WO2021200503A1 - 学習システム及びデータ収集装置 - Google Patents
学習システム及びデータ収集装置 Download PDFInfo
- Publication number
- WO2021200503A1 WO2021200503A1 PCT/JP2021/012368 JP2021012368W WO2021200503A1 WO 2021200503 A1 WO2021200503 A1 WO 2021200503A1 JP 2021012368 W JP2021012368 W JP 2021012368W WO 2021200503 A1 WO2021200503 A1 WO 2021200503A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- learning
- unit
- model
- segment
- Prior art date
Links
- 238000013480 data collection Methods 0.000 title claims abstract description 106
- 238000010801 machine learning Methods 0.000 claims abstract description 101
- 238000012549 training Methods 0.000 claims abstract description 38
- 230000008451 emotion Effects 0.000 claims description 110
- 238000004458 analytical method Methods 0.000 claims description 68
- 230000008921 facial expression Effects 0.000 claims description 67
- 238000001514 detection method Methods 0.000 claims description 36
- 230000002996 emotional effect Effects 0.000 claims description 36
- 238000011156 evaluation Methods 0.000 claims description 36
- 238000000605 extraction Methods 0.000 claims description 34
- 230000006870 function Effects 0.000 claims description 32
- 230000005540 biological transmission Effects 0.000 claims description 31
- 239000000284 extract Substances 0.000 claims description 27
- 238000004364 calculation method Methods 0.000 claims description 22
- 230000010365 information processing Effects 0.000 claims description 22
- 230000000694 effects Effects 0.000 claims description 13
- 230000004044 response Effects 0.000 claims description 11
- 238000003062 neural network model Methods 0.000 description 81
- 238000000034 method Methods 0.000 description 44
- 238000007405 data analysis Methods 0.000 description 43
- 238000012545 processing Methods 0.000 description 32
- 238000010586 diagram Methods 0.000 description 22
- 238000013527 convolutional neural network Methods 0.000 description 18
- 230000008569 process Effects 0.000 description 17
- 238000013473 artificial intelligence Methods 0.000 description 15
- 241000282414 Homo sapiens Species 0.000 description 13
- 210000004556 brain Anatomy 0.000 description 13
- 241000282412 Homo Species 0.000 description 11
- 238000003384 imaging method Methods 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 7
- 230000007246 mechanism Effects 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 5
- 230000003287 optical effect Effects 0.000 description 5
- 230000002787 reinforcement Effects 0.000 description 5
- 238000013528 artificial neural network Methods 0.000 description 4
- 238000013135 deep learning Methods 0.000 description 4
- 230000036651 mood Effects 0.000 description 4
- 230000001276 controlling effect Effects 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 230000000295 complement effect Effects 0.000 description 2
- 238000012937 correction Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 230000003183 myoelectrical effect Effects 0.000 description 2
- 210000002569 neuron Anatomy 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 210000004761 scalp Anatomy 0.000 description 2
- 230000035900 sweating Effects 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 238000012935 Averaging Methods 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000002730 additional effect Effects 0.000 description 1
- 230000003416 augmentation Effects 0.000 description 1
- 235000000332 black box Nutrition 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000000875 corresponding effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 210000004709 eyebrow Anatomy 0.000 description 1
- 230000001815 facial effect Effects 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000015654 memory Effects 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 238000003058 natural language processing Methods 0.000 description 1
- HAHMABKERDVYCH-ZUQRMPMESA-N neticonazole hydrochloride Chemical compound Cl.CCCCCOC1=CC=CC=C1\C(=C/SC)N1C=NC=C1 HAHMABKERDVYCH-ZUQRMPMESA-N 0.000 description 1
- 238000003672 processing method Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/174—Facial expression recognition
- G06V40/176—Dynamic expression
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/012—Head tracking input arrangements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/015—Input arrangements based on nervous system activity detection, e.g. brain waves [EEG] detection, electromyograms [EMG] detection, electrodermal response detection
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/25—Management operations performed by the server for facilitating the content distribution or administrating data related to end-users or client devices, e.g. end-user or client device authentication, learning user preferences for recommending movies
- H04N21/258—Client or end-user data management, e.g. managing client capabilities, user preferences or demographics, processing of multiple end-users preferences to derive collaborative data
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/16—Devices for psychotechnics; Testing reaction times ; Devices for evaluating the psychological state
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2203/00—Indexing scheme relating to G06F3/00 - G06F3/048
- G06F2203/01—Indexing scheme relating to G06F3/01
- G06F2203/011—Emotion or mood input determined on the basis of sensed human body parameters such as pulse, heart rate or beat, temperature of skin, facial expressions, iris, voice pitch, brain activity patterns
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
Definitions
- the technology disclosed in the present specification includes a learning system for learning a machine learning model, a data collecting device for collecting learning data for learning a machine learning model, and data.
- the information processing device that performs the analysis processing of.
- digital cameras are widespread. For example, in each home, digital video cameras and digital still cameras are used to record various events such as daily life, entrance ceremonies, graduation ceremonies, and weddings of children. It is desirable to shoot a more moving scene, but it is difficult to determine whether the scene that a general user is observing through the viewfinder is a moving scene. Of course, even for professional photographers, it is difficult to determine whether the scene they are shooting is moving.
- a method of handling emotional content can be considered using artificial intelligence technology equipped with a trained neural network model.
- a deep learning neural network model (hereinafter, also referred to as "DNN") having multiple layers of convolutional neural networks extracts features that developers cannot imagine through training, that is, deep learning, from a large amount of data. It is possible to develop artificial intelligence functions that can solve complex problems that developers cannot imagine algorithms.
- learning data for learning artificial intelligence is required.
- a learning data collection unit that collects learning data for machine learning of a specified ability and a learning processing unit that performs machine learning of a learning device so as to acquire a specified ability using the collected learning data.
- a proposal has been made for a learning device provided see Patent Document 1).
- To handle inspiring content using artificial intelligence technology first a large amount of learning used to learn machine learning models that estimate camera operations to generate inspiring content or shoot inspiring content. I need data.
- a data collection method that reflects subjectivity can be considered by utilizing favorite information that appears on SNS (Social Network Service), but it is not easy to execute because it may threaten privacy.
- SNS Social Network Service
- the context of the scenes before and after is also considered to be an element that creates excitement, but the method of collecting data depending only on the image collects data that reflects the context. It's difficult to do.
- An object of the present disclosure is a learning system that learns a machine learning model that estimates camera operation for generating moving content or shooting moving content, and for generating moving content or shooting moving content. It is an object of the present invention to provide a data collecting device that collects learning data of a machine learning model that estimates camera operation, and an information processing device that analyzes the impression given by the collected data.
- a data collecting device for collecting data and a learning device for learning a machine learning model using the data collected by the data collecting device are provided.
- the learning device collects learning data that affects the learning of the machine learning model based on the results of analysis, learning data that affects the learning of the machine learning model by a predetermined value or more, missing learning data, and the like.
- the machine learning model is retrained using data similar to these. It is a learning system.
- system here means a logical assembly of a plurality of devices (or functional modules that realize a specific function), and each device or functional module is in a single housing. It does not matter whether or not it is.
- the learning device learns a machine learning model that estimates a camera operation for generating moving content or shooting moving content.
- the analysis can also be performed by XAI, confidence score calculation, influence function, or Bayesian DNN.
- the learning device analyzes learning data that affects the learning of the machine learning model, and based on the analysis result, learning data that affects the learning of the machine learning model by a predetermined amount or more, and missing learning data. , Or a request signal requesting the transmission of data similar to these is transmitted to the data acquisition device. Then, the data collecting device transmits the data collected based on the received request signal to the learning device, so that the learning device can use the data transmitted from the data collecting device in response to the request signal. Based on this, the machine learning model can be retrained.
- the machine learning model among the collected data is based on the result of analyzing the influence of the collected data on the learning of the machine learning model.
- the learning data having a predetermined or greater effect on the learning of the above, the missing learning data, or data similar thereto is transmitted to the learning device.
- the learning device can relearn the machine learning model based on the data transmitted from the data collecting device in response to the request signal.
- the learning device may transmit the information necessary for the analysis to the data acquisition device at the time of transmitting the request signal.
- the second aspect of the present disclosure is A receiving unit that receives a request signal requesting transmission of learning data of the machine learning model from a learning device that learns the machine learning model.
- a data collection unit that collects learning data that has a predetermined or greater effect on the learning of the machine learning model, missing learning data, or data similar thereto in response to receiving the request signal.
- a transmission unit that transmits the data collected by the data collection unit to the learning device, and a transmission unit. It is a data collection device provided with.
- the receiving unit receives from the learning device the learning data that affects the learning of the machine learning model by a predetermined value or more, the missing learning data, or the request signal that requests data similar thereto. Then, the data collecting unit collects data based on the received request signal, and the transmitting unit transmits the data collected by the data collecting unit to the learning device.
- the data collection device further includes an analysis unit that analyzes the influence of the data collected by the data collection unit on the learning of the machine learning model. Then, based on the analysis result by the analysis unit, the transmission unit receives learning data having a predetermined or greater effect on the learning of the machine learning model among the data collected by the data collection unit, and missing learning data. Alternatively, data similar to these is transmitted to the learning device.
- the third aspect of the present disclosure is A segment extraction unit that extracts segments from the content based on the content evaluation information of the content and the biometric information of the person who views the content.
- a facial expression identification unit that detects the face of a person in a segment and identifies the facial expression
- a relationship estimation unit that estimates the relationships between people in the segment
- An emotional identification unit that identifies the emotional label of a segment based on the facial expression of the person in the segment and the relationship between the persons. It is an information processing device provided with.
- the segment extraction unit extracts the segment of the content in which the biometric information having a high audience rating and positive emotions matches. In addition, the segment extraction unit further extracts segments in which the biometric information having a high audience rating and positive emotions does not match.
- the relationship estimation unit estimates the relationship between the persons in the current segment by using the face detection of the person in the past segment and the facial expression identification result of the detected face as the context.
- the information processing apparatus detects the first emotion analysis unit that analyzes emotions based on the text information obtained by recognizing the voice included in the segment, and the music included in the segment.
- a second sentiment analysis unit that analyzes the emotions given by the music is further provided.
- the emotion identification unit identifies the emotion label of the segment by further considering the emotion identified by the first emotion analysis unit from the text information and the emotion identified by the second emotion analysis unit from the music. ..
- the data acquisition device performs the analysis by calculating the reliability score.
- the learning device transmits the information of the neural network model that has been learned by the current time to the data collecting device as the information necessary for the analysis.
- a learning system that learns a machine learning model that estimates camera operation for generating moving content or shooting moving content, and for generating moving content or shooting moving content. It is possible to provide a data collecting device that collects learning data of a machine learning model that estimates the camera operation of the content, and an information processing device that identifies the impression given by the content.
- FIG. 1 is a diagram showing a functional configuration of the data collection system 100.
- FIG. 2 is a flowchart showing the operation of the data collection system 100.
- FIG. 3 is a diagram showing a mechanism for estimating the relationship between people based on the context of the segment and the results of face detection and facial expression identification.
- FIG. 4 is a diagram showing the overall flow of the learning process of the impression discriminator using the collected learning data.
- FIG. 5 is a diagram showing a configuration example of the digital camera 500.
- FIG. 6 is a diagram showing a functional configuration for performing emotional identification labeling of content captured by the digital camera 500.
- FIG. 7 is a diagram showing a functional configuration of a digital camera 500 for automatically controlling camera work based on a moving identification result of captured content.
- FIG. 8 is a diagram showing a functional configuration of the digital camera 500 for automatically generating captions based on the impression identification result of the captured content.
- FIG. 9 is a diagram showing a functional configuration of the digital camera 500 for automatically adding background music based on the impression identification result of the captured content.
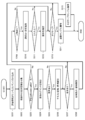
- FIG. 10 is a diagram showing a configuration of a learning system 1000 for efficiently learning a neural network model for automatic operation of a camera.
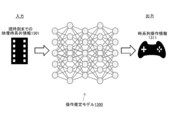
- FIG. 11 is a diagram showing the configuration of the observation prediction model 1100.
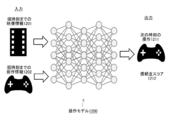
- FIG. 12 is a diagram showing the configuration of the operation model 1200.
- FIG. 13 is a diagram showing the configuration of the operation estimation model 1300.
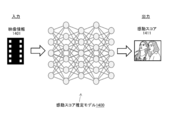
- FIG. 14 is a diagram showing an impression score estimation model 1400.
- FIG. 15 is a diagram showing the relationship between the controlled object and the average impression score.
- FIG. 16 is a diagram showing a neural network model trained to estimate output error.
- FIG. 17 is a diagram showing an example of the internal configuration of the data acquisition device 1010.
- FIG. 18 is a diagram showing another internal configuration example of the data acquisition device 1010.
- FIG. 19 is a diagram showing an example of the internal configuration of the learning device 1030.
- FIG. 20 is a diagram showing another internal configuration example of the learning device 1030.
- FIG. 21 is a diagram showing still another internal configuration example of the learning device 1030.
- FIG. 22 is a diagram showing an example of the internal configuration of the model utilization device 1020.
- FIG. 23 is a diagram showing an example of the internal configuration of the model utilization device 1020 as the edge AI.
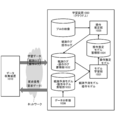
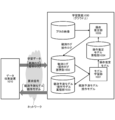
- FIG. 1 schematically shows a functional configuration of a data collection system 100 that performs data collection processing according to the present disclosure.
- the illustrated data collection system 100 collects data used for learning a machine learning model that estimates camera operation for generating moving content or shooting moving content from a huge amount of video content 101. Perform processing.
- the data collected by the data collection system 100 is basically a machine learning model (for example, for inferring whether or not it is a scene or content that impresses humans) for handling content that impresses humans (for example, for inferring whether the data is a scene or content that impresses humans).
- it is used for training data for training a neural network), but of course it may be used for other purposes.
- the data collection system 100 handles the content that is broadcast on a television, an Internet broadcasting station, or the like as the video content 101 and is provided with the content evaluation information such as the audience rating information, and the content is mainly a video. It consists of data and audio data. Further, as the video content 101, content evaluation information that evaluates the content that is similar to the audience rate information (or can be replaced with the audience rate information) such as "Like! (Like, fun, supportable)" is provided. If it is given, it may include various contents such as a video sharing site. Further, the data collection system 100 shall process the content extracted from the video content 101 in units of fixed-length or variable-length segments.
- the data collection system 100 includes a content evaluation information acquisition unit 102, a biometric information acquisition unit 103, a comparison unit 104, a segment extraction unit 105, a context extraction unit 106, a voice recognition unit 107, and a music detection unit 108. It includes a face detection unit 109, a first emotion analysis unit 110, a second emotion analysis unit 111, a facial expression identification unit 112, a relationship estimation unit 113, and an emotion identification unit 114.
- the data collection system 100 is assumed to be configured as a service in which computer resources are provided on a wide-area computer network such as the cloud, that is, the Internet. Each component of the data collection system 100 may be integrated in one computer or distributed in a plurality of computers. Each part will be described below.
- the content evaluation information acquisition unit 102 acquires content evaluation information such as an audience rating given to the content extracted from the video content 101.
- the content evaluation information acquisition unit 102 may acquire the audience rating information of the target content from the audience rating research company.
- the data collection system 100 uses the audience rating information in order to determine whether or not each scene of the content impresses a human being.
- the merits of using the audience rating information are that it does not conflict with privacy issues and that the information already reflects the reaction of a large number of people.
- the audience rating information also reflects the context such as the origination and transfer of the content in the story, the context information before and after the scene with a high audience rating can be effectively used.
- the content evaluation information acquisition unit 102 provides content evaluation information such as "Like! (Like, fun, supportable)" attached by SNS or the like. May be obtained.
- the biometric information acquisition unit 103 acquires biometric information of a human being who views the content extracted from the video content 101.
- a biometric information sensor that detects biometric information such as brain waves, sweating, gaze, and myoelectric potential is installed in the home, and the biometric information detected when viewing content such as television or Internet broadcasting is used as biometric information.
- the acquisition unit 103 may collect the information. When a huge amount of biometric information is collected from a large number of households, the biometric information acquisition unit 103 may be used after performing statistical processing such as averaging.
- Biological information such as brain wave information acquired by the biological information acquisition unit 103 is used. Studies to identify emotions from brain wave information have already been conducted (see, for example, Non-Patent Document 1).
- An electroencephalogram is an electric potential measured from the scalp of electrical activity generated from the brain.
- An electroencephalograph is generally configured to measure an electroencephalograph from an electrode placed on the scalp. The international 10-20 method is known as the position of the electrode, but the present disclosure is not particularly limited to this.
- the comparison unit 104 compares the content evaluation information such as the audience rating acquired by the content evaluation information acquisition unit 102 with the human biometric information acquired by the biometric information acquisition unit 103. Then, the segment extraction unit 105 uses the segment in which the biometric information having a high audience rating and positive emotions (such as “impressed”) matches among the contents extracted from the video content 101 for learning the emotional identification. Extract as data. In addition, the segment extraction unit 105 extracts a segment in which the biometric information having a high audience rating and positive emotions does not match as a negative sample (such as "not impressed”).
- the context extraction unit 106 extracts the context of the content extracted from the video content 101. More specifically, the context extraction unit 106 extracts the context before and after the scene with a high audience rating and the context before and after the segment extracted by the segment extraction unit 105.
- the context extraction unit 106 may extract the context using a trained neural network model trained to estimate the context from the content consisting of video and audio data.
- the voice recognition unit 107 applies voice recognition processing (ASR: Automatic Speech Recognition) to the voice component of the audio data included in the segment extracted by the segment extraction unit 105, and recognizes the voice such as dialogue. Convert to text (speech translation).
- ASR Automatic Speech Recognition
- the first sentiment analysis unit 110 applies natural language processing that performs sentiment analysis to text information such as dialogue output from the voice recognition unit 107, and the segment (scene) is composed of what kind of emotion. Analyze if it is.
- the first sentiment analysis unit 110 may perform the sentiment analysis in a wider context by referring to the lines of the preceding and following segments (scenes). Based on the emotion analysis result of the dialogue, the emotion of the segment (scene) can be grasped more accurately.
- the voice recognition unit 107 and the first sentiment analysis unit 110 can each be configured by using a trained machine learning model such as a convolutional neural network (CNN). Further, the voice recognition unit 107 and the first sentiment analysis unit 110 can be combined as a "speech discriminator" and can be configured by a machine learning model such as one CNN.
- CNN convolutional neural network
- the music detection unit 108 applies music detection processing to the audio data included in the segment extracted by the segment extraction unit 105, and detects the background music added to the video.
- the second emotion analysis unit 111 identifies whether or not the background music detected by the music detection unit 108 is mood or moving.
- Several techniques for identifying emotions given by music have been proposed (see, for example, Non-Patent Document 2). Based on the emotion analysis result of the background music, the emotion of the segment (scene) can be grasped more accurately.
- the music detection unit 108 and the second emotion analysis unit 111 can be configured by using a trained machine learning model such as CNN, respectively. Further, the music detection unit 108 and the second emotion analysis unit 111 can be combined as a "music discriminator" and configured by a machine learning model such as one CNN.
- the face detection unit 109 executes face detection processing (face detection) of a person appearing in the video data included in the segment extracted by the segment extraction unit 105.
- the facial expression identification unit 112 identifies the facial expression of the face detected by the face detection unit 109. For example, the facial expression identification unit 112 analyzes the pattern of the face image from the detected face and estimates which emotion the pattern of the face image corresponds to. Human emotions can be estimated using artificial intelligence that has pre-learned the correlation between facial image patterns and human emotions.
- the pattern of the face image can be composed of a combination of face parts such as eyebrows, eyes, nose, mouth, and cheeks, but can also be composed of an image of the entire face image without being divided into face parts.
- the face detection unit 109 and the facial expression identification unit 112 can each be configured by using a learned machine learning model such as CNN. Further, the face detection unit 109 and the facial expression identification unit 112 can be combined as a "facial expression identification machine" and can be configured by a machine learning model such as one CNN.
- the relationship estimation unit 113 is based on the context between the facial expressions of the individual persons identified by the facial expression identification unit 112 and the segments before and after the person extracted by the context extraction unit 106 when there are two or more persons in the segment. To estimate the relationships and intimacy between people. Because, even if one person has the same facial expression, it depends on the relationship and intimacy with the other person in the picture (for example, whether it is in the picture with family or close friends). This is because there is a difference in the ease of connecting to the impression of the human being who sees it, which affects the impression identification process in the subsequent stage.
- the emotion identification unit 114 includes the emotion identification result of the voice (such as dialogue) in the segment by the voice recognition unit 107 and the first emotion analysis unit 110, and the background music in the segment by the music detection 108 and the second emotion analysis unit 111.
- the emotion identification unit 114 estimates the emotion of the segment from the above input data using, for example, a trained neural network model, and outputs an emotion identification label indicating the emotion level of the segment.
- the emotional identification label may be two simple binary labels, positive (such as “impressed") and negative (such as “not impressed"), but “anger", “disgust”, “fear”, “happiness”, etc. It may be a label that expresses emotions that are divided into various types such as “sadness", “surprise”, and so on.
- the emotional identification unit 114 may output an emotional identification label defined based on an emotional model such as a Wundt model or a Plutchik model.
- FIG. 2 shows the operation of the data collection system 100 in the form of a flowchart.
- the content that is broadcast on a television or an Internet broadcasting station and is given content evaluation information such as the viewing rate is taken into the data collection system 100 (step SS201).
- the content evaluation information acquisition unit 102 acquires the content evaluation information given to this content. It is assumed that the content is composed of a plurality of segments and the content evaluation information is given to each segment.
- the biometric information acquisition unit 103 acquires biometric information such as brain waves representing the reaction of a human being viewing the content captured in step S201 (step S202).
- biometric information such as brain waves representing the reaction of a human being viewing the content captured in step S201 (step S202).
- the content is a television broadcast, it is assumed that biometric information including at least brain waves will be collected from a large number of households watching the program.
- the comparison unit 104 compares the content evaluation information acquired by the content evaluation information acquisition unit 102 with the human bioinformation acquired by the biometric information acquisition unit 103 for each segment, and has a high audience rating and positive emotions. Check if the information matches (step S203).
- the segment extraction unit 105 uses, among the contents extracted from the video content 101, the segment in which the biometric information having a high audience rating and the positive emotion matches (Yes in step S203) for learning the impression identification. Extract as data (step S204). Further, the segment extraction unit 105 extracts a segment in which the biometric information having a high audience rating and positive emotion does not match (No in step S203) as a negative sample (step S215).
- step S204 When the segment extracted in step S204 contains voice data (Yes in step S205), the voice recognition unit 107 recognizes the voice and converts it into text, and the first sentiment analysis unit 110 identifies emotions from the text information. (Step S206).
- step S204 If the segment extracted in step S204 contains music data (Yes in step S207), the music detection unit 108 detects the music, and the second sentiment analysis unit 111 identifies the emotion given by the music. (Step S208).
- step S210 If a person appears in the segment extracted in step S204 (Yes in step S209), the face detection unit 109 detects the person's face, and the facial expression identification unit 112 identifies the facial expression of the detected face (step). S210).
- the relationship estimation unit 113 has the facial expressions of the individual persons identified by the facial expression identification unit 112 and the context. The relationship between the persons is estimated based on the context with the segments before and after the extraction by the extraction unit 106 (step S212).
- the emotion identification unit 114 includes the emotion identification result of the voice (such as dialogue) in the segment by the voice recognition unit 107 and the first emotion analysis unit 110, and the background music in the segment by the music detection 108 and the second emotion analysis unit 111.
- the emotion identification unit 114 estimates the emotion of the segment and outputs an emotion identification label indicating the emotion level of the segment.
- the emotional identification label may be two types of simple binary labels, positive and negative, but there are various types such as “anger”, “disgust”, “fear”, “happiness”, “sadness”, “surprise”, and so on. It may be a label that expresses emotion. As a result, it is possible to obtain samples with labels representing various kinds of emotions such as positive or “anger”, “disgust”, “fear”, “happiness”, “sadness”, “surprise”, and so on. (Step S214). In addition, a negative sample that does not give positive emotions to humans is also acquired (step S215).
- the data collection system 100 extracts segments (scenes) that impress humans from contents such as televisions and Internet broadcasts according to the processing procedure shown in FIG. 2, and further, emotions of voice and background music included in the segments. It is possible to identify the emotional label of each segment based on the analysis result, the facial expression identification result of the person in the segment, and the estimation result of the relationship between the people when two or more people are shown in the segment. can. Then, the segment with the emotion label collected by the data collection system 100 can be used for learning data for training the impression discriminator using artificial intelligence (neural network model).
- artificial intelligence neural network model
- the image shows the same person A
- the person B who appears together with the person A has a close relationship with family and friends and has a high degree of intimacy
- the image is likely to lead to impression.
- the intimacy between the person A and the person B is low, no impression may be given. In this way, grasping the relationship between subjects is very important in estimating whether or not the image gives an impression.
- the relationship estimation unit 113 describes the relationship between the persons based on the context between the facial expressions of the individual persons identified by the facial expression identification unit 112 and the segments before and after the segments extracted by the context extraction unit 106. Since the sex is estimated, there is no privacy problem.
- the relationship estimation unit 113 uses not only the information of the segment extracted by the segment extraction unit 105 (for example, the facial expression of a person identified from the video in the segment) but also the context with the segments before and after the information. Since the relationship between the persons is estimated, it can be expected that the accuracy of the estimation will be improved. Further, it is also conceivable to use meta information of the content itself (for example, information of a broadcast program) easily obtained from an information source such as the Internet for estimating the relationship between people.
- an information source such as the Internet
- FIG. 3 illustrates a mechanism in which the relationship estimation unit 113 estimates the relationship between people based on the segment context and the results of face detection and facial expression identification.
- the relationship estimation unit 113 includes the face detection and facial expression identification results of the detected face in the current segment extracted by the segment extraction unit 105, as well as the facial expression identification result of the person in the past segment. Face detection and the facial expression identification result of the detected face are used as a context.
- the past segment 301 is input to the CNN311 constituting the face detection unit 109 and the facial expression identification unit 112, and the CNN311 performs face detection and facial expression identification of each person reflected in the past segment 301. Then, the relationship estimation unit 113 registers the person whose face is detected from the past segment 301 and the facial expression identification result 303 in the person registration unit 313.
- the current segment 302 extracted by the segment extraction unit 105 is input to the CNN 312 constituting the face detection unit 109 and the facial expression identification unit 112, and this CNN is used for face detection and detection of each person in the current segment 302.
- the facial expression is identified, and the face detection and the facial expression identification result 304 of the detected face are output.
- the relationship estimation unit 113 inquires of the person registration unit 313 to check whether the person detected from the current segment 302 is a person pre-registered from the past segment 301.
- the relationship estimation unit 113 estimates from the current segment 302 for the same person.
- the facial expression identification result estimated from the past segment 301 is used to estimate the relationship between the persons.
- the relationship estimation unit 113 only identifies the facial expression estimated from the current segment 302. Estimate the relationship between people based on.
- the emotional identification unit 113 in the latter stage identifies the emotional label of the current segment based on the facial expression identification result estimated from the current segment without utilizing the relationship between the persons.
- the impression identification unit 114 identifies the impression label of the current segment by collecting the following multidimensional information.
- Emotion identification result of voice (such as dialogue) in the segment by voice recognition unit 107 and first emotion analysis unit 110
- mood identification results (3)
- the moving identification unit 114 labels the current segment as a moving scene.
- the moving discriminator 114 may label the current segment as a moving scene. If some information is missing, the reliability of impression identification may decrease, but since the segment itself has already passed the filter of matching the content evaluation information and the brain wave information in the segment extraction unit 105, It is believed that reliability will not drop sharply.
- the moving identification unit 114 attaches a negative label to the segment. You may. Negatively labeled segments can be used as training data to train the impression discriminator as a negative sample.
- each discriminator that identifies the voice, music, and facial expression of a person included in the segment is composed of a trained machine learning model such as CNN.
- the emotional discriminator 114 is not a simple binary label of two types, positive and negative, but “anger”, “disgust”, “fear”, “happiness”, “happiness”. It is also possible to attach labels that express emotions that are divided into various types such as “sadness”, “surprise”, and so on. That is, the data collection system 100 can collect learning data having various impression identification labels, and can be used for training an impression discriminator that identifies various types of impressions.
- the impression discriminator is a device that identifies what kind of impression the content gives.
- the device referred to here means both a device composed of dedicated hardware and a device that executes software to realize a predetermined function.
- FIG. 4 schematically shows the overall flow of the learning process of the impression discriminator using the collected learning data.
- the learning data collected by using the data collection system 100 is stored in the data storage unit 410.
- the individual training data correspond to what is called a "segment" in the above terms A to D.
- a segment as learning data is an element of contents such as television and Internet broadcasting, and is composed of video data consisting of a frame sequence and audio data synchronized with the video. Further, a moving identification label is finally attached to the segment as learning data as teacher data in the processing process in the data collection system 100. Impressive identification labels may be divided into various types, but in this section, for the sake of simplification of explanation, it is assumed that two types of simple binary labels, positive and negative, are given.
- the impression discriminator 420 is a network unit 421 composed of a plurality of network models for inputting video and audio data as learning data, and an identification unit 422 that identifies the impression label of the content based on the feature amount acquired by the network unit 421. It is composed.
- Each network in the network unit 421 has a parameter (such as a coupling weighting coefficient between nodes).
- each feature amount is acquired through a trained neural network model (CNN) in the network unit 421 for each frame, and by putting them together, the feature amount (Video Feature) of the entire video can be obtained.
- CNN trained neural network model
- LSTM Long Short Term Memory
- audio data it is converted into features such as Mel-Frequency Cepstrum Coafficients (MFCC) and Mel-Spectrogram, which are converted into a time-series network such as RSTM in the network unit 421.
- the audio feature amount (Audio Frequency) can be acquired by putting it in.
- the text feature amount (Text Feature) can be obtained by rewriting the voice feature amount into text (transcription) and putting it in a time-series network such as LSTM in the network unit 421.
- the identification unit 422 projects the feature amount (Video Feature), the audio feature amount (Audio Feature), and the text feature amount (Text Feature) of the entire image obtained as described above into a common space, and is a moving classifier.
- a moving identification label is given to the learning data input to 420.
- the identification unit 422 shall assign either a positive or negative binary label.
- the evaluation unit 423 performs a loss function Loss such as softmax based on an error between the impression identification label given to the learning data by the identification unit 422 and the impression identification label as the teacher data given to the learning data by the data collection system 100. calculate.
- the loss function Loss individually identifies the impression identification label based on the video feature amount, the impression identification label based on the audio feature amount, and the impression identification label based on the audio feature amount, and each error L video.
- the loss function Loss may be calculated based on the sum of, L text , and L Audio.
- the loss function Loss obtained based on the error is backpropagated to each network having the parameters in the network unit 421, and each network (CNN, CNN,) in the network unit 421 so that the loss function Loss is minimized.
- the parameters of LSTM) are updated.
- the impression discriminator 420 proceeds with learning so as to output an impression identification label equal to the teacher data with respect to the input learning data.
- the impression discriminator 420 learned through the learning process can identify the content that impresses or what kind of impression the content gives.
- the content referred to here includes various contents such as contents such as TV and Internet broadcasting, video contents shared on video sharing sites, videos taken by users with digital cameras and still images, and content evaluation information. It is not necessary to add biological information such as brain waves and brain waves.
- the learning data collected by the data collection system according to the present disclosure can be used to train a machine learning model for an emotion discriminator that identifies the emotions that the content gives to humans.
- various applications are expected for the emotion discriminator developed in this way.
- G-1 Configuration of Digital Camera
- the emotion discriminator developed based on this disclosure can be installed in various content processing devices that process content such as recording, playback, and editing of content, such as digital cameras. can.
- FIG. 5 shows a configuration example of the digital camera 500.
- the illustrated digital camera 500 includes an optical system 501, an imaging unit 502, an AFE (Analog Front End: analog preprocessing) unit 503, a camera signal processing unit 504, a code code 505, a main processing unit 506, and a microphone 514.
- the A / D conversion unit 515, the display unit 516, the sound reproduction unit 517, and the recording unit 518 are provided. It is assumed that the digital camera 500 is equipped with an emotion discriminator developed based on the present disclosure.
- the optical system 501 includes a lens for condensing light from the subject on the imaging surface of the imaging unit 502, a drive mechanism for moving the lens to perform focusing and zooming, and opening and closing the light from the subject for a predetermined time. It includes a shutter mechanism that only incidents on the imaging surface, and an iris (aperture) mechanism (neither shown) that limits the direction and range of the light beam bundle from the subject.
- the driver (not shown) drives each mechanism in the optical system 501 based on a control signal from the main processing unit 506 described later (for example, subject focusing, iris, pan and tilt, shutter or self-timer setting). Control camera work such as timing).
- the image pickup unit 502 is composed of an image pickup element such as a CCD (Charge Coupled Device) or a CMOS (Complementary Metal Oxyde Semiconductor), has an image pickup surface in which each pixel having a photoelectric conversion effect is arranged two-dimensionally, and is incident from the subject. Converts light into an electrical signal.
- a G checkered RB color coding veneer is arranged on the light receiving side. The signal charge corresponding to the amount of incident light passed through each color filter is accumulated in each pixel, and the color of the incident light at the pixel position can be reproduced from each signal charge amount of the three colors read from each pixel.
- the analog image signal output from the image pickup unit 502 is a primary color signal of each RGB color, but may be a complementary color system color signal.
- the AFE unit 503 suppresses the low noise of the imaging signal with high accuracy (Correlated Double Sampling (correlation double sampling): CDS), then performs sample hold, and further uses AGC (Automatic Gain Control: automatic gain control circuit). Appropriate gain control is applied, AD conversion is performed, and a digital image signal is output. Further, the AFE unit 503 outputs a timing pulse signal for driving the image sensor and a drive signal for outputting the electric charge of each pixel of the image sensor in the vertical direction in line units according to the timing pulse signal to the image sensor 502. do.
- CDS Correlated Double Sampling
- AGC Automatic Gain Control: automatic gain control circuit
- the camera signal processing unit 504 performs preprocessing such as defect pixel correction, digital clamp, and digital gain control on the image signal sent from the AFE unit 503, and then applies white balance gain by AWB and sharpness. -Reproduce the appropriate color state by performing image quality correction processing such as gain adjustment again, and further create an RGB screen signal by demosaic processing. Further, the camera signal processing unit 504 performs resolution conversion depending on whether the captured image is displayed and output as a through image on the display unit 516 or saved in the recording unit 518, or a codec such as MPEG (Moving Picture Experts Group). Perform processing.
- preprocessing such as defect pixel correction, digital clamp, and digital gain control
- image quality correction processing such as gain adjustment again
- RGB screen signal by demosaic processing.
- the camera signal processing unit 504 performs resolution conversion depending on whether the captured image is displayed and output as
- the main processing unit 506 is composed of a processor, a RAM (Random Access Memory), and a ROM (Read Only Memory), and comprehensively controls the operation of the entire digital camera 500.
- the processor is a CPU (Central Processing Unit), a GPU having a multi-core (Graphic Processing Unit), or the like.
- the main processing unit 506 stores the video data captured by the photographing unit 502 and the audio data collected by the microphone 514 in the recording unit 518. Further, the main processing unit 506 reads out video and audio data from the recording unit 518 at the time of reproduction, and outputs the video and audio data to the display unit 516 and the sound reproduction unit 517. Further, in the present embodiment, it is assumed that the main processing unit 506 is equipped with the emotion discriminator developed based on the present disclosure.
- the display unit 516 is a device that displays a video being shot or a recorded video, such as a liquid crystal display panel mounted on the digital camera 500, an external television or a projector.
- the sound reproduction unit 517 is a device that reproduces recorded sound such as a speaker mounted on the digital camera 5100 and an external speaker.
- the recording unit 518 is a large-capacity recording device such as an HDD (hard disk drive) or SSD (Solid State Drive).
- the recording unit 518 records the video captured by the imaging unit 502 and the content composed of audio data collected by the microphone 514 in synchronization with the video. Further, the parameters of the machine learning model for the emotion discriminator (for example, the connection weight coefficient between neurons in the neural network model) are recorded in the recording unit 518.
- FIG. 6 shows a functional configuration for performing emotional identification labeling of content captured by the digital camera 500.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421.
- CNN trained neural network model
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label.
- the identification unit 422 assigns either a positive or negative binary label. Alternatively, the identification unit 422 may be provided with labels representing emotions differentiated into various types.
- the identification unit 422 assigns a moving identification label to the captured content for each scene (or segment).
- the given impression identification label is recorded as, for example, meta information of the content.
- the moving identification label can be used as a search key to select and watch a moving scene.
- the emotional identification label can be used as a search key to select only scenes having a specific emotion, such as "happy" scenes and "sad” scenes.
- the data collection system 100 can assign an impression identification label that identifies the type of impression that can be given to a human being for each input content or segment in the content. Therefore, the data collection system 100 is used to collect content or segments to which a specific moving identification label (for example, "happy", “sad”, etc.) is attached from a huge amount of video content 101, and identify the content or segment. It can be used for learning a machine learning model that estimates the camera operation for generating the moving content or shooting the moving content.
- a specific moving identification label for example, "happy", "sad”, etc.
- Support or control of camera work can be performed based on the result obtained by applying the content captured by the digital camera 500 to the moving identification device. For example, you can automatically control the line-of-sight direction and zoom of the subject to increase the degree of impression, or obtain a specific type of impression identification label, or the brightness, color, angle of view, and composition of the captured image. , Focus, etc. may be automatically controlled, or the recommended angle may be taught by using the guidance display of the display unit 516 or the voice guidance from the sound reproduction unit 517.
- FIG. 7 shows the functional configuration of the digital camera 500 for automatically controlling the camera work based on the impression identification result of the captured content.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421.
- CNN trained neural network model
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label. Then, the evaluation unit 423 outputs a control signal of the camera work to the optical system 501 so that the degree of impression is increased or a specific type of impression identification label can be acquired.
- G-4 Add caption Based on the result obtained by subjecting the content captured by the digital camera 500 to the emotional identification device, it is possible to automatically add a caption that is appropriate for the video scene and increases the degree of emotionalization.
- FIG. 8 shows the functional configuration of the digital camera 500 for automatically generating captions based on the impression identification result of the captured content.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421. Further, the caption generation unit 801 generates a caption for each scene by using, for example, a trained machine-learned model. The text information of the caption generated by the caption generation unit 801 is superimposed on the text information obtained from the voice recognition of the content and put into a time series network such as LSTM in the network unit 421.
- CNN trained neural network model
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label.
- the evaluation unit 423 calculates the loss function for the emotional identification label output from the identification unit 422. Then, the caption generation unit 801 relearns so that the degree of impression increases or a specific type of impression identification label can be acquired.
- the caption generated by the caption generation unit 801 is superimposed and recorded on the audio data of the content.
- FIG. 9 shows the functional configuration of the digital camera 500 for automatically adding background music based on the impression identification result of the captured content.
- the configuration of the impression discriminator 420 is the same as that shown in FIG.
- the impression identification device 420 is assumed to operate in the main processing unit 506 in the digital camera 500.
- the feature amount of the content taken by the digital camera 500 is acquired for each frame through the trained neural network model (CNN) in the network unit 421, and the feature amount of the entire image is obtained by putting them together. Be done. Further, the audio data recorded in synchronization with the video is converted into a feature amount such as MFCC and put into a time series network such as LSTM in the network unit 421 to obtain the audio feature amount. Further, the text feature amount can be obtained by rewriting the voice feature amount into text and putting it in a time-series network such as LSTM in the network unit 421. Further, the music search unit 901 searches for a music that becomes the background music of the scene by using, for example, a trained machine-learned model.
- CNN trained neural network model
- the music search unit 901 may search for music that is the background music of the scene, for example, on a music database (not shown) that stores a huge amount of music data.
- the music data of the music found by the music search unit 901 is superimposed on the audio data of the content and put into a time-series network such as LSTM in the network unit 421.
- the identification unit 422 projects the feature amount, the audio feature amount, and the text feature amount of the entire video obtained as described above into a common space, and impresses and identifies the learning data input to the impression discriminator 420. Give a label.
- the evaluation unit 423 calculates the loss function for the emotional identification label output from the identification unit 422. Then, the music search unit 901 relearns to find background music that can increase the degree of impression or acquire a specific type of impression identification label. The music data of the leg found by the music search unit 901 is superimposed and recorded on the audio data of the content.
- the content (or each segment constituting the content) represents the level of impression. Captions and backgrounds for assigning impression identification labels, providing camera work support or control (automatic camera operation) for shooting content that gives a high level of impression, and improving the impression score of content. Music can be added.
- this section H a method for efficiently learning the neural network model in the digital camera 500 will be described.
- the description will be limited to the learning method of the neural network model for automatic operation of the camera, but the neural network model for adding captions and adding background music will also be efficiently learned by the same method. Please understand that you can.
- FIG. 10 schematically shows the configuration of the learning system 1000 for efficiently learning a neural network model for camera operation support and automatic operation.
- a neural network model that mainly generates a moving content or estimates a camera operation for shooting the moving content is assumed.
- the learning system 1000 can also be used to train other types of neural network models.
- the learning system 1000 shown in FIG. 10 analyzes the training data, the data collection device 1010 that collects the training data, the learning device 1030 that learns the neural network model based on the learning data collected by the data collection device 1010, and the learning device 1030. It is composed of a data analysis device 1040 and a model utilization device 1020 that uses a neural network model 1050 trained by the learning device 1030.
- the data collection device 1010 collects data including image data taken by a camera and operation information at the time of camera shooting, for example.
- the data collection device 1010 includes a still camera, a video camera, an image sensor used in the camera, a multifunctional information terminal such as a smartphone, a TV, headphones or earphones, a game machine, an IoT device such as a refrigerator or a washing machine, a drone or a robot, and the like. It is possible to collect a huge amount of data from a huge number of data collecting devices 1010 including many kinds of huge devices such as a mobile device of the above.
- the data collection device 1010 is a camera used by an expert such as a professional cameraman, it is possible to collect a moving image and camera operation information for capturing such an image. Further, the data collection device 1010 may include not only a device that collects data in real time as illustrated above, but also a device that has already accumulated a large amount of data such as a content database.
- the learning device 1030 transmits a request signal requesting transmission of the collected data to each data collecting device 1010.
- the data acquisition device 1010 may spontaneously transmit the data instead of responding to the request signal.
- the learning device 1030 uses a huge amount of data collected by a large number of data collecting devices 1010, and various types such as an "observation prediction model”, an "operation model”, an “operation estimation model”, and an “impression score estimation model” are used. Neural network model learning and re-learning. Details of the neural network model used in the learning system 1000 will be described later.
- the data analysis device 1040 analyzes the learning data that affects the learning of the neural network model to be trained, and learns the neural network model based on the analysis result. Meaningful learning data such as learning data having an influence on or more than a predetermined value, missing learning data, and data similar to these is extracted, and the learning device 1030 extracts the meaningful learning data extracted by the data analysis unit 1040. It is used to efficiently train and relearn neural network models.
- the data analyzer 1040 is based on, for example, a method such as XAI (eXplainable AI), confidence score calculation of training data, influence function calculation, and data shortage estimation by Bayesian DNN (Deep Newral Network). ,
- XAI eXplainable AI
- confidence score calculation of training data e.g., confidence score of training data
- influence function calculation e.g., influence function calculation
- data shortage estimation e.g., Bayep Newral Network
- the model utilization device 1020 is a device that shoots moving contents by using the neural network model 1050 learned by the learning device 1030.
- the model utilization device 1020 is, for example, a camera used by a general user who is not accustomed to operating the camera.
- the model utilization device 1020 uses a neural network model trained by the learning device 1030 to automatically operate a camera comparable to a shooting expert such as a professional photographer, or automatically shoot a video having a high impression score. can do.
- the learning device 1030 requires a huge amount of computational resources to train various neural network models. Therefore, in FIG. 10, it is assumed that the learning device 1030 is constructed on, for example, a cloud (that is, cloud AI (Artificial Intelligence)). Further, the learning device 1030 may perform distributed learning using a plurality of calculation nodes. However, it is also assumed that the learning device 1030 is integrally configured with a model utilization device that uses the trained neural network model (that is, edge AI). Alternatively, the learning device 1030 may be integrally configured with the data collecting device 1010 that provides the learning data.
- a cloud that is, cloud AI (Artificial Intelligence)
- the learning device 1030 may perform distributed learning using a plurality of calculation nodes.
- the learning device 1030 is integrally configured with a model utilization device that uses the trained neural network model (that is, edge AI).
- the learning device 1030 may be integrally configured with the data collecting device 1010 that provides the learning data.
- the data analyzer 1040 may be built in either the cloud or the edge.
- the data analysis device 1040 may be configured as a device integrated with the learning device 1030.
- the learning device 1030 internally analyzes the learning data that affects the learning of the neural network model, and the learning data that affects the learning of the neural network model more than a predetermined amount, the missing training data, or these.
- the data collection device 1010 may be requested to transmit data similar to the above.
- the data analysis device 1040 may be configured as a device integrated with the data collection device 1010.
- the learning device 1030 provides the data collecting device 1010 with information necessary for data analysis (for example, information of the neural network model learned at that time) at the time of requesting transmission of training data. Then, the data collection device 1010 analyzes the influence of the collected data on the neural network model, and among the collected data, the training data having a predetermined influence on the learning of the neural network model, the missing training data, and the like. Alternatively, data similar to these may be transmitted to the learning device 1030.
- a data collection device 1010 for collecting training data and a model utilization device 1020 using a neural network model are drawn as separate devices, but one device is a data collection device 1010 and a model utilization device 1020. It is also expected to operate as both.
- one camera operates as a data collection device 1010 in the manual operation mode, collects data such as shooting data and camera operation information and transmits the data to the learning device 1030, while switching to the automatic operation mode is a model utilization device. It may operate as 1020 and perform automatic imaging using the neural network model trained by the learning device 1030.
- the learning device 1030 uses the data collected by the data collecting device 1040 to perform a neural network such as an "observation prediction model”, an "operation model”, an “operation estimation model”, and an "impression score estimation model”. Learn and relearn. Further, the model utilization device 1020 utilizes at least a part of these neural network models trained by the learning device 1030.
- FIG. 11 schematically shows the configuration of the observation prediction model 1100.
- the observation prediction model 1100 uses the image information 1101 up to the current time taken by the camera and the operation information 1102 up to the current time for the camera to capture an image taken by the camera at the next time (that is, an "image at the next time”).
- a neural network model that predicts 1111.
- the operation information 1102 referred to here is information regarding operations performed on the camera for determining imaging conditions such as frame rate, aperture, exposure value, magnification, and focus (hereinafter, the same applies).
- the remote control operation (camera work indicated by roll, pitch, yaw, etc.) performed on the mobile device is also included in the operation information. It may be (hereinafter, the same applies).
- the observation prediction model 1100 also outputs a reliability score 1112 for the image 1111 at the next time predicted.
- the reliability score 1112 is a value indicating how accurately the image 1111 at the next time can be predicted.
- a confidence score is used to identify data that is lacking in learning or has a high impact on learning.
- the data analyzer 1040 can be used to train the observation prediction model 1100 based on methods such as explanation of the basis for prediction of the observation prediction model 1100 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Meaningful learning data such as learning data that affects more than a predetermined value, missing learning data, and data similar to these are extracted.
- the calculation function of the reliability score 1112 by the observation prediction model 1100 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the observation prediction model 1100 based on the data set including the video information and the operation information transmitted from the data collecting device 1010.
- the learning device 1030 can learn the observation prediction model 1100 so that it can predict an image that can give more impression by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 efficiently retrains the observation prediction model 1100 using the meaningful learning data. Can be done
- FIG. 12 schematically shows the configuration of the operation model 1200.
- the operation model 1200 is a neural network model that predicts the operation 1211 to be performed on the camera at the next time from the video information 1201 taken by the camera up to the current time and the operation information 1202 up to the current time for the camera.
- the operation model 1200 also outputs a reliability score 1212 for the operation 1211 at the predicted next time.
- the reliability score 1212 is a value indicating how accurately the image 1111 at the next time can be predicted.
- the data analyzer 1040 is required to train the operation model 1200 based on a method such as explanation of the basis for prediction of the operation model 1200 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Extract meaningful learning data such as learning data that is affected by the above, missing learning data, and data similar to these.
- the calculation function of the reliability score 1212 according to the operation model 1200 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the operation model 1200 based on the data set consisting of the video information and the operation information transmitted from the data collection device 1010.
- the learning device 1030 can learn the operation model 1200 so that the camera operation information capable of capturing an image that can give a more impression can be predicted by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 efficiently retrains the operation model 1200 using the meaningful learning data. Can be done.
- FIG. 13 schematically shows the configuration of the operation estimation model 1300.
- the operation estimation model 1300 is a neural network model that estimates the time-series operation information 1311 for capturing the video time-series information 1301 up to the current time with a camera. For example, using the operation estimation model 1300, it is possible to estimate the time-series operation information of the camera performed by the expert from the high-quality video time-series information taken by an expert who is familiar with camera operation such as a professional cameraman.
- the operation estimation model 1300 may also output the reliability score for the estimated time series operation information 1311.
- the data analyzer 1040 can be used to train the operation estimation model 1300 based on methods such as explanation of the basis for prediction of the operation estimation model 1300 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Meaningful learning data such as learning data that affects more than a predetermined value, missing learning data, and data similar to these are extracted.
- the function of calculating the reliability score by the operation estimation model 1300 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the operation estimation model 1300 based on the data set consisting of the video information and the operation information transmitted from the data collection device 1010.
- the learning device 1030 can learn the operation estimation model 1300 so as to predict the time-series operation information capable of capturing an image that can give more impression by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 efficiently retrains the operation estimation model 1300 using the meaningful learning data. Can be done
- FIG. 14 schematically shows the configuration of the impression score estimation model 1400.
- the emotion score estimation model 1400 is a neural network model that estimates the emotion score 1411 of the video information 1401, and corresponds to the above-mentioned emotion discriminator. For example, according to the learning process shown in FIG. 4, the impression score estimation model 1400 can be learned.
- FIG. 15 shows the relationship between the control target (frame rate, resolution, etc.) and the average impression score.
- the predicted value output from the neural network model is shown by a solid line, and the variance is shown by a dot.
- FIG. 15 shows an average impression score obtained when the operation model is learned by reinforcement learning so that the impression score becomes high based on the video data acquired at a certain frame rate, and the camera is operated using the learned operation model. Is shown.
- the data points indicated by black circles are points for which data already exists.
- the variance is small at some points of the data. The point where there is no data has a large variance. The larger the variance and the higher the score can be expected, the greater the value of observation. For example, an implementation that optimistically considers the variance and acquires the data of the points where the highest score can be expected can be considered.
- the impression score estimation model 1400 may also output the reliability score for the estimated impression score 1411.
- the data analyzer 1040 may use the impression score estimation model 1400 based on methods such as explanation of the basis for prediction of the impression score estimation model 1400 by XAI, reliability score calculation, influence function calculation, and data shortage estimation by Basian DNN. Meaningful learning data such as learning data that affects learning more than a predetermined value, missing learning data, and data similar to these are extracted.
- the function of calculating the reliability score by the impression score estimation model 1400 may be implemented as a part of the data analyzer 1040.
- the learning device 1030 can learn the impression score estimation model 1400 based on the data set consisting of the video information and the operation information transmitted from the data collecting device 1010.
- the learning device 1030 can learn the impression score estimation model 1400 so that a higher impression score can be estimated for the video information that can give impression by reinforcement learning.
- the data analysis device 1040 extracts meaningful learning data from the data set transmitted from the data collection device 1010, and the learning device 1030 retrains the impression score estimation model 1400 using the meaningful learning data. It can be done efficiently.
- the data analyzer 1040 analyzes the learning data of the neural network model to be learned, and the learning data that affects the learning more than a predetermined value, the missing learning data, and the like. Identifying meaningful learning data, such as data similar to, the learning device 1020 uses such meaningful learning data to efficiently train and relearn the neural network model.
- the data analyzer 1040 may be built in either the cloud or the edge.
- the data analysis device 1040 may be configured as a device integrated with the learning device 1030.
- the learning device 1030 internally analyzes the learning data that affects the learning of the neural network model, and the learning data that affects the learning of the neural network model more than a predetermined amount, the missing training data, or these.
- the data collection device 1010 is requested to transmit data similar to the above.
- the data analysis device 1040 may be configured as a device integrated with the data collection device 1010.
- the learning device 1030 provides the data collecting device 1010 with information necessary for data analysis (for example, information of the neural network model learned at that time) at the time of requesting transmission of training data. Then, the data collection device 1010 analyzes the influence of the collected data on the neural network model, and among the collected data, the training data having a predetermined influence on the learning of the neural network model, the missing training data, and the like. Alternatively, data similar to these is transmitted to the learning device 1030.
- Examples of the method for the data analysis device 1040 to analyze the data include XAI, calculation of the reliability score of the training data, calculation of the influence function, and estimation of data shortage by Bayesian DNN.
- the reliability score is a numerical value of the degree of correctness of the predicted value by the neural network model.
- the observation prediction model 1100 and the operation model 1200 are configured to output the reliability score together with the prediction value.
- the data collection device 1010 filters the learning data to be transmitted to the learning device 1030 using the reliability score, and the details of this point will be described later.
- Neural network model trained to estimate output error As shown in FIG. 16, the neural network model 1500 is trained to output the output error as a reliability score together with the original output. ..
- the influence function is a formulation of the influence of the presence or absence of individual learning data and perturbations on the prediction result of the neural network model (see, for example, Non-Patent Document 4).
- Bayesian DNN is constructed by combining Bayesian estimation and deep learning, and by using Bayesian estimation, it is possible to evaluate the uncertainty due to lack of data when the neural network model outputs the prediction result.
- the data collection device 1010 is a still camera, a video camera, an image sensor used in a camera, a multifunctional information terminal such as a smartphone, a TV, headphones or earphones, a game machine, an IoT device such as a refrigerator or a washing machine.
- a multifunctional information terminal such as a smartphone, a TV, headphones or earphones, a game machine, an IoT device such as a refrigerator or a washing machine.
- IoT device such as a refrigerator or a washing machine.
- mobile devices such as drones and robots.
- FIG. 17 shows an example of the internal configuration of the data collection device 1010.
- the data collection device 1010 shown in FIG. 17 includes a sensor unit 1011, an operation input unit 1012, a control unit 1013, a log transmission unit 1014, and a data analysis unit 1015.
- FIG. 17 is an abstraction of a typical functional configuration related to the realization of the present disclosure among various types of data acquisition devices 1010, and each data collection device 1010 has various configurations (not shown). It is assumed to have elements.
- the sensor unit 1011 is composed of an image sensor composed of CMOS or the like and other sensors equipped in the data acquisition device 1010, and performs observations such as taking images and videos. Further, when the data collection device 1010 is mounted on a mobile device such as a robot or a drone, various sensors mounted on the mobile device such as an IMU (Inertial Measurement Unit) are also included in the sensor unit 1011. do.
- IMU Inertial Measurement Unit
- the operation input unit 1012 is a function module that performs an input operation for adjusting operation information such as shooting conditions in the data collection device 1010.
- the operation input unit 1012 includes controls such as buttons and knobs, a touch panel screen, and the like. Further, when the data collection device 1010 is mounted on a mobile device such as a robot or a drone, the operation input unit 1012 also includes a remote controller used when remotely controlling the mobile device.
- the control unit 1013 comprehensively controls the operation of the entire data collection device 1010. Further, the control unit 1013 controls the observation of the sensor unit 1011 to capture an image or video based on the operation information input via the operation input unit 1012.
- the log transmission unit 1014 transmits a data set consisting of the observation log observed by the sensor unit 1011 and the operation log input to the operation input unit 1012 to the learning device 1030.
- the log transmission unit 1014 transmits a data set to the learning device 103 in response to receiving a request signal requesting data transmission from the learning device 1030.
- the data collection device 1010 newly collects data in response to receiving the request signal from the learning device 1030 and transmits it to the learning device 1030, but the learning device extracts data extracted from the already collected data based on the request signal. It may be sent to 1030.
- the data acquisition device 1010 may spontaneously transmit the data rather than responding to the request signal.
- the data analysis unit 1015 analyzes the influence of the data set consisting of the observation log observed by the sensor unit 1011 and the operation log input to the operation input unit 1012 on the learning of each neural network model to be learned. Identify whether the data is meaningful for learning, such as learning data that affects learning more than a certain amount, missing learning data, or similar data.
- the learning device 1030 may send a request signal by designating data meaningful for learning, or may instruct analysis of the collected data and send a request signal.
- the data analysis unit 1015 checks whether the data set consisting of the observation log observed by the sensor unit 1011 and the operation log input to the operation input unit 1012 corresponds to the data specified by the request signal. Therefore, the log transmission unit 1014 transmits only the data conforming to the request to the learning device 1030.
- the data analysis unit 1015 corresponds to the data analysis device 1040 in FIG.
- the data analysis unit 1015 analyzes the learning data that affects the learning of the neural network model to be learned in the learning device 1030, and inputs the observation log observed by the sensor unit 1011 and the operation input unit 1012. Check whether the data set consisting of the operation logs corresponds to meaningful training data such as training data that affects the training of the neural network model more than a predetermined value, missing training data, and similar data. .. Then, the log transmission unit 1014 transmits only the data set that is meaningful learning data to the learning device 1030.
- the data analysis unit 1015 analyzes the neural network model using, for example, at least one or a combination of XAI, reliability score, influence function, and Bayesian DNN. For example, when the data analysis unit 1015 analyzes data using the reliability score, the neural network when the learning device 1030 receives the information of the neural network model trained by the current time and inputs the data set. Calculate the confidence score of the inference by the model. See Section H-3 above for how to calculate the confidence score. Observation logs and operation logs with high reliability scores are learning data that are not lacking and have low value, but observation logs and operation logs with low reliability scores are learning data that are lacking and have high value. Can be done. By collecting the learning data having a low reliability score and lacking it and providing it to the learning device 1030, the learning device 103 can efficiently learn and relearn the neural network model.
- the data analysis unit 1015 may feed back the analysis result to the sensor unit 1011 and the operation input unit 1012. Then, the sensor unit 1011 and the operation input unit 1012 take pictures by changing the resolution, frame rate, brightness, color, angle of view, viewpoint position, or line-of-sight direction based on the degree of influence on the learning of the neural network model to be learned. May be done.
- FIG. 18 shows another internal configuration example of the data acquisition device 1010.
- the data collection device 1010 shown in FIG. 18 includes a sensor unit 1011, an operation input unit 1012, a control unit 1013, and a log transmission unit 1014.
- the main difference from the configuration example shown in FIG. 17 is that the data analysis unit 1015 is not provided.
- the data collection device 1010 shown in FIG. 18 does not analyze the collected data, in other words, regardless of whether the collected data is meaningful training data for learning or re-learning the neural network model, it is all a learning device. Send to 1030.
- FIG. 19 shows an example of the internal configuration of the learning device 1030.
- the learning device 1030 shown in FIG. 19 includes a model learning unit 1031, an observation / operation log storage unit 1032, an observation prediction model / operation model storage unit 1033, an operation estimation model storage unit 1034, an operation estimation unit 1035, and data.
- the analysis unit 1036 is provided.
- the model learning unit 1031 learns various neural network models using the learning data.
- the model learning unit 1031 includes an observation prediction model (see FIG. 11), an operation model (see FIG. 12), an operation estimation model (see FIG. 13), and an impression score estimation model. (See FIG. 14) and the like.
- the model learning unit 1031 may be configured by using a plurality of calculation nodes to perform distributed learning of the neural network model.
- the observation / operation log storage unit 1032 stores the observation log and the operation log transmitted from the data collection device 1010. It is assumed that the data acquisition device 1010 sends an observation log and an operation log that are meaningful learning data.
- the model learning unit 1031 learns the observation prediction model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained observation prediction model is stored in the observation prediction model / operation model storage unit 1033.
- model learning unit 1031 learns the operation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained operation model is accumulated in the observation prediction model / operation model storage unit 1033.
- model learning unit 1031 learns the operation estimation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained operation estimation model is accumulated in the operation estimation model storage unit 1034.
- the data analysis unit 1036 corresponds to the data analysis device 1040 in FIG.
- the data analysis unit 1036 analyzes the learning data that affects the learning of each trained neural network stored in the observation prediction model / operation model storage unit 1033 and the operation estimation model storage unit 1034. Then, based on the analysis result, a request signal requesting transmission of learning data having a predetermined or greater effect, missing learning data, or data similar thereto is transmitted from the learning device 1030 to the data collecting device 1010. Will be done. Therefore, the data acquisition device 1010 sends an observation log and an operation log that are meaningful learning data.
- the data analysis unit 1036 analyzes the training data based on a method such as XAI, reliability score calculation, influence function, or Bayesian DNN.
- the operation estimation unit 1035 uses the trained operation estimation model to shoot the image from the image (hereinafter, also referred to as "professional image") taken by an expert who is familiar with camera operation such as a professional cameraman. Estimate the time-series operation information of. Then, a data set consisting of a professional image (observation log) input to the operation estimation unit 1035 and operation information (estimated operation log) estimated by the operation estimation unit 1035 learns a professional-level operation model. As high-quality learning data for this purpose, it is stored in the observation / operation log storage unit 1032. Therefore, the model learning unit 1031 can learn an operation model capable of predicting a professional-level camera operation by using the high-quality learning data stored in the observation / operation log storage unit 1032.
- Professional video content is optional and is expected to be provided to the cloud via the network. By collecting a large amount of high-quality learning data using professional video content, it becomes possible to learn an operation model to realize professional-level camera automatic operation.
- FIG. 20 shows another internal configuration example of the learning device 1030.
- the learning device 1030 shown in FIG. 20 includes a model learning unit 1031, an observation / operation log storage unit 1032, an observation prediction model / operation model storage unit 1033, an operation estimation model storage unit 1034, and an operation estimation unit 1035. There is.
- the main difference from the configuration example shown in FIG. 19 is that the data analysis unit 1036 is not provided.
- the learning device 1030 shown in FIG. 20 does not analyze the learning data by itself, but instead transmits the information of the neural network model to be learned to the data collecting device 1010.
- the data analysis unit 1015 analyzes the learning data that affects the learning of the neural network model to be learned in the learning device 1030, and the observation log observed by the sensor unit 1011 and the observation log
- the data set consisting of the operation logs input to the operation input unit 1012 becomes meaningful training data such as training data that affects the training of the neural network model more than a predetermined value, insufficient training data, and data similar to these. Check if applicable (mentioned above). Then, only the data set that is meaningful learning data is transmitted from the data collecting device 1010 to the learning device 1030.
- FIG. 21 shows yet another internal configuration example of the learning device 1030.
- the learning device 1030 shown in FIG. 21 includes a model learning unit 1031, an observation / operation log storage unit 1032, an observation prediction model / operation model storage unit 1033, an operation estimation model storage unit 1034, an operation estimation unit 1035, and data.
- the analysis unit 1037 is provided. The main difference from the configuration examples shown in FIGS. 19 and 20 is that the learning device 1030 receives all the collected data from the data collection device 1010 including the configuration example shown in FIG. 18, and is a data analysis unit. At 1037, it is checked whether each received data is meaningful training data.
- the data analysis unit 1037 corresponds to the data analysis device 1040 in FIG.
- each received data stored in the observation / operation log storage unit 1032 is stored in the observation prediction model / operation model storage unit 1033 and the operation estimation model storage unit 1034. Analyze the impact on learning. Then, the data analysis unit 1037 accumulates only meaningful learning data such as learning data that affects the learning of each neural network model more than a predetermined value, missing learning data, and data similar to these, and accumulates observation / operation logs. It is extracted from the unit 1032 and output to the model learning unit 1031. Therefore, the model learning unit 1031 can efficiently learn and relearn various neural network models using meaningful learning data.
- FIG. 22 shows an example of the internal configuration of the model utilization device 1020.
- the model utilization device 1020 includes a sensor unit 1021, an automatic operation unit 1022, a control unit 1023, and a presentation unit 1024.
- the sensor unit 1021 is composed of an image sensor composed of CMOS or the like and other sensors equipped in the model utilization device 1020, and performs observations such as taking images and videos. Further, when the model utilization device 1020 is mounted on a mobile device such as a robot or a drone, various sensors mounted on the mobile device such as an IMU are also included in the sensor unit 1021.
- the automatic operation unit 1022 predicts the operation information of the next time from the observation information (video information up to the current time and operation information up to the current time) of the sensor unit 1021 using the operation model provided by the learning device 1030. At the same time, the data analysis result such as the reliability score of the predicted operation information is output.
- the control unit 1023 controls observations such as capturing images and videos in the sensor unit 1011 based on the operation information of the next time predicted by the automatic operation unit 1022.
- the learning device 1030 provides an operation model that has been sufficiently learned, even if the user of the model utilization device 1020 is not familiar with camera operation, it is based on the operation information predicted by the automatic operation unit 1022. , Professional photographers and other experts who are familiar with camera operation can take pictures.
- the presentation unit 1024 presents the data analysis result such as the reliability score of the operation information predicted by the automatic operation unit 1022. From the presented reliability score, the user of the model utilization device 1020 can determine whether or not the image is shot with professional-level skill by automatic operation.
- FIG. 23 shows an example of the internal configuration of the model utilization device 1020 as the edge AI.
- the illustrated model utilization device 1020 includes a sensor unit 1021, an automatic operation unit 1022, a control unit 1023, a presentation unit 1024, a model learning unit 1031, an observation / operation log storage unit 1032, and an observation prediction model. It includes an operation model storage unit 1033, an operation estimation model storage unit 1034, and an operation estimation unit 1035.
- the observation / operation log storage unit 1032 stores the observation log and the operation log transmitted from the data collection device 1010.
- the model learning unit 1031 learns the observation prediction model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Further, the model learning unit 1031 learns the operation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the learned observation prediction model and operation model are accumulated in the observation prediction model / operation model storage unit 1033.
- the model learning unit 1031 learns the operation estimation model based on the data set consisting of the observation log and the operation log stored in the observation / operation log storage unit 1032. Then, the trained operation estimation model is accumulated in the operation estimation model storage unit 1034.
- the operation estimation unit 1035 estimates the time-series operation information for shooting the image from the image taken by an expert who is familiar with camera operation such as a professional cameraman by using the learned operation estimation model, and the professional It is stored in the observation / operation log storage unit 1032 as high-quality learning data for learning an ordinary operation model. Therefore, the model learning unit 1031 can learn an operation model capable of predicting a professional-level camera operation by using the high-quality learning data stored in the observation / operation log storage unit 1032.
- the sensor unit 1021 is composed of an image sensor composed of CMOS or the like and other sensors equipped in the model utilization device 1020, and performs observations such as taking images and videos.
- the automatic operation unit 1022 uses the operation model read from the observation prediction model / operation model storage unit 1033 to obtain the next time from the observation information (video information up to the current time and operation information up to the current time) of the sensor unit 1021.
- the operation information is predicted, and the data analysis result such as the reliability score of the predicted operation information is output.
- the control unit 1023 controls observations such as capturing images and videos in the sensor unit 1011 based on the operation information of the next time predicted by the automatic operation unit 1022.
- the learning device 1030 provides an operation model that has been sufficiently learned, even if the user of the model utilization device 1020 is not familiar with camera operation, it is based on the operation information predicted by the automatic operation unit 1022. , Professional photographers and other experts who are familiar with camera operation can take pictures.
- the presentation unit 1024 presents the data analysis result such as the reliability score of the operation information predicted by the automatic operation unit 1022. From the presented reliability score, the model utilization device 1020 can determine whether or not the image is shot with professional-level skill by automatic operation.
- This disclosure can be applied to the data collection process used for learning a machine learning model that generates content that impresses humans.
- the data collected based on the present disclosure is a machine for handling content that impresses human beings (specifically, for estimating camera operation for generating moving content or shooting moving content). It is used for learning data for training a learning model (for example, a neural network model), but of course it can also be used for learning a machine learning model for other purposes.
- the data collected based on this disclosure can be used to train a machine learning model that identifies the emotions that content gives to humans, and an emotion discriminator equipped with the machine learning model developed in this way can be used. It can be installed in content processing devices such as digital cameras.
- a data collecting device for collecting data and a learning device for learning a machine learning model using the data collected by the data collecting device are provided.
- the learning device collects learning data that affects the learning of the machine learning model based on the results of analysis, learning data that affects the learning of the machine learning model by a predetermined value or more, missing learning data, and the like.
- the machine learning model is retrained using data similar to these. Learning system.
- the learning device learns a machine learning model that estimates a camera operation for generating moving contents or shooting moving contents.
- the learning device analyzes learning data that affects the learning of the machine learning model, and based on the analysis result, the learning data that affects the learning of the machine learning model by a predetermined value or more is insufficient.
- a request signal requesting transmission of the learning data or data similar thereto is transmitted to the data acquisition device, and the data is collected.
- the data acquisition device transmits the data collected based on the received request signal to the learning device, and the data acquisition device transmits the data to the learning device.
- the learning device relearns the machine learning model based on the data transmitted from the data collecting device in response to the request signal.
- the learning system according to any one of (1) to (3) above.
- the data acquisition device is a camera or imager that captures an image, and is a resolution, frame rate, brightness, color, angle of view, viewpoint position, or line of sight based on the degree of influence of the machine learning model on learning.
- the image data taken by changing the direction is transmitted to the learning device.
- the learning system according to any one of (1) to (4) above.
- the learning device transmits a request signal requesting transmission of training data of the machine learning model to the data collecting device. Based on the result of analyzing the influence of the collected data on the learning of the machine learning model, the data collecting device lacks the learning data having a predetermined or more influence on the learning of the machine learning model among the collected data. The learning data that is being used, or data similar to these, is transmitted to the learning device. The learning device relearns the machine learning model based on the data transmitted from the data collecting device in response to the request signal.
- the learning system according to any one of (1) to (3) above.
- the learning device transmits information necessary for the analysis to the data collecting device.
- a receiving unit that receives a request signal requesting transmission of learning data of the machine learning model from a learning device that learns the machine learning model.
- a data collection unit that collects learning data that has a predetermined or greater effect on the learning of the machine learning model, missing learning data, or data similar thereto in response to receiving the request signal.
- a transmission unit that transmits the data collected by the data collection unit to the learning device, and a transmission unit.
- a data collection device comprising.
- the receiving unit receives from the learning device the request signal requesting learning data having a predetermined or greater effect on the learning of the machine learning model, missing learning data, or data similar thereto.
- the data collection unit collects data based on the received request signal, and the data collection unit collects data.
- the transmitting unit transmits the data collected by the data collecting unit to the learning device.
- the data collection device according to (8) above.
- the data collection unit newly collects data based on the received request signal, or the transmission unit transmits data extracted based on the request signal from the data already collected by the data collection unit. do, The data collection device according to (9) above.
- the transmission unit uses the data collected by the data collection unit to have a learning data that affects the learning of the machine learning model by a predetermined value or more, a lack of learning data, or these. Sends data similar to the above to the learning device, The data collection device according to (8) above.
- the data collection unit determines the resolution, frame rate, brightness, color, angle of view, viewpoint position, or line-of-sight direction of the camera or imager that captures an image based on the degree of influence of the machine learning model on learning. Collect image data taken by changing, The data collection device according to any one of (8) to (11) above.
- a segment extraction unit that extracts segments from the content based on the content evaluation information of the content and the biometric information of the person who views the content.
- a facial expression identification unit that detects the face of a person in a segment and identifies the facial expression
- a relationship estimation unit that estimates the relationships between people in the segment
- An emotional identification unit that identifies the emotional label of a segment based on the facial expression of the person in the segment and the relationship between the persons.
- the biological information includes at least electroencephalogram information.
- the information processing device according to (13) above.
- the segment extraction unit extracts a segment of the content in which biometric information having a high evaluation and positive emotion matches.
- the information processing device according to any one of (13) and (14) above.
- the segment extraction unit further extracts segments in which biometric information having a high evaluation and positive emotions does not match.
- the information processing device according to (15) above.
- the relationship estimation unit estimates the relationship between the persons in the segment based on the context with the preceding and following segments and the facial expression of the person.
- the information processing device according to any one of (13) to (16) above.
- the relationship estimation unit estimates the relationship between the persons in the current segment by using the face detection of the person in the past segment and the facial expression identification result of the detected face as the context. do, The information processing device according to (17) above.
- the emotion identification unit identifies the emotion label of the segment by further considering the emotion identified by the first emotion analysis unit from the text information.
- the information processing device according to any one of (13) to (18) above.
- the emotional identification unit identifies the emotional label of the segment by further considering the emotions identified by the second emotional analysis unit from the music.
- Information processing method having.
- a segment extraction unit that extracts segments from the content based on the content evaluation information of the content and the biometric information of the person who views the content.
- a facial expression identification unit that detects the face of a person in a segment and identifies the facial expression.
- Relationship estimation unit that estimates the relationships between people in the segment.
- An emotional identification unit that identifies the emotional label of a segment based on the facial expression of the person in the segment and the relationship between the persons.
- a generation method for generating a trained machine learning model that identifies the emotion given by the content Steps to enter content into a machine learning model, The step that the machine learning model acquires the video feature amount estimated from the content, and The step that the machine learning model acquires the audio features estimated from the content, and The step that the machine learning model acquires the text feature amount of the speech estimated from the content, and A step of identifying the moving label of the content based on the video feature amount, the audio feature amount, and the text feature amount estimated by the machine learning model, and A step of calculating a loss function based on an error between the identified impression label and the impression label attached to the content, and A step of updating the parameters of the machine learning model based on the loss function, How to generate a trained machine learning model with.
- the video feature amount includes a relationship between people estimated based on the context of a plurality of consecutive frames when there are two or more people in the video frame.
- 100 ... Data collection system, 101 ... Video content 102 ... Content evaluation information acquisition unit, 103 ... Biometric information acquisition unit 104 ... Comparison unit, 105 ... Segment extraction unit 106 ... Context extraction unit, 107 ... Voice recognition unit 108 ... Music detection unit , 109 ... Face detection unit 110 ... First emotion analysis unit, 111 ... Second emotion analysis unit 112 ... Expression identification unit, 113 ... Relationship estimation unit 114 ... Impression identification unit 410 ... Data storage unit, 420 ... Impression identification Machine 421 ... Network unit 422 ... Identification unit 423 ... Evaluation unit 500 ... Digital camera, 501 ... Optical system, 502 ... Imaging unit 503 ... AFE unit, 504 ...
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Human Computer Interaction (AREA)
- Artificial Intelligence (AREA)
- Computing Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Biomedical Technology (AREA)
- Mathematical Physics (AREA)
- Databases & Information Systems (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Medical Informatics (AREA)
- Molecular Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biophysics (AREA)
- Neurosurgery (AREA)
- Neurology (AREA)
- Dermatology (AREA)
- Computer Graphics (AREA)
- Signal Processing (AREA)
- Image Analysis (AREA)
Abstract
感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行う学習システムを提供する。 学習システムは、データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、 前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う。
Description
本明細書で開示する技術(以下、「本開示」とする)は、機械学習モデルの学習を行う学習システム、機械学習モデルを学習するための学習データの収集処理を行うデータ収集装置、並びにデータの分析処理を行う情報処理装置に関する。
現在、デジタルカメラは広範に普及している。例えば、各家庭では、日常生活や、子供の入学式や卒業式、結婚式といったさまざまな行事を記録するために、デジタルビデオカメラやデジタルスチルカメラが利用される。より感動的なシーンを撮影することが望ましいが、一般ユーザがファインダ越しに観察しているシーンが感動を与えるシーンかどうかを判別することは難しい。もちろん、プロのカメラマンにとっても、撮影しているシーンが感動的かどうかを判別することは難しい。
例えば、学習済みニューラルネットワークモデルを搭載した人工知能技術を用いて、感動を与えるコンテンツを扱う方法が考えられる。特に、複数の畳み込みニューラルネットワークの層を備えたディープラーニングのニューラルネットワークモデル(以下、「DNN」とも呼ぶ)は、訓練すなわちディープラーニングを通じて開発者には想像できない特徴を多くのデータから抽出して、開発者がアルゴリズムを想定し得ないような複雑な問題解決を行うことのできる人工知能機能を開発することができる。
人工知能技術を利用するには、人工知能を学習するための学習データが必要である。例えば、指定された能力の機械学習のための学習データを収集する学習データ収集部と、収集した学習データを用いて指定された能力を獲得させるように学習器の機械学習を行う学習処理部を備えた学習装置について提案がなされている(特許文献1を参照のこと)。人工知能技術を用いて感動を与えるコンテンツを扱うには、まず人間に感動を与えるコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習に用いられる大量の学習データが必要である。
ところが、感動の主観的な性質上、学習データの収集は大変に困難である。SNS(Social Network Service)などで現れる好みの情報を活用することによって、主観性を反映するデータ収集方法が考えられるが、プライバシーを脅かすおそれがあるため実行が容易でない。また、コンテンツ中の個々のシーンの画像や背景音楽だけでなく前後のシーンのコンテキストも感動を生み出す要素と考えられるが、画像のみに依存してデータ収集を行う方法ではコンテキストを反映したデータを収集することは難しい。
Using Brain Data for Sentiment Analysis.Gu et al.JLCL 2014.
Music Emotion Classification: A Fuzzy Approach.Yang et al.ACM MM 2006.
Visual Social Relationship Recognition.Li et al.arxiv 2018.
Understanding Black-box Predictions via Influence Functions,Pang Wei Kho and Percy Liang <https://arxiv.org/abs/1703.04730>
Alex Kendall,Yarin Gal,"What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vison",NIPS 2017
本開示の目的は、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行う学習システム、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習データの収集処理を行うデータ収集装置、並びに収集したデータが与える感動を分析する情報処理装置を提供することにある。
本開示は、上記課題を参酌してなされたものであり、その第1の側面は、
データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システムである。
データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システムである。
但し、ここで言う「システム」とは、複数の装置(又は特定の機能を実現する機能モジュール)が論理的に集合した物のことを言い、各装置や機能モジュールが単一の筐体内にあるか否かは特に問わない。
前記学習装置は、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行う。また、前記分析は、XAI、信頼度スコア計算、影響関数、又はベイジアンDNNにより行うことができる。
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析し、その分析結果に基づいて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を要求する要求信号を前記データ収集装置に送信する。そして、前記データ収集装置は、受信した前記要求信号に基づいて収集したデータを前記学習装置に送信することで、前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行うことができる。
あるいは、前記データ収集装置は、前記学習装置から前記要求信号を受信すると、収集したデータが前記機械学習モデルの学習に与える影響を分析した結果に基づいて、前記収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する。そして、前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行うことができる。前記学習装置は、前記要求信号の送信時に、前記分析に必要な情報を前記データ収集装置に送信するようにしてもよい。
また、本開示の第2の側面は、
機械学習モデルの学習を行う学習装置から、前記機械学習モデルの学習データの送信を要求する要求信号を受信する受信部と、
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置である。
機械学習モデルの学習を行う学習装置から、前記機械学習モデルの学習データの送信を要求する要求信号を受信する受信部と、
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置である。
前記受信部は、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを要求する前記要求信号を前記学習装置から受信する。そして、前記データ収集部は、受信した前記要求信号に基づいてデータを収集し、前記送信部は、前記データ収集部が収集したデータを前記学習装置に送信する。
あるいは、第2の側面に係るデータ収集装置は、前記データ収集部が収集したデータが前記機械学習モデルの学習に与える影響を分析する分析部をさらに備えている。そして、前記送信部は、前記分析部による分析結果に基づいて、前記データ収集部が収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する。
また、本開示の第3の側面は、
コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部と、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置である。
コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部と、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置である。
前記セグメント抽出部は、コンテンツのうち高視聴率とポジティブな感情を持つ生体情報が一致しているセグメントを抽出する。また、前記セグメント抽出部は、高視聴率とポジティブな感情を持つ生体情報が一致しないセグメントをさらに抽出する。
前記関係性推定部は、前記コンテキストとして、過去のセグメントに写っている人物の顔検出及び検出顔の表情識別結果を用いて、現在のセグメントに写っている人物間の関係性を推定する。
第3の側面に係る情報処理装置は、前記セグメントに含まれる音声を認識して得られたテキスト情報に基づいて感情を分析する第1の感情分析部と、前記セグメントに含まれる音楽を検出して、その音楽が与える感情を分析する第2の感情分析部をさらに備える。そして、前記感動識別部は、前記第1の感情分析部がテキスト情報から識別した感情と、前記第2の感情分析部が音楽から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する。
前記データ収集装置は、信頼度スコア計算により前記分析を行う。この場合、前記学習装置は、前記分析に必要な情報として、現時刻までに学習済みの前記ニューラルネットワークモデルの情報を前記データ収集装置に送信する。
本開示によれば、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行う学習システム、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習データの収集処理を行うデータ収集装置、並びにコンテンツが与える感動を識別する情報処理装置を提供することができる。
なお、本明細書に記載された効果は、あくまでも例示であり、本開示によりもたらされる効果はこれに限定されるものではない。また、本開示が、上記の効果以外に、さらに付加的な効果を奏する場合もある。
本開示のさらに他の目的、特徴や利点は、後述する実施形態や添付する図面に基づくより詳細な説明によって明らかになるであろう。
以下、図面を参照しながら本開示の実施形態について、以下の順に従って詳細に説明する。
A.感動を与えるコンテンツを生成する機械学習モデルに関するデータの収集処理を行うシステムの構成
B.感動を与えるコンテンツを生成する機械学習モデルに関するデータの収集処理を行うシステムの動作
C.コンテンツに含まれる人物間などの関係性の推定
D.感動識別
E.収集したデータを用いた学習プロセス
F.推論
G.アプリケーション
H.機械学習モデルの効率的学習
B.感動を与えるコンテンツを生成する機械学習モデルに関するデータの収集処理を行うシステムの動作
C.コンテンツに含まれる人物間などの関係性の推定
D.感動識別
E.収集したデータを用いた学習プロセス
F.推論
G.アプリケーション
H.機械学習モデルの効率的学習
A.感動を与えるコンテンツを生成する学習モデルに関するデータの収集処理を行うシステムの構成
図1には、本開示に係るデータ収集処理を行うデータ収集システム100の機能的構成を模式的に示している。
図1には、本開示に係るデータ収集処理を行うデータ収集システム100の機能的構成を模式的に示している。
図示のデータ収集システム100は、膨大な映像コンテンツ101の中から人間に感動を与えるコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習に用いられるデータの収集処理を行う。データ収集システム100で収集したデータは、基本的には、人間に感動を与えるコンテンツを扱うための(例えば、人間に感動を与えるシーンやコンテンツであるかどうかを推論するための)機械学習モデル(例えば、ニューラルネットワーク)を学習させるための学習データに用いられるが、もちろんそれ以外の用途に利用してもよい。
本実施形態では、データ収集システム100は、映像コンテンツ101として、テレビやインターネット放送局などで放送され、視聴率情報などのコンテンツ評価情報が付与されたコンテンツを扱うものとし、コンテンツは、主に映像データとオーディオデータなどで構成される。また、映像コンテンツ101として、例えば「いいね!(好き、楽しい、支持できる)」など視聴率情報に類似する(又は、視聴率情報に置き換えることが可能な)、コンテンツを評価するコンテンツ評価情報が付与されていれば、動画共有サイトなどさまざまなコンテンツを含んでいてもよい。また、データ収集システム100は、固定長又は可変長のセグメント単位で、映像コンテンツ101から取り出したコンテンツの処理を行うものとする。
データ収集システム100は、コンテンツ評価情報取得部102と、生体情報取得部103と、比較部104と、セグメント抽出部105と、コンテキスト抽出部106と、音声認識部107と、音楽検出部108と、顔検出部109と、第1の感情分析部110と、第2の感情分析部111と、表情識別部112と、関係性推定部113と、感動識別部114を備えている。データ収集システム100は、例えばクラウド、すなわちインターネットなどの広域的なコンピュータネットワーク上でコンピュータ資源が提供されるサービスとして構成されることを想定している。データ収集システム100の各構成要素は、1台のコンピュータ内に集約される場合と複数のコンピュータに分散して配置される場合がある。以下、各部について説明する。
コンテンツ評価情報取得部102は、映像コンテンツ101から取り出されたコンテンツに付与されている視聴率などのコンテンツ評価情報を取得する。コンテンツ評価情報取得部102は、対象とするコンテンツの視聴率情報を、視聴率調査会社から取得するようにしてもよい。本実施形態では、データ収集システム100は、コンテンツの各シーンが人間に感動を与えるかどうかを判別するために、視聴率情報を利用する。視聴率情報を利用するメリットとして、プライバシー問題に抵触しないことや、既に多人数の反応が反映される情報であることなどが挙げられる。また、視聴率情報は、コンテンツのストーリー上の起承転結などのコンテキストも反映されているので、視聴率が高いシーンの前後のコンテキスト情報も有効に使うことができる。さらに、視聴率情報が付与されているコンテンツの場合、高い頻度でそのシーンに付随する追加情報(例えば、セリフや背景音楽など)などが付いている。後述するように、感動的なシーンのセリフと背景の音楽は、人間に感動を与えることに関して大きな役割を持つとともに、アプリケーションの余地を広げるために、活用するべきである。なお、コンテンツ評価情報取得部102は、視聴率情報に加えて(又は、視聴率情報の代わりに)、SNSなどで付けられる「いいね!(好き、楽しい、支持できる)」などのコンテンツ評価情報を取得するようにしてもよい。
生体情報取得部103は、映像コンテンツ101から取り出されたコンテンツを視聴する人間の生体情報を取得する。例えば、家庭内に脳波や発汗、視線、筋電位などの生体情報を検出する生体情報センサーを設置しておき、テレビやインターネット放送などのコンテンツを視聴する際に検出された生体情報を、生体情報取得部103が収集するようにしてもよい。生体情報取得部103は、多数の家庭から膨大量の生体情報を収集した場合には、平均化などの統計処理を行った後に利用するようにしてもよい。
再生コンテンツを視聴する人間は、緊張感や悲しみ、怒りなどの感動を覚えたシーンでは、脳波や発汗、視線、筋電位などの生体情報に反応が現れる。他方、視聴率情報はコンテンツがどれくらいの世帯や人々に見られているのかを示す指標であるが、必ずしも人間が感動したシーンが視聴率情報に反映されるとは限らない。そこで、データ収集システム100では、視聴率などのコンテンツ評価情報のみではコンテンツの各シーンが人間に感動を与えるかどうかを正確に判別できないというリスクを考慮して、コンテンツ評価情報を補間するために、生体情報取得部103が取得する脳波情報などの生体情報を利用する。脳波情報から感情を識別する研究は、既に行われている(例えば、非特許文献1を参照のこと)。したがって、コンテンツの各シーンを視聴する人間の脳波情報に基づいて、高視聴率がどのような感情に起因しているのかを推定することができる。なお、脳波は、脳から生じる電気活動を頭皮から計測した電位のことである。脳波計は、一般に、頭皮上に設置した電極から脳電位を計測するように構成される。電極の配置位置として国際10-20法が知られているが、本開示は特にこれに限定されない。
比較部104は、コンテンツ評価情報取得部102が取得する視聴率などのコンテンツ評価情報と、生体情報取得部103が取得する人間の生体情報を比較する。そして、セグメント抽出部105は、映像コンテンツ101から取り出したコンテンツのうち、高視聴率とポジティブな感情(「感動した」など)を持つ生体情報が一致しているセグメントを、感動識別の学習に用いるデータとして抽出する。また、セグメント抽出部105は、高視聴率とポジティブな感情を持つ生体情報が一致しないセグメントも、ネガティブ(「感動しない」など)なサンプルとして抽出する。
コンテキスト抽出部106は、映像コンテンツ101から取り出したコンテンツのコンテキストを抽出する。より具体的には、コンテキスト抽出部106は、視聴率が高いシーンの前後のコンテキストや、セグメント抽出部105が抽出するセグメントの前後のコンテキストを抽出する。コンテキスト抽出部106は、映像及びオーディオデータからなるコンテンツからコンテキストを推定するように学習された学習済みニューラルネットワークモデルを用いて、コンテキストを抽出するようにしてもよい。
音声認識部107は、セグメント抽出部105が抽出したセグメントに含まれるオーディオデータのうち音声の成分に対して音声認識処理(ASR:Automatic Speech Recognition)を適用して、セリフなどの音声を認識してテキストに変換(speech transcription)する。
第1の感情分析部110は、音声認識部107から出力されるセリフなどのテキスト情報に対して感情分析を行う自然言語処理を適用して、そのセグメント(シーン)がどのような感情で構成されているのかを分析する。第1の感情分析部110は、前後のセグメント(シーン)のセリフを参考にして、より広いコンテキストの中で感情分析を行うようにしてもよい。セリフの感情分析結果に基づいて、セグメント(シーン)の感情をより正確に把握することができる。
音声認識部107や第1の感情分析部110はそれぞれ、畳み込みニューラルネットワーク(Convolutional Newral Network:CNN)などの学習済み機械学習モデルを用いて構成することができる。また、音声認識部107と第1の感情分析部110を併せて「音声識別機」として、1つのCNNなどの機械学習モデルで構成することもできる。
音楽検出部108は、セグメント抽出部105が抽出したセグメントに含まれるオーディオデータに対して音楽検出処理を適用して、映像に付与された背景音楽を検出する。
第2の感情分析部111は、音楽検出部108が検出した背景音楽が持つムードや感動的であるかどうかを識別する。音楽が与える感情を識別する技術はいくつか提案されている(例えば、非特許文献2を参照のこと)。背景音楽の感情分析結果に基づいて、セグメント(シーン)の感情をより正確に把握することができる。
音楽検出部108や第2の感情分析部111は、それぞれCNNなどの学習済み機械学習モデルを用いて構成することができる。また、音楽検出部108と第2の感情分析部111を併せて「音楽識別機」として、1つのCNNなどの機械学習モデルで構成することもできる。
顔検出部109は、セグメント抽出部105が抽出したセグメントに含まれる映像データに写っている人物の顔検出処理(face detection)を実行する。
表情識別部112は、顔検出部109が検出した顔の表情を識別する。表情識別部112は、例えば、検出顔から顔画像のパターンを解析し、その顔画像のパターンがどの感情に対応するかを推定する。顔画像のパターンと人間の感情との相関関係を事前学習した人工知能を用いて、人間の感情を推定することができる。なお、顔画像のパターンは、眉毛、目、鼻、口、頬といった顔パーツの組み合わせで構成することもできるが、顔パーツに分けず顔画像全体のイメージで構成することもできる。
顔検出部109や表情識別部112は、それぞれCNNなどの学習済み機械学習モデルを用いて構成することができる。また、顔検出部109と表情識別部112を併せて「表情識別機」として、1つのCNNなどの機械学習モデルで構成することもできる。
関係性推定部113は、セグメントに写っている人物が二人以上の場合において、表情識別部112が識別した個々の人物の表情と、コンテキスト抽出部106が抽出した前後のセグメントとのコンテキストに基づいて、人物間の関係性や親密度を推定する。何故ならば、ある人物が同じ表情をしていても、一緒に写っている他の人物との関係性や親密度(例えば、家族や親しい友人と一緒に写っているか)に応じて、それを見た人間の感動に繋がり易さに違いがあり、後段の感動識別処理に影響を与えるからである。
感動識別部114は、音声認識部107及び第1の感情分析部110によるセグメント内の音声(セリフなど)の感情識別結果と、音楽検出108及び第2の感情分析部111によるセグメント内の背景音楽の感情やムードの識別結果と、顔検出部109及び表情識別部112によるセグメントに写っている人物の表情の識別結果と、関係性推定部113によるセグメントに写っている人物間の関係性や親密度の推定結果に基づいて、セグメントの感動を識別する。
感動識別部114は、例えば学習済みニューラルネットワークモデルを用いて、上記の入力データからセグメントの感動を推定処理して、セグメントの感動のレベルを示す感動識別ラベルを出力する。感動識別ラベルは、ポジティブ(「感動した」など)とネガティブ(「感動しない」など)の2種類の簡単なバイナリラベルでもよいが、「怒り」、「嫌悪」、「恐れ」、「幸福」、「悲しみ」、「驚き」、…などさまざまな種類に分化した感動を表すラベルであってもよい。感動識別部114は、例えばWundtモデルやPlutchikモデルなどの感情モデルに基づいて定義された感動識別ラベルを出力するようにしてもよい。
B.感動を与えるコンテンツを生成する機械学習モデルに関するデータの収集処理を行うシステムの動作
図2には、データ収集システム100の動作をフローチャートの形式で示している。
図2には、データ収集システム100の動作をフローチャートの形式で示している。
まず、テレビやインターネット放送局などで放送され、視聴率などのコンテンツ評価情報が付与されたコンテンツがデータ収集システム100に取り込まれる(ステップSS201)。コンテンツ評価情報取得部102は、このコンテンツに付与されているコンテンツ評価情報を取得する。コンテンツは複数のセグメントで構成され、セグメント毎にコンテンツ評価情報が付与されているものとする。
生体情報取得部103は、ステップS201で取り込んだコンテンツを視聴中の人間の反応を表す脳波などの生体情報を取得する(ステップS202)。コンテンツがテレビ放送の場合、その番組を視聴する多数の家庭から、少なくとも脳波を含む生体情報を収集することを想定している。
比較部104は、セグメント毎に、コンテンツ評価情報取得部102が取得したコンテンツ評価情報と、生体情報取得部103が取得する人間の生体情報を比較して、高視聴率とポジティブな感情を持つ生体情報が一致するかどうかをチェックする(ステップS203)。
ここで、セグメント抽出部105は、映像コンテンツ101から取り出したコンテンツのうち、高視聴率とポジティブな感情を持つ生体情報が一致しているセグメントを(ステップS203のYes)、感動識別の学習に用いるデータとして抽出する(ステップS204)。また、セグメント抽出部105は、高視聴率とポジティブな感情を持つ生体情報が一致しないセグメントを(ステップS203のNo)、ネガティブなサンプルとして抽出する(ステップS215)。
ステップS204で抽出したセグメントが音声データを含む場合には(ステップS205のYes)、音声認識部107が音声認識してテキストに変換し、第1の感情分析部110がそのテキスト情報から感情を識別する(ステップS206)。
また、ステップS204で抽出したセグメントが音楽データを含む場合には(ステップS207のYes)、音楽検出部108がその音楽を検出し、第2の感情分析部111がその音楽が与える感情を識別する(ステップS208)。
また、ステップS204で抽出したセグメントに人物が写っている場合には(ステップS209のYes)、顔検出部109が人物の顔を検出し、表情識別部112が検出顔の表情を識別する(ステップS210)。
また、ステップS204で抽出したセグメントに二人以上の人物が写っている場合には(ステップS211のYes)、関係性推定部113は、表情識別部112が識別した個々の人物の表情と、コンテキスト抽出部106が抽出した前後のセグメントとのコンテキストに基づいて、人物間の関係性を推定する(ステップS212)。
感動識別部114は、音声認識部107及び第1の感情分析部110によるセグメント内の音声(セリフなど)の感情識別結果と、音楽検出108及び第2の感情分析部111によるセグメント内の背景音楽の感情やムードの識別結果と、顔検出部109及び表情識別部112によるセグメントに写っている人物の表情の識別結果と、関係性推定部113によるセグメントに写っている人物間の関係性の推定結果に基づいて、セグメントの感動を識別する(ステップS213)。
感動識別部114は、セグメントの感動を推定処理して、セグメントの感動のレベルを示す感動識別ラベルを出力する。感動識別ラベルは、ポジティブとネガティブの2種類の簡単なバイナリラベルでもよいが、「怒り」、「嫌悪」、「恐れ」、「幸福」、「悲しみ」、「驚き」、…などさまざまな種類の感動を表すラベルであってもよい。この結果、ポジティブ、又は、「怒り」、「嫌悪」、「恐れ」、「幸福」、「悲しみ」、「驚き」、…などさまざまな種類の感動を表すラベルを持つサンプルを獲得することができる(ステップS214)。また、人間にポジティブな感情を与えないネガティブなサンプルも獲得する(ステップS215)。
データ収集システム100は、図2に示した処理手順に従って、テレビやインターネット放送などのコンテンツから、人間に感動を与えるようなセグメント(シーン)を抽出し、さらにセグメントに含まれる音声や背景音楽の感情分析結果、セグメントに写っている人物の表情識別結果、さらにセグメントに二人以上の人物が映っている場合の人物間の関係性の推定結果に基づいて、各セグメントの感動ラベルを識別することができる。そして、データ収集システム100によって収集された感情ラベル付きのセグメントは、人工知能(ニューラルネットワークモデル)を用いた感動識別機を訓練するための学習データに使用することができる。
C.コンテンツに含まれる人物間などの関係性の推定
この項では、関係性推定部113で実施される、映像中の人物間の関係性を推定する処理について、詳細に説明する。
この項では、関係性推定部113で実施される、映像中の人物間の関係性を推定する処理について、詳細に説明する。
映像に写っている人物が一人の場合、その人物の検出顔の表情から感情を識別することができる。これに対し、映像に二人の人物が写っている場合には、人物間の関係性が生じるので、人物から感動を識別する際に人物間の関係性も考慮する必要がある。
例えば、同じ人物Aが写っている映像であっても、人物Aと一緒に写っている人物Bが家族や友人など深い関係性があり親密度が高いと、その映像は感動に繋がり易い。一方、人物Aと人物Bの親密度が低いと、どの感動も与えられない場合もある。このように、被写体間の関係性を把握することは、映像が感動を与えるかを推定する上で非常に重要である。
SNSなどに投稿された情報に基づいて被写体の情報を機械学習する技術は既に知られている。しかしながら、被写体間の関係性などの人間関係をSNSの投稿情報から把握しようとすると、被写体のプライバシーを脅かすおそれがあるため実行が容易でない。これに対し、本開示では、関係性推定部113は、表情識別部112が識別した個々の人物の表情と、コンテキスト抽出部106が抽出した前後のセグメントとのコンテキストに基づいて、人物間の関係性を推定するので、プライバシーの問題を生じない。
各人物の表情識別に基づいて人物間の関係性を推定する技術は既に知られているが、この種の技術の多くは、単純にポジティブな表情をポジティブな感情に繋ぐという1次元的なレベルにとどまる。しかしながら、表情から表面的に識別された感情ラベルが必ずしもその人物の感情と一致するとは限らない。例えば、友達と撮った写真で、わざと怒っているような表情を作る場合がある。また、重たい雰囲気の公式イベントで撮った写真では、笑顔を作っていても、明らかに親密な関係ではないことが分かる場合もある。すなわち、人物の表情を識別して単純に人物間の関係性を推定することはできない。写っている人物の顔の表情から単純に感動を与えるかどうかを識別することだけではなく、写っている2人以上の人物間の親密度を把握する必要がある。親密度が高い人物が写っている映像であれば、それが感動を与える可能性は必然的に高くなる。
視覚データに基づいて人物間の関係性を認識する研究は既に活発に行われている(例えば、非特許文献3を参照のこと)。本開示では、関係性推定部113は、セグメント抽出部105が抽出した当該セグメントの情報(例えば、セグメント内の映像から識別される人物の表情)だけでなく、その前後のセグメントとのコンテキストを利用して人物間の関係性を推定するので、推定の正確性が向上することを期待できる。さらに、インターネットなどの情報源から簡単に得られるコンテンツ自体のメタ情報(例えば、放送番組の情報)を、人物間の関係性の推定に利用することも考えられる。
図3には、関係性推定部113がセグメントのコンテキストと顔検出及び表情識別結果に基づいて人物間の関係性を推定する仕組みを図解している。図3に示す例では、関係性推定部113は、セグメント抽出部105が抽出した現在のセグメントに写っている人物の顔検出及び検出顔の表情識別結果とともに、過去のセグメントに写っている人物の顔検出及び検出顔の表情識別結果をコンテキストとして利用する。
まず、過去のセグメント301が、顔検出部109と表情識別部112を構成するCNN311に入力され、このCNN311が過去のセグメント301に写っている各人物の顔検出及び検出顔の表情識別を行う。そして、関係性推定部113は、過去のセグメント301から顔検出された人物とその表情識別結果303を人物登録部313に登録しておく。
次いで、セグメント抽出部105が抽出した現在のセグメント302が、顔検出部109と表情識別部112を構成するCNN312に入力され、このCNNが現在のセグメント302に写っている各人物の顔検出及び検出顔の表情識別を行い、顔検出及び検出顔の表情識別結果304を出力する。そして、関係性推定部113は、現在のセグメント302から検出された人物が、人物登録部313に問い合わせて、過去のセグメント301から事前登録されている人物であるかどうかをチェックする。
ここで、現在のセグメント302から検出された人物が、過去のセグメント301から事前に登録されている人物である場合には、関係性推定部113は、同じ人物についての、現在のセグメント302から推定された表情の識別結果に加えて、過去のセグメント301から推定された表情識別の結果を用いて、人物間の関係性を推定する。関係性推定部113からセグメントのコンテキストを利用して人物間の関係性をより正確に推定すると、後段の感動識別部114は、現在のセグメントの感動ラベルをより正確に識別することができるようになる。
また、現在のセグメント302から検出された人物が、過去のセグメント301から事前に登録されている人物でない場合には、関係性推定部113は、現在のセグメント302から推定された表情の識別結果のみに基づいて、人物間の関係性を推定する。あるいは、後段の感動識別部113は、人物間の関係性を利用しないで、現在のセグメントから推定された表情の識別結果に基づいて、現在のセグメントの感動ラベルを識別する。
D.感動識別
この項では、感動識別部114で実施される、セグメントが与える感動を識別する処理について、詳細に説明する。
この項では、感動識別部114で実施される、セグメントが与える感動を識別する処理について、詳細に説明する。
感動識別部114は、以下の多元的な情報をまとめて、現在のセグメントの感動ラベルを識別する。
(1)音声認識部107及び第1の感情分析部110によるセグメント内の音声(セリフなど)の感情識別結果
(2)音楽検出108及び第2の感情分析部111によるセグメント内の背景音楽の感情やムードの識別結果
(3)顔検出部109及び表情識別部112によるセグメントに写っている人物の表情の識別結果
(4)関係性推定部113によるセグメントに写っている人物間の関係性や親密度の推定結果
(2)音楽検出108及び第2の感情分析部111によるセグメント内の背景音楽の感情やムードの識別結果
(3)顔検出部109及び表情識別部112によるセグメントに写っている人物の表情の識別結果
(4)関係性推定部113によるセグメントに写っている人物間の関係性や親密度の推定結果
上記の(1)~(4)がすべてポジティブな感情を示す場合には、感動識別部114は、現在のセグメントに感動的な場面としてラベルを付ける。
また、上記の(1)~(4)のうち一部の情報が抜けている場合には(例えば、現在のセグメントに背景音楽が不在である場合や、人物が写っておらず、表情識別結果が不在である場合)、存在しているすべての情報がポジティブであれば、感動識別部114は、現在のセグメントに感動的な場面としてラベルを付けるようにしてもよい。一部の情報が抜けていると、感動識別の信頼性が低下する可能性はあるが、セグメント自体が既にセグメント抽出部105においてコンテンツ評価情報と脳波情報の一致というフィルターを通過しているので、信頼性が急激に低下することはないと思料される。
また、上記(1)~(4)のいずれの情報からも現在のセグメントに対して感動的なラベルを付けられない場合には、感動識別部114は、そのセグメントにネガティブのラベルを付けるようにしてもよい。ネガティブのラベルが付けられたセグメントは、ネガティブサンプルとして感動識別機を訓練するための学習データに使用することができる。
上述したように、セグメントに含まれる音声、音楽、人物の顔の表情を識別する各識別機は、それぞれCNNなどの学習済み機械学習モデルで構成される。各識別機がどのように事前学習したかによって、感動識別部114は、ポジティブとネガティブの2種類の簡単なバイナリラベルでなく、「怒り」、「嫌悪」、「恐れ」、「幸福」、「悲しみ」、「驚き」、…などさまざまな種類に分化した感動を表すラベルを付けることもできる。すなわち、データ収集システム100は、さまざまな感動識別ラベルを持つ学習データを収集することができ、さまざまな種類の感動を識別する感動識別機の訓練に使用することができる。
E.収集したデータを用いた学習プロセス
この項では、本開示に係るデータ収集システム100を用いて収集した学習データを利用して、感動識別機を訓練する学習プロセスについて、詳細に説明する。感動識別機は、コンテンツがどのような感動を与えるかを識別する装置である。ここで言う装置は、専用のハードウェアで構成される装置と、ソフトウェアを実行して所定の機能を実現する装置の両方を意味する。
この項では、本開示に係るデータ収集システム100を用いて収集した学習データを利用して、感動識別機を訓練する学習プロセスについて、詳細に説明する。感動識別機は、コンテンツがどのような感動を与えるかを識別する装置である。ここで言う装置は、専用のハードウェアで構成される装置と、ソフトウェアを実行して所定の機能を実現する装置の両方を意味する。
図4には、収集した学習データを利用した感動識別機の学習プロセスの全体の流れを模式的に示している。
データ収集システム100を用いて収集した学習データは、データ蓄積部410に格納されている。個々の学習データは、上記A~D項で「セグメント」と呼ばれるものに相当する。学習データとしてのセグメントは、テレビやインターネット放送などのコンテンツの要素であり、フレームシーケンスからなる映像データと、映像に同期したオーディオデータで構成される。また、学習データとしてのセグメントにはデータ収集システム100における処理過程で最終的に感動識別ラベルが教師データとして付与されている。感動識別ラベルは、さまざまな種類に分化される場合もあるが、この項では説明の簡素化のため、ポジティブとネガティブの2種類の簡単なバイナリラベルが付与されているものとする。
感動識別機420は、学習データとしての映像とオーディオデータを入力する複数のネットワークモデルからなるネットワーク部421と、ネットワーク部421で獲得した特徴量に基づいてコンテンツの感動ラベルを識別する識別部422で構成される。ネットワーク部421内の各ネットワークは、パラメータ(ノード間の結合重み係数など)を持つ。
映像の場合は、フレーム毎にネットワーク部421内の学習済みのニューラルネットワークモデル(CNN)を通して各々の特徴量を獲得して、それらをまとめることによって映像全体の特徴量(Video Feature)が得られる。フレームの特徴量のまとめ方としてはさまざまな方法があるが、単純なconcatenate、又はLSTM(Long Short Term Memory)などの時系列ネットワークに順番に入れる方法などが挙げられる。本実施形態では、フレームに写っている人物が二人以上の場合において、連続する複数のフレームのコンテキストに基づいて推定される人物間の関係性を映像特徴量として獲得する。
一方、オーディオデータの場合は、メル周波数ケプストラム係数(Mel-Frequency Cepstrum Coefficients:MFCC)やメルスペクトログラム(mel-spectrogram)などの特徴量に変換し、それをネットワーク部421内のLSTMなどの時系列ネットワークに入れることによってオーディオ特徴量(Audio Faeture)を獲得することができる。また、音声の特徴量をテキストに書き換えて(transcription)、同じくネットワーク部421内のLSTMなどの時系列ネットワークに入れることによってテキスト特徴量(Text Feature)を獲得することができる。
識別部422は、上記のようにして得られた映像全体の特徴量(Video Feature)、オーディオ特徴量(Audio Faeture)、及びテキスト特徴量(Text Feature)を共通空間に射影して、感動識別機420に入力された学習データに対して感動識別ラベルを付与する。ここでは、識別部422は、ポジティブ又はネガティブのいずれかのバイナリラベルを付与するものとする。
評価部423は、識別部422が学習データに付与した感動識別ラベルと、データ収集システム100によって学習データに付与された教師データとしての感動識別ラベルとの誤差に基づくソフトマックスなどの損失関数Lossを計算する。あるいは、損失関数Lossは、映像の特徴量に基づく感動識別ラベルと、音声の特徴量に基づく感動識別ラベルと、オーディオの特徴量に基づく感動識別ラベルを個別に識別して、各々の誤差Lvideo、Ltext、LAudioの合計に基づいて損失関数Lossを求めるようにしてもよい。そして、誤差に基づいて求めた損失関数Lossは、ネットワーク部421内のパラメータを持つ各ネットワークに逆伝播(Backpropagate)され、損失関数Lossが最小となるようにネットワーク部421内の各ネットワーク(CNN、LSTM)のパラメータが更新される。これによって、感動識別機420は、入力された学習データに対して教師データと等しくなるような感動識別ラベルを出力するように、学習が進む。
F.推論
上記A項では、データ収集システム100が、テレビやインターネット放送などのコンテンツからコンテンツ評価情報と脳波などの生体情報を利用してデータを収集する方法について説明した。また、上記E項では、データ収集システム100によって収集されたデータを用いて、感動識別機420の学習を行うプロセスについて説明した。
上記A項では、データ収集システム100が、テレビやインターネット放送などのコンテンツからコンテンツ評価情報と脳波などの生体情報を利用してデータを収集する方法について説明した。また、上記E項では、データ収集システム100によって収集されたデータを用いて、感動識別機420の学習を行うプロセスについて説明した。
学習プロセスを経て学習された感動識別機420は、感動を与えるコンテンツ、あるいはコンテンツがどのような感動を与えるかを識別することができる。ここで言うコンテンツは、テレビやインターネット放送などのコンテンツを始め、動画共有サイトで共有される動画コンテンツ、ユーザがデジタルカメラで撮影した動画及び静止画のコンテンツなど、さまざまなコンテンツを含み、コンテンツ評価情報や脳波などの生体情報が付与されている必要はない。
G.アプリケーション
これまで説明してきたように、本開示に係るデータ収集システムが収集した学習データを使って、コンテンツが人間に与える感情を識別する感情識別機用の機械学習モデルを訓練することができる。また、このようにして開発した感情識別機にはさまざまなアプリケーションが期待される。
これまで説明してきたように、本開示に係るデータ収集システムが収集した学習データを使って、コンテンツが人間に与える感情を識別する感情識別機用の機械学習モデルを訓練することができる。また、このようにして開発した感情識別機にはさまざまなアプリケーションが期待される。
G-1.デジタルカメラの構成
本開示に基づいて開発された感情識別機は、例えばデジタルカメラを始めとする、コンテンツの記録、再生、編集などコンテンツに対して処理を行うさまざまなコンテンツ処理装置に搭載することができる。
本開示に基づいて開発された感情識別機は、例えばデジタルカメラを始めとする、コンテンツの記録、再生、編集などコンテンツに対して処理を行うさまざまなコンテンツ処理装置に搭載することができる。
図5には、デジタルカメラ500の構成例を示している。図示のデジタルカメラ500は、光学系501と、撮像部502と、AFE(Analog Front End:アナログ前処理)部503と、カメラ信号処理部504と、コーデック505と、メイン処理部506と、マイク514と、A/D変換部515と、表示部516と、音再生部517と、記録部518を備えている。このデジタルカメラ500には、本開示に基づいて開発された感情識別機が搭載されることを想定している。
光学系501は、被写体からの光を撮像部502の撮像面に集光するためのレンズ、レンズを移動させてフォーカス合わせやズーミングを行なうための駆動機構、開閉操作により被写体からの光を所定時間だけ撮像面に入射させるシャッター機構、被写体からの光線束の方向並びに範囲を限定するアイリス(絞り)機構(いずれも図示しない)を含んでいる。ドライバ(図示しない)は、後述するメイン処理部506からの制御信号に基づいて、光学系501内の各機構の駆動(例えば、被写体のフォーカス合わせやアイリス、パン及びチルト、シャッター又はセルフ・タイマー設定のタイミング)などのカメラワークを制御する。
撮像部502は、CCD(Charge Coupled Device)やCMOS(Comprementary Metal Oxyde Semiconductor)などの撮像素子からなり、光電変換効果を持つ各画素が2次元に配列された撮像面を有し、被写体からの入射光を電気信号に変換する。受光側には、例えばG市松RB色コーディング単板が配設されている。各色フィルターを通した入射光量に対応する信号電荷が各画素に蓄積され、各画素から読み出される3色の各信号電荷量からその画素位置における入射光の色を再現することができる。なお、撮像部502から出力されるアナログ画像信号は、RGB各色の原色信号であるが、補色系の色信号であってもよい。
AFE部503は、撮像信号の低雑音を高精度に抑圧した後(Correlated Double Sampling(相関二重サンプリング):CDS)、サンプル・ホールドを行ない、さらにAGC(Automatic Gain Control:自動利得制御回路)により適正なゲイン・コントロールをかけて、AD変換を施してデジタル画像信号を出力する。また、AFE部503は、撮像素子を駆動するためのタイミングパルス信号と、このタイミングパルス信号に従って撮像素子の各画素の電荷を垂直方向にライン単位で出力するための駆動信号を撮像部502に出力する。
カメラ信号処理部504は、AFE部503から送られてくる画像信号に対して、欠陥画素補正やデジタルクランプ、デジタルゲイン制御などの前処理を施した後、AWBによりホワイトバランスゲインを掛けるとともに、シャープネス・再度コントラスト調整などの画質補正処理を施して適正な色状態を再現し、さらにデモザイク処理によりRGB画面信号を作成する。また、カメラ信号処理部504は、撮影画像を表示部516にスルー画像として表示出力するか又は記録部518に保存するかに応じて解像度変換を行ったり、MPEG(Moving Picture Experts Group)などのコーデック処理を行ったりする。
メイン処理部506は、プロセッサとRAM(Random Access Memory)及びROM(Read Only Memory)で構成され、デジタルカメラ500全体の動作を統括的に制御する。プロセッサは、CPU(Central Processing Unit)やマルチコアを持つGPU(Graphic Processing Unit)などである。メイン処理部506は、記録時には、撮影部502で撮像した映像データとマイク514で収音したオーディオデータを記録部518に保存する。また、メイン処理部506は、再生時には、記録部518から映像及びオーディオデータを読み出して、表示部516及び音再生部517で出力する。また、本実施形態では、メイン処理部506は、本開示に基づいて開発された感情識別機が搭載されることを想定している。
表示部516は、デジタルカメラ500に搭載された液晶表示パネル、外部のテレビやプロジェクタなど、撮影中の映像又は記録した映像を表示する装置である。
音再生部517は、デジタルカメラ5100に搭載されたスピーカ、外部のスピーカなど、記録した音声を再生する装置である。
記録部518は、HDD(hard Disc Drive)やSSD(Solid State Drive)などの大容量の記録装置である。記録部518には、撮像部502で撮影した映像及び映像と同期してマイク514で収音したオーディオデータからなるコンテンツが記録される。また、感情識別機用の機械学習モデルのパラメータ(例えば、ニューラルネットワークモデルにおけるニューロン間の結合重み係数)が記録部518に記録されている。
G-2.撮影したコンテンツのラベリング
続いて、本開示に基づいて開発された感情識別機をデジタルカメラ500に搭載して実現される機能について説明する。
続いて、本開示に基づいて開発された感情識別機をデジタルカメラ500に搭載して実現される機能について説明する。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけることによって、コンテンツの感動識別ラベルを付与したり、コンテンツ中で感動を与えるシーン(セグメント)を抽出したりすることができる。
図6には、デジタルカメラ500で撮影したコンテンツの感動識別ラベリングを行うための機能的構成を示している。同図中、感動識別機420の構成は図4に示したものと同じとする。感動識別機420は、デジタルカメラ500内のメイン処理部506で動作することを想定している。
デジタルカメラ500で撮影したコンテンツの映像は、フレーム毎にネットワーク部421内の学習済みのニューラルネットワークモデル(CNN)を通して各々の特徴量を獲得して、それらをまとめることによって映像全体の特徴量が得られる。また、映像と同期して記録されたオーディオデータは、MFCCなどの特徴量に変換し、ネットワーク部421内のLSTMなどの時系列ネットワークに入れることによって、オーディオ特徴量が得られる。また、音声の特徴量をテキストに書き換えて、同じくネットワーク部421内のLSTMなどの時系列ネットワークに入れることによってテキスト特徴量が得られる。
識別部422は、上記のようにして得られた映像全体の特徴量、オーディオ特徴量、及びテキスト特徴量を共通空間に射影して、感動識別機420に入力された学習データに対して感動識別ラベルを付与する。識別部422は、ポジティブ又はネガティブのいずれかのバイナリラベルを付与する。あるいは、識別部422は、さまざまな種類に分化した感動を表すラベルを付与してもよい。
いずれにせよ、識別部422は、撮影したコンテンツに対して、シーン(又はセグメント)毎に感動識別ラベルを付与する。付与された感動識別ラベルは、例えばコンテンツのメタ情報として記録される。録画したコンテンツを再生するときには、感動識別ラベルを検索キーに用いて、感動的なシーンを選択して視聴することができる。また、録画したコンテンツを編集するときには、感動識別ラベルを検索キーにして、「うれしい」シーンや「悲しい」シーンなど、特定の感情を抱くシーンだけを取捨選択することができる。
このように、本開示に係るデータ収集システム100は、入力された各コンテンツ又はコンテンツ中のセグメント毎に、人間に与えることができる感動の種類を識別する感動識別ラベルを付与することができる。したがって、データ収集システム100を用いて、膨大な映像コンテンツ101の中から、特定の感動識別ラベル(例えば、「うれしい」、「悲しい」など)が付与されたコンテンツ又はセグメントを収集して、その特定の感動を与えるコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習に用いることができる。
G-3.カメラワークの支援又は制御
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、カメラワークの支援や自動制御を行うことができる。例えば、感動の度合いが増すように、あるいは特定の種類の感動識別ラベルを獲得できるように、被写体を撮影する視線方向やズームを自動制御したり、又は撮影画像の輝度、色彩、画角、構図、フォーカスなどを自動制御したり、表示部516のガイダンス表示や音再生部517からの音声ガイダンスを使っておすすめのアングルを教えたりするようにしてもよい。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、カメラワークの支援や自動制御を行うことができる。例えば、感動の度合いが増すように、あるいは特定の種類の感動識別ラベルを獲得できるように、被写体を撮影する視線方向やズームを自動制御したり、又は撮影画像の輝度、色彩、画角、構図、フォーカスなどを自動制御したり、表示部516のガイダンス表示や音再生部517からの音声ガイダンスを使っておすすめのアングルを教えたりするようにしてもよい。
図7には、撮影したコンテンツの感動識別結果に基づいてカメラワークを自動制御するためのデジタルカメラ500の機能的構成を示している。同図中、感動識別機420の構成は図4に示したものと同じとする。感動識別機420は、デジタルカメラ500内のメイン処理部506で動作することを想定している。
デジタルカメラ500で撮影したコンテンツの映像は、フレーム毎にネットワーク部421内の学習済みのニューラルネットワークモデル(CNN)を通して各々の特徴量を獲得して、それらをまとめることによって映像全体の特徴量が得られる。また、映像と同期して記録されたオーディオデータは、MFCCなどの特徴量に変換し、ネットワーク部421内のLSTMなどの時系列ネットワークに入れることによって、オーディオ特徴量が得られる。また、音声の特徴量をテキストに書き換えて、同じくネットワーク部421内のLSTMなどの時系列ネットワークに入れることによってテキスト特徴量が得られる。
識別部422は、上記のようにして得られた映像全体の特徴量、オーディオ特徴量、及びテキスト特徴量を共通空間に射影して、感動識別機420に入力された学習データに対して感動識別ラベルを付与する。そして、評価部423は、感動の度合いが増すように、あるいは特定の種類の感動識別ラベルを獲得できるように、光学系501に対してカメラワークの制御信号を出力する。
G-4.キャプションの追加
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、映像のシーンに対して適切で、且つ感動の度合いが増すようなキャプションを自動付与することができる。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、映像のシーンに対して適切で、且つ感動の度合いが増すようなキャプションを自動付与することができる。
図8には、撮影したコンテンツの感動識別結果に基づいてキャプションを自動生成するためのデジタルカメラ500の機能的構成を示している。同図中、感動識別機420の構成は図4に示したものと同じとする。感動識別機420は、デジタルカメラ500内のメイン処理部506で動作することを想定している。
デジタルカメラ500で撮影したコンテンツの映像は、フレーム毎にネットワーク部421内の学習済みのニューラルネットワークモデル(CNN)を通して各々の特徴量を獲得して、それらをまとめることによって映像全体の特徴量が得られる。また、映像と同期して記録されたオーディオデータは、MFCCなどの特徴量に変換し、ネットワーク部421内のLSTMなどの時系列ネットワークに入れることによって、オーディオ特徴量が得られる。また、音声の特徴量をテキストに書き換えて、同じくネットワーク部421内のLSTMなどの時系列ネットワークに入れることによってテキスト特徴量が得られる。また、キャプション生成部801は、例えば学習済みの機械学習済みモデルを用いて、シーン毎のキャプションを生成する。キャプション生成部801が生成したキャプションのテキスト情報は、コンテンツの音声認識から得られたテキスト情報に重畳されて、ネットワーク部421内のLSTMなどの時系列ネットワークに入れられる。
識別部422は、上記のようにして得られた映像全体の特徴量、オーディオ特徴量、及びテキスト特徴量を共通空間に射影して、感動識別機420に入力された学習データに対して感動識別ラベルを付与する。評価部423は、識別部422から出力される感動識別ラベルについての損失関数を計算する。そして、キャプション生成部801は、感動の度合いが増すように、あるいは特定の種類の感動識別ラベルを獲得できるように再学習する。キャプション生成部801が生成したキャプションは、コンテンツの音声データに重畳して記録される。
G-5.背景音楽の付与
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、映像のシーンに対して適切で、且つ感動の度合いが増すような背景音楽を自動付与することができる。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、映像のシーンに対して適切で、且つ感動の度合いが増すような背景音楽を自動付与することができる。
図9には、撮影したコンテンツの感動識別結果に基づいて背景音楽を自動付与するためのデジタルカメラ500の機能的構成を示している。同図中、感動識別機420の構成は図4に示したものと同じとする。感動識別機420は、デジタルカメラ500内のメイン処理部506で動作することを想定している。
デジタルカメラ500で撮影したコンテンツの映像は、フレーム毎にネットワーク部421内の学習済みのニューラルネットワークモデル(CNN)を通して各々の特徴量を獲得して、それらをまとめることによって映像全体の特徴量が得られる。また、映像と同期して記録されたオーディオデータは、MFCCなどの特徴量に変換し、ネットワーク部421内のLSTMなどの時系列ネットワークに入れることによって、オーディオ特徴量が得られる。また、音声の特徴量をテキストに書き換えて、同じくネットワーク部421内のLSTMなどの時系列ネットワークに入れることによってテキスト特徴量が得られる。また、音楽検索部901は、例えば学習済みの機械学習済みモデルを用いて、シーンの背景音楽となる楽曲を検索する。音楽検索部901は、例えば膨大量の音楽データを蓄積している音楽データベース(図示しない)上で、シーンの背景音楽となる楽曲を検索するようにしてもよい。音楽検索部901が見つけ出した楽曲の音楽データは、コンテンツのオーディオデータに重畳されて、ネットワーク部421内のLSTMなどの時系列ネットワークに入れられる。
識別部422は、上記のようにして得られた映像全体の特徴量、オーディオ特徴量、及びテキスト特徴量を共通空間に射影して、感動識別機420に入力された学習データに対して感動識別ラベルを付与する。評価部423は、識別部422から出力される感動識別ラベルについての損失関数を計算する。そして、音楽検索部901は、感動の度合いが増す、あるいは特定の種類の感動識別ラベルを獲得できる背景音楽を見つけ出すように再学習する。音楽検索部901が見つけたがっ脚の音楽データは、コンテンツのオーディオデータに重畳して記録される。
H.モデルの効率的学習
上記G項で説明したように、本開示によれば、デジタルカメラ500にニューラルネットワークモデルを搭載することにより、コンテンツ(又は、コンテンツを構成するセグメント毎)に感動のレベルを表す感動識別ラベルを付与したり、高レベルの感動が得られるコンテンツを撮影するためのカメラワークの支援又は制御(カメラの自動操作)を提供したり、コンテンツの感動スコアを向上させるためのキャプションや背景音楽を付与したりすることができる。このH項では、デジタルカメラ500にニューラルネットワークモデルを効率的に学習するための方法について説明する。
上記G項で説明したように、本開示によれば、デジタルカメラ500にニューラルネットワークモデルを搭載することにより、コンテンツ(又は、コンテンツを構成するセグメント毎)に感動のレベルを表す感動識別ラベルを付与したり、高レベルの感動が得られるコンテンツを撮影するためのカメラワークの支援又は制御(カメラの自動操作)を提供したり、コンテンツの感動スコアを向上させるためのキャプションや背景音楽を付与したりすることができる。このH項では、デジタルカメラ500にニューラルネットワークモデルを効率的に学習するための方法について説明する。
なお、便宜上、カメラの自動操作のためのニューラルネットワークモデルの学習方法に限定して説明するが、キャプションの追加や背景音楽の付与を行うニューラルネットワークモデルに関しても同様の方法により効率的に学習を行うことができることを理解されたい。
H-1.学習システムの構成
図10には、カメラの操作支援や自動操作のためのニューラルネットワークモデルを効率的に学習するための学習システム1000の構成を模式的に示している。本実施形態では、学習の対象とするニューラルネットワークモデルとして、主に、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定するニューラルネットワークモデルを想定している。もちろん、学習システム1000を使って、その他のタイプのニューラルネットワークモデルの学習にも活用することができる。
図10には、カメラの操作支援や自動操作のためのニューラルネットワークモデルを効率的に学習するための学習システム1000の構成を模式的に示している。本実施形態では、学習の対象とするニューラルネットワークモデルとして、主に、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定するニューラルネットワークモデルを想定している。もちろん、学習システム1000を使って、その他のタイプのニューラルネットワークモデルの学習にも活用することができる。
図10に示す学習システム1000は、学習データを収集するデータ収集装置1010と、データ収集装置1010が収集した学習データに基づいてニューラルネットワークモデルの学習を行う学習装置1030と、学習データに関する分析を行うデータ分析装置1040と、学習装置1030によって学習されたニューラルネットワークモデル1050を使用するモデル利用装置1020で構成される。
データ収集装置1010は、例えばカメラで撮影した画像データと、カメラ撮影時の操作情報などからなるデータを収集する。データ収集装置1010は、スチルカメラやビデオカメラ、カメラで使用されるイメージセンサー、スマートフォンなどの多機能情報端末、TV、ヘッドホン又はイヤホン、ゲーム機、冷蔵庫や洗濯機などのIoTデバイス、ドローンやロボットなどの移動体装置など、多種類の膨大な装置を含み、これら膨大数のデータ収集装置1010から膨大量のデータを収集することができる。例えば、データ収集装置1010が、プロのカメラマンなどのエキスパートが使用するカメラであれば、感動を与える撮影画像と、そのような画像を撮影するためのカメラ操作情報を収集することができる。また、データ収集装置1010は、上記で例示したようなリアルタイムでデータを収集する装置だけでなく、コンテンツデータベースのように既に大量のデータを蓄積している装置を含んでいてもよい。
学習装置1030は、各データ収集装置1010に対して収集したデータの送信を要求する要求信号を送信する。もちろん、データ収集装置1010は、要求信号に応じてではなく、自発的にデータを送信するようにしてもよい。そして、学習装置1030は、多数のデータ収集装置1010によって収集された膨大なデータを使って、「観測予測モデル」、「操作モデル」、「操作推定モデル」、「感動スコア推定モデル」などのさまざまなニューラルネットワークモデルの学習及び再学習を行う。学習システム1000において利用されるニューラルネットワークモデルの詳細については、後述に譲る。
膨大量のデータを使用することでニューラルネットワークモデルの学習精度は向上するが、学習にあまり寄与しないデータを使って学習や再学習を行うのは非効率的である。そこで、本開示に係る学習システム1000では、データ分析装置1040は、学習の対象とするニューラルネットワークモデルの学習に影響を与える学習データの分析を行い、その分析結果に基づいて、ニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出し、学習装置1030は、データ分析部1040によって抽出された有意義な学習データを使って、ニューラルネットワークモデルの学習及び再学習を効率的に行うようにしている。
データ分析装置1040は、例えば、XAI(eXplainable AI)、学習データの信頼度(Confidence)スコア計算、影響関数(Influence Function)計算、ベイジアンDNN(Deep Newral Network)によるデータ不足推定などの手法に基づいて、データ収集装置1010が収集したデータの分析を行うことができる。
モデル利用装置1020は、学習装置1030によって学習されたニューラルネットワークモデル1050を使用して、感動するコンテンツの撮影を行う装置である。モデル利用装置1020は、例えば、カメラ操作に慣れていない一般のユーザなどが使用するカメラである。モデル利用装置1020は、学習装置1030による学習済みのニューラルネットワークモデルを使用して、プロのカメラマンなど撮影のエキスパートに匹敵するカメラの自動操作を行ったり、感動スコアの高い映像の自動撮影を行ったりすることができる。
ここで、学習システム1000の変形例について説明しておく。
学習装置1030は、さまざまなニューラルネットワークモデルの学習を行うために膨大な計算リソースが必要である。したがって、図10では、学習装置1030は、例えばクラウド上に構築されること(すなわち、クラウドAI(Artificial Intelligence))を想定している。また、学習装置1030は、複数の計算ノードを用いて分散学習を行うようにしてもよい。但し、学習装置1030は、学習済みニューラルネットワークモデルを利用するモデル利用装置と一体で構成されること(すなわち、エッジAI)も想定される。あるいは、学習装置1030は、学習データを提供するデータ収集装置1010と一体で構成されていてもよい。
また、データ分析装置1040は、クラウド又はエッジのいずれに構築されていてもよい。例えばデータ分析装置1040は、学習装置1030と一体の装置として構成されていてもよい。この場合、学習装置1030は、内部でニューラルネットワークモデルの学習に影響を与える学習データを分析して、ニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を、データ収集装置1010に対して要求するようにしてもよい。
あるいは、データ分析装置1040は、データ収集装置1010と一体の装置として構成されていてもよい。この場合、学習装置1030は、学習データの送信要求時などに、データ分析に必要な情報(例えば、その時点で学習済みのニューラルネットワークモデルの情報)を、データ収集装置1010に提供する。そして、データ収集装置1010は、収集したデータがニューラルネットワークモデルに与える影響を分析して、収集したデータのうちニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを学習装置1030に送信するようにしてもよい。
また、図10では、学習データを収集するデータ収集装置1010と、ニューラルネットワークモデルを利用するモデル利用装置1020を別々の装置として描いているが、1つの装置がデータ収集装置1010及びモデル利用装置1020の双方として動作することも想定される。例えば1台のカメラが、マニュアル操作モードではデータ収集装置1010として動作して、撮影データとカメラ操作情報などのデータを収集して学習装置1030に送信する一方、自動操作モードに切り替えるとモデル利用装置1020として動作して、学習装置1030で学習済みのニューラルネットワークモデルを用いて自動撮影を行うようにしてもよい。
H-2.ニューラルネットワークモデルの構成
図10に示した学習システム1000において利用されるニューラルネットワークモデルについて説明しておく。学習システム1000では、学習装置1030は、データ収集装置1040によって収集されたデータを使って、「観測予測モデル」、「操作モデル」、「操作推定モデル」、「感動スコア推定モデル」などのニューラルネットワークの学習及び再学習を行う。また、モデル利用装置1020は、学習装置1030によって学習が行われたこれらのニューラルネットワークモデルのうち少なくとも一部を利用する。
図10に示した学習システム1000において利用されるニューラルネットワークモデルについて説明しておく。学習システム1000では、学習装置1030は、データ収集装置1040によって収集されたデータを使って、「観測予測モデル」、「操作モデル」、「操作推定モデル」、「感動スコア推定モデル」などのニューラルネットワークの学習及び再学習を行う。また、モデル利用装置1020は、学習装置1030によって学習が行われたこれらのニューラルネットワークモデルのうち少なくとも一部を利用する。
観測予測モデル:
図11には、観測予測モデル1100の構成を模式的に示している。観測予測モデル1100は、カメラで撮影した現時刻までの映像情報1101と、カメラに対する現時刻までの操作情報1102から、次の時刻にカメラで撮影される画像(すなわち、「次の時刻の画像」)1111を予測するニューラルネットワークモデルである。
図11には、観測予測モデル1100の構成を模式的に示している。観測予測モデル1100は、カメラで撮影した現時刻までの映像情報1101と、カメラに対する現時刻までの操作情報1102から、次の時刻にカメラで撮影される画像(すなわち、「次の時刻の画像」)1111を予測するニューラルネットワークモデルである。
ここで言う操作情報1102は、例えば、フレームレートや絞り、露出値、倍率、焦点などの撮像条件を決めるためにカメラに対して行われた操作に関する情報である(以下、同様)。また、ロボットやドローンなどの移動体装置にカメラを搭載して行う場合には、移動体装置に対して行われたリモコン操作(ロール、ピッチ、ヨーで示されるカメラワークなど)も操作情報に含んでもよい(以下、同様)。
また、観測予測モデル1100は、予測した次の時刻の画像1111に対する信頼度スコア1112も併せて出力する。信頼度スコア1112は、次の時刻の画像1111がどの程度正しく予測できているかを示す値である。本開示では、学習に不足しているデータ、又は学習への影響度の高いデータを特定するために、信頼度スコアが用いられる。あるいは、データ分析装置1040が、XAIによる観測予測モデル1100の予測の根拠の説明、信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などの手法に基づいて、観測予測モデル1100の学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出する。観測予測モデル1100による信頼度スコア1112の計算機能は、データ分析装置1040の一部として実装されていてもよい。
、
学習システム1000では、学習装置1030が、データ収集装置1010から送信された映像情報と操作情報からなるデータセットに基づいて、観測予測モデル1100の学習を行うことができる。学習装置1030は、強化学習により、より感動を与えることができる画像を予測できるように観測予測モデル1100の学習を行うことができる。また、データ分析装置1040は、データ収集装置1010から送信されたデータセットの中から有意義な学習データを抽出し、学習装置1030はこの有意義な学習データを用いて観測予測モデル1100の再学習を効率的に行うことができる。
学習システム1000では、学習装置1030が、データ収集装置1010から送信された映像情報と操作情報からなるデータセットに基づいて、観測予測モデル1100の学習を行うことができる。学習装置1030は、強化学習により、より感動を与えることができる画像を予測できるように観測予測モデル1100の学習を行うことができる。また、データ分析装置1040は、データ収集装置1010から送信されたデータセットの中から有意義な学習データを抽出し、学習装置1030はこの有意義な学習データを用いて観測予測モデル1100の再学習を効率的に行うことができる。
操作モデル:
図12には、操作モデル1200の構成を模式的に示している。操作モデル1200は、カメラで撮影した現時刻までの映像情報1201と、カメラに対する現時刻までの操作情報1202から、次の時刻にカメラに対して行われる操作1211を予測するニューラルネットワークモデルである。また、操作モデル1200は、予測した次の時刻の操作1211に対する信頼度スコア1212も併せて出力する。信頼度スコア1212は、次の時刻の画像1111がどの程度正しく予測できているかを示す値である。あるいは、データ分析装置1040が、XAIによる操作モデル1200の予測の根拠の説明、信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などの手法に基づいて、操作モデル1200の学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出する。操作モデル1200による信頼度スコア1212の計算機能は、データ分析装置1040の一部として実装されていてもよい。
図12には、操作モデル1200の構成を模式的に示している。操作モデル1200は、カメラで撮影した現時刻までの映像情報1201と、カメラに対する現時刻までの操作情報1202から、次の時刻にカメラに対して行われる操作1211を予測するニューラルネットワークモデルである。また、操作モデル1200は、予測した次の時刻の操作1211に対する信頼度スコア1212も併せて出力する。信頼度スコア1212は、次の時刻の画像1111がどの程度正しく予測できているかを示す値である。あるいは、データ分析装置1040が、XAIによる操作モデル1200の予測の根拠の説明、信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などの手法に基づいて、操作モデル1200の学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出する。操作モデル1200による信頼度スコア1212の計算機能は、データ分析装置1040の一部として実装されていてもよい。
学習システム1000では、学習装置1030が、データ収集装置1010から送信された映像情報と操作情報からなるデータセットに基づいて、操作モデル1200の学習を行うことができる。学習装置1030は、強化学習により、より感動を与えることができる画像を撮影できるカメラ操作情報を予測できるように操作モデル1200の学習を行うことができる。また、データ分析装置1040は、データ収集装置1010から送信されたデータセットの中から有意義な学習データを抽出し、学習装置1030はこの有意義な学習データを用いて操作モデル1200の再学習を効率的に行うことができる。
操作推定モデル:
図13には、操作推定モデル1300の構成を模式的に示している。操作推定モデル1300は、現時刻までの映像時系列情報1301をカメラで撮影するための時系列操作情報1311を推定するニューラルネットワークモデルである。例えば、操作推定モデル1300を使って、プロのカメラマンなどカメラ操作に精通したエキスパートが撮影した高品質な映像時系列情報から、エキスパートが行うカメラの時系列操作情報を推定することができる。
図13には、操作推定モデル1300の構成を模式的に示している。操作推定モデル1300は、現時刻までの映像時系列情報1301をカメラで撮影するための時系列操作情報1311を推定するニューラルネットワークモデルである。例えば、操作推定モデル1300を使って、プロのカメラマンなどカメラ操作に精通したエキスパートが撮影した高品質な映像時系列情報から、エキスパートが行うカメラの時系列操作情報を推定することができる。
操作推定モデル1300は、推定した時系列操作情報1311に対する信頼度スコアも併せて出力するようにしてもよい。あるいは、データ分析装置1040が、XAIによる操作推定モデル1300の予測の根拠の説明、信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などの手法に基づいて、操作推定モデル1300の学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出する。操作推定モデル1300による信頼度スコアの計算機能は、データ分析装置1040の一部として実装されていてもよい。
学習システム1000では、学習装置1030が、データ収集装置1010から送信された映像情報と操作情報からなるデータセットに基づいて、操作推定モデル1300の学習を行うことができる。学習装置1030は、強化学習により、より感動を与えることができる画像を撮影できる時系列操作情報を予測できるように操作推定モデル1300の学習を行うことができる。また、データ分析装置1040は、データ収集装置1010から送信されたデータセットの中から有意義な学習データを抽出し、学習装置1030はこの有意義な学習データを用いて操作推定モデル1300の再学習を効率的に行うことができる。
感動スコア推定モデル:
図14には、感動スコア推定モデル1400の構成を模式的に示している。感動スコア推定モデル1400は、映像情報1401の感動スコア1411を推定するニューラルネットワークモデルであり、上記の感情識別機に相当する。例えば図4に示した学習プロセスに従って、感動スコア推定モデル1400の学習を行うことができる。
図14には、感動スコア推定モデル1400の構成を模式的に示している。感動スコア推定モデル1400は、映像情報1401の感動スコア1411を推定するニューラルネットワークモデルであり、上記の感情識別機に相当する。例えば図4に示した学習プロセスに従って、感動スコア推定モデル1400の学習を行うことができる。
図15には、制御対象(フレームレート、解像度など)と平均感動スコアの関係を示している。但し、ニューラルネットワークモデルから出力される予測値を実線で示し、分散を点で示している。図15は、あるフレームレートで取得した映像データに基づいて感動スコアが高くなるように操作モデルを強化学習により学習し、学習した操作モデルを用いてカメラを操作したときに得られた平均感動スコアを示している。同図中、黒丸で示すデータ点は、既にデータのある点である。データのある点は分散が小さくなる。データのない点は分散が大きい。分散が大きく、且つ高いスコアが期待できる点ほど観測する価値が大きい。例えば楽観的に分散を考慮した上で最も高いスコアが期待できる点のデータを取得するという実装が考えられる。
感動スコア推定モデル1400は、推定した感動スコア1411に対する信頼度スコアも併せて出力するようにしてもよい。あるいは、データ分析装置1040が、XAIによる感動スコア推定モデル1400の予測の根拠の説明、信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などの手法に基づいて、感動スコア推定モデル1400の学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出する。感動スコア推定モデル1400による信頼度スコアの計算機能は、データ分析装置1040の一部として実装されていてもよい。
学習システム1000では、学習装置1030が、データ収集装置1010から送信された映像情報と操作情報からなるデータセットに基づいて、感動スコア推定モデル1400の学習を行うことができる。学習装置1030は、強化学習により、感動を与えることができる映像情報に対してより高い感動スコアを推定できるように感動スコア推定モデル1400の学習を行うことができる。また、データ分析装置1040は、データ収集装置1010から送信されたデータセットの中から有意義な学習データを抽出し、学習装置1030はこの有意義な学習データを用いて感動スコア推定モデル1400の再学習を効率的に行うことができる。
H-3.学習データの分析について
学習システム1000では、データ分析装置1040が、学習対象となるニューラルネットワークモデルの学習データを分析して、学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを特定して、学習装置1020はそのような有意義な学習データを用いてニューラルネットワークモデルの効率的な学習や再学習を行う。
学習システム1000では、データ分析装置1040が、学習対象となるニューラルネットワークモデルの学習データを分析して、学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを特定して、学習装置1020はそのような有意義な学習データを用いてニューラルネットワークモデルの効率的な学習や再学習を行う。
データ分析装置1040は、クラウド又はエッジのいずれに構築されていてもよい。例えばデータ分析装置1040は、学習装置1030と一体の装置として構成されていてもよい。この場合、学習装置1030は、内部でニューラルネットワークモデルの学習に影響を与える学習データを分析して、ニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を、データ収集装置1010に対して要求する。
あるいは、データ分析装置1040は、データ収集装置1010と一体の装置として構成されていてもよい。この場合、学習装置1030は、学習データの送信要求時などに、データ分析に必要な情報(例えば、その時点で学習済みのニューラルネットワークモデルの情報)を、データ収集装置1010に提供する。そして、データ収集装置1010は、収集したデータがニューラルネットワークモデルに与える影響を分析して、収集したデータのうちニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを学習装置1030に送信する。
データ分析装置1040がデータを分析する方法として、XAI、学習データの信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などが挙げられる。
信頼度スコアは、ニューラルネットワークモデルによる予測値の正しさの程度を数値化したものである。上記で説明したニューラルネットワークモデルのうち、観測予測モデル1100及び操作モデル1200は、予測値とともに信頼度スコアを出力するように構成されている。
学習システム1000では、データ収集装置1010が、信頼度スコアを用いて学習装置1030に送信する学習データのフィルタリングを行うが、この点の詳細については後述に譲る。
ニューラルネットワークモデルの出力値の信頼度スコアを計算する方法はいくつかあり、本開示では特定の計算方法に限定されない。ここでは、3種類の信頼度スコアの計算方法(1)~(3)について説明しておく。
(1)出力の誤差を推定するように学習されたニューラルネットワークモデル
図16に示すように、ニューラルネットワークモデル1500において、本来の出力とともに、その出力の誤差を信頼度スコアとして出力するように学習する。
図16に示すように、ニューラルネットワークモデル1500において、本来の出力とともに、その出力の誤差を信頼度スコアとして出力するように学習する。
(2)ベイズ推定を用いる方法
Image Augmentation(画像拡張)及びDropoutなど乱数を用い、入力データや中間ニューロンの構成に摂動を加え、摂動の下でも正しい予測が得られるような学習を行う。推論時は摂動を加えながら何度も推定を行う。結果の分散が大きいほど、信頼度スコアが低いことを表す。
Image Augmentation(画像拡張)及びDropoutなど乱数を用い、入力データや中間ニューロンの構成に摂動を加え、摂動の下でも正しい予測が得られるような学習を行う。推論時は摂動を加えながら何度も推定を行う。結果の分散が大きいほど、信頼度スコアが低いことを表す。
(3)予測確率を用いる方法(分類問題の場合)
0.0~1.0の確率で予測が得られる分類問題の場合、0.0、1.0などの結果が得られた場合は信頼度スコアが高い、2値分類の場合は0.5(50%に近い)、他クラス分類の場合は最も確率の高いクラスの確率が低い場合は信頼度スコアが低いと判断できる。
0.0~1.0の確率で予測が得られる分類問題の場合、0.0、1.0などの結果が得られた場合は信頼度スコアが高い、2値分類の場合は0.5(50%に近い)、他クラス分類の場合は最も確率の高いクラスの確率が低い場合は信頼度スコアが低いと判断できる。
また、影響関数は、個々の学習データの有無や摂動がニューラルネットワークモデルの予測結果に与える影響を定式化したものである(例えば、非特許文献4を参照のこと)。また、ベイジアンDNNは、ベイズ推定とディープラーニングを結び付けて構成されるが、ベイズ推定を使うことにより、ニューラルネットワークモデルが予測結果を出力する際のデータ不足による不確実性を評価することができる。
H-4.データ収集装置の構成
データ収集装置1010は、スチルカメラやビデオカメラ、カメラで使用されるイメージセンサー、スマートフォンなどの多機能情報端末、TV、ヘッドホン又はイヤホン、ゲーム機、冷蔵庫や洗濯機などのIoTデバイス、ドローンやロボットなどの移動体装置など、多種類の装置である。
データ収集装置1010は、スチルカメラやビデオカメラ、カメラで使用されるイメージセンサー、スマートフォンなどの多機能情報端末、TV、ヘッドホン又はイヤホン、ゲーム機、冷蔵庫や洗濯機などのIoTデバイス、ドローンやロボットなどの移動体装置など、多種類の装置である。
図17には、データ収集装置1010の内部構成例を示している。図17に示すデータ収集装置1010は、センサー部1011と、操作入力部1012と、制御部1013と、ログ送信部1014と、データ分析部1015を備えている。但し、図17は、多種類のデータ収集装置1010のうち、本開示の実現に関わる代表的な機能的構成を抽象化して描いたものであり、個々のデータ収集装置1010は図示しないさまざまな構成要素を備えていることが想定される。
センサー部1011は、CMOSなどで構成されるイメージセンサーや、データ収集装置1010に装備されるその他のセンサーからなり、画像や映像の撮影を始めとする観測を行う。また、データ収集装置1010がロボットやドローンなどの移動体装置に搭載されている場合には、IMU(Inertial Measurement Unit)などの移動体装置に装備される各種センサーもセンサー部1011に含まれるものとする。
操作入力部1012は、データ収集装置1010における撮影条件などの操作情報を調整するための入力操作を行う機能モジュールである。操作入力部1012は、ボタンやつまみなどの操作子やタッチパネル画面などからなる。また、データ収集装置1010がロボットやドローンなどの移動体装置に搭載されている場合には、移動体装置を遠隔操作する際に使用するリモコンも操作入力部1012に含まれる。
制御部1013は、データ収集装置1010全体の動作を統括的に制御する。また、制御部1013は、操作入力部1012を介して入力された操作情報に基づいて、センサー部1011における画像や映像の撮影とする観測の制御を行う。
ログ送信部1014は、センサー部1011で観測された観測ログ及び操作入力部1012に入力された操作ログからなるデータセットを、学習装置1030に送信する。基本的には、ログ送信部1014は、学習装置1030からデータの送信を要求する要求信号を受信したことに応じて学習装置103にデータセットを送信する。データ収集装置1010は、学習装置1030から要求信号を受信したことに応じて新たにデータを収集して学習装置1030に送信するが、既に収集したデータから要求信号に基づいて抽出したデータを学習装置1030に送信するようにしてもよい。もちろん、データ収集装置1010は、要求信号に応じてではなく自発的にデータを送信するようにしてもよい。
データ分析部1015は、センサー部1011で観測された観測ログ及び操作入力部1012に入力された操作ログからなるデータセットが、学習対象となる各ニューラルネットワークモデルの学習に与える影響を分析して、学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータなどの、学習に有意義なデータであるかどうかを特定する。
学習装置1030から、学習に有意義なデータを指定して要求信号が送信される場合と、収集したデータの分析を指示して要求信号が送信される場合がある。前者の場合、データ分析部1015は、センサー部1011で観測された観測ログ及び操作入力部1012に入力された操作ログからなるデータセットが要求信号で指定されたデータに該当するかどうかをチェックして、ログ送信部1014は、要求に適合するデータのみを学習装置1030に送信する。
また、後者の場合、データ分析部1015は、図10中のデータ分析装置1040に相当する。この場合のデータ分析部1015は、学習装置1030において学習対象とするニューラルネットワークモデルの学習に影響を与える学習データを分析して、センサー部1011で観測された観測ログ及び操作入力部1012に入力された操作ログからなるデータセットが、ニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データに該当するかどうかをチェックする。そして、ログ送信部1014は、有意義な学習データとなるデータセットのみを学習装置1030に送信する。データ分析部1015は、例えばXAI、信頼度スコア、影響関数、ベイジアンDNNのうち少なくとも1つ、又は2以上の組み合わせを用いて、ニューラルネットワークモデルの分析を行う。例えば、データ分析部1015が信頼度スコアを用いてデータの分析を行う場合には、学習装置1030から現時刻までに学習済みのニューラルネットワークモデルの情報を受け取り、データセットを入力したときのニューラルネットワークモデルによる推論の信頼度スコアを計算する。信頼度スコアを計算する方法については、上記H-3項を参照されたい。そして、信頼度スコアが高い観測ログ及び操作ログは不足していない学習データであり価値は低いが、信頼度スコアが低い観測ログ及び操作ログは不足している学習データであり価値が高いということができる。信頼度スコアが低く不足している学習データを収集して学習装置1030に提供することにより、学習装置103側ではニューラルネットワークモデルの学習や再学習を効率的に行うことができるようになる。
また、データ分析部1015は、分析結果をセンサー部1011及び操作入力部1012にフィードバックするようにしてもよい。そして、センサー部1011及び操作入力部1012は、学習対象のニューラルネットワークモデルの学習への影響度に基づいて、解像度、フレームレート、輝度、色彩、画角、視点位置又は視線方向を変化させて撮影を行うようにしてもよい。
図18には、データ収集装置1010の他の内部構成例を示している。図18に示すデータ収集装置1010は、センサー部1011と、操作入力部1012と、制御部1013と、ログ送信部1014を備えている。図17に示した構成例との主な相違は、データ分析部1015を備えていない点である。図18に示すデータ収集装置1010は、収集したデータの分析を行わず、言い換えれば、収集したデータがニューラルネットワークモデルの学習や再学習に有意義な学習データであるかどうかに関わらず、すべて学習装置1030に送信する。
H-5.学習装置の構成
図19には、学習装置1030の内部構成例を示している。図19に示す学習装置1030は、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035と、データ分析部1036を備えている。
図19には、学習装置1030の内部構成例を示している。図19に示す学習装置1030は、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035と、データ分析部1036を備えている。
モデル学習部1031は、学習データを使って各種のニューラルネットワークモデルの学習を行う。具体的には、モデル学習部1031は、観測予測モデル(図11を参照のこと)、操作モデル(図12を参照のこと)、操作推定モデル(図13を参照のこと)、感動スコア推定モデル(図14を参照のこと)などの学習を行う。学習装置1030がクラウド上に設置されるクラウドAIの場合、例えば複数の計算ノードを用いてモデル学習部1031を構成して、ニューラルネットワークモデルの分散学習を行うようにしてもよい。
観測・操作ログ蓄積部1032は、データ収集装置1010から送信された観測ログと操作ログを蓄積する。データ収集装置1010からは、有意義な学習データとなる観測ログ及び操作ログが送られてくるものとする。
モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている観測ログと操作ログからなるデータセットに基づいて、観測予測モデルの学習を行う。そして、学習済みの観測予測モデルは観測予測モデル・操作モデル蓄積部1033に蓄積される。
また、モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている観測ログと操作ログからなるデータセットに基づいて、操作モデルの学習を行う。そして、学習済みの操作モデルは観測予測モデル・操作モデル蓄積部1033に蓄積される。
また、モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている観測ログと操作ログからなるデータセットに基づいて、操作推定モデルの学習を行う。そして、学習済みの操作推定モデルは操作推定モデル蓄積部1034に蓄積される。
データ分析部1036は、図10中のデータ分析装置1040に相当する。データ分析部1036は、観測予測モデル・操作モデル蓄積部1033及び操作推定モデル蓄積部1034に蓄積されている学習済みの各ニューラルネットワークの学習に影響を与える学習データを分析する。そして、この分析結果に基づいて、所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を要求する要求信号が、学習装置1030からデータ収集装置1010へ送信される。したがって、データ収集装置1010からは、有意義な学習データとなる観測ログ及び操作ログが送られてくる。データ分析部1036は、例えば、XAI、信頼度スコア計算、影響関数、又はベイジアンDNNなどの手法に基づいて、学習データの分析を行う。
操作推定部1035は、学習済みの操作推定モデルを用いて、プロのカメラマンなどのカメラ操作に精通したエキスパートが撮影した映像(以下、「プロの映像」とも呼ぶ)から、その映像を撮影するための時系列操作情報を推定する。そして、操作推定部1035に入力されたプロの映像(観測ログ)と、操作推定部1035で推定された操作情報(推定された操作ログ)からなるデータセットが、プロ並みの操作モデルを学習するための高品質な学習データとして、観測・操作ログ蓄積部1032に蓄積される。したがって、モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている高品質な学習データを用いて、プロ並みのカメラ操作を予測することが可能な操作モデルを学習することができる。
なお、プロの映像コンテンツは任意であり、ネットワーク経由でクラウドに提供されることを想定している。プロの映像コンテンツを使って大量の高品質な学習データを収集していくことで、プロ並みのカメラ自動操作を実現するための操作モデルの学習を行うことが可能になる。
図20には、学習装置1030の他の内部構成例を示している。図20に示す学習装置1030は、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035を備えている。図19に示した構成例との主な相違点は、データ分析部1036を備えていない点である。
図20に示す学習装置1030は、自らは学習データの分析を行わず、その代わりに学習対象となるニューラルネットワークモデルの情報をデータ収集装置1010に送信する。この場合、データ収集装置1010側では、データ分析部1015が、学習装置1030において学習対象とするニューラルネットワークモデルの学習に影響を与える学習データを分析して、センサー部1011で観測された観測ログ及び操作入力部1012に入力された操作ログからなるデータセットが、ニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データに該当するかどうかをチェックする(前述)。そして、データ収集装置1010から学習装置1030へ、有意義な学習データとなるデータセットのみが送信される。
図21には、学習装置1030のさらに他の内部構成例を示している。図21に示す学習装置1030は、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035と、データ分析部1037を備えている。図19及び図20に示した構成例との主な相違点は、学習装置1030は、図18に示した構成例からなるデータ収集装置1010から、すべての収集データを受信して、データ分析部1037において各受信データが有意義な学習データかどうかをチェックする点である。
データ分析部1037は、図10中のデータ分析装置1040に相当する。データ分析部1037は、観測・操作ログ蓄積部1032に蓄積されている各受信データが、観測予測モデル・操作モデル蓄積部1033及び操作推定モデル蓄積部1034に蓄積されている学習済みの各ニューラルネットワークの学習に与える影響を分析する。そして、データ分析部1037は、各ニューラルネットワークモデルの学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データのみを、観測・操作ログ蓄積部1032から抽出して、モデル学習部1031に出力する。したがって、モデル学習部1031は、有意義な学習データを使って各種のニューラルネットワークモデルの学習や再学習を効率的に行うことができる。
H-6.モデル利用装置の構成
図22には、モデル利用装置1020の内部構成例を示している。モデル利用装置1020は、センサー部1021と、自動操作部1022と、制御部1023と、提示部1024を備えている。
図22には、モデル利用装置1020の内部構成例を示している。モデル利用装置1020は、センサー部1021と、自動操作部1022と、制御部1023と、提示部1024を備えている。
センサー部1021は、CMOSなどで構成されるイメージセンサーや、モデル利用装置1020に装備されるその他のセンサーからなり、画像や映像の撮影を始めとする観測を行う。また、モデル利用装置1020がロボットやドローンなどの移動体装置に搭載されている場合には、IMUなどの移動体装置に装備される各種センサーもセンサー部1021に含まれるものとする。
自動操作部1022は、学習装置1030から提供された操作モデルを用いて、センサー部1021の観測情報(現時刻までの映像情報及び現時刻までの操作情報)から次の時刻の操作情報を予測するとともに、予測した操作情報の信頼度スコアなどのデータ分析結果を出力する。
制御部1023は、自動操作部1022によって予測された次の時刻の操作情報に基づいて、センサー部1011における画像や映像の撮影とする観測の制御を行う。
学習装置1030において十分な学習が行われた操作モデルが提供される場合、モデル利用装置1020のユーザ自身はカメラ操作に精通していなくても、自動操作部1022によって予測された操作情報に基づいて、プロのカメラマンなどカメラ操作に精通したエキスパートと同等の撮影を行うことができる。
提示部1024は、自動操作部1022において予測した操作情報の信頼度スコアなどのデータ分析結果を提示する。モデル利用装置1020のユーザは、提示された信頼度スコアから、自動操作によりプロ並みの腕前で映像の撮影が行われるかどうかを判断することができる。
H-7.エッジAIの構成
学習済みのニューラルネットワークモデルを利用するモデル利用装置1020が、ニューラルネットワークモデルの学習を行う学習装置の機能と一体となって構成されること(すなわち、エッジAI)も想定される。図23には、エッジAIとしてのモデル利用装置1020の内部構成例を示している。図示のモデル利用装置1020は、センサー部1021と、自動操作部1022と、制御部1023と、提示部1024に加えて、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035を備えている。
学習済みのニューラルネットワークモデルを利用するモデル利用装置1020が、ニューラルネットワークモデルの学習を行う学習装置の機能と一体となって構成されること(すなわち、エッジAI)も想定される。図23には、エッジAIとしてのモデル利用装置1020の内部構成例を示している。図示のモデル利用装置1020は、センサー部1021と、自動操作部1022と、制御部1023と、提示部1024に加えて、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035を備えている。
観測・操作ログ蓄積部1032は、データ収集装置1010から送信された観測ログと操作ログを蓄積する。モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている観測ログと操作ログからなるデータセットに基づいて、観測予測モデルの学習を行う。また、モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている観測ログと操作ログからなるデータセットに基づいて、操作モデルの学習を行う。そして、学習済みの観測予測モデル及び操作モデルは観測予測モデル・操作モデル蓄積部1033に蓄積される。
また、モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている観測ログと操作ログからなるデータセットに基づいて、操作推定モデルの学習を行う。そして、学習済みの操作推定モデルは操作推定モデル蓄積部1034に蓄積される。操作推定部1035は、学習済みの操作推定モデルを用いて、プロのカメラマンなどのカメラ操作に精通したエキスパートが撮影した映像から、その映像を撮影するための時系列操作情報を推定して、プロ並みの操作モデルを学習するための高品質な学習データとして、観測・操作ログ蓄積部1032に蓄積される。したがって、モデル学習部1031は、観測・操作ログ蓄積部1032に蓄積されている高品質な学習データを用いて、プロ並みのカメラ操作を予測することが可能な操作モデルを学習することができる。
センサー部1021は、CMOSなどで構成されるイメージセンサーや、モデル利用装置1020に装備されるその他のセンサーからなり、画像や映像の撮影を始めとする観測を行う。
自動操作部1022は、観測予測モデル・操作モデル蓄積部1033から読み出した操作モデルを用いて、センサー部1021の観測情報(現時刻までの映像情報及び現時刻までの操作情報)から次の時刻の操作情報を予測するとともに、予測した操作情報の信頼度スコアなどのデータ分析結果を出力する。
制御部1023は、自動操作部1022によって予測された次の時刻の操作情報に基づいて、センサー部1011における画像や映像の撮影とする観測の制御を行う。学習装置1030において十分な学習が行われた操作モデルが提供される場合、モデル利用装置1020のユーザ自身はカメラ操作に精通していなくても、自動操作部1022によって予測された操作情報に基づいて、プロのカメラマンなどカメラ操作に精通したエキスパートと同等の撮影を行うことができる。
提示部1024は、自動操作部1022において予測した操作情報の信頼度スコアなどのデータ分析結果を提示する。モデル利用装置1020は、提示された信頼度スコアから、自動操作によりプロ並みの腕前で映像の撮影が行われるかどうかを判断することができる。
以上、特定の実施形態を参照しながら、本開示について詳細に説明してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が該実施形態の修正や代用を成し得ることは自明である。
本開示は、人間に感動を与えるコンテンツを生成する機械学習モデルの学習に用いられるデータの収集処理に適用することができる。本開示に基づいて収集したデータは、人間に感動を与えるコンテンツを扱うための(具体的には、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定するための)機械学習モデル(例えば、ニューラルネットワークモデル)を学習させるための学習データに用いられるが、もちろんそれ以外の用途の機械学習モデルの学習に利用することも可能である。
また、本開示に基づいて収集したデータを使って、コンテンツが人間に与える感情を識別する機械学習モデルを訓練することができ、このようにして開発した機械学習モデルを備えた感情識別機を、デジタルカメラを始めとするコンテンツ処理装置に搭載することができる。
要するに、例示という形態により本開示について説明してきたのであり、本明細書の記載内容を限定的に解釈するべきではない。本開示の要旨を判断するためには、特許請求の範囲を参酌すべきである。
なお、本開示は、以下のような構成をとることも可能である。
(1)データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システム。
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システム。
(2)前記学習装置は、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行う、
上記(1)に記載の学習システム。
上記(1)に記載の学習システム。
(3)XAI、信頼度スコア計算、影響関数、又はベイジアンDNNによる前記分析を行う、
上記(1)又は(2)のいずれかに記載の学習システム。
上記(1)又は(2)のいずれかに記載の学習システム。
(4)前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析し、その分析結果に基づいて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を要求する要求信号を前記データ収集装置に送信し、
前記データ収集装置は、受信した前記要求信号に基づいて収集したデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
上記(1)乃至(3)のいずれかに記載の学習システム。
前記データ収集装置は、受信した前記要求信号に基づいて収集したデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
上記(1)乃至(3)のいずれかに記載の学習システム。
(5)前記データ収集装置は、画像を撮影するカメラ又はイメージャであり、前記機械学習モデルの学習への影響度に基づいて、解像度、フレームレート、輝度、色彩、画角、視点位置、又は視線方向を変化させて撮影した画像データを前記学習装置に送信する、
上記(1)乃至(4)のいずれかに記載の学習システム。
上記(1)乃至(4)のいずれかに記載の学習システム。
(6)前記学習装置は、前記機械学習モデルの学習データの送信を要求する要求信号を前記データ収集装置に送信し、
前記データ収集装置は、収集したデータが前記機械学習モデルの学習に与える影響を分析した結果に基づいて、前記収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
上記(1)乃至(3)のいずれかに記載の学習システム。
前記データ収集装置は、収集したデータが前記機械学習モデルの学習に与える影響を分析した結果に基づいて、前記収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
上記(1)乃至(3)のいずれかに記載の学習システム。
(7)前記学習装置は、前記要求信号の送信時に、前記分析に必要な情報を前記データ収集装置に送信する、
上記(6)に記載の学習システム。
上記(6)に記載の学習システム。
(8)機械学習モデルの学習を行う学習装置から、前記機械学習モデルの学習データの送信を要求する要求信号を受信する受信部と、
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置。
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置。
(9)前記受信部は、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを要求する前記要求信号を前記学習装置から受信し、
前記データ収集部は、受信した前記要求信号に基づいてデータを収集し、
前記送信部は、前記データ収集部が収集したデータを前記学習装置に送信する、
上記(8)に記載のデータ収集装置。
前記データ収集部は、受信した前記要求信号に基づいてデータを収集し、
前記送信部は、前記データ収集部が収集したデータを前記学習装置に送信する、
上記(8)に記載のデータ収集装置。
(10)前記データ収集部は受信した前記要求信号に基づいて新たにデータを収集し、又は、前記送信部は前記データ収集部が既に収集したデータから前記要求信号に基づいて抽出したデータを送信する、
上記(9)に記載のデータ収集装置。
上記(9)に記載のデータ収集装置。
(11)前記データ収集部が収集したデータが前記機械学習モデルの学習に与える影響を分析する分析部をさらに備え、
前記送信部は、前記分析部による分析結果に基づいて、前記データ収集部が収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する、
上記(8)に記載のデータ収集装置。
前記送信部は、前記分析部による分析結果に基づいて、前記データ収集部が収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する、
上記(8)に記載のデータ収集装置。
(12)前記データ収集部は、前記機械学習モデルの学習への影響度に基づいて、画像を撮影するカメラ又はイメージャの解像度、フレームレート、輝度、色彩、画角、視点位置、又は視線方向を変化させて撮影した画像データを収集する、
上記(8)乃至(11)のいずれかに記載のデータ収集装置。
上記(8)乃至(11)のいずれかに記載のデータ収集装置。
(13)コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部と、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置。
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置。
(14)前記生体情報は少なくとも脳波情報を含む、
上記(13)に記載の情報処理装置。
上記(13)に記載の情報処理装置。
(15)前記セグメント抽出部は、コンテンツのうち高評価とポジティブな感情を持つ生体情報が一致しているセグメントを抽出する、
上記(13)又は(14)のいずれかに記載の情報処理装置。
上記(13)又は(14)のいずれかに記載の情報処理装置。
(16)前記セグメント抽出部は、高評価とポジティブな感情を持つ生体情報が一致しないセグメントをさらに抽出する、
上記(15)に記載の情報処理装置。
上記(15)に記載の情報処理装置。
(17)前記関係性推定部は、前後のセグメントとのコンテキストと、人物の顔の表情に基づいて、セグメントに写っている人物間の関係性を推定する、
上記(13)乃至(16)のいずれかに記載の情報処理装置。
上記(13)乃至(16)のいずれかに記載の情報処理装置。
(18)前記関係性推定部は、前記コンテキストとして、過去のセグメントに写っている人物の顔検出及び検出顔の表情識別結果を用いて、現在のセグメントに写っている人物間の関係性を推定する、
上記(17)に記載の情報処理装置。
上記(17)に記載の情報処理装置。
(19)前記セグメントに含まれる音声を認識して得られたテキスト情報に基づいて感情を分析する第1の感情分析部をさらに備え、
前記感動識別部は、前記第1の感情分析部がテキスト情報から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
上記(13)乃至(18)のいずれかに記載の情報処理装置。
前記感動識別部は、前記第1の感情分析部がテキスト情報から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
上記(13)乃至(18)のいずれかに記載の情報処理装置。
(20)前記セグメントに含まれる音楽を検出して、その音楽が与える感情を分析する第2の感情分析部をさらに備え、
前記感動識別部は、前記第2の感情分析部が音楽から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
上記(13)乃至(19)のいずれかに記載の情報処理装置。
前記感動識別部は、前記第2の感情分析部が音楽から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
上記(13)乃至(19)のいずれかに記載の情報処理装置。
(21)コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出ステップと、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別ステップと、
セグメントに写っている人物間の関係性を推定する関係性推定ステップと、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別ステップと、
を有する情報処理方法。
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別ステップと、
セグメントに写っている人物間の関係性を推定する関係性推定ステップと、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別ステップと、
を有する情報処理方法。
(22)コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部、
セグメントに写っている人物間の関係性を推定する関係性推定部、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部、
としてコンピュータを機能させるようにコンピュータ可読形式で記述されたコンピュータプログラム。
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部、
セグメントに写っている人物間の関係性を推定する関係性推定部、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部、
としてコンピュータを機能させるようにコンピュータ可読形式で記述されたコンピュータプログラム。
(23)コンテンツが与える感動を識別する学習済み機械学習モデルを生成する生成方法であって、
機械学習モデルにコンテンツを入力するステップと、
前記機械学習モデルが前記コンテンツから推定した映像特徴量を獲得するステップと、
前記機械学習モデルが前記コンテンツから推定したオーディオ特徴量を獲得するステップと、
前記機械学習モデルが前記コンテンツから推定した音声のテキスト特徴量を獲得するステップと、
前記機械学習モデルが推定した映像特徴量、オーディオ特徴量、及びテキスト特徴量に基づいてコンテンツの感動ラベルを識別するステップと、
前記識別した感動ラベルと前記コンテンツに付けられた感動ラベルとの誤差に基づく損失関数を計算するステップと、
前記損失関数に基づいて前記機械学習モデルのパラメータを更新するステップと、
を有する学習済み機械学習モデルの生成方法。
機械学習モデルにコンテンツを入力するステップと、
前記機械学習モデルが前記コンテンツから推定した映像特徴量を獲得するステップと、
前記機械学習モデルが前記コンテンツから推定したオーディオ特徴量を獲得するステップと、
前記機械学習モデルが前記コンテンツから推定した音声のテキスト特徴量を獲得するステップと、
前記機械学習モデルが推定した映像特徴量、オーディオ特徴量、及びテキスト特徴量に基づいてコンテンツの感動ラベルを識別するステップと、
前記識別した感動ラベルと前記コンテンツに付けられた感動ラベルとの誤差に基づく損失関数を計算するステップと、
前記損失関数に基づいて前記機械学習モデルのパラメータを更新するステップと、
を有する学習済み機械学習モデルの生成方法。
(24)前記映像特徴量は、映像のフレームに写っている人物が2人以上の場合において、連続する複数のフレームのコンテキストに基づいて推定される人物間の関係性を含む、
上記(23)に記載の学習済み機械学習モデルの生成方法。
上記(23)に記載の学習済み機械学習モデルの生成方法。
100…データ収集システム、101…映像コンテンツ
102…コンテンツ評価情報取得部、103…生体情報取得部
104…比較部、105…セグメント抽出部
106…コンテキスト抽出部、107…音声認識部
108…音楽検出部、109…顔検出部
110…第1の感情分析部、111…第2の感情分析部
112…表情識別部、113…関係性推定部
114…感動識別部
410…データ蓄積部、420…感動識別機
421…ネットワーク部、422…識別部、423…評価部
500…デジタルカメラ、501…光学系、502…撮像部
503…AFE部、504…カメラ信号処理部、506…メイン処理部
514…マイク、515…A/D変換部、516…表示部
517…音再生部、518…記録部
1000…学習システム、1010…データ収集装置
1011…センサー部、1012…操作入力部、1013…制御部
1014…ログ送信部、1015…データ分析部
1020…モデル利用装置、1021…センサー部
1022…自動操作部、1023…制御部、1024…提示部
1030…学習装置、1031…モデル学習部
1032…観測・操作ログ蓄積部
1033…観測予測モデル・操作モデル蓄積部
1034…操作推定モデル蓄積部、1035…操作推定部
1036…データ分析部、1037…データ分析部
1040…データ分析装置
1100…観測予測モデル、1200…操作モデル
1300…操作推定モデル、1400…感動スコア推定モデル
102…コンテンツ評価情報取得部、103…生体情報取得部
104…比較部、105…セグメント抽出部
106…コンテキスト抽出部、107…音声認識部
108…音楽検出部、109…顔検出部
110…第1の感情分析部、111…第2の感情分析部
112…表情識別部、113…関係性推定部
114…感動識別部
410…データ蓄積部、420…感動識別機
421…ネットワーク部、422…識別部、423…評価部
500…デジタルカメラ、501…光学系、502…撮像部
503…AFE部、504…カメラ信号処理部、506…メイン処理部
514…マイク、515…A/D変換部、516…表示部
517…音再生部、518…記録部
1000…学習システム、1010…データ収集装置
1011…センサー部、1012…操作入力部、1013…制御部
1014…ログ送信部、1015…データ分析部
1020…モデル利用装置、1021…センサー部
1022…自動操作部、1023…制御部、1024…提示部
1030…学習装置、1031…モデル学習部
1032…観測・操作ログ蓄積部
1033…観測予測モデル・操作モデル蓄積部
1034…操作推定モデル蓄積部、1035…操作推定部
1036…データ分析部、1037…データ分析部
1040…データ分析装置
1100…観測予測モデル、1200…操作モデル
1300…操作推定モデル、1400…感動スコア推定モデル
Claims (20)
- データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システム。 - 前記学習装置は、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行う、
請求項1に記載の学習システム。 - XAI(Explainable AI)、信頼度スコア計算、影響関数、又はベイジアンDNNによる前記分析を行う、
請求項1に記載の学習システム。 - 前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析し、その分析結果に基づいて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を要求する要求信号を前記データ収集装置に送信し、
前記データ収集装置は、受信した前記要求信号に基づいて収集したデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
請求項1に記載の学習システム。 - 前記データ収集装置は、画像を撮影するカメラ又はイメージャであり、前記機械学習モデルの学習への影響度に基づいて、解像度、フレームレート、輝度、色彩、画角、視点位置、又は視線方向を変化させて撮影した画像データを前記学習装置に送信する、
請求項1に記載の学習システム。 - 前記学習装置は、前記機械学習モデルの学習データの送信を要求する要求信号を前記データ収集装置に送信し、
前記データ収集装置は、収集したデータが前記機械学習モデルの学習に与える影響を分析した結果に基づいて、前記収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
請求項1に記載の学習システム。 - 前記学習装置は、前記要求信号の送信時に、前記分析に必要な情報を前記データ収集装置に送信する、
請求項6に記載の学習システム。 - 機械学習モデルの学習を行う学習装置から、前記機械学習モデルの学習データの送信を要求する要求信号を受信する受信部と、
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置。 - 前記受信部は、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを要求する前記要求信号を前記学習装置から受信し、
前記データ収集部は、受信した前記要求信号に基づいてデータを収集し、
前記送信部は、前記データ収集部が収集したデータを前記学習装置に送信する、
請求項8に記載のデータ収集装置。 - 前記データ収集部は受信した前記要求信号に基づいて新たにデータを収集し、又は、前記送信部は前記データ収集部が既に収集したデータから前記要求信号に基づいて抽出したデータを送信する、
請求項9に記載のデータ収集装置。 - 前記データ収集部が収集したデータが前記機械学習モデルの学習に与える影響を分析する分析部をさらに備え、
前記送信部は、前記分析部による分析結果に基づいて、前記データ収集部が収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する、
請求項8に記載のデータ収集装置。 - 前記データ収集部は、前記機械学習モデルの学習への影響度に基づいて、画像を撮影するカメラ又はイメージャの解像度、フレームレート、輝度、色彩、画角、視点位置、又は視線方向を変化させて撮影した画像データを収集する、
請求項8に記載のデータ収集装置。 - コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部と、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置。 - 前記生体情報は少なくとも脳波情報を含む、
請求項13に記載の情報処理装置。 - 前記セグメント抽出部は、コンテンツのうち高評価とポジティブな感情を持つ生体情報が一致しているセグメントを抽出する、
請求項13に記載の情報処理装置。 - 前記セグメント抽出部は、高評価とポジティブな感情を持つ生体情報が一致しないセグメントをさらに抽出する、
請求項15に記載の情報処理装置。 - 前記関係性推定部は、前後のセグメントとのコンテキストと、人物の顔の表情に基づいて、セグメントに写っている人物間の関係性を推定する、
請求項13に記載の情報処理装置。 - 前記関係性推定部は、前記コンテキストとして、過去のセグメントに写っている人物の顔検出及び検出顔の表情識別結果を用いて、現在のセグメントに写っている人物間の関係性を推定する、
請求項17に記載の情報処理装置。 - 前記セグメントに含まれる音声を認識して得られたテキスト情報に基づいて感情を分析する第1の感情分析部をさらに備え、
前記感動識別部は、前記第1の感情分析部がテキスト情報から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
請求項13に記載の情報処理装置。 - 前記セグメントに含まれる音楽を検出して、その音楽が与える感情を分析する第2の感情分析部をさらに備え、
前記感動識別部は、前記第2の感情分析部が音楽から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
請求項13に記載の情報処理装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022512040A JPWO2021200503A1 (ja) | 2020-03-31 | 2021-03-24 | |
| US17/906,761 US20230360437A1 (en) | 2020-03-31 | 2021-03-24 | Training system and data collection device |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020-065069 | 2020-03-31 | ||
| JP2020065069 | 2020-03-31 | ||
| JP2020-120049 | 2020-07-13 | ||
| JP2020120049 | 2020-07-13 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021200503A1 true WO2021200503A1 (ja) | 2021-10-07 |
Family
ID=77928815
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2021/012368 WO2021200503A1 (ja) | 2020-03-31 | 2021-03-24 | 学習システム及びデータ収集装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20230360437A1 (ja) |
| JP (1) | JPWO2021200503A1 (ja) |
| WO (1) | WO2021200503A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023119577A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| WO2023119578A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| US20230419722A1 (en) * | 2022-06-24 | 2023-12-28 | Microsoft Technology Licensing, Llc | Simulated capacitance measurements for facial expression recognition training |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6800453B1 (ja) * | 2020-05-07 | 2020-12-16 | 株式会社 情報システムエンジニアリング | 情報処理装置及び情報処理方法 |
| US20240037824A1 (en) * | 2022-07-26 | 2024-02-01 | Verizon Patent And Licensing Inc. | System and method for generating emotionally-aware virtual facial expressions |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185719A (ja) * | 1997-09-03 | 1999-03-30 | Matsushita Electric Ind Co Ltd | パラメータ推定装置 |
| WO2018030206A1 (ja) * | 2016-08-10 | 2018-02-15 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | カメラワーク生成方法及び映像処理装置 |
-
2021
- 2021-03-24 US US17/906,761 patent/US20230360437A1/en active Pending
- 2021-03-24 JP JP2022512040A patent/JPWO2021200503A1/ja active Pending
- 2021-03-24 WO PCT/JP2021/012368 patent/WO2021200503A1/ja active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185719A (ja) * | 1997-09-03 | 1999-03-30 | Matsushita Electric Ind Co Ltd | パラメータ推定装置 |
| WO2018030206A1 (ja) * | 2016-08-10 | 2018-02-15 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | カメラワーク生成方法及び映像処理装置 |
Non-Patent Citations (1)
| Title |
|---|
| NAOAKI YOKOI, MASASHI EGI: "A Study of Business Interpretation Technique for AI Predictions", IEICE TECHNICAL REPORT, vol. 118, no. 513 (PRMU2018-143), 10 March 2019 (2019-03-10), JP , pages 61 - 66, XP009536159, ISSN: 2432-6380 * |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023119577A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| WO2023119578A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| JPWO2023119577A1 (ja) * | 2021-12-23 | 2023-06-29 | ||
| JP7345689B1 (ja) * | 2021-12-23 | 2023-09-15 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| JP7437538B2 (ja) | 2021-12-23 | 2024-02-22 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| US20230419722A1 (en) * | 2022-06-24 | 2023-12-28 | Microsoft Technology Licensing, Llc | Simulated capacitance measurements for facial expression recognition training |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230360437A1 (en) | 2023-11-09 |
| JPWO2021200503A1 (ja) | 2021-10-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021200503A1 (ja) | 学習システム及びデータ収集装置 | |
| Mroueh et al. | Deep multimodal learning for audio-visual speech recognition | |
| WO2019085585A1 (zh) | 设备控制处理方法及装置 | |
| US20200371535A1 (en) | Automatic image capturing method and device, unmanned aerial vehicle and storage medium | |
| CN113052085B (zh) | 视频剪辑方法、装置、电子设备以及存储介质 | |
| US9661208B1 (en) | Enhancing video conferences | |
| US11509818B2 (en) | Intelligent photography with machine learning | |
| KR20210059576A (ko) | 인공 지능 기반의 영상 처리 방법 및 이를 수행하는 영상 처리 장치 | |
| US20220335246A1 (en) | System And Method For Video Processing | |
| CN114222077A (zh) | 视频处理方法、装置、存储介质及电子设备 | |
| CN113920354A (zh) | 一种基于事件相机的动作识别方法 | |
| KR20200111104A (ko) | 인공지능에 기반하여 영상을 분석하는 카메라 및 그것의 동작 방법 | |
| WO2021008025A1 (zh) | 基于语音识别的信息分析方法、装置和计算机设备 | |
| Youoku et al. | Multi-modal affect analysis using standardized data within subjects in the wild | |
| WO2022044367A1 (ja) | 機械学習装置及び遠赤外線撮像装置 | |
| JP6754154B1 (ja) | 翻訳プログラム、翻訳装置、翻訳方法、及びウェアラブル端末 | |
| KR20230173667A (ko) | Ai 기반 객체인식을 통한 감시 카메라의 셔터값 조절 | |
| Wang et al. | Blind Multimodal Quality Assessment of Low-light Images | |
| US8203593B2 (en) | Audio visual tracking with established environmental regions | |
| WO2022014143A1 (ja) | 撮像システム | |
| Al-Hames et al. | Automatic multi-modal meeting camera selection for video-conferences and meeting browsers | |
| TWI857242B (zh) | 光流資訊預測方法、裝置、電子設備和儲存媒體 | |
| CN118260380B (zh) | 多媒体情景互动数据的处理方法及系统 | |
| JP7572200B2 (ja) | キーワード抽出装置、キーワード抽出プログラム及び発話生成装置 | |
| CN117478824B (zh) | 会议视频生成方法、装置、电子设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21781058 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022512040 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 21781058 Country of ref document: EP Kind code of ref document: A1 |