WO2002028891A2 - Listeria innocua, genome et applications - Google Patents
Listeria innocua, genome et applications Download PDFInfo
- Publication number
- WO2002028891A2 WO2002028891A2 PCT/FR2001/003061 FR0103061W WO0228891A2 WO 2002028891 A2 WO2002028891 A2 WO 2002028891A2 FR 0103061 W FR0103061 W FR 0103061W WO 0228891 A2 WO0228891 A2 WO 0228891A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- monocytogenes
- unknown
- listeria monocytogenes
- former
- Prior art date
Links
- 241000186781 Listeria Species 0.000 title claims abstract description 53
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 184
- 239000002773 nucleotide Substances 0.000 claims abstract description 181
- 241000186779 Listeria monocytogenes Species 0.000 claims abstract description 88
- 241000751185 Listeria monocytogenes ATCC 19115 Species 0.000 claims description 898
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 262
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 258
- 229920001184 polypeptide Polymers 0.000 claims description 242
- 108090000623 proteins and genes Proteins 0.000 claims description 241
- 102000004169 proteins and genes Human genes 0.000 claims description 187
- 241000186805 Listeria innocua Species 0.000 claims description 150
- 238000000034 method Methods 0.000 claims description 132
- 239000012634 fragment Substances 0.000 claims description 104
- 244000005700 microbiome Species 0.000 claims description 76
- 239000000523 sample Substances 0.000 claims description 70
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 67
- 210000004027 cell Anatomy 0.000 claims description 54
- 108020004414 DNA Proteins 0.000 claims description 48
- 150000007523 nucleic acids Chemical class 0.000 claims description 47
- 241000894006 Bacteria Species 0.000 claims description 46
- 230000014509 gene expression Effects 0.000 claims description 42
- 150000001875 compounds Chemical class 0.000 claims description 38
- 102000039446 nucleic acids Human genes 0.000 claims description 36
- 108020004707 nucleic acids Proteins 0.000 claims description 36
- 238000001514 detection method Methods 0.000 claims description 34
- 239000000203 mixture Substances 0.000 claims description 34
- 239000013598 vector Substances 0.000 claims description 33
- 150000001413 amino acids Chemical class 0.000 claims description 32
- 239000012472 biological sample Substances 0.000 claims description 31
- 238000009396 hybridization Methods 0.000 claims description 31
- 238000013518 transcription Methods 0.000 claims description 30
- 230000035897 transcription Effects 0.000 claims description 30
- 238000000018 DNA microarray Methods 0.000 claims description 27
- 230000003321 amplification Effects 0.000 claims description 27
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 27
- 230000008569 process Effects 0.000 claims description 26
- 229960005486 vaccine Drugs 0.000 claims description 26
- 230000015572 biosynthetic process Effects 0.000 claims description 25
- 241000440393 Listeria monocytogenes EGD-e Species 0.000 claims description 23
- 241001465754 Metazoa Species 0.000 claims description 23
- 102000040430 polynucleotide Human genes 0.000 claims description 23
- 108091033319 polynucleotide Proteins 0.000 claims description 23
- 239000002157 polynucleotide Substances 0.000 claims description 23
- 238000003786 synthesis reaction Methods 0.000 claims description 21
- 208000015181 infectious disease Diseases 0.000 claims description 18
- 230000010076 replication Effects 0.000 claims description 18
- 230000004060 metabolic process Effects 0.000 claims description 16
- 239000013612 plasmid Substances 0.000 claims description 16
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 15
- 238000006243 chemical reaction Methods 0.000 claims description 15
- 239000003153 chemical reaction reagent Substances 0.000 claims description 15
- 230000000295 complement effect Effects 0.000 claims description 15
- 230000027455 binding Effects 0.000 claims description 14
- 239000000427 antigen Substances 0.000 claims description 13
- 108091007433 antigens Proteins 0.000 claims description 13
- 102000036639 antigens Human genes 0.000 claims description 13
- 230000001939 inductive effect Effects 0.000 claims description 13
- 230000002163 immunogen Effects 0.000 claims description 12
- 230000001105 regulatory effect Effects 0.000 claims description 12
- 230000035772 mutation Effects 0.000 claims description 11
- 230000006870 function Effects 0.000 claims description 10
- 230000007170 pathology Effects 0.000 claims description 10
- 230000001413 cellular effect Effects 0.000 claims description 9
- 230000002401 inhibitory effect Effects 0.000 claims description 9
- 241001426082 Listeria monocytogenes serotype 4b Species 0.000 claims description 8
- 239000002299 complementary DNA Substances 0.000 claims description 8
- LWGJTAZLEJHCPA-UHFFFAOYSA-N n-(2-chloroethyl)-n-nitrosomorpholine-4-carboxamide Chemical compound ClCCN(N=O)C(=O)N1CCOCC1 LWGJTAZLEJHCPA-UHFFFAOYSA-N 0.000 claims description 8
- 238000002360 preparation method Methods 0.000 claims description 8
- 230000002285 radioactive effect Effects 0.000 claims description 8
- 238000013519 translation Methods 0.000 claims description 8
- 108020004635 Complementary DNA Proteins 0.000 claims description 7
- 230000004544 DNA amplification Effects 0.000 claims description 6
- 241000282412 Homo Species 0.000 claims description 6
- 241000282414 Homo sapiens Species 0.000 claims description 6
- 239000008194 pharmaceutical composition Substances 0.000 claims description 6
- 230000002265 prevention Effects 0.000 claims description 6
- 210000001236 prokaryotic cell Anatomy 0.000 claims description 6
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 5
- 230000008105 immune reaction Effects 0.000 claims description 5
- 230000028993 immune response Effects 0.000 claims description 5
- 108020005187 Oligonucleotide Probes Proteins 0.000 claims description 4
- 239000002671 adjuvant Substances 0.000 claims description 4
- 235000014113 dietary fatty acids Nutrition 0.000 claims description 4
- 229940079593 drug Drugs 0.000 claims description 4
- 239000003814 drug Substances 0.000 claims description 4
- 229930195729 fatty acid Natural products 0.000 claims description 4
- 239000000194 fatty acid Substances 0.000 claims description 4
- 150000004665 fatty acids Chemical class 0.000 claims description 4
- 230000036039 immunity Effects 0.000 claims description 4
- 238000002955 isolation Methods 0.000 claims description 4
- 238000004519 manufacturing process Methods 0.000 claims description 4
- 239000002777 nucleoside Substances 0.000 claims description 4
- 125000003835 nucleoside group Chemical group 0.000 claims description 4
- 239000002751 oligonucleotide probe Substances 0.000 claims description 4
- 150000003904 phospholipids Chemical class 0.000 claims description 4
- 238000012545 processing Methods 0.000 claims description 4
- 150000003212 purines Chemical class 0.000 claims description 4
- 150000003230 pyrimidines Chemical class 0.000 claims description 4
- 230000035945 sensitivity Effects 0.000 claims description 4
- 230000001486 biosynthesis of amino acids Effects 0.000 claims description 3
- 230000010261 cell growth Effects 0.000 claims description 3
- 230000037149 energy metabolism Effects 0.000 claims description 3
- 239000013604 expression vector Substances 0.000 claims description 3
- 230000009711 regulatory function Effects 0.000 claims description 3
- 238000010839 reverse transcription Methods 0.000 claims description 3
- 238000010367 cloning Methods 0.000 claims description 2
- 230000008030 elimination Effects 0.000 claims description 2
- 238000003379 elimination reaction Methods 0.000 claims description 2
- 230000002779 inactivation Effects 0.000 claims description 2
- 230000002018 overexpression Effects 0.000 claims description 2
- 238000011002 quantification Methods 0.000 claims description 2
- 230000024932 T cell mediated immunity Effects 0.000 claims 1
- 239000013599 cloning vector Substances 0.000 claims 1
- 230000028996 humoral immune response Effects 0.000 claims 1
- 238000010835 comparative analysis Methods 0.000 abstract description 2
- 230000000875 corresponding effect Effects 0.000 description 743
- 235000018102 proteins Nutrition 0.000 description 179
- 241001515965 unidentified phage Species 0.000 description 54
- 239000013615 primer Substances 0.000 description 30
- 102000008579 Transposases Human genes 0.000 description 28
- 108010020764 Transposases Proteins 0.000 description 28
- 101710100170 Unknown protein Proteins 0.000 description 27
- 235000014469 Bacillus subtilis Nutrition 0.000 description 26
- 229940024606 amino acid Drugs 0.000 description 22
- 235000001014 amino acid Nutrition 0.000 description 22
- 102000004190 Enzymes Human genes 0.000 description 17
- 108090000790 Enzymes Proteins 0.000 description 17
- 229940088598 enzyme Drugs 0.000 description 17
- 108700010839 phage proteins Proteins 0.000 description 17
- MSFSPUZXLOGKHJ-UHFFFAOYSA-N Muraminsaeure Natural products OC(=O)C(C)OC1C(N)C(O)OC(CO)C1O MSFSPUZXLOGKHJ-UHFFFAOYSA-N 0.000 description 16
- 108010013639 Peptidoglycan Proteins 0.000 description 16
- 210000004899 c-terminal region Anatomy 0.000 description 15
- 230000000694 effects Effects 0.000 description 12
- 239000002987 primer (paints) Substances 0.000 description 12
- 102000005416 ATP-Binding Cassette Transporters Human genes 0.000 description 11
- 108010006533 ATP-Binding Cassette Transporters Proteins 0.000 description 11
- 108010052285 Membrane Proteins Proteins 0.000 description 11
- 108091034117 Oligonucleotide Chemical group 0.000 description 11
- 241001641686 Lactococcus phage bIL285 Species 0.000 description 10
- 102000018697 Membrane Proteins Human genes 0.000 description 10
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 108091011108 ATP binding proteins Proteins 0.000 description 8
- 102000021527 ATP binding proteins Human genes 0.000 description 8
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 8
- 235000013305 food Nutrition 0.000 description 8
- 230000012010 growth Effects 0.000 description 8
- 239000000047 product Substances 0.000 description 8
- 230000002103 transcriptional effect Effects 0.000 description 8
- 108010061833 Integrases Proteins 0.000 description 7
- 108700026244 Open Reading Frames Proteins 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 7
- 238000011109 contamination Methods 0.000 description 7
- 230000028327 secretion Effects 0.000 description 7
- GUBGYTABKSRVRQ-CUHNMECISA-N D-Cellobiose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-CUHNMECISA-N 0.000 description 6
- 102100034343 Integrase Human genes 0.000 description 6
- 108091000080 Phosphotransferase Proteins 0.000 description 6
- 238000010168 coupling process Methods 0.000 description 6
- 238000005859 coupling reaction Methods 0.000 description 6
- 150000002894 organic compounds Chemical class 0.000 description 6
- 230000001717 pathogenic effect Effects 0.000 description 6
- 102000020233 phosphotransferase Human genes 0.000 description 6
- 238000006467 substitution reaction Methods 0.000 description 6
- 230000014616 translation Effects 0.000 description 6
- 241000701950 Bacillus phage phi105 Species 0.000 description 5
- 108010078791 Carrier Proteins Proteins 0.000 description 5
- 241000588724 Escherichia coli Species 0.000 description 5
- 206010024641 Listeriosis Diseases 0.000 description 5
- 108010090665 Mannosyl-Glycoprotein Endo-beta-N-Acetylglucosaminidase Proteins 0.000 description 5
- 102100030397 N-acetylmuramoyl-L-alanine amidase Human genes 0.000 description 5
- RSPISYXLHRIGJD-UHFFFAOYSA-N OOOO Chemical compound OOOO RSPISYXLHRIGJD-UHFFFAOYSA-N 0.000 description 5
- RRCYYLHJWRYWEI-UHFFFAOYSA-N OOOOOOOOOOOOOOOOOOOOO Chemical compound OOOOOOOOOOOOOOOOOOOOO RRCYYLHJWRYWEI-UHFFFAOYSA-N 0.000 description 5
- 108090000854 Oxidoreductases Proteins 0.000 description 5
- 102000004316 Oxidoreductases Human genes 0.000 description 5
- 108091005804 Peptidases Proteins 0.000 description 5
- 102000035195 Peptidases Human genes 0.000 description 5
- 102100034014 Prolyl 3-hydroxylase 3 Human genes 0.000 description 5
- 101710197208 Regulatory protein cro Proteins 0.000 description 5
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 5
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 5
- 241001234601 Staphylococcus phage PVL Species 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 230000001580 bacterial effect Effects 0.000 description 5
- 230000033228 biological regulation Effects 0.000 description 5
- 238000010276 construction Methods 0.000 description 5
- 230000008878 coupling Effects 0.000 description 5
- 239000012528 membrane Substances 0.000 description 5
- 210000004379 membrane Anatomy 0.000 description 5
- 239000002243 precursor Substances 0.000 description 5
- 238000012163 sequencing technique Methods 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 229930091371 Fructose Natural products 0.000 description 4
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 4
- 239000005715 Fructose Substances 0.000 description 4
- VYZAGTDAHUIRQA-CRCLSJGQSA-N L-alanyl-D-glutamic acid Chemical compound C[C@H](N)C(=O)N[C@@H](C(O)=O)CCC(O)=O VYZAGTDAHUIRQA-CRCLSJGQSA-N 0.000 description 4
- 108060004795 Methyltransferase Proteins 0.000 description 4
- KUGRPPRAQNPSQD-UHFFFAOYSA-N OOOOO Chemical compound OOOOO KUGRPPRAQNPSQD-UHFFFAOYSA-N 0.000 description 4
- 101710188003 Replication and maintenance protein Proteins 0.000 description 4
- 102000009661 Repressor Proteins Human genes 0.000 description 4
- 238000007792 addition Methods 0.000 description 4
- 230000004071 biological effect Effects 0.000 description 4
- 239000013611 chromosomal DNA Substances 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 239000000499 gel Substances 0.000 description 4
- 150000002484 inorganic compounds Chemical class 0.000 description 4
- 229910010272 inorganic material Inorganic materials 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 239000012071 phase Substances 0.000 description 4
- 235000019833 protease Nutrition 0.000 description 4
- 230000006798 recombination Effects 0.000 description 4
- 230000032258 transport Effects 0.000 description 4
- 229910052720 vanadium Inorganic materials 0.000 description 4
- 239000003981 vehicle Substances 0.000 description 4
- 150000008495 β-glucosides Chemical class 0.000 description 4
- 108700023418 Amidases Proteins 0.000 description 3
- 101710167800 Capsid assembly scaffolding protein Proteins 0.000 description 3
- 102000014914 Carrier Proteins Human genes 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 102000004157 Hydrolases Human genes 0.000 description 3
- 108090000604 Hydrolases Proteins 0.000 description 3
- 108010042653 IgA receptor Proteins 0.000 description 3
- 241000587801 Lactobacillus phage phi-gle Species 0.000 description 3
- 102000003939 Membrane transport proteins Human genes 0.000 description 3
- 108090000301 Membrane transport proteins Proteins 0.000 description 3
- 239000004677 Nylon Substances 0.000 description 3
- 101710124413 Portal protein Proteins 0.000 description 3
- 101710194805 Putative repressor Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 102000018120 Recombinases Human genes 0.000 description 3
- 108010091086 Recombinases Proteins 0.000 description 3
- 108010052160 Site-specific recombinase Proteins 0.000 description 3
- 244000057717 Streptococcus lactis Species 0.000 description 3
- 235000014897 Streptococcus lactis Nutrition 0.000 description 3
- 102000004357 Transferases Human genes 0.000 description 3
- 108090000992 Transferases Proteins 0.000 description 3
- 101800000385 Transmembrane protein Proteins 0.000 description 3
- 102000005922 amidase Human genes 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 238000006065 biodegradation reaction Methods 0.000 description 3
- 239000003795 chemical substances by application Substances 0.000 description 3
- 230000002759 chromosomal effect Effects 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 3
- 230000029087 digestion Effects 0.000 description 3
- 102000034356 gene-regulatory proteins Human genes 0.000 description 3
- 108091006104 gene-regulatory proteins Proteins 0.000 description 3
- 238000011065 in-situ storage Methods 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 229920001778 nylon Polymers 0.000 description 3
- 229920002401 polyacrylamide Polymers 0.000 description 3
- 108010079133 potassium transporting ATPase Proteins 0.000 description 3
- 230000008439 repair process Effects 0.000 description 3
- 239000007790 solid phase Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 108010034869 6-phospho-beta-glucosidase Proteins 0.000 description 2
- 101710188633 Arsenical resistance operon repressor Proteins 0.000 description 2
- 241000935762 Bacillus virus SPbeta Species 0.000 description 2
- 208000035143 Bacterial infection Diseases 0.000 description 2
- 108090000565 Capsid Proteins Proteins 0.000 description 2
- 102100023321 Ceruloplasmin Human genes 0.000 description 2
- 241000193468 Clostridium perfringens Species 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 101710090058 Conjugated bile acid hydrolase Proteins 0.000 description 2
- 238000009007 Diagnostic Kit Methods 0.000 description 2
- 101000809889 Dinoponera quadriceps M-poneratoxin-Dq4e Proteins 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 101000918259 Enterobacteria phage T4 Exonuclease subunit 1 Proteins 0.000 description 2
- 101000877444 Enterobacteria phage T4 Recombination endonuclease VII Proteins 0.000 description 2
- 101100046554 Escherichia coli (strain K12) tnpX gene Proteins 0.000 description 2
- 101000896152 Escherichia phage Mu Baseplate protein gp47 Proteins 0.000 description 2
- 101000906736 Escherichia phage Mu DNA circularization protein N Proteins 0.000 description 2
- 101000653753 Escherichia phage Mu Tail fiber protein S Proteins 0.000 description 2
- 241000701533 Escherichia virus T4 Species 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 2
- 108010072039 Histidine kinase Proteins 0.000 description 2
- 101700012268 Holin Proteins 0.000 description 2
- 101000800502 Homo sapiens Transketolase-like protein 2 Proteins 0.000 description 2
- 102000012330 Integrases Human genes 0.000 description 2
- 102000003960 Ligases Human genes 0.000 description 2
- 108090000364 Ligases Proteins 0.000 description 2
- 101710125418 Major capsid protein Proteins 0.000 description 2
- 102000016397 Methyltransferase Human genes 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 102000012288 Phosphopyruvate Hydratase Human genes 0.000 description 2
- 108010022181 Phosphopyruvate Hydratase Proteins 0.000 description 2
- 101710176276 SSB protein Proteins 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- 241000624640 Staphylococcus prophage phiPV83 Species 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 101000764570 Streptomyces phage phiC31 Probable tape measure protein Proteins 0.000 description 2
- 108020000005 Sucrose phosphorylase Proteins 0.000 description 2
- 101800001271 Surface protein Proteins 0.000 description 2
- 101710177717 Terminase small subunit Proteins 0.000 description 2
- 102100033109 Transketolase-like protein 2 Human genes 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 2
- 238000000246 agarose gel electrophoresis Methods 0.000 description 2
- 208000022362 bacterial infectious disease Diseases 0.000 description 2
- 230000004888 barrier function Effects 0.000 description 2
- 102000006995 beta-Glucosidase Human genes 0.000 description 2
- 108010047754 beta-Glucosidase Proteins 0.000 description 2
- 238000010804 cDNA synthesis Methods 0.000 description 2
- 229910052793 cadmium Inorganic materials 0.000 description 2
- BDOSMKKIYDKNTQ-UHFFFAOYSA-N cadmium atom Chemical compound [Cd] BDOSMKKIYDKNTQ-UHFFFAOYSA-N 0.000 description 2
- 230000000052 comparative effect Effects 0.000 description 2
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 2
- HEBKCHPVOIAQTA-NGQZWQHPSA-N d-xylitol Chemical compound OC[C@H](O)C(O)[C@H](O)CO HEBKCHPVOIAQTA-NGQZWQHPSA-N 0.000 description 2
- 235000013365 dairy product Nutrition 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 238000002405 diagnostic procedure Methods 0.000 description 2
- 201000010099 disease Diseases 0.000 description 2
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 2
- 238000006073 displacement reaction Methods 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 238000011066 ex-situ storage Methods 0.000 description 2
- 238000002474 experimental method Methods 0.000 description 2
- -1 for example Chemical class 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 230000003308 immunostimulating effect Effects 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 230000002458 infectious effect Effects 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 230000035800 maturation Effects 0.000 description 2
- HEBKCHPVOIAQTA-UHFFFAOYSA-N meso ribitol Natural products OCC(O)C(O)C(O)CO HEBKCHPVOIAQTA-UHFFFAOYSA-N 0.000 description 2
- 230000037353 metabolic pathway Effects 0.000 description 2
- 230000005012 migration Effects 0.000 description 2
- 238000013508 migration Methods 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 230000007918 pathogenicity Effects 0.000 description 2
- 230000035515 penetration Effects 0.000 description 2
- 230000035755 proliferation Effects 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 230000033458 reproduction Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 238000010187 selection method Methods 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 230000035939 shock Effects 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 210000001519 tissue Anatomy 0.000 description 2
- 239000003053 toxin Substances 0.000 description 2
- 231100000765 toxin Toxicity 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 230000009261 transgenic effect Effects 0.000 description 2
- 238000002255 vaccination Methods 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- MSWZFWKMSRAUBD-GASJEMHNSA-N 2-amino-2-deoxy-D-galactopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O MSWZFWKMSRAUBD-GASJEMHNSA-N 0.000 description 1
- NKDFYOWSKOHCCO-YPVLXUMRSA-N 20-hydroxyecdysone Chemical compound C1[C@@H](O)[C@@H](O)C[C@]2(C)[C@@H](CC[C@@]3([C@@H]([C@@](C)(O)[C@H](O)CCC(C)(O)C)CC[C@]33O)C)C3=CC(=O)[C@@H]21 NKDFYOWSKOHCCO-YPVLXUMRSA-N 0.000 description 1
- 230000005730 ADP ribosylation Effects 0.000 description 1
- 208000030507 AIDS Diseases 0.000 description 1
- 101710157736 ATP-dependent 6-phosphofructokinase Proteins 0.000 description 1
- 101710200244 ATP-dependent 6-phosphofructokinase isozyme 2 Proteins 0.000 description 1
- 102100035972 ATPase GET3 Human genes 0.000 description 1
- 108091006112 ATPases Proteins 0.000 description 1
- 101710135803 Actin assembly-inducing protein Proteins 0.000 description 1
- 102000057290 Adenosine Triphosphatases Human genes 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 101000774529 Alkalihalobacillus pseudofirmus (strain ATCC BAA-2126 / JCM 17055 / OF4) Uncharacterized protein BpOF4_21049 Proteins 0.000 description 1
- 102000004092 Amidohydrolases Human genes 0.000 description 1
- 108090000531 Amidohydrolases Proteins 0.000 description 1
- 108050005265 Amino acid antiporter Proteins 0.000 description 1
- 108050005273 Amino acid transporters Proteins 0.000 description 1
- 102000034263 Amino acid transporters Human genes 0.000 description 1
- 102000003669 Antiporters Human genes 0.000 description 1
- 108090000084 Antiporters Proteins 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 108050007508 Arsenical pump-driving ATPases Proteins 0.000 description 1
- 101710161968 Arsenical resistance operon trans-acting repressor ArsD Proteins 0.000 description 1
- 108090000716 Arsenite Transporting ATPases Proteins 0.000 description 1
- 102000004220 Arsenite Transporting ATPases Human genes 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 101100058999 Bacillus anthracis capA gene Proteins 0.000 description 1
- 101000780391 Bacillus licheniformis Uncharacterized protein in ansA 5'region Proteins 0.000 description 1
- 101000870242 Bacillus phage Nf Tail knob protein gp9 Proteins 0.000 description 1
- 101000743092 Bacillus spizizenii (strain DSM 15029 / JCM 12233 / NBRC 101239 / NRRL B-23049 / TU-B-10) tRNA3(Ser)-specific nuclease WapA Proteins 0.000 description 1
- 101000796998 Bacillus subtilis (strain 168) Methylated-DNA-protein-cysteine methyltransferase, inducible Proteins 0.000 description 1
- 101000818144 Bacillus subtilis (strain 168) Uncharacterized oxidoreductase YusZ Proteins 0.000 description 1
- 101100060912 Bacillus subtilis (strain 168) comFC gene Proteins 0.000 description 1
- 101100221532 Bacillus subtilis (strain 168) comGD gene Proteins 0.000 description 1
- 101100221535 Bacillus subtilis (strain 168) comGG gene Proteins 0.000 description 1
- 101100128224 Bacillus subtilis (strain 168) licR gene Proteins 0.000 description 1
- 101100159851 Bacillus subtilis (strain 168) yfkA gene Proteins 0.000 description 1
- 101100106626 Bacillus subtilis (strain 168) yoaZ gene Proteins 0.000 description 1
- 101100488938 Bacillus subtilis (strain 168) yqaS gene Proteins 0.000 description 1
- 101000743093 Bacillus subtilis subsp. natto (strain BEST195) tRNA(Glu)-specific nuclease WapA Proteins 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 101710165600 Bile acid 7alpha-dehydratase Proteins 0.000 description 1
- 241000588832 Bordetella pertussis Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 101100453077 Botryococcus braunii HDR gene Proteins 0.000 description 1
- 101710104338 Cadmium resistance transcriptional regulatory protein CadC Proteins 0.000 description 1
- 101710132601 Capsid protein Proteins 0.000 description 1
- 101710197658 Capsid protein VP1 Proteins 0.000 description 1
- 108020004827 Carbamate kinase Proteins 0.000 description 1
- 102000007132 Carboxyl and Carbamoyl Transferases Human genes 0.000 description 1
- 108010072957 Carboxyl and Carbamoyl Transferases Proteins 0.000 description 1
- 101710113978 Chaperone protein HtpG Proteins 0.000 description 1
- 101000790711 Chlamydomonas reinhardtii Uncharacterized membrane protein ycf78 Proteins 0.000 description 1
- 108010033170 Chloromuconate cycloisomerase Proteins 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 108060005980 Collagenase Proteins 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 101710189243 ComG operon protein 4 Proteins 0.000 description 1
- 101710189324 ComG operon protein 6 Proteins 0.000 description 1
- 101710189329 ComG operon protein 7 Proteins 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 101710174970 Competence transcription factor Proteins 0.000 description 1
- 108050007892 Creatinine amidohydrolases Proteins 0.000 description 1
- 102000038945 DEAH family Human genes 0.000 description 1
- 108091065237 DEAH family Proteins 0.000 description 1
- 239000003155 DNA primer Substances 0.000 description 1
- 102000052510 DNA-Binding Proteins Human genes 0.000 description 1
- 101710116602 DNA-Binding protein G5P Proteins 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 101000827225 Dichelobacter nodosus Uncharacterized protein in lpsA 5'region Proteins 0.000 description 1
- 108010071079 Dinitrogenase Reductase Proteins 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- 108010053187 Diphtheria Toxin Proteins 0.000 description 1
- 102000016607 Diphtheria Toxin Human genes 0.000 description 1
- 108010067770 Endopeptidase K Proteins 0.000 description 1
- 108010059378 Endopeptidases Proteins 0.000 description 1
- 102000005593 Endopeptidases Human genes 0.000 description 1
- 101000621107 Enterobacteria phage N4 Probable portal protein Proteins 0.000 description 1
- 101000830026 Enterobacteria phage T4 Baseplate hub assembly protein gp28 Proteins 0.000 description 1
- 101800001466 Envelope glycoprotein E1 Proteins 0.000 description 1
- 101000599641 Escherichia coli (strain K12) Insertion element IS150 protein InsJ Proteins 0.000 description 1
- 101000819098 Escherichia coli Insertion element IS1397 uncharacterized 20.1 kDa protein Proteins 0.000 description 1
- 101000763543 Escherichia coli Uncharacterized endonuclease Proteins 0.000 description 1
- 101100184605 Escherichia coli mobA gene Proteins 0.000 description 1
- 101000653449 Escherichia phage Mu Probable terminase, large subunit gp28 Proteins 0.000 description 1
- 101000758678 Escherichia phage P1 Uncharacterized 36.0 kDa protein in doc-Gp10 intergenic region Proteins 0.000 description 1
- 241000702192 Escherichia virus P2 Species 0.000 description 1
- 101710128530 Fibrinogen-binding protein Proteins 0.000 description 1
- 108010057573 Flavoproteins Proteins 0.000 description 1
- 102000003983 Flavoproteins Human genes 0.000 description 1
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 description 1
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 description 1
- 206010071602 Genetic polymorphism Diseases 0.000 description 1
- 102000008214 Glutamate decarboxylase Human genes 0.000 description 1
- 108091022930 Glutamate decarboxylase Proteins 0.000 description 1
- 102000057621 Glycerol kinases Human genes 0.000 description 1
- 108700016170 Glycerol kinases Proteins 0.000 description 1
- 101710122529 Glycine-betaine-binding protein Proteins 0.000 description 1
- 101710170453 Glycoprotein 55 Proteins 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 102000051366 Glycosyltransferases Human genes 0.000 description 1
- 241000606768 Haemophilus influenzae Species 0.000 description 1
- 101000743338 Haemophilus phage HP1 (strain HP1c1) Probable head completion/stabilization protein Proteins 0.000 description 1
- 101000976893 Haemophilus phage HP1 (strain HP1c1) Uncharacterized 14.1 kDa protein in cox-rep intergenic region Proteins 0.000 description 1
- 101000976889 Haemophilus phage HP1 (strain HP1c1) Uncharacterized 19.2 kDa protein in cox-rep intergenic region Proteins 0.000 description 1
- 101000786896 Haemophilus phage HP1 (strain HP1c1) Uncharacterized 19.2 kDa protein in rep-hol intergenic region Proteins 0.000 description 1
- 101000786921 Haemophilus phage HP1 (strain HP1c1) Uncharacterized 26.0 kDa protein in rep-hol intergenic region Proteins 0.000 description 1
- 108010039976 Haloacetate dehalogenase Proteins 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 101710121996 Hexon protein p72 Proteins 0.000 description 1
- 101001028836 Homo sapiens M-phase-specific PLK1-interacting protein Proteins 0.000 description 1
- 101000664418 Homo sapiens Secreted Ly-6/uPAR-related protein 1 Proteins 0.000 description 1
- 101000855256 Homo sapiens Uncharacterized protein C16orf74 Proteins 0.000 description 1
- 101710145256 Immunity repressor protein Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000015696 Interleukins Human genes 0.000 description 1
- 108010063738 Interleukins Proteins 0.000 description 1
- 101710150293 Iron-sulfur flavoprotein Proteins 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 101000828374 Lactobacillus johnsonii Insertion element IS1223 uncharacterized 20.7 kDa protein Proteins 0.000 description 1
- 241000499376 Lactobacillus phage A2 Species 0.000 description 1
- 241000724191 Lactobacillus phage mv4 Species 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 229920002097 Lichenin Polymers 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 239000004367 Lipase Substances 0.000 description 1
- 206010024639 Listeria infections Diseases 0.000 description 1
- 101100111995 Listeria innocua serovar 6a (strain ATCC BAA-680 / CLIP 11262) cadC gene Proteins 0.000 description 1
- 101100019880 Listeria innocua serovar 6a (strain ATCC BAA-680 / CLIP 11262) kdpB2 gene Proteins 0.000 description 1
- 241000092431 Listeria monocytogenes EGD Species 0.000 description 1
- 108700027766 Listeria monocytogenes hlyA Proteins 0.000 description 1
- 241000617782 Listeria monocytogenes serotype 1/2a Species 0.000 description 1
- 101100452614 Listeria monocytogenes serotype 1/2a (strain EGD / Mackaness) inlC gene Proteins 0.000 description 1
- 101000750781 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) Uncharacterized oxidoreductase Lmo0432 Proteins 0.000 description 1
- 101100215701 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) aguA2 gene Proteins 0.000 description 1
- 101100116179 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) gadA gene Proteins 0.000 description 1
- 101100452615 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) inlH gene Proteins 0.000 description 1
- 101100452617 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) inlI gene Proteins 0.000 description 1
- 101100452619 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) inlJ gene Proteins 0.000 description 1
- 101100542030 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) lmo0206 gene Proteins 0.000 description 1
- 101100182105 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) lntA gene Proteins 0.000 description 1
- 101100354185 Listeria monocytogenes serovar 1/2a (strain ATCC BAA-679 / EGD-e) ptcA gene Proteins 0.000 description 1
- 241000123765 Listeria phage A118 Species 0.000 description 1
- 241000123767 Listeria phage A500 Species 0.000 description 1
- 241000186807 Listeria seeligeri Species 0.000 description 1
- 101710164436 Listeriolysin O Proteins 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 102100037185 M-phase-specific PLK1-interacting protein Human genes 0.000 description 1
- 240000002129 Malva sylvestris Species 0.000 description 1
- 235000006770 Malva sylvestris Nutrition 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 108091022912 Mannose-6-Phosphate Isomerase Proteins 0.000 description 1
- 101710117393 Membrane-associated lipoprotein Proteins 0.000 description 1
- 201000009906 Meningitis Diseases 0.000 description 1
- 102100025825 Methylated-DNA-protein-cysteine methyltransferase Human genes 0.000 description 1
- 101710157639 Minor capsid protein Proteins 0.000 description 1
- 101710133166 Minor teichoic acid biosynthesis protein GgaA Proteins 0.000 description 1
- 108010006519 Molecular Chaperones Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 241001467552 Mycobacterium bovis BCG Species 0.000 description 1
- 101100276041 Mycolicibacterium smegmatis (strain ATCC 700084 / mc(2)155) ctpD gene Proteins 0.000 description 1
- 101000861628 Mycoplasma capricolum subsp. capricolum (strain California kid / ATCC 27343 / NCTC 10154) Uncharacterized lipoprotein MCAP_0231 Proteins 0.000 description 1
- 101000707209 Mycoplasma mycoides subsp. mycoides SC Insertion element IS1296 uncharacterized 21.4 kDa protein Proteins 0.000 description 1
- 108010084238 NAD+ peroxidase Proteins 0.000 description 1
- 108091061960 Naked DNA Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 102000007999 Nuclear Proteins Human genes 0.000 description 1
- 108010089610 Nuclear Proteins Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- JLNTWVDSQRNWFU-UHFFFAOYSA-N OOOOOOO Chemical compound OOOOOOO JLNTWVDSQRNWFU-UHFFFAOYSA-N 0.000 description 1
- MOMWFXLCFJOAFX-UHFFFAOYSA-N OOOOOOOO Chemical compound OOOOOOOO MOMWFXLCFJOAFX-UHFFFAOYSA-N 0.000 description 1
- OZBZONOEYUBXTD-UHFFFAOYSA-N OOOOOOOOO Chemical compound OOOOOOOOO OZBZONOEYUBXTD-UHFFFAOYSA-N 0.000 description 1
- HFEFMUSTGZNOPY-UHFFFAOYSA-N OOOOOOOOOOOOOOOO Chemical compound OOOOOOOOOOOOOOOO HFEFMUSTGZNOPY-UHFFFAOYSA-N 0.000 description 1
- ZQTQPYJGMWHXMO-UHFFFAOYSA-N OOOOOOOOOOOOOOOOO Chemical compound OOOOOOOOOOOOOOOOO ZQTQPYJGMWHXMO-UHFFFAOYSA-N 0.000 description 1
- IVDBGHPEQSTHRK-UHFFFAOYSA-N OOOOOOOOOOOOOOOOOOOOOO Chemical compound OOOOOOOOOOOOOOOOOOOOOO IVDBGHPEQSTHRK-UHFFFAOYSA-N 0.000 description 1
- 101710113540 ORF2 protein Proteins 0.000 description 1
- 101000770899 Orgyia pseudotsugata multicapsid polyhedrosis virus Uncharacterized 24.3 kDa protein Proteins 0.000 description 1
- 101000805098 Orgyia pseudotsugata multicapsid polyhedrosis virus Uncharacterized 73.1 kDa protein Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 108010073038 Penicillin Amidase Proteins 0.000 description 1
- 108010087702 Penicillinase Proteins 0.000 description 1
- 201000005702 Pertussis Diseases 0.000 description 1
- 102100037170 Phosphate carrier protein, mitochondrial Human genes 0.000 description 1
- 101710128683 Phosphate carrier protein, mitochondrial Proteins 0.000 description 1
- 102000006486 Phosphoinositide Phospholipase C Human genes 0.000 description 1
- 108010044302 Phosphoinositide phospholipase C Proteins 0.000 description 1
- 102100035362 Phosphomannomutase 2 Human genes 0.000 description 1
- 101710176156 Phosphotriesterase-related protein Proteins 0.000 description 1
- 102100030961 Phosphotriesterase-related protein Human genes 0.000 description 1
- 208000000474 Poliomyelitis Diseases 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 101710159752 Poly(3-hydroxyalkanoate) polymerase subunit PhaE Proteins 0.000 description 1
- 108010020346 Polyglutamic Acid Proteins 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- 101710130262 Probable Vpr-like protein Proteins 0.000 description 1
- 101710188472 Probable portal protein Proteins 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 101710136297 Protein VP2 Proteins 0.000 description 1
- 101100371218 Pseudomonas putida (strain DOT-T1E) ttgD gene Proteins 0.000 description 1
- 101100391699 Pseudomonas viridiflava gacA gene Proteins 0.000 description 1
- 101710165374 Putative helicase Proteins 0.000 description 1
- 101710090523 Putative movement protein Proteins 0.000 description 1
- 108010066717 Q beta Replicase Proteins 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 101710118046 RNA-directed RNA polymerase Proteins 0.000 description 1
- 102000004879 Racemases and epimerases Human genes 0.000 description 1
- 108090001066 Racemases and epimerases Proteins 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108091007187 Reductases Proteins 0.000 description 1
- 108700005075 Regulator Genes Proteins 0.000 description 1
- 101710162453 Replication factor A Proteins 0.000 description 1
- 101710088839 Replication initiation protein Proteins 0.000 description 1
- 101710176758 Replication protein A 70 kDa DNA-binding subunit Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 108010034634 Repressor Proteins Proteins 0.000 description 1
- 101000770286 Rhizobium meliloti Uncharacterized protein ORF8 in nfe locus Proteins 0.000 description 1
- 101000791677 Rhizobium meliloti Uncharacterized protein in ackA 5'region Proteins 0.000 description 1
- 102100021688 Rho guanine nucleotide exchange factor 5 Human genes 0.000 description 1
- 101000748505 Rhodobacter capsulatus Uncharacterized 16.1 kDa protein in hypE 3'region Proteins 0.000 description 1
- 102000007382 Ribose-5-phosphate isomerase Human genes 0.000 description 1
- 102100039270 Ribulose-phosphate 3-epimerase Human genes 0.000 description 1
- 108060007030 Ribulose-phosphate 3-epimerase Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- SZKKRCSOSQAJDE-UHFFFAOYSA-N Schradan Chemical compound CN(C)P(=O)(N(C)C)OP(=O)(N(C)C)N(C)C SZKKRCSOSQAJDE-UHFFFAOYSA-N 0.000 description 1
- 102100038583 Secreted Ly-6/uPAR-related protein 1 Human genes 0.000 description 1
- 101710145911 Sensor protein KdpD Proteins 0.000 description 1
- 206010040047 Sepsis Diseases 0.000 description 1
- 108090000233 Signal peptidase II Proteins 0.000 description 1
- 101710126859 Single-stranded DNA-binding protein Proteins 0.000 description 1
- 101710142606 Sliding clamp Proteins 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000194017 Streptococcus Species 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- 108010006785 Taq Polymerase Proteins 0.000 description 1
- 108010055044 Tetanus Toxin Proteins 0.000 description 1
- 101000759701 Thermus thermophilus Uncharacterized protein in scsB 5'region Proteins 0.000 description 1
- 101000623306 Trypanosoma brucei brucei Uncharacterized 1.9 kDa protein in aldolase locus Proteins 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 108010020713 Tth polymerase Proteins 0.000 description 1
- 102100026890 Tumor necrosis factor ligand superfamily member 4 Human genes 0.000 description 1
- 102000014384 Type C Phospholipases Human genes 0.000 description 1
- 108010079194 Type C Phospholipases Proteins 0.000 description 1
- 101710198378 Uncharacterized 10.8 kDa protein in cox-rep intergenic region Proteins 0.000 description 1
- 101710110895 Uncharacterized 7.3 kDa protein in cox-rep intergenic region Proteins 0.000 description 1
- 102100026591 Uncharacterized protein C16orf74 Human genes 0.000 description 1
- 101710173814 UvrABC system protein A Proteins 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 101710108545 Viral protein 1 Proteins 0.000 description 1
- 101710136524 X polypeptide Proteins 0.000 description 1
- 101000679337 Zea mays Putative AC transposase Proteins 0.000 description 1
- 101710151579 Zinc metalloproteinase Proteins 0.000 description 1
- 206010000210 abortion Diseases 0.000 description 1
- 231100000176 abortion Toxicity 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 239000011543 agarose gel Substances 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 229910052785 arsenic Inorganic materials 0.000 description 1
- RQNWIZPPADIBDY-UHFFFAOYSA-N arsenic atom Chemical compound [As] RQNWIZPPADIBDY-UHFFFAOYSA-N 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 235000013405 beer Nutrition 0.000 description 1
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 1
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 102000006635 beta-lactamase Human genes 0.000 description 1
- 239000012620 biological material Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 230000008499 blood brain barrier function Effects 0.000 description 1
- 210000001218 blood-brain barrier Anatomy 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 235000008429 bread Nutrition 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 101150008667 cadA gene Proteins 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 150000001769 cdp-glycerols Chemical class 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 210000003855 cell nucleus Anatomy 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 235000013351 cheese Nutrition 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 229960002424 collagenase Drugs 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 239000003431 cross linking reagent Substances 0.000 description 1
- 230000001351 cycling effect Effects 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 102100032354 dTDP-D-glucose 4,6-dehydratase Human genes 0.000 description 1
- 101710115238 dTDP-D-glucose 4,6-dehydratase Proteins 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 229960002086 dextran Drugs 0.000 description 1
- 229940041984 dextran 1 Drugs 0.000 description 1
- 229960000633 dextran sulfate Drugs 0.000 description 1
- 229960003983 diphtheria toxoid Drugs 0.000 description 1
- 230000006806 disease prevention Effects 0.000 description 1
- 108010088016 dolichyl-phosphate beta-D-mannosyltransferase Proteins 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 206010014599 encephalitis Diseases 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 102000025748 fibrinogen binding proteins Human genes 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 238000009432 framing Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 229920000370 gamma-poly(glutamate) polymer Polymers 0.000 description 1
- 238000001641 gel filtration chromatography Methods 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 229950010772 glucose-1-phosphate Drugs 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 108700014210 glycosyltransferase activity proteins Proteins 0.000 description 1
- 229940047650 haemophilus influenzae Drugs 0.000 description 1
- 229910001385 heavy metal Inorganic materials 0.000 description 1
- 208000002672 hepatitis B Diseases 0.000 description 1
- 150000002402 hexoses Chemical class 0.000 description 1
- 230000008348 humoral response Effects 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 230000003100 immobilizing effect Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 229940127121 immunoconjugate Drugs 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 101150046348 inlB gene Proteins 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 210000005027 intestinal barrier Anatomy 0.000 description 1
- 230000007358 intestinal barrier function Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 239000001573 invertase Substances 0.000 description 1
- 235000011073 invertase Nutrition 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 231100000225 lethality Toxicity 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 238000007834 ligase chain reaction Methods 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 235000019421 lipase Nutrition 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000000891 luminescent agent Substances 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 201000011475 meningoencephalitis Diseases 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 238000012269 metabolic engineering Methods 0.000 description 1
- 244000000010 microbial pathogen Species 0.000 description 1
- 230000002906 microbiologic effect Effects 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000000302 molecular modelling Methods 0.000 description 1
- 125000001446 muramyl group Chemical group N[C@@H](C=O)[C@@H](O[C@@H](C(=O)*)C)[C@H](O)[C@H](O)CO 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 238000002703 mutagenesis Methods 0.000 description 1
- 231100000350 mutagenesis Toxicity 0.000 description 1
- 238000002663 nebulization Methods 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 102000022744 oligopeptide binding proteins Human genes 0.000 description 1
- 108091013547 oligopeptide binding proteins Proteins 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- LMJVXGOFWKVXAW-OXOINMOOSA-N oxetanocin A Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@H]1CO LMJVXGOFWKVXAW-OXOINMOOSA-N 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 229950009506 penicillinase Drugs 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 239000008363 phosphate buffer Substances 0.000 description 1
- 239000005080 phosphorescent agent Substances 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 101150114864 plcA gene Proteins 0.000 description 1
- 101150050662 plcB gene Proteins 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 101150093386 prfA gene Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 230000005180 public health Effects 0.000 description 1
- 238000003906 pulsed field gel electrophoresis Methods 0.000 description 1
- 238000003751 purification from natural source Methods 0.000 description 1
- 101150027417 recU gene Proteins 0.000 description 1
- 101150055347 repA2 gene Proteins 0.000 description 1
- 101150107738 repB gene Proteins 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000008261 resistance mechanism Effects 0.000 description 1
- 108091008020 response regulators Proteins 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 108020005610 ribose 5-phosphate isomerase Proteins 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 101150085300 sepA gene Proteins 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 208000013223 septicemia Diseases 0.000 description 1
- 238000007086 side reaction Methods 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 101150063780 spp1 gene Proteins 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 108010040614 terminase Proteins 0.000 description 1
- 229940118376 tetanus toxin Drugs 0.000 description 1
- 229960000814 tetanus toxoid Drugs 0.000 description 1
- 238000005382 thermal cycling Methods 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 230000013819 transposition, DNA-mediated Effects 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical class OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 229960001322 trypsin Drugs 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 101150116095 uhpT gene Proteins 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 230000035899 viability Effects 0.000 description 1
- 230000001018 virulence Effects 0.000 description 1
- 239000000304 virulence factor Substances 0.000 description 1
- 230000007923 virulence factor Effects 0.000 description 1
- 101150068705 wapA gene Proteins 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 101150008753 ykfB gene Proteins 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/195—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from bacteria
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6888—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms
- C12Q1/689—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for detection or identification of organisms for bacteria
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/53—DNA (RNA) vaccination
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
Definitions
- the subject of the invention is a method making it possible to demonstrate the specific nucleotide sequences of the genome of a strain of bacteria of the genus Listeria, in particular of a strain of L. innocua or L. monocytogenes.
- the subject of the present invention is also the genomic sequence and nucleotide sequences coding for Listeria innocua polypeptides, such as cell envelope polypeptides, secreted or specific, or involved in metabolism and in the replication process, as well as vectors including said sequences and cells or animals transformed by these vectors.
- the invention also relates to the comparison of these nucleotide sequences with those coding for the polypeptides of Listeria monocytogenes, strain EGDe or L.
- the invention also relates to methods for detecting these nucleic acids or polypeptides and to kits for diagnosing contamination by bacteria of the genus Listeria and kits for typing contaminating strains.
- the invention also relates to a method of selecting compounds capable of modulating the bacterial infection caused by other Listeria and a method of biosynthesis or biodegradation of molecules of interest using said nucleotide sequences or said polypeptides.
- the invention finally comprises pharmaceutical compositions, in particular vaccine compositions, for the prevention and / or treatment of bacterial infections, in particular by Listeria, in particular monocytogenes, and compositions containing antibodies directed against specific polypeptides of L.
- Listeriosis is the most lethal food-borne infection (approximately 30% mortality).
- Listeria monocytogenes has the unusual property of being able to cross three barriers: the intestinal barrier, the blood-brain barrier and the placental barrier. The clinical manifestations of listeriosis include meningitis, meningoencephalitis, abortion and septicemia.
- This infection is opportunistic and mainly affects pregnant women, babies, the elderly and people who are immunosuppressed, especially people with AIDS. This disease also affects healthy individuals and is responsible for a significant number of epidemics due to contaminated food products.
- Listeria monocytogenes is also of veterinary importance with a main risk for sheep (sheep) and cattle. Listeria monocytogenes is particularly resistant to stress or extreme conditions and it is important to look for its presence carefully not only for food safety problems but also for environmental safety issues.
- listeriosis is very variable depending on the contaminating Listeria strain. In the extreme, some strains could be considered dangerous and others harmless (like Listeria innocua). Thus, while Listeria contaminations are very frequent, the number of cases described is low. In this perspective, the availability of a tool to identify the risk associated with contamination (depending on the genomic type of the strain and the number of bacteria per gram of food) would allow manufacturers to react based on this risk .
- the subject of the present invention is therefore a method making it possible to demonstrate nucleotide sequences specific for the genome of a strain of bacteria of the genus Listeria, in particular specific for a strain of L. innocua or L. monocytogenes, such as the strain L monocytogenes EGDe or L. monocytogenes 4b.
- Such a method according to the invention pe ⁇ net in particular the identification of specific sequences of:
- L. innocua compared to L. monocytogenes, in particular compared to L. monocytogenes EGDe and / or L. monocytogenes 4b;
- L. monocytogenes in particular L. monocytogenes EGDe or L. monocytogenes 4b, compared to L. innocua;
- Said method according to the invention is preferably characterized in that it comprises at least the following steps: a) alignment of the nucleotide sequences of L. monocytogenes, in particular those of L. monocytogenes EGDe and / or L. monocytogenes 4b, and those of L. innocua according to the invention; and b) processing the data obtained by this alignment to isolate said specific sequences.
- the method according to the invention is characterized in that the nucleotide sequences of L. monocytogenes, in particular those of L. monocytogenes EGDe and / or L. monocytogenes 4b are chosen from the genomic nucleotide sequences: - such as described in French patent application N ° 00 04629 filed on
- the method according to the invention is characterized in that the nucleotide sequences specific for L. inocua or L. monocytogenes, in particular those of L. monocytogenes EGDe and / or L. monocytogenes 4b, hybridize in high stringency conditions with the sequences respectively nucleotides, or their complementary sequence, of L. inocua or L. monocytogenes, in particular those of L. monocytogenes EGDe and / or L. monocytogenes 4b.
- the present invention relates to the nucleotide and polypeptide sequences of Listeria innocua and the comparison of the corresponding sequences with those of Listeria monocytogenes strain EGDe and / or 4b.
- the invention relates in particular to:
- nucleic sequences SEQ ID Nos. 3892 to 4025 specific for Listeria monocytogenes 4b compared to Listeria innocua and Listeria monocytogenes strain EGDe, their fragments of sufficient length to retain their aforesaid specificity, their complementary sequence, primers or specific probes, the peptides encoded by these nucleic acid sequences or antibodies directed against these peptides, as well as in particular their uses, for the identification of a strain of Listeria, or for the distinction between a pathogenic or non-pathogenic strain of Listeria in a biological sample, in particular using diagnostic methods or kit as below presented or known to those skilled in the art.
- CLIP 1 1262 contained in the genomic bank prepared from the genome of this strain and deposited at the CNCM on October 2, 2000 under the number 1-2565 as well as all the non-coding regulatory genes and sequences contained in said genome.
- the CLIP 1 1262 strain was isolated from a dairy product. This strain is kept at the National Reference Center of Listeria at the INSTITUT PASTEUR (WHO collaborating center).
- the Listeria monocytogenes serotype 4b strain is also identified in the present application by Listeria monocytogenes 4b and interchangeably.
- the invention also relates to new tools for typing Listeria strains. These tools could be of the DNA "chip" type or of another type.
- the new features of these typing tools will be as follows:
- the present invention therefore relates to a nucleotide sequence of Listeria innocua characterized in that it corresponds to a sequence chosen from SEQ ID No. 1 to SEQ ID No. 11, SEQ ID No. 2057 and SEQ ID No. 2058, in particular from SEQ ID No. 2057 and SEQ ID No. 2058.
- the present invention also relates to a nucleotide sequence derived from Listeria innocua, characterized in that it is chosen from: a) a nucleotide sequence comprising at least 75%, 80%, 85%, 90%, 95% or 98% of identity with a sequence chosen from SEQ ID No. 1 to SEQ ID No. 11, SEQ ID No. 2057 and SEQ ID No. 2058, in particular from SEQ ID No. 2057 and SEQ ID No. 2058; b) a nucleotide sequence hybridizing under conditions of high stringency with a sequence chosen from SEQ ID No. 1 to SEQ ID No. 11, SEQ ID No. 2057 and SEQ ID No.
- the present invention also relates to the nucleotide sequences characterized in that they come from SEQ ID No. 1 to SEQ ID No. 11, SEQ ID No. 2057 and SEQ ID No. 2058 and in what they code for a polypeptide, chosen from the sequences SEQ ID No. 12 to SEQ ID No. 689, SEQ ID No.
- the present invention also relates more generally to the nucleotide sequences originating from SEQ ID No. 1 to SEQ ID No. 11, SEQ ID No. 2057 and SEQ ID
- nucleotide sequences characterized in that they comprise a nucleotide sequence chosen from: a) a nucleotide sequence coding for a polypeptide, chosen from the sequences SEQ ID No. 12 to SEQ ID No. 689, SEQ ID No. 2053 to SEQ ID No. 2056 and SEQ ID No. 2059 to SEQ ID No. 2601, in particular from SEQ ID No. 2059 to SEQ ID No. 2601; b) a nucleotide sequence comprising at least 75%, 80%, 85%, 90%, 95% or 98% of identity with a nucleotide sequence coding for a polypeptide, chosen from the sequences SEQ ID No.
- the present invention also relates to a nucleotide sequence of Listeria monocytogenes serotype 4b of sequence SEQ ID No. 1068 to SEQ ID No. 2041 and SEQ ID No. 2872 to SEQ ID No. 3891, in particular SEQ ID No. 2872 to SEQ ID No. 3891.
- the present invention also relates to a nucleotide sequence of Listeria monocytogenes serotype 4b characterized in that it is chosen from: a) a nucleotide sequence comprising at least 75%, 80%, 85%, 90%, 95% or 98% identity with SEQ ID No. 1068 to SEQ ID No. 2041, SEQ ID No. 2872 to SEQ ID No 3891, in particular with SEQ ID No. 2872 to SEQ ID No. 3891; b) a nucleotide sequence hybridizing under conditions of high stringency with SEQ ID No. 1068 to SEQ ID No. 2041, SEQ ID No. 2872 to SEQ ID
- SEQ ID No. 3891 in particular with SEQ ID No. 2872 to SEQ ID No. 3891; c) a nucleotide sequence complementary to SEQ ID No. 1068 to SEQ ID No. 2041, SEQ ID No. 2872 to SEQ ID No. 3891, in particular from SEQ ID No. 2872 to SEQ ID No. 3891 or complementary to a sequence nucleotide as defined in a) or b), or an RNA nucleotide sequence corresponding to one of the sequences a) or b); d) a nucleotide sequence of a fragment representative of SEQ ID No. 1068 to SEQ ID No. 2041, SEQ ID No. 2872 to SEQ ID No. 3891, in particular from SEQ ID No.
- the present invention also relates to the nucleotide sequences characterized in that they come from SEQ ID No. 1068 to SEQ ID No. 2041, SEQ ID No. 2872 to SEQ ID No. 3891, in particular from SEQ ID No. 2872 to SEQ ID No.
- polypeptide 3891 and in that they code for a polypeptide, chosen from the sequences SEQ ID No. 690 to SEQ ID No. 1067, SEQ ID No. 2049 to SEQ ID No. 2052 and SEQ ID No. 2602 to SEQ ID No. 2871, in particular from SEQ ID No. 2602 to SEQ ID No. 2871.
- the present invention also relates more generally to the nucleotide sequences originating from SEQ ID No. 1068 to 2041, SEQ ID No. 2872 to SEQ ID No. 3891, in particular from SEQ ID No. 2872 to SEQ ID No. 3891, and coding for a polypeptide of E monocytogenes, as they can be isolated from S ⁇ Q ID No. 690 to 1067, S ⁇ Q ID No. 2049 to S ⁇ Q ID No. 2052 and S ⁇ Q ID No. 2602 to S ⁇ Q ID No. 2871, in particular from S ⁇ Q ID No. 2602 to S ⁇ Q ID No. 2871.
- nucleotide sequences characterized in that they comprise a nucleotide sequence chosen from: a) a nucleotide sequence coding for a polypeptide, chosen from the sequences SEQ ID No. 690 to SEQ ID No. 1067, SEQ ID No. 2602 to SEQ ID No. 2871, in particular from SEQ ID No. 2602 to SEQ ID No. 2871; b) a nucleotide sequence comprising at least 75%, 80%, 85%, 90%, 95% or 98% of identity with a nucleotide sequence coding for a polypeptide, chosen from the sequences SEQ ID No. 690 to SEQ ID No 1067, SEQ ID No. 2602 to SEQ ID No.
- nucleic acid nucleic or nucleic acid sequence, polynucleotide, oligonucleotide, polynucleotide sequence, nucleotide sequence, terms which will be used interchangeably in the present description, is intended to denote a precise sequence of nucleotides, modified or not, making it possible to define a fragment or region of a nucleic acid, which may or may not contain unnatural nucleotides, and which may correspond both to double-stranded DNA, single-stranded DNA and to transcripts of said DNAs.
- the nucleic acid sequences according to the invention also include PNA (Peptid Nucleic Acid).
- nucleotide sequences in their natural chromosomal environment that is to say in the natural state.
- sequences which have been isolated and / or purified that is to say that they have been taken directly or indirectly, for example by copying, their environment having been at least partially modified.
- This also means the nucleic acids obtained by chemical synthesis.
- percentage of identity between two nucleic acid or amino acid sequences within the meaning of the present invention is meant a percentage of identical nucleotides or amino acid residues between the two sequences to compare, obtained after the best alignment, this percentage being purely statistical and the differences between the two sequences being distributed randomly and over their entire length.
- the term “best alignment” or “optimal alignment” is intended to denote the alignment for which the percentage of identity determined as below is the highest. Sequence comparisons between two nucleic acid or amino acid sequences are traditionally carried out by comparing these sequences after having optimally aligned them, said comparison being carried out by segment or by "comparison window” to identify and compare the regions. sequence similarity locale.
- the optimal alignment of the sequences for the comparison can be carried out, besides manually, by means of the algorithm of local homology of Smith and Waterman (1981, Ad. App. Math. 2: 482), by means of the algorithm of local homology by Neddleman and Wunsch (1970, J. Mol. Biol. 48: 443), using the similarity search method of Pearson and Lipman (1988, Proc. Natl. Acad. Sci. USA 85: 2444 ), using computer software using these algorithms (GAP, BESTFIT, BLAST P, BLAST N, FASTA and TFASTA in the Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Dr., Madison, WI).
- the BLAST program is preferably used with the BLOSUM 62 matrix.
- the PAM or PAM250 matrices can also be used.
- the percentage of identity between two nucleic acid or amino acid sequences is determined by comparing these two optimally aligned sequences, the nucleic acid or amino acid sequence to be compared can include additions or deletions by compared to the reference sequence for optimal alignment between these two sequences.
- the percentage identity is calculated by determining the number of identical positions for which the nucleotide or the amino acid residue is identical in the two sequences, by dividing this number of identical positions by the total number of positions compared and by multiplying the result obtained by 100 to obtain the percentage of identity between these two sequences.
- nucleic acid sequences having a percentage identity of at least 75%, preferably 80%, 85% or 90%, more preferably 95% or even 98%, after optimal alignment with a reference sequence is meant the nucleic acid sequences having, with respect to the reference nucleic acid sequence, certain modifications such as in particular a deletion, a truncation, an elongation, a chimeric fusion and / or a substitution, in particular punctual, and whose sequence nucleic acid present at least 75%, preferably 80%, 85%, 90%, 95% or 98%, of identity after optimal alignment with the reference nucleic sequence.
- They are preferably sequences whose complementary sequences are capable of hybridizing specifically with the reference sequences.
- the specific hybridization conditions or high stringency will be such that they ensure at least 75%, preferably 80%, 85%, 90%, 95% or 98% identity after optimal alignment between one of the two sequences and its complementary sequence.
- Hybridization under conditions of high stringency means that the conditions of temperature and ionic strength are chosen in such a way that they allow hybridization to be maintained between two complementary DNA fragments.
- high stringency conditions of the hybridization step for the purpose of defining the polynucleotide fragments described above are advantageously as follows.
- DNA-DNA or DNA-RNA hybridization is carried out in two stages: (1) prehybridization at 42 ° C for 3 hours in phosphate buffer (20 mM, pH 7.5) containing 5 x SSC (1 x SSC corresponds to a 0.15 M NaCl + 0.015 M sodium citrate solution), 50% formamide, 7% sodium dodecyl sulfate (SDS), 10 x Denhardt's, 5% dextran sulfate and 1% salmon sperm DNA; (2) actual hybridization for 20 hours at a temperature depending on the size of the probe (ie: 42 ° C, for a probe of size> 100 nucleotides) followed by 2 washes of 20 minutes at 20 ° C in 2 x SSC + 2% SDS, 1 wash for 20 minutes at 20 ° C in 0.1 x SSC + 0.1% SDS.
- the last washing is carried out in 0.1 x SSC + 0.1% SDS for 30 minutes at 60 ° C. for a probe of size> 100 nucleotides.
- the high stringency hybridization conditions described above for a polynucleotide of defined size can be adapted by the skilled person for oligonucleotides of larger or smaller size, according to the teaching of Sambrook et al. (1989, Molecular cloning: a laboratory manual, 2 nd Ed. Cold Spring Harbor).
- fragment representative of sequences according to the invention is intended to denote any nucleotide fragment having at least 15 nucleotides, preferably at least 30, 75, 150, 300 and 450 consecutive nucleotides of the sequence from which it is derived.
- nucleic sequence coding for a biologically active fragment of a polypeptide, as defined below.
- fragment is also meant the intergenic sequences, and in particular the nucleotide sequences carrying the regulatory signals (promoters, terminators, or even enhancers, etc.).
- ORFs sequences ORFs for "Open Reading Frame"
- ORFs sequences ORFs for "Open Reading Frame"
- initiation codon and a stop codon or between two stop codons
- polypeptides preferably at least 100 amino acids, such as for example, without limitation, the ORFs sequences which will be described later.
- the numbering of the nucleotide sequences ORFs which will be used subsequently in the present description corresponds to the numbering of the amino acid sequences of the proteins encoded by said ORFs.
- the representative fragments according to the invention can be obtained for example by specific amplification such as PCR or after digestion with appropriate restriction enzymes of nucleotide sequences according to the invention, this method being described in particular in the work by Sambrook et al. .. Said representative fragments can also be obtained by chemical synthesis when their size is not too large, according to methods well known to those skilled in the art.
- sequences containing sequences of the invention we also mean the sequences which are naturally framed by sequences which have at least 75%, 80%, 85%, 90%, 95% or 98% d identity with the sequences according to the invention.
- modified nucleotide sequence any nucleotide sequence obtained by mutagenesis according to techniques well known to those skilled in the art, and comprising modifications with respect to the normal sequences, for example mutations in the regulatory and / or promoter sequences of the expression of the polypeptide, in particular leading to a modification of the level of expression or of the activity of said polypeptide.
- modified nucleotide sequence is also meant any nucleotide sequence coding for a modified polypeptide as defined below.
- the representative fragments according to the invention can also be probes or primers, which can be used in methods of detection, identification, assay or amplification of nucleic sequences.
- a probe or primer is defined, within the meaning of the invention, as being a fragment of single-stranded nucleic acids or a denatured double-stranded fragment comprising for example from 12 bases to a few kb, in particular from 15 to a few hundred bases, preferably from 15 to 50 or 100 bases, and having a specificity of hybridization under determined conditions to form a hybridization complex with a target nucleic acid.
- the probes and primers according to the invention can be labeled directly or indirectly with a radioactive or non-radioactive compound by methods well known to those skilled in the art, in order to obtain a detectable and / or quantifiable signal (patent FR 78 10975 and bDNA of Chiron EP 225 807 and EP 510 085).
- the unlabeled polynucleotide sequences according to the invention can be used directly as a probe or primer.
- sequences are generally marked to obtain sequences which can be used for numerous applications.
- the labeling of the primers or probes according to the invention is carried out with radioactive elements or with non-radioactive molecules.
- the non-radioactive entities are selected from ligands such as biotin, avidin, streptavidin, dioxygenin, haptens, dyes, luminescent agents such as radioluminescent, chemoluminescent, bioluminescent, fluorescent, phosphorescent agents.
- the polynucleotides according to the invention can thus be used as a primer and / or probe in methods using in particular the PCR technique (polymerase chain reaction) (Rolfs et al., 1991, Berlin: Springer-Verlag).
- This technique requires the choice of pairs of oligonucleotide primers framing the fragment which must be amplified.
- the amplified fragments can be identified, for example after agarose or polyacrylamide gel electrophoresis, or after a chromatographic technique such as gel filtration or ion exchange chromatography, and then sequenced.
- the specificity of the amplification can be controlled by using the nucleotide sequences of polynucleotides of the invention as template, plasmids containing these sequences or even the amplification products derived therefrom.
- the amplified nucleotide fragments can be used as reagents in hybridization reactions in order to demonstrate the presence, in a biological sample, of a target nucleic acid of sequence complementary to that of said amplified nucleotide fragments.
- the invention also relates to the nucleic acids capable of being obtained by amplification using primers according to the invention.
- Other techniques for amplifying the target nucleic acid can advantageously be used as an alternative to PCR (PCR-like) using pairs of primers of nucleotide sequences according to the invention.
- PCR-like is meant to denote all the methods implementing direct or indirect reproductions of the nucleic acid sequences, or in which the labeling systems have been amplified, these techniques are of course known. In general, it is the amplification of DNA by a polymerase; when the original sample is an RNA, a reverse transcription should be carried out beforehand.
- the target polynucleotide to be detected is an mRNA
- an enzyme of reverse transcriptase type in order to obtain a cDNA from the mRNA contained in the biological sample.
- the cDNA obtained will then serve as a target for the primers or probes used in the amplification or detection method according to the invention.
- the probe hybridization technique can be performed in various ways (Matthews et al., 1988, Anal. Biochem., 169, 1-25).
- the most general method consists in immobilizing the nucleic acid extracted from cells of different tissues or cells in culture on a support (such as nitrocellulose, nylon, polystyrene) and incubating, under well defined conditions, the target nucleic acid immobilized with the probe. After hybridization, the excess probe is eliminated and the hybrid molecules formed are detected by the appropriate method (measurement of radioactivity, fluorescence or enzymatic activity linked to the probe).
- a support such as nitrocellulose, nylon, polystyrene
- the latter can be used as capture probes.
- a probe called a “capture probe”
- a probe is immobilized on a support and is used to capture by specific hybridization the target nucleic acid obtained from the biological sample to be tested and the target nucleic acid is then detected.
- a second probe called a “detection probe”, marked by an easily detectable element.
- the antisense oligonucleotides that is to say those whose structure ensures, by hybridization with the target sequence, an inhibition of the expression of the corresponding product. Mention should also be made of sense oligonucleotides which, by interaction with proteins involved in the regulation of the expression of the corresponding product, will induce either an inhibition or an activation of this expression.
- the probes or primers according to the invention are immobilized on a support, covalently or non-covalently.
- the support can be a DNA chip or a high or medium density filter, also objects of the present invention (patents WO 97/29212, WO 98/27317, WO 97/10365 and WO 92/10588).
- DNA chip or high density filter is intended to denote a support on which DNA sequences are fixed, each of which can be identified by its geographic location. These chips or filters differ mainly in their size, the material of the support, and possibly the number of DNA sequences attached to them.
- the probes or primers according to the first invention can be fixed on solid supports, in particular DNA chips, by various manufacturing methods.
- a synthesis can be carried out in situ by photochemical addressing or by ink jet.
- Other techniques consist in carrying out an ex situ synthesis and in fixing the probes on the support of the DNA chip by mechanical, electronic or inkjet addressing. These different methods are well known to those skilled in the art.
- a nucleotide sequence (probe or primer) according to the invention therefore allows the detection and / or amplification of specific nucleic sequences.
- the detection of these said sequences is facilitated when the probe is fixed to a DNA chip, or to a high density filter.
- DNA chips or high density filters makes it possible to determine the expression of genes in an organism having a genomic sequence close to L. monocytogenes or innocua and the typing of the strain in question.
- the genomic sequence of L. innocua and the partial sequences of L. monocytogenes 4b serve as a basis for the construction of these DNA chips or filter.
- the preparation of these filters or chips consists in synthesizing oligonucleotides, corresponding to the 5 ′ and 3 ′ ends of the genes or to more internal fragments to amplify fragments of a suitable size, for example between approximately 300 and 800 bases.
- oligonucleotides are chosen using the genomic sequence and its annotations disclosed by the present invention.
- the pairing temperature of these oligonucleotides at the corresponding places on the DNA should be approximately the same for each oligonucleotide. This makes it possible to prepare DNA fragments corresponding to each gene by the use of appropriate PCR conditions in a highly automated environment.
- the amplified fragments are then immobilized on filters or supports in glass, silicon or synthetic polymers and these media are used for hybridization.
- filters and / or chips and of the corresponding annotated genomic sequence makes it possible to study the expression of large sets, or even of all of the genes in the microorganisms associated with Listeria innocua and L. monocytogenes 4b, by preparing the complementary DNAs, and by hybridizing them to the DNA or to the oligonucleotides immobilized on the filters or the chips.
- the filters and / or the chips make it possible to study the variability of the strains or of the species, by preparing the DNA of these organisms and by hybridizing them to the DNA or to the oligonucleotides immobilized on the filters or the chips.
- the nucleotide sequences according to the invention can be used in DNA chips to carry out the analysis of mutations. This analysis is based on the constitution of chips capable of analyzing each base of a nucleotide sequence according to the invention. In particular, it will be possible to implement micro-sequencing techniques on a DNA chip.
- the mutations are detected by extension of immobilized primers hybridizing to the matrix of the sequences analyzed, just in position adjacent to that of the mutated nucleotide sought.
- a single-stranded matrix, RNA or DNA, of the sequences to be analyzed will advantageously be prepared according to conventional methods, from products amplified according to PCR type techniques.
- the single-stranded DNA or RNA matrices thus obtained are then deposited on the DNA chip, under conditions allowing their specific hybridization to the immobilized primers.
- a thermostable polymerase for example Tth or Taq DNA polymerase, specifically extends the 3 'end of the immobilized primer with a labeled nucleotide analog complementary to the nucleotide at the variable site position; for example, thermal cycling is carried out in the presence of fluorescent dideoxyribonucleotides.
- the experimental conditions will be adapted in particular to the chips used, to the immobilized primers, to the polymerases used, and to the chosen labeling system.
- microsequencing compared to techniques based on probe hybridization, is that it makes it possible to identify all the variable nucleotides with optimal discrimination under homogeneous reaction conditions; used on DNA chips, it allows optimal resolution and specificity for routine and industrial detection of mutations in multiplex.
- the use of high density filters and / or chips thus makes it possible to obtain new knowledge on the regulation of genes in organisms of industrial importance, and in particular the listeria propagated under various conditions. It also allows rapid identification of the differences between the genomes of the strains used in multiple industrial applications.
- a DNA chip or filter can be an extremely useful tool for the determination, detection and / or identification of a microorganism.
- the DNA chips according to the invention are also preferred, which also contain at least one nucleotide sequence of a microorganism other than Listeria monocytogenes 4b or Listeria innocua, immobilized on the support of said chip.
- the microorganism chosen is from bacteria of the genus Listeria (hereinafter designated as bacteria associated with L. monocytogenes), or variants of Listeria monocytogenes EGD-e.
- a DNA chip or a filter according to the invention is a very useful element in certain kits or necessary for the detection and / or identification of microorganisms, in particular bacteria belonging to the species Listeria monocytogenes or the associated microorganisms , also objects of the invention.
- DNA chips or filters according to the invention containing probes or primers specific for Listeria innocua or monocytogenes, are very advantageous elements of kits or necessary for the detection and / or quantification of the expression of genes Listeria innocua or monocytogenes (or associated microorganisms).
- the control of gene expression is a critical point for optimizing the growth and yield of a strain, either by allowing the expression of one or more new genes, or by modifying the expression of genes already present in the cell.
- the present invention provides all the naturally active sequences in L. innocua allowing the expression of genes. It thus allows the determination of all the sequences expressed in L. innocua. It also provides a tool for identifying genes whose expression follows a given pattern. To achieve this, the DNA of all or part of the genes of L. innocua and monocytogenes can be amplified using primers according to the invention, then fixed to a support such as for example glass or nylon or a DNA chip, in order to build a tool to monitor the expression profile of these genes.
- This tool consisting of this support containing the coding sequences, serves as a hybridization matrix for a mixture of labeled molecules reflecting the messenger RNAs expressed in the cell (in particular the labeled probes according to the invention).
- each control sequence present upstream of the segments serving as probes and to monitor their activity using an appropriate means such as a reporter gene (luciferase, ⁇ -galactosidase, GFP).
- a reporter gene luciferase, ⁇ -galactosidase, GFP
- the invention also relates to the polypeptides encoded by a nucleotide sequence according to the invention, preferably, by a fragment representative of the preceding sequences and corresponding to an ORF sequence.
- the Listeria innocua polypeptides encoded by the sequences SEQ ID No. 12 to SEQ ID No. 689, SEQ ID Nos. 2042 and 2043, SEQ ID Nos. 2047 and 2048, SEQ ID Nos. 2053 to 2056 and SEQ ID Nos. 2059 to 2601 in particular by SEQ ID Nos. 2059 to 2601, or those of Listeria monocytogenes EGDe, characterized in that they are chosen from the polypeptides coded by the sequences SEQ ID No.
- SEQ ID No. 1067 SEQ ID No. 2049 to SEQ ID No. 2052 and SEQ ID Nos. 2602 to 2871, notably among SEQ ID Nos. 2602 to 2871, or those of Listeria monocytogenes 4b, characterized in that they are chosen from the polypeptides coded by the sequences SEQ ID No. 3892 to SEQ ID No. 4025, are subject of the invention.
- the invention also includes the polypeptides characterized in that they comprise a polypeptide chosen from: a) a polypeptide according to the invention; b) a polypeptide having at least 80%, preferably 85%, 90%, 95% and 98% identity with a polypeptide according to the invention; c) a fragment of at least 5 amino acids of a polypeptide according to the invention, or as defined in b); d) a biologically active fragment of a polypeptide according to the invention, or as defined in b) or c); and e) a polypeptide according to the invention, or as defined in b), c) or d) modified.
- the nucleotide sequences coding for the polypeptides described above are also subject of the invention.
- polypeptides includes any amino acid sequence used to generate an antibody response.
- polypeptide includes any amino acid sequence used to generate an antibody response. It should be understood that the invention does not relate to polypeptides in natural form, that is to say that they are not taken in their natural environment. On the other hand, it relates to those which could have been isolated or obtained by purification from natural sources, or else obtained by genetic recombination, or by chemical synthesis, and which they can then comprise non-natural amino acids as will be described more far.
- polypeptide having a certain percentage of identity with another which will also be designated by homologous polypeptide, is intended to denote the polypeptides having, with respect to the natural polypeptides, certain modifications, in particular a deletion, addition or substitution of at least an amino acid, truncation, elongation, chimeric solution and / or mutation, or polypeptides with post-translational modifications.
- homologous polypeptides those whose amino acid sequence have at least 80%, preferably 85%, 90%, 95% and 98% of homology with the amino acid sequences of the polypeptides according to the invention are preferred. .
- equivalent amino acids is intended here to denote any amino acid capable of being substituted for one of the amino acids of the basic structure without, however, essentially modifying the biological activities of the corresponding peptides as defined by after.
- Leucine can thus be replaced by valine or isoleucine, aspartic acid by glutamine acid, glutamine by asparagine, arginine by lysine, etc., the reverse substitutions being naturally possible in the same conditions.
- homologous polypeptides also correspond to the polypeptides encoded by the homologous or identical nucleotide sequences, as defined above and thus include, in the present definition, polypeptides which are mutated or correspond to inter or intra species variations, which may exist in Listeria, and which correspond in particular to truncations, substitutions, deletions and / or additions, of at least one amino acid residue.
- the percentage of identity between two polypeptides is calculated in the same way as between two nucleic acid sequences.
- the percentage of identity between two polypeptides is calculated after optimal alignment of these two sequences, over a window of maximum homology.
- the same algorithms can be used as for the nucleic acid sequences.
- biologically active fragment of a polypeptide according to the invention is intended to denote in particular a fragment of polypeptide, as defined below, having at least one of the biological characteristics of the polypeptides according to the invention, in particular in that it is able to exercise in general even partial activity, such as for example:
- polypeptide fragment according to the invention is intended to denote a polypeptide comprising at least 5 amino acids, preferably 10, 15, 25, 50, 100 and 150 amino acids.
- Polypeptide fragments can also be prepared by chemical synthesis, from hosts transformed by an expression vector according to the invention which contain a nucleic acid allowing the expression of said fragment, and placed under the control of regulatory elements and / or appropriate expression.
- modified polypeptide of a polypeptide according to the invention is intended to denote a polypeptide obtained by genetic recombination or by chemical synthesis as described below, which exhibits at least one modification with respect to the normal sequence. These modifications can be carried in particular on amino acids necessary for the specificity or the efficiency of the activity, or at the origin of the structural conformation, of the charge, or of the hydrophobicity of the polypeptide according to the invention. It is thus possible to create polypeptides of equivalent, increased or decreased activity, or of equivalent specificity, narrower or wider.
- modified polypeptides mention should be made of the polypeptides in which up to five amino acids can be modified, truncated at the N or C-terminus, or else deleted, or added.
- Chemical synthesis also has the advantage of being able to use unnatural amino acids or non-peptide bonds. Thus, it may be advantageous to use unnatural amino acids, for example in D form, or analogs of amino acids, in particular suffering forms.
- the present invention provides the nucleotide sequence of the Listeria innocua genome and the partial sequence of Listeria monocytogenes serotype 4b, as well as certain polypeptide sequences.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the biosynthesis of amino acids.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the biosynthesis of cofactors, prosthetic groups and transporters .
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a cell envelope polypeptide or present on the surface of Listeria innocua or monocytogenes 4b or for one of its fragments.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the cellular machinery.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the central intermediate metabolism.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in energy metabolism.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the metabolism of fatty acids and phospholipids.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the metabolism of nucleotides, purines, pyrimidines or nucleosides.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the regulatory functions.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a Listeria innocua or monocytogenes 4b polypeptide or one of its fragments involved in the replication process.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a Listeria innocua or monocytogenes 4b polypeptide or one of its fragments involved in the transcription process.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a Listeria innocua or monocytogenes 4b polypeptide or one of its fragments involved in the translation process.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the protein transport and binding process .
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a Listeria innocua or monocytogenes 4b polypeptide or one of its fragments involved in the adaptation to atypical conditions.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments in the sensitivity to drugs and the like.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the functions relating to transposons.
- the invention relates to a nucleotide sequence according to the invention, characterized in that it codes for a specific polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in biosynthesis amino acids.
- the invention relates to a polypeptide according to the invention, characterized in that it is a Listeria polypeptide innocua or monocytogenes 4b or one of its fragments involved in the biosynthesis of cofactors, prosthetic groups and transporters.
- the invention relates to a polypeptide according to the invention, characterized in that it is a cell envelope or surface polypeptide of Listeria innocua or monocytogenes 4b or a of its fragments.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the machinery cellular.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in metabolism central intermediary. In another aspect, preferably, the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in metabolism energy.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in metabolism fatty acids and phospholipids.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in metabolism nucleotides, purines, pyrimidines or nucleosides.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the functions of regulation.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the process replication. In another aspect, preferably, the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the process of transcription. In another aspect, preferably, the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the process translation.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the process protein transport and binding.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the adaptation to atypical conditions.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments in sensitivity to drugs and the like.
- the invention relates to a polypeptide according to the invention, characterized in that it is a polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments involved in the functions relating to transposons.
- the invention relates to a polypeptide according to the invention, characterized in that it is a specific polypeptide of Listeria innocua or monocytogenes 4b or one of its fragments.
- the present invention also relates to the nucleotide and / or polypeptide sequences according to the invention, characterized in that said sequences are recorded on a recording medium whose shape and nature facilitate the reading, analysis and / or exploitation of said sequence (s).
- These supports can also contain other information extracted from the present invention, in particular analogies with already known sequences, and / or information concerning the nucleotide sequences and / or polypeptides of other microorganisms in order to facilitate the comparative analysis and the exploitation of the results obtained.
- these recording media particular preference is given to media readable by a computer, such as magnetic, optical, electrical or hybrid media, in particular computer floppy disks, CD-ROMs, computer servers. Such recording media are also subject of the invention.
- the recording media according to the invention are very useful for the choice of primers or nucleotide probes for the determination of genes in Listeria innocua or monocytogenes 4b or strains close to this organism.
- these supports for the study of the genetic polymorphism of strains close to Listeria irmocua or monocytogenes 4b, in particular by the determination of the regions of collinearity, is very useful insofar as these supports provide not only the sequence nucleotide of the genome of Listeria innocua or monocytogenes 4b, but also the genomic organization in said sequence.
- the uses of recording media according to the invention are also objects of the invention.
- sequence comparison software such as the Blast software, or the software of the GCG kit, described above.
- the invention also relates to the cloning and / or expression vectors, which contain a nucleotide sequence according to the invention.
- the vectors according to the invention preferably comprise elements which allow the expression and / or the secretion of the nucleotide sequences in a determined host cell.
- the vector must then include a promoter, translation initiation and termination signals, as well as suitable regions for transcription regulation. It must be able to be maintained stably in the host cell and may possibly have specific signals which specify the secretion of the translated protein. These various elements are chosen and optimized by a person skilled in the art according to the cell host used. To this end, the nucleotide sequences according to the invention can be inserted into vectors with autonomous replication within the chosen host, or be integrative vectors of the chosen host.
- Such vectors are prepared by methods commonly used by those skilled in the art, and the resulting clones can be introduced into an appropriate host by standard methods, such as lipofection, electroporation, heat shock, or chemical methods .
- the vectors according to the invention are for example vectors of plasmid or viral origin. They are useful for transforming host cells in order to clone or express the nucleotide sequences according to the invention.
- the invention also includes host cells transformed with a vector according to the invention.
- the cell host can be chosen from prokaryotic or eukaryotic systems, for example bacterial cells but also yeast cells or animal cells, in particular mammalian cells. You can also use insect cells or plant cells.
- the preferred host cells according to the invention are in particular prokaryotic cells, preferably bacteria belonging to the genus Listeria, to the species Listeria innocua or monocytogenes 4b, or the microorganisms associated with the species Listeria innocua or monocytogenes 4b.
- the invention also relates to plants and animals, except humans, which comprise a transformed cell according to the invention.
- the cells transformed according to the invention can be used in processes for the preparation of recombinant polypeptides according to the invention.
- the methods for preparing a polypeptide according to the invention in recombinant form characterized in that they use a vector and / or a cell transformed with a vector according to the invention are themselves included in the present invention.
- a cell transformed with a vector according to the invention is cultivated under conditions which allow the expression of said polypeptide and said recombinant peptide is recovered.
- the cell host can be chosen from prokaryotic or eukaryotic systems.
- a vector according to the invention carrying such a sequence can therefore be advantageously used for the production of recombinant proteins, intended to be secreted. Indeed, the purification of these recombinant proteins of interest will be facilitated by the fact that they are present in the supernatant of the cell culture rather than inside the host cells.
- the polypeptides according to the invention can also be prepared by chemical synthesis. Such a preparation process is also an object of the invention.
- a person skilled in the art knows the chemical synthesis processes, for example the techniques implementing solid phases (see in particular Steward et al., 1984, Solid phase peptides synthesis, Pierce Chem. Company, Rockford, 11 1, 2nd ed. , (1984)) or techniques using partial solid phases, by condensation of fragments or by synthesis in conventional solution.
- the polypeptides obtained by chemical synthesis and which may contain corresponding unnatural amino acids are also included in the invention.
- the invention further relates to hybrid polypeptides having at least one polypeptide or a fragment thereof according to the invention, and a sequence of a polypeptide capable of inducing an immune response in humans or animals.
- the antigenic determinant is such that it is capable of inducing a humoral and / or cellular response.
- Such a determinant may comprise a polypeptide or one of its fragments according to the invention in glycosylated form used with a view to obtaining immunogenic compositions capable of inducing the synthesis of antibodies directed against multiple epitopes.
- Said polypeptides or their glycosylated fragments also form part of the invention.
- hybrid molecules can consist in part of a molecule carrying polypeptides or their fragments according to the invention, associated with a possibly immunogenic part, in particular an epitope of diphtheria toxin, tetanus toxin, a surface antigen of the virus.
- hepatitis B (patent FR 79 2181 1), the VP1 antigen of the poliomyelitis virus or any other toxin or viral or bacterial antigen.
- the methods of synthesis of the hybrid molecules include the methods used in genetic engineering to construct hybrid nucleotide sequences coding for the polypeptide sequences sought.
- hybrid nucleotide sequences coding for a hybrid polypeptide as well as the hybrid polypeptides according to the invention characterized in that they are Recombinant polypeptides obtained by the expression of said hybrid nucleotide sequences, also form part of the invention.
- the invention also includes the vectors characterized in that they contain one of said hybrid nucleotide sequences.
- Host cells transformed by said vectors, transgenic animals comprising one of said transformed cells as well as methods for preparing recombinant polypeptides using said vectors, said transformed cells and / or said transgenic animals also form part of the invention.
- the coupling between a polypeptide according to the invention and an immunogenic polypeptide can be carried out chemically, or biologically.
- one or more binding element (s), in particular amino acids to facilitate the coupling reactions between the polypeptide according to the invention, and the immunostimulatory polypeptide
- the covalent coupling of the immunostimulatory antigen can be produced at the N or C-terminal end of the polypeptide according to the invention.
- the bifunctional reagents allowing this coupling are determined as a function of the end chosen to achieve this coupling, and the coupling techniques are well known to those skilled in the art.
- the conjugates resulting from a coupling of peptides can also be prepared by genetic recombination.
- the hybrid (conjugated) peptide can in fact be produced by recombinant DNA techniques, by insertion or addition to the DNA sequence coding for the polypeptide according to the invention, of a sequence coding for the peptide (s) ) antigen (s), immunogen (s) or hapten (s). These techniques for preparing hybrid peptides by genetic recombination are well known to those skilled in the art (see for example Makrides, 1996, Microbiological Reviews 60, 512-538).
- said immune polypeptide is chosen from the group of peptides containing toxoids, in particular the diphtheria toxoid or the tetanus toxoid, proteins derived from Streptococcus (such as the protein for binding to human seralbumin), OMPA membrane proteins and complexes. proteins from external membranes, vesicles from external membranes or thermal shock proteins.
- hybrid polypeptides according to the invention are very useful for obtaining monoclonal or polyclonal antibodies capable of specifically recognizing the polypeptides according to the invention. Indeed, a hybrid polypeptide according to the invention allows the potentiation of the immune response, against the polypeptide according to the invention coupled to the immunogenic molecule. Such monoclonal or polyclonal antibodies, their fragments, or chimeric antibodies, recognizing the polypeptides according to the invention, are also objects of the invention.
- the specific monoclonal antibodies can be obtained according to the conventional method of hybridoma culture described by Kohler and Milstein (1975, Nature 256, 495).
- the antibodies according to the invention are for example chimeric antibodies, humanized antibodies, Fab fragments, or F (ab '). They can also be in the form of immunoconjugates or labeled antibodies in order to obtain a detectable and / or quantifiable signal.
- the antibodies according to the invention can be used in a method for the detection and / or identification of bacteria belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism in a biological sample, characterized in that that it comprises the following stages: a) bringing the biological sample into contact with an antibody according to the invention; b) highlighting of the antigen-antibody complex possibly formed.
- the antibodies according to the present invention can also be used in order to detect an expression of a gene of Listeria innocua or monocytogenes 4b or of associated microorganisms.
- the presence of the expression product of a gene recognized by an antibody specific for said expression product can be detected by the presence of an antigen-antibody complex formed after contacting the strain of Listeria innocua or monocytogenes 4b or of the microorganism associated with an antibody according to the invention.
- the bacterial strain used may have been "prepared", that is to say centrifuged, lysed, placed in a reagent suitable for constituting the medium suitable for the immunological reaction.
- a method of detecting expression in the gene, corresponding to a Western blot which can be carried out after an electrophoresis on polyacrylamide gel of a lysate of the bacterial strain, is preferred, in the presence or in the absence of reducing conditions (SDS-PAGE).
- the present invention also comprises the kits or kits necessary for the implementation of a method as described (for detecting the expression of a gene for
- Listeria innocua or monocytogenes 4b or an associated microorganism or for the detection and / or identification of bacteria belonging to the species Listeria innocua or monocytogenes 4b or an associated microorganism), comprising the following elements: a ) a polyclonal or monoclonal antibody according to the invention; b) optionally, the reagents for constituting the medium suitable for the immunological reaction; c) optionally, the reagents allowing the detection of the antigen-antibody complexes produced by the immunological reaction.
- polypeptides and antibodies according to the invention can advantageously be immobilized on a support, in particular a protein chip.
- a protein chip is an object of the invention, and may also contain at least one polypeptide from a microorganism other than Listeria innocua or monocytogenes 4b or an antibody directed against a compound of a microorganism other than Listeria innocua or monocytogenes 4b.
- the protein chips or high density filters containing proteins according to the invention can be constructed in the same way as the DNA chips according to the invention.
- the latter method is preferable, when it is desired to attach proteins of large size to the support, these proteins being advantageously prepared by genetic engineering.
- the protein chips according to the invention can advantageously be used in kits or necessary for the detection and / or identification of bacteria associated with the species Listeria innocua or monocytogenes 4b or with a microorganism, or more generally in kits or kits for the detection and / or identification of microorganisms.
- the polypeptides according to the invention are fixed on the DNA chips, the presence of antibodies is sought in the samples tested, the fixing of an antibody according to the invention on the support of the protein chip allowing the identification of the protein of which said antibody is specific.
- an antibody according to the invention is fixed on the support of the protein chip, and the presence of the corresponding antigen, specific for Listeria innocua or monocytogenes 4b or an associated microorganism, is detected.
- a protein chip described above can be used for the detection of gene products, to establish an expression profile of said genes, in addition to a DNA chip according to the invention.
- the protein chips according to the invention are also extremely useful for proteomics experiments, which studies the interactions between the different proteins of a given microorganism.
- proteomics experiments which studies the interactions between the different proteins of a given microorganism.
- peptides representative of the various proteins of an organism are fixed on a support. Then, said support is brought into contact with labeled proteins, and after an optional rinsing step, interactions between said labeled proteins and the peptides fixed on the protein chip are detected.
- protein chips comprising a polypeptide sequence according to the invention or an antibody according to the invention are subject of the invention, as well as the kits or kits containing them.
- the present invention also covers a method for detecting and / or identifying bacteria belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism in a biological sample, which implements a nucleotide sequence according to the invention .
- the te ⁇ ne biological sample relates in the present invention to the samples taken from a living organism (in particular blood, tissues, organs or others taken from a mammal) or a sample containing biological material, that is, DNA or RNA.
- a biological sample also includes food compositions containing bacteria (for example cheeses, dairy products), but also food compositions containing yeasts (beers, breads) or others.
- the third biological sample also relates to the bacteria isolated from these samples or food compositions.
- the detection and / or identification process using the nucleotide sequences according to the invention can be of various nature.
- a method comprising the following steps: a) optionally, isolation of the DNA from the biological sample to be analyzed, or obtaining a cDNA from the RNA of the biological sample; b) specific amplification of the DNA of bacteria belonging to the species Listeria innocua or monocytogenes 4b or to a microorganism associated with the aid of at least one primer according to the invention; c) highlighting of the amplification products. This process is based on specific amplification of DNA, in particular by an amplification chain reaction.
- a method is also preferred comprising the following steps: a) bringing a nucleotide probe according to the invention into contact with a biological sample, the nucleic acid contained in the biological sample having, if necessary, previously been made accessible to hybridization, under conditions allowing hybridization of the probe to the nucleic acid of a bacterium belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism; b) demonstration of the hybrid possibly formed between the nucleotide probe and the DNA of the biological sample.
- Such a method should not be limited to the detection of the presence of the DNA contained in the biological sample to be tested, it can also be implemented to detect the RNA contained in said sample. This process includes in particular the Southern and Northern blot.
- Another preferred method according to the invention comprises the following steps: a) bringing a nucleotide probe immobilized on a support according to the invention into contact with a biological sample, the nucleic acid of the sample, having, where appropriate , been previously made accessible for hybridization, under conditions allowing hybridization of the probe to the nucleic acid of a bacterium belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism; b) bringing the hybrid formed into contact between the nucleotide probe immobilized on a support and the nucleic acid contained in the biological sample, where appropriate after elimination of the DNA from the biological sample which has not hybridized with the probe, with a labeled nucleotide probe according to the invention; c) highlighting of the new hybrid formed in step b).
- This method is advantageously used with a DNA chip according to the invention, the desired nucleic acid hybridizing with a probe present on the surface of said chip, and being detected by the use of a labeled probe.
- This process is advantageously implemented by combining a prior step of amplification of DNA or complementary DNA optionally obtained by reverse transcription, using primers according to the invention.
- kits or kits for the detection and / or identification of bacteria belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism characterized in that it comprises the following elements : a) a nucleotide probe according to the invention; b) optionally, the reagents necessary for carrying out a hybridization reaction; c) optionally, at least one primer according to the invention as well as the reagents necessary for a DNA amplification reaction.
- kits or kits for the detection and / or identification of bacteria belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism characterized in that it comprises the elements following: a) a nucleotide probe, called capture probe, according to the invention; b) an oligonucleotide probe, called the revelation probe, according to the invention; c) optionally, at least one primer according to the invention as well as the reagents necessary for a DNA amplification reaction.
- kits or kits for the detection and / or identification of bacteria belonging to the species Listeria innocua or monocytogenes 4b or to an associated microorganism characterized in that it comprises the following elements: a) at least a primer according to the invention; b) optionally, the reagents necessary to carry out a DNA amplification reaction; c) optionally, a component making it possible to verify the sequence of the amplified fragment, more particularly an oligonucleotide probe according to the invention, are also objects of the present invention.
- said primers and / or probes and / or polypeptides and / or antibodies according to the present invention used in the methods and / or kits or necessary according to the present invention are chosen from primers and / or probes and / or polypeptides and / or antibodies specific for the species Listeria innocua or monocytogenes 4b.
- these elements are chosen from the nucleotide sequences coding for a secreted protein, among secreted polypeptides, or among antibodies directed against secreted polypeptides of Listeria innocua or monocytogenes 4b.
- the present invention also relates to strains of Listeria innocua or monocytogenes 4b and / or associated microorganisms containing one or more mutation (s) in a nucleotide sequence according to the invention, in particular an ORF sequence, or their regulatory elements. (in particular promoters).
- the strains of Listeria innocua or monocytogenes 4b are preferred, having one or more mutation (s) in the nucleotide sequences coding for polypeptides involved in the cellular machinery, in particular secretion, central intermediate metabolism, metabolism. energy, the processes of amino acid synthesis, transcription and translation, synthesis of polypeptides.
- Said mutations can lead to inactivation of the gene, or in particular when they are located in the regulatory elements of said gene, to overexpression of the latter.
- the invention further relates to the use of a nucleotide sequence according to the invention, a polypeptide according to the invention, an antibody according to the invention, a cell according to the invention, and / or d '' an animal transformed according to the invention, for the selection of organic or inorganic compound capable of modulating, regulating, inducing or inhibiting the expression of genes, and / or modifying the cellular replication of eukaryotic or prokaryotic cells or capable of inducing, inhibiting or aggravating the pathologies linked to infection with Listeria innocua or monocytogenes 4b or one of its associated microorganisms.
- the invention also includes a method of selecting compounds capable of binding to a polypeptide or a fragment thereof according to the invention, capable of binding to a nucleotide sequence according to the invention, or capable of recognizing an antibody according to claim , and / or capable of modulating, regulating, inducing or inhibiting gene expression, and / or modifying the growth or cellular replication of eukaryotic or prokaryotic cells, or capable of inducing, inhibiting or aggravate in an animal or human organism the pathologies linked to an infection by Listeria, for example by L.
- monocytogenes 4b or one of its associated microorganisms, characterized in that it comprises the following stages: a) bringing said compound into contact with said polypeptide, said nucleotide sequence, with a cell transformed according to the invention and / or administering said compound to an animal transformed according to the invention; b) determining the capacity of said compound to bind with said polypeptide or said nucleotide sequence, or to modulate, regulate, induce or inhibit the expression of genes, or to modulate cell growth or replication, or induce, inhibit or aggravate in said transformed animal the pathologies linked to an infection with Listeria, for example L. monocytogenes 4b or one of its associated microorganisms.
- the cells and / or animals transformed according to the invention can advantageously serve as a model and be used in methods for studying, identifying and / or selecting compounds capable of being responsible for pathologies induced or aggravated by Listeria monocytogenes, or susceptible to prevent and / or treat these pathologies.
- the transformed host cells in particular bacteria of the Listeria family, the transformation of which by a vector according to the invention can, for example, increase or inhibit its infectious power, or modulate the pathologies usually induced or aggravated by the infection, may be used to infect animals whose pathologies will be monitored.
- These unprocessed animals, infected for example with transformed Listeria bacteria could serve as a study model.
- the animals transformed according to the invention may be used in methods of selecting compounds capable of preventing and / or treating diseases due to Listeria. Said methods using said transformed cells and / or transformed animals form part of the invention.
- the compounds which can be selected can be organic compounds such as polypeptides or carbohydrates or any other organic or inorganic compounds already known, or new organic compounds produced from molecular modeling techniques and obtained by chemical or biochemical synthesis. , these techniques being known to those skilled in the art.
- Said selected compounds may be used to modulate the growth and / or cell replication of Listeria innocua or monocytogenes 4b or any other associated microorganism and thus to control infection by these microorganisms.
- Said compounds according to the invention may also be used to modulate the growth and / or cell replication of all eukaryotic or prokaryotic cells, in particular tumor cells and infectious microorganisms, for which said compounds will prove to be active, the methods making it possible to determine said modulations being well known to those skilled in the art.
- compound capable of modulating the growth of a microorganism is intended to denote any compound which makes it possible to intervene, modify, limit and / or reduce the development, growth, rate of proliferation and / or viability of said microorganism. .
- This modulation can be carried out for example by an agent capable of binding to a protein and thus of inhibiting or potentiating its biological activity, or capable of binding to a membrane protein of the external surface of a microorganism and of block the penetration of said microorganism into the host cell or promote the action of the immune system of the infected organism directed against said microorganism.
- This modulation can also be carried out by an agent capable of binding to a nucleotide sequence of a DNA or RNA of a microorganism and of blocking for example the expression of a polypeptide whose biological or structural activity is necessary to the growth or reproduction of said microorganism.
- associated microorganism is intended to denote any microorganism whose gene expression can be modulated, regulated, induced or inhibited, or whose cell growth or replication can also be modulated by a compound of l 'invention.
- associated microorganism in the present invention is also intended to denote any microorganism comprising nucleotide sequences or polypeptides according to the invention. These microorganisms may in certain cases contain polypeptides or nucleotide sequences identical or homologous to those of the invention and may also be detected and / or identified by the methods or kit for detection and / or identification according to the invention and also serve as a target for the compounds of the invention.
- microorganism is also intended to denote any Listeria monocytogenes microorganism of any serotype.
- the invention relates to compounds capable of being selected by a selection method according to the invention.
- the invention also relates to a pharmaceutical composition
- a pharmaceutical composition comprising a compound chosen from the following compounds: a) a nucleotide sequence according to the invention; b) a polypeptide according to the invention; c) a vector according to the invention; d) an antibody according to the invention; and e) a compound capable of being selected by a selection method according to the invention, optionally in combination with a pharmaceutically acceptable vehicle.
- the term effective quantity is intended to denote a sufficient quantity of the said compound or antibody, or of the polypeptide of the invention, making it possible to modulate the growth of Listeria innocua or monocytogenes 4b or of an associated microorganism.
- the invention also relates to a pharmaceutical composition according to the invention for the prevention or treatment of an infection by a bacterium belonging to the genus Listeria or by an associated microorganism.
- the invention further relates to an immunogenic and / or vaccine composition, characterized in that it comprises one or more polypeptides according to the invention and / or one or more hybrid polypeptides according to the invention.
- the invention also includes the use of a transformed cell according to the invention, for the preparation of a vaccine composition.
- the invention also relates to a vaccine composition, characterized in that it contains a nucleotide sequence according to the invention, a vector according to the invention and / or a transformed cell according to the invention.
- the invention also relates to the vaccine compositions according to the invention, for the prevention or treatment of an infection by a bacterium belonging to the genus Listeria or by an associated microorganism.
- the immunogenic and / or vaccine compositions according to the invention intended for the prevention and / or treatment of infection by Listeria or by an associated microorganism will be chosen from the immunogenic and / or vaccine compositions comprising a polypeptide or one of its fragments corresponding to a protein, or one of its fragments, of the Listeria cell envelope.
- the vaccine compositions comprising nucleotide sequences will preferably also comprise nucleotide sequences coding for a polypeptide or one of its fragments corresponding to a protein, or one of its fragments, of the cell envelope of Listeria.
- polypeptides of the invention or their fragments entering into the immunogenic compositions according to the invention can be selected by techniques known to those skilled in the art, for example on the capacity of said polypeptides to stimulate the T cells, which results, for example, in their proliferation or the secretion of interleukins, and which results in the production of antibodies directed against said polypeptides.
- mice In mice, in which a weight dose of the vaccine composition comparable to the dose used in humans is administered, the antibody reaction is tested by sampling the serum followed by a study of the formation of a complex between the antibodies present in the serum and the antigen of the vaccine composition, according to the usual techniques.
- said vaccine compositions will preferably be in association with a pharmaceutically acceptable vehicle and, where appropriate, with one or more appropriate immunity adjuvants.
- This type of vaccination is carried out with a particular plasmid derived from an E. coli plasmid which does not replicate in vivo and which codes only for the vaccinating protein. Animals have been immunized by simply injecting naked plasmid DNA into the muscle. This technique leads to the expression of the vaccine protein in situ and to an immune response of cell type (CTL) and of humoral type (antibody). This double induction of the immune response is one of the main advantages of the vaccination technique with naked DNA.
- CTL cell type
- antibody humoral type
- compositions comprising nucleotide sequences or vectors into which said sequences are inserted, are in particular described in international application No. WO 90/1 1092 and also in international application No. WO 95/1 1307.
- the nucleotide sequence constituting the vaccine composition according to the invention can be injected into the host after being coupled to compounds which promote the penetration of this polynucleotide inside the cell or its transport to the cell nucleus.
- the resulting conjugates can be encapsulated in polymer microparticles, as described in international application No. WO 94/27238 (Medisorb Technologies International).
- the nucleotide sequence preferably DNA
- the nucleotide sequence is complexed with DEAE-dextran, with nuclear proteins, with lipids or encapsulated in liposomes or even introduced under the form of a gel facilitating its transfection into cells.
- the polynucleotide or the vector according to the invention can also be in suspension in a buffer solution or be associated with liposomes.
- such a vaccine will be prepared according to the technique described by Tacson et al. or Huygen et al. in 1996 or according to the technique described by Davis et al. in international application No. WO 95/1 1307.
- Such a vaccine can also be prepared in the form of a composition containing a vector according to the invention, placed under the control of regulatory elements allowing its expression in humans or animals. It is possible, for example, to use, as a vector for the in vivo expression of the polypeptide antigen of interest, the plasmid pcDNA3 or the plasmid pcDNAl / neo, both marketed by Invitrogen (R & D Systems, Abingdon, United Kingdom). United). Such a vaccine will advantageously comprise, in addition to the recombinant vector, a saline solution, for example a sodium chloride solution.
- a saline solution for example a sodium chloride solution.
- pharmaceutically acceptable vehicle is intended to denote a compound or a combination of compounds entering into a pharmaceutical or vaccine composition which does not cause side reactions and which allows for example the facilitation of the administration of the active compound, the increase in its duration of life and / or its efficiency in the organism, increasing its solubility in solution or improving its conservation.
- pharmaceutically acceptable vehicles are well known and will be adapted by those skilled in the art depending on the nature and the mode of administration of the active compound chosen.
- these can include suitable immunity adjuvants which are known to those skilled in the art, such as, for example, aluminum hydroxide, a representative of the family of muramyl peptides. as one of the peptide derivatives of N-acetyl-muramyl, a bacterial lysate, or even the incomplete adjuvant of Freund.
- these compounds will be administered by the systemic route, in particular by the intravenous route, by the intramuscular, intradermal or subcutaneous route, or by the oral route. More preferably, the vaccine composition comprising polypeptides according to the invention will be administered several times, over a period of time, by the intradermal or subcutaneous route.
- dosages and dosage forms can be determined according to the criteria generally taken into account in establishing a treatment adapted to a patient such as, for example, the patient's age or body weight, the severity of his general condition, tolerance to treatment and side effects observed.
- the invention comprises the use of a composition according to the invention, for the treatment or prevention of diseases induced or aggravated by the presence of Listeria.
- the present invention also relates to a genomic DNA library of a bacterium of the genus Listeria, preferably, Listeria innocua or monocytogenes, preferably the strain 4b.
- the genomic DNA banks described in the present invention cover the genome of Listeria innocua and Listeria monocytogenes 4b respectively.
- these regions could not be cloned into said library, due to lethality problems in Escherichia coli, these regions can easily be amplified and identified by a person skilled in the art, using oligonucleotides specific for the sequences of the sequences. ends of the different clones which form the contigs.
- the present invention also relates to methods for the isolation of a polynucleotide of interest present in a strain of Listeria and absent in another strain, which uses at least one DNA library based for example on a plasmid pcDNA2.1 containing the Listeria genome.
- the method according to the invention for the isolation of a polynucleotide of interest can comprise the following steps: a) isolating at least one polynucleotide contained in a clone of the DNA library of Listeria origin, b) isolating: at least one genomic polynucleotide or cDNA of a listeria, said listeria belonging to a strain different from the strain used for the construction of the DNA library of step a) or, alternatively,
- step a) at least one polynucleotide contained in a clone of a DNA library prepared from the genome of a Listeria which is different from the Listeria used for the construction of the DNA library of step a); c) hybridizing the polynucleotide of step a) to the polynucleotide of step b); d) selecting the polynucleotides of step a) which have not formed a hybridization complex with the polynucleotides of step b); e) characterize the selected polynucleotide.
- the polynucleotide of step a) can be prepared by digestion of at least one recombinant clone with an appropriate restriction enzyme, and optionally, the amplification of the resulting polynucleotide insert.
- the method of the invention allows a person skilled in the art to carry out comparative genomic studies between the different strains or species of the genus
- Listeria for example between pathogenic strains and their non-pathogenic equivalents.
- the chromosomal DNA of the strains studied was prepared by a conventional method including treatment with proteinase K and phenol extraction (Jacquet, C, et al., Monellanase K and phenol extraction (Jacquet, C, et al., Monellanase K and phenol extraction (Jacquet, C, et al., Monellanase K and phenol extraction (Jacquet, C,
- the plasmids were prepared by a semi-automatic preparation method developed in the GMP laboratory (Genomics of Pathogenic Microorganisms of the Institut Pasteur) based on the alkaline lysis method (Birnboim, H. C , Methods Enzymol., 100: 243-255, 1983).
- the chromosomal inserts were sequenced from their two ends using the T7 and universal primer following the recommendations of the supplier (PE-biosystems). The sequences were determined using automatic sequencers of type 377 and 3700 (PE-Biosystem).
- the sequences were assembled using the software package developed at the University of Washington, Phred, Phrap and Consed (Ewing, B., et al., Génome Res., 8: 186-194, 1998; Gordon, D ., et al., Genome Res., 8: 195-202, 1998).
- the finishing of the sequence was carried out using the GMPTB software package (Frangeul, L., et al., Microbiology, 145: 2625-2634, 1999).
- the finishing step corresponds to the resequencing of the regions where the sequence is insecure and the sequencing of the regions located between the contigs. It was carried out either by sequencing PCR products or by walking on the clones of the bank.
- the sequences of the oligonucleotides were defined using the consed and Primo software (Gordon, D., et al., 1998; Li, P., et al., Genomics, 40: 476-485, 1997).
- the identification of the coding phases was carried out using the GMPTB software package. This program combines the results of different methods: (i) identifying open reading phases and sorting them according to their size, (ii) analyzing the probability of being coding using Genemark software (Lukashin, AV, et al., Nucleic Acids Res., 15: 1 107-1 1 15, 1998), (iii) identification of the start of translation (initiation codon and ribosome binding sequence), (iv ) similarity of protein sequence deduced with the protein sequences contained in the sequence banks using the BLASTP software.
- the chromosomal regions of the strain L. monocytogenes of serotype 4b which are absent from the strains L. monocytogenes EGDe and L. innocua were identified using the Crossmatch / Phrap Package (Phil Green, University of Washington, Seattle, unpublished). This software makes it possible to assemble nucleotide sequences (Phrap) by masking all the sequences or parts of sequence similar to one or more reference sequences (Crossmatch).
- the reference sequences used were: the complete genome sequence of L. monocytogenes EGD, the complete genome sequence of L. innocua and the sequence of its plasmid.
- SEQ ID Nos. 1 - 1 1 nucleotide sequences of 10 Contigs and 1 plasmid from the Listeria innocua assembly.
- SEQ ID Nos. 12 - 689 nucleotide sequences of specific proteins of L. innocua (absent from Z. monocytogenes-EGD).
- SEQ ID Nos. 690 - 1067 nucleotide sequences of the specific proteins of L. monocytogenes-EGD (absent from L. innocua).
- SEQ ID Nos. 1068 - 2041 nucleotide sequences of 974 contigs originating from the assembly of Listeria monocytogenes-4b (1,231,537 bases).
- SEQ ID Nos. 2059-2601 nucleotide sequences of 543 genes specific for Listeria innocua Clipl 1262; with the SEQ ID identifier in the first column, the gene name in the second column, the IPF number in the third column (“Institut Pasteur” identifier number allowing the sequence to be correlated with the sequences in Table V) and in the last column the corresponding annotation.
- SEQ ID Nos. 2602 - 2871 nucleotide sequences of the 270 genes specific for Listeria monocytogenes EGDe; with the SEQ ID identifier in the first column, the gene name in the second column, the IPF number in the third column (“Institut Pasteur” identifier number allowing the sequence to be correlated with the sequences in Table V) and in the last column the corresponding annotation.
Landscapes
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Health & Medical Sciences (AREA)
- Analytical Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Immunology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Oncology (AREA)
- Communicable Diseases (AREA)
- Gastroenterology & Hepatology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines Containing Material From Animals Or Micro-Organisms (AREA)
- Investigating Or Analysing Biological Materials (AREA)
Abstract
Description









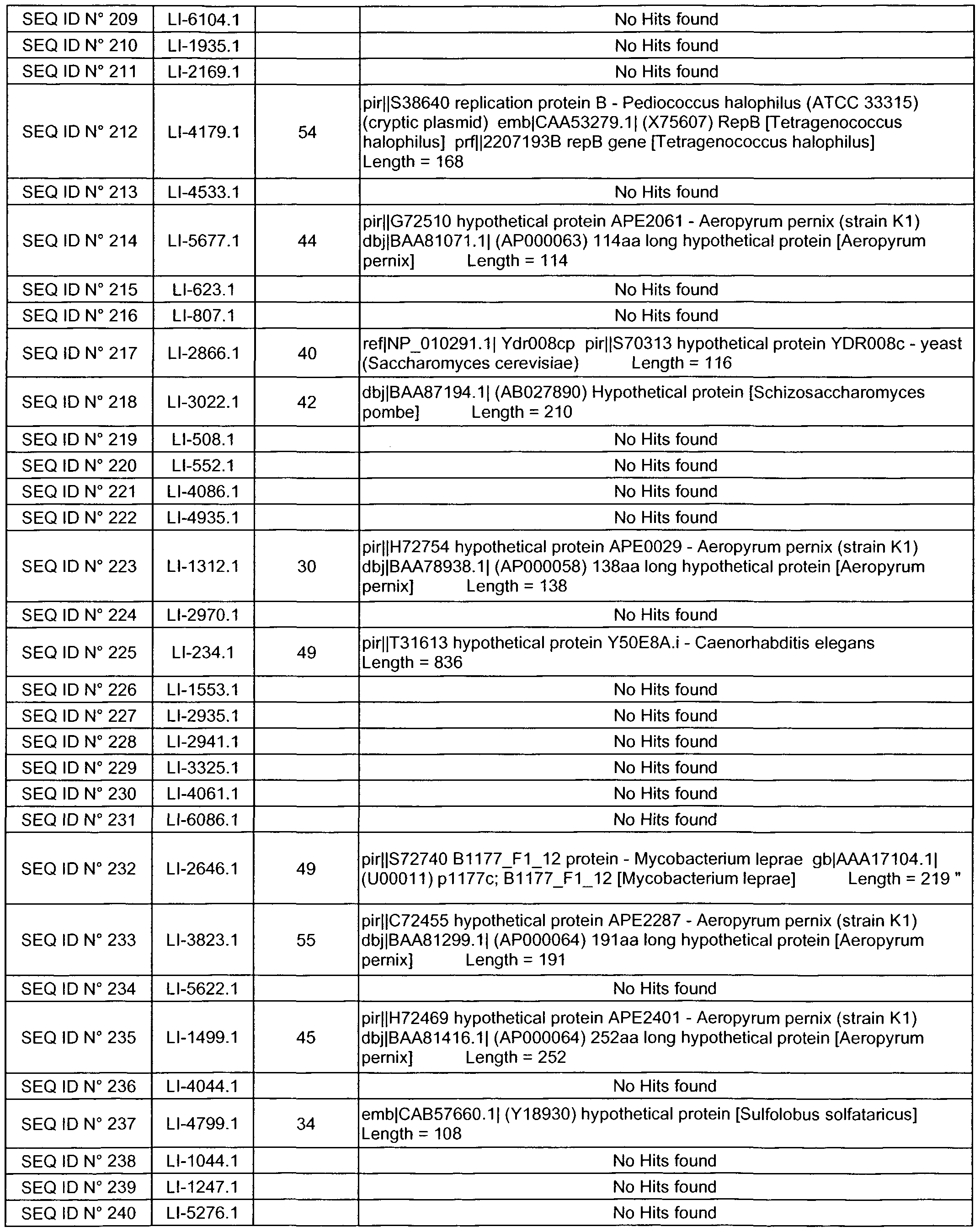


































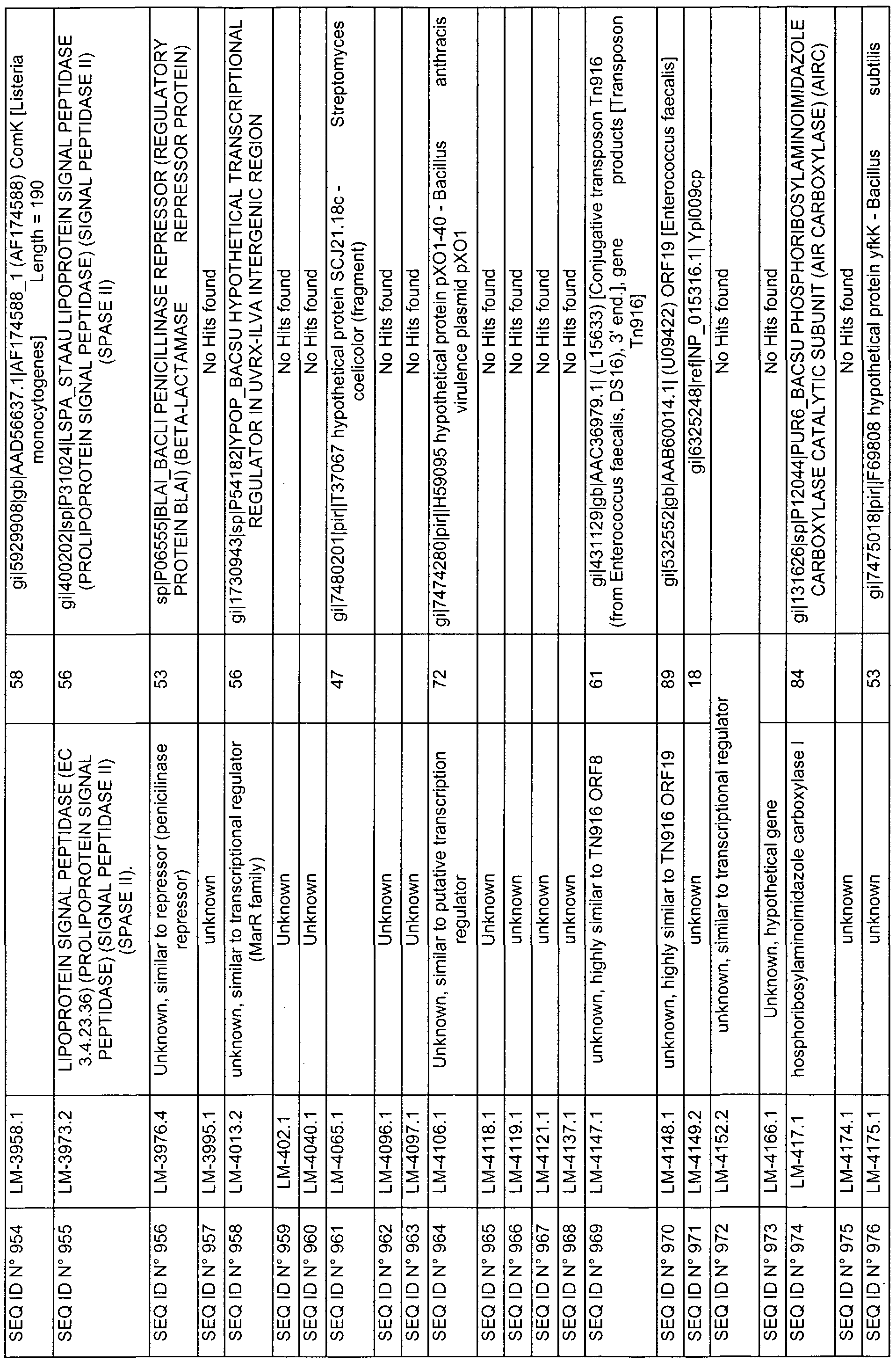
















Claims
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/398,221 US20040018514A1 (en) | 2000-10-04 | 2001-10-04 | Listeria inocua, genome and applications |
| EP01982519A EP1322763A2 (fr) | 2000-10-04 | 2001-10-04 | Listeria innocua , genome et applications |
| AU2002214081A AU2002214081A1 (en) | 2000-10-04 | 2001-10-04 | Listeria inocua, genome and applications |
| KR10-2003-7004886A KR20030064404A (ko) | 2000-10-04 | 2001-10-04 | 리스테리아 이노큐아, 게놈 및 이의 용도 |
| JP2002532473A JP2004515227A (ja) | 2000-10-04 | 2001-10-04 | リステリア・インノキュア、ゲノムおよびその用途 |
| CA002424952A CA2424952A1 (fr) | 2000-10-04 | 2001-10-04 | Listeria innocua, genome et applications |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR0012697A FR2814754B1 (fr) | 2000-10-04 | 2000-10-04 | Listeria innocua, genome et applications |
| FR00/12697 | 2000-10-04 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2002028891A2 true WO2002028891A2 (fr) | 2002-04-11 |
| WO2002028891A3 WO2002028891A3 (fr) | 2003-01-03 |
Family
ID=8855008
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/FR2001/003061 WO2002028891A2 (fr) | 2000-10-04 | 2001-10-04 | Listeria innocua, genome et applications |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20040018514A1 (fr) |
| EP (1) | EP1322763A2 (fr) |
| JP (1) | JP2004515227A (fr) |
| KR (1) | KR20030064404A (fr) |
| AU (1) | AU2002214081A1 (fr) |
| CA (1) | CA2424952A1 (fr) |
| FR (1) | FR2814754B1 (fr) |
| WO (1) | WO2002028891A2 (fr) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2006002546A1 (fr) * | 2004-07-06 | 2006-01-12 | Warnex Research Inc. | Polynucleotides pour la detection de l'espece listeria |
| US7368547B2 (en) * | 2003-02-03 | 2008-05-06 | Mississippi State University | Use of novel virulence-specific genes as targets for diagnosis and potential control of virulent strains of Listeria monocytogenes |
| WO2009092790A1 (fr) * | 2008-01-24 | 2009-07-30 | Teagasc, The Agriculture And Food Development Authority | Cytotoxine de listeria monocytogenes, la listériolysine s |
| WO2012003409A1 (fr) * | 2010-06-30 | 2012-01-05 | Life Technologies Corporation | Détection d'espèces listeria dans des échantillons alimentaires et environnementaux et procédés et compositions afférents |
| CN103981275A (zh) * | 2014-05-30 | 2014-08-13 | 浙江万里学院 | 用于同时检测海洋中四种致病菌的多重pcr引物及其设计方法 |
| CN104017873A (zh) * | 2014-05-30 | 2014-09-03 | 浙江万里学院 | 用于同时检测海洋中五种致病菌以及三种毒力基因的多重pcr引物及其设计方法 |
| EP2896629A1 (fr) * | 2000-10-27 | 2015-07-22 | Novartis Vaccines and Diagnostics S.r.l. | Acides nucléiques et protéines de streptocoques des groupes A et B |
| AU2014274586B2 (en) * | 2000-10-27 | 2017-01-05 | J. Craig Venter Institute, Inc. | Nucleic acids and proteins from streptococcus groups A & B |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20060257894A1 (en) * | 2003-09-16 | 2006-11-16 | Michel Doumith | Molecular typing of listeria monocytogenes, hybridization supports and kits for said molecular typing |
| US20060057613A1 (en) * | 2004-07-26 | 2006-03-16 | Nanosphere, Inc. | Method for distinguishing methicillin resistant S. aureus from methicillin sensitive S. aureus in a mixed culture |
| US7439022B2 (en) * | 2005-06-15 | 2008-10-21 | Kraft Foods Holdings, Inc. | Nucleic acids for detection of Listeria |
| WO2007123386A1 (fr) * | 2006-04-24 | 2007-11-01 | Sigma Alimentos, S.A. De C.V. | Procédé de détection et de quantification multiple et simultanée de pathogènes par réaction en chaîne par polymérase en temps réel |
| WO2009035954A1 (fr) * | 2007-09-12 | 2009-03-19 | 3M Innovative Properties Company | Procédés de détection de listeria monocytogenes |
| US20120052495A1 (en) * | 2010-08-30 | 2012-03-01 | Samsung Techwin Co., Ltd. | Oligonucleotides for detecting listeria monocytogenes and use thereof |
| US20120052492A1 (en) * | 2010-08-30 | 2012-03-01 | Samsung Techwin Co., Ltd. | Oligonucleotides for detecting listeria spp. and use thereof |
| US9422529B2 (en) | 2010-12-22 | 2016-08-23 | The Board Of Regents Of The University Of Texas System | Alphavirus compositions and methods of use |
| WO2012088473A1 (fr) | 2010-12-22 | 2012-06-28 | The Board Of Regents Of The University Of Texas System | Compositions à base d'alphavirus et leurs procédés d'utilisation |
| CN102676506A (zh) * | 2012-05-30 | 2012-09-19 | 曹际娟 | 单核细胞增生李斯特氏菌核酸标准样品、其建立方法及应用 |
| CA2957938A1 (fr) * | 2014-08-25 | 2016-03-03 | GeneWeave Biosciences, Inc. | Particules de transduction non replicatives et systemes rapporteurs les utilisant |
| US11008602B2 (en) | 2017-12-20 | 2021-05-18 | Roche Molecular Systems, Inc. | Non-replicative transduction particles and transduction particle-based reporter systems |
| CN110511987B (zh) * | 2019-08-28 | 2023-07-18 | 华南理工大学 | 一种基于特异性基因靶标lmo1341的单增李斯特菌的PCR检测方法 |
| CN112725474B (zh) * | 2020-12-30 | 2022-05-20 | 广东省微生物研究所(广东省微生物分析检测中心) | 含有特异性分子靶标的单核细胞增生李斯特菌标准菌株及其检测和应用 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0805214A2 (fr) * | 1996-04-30 | 1997-11-05 | Universita' Degli Studi di Udine | Procédé et amorces d'identification de Listeria monocytogenes dans un substrat organique |
| WO2001077335A2 (fr) * | 2000-04-11 | 2001-10-18 | Institut Pasteur | Genome de listeria monocytogenes, polypeptides et utilisations |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5610012A (en) * | 1994-04-08 | 1997-03-11 | Wisconsin Alumni Research Foundation | DNA probes specific for virulent listeria monocytogenes |
-
2000
- 2000-10-04 FR FR0012697A patent/FR2814754B1/fr not_active Expired - Fee Related
-
2001
- 2001-10-04 AU AU2002214081A patent/AU2002214081A1/en not_active Abandoned
- 2001-10-04 EP EP01982519A patent/EP1322763A2/fr not_active Ceased
- 2001-10-04 US US10/398,221 patent/US20040018514A1/en not_active Abandoned
- 2001-10-04 WO PCT/FR2001/003061 patent/WO2002028891A2/fr not_active Application Discontinuation
- 2001-10-04 KR KR10-2003-7004886A patent/KR20030064404A/ko not_active Application Discontinuation
- 2001-10-04 JP JP2002532473A patent/JP2004515227A/ja active Pending
- 2001-10-04 CA CA002424952A patent/CA2424952A1/fr not_active Abandoned
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0805214A2 (fr) * | 1996-04-30 | 1997-11-05 | Universita' Degli Studi di Udine | Procédé et amorces d'identification de Listeria monocytogenes dans un substrat organique |
| WO2001077335A2 (fr) * | 2000-04-11 | 2001-10-18 | Institut Pasteur | Genome de listeria monocytogenes, polypeptides et utilisations |
Non-Patent Citations (3)
| Title |
|---|
| ANDREAS BUBERT ET AL.: "Detection and differentiation of Listeria spp. by a single reaction based on multiplex PCR" APPLIED AND ENVIRONMENTAL MICROBIOLOGY, vol. 65, no. 10, octobre 1999 (1999-10), pages 4688-4692, XP002172242 * |
| ANDREAS BUBERT ET AL.: "The homologous and heterologous regions within the iap gene allow genus- and species-specific identification of Listeria spp. by polymerase chain reaction" APPLIED AND ENVIRONMENTAL MICROBIOLOGY, vol. 58, no. 8, août 1992 (1992-08), pages 2625-2632, XP001010399 cité dans la demande * |
| T. CHAKRABORTY ET AL.: "Genome organization and the evolution of the virulence gene locus in Listeria species" INTERNATIONAL JOURNAL OF MEDICAL MICROBIOLOGY, vol. 290, no. 2, mai 2000 (2000-05), pages 167-174, XP001010398 * |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2014274586B2 (en) * | 2000-10-27 | 2017-01-05 | J. Craig Venter Institute, Inc. | Nucleic acids and proteins from streptococcus groups A & B |
| US10428121B2 (en) | 2000-10-27 | 2019-10-01 | Novartis Ag | Nucleic acids and proteins from streptococcus groups A and B |
| US9840538B2 (en) | 2000-10-27 | 2017-12-12 | Novartis Ag | Nucleic acids and proteins from Streptococcus groups A and B |
| EP2896629A1 (fr) * | 2000-10-27 | 2015-07-22 | Novartis Vaccines and Diagnostics S.r.l. | Acides nucléiques et protéines de streptocoques des groupes A et B |
| US9738693B2 (en) | 2000-10-27 | 2017-08-22 | Novartis Ag | Nucleic acids and proteins from streptococcus groups A and B |
| US7368547B2 (en) * | 2003-02-03 | 2008-05-06 | Mississippi State University | Use of novel virulence-specific genes as targets for diagnosis and potential control of virulent strains of Listeria monocytogenes |
| WO2006002546A1 (fr) * | 2004-07-06 | 2006-01-12 | Warnex Research Inc. | Polynucleotides pour la detection de l'espece listeria |
| WO2009092790A1 (fr) * | 2008-01-24 | 2009-07-30 | Teagasc, The Agriculture And Food Development Authority | Cytotoxine de listeria monocytogenes, la listériolysine s |
| WO2012003409A1 (fr) * | 2010-06-30 | 2012-01-05 | Life Technologies Corporation | Détection d'espèces listeria dans des échantillons alimentaires et environnementaux et procédés et compositions afférents |
| US9546405B2 (en) | 2010-06-30 | 2017-01-17 | Life Technologies Corporation | Detection of Listeria species in food and environmental samples, methods and compositions thereof |
| EP2902506A1 (fr) * | 2010-06-30 | 2015-08-05 | Life Technologies Corporation | Détection d'espèces listeria dans des échantillons alimentaires et environnementaux et procédés et compositions afférents |
| CN104017873B (zh) * | 2014-05-30 | 2017-05-10 | 浙江万里学院 | 用于同时检测海洋中五种致病菌以及三种毒力基因的多重pcr引物及其设计方法 |
| CN104017873A (zh) * | 2014-05-30 | 2014-09-03 | 浙江万里学院 | 用于同时检测海洋中五种致病菌以及三种毒力基因的多重pcr引物及其设计方法 |
| CN103981275A (zh) * | 2014-05-30 | 2014-08-13 | 浙江万里学院 | 用于同时检测海洋中四种致病菌的多重pcr引物及其设计方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| FR2814754A1 (fr) | 2002-04-05 |
| EP1322763A2 (fr) | 2003-07-02 |
| CA2424952A1 (fr) | 2002-04-11 |
| FR2814754B1 (fr) | 2005-09-09 |
| KR20030064404A (ko) | 2003-07-31 |
| US20040018514A1 (en) | 2004-01-29 |
| WO2002028891A3 (fr) | 2003-01-03 |
| AU2002214081A1 (en) | 2002-04-15 |
| JP2004515227A (ja) | 2004-05-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2002028891A2 (fr) | Listeria innocua, genome et applications | |
| WO2002092818A2 (fr) | Sequence du genome streptococcus agalactiae et ses utilisations | |
| CN107257853B (zh) | 新型肠出血性大肠杆菌噬菌体Esc-CHP-1及其用于抑制肠出血性大肠杆菌增殖的用途 | |
| WO2001077335A2 (fr) | Genome de listeria monocytogenes, polypeptides et utilisations | |
| EP1003888A2 (fr) | Sequences nucleiques de polypeptides exportes de mycobacteries, vecteurs les comprenant et applications au diagnostic et a la prevention de la tuberculose | |
| JP2010189411A (ja) | 病原菌株に特異的な新規生成物およびそのワクチンとしての使用および免疫療法における使用 | |
| CA2708167C (fr) | Antigenes de vaccin provenant de la piscirickettsia salmonis | |
| Zhou et al. | Adhesion protein ApfA of Actinobacillus pleuropneumoniae is required for pathogenesis and is a potential target for vaccine development | |
| CN108330142B (zh) | 一种具有免疫保护作用的美人鱼发光杆菌溶血素Hlych蛋白 | |
| US7815896B2 (en) | Type III secretion pathway in Aeromonas salmonicida and uses therefor | |
| US10801030B2 (en) | General secretory pathway (GSP) mutant listeria SPP., and methods for making and using the same | |
| JP2001524803A (ja) | インフルエンザ菌(Haemophilus influenzae)のNucAタンパク質およびそのタンパク質をコードする遺伝子 | |
| WO2017108515A1 (fr) | Souches bactériennes à gram négatif modifiées et leurs utilisations | |
| WO2000001825A1 (fr) | ANTIGENE D'HELICOBACTER (η-GLUTAMYLTRANSPEPTIDASE) ET SEQUENCES CODANT POUR CET ANTIGENE | |
| JP2001523954A (ja) | 76 kDa、32 kDa、および50 kDaヘリコバクター(Helicobacter)ポリペプチドおよび対応するポリヌクレオチド分子 | |
| US20100129408A1 (en) | Klebsiella pneumoniae attenuated virulence mutant and method of production | |
| Naser et al. | Effect of IS900 gene of Mycobacterium paratuberculosis on Mycobacterium smegmatis | |
| JP4183504B2 (ja) | ストレプトコッカス遺伝子 | |
| US20030124567A1 (en) | Use of a leptospire protein preventing and/or diagnosing and/or treating animal or human leptospirosis | |
| JP2002539763A (ja) | ヘリコバクター・ピロリ抗原 | |
| JP2000516449A (ja) | 細胞結合と細胞侵入に関与するミコバクテリア由来タンパク質をコードしている遺伝子とその使用法 | |
| US20050226895A1 (en) | Sequences from piscirickettsia salmonis | |
| FR2767336A1 (fr) | Vecteurs recombinants, polynucleotide codant pour un polypeptide pd428 de 12kd de mycobacteries appartenant au complexe de mycobacterium tuberculosis et applications au diagnostic et a la prevention de la tuberculose | |
| JPH11509401A (ja) | プロテアーゼ活性低下型のHaemophilus Hin47の類似体 | |
| FREY et al. | Patent 2467309 Summary |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Kind code of ref document: A2 Designated state(s): AE AG AL AM AT AU AZ BA BB BG BR BY BZ CA CH CN CO CR CU CZ DE DK DM DZ EC EE ES FI GB GD GE GH GM HR HU ID IL IN IS JP KE KG KP KR KZ LC LK LR LS LT LU LV MA MD MG MK MN MW MX MZ NO NZ PH PL PT RO RU SD SE SG SI SK SL TJ TM TR TT TZ UA UG US UZ VN YU ZA ZW |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A2 Designated state(s): GH GM KE LS MW MZ SD SL SZ TZ UG ZW AM AZ BY KG KZ MD RU TJ TM AT BE CH CY DE DK ES FI FR GB GR IE IT LU MC NL PT SE TR BF BJ CF CG CI CM GA GN GQ GW ML MR NE SN TD TG |
|
| DFPE | Request for preliminary examination filed prior to expiration of 19th month from priority date (pct application filed before 20040101) | ||
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 2001982519 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2424952 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2002532473 Country of ref document: JP Ref document number: 1020037004886 Country of ref document: KR |
|
| WWP | Wipo information: published in national office |
Ref document number: 2001982519 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 10398221 Country of ref document: US |
|
| WWP | Wipo information: published in national office |
Ref document number: 1020037004886 Country of ref document: KR |
|
| REG | Reference to national code |
Ref country code: DE Ref legal event code: 8642 |
|
| WWR | Wipo information: refused in national office |
Ref document number: 2001982519 Country of ref document: EP |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2001982519 Country of ref document: EP |