JP7635779B2 - 学習システム及びデータ収集装置 - Google Patents
学習システム及びデータ収集装置 Download PDFInfo
- Publication number
- JP7635779B2 JP7635779B2 JP2022512040A JP2022512040A JP7635779B2 JP 7635779 B2 JP7635779 B2 JP 7635779B2 JP 2022512040 A JP2022512040 A JP 2022512040A JP 2022512040 A JP2022512040 A JP 2022512040A JP 7635779 B2 JP7635779 B2 JP 7635779B2
- Authority
- JP
- Japan
- Prior art keywords
- learning
- data
- unit
- emotion
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/174—Facial expression recognition
- G06V40/176—Dynamic expression
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/012—Head tracking input arrangements
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/015—Input arrangements based on nervous system activity detection, e.g. brain waves [EEG] detection, electromyograms [EMG] detection, electrodermal response detection
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G06N3/0442—Recurrent networks, e.g. Hopfield networks characterised by memory or gating, e.g. long short-term memory [LSTM] or gated recurrent units [GRU]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/091—Active learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/092—Reinforcement learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/098—Distributed learning, e.g. federated learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/25—Management operations performed by the server for facilitating the content distribution or administrating data related to end-users or client devices, e.g. end-user or client device authentication, learning user preferences for recommending movies
- H04N21/258—Client or end-user data management, e.g. managing client capabilities, user preferences or demographics, processing of multiple end-users preferences to derive collaborative data
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/16—Devices for psychotechnics; Testing reaction times ; Devices for evaluating the psychological state
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2203/00—Indexing scheme relating to G06F3/00 - G06F3/048
- G06F2203/01—Indexing scheme relating to G06F3/01
- G06F2203/011—Emotion or mood input determined on the basis of sensed human body parameters such as pulse, heart rate or beat, temperature of skin, facial expressions, iris, voice pitch, brain activity patterns
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Medical Informatics (AREA)
- Neurosurgery (AREA)
- Neurology (AREA)
- Dermatology (AREA)
- Computer Graphics (AREA)
- Signal Processing (AREA)
- Image Analysis (AREA)
Description
データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システムである。
機械学習モデルの学習を行う学習装置から、前記機械学習モデルの学習データの送信を要求する要求信号を受信する受信部と、
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置である。
コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部と、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置である。
B.感動を与えるコンテンツを生成する機械学習モデルに関するデータの収集処理を行うシステムの動作
C.コンテンツに含まれる人物間などの関係性の推定
D.感動識別
E.収集したデータを用いた学習プロセス
F.推論
G.アプリケーション
H.機械学習モデルの効率的学習
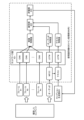
図1には、本開示に係るデータ収集処理を行うデータ収集システム100の機能的構成を模式的に示している。
図2には、データ収集システム100の動作をフローチャートの形式で示している。
この項では、関係性推定部113で実施される、映像中の人物間の関係性を推定する処理について、詳細に説明する。
この項では、感動識別部114で実施される、セグメントが与える感動を識別する処理について、詳細に説明する。
(2)音楽検出108及び第2の感情分析部111によるセグメント内の背景音楽の感情やムードの識別結果
(3)顔検出部109及び表情識別部112によるセグメントに写っている人物の表情の識別結果
(4)関係性推定部113によるセグメントに写っている人物間の関係性や親密度の推定結果
この項では、本開示に係るデータ収集システム100を用いて収集した学習データを利用して、感動識別機を訓練する学習プロセスについて、詳細に説明する。感動識別機は、コンテンツがどのような感動を与えるかを識別する装置である。ここで言う装置は、専用のハードウェアで構成される装置と、ソフトウェアを実行して所定の機能を実現する装置の両方を意味する。
上記A項では、データ収集システム100が、テレビやインターネット放送などのコンテンツからコンテンツ評価情報と脳波などの生体情報を利用してデータを収集する方法について説明した。また、上記E項では、データ収集システム100によって収集されたデータを用いて、感動識別機420の学習を行うプロセスについて説明した。
これまで説明してきたように、本開示に係るデータ収集システムが収集した学習データを使って、コンテンツが人間に与える感情を識別する感情識別機用の機械学習モデルを訓練することができる。また、このようにして開発した感情識別機にはさまざまなアプリケーションが期待される。
本開示に基づいて開発された感情識別機は、例えばデジタルカメラを始めとする、コンテンツの記録、再生、編集などコンテンツに対して処理を行うさまざまなコンテンツ処理装置に搭載することができる。
続いて、本開示に基づいて開発された感情識別機をデジタルカメラ500に搭載して実現される機能について説明する。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、カメラワークの支援や自動制御を行うことができる。例えば、感動の度合いが増すように、あるいは特定の種類の感動識別ラベルを獲得できるように、被写体を撮影する視線方向やズームを自動制御したり、又は撮影画像の輝度、色彩、画角、構図、フォーカスなどを自動制御したり、表示部516のガイダンス表示や音再生部517からの音声ガイダンスを使っておすすめのアングルを教えたりするようにしてもよい。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、映像のシーンに対して適切で、且つ感動の度合いが増すようなキャプションを自動付与することができる。
デジタルカメラ500で撮影したコンテンツを感動識別機にかけて得られた結果に基づいて、映像のシーンに対して適切で、且つ感動の度合いが増すような背景音楽を自動付与することができる。
上記G項で説明したように、本開示によれば、デジタルカメラ500にニューラルネットワークモデルを搭載することにより、コンテンツ(又は、コンテンツを構成するセグメント毎)に感動のレベルを表す感動識別ラベルを付与したり、高レベルの感動が得られるコンテンツを撮影するためのカメラワークの支援又は制御(カメラの自動操作)を提供したり、コンテンツの感動スコアを向上させるためのキャプションや背景音楽を付与したりすることができる。このH項では、デジタルカメラ500に搭載されたニューラルネットワークモデルを効率的に学習するための方法について説明する。
図10には、カメラの操作支援や自動操作のためのニューラルネットワークモデルを効率的に学習するための学習システム1000の構成を模式的に示している。本実施形態では、学習の対象とするニューラルネットワークモデルとして、主に、感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定するニューラルネットワークモデルを想定している。もちろん、学習システム1000を使って、その他のタイプのニューラルネットワークモデルの学習にも活用することができる。
図10に示した学習システム1000において利用されるニューラルネットワークモデルについて説明しておく。学習システム1000では、学習装置1030は、データ収集装置1040によって収集されたデータを使って、「観測予測モデル」、「操作モデル」、「操作推定モデル」、「感動スコア推定モデル」などのニューラルネットワークの学習及び再学習を行う。また、モデル利用装置1020は、学習装置1030によって学習が行われたこれらのニューラルネットワークモデルのうち少なくとも一部を利用する。
図11には、観測予測モデル1100の構成を模式的に示している。観測予測モデル1100は、カメラで撮影した現時刻までの映像情報1101と、カメラに対する現時刻までの操作情報1102から、次の時刻にカメラで撮影される画像(すなわち、「次の時刻の画像」)1111を予測するニューラルネットワークモデルである。
学習システム1000では、学習装置1030が、データ収集装置1010から送信された映像情報と操作情報からなるデータセットに基づいて、観測予測モデル1100の学習を行うことができる。学習装置1030は、強化学習により、より感動を与えることができる画像を予測できるように観測予測モデル1100の学習を行うことができる。また、データ分析装置1040は、データ収集装置1010から送信されたデータセットの中から有意義な学習データを抽出し、学習装置1030はこの有意義な学習データを用いて観測予測モデル1100の再学習を効率的に行うことができる。
図12には、操作モデル1200の構成を模式的に示している。操作モデル1200は、カメラで撮影した現時刻までの映像情報1201と、カメラに対する現時刻までの操作情報1202から、次の時刻にカメラに対して行われる操作1211を予測するニューラルネットワークモデルである。また、操作モデル1200は、予測した次の時刻の操作1211に対する信頼度スコア1212も併せて出力する。信頼度スコア1212は、次の時刻の画像1111がどの程度正しく予測できているかを示す値である。あるいは、データ分析装置1040が、XAIによる操作モデル1200の予測の根拠の説明、信頼度スコア計算、影響関数計算、ベイジアンDNNによるデータ不足推定などの手法に基づいて、操作モデル1200の学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを抽出する。操作モデル1200による信頼度スコア1212の計算機能は、データ分析装置1040の一部として実装されていてもよい。
図13には、操作推定モデル1300の構成を模式的に示している。操作推定モデル1300は、現時刻までの映像時系列情報1301をカメラで撮影するための時系列操作情報1311を推定するニューラルネットワークモデルである。例えば、操作推定モデル1300を使って、プロのカメラマンなどカメラ操作に精通したエキスパートが撮影した高品質な映像時系列情報から、エキスパートが行うカメラの時系列操作情報を推定することができる。
図14には、感動スコア推定モデル1400の構成を模式的に示している。感動スコア推定モデル1400は、映像情報1401の感動スコア1411を推定するニューラルネットワークモデルであり、上記の感情識別機に相当する。例えば図4に示した学習プロセスに従って、感動スコア推定モデル1400の学習を行うことができる。
学習システム1000では、データ分析装置1040が、学習対象となるニューラルネットワークモデルの学習データを分析して、学習に所定以上の影響を及ぼす学習データや不足している学習データ、これらに類似するデータなど、有意義な学習データを特定して、学習装置1020はそのような有意義な学習データを用いてニューラルネットワークモデルの効率的な学習や再学習を行う。
図16に示すように、ニューラルネットワークモデル1500において、本来の出力とともに、その出力の誤差を信頼度スコアとして出力するように学習する。
Image Augmentation(画像拡張)及びDropoutなど乱数を用い、入力データや中間ニューロンの構成に摂動を加え、摂動の下でも正しい予測が得られるような学習を行う。推論時は摂動を加えながら何度も推定を行う。結果の分散が大きいほど、信頼度スコアが低いことを表す。
0.0~1.0の確率で予測が得られる分類問題の場合、0.0、1.0などの結果が得られた場合は信頼度スコアが高い、2値分類の場合は0.5(50%に近い)、他クラス分類の場合は最も確率の高いクラスの確率が低い場合は信頼度スコアが低いと判断できる。
データ収集装置1010は、スチルカメラやビデオカメラ、カメラで使用されるイメージセンサー、スマートフォンなどの多機能情報端末、TV、ヘッドホン又はイヤホン、ゲーム機、冷蔵庫や洗濯機などのIoTデバイス、ドローンやロボットなどの移動体装置など、多種類の装置である。
図19には、学習装置1030の内部構成例を示している。図19に示す学習装置1030は、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035と、データ分析部1036を備えている。
図22には、モデル利用装置1020の内部構成例を示している。モデル利用装置1020は、センサー部1021と、自動操作部1022と、制御部1023と、提示部1024を備えている。
学習済みのニューラルネットワークモデルを利用するモデル利用装置1020が、ニューラルネットワークモデルの学習を行う学習装置の機能と一体となって構成されること(すなわち、エッジAI)も想定される。図23には、エッジAIとしてのモデル利用装置1020の内部構成例を示している。図示のモデル利用装置1020は、センサー部1021と、自動操作部1022と、制御部1023と、提示部1024に加えて、モデル学習部1031と、観測・操作ログ蓄積部1032と、観測予測モデル・操作モデル蓄積部1033と、操作推定モデル蓄積部1034と、操作推定部1035を備えている。
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システム。
上記(1)に記載の学習システム。
上記(1)又は(2)のいずれかに記載の学習システム。
前記データ収集装置は、受信した前記要求信号に基づいて収集したデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
上記(1)乃至(3)のいずれかに記載の学習システム。
上記(1)乃至(4)のいずれかに記載の学習システム。
前記データ収集装置は、収集したデータが前記機械学習モデルの学習に与える影響を分析した結果に基づいて、前記収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
上記(1)乃至(3)のいずれかに記載の学習システム。
上記(6)に記載の学習システム。
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置。
前記データ収集部は、受信した前記要求信号に基づいてデータを収集し、
前記送信部は、前記データ収集部が収集したデータを前記学習装置に送信する、
上記(8)に記載のデータ収集装置。
上記(9)に記載のデータ収集装置。
前記送信部は、前記分析部による分析結果に基づいて、前記データ収集部が収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する、
上記(8)に記載のデータ収集装置。
上記(8)乃至(11)のいずれかに記載のデータ収集装置。
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備する情報処理装置。
上記(13)に記載の情報処理装置。
上記(13)又は(14)のいずれかに記載の情報処理装置。
上記(15)に記載の情報処理装置。
上記(13)乃至(16)のいずれかに記載の情報処理装置。
上記(17)に記載の情報処理装置。
前記感動識別部は、前記第1の感情分析部がテキスト情報から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
上記(13)乃至(18)のいずれかに記載の情報処理装置。
前記感動識別部は、前記第2の感情分析部が音楽から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
上記(13)乃至(19)のいずれかに記載の情報処理装置。
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別ステップと、
セグメントに写っている人物間の関係性を推定する関係性推定ステップと、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別ステップと、
を有する情報処理方法。
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部、
セグメントに写っている人物間の関係性を推定する関係性推定部、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部、
としてコンピュータを機能させるようにコンピュータ可読形式で記述されたコンピュータプログラム。
機械学習モデルにコンテンツを入力するステップと、
前記機械学習モデルが前記コンテンツから推定した映像特徴量を獲得するステップと、
前記機械学習モデルが前記コンテンツから推定したオーディオ特徴量を獲得するステップと、
前記機械学習モデルが前記コンテンツから推定した音声のテキスト特徴量を獲得するステップと、
前記機械学習モデルが推定した映像特徴量、オーディオ特徴量、及びテキスト特徴量に基づいてコンテンツの感動ラベルを識別するステップと、
前記識別した感動ラベルと前記コンテンツに付けられた感動ラベルとの誤差に基づく損失関数を計算するステップと、
前記損失関数に基づいて前記機械学習モデルのパラメータを更新するステップと、
を有する学習済み機械学習モデルの生成方法。
上記(23)に記載の学習済み機械学習モデルの生成方法。
102…コンテンツ評価情報取得部、103…生体情報取得部
104…比較部、105…セグメント抽出部
106…コンテキスト抽出部、107…音声認識部
108…音楽検出部、109…顔検出部
110…第1の感情分析部、111…第2の感情分析部
112…表情識別部、113…関係性推定部
114…感動識別部
410…データ蓄積部、420…感動識別機
421…ネットワーク部、422…識別部、423…評価部
500…デジタルカメラ、501…光学系、502…撮像部
503…AFE部、504…カメラ信号処理部、506…メイン処理部
514…マイク、515…A/D変換部、516…表示部
517…音再生部、518…記録部
1000…学習システム、1010…データ収集装置
1011…センサー部、1012…操作入力部、1013…制御部
1014…ログ送信部、1015…データ分析部
1020…モデル利用装置、1021…センサー部
1022…自動操作部、1023…制御部、1024…提示部
1030…学習装置、1031…モデル学習部
1032…観測・操作ログ蓄積部
1033…観測予測モデル・操作モデル蓄積部
1034…操作推定モデル蓄積部、1035…操作推定部
1036…データ分析部、1037…データ分析部
1040…データ分析装置
1100…観測予測モデル、1200…操作モデル
1300…操作推定モデル、1400…感動スコア推定モデル
Claims (19)
- 感動するコンテンツを生成し又は感動するコンテンツを撮影するためのカメラ操作を推定する機械学習モデルの学習を行うための学習システムであって、
データを収集するデータ収集装置と、前記データ収集装置が収集したデータを用いて機械学習モデルの学習を行う学習装置を備え、
前記データ収集装置は、カメラで撮影した画像データ及び前記カメラの撮影時の操作情報を含む学習データを収集し、
前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析した結果に基づいて収集した、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを用いて、前記機械学習モデルの再学習を行う、
学習システム。 - XAI(Explainable AI)、信頼度スコア計算、影響関数、又はベイジアンDNNによる前記分析を行う、
請求項1に記載の学習システム。 - 前記学習装置は、前記機械学習モデルの学習に影響を与える学習データを分析し、その分析結果に基づいて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータの送信を要求する要求信号を前記データ収集装置に送信し、
前記データ収集装置は、受信した前記要求信号に基づいて収集したデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
請求項1に記載の学習システム。 - 前記データ収集装置は、画像を撮影するカメラ又はイメージャであり、前記機械学習モデルの学習への影響度に基づいて、解像度、フレームレート、輝度、色彩、画角、視点位置、又は視線方向を変化させて撮影した画像データを前記学習装置に送信する、
請求項1に記載の学習システム。 - 前記学習装置は、前記機械学習モデルの学習データの送信を要求する要求信号を前記データ収集装置に送信し、
前記データ収集装置は、収集したデータが前記機械学習モデルの学習に与える影響を分析した結果に基づいて、前記収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信し、
前記学習装置は、前記要求信号に応じて前記データ収集装置から送信されたデータに基づいて前記機械学習モデルの再学習を行う、
請求項1に記載の学習システム。 - 前記学習装置は、前記要求信号の送信時に、前記分析に必要な情報を前記データ収集装置に送信する、
請求項5に記載の学習システム。 - 請求項1に記載の学習システムにおける前記学習装置から、前記機械学習モデルの学習データの送信を要求する要求信号を受信する受信部と、
前記要求信号を受信したことに応じて、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを収集するデータ収集部と、
前記データ収集部が収集したデータを前記学習装置に送信する送信部と、
を具備するデータ収集装置。 - 前記受信部は、前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを要求する前記要求信号を前記学習装置から受信し、
前記データ収集部は、受信した前記要求信号に基づいてデータを収集し、
前記送信部は、前記データ収集部が収集したデータを前記学習装置に送信する、
請求項7に記載のデータ収集装置。 - 前記データ収集部は受信した前記要求信号に基づいて新たにデータを収集し、又は、前記送信部は前記データ収集部が既に収集したデータから前記要求信号に基づいて抽出したデータを送信する、
請求項8に記載のデータ収集装置。 - 前記データ収集部が収集したデータが前記機械学習モデルの学習に与える影響を分析する分析部をさらに備え、
前記送信部は、前記分析部による分析結果に基づいて、前記データ収集部が収集したデータのうち前記機械学習モデルの学習に所定以上の影響を及ぼす学習データ、不足している学習データ、又はこれらに類似するデータを前記学習装置に送信する、
請求項7に記載のデータ収集装置。 - 前記データ収集部は、前記機械学習モデルの学習への影響度に基づいて、画像を撮影するカメラ又はイメージャの解像度、フレームレート、輝度、色彩、画角、視点位置、又は視線方向を変化させて撮影した画像データを収集する、
請求項7に記載のデータ収集装置。 - コンテンツのコンテンツ評価情報とコンテンツを視聴する人間の生体情報に基づいて、コンテンツからセグメントを抽出するセグメント抽出部と、
セグメントに写っている人物の顔を検出して顔の表情を識別する表情識別部と、
セグメントに写っている人物間の関係性を推定する関係性推定部と、
セグメントに写っている人物の顔の表情と、人物間の関係性に基づいてセグメントの感動ラベルを識別する感動識別部と、
を具備し、
前記感動識別部は、請求項1に記載の学習システムにおける前記学習装置が学習を行った感動スコア推定モデルを用いて感動ラベルを識別する、
情報処理装置。 - 前記生体情報は少なくとも脳波情報を含む、
請求項12に記載の情報処理装置。 - 前記セグメント抽出部は、コンテンツのうち高評価とポジティブな感情を持つ生体情報が一致しているセグメントを抽出する、
請求項12に記載の情報処理装置。 - 前記セグメント抽出部は、高評価とポジティブな感情を持つ生体情報が一致しないセグメントをさらに抽出する、
請求項14に記載の情報処理装置。 - 前記関係性推定部は、前後のセグメントとのコンテキストと、人物の顔の表情に基づいて、セグメントに写っている人物間の関係性を推定する、
請求項12に記載の情報処理装置。 - 前記関係性推定部は、前記コンテキストとして、過去のセグメントに写っている人物の顔検出及び検出顔の表情識別結果を用いて、現在のセグメントに写っている人物間の関係性を推定する、
請求項16に記載の情報処理装置。 - 前記セグメントに含まれる音声を認識して得られたテキスト情報に基づいて感情を分析する第1の感情分析部をさらに備え、
前記感動識別部は、前記第1の感情分析部がテキスト情報から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
請求項12に記載の情報処理装置。 - 前記セグメントに含まれる音楽を検出して、その音楽が与える感情を分析する第2の感情分析部をさらに備え、
前記感動識別部は、前記第2の感情分析部が音楽から識別した感情をさらに考慮して、セグメントの感動ラベルを識別する、
請求項12に記載の情報処理装置。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020065069 | 2020-03-31 | ||
| JP2020065069 | 2020-03-31 | ||
| JP2020120049 | 2020-07-13 | ||
| JP2020120049 | 2020-07-13 | ||
| PCT/JP2021/012368 WO2021200503A1 (ja) | 2020-03-31 | 2021-03-24 | 学習システム及びデータ収集装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2021200503A1 JPWO2021200503A1 (ja) | 2021-10-07 |
| JP7635779B2 true JP7635779B2 (ja) | 2025-02-26 |
Family
ID=77928815
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022512040A Active JP7635779B2 (ja) | 2020-03-31 | 2021-03-24 | 学習システム及びデータ収集装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20230360437A1 (ja) |
| JP (1) | JP7635779B2 (ja) |
| WO (1) | WO2021200503A1 (ja) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6800453B1 (ja) * | 2020-05-07 | 2020-12-16 | 株式会社 情報システムエンジニアリング | 情報処理装置及び情報処理方法 |
| CN117615709A (zh) * | 2021-07-15 | 2024-02-27 | 索尼集团公司 | 信号处理设备和方法 |
| EP4137801B1 (en) * | 2021-08-17 | 2025-09-24 | Hitachi High-Tech Analytical Science Finland Oy | Monitoring reliability of analysis of elemental composition of a sample |
| KR20230089215A (ko) * | 2021-12-13 | 2023-06-20 | 삼성전자주식회사 | 획득된 정보에 기반하여 화면을 구성하기 위한 전자 장치 및 방법 |
| US20240232675A1 (en) * | 2021-12-23 | 2024-07-11 | Rakuten Group, Inc. | Information processing system, information processing method and program |
| WO2023119578A1 (ja) * | 2021-12-23 | 2023-06-29 | 楽天グループ株式会社 | 情報処理システム、情報処理方法及びプログラム |
| JP2023106888A (ja) * | 2022-01-21 | 2023-08-02 | オムロン株式会社 | 情報処理装置および情報処理方法 |
| US12327430B2 (en) * | 2022-06-24 | 2025-06-10 | Microsoft Technology Licensing, Llc | Simulated capacitance measurements for facial expression recognition training |
| US12450806B2 (en) * | 2022-07-26 | 2025-10-21 | Verizon Patent And Licensing Inc. | System and method for generating emotionally-aware virtual facial expressions |
| US12347135B2 (en) * | 2022-11-14 | 2025-07-01 | Adobe Inc. | Generating gesture reenactment video from video motion graphs using machine learning |
| US20240371397A1 (en) * | 2023-05-03 | 2024-11-07 | KAI Conversations Limited | System for processing text, image and audio signals using artificial intelligence and method thereof |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008269065A (ja) | 2007-04-17 | 2008-11-06 | Nippon Telegr & Teleph Corp <Ntt> | ユーザ支援方法、ユーザ支援装置およびユーザ支援プログラム |
| JP2009111938A (ja) | 2007-11-01 | 2009-05-21 | Nippon Telegr & Teleph Corp <Ntt> | 情報編集装置、情報編集方法、情報編集プログラムおよびそのプログラムを記録した記録媒体 |
| JP2010093584A (ja) | 2008-10-08 | 2010-04-22 | Nippon Telegr & Teleph Corp <Ntt> | 視聴印象推定方法及び装置及びプログラム及びコンピュータ読み取り可能な記録媒体 |
| JP2012160082A (ja) | 2011-02-01 | 2012-08-23 | Bond:Kk | 入力支援装置、入力支援方法及びプログラム |
| WO2018030206A1 (ja) | 2016-08-10 | 2018-02-15 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | カメラワーク生成方法及び映像処理装置 |
| WO2019215778A1 (ja) | 2018-05-07 | 2019-11-14 | 日本電気株式会社 | データ提供システムおよびデータ収集システム |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1185719A (ja) * | 1997-09-03 | 1999-03-30 | Matsushita Electric Ind Co Ltd | パラメータ推定装置 |
| US10726078B2 (en) * | 2017-05-09 | 2020-07-28 | Oath Inc. | Method and system for dynamic score floor modeling and application thereof |
| US11210504B2 (en) * | 2017-09-06 | 2021-12-28 | Hitachi Vantara Llc | Emotion detection enabled video redaction |
| CN113168439A (zh) * | 2019-02-22 | 2021-07-23 | 居米奥公司 | 为算法决定提供结果解释 |
| US11393144B2 (en) * | 2019-04-11 | 2022-07-19 | City University Of Hong Kong | System and method for rendering an image |
-
2021
- 2021-03-24 JP JP2022512040A patent/JP7635779B2/ja active Active
- 2021-03-24 US US17/906,761 patent/US20230360437A1/en active Pending
- 2021-03-24 WO PCT/JP2021/012368 patent/WO2021200503A1/ja not_active Ceased
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008269065A (ja) | 2007-04-17 | 2008-11-06 | Nippon Telegr & Teleph Corp <Ntt> | ユーザ支援方法、ユーザ支援装置およびユーザ支援プログラム |
| JP2009111938A (ja) | 2007-11-01 | 2009-05-21 | Nippon Telegr & Teleph Corp <Ntt> | 情報編集装置、情報編集方法、情報編集プログラムおよびそのプログラムを記録した記録媒体 |
| JP2010093584A (ja) | 2008-10-08 | 2010-04-22 | Nippon Telegr & Teleph Corp <Ntt> | 視聴印象推定方法及び装置及びプログラム及びコンピュータ読み取り可能な記録媒体 |
| JP2012160082A (ja) | 2011-02-01 | 2012-08-23 | Bond:Kk | 入力支援装置、入力支援方法及びプログラム |
| WO2018030206A1 (ja) | 2016-08-10 | 2018-02-15 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | カメラワーク生成方法及び映像処理装置 |
| WO2019215778A1 (ja) | 2018-05-07 | 2019-11-14 | 日本電気株式会社 | データ提供システムおよびデータ収集システム |
Non-Patent Citations (2)
| Title |
|---|
| 横井直明 ほか,"AIの予測結果に対する納得度を高める予測根拠解釈支援技術の提案",電子情報通信学会技術研究報告,一般社団法人電子情報通信学会,2019年03月10日,Vol. 118,No. 513,p. 61-66 |
| 猪貝光祥,"ディープラーニング技術を用いた高速な画像認識ソリューション",月刊自動認識,2020年03月10日,Vol. 33,No .3,p. 33-38,ISSN: 0915-1060 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021200503A1 (ja) | 2021-10-07 |
| WO2021200503A1 (ja) | 2021-10-07 |
| US20230360437A1 (en) | 2023-11-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7635779B2 (ja) | 学習システム及びデータ収集装置 | |
| WO2019085585A1 (zh) | 设备控制处理方法及装置 | |
| US20190332952A1 (en) | Learning device, image pickup apparatus, image processing device, learning method, non-transient computer-readable recording medium for recording learning program, display control method and inference model manufacturing method | |
| KR20100055946A (ko) | 동영상 썸네일 생성 방법 및 장치 | |
| US20220335246A1 (en) | System And Method For Video Processing | |
| TWI857242B (zh) | 光流資訊預測方法、裝置、電子設備和儲存媒體 | |
| CN116453022A (zh) | 一种基于多模态融合和Transformer网络的视频情感内容分析方法 | |
| Vacher et al. | The CIRDO corpus: comprehensive audio/video database of domestic falls of elderly people | |
| US20150281586A1 (en) | Method and apparatus for forming a video sequence | |
| CN116016978B (zh) | 在线课堂的画面导播方法、装置、电子设备及存储介质 | |
| US11509818B2 (en) | Intelligent photography with machine learning | |
| KR101839406B1 (ko) | 디스플레이장치 및 그 제어방법 | |
| WO2023149135A1 (ja) | 画像処理装置、画像処理方法及びプログラム | |
| CN115035007A (zh) | 基于像素级对齐生成对抗网络的人脸老化系统及建立方法 | |
| Chen et al. | Hierarchical cross-modal talking face generationwith dynamic pixel-wise loss | |
| CN120434504A (zh) | 一种基于跨模态蒸馏的声视协同调焦方法、装置及设备 | |
| CN108810398A (zh) | 图像处理装置、图像处理方法以及记录介质 | |
| CN104780341B (zh) | 一种信息处理方法以及信息处理装置 | |
| US20240348885A1 (en) | System and method for question answering | |
| JP2017041857A (ja) | 画像処理装置、その制御方法、プログラム及び撮像装置 | |
| US11523047B2 (en) | Imaging device, imaging method, and program | |
| Vrochidis et al. | A Deep Learning Framework for Monitoring Audience Engagement in Online Video Events | |
| CN115174845A (zh) | 一种针对视频会议中特殊行为动作的特写拍摄方法及装置 | |
| CN114296589A (zh) | 一种基于影片观看体验的虚拟现实交互方法及装置 | |
| US8203593B2 (en) | Audio visual tracking with established environmental regions |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240202 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240827 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20241009 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250127 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7635779 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |