voice (such as dialogue) in the segment by the voice recognition unit 107 and the first emotion analysis unit 110, and the background music in the segment by the music detection 108 and the second emotion analysis unit 111.
- the emotion identification unit 114 estimates the emotion of the segment from the above input data using, for example, a trained neural network model, and outputs an emotion identification label indicating the emotion level of the segment.
- the emotional identification label may be two simple binary labels, positive (such as “impressed") and negative (such as “not impressed"), but “anger", “disgust”, “fear”, “happiness”, etc. It may be a label that expresses emotions that are divided into various types such as “sadness", “surprise”, and so on.
- the emotional identification unit 114 may output an emotional identification label defined based on an emotional model such as a Wundt model or a Plutchik model.
- FIG. 2 shows the operation of the data collection system 100 in the form of a flowchart.
- the content that is broadcast on a television or an Internet broadcasting station and is given content evaluation information such as the viewing rate is taken into the data collection system 100 (step SS201).
- the content evaluation information acquisition unit 102 acquires the content evaluation information given to this content. It is assumed that the content is composed of a plurality of segments and the content evaluation information is given to each segment.
- the biometric information acquisition unit 103 acquires biometric information such as brain waves representing the reaction of a human being viewing the content captured in step S201 (step S202).
- biometric information such as brain waves representing the reaction of a human being viewing the content captured in step S201 (step S202).
- the content is a television broadcast, it is assumed that biometric information including at least brain waves will be collected from a large number of households watching the program.
- the comparison unit 104 compares the content evaluation information acquired by the content evaluation information acquisition unit 102 with the human bioinformation acquired by the biometric information acquisition unit 103 for each segment, and has a high audience rating and positive emotions. Check if the information matches (step S203).
- the segment extraction unit 105 uses, among the contents extracted from the video content 101, the segment in which the biometric information having a high audience rating and the positive emotion matches (Yes in step S203) for learning the impression identification. Extract as data (step S204). Further, the segment extraction unit 105 extracts a segment in which the biometric information having a high audience rating and positive emotion does not match (No in step S203) as a negative sample (step S215).
- step S204 When the segment extracted in step S204 contains voice data (Yes in step S205), the voice recognition unit 107 recognizes the voice and converts it into text, and the first sentiment analysis unit 110 identifies emotions from the text information. (Step S206).
- step S204 If the segment extracted in step S204 contains music data (Yes in step S207), the music detection unit 108 detects the music, and the second sentiment analysis unit 111 identifies the emotion given by the music. (Step S208).
- step S210 If a person appears in the segment extracted in step S204 (Yes in step S209), the face detection unit 109 detects the person's face, and the facial expression identification unit 112 identifies the facial expression of the detected face (step). S210).
- the relationship estimation unit 113 has the facial expressions of the individual persons identified by the facial expression identification unit 112 and the context. The relationship between the persons is estimated based on the context with the segments before and after the extraction by the extraction unit 106 (step S212).
- the emotion identification unit 114 includes the emotion identification result of the voice (such as dialogue) in the segment by the voice recognition unit 107 and the first emotion analysis unit 110, and the background music in the segment by the music detection 108 and the second emotion analysis unit 111.
- the emotion identification unit 114 estimates the emotion of the segment and outputs an emotion identification label indicating the emotion level of the segment.
- the emotional identification label may be two types of simple binary labels, positive and negative, but there are various types such as “anger”, “disgust”, “fear”, “happiness”, “sadness”, “surprise”, and so on. It may be a label that expresses emotion. As a result, it is possible to obtain samples with labels representing various kinds of emotions such as positive or “anger”, “disgust”, “fear”, “happiness”, “sadness”, “surprise”, and so on. (Step S214). In addition, a negative sample that does not give positive emotions to humans is also acquired (step S215).
- the data collection system 100 extracts segments (scenes) that impress humans from contents such as televisions and Internet broadcasts according to the processing procedure shown in FIG. 2, and further, emotions of voice and background music included in the segments. It is possible to identify the emotional label of each segment based on the analysis result, the facial expression identification result of the person in the segment, and the estimation result of the relationship between the people when two or more people are shown in the segment. can. Then, the segment with the emotion label collected by the data collection system 100 can be used for learning data for training the impression discriminator using artificial intelligence (neural network model).
- artificial intelligence neural network model
- the image shows the same person A
- the person B who appears together with the person A has a close relationship with family and friends and has a high degree of intimacy
- the image is likely to lead to impression.
- the intimacy between the person A and the person B is low, no impression may be given. In this way, grasping the relationship between subjects is very important in estimating whether or not the image gives an impression.
- the relationship estimation unit 113 describes the relationship between the persons based on the context between the facial expressions of the individual persons identified by the facial expression identification unit 112 and the segments before and after the segments extracted by the context extraction unit 106. Since the sex is estimated, there is no privacy problem.
- the relationship estimation unit 113 uses not only the information of the segment extracted by the segment extraction unit 105 (for example, the facial expression of a person identified from the video in the segment) but also the context with the segments before and after the information. Since the relationship between the persons is estimated, it can be expected that the accuracy of the estimation will be improved. Further, it is also conceivable to use meta information of the content itself (for example, information of a broadcast program) easily obtained from an information source such as the Internet for estimating the relationship between people.
- an information source such as the Internet
- FIG. 3 illustrates a mechanism in which the relationship estimation unit 113 estimates the relationship between people based on the segment context and the results of face detection and facial expression identification.
- the relationship estimation unit 113 includes the face detection and facial expression identification results of the detected face in the current segment extracted by the segment extraction unit 105, as well as the facial expression identification result of the person in the past segment. Face detection and the facial expression identification result of the detected face are used as a context.
- the past segment 301 is input to the CNN311 constituting the face detection unit 109 and the facial expression identification unit 112, and the CNN311 performs face detection and facial expression identification of each person reflected in the past segment 301. Then, the relationship estimation unit 113 registers the person whose face is detected from the past segment 301 and the facial expression identification result 303 in the person registration unit 313.
- the current segment 302 extracted by the segment extraction unit 105 is input to the CNN 312 constituting the face detection unit 109 and the facial expression identification unit 112, and this CNN is used for face detection and detection of each person in the current segment 302.
- the facial expression is identified, and the face detection and the facial expression identification result 304 of the detected face are output.
- the relationship estimation unit 113 inquires of the person registration unit 313 to check whether the person detected from the current segment 302 is a person pre-registered from the past segment 301.
- the relationship estimation unit 113 estimates from the current segment 302 for the same person.
- the facial expression identification result estimated from the past segment 301 is used to estimate the relationship between the persons.
- the relationship estimation unit 113 only identifies the facial expression estimated from the current segment 302. Estimate the relationship between people based on.
- the emotional identification unit 113 in the latter stage identifies the emotional label of the current segment based on the facial expression identification result estimated from the current segment without utilizing the relationship between the persons.
- the impression identification unit 114 identifies the impression label of the current segment by collecting the following multidimensional information.
- Emotion identification result of voice (such as dialogue) in the segment by voice recognition unit 107 and first emotion analysis unit 110
- mood identification results (3)
- the moving identification unit 114 labels the current segment as a moving scene.
- the moving discriminator 114 may label the current segment as a moving scene. If some information is missing, the reliability of impression identification may decrease, but since the segment itself has already passed the filter of matching the content evaluation information and the brain wave information in the segment extraction unit 105, It is believed that reliability will not drop sharply.
- the moving identification unit 114 attaches a negative label to the segment. You may. Negatively labeled segments can be used as training data to train the impression discriminator as a negative sample.
- each discriminator that identifies the voice, music, and facial expression of a person included in the segment is composed of a trained machine learning model such as CNN.
- the emotional discriminator 114 is not a simple binary label of two types, positive and negative, but “anger”, “disgust”, “fear”, “happiness”, “happiness”. It is also possible to attach labels that express emotions that are divided into various types such as “sadness”, “surprise”, and so on. That is, the data collection system 100 can collect learning data having various impression identification labels, and can be used for training an impression discriminator that identifies various types of impressions.
- the impression discriminator is a device that identifies what kind of impression the content gives.
- the device referred to here means both a device composed of dedicated hardware and a device that executes software to realize a predetermined function.
- FIG. 4 schematically shows the overall flow of the learning process of the impression discriminator using the collected learning data.
- the learning data collected by using the data collection system 100 is stored in the data storage unit 410.
- the individual training data correspond to what is called a "segment" in the above terms A to D.
- a segment as learning data is an element of contents such as television and Internet broadcasting, and is composed of video data consisting of a frame sequence and audio data synchronized with the video. Further, a moving identification label is finally attached to the segment as learning data as teacher data in the processing process in the data collection system 100. Impressive identification labels may be divided into various types, but in this section, for the sake of simplification of explanation, it is assumed that two types of simple binary labels, positive and negative, are given.
- the impression discriminator 420 is a network unit 421 composed of a plurality of network models for inputting video and audio data as learning data, and an identification unit 422 that identifies the impression label of the content based on the feature amount acquired by the network unit 421. It is composed.
- Each network in the network unit 421 has a parameter (such as a coupling weighting coefficient between nodes).
- each feature amount is acquired through a trained neural network model (CNN) in the network unit 421 for each frame, and by putting them together, the feature amount (Video Feature) of the entire video can be obtained.
- CNN trained neural network model
- LSTM Long Short Term Memory
- audio data it is converted into features such as Mel-Frequency Cepstrum Coafficients (MFCC) and Mel-Spectrogram, which are converted into a time-series network such as RSTM in the network unit 421.
- the audio feature amount (Audio Frequency) can be acquired by putting it in.
- the text feature amount (Text Feature) can be obtained by rewriting the voice feature amount into text (transcription) and putting it in a time-series network such as LSTM in the network unit 421.
- the identification unit 422 projects the feature amount (Video Feature), the audio feature amount (Audio Feature), and the text feature amount (Text Feature) of the entire image obtained as described above into a common space, and is a moving classifier.
- a moving identification label is given to the learning data input to 420.
- the identification unit 422 shall assign either a positive or negative binary label.
- the evaluation unit 423 performs a loss function Loss such as softmax based on an error between the impression identification label given to the learning data by the identification unit 422 and the impression identification label as the teacher data given to the learning data by the data collection system 100. calculate.
- the loss function Loss individually identifies the impression identification label based on the video feature amount, the impression identification label based on the audio feature amount, and the impression identification label based on the audio feature amount, and each error L video.
- the loss function Loss may be calculated based on the sum of, L text , and L Audio.
- the loss function Loss obtained based on the error is backpropagated to each network having the parameters in the network unit 421, and each network (CNN, CNN,) in the network unit 421 so that the loss function Loss is minimized.
- the parameters of LSTM) are updated.
- the impression discriminator 420 proceeds with learning so as to output an impression identification label equal to the teacher data with respect to the input learning data.
- the impression discriminator 420 learned through the learning process can identify the content that impresses or what kind of impression the content gives.
- the content referred to here includes various contents such as contents such as TV and Internet broadcasting, video contents shared on video sharing sites, videos taken by users with digital cameras and still images, and content evaluation information. It is not necessary to add biological information such as brain waves and brain waves.
- the learning data collected by the data collection system according to the present disclosure can be used to train a machine learning model for an emotion discriminator that identifies the emotions that the content gives to humans.
- various applications are expected for the emotion discriminator developed in this way.
- G-1 Configuration of Digital Camera
- the emotion discriminator developed based on this disclosure can be installed in various content processing devices that process content such as recording, playback, and editing of content, such as digital cameras. can.
- FIG. 5 shows a configuration example of the digital camera 500.
- the illustrated digital camera 500 includes an optical system 501, an imaging unit 502, an AFE (Analog Front End: analog preprocessing) unit 503, a camera signal processing unit 504, a code code 505, a main processing unit 506, and a microphone 514.
- the A / D conversion unit 515, the display unit 516, the sound reproduction unit 517, and the recording unit 518 are provided. It is assumed that the digital camera 500 is equipped with an emotion discriminator developed based on the present disclosure.
- the optical system 501 includes a lens for condensing light from the subject on the imaging surface of the imaging unit 502, a drive mechanism for moving the lens to perform focusing and zooming, and opening and closing the light from the subject for a predetermined time. It includes a shutter mechanism that only incidents on the imaging surface, and an iris (aperture) mechanism (neither shown) that limits the direction and range of the light beam bundle from the subject.
- the driver (not shown) drives each mechanism in the optical system 501 based on a control signal from the main processing unit 506 described later (for example, subject focusing, iris, pan and tilt, shutter or self-timer setting). Control camera work such as timing).
- the image pickup unit 502 is composed of an image pickup element such as a CCD (Charge Coupled Device) or a CMOS (Complementary Metal Oxyde Semiconductor), has an image pickup surface in which each pixel having a photoelectric conversion effect is arranged two-dimensionally, and is incident from the subject. Converts light into an electrical signal.
- a G checkered RB color coding veneer is arranged on the light receiving side. The signal charge corresponding to the amount of incident light passed through each color filter is accumulated in each pixel, and the color of the incident light at the pixel position can be reproduced from each signal charge amount of the three colors read from each pixel.
- the analog image signal output from the image pickup unit 502 is a primary color signal of each RGB color, but may be a complementary color system color signal.
- the AFE unit 503 suppresses the low noise of the imaging signal with high accuracy (Correlated Double Sampling (correlation double sampling): CDS), then performs sample hold, and further uses AGC (Automatic Gain Control: automatic gain control circuit). Appropriate gain control is applied, AD conversion is performed, and a digital image signal is output. Further, the AFE unit 503 outputs a timing pulse signal for driving the image sensor and a drive signal for outputting the electric charge of each pixel of the image sensor in the vertical direction in line units according to the timing pulse signal to the image sensor 502. do.
- CDS Correlated Double Sampling
- AGC Automatic Gain Control: automatic gain control circuit
- the camera signal processing unit 504 performs preprocessing such as defect pixel correction, digital clamp, and digital gain control on the image signal sent from the AFE unit 503, and then applies white balance gain by AWB and sharpness. -Reproduce the appropriate color state by performing image quality correction processing such as gain adjustment again, and further create an RGB screen signal by demosaic processing. Further, the camera signal processing unit 504 performs resolution conversion depending on whether the captured image is displayed and output as a through image on the display unit 516 or saved in the recording unit 518, or a codec such as MPEG (Moving Picture Experts Group). Perform processing.
- preprocessing such as defect pixel correction, digital clamp, and digital gain control
- image quality correction processing such as gain adjustment again
- RGB screen signal by demosaic processing.
- the camera signal processing unit 504 performs resolution conversion depending on whether the captured image is displayed and output as
- the main processing unit 506 is composed of a processor, a RAM (Random Access Memory), and a ROM (Read Only Memory), and comprehensively controls the operation of the entire digital camera 500.
- the processor is a CPU (Central Processing Unit), a GPU having a multi-core (Graphic Processing Unit), or the like.
- the main processing unit 506 stores the video data captured by the photographing unit 502 and the audio data collected by the microphone 514 in the recording unit 518. Further, the main processing unit 506 reads out video and audio data from the recording unit 518 at the time of reproduction, and outputs the video and audio data to the display unit 516 and the sound reproduction unit 517. Further, in the present embodiment, it is assumed that the main processing unit 506 is equipped with the emotion discriminator developed based on the present disclosure.
- the display unit 516 is a device that displays a video being shot or a recorded video, such as a liquid crystal display panel mounted on the digital camera 500, an external television or a projector.
- the sound reproduction unit 517 is a device that reproduces recorded sound such as a speaker mounted on the digital camera 5100 and an external speaker.
- the recording unit 518 is a large-capacity recording device such as an HDD (hard disk drive) or SSD (Solid State Drive).
- the recording unit 518 records the video captured by the imaging unit 502 and the content composed of audio data collected by the microphone 514 in synchronization with the video. Further, the parameters of the machine learning model for the emotion discriminator (for example, the connection weight coefficient between neurons in the neural network model) are recorded in the recording unit 518.
- FIG. 6 shows a functional configuration for performing emotional identification labeling of content captured by the digital camera 500.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421.
- CNN trained neural network model
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label.
- the identification unit 422 assigns either a positive or negative binary label. Alternatively, the identification unit 422 may be provided with labels representing emotions differentiated into various types.
- the identification unit 422 assigns a moving identification label to the captured content for each scene (or segment).
- the given impression identification label is recorded as, for example, meta information of the content.
- the moving identification label can be used as a search key to select and watch a moving scene.
- the emotional identification label can be used as a search key to select only scenes having a specific emotion, such as "happy" scenes and "sad” scenes.
- the data collection system 100 can assign an impression identification label that identifies the type of impression that can be given to a human being for each input content or segment in the content. Therefore, the data collection system 100 is used to collect content or segments to which a specific moving identification label (for example, "happy", “sad”, etc.) is attached from a huge amount of video content 101, and identify the content or segment. It can be used for learning a machine learning model that estimates the camera operation for generating the moving content or shooting the moving content.
- a specific moving identification label for example, "happy", "sad”, etc.
- Support or control of camera work can be performed based on the result obtained by applying the content captured by the digital camera 500 to the moving identification device. For example, you can automatically control the line-of-sight direction and zoom of the subject to increase the degree of impression, or obtain a specific type of impression identification label, or the brightness, color, angle of view, and composition of the captured image. , Focus, etc. may be automatically controlled, or the recommended angle may be taught by using the guidance display of the display unit 516 or the voice guidance from the sound reproduction unit 517.
- FIG. 7 shows the functional configuration of the digital camera 500 for automatically controlling the camera work based on the impression identification result of the captured content.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421.
- CNN trained neural network model
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label. Then, the evaluation unit 423 outputs a control signal of the camera work to the optical system 501 so that the degree of impression is increased or a specific type of impression identification label can be acquired.
- G-4 Add caption Based on the result obtained by subjecting the content captured by the digital camera 500 to the emotional identification device, it is possible to automatically add a caption that is appropriate for the video scene and increases the degree of emotionalization.
- FIG. 8 shows the functional configuration of the digital camera 500 for automatically generating captions based on the impression identification result of the captured content.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421. Further, the caption generation unit 801 generates a caption for each scene by using, for example, a trained machine-learned model. The text information of the caption generated by the caption generation unit 801 is superimposed on the text information obtained from the voice recognition of the content and put into a time series network such as LSTM in the network unit 421.
- CNN trained neural network model
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label.
- the evaluation unit 423 calculates the loss function for the emotional identification label output from the identification unit 422. Then, the caption generation unit 801 relearns so that the degree of impression increases or a specific type of impression identification label can be acquired.
- the caption generated by the caption generation unit 801 is superimposed and recorded on the audio data of the content.
- FIG. 9 shows the functional configuration of the digital camera 500 for automatically adding background music based on the impression identification result of the captured content.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421. Further, the music search unit 901 searches for a music that becomes the background music of the scene by using, for example, a trained machine-learned model.
- CNN trained neural network model
- the music search unit 901 may search for music that is the background music of the scene, for example, on a music database (not shown) that stores a huge amount of music data.
- the music data of the music found by the music search unit 901 is superimposed on the audio data of the content and put into a time-series network such as LSTM in the network unit 421.
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label.
- the evaluation unit 423 calculates the loss function for the emotional identification label output from the identification unit 422. Then, the music search unit 901 relearns to find background music that can increase the degree of impression or acquire a specific type of impression identification label. The music data of the leg found by the music search unit 901 is superimposed and recorded on the audio data of the content.
- the content (or each segment constituting the content) represents the level of impression. Captions and backgrounds for assigning impression identification labels, providing camera work support or control (automatic camera operation) for shooting content that gives a high level of impression, and improving the impression score of content. Music can be added.
- this section H a method for efficiently learning the neural network model in the digital camera 500 will be described.
- the description will be limited to the learning method of the neural network model for automatic operation of the camera, but the neural network model for adding captions and adding background music will also be efficiently learned by the same method. Please understand that you can.
- FIG. 10 schematically shows the configuration of the learning system 1000 for efficiently learning a neural network model for camera operation support and automatic operation.
- a neural network model that mainly generates a moving content or estimates a camera operation for shooting the moving content is assumed.
- the learning system 1000 can also be used to train other types of neural network models.
- the learning system 1000 shown in FIG. 10 analyzes the training data, the data collection device 1010 that collects the training data, the learning device 1030 that learns the neural network model based on the learning data collected by the data collection device 1010, and the learning device 1030. It is composed of a data analysis device 1040 and a model utilization device 1020 that uses a neural network model 1050 trained by the learning device 1030.
- the data collection device 1010 collects data including image data taken by a camera and operation information at the time of camera shooting, for example.
- the data collection device 1010 includes a still camera, a video camera, an image sensor used in the camera, a multifunctional information terminal such as a smartphone, a TV, headphones or earphones, a game machine, an IoT device such as a refrigerator or a washing machine, a drone or a robot, and the like. It is possible to collect a huge amount of data from a huge number of data collecting devices 1010 including many kinds of huge devices such as a mobile device of the above.
- the data collection device 1010 is a camera used by an expert such as a professional cameraman, it is possible to collect a moving image and camera operation information for capturing such an image. Further, the data collection device 1010 may include not only a device that collects data in real time as illustrated above, but also a device that has already accumulated a large amount of data such as a content database.
- the learning device 1030 transmits a request signal requesting transmission of the collected data to each data collecting device 1010.
- the data acquisition device 1010 may spontaneously transmit the data instead of responding to the request signal.
- the learning device 1030 uses a huge amount of data collected by a large number of data collecting devices 1010, and various types such as an "observation prediction model”, an "operation model”, an “operation estimation model”, and an “impression score estimation model” are used. Neural network model learning and re-learning. Details of the neural network model used in the learning system 1000 will be described later.
- the data analysis device 1040 analyzes the learning data that affects the learning of the neural network model to be trained, and learns the neural network model based on the analysis result. Meaningful learning data such as learning data having an influence on or more than a predetermined value, missing learning data, and data similar to these is extracted, and the learning device 1030 extracts the meaningful learning data extracted by the data analysis unit 1040. It is used to efficiently train and relearn neural network models.
- the data analyzer 1040 is based on, for example, a method such as XAI (eXplainable AI), confidence score calculation of training data, influence function calculation, and data shortage estimation by Bayesian DNN (Deep Newral Network). ,
- XAI eXplainable AI
- confidence score calculation of training data e.g., confidence score of training data
- influence function calculation e.g., influence function calculation
- data shortage estimation e.g., Bayep Newral Network
- the model utilization device 1020 is a device that shoots moving contents by using the neural network model 1050 learned by the learning device 1030.
- the model utilization device 1020 is, for example, a camera used by a general user who is not accustomed to operating the camera.
- the model utilization device 1020 uses a neural network model trained by the learning device 1030 to automatically operate a camera comparable to a shooting expert such as a professional photographer, or automatically shoot a video having a high impression score. can do.
- the learning device 1030 requires a huge amount of computational resources to train various neural network models. Therefore, in FIG. 10, it is assumed that the learning device 1030 is constructed on, for example, a cloud (that is, cloud AI (Artificial Intelligence)). Further, the learning device 1030 may perform distributed learning using a plurality of calculation nodes. However, it is also assumed that the learning device 1030 is integrally configured with a model utilization device that uses the trained neural network model (that is, edge AI). Alternatively, the learning device 1030 may be integrally configured with the data collecting device 1010 that provides the learning data.
- a cloud that is, cloud AI (Artificial Intelligence)
- the learning device 1030 may perform distributed learning using a plurality of calculation nodes.
- the learning device 1030 is integrally configured with a model utilization device that uses the trained neural network model (that is, edge AI).
- the learning device 1030 may be integrally configured with the data collecting device 1010 that provides the learning data.
- the data analyzer 1040 may be built in either the cloud or the edge.
- the data analysis device 1040 may be configured as a device integrated with the learning device 1030.
- the learning device 1030 internally analyzes the learning data that affects the learning of the neural network model, and the learning data that affects the learning of the neural network model more than a predetermined amount, the missing training data, or these.
- the data collection device 1010 may be requested to transmit data similar to the above.
- the data analysis device 1040 may be configured as a device integrated with the data collection device 1010.
- the learning device 1030 provides the data collecting device 1010 with information necessary for data analysis (for example, information of the neural network model learned at that time) at the time of requesting transmission of training data. Then, the data collection device 1010 analyzes the influence of the collected data on the neural network model, and among the collected data, the training data having a predetermined influence on the learning of the neural network model, the missing training data, and the like. Alternatively, data similar to these may be transmitted to the learning device 1030.
- a data collection device 1010 for collecting training data and a model utilization device 1020 using a neural network model are drawn as separate devices, but one device is a data collection device 1010 and a model utilization device 1020. It is also expected to operate as both.
- one camera operates as a data collection device 1010 in the manual operation mode, collects data such as shooting data and camera operation information and transmits the data to the learning device 1030, while switching to the automatic operation mode is a model utilization device. It may operate as 1020 and perform automatic imaging using the neural network model trained by the learning device 1030.
- the learning device 1030 uses the data collected by the data collecting device 1040 to perform a neural network such as an "observation prediction model”, an "operation model”, an “operation estimation model”, and an "impression score estimation model”. Learn and relearn. Further, the model utilization device 1020 utilizes at least a part of these neural network models trained by the learning device 1030.
- FIG. 11 schematically shows the configuration of the observation prediction model 1100.
- the observation prediction model 1100 uses the image information 1101 up to the current time taken by the camera and the operation information 1102 up to the current time for the camera to capture an image taken by the camera at the next time (that is, an "image at the next time”).
- a neural network model that predicts 1111.
- the operation information 1102 referred to here is information regarding operations performed on the camera for determining imaging conditions such as frame rate, aperture, exposure value, magnification, and focus (hereinafter, the same applies).
- the remote control operation (camera work indicated by roll, pitch, yaw, etc.) performed on the mobile device is also included in the operation information. It may be (hereinafter, the same applies).
- the observation prediction model 1100 also outputs a reliability score 1112 for the image 1111 at the next time predicted.
- the reliability score 1112 is a value indicating how accurately the image 1111 at the next time can be predicted.
- a confidence score is used to identify data that is lacking in learning or has a high impact on learning.
- the data analyzer 1040 can be used to train the observation prediction model 1100 based on methods such as explanation of the basis for prediction of the observation prediction model 1100 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Meaningful learning data such as learning data that affects more than a predetermined value, missing learning data, and data similar to these are extracted.
- the calculation function of the reliability score 1112 by the observation prediction model 1100 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the observation prediction model 1100 based on the data set including the video information and the operation information transmitted from the data collecting device 1010.
- the learning device 1030 can learn the observation prediction model 1100 so that it can predict an image that can give more impression by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 efficiently retrains the observation prediction model 1100 using the meaningful learning data. Can be done
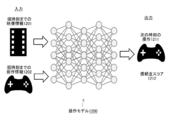
- FIG. 12 schematically shows the configuration of the operation model 1200.
- the operation model 1200 is a neural network model that predicts the operation 1211 to be performed on the camera at the next time from the video information 1201 taken by the camera up to the current time and the operation information 1202 up to the current time for the camera.
- the operation model 1200 also outputs a reliability score 1212 for the operation 1211 at the predicted next time.
- the reliability score 1212 is a value indicating how accurately the image 1111 at the next time can be predicted.
- the data analyzer 1040 is required to train the operation model 1200 based on a method such as explanation of the basis for prediction of the operation model 1200 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Extract meaningful learning data such as learning data that is affected by the above, missing learning data, and data similar to these.
- the calculation function of the reliability score 1212 according to the operation model 1200 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the operation model 1200 based on the data set consisting of the video information and the operation information transmitted from the data collection device 1010.
- the learning device 1030 can learn the operation model 1200 so that the camera operation information capable of capturing an image that can give a more impression can be predicted by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 efficiently retrains the operation model 1200 using the meaningful learning data. Can be done.
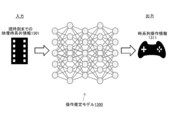
- FIG. 13 schematically shows the configuration of the operation estimation model 1300.
- the operation estimation model 1300 is a neural network model that estimates the time-series operation information 1311 for capturing the video time-series information 1301 up to the current time with a camera. For example, using the operation estimation model 1300, it is possible to estimate the time-series operation information of the camera performed by the expert from the high-quality video time-series information taken by an expert who is familiar with camera operation such as a professional cameraman.
- the operation estimation model 1300 may also output the reliability score for the estimated time series operation information 1311.
- the data analyzer 1040 can be used to train the operation estimation model 1300 based on methods such as explanation of the basis for prediction of the operation estimation model 1300 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Meaningful learning data such as learning data that affects more than a predetermined value, missing learning data, and data similar to these are extracted.
- the function of calculating the reliability score by the operation estimation model 1300 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the operation estimation model 1300 based on the data set consisting of the video information and the operation information transmitted from the data collection device 1010.
- the learning device 1030 can learn the operation estimation model 1300 so as to predict the time-series operation information capable of capturing an image that can give more impression by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 efficiently retrains the operation estimation model 1300 using the meaningful learning data. Can be done
- FIG. 14 schematically shows the configuration of the impression score estimation model 1400.
- the emotion score estimation model 1400 is a neural network model that estimates the emotion score 1411 of the video information 1401, and corresponds to the above-mentioned emotion discriminator. For example, according to the learning process shown in FIG. 4, the impression score estimation model 1400 can be learned.
- FIG. 15 shows the relationship between the control target (frame rate, resolution, etc.) and the average impression score.
- the predicted value output from the neural network model is shown by a solid line, and the variance is shown by a dot.
- FIG. 15 shows an average impression score obtained when the operation model is learned by reinforcement learning so that the impression score becomes high based on the video data acquired at a certain frame rate, and the camera is operated using the learned operation model. Is shown.
- the data points indicated by black circles are points for which data already exists.
- the variance is small at some points of the data. The point where there is no data has a large variance. The larger the variance and the higher the score can be expected, the greater the value of observation. For example, an implementation that optimistically considers the variance and acquires the data of the points where the highest score can be expected can be considered.
- the impression score estimation model 1400 may also output the reliability score for the estimated impression score 1411.
- the data analyzer 1040 may use the impression score estimation model 1400 based on methods such as explanation of the basis for prediction of the impression score estimation model 1400 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Meaningful learning data such as learning data that affects learning more than a predetermined value, missing learning data, and data similar to these are extracted.
- the function of calculating the reliability score by the impression score estimation model 1400 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the impression score estimation model 1400 based on the data set consisting of the video information and the operation information transmitted from the data collecting device 1010.
- the learning device 1030 can learn the impression score estimation model 1400 so that a higher impression score can be estimated for the video information that can give impression by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 retrains the impression score estimation model 1400 using the meaningful learning data. It can be done efficiently.
- the data analyzer 1040 analyzes the learning data of the neural network model to be learned, and the learning data that affects the learning more than a predetermined value, the missing learning data, and the like. Identifying meaningful learning data, such as data similar to, the learning device 1020 uses such meaningful learning data to efficiently train and relearn the neural network model.
- the data analyzer 1040 may be built in either the cloud or the edge.
- the data analysis device 1040 may be configured as a device integrated with the learning device 1030.
- the learning device 1030 internally analyzes the learning data that affects the learning of the neural network model, and the learning data that affects the learning of the neural network model more than a predetermined amount, the missing training data, or these.
- the data collection device 1010 is requested to transmit data similar to the above.
- the data analysis device 1040 may be configured as a device integrated with the data collection device 1010.
- the learning device 1030 provides the data collecting device 1010 with information necessary for data analysis (for example, information of the neural network model learned at that time) at the time of requesting transmission of training data. Then, the data collection device 1010 analyzes the influence of the collected data on the neural network model, and among the collected data, the training data having a predetermined influence on the learning of the neural network model, the missing training data, and the like. Alternatively, data similar to these is transmitted to the learning device 1030.
- Examples of the method for the data analysis device 1040 to analyze the data include XAI, calculation of the reliability score of the training data, calculation of the influence function, and estimation of data shortage by Bayesian DNN.
- the reliability score is a numerical value of the degree of correctness of the predicted value by the neural network model.
- the observation prediction model 1100 and the operation model 1200 are configured to output the reliability score together with the prediction value.
- the data collection device 1010 filters the learning data to be transmitted to the learning device 1030 using the reliability score, and the details of this point will be described later.
- Neural network model trained to estimate output error As shown in FIG. 16, the neural network model 1500 is trained to output the output error as a reliability score together with the original output. ..
- the influence function is a formulation of the influence of the presence or absence of individual learning data and perturbations on the prediction result of the neural network model (see, for example, Non-Patent Document 4).
- Bayesian DNN is constructed by combining Bayesian estimation and deep learning, and by using Bayesian estimation, it is possible to evaluate the uncertainty due to lack of data when the neural network model outputs the prediction result.
- the data collection device 1010 is a still camera, a video camera, an image sensor used in a camera, a multifunctional information terminal such as a smartphone, a TV, headphones or earphones, a game machine, an IoT device such as a refrigerator or a washing machine.
- a multifunctional information terminal such as a smartphone, a TV, headphones or earphones, a game machine, an IoT device such as a refrigerator or a washing machine.
- IoT device such as a refrigerator or a washing machine.
- mobile devices such as drones and robots.
- FIG. 17 shows an example of the internal configuration of the data collection device 1010.
- the data collection device 1010 shown in FIG. 17 includes a sensor unit 1011, an operation input unit 1012, a control unit 1013, a log transmission unit 1014, and a data analysis unit 1015.
- FIG. 17 is an abstraction of a typical functional configuration related to the realization of the present disclosure among various types of data acquisition devices 1010, and each data collection device 1010 has various configurations (not shown). It is assumed to have elements.
- the sensor unit 1011 is composed of an image sensor composed of CMOS or the like and other sensors equipped in the data acquisition device 1010, and performs observations such as taking images and videos. Further, when the data collection device 1010 is mounted on a mobile device such as a robot or a drone, various sensors mounted on the mobile device such as an IMU (Inertial Measurement Unit) are also included in the sensor unit 1011. do.
- IMU Inertial Measurement Unit
- the operation input unit 1012 is a function module that performs an input operation for adjusting operation information such as shooting conditions in the data collection device 1010.
- the operation input unit 1012 includes controls such as buttons and knobs, a touch panel screen, and the like. Further, when the data collection device 1010 is mounted on a mobile device such as a robot or a drone, the operation input unit 1012 also includes a remote controller used when remotely controlling the mobile device.
- the control unit 1013 comprehensively controls the operation of the entire data collection device 1010. Further, the control unit 1013 controls the observation of the sensor unit 1011 to capture an image or video based on the operation information input via the operation input unit 1012.
- the log transmission unit 1014 transmits a data set consisting of the observation log observed by the sensor unit 1011 and the operation log input to the operation input unit 1012 to the learning device 1030.
- the log transmission unit 1014 transmits a data set to the learning device 103 in response to receiving a request signal requesting data transmission from the learning device 1030.
- the data collection device 1010 newly collects data in response to receiving the request signal from the learning device 1030 and transmits it to the learning device 1030, but the learning device extracts data extracted from the already collected data based on the request signal. It may be sent to 1030.
- the data acquisition device 1010 may spontaneously transmit the data rather than responding to the request signal.
- the data analysis unit 1015 analyzes the influence of the data set consisting of the observation log observed by the sensor unit 1011 and the operation log input to the operation input unit 1012 on the learning of each neural network model to be learned. Identify whether the data is meaningful for learning, such as learning data that affects learning more than a certain amount, missing learning data, or similar data.
- the learning device 1030 may send a request signal by designating data meaningful for learning, or may instruct analysis of the collected data and send a request signal.
- the data analysis unit 1015 checks whether the data set consisting of the observation log observed by the sensor unit 1011 and the operation log input to the operation input unit 1012 corresponds to the data specified by the request signal. Therefore, the log transmission unit 1014 transmits only the data conforming to the request to the learning device 1030.
- the data analysis unit 1015 corresponds to the data analysis device 1040 in FIG.
- the data analysis unit 1015 analyzes the learning data that affects the learning of the neural network model to be learned in the learning device 1030, and inputs the observation log observed by the sensor unit 1011 and the operation input unit 1012. Check whether the data set consisting of the operation logs corresponds to meaningful training data such as training data that affects the training of the neural network model more than a predetermined value, missing training data, and similar data. .. Then, the log transmission unit 1014 transmits only the data set that is meaningful learning data to the learning device 1030.
- the data analysis unit 1015 analyzes the neural network model using, for example, at least one or a combination of XAI, reliability score, influence function, and Bayesian DNN. For example, when the data analysis unit 1015 analyzes data using the reliability score, the neural network when the learning device 1030 receives the information of the neural network model trained by the current time and inputs the data set. Calculate the confidence score of the inference by the model. See Section H-3 above for how to calculate the confidence score. Observation logs and operation logs with high reliability scores are learning data that are not lacking and have low value, but observation logs and operation logs with low reliability scores are learning data that are lacking and have high value. Can be done. By collecting the learning data having a low reliability score and lacking it and providing it to the learning device 1030, the learning device 103 can efficiently learn and relearn the neural network model.
- the data analysis unit 1015 may feed back the analysis result to the sensor unit 1011 and the operation input unit 1012. Then, the sensor unit 1011 and the operation input unit 1012 take pictures by changing the resolution, frame rate, brightness, color, angle of view, viewpoint position, or line-of-sight direction based on the degree of influence on the learning of the neural network model to be learned. May be done.
- FIG. 18 shows another internal configuration example of the data acquisition device 1010.
- the data collection device 1010 shown in FIG. 18 includes a sensor unit 1011, an operation input unit 1012, a control unit 1013, and a log transmission unit 1014.
- the main difference from the configuration example shown in FIG. 17 is that the data analysis unit 1015 is not provided.
- the data collection device 1010 shown in FIG. 18 does not analyze the collected data, in other words, regardless of whether the collected data is meaningful training data for learning or re-learning the neural network model, it is all a learning device. Send to 1030.
- FIG. 19 shows an example of the internal configuration of the learning device 1030.
- the learning device 1030 shown in FIG. 19 includes a model learning unit 1031, an observation / operation log storage unit 1032, an observation prediction model / operation model storage unit 1033, an operation estimation model storage unit 1034, an operation estimation unit 1035, and data.
- the analysis unit 1036 is provided.
- the model learning unit 1031 learns various neural network models using the learning data.
- the model learning unit 1031 includes an observation prediction model (see FIG. 11), an operation model (see FIG. 12), an operation estimation model (see FIG. 13), and an impression score estimation model. (See FIG. 14) and the like.
- the model learning unit 1031 may be configured by using a plurality of calculation nodes to perform distributed learning of the neural network model.
- the observation / operation log storage unit 1032 stores the observation log and the operation log transmitted from the data collection device 1010. It is assumed that the data acquisition device 1010 sends an observation log and an operation log that are meaningful learning data.
- the model learning unit 1031 learns the observation prediction model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained observation prediction model is stored in the observation prediction model / operation model storage unit 1033.
- model learning unit 1031 learns the operation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained operation model is accumulated in the observation prediction model / operation model storage unit 1033.
- model learning unit 1031 learns the operation estimation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained operation estimation model is accumulated in the operation estimation model storage unit 1034.
- the data analysis unit 1036 corresponds to the data analysis device 1040 in FIG.
- the data analysis unit 1036 analyzes the learning data that affects the learning of each trained neural network stored in the observation prediction model / operation model storage unit 1033 and the operation estimation model storage unit 1034. Then, based on the analysis result, a request signal requesting transmission of learning data having a predetermined or greater effect, missing learning data, or data similar thereto is transmitted from the learning device 1030 to the data collecting device 1010. Will be done. Therefore, the data acquisition device 1010 sends an observation log and an operation log that are meaningful learning data.
- the data analysis unit 1036 analyzes the training data based on a method such as XAI, reliability score calculation, influence function, or Bayesian DNN.
- the operation estimation unit 1035 uses the trained operation estimation model to shoot the image from the image (hereinafter, also referred to as "professional image") taken by an expert who is familiar with camera operation such as a professional cameraman. Estimate the time-series operation information of. Then, a data set consisting of a professional image (observation log) input to the operation estimation unit 1035 and operation information (estimated operation log) estimated by the operation estimation unit 1035 learns a professional-level operation model. As high-quality learning data for this purpose, it is stored in the observation / operation log storage unit 1032. Therefore, the model learning unit 1031 can learn an operation model capable of predicting a professional-level camera operation by using the high-quality learning data stored in the observation / operation log storage unit 1032.
- Professional video content is optional and is expected to be provided to the cloud via the network. By collecting a large amount of high-quality learning data using professional video content, it becomes possible to learn an operation model to realize professional-level camera automatic operation.
- FIG. 20 shows another internal configuration example of the learning device 1030.
- the learning device 1030 shown in FIG. 20 includes a model learning unit 1031, an observation / operation log storage unit 1032, an observation prediction model / operation model storage unit 1033, an operation estimation model storage unit 1034, and an operation estimation unit 1035. There is.
- the main difference from the configuration example shown in FIG. 19 is that the data analysis unit 1036 is not provided.
- the learning device 1030 shown in FIG. 20 does not analyze the learning data by itself, but instead transmits the information of the neural network model to be learned to the data collecting device 1010.
- the data analysis unit 1015 analyzes the learning data that affects the learning of the neural network model to be learned in the learning device 1030, and the observation log observed by the sensor unit 1011 and the observation log
- the data set consisting of the operation logs input to the operation input unit 1012 becomes meaningful training data such as training data that affects the training of the neural network model more than a predetermined value, insufficient training data, and data similar to these. Check if applicable (mentioned above). Then, only the data set that is meaningful learning data is transmitted from the data collecting device 1010 to the learning device 1030.
- FIG. 21 shows yet another internal configuration example of the learning device 1030.
- the learning device 1030 shown in FIG. 21 includes a model learning unit 1031, an observation / operation log storage unit 1032, an observation prediction model / operation model storage unit 1033, an operation estimation model storage unit 1034, an operation estimation unit 1035, and data.
- the analysis unit 1037 is provided. The main difference from the configuration examples shown in FIGS. 19 and 20 is that the learning device 1030 receives all the collected data from the data collection device 1010 including the configuration example shown in FIG. 18, and is a data analysis unit. At 1037, it is checked whether each received data is meaningful training data.
- the data analysis unit 1037 corresponds to the data analysis device 1040 in FIG.
- each received data stored in the observation / operation log storage unit 1032 is stored in the observation prediction model / operation model storage unit 1033 and the operation estimation model storage unit 1034. Analyze the impact on learning. Then, the data analysis unit 1037 accumulates only meaningful learning data such as learning data that affects the learning of each neural network model more than a predetermined value, missing learning data, and data similar to these, and accumulates observation / operation logs. It is extracted from the unit 1032 and output to the model learning unit 1031. Therefore, the model learning unit 1031 can efficiently learn and relearn various neural network models using meaningful learning data.
- FIG. 22 shows an example of the internal configuration of the model utilization device 1020.
- the model utilization device 1020 includes a sensor unit 1021, an automatic operation unit 1022, a control unit 1023, and a presentation unit 1024.
- the sensor unit 1021 is composed of an image sensor composed of CMOS or the like and other sensors equipped in the model utilization device 1020, and performs observations such as taking images and videos. Further, when the model utilization device 1020 is mounted on a mobile device such as a robot or a drone, various sensors mounted on the mobile device such as an IMU are also included in the sensor unit 1021.
- the automatic operation unit 1022 predicts the operation information of the next time from the observation information (video information up to the current time and operation information up to the current time) of the sensor unit 1021 using the operation model provided by the learning device 1030. At the same time, the data analysis result such as the reliability score of the predicted operation information is output.
- the control unit 1023 controls observations such as capturing images and videos in the sensor unit 1011 based on the operation information of the next time predicted by the automatic operation unit 1022.
- the learning device 1030 provides an operation model that has been sufficiently learned, even if the user of the model utilization device 1020 is not familiar with camera operation, it is based on the operation information predicted by the automatic operation unit 1022. , Professional photographers and other experts who are familiar with camera operation can take pictures.
- the presentation unit 1024 presents the data analysis result such as the reliability score of the operation information predicted by the automatic operation unit 1022. From the presented reliability score, the user of the model utilization device 1020 can determine whether or not the image is shot with professional-level skill by automatic operation.
- FIG. 23 shows an example of the internal configuration of the model utilization device 1020 as the edge AI.
- the illustrated model utilization device 1020 includes a sensor unit 1021, an automatic operation unit 1022, a control unit 1023, a presentation unit 1024, a model learning unit 1031, an observation / operation log storage unit 1032, and an observation prediction model. It includes an operation model storage unit 1033, an operation estimation model storage unit 1034, and an operation estimation unit 1035.
- the observation / operation log storage unit 1032 stores the observation log and the operation log transmitted from the data collection device 1010.
- the model learning unit 1031 learns the observation prediction model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Further, the model learning unit 1031 learns the operation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the learned observation prediction model and operation model are accumulated in the observation prediction model / operation model storage unit 1033.
- the model learning unit 1031 learns the operation estimation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained operation estimation model is accumulated in the operation estimation model storage unit 1034.
- the operation estimation unit 1035 estimates the time-series operation information for shooting the image from the image taken by an expert who is familiar with camera operation such as a professional cameraman by using the learned operation estimation model, and the professional It is stored in the observation / operation log storage unit 1032 as high-quality learning data for learning an ordinary operation model. Therefore, the model learning unit 1031 can learn an operation model capable of predicting a professional-level camera operation by using the high-quality learning data stored in the observation / operation log storage unit 1032.
- the sensor unit 1021 is composed of an image sensor composed of CMOS or the like and other sensors equipped in the model utilization device 1020, and performs observations such as taking images and videos.
- the automatic operation unit 1022 uses the operation model read from the observation prediction model / operation model storage unit 1033 to obtain the next time from the observation information (video information up to the current time and operation information up to the current time) of the sensor unit 1021.
- the operation information is predicted, and the data analysis result such as the reliability score of the predicted operation information is output.
- the control unit 1023 controls observations such as capturing images and videos in the sensor unit 1011 based on the operation information of the next time predicted by the automatic operation unit 1022.
- the learning device 1030 provides an operation model that has been sufficiently learned, even if the user of the model utilization device 1020 is not familiar with camera operation, it is based on the operation information predicted by the automatic operation unit 1022. , Professional photographers and other experts who are familiar with camera operation can take pictures.
- the presentation unit 1024 presents the data analysis result such as the reliability score of the operation information predicted by the automatic operation unit 1022. From the presented reliability score, the model utilization device 1020 can determine whether or not the image is shot with professional-level skill by automatic operation.
- This disclosure can be applied to the data collection process used for learning a machine learning model that generates content that impresses humans.
- the data collected based on the present disclosure is a machine for handling content that impresses human beings (specifically, for estimating camera operation for generating moving content or shooting moving content). It is used for learning data for training a learning model (for example, a neural network model), but of course it can also be used for learning a machine learning model for other purposes.
- the data collected based on this disclosure can be used to train a machine learning model that identifies the emotions that content gives to humans, and an emotion discriminator equipped with the machine learning model developed in this way can be used. It can be installed in content processing devices such as digital cameras.
- a data collecting device for collecting data and a learning device for learning a machine learning model using the data collected by the data collecting device are provided.
- the learning device collects learning data that affects the learning of the machine learning model based on the results of analysis, learning data that affects the learning of the machine learning model by a predetermined value or more, missing learning data, and the like.
- the machine learning model is retrained using data similar to these. Learning system.
- the learning device learns a machine learning model that estimates a camera operation for generating moving contents or shooting moving contents.
- the learning device analyzes learning data that affects the learning of the machine learning model, and based on the analysis result, the learning data that affects the learning of the machine learning model by a predetermined value or more is insufficient.
- a request signal requesting transmission of the learning data or data similar thereto is transmitted to the data acquisition device, and the data is collected.
- the data acquisition device transmits the data collected based on the received request signal to the learning device, and the data acquisition device transmits the data to the learning device.
- the learning device relearns the machine learning model based on the data transmitted from the data collecting device in response to the request signal.
- the learning system according to any one of (1) to (3) above.
- the data acquisition device is a camera or imager that captures an image, and is a resolution, frame rate, brightness, color, angle of view, viewpoint position, or line of sight based on the degree of influence of the machine learning model on learning.
- the image data taken by changing the direction is transmitted to the learning device.
- the learning system according to any one of (1) to (4) above.
- the learning device transmits a request signal requesting transmission of training data of the machine learning model to the data collecting device. Based on the result of analyzing the influence of the collected data on the learning of the machine learning model, the data collecting device lacks the learning data having a predetermined or more influence on the learning of the machine learning model among the collected data. The learning data that is being used, or data similar to these, is transmitted to the learning device. The learning device relearns the machine learning model based on the data transmitted from the data collecting device in response to the request signal.
- the learning system according to any one of (1) to (3) above.
- the learning device transmits information necessary for the analysis to the data collecting device.
- a receiving unit that receives a request signal requesting transmission of learning data of the machine learning model from a learning device that learns the machine learning model.
- a data collection unit that collects learning data that has a predetermined or greater effect on the learning of the machine learning model, missing learning data, or data similar thereto in response to receiving the request signal.
- a transmission unit that transmits the data collected by the data collection unit to the learning device, and a transmission unit.
- a data collection device comprising.
- the receiving unit receives from the learning device the request signal requesting learning data having a predetermined or greater effect on the learning of the machine learning model, missing learning data, or data similar thereto.
- the data collection unit collects data based on the received request signal, and the data collection unit collects data.
- the transmitting unit transmits the data collected by the data collecting unit to the learning device.
- the data collection device according to (8) above.
- the data collection unit newly collects data based on the received request signal, or the transmission unit transmits data extracted based on the request signal from the data already collected by the data collection unit. do, The data collection device according to (9) above.
- the transmission unit uses the data collected by the data collection unit to have a learning data that affects the learning of the machine learning model by a predetermined value or more, a lack of learning data, or these. Sends data similar to the above to the learning device, The data collection device according to (8) above.
- the data collection unit determines the resolution, frame rate, brightness, color, angle of view, viewpoint position, or line-of-sight direction of the camera or imager that captures an image based on the degree of influence of the machine learning model on learning. Collect image data taken by changing, The data collection device according to any one of (8) to (11) above.
- a segment extraction unit that extracts segments from the content based on the content evaluation information of the content and the biometric information of the person who views the content.
- a facial expression identification unit that detects the face of a person in a segment and identifies the facial expression
- a relationship estimation unit that estimates the relationships between people in the segment
- An emotional identification unit that identifies the emotional label of a segment based on the facial expression of the person in the segment and the relationship between the persons.
- the biological information includes at least electroencephalogram information.
- the information processing device according to (13) above.
- the segment extraction unit extracts a segment of the content in which biometric information having a high evaluation and positive emotion matches.
- the information processing device according to any one of (13) and (14) above.
- the segment extraction unit further extracts segments in which biometric information having a high evaluation and positive emotions does not match.
- the information processing device according to (15) above.
- the relationship estimation unit estimates the relationship between the persons in the segment based on the context with the preceding and following segments and the facial expression of the person.
- the information processing device according to any one of (13) to (16) above.
- the relationship estimation unit estimates the relationship between the persons in the current segment by using the face detection of the person in the past segment and the facial expression identification result of the detected face as the context. do, The information processing device according to (17) above.
- the emotion identification unit identifies the emotion label of the segment by further considering the emotion identified by the first emotion analysis unit from the text information.
- the information processing device according to any one of (13) to (18) above.
- the emotional identification unit identifies the emotional label of the segment by further considering the emotions identified by the second emotional analysis unit from the music.
- Information processing method having.
- a segment extraction unit that extracts segments from the content based on the content evaluation information of the content and the biometric information of the person who views the content.
- a facial expression identification unit that detects the face of a person in a segment and identifies the facial expression.
- Relationship estimation unit that estimates the relationships between people in the segment.
- An emotional identification unit that identifies the emotional label of a segment based on the facial expression of the person in the segment and the relationship between the persons.
- a generation method for generating a trained machine learning model that identifies the emotion given by the content Steps to enter content into a machine learning model, The step that the machine learning model acquires the video feature amount estimated from the content, and The step that the machine learning model acquires the audio features estimated from the content, and The step that the machine learning model acquires the text feature amount of the speech estimated from the content, and A step of identifying the moving label of the content based on the video feature amount, the audio feature amount, and the text feature amount estimated by the machine learning model, and A step of calculating a loss function based on an error between the identified impression label and the impression label attached to the content, and A step of updating the parameters of the machine learning model based on the loss function, How to generate a trained machine learning model with.
- the video feature amount includes a relationship between people estimated based on the context of a plurality of consecutive frames when there are two or more people in the video frame.
- 100 ... Data collection system, 101 ... Video content 102 ... Content evaluation information acquisition unit, 103 ... Biometric information acquisition unit 104 ... Comparison unit, 105 ... Segment extraction unit 106 ... Context extraction unit, 107 ... Voice recognition unit 108 ... Music detection unit , 109 ... Face detection unit 110 ... First emotion analysis unit, 111 ... Second emotion analysis unit 112 ... Expression identification unit, 113 ... Relationship estimation unit 114 ... Impression identification unit 410 ... Data storage unit, 420 ... Impression identification Machine 421 ... Network unit 422 ... Identification unit 423 ... Evaluation unit 500 ... Digital camera, 501 ... Optical system, 502 ... Imaging unit 503 ... AFE unit, 504 ...
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Medical Informatics (AREA)
- Dermatology (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Computer Graphics (AREA)
- Signal Processing (AREA)
- Image Analysis (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/906,761 US12541997B2 (en) | 2020-03-31 | 2021-03-24 | Training system and data collection device |
| JP2022512040A JP7635779B2 (ja) | 2020-03-31 | 2021-03-24 | 学習システム及びデータ収集装置 |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-065069 | 2020-03-31 | ||
| JP2020065069 | 2020-03-31 | ||
| JP2020-120049 | 2020-07-13 | ||
| JP2020120049 | 2020-07-13 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021200503A1 true WO2021200503A1 (ja) | 2021-10-07 |
Family
ID=77928815
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/012368 Ceased WO2021200503A1 (ja) | 2020-03-31 | 2021-03-24 | 学習システム及びデータ収集装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12541997B2 (https=) |
| JP (1) | JP7635779B2 (https=) |
| WO (1) | WO2021200503A1 (https=) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2023286313A1 (https=) * | 2021-07-15 | 2023-01-19 | ||
| WO2023119577A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| WO2023119578A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| US20230419722A1 (en) * | 2022-06-24 | 2023-12-28 | Microsoft Technology Licensing, Llc | Simulated capacitance measurements for facial expression recognition training |
| WO2026028784A1 (ja) * | 2024-07-29 | 2026-02-05 | 富士フイルム株式会社 | 情報処理装置、情報処理装置の作動方法及び作動プログラム |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6800453B1 (ja) * | 2020-05-07 | 2020-12-16 | 株式会社 情報システムエンジニアリング | 情報処理装置及び情報処理方法 |
| EP4137801B1 (en) * | 2021-08-17 | 2025-09-24 | Hitachi High-Tech Analytical Science Finland Oy | Monitoring reliability of analysis of elemental composition of a sample |
| WO2023055267A1 (en) * | 2021-09-29 | 2023-04-06 | Telefonaktiebolaget Lm Ericsson (Publ) | Efficient transmission of decoding information |
| KR20230089215A (ko) * | 2021-12-13 | 2023-06-20 | 삼성전자주식회사 | 획득된 정보에 기반하여 화면을 구성하기 위한 전자 장치 및 방법 |
| JP2023106888A (ja) * | 2022-01-21 | 2023-08-02 | オムロン株式会社 | 情報処理装置および情報処理方法 |
| US12450806B2 (en) * | 2022-07-26 | 2025-10-21 | Verizon Patent And Licensing Inc. | System and method for generating emotionally-aware virtual facial expressions |
| US12347135B2 (en) * | 2022-11-14 | 2025-07-01 | Adobe Inc. | Generating gesture reenactment video from video motion graphs using machine learning |
| US20240193920A1 (en) * | 2022-12-13 | 2024-06-13 | Korea Electronics Technology Institute | Method for predicting user personality by mapping multimodal information on personality expression space |
| US20240371397A1 (en) * | 2023-05-03 | 2024-11-07 | KAI Conversations Limited | System for processing text, image and audio signals using artificial intelligence and method thereof |
| KR20250031866A (ko) * | 2023-08-29 | 2025-03-07 | 포항공과대학교 산학협력단 | 이미지 변화 데이터 생성 방법 및 장치 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185719A (ja) * | 1997-09-03 | 1999-03-30 | Matsushita Electric Ind Co Ltd | パラメータ推定装置 |
| WO2018030206A1 (ja) * | 2016-08-10 | 2018-02-15 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | カメラワーク生成方法及び映像処理装置 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4965322B2 (ja) * | 2007-04-17 | 2012-07-04 | 日本電信電話株式会社 | ユーザ支援方法、ユーザ支援装置およびユーザ支援プログラム |
| JP4812733B2 (ja) * | 2007-11-01 | 2011-11-09 | 日本電信電話株式会社 | 情報編集装置、情報編集方法、情報編集プログラムおよびそのプログラムを記録した記録媒体 |
| JP5054653B2 (ja) * | 2008-10-08 | 2012-10-24 | 日本電信電話株式会社 | 視聴印象推定方法及び装置及びプログラム及びコンピュータ読み取り可能な記録媒体 |
| JP4725936B1 (ja) * | 2011-02-01 | 2011-07-13 | 有限会社Bond | 入力支援装置、入力支援方法及びプログラム |
| JP6900918B2 (ja) | 2017-03-14 | 2021-07-07 | オムロン株式会社 | 学習装置及び学習方法 |
| US10726078B2 (en) * | 2017-05-09 | 2020-07-28 | Oath Inc. | Method and system for dynamic score floor modeling and application thereof |
| WO2019050508A1 (en) * | 2017-09-06 | 2019-03-14 | Hitachi Data Systems Corporation | EMOTION DETECTION ACTIVATED VIDEO CUSHIONING |
| WO2019215778A1 (ja) * | 2018-05-07 | 2019-11-14 | 日本電気株式会社 | データ提供システムおよびデータ収集システム |
| CN113168439A (zh) * | 2019-02-22 | 2021-07-23 | 居米奥公司 | 为算法决定提供结果解释 |
| US11393144B2 (en) * | 2019-04-11 | 2022-07-19 | City University Of Hong Kong | System and method for rendering an image |
-
2021
- 2021-03-24 JP JP2022512040A patent/JP7635779B2/ja active Active
- 2021-03-24 WO PCT/JP2021/012368 patent/WO2021200503A1/ja not_active Ceased
- 2021-03-24 US US17/906,761 patent/US12541997B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185719A (ja) * | 1997-09-03 | 1999-03-30 | Matsushita Electric Ind Co Ltd | パラメータ推定装置 |
| WO2018030206A1 (ja) * | 2016-08-10 | 2018-02-15 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | カメラワーク生成方法及び映像処理装置 |
Non-Patent Citations (1)
| Title |
|---|
| NAOAKI YOKOI, MASASHI EGI: "A Study of Business Interpretation Technique for AI Predictions", IEICE TECHNICAL REPORT, vol. 118, no. 513 (PRMU2018-143), 10 March 2019 (2019-03-10), JP , pages 61 - 66, XP009536159, ISSN: 2432-6380 * |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2023286313A1 (https=) * | 2021-07-15 | 2023-01-19 | ||
| JP7794199B2 (ja) | 2021-07-15 | 2026-01-06 | ソニーグループ株式会社 | 信号処理装置および方法 |
| WO2023119577A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| WO2023119578A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| JPWO2023119577A1 (https=) * | 2021-12-23 | 2023-06-29 | ||
| JP7345689B1 (ja) * | 2021-12-23 | 2023-09-15 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| JP7437538B2 (ja) | 2021-12-23 | 2024-02-22 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| US20230419722A1 (en) * | 2022-06-24 | 2023-12-28 | Microsoft Technology Licensing, Llc | Simulated capacitance measurements for facial expression recognition training |
| US12327430B2 (en) * | 2022-06-24 | 2025-06-10 | Microsoft Technology Licensing, Llc | Simulated capacitance measurements for facial expression recognition training |
| WO2026028784A1 (ja) * | 2024-07-29 | 2026-02-05 | 富士フイルム株式会社 | 情報処理装置、情報処理装置の作動方法及び作動プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7635779B2 (ja) | 2025-02-26 |
| US12541997B2 (en) | 2026-02-03 |
| JPWO2021200503A1 (https=) | 2021-10-07 |
| US20230360437A1 (en) | 2023-11-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7635779B2 (ja) | 学習システム及びデータ収集装置 | |
| Mroueh et al. | Deep multimodal learning for audio-visual speech recognition | |
| US20200371535A1 (en) | Automatic image capturing method and device, unmanned aerial vehicle and storage medium | |
| WO2022161298A1 (zh) | 信息生成方法、装置、设备、存储介质及程序产品 | |
| WO2019085585A1 (zh) | 设备控制处理方法及装置 | |
| US20190332952A1 (en) | Learning device, image pickup apparatus, image processing device, learning method, non-transient computer-readable recording medium for recording learning program, display control method and inference model manufacturing method | |
| TWI857242B (zh) | 光流資訊預測方法、裝置、電子設備和儲存媒體 | |
| CN103079034A (zh) | 一种感知拍摄方法及系统 | |
| US20220335246A1 (en) | System And Method For Video Processing | |
| CN114078275A (zh) | 表情识别方法、系统及计算机设备 | |
| US9661208B1 (en) | Enhancing video conferences | |
| CN114222077A (zh) | 视频处理方法、装置、存储介质及电子设备 | |
| Wang et al. | Blind multimodal quality assessment of low-light images | |
| JP2007074143A (ja) | 撮像装置及び撮像システム | |
| CN113920354A (zh) | 一种基于事件相机的动作识别方法 | |
| CN116016978B (zh) | 在线课堂的画面导播方法、装置、电子设备及存储介质 | |
| US20200259999A1 (en) | Intelligent photography with machine learning | |
| EP4482134A1 (en) | Noise removal from surveillance camera image by means of ai-based object recognition | |
| KR20200111104A (ko) | 인공지능에 기반하여 영상을 분석하는 카메라 및 그것의 동작 방법 | |
| JP7483532B2 (ja) | キーワード抽出装置、キーワード抽出方法及びキーワード抽出プログラム | |
| JP6754154B1 (ja) | 翻訳プログラム、翻訳装置、翻訳方法、及びウェアラブル端末 | |
| US20240348885A1 (en) | System and method for question answering | |
| WO2024062971A1 (ja) | 情報処理装置、情報処理方法および情報処理プログラム | |
| WO2022014143A1 (ja) | 撮像システム | |
| Valles et al. | Data Collection and Real-Time Facial Emotion Recognition in iOS Apps with CNN-Based Models |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21781058 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022512040 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21781058 Country of ref document: EP Kind code of ref document: A1 |
|
| WWG | Wipo information: grant in national office |
Ref document number: 17906761 Country of ref document: US |