WO2023119578A1 - 情報処理システム、情報処理方法及びプログラム - Google Patents
情報処理システム、情報処理方法及びプログラム Download PDFInfo
- Publication number
- WO2023119578A1 WO2023119578A1 PCT/JP2021/047950 JP2021047950W WO2023119578A1 WO 2023119578 A1 WO2023119578 A1 WO 2023119578A1 JP 2021047950 W JP2021047950 W JP 2021047950W WO 2023119578 A1 WO2023119578 A1 WO 2023119578A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- household
- user
- relationship
- users
- data
- Prior art date
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 47
- 238000003672 processing method Methods 0.000 title claims description 5
- 230000006870 function Effects 0.000 description 46
- 238000012545 processing Methods 0.000 description 31
- 238000000034 method Methods 0.000 description 27
- 238000010586 diagram Methods 0.000 description 21
- 238000010801 machine learning Methods 0.000 description 16
- 238000007726 management method Methods 0.000 description 15
- 238000004891 communication Methods 0.000 description 6
- 230000003993 interaction Effects 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000012800 visualization Methods 0.000 description 2
- 230000004308 accommodation Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 235000012054 meals Nutrition 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000012549 training Methods 0.000 description 1
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
Definitions
- the present invention relates to an information processing system, an information processing method, and a program.
- Japanese Patent Application Laid-Open No. 2019-087212 discloses that, in a financial transaction service, information regarding a user's family structure is specified based on transaction information (see paragraphs 0048 and 0099).
- Japanese Unexamined Patent Application Publication No. 2021-144451 discloses an information processing device that identifies a user's income amount and expenditure amount, and determines details of liability compensation based on them and the user's family structure (No. 0038). paragraph).
- the present invention has been made in view of the above problems, and its purpose is to provide a technology that enables a more detailed grasp of the situation of the household to which the user belongs.
- An information processing system includes household identification means for acquiring household information indicating a first household and a second household each including one or more users living together; household relationship estimation means for estimating the type of relationship between the first household and the second household based on the attributes of the users belonging to the second household.
- An information processing method comprises the steps of acquiring a first household and a second household each including one or more users living together; and estimating the type of relationship between the first household and the second household based on attributes of users belonging to.
- a program according to the present invention includes household identification means for acquiring household information indicating a first household and a second household each including one or more users living together, and attributes of users belonging to the first household.
- the computer functions as household relationship estimation means for estimating the type of relationship between the first household and the second household based on attributes of users belonging to the second household.
- the household specifying means selects from the plurality of users a first household including one or a plurality of users living together, based on the surnames and addresses of the plurality of users stored in a user database.
- a second household may be obtained.
- the household relationship estimating means is configured to use a plurality of parameters relating to the type of relationship between a first user included in the first household and a second user included in the second household. Based on this, the type of relationship between the first household and the second household may be estimated.
- the plurality of parameters include identity of the last name, frequency of telephone contact, presence or absence of gifts on a specific day, frequency of mutual gifts, age difference, mutual friends, whether the gender is the same , may include at least some of the address similarities.
- the household relationship estimation means determines that the type of relationship between the first user included in the first household and the second user included in the second household is parent-child, parent-child, The type of relationship between the first and second households may be inferred as a function of whether they are siblings or at least part of a neighbor.
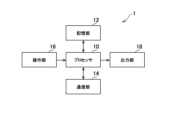
- FIG. 1 is a diagram showing an example of the overall configuration of an information processing system according to one embodiment of the present invention
- FIG. 1 is a functional block diagram showing an example of functions of an information processing system according to an embodiment of the present invention
- FIG. 4 is a diagram schematically showing an example of common IP address data values; It is a figure which shows an example of graph data.
- FIG. 4 is a diagram schematically showing an example of common address data values; It is a figure which shows an example of graph data.
- FIG. 4 is a diagram schematically showing an example of common credit card number data values; It is a figure which shows an example of graph data. It is a figure which shows an example of graph data. It is a figure which shows an example of a cluster.
- FIG. 10 is a diagram showing an example of classification visualization
- FIG. 4 is a flowchart showing an example of processing related to creating a social graph, which is performed in the information processing system according to one embodiment of the present invention
- FIG. 10 is a flow chart showing an example of processing involved in identifying family relationships of users within a household
- It is a figure explaining an example of the machine-learning model used by the presence-or-absence identification part.
- It is a flowchart which shows an example of the process of a family identification part, an age estimation part, and a relationship recording part. It is a figure explaining the relationship of users etc. in a household.
- FIG. 4 is a diagram showing an example of information stored in a household member table;
- FIG. 4 is a diagram showing an example of information stored in a user relationship table;
- FIG. 4 is a diagram showing an example of information stored in a member attribute table;
- FIG. 4 is a flow chart showing an example of processing for estimating relationships between households; It is a figure explaining an example of the relationship between households.
- 3 is a functional block diagram showing an example of a functional configuration of a user relationship specifying unit;
- an information processing system 1 that identifies a plurality of households each containing one or more users from information about users and estimates more detailed information about the identified households will be described.
- FIG. 1 is a diagram showing an example of the overall configuration of an information processing system 1 according to one embodiment of the present invention.
- an information processing system 1 is a computer such as a server computer or a personal computer, and includes a processor 10, a storage unit 12, a communication unit 14, an operation unit 16, and an output unit. 18 included.
- the information processing system 1 according to this embodiment may include a plurality of computers.
- the processor 10 is, for example, a program-controlled device such as a microprocessor that operates according to a program installed in the information processing system 1.
- Information processing system 1 may include one or more processors 10 .
- the storage unit 12 is, for example, a storage element such as ROM or RAM, a hard disk drive (HDD), a solid state drive (SSD) including flash memory, or the like.
- the storage unit 12 stores programs and the like executed by the processor 10 .
- the communication unit 14 is a communication interface for wired communication or wireless communication, such as a network interface card, and exchanges data with other computers or terminals via a computer network such as the Internet.
- the operation unit 16 is an input device, and includes, for example, a touch panel, a pointing device such as a mouse, a keyboard, and the like.
- the operation unit 16 transmits operation contents to the processor 10 .
- the output unit 18 is, for example, a display such as a liquid crystal display unit or an organic EL display unit, or an output device such as an audio output device such as a speaker.
- the programs and data described as being stored in the storage unit 12 may be supplied from another computer via a network.
- the hardware configuration of the information processing system 1 is not limited to the above example, and various hardware can be applied.
- the information processing system 1 includes a reading unit (for example, an optical disk drive or a memory card slot) for reading a computer-readable information storage medium, and an input/output unit (for example, a USB port) for inputting/outputting data with an external device. may be included.
- programs and data stored in an information storage medium may be supplied to the information processing system 1 via a reading section or an input/output section.
- the information processing system 1 identifies a household that includes multiple users.
- the information processing system 1 executes a process of acquiring more detailed information on the situation within a household and a process of identifying relationships between households.
- the information processing system 1 identifies the type of relationship between users, estimates whether or not the user includes a spouse, children, etc. based on information about the user, It checks whether there is a user corresponding to a person, child, etc., and if not, registers a new user.
- the information processing system 1 determines the relationship between a user who is the target of the process (hereinafter also referred to as a person of interest) and a user who has a relationship with the user (hereinafter also referred to as a reference person). use the type of
- FIG. 2 is a functional block diagram showing an example of functions implemented in the information processing system 1 according to this embodiment. Note that the information processing system 1 according to the present embodiment does not need to implement all the functions shown in FIG. 2, and functions other than the functions shown in FIG. 2 may be installed.
- the information processing system 1 functionally includes a user relationship identifying unit 30, a presence/absence identifying unit 32, a household identifying unit 33, a family identifying unit 34, an age estimating unit 35, a relationship record A unit 36 and a household relation estimation unit 38 are included.
- the user relationship identifying unit 30 is implemented mainly by the processor 10, the storage unit 12 and the communication unit 14.
- Presence/absence identifying unit 32 , household identifying unit 33 , family identifying unit 34 , age estimating unit 35 , relationship recording unit 36 , and household relationship estimating unit 38 are mainly implemented by processor 10 and storage unit 12 .
- the functions described above may be implemented by causing the processor 10 to execute a program installed in the information processing system 1, which is a computer, and including execution instructions corresponding to the functions described above. Also, this program may be supplied to the information processing system 1 via a computer-readable information storage medium such as an optical disk, a magnetic disk, or a flash memory, or via the Internet or the like.
- a computer-readable information storage medium such as an optical disk, a magnetic disk, or a flash memory, or via the Internet or the like.
- the user relationship identification unit 30 mainly identifies relationship information indicating the type of relationship between users in a pair of users.
- the user relationship identifying unit 30 may output relationship information based on at least one of last name, IP address, address, age difference, and gender associated with the paired users. Note that the user relationship identifying unit 30 may acquire relationship information created outside the information processing system 1 .
- the user relationship identification unit 30 may also be called a relationship identification unit.
- the presence/absence identifying unit 32 stores presence/absence information indicating the presence/absence of the target user's spouse, children, or parents based on information stored in association with the target user and stored without being associated with other users. to get In addition, the presence/absence identifying unit 32 estimates the presence/absence of the target user's spouse, the target user's child, or the target user's parent based on the output when the value of the input parameter regarding the target user is input to the machine learning model. , to obtain the presence/absence information indicating the estimation result.
- An input parameter is a predetermined item of information about a user, and the machine learning model may be trained with training data containing the values of the input parameter.
- the household identification unit 33 acquires household information indicating one or more households including one or more users living together.
- at least one of the one or more households may include the target user and one or more family users.
- the household identification unit 33 may identify one or more family users who are included in the household including the target user and live together with the target user, from a plurality of users registered in the user database.
- the family identification unit 34 identifies, among family users included in the household indicated by the household information, family users whose presence/absence information indicates the existence of spouses, children, and parents.
- the age estimating unit 35 determines the spouse, child, or parent whose existence is estimated to exist for the target user, but whose corresponding family user has not been specified. Estimate age. Furthermore, when the user corresponding to the spouse, child, or parent whose existence is estimated to exist is specified and the user's age is not registered, the age estimation unit 35 estimates the user's age. may be the target of At this time, the age estimation unit 35 may store the estimated age as information related to the corresponding user, or the estimated age may be used for other processes.
- the relationship recording unit 36 selects a spouse, child, or parent whose corresponding family user has not been specified among the spouse, child, and/or parent whose existence is presumed to exist of the target user, as a new member belonging to the household.
- the relevant user is stored in the storage unit 12 in association with relationship information indicating the type of relationship between the related user and the target user.
- the household relationship estimation unit 38 estimates the type of relationship between the first household and the second household based on the attribute of the user belonging to the first household and the attribute of the user belonging to the second household.
- the first household and the second household are included in one or more households specified by the household specifying unit 33 .
- the household relationship estimating unit 38 determines that the type of relationship between the first user included in the first household and the second user included in the second household is at least parent-child, sibling, and neighbor.
- the type of relationship between the first and second households may be inferred depending on whether they are part of.
- FIG. 22 is a functional block diagram showing an example of the functional configuration of the user relationship identification unit 30.
- the user relationship identification unit 30 includes a person attribute data acquisition unit 20, a graph data generation unit 22, a reference person identification unit 24, and a relationship identification unit 26.
- the personal attribute data acquisition unit 20 communicates with a plurality of computer systems and acquires personal attribute data indicating personal attributes.
- the information processing system 1 can communicate with various computer systems such as an electronic commerce system 40, a golf course reservation system 42, a travel reservation system 44, a card management system 46, and the like ( 3, 5 and 7). Each of these computer systems is registered with account data, which is information about users who use the computer system.
- the information processing system 1 can access these computer systems and acquire account data registered in the computer systems.
- Various computer systems in the present embodiment may include, for example, a payment management system, an internet banking management system, a financial product management system, an insurance product management system, a mobile service management system, etc. There are no restrictions on the type of business as long as it is a field in which services can be provided.
- Account data includes, for example, user ID, name data, address data, age data, gender data, phone number data, mobile phone number data, credit card number data, IP address data, and the like.
- the user ID is, for example, identification information of the user in the computer system.
- the name data is, for example, data indicating the user's name (surname (surname) and given name).
- the address data is, for example, data indicating the address of the user. When the computer system is the electronic commerce system 40, the address data may indicate the address of the delivery destination of the product purchased by the user.
- Age data is, for example, data indicating the age of the user.
- Gender data is, for example, data indicating the gender of the user.
- the telephone number data is, for example, data indicating the telephone number of the user.
- the mobile phone number data is, for example, data indicating the mobile phone number of the user.
- the credit card number data is, for example, data indicating the card number of the credit card used by the user for payment in the computer system.
- the IP address data is, for example, data indicating the IP address of the computer used by the user (for example, the IP address of the sender).
- the person attribute data acquisition unit 20 acquires person attribute data indicating attributes of a plurality of persons including a person of interest.
- An example of the personal attribute data is the account data described above.
- the person attribute data acquisition unit 20 acquires account data of the person, for example, from each of the plurality of systems described above.
- the graph data generation unit 22 identifies pairs of persons who are related to each other, for example, based on the attributes of each of the plurality of persons.
- the graph data generator 22 may identify pairs of persons who are related to each other based on the person attribute data of a plurality of persons.
- the graph data generation unit 22 according to the present embodiment corresponds to an example of a pair identifying unit that identifies a pair of persons who are related to each other based on the attributes of each of the plurality of persons.
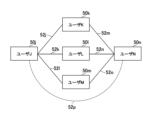
- the graph data generation unit 22 generates, for example, graph data including node data 50 associated with a plurality of persons including a person of interest, and link data 52 associated with a pair of mutually related persons ( 4, 6, 8 and 9).
- the graph data generation unit 22 also stores the generated graph data in the storage unit 12 .
- user A's account data is registered in the electronic commerce system 40, as shown in FIG. It is also assumed that user B's account data is registered in the golf course reservation system 42 . It is also assumed that user C's account data is registered in the travel reservation system 44 .
- IP address data value of user A registered in the electronic commerce system 40 the IP address data value of user B registered in the golf course reservation system 42, and the IP address data value registered in the travel reservation system 44. Assume that the IP address data values of user C are the same.
- the graph data generating unit 22 generates node data 50a associated with user A, node data 50b associated with user B, node data 50c associated with user C, and Graph data including link data 52a indicating a relationship with user B, link data 52b indicating a relationship between user A and user C, and link data 52c indicating a relationship between user B and user C. Generate.
- the graph data generation unit 22 generates node data 50d associated with user D, node data 50e associated with user E, node data 50f associated with user F, and Graph data including link data 52d indicating a relationship with user E, link data 52e indicating a relationship between user D and user F, and link data 52f indicating a relationship between user E and user F. Generate.
- user G's account data is registered in the electronic commerce system 40 . It is also assumed that user H's account data is registered in the golf course reservation system 42 . It is also assumed that user I's account data is registered in the travel reservation system 44 .
- the graph data generation unit 22 generates node data 50g associated with user G, node data 50h associated with user H, node data 50i associated with user I, and user G Graph data including link data 52g indicating a relationship with user H, link data 52h indicating a relationship between user G and user I, and link data 52i indicating a relationship between user H and user I Generate.
- link indicated by the link data 52 that associates the persons identified as being related to each other, as described above, will be referred to as an explicit link.
- a person connected to the first person by an explicit link and a person connected to the second person by an explicit link are a predetermined number or more (for example, three or more) in common.
- the graph data generator 22 generates link data 52 indicating that the first person is related to the second person.
- a link indicated by the link data 52 generated in this way is called an implicit link.
- node data 50j associated with user J and node data 50k associated with user K are connected by link data 52j indicating an explicit link. It is also assumed that node data 50j associated with user J and node data 50l associated with user L are connected by link data 52k indicating an explicit link. It is also assumed that node data 50j associated with user J and node data 50m associated with user M are connected by link data 52l indicating an explicit link.
- node data 50k associated with user K and node data 50n associated with user N are connected by link data 52m indicating an explicit link. It is also assumed that node data 50l associated with user L and node data 50n associated with user N are connected by link data 52n indicating an explicit link. It is also assumed that node data 50m associated with user M and node data 50n associated with user N are connected by link data 52o indicating an explicit link.
- the graph data generator 22 generates link data 52p indicating that user J is related to user N (link data 52p indicating an implicit link). In this manner, user N is identified as a person who has a relationship with user J.
- the graph data generator 22 may generate link data 52 (link data 52 indicating an implied link) indicating that the first person is related to the second person.
- the graph data generation unit 22 may generate graph data based on personal attribute data different from account data.
- the reference person identification unit 24 identifies a reference person who is related to the person to be processed (including the person of interest, for example).
- the reference person identifying unit 24 identifies a person who is related to the person to be processed (for example, a person registered as a friend in the electronic commerce system 40 or the like), and a person who is identified as a person who is related to the person to be processed.
- a person who has more than a predetermined number of (for example, registered friends) in common with the person to be processed may be specified as the reference person.
- the reference person specifying unit 24 may specify the reference person from among the plurality of persons based on the attributes of the person to be processed and the attributes of the plurality of persons.
- the reference person identification unit 24 identifies a person associated with the node data 50 connected by the link data 52 indicating an explicit link or an implicit link with the node data 50 associated with the person to be processed, as the person to be processed. It may be specified as a reference person for a person.
- the relationship identifying unit 26 identifies the relationship between the person to be processed (including the person of interest, for example) and the reference person.
- the relationship identifying unit 26 may identify the relationship between the person to be processed and the reference person based on the account data of the person to be processed and the account data of the reference person.
- the computer system in which the account data of the person to be processed is registered may be different from the computer system in which the account data of the reference person is registered.
- the person to be processed and the reference person A relationship (more specifically, a relationship type) may be specified.
- the relationship identification unit 26 may store the identified relationship type in the storage unit 12 in association with the pair of the person to be processed and the reference person.
- the relationship identifying unit 26 may identify the family relationship between the person to be processed and the reference person (for example, parent and child, spouse, sibling). Further, the relationship identifying unit 26 may select one of candidates including at least part of parent and child, spouse, sibling, colleague, neighbor, and friend as the type of relationship to be identified.
- the relationship identifying unit 26 identifies pairs of node data 50 connected by link data 52, for example. Then, the relationship identifying unit 26 generates pair attribute data associated with the pair based on the person attribute data of the two persons associated with the pair.
- the pair attribute data includes, for example, IP common flag, address common flag, credit card number common flag, surname same flag, age difference data, pair gender data, and the like.
- the common IP flag is, for example, a flag indicating whether or not the value of the IP address data included in one account data of the pair is the same as the value of the IP address data included in the other account data. . For example, if the IP address data values are the same on a given day, the IP common flag value is set to 1, and if the IP address data values are different, the IP common flag value is set to 0. good.
- the common address flag is, for example, a flag that indicates whether or not the value of the address data included in one account data of the pair is the same as the value of the address data included in the other account data. For example, if the address data values are the same, the common address flag value may be set to 1, and if the address data values are different, the common address flag value may be set to 0. Further, similarity between addresses may be used as the common address flag. For example, the common address flag is set to 0 if the town name and street address are different, 1 if the building name and room number after the street address are different, and 2 if the building name and room number are the same. may be set.
- the common credit card number flag indicates, for example, whether or not the value of credit card number data included in one account data of the pair is the same as the value of credit card number data included in the other account data. flag to indicate For example, if the credit card number data values are the same, the credit card number common flag value is set to 1, and if the credit card number data values are different, the credit card number common flag value is set to 0. good too.
- the same surname flag is a flag that indicates, for example, whether the surname indicated by the name data included in one of the account data of the pair is the same as the surname indicated by the name data included in the other account data. . For example, if the surnames indicated by the name data are the same, the value of the same last name flag may be set to 1, and if the surnames indicated by the name data are different, the value of the same last name flag may be set to 0.
- Age difference data is, for example, data that indicates the difference between the value of age data included in one account data of the pair and the value of age data included in the other account data.
- Paired gender data is, for example, data that indicates a combination of a gender data value included in one account data of the pair and a gender data value included in the other account data.
- the relationship identifying unit 26 performs clustering using a general clustering method based on the values of the pair attribute data associated with each of the plurality of pairs, thereby classifying the plurality of pairs as shown in FIG. are classified into a plurality of clusters 54 as shown in FIG.
- FIG. 10 is a diagram schematically showing an example of how a plurality of pairs are classified into five clusters 54 (54a, 54b, 54c, 54d, and 54e).
- the crosses shown in FIG. 10 correspond to pairs.
- Each of the plurality of cross marks is arranged at a position associated with the value of the paired attribute data of the pair corresponding to the cross mark.
- multiple pairs are classified into five clusters 54, but the number of clusters 54 into which multiple pairs are classified is not limited to five. 54 may be classified.
- FIG. 11 is a diagram showing an example of visualization of the classification when multiple pairs are classified into four clusters 54 .
- pairs having the same address, the same gender, an age difference greater than X years, and the same surname may be classified into the first cluster. Also, pairs having the same address, the same gender, an age difference of X years or less, and the same surname may be classified into the second cluster. Also, a pair having the same address, different gender, an age difference larger than Y years, and the same surname may be classified into the third cluster. Also, a pair having the same address, different gender, an age difference of Y years or less, and the same surname may be classified into the fourth cluster.
- the first cluster is presumed to be, for example, the cluster 54 associated with the same-sex parent and child.
- the second cluster is presumed to be the cluster 54 associated with siblings of the same sex, for example.
- the third cluster is presumed to be the cluster 54 associated with the parent and child of the opposite sex, for example.
- the fourth cluster is presumed to be the cluster 54 associated with married couples or opposite-sex siblings, for example.
- the number of friends in common between one and the other of the pair may be used to specify the type of relationship between the person to be processed and the reference person.
- the relationship identifying unit 26 determines the relationship between the person to be processed and the reference person based on the clustering result based on at least one of the surname, IP address, address, credit card number, age difference, and gender. You may specify the type of gender.
- the relationship identifying unit 26 may identify the type of relationship between the person to be processed and the reference person further based on records of exchanges of information or objects between the person to be processed and the reference person.
- a record of information or exchange of goods may be, for example, a history of sending gifts on a particular date such as Father's Day, Mother's Day, or Christmas, or a log of messages sent and received on that particular date.
- FIG. 12 mainly explains the processing of the reference person identification unit 24 and the relationship identification unit 26.
- FIG. 12 mainly explains the processing of the reference person identification unit 24 and the relationship identification unit 26.
- the processing described in FIG. 12 is repeatedly executed for each person for whom graph data has been generated.
- a person for whom graph data is generated includes a person of interest, and a person to be processed in FIG. 12 is hereinafter referred to as a person to be processed.
- graph data for a plurality of persons including a person of interest has already been generated, and for a plurality of pairs, clusters 54 associated with the pairs have been identified. It is also assumed that the proximity machine learning model associated with each cluster 54 has already been learned.
- the reference person identification unit 24 identifies, as a reference person, the person corresponding to the node data 50 connected to the node data 50 corresponding to the person to be processed by an explicit link or an implicit link (S101).
- an explicit link or an implicit link S101
- the relationship identifying unit 26 selects one reference person for whom the processes shown in S104 to S108 have not yet been executed from among the reference persons identified in the process shown in S101 (S103).
- the relationship identifying unit 26 identifies the cluster 54 corresponding to the pair of the person to be processed and the reference person selected in the process shown in S102 as the relationship type of the pair (S104).
- the relationship specifying unit 26 stores the type of relationship between the person to be processed and the reference person in the storage unit 12 (S108).
- the relationship identifying unit 26 confirms whether or not the processes shown in S104 and S108 have been executed for all of the reference persons identified in the process shown in S101 (S110).
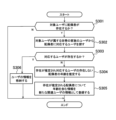
- FIG. 13 is a flow chart showing an example of processing involved in identifying family relationships of users within a household.
- the processing shown in FIG. 13 is executed by the presence/absence identification unit 32, the household identification unit 33, the family identification unit 34, the age estimation unit 35, and the relationship recording unit .
- the household identification unit 33 acquires household information of households including one or more users living together based on the address and surname of the user (S201). More specifically, the household identification unit 33 acquires account data of multiple users registered in user databases of multiple computer systems. The household specifying unit 33 then selects a plurality of users who have the same address and surname included in the account data as users who are included in the household and live together, and generates household information of households including the selected users. The household identification unit 33 may also generate household information of households of users who do not have users with the same address and surname.
- the conditions for selecting users who are included in a household and live together are not only the same address and surname, but also, for example, a high degree of similarity with matching addresses excluding the building name and a matching surname.
- the household identification unit 33 may acquire household information about households including users included in a target user group set in advance as targets of processing, or may obtain household information about a plurality of households regardless of target users without setting a target user group. Household information may be obtained.
- the user database may be obtained in advance from a plurality of computer systems and stored in the storage unit 12 , or may be generated separately and stored in the storage unit 12 .
- the family identification unit 34 selects one target user to be processed for identifying family users (S202).
- the family identification unit 34 may select a target user from users included in the target user group to be processed by the household identification unit 33, or the family identification unit 34 may Any user in multiple households may be selected.
- the presence/absence specifying unit 32 acquires the presence/absence information indicating the presence/absence of the target user's spouse based on the information stored in association with the target user and stored without being associated with other users.
- the presence/absence identifying unit 32 estimates the presence/absence of the target user's spouse based on the output when the value of the input parameter regarding the target user is input to the spouse presence/absence estimation model, which is a machine learning model, and estimates the presence/absence of the target user. Get the presence/absence information indicating the result.
- the input parameter is an item of predetermined information about the user, and the spouse presence/absence estimation model may be learned in advance using learning data including the value of the input parameter. The details of the spouse presence/absence estimation model will be described later.
- the family identification unit 34 confirms the correspondence between the spouse presence/absence information and the users in the household. Information is registered (S204). Details of the processing of S204 will be described later.
- the presence/absence identifying unit 32 acquires the presence/absence information indicating the presence/absence of children of the target user based on the information stored in association with the target user and stored without being associated with other users. (S205).
- the presence/absence identifying unit 32 determines the presence/absence of a child of the target user, more specifically, the child based on the output when the value of the input parameter related to the target user is input to the child presence/absence estimation model, which is a pre-learned machine learning model. , and acquire presence/absence information indicating the estimation result.
- the family identification unit 34 confirms the correspondence between the child presence/absence information and the users in the household. User information is registered (S206).
- the presence/absence identifying unit 32 acquires the presence/absence information indicating the presence/absence of the parent of the target user based on the information stored in association with the target user and stored without being associated with other users. (S207).
- the presence/absence identifying unit 32 determines the presence/absence of the parent of the target user, more specifically, based on the output when the value of the input parameter regarding the target user is input to the parent presence/absence estimation model, which is a pre-learned machine learning model. , and acquire presence/absence information indicating the estimation result.
- the family identification unit 34 confirms the correspondence between the parent's presence/absence information and the users in the household. User information is registered (S208).
- the family identification unit 34 determines whether there is a user who has not been selected yet (S210). If the user exists (S210: Y), the process is repeated from S202. If the user does not exist (S210:N), the process of FIG. 13 is terminated.
- FIG. 14 is a diagram illustrating an example of a presence/absence estimation model, which is a machine learning model used by the presence/absence identification unit 32. As shown in FIG. The presence/absence estimation model is learned by weakly supervised learning.
- the presence/absence estimation model includes a plurality of label functions 61 a to 61 c (referred to as label function 61 unless otherwise distinguished) and a generative model 64 .
- Outputs 62a-62c of the label functions 61a-61c are input to a generative model 64, and the generative model 64 outputs a label 65 indicating the presence/absence estimation result.
- the number of label functions is not particularly limited.
- the machine learning model shown in FIG. 14 may be a known one provided under the name Snorkel, for example.
- the label 65 determined in the presence/absence estimation model may be the output of each label function 61, or may be information estimated based on statistical information whose output is statistically processed by a predetermined method. , information determined on a rule basis such as a majority vote in accordance with statistical information based on the output of each label function 61 .
- Each of the plurality of label functions 61 included in the spouse presence/absence estimation model outputs a score regarding whether or not the target user has a spouse based on one or more input parameters regarding the user.
- Each of the plurality of label functions 61 included in the child presence/absence estimation model outputs a score regarding whether or not the target user has children based on one or more input parameters regarding the user.
- Each of the plurality of label functions 61 included in the parent presence/absence estimation model outputs a score regarding whether or not the target user's parents exist based on one or more input parameters regarding the user. Note that the input parameters consist of information associated with the user and not associated with other users.
- the generative model 64 calculates the score of the label 65 from the output 62 according to each weight of the label function 61.
- the generative model 64 estimates the presence or absence of the target user's spouse (child, parent) based on the outputs of the plurality of label functions 61 and the weights of the plurality of functions determined by learning, and presents the presence/absence information indicating the estimation results. decide.
- the label function 61 is a function that generates an output 62 that is a temporary label for the input parameter, and may be determined by an administrator or the like.
- the value of output 62 may be, for example, one of negative (0), positive (1), skip, or some value and skip.
- the accuracy of the output 62 produced by the label function 61 does not necessarily have to be high.
- the generative model 64 is trained to minimize the loss based on the label probabilities calculated for the multiple outputs 62 of the multiple label functions 61 . In learning, for example, a weight for each output 62 of the label function 61 may be determined. Also, this machine learning model can learn without labels as correct answers.
- the following label function 61 may be provided.
- One of the label functions 61 may output positive when the travel reservation system 44 has a history of travel reservations for two adults by the user, and output negative when it does not exist.
- Another one of the label functions 61 may output positive when information about the user's child is registered in the member information of the electronic commerce system 40, and output negative when not registered.
- Another one of the label functions 61 may output positive when the registered information of the card management system 46 is registered as married and have children or married, and may output negative when not registered.
- the following label function 61 may be provided.
- One of the label functions 61 may output the number of children most frequently booked in the history present in the travel booking system 44 .
- Another one of the label functions 61 may output the number of children of the user registered in the member information of the electronic commerce system 40 .
- Another one of the label functions 61 may output the number of children stored in the card management system 46 registration information. Any one of "0", “1", “2", and "3 or more" may be output as the number of children.
- the following label function 61 may be provided.
- One of the label functions 61 may output the number of contacts registered with the computer system that have the same address as the user.
- Another one of the label functions 61 may output the number of parents stored in the card management system 46 registration information. Any one of "0", “1", and “2" may be output as the number of parents.
- FIG. 15 is a flow chart showing an example of the processing of the family identifying unit 34, the age estimating unit 35, and the relationship recording unit 36, and is a flow chart showing an example of processing regarding the presence or absence of a spouse in particular.
- the age estimation models such as the spouse age estimation model, the child age estimation model, and the parent age estimation model included in the age estimation unit 35 have the same configuration as the presence/absence estimation model, for example, a publicly known model provided under the name of Snorkel. can be
- the age estimation model may be a model that estimates age using the output of a label function (corresponding to a labeling function) to which each input parameter is given.
- the family identification unit 34 determines whether or not the presence/absence identification unit 32 has estimated that the target user has a spouse (S301). If it is estimated that the spouse does not exist (S301:N), the process of FIG. 15 is terminated. On the other hand, when it is estimated that a spouse exists (S301: Y), the family identification unit 34 selects the user indicated by the household information and the user of the family of the household to which the target user belongs to correspond to the spouse. Search for a user (S302). More specifically, the family identification unit 34 selects users (family users) who are users indicated by the household information and who belong to the same household as the target user, and who have a type of relationship with the target user that is a spouse. Find a user. Here, the type of relationship between the target user and family users may be specified in advance by the user relationship specifying unit 30 . The family identification unit 34 then determines whether there is a corresponding user (S303).
- the age estimation unit 35 estimates the age of the spouse whose existence is estimated by the presence/absence identification unit 32 and whose corresponding user does not exist (S304).
- the age estimation unit 35 estimates the age of the spouse whose existence is estimated by inputting input parameters related to the user into the spouse age estimation model, which is a machine learning model.
- the spouse age estimation model input data including, for example, the age and gender of the target user, and usage history of various computer systems such as purchase and browsing history of the electronic commerce system 40 are input. may output the person's estimated age.
- the spouse age estimation model includes the age and gender of one of the users who are estimated to be spouses of each other by the user relationship identification unit 30, and the usage history of various computer systems such as the purchase and browsing history of the electronic commerce system 40. and learning data with the other age group as correct data.
- Age tiers may be set, for example, such that each tier includes a five-year range.
- the relationship recording unit 36 registers the information (including the age) of the spouse whose existence is estimated by the presence/absence specifying unit 32 as new related user information (S305). If a user corresponding to the spouse presumed to exist in the presence/absence identification unit 32 already exists (Y in S303), the relationship recording unit 36 stores information on the user in the storage unit 12 (S306). . Note that when information is added to an existing user database in S305, S306 does not have to be executed.
- the processing of S206 is similar to the processing shown in FIG. 15, and targets children instead of spouses.
- the family identification unit 34 determines whether or not the presence/absence identification unit 32 has estimated that the target user has a child. If it is estimated that children exist (S301: Y), the family identification unit 34 selects (estimated number of) children from the user indicated by the household information and belonging to the household to which the target user belongs. Search for users corresponding to . If there is an uncorresponding user (S303: N), the age estimation unit 35 estimates the age of the child whose presence is estimated by the presence/absence identification unit 32 and whose corresponding user does not exist (S304).
- the age estimation unit 35 estimates the age of the child whose presence is estimated by inputting input parameters related to the user into the child age estimation model, which is a machine learning model.
- the child age estimation model may be a weakly supervised machine learning model as shown in FIG.
- One of the label functions 61 included in the child age estimation model may output an age group based on child information included in the member information of the e-commerce system 40, for example.
- Another label function may output an age group based on information on children's meals and bedding that exists in lodging reservations that exist in the travel reservation system 44 .
- Another label function may output an age hierarchy based on the types of products included in the purchase history of the e-commerce system 40 .
- the label 65 may be information indicating the age class of the child whose age is estimated.
- the child age estimation model includes inputs including age and gender of parents among users estimated to be parents and children by the user relationship identification unit 30, and usage histories of various computer systems such as purchase and browsing histories of the e-commerce system 40. Learning may be performed using data and learning data in which the child's age group is correct data.
- the relationship recording unit 36 registers the information (including age) of the child whose existence is estimated by the presence/absence specifying unit 32 as new related user information (S305).
- the processing of S208 is similar to the processing shown in FIG. 15, and targets parents instead of spouses.
- the major differences in processing are described below.
- the family identification unit 34 determines whether or not the presence/absence identification unit 32 has estimated that the target user has a parent. If it is estimated that there are parents (S301: Y), the family identification unit 34 selects (estimated number of) parents from the users indicated by the household information and belonging to the household to which the target user belongs. Search for users corresponding to . If there is an uncorresponding user (S303: N), the age estimation unit 35 estimates the age of the parent whose existence is estimated by the presence/absence specifying unit 32 and whose corresponding user does not exist (S304).
- the age estimation unit 35 estimates the age of the parent whose existence is estimated by inputting the input parameters related to the user into the parent age estimation model, which is a machine learning model.
- the parental age estimation model may be a weakly supervised machine learning model as shown in FIG.
- One of the label functions 61 included in the parental age estimation model may output a parental age hierarchy based on the target user's age.
- Another one of the label functions 61 may output an age hierarchy based on the types of products included in the purchase history of the e-commerce system 40 .
- the label 65 may be information indicating the parent's age class whose age was estimated.
- the parent age estimation model includes the age and gender of child users among the users who are estimated to be parents and children by the user relationship identification unit 30, and the usage history of various computer systems such as the purchase and browsing history of the electronic commerce system 40. You may learn by the input data including and the learning data which makes the parent's age class correct data.
- the relationship recording unit 36 registers the information (including the age) of the parent whose existence is estimated by the presence/absence specifying unit 32 as new related user information (S305).
- the processing described so far not only clarifies the relationship between multiple users included in the household, but also makes it possible to detect persons who exist in the household but are not registered as users. .
- FIG. 16 is a diagram for explaining the relationship between users, etc. within a household.
- a range surrounded by a dashed rectangle indicates a household, and the household includes users 70a and 70b and a related user 70e.
- the character strings written in the ellipses of the users 70a and 70b indicate the user IDs
- the character strings written in the ellipses of the related user 70e indicate the user ID given when the relationship recording unit 36 records the related users. show.
- users (or related users) connected only by a horizontal line indicate that they are spouses
- users (or related users) connected by a vertical line extending downward from the horizontal line indicate children.
- FIG. 17 is a diagram showing an example of information stored in a household member table.
- FIG. 18 is a diagram showing an example of information stored in the user relationship table.
- FIG. 19 is a diagram showing an example of information stored in the member attribute table.
- the household member table, user relationship table, and member attribute table may be stored in the storage unit 12 . Also, instead of the storage unit 12, it may be stored in a database in another member management system.
- the household member table stores, for each household, a household ID for identifying the household and user IDs of one or more users belonging to that household.
- the user ID As the user ID, the user ID of the related user registered by the relationship recording unit 36 (social_456 in the example of FIG. 17) is also registered.
- the user relationship table stores, for each user pair, the user ID1 and user ID2 of the users in that pair and the type of relationship in that pair.
- the pair of users may be a pair specified by the user relationship specifying unit 30, or a pair of the target user and the related user (in FIG. 18, a pair of user ID 1: social_456 and user ID 2: 123). good too.
- the member attribute table stores the attributes of each user or related user.
- User attributes include a flag indicating whether or not the user is a member, gender, and age. In the case of related users, the flag indicating whether or not they are members is False. In the case of the related user, the age class estimated by the age estimation unit 35 is stored as the age.
- each of the computer systems including the information processing system 1 and the electronic commerce system 40 may recommend products, services, etc., based on information on users and related users in each household.
- FIG. 20 is a flow chart showing an example of processing for estimating relationships between households.
- the processing shown in FIG. 20 is executed in the household relationship estimation unit 38.
- FIG. The processing shown in FIG. 20 is performed after the processing of the household identification unit 33, in other words, the processing of S201 of FIG. 13 is performed.
- the processing shown in FIG. 20 may be repeatedly performed for each pair of a plurality of households identified by the household identification unit 33, or may be performed once for a plurality of pairs of households.
- the household relationship estimating unit 38 selects a pair of the first household and the second household to be the target of relationship estimation (S251).
- the household relationship estimating unit 38 acquires parameters regarding the type of relationship between the first user belonging to the first household and the second user belonging to the second household (S252).
- the parameters may include at least some of information based on attributes of the first user and attributes of the second user, and information based on interactions between the first user and the second user.
- Information based on the attributes of the first user and the attributes of the second user includes, for example, the identity of the surname, the age difference, whether the gender is the same, the similarity of the address (for example, whether or not).
- Information based on interactions between the first user and the second user includes, for example, the presence or absence of gifts related to specific days (Father's Day, Mother's Day, Christmas), the presence or absence of messages sent and received on specific dates, Including frequency of gifts, number of mutual friends.
- the relationship type parameter may be information pre-selected from the above information.
- the household relationship estimation unit 38 estimates the relationship type of the pair of the first and second households based on the parameters related to the relationship type (S254).
- the household relationship estimation unit 38 may select one of candidates including at least part of parent and child, siblings, friends, colleagues, and neighbors as the type of relationship to be estimated.
- the household relationship estimation unit 38 may estimate household relationships using a method similar to that used by the relationship identification unit 26 . More specifically, the household relationship estimating unit 38 performs clustering using a general clustering method based on the parameter values obtained for each of the pairs of households, thereby determining the households , may be sorted into a plurality of clusters 54 as shown in FIG. 10, for example. Then, the household relationship estimation unit 38 selects the relationship type corresponding to the cluster 54 to which the first and second households belong as the relationship type between the first and second households. you can
- the parameters used for the type of relationship of the household relationship estimation unit 38 are not only information about one first user belonging to the first household and one second user belonging to the second household, Information about other first users belonging to the first household and other second users belonging to the second household may also be included.
- the parameters include information based on attributes of one of the first users and one of the second users (e.g., age difference) and information about interactions from other first users to other second users (for example whether or not a gift is sent on a particular day).
- the household relationship estimation unit 38 may estimate the type of relationship between the first household and the second household using a household relationship estimation model, which is a machine learning model.
- the household relationship estimation model may be learned using learning data including input data including parameter values obtained for pairs of households and correct data indicating the type of relationship that is the correct answer.
- the household relationship estimation unit 38 may estimate the relationship between households based on the type of relationship in the pair of users identified by the user relationship identification unit 30. For example, when the user relationship specifying unit 30 specifies that the first user included in the first household and the second user included in the second household have a parent-child relationship, the household relationship estimation unit 38 may infer parentage as a type of relationship between households.
- FIG. 21 is a diagram illustrating an example of relationships between households.
- household 2 includes user 70c and associated user 70f
- household 3 includes user 70g and associated user 70h.
- parent-child is estimated as the type of relationship between households 2 and 1
- siblings is determined as the type of relationship between households 1 and 3.
- This relationship corresponds to the fact that the type of relationship between the user 70c belonging to household 2 and the user 70a belonging to household 1 is parent-child.
- the household relationship estimating unit 38 may estimate the type of relationship between households in consideration of the sending of gifts between users 70b and 70c who do not have a direct parent-child relationship. is also possible.
- the usage history of various computer systems in the present embodiment may be, for example, a history of purchases and viewings made by the target user in the electronic commerce system 42, and may be a history of purchases and browsing made by the target user in the golf course reservation system 44. It may be the type and geographical location of the golf course, the type and geographical location of the accommodation or room reserved by the target user in the travel reservation system 46, and the limit of the target user in the card management system 50. etc., and may be the geographic location and purchase history of the store where payment was made by the target user in the payment management system. It may be a history indicating a payment, it may be the type of financial product purchased or contracted by the target user in the financial product management system, or the type of insurance product purchased or contracted by the target user in the insurance product management system. It may well be a history including the location information of the target user, call destinations, message transmission destinations, etc. that can be acquired in the mobile service management system. The usage history is not limited as long as it is a history of usage of various computer systems by the target user.
Landscapes
- Business, Economics & Management (AREA)
- Tourism & Hospitality (AREA)
- Health & Medical Sciences (AREA)
- Economics (AREA)
- General Health & Medical Sciences (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- Physics & Mathematics (AREA)
- General Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
ユーザの属する世帯の状況をより詳細に把握する。 情報処理システム(1)に含まれる世帯特定手段(33)は、それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を示す世帯情報を取得し、前記情報処理システム1に含まれる世帯関係推定手段(38)は、前記第1の世帯に属するユーザの属性と前記第2世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定する。
Description
本発明は、情報処理システム、情報処理方法及びプログラムに関する。
何らかの方法で収集された情報から、各ユーザに配偶者や子どもがいるか推定する技術がある。
特開2019-087212号公報には、金融取引サービスにおいて、取引情報に基づいてユーザの家族構成に関する情報を特定することが開示されている(第0048段落および第0099段落参照)。
特開2021-144451号公報には、ユーザの収入額および支出額を特定し、それらとユーザの家族構成とに基づいて負債の補償の内容を決定する情報処理装置が開示されている(第0038段落参照)。
これまでは単にユーザの属性として配偶者や子どもの有無を推定しているに過ぎず、そのユーザの属する世帯の状況、例えばそのユーザの属する世帯の詳細については十分に把握できていなかった。
本発明は上記課題を鑑みてなされたものであって、その目的は、ユーザの属する世帯の状況をより詳細に把握することを可能にする技術を提供することにある。
本発明にかかる情報処理システムは、それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を示す世帯情報を取得する世帯特定手段と、前記第1の世帯に属するユーザの属性と前記第2の世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定する世帯関係推定手段と、を含む。
本発明にかかる情報処理方法は、それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を取得するステップと、前記第1の世帯に属するユーザの属性と前記第2の世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定するステップと、を含む。
本発明にかかるプログラムは、それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を示す世帯情報を取得する世帯特定手段、および、前記第1の世帯に属するユーザの属性と前記第2の世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定する世帯関係推定手段、としてコンピュータを機能させる。
本発明の一態様では、前記世帯特定手段は、ユーザデータベースに格納される複数のユーザの名字および住所に基づいて、前記複数のユーザからそれぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を取得してよい。
本発明の一態様では、前記世帯関係推定手段は、前記第1の世帯に含まれる第1のユーザと前記第2の世帯に含まれる第2のユーザとの関係性の種類に関する複数のパラメータに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定してよい。
本発明の一態様では、前記複数のパラメータは、名字の同一性、電話連絡の頻度、特定の日に関するギフトの有無、互いのギフトの頻度、年齢差、共通の友人、性が同じか否か、住所の類似性のうち少なくとも一部を含んでよい。
本発明の一態様では、前記世帯関係推定手段は、前記第1の世帯に含まれる第1のユーザと、前記第2の世帯に含まれる第2のユーザとの関係性の種類が、親子、きょうだい、隣人の少なくとも一部のうちいずれであるか否かに応じた、前記第1の世帯と前記第2の世帯との関係性の種類を推定してよい。
本発明によれば、ユーザの属する世帯の状況をより詳細に把握することができる。
以下、本発明の一実施形態について図面に基づき詳細に説明する。この実施形態では、ユーザに関する情報から、それぞれ1または複数のユーザを含む複数の世帯を特定し、その特定された世帯に関するより詳細な情報を推定する情報処理システム1について説明する。
図1は、本発明の一実施形態に係る情報処理システム1の全体構成の一例を示す図である。図1に示すように、本実施形態に係る情報処理システム1は、例えば、サーバコンピュータやパーソナルコンピュータなどのコンピュータであり、プロセッサ10、記憶部12、通信部14、操作部16、及び、出力部18を含む。なお、本実施形態に係る情報処理システム1に、複数台のコンピュータが含まれていてもよい。
プロセッサ10は、例えば、情報処理システム1にインストールされるプログラムに従って動作するマイクロプロセッサ等のプログラム制御デバイスである。情報処理システム1は、1または複数のプロセッサ10を含んでよい。記憶部12は、例えばROMやRAM等の記憶素子や、ハードディスクドライブ(HDD)、フラッシュメモリを含むソリッドステートドライブ(SSD)などである。記憶部12には、プロセッサ10によって実行されるプログラムなどが記憶される。通信部14は、例えばネットワークインタフェースカードのような、有線通信又は無線通信用の通信インタフェースであり、インターネット等のコンピュータネットワークを介して、他のコンピュータや端末との間でデータを授受する。
操作部16は、入力デバイスであり、例えば、タッチパネルやマウス等のポインティングデバイスやキーボード等を含む。操作部16は、操作内容をプロセッサ10に伝達する。出力部18は、例えば、液晶表示部又は有機EL表示部等のディスプレイや、スピーカ等の音声出力デバイス等の出力デバイスである。
なお、記憶部12に記憶されるものとして説明するプログラム及びデータは、ネットワークを介して他のコンピュータから供給されるようにしてもよい。また、情報処理システム1のハードウェア構成は、上記の例に限られず、種々のハードウェアを適用可能である。例えば、情報処理システム1に、コンピュータ読み取り可能な情報記憶媒体を読み取る読取部(例えば、光ディスクドライブやメモリカードスロット)や外部機器とデータの入出力をするための入出力部(例えば、USBポート)が含まれていてもよい。例えば、情報記憶媒体に記憶されたプログラムやデータが読取部や入出力部を介して情報処理システム1に供給されるようにしてもよい。
本実施形態に係る情報処理システム1は、複数のユーザを含む世帯を特定する。情報処理システム1は、世帯内の状況をより詳細に取得する処理と、世帯間の関係を特定する処理とを実行する。前者の処理として、情報処理システム1は、ユーザ間の関係性の種類を特定し、ユーザに関する情報からそのユーザが配偶者、子どもなどを含むか否か推定し、世帯内にその推定された配偶者、子どもなどに対応するユーザが居るかチェックし、いない場合には新たなユーザを登録する。前者の処理のために、情報処理システム1はその処理の対象となるユーザ(以下では注目人物とも記載する)と、そのユーザと関係を有するユーザ(以下では参照人物とも記載する)との関係性の種類を利用する。
以下、本実施形態に係る情報処理システム1の機能、及び、情報処理システム1で実行される処理についてさらに説明する。
図2は、本実施形態に係る情報処理システム1で実装される機能の一例を示す機能ブロック図である。なお、本実施形態に係る情報処理システム1に、図2に示す機能のすべてが実装される必要はなく、また、図2に示す機能以外の機能が実装されていても構わない。
図2に示すように、本実施形態に係る情報処理システム1は、機能的に、ユーザ関係特定部30、存否特定部32、世帯特定部33、家族特定部34、年齢推定部35、関係記録部36、世帯関係推定部38を含む。
ユーザ関係特定部30は、主にプロセッサ10、記憶部12および通信部14により実装される。存否特定部32、世帯特定部33、家族特定部34、年齢推定部35、関係記録部36、世帯関係推定部38は、主にプロセッサ10及び記憶部12により実装される。
以上の機能は、コンピュータである情報処理システム1にインストールされた、以上の機能に対応する実行命令を含むプログラムをプロセッサ10で実行することにより実装されてよい。また、このプログラムは、例えば、光学的ディスク、磁気ディスク、フラッシュメモリ等のコンピュータ読み取り可能な情報記憶媒体を介して、あるいは、インターネットなどを介して情報処理システム1に供給されてもよい。
ユーザ関係特定部30は、主に、ユーザのペアにおけるユーザ間の関係性の種類を示す関係情報を特定する。ユーザ関係特定部30は、ペアに含まれるユーザと関連付けられた、名字、IPアドレス、住所、年齢差、および性別のうちの少なくとも1つに基づいて、関係情報を出力してよい。なお、ユーザ関係特定部30は、情報処理システム1の外で作成された関係情報を取得してもよい。ここで、ユーザ関係特定部30は、関係特定部とも呼称され得る。
存否特定部32は、対象ユーザと関連付けて格納される情報であって他のユーザと関連付けずに格納される情報に基づいて、対象ユーザの配偶者、子ども、または、親の存否を示す存否情報を取得する。また存否特定部32は、機械学習モデルに対象ユーザに関する入力パラメータの値を入力した際の出力に基づいて、対象ユーザの配偶者、対象ユーザの子ども、または、対象ユーザの親の存否を推定し、推定結果を示す存否情報を取得する。入力パラメータはユーザに関するあらかじめ定められた情報の項目であり、その機械学習モデルはその入力パラメータの値を含む学習データにより学習されてよい。
世帯特定部33は、それぞれ同居する1または複数のユーザを含む1または複数の世帯を示す世帯情報を取得する。ここで、この1または複数の世帯の少なくとも1つは、対象ユーザおよび1または複数の家族ユーザを含んでよい。世帯特定部33は、ユーザデータベースに登録された複数のユーザから、対象ユーザを含む世帯に含まれその対象ユーザと同居する1または複数の家族ユーザを特定してよい。
家族特定部34は、関係情報に基づいて、世帯情報が示す世帯に含まれる家族ユーザから、配偶者、子ども、および親のうち存否情報が存在を示す家族ユーザを特定する。
年齢推定部35は、対象ユーザに関する情報に基づいて、対象ユーザにおいて存在が推定された配偶者、子ども、または親のうち、対応する家族ユーザが特定されなかった配偶者、子ども、または、親の年齢を推定する。なお、さらに、年齢推定部35は、存在が推定された配偶者、子ども、または、親に対応するユーザが特定され、かつ、そのユーザの年齢が登録されていない場合に、そのユーザを年齢推定の対象としてもよい。このとき、年齢推定部35は、推定された年齢をその対応するユーザに係る情報として記憶させてもよいし、推定された年齢はその他の処理に利用されてもよい。
関係記録部36は、対象ユーザの、存在が推定された配偶者、子ども、および/または親のうち、対応する家族ユーザが特定されなかった配偶者、子ども、または、親を、世帯に属する新たな関連ユーザとして、関連ユーザと対象ユーザとの関係性の種類を示す関係情報に関連付けて記憶部12に記憶させる。
世帯関係推定部38は、第1の世帯に属するユーザの属性と第2世帯に属するユーザの属性とに基づいて、第1の世帯と、第2の世帯との関係性の種類を推定する。ここで、第1の世帯および第2の世帯は、世帯特定部33により特定される1または複数の世帯に含まれる。世帯関係推定部38は、第1の世帯に含まれる第1のユーザと、第2の世帯に含まれる第2のユーザとの関係性の種類が、親子、きょうだい(Sibling)、隣人の少なくとも一部のうちいずれであるか否かに応じた、第1の世帯と第2の世帯との関係性の種類を推定してよい。
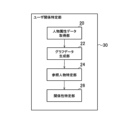
ユーザ関係特定部30の詳細について説明する。図22は、ユーザ関係特定部30の機能的な構成の一例を示す機能ブロック図である。ユーザ関係特定部30は、人物属性データ取得部20、グラフデータ生成部22、参照人物特定部24、関係性特定部26、を含む。
人物属性データ取得部20は、複数のコンピュータシステムと通信し、人物の属性を示す人物属性データを取得する。ここで、本実施形態に係る情報処理システム1は、例えば、電子商取引システム40、ゴルフ場予約システム42、旅行予約システム44、カード管理システム46、などといった各種コンピュータシステムと通信可能になっている(図3、図5、及び、図7参照)。これらのコンピュータシステムのそれぞれには、当該コンピュータシステムを利用するユーザに関する情報であるアカウントデータが登録されている。そして、情報処理システム1は、これらのコンピュータシステムにアクセスして、当該コンピュータシステムに登録されているアカウントデータを取得できるようになっている。なお、本実施の形態における各種コンピュータシステムは、例として、ペイメント管理システム、ネットバンキング管理システム、金融商品管理システム、保険商品管理システム、モバイルサービス管理システムなどを含んでもよく、インターネットを介して商品または役務を提供し得る分野であれば、その種別に制限はない。
アカウントデータには、例えば、ユーザID、氏名データ、住所データ、年齢データ、性別データ、電話番号データ、携帯電話番号データ、クレジットカード番号データ、IPアドレスデータ、などが含まれる。
ユーザIDは、例えば、当該コンピュータシステムにおける当該ユーザの識別情報である。氏名データは、例えば、当該ユーザの氏名(姓(名字)及び名)を示すデータである。住所データは、例えば、当該ユーザの住所を示すデータである。当該コンピュータシステムが電子商取引システム40である場合に、住所データが、当該ユーザが購入した商品の送付先の住所を示していてもよい。年齢データは、例えば、当該ユーザの年齢を示すデータである。性別データは、例えば、当該ユーザの性別を示すデータである。電話番号データは、例えば、当該ユーザの電話番号を示すデータである。携帯電話番号データは、例えば、当該ユーザの携帯電話番号を示すデータである。クレジットカード番号データは、例えば、当該ユーザが当該コンピュータシステムでの決済において利用するクレジットカードのカード番号を示すデータである。IPアドレスデータは、例えば、当該ユーザが使用するコンピュータのIPアドレス(例えば、送信元のIPアドレス)を示すデータである。
人物属性データ取得部20は、本実施形態では例えば、注目人物を含む複数の人物についての、当該人物の属性を示す人物属性データを取得する。ここで人物属性データの一例としては、上述のアカウントデータが挙げられる。人物属性データ取得部20は、例えば、上述の複数のシステムのそれぞれから、当該人物のアカウントデータを取得する。
グラフデータ生成部22は、本実施形態では例えば、複数の人物のそれぞれの属性に基づいて、互いに関係がある人物のペアを特定する。グラフデータ生成部22は、複数の人物の人物属性データに基づいて、互いに関係がある人物のペアを特定してもよい。なお、本実施形態に係るグラフデータ生成部22は、複数の人物のそれぞれの属性に基づいて、互いに関係がある人物のペアを特定するペア特定手段の一例に相当する。
グラフデータ生成部22は、例えば、注目人物を含む複数の人物にそれぞれ対応付けられるノードデータ50と、互いに関係がある人物のペアに対応付けられるリンクデータ52と、を含むグラフデータを生成する(図4、図6、図8、及び、図9参照)。またグラフデータ生成部22は、生成されたグラフデータを記憶部12に格納する。
例えば、図3に示すように、電子商取引システム40に、ユーザAのアカウントデータが登録されていることとする。また、ゴルフ場予約システム42に、ユーザBのアカウントデータが登録されていることとする。また、旅行予約システム44に、ユーザCのアカウントデータが登録されていることとする。
そして、電子商取引システム40に登録されているユーザAのIPアドレスデータの値、ゴルフ場予約システム42に登録されているユーザBのIPアドレスデータの値、及び、旅行予約システム44に登録されているユーザCのIPアドレスデータの値が同じであるとする。
この場合、グラフデータ生成部22は、図4に示すように、ユーザAに対応付けられるノードデータ50a、ユーザBに対応付けられるノードデータ50b、ユーザCに対応付けられるノードデータ50c、ユーザAがユーザBと関係があることを示すリンクデータ52a、ユーザAがユーザCと関係があることを示すリンクデータ52b、ユーザBがユーザCと関係があることを示すリンクデータ52c、を含むグラフデータを生成する。
IPアドレスが同じであるユーザは同じコンピュータを利用しているものと推察される。そのため、本実施形態ではこのようなユーザは互いに関連付けられるようになっている。
また、例えば、図5に示すように、電子商取引システム40に、ユーザD、ユーザE、及び、ユーザFのアカウントデータが登録されていることとする。
そして、電子商取引システム40に登録されているユーザDの住所データの値、ユーザEの住所データの値、及び、ユーザFの住所データの値が同じであるとする。
この場合、グラフデータ生成部22は、図6に示すように、ユーザDに対応付けられるノードデータ50d、ユーザEに対応付けられるノードデータ50e、ユーザFに対応付けられるノードデータ50f、ユーザDがユーザEと関係があることを示すリンクデータ52d、ユーザDがユーザFと関係があることを示すリンクデータ52e、ユーザEがユーザFと関係があることを示すリンクデータ52f、を含むグラフデータを生成する。
住所が同じであるユーザは同居しているものと推察される。そのため、本実施形態ではこのようなユーザは互いに関連付けられるようになっている。
また、例えば、図7に示すように、電子商取引システム40に、ユーザGのアカウントデータが登録されていることとする。また、ゴルフ場予約システム42に、ユーザHのアカウントデータが登録されていることとする。また、旅行予約システム44に、ユーザIのアカウントデータが登録されていることとする。
そして、電子商取引システム40に登録されているユーザGのクレジットカード番号データの値、ゴルフ場予約システム42に登録されているユーザHのクレジットカード番号データの値、及び、旅行予約システム44に登録されているユーザIのクレジットカード番号データの値が同じであるとする。
この場合、グラフデータ生成部22は、図8に示すように、ユーザGに対応付けられるノードデータ50g、ユーザHに対応付けられるノードデータ50h、ユーザIに対応付けられるノードデータ50i、ユーザGがユーザHと関係があることを示すリンクデータ52g、ユーザGがユーザIと関係があることを示すリンクデータ52h、ユーザHがユーザIと関係があることを示すリンクデータ52i、を含むグラフデータを生成する。
クレジットカード番号が同じであるユーザは親子等の家族であるものと推察される。そのため、本実施形態ではこのようなユーザは互いに関連付けられるようになっている。
なお、互いに関係がある人物のペアに該当するか否かの判断基準は、以上で説明したものには限定されない。
また、以上で説明した、互いに関係があると特定された人物を関連付けるリンクデータ52が示すリンクを明示的リンクと呼ぶこととする。
ここで例えば、第1の人物と明示的リンクで接続されている人物と、第2の人物と明示的リンクで接続されている人物と、が所定数以上(例えば、3人以上)共通しているとする。この場合、本実施形態では例えば、グラフデータ生成部22は、当該第1の人物が当該第2の人物と関係があることを示すリンクデータ52を生成する。このようにして生成されるリンクデータ52が示すリンクを黙示的リンクと呼ぶこととする。
例えば、図9に示すように、明示的リンクを示すリンクデータ52jによって、ユーザJに対応付けられるノードデータ50jとユーザKに対応付けられるノードデータ50kとが接続されていることとする。また、明示的リンクを示すリンクデータ52kによって、ユーザJに対応付けられるノードデータ50jとユーザLに対応付けられるノードデータ50lとが接続されていることとする。また、明示的リンクを示すリンクデータ52lによって、ユーザJに対応付けられるノードデータ50jとユーザMに対応付けられるノードデータ50mとが接続されていることとする。
また、明示的リンクを示すリンクデータ52mによって、ユーザKに対応付けられるノードデータ50kとユーザNに対応付けられるノードデータ50nとが接続されていることとする。また、明示的リンクを示すリンクデータ52nによって、ユーザLに対応付けられるノードデータ50lとユーザNに対応付けられるノードデータ50nとが接続されていることとする。また、明示的リンクを示すリンクデータ52oによって、ユーザMに対応付けられるノードデータ50mとユーザNに対応付けられるノードデータ50nとが接続されていることとする。
この場合、グラフデータ生成部22は、ユーザJがユーザNと関係があることを示すリンクデータ52p(黙示的リンクを示すリンクデータ52p)を生成する。このようにして、ユーザNが、ユーザJと関係がある人物として特定されることとなる。
また、例えば、第1の人物と明示的リンク又は黙示的リンクで接続されている人物と、第2の人物と明示的リンク又は黙示的リンクで接続されている人物と、が所定数以上(例えば、3人以上)共通しているとする。この場合、グラフデータ生成部22が、当該第1の人物が当該第2の人物と関係があることを示すリンクデータ52(黙示的リンクを示すリンクデータ52)を生成してもよい。
なお、グラフデータ生成部22は、アカウントデータとは異なる人物属性データに基づいて、グラフデータを生成してもよい。
参照人物特定部24は、処理対象人物(例えば注目人物を含む)と関係がある人物である参照人物を特定する。ここで、参照人物特定部24は、処理対象人物と関係がある人物として特定される人物(例えば友人として電子商取引システム40等に登録される人物)、及び、関係がある人物として特定される人物(例えば登録された友人)が所定数以上、処理対象人物と共通する人物を、参照人物として特定してもよい。また、参照人物特定部24は、処理対象人物の属性と、複数の人物の属性と、に基づいて、当該複数の人物のうちから、参照人物を特定してもよい。
参照人物特定部24は、例えば、処理対象人物に対応付けられるノードデータ50と、明示的リンク又は黙示的リンクを示すリンクデータ52によって接続されるノードデータ50に対応付けられる人物を、当該処理対象人物に対する参照人物として特定してもよい。
関係性特定部26は、処理対象人物(例えば注目人物を含む)と参照人物との関係性を特定する。ここで、関係性特定部26が、処理対象人物のアカウントデータと、参照人物のアカウントデータと、に基づいて、処理対象人物と参照人物との関係性を特定してもよい。ここで、処理対象人物のアカウントデータが登録されているコンピュータシステムと参照人物のアカウントデータが登録されているコンピュータシステムとは異なっていてもよい。例えば、電子商取引システム40に登録されている、処理対象人物のアカウントデータと、ゴルフ場予約システム42に登録されている、参照人物のアカウントデータと、に基づいて、処理対象人物と参照人物との関係性(より具体的には関係性の種類)を特定してもよい。関係性特定部26は、特定された関係性の種類を、処理対象人物および参照人物のペアと関連付けて記憶部12に格納してよい。
また、関係性特定部26は、処理対象人物と参照人物との家族としての関係(例えば親子、配偶者、きょうだい)を特定してよい。さらに、関係性特定部26は、特定される関係性の種類として、親子、配偶者、きょうだい、同僚、隣人、友人のうち少なくとも一部を含む候補のうちいずれかを選択してよい。
次に関係性特定部26の処理についてより詳細に説明する。関係性特定部26は、例えば、リンクデータ52で接続されているノードデータ50のペアを特定する。そして、関係性特定部26は、当該ペアに対応付けられる2人の人物の人物属性データに基づいて、当該ペアに対応付けられるペア属性データを生成する。
ペア属性データには、例えば、IP共通フラグ、住所共通フラグ、クレジットカード番号共通フラグ、名字同一フラグ、年齢差データ、ペア性別データ、などが含まれる。
IP共通フラグは、例えば、当該ペアのうちの一方のアカウントデータに含まれるIPアドレスデータの値と他方のアカウントデータに含まれるIPアドレスデータの値とが同じであるか否かを示すフラグである。例えば、所与の日においてIPアドレスデータの値が同じである場合はIP共通フラグの値に1が設定され、IPアドレスデータの値が異なる場合はIP共通フラグの値に0が設定されてもよい。
住所共通フラグは、例えば、当該ペアのうちの一方のアカウントデータに含まれる住所データの値と他方のアカウントデータに含まれる住所データの値とが同じであるか否かを示すフラグである。例えば、住所データの値が同じである場合は住所共通フラグの値に1が設定され、住所データの値が異なる場合は住所共通フラグの値に0が設定されてもよい。また住所共通フラグとして、住所どうしの類似性が用いられてもよい。例えば、住所共通フラグに、住所のうち町名および番地までも異なる場合には0、番地の後にある建物名および部屋番号が異なる場合には1、建物名および部屋番号が同じである場合は2が設定されてよい。
クレジットカード番号共通フラグは、例えば、当該ペアのうちの一方のアカウントデータに含まれるクレジットカード番号データの値と他方のアカウントデータに含まれるクレジットカード番号データの値とが同じであるか否かを示すフラグである。例えば、クレジットカード番号データの値が同じである場合はクレジットカード番号共通フラグの値に1が設定され、クレジットカード番号データの値が異なる場合はクレジットカード番号共通フラグの値に0が設定されてもよい。
名字同一フラグは、例えば、当該ペアのうちの一方のアカウントデータに含まれる氏名データが示す名字と他方のアカウントデータに含まれる氏名データが示す名字とが同じであるか否かを示すフラグである。例えば、氏名データが示す名字が同じである場合は名字同一フラグの値に1が設定され、氏名データが示す名字が異なる場合は名字同一フラグの値に0が設定されてもよい。
年齢差データは、例えば、当該ペアのうちの一方のアカウントデータに含まれる年齢データの値と他方のアカウントデータに含まれる年齢データの値との差を示すデータである。
ペア性別データは、例えば、当該ペアのうちの一方のアカウントデータに含まれる性別データの値と他方のアカウントデータに含まれる性別データの値との組合せを示すデータである。
そして、関係性特定部26は、複数のペアのそれぞれに対応付けられるペア属性データの値に基づいて、一般的なクラスタリング手法を用いたクラスタリングを実行することで、当該複数のペアを、図10に示すような複数のクラスタ54に分類する。
図10は、複数のペアが、5つのクラスタ54(54a、54b、54c、54d、及び、54e)に分類された様子の一例を模式的に示す図である。図10に示されているバツ印は、ペアに対応付けられる。そして、複数のバツ印のそれぞれは、当該バツ印に対応するペアのペア属性データの値に対応付けられる位置に配置されている。
図10の例では、複数のペアが5つのクラスタ54に分類されているが、複数のペアが分類されるクラスタ54の数は5つには限定されず、例えば、複数のペアが4つのクラスタ54に分類されてもよい。
図11は、複数のペアが4つのクラスタ54に分類された場合における、当該分類の可視化の一例を示す図である。
図11に示すように、住所が同じであり、性別が同じであり、年齢差がX歳より大きく、名字が同じペアは、第1クラスタに分類されてもよい。また、住所が同じであり、性別が同じであり、年齢差がX歳以下であり、名字が同じペアは、第2クラスタに分類されてもよい。また、住所が同じであり、性別が異なり、年齢差がY歳より大きく、名字が同じペアは、第3クラスタに分類されてもよい。また、住所が同じであり、性別が異なり、年齢差がY歳以下であり、名字が同じペアは、第4クラスタに分類されてもよい。
この場合、第1クラスタは、例えば同性の親子に対応付けられるクラスタ54であるものと推察される。また、第2クラスタは、例えば同性の兄弟に対応付けられるクラスタ54であるものと推察される。また、第3クラスタは、例えば異性の親子に対応付けられるクラスタ54であるものと推察される。また、第4クラスタは、例えば夫婦、または異性の兄弟に対応付けられるクラスタ54であるものと推察される。
なお、処理対象人物と参照人物との関係性の種類を特定に、さらにペアのうちの一方と他方とにおける共通の友人の数を用いてもよい。
以上で説明したようにして、関係性特定部26が、人物間の関係に対応付けられる値に基づくクラスタリングの結果に基づいて、処理対象人物と参照人物との関係性の種類を特定してもよい。また、関係性特定部26が、名字、IPアドレス、住所、クレジットカード番号、年齢差、又は、性別のうちの少なくとも1つに基づくクラスタリングの結果に基づいて、処理対象人物と参照人物との関係性の種類を特定してもよい。
関係性特定部26は、処理対象人物と参照人物との間で行われる情報または物のやりとりの記録にさらに基づいて、処理対象人物と参照人物との関係性の種類を特定してもよい。情報または物のやりとりの記録は、例えば、父の日、母の日、またはクリスマスのような特定の日付におけるギフトの送付履歴や、その特定の日付におけるメッセージの送受信ログであってよい。
ここで、本実施形態に係る情報処理システム1で行われる、ソーシャルグラフにかかる情報の作成についての処理の一例を、図12に例示するフロー図を参照しながら説明する。図12は、主に参照人物特定部24、関係性特定部26の処理について説明する。
図12に記載される処理は、グラフデータが生成された人物のそれぞれについて繰り返し実行される。グラフデータが生成された人物は注目人物を含み、図12の処理の対象となる人物を以下では処理対象人物と記載する。図12の処理例では、注目人物を含む複数の人物についてのグラフデータが既に生成されており、複数のペアについて、当該ペアに対応付けられるクラスタ54が特定されていることとする。また、各クラスタ54に対応付けられる近さ機械学習モデルが既に学習済であることとする。
まず、参照人物特定部24は、処理対象人物に対応するノードデータ50と明示的リンク又は黙示的リンクで接続されているノードデータ50に対応する人物を、参照人物として特定する(S101)。ここでは例えば、少なくとも1人の参照人物が特定されるとする。
そして、関係性特定部26が、S101に示す処理で特定された参照人物のうちから、S104~S108に示す処理がまだ実行されていない参照人物を1人選択する(S103)。
そして、関係性特定部26が、処理対象人物とS102に示す処理で選択された参照人物とのペアに対応するクラスタ54をそのペアの関係性の種類として特定する(S104)。
関係性特定部26は処理対象人物と参照人物との関係性の種類を記憶部12に格納する(S108)。
そして、関係性特定部26が、S101に示す処理で特定された参照人物のすべてについてS104,S108に示す処理が実行されたか否かを確認する(S110)。
S101に示す処理で特定された参照人物のすべてについてS104,S108に示す処理が実行されていない場合は(S110:N)、S103に示す処理に戻る。
S101に示す処理で特定された参照人物のすべてについてS104,S108に示す処理が実行された場合は(S110:Y)、図12に示される処理は終了する。
次に、世帯内の状況をより詳細に取得するための処理についてより詳細に説明する。図13は、世帯内のユーザの家族関係の特定にかかわる処理の一例を示すフロー図である。図13に示される処理は、存否特定部32、世帯特定部33、家族特定部34、年齢推定部35、関係記録部36において実行される。
はじめに、世帯特定部33は、ユーザの住所及び名字に基づいて、同居する1または複数のユーザを含む世帯の世帯情報を取得する(S201)。より具体的には、世帯特定部33は、複数のコンピュータシステムのユーザデータベースに登録されている複数のユーザのアカウントデータを取得する。そして世帯特定部33は、アカウントデータに含まれる住所および名字が同じ複数のユーザを、世帯に含まれ同居するユーザとして選択し、その選択されたユーザを含む世帯の世帯情報を生成する。また世帯特定部33は、住所および名字が同じユーザが存在しないユーザからなる世帯の世帯情報を生成してよい。世帯に含まれ同居するユーザを選択する条件は、住所および名字が同じだけでなく、例えば、住所のうち建物名を除く部分が一致し類似性が高いことおよび名字が一致することであってもよい。世帯特定部33は、予め処理の対象として設定される対象ユーザ群に含まれるユーザを含む世帯について世帯情報を取得してもよいし、対象ユーザ群を設けず対象ユーザと関係なく複数の世帯について世帯情報を取得してもよい。なおユーザデータベースは、予め複数のコンピュータシステムから取得され記憶部12に格納されたものであってもよいし、別途生成され記憶部12に格納されるものであってもよい。
世帯情報が取得されると、家族特定部34は、家族ユーザを特定する処理の対象となる1人の対象ユーザを選択する(S202)。この処理において、家族特定部34は、世帯特定部33の処理の対象となる対象ユーザ群に含まれるユーザから対象ユーザを選択してもよいし、家族特定部34は世帯特定部33により取得された複数の世帯に含まれる任意のユーザを選択してもよい。
つぎに、存否特定部32は、対象ユーザと関連付けて格納される情報であって他のユーザと関連付けずに格納される情報に基づいて、対象ユーザの配偶者の存否を示す存否情報を取得する(S203)。ここで、存否特定部32は、機械学習モデルである配偶者存否推定モデルに対象ユーザに関する入力パラメータの値を入力した際の出力に基づいて、対象ユーザの配偶者の存否を推定し、その推定結果を示す存否情報を取得する。ここで入力パラメータはユーザに関するあらかじめ定められた情報の項目であり、配偶者存否推定モデルは、予め、その入力パラメータの値を含む学習データにより学習されてよい。配偶者存否推定モデルの詳細については後述する。
そして、家族特定部34は配偶者の存否情報と世帯内のユーザとの対応を確認し、また、その対応に応じて、年齢推定部35は年齢を推定し、関係記録部36は関連ユーザの情報を登録する(S204)。S204の処理の詳細については後述する。
S203と同様に、存否特定部32は、対象ユーザと関連付けて格納される情報であって他のユーザと関連付けずに格納される情報に基づいて、対象ユーザの子どもの存否を示す存否情報を取得する(S205)。存否特定部32は、予め学習された機械学習モデルである子存否推定モデルに対象ユーザに関する入力パラメータの値を入力した際の出力に基づいて、対象ユーザの子どもの存否、より具体的には子どもの人数を推定し、その推定結果を示す存否情報を取得する。
S204と同様に、家族特定部34は子どもの存否情報と世帯内のユーザとの対応を確認し、また、その対応に応じて、年齢推定部35は年齢を推定し、関係記録部36は関連ユーザの情報を登録する(S206)。
S203と同様に、存否特定部32は、対象ユーザと関連付けて格納される情報であって他のユーザと関連付けずに格納される情報に基づいて、対象ユーザの親の存否を示す存否情報を取得する(S207)。存否特定部32は、予め学習された機械学習モデルである親存否推定モデルに対象ユーザに関する入力パラメータの値を入力した際の出力に基づいて、対象ユーザの親の存否、より具体的には親の人数を推定し、その推定結果を示す存否情報を取得する。
S204と同様に、家族特定部34は親の存否情報と世帯内のユーザとの対応を確認し、また、その対応に応じて、年齢推定部35は年齢を推定し、関係記録部36は関連ユーザの情報を登録する(S208)。
そして、家族特定部34は、まだ選択されていないユーザが存在するか判定する(S210)。ユーザが存在する場合は(S210:Y)、S202の処理から繰り返す。ユーザが存在しない場合は(S210:N)、図13の処理を終了する。
次に存否特定部32に含まれる、配偶者存否推定モデルと、子存否推定モデルと、親存否推定モデルとについて説明する。配偶者存否推定モデル、子存否推定モデル、親存否推定モデルは構造を存否推定モデルと総称する。本実施の形態において、存否推定モデルに係る入力パラメータは、例として、各種コンピュータシステムに係る取引履歴などの利用履歴を含んでよく、対象ユーザに係る人物属性データの少なくとも一部を含んでよい。図14は、存否特定部32で用いる機械学習モデルである存否推定モデルの一例を説明する図である。存否推定モデルは、弱教師あり学習により学習される。存否推定モデルは複数のラベル関数61a~61c(特に区別しない場合はラベル関数61と記載する)および生成モデル64を含む。ラベル関数61a~61cの出力62a~62c(特に区別しない場合は出力62と記載する)は生成モデル64に入力され、生成モデル64は存否の推定結果を示すラベル65を出力する。ここで、ラベル関数(ラベリング関数に相当)の数に特に制限はない。図14に示される機械学習モデルは、例えばSnorkelという名称で提供される公知のものであってよい。存否推定モデルにおいて決定されるラベル65は、各ラベル関数61の出力であってもよいし、その出力が所定の手法で統計処理された統計情報に基づいて推定された情報であってもよいし、各ラベル関数61の出力に基づく統計情報に応じ多数決等のルールベースで決定された情報であってもよい。
配偶者存否推定モデルに含まれる複数のラベル関数61のそれぞれは、ユーザに関する1または複数の入力パラメータに基づいて対象ユーザの配偶者が存在するか否かに関するスコアを出力する。子存否推定モデルに含まれる複数のラベル関数61のそれぞれは、ユーザに関する1または複数の入力パラメータに基づいて対象ユーザの子どもが存在するか否かに関するスコアを出力する。親存否推定モデルに含まれる複数のラベル関数61のそれぞれは、ユーザに関する1または複数の入力パラメータに基づいて対象ユーザの親が存在するか否かに関するスコアを出力する。なお、入力パラメータはユーザに関連付けられ、かつ他のユーザと関連付けられていない情報からなる。
生成モデル64は、ラベル関数61のそれぞれの重みに応じて、出力62からラベル65のスコアを算出する。生成モデル64は、複数のラベル関数61の出力および学習により決定される複数の関数の重みに基づいて、対象ユーザの配偶者(子ども、親)の存否を推定し、推定結果を示す存否情報を決定する。
ラベル関数61は、入力パラメータに対して仮のラベルとなる出力62を生成する関数であり、管理者等により決定されてよい。出力62の値は、例えば、negative(0),positive(1),skipの3つのうちいずれかであってよいし、何らかの値とskipであってもよい。ラベル関数61が生成する出力62の精度は必ずしも高くなくてよい。生成モデル64は、複数のラベル関数61の複数の出力62について算出されるラベルの確率に基づいて、損失が最小になるように学習される。学習においては、例えばラベル関数61の出力62ごとの重みが決定されてよい。また、この機械学習モデルは正解としてのラベルが存在しなくても学習することができる。
配偶者存否推定モデルにおいて、例えば以下に示すラベル関数61が設けられてよい。ラベル関数61の1つは、旅行予約システム44に、ユーザによる大人2人の旅行予約の履歴が存在する場合にpositiveを出力し、存在しない場合にnegativeを出力してよい。ラベル関数61の他の1つは、電子商取引システム40の会員情報に、ユーザの子どもに関する情報が登録されている場合にpositiveを出力し、登録されていない場合にnegativeを出力してよい。ラベル関数61の他の1つは、カード管理システム46の登録情報に、既婚かつ子どもありまたは既婚と登録されている場合にpositiveを出力し、登録されていない場合にnegativeを出力してよい。
子存否推定モデルにおいて、例えば以下に示すラベル関数61が設けられてよい。ラベル関数61の1つは、旅行予約システム44に存在する履歴において、最も予約の頻度の多い子どもの人数を出力してよい。ラベル関数61の他の1つは、電子商取引システム40の会員情報に登録される、ユーザの子どもの人数を出力してよい。ラベル関数61の他の1つは、カード管理システム46の登録情報に格納される子どもの人数を出力してよい。なお、子どもの人数として、「0」,「1」,「2」,「3以上」のうちいずれかが出力されてよい。
親存否推定モデルにおいて、例えば以下に示すラベル関数61が設けられてよい。ラベル関数61の1つは、コンピュータシステムに登録される連絡先において、ユーザと同じ住所を有する者の人数を出力してよい。ラベル関数61の他の1つは、カード管理システム46の登録情報に格納される親の人数を出力してよい。なお、親の人数として、「0」,「1」,「2」のうちいずれかが出力されてよい。
次にステップS204の処理についてさらに詳細に説明する。図15は家族特定部34、年齢推定部35、関係記録部36の処理の一例を示すフロー図であり、特に配偶者の存否に関する処理の一例を示すフロー図である。なお、年齢推定部35に含まれる配偶者年齢推定モデル、子年齢推定モデル、親年齢推定モデルなどの年齢推定モデルは、存否推定モデルと同様の構成、例えばSnorkelという名称で提供される公知のものであってよい。年齢推定モデルは、各入力パラメータが与えられたラベル関数(ラベリング関数に相当)の出力を利用し年齢推定を行うモデルであってよい。
はじめに家族特定部34は、存否特定部32により対象ユーザに配偶者が存在すると推定された否かを判定する(S301)。配偶者が存在しないと推定された場合には(S301:N)、図15の処理を終了する。一方、配偶者が存在すると推定された場合には(S301:Y)、家族特定部34は、世帯情報が示すユーザであって、対象ユーザが属する世帯の家族のユーザから、配偶者に対応するユーザを検索する(S302)。より具体的には、家族特定部34は、世帯情報が示すユーザであって、対象ユーザと同一の世帯に含まれるユーザ(家族のユーザ)から、対象ユーザとの関係性の種類が配偶者であるユーザを探す。ここで、対象ユーザと家族のユーザとの関係性の種類は、予めユーザ関係特定部30により特定されていてよい。そして家族特定部34は、対応するユーザが存在するか判定する(S303)。
対応するユーザが存在しない場合には(S303:N)、年齢推定部35は、存否特定部32により存在が推定され対応するユーザが存在しない配偶者の年齢を推定する(S304)。
年齢推定部35は、機械学習モデルである配偶者年齢推定モデルにユーザに関する入力パラメータを入力することにより存在が推定された配偶者の年齢を推定する。配偶者年齢推定モデルには、例として、対象ユーザの年齢および性別、電子商取引システム40の購入および閲覧履歴などの各種コンピュータシステムの利用履歴を含む入力データが入力され、配偶者年齢推定モデルは配偶者の推定された年齢を出力してよい。なお、配偶者年齢推定モデルは、ユーザ関係特定部30により互いに配偶者であると推定されたユーザのうち一方の年齢および性別、電子商取引システム40の購入および閲覧履歴などの各種コンピュータシステムの利用履歴を含む入力データと、他方の年齢の階層を正解データとする学習データにより学習されてよい。年齢の階層は、例えば各階層が5歳の範囲を含むように設定されてよい。
年齢が推定されると、関係記録部36は、存否特定部32により存在が推定される配偶者の情報(年齢を含む)を、新たな関連ユーザの情報として登録する(S305)。なお、存否特定部32において存在すると推定された配偶者に対応するユーザが既に存在する場合には(S303のY)、関係記録部36はそのユーザに関する情報を記憶部12に格納する(S306)。なお、S305において既存のユーザデータベースに情報を追加する場合には、S306は実行されなくてもよい。
S206の処理は、図15に示される処理に類似し、配偶者の代わりに子どもが対象になる。以下では処理上の大きな相違点について説明する。S301において、家族特定部34は、存否特定部32により対象ユーザに子どもが存在すると推定された否かを判定する。子どもが存在すると推定された場合には(S301:Y)、家族特定部34は、世帯情報が示すユーザであって、対象ユーザが属する世帯の家族のユーザから、(推定された人数の)子どもに対応するユーザを検索する。対応しないユーザが存在する場合には(S303:N)、年齢推定部35は、存否特定部32により存在が推定され対応するユーザが存在しない子どもの年齢を推定する(S304)。
年齢推定部35は、機械学習モデルである子年齢推定モデルにユーザに関する入力パラメータを入力することにより存在が推定された子どもの年齢を推定する。子年齢推定モデルは、図14に示されるような弱教師ありの機械学習モデルであってよい。子年齢推定モデルに含まれるラベル関数61の1つは、例えば電子商取引システム40の会員情報に含まれる子どもに情報に基づいて、年齢の階層を出力してよい。他の1つのラベル関数は、旅行予約システム44に存在する宿泊予約に存在する子どもの食事、寝具の情報に基づいて年齢の階層を出力してよい。他の1つのラベル関数は、電子商取引システム40の購入履歴に含まれる商品の種類に基づいて年齢の階層を出力してよい。ここで、ラベル65は、年齢の推定された子どもの年齢の階層を示す情報であってよい。なお、子年齢推定モデルは、ユーザ関係特定部30により親子であると推定されたユーザのうち親の年齢および性別、電子商取引システム40の購入および閲覧履歴などの各種コンピュータシステムの利用履歴を含む入力データと、子どもの年齢の階層を正解データとする学習データにより学習されてもよい。
年齢が推定されると、関係記録部36は、存否特定部32により存在が推定される子どもの情報(年齢を含む)を、新たな関連ユーザの情報として登録する(S305)。
S208の処理は、図15に示される処理に類似し、配偶者の代わりに親が対象になる。以下では処理上の大きな相違点について説明する。S301において、家族特定部34は、存否特定部32により対象ユーザに親が存在すると推定された否かを判定する。親が存在すると推定された場合には(S301:Y)、家族特定部34は、世帯情報が示すユーザであって、対象ユーザが属する世帯の家族のユーザから、(推定された人数の)親に対応するユーザを検索する。対応しないユーザが存在する場合には(S303:N)、年齢推定部35は、存否特定部32により存在が推定され対応するユーザが存在しない親の年齢を推定する(S304)。
年齢推定部35は、機械学習モデルである親年齢推定モデルにユーザに関する入力パラメータを入力することにより存在が推定された親の年齢を推定する。親年齢推定モデルは、図14に示されるような弱教師ありの機械学習モデルであってよい。親年齢推定モデルに含まれるラベル関数61の1つは、対象ユーザの年齢に基づいて親の年齢の階層を出力してよい。ラベル関数61の他の1つは、電子商取引システム40の購入履歴に含まれる商品の種類に基づいて年齢の階層を出力してよい。ここで、ラベル65は、年齢の推定された親の年齢の階層を示す情報であってよい。なお、親年齢推定モデルは、ユーザ関係特定部30により親子であると推定されたユーザのうち子どものユーザの年齢および性別、電子商取引システム40の購入および閲覧履歴などの各種コンピュータシステムの利用履歴を含む入力データと、親の年齢の階層を正解データとする学習データにより学習されてもよい。
年齢が推定されると、関係記録部36は、存否特定部32により存在が推定される親の情報(年齢を含む)を、新たな関連ユーザの情報として登録する(S305)。
これまでに説明された処理により、世帯に含まれる複数のユーザ間の関係が明確になるだけでなく、世帯内に存在する人物であるがユーザ登録されていない人物を検出することが可能になる。
図16は、世帯内のユーザ等の関係を説明する図である。この例では、破線の矩形で囲まれた範囲が世帯を示し、その世帯がユーザ70a,70b、関連ユーザ70eを含むことが図示されている。ユーザ70a,70bの楕円中に記載された文字列はユーザIDを示し、関連ユーザ70eの楕円中に記載された文字列は関係記録部36が関連ユーザを記録する際に付与されたユーザIDを示す。また横線のみで接続されるユーザ(または関連ユーザ)は互いに配偶者であることを示し、その横線から下に延びる縦線に接続されるユーザ(または関連ユーザ)は子どもを示す。
さらに関係記録部36により出力されるデータの構造について説明する。図17は世帯メンバテーブルに格納される情報の一例を示す図である。図18はユーザ関係テーブルに格納される情報の一例を示す図である。図19はメンバ属性テーブルに格納される情報の一例を示す図である。世帯メンバテーブル、ユーザ関係テーブル、メンバ属性テーブルは記憶部12に格納されてよい。また記憶部12の代わりに、他の会員管理システム内のデータベースに格納されてもよい。
世帯メンバテーブルには、世帯ごとに、世帯を識別するための世帯IDと、その世帯に属する1または複数のユーザのユーザIDとが格納される。またユーザIDとして、関係記録部36により登録される関連ユーザのユーザID(図17の例ではsocial_456)も登録される。
ユーザ関係テーブルには、ユーザのペアごとに、そのペアに蔵するユーザのユーザID1,ユーザID2と、そのペアにおける関係性の種類とが格納される。ユーザのペアは、ユーザ関係特定部30により特定されたペアであってもよいし、対象ユーザと関連ユーザとのペア(図18ではユーザID1:social_456とユーザID2:123とのペア)であってもよい。
メンバ属性テーブルには、ユーザまたは関連ユーザごとに、そのユーザの属性が格納されている。ユーザの属性は、会員であるか否かのフラグ、性別、年齢を含む。関連ユーザの場合、会員であるか否かのフラグがFalseとなる。また関連ユーザの場合、年齢として、年齢推定部35により推定された年齢の階層が格納される。
このように関連ユーザの存在を推定し、その情報を出力することで、既存のアカウントデータとして存在するユーザだけでなく、既存のユーザから推定される世帯内の関連ユーザについても管理を可能にしている。またこの情報処理システム1、電子商取引システム40を含むコンピュータシステムのそれぞれは、各世帯におけるユーザおよび関連ユーザの情報に基づいて、商品やサービスなどをレコメンドしてよい。
以下では、世帯間の関係を特定するための処理についてより詳細に説明する。図20は、世帯間の関係の推定にかかる処理の一例を示すフロー図である。図20に示される処理は、世帯関係推定部38において実行される。図20に示される処理は、世帯特定部33の処理、言い換えると図13のS201の処理が実行された後に実行される。図20に示される処理は、世帯特定部33により特定された複数の世帯のそれぞれのペアについて繰り返し行われてもよいし、複数の世帯のペアについて一度に実行されてもよい。
はじめに世帯関係推定部38は、関係の推定の対象となる、第1の世帯および第2の世帯のペアを選択する(S251)。
そして、世帯関係推定部38は、第1の世帯に属する第1のユーザおよび第2の世帯の属する第2のユーザについて、それらの関係性の種類に関するパラメータを取得する(S252)。このパラメータは、第1のユーザの属性および第2のユーザの属性に基づく情報、および第1のユーザと第2のユーザとのやりとりに基づく情報、のうち少なくとも一部を含んでよい。第1のユーザの属性および第2のユーザの属性に基づく情報は、例えば、名字の同一性、年齢差、性が同じか否か、住所の類似性(例えば市区町村および町丁字名が同じか否か)を含む。第1のユーザと第2のユーザとのやりとりに基づく情報は、例えば、特定の日(父の日、母の日、クリスマス)に関するギフトの有無、特定の日付におけるメッセージの送受信の有無、互いのギフトの頻度、共通の友人の数、を含む。関係性の種類に関するパラメータは、上記の情報から予め選択された情報であってよい。
世帯関係推定部38は、その関係性の種類に関するパラメータに基づいて、第1の世帯と第2の世帯のペアの関係性の種類を推定する(S254)。世帯関係推定部38は、推定される関係性の種類として、親子、きょうだい、友人、同僚、隣人の少なくとも一部を含む候補からいずれかを選択してよい。
世帯関係推定部38は、関係性特定部26と同様の手法を用いて世帯の関係を推定してよい。より具体的には、世帯関係推定部38は、複数の世帯のペアのそれぞれについて取得されるパラメータの値に基づいて、一般的なクラスタリング手法を用いたクラスタリングを実行することで、当該複数の世帯のペアを、例えば図10に示すような複数のクラスタ54に分類してよい。そして、世帯関係推定部38は、第1の世帯および第2の世帯が属するクラスタ54に対応する関係性の種類を、第1の世帯および第2の世帯の間の関係性の種類として選択してよい。
ここで、世帯関係推定部38の関係性の種類に用いるパラメータは、第1の世帯に属する1つの第1のユーザと第2の世帯の属する1つの第2のユーザとに関する情報だけでなく、第1の世帯に属する他の第1のユーザや第2の世帯に属する他の第2のユーザに関する情報も含んでよい。パラメータが、第1のユーザのうち1つと第2のユーザのうち1つとの属性に基づく情報(例えば年齢差)と、他の第1のユーザから他の第2のユーザへのやり取りに関する情報(例えば特定の日のギフトの送付の有無)との組み合わせを含んでよい。
また、世帯関係推定部38は、機械学習モデルである世帯関係推定モデルを用いて第1の世帯と第2の世帯の関係性の種類を推定してもよい。世帯関係推定モデルは、世帯のペアについて取得されるパラメータの値を含む入力データと、正解となる関係性の種類を示す正解データとを含む学習データによって学習されてよい。
世帯関係推定部38は、ユーザ関係特定部30により特定されたユーザのペアにおける関係性の種類に基づいて世帯間の関係を推定してよい。例えば、ユーザ関係特定部30により、第1の世帯に含まれる第1のユーザと、第2の世帯に含まれる第2のユーザとが親子関係があると特定された場合に、世帯関係推定部38は、世帯間の関係性の種類として親子関係を推定してよい。
これまでに説明した処理により世帯間の関係を把握することが可能になる。図21は、世帯間の関係の一例を説明する図である。図21の例では、世帯2はユーザ70cと関連ユーザ70fとを含み、世帯3はユーザ70gと関連ユーザ70hを含む。
図21の例では、世帯2と世帯1との関係性の種類として親子が推定され、世帯1と世帯3との関係性の種類としてきょうだいがス一定される。この関係は世帯2に属するユーザ70cと世帯1に属するユーザ70aとの関係性の種類が親子であることと対応している。一方、世帯関係推定部38では、その処理の方法によっては、直接の親子関係のないユーザ70bとユーザ70cと間でのギフトの送付などを考慮して世帯間の関係性の種類を推定することも可能である。
なお、本実施の形態における各種コンピュータシステムの利用履歴は、例えば、電子商取引システム42において対象ユーザにより行われた購入および閲覧に係る履歴であってよく、ゴルフ場予約システム44において対象ユーザにより予約されたゴルフ場の種別や地理的位置であってよく、旅行予約システム46において対象ユーザによる予約された宿泊先や部屋の種別や地理的位置であってよく、カード管理システム50における対象ユーザの限度額等を含む契約内容や購入履歴であってよく、ペイメント管理システムにおいて対象ユーザによる決済がなされた店舗等の地理的位置や購入履歴であってよく、ネットバンキング管理システムにおける対象ユーザの預金残高や入出金先を示す履歴であってよく、金融商品管理システムにおいて対象ユーザが購入または契約した金融商品の種別であってよく、保険商品管理システムにおいて対象ユーザが購入または契約した保険商品の種別であってよく、モバイルサービス管理システムにおいて取得され得る対象ユーザの位置情報や通話先やメッセージ送信先等を含む履歴であってよい。利用履歴は、対象ユーザによる各種コンピュータシステムの利用にかかる履歴であればその態様に制限はない。
なお、本発明は上述の実施形態に限定されるものではなく、様々な変形が行われてよい。また、特許請求の範囲の記載は、本発明の要旨および範囲内にあるようなすべての変更を網羅することが意図されている。また、上記の具体的な文字列や数値及び図面中の具体的な文字列や数値は例示であり、これらの文字列や数値には限定されない。
Claims (7)
- それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を示す世帯情報を取得する世帯特定手段と、
前記第1の世帯に属するユーザの属性と前記第2の世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定する世帯関係推定手段と、
を含む情報処理システム。 - 請求項1に記載の情報処理システムにおいて、
前記世帯特定手段は、ユーザデータベースに格納される複数のユーザの名字および住所に基づいて、前記複数のユーザからそれぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を取得する、
情報処理システム。 - 請求項1または2に記載の情報処理システムにおいて、
前記世帯関係推定手段は、前記第1の世帯に含まれる第1のユーザと前記第2の世帯に含まれる第2のユーザとの関係性の種類に関する複数のパラメータに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定する、
情報処理システム。 - 請求項3に記載の情報処理システムにおいて、
前記複数のパラメータは、名字の同一性、電話連絡の頻度、特定の日に関するギフトの有無、互いのギフトの頻度、年齢差、共通の友人、性が同じか否か、住所の類似性のうち少なくとも一部を含む、
情報処理システム。 - 請求項1から4のいずれかに記載の情報処理システムにおいて、
前記世帯関係推定手段は、前記第1の世帯に含まれる第1のユーザと、前記第2の世帯に含まれる第2のユーザとの関係性の種類が、親子、きょうだい、隣人の少なくとも一部のうちいずれであるか否かに応じた、前記第1の世帯と前記第2の世帯との関係性の種類を推定する、
情報処理システム。 - それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を取得するステップと、
前記第1の世帯に属するユーザの属性と前記第2の世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定するステップと、
を含む情報処理方法。 - それぞれ同居する1または複数のユーザを含む第1の世帯および第2の世帯を示す世帯情報を取得する世帯特定手段、および、
前記第1の世帯に属するユーザの属性と前記第2の世帯に属するユーザの属性とに基づいて、前記第1の世帯と、前記第2の世帯との関係性の種類を推定する世帯関係推定手段、
としてコンピュータを機能させるためのプログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/047950 WO2023119578A1 (ja) | 2021-12-23 | 2021-12-23 | 情報処理システム、情報処理方法及びプログラム |
| JP2022573525A JP7345689B1 (ja) | 2021-12-23 | 2021-12-23 | 情報処理システム、情報処理方法及びプログラム |
| TW111145786A TWI835439B (zh) | 2021-12-23 | 2022-11-30 | 資訊處理系統、資訊處理方法及程式產品 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/047950 WO2023119578A1 (ja) | 2021-12-23 | 2021-12-23 | 情報処理システム、情報処理方法及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023119578A1 true WO2023119578A1 (ja) | 2023-06-29 |
Family
ID=86901879
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/047950 WO2023119578A1 (ja) | 2021-12-23 | 2021-12-23 | 情報処理システム、情報処理方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7345689B1 (ja) |
| WO (1) | WO2023119578A1 (ja) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010165097A (ja) * | 2009-01-14 | 2010-07-29 | Ntt Docomo Inc | 人間関係推定装置、及び、人間関係推定方法 |
| JP2017126215A (ja) * | 2016-01-14 | 2017-07-20 | ヤフー株式会社 | 情報選択装置、情報選択方法および情報選択プログラム |
| JP2018106502A (ja) * | 2016-12-27 | 2018-07-05 | 株式会社Nttドコモ | 情報処理装置及びプログラム |
| WO2021199101A1 (ja) * | 2020-03-30 | 2021-10-07 | 日本電気株式会社 | 犯罪捜査支援システム、犯罪捜査支援装置、犯罪捜査支援方法、及び、犯罪捜査支援プログラムが格納された記録媒体 |
| WO2021200503A1 (ja) * | 2020-03-31 | 2021-10-07 | ソニーグループ株式会社 | 学習システム及びデータ収集装置 |
-
2021
- 2021-12-23 JP JP2022573525A patent/JP7345689B1/ja active Active
- 2021-12-23 WO PCT/JP2021/047950 patent/WO2023119578A1/ja active Application Filing
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010165097A (ja) * | 2009-01-14 | 2010-07-29 | Ntt Docomo Inc | 人間関係推定装置、及び、人間関係推定方法 |
| JP2017126215A (ja) * | 2016-01-14 | 2017-07-20 | ヤフー株式会社 | 情報選択装置、情報選択方法および情報選択プログラム |
| JP2018106502A (ja) * | 2016-12-27 | 2018-07-05 | 株式会社Nttドコモ | 情報処理装置及びプログラム |
| WO2021199101A1 (ja) * | 2020-03-30 | 2021-10-07 | 日本電気株式会社 | 犯罪捜査支援システム、犯罪捜査支援装置、犯罪捜査支援方法、及び、犯罪捜査支援プログラムが格納された記録媒体 |
| WO2021200503A1 (ja) * | 2020-03-31 | 2021-10-07 | ソニーグループ株式会社 | 学習システム及びデータ収集装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| TW202341054A (zh) | 2023-10-16 |
| JP7345689B1 (ja) | 2023-09-15 |
| JPWO2023119578A1 (ja) | 2023-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Meisel et al. | Synergies of operations research and data mining | |
| WO2019169756A1 (zh) | 产品推荐方法、装置及存储介质 | |
| US20160261544A1 (en) | Increasing interaction between clusters with low connectivity in a social network | |
| Chorianopoulos | Effective CRM using predictive analytics | |
| US8688603B1 (en) | System and method for identifying and correcting marginal false positives in machine learning models | |
| US9275125B1 (en) | System for organizing data from a plurality of users to create individual user profiles | |
| JP6810745B2 (ja) | ターゲットクラスタリング手法を利用して、属性タイプが混合した顧客をセグメント化するためのシステムおよび方法 | |
| US20160224994A1 (en) | Classification engine for classifying businesses | |
| CN113032668A (zh) | 基于用户画像的产品推荐方法、装置、设备及存储介质 | |
| WO2023119578A1 (ja) | 情報処理システム、情報処理方法及びプログラム | |
| WO2023119577A1 (ja) | 情報処理システム、情報処理方法及びプログラム | |
| TWI835439B (zh) | 資訊處理系統、資訊處理方法及程式產品 | |
| Shmueli et al. | Machine Learning for Business Analytics: Concepts, Techniques and Applications with JMP Pro | |
| CN115936758A (zh) | 基于大数据的智能拓客方法及相关装置 | |
| US20190325262A1 (en) | Managing derived and multi-entity features across environments | |
| JP7302106B1 (ja) | 情報処理システム、情報処理方法及びプログラム | |
| JP7459189B2 (ja) | 近さスコア決定システム、近さスコア決定方法及びプログラム | |
| JP7312923B1 (ja) | 情報処理システム、情報処理方法及びプログラム | |
| TWI839978B (zh) | 資訊處理系統、資訊處理方法及程式產品 | |
| Wang et al. | Discovering consumer's behavior changes based on purchase sequences | |
| JP2024069608A (ja) | グラフデータ生成システム、グラフデータ生成方法及びプログラム | |
| Rahul et al. | Introduction to Data Mining and Machine Learning Algorithms | |
| JP2023148437A (ja) | 情報処理システム、方法及びプログラム | |
| Das | Data science using oracle data miner and oracle r enterprise | |
| US11704370B2 (en) | Framework for managing features across environments |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 17928614 Country of ref document: US Ref document number: 2022573525 Country of ref document: JP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21969013 Country of ref document: EP Kind code of ref document: A1 |